
可靠的采集神器
可靠的采集神器:新浪微博api开放平台【开发者招募】
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-08-09 06:12
可靠的采集神器:新浪微博api开放平台【开发者招募】基于新浪微博api接口的微博抓取本教程可以用我们的小工具开发的代码抓取的效果:小结:新浪微博自己的微博接口,官方也要收费,开发api的人也要收费。微博的客户端已经很方便了,
解决微博抓取难的问题,主要有两个问题:如何去抓取微博?如何更好的利用微博去获取更多的信息?如何更好的利用目标微博去获取更多的信息?以天天快报为例,每天推送几十条的内容就是一个页面,上百条的内容就需要渲染几百页面。本人常用的抓取工具有:新浪微博api开放平台:微博采集器-微博爬虫-新浪微博抓取工具公众号:ai_web代码分享论坛。
postman或者fiddler可以帮你
熟悉新浪微博,用javascript,
目前中国版的微博爬虫工具都是基于scrapy模式的,api开放平台的也不错,是新浪微博自己开发的,好像都需要收费,收费之后,用起来更方便吧,主要看你的实际需求,如果你需要知道的话,可以去他们官网上看看,
需要一定的前端知识。前端肯定会遇到浏览器支持的问题。并且除了有公司提供项目之外,有相应的文档可以查阅。 查看全部
可靠的采集神器:新浪微博api开放平台【开发者招募】
可靠的采集神器:新浪微博api开放平台【开发者招募】基于新浪微博api接口的微博抓取本教程可以用我们的小工具开发的代码抓取的效果:小结:新浪微博自己的微博接口,官方也要收费,开发api的人也要收费。微博的客户端已经很方便了,
解决微博抓取难的问题,主要有两个问题:如何去抓取微博?如何更好的利用微博去获取更多的信息?如何更好的利用目标微博去获取更多的信息?以天天快报为例,每天推送几十条的内容就是一个页面,上百条的内容就需要渲染几百页面。本人常用的抓取工具有:新浪微博api开放平台:微博采集器-微博爬虫-新浪微博抓取工具公众号:ai_web代码分享论坛。
postman或者fiddler可以帮你
熟悉新浪微博,用javascript,
目前中国版的微博爬虫工具都是基于scrapy模式的,api开放平台的也不错,是新浪微博自己开发的,好像都需要收费,收费之后,用起来更方便吧,主要看你的实际需求,如果你需要知道的话,可以去他们官网上看看,
需要一定的前端知识。前端肯定会遇到浏览器支持的问题。并且除了有公司提供项目之外,有相应的文档可以查阅。
可靠的采集神器,我找了好久,终于找到了
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-08-06 07:05
可靠的采集神器我找了好久,终于找到了,
从新浪微博搜索栏中输入zhihu进入知乎,点击进入相关主页后,点击通用按钮,选择采集知乎即可。如果想上传图片,点击上传,图片会变灰色,然后重新进入知乎主页,再点击图片,就可以正常显示图片了。在这种情况下,还可以点击添加到剪贴板,实现复制粘贴,
直接用replace或者chrome
。
出来没有图片呀,
我发现是百度经验一类的类似网站,你会发现那些主页都是一些人写的。如果你浏览了,可以写一些自己的博客,或者干脆转到自己的blog,那些人就会重新发布在其他网站上。
目前遇到了同样的问题,在同样的帖子里回复了同样的内容,他们就能全部采集过来,而我写的不太好,一般不会在这么大规模的话题里回复,不然回复太多就成回帖了,而且他们也能以一篇的形式流传,或者知乎官方吧,如果只是在一个问题下回复,确实不会有图片。正在找一个更简单的方法解决。谢谢。
用google的api
搜狗百度是有个数据接口的
安卓手机暂时不可能(ios暂时来说是可以的),知乎的动态还是知乎网站有权限的。另外,你可以试试把自己写好的内容之类的共享出去。 查看全部
可靠的采集神器,我找了好久,终于找到了
可靠的采集神器我找了好久,终于找到了,
从新浪微博搜索栏中输入zhihu进入知乎,点击进入相关主页后,点击通用按钮,选择采集知乎即可。如果想上传图片,点击上传,图片会变灰色,然后重新进入知乎主页,再点击图片,就可以正常显示图片了。在这种情况下,还可以点击添加到剪贴板,实现复制粘贴,
直接用replace或者chrome
。
出来没有图片呀,
我发现是百度经验一类的类似网站,你会发现那些主页都是一些人写的。如果你浏览了,可以写一些自己的博客,或者干脆转到自己的blog,那些人就会重新发布在其他网站上。
目前遇到了同样的问题,在同样的帖子里回复了同样的内容,他们就能全部采集过来,而我写的不太好,一般不会在这么大规模的话题里回复,不然回复太多就成回帖了,而且他们也能以一篇的形式流传,或者知乎官方吧,如果只是在一个问题下回复,确实不会有图片。正在找一个更简单的方法解决。谢谢。
用google的api
搜狗百度是有个数据接口的
安卓手机暂时不可能(ios暂时来说是可以的),知乎的动态还是知乎网站有权限的。另外,你可以试试把自己写好的内容之类的共享出去。
Flume架构及核心组件Flume的架构图:Flume实战案例
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-07-31 22:14
Flume 概览
官方文档:
Flume 是一个分布式、高可靠、高可用的日志数据采集服务,可以高效地采集、聚合和移动大量的日志数据。它具有基于流数据的简单灵活的架构。它具有健壮性和容错性,具有可调节的可靠性机制以及许多故障转移和恢复机制。它使用简单且可扩展的数据模型来允许对应用程序进行在线分析。
Flume 架构和核心组件
Flume 的架构图:
Flume 部署
准备JDK环境:
[root@hadoop01 ~]# java -version
java version "11.0.8" 2020-07-14 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.8+10-LTS)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.8+10-LTS, mixed mode)
[root@hadoop01 ~]#
下载 Flum:
复制下载链接下载:
[root@hadoop01 ~]# cd /usr/local/src
[root@hadoop01 /usr/local/src]# wget https://archive.cloudera.com/c ... ar.gz
解压到合适的目录:
[root@hadoop01 /usr/local/src]# tar -zxvf flume-ng-1.6.0-cdh5.16.2.tar.gz -C /usr/local
[root@hadoop01 /usr/local/src]# cd /usr/local/apache-flume-1.6.0-cdh5.16.2-bin/
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# ls
bin CHANGELOG cloudera conf DEVNOTES docs lib LICENSE NOTICE README RELEASE-NOTES tools
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]#
配置环境变量:
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# vim ~/.bash_profile
export FLUME_HOME=/usr/local/apache-flume-1.6.0-cdh5.16.2-bin
export PATH=$PATH:$FLUME_HOME/bin
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# source ~/.bash_profile
编辑配置文件:
[root@hadoop01 ~]# cp $FLUME_HOME/conf/flume-env.sh.template $FLUME_HOME/conf/flume-env.sh
[root@hadoop01 ~]# vim $FLUME_HOME/conf/flume-env.sh
# 配置JDK
export JAVA_HOME=/usr/local/jdk/11
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
测试flume-ng命令:
[root@hadoop01 ~]# flume-ng version
Flume 1.6.0-cdh5.16.2
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: df92badde3691ee3eb6074a177f0e96682345381
Compiled by jenkins on Mon Jun 3 03:49:33 PDT 2019
From source with checksum 9336bfa3ff8cfb5e20cd9d700135a2c1
[root@hadoop01 ~]#
Flume实战案例-从指定网口采集输出数据到控制台
使用Flume的关键是写配置文件:
配置Source,配置Channel,配置Sink,将以上三个组件串起来
所以先创建一个配置文件:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/netcat-example.conf
# a1是agent的名称
a1.sources = r1 # source的名称
a1.sinks = k1 # sink的名称
a1.channels = c1 # channel的名称
# 描述和配置source
a1.sources.r1.type = netcat # 指定source的类型为netcat
a1.sources.r1.bind = localhost # 指定source的ip
a1.sources.r1.port = 44444 # 指定source的端口
# 定义sink
a1.sinks.k1.type = logger # 指定sink类型,logger就是将数据输出到控制台
# 定义一个基于内存的channel
a1.channels.c1.type = memory # channel类型
a1.channels.c1.capacity = 1000 # channel的容量
a1.channels.c1.transactionCapacity = 100 # channel中每个事务的最大事件数
# 将source和sink绑定到channel上,即将三者串连起来
a1.sources.r1.channels = c1 # 指定r1这个source的channel为c1
a1.sinks.k1.channel = c1 # 指定k1这个sink的channel为c1
启动代理:
[root@hadoop01 ~]# flume-ng agent --name a1 -c $FLUME_HOME/conf -f $FLUME_HOME/conf/netcat-example.conf -Dflume.root.logger=INFO,console
然后通过telnet命令向44444端口发送一些数据:
[root@hadoop01 ~]# telnet localhost 44444
...
hello flume
OK
此时会看到flume的输出中打印了接收到的数据:
2020-11-02 16:08:47,965 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 0D hello flume. }
Flume实战案例-实时监控一个文件采集新增数据输出到控制台
同理,先创建一个配置文件:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/file-example.conf
# a1是agent的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -f /data/data.log
a1.sources.r1.shell = /bin/sh -c
# 定义sink
a1.sinks.k1.type = logger
# 定义一个基于内存的channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
创建一个测试文件:
[root@hadoop01 ~]# touch /data/data.log
启动代理:
[root@hadoop01 ~]# flume-ng agent --name a1 -c $FLUME_HOME/conf -f $FLUME_HOME/conf/file-example.conf -Dflume.root.logger=INFO,console
向 data.log 写入一些内容:
[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello world" >> /data/data.log
此时flume的输出中,会看到打印了监控文件的新数据:
2020-11-02 16:21:26,946 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 hello flume }
2020-11-02 16:21:38,707 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 77 6F 72 6C 64 hello world }
Flume 实际案例-实时采集 登录服务器 A 到服务器 B
要达到这个要求,需要使用Avro的Source和SInk。流程图如下:
为了测试方便,我这里用机器进行模拟。首先,A机的配置文件如下:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/exec-memory-avro.conf
# 定义各个组件的名称
exec-memory-avro.sources = exec-source
exec-memory-avro.sinks = avro-sink
exec-memory-avro.channels = memory-channel
# 描述和配置source
exec-memory-avro.sources.exec-source.type = exec
exec-memory-avro.sources.exec-source.command = tail -f /data/data.log
exec-memory-avro.sources.exec-source.shell = /bin/sh -c
# 定义sink
exec-memory-avro.sinks.avro-sink.type = avro
exec-memory-avro.sinks.avro-sink.hostname = hadoop01
exec-memory-avro.sinks.avro-sink.port = 44444
# 定义一个基于内存的channel
exec-memory-avro.channels.memory-channel.type = memory
exec-memory-avro.channels.memory-channel.capacity = 1000
exec-memory-avro.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
exec-memory-avro.sources.exec-source.channels = memory-channel
exec-memory-avro.sinks.avro-sink.channel = memory-channel
机器B的配置文件如下:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/avro-memory-logger.conf
# 定义各个组件的名称
avro-memory-logger.sources = avro-source
avro-memory-logger.sinks = logger-sink
avro-memory-logger.channels = memory-channel
# 描述和配置source
avro-memory-logger.sources.avro-source.type = avro
avro-memory-logger.sources.avro-source.bind = hadoop01
avro-memory-logger.sources.avro-source.port = 44444
# 定义sink
avro-memory-logger.sinks.logger-sink.type = logger
# 定义一个基于内存的channel
avro-memory-logger.channels.memory-channel.type = memory
avro-memory-logger.channels.memory-channel.capacity = 1000
avro-memory-logger.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
avro-memory-logger.sources.avro-source.channels = memory-channel
avro-memory-logger.sinks.logger-sink.channel = memory-channel
先启动机器B的agent,否则机器A的agent如果不能监听目标机器的端口可能会报错:
[root@hadoop01 ~]# flume-ng agent --name avro-memory-logger -c $FLUME_HOME/conf -f $FLUME_HOME/conf/avro-memory-logger.conf -Dflume.root.logger=INFO,console
启动机器A的代理:
[root@hadoop01 ~]# flume-ng agent --name exec-memory-avro -c $FLUME_HOME/conf -f $FLUME_HOME/conf/exec-memory-avro.conf -Dflume.root.logger=INFO,console
向 data.log 写入一些内容:
[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello world" >> /data/data.log
[root@hadoop01 ~]# echo "hello avro" >> /data/data.log
此时B机的agent在控制台的输出如下,于是我们就实现了A服务器上的日志实时采集到B服务器的功能:
2020-11-02 17:05:20,929 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 hello flume }
2020-11-02 17:05:21,486 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 77 6F 72 6C 64 hello world }
2020-11-02 17:05:51,505 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 61 76 72 6F hello avro }
集成Flume和Kafka完成实时数据采集
在上面的例子中,Agent B 将采集到的数据下沉到控制台,但在实际应用中它显然不会这样做。相反,它通常将数据接收到外部数据源。如HDFS、ES、Kafka等。在实时流处理架构中,大多数情况下,Sink到Kafka,然后下游消费者(一个或多个)接收数据进行实时处理。如下图所示:
所以基于前面的例子,这里是如何集成Kafka的。其实很简单,把Logger Sink改成Kafka Sink就可以了。切换到Kafka后的流程如下:
新建一个配置文件,内容如下:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/avro-memory-kafka.conf
# 定义各个组件的名称
avro-memory-kafka.sources = avro-source
avro-memory-kafka.sinks = kafka-sink
avro-memory-kafka.channels = memory-channel
# 描述和配置source
avro-memory-kafka.sources.avro-source.type = avro
avro-memory-kafka.sources.avro-source.bind = hadoop01
avro-memory-kafka.sources.avro-source.port = 44444
# 定义sink
avro-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
avro-memory-kafka.sinks.kafka-sink.brokerList = kafka01:9092
avro-memory-kafka.sinks.kafka-sink.topic = flume-topic
# 一个批次里发送多少消息
avro-memory-kafka.sinks.kafka-sink.batchSize = 5
# 指定采用的ack模式,可以参考kafka的ack机制
avro-memory-kafka.sinks.kafka-sink.requiredAcks = 1
# 定义一个基于内存的channel
avro-memory-kafka.channels.memory-channel.type = memory
avro-memory-kafka.channels.memory-channel.capacity = 1000
avro-memory-kafka.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
avro-memory-kafka.sources.avro-source.channels = memory-channel
avro-memory-kafka.sinks.kafka-sink.channel = memory-channel
配置完成后,启动Agent:
[root@hadoop01 ~]# flume-ng agent --name avro-memory-kafka -c $FLUME_HOME/conf -f $FLUME_HOME/conf/avro-memory-kafka.conf -Dflume.root.logger=INFO,console
然后启动另一个代理:
[root@hadoop01 ~]# flume-ng agent --name exec-memory-avro -c $FLUME_HOME/conf -f $FLUME_HOME/conf/exec-memory-avro.conf -Dflume.root.logger=INFO,console
启动一个Kafka消费者,方便观察Kafka收到的数据:
[root@kafka01 ~]# kafka-console-consumer.sh --bootstrap-server kafka01:9092 --topic flume-topic --from-beginning
向 data.log 写入一些内容:
[root@hadoop01 ~]# echo "hello kafka sink" >> /data/data.log
[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello agent" >> /data/data.log
此时Kafka消费者控制台会正常输出如下内容,证明Flume和Kafka已经成功集成:
[root@kafka01 ~]# kafka-console-consumer.sh --bootstrap-server kafka01:9092 --topic flume-topic --from-beginning
hello kafka sink
hello flume
hello agent 查看全部
Flume架构及核心组件Flume的架构图:Flume实战案例
Flume 概览
官方文档:
Flume 是一个分布式、高可靠、高可用的日志数据采集服务,可以高效地采集、聚合和移动大量的日志数据。它具有基于流数据的简单灵活的架构。它具有健壮性和容错性,具有可调节的可靠性机制以及许多故障转移和恢复机制。它使用简单且可扩展的数据模型来允许对应用程序进行在线分析。
Flume 架构和核心组件
Flume 的架构图:

Flume 部署
准备JDK环境:
[root@hadoop01 ~]# java -version
java version "11.0.8" 2020-07-14 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.8+10-LTS)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.8+10-LTS, mixed mode)
[root@hadoop01 ~]#
下载 Flum:
复制下载链接下载:
[root@hadoop01 ~]# cd /usr/local/src
[root@hadoop01 /usr/local/src]# wget https://archive.cloudera.com/c ... ar.gz
解压到合适的目录:
[root@hadoop01 /usr/local/src]# tar -zxvf flume-ng-1.6.0-cdh5.16.2.tar.gz -C /usr/local
[root@hadoop01 /usr/local/src]# cd /usr/local/apache-flume-1.6.0-cdh5.16.2-bin/
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# ls
bin CHANGELOG cloudera conf DEVNOTES docs lib LICENSE NOTICE README RELEASE-NOTES tools
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]#
配置环境变量:
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# vim ~/.bash_profile
export FLUME_HOME=/usr/local/apache-flume-1.6.0-cdh5.16.2-bin
export PATH=$PATH:$FLUME_HOME/bin
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# source ~/.bash_profile
编辑配置文件:
[root@hadoop01 ~]# cp $FLUME_HOME/conf/flume-env.sh.template $FLUME_HOME/conf/flume-env.sh
[root@hadoop01 ~]# vim $FLUME_HOME/conf/flume-env.sh
# 配置JDK
export JAVA_HOME=/usr/local/jdk/11
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
测试flume-ng命令:
[root@hadoop01 ~]# flume-ng version
Flume 1.6.0-cdh5.16.2
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: df92badde3691ee3eb6074a177f0e96682345381
Compiled by jenkins on Mon Jun 3 03:49:33 PDT 2019
From source with checksum 9336bfa3ff8cfb5e20cd9d700135a2c1
[root@hadoop01 ~]#
Flume实战案例-从指定网口采集输出数据到控制台
使用Flume的关键是写配置文件:
配置Source,配置Channel,配置Sink,将以上三个组件串起来
所以先创建一个配置文件:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/netcat-example.conf
# a1是agent的名称
a1.sources = r1 # source的名称
a1.sinks = k1 # sink的名称
a1.channels = c1 # channel的名称
# 描述和配置source
a1.sources.r1.type = netcat # 指定source的类型为netcat
a1.sources.r1.bind = localhost # 指定source的ip
a1.sources.r1.port = 44444 # 指定source的端口
# 定义sink
a1.sinks.k1.type = logger # 指定sink类型,logger就是将数据输出到控制台
# 定义一个基于内存的channel
a1.channels.c1.type = memory # channel类型
a1.channels.c1.capacity = 1000 # channel的容量
a1.channels.c1.transactionCapacity = 100 # channel中每个事务的最大事件数
# 将source和sink绑定到channel上,即将三者串连起来
a1.sources.r1.channels = c1 # 指定r1这个source的channel为c1
a1.sinks.k1.channel = c1 # 指定k1这个sink的channel为c1
启动代理:
[root@hadoop01 ~]# flume-ng agent --name a1 -c $FLUME_HOME/conf -f $FLUME_HOME/conf/netcat-example.conf -Dflume.root.logger=INFO,console
然后通过telnet命令向44444端口发送一些数据:
[root@hadoop01 ~]# telnet localhost 44444
...
hello flume
OK
此时会看到flume的输出中打印了接收到的数据:
2020-11-02 16:08:47,965 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 0D hello flume. }
Flume实战案例-实时监控一个文件采集新增数据输出到控制台
同理,先创建一个配置文件:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/file-example.conf
# a1是agent的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -f /data/data.log
a1.sources.r1.shell = /bin/sh -c
# 定义sink
a1.sinks.k1.type = logger
# 定义一个基于内存的channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
创建一个测试文件:
[root@hadoop01 ~]# touch /data/data.log
启动代理:
[root@hadoop01 ~]# flume-ng agent --name a1 -c $FLUME_HOME/conf -f $FLUME_HOME/conf/file-example.conf -Dflume.root.logger=INFO,console
向 data.log 写入一些内容:
[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello world" >> /data/data.log
此时flume的输出中,会看到打印了监控文件的新数据:
2020-11-02 16:21:26,946 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 hello flume }
2020-11-02 16:21:38,707 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 77 6F 72 6C 64 hello world }
Flume 实际案例-实时采集 登录服务器 A 到服务器 B
要达到这个要求,需要使用Avro的Source和SInk。流程图如下:

为了测试方便,我这里用机器进行模拟。首先,A机的配置文件如下:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/exec-memory-avro.conf
# 定义各个组件的名称
exec-memory-avro.sources = exec-source
exec-memory-avro.sinks = avro-sink
exec-memory-avro.channels = memory-channel
# 描述和配置source
exec-memory-avro.sources.exec-source.type = exec
exec-memory-avro.sources.exec-source.command = tail -f /data/data.log
exec-memory-avro.sources.exec-source.shell = /bin/sh -c
# 定义sink
exec-memory-avro.sinks.avro-sink.type = avro
exec-memory-avro.sinks.avro-sink.hostname = hadoop01
exec-memory-avro.sinks.avro-sink.port = 44444
# 定义一个基于内存的channel
exec-memory-avro.channels.memory-channel.type = memory
exec-memory-avro.channels.memory-channel.capacity = 1000
exec-memory-avro.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
exec-memory-avro.sources.exec-source.channels = memory-channel
exec-memory-avro.sinks.avro-sink.channel = memory-channel
机器B的配置文件如下:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/avro-memory-logger.conf
# 定义各个组件的名称
avro-memory-logger.sources = avro-source
avro-memory-logger.sinks = logger-sink
avro-memory-logger.channels = memory-channel
# 描述和配置source
avro-memory-logger.sources.avro-source.type = avro
avro-memory-logger.sources.avro-source.bind = hadoop01
avro-memory-logger.sources.avro-source.port = 44444
# 定义sink
avro-memory-logger.sinks.logger-sink.type = logger
# 定义一个基于内存的channel
avro-memory-logger.channels.memory-channel.type = memory
avro-memory-logger.channels.memory-channel.capacity = 1000
avro-memory-logger.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
avro-memory-logger.sources.avro-source.channels = memory-channel
avro-memory-logger.sinks.logger-sink.channel = memory-channel
先启动机器B的agent,否则机器A的agent如果不能监听目标机器的端口可能会报错:
[root@hadoop01 ~]# flume-ng agent --name avro-memory-logger -c $FLUME_HOME/conf -f $FLUME_HOME/conf/avro-memory-logger.conf -Dflume.root.logger=INFO,console
启动机器A的代理:
[root@hadoop01 ~]# flume-ng agent --name exec-memory-avro -c $FLUME_HOME/conf -f $FLUME_HOME/conf/exec-memory-avro.conf -Dflume.root.logger=INFO,console
向 data.log 写入一些内容:
[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello world" >> /data/data.log
[root@hadoop01 ~]# echo "hello avro" >> /data/data.log
此时B机的agent在控制台的输出如下,于是我们就实现了A服务器上的日志实时采集到B服务器的功能:
2020-11-02 17:05:20,929 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 hello flume }
2020-11-02 17:05:21,486 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 77 6F 72 6C 64 hello world }
2020-11-02 17:05:51,505 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 61 76 72 6F hello avro }
集成Flume和Kafka完成实时数据采集
在上面的例子中,Agent B 将采集到的数据下沉到控制台,但在实际应用中它显然不会这样做。相反,它通常将数据接收到外部数据源。如HDFS、ES、Kafka等。在实时流处理架构中,大多数情况下,Sink到Kafka,然后下游消费者(一个或多个)接收数据进行实时处理。如下图所示:

所以基于前面的例子,这里是如何集成Kafka的。其实很简单,把Logger Sink改成Kafka Sink就可以了。切换到Kafka后的流程如下:

