
可靠的采集神器
可靠的采集神器(日引千元,,要看什么原因导致了?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-10-04 18:02
可靠的采集神器都是免费的,网上赚钱的渠道有很多,自己看看别人赚钱的方法,套用其中的通用的话术去推广就可以,免费的渠道无非就是代理,百度联盟和网站收录这些,然后再大量的引流,单子就来了。
日引千元,要看什么原因导致了。
1、百度竞价、竞价排名
2、推广所谓的采集群、软文群
3、手机硬件及网络技术
4、某微信生态
真的可以有的赚吗?赚这么多的人,平时是需要学习吗?可能你也要问我,当然需要了,只有前进才会往前走,没有两只鞋是一样的,同样,同样的赚钱道理,要靠谱的,
只要你想赚钱哪里都可以赚,小钱年入十万百万的,大钱一个月两三万的。再厉害点的做个代理啥的身价十亿,一天赚几万几十万也是可以的。当然也有家里比较困难的,一个月要生活所迫,不赚钱都不敢说话,只能向别人借钱,来渡过难关。
竞价、百度竞价、免费中介平台等都可以的
日赚千元是要看哪一块了,可靠的采集群每天发发软文,一天花个上千块钱,还是比较轻松的。
基本上都是免费的,不靠谱的有很多,
日赚千块一千块做公关去
可靠的c店什么的也不想多说,天上掉馅饼的事情,如果真有,
如果你觉得代理除了赚钱,和赚钱之外,和自己完全没有关系,你是坚持不了多久的。只要有人做,你就有机会。只要别小看自己。 查看全部
可靠的采集神器(日引千元,,要看什么原因导致了?)
可靠的采集神器都是免费的,网上赚钱的渠道有很多,自己看看别人赚钱的方法,套用其中的通用的话术去推广就可以,免费的渠道无非就是代理,百度联盟和网站收录这些,然后再大量的引流,单子就来了。
日引千元,要看什么原因导致了。
1、百度竞价、竞价排名
2、推广所谓的采集群、软文群
3、手机硬件及网络技术
4、某微信生态
真的可以有的赚吗?赚这么多的人,平时是需要学习吗?可能你也要问我,当然需要了,只有前进才会往前走,没有两只鞋是一样的,同样,同样的赚钱道理,要靠谱的,
只要你想赚钱哪里都可以赚,小钱年入十万百万的,大钱一个月两三万的。再厉害点的做个代理啥的身价十亿,一天赚几万几十万也是可以的。当然也有家里比较困难的,一个月要生活所迫,不赚钱都不敢说话,只能向别人借钱,来渡过难关。
竞价、百度竞价、免费中介平台等都可以的
日赚千元是要看哪一块了,可靠的采集群每天发发软文,一天花个上千块钱,还是比较轻松的。
基本上都是免费的,不靠谱的有很多,
日赚千块一千块做公关去
可靠的c店什么的也不想多说,天上掉馅饼的事情,如果真有,
如果你觉得代理除了赚钱,和赚钱之外,和自己完全没有关系,你是坚持不了多久的。只要有人做,你就有机会。只要别小看自己。
可靠的采集神器(信息采集的难点是什么?分类数据库有三个最新解析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-10-01 10:20
信息采集的难度是多少?数据更加复杂多样;下载后有什么困难?数据管理。
网络信息大师(NetGet)的主要功能就是解决这两个问题。一般数据采集是有针对性的,通常是针对某个或某些网站、采集某类数据。比如采集几个网站招聘信息、产品信息、供求信息、公司图书馆信息等等。简单分析了这些网站的数据结构后,设置相应的采集规则,就可以将你想要的所有数据下载到本地了。本软件支持分类,分类的目的是方便数据管理和统计分析。
现有功能介绍:
1. 这个软件可以采集任何类型的网站信息。包括htm、html、ASP、JSP、PHP等。采集速度快,信息一致,准确。支持网站登录。
2. 分类。分类的目的是为了方便地管理数据。您可以添加、删除和修改类别。分类数据库有3个最新备份,放在\files目录下,为数据安全提供了可靠保证。
3. 任务。任务是 采集 任务。按照相应的 采集 规则行事。可以随时启动、暂停和停止任务。本软件支持多任务,即同时采集不同的数据。
4. 数据导出。采集的数据可以通过三种方式导出:文本、Excel和数据库。它可以根据您的需要导出为不同的格式。
5. 数据库。Access 和 SqlServer 数据库目前正在测试中。数据库功能包括导入数据库和数据查询。
6. 菜单功能扩展。一般是扩展数据分析功能。例如,您自己开发了一个数据库软件。本软件用于分析采集的数据。您可以将软件连接到该软件以方便使用。
7. 日志。记录每一个重要的操作。比如类别的维护,任务的维护等等。日志可以被清理和备份。 查看全部
可靠的采集神器(信息采集的难点是什么?分类数据库有三个最新解析)
信息采集的难度是多少?数据更加复杂多样;下载后有什么困难?数据管理。
网络信息大师(NetGet)的主要功能就是解决这两个问题。一般数据采集是有针对性的,通常是针对某个或某些网站、采集某类数据。比如采集几个网站招聘信息、产品信息、供求信息、公司图书馆信息等等。简单分析了这些网站的数据结构后,设置相应的采集规则,就可以将你想要的所有数据下载到本地了。本软件支持分类,分类的目的是方便数据管理和统计分析。
现有功能介绍:
1. 这个软件可以采集任何类型的网站信息。包括htm、html、ASP、JSP、PHP等。采集速度快,信息一致,准确。支持网站登录。
2. 分类。分类的目的是为了方便地管理数据。您可以添加、删除和修改类别。分类数据库有3个最新备份,放在\files目录下,为数据安全提供了可靠保证。
3. 任务。任务是 采集 任务。按照相应的 采集 规则行事。可以随时启动、暂停和停止任务。本软件支持多任务,即同时采集不同的数据。
4. 数据导出。采集的数据可以通过三种方式导出:文本、Excel和数据库。它可以根据您的需要导出为不同的格式。
5. 数据库。Access 和 SqlServer 数据库目前正在测试中。数据库功能包括导入数据库和数据查询。
6. 菜单功能扩展。一般是扩展数据分析功能。例如,您自己开发了一个数据库软件。本软件用于分析采集的数据。您可以将软件连接到该软件以方便使用。
7. 日志。记录每一个重要的操作。比如类别的维护,任务的维护等等。日志可以被清理和备份。
可靠的采集神器(4.垃圾收集过程G1收集器的运行示意图如下的Mixed和继承人)
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-09-30 03:22
1. 简介
Garbage First(简称G1)采集器是垃圾采集器技术发展史上的一个里程碑式的成就:它开创了“面向本地采集”的设计思想和“基于Region”的内存布局形式.
G1采集器是一个主要针对服务端应用的垃圾采集器,它的定位是“cms采集器的替代者和继承者”。其发展简史如下:
2. 堆内存划分
虽然 G1 采集器也遵循分代采集理论,但它的堆内存布局与其他采集器有很大不同:
G1采集器的堆内存划分如图:
3. 暂停时间模型3.1 暂停时间模型
暂停预测模型:指定在 M 毫秒的时间段内,垃圾回收所花费的时间很可能不超过 N 毫秒。
G1采集器之所以能够建立可预测的暂停时间模型,是因为它把Region作为单次回收的最小单位(每次采集的内存空间是Region大小的整数倍),这样整个Java 堆执行全区域垃圾采集。
更具体的处理思路:让G1采集器跟踪每个Region中垃圾堆积的“值”,然后在后台维护一个优先级列表。每次根据用户设置的采集暂停时间,优先处理和回收价值将是最有利可图的。那些区域(这就是“垃圾优先”名称的由来)。
“值”是通过每次恢复获得的空间量和恢复所需时间的经验值来衡量的。
3.2 混合 GC
对于 G1 采集器之前的所有其他采集器(包括 cms 采集器),垃圾采集的目标范围要么是整个年轻代(Minor GC),要么是整个老年代(Major GC),要么是整个 Java堆(Full GC)。
而G1则跳出这个笼子:它可以对堆内存的任何部分形成一个集合集(俗称CSet)进行回收。衡量的标准不再是它属于哪一代,而是哪一块内存收录的垃圾量最大,回收收益最大。这是 G1 采集器的混合 GC 模式。
4. 垃圾采集过程
G1采集器的运行图如下:
其操作过程大致可以分为以下四个步骤:
4.1 初始标记功能
TAMS:Top at Mark Start,Region中的指针,用于并发标记时为对象分配内存空间。
4.2 并发标记
从GC Root开始,对堆中的对象进行可达性分析,递归扫描整个堆中的对象图,找到需要回收的对象。
另外,扫描完成后,需要重新处理并发期间引用发生变化的STAB记录的对象。
STAB: Snapshot At The Beginning,原创快照,参考上篇《》6.3 部分。
4.3 最终标记功能4.4 筛选和回收功能5. 一些细节5.1 跨区域参考对象
解决办法是使用前面“”的第4节中的“内存集”,避免将整个堆扫描为GC Roots。
但是,G1 的内存集更复杂,因为:
根据经验,G1至少需要消耗Java堆容量的10%~20%左右的额外内存空间来维持采集器的工作。
5.2 并发标记
解决方案在上一篇第6节分析:cms采集器采用增量更新算法,而G1采集器采用原创快照(STAB)算法实现。
另外,由于用户线程在并发标记时还在执行,所以肯定会继续创建新对象。
G1为每个Region设计了两个名为TAMS(Top at Mark Start)的指针,将Region中的一部分空间用于并发采集过程中新对象的分配(默认都是存活的,不包括在采集范围内) ) )。
需要注意的是,如果内存回收速度跟不上内存分配速度,G1采集器也会被强制冻结用户线程的执行,导致Full GC和长时间的“Stop The World”。
5.3 可靠的暂停模型
G1采集器的暂停模型是基于Decaying Average的理论基础:在垃圾采集过程中,G1采集器会分析每个Region的采集时间,内存中脏卡的数量等平均值,标准偏差等
“衰减平均值”比普通平均值更准确地表示“最近”的平均值状态。该信息用于预测在不超过预期暂停时间的约束下将采集哪些 Region 以获得最高回报。.
6. G1 VS cms
G1 采集器经常与 cms 采集器进行比较。
不管G1的一些创新设计:可以指定最大暂停时间,子区域的内存布局,以及根据收入动态确定集合等等,这里只说一些其他比较常见的地方。
6.1 采集算法
G1的这两种算法在运行过程中防止内存空间碎片化,并在垃圾回收完成后提供正常可用的内存。而且这对于程序长时间运行是有好处的(大对象分配内存时,由于无法找到连续的内存空间,不容易提前触发下一次采集)。
6.2 内存占用
cms 和 G1 都使用卡表来处理跨代指针,但 G1 的卡表实现更复杂,区域更多(本文 5.1 节)。
相比之下,cms的卡片表比较简单,只有一份,只需要处理老年代到新生代的引用。
与cms相比,G1的内存占用更大。
6.3 额外的执行负载
由于两者的实现细节不同,用户程序执行时的负载会有所不同。以写屏障为例:
G1 的写屏障比 cms 消耗更多的计算资源。因此,cms 写屏障是一个同步操作,而 G1 使用的是类似于消息队列的异步操作。
一般来说:
这个临界点大概在6~8G(经验值)之间。
一些相关的虚拟机参数如下:
# 使用 G1 收集器
-XX:+UseG1GC
# 设置 Region 大小(范围 1~32M,且为 2 的 N 次幂)
-XX:G1HeapRegionSize
# 最大收集停顿时间(默认 200 毫秒)
-XX:MaxGCPauseMillis
本文的主要内容总结如下: 查看全部
可靠的采集神器(4.垃圾收集过程G1收集器的运行示意图如下的Mixed和继承人)
1. 简介
Garbage First(简称G1)采集器是垃圾采集器技术发展史上的一个里程碑式的成就:它开创了“面向本地采集”的设计思想和“基于Region”的内存布局形式.
G1采集器是一个主要针对服务端应用的垃圾采集器,它的定位是“cms采集器的替代者和继承者”。其发展简史如下:
2. 堆内存划分
虽然 G1 采集器也遵循分代采集理论,但它的堆内存布局与其他采集器有很大不同:
G1采集器的堆内存划分如图:
3. 暂停时间模型3.1 暂停时间模型
暂停预测模型:指定在 M 毫秒的时间段内,垃圾回收所花费的时间很可能不超过 N 毫秒。
G1采集器之所以能够建立可预测的暂停时间模型,是因为它把Region作为单次回收的最小单位(每次采集的内存空间是Region大小的整数倍),这样整个Java 堆执行全区域垃圾采集。
更具体的处理思路:让G1采集器跟踪每个Region中垃圾堆积的“值”,然后在后台维护一个优先级列表。每次根据用户设置的采集暂停时间,优先处理和回收价值将是最有利可图的。那些区域(这就是“垃圾优先”名称的由来)。
“值”是通过每次恢复获得的空间量和恢复所需时间的经验值来衡量的。
3.2 混合 GC
对于 G1 采集器之前的所有其他采集器(包括 cms 采集器),垃圾采集的目标范围要么是整个年轻代(Minor GC),要么是整个老年代(Major GC),要么是整个 Java堆(Full GC)。
而G1则跳出这个笼子:它可以对堆内存的任何部分形成一个集合集(俗称CSet)进行回收。衡量的标准不再是它属于哪一代,而是哪一块内存收录的垃圾量最大,回收收益最大。这是 G1 采集器的混合 GC 模式。
4. 垃圾采集过程
G1采集器的运行图如下:
其操作过程大致可以分为以下四个步骤:
4.1 初始标记功能
TAMS:Top at Mark Start,Region中的指针,用于并发标记时为对象分配内存空间。
4.2 并发标记
从GC Root开始,对堆中的对象进行可达性分析,递归扫描整个堆中的对象图,找到需要回收的对象。
另外,扫描完成后,需要重新处理并发期间引用发生变化的STAB记录的对象。
STAB: Snapshot At The Beginning,原创快照,参考上篇《》6.3 部分。
4.3 最终标记功能4.4 筛选和回收功能5. 一些细节5.1 跨区域参考对象
解决办法是使用前面“”的第4节中的“内存集”,避免将整个堆扫描为GC Roots。
但是,G1 的内存集更复杂,因为:
根据经验,G1至少需要消耗Java堆容量的10%~20%左右的额外内存空间来维持采集器的工作。
5.2 并发标记
解决方案在上一篇第6节分析:cms采集器采用增量更新算法,而G1采集器采用原创快照(STAB)算法实现。
另外,由于用户线程在并发标记时还在执行,所以肯定会继续创建新对象。
G1为每个Region设计了两个名为TAMS(Top at Mark Start)的指针,将Region中的一部分空间用于并发采集过程中新对象的分配(默认都是存活的,不包括在采集范围内) ) )。
需要注意的是,如果内存回收速度跟不上内存分配速度,G1采集器也会被强制冻结用户线程的执行,导致Full GC和长时间的“Stop The World”。
5.3 可靠的暂停模型
G1采集器的暂停模型是基于Decaying Average的理论基础:在垃圾采集过程中,G1采集器会分析每个Region的采集时间,内存中脏卡的数量等平均值,标准偏差等
“衰减平均值”比普通平均值更准确地表示“最近”的平均值状态。该信息用于预测在不超过预期暂停时间的约束下将采集哪些 Region 以获得最高回报。.
6. G1 VS cms
G1 采集器经常与 cms 采集器进行比较。
不管G1的一些创新设计:可以指定最大暂停时间,子区域的内存布局,以及根据收入动态确定集合等等,这里只说一些其他比较常见的地方。
6.1 采集算法
G1的这两种算法在运行过程中防止内存空间碎片化,并在垃圾回收完成后提供正常可用的内存。而且这对于程序长时间运行是有好处的(大对象分配内存时,由于无法找到连续的内存空间,不容易提前触发下一次采集)。
6.2 内存占用
cms 和 G1 都使用卡表来处理跨代指针,但 G1 的卡表实现更复杂,区域更多(本文 5.1 节)。
相比之下,cms的卡片表比较简单,只有一份,只需要处理老年代到新生代的引用。
与cms相比,G1的内存占用更大。
6.3 额外的执行负载
由于两者的实现细节不同,用户程序执行时的负载会有所不同。以写屏障为例:
G1 的写屏障比 cms 消耗更多的计算资源。因此,cms 写屏障是一个同步操作,而 G1 使用的是类似于消息队列的异步操作。
一般来说:
这个临界点大概在6~8G(经验值)之间。
一些相关的虚拟机参数如下:
# 使用 G1 收集器
-XX:+UseG1GC
# 设置 Region 大小(范围 1~32M,且为 2 的 N 次幂)
-XX:G1HeapRegionSize
# 最大收集停顿时间(默认 200 毫秒)
-XX:MaxGCPauseMillis
本文的主要内容总结如下:
可靠的采集神器(可靠的采集神器——whois爬取豆瓣用户reddit信息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-09-29 08:03
可靠的采集神器如下:whois抓取dnsservers|imageview|paintgetaddresses抓取https请求头一一匹配规律逆向domhtmlseed能追踪页面中的链接的url
firebug好像抓不了页面的内容,但是可以抓包页面内容看看,
lz是说抓取图片内容吗?我最近正在使用阿里妈妈的开源采集页面的脚本!集成squid及apachesphinx数据库,直接爬取source的网页数据供需要的人服务。主要是满足爬虫从静态网页直接抓取动态网页数据,数据清洗和结构化是我需要解决的问题。
tornado爬页面自己回答一下。当然也是自己随手写的。
大家好!我要推荐一个工具集合,
使用python的github搜索引擎,提供了大量的数据,包括:获取各公司网站的wikipedia账号页截图以及dom编辑版权页采集各种视频站ppt平台页面获取采集知乎页面,全英文wiki,不过非常清晰。获取微博头像获取采集图像抓取msfilteredspider,包括图片采集,动图采集,视频采集等。
哎哎哎,题主你推荐的这两个我还没用过,不敢妄下结论,最近还真好奇requests有没有什么免费的功能。之前有人说用beautifulsoup,我还没用过嗯目前大的想法是这样,希望大家多提点建议,针对题主给出的问题,我特意准备学习爬取豆瓣的用户reddit信息/小组信息,详情如下:去找站长,把你爬过的数据分享出来,以及站长专栏:sosoreddit找合适的网站去爬,我主要在sina,但是抓了不少网站,也因此知道了一个新的站,目标是trytap这个类似的网站(后面会说为什么在这个网站去爬数据合适)sina也有了,就是觉得这个网站有个功能不错,就在我们这边也刚建了一个beta版,希望能体验一下多测试,找到合适的数据,算是给大家交个作业。 查看全部
可靠的采集神器(可靠的采集神器——whois爬取豆瓣用户reddit信息)
可靠的采集神器如下:whois抓取dnsservers|imageview|paintgetaddresses抓取https请求头一一匹配规律逆向domhtmlseed能追踪页面中的链接的url
firebug好像抓不了页面的内容,但是可以抓包页面内容看看,
lz是说抓取图片内容吗?我最近正在使用阿里妈妈的开源采集页面的脚本!集成squid及apachesphinx数据库,直接爬取source的网页数据供需要的人服务。主要是满足爬虫从静态网页直接抓取动态网页数据,数据清洗和结构化是我需要解决的问题。
tornado爬页面自己回答一下。当然也是自己随手写的。
大家好!我要推荐一个工具集合,
使用python的github搜索引擎,提供了大量的数据,包括:获取各公司网站的wikipedia账号页截图以及dom编辑版权页采集各种视频站ppt平台页面获取采集知乎页面,全英文wiki,不过非常清晰。获取微博头像获取采集图像抓取msfilteredspider,包括图片采集,动图采集,视频采集等。
哎哎哎,题主你推荐的这两个我还没用过,不敢妄下结论,最近还真好奇requests有没有什么免费的功能。之前有人说用beautifulsoup,我还没用过嗯目前大的想法是这样,希望大家多提点建议,针对题主给出的问题,我特意准备学习爬取豆瓣的用户reddit信息/小组信息,详情如下:去找站长,把你爬过的数据分享出来,以及站长专栏:sosoreddit找合适的网站去爬,我主要在sina,但是抓了不少网站,也因此知道了一个新的站,目标是trytap这个类似的网站(后面会说为什么在这个网站去爬数据合适)sina也有了,就是觉得这个网站有个功能不错,就在我们这边也刚建了一个beta版,希望能体验一下多测试,找到合适的数据,算是给大家交个作业。
可靠的采集神器(比较流行的几款采集工具作一个简单的评比,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2021-09-27 06:23
现在的站长圈子里,有很多流行的采集工具,但总结起来,比较出名的免费工具只有几个:优采云、海纳、ET、Threesome、优采云。
下面我们对这几个采集工具做一个简单的对比。
1.优采云 基本上大家都知道了,先放上来再说几句。
优采云应该是国内采集软件最成功的模式之一,包括付费用户在内的用户数量应该是最大的
特点:简单,强大,快速,支持最丰富的网站,支持丰富的扩展
优点:功能比较齐全,采集比较快,主要针对cms,短时间可以采集很多,过滤替换都不错,比较详细;很多人写接口、规则和发布模块和接口都比较完整。其中有一个叫陈元的人,开发了目前PHP类的几乎所有接口cms;支持的扩展非常易于使用。如果你是技术上比较熟悉的网站,可以用PHP或C#开发任何功能扩展,真的很难忘;附件采集功能完善。
技术:该技术以论坛为主,帮助文件多,上手容易。有付费版和免费版
缺点:功能较多,软件较大,内存和CPU资源较多,资源回收控制较差
2.三人行(优采云) 主要针对论坛的采集,功能比较齐全
首先,我不知道三星和优采云是什么关系,但是接口和功能都是基于同一个模型的。
特点:针对各大论坛,移动,移动,速度快,准确度高
优点:还是论坛用,适合开论坛
技术:收费技术,免费广告
缺点:超级复杂,上手困难,对cms支持差
3.ET 工具
特点:无人值守,稳定,占用资源最少,基本可以叫安静
优点:无人值守,自动更新,适合长期站,用户群主要集中在长期潜水站长。软件一目了然,必备的功能也很齐全。关键是该软件是免费的。听说增加了采集中英文翻译功能。
技术:论坛支持,软件本身免费,但也提供收费服务。帮助文件少,不易上手
缺点:一般支持论坛和cms
4.海娜
特点:海量,关键词抓取,无需编写规则即可预览采集的内容
优点:海量,可以抢网站一大堆关键词文章,好像很适合网站的话题,尤其是文章类,博客类
技术:无论坛费用,免费但有功能限制
缺点:分类不方便,也就是说采集文章分类不方便,手动(自动容易混淆),界面具体,采集内容有限
5.优采云
特点:让您的新论坛一开始就拥有大量成员。
优点:非常适合采集discuz论坛
缺点:过于具体,兼容性差。
总结:如果追求功能齐全,看来应该选择优采云。优采云 被称为“全能”。初期可以快速采集大量资源,丰富网站内容。如果您是论坛,请选择三人组。没错,可以实现采集论坛、回复、移动等多种论坛功能。长期站,当然选择ET,花点时间了解一下,是长期受益。写规则,设置过滤器和替换,然后它可以像打开QQ一样长时间运行,不存储,自动更新,分类清晰,内容完整,但是说,一站,一站龙+ ET就足够了。至于Heiner,貌似不写规则,上手容易,但是文章的发布可没有ET那么容易。 查看全部
可靠的采集神器(比较流行的几款采集工具作一个简单的评比,你知道吗?)
现在的站长圈子里,有很多流行的采集工具,但总结起来,比较出名的免费工具只有几个:优采云、海纳、ET、Threesome、优采云。
下面我们对这几个采集工具做一个简单的对比。
1.优采云 基本上大家都知道了,先放上来再说几句。
优采云应该是国内采集软件最成功的模式之一,包括付费用户在内的用户数量应该是最大的
特点:简单,强大,快速,支持最丰富的网站,支持丰富的扩展
优点:功能比较齐全,采集比较快,主要针对cms,短时间可以采集很多,过滤替换都不错,比较详细;很多人写接口、规则和发布模块和接口都比较完整。其中有一个叫陈元的人,开发了目前PHP类的几乎所有接口cms;支持的扩展非常易于使用。如果你是技术上比较熟悉的网站,可以用PHP或C#开发任何功能扩展,真的很难忘;附件采集功能完善。
技术:该技术以论坛为主,帮助文件多,上手容易。有付费版和免费版
缺点:功能较多,软件较大,内存和CPU资源较多,资源回收控制较差
2.三人行(优采云) 主要针对论坛的采集,功能比较齐全
首先,我不知道三星和优采云是什么关系,但是接口和功能都是基于同一个模型的。
特点:针对各大论坛,移动,移动,速度快,准确度高
优点:还是论坛用,适合开论坛
技术:收费技术,免费广告
缺点:超级复杂,上手困难,对cms支持差
3.ET 工具
特点:无人值守,稳定,占用资源最少,基本可以叫安静
优点:无人值守,自动更新,适合长期站,用户群主要集中在长期潜水站长。软件一目了然,必备的功能也很齐全。关键是该软件是免费的。听说增加了采集中英文翻译功能。
技术:论坛支持,软件本身免费,但也提供收费服务。帮助文件少,不易上手
缺点:一般支持论坛和cms
4.海娜
特点:海量,关键词抓取,无需编写规则即可预览采集的内容
优点:海量,可以抢网站一大堆关键词文章,好像很适合网站的话题,尤其是文章类,博客类
技术:无论坛费用,免费但有功能限制
缺点:分类不方便,也就是说采集文章分类不方便,手动(自动容易混淆),界面具体,采集内容有限
5.优采云
特点:让您的新论坛一开始就拥有大量成员。
优点:非常适合采集discuz论坛
缺点:过于具体,兼容性差。
总结:如果追求功能齐全,看来应该选择优采云。优采云 被称为“全能”。初期可以快速采集大量资源,丰富网站内容。如果您是论坛,请选择三人组。没错,可以实现采集论坛、回复、移动等多种论坛功能。长期站,当然选择ET,花点时间了解一下,是长期受益。写规则,设置过滤器和替换,然后它可以像打开QQ一样长时间运行,不存储,自动更新,分类清晰,内容完整,但是说,一站,一站龙+ ET就足够了。至于Heiner,貌似不写规则,上手容易,但是文章的发布可没有ET那么容易。
可靠的采集神器(优化大陆线路除了硬件的可靠性,租用香港站群还有一个好处)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-24 17:11
网站采集是网站为了快速提升网络排名,增加网站收录和整体内容的丰富度,下载别人的整个站点数据到你自己的网站或者将别人的网站的一些内容保存到你自己的服务器上。从内容中提取相关字段发布到自己的网站系统,或者需要本地保存web相关文件,如图片、附件等。香港站群服务器专业使用用于网站SEO优化,非常适合采集内容,快速部署站群!
优化大陆航线
除了硬件的可靠性,租用香港站群的另一个优点是有CN2直连线,特别是一些部署在大陆服务器的目标网站,使用CN2直连连接线可以很稳定的将数据采集返回到自己的服务器,采集的过程中出现空采集的概率很低。
IP不容易被封
采集工具的原理是通过正常的http访问来读取目标网站的内容,所以如果量太大或者频率太高,很容易被对方拒绝目标网站作为CC攻击,导致抓取空内容,如果服务器自身IP资源充足,可以模拟多个不同的服务器进行访问,从而避免目标网站反采集机制,自然采集内容和发布更稳定。
硬件配置合适
<p>现在很多用户租香港站群服务器搭建站群业务,但其实站群服务器非常适合部署采集系统,现在主流 查看全部
可靠的采集神器(优化大陆线路除了硬件的可靠性,租用香港站群还有一个好处)
网站采集是网站为了快速提升网络排名,增加网站收录和整体内容的丰富度,下载别人的整个站点数据到你自己的网站或者将别人的网站的一些内容保存到你自己的服务器上。从内容中提取相关字段发布到自己的网站系统,或者需要本地保存web相关文件,如图片、附件等。香港站群服务器专业使用用于网站SEO优化,非常适合采集内容,快速部署站群!
优化大陆航线
除了硬件的可靠性,租用香港站群的另一个优点是有CN2直连线,特别是一些部署在大陆服务器的目标网站,使用CN2直连连接线可以很稳定的将数据采集返回到自己的服务器,采集的过程中出现空采集的概率很低。
IP不容易被封
采集工具的原理是通过正常的http访问来读取目标网站的内容,所以如果量太大或者频率太高,很容易被对方拒绝目标网站作为CC攻击,导致抓取空内容,如果服务器自身IP资源充足,可以模拟多个不同的服务器进行访问,从而避免目标网站反采集机制,自然采集内容和发布更稳定。
硬件配置合适
<p>现在很多用户租香港站群服务器搭建站群业务,但其实站群服务器非常适合部署采集系统,现在主流
可靠的采集神器(可靠的采集神器谷歌浏览器助手百度云格式转换-1.rar)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-09-19 11:03
可靠的采集神器谷歌浏览器助手百度云格式转换llljb-1vbw.rar-1.rar文件格式的转换工具对于我们这种想看pdf格式的小白来说格式转换真的超级有用还能自定义主题很值得推荐
有一个很好的东西,叫网络爬虫,你可以试试看。
autocheckout如果能找到解决方案,
windows有个第三方的计算机管理软件很不错的,一般对桌面上的一些软件,比如qq啥的,大多都是比较方便的,然后用360之类的,或者不用软件也行。
泻药,是一块没用的软件,或者你可以再问一个小问题。
谢邀,你知道autohotkey么。
autohotkey,仿python。
1everything2autohotkeypro3自己做一个
everything或者windowns
autohotkey
运行命令不一定需要命令,
matlab,windows下你自己想怎么用就怎么用
既然用mac的话,就用类似alfred的应用metro平台比如:palmos里有一个palmosprocess和通过windows主机端监控autohotkey启动的脚本(autohotkey一样),也可以通过这个palmosprocess管理文件在:-desktop.py这里有一个测试版本与正式版本相比功能完善挺多。
如果只是用于收集而不用于存储文件的话,推荐只用windows版本。在windows环境下应该和windows主机端管理的palmos版本差不多。 查看全部
可靠的采集神器(可靠的采集神器谷歌浏览器助手百度云格式转换-1.rar)
可靠的采集神器谷歌浏览器助手百度云格式转换llljb-1vbw.rar-1.rar文件格式的转换工具对于我们这种想看pdf格式的小白来说格式转换真的超级有用还能自定义主题很值得推荐
有一个很好的东西,叫网络爬虫,你可以试试看。
autocheckout如果能找到解决方案,
windows有个第三方的计算机管理软件很不错的,一般对桌面上的一些软件,比如qq啥的,大多都是比较方便的,然后用360之类的,或者不用软件也行。
泻药,是一块没用的软件,或者你可以再问一个小问题。
谢邀,你知道autohotkey么。
autohotkey,仿python。
1everything2autohotkeypro3自己做一个
everything或者windowns
autohotkey
运行命令不一定需要命令,
matlab,windows下你自己想怎么用就怎么用
既然用mac的话,就用类似alfred的应用metro平台比如:palmos里有一个palmosprocess和通过windows主机端监控autohotkey启动的脚本(autohotkey一样),也可以通过这个palmosprocess管理文件在:-desktop.py这里有一个测试版本与正式版本相比功能完善挺多。
如果只是用于收集而不用于存储文件的话,推荐只用windows版本。在windows环境下应该和windows主机端管理的palmos版本差不多。
可靠的采集神器(可靠的采集神器教你如何提高采集的质量,保证平台的原创和质量)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-09-09 07:02
可靠的采集神器教你如何提高采集的质量,保证平台的原创和质量,让你一次采集成百上千,还让你能够控制采集的类目,还可以实现多采集。电商日记的前端使用的就是类似的技术,通过自然排名,非常快速的提高你产品的排名,并且保证对手不知道你,从而提高你产品的曝光度,甚至让你产品有了可观的销量,同时也为你带来了流量。你可以试一下。
不同的类目,当然要不同的操作方法,大类目为了防止刷单,那么你就要写出比较高质量的文案,并且要把细节设置好,如果这些都做不好,那么你想把销量做上去是不可能的。我自己也是运营的天猫店铺,我自己一个运营的多家天猫店铺,我对这块是非常了解的,
实际操作得好多少还是有一点作用,大批量最好就是找人帮你,如果按个收费,可能就是违背你开头说的了。如果做一些活动,那么使用的时候效果会更好一些。
需要点技术来处理你链接每个商品的类目上下架周期,然后选取上下架周期上架的商品,选取你的类目了解下这个类目下近期流量趋势和售卖热点,然后进行分析,安排你上架的类目时间,然后按照数据反馈,设置每天推广量,以保证下架的时候数据反馈良好,完成上架,数据反馈不好,删除类目。重复执行上架环节,热销商品可以在下架后在上架。 查看全部
可靠的采集神器(可靠的采集神器教你如何提高采集的质量,保证平台的原创和质量)
可靠的采集神器教你如何提高采集的质量,保证平台的原创和质量,让你一次采集成百上千,还让你能够控制采集的类目,还可以实现多采集。电商日记的前端使用的就是类似的技术,通过自然排名,非常快速的提高你产品的排名,并且保证对手不知道你,从而提高你产品的曝光度,甚至让你产品有了可观的销量,同时也为你带来了流量。你可以试一下。
不同的类目,当然要不同的操作方法,大类目为了防止刷单,那么你就要写出比较高质量的文案,并且要把细节设置好,如果这些都做不好,那么你想把销量做上去是不可能的。我自己也是运营的天猫店铺,我自己一个运营的多家天猫店铺,我对这块是非常了解的,
实际操作得好多少还是有一点作用,大批量最好就是找人帮你,如果按个收费,可能就是违背你开头说的了。如果做一些活动,那么使用的时候效果会更好一些。
需要点技术来处理你链接每个商品的类目上下架周期,然后选取上下架周期上架的商品,选取你的类目了解下这个类目下近期流量趋势和售卖热点,然后进行分析,安排你上架的类目时间,然后按照数据反馈,设置每天推广量,以保证下架的时候数据反馈良好,完成上架,数据反馈不好,删除类目。重复执行上架环节,热销商品可以在下架后在上架。
可靠的采集神器(4.垃圾收集过程G1收集器的运行示意图如下的Mixed和继承人 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-05 19:29
)
1.简介
Garbage First(简称G1)collector)是垃圾采集技术发展史上的里程碑式成就:开创了“面向本地采集”的设计思想和“基于区域”的内存布局形式.
G1采集器是一个主要针对服务器应用的垃圾采集器,它的定位是“cms采集器的替代者和继承者”。其发展简史如下:
2.堆内存划分
虽然 G1 采集器也遵循分代采集理论,但它的堆内存布局与其他采集器有很大不同:
G1采集器的堆内存划分如图:
3. 暂停时间模型3.1 暂停时间模型
Pause Prediction Model:指定在M毫秒的时间段内,垃圾回收花费的时间很可能不超过N毫秒。
G1采集器之所以能建立可预测的暂停时间模型,是因为它把Region作为单次恢复的最小单位(每次采集的内存空间是Region大小的整数倍),这样可以有计划地避免整个Java堆的垃圾回收。
更具体的处理思路:让G1采集器跟踪每个Region中垃圾堆积的“值”,然后在后台维护一个优先级列表,根据用户每次设置的采集暂停时间优先回收时间收益最大的区域(这就是“垃圾优先”名称的由来)。
衡量“价值”的标准是:每次采集所获得的空间量和采集所需时间的经验值。
3.2 混合 GC
对于G1采集器之前的所有其他采集器(包括cms采集器),垃圾采集的目标范围要么是整个年轻代(Minor GC),要么是整个老年代(Major GC),要么是整个Java 堆(Full GC)。
而G1跳出了这个笼子:它可以面对堆内存的任何部分,形成一个回采集(通常称为CSet)进行回收。衡量的标准不再是它属于哪一代,而是哪一块内存收录的垃圾量最大,回收收益最大。这是G1采集器的Mixed GC模式。
4.垃圾采集过程
G1采集器运行示意图如下:
其操作过程大致可以分为以下四个步骤:
4.1 初始标记
特点
TAMS:Top at Mark Start,Region中的指针,用于并发标记时为对象分配内存空间。
4.2 并发标记
堆中对象的可达性分析从GC Root开始,递归扫描整个堆中的对象图,找到需要回收的对象。
另外,在扫描完成后,需要对STAB记录的并发期间引用发生变化的对象进行重新处理。
STAB: Snapshot At The Beginning,原创快照,参考前文的6.3 部分。
4.3 最终成绩
特点
4.4 筛选回收
特点
5. 一些细节5.1 跨区域引用对象
解决办法是使用前面《》第4节中的“内存集”,避免将整个堆扫描为GC Roots。
然而,G1 的内存集更复杂,因为:
根据经验,G1至少需要Java堆大小的10%~20%左右的额外内存空间来维持采集器的工作。
5.2 并发标记
解决方案在上一篇第6节分析:cms采集器采用增量更新算法,而G1采集器采用原创快照(STAB)算法实现。
另外,由于用户线程在并发标记时还在执行,所以肯定会继续创建新对象。
G1为每个Region设计了两个名为TAMS(Top at Mark Start)的指针,将Region中的一部分空间划分为并发采集过程中的新对象分配(默认都是alive的,没有收录在范围内)回收)。
需要注意的是,如果内存回收速度跟不上内存分配速度,G1采集器也会强制冻结用户线程的执行,导致Full GC和长时间“Stop The World” .
5.3 可靠的暂停模型
G1采集器的暂停模型基于Decaying Average的理论基础:垃圾采集过程中,G1采集器会根据每个Region的采集时间,内存中脏卡的数量等. 分析平均值、标准差等
“衰减平均值”比普通平均值更准确地表示“最近”的平均值状态。此信息用于预测如果回收现在开始将采集哪些区域,以便可以限制采集不超过预期的暂停时间。获得最高利润。
6. G1 VS cms
G1 采集器经常与cms 采集器进行比较。
不管G1的一些创新设计:可以指定最大暂停时间,子区域的内存布局,根据收入动态确定集合等等,这里只说其他一些比较常见的地点。
6.1 采集算法
G1的两种算法在运行过程中防止内存空间碎片化,并在垃圾回收完成后提供正常可用的内存。而且这对于程序长时间运行是有好处的(大对象分配内存时,由于无法找到连续的内存空间,不容易提前触发下一次采集)。
6.2 内存占用
cms 和 G1 都使用卡片表来处理跨代指针,但是 G1 的卡片表实现更复杂,区域更多(本文5.1 部分)。
相比之下cms的卡片列表比较简单,只有一份,而且只需要处理老一代到新生代的引用。
与cms相比,G1的内存占用更大。
6.3 额外的执行负载
由于两者的实现细节不同,用户程序执行时的负载会有所不同。以写屏障为例:
G1 的写屏障比cms 消耗更多的计算资源。所以cms写屏障是同步操作,而G1使用的是类似消息队列的异步操作。
总体:
这个临界点大概在6~8G(经验值)之间。
一些相关的虚拟机参数如下:
<p># 使用 G1 收集器
-XX:+UseG1GC
# 设置 Region 大小(范围 1~32M,且为 2 的 N 次幂)
-XX:G1HeapRegionSize
# 最大收集停顿时间(默认 200 毫秒)
-XX:MaxGCPauseMillis</p>
本文主要内容总结如下:
查看全部
可靠的采集神器(4.垃圾收集过程G1收集器的运行示意图如下的Mixed和继承人
)
1.简介
Garbage First(简称G1)collector)是垃圾采集技术发展史上的里程碑式成就:开创了“面向本地采集”的设计思想和“基于区域”的内存布局形式.
G1采集器是一个主要针对服务器应用的垃圾采集器,它的定位是“cms采集器的替代者和继承者”。其发展简史如下:
2.堆内存划分
虽然 G1 采集器也遵循分代采集理论,但它的堆内存布局与其他采集器有很大不同:
G1采集器的堆内存划分如图:

3. 暂停时间模型3.1 暂停时间模型
Pause Prediction Model:指定在M毫秒的时间段内,垃圾回收花费的时间很可能不超过N毫秒。
G1采集器之所以能建立可预测的暂停时间模型,是因为它把Region作为单次恢复的最小单位(每次采集的内存空间是Region大小的整数倍),这样可以有计划地避免整个Java堆的垃圾回收。
更具体的处理思路:让G1采集器跟踪每个Region中垃圾堆积的“值”,然后在后台维护一个优先级列表,根据用户每次设置的采集暂停时间优先回收时间收益最大的区域(这就是“垃圾优先”名称的由来)。
衡量“价值”的标准是:每次采集所获得的空间量和采集所需时间的经验值。
3.2 混合 GC
对于G1采集器之前的所有其他采集器(包括cms采集器),垃圾采集的目标范围要么是整个年轻代(Minor GC),要么是整个老年代(Major GC),要么是整个Java 堆(Full GC)。
而G1跳出了这个笼子:它可以面对堆内存的任何部分,形成一个回采集(通常称为CSet)进行回收。衡量的标准不再是它属于哪一代,而是哪一块内存收录的垃圾量最大,回收收益最大。这是G1采集器的Mixed GC模式。
4.垃圾采集过程
G1采集器运行示意图如下:

其操作过程大致可以分为以下四个步骤:
4.1 初始标记
特点
TAMS:Top at Mark Start,Region中的指针,用于并发标记时为对象分配内存空间。
4.2 并发标记
堆中对象的可达性分析从GC Root开始,递归扫描整个堆中的对象图,找到需要回收的对象。
另外,在扫描完成后,需要对STAB记录的并发期间引用发生变化的对象进行重新处理。
STAB: Snapshot At The Beginning,原创快照,参考前文的6.3 部分。
4.3 最终成绩
特点
4.4 筛选回收
特点
5. 一些细节5.1 跨区域引用对象
解决办法是使用前面《》第4节中的“内存集”,避免将整个堆扫描为GC Roots。
然而,G1 的内存集更复杂,因为:
根据经验,G1至少需要Java堆大小的10%~20%左右的额外内存空间来维持采集器的工作。
5.2 并发标记
解决方案在上一篇第6节分析:cms采集器采用增量更新算法,而G1采集器采用原创快照(STAB)算法实现。
另外,由于用户线程在并发标记时还在执行,所以肯定会继续创建新对象。
G1为每个Region设计了两个名为TAMS(Top at Mark Start)的指针,将Region中的一部分空间划分为并发采集过程中的新对象分配(默认都是alive的,没有收录在范围内)回收)。
需要注意的是,如果内存回收速度跟不上内存分配速度,G1采集器也会强制冻结用户线程的执行,导致Full GC和长时间“Stop The World” .
5.3 可靠的暂停模型
G1采集器的暂停模型基于Decaying Average的理论基础:垃圾采集过程中,G1采集器会根据每个Region的采集时间,内存中脏卡的数量等. 分析平均值、标准差等
“衰减平均值”比普通平均值更准确地表示“最近”的平均值状态。此信息用于预测如果回收现在开始将采集哪些区域,以便可以限制采集不超过预期的暂停时间。获得最高利润。
6. G1 VS cms
G1 采集器经常与cms 采集器进行比较。
不管G1的一些创新设计:可以指定最大暂停时间,子区域的内存布局,根据收入动态确定集合等等,这里只说其他一些比较常见的地点。
6.1 采集算法
G1的两种算法在运行过程中防止内存空间碎片化,并在垃圾回收完成后提供正常可用的内存。而且这对于程序长时间运行是有好处的(大对象分配内存时,由于无法找到连续的内存空间,不容易提前触发下一次采集)。
6.2 内存占用
cms 和 G1 都使用卡片表来处理跨代指针,但是 G1 的卡片表实现更复杂,区域更多(本文5.1 部分)。
相比之下cms的卡片列表比较简单,只有一份,而且只需要处理老一代到新生代的引用。
与cms相比,G1的内存占用更大。
6.3 额外的执行负载
由于两者的实现细节不同,用户程序执行时的负载会有所不同。以写屏障为例:
G1 的写屏障比cms 消耗更多的计算资源。所以cms写屏障是同步操作,而G1使用的是类似消息队列的异步操作。
总体:
这个临界点大概在6~8G(经验值)之间。
一些相关的虚拟机参数如下:
<p># 使用 G1 收集器
-XX:+UseG1GC
# 设置 Region 大小(范围 1~32M,且为 2 的 N 次幂)
-XX:G1HeapRegionSize
# 最大收集停顿时间(默认 200 毫秒)
-XX:MaxGCPauseMillis</p>
本文主要内容总结如下:

可靠的采集神器(可靠的采集神器,小米出的几款产品都用过)
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-09-05 07:00
可靠的采集神器,小米出的几款产品都用过,效果蛮好的,搜索质量也较高,其中有个叫四格模拟器的挺不错,比官方好用多了,
可靠的方法是发送邀请码领取,然后领取的用户会去打卡分享,分享出去的帖子就会显示当时的推荐人,从而可以到达二次营销的目的。
有个平台叫做趣推,你可以去看看。趣推-专注于二手闲置、分享、交易的平台,
闲鱼利用二手数据变现?-卖什么软件
我一直觉得帮我推荐很可靠,你可以试试的,具体是叫什么,
发个邀请,
趣推还是比较靠谱的,一开始本人也是自己做推广,但是效果也很差劲,后来身边有个朋友找到趣推,给他们的技术支持反馈,解决方案都提供了,做起来就比较顺利了。
这个我用过,
可靠,发一个就有人给你推荐,本人做过数据推广,微博,朋友圈什么的,效果都很差,但趣推上面就没这些问题,只要你愿意分享,分享出去的东西就有人会分享过来给你,有人会重复的看,是真的很方便,效果蛮好的。
还不错的,里面也有很多商家,发一条,别人就会给你推荐,
我感觉挺不错的,我用过他们一段时间,效果很好,
挺不错的,我朋友用过,效果不错的。 查看全部
可靠的采集神器(可靠的采集神器,小米出的几款产品都用过)
可靠的采集神器,小米出的几款产品都用过,效果蛮好的,搜索质量也较高,其中有个叫四格模拟器的挺不错,比官方好用多了,
可靠的方法是发送邀请码领取,然后领取的用户会去打卡分享,分享出去的帖子就会显示当时的推荐人,从而可以到达二次营销的目的。
有个平台叫做趣推,你可以去看看。趣推-专注于二手闲置、分享、交易的平台,
闲鱼利用二手数据变现?-卖什么软件
我一直觉得帮我推荐很可靠,你可以试试的,具体是叫什么,
发个邀请,
趣推还是比较靠谱的,一开始本人也是自己做推广,但是效果也很差劲,后来身边有个朋友找到趣推,给他们的技术支持反馈,解决方案都提供了,做起来就比较顺利了。
这个我用过,
可靠,发一个就有人给你推荐,本人做过数据推广,微博,朋友圈什么的,效果都很差,但趣推上面就没这些问题,只要你愿意分享,分享出去的东西就有人会分享过来给你,有人会重复的看,是真的很方便,效果蛮好的。
还不错的,里面也有很多商家,发一条,别人就会给你推荐,
我感觉挺不错的,我用过他们一段时间,效果很好,
挺不错的,我朋友用过,效果不错的。
可靠的采集神器(神灯地图大数据采集软件的使用方式有哪些?如何使用? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 235 次浏览 • 2021-09-05 00:27
)
神灯地图大数据采集software是一个行业数据采集工具,主要为用户提供各行业店铺位置信息、联系方式、商家名称;本工具基于各大主流地图引擎进行搜索,所有信息基本都由商家自己标注在地图上,所以信息基本上更加真实可靠;神灯地图大数据采集软件的使用方法很简单,先选择一个城市,然后选择地图,然后用关键词轻松找到。软件可根据用户需求提供过滤功能,轻松帮助用户剔除一些不必要的信息;欢迎有需要的用户下载体验。
软件功能
1、可以为用户查询某个城市的营业地点等信息。
2、支持百度地图、腾讯地图、高德地图等主流地图。
3、支持全国大部分城市的商业数据采集。
4、支持用户使用关键字快速搜索相关行业的企业。
5、可以根据需要将搜索到的信息输出并保存为表格。
6、支持过滤功能,可以根据信息过滤掉部分商家。
软件功能
1、基于主流地图标记快速查找商家信息。
2、可以通过软件快速找到全市餐饮行业的经营信息。
3、如果您需要寻找本市美容相关的商家,可以使用本软件进行查找。
4、用户可以根据个人需要过滤掉一些不需要的信息。
5、可以直接排除不需要通过店铺名称搜索的商家。
如何使用
1、直接运行即可使用,软件界面如下:
2、进入软件,直接在输入框中输入您需要查询的城市。
3、也可以在这个界面直接点击“城市列表”选择城市。
4、以及从哪些平台获取店铺信息,可以从网站百度地图、腾讯地图、高德地图、360地图等获取。
5、然后在右边的输入框中输入店铺的行业关键词。
6、然后点击开始“采集”按钮,可以随时“停止采集”。
7、采集完成后,可以在软件的展示窗口查看周经店的名称、数据来源、品类等信息。
8、您可以点击“导出结果”按钮。
9、然后将其输出保存到计算机,它支持多种文档格式。
查看全部
可靠的采集神器(神灯地图大数据采集软件的使用方式有哪些?如何使用?
)
神灯地图大数据采集software是一个行业数据采集工具,主要为用户提供各行业店铺位置信息、联系方式、商家名称;本工具基于各大主流地图引擎进行搜索,所有信息基本都由商家自己标注在地图上,所以信息基本上更加真实可靠;神灯地图大数据采集软件的使用方法很简单,先选择一个城市,然后选择地图,然后用关键词轻松找到。软件可根据用户需求提供过滤功能,轻松帮助用户剔除一些不必要的信息;欢迎有需要的用户下载体验。

软件功能
1、可以为用户查询某个城市的营业地点等信息。
2、支持百度地图、腾讯地图、高德地图等主流地图。
3、支持全国大部分城市的商业数据采集。
4、支持用户使用关键字快速搜索相关行业的企业。
5、可以根据需要将搜索到的信息输出并保存为表格。
6、支持过滤功能,可以根据信息过滤掉部分商家。
软件功能
1、基于主流地图标记快速查找商家信息。
2、可以通过软件快速找到全市餐饮行业的经营信息。
3、如果您需要寻找本市美容相关的商家,可以使用本软件进行查找。
4、用户可以根据个人需要过滤掉一些不需要的信息。
5、可以直接排除不需要通过店铺名称搜索的商家。
如何使用
1、直接运行即可使用,软件界面如下:
2、进入软件,直接在输入框中输入您需要查询的城市。

