
利用采集器 采集的平台
利用采集器 采集的平台(优采云数据采集系统能做的包括但不局限于以下内容 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-09-05 00:09
)
Data采集器 是一个强大的免费 data采集 系统。 Data采集器 可以从任何网页获取信息。即使您根本不了解任何网络技术,也可以轻松地从该软件中获取信息。抓取网络上的任何资源数据,例如文本、图片、文件和视频。
软件功能
简单来说,使用优采云可以轻松地从任何网页生成自定义的常规数据格式,以准确采集您需要的数据。 优采云数据采集系统能做的包括但不限于以下内容:
1、财务数据,如季报、年报、财报,包括最新的每日净值采集;
2、各种新闻门户网站实时监控,自动更新上传最新新闻;
3、监控竞争对手的最新信息,包括商品价格和库存;
4、monitoring各大社交网络网站,博客,自动抓取企业产品相关评论;
5、采集最新最全的招聘信息;
6、监控各大地产相关网站、采集新房二手房的最新报价;
7、采集个别汽车网站具体新车及二手车信息;
8、发现并采集潜在客户信息;
9、采集工业网站的产品目录和产品信息;
10、 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
软件功能
1、操作简单
操作简单,图形化操作完全可视化,无需专业IT人员,任何会电脑上网的人都可以轻松掌握。
2、云采集
采集任务自动分发到云端多台服务器同时执行,提高了采集的效率,短时间内可以获得数千条消息。
3、drag and drop采集process
模仿人类的操作思维方式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采用不同的采集流程。
4、图形识别
内置可扩展OCR接口,支持解析图片中的文字,提取图片上的文字。
5、timing automatic采集
采集任务自动运行,可以按照指定周期自动采集,同时支持实时采集,最快一分钟一次。
6、2 分钟快速入门
内置从入门到精通的视频教程,2分钟即可上手,还有文档、论坛、qq群等
7、免费使用
它是免费的,免费版没有功能限制。您可以立即试用,立即下载并安装。
使用教程
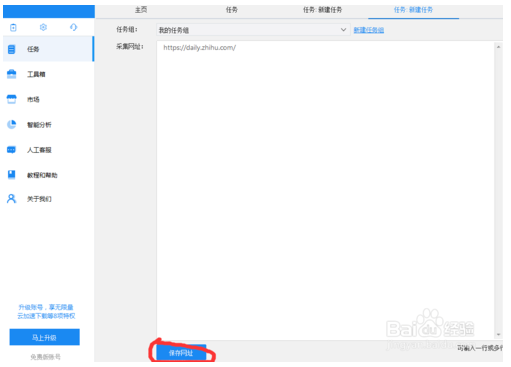
下载优采云数据采集器安装包,安装后注册账号,登录,登录后进入软件首页,点击任务->新建->自定义采集,输入网址采集 网页并保存;
保存后软件会自动打开页面。您可以在页面中一一点击要抓取的内容,也可以在右侧的操作提示区点击取消要抓取的内容;确认无误后点击采集;
保存采集后,选择启用本地采集,然后静静等待即可看到采集收到的数据;也可以选择从采集导出数据;另外优采云也可以同时使用采集多个页面,开始输入网址时只需要输入多个网址;
查看全部
利用采集器 采集的平台(优采云数据采集系统能做的包括但不局限于以下内容
)
Data采集器 是一个强大的免费 data采集 系统。 Data采集器 可以从任何网页获取信息。即使您根本不了解任何网络技术,也可以轻松地从该软件中获取信息。抓取网络上的任何资源数据,例如文本、图片、文件和视频。
软件功能
简单来说,使用优采云可以轻松地从任何网页生成自定义的常规数据格式,以准确采集您需要的数据。 优采云数据采集系统能做的包括但不限于以下内容:
1、财务数据,如季报、年报、财报,包括最新的每日净值采集;
2、各种新闻门户网站实时监控,自动更新上传最新新闻;
3、监控竞争对手的最新信息,包括商品价格和库存;
4、monitoring各大社交网络网站,博客,自动抓取企业产品相关评论;
5、采集最新最全的招聘信息;
6、监控各大地产相关网站、采集新房二手房的最新报价;
7、采集个别汽车网站具体新车及二手车信息;
8、发现并采集潜在客户信息;
9、采集工业网站的产品目录和产品信息;
10、 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
软件功能
1、操作简单
操作简单,图形化操作完全可视化,无需专业IT人员,任何会电脑上网的人都可以轻松掌握。
2、云采集
采集任务自动分发到云端多台服务器同时执行,提高了采集的效率,短时间内可以获得数千条消息。
3、drag and drop采集process
模仿人类的操作思维方式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采用不同的采集流程。
4、图形识别
内置可扩展OCR接口,支持解析图片中的文字,提取图片上的文字。
5、timing automatic采集
采集任务自动运行,可以按照指定周期自动采集,同时支持实时采集,最快一分钟一次。
6、2 分钟快速入门
内置从入门到精通的视频教程,2分钟即可上手,还有文档、论坛、qq群等
7、免费使用
它是免费的,免费版没有功能限制。您可以立即试用,立即下载并安装。
使用教程
下载优采云数据采集器安装包,安装后注册账号,登录,登录后进入软件首页,点击任务->新建->自定义采集,输入网址采集 网页并保存;
保存后软件会自动打开页面。您可以在页面中一一点击要抓取的内容,也可以在右侧的操作提示区点击取消要抓取的内容;确认无误后点击采集;
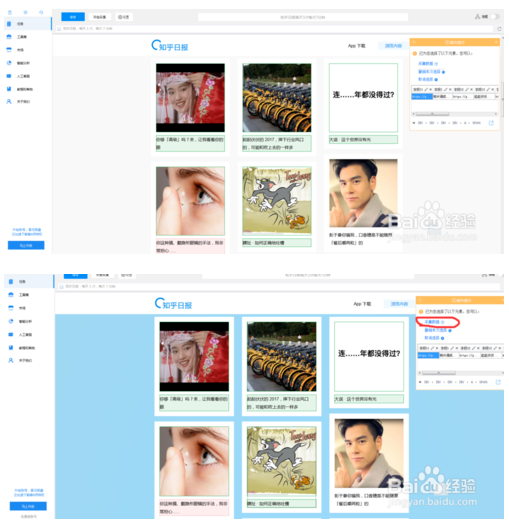
保存采集后,选择启用本地采集,然后静静等待即可看到采集收到的数据;也可以选择从采集导出数据;另外优采云也可以同时使用采集多个页面,开始输入网址时只需要输入多个网址;
利用采集器 采集的平台(常见问答:XX网站能不能采集?官网视频讲解教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 413 次浏览 • 2021-09-03 21:12
常见问题:
1、XX 网站你能采集吗? XX数据可以采集吗?
在官网的视频教程中,我们已经介绍过优采云采集器是一个通用的网页采集软件。只要有网站,就可以浏览网页。你能看到的大部分内容是可以采集(视频很特殊,所以要具体情况具体分析)。
为了保护您的隐私,您的所有任务和配置都以加密形式存储在云端。没有人,但您可以查看具体内容。你在采集过程中输入的账号密码和你的采集结果都存储在你的本地电脑上。但请严格遵守相关法律法规。如优采云采集器官方收到采集违法举报,将第一时间暂停账号。
2、为什么采集data 过早停止?
如果遇到采集提前停车的问题,请按照以下步骤进行自检:
第一步:请确认浏览器能看到多少内容
有时搜索中显示的数字与您最后看到的数字不同。请确认你能看到多少条数据,然后判断采集是提前停止还是正常停止。
第2步:采集结果的数量与浏览器中看到的数量不一致
在采集的过程中,如果遇到这个问题,有两种可能:
第一种可能是采集太快,页面加载时间太慢,导致采集无法访问页面中的数据。
在这种情况下,请增加请求的等待时间。等待时间变长之后,网页就会有足够的时间加载内容。
请求等待时间的设置在启动设置->智能策略中,如下图:
第二种可能是你遇到了其他问题
在操作过程中,我们可以在操作界面点击“查看网页”,观察当前网页内容是否正常,是否无法正常显示,是否有异常提示等
如果出现上述情况,我们可以降低采集的速度,切换代理IP,手动编码等,至于哪种方法可以工作,这个需要测试一下才知道不同的网站问题是不同的。没有一种统一的解决方案。
如果您在尝试上述解决方案后仍然无法解决问题,您可以在帮助中心给我们反馈,我们将为您提供支持。
3、为什么采集不见了?
不完整的字段一般有以下两种情况:
首先,由于列表元素的结构不同,有些元素有其他元素没有的字段。这是正常现象。请在网页上确认相应元素中是否存在您想要的字段。
其次,页面结构发生了变化。这通常发生在收录多个页面结构的同一个搜索结果中,例如搜索引擎搜索结果(包括多种网站)。
这种情况需要具体问题具体分析。您可以将您的采集任务导出并发送到我们的官方帮助中心,我们的客服会帮您测试分析。 查看全部
利用采集器 采集的平台(常见问答:XX网站能不能采集?官网视频讲解教程)
常见问题:
1、XX 网站你能采集吗? XX数据可以采集吗?
在官网的视频教程中,我们已经介绍过优采云采集器是一个通用的网页采集软件。只要有网站,就可以浏览网页。你能看到的大部分内容是可以采集(视频很特殊,所以要具体情况具体分析)。
为了保护您的隐私,您的所有任务和配置都以加密形式存储在云端。没有人,但您可以查看具体内容。你在采集过程中输入的账号密码和你的采集结果都存储在你的本地电脑上。但请严格遵守相关法律法规。如优采云采集器官方收到采集违法举报,将第一时间暂停账号。
2、为什么采集data 过早停止?
如果遇到采集提前停车的问题,请按照以下步骤进行自检:
第一步:请确认浏览器能看到多少内容
有时搜索中显示的数字与您最后看到的数字不同。请确认你能看到多少条数据,然后判断采集是提前停止还是正常停止。
第2步:采集结果的数量与浏览器中看到的数量不一致
在采集的过程中,如果遇到这个问题,有两种可能:
第一种可能是采集太快,页面加载时间太慢,导致采集无法访问页面中的数据。
在这种情况下,请增加请求的等待时间。等待时间变长之后,网页就会有足够的时间加载内容。
请求等待时间的设置在启动设置->智能策略中,如下图:
第二种可能是你遇到了其他问题
在操作过程中,我们可以在操作界面点击“查看网页”,观察当前网页内容是否正常,是否无法正常显示,是否有异常提示等
如果出现上述情况,我们可以降低采集的速度,切换代理IP,手动编码等,至于哪种方法可以工作,这个需要测试一下才知道不同的网站问题是不同的。没有一种统一的解决方案。
如果您在尝试上述解决方案后仍然无法解决问题,您可以在帮助中心给我们反馈,我们将为您提供支持。
3、为什么采集不见了?
不完整的字段一般有以下两种情况:
首先,由于列表元素的结构不同,有些元素有其他元素没有的字段。这是正常现象。请在网页上确认相应元素中是否存在您想要的字段。
其次,页面结构发生了变化。这通常发生在收录多个页面结构的同一个搜索结果中,例如搜索引擎搜索结果(包括多种网站)。
这种情况需要具体问题具体分析。您可以将您的采集任务导出并发送到我们的官方帮助中心,我们的客服会帮您测试分析。
利用采集器 采集的平台(爬虫实战:利用软件采集招聘信息(一)(基于优采云和优采云采集器))
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-09-02 16:09
爬虫实战:使用软件采集Job Information(一)
(基于优采云和优采云采集器software-easy mode采集)
一、什么是爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不常用的名称包括蚂蚁、自动索引、模拟程序或蠕虫(百度复制粘贴内容^^)。
说白了,爬虫就是利用工具来抓取网页上的内容(数据、文字、图片等)。是不是觉得写论文找资料不仅仅是翻阅年鉴……爬虫工具除了python(手写代码)等编程语言,还有采集通过一些第三方软件(比如如优采云、优采云采集器、优采云采集器 等)。至于自己写代码的方式,我会在文章中介绍。本文从基础介绍软件傻瓜式crawler的使用。这个方法已经可以满足采集的大部分需求了,只是拖拽也不容易。
二、优采云采集器 和优采云简介
这两个采集器是笔者认为目前市面上比较优秀的两个采集软件。 优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。该软件功能强大且易于操作。可谓是居家旅行的随身神器。 优采云大数据采集是一个集网页数据采集、移动互联网数据和API接口服务(包括数据爬虫、数据优化、数据挖掘、数据存储、数据备份)等为一体的自主研发平台服务。数据服务平台连续4年位居互联网Data采集software榜单第一。两款软件的采集模式基本相同,主要有两种:智能模式采集或简单采集,自定义模式采集。本期主要介绍智能模式采集或简单采集。
三、简单模式
(1)优采云采集器
软件下载地址:至于如何安装软件,一直是下一步。
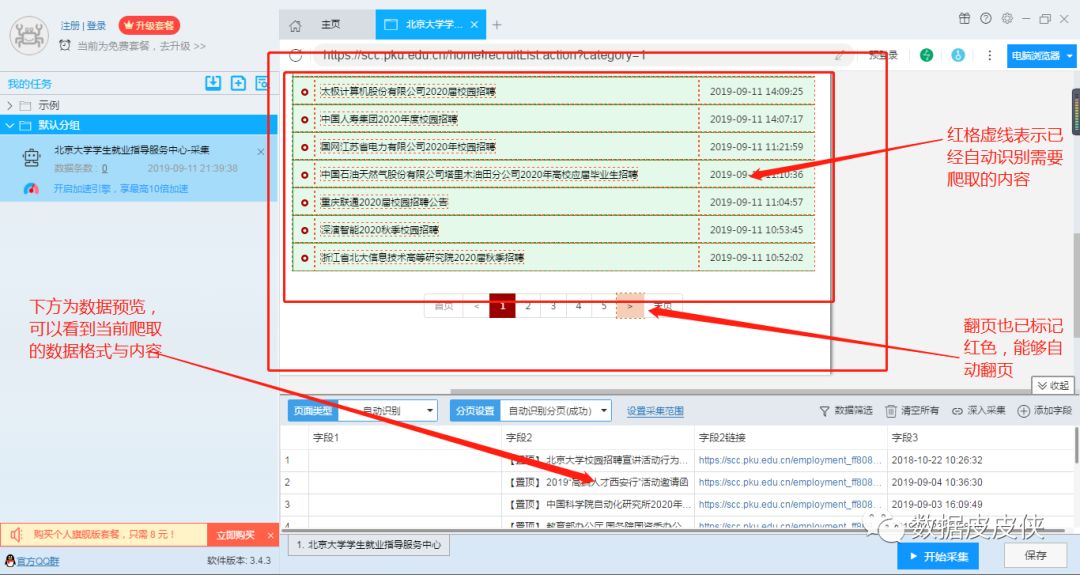
优采云采集器的智能模式采集只需将您要抓取的页面放入网址框,软件就会自动识别您可能需要抓取的内容。我们直接来看例子。比如要爬取某所大学的就业信息(以北大为例),北大就业指导服务中心的网址是!recruitList.action?category=1(不知道后面看到的,不管是无效还是反爬虫,反正我能用,能用,能用。
1.打开软件,选择智能模式
2.在右边的框中输入抓取网址
3.点击下方立即创建,可以看到软件自动识别出需要抓取的内容
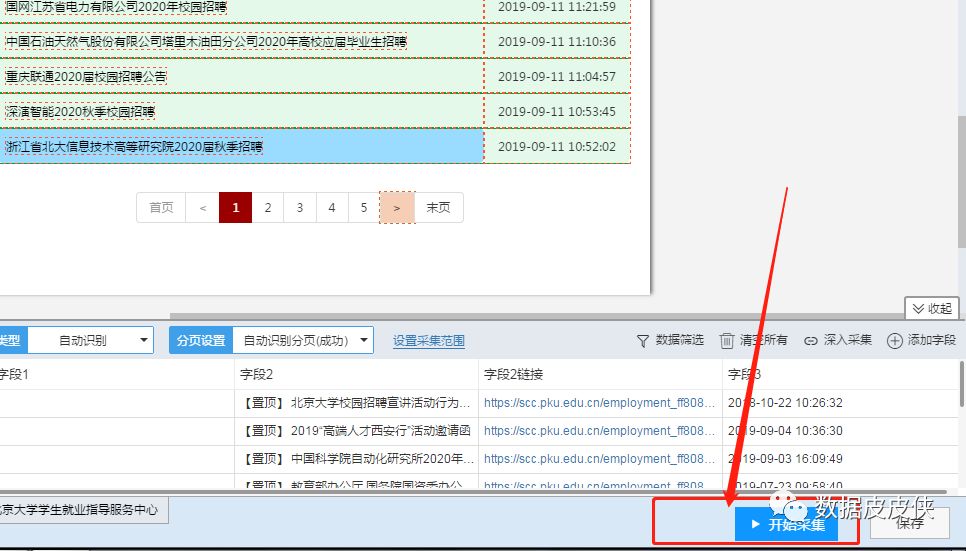
4.点击启动采集并启动,软件会自动采集当前页面信息并翻页。
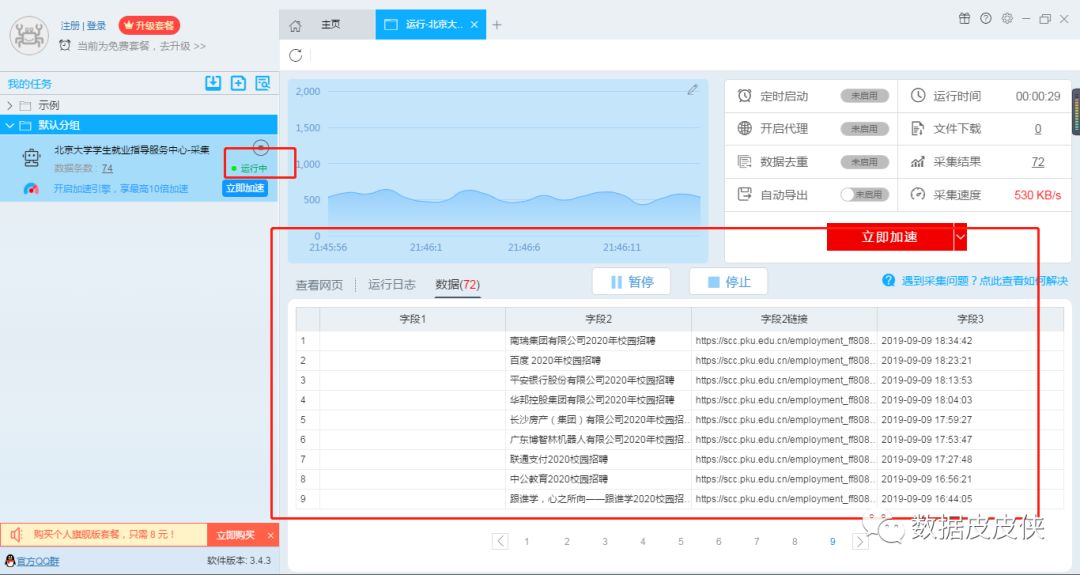
5.software is crawling...(注意:由于没有选择深度爬取,所以只会爬取当前页面,链接中不会访问到具体信息)
6.因为内容的原因,作者选择了强制结束。最后导出文件,可以选择导出excel格式。
7.最终的excel数据如下
(2)优采云
软件下载地址:。 优采云简单方便,软件自带了很多常用的网站和数据模板,如下图:
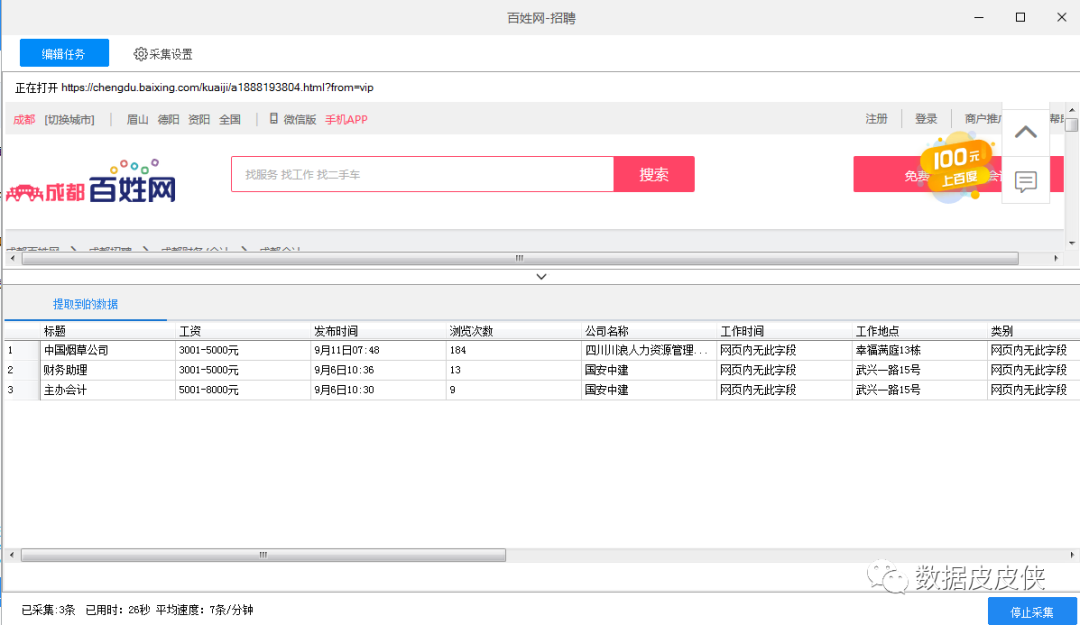
比如要抓取百星网的招聘信息,在百星网选择要爬取的职位,复制链接(以示例为例)。
1.点击人脉模板,选择并点击采集
2.输入网址,翻页次数
3.选择开始local采集
4.可以看到正在抓取数据
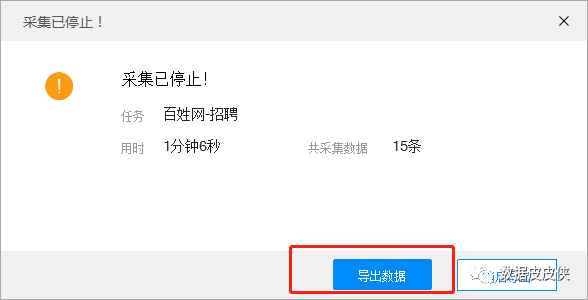
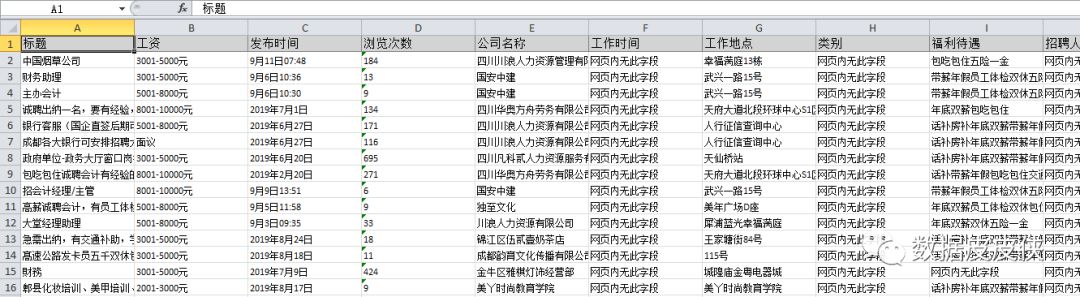
5.最终爬取的数据可以导出
以上是本期内容:关于优采云采集器和优采云采集器的简单模式采集。下一期我们会推送流程图或者自定义采集数据。
终于! ! ! ! ! !发送彩蛋解决上一篇提到的问题,在使用优采云采集器时,由于没有深度爬取选项,只会爬取当前页面,链接中无法访问具体信息.
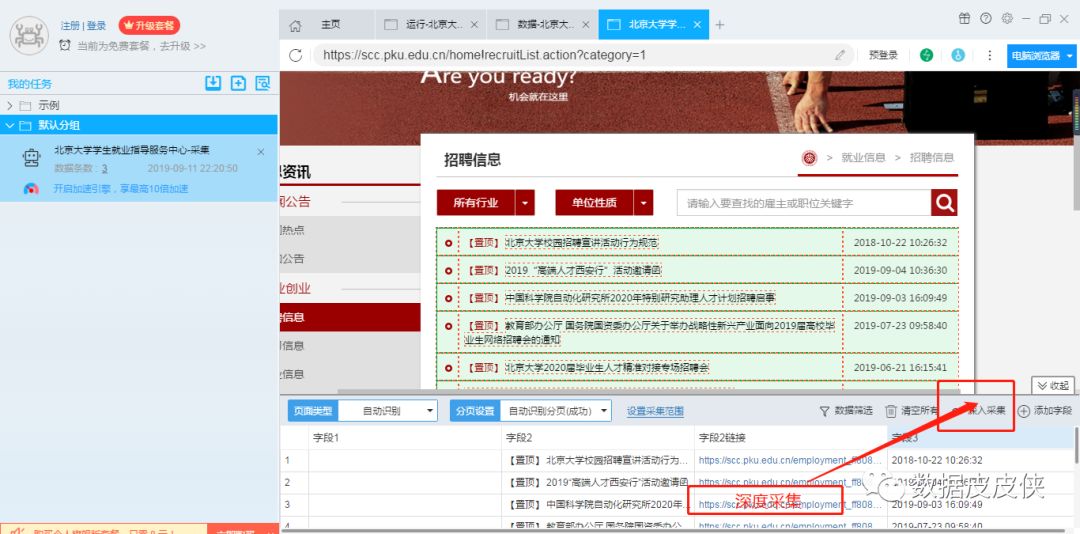
因为抓取的数据只是每个链接的标题,所以需要在链接抓取中输入内容。 优采云采集器提供了“depth采集”功能,可以输入链接采集。这里:
点击“Depth采集”进入页面,即最外层链接里面的内容。这时候下面会抓取这个页面的内容。点击开始采集到采集每个标题链接中的内容。
欢迎关注(数据皮皮下) 查看全部
利用采集器 采集的平台(爬虫实战:利用软件采集招聘信息(一)(基于优采云和优采云采集器))
爬虫实战:使用软件采集Job Information(一)
(基于优采云和优采云采集器software-easy mode采集)