新建一个配置文件,内容如下:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/avro-memory-kafka.conf
# 定义各个组件的名称
avro-memory-kafka.sources = avro-source
avro-memory-kafka.sinks = kafka-sink
avro-memory-kafka.channels = memory-channel
# 描述和配置source
avro-memory-kafka.sources.avro-source.type = avro
avro-memory-kafka.sources.avro-source.bind = hadoop01
avro-memory-kafka.sources.avro-source.port = 44444
# 定义sink
avro-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
avro-memory-kafka.sinks.kafka-sink.brokerList = kafka01:9092
avro-memory-kafka.sinks.kafka-sink.topic = flume-topic
# 一个批次里发送多少消息
avro-memory-kafka.sinks.kafka-sink.batchSize = 5
# 指定采用的ack模式,可以参考kafka的ack机制
avro-memory-kafka.sinks.kafka-sink.requiredAcks = 1
# 定义一个基于内存的channel
avro-memory-kafka.channels.memory-channel.type = memory
avro-memory-kafka.channels.memory-channel.capacity = 1000
avro-memory-kafka.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
avro-memory-kafka.sources.avro-source.channels = memory-channel
avro-memory-kafka.sinks.kafka-sink.channel = memory-channel
配置完成后,启动Agent:
[root@hadoop01 ~]# flume-ng agent --name avro-memory-kafka -c $FLUME_HOME/conf -f $FLUME_HOME/conf/avro-memory-kafka.conf -Dflume.root.logger=INFO,console
然后启动另一个代理:
[root@hadoop01 ~]# flume-ng agent --name exec-memory-avro -c $FLUME_HOME/conf -f $FLUME_HOME/conf/exec-memory-avro.conf -Dflume.root.logger=INFO,console
启动一个Kafka消费者,方便观察Kafka收到的数据:
[root@kafka01 ~]# kafka-console-consumer.sh --bootstrap-server kafka01:9092 --topic flume-topic --from-beginning
向 data.log 写入一些内容:
[root@hadoop01 ~]# echo "hello kafka sink" >> /data/data.log
[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello agent" >> /data/data.log
此时Kafka消费者控制台会正常输出如下内容,证明Flume和Kafka已经成功集成:
[root@kafka01 ~]# kafka-console-consumer.sh --bootstrap-server kafka01:9092 --topic flume-topic --from-beginning
hello kafka sink
hello flume
hello agent
怎么获取登录登录网站后的cookie?(一)(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-07-30 19:13
有些网站需要用户登录才能显示相关信息。如果你想要采集这种网站,有以下几种方式:
1.编写发布模块,捕获post数据;
2. 一些采集器内置浏览器会得到这些信息,但往往不准确,可靠性低;
3.获取登录名网站cookie后,使用采集器模拟用户登录采集;
这里介绍第三种方法,比较简单,可靠性高。
一、登录网站后如何获取cookie?
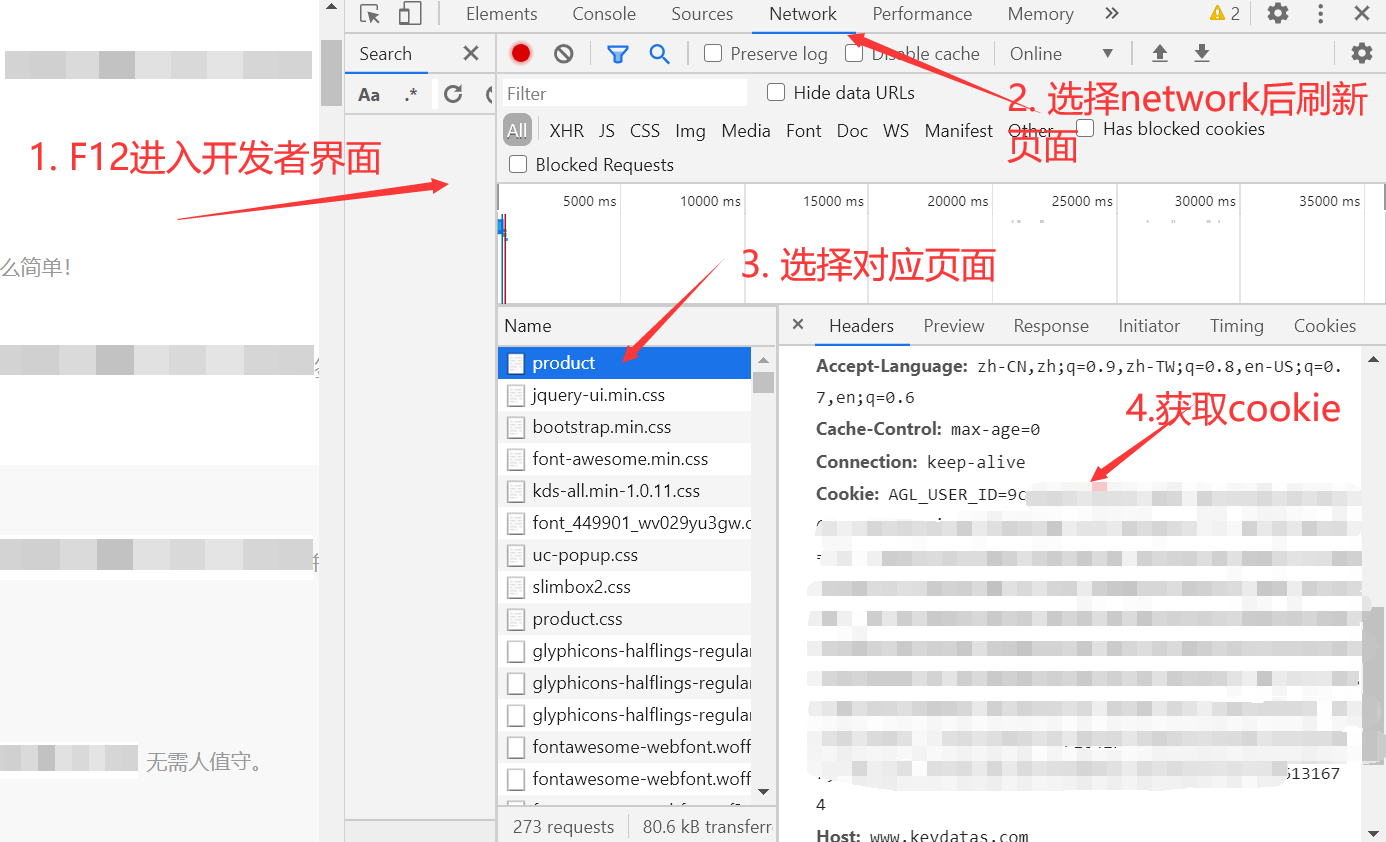
方法一---最简单的方法是通过现代浏览器获取,以chrome为例:
1. F12 或右键勾选进入开发者模式界面;
2.点击网络,F5重新加载页面;
3.选择页面名称对应的html文件;
4.获取cookies;
方法二---也可以使用fiddler工具爬取; (如果你已经用浏览器获取了cookie,可以跳过这一步直接去)
fiddler 是客户端和服务器之间的 HTTP 代理,也是常用的 http 抓包工具之一。它可以记录客户端和服务器之间的所有 HTTP 请求。它还可以分析请求数据,设置断点,修改请求的数据,甚至修改服务器为指定的HTTP请求返回的数据。它非常强大。是网站调试的得力助手。
从fiddler官网下载:
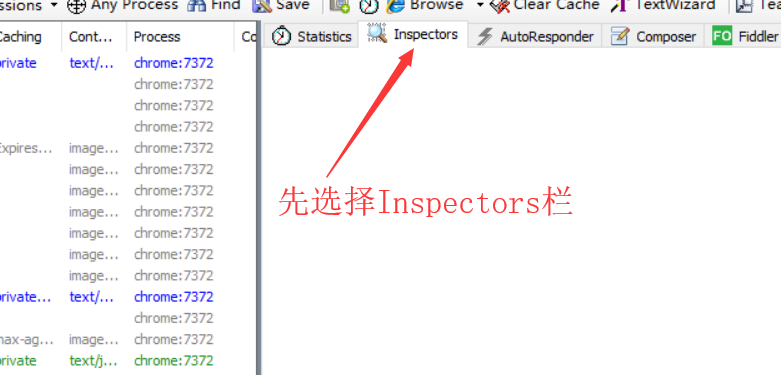
下载安装完成后,请按照以下步骤操作:(此文章基于Fiddler 4版本)
1.首先在右侧显示的页面中选择Inspectors栏;
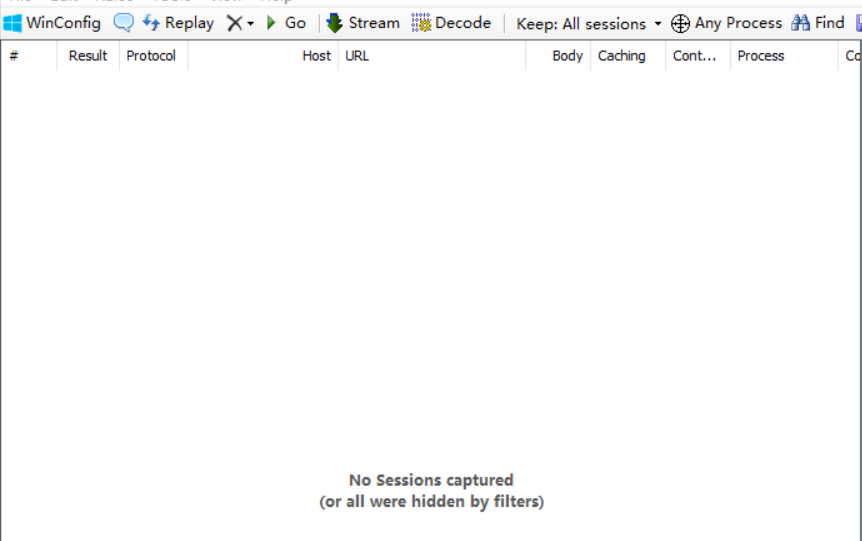
2.由于左边显示的页面已经有很多访问网站的信息了,我们先把它清除一下,以便接下来找到指定的网页;
可以使用快捷键ctrl+x或在页面左侧右键点击显示页面删除------>>所有会话;
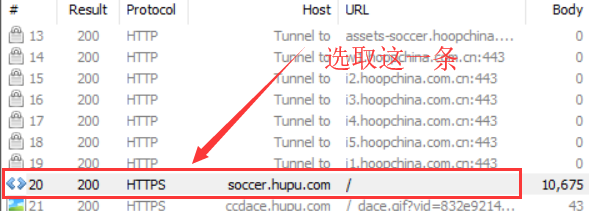
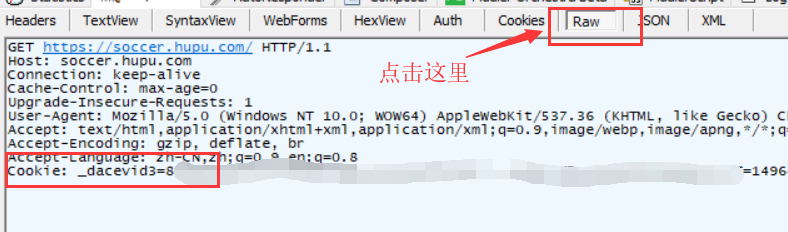
3. 接下来登录网站,需要抓取cookies或者刷新登录的网页。您可以在左侧显示栏中轻松找到网站的Host(网站域名)+ URL。这个
比如这个是选中的,注意URL内容中带斜线/的信息;
4.在右侧显示栏中选择raw栏,即可看到获取到的cookie;
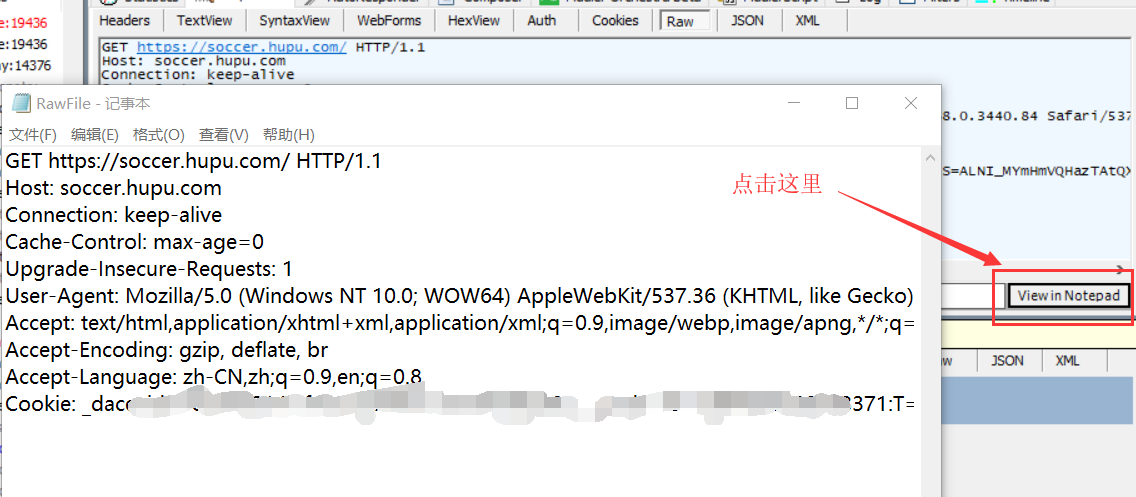
5.为了获取完整的cookie,我们点击右侧显示栏中间的在记事本中查看,打开记事本获取完整的cookie;
将二、获取的cookie填入优采云
最后将获取到的cookie和user-ent信息复制到采集器,然后打开detail extractor查看之前隐藏的内容;
优采云采集 填写cookies有3个入口:
我。创建新任务时,高级选项:
二。点击“Start | Timing采集”,在网络配置中填写相关信息;
三。细节提升器左侧列表中的网络配置:
注意:如果填写cookie后刷新页面无法显示采集的内容,可以尝试填写[cookie域名],例如采集百度就是填写 查看全部
怎么获取登录登录网站后的cookie?(一)(组图)
有些网站需要用户登录才能显示相关信息。如果你想要采集这种网站,有以下几种方式:
1.编写发布模块,捕获post数据;
2. 一些采集器内置浏览器会得到这些信息,但往往不准确,可靠性低;
3.获取登录名网站cookie后,使用采集器模拟用户登录采集;
这里介绍第三种方法,比较简单,可靠性高。
一、登录网站后如何获取cookie?
方法一---最简单的方法是通过现代浏览器获取,以chrome为例:
1. F12 或右键勾选进入开发者模式界面;
2.点击网络,F5重新加载页面;
3.选择页面名称对应的html文件;
4.获取cookies;
方法二---也可以使用fiddler工具爬取; (如果你已经用浏览器获取了cookie,可以跳过这一步直接去)
fiddler 是客户端和服务器之间的 HTTP 代理,也是常用的 http 抓包工具之一。它可以记录客户端和服务器之间的所有 HTTP 请求。它还可以分析请求数据,设置断点,修改请求的数据,甚至修改服务器为指定的HTTP请求返回的数据。它非常强大。是网站调试的得力助手。
从fiddler官网下载:
下载安装完成后,请按照以下步骤操作:(此文章基于Fiddler 4版本)
1.首先在右侧显示的页面中选择Inspectors栏;
2.由于左边显示的页面已经有很多访问网站的信息了,我们先把它清除一下,以便接下来找到指定的网页;
可以使用快捷键ctrl+x或在页面左侧右键点击显示页面删除------>>所有会话;
3. 接下来登录网站,需要抓取cookies或者刷新登录的网页。您可以在左侧显示栏中轻松找到网站的Host(网站域名)+ URL。这个
比如这个是选中的,注意URL内容中带斜线/的信息;
4.在右侧显示栏中选择raw栏,即可看到获取到的cookie;
5.为了获取完整的cookie,我们点击右侧显示栏中间的在记事本中查看,打开记事本获取完整的cookie;
将二、获取的cookie填入优采云
最后将获取到的cookie和user-ent信息复制到采集器,然后打开detail extractor查看之前隐藏的内容;
优采云采集 填写cookies有3个入口:
我。创建新任务时,高级选项:

二。点击“Start | Timing采集”,在网络配置中填写相关信息;

三。细节提升器左侧列表中的网络配置:

注意:如果填写cookie后刷新页面无法显示采集的内容,可以尝试填写[cookie域名],例如采集百度就是填写
机极视听与网信详细对比采集大师(NetGet)下载评测软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-07-29 01:21
information采集的难度是什么?数据更加复杂多样;下载后有什么困难?数据管理。
网络信息采集大师(NetGet)的主要功能就是解决这两个问题。一般数据采集是有针对性的,通常是针对某某或某某网站、采集某类数据。比如采集几个网站人才招聘信息、产品信息、供求信息、公司图书馆信息等等。简单分析了这些网站的数据结构后,设置相应的采集规则,就可以将你想要的所有数据下载到本地了。本软件支持分类,分类的目的是方便数据管理和统计分析。
现有功能介绍:
1. 这个软件可以采集任何类型的网站信息。包括htm、html、ASP、JSP、PHP等。采集速度快,信息一致,准确。支持网站login。
2. 类别。分类的目的是为了方便地管理数据。您可以添加、删除和修改类别。分类数据库有3个最新备份,放在\files目录下,为数据安全提供了可靠保证。
3. 任务。任务是采集task。按照相应的采集 规则行事。可以随时启动、暂停和停止任务。本软件支持多任务处理,即采集同时处理不同的数据。
4. 数据导出。 采集的数据可以通过三种方式导出:文本、Excel和数据库。可以根据需要导出为不同的格式。
5. 数据库。 Access 和 SqlServer 数据库目前正在测试中。数据库功能包括导入数据库和数据查询。
6. 菜单功能扩展。一般是扩展数据分析功能。例如,您自己开发了一个数据库软件。本软件用于分析采集的数据。您可以将软件连接到本软件以方便使用。
7. 日志。记录每一个重要的操作。比如类别的维护,任务的维护等等。日志可以清理和备份。 查看全部
机极视听与网信详细对比采集大师(NetGet)下载评测软件
information采集的难度是什么?数据更加复杂多样;下载后有什么困难?数据管理。
网络信息采集大师(NetGet)的主要功能就是解决这两个问题。一般数据采集是有针对性的,通常是针对某某或某某网站、采集某类数据。比如采集几个网站人才招聘信息、产品信息、供求信息、公司图书馆信息等等。简单分析了这些网站的数据结构后,设置相应的采集规则,就可以将你想要的所有数据下载到本地了。本软件支持分类,分类的目的是方便数据管理和统计分析。
现有功能介绍:
1. 这个软件可以采集任何类型的网站信息。包括htm、html、ASP、JSP、PHP等。采集速度快,信息一致,准确。支持网站login。
2. 类别。分类的目的是为了方便地管理数据。您可以添加、删除和修改类别。分类数据库有3个最新备份,放在\files目录下,为数据安全提供了可靠保证。
3. 任务。任务是采集task。按照相应的采集 规则行事。可以随时启动、暂停和停止任务。本软件支持多任务处理,即采集同时处理不同的数据。
4. 数据导出。 采集的数据可以通过三种方式导出:文本、Excel和数据库。可以根据需要导出为不同的格式。
5. 数据库。 Access 和 SqlServer 数据库目前正在测试中。数据库功能包括导入数据库和数据查询。
6. 菜单功能扩展。一般是扩展数据分析功能。例如,您自己开发了一个数据库软件。本软件用于分析采集的数据。您可以将软件连接到本软件以方便使用。
7. 日志。记录每一个重要的操作。比如类别的维护,任务的维护等等。日志可以清理和备份。
10款最好用的数据采集工具,可采集99%网页
采集交流 • 优采云 发表了文章 • 0 个评论 • 753 次浏览 • 2021-07-28 02:55
10个最好的数据采集tools,免费采集tools,网站webpage采集工具,各行各业采集tools,这里有一些更好的免费数据采集tools,希望可以帮助大家。
1、优采云采集器优采云是一个基于互联网运营商实名实名数据,整合网页数据采集、移动互联网数据和API接口服务的数据服务平台。其最大的特点是无需了解网络爬虫技术即可轻松完成采集。
2、优采云采集器优采云采集器是最常用的互联网数据采集软件。凭借灵活的配置和强大的性能,在国内同类产品中处于领先地位,获得了众多用户的一致认可。使用优采云采集器几乎采集所有网页。
3、近探中国近探中国的数据服务平台有很多采集开发者上传的工具,很多都是免费的。无论是采集internal网站、industry网站、government网站、app、微博、搜索引擎、公众号、小程序等数据,还是其他数据,近期都可以搞定采集还可以定制。这是他们最大的亮点之一。
4、大飞采集器大飞采集器可采集99%网页,速度是普通采集器的7倍,复制粘贴一样准确。它最大的特点是网页采集的同义词,因为专注而单一。
5、Import.io 使用 Import.io 适配任何 URL。只需输入网址,即可整齐抓取网页数据。操作非常简单,采集、采集的结果自动可视化。但是无法选择特定数据,无法自动翻页采集。
6、ParseHub ParseHub 分为免费版和付费版。从数百万个网页中获取数据。输入数千个链接和关键字,ParseHub 会自动搜索这些链接和关键字。使用我们的休息 API。以 Excel 和 JSON 格式下载提取的数据。将您的结果导入 Google 表格和 Tableau。
7、Content GrabberContent Grabber是外国大神制作的神器,可以从网页中抓取内容(视频、图片、文字),并提取到Excel、XML、CSV和大多数数据库中。该软件基于网络捕获获取和网络自动化。它完全免费使用,通常用于数据调查和测试目的。
8、ForeSpiderForeSpider 是一个非常有用的网页数据采集 工具。用户可以使用该工具帮助您自动检索网页中的各种数据信息,而且该软件使用起来非常简单。可以免费使用。基本上只要在一步一步的操作中输入网址链接就可以了。有特殊情况需要特殊处理才能采集,也支持配置脚本。
9、阿里数据采集阿里数据采集大平台稳定不死机,并且可以实现实时查询,软件开发数据采集,他们可以做到,除了有贵没问题。
10、优采云采集器优采云采集器 操作非常简单,按照流程简单上手,还可以支持多种形式的导出。 查看全部
10款最好用的数据采集工具,可采集99%网页
10个最好的数据采集tools,免费采集tools,网站webpage采集工具,各行各业采集tools,这里有一些更好的免费数据采集tools,希望可以帮助大家。