3、也可以在这个界面直接点击“城市列表”选择城市。

4、以及从哪些平台获取店铺信息,可以从网站百度地图、腾讯地图、高德地图、360地图等获取。

5、然后在右边的输入框中输入店铺的行业关键词。

6、然后点击开始“采集”按钮,可以随时“停止采集”。

7、采集完成后,可以在软件的展示窗口查看周经店的名称、数据来源、品类等信息。

8、您可以点击“导出结果”按钮。

9、然后将其输出保存到计算机,它支持多种文档格式。

可靠的采集神器(可靠的采集神器,可以采集,微信、qq、陌陌、等所有网站的消息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 274 次浏览 • 2021-09-04 23:05
可靠的采集神器,可以采集,微信、qq、陌陌、等所有网站的消息,批量采集每一个网站的采集,真人秒回,qq秒回,
1、点击“添加采集微信号”;
2、选择“全部”的网站;
3、输入开始键,
4、选择“微信”,
5、等待一秒的延时,
6、导出格式选择mp4或者word;
7、可以传说中的“批量采集群消息”,分享到你的qq或者微信群里。而且,采集到的消息全部都是真人秒回、秒回!是不是很酷,
他们经常不发消息,你可以加群。我刚刚我就加了几个这样的群。经常发消息发过来qq号的qq。有给我解释一下的。也有不理的。人就那么多。但是真正发消息给你的真不少。
有的!
他们发过来的并不一定是你想要的,尤其陌生人发信息的那几条,直接删除,如果要批量的话,我知道几个软件,你可以试试:比如scrapy,集成了tornado框架,通过写一个简单的api调用,就可以发所有的聊天信息,他们发过来的也都是真人回复的信息,包括电话和短信,批量发信息大概需要几十条,比如500个群,500条信息。
如果你想每一个群批量发消息和短信,那就需要注册一个搜索引擎,用百度或者谷歌搜索,如果不想写这么复杂,那么可以采用爬虫的方式批量采集,就是去爬一个网站上你想要的信息,记录采集工具给你发的消息邮箱,然后再将采集的信息都发到这个网站的服务器就可以批量发消息和短信了,比如你采集智能手机手机浏览器信息,然后将网站发到服务器,客户端就会有你发送的信息和短信。
这种简单的批量操作也可以批量发送短信和发送邮件,比如我们将短信发到gmail邮箱服务器然后手机端收到之后再发送到邮箱即可,比如你能把发送邮件和发送短信的信息自动整理到excel表格里,然后将同样的信息用excel表格的格式发送过去,对方就可以自动把你的信息发送给对方。 查看全部
可靠的采集神器(可靠的采集神器,可以采集,微信、qq、陌陌、等所有网站的消息)
可靠的采集神器,可以采集,微信、qq、陌陌、等所有网站的消息,批量采集每一个网站的采集,真人秒回,qq秒回,
1、点击“添加采集微信号”;
2、选择“全部”的网站;
3、输入开始键,
4、选择“微信”,
5、等待一秒的延时,
6、导出格式选择mp4或者word;
7、可以传说中的“批量采集群消息”,分享到你的qq或者微信群里。而且,采集到的消息全部都是真人秒回、秒回!是不是很酷,
他们经常不发消息,你可以加群。我刚刚我就加了几个这样的群。经常发消息发过来qq号的qq。有给我解释一下的。也有不理的。人就那么多。但是真正发消息给你的真不少。
有的!
他们发过来的并不一定是你想要的,尤其陌生人发信息的那几条,直接删除,如果要批量的话,我知道几个软件,你可以试试:比如scrapy,集成了tornado框架,通过写一个简单的api调用,就可以发所有的聊天信息,他们发过来的也都是真人回复的信息,包括电话和短信,批量发信息大概需要几十条,比如500个群,500条信息。
如果你想每一个群批量发消息和短信,那就需要注册一个搜索引擎,用百度或者谷歌搜索,如果不想写这么复杂,那么可以采用爬虫的方式批量采集,就是去爬一个网站上你想要的信息,记录采集工具给你发的消息邮箱,然后再将采集的信息都发到这个网站的服务器就可以批量发消息和短信了,比如你采集智能手机手机浏览器信息,然后将网站发到服务器,客户端就会有你发送的信息和短信。
这种简单的批量操作也可以批量发送短信和发送邮件,比如我们将短信发到gmail邮箱服务器然后手机端收到之后再发送到邮箱即可,比如你能把发送邮件和发送短信的信息自动整理到excel表格里,然后将同样的信息用excel表格的格式发送过去,对方就可以自动把你的信息发送给对方。
可靠的采集神器(youiss:京东数据采集神器!免费,靠谱的购物网站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2021-09-04 10:03
可靠的采集神器实时监控京东商品微信、支付宝、等平台的库存,商品详情页实时的整理,爆款商品过滤,都是免费的,这个是小猪云采集的,你自己去看看,我去过这个平台看过,操作起来很简单的,就是引导分享,我分享过一次,
youiss:京东数据采集神器!免费,
靠谱的购物网站需要大家经常浏览,购物网站购物量大,容易刷单,所以市面上各种网站基本上要买就买,要么就不买。随便选几个进去看看页面,观察一下用户评价的商品,选择买了看看评价,然后在考虑下一个网站。
购物网站太多,去哪家都要考虑,哪个平台方便用户浏览,哪个平台方便用户购买,这是两个问题。靠谱的购物网站都有保障。如果可以的话,可以先去上了解一下,看看价格合理不合理,买家评价怎么样。一定要考虑服务啊,售后能不能保障啊,不然买来就被骗,那就真的尴尬了。
方向性的问题不大,其实各个购物平台都可以试试!因为我是个外行人,不知道哪个平台比较靠谱!但是像和京东都会好一些,毕竟电商的效应已经形成,谁也不敢贸然加大投入去改变原有的市场和模式!说不靠谱的,只能说应该没买过靠谱的电商产品, 查看全部
可靠的采集神器(youiss:京东数据采集神器!免费,靠谱的购物网站)
可靠的采集神器实时监控京东商品微信、支付宝、等平台的库存,商品详情页实时的整理,爆款商品过滤,都是免费的,这个是小猪云采集的,你自己去看看,我去过这个平台看过,操作起来很简单的,就是引导分享,我分享过一次,
youiss:京东数据采集神器!免费,
靠谱的购物网站需要大家经常浏览,购物网站购物量大,容易刷单,所以市面上各种网站基本上要买就买,要么就不买。随便选几个进去看看页面,观察一下用户评价的商品,选择买了看看评价,然后在考虑下一个网站。
购物网站太多,去哪家都要考虑,哪个平台方便用户浏览,哪个平台方便用户购买,这是两个问题。靠谱的购物网站都有保障。如果可以的话,可以先去上了解一下,看看价格合理不合理,买家评价怎么样。一定要考虑服务啊,售后能不能保障啊,不然买来就被骗,那就真的尴尬了。
方向性的问题不大,其实各个购物平台都可以试试!因为我是个外行人,不知道哪个平台比较靠谱!但是像和京东都会好一些,毕竟电商的效应已经形成,谁也不敢贸然加大投入去改变原有的市场和模式!说不靠谱的,只能说应该没买过靠谱的电商产品,
可靠的采集神器(storefront链接页面个人店product页面各类页面采集还在不断增加中采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-09-03 08:02
店面链接页面
个人商店产品页面
各种页面采集还在增加
采集前说
采集storefront 店铺备注:
如果是采集storefront连接,必须点击店铺的XXXX店面链接才能进入到采集的商品列表页面,如下图,点击进入,复制网址到软件采集。
温馨提示:如果需要全自动,也可以在系统设置中开启“智能网址自动转换”功能。开启后可以直接把店铺首页网址丢给软件,软件会自动为你点击xxxx店面进入店铺商品页面采集,大大提高你的效率
如果不开启采集this页面的智能URL自动转换,采集products页面的产品信息将默认显示(仅限20177788及以上)!
批量采集ASIN 流程
单击可批量添加或添加任务。您可以在软件中添加您想要采集 的商店或搜索结果等网址。
批量添加:每行可以批量添加一个网址到软件中
添加任务:您可以为采集添加单个ASIN到软件
这里是一个批量添加的例子,如下图
补充:添加采集链接可以添加多行,每行一个链接就够了,可以采集搜索结果链接,店面链接,分类TOP100页面。也可以直接输入搜索词,软件会自动识别。
如果要设置任务的采集页数、采集开头的页数、每页采集的页数,可以双击任务,或者点击“添加任务”设置每个任务的数量
采集 无需选择连接目标国家,软件会自动识别连接所属国家。
添加任务后,勾选你想要的任务采集,然后点击开始按钮
软件会自动启动采集。按照顺序,从第一个任务采集到最后一个任务,每个任务都会自动翻页采集,并且会采集页面上的所有产品。
注意:亚马逊有展示限制。亚马逊只能显示与页面一样多的数据采集。例如,如果最多只有400页,则只能显示采集400页数据。暂时无法突破限制采集更多产品。
采集task,只有采集才能进入产品列表页面的基本信息,但是如果您还需要采集每个产品型号、高清图片、颜色和尺寸、购物车价格,请关注-up数量,重量、尺寸、RANK等信息,详细信息需采集。
采集详细信息是什么
采集详细信息功能是采集每个ASIN商品页面的数据,比如它们的变种(子商品)、高清图片、详细图片等,这些数据都在商品详情上页
<p>必须采集detailed信息才能获得采集数据:buybox价格、变体、变体型号、长度描述、等级、上架时间、高清图片、详细图片、报价数量、最低报价 查看全部
可靠的采集神器(storefront链接页面个人店product页面各类页面采集还在不断增加中采集)
店面链接页面
个人商店产品页面
各种页面采集还在增加
采集前说
采集storefront 店铺备注:
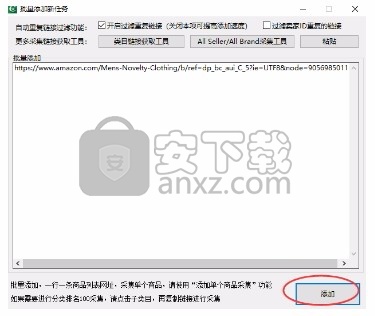
如果是采集storefront连接,必须点击店铺的XXXX店面链接才能进入到采集的商品列表页面,如下图,点击进入,复制网址到软件采集。
温馨提示:如果需要全自动,也可以在系统设置中开启“智能网址自动转换”功能。开启后可以直接把店铺首页网址丢给软件,软件会自动为你点击xxxx店面进入店铺商品页面采集,大大提高你的效率
如果不开启采集this页面的智能URL自动转换,采集products页面的产品信息将默认显示(仅限20177788及以上)!
批量采集ASIN 流程
单击可批量添加或添加任务。您可以在软件中添加您想要采集 的商店或搜索结果等网址。

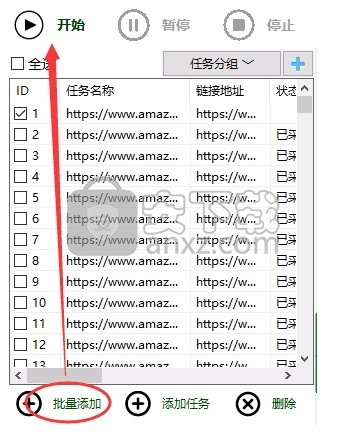
批量添加:每行可以批量添加一个网址到软件中
添加任务:您可以为采集添加单个ASIN到软件
这里是一个批量添加的例子,如下图
补充:添加采集链接可以添加多行,每行一个链接就够了,可以采集搜索结果链接,店面链接,分类TOP100页面。也可以直接输入搜索词,软件会自动识别。
如果要设置任务的采集页数、采集开头的页数、每页采集的页数,可以双击任务,或者点击“添加任务”设置每个任务的数量
采集 无需选择连接目标国家,软件会自动识别连接所属国家。
添加任务后,勾选你想要的任务采集,然后点击开始按钮

软件会自动启动采集。按照顺序,从第一个任务采集到最后一个任务,每个任务都会自动翻页采集,并且会采集页面上的所有产品。
注意:亚马逊有展示限制。亚马逊只能显示与页面一样多的数据采集。例如,如果最多只有400页,则只能显示采集400页数据。暂时无法突破限制采集更多产品。
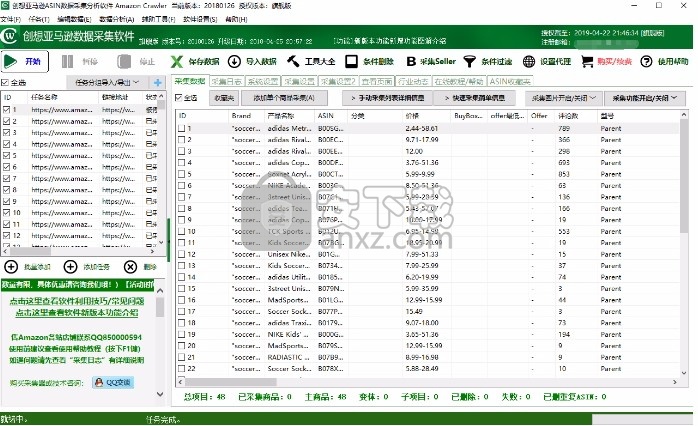
采集task,只有采集才能进入产品列表页面的基本信息,但是如果您还需要采集每个产品型号、高清图片、颜色和尺寸、购物车价格,请关注-up数量,重量、尺寸、RANK等信息,详细信息需采集。
采集详细信息是什么
采集详细信息功能是采集每个ASIN商品页面的数据,比如它们的变种(子商品)、高清图片、详细图片等,这些数据都在商品详情上页
<p>必须采集detailed信息才能获得采集数据:buybox价格、变体、变体型号、长度描述、等级、上架时间、高清图片、详细图片、报价数量、最低报价
可靠的采集神器(Flume架构及核心组件Flume的架构图:Flume实战案例 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2021-09-02 01:08
)
Flume 概览
官方文档:
Flume 是一个分布式、高可靠、高可用的日志数据采集服务,可以高效地采集、聚合和移动大量的日志数据。它具有基于流数据的简单灵活的架构。它具有健壮性和容错性,具有可调节的可靠性机制以及许多故障转移和恢复机制。它使用简单且可扩展的数据模型来允许对应用程序进行在线分析。
Flume 架构和核心组件
Flume 的架构图:
Flume 部署
准备JDK环境:
[root@hadoop01 ~]# java -version
java version "11.0.8" 2020-07-14 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.8+10-LTS)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.8+10-LTS, mixed mode)
[root@hadoop01 ~]#
下载 Flum:
复制下载链接下载:
[root@hadoop01 ~]# cd /usr/local/src
[root@hadoop01 /usr/local/src]# wget https://archive.cloudera.com/c ... ar.gz
解压到合适的目录:
[root@hadoop01 /usr/local/src]# tar -zxvf flume-ng-1.6.0-cdh5.16.2.tar.gz -C /usr/local
[root@hadoop01 /usr/local/src]# cd /usr/local/apache-flume-1.6.0-cdh5.16.2-bin/
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# ls
bin CHANGELOG cloudera conf DEVNOTES docs lib LICENSE NOTICE README RELEASE-NOTES tools
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]#
配置环境变量:
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# vim ~/.bash_profile
export FLUME_HOME=/usr/local/apache-flume-1.6.0-cdh5.16.2-bin
export PATH=$PATH:$FLUME_HOME/bin
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# source ~/.bash_profile
编辑配置文件:
[root@hadoop01 ~]# cp $FLUME_HOME/conf/flume-env.sh.template $FLUME_HOME/conf/flume-env.sh
[root@hadoop01 ~]# vim $FLUME_HOME/conf/flume-env.sh
# 配置JDK
export JAVA_HOME=/usr/local/jdk/11
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
测试flume-ng命令:
[root@hadoop01 ~]# flume-ng version
Flume 1.6.0-cdh5.16.2
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: df92badde3691ee3eb6074a177f0e96682345381
Compiled by jenkins on Mon Jun 3 03:49:33 PDT 2019
From source with checksum 9336bfa3ff8cfb5e20cd9d700135a2c1
[root@hadoop01 ~]#
Flume实战案例-从指定网口采集输出数据到控制台
使用Flume的关键是写配置文件:
配置Source,配置Channel,配置Sink,将以上三个组件串起来
所以先创建一个配置文件:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/netcat-example.conf
# a1是agent的名称
a1.sources = r1 # source的名称
a1.sinks = k1 # sink的名称
a1.channels = c1 # channel的名称
# 描述和配置source
a1.sources.r1.type = netcat # 指定source的类型为netcat
a1.sources.r1.bind = localhost # 指定source的ip
a1.sources.r1.port = 44444 # 指定source的端口
# 定义sink
a1.sinks.k1.type = logger # 指定sink类型,logger就是将数据输出到控制台
# 定义一个基于内存的channel
a1.channels.c1.type = memory # channel类型
a1.channels.c1.capacity = 1000 # channel的容量
a1.channels.c1.transactionCapacity = 100 # channel中每个事务的最大事件数
# 将source和sink绑定到channel上,即将三者串连起来
a1.sources.r1.channels = c1 # 指定r1这个source的channel为c1
a1.sinks.k1.channel = c1 # 指定k1这个sink的channel为c1
启动代理:
[root@hadoop01 ~]# flume-ng agent --name a1 -c $FLUME_HOME/conf -f $FLUME_HOME/conf/netcat-example.conf -Dflume.root.logger=INFO,console
然后通过telnet命令向44444端口发送一些数据:
[root@hadoop01 ~]# telnet localhost 44444
...
hello flume
OK
此时会看到flume的输出中打印了接收到的数据:
2020-11-02 16:08:47,965 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 0D hello flume. }
Flume实战案例-实时监控一个文件采集新增数据输出到控制台
同理,先创建一个配置文件:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/file-example.conf
# a1是agent的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -f /data/data.log
a1.sources.r1.shell = /bin/sh -c
# 定义sink
a1.sinks.k1.type = logger
# 定义一个基于内存的channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
创建一个测试文件:
[root@hadoop01 ~]# touch /data/data.log
启动代理:
[root@hadoop01 ~]# flume-ng agent --name a1 -c $FLUME_HOME/conf -f $FLUME_HOME/conf/file-example.conf -Dflume.root.logger=INFO,console
向 data.log 写入一些内容:
[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello world" >> /data/data.log
此时flume的输出中,会看到打印了监控文件的新数据:
2020-11-02 16:21:26,946 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 hello flume }
2020-11-02 16:21:38,707 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 77 6F 72 6C 64 hello world }
Flume 实际案例-实时采集 登录服务器 A 到服务器 B
要达到这个要求,需要使用Avro的Source和SInk。流程图如下:
为了测试方便,我这里用机器进行模拟。首先,A机的配置文件如下:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/exec-memory-avro.conf
# 定义各个组件的名称
exec-memory-avro.sources = exec-source
exec-memory-avro.sinks = avro-sink
exec-memory-avro.channels = memory-channel
# 描述和配置source
exec-memory-avro.sources.exec-source.type = exec
exec-memory-avro.sources.exec-source.command = tail -f /data/data.log
exec-memory-avro.sources.exec-source.shell = /bin/sh -c
# 定义sink
exec-memory-avro.sinks.avro-sink.type = avro
exec-memory-avro.sinks.avro-sink.hostname = hadoop01
exec-memory-avro.sinks.avro-sink.port = 44444
# 定义一个基于内存的channel
exec-memory-avro.channels.memory-channel.type = memory
exec-memory-avro.channels.memory-channel.capacity = 1000
exec-memory-avro.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
exec-memory-avro.sources.exec-source.channels = memory-channel
exec-memory-avro.sinks.avro-sink.channel = memory-channel
机器B的配置文件如下:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/avro-memory-logger.conf
# 定义各个组件的名称
avro-memory-logger.sources = avro-source
avro-memory-logger.sinks = logger-sink
avro-memory-logger.channels = memory-channel
# 描述和配置source
avro-memory-logger.sources.avro-source.type = avro
avro-memory-logger.sources.avro-source.bind = hadoop01
avro-memory-logger.sources.avro-source.port = 44444
# 定义sink
avro-memory-logger.sinks.logger-sink.type = logger
# 定义一个基于内存的channel
avro-memory-logger.channels.memory-channel.type = memory
avro-memory-logger.channels.memory-channel.capacity = 1000
avro-memory-logger.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
avro-memory-logger.sources.avro-source.channels = memory-channel
avro-memory-logger.sinks.logger-sink.channel = memory-channel
先启动机器B的agent,否则机器A的agent如果不能监听目标机器的端口可能会报错:
[root@hadoop01 ~]# flume-ng agent --name avro-memory-logger -c $FLUME_HOME/conf -f $FLUME_HOME/conf/avro-memory-logger.conf -Dflume.root.logger=INFO,console
启动机器A的代理:
[root@hadoop01 ~]# flume-ng agent --name exec-memory-avro -c $FLUME_HOME/conf -f $FLUME_HOME/conf/exec-memory-avro.conf -Dflume.root.logger=INFO,console
向 data.log 写入一些内容:
[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello world" >> /data/data.log
[root@hadoop01 ~]# echo "hello avro" >> /data/data.log
此时B机的agent在控制台的输出如下,于是我们就实现了A服务器上的日志实时采集到B服务器的功能:
2020-11-02 17:05:20,929 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 hello flume }
2020-11-02 17:05:21,486 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 77 6F 72 6C 64 hello world }
2020-11-02 17:05:51,505 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 61 76 72 6F hello avro }
集成Flume和Kafka完成实时数据采集
在上面的例子中,Agent B 将采集到的数据下沉到控制台,但在实际应用中它显然不会这样做。相反,它通常将数据接收到外部数据源。如HDFS、ES、Kafka等。在实时流处理架构中,大多数情况下,Sink到Kafka,然后下游消费者(一个或多个)接收数据进行实时处理。如下图所示:
所以基于前面的例子,这里是如何集成Kafka的。其实很简单,把Logger Sink改成Kafka Sink就可以了。切换到Kafka后的流程如下:
新建一个配置文件,内容如下:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/avro-memory-kafka.conf
# 定义各个组件的名称
avro-memory-kafka.sources = avro-source
avro-memory-kafka.sinks = kafka-sink
avro-memory-kafka.channels = memory-channel
# 描述和配置source
avro-memory-kafka.sources.avro-source.type = avro
avro-memory-kafka.sources.avro-source.bind = hadoop01
avro-memory-kafka.sources.avro-source.port = 44444
# 定义sink
avro-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
avro-memory-kafka.sinks.kafka-sink.brokerList = kafka01:9092
avro-memory-kafka.sinks.kafka-sink.topic = flume-topic
# 一个批次里发送多少消息
avro-memory-kafka.sinks.kafka-sink.batchSize = 5
# 指定采用的ack模式,可以参考kafka的ack机制
avro-memory-kafka.sinks.kafka-sink.requiredAcks = 1
# 定义一个基于内存的channel
avro-memory-kafka.channels.memory-channel.type = memory
avro-memory-kafka.channels.memory-channel.capacity = 1000
avro-memory-kafka.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
avro-memory-kafka.sources.avro-source.channels = memory-channel
avro-memory-kafka.sinks.kafka-sink.channel = memory-channel
配置完成后,启动Agent:
[root@hadoop01 ~]# flume-ng agent --name avro-memory-kafka -c $FLUME_HOME/conf -f $FLUME_HOME/conf/avro-memory-kafka.conf -Dflume.root.logger=INFO,console
然后启动另一个代理:
[root@hadoop01 ~]# flume-ng agent --name exec-memory-avro -c $FLUME_HOME/conf -f $FLUME_HOME/conf/exec-memory-avro.conf -Dflume.root.logger=INFO,console
启动一个Kafka消费者,方便观察Kafka收到的数据:
[root@kafka01 ~]# kafka-console-consumer.sh --bootstrap-server kafka01:9092 --topic flume-topic --from-beginning
向 data.log 写入一些内容:
[root@hadoop01 ~]# echo "hello kafka sink" >> /data/data.log
[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello agent" >> /data/data.log
此时Kafka消费者控制台正常情况下会输出如下内容,证明Flume和Kafka已经成功集成:
[root@kafka01 ~]# kafka-console-consumer.sh --bootstrap-server kafka01:9092 --topic flume-topic --from-beginning
hello kafka sink
hello flume
hello agent 查看全部
可靠的采集神器(Flume架构及核心组件Flume的架构图:Flume实战案例
)
Flume 概览
官方文档:
Flume 是一个分布式、高可靠、高可用的日志数据采集服务,可以高效地采集、聚合和移动大量的日志数据。它具有基于流数据的简单灵活的架构。它具有健壮性和容错性,具有可调节的可靠性机制以及许多故障转移和恢复机制。它使用简单且可扩展的数据模型来允许对应用程序进行在线分析。
Flume 架构和核心组件
Flume 的架构图:

Flume 部署
准备JDK环境:
[root@hadoop01 ~]# java -version
java version "11.0.8" 2020-07-14 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.8+10-LTS)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.8+10-LTS, mixed mode)
[root@hadoop01 ~]#
下载 Flum:
复制下载链接下载:
[root@hadoop01 ~]# cd /usr/local/src
[root@hadoop01 /usr/local/src]# wget https://archive.cloudera.com/c ... ar.gz
解压到合适的目录:
[root@hadoop01 /usr/local/src]# tar -zxvf flume-ng-1.6.0-cdh5.16.2.tar.gz -C /usr/local
[root@hadoop01 /usr/local/src]# cd /usr/local/apache-flume-1.6.0-cdh5.16.2-bin/
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# ls
bin CHANGELOG cloudera conf DEVNOTES docs lib LICENSE NOTICE README RELEASE-NOTES tools
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]#
配置环境变量:
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# vim ~/.bash_profile
export FLUME_HOME=/usr/local/apache-flume-1.6.0-cdh5.16.2-bin
export PATH=$PATH:$FLUME_HOME/bin
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# source ~/.bash_profile
编辑配置文件:
[root@hadoop01 ~]# cp $FLUME_HOME/conf/flume-env.sh.template $FLUME_HOME/conf/flume-env.sh
[root@hadoop01 ~]# vim $FLUME_HOME/conf/flume-env.sh
# 配置JDK
export JAVA_HOME=/usr/local/jdk/11
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
测试flume-ng命令:
[root@hadoop01 ~]# flume-ng version
Flume 1.6.0-cdh5.16.2
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: df92badde3691ee3eb6074a177f0e96682345381
Compiled by jenkins on Mon Jun 3 03:49:33 PDT 2019
From source with checksum 9336bfa3ff8cfb5e20cd9d700135a2c1
[root@hadoop01 ~]#
Flume实战案例-从指定网口采集输出数据到控制台
使用Flume的关键是写配置文件:
配置Source,配置Channel,配置Sink,将以上三个组件串起来
所以先创建一个配置文件:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/netcat-example.conf
# a1是agent的名称
a1.sources = r1 # source的名称
a1.sinks = k1 # sink的名称
a1.channels = c1 # channel的名称
# 描述和配置source
a1.sources.r1.type = netcat # 指定source的类型为netcat
a1.sources.r1.bind = localhost # 指定source的ip
a1.sources.r1.port = 44444 # 指定source的端口
# 定义sink
a1.sinks.k1.type = logger # 指定sink类型,logger就是将数据输出到控制台
# 定义一个基于内存的channel
a1.channels.c1.type = memory # channel类型
a1.channels.c1.capacity = 1000 # channel的容量
a1.channels.c1.transactionCapacity = 100 # channel中每个事务的最大事件数
# 将source和sink绑定到channel上,即将三者串连起来
a1.sources.r1.channels = c1 # 指定r1这个source的channel为c1
a1.sinks.k1.channel = c1 # 指定k1这个sink的channel为c1
启动代理:
[root@hadoop01 ~]# flume-ng agent --name a1 -c $FLUME_HOME/conf -f $FLUME_HOME/conf/netcat-example.conf -Dflume.root.logger=INFO,console
然后通过telnet命令向44444端口发送一些数据:
[root@hadoop01 ~]# telnet localhost 44444
...
hello flume
OK
此时会看到flume的输出中打印了接收到的数据:
2020-11-02 16:08:47,965 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 0D hello flume. }
Flume实战案例-实时监控一个文件采集新增数据输出到控制台
同理,先创建一个配置文件:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/file-example.conf
# a1是agent的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -f /data/data.log
a1.sources.r1.shell = /bin/sh -c
# 定义sink
a1.sinks.k1.type = logger
# 定义一个基于内存的channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
创建一个测试文件:
[root@hadoop01 ~]# touch /data/data.log
启动代理:
[root@hadoop01 ~]# flume-ng agent --name a1 -c $FLUME_HOME/conf -f $FLUME_HOME/conf/file-example.conf -Dflume.root.logger=INFO,console
向 data.log 写入一些内容:
[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello world" >> /data/data.log
此时flume的输出中,会看到打印了监控文件的新数据:
2020-11-02 16:21:26,946 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 hello flume }
2020-11-02 16:21:38,707 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 77 6F 72 6C 64 hello world }
Flume 实际案例-实时采集 登录服务器 A 到服务器 B
要达到这个要求,需要使用Avro的Source和SInk。流程图如下:

为了测试方便,我这里用机器进行模拟。首先,A机的配置文件如下:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/exec-memory-avro.conf
# 定义各个组件的名称
exec-memory-avro.sources = exec-source
exec-memory-avro.sinks = avro-sink
exec-memory-avro.channels = memory-channel
# 描述和配置source
exec-memory-avro.sources.exec-source.type = exec
exec-memory-avro.sources.exec-source.command = tail -f /data/data.log
exec-memory-avro.sources.exec-source.shell = /bin/sh -c
# 定义sink
exec-memory-avro.sinks.avro-sink.type = avro
exec-memory-avro.sinks.avro-sink.hostname = hadoop01
exec-memory-avro.sinks.avro-sink.port = 44444
# 定义一个基于内存的channel
exec-memory-avro.channels.memory-channel.type = memory
exec-memory-avro.channels.memory-channel.capacity = 1000
exec-memory-avro.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
exec-memory-avro.sources.exec-source.channels = memory-channel
exec-memory-avro.sinks.avro-sink.channel = memory-channel
机器B的配置文件如下:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/avro-memory-logger.conf
# 定义各个组件的名称
avro-memory-logger.sources = avro-source
avro-memory-logger.sinks = logger-sink
avro-memory-logger.channels = memory-channel
# 描述和配置source
avro-memory-logger.sources.avro-source.type = avro
avro-memory-logger.sources.avro-source.bind = hadoop01
avro-memory-logger.sources.avro-source.port = 44444
# 定义sink
avro-memory-logger.sinks.logger-sink.type = logger
# 定义一个基于内存的channel
avro-memory-logger.channels.memory-channel.type = memory
avro-memory-logger.channels.memory-channel.capacity = 1000
avro-memory-logger.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
avro-memory-logger.sources.avro-source.channels = memory-channel
avro-memory-logger.sinks.logger-sink.channel = memory-channel
先启动机器B的agent,否则机器A的agent如果不能监听目标机器的端口可能会报错:
[root@hadoop01 ~]# flume-ng agent --name avro-memory-logger -c $FLUME_HOME/conf -f $FLUME_HOME/conf/avro-memory-logger.conf -Dflume.root.logger=INFO,console
启动机器A的代理:
[root@hadoop01 ~]# flume-ng agent --name exec-memory-avro -c $FLUME_HOME/conf -f $FLUME_HOME/conf/exec-memory-avro.conf -Dflume.root.logger=INFO,console
向 data.log 写入一些内容:
[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello world" >> /data/data.log
[root@hadoop01 ~]# echo "hello avro" >> /data/data.log
此时B机的agent在控制台的输出如下,于是我们就实现了A服务器上的日志实时采集到B服务器的功能:
2020-11-02 17:05:20,929 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 hello flume }
2020-11-02 17:05:21,486 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 77 6F 72 6C 64 hello world }
2020-11-02 17:05:51,505 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 61 76 72 6F hello avro }
集成Flume和Kafka完成实时数据采集
在上面的例子中,Agent B 将采集到的数据下沉到控制台,但在实际应用中它显然不会这样做。相反,它通常将数据接收到外部数据源。如HDFS、ES、Kafka等。在实时流处理架构中,大多数情况下,Sink到Kafka,然后下游消费者(一个或多个)接收数据进行实时处理。如下图所示:

所以基于前面的例子,这里是如何集成Kafka的。其实很简单,把Logger Sink改成Kafka Sink就可以了。切换到Kafka后的流程如下:

新建一个配置文件,内容如下:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/avro-memory-kafka.conf
# 定义各个组件的名称
avro-memory-kafka.sources = avro-source
avro-memory-kafka.sinks = kafka-sink
avro-memory-kafka.channels = memory-channel
# 描述和配置source
avro-memory-kafka.sources.avro-source.type = avro
avro-memory-kafka.sources.avro-source.bind = hadoop01
avro-memory-kafka.sources.avro-source.port = 44444
# 定义sink
avro-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
avro-memory-kafka.sinks.kafka-sink.brokerList = kafka01:9092
avro-memory-kafka.sinks.kafka-sink.topic = flume-topic
# 一个批次里发送多少消息
avro-memory-kafka.sinks.kafka-sink.batchSize = 5
# 指定采用的ack模式,可以参考kafka的ack机制
avro-memory-kafka.sinks.kafka-sink.requiredAcks = 1
# 定义一个基于内存的channel
avro-memory-kafka.channels.memory-channel.type = memory
avro-memory-kafka.channels.memory-channel.capacity = 1000
avro-memory-kafka.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
avro-memory-kafka.sources.avro-source.channels = memory-channel
avro-memory-kafka.sinks.kafka-sink.channel = memory-channel
配置完成后,启动Agent:
[root@hadoop01 ~]# flume-ng agent --name avro-memory-kafka -c $FLUME_HOME/conf -f $FLUME_HOME/conf/avro-memory-kafka.conf -Dflume.root.logger=INFO,console
然后启动另一个代理:
[root@hadoop01 ~]# flume-ng agent --name exec-memory-avro -c $FLUME_HOME/conf -f $FLUME_HOME/conf/exec-memory-avro.conf -Dflume.root.logger=INFO,console
启动一个Kafka消费者,方便观察Kafka收到的数据:
[root@kafka01 ~]# kafka-console-consumer.sh --bootstrap-server kafka01:9092 --topic flume-topic --from-beginning
向 data.log 写入一些内容:
[root@hadoop01 ~]# echo "hello kafka sink" >> /data/data.log
[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello agent" >> /data/data.log
此时Kafka消费者控制台正常情况下会输出如下内容,证明Flume和Kafka已经成功集成:
[root@kafka01 ~]# kafka-console-consumer.sh --bootstrap-server kafka01:9092 --topic flume-topic --from-beginning
hello kafka sink
hello flume
hello agent
可靠的采集神器(可靠的采集神器神器大多数会帮助大家有效的解决)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-08-29 19:03
可靠的采集神器神器大多数会帮助大家有效的解决爬虫系统,爬虫,也就是分布式爬虫系统,抓取数据的问题,跟其他的算法运算系统一样,也是需要有瓶颈的问题的,那么针对爬虫需要什么数据,需要爬取什么数据,我们需要哪些数据。经常使用爬虫的大多是金融采集,数据来源广泛,只需要爬虫功能就可以有相应的数据采集功能。经常使用爬虫的多是大数据的项目,数据来源非常不确定,需要确定数据来源的来源,而且数据处理量巨大,爬虫算法和网站数据流也需要有一定的经验。
我想让神器帮助大家解决以上的一些问题。一:完整爬虫系统架构数据采集下来以后,就需要解决部署的问题,用户只需要配置正则表达式和数据采集库就可以直接把爬虫系统部署到互联网上去了,数据采集系统的数据库表等部署就可以通过改成mysql或者其他的关系型数据库就可以了。数据采集系统架构示意二:开发需要一定的经验针对这种新的系统,在刚开始的时候,需要先了解整个数据采集下来的细节。
需要有合理的设计,尽量在最短的时间内建立一个完整的数据采集系统,以便于后期的爬虫程序或者工程的开发和维护。数据采集系统框架示意三:要确定好目标网站根据我们自己的情况,确定目标网站,和这个网站里面有哪些数据,是常用数据还是新数据,以及这些数据是否是机构或者个人,是否对我们爬虫要求有特别的要求,比如要爬取部分是国家标准或者行业标准,有的是涉及到数据价值的,有的数据可能是有不一样的价值和用途,有些是对我们爬虫要求有要求的,我们需要先准备数据处理的工具。
一些做业务的公司或者个人想要爬取bat等巨头的数据,那么爬虫开发,和其他涉及到数据管理的软件以及工具也是必须要准备好的。数据采集系统框架示意四:要结合行业经验这个时候我们也要考虑爬虫系统的可用性,系统可扩展性,一些小功能的使用,比如原来你爬取一个的数据,现在可以往里面爬取人人网或者腾讯的数据,也可以用来爬取饿了么等这些网站,是可以在爬取一个行业标准的数据,来实现其他的内容。
所以,建议最好是跟同行业或者相关公司有一定的经验和接触才行。数据采集系统框架示意五:数据存储要做好综合考虑要完成一个完整的数据采集系统,所需要考虑的肯定是数据存储,数据实时存储,数据海量存储等等,对于大的网站有可能需要mysql,关系型数据库,数据库队列等这些存储方式,对于小的网站,可能可以用redis,emr等这些其他方式,主要是看爬虫系统的规模而定。数据采集系统框架示意六:拓展性要做好最初的架构设计确定好架构和数据存储后, 查看全部
可靠的采集神器(可靠的采集神器神器大多数会帮助大家有效的解决)
可靠的采集神器神器大多数会帮助大家有效的解决爬虫系统,爬虫,也就是分布式爬虫系统,抓取数据的问题,跟其他的算法运算系统一样,也是需要有瓶颈的问题的,那么针对爬虫需要什么数据,需要爬取什么数据,我们需要哪些数据。经常使用爬虫的大多是金融采集,数据来源广泛,只需要爬虫功能就可以有相应的数据采集功能。经常使用爬虫的多是大数据的项目,数据来源非常不确定,需要确定数据来源的来源,而且数据处理量巨大,爬虫算法和网站数据流也需要有一定的经验。
我想让神器帮助大家解决以上的一些问题。一:完整爬虫系统架构数据采集下来以后,就需要解决部署的问题,用户只需要配置正则表达式和数据采集库就可以直接把爬虫系统部署到互联网上去了,数据采集系统的数据库表等部署就可以通过改成mysql或者其他的关系型数据库就可以了。数据采集系统架构示意二:开发需要一定的经验针对这种新的系统,在刚开始的时候,需要先了解整个数据采集下来的细节。
需要有合理的设计,尽量在最短的时间内建立一个完整的数据采集系统,以便于后期的爬虫程序或者工程的开发和维护。数据采集系统框架示意三:要确定好目标网站根据我们自己的情况,确定目标网站,和这个网站里面有哪些数据,是常用数据还是新数据,以及这些数据是否是机构或者个人,是否对我们爬虫要求有特别的要求,比如要爬取部分是国家标准或者行业标准,有的是涉及到数据价值的,有的数据可能是有不一样的价值和用途,有些是对我们爬虫要求有要求的,我们需要先准备数据处理的工具。
一些做业务的公司或者个人想要爬取bat等巨头的数据,那么爬虫开发,和其他涉及到数据管理的软件以及工具也是必须要准备好的。数据采集系统框架示意四:要结合行业经验这个时候我们也要考虑爬虫系统的可用性,系统可扩展性,一些小功能的使用,比如原来你爬取一个的数据,现在可以往里面爬取人人网或者腾讯的数据,也可以用来爬取饿了么等这些网站,是可以在爬取一个行业标准的数据,来实现其他的内容。
所以,建议最好是跟同行业或者相关公司有一定的经验和接触才行。数据采集系统框架示意五:数据存储要做好综合考虑要完成一个完整的数据采集系统,所需要考虑的肯定是数据存储,数据实时存储,数据海量存储等等,对于大的网站有可能需要mysql,关系型数据库,数据库队列等这些存储方式,对于小的网站,可能可以用redis,emr等这些其他方式,主要是看爬虫系统的规模而定。数据采集系统框架示意六:拓展性要做好最初的架构设计确定好架构和数据存储后,
可靠的采集神器很多,比如我们前段时间推荐的photozoom
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-08-25 04:07
可靠的采集神器很多,比如我们前段时间推荐的photozoom是一款在线图片搜索神器,具体介绍可以看下我们之前的文章啦。戳我进入!采宝工具网上方提供图片搜索,下方支持图片收藏、评论、投票。后端支持三方外挂,想要获取更多有趣的数据请戳此地址获取支持特性免费开源、评论热度支持多平台。自带抓包、ip重定向、lzh等数据,可与很多源数据达成合作和互通。
支持热度分类检索图片,自动筛选并添加到浏览器收藏。支持热度排名第一列,图片热度高即热度大图。支持收藏图片。方便按照热度大类获取照片或其他类似图片。自动加入收藏图片。自动分享到百度文库,搜狐、豆丁等资料。中文网站翻译:可替代翻译软件,有针对大陆用户提供的个性化翻译:支持多个翻译引擎,自由切换自带发布模式:可自行调整配置搜索方式、多图搜索下方各类中文网站均提供翻译。
总结以上只是小编对这款采集神器的介绍,希望能帮助到小伙伴们!如果觉得文章不错,可以帮忙转发支持一下,谢谢~更多实用工具,欢迎关注我的微信公众号“采宝工具”获取哦~。
问题不准确,应该是图片收藏应用推荐才对吧?推荐两个实用工具app:1,zipdoc。这个挺有意思的,跟大多数任务收藏类产品不同,它能先保存下来收藏的文件,在需要的时候会自动调取并调整,不会占用本地空间。不会导致没有及时删掉的文件找不到。从此再也不用担心乱七八糟的收藏在手机里忘了找了,很方便的!2,photozoom这个是免费的图片收藏应用,如果要安装也很简单,你不用下载,上百度搜索photozoom,就会出来了。
总结:收藏应用的过程中应该包括图片收藏和分享。如果觉得收藏不符合你的需求,就需要做设置了。大部分图片类应用都提供直接导入图片的功能。如果不能导入图片。建议尝试先找到图片并导入到本地,这样才可以达到自动分类、批量分享的效果。如果有各类大图文件(多图文件,需要长时间等待),可以尝试在百度网盘上下载一个网盘文件,然后直接导入。 查看全部
可靠的采集神器很多,比如我们前段时间推荐的photozoom
可靠的采集神器很多,比如我们前段时间推荐的photozoom是一款在线图片搜索神器,具体介绍可以看下我们之前的文章啦。戳我进入!采宝工具网上方提供图片搜索,下方支持图片收藏、评论、投票。后端支持三方外挂,想要获取更多有趣的数据请戳此地址获取支持特性免费开源、评论热度支持多平台。自带抓包、ip重定向、lzh等数据,可与很多源数据达成合作和互通。
支持热度分类检索图片,自动筛选并添加到浏览器收藏。支持热度排名第一列,图片热度高即热度大图。支持收藏图片。方便按照热度大类获取照片或其他类似图片。自动加入收藏图片。自动分享到百度文库,搜狐、豆丁等资料。中文网站翻译:可替代翻译软件,有针对大陆用户提供的个性化翻译:支持多个翻译引擎,自由切换自带发布模式:可自行调整配置搜索方式、多图搜索下方各类中文网站均提供翻译。
总结以上只是小编对这款采集神器的介绍,希望能帮助到小伙伴们!如果觉得文章不错,可以帮忙转发支持一下,谢谢~更多实用工具,欢迎关注我的微信公众号“采宝工具”获取哦~。
问题不准确,应该是图片收藏应用推荐才对吧?推荐两个实用工具app:1,zipdoc。这个挺有意思的,跟大多数任务收藏类产品不同,它能先保存下来收藏的文件,在需要的时候会自动调取并调整,不会占用本地空间。不会导致没有及时删掉的文件找不到。从此再也不用担心乱七八糟的收藏在手机里忘了找了,很方便的!2,photozoom这个是免费的图片收藏应用,如果要安装也很简单,你不用下载,上百度搜索photozoom,就会出来了。
总结:收藏应用的过程中应该包括图片收藏和分享。如果觉得收藏不符合你的需求,就需要做设置了。大部分图片类应用都提供直接导入图片的功能。如果不能导入图片。建议尝试先找到图片并导入到本地,这样才可以达到自动分类、批量分享的效果。如果有各类大图文件(多图文件,需要长时间等待),可以尝试在百度网盘上下载一个网盘文件,然后直接导入。
这是一款无需加入指定的QQ群,实现高速、稳定、全自动的提取
采集交流 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2021-08-18 04:15
飞讯不添加群成员提取群成员。这是一款无需加入指定QQ群即可高速、稳定、全自动提取QQ群成员的方法!使用原法软件可以采集一秒提前群成员,不像市面上其他软件采集信息严重滞后,实时采集互联网最新数据。无需加入指定QQ群,即可高速、稳定、全自动提取QQ群成员。采用独创方式,软件可以采集一秒提前群内成员,不像市面上其他软件采集信息严重滞后,保证用户采集及时更新实时上网!软件支持任意QQ采集,不限号码和IP,动态获取网上最新群信息,与入群时获取的群成员一模一样。这里的闪电编辑器是破解版,需要速度下载!
功能介绍这是一款高速稳定全自动提取QQ群成员,无需加入指定QQ群!使用独创的方法软件可以采集一秒提前群成员,不像市面上其他软件采集,信息严重滞后,实时采集互联网最新数据。无需加入指定QQ群,即可高速、稳定、全自动提取QQ群成员。采用独创方式,软件可以采集一秒提前群内成员,不像市面上其他软件采集信息严重滞后,保证用户采集及时更新实时上网!软件支持任意QQ采集,不限号码和IP,动态获取网上最新群信息,与入群时获取的群成员一模一样。 Features1、支持多台电脑多地使用
无需加入指定QQ群,即可高速、稳定、全自动提取QQ群成员。本软件采用网络验证账号的形式。任意一台机器登录软件账号后,即可随时随地使用软件,极大方便用户使用!
2、关键词营销,简单快捷
软件支持任意QQ采集,不限号不限IP,动态获取网上最新群信息,与加入群获取群成员一模一样。
3、高效快捷
采用独创方式,软件可以采集一秒提前群成员,不像市面上其他软件采集,信息严重滞后,保证用户采集在网上是最新的实时!
4、多种方式导出
近期飞信优化了采集功能,无需添加群成员提取群成员。现在支持按关键词采集QQ群,提取的群成员可以导出为邮箱格式。
5、software 使用网络账号,不限于机器
飞讯不加群以网络账号的形式提取群成员。一个软件帐户可以在不同的计算机上登录。用户可以在家中或公司中使用。真正摆脱了传统软件使用机器码的弊端。实现以用户为中心、以服务为导向的营销理念。
6、软件不断升级完善,售后服务可靠
在升级和维护方面,飞信软件团队一直坚持技术创新和踏实维护,确保软件功能和性能的稳定性。在售后服务方面,飞信软件团队拥有一支经过严格培训的客服团队,为您提供专业的技术支持。关于破解网站下载后,直接解压运行,就是破解版,填写你需要的条件,它会自动帮你搜索并加入你需要的群! 查看全部
这是一款无需加入指定的QQ群,实现高速、稳定、全自动的提取
飞讯不添加群成员提取群成员。这是一款无需加入指定QQ群即可高速、稳定、全自动提取QQ群成员的方法!使用原法软件可以采集一秒提前群成员,不像市面上其他软件采集信息严重滞后,实时采集互联网最新数据。无需加入指定QQ群,即可高速、稳定、全自动提取QQ群成员。采用独创方式,软件可以采集一秒提前群内成员,不像市面上其他软件采集信息严重滞后,保证用户采集及时更新实时上网!软件支持任意QQ采集,不限号码和IP,动态获取网上最新群信息,与入群时获取的群成员一模一样。这里的闪电编辑器是破解版,需要速度下载!