一、什么是爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不常用的名称包括蚂蚁、自动索引、模拟程序或蠕虫(百度复制粘贴内容^^)。
说白了,爬虫就是利用工具来抓取网页上的内容(数据、文字、图片等)。是不是觉得写论文找资料不仅仅是翻阅年鉴……爬虫工具除了python(手写代码)等编程语言,还有采集通过一些第三方软件(比如如优采云、优采云采集器、优采云采集器 等)。至于自己写代码的方式,我会在文章中介绍。本文从基础介绍软件傻瓜式crawler的使用。这个方法已经可以满足采集的大部分需求了,只是拖拽也不容易。

二、优采云采集器 和优采云简介
这两个采集器是笔者认为目前市面上比较优秀的两个采集软件。 优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。该软件功能强大且易于操作。可谓是居家旅行的随身神器。 优采云大数据采集是一个集网页数据采集、移动互联网数据和API接口服务(包括数据爬虫、数据优化、数据挖掘、数据存储、数据备份)等为一体的自主研发平台服务。数据服务平台连续4年位居互联网Data采集software榜单第一。两款软件的采集模式基本相同,主要有两种:智能模式采集或简单采集,自定义模式采集。本期主要介绍智能模式采集或简单采集。

三、简单模式
(1)优采云采集器
软件下载地址:至于如何安装软件,一直是下一步。
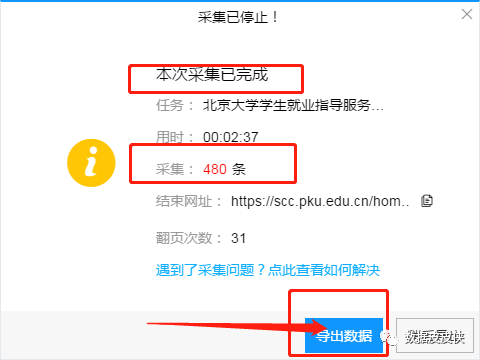
优采云采集器的智能模式采集只需将您要抓取的页面放入网址框,软件就会自动识别您可能需要抓取的内容。我们直接来看例子。比如要爬取某所大学的就业信息(以北大为例),北大就业指导服务中心的网址是!recruitList.action?category=1(不知道后面看到的,不管是无效还是反爬虫,反正我能用,能用,能用。
1.打开软件,选择智能模式
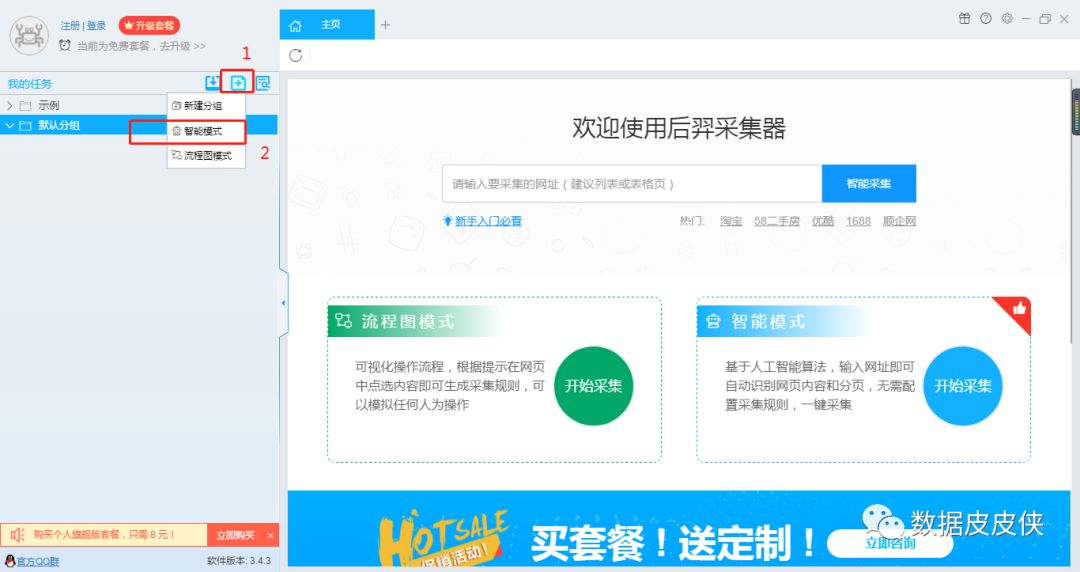
2.在右边的框中输入抓取网址
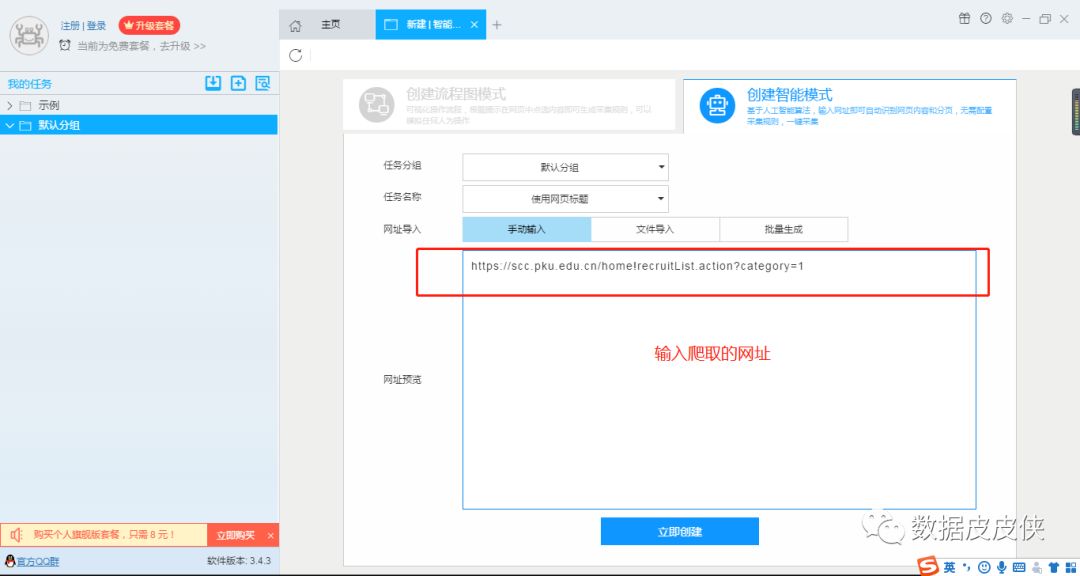
3.点击下方立即创建,可以看到软件自动识别出需要抓取的内容
4.点击启动采集并启动,软件会自动采集当前页面信息并翻页。
5.software is crawling...(注意:由于没有选择深度爬取,所以只会爬取当前页面,链接中不会访问到具体信息)
6.因为内容的原因,作者选择了强制结束。最后导出文件,可以选择导出excel格式。
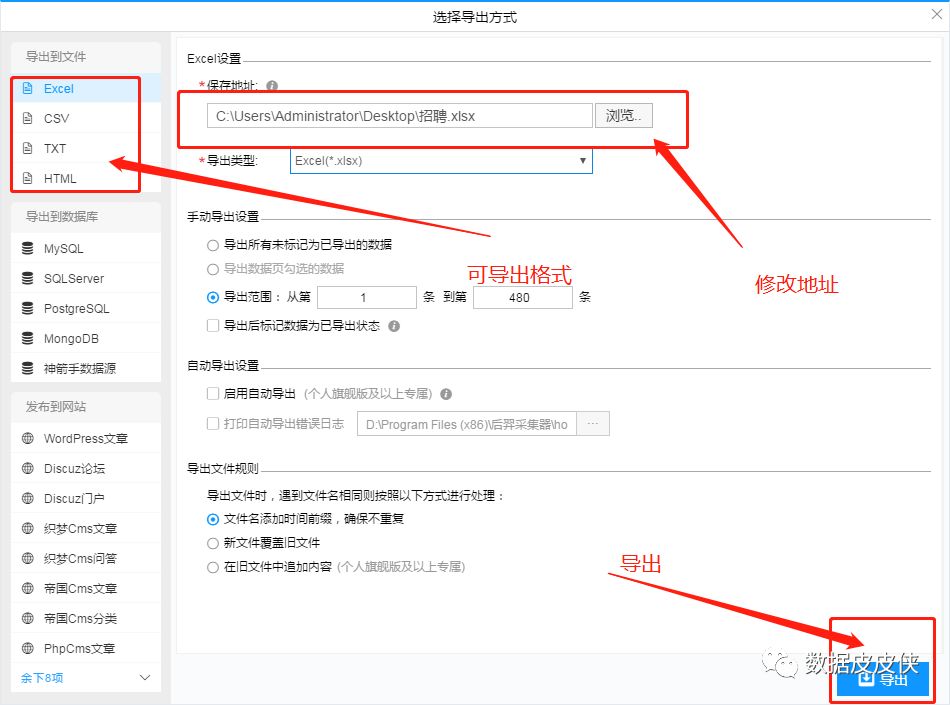
7.最终的excel数据如下
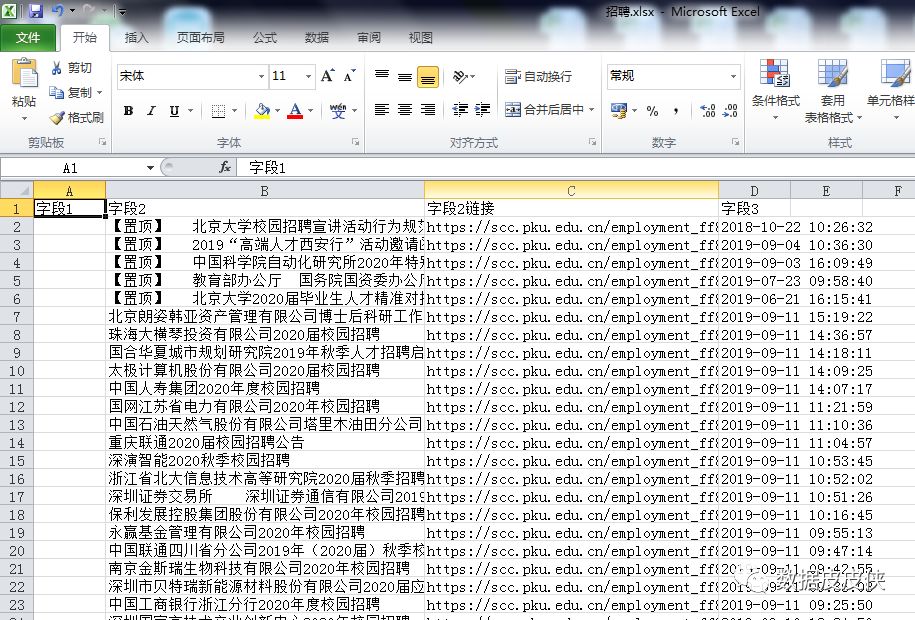
(2)优采云
软件下载地址:。 优采云简单方便,软件自带了很多常用的网站和数据模板,如下图:
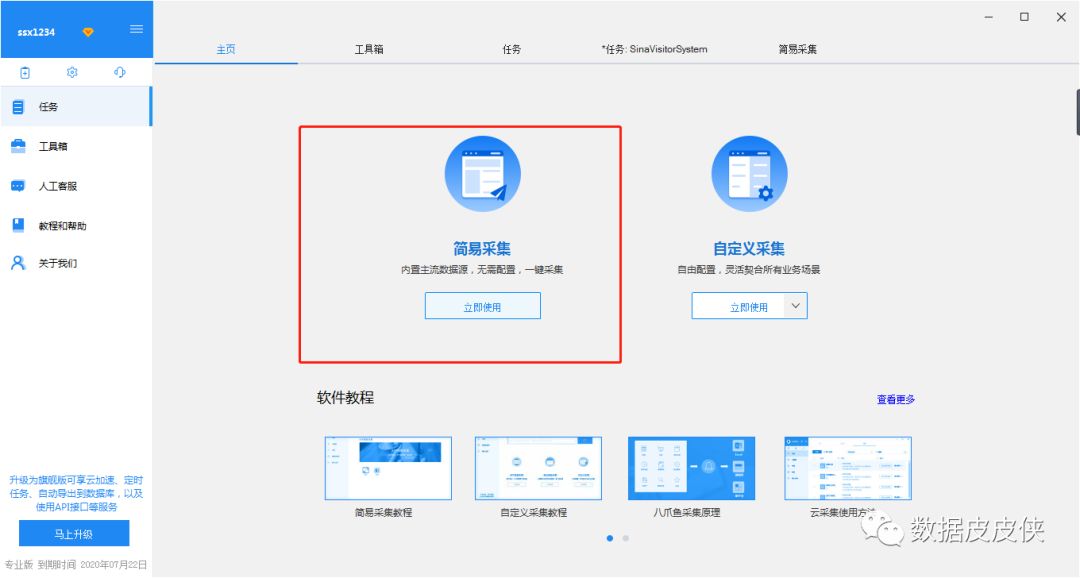
比如要抓取百星网的招聘信息,在百星网选择要爬取的职位,复制链接(以示例为例)。
1.点击人脉模板,选择并点击采集
2.输入网址,翻页次数
3.选择开始local采集
4.可以看到正在抓取数据
5.最终爬取的数据可以导出
以上是本期内容:关于优采云采集器和优采云采集器的简单模式采集。下一期我们会推送流程图或者自定义采集数据。
终于! ! ! ! ! !发送彩蛋解决上一篇提到的问题,在使用优采云采集器时,由于没有深度爬取选项,只会爬取当前页面,链接中无法访问具体信息.
因为抓取的数据只是每个链接的标题,所以需要在链接抓取中输入内容。 优采云采集器提供了“depth采集”功能,可以输入链接采集。这里:
点击“Depth采集”进入页面,即最外层链接里面的内容。这时候下面会抓取这个页面的内容。点击开始采集到采集每个标题链接中的内容。


欢迎关注(数据皮皮下)
利用采集器 采集的平台(UC头图像采集的应用方法及解决办法(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-01 06:02
注意:根据网页的加载情况设置滚动条的数量和滚动间隔。如果向下滚动,页面信息会加载缓慢。建议将滚动间隔设置的大一些。滚动的次数应该取决于我们滚动加载我们需要的所有数据的次数。建议准备一两次。滚动方法是看页面滚动时是否能顺利加载所有数据,或者是否需要一次滚动一屏。一般来说,一次滚动一屏更好,但更耗时。滚动屏幕取决于屏幕大小,云抓图默认为全屏。
3)文章图文集
文章中文字和图片的采集方式有两种。
方法一:设置判断条件,分别采集文字和图片。
采集 示例:腾讯新闻图片文字采集
方法二:先采集全文,再采集图片。
Sample采集:UC 标题图片采集
3、课程目的
这一步采集图片网址在上面的图片采集教程中有详细介绍,不再赘述。本文将重点介绍图片采集的技术和注意事项。
4、图片URL采集process
以下是具体操作步骤的演示。以百度图片的URL采集为例,抓取图片的URL。不同的网站picture URL会遇到不同的情况,请灵活处理。
选择图片,全选,采集以下图片地址
(2)开始采集查看结果。采集图片网址。
具体流程参考:瀑布图采集,以百度图为例,步骤1-4。
5、图片批量导出操作步骤
经过以上操作,我们就得到了采集的图片地址。接下来我们使用章鱼图片批量下载工具将图片下载并保存到本地电脑的图片网址。
1)Download八达通图片批量下载工具,双击文件中的mydownloader.app.exe打开软件。
2)打开文件菜单,选择从Excel导入(目前只支持Excel格式的文件)
3)设置
选择Excel文件:导入需要下载图片地址的Excel文件
Excel表名:对应数据表的名称
文件URL列名:表中对应URL的列名
保存文件夹名称:Excel 需要一个单独的列来列出要保存到此文件夹的图像的路径。在上面的例子中,我们在excel中添加了一个名为“picturesavefolder”的列,该列中的数据为“d:baidupicture采集”,然后“d:baidupicture采集”成为保存图片的路径(其他盘可以自定义存储,文件夹名称可自定义修改;“d:\”需输入英文)。 查看全部
利用采集器 采集的平台(UC头图像采集的应用方法及解决办法(一))
注意:根据网页的加载情况设置滚动条的数量和滚动间隔。如果向下滚动,页面信息会加载缓慢。建议将滚动间隔设置的大一些。滚动的次数应该取决于我们滚动加载我们需要的所有数据的次数。建议准备一两次。滚动方法是看页面滚动时是否能顺利加载所有数据,或者是否需要一次滚动一屏。一般来说,一次滚动一屏更好,但更耗时。滚动屏幕取决于屏幕大小,云抓图默认为全屏。

