
工具采集文章
如何用新媒体管家采集文章和素材?(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 390 次浏览 • 2022-07-22 08:00
工具采集文章和素材。第一步:首先打开新媒体管家(比如我是win10系统,用的是windows7版本)第二步:右键点击你要抓取的文章或素材,点击微信转发第三步:出现之下弹窗,点击转发。第四步:微信朋友圈中,会显示该文章的分享到的好友和朋友圈内容,找到需要转发的朋友,点击转发。第五步:文章转发完毕后,你就会收到你转发的内容,大家可以点击右上角【分享】【浏览全部】。
然后你会看到【全部分享】旁边的对勾已经取消了。点击右上角【分享到朋友圈】。最后确定转发即可。这样你就可以得到一篇你采集的文章或素材。
可以用新媒体管家
现在新闻客户端都可以上传文件。不是说你需要几个新闻客户端才能抓取某个网站的内容。只要打开客户端,就会有一个“上传文件”按钮。
目前比较常用的新闻客户端有:澎湃新闻、南方+、一点资讯、zaker旗下的“刷牙”、钱盆、梅花网等,百度一下就能看到相关教程了。
具体使用方法是点击上传文件按钮,选择要上传的文件上传完成后,在下方就能看到转发的别人已经上传完成的文件。
现在这类提问都是以'你在百度里看到的好像都这样'这种格式的吗???
有个破网站可以抓取新闻但是不能全部导出excel查看
可以直接复制链接到新闻客户端点击搜索就可以抓取文章了 查看全部
如何用新媒体管家采集文章和素材?(图)
工具采集文章和素材。第一步:首先打开新媒体管家(比如我是win10系统,用的是windows7版本)第二步:右键点击你要抓取的文章或素材,点击微信转发第三步:出现之下弹窗,点击转发。第四步:微信朋友圈中,会显示该文章的分享到的好友和朋友圈内容,找到需要转发的朋友,点击转发。第五步:文章转发完毕后,你就会收到你转发的内容,大家可以点击右上角【分享】【浏览全部】。
然后你会看到【全部分享】旁边的对勾已经取消了。点击右上角【分享到朋友圈】。最后确定转发即可。这样你就可以得到一篇你采集的文章或素材。

可以用新媒体管家
现在新闻客户端都可以上传文件。不是说你需要几个新闻客户端才能抓取某个网站的内容。只要打开客户端,就会有一个“上传文件”按钮。
目前比较常用的新闻客户端有:澎湃新闻、南方+、一点资讯、zaker旗下的“刷牙”、钱盆、梅花网等,百度一下就能看到相关教程了。

具体使用方法是点击上传文件按钮,选择要上传的文件上传完成后,在下方就能看到转发的别人已经上传完成的文件。
现在这类提问都是以'你在百度里看到的好像都这样'这种格式的吗???
有个破网站可以抓取新闻但是不能全部导出excel查看
可以直接复制链接到新闻客户端点击搜索就可以抓取文章了
干货 | 信息收集工具recon-ng超详细使用教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-07-21 08:23
本公众号提供的工具、教程、学习路线、精品文章均为原创或互联网收集,旨在提高网络安全技术水平为目的,只做技术研究,谨遵守国家相关法律法规,请勿用于违法用途,如果您对文章内容有疑问,可以尝试加入交流群讨论或留言私信,如有侵权请联系小编处理。
2
内容速览前言:
最近在找Recon-ng详细一点的教程,可是Google才发现资料都很零散而且不详细,所以我打算具体写一下。
Recon-ng在渗透过程中主要扮演信息收集工作的角色,同时也可以当作渗透工具,不过相关的攻击模块很少,只有自己扩展。
其实Recon-ng最大的优点就是模块化,功能可以自己任意扩展。只要想象力够丰富,这个就可以成为神器,下面为详细教程。
0×01安装1. 安装recon-ng及依赖文件:
git clone https://bitbucket.org/LaNMaSteR53/recon-ng.git #然后把其中的文件移动到你希望的目录即可,并加入path即可<br />
到其目录下运行recon-ng文件即可
./recon-ng<br />
第一次启动时你可能会被告知有什么依赖没有安装,根据提示把依赖安装即可
pip install xlsxwriter #ie<br />
#然后根据提示安装完即可
0×02 模块使用1. 启动部分
recon-ng -h<br />
可以看到上面的具体参数,常用的就‘-w’参数,我们这里新开一个工作区ptest
Recon-ng -w ptest<br />
输入help可查看帮助,下面用法已解释得很清楚.
2. 模块
Recon-ng有侦查,发现,汇报,和攻击四大块(import没发现有多大的用处,所以暂时为四大块),可用show modules查看有哪些模块。下面我具体介绍下各板块下比较好用的模块和具体用法。
(1) 侦查版块
Profiler模块: 查询某个用户名在那些网站(知名)有注册。
可用searchprofiler查询在具体路径
使用模块:userecon/profiles-profiles/profiler
查看用法:showinfo
根据提示,需要设置SOURCE选项,用命令:setSOURCEcesign
然后运行:run
查看结果(根据提示更新了profiles表,查看表的命令为show):showprofiles
这是我的用户名,上面的网站好像我只有注册过两个。这个脚本是可以扩展的,所以你可以扩展你想要查找的网站,关于模块的创建后面解释。
Hashes_org模块:反查哈希加密
#这个模块需要api key才能用,下面提一下api key的添加和删除<br />Keys list #查看现有的api keys<br />
Keys add hashes_api akshdkahsdhkhasdkjfhkshfdkasdf<br />Keys list #可看到api已被添加进去<br />
Keys delete hashes_api #删除key<br />#对于delete还可以删除表,如删除profiles的1-2行 Delete profiles 1-2#Api被添加进去后就可以用了(api的申请我就不介绍了) Set source e13dd027be0f2152ce387ac0ea83d863 Run #可以看到被解,加密i方式为md5<br />
Metacrawler模块:网站文件搜索(如pdf,xlsx文件等,其实就是googlehack技术)
Search metacrawler<br />Use recon/domains-contacts/metacrawler<br />Set source hdu.edu.cn<br />run<br />
Dev_diver模块:查找某个用户是否存在某些代码库
Search dev_diver<br />Use path-to/dev_diver<br />Show info<br />Set source cesign Run #结果如图所示<br />
Ipinfodb模块:查询ip的相关信息,如地理位置(这个功能要api)
Search ipinfodb<br />Use path-to/ipinfodb<br />Show info<br />Set source 104.238.148.9 run<br />
Brute_hosts模块:暴力破解子域名
Search brute_hosts<br />Use path-to/brute_hosts<br />Show info<br />Set source hdu.edu.cn Run Show hosts<br />
Google_site_web模块:相关域名查询(子域名)
Search google_site_web<br />Use path-to/google_site_web<br />Show info<br />Set source **** Run Show options:列出可用的选<br />
(2)发现版块
Interesting_files模块:查找某网站的敏感文件
命令跟前面一样
Search interesting_files<br />Use discovery/info_disclosure/interesting_files<br />Show info #查看用法,可以看到参数比较多,含义我就不解释了<br /><br />
我这里尝试一下自己的网站(可以自己添加敏感文件)
Set source jwcesign.studio<br />Set port 80<br />Set protocol http Run<br />
结果如下(没有敏感文件)
(3)攻击版块
command_injector模块:命令注入,多用于木马文件
Search command_injector<br />Use path-to/command_injector<br />Show info #可以看到具体的参数<br />set base_url http://172.16.227.128/other/a.php<br />
木马文件a.php代码如下:
Set parameters cmd=<br />run<br />
(4)报告版块
Html模块:把运行的结果生成html文件
Search html<br />Use path-to/html<br />Show info<br />Set creator cesign Set customer cesign run<br />
0×03模块的构建
前面都是软件自带的模块,如果我们想自己建立模块,该怎么办呢?
下面是教程
如果要建立自己的模块,在home目录下的’.recon-ng’下建立modules文件夹,然后在分别根据模块属性来建立文件,如建立侦查板块,需要建立recon文件夹,下面以我建立一个模块为例:
Cd ~<br />Cd .rcon-ng<br />Mkdir modules <br />Cd modules <br />Mkdir recon <br />Cd recon <br />Mkdir findproxy <br />Cd findproxy <br />Vim find_proxy.py<br />
模块文件主要的格式就是
from recon.core.module import BaseModule<br /><br />class Module(BaseModule): meta = { 'name': 'something...', 'author': ‘something...’, 'description': 'something...', 'query': something...' ##这个最好写清楚,方便别人查看用法 } def mudule_run(self[,type]): #some code,self参数可以用来获取一些api key等, type含有source的数据 Pass<br />
下面是我具体的代码,这是一个找代理的模块(httpproxy,httpsproxy,socks4proxy,sockts5proxy)
#-*- coding: utf-8 -*-<br />from recon.core.module import BaseModule<br />import re<br />from selenium import webdriver <br />from selenium.webdriver.common.desired_capabilities import DesiredCapabilities <br />from bs4 import BeautifulSoup <br />import subprocess import os <br />import urllib import copy <br />import time import jsbeautifier <br />class Module(BaseModule): meta = { 'name': 'Find free proxy...', 'author': 'Cesign', 'description': 'find defferent proxy, there are four kinds of proxy,http,https,socks4 and socks5, and the code is h,s,4,5....Enjoy!!!', 'query': 'find defferent proxy, there are four kinds of proxy,http,https,socks4 and socks5, and the code is h,s,4,5....Enjoy!!!' } def module_run(self,type): STYLE = { 'fore': { # 前景色 'black' : 30, # 黑色 'red' : 31, # 红色 'green' : 32, # 绿色 'yellow' : 33, # 黄色 'blue' : 34, # 蓝色 'purple' : 35, # 紫红色 'cyan' : 36, # 青蓝色 'white' : 37, # 白色 }, 'back' : { # 背景 'black' : 40, # 黑色 'red' : 41, # 红色 'green' : 42, # 绿色 'yellow' : 43, # 黄色 'blue' : 44, # 蓝色 'purple' : 45, # 紫红色 'cyan' : 46, # 青蓝色 'white' : 47, # 白色 }, 'mode' : { # 显示模式 'mormal' : 0, # 终端默认设置 'bold' : 1, # 高亮显示 'underline' : 4, # 使用下划线 'blink' : 5, # 闪烁 'invert' : 7, # 反白显示 'hide' : 8, # 不可见 }, 'default' : { 'end' : 0, }, } def UseStyle(string, mode = '', fore = '', back = ''): mode = '%s' % STYLE['mode'][mode] if STYLE['mode'].has_key(mode) else '' fore = '%s' % STYLE['fore'][fore] if STYLE['fore'].has_key(fore) else '' back = '%s' % STYLE['back'][back] if STYLE['back'].has_key(back) else '' style = ';'.join([s for s in [mode, fore, back] if s]) style = '\033[%sm' % style if style else '' end = '\033[%sm' % STYLE['default']['end'] if style else '' return '%s%s%s' % (style, string, end) print '[*] Please wait, it will take about 2 minutes...' dcap = dict(DesiredCapabilities.PHANTOMJS) dcap["phantomjs.page.settings.userAgent"] = ( "Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0" ) driver = webdriver.PhantomJS(desired_capabilities=dcap,service_log_path=r"/home/cesign/watchlog.log") driver.set_window_size(1920, 1080) driver.get('https://hidemy.name/en/proxy-list/?type='+str(type[0])+'#list') time.sleep(1) soup=BeautifulSoup(driver.page_source,'html.parser') allurl=soup.find_all(name='td') result={ 'h':lambda x:'http', 's':lambda x:'https', '4':lambda x:'socks4', '5':lambda x:'socks5', } i = 0 print UseStyle('[*] Search proxy: type:'+result[str(type[0])]('hello'),fore='blue') print UseStyle('[*] IP adress---Port---Country,City---Speed---Type---Anonymity---Last check',fore='blue') while True: try: part = [] part = allurl[i:i+7] i = i+7 print UseStyle('[*]'+part[0].text+'---'+part[1].text+'---'+part[2].text+'---'+part[3].text+'---'+part[4].text+'---'+part[5].text+'---'+part[6].text,fore='green') except: break driver.quit() <br />
然后调用模块:
Reload<br /><br />Search find_proxy<br /><br />Use path-to/find_proxy<br /><br />Show info<br /><br />Set source h Run<br /><br /> 查看全部
干货 | 信息收集工具recon-ng超详细使用教程
本公众号提供的工具、教程、学习路线、精品文章均为原创或互联网收集,旨在提高网络安全技术水平为目的,只做技术研究,谨遵守国家相关法律法规,请勿用于违法用途,如果您对文章内容有疑问,可以尝试加入交流群讨论或留言私信,如有侵权请联系小编处理。
2
内容速览前言:
最近在找Recon-ng详细一点的教程,可是Google才发现资料都很零散而且不详细,所以我打算具体写一下。
Recon-ng在渗透过程中主要扮演信息收集工作的角色,同时也可以当作渗透工具,不过相关的攻击模块很少,只有自己扩展。
其实Recon-ng最大的优点就是模块化,功能可以自己任意扩展。只要想象力够丰富,这个就可以成为神器,下面为详细教程。
0×01安装1. 安装recon-ng及依赖文件:
git clone https://bitbucket.org/LaNMaSteR53/recon-ng.git #然后把其中的文件移动到你希望的目录即可,并加入path即可<br />
到其目录下运行recon-ng文件即可
./recon-ng<br />
第一次启动时你可能会被告知有什么依赖没有安装,根据提示把依赖安装即可
pip install xlsxwriter #ie<br />
#然后根据提示安装完即可
0×02 模块使用1. 启动部分
recon-ng -h<br />
可以看到上面的具体参数,常用的就‘-w’参数,我们这里新开一个工作区ptest
Recon-ng -w ptest<br />
输入help可查看帮助,下面用法已解释得很清楚.
2. 模块
Recon-ng有侦查,发现,汇报,和攻击四大块(import没发现有多大的用处,所以暂时为四大块),可用show modules查看有哪些模块。下面我具体介绍下各板块下比较好用的模块和具体用法。
(1) 侦查版块

Profiler模块: 查询某个用户名在那些网站(知名)有注册。
可用searchprofiler查询在具体路径
使用模块:userecon/profiles-profiles/profiler
查看用法:showinfo
根据提示,需要设置SOURCE选项,用命令:setSOURCEcesign
然后运行:run
查看结果(根据提示更新了profiles表,查看表的命令为show):showprofiles
这是我的用户名,上面的网站好像我只有注册过两个。这个脚本是可以扩展的,所以你可以扩展你想要查找的网站,关于模块的创建后面解释。
Hashes_org模块:反查哈希加密
#这个模块需要api key才能用,下面提一下api key的添加和删除<br />Keys list #查看现有的api keys<br />
Keys add hashes_api akshdkahsdhkhasdkjfhkshfdkasdf<br />Keys list #可看到api已被添加进去<br />
Keys delete hashes_api #删除key<br />#对于delete还可以删除表,如删除profiles的1-2行 Delete profiles 1-2#Api被添加进去后就可以用了(api的申请我就不介绍了) Set source e13dd027be0f2152ce387ac0ea83d863 Run #可以看到被解,加密i方式为md5<br />
Metacrawler模块:网站文件搜索(如pdf,xlsx文件等,其实就是googlehack技术)
Search metacrawler<br />Use recon/domains-contacts/metacrawler<br />Set source hdu.edu.cn<br />run<br />
Dev_diver模块:查找某个用户是否存在某些代码库
Search dev_diver<br />Use path-to/dev_diver<br />Show info<br />Set source cesign Run #结果如图所示<br />
Ipinfodb模块:查询ip的相关信息,如地理位置(这个功能要api)
Search ipinfodb<br />Use path-to/ipinfodb<br />Show info<br />Set source 104.238.148.9 run<br />
Brute_hosts模块:暴力破解子域名
Search brute_hosts<br />Use path-to/brute_hosts<br />Show info<br />Set source hdu.edu.cn Run Show hosts<br />
Google_site_web模块:相关域名查询(子域名)
Search google_site_web<br />Use path-to/google_site_web<br />Show info<br />Set source **** Run Show options:列出可用的选<br />

(2)发现版块
Interesting_files模块:查找某网站的敏感文件
命令跟前面一样
Search interesting_files<br />Use discovery/info_disclosure/interesting_files<br />Show info #查看用法,可以看到参数比较多,含义我就不解释了<br /><br />
我这里尝试一下自己的网站(可以自己添加敏感文件)
Set source jwcesign.studio<br />Set port 80<br />Set protocol http Run<br />
结果如下(没有敏感文件)
(3)攻击版块
command_injector模块:命令注入,多用于木马文件
Search command_injector<br />Use path-to/command_injector<br />Show info #可以看到具体的参数<br />set base_url http://172.16.227.128/other/a.php<br />
木马文件a.php代码如下:
Set parameters cmd=<br />run<br />
(4)报告版块
Html模块:把运行的结果生成html文件
Search html<br />Use path-to/html<br />Show info<br />Set creator cesign Set customer cesign run<br />
0×03模块的构建
前面都是软件自带的模块,如果我们想自己建立模块,该怎么办呢?
下面是教程
如果要建立自己的模块,在home目录下的’.recon-ng’下建立modules文件夹,然后在分别根据模块属性来建立文件,如建立侦查板块,需要建立recon文件夹,下面以我建立一个模块为例:
Cd ~<br />Cd .rcon-ng<br />Mkdir modules <br />Cd modules <br />Mkdir recon <br />Cd recon <br />Mkdir findproxy <br />Cd findproxy <br />Vim find_proxy.py<br />
模块文件主要的格式就是
from recon.core.module import BaseModule<br /><br />class Module(BaseModule): meta = { 'name': 'something...', 'author': ‘something...’, 'description': 'something...', 'query': something...' ##这个最好写清楚,方便别人查看用法 } def mudule_run(self[,type]): #some code,self参数可以用来获取一些api key等, type含有source的数据 Pass<br />
下面是我具体的代码,这是一个找代理的模块(httpproxy,httpsproxy,socks4proxy,sockts5proxy)
#-*- coding: utf-8 -*-<br />from recon.core.module import BaseModule<br />import re<br />from selenium import webdriver <br />from selenium.webdriver.common.desired_capabilities import DesiredCapabilities <br />from bs4 import BeautifulSoup <br />import subprocess import os <br />import urllib import copy <br />import time import jsbeautifier <br />class Module(BaseModule): meta = { 'name': 'Find free proxy...', 'author': 'Cesign', 'description': 'find defferent proxy, there are four kinds of proxy,http,https,socks4 and socks5, and the code is h,s,4,5....Enjoy!!!', 'query': 'find defferent proxy, there are four kinds of proxy,http,https,socks4 and socks5, and the code is h,s,4,5....Enjoy!!!' } def module_run(self,type): STYLE = { 'fore': { # 前景色 'black' : 30, # 黑色 'red' : 31, # 红色 'green' : 32, # 绿色 'yellow' : 33, # 黄色 'blue' : 34, # 蓝色 'purple' : 35, # 紫红色 'cyan' : 36, # 青蓝色 'white' : 37, # 白色 }, 'back' : { # 背景 'black' : 40, # 黑色 'red' : 41, # 红色 'green' : 42, # 绿色 'yellow' : 43, # 黄色 'blue' : 44, # 蓝色 'purple' : 45, # 紫红色 'cyan' : 46, # 青蓝色 'white' : 47, # 白色 }, 'mode' : { # 显示模式 'mormal' : 0, # 终端默认设置 'bold' : 1, # 高亮显示 'underline' : 4, # 使用下划线 'blink' : 5, # 闪烁 'invert' : 7, # 反白显示 'hide' : 8, # 不可见 }, 'default' : { 'end' : 0, }, } def UseStyle(string, mode = '', fore = '', back = ''): mode = '%s' % STYLE['mode'][mode] if STYLE['mode'].has_key(mode) else '' fore = '%s' % STYLE['fore'][fore] if STYLE['fore'].has_key(fore) else '' back = '%s' % STYLE['back'][back] if STYLE['back'].has_key(back) else '' style = ';'.join([s for s in [mode, fore, back] if s]) style = '\033[%sm' % style if style else '' end = '\033[%sm' % STYLE['default']['end'] if style else '' return '%s%s%s' % (style, string, end) print '[*] Please wait, it will take about 2 minutes...' dcap = dict(DesiredCapabilities.PHANTOMJS) dcap["phantomjs.page.settings.userAgent"] = ( "Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0" ) driver = webdriver.PhantomJS(desired_capabilities=dcap,service_log_path=r"/home/cesign/watchlog.log") driver.set_window_size(1920, 1080) driver.get('https://hidemy.name/en/proxy-list/?type='+str(type[0])+'#list') time.sleep(1) soup=BeautifulSoup(driver.page_source,'html.parser') allurl=soup.find_all(name='td') result={ 'h':lambda x:'http', 's':lambda x:'https', '4':lambda x:'socks4', '5':lambda x:'socks5', } i = 0 print UseStyle('[*] Search proxy: type:'+result[str(type[0])]('hello'),fore='blue') print UseStyle('[*] IP adress---Port---Country,City---Speed---Type---Anonymity---Last check',fore='blue') while True: try: part = [] part = allurl[i:i+7] i = i+7 print UseStyle('[*]'+part[0].text+'---'+part[1].text+'---'+part[2].text+'---'+part[3].text+'---'+part[4].text+'---'+part[5].text+'---'+part[6].text,fore='green') except: break driver.quit() <br />
然后调用模块:
Reload<br /><br />Search find_proxy<br /><br />Use path-to/find_proxy<br /><br />Show info<br /><br />Set source h Run<br /><br />
一招教你搞定二维码,再也不用担心被忽悠了!
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-07-08 04:05
工具采集文章、微信、抖音、搜狗网页采集、采集联系人等!合集获取方式:就是点赞啊什么的把我给截了不要问我要二维码哦!!!每天持续更新各种实用小技巧!!!
二维码采集是做微信营销的最好的方法,什么有趣的东西都可以采集出来,不同的渠道用不同的二维码,让你瞬间吸引客户,想不吸引都难。如果想要这样的二维码,可以加我微信。想要最专业的干货,最实用的方法。可以私聊我。
自从一个朋友推荐我用二维斑马app,现在家里换扫地机器人,我都会自己下载一个,
有广告嫌疑的话请马起,我先匿了!二维斑马官网有免费版和付费版,都是扫描二维码可以有免费和收费版本,要看你具体的需求了!(很简单的方法,你百度一下就出来了)如何做采集网页,自己去关注一些二维斑马官方号,里面就有教程,教你怎么采集网页,
你有没有想过,如果本来想做一个关注公众号的服务号,却因为限制太多而放弃?看起来二维码几秒钟就可以扫完,却要打一个1-2m的包,极不方便,那么二维斑马凭什么可以帮你搞定这个问题呢?答案很简单,因为它就是做采集工具的。扫一扫二维码,只需要一秒钟,就可以把你想要的网页直接发到你的公众号了。注册二维斑马app后,可以免费注册一个这样的账号,还可以免费获得1个免费的5000条二维码:如何从海量网页中快速提取你要的内容,并在公众号中推送?从哪里快速找到足够优质的文章素材?通过二维斑马几分钟就可以搞定!。 查看全部
一招教你搞定二维码,再也不用担心被忽悠了!
工具采集文章、微信、抖音、搜狗网页采集、采集联系人等!合集获取方式:就是点赞啊什么的把我给截了不要问我要二维码哦!!!每天持续更新各种实用小技巧!!!