功能介绍这是一款高速稳定全自动提取QQ群成员,无需加入指定QQ群!使用独创的方法软件可以采集一秒提前群成员,不像市面上其他软件采集,信息严重滞后,实时采集互联网最新数据。无需加入指定QQ群,即可高速、稳定、全自动提取QQ群成员。采用独创方式,软件可以采集一秒提前群内成员,不像市面上其他软件采集信息严重滞后,保证用户采集及时更新实时上网!软件支持任意QQ采集,不限号码和IP,动态获取网上最新群信息,与入群时获取的群成员一模一样。 Features1、支持多台电脑多地使用
无需加入指定QQ群,即可高速、稳定、全自动提取QQ群成员。本软件采用网络验证账号的形式。任意一台机器登录软件账号后,即可随时随地使用软件,极大方便用户使用!
2、关键词营销,简单快捷
软件支持任意QQ采集,不限号不限IP,动态获取网上最新群信息,与加入群获取群成员一模一样。
3、高效快捷
采用独创方式,软件可以采集一秒提前群成员,不像市面上其他软件采集,信息严重滞后,保证用户采集在网上是最新的实时!
4、多种方式导出
近期飞信优化了采集功能,无需添加群成员提取群成员。现在支持按关键词采集QQ群,提取的群成员可以导出为邮箱格式。
5、software 使用网络账号,不限于机器
飞讯不加群以网络账号的形式提取群成员。一个软件帐户可以在不同的计算机上登录。用户可以在家中或公司中使用。真正摆脱了传统软件使用机器码的弊端。实现以用户为中心、以服务为导向的营销理念。
6、软件不断升级完善,售后服务可靠
在升级和维护方面,飞信软件团队一直坚持技术创新和踏实维护,确保软件功能和性能的稳定性。在售后服务方面,飞信软件团队拥有一支经过严格培训的客服团队,为您提供专业的技术支持。关于破解网站下载后,直接解压运行,就是破解版,填写你需要的条件,它会自动帮你搜索并加入你需要的群!
微软的付费技术支持计划,你的速度应该不会太差
采集交流 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-08-12 00:04
可靠的采集神器viable出品。其他免费领取方式参见文末。已经到付的话,积分不会因为你付出多少而减少,就像你付费买了一份保险,但依然有发生风险的可能。微软的付费技术支持计划,还是相当可靠的,上下班出差,在外都可以给你通知insider的issue。
官网有教程,除了付费的,其余都免费哈。protonium最新版142.1但是都很稳定,不用担心安全性什么的,破解版的话,百度出来一堆,你都可以尝试的。应该就是速度的话,服务器的稳定性,才是目前最重要的因素吧,服务器稳定,你的速度应该不会太差,
微软官网的insider计划
1、免费的:由bluenotes提供的最新的技术支持信息。
2、特惠的:购买为期一年的技术支持服务仅需29美元。
3、已发布的:这些是微软自定义的技术支持服务列表。你还可以选择“我有个朋友会帮助你,你也可以帮助我”,以及“关于我们的技术支持,有什么问题需要咨询我们的技术支持团队吗?”等链接。看官网啊。
关于我的技术支持我参与了几个jeffklein系列文章的策划工作,这个问题我最有发言权。为了保持专业,我将把所有jeffklein关于技术支持的所有内容都会在这里公布出来。有更多关于微软技术支持方面的问题,或者想跟大家交流一下心得体会,请加我的技术支持。 查看全部
微软的付费技术支持计划,你的速度应该不会太差
可靠的采集神器viable出品。其他免费领取方式参见文末。已经到付的话,积分不会因为你付出多少而减少,就像你付费买了一份保险,但依然有发生风险的可能。微软的付费技术支持计划,还是相当可靠的,上下班出差,在外都可以给你通知insider的issue。
官网有教程,除了付费的,其余都免费哈。protonium最新版142.1但是都很稳定,不用担心安全性什么的,破解版的话,百度出来一堆,你都可以尝试的。应该就是速度的话,服务器的稳定性,才是目前最重要的因素吧,服务器稳定,你的速度应该不会太差,
微软官网的insider计划
1、免费的:由bluenotes提供的最新的技术支持信息。
2、特惠的:购买为期一年的技术支持服务仅需29美元。
3、已发布的:这些是微软自定义的技术支持服务列表。你还可以选择“我有个朋友会帮助你,你也可以帮助我”,以及“关于我们的技术支持,有什么问题需要咨询我们的技术支持团队吗?”等链接。看官网啊。
关于我的技术支持我参与了几个jeffklein系列文章的策划工作,这个问题我最有发言权。为了保持专业,我将把所有jeffklein关于技术支持的所有内容都会在这里公布出来。有更多关于微软技术支持方面的问题,或者想跟大家交流一下心得体会,请加我的技术支持。
如何在谷歌浏览器中安装扩展迷上一劳永逸的Chrome插件?
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-08-11 06:22
对于大多数搜索资源的人来说,使用搜索引擎的核心需求之一就是下载资源。
但是每次想看电影,需要什么软件,都得在网上找很久。
此外,搜索到的项目要么是垃圾邮件广告,要么是莫名其妙的病毒软件。
如果您厌倦了在传统搜索工具上查找资源,那么您不妨试试这个一劳永逸的 Chrome 插件。
功能介绍
easySearch 插件是最近在 Chrome 商店推出的聚合搜索引擎工具。它支持自定义并有许多有用的小部件。
它的主要功能是磁力搜索,拥有非常全面的磁力搜索引擎,支持一键查询BT种子和磁力链接。
同时还可以通过easySearch插件进行学术搜索、云盘搜索、软件搜索、影视资源搜索、音乐资源搜索,甚至图片识别。
据开发者介绍,目前系统内置了223个资源站,网站最新地址会自动更新。
只要是你能想到的,都可以通过它搜索,几乎可以满足我们所有的搜索需求。
如何使用
一、安装插件
如果条件允许,您可以直接在谷歌浏览器商店下载安装。
如果无法访问,请到扩展名fan网站下载easySearch插件安装包,解压后将crx文件拖放到谷歌浏览器。
安装方法【安装教程】如何在谷歌浏览器中安装扩展迷下载的插件?
二、search
点击浏览器右上角的插件图标,选择第一个功能“搜索”。
然后,系统会在一个新的标签页Ju BT中打开一个聚合资源搜索引擎页面。
在搜索框中输入要查找的资源关键词,在后面的下拉选项中可以选择子分类(或不分类),然后就可以看到种子的搜索结果资源如下。
三、Custom
在菜单中选择“设置”以自定义搜索引擎。
比如添加自定义搜索引擎、对搜索引擎进行分类、显示每个网站的结果数、排序规则等
根据自己的习惯,管理常用的搜索引擎,使其成为您专属的搜索定制工具。
四、其他工具
easySearch 插件中有很多有用的搜索功能。为避免被统一,这里就不一一介绍了。
简而言之,包括图片搜索、商业搜索、乐谱搜索、线路搜索,以及影视动画、热门软件、云盘资源搜索等,都可以在这个插件中找到——
还有很多隐藏的好处等着大家自己去发现。
老司机资源搜索神器,一键搜索上百个资源站,有兴趣的不妨一试。 查看全部
如何在谷歌浏览器中安装扩展迷上一劳永逸的Chrome插件?
对于大多数搜索资源的人来说,使用搜索引擎的核心需求之一就是下载资源。
但是每次想看电影,需要什么软件,都得在网上找很久。
此外,搜索到的项目要么是垃圾邮件广告,要么是莫名其妙的病毒软件。
如果您厌倦了在传统搜索工具上查找资源,那么您不妨试试这个一劳永逸的 Chrome 插件。
功能介绍
easySearch 插件是最近在 Chrome 商店推出的聚合搜索引擎工具。它支持自定义并有许多有用的小部件。
它的主要功能是磁力搜索,拥有非常全面的磁力搜索引擎,支持一键查询BT种子和磁力链接。
同时还可以通过easySearch插件进行学术搜索、云盘搜索、软件搜索、影视资源搜索、音乐资源搜索,甚至图片识别。
据开发者介绍,目前系统内置了223个资源站,网站最新地址会自动更新。
只要是你能想到的,都可以通过它搜索,几乎可以满足我们所有的搜索需求。
如何使用
一、安装插件
如果条件允许,您可以直接在谷歌浏览器商店下载安装。
如果无法访问,请到扩展名fan网站下载easySearch插件安装包,解压后将crx文件拖放到谷歌浏览器。
安装方法【安装教程】如何在谷歌浏览器中安装扩展迷下载的插件?
二、search
点击浏览器右上角的插件图标,选择第一个功能“搜索”。
然后,系统会在一个新的标签页Ju BT中打开一个聚合资源搜索引擎页面。
在搜索框中输入要查找的资源关键词,在后面的下拉选项中可以选择子分类(或不分类),然后就可以看到种子的搜索结果资源如下。
三、Custom
在菜单中选择“设置”以自定义搜索引擎。
比如添加自定义搜索引擎、对搜索引擎进行分类、显示每个网站的结果数、排序规则等
根据自己的习惯,管理常用的搜索引擎,使其成为您专属的搜索定制工具。
四、其他工具
easySearch 插件中有很多有用的搜索功能。为避免被统一,这里就不一一介绍了。
简而言之,包括图片搜索、商业搜索、乐谱搜索、线路搜索,以及影视动画、热门软件、云盘资源搜索等,都可以在这个插件中找到——
还有很多隐藏的好处等着大家自己去发现。
老司机资源搜索神器,一键搜索上百个资源站,有兴趣的不妨一试。
可靠的采集神器(日引千元,,要看什么原因导致了?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-10-04 18:02
可靠的采集神器都是免费的,网上赚钱的渠道有很多,自己看看别人赚钱的方法,套用其中的通用的话术去推广就可以,免费的渠道无非就是代理,百度联盟和网站收录这些,然后再大量的引流,单子就来了。
日引千元,要看什么原因导致了。
1、百度竞价、竞价排名
2、推广所谓的采集群、软文群
3、手机硬件及网络技术
4、某微信生态
真的可以有的赚吗?赚这么多的人,平时是需要学习吗?可能你也要问我,当然需要了,只有前进才会往前走,没有两只鞋是一样的,同样,同样的赚钱道理,要靠谱的,
只要你想赚钱哪里都可以赚,小钱年入十万百万的,大钱一个月两三万的。再厉害点的做个代理啥的身价十亿,一天赚几万几十万也是可以的。当然也有家里比较困难的,一个月要生活所迫,不赚钱都不敢说话,只能向别人借钱,来渡过难关。
竞价、百度竞价、免费中介平台等都可以的
日赚千元是要看哪一块了,可靠的采集群每天发发软文,一天花个上千块钱,还是比较轻松的。
基本上都是免费的,不靠谱的有很多,
日赚千块一千块做公关去
可靠的c店什么的也不想多说,天上掉馅饼的事情,如果真有,
如果你觉得代理除了赚钱,和赚钱之外,和自己完全没有关系,你是坚持不了多久的。只要有人做,你就有机会。只要别小看自己。 查看全部
可靠的采集神器(日引千元,,要看什么原因导致了?)
可靠的采集神器都是免费的,网上赚钱的渠道有很多,自己看看别人赚钱的方法,套用其中的通用的话术去推广就可以,免费的渠道无非就是代理,百度联盟和网站收录这些,然后再大量的引流,单子就来了。
日引千元,要看什么原因导致了。
1、百度竞价、竞价排名
2、推广所谓的采集群、软文群
3、手机硬件及网络技术
4、某微信生态
真的可以有的赚吗?赚这么多的人,平时是需要学习吗?可能你也要问我,当然需要了,只有前进才会往前走,没有两只鞋是一样的,同样,同样的赚钱道理,要靠谱的,
只要你想赚钱哪里都可以赚,小钱年入十万百万的,大钱一个月两三万的。再厉害点的做个代理啥的身价十亿,一天赚几万几十万也是可以的。当然也有家里比较困难的,一个月要生活所迫,不赚钱都不敢说话,只能向别人借钱,来渡过难关。
竞价、百度竞价、免费中介平台等都可以的
日赚千元是要看哪一块了,可靠的采集群每天发发软文,一天花个上千块钱,还是比较轻松的。
基本上都是免费的,不靠谱的有很多,
日赚千块一千块做公关去
可靠的c店什么的也不想多说,天上掉馅饼的事情,如果真有,
如果你觉得代理除了赚钱,和赚钱之外,和自己完全没有关系,你是坚持不了多久的。只要有人做,你就有机会。只要别小看自己。
可靠的采集神器(信息采集的难点是什么?分类数据库有三个最新解析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-10-01 10:20
信息采集的难度是多少?数据更加复杂多样;下载后有什么困难?数据管理。
网络信息大师(NetGet)的主要功能就是解决这两个问题。一般数据采集是有针对性的,通常是针对某个或某些网站、采集某类数据。比如采集几个网站招聘信息、产品信息、供求信息、公司图书馆信息等等。简单分析了这些网站的数据结构后,设置相应的采集规则,就可以将你想要的所有数据下载到本地了。本软件支持分类,分类的目的是方便数据管理和统计分析。
现有功能介绍:
1. 这个软件可以采集任何类型的网站信息。包括htm、html、ASP、JSP、PHP等。采集速度快,信息一致,准确。支持网站登录。
2. 分类。分类的目的是为了方便地管理数据。您可以添加、删除和修改类别。分类数据库有3个最新备份,放在\files目录下,为数据安全提供了可靠保证。
3. 任务。任务是 采集 任务。按照相应的 采集 规则行事。可以随时启动、暂停和停止任务。本软件支持多任务,即同时采集不同的数据。
4. 数据导出。采集的数据可以通过三种方式导出:文本、Excel和数据库。它可以根据您的需要导出为不同的格式。
5. 数据库。Access 和 SqlServer 数据库目前正在测试中。数据库功能包括导入数据库和数据查询。
6. 菜单功能扩展。一般是扩展数据分析功能。例如,您自己开发了一个数据库软件。本软件用于分析采集的数据。您可以将软件连接到该软件以方便使用。
7. 日志。记录每一个重要的操作。比如类别的维护,任务的维护等等。日志可以被清理和备份。 查看全部
可靠的采集神器(信息采集的难点是什么?分类数据库有三个最新解析)
信息采集的难度是多少?数据更加复杂多样;下载后有什么困难?数据管理。
网络信息大师(NetGet)的主要功能就是解决这两个问题。一般数据采集是有针对性的,通常是针对某个或某些网站、采集某类数据。比如采集几个网站招聘信息、产品信息、供求信息、公司图书馆信息等等。简单分析了这些网站的数据结构后,设置相应的采集规则,就可以将你想要的所有数据下载到本地了。本软件支持分类,分类的目的是方便数据管理和统计分析。
现有功能介绍:
1. 这个软件可以采集任何类型的网站信息。包括htm、html、ASP、JSP、PHP等。采集速度快,信息一致,准确。支持网站登录。
2. 分类。分类的目的是为了方便地管理数据。您可以添加、删除和修改类别。分类数据库有3个最新备份,放在\files目录下,为数据安全提供了可靠保证。
3. 任务。任务是 采集 任务。按照相应的 采集 规则行事。可以随时启动、暂停和停止任务。本软件支持多任务,即同时采集不同的数据。
4. 数据导出。采集的数据可以通过三种方式导出:文本、Excel和数据库。它可以根据您的需要导出为不同的格式。
5. 数据库。Access 和 SqlServer 数据库目前正在测试中。数据库功能包括导入数据库和数据查询。
6. 菜单功能扩展。一般是扩展数据分析功能。例如,您自己开发了一个数据库软件。本软件用于分析采集的数据。您可以将软件连接到该软件以方便使用。
7. 日志。记录每一个重要的操作。比如类别的维护,任务的维护等等。日志可以被清理和备份。
可靠的采集神器(4.垃圾收集过程G1收集器的运行示意图如下的Mixed和继承人)
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-09-30 03:22
1. 简介
Garbage First(简称G1)采集器是垃圾采集器技术发展史上的一个里程碑式的成就:它开创了“面向本地采集”的设计思想和“基于Region”的内存布局形式.
G1采集器是一个主要针对服务端应用的垃圾采集器,它的定位是“cms采集器的替代者和继承者”。其发展简史如下:
2. 堆内存划分
虽然 G1 采集器也遵循分代采集理论,但它的堆内存布局与其他采集器有很大不同:
G1采集器的堆内存划分如图:
3. 暂停时间模型3.1 暂停时间模型
暂停预测模型:指定在 M 毫秒的时间段内,垃圾回收所花费的时间很可能不超过 N 毫秒。
G1采集器之所以能够建立可预测的暂停时间模型,是因为它把Region作为单次回收的最小单位(每次采集的内存空间是Region大小的整数倍),这样整个Java 堆执行全区域垃圾采集。
更具体的处理思路:让G1采集器跟踪每个Region中垃圾堆积的“值”,然后在后台维护一个优先级列表。每次根据用户设置的采集暂停时间,优先处理和回收价值将是最有利可图的。那些区域(这就是“垃圾优先”名称的由来)。
“值”是通过每次恢复获得的空间量和恢复所需时间的经验值来衡量的。
3.2 混合 GC
对于 G1 采集器之前的所有其他采集器(包括 cms 采集器),垃圾采集的目标范围要么是整个年轻代(Minor GC),要么是整个老年代(Major GC),要么是整个 Java堆(Full GC)。
而G1则跳出这个笼子:它可以对堆内存的任何部分形成一个集合集(俗称CSet)进行回收。衡量的标准不再是它属于哪一代,而是哪一块内存收录的垃圾量最大,回收收益最大。这是 G1 采集器的混合 GC 模式。
4. 垃圾采集过程
G1采集器的运行图如下:
其操作过程大致可以分为以下四个步骤:
4.1 初始标记功能
TAMS:Top at Mark Start,Region中的指针,用于并发标记时为对象分配内存空间。
4.2 并发标记
从GC Root开始,对堆中的对象进行可达性分析,递归扫描整个堆中的对象图,找到需要回收的对象。
另外,扫描完成后,需要重新处理并发期间引用发生变化的STAB记录的对象。
STAB: Snapshot At The Beginning,原创快照,参考上篇《》6.3 部分。
4.3 最终标记功能4.4 筛选和回收功能5. 一些细节5.1 跨区域参考对象
解决办法是使用前面“”的第4节中的“内存集”,避免将整个堆扫描为GC Roots。
但是,G1 的内存集更复杂,因为:
根据经验,G1至少需要消耗Java堆容量的10%~20%左右的额外内存空间来维持采集器的工作。
5.2 并发标记
解决方案在上一篇第6节分析:cms采集器采用增量更新算法,而G1采集器采用原创快照(STAB)算法实现。
另外,由于用户线程在并发标记时还在执行,所以肯定会继续创建新对象。
G1为每个Region设计了两个名为TAMS(Top at Mark Start)的指针,将Region中的一部分空间用于并发采集过程中新对象的分配(默认都是存活的,不包括在采集范围内) ) )。
需要注意的是,如果内存回收速度跟不上内存分配速度,G1采集器也会被强制冻结用户线程的执行,导致Full GC和长时间的“Stop The World”。
5.3 可靠的暂停模型
G1采集器的暂停模型是基于Decaying Average的理论基础:在垃圾采集过程中,G1采集器会分析每个Region的采集时间,内存中脏卡的数量等平均值,标准偏差等
“衰减平均值”比普通平均值更准确地表示“最近”的平均值状态。该信息用于预测在不超过预期暂停时间的约束下将采集哪些 Region 以获得最高回报。.
6. G1 VS cms
G1 采集器经常与 cms 采集器进行比较。
不管G1的一些创新设计:可以指定最大暂停时间,子区域的内存布局,以及根据收入动态确定集合等等,这里只说一些其他比较常见的地方。
6.1 采集算法
G1的这两种算法在运行过程中防止内存空间碎片化,并在垃圾回收完成后提供正常可用的内存。而且这对于程序长时间运行是有好处的(大对象分配内存时,由于无法找到连续的内存空间,不容易提前触发下一次采集)。
6.2 内存占用
cms 和 G1 都使用卡表来处理跨代指针,但 G1 的卡表实现更复杂,区域更多(本文 5.1 节)。
相比之下,cms的卡片表比较简单,只有一份,只需要处理老年代到新生代的引用。
与cms相比,G1的内存占用更大。
6.3 额外的执行负载
由于两者的实现细节不同,用户程序执行时的负载会有所不同。以写屏障为例:
G1 的写屏障比 cms 消耗更多的计算资源。因此,cms 写屏障是一个同步操作,而 G1 使用的是类似于消息队列的异步操作。
一般来说:
这个临界点大概在6~8G(经验值)之间。
一些相关的虚拟机参数如下:
# 使用 G1 收集器
-XX:+UseG1GC
# 设置 Region 大小(范围 1~32M,且为 2 的 N 次幂)
-XX:G1HeapRegionSize
# 最大收集停顿时间(默认 200 毫秒)
-XX:MaxGCPauseMillis
本文的主要内容总结如下: 查看全部
可靠的采集神器(4.垃圾收集过程G1收集器的运行示意图如下的Mixed和继承人)
1. 简介
Garbage First(简称G1)采集器是垃圾采集器技术发展史上的一个里程碑式的成就:它开创了“面向本地采集”的设计思想和“基于Region”的内存布局形式.
G1采集器是一个主要针对服务端应用的垃圾采集器,它的定位是“cms采集器的替代者和继承者”。其发展简史如下:
2. 堆内存划分
虽然 G1 采集器也遵循分代采集理论,但它的堆内存布局与其他采集器有很大不同:
G1采集器的堆内存划分如图:
3. 暂停时间模型3.1 暂停时间模型
暂停预测模型:指定在 M 毫秒的时间段内,垃圾回收所花费的时间很可能不超过 N 毫秒。
G1采集器之所以能够建立可预测的暂停时间模型,是因为它把Region作为单次回收的最小单位(每次采集的内存空间是Region大小的整数倍),这样整个Java 堆执行全区域垃圾采集。
更具体的处理思路:让G1采集器跟踪每个Region中垃圾堆积的“值”,然后在后台维护一个优先级列表。每次根据用户设置的采集暂停时间,优先处理和回收价值将是最有利可图的。那些区域(这就是“垃圾优先”名称的由来)。
“值”是通过每次恢复获得的空间量和恢复所需时间的经验值来衡量的。
3.2 混合 GC
对于 G1 采集器之前的所有其他采集器(包括 cms 采集器),垃圾采集的目标范围要么是整个年轻代(Minor GC),要么是整个老年代(Major GC),要么是整个 Java堆(Full GC)。
而G1则跳出这个笼子:它可以对堆内存的任何部分形成一个集合集(俗称CSet)进行回收。衡量的标准不再是它属于哪一代,而是哪一块内存收录的垃圾量最大,回收收益最大。这是 G1 采集器的混合 GC 模式。
4. 垃圾采集过程
G1采集器的运行图如下:
其操作过程大致可以分为以下四个步骤:
4.1 初始标记功能
TAMS:Top at Mark Start,Region中的指针,用于并发标记时为对象分配内存空间。
4.2 并发标记
从GC Root开始,对堆中的对象进行可达性分析,递归扫描整个堆中的对象图,找到需要回收的对象。
另外,扫描完成后,需要重新处理并发期间引用发生变化的STAB记录的对象。
STAB: Snapshot At The Beginning,原创快照,参考上篇《》6.3 部分。
4.3 最终标记功能4.4 筛选和回收功能5. 一些细节5.1 跨区域参考对象
解决办法是使用前面“”的第4节中的“内存集”,避免将整个堆扫描为GC Roots。
但是,G1 的内存集更复杂,因为:
根据经验,G1至少需要消耗Java堆容量的10%~20%左右的额外内存空间来维持采集器的工作。
5.2 并发标记
解决方案在上一篇第6节分析:cms采集器采用增量更新算法,而G1采集器采用原创快照(STAB)算法实现。
另外,由于用户线程在并发标记时还在执行,所以肯定会继续创建新对象。
G1为每个Region设计了两个名为TAMS(Top at Mark Start)的指针,将Region中的一部分空间用于并发采集过程中新对象的分配(默认都是存活的,不包括在采集范围内) ) )。
需要注意的是,如果内存回收速度跟不上内存分配速度,G1采集器也会被强制冻结用户线程的执行,导致Full GC和长时间的“Stop The World”。
5.3 可靠的暂停模型
G1采集器的暂停模型是基于Decaying Average的理论基础:在垃圾采集过程中,G1采集器会分析每个Region的采集时间,内存中脏卡的数量等平均值,标准偏差等
“衰减平均值”比普通平均值更准确地表示“最近”的平均值状态。该信息用于预测在不超过预期暂停时间的约束下将采集哪些 Region 以获得最高回报。.
6. G1 VS cms
G1 采集器经常与 cms 采集器进行比较。
不管G1的一些创新设计:可以指定最大暂停时间,子区域的内存布局,以及根据收入动态确定集合等等,这里只说一些其他比较常见的地方。
6.1 采集算法
G1的这两种算法在运行过程中防止内存空间碎片化,并在垃圾回收完成后提供正常可用的内存。而且这对于程序长时间运行是有好处的(大对象分配内存时,由于无法找到连续的内存空间,不容易提前触发下一次采集)。
6.2 内存占用
cms 和 G1 都使用卡表来处理跨代指针,但 G1 的卡表实现更复杂,区域更多(本文 5.1 节)。
相比之下,cms的卡片表比较简单,只有一份,只需要处理老年代到新生代的引用。
与cms相比,G1的内存占用更大。
6.3 额外的执行负载
由于两者的实现细节不同,用户程序执行时的负载会有所不同。以写屏障为例:
G1 的写屏障比 cms 消耗更多的计算资源。因此,cms 写屏障是一个同步操作,而 G1 使用的是类似于消息队列的异步操作。
一般来说:
这个临界点大概在6~8G(经验值)之间。
一些相关的虚拟机参数如下:
# 使用 G1 收集器
-XX:+UseG1GC
# 设置 Region 大小(范围 1~32M,且为 2 的 N 次幂)
-XX:G1HeapRegionSize
# 最大收集停顿时间(默认 200 毫秒)
-XX:MaxGCPauseMillis
本文的主要内容总结如下:
可靠的采集神器(可靠的采集神器——whois爬取豆瓣用户reddit信息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-09-29 08:03
可靠的采集神器如下:whois抓取dnsservers|imageview|paintgetaddresses抓取https请求头一一匹配规律逆向domhtmlseed能追踪页面中的链接的url
firebug好像抓不了页面的内容,但是可以抓包页面内容看看,
lz是说抓取图片内容吗?我最近正在使用阿里妈妈的开源采集页面的脚本!集成squid及apachesphinx数据库,直接爬取source的网页数据供需要的人服务。主要是满足爬虫从静态网页直接抓取动态网页数据,数据清洗和结构化是我需要解决的问题。
tornado爬页面自己回答一下。当然也是自己随手写的。
大家好!我要推荐一个工具集合,
使用python的github搜索引擎,提供了大量的数据,包括:获取各公司网站的wikipedia账号页截图以及dom编辑版权页采集各种视频站ppt平台页面获取采集知乎页面,全英文wiki,不过非常清晰。获取微博头像获取采集图像抓取msfilteredspider,包括图片采集,动图采集,视频采集等。
哎哎哎,题主你推荐的这两个我还没用过,不敢妄下结论,最近还真好奇requests有没有什么免费的功能。之前有人说用beautifulsoup,我还没用过嗯目前大的想法是这样,希望大家多提点建议,针对题主给出的问题,我特意准备学习爬取豆瓣的用户reddit信息/小组信息,详情如下:去找站长,把你爬过的数据分享出来,以及站长专栏:sosoreddit找合适的网站去爬,我主要在sina,但是抓了不少网站,也因此知道了一个新的站,目标是trytap这个类似的网站(后面会说为什么在这个网站去爬数据合适)sina也有了,就是觉得这个网站有个功能不错,就在我们这边也刚建了一个beta版,希望能体验一下多测试,找到合适的数据,算是给大家交个作业。 查看全部
可靠的采集神器(可靠的采集神器——whois爬取豆瓣用户reddit信息)
可靠的采集神器如下:whois抓取dnsservers|imageview|paintgetaddresses抓取https请求头一一匹配规律逆向domhtmlseed能追踪页面中的链接的url
firebug好像抓不了页面的内容,但是可以抓包页面内容看看,
lz是说抓取图片内容吗?我最近正在使用阿里妈妈的开源采集页面的脚本!集成squid及apachesphinx数据库,直接爬取source的网页数据供需要的人服务。主要是满足爬虫从静态网页直接抓取动态网页数据,数据清洗和结构化是我需要解决的问题。
tornado爬页面自己回答一下。当然也是自己随手写的。
大家好!我要推荐一个工具集合,
使用python的github搜索引擎,提供了大量的数据,包括:获取各公司网站的wikipedia账号页截图以及dom编辑版权页采集各种视频站ppt平台页面获取采集知乎页面,全英文wiki,不过非常清晰。获取微博头像获取采集图像抓取msfilteredspider,包括图片采集,动图采集,视频采集等。
哎哎哎,题主你推荐的这两个我还没用过,不敢妄下结论,最近还真好奇requests有没有什么免费的功能。之前有人说用beautifulsoup,我还没用过嗯目前大的想法是这样,希望大家多提点建议,针对题主给出的问题,我特意准备学习爬取豆瓣的用户reddit信息/小组信息,详情如下:去找站长,把你爬过的数据分享出来,以及站长专栏:sosoreddit找合适的网站去爬,我主要在sina,但是抓了不少网站,也因此知道了一个新的站,目标是trytap这个类似的网站(后面会说为什么在这个网站去爬数据合适)sina也有了,就是觉得这个网站有个功能不错,就在我们这边也刚建了一个beta版,希望能体验一下多测试,找到合适的数据,算是给大家交个作业。
可靠的采集神器(比较流行的几款采集工具作一个简单的评比,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2021-09-27 06:23
现在的站长圈子里,有很多流行的采集工具,但总结起来,比较出名的免费工具只有几个:优采云、海纳、ET、Threesome、优采云。
下面我们对这几个采集工具做一个简单的对比。
1.优采云 基本上大家都知道了,先放上来再说几句。
优采云应该是国内采集软件最成功的模式之一,包括付费用户在内的用户数量应该是最大的
特点:简单,强大,快速,支持最丰富的网站,支持丰富的扩展
优点:功能比较齐全,采集比较快,主要针对cms,短时间可以采集很多,过滤替换都不错,比较详细;很多人写接口、规则和发布模块和接口都比较完整。其中有一个叫陈元的人,开发了目前PHP类的几乎所有接口cms;支持的扩展非常易于使用。如果你是技术上比较熟悉的网站,可以用PHP或C#开发任何功能扩展,真的很难忘;附件采集功能完善。
技术:该技术以论坛为主,帮助文件多,上手容易。有付费版和免费版
缺点:功能较多,软件较大,内存和CPU资源较多,资源回收控制较差
2.三人行(优采云) 主要针对论坛的采集,功能比较齐全
首先,我不知道三星和优采云是什么关系,但是接口和功能都是基于同一个模型的。
特点:针对各大论坛,移动,移动,速度快,准确度高
优点:还是论坛用,适合开论坛
技术:收费技术,免费广告
缺点:超级复杂,上手困难,对cms支持差
3.ET 工具
特点:无人值守,稳定,占用资源最少,基本可以叫安静
优点:无人值守,自动更新,适合长期站,用户群主要集中在长期潜水站长。软件一目了然,必备的功能也很齐全。关键是该软件是免费的。听说增加了采集中英文翻译功能。
技术:论坛支持,软件本身免费,但也提供收费服务。帮助文件少,不易上手
缺点:一般支持论坛和cms
4.海娜
特点:海量,关键词抓取,无需编写规则即可预览采集的内容
优点:海量,可以抢网站一大堆关键词文章,好像很适合网站的话题,尤其是文章类,博客类
技术:无论坛费用,免费但有功能限制
缺点:分类不方便,也就是说采集文章分类不方便,手动(自动容易混淆),界面具体,采集内容有限
5.优采云
特点:让您的新论坛一开始就拥有大量成员。
优点:非常适合采集discuz论坛
缺点:过于具体,兼容性差。
总结:如果追求功能齐全,看来应该选择优采云。优采云 被称为“全能”。初期可以快速采集大量资源,丰富网站内容。如果您是论坛,请选择三人组。没错,可以实现采集论坛、回复、移动等多种论坛功能。长期站,当然选择ET,花点时间了解一下,是长期受益。写规则,设置过滤器和替换,然后它可以像打开QQ一样长时间运行,不存储,自动更新,分类清晰,内容完整,但是说,一站,一站龙+ ET就足够了。至于Heiner,貌似不写规则,上手容易,但是文章的发布可没有ET那么容易。 查看全部
可靠的采集神器(比较流行的几款采集工具作一个简单的评比,你知道吗?)
现在的站长圈子里,有很多流行的采集工具,但总结起来,比较出名的免费工具只有几个:优采云、海纳、ET、Threesome、优采云。
下面我们对这几个采集工具做一个简单的对比。
1.优采云 基本上大家都知道了,先放上来再说几句。
优采云应该是国内采集软件最成功的模式之一,包括付费用户在内的用户数量应该是最大的
特点:简单,强大,快速,支持最丰富的网站,支持丰富的扩展
优点:功能比较齐全,采集比较快,主要针对cms,短时间可以采集很多,过滤替换都不错,比较详细;很多人写接口、规则和发布模块和接口都比较完整。其中有一个叫陈元的人,开发了目前PHP类的几乎所有接口cms;支持的扩展非常易于使用。如果你是技术上比较熟悉的网站,可以用PHP或C#开发任何功能扩展,真的很难忘;附件采集功能完善。