3)文章图文集
文章中文字和图片的采集方式有两种。
方法一:设置判断条件,分别采集文字和图片。
采集 示例:腾讯新闻图片文字采集
方法二:先采集全文,再采集图片。
Sample采集:UC 标题图片采集
3、课程目的
这一步采集图片网址在上面的图片采集教程中有详细介绍,不再赘述。本文将重点介绍图片采集的技术和注意事项。
4、图片URL采集process
以下是具体操作步骤的演示。以百度图片的URL采集为例,抓取图片的URL。不同的网站picture URL会遇到不同的情况,请灵活处理。
选择图片,全选,采集以下图片地址
(2)开始采集查看结果。采集图片网址。
具体流程参考:瀑布图采集,以百度图为例,步骤1-4。
5、图片批量导出操作步骤
经过以上操作,我们就得到了采集的图片地址。接下来我们使用章鱼图片批量下载工具将图片下载并保存到本地电脑的图片网址。
1)Download八达通图片批量下载工具,双击文件中的mydownloader.app.exe打开软件。
2)打开文件菜单,选择从Excel导入(目前只支持Excel格式的文件)
3)设置
选择Excel文件:导入需要下载图片地址的Excel文件
Excel表名:对应数据表的名称
文件URL列名:表中对应URL的列名
保存文件夹名称:Excel 需要一个单独的列来列出要保存到此文件夹的图像的路径。在上面的例子中,我们在excel中添加了一个名为“picturesavefolder”的列,该列中的数据为“d:baidupicture采集”,然后“d:baidupicture采集”成为保存图片的路径(其他盘可以自定义存储,文件夹名称可自定义修改;“d:\”需输入英文)。
利用采集器 采集的平台(企业在数据采集、数据分析过程中遇到的7大难点 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-08-30 05:08
)
在这个数字世界中,每分钟都会产生大量数据。数据已成为新时代企业发展的必要因素。如今,企业产生的数据量正以每年 40% 到 60% 的速度增长。如何有效解决全链条的数据采集和数据分析,已经成为每个业务经理的首要问题。
下面将告诉你企业在数据采集和数据分析过程中遇到的7大难点!
Data采集数据需求调查
明确过程中数据采集的需求,就是确定我们的采集场景和需要的采集字段,既简化了采集工作的复杂性,又节省了采集的工作量!
数据清洗
数据清理——重新检查和验证采集的数据的过程,目的是去除重复信息,纠正现有错误,并提供数据一致性。如果没有这一步,我们会增加数据采集的存储空间,同时也会降低数据的有效价值!
数据合并
数据合并——以统一标准化的格式展示清洗后的数据源。缺少这一步会导致数据存储过程中的格式杂乱无章,不便于分析人员使用!
任务调度
任务调度是data采集系统的重要组成部分——它可以设置各个爬虫程序的定时启停时间,查看抓取的信息记录。任务调度环节的缺失将直接影响其时效性。
搜索引擎系统
搜索引擎系统可以通过条件+关键字组合查询采集数据库中的数据,无论采集的数量有多大,一个好的搜索引擎系统都会帮助分析师检索他们想要使用的数据在最快的时间内。缩短数据分析时间,提高整体工作效率!
数据分析
数据分析是指用适当的统计分析方法对采集到的大量数据进行分析,提取有用信息,形成结论,并对数据进行详细研究和概括的过程。这个过程也是质量管理体系的一个支持过程。在实践中,数据分析可以帮助企业做出商业判断,从而采取适当的行动,帮助企业赢得商机。
数据可视化展示
数据可视化主要使用图形、图像处理、计算机视觉和用户界面,通过显示三维图形或动画来直观地解释数据。可视化展示,让更多人能够清晰直观地分辨数据分析的结果,提升用户体验!
总结
数据采集和数据分析是很专业的东西。如果不是特别大的企业,就没有必要投入太多的财力和时间来搭建自己的数据采集和分析系统。由于缺乏专业性,采集的数据分析结果并不能指导公司做出正确的商业判断,最终不得不尝试。
天马科技自主研发的DYSON Smart采集系统是一个强大的大数据采集、分析和可视化平台。采用天马科技自主研发的TMF框架为主体架构,支持运营智能发展。用户通过一系列分析选项来使用采集的数据,以发现复杂的联系并探索其数据中的各种关系,包括图形可视化、全文多面搜索、动态直方图、交互式地理空间视图和实时共享协作工作区。探测码 戴森智能采集系统可以专业地捕捉、处理、分析和挖掘互联网数据。并灵活快速地抓取网络上分散的信息,通过智能数据中心提供存储和计算,利用网络应用服务器和开放平台服务器进行大数据存储、管理和挖掘服务,并调整平台服务器的中心帮助企业实现大数据。智能分析,准确挖掘出所需数据。并已应用于金融机构、电子商务、新闻媒体和旅游行业。
功能亮点
查看全部
利用采集器 采集的平台(企业在数据采集、数据分析过程中遇到的7大难点
)
在这个数字世界中,每分钟都会产生大量数据。数据已成为新时代企业发展的必要因素。如今,企业产生的数据量正以每年 40% 到 60% 的速度增长。如何有效解决全链条的数据采集和数据分析,已经成为每个业务经理的首要问题。
下面将告诉你企业在数据采集和数据分析过程中遇到的7大难点!
Data采集数据需求调查
明确过程中数据采集的需求,就是确定我们的采集场景和需要的采集字段,既简化了采集工作的复杂性,又节省了采集的工作量!
数据清洗
数据清理——重新检查和验证采集的数据的过程,目的是去除重复信息,纠正现有错误,并提供数据一致性。如果没有这一步,我们会增加数据采集的存储空间,同时也会降低数据的有效价值!
数据合并
数据合并——以统一标准化的格式展示清洗后的数据源。缺少这一步会导致数据存储过程中的格式杂乱无章,不便于分析人员使用!
任务调度
任务调度是data采集系统的重要组成部分——它可以设置各个爬虫程序的定时启停时间,查看抓取的信息记录。任务调度环节的缺失将直接影响其时效性。
搜索引擎系统
搜索引擎系统可以通过条件+关键字组合查询采集数据库中的数据,无论采集的数量有多大,一个好的搜索引擎系统都会帮助分析师检索他们想要使用的数据在最快的时间内。缩短数据分析时间,提高整体工作效率!
数据分析
数据分析是指用适当的统计分析方法对采集到的大量数据进行分析,提取有用信息,形成结论,并对数据进行详细研究和概括的过程。这个过程也是质量管理体系的一个支持过程。在实践中,数据分析可以帮助企业做出商业判断,从而采取适当的行动,帮助企业赢得商机。
数据可视化展示
数据可视化主要使用图形、图像处理、计算机视觉和用户界面,通过显示三维图形或动画来直观地解释数据。可视化展示,让更多人能够清晰直观地分辨数据分析的结果,提升用户体验!
总结
数据采集和数据分析是很专业的东西。如果不是特别大的企业,就没有必要投入太多的财力和时间来搭建自己的数据采集和分析系统。由于缺乏专业性,采集的数据分析结果并不能指导公司做出正确的商业判断,最终不得不尝试。
天马科技自主研发的DYSON Smart采集系统是一个强大的大数据采集、分析和可视化平台。采用天马科技自主研发的TMF框架为主体架构,支持运营智能发展。用户通过一系列分析选项来使用采集的数据,以发现复杂的联系并探索其数据中的各种关系,包括图形可视化、全文多面搜索、动态直方图、交互式地理空间视图和实时共享协作工作区。探测码 戴森智能采集系统可以专业地捕捉、处理、分析和挖掘互联网数据。并灵活快速地抓取网络上分散的信息,通过智能数据中心提供存储和计算,利用网络应用服务器和开放平台服务器进行大数据存储、管理和挖掘服务,并调整平台服务器的中心帮助企业实现大数据。智能分析,准确挖掘出所需数据。并已应用于金融机构、电子商务、新闻媒体和旅游行业。
功能亮点

利用采集器 采集的平台(百度的开发者平台你是指webapp还是网页app?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-08-28 14:09
利用采集器采集的平台,下面是我已经采集好的功能区域app采集app采集共分为几大块业务区域,涉及到一些手机各方面的全网通,全屏等app的内容信息获取,就是目前一些app的信息采集,也是现在app的用户量的直接体现!一键生成采集app如果需要进行app的采集,一般都是采集一些app中的某个版块中的app功能信息,就需要一键生成app。
shortcut采集这种采集方式因为适用性更广,所以目前也是一种新的采集方式。采集的app区域基本都是包含着各个版块的,一般这种采集方式很适合第三方应用!对于业务进行个性化定制的比较多!来自一家专业的采集平台山火采集,转载请告知!!!。
百度的开发者平台
你是指webapp还是网页app呢?webapp的话:appstore+各大厂商自家的平台(最常见的就是三方的,app推广平台),ios的话appstore+各大厂商自家的平台。网页app的话:一般很多第三方app采集平台都是这种模式,小平台类似于易观,腾讯应用宝,app115,515等。
不止是app,任何网站都可以找到,可以关注我的微信公众号,专门做app收集网站做app和seo必不可少的一个服务,
91query网就是最好的app采集平台,
我用过的app分析平台:【app分析工具appspot】【appstore图片分析】【appxi安卓】【ios工具】【广告投放工具】【app注册平台】【app评论工具】 查看全部
利用采集器 采集的平台(百度的开发者平台你是指webapp还是网页app?)
利用采集器采集的平台,下面是我已经采集好的功能区域app采集app采集共分为几大块业务区域,涉及到一些手机各方面的全网通,全屏等app的内容信息获取,就是目前一些app的信息采集,也是现在app的用户量的直接体现!一键生成采集app如果需要进行app的采集,一般都是采集一些app中的某个版块中的app功能信息,就需要一键生成app。
shortcut采集这种采集方式因为适用性更广,所以目前也是一种新的采集方式。采集的app区域基本都是包含着各个版块的,一般这种采集方式很适合第三方应用!对于业务进行个性化定制的比较多!来自一家专业的采集平台山火采集,转载请告知!!!。
百度的开发者平台
你是指webapp还是网页app呢?webapp的话:appstore+各大厂商自家的平台(最常见的就是三方的,app推广平台),ios的话appstore+各大厂商自家的平台。网页app的话:一般很多第三方app采集平台都是这种模式,小平台类似于易观,腾讯应用宝,app115,515等。
不止是app,任何网站都可以找到,可以关注我的微信公众号,专门做app收集网站做app和seo必不可少的一个服务,
91query网就是最好的app采集平台,
我用过的app分析平台:【app分析工具appspot】【appstore图片分析】【appxi安卓】【ios工具】【广告投放工具】【app注册平台】【app评论工具】
为何探码Dyson选择定制采集服务科技(组图)!
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-08-19 05:03
随着大数据的发展,传统的采集工具已经难以满足用户的需求。首先,传统的采集工具在日常实用工具中无法照顾到用户的使用习惯,用户需要花费大量时间来熟悉工具。其次,传统的采集工具无法满足不同用户的需求,导致采集来满足不同的结果。数据采集的定制更符合时代发展趋势!
为什么戴森选择定制采集service
作为成都一家专门从事该行业的大数据公司,我们发现他们对采集的要求很难统一,而且用户在前期与客户沟通的过程中,使用软件的习惯非常难阶段。方面也不同。很难创造一个大家都非常满意的采集工具。市面上没有大家喜欢的采集工具吧?所以我们选择使用自主研发的Dyson采集系统为我们的客户做专业的采集定制。
什么是定制采集
数据定制是指根据用户的需求,根据互联网上的海量数据信息,对特定数据进行采集过滤、清洗、计算和处理输出数据结果的过程称为数据定制。让客户对工具的需求转变为与技术人员面对面的交流。以下是戴森采集为国内知名国企打造的投融资并购平台,告诉你定制采集!
戴森定制采集解决方案:
确定客户需求
在与客户沟通的过程中,他们希望结合自己在产权行业的深刻理解和沉淀,利用技术手段设计出一个模式,能够解决当前并购市场和投融资行业的问题,信息不完整、不对称、不透明,缺乏对行业痛点进行客观分析评估的金融信息交易平台。
确定客户需要采集的现场要求
根据客户需要采集的投融资项目信息与客户沟通后,我们总结了需要采集的领域。
确定采集数据的页面和平台
当我们澄清采集字段时,发现匹配度高的网站,使用探码自主研发的Dyson采集系统对采集这些网站进行处理。下图是爬取的网站截图的一小部分。
采集数据展示
采集结果出来后,筛选出来的反馈会反馈给客户进行审核确认,然后更新到前台展示,保持经常沟通。
数据清理以去除重复项
在数据采集的过程中,难免会出现重复的过时消息。 Dyson采集系统显示爬虫程序抓取的数据,方便我们清理。数据清洗系统主要由两部分组成:
计时采集
客户需要搭建大型投融资聚集平台。信息每时每刻都充斥着大量的新数据。为保证平台的权威性和专业性,我们会随时核对信息真实可靠采集更新到平台。
24/7 技术支持
在后期的平台维护中,我们会指派平台开发者定期检查后台数据采集等任务,保证系统的顺利运行。并不定期与客户沟通,采集后期使用过程中的修改意见。平台运行后,根据客户需求调整功能。
戴森 data采集定制行业应用
金融机构
在数据快速膨胀的今天,金融金融行业面临着大数据的诸多挑战,如数据应用深度不断增加、数据分析技术更新频率加快、数据类型日益增多等基于业务和策略需求,数据的采集、整理、传输、分析和发布是一个连续而复杂的过程。但是,传统的采集工具根本无法实现采集这样专业的数据。数据的准确性对财务很重要。对于行业来说,它是生命之门,数据不能有出入。定制数据采集是金融行业的最佳选择。
电子商务
电商平台数据庞大且繁琐。传统的采集工具无法实现详细的采集。需要专业数据采集人员提供采集方向并增加相应功能设置。数据的准确性采集。具体案例请参考Dyson采集为成都客户打造的服装电商平台。
旅行社
旅行者拥有比以往任何时候都多的信息,因为大数据允许他们在社交媒体上与同行分享信息。因此,旅游企业需要了解以下问题,并找到应对即将到来的情况的策略。但是传统的采集工具大多没有进行仔细的筛选,使得来自采集的数据价值不高,容易误导管理者的决策。定制化的采集会进行人工筛选和机器筛选,让采集更有价值!
新闻媒体
随着互联网技术的发展和新闻媒体的不断涌现,尤其是大数据技术的出现,传统的采集新闻方式(通过访问、信函、电话)已经无法适应互联网发展的需要。在信息流高度发达的今天,新闻行业需要抓住事件的热点才能生存。如果使用传统的采集工具,则无法追踪热点采集,这个行业对这些信息极为敏感。定制数据采集无非就是最好的选择!
总结:再好的音乐不符合你的心情,也会变成噪音。当大数据不能满足你的需求时,它也是一堆废品。摆脱与机器的枯燥对话,让你的需求成为真正懂你的人,高速发挥数据的真正价值---戴森数据采集定制就在你身边! 查看全部
为何探码Dyson选择定制采集服务科技(组图)!
随着大数据的发展,传统的采集工具已经难以满足用户的需求。首先,传统的采集工具在日常实用工具中无法照顾到用户的使用习惯,用户需要花费大量时间来熟悉工具。其次,传统的采集工具无法满足不同用户的需求,导致采集来满足不同的结果。数据采集的定制更符合时代发展趋势!
为什么戴森选择定制采集service
作为成都一家专门从事该行业的大数据公司,我们发现他们对采集的要求很难统一,而且用户在前期与客户沟通的过程中,使用软件的习惯非常难阶段。方面也不同。很难创造一个大家都非常满意的采集工具。市面上没有大家喜欢的采集工具吧?所以我们选择使用自主研发的Dyson采集系统为我们的客户做专业的采集定制。
什么是定制采集
数据定制是指根据用户的需求,根据互联网上的海量数据信息,对特定数据进行采集过滤、清洗、计算和处理输出数据结果的过程称为数据定制。让客户对工具的需求转变为与技术人员面对面的交流。以下是戴森采集为国内知名国企打造的投融资并购平台,告诉你定制采集!
戴森定制采集解决方案:
确定客户需求
在与客户沟通的过程中,他们希望结合自己在产权行业的深刻理解和沉淀,利用技术手段设计出一个模式,能够解决当前并购市场和投融资行业的问题,信息不完整、不对称、不透明,缺乏对行业痛点进行客观分析评估的金融信息交易平台。
确定客户需要采集的现场要求
根据客户需要采集的投融资项目信息与客户沟通后,我们总结了需要采集的领域。
确定采集数据的页面和平台
当我们澄清采集字段时,发现匹配度高的网站,使用探码自主研发的Dyson采集系统对采集这些网站进行处理。下图是爬取的网站截图的一小部分。

采集数据展示
采集结果出来后,筛选出来的反馈会反馈给客户进行审核确认,然后更新到前台展示,保持经常沟通。
数据清理以去除重复项
在数据采集的过程中,难免会出现重复的过时消息。 Dyson采集系统显示爬虫程序抓取的数据,方便我们清理。数据清洗系统主要由两部分组成:
计时采集
客户需要搭建大型投融资聚集平台。信息每时每刻都充斥着大量的新数据。为保证平台的权威性和专业性,我们会随时核对信息真实可靠采集更新到平台。
24/7 技术支持
在后期的平台维护中,我们会指派平台开发者定期检查后台数据采集等任务,保证系统的顺利运行。并不定期与客户沟通,采集后期使用过程中的修改意见。平台运行后,根据客户需求调整功能。
戴森 data采集定制行业应用
金融机构
在数据快速膨胀的今天,金融金融行业面临着大数据的诸多挑战,如数据应用深度不断增加、数据分析技术更新频率加快、数据类型日益增多等基于业务和策略需求,数据的采集、整理、传输、分析和发布是一个连续而复杂的过程。但是,传统的采集工具根本无法实现采集这样专业的数据。数据的准确性对财务很重要。对于行业来说,它是生命之门,数据不能有出入。定制数据采集是金融行业的最佳选择。
电子商务
电商平台数据庞大且繁琐。传统的采集工具无法实现详细的采集。需要专业数据采集人员提供采集方向并增加相应功能设置。数据的准确性采集。具体案例请参考Dyson采集为成都客户打造的服装电商平台。
旅行社
旅行者拥有比以往任何时候都多的信息,因为大数据允许他们在社交媒体上与同行分享信息。因此,旅游企业需要了解以下问题,并找到应对即将到来的情况的策略。但是传统的采集工具大多没有进行仔细的筛选,使得来自采集的数据价值不高,容易误导管理者的决策。定制化的采集会进行人工筛选和机器筛选,让采集更有价值!
新闻媒体
随着互联网技术的发展和新闻媒体的不断涌现,尤其是大数据技术的出现,传统的采集新闻方式(通过访问、信函、电话)已经无法适应互联网发展的需要。在信息流高度发达的今天,新闻行业需要抓住事件的热点才能生存。如果使用传统的采集工具,则无法追踪热点采集,这个行业对这些信息极为敏感。定制数据采集无非就是最好的选择!
总结:再好的音乐不符合你的心情,也会变成噪音。当大数据不能满足你的需求时,它也是一堆废品。摆脱与机器的枯燥对话,让你的需求成为真正懂你的人,高速发挥数据的真正价值---戴森数据采集定制就在你身边!
利用采集器采集的平台和url的区别?
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-08-17 20:06
利用采集器采集的平台,对,不是程序采集的。那么,可以问问probot都能找到哪些平台和url了。因为它是通过设置默认采集规则采集,这个过程中,你就必须要考虑选择哪些站点。对了,这个过程中,你也不要忘记绑定你的域名解析服务。
最原始的方法是用软件抓取,一些高版本的浏览器都有这种功能,但高版本可能有些例外,为了提高效率,都是用rooted去抓取。所以最简单的方法还是rooted抓取url。
平台都很多,其中用得比较多的是quickspider。其它关于quickspider的讨论,你可以参考下这个[1]。还有,推荐使用python写爬虫,resquests这些库也支持javascript,甚至mediaquery都比resquests好用。
以我近2年的工作经验来看,有很多,不过常见的有:googleprojects/googlewebspider/webrtcquickspiderspidersourceapi或者自己写也可以[e.g.]java下我用的多的是processjsguika.js[bestresources]-lowdimensionalabsolutely-convertfeatureswithprocessjsonwindowsquerysourceawebparameter:storeglobaldictionaryquerystringbundlehavingopenfeatures,etc.其实可以直接网上搜,很多文章,高阶爬虫技术很多的。
可以在web端直接请求ip/本地dom的url。 查看全部
利用采集器采集的平台和url的区别?
利用采集器采集的平台,对,不是程序采集的。那么,可以问问probot都能找到哪些平台和url了。因为它是通过设置默认采集规则采集,这个过程中,你就必须要考虑选择哪些站点。对了,这个过程中,你也不要忘记绑定你的域名解析服务。
最原始的方法是用软件抓取,一些高版本的浏览器都有这种功能,但高版本可能有些例外,为了提高效率,都是用rooted去抓取。所以最简单的方法还是rooted抓取url。
平台都很多,其中用得比较多的是quickspider。其它关于quickspider的讨论,你可以参考下这个[1]。还有,推荐使用python写爬虫,resquests这些库也支持javascript,甚至mediaquery都比resquests好用。
以我近2年的工作经验来看,有很多,不过常见的有:googleprojects/googlewebspider/webrtcquickspiderspidersourceapi或者自己写也可以[e.g.]java下我用的多的是processjsguika.js[bestresources]-lowdimensionalabsolutely-convertfeatureswithprocessjsonwindowsquerysourceawebparameter:storeglobaldictionaryquerystringbundlehavingopenfeatures,etc.其实可以直接网上搜,很多文章,高阶爬虫技术很多的。
可以在web端直接请求ip/本地dom的url。
明威微信群采集器微信信息采集工具免费下载(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2021-08-12 00:00
本站提供最新版明微微信群采集器(微信信息采集工具)软件免费下载。
[软件截图]
【基本介绍】
名微微信群采集器是强大的信息采集必备工具。这个工具可以自动搜索加入微信群,也可以自动采集微信二维码。非常适合有推广需求的商家,以及需要在网上推广的网友和朋友。欢迎有需要的朋友点击下载。
主要功能
一键采集当前最新二维码、微信群二维码采集、个人微信账号采集、群主微信账号采集、公众账号采集、明微微信群采集器Software具有自动扫码进群功能。
性能提示
1、支持系统:
Windows(窗口化操作系统)系统(win7或win8高版本系统)
2、数据信息量:
软件采集来自对应的数据源网站。该软件不产生数据。本软件只负责采集和识别。每天更新的总数是几千到几万个微信群二维码。
3、可用性:
我们本人不保证软件采集的微信群二维码可以100%扫描,因为有几个不可控因素
楼主已经离开了他建的微信群。
群人数超过100人(这是腾讯官网规定,群内人数只能扫码少于100人,扫码时超过100人人,说明有其他顾客也扫描了这个二维码,导致群满了。)
二级码发布时间超过7天有效期。 查看全部
明威微信群采集器微信信息采集工具免费下载(图)
本站提供最新版明微微信群采集器(微信信息采集工具)软件免费下载。
[软件截图]