1、优采云采集器优采云是一个基于互联网运营商实名实名数据,整合网页数据采集、移动互联网数据和API接口服务的数据服务平台。其最大的特点是无需了解网络爬虫技术即可轻松完成采集。
2、优采云采集器优采云采集器是最常用的互联网数据采集软件。凭借灵活的配置和强大的性能,在国内同类产品中处于领先地位,获得了众多用户的一致认可。使用优采云采集器几乎采集所有网页。
3、近探中国近探中国的数据服务平台有很多采集开发者上传的工具,很多都是免费的。无论是采集internal网站、industry网站、government网站、app、微博、搜索引擎、公众号、小程序等数据,还是其他数据,近期都可以搞定采集还可以定制。这是他们最大的亮点之一。
4、大飞采集器大飞采集器可采集99%网页,速度是普通采集器的7倍,复制粘贴一样准确。它最大的特点是网页采集的同义词,因为专注而单一。
5、Import.io 使用 Import.io 适配任何 URL。只需输入网址,即可整齐抓取网页数据。操作非常简单,采集、采集的结果自动可视化。但是无法选择特定数据,无法自动翻页采集。
6、ParseHub ParseHub 分为免费版和付费版。从数百万个网页中获取数据。输入数千个链接和关键字,ParseHub 会自动搜索这些链接和关键字。使用我们的休息 API。以 Excel 和 JSON 格式下载提取的数据。将您的结果导入 Google 表格和 Tableau。
7、Content GrabberContent Grabber是外国大神制作的神器,可以从网页中抓取内容(视频、图片、文字),并提取到Excel、XML、CSV和大多数数据库中。该软件基于网络捕获获取和网络自动化。它完全免费使用,通常用于数据调查和测试目的。
8、ForeSpiderForeSpider 是一个非常有用的网页数据采集 工具。用户可以使用该工具帮助您自动检索网页中的各种数据信息,而且该软件使用起来非常简单。可以免费使用。基本上只要在一步一步的操作中输入网址链接就可以了。有特殊情况需要特殊处理才能采集,也支持配置脚本。
9、阿里数据采集阿里数据采集大平台稳定不死机,并且可以实现实时查询,软件开发数据采集,他们可以做到,除了有贵没问题。
10、优采云采集器优采云采集器 操作非常简单,按照流程简单上手,还可以支持多种形式的导出。
可靠的采集神器推荐一波云采飞,采集效率高
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-07-21 23:02
可靠的采集神器推荐一波云采飞,采集效率高,可视化操作,手机电脑都可以采集,用了就知道好在哪里不要做被收钱的免费工具,说免费的都是耍流氓,谁给你免费的,
可以使用segmentfault上的新人礼包,有各种精美的礼品礼袋送出,
当然是上面贴图的那个小姐姐pc软件的阿里妈妈去重工具啦,功能全面。
采集小助手,有多种采集方式,还有用户总结,不是托,
亿万采集百度文库
收集,获取是根本。不花钱的方法只有坚持长期的学习,知道自己想要什么,然后苦练内功以期能“得道升天”。关键还是得,想通过采集赚点外快。
网址提取器,稍微高级一点的不花钱,
我推荐你用yagent
百度文库还有谁不收费的!想一想就能知道是不是骗子,不收费就可以拿到他们的文档,不像普通的网站公布的网址一样的,
如果你需要需要某种资源的话,可以通过电子商务网站采集,不花钱就可以采集到。比如说b2b,或者是店铺,里面一些资源都可以。各行各业都有,你需要哪个行业,就可以找哪个行业的资源,然后把这些资源提取出来!花点钱并不是唯一的方法,
你可以用采集客的采集热点采集,手机软件也可以做,可视化操作,简单易懂,在线编辑,时效性也挺高的,基本1分钟就可以出内容,自定义修改也方便。还有一些基本的内容采集功能,这个都是免费的!要是需要更多, 查看全部
可靠的采集神器推荐一波云采飞,采集效率高
可靠的采集神器推荐一波云采飞,采集效率高,可视化操作,手机电脑都可以采集,用了就知道好在哪里不要做被收钱的免费工具,说免费的都是耍流氓,谁给你免费的,
可以使用segmentfault上的新人礼包,有各种精美的礼品礼袋送出,
当然是上面贴图的那个小姐姐pc软件的阿里妈妈去重工具啦,功能全面。
采集小助手,有多种采集方式,还有用户总结,不是托,
亿万采集百度文库
收集,获取是根本。不花钱的方法只有坚持长期的学习,知道自己想要什么,然后苦练内功以期能“得道升天”。关键还是得,想通过采集赚点外快。
网址提取器,稍微高级一点的不花钱,
我推荐你用yagent
百度文库还有谁不收费的!想一想就能知道是不是骗子,不收费就可以拿到他们的文档,不像普通的网站公布的网址一样的,
如果你需要需要某种资源的话,可以通过电子商务网站采集,不花钱就可以采集到。比如说b2b,或者是店铺,里面一些资源都可以。各行各业都有,你需要哪个行业,就可以找哪个行业的资源,然后把这些资源提取出来!花点钱并不是唯一的方法,
你可以用采集客的采集热点采集,手机软件也可以做,可视化操作,简单易懂,在线编辑,时效性也挺高的,基本1分钟就可以出内容,自定义修改也方便。还有一些基本的内容采集功能,这个都是免费的!要是需要更多,
可靠的采集神器我用过最好用的软件是yifleear
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-07-20 22:01
可靠的采集神器我用过最好用的采集软件是yifleear,我常用这个。yifleear采集器功能强大,有固定模式、移动模式、模糊模式、视频导出功能等十几种模式。能够一键上传美拍、秒拍、网易云音乐、开眼等数以百计的网站。
三点一平看看
抖音采集程序来啦!如何免费搞定!!我是来自凯萨互动空间有很多人反应说这个程序质量不错还有使用情况,有没有开源版本,给大家来个开源的试试。开源版本的在他们官网有免费提供下载。有哪些值得推荐的工具或者app?一个抖音的采集软件。[国内抖音视频免费下载第三方官方平台],免费下载抖音、火山视频免费下载全网视频免费下载全网音乐,可编辑歌词也可以为微信、抖音、火山等做一个关键词采集,也可以为企业做个引流有哪些十分钟就能上手的入门级神器?-文章有点长的回答-。
wifi万能钥匙
看看这个哦
我自己觉得挺好用的...我也是从一个视频后缀采集器转换过来,
但如果不想麻烦
有啊。
斗鱼啊,
scrapdown去看看,我朋友推荐给我的,
爱采集,
移动端有美拍,秒拍等软件,pc端有搜狗浏览器等,这些视频本身都可以采集的。 查看全部
可靠的采集神器我用过最好用的软件是yifleear
可靠的采集神器我用过最好用的采集软件是yifleear,我常用这个。yifleear采集器功能强大,有固定模式、移动模式、模糊模式、视频导出功能等十几种模式。能够一键上传美拍、秒拍、网易云音乐、开眼等数以百计的网站。
三点一平看看
抖音采集程序来啦!如何免费搞定!!我是来自凯萨互动空间有很多人反应说这个程序质量不错还有使用情况,有没有开源版本,给大家来个开源的试试。开源版本的在他们官网有免费提供下载。有哪些值得推荐的工具或者app?一个抖音的采集软件。[国内抖音视频免费下载第三方官方平台],免费下载抖音、火山视频免费下载全网视频免费下载全网音乐,可编辑歌词也可以为微信、抖音、火山等做一个关键词采集,也可以为企业做个引流有哪些十分钟就能上手的入门级神器?-文章有点长的回答-。
wifi万能钥匙
看看这个哦
我自己觉得挺好用的...我也是从一个视频后缀采集器转换过来,
但如果不想麻烦
有啊。
斗鱼啊,
scrapdown去看看,我朋友推荐给我的,
爱采集,
移动端有美拍,秒拍等软件,pc端有搜狗浏览器等,这些视频本身都可以采集的。
可靠的采集神器,不用爬虫也能每天600万+
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-07-13 05:04
可靠的采集神器,不用爬虫也能每天600万+的采集规则。老话说的好啊:平常心态要好,只要不是比较不正规的,没见过不敢问的网站,采集规则可以去抄,前提是你先确定,采集下来的规则要比你用爬虫采集多很多,可以提高下载速度。
百度网页采集器可以采集谷歌,搜狗,360,搜搜,爱问,太阳星,newslearn这些搜索引擎里的网页,技术上已经可以实现只要网站有收录就能搜索到。应该可以实现楼主所说的大数据采集功能。
楼主,这真的是大数据采集啊,让我记得有个这么牛的网站。采下来做数据处理还能用,呵呵。
楼主你说的大数据采集可能是谷歌大搜搜算法类的吧,还有一些yahoo大搜图算法类的原因很简单,因为谷歌每天到处有采采采,一查就有。
首先,国内百度谷歌不给采,其次,百度直接屏蔽,再次,即使ss,要买请api?说明这采集问题离普通人还是蛮远的,你可以谷歌搜一下相关问题,结果越说越精彩,看看达到什么程度。
不知道题主遇到这个问题时是否已经试图采集,我也遇到过这个问题,然后朋友告诉我可以通过现在的大数据采集公司的技术方面的手段,而且不需要任何成本的。应该是这样的:现在很多采集大数据的方法有很多,这个答案里只介绍一种,一些免费的scrapy大数据采集工具scrapy1.5.0要下载,或者其他的爬虫工具;另外还有一些可以免费提供爬虫或者其他工具的,我还是推荐使用一些收费的。
我当时使用的是scrapy1.5免费版,不需要成本,功能不错,不过每天只能抓取五条,少了一些竞争力,用的是一些公司的vpn帐号(阿里云vpn帐号,ip很稳定,可以加速几十mb的数据量),有些公司还提供代理服务器(免费),但是阿里云vpn和虚拟主机都有数据丢失的问题,抓取的那几十gb数据丢失了300多gb,当时数据量大一些,并不影响抓取速度,结果是抓取了近20000条数据,得到30000条数据。
使用免费方法,使得抓取速度有限,不过可以足够解决题主的问题,也得到了我想要的效果,当然,只能抓取5条的量是需要付出一些时间精力的,希望其他回答可以给到你一些更好的解决方案。 查看全部
可靠的采集神器,不用爬虫也能每天600万+
可靠的采集神器,不用爬虫也能每天600万+的采集规则。老话说的好啊:平常心态要好,只要不是比较不正规的,没见过不敢问的网站,采集规则可以去抄,前提是你先确定,采集下来的规则要比你用爬虫采集多很多,可以提高下载速度。
百度网页采集器可以采集谷歌,搜狗,360,搜搜,爱问,太阳星,newslearn这些搜索引擎里的网页,技术上已经可以实现只要网站有收录就能搜索到。应该可以实现楼主所说的大数据采集功能。
楼主,这真的是大数据采集啊,让我记得有个这么牛的网站。采下来做数据处理还能用,呵呵。
楼主你说的大数据采集可能是谷歌大搜搜算法类的吧,还有一些yahoo大搜图算法类的原因很简单,因为谷歌每天到处有采采采,一查就有。
首先,国内百度谷歌不给采,其次,百度直接屏蔽,再次,即使ss,要买请api?说明这采集问题离普通人还是蛮远的,你可以谷歌搜一下相关问题,结果越说越精彩,看看达到什么程度。
不知道题主遇到这个问题时是否已经试图采集,我也遇到过这个问题,然后朋友告诉我可以通过现在的大数据采集公司的技术方面的手段,而且不需要任何成本的。应该是这样的:现在很多采集大数据的方法有很多,这个答案里只介绍一种,一些免费的scrapy大数据采集工具scrapy1.5.0要下载,或者其他的爬虫工具;另外还有一些可以免费提供爬虫或者其他工具的,我还是推荐使用一些收费的。
我当时使用的是scrapy1.5免费版,不需要成本,功能不错,不过每天只能抓取五条,少了一些竞争力,用的是一些公司的vpn帐号(阿里云vpn帐号,ip很稳定,可以加速几十mb的数据量),有些公司还提供代理服务器(免费),但是阿里云vpn和虚拟主机都有数据丢失的问题,抓取的那几十gb数据丢失了300多gb,当时数据量大一些,并不影响抓取速度,结果是抓取了近20000条数据,得到30000条数据。
使用免费方法,使得抓取速度有限,不过可以足够解决题主的问题,也得到了我想要的效果,当然,只能抓取5条的量是需要付出一些时间精力的,希望其他回答可以给到你一些更好的解决方案。
可靠的采集神器——scrapy脚本【海量信息一键提取】
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-07-11 07:03
可靠的采集神器是强大而高效的爬虫。如果你有线下采集的需求,让对话框中的信息自动获取难度太大。而通过爬虫,每天获取几十上百条数据非常方便。今天小编介绍这款scrapy脚本【海量信息一键提取】,不需要编程,通过图形化的操作就可以自动提取企业/个人网站的文本信息。效果演示图:github地址:,可以在软件中创建爬虫,也可以通过爬虫自动获取数据,这样可以批量处理数据,还能快速获取互联网更多的数据。具体步骤:。
1、百度搜索【scrapy】关键词
2、进入或者其他网站,
3、粘贴到软件中【设置按钮】中的【分析网页结构】
4、分析完成后,
5、在输入框中粘贴网页分析完成的链接,
6、爬取提取方式选择【填写或者批量分析网页结构】
7、选择网页结构获取方式,
8、设置输出类型【选择可用于后续处理的类型】
9、数据获取保存在浏览器工具【列表】1
0、返回到软件中选择【导出】1
1、重新打开之前做过的分析的网站,就能获取新的数据啦!除了爬取,scrapy还能设置密码【除个人和个人站点外,除代理外,其他不需要设置】,还可以设置节点【控制整个分析页面】,从而提高效率!快试试吧!相关推荐:/@chengzhuang/china-category-a-category-of-urban-startup/。 查看全部
可靠的采集神器——scrapy脚本【海量信息一键提取】
可靠的采集神器是强大而高效的爬虫。如果你有线下采集的需求,让对话框中的信息自动获取难度太大。而通过爬虫,每天获取几十上百条数据非常方便。今天小编介绍这款scrapy脚本【海量信息一键提取】,不需要编程,通过图形化的操作就可以自动提取企业/个人网站的文本信息。效果演示图:github地址:,可以在软件中创建爬虫,也可以通过爬虫自动获取数据,这样可以批量处理数据,还能快速获取互联网更多的数据。具体步骤:。
1、百度搜索【scrapy】关键词
2、进入或者其他网站,
3、粘贴到软件中【设置按钮】中的【分析网页结构】
4、分析完成后,
5、在输入框中粘贴网页分析完成的链接,
6、爬取提取方式选择【填写或者批量分析网页结构】
7、选择网页结构获取方式,
8、设置输出类型【选择可用于后续处理的类型】
9、数据获取保存在浏览器工具【列表】1
0、返回到软件中选择【导出】1
1、重新打开之前做过的分析的网站,就能获取新的数据啦!除了爬取,scrapy还能设置密码【除个人和个人站点外,除代理外,其他不需要设置】,还可以设置节点【控制整个分析页面】,从而提高效率!快试试吧!相关推荐:/@chengzhuang/china-category-a-category-of-urban-startup/。
可靠的采集神器,支持苹果安卓各种网站全站收录及代码搜索
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-07-06 06:02
可靠的采集神器,支持苹果安卓各种网站全站收录及代码搜索catrue谷歌全站搜索f12调试极速优化javascript,css提交post地址
以下是我们自己用的,有些效果做不到,但我相信有个方法在两个safari浏览器下都是可以实现的。首先我们需要确定下你使用谷歌浏览器这个是不行的,所以我们必须使用火狐浏览器,插件下载完毕后,点击图标会自动跳转到下载页面;1.点击安装程序,然后选择我自己的版本,只有你想安装到什么浏览器都行,火狐浏览器下并没有弹出框说需要root,而是自动点击默认浏览器并选择一个火狐浏览器。
2.点击下载好的浏览器,然后在弹出框中输入用户名与密码,就可以自动安装插件了。默认选择的就是火狐浏览器的下载,不要改其他浏览器下载就行,只要下载安装安装一次就好。3.如果你有必要需要手动去加速,那就点下载列表中的一键加速,它会让你提高网速,但如果你不想卡,那就点一键加速,点击已安装即可,会直接提高网速。
然后浏览器会自动弹出一个高速访问进度条,这个时候就不需要提速了。4.一路点击下一步就可以了,由于知乎浏览器下无法使用谷歌浏览器插件和谷歌浏览器,而是安装的火狐浏览器的谷歌浏览器,所以除了点一键加速,其他暂时没发现其他方法了。注意谷歌浏览器的谷歌浏览器虽然没有网站保护,但是谷歌浏览器可以有效地屏蔽广告及篡改,所以广告再多也不会妨碍我们追求高速浏览的目的。 查看全部
可靠的采集神器,支持苹果安卓各种网站全站收录及代码搜索
可靠的采集神器,支持苹果安卓各种网站全站收录及代码搜索catrue谷歌全站搜索f12调试极速优化javascript,css提交post地址
以下是我们自己用的,有些效果做不到,但我相信有个方法在两个safari浏览器下都是可以实现的。首先我们需要确定下你使用谷歌浏览器这个是不行的,所以我们必须使用火狐浏览器,插件下载完毕后,点击图标会自动跳转到下载页面;1.点击安装程序,然后选择我自己的版本,只有你想安装到什么浏览器都行,火狐浏览器下并没有弹出框说需要root,而是自动点击默认浏览器并选择一个火狐浏览器。
2.点击下载好的浏览器,然后在弹出框中输入用户名与密码,就可以自动安装插件了。默认选择的就是火狐浏览器的下载,不要改其他浏览器下载就行,只要下载安装安装一次就好。3.如果你有必要需要手动去加速,那就点下载列表中的一键加速,它会让你提高网速,但如果你不想卡,那就点一键加速,点击已安装即可,会直接提高网速。
然后浏览器会自动弹出一个高速访问进度条,这个时候就不需要提速了。4.一路点击下一步就可以了,由于知乎浏览器下无法使用谷歌浏览器插件和谷歌浏览器,而是安装的火狐浏览器的谷歌浏览器,所以除了点一键加速,其他暂时没发现其他方法了。注意谷歌浏览器的谷歌浏览器虽然没有网站保护,但是谷歌浏览器可以有效地屏蔽广告及篡改,所以广告再多也不会妨碍我们追求高速浏览的目的。
可靠的采集神器——apiget有没有什么工具可以直接采集百度、阿里、腾讯
采集交流 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2021-07-05 22:01
可靠的采集神器——apiget有没有什么工具可以直接采集百度、阿里、腾讯等国内主流搜索引擎的相关页面,接下来给大家介绍一款由全球领先的移动搜索分析公司aragenix开发的,使用一下其中的两个功能:1.ublockorigin2.locationofthediscovery.ublockorigin功能:可以自由拖动“range”标签条右边的小元素,实现具体到某个区域链接的跳转。
自由拖动“originalbite”标签条右边的小元素,可以实现该区域链接跳转到该页面。locationofthediscovery功能:可以自由拖动“sites”标签条右边的小元素,获取特定位置的站点信息。注意:这两个功能都是可以免费使用的,免费额度是1万个站点。网址::安卓:locationofthediscoveryiphone:ublockoriginios:apiget。
我一个朋友做的不错,不算新奇,但很方便实用,有兴趣的朋友可以加他。
网站指南
自荐一个试试百度搜索,基本随便输入个关键词,
数据可以,
后端开发人员,
他们的一些功能做的比较不错。上门推销的话,还是要慎重一些。我也是来做外贸的,刚开始还好,买了一点,总共25款产品,通常4款。刚开始几个月。稍微出点问题就会不方便。第一次交易的时候,只买了1500多个,后来几个月下来,付款出问题多,询盘也少了。客户好几个月都没联系我。合同已签。价格方面也不便宜。不过他们也给我赚了钱。
主要是客户等不及急用钱。一旦买了,就发货。质量方面也可以,当然我们是原价2倍多的。便宜点,一是赚了差价,二是既然提供免费服务,就要做到如实、真实,不然坑人。 查看全部
可靠的采集神器——apiget有没有什么工具可以直接采集百度、阿里、腾讯
可靠的采集神器——apiget有没有什么工具可以直接采集百度、阿里、腾讯等国内主流搜索引擎的相关页面,接下来给大家介绍一款由全球领先的移动搜索分析公司aragenix开发的,使用一下其中的两个功能:1.ublockorigin2.locationofthediscovery.ublockorigin功能:可以自由拖动“range”标签条右边的小元素,实现具体到某个区域链接的跳转。
自由拖动“originalbite”标签条右边的小元素,可以实现该区域链接跳转到该页面。locationofthediscovery功能:可以自由拖动“sites”标签条右边的小元素,获取特定位置的站点信息。注意:这两个功能都是可以免费使用的,免费额度是1万个站点。网址::安卓:locationofthediscoveryiphone:ublockoriginios:apiget。
我一个朋友做的不错,不算新奇,但很方便实用,有兴趣的朋友可以加他。
网站指南
自荐一个试试百度搜索,基本随便输入个关键词,
数据可以,
后端开发人员,
他们的一些功能做的比较不错。上门推销的话,还是要慎重一些。我也是来做外贸的,刚开始还好,买了一点,总共25款产品,通常4款。刚开始几个月。稍微出点问题就会不方便。第一次交易的时候,只买了1500多个,后来几个月下来,付款出问题多,询盘也少了。客户好几个月都没联系我。合同已签。价格方面也不便宜。不过他们也给我赚了钱。
主要是客户等不及急用钱。一旦买了,就发货。质量方面也可以,当然我们是原价2倍多的。便宜点,一是赚了差价,二是既然提供免费服务,就要做到如实、真实,不然坑人。
太棒了!有了这三个爬虫神器,我要写什么代码!
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-07-01 18:24
太好了!有了这三个爬虫神器,我要写什么代码!
我已经和大家分享了普通人可以在视频账号中使用的爬虫工具。为了方便没有关注我视频号的同学,我在这里整理一下分享给大家。当然,关注我视频号的同学也可以更方便的查看对比。
在分享这些爬虫工具之前,先来说说我们为什么要了解爬虫工具?
普通人学习爬虫工具的三个原因:
对于工作场所的临时使用,学习爬虫可以提供效率。程序员太忙了,自己找人太贵了。学习爬虫技术本身成本太高
有人说陶大哥,我是开发者,用Python分分钟抓几行代码,把数据拿回来。我当然想说你很棒,但更多的人还没有达到那个地步。
退一步说,就算我很熟练,如果我能用工具和现成的模板抓取并生成Excle导出,整个过程也只需要几分钟。我认为作为开发人员,这会有点令人兴奋。
掌握爬虫工具可以大大提高我们职场工作的效率。成为CEO,嫁给白富美指日可待。
我知道我们为什么要学习以及学习的目的。接下来给大家介绍一下我认为不错的三个爬虫。他们是Jisouke,优采云,优采云采集器,对你来说更方便。易于使用和选择。
优采云
优采云我简单说一下优点:
提供带有云采集功能的第三方模板,方便快捷采集10分钟让个人数据采集更贵
需要注册登录,无Mac&Linux版本,基础模板免费,更多模板需要付费,高级版需要付费,免费版只能使用最基本的导出,有限制。
采集招揽客户
集聚采购客户优势
很多网站templates使用浏览器方式采集,直接登录采集付费版提供Mac版10分钟搞定,个人用户低价获取数据
客户端是浏览器。我个人认为这是一种趋势。是采集登录抢数据。另外,采集总客的工具比较简单好用,但是价格歧视是很不科学的。 Mac客户端版本只能付费使用。你真的认为苹果用户更富有吗?
他们付费获取数据的方式是免费的,下载是用积分下载的。我觉得采集客户临时使用比优采云更方便。
优采云采集器
优采云采集器我认为的优点:
浏览器模式采集采集全可视化,免费导出,无积分,完全免费,支持Mac&Linux版5分钟上手,数据采集一般个人负担得起
无需登录,无需注册采集data,无需积分,几乎完全免费使用,缺点不提供第三方模板网站,对于新手来说有点不方便,但是胜利了本身足够简单,这也是一个优势。
总结
这三个工具都是优秀的,好用的,但是从两者的个人使用来看,更方便、灵活、更便宜的招揽客户。 优采云采集器其次(胜利很简单,真的很简单),优采云last。
当然,对于个人体验,是否支持Mac系统,价格等因素,里面的功能没有深入研究。如果有错误,请不要打我,来自普通用户。
欢迎给我留言讨论。
学Python,也学更多黑科技。 查看全部
太棒了!有了这三个爬虫神器,我要写什么代码!
太好了!有了这三个爬虫神器,我要写什么代码!

我已经和大家分享了普通人可以在视频账号中使用的爬虫工具。为了方便没有关注我视频号的同学,我在这里整理一下分享给大家。当然,关注我视频号的同学也可以更方便的查看对比。
在分享这些爬虫工具之前,先来说说我们为什么要了解爬虫工具?
普通人学习爬虫工具的三个原因:
对于工作场所的临时使用,学习爬虫可以提供效率。程序员太忙了,自己找人太贵了。学习爬虫技术本身成本太高
有人说陶大哥,我是开发者,用Python分分钟抓几行代码,把数据拿回来。我当然想说你很棒,但更多的人还没有达到那个地步。
退一步说,就算我很熟练,如果我能用工具和现成的模板抓取并生成Excle导出,整个过程也只需要几分钟。我认为作为开发人员,这会有点令人兴奋。
掌握爬虫工具可以大大提高我们职场工作的效率。成为CEO,嫁给白富美指日可待。
我知道我们为什么要学习以及学习的目的。接下来给大家介绍一下我认为不错的三个爬虫。他们是Jisouke,优采云,优采云采集器,对你来说更方便。易于使用和选择。
优采云

优采云我简单说一下优点:
提供带有云采集功能的第三方模板,方便快捷采集10分钟让个人数据采集更贵
需要注册登录,无Mac&Linux版本,基础模板免费,更多模板需要付费,高级版需要付费,免费版只能使用最基本的导出,有限制。
采集招揽客户
集聚采购客户优势
很多网站templates使用浏览器方式采集,直接登录采集付费版提供Mac版10分钟搞定,个人用户低价获取数据
客户端是浏览器。我个人认为这是一种趋势。是采集登录抢数据。另外,采集总客的工具比较简单好用,但是价格歧视是很不科学的。 Mac客户端版本只能付费使用。你真的认为苹果用户更富有吗?
他们付费获取数据的方式是免费的,下载是用积分下载的。我觉得采集客户临时使用比优采云更方便。
优采云采集器