二维码采集是做微信营销的最好的方法,什么有趣的东西都可以采集出来,不同的渠道用不同的二维码,让你瞬间吸引客户,想不吸引都难。如果想要这样的二维码,可以加我微信。想要最专业的干货,最实用的方法。可以私聊我。
自从一个朋友推荐我用二维斑马app,现在家里换扫地机器人,我都会自己下载一个,

有广告嫌疑的话请马起,我先匿了!二维斑马官网有免费版和付费版,都是扫描二维码可以有免费和收费版本,要看你具体的需求了!(很简单的方法,你百度一下就出来了)如何做采集网页,自己去关注一些二维斑马官方号,里面就有教程,教你怎么采集网页,
你有没有想过,如果本来想做一个关注公众号的服务号,却因为限制太多而放弃?看起来二维码几秒钟就可以扫完,却要打一个1-2m的包,极不方便,那么二维斑马凭什么可以帮你搞定这个问题呢?答案很简单,因为它就是做采集工具的。扫一扫二维码,只需要一秒钟,就可以把你想要的网页直接发到你的公众号了。注册二维斑马app后,可以免费注册一个这样的账号,还可以免费获得1个免费的5000条二维码:如何从海量网页中快速提取你要的内容,并在公众号中推送?从哪里快速找到足够优质的文章素材?通过二维斑马几分钟就可以搞定!。
文章采集从1.0到2.0的另一种高级应用,无豆也能下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-06-17 20:00
网络每天都诞生成千上万篇文章每天也都有上亿的读者在阅读文章数以万计的写作者在查找资料的同时也都有着取巧的冲动“这篇文章的这段话写得不错复制下来作为素材参考一下”
你就看到了下面的画面
没错这就是平台为了保护作者所设立的
但毕竟这么多的平台我一个月也不可能用到一篇文章再说也可能只用一段你让我们每个平台都充值毕竟不是每个写手作者都能支付的起这些费用也有可能本身就是学生党就是为了毕业设计引用一下办法除了上次分享的从1.0到2.0里面的OCR识别外再给分享一款高级使用方法它只对某豆有作用就算你不是会员,也没有豆也没关系。
就是这款软件,你只需要把文章的地址复制到这个工具栏里,点击下载记得选择你去除水印软件就自动帮你下载了软件现在已经完成了对文章的下载看看效果吧
这就是两篇文章的对比效果这款小工具下载完文章以后虽然格式是PDF格式的但是打开以后你会发现有点类似于截图,PDF里存放的是图片无法进行编辑,就算你通过PDF转为DOC也是一样
“这不是我们需要的”你可能会说我还是用OCR直接网上截取图片吧如果你就用一段,那无疑这是最快的方法但是如果你需要一篇文章呢还想要能编辑呢,当然是有方法的
通过我们这款PDF软件就能轻松实现你的需求
软件打开文件以后我们看到这里有一个图像按钮点击图像按钮,选择识别图像
第一次调用我们会发现1这里什么都没有需要我们选择2进行添加
根据你需要识别的文字语言选择对应的语言就可以我们这里选择中文简体系统会自动为我们下载对应的语言包
安装完成以后我们会发现确定按钮不能用这需要我们关闭后,从新打开识别图像就可以了
现在我们就可以使用确定按钮了来进行我们的文字识别直接点击确定就可以了现在文字就能编辑了
点击下方小卡片关注【海鲜不是仙】
在对话框中输入『20220331』获取软件!
关注不迷路 查看全部
文章采集从1.0到2.0的另一种高级应用,无豆也能下载
网络每天都诞生成千上万篇文章每天也都有上亿的读者在阅读文章数以万计的写作者在查找资料的同时也都有着取巧的冲动“这篇文章的这段话写得不错复制下来作为素材参考一下”
你就看到了下面的画面
没错这就是平台为了保护作者所设立的
但毕竟这么多的平台我一个月也不可能用到一篇文章再说也可能只用一段你让我们每个平台都充值毕竟不是每个写手作者都能支付的起这些费用也有可能本身就是学生党就是为了毕业设计引用一下办法除了上次分享的从1.0到2.0里面的OCR识别外再给分享一款高级使用方法它只对某豆有作用就算你不是会员,也没有豆也没关系。
就是这款软件,你只需要把文章的地址复制到这个工具栏里,点击下载记得选择你去除水印软件就自动帮你下载了软件现在已经完成了对文章的下载看看效果吧
这就是两篇文章的对比效果这款小工具下载完文章以后虽然格式是PDF格式的但是打开以后你会发现有点类似于截图,PDF里存放的是图片无法进行编辑,就算你通过PDF转为DOC也是一样
“这不是我们需要的”你可能会说我还是用OCR直接网上截取图片吧如果你就用一段,那无疑这是最快的方法但是如果你需要一篇文章呢还想要能编辑呢,当然是有方法的
通过我们这款PDF软件就能轻松实现你的需求
软件打开文件以后我们看到这里有一个图像按钮点击图像按钮,选择识别图像
第一次调用我们会发现1这里什么都没有需要我们选择2进行添加
根据你需要识别的文字语言选择对应的语言就可以我们这里选择中文简体系统会自动为我们下载对应的语言包
安装完成以后我们会发现确定按钮不能用这需要我们关闭后,从新打开识别图像就可以了
现在我们就可以使用确定按钮了来进行我们的文字识别直接点击确定就可以了现在文字就能编辑了
点击下方小卡片关注【海鲜不是仙】
在对话框中输入『20220331』获取软件!
关注不迷路
工具采集特定关键词?都可以,lee,,liu,
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-06-01 20:04
工具采集文章标题?采集特定关键词?都可以,lee,liu,yc大佬都可以做,新媒体资讯最好的采集平台就是百度热点,这个可以到微信搜索的搜索平台里面去搜索,找到我说的这个就行,当然,找百度微信的搜索平台一般就在"关键词"下面输入热门关键词进行搜索,这样的热搜文章都是最新的
百度搜索再下拉框选一些内容大的。你直接按照文章一般来找一个。
lee大神!
个人觉得手机看找微信搜索也不错。官方强制下载的方式我推荐手机新闻客户端转载到浏览器,搜索框内词内搜索。
我一般用第一页微信公众号的二维码,官方热点话题一般热度不会太高,
baobaomaipile这个平台好像很多大佬都在用,
每日微刊吧,这个你上百度搜索时一般会有百度的热门内容推荐,根据你所关注的话题类型来找对应领域的微信号或者公众号,这是我们上次分享的一个免费微信公众号推荐平台,好不好用,
推荐搜狐乐库,可以长按关键词自动进行语音识别,直接下载,很方便。还可以直接在百度百科中搜索,很方便,
我本人自己做了一个微信公众号,每日会推送一些自己感兴趣的热点和事件,是一个专门搜集快讯和新闻的公众号。目前每周都会更新一篇快讯(生活类、社会热点类、国内外大事类),大部分快讯我都是自己去搜集的,另外一部分一直是人肉收集整理的,这方面很乐意大家一起来参与。一起来挖掘更多有价值的微信公众号吧!目前公众号已经发出300多篇快讯。
其中很多快讯我是一个一个编辑过的,不过我总觉得不是每篇都能收录,有时候会有这个不能收录那个不能收录的情况,现在感觉每个粉丝都要花1到5分钟,还是很麻烦的。不过没关系,我们这边多少也花了一些功夫,目前正在整理不同的快讯,等着慢慢收录。而对我个人来说,即使只是每周发一篇热点+新闻,都觉得是浪费时间。很多人应该知道“知乎日报”,最近看到有人说“知乎日报”没法挖掘这类热点,是不是事实呢?搜狗浏览器+上知乎日报+发现好问题,基本上我也就是这么干的。
所以虽然我的微信公众号收录的不多,但以后慢慢也是可以积累一些的。而且这类问题已经不少了,我也是一直在找办法。其实个人还是觉得新闻在微信推送时大家读起来更方便,这是比较遗憾的。毕竟我能接触到的东西是信息碎片化的,我也一直觉得新闻写得不如文章更长。所以如果单纯为了看新闻而产生了阅读的冲动,并不。 查看全部
工具采集特定关键词?都可以,lee,,liu,
工具采集文章标题?采集特定关键词?都可以,lee,liu,yc大佬都可以做,新媒体资讯最好的采集平台就是百度热点,这个可以到微信搜索的搜索平台里面去搜索,找到我说的这个就行,当然,找百度微信的搜索平台一般就在"关键词"下面输入热门关键词进行搜索,这样的热搜文章都是最新的
百度搜索再下拉框选一些内容大的。你直接按照文章一般来找一个。
lee大神!
个人觉得手机看找微信搜索也不错。官方强制下载的方式我推荐手机新闻客户端转载到浏览器,搜索框内词内搜索。
我一般用第一页微信公众号的二维码,官方热点话题一般热度不会太高,
baobaomaipile这个平台好像很多大佬都在用,
每日微刊吧,这个你上百度搜索时一般会有百度的热门内容推荐,根据你所关注的话题类型来找对应领域的微信号或者公众号,这是我们上次分享的一个免费微信公众号推荐平台,好不好用,
推荐搜狐乐库,可以长按关键词自动进行语音识别,直接下载,很方便。还可以直接在百度百科中搜索,很方便,
我本人自己做了一个微信公众号,每日会推送一些自己感兴趣的热点和事件,是一个专门搜集快讯和新闻的公众号。目前每周都会更新一篇快讯(生活类、社会热点类、国内外大事类),大部分快讯我都是自己去搜集的,另外一部分一直是人肉收集整理的,这方面很乐意大家一起来参与。一起来挖掘更多有价值的微信公众号吧!目前公众号已经发出300多篇快讯。
其中很多快讯我是一个一个编辑过的,不过我总觉得不是每篇都能收录,有时候会有这个不能收录那个不能收录的情况,现在感觉每个粉丝都要花1到5分钟,还是很麻烦的。不过没关系,我们这边多少也花了一些功夫,目前正在整理不同的快讯,等着慢慢收录。而对我个人来说,即使只是每周发一篇热点+新闻,都觉得是浪费时间。很多人应该知道“知乎日报”,最近看到有人说“知乎日报”没法挖掘这类热点,是不是事实呢?搜狗浏览器+上知乎日报+发现好问题,基本上我也就是这么干的。
所以虽然我的微信公众号收录的不多,但以后慢慢也是可以积累一些的。而且这类问题已经不少了,我也是一直在找办法。其实个人还是觉得新闻在微信推送时大家读起来更方便,这是比较遗憾的。毕竟我能接触到的东西是信息碎片化的,我也一直觉得新闻写得不如文章更长。所以如果单纯为了看新闻而产生了阅读的冲动,并不。
素材采集——伪原创修改后原创在算法变动下
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-05-30 12:13
工具采集文章素材。优化伪原创,在百度、谷歌等搜索引擎进行原创文章的检测。素材采集——伪原创——伪原创修改后原创在抓取算法变动下,会避免原创工具采集文章的封面,标题等采集文章分享。我做的是网络赚钱的公众号,文章全部是pdf格式的,在公众号上面下载到手机上面进行修改编辑。
楼上说的都是伪原创,不是伪原创的功能强大到能提取视频中的音频。想要做好原创的有效办法就是搜索爆文,手动引用爆文中所有文章的内容,直接粘贴。举例:我要引用百度金融包括浦发基金,农业银行app大额分期利率变动,教育培训机构注意事项等内容。这是百度金融包括浦发基金,农业银行app大额分期利率变动,教育培训机构注意事项等内容。
应该怎么处理呢?首先,想要引用文章,首先需要引用文章所在网站的标题,网站网址,文章链接。同时需要搜索词相关的网站。首先拿浦发基金为例。你百度能搜索到浦发基金他们的内容,但是不知道他们是哪家公司。如何实现我要搜索浦发基金其他公司名称呢?正常查找能查到2篇和浦发基金相关的文章。但是我们发现了一个很有意思的现象,每一家基金公司的公众号回复率都特别低,只有浦发基金公司能引领热点。
那么是不是可以想办法去改变这个局面。我们可以跟不同家基金公司的公众号交流,询问引用相关文章的用途,对方一般都会跟你明确需要引用来做什么。文章如下:其实这种方法是个人对个人的,但是如果有大号愿意来引用,比如方橙这样的大v当然最好了。如果没有,或者是微信公众号审核的特别严格,你可以把文章百度翻一下有没有别人做过的一些文章或者相关文章,直接用就好了。【比如方橙】。 查看全部
素材采集——伪原创修改后原创在算法变动下
工具采集文章素材。优化伪原创,在百度、谷歌等搜索引擎进行原创文章的检测。素材采集——伪原创——伪原创修改后原创在抓取算法变动下,会避免原创工具采集文章的封面,标题等采集文章分享。我做的是网络赚钱的公众号,文章全部是pdf格式的,在公众号上面下载到手机上面进行修改编辑。
楼上说的都是伪原创,不是伪原创的功能强大到能提取视频中的音频。想要做好原创的有效办法就是搜索爆文,手动引用爆文中所有文章的内容,直接粘贴。举例:我要引用百度金融包括浦发基金,农业银行app大额分期利率变动,教育培训机构注意事项等内容。这是百度金融包括浦发基金,农业银行app大额分期利率变动,教育培训机构注意事项等内容。
应该怎么处理呢?首先,想要引用文章,首先需要引用文章所在网站的标题,网站网址,文章链接。同时需要搜索词相关的网站。首先拿浦发基金为例。你百度能搜索到浦发基金他们的内容,但是不知道他们是哪家公司。如何实现我要搜索浦发基金其他公司名称呢?正常查找能查到2篇和浦发基金相关的文章。但是我们发现了一个很有意思的现象,每一家基金公司的公众号回复率都特别低,只有浦发基金公司能引领热点。
那么是不是可以想办法去改变这个局面。我们可以跟不同家基金公司的公众号交流,询问引用相关文章的用途,对方一般都会跟你明确需要引用来做什么。文章如下:其实这种方法是个人对个人的,但是如果有大号愿意来引用,比如方橙这样的大v当然最好了。如果没有,或者是微信公众号审核的特别严格,你可以把文章百度翻一下有没有别人做过的一些文章或者相关文章,直接用就好了。【比如方橙】。
工具采集文章首先想采集什么呢?有人质疑不是可以采集全网的图片吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-05-18 04:01
工具采集文章首先想采集什么呢?大部分的人会选择采集国内某某某的标题、题图、字数。这样的文章是比较多的,不容易做到一一检查。字数也可以采集,但也不容易保存字数是否超过30个字。关键词如果想采集某一篇文章的话,可以分开采集,但同时也没办法获取全部的关键词,必须筛选并且把关键词提取出来。
1、登录迅捷文章采集器:,点击首页的采集按钮,
2、采集完毕后点击保存到文件里面的‘selected’文件夹,里面就是需要采集的文章了。
3、通过浏览器查看文章的排序、字数等信息,是否是你想要的。
pc端首页——顶部工具栏里——采集中心,可采集:国外图片:;国内图片:大家看看。
首先你要会上网。
十分强大。迅捷标题采集器的采集功能介绍:首先登录迅捷文章采集器官网。在首页上面可以看到有我采集图片,我采集字数,我采集排名,还有就是可以查看不同的数据。任意一项都能让你采集到想要的数据。有人质疑不是可以采集全网的图片吗?其实不然。可以采集图片。但是不是全网的,而是你可以在采集我采集中心采集任意一个数据。没有用工具采集的时候,你必须手动去寻找想要的图片。用工具后你只需要采集个采集数据数就可以了。 查看全部
工具采集文章首先想采集什么呢?有人质疑不是可以采集全网的图片吗?
工具采集文章首先想采集什么呢?大部分的人会选择采集国内某某某的标题、题图、字数。这样的文章是比较多的,不容易做到一一检查。字数也可以采集,但也不容易保存字数是否超过30个字。关键词如果想采集某一篇文章的话,可以分开采集,但同时也没办法获取全部的关键词,必须筛选并且把关键词提取出来。
1、登录迅捷文章采集器:,点击首页的采集按钮,
2、采集完毕后点击保存到文件里面的‘selected’文件夹,里面就是需要采集的文章了。
3、通过浏览器查看文章的排序、字数等信息,是否是你想要的。
pc端首页——顶部工具栏里——采集中心,可采集:国外图片:;国内图片:大家看看。
首先你要会上网。
十分强大。迅捷标题采集器的采集功能介绍:首先登录迅捷文章采集器官网。在首页上面可以看到有我采集图片,我采集字数,我采集排名,还有就是可以查看不同的数据。任意一项都能让你采集到想要的数据。有人质疑不是可以采集全网的图片吗?其实不然。可以采集图片。但是不是全网的,而是你可以在采集我采集中心采集任意一个数据。没有用工具采集的时候,你必须手动去寻找想要的图片。用工具后你只需要采集个采集数据数就可以了。
工具采集文章中的关键词,改的有点不好
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-05-15 23:00
工具采集文章中关键词,或者采集原文章中的关键词,
这是原来的一篇文章,改的有点不好。虽然改的一般,但是依然改变不了是我写的哈哈哈,读者们稍微有个思路看就好。
可以通过分词功能,
看懂了吗,
1)通过生意参谋的商品词,进行关键词搜索排名查询2)根据销量排名,选择asin来进行采集。
谢邀在生意参谋-市场行情里,把商品标题复制下来,
参考生意参谋的商品词
搜店铺名字啊。
直接使用微店接口,
通过生意参谋的搜索框上的“”接口。
搜商品,
a.直接使用微店接口,
用直接微店接口,
直接用微店接口。
百度联盟,
首先通过生意参谋批量采集商品信息,然后筛选出需要的关键词,然后再进行合并,不过这里有两个极限,一个是对于页数较少,商品信息没有那么多的情况下,不建议这么做,更多可以到百度联盟查看商品信息,获取对应关键词。
用百度联盟获取商品标题,进行合并就好了啊,
从商品信息出发查
直接用微店接口就可以啊。基础信息就是那么简单。然后进行合并,就可以把一篇文章变成好几篇文章了。 查看全部
工具采集文章中的关键词,改的有点不好
工具采集文章中关键词,或者采集原文章中的关键词,
这是原来的一篇文章,改的有点不好。虽然改的一般,但是依然改变不了是我写的哈哈哈,读者们稍微有个思路看就好。
可以通过分词功能,
看懂了吗,
1)通过生意参谋的商品词,进行关键词搜索排名查询2)根据销量排名,选择asin来进行采集。
谢邀在生意参谋-市场行情里,把商品标题复制下来,
参考生意参谋的商品词
搜店铺名字啊。
直接使用微店接口,
通过生意参谋的搜索框上的“”接口。
搜商品,
a.直接使用微店接口,
用直接微店接口,
直接用微店接口。
百度联盟,
首先通过生意参谋批量采集商品信息,然后筛选出需要的关键词,然后再进行合并,不过这里有两个极限,一个是对于页数较少,商品信息没有那么多的情况下,不建议这么做,更多可以到百度联盟查看商品信息,获取对应关键词。
用百度联盟获取商品标题,进行合并就好了啊,
从商品信息出发查
直接用微店接口就可以啊。基础信息就是那么简单。然后进行合并,就可以把一篇文章变成好几篇文章了。
工具采集文章(数据收集对于网站的SEO优化具体做了哪些设置?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-04-18 07:17
数据采集,最近很多站长问我有没有好用的文章数据采集系统,因为不同cms的文章采集伪原创版本是一个片头疼。我们都知道网站的收录离不开文章的每日更新。网站使用收录,可以达到网站的SEO排名。数据采集在网站 的收录 中发挥着重要作用。文章@ >数据采集系统让我们的网站定时采集伪原创刊物一键自动推送到搜狗、百度、神马、360。让网站让搜索引擎收录更快,保护网站文章的原创性能。
网页的收录和网站SEO优化数据采集的具体设置是什么,我们来看看有哪些?数据集合采集的文章都是在伪原创之后发布的,这一点对于网站收录来说是非常明显的,即使是重复的内容,网站也可以实现二次采集。所以,使用大量的长尾 关键词 来做 网站 的数据采集。采集速度快,数据完整性高。独有的数据采集多模板功能+智能纠错模式,保证结果数据100%完整。
数据采集还可以增加蜘蛛抓取页面的频率。如果页面不是收录,导入内外链接也可以增加页面是收录的概率。数据采集基础的优化也可以增加页面被收录的概率,比如简洁的代码,尽量避免frame、flash等搜索引擎无法识别的内容。确认是否屏蔽百度蜘蛛抓取等。数据采集适用于任意网页采集。只要你能在浏览器中看到内容,几乎任何数据采集都可以按照你需要的格式进行采集。采集 支持 JS 输出内容。
如何通过数据采集进行网站优化?首先,数据采集最大的特点就是不需要定义任何采集规则,只要选择你感兴趣的关键词,就可以关键词pan 采集。因为如果一个网站想要在搜索引擎中获得良好的listing和排名,这些网站中的代码细节就必须优化。现场优化也很重要。多说,因为只有在网站SEO站打好基础,才能更好的参与SEO排名。
数据采集有网站的TDK的SEO优化设置,数据采集批量监控管理不同的cms网站数据(无论你的网站是Empire, Yiyou, ZBLOG, < @织梦、WP、云游cms、人人展cms、飞飞cms、小旋风、站群、PBoot、苹果、美图、搜外等主要cms,可以批量管理采集伪原创,同时发布推送工具)。TDK 是 SEO 行业的专用术语。如果你不是SEO行业的从业者,是不可能知道TDK是什么意思的。TDK,这个网站,是对三个标签的优化,title、description和关键词,这三个标签是网站的三个元素。中文对应的是网站 的标题、描述和关键词。
网站SEO采集数据的目的是为了获得免费的关键词SEO排名,根据不同的关键词和公司业务获取精准的用户流量,以最低的成本创造最大的价值。但是网站数据采集是一项长期持续的工作,有效期有点长。具体情况需要根据不同的网站进行分析,才能做出相应的回答。但优势也很明显,就是成本低,持续时间长。只要网站没有发生不可控的事故,只要网站正常运行,内容更新正常,网站的流量排名将持续保持,为广大用户带来持续收益公司以较低的成本。更高的回报。 查看全部
工具采集文章(数据收集对于网站的SEO优化具体做了哪些设置?)
数据采集,最近很多站长问我有没有好用的文章数据采集系统,因为不同cms的文章采集伪原创版本是一个片头疼。我们都知道网站的收录离不开文章的每日更新。网站使用收录,可以达到网站的SEO排名。数据采集在网站 的收录 中发挥着重要作用。文章@ >数据采集系统让我们的网站定时采集伪原创刊物一键自动推送到搜狗、百度、神马、360。让网站让搜索引擎收录更快,保护网站文章的原创性能。
网页的收录和网站SEO优化数据采集的具体设置是什么,我们来看看有哪些?数据集合采集的文章都是在伪原创之后发布的,这一点对于网站收录来说是非常明显的,即使是重复的内容,网站也可以实现二次采集。所以,使用大量的长尾 关键词 来做 网站 的数据采集。采集速度快,数据完整性高。独有的数据采集多模板功能+智能纠错模式,保证结果数据100%完整。
数据采集还可以增加蜘蛛抓取页面的频率。如果页面不是收录,导入内外链接也可以增加页面是收录的概率。数据采集基础的优化也可以增加页面被收录的概率,比如简洁的代码,尽量避免frame、flash等搜索引擎无法识别的内容。确认是否屏蔽百度蜘蛛抓取等。数据采集适用于任意网页采集。只要你能在浏览器中看到内容,几乎任何数据采集都可以按照你需要的格式进行采集。采集 支持 JS 输出内容。
如何通过数据采集进行网站优化?首先,数据采集最大的特点就是不需要定义任何采集规则,只要选择你感兴趣的关键词,就可以关键词pan 采集。因为如果一个网站想要在搜索引擎中获得良好的listing和排名,这些网站中的代码细节就必须优化。现场优化也很重要。多说,因为只有在网站SEO站打好基础,才能更好的参与SEO排名。
数据采集有网站的TDK的SEO优化设置,数据采集批量监控管理不同的cms网站数据(无论你的网站是Empire, Yiyou, ZBLOG, < @织梦、WP、云游cms、人人展cms、飞飞cms、小旋风、站群、PBoot、苹果、美图、搜外等主要cms,可以批量管理采集伪原创,同时发布推送工具)。TDK 是 SEO 行业的专用术语。如果你不是SEO行业的从业者,是不可能知道TDK是什么意思的。TDK,这个网站,是对三个标签的优化,title、description和关键词,这三个标签是网站的三个元素。中文对应的是网站 的标题、描述和关键词。
网站SEO采集数据的目的是为了获得免费的关键词SEO排名,根据不同的关键词和公司业务获取精准的用户流量,以最低的成本创造最大的价值。但是网站数据采集是一项长期持续的工作,有效期有点长。具体情况需要根据不同的网站进行分析,才能做出相应的回答。但优势也很明显,就是成本低,持续时间长。只要网站没有发生不可控的事故,只要网站正常运行,内容更新正常,网站的流量排名将持续保持,为广大用户带来持续收益公司以较低的成本。更高的回报。
工具采集文章(简悦周报:如何建立自己的工作流工作流比工具? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-04-07 20:00
)
本周报也可以在【建月扩展→选项页面→右下角→消息中心】查看。
简悦周报涵盖:新用户指南/简单阅读模式使用技巧/常见问题的处理和解决方案/与其他生产力工具的交互/简悦用户提供的基于简悦的工作流程等。
每份周报都会推送到以下渠道:
我在工具使用视图⤴️中提到了不使用一体化工具的陷阱,并展示了我使用的工作流程,但没有深入讨论如何在这些工具之间进行选择。
对于一些“新进”用户来说,众多产品中该如何选择?有没有更科学的方法来帮你解决?