技术:该技术以论坛为主,帮助文件多,上手容易。有付费版和免费版
缺点:功能较多,软件较大,内存和CPU资源较多,资源回收控制较差
2.三人行(优采云) 主要针对论坛的采集,功能比较齐全
首先,我不知道三星和优采云是什么关系,但是接口和功能都是基于同一个模型的。
特点:针对各大论坛,移动,移动,速度快,准确度高
优点:还是论坛用,适合开论坛
技术:收费技术,免费广告
缺点:超级复杂,上手困难,对cms支持差
3.ET 工具
特点:无人值守,稳定,占用资源最少,基本可以叫安静
优点:无人值守,自动更新,适合长期站,用户群主要集中在长期潜水站长。软件一目了然,必备的功能也很齐全。关键是该软件是免费的。听说增加了采集中英文翻译功能。
技术:论坛支持,软件本身免费,但也提供收费服务。帮助文件少,不易上手
缺点:一般支持论坛和cms
4.海娜
特点:海量,关键词抓取,无需编写规则即可预览采集的内容
优点:海量,可以抢网站一大堆关键词文章,好像很适合网站的话题,尤其是文章类,博客类
技术:无论坛费用,免费但有功能限制
缺点:分类不方便,也就是说采集文章分类不方便,手动(自动容易混淆),界面具体,采集内容有限
5.优采云
特点:让您的新论坛一开始就拥有大量成员。
优点:非常适合采集discuz论坛
缺点:过于具体,兼容性差。
总结:如果追求功能齐全,看来应该选择优采云。优采云 被称为“全能”。初期可以快速采集大量资源,丰富网站内容。如果您是论坛,请选择三人组。没错,可以实现采集论坛、回复、移动等多种论坛功能。长期站,当然选择ET,花点时间了解一下,是长期受益。写规则,设置过滤器和替换,然后它可以像打开QQ一样长时间运行,不存储,自动更新,分类清晰,内容完整,但是说,一站,一站龙+ ET就足够了。至于Heiner,貌似不写规则,上手容易,但是文章的发布可没有ET那么容易。
可靠的采集神器(优化大陆线路除了硬件的可靠性,租用香港站群还有一个好处)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-24 17:11
网站采集是网站为了快速提升网络排名,增加网站收录和整体内容的丰富度,下载别人的整个站点数据到你自己的网站或者将别人的网站的一些内容保存到你自己的服务器上。从内容中提取相关字段发布到自己的网站系统,或者需要本地保存web相关文件,如图片、附件等。香港站群服务器专业使用用于网站SEO优化,非常适合采集内容,快速部署站群!
优化大陆航线
除了硬件的可靠性,租用香港站群的另一个优点是有CN2直连线,特别是一些部署在大陆服务器的目标网站,使用CN2直连连接线可以很稳定的将数据采集返回到自己的服务器,采集的过程中出现空采集的概率很低。
IP不容易被封
采集工具的原理是通过正常的http访问来读取目标网站的内容,所以如果量太大或者频率太高,很容易被对方拒绝目标网站作为CC攻击,导致抓取空内容,如果服务器自身IP资源充足,可以模拟多个不同的服务器进行访问,从而避免目标网站反采集机制,自然采集内容和发布更稳定。
硬件配置合适
<p>现在很多用户租香港站群服务器搭建站群业务,但其实站群服务器非常适合部署采集系统,现在主流 查看全部
可靠的采集神器(优化大陆线路除了硬件的可靠性,租用香港站群还有一个好处)
网站采集是网站为了快速提升网络排名,增加网站收录和整体内容的丰富度,下载别人的整个站点数据到你自己的网站或者将别人的网站的一些内容保存到你自己的服务器上。从内容中提取相关字段发布到自己的网站系统,或者需要本地保存web相关文件,如图片、附件等。香港站群服务器专业使用用于网站SEO优化,非常适合采集内容,快速部署站群!
优化大陆航线
除了硬件的可靠性,租用香港站群的另一个优点是有CN2直连线,特别是一些部署在大陆服务器的目标网站,使用CN2直连连接线可以很稳定的将数据采集返回到自己的服务器,采集的过程中出现空采集的概率很低。
IP不容易被封
采集工具的原理是通过正常的http访问来读取目标网站的内容,所以如果量太大或者频率太高,很容易被对方拒绝目标网站作为CC攻击,导致抓取空内容,如果服务器自身IP资源充足,可以模拟多个不同的服务器进行访问,从而避免目标网站反采集机制,自然采集内容和发布更稳定。
硬件配置合适
<p>现在很多用户租香港站群服务器搭建站群业务,但其实站群服务器非常适合部署采集系统,现在主流
可靠的采集神器(可靠的采集神器谷歌浏览器助手百度云格式转换-1.rar)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-09-19 11:03
可靠的采集神器谷歌浏览器助手百度云格式转换llljb-1vbw.rar-1.rar文件格式的转换工具对于我们这种想看pdf格式的小白来说格式转换真的超级有用还能自定义主题很值得推荐
有一个很好的东西,叫网络爬虫,你可以试试看。
autocheckout如果能找到解决方案,
windows有个第三方的计算机管理软件很不错的,一般对桌面上的一些软件,比如qq啥的,大多都是比较方便的,然后用360之类的,或者不用软件也行。
泻药,是一块没用的软件,或者你可以再问一个小问题。
谢邀,你知道autohotkey么。
autohotkey,仿python。
1everything2autohotkeypro3自己做一个
everything或者windowns
autohotkey
运行命令不一定需要命令,
matlab,windows下你自己想怎么用就怎么用
既然用mac的话,就用类似alfred的应用metro平台比如:palmos里有一个palmosprocess和通过windows主机端监控autohotkey启动的脚本(autohotkey一样),也可以通过这个palmosprocess管理文件在:-desktop.py这里有一个测试版本与正式版本相比功能完善挺多。
如果只是用于收集而不用于存储文件的话,推荐只用windows版本。在windows环境下应该和windows主机端管理的palmos版本差不多。 查看全部
可靠的采集神器(可靠的采集神器谷歌浏览器助手百度云格式转换-1.rar)
可靠的采集神器谷歌浏览器助手百度云格式转换llljb-1vbw.rar-1.rar文件格式的转换工具对于我们这种想看pdf格式的小白来说格式转换真的超级有用还能自定义主题很值得推荐
有一个很好的东西,叫网络爬虫,你可以试试看。
autocheckout如果能找到解决方案,
windows有个第三方的计算机管理软件很不错的,一般对桌面上的一些软件,比如qq啥的,大多都是比较方便的,然后用360之类的,或者不用软件也行。
泻药,是一块没用的软件,或者你可以再问一个小问题。
谢邀,你知道autohotkey么。
autohotkey,仿python。
1everything2autohotkeypro3自己做一个
everything或者windowns
autohotkey
运行命令不一定需要命令,
matlab,windows下你自己想怎么用就怎么用
既然用mac的话,就用类似alfred的应用metro平台比如:palmos里有一个palmosprocess和通过windows主机端监控autohotkey启动的脚本(autohotkey一样),也可以通过这个palmosprocess管理文件在:-desktop.py这里有一个测试版本与正式版本相比功能完善挺多。
如果只是用于收集而不用于存储文件的话,推荐只用windows版本。在windows环境下应该和windows主机端管理的palmos版本差不多。
可靠的采集神器(可靠的采集神器教你如何提高采集的质量,保证平台的原创和质量)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-09-09 07:02
可靠的采集神器教你如何提高采集的质量,保证平台的原创和质量,让你一次采集成百上千,还让你能够控制采集的类目,还可以实现多采集。电商日记的前端使用的就是类似的技术,通过自然排名,非常快速的提高你产品的排名,并且保证对手不知道你,从而提高你产品的曝光度,甚至让你产品有了可观的销量,同时也为你带来了流量。你可以试一下。
不同的类目,当然要不同的操作方法,大类目为了防止刷单,那么你就要写出比较高质量的文案,并且要把细节设置好,如果这些都做不好,那么你想把销量做上去是不可能的。我自己也是运营的天猫店铺,我自己一个运营的多家天猫店铺,我对这块是非常了解的,
实际操作得好多少还是有一点作用,大批量最好就是找人帮你,如果按个收费,可能就是违背你开头说的了。如果做一些活动,那么使用的时候效果会更好一些。
需要点技术来处理你链接每个商品的类目上下架周期,然后选取上下架周期上架的商品,选取你的类目了解下这个类目下近期流量趋势和售卖热点,然后进行分析,安排你上架的类目时间,然后按照数据反馈,设置每天推广量,以保证下架的时候数据反馈良好,完成上架,数据反馈不好,删除类目。重复执行上架环节,热销商品可以在下架后在上架。 查看全部
可靠的采集神器(可靠的采集神器教你如何提高采集的质量,保证平台的原创和质量)
可靠的采集神器教你如何提高采集的质量,保证平台的原创和质量,让你一次采集成百上千,还让你能够控制采集的类目,还可以实现多采集。电商日记的前端使用的就是类似的技术,通过自然排名,非常快速的提高你产品的排名,并且保证对手不知道你,从而提高你产品的曝光度,甚至让你产品有了可观的销量,同时也为你带来了流量。你可以试一下。
不同的类目,当然要不同的操作方法,大类目为了防止刷单,那么你就要写出比较高质量的文案,并且要把细节设置好,如果这些都做不好,那么你想把销量做上去是不可能的。我自己也是运营的天猫店铺,我自己一个运营的多家天猫店铺,我对这块是非常了解的,
实际操作得好多少还是有一点作用,大批量最好就是找人帮你,如果按个收费,可能就是违背你开头说的了。如果做一些活动,那么使用的时候效果会更好一些。
需要点技术来处理你链接每个商品的类目上下架周期,然后选取上下架周期上架的商品,选取你的类目了解下这个类目下近期流量趋势和售卖热点,然后进行分析,安排你上架的类目时间,然后按照数据反馈,设置每天推广量,以保证下架的时候数据反馈良好,完成上架,数据反馈不好,删除类目。重复执行上架环节,热销商品可以在下架后在上架。
可靠的采集神器(4.垃圾收集过程G1收集器的运行示意图如下的Mixed和继承人 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-05 19:29
)
1.简介
Garbage First(简称G1)collector)是垃圾采集技术发展史上的里程碑式成就:开创了“面向本地采集”的设计思想和“基于区域”的内存布局形式.
G1采集器是一个主要针对服务器应用的垃圾采集器,它的定位是“cms采集器的替代者和继承者”。其发展简史如下:
2.堆内存划分
虽然 G1 采集器也遵循分代采集理论,但它的堆内存布局与其他采集器有很大不同:
G1采集器的堆内存划分如图:
3. 暂停时间模型3.1 暂停时间模型
Pause Prediction Model:指定在M毫秒的时间段内,垃圾回收花费的时间很可能不超过N毫秒。
G1采集器之所以能建立可预测的暂停时间模型,是因为它把Region作为单次恢复的最小单位(每次采集的内存空间是Region大小的整数倍),这样可以有计划地避免整个Java堆的垃圾回收。
更具体的处理思路:让G1采集器跟踪每个Region中垃圾堆积的“值”,然后在后台维护一个优先级列表,根据用户每次设置的采集暂停时间优先回收时间收益最大的区域(这就是“垃圾优先”名称的由来)。
衡量“价值”的标准是:每次采集所获得的空间量和采集所需时间的经验值。
3.2 混合 GC
对于G1采集器之前的所有其他采集器(包括cms采集器),垃圾采集的目标范围要么是整个年轻代(Minor GC),要么是整个老年代(Major GC),要么是整个Java 堆(Full GC)。
而G1跳出了这个笼子:它可以面对堆内存的任何部分,形成一个回采集(通常称为CSet)进行回收。衡量的标准不再是它属于哪一代,而是哪一块内存收录的垃圾量最大,回收收益最大。这是G1采集器的Mixed GC模式。
4.垃圾采集过程
G1采集器运行示意图如下:
其操作过程大致可以分为以下四个步骤:
4.1 初始标记
特点
TAMS:Top at Mark Start,Region中的指针,用于并发标记时为对象分配内存空间。
4.2 并发标记
堆中对象的可达性分析从GC Root开始,递归扫描整个堆中的对象图,找到需要回收的对象。
另外,在扫描完成后,需要对STAB记录的并发期间引用发生变化的对象进行重新处理。
STAB: Snapshot At The Beginning,原创快照,参考前文的6.3 部分。
4.3 最终成绩
特点
4.4 筛选回收
特点
5. 一些细节5.1 跨区域引用对象
解决办法是使用前面《》第4节中的“内存集”,避免将整个堆扫描为GC Roots。
然而,G1 的内存集更复杂,因为:
根据经验,G1至少需要Java堆大小的10%~20%左右的额外内存空间来维持采集器的工作。
5.2 并发标记
解决方案在上一篇第6节分析:cms采集器采用增量更新算法,而G1采集器采用原创快照(STAB)算法实现。
另外,由于用户线程在并发标记时还在执行,所以肯定会继续创建新对象。
G1为每个Region设计了两个名为TAMS(Top at Mark Start)的指针,将Region中的一部分空间划分为并发采集过程中的新对象分配(默认都是alive的,没有收录在范围内)回收)。
需要注意的是,如果内存回收速度跟不上内存分配速度,G1采集器也会强制冻结用户线程的执行,导致Full GC和长时间“Stop The World” .
5.3 可靠的暂停模型
G1采集器的暂停模型基于Decaying Average的理论基础:垃圾采集过程中,G1采集器会根据每个Region的采集时间,内存中脏卡的数量等. 分析平均值、标准差等
“衰减平均值”比普通平均值更准确地表示“最近”的平均值状态。此信息用于预测如果回收现在开始将采集哪些区域,以便可以限制采集不超过预期的暂停时间。获得最高利润。
6. G1 VS cms
G1 采集器经常与cms 采集器进行比较。
不管G1的一些创新设计:可以指定最大暂停时间,子区域的内存布局,根据收入动态确定集合等等,这里只说其他一些比较常见的地点。
6.1 采集算法
G1的两种算法在运行过程中防止内存空间碎片化,并在垃圾回收完成后提供正常可用的内存。而且这对于程序长时间运行是有好处的(大对象分配内存时,由于无法找到连续的内存空间,不容易提前触发下一次采集)。
6.2 内存占用
cms 和 G1 都使用卡片表来处理跨代指针,但是 G1 的卡片表实现更复杂,区域更多(本文5.1 部分)。
相比之下cms的卡片列表比较简单,只有一份,而且只需要处理老一代到新生代的引用。
与cms相比,G1的内存占用更大。
6.3 额外的执行负载
由于两者的实现细节不同,用户程序执行时的负载会有所不同。以写屏障为例:
G1 的写屏障比cms 消耗更多的计算资源。所以cms写屏障是同步操作,而G1使用的是类似消息队列的异步操作。
总体:
这个临界点大概在6~8G(经验值)之间。
一些相关的虚拟机参数如下:
<p># 使用 G1 收集器
-XX:+UseG1GC
# 设置 Region 大小(范围 1~32M,且为 2 的 N 次幂)
-XX:G1HeapRegionSize
# 最大收集停顿时间(默认 200 毫秒)
-XX:MaxGCPauseMillis</p>
本文主要内容总结如下:
查看全部
可靠的采集神器(4.垃圾收集过程G1收集器的运行示意图如下的Mixed和继承人
)
1.简介
Garbage First(简称G1)collector)是垃圾采集技术发展史上的里程碑式成就:开创了“面向本地采集”的设计思想和“基于区域”的内存布局形式.
G1采集器是一个主要针对服务器应用的垃圾采集器,它的定位是“cms采集器的替代者和继承者”。其发展简史如下:
2.堆内存划分
虽然 G1 采集器也遵循分代采集理论,但它的堆内存布局与其他采集器有很大不同:
G1采集器的堆内存划分如图:
3. 暂停时间模型3.1 暂停时间模型
Pause Prediction Model:指定在M毫秒的时间段内,垃圾回收花费的时间很可能不超过N毫秒。
G1采集器之所以能建立可预测的暂停时间模型,是因为它把Region作为单次恢复的最小单位(每次采集的内存空间是Region大小的整数倍),这样可以有计划地避免整个Java堆的垃圾回收。
更具体的处理思路:让G1采集器跟踪每个Region中垃圾堆积的“值”,然后在后台维护一个优先级列表,根据用户每次设置的采集暂停时间优先回收时间收益最大的区域(这就是“垃圾优先”名称的由来)。
衡量“价值”的标准是:每次采集所获得的空间量和采集所需时间的经验值。
3.2 混合 GC
对于G1采集器之前的所有其他采集器(包括cms采集器),垃圾采集的目标范围要么是整个年轻代(Minor GC),要么是整个老年代(Major GC),要么是整个Java 堆(Full GC)。
而G1跳出了这个笼子:它可以面对堆内存的任何部分,形成一个回采集(通常称为CSet)进行回收。衡量的标准不再是它属于哪一代,而是哪一块内存收录的垃圾量最大,回收收益最大。这是G1采集器的Mixed GC模式。
4.垃圾采集过程
G1采集器运行示意图如下:
其操作过程大致可以分为以下四个步骤:
4.1 初始标记
特点
TAMS:Top at Mark Start,Region中的指针,用于并发标记时为对象分配内存空间。
4.2 并发标记
堆中对象的可达性分析从GC Root开始,递归扫描整个堆中的对象图,找到需要回收的对象。
另外,在扫描完成后,需要对STAB记录的并发期间引用发生变化的对象进行重新处理。
STAB: Snapshot At The Beginning,原创快照,参考前文的6.3 部分。
4.3 最终成绩
特点
4.4 筛选回收
特点
5. 一些细节5.1 跨区域引用对象
解决办法是使用前面《》第4节中的“内存集”,避免将整个堆扫描为GC Roots。
然而,G1 的内存集更复杂,因为:
根据经验,G1至少需要Java堆大小的10%~20%左右的额外内存空间来维持采集器的工作。
5.2 并发标记
解决方案在上一篇第6节分析:cms采集器采用增量更新算法,而G1采集器采用原创快照(STAB)算法实现。
另外,由于用户线程在并发标记时还在执行,所以肯定会继续创建新对象。
G1为每个Region设计了两个名为TAMS(Top at Mark Start)的指针,将Region中的一部分空间划分为并发采集过程中的新对象分配(默认都是alive的,没有收录在范围内)回收)。
需要注意的是,如果内存回收速度跟不上内存分配速度,G1采集器也会强制冻结用户线程的执行,导致Full GC和长时间“Stop The World” .
5.3 可靠的暂停模型
G1采集器的暂停模型基于Decaying Average的理论基础:垃圾采集过程中,G1采集器会根据每个Region的采集时间,内存中脏卡的数量等. 分析平均值、标准差等
“衰减平均值”比普通平均值更准确地表示“最近”的平均值状态。此信息用于预测如果回收现在开始将采集哪些区域,以便可以限制采集不超过预期的暂停时间。获得最高利润。
6. G1 VS cms
G1 采集器经常与cms 采集器进行比较。
不管G1的一些创新设计:可以指定最大暂停时间,子区域的内存布局,根据收入动态确定集合等等,这里只说其他一些比较常见的地点。
6.1 采集算法
G1的两种算法在运行过程中防止内存空间碎片化,并在垃圾回收完成后提供正常可用的内存。而且这对于程序长时间运行是有好处的(大对象分配内存时,由于无法找到连续的内存空间,不容易提前触发下一次采集)。
6.2 内存占用
cms 和 G1 都使用卡片表来处理跨代指针,但是 G1 的卡片表实现更复杂,区域更多(本文5.1 部分)。
相比之下cms的卡片列表比较简单,只有一份,而且只需要处理老一代到新生代的引用。
与cms相比,G1的内存占用更大。
6.3 额外的执行负载
由于两者的实现细节不同,用户程序执行时的负载会有所不同。以写屏障为例:
G1 的写屏障比cms 消耗更多的计算资源。所以cms写屏障是同步操作,而G1使用的是类似消息队列的异步操作。
总体:
这个临界点大概在6~8G(经验值)之间。
一些相关的虚拟机参数如下:
<p># 使用 G1 收集器
-XX:+UseG1GC
# 设置 Region 大小(范围 1~32M,且为 2 的 N 次幂)
-XX:G1HeapRegionSize
# 最大收集停顿时间(默认 200 毫秒)
-XX:MaxGCPauseMillis</p>
本文主要内容总结如下:
可靠的采集神器(可靠的采集神器,小米出的几款产品都用过)
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-09-05 07:00
可靠的采集神器,小米出的几款产品都用过,效果蛮好的,搜索质量也较高,其中有个叫四格模拟器的挺不错,比官方好用多了,
可靠的方法是发送邀请码领取,然后领取的用户会去打卡分享,分享出去的帖子就会显示当时的推荐人,从而可以到达二次营销的目的。
有个平台叫做趣推,你可以去看看。趣推-专注于二手闲置、分享、交易的平台,
闲鱼利用二手数据变现?-卖什么软件
我一直觉得帮我推荐很可靠,你可以试试的,具体是叫什么,
发个邀请,
趣推还是比较靠谱的,一开始本人也是自己做推广,但是效果也很差劲,后来身边有个朋友找到趣推,给他们的技术支持反馈,解决方案都提供了,做起来就比较顺利了。
这个我用过,
可靠,发一个就有人给你推荐,本人做过数据推广,微博,朋友圈什么的,效果都很差,但趣推上面就没这些问题,只要你愿意分享,分享出去的东西就有人会分享过来给你,有人会重复的看,是真的很方便,效果蛮好的。
还不错的,里面也有很多商家,发一条,别人就会给你推荐,
我感觉挺不错的,我用过他们一段时间,效果很好,
挺不错的,我朋友用过,效果不错的。 查看全部
可靠的采集神器(可靠的采集神器,小米出的几款产品都用过)
可靠的采集神器,小米出的几款产品都用过,效果蛮好的,搜索质量也较高,其中有个叫四格模拟器的挺不错,比官方好用多了,
可靠的方法是发送邀请码领取,然后领取的用户会去打卡分享,分享出去的帖子就会显示当时的推荐人,从而可以到达二次营销的目的。
有个平台叫做趣推,你可以去看看。趣推-专注于二手闲置、分享、交易的平台,
闲鱼利用二手数据变现?-卖什么软件
我一直觉得帮我推荐很可靠,你可以试试的,具体是叫什么,
发个邀请,
趣推还是比较靠谱的,一开始本人也是自己做推广,但是效果也很差劲,后来身边有个朋友找到趣推,给他们的技术支持反馈,解决方案都提供了,做起来就比较顺利了。
这个我用过,
可靠,发一个就有人给你推荐,本人做过数据推广,微博,朋友圈什么的,效果都很差,但趣推上面就没这些问题,只要你愿意分享,分享出去的东西就有人会分享过来给你,有人会重复的看,是真的很方便,效果蛮好的。
还不错的,里面也有很多商家,发一条,别人就会给你推荐,
我感觉挺不错的,我用过他们一段时间,效果很好,
挺不错的,我朋友用过,效果不错的。
可靠的采集神器(神灯地图大数据采集软件的使用方式有哪些?如何使用? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 235 次浏览 • 2021-09-05 00:27
)
神灯地图大数据采集software是一个行业数据采集工具,主要为用户提供各行业店铺位置信息、联系方式、商家名称;本工具基于各大主流地图引擎进行搜索,所有信息基本都由商家自己标注在地图上,所以信息基本上更加真实可靠;神灯地图大数据采集软件的使用方法很简单,先选择一个城市,然后选择地图,然后用关键词轻松找到。软件可根据用户需求提供过滤功能,轻松帮助用户剔除一些不必要的信息;欢迎有需要的用户下载体验。
软件功能
1、可以为用户查询某个城市的营业地点等信息。
2、支持百度地图、腾讯地图、高德地图等主流地图。
3、支持全国大部分城市的商业数据采集。
4、支持用户使用关键字快速搜索相关行业的企业。
5、可以根据需要将搜索到的信息输出并保存为表格。
6、支持过滤功能,可以根据信息过滤掉部分商家。
软件功能
1、基于主流地图标记快速查找商家信息。
2、可以通过软件快速找到全市餐饮行业的经营信息。
3、如果您需要寻找本市美容相关的商家,可以使用本软件进行查找。
4、用户可以根据个人需要过滤掉一些不需要的信息。
5、可以直接排除不需要通过店铺名称搜索的商家。
如何使用
1、直接运行即可使用,软件界面如下:
2、进入软件,直接在输入框中输入您需要查询的城市。
3、也可以在这个界面直接点击“城市列表”选择城市。
4、以及从哪些平台获取店铺信息,可以从网站百度地图、腾讯地图、高德地图、360地图等获取。
5、然后在右边的输入框中输入店铺的行业关键词。
6、然后点击开始“采集”按钮,可以随时“停止采集”。
7、采集完成后,可以在软件的展示窗口查看周经店的名称、数据来源、品类等信息。
8、您可以点击“导出结果”按钮。
9、然后将其输出保存到计算机,它支持多种文档格式。
查看全部
可靠的采集神器(神灯地图大数据采集软件的使用方式有哪些?如何使用?
)
神灯地图大数据采集software是一个行业数据采集工具,主要为用户提供各行业店铺位置信息、联系方式、商家名称;本工具基于各大主流地图引擎进行搜索,所有信息基本都由商家自己标注在地图上,所以信息基本上更加真实可靠;神灯地图大数据采集软件的使用方法很简单,先选择一个城市,然后选择地图,然后用关键词轻松找到。软件可根据用户需求提供过滤功能,轻松帮助用户剔除一些不必要的信息;欢迎有需要的用户下载体验。
软件功能
1、可以为用户查询某个城市的营业地点等信息。
2、支持百度地图、腾讯地图、高德地图等主流地图。
3、支持全国大部分城市的商业数据采集。
4、支持用户使用关键字快速搜索相关行业的企业。
5、可以根据需要将搜索到的信息输出并保存为表格。
6、支持过滤功能,可以根据信息过滤掉部分商家。
软件功能
1、基于主流地图标记快速查找商家信息。
2、可以通过软件快速找到全市餐饮行业的经营信息。
3、如果您需要寻找本市美容相关的商家,可以使用本软件进行查找。
4、用户可以根据个人需要过滤掉一些不需要的信息。
5、可以直接排除不需要通过店铺名称搜索的商家。
如何使用
1、直接运行即可使用,软件界面如下:
2、进入软件,直接在输入框中输入您需要查询的城市。
3、也可以在这个界面直接点击“城市列表”选择城市。
4、以及从哪些平台获取店铺信息,可以从网站百度地图、腾讯地图、高德地图、360地图等获取。
5、然后在右边的输入框中输入店铺的行业关键词。
6、然后点击开始“采集”按钮,可以随时“停止采集”。
7、采集完成后,可以在软件的展示窗口查看周经店的名称、数据来源、品类等信息。
8、您可以点击“导出结果”按钮。
9、然后将其输出保存到计算机,它支持多种文档格式。
可靠的采集神器(可靠的采集神器,可以采集,微信、qq、陌陌、等所有网站的消息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 274 次浏览 • 2021-09-04 23:05
可靠的采集神器,可以采集,微信、qq、陌陌、等所有网站的消息,批量采集每一个网站的采集,真人秒回,qq秒回,
1、点击“添加采集微信号”;
2、选择“全部”的网站;
3、输入开始键,
4、选择“微信”,
5、等待一秒的延时,
6、导出格式选择mp4或者word;
7、可以传说中的“批量采集群消息”,分享到你的qq或者微信群里。而且,采集到的消息全部都是真人秒回、秒回!是不是很酷,
他们经常不发消息,你可以加群。我刚刚我就加了几个这样的群。经常发消息发过来qq号的qq。有给我解释一下的。也有不理的。人就那么多。但是真正发消息给你的真不少。
有的!
他们发过来的并不一定是你想要的,尤其陌生人发信息的那几条,直接删除,如果要批量的话,我知道几个软件,你可以试试:比如scrapy,集成了tornado框架,通过写一个简单的api调用,就可以发所有的聊天信息,他们发过来的也都是真人回复的信息,包括电话和短信,批量发信息大概需要几十条,比如500个群,500条信息。
如果你想每一个群批量发消息和短信,那就需要注册一个搜索引擎,用百度或者谷歌搜索,如果不想写这么复杂,那么可以采用爬虫的方式批量采集,就是去爬一个网站上你想要的信息,记录采集工具给你发的消息邮箱,然后再将采集的信息都发到这个网站的服务器就可以批量发消息和短信了,比如你采集智能手机手机浏览器信息,然后将网站发到服务器,客户端就会有你发送的信息和短信。
这种简单的批量操作也可以批量发送短信和发送邮件,比如我们将短信发到gmail邮箱服务器然后手机端收到之后再发送到邮箱即可,比如你能把发送邮件和发送短信的信息自动整理到excel表格里,然后将同样的信息用excel表格的格式发送过去,对方就可以自动把你的信息发送给对方。 查看全部
可靠的采集神器(可靠的采集神器,可以采集,微信、qq、陌陌、等所有网站的消息)
可靠的采集神器,可以采集,微信、qq、陌陌、等所有网站的消息,批量采集每一个网站的采集,真人秒回,qq秒回,
1、点击“添加采集微信号”;
2、选择“全部”的网站;
3、输入开始键,
4、选择“微信”,
5、等待一秒的延时,
6、导出格式选择mp4或者word;
7、可以传说中的“批量采集群消息”,分享到你的qq或者微信群里。而且,采集到的消息全部都是真人秒回、秒回!是不是很酷,
他们经常不发消息,你可以加群。我刚刚我就加了几个这样的群。经常发消息发过来qq号的qq。有给我解释一下的。也有不理的。人就那么多。但是真正发消息给你的真不少。
有的!
他们发过来的并不一定是你想要的,尤其陌生人发信息的那几条,直接删除,如果要批量的话,我知道几个软件,你可以试试:比如scrapy,集成了tornado框架,通过写一个简单的api调用,就可以发所有的聊天信息,他们发过来的也都是真人回复的信息,包括电话和短信,批量发信息大概需要几十条,比如500个群,500条信息。
如果你想每一个群批量发消息和短信,那就需要注册一个搜索引擎,用百度或者谷歌搜索,如果不想写这么复杂,那么可以采用爬虫的方式批量采集,就是去爬一个网站上你想要的信息,记录采集工具给你发的消息邮箱,然后再将采集的信息都发到这个网站的服务器就可以批量发消息和短信了,比如你采集智能手机手机浏览器信息,然后将网站发到服务器,客户端就会有你发送的信息和短信。
这种简单的批量操作也可以批量发送短信和发送邮件,比如我们将短信发到gmail邮箱服务器然后手机端收到之后再发送到邮箱即可,比如你能把发送邮件和发送短信的信息自动整理到excel表格里,然后将同样的信息用excel表格的格式发送过去,对方就可以自动把你的信息发送给对方。
可靠的采集神器(youiss:京东数据采集神器!免费,靠谱的购物网站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2021-09-04 10:03
可靠的采集神器实时监控京东商品微信、支付宝、等平台的库存,商品详情页实时的整理,爆款商品过滤,都是免费的,这个是小猪云采集的,你自己去看看,我去过这个平台看过,操作起来很简单的,就是引导分享,我分享过一次,
youiss:京东数据采集神器!免费,
靠谱的购物网站需要大家经常浏览,购物网站购物量大,容易刷单,所以市面上各种网站基本上要买就买,要么就不买。随便选几个进去看看页面,观察一下用户评价的商品,选择买了看看评价,然后在考虑下一个网站。
购物网站太多,去哪家都要考虑,哪个平台方便用户浏览,哪个平台方便用户购买,这是两个问题。靠谱的购物网站都有保障。如果可以的话,可以先去上了解一下,看看价格合理不合理,买家评价怎么样。一定要考虑服务啊,售后能不能保障啊,不然买来就被骗,那就真的尴尬了。
方向性的问题不大,其实各个购物平台都可以试试!因为我是个外行人,不知道哪个平台比较靠谱!但是像和京东都会好一些,毕竟电商的效应已经形成,谁也不敢贸然加大投入去改变原有的市场和模式!说不靠谱的,只能说应该没买过靠谱的电商产品, 查看全部
可靠的采集神器(youiss:京东数据采集神器!免费,靠谱的购物网站)
可靠的采集神器实时监控京东商品微信、支付宝、等平台的库存,商品详情页实时的整理,爆款商品过滤,都是免费的,这个是小猪云采集的,你自己去看看,我去过这个平台看过,操作起来很简单的,就是引导分享,我分享过一次,
youiss:京东数据采集神器!免费,
靠谱的购物网站需要大家经常浏览,购物网站购物量大,容易刷单,所以市面上各种网站基本上要买就买,要么就不买。随便选几个进去看看页面,观察一下用户评价的商品,选择买了看看评价,然后在考虑下一个网站。
购物网站太多,去哪家都要考虑,哪个平台方便用户浏览,哪个平台方便用户购买,这是两个问题。靠谱的购物网站都有保障。如果可以的话,可以先去上了解一下,看看价格合理不合理,买家评价怎么样。一定要考虑服务啊,售后能不能保障啊,不然买来就被骗,那就真的尴尬了。