【基本介绍】
名微微信群采集器是强大的信息采集必备工具。这个工具可以自动搜索加入微信群,也可以自动采集微信二维码。非常适合有推广需求的商家,以及需要在网上推广的网友和朋友。欢迎有需要的朋友点击下载。
主要功能
一键采集当前最新二维码、微信群二维码采集、个人微信账号采集、群主微信账号采集、公众账号采集、明微微信群采集器Software具有自动扫码进群功能。
性能提示
1、支持系统:
Windows(窗口化操作系统)系统(win7或win8高版本系统)
2、数据信息量:
软件采集来自对应的数据源网站。该软件不产生数据。本软件只负责采集和识别。每天更新的总数是几千到几万个微信群二维码。
3、可用性:
我们本人不保证软件采集的微信群二维码可以100%扫描,因为有几个不可控因素
楼主已经离开了他建的微信群。
群人数超过100人(这是腾讯官网规定,群内人数只能扫码少于100人,扫码时超过100人人,说明有其他顾客也扫描了这个二维码,导致群满了。)
二级码发布时间超过7天有效期。
利用采集器 采集的平台 看到本文内容请勿诧异,因为本文由考拉SEO【批量写SEO原创文章】
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-08-11 01:05
看到这篇文章的内容不要惊讶,因为这篇文章是由考拉SEO【批量写SEO原创文章】平台支持的。有了考拉,一天可以产出上万条优质SEO文章!如果还需要批量编辑SEO文章,可以进入平台用户中心试用!
非常抱歉。这时候你看这个文章,你可能看到文章不包括qq采集器平台的报道。这是因为页面是我们平台SEO文章自动编译的。如果大家对批量创建内容的信息有需求,可以先放弃qq采集器平台,推荐大家了解一下:如何使用系统在24小时内生成上万篇好的网页文本!很多客户看到我编辑的小广告以为这是伪原创software,误会了!事实上,我们是一个原创系统。 关键词和模板都是独立写的,网上基本没有类似这篇文章的内容。我们是如何完成的?我将在下面为您解读!
想要搞清楚qq采集器平台的用户,其实最关心的是上面讨论的话题。写一个高流量的网站陆文是超级容易的,但这些文章能产生的访问量实际上是一点点。希望通过信息的积累,达到引流的目的。最重要的一点是量化!如果一篇文章文章可以得到1个pageview(每24小时),如果我可以编辑10000篇文章,那么平均每天的pageview可以增加几万。但简单的说,其实在编辑的时候,一个人一天只能出四十篇左右,最好是七十多篇。就算用了一些伪原创软件,最多也就100篇吧!浏览到这里,大家应该放弃qq采集器平台,充分探索如何实现文章的智能写作!
杜娘认可的真正编辑是什么? 文章原创不仅仅是一一关键词原创edit!在每个搜索者的平台词典中,原创并不代表没有重复的内容。其实只要你的文章不复制别人的网页内容,被爬取的可能性就可能会增加。 1 好文章,核心够抢眼,坚持同一个核心思想,只要没有大段重复,那么这个文章还是很有可能被认出来的,甚至变成一个好排水用的物品。比如下一篇文章,我们可能搜索过网站搜qq采集器平台,最后点击查看。其实下一篇文章是AI编辑文章platform独立使用考拉SEO制作的!
考拉SEO的AI原创software,结论性的表达应该叫批量写作文章software,24小时内可以写出几万条高质量优化的文章,你的网页权重通常够高,收录 可以高达至少 66%。详细的操作教程,个人中心有视频展示和小白的指导。您可以免费测试!非常抱歉,我没有编辑qq采集器平台的详细解释,让你看了这么多系统语言。但是,如果您对批量编写文章技术感兴趣,只需查看导航栏,您的站点每天就会增加数百个UV。不靠谱吗? 查看全部
利用采集器 采集的平台 看到本文内容请勿诧异,因为本文由考拉SEO【批量写SEO原创文章】
看到这篇文章的内容不要惊讶,因为这篇文章是由考拉SEO【批量写SEO原创文章】平台支持的。有了考拉,一天可以产出上万条优质SEO文章!如果还需要批量编辑SEO文章,可以进入平台用户中心试用!
非常抱歉。这时候你看这个文章,你可能看到文章不包括qq采集器平台的报道。这是因为页面是我们平台SEO文章自动编译的。如果大家对批量创建内容的信息有需求,可以先放弃qq采集器平台,推荐大家了解一下:如何使用系统在24小时内生成上万篇好的网页文本!很多客户看到我编辑的小广告以为这是伪原创software,误会了!事实上,我们是一个原创系统。 关键词和模板都是独立写的,网上基本没有类似这篇文章的内容。我们是如何完成的?我将在下面为您解读!

想要搞清楚qq采集器平台的用户,其实最关心的是上面讨论的话题。写一个高流量的网站陆文是超级容易的,但这些文章能产生的访问量实际上是一点点。希望通过信息的积累,达到引流的目的。最重要的一点是量化!如果一篇文章文章可以得到1个pageview(每24小时),如果我可以编辑10000篇文章,那么平均每天的pageview可以增加几万。但简单的说,其实在编辑的时候,一个人一天只能出四十篇左右,最好是七十多篇。就算用了一些伪原创软件,最多也就100篇吧!浏览到这里,大家应该放弃qq采集器平台,充分探索如何实现文章的智能写作!
杜娘认可的真正编辑是什么? 文章原创不仅仅是一一关键词原创edit!在每个搜索者的平台词典中,原创并不代表没有重复的内容。其实只要你的文章不复制别人的网页内容,被爬取的可能性就可能会增加。 1 好文章,核心够抢眼,坚持同一个核心思想,只要没有大段重复,那么这个文章还是很有可能被认出来的,甚至变成一个好排水用的物品。比如下一篇文章,我们可能搜索过网站搜qq采集器平台,最后点击查看。其实下一篇文章是AI编辑文章platform独立使用考拉SEO制作的!

考拉SEO的AI原创software,结论性的表达应该叫批量写作文章software,24小时内可以写出几万条高质量优化的文章,你的网页权重通常够高,收录 可以高达至少 66%。详细的操作教程,个人中心有视频展示和小白的指导。您可以免费测试!非常抱歉,我没有编辑qq采集器平台的详细解释,让你看了这么多系统语言。但是,如果您对批量编写文章技术感兴趣,只需查看导航栏,您的站点每天就会增加数百个UV。不靠谱吗?
如何利用采集器采集的平台的url下载采集文件目录
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-08-06 18:01
利用采集器采集的平台的url,下载采集的文件,然后去放置java后台的目录找下,index目录一般就是本地文件目录。建议你自己先动手,最起码了解一下采集器,或者多问问牛人。
应该是那个excel下面的“simulation”文件夹,本地的应该也是那个project,可以自己建一个脚本,把url抓过来,然后直接放到java脚本里。
lz学学爬虫吧。简单来说就是selenium。
前端爬虫发,后端app的话,
需要读懂中cookie的实现原理,把url的httpget拿过来,然后做一个简单的模拟登录,然后直接把获取的信息放到爬虫里面去,你得说清楚,
你好,这是java后端基础中的模拟登录功能,自己封装一个小功能用于管理和统计:然后集中挂机工作,每天登录过的url,更新的url,需要的工具,都记录进行统计吧。
不考虑学习的可能。如果是要爬取手机号码码段的话就不需要爬取相关的固定url,如果觉得手机号难道就是空格?那是没有抓到核心需求,那么可以做个模拟登录的功能,获取账号密码为核心如果有变量需要填写,可以参考requests或aiohttp的define方法方法。前端可以用jquery来实现。有些技术在学习中可能比实际工作需要多一些,但是一旦掌握,非常有用,做项目就可以解决。比如前端中的ajax的使用。 查看全部
如何利用采集器采集的平台的url下载采集文件目录
利用采集器采集的平台的url,下载采集的文件,然后去放置java后台的目录找下,index目录一般就是本地文件目录。建议你自己先动手,最起码了解一下采集器,或者多问问牛人。
应该是那个excel下面的“simulation”文件夹,本地的应该也是那个project,可以自己建一个脚本,把url抓过来,然后直接放到java脚本里。
lz学学爬虫吧。简单来说就是selenium。
前端爬虫发,后端app的话,
需要读懂中cookie的实现原理,把url的httpget拿过来,然后做一个简单的模拟登录,然后直接把获取的信息放到爬虫里面去,你得说清楚,
你好,这是java后端基础中的模拟登录功能,自己封装一个小功能用于管理和统计:然后集中挂机工作,每天登录过的url,更新的url,需要的工具,都记录进行统计吧。
不考虑学习的可能。如果是要爬取手机号码码段的话就不需要爬取相关的固定url,如果觉得手机号难道就是空格?那是没有抓到核心需求,那么可以做个模拟登录的功能,获取账号密码为核心如果有变量需要填写,可以参考requests或aiohttp的define方法方法。前端可以用jquery来实现。有些技术在学习中可能比实际工作需要多一些,但是一旦掌握,非常有用,做项目就可以解决。比如前端中的ajax的使用。
本发明提供一种基于云平台的网站信息采集系统(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-08-03 01:24
本发明提供一种基于云平台的网站信息采集系统(图)
本发明涉及信息采集领域,尤其涉及一种基于云平台的网站信息采集系统。
背景技术:
在现有技术中,对网站信息的获取一般是通过爬虫技术来实现的。但是为了防止爬虫的访问连接占用正常的访问带宽,很多网站都设置了反爬虫机制。如果使用单个客户端爬取网站的信息,很容易被反爬虫机制识别,导致网站的信息采集失败。
技术实现要素:
针对上述问题,本发明的目的在于提供一种基于云平台的网站信息采集系统。
本发明提供了一种基于云平台的网站信息采集系统,包括任务管理模块、代理服务模块和数据管理模块;
任务管理模块用于生成网站信息采集任务,并将网站信息采集任务发送给代理服务模块;
代理服务模块用于通过代理服务器处理网站信息采集任务,生成爬虫任务,利用代理服务器实现爬虫任务获取网站数据;
p>
数据管理模块用于将网站数据存储到云计算存储服务器,并对存储在云计算存储服务器中的网站数据进行管理。
优选地,任务管理模块包括权限控制单元和任务管理单元;
权限控制单元用于验证使用任务管理单元的人的身份,判断此人是否有使用任务管理单元的权限,如果有,则将任务开放给此人的权限管理单元,否则禁止该人使用任务管理单元;
任务管理单元用于为通过身份验证的人员新建网站信息采集任务。
最好也使用任务管理单元来管理现有的网站信息采集任务,具体包括:
删除现有网站信息采集任务,修改现有网站信息采集任务。
优选地,网站信息采集任务包括需要信息采集的网站的URL,需要信息采集的网站的登录信息,以及代理服务器Identity的使用用公钥加密的验证信息进行身份验证。
优选地,代理服务器在处理网站信息采集任务并生成爬虫任务之前,还包括:
使用与身份验证公钥对应的身份验证私钥对身份验证信息进行解密,得到身份验证识别码;
将身份验证信息中收录的身份验证识别码与代理服务器中预先存储的身份验证识别码进行比较,判断两者是否一致。执行处理并生成爬虫任务。如果不是,则不处理网站信息采集任务。
优选地,基于网站信息采集任务生成爬虫任务包括:
使用代理服务器访问网站,下载网站对应的网页数据;
判断网页数据中是否存在统一资源定位器,如果有,获取每个统一资源定位器对应的URL,并根据该URL生成爬虫任务。
优选地,爬虫任务包括统一资源定位器对应的网址和从统一资源定位器对应的网址下载数据的时间间隔。
优选地,数据管理模块包括设置在云计算服务器上的数据管理单元和存储单元;
数据管理单元用于将网站数据存存到存储单元;
存储单元用于存储网站数据。
与现有技术相比,本发明的优点是:
本发明通过代理服务器为目标网站获取网站信息,从而实现网站中数据的下载。由于采用代理方式,本应用中用于实现任务管理模块的客户端不会受到网站反爬虫机制的影响,可以灵活地为网站信息的采集使用不同的代理服务器,有效提高网站信息采集的成功率。
图纸说明
以下结合附图对本发明作进一步说明,但附图中的实施例并不构成对本发明的任何限制。对于本领域普通技术人员来说,在没有创造性劳动的情况下,也可以使用下面的图纸获取其他图纸。
图1为本发明基于云平台的网站信息采集系统的一个示例性实施例示意图。
具体实现方法
下面详细描述本发明的实施例。实施例的示例在附图中示出,其中相同或相似的附图标记表示相同或相似的元件或具有相同或相似功能的元件。以下结合附图所描述的实施例仅为示例性的,仅用以解释本发明,而不能理解为对本发明的限制。
如图1所示实施例所示,本发明提供了一种基于云平台的网站信息采集系统,包括任务管理模块、代理服务模块和数据管理模块;
任务管理模块用于生成网站信息采集任务,并将网站信息采集任务发送给代理服务模块;
代理服务模块用于通过代理服务器处理网站信息采集任务,生成爬虫任务,利用代理服务器实现爬虫任务获取网站数据;
p>
数据管理模块用于将网站数据存储到云计算存储服务器,并对存储在云计算存储服务器中的网站数据进行管理。
网站信息采集任务管理和网站信息采集任务管理的分离,有利于灵活选择不同的代理服务器来执行网站信息采集任务,避免后单客户端被反爬虫机制识别,影响网页下载效率。
在一个实施例中,任务管理模块包括权限控制单元和任务管理单元;
权限控制单元用于验证使用任务管理单元的人的身份,判断此人是否有使用任务管理单元的权限,如果有,则将任务开放给此人的权限管理单元,否则禁止该人使用任务管理单元;
任务管理单元用于为通过身份验证的人员新建网站信息采集任务。
在一实施例中,任务管理模块包括输入单元和判断单元;
输入单元用于人员输入任务管理单元的账号和密码;
判断单元用于判断使用账号和使用密码是否正确,如果正确,则判断此人有权限使用任务管理单元;如果不是,则判断该人没有使用任务管理单元的权利。任务管理单元的权限。
在另一个实施例中,任务管理模块包括拍照单元、图像处理单元和权限判断单元;
拍摄单元用于获取人脸图像;
图像处理单元用于对人脸图像进行图像识别处理,得到人脸图像中收录的特征信息;
权限判断单元用于将图像处理单元获取的特征信息与任务管理模块中预存的所有具有使用任务管理单元权限的人的面部图像的特征信息进行匹配,如果如果匹配成功,则确定此人具有使用任务管理单元的权限;如果匹配失败,则确定此人没有使用任务管理单元的权限。
在一个实施例中,对人脸图像进行图像识别处理以获得人脸图像中收录的特征信息包括:
对人脸图像进行灰度处理,得到灰度图像;
计算人脸图像的差异度,得到差异图像;
对灰度图像进行边缘检测,得到边缘图像;
对灰度图像进行降噪处理,得到降噪图像;
对降噪图像进行图像分割处理,得到前景图像;
根据差分图像、前景图像和边缘图像生成目标图像;
使用预设的特征信息采集算法获取目标图像中收录的特征信息。
在本发明上述实施例中,通过差分图像、前景图像和边缘图像生成目标图像,然后提取目标图像中收录的特征信息,极大地提高了特征信息的准确性。现有技术中,一般在对灰度图像进行去噪后,直接提取去噪后图像的特征信息。但是,由于降噪是减少图像中有效信息的过程,因此得到的特征信息不够准确。在本应用中,从目标图像中提取特征信息,可以有效地获取准确的特征信息。可以将差异图像中收录的像素之间的差异信息、边缘图像中收录的边缘信息以及前景信息体现在目标图像中,从而实现对降噪图像中丢失的特征信息的补偿。
在一个实施例中,计算人脸图像的差异度以获得差异图像包括:
将人脸图像转换到lab颜色空间,得到lab颜色空间中人脸图像对应的l分量图像、a分量图像和b分量图像;
分别获取人脸图像中每个像素的差分参数:
式中,csn(nod)表示人脸图像中像素nod的差分参数,nodu表示nod的d×d邻域内所有像素的集合,nodu表示nodu w1、的元素@w2、w3代表预设的尺度参数,w1+w2+w3=1,l(nod)和l(nodu)分别代表l分量图像中nod和nodu的像素值,a(nod)和a (nodu)表示a分量图像中nod和nodu的像素值,b(nod)和b(nodu)分别表示b分量图像中nod和nodu的像素值,numnodu表示总和nodu中收录的元素个数;
获取l分量图像中像素值的中值对应的像素点,将像素点标记为mxn;
通过以下方法获取差异图像:
将l分量图像中的像素点保存到集合dlul中,对于dlul中的像素点dlu,通过下式计算差分图像中的像素值:
式中,xc(dlu)代表差异图像中dlu的像素值,csn(dlu)和csn(mxn)分别代表dlu和mxn的差异程度参数,l(mxn)代表mxn l 分量图像的像素值;
计算差分图像中dlul中每个像素的像素值,得到差分图像。
在本发明的上述实施例中,在获取差异图像时,首先将人脸图像转换为lab色彩空间,然后根据其中的三个变量计算每个像素的差异度参数lab 颜色空间,然后从 l 计算差异度参数 在分量图像中,选择一个像素作为参考像素,针对不同的像素计算差异图像中不同像素的像素值,有利于全面获取像素间的差异信息,同时避免光线的影响。差异度参数与计算时的邻域像素有关。差异度参数由邻域像素点与当前正在计算的像素点在三个分量中的差异的加权值得到,有利于差异度参数充分反映当前的进展情况。计算出的像素与相邻像素之间的差异。在选择参考像素时,选择l分量图像中像素值的中值对应的像素作为参考像素。这种设置方法有助于避免错误地将噪声的像素值用作参考像素值。 , 有利于获得准确的差分图像。
在一个实施例中,对灰度图像进行边缘检测得到边缘图像包括:
使用sobel边缘检测算法对灰度图像进行边缘检测,得到边缘图像。
在一个实施例中,对灰度图像进行降噪处理得到降噪图像包括:
对灰度图像进行小波分解处理,得到小波高频系数和小波低频系数;
对小波高频系数中的像素进行如下处理:
式中,tsl(p)表示小波高频系数中位置p对应的像素的像素值,btsl(p)表示上述对tsl(p)的处理结果; vb和vc代表预先设置的处理阈值,sh代表判断操作,如果tsl(p)大于预设阈值tp,则sh[tsl(p)]的值为1.2,如果tsl (p) 小于等于预设阈值 tp ,则 sh[tsl(p)] 的值为1.05,
对小波高频系数中的所有像素进行上述处理,得到第一处理系数;
对小波低频系数中的像素进行如下处理:
式中,tlluq表示小波低频系数中位置q对应的像素点k×k邻域内的像素集合,lon(q,u)表示位置q对应的像素点小波低频系数中像素点u与tlluq收录的像素点u之间的直线距离,tll(u)表示低频小波系数图像中u的像素值,btll(q)表示小波低频系数中位置q对应的像素使用上式点处理的结果; tll(q)表示小波低频系数中q位置对应的像素点的像素值;
公式中ntlluq表示tlluq中收录的像素总数;
对小波低频系数中的所有像素进行上述处理,得到第二处理系数;
对第一处理系数和第二处理系数进行小波重构,得到降噪图像。
在本发明的上述实施例中,在进行降噪处理时,将灰度图像分解为小波高频系数和小波低频系数,然后小波高频系数和小波分别对低频系数进行处理,对处理后的小波高频系数和小波低频系数进行重构,得到去噪图像。有利于在保持图像边缘信息等特征信息的同时实现准确的降噪处理。现有技术中,例如使用高斯函数进行降噪时,像素点会变得模糊,像素之间的差异会变小,从而导致细节信息丢失。这个应用程序能够很好地避免这个问题。本应用在处理小波高频系数时,采用了改进的处理功能。通过处理阈值与当前处理像素的像素值之间的关系,对当前处理的像素自适应选择不同的处理函数处理,有助于提高小波高频系数的处理精度。此外,该应用程序还处理小波低频系数。在处理中,低频小波系数中的像素与其邻域内的像素之间的线性距离和像素值的差异就是低频小波系数中的当前处理。像素提供准确的处理结果。因此,有效提高了降噪的准确性,提高了本发明采集系统的安全性。
在一个实施例中,对降噪图像进行图像分割处理得到前景图像包括:
使用otsu算法对去噪后的图像进行图像分割处理,得到所有前景像素的集合fru1;
用下面的方法对fru1中的像素进行过滤,得到集合fru2:
<p>对于 fru1 中的像素 fru,计算 fru 和参考像素 stad 之间的距离 dist(fru,stad)。如果dist(fru,stad)小于预设的距离阈值,则下一步判断fru,如果dist(fru,stad)大于或等于预设的距离阈值,则从fru1中删除fru; 查看全部
本发明提供一种基于云平台的网站信息采集系统(图)