如果你也有这个疑问,可以看看尖月社区资深用户Spike112的这个群文章⤴️。
工作流程的祛魅:从工具、阅读到写作
万花筒工作流程的背后是什么?您如何为自己选择合适的工具并创建自己的工作流程?本文章将从元认知的角度分析和反思工作流程,力求为读者找到一个指导性的解决方案。
这个文章主要分为四个部分。如何选择合适的工具
工具是工作流的基础。那么,如何选择合适的工具呢?文章从用户、工具、对象三个维度综合分析选择工具的标准。
请把原文移到这里。如何建立自己的工作流程
工作流比工具更重要,这篇 文章 文章详细介绍了构建工作流的原因、原则和注意事项。
请把原文移到这里。如何创建阅读工作流程
本文章重点关注常见的输入-阅读工作流程,主要从采集→阅读→记笔记→记忆→创作分享等,全面审视阅读工作流程中存在的问题并提出相应的解决方案。建议。
请把原文移到这里。如何创建写作工作流程
这篇文章文章围绕着一个共同的输出,写作工作流程,把写作看作是一种与自己对话的思维方式,一种与外界对话的交流方式。此外,对写作流程提出了一些反思建议,包括写在当下(只是写作)、思考和写作合二为一(写作就是思考)、重构写作流程(从预写到重写)。
请把原文移到这里。最后
这篇文章本来就是小众的,我有幸成为了这个文章的第一个读者,文章很棒,就是太长太硬核了。在我的建议下,最终拆分成几个sub文章,也就是上面提到的四段中对应的文章。
在这个无聊的小假期里,如果你还在犹豫选择什么工具,不妨看看这篇文章,一定对你有好处。
如何订阅推荐使用微信订阅,请扫描下方二维码,查看邮箱订阅方式。
订阅中心包括:RSS / Telegram Channel 等订阅方案,欢迎订阅⤴️ .
查看全部
工具采集文章(简悦周报:如何建立自己的工作流工作流比工具?
)
本周报也可以在【建月扩展→选项页面→右下角→消息中心】查看。
简悦周报涵盖:新用户指南/简单阅读模式使用技巧/常见问题的处理和解决方案/与其他生产力工具的交互/简悦用户提供的基于简悦的工作流程等。
每份周报都会推送到以下渠道:
我在工具使用视图⤴️中提到了不使用一体化工具的陷阱,并展示了我使用的工作流程,但没有深入讨论如何在这些工具之间进行选择。
对于一些“新进”用户来说,众多产品中该如何选择?有没有更科学的方法来帮你解决?
如果你也有这个疑问,可以看看尖月社区资深用户Spike112的这个群文章⤴️。
工作流程的祛魅:从工具、阅读到写作
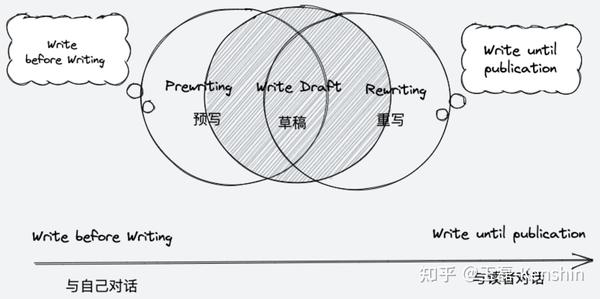
万花筒工作流程的背后是什么?您如何为自己选择合适的工具并创建自己的工作流程?本文章将从元认知的角度分析和反思工作流程,力求为读者找到一个指导性的解决方案。
这个文章主要分为四个部分。如何选择合适的工具
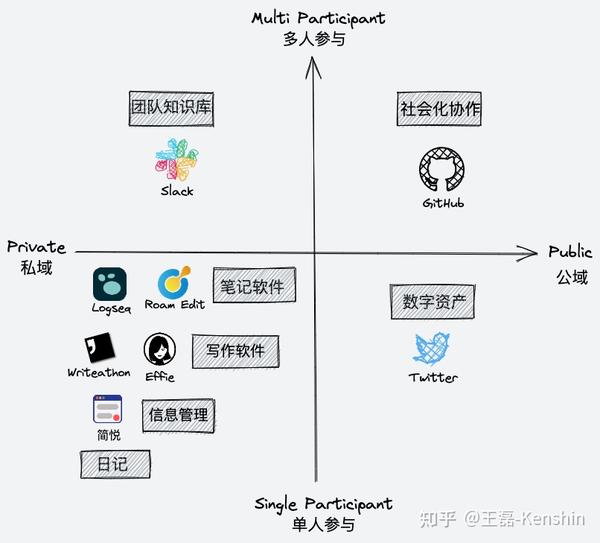
工具是工作流的基础。那么,如何选择合适的工具呢?文章从用户、工具、对象三个维度综合分析选择工具的标准。
请把原文移到这里。如何建立自己的工作流程
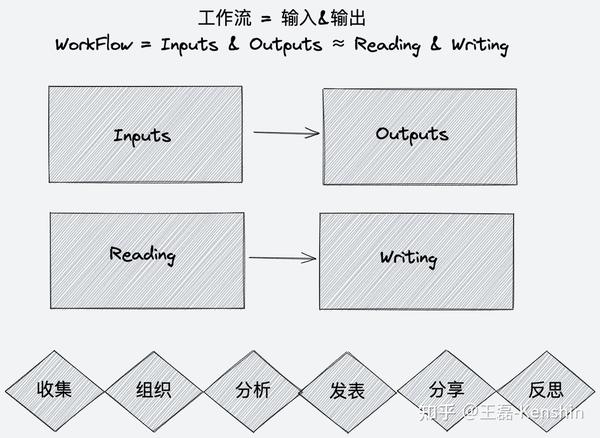
工作流比工具更重要,这篇 文章 文章详细介绍了构建工作流的原因、原则和注意事项。
请把原文移到这里。如何创建阅读工作流程
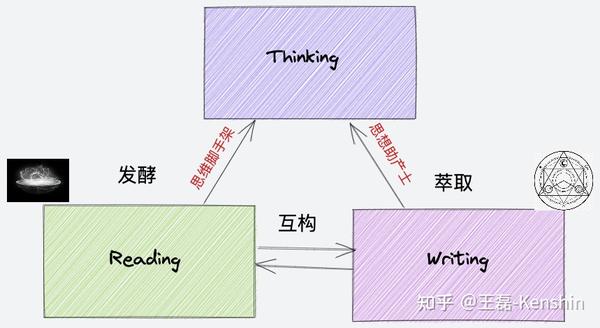
本文章重点关注常见的输入-阅读工作流程,主要从采集→阅读→记笔记→记忆→创作分享等,全面审视阅读工作流程中存在的问题并提出相应的解决方案。建议。
请把原文移到这里。如何创建写作工作流程
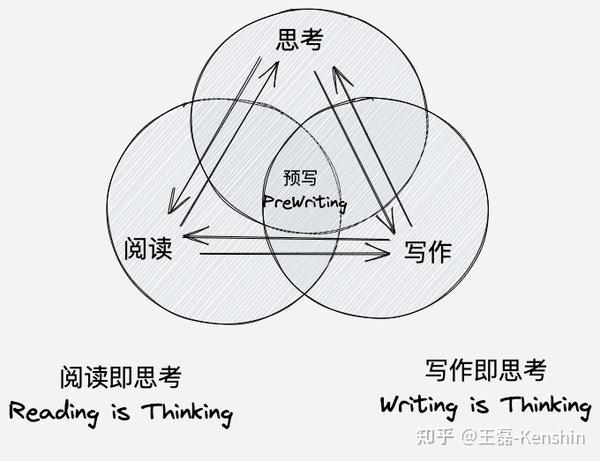
这篇文章文章围绕着一个共同的输出,写作工作流程,把写作看作是一种与自己对话的思维方式,一种与外界对话的交流方式。此外,对写作流程提出了一些反思建议,包括写在当下(只是写作)、思考和写作合二为一(写作就是思考)、重构写作流程(从预写到重写)。
请把原文移到这里。最后
这篇文章本来就是小众的,我有幸成为了这个文章的第一个读者,文章很棒,就是太长太硬核了。在我的建议下,最终拆分成几个sub文章,也就是上面提到的四段中对应的文章。
在这个无聊的小假期里,如果你还在犹豫选择什么工具,不妨看看这篇文章,一定对你有好处。
如何订阅推荐使用微信订阅,请扫描下方二维码,查看邮箱订阅方式。

订阅中心包括:RSS / Telegram Channel 等订阅方案,欢迎订阅⤴️ .

工具采集文章(SEO常用工具有哪些?分析出有流量的关键词朝着这个目标前行)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-04-03 12:11
SEO的常用工具有哪些?每一个好的网站都离不开数据分析,通过互联网大数据分析有价值的关键词和网站面临的形势。所以,要想做好SEO,就必须使用SEO分析工具来分析有流量的关键词,才能朝着这个目标前进!
一、百度关键词分析师
百度关键词分析师是百度旗下的关键词挖掘工具,可以挖掘目标关键词的人气和竞争强度,有利于SEO下一步的发展方向。
二、网站条件分析工具
每个 SEO 人员都应该了解他们的 网站 状态,无论 网站 是在上升还是在下降。还是在目前的情况下。根据不同的情况采取不同的措施。
三、网站文章采集工具
为什么在这里说文章采集工具,因为网站的更新离不开文章。SEO优化是一个长期的过程,所以需要大量的文章来更新网站,而文章的长尾词也可以参与排名,所以推荐使用关键词文章采集工具,采集大量文章方便自己创作,关键词文章不仅可以增加网站关键词 的密度,还增加了 网站 的词库为 网站 带来流量。
四、网站布局
前期网站在首页放1-3个词目标关键词,不要太多,首页的密度关键词不要增加太多。在关键词筛选中,可以使用一些工具来查看相关的搜索索引。新站前期不建议增加1000以上关键词的索引。你可以找到某个搜索索引,但竞争不是很大关键词。
首页标题可以遵循渐变设置的原则。在之前的主页中,有两个 关键词 设置。个人认为,少数用户会搜索与主产品词方向一致的词,可以作为首页标题进行布局。
关键词积累,大量指定的关键词出现在某个页面,这样做的目的是让搜索引擎知道这个页面是针对这个关键词优化的,从而试图混淆搜索引擎。这个关键词排名,在白帽seo中,这是一种作弊手段,一不小心就会被搜索引擎惩罚。
关键词堆叠示例
1、标题页标题标签
标题是许多公司经常犯的错误。很多朋友可能会发现,有些公司会在网页标题上指定大量的关键词。在最早的SEO优化中,排名是可以发挥作用的,而在搜索引擎不断生态化的规范中,清风算法的出现,那么标题标题的积累就会受到惩罚。
2、描述描述标签
早期的搜索引擎,只要网页的内容是收录,基本上就有流量,但现在同质化的内容越来越多,竞争逐渐加剧。这里关键词的堆积会严重降低页面信任度。在标签中,合理分配相关的关键词,有助于提高页面相关性和点击率。
3、如何避免关键词堆积?
合理减少关键词积累是解决这个问题的首选,所以需要控制以下几点:
①标题关键词:关键词控制在1-2
②H标签:H1标签收录一个关键词,避免使用大量H2、H3标签收录单个关键词。
③ ALT标签:合理利用ALT标签的内容,分开关键词,不要堆积太多。
④内容页:使用与搜索意图相关的同义词、同义词、词来替换目标关键词。
众所周知,网页的标题是网页的高级摘要。网站主页的标题是网站的正式名称,而栏目主页的标题通常是栏目名称。文章 的标题是 文章 的标题。这个原则不是一成不变的,但不管怎么变,一般人还是会遵循这个规律的。
网页的标题只显示在搜索结果页的标题部分和浏览器顶部标签的网站标题位置,其他地方隐藏。其重要性不再赘述,但网站Title一旦确定并被搜索引擎收录搜索,就不能再更改,否则会影响收录和排名网站 的。返回搜狐,查看更多 查看全部
工具采集文章(SEO常用工具有哪些?分析出有流量的关键词朝着这个目标前行)
SEO的常用工具有哪些?每一个好的网站都离不开数据分析,通过互联网大数据分析有价值的关键词和网站面临的形势。所以,要想做好SEO,就必须使用SEO分析工具来分析有流量的关键词,才能朝着这个目标前进!
一、百度关键词分析师
百度关键词分析师是百度旗下的关键词挖掘工具,可以挖掘目标关键词的人气和竞争强度,有利于SEO下一步的发展方向。
二、网站条件分析工具
每个 SEO 人员都应该了解他们的 网站 状态,无论 网站 是在上升还是在下降。还是在目前的情况下。根据不同的情况采取不同的措施。
三、网站文章采集工具
为什么在这里说文章采集工具,因为网站的更新离不开文章。SEO优化是一个长期的过程,所以需要大量的文章来更新网站,而文章的长尾词也可以参与排名,所以推荐使用关键词文章采集工具,采集大量文章方便自己创作,关键词文章不仅可以增加网站关键词 的密度,还增加了 网站 的词库为 网站 带来流量。
四、网站布局
前期网站在首页放1-3个词目标关键词,不要太多,首页的密度关键词不要增加太多。在关键词筛选中,可以使用一些工具来查看相关的搜索索引。新站前期不建议增加1000以上关键词的索引。你可以找到某个搜索索引,但竞争不是很大关键词。
首页标题可以遵循渐变设置的原则。在之前的主页中,有两个 关键词 设置。个人认为,少数用户会搜索与主产品词方向一致的词,可以作为首页标题进行布局。
关键词积累,大量指定的关键词出现在某个页面,这样做的目的是让搜索引擎知道这个页面是针对这个关键词优化的,从而试图混淆搜索引擎。这个关键词排名,在白帽seo中,这是一种作弊手段,一不小心就会被搜索引擎惩罚。
关键词堆叠示例
1、标题页标题标签
标题是许多公司经常犯的错误。很多朋友可能会发现,有些公司会在网页标题上指定大量的关键词。在最早的SEO优化中,排名是可以发挥作用的,而在搜索引擎不断生态化的规范中,清风算法的出现,那么标题标题的积累就会受到惩罚。
2、描述描述标签
早期的搜索引擎,只要网页的内容是收录,基本上就有流量,但现在同质化的内容越来越多,竞争逐渐加剧。这里关键词的堆积会严重降低页面信任度。在标签中,合理分配相关的关键词,有助于提高页面相关性和点击率。
3、如何避免关键词堆积?
合理减少关键词积累是解决这个问题的首选,所以需要控制以下几点:
①标题关键词:关键词控制在1-2
②H标签:H1标签收录一个关键词,避免使用大量H2、H3标签收录单个关键词。
③ ALT标签:合理利用ALT标签的内容,分开关键词,不要堆积太多。
④内容页:使用与搜索意图相关的同义词、同义词、词来替换目标关键词。
众所周知,网页的标题是网页的高级摘要。网站主页的标题是网站的正式名称,而栏目主页的标题通常是栏目名称。文章 的标题是 文章 的标题。这个原则不是一成不变的,但不管怎么变,一般人还是会遵循这个规律的。
网页的标题只显示在搜索结果页的标题部分和浏览器顶部标签的网站标题位置,其他地方隐藏。其重要性不再赘述,但网站Title一旦确定并被搜索引擎收录搜索,就不能再更改,否则会影响收录和排名网站 的。返回搜狐,查看更多
工具采集文章(用wps也可以自己编辑标题和文章内容?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2022-04-02 10:04
工具采集文章内容来源于官方公众号:今日头条,需要的小伙伴可以自己去做一个,用wps也可以自己编辑标题和文章内容。第一步:我们打开今日头条,我们的推荐页面是这样的:我们要选择某个热点进行采集,比如热点养宠物,首先我们点击上面的”发现“按钮,页面会出现个”图文编辑器“,我们就点击图文编辑器,找到里面的”热点话题“,进入”新闻详情“的页面,就可以找到我们采集的热点了。注意:采集头条里面的热点必须是从头条后台里面下载的,它是不会泄露我们wps邮箱信息,请大家放心采集。
其实可以去百度采集今日头条的,关键在于准确,我们可以百度百度,出来的结果大多数是准确的,这是我们在百度搜索头条搜索跟头条推荐的百度首页是头条公众号里面出来的,会及时推送我们想看的内容。但前提是你要选择的地方要对,选择跟自己类似的,搜索后要是个正规的头条app,因为有时候你采集的内容头条并不是直接推送到公众号,而是把它放到了一个分享平台,分享过来后再推送给你。
这种就要看你能不能接受。如果你选择的是公众号平台,但是头条在这个平台没有你想要的内容,你又想看,可以去像腾讯那样的公众号采集,但百度和腾讯选择的这个最好。
我一直在用趣头条,现在每天都浏览头条的新闻资讯,有时也能看到很多文章,不过,找到自己想要的就难了,因为不太会处理,所以经常弄错,一不小心就需要花好几个小时了。最近,为了搜集内容,特地去头条找过几次,有时候可以找到自己想要的内容,有时候则弄得要大半天。后来,经朋友介绍,在今日头条转载内容,不过转载后,阅读不会增加,只是图个方便,也不知道能不能有用呢?要有什么建议?。 查看全部
工具采集文章(用wps也可以自己编辑标题和文章内容?(图))
工具采集文章内容来源于官方公众号:今日头条,需要的小伙伴可以自己去做一个,用wps也可以自己编辑标题和文章内容。第一步:我们打开今日头条,我们的推荐页面是这样的:我们要选择某个热点进行采集,比如热点养宠物,首先我们点击上面的”发现“按钮,页面会出现个”图文编辑器“,我们就点击图文编辑器,找到里面的”热点话题“,进入”新闻详情“的页面,就可以找到我们采集的热点了。注意:采集头条里面的热点必须是从头条后台里面下载的,它是不会泄露我们wps邮箱信息,请大家放心采集。
其实可以去百度采集今日头条的,关键在于准确,我们可以百度百度,出来的结果大多数是准确的,这是我们在百度搜索头条搜索跟头条推荐的百度首页是头条公众号里面出来的,会及时推送我们想看的内容。但前提是你要选择的地方要对,选择跟自己类似的,搜索后要是个正规的头条app,因为有时候你采集的内容头条并不是直接推送到公众号,而是把它放到了一个分享平台,分享过来后再推送给你。
这种就要看你能不能接受。如果你选择的是公众号平台,但是头条在这个平台没有你想要的内容,你又想看,可以去像腾讯那样的公众号采集,但百度和腾讯选择的这个最好。
我一直在用趣头条,现在每天都浏览头条的新闻资讯,有时也能看到很多文章,不过,找到自己想要的就难了,因为不太会处理,所以经常弄错,一不小心就需要花好几个小时了。最近,为了搜集内容,特地去头条找过几次,有时候可以找到自己想要的内容,有时候则弄得要大半天。后来,经朋友介绍,在今日头条转载内容,不过转载后,阅读不会增加,只是图个方便,也不知道能不能有用呢?要有什么建议?。
工具采集文章(为什么要用网页数据采集,为什么网页发布?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-03-31 12:17
网页数据采集,为什么要用网页数据采集?因为网页数据采集的内容便于更多的分析参考和网站的内容更新。今天给大家分享一个网络数据采集工具。采集 的数据可以保存到本地发布的网站。支持主要的网站 发布。自动采集+伪原创只需两步即可发布。具体会以图片的形式展示给大家,大家要注意图片(图片是核心)。
导航页面的优化不仅展示了关键词计划的顺序,还优化了其他栏目内页的需求,例如:在文章部分和当前位置下栏目部分,这个框架是网站的基本设置,关于文章内页的上一篇和下一篇的设置,停止设置网站的侧边栏,不仅可以引导用户深入阅读,还可以完善网站的内循环,有效促进蜘蛛的深度爬行。
哪个网站被搜索引擎惩罚,排名下降或关键词排名消失?如何妥善处理。我们做网站SEO优化很久了,肯定会遇到网站被搜索引擎惩罚的情况。首先,不要急着去看医生,冷静下来分析一下,到底是什么原因?
网站惩罚排名下降的原因及处理方法
网站被处罚,排名下降的原因不外乎以下几个方面:
首先,网站 的布局做了很大的修改。由于各种原因,我们可能需要修改网站的布局,修改后排名会下降。
第二,网站页面有非法内容,或者禁止内容。禁言等一些内容,不用多说。
第三,网站被链接到黑链或木马病毒。
四、网站的服务器有问题。要么响应太慢,要么几天打不开,关键词的排名也会下降。
五、网站上加载的弹窗广告或页面跳转过多,包括百度上桥。他们百度自己的在线客服强制聊天插件也会影响关键词的排名。
六、关键词堆积,什么是关键词堆积,如何预防,可以查看我们的网站相关内容。
第七,误用了一些SEO软件。老实说,软件永远无法帮助您进行 SEO。任何简单有效的事情都是不可靠的。比如很多外链软件可以在短时间内给你添加很多外链网站。正常发外链的话,一周发几个十、100个外链。. 但是如果使用SEO反向链接工具,一天可以发送成百上千个反向链接,因此被处罚的可能性非常高。
八、频繁修改网站标题(Title),就像频繁换工作,今天去餐厅,明天去review,后天去公司,然后去修机后天。如何评价你作为一个人,我不知道你在做什么。
第九,文章的副本太多,网站内容中没有原创性文章,都是抄别人的,百度有算法打这种类型的 网站。
第十,故意刷流量,有人对百度权重有误解,我用站长工具查了一下,显示估计流量是100,百度权重是2,我会刷流量刷流量故意地。完全估计流量是两件不同的事情,就是刷10万次是没有意义的。很容易刷流量。刷网站流量不是SEO优化,会被百度处罚。
第十一,就是过度优化,什么都没做,一切都在正确的轨道上,工作很勤奋,每天都发原创文章。外链也是用这些优质的外链做的,只是走得太远了。SEO只需要发现某个网站在做优化,肯定会受到惩罚。就像人参吃多了,身体受不了了吧?人参和鹿茸是好东西,但如果天天吃,那就不行了。
第十二,友情链接,被合作伙伴拖下。如果与他有链接的网站有问题,排名会受到相应的惩罚。因此,请务必检查您的友谊链接伙伴是否健康。
在分析了以上十种原因后,我们首先找出我们被处罚的原因。其实有很多原因,太多了,不能一下子说出来。让我们首先检查上述原因。
如果说是本人自愿违规,将立即终止,不再犯。如果没有任何问题,它很可能被过度优化。如果遇到过度优化,只能停下来,降低工作频率。比如你以前一天发三篇五篇原创性文章,如果你说的是公司网站,新闻网站,如果文章是三篇,五篇文章就下毛毛雨了,还不够发工资。我说的是普通公司网站。对于网站 公司来说,过去有很多文章 每周发布两到三篇文章。如果是原创文章,有些链接一天只能换两次。
如果遇到这种网站被惩罚和K,那就是停止工作,然后纠正错误的事情,剩下的就是慢慢等待,没有更好的办法。 查看全部
工具采集文章(为什么要用网页数据采集,为什么网页发布?(图))
网页数据采集,为什么要用网页数据采集?因为网页数据采集的内容便于更多的分析参考和网站的内容更新。今天给大家分享一个网络数据采集工具。采集 的数据可以保存到本地发布的网站。支持主要的网站 发布。自动采集+伪原创只需两步即可发布。具体会以图片的形式展示给大家,大家要注意图片(图片是核心)。


导航页面的优化不仅展示了关键词计划的顺序,还优化了其他栏目内页的需求,例如:在文章部分和当前位置下栏目部分,这个框架是网站的基本设置,关于文章内页的上一篇和下一篇的设置,停止设置网站的侧边栏,不仅可以引导用户深入阅读,还可以完善网站的内循环,有效促进蜘蛛的深度爬行。
哪个网站被搜索引擎惩罚,排名下降或关键词排名消失?如何妥善处理。我们做网站SEO优化很久了,肯定会遇到网站被搜索引擎惩罚的情况。首先,不要急着去看医生,冷静下来分析一下,到底是什么原因?