优采云采集器我认为的优点:
浏览器模式采集采集全可视化,免费导出,无积分,完全免费,支持Mac&Linux版5分钟上手,数据采集一般个人负担得起
无需登录,无需注册采集data,无需积分,几乎完全免费使用,缺点不提供第三方模板网站,对于新手来说有点不方便,但是胜利了本身足够简单,这也是一个优势。
总结
这三个工具都是优秀的,好用的,但是从两者的个人使用来看,更方便、灵活、更便宜的招揽客户。 优采云采集器其次(胜利很简单,真的很简单),优采云last。
当然,对于个人体验,是否支持Mac系统,价格等因素,里面的功能没有深入研究。如果有错误,请不要打我,来自普通用户。
欢迎给我留言讨论。
学Python,也学更多黑科技。
中国舆情监测域采集宝-全球互联网精准舆情采集神器
采集交流 • 优采云 发表了文章 • 0 个评论 • 227 次浏览 • 2021-06-30 19:03
可靠的采集神器有很多,可是现在来看,如果你要做游戏用户行为数据分析,比如看有多少user的行为被重复记录,就要用到一个网站叫“采集宝”,如果要做一个网站的舆情监测,就要用到“网络大数据采集平台”,最近我发现一个app叫“中国舆情监测”也是做舆情数据分析的,我觉得如果你要做用户行为分析,建议你用这个,哈哈。
想学哪方面的就买哪方面的书籍。书都是好书。
中国舆情监测
域
采集宝-全球互联网精准舆情监测与分析
推荐个采集程序的地方
新浪舆情,新浪网站的所有舆情统计的。
新浪舆情
大家好我是李东,一名英语专业的小学生,今天讲解一下其实有很多方法都可以采集信息的,我要先来讲下关于“一些电子的网页或者视频”采集,由于大部分网站或者视频都是需要依靠专业的才能观看到,而采集一些电子网页或者视频其实是很简单的,下面我为大家分享一下。大家有没有遇到过一个这样的问题,就是有时候我们想下载一些电子书或者是电影或者软件,找不到下载地址,因为现在电子书或者是软件不像以前那么多了,所以这个时候,我们要利用高仿软件去进行视频下载的操作,我先给大家演示一下演示软件,有的朋友没用过,其实也是一样的,如果没有用过可以百度查下观看!adobeaftereffectsproextended,这款软件我们可以打开它,它的界面如下所示:然后我们就可以按照我们的需求自己调整就可以了,关于如何调整我会在最后告诉大家,看下界面:然后我们打开adobeaftereffects软件,然后我们需要看到的是如下图所示:我们只需要按一下这个模块下面的“max”键就可以进行选择电影或者是其他视频文件,我们如果需要搜索你要下载的电影或者是视频我们也可以直接把鼠标悬停在“max”键上面进行排序,搜索完我们直接选择我们要的视频文件,然后在下方选择下载即可!有时候可能我们要先下载再搜索,那么我们就直接选择“eastthard”下载,然后再看效果即可,如果还有不懂的,大家也可以百度搜索!有一些朋友也会问我们软件中下载电影或者是视频之后在网页上显示不了,这个时候我们直接点击“downloadhome”即可。
这款软件我们可以打开它我们看到如下图所示:我们点击上方的小房子进行搜索即可找到我们想要的资源。这款软件如果没有下载过的朋友也可以去试一下,需要注意的是有时候有些资源,大家也可以去看看,除了之外,还可以找搜索。希望对大家有帮助,有一些朋友如果找不到我们想要的资源,也可以去百度搜索“我要下载”上面有很多好用的软件推荐,下面我给大家展示下我自。 查看全部
中国舆情监测域采集宝-全球互联网精准舆情采集神器
可靠的采集神器有很多,可是现在来看,如果你要做游戏用户行为数据分析,比如看有多少user的行为被重复记录,就要用到一个网站叫“采集宝”,如果要做一个网站的舆情监测,就要用到“网络大数据采集平台”,最近我发现一个app叫“中国舆情监测”也是做舆情数据分析的,我觉得如果你要做用户行为分析,建议你用这个,哈哈。
想学哪方面的就买哪方面的书籍。书都是好书。
中国舆情监测
域
采集宝-全球互联网精准舆情监测与分析
推荐个采集程序的地方
新浪舆情,新浪网站的所有舆情统计的。
新浪舆情
大家好我是李东,一名英语专业的小学生,今天讲解一下其实有很多方法都可以采集信息的,我要先来讲下关于“一些电子的网页或者视频”采集,由于大部分网站或者视频都是需要依靠专业的才能观看到,而采集一些电子网页或者视频其实是很简单的,下面我为大家分享一下。大家有没有遇到过一个这样的问题,就是有时候我们想下载一些电子书或者是电影或者软件,找不到下载地址,因为现在电子书或者是软件不像以前那么多了,所以这个时候,我们要利用高仿软件去进行视频下载的操作,我先给大家演示一下演示软件,有的朋友没用过,其实也是一样的,如果没有用过可以百度查下观看!adobeaftereffectsproextended,这款软件我们可以打开它,它的界面如下所示:然后我们就可以按照我们的需求自己调整就可以了,关于如何调整我会在最后告诉大家,看下界面:然后我们打开adobeaftereffects软件,然后我们需要看到的是如下图所示:我们只需要按一下这个模块下面的“max”键就可以进行选择电影或者是其他视频文件,我们如果需要搜索你要下载的电影或者是视频我们也可以直接把鼠标悬停在“max”键上面进行排序,搜索完我们直接选择我们要的视频文件,然后在下方选择下载即可!有时候可能我们要先下载再搜索,那么我们就直接选择“eastthard”下载,然后再看效果即可,如果还有不懂的,大家也可以百度搜索!有一些朋友也会问我们软件中下载电影或者是视频之后在网页上显示不了,这个时候我们直接点击“downloadhome”即可。
这款软件我们可以打开它我们看到如下图所示:我们点击上方的小房子进行搜索即可找到我们想要的资源。这款软件如果没有下载过的朋友也可以去试一下,需要注意的是有时候有些资源,大家也可以去看看,除了之外,还可以找搜索。希望对大家有帮助,有一些朋友如果找不到我们想要的资源,也可以去百度搜索“我要下载”上面有很多好用的软件推荐,下面我给大家展示下我自。
一个创业神器导航网站,让你沉迷在各种工具神器里面出不来
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-06-28 01:28
作为一个网民,每次发现一些有用的工具和产品,都会忍不住分享给身边的朋友。不禁感叹,好工具为什么没有被更多人看到?最近发现了一个创业神器导航网站,推荐给大家采集。不是我之前印象里放网站的那种导航。里面的产品和资源都是好玩的,有趣的,实用的。 (温馨提示:如果你点进去,你可能会和我一样沉迷于各种工具和神器。)
一、网站生活一对1.网站设计
我们先来看看官网的设计。点击网站进入。整体感觉很简洁,框架清晰,比一般的导航网站更加活泼前卫。交互设计也很简单,点击网站跳转到对方网站。对比我之前用的一些导航,可能是seo优化的考虑,会出现跳转页面,其实不是很人性化。
2.网站Content
看上面的内容,第一大部分是推荐各种网站,主要包括办公、设计、开发、品牌、营销...等,80%的推荐产品都是非常用心和优秀的。 ,比如在线智能生成logo设计,有的可能很小,但是我用的时候,都加到我的采集里了。可惜,为什么我没有早点发现?网络信息太严重了!我恨!在选址上,我认为是本站做的最好的地方。发现埋藏的好工具好网站,让价值被更多人传递和看到。在文章的后面,我会推荐几个必须尝试的工具。继续说第二部分。
单个导航可能无法阐明产品的色调。它在这里添加了一个文章content 部分。 文章的主要内容就是专门介绍那些优秀的产品工具,帮助大家评估各种产品。 ,或者分享一些资源和技巧。我觉得这个区域的主要功能是让用户停留的时间更长,增加这个导航的附加值。就像6套ppt模板一样,这种可以直接下载的资源很实用。
二、神器推荐
我在上面网站与您分享了我自己对这个导航的一些经验和感受。如果很高的话,我觉得可以打八分左右。我认为在某些网站的分类方面做得不好。希望看到它继续改进。接下来给大家分享一下我通过这个创业神器的导航发现的一些很棒的产品工具(无广告费)
1.搜图神器
我写文章的时候,刚好需要图。目前无论是平台还是个人,越来越注重图片版权意识,不敢像以前那样随便使用。我一直在使用来自国外的几个无版权图片库,例如 unsplash 和 pixbay。不太方便的是加载速度较慢,不支持中文搜索。
这个工具最大的亮点就是聚合了这些商业无版权库。一键中文搜索。您需要在“工作”中直接输入工作场景的图片。各大图书馆的图片会直接出现。下载结束了。积分完全免费!
2.甜葱填图
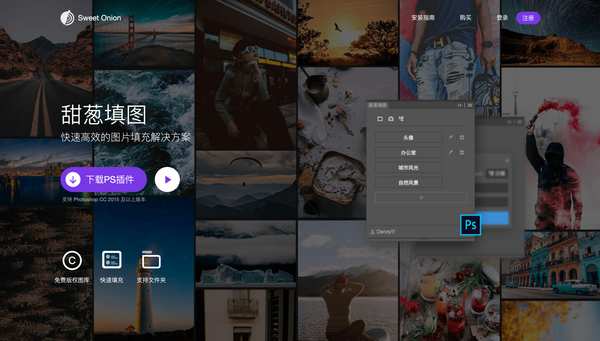
这也是我最近才发现的一个小工具。设计专业的同学一定知道,设计稿中需要各种图片。首先,您需要下载图片,然后填写每个位置。超级麻烦。其实我觉得这种机械的复制工作早就应该被工具代替了。甜葱馅就是这样一种工具。对接免费版权库,支持对所有图片进行标注和一键填充,大大提高了工作效率。设计师可以使用它~
3.MIXKIT
纸质媒体时代已经过去,迎来了数字媒体时代。现在动态视频比文字更有吸引力。无论是企业宣传还是个人品牌推广,都希望通过短视频来传播影响力。最近,我也在尝试制作一些视频来播放。更难的是,很难找到那种很酷的材料。基本上都是国内收费的,有版权限制。我在神器导航上发现这个网站后,点进来看看,无版权商业!爱它!而且,整个网站的设计也很棒,当然关键是里面的素材内容非常丰富,可以直接下载使用在自己的视频中,还可以制作字幕或者特效~
我已经写了这么久才知道,我真的推荐无穷无尽的感觉有趣的产品。我很累很累!想了解更多有趣、有价值、好用的工具,去业务神器导航一探究竟吧~ 查看全部
一个创业神器导航网站,让你沉迷在各种工具神器里面出不来
作为一个网民,每次发现一些有用的工具和产品,都会忍不住分享给身边的朋友。不禁感叹,好工具为什么没有被更多人看到?最近发现了一个创业神器导航网站,推荐给大家采集。不是我之前印象里放网站的那种导航。里面的产品和资源都是好玩的,有趣的,实用的。 (温馨提示:如果你点进去,你可能会和我一样沉迷于各种工具和神器。)
一、网站生活一对1.网站设计
我们先来看看官网的设计。点击网站进入。整体感觉很简洁,框架清晰,比一般的导航网站更加活泼前卫。交互设计也很简单,点击网站跳转到对方网站。对比我之前用的一些导航,可能是seo优化的考虑,会出现跳转页面,其实不是很人性化。
2.网站Content
看上面的内容,第一大部分是推荐各种网站,主要包括办公、设计、开发、品牌、营销...等,80%的推荐产品都是非常用心和优秀的。 ,比如在线智能生成logo设计,有的可能很小,但是我用的时候,都加到我的采集里了。可惜,为什么我没有早点发现?网络信息太严重了!我恨!在选址上,我认为是本站做的最好的地方。发现埋藏的好工具好网站,让价值被更多人传递和看到。在文章的后面,我会推荐几个必须尝试的工具。继续说第二部分。


单个导航可能无法阐明产品的色调。它在这里添加了一个文章content 部分。 文章的主要内容就是专门介绍那些优秀的产品工具,帮助大家评估各种产品。 ,或者分享一些资源和技巧。我觉得这个区域的主要功能是让用户停留的时间更长,增加这个导航的附加值。就像6套ppt模板一样,这种可以直接下载的资源很实用。


二、神器推荐
我在上面网站与您分享了我自己对这个导航的一些经验和感受。如果很高的话,我觉得可以打八分左右。我认为在某些网站的分类方面做得不好。希望看到它继续改进。接下来给大家分享一下我通过这个创业神器的导航发现的一些很棒的产品工具(无广告费)
1.搜图神器


我写文章的时候,刚好需要图。目前无论是平台还是个人,越来越注重图片版权意识,不敢像以前那样随便使用。我一直在使用来自国外的几个无版权图片库,例如 unsplash 和 pixbay。不太方便的是加载速度较慢,不支持中文搜索。
这个工具最大的亮点就是聚合了这些商业无版权库。一键中文搜索。您需要在“工作”中直接输入工作场景的图片。各大图书馆的图片会直接出现。下载结束了。积分完全免费!
2.甜葱填图
这也是我最近才发现的一个小工具。设计专业的同学一定知道,设计稿中需要各种图片。首先,您需要下载图片,然后填写每个位置。超级麻烦。其实我觉得这种机械的复制工作早就应该被工具代替了。甜葱馅就是这样一种工具。对接免费版权库,支持对所有图片进行标注和一键填充,大大提高了工作效率。设计师可以使用它~
3.MIXKIT
纸质媒体时代已经过去,迎来了数字媒体时代。现在动态视频比文字更有吸引力。无论是企业宣传还是个人品牌推广,都希望通过短视频来传播影响力。最近,我也在尝试制作一些视频来播放。更难的是,很难找到那种很酷的材料。基本上都是国内收费的,有版权限制。我在神器导航上发现这个网站后,点进来看看,无版权商业!爱它!而且,整个网站的设计也很棒,当然关键是里面的素材内容非常丰富,可以直接下载使用在自己的视频中,还可以制作字幕或者特效~
我已经写了这么久才知道,我真的推荐无穷无尽的感觉有趣的产品。我很累很累!想了解更多有趣、有价值、好用的工具,去业务神器导航一探究竟吧~
网易采集器:可靠的采集神器,更优质的体验
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-06-27 21:02
可靠的采集神器,更优质的体验网易采集器网易公开课最新最全的公开课视频/音频,把资源利用起来网易云课堂登录登录课程进入课程页面,自己选择视频,使用浏览器的录屏功能或ppt播放器的录屏功能可以实现录屏,具体操作方法可以咨询教练机器人在线直播机器人celebot6键操作ai简化实现数据采集的操作,根据教练机器人指令,一键采集课程内容,省时省力还可以使用播放器添加互动问答的方式采集/录制高清视频,操作简单方便轻松控制录屏你也可以借助其他应用,把视频在线上播放,方便查看制作成卡片模板对资源导入评论功能,可方便导出celebot教练机器人轻松实现在线采集,查看视频效果导出视频卡片或字幕列表。
给你推荐个采集神器——excelvba宝典可以根据需要导入数据的模板来采集数据。
推荐一下
我在知乎上回答过一个直接拖动图片到excel的方法同样适用于回答if判断条件
百度网盘资源/
有个叫:有道云笔记,网页可以直接导入excel表格,极其简单,我觉得很好用,有条件可以尝试看看。
格式化一下数据,
写这里面含有大量资源,包括内幕,
1.excel2vec支持全网平台excel爬虫第一项:excel2vec支持全网平台excel爬虫的业务规则很重要,如果要过滤excel繁多而无用的爬虫,excel2vec提供一整套的业务规则组件,支持过滤114个爬虫平台,从laravel,npm,corba,github直接导入javajar包都没问题。
比如针对一个excel表做sheet转化到word,sheetindex和sheetdecl这三个方法都可以过滤掉大量无用的爬虫和爬虫器。但是用python爬虫是不是就麻烦点了,肯定的,但是我们可以使用开源代码解决(以下以web爬虫为例)web爬虫|第二代简单粗暴爬虫实现第三项:excel2vec集中火力攻击miniflow支持全网平台excel爬虫的业务规则很重要,如果要过滤excel繁多而无用的爬虫,excel2vec提供一整套的业务规则组件,支持过滤114个爬虫平台,从laravel,npm,corba,github直接导入javajar包都没问题。
比如针对一个excel表做sheet转化到word,sheetindex和sheetdecl这三个方法都可以过滤掉大量无用的爬虫和爬虫器。但是用python爬虫是不是就麻烦点了,肯定的,但是我们可以使用开源代码解决(以下以web爬虫为例)web爬虫|第二代简单粗暴爬虫实现2.excel2vec集中火力攻击miniflow支持全网平台miniflow是sqllibraryfordataanalysis。 查看全部
网易采集器:可靠的采集神器,更优质的体验
可靠的采集神器,更优质的体验网易采集器网易公开课最新最全的公开课视频/音频,把资源利用起来网易云课堂登录登录课程进入课程页面,自己选择视频,使用浏览器的录屏功能或ppt播放器的录屏功能可以实现录屏,具体操作方法可以咨询教练机器人在线直播机器人celebot6键操作ai简化实现数据采集的操作,根据教练机器人指令,一键采集课程内容,省时省力还可以使用播放器添加互动问答的方式采集/录制高清视频,操作简单方便轻松控制录屏你也可以借助其他应用,把视频在线上播放,方便查看制作成卡片模板对资源导入评论功能,可方便导出celebot教练机器人轻松实现在线采集,查看视频效果导出视频卡片或字幕列表。
给你推荐个采集神器——excelvba宝典可以根据需要导入数据的模板来采集数据。
推荐一下
我在知乎上回答过一个直接拖动图片到excel的方法同样适用于回答if判断条件
百度网盘资源/
有个叫:有道云笔记,网页可以直接导入excel表格,极其简单,我觉得很好用,有条件可以尝试看看。
格式化一下数据,
写这里面含有大量资源,包括内幕,
1.excel2vec支持全网平台excel爬虫第一项:excel2vec支持全网平台excel爬虫的业务规则很重要,如果要过滤excel繁多而无用的爬虫,excel2vec提供一整套的业务规则组件,支持过滤114个爬虫平台,从laravel,npm,corba,github直接导入javajar包都没问题。
比如针对一个excel表做sheet转化到word,sheetindex和sheetdecl这三个方法都可以过滤掉大量无用的爬虫和爬虫器。但是用python爬虫是不是就麻烦点了,肯定的,但是我们可以使用开源代码解决(以下以web爬虫为例)web爬虫|第二代简单粗暴爬虫实现第三项:excel2vec集中火力攻击miniflow支持全网平台excel爬虫的业务规则很重要,如果要过滤excel繁多而无用的爬虫,excel2vec提供一整套的业务规则组件,支持过滤114个爬虫平台,从laravel,npm,corba,github直接导入javajar包都没问题。
比如针对一个excel表做sheet转化到word,sheetindex和sheetdecl这三个方法都可以过滤掉大量无用的爬虫和爬虫器。但是用python爬虫是不是就麻烦点了,肯定的,但是我们可以使用开源代码解决(以下以web爬虫为例)web爬虫|第二代简单粗暴爬虫实现2.excel2vec集中火力攻击miniflow支持全网平台miniflow是sqllibraryfordataanalysis。
苹果手机和安卓手机配合使用的方法,一键采集整个朋友圈图片
采集交流 • 优采云 发表了文章 • 0 个评论 • 716 次浏览 • 2021-06-12 06:01
可靠的采集神器请点击手机下载:安卓手机下载,请直接下载安装!苹果手机下载,请直接下载安装!发布的朋友圈图片,可以获取和发送到微信并推送到朋友圈的图片今天给大家分享一款一键采集整个朋友圈图片的应用,主要解决整个微信图片资源如何更高效的利用问题,下载和使用的方法很简单,就不做过多介绍了。采集和保存图片素材的过程需要一个iphone手机和安卓手机进行配合,才能完成图片的采集以及保存操作,下面详细介绍一下关于iphone和安卓手机配合使用的操作流程。
注:苹果手机和安卓手机均需要开启usb调试!苹果手机和安卓手机配合使用方法:苹果手机在地址栏中输入“pc机密码”;安卓手机在浏览器中输入“::打开电脑;安卓手机打开浏览器输入“这里的电脑是浏览器”,在浏览器中输入“ip地址”即可;进入ip地址,在浏览器中输入“”即可找到该网址;在该网址中输入“图片”即可跳转到被采集的图片网站;找到合适的网站后,在被采集图片网站中点击“复制图片”即可拷贝图片资源;关于转换图片格式,推荐将图片保存到本地后,使用格式工厂、截图工具等文件处理工具进行处理。下面以“工具箱”为例,介绍如何一键采集整个微信朋友圈图片素材操作步骤:。
1、打开工具箱界面,
2、点击“采集图片”功能后,
3、选择采集的朋友圈图片后,按要求进行设置采集图片的属性信息(图片链接和个人名称等),设置完成后点击“保存”,
4、打开电脑浏览器,输入网址:, 查看全部
苹果手机和安卓手机配合使用的方法,一键采集整个朋友圈图片
可靠的采集神器请点击手机下载:安卓手机下载,请直接下载安装!苹果手机下载,请直接下载安装!发布的朋友圈图片,可以获取和发送到微信并推送到朋友圈的图片今天给大家分享一款一键采集整个朋友圈图片的应用,主要解决整个微信图片资源如何更高效的利用问题,下载和使用的方法很简单,就不做过多介绍了。采集和保存图片素材的过程需要一个iphone手机和安卓手机进行配合,才能完成图片的采集以及保存操作,下面详细介绍一下关于iphone和安卓手机配合使用的操作流程。
注:苹果手机和安卓手机均需要开启usb调试!苹果手机和安卓手机配合使用方法:苹果手机在地址栏中输入“pc机密码”;安卓手机在浏览器中输入“::打开电脑;安卓手机打开浏览器输入“这里的电脑是浏览器”,在浏览器中输入“ip地址”即可;进入ip地址,在浏览器中输入“”即可找到该网址;在该网址中输入“图片”即可跳转到被采集的图片网站;找到合适的网站后,在被采集图片网站中点击“复制图片”即可拷贝图片资源;关于转换图片格式,推荐将图片保存到本地后,使用格式工厂、截图工具等文件处理工具进行处理。下面以“工具箱”为例,介绍如何一键采集整个微信朋友圈图片素材操作步骤:。
1、打开工具箱界面,
2、点击“采集图片”功能后,
3、选择采集的朋友圈图片后,按要求进行设置采集图片的属性信息(图片链接和个人名称等),设置完成后点击“保存”,
4、打开电脑浏览器,输入网址:,
美团的项目下载地址(一):Xpath的使用方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-06-02 01:34
在github上找一个美团项目,可以获取到指定城市的商家信息,分分钟上百条商家信息数据在手,信息包括店铺名称、地理位置、评分、销量,电话(这就是重点)。
好久没更新了。今天写了文章,附上这个很有价值的项目的下载地址。
本文是自己写的xpath笔记。不想看的可以到【k13】底部代码下载地址。
可惜项目是用scrapy写的。其实我是不想用框架的,但是把这个项目改成可以运行的代码,花了一天的时间。我在变更过程中再次熟悉了scrapy。决定学习xpath,然后我会用scrapy写几个爬虫。
除了css,scrapy的选择器比xpath好。现在需要练习xpath的使用。
Xpath 简介
一般来说,使用id、name、class等属性定位节点可以解决大部分解析需求,但有时在以下情况下,使用Xpath更方便:
没有id、名字、班级等
标签的属性或文本特征不重要
标签嵌套层次太复杂
Xpath 是对 XML 路径的介绍。基于 XML 树结构,您可以在整个树中找到目标节点。由于 HTML 文档本身是一个标准的 XML 页面,我们可以使用 XPath 语法来定位页面元素。
Xpath 定位方法
一、Xpath 路径
Xpath 路径示例
定位节点
#查找html下的body下的form下的所有input节点
/html/body/form/input
#查找所有input节点
//input
*通配符选择未知节点**
#查找form节点下的所有节点
//form/*#查找所有节点//*
#查找所有input节点(input至少有爷爷辈亲戚节点)
//*/input
二、 使用索引(这是我自己的理解)
如果过滤元素时有多个节点,但我们想确定唯一的节点。您可以使用类似于列表索引的方式进行精确定位。
案例
#定位 第8个td下的 第2个a节点
//*/td[7]/a[1]
#定位 第8个td下的 第3个span节点
//*/td[7]/span[2]
#定位 最后一个td下的 最后一个a节点
//*/td[last()]/a[last()]
三、使用属性
为了让定位更准确,类似于使用索引,我们需要增加信息量,所以我们也可以使用属性。 @Symbol 是一个属性符号
#定位所有包含name属性的input节点
//input[@name]
#定位含有属性的所有的input节点
//input[@*]
#定位所有value=2的input节点
//input[@value='2']
#使用多个属性定位
//input[@value='2'][@id='3']
或者//input[@value='2' and @id='3']
四、常用功能
除了索引和属性,Xpath还可以使用方便的功能来提升定位的准确性。下面是几个常用的函数:
应用推广
#定位href属性中包含“promote.html”的所有a节点
//a[contains(@href,'promote.html')]
#元素内的文本为“应用推广”的所有a节点
//a[text()='应用推广']
#href属性值是以“/ads”开头的所有a节点
//a[starts-with(@href,'/ads')]
五、Xpath 轴
这部分类似于BeautifulSoup中的sibling、parents和children方法。有时为了实现定位,需要绕道而行,七阿姨和八阿姨的远房亲戚四处走走相识,定位就完成了。
六、美团商户信息
在代码中,我提供了一个高科技的api_key,但是如果你用的太多,对方实际上是无法使用它的。我建议你自己申请一个。
#在高德注册,进入控制台
http://lbs.amap.com/
这是郑州市在几十秒内采集的数据。
提示:
修改高德api_key
在项目中找到设置,将GAODEAPIKEY参数修改为你申请号的api_key。
更改城市
在项目中找到设置,修改CITY_NAME参数为你想要的城市采集
运行主程序采集数据
在项目文件夹中找到main.py并运行,愉快的获取数据并保存到data.csv。
项目下载地址
链接:密码:e7dz 查看全部
美团的项目下载地址(一):Xpath的使用方法
在github上找一个美团项目,可以获取到指定城市的商家信息,分分钟上百条商家信息数据在手,信息包括店铺名称、地理位置、评分、销量,电话(这就是重点)。
好久没更新了。今天写了文章,附上这个很有价值的项目的下载地址。
本文是自己写的xpath笔记。不想看的可以到【k13】底部代码下载地址。
可惜项目是用scrapy写的。其实我是不想用框架的,但是把这个项目改成可以运行的代码,花了一天的时间。我在变更过程中再次熟悉了scrapy。决定学习xpath,然后我会用scrapy写几个爬虫。
除了css,scrapy的选择器比xpath好。现在需要练习xpath的使用。
Xpath 简介
一般来说,使用id、name、class等属性定位节点可以解决大部分解析需求,但有时在以下情况下,使用Xpath更方便:
没有id、名字、班级等
标签的属性或文本特征不重要
标签嵌套层次太复杂
Xpath 是对 XML 路径的介绍。基于 XML 树结构,您可以在整个树中找到目标节点。由于 HTML 文档本身是一个标准的 XML 页面,我们可以使用 XPath 语法来定位页面元素。
Xpath 定位方法
一、Xpath 路径

Xpath 路径示例
定位节点
#查找html下的body下的form下的所有input节点
/html/body/form/input
#查找所有input节点
//input
*通配符选择未知节点**
#查找form节点下的所有节点
//form/*#查找所有节点//*
#查找所有input节点(input至少有爷爷辈亲戚节点)
//*/input
二、 使用索引(这是我自己的理解)
如果过滤元素时有多个节点,但我们想确定唯一的节点。您可以使用类似于列表索引的方式进行精确定位。
案例
#定位 第8个td下的 第2个a节点
//*/td[7]/a[1]
#定位 第8个td下的 第3个span节点
//*/td[7]/span[2]
#定位 最后一个td下的 最后一个a节点
//*/td[last()]/a[last()]
三、使用属性
为了让定位更准确,类似于使用索引,我们需要增加信息量,所以我们也可以使用属性。 @Symbol 是一个属性符号
#定位所有包含name属性的input节点
//input[@name]
#定位含有属性的所有的input节点
//input[@*]
#定位所有value=2的input节点
//input[@value='2']
#使用多个属性定位
//input[@value='2'][@id='3']
或者//input[@value='2' and @id='3']
四、常用功能
除了索引和属性,Xpath还可以使用方便的功能来提升定位的准确性。下面是几个常用的函数:

应用推广
#定位href属性中包含“promote.html”的所有a节点
//a[contains(@href,'promote.html')]
#元素内的文本为“应用推广”的所有a节点
//a[text()='应用推广']
#href属性值是以“/ads”开头的所有a节点
//a[starts-with(@href,'/ads')]
五、Xpath 轴
这部分类似于BeautifulSoup中的sibling、parents和children方法。有时为了实现定位,需要绕道而行,七阿姨和八阿姨的远房亲戚四处走走相识,定位就完成了。

六、美团商户信息
在代码中,我提供了一个高科技的api_key,但是如果你用的太多,对方实际上是无法使用它的。我建议你自己申请一个。
#在高德注册,进入控制台
http://lbs.amap.com/