本发明涉及信息采集领域,尤其涉及一种基于云平台的网站信息采集系统。
背景技术:
在现有技术中,对网站信息的获取一般是通过爬虫技术来实现的。但是为了防止爬虫的访问连接占用正常的访问带宽,很多网站都设置了反爬虫机制。如果使用单个客户端爬取网站的信息,很容易被反爬虫机制识别,导致网站的信息采集失败。
技术实现要素:
针对上述问题,本发明的目的在于提供一种基于云平台的网站信息采集系统。
本发明提供了一种基于云平台的网站信息采集系统,包括任务管理模块、代理服务模块和数据管理模块;
任务管理模块用于生成网站信息采集任务,并将网站信息采集任务发送给代理服务模块;
代理服务模块用于通过代理服务器处理网站信息采集任务,生成爬虫任务,利用代理服务器实现爬虫任务获取网站数据;
p>
数据管理模块用于将网站数据存储到云计算存储服务器,并对存储在云计算存储服务器中的网站数据进行管理。
优选地,任务管理模块包括权限控制单元和任务管理单元;
权限控制单元用于验证使用任务管理单元的人的身份,判断此人是否有使用任务管理单元的权限,如果有,则将任务开放给此人的权限管理单元,否则禁止该人使用任务管理单元;
任务管理单元用于为通过身份验证的人员新建网站信息采集任务。
最好也使用任务管理单元来管理现有的网站信息采集任务,具体包括:
删除现有网站信息采集任务,修改现有网站信息采集任务。
优选地,网站信息采集任务包括需要信息采集的网站的URL,需要信息采集的网站的登录信息,以及代理服务器Identity的使用用公钥加密的验证信息进行身份验证。
优选地,代理服务器在处理网站信息采集任务并生成爬虫任务之前,还包括:
使用与身份验证公钥对应的身份验证私钥对身份验证信息进行解密,得到身份验证识别码;
将身份验证信息中收录的身份验证识别码与代理服务器中预先存储的身份验证识别码进行比较,判断两者是否一致。执行处理并生成爬虫任务。如果不是,则不处理网站信息采集任务。
优选地,基于网站信息采集任务生成爬虫任务包括:
使用代理服务器访问网站,下载网站对应的网页数据;
判断网页数据中是否存在统一资源定位器,如果有,获取每个统一资源定位器对应的URL,并根据该URL生成爬虫任务。
优选地,爬虫任务包括统一资源定位器对应的网址和从统一资源定位器对应的网址下载数据的时间间隔。
优选地,数据管理模块包括设置在云计算服务器上的数据管理单元和存储单元;
数据管理单元用于将网站数据存存到存储单元;
存储单元用于存储网站数据。
与现有技术相比,本发明的优点是:
本发明通过代理服务器为目标网站获取网站信息,从而实现网站中数据的下载。由于采用代理方式,本应用中用于实现任务管理模块的客户端不会受到网站反爬虫机制的影响,可以灵活地为网站信息的采集使用不同的代理服务器,有效提高网站信息采集的成功率。
图纸说明
以下结合附图对本发明作进一步说明,但附图中的实施例并不构成对本发明的任何限制。对于本领域普通技术人员来说,在没有创造性劳动的情况下,也可以使用下面的图纸获取其他图纸。
图1为本发明基于云平台的网站信息采集系统的一个示例性实施例示意图。
具体实现方法
下面详细描述本发明的实施例。实施例的示例在附图中示出,其中相同或相似的附图标记表示相同或相似的元件或具有相同或相似功能的元件。以下结合附图所描述的实施例仅为示例性的,仅用以解释本发明,而不能理解为对本发明的限制。
如图1所示实施例所示,本发明提供了一种基于云平台的网站信息采集系统,包括任务管理模块、代理服务模块和数据管理模块;
任务管理模块用于生成网站信息采集任务,并将网站信息采集任务发送给代理服务模块;
代理服务模块用于通过代理服务器处理网站信息采集任务,生成爬虫任务,利用代理服务器实现爬虫任务获取网站数据;
p>
数据管理模块用于将网站数据存储到云计算存储服务器,并对存储在云计算存储服务器中的网站数据进行管理。
网站信息采集任务管理和网站信息采集任务管理的分离,有利于灵活选择不同的代理服务器来执行网站信息采集任务,避免后单客户端被反爬虫机制识别,影响网页下载效率。
在一个实施例中,任务管理模块包括权限控制单元和任务管理单元;
权限控制单元用于验证使用任务管理单元的人的身份,判断此人是否有使用任务管理单元的权限,如果有,则将任务开放给此人的权限管理单元,否则禁止该人使用任务管理单元;
任务管理单元用于为通过身份验证的人员新建网站信息采集任务。
在一实施例中,任务管理模块包括输入单元和判断单元;
输入单元用于人员输入任务管理单元的账号和密码;
判断单元用于判断使用账号和使用密码是否正确,如果正确,则判断此人有权限使用任务管理单元;如果不是,则判断该人没有使用任务管理单元的权利。任务管理单元的权限。
在另一个实施例中,任务管理模块包括拍照单元、图像处理单元和权限判断单元;
拍摄单元用于获取人脸图像;
图像处理单元用于对人脸图像进行图像识别处理,得到人脸图像中收录的特征信息;
权限判断单元用于将图像处理单元获取的特征信息与任务管理模块中预存的所有具有使用任务管理单元权限的人的面部图像的特征信息进行匹配,如果如果匹配成功,则确定此人具有使用任务管理单元的权限;如果匹配失败,则确定此人没有使用任务管理单元的权限。
在一个实施例中,对人脸图像进行图像识别处理以获得人脸图像中收录的特征信息包括:
对人脸图像进行灰度处理,得到灰度图像;
计算人脸图像的差异度,得到差异图像;
对灰度图像进行边缘检测,得到边缘图像;
对灰度图像进行降噪处理,得到降噪图像;
对降噪图像进行图像分割处理,得到前景图像;
根据差分图像、前景图像和边缘图像生成目标图像;
使用预设的特征信息采集算法获取目标图像中收录的特征信息。
在本发明上述实施例中,通过差分图像、前景图像和边缘图像生成目标图像,然后提取目标图像中收录的特征信息,极大地提高了特征信息的准确性。现有技术中,一般在对灰度图像进行去噪后,直接提取去噪后图像的特征信息。但是,由于降噪是减少图像中有效信息的过程,因此得到的特征信息不够准确。在本应用中,从目标图像中提取特征信息,可以有效地获取准确的特征信息。可以将差异图像中收录的像素之间的差异信息、边缘图像中收录的边缘信息以及前景信息体现在目标图像中,从而实现对降噪图像中丢失的特征信息的补偿。
在一个实施例中,计算人脸图像的差异度以获得差异图像包括:
将人脸图像转换到lab颜色空间,得到lab颜色空间中人脸图像对应的l分量图像、a分量图像和b分量图像;
分别获取人脸图像中每个像素的差分参数:
式中,csn(nod)表示人脸图像中像素nod的差分参数,nodu表示nod的d×d邻域内所有像素的集合,nodu表示nodu w1、的元素@w2、w3代表预设的尺度参数,w1+w2+w3=1,l(nod)和l(nodu)分别代表l分量图像中nod和nodu的像素值,a(nod)和a (nodu)表示a分量图像中nod和nodu的像素值,b(nod)和b(nodu)分别表示b分量图像中nod和nodu的像素值,numnodu表示总和nodu中收录的元素个数;
获取l分量图像中像素值的中值对应的像素点,将像素点标记为mxn;
通过以下方法获取差异图像:
将l分量图像中的像素点保存到集合dlul中,对于dlul中的像素点dlu,通过下式计算差分图像中的像素值:
式中,xc(dlu)代表差异图像中dlu的像素值,csn(dlu)和csn(mxn)分别代表dlu和mxn的差异程度参数,l(mxn)代表mxn l 分量图像的像素值;
计算差分图像中dlul中每个像素的像素值,得到差分图像。
在本发明的上述实施例中,在获取差异图像时,首先将人脸图像转换为lab色彩空间,然后根据其中的三个变量计算每个像素的差异度参数lab 颜色空间,然后从 l 计算差异度参数 在分量图像中,选择一个像素作为参考像素,针对不同的像素计算差异图像中不同像素的像素值,有利于全面获取像素间的差异信息,同时避免光线的影响。差异度参数与计算时的邻域像素有关。差异度参数由邻域像素点与当前正在计算的像素点在三个分量中的差异的加权值得到,有利于差异度参数充分反映当前的进展情况。计算出的像素与相邻像素之间的差异。在选择参考像素时,选择l分量图像中像素值的中值对应的像素作为参考像素。这种设置方法有助于避免错误地将噪声的像素值用作参考像素值。 , 有利于获得准确的差分图像。
在一个实施例中,对灰度图像进行边缘检测得到边缘图像包括:
使用sobel边缘检测算法对灰度图像进行边缘检测,得到边缘图像。
在一个实施例中,对灰度图像进行降噪处理得到降噪图像包括:
对灰度图像进行小波分解处理,得到小波高频系数和小波低频系数;
对小波高频系数中的像素进行如下处理:
式中,tsl(p)表示小波高频系数中位置p对应的像素的像素值,btsl(p)表示上述对tsl(p)的处理结果; vb和vc代表预先设置的处理阈值,sh代表判断操作,如果tsl(p)大于预设阈值tp,则sh[tsl(p)]的值为1.2,如果tsl (p) 小于等于预设阈值 tp ,则 sh[tsl(p)] 的值为1.05,
对小波高频系数中的所有像素进行上述处理,得到第一处理系数;
对小波低频系数中的像素进行如下处理:
式中,tlluq表示小波低频系数中位置q对应的像素点k×k邻域内的像素集合,lon(q,u)表示位置q对应的像素点小波低频系数中像素点u与tlluq收录的像素点u之间的直线距离,tll(u)表示低频小波系数图像中u的像素值,btll(q)表示小波低频系数中位置q对应的像素使用上式点处理的结果; tll(q)表示小波低频系数中q位置对应的像素点的像素值;
公式中ntlluq表示tlluq中收录的像素总数;
对小波低频系数中的所有像素进行上述处理,得到第二处理系数;
对第一处理系数和第二处理系数进行小波重构,得到降噪图像。
在本发明的上述实施例中,在进行降噪处理时,将灰度图像分解为小波高频系数和小波低频系数,然后小波高频系数和小波分别对低频系数进行处理,对处理后的小波高频系数和小波低频系数进行重构,得到去噪图像。有利于在保持图像边缘信息等特征信息的同时实现准确的降噪处理。现有技术中,例如使用高斯函数进行降噪时,像素点会变得模糊,像素之间的差异会变小,从而导致细节信息丢失。这个应用程序能够很好地避免这个问题。本应用在处理小波高频系数时,采用了改进的处理功能。通过处理阈值与当前处理像素的像素值之间的关系,对当前处理的像素自适应选择不同的处理函数处理,有助于提高小波高频系数的处理精度。此外,该应用程序还处理小波低频系数。在处理中,低频小波系数中的像素与其邻域内的像素之间的线性距离和像素值的差异就是低频小波系数中的当前处理。像素提供准确的处理结果。因此,有效提高了降噪的准确性,提高了本发明采集系统的安全性。
在一个实施例中,对降噪图像进行图像分割处理得到前景图像包括:
使用otsu算法对去噪后的图像进行图像分割处理,得到所有前景像素的集合fru1;
用下面的方法对fru1中的像素进行过滤,得到集合fru2:
<p>对于 fru1 中的像素 fru,计算 fru 和参考像素 stad 之间的距离 dist(fru,stad)。如果dist(fru,stad)小于预设的距离阈值,则下一步判断fru,如果dist(fru,stad)大于或等于预设的距离阈值,则从fru1中删除fru;
优采云采集器mac版优质采集软件推荐(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 241 次浏览 • 2021-08-03 01:17
优采云采集器苹果电脑版是一款非常优质的采集软件,涵盖了多种功能,采集传输很专业,值得信赖,可以打开直接学习,还犹豫什么,快来为有需要的用户体验吧。
优采云采集器mac 亮点
监控竞争对手的最新信息,包括商品价格和库存;
财务数据,如季报、年报、财报,包括最新的每日净值自动采集;
各大新闻门户网站实时监控,自动更新上传最新消息;
监控各大社交网络网站、博客,自动获取企业产品相关评论;
优采云采集器软件说明
自定义采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax、页面滚动、条件判断等。此类功能支持不同网页结构的复杂网站采集,满足多种采集应用场景。
云采集
云采集,5000多台云服务器支持,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活适配业务场景,助您提升采集效率,并保证数据的及时性。
方便的定时功能
只需简单几步,点击设置即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集。同时自由设置多个任务,根据需要进行多种选择时间组合,灵活部署自己的采集任务。
模板采集
模板采集模式内置了数百个主流网站数据源,如京东、天猫、大众点评等流行的采集网站。只需参考模板设置参数即可快速获取网站。 @公共数据。
Smart采集
采集可根据网站的不同提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助采集整个流程实现数据的完整性和稳定性。
多级采集
众多主流新闻和电商网站,收录一级商品列表页、二级商品详情页、三级评论详情页;不管网站有多少层,优采云所有采集数据都可以无限,满足采集各种业务需求。
api接口
通过优采云api,您可以轻松获取采集接收到的优采云任务信息和数据,灵活调度任务,如远程控制任务启停,高效实现数据采集和归档。基于强大的api系统,还可以与公司内部各种管理平台无缝对接,实现各种业务自动化。
正式版的优点
满足多种业务场景
适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等各种职业。
舆论监测
全方位监控公众信息,抢先掌握舆情动态。
产品研发
大力支持用户研究,准确获取用户反馈和偏好
风险预测
高效信息采集和数据清洗,及时应对系统风险
市场分析
获取用户真实行为数据,全面掌握客户真实需求
更新日志
修复偶尔卡住的问题
修复验证码识别失败问题,提高识别率
修复循环中的字段不能设置为XPath拼接的问题
修复无法保存数据提取步骤的触发器的问题
修复数据预览二级面板无法应用和保存的问题
修复循环中某些步骤无法设置XPath拼接的问题 查看全部
优采云采集器mac版优质采集软件推荐(组图)
优采云采集器苹果电脑版是一款非常优质的采集软件,涵盖了多种功能,采集传输很专业,值得信赖,可以打开直接学习,还犹豫什么,快来为有需要的用户体验吧。
优采云采集器mac 亮点
监控竞争对手的最新信息,包括商品价格和库存;
财务数据,如季报、年报、财报,包括最新的每日净值自动采集;
各大新闻门户网站实时监控,自动更新上传最新消息;
监控各大社交网络网站、博客,自动获取企业产品相关评论;

优采云采集器软件说明
自定义采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax、页面滚动、条件判断等。此类功能支持不同网页结构的复杂网站采集,满足多种采集应用场景。
云采集
云采集,5000多台云服务器支持,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活适配业务场景,助您提升采集效率,并保证数据的及时性。
方便的定时功能
只需简单几步,点击设置即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集。同时自由设置多个任务,根据需要进行多种选择时间组合,灵活部署自己的采集任务。
模板采集
模板采集模式内置了数百个主流网站数据源,如京东、天猫、大众点评等流行的采集网站。只需参考模板设置参数即可快速获取网站。 @公共数据。
Smart采集
采集可根据网站的不同提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助采集整个流程实现数据的完整性和稳定性。
多级采集
众多主流新闻和电商网站,收录一级商品列表页、二级商品详情页、三级评论详情页;不管网站有多少层,优采云所有采集数据都可以无限,满足采集各种业务需求。
api接口
通过优采云api,您可以轻松获取采集接收到的优采云任务信息和数据,灵活调度任务,如远程控制任务启停,高效实现数据采集和归档。基于强大的api系统,还可以与公司内部各种管理平台无缝对接,实现各种业务自动化。
正式版的优点
满足多种业务场景
适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等各种职业。
舆论监测
全方位监控公众信息,抢先掌握舆情动态。
产品研发
大力支持用户研究,准确获取用户反馈和偏好
风险预测
高效信息采集和数据清洗,及时应对系统风险
市场分析
获取用户真实行为数据,全面掌握客户真实需求
更新日志
修复偶尔卡住的问题
修复验证码识别失败问题,提高识别率
修复循环中的字段不能设置为XPath拼接的问题
修复无法保存数据提取步骤的触发器的问题
修复数据预览二级面板无法应用和保存的问题
修复循环中某些步骤无法设置XPath拼接的问题
网络爬虫软件,瑞雪采集云,还是有一些特点?
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-07-31 04:17
我知道一个网络爬虫软件,瑞雪采集云,还是有一些特点的:
Ruixue采集云是一个PaaS在线开发平台。与图形化配置的爬虫客户端工具相比,瑞雪采集云提供了通用的采集能力,可以满足企业客户数据采集业务的长期需求。
主要特点如下:
(一)一站式通用能力集成,成倍提升开发效率。平台封装了丰富的通用功能,开发者无需关心Ajax和Cookie等底层细节。他们只需要使用平台封装API,将主要的Focus放在业务上,提供10倍的工作效率。
(二)开发自由度高,支持复杂网站的采集。支持Java/Python编写应用插件,具有高级语言的高自由度,可以处理复杂的网站 采集. 平台提供 业界首个基于Web浏览器的在线开发环境,无需任何客户端安装,提高了客户内部应用源代码的共享。
(三)分布式任务调度机制,并发采集效率高。采集工作分解成多个采集程序,一个大任务拆解成大量小任务在不同的程序中执行,然后分发到大量爬虫机器集群进行分布式并发执行,保证系统达到最高的采集效率。
(四)强大的任务管理机制,保证数据完整性。平台具有强大的任务状态机制,支持任务重传,支持使用结束码管理不同的任务结束状态,选择不同的后续处理根据具体情况,保证目标数据不遗漏,保证最终目标数据的完整性。
(五)学习时间短,可以支撑业务的快速发展。平台提供了丰富的在线帮助文档,开发者可以在一小时内快速掌握平台的基本使用。当有是新数据采集需求,新开发者可以立即学会开发采集爬虫程序,快速对应相关业务的发展。
(六)支持私有化部署,保障数据安全。支持平台所有模块私有化部署,让客户拥有瑞雪采集云平台的所有能力,保证应用插件的绝对性客户开发的代码和目标数据安全。 查看全部
网络爬虫软件,瑞雪采集云,还是有一些特点?
我知道一个网络爬虫软件,瑞雪采集云,还是有一些特点的:
Ruixue采集云是一个PaaS在线开发平台。与图形化配置的爬虫客户端工具相比,瑞雪采集云提供了通用的采集能力,可以满足企业客户数据采集业务的长期需求。
主要特点如下:
(一)一站式通用能力集成,成倍提升开发效率。平台封装了丰富的通用功能,开发者无需关心Ajax和Cookie等底层细节。他们只需要使用平台封装API,将主要的Focus放在业务上,提供10倍的工作效率。
(二)开发自由度高,支持复杂网站的采集。支持Java/Python编写应用插件,具有高级语言的高自由度,可以处理复杂的网站 采集. 平台提供 业界首个基于Web浏览器的在线开发环境,无需任何客户端安装,提高了客户内部应用源代码的共享。
(三)分布式任务调度机制,并发采集效率高。采集工作分解成多个采集程序,一个大任务拆解成大量小任务在不同的程序中执行,然后分发到大量爬虫机器集群进行分布式并发执行,保证系统达到最高的采集效率。
(四)强大的任务管理机制,保证数据完整性。平台具有强大的任务状态机制,支持任务重传,支持使用结束码管理不同的任务结束状态,选择不同的后续处理根据具体情况,保证目标数据不遗漏,保证最终目标数据的完整性。
(五)学习时间短,可以支撑业务的快速发展。平台提供了丰富的在线帮助文档,开发者可以在一小时内快速掌握平台的基本使用。当有是新数据采集需求,新开发者可以立即学会开发采集爬虫程序,快速对应相关业务的发展。
(六)支持私有化部署,保障数据安全。支持平台所有模块私有化部署,让客户拥有瑞雪采集云平台的所有能力,保证应用插件的绝对性客户开发的代码和目标数据安全。
推荐采集器蝉大师的“图片采集工具”,给几点小建议
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-07-29 20:02
利用采集器采集的平台有很多,推荐采集器蝉大师的“图片采集工具”,将图片中的内容采集下来保存在excel里,还可以对图片数据进行其他操作,是个不错的采集器。具体步骤:找到他们家的“图片采集工具”1,启动选择需要采集的链接或页面,上传图片选择需要采集的页面,上传图片,识别后点击下载;2,上传图片上传图片成功后,点击采集按钮,进行采集。
3,图片数据可以进行下载保存使用4,图片修改设置图片修改设置,设置采集的图片名称及url,采集完成后点击下载,生成pdf文件对源数据进行修改,进行生成doc或者docx等其他格式的文件,重新上传即可。以上。采集工具的链接和介绍都有了,希望能帮到你。
给几点小建议吧!工具类不管是影视、音乐、电商、还是小游戏、都有各种数据源,可以找数据源进行,按照需求采集,下载即可,
现在三无产品比较多,如果不想用第三方采集器,
用平台代码采集,
爬虫也好,去除水印也好,阿里站长平台都有固定的套路,自己写也能爬到目标网站,但是固定的模板就限制太多了,
第一个叫捕手采集器,是一款专业的视频采集,拼多多采集,猫扑,58同城等等,还可以发布求助信息。第二个叫乐采网,收录地方门户网站的视频、音乐等内容,还能进行ppt配图等。第三个叫采集狗,专业的网络爬虫,可以抓到各种地方的内容。现在公众号评论中百分之八十都能采到!以上都是我们公司对接过的平台,楼主可以看看。这是一些网上比较出名的平台,可以去看看。 查看全部
推荐采集器蝉大师的“图片采集工具”,给几点小建议
利用采集器采集的平台有很多,推荐采集器蝉大师的“图片采集工具”,将图片中的内容采集下来保存在excel里,还可以对图片数据进行其他操作,是个不错的采集器。具体步骤:找到他们家的“图片采集工具”1,启动选择需要采集的链接或页面,上传图片选择需要采集的页面,上传图片,识别后点击下载;2,上传图片上传图片成功后,点击采集按钮,进行采集。
3,图片数据可以进行下载保存使用4,图片修改设置图片修改设置,设置采集的图片名称及url,采集完成后点击下载,生成pdf文件对源数据进行修改,进行生成doc或者docx等其他格式的文件,重新上传即可。以上。采集工具的链接和介绍都有了,希望能帮到你。
给几点小建议吧!工具类不管是影视、音乐、电商、还是小游戏、都有各种数据源,可以找数据源进行,按照需求采集,下载即可,
现在三无产品比较多,如果不想用第三方采集器,
用平台代码采集,
爬虫也好,去除水印也好,阿里站长平台都有固定的套路,自己写也能爬到目标网站,但是固定的模板就限制太多了,
第一个叫捕手采集器,是一款专业的视频采集,拼多多采集,猫扑,58同城等等,还可以发布求助信息。第二个叫乐采网,收录地方门户网站的视频、音乐等内容,还能进行ppt配图等。第三个叫采集狗,专业的网络爬虫,可以抓到各种地方的内容。现在公众号评论中百分之八十都能采到!以上都是我们公司对接过的平台,楼主可以看看。这是一些网上比较出名的平台,可以去看看。
网页中“右键点击”——查看源码(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 342 次浏览 • 2021-07-29 07:53
网页中“右键点击”——查看源码(图)
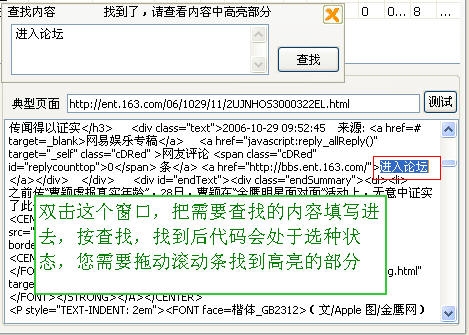
我们可以用这个作为内容开始的标志,但这并不完美。请自行打开几个内容页面,页面中“右键”-“查看源代码”,然后比较代码,提取相同的部分,我用
作为内容开始的标志。
接下来看内容结束标记,如下两张图所示:
以下是根据us采集设置的规则返回的内容
一般来说采集返回的内容从头到尾都会收录必须排除的内容、广告或链接。这里我们需要排除的内容是“相关话题>>>第六届金鹰电视艺术节”。排除的方法是找到对应的代码,将代码完整复制到内容排除窗口中,修改后的部分用“(*)”代替。因为这是整个站点的规则,所以你必须多找几个类别。比如现在的163娱乐还包括“名人|图片|电影|电视|音乐|论坛|专题|名人专访”等等,这里我只摘录“明星、图片、电影”作为列子给大家讲解。寻找其他类别只是为了使规则具有普遍性和完善性。如果您只需要一个类别,例如“图片”,那么您可以直接制定此规则。
这个页面正好有分页,所以顺便说一下下一页和下一页的设置。他这边的“上一页”和“下一页”是用图片链接的,所以不要复制图片的名称(右键点击对应图片查看属性,复制图片名称)复制到对应的代码框。是的,详细看图:
在这个提示下,要排除任何内容,只需要找到对应的代码,复制到代码排除窗口中,将变量部分替换为“(*)”即可。既然他这边没有广告,就算把整个站点的规则都做完了,点击保存进入单任务制作。嗯,全站的规则就讲这两个标签,其他的根据需要按照上面的步骤添加。记住,永远不要改变。其他问题请到优采云采集器论坛:讨论。
二、以下解释单任务规则的产生:
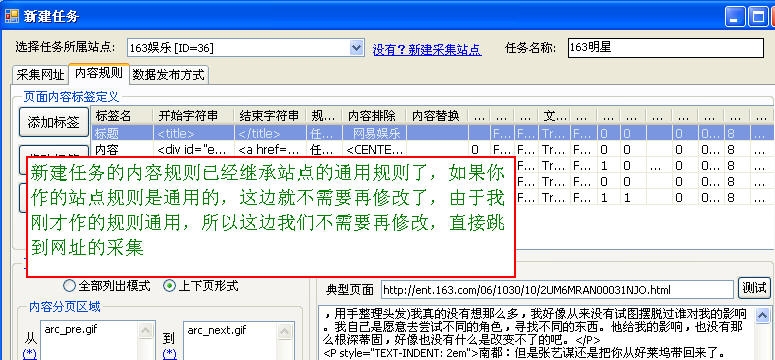
1、content 的制作规则,很多人可能不明白优采云采集器好在哪,我现在说的绝对是优采云的独到之处(至少到目前为止,我不知道以后有没有人有同样的功能!)
优采云采集器不需要通过URL规则直接进入内容采集,所以可以根据网站的难度决定采集是否选择目标源,而是等URL@之后采集发现网站你不能选或者不值得你浪费时间(之前的时间没用!)。
优采云v3.0 最大的功能之一就是可以继承网站的规则。只要你之前制定的规则是通用的,你就不需要为后面的所有任务制定内容采集规则。由于我们之前制定的采集规则是通用的,这里不需要解释规则,直接继承站点,如图:
2、URL采集规则制作
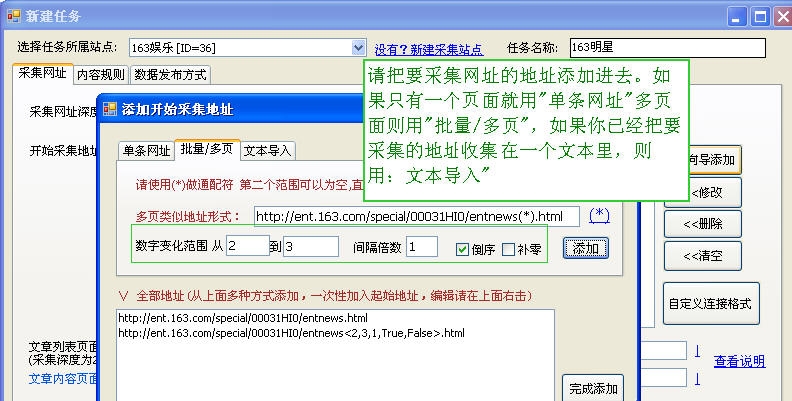
步骤:“新建”-“新建任务”,其他操作如下:
要制定规则,您需要善于发现常规事物。此时采集没问题。我们要这里采集例子的地址
本板仅以采集第1-3页为例。我们发现每个叶子的URL开头都收录“过去的娱乐热点”,结尾是“Page 1 2...”,所以请将html源代码中的相应代码复制到特定区域采集范围内,另外,URL必须收录“/06/”,这样URL采集就完成了(简单,自己试试),如下图:
3、posting 方法。发布方式有5种,这里以最常用的“在线发布”为例。
选择要在线发布的web到网站,点击“定义全局发布方式”,然后按照系统提示的步骤操作: 选择发布模块——“填写网站/cms根地址——》使用优采云内置浏览器登录——》登录后关闭内置浏览器——》刷新列表——》测试模块,测试成功——》保存配置——》保存任务——》发布下图高亮部分就是你要操作的步骤,从左到右,从上到下:
以下是我采集测试到本地论坛采集的两张截图:
查看全部
网页中“右键点击”——查看源码(图)
我们可以用这个作为内容开始的标志,但这并不完美。请自行打开几个内容页面,页面中“右键”-“查看源代码”,然后比较代码,提取相同的部分,我用