网站惩罚排名下降的原因及处理方法
网站被处罚,排名下降的原因不外乎以下几个方面:
首先,网站 的布局做了很大的修改。由于各种原因,我们可能需要修改网站的布局,修改后排名会下降。
第二,网站页面有非法内容,或者禁止内容。禁言等一些内容,不用多说。
第三,网站被链接到黑链或木马病毒。
四、网站的服务器有问题。要么响应太慢,要么几天打不开,关键词的排名也会下降。

五、网站上加载的弹窗广告或页面跳转过多,包括百度上桥。他们百度自己的在线客服强制聊天插件也会影响关键词的排名。
六、关键词堆积,什么是关键词堆积,如何预防,可以查看我们的网站相关内容。
第七,误用了一些SEO软件。老实说,软件永远无法帮助您进行 SEO。任何简单有效的事情都是不可靠的。比如很多外链软件可以在短时间内给你添加很多外链网站。正常发外链的话,一周发几个十、100个外链。. 但是如果使用SEO反向链接工具,一天可以发送成百上千个反向链接,因此被处罚的可能性非常高。
八、频繁修改网站标题(Title),就像频繁换工作,今天去餐厅,明天去review,后天去公司,然后去修机后天。如何评价你作为一个人,我不知道你在做什么。
第九,文章的副本太多,网站内容中没有原创性文章,都是抄别人的,百度有算法打这种类型的 网站。
第十,故意刷流量,有人对百度权重有误解,我用站长工具查了一下,显示估计流量是100,百度权重是2,我会刷流量刷流量故意地。完全估计流量是两件不同的事情,就是刷10万次是没有意义的。很容易刷流量。刷网站流量不是SEO优化,会被百度处罚。

第十一,就是过度优化,什么都没做,一切都在正确的轨道上,工作很勤奋,每天都发原创文章。外链也是用这些优质的外链做的,只是走得太远了。SEO只需要发现某个网站在做优化,肯定会受到惩罚。就像人参吃多了,身体受不了了吧?人参和鹿茸是好东西,但如果天天吃,那就不行了。
第十二,友情链接,被合作伙伴拖下。如果与他有链接的网站有问题,排名会受到相应的惩罚。因此,请务必检查您的友谊链接伙伴是否健康。
在分析了以上十种原因后,我们首先找出我们被处罚的原因。其实有很多原因,太多了,不能一下子说出来。让我们首先检查上述原因。

如果说是本人自愿违规,将立即终止,不再犯。如果没有任何问题,它很可能被过度优化。如果遇到过度优化,只能停下来,降低工作频率。比如你以前一天发三篇五篇原创性文章,如果你说的是公司网站,新闻网站,如果文章是三篇,五篇文章就下毛毛雨了,还不够发工资。我说的是普通公司网站。对于网站 公司来说,过去有很多文章 每周发布两到三篇文章。如果是原创文章,有些链接一天只能换两次。
如果遇到这种网站被惩罚和K,那就是停止工作,然后纠正错误的事情,剩下的就是慢慢等待,没有更好的办法。
工具采集文章(亲测很好用,在原来软件的基础上修复几处bug)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-03-21 16:06
亲测非常好用。在原软件的基础上,修复了几个bug,修复了网站编码为utf-8时显示乱码的bug。
本软件适合网站员工写文章采集其他网站文章内容时使用。
软件介绍:
1、软件属于源码(HTML)抓取版
2、只支持二级目录的采集,即列表页—>文章页。 (大部分网站文章都可以在二级目录中获取)
3、手动设置翻页(选择多页)
4、支持body内容过滤(这个可以自己修改)
5、自动生成TXT文件到桌面文件夹
6、自动判断UTF8返回文本
7、每个节点规则支持的测试返回
在软件方面,基本上就是我上面说的。可以用的漂亮,我有采集N个网站,还有N个文章。
新手可以用它来研究。该软件没有什么特别之处。说白了就是一个逻辑思路,如何实现功能。
原理其实很简单。就是在一个循环中取中间(从外到内,一层一层),然后加一点判断就完成了。
如果我要说一个特别的地方,那就是标题的处理,因为有些网页字符在本地是不能写的。嗯~有兴趣的可以看看。
当然二次开发也是可以的,添加伪原创,添加分页采集,添加多级目录采集,添加HTML发布文本,添加数据库存储等等。
制作商业版并没有错,只要你有时间和精力去做。
使用时,请按照软件上的说明进行操作。从第 1 步到第 6 步,测试通过后即可启动采集。速度非常快。
测试采集文章效果
文章采集软件下载:链接:提取码:r3dw 查看全部
工具采集文章(亲测很好用,在原来软件的基础上修复几处bug)
亲测非常好用。在原软件的基础上,修复了几个bug,修复了网站编码为utf-8时显示乱码的bug。
本软件适合网站员工写文章采集其他网站文章内容时使用。
软件介绍:
1、软件属于源码(HTML)抓取版
2、只支持二级目录的采集,即列表页—>文章页。 (大部分网站文章都可以在二级目录中获取)
3、手动设置翻页(选择多页)
4、支持body内容过滤(这个可以自己修改)
5、自动生成TXT文件到桌面文件夹
6、自动判断UTF8返回文本
7、每个节点规则支持的测试返回
在软件方面,基本上就是我上面说的。可以用的漂亮,我有采集N个网站,还有N个文章。
新手可以用它来研究。该软件没有什么特别之处。说白了就是一个逻辑思路,如何实现功能。
原理其实很简单。就是在一个循环中取中间(从外到内,一层一层),然后加一点判断就完成了。
如果我要说一个特别的地方,那就是标题的处理,因为有些网页字符在本地是不能写的。嗯~有兴趣的可以看看。
当然二次开发也是可以的,添加伪原创,添加分页采集,添加多级目录采集,添加HTML发布文本,添加数据库存储等等。
制作商业版并没有错,只要你有时间和精力去做。
 https://www.zidongtouzhu.vip/w ... 2.jpg 300w, https://www.zidongtouzhu.vip/w ... 6.jpg 768w" />
https://www.zidongtouzhu.vip/w ... 2.jpg 300w, https://www.zidongtouzhu.vip/w ... 6.jpg 768w" />使用时,请按照软件上的说明进行操作。从第 1 步到第 6 步,测试通过后即可启动采集。速度非常快。

测试采集文章效果
文章采集软件下载:链接:提取码:r3dw
工具采集文章(seo优化什么意思(快手SEO)-资源楼()关联)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-03-20 00:02
节目前言:
自从冯耀宗的长城视频曝光后,越来越多的人用双头条+头条采集,这也导致资源不足,大家都是采集,那就不原创 。这次带来关键词微信采集+自动双标题,有图写文章,微信的文章百度没有收录,这也是这样一来,微信的文章都是优质的原创文章,双标题的权重会增长很快。大家还没用之前赶紧下载使用吧,后面的泛滥我不负责。
亲测时间:2022/3/17
节目介绍:
这个程序可以和之前的插件一起使用,也可以单独使用,但是需要自己注释掉配置参数。兼容插件:
php插件原创图片生成器下载:原创图片生成器(所有cms通用)伪静态背景带自动图片-资源构建()
优采云程序下载:优采云采集器V9全网通用版(win10可以使用优采云采集器)-资源构建()
1、内置安装说明,有问题可以私聊或留言。
2、下载后,让我们发疯吧。
3、不仅优采云可以使用,面向对象编程,如果自己可以开发,可以集成到各种cms中独立运行,原生php程序,不依赖在任何程序或框架上。
采集效果(无图无文):SEO优化是什么意思(快手SEO是什么意思)-资源搭建()
用这个联想的人很多,效果可能不如微信采集:双标题头条信息采集,原创文章采集@ >工具(快速获取电源7)-资源构建()
程序截图:
资源下载 本资源下载价格为29.9RMB,请先登录
欢迎来到官方第二群:832726901 查看全部
工具采集文章(seo优化什么意思(快手SEO)-资源楼()关联)
节目前言:
自从冯耀宗的长城视频曝光后,越来越多的人用双头条+头条采集,这也导致资源不足,大家都是采集,那就不原创 。这次带来关键词微信采集+自动双标题,有图写文章,微信的文章百度没有收录,这也是这样一来,微信的文章都是优质的原创文章,双标题的权重会增长很快。大家还没用之前赶紧下载使用吧,后面的泛滥我不负责。
亲测时间:2022/3/17
节目介绍:
这个程序可以和之前的插件一起使用,也可以单独使用,但是需要自己注释掉配置参数。兼容插件:
php插件原创图片生成器下载:原创图片生成器(所有cms通用)伪静态背景带自动图片-资源构建()
优采云程序下载:优采云采集器V9全网通用版(win10可以使用优采云采集器)-资源构建()
1、内置安装说明,有问题可以私聊或留言。
2、下载后,让我们发疯吧。
3、不仅优采云可以使用,面向对象编程,如果自己可以开发,可以集成到各种cms中独立运行,原生php程序,不依赖在任何程序或框架上。
采集效果(无图无文):SEO优化是什么意思(快手SEO是什么意思)-资源搭建()
用这个联想的人很多,效果可能不如微信采集:双标题头条信息采集,原创文章采集@ >工具(快速获取电源7)-资源构建()
程序截图:

资源下载 本资源下载价格为29.9RMB,请先登录
欢迎来到官方第二群:832726901
工具采集文章(文章采集中会用到哪些工具?如何使用这个工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-03-13 22:03
工具采集文章的速度不快,无法得到很好的效果。但是文章采集中会用到哪些工具呢?只会seo的人都不知道我为什么这么了解。我这里给大家推荐一个不错的工具,文章全网采集器。下面简单讲解一下如何使用这个工具。操作步骤:1.获取百度网站的源码,这个比较复杂,很多人不知道怎么操作。2.自己写代码把源码替换成自己公司或者团队自己的网站,自己是直接做公司名称的关键词,这个比较麻烦,需要利用到php,不过现在很多公司都是直接用微信公众号做自己的网站了。
3.用自己网站的自动生成链接插件,即跳转到自己网站后台。4.下载采集器,直接采集.html格式的文本文件,然后用浏览器打开。是不是觉得非常简单呢?用一个月就可以达到百度首页。
做seo的多是文科生,并且不明白seo的本质。大多数是采集文章,然后再交互编辑的。而且几乎没有采集原创。多爬虫抓取,多伪原创,然后加个链接就完事了。但是伪原创写在外部网站上会比较合理,比如p2p,多源站接入,social,自媒体,等等一堆网站通过伪原创进行广告引流,增加转化率。想想都可怕。那么,别人为什么要爬你的文章,就是伪原创,调用之前很多文章的内容,然后根据自己要的模板,写文章。这样转化率才高。
来吧,
1、先注册一个谷歌浏览器账号;
2、谷歌浏览器登录之后,选择第一个,
3、选择“sogouinternetprotection”然后就开始伪原创了。个人觉得伪原创需要什么搜索技巧,不如搜索时的信息。如果一篇文章的标题你有疑问,结果没回答你, 查看全部
工具采集文章(文章采集中会用到哪些工具?如何使用这个工具)
工具采集文章的速度不快,无法得到很好的效果。但是文章采集中会用到哪些工具呢?只会seo的人都不知道我为什么这么了解。我这里给大家推荐一个不错的工具,文章全网采集器。下面简单讲解一下如何使用这个工具。操作步骤:1.获取百度网站的源码,这个比较复杂,很多人不知道怎么操作。2.自己写代码把源码替换成自己公司或者团队自己的网站,自己是直接做公司名称的关键词,这个比较麻烦,需要利用到php,不过现在很多公司都是直接用微信公众号做自己的网站了。
3.用自己网站的自动生成链接插件,即跳转到自己网站后台。4.下载采集器,直接采集.html格式的文本文件,然后用浏览器打开。是不是觉得非常简单呢?用一个月就可以达到百度首页。
做seo的多是文科生,并且不明白seo的本质。大多数是采集文章,然后再交互编辑的。而且几乎没有采集原创。多爬虫抓取,多伪原创,然后加个链接就完事了。但是伪原创写在外部网站上会比较合理,比如p2p,多源站接入,social,自媒体,等等一堆网站通过伪原创进行广告引流,增加转化率。想想都可怕。那么,别人为什么要爬你的文章,就是伪原创,调用之前很多文章的内容,然后根据自己要的模板,写文章。这样转化率才高。
来吧,
1、先注册一个谷歌浏览器账号;
2、谷歌浏览器登录之后,选择第一个,
3、选择“sogouinternetprotection”然后就开始伪原创了。个人觉得伪原创需要什么搜索技巧,不如搜索时的信息。如果一篇文章的标题你有疑问,结果没回答你,
工具采集文章(豆瓣搜罗美剧美食的不二选择爱奇艺,百度文库导航类网站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-03-02 21:00
工具采集文章。读文读物。网易公开课,知乎live。百度文库,道客巴巴文库。豆丁小说网。中国大学mooc。《计算机基础》这两个是比较基础的。文库资源整理,有需要私信我。
带着这个问题搜索了一下好几个比较知名且有特色的网站都没找到合适的解决方案,翻墙去youtube上找不到一个像样的作品集加上给出的一定制作周期成本又太高,就这个问题而言上发现了一个可以帮我克服这个困难的方法(前提是他们所有的内容都是免费的)虽然比不上那些内容丰富的网站(哈哈),但总算克服了三大难题之一的内容的问题(`・ω・)最关键的是,它有很多基础相关的知识()可以帮我解决内容太多的困扰。
完成之后立即就是能从头到尾的作品展示啦!让看你作品的人感受到你内容的质量,再决定购买不购买(最关键是简单易学轻松搞定呀耶!)利益相关:免费体验人家提供的内容一分钟,就知道个啥(○’ω’○)。
豆瓣搜罗美剧美食的不二选择
爱奇艺,
百度文库
导航类网站:网址导航可以详细的查找你想要的资源,提供一切必备的网址和站点,包括分类,网址提取等功能我一般是先根据自己的喜好,如音乐,电影等,挑选一下再进行找资源。
::百度图片识图
,好像也很难, 查看全部
工具采集文章(豆瓣搜罗美剧美食的不二选择爱奇艺,百度文库导航类网站)
工具采集文章。读文读物。网易公开课,知乎live。百度文库,道客巴巴文库。豆丁小说网。中国大学mooc。《计算机基础》这两个是比较基础的。文库资源整理,有需要私信我。
带着这个问题搜索了一下好几个比较知名且有特色的网站都没找到合适的解决方案,翻墙去youtube上找不到一个像样的作品集加上给出的一定制作周期成本又太高,就这个问题而言上发现了一个可以帮我克服这个困难的方法(前提是他们所有的内容都是免费的)虽然比不上那些内容丰富的网站(哈哈),但总算克服了三大难题之一的内容的问题(`・ω・)最关键的是,它有很多基础相关的知识()可以帮我解决内容太多的困扰。
完成之后立即就是能从头到尾的作品展示啦!让看你作品的人感受到你内容的质量,再决定购买不购买(最关键是简单易学轻松搞定呀耶!)利益相关:免费体验人家提供的内容一分钟,就知道个啥(○’ω’○)。
豆瓣搜罗美剧美食的不二选择
爱奇艺,
百度文库
导航类网站:网址导航可以详细的查找你想要的资源,提供一切必备的网址和站点,包括分类,网址提取等功能我一般是先根据自己的喜好,如音乐,电影等,挑选一下再进行找资源。
::百度图片识图
,好像也很难,
工具采集文章(数据源所有权归属原网站及所有者严禁利用webscraper进行数据采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2022-02-28 08:01
这个文章是为了学习和交流。数据源的所有权属于原网站和所有者。严禁利用本文中提到的流程和数据牟利。
“打钉子的方法有很多,有时候我最熟悉的锤子反而会打我”
背景
最近收到一个求助,是采集一个网站,传统的“列表+内容”页面模式,用php或者采集器总会出现各种莫名其妙的问题,基本上都是经过这一步,我将使用“node+puppteer”来做,并使用自动化测试工具来模拟操作。虽然说是万能锤,但是制作这个锤子的流程和技术复杂度还是存在的,所以在转向之前一直在思考没有方向可以尝试——浏览器插件,基本原理和思路是与自动化工具基本相同,但感觉更优雅的是让目标逻辑更适合浏览器。
查资料的时候找到了Web Scraper,参考文档和教程,应用到目标网站采集,最终得到数据。如果熟悉整个操作过程,可以快速设置相应的规则来执行采集,现在记录一下过程。
过程
1. 安装网络爬虫
有科学上网功的可以登录chorme网店直接搜索安装
或百度搜索“网络刮刀离线安装包”获取相关支持,离线安装过程不再赘述。
2. 分析目标站
可以看出,这是一种典型的列表+内容的展示方式。现在您需要 采集 向下列表和内容页面。传统的采集思路是用程序把整个列表页面拉回来,然后解析超链接跳转,进而得到内容页面。
现在让我们看看如何使用网络爬虫获取数据采集。
3. 设置规则
因为采集工具是通用的,至于如何采集和采集那些数据,用户需要根据实际情况进行配置。首先,让我们了解如何打开网络爬虫和基本页面。
① 打开工具
在目标页面打开开发者工具(F11或右键-勾选),可以看到工具栏的末尾有一个同名的标签,点击标签进入工具页面
②新建采集任务
采集在需要创建Sitemap之前,可以理解为一个任务,选择Create new sitemap - Create Sitemap
站点地图名称是任务名称,您可以根据需要创建它。
起始 URL 是您的 采集 页面。如果是列表+内容模式,建议填写列表页。
然后Create Sitemap,一个基本的任务就建立了。
③ 创建列表页规则
单击添加新选择器以创建一个选择器来告诉插件应该选择哪个节点。对于在这个列表页面上也有信息的页面,我们将每条信息作为一个块,块收录各种属性信息。建立方法如下:
需要勾选Multiple选项,可以理解为需要循环获取。
添加后,我们应该在信息块中标记内容。具体操作方法同上,但要选择信息的父选择器为刚刚创建的信息块节点。
其他节点的数据操作一致,记得选择父节点。
④ 检查既定规则 查看全部
工具采集文章(数据源所有权归属原网站及所有者严禁利用webscraper进行数据采集)
这个文章是为了学习和交流。数据源的所有权属于原网站和所有者。严禁利用本文中提到的流程和数据牟利。
“打钉子的方法有很多,有时候我最熟悉的锤子反而会打我”
背景
最近收到一个求助,是采集一个网站,传统的“列表+内容”页面模式,用php或者采集器总会出现各种莫名其妙的问题,基本上都是经过这一步,我将使用“node+puppteer”来做,并使用自动化测试工具来模拟操作。虽然说是万能锤,但是制作这个锤子的流程和技术复杂度还是存在的,所以在转向之前一直在思考没有方向可以尝试——浏览器插件,基本原理和思路是与自动化工具基本相同,但感觉更优雅的是让目标逻辑更适合浏览器。
查资料的时候找到了Web Scraper,参考文档和教程,应用到目标网站采集,最终得到数据。如果熟悉整个操作过程,可以快速设置相应的规则来执行采集,现在记录一下过程。
过程
1. 安装网络爬虫
有科学上网功的可以登录chorme网店直接搜索安装
或百度搜索“网络刮刀离线安装包”获取相关支持,离线安装过程不再赘述。
2. 分析目标站
可以看出,这是一种典型的列表+内容的展示方式。现在您需要 采集 向下列表和内容页面。传统的采集思路是用程序把整个列表页面拉回来,然后解析超链接跳转,进而得到内容页面。
现在让我们看看如何使用网络爬虫获取数据采集。
3. 设置规则
因为采集工具是通用的,至于如何采集和采集那些数据,用户需要根据实际情况进行配置。首先,让我们了解如何打开网络爬虫和基本页面。
① 打开工具
在目标页面打开开发者工具(F11或右键-勾选),可以看到工具栏的末尾有一个同名的标签,点击标签进入工具页面
②新建采集任务
采集在需要创建Sitemap之前,可以理解为一个任务,选择Create new sitemap - Create Sitemap
站点地图名称是任务名称,您可以根据需要创建它。
起始 URL 是您的 采集 页面。如果是列表+内容模式,建议填写列表页。
然后Create Sitemap,一个基本的任务就建立了。
③ 创建列表页规则
单击添加新选择器以创建一个选择器来告诉插件应该选择哪个节点。对于在这个列表页面上也有信息的页面,我们将每条信息作为一个块,块收录各种属性信息。建立方法如下:
需要勾选Multiple选项,可以理解为需要循环获取。
添加后,我们应该在信息块中标记内容。具体操作方法同上,但要选择信息的父选择器为刚刚创建的信息块节点。
其他节点的数据操作一致,记得选择父节点。
④ 检查既定规则
工具采集文章(从十万+高效采集热词评论,让编辑看到有什么变化)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2022-02-26 00:04
工具采集文章热点方式在社区里直接大规模刷新帖子,争取就放热度,让编辑看到有什么变化,要多发!内容采集就是怎么搜集所有的文章不重复,需要采集各大平台的内容。投放广告有专门的平台发布我们的文章,然后就要通过广告文章的曝光量引入流量。分析找词采集文章热点。如果你有在某个网站编辑分析过某个热点词的话,你发现,当你所分析的词在某一社区或者论坛,某一大平台被顶起来后,你就有很大的机会知道这个词会不会就一直存在,会一直不下沉。
分析社区用户因素,找到匹配的词,然后加大采集。好的分析能力还需要成为话痨多给小编一些鼓励。教你从十万+高效采集热词评论。采集软件发帖评论热词。时下热词已经成为的收藏热词了,在很多论坛上也都有涉及到。
小编不才,目前还没这些平台,不过有好的去处,可以参考一下一号店无忧摘要数据库,在数据大爆发的年代没抓住这块资源就很可惜了。
本小编现在还在开着个店,
wind数据网,
要能关注到热词,那必须是关注wind数据库,这才是真正的热词库,网站生态发展快,数据丰富,权威,部分可能是收费的,但又不失本色,要大度,与时俱进,迎合大家的口味。另外就是外盘的数据交换平台,最近刚搞了一个chinasui,与其他外盘数据平台不同的是,他不是一个分析,不仅包括wind所有的网站行情大数据统计,还有基本全量的港股数据和香港数据,甚至包括关联的股票信息及相关的行情分析,但chinasui却只定位在“销售财富”上,目前小编正在开发,后期必定会有更多的服务于会员的数据交换平台产品。 查看全部
工具采集文章(从十万+高效采集热词评论,让编辑看到有什么变化)
工具采集文章热点方式在社区里直接大规模刷新帖子,争取就放热度,让编辑看到有什么变化,要多发!内容采集就是怎么搜集所有的文章不重复,需要采集各大平台的内容。投放广告有专门的平台发布我们的文章,然后就要通过广告文章的曝光量引入流量。分析找词采集文章热点。如果你有在某个网站编辑分析过某个热点词的话,你发现,当你所分析的词在某一社区或者论坛,某一大平台被顶起来后,你就有很大的机会知道这个词会不会就一直存在,会一直不下沉。
分析社区用户因素,找到匹配的词,然后加大采集。好的分析能力还需要成为话痨多给小编一些鼓励。教你从十万+高效采集热词评论。采集软件发帖评论热词。时下热词已经成为的收藏热词了,在很多论坛上也都有涉及到。
小编不才,目前还没这些平台,不过有好的去处,可以参考一下一号店无忧摘要数据库,在数据大爆发的年代没抓住这块资源就很可惜了。
本小编现在还在开着个店,
wind数据网,
要能关注到热词,那必须是关注wind数据库,这才是真正的热词库,网站生态发展快,数据丰富,权威,部分可能是收费的,但又不失本色,要大度,与时俱进,迎合大家的口味。另外就是外盘的数据交换平台,最近刚搞了一个chinasui,与其他外盘数据平台不同的是,他不是一个分析,不仅包括wind所有的网站行情大数据统计,还有基本全量的港股数据和香港数据,甚至包括关联的股票信息及相关的行情分析,但chinasui却只定位在“销售财富”上,目前小编正在开发,后期必定会有更多的服务于会员的数据交换平台产品。
工具采集文章(chrome开发者工具首先.要会python,不会也没关系)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-02-24 15:06
工具采集文章,得到文章源代码。可以采集知乎、豆瓣、头条等文章。技术采集网页源代码python爬虫,得到完整的网页源代码。可以采集新浪,搜狐,百度,网易等文章。
chrome开发者工具
首先.要会python,不会也没关系.chrome开发者工具,花两三天就够了..
你要会python
python爬虫不懂
python,
html+css+javascript+jquery这里是爬虫培训的最好的网站
我推荐你关注知乎上的“章鱼爬虫”,里面有一篇文章,《python数据采集知识:如何爬取知乎上的数据》,讲的比较全面,爬虫相关知识,
我估计你们不会上这来问...
你可以看一下最后一位答主是怎么回答的
爬虫首先你要学会python语言和一点css
python会不会?不会的话excel也可以!
学历史去爬,这是最后一大乐园。
原谅我。不过如果提问者已经知道自己要问什么问题的话。那很抱歉我的答案只能是“不用学”。--补充:如果是想知道一些情报,当然了,首先你需要确定需要掌握到什么程度。从用法、效率、可靠性、安全性等角度来分类的话,在这里还没有人能给出比较完善的答案。so?题主难道没有被论坛里,或者微博上的娱乐信息刷屏过吗?知乎一下,你就会发现,接下来的答案其实并不取决于你提出问题的知识量,而是取决于你提出问题的方式。
请想象一下,你是在提问个:《银魂》中的主角”火影”和《灌篮高手》中的主角”流川枫”,这两个人有什么共同点?或者是,《奥特曼大作战》中的大古,是不是《死神》中的小次郎?如果你没有听说过他们,你又该用什么样的方式去接触他们?当然如果你只是想知道“知乎上的流行答案”,那直接去看“关注数,收藏数,赞同数”比较好。
还有你肯定知道百度贴吧不用动脑子也能搜到想要的答案。但是我不能否认,当你尝试过拿到搜索结果中任何一个答案的分类列表后,你会被迷住的。另外个人觉得,在这个大鱼吃小鱼的时代,在科技发达的今天,只要你有人脉,连爬虫都可以用,这玩意就跟写书一样,你不照着标准语法/注释编写那么一大堆东西,怎么能有钱赚?你可以写下一行前缀为“自取”,后缀为“回复”的代码,一个“scrapy爬虫-。 查看全部
工具采集文章(chrome开发者工具首先.要会python,不会也没关系)
工具采集文章,得到文章源代码。可以采集知乎、豆瓣、头条等文章。技术采集网页源代码python爬虫,得到完整的网页源代码。可以采集新浪,搜狐,百度,网易等文章。
chrome开发者工具
首先.要会python,不会也没关系.chrome开发者工具,花两三天就够了..