这是郑州市在几十秒内采集的数据。

提示:
修改高德api_key
在项目中找到设置,将GAODEAPIKEY参数修改为你申请号的api_key。
更改城市
在项目中找到设置,修改CITY_NAME参数为你想要的城市采集
运行主程序采集数据
在项目文件夹中找到main.py并运行,愉快的获取数据并保存到data.csv。
项目下载地址
链接:密码:e7dz
使用爆搜-数据采集神器,中国领先的采集系统(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-05-28 19:03
可靠的采集神器,可以让你省下99%的时间和精力,不用为发票、收据、电子合同、发票、发票代开、在线身份验证、生产商跟踪记录、个人云报销等琐碎的事情烦恼。免费链接:/#/baiduyang/share?url=q531%3a51%26fsyqbmr-mgw%26wukkjb8qab%26fxbmkfr08ywsz2q&wtdocshowareauth_wsslx_wsslchop&pcffset=0&pcffset_ryf=0&pcffset_synce=0&pcffset_type=0&pcffset_penduri=0&pcffset_channels=0&pcffset_credit=0&pcffset_useroriginal=0&pcffset_trans_cmd=0&pcffset_savearray=0&pcffset_trans_cms=0&pcffset_serial_url=mc41/url?var=manfortransformoutputshaderpreviewer、overviewmega代码-rfbkhomyvmfewgzbc&viewer=gluva。
fiddler或者java的explorer(需要安装jdk1.8或以上版本)
我推荐使用爆搜爆搜-数据采集神器,中国领先的采集系统我在appstore应用市场查到的:
企业版的话:excel是可以建立索引,可以用来搜索指定方向的信息。然后,用企业版的数据透视表,插入大量的filter控件来处理不同方向的信息(按照月份、数字、人名、国家、日期等等方向进行筛选),一定程度上可以形成一个中间体,然后下载case文件就可以搜索具体方向的信息(很实用啊)。针对各方向的数据,都可以以表格的形式导出到excel。如果知道什么样的数据来自哪个方向,又不需要进行数据整理之类的工作,可以自己写爬虫来爬信息,查看结果。 查看全部
使用爆搜-数据采集神器,中国领先的采集系统(图)
可靠的采集神器,可以让你省下99%的时间和精力,不用为发票、收据、电子合同、发票、发票代开、在线身份验证、生产商跟踪记录、个人云报销等琐碎的事情烦恼。免费链接:/#/baiduyang/share?url=q531%3a51%26fsyqbmr-mgw%26wukkjb8qab%26fxbmkfr08ywsz2q&wtdocshowareauth_wsslx_wsslchop&pcffset=0&pcffset_ryf=0&pcffset_synce=0&pcffset_type=0&pcffset_penduri=0&pcffset_channels=0&pcffset_credit=0&pcffset_useroriginal=0&pcffset_trans_cmd=0&pcffset_savearray=0&pcffset_trans_cms=0&pcffset_serial_url=mc41/url?var=manfortransformoutputshaderpreviewer、overviewmega代码-rfbkhomyvmfewgzbc&viewer=gluva。
fiddler或者java的explorer(需要安装jdk1.8或以上版本)
我推荐使用爆搜爆搜-数据采集神器,中国领先的采集系统我在appstore应用市场查到的:
企业版的话:excel是可以建立索引,可以用来搜索指定方向的信息。然后,用企业版的数据透视表,插入大量的filter控件来处理不同方向的信息(按照月份、数字、人名、国家、日期等等方向进行筛选),一定程度上可以形成一个中间体,然后下载case文件就可以搜索具体方向的信息(很实用啊)。针对各方向的数据,都可以以表格的形式导出到excel。如果知道什么样的数据来自哪个方向,又不需要进行数据整理之类的工作,可以自己写爬虫来爬信息,查看结果。
可靠的采集神器:,能帮你快速实现网站采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-05-25 05:06
可靠的采集神器:,能帮你快速实现网站采集。它不仅可以采集百度、搜狗、360、uc等多家搜索引擎的结果,还能采集新浪微博、天涯、豆瓣、知乎、简书、简书等多家平台的信息。
我之前试了下最新版本网易优采云。全网大多数网站都能采到。但是运营商的大页面你要费很大力气才能采到。但是采到了就是你的,搜索引擎对优采云限制得不严格,你想抓到什么抓什么。
之前我也是谷歌浏览器插件安装安不上看到有人说优采云。我就用了一下。之前提供mac版的谷歌浏览器插件。不知道现在怎么样。但是我直接挂梯子连国内谷歌服务器加速优采云采集确实还是挺快的。另外就是点优采云的安装图片可以看到一共有9个配置文件。我现在第二个改成付费vip主机了。没必要再采集广告。当然可以试试各种在线工具。
云采集可以看下。不需要注册,不需要下载软件。获取这几篇文章,百度云分享给你百度云搜索,
采云采集,免费的,
看要采那些渠道,上采云采集网站,不仅可以采到企业的公众号,个人的公众号也可以采到。直接输入关键词搜索即可。 查看全部
可靠的采集神器:,能帮你快速实现网站采集
可靠的采集神器:,能帮你快速实现网站采集。它不仅可以采集百度、搜狗、360、uc等多家搜索引擎的结果,还能采集新浪微博、天涯、豆瓣、知乎、简书、简书等多家平台的信息。
我之前试了下最新版本网易优采云。全网大多数网站都能采到。但是运营商的大页面你要费很大力气才能采到。但是采到了就是你的,搜索引擎对优采云限制得不严格,你想抓到什么抓什么。
之前我也是谷歌浏览器插件安装安不上看到有人说优采云。我就用了一下。之前提供mac版的谷歌浏览器插件。不知道现在怎么样。但是我直接挂梯子连国内谷歌服务器加速优采云采集确实还是挺快的。另外就是点优采云的安装图片可以看到一共有9个配置文件。我现在第二个改成付费vip主机了。没必要再采集广告。当然可以试试各种在线工具。
云采集可以看下。不需要注册,不需要下载软件。获取这几篇文章,百度云分享给你百度云搜索,
采云采集,免费的,
看要采那些渠道,上采云采集网站,不仅可以采到企业的公众号,个人的公众号也可以采到。直接输入关键词搜索即可。
可靠的采集神器:新浪微博api开放平台【开发者招募】
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-08-09 06:12
可靠的采集神器:新浪微博api开放平台【开发者招募】基于新浪微博api接口的微博抓取本教程可以用我们的小工具开发的代码抓取的效果:小结:新浪微博自己的微博接口,官方也要收费,开发api的人也要收费。微博的客户端已经很方便了,
解决微博抓取难的问题,主要有两个问题:如何去抓取微博?如何更好的利用微博去获取更多的信息?如何更好的利用目标微博去获取更多的信息?以天天快报为例,每天推送几十条的内容就是一个页面,上百条的内容就需要渲染几百页面。本人常用的抓取工具有:新浪微博api开放平台:微博采集器-微博爬虫-新浪微博抓取工具公众号:ai_web代码分享论坛。
postman或者fiddler可以帮你
熟悉新浪微博,用javascript,
目前中国版的微博爬虫工具都是基于scrapy模式的,api开放平台的也不错,是新浪微博自己开发的,好像都需要收费,收费之后,用起来更方便吧,主要看你的实际需求,如果你需要知道的话,可以去他们官网上看看,
需要一定的前端知识。前端肯定会遇到浏览器支持的问题。并且除了有公司提供项目之外,有相应的文档可以查阅。 查看全部
可靠的采集神器:新浪微博api开放平台【开发者招募】
可靠的采集神器:新浪微博api开放平台【开发者招募】基于新浪微博api接口的微博抓取本教程可以用我们的小工具开发的代码抓取的效果:小结:新浪微博自己的微博接口,官方也要收费,开发api的人也要收费。微博的客户端已经很方便了,
解决微博抓取难的问题,主要有两个问题:如何去抓取微博?如何更好的利用微博去获取更多的信息?如何更好的利用目标微博去获取更多的信息?以天天快报为例,每天推送几十条的内容就是一个页面,上百条的内容就需要渲染几百页面。本人常用的抓取工具有:新浪微博api开放平台:微博采集器-微博爬虫-新浪微博抓取工具公众号:ai_web代码分享论坛。
postman或者fiddler可以帮你
熟悉新浪微博,用javascript,
目前中国版的微博爬虫工具都是基于scrapy模式的,api开放平台的也不错,是新浪微博自己开发的,好像都需要收费,收费之后,用起来更方便吧,主要看你的实际需求,如果你需要知道的话,可以去他们官网上看看,
需要一定的前端知识。前端肯定会遇到浏览器支持的问题。并且除了有公司提供项目之外,有相应的文档可以查阅。
可靠的采集神器,我找了好久,终于找到了
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-08-06 07:05
可靠的采集神器我找了好久,终于找到了,
从新浪微博搜索栏中输入zhihu进入知乎,点击进入相关主页后,点击通用按钮,选择采集知乎即可。如果想上传图片,点击上传,图片会变灰色,然后重新进入知乎主页,再点击图片,就可以正常显示图片了。在这种情况下,还可以点击添加到剪贴板,实现复制粘贴,
直接用replace或者chrome
。
出来没有图片呀,
我发现是百度经验一类的类似网站,你会发现那些主页都是一些人写的。如果你浏览了,可以写一些自己的博客,或者干脆转到自己的blog,那些人就会重新发布在其他网站上。
目前遇到了同样的问题,在同样的帖子里回复了同样的内容,他们就能全部采集过来,而我写的不太好,一般不会在这么大规模的话题里回复,不然回复太多就成回帖了,而且他们也能以一篇的形式流传,或者知乎官方吧,如果只是在一个问题下回复,确实不会有图片。正在找一个更简单的方法解决。谢谢。
用google的api
搜狗百度是有个数据接口的
安卓手机暂时不可能(ios暂时来说是可以的),知乎的动态还是知乎网站有权限的。另外,你可以试试把自己写好的内容之类的共享出去。 查看全部
可靠的采集神器,我找了好久,终于找到了
可靠的采集神器我找了好久,终于找到了,
从新浪微博搜索栏中输入zhihu进入知乎,点击进入相关主页后,点击通用按钮,选择采集知乎即可。如果想上传图片,点击上传,图片会变灰色,然后重新进入知乎主页,再点击图片,就可以正常显示图片了。在这种情况下,还可以点击添加到剪贴板,实现复制粘贴,
直接用replace或者chrome
。
出来没有图片呀,
我发现是百度经验一类的类似网站,你会发现那些主页都是一些人写的。如果你浏览了,可以写一些自己的博客,或者干脆转到自己的blog,那些人就会重新发布在其他网站上。
目前遇到了同样的问题,在同样的帖子里回复了同样的内容,他们就能全部采集过来,而我写的不太好,一般不会在这么大规模的话题里回复,不然回复太多就成回帖了,而且他们也能以一篇的形式流传,或者知乎官方吧,如果只是在一个问题下回复,确实不会有图片。正在找一个更简单的方法解决。谢谢。
用google的api
搜狗百度是有个数据接口的
安卓手机暂时不可能(ios暂时来说是可以的),知乎的动态还是知乎网站有权限的。另外,你可以试试把自己写好的内容之类的共享出去。
Flume架构及核心组件Flume的架构图:Flume实战案例
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-07-31 22:14
Flume 概览
官方文档:
Flume 是一个分布式、高可靠、高可用的日志数据采集服务,可以高效地采集、聚合和移动大量的日志数据。它具有基于流数据的简单灵活的架构。它具有健壮性和容错性,具有可调节的可靠性机制以及许多故障转移和恢复机制。它使用简单且可扩展的数据模型来允许对应用程序进行在线分析。
Flume 架构和核心组件
Flume 的架构图:
Flume 部署
准备JDK环境:
[root@hadoop01 ~]# java -version
java version "11.0.8" 2020-07-14 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.8+10-LTS)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.8+10-LTS, mixed mode)
[root@hadoop01 ~]#
下载 Flum:
复制下载链接下载:
[root@hadoop01 ~]# cd /usr/local/src
[root@hadoop01 /usr/local/src]# wget https://archive.cloudera.com/c ... ar.gz
解压到合适的目录:
[root@hadoop01 /usr/local/src]# tar -zxvf flume-ng-1.6.0-cdh5.16.2.tar.gz -C /usr/local
[root@hadoop01 /usr/local/src]# cd /usr/local/apache-flume-1.6.0-cdh5.16.2-bin/
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# ls
bin CHANGELOG cloudera conf DEVNOTES docs lib LICENSE NOTICE README RELEASE-NOTES tools
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]#
配置环境变量:
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# vim ~/.bash_profile
export FLUME_HOME=/usr/local/apache-flume-1.6.0-cdh5.16.2-bin
export PATH=$PATH:$FLUME_HOME/bin
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# source ~/.bash_profile
编辑配置文件:
[root@hadoop01 ~]# cp $FLUME_HOME/conf/flume-env.sh.template $FLUME_HOME/conf/flume-env.sh
[root@hadoop01 ~]# vim $FLUME_HOME/conf/flume-env.sh
# 配置JDK
export JAVA_HOME=/usr/local/jdk/11
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
测试flume-ng命令:
[root@hadoop01 ~]# flume-ng version
Flume 1.6.0-cdh5.16.2
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: df92badde3691ee3eb6074a177f0e96682345381
Compiled by jenkins on Mon Jun 3 03:49:33 PDT 2019
From source with checksum 9336bfa3ff8cfb5e20cd9d700135a2c1
[root@hadoop01 ~]#
Flume实战案例-从指定网口采集输出数据到控制台
使用Flume的关键是写配置文件:
配置Source,配置Channel,配置Sink,将以上三个组件串起来
所以先创建一个配置文件:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/netcat-example.conf
# a1是agent的名称
a1.sources = r1 # source的名称
a1.sinks = k1 # sink的名称
a1.channels = c1 # channel的名称
# 描述和配置source
a1.sources.r1.type = netcat # 指定source的类型为netcat
a1.sources.r1.bind = localhost # 指定source的ip
a1.sources.r1.port = 44444 # 指定source的端口
# 定义sink
a1.sinks.k1.type = logger # 指定sink类型,logger就是将数据输出到控制台
# 定义一个基于内存的channel
a1.channels.c1.type = memory # channel类型
a1.channels.c1.capacity = 1000 # channel的容量
a1.channels.c1.transactionCapacity = 100 # channel中每个事务的最大事件数
# 将source和sink绑定到channel上,即将三者串连起来
a1.sources.r1.channels = c1 # 指定r1这个source的channel为c1
a1.sinks.k1.channel = c1 # 指定k1这个sink的channel为c1
启动代理:
[root@hadoop01 ~]# flume-ng agent --name a1 -c $FLUME_HOME/conf -f $FLUME_HOME/conf/netcat-example.conf -Dflume.root.logger=INFO,console
然后通过telnet命令向44444端口发送一些数据:
[root@hadoop01 ~]# telnet localhost 44444
...
hello flume
OK
此时会看到flume的输出中打印了接收到的数据:
2020-11-02 16:08:47,965 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 0D hello flume. }
Flume实战案例-实时监控一个文件采集新增数据输出到控制台
同理,先创建一个配置文件:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/file-example.conf
# a1是agent的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -f /data/data.log
a1.sources.r1.shell = /bin/sh -c
# 定义sink
a1.sinks.k1.type = logger
# 定义一个基于内存的channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
创建一个测试文件:
[root@hadoop01 ~]# touch /data/data.log
启动代理:
[root@hadoop01 ~]# flume-ng agent --name a1 -c $FLUME_HOME/conf -f $FLUME_HOME/conf/file-example.conf -Dflume.root.logger=INFO,console
向 data.log 写入一些内容:
[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello world" >> /data/data.log
此时flume的输出中,会看到打印了监控文件的新数据:
2020-11-02 16:21:26,946 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 hello flume }
2020-11-02 16:21:38,707 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 77 6F 72 6C 64 hello world }
Flume 实际案例-实时采集 登录服务器 A 到服务器 B
要达到这个要求,需要使用Avro的Source和SInk。流程图如下:
为了测试方便,我这里用机器进行模拟。首先,A机的配置文件如下:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/exec-memory-avro.conf
# 定义各个组件的名称
exec-memory-avro.sources = exec-source
exec-memory-avro.sinks = avro-sink
exec-memory-avro.channels = memory-channel
# 描述和配置source
exec-memory-avro.sources.exec-source.type = exec
exec-memory-avro.sources.exec-source.command = tail -f /data/data.log
exec-memory-avro.sources.exec-source.shell = /bin/sh -c
# 定义sink
exec-memory-avro.sinks.avro-sink.type = avro
exec-memory-avro.sinks.avro-sink.hostname = hadoop01
exec-memory-avro.sinks.avro-sink.port = 44444
# 定义一个基于内存的channel
exec-memory-avro.channels.memory-channel.type = memory
exec-memory-avro.channels.memory-channel.capacity = 1000
exec-memory-avro.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
exec-memory-avro.sources.exec-source.channels = memory-channel
exec-memory-avro.sinks.avro-sink.channel = memory-channel
机器B的配置文件如下:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/avro-memory-logger.conf
# 定义各个组件的名称
avro-memory-logger.sources = avro-source
avro-memory-logger.sinks = logger-sink
avro-memory-logger.channels = memory-channel
# 描述和配置source
avro-memory-logger.sources.avro-source.type = avro
avro-memory-logger.sources.avro-source.bind = hadoop01
avro-memory-logger.sources.avro-source.port = 44444
# 定义sink
avro-memory-logger.sinks.logger-sink.type = logger
# 定义一个基于内存的channel
avro-memory-logger.channels.memory-channel.type = memory
avro-memory-logger.channels.memory-channel.capacity = 1000
avro-memory-logger.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
avro-memory-logger.sources.avro-source.channels = memory-channel
avro-memory-logger.sinks.logger-sink.channel = memory-channel
先启动机器B的agent,否则机器A的agent如果不能监听目标机器的端口可能会报错:
[root@hadoop01 ~]# flume-ng agent --name avro-memory-logger -c $FLUME_HOME/conf -f $FLUME_HOME/conf/avro-memory-logger.conf -Dflume.root.logger=INFO,console
启动机器A的代理:
[root@hadoop01 ~]# flume-ng agent --name exec-memory-avro -c $FLUME_HOME/conf -f $FLUME_HOME/conf/exec-memory-avro.conf -Dflume.root.logger=INFO,console
向 data.log 写入一些内容:
[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello world" >> /data/data.log
[root@hadoop01 ~]# echo "hello avro" >> /data/data.log
此时B机的agent在控制台的输出如下,于是我们就实现了A服务器上的日志实时采集到B服务器的功能:
2020-11-02 17:05:20,929 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 hello flume }
2020-11-02 17:05:21,486 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 77 6F 72 6C 64 hello world }
2020-11-02 17:05:51,505 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 61 76 72 6F hello avro }
集成Flume和Kafka完成实时数据采集
在上面的例子中,Agent B 将采集到的数据下沉到控制台,但在实际应用中它显然不会这样做。相反,它通常将数据接收到外部数据源。如HDFS、ES、Kafka等。在实时流处理架构中,大多数情况下,Sink到Kafka,然后下游消费者(一个或多个)接收数据进行实时处理。如下图所示:
所以基于前面的例子,这里是如何集成Kafka的。其实很简单,把Logger Sink改成Kafka Sink就可以了。切换到Kafka后的流程如下:
新建一个配置文件,内容如下:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/avro-memory-kafka.conf
# 定义各个组件的名称
avro-memory-kafka.sources = avro-source
avro-memory-kafka.sinks = kafka-sink
avro-memory-kafka.channels = memory-channel
# 描述和配置source
avro-memory-kafka.sources.avro-source.type = avro
avro-memory-kafka.sources.avro-source.bind = hadoop01
avro-memory-kafka.sources.avro-source.port = 44444
# 定义sink
avro-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
avro-memory-kafka.sinks.kafka-sink.brokerList = kafka01:9092
avro-memory-kafka.sinks.kafka-sink.topic = flume-topic
# 一个批次里发送多少消息
avro-memory-kafka.sinks.kafka-sink.batchSize = 5
# 指定采用的ack模式,可以参考kafka的ack机制
avro-memory-kafka.sinks.kafka-sink.requiredAcks = 1
# 定义一个基于内存的channel
avro-memory-kafka.channels.memory-channel.type = memory
avro-memory-kafka.channels.memory-channel.capacity = 1000
avro-memory-kafka.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
avro-memory-kafka.sources.avro-source.channels = memory-channel
avro-memory-kafka.sinks.kafka-sink.channel = memory-channel
配置完成后,启动Agent:
[root@hadoop01 ~]# flume-ng agent --name avro-memory-kafka -c $FLUME_HOME/conf -f $FLUME_HOME/conf/avro-memory-kafka.conf -Dflume.root.logger=INFO,console
然后启动另一个代理:
[root@hadoop01 ~]# flume-ng agent --name exec-memory-avro -c $FLUME_HOME/conf -f $FLUME_HOME/conf/exec-memory-avro.conf -Dflume.root.logger=INFO,console
启动一个Kafka消费者,方便观察Kafka收到的数据:
[root@kafka01 ~]# kafka-console-consumer.sh --bootstrap-server kafka01:9092 --topic flume-topic --from-beginning
向 data.log 写入一些内容:
[root@hadoop01 ~]# echo "hello kafka sink" >> /data/data.log
[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello agent" >> /data/data.log