作为内容开始的标志。
接下来看内容结束标记,如下两张图所示:


以下是根据us采集设置的规则返回的内容

一般来说采集返回的内容从头到尾都会收录必须排除的内容、广告或链接。这里我们需要排除的内容是“相关话题>>>第六届金鹰电视艺术节”。排除的方法是找到对应的代码,将代码完整复制到内容排除窗口中,修改后的部分用“(*)”代替。因为这是整个站点的规则,所以你必须多找几个类别。比如现在的163娱乐还包括“名人|图片|电影|电视|音乐|论坛|专题|名人专访”等等,这里我只摘录“明星、图片、电影”作为列子给大家讲解。寻找其他类别只是为了使规则具有普遍性和完善性。如果您只需要一个类别,例如“图片”,那么您可以直接制定此规则。
这个页面正好有分页,所以顺便说一下下一页和下一页的设置。他这边的“上一页”和“下一页”是用图片链接的,所以不要复制图片的名称(右键点击对应图片查看属性,复制图片名称)复制到对应的代码框。是的,详细看图:

在这个提示下,要排除任何内容,只需要找到对应的代码,复制到代码排除窗口中,将变量部分替换为“(*)”即可。既然他这边没有广告,就算把整个站点的规则都做完了,点击保存进入单任务制作。嗯,全站的规则就讲这两个标签,其他的根据需要按照上面的步骤添加。记住,永远不要改变。其他问题请到优采云采集器论坛:讨论。
二、以下解释单任务规则的产生:
1、content 的制作规则,很多人可能不明白优采云采集器好在哪,我现在说的绝对是优采云的独到之处(至少到目前为止,我不知道以后有没有人有同样的功能!)
优采云采集器不需要通过URL规则直接进入内容采集,所以可以根据网站的难度决定采集是否选择目标源,而是等URL@之后采集发现网站你不能选或者不值得你浪费时间(之前的时间没用!)。
优采云v3.0 最大的功能之一就是可以继承网站的规则。只要你之前制定的规则是通用的,你就不需要为后面的所有任务制定内容采集规则。由于我们之前制定的采集规则是通用的,这里不需要解释规则,直接继承站点,如图:
2、URL采集规则制作
步骤:“新建”-“新建任务”,其他操作如下:
要制定规则,您需要善于发现常规事物。此时采集没问题。我们要这里采集例子的地址
本板仅以采集第1-3页为例。我们发现每个叶子的URL开头都收录“过去的娱乐热点”,结尾是“Page 1 2...”,所以请将html源代码中的相应代码复制到特定区域采集范围内,另外,URL必须收录“/06/”,这样URL采集就完成了(简单,自己试试),如下图:

3、posting 方法。发布方式有5种,这里以最常用的“在线发布”为例。
选择要在线发布的web到网站,点击“定义全局发布方式”,然后按照系统提示的步骤操作: 选择发布模块——“填写网站/cms根地址——》使用优采云内置浏览器登录——》登录后关闭内置浏览器——》刷新列表——》测试模块,测试成功——》保存配置——》保存任务——》发布下图高亮部分就是你要操作的步骤,从左到右,从上到下:

以下是我采集测试到本地论坛采集的两张截图:
让数据触手可及2017年04月
采集交流 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-07-27 04:38
让数据触手可及2017年4月优采云采集器销售客服部一、优采云简介二、采集器作文三、简例四、基本简介五、采集Instance目录浏览器优采云采集器,是一种模拟人访问网页文档的互联网数据采集器。通过设计流程操作,采集可以自动化实现网页数据的快速采集集成,完成用户数据采集的目的。原理:1.imperson 浏览网页2.通过设计过程操作完成采集Automation 优采云principle 通常,我们将一个采集任务称为一个规则。规则是优采云采集器的核心组件。我们按照规则来划分章鱼的构成,可以分为以下几种:一、Task List:Task List是指优采云采集器中的已编辑任务,已编辑的任务可以直接从等待状态二、任务规则:任务规则是指根据特定网页以及人们使用浏览器访问网页的过程开发的自动化任务程序,一般来说,类似网站的类型对应于一个任务规则三、task状态:1)task生命周期:可执行状态、等待状态、运行状态、完成状态、停止状态2)运行状态:1)local采集况、云采集State 优采云采集器构成一、打开网页:打开网页,一般指的是我们想要的采集数据的网站,就像我们平时浏览这个网站需要输入相同的网址数据信息二、循环翻页:循环翻页是指当我们需要快速采集整合时,需要实现翻页c周。循环翻页的本质是单个元素。 Cycle 三、Extracting data 正式采集Step 四、 点击元素 循环本身没有任何执行操作。如果要循环翻页,则需要一个click元素来生成与循环的联动。流程简单设计实例一、Settings 基本信息:此处用于填写规则名称和规则备注二、设计工作流:此处用于设计任务规则的自动化流程步骤,例如:which web页面要打开的任务和步骤这些都是在设计工作流中完成的。设计工作流是任务规则的核心步骤三、设置执行计划:这里可以设置任务规则的相关选项,例如:禁止浏览器加载图片,云采集不拆分任务,启动增加采集等四、task启动选择:如果规则写得正确,这里可以启动一个任务规则的生命周期,此时,如果编辑正确,任务应该在可执行文件中状态。流程设计步骤介绍:优采云采集器一共11个流程设计操作,分为基本步骤和高级步骤,分为以下几个: 基本步骤:基本步骤本身比较多应用流程设计操作 一般来说,这些步骤对于用采集实现网页数据的快速排序是必不可少的。基本步骤如下:1)打开网页2)点击元素3)环4)提取数据到高级步骤:除了基本步骤,我们还需要使用以下操作来辅助完成我们的数据采集。例如:有时我们的采集数据需要在采集之前输入文字,高级步骤如下:1)input文字Word2)身份验证码3)toggle下拉选项4)judgment conditions 5)将鼠标移到元素6)end cycle7)end 工艺流程设计步骤优采云,工艺操作由基本信息决定 由两部分组成,带有高级选项一、基本信息:基本信息信息一般会显示操作过程的基本信息,例如:打开一个网页会显示你打开的网页的网址,点击一个元素会显示你点击的元素的文字等。二、Advanced options:高级选项,可以为辅助规则的正确有效执行设置一些额外的选项设置,例如:执行前等待、iframe中的元素等高级选项的基本信息和简单示例 查看全部
让数据触手可及2017年04月
让数据触手可及2017年4月优采云采集器销售客服部一、优采云简介二、采集器作文三、简例四、基本简介五、采集Instance目录浏览器优采云采集器,是一种模拟人访问网页文档的互联网数据采集器。通过设计流程操作,采集可以自动化实现网页数据的快速采集集成,完成用户数据采集的目的。原理:1.imperson 浏览网页2.通过设计过程操作完成采集Automation 优采云principle 通常,我们将一个采集任务称为一个规则。规则是优采云采集器的核心组件。我们按照规则来划分章鱼的构成,可以分为以下几种:一、Task List:Task List是指优采云采集器中的已编辑任务,已编辑的任务可以直接从等待状态二、任务规则:任务规则是指根据特定网页以及人们使用浏览器访问网页的过程开发的自动化任务程序,一般来说,类似网站的类型对应于一个任务规则三、task状态:1)task生命周期:可执行状态、等待状态、运行状态、完成状态、停止状态2)运行状态:1)local采集况、云采集State 优采云采集器构成一、打开网页:打开网页,一般指的是我们想要的采集数据的网站,就像我们平时浏览这个网站需要输入相同的网址数据信息二、循环翻页:循环翻页是指当我们需要快速采集整合时,需要实现翻页c周。循环翻页的本质是单个元素。 Cycle 三、Extracting data 正式采集Step 四、 点击元素 循环本身没有任何执行操作。如果要循环翻页,则需要一个click元素来生成与循环的联动。流程简单设计实例一、Settings 基本信息:此处用于填写规则名称和规则备注二、设计工作流:此处用于设计任务规则的自动化流程步骤,例如:which web页面要打开的任务和步骤这些都是在设计工作流中完成的。设计工作流是任务规则的核心步骤三、设置执行计划:这里可以设置任务规则的相关选项,例如:禁止浏览器加载图片,云采集不拆分任务,启动增加采集等四、task启动选择:如果规则写得正确,这里可以启动一个任务规则的生命周期,此时,如果编辑正确,任务应该在可执行文件中状态。流程设计步骤介绍:优采云采集器一共11个流程设计操作,分为基本步骤和高级步骤,分为以下几个: 基本步骤:基本步骤本身比较多应用流程设计操作 一般来说,这些步骤对于用采集实现网页数据的快速排序是必不可少的。基本步骤如下:1)打开网页2)点击元素3)环4)提取数据到高级步骤:除了基本步骤,我们还需要使用以下操作来辅助完成我们的数据采集。例如:有时我们的采集数据需要在采集之前输入文字,高级步骤如下:1)input文字Word2)身份验证码3)toggle下拉选项4)judgment conditions 5)将鼠标移到元素6)end cycle7)end 工艺流程设计步骤优采云,工艺操作由基本信息决定 由两部分组成,带有高级选项一、基本信息:基本信息信息一般会显示操作过程的基本信息,例如:打开一个网页会显示你打开的网页的网址,点击一个元素会显示你点击的元素的文字等。二、Advanced options:高级选项,可以为辅助规则的正确有效执行设置一些额外的选项设置,例如:执行前等待、iframe中的元素等高级选项的基本信息和简单示例
利用网页采集技术消除“信息孤岛”,搭建内部新闻平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-07-25 07:23
利用webpage采集technology搭建内部新闻平台,医务人员可以通过信息系统的内部网络及时了解国内外新闻动态。 关键词网页采集内网新闻cms简介 我院信息系统网络与公网均采取了严格的物理隔离措施,内外网之间的数据访问通过一个网守实现。医院在内网上建立了内部网站,用于发布医院新闻、通知等信息。信息系统用户只能浏览网站提供的内部新闻,不能浏览公网信息。随着医院的不断发展和互联网的普及,临床工作人员通过网络渴望通过信息系统网络了解他们关心的国家的时事、新闻、政策和法规。利用信息技术消除“信息孤岛”,为临床医生和医院管理人员提供更多的服务选项来实现上述功能。有两种方案: 方案一:利用现有的网守将公网地址映射到内网,解决用户浏览新闻的问题。方案二:在外网搭建自己的新闻平台,及时发布新闻信息,通过看门人将网站映射到内网。方案一实现起来比较简单,只需要简单的配置就可以实现上述功能,但是也有缺点。主要原因是一旦将公网网站上的内容映射到内网,用户就可以浏览网站中的所有信息。部分娱乐信息和无关信息无法屏蔽,浏览无法控制,故未采用该方案。方案二需要自己搭建新闻平台,实现起来比方案一复杂,但是可以对新闻信息进行管理,避免一些不相关的信息,所以采用了第二套方案。
按照第二个方案,问题是依靠人力逐条复制录入新闻,必然造成资源的巨大浪费。因此,可以考虑使用网页信息采集技术来实现新闻信息的批量获取和发布。网页信息采集技术是通过分析网页的HTML代码,获取网络中的超链接信息,采用广度优先搜索算法和增量存储算法,实现自动连续分析链接、抓取文件、处理和处理的过程。保存数据。具体实现过程如下:3.1 cms选型cms是Content Management System的缩写,意思是“内容管理系统”。它有很多优秀的基于模板的设计,可以加快网站的开发速度,降低开发成本。为了节省投资,比较了比较流行的“empirecms”、“PHPcms”、“织梦cms”等免费的cms。感觉织梦cms好用。模板很多,尤其是后端的网页采集模块,最终选择了织梦内容管理系统(以下简称Dedecms)。 3.2 搭建服务器环境,作者使用Windows2003 Server IIS+PHP+ MySQL模型搭建。 PHP 是超文本预处理器的缩写。 PHP 是一种 HTML 嵌入语言,一种嵌入在服务器端执行的 HTML 文档中的脚本语言。语言风格与语言相似,应用广泛。
现在PHP部署很简单,下载5.4.0版本安装包安装即可。 MySQL 是一个小型的关系型数据库管理系统。由于其体积小、速度快、总拥有成本低,尤其是其开源特性,很多网站选择了MySQL作为网站数据库。下载并安装 MySQL Installer 5.5.21 版本进行安装。为了保证数据库的安全,在MySQL安装过程中要注意设置root用户密码。如果忘记设置,可以在系统安装后使用mysqladmin命令设置密码。安装完成后,测试PHP和MySQL服务是否正常。 3.3 MySQL 数据库管理,可以使用 PhpMyAdmin 或 Navicat MySQL。 PhpMyAdmin 的缺点是必须安装在Web 服务器中,如果没有适当的访问权限,其他用户可能会损坏SQL 数据。 Navicat MySQL 是一个强大的 MySQL 数据库服务器管理和开发工具。它可以与任何3.21或更高版本的MySQL一起工作,并支持大多数最新的MySQL特性,包括触发器、存储过程、函数、事件、视图、管理用户等。它不仅对专业开发人员来说是一项非常前沿的技术,而且对于新手来说也很容易学习和使用。因为是本地服务器,综合考虑,安装了Navicat MySQL,用于MySQL数据库管理。
3.4 安装Dedecms并下载“Dedecms V5.7”版本。按照网站提供的教程进行安装,安装过程中注意以下问题。 3.4.1 数据,模板,上传,一个或html目录,设置读写,非执行权限; 3.4.2 不需要设置topic,建议删除special目录,需要能生成HTML后,删除special/index.php,设置该目录为可读写和不可执行的权限; 3.4.3 include、member、plus、后台管理目录设置为可执行脚本,可读,但不可写(如果安装了附加模块,book、ask、company、group目录为也以同样的方式设置)。 3.4.4 安装完成后,删除安装目录。 3.5 设置网站列,根据自己的需要设置不同的网站列。作者开设人民网、健康日报、地方报等栏目。 3.6 网页采集的实现是本方案的核心部分。 dedecms自带的网络采集模块也可以实现网页自动采集,但是采集比较瘦,不能同时采集和发布多个网站,需要登录网站后台操作,操作过程繁琐,需要找一套可以实现自动批量采集的软件。目前采集software的在线数据主要包括以下几类:“优采云”、“网络矿工”、“优讯软件”、“网络神才”、“一菜”、“优采云”、“三人行”“等等。
以上都是付费软件。有免费试用版,但有功能限制。因为采集大部分是纯静态页面,数据结构简单,尝试了很多采集软件后,最终选择了“优采云采集器V7免费版”。 “优采云采集器V7”自带“Dedecms5.7”版本的Web发布模块,无需编写发布接口代码。直接运行“优采云采集器”,在任务栏中添加需要采集网页的任务,编辑采集网址规则,采集内容规则,发布内容设置等,实现网页批量自动化页采集 和批量发布。在实际操作中,需要注意以下几个方面: 3.6.1 在采集中,涉及到如何采集将远程图片发布到本地服务器。在采集content规则中选择“把相对地址作为绝对地址完成”,因为Dedecms本身有下载远程图片和资源的模块,可以自动下载远程图片。由于免费版的使用和限制,笔者在这里走了很多弯路。 3.6.2 由于采集数量众多,难免出现文章重复。 “Dedecms”提供的重复文档检测功能可以批量删除重复文档。 3.6.3 可以通过优采云采集器批量发布文章。当你还需要登录后台点时,使用易鉴更新网站功能,更新网页链接。 3.6.4 编辑采集规则时,应用过滤功能过滤和调整冗余代码。讨论通过以上方式搭建的医院新闻平台,可以及时批量更新网站,网络信息采集在信息采集,在资源整合方面节省了大量的人力和资金。
但是,一些网站采取了阻止采集的措施,无法采集数据。另外,由于全部使用免费软件,目前只实现了图片的自动发布,没有更好的发布附件的方式,需要进一步改进。参考文献 校园网新闻及其管理[J].计算机知识与技术(学术交流),2007,05:1191-1197 李强。院内网站建设的一些经验与建议[J].现代医院管理,2011,41(2):66-68 查看全部
利用网页采集技术消除“信息孤岛”,搭建内部新闻平台
利用webpage采集technology搭建内部新闻平台,医务人员可以通过信息系统的内部网络及时了解国内外新闻动态。 关键词网页采集内网新闻cms简介 我院信息系统网络与公网均采取了严格的物理隔离措施,内外网之间的数据访问通过一个网守实现。医院在内网上建立了内部网站,用于发布医院新闻、通知等信息。信息系统用户只能浏览网站提供的内部新闻,不能浏览公网信息。随着医院的不断发展和互联网的普及,临床工作人员通过网络渴望通过信息系统网络了解他们关心的国家的时事、新闻、政策和法规。利用信息技术消除“信息孤岛”,为临床医生和医院管理人员提供更多的服务选项来实现上述功能。有两种方案: 方案一:利用现有的网守将公网地址映射到内网,解决用户浏览新闻的问题。方案二:在外网搭建自己的新闻平台,及时发布新闻信息,通过看门人将网站映射到内网。方案一实现起来比较简单,只需要简单的配置就可以实现上述功能,但是也有缺点。主要原因是一旦将公网网站上的内容映射到内网,用户就可以浏览网站中的所有信息。部分娱乐信息和无关信息无法屏蔽,浏览无法控制,故未采用该方案。方案二需要自己搭建新闻平台,实现起来比方案一复杂,但是可以对新闻信息进行管理,避免一些不相关的信息,所以采用了第二套方案。
按照第二个方案,问题是依靠人力逐条复制录入新闻,必然造成资源的巨大浪费。因此,可以考虑使用网页信息采集技术来实现新闻信息的批量获取和发布。网页信息采集技术是通过分析网页的HTML代码,获取网络中的超链接信息,采用广度优先搜索算法和增量存储算法,实现自动连续分析链接、抓取文件、处理和处理的过程。保存数据。具体实现过程如下:3.1 cms选型cms是Content Management System的缩写,意思是“内容管理系统”。它有很多优秀的基于模板的设计,可以加快网站的开发速度,降低开发成本。为了节省投资,比较了比较流行的“empirecms”、“PHPcms”、“织梦cms”等免费的cms。感觉织梦cms好用。模板很多,尤其是后端的网页采集模块,最终选择了织梦内容管理系统(以下简称Dedecms)。 3.2 搭建服务器环境,作者使用Windows2003 Server IIS+PHP+ MySQL模型搭建。 PHP 是超文本预处理器的缩写。 PHP 是一种 HTML 嵌入语言,一种嵌入在服务器端执行的 HTML 文档中的脚本语言。语言风格与语言相似,应用广泛。
现在PHP部署很简单,下载5.4.0版本安装包安装即可。 MySQL 是一个小型的关系型数据库管理系统。由于其体积小、速度快、总拥有成本低,尤其是其开源特性,很多网站选择了MySQL作为网站数据库。下载并安装 MySQL Installer 5.5.21 版本进行安装。为了保证数据库的安全,在MySQL安装过程中要注意设置root用户密码。如果忘记设置,可以在系统安装后使用mysqladmin命令设置密码。安装完成后,测试PHP和MySQL服务是否正常。 3.3 MySQL 数据库管理,可以使用 PhpMyAdmin 或 Navicat MySQL。 PhpMyAdmin 的缺点是必须安装在Web 服务器中,如果没有适当的访问权限,其他用户可能会损坏SQL 数据。 Navicat MySQL 是一个强大的 MySQL 数据库服务器管理和开发工具。它可以与任何3.21或更高版本的MySQL一起工作,并支持大多数最新的MySQL特性,包括触发器、存储过程、函数、事件、视图、管理用户等。它不仅对专业开发人员来说是一项非常前沿的技术,而且对于新手来说也很容易学习和使用。因为是本地服务器,综合考虑,安装了Navicat MySQL,用于MySQL数据库管理。
3.4 安装Dedecms并下载“Dedecms V5.7”版本。按照网站提供的教程进行安装,安装过程中注意以下问题。 3.4.1 数据,模板,上传,一个或html目录,设置读写,非执行权限; 3.4.2 不需要设置topic,建议删除special目录,需要能生成HTML后,删除special/index.php,设置该目录为可读写和不可执行的权限; 3.4.3 include、member、plus、后台管理目录设置为可执行脚本,可读,但不可写(如果安装了附加模块,book、ask、company、group目录为也以同样的方式设置)。 3.4.4 安装完成后,删除安装目录。 3.5 设置网站列,根据自己的需要设置不同的网站列。作者开设人民网、健康日报、地方报等栏目。 3.6 网页采集的实现是本方案的核心部分。 dedecms自带的网络采集模块也可以实现网页自动采集,但是采集比较瘦,不能同时采集和发布多个网站,需要登录网站后台操作,操作过程繁琐,需要找一套可以实现自动批量采集的软件。目前采集software的在线数据主要包括以下几类:“优采云”、“网络矿工”、“优讯软件”、“网络神才”、“一菜”、“优采云”、“三人行”“等等。
以上都是付费软件。有免费试用版,但有功能限制。因为采集大部分是纯静态页面,数据结构简单,尝试了很多采集软件后,最终选择了“优采云采集器V7免费版”。 “优采云采集器V7”自带“Dedecms5.7”版本的Web发布模块,无需编写发布接口代码。直接运行“优采云采集器”,在任务栏中添加需要采集网页的任务,编辑采集网址规则,采集内容规则,发布内容设置等,实现网页批量自动化页采集 和批量发布。在实际操作中,需要注意以下几个方面: 3.6.1 在采集中,涉及到如何采集将远程图片发布到本地服务器。在采集content规则中选择“把相对地址作为绝对地址完成”,因为Dedecms本身有下载远程图片和资源的模块,可以自动下载远程图片。由于免费版的使用和限制,笔者在这里走了很多弯路。 3.6.2 由于采集数量众多,难免出现文章重复。 “Dedecms”提供的重复文档检测功能可以批量删除重复文档。 3.6.3 可以通过优采云采集器批量发布文章。当你还需要登录后台点时,使用易鉴更新网站功能,更新网页链接。 3.6.4 编辑采集规则时,应用过滤功能过滤和调整冗余代码。讨论通过以上方式搭建的医院新闻平台,可以及时批量更新网站,网络信息采集在信息采集,在资源整合方面节省了大量的人力和资金。
但是,一些网站采取了阻止采集的措施,无法采集数据。另外,由于全部使用免费软件,目前只实现了图片的自动发布,没有更好的发布附件的方式,需要进一步改进。参考文献 校园网新闻及其管理[J].计算机知识与技术(学术交流),2007,05:1191-1197 李强。院内网站建设的一些经验与建议[J].现代医院管理,2011,41(2):66-68
利用采集器 采集的平台 最新最全的学术论文期刊文献年终总结(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-07-24 03:26
利用网页信息采集技术搭建医院内网新闻平台-精美素材本文档格式为WORD,感谢阅读。最新最全的学术论文、期刊、文献、年终总结、年终报告、工作总结、个人总述职报告、实习报告、单位总结总结:利用网页采集技术搭建内部新闻平台,医务人员可以通过信息系统内部网络及时了解国内外新闻动态关键词:webpage采集;内网新闻; cmsG640 文件标识码:A 1674-9324 (2013)51-0198-02 一、 简介 采用严格的物理隔离措施,通过一个看门人实现内外网的数据访问。医院建立了内部网络网站发布医院新闻、通知等信息 信息系统用户只能浏览内部网站提供的医院新闻无法浏览公共网络信息 随着医院的不断发展和随着互联网的普及,临床工作人员通过网络渴望通过信息系统网络了解自己关心的国家的时事、新闻、政策法规。临床医生和医院管理者。二、方案选择实现上述功能,有如下两种方案: 方案一:使用exis ting gatekeeper 映射公网地址 去内网解决用户浏览新闻的问题。方案二:在外网搭建自己的新闻平台,及时发布新闻信息,通过看门人将网站映射到内网。
方案一实现起来比较简单,只需要简单的配置就可以实现上述功能,但是也有弊端。主要原因是一旦公网网站内容映射到内网,用户就可以浏览所有网站信息,对于一些娱乐信息和无关信息无法屏蔽,浏览无法控制,所以该计划未获通过。第二套方案需要建立自己的新闻平台,实施起来比第一套方案复杂,但是可以对新闻信息进行管理,避免一些不相关的信息,所以采用了第二套方案。按照第二个方案,问题是依靠人力逐条复制录入新闻,必然造成资源的极大浪费。因此,可以考虑使用网络信息采集技术来实现新闻信息的批量获取和发布。网页信息采集技术是通过分析网页的HTML代码,获取网络中的超链接信息,采用广度优先搜索算法和增量存储算法,实现自动连续分析链接、抓取文件、处理和处理的过程。保存数据。 三、的具体实现过程如下: 1.cms选择:cms由Content Management System编写,意为“内容管理系统”。它有很多优秀的基于模板的设计,可以加快网站Speed的开发速度,降低开发成本。为了节省投资,比较了比较流行的“empirecms”、“PHPcms”、“织梦cms”等免费的cms。感觉织梦cms好用。模板很多,尤其是后端的网页采集模块,最终选择了织梦内容管理系统(以下简称Dedecms)。
2.搭建服务器环境,作者使用Windows2003 Server IIS+PHP+ MySQL模型搭建。 PHP是Hypertext Preprocessor的缩写,英文超文本预处理语言。 PHP 是一种 HTML 嵌入语言,一种嵌入在服务器端执行的 HTML 文档中的脚本语言。语言风格与C语言相似,应用广泛。现在 PHP 管理非常简单。直接从下载5.4.0版本安装包后,安装。 MySQL 是一个小型的关系型数据库管理系统。由于其体积小、速度快、总拥有成本低,尤其是其开源特性,很多网站选择了MySQL作为网站数据库。从 下载并安装 MySQL Installer 5.5.21 版本进行安装。为了保证数据库的安全,在MySQL安装过程中要注意设置root用户密码。如果忘记设置,可以在系统安装后使用mysqladmin命令设置密码。安装完成后,测试PHP和MySQL服务是否正常。 3.MySQL 数据库管理,可以使用PhpMyAdmin 或Navicat MySQL。 PhpMyAdmin的缺点是必须安装在Web服务器上,如果没有适当的访问权限,其他用户可能会损坏SQL数据。
Navicat MySQL 是一个强大的 MySQL 数据库服务器管理和开发工具。它可以与任何3.21或以上版本的MySQL一起工作,并支持大多数最新的MySQL特性,包括触发器、存储过程、函数、事件、视图、用户管理等。它不仅对专业开发人员来说是一项非常前沿的技术,而且对于新手来说也很容易学习和使用。因为是本地服务器,综合考虑后安装了Navicat MySQL,用于MySQL数据库管理。 4.安装Dedecms,从下载“DedecmsV5.7”版本。按照网站提供的教程安装,安装过程中注意以下问题:(1)data,templates,uploads,a或html目录,设置读写,非执行权限。(2)不需要设置专题,建议删除专题目录,生成HTML后需要能删除special/index.php,然后将该目录设置为可读写,不可执行权限。(3)include、member、plus、后台管理目录设置为可执行脚本,可读不可写(如果安装了附加模块,book、ask、company、group目录也同样设置) .
(4)安装完成后删除install目录。5.Set网站column,根据自己的需要设置不同的网站栏目,作者设置人民网、健康报网和本地报纸等栏目6.实现网页采集是本方案最核心的部分,网络采集模块加上Dedecms也可以实现网页自动采集,但采集比较薄不能同时采集。@并发布多个网站,并且需要登录网站后台操作,操作过程繁琐,所以需要找一套可以实现自动批量网站的软件采集.现在采集软件的在线数据主要有以下几种:“优采云”、“网络矿工”、“优讯软件”、“网络神彩”、“一菜”、“优采云”、“三人行”等 以上都是付费软件,有免费版 可以试用,但是功能上有限制。因为采集大部分都是纯静态页面,并且数据结构简单,尝试了很多采集软件后,最终选择了“Train采集器V7免费版”。 “优采云采集器V7”Web发布模块带有“Dedecms5.7”版本,省去编写发布接口代码的需要。直接在任务栏运行“优采云采集器”添加需要采集网页的任务,编辑采集网址规则,采集内容规则,发布内容设置等,实现批量自动采集和批量发布网页。实际操作中要注意几个方面问题:(采集中的1)涉及如何采集将远程图片发布到本地服务器的问题。在采集内容规则中,选择“完成相对地址为绝对地址”,因为Dedecms有下载远程图片和资源的模块,可以自动下载远程图片。
由于使用的是免费版,由于限制,笔者在这里走了很多弯路。 (2)由于采集数量众多,难免会出现重复文章。“Dedecms”提供的重复文档检测功能可以批量删除重复文档。(3)通优采云采集设备可以批量发布文章,当您还需要登录后台时,使用一键更新网站功能更新网页链接。(4)编辑时采集规则,应用过滤功能过滤掉多余的四、讨论通过上述方法搭建的医院新闻平台,可及时批量更新新闻网站,网络信息采集信息采集,资源整合,节省了大量的人力和资金。但是有一些网站采取了防止采集的措施,而且采集数据不可用。另外,因为全部是免费软件,所以只有自动发布图片目前已经实现,没有更好的发布附件的方式,需要进一步改进。文献:[1]郑希敖松,袁继先,徐铭。校园网新闻与管理[J].计算机知识与技术(学术交流),2007,(5).[2]李强.医院内部网站建筑的一些经验与建议[J].现代医院管理,2011,41(2).通讯作者:张伟 阅读相关文献:建筑工程技术专业毕业生与本科生服务驱动型人才培养模式实践结对引领实践成果职业素养教育融入会计教学的研究与实践初探。初中语文自主、合作、探究式学习方法探讨 嵌入式实践教学模式在工商管理本科人才培养中的应用 工业设计基础军品设计课程 学生“画”创情智共生的语文课堂快乐教学——小学情景教学法的创设之道音乐厅数学课堂 如何有效开展小学语文综合实践活动 如何激发初中生思政课学习兴趣 优化活动策略 重视问题 解决试讨论如何培养小学生数学思维和问题意识 利用本地资源诠释智慧课堂 激活小学生数学课堂 具体举措 探索最新、最完整的中学生生活[学术论文][总结报告][演讲][领导讲话] ] [心得] [党建资料] [常用范文] [分析报告] [申请文件] 免费阅读下载 *本文采集于网络,版权归原作者所有。如果您侵犯了您的权利,请留言。我会尽快处理。谢谢。* 查看全部
利用采集器 采集的平台 最新最全的学术论文期刊文献年终总结(组图)
利用网页信息采集技术搭建医院内网新闻平台-精美素材本文档格式为WORD,感谢阅读。最新最全的学术论文、期刊、文献、年终总结、年终报告、工作总结、个人总述职报告、实习报告、单位总结总结:利用网页采集技术搭建内部新闻平台,医务人员可以通过信息系统内部网络及时了解国内外新闻动态关键词:webpage采集;内网新闻; cmsG640 文件标识码:A 1674-9324 (2013)51-0198-02 一、 简介 采用严格的物理隔离措施,通过一个看门人实现内外网的数据访问。医院建立了内部网络网站发布医院新闻、通知等信息 信息系统用户只能浏览内部网站提供的医院新闻无法浏览公共网络信息 随着医院的不断发展和随着互联网的普及,临床工作人员通过网络渴望通过信息系统网络了解自己关心的国家的时事、新闻、政策法规。临床医生和医院管理者。二、方案选择实现上述功能,有如下两种方案: 方案一:使用exis ting gatekeeper 映射公网地址 去内网解决用户浏览新闻的问题。方案二:在外网搭建自己的新闻平台,及时发布新闻信息,通过看门人将网站映射到内网。
方案一实现起来比较简单,只需要简单的配置就可以实现上述功能,但是也有弊端。主要原因是一旦公网网站内容映射到内网,用户就可以浏览所有网站信息,对于一些娱乐信息和无关信息无法屏蔽,浏览无法控制,所以该计划未获通过。第二套方案需要建立自己的新闻平台,实施起来比第一套方案复杂,但是可以对新闻信息进行管理,避免一些不相关的信息,所以采用了第二套方案。按照第二个方案,问题是依靠人力逐条复制录入新闻,必然造成资源的极大浪费。因此,可以考虑使用网络信息采集技术来实现新闻信息的批量获取和发布。网页信息采集技术是通过分析网页的HTML代码,获取网络中的超链接信息,采用广度优先搜索算法和增量存储算法,实现自动连续分析链接、抓取文件、处理和处理的过程。保存数据。 三、的具体实现过程如下: 1.cms选择:cms由Content Management System编写,意为“内容管理系统”。它有很多优秀的基于模板的设计,可以加快网站Speed的开发速度,降低开发成本。为了节省投资,比较了比较流行的“empirecms”、“PHPcms”、“织梦cms”等免费的cms。感觉织梦cms好用。模板很多,尤其是后端的网页采集模块,最终选择了织梦内容管理系统(以下简称Dedecms)。