你要会python
python爬虫不懂
python,
html+css+javascript+jquery这里是爬虫培训的最好的网站
我推荐你关注知乎上的“章鱼爬虫”,里面有一篇文章,《python数据采集知识:如何爬取知乎上的数据》,讲的比较全面,爬虫相关知识,
我估计你们不会上这来问...
你可以看一下最后一位答主是怎么回答的
爬虫首先你要学会python语言和一点css
python会不会?不会的话excel也可以!
学历史去爬,这是最后一大乐园。
原谅我。不过如果提问者已经知道自己要问什么问题的话。那很抱歉我的答案只能是“不用学”。--补充:如果是想知道一些情报,当然了,首先你需要确定需要掌握到什么程度。从用法、效率、可靠性、安全性等角度来分类的话,在这里还没有人能给出比较完善的答案。so?题主难道没有被论坛里,或者微博上的娱乐信息刷屏过吗?知乎一下,你就会发现,接下来的答案其实并不取决于你提出问题的知识量,而是取决于你提出问题的方式。
请想象一下,你是在提问个:《银魂》中的主角”火影”和《灌篮高手》中的主角”流川枫”,这两个人有什么共同点?或者是,《奥特曼大作战》中的大古,是不是《死神》中的小次郎?如果你没有听说过他们,你又该用什么样的方式去接触他们?当然如果你只是想知道“知乎上的流行答案”,那直接去看“关注数,收藏数,赞同数”比较好。
还有你肯定知道百度贴吧不用动脑子也能搜到想要的答案。但是我不能否认,当你尝试过拿到搜索结果中任何一个答案的分类列表后,你会被迷住的。另外个人觉得,在这个大鱼吃小鱼的时代,在科技发达的今天,只要你有人脉,连爬虫都可以用,这玩意就跟写书一样,你不照着标准语法/注释编写那么一大堆东西,怎么能有钱赚?你可以写下一行前缀为“自取”,后缀为“回复”的代码,一个“scrapy爬虫-。
如何用新媒体管家采集文章和素材?(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 390 次浏览 • 2022-07-22 08:00
工具采集文章和素材。第一步:首先打开新媒体管家(比如我是win10系统,用的是windows7版本)第二步:右键点击你要抓取的文章或素材,点击微信转发第三步:出现之下弹窗,点击转发。第四步:微信朋友圈中,会显示该文章的分享到的好友和朋友圈内容,找到需要转发的朋友,点击转发。第五步:文章转发完毕后,你就会收到你转发的内容,大家可以点击右上角【分享】【浏览全部】。
然后你会看到【全部分享】旁边的对勾已经取消了。点击右上角【分享到朋友圈】。最后确定转发即可。这样你就可以得到一篇你采集的文章或素材。
可以用新媒体管家
现在新闻客户端都可以上传文件。不是说你需要几个新闻客户端才能抓取某个网站的内容。只要打开客户端,就会有一个“上传文件”按钮。
目前比较常用的新闻客户端有:澎湃新闻、南方+、一点资讯、zaker旗下的“刷牙”、钱盆、梅花网等,百度一下就能看到相关教程了。
具体使用方法是点击上传文件按钮,选择要上传的文件上传完成后,在下方就能看到转发的别人已经上传完成的文件。
现在这类提问都是以'你在百度里看到的好像都这样'这种格式的吗???
有个破网站可以抓取新闻但是不能全部导出excel查看
可以直接复制链接到新闻客户端点击搜索就可以抓取文章了 查看全部
如何用新媒体管家采集文章和素材?(图)
工具采集文章和素材。第一步:首先打开新媒体管家(比如我是win10系统,用的是windows7版本)第二步:右键点击你要抓取的文章或素材,点击微信转发第三步:出现之下弹窗,点击转发。第四步:微信朋友圈中,会显示该文章的分享到的好友和朋友圈内容,找到需要转发的朋友,点击转发。第五步:文章转发完毕后,你就会收到你转发的内容,大家可以点击右上角【分享】【浏览全部】。
然后你会看到【全部分享】旁边的对勾已经取消了。点击右上角【分享到朋友圈】。最后确定转发即可。这样你就可以得到一篇你采集的文章或素材。
可以用新媒体管家
现在新闻客户端都可以上传文件。不是说你需要几个新闻客户端才能抓取某个网站的内容。只要打开客户端,就会有一个“上传文件”按钮。
目前比较常用的新闻客户端有:澎湃新闻、南方+、一点资讯、zaker旗下的“刷牙”、钱盆、梅花网等,百度一下就能看到相关教程了。
具体使用方法是点击上传文件按钮,选择要上传的文件上传完成后,在下方就能看到转发的别人已经上传完成的文件。
现在这类提问都是以'你在百度里看到的好像都这样'这种格式的吗???
有个破网站可以抓取新闻但是不能全部导出excel查看
可以直接复制链接到新闻客户端点击搜索就可以抓取文章了
干货 | 信息收集工具recon-ng超详细使用教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-07-21 08:23
本公众号提供的工具、教程、学习路线、精品文章均为原创或互联网收集,旨在提高网络安全技术水平为目的,只做技术研究,谨遵守国家相关法律法规,请勿用于违法用途,如果您对文章内容有疑问,可以尝试加入交流群讨论或留言私信,如有侵权请联系小编处理。
2
内容速览前言:
最近在找Recon-ng详细一点的教程,可是Google才发现资料都很零散而且不详细,所以我打算具体写一下。
Recon-ng在渗透过程中主要扮演信息收集工作的角色,同时也可以当作渗透工具,不过相关的攻击模块很少,只有自己扩展。
其实Recon-ng最大的优点就是模块化,功能可以自己任意扩展。只要想象力够丰富,这个就可以成为神器,下面为详细教程。
0×01安装1. 安装recon-ng及依赖文件:
git clone https://bitbucket.org/LaNMaSteR53/recon-ng.git #然后把其中的文件移动到你希望的目录即可,并加入path即可<br />
到其目录下运行recon-ng文件即可
./recon-ng<br />
第一次启动时你可能会被告知有什么依赖没有安装,根据提示把依赖安装即可
pip install xlsxwriter #ie<br />
#然后根据提示安装完即可
0×02 模块使用1. 启动部分
recon-ng -h<br />
可以看到上面的具体参数,常用的就‘-w’参数,我们这里新开一个工作区ptest
Recon-ng -w ptest<br />
输入help可查看帮助,下面用法已解释得很清楚.
2. 模块
Recon-ng有侦查,发现,汇报,和攻击四大块(import没发现有多大的用处,所以暂时为四大块),可用show modules查看有哪些模块。下面我具体介绍下各板块下比较好用的模块和具体用法。
(1) 侦查版块
Profiler模块: 查询某个用户名在那些网站(知名)有注册。
可用searchprofiler查询在具体路径
使用模块:userecon/profiles-profiles/profiler
查看用法:showinfo
根据提示,需要设置SOURCE选项,用命令:setSOURCEcesign
然后运行:run
查看结果(根据提示更新了profiles表,查看表的命令为show):showprofiles
这是我的用户名,上面的网站好像我只有注册过两个。这个脚本是可以扩展的,所以你可以扩展你想要查找的网站,关于模块的创建后面解释。
Hashes_org模块:反查哈希加密
#这个模块需要api key才能用,下面提一下api key的添加和删除<br />Keys list #查看现有的api keys<br />
Keys add hashes_api akshdkahsdhkhasdkjfhkshfdkasdf<br />Keys list #可看到api已被添加进去<br />
Keys delete hashes_api #删除key<br />#对于delete还可以删除表,如删除profiles的1-2行 Delete profiles 1-2#Api被添加进去后就可以用了(api的申请我就不介绍了) Set source e13dd027be0f2152ce387ac0ea83d863 Run #可以看到被解,加密i方式为md5<br />
Metacrawler模块:网站文件搜索(如pdf,xlsx文件等,其实就是googlehack技术)
Search metacrawler<br />Use recon/domains-contacts/metacrawler<br />Set source hdu.edu.cn<br />run<br />
Dev_diver模块:查找某个用户是否存在某些代码库
Search dev_diver<br />Use path-to/dev_diver<br />Show info<br />Set source cesign Run #结果如图所示<br />
Ipinfodb模块:查询ip的相关信息,如地理位置(这个功能要api)
Search ipinfodb<br />Use path-to/ipinfodb<br />Show info<br />Set source 104.238.148.9 run<br />
Brute_hosts模块:暴力破解子域名
Search brute_hosts<br />Use path-to/brute_hosts<br />Show info<br />Set source hdu.edu.cn Run Show hosts<br />
Google_site_web模块:相关域名查询(子域名)
Search google_site_web<br />Use path-to/google_site_web<br />Show info<br />Set source **** Run Show options:列出可用的选<br />
(2)发现版块
Interesting_files模块:查找某网站的敏感文件
命令跟前面一样
Search interesting_files<br />Use discovery/info_disclosure/interesting_files<br />Show info #查看用法,可以看到参数比较多,含义我就不解释了<br /><br />
我这里尝试一下自己的网站(可以自己添加敏感文件)
Set source jwcesign.studio<br />Set port 80<br />Set protocol http Run<br />
结果如下(没有敏感文件)
(3)攻击版块
command_injector模块:命令注入,多用于木马文件
Search command_injector<br />Use path-to/command_injector<br />Show info #可以看到具体的参数<br />set base_url http://172.16.227.128/other/a.php<br />
木马文件a.php代码如下:
Set parameters cmd=<br />run<br />
(4)报告版块
Html模块:把运行的结果生成html文件
Search html<br />Use path-to/html<br />Show info<br />Set creator cesign Set customer cesign run<br />
0×03模块的构建
前面都是软件自带的模块,如果我们想自己建立模块,该怎么办呢?
下面是教程
如果要建立自己的模块,在home目录下的’.recon-ng’下建立modules文件夹,然后在分别根据模块属性来建立文件,如建立侦查板块,需要建立recon文件夹,下面以我建立一个模块为例:
Cd ~<br />Cd .rcon-ng<br />Mkdir modules <br />Cd modules <br />Mkdir recon <br />Cd recon <br />Mkdir findproxy <br />Cd findproxy <br />Vim find_proxy.py<br />
模块文件主要的格式就是
from recon.core.module import BaseModule<br /><br />class Module(BaseModule): meta = { 'name': 'something...', 'author': ‘something...’, 'description': 'something...', 'query': something...' ##这个最好写清楚,方便别人查看用法 } def mudule_run(self[,type]): #some code,self参数可以用来获取一些api key等, type含有source的数据 Pass<br />
下面是我具体的代码,这是一个找代理的模块(httpproxy,httpsproxy,socks4proxy,sockts5proxy)
#-*- coding: utf-8 -*-<br />from recon.core.module import BaseModule<br />import re<br />from selenium import webdriver <br />from selenium.webdriver.common.desired_capabilities import DesiredCapabilities <br />from bs4 import BeautifulSoup <br />import subprocess import os <br />import urllib import copy <br />import time import jsbeautifier <br />class Module(BaseModule): meta = { 'name': 'Find free proxy...', 'author': 'Cesign', 'description': 'find defferent proxy, there are four kinds of proxy,http,https,socks4 and socks5, and the code is h,s,4,5....Enjoy!!!', 'query': 'find defferent proxy, there are four kinds of proxy,http,https,socks4 and socks5, and the code is h,s,4,5....Enjoy!!!' } def module_run(self,type): STYLE = { 'fore': { # 前景色 'black' : 30, # 黑色 'red' : 31, # 红色 'green' : 32, # 绿色 'yellow' : 33, # 黄色 'blue' : 34, # 蓝色 'purple' : 35, # 紫红色 'cyan' : 36, # 青蓝色 'white' : 37, # 白色 }, 'back' : { # 背景 'black' : 40, # 黑色 'red' : 41, # 红色 'green' : 42, # 绿色 'yellow' : 43, # 黄色 'blue' : 44, # 蓝色 'purple' : 45, # 紫红色 'cyan' : 46, # 青蓝色 'white' : 47, # 白色 }, 'mode' : { # 显示模式 'mormal' : 0, # 终端默认设置 'bold' : 1, # 高亮显示 'underline' : 4, # 使用下划线 'blink' : 5, # 闪烁 'invert' : 7, # 反白显示 'hide' : 8, # 不可见 }, 'default' : { 'end' : 0, }, } def UseStyle(string, mode = '', fore = '', back = ''): mode = '%s' % STYLE['mode'][mode] if STYLE['mode'].has_key(mode) else '' fore = '%s' % STYLE['fore'][fore] if STYLE['fore'].has_key(fore) else '' back = '%s' % STYLE['back'][back] if STYLE['back'].has_key(back) else '' style = ';'.join([s for s in [mode, fore, back] if s]) style = '\033[%sm' % style if style else '' end = '\033[%sm' % STYLE['default']['end'] if style else '' return '%s%s%s' % (style, string, end) print '[*] Please wait, it will take about 2 minutes...' dcap = dict(DesiredCapabilities.PHANTOMJS) dcap["phantomjs.page.settings.userAgent"] = ( "Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0" ) driver = webdriver.PhantomJS(desired_capabilities=dcap,service_log_path=r"/home/cesign/watchlog.log") driver.set_window_size(1920, 1080) driver.get('https://hidemy.name/en/proxy-list/?type='+str(type[0])+'#list') time.sleep(1) soup=BeautifulSoup(driver.page_source,'html.parser') allurl=soup.find_all(name='td') result={ 'h':lambda x:'http', 's':lambda x:'https', '4':lambda x:'socks4', '5':lambda x:'socks5', } i = 0 print UseStyle('[*] Search proxy: type:'+result[str(type[0])]('hello'),fore='blue') print UseStyle('[*] IP adress---Port---Country,City---Speed---Type---Anonymity---Last check',fore='blue') while True: try: part = [] part = allurl[i:i+7] i = i+7 print UseStyle('[*]'+part[0].text+'---'+part[1].text+'---'+part[2].text+'---'+part[3].text+'---'+part[4].text+'---'+part[5].text+'---'+part[6].text,fore='green') except: break driver.quit() <br />
然后调用模块:
Reload<br /><br />Search find_proxy<br /><br />Use path-to/find_proxy<br /><br />Show info<br /><br />Set source h Run<br /><br /> 查看全部
干货 | 信息收集工具recon-ng超详细使用教程
本公众号提供的工具、教程、学习路线、精品文章均为原创或互联网收集,旨在提高网络安全技术水平为目的,只做技术研究,谨遵守国家相关法律法规,请勿用于违法用途,如果您对文章内容有疑问,可以尝试加入交流群讨论或留言私信,如有侵权请联系小编处理。
2
内容速览前言:
最近在找Recon-ng详细一点的教程,可是Google才发现资料都很零散而且不详细,所以我打算具体写一下。
Recon-ng在渗透过程中主要扮演信息收集工作的角色,同时也可以当作渗透工具,不过相关的攻击模块很少,只有自己扩展。
其实Recon-ng最大的优点就是模块化,功能可以自己任意扩展。只要想象力够丰富,这个就可以成为神器,下面为详细教程。
0×01安装1. 安装recon-ng及依赖文件:
git clone https://bitbucket.org/LaNMaSteR53/recon-ng.git #然后把其中的文件移动到你希望的目录即可,并加入path即可<br />
到其目录下运行recon-ng文件即可
./recon-ng<br />
第一次启动时你可能会被告知有什么依赖没有安装,根据提示把依赖安装即可
pip install xlsxwriter #ie<br />
#然后根据提示安装完即可
0×02 模块使用1. 启动部分
recon-ng -h<br />
可以看到上面的具体参数,常用的就‘-w’参数,我们这里新开一个工作区ptest
Recon-ng -w ptest<br />
输入help可查看帮助,下面用法已解释得很清楚.
2. 模块
Recon-ng有侦查,发现,汇报,和攻击四大块(import没发现有多大的用处,所以暂时为四大块),可用show modules查看有哪些模块。下面我具体介绍下各板块下比较好用的模块和具体用法。
(1) 侦查版块
Profiler模块: 查询某个用户名在那些网站(知名)有注册。
可用searchprofiler查询在具体路径
使用模块:userecon/profiles-profiles/profiler
查看用法:showinfo
根据提示,需要设置SOURCE选项,用命令:setSOURCEcesign
然后运行:run
查看结果(根据提示更新了profiles表,查看表的命令为show):showprofiles
这是我的用户名,上面的网站好像我只有注册过两个。这个脚本是可以扩展的,所以你可以扩展你想要查找的网站,关于模块的创建后面解释。
Hashes_org模块:反查哈希加密
#这个模块需要api key才能用,下面提一下api key的添加和删除<br />Keys list #查看现有的api keys<br />
Keys add hashes_api akshdkahsdhkhasdkjfhkshfdkasdf<br />Keys list #可看到api已被添加进去<br />
Keys delete hashes_api #删除key<br />#对于delete还可以删除表,如删除profiles的1-2行 Delete profiles 1-2#Api被添加进去后就可以用了(api的申请我就不介绍了) Set source e13dd027be0f2152ce387ac0ea83d863 Run #可以看到被解,加密i方式为md5<br />
Metacrawler模块:网站文件搜索(如pdf,xlsx文件等,其实就是googlehack技术)
Search metacrawler<br />Use recon/domains-contacts/metacrawler<br />Set source hdu.edu.cn<br />run<br />
Dev_diver模块:查找某个用户是否存在某些代码库
Search dev_diver<br />Use path-to/dev_diver<br />Show info<br />Set source cesign Run #结果如图所示<br />
Ipinfodb模块:查询ip的相关信息,如地理位置(这个功能要api)
Search ipinfodb<br />Use path-to/ipinfodb<br />Show info<br />Set source 104.238.148.9 run<br />
Brute_hosts模块:暴力破解子域名
Search brute_hosts<br />Use path-to/brute_hosts<br />Show info<br />Set source hdu.edu.cn Run Show hosts<br />
Google_site_web模块:相关域名查询(子域名)
Search google_site_web<br />Use path-to/google_site_web<br />Show info<br />Set source **** Run Show options:列出可用的选<br />
(2)发现版块
Interesting_files模块:查找某网站的敏感文件
命令跟前面一样
Search interesting_files<br />Use discovery/info_disclosure/interesting_files<br />Show info #查看用法,可以看到参数比较多,含义我就不解释了<br /><br />
我这里尝试一下自己的网站(可以自己添加敏感文件)
Set source jwcesign.studio<br />Set port 80<br />Set protocol http Run<br />
结果如下(没有敏感文件)
(3)攻击版块
command_injector模块:命令注入,多用于木马文件
Search command_injector<br />Use path-to/command_injector<br />Show info #可以看到具体的参数<br />set base_url http://172.16.227.128/other/a.php<br />
木马文件a.php代码如下:
Set parameters cmd=<br />run<br />
(4)报告版块
Html模块:把运行的结果生成html文件
Search html<br />Use path-to/html<br />Show info<br />Set creator cesign Set customer cesign run<br />
0×03模块的构建
前面都是软件自带的模块,如果我们想自己建立模块,该怎么办呢?
下面是教程
如果要建立自己的模块,在home目录下的’.recon-ng’下建立modules文件夹,然后在分别根据模块属性来建立文件,如建立侦查板块,需要建立recon文件夹,下面以我建立一个模块为例:
Cd ~<br />Cd .rcon-ng<br />Mkdir modules <br />Cd modules <br />Mkdir recon <br />Cd recon <br />Mkdir findproxy <br />Cd findproxy <br />Vim find_proxy.py<br />
模块文件主要的格式就是
from recon.core.module import BaseModule<br /><br />class Module(BaseModule): meta = { 'name': 'something...', 'author': ‘something...’, 'description': 'something...', 'query': something...' ##这个最好写清楚,方便别人查看用法 } def mudule_run(self[,type]): #some code,self参数可以用来获取一些api key等, type含有source的数据 Pass<br />
下面是我具体的代码,这是一个找代理的模块(httpproxy,httpsproxy,socks4proxy,sockts5proxy)
#-*- coding: utf-8 -*-<br />from recon.core.module import BaseModule<br />import re<br />from selenium import webdriver <br />from selenium.webdriver.common.desired_capabilities import DesiredCapabilities <br />from bs4 import BeautifulSoup <br />import subprocess import os <br />import urllib import copy <br />import time import jsbeautifier <br />class Module(BaseModule): meta = { 'name': 'Find free proxy...', 'author': 'Cesign', 'description': 'find defferent proxy, there are four kinds of proxy,http,https,socks4 and socks5, and the code is h,s,4,5....Enjoy!!!', 'query': 'find defferent proxy, there are four kinds of proxy,http,https,socks4 and socks5, and the code is h,s,4,5....Enjoy!!!' } def module_run(self,type): STYLE = { 'fore': { # 前景色 'black' : 30, # 黑色 'red' : 31, # 红色 'green' : 32, # 绿色 'yellow' : 33, # 黄色 'blue' : 34, # 蓝色 'purple' : 35, # 紫红色 'cyan' : 36, # 青蓝色 'white' : 37, # 白色 }, 'back' : { # 背景 'black' : 40, # 黑色 'red' : 41, # 红色 'green' : 42, # 绿色 'yellow' : 43, # 黄色 'blue' : 44, # 蓝色 'purple' : 45, # 紫红色 'cyan' : 46, # 青蓝色 'white' : 47, # 白色 }, 'mode' : { # 显示模式 'mormal' : 0, # 终端默认设置 'bold' : 1, # 高亮显示 'underline' : 4, # 使用下划线 'blink' : 5, # 闪烁 'invert' : 7, # 反白显示 'hide' : 8, # 不可见 }, 'default' : { 'end' : 0, }, } def UseStyle(string, mode = '', fore = '', back = ''): mode = '%s' % STYLE['mode'][mode] if STYLE['mode'].has_key(mode) else '' fore = '%s' % STYLE['fore'][fore] if STYLE['fore'].has_key(fore) else '' back = '%s' % STYLE['back'][back] if STYLE['back'].has_key(back) else '' style = ';'.join([s for s in [mode, fore, back] if s]) style = '\033[%sm' % style if style else '' end = '\033[%sm' % STYLE['default']['end'] if style else '' return '%s%s%s' % (style, string, end) print '[*] Please wait, it will take about 2 minutes...' dcap = dict(DesiredCapabilities.PHANTOMJS) dcap["phantomjs.page.settings.userAgent"] = ( "Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0" ) driver = webdriver.PhantomJS(desired_capabilities=dcap,service_log_path=r"/home/cesign/watchlog.log") driver.set_window_size(1920, 1080) driver.get('https://hidemy.name/en/proxy-list/?type='+str(type[0])+'#list') time.sleep(1) soup=BeautifulSoup(driver.page_source,'html.parser') allurl=soup.find_all(name='td') result={ 'h':lambda x:'http', 's':lambda x:'https', '4':lambda x:'socks4', '5':lambda x:'socks5', } i = 0 print UseStyle('[*] Search proxy: type:'+result[str(type[0])]('hello'),fore='blue') print UseStyle('[*] IP adress---Port---Country,City---Speed---Type---Anonymity---Last check',fore='blue') while True: try: part = [] part = allurl[i:i+7] i = i+7 print UseStyle('[*]'+part[0].text+'---'+part[1].text+'---'+part[2].text+'---'+part[3].text+'---'+part[4].text+'---'+part[5].text+'---'+part[6].text,fore='green') except: break driver.quit() <br />
然后调用模块:
Reload<br /><br />Search find_proxy<br /><br />Use path-to/find_proxy<br /><br />Show info<br /><br />Set source h Run<br /><br />
一招教你搞定二维码,再也不用担心被忽悠了!
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-07-08 04:05
工具采集文章、微信、抖音、搜狗网页采集、采集联系人等!合集获取方式:就是点赞啊什么的把我给截了不要问我要二维码哦!!!每天持续更新各种实用小技巧!!!
二维码采集是做微信营销的最好的方法,什么有趣的东西都可以采集出来,不同的渠道用不同的二维码,让你瞬间吸引客户,想不吸引都难。如果想要这样的二维码,可以加我微信。想要最专业的干货,最实用的方法。可以私聊我。
自从一个朋友推荐我用二维斑马app,现在家里换扫地机器人,我都会自己下载一个,
有广告嫌疑的话请马起,我先匿了!二维斑马官网有免费版和付费版,都是扫描二维码可以有免费和收费版本,要看你具体的需求了!(很简单的方法,你百度一下就出来了)如何做采集网页,自己去关注一些二维斑马官方号,里面就有教程,教你怎么采集网页,
你有没有想过,如果本来想做一个关注公众号的服务号,却因为限制太多而放弃?看起来二维码几秒钟就可以扫完,却要打一个1-2m的包,极不方便,那么二维斑马凭什么可以帮你搞定这个问题呢?答案很简单,因为它就是做采集工具的。扫一扫二维码,只需要一秒钟,就可以把你想要的网页直接发到你的公众号了。注册二维斑马app后,可以免费注册一个这样的账号,还可以免费获得1个免费的5000条二维码:如何从海量网页中快速提取你要的内容,并在公众号中推送?从哪里快速找到足够优质的文章素材?通过二维斑马几分钟就可以搞定!。 查看全部
一招教你搞定二维码,再也不用担心被忽悠了!