此时Kafka消费者控制台会正常输出如下内容,证明Flume和Kafka已经成功集成:
[root@kafka01 ~]# kafka-console-consumer.sh --bootstrap-server kafka01:9092 --topic flume-topic --from-beginning
hello kafka sink
hello flume
hello agent 查看全部
Flume架构及核心组件Flume的架构图:Flume实战案例
Flume 概览
官方文档:
Flume 是一个分布式、高可靠、高可用的日志数据采集服务,可以高效地采集、聚合和移动大量的日志数据。它具有基于流数据的简单灵活的架构。它具有健壮性和容错性,具有可调节的可靠性机制以及许多故障转移和恢复机制。它使用简单且可扩展的数据模型来允许对应用程序进行在线分析。
Flume 架构和核心组件
Flume 的架构图:
Flume 部署
准备JDK环境:
[root@hadoop01 ~]# java -version
java version "11.0.8" 2020-07-14 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.8+10-LTS)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.8+10-LTS, mixed mode)
[root@hadoop01 ~]#
下载 Flum:
复制下载链接下载:
[root@hadoop01 ~]# cd /usr/local/src
[root@hadoop01 /usr/local/src]# wget https://archive.cloudera.com/c ... ar.gz
解压到合适的目录:
[root@hadoop01 /usr/local/src]# tar -zxvf flume-ng-1.6.0-cdh5.16.2.tar.gz -C /usr/local
[root@hadoop01 /usr/local/src]# cd /usr/local/apache-flume-1.6.0-cdh5.16.2-bin/
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# ls
bin CHANGELOG cloudera conf DEVNOTES docs lib LICENSE NOTICE README RELEASE-NOTES tools
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]#
配置环境变量:
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# vim ~/.bash_profile
export FLUME_HOME=/usr/local/apache-flume-1.6.0-cdh5.16.2-bin
export PATH=$PATH:$FLUME_HOME/bin
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# source ~/.bash_profile
编辑配置文件:
[root@hadoop01 ~]# cp $FLUME_HOME/conf/flume-env.sh.template $FLUME_HOME/conf/flume-env.sh
[root@hadoop01 ~]# vim $FLUME_HOME/conf/flume-env.sh
# 配置JDK
export JAVA_HOME=/usr/local/jdk/11
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
测试flume-ng命令:
[root@hadoop01 ~]# flume-ng version
Flume 1.6.0-cdh5.16.2
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: df92badde3691ee3eb6074a177f0e96682345381
Compiled by jenkins on Mon Jun 3 03:49:33 PDT 2019
From source with checksum 9336bfa3ff8cfb5e20cd9d700135a2c1
[root@hadoop01 ~]#
Flume实战案例-从指定网口采集输出数据到控制台
使用Flume的关键是写配置文件:
配置Source,配置Channel,配置Sink,将以上三个组件串起来
所以先创建一个配置文件:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/netcat-example.conf
# a1是agent的名称
a1.sources = r1 # source的名称
a1.sinks = k1 # sink的名称
a1.channels = c1 # channel的名称
# 描述和配置source
a1.sources.r1.type = netcat # 指定source的类型为netcat
a1.sources.r1.bind = localhost # 指定source的ip
a1.sources.r1.port = 44444 # 指定source的端口
# 定义sink
a1.sinks.k1.type = logger # 指定sink类型,logger就是将数据输出到控制台
# 定义一个基于内存的channel
a1.channels.c1.type = memory # channel类型
a1.channels.c1.capacity = 1000 # channel的容量
a1.channels.c1.transactionCapacity = 100 # channel中每个事务的最大事件数
# 将source和sink绑定到channel上,即将三者串连起来
a1.sources.r1.channels = c1 # 指定r1这个source的channel为c1
a1.sinks.k1.channel = c1 # 指定k1这个sink的channel为c1
启动代理:
[root@hadoop01 ~]# flume-ng agent --name a1 -c $FLUME_HOME/conf -f $FLUME_HOME/conf/netcat-example.conf -Dflume.root.logger=INFO,console
然后通过telnet命令向44444端口发送一些数据:
[root@hadoop01 ~]# telnet localhost 44444
...
hello flume
OK
此时会看到flume的输出中打印了接收到的数据:
2020-11-02 16:08:47,965 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 0D hello flume. }
Flume实战案例-实时监控一个文件采集新增数据输出到控制台
同理,先创建一个配置文件:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/file-example.conf
# a1是agent的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -f /data/data.log
a1.sources.r1.shell = /bin/sh -c
# 定义sink
a1.sinks.k1.type = logger
# 定义一个基于内存的channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
创建一个测试文件:
[root@hadoop01 ~]# touch /data/data.log
启动代理:
[root@hadoop01 ~]# flume-ng agent --name a1 -c $FLUME_HOME/conf -f $FLUME_HOME/conf/file-example.conf -Dflume.root.logger=INFO,console
向 data.log 写入一些内容:
[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello world" >> /data/data.log
此时flume的输出中,会看到打印了监控文件的新数据:
2020-11-02 16:21:26,946 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 hello flume }
2020-11-02 16:21:38,707 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 77 6F 72 6C 64 hello world }
Flume 实际案例-实时采集 登录服务器 A 到服务器 B
要达到这个要求,需要使用Avro的Source和SInk。流程图如下:
为了测试方便,我这里用机器进行模拟。首先,A机的配置文件如下:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/exec-memory-avro.conf
# 定义各个组件的名称
exec-memory-avro.sources = exec-source
exec-memory-avro.sinks = avro-sink
exec-memory-avro.channels = memory-channel
# 描述和配置source
exec-memory-avro.sources.exec-source.type = exec
exec-memory-avro.sources.exec-source.command = tail -f /data/data.log
exec-memory-avro.sources.exec-source.shell = /bin/sh -c
# 定义sink
exec-memory-avro.sinks.avro-sink.type = avro
exec-memory-avro.sinks.avro-sink.hostname = hadoop01
exec-memory-avro.sinks.avro-sink.port = 44444
# 定义一个基于内存的channel
exec-memory-avro.channels.memory-channel.type = memory
exec-memory-avro.channels.memory-channel.capacity = 1000
exec-memory-avro.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
exec-memory-avro.sources.exec-source.channels = memory-channel
exec-memory-avro.sinks.avro-sink.channel = memory-channel
机器B的配置文件如下:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/avro-memory-logger.conf
# 定义各个组件的名称
avro-memory-logger.sources = avro-source
avro-memory-logger.sinks = logger-sink
avro-memory-logger.channels = memory-channel
# 描述和配置source
avro-memory-logger.sources.avro-source.type = avro
avro-memory-logger.sources.avro-source.bind = hadoop01
avro-memory-logger.sources.avro-source.port = 44444
# 定义sink
avro-memory-logger.sinks.logger-sink.type = logger
# 定义一个基于内存的channel
avro-memory-logger.channels.memory-channel.type = memory
avro-memory-logger.channels.memory-channel.capacity = 1000
avro-memory-logger.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
avro-memory-logger.sources.avro-source.channels = memory-channel
avro-memory-logger.sinks.logger-sink.channel = memory-channel
先启动机器B的agent,否则机器A的agent如果不能监听目标机器的端口可能会报错:
[root@hadoop01 ~]# flume-ng agent --name avro-memory-logger -c $FLUME_HOME/conf -f $FLUME_HOME/conf/avro-memory-logger.conf -Dflume.root.logger=INFO,console
启动机器A的代理:
[root@hadoop01 ~]# flume-ng agent --name exec-memory-avro -c $FLUME_HOME/conf -f $FLUME_HOME/conf/exec-memory-avro.conf -Dflume.root.logger=INFO,console
向 data.log 写入一些内容:
[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello world" >> /data/data.log
[root@hadoop01 ~]# echo "hello avro" >> /data/data.log
此时B机的agent在控制台的输出如下,于是我们就实现了A服务器上的日志实时采集到B服务器的功能:
2020-11-02 17:05:20,929 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 hello flume }
2020-11-02 17:05:21,486 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 77 6F 72 6C 64 hello world }
2020-11-02 17:05:51,505 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 61 76 72 6F hello avro }
集成Flume和Kafka完成实时数据采集
在上面的例子中,Agent B 将采集到的数据下沉到控制台,但在实际应用中它显然不会这样做。相反,它通常将数据接收到外部数据源。如HDFS、ES、Kafka等。在实时流处理架构中,大多数情况下,Sink到Kafka,然后下游消费者(一个或多个)接收数据进行实时处理。如下图所示:
所以基于前面的例子,这里是如何集成Kafka的。其实很简单,把Logger Sink改成Kafka Sink就可以了。切换到Kafka后的流程如下:
新建一个配置文件,内容如下:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/avro-memory-kafka.conf
# 定义各个组件的名称
avro-memory-kafka.sources = avro-source
avro-memory-kafka.sinks = kafka-sink
avro-memory-kafka.channels = memory-channel
# 描述和配置source
avro-memory-kafka.sources.avro-source.type = avro
avro-memory-kafka.sources.avro-source.bind = hadoop01
avro-memory-kafka.sources.avro-source.port = 44444
# 定义sink
avro-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
avro-memory-kafka.sinks.kafka-sink.brokerList = kafka01:9092
avro-memory-kafka.sinks.kafka-sink.topic = flume-topic
# 一个批次里发送多少消息
avro-memory-kafka.sinks.kafka-sink.batchSize = 5
# 指定采用的ack模式,可以参考kafka的ack机制
avro-memory-kafka.sinks.kafka-sink.requiredAcks = 1
# 定义一个基于内存的channel
avro-memory-kafka.channels.memory-channel.type = memory
avro-memory-kafka.channels.memory-channel.capacity = 1000
avro-memory-kafka.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
avro-memory-kafka.sources.avro-source.channels = memory-channel
avro-memory-kafka.sinks.kafka-sink.channel = memory-channel
配置完成后,启动Agent:
[root@hadoop01 ~]# flume-ng agent --name avro-memory-kafka -c $FLUME_HOME/conf -f $FLUME_HOME/conf/avro-memory-kafka.conf -Dflume.root.logger=INFO,console
然后启动另一个代理:
[root@hadoop01 ~]# flume-ng agent --name exec-memory-avro -c $FLUME_HOME/conf -f $FLUME_HOME/conf/exec-memory-avro.conf -Dflume.root.logger=INFO,console
启动一个Kafka消费者,方便观察Kafka收到的数据:
[root@kafka01 ~]# kafka-console-consumer.sh --bootstrap-server kafka01:9092 --topic flume-topic --from-beginning
向 data.log 写入一些内容:
[root@hadoop01 ~]# echo "hello kafka sink" >> /data/data.log
[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello agent" >> /data/data.log
此时Kafka消费者控制台会正常输出如下内容,证明Flume和Kafka已经成功集成:
[root@kafka01 ~]# kafka-console-consumer.sh --bootstrap-server kafka01:9092 --topic flume-topic --from-beginning
hello kafka sink
hello flume
hello agent
怎么获取登录登录网站后的cookie?(一)(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-07-30 19:13
有些网站需要用户登录才能显示相关信息。如果你想要采集这种网站,有以下几种方式:
1.编写发布模块,捕获post数据;
2. 一些采集器内置浏览器会得到这些信息,但往往不准确,可靠性低;
3.获取登录名网站cookie后,使用采集器模拟用户登录采集;
这里介绍第三种方法,比较简单,可靠性高。
一、登录网站后如何获取cookie?
方法一---最简单的方法是通过现代浏览器获取,以chrome为例:
1. F12 或右键勾选进入开发者模式界面;
2.点击网络,F5重新加载页面;
3.选择页面名称对应的html文件;
4.获取cookies;
方法二---也可以使用fiddler工具爬取; (如果你已经用浏览器获取了cookie,可以跳过这一步直接去)
fiddler 是客户端和服务器之间的 HTTP 代理,也是常用的 http 抓包工具之一。它可以记录客户端和服务器之间的所有 HTTP 请求。它还可以分析请求数据,设置断点,修改请求的数据,甚至修改服务器为指定的HTTP请求返回的数据。它非常强大。是网站调试的得力助手。
从fiddler官网下载:
下载安装完成后,请按照以下步骤操作:(此文章基于Fiddler 4版本)
1.首先在右侧显示的页面中选择Inspectors栏;
2.由于左边显示的页面已经有很多访问网站的信息了,我们先把它清除一下,以便接下来找到指定的网页;
可以使用快捷键ctrl+x或在页面左侧右键点击显示页面删除------>>所有会话;
3. 接下来登录网站,需要抓取cookies或者刷新登录的网页。您可以在左侧显示栏中轻松找到网站的Host(网站域名)+ URL。这个
比如这个是选中的,注意URL内容中带斜线/的信息;
4.在右侧显示栏中选择raw栏,即可看到获取到的cookie;
5.为了获取完整的cookie,我们点击右侧显示栏中间的在记事本中查看,打开记事本获取完整的cookie;
将二、获取的cookie填入优采云
最后将获取到的cookie和user-ent信息复制到采集器,然后打开detail extractor查看之前隐藏的内容;
优采云采集 填写cookies有3个入口:
我。创建新任务时,高级选项:
二。点击“Start | Timing采集”,在网络配置中填写相关信息;
三。细节提升器左侧列表中的网络配置:
注意:如果填写cookie后刷新页面无法显示采集的内容,可以尝试填写[cookie域名],例如采集百度就是填写 查看全部
怎么获取登录登录网站后的cookie?(一)(组图)
有些网站需要用户登录才能显示相关信息。如果你想要采集这种网站,有以下几种方式:
1.编写发布模块,捕获post数据;
2. 一些采集器内置浏览器会得到这些信息,但往往不准确,可靠性低;
3.获取登录名网站cookie后,使用采集器模拟用户登录采集;
这里介绍第三种方法,比较简单,可靠性高。
一、登录网站后如何获取cookie?
方法一---最简单的方法是通过现代浏览器获取,以chrome为例:
1. F12 或右键勾选进入开发者模式界面;
2.点击网络,F5重新加载页面;
3.选择页面名称对应的html文件;
4.获取cookies;
方法二---也可以使用fiddler工具爬取; (如果你已经用浏览器获取了cookie,可以跳过这一步直接去)
fiddler 是客户端和服务器之间的 HTTP 代理,也是常用的 http 抓包工具之一。它可以记录客户端和服务器之间的所有 HTTP 请求。它还可以分析请求数据,设置断点,修改请求的数据,甚至修改服务器为指定的HTTP请求返回的数据。它非常强大。是网站调试的得力助手。
从fiddler官网下载:
下载安装完成后,请按照以下步骤操作:(此文章基于Fiddler 4版本)
1.首先在右侧显示的页面中选择Inspectors栏;
2.由于左边显示的页面已经有很多访问网站的信息了,我们先把它清除一下,以便接下来找到指定的网页;
可以使用快捷键ctrl+x或在页面左侧右键点击显示页面删除------>>所有会话;
3. 接下来登录网站,需要抓取cookies或者刷新登录的网页。您可以在左侧显示栏中轻松找到网站的Host(网站域名)+ URL。这个
比如这个是选中的,注意URL内容中带斜线/的信息;
4.在右侧显示栏中选择raw栏,即可看到获取到的cookie;
5.为了获取完整的cookie,我们点击右侧显示栏中间的在记事本中查看,打开记事本获取完整的cookie;
将二、获取的cookie填入优采云
最后将获取到的cookie和user-ent信息复制到采集器,然后打开detail extractor查看之前隐藏的内容;
优采云采集 填写cookies有3个入口:
我。创建新任务时,高级选项:
二。点击“Start | Timing采集”,在网络配置中填写相关信息;
三。细节提升器左侧列表中的网络配置:
注意:如果填写cookie后刷新页面无法显示采集的内容,可以尝试填写[cookie域名],例如采集百度就是填写
机极视听与网信详细对比采集大师(NetGet)下载评测软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-07-29 01:21
information采集的难度是什么?数据更加复杂多样;下载后有什么困难?数据管理。
网络信息采集大师(NetGet)的主要功能就是解决这两个问题。一般数据采集是有针对性的,通常是针对某某或某某网站、采集某类数据。比如采集几个网站人才招聘信息、产品信息、供求信息、公司图书馆信息等等。简单分析了这些网站的数据结构后,设置相应的采集规则,就可以将你想要的所有数据下载到本地了。本软件支持分类,分类的目的是方便数据管理和统计分析。
现有功能介绍:
1. 这个软件可以采集任何类型的网站信息。包括htm、html、ASP、JSP、PHP等。采集速度快,信息一致,准确。支持网站login。
2. 类别。分类的目的是为了方便地管理数据。您可以添加、删除和修改类别。分类数据库有3个最新备份,放在\files目录下,为数据安全提供了可靠保证。
3. 任务。任务是采集task。按照相应的采集 规则行事。可以随时启动、暂停和停止任务。本软件支持多任务处理,即采集同时处理不同的数据。
4. 数据导出。 采集的数据可以通过三种方式导出:文本、Excel和数据库。可以根据需要导出为不同的格式。
5. 数据库。 Access 和 SqlServer 数据库目前正在测试中。数据库功能包括导入数据库和数据查询。
6. 菜单功能扩展。一般是扩展数据分析功能。例如,您自己开发了一个数据库软件。本软件用于分析采集的数据。您可以将软件连接到本软件以方便使用。
7. 日志。记录每一个重要的操作。比如类别的维护,任务的维护等等。日志可以清理和备份。 查看全部
机极视听与网信详细对比采集大师(NetGet)下载评测软件
information采集的难度是什么?数据更加复杂多样;下载后有什么困难?数据管理。
网络信息采集大师(NetGet)的主要功能就是解决这两个问题。一般数据采集是有针对性的,通常是针对某某或某某网站、采集某类数据。比如采集几个网站人才招聘信息、产品信息、供求信息、公司图书馆信息等等。简单分析了这些网站的数据结构后,设置相应的采集规则,就可以将你想要的所有数据下载到本地了。本软件支持分类,分类的目的是方便数据管理和统计分析。
现有功能介绍:
1. 这个软件可以采集任何类型的网站信息。包括htm、html、ASP、JSP、PHP等。采集速度快,信息一致,准确。支持网站login。
2. 类别。分类的目的是为了方便地管理数据。您可以添加、删除和修改类别。分类数据库有3个最新备份,放在\files目录下,为数据安全提供了可靠保证。
3. 任务。任务是采集task。按照相应的采集 规则行事。可以随时启动、暂停和停止任务。本软件支持多任务处理,即采集同时处理不同的数据。
4. 数据导出。 采集的数据可以通过三种方式导出:文本、Excel和数据库。可以根据需要导出为不同的格式。
5. 数据库。 Access 和 SqlServer 数据库目前正在测试中。数据库功能包括导入数据库和数据查询。
6. 菜单功能扩展。一般是扩展数据分析功能。例如,您自己开发了一个数据库软件。本软件用于分析采集的数据。您可以将软件连接到本软件以方便使用。
7. 日志。记录每一个重要的操作。比如类别的维护,任务的维护等等。日志可以清理和备份。
10款最好用的数据采集工具,可采集99%网页
采集交流 • 优采云 发表了文章 • 0 个评论 • 753 次浏览 • 2021-07-28 02:55
10个最好的数据采集tools,免费采集tools,网站webpage采集工具,各行各业采集tools,这里有一些更好的免费数据采集tools,希望可以帮助大家。
1、优采云采集器优采云是一个基于互联网运营商实名实名数据,整合网页数据采集、移动互联网数据和API接口服务的数据服务平台。其最大的特点是无需了解网络爬虫技术即可轻松完成采集。
2、优采云采集器优采云采集器是最常用的互联网数据采集软件。凭借灵活的配置和强大的性能,在国内同类产品中处于领先地位,获得了众多用户的一致认可。使用优采云采集器几乎采集所有网页。
3、近探中国近探中国的数据服务平台有很多采集开发者上传的工具,很多都是免费的。无论是采集internal网站、industry网站、government网站、app、微博、搜索引擎、公众号、小程序等数据,还是其他数据,近期都可以搞定采集还可以定制。这是他们最大的亮点之一。
4、大飞采集器大飞采集器可采集99%网页,速度是普通采集器的7倍,复制粘贴一样准确。它最大的特点是网页采集的同义词,因为专注而单一。
5、Import.io 使用 Import.io 适配任何 URL。只需输入网址,即可整齐抓取网页数据。操作非常简单,采集、采集的结果自动可视化。但是无法选择特定数据,无法自动翻页采集。
6、ParseHub ParseHub 分为免费版和付费版。从数百万个网页中获取数据。输入数千个链接和关键字,ParseHub 会自动搜索这些链接和关键字。使用我们的休息 API。以 Excel 和 JSON 格式下载提取的数据。将您的结果导入 Google 表格和 Tableau。
7、Content GrabberContent Grabber是外国大神制作的神器,可以从网页中抓取内容(视频、图片、文字),并提取到Excel、XML、CSV和大多数数据库中。该软件基于网络捕获获取和网络自动化。它完全免费使用,通常用于数据调查和测试目的。
8、ForeSpiderForeSpider 是一个非常有用的网页数据采集 工具。用户可以使用该工具帮助您自动检索网页中的各种数据信息,而且该软件使用起来非常简单。可以免费使用。基本上只要在一步一步的操作中输入网址链接就可以了。有特殊情况需要特殊处理才能采集,也支持配置脚本。