方向性的问题不大,其实各个购物平台都可以试试!因为我是个外行人,不知道哪个平台比较靠谱!但是像和京东都会好一些,毕竟电商的效应已经形成,谁也不敢贸然加大投入去改变原有的市场和模式!说不靠谱的,只能说应该没买过靠谱的电商产品,
可靠的采集神器(storefront链接页面个人店product页面各类页面采集还在不断增加中采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-09-03 08:02
店面链接页面
个人商店产品页面
各种页面采集还在增加
采集前说
采集storefront 店铺备注:
如果是采集storefront连接,必须点击店铺的XXXX店面链接才能进入到采集的商品列表页面,如下图,点击进入,复制网址到软件采集。
温馨提示:如果需要全自动,也可以在系统设置中开启“智能网址自动转换”功能。开启后可以直接把店铺首页网址丢给软件,软件会自动为你点击xxxx店面进入店铺商品页面采集,大大提高你的效率
如果不开启采集this页面的智能URL自动转换,采集products页面的产品信息将默认显示(仅限20177788及以上)!
批量采集ASIN 流程
单击可批量添加或添加任务。您可以在软件中添加您想要采集 的商店或搜索结果等网址。
批量添加:每行可以批量添加一个网址到软件中
添加任务:您可以为采集添加单个ASIN到软件
这里是一个批量添加的例子,如下图
补充:添加采集链接可以添加多行,每行一个链接就够了,可以采集搜索结果链接,店面链接,分类TOP100页面。也可以直接输入搜索词,软件会自动识别。
如果要设置任务的采集页数、采集开头的页数、每页采集的页数,可以双击任务,或者点击“添加任务”设置每个任务的数量
采集 无需选择连接目标国家,软件会自动识别连接所属国家。
添加任务后,勾选你想要的任务采集,然后点击开始按钮
软件会自动启动采集。按照顺序,从第一个任务采集到最后一个任务,每个任务都会自动翻页采集,并且会采集页面上的所有产品。
注意:亚马逊有展示限制。亚马逊只能显示与页面一样多的数据采集。例如,如果最多只有400页,则只能显示采集400页数据。暂时无法突破限制采集更多产品。
采集task,只有采集才能进入产品列表页面的基本信息,但是如果您还需要采集每个产品型号、高清图片、颜色和尺寸、购物车价格,请关注-up数量,重量、尺寸、RANK等信息,详细信息需采集。
采集详细信息是什么
采集详细信息功能是采集每个ASIN商品页面的数据,比如它们的变种(子商品)、高清图片、详细图片等,这些数据都在商品详情上页
<p>必须采集detailed信息才能获得采集数据:buybox价格、变体、变体型号、长度描述、等级、上架时间、高清图片、详细图片、报价数量、最低报价 查看全部
可靠的采集神器(storefront链接页面个人店product页面各类页面采集还在不断增加中采集)
店面链接页面
个人商店产品页面
各种页面采集还在增加
采集前说
采集storefront 店铺备注:
如果是采集storefront连接,必须点击店铺的XXXX店面链接才能进入到采集的商品列表页面,如下图,点击进入,复制网址到软件采集。
温馨提示:如果需要全自动,也可以在系统设置中开启“智能网址自动转换”功能。开启后可以直接把店铺首页网址丢给软件,软件会自动为你点击xxxx店面进入店铺商品页面采集,大大提高你的效率
如果不开启采集this页面的智能URL自动转换,采集products页面的产品信息将默认显示(仅限20177788及以上)!
批量采集ASIN 流程
单击可批量添加或添加任务。您可以在软件中添加您想要采集 的商店或搜索结果等网址。
批量添加:每行可以批量添加一个网址到软件中
添加任务:您可以为采集添加单个ASIN到软件
这里是一个批量添加的例子,如下图
补充:添加采集链接可以添加多行,每行一个链接就够了,可以采集搜索结果链接,店面链接,分类TOP100页面。也可以直接输入搜索词,软件会自动识别。
如果要设置任务的采集页数、采集开头的页数、每页采集的页数,可以双击任务,或者点击“添加任务”设置每个任务的数量
采集 无需选择连接目标国家,软件会自动识别连接所属国家。
添加任务后,勾选你想要的任务采集,然后点击开始按钮
软件会自动启动采集。按照顺序,从第一个任务采集到最后一个任务,每个任务都会自动翻页采集,并且会采集页面上的所有产品。
注意:亚马逊有展示限制。亚马逊只能显示与页面一样多的数据采集。例如,如果最多只有400页,则只能显示采集400页数据。暂时无法突破限制采集更多产品。
采集task,只有采集才能进入产品列表页面的基本信息,但是如果您还需要采集每个产品型号、高清图片、颜色和尺寸、购物车价格,请关注-up数量,重量、尺寸、RANK等信息,详细信息需采集。
采集详细信息是什么
采集详细信息功能是采集每个ASIN商品页面的数据,比如它们的变种(子商品)、高清图片、详细图片等,这些数据都在商品详情上页
<p>必须采集detailed信息才能获得采集数据:buybox价格、变体、变体型号、长度描述、等级、上架时间、高清图片、详细图片、报价数量、最低报价
可靠的采集神器(Flume架构及核心组件Flume的架构图:Flume实战案例 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2021-09-02 01:08
)
Flume 概览
官方文档:
Flume 是一个分布式、高可靠、高可用的日志数据采集服务,可以高效地采集、聚合和移动大量的日志数据。它具有基于流数据的简单灵活的架构。它具有健壮性和容错性,具有可调节的可靠性机制以及许多故障转移和恢复机制。它使用简单且可扩展的数据模型来允许对应用程序进行在线分析。
Flume 架构和核心组件
Flume 的架构图:
Flume 部署
准备JDK环境:
[root@hadoop01 ~]# java -version
java version "11.0.8" 2020-07-14 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.8+10-LTS)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.8+10-LTS, mixed mode)
[root@hadoop01 ~]#
下载 Flum:
复制下载链接下载:
[root@hadoop01 ~]# cd /usr/local/src
[root@hadoop01 /usr/local/src]# wget https://archive.cloudera.com/c ... ar.gz
解压到合适的目录:
[root@hadoop01 /usr/local/src]# tar -zxvf flume-ng-1.6.0-cdh5.16.2.tar.gz -C /usr/local
[root@hadoop01 /usr/local/src]# cd /usr/local/apache-flume-1.6.0-cdh5.16.2-bin/
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# ls
bin CHANGELOG cloudera conf DEVNOTES docs lib LICENSE NOTICE README RELEASE-NOTES tools
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]#
配置环境变量:
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# vim ~/.bash_profile
export FLUME_HOME=/usr/local/apache-flume-1.6.0-cdh5.16.2-bin
export PATH=$PATH:$FLUME_HOME/bin
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# source ~/.bash_profile
编辑配置文件:
[root@hadoop01 ~]# cp $FLUME_HOME/conf/flume-env.sh.template $FLUME_HOME/conf/flume-env.sh
[root@hadoop01 ~]# vim $FLUME_HOME/conf/flume-env.sh
# 配置JDK
export JAVA_HOME=/usr/local/jdk/11
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
测试flume-ng命令:
[root@hadoop01 ~]# flume-ng version
Flume 1.6.0-cdh5.16.2
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: df92badde3691ee3eb6074a177f0e96682345381
Compiled by jenkins on Mon Jun 3 03:49:33 PDT 2019
From source with checksum 9336bfa3ff8cfb5e20cd9d700135a2c1
[root@hadoop01 ~]#
Flume实战案例-从指定网口采集输出数据到控制台
使用Flume的关键是写配置文件:
配置Source,配置Channel,配置Sink,将以上三个组件串起来
所以先创建一个配置文件:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/netcat-example.conf
# a1是agent的名称
a1.sources = r1 # source的名称
a1.sinks = k1 # sink的名称
a1.channels = c1 # channel的名称
# 描述和配置source
a1.sources.r1.type = netcat # 指定source的类型为netcat
a1.sources.r1.bind = localhost # 指定source的ip
a1.sources.r1.port = 44444 # 指定source的端口
# 定义sink
a1.sinks.k1.type = logger # 指定sink类型,logger就是将数据输出到控制台
# 定义一个基于内存的channel
a1.channels.c1.type = memory # channel类型
a1.channels.c1.capacity = 1000 # channel的容量
a1.channels.c1.transactionCapacity = 100 # channel中每个事务的最大事件数
# 将source和sink绑定到channel上,即将三者串连起来
a1.sources.r1.channels = c1 # 指定r1这个source的channel为c1
a1.sinks.k1.channel = c1 # 指定k1这个sink的channel为c1
启动代理:
[root@hadoop01 ~]# flume-ng agent --name a1 -c $FLUME_HOME/conf -f $FLUME_HOME/conf/netcat-example.conf -Dflume.root.logger=INFO,console
然后通过telnet命令向44444端口发送一些数据:
[root@hadoop01 ~]# telnet localhost 44444
...
hello flume
OK
此时会看到flume的输出中打印了接收到的数据:
2020-11-02 16:08:47,965 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 0D hello flume. }
Flume实战案例-实时监控一个文件采集新增数据输出到控制台
同理,先创建一个配置文件:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/file-example.conf
# a1是agent的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -f /data/data.log
a1.sources.r1.shell = /bin/sh -c
# 定义sink
a1.sinks.k1.type = logger
# 定义一个基于内存的channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
创建一个测试文件:
[root@hadoop01 ~]# touch /data/data.log
启动代理:
[root@hadoop01 ~]# flume-ng agent --name a1 -c $FLUME_HOME/conf -f $FLUME_HOME/conf/file-example.conf -Dflume.root.logger=INFO,console
向 data.log 写入一些内容:
[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello world" >> /data/data.log
此时flume的输出中,会看到打印了监控文件的新数据:
2020-11-02 16:21:26,946 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 hello flume }
2020-11-02 16:21:38,707 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 77 6F 72 6C 64 hello world }
Flume 实际案例-实时采集 登录服务器 A 到服务器 B
要达到这个要求,需要使用Avro的Source和SInk。流程图如下:
为了测试方便,我这里用机器进行模拟。首先,A机的配置文件如下:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/exec-memory-avro.conf
# 定义各个组件的名称
exec-memory-avro.sources = exec-source
exec-memory-avro.sinks = avro-sink
exec-memory-avro.channels = memory-channel
# 描述和配置source
exec-memory-avro.sources.exec-source.type = exec
exec-memory-avro.sources.exec-source.command = tail -f /data/data.log
exec-memory-avro.sources.exec-source.shell = /bin/sh -c
# 定义sink
exec-memory-avro.sinks.avro-sink.type = avro
exec-memory-avro.sinks.avro-sink.hostname = hadoop01
exec-memory-avro.sinks.avro-sink.port = 44444
# 定义一个基于内存的channel
exec-memory-avro.channels.memory-channel.type = memory
exec-memory-avro.channels.memory-channel.capacity = 1000
exec-memory-avro.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
exec-memory-avro.sources.exec-source.channels = memory-channel
exec-memory-avro.sinks.avro-sink.channel = memory-channel
机器B的配置文件如下:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/avro-memory-logger.conf
# 定义各个组件的名称
avro-memory-logger.sources = avro-source
avro-memory-logger.sinks = logger-sink
avro-memory-logger.channels = memory-channel
# 描述和配置source
avro-memory-logger.sources.avro-source.type = avro
avro-memory-logger.sources.avro-source.bind = hadoop01
avro-memory-logger.sources.avro-source.port = 44444
# 定义sink
avro-memory-logger.sinks.logger-sink.type = logger
# 定义一个基于内存的channel
avro-memory-logger.channels.memory-channel.type = memory
avro-memory-logger.channels.memory-channel.capacity = 1000
avro-memory-logger.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
avro-memory-logger.sources.avro-source.channels = memory-channel
avro-memory-logger.sinks.logger-sink.channel = memory-channel
先启动机器B的agent,否则机器A的agent如果不能监听目标机器的端口可能会报错:
[root@hadoop01 ~]# flume-ng agent --name avro-memory-logger -c $FLUME_HOME/conf -f $FLUME_HOME/conf/avro-memory-logger.conf -Dflume.root.logger=INFO,console
启动机器A的代理:
[root@hadoop01 ~]# flume-ng agent --name exec-memory-avro -c $FLUME_HOME/conf -f $FLUME_HOME/conf/exec-memory-avro.conf -Dflume.root.logger=INFO,console
向 data.log 写入一些内容:
[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello world" >> /data/data.log
[root@hadoop01 ~]# echo "hello avro" >> /data/data.log
此时B机的agent在控制台的输出如下,于是我们就实现了A服务器上的日志实时采集到B服务器的功能:
2020-11-02 17:05:20,929 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 hello flume }
2020-11-02 17:05:21,486 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 77 6F 72 6C 64 hello world }
2020-11-02 17:05:51,505 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 61 76 72 6F hello avro }
集成Flume和Kafka完成实时数据采集
在上面的例子中,Agent B 将采集到的数据下沉到控制台,但在实际应用中它显然不会这样做。相反,它通常将数据接收到外部数据源。如HDFS、ES、Kafka等。在实时流处理架构中,大多数情况下,Sink到Kafka,然后下游消费者(一个或多个)接收数据进行实时处理。如下图所示:
所以基于前面的例子,这里是如何集成Kafka的。其实很简单,把Logger Sink改成Kafka Sink就可以了。切换到Kafka后的流程如下:
新建一个配置文件,内容如下:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/avro-memory-kafka.conf
# 定义各个组件的名称
avro-memory-kafka.sources = avro-source
avro-memory-kafka.sinks = kafka-sink
avro-memory-kafka.channels = memory-channel
# 描述和配置source
avro-memory-kafka.sources.avro-source.type = avro
avro-memory-kafka.sources.avro-source.bind = hadoop01
avro-memory-kafka.sources.avro-source.port = 44444
# 定义sink
avro-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
avro-memory-kafka.sinks.kafka-sink.brokerList = kafka01:9092
avro-memory-kafka.sinks.kafka-sink.topic = flume-topic
# 一个批次里发送多少消息
avro-memory-kafka.sinks.kafka-sink.batchSize = 5
# 指定采用的ack模式,可以参考kafka的ack机制
avro-memory-kafka.sinks.kafka-sink.requiredAcks = 1
# 定义一个基于内存的channel
avro-memory-kafka.channels.memory-channel.type = memory
avro-memory-kafka.channels.memory-channel.capacity = 1000
avro-memory-kafka.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
avro-memory-kafka.sources.avro-source.channels = memory-channel
avro-memory-kafka.sinks.kafka-sink.channel = memory-channel
配置完成后,启动Agent:
[root@hadoop01 ~]# flume-ng agent --name avro-memory-kafka -c $FLUME_HOME/conf -f $FLUME_HOME/conf/avro-memory-kafka.conf -Dflume.root.logger=INFO,console
然后启动另一个代理:
[root@hadoop01 ~]# flume-ng agent --name exec-memory-avro -c $FLUME_HOME/conf -f $FLUME_HOME/conf/exec-memory-avro.conf -Dflume.root.logger=INFO,console
启动一个Kafka消费者,方便观察Kafka收到的数据:
[root@kafka01 ~]# kafka-console-consumer.sh --bootstrap-server kafka01:9092 --topic flume-topic --from-beginning
向 data.log 写入一些内容:
[root@hadoop01 ~]# echo "hello kafka sink" >> /data/data.log
[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello agent" >> /data/data.log
此时Kafka消费者控制台正常情况下会输出如下内容,证明Flume和Kafka已经成功集成:
[root@kafka01 ~]# kafka-console-consumer.sh --bootstrap-server kafka01:9092 --topic flume-topic --from-beginning
hello kafka sink
hello flume
hello agent 查看全部
可靠的采集神器(Flume架构及核心组件Flume的架构图:Flume实战案例
)
Flume 概览
官方文档:
Flume 是一个分布式、高可靠、高可用的日志数据采集服务,可以高效地采集、聚合和移动大量的日志数据。它具有基于流数据的简单灵活的架构。它具有健壮性和容错性,具有可调节的可靠性机制以及许多故障转移和恢复机制。它使用简单且可扩展的数据模型来允许对应用程序进行在线分析。
Flume 架构和核心组件
Flume 的架构图:
Flume 部署
准备JDK环境:
[root@hadoop01 ~]# java -version
java version "11.0.8" 2020-07-14 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.8+10-LTS)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.8+10-LTS, mixed mode)
[root@hadoop01 ~]#
下载 Flum:
复制下载链接下载:
[root@hadoop01 ~]# cd /usr/local/src
[root@hadoop01 /usr/local/src]# wget https://archive.cloudera.com/c ... ar.gz
解压到合适的目录:
[root@hadoop01 /usr/local/src]# tar -zxvf flume-ng-1.6.0-cdh5.16.2.tar.gz -C /usr/local
[root@hadoop01 /usr/local/src]# cd /usr/local/apache-flume-1.6.0-cdh5.16.2-bin/
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# ls
bin CHANGELOG cloudera conf DEVNOTES docs lib LICENSE NOTICE README RELEASE-NOTES tools
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]#
配置环境变量:
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# vim ~/.bash_profile
export FLUME_HOME=/usr/local/apache-flume-1.6.0-cdh5.16.2-bin
export PATH=$PATH:$FLUME_HOME/bin
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# source ~/.bash_profile
编辑配置文件:
[root@hadoop01 ~]# cp $FLUME_HOME/conf/flume-env.sh.template $FLUME_HOME/conf/flume-env.sh
[root@hadoop01 ~]# vim $FLUME_HOME/conf/flume-env.sh
# 配置JDK
export JAVA_HOME=/usr/local/jdk/11
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
测试flume-ng命令:
[root@hadoop01 ~]# flume-ng version
Flume 1.6.0-cdh5.16.2
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: df92badde3691ee3eb6074a177f0e96682345381
Compiled by jenkins on Mon Jun 3 03:49:33 PDT 2019
From source with checksum 9336bfa3ff8cfb5e20cd9d700135a2c1
[root@hadoop01 ~]#
Flume实战案例-从指定网口采集输出数据到控制台
使用Flume的关键是写配置文件:
配置Source,配置Channel,配置Sink,将以上三个组件串起来
所以先创建一个配置文件:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/netcat-example.conf
# a1是agent的名称
a1.sources = r1 # source的名称
a1.sinks = k1 # sink的名称
a1.channels = c1 # channel的名称
# 描述和配置source
a1.sources.r1.type = netcat # 指定source的类型为netcat
a1.sources.r1.bind = localhost # 指定source的ip
a1.sources.r1.port = 44444 # 指定source的端口
# 定义sink
a1.sinks.k1.type = logger # 指定sink类型,logger就是将数据输出到控制台
# 定义一个基于内存的channel
a1.channels.c1.type = memory # channel类型
a1.channels.c1.capacity = 1000 # channel的容量
a1.channels.c1.transactionCapacity = 100 # channel中每个事务的最大事件数
# 将source和sink绑定到channel上,即将三者串连起来
a1.sources.r1.channels = c1 # 指定r1这个source的channel为c1
a1.sinks.k1.channel = c1 # 指定k1这个sink的channel为c1
启动代理:
[root@hadoop01 ~]# flume-ng agent --name a1 -c $FLUME_HOME/conf -f $FLUME_HOME/conf/netcat-example.conf -Dflume.root.logger=INFO,console
然后通过telnet命令向44444端口发送一些数据:
[root@hadoop01 ~]# telnet localhost 44444
...
hello flume
OK
此时会看到flume的输出中打印了接收到的数据:
2020-11-02 16:08:47,965 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 0D hello flume. }
Flume实战案例-实时监控一个文件采集新增数据输出到控制台
同理,先创建一个配置文件:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/file-example.conf
# a1是agent的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -f /data/data.log
a1.sources.r1.shell = /bin/sh -c
# 定义sink
a1.sinks.k1.type = logger
# 定义一个基于内存的channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
创建一个测试文件:
[root@hadoop01 ~]# touch /data/data.log
启动代理:
[root@hadoop01 ~]# flume-ng agent --name a1 -c $FLUME_HOME/conf -f $FLUME_HOME/conf/file-example.conf -Dflume.root.logger=INFO,console
向 data.log 写入一些内容:
[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello world" >> /data/data.log