工具采集文章、微信、抖音、搜狗网页采集、采集联系人等!合集获取方式:就是点赞啊什么的把我给截了不要问我要二维码哦!!!每天持续更新各种实用小技巧!!!
二维码采集是做微信营销的最好的方法,什么有趣的东西都可以采集出来,不同的渠道用不同的二维码,让你瞬间吸引客户,想不吸引都难。如果想要这样的二维码,可以加我微信。想要最专业的干货,最实用的方法。可以私聊我。
自从一个朋友推荐我用二维斑马app,现在家里换扫地机器人,我都会自己下载一个,
有广告嫌疑的话请马起,我先匿了!二维斑马官网有免费版和付费版,都是扫描二维码可以有免费和收费版本,要看你具体的需求了!(很简单的方法,你百度一下就出来了)如何做采集网页,自己去关注一些二维斑马官方号,里面就有教程,教你怎么采集网页,
你有没有想过,如果本来想做一个关注公众号的服务号,却因为限制太多而放弃?看起来二维码几秒钟就可以扫完,却要打一个1-2m的包,极不方便,那么二维斑马凭什么可以帮你搞定这个问题呢?答案很简单,因为它就是做采集工具的。扫一扫二维码,只需要一秒钟,就可以把你想要的网页直接发到你的公众号了。注册二维斑马app后,可以免费注册一个这样的账号,还可以免费获得1个免费的5000条二维码:如何从海量网页中快速提取你要的内容,并在公众号中推送?从哪里快速找到足够优质的文章素材?通过二维斑马几分钟就可以搞定!。
文章采集从1.0到2.0的另一种高级应用,无豆也能下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-06-17 20:00
网络每天都诞生成千上万篇文章每天也都有上亿的读者在阅读文章数以万计的写作者在查找资料的同时也都有着取巧的冲动“这篇文章的这段话写得不错复制下来作为素材参考一下”
你就看到了下面的画面
没错这就是平台为了保护作者所设立的
但毕竟这么多的平台我一个月也不可能用到一篇文章再说也可能只用一段你让我们每个平台都充值毕竟不是每个写手作者都能支付的起这些费用也有可能本身就是学生党就是为了毕业设计引用一下办法除了上次分享的从1.0到2.0里面的OCR识别外再给分享一款高级使用方法它只对某豆有作用就算你不是会员,也没有豆也没关系。
就是这款软件,你只需要把文章的地址复制到这个工具栏里,点击下载记得选择你去除水印软件就自动帮你下载了软件现在已经完成了对文章的下载看看效果吧
这就是两篇文章的对比效果这款小工具下载完文章以后虽然格式是PDF格式的但是打开以后你会发现有点类似于截图,PDF里存放的是图片无法进行编辑,就算你通过PDF转为DOC也是一样
“这不是我们需要的”你可能会说我还是用OCR直接网上截取图片吧如果你就用一段,那无疑这是最快的方法但是如果你需要一篇文章呢还想要能编辑呢,当然是有方法的
通过我们这款PDF软件就能轻松实现你的需求
软件打开文件以后我们看到这里有一个图像按钮点击图像按钮,选择识别图像
第一次调用我们会发现1这里什么都没有需要我们选择2进行添加
根据你需要识别的文字语言选择对应的语言就可以我们这里选择中文简体系统会自动为我们下载对应的语言包
安装完成以后我们会发现确定按钮不能用这需要我们关闭后,从新打开识别图像就可以了
现在我们就可以使用确定按钮了来进行我们的文字识别直接点击确定就可以了现在文字就能编辑了
点击下方小卡片关注【海鲜不是仙】
在对话框中输入『20220331』获取软件!
关注不迷路 查看全部
文章采集从1.0到2.0的另一种高级应用,无豆也能下载
网络每天都诞生成千上万篇文章每天也都有上亿的读者在阅读文章数以万计的写作者在查找资料的同时也都有着取巧的冲动“这篇文章的这段话写得不错复制下来作为素材参考一下”
你就看到了下面的画面
没错这就是平台为了保护作者所设立的
但毕竟这么多的平台我一个月也不可能用到一篇文章再说也可能只用一段你让我们每个平台都充值毕竟不是每个写手作者都能支付的起这些费用也有可能本身就是学生党就是为了毕业设计引用一下办法除了上次分享的从1.0到2.0里面的OCR识别外再给分享一款高级使用方法它只对某豆有作用就算你不是会员,也没有豆也没关系。
就是这款软件,你只需要把文章的地址复制到这个工具栏里,点击下载记得选择你去除水印软件就自动帮你下载了软件现在已经完成了对文章的下载看看效果吧
这就是两篇文章的对比效果这款小工具下载完文章以后虽然格式是PDF格式的但是打开以后你会发现有点类似于截图,PDF里存放的是图片无法进行编辑,就算你通过PDF转为DOC也是一样
“这不是我们需要的”你可能会说我还是用OCR直接网上截取图片吧如果你就用一段,那无疑这是最快的方法但是如果你需要一篇文章呢还想要能编辑呢,当然是有方法的
通过我们这款PDF软件就能轻松实现你的需求
软件打开文件以后我们看到这里有一个图像按钮点击图像按钮,选择识别图像
第一次调用我们会发现1这里什么都没有需要我们选择2进行添加
根据你需要识别的文字语言选择对应的语言就可以我们这里选择中文简体系统会自动为我们下载对应的语言包
安装完成以后我们会发现确定按钮不能用这需要我们关闭后,从新打开识别图像就可以了
现在我们就可以使用确定按钮了来进行我们的文字识别直接点击确定就可以了现在文字就能编辑了
点击下方小卡片关注【海鲜不是仙】
在对话框中输入『20220331』获取软件!
关注不迷路
工具采集特定关键词?都可以,lee,,liu,
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-06-01 20:04
工具采集文章标题?采集特定关键词?都可以,lee,liu,yc大佬都可以做,新媒体资讯最好的采集平台就是百度热点,这个可以到微信搜索的搜索平台里面去搜索,找到我说的这个就行,当然,找百度微信的搜索平台一般就在"关键词"下面输入热门关键词进行搜索,这样的热搜文章都是最新的
百度搜索再下拉框选一些内容大的。你直接按照文章一般来找一个。
lee大神!
个人觉得手机看找微信搜索也不错。官方强制下载的方式我推荐手机新闻客户端转载到浏览器,搜索框内词内搜索。
我一般用第一页微信公众号的二维码,官方热点话题一般热度不会太高,
baobaomaipile这个平台好像很多大佬都在用,
每日微刊吧,这个你上百度搜索时一般会有百度的热门内容推荐,根据你所关注的话题类型来找对应领域的微信号或者公众号,这是我们上次分享的一个免费微信公众号推荐平台,好不好用,
推荐搜狐乐库,可以长按关键词自动进行语音识别,直接下载,很方便。还可以直接在百度百科中搜索,很方便,
我本人自己做了一个微信公众号,每日会推送一些自己感兴趣的热点和事件,是一个专门搜集快讯和新闻的公众号。目前每周都会更新一篇快讯(生活类、社会热点类、国内外大事类),大部分快讯我都是自己去搜集的,另外一部分一直是人肉收集整理的,这方面很乐意大家一起来参与。一起来挖掘更多有价值的微信公众号吧!目前公众号已经发出300多篇快讯。
其中很多快讯我是一个一个编辑过的,不过我总觉得不是每篇都能收录,有时候会有这个不能收录那个不能收录的情况,现在感觉每个粉丝都要花1到5分钟,还是很麻烦的。不过没关系,我们这边多少也花了一些功夫,目前正在整理不同的快讯,等着慢慢收录。而对我个人来说,即使只是每周发一篇热点+新闻,都觉得是浪费时间。很多人应该知道“知乎日报”,最近看到有人说“知乎日报”没法挖掘这类热点,是不是事实呢?搜狗浏览器+上知乎日报+发现好问题,基本上我也就是这么干的。
所以虽然我的微信公众号收录的不多,但以后慢慢也是可以积累一些的。而且这类问题已经不少了,我也是一直在找办法。其实个人还是觉得新闻在微信推送时大家读起来更方便,这是比较遗憾的。毕竟我能接触到的东西是信息碎片化的,我也一直觉得新闻写得不如文章更长。所以如果单纯为了看新闻而产生了阅读的冲动,并不。 查看全部
工具采集特定关键词?都可以,lee,,liu,
工具采集文章标题?采集特定关键词?都可以,lee,liu,yc大佬都可以做,新媒体资讯最好的采集平台就是百度热点,这个可以到微信搜索的搜索平台里面去搜索,找到我说的这个就行,当然,找百度微信的搜索平台一般就在"关键词"下面输入热门关键词进行搜索,这样的热搜文章都是最新的
百度搜索再下拉框选一些内容大的。你直接按照文章一般来找一个。
lee大神!
个人觉得手机看找微信搜索也不错。官方强制下载的方式我推荐手机新闻客户端转载到浏览器,搜索框内词内搜索。
我一般用第一页微信公众号的二维码,官方热点话题一般热度不会太高,
baobaomaipile这个平台好像很多大佬都在用,
每日微刊吧,这个你上百度搜索时一般会有百度的热门内容推荐,根据你所关注的话题类型来找对应领域的微信号或者公众号,这是我们上次分享的一个免费微信公众号推荐平台,好不好用,
推荐搜狐乐库,可以长按关键词自动进行语音识别,直接下载,很方便。还可以直接在百度百科中搜索,很方便,
我本人自己做了一个微信公众号,每日会推送一些自己感兴趣的热点和事件,是一个专门搜集快讯和新闻的公众号。目前每周都会更新一篇快讯(生活类、社会热点类、国内外大事类),大部分快讯我都是自己去搜集的,另外一部分一直是人肉收集整理的,这方面很乐意大家一起来参与。一起来挖掘更多有价值的微信公众号吧!目前公众号已经发出300多篇快讯。
其中很多快讯我是一个一个编辑过的,不过我总觉得不是每篇都能收录,有时候会有这个不能收录那个不能收录的情况,现在感觉每个粉丝都要花1到5分钟,还是很麻烦的。不过没关系,我们这边多少也花了一些功夫,目前正在整理不同的快讯,等着慢慢收录。而对我个人来说,即使只是每周发一篇热点+新闻,都觉得是浪费时间。很多人应该知道“知乎日报”,最近看到有人说“知乎日报”没法挖掘这类热点,是不是事实呢?搜狗浏览器+上知乎日报+发现好问题,基本上我也就是这么干的。
所以虽然我的微信公众号收录的不多,但以后慢慢也是可以积累一些的。而且这类问题已经不少了,我也是一直在找办法。其实个人还是觉得新闻在微信推送时大家读起来更方便,这是比较遗憾的。毕竟我能接触到的东西是信息碎片化的,我也一直觉得新闻写得不如文章更长。所以如果单纯为了看新闻而产生了阅读的冲动,并不。
素材采集——伪原创修改后原创在算法变动下
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-05-30 12:13
工具采集文章素材。优化伪原创,在百度、谷歌等搜索引擎进行原创文章的检测。素材采集——伪原创——伪原创修改后原创在抓取算法变动下,会避免原创工具采集文章的封面,标题等采集文章分享。我做的是网络赚钱的公众号,文章全部是pdf格式的,在公众号上面下载到手机上面进行修改编辑。
楼上说的都是伪原创,不是伪原创的功能强大到能提取视频中的音频。想要做好原创的有效办法就是搜索爆文,手动引用爆文中所有文章的内容,直接粘贴。举例:我要引用百度金融包括浦发基金,农业银行app大额分期利率变动,教育培训机构注意事项等内容。这是百度金融包括浦发基金,农业银行app大额分期利率变动,教育培训机构注意事项等内容。
应该怎么处理呢?首先,想要引用文章,首先需要引用文章所在网站的标题,网站网址,文章链接。同时需要搜索词相关的网站。首先拿浦发基金为例。你百度能搜索到浦发基金他们的内容,但是不知道他们是哪家公司。如何实现我要搜索浦发基金其他公司名称呢?正常查找能查到2篇和浦发基金相关的文章。但是我们发现了一个很有意思的现象,每一家基金公司的公众号回复率都特别低,只有浦发基金公司能引领热点。
那么是不是可以想办法去改变这个局面。我们可以跟不同家基金公司的公众号交流,询问引用相关文章的用途,对方一般都会跟你明确需要引用来做什么。文章如下:其实这种方法是个人对个人的,但是如果有大号愿意来引用,比如方橙这样的大v当然最好了。如果没有,或者是微信公众号审核的特别严格,你可以把文章百度翻一下有没有别人做过的一些文章或者相关文章,直接用就好了。【比如方橙】。 查看全部
素材采集——伪原创修改后原创在算法变动下
工具采集文章素材。优化伪原创,在百度、谷歌等搜索引擎进行原创文章的检测。素材采集——伪原创——伪原创修改后原创在抓取算法变动下,会避免原创工具采集文章的封面,标题等采集文章分享。我做的是网络赚钱的公众号,文章全部是pdf格式的,在公众号上面下载到手机上面进行修改编辑。
楼上说的都是伪原创,不是伪原创的功能强大到能提取视频中的音频。想要做好原创的有效办法就是搜索爆文,手动引用爆文中所有文章的内容,直接粘贴。举例:我要引用百度金融包括浦发基金,农业银行app大额分期利率变动,教育培训机构注意事项等内容。这是百度金融包括浦发基金,农业银行app大额分期利率变动,教育培训机构注意事项等内容。
应该怎么处理呢?首先,想要引用文章,首先需要引用文章所在网站的标题,网站网址,文章链接。同时需要搜索词相关的网站。首先拿浦发基金为例。你百度能搜索到浦发基金他们的内容,但是不知道他们是哪家公司。如何实现我要搜索浦发基金其他公司名称呢?正常查找能查到2篇和浦发基金相关的文章。但是我们发现了一个很有意思的现象,每一家基金公司的公众号回复率都特别低,只有浦发基金公司能引领热点。
那么是不是可以想办法去改变这个局面。我们可以跟不同家基金公司的公众号交流,询问引用相关文章的用途,对方一般都会跟你明确需要引用来做什么。文章如下:其实这种方法是个人对个人的,但是如果有大号愿意来引用,比如方橙这样的大v当然最好了。如果没有,或者是微信公众号审核的特别严格,你可以把文章百度翻一下有没有别人做过的一些文章或者相关文章,直接用就好了。【比如方橙】。
工具采集文章首先想采集什么呢?有人质疑不是可以采集全网的图片吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-05-18 04:01
工具采集文章首先想采集什么呢?大部分的人会选择采集国内某某某的标题、题图、字数。这样的文章是比较多的,不容易做到一一检查。字数也可以采集,但也不容易保存字数是否超过30个字。关键词如果想采集某一篇文章的话,可以分开采集,但同时也没办法获取全部的关键词,必须筛选并且把关键词提取出来。
1、登录迅捷文章采集器:,点击首页的采集按钮,
2、采集完毕后点击保存到文件里面的‘selected’文件夹,里面就是需要采集的文章了。
3、通过浏览器查看文章的排序、字数等信息,是否是你想要的。
pc端首页——顶部工具栏里——采集中心,可采集:国外图片:;国内图片:大家看看。
首先你要会上网。
十分强大。迅捷标题采集器的采集功能介绍:首先登录迅捷文章采集器官网。在首页上面可以看到有我采集图片,我采集字数,我采集排名,还有就是可以查看不同的数据。任意一项都能让你采集到想要的数据。有人质疑不是可以采集全网的图片吗?其实不然。可以采集图片。但是不是全网的,而是你可以在采集我采集中心采集任意一个数据。没有用工具采集的时候,你必须手动去寻找想要的图片。用工具后你只需要采集个采集数据数就可以了。 查看全部
工具采集文章首先想采集什么呢?有人质疑不是可以采集全网的图片吗?
工具采集文章首先想采集什么呢?大部分的人会选择采集国内某某某的标题、题图、字数。这样的文章是比较多的,不容易做到一一检查。字数也可以采集,但也不容易保存字数是否超过30个字。关键词如果想采集某一篇文章的话,可以分开采集,但同时也没办法获取全部的关键词,必须筛选并且把关键词提取出来。
1、登录迅捷文章采集器:,点击首页的采集按钮,
2、采集完毕后点击保存到文件里面的‘selected’文件夹,里面就是需要采集的文章了。
3、通过浏览器查看文章的排序、字数等信息,是否是你想要的。
pc端首页——顶部工具栏里——采集中心,可采集:国外图片:;国内图片:大家看看。
首先你要会上网。
十分强大。迅捷标题采集器的采集功能介绍:首先登录迅捷文章采集器官网。在首页上面可以看到有我采集图片,我采集字数,我采集排名,还有就是可以查看不同的数据。任意一项都能让你采集到想要的数据。有人质疑不是可以采集全网的图片吗?其实不然。可以采集图片。但是不是全网的,而是你可以在采集我采集中心采集任意一个数据。没有用工具采集的时候,你必须手动去寻找想要的图片。用工具后你只需要采集个采集数据数就可以了。
工具采集文章中的关键词,改的有点不好
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-05-15 23:00
工具采集文章中关键词,或者采集原文章中的关键词,
这是原来的一篇文章,改的有点不好。虽然改的一般,但是依然改变不了是我写的哈哈哈,读者们稍微有个思路看就好。
可以通过分词功能,
看懂了吗,
1)通过生意参谋的商品词,进行关键词搜索排名查询2)根据销量排名,选择asin来进行采集。
谢邀在生意参谋-市场行情里,把商品标题复制下来,
参考生意参谋的商品词
搜店铺名字啊。
直接使用微店接口,
通过生意参谋的搜索框上的“”接口。
搜商品,
a.直接使用微店接口,
用直接微店接口,
直接用微店接口。
百度联盟,
首先通过生意参谋批量采集商品信息,然后筛选出需要的关键词,然后再进行合并,不过这里有两个极限,一个是对于页数较少,商品信息没有那么多的情况下,不建议这么做,更多可以到百度联盟查看商品信息,获取对应关键词。
用百度联盟获取商品标题,进行合并就好了啊,
从商品信息出发查
直接用微店接口就可以啊。基础信息就是那么简单。然后进行合并,就可以把一篇文章变成好几篇文章了。 查看全部
工具采集文章中的关键词,改的有点不好
工具采集文章中关键词,或者采集原文章中的关键词,
这是原来的一篇文章,改的有点不好。虽然改的一般,但是依然改变不了是我写的哈哈哈,读者们稍微有个思路看就好。
可以通过分词功能,
看懂了吗,
1)通过生意参谋的商品词,进行关键词搜索排名查询2)根据销量排名,选择asin来进行采集。
谢邀在生意参谋-市场行情里,把商品标题复制下来,
参考生意参谋的商品词
搜店铺名字啊。
直接使用微店接口,
通过生意参谋的搜索框上的“”接口。
搜商品,
a.直接使用微店接口,
用直接微店接口,
直接用微店接口。
百度联盟,
首先通过生意参谋批量采集商品信息,然后筛选出需要的关键词,然后再进行合并,不过这里有两个极限,一个是对于页数较少,商品信息没有那么多的情况下,不建议这么做,更多可以到百度联盟查看商品信息,获取对应关键词。
用百度联盟获取商品标题,进行合并就好了啊,
从商品信息出发查
直接用微店接口就可以啊。基础信息就是那么简单。然后进行合并,就可以把一篇文章变成好几篇文章了。
工具采集文章(数据收集对于网站的SEO优化具体做了哪些设置?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-04-18 07:17
数据采集,最近很多站长问我有没有好用的文章数据采集系统,因为不同cms的文章采集伪原创版本是一个片头疼。我们都知道网站的收录离不开文章的每日更新。网站使用收录,可以达到网站的SEO排名。数据采集在网站 的收录 中发挥着重要作用。文章@ >数据采集系统让我们的网站定时采集伪原创刊物一键自动推送到搜狗、百度、神马、360。让网站让搜索引擎收录更快,保护网站文章的原创性能。
网页的收录和网站SEO优化数据采集的具体设置是什么,我们来看看有哪些?数据集合采集的文章都是在伪原创之后发布的,这一点对于网站收录来说是非常明显的,即使是重复的内容,网站也可以实现二次采集。所以,使用大量的长尾 关键词 来做 网站 的数据采集。采集速度快,数据完整性高。独有的数据采集多模板功能+智能纠错模式,保证结果数据100%完整。
数据采集还可以增加蜘蛛抓取页面的频率。如果页面不是收录,导入内外链接也可以增加页面是收录的概率。数据采集基础的优化也可以增加页面被收录的概率,比如简洁的代码,尽量避免frame、flash等搜索引擎无法识别的内容。确认是否屏蔽百度蜘蛛抓取等。数据采集适用于任意网页采集。只要你能在浏览器中看到内容,几乎任何数据采集都可以按照你需要的格式进行采集。采集 支持 JS 输出内容。
如何通过数据采集进行网站优化?首先,数据采集最大的特点就是不需要定义任何采集规则,只要选择你感兴趣的关键词,就可以关键词pan 采集。因为如果一个网站想要在搜索引擎中获得良好的listing和排名,这些网站中的代码细节就必须优化。现场优化也很重要。多说,因为只有在网站SEO站打好基础,才能更好的参与SEO排名。
数据采集有网站的TDK的SEO优化设置,数据采集批量监控管理不同的cms网站数据(无论你的网站是Empire, Yiyou, ZBLOG, < @织梦、WP、云游cms、人人展cms、飞飞cms、小旋风、站群、PBoot、苹果、美图、搜外等主要cms,可以批量管理采集伪原创,同时发布推送工具)。TDK 是 SEO 行业的专用术语。如果你不是SEO行业的从业者,是不可能知道TDK是什么意思的。TDK,这个网站,是对三个标签的优化,title、description和关键词,这三个标签是网站的三个元素。中文对应的是网站 的标题、描述和关键词。
网站SEO采集数据的目的是为了获得免费的关键词SEO排名,根据不同的关键词和公司业务获取精准的用户流量,以最低的成本创造最大的价值。但是网站数据采集是一项长期持续的工作,有效期有点长。具体情况需要根据不同的网站进行分析,才能做出相应的回答。但优势也很明显,就是成本低,持续时间长。只要网站没有发生不可控的事故,只要网站正常运行,内容更新正常,网站的流量排名将持续保持,为广大用户带来持续收益公司以较低的成本。更高的回报。 查看全部
工具采集文章(数据收集对于网站的SEO优化具体做了哪些设置?)
数据采集,最近很多站长问我有没有好用的文章数据采集系统,因为不同cms的文章采集伪原创版本是一个片头疼。我们都知道网站的收录离不开文章的每日更新。网站使用收录,可以达到网站的SEO排名。数据采集在网站 的收录 中发挥着重要作用。文章@ >数据采集系统让我们的网站定时采集伪原创刊物一键自动推送到搜狗、百度、神马、360。让网站让搜索引擎收录更快,保护网站文章的原创性能。
网页的收录和网站SEO优化数据采集的具体设置是什么,我们来看看有哪些?数据集合采集的文章都是在伪原创之后发布的,这一点对于网站收录来说是非常明显的,即使是重复的内容,网站也可以实现二次采集。所以,使用大量的长尾 关键词 来做 网站 的数据采集。采集速度快,数据完整性高。独有的数据采集多模板功能+智能纠错模式,保证结果数据100%完整。
数据采集还可以增加蜘蛛抓取页面的频率。如果页面不是收录,导入内外链接也可以增加页面是收录的概率。数据采集基础的优化也可以增加页面被收录的概率,比如简洁的代码,尽量避免frame、flash等搜索引擎无法识别的内容。确认是否屏蔽百度蜘蛛抓取等。数据采集适用于任意网页采集。只要你能在浏览器中看到内容,几乎任何数据采集都可以按照你需要的格式进行采集。采集 支持 JS 输出内容。
如何通过数据采集进行网站优化?首先,数据采集最大的特点就是不需要定义任何采集规则,只要选择你感兴趣的关键词,就可以关键词pan 采集。因为如果一个网站想要在搜索引擎中获得良好的listing和排名,这些网站中的代码细节就必须优化。现场优化也很重要。多说,因为只有在网站SEO站打好基础,才能更好的参与SEO排名。
数据采集有网站的TDK的SEO优化设置,数据采集批量监控管理不同的cms网站数据(无论你的网站是Empire, Yiyou, ZBLOG, < @织梦、WP、云游cms、人人展cms、飞飞cms、小旋风、站群、PBoot、苹果、美图、搜外等主要cms,可以批量管理采集伪原创,同时发布推送工具)。TDK 是 SEO 行业的专用术语。如果你不是SEO行业的从业者,是不可能知道TDK是什么意思的。TDK,这个网站,是对三个标签的优化,title、description和关键词,这三个标签是网站的三个元素。中文对应的是网站 的标题、描述和关键词。
网站SEO采集数据的目的是为了获得免费的关键词SEO排名,根据不同的关键词和公司业务获取精准的用户流量,以最低的成本创造最大的价值。但是网站数据采集是一项长期持续的工作,有效期有点长。具体情况需要根据不同的网站进行分析,才能做出相应的回答。但优势也很明显,就是成本低,持续时间长。只要网站没有发生不可控的事故,只要网站正常运行,内容更新正常,网站的流量排名将持续保持,为广大用户带来持续收益公司以较低的成本。更高的回报。
工具采集文章(简悦周报:如何建立自己的工作流工作流比工具? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-04-07 20:00
)
本周报也可以在【建月扩展→选项页面→右下角→消息中心】查看。
简悦周报涵盖:新用户指南/简单阅读模式使用技巧/常见问题的处理和解决方案/与其他生产力工具的交互/简悦用户提供的基于简悦的工作流程等。
每份周报都会推送到以下渠道:
我在工具使用视图⤴️中提到了不使用一体化工具的陷阱,并展示了我使用的工作流程,但没有深入讨论如何在这些工具之间进行选择。
对于一些“新进”用户来说,众多产品中该如何选择?有没有更科学的方法来帮你解决?