9、阿里数据采集阿里数据采集大平台稳定不死机,并且可以实现实时查询,软件开发数据采集,他们可以做到,除了有贵没问题。
10、优采云采集器优采云采集器 操作非常简单,按照流程简单上手,还可以支持多种形式的导出。 查看全部
10款最好用的数据采集工具,可采集99%网页
10个最好的数据采集tools,免费采集tools,网站webpage采集工具,各行各业采集tools,这里有一些更好的免费数据采集tools,希望可以帮助大家。
1、优采云采集器优采云是一个基于互联网运营商实名实名数据,整合网页数据采集、移动互联网数据和API接口服务的数据服务平台。其最大的特点是无需了解网络爬虫技术即可轻松完成采集。
2、优采云采集器优采云采集器是最常用的互联网数据采集软件。凭借灵活的配置和强大的性能,在国内同类产品中处于领先地位,获得了众多用户的一致认可。使用优采云采集器几乎采集所有网页。
3、近探中国近探中国的数据服务平台有很多采集开发者上传的工具,很多都是免费的。无论是采集internal网站、industry网站、government网站、app、微博、搜索引擎、公众号、小程序等数据,还是其他数据,近期都可以搞定采集还可以定制。这是他们最大的亮点之一。
4、大飞采集器大飞采集器可采集99%网页,速度是普通采集器的7倍,复制粘贴一样准确。它最大的特点是网页采集的同义词,因为专注而单一。
5、Import.io 使用 Import.io 适配任何 URL。只需输入网址,即可整齐抓取网页数据。操作非常简单,采集、采集的结果自动可视化。但是无法选择特定数据,无法自动翻页采集。
6、ParseHub ParseHub 分为免费版和付费版。从数百万个网页中获取数据。输入数千个链接和关键字,ParseHub 会自动搜索这些链接和关键字。使用我们的休息 API。以 Excel 和 JSON 格式下载提取的数据。将您的结果导入 Google 表格和 Tableau。
7、Content GrabberContent Grabber是外国大神制作的神器,可以从网页中抓取内容(视频、图片、文字),并提取到Excel、XML、CSV和大多数数据库中。该软件基于网络捕获获取和网络自动化。它完全免费使用,通常用于数据调查和测试目的。
8、ForeSpiderForeSpider 是一个非常有用的网页数据采集 工具。用户可以使用该工具帮助您自动检索网页中的各种数据信息,而且该软件使用起来非常简单。可以免费使用。基本上只要在一步一步的操作中输入网址链接就可以了。有特殊情况需要特殊处理才能采集,也支持配置脚本。
9、阿里数据采集阿里数据采集大平台稳定不死机,并且可以实现实时查询,软件开发数据采集,他们可以做到,除了有贵没问题。
10、优采云采集器优采云采集器 操作非常简单,按照流程简单上手,还可以支持多种形式的导出。
可靠的采集神器推荐一波云采飞,采集效率高
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-07-21 23:02
可靠的采集神器推荐一波云采飞,采集效率高,可视化操作,手机电脑都可以采集,用了就知道好在哪里不要做被收钱的免费工具,说免费的都是耍流氓,谁给你免费的,
可以使用segmentfault上的新人礼包,有各种精美的礼品礼袋送出,
当然是上面贴图的那个小姐姐pc软件的阿里妈妈去重工具啦,功能全面。
采集小助手,有多种采集方式,还有用户总结,不是托,
亿万采集百度文库
收集,获取是根本。不花钱的方法只有坚持长期的学习,知道自己想要什么,然后苦练内功以期能“得道升天”。关键还是得,想通过采集赚点外快。
网址提取器,稍微高级一点的不花钱,
我推荐你用yagent
百度文库还有谁不收费的!想一想就能知道是不是骗子,不收费就可以拿到他们的文档,不像普通的网站公布的网址一样的,
如果你需要需要某种资源的话,可以通过电子商务网站采集,不花钱就可以采集到。比如说b2b,或者是店铺,里面一些资源都可以。各行各业都有,你需要哪个行业,就可以找哪个行业的资源,然后把这些资源提取出来!花点钱并不是唯一的方法,
你可以用采集客的采集热点采集,手机软件也可以做,可视化操作,简单易懂,在线编辑,时效性也挺高的,基本1分钟就可以出内容,自定义修改也方便。还有一些基本的内容采集功能,这个都是免费的!要是需要更多, 查看全部
可靠的采集神器推荐一波云采飞,采集效率高
可靠的采集神器推荐一波云采飞,采集效率高,可视化操作,手机电脑都可以采集,用了就知道好在哪里不要做被收钱的免费工具,说免费的都是耍流氓,谁给你免费的,
可以使用segmentfault上的新人礼包,有各种精美的礼品礼袋送出,
当然是上面贴图的那个小姐姐pc软件的阿里妈妈去重工具啦,功能全面。
采集小助手,有多种采集方式,还有用户总结,不是托,
亿万采集百度文库
收集,获取是根本。不花钱的方法只有坚持长期的学习,知道自己想要什么,然后苦练内功以期能“得道升天”。关键还是得,想通过采集赚点外快。
网址提取器,稍微高级一点的不花钱,
我推荐你用yagent
百度文库还有谁不收费的!想一想就能知道是不是骗子,不收费就可以拿到他们的文档,不像普通的网站公布的网址一样的,
如果你需要需要某种资源的话,可以通过电子商务网站采集,不花钱就可以采集到。比如说b2b,或者是店铺,里面一些资源都可以。各行各业都有,你需要哪个行业,就可以找哪个行业的资源,然后把这些资源提取出来!花点钱并不是唯一的方法,
你可以用采集客的采集热点采集,手机软件也可以做,可视化操作,简单易懂,在线编辑,时效性也挺高的,基本1分钟就可以出内容,自定义修改也方便。还有一些基本的内容采集功能,这个都是免费的!要是需要更多,
可靠的采集神器我用过最好用的软件是yifleear
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-07-20 22:01
可靠的采集神器我用过最好用的采集软件是yifleear,我常用这个。yifleear采集器功能强大,有固定模式、移动模式、模糊模式、视频导出功能等十几种模式。能够一键上传美拍、秒拍、网易云音乐、开眼等数以百计的网站。
三点一平看看
抖音采集程序来啦!如何免费搞定!!我是来自凯萨互动空间有很多人反应说这个程序质量不错还有使用情况,有没有开源版本,给大家来个开源的试试。开源版本的在他们官网有免费提供下载。有哪些值得推荐的工具或者app?一个抖音的采集软件。[国内抖音视频免费下载第三方官方平台],免费下载抖音、火山视频免费下载全网视频免费下载全网音乐,可编辑歌词也可以为微信、抖音、火山等做一个关键词采集,也可以为企业做个引流有哪些十分钟就能上手的入门级神器?-文章有点长的回答-。
wifi万能钥匙
看看这个哦
我自己觉得挺好用的...我也是从一个视频后缀采集器转换过来,
但如果不想麻烦
有啊。
斗鱼啊,
scrapdown去看看,我朋友推荐给我的,
爱采集,
移动端有美拍,秒拍等软件,pc端有搜狗浏览器等,这些视频本身都可以采集的。 查看全部
可靠的采集神器我用过最好用的软件是yifleear
可靠的采集神器我用过最好用的采集软件是yifleear,我常用这个。yifleear采集器功能强大,有固定模式、移动模式、模糊模式、视频导出功能等十几种模式。能够一键上传美拍、秒拍、网易云音乐、开眼等数以百计的网站。
三点一平看看
抖音采集程序来啦!如何免费搞定!!我是来自凯萨互动空间有很多人反应说这个程序质量不错还有使用情况,有没有开源版本,给大家来个开源的试试。开源版本的在他们官网有免费提供下载。有哪些值得推荐的工具或者app?一个抖音的采集软件。[国内抖音视频免费下载第三方官方平台],免费下载抖音、火山视频免费下载全网视频免费下载全网音乐,可编辑歌词也可以为微信、抖音、火山等做一个关键词采集,也可以为企业做个引流有哪些十分钟就能上手的入门级神器?-文章有点长的回答-。
wifi万能钥匙
看看这个哦
我自己觉得挺好用的...我也是从一个视频后缀采集器转换过来,
但如果不想麻烦
有啊。
斗鱼啊,
scrapdown去看看,我朋友推荐给我的,
爱采集,
移动端有美拍,秒拍等软件,pc端有搜狗浏览器等,这些视频本身都可以采集的。
可靠的采集神器,不用爬虫也能每天600万+
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-07-13 05:04
可靠的采集神器,不用爬虫也能每天600万+的采集规则。老话说的好啊:平常心态要好,只要不是比较不正规的,没见过不敢问的网站,采集规则可以去抄,前提是你先确定,采集下来的规则要比你用爬虫采集多很多,可以提高下载速度。
百度网页采集器可以采集谷歌,搜狗,360,搜搜,爱问,太阳星,newslearn这些搜索引擎里的网页,技术上已经可以实现只要网站有收录就能搜索到。应该可以实现楼主所说的大数据采集功能。
楼主,这真的是大数据采集啊,让我记得有个这么牛的网站。采下来做数据处理还能用,呵呵。
楼主你说的大数据采集可能是谷歌大搜搜算法类的吧,还有一些yahoo大搜图算法类的原因很简单,因为谷歌每天到处有采采采,一查就有。
首先,国内百度谷歌不给采,其次,百度直接屏蔽,再次,即使ss,要买请api?说明这采集问题离普通人还是蛮远的,你可以谷歌搜一下相关问题,结果越说越精彩,看看达到什么程度。
不知道题主遇到这个问题时是否已经试图采集,我也遇到过这个问题,然后朋友告诉我可以通过现在的大数据采集公司的技术方面的手段,而且不需要任何成本的。应该是这样的:现在很多采集大数据的方法有很多,这个答案里只介绍一种,一些免费的scrapy大数据采集工具scrapy1.5.0要下载,或者其他的爬虫工具;另外还有一些可以免费提供爬虫或者其他工具的,我还是推荐使用一些收费的。
我当时使用的是scrapy1.5免费版,不需要成本,功能不错,不过每天只能抓取五条,少了一些竞争力,用的是一些公司的vpn帐号(阿里云vpn帐号,ip很稳定,可以加速几十mb的数据量),有些公司还提供代理服务器(免费),但是阿里云vpn和虚拟主机都有数据丢失的问题,抓取的那几十gb数据丢失了300多gb,当时数据量大一些,并不影响抓取速度,结果是抓取了近20000条数据,得到30000条数据。
使用免费方法,使得抓取速度有限,不过可以足够解决题主的问题,也得到了我想要的效果,当然,只能抓取5条的量是需要付出一些时间精力的,希望其他回答可以给到你一些更好的解决方案。 查看全部
可靠的采集神器,不用爬虫也能每天600万+
可靠的采集神器,不用爬虫也能每天600万+的采集规则。老话说的好啊:平常心态要好,只要不是比较不正规的,没见过不敢问的网站,采集规则可以去抄,前提是你先确定,采集下来的规则要比你用爬虫采集多很多,可以提高下载速度。
百度网页采集器可以采集谷歌,搜狗,360,搜搜,爱问,太阳星,newslearn这些搜索引擎里的网页,技术上已经可以实现只要网站有收录就能搜索到。应该可以实现楼主所说的大数据采集功能。
楼主,这真的是大数据采集啊,让我记得有个这么牛的网站。采下来做数据处理还能用,呵呵。
楼主你说的大数据采集可能是谷歌大搜搜算法类的吧,还有一些yahoo大搜图算法类的原因很简单,因为谷歌每天到处有采采采,一查就有。
首先,国内百度谷歌不给采,其次,百度直接屏蔽,再次,即使ss,要买请api?说明这采集问题离普通人还是蛮远的,你可以谷歌搜一下相关问题,结果越说越精彩,看看达到什么程度。
不知道题主遇到这个问题时是否已经试图采集,我也遇到过这个问题,然后朋友告诉我可以通过现在的大数据采集公司的技术方面的手段,而且不需要任何成本的。应该是这样的:现在很多采集大数据的方法有很多,这个答案里只介绍一种,一些免费的scrapy大数据采集工具scrapy1.5.0要下载,或者其他的爬虫工具;另外还有一些可以免费提供爬虫或者其他工具的,我还是推荐使用一些收费的。
我当时使用的是scrapy1.5免费版,不需要成本,功能不错,不过每天只能抓取五条,少了一些竞争力,用的是一些公司的vpn帐号(阿里云vpn帐号,ip很稳定,可以加速几十mb的数据量),有些公司还提供代理服务器(免费),但是阿里云vpn和虚拟主机都有数据丢失的问题,抓取的那几十gb数据丢失了300多gb,当时数据量大一些,并不影响抓取速度,结果是抓取了近20000条数据,得到30000条数据。
使用免费方法,使得抓取速度有限,不过可以足够解决题主的问题,也得到了我想要的效果,当然,只能抓取5条的量是需要付出一些时间精力的,希望其他回答可以给到你一些更好的解决方案。
可靠的采集神器——scrapy脚本【海量信息一键提取】
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-07-11 07:03
可靠的采集神器是强大而高效的爬虫。如果你有线下采集的需求,让对话框中的信息自动获取难度太大。而通过爬虫,每天获取几十上百条数据非常方便。今天小编介绍这款scrapy脚本【海量信息一键提取】,不需要编程,通过图形化的操作就可以自动提取企业/个人网站的文本信息。效果演示图:github地址:,可以在软件中创建爬虫,也可以通过爬虫自动获取数据,这样可以批量处理数据,还能快速获取互联网更多的数据。具体步骤:。
1、百度搜索【scrapy】关键词
2、进入或者其他网站,
3、粘贴到软件中【设置按钮】中的【分析网页结构】
4、分析完成后,
5、在输入框中粘贴网页分析完成的链接,
6、爬取提取方式选择【填写或者批量分析网页结构】
7、选择网页结构获取方式,
8、设置输出类型【选择可用于后续处理的类型】
9、数据获取保存在浏览器工具【列表】1
0、返回到软件中选择【导出】1
1、重新打开之前做过的分析的网站,就能获取新的数据啦!除了爬取,scrapy还能设置密码【除个人和个人站点外,除代理外,其他不需要设置】,还可以设置节点【控制整个分析页面】,从而提高效率!快试试吧!相关推荐:/@chengzhuang/china-category-a-category-of-urban-startup/。 查看全部
可靠的采集神器——scrapy脚本【海量信息一键提取】
可靠的采集神器是强大而高效的爬虫。如果你有线下采集的需求,让对话框中的信息自动获取难度太大。而通过爬虫,每天获取几十上百条数据非常方便。今天小编介绍这款scrapy脚本【海量信息一键提取】,不需要编程,通过图形化的操作就可以自动提取企业/个人网站的文本信息。效果演示图:github地址:,可以在软件中创建爬虫,也可以通过爬虫自动获取数据,这样可以批量处理数据,还能快速获取互联网更多的数据。具体步骤:。
1、百度搜索【scrapy】关键词
2、进入或者其他网站,
3、粘贴到软件中【设置按钮】中的【分析网页结构】
4、分析完成后,
5、在输入框中粘贴网页分析完成的链接,
6、爬取提取方式选择【填写或者批量分析网页结构】
7、选择网页结构获取方式,
8、设置输出类型【选择可用于后续处理的类型】
9、数据获取保存在浏览器工具【列表】1
0、返回到软件中选择【导出】1
1、重新打开之前做过的分析的网站,就能获取新的数据啦!除了爬取,scrapy还能设置密码【除个人和个人站点外,除代理外,其他不需要设置】,还可以设置节点【控制整个分析页面】,从而提高效率!快试试吧!相关推荐:/@chengzhuang/china-category-a-category-of-urban-startup/。
可靠的采集神器,支持苹果安卓各种网站全站收录及代码搜索
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-07-06 06:02
可靠的采集神器,支持苹果安卓各种网站全站收录及代码搜索catrue谷歌全站搜索f12调试极速优化javascript,css提交post地址
以下是我们自己用的,有些效果做不到,但我相信有个方法在两个safari浏览器下都是可以实现的。首先我们需要确定下你使用谷歌浏览器这个是不行的,所以我们必须使用火狐浏览器,插件下载完毕后,点击图标会自动跳转到下载页面;1.点击安装程序,然后选择我自己的版本,只有你想安装到什么浏览器都行,火狐浏览器下并没有弹出框说需要root,而是自动点击默认浏览器并选择一个火狐浏览器。
2.点击下载好的浏览器,然后在弹出框中输入用户名与密码,就可以自动安装插件了。默认选择的就是火狐浏览器的下载,不要改其他浏览器下载就行,只要下载安装安装一次就好。3.如果你有必要需要手动去加速,那就点下载列表中的一键加速,它会让你提高网速,但如果你不想卡,那就点一键加速,点击已安装即可,会直接提高网速。
然后浏览器会自动弹出一个高速访问进度条,这个时候就不需要提速了。4.一路点击下一步就可以了,由于知乎浏览器下无法使用谷歌浏览器插件和谷歌浏览器,而是安装的火狐浏览器的谷歌浏览器,所以除了点一键加速,其他暂时没发现其他方法了。注意谷歌浏览器的谷歌浏览器虽然没有网站保护,但是谷歌浏览器可以有效地屏蔽广告及篡改,所以广告再多也不会妨碍我们追求高速浏览的目的。 查看全部
可靠的采集神器,支持苹果安卓各种网站全站收录及代码搜索
可靠的采集神器,支持苹果安卓各种网站全站收录及代码搜索catrue谷歌全站搜索f12调试极速优化javascript,css提交post地址
以下是我们自己用的,有些效果做不到,但我相信有个方法在两个safari浏览器下都是可以实现的。首先我们需要确定下你使用谷歌浏览器这个是不行的,所以我们必须使用火狐浏览器,插件下载完毕后,点击图标会自动跳转到下载页面;1.点击安装程序,然后选择我自己的版本,只有你想安装到什么浏览器都行,火狐浏览器下并没有弹出框说需要root,而是自动点击默认浏览器并选择一个火狐浏览器。
2.点击下载好的浏览器,然后在弹出框中输入用户名与密码,就可以自动安装插件了。默认选择的就是火狐浏览器的下载,不要改其他浏览器下载就行,只要下载安装安装一次就好。3.如果你有必要需要手动去加速,那就点下载列表中的一键加速,它会让你提高网速,但如果你不想卡,那就点一键加速,点击已安装即可,会直接提高网速。
然后浏览器会自动弹出一个高速访问进度条,这个时候就不需要提速了。4.一路点击下一步就可以了,由于知乎浏览器下无法使用谷歌浏览器插件和谷歌浏览器,而是安装的火狐浏览器的谷歌浏览器,所以除了点一键加速,其他暂时没发现其他方法了。注意谷歌浏览器的谷歌浏览器虽然没有网站保护,但是谷歌浏览器可以有效地屏蔽广告及篡改,所以广告再多也不会妨碍我们追求高速浏览的目的。
可靠的采集神器——apiget有没有什么工具可以直接采集百度、阿里、腾讯
采集交流 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2021-07-05 22:01
可靠的采集神器——apiget有没有什么工具可以直接采集百度、阿里、腾讯等国内主流搜索引擎的相关页面,接下来给大家介绍一款由全球领先的移动搜索分析公司aragenix开发的,使用一下其中的两个功能:1.ublockorigin2.locationofthediscovery.ublockorigin功能:可以自由拖动“range”标签条右边的小元素,实现具体到某个区域链接的跳转。
自由拖动“originalbite”标签条右边的小元素,可以实现该区域链接跳转到该页面。locationofthediscovery功能:可以自由拖动“sites”标签条右边的小元素,获取特定位置的站点信息。注意:这两个功能都是可以免费使用的,免费额度是1万个站点。网址::安卓:locationofthediscoveryiphone:ublockoriginios:apiget。
我一个朋友做的不错,不算新奇,但很方便实用,有兴趣的朋友可以加他。
网站指南
自荐一个试试百度搜索,基本随便输入个关键词,
数据可以,
后端开发人员,
他们的一些功能做的比较不错。上门推销的话,还是要慎重一些。我也是来做外贸的,刚开始还好,买了一点,总共25款产品,通常4款。刚开始几个月。稍微出点问题就会不方便。第一次交易的时候,只买了1500多个,后来几个月下来,付款出问题多,询盘也少了。客户好几个月都没联系我。合同已签。价格方面也不便宜。不过他们也给我赚了钱。
主要是客户等不及急用钱。一旦买了,就发货。质量方面也可以,当然我们是原价2倍多的。便宜点,一是赚了差价,二是既然提供免费服务,就要做到如实、真实,不然坑人。 查看全部
可靠的采集神器——apiget有没有什么工具可以直接采集百度、阿里、腾讯
可靠的采集神器——apiget有没有什么工具可以直接采集百度、阿里、腾讯等国内主流搜索引擎的相关页面,接下来给大家介绍一款由全球领先的移动搜索分析公司aragenix开发的,使用一下其中的两个功能:1.ublockorigin2.locationofthediscovery.ublockorigin功能:可以自由拖动“range”标签条右边的小元素,实现具体到某个区域链接的跳转。
自由拖动“originalbite”标签条右边的小元素,可以实现该区域链接跳转到该页面。locationofthediscovery功能:可以自由拖动“sites”标签条右边的小元素,获取特定位置的站点信息。注意:这两个功能都是可以免费使用的,免费额度是1万个站点。网址::安卓:locationofthediscoveryiphone:ublockoriginios:apiget。
我一个朋友做的不错,不算新奇,但很方便实用,有兴趣的朋友可以加他。
网站指南
自荐一个试试百度搜索,基本随便输入个关键词,
数据可以,
后端开发人员,
他们的一些功能做的比较不错。上门推销的话,还是要慎重一些。我也是来做外贸的,刚开始还好,买了一点,总共25款产品,通常4款。刚开始几个月。稍微出点问题就会不方便。第一次交易的时候,只买了1500多个,后来几个月下来,付款出问题多,询盘也少了。客户好几个月都没联系我。合同已签。价格方面也不便宜。不过他们也给我赚了钱。
主要是客户等不及急用钱。一旦买了,就发货。质量方面也可以,当然我们是原价2倍多的。便宜点,一是赚了差价,二是既然提供免费服务,就要做到如实、真实,不然坑人。
太棒了!有了这三个爬虫神器,我要写什么代码!
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-07-01 18:24
太好了!有了这三个爬虫神器,我要写什么代码!
我已经和大家分享了普通人可以在视频账号中使用的爬虫工具。为了方便没有关注我视频号的同学,我在这里整理一下分享给大家。当然,关注我视频号的同学也可以更方便的查看对比。
在分享这些爬虫工具之前,先来说说我们为什么要了解爬虫工具?
普通人学习爬虫工具的三个原因:
对于工作场所的临时使用,学习爬虫可以提供效率。程序员太忙了,自己找人太贵了。学习爬虫技术本身成本太高
有人说陶大哥,我是开发者,用Python分分钟抓几行代码,把数据拿回来。我当然想说你很棒,但更多的人还没有达到那个地步。
退一步说,就算我很熟练,如果我能用工具和现成的模板抓取并生成Excle导出,整个过程也只需要几分钟。我认为作为开发人员,这会有点令人兴奋。
掌握爬虫工具可以大大提高我们职场工作的效率。成为CEO,嫁给白富美指日可待。
我知道我们为什么要学习以及学习的目的。接下来给大家介绍一下我认为不错的三个爬虫。他们是Jisouke,优采云,优采云采集器,对你来说更方便。易于使用和选择。
优采云
优采云我简单说一下优点:
提供带有云采集功能的第三方模板,方便快捷采集10分钟让个人数据采集更贵
需要注册登录,无Mac&Linux版本,基础模板免费,更多模板需要付费,高级版需要付费,免费版只能使用最基本的导出,有限制。
采集招揽客户
集聚采购客户优势
很多网站templates使用浏览器方式采集,直接登录采集付费版提供Mac版10分钟搞定,个人用户低价获取数据
客户端是浏览器。我个人认为这是一种趋势。是采集登录抢数据。另外,采集总客的工具比较简单好用,但是价格歧视是很不科学的。 Mac客户端版本只能付费使用。你真的认为苹果用户更富有吗?
他们付费获取数据的方式是免费的,下载是用积分下载的。我觉得采集客户临时使用比优采云更方便。
优采云采集器
优采云采集器我认为的优点:
浏览器模式采集采集全可视化,免费导出,无积分,完全免费,支持Mac&Linux版5分钟上手,数据采集一般个人负担得起
无需登录,无需注册采集data,无需积分,几乎完全免费使用,缺点不提供第三方模板网站,对于新手来说有点不方便,但是胜利了本身足够简单,这也是一个优势。
总结
这三个工具都是优秀的,好用的,但是从两者的个人使用来看,更方便、灵活、更便宜的招揽客户。 优采云采集器其次(胜利很简单,真的很简单),优采云last。
当然,对于个人体验,是否支持Mac系统,价格等因素,里面的功能没有深入研究。如果有错误,请不要打我,来自普通用户。
欢迎给我留言讨论。
学Python,也学更多黑科技。 查看全部
太棒了!有了这三个爬虫神器,我要写什么代码!
太好了!有了这三个爬虫神器,我要写什么代码!
我已经和大家分享了普通人可以在视频账号中使用的爬虫工具。为了方便没有关注我视频号的同学,我在这里整理一下分享给大家。当然,关注我视频号的同学也可以更方便的查看对比。
在分享这些爬虫工具之前,先来说说我们为什么要了解爬虫工具?
普通人学习爬虫工具的三个原因:
对于工作场所的临时使用,学习爬虫可以提供效率。程序员太忙了,自己找人太贵了。学习爬虫技术本身成本太高
有人说陶大哥,我是开发者,用Python分分钟抓几行代码,把数据拿回来。我当然想说你很棒,但更多的人还没有达到那个地步。
退一步说,就算我很熟练,如果我能用工具和现成的模板抓取并生成Excle导出,整个过程也只需要几分钟。我认为作为开发人员,这会有点令人兴奋。
掌握爬虫工具可以大大提高我们职场工作的效率。成为CEO,嫁给白富美指日可待。
我知道我们为什么要学习以及学习的目的。接下来给大家介绍一下我认为不错的三个爬虫。他们是Jisouke,优采云,优采云采集器,对你来说更方便。易于使用和选择。
优采云
优采云我简单说一下优点:
提供带有云采集功能的第三方模板,方便快捷采集10分钟让个人数据采集更贵
需要注册登录,无Mac&Linux版本,基础模板免费,更多模板需要付费,高级版需要付费,免费版只能使用最基本的导出,有限制。
采集招揽客户
集聚采购客户优势
很多网站templates使用浏览器方式采集,直接登录采集付费版提供Mac版10分钟搞定,个人用户低价获取数据
客户端是浏览器。我个人认为这是一种趋势。是采集登录抢数据。另外,采集总客的工具比较简单好用,但是价格歧视是很不科学的。 Mac客户端版本只能付费使用。你真的认为苹果用户更富有吗?
他们付费获取数据的方式是免费的,下载是用积分下载的。我觉得采集客户临时使用比优采云更方便。
优采云采集器
优采云采集器我认为的优点:
浏览器模式采集采集全可视化,免费导出,无积分,完全免费,支持Mac&Linux版5分钟上手,数据采集一般个人负担得起
无需登录,无需注册采集data,无需积分,几乎完全免费使用,缺点不提供第三方模板网站,对于新手来说有点不方便,但是胜利了本身足够简单,这也是一个优势。
总结
这三个工具都是优秀的,好用的,但是从两者的个人使用来看,更方便、灵活、更便宜的招揽客户。 优采云采集器其次(胜利很简单,真的很简单),优采云last。
当然,对于个人体验,是否支持Mac系统,价格等因素,里面的功能没有深入研究。如果有错误,请不要打我,来自普通用户。
欢迎给我留言讨论。
学Python,也学更多黑科技。
中国舆情监测域采集宝-全球互联网精准舆情采集神器
采集交流 • 优采云 发表了文章 • 0 个评论 • 227 次浏览 • 2021-06-30 19:03
可靠的采集神器有很多,可是现在来看,如果你要做游戏用户行为数据分析,比如看有多少user的行为被重复记录,就要用到一个网站叫“采集宝”,如果要做一个网站的舆情监测,就要用到“网络大数据采集平台”,最近我发现一个app叫“中国舆情监测”也是做舆情数据分析的,我觉得如果你要做用户行为分析,建议你用这个,哈哈。
想学哪方面的就买哪方面的书籍。书都是好书。
中国舆情监测
域
采集宝-全球互联网精准舆情监测与分析
推荐个采集程序的地方
新浪舆情,新浪网站的所有舆情统计的。
新浪舆情
大家好我是李东,一名英语专业的小学生,今天讲解一下其实有很多方法都可以采集信息的,我要先来讲下关于“一些电子的网页或者视频”采集,由于大部分网站或者视频都是需要依靠专业的才能观看到,而采集一些电子网页或者视频其实是很简单的,下面我为大家分享一下。大家有没有遇到过一个这样的问题,就是有时候我们想下载一些电子书或者是电影或者软件,找不到下载地址,因为现在电子书或者是软件不像以前那么多了,所以这个时候,我们要利用高仿软件去进行视频下载的操作,我先给大家演示一下演示软件,有的朋友没用过,其实也是一样的,如果没有用过可以百度查下观看!adobeaftereffectsproextended,这款软件我们可以打开它,它的界面如下所示:然后我们就可以按照我们的需求自己调整就可以了,关于如何调整我会在最后告诉大家,看下界面:然后我们打开adobeaftereffects软件,然后我们需要看到的是如下图所示:我们只需要按一下这个模块下面的“max”键就可以进行选择电影或者是其他视频文件,我们如果需要搜索你要下载的电影或者是视频我们也可以直接把鼠标悬停在“max”键上面进行排序,搜索完我们直接选择我们要的视频文件,然后在下方选择下载即可!有时候可能我们要先下载再搜索,那么我们就直接选择“eastthard”下载,然后再看效果即可,如果还有不懂的,大家也可以百度搜索!有一些朋友也会问我们软件中下载电影或者是视频之后在网页上显示不了,这个时候我们直接点击“downloadhome”即可。
这款软件我们可以打开它我们看到如下图所示:我们点击上方的小房子进行搜索即可找到我们想要的资源。这款软件如果没有下载过的朋友也可以去试一下,需要注意的是有时候有些资源,大家也可以去看看,除了之外,还可以找搜索。希望对大家有帮助,有一些朋友如果找不到我们想要的资源,也可以去百度搜索“我要下载”上面有很多好用的软件推荐,下面我给大家展示下我自。 查看全部
中国舆情监测域采集宝-全球互联网精准舆情采集神器
可靠的采集神器有很多,可是现在来看,如果你要做游戏用户行为数据分析,比如看有多少user的行为被重复记录,就要用到一个网站叫“采集宝”,如果要做一个网站的舆情监测,就要用到“网络大数据采集平台”,最近我发现一个app叫“中国舆情监测”也是做舆情数据分析的,我觉得如果你要做用户行为分析,建议你用这个,哈哈。
想学哪方面的就买哪方面的书籍。书都是好书。
中国舆情监测
域
采集宝-全球互联网精准舆情监测与分析
推荐个采集程序的地方
新浪舆情,新浪网站的所有舆情统计的。
新浪舆情