此时flume的输出中,会看到打印了监控文件的新数据:
2020-11-02 16:21:26,946 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 hello flume }
2020-11-02 16:21:38,707 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 77 6F 72 6C 64 hello world }
Flume 实际案例-实时采集 登录服务器 A 到服务器 B
要达到这个要求,需要使用Avro的Source和SInk。流程图如下:
为了测试方便,我这里用机器进行模拟。首先,A机的配置文件如下:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/exec-memory-avro.conf
# 定义各个组件的名称
exec-memory-avro.sources = exec-source
exec-memory-avro.sinks = avro-sink
exec-memory-avro.channels = memory-channel
# 描述和配置source
exec-memory-avro.sources.exec-source.type = exec
exec-memory-avro.sources.exec-source.command = tail -f /data/data.log
exec-memory-avro.sources.exec-source.shell = /bin/sh -c
# 定义sink
exec-memory-avro.sinks.avro-sink.type = avro
exec-memory-avro.sinks.avro-sink.hostname = hadoop01
exec-memory-avro.sinks.avro-sink.port = 44444
# 定义一个基于内存的channel
exec-memory-avro.channels.memory-channel.type = memory
exec-memory-avro.channels.memory-channel.capacity = 1000
exec-memory-avro.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
exec-memory-avro.sources.exec-source.channels = memory-channel
exec-memory-avro.sinks.avro-sink.channel = memory-channel
机器B的配置文件如下:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/avro-memory-logger.conf
# 定义各个组件的名称
avro-memory-logger.sources = avro-source
avro-memory-logger.sinks = logger-sink
avro-memory-logger.channels = memory-channel
# 描述和配置source
avro-memory-logger.sources.avro-source.type = avro
avro-memory-logger.sources.avro-source.bind = hadoop01
avro-memory-logger.sources.avro-source.port = 44444
# 定义sink
avro-memory-logger.sinks.logger-sink.type = logger
# 定义一个基于内存的channel
avro-memory-logger.channels.memory-channel.type = memory
avro-memory-logger.channels.memory-channel.capacity = 1000
avro-memory-logger.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
avro-memory-logger.sources.avro-source.channels = memory-channel
avro-memory-logger.sinks.logger-sink.channel = memory-channel
先启动机器B的agent,否则机器A的agent如果不能监听目标机器的端口可能会报错:
[root@hadoop01 ~]# flume-ng agent --name avro-memory-logger -c $FLUME_HOME/conf -f $FLUME_HOME/conf/avro-memory-logger.conf -Dflume.root.logger=INFO,console
启动机器A的代理:
[root@hadoop01 ~]# flume-ng agent --name exec-memory-avro -c $FLUME_HOME/conf -f $FLUME_HOME/conf/exec-memory-avro.conf -Dflume.root.logger=INFO,console
向 data.log 写入一些内容:
[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello world" >> /data/data.log
[root@hadoop01 ~]# echo "hello avro" >> /data/data.log
此时B机的agent在控制台的输出如下,于是我们就实现了A服务器上的日志实时采集到B服务器的功能:
2020-11-02 17:05:20,929 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 hello flume }
2020-11-02 17:05:21,486 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 77 6F 72 6C 64 hello world }
2020-11-02 17:05:51,505 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 61 76 72 6F hello avro }
集成Flume和Kafka完成实时数据采集
在上面的例子中,Agent B 将采集到的数据下沉到控制台,但在实际应用中它显然不会这样做。相反,它通常将数据接收到外部数据源。如HDFS、ES、Kafka等。在实时流处理架构中,大多数情况下,Sink到Kafka,然后下游消费者(一个或多个)接收数据进行实时处理。如下图所示:
所以基于前面的例子,这里是如何集成Kafka的。其实很简单,把Logger Sink改成Kafka Sink就可以了。切换到Kafka后的流程如下:
新建一个配置文件,内容如下:
[root@hadoop01 ~]# vim $FLUME_HOME/conf/avro-memory-kafka.conf
# 定义各个组件的名称
avro-memory-kafka.sources = avro-source
avro-memory-kafka.sinks = kafka-sink
avro-memory-kafka.channels = memory-channel
# 描述和配置source
avro-memory-kafka.sources.avro-source.type = avro
avro-memory-kafka.sources.avro-source.bind = hadoop01
avro-memory-kafka.sources.avro-source.port = 44444
# 定义sink
avro-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
avro-memory-kafka.sinks.kafka-sink.brokerList = kafka01:9092
avro-memory-kafka.sinks.kafka-sink.topic = flume-topic
# 一个批次里发送多少消息
avro-memory-kafka.sinks.kafka-sink.batchSize = 5
# 指定采用的ack模式,可以参考kafka的ack机制
avro-memory-kafka.sinks.kafka-sink.requiredAcks = 1
# 定义一个基于内存的channel
avro-memory-kafka.channels.memory-channel.type = memory
avro-memory-kafka.channels.memory-channel.capacity = 1000
avro-memory-kafka.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
avro-memory-kafka.sources.avro-source.channels = memory-channel
avro-memory-kafka.sinks.kafka-sink.channel = memory-channel
配置完成后,启动Agent:
[root@hadoop01 ~]# flume-ng agent --name avro-memory-kafka -c $FLUME_HOME/conf -f $FLUME_HOME/conf/avro-memory-kafka.conf -Dflume.root.logger=INFO,console
然后启动另一个代理:
[root@hadoop01 ~]# flume-ng agent --name exec-memory-avro -c $FLUME_HOME/conf -f $FLUME_HOME/conf/exec-memory-avro.conf -Dflume.root.logger=INFO,console
启动一个Kafka消费者,方便观察Kafka收到的数据:
[root@kafka01 ~]# kafka-console-consumer.sh --bootstrap-server kafka01:9092 --topic flume-topic --from-beginning
向 data.log 写入一些内容:
[root@hadoop01 ~]# echo "hello kafka sink" >> /data/data.log
[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello agent" >> /data/data.log
此时Kafka消费者控制台正常情况下会输出如下内容,证明Flume和Kafka已经成功集成:
[root@kafka01 ~]# kafka-console-consumer.sh --bootstrap-server kafka01:9092 --topic flume-topic --from-beginning
hello kafka sink
hello flume
hello agent
可靠的采集神器(可靠的采集神器神器大多数会帮助大家有效的解决)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-08-29 19:03
可靠的采集神器神器大多数会帮助大家有效的解决爬虫系统,爬虫,也就是分布式爬虫系统,抓取数据的问题,跟其他的算法运算系统一样,也是需要有瓶颈的问题的,那么针对爬虫需要什么数据,需要爬取什么数据,我们需要哪些数据。经常使用爬虫的大多是金融采集,数据来源广泛,只需要爬虫功能就可以有相应的数据采集功能。经常使用爬虫的多是大数据的项目,数据来源非常不确定,需要确定数据来源的来源,而且数据处理量巨大,爬虫算法和网站数据流也需要有一定的经验。
我想让神器帮助大家解决以上的一些问题。一:完整爬虫系统架构数据采集下来以后,就需要解决部署的问题,用户只需要配置正则表达式和数据采集库就可以直接把爬虫系统部署到互联网上去了,数据采集系统的数据库表等部署就可以通过改成mysql或者其他的关系型数据库就可以了。数据采集系统架构示意二:开发需要一定的经验针对这种新的系统,在刚开始的时候,需要先了解整个数据采集下来的细节。
需要有合理的设计,尽量在最短的时间内建立一个完整的数据采集系统,以便于后期的爬虫程序或者工程的开发和维护。数据采集系统框架示意三:要确定好目标网站根据我们自己的情况,确定目标网站,和这个网站里面有哪些数据,是常用数据还是新数据,以及这些数据是否是机构或者个人,是否对我们爬虫要求有特别的要求,比如要爬取部分是国家标准或者行业标准,有的是涉及到数据价值的,有的数据可能是有不一样的价值和用途,有些是对我们爬虫要求有要求的,我们需要先准备数据处理的工具。
一些做业务的公司或者个人想要爬取bat等巨头的数据,那么爬虫开发,和其他涉及到数据管理的软件以及工具也是必须要准备好的。数据采集系统框架示意四:要结合行业经验这个时候我们也要考虑爬虫系统的可用性,系统可扩展性,一些小功能的使用,比如原来你爬取一个的数据,现在可以往里面爬取人人网或者腾讯的数据,也可以用来爬取饿了么等这些网站,是可以在爬取一个行业标准的数据,来实现其他的内容。
所以,建议最好是跟同行业或者相关公司有一定的经验和接触才行。数据采集系统框架示意五:数据存储要做好综合考虑要完成一个完整的数据采集系统,所需要考虑的肯定是数据存储,数据实时存储,数据海量存储等等,对于大的网站有可能需要mysql,关系型数据库,数据库队列等这些存储方式,对于小的网站,可能可以用redis,emr等这些其他方式,主要是看爬虫系统的规模而定。数据采集系统框架示意六:拓展性要做好最初的架构设计确定好架构和数据存储后, 查看全部
可靠的采集神器(可靠的采集神器神器大多数会帮助大家有效的解决)
可靠的采集神器神器大多数会帮助大家有效的解决爬虫系统,爬虫,也就是分布式爬虫系统,抓取数据的问题,跟其他的算法运算系统一样,也是需要有瓶颈的问题的,那么针对爬虫需要什么数据,需要爬取什么数据,我们需要哪些数据。经常使用爬虫的大多是金融采集,数据来源广泛,只需要爬虫功能就可以有相应的数据采集功能。经常使用爬虫的多是大数据的项目,数据来源非常不确定,需要确定数据来源的来源,而且数据处理量巨大,爬虫算法和网站数据流也需要有一定的经验。
我想让神器帮助大家解决以上的一些问题。一:完整爬虫系统架构数据采集下来以后,就需要解决部署的问题,用户只需要配置正则表达式和数据采集库就可以直接把爬虫系统部署到互联网上去了,数据采集系统的数据库表等部署就可以通过改成mysql或者其他的关系型数据库就可以了。数据采集系统架构示意二:开发需要一定的经验针对这种新的系统,在刚开始的时候,需要先了解整个数据采集下来的细节。
需要有合理的设计,尽量在最短的时间内建立一个完整的数据采集系统,以便于后期的爬虫程序或者工程的开发和维护。数据采集系统框架示意三:要确定好目标网站根据我们自己的情况,确定目标网站,和这个网站里面有哪些数据,是常用数据还是新数据,以及这些数据是否是机构或者个人,是否对我们爬虫要求有特别的要求,比如要爬取部分是国家标准或者行业标准,有的是涉及到数据价值的,有的数据可能是有不一样的价值和用途,有些是对我们爬虫要求有要求的,我们需要先准备数据处理的工具。
一些做业务的公司或者个人想要爬取bat等巨头的数据,那么爬虫开发,和其他涉及到数据管理的软件以及工具也是必须要准备好的。数据采集系统框架示意四:要结合行业经验这个时候我们也要考虑爬虫系统的可用性,系统可扩展性,一些小功能的使用,比如原来你爬取一个的数据,现在可以往里面爬取人人网或者腾讯的数据,也可以用来爬取饿了么等这些网站,是可以在爬取一个行业标准的数据,来实现其他的内容。
所以,建议最好是跟同行业或者相关公司有一定的经验和接触才行。数据采集系统框架示意五:数据存储要做好综合考虑要完成一个完整的数据采集系统,所需要考虑的肯定是数据存储,数据实时存储,数据海量存储等等,对于大的网站有可能需要mysql,关系型数据库,数据库队列等这些存储方式,对于小的网站,可能可以用redis,emr等这些其他方式,主要是看爬虫系统的规模而定。数据采集系统框架示意六:拓展性要做好最初的架构设计确定好架构和数据存储后,
可靠的采集神器很多,比如我们前段时间推荐的photozoom
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-08-25 04:07
可靠的采集神器很多,比如我们前段时间推荐的photozoom是一款在线图片搜索神器,具体介绍可以看下我们之前的文章啦。戳我进入!采宝工具网上方提供图片搜索,下方支持图片收藏、评论、投票。后端支持三方外挂,想要获取更多有趣的数据请戳此地址获取支持特性免费开源、评论热度支持多平台。自带抓包、ip重定向、lzh等数据,可与很多源数据达成合作和互通。
支持热度分类检索图片,自动筛选并添加到浏览器收藏。支持热度排名第一列,图片热度高即热度大图。支持收藏图片。方便按照热度大类获取照片或其他类似图片。自动加入收藏图片。自动分享到百度文库,搜狐、豆丁等资料。中文网站翻译:可替代翻译软件,有针对大陆用户提供的个性化翻译:支持多个翻译引擎,自由切换自带发布模式:可自行调整配置搜索方式、多图搜索下方各类中文网站均提供翻译。
总结以上只是小编对这款采集神器的介绍,希望能帮助到小伙伴们!如果觉得文章不错,可以帮忙转发支持一下,谢谢~更多实用工具,欢迎关注我的微信公众号“采宝工具”获取哦~。
问题不准确,应该是图片收藏应用推荐才对吧?推荐两个实用工具app:1,zipdoc。这个挺有意思的,跟大多数任务收藏类产品不同,它能先保存下来收藏的文件,在需要的时候会自动调取并调整,不会占用本地空间。不会导致没有及时删掉的文件找不到。从此再也不用担心乱七八糟的收藏在手机里忘了找了,很方便的!2,photozoom这个是免费的图片收藏应用,如果要安装也很简单,你不用下载,上百度搜索photozoom,就会出来了。
总结:收藏应用的过程中应该包括图片收藏和分享。如果觉得收藏不符合你的需求,就需要做设置了。大部分图片类应用都提供直接导入图片的功能。如果不能导入图片。建议尝试先找到图片并导入到本地,这样才可以达到自动分类、批量分享的效果。如果有各类大图文件(多图文件,需要长时间等待),可以尝试在百度网盘上下载一个网盘文件,然后直接导入。 查看全部
可靠的采集神器很多,比如我们前段时间推荐的photozoom
可靠的采集神器很多,比如我们前段时间推荐的photozoom是一款在线图片搜索神器,具体介绍可以看下我们之前的文章啦。戳我进入!采宝工具网上方提供图片搜索,下方支持图片收藏、评论、投票。后端支持三方外挂,想要获取更多有趣的数据请戳此地址获取支持特性免费开源、评论热度支持多平台。自带抓包、ip重定向、lzh等数据,可与很多源数据达成合作和互通。
支持热度分类检索图片,自动筛选并添加到浏览器收藏。支持热度排名第一列,图片热度高即热度大图。支持收藏图片。方便按照热度大类获取照片或其他类似图片。自动加入收藏图片。自动分享到百度文库,搜狐、豆丁等资料。中文网站翻译:可替代翻译软件,有针对大陆用户提供的个性化翻译:支持多个翻译引擎,自由切换自带发布模式:可自行调整配置搜索方式、多图搜索下方各类中文网站均提供翻译。
总结以上只是小编对这款采集神器的介绍,希望能帮助到小伙伴们!如果觉得文章不错,可以帮忙转发支持一下,谢谢~更多实用工具,欢迎关注我的微信公众号“采宝工具”获取哦~。
问题不准确,应该是图片收藏应用推荐才对吧?推荐两个实用工具app:1,zipdoc。这个挺有意思的,跟大多数任务收藏类产品不同,它能先保存下来收藏的文件,在需要的时候会自动调取并调整,不会占用本地空间。不会导致没有及时删掉的文件找不到。从此再也不用担心乱七八糟的收藏在手机里忘了找了,很方便的!2,photozoom这个是免费的图片收藏应用,如果要安装也很简单,你不用下载,上百度搜索photozoom,就会出来了。
总结:收藏应用的过程中应该包括图片收藏和分享。如果觉得收藏不符合你的需求,就需要做设置了。大部分图片类应用都提供直接导入图片的功能。如果不能导入图片。建议尝试先找到图片并导入到本地,这样才可以达到自动分类、批量分享的效果。如果有各类大图文件(多图文件,需要长时间等待),可以尝试在百度网盘上下载一个网盘文件,然后直接导入。
这是一款无需加入指定的QQ群,实现高速、稳定、全自动的提取
采集交流 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2021-08-18 04:15
飞讯不添加群成员提取群成员。这是一款无需加入指定QQ群即可高速、稳定、全自动提取QQ群成员的方法!使用原法软件可以采集一秒提前群成员,不像市面上其他软件采集信息严重滞后,实时采集互联网最新数据。无需加入指定QQ群,即可高速、稳定、全自动提取QQ群成员。采用独创方式,软件可以采集一秒提前群内成员,不像市面上其他软件采集信息严重滞后,保证用户采集及时更新实时上网!软件支持任意QQ采集,不限号码和IP,动态获取网上最新群信息,与入群时获取的群成员一模一样。这里的闪电编辑器是破解版,需要速度下载!
功能介绍这是一款高速稳定全自动提取QQ群成员,无需加入指定QQ群!使用独创的方法软件可以采集一秒提前群成员,不像市面上其他软件采集,信息严重滞后,实时采集互联网最新数据。无需加入指定QQ群,即可高速、稳定、全自动提取QQ群成员。采用独创方式,软件可以采集一秒提前群内成员,不像市面上其他软件采集信息严重滞后,保证用户采集及时更新实时上网!软件支持任意QQ采集,不限号码和IP,动态获取网上最新群信息,与入群时获取的群成员一模一样。 Features1、支持多台电脑多地使用
无需加入指定QQ群,即可高速、稳定、全自动提取QQ群成员。本软件采用网络验证账号的形式。任意一台机器登录软件账号后,即可随时随地使用软件,极大方便用户使用!
2、关键词营销,简单快捷
软件支持任意QQ采集,不限号不限IP,动态获取网上最新群信息,与加入群获取群成员一模一样。
3、高效快捷
采用独创方式,软件可以采集一秒提前群成员,不像市面上其他软件采集,信息严重滞后,保证用户采集在网上是最新的实时!
4、多种方式导出
近期飞信优化了采集功能,无需添加群成员提取群成员。现在支持按关键词采集QQ群,提取的群成员可以导出为邮箱格式。
5、software 使用网络账号,不限于机器
飞讯不加群以网络账号的形式提取群成员。一个软件帐户可以在不同的计算机上登录。用户可以在家中或公司中使用。真正摆脱了传统软件使用机器码的弊端。实现以用户为中心、以服务为导向的营销理念。
6、软件不断升级完善,售后服务可靠
在升级和维护方面,飞信软件团队一直坚持技术创新和踏实维护,确保软件功能和性能的稳定性。在售后服务方面,飞信软件团队拥有一支经过严格培训的客服团队,为您提供专业的技术支持。关于破解网站下载后,直接解压运行,就是破解版,填写你需要的条件,它会自动帮你搜索并加入你需要的群! 查看全部
这是一款无需加入指定的QQ群,实现高速、稳定、全自动的提取
飞讯不添加群成员提取群成员。这是一款无需加入指定QQ群即可高速、稳定、全自动提取QQ群成员的方法!使用原法软件可以采集一秒提前群成员,不像市面上其他软件采集信息严重滞后,实时采集互联网最新数据。无需加入指定QQ群,即可高速、稳定、全自动提取QQ群成员。采用独创方式,软件可以采集一秒提前群内成员,不像市面上其他软件采集信息严重滞后,保证用户采集及时更新实时上网!软件支持任意QQ采集,不限号码和IP,动态获取网上最新群信息,与入群时获取的群成员一模一样。这里的闪电编辑器是破解版,需要速度下载!
功能介绍这是一款高速稳定全自动提取QQ群成员,无需加入指定QQ群!使用独创的方法软件可以采集一秒提前群成员,不像市面上其他软件采集,信息严重滞后,实时采集互联网最新数据。无需加入指定QQ群,即可高速、稳定、全自动提取QQ群成员。采用独创方式,软件可以采集一秒提前群内成员,不像市面上其他软件采集信息严重滞后,保证用户采集及时更新实时上网!软件支持任意QQ采集,不限号码和IP,动态获取网上最新群信息,与入群时获取的群成员一模一样。 Features1、支持多台电脑多地使用
无需加入指定QQ群,即可高速、稳定、全自动提取QQ群成员。本软件采用网络验证账号的形式。任意一台机器登录软件账号后,即可随时随地使用软件,极大方便用户使用!
2、关键词营销,简单快捷
软件支持任意QQ采集,不限号不限IP,动态获取网上最新群信息,与加入群获取群成员一模一样。
3、高效快捷
采用独创方式,软件可以采集一秒提前群成员,不像市面上其他软件采集,信息严重滞后,保证用户采集在网上是最新的实时!
4、多种方式导出
近期飞信优化了采集功能,无需添加群成员提取群成员。现在支持按关键词采集QQ群,提取的群成员可以导出为邮箱格式。
5、software 使用网络账号,不限于机器
飞讯不加群以网络账号的形式提取群成员。一个软件帐户可以在不同的计算机上登录。用户可以在家中或公司中使用。真正摆脱了传统软件使用机器码的弊端。实现以用户为中心、以服务为导向的营销理念。
6、软件不断升级完善,售后服务可靠
在升级和维护方面,飞信软件团队一直坚持技术创新和踏实维护,确保软件功能和性能的稳定性。在售后服务方面,飞信软件团队拥有一支经过严格培训的客服团队,为您提供专业的技术支持。关于破解网站下载后,直接解压运行,就是破解版,填写你需要的条件,它会自动帮你搜索并加入你需要的群!
微软的付费技术支持计划,你的速度应该不会太差
采集交流 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-08-12 00:04
可靠的采集神器viable出品。其他免费领取方式参见文末。已经到付的话,积分不会因为你付出多少而减少,就像你付费买了一份保险,但依然有发生风险的可能。微软的付费技术支持计划,还是相当可靠的,上下班出差,在外都可以给你通知insider的issue。
官网有教程,除了付费的,其余都免费哈。protonium最新版142.1但是都很稳定,不用担心安全性什么的,破解版的话,百度出来一堆,你都可以尝试的。应该就是速度的话,服务器的稳定性,才是目前最重要的因素吧,服务器稳定,你的速度应该不会太差,
微软官网的insider计划
1、免费的:由bluenotes提供的最新的技术支持信息。
2、特惠的:购买为期一年的技术支持服务仅需29美元。
3、已发布的:这些是微软自定义的技术支持服务列表。你还可以选择“我有个朋友会帮助你,你也可以帮助我”,以及“关于我们的技术支持,有什么问题需要咨询我们的技术支持团队吗?”等链接。看官网啊。
关于我的技术支持我参与了几个jeffklein系列文章的策划工作,这个问题我最有发言权。为了保持专业,我将把所有jeffklein关于技术支持的所有内容都会在这里公布出来。有更多关于微软技术支持方面的问题,或者想跟大家交流一下心得体会,请加我的技术支持。 查看全部
微软的付费技术支持计划,你的速度应该不会太差
可靠的采集神器viable出品。其他免费领取方式参见文末。已经到付的话,积分不会因为你付出多少而减少,就像你付费买了一份保险,但依然有发生风险的可能。微软的付费技术支持计划,还是相当可靠的,上下班出差,在外都可以给你通知insider的issue。
官网有教程,除了付费的,其余都免费哈。protonium最新版142.1但是都很稳定,不用担心安全性什么的,破解版的话,百度出来一堆,你都可以尝试的。应该就是速度的话,服务器的稳定性,才是目前最重要的因素吧,服务器稳定,你的速度应该不会太差,
微软官网的insider计划
1、免费的:由bluenotes提供的最新的技术支持信息。
2、特惠的:购买为期一年的技术支持服务仅需29美元。
3、已发布的:这些是微软自定义的技术支持服务列表。你还可以选择“我有个朋友会帮助你,你也可以帮助我”,以及“关于我们的技术支持,有什么问题需要咨询我们的技术支持团队吗?”等链接。看官网啊。
关于我的技术支持我参与了几个jeffklein系列文章的策划工作,这个问题我最有发言权。为了保持专业,我将把所有jeffklein关于技术支持的所有内容都会在这里公布出来。有更多关于微软技术支持方面的问题,或者想跟大家交流一下心得体会,请加我的技术支持。
如何在谷歌浏览器中安装扩展迷上一劳永逸的Chrome插件?
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-08-11 06:22
对于大多数搜索资源的人来说,使用搜索引擎的核心需求之一就是下载资源。
但是每次想看电影,需要什么软件,都得在网上找很久。
此外,搜索到的项目要么是垃圾邮件广告,要么是莫名其妙的病毒软件。
如果您厌倦了在传统搜索工具上查找资源,那么您不妨试试这个一劳永逸的 Chrome 插件。
功能介绍
easySearch 插件是最近在 Chrome 商店推出的聚合搜索引擎工具。它支持自定义并有许多有用的小部件。
它的主要功能是磁力搜索,拥有非常全面的磁力搜索引擎,支持一键查询BT种子和磁力链接。
同时还可以通过easySearch插件进行学术搜索、云盘搜索、软件搜索、影视资源搜索、音乐资源搜索,甚至图片识别。
据开发者介绍,目前系统内置了223个资源站,网站最新地址会自动更新。
只要是你能想到的,都可以通过它搜索,几乎可以满足我们所有的搜索需求。
如何使用
一、安装插件
如果条件允许,您可以直接在谷歌浏览器商店下载安装。
如果无法访问,请到扩展名fan网站下载easySearch插件安装包,解压后将crx文件拖放到谷歌浏览器。
安装方法【安装教程】如何在谷歌浏览器中安装扩展迷下载的插件?
二、search
点击浏览器右上角的插件图标,选择第一个功能“搜索”。
然后,系统会在一个新的标签页Ju BT中打开一个聚合资源搜索引擎页面。
在搜索框中输入要查找的资源关键词,在后面的下拉选项中可以选择子分类(或不分类),然后就可以看到种子的搜索结果资源如下。
三、Custom
在菜单中选择“设置”以自定义搜索引擎。
比如添加自定义搜索引擎、对搜索引擎进行分类、显示每个网站的结果数、排序规则等
根据自己的习惯,管理常用的搜索引擎,使其成为您专属的搜索定制工具。
四、其他工具
easySearch 插件中有很多有用的搜索功能。为避免被统一,这里就不一一介绍了。
简而言之,包括图片搜索、商业搜索、乐谱搜索、线路搜索,以及影视动画、热门软件、云盘资源搜索等,都可以在这个插件中找到——
还有很多隐藏的好处等着大家自己去发现。
老司机资源搜索神器,一键搜索上百个资源站,有兴趣的不妨一试。 查看全部
如何在谷歌浏览器中安装扩展迷上一劳永逸的Chrome插件?
对于大多数搜索资源的人来说,使用搜索引擎的核心需求之一就是下载资源。
但是每次想看电影,需要什么软件,都得在网上找很久。
此外,搜索到的项目要么是垃圾邮件广告,要么是莫名其妙的病毒软件。
如果您厌倦了在传统搜索工具上查找资源,那么您不妨试试这个一劳永逸的 Chrome 插件。
功能介绍
easySearch 插件是最近在 Chrome 商店推出的聚合搜索引擎工具。它支持自定义并有许多有用的小部件。
它的主要功能是磁力搜索,拥有非常全面的磁力搜索引擎,支持一键查询BT种子和磁力链接。
同时还可以通过easySearch插件进行学术搜索、云盘搜索、软件搜索、影视资源搜索、音乐资源搜索,甚至图片识别。
据开发者介绍,目前系统内置了223个资源站,网站最新地址会自动更新。
只要是你能想到的,都可以通过它搜索,几乎可以满足我们所有的搜索需求。
如何使用
一、安装插件
如果条件允许,您可以直接在谷歌浏览器商店下载安装。
如果无法访问,请到扩展名fan网站下载easySearch插件安装包,解压后将crx文件拖放到谷歌浏览器。
安装方法【安装教程】如何在谷歌浏览器中安装扩展迷下载的插件?
二、search
点击浏览器右上角的插件图标,选择第一个功能“搜索”。
然后,系统会在一个新的标签页Ju BT中打开一个聚合资源搜索引擎页面。
在搜索框中输入要查找的资源关键词,在后面的下拉选项中可以选择子分类(或不分类),然后就可以看到种子的搜索结果资源如下。
三、Custom
在菜单中选择“设置”以自定义搜索引擎。
比如添加自定义搜索引擎、对搜索引擎进行分类、显示每个网站的结果数、排序规则等
根据自己的习惯,管理常用的搜索引擎,使其成为您专属的搜索定制工具。
四、其他工具
easySearch 插件中有很多有用的搜索功能。为避免被统一,这里就不一一介绍了。
简而言之,包括图片搜索、商业搜索、乐谱搜索、线路搜索,以及影视动画、热门软件、云盘资源搜索等,都可以在这个插件中找到——
还有很多隐藏的好处等着大家自己去发现。
老司机资源搜索神器,一键搜索上百个资源站,有兴趣的不妨一试。