如果你也有这个疑问,可以看看尖月社区资深用户Spike112的这个群文章⤴️。
工作流程的祛魅:从工具、阅读到写作
万花筒工作流程的背后是什么?您如何为自己选择合适的工具并创建自己的工作流程?本文章将从元认知的角度分析和反思工作流程,力求为读者找到一个指导性的解决方案。
这个文章主要分为四个部分。如何选择合适的工具
工具是工作流的基础。那么,如何选择合适的工具呢?文章从用户、工具、对象三个维度综合分析选择工具的标准。
请把原文移到这里。如何建立自己的工作流程
工作流比工具更重要,这篇 文章 文章详细介绍了构建工作流的原因、原则和注意事项。
请把原文移到这里。如何创建阅读工作流程
本文章重点关注常见的输入-阅读工作流程,主要从采集→阅读→记笔记→记忆→创作分享等,全面审视阅读工作流程中存在的问题并提出相应的解决方案。建议。
请把原文移到这里。如何创建写作工作流程
这篇文章文章围绕着一个共同的输出,写作工作流程,把写作看作是一种与自己对话的思维方式,一种与外界对话的交流方式。此外,对写作流程提出了一些反思建议,包括写在当下(只是写作)、思考和写作合二为一(写作就是思考)、重构写作流程(从预写到重写)。
请把原文移到这里。最后
这篇文章本来就是小众的,我有幸成为了这个文章的第一个读者,文章很棒,就是太长太硬核了。在我的建议下,最终拆分成几个sub文章,也就是上面提到的四段中对应的文章。
在这个无聊的小假期里,如果你还在犹豫选择什么工具,不妨看看这篇文章,一定对你有好处。
如何订阅推荐使用微信订阅,请扫描下方二维码,查看邮箱订阅方式。
订阅中心包括:RSS / Telegram Channel 等订阅方案,欢迎订阅⤴️ .
查看全部
工具采集文章(简悦周报:如何建立自己的工作流工作流比工具?
)
本周报也可以在【建月扩展→选项页面→右下角→消息中心】查看。
简悦周报涵盖:新用户指南/简单阅读模式使用技巧/常见问题的处理和解决方案/与其他生产力工具的交互/简悦用户提供的基于简悦的工作流程等。
每份周报都会推送到以下渠道:
我在工具使用视图⤴️中提到了不使用一体化工具的陷阱,并展示了我使用的工作流程,但没有深入讨论如何在这些工具之间进行选择。
对于一些“新进”用户来说,众多产品中该如何选择?有没有更科学的方法来帮你解决?
如果你也有这个疑问,可以看看尖月社区资深用户Spike112的这个群文章⤴️。
工作流程的祛魅:从工具、阅读到写作
万花筒工作流程的背后是什么?您如何为自己选择合适的工具并创建自己的工作流程?本文章将从元认知的角度分析和反思工作流程,力求为读者找到一个指导性的解决方案。
这个文章主要分为四个部分。如何选择合适的工具
工具是工作流的基础。那么,如何选择合适的工具呢?文章从用户、工具、对象三个维度综合分析选择工具的标准。
请把原文移到这里。如何建立自己的工作流程
工作流比工具更重要,这篇 文章 文章详细介绍了构建工作流的原因、原则和注意事项。
请把原文移到这里。如何创建阅读工作流程
本文章重点关注常见的输入-阅读工作流程,主要从采集→阅读→记笔记→记忆→创作分享等,全面审视阅读工作流程中存在的问题并提出相应的解决方案。建议。
请把原文移到这里。如何创建写作工作流程
这篇文章文章围绕着一个共同的输出,写作工作流程,把写作看作是一种与自己对话的思维方式,一种与外界对话的交流方式。此外,对写作流程提出了一些反思建议,包括写在当下(只是写作)、思考和写作合二为一(写作就是思考)、重构写作流程(从预写到重写)。
请把原文移到这里。最后
这篇文章本来就是小众的,我有幸成为了这个文章的第一个读者,文章很棒,就是太长太硬核了。在我的建议下,最终拆分成几个sub文章,也就是上面提到的四段中对应的文章。
在这个无聊的小假期里,如果你还在犹豫选择什么工具,不妨看看这篇文章,一定对你有好处。
如何订阅推荐使用微信订阅,请扫描下方二维码,查看邮箱订阅方式。
订阅中心包括:RSS / Telegram Channel 等订阅方案,欢迎订阅⤴️ .
工具采集文章(SEO常用工具有哪些?分析出有流量的关键词朝着这个目标前行)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-04-03 12:11
SEO的常用工具有哪些?每一个好的网站都离不开数据分析,通过互联网大数据分析有价值的关键词和网站面临的形势。所以,要想做好SEO,就必须使用SEO分析工具来分析有流量的关键词,才能朝着这个目标前进!
一、百度关键词分析师
百度关键词分析师是百度旗下的关键词挖掘工具,可以挖掘目标关键词的人气和竞争强度,有利于SEO下一步的发展方向。
二、网站条件分析工具
每个 SEO 人员都应该了解他们的 网站 状态,无论 网站 是在上升还是在下降。还是在目前的情况下。根据不同的情况采取不同的措施。
三、网站文章采集工具
为什么在这里说文章采集工具,因为网站的更新离不开文章。SEO优化是一个长期的过程,所以需要大量的文章来更新网站,而文章的长尾词也可以参与排名,所以推荐使用关键词文章采集工具,采集大量文章方便自己创作,关键词文章不仅可以增加网站关键词 的密度,还增加了 网站 的词库为 网站 带来流量。
四、网站布局
前期网站在首页放1-3个词目标关键词,不要太多,首页的密度关键词不要增加太多。在关键词筛选中,可以使用一些工具来查看相关的搜索索引。新站前期不建议增加1000以上关键词的索引。你可以找到某个搜索索引,但竞争不是很大关键词。
首页标题可以遵循渐变设置的原则。在之前的主页中,有两个 关键词 设置。个人认为,少数用户会搜索与主产品词方向一致的词,可以作为首页标题进行布局。
关键词积累,大量指定的关键词出现在某个页面,这样做的目的是让搜索引擎知道这个页面是针对这个关键词优化的,从而试图混淆搜索引擎。这个关键词排名,在白帽seo中,这是一种作弊手段,一不小心就会被搜索引擎惩罚。
关键词堆叠示例
1、标题页标题标签
标题是许多公司经常犯的错误。很多朋友可能会发现,有些公司会在网页标题上指定大量的关键词。在最早的SEO优化中,排名是可以发挥作用的,而在搜索引擎不断生态化的规范中,清风算法的出现,那么标题标题的积累就会受到惩罚。
2、描述描述标签
早期的搜索引擎,只要网页的内容是收录,基本上就有流量,但现在同质化的内容越来越多,竞争逐渐加剧。这里关键词的堆积会严重降低页面信任度。在标签中,合理分配相关的关键词,有助于提高页面相关性和点击率。
3、如何避免关键词堆积?
合理减少关键词积累是解决这个问题的首选,所以需要控制以下几点:
①标题关键词:关键词控制在1-2
②H标签:H1标签收录一个关键词,避免使用大量H2、H3标签收录单个关键词。
③ ALT标签:合理利用ALT标签的内容,分开关键词,不要堆积太多。
④内容页:使用与搜索意图相关的同义词、同义词、词来替换目标关键词。
众所周知,网页的标题是网页的高级摘要。网站主页的标题是网站的正式名称,而栏目主页的标题通常是栏目名称。文章 的标题是 文章 的标题。这个原则不是一成不变的,但不管怎么变,一般人还是会遵循这个规律的。
网页的标题只显示在搜索结果页的标题部分和浏览器顶部标签的网站标题位置,其他地方隐藏。其重要性不再赘述,但网站Title一旦确定并被搜索引擎收录搜索,就不能再更改,否则会影响收录和排名网站 的。返回搜狐,查看更多 查看全部
工具采集文章(SEO常用工具有哪些?分析出有流量的关键词朝着这个目标前行)
SEO的常用工具有哪些?每一个好的网站都离不开数据分析,通过互联网大数据分析有价值的关键词和网站面临的形势。所以,要想做好SEO,就必须使用SEO分析工具来分析有流量的关键词,才能朝着这个目标前进!
一、百度关键词分析师
百度关键词分析师是百度旗下的关键词挖掘工具,可以挖掘目标关键词的人气和竞争强度,有利于SEO下一步的发展方向。
二、网站条件分析工具
每个 SEO 人员都应该了解他们的 网站 状态,无论 网站 是在上升还是在下降。还是在目前的情况下。根据不同的情况采取不同的措施。
三、网站文章采集工具
为什么在这里说文章采集工具,因为网站的更新离不开文章。SEO优化是一个长期的过程,所以需要大量的文章来更新网站,而文章的长尾词也可以参与排名,所以推荐使用关键词文章采集工具,采集大量文章方便自己创作,关键词文章不仅可以增加网站关键词 的密度,还增加了 网站 的词库为 网站 带来流量。
四、网站布局
前期网站在首页放1-3个词目标关键词,不要太多,首页的密度关键词不要增加太多。在关键词筛选中,可以使用一些工具来查看相关的搜索索引。新站前期不建议增加1000以上关键词的索引。你可以找到某个搜索索引,但竞争不是很大关键词。
首页标题可以遵循渐变设置的原则。在之前的主页中,有两个 关键词 设置。个人认为,少数用户会搜索与主产品词方向一致的词,可以作为首页标题进行布局。
关键词积累,大量指定的关键词出现在某个页面,这样做的目的是让搜索引擎知道这个页面是针对这个关键词优化的,从而试图混淆搜索引擎。这个关键词排名,在白帽seo中,这是一种作弊手段,一不小心就会被搜索引擎惩罚。
关键词堆叠示例
1、标题页标题标签
标题是许多公司经常犯的错误。很多朋友可能会发现,有些公司会在网页标题上指定大量的关键词。在最早的SEO优化中,排名是可以发挥作用的,而在搜索引擎不断生态化的规范中,清风算法的出现,那么标题标题的积累就会受到惩罚。
2、描述描述标签
早期的搜索引擎,只要网页的内容是收录,基本上就有流量,但现在同质化的内容越来越多,竞争逐渐加剧。这里关键词的堆积会严重降低页面信任度。在标签中,合理分配相关的关键词,有助于提高页面相关性和点击率。
3、如何避免关键词堆积?
合理减少关键词积累是解决这个问题的首选,所以需要控制以下几点:
①标题关键词:关键词控制在1-2
②H标签:H1标签收录一个关键词,避免使用大量H2、H3标签收录单个关键词。
③ ALT标签:合理利用ALT标签的内容,分开关键词,不要堆积太多。
④内容页:使用与搜索意图相关的同义词、同义词、词来替换目标关键词。
众所周知,网页的标题是网页的高级摘要。网站主页的标题是网站的正式名称,而栏目主页的标题通常是栏目名称。文章 的标题是 文章 的标题。这个原则不是一成不变的,但不管怎么变,一般人还是会遵循这个规律的。
网页的标题只显示在搜索结果页的标题部分和浏览器顶部标签的网站标题位置,其他地方隐藏。其重要性不再赘述,但网站Title一旦确定并被搜索引擎收录搜索,就不能再更改,否则会影响收录和排名网站 的。返回搜狐,查看更多
工具采集文章(用wps也可以自己编辑标题和文章内容?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2022-04-02 10:04
工具采集文章内容来源于官方公众号:今日头条,需要的小伙伴可以自己去做一个,用wps也可以自己编辑标题和文章内容。第一步:我们打开今日头条,我们的推荐页面是这样的:我们要选择某个热点进行采集,比如热点养宠物,首先我们点击上面的”发现“按钮,页面会出现个”图文编辑器“,我们就点击图文编辑器,找到里面的”热点话题“,进入”新闻详情“的页面,就可以找到我们采集的热点了。注意:采集头条里面的热点必须是从头条后台里面下载的,它是不会泄露我们wps邮箱信息,请大家放心采集。
其实可以去百度采集今日头条的,关键在于准确,我们可以百度百度,出来的结果大多数是准确的,这是我们在百度搜索头条搜索跟头条推荐的百度首页是头条公众号里面出来的,会及时推送我们想看的内容。但前提是你要选择的地方要对,选择跟自己类似的,搜索后要是个正规的头条app,因为有时候你采集的内容头条并不是直接推送到公众号,而是把它放到了一个分享平台,分享过来后再推送给你。
这种就要看你能不能接受。如果你选择的是公众号平台,但是头条在这个平台没有你想要的内容,你又想看,可以去像腾讯那样的公众号采集,但百度和腾讯选择的这个最好。
我一直在用趣头条,现在每天都浏览头条的新闻资讯,有时也能看到很多文章,不过,找到自己想要的就难了,因为不太会处理,所以经常弄错,一不小心就需要花好几个小时了。最近,为了搜集内容,特地去头条找过几次,有时候可以找到自己想要的内容,有时候则弄得要大半天。后来,经朋友介绍,在今日头条转载内容,不过转载后,阅读不会增加,只是图个方便,也不知道能不能有用呢?要有什么建议?。 查看全部
工具采集文章(用wps也可以自己编辑标题和文章内容?(图))
工具采集文章内容来源于官方公众号:今日头条,需要的小伙伴可以自己去做一个,用wps也可以自己编辑标题和文章内容。第一步:我们打开今日头条,我们的推荐页面是这样的:我们要选择某个热点进行采集,比如热点养宠物,首先我们点击上面的”发现“按钮,页面会出现个”图文编辑器“,我们就点击图文编辑器,找到里面的”热点话题“,进入”新闻详情“的页面,就可以找到我们采集的热点了。注意:采集头条里面的热点必须是从头条后台里面下载的,它是不会泄露我们wps邮箱信息,请大家放心采集。
其实可以去百度采集今日头条的,关键在于准确,我们可以百度百度,出来的结果大多数是准确的,这是我们在百度搜索头条搜索跟头条推荐的百度首页是头条公众号里面出来的,会及时推送我们想看的内容。但前提是你要选择的地方要对,选择跟自己类似的,搜索后要是个正规的头条app,因为有时候你采集的内容头条并不是直接推送到公众号,而是把它放到了一个分享平台,分享过来后再推送给你。
这种就要看你能不能接受。如果你选择的是公众号平台,但是头条在这个平台没有你想要的内容,你又想看,可以去像腾讯那样的公众号采集,但百度和腾讯选择的这个最好。
我一直在用趣头条,现在每天都浏览头条的新闻资讯,有时也能看到很多文章,不过,找到自己想要的就难了,因为不太会处理,所以经常弄错,一不小心就需要花好几个小时了。最近,为了搜集内容,特地去头条找过几次,有时候可以找到自己想要的内容,有时候则弄得要大半天。后来,经朋友介绍,在今日头条转载内容,不过转载后,阅读不会增加,只是图个方便,也不知道能不能有用呢?要有什么建议?。
工具采集文章(为什么要用网页数据采集,为什么网页发布?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-03-31 12:17
网页数据采集,为什么要用网页数据采集?因为网页数据采集的内容便于更多的分析参考和网站的内容更新。今天给大家分享一个网络数据采集工具。采集 的数据可以保存到本地发布的网站。支持主要的网站 发布。自动采集+伪原创只需两步即可发布。具体会以图片的形式展示给大家,大家要注意图片(图片是核心)。
导航页面的优化不仅展示了关键词计划的顺序,还优化了其他栏目内页的需求,例如:在文章部分和当前位置下栏目部分,这个框架是网站的基本设置,关于文章内页的上一篇和下一篇的设置,停止设置网站的侧边栏,不仅可以引导用户深入阅读,还可以完善网站的内循环,有效促进蜘蛛的深度爬行。
哪个网站被搜索引擎惩罚,排名下降或关键词排名消失?如何妥善处理。我们做网站SEO优化很久了,肯定会遇到网站被搜索引擎惩罚的情况。首先,不要急着去看医生,冷静下来分析一下,到底是什么原因?
网站惩罚排名下降的原因及处理方法
网站被处罚,排名下降的原因不外乎以下几个方面:
首先,网站 的布局做了很大的修改。由于各种原因,我们可能需要修改网站的布局,修改后排名会下降。
第二,网站页面有非法内容,或者禁止内容。禁言等一些内容,不用多说。
第三,网站被链接到黑链或木马病毒。
四、网站的服务器有问题。要么响应太慢,要么几天打不开,关键词的排名也会下降。
五、网站上加载的弹窗广告或页面跳转过多,包括百度上桥。他们百度自己的在线客服强制聊天插件也会影响关键词的排名。
六、关键词堆积,什么是关键词堆积,如何预防,可以查看我们的网站相关内容。
第七,误用了一些SEO软件。老实说,软件永远无法帮助您进行 SEO。任何简单有效的事情都是不可靠的。比如很多外链软件可以在短时间内给你添加很多外链网站。正常发外链的话,一周发几个十、100个外链。. 但是如果使用SEO反向链接工具,一天可以发送成百上千个反向链接,因此被处罚的可能性非常高。
八、频繁修改网站标题(Title),就像频繁换工作,今天去餐厅,明天去review,后天去公司,然后去修机后天。如何评价你作为一个人,我不知道你在做什么。
第九,文章的副本太多,网站内容中没有原创性文章,都是抄别人的,百度有算法打这种类型的 网站。
第十,故意刷流量,有人对百度权重有误解,我用站长工具查了一下,显示估计流量是100,百度权重是2,我会刷流量刷流量故意地。完全估计流量是两件不同的事情,就是刷10万次是没有意义的。很容易刷流量。刷网站流量不是SEO优化,会被百度处罚。
第十一,就是过度优化,什么都没做,一切都在正确的轨道上,工作很勤奋,每天都发原创文章。外链也是用这些优质的外链做的,只是走得太远了。SEO只需要发现某个网站在做优化,肯定会受到惩罚。就像人参吃多了,身体受不了了吧?人参和鹿茸是好东西,但如果天天吃,那就不行了。
第十二,友情链接,被合作伙伴拖下。如果与他有链接的网站有问题,排名会受到相应的惩罚。因此,请务必检查您的友谊链接伙伴是否健康。
在分析了以上十种原因后,我们首先找出我们被处罚的原因。其实有很多原因,太多了,不能一下子说出来。让我们首先检查上述原因。
如果说是本人自愿违规,将立即终止,不再犯。如果没有任何问题,它很可能被过度优化。如果遇到过度优化,只能停下来,降低工作频率。比如你以前一天发三篇五篇原创性文章,如果你说的是公司网站,新闻网站,如果文章是三篇,五篇文章就下毛毛雨了,还不够发工资。我说的是普通公司网站。对于网站 公司来说,过去有很多文章 每周发布两到三篇文章。如果是原创文章,有些链接一天只能换两次。
如果遇到这种网站被惩罚和K,那就是停止工作,然后纠正错误的事情,剩下的就是慢慢等待,没有更好的办法。 查看全部
工具采集文章(为什么要用网页数据采集,为什么网页发布?(图))
网页数据采集,为什么要用网页数据采集?因为网页数据采集的内容便于更多的分析参考和网站的内容更新。今天给大家分享一个网络数据采集工具。采集 的数据可以保存到本地发布的网站。支持主要的网站 发布。自动采集+伪原创只需两步即可发布。具体会以图片的形式展示给大家,大家要注意图片(图片是核心)。
导航页面的优化不仅展示了关键词计划的顺序,还优化了其他栏目内页的需求,例如:在文章部分和当前位置下栏目部分,这个框架是网站的基本设置,关于文章内页的上一篇和下一篇的设置,停止设置网站的侧边栏,不仅可以引导用户深入阅读,还可以完善网站的内循环,有效促进蜘蛛的深度爬行。
哪个网站被搜索引擎惩罚,排名下降或关键词排名消失?如何妥善处理。我们做网站SEO优化很久了,肯定会遇到网站被搜索引擎惩罚的情况。首先,不要急着去看医生,冷静下来分析一下,到底是什么原因?