大家好我是李东,一名英语专业的小学生,今天讲解一下其实有很多方法都可以采集信息的,我要先来讲下关于“一些电子的网页或者视频”采集,由于大部分网站或者视频都是需要依靠专业的才能观看到,而采集一些电子网页或者视频其实是很简单的,下面我为大家分享一下。大家有没有遇到过一个这样的问题,就是有时候我们想下载一些电子书或者是电影或者软件,找不到下载地址,因为现在电子书或者是软件不像以前那么多了,所以这个时候,我们要利用高仿软件去进行视频下载的操作,我先给大家演示一下演示软件,有的朋友没用过,其实也是一样的,如果没有用过可以百度查下观看!adobeaftereffectsproextended,这款软件我们可以打开它,它的界面如下所示:然后我们就可以按照我们的需求自己调整就可以了,关于如何调整我会在最后告诉大家,看下界面:然后我们打开adobeaftereffects软件,然后我们需要看到的是如下图所示:我们只需要按一下这个模块下面的“max”键就可以进行选择电影或者是其他视频文件,我们如果需要搜索你要下载的电影或者是视频我们也可以直接把鼠标悬停在“max”键上面进行排序,搜索完我们直接选择我们要的视频文件,然后在下方选择下载即可!有时候可能我们要先下载再搜索,那么我们就直接选择“eastthard”下载,然后再看效果即可,如果还有不懂的,大家也可以百度搜索!有一些朋友也会问我们软件中下载电影或者是视频之后在网页上显示不了,这个时候我们直接点击“downloadhome”即可。
这款软件我们可以打开它我们看到如下图所示:我们点击上方的小房子进行搜索即可找到我们想要的资源。这款软件如果没有下载过的朋友也可以去试一下,需要注意的是有时候有些资源,大家也可以去看看,除了之外,还可以找搜索。希望对大家有帮助,有一些朋友如果找不到我们想要的资源,也可以去百度搜索“我要下载”上面有很多好用的软件推荐,下面我给大家展示下我自。
一个创业神器导航网站,让你沉迷在各种工具神器里面出不来
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-06-28 01:28
作为一个网民,每次发现一些有用的工具和产品,都会忍不住分享给身边的朋友。不禁感叹,好工具为什么没有被更多人看到?最近发现了一个创业神器导航网站,推荐给大家采集。不是我之前印象里放网站的那种导航。里面的产品和资源都是好玩的,有趣的,实用的。 (温馨提示:如果你点进去,你可能会和我一样沉迷于各种工具和神器。)
一、网站生活一对1.网站设计
我们先来看看官网的设计。点击网站进入。整体感觉很简洁,框架清晰,比一般的导航网站更加活泼前卫。交互设计也很简单,点击网站跳转到对方网站。对比我之前用的一些导航,可能是seo优化的考虑,会出现跳转页面,其实不是很人性化。
2.网站Content
看上面的内容,第一大部分是推荐各种网站,主要包括办公、设计、开发、品牌、营销...等,80%的推荐产品都是非常用心和优秀的。 ,比如在线智能生成logo设计,有的可能很小,但是我用的时候,都加到我的采集里了。可惜,为什么我没有早点发现?网络信息太严重了!我恨!在选址上,我认为是本站做的最好的地方。发现埋藏的好工具好网站,让价值被更多人传递和看到。在文章的后面,我会推荐几个必须尝试的工具。继续说第二部分。
单个导航可能无法阐明产品的色调。它在这里添加了一个文章content 部分。 文章的主要内容就是专门介绍那些优秀的产品工具,帮助大家评估各种产品。 ,或者分享一些资源和技巧。我觉得这个区域的主要功能是让用户停留的时间更长,增加这个导航的附加值。就像6套ppt模板一样,这种可以直接下载的资源很实用。
二、神器推荐
我在上面网站与您分享了我自己对这个导航的一些经验和感受。如果很高的话,我觉得可以打八分左右。我认为在某些网站的分类方面做得不好。希望看到它继续改进。接下来给大家分享一下我通过这个创业神器的导航发现的一些很棒的产品工具(无广告费)
1.搜图神器
我写文章的时候,刚好需要图。目前无论是平台还是个人,越来越注重图片版权意识,不敢像以前那样随便使用。我一直在使用来自国外的几个无版权图片库,例如 unsplash 和 pixbay。不太方便的是加载速度较慢,不支持中文搜索。
这个工具最大的亮点就是聚合了这些商业无版权库。一键中文搜索。您需要在“工作”中直接输入工作场景的图片。各大图书馆的图片会直接出现。下载结束了。积分完全免费!
2.甜葱填图
这也是我最近才发现的一个小工具。设计专业的同学一定知道,设计稿中需要各种图片。首先,您需要下载图片,然后填写每个位置。超级麻烦。其实我觉得这种机械的复制工作早就应该被工具代替了。甜葱馅就是这样一种工具。对接免费版权库,支持对所有图片进行标注和一键填充,大大提高了工作效率。设计师可以使用它~
3.MIXKIT
纸质媒体时代已经过去,迎来了数字媒体时代。现在动态视频比文字更有吸引力。无论是企业宣传还是个人品牌推广,都希望通过短视频来传播影响力。最近,我也在尝试制作一些视频来播放。更难的是,很难找到那种很酷的材料。基本上都是国内收费的,有版权限制。我在神器导航上发现这个网站后,点进来看看,无版权商业!爱它!而且,整个网站的设计也很棒,当然关键是里面的素材内容非常丰富,可以直接下载使用在自己的视频中,还可以制作字幕或者特效~
我已经写了这么久才知道,我真的推荐无穷无尽的感觉有趣的产品。我很累很累!想了解更多有趣、有价值、好用的工具,去业务神器导航一探究竟吧~ 查看全部
一个创业神器导航网站,让你沉迷在各种工具神器里面出不来
作为一个网民,每次发现一些有用的工具和产品,都会忍不住分享给身边的朋友。不禁感叹,好工具为什么没有被更多人看到?最近发现了一个创业神器导航网站,推荐给大家采集。不是我之前印象里放网站的那种导航。里面的产品和资源都是好玩的,有趣的,实用的。 (温馨提示:如果你点进去,你可能会和我一样沉迷于各种工具和神器。)
一、网站生活一对1.网站设计
我们先来看看官网的设计。点击网站进入。整体感觉很简洁,框架清晰,比一般的导航网站更加活泼前卫。交互设计也很简单,点击网站跳转到对方网站。对比我之前用的一些导航,可能是seo优化的考虑,会出现跳转页面,其实不是很人性化。
2.网站Content
看上面的内容,第一大部分是推荐各种网站,主要包括办公、设计、开发、品牌、营销...等,80%的推荐产品都是非常用心和优秀的。 ,比如在线智能生成logo设计,有的可能很小,但是我用的时候,都加到我的采集里了。可惜,为什么我没有早点发现?网络信息太严重了!我恨!在选址上,我认为是本站做的最好的地方。发现埋藏的好工具好网站,让价值被更多人传递和看到。在文章的后面,我会推荐几个必须尝试的工具。继续说第二部分。
单个导航可能无法阐明产品的色调。它在这里添加了一个文章content 部分。 文章的主要内容就是专门介绍那些优秀的产品工具,帮助大家评估各种产品。 ,或者分享一些资源和技巧。我觉得这个区域的主要功能是让用户停留的时间更长,增加这个导航的附加值。就像6套ppt模板一样,这种可以直接下载的资源很实用。
二、神器推荐
我在上面网站与您分享了我自己对这个导航的一些经验和感受。如果很高的话,我觉得可以打八分左右。我认为在某些网站的分类方面做得不好。希望看到它继续改进。接下来给大家分享一下我通过这个创业神器的导航发现的一些很棒的产品工具(无广告费)
1.搜图神器
我写文章的时候,刚好需要图。目前无论是平台还是个人,越来越注重图片版权意识,不敢像以前那样随便使用。我一直在使用来自国外的几个无版权图片库,例如 unsplash 和 pixbay。不太方便的是加载速度较慢,不支持中文搜索。
这个工具最大的亮点就是聚合了这些商业无版权库。一键中文搜索。您需要在“工作”中直接输入工作场景的图片。各大图书馆的图片会直接出现。下载结束了。积分完全免费!
2.甜葱填图
这也是我最近才发现的一个小工具。设计专业的同学一定知道,设计稿中需要各种图片。首先,您需要下载图片,然后填写每个位置。超级麻烦。其实我觉得这种机械的复制工作早就应该被工具代替了。甜葱馅就是这样一种工具。对接免费版权库,支持对所有图片进行标注和一键填充,大大提高了工作效率。设计师可以使用它~
3.MIXKIT
纸质媒体时代已经过去,迎来了数字媒体时代。现在动态视频比文字更有吸引力。无论是企业宣传还是个人品牌推广,都希望通过短视频来传播影响力。最近,我也在尝试制作一些视频来播放。更难的是,很难找到那种很酷的材料。基本上都是国内收费的,有版权限制。我在神器导航上发现这个网站后,点进来看看,无版权商业!爱它!而且,整个网站的设计也很棒,当然关键是里面的素材内容非常丰富,可以直接下载使用在自己的视频中,还可以制作字幕或者特效~
我已经写了这么久才知道,我真的推荐无穷无尽的感觉有趣的产品。我很累很累!想了解更多有趣、有价值、好用的工具,去业务神器导航一探究竟吧~
网易采集器:可靠的采集神器,更优质的体验
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-06-27 21:02
可靠的采集神器,更优质的体验网易采集器网易公开课最新最全的公开课视频/音频,把资源利用起来网易云课堂登录登录课程进入课程页面,自己选择视频,使用浏览器的录屏功能或ppt播放器的录屏功能可以实现录屏,具体操作方法可以咨询教练机器人在线直播机器人celebot6键操作ai简化实现数据采集的操作,根据教练机器人指令,一键采集课程内容,省时省力还可以使用播放器添加互动问答的方式采集/录制高清视频,操作简单方便轻松控制录屏你也可以借助其他应用,把视频在线上播放,方便查看制作成卡片模板对资源导入评论功能,可方便导出celebot教练机器人轻松实现在线采集,查看视频效果导出视频卡片或字幕列表。
给你推荐个采集神器——excelvba宝典可以根据需要导入数据的模板来采集数据。
推荐一下
我在知乎上回答过一个直接拖动图片到excel的方法同样适用于回答if判断条件
百度网盘资源/
有个叫:有道云笔记,网页可以直接导入excel表格,极其简单,我觉得很好用,有条件可以尝试看看。
格式化一下数据,
写这里面含有大量资源,包括内幕,
1.excel2vec支持全网平台excel爬虫第一项:excel2vec支持全网平台excel爬虫的业务规则很重要,如果要过滤excel繁多而无用的爬虫,excel2vec提供一整套的业务规则组件,支持过滤114个爬虫平台,从laravel,npm,corba,github直接导入javajar包都没问题。
比如针对一个excel表做sheet转化到word,sheetindex和sheetdecl这三个方法都可以过滤掉大量无用的爬虫和爬虫器。但是用python爬虫是不是就麻烦点了,肯定的,但是我们可以使用开源代码解决(以下以web爬虫为例)web爬虫|第二代简单粗暴爬虫实现第三项:excel2vec集中火力攻击miniflow支持全网平台excel爬虫的业务规则很重要,如果要过滤excel繁多而无用的爬虫,excel2vec提供一整套的业务规则组件,支持过滤114个爬虫平台,从laravel,npm,corba,github直接导入javajar包都没问题。
比如针对一个excel表做sheet转化到word,sheetindex和sheetdecl这三个方法都可以过滤掉大量无用的爬虫和爬虫器。但是用python爬虫是不是就麻烦点了,肯定的,但是我们可以使用开源代码解决(以下以web爬虫为例)web爬虫|第二代简单粗暴爬虫实现2.excel2vec集中火力攻击miniflow支持全网平台miniflow是sqllibraryfordataanalysis。 查看全部
网易采集器:可靠的采集神器,更优质的体验
可靠的采集神器,更优质的体验网易采集器网易公开课最新最全的公开课视频/音频,把资源利用起来网易云课堂登录登录课程进入课程页面,自己选择视频,使用浏览器的录屏功能或ppt播放器的录屏功能可以实现录屏,具体操作方法可以咨询教练机器人在线直播机器人celebot6键操作ai简化实现数据采集的操作,根据教练机器人指令,一键采集课程内容,省时省力还可以使用播放器添加互动问答的方式采集/录制高清视频,操作简单方便轻松控制录屏你也可以借助其他应用,把视频在线上播放,方便查看制作成卡片模板对资源导入评论功能,可方便导出celebot教练机器人轻松实现在线采集,查看视频效果导出视频卡片或字幕列表。
给你推荐个采集神器——excelvba宝典可以根据需要导入数据的模板来采集数据。
推荐一下
我在知乎上回答过一个直接拖动图片到excel的方法同样适用于回答if判断条件
百度网盘资源/
有个叫:有道云笔记,网页可以直接导入excel表格,极其简单,我觉得很好用,有条件可以尝试看看。
格式化一下数据,
写这里面含有大量资源,包括内幕,
1.excel2vec支持全网平台excel爬虫第一项:excel2vec支持全网平台excel爬虫的业务规则很重要,如果要过滤excel繁多而无用的爬虫,excel2vec提供一整套的业务规则组件,支持过滤114个爬虫平台,从laravel,npm,corba,github直接导入javajar包都没问题。
比如针对一个excel表做sheet转化到word,sheetindex和sheetdecl这三个方法都可以过滤掉大量无用的爬虫和爬虫器。但是用python爬虫是不是就麻烦点了,肯定的,但是我们可以使用开源代码解决(以下以web爬虫为例)web爬虫|第二代简单粗暴爬虫实现第三项:excel2vec集中火力攻击miniflow支持全网平台excel爬虫的业务规则很重要,如果要过滤excel繁多而无用的爬虫,excel2vec提供一整套的业务规则组件,支持过滤114个爬虫平台,从laravel,npm,corba,github直接导入javajar包都没问题。
比如针对一个excel表做sheet转化到word,sheetindex和sheetdecl这三个方法都可以过滤掉大量无用的爬虫和爬虫器。但是用python爬虫是不是就麻烦点了,肯定的,但是我们可以使用开源代码解决(以下以web爬虫为例)web爬虫|第二代简单粗暴爬虫实现2.excel2vec集中火力攻击miniflow支持全网平台miniflow是sqllibraryfordataanalysis。
苹果手机和安卓手机配合使用的方法,一键采集整个朋友圈图片
采集交流 • 优采云 发表了文章 • 0 个评论 • 716 次浏览 • 2021-06-12 06:01
可靠的采集神器请点击手机下载:安卓手机下载,请直接下载安装!苹果手机下载,请直接下载安装!发布的朋友圈图片,可以获取和发送到微信并推送到朋友圈的图片今天给大家分享一款一键采集整个朋友圈图片的应用,主要解决整个微信图片资源如何更高效的利用问题,下载和使用的方法很简单,就不做过多介绍了。采集和保存图片素材的过程需要一个iphone手机和安卓手机进行配合,才能完成图片的采集以及保存操作,下面详细介绍一下关于iphone和安卓手机配合使用的操作流程。
注:苹果手机和安卓手机均需要开启usb调试!苹果手机和安卓手机配合使用方法:苹果手机在地址栏中输入“pc机密码”;安卓手机在浏览器中输入“::打开电脑;安卓手机打开浏览器输入“这里的电脑是浏览器”,在浏览器中输入“ip地址”即可;进入ip地址,在浏览器中输入“”即可找到该网址;在该网址中输入“图片”即可跳转到被采集的图片网站;找到合适的网站后,在被采集图片网站中点击“复制图片”即可拷贝图片资源;关于转换图片格式,推荐将图片保存到本地后,使用格式工厂、截图工具等文件处理工具进行处理。下面以“工具箱”为例,介绍如何一键采集整个微信朋友圈图片素材操作步骤:。
1、打开工具箱界面,
2、点击“采集图片”功能后,
3、选择采集的朋友圈图片后,按要求进行设置采集图片的属性信息(图片链接和个人名称等),设置完成后点击“保存”,
4、打开电脑浏览器,输入网址:, 查看全部
苹果手机和安卓手机配合使用的方法,一键采集整个朋友圈图片
可靠的采集神器请点击手机下载:安卓手机下载,请直接下载安装!苹果手机下载,请直接下载安装!发布的朋友圈图片,可以获取和发送到微信并推送到朋友圈的图片今天给大家分享一款一键采集整个朋友圈图片的应用,主要解决整个微信图片资源如何更高效的利用问题,下载和使用的方法很简单,就不做过多介绍了。采集和保存图片素材的过程需要一个iphone手机和安卓手机进行配合,才能完成图片的采集以及保存操作,下面详细介绍一下关于iphone和安卓手机配合使用的操作流程。
注:苹果手机和安卓手机均需要开启usb调试!苹果手机和安卓手机配合使用方法:苹果手机在地址栏中输入“pc机密码”;安卓手机在浏览器中输入“::打开电脑;安卓手机打开浏览器输入“这里的电脑是浏览器”,在浏览器中输入“ip地址”即可;进入ip地址,在浏览器中输入“”即可找到该网址;在该网址中输入“图片”即可跳转到被采集的图片网站;找到合适的网站后,在被采集图片网站中点击“复制图片”即可拷贝图片资源;关于转换图片格式,推荐将图片保存到本地后,使用格式工厂、截图工具等文件处理工具进行处理。下面以“工具箱”为例,介绍如何一键采集整个微信朋友圈图片素材操作步骤:。
1、打开工具箱界面,
2、点击“采集图片”功能后,
3、选择采集的朋友圈图片后,按要求进行设置采集图片的属性信息(图片链接和个人名称等),设置完成后点击“保存”,
4、打开电脑浏览器,输入网址:,
美团的项目下载地址(一):Xpath的使用方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-06-02 01:34
在github上找一个美团项目,可以获取到指定城市的商家信息,分分钟上百条商家信息数据在手,信息包括店铺名称、地理位置、评分、销量,电话(这就是重点)。
好久没更新了。今天写了文章,附上这个很有价值的项目的下载地址。
本文是自己写的xpath笔记。不想看的可以到【k13】底部代码下载地址。
可惜项目是用scrapy写的。其实我是不想用框架的,但是把这个项目改成可以运行的代码,花了一天的时间。我在变更过程中再次熟悉了scrapy。决定学习xpath,然后我会用scrapy写几个爬虫。
除了css,scrapy的选择器比xpath好。现在需要练习xpath的使用。
Xpath 简介
一般来说,使用id、name、class等属性定位节点可以解决大部分解析需求,但有时在以下情况下,使用Xpath更方便:
没有id、名字、班级等
标签的属性或文本特征不重要
标签嵌套层次太复杂
Xpath 是对 XML 路径的介绍。基于 XML 树结构,您可以在整个树中找到目标节点。由于 HTML 文档本身是一个标准的 XML 页面,我们可以使用 XPath 语法来定位页面元素。
Xpath 定位方法
一、Xpath 路径
Xpath 路径示例
定位节点
#查找html下的body下的form下的所有input节点
/html/body/form/input
#查找所有input节点
//input
*通配符选择未知节点**
#查找form节点下的所有节点
//form/*#查找所有节点//*
#查找所有input节点(input至少有爷爷辈亲戚节点)
//*/input
二、 使用索引(这是我自己的理解)
如果过滤元素时有多个节点,但我们想确定唯一的节点。您可以使用类似于列表索引的方式进行精确定位。
案例
#定位 第8个td下的 第2个a节点
//*/td[7]/a[1]
#定位 第8个td下的 第3个span节点
//*/td[7]/span[2]
#定位 最后一个td下的 最后一个a节点
//*/td[last()]/a[last()]
三、使用属性
为了让定位更准确,类似于使用索引,我们需要增加信息量,所以我们也可以使用属性。 @Symbol 是一个属性符号
#定位所有包含name属性的input节点
//input[@name]
#定位含有属性的所有的input节点
//input[@*]
#定位所有value=2的input节点
//input[@value='2']
#使用多个属性定位
//input[@value='2'][@id='3']
或者//input[@value='2' and @id='3']
四、常用功能
除了索引和属性,Xpath还可以使用方便的功能来提升定位的准确性。下面是几个常用的函数:
应用推广
#定位href属性中包含“promote.html”的所有a节点
//a[contains(@href,'promote.html')]
#元素内的文本为“应用推广”的所有a节点
//a[text()='应用推广']
#href属性值是以“/ads”开头的所有a节点
//a[starts-with(@href,'/ads')]
五、Xpath 轴
这部分类似于BeautifulSoup中的sibling、parents和children方法。有时为了实现定位,需要绕道而行,七阿姨和八阿姨的远房亲戚四处走走相识,定位就完成了。
六、美团商户信息
在代码中,我提供了一个高科技的api_key,但是如果你用的太多,对方实际上是无法使用它的。我建议你自己申请一个。
#在高德注册,进入控制台
http://lbs.amap.com/
这是郑州市在几十秒内采集的数据。
提示:
修改高德api_key
在项目中找到设置,将GAODEAPIKEY参数修改为你申请号的api_key。
更改城市
在项目中找到设置,修改CITY_NAME参数为你想要的城市采集
运行主程序采集数据
在项目文件夹中找到main.py并运行,愉快的获取数据并保存到data.csv。
项目下载地址
链接:密码:e7dz 查看全部
美团的项目下载地址(一):Xpath的使用方法
在github上找一个美团项目,可以获取到指定城市的商家信息,分分钟上百条商家信息数据在手,信息包括店铺名称、地理位置、评分、销量,电话(这就是重点)。
好久没更新了。今天写了文章,附上这个很有价值的项目的下载地址。
本文是自己写的xpath笔记。不想看的可以到【k13】底部代码下载地址。
可惜项目是用scrapy写的。其实我是不想用框架的,但是把这个项目改成可以运行的代码,花了一天的时间。我在变更过程中再次熟悉了scrapy。决定学习xpath,然后我会用scrapy写几个爬虫。
除了css,scrapy的选择器比xpath好。现在需要练习xpath的使用。
Xpath 简介
一般来说,使用id、name、class等属性定位节点可以解决大部分解析需求,但有时在以下情况下,使用Xpath更方便:
没有id、名字、班级等
标签的属性或文本特征不重要
标签嵌套层次太复杂
Xpath 是对 XML 路径的介绍。基于 XML 树结构,您可以在整个树中找到目标节点。由于 HTML 文档本身是一个标准的 XML 页面,我们可以使用 XPath 语法来定位页面元素。
Xpath 定位方法
一、Xpath 路径
Xpath 路径示例
定位节点
#查找html下的body下的form下的所有input节点
/html/body/form/input
#查找所有input节点
//input
*通配符选择未知节点**
#查找form节点下的所有节点
//form/*#查找所有节点//*
#查找所有input节点(input至少有爷爷辈亲戚节点)
//*/input
二、 使用索引(这是我自己的理解)
如果过滤元素时有多个节点,但我们想确定唯一的节点。您可以使用类似于列表索引的方式进行精确定位。
案例
#定位 第8个td下的 第2个a节点
//*/td[7]/a[1]
#定位 第8个td下的 第3个span节点
//*/td[7]/span[2]
#定位 最后一个td下的 最后一个a节点
//*/td[last()]/a[last()]
三、使用属性
为了让定位更准确,类似于使用索引,我们需要增加信息量,所以我们也可以使用属性。 @Symbol 是一个属性符号
#定位所有包含name属性的input节点
//input[@name]
#定位含有属性的所有的input节点
//input[@*]
#定位所有value=2的input节点
//input[@value='2']
#使用多个属性定位
//input[@value='2'][@id='3']
或者//input[@value='2' and @id='3']
四、常用功能
除了索引和属性,Xpath还可以使用方便的功能来提升定位的准确性。下面是几个常用的函数:
应用推广
#定位href属性中包含“promote.html”的所有a节点
//a[contains(@href,'promote.html')]
#元素内的文本为“应用推广”的所有a节点
//a[text()='应用推广']
#href属性值是以“/ads”开头的所有a节点
//a[starts-with(@href,'/ads')]
五、Xpath 轴
这部分类似于BeautifulSoup中的sibling、parents和children方法。有时为了实现定位,需要绕道而行,七阿姨和八阿姨的远房亲戚四处走走相识,定位就完成了。
六、美团商户信息
在代码中,我提供了一个高科技的api_key,但是如果你用的太多,对方实际上是无法使用它的。我建议你自己申请一个。
#在高德注册,进入控制台
http://lbs.amap.com/
这是郑州市在几十秒内采集的数据。
提示:
修改高德api_key
在项目中找到设置,将GAODEAPIKEY参数修改为你申请号的api_key。
更改城市
在项目中找到设置,修改CITY_NAME参数为你想要的城市采集
运行主程序采集数据
在项目文件夹中找到main.py并运行,愉快的获取数据并保存到data.csv。
项目下载地址
链接:密码:e7dz
使用爆搜-数据采集神器,中国领先的采集系统(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-05-28 19:03
可靠的采集神器,可以让你省下99%的时间和精力,不用为发票、收据、电子合同、发票、发票代开、在线身份验证、生产商跟踪记录、个人云报销等琐碎的事情烦恼。免费链接:/#/baiduyang/share?url=q531%3a51%26fsyqbmr-mgw%26wukkjb8qab%26fxbmkfr08ywsz2q&wtdocshowareauth_wsslx_wsslchop&pcffset=0&pcffset_ryf=0&pcffset_synce=0&pcffset_type=0&pcffset_penduri=0&pcffset_channels=0&pcffset_credit=0&pcffset_useroriginal=0&pcffset_trans_cmd=0&pcffset_savearray=0&pcffset_trans_cms=0&pcffset_serial_url=mc41/url?var=manfortransformoutputshaderpreviewer、overviewmega代码-rfbkhomyvmfewgzbc&viewer=gluva。
fiddler或者java的explorer(需要安装jdk1.8或以上版本)
我推荐使用爆搜爆搜-数据采集神器,中国领先的采集系统我在appstore应用市场查到的:
企业版的话:excel是可以建立索引,可以用来搜索指定方向的信息。然后,用企业版的数据透视表,插入大量的filter控件来处理不同方向的信息(按照月份、数字、人名、国家、日期等等方向进行筛选),一定程度上可以形成一个中间体,然后下载case文件就可以搜索具体方向的信息(很实用啊)。针对各方向的数据,都可以以表格的形式导出到excel。如果知道什么样的数据来自哪个方向,又不需要进行数据整理之类的工作,可以自己写爬虫来爬信息,查看结果。 查看全部
使用爆搜-数据采集神器,中国领先的采集系统(图)
可靠的采集神器,可以让你省下99%的时间和精力,不用为发票、收据、电子合同、发票、发票代开、在线身份验证、生产商跟踪记录、个人云报销等琐碎的事情烦恼。免费链接:/#/baiduyang/share?url=q531%3a51%26fsyqbmr-mgw%26wukkjb8qab%26fxbmkfr08ywsz2q&wtdocshowareauth_wsslx_wsslchop&pcffset=0&pcffset_ryf=0&pcffset_synce=0&pcffset_type=0&pcffset_penduri=0&pcffset_channels=0&pcffset_credit=0&pcffset_useroriginal=0&pcffset_trans_cmd=0&pcffset_savearray=0&pcffset_trans_cms=0&pcffset_serial_url=mc41/url?var=manfortransformoutputshaderpreviewer、overviewmega代码-rfbkhomyvmfewgzbc&viewer=gluva。
fiddler或者java的explorer(需要安装jdk1.8或以上版本)
我推荐使用爆搜爆搜-数据采集神器,中国领先的采集系统我在appstore应用市场查到的:
企业版的话:excel是可以建立索引,可以用来搜索指定方向的信息。然后,用企业版的数据透视表,插入大量的filter控件来处理不同方向的信息(按照月份、数字、人名、国家、日期等等方向进行筛选),一定程度上可以形成一个中间体,然后下载case文件就可以搜索具体方向的信息(很实用啊)。针对各方向的数据,都可以以表格的形式导出到excel。如果知道什么样的数据来自哪个方向,又不需要进行数据整理之类的工作,可以自己写爬虫来爬信息,查看结果。
可靠的采集神器:,能帮你快速实现网站采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-05-25 05:06
可靠的采集神器:,能帮你快速实现网站采集。它不仅可以采集百度、搜狗、360、uc等多家搜索引擎的结果,还能采集新浪微博、天涯、豆瓣、知乎、简书、简书等多家平台的信息。
我之前试了下最新版本网易优采云。全网大多数网站都能采到。但是运营商的大页面你要费很大力气才能采到。但是采到了就是你的,搜索引擎对优采云限制得不严格,你想抓到什么抓什么。
之前我也是谷歌浏览器插件安装安不上看到有人说优采云。我就用了一下。之前提供mac版的谷歌浏览器插件。不知道现在怎么样。但是我直接挂梯子连国内谷歌服务器加速优采云采集确实还是挺快的。另外就是点优采云的安装图片可以看到一共有9个配置文件。我现在第二个改成付费vip主机了。没必要再采集广告。当然可以试试各种在线工具。
云采集可以看下。不需要注册,不需要下载软件。获取这几篇文章,百度云分享给你百度云搜索,
采云采集,免费的,
看要采那些渠道,上采云采集网站,不仅可以采到企业的公众号,个人的公众号也可以采到。直接输入关键词搜索即可。 查看全部
可靠的采集神器:,能帮你快速实现网站采集
可靠的采集神器:,能帮你快速实现网站采集。它不仅可以采集百度、搜狗、360、uc等多家搜索引擎的结果,还能采集新浪微博、天涯、豆瓣、知乎、简书、简书等多家平台的信息。
我之前试了下最新版本网易优采云。全网大多数网站都能采到。但是运营商的大页面你要费很大力气才能采到。但是采到了就是你的,搜索引擎对优采云限制得不严格,你想抓到什么抓什么。
之前我也是谷歌浏览器插件安装安不上看到有人说优采云。我就用了一下。之前提供mac版的谷歌浏览器插件。不知道现在怎么样。但是我直接挂梯子连国内谷歌服务器加速优采云采集确实还是挺快的。另外就是点优采云的安装图片可以看到一共有9个配置文件。我现在第二个改成付费vip主机了。没必要再采集广告。当然可以试试各种在线工具。
云采集可以看下。不需要注册,不需要下载软件。获取这几篇文章,百度云分享给你百度云搜索,
采云采集,免费的,
看要采那些渠道,上采云采集网站,不仅可以采到企业的公众号,个人的公众号也可以采到。直接输入关键词搜索即可。