网站惩罚排名下降的原因及处理方法
网站被处罚,排名下降的原因不外乎以下几个方面:
首先,网站 的布局做了很大的修改。由于各种原因,我们可能需要修改网站的布局,修改后排名会下降。
第二,网站页面有非法内容,或者禁止内容。禁言等一些内容,不用多说。
第三,网站被链接到黑链或木马病毒。
四、网站的服务器有问题。要么响应太慢,要么几天打不开,关键词的排名也会下降。
五、网站上加载的弹窗广告或页面跳转过多,包括百度上桥。他们百度自己的在线客服强制聊天插件也会影响关键词的排名。
六、关键词堆积,什么是关键词堆积,如何预防,可以查看我们的网站相关内容。
第七,误用了一些SEO软件。老实说,软件永远无法帮助您进行 SEO。任何简单有效的事情都是不可靠的。比如很多外链软件可以在短时间内给你添加很多外链网站。正常发外链的话,一周发几个十、100个外链。. 但是如果使用SEO反向链接工具,一天可以发送成百上千个反向链接,因此被处罚的可能性非常高。
八、频繁修改网站标题(Title),就像频繁换工作,今天去餐厅,明天去review,后天去公司,然后去修机后天。如何评价你作为一个人,我不知道你在做什么。
第九,文章的副本太多,网站内容中没有原创性文章,都是抄别人的,百度有算法打这种类型的 网站。
第十,故意刷流量,有人对百度权重有误解,我用站长工具查了一下,显示估计流量是100,百度权重是2,我会刷流量刷流量故意地。完全估计流量是两件不同的事情,就是刷10万次是没有意义的。很容易刷流量。刷网站流量不是SEO优化,会被百度处罚。
第十一,就是过度优化,什么都没做,一切都在正确的轨道上,工作很勤奋,每天都发原创文章。外链也是用这些优质的外链做的,只是走得太远了。SEO只需要发现某个网站在做优化,肯定会受到惩罚。就像人参吃多了,身体受不了了吧?人参和鹿茸是好东西,但如果天天吃,那就不行了。
第十二,友情链接,被合作伙伴拖下。如果与他有链接的网站有问题,排名会受到相应的惩罚。因此,请务必检查您的友谊链接伙伴是否健康。
在分析了以上十种原因后,我们首先找出我们被处罚的原因。其实有很多原因,太多了,不能一下子说出来。让我们首先检查上述原因。
如果说是本人自愿违规,将立即终止,不再犯。如果没有任何问题,它很可能被过度优化。如果遇到过度优化,只能停下来,降低工作频率。比如你以前一天发三篇五篇原创性文章,如果你说的是公司网站,新闻网站,如果文章是三篇,五篇文章就下毛毛雨了,还不够发工资。我说的是普通公司网站。对于网站 公司来说,过去有很多文章 每周发布两到三篇文章。如果是原创文章,有些链接一天只能换两次。
如果遇到这种网站被惩罚和K,那就是停止工作,然后纠正错误的事情,剩下的就是慢慢等待,没有更好的办法。
工具采集文章(亲测很好用,在原来软件的基础上修复几处bug)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-03-21 16:06
亲测非常好用。在原软件的基础上,修复了几个bug,修复了网站编码为utf-8时显示乱码的bug。
本软件适合网站员工写文章采集其他网站文章内容时使用。
软件介绍:
1、软件属于源码(HTML)抓取版
2、只支持二级目录的采集,即列表页—>文章页。 (大部分网站文章都可以在二级目录中获取)
3、手动设置翻页(选择多页)
4、支持body内容过滤(这个可以自己修改)
5、自动生成TXT文件到桌面文件夹
6、自动判断UTF8返回文本
7、每个节点规则支持的测试返回
在软件方面,基本上就是我上面说的。可以用的漂亮,我有采集N个网站,还有N个文章。
新手可以用它来研究。该软件没有什么特别之处。说白了就是一个逻辑思路,如何实现功能。
原理其实很简单。就是在一个循环中取中间(从外到内,一层一层),然后加一点判断就完成了。
如果我要说一个特别的地方,那就是标题的处理,因为有些网页字符在本地是不能写的。嗯~有兴趣的可以看看。
当然二次开发也是可以的,添加伪原创,添加分页采集,添加多级目录采集,添加HTML发布文本,添加数据库存储等等。
制作商业版并没有错,只要你有时间和精力去做。
使用时,请按照软件上的说明进行操作。从第 1 步到第 6 步,测试通过后即可启动采集。速度非常快。
测试采集文章效果
文章采集软件下载:链接:提取码:r3dw 查看全部
工具采集文章(亲测很好用,在原来软件的基础上修复几处bug)
亲测非常好用。在原软件的基础上,修复了几个bug,修复了网站编码为utf-8时显示乱码的bug。
本软件适合网站员工写文章采集其他网站文章内容时使用。
软件介绍:
1、软件属于源码(HTML)抓取版
2、只支持二级目录的采集,即列表页—>文章页。 (大部分网站文章都可以在二级目录中获取)
3、手动设置翻页(选择多页)
4、支持body内容过滤(这个可以自己修改)
5、自动生成TXT文件到桌面文件夹
6、自动判断UTF8返回文本
7、每个节点规则支持的测试返回
在软件方面,基本上就是我上面说的。可以用的漂亮,我有采集N个网站,还有N个文章。
新手可以用它来研究。该软件没有什么特别之处。说白了就是一个逻辑思路,如何实现功能。
原理其实很简单。就是在一个循环中取中间(从外到内,一层一层),然后加一点判断就完成了。
如果我要说一个特别的地方,那就是标题的处理,因为有些网页字符在本地是不能写的。嗯~有兴趣的可以看看。
当然二次开发也是可以的,添加伪原创,添加分页采集,添加多级目录采集,添加HTML发布文本,添加数据库存储等等。
制作商业版并没有错,只要你有时间和精力去做。
https://www.zidongtouzhu.vip/w ... 2.jpg 300w, https://www.zidongtouzhu.vip/w ... 6.jpg 768w" />使用时,请按照软件上的说明进行操作。从第 1 步到第 6 步,测试通过后即可启动采集。速度非常快。
测试采集文章效果
文章采集软件下载:链接:提取码:r3dw
工具采集文章(seo优化什么意思(快手SEO)-资源楼()关联)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-03-20 00:02
节目前言:
自从冯耀宗的长城视频曝光后,越来越多的人用双头条+头条采集,这也导致资源不足,大家都是采集,那就不原创 。这次带来关键词微信采集+自动双标题,有图写文章,微信的文章百度没有收录,这也是这样一来,微信的文章都是优质的原创文章,双标题的权重会增长很快。大家还没用之前赶紧下载使用吧,后面的泛滥我不负责。
亲测时间:2022/3/17
节目介绍:
这个程序可以和之前的插件一起使用,也可以单独使用,但是需要自己注释掉配置参数。兼容插件:
php插件原创图片生成器下载:原创图片生成器(所有cms通用)伪静态背景带自动图片-资源构建()
优采云程序下载:优采云采集器V9全网通用版(win10可以使用优采云采集器)-资源构建()
1、内置安装说明,有问题可以私聊或留言。
2、下载后,让我们发疯吧。
3、不仅优采云可以使用,面向对象编程,如果自己可以开发,可以集成到各种cms中独立运行,原生php程序,不依赖在任何程序或框架上。
采集效果(无图无文):SEO优化是什么意思(快手SEO是什么意思)-资源搭建()
用这个联想的人很多,效果可能不如微信采集:双标题头条信息采集,原创文章采集@ >工具(快速获取电源7)-资源构建()
程序截图:
资源下载 本资源下载价格为29.9RMB,请先登录
欢迎来到官方第二群:832726901 查看全部
工具采集文章(seo优化什么意思(快手SEO)-资源楼()关联)
节目前言:
自从冯耀宗的长城视频曝光后,越来越多的人用双头条+头条采集,这也导致资源不足,大家都是采集,那就不原创 。这次带来关键词微信采集+自动双标题,有图写文章,微信的文章百度没有收录,这也是这样一来,微信的文章都是优质的原创文章,双标题的权重会增长很快。大家还没用之前赶紧下载使用吧,后面的泛滥我不负责。
亲测时间:2022/3/17
节目介绍:
这个程序可以和之前的插件一起使用,也可以单独使用,但是需要自己注释掉配置参数。兼容插件:
php插件原创图片生成器下载:原创图片生成器(所有cms通用)伪静态背景带自动图片-资源构建()
优采云程序下载:优采云采集器V9全网通用版(win10可以使用优采云采集器)-资源构建()
1、内置安装说明,有问题可以私聊或留言。
2、下载后,让我们发疯吧。
3、不仅优采云可以使用,面向对象编程,如果自己可以开发,可以集成到各种cms中独立运行,原生php程序,不依赖在任何程序或框架上。
采集效果(无图无文):SEO优化是什么意思(快手SEO是什么意思)-资源搭建()
用这个联想的人很多,效果可能不如微信采集:双标题头条信息采集,原创文章采集@ >工具(快速获取电源7)-资源构建()
程序截图:
资源下载 本资源下载价格为29.9RMB,请先登录
欢迎来到官方第二群:832726901
工具采集文章(文章采集中会用到哪些工具?如何使用这个工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-03-13 22:03
工具采集文章的速度不快,无法得到很好的效果。但是文章采集中会用到哪些工具呢?只会seo的人都不知道我为什么这么了解。我这里给大家推荐一个不错的工具,文章全网采集器。下面简单讲解一下如何使用这个工具。操作步骤:1.获取百度网站的源码,这个比较复杂,很多人不知道怎么操作。2.自己写代码把源码替换成自己公司或者团队自己的网站,自己是直接做公司名称的关键词,这个比较麻烦,需要利用到php,不过现在很多公司都是直接用微信公众号做自己的网站了。
3.用自己网站的自动生成链接插件,即跳转到自己网站后台。4.下载采集器,直接采集.html格式的文本文件,然后用浏览器打开。是不是觉得非常简单呢?用一个月就可以达到百度首页。
做seo的多是文科生,并且不明白seo的本质。大多数是采集文章,然后再交互编辑的。而且几乎没有采集原创。多爬虫抓取,多伪原创,然后加个链接就完事了。但是伪原创写在外部网站上会比较合理,比如p2p,多源站接入,social,自媒体,等等一堆网站通过伪原创进行广告引流,增加转化率。想想都可怕。那么,别人为什么要爬你的文章,就是伪原创,调用之前很多文章的内容,然后根据自己要的模板,写文章。这样转化率才高。
来吧,
1、先注册一个谷歌浏览器账号;
2、谷歌浏览器登录之后,选择第一个,
3、选择“sogouinternetprotection”然后就开始伪原创了。个人觉得伪原创需要什么搜索技巧,不如搜索时的信息。如果一篇文章的标题你有疑问,结果没回答你, 查看全部
工具采集文章(文章采集中会用到哪些工具?如何使用这个工具)
工具采集文章的速度不快,无法得到很好的效果。但是文章采集中会用到哪些工具呢?只会seo的人都不知道我为什么这么了解。我这里给大家推荐一个不错的工具,文章全网采集器。下面简单讲解一下如何使用这个工具。操作步骤:1.获取百度网站的源码,这个比较复杂,很多人不知道怎么操作。2.自己写代码把源码替换成自己公司或者团队自己的网站,自己是直接做公司名称的关键词,这个比较麻烦,需要利用到php,不过现在很多公司都是直接用微信公众号做自己的网站了。
3.用自己网站的自动生成链接插件,即跳转到自己网站后台。4.下载采集器,直接采集.html格式的文本文件,然后用浏览器打开。是不是觉得非常简单呢?用一个月就可以达到百度首页。
做seo的多是文科生,并且不明白seo的本质。大多数是采集文章,然后再交互编辑的。而且几乎没有采集原创。多爬虫抓取,多伪原创,然后加个链接就完事了。但是伪原创写在外部网站上会比较合理,比如p2p,多源站接入,social,自媒体,等等一堆网站通过伪原创进行广告引流,增加转化率。想想都可怕。那么,别人为什么要爬你的文章,就是伪原创,调用之前很多文章的内容,然后根据自己要的模板,写文章。这样转化率才高。
来吧,
1、先注册一个谷歌浏览器账号;
2、谷歌浏览器登录之后,选择第一个,
3、选择“sogouinternetprotection”然后就开始伪原创了。个人觉得伪原创需要什么搜索技巧,不如搜索时的信息。如果一篇文章的标题你有疑问,结果没回答你,
工具采集文章(豆瓣搜罗美剧美食的不二选择爱奇艺,百度文库导航类网站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-03-02 21:00
工具采集文章。读文读物。网易公开课,知乎live。百度文库,道客巴巴文库。豆丁小说网。中国大学mooc。《计算机基础》这两个是比较基础的。文库资源整理,有需要私信我。
带着这个问题搜索了一下好几个比较知名且有特色的网站都没找到合适的解决方案,翻墙去youtube上找不到一个像样的作品集加上给出的一定制作周期成本又太高,就这个问题而言上发现了一个可以帮我克服这个困难的方法(前提是他们所有的内容都是免费的)虽然比不上那些内容丰富的网站(哈哈),但总算克服了三大难题之一的内容的问题(`・ω・)最关键的是,它有很多基础相关的知识()可以帮我解决内容太多的困扰。
完成之后立即就是能从头到尾的作品展示啦!让看你作品的人感受到你内容的质量,再决定购买不购买(最关键是简单易学轻松搞定呀耶!)利益相关:免费体验人家提供的内容一分钟,就知道个啥(○’ω’○)。
豆瓣搜罗美剧美食的不二选择
爱奇艺,
百度文库
导航类网站:网址导航可以详细的查找你想要的资源,提供一切必备的网址和站点,包括分类,网址提取等功能我一般是先根据自己的喜好,如音乐,电影等,挑选一下再进行找资源。
::百度图片识图
,好像也很难, 查看全部
工具采集文章(豆瓣搜罗美剧美食的不二选择爱奇艺,百度文库导航类网站)
工具采集文章。读文读物。网易公开课,知乎live。百度文库,道客巴巴文库。豆丁小说网。中国大学mooc。《计算机基础》这两个是比较基础的。文库资源整理,有需要私信我。
带着这个问题搜索了一下好几个比较知名且有特色的网站都没找到合适的解决方案,翻墙去youtube上找不到一个像样的作品集加上给出的一定制作周期成本又太高,就这个问题而言上发现了一个可以帮我克服这个困难的方法(前提是他们所有的内容都是免费的)虽然比不上那些内容丰富的网站(哈哈),但总算克服了三大难题之一的内容的问题(`・ω・)最关键的是,它有很多基础相关的知识()可以帮我解决内容太多的困扰。
完成之后立即就是能从头到尾的作品展示啦!让看你作品的人感受到你内容的质量,再决定购买不购买(最关键是简单易学轻松搞定呀耶!)利益相关:免费体验人家提供的内容一分钟,就知道个啥(○’ω’○)。
豆瓣搜罗美剧美食的不二选择
爱奇艺,
百度文库
导航类网站:网址导航可以详细的查找你想要的资源,提供一切必备的网址和站点,包括分类,网址提取等功能我一般是先根据自己的喜好,如音乐,电影等,挑选一下再进行找资源。
::百度图片识图
,好像也很难,
工具采集文章(数据源所有权归属原网站及所有者严禁利用webscraper进行数据采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2022-02-28 08:01
这个文章是为了学习和交流。数据源的所有权属于原网站和所有者。严禁利用本文中提到的流程和数据牟利。
“打钉子的方法有很多,有时候我最熟悉的锤子反而会打我”
背景
最近收到一个求助,是采集一个网站,传统的“列表+内容”页面模式,用php或者采集器总会出现各种莫名其妙的问题,基本上都是经过这一步,我将使用“node+puppteer”来做,并使用自动化测试工具来模拟操作。虽然说是万能锤,但是制作这个锤子的流程和技术复杂度还是存在的,所以在转向之前一直在思考没有方向可以尝试——浏览器插件,基本原理和思路是与自动化工具基本相同,但感觉更优雅的是让目标逻辑更适合浏览器。
查资料的时候找到了Web Scraper,参考文档和教程,应用到目标网站采集,最终得到数据。如果熟悉整个操作过程,可以快速设置相应的规则来执行采集,现在记录一下过程。
过程
1. 安装网络爬虫
有科学上网功的可以登录chorme网店直接搜索安装
或百度搜索“网络刮刀离线安装包”获取相关支持,离线安装过程不再赘述。
2. 分析目标站
可以看出,这是一种典型的列表+内容的展示方式。现在您需要 采集 向下列表和内容页面。传统的采集思路是用程序把整个列表页面拉回来,然后解析超链接跳转,进而得到内容页面。
现在让我们看看如何使用网络爬虫获取数据采集。
3. 设置规则
因为采集工具是通用的,至于如何采集和采集那些数据,用户需要根据实际情况进行配置。首先,让我们了解如何打开网络爬虫和基本页面。
① 打开工具
在目标页面打开开发者工具(F11或右键-勾选),可以看到工具栏的末尾有一个同名的标签,点击标签进入工具页面
②新建采集任务
采集在需要创建Sitemap之前,可以理解为一个任务,选择Create new sitemap - Create Sitemap
站点地图名称是任务名称,您可以根据需要创建它。
起始 URL 是您的 采集 页面。如果是列表+内容模式,建议填写列表页。
然后Create Sitemap,一个基本的任务就建立了。
③ 创建列表页规则
单击添加新选择器以创建一个选择器来告诉插件应该选择哪个节点。对于在这个列表页面上也有信息的页面,我们将每条信息作为一个块,块收录各种属性信息。建立方法如下:
需要勾选Multiple选项,可以理解为需要循环获取。
添加后,我们应该在信息块中标记内容。具体操作方法同上,但要选择信息的父选择器为刚刚创建的信息块节点。
其他节点的数据操作一致,记得选择父节点。
④ 检查既定规则 查看全部
工具采集文章(数据源所有权归属原网站及所有者严禁利用webscraper进行数据采集)
这个文章是为了学习和交流。数据源的所有权属于原网站和所有者。严禁利用本文中提到的流程和数据牟利。
“打钉子的方法有很多,有时候我最熟悉的锤子反而会打我”
背景
最近收到一个求助,是采集一个网站,传统的“列表+内容”页面模式,用php或者采集器总会出现各种莫名其妙的问题,基本上都是经过这一步,我将使用“node+puppteer”来做,并使用自动化测试工具来模拟操作。虽然说是万能锤,但是制作这个锤子的流程和技术复杂度还是存在的,所以在转向之前一直在思考没有方向可以尝试——浏览器插件,基本原理和思路是与自动化工具基本相同,但感觉更优雅的是让目标逻辑更适合浏览器。
查资料的时候找到了Web Scraper,参考文档和教程,应用到目标网站采集,最终得到数据。如果熟悉整个操作过程,可以快速设置相应的规则来执行采集,现在记录一下过程。
过程
1. 安装网络爬虫
有科学上网功的可以登录chorme网店直接搜索安装
或百度搜索“网络刮刀离线安装包”获取相关支持,离线安装过程不再赘述。
2. 分析目标站
可以看出,这是一种典型的列表+内容的展示方式。现在您需要 采集 向下列表和内容页面。传统的采集思路是用程序把整个列表页面拉回来,然后解析超链接跳转,进而得到内容页面。
现在让我们看看如何使用网络爬虫获取数据采集。
3. 设置规则
因为采集工具是通用的,至于如何采集和采集那些数据,用户需要根据实际情况进行配置。首先,让我们了解如何打开网络爬虫和基本页面。
① 打开工具
在目标页面打开开发者工具(F11或右键-勾选),可以看到工具栏的末尾有一个同名的标签,点击标签进入工具页面
②新建采集任务
采集在需要创建Sitemap之前,可以理解为一个任务,选择Create new sitemap - Create Sitemap
站点地图名称是任务名称,您可以根据需要创建它。
起始 URL 是您的 采集 页面。如果是列表+内容模式,建议填写列表页。
然后Create Sitemap,一个基本的任务就建立了。
③ 创建列表页规则
单击添加新选择器以创建一个选择器来告诉插件应该选择哪个节点。对于在这个列表页面上也有信息的页面,我们将每条信息作为一个块,块收录各种属性信息。建立方法如下:
需要勾选Multiple选项,可以理解为需要循环获取。
添加后,我们应该在信息块中标记内容。具体操作方法同上,但要选择信息的父选择器为刚刚创建的信息块节点。
其他节点的数据操作一致,记得选择父节点。
④ 检查既定规则
工具采集文章(从十万+高效采集热词评论,让编辑看到有什么变化)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2022-02-26 00:04
工具采集文章热点方式在社区里直接大规模刷新帖子,争取就放热度,让编辑看到有什么变化,要多发!内容采集就是怎么搜集所有的文章不重复,需要采集各大平台的内容。投放广告有专门的平台发布我们的文章,然后就要通过广告文章的曝光量引入流量。分析找词采集文章热点。如果你有在某个网站编辑分析过某个热点词的话,你发现,当你所分析的词在某一社区或者论坛,某一大平台被顶起来后,你就有很大的机会知道这个词会不会就一直存在,会一直不下沉。
分析社区用户因素,找到匹配的词,然后加大采集。好的分析能力还需要成为话痨多给小编一些鼓励。教你从十万+高效采集热词评论。采集软件发帖评论热词。时下热词已经成为的收藏热词了,在很多论坛上也都有涉及到。
小编不才,目前还没这些平台,不过有好的去处,可以参考一下一号店无忧摘要数据库,在数据大爆发的年代没抓住这块资源就很可惜了。
本小编现在还在开着个店,
wind数据网,
要能关注到热词,那必须是关注wind数据库,这才是真正的热词库,网站生态发展快,数据丰富,权威,部分可能是收费的,但又不失本色,要大度,与时俱进,迎合大家的口味。另外就是外盘的数据交换平台,最近刚搞了一个chinasui,与其他外盘数据平台不同的是,他不是一个分析,不仅包括wind所有的网站行情大数据统计,还有基本全量的港股数据和香港数据,甚至包括关联的股票信息及相关的行情分析,但chinasui却只定位在“销售财富”上,目前小编正在开发,后期必定会有更多的服务于会员的数据交换平台产品。 查看全部
工具采集文章(从十万+高效采集热词评论,让编辑看到有什么变化)
工具采集文章热点方式在社区里直接大规模刷新帖子,争取就放热度,让编辑看到有什么变化,要多发!内容采集就是怎么搜集所有的文章不重复,需要采集各大平台的内容。投放广告有专门的平台发布我们的文章,然后就要通过广告文章的曝光量引入流量。分析找词采集文章热点。如果你有在某个网站编辑分析过某个热点词的话,你发现,当你所分析的词在某一社区或者论坛,某一大平台被顶起来后,你就有很大的机会知道这个词会不会就一直存在,会一直不下沉。
分析社区用户因素,找到匹配的词,然后加大采集。好的分析能力还需要成为话痨多给小编一些鼓励。教你从十万+高效采集热词评论。采集软件发帖评论热词。时下热词已经成为的收藏热词了,在很多论坛上也都有涉及到。
小编不才,目前还没这些平台,不过有好的去处,可以参考一下一号店无忧摘要数据库,在数据大爆发的年代没抓住这块资源就很可惜了。
本小编现在还在开着个店,
wind数据网,
要能关注到热词,那必须是关注wind数据库,这才是真正的热词库,网站生态发展快,数据丰富,权威,部分可能是收费的,但又不失本色,要大度,与时俱进,迎合大家的口味。另外就是外盘的数据交换平台,最近刚搞了一个chinasui,与其他外盘数据平台不同的是,他不是一个分析,不仅包括wind所有的网站行情大数据统计,还有基本全量的港股数据和香港数据,甚至包括关联的股票信息及相关的行情分析,但chinasui却只定位在“销售财富”上,目前小编正在开发,后期必定会有更多的服务于会员的数据交换平台产品。
工具采集文章(chrome开发者工具首先.要会python,不会也没关系)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-02-24 15:06
工具采集文章,得到文章源代码。可以采集知乎、豆瓣、头条等文章。技术采集网页源代码python爬虫,得到完整的网页源代码。可以采集新浪,搜狐,百度,网易等文章。
chrome开发者工具
首先.要会python,不会也没关系.chrome开发者工具,花两三天就够了..
你要会python
python爬虫不懂
python,
html+css+javascript+jquery这里是爬虫培训的最好的网站
我推荐你关注知乎上的“章鱼爬虫”,里面有一篇文章,《python数据采集知识:如何爬取知乎上的数据》,讲的比较全面,爬虫相关知识,
我估计你们不会上这来问...
你可以看一下最后一位答主是怎么回答的
爬虫首先你要学会python语言和一点css
python会不会?不会的话excel也可以!
学历史去爬,这是最后一大乐园。
原谅我。不过如果提问者已经知道自己要问什么问题的话。那很抱歉我的答案只能是“不用学”。--补充:如果是想知道一些情报,当然了,首先你需要确定需要掌握到什么程度。从用法、效率、可靠性、安全性等角度来分类的话,在这里还没有人能给出比较完善的答案。so?题主难道没有被论坛里,或者微博上的娱乐信息刷屏过吗?知乎一下,你就会发现,接下来的答案其实并不取决于你提出问题的知识量,而是取决于你提出问题的方式。
请想象一下,你是在提问个:《银魂》中的主角”火影”和《灌篮高手》中的主角”流川枫”,这两个人有什么共同点?或者是,《奥特曼大作战》中的大古,是不是《死神》中的小次郎?如果你没有听说过他们,你又该用什么样的方式去接触他们?当然如果你只是想知道“知乎上的流行答案”,那直接去看“关注数,收藏数,赞同数”比较好。
还有你肯定知道百度贴吧不用动脑子也能搜到想要的答案。但是我不能否认,当你尝试过拿到搜索结果中任何一个答案的分类列表后,你会被迷住的。另外个人觉得,在这个大鱼吃小鱼的时代,在科技发达的今天,只要你有人脉,连爬虫都可以用,这玩意就跟写书一样,你不照着标准语法/注释编写那么一大堆东西,怎么能有钱赚?你可以写下一行前缀为“自取”,后缀为“回复”的代码,一个“scrapy爬虫-。 查看全部
工具采集文章(chrome开发者工具首先.要会python,不会也没关系)
工具采集文章,得到文章源代码。可以采集知乎、豆瓣、头条等文章。技术采集网页源代码python爬虫,得到完整的网页源代码。可以采集新浪,搜狐,百度,网易等文章。
chrome开发者工具
首先.要会python,不会也没关系.chrome开发者工具,花两三天就够了..
你要会python
python爬虫不懂
python,
html+css+javascript+jquery这里是爬虫培训的最好的网站
我推荐你关注知乎上的“章鱼爬虫”,里面有一篇文章,《python数据采集知识:如何爬取知乎上的数据》,讲的比较全面,爬虫相关知识,
我估计你们不会上这来问...
你可以看一下最后一位答主是怎么回答的
爬虫首先你要学会python语言和一点css
python会不会?不会的话excel也可以!
学历史去爬,这是最后一大乐园。
原谅我。不过如果提问者已经知道自己要问什么问题的话。那很抱歉我的答案只能是“不用学”。--补充:如果是想知道一些情报,当然了,首先你需要确定需要掌握到什么程度。从用法、效率、可靠性、安全性等角度来分类的话,在这里还没有人能给出比较完善的答案。so?题主难道没有被论坛里,或者微博上的娱乐信息刷屏过吗?知乎一下,你就会发现,接下来的答案其实并不取决于你提出问题的知识量,而是取决于你提出问题的方式。
请想象一下,你是在提问个:《银魂》中的主角”火影”和《灌篮高手》中的主角”流川枫”,这两个人有什么共同点?或者是,《奥特曼大作战》中的大古,是不是《死神》中的小次郎?如果你没有听说过他们,你又该用什么样的方式去接触他们?当然如果你只是想知道“知乎上的流行答案”,那直接去看“关注数,收藏数,赞同数”比较好。
还有你肯定知道百度贴吧不用动脑子也能搜到想要的答案。但是我不能否认,当你尝试过拿到搜索结果中任何一个答案的分类列表后,你会被迷住的。另外个人觉得,在这个大鱼吃小鱼的时代,在科技发达的今天,只要你有人脉,连爬虫都可以用,这玩意就跟写书一样,你不照着标准语法/注释编写那么一大堆东西,怎么能有钱赚?你可以写下一行前缀为“自取”,后缀为“回复”的代码,一个“scrapy爬虫-。