2.搭建服务器环境,作者使用Windows2003 Server IIS+PHP+ MySQL模型搭建。 PHP是Hypertext Preprocessor的缩写,英文超文本预处理语言。 PHP 是一种 HTML 嵌入语言,一种嵌入在服务器端执行的 HTML 文档中的脚本语言。语言风格与C语言相似,应用广泛。现在 PHP 管理非常简单。直接从下载5.4.0版本安装包后,安装。 MySQL 是一个小型的关系型数据库管理系统。由于其体积小、速度快、总拥有成本低,尤其是其开源特性,很多网站选择了MySQL作为网站数据库。从 下载并安装 MySQL Installer 5.5.21 版本进行安装。为了保证数据库的安全,在MySQL安装过程中要注意设置root用户密码。如果忘记设置,可以在系统安装后使用mysqladmin命令设置密码。安装完成后,测试PHP和MySQL服务是否正常。 3.MySQL 数据库管理,可以使用PhpMyAdmin 或Navicat MySQL。 PhpMyAdmin的缺点是必须安装在Web服务器上,如果没有适当的访问权限,其他用户可能会损坏SQL数据。
Navicat MySQL 是一个强大的 MySQL 数据库服务器管理和开发工具。它可以与任何3.21或以上版本的MySQL一起工作,并支持大多数最新的MySQL特性,包括触发器、存储过程、函数、事件、视图、用户管理等。它不仅对专业开发人员来说是一项非常前沿的技术,而且对于新手来说也很容易学习和使用。因为是本地服务器,综合考虑后安装了Navicat MySQL,用于MySQL数据库管理。 4.安装Dedecms,从下载“DedecmsV5.7”版本。按照网站提供的教程安装,安装过程中注意以下问题:(1)data,templates,uploads,a或html目录,设置读写,非执行权限。(2)不需要设置专题,建议删除专题目录,生成HTML后需要能删除special/index.php,然后将该目录设置为可读写,不可执行权限。(3)include、member、plus、后台管理目录设置为可执行脚本,可读不可写(如果安装了附加模块,book、ask、company、group目录也同样设置) .
(4)安装完成后删除install目录。5.Set网站column,根据自己的需要设置不同的网站栏目,作者设置人民网、健康报网和本地报纸等栏目6.实现网页采集是本方案最核心的部分,网络采集模块加上Dedecms也可以实现网页自动采集,但采集比较薄不能同时采集。@并发布多个网站,并且需要登录网站后台操作,操作过程繁琐,所以需要找一套可以实现自动批量网站的软件采集.现在采集软件的在线数据主要有以下几种:“优采云”、“网络矿工”、“优讯软件”、“网络神彩”、“一菜”、“优采云”、“三人行”等 以上都是付费软件,有免费版 可以试用,但是功能上有限制。因为采集大部分都是纯静态页面,并且数据结构简单,尝试了很多采集软件后,最终选择了“Train采集器V7免费版”。 “优采云采集器V7”Web发布模块带有“Dedecms5.7”版本,省去编写发布接口代码的需要。直接在任务栏运行“优采云采集器”添加需要采集网页的任务,编辑采集网址规则,采集内容规则,发布内容设置等,实现批量自动采集和批量发布网页。实际操作中要注意几个方面问题:(采集中的1)涉及如何采集将远程图片发布到本地服务器的问题。在采集内容规则中,选择“完成相对地址为绝对地址”,因为Dedecms有下载远程图片和资源的模块,可以自动下载远程图片。
由于使用的是免费版,由于限制,笔者在这里走了很多弯路。 (2)由于采集数量众多,难免会出现重复文章。“Dedecms”提供的重复文档检测功能可以批量删除重复文档。(3)通优采云采集设备可以批量发布文章,当您还需要登录后台时,使用一键更新网站功能更新网页链接。(4)编辑时采集规则,应用过滤功能过滤掉多余的四、讨论通过上述方法搭建的医院新闻平台,可及时批量更新新闻网站,网络信息采集信息采集,资源整合,节省了大量的人力和资金。但是有一些网站采取了防止采集的措施,而且采集数据不可用。另外,因为全部是免费软件,所以只有自动发布图片目前已经实现,没有更好的发布附件的方式,需要进一步改进。文献:[1]郑希敖松,袁继先,徐铭。校园网新闻与管理[J].计算机知识与技术(学术交流),2007,(5).[2]李强.医院内部网站建筑的一些经验与建议[J].现代医院管理,2011,41(2).通讯作者:张伟 阅读相关文献:建筑工程技术专业毕业生与本科生服务驱动型人才培养模式实践结对引领实践成果职业素养教育融入会计教学的研究与实践初探。初中语文自主、合作、探究式学习方法探讨 嵌入式实践教学模式在工商管理本科人才培养中的应用 工业设计基础军品设计课程 学生“画”创情智共生的语文课堂快乐教学——小学情景教学法的创设之道音乐厅数学课堂 如何有效开展小学语文综合实践活动 如何激发初中生思政课学习兴趣 优化活动策略 重视问题 解决试讨论如何培养小学生数学思维和问题意识 利用本地资源诠释智慧课堂 激活小学生数学课堂 具体举措 探索最新、最完整的中学生生活[学术论文][总结报告][演讲][领导讲话] ] [心得] [党建资料] [常用范文] [分析报告] [申请文件] 免费阅读下载 *本文采集于网络,版权归原作者所有。如果您侵犯了您的权利,请留言。我会尽快处理。谢谢。*
使用优采云采集器采集大众点评商家的方法采集教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-07-22 01:25
使用优采云采集器采集全球评商数据 本文介绍采集用优采云7.0采集全球评商的方法采集网站:/search/category /7/0 使用功能点:网页列表内容提取相关采集教程:美团商家信息采集黄页88 data采集追集招聘信息采集第一步:/article/javascript:;创建采集任务1)进入主界面选择,选择自定义模式并使用优采云采集器采集众评商数据图12)将以上网址的网址复制粘贴到网站输入中框,点击“保存网址”用优采云采集器采集全球评商数据保存网址后如图23),页面会在优采云采集器打开,红框中的列表是我们需要的信息采集 使用优采云采集器采集全球评商数据 图3 第二步:/article/javascript:; 创建翻页循环找到翻页按钮,设置翻页循环1)页面下拉到底部,找到下一页按钮,点击鼠标,在右侧操作提示框中选择“循环点击下一页”使用优采云采集器采集众评商数据 图4 S第三步:/article/javascript:;商信息采集选择需要采集的字段信息,创建一个采集列表edit采集field name1)如图,移动鼠标选择列表中的商家名称,右击,需要采集的内容会变成绿色 使用优采云采集器采集直播评商数据 图5 注:点击“处理”按钮右上角显示可视化流程图。
2) 移动鼠标选中红框中任意一个文本框后,列表中所有适配的内容都会变成绿色。在右侧操作提示框中勾选提取的字段,删除不需要的字段。然后点击“全选”使用优采云采集器采集k15@众评商数据 图6 注意:当鼠标放在这个字段上时,会出现一个删除图标,点击删除该字段。使用优采云采集器采集全球评商数据图73)点击“采集下数据”使用优采云采集器采集全球评商数据图84)改采集字段名使用优采云采集器采集全球评商数据 图95)点击下方红框中的“保存并启动采集”使用优采云采集器采集众评商数据图106)根据采集的情况选择合适的采集方式。这里选择“启动local采集”使用优采云采集器采集全球评商数据 图11 说明:Local采集 占用采集的当前计算机资源,如果有采集时间要求或当前电脑不能长时间使用采集可以使用cloud采集功能,云端采集在网络采集上进行,没有当前电脑支持,电脑可以关闭,可以设置多个云节点共享任务。 10个节点相当于10台电脑分配任务帮你采集,速度降低到原来速度的十分之一; 采集到达的数据可以在云端保存三个月,随时可以导出。第 4 步:/article/javascript:;数据采集和导出1)采集完成后会弹出提示,选择使用优采云采集器采集全球评商数据图122)导出数据,选择合适的导出方式,使用采集好数据导出优采云采集器采集全球评商数据 图13优采云——70万用户采集器选择的网页数据。
1、操作简单,任何人都可以使用:无需技术背景,可以在网上采集。过程完全可视化,点击鼠标即可完成操作,2分钟即可快速上手。 2、功能强大,任何网站都可以:点击、登录、翻页、识别验证码、瀑布流、异步加载数据页的Ajax脚本,都可以通过简单的设置成为采集 . 3、云采集,可以关闭。 采集任务配置完成后可以关闭采集任务,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。 4、功能免费+增值服务,可根据需要选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。 优采云·云采集服务平台 查看全部
使用优采云采集器采集大众点评商家的方法采集教程
使用优采云采集器采集全球评商数据 本文介绍采集用优采云7.0采集全球评商的方法采集网站:/search/category /7/0 使用功能点:网页列表内容提取相关采集教程:美团商家信息采集黄页88 data采集追集招聘信息采集第一步:/article/javascript:;创建采集任务1)进入主界面选择,选择自定义模式并使用优采云采集器采集众评商数据图12)将以上网址的网址复制粘贴到网站输入中框,点击“保存网址”用优采云采集器采集全球评商数据保存网址后如图23),页面会在优采云采集器打开,红框中的列表是我们需要的信息采集 使用优采云采集器采集全球评商数据 图3 第二步:/article/javascript:; 创建翻页循环找到翻页按钮,设置翻页循环1)页面下拉到底部,找到下一页按钮,点击鼠标,在右侧操作提示框中选择“循环点击下一页”使用优采云采集器采集众评商数据 图4 S第三步:/article/javascript:;商信息采集选择需要采集的字段信息,创建一个采集列表edit采集field name1)如图,移动鼠标选择列表中的商家名称,右击,需要采集的内容会变成绿色 使用优采云采集器采集直播评商数据 图5 注:点击“处理”按钮右上角显示可视化流程图。
2) 移动鼠标选中红框中任意一个文本框后,列表中所有适配的内容都会变成绿色。在右侧操作提示框中勾选提取的字段,删除不需要的字段。然后点击“全选”使用优采云采集器采集k15@众评商数据 图6 注意:当鼠标放在这个字段上时,会出现一个删除图标,点击删除该字段。使用优采云采集器采集全球评商数据图73)点击“采集下数据”使用优采云采集器采集全球评商数据图84)改采集字段名使用优采云采集器采集全球评商数据 图95)点击下方红框中的“保存并启动采集”使用优采云采集器采集众评商数据图106)根据采集的情况选择合适的采集方式。这里选择“启动local采集”使用优采云采集器采集全球评商数据 图11 说明:Local采集 占用采集的当前计算机资源,如果有采集时间要求或当前电脑不能长时间使用采集可以使用cloud采集功能,云端采集在网络采集上进行,没有当前电脑支持,电脑可以关闭,可以设置多个云节点共享任务。 10个节点相当于10台电脑分配任务帮你采集,速度降低到原来速度的十分之一; 采集到达的数据可以在云端保存三个月,随时可以导出。第 4 步:/article/javascript:;数据采集和导出1)采集完成后会弹出提示,选择使用优采云采集器采集全球评商数据图122)导出数据,选择合适的导出方式,使用采集好数据导出优采云采集器采集全球评商数据 图13优采云——70万用户采集器选择的网页数据。
1、操作简单,任何人都可以使用:无需技术背景,可以在网上采集。过程完全可视化,点击鼠标即可完成操作,2分钟即可快速上手。 2、功能强大,任何网站都可以:点击、登录、翻页、识别验证码、瀑布流、异步加载数据页的Ajax脚本,都可以通过简单的设置成为采集 . 3、云采集,可以关闭。 采集任务配置完成后可以关闭采集任务,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。 4、功能免费+增值服务,可根据需要选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。 优采云·云采集服务平台
利用采集器 采集的平台(优采云数据采集系统能做的包括但不局限于以下内容 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-09-05 00:09
)
Data采集器 是一个强大的免费 data采集 系统。 Data采集器 可以从任何网页获取信息。即使您根本不了解任何网络技术,也可以轻松地从该软件中获取信息。抓取网络上的任何资源数据,例如文本、图片、文件和视频。
软件功能
简单来说,使用优采云可以轻松地从任何网页生成自定义的常规数据格式,以准确采集您需要的数据。 优采云数据采集系统能做的包括但不限于以下内容:
1、财务数据,如季报、年报、财报,包括最新的每日净值采集;
2、各种新闻门户网站实时监控,自动更新上传最新新闻;
3、监控竞争对手的最新信息,包括商品价格和库存;
4、monitoring各大社交网络网站,博客,自动抓取企业产品相关评论;
5、采集最新最全的招聘信息;
6、监控各大地产相关网站、采集新房二手房的最新报价;
7、采集个别汽车网站具体新车及二手车信息;
8、发现并采集潜在客户信息;
9、采集工业网站的产品目录和产品信息;
10、 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
软件功能
1、操作简单
操作简单,图形化操作完全可视化,无需专业IT人员,任何会电脑上网的人都可以轻松掌握。
2、云采集
采集任务自动分发到云端多台服务器同时执行,提高了采集的效率,短时间内可以获得数千条消息。
3、drag and drop采集process
模仿人类的操作思维方式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采用不同的采集流程。
4、图形识别
内置可扩展OCR接口,支持解析图片中的文字,提取图片上的文字。
5、timing automatic采集
采集任务自动运行,可以按照指定周期自动采集,同时支持实时采集,最快一分钟一次。
6、2 分钟快速入门
内置从入门到精通的视频教程,2分钟即可上手,还有文档、论坛、qq群等
7、免费使用
它是免费的,免费版没有功能限制。您可以立即试用,立即下载并安装。
使用教程
下载优采云数据采集器安装包,安装后注册账号,登录,登录后进入软件首页,点击任务->新建->自定义采集,输入网址采集 网页并保存;
保存后软件会自动打开页面。您可以在页面中一一点击要抓取的内容,也可以在右侧的操作提示区点击取消要抓取的内容;确认无误后点击采集;
保存采集后,选择启用本地采集,然后静静等待即可看到采集收到的数据;也可以选择从采集导出数据;另外优采云也可以同时使用采集多个页面,开始输入网址时只需要输入多个网址;
查看全部
利用采集器 采集的平台(优采云数据采集系统能做的包括但不局限于以下内容
)
Data采集器 是一个强大的免费 data采集 系统。 Data采集器 可以从任何网页获取信息。即使您根本不了解任何网络技术,也可以轻松地从该软件中获取信息。抓取网络上的任何资源数据,例如文本、图片、文件和视频。
软件功能
简单来说,使用优采云可以轻松地从任何网页生成自定义的常规数据格式,以准确采集您需要的数据。 优采云数据采集系统能做的包括但不限于以下内容:
1、财务数据,如季报、年报、财报,包括最新的每日净值采集;
2、各种新闻门户网站实时监控,自动更新上传最新新闻;
3、监控竞争对手的最新信息,包括商品价格和库存;
4、monitoring各大社交网络网站,博客,自动抓取企业产品相关评论;
5、采集最新最全的招聘信息;
6、监控各大地产相关网站、采集新房二手房的最新报价;
7、采集个别汽车网站具体新车及二手车信息;
8、发现并采集潜在客户信息;
9、采集工业网站的产品目录和产品信息;
10、 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
软件功能
1、操作简单
操作简单,图形化操作完全可视化,无需专业IT人员,任何会电脑上网的人都可以轻松掌握。
2、云采集
采集任务自动分发到云端多台服务器同时执行,提高了采集的效率,短时间内可以获得数千条消息。
3、drag and drop采集process
模仿人类的操作思维方式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采用不同的采集流程。
4、图形识别
内置可扩展OCR接口,支持解析图片中的文字,提取图片上的文字。
5、timing automatic采集
采集任务自动运行,可以按照指定周期自动采集,同时支持实时采集,最快一分钟一次。
6、2 分钟快速入门
内置从入门到精通的视频教程,2分钟即可上手,还有文档、论坛、qq群等
7、免费使用
它是免费的,免费版没有功能限制。您可以立即试用,立即下载并安装。
使用教程
下载优采云数据采集器安装包,安装后注册账号,登录,登录后进入软件首页,点击任务->新建->自定义采集,输入网址采集 网页并保存;
保存后软件会自动打开页面。您可以在页面中一一点击要抓取的内容,也可以在右侧的操作提示区点击取消要抓取的内容;确认无误后点击采集;
保存采集后,选择启用本地采集,然后静静等待即可看到采集收到的数据;也可以选择从采集导出数据;另外优采云也可以同时使用采集多个页面,开始输入网址时只需要输入多个网址;
利用采集器 采集的平台(常见问答:XX网站能不能采集?官网视频讲解教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 413 次浏览 • 2021-09-03 21:12
常见问题:
1、XX 网站你能采集吗? XX数据可以采集吗?
在官网的视频教程中,我们已经介绍过优采云采集器是一个通用的网页采集软件。只要有网站,就可以浏览网页。你能看到的大部分内容是可以采集(视频很特殊,所以要具体情况具体分析)。
为了保护您的隐私,您的所有任务和配置都以加密形式存储在云端。没有人,但您可以查看具体内容。你在采集过程中输入的账号密码和你的采集结果都存储在你的本地电脑上。但请严格遵守相关法律法规。如优采云采集器官方收到采集违法举报,将第一时间暂停账号。
2、为什么采集data 过早停止?
如果遇到采集提前停车的问题,请按照以下步骤进行自检:
第一步:请确认浏览器能看到多少内容
有时搜索中显示的数字与您最后看到的数字不同。请确认你能看到多少条数据,然后判断采集是提前停止还是正常停止。
第2步:采集结果的数量与浏览器中看到的数量不一致
在采集的过程中,如果遇到这个问题,有两种可能:
第一种可能是采集太快,页面加载时间太慢,导致采集无法访问页面中的数据。
在这种情况下,请增加请求的等待时间。等待时间变长之后,网页就会有足够的时间加载内容。
请求等待时间的设置在启动设置->智能策略中,如下图:
第二种可能是你遇到了其他问题
在操作过程中,我们可以在操作界面点击“查看网页”,观察当前网页内容是否正常,是否无法正常显示,是否有异常提示等
如果出现上述情况,我们可以降低采集的速度,切换代理IP,手动编码等,至于哪种方法可以工作,这个需要测试一下才知道不同的网站问题是不同的。没有一种统一的解决方案。
如果您在尝试上述解决方案后仍然无法解决问题,您可以在帮助中心给我们反馈,我们将为您提供支持。
3、为什么采集不见了?
不完整的字段一般有以下两种情况:
首先,由于列表元素的结构不同,有些元素有其他元素没有的字段。这是正常现象。请在网页上确认相应元素中是否存在您想要的字段。
其次,页面结构发生了变化。这通常发生在收录多个页面结构的同一个搜索结果中,例如搜索引擎搜索结果(包括多种网站)。
这种情况需要具体问题具体分析。您可以将您的采集任务导出并发送到我们的官方帮助中心,我们的客服会帮您测试分析。 查看全部
利用采集器 采集的平台(常见问答:XX网站能不能采集?官网视频讲解教程)
常见问题:
1、XX 网站你能采集吗? XX数据可以采集吗?
在官网的视频教程中,我们已经介绍过优采云采集器是一个通用的网页采集软件。只要有网站,就可以浏览网页。你能看到的大部分内容是可以采集(视频很特殊,所以要具体情况具体分析)。
为了保护您的隐私,您的所有任务和配置都以加密形式存储在云端。没有人,但您可以查看具体内容。你在采集过程中输入的账号密码和你的采集结果都存储在你的本地电脑上。但请严格遵守相关法律法规。如优采云采集器官方收到采集违法举报,将第一时间暂停账号。
2、为什么采集data 过早停止?
如果遇到采集提前停车的问题,请按照以下步骤进行自检:
第一步:请确认浏览器能看到多少内容
有时搜索中显示的数字与您最后看到的数字不同。请确认你能看到多少条数据,然后判断采集是提前停止还是正常停止。
第2步:采集结果的数量与浏览器中看到的数量不一致
在采集的过程中,如果遇到这个问题,有两种可能:
第一种可能是采集太快,页面加载时间太慢,导致采集无法访问页面中的数据。
在这种情况下,请增加请求的等待时间。等待时间变长之后,网页就会有足够的时间加载内容。
请求等待时间的设置在启动设置->智能策略中,如下图:
第二种可能是你遇到了其他问题
在操作过程中,我们可以在操作界面点击“查看网页”,观察当前网页内容是否正常,是否无法正常显示,是否有异常提示等
如果出现上述情况,我们可以降低采集的速度,切换代理IP,手动编码等,至于哪种方法可以工作,这个需要测试一下才知道不同的网站问题是不同的。没有一种统一的解决方案。
如果您在尝试上述解决方案后仍然无法解决问题,您可以在帮助中心给我们反馈,我们将为您提供支持。
3、为什么采集不见了?
不完整的字段一般有以下两种情况:
首先,由于列表元素的结构不同,有些元素有其他元素没有的字段。这是正常现象。请在网页上确认相应元素中是否存在您想要的字段。
其次,页面结构发生了变化。这通常发生在收录多个页面结构的同一个搜索结果中,例如搜索引擎搜索结果(包括多种网站)。
这种情况需要具体问题具体分析。您可以将您的采集任务导出并发送到我们的官方帮助中心,我们的客服会帮您测试分析。
利用采集器 采集的平台(爬虫实战:利用软件采集招聘信息(一)(基于优采云和优采云采集器))
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-09-02 16:09
爬虫实战:使用软件采集Job Information(一)
(基于优采云和优采云采集器software-easy mode采集)
一、什么是爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不常用的名称包括蚂蚁、自动索引、模拟程序或蠕虫(百度复制粘贴内容^^)。
说白了,爬虫就是利用工具来抓取网页上的内容(数据、文字、图片等)。是不是觉得写论文找资料不仅仅是翻阅年鉴……爬虫工具除了python(手写代码)等编程语言,还有采集通过一些第三方软件(比如如优采云、优采云采集器、优采云采集器 等)。至于自己写代码的方式,我会在文章中介绍。本文从基础介绍软件傻瓜式crawler的使用。这个方法已经可以满足采集的大部分需求了,只是拖拽也不容易。
二、优采云采集器 和优采云简介
这两个采集器是笔者认为目前市面上比较优秀的两个采集软件。 优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。该软件功能强大且易于操作。可谓是居家旅行的随身神器。 优采云大数据采集是一个集网页数据采集、移动互联网数据和API接口服务(包括数据爬虫、数据优化、数据挖掘、数据存储、数据备份)等为一体的自主研发平台服务。数据服务平台连续4年位居互联网Data采集software榜单第一。两款软件的采集模式基本相同,主要有两种:智能模式采集或简单采集,自定义模式采集。本期主要介绍智能模式采集或简单采集。
三、简单模式
(1)优采云采集器
软件下载地址:至于如何安装软件,一直是下一步。
优采云采集器的智能模式采集只需将您要抓取的页面放入网址框,软件就会自动识别您可能需要抓取的内容。我们直接来看例子。比如要爬取某所大学的就业信息(以北大为例),北大就业指导服务中心的网址是!recruitList.action?category=1(不知道后面看到的,不管是无效还是反爬虫,反正我能用,能用,能用。
1.打开软件,选择智能模式
2.在右边的框中输入抓取网址
3.点击下方立即创建,可以看到软件自动识别出需要抓取的内容
4.点击启动采集并启动,软件会自动采集当前页面信息并翻页。
5.software is crawling...(注意:由于没有选择深度爬取,所以只会爬取当前页面,链接中不会访问到具体信息)
6.因为内容的原因,作者选择了强制结束。最后导出文件,可以选择导出excel格式。
7.最终的excel数据如下
(2)优采云
软件下载地址:。 优采云简单方便,软件自带了很多常用的网站和数据模板,如下图:
比如要抓取百星网的招聘信息,在百星网选择要爬取的职位,复制链接(以示例为例)。
1.点击人脉模板,选择并点击采集
2.输入网址,翻页次数
3.选择开始local采集
4.可以看到正在抓取数据
5.最终爬取的数据可以导出
以上是本期内容:关于优采云采集器和优采云采集器的简单模式采集。下一期我们会推送流程图或者自定义采集数据。
终于! ! ! ! ! !发送彩蛋解决上一篇提到的问题,在使用优采云采集器时,由于没有深度爬取选项,只会爬取当前页面,链接中无法访问具体信息.
因为抓取的数据只是每个链接的标题,所以需要在链接抓取中输入内容。 优采云采集器提供了“depth采集”功能,可以输入链接采集。这里:
点击“Depth采集”进入页面,即最外层链接里面的内容。这时候下面会抓取这个页面的内容。点击开始采集到采集每个标题链接中的内容。
欢迎关注(数据皮皮下) 查看全部
利用采集器 采集的平台(爬虫实战:利用软件采集招聘信息(一)(基于优采云和优采云采集器))
爬虫实战:使用软件采集Job Information(一)
(基于优采云和优采云采集器software-easy mode采集)
一、什么是爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不常用的名称包括蚂蚁、自动索引、模拟程序或蠕虫(百度复制粘贴内容^^)。
说白了,爬虫就是利用工具来抓取网页上的内容(数据、文字、图片等)。是不是觉得写论文找资料不仅仅是翻阅年鉴……爬虫工具除了python(手写代码)等编程语言,还有采集通过一些第三方软件(比如如优采云、优采云采集器、优采云采集器 等)。至于自己写代码的方式,我会在文章中介绍。本文从基础介绍软件傻瓜式crawler的使用。这个方法已经可以满足采集的大部分需求了,只是拖拽也不容易。
二、优采云采集器 和优采云简介
这两个采集器是笔者认为目前市面上比较优秀的两个采集软件。 优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。该软件功能强大且易于操作。可谓是居家旅行的随身神器。 优采云大数据采集是一个集网页数据采集、移动互联网数据和API接口服务(包括数据爬虫、数据优化、数据挖掘、数据存储、数据备份)等为一体的自主研发平台服务。数据服务平台连续4年位居互联网Data采集software榜单第一。两款软件的采集模式基本相同,主要有两种:智能模式采集或简单采集,自定义模式采集。本期主要介绍智能模式采集或简单采集。
三、简单模式
(1)优采云采集器
软件下载地址:至于如何安装软件,一直是下一步。
优采云采集器的智能模式采集只需将您要抓取的页面放入网址框,软件就会自动识别您可能需要抓取的内容。我们直接来看例子。比如要爬取某所大学的就业信息(以北大为例),北大就业指导服务中心的网址是!recruitList.action?category=1(不知道后面看到的,不管是无效还是反爬虫,反正我能用,能用,能用。
1.打开软件,选择智能模式
2.在右边的框中输入抓取网址
3.点击下方立即创建,可以看到软件自动识别出需要抓取的内容
4.点击启动采集并启动,软件会自动采集当前页面信息并翻页。
5.software is crawling...(注意:由于没有选择深度爬取,所以只会爬取当前页面,链接中不会访问到具体信息)
6.因为内容的原因,作者选择了强制结束。最后导出文件,可以选择导出excel格式。
7.最终的excel数据如下
(2)优采云
软件下载地址:。 优采云简单方便,软件自带了很多常用的网站和数据模板,如下图:
比如要抓取百星网的招聘信息,在百星网选择要爬取的职位,复制链接(以示例为例)。
1.点击人脉模板,选择并点击采集
2.输入网址,翻页次数
3.选择开始local采集
4.可以看到正在抓取数据
5.最终爬取的数据可以导出
以上是本期内容:关于优采云采集器和优采云采集器的简单模式采集。下一期我们会推送流程图或者自定义采集数据。
终于! ! ! ! ! !发送彩蛋解决上一篇提到的问题,在使用优采云采集器时,由于没有深度爬取选项,只会爬取当前页面,链接中无法访问具体信息.
因为抓取的数据只是每个链接的标题,所以需要在链接抓取中输入内容。 优采云采集器提供了“depth采集”功能,可以输入链接采集。这里:
点击“Depth采集”进入页面,即最外层链接里面的内容。这时候下面会抓取这个页面的内容。点击开始采集到采集每个标题链接中的内容。
欢迎关注(数据皮皮下)
利用采集器 采集的平台(UC头图像采集的应用方法及解决办法(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-01 06:02
注意:根据网页的加载情况设置滚动条的数量和滚动间隔。如果向下滚动,页面信息会加载缓慢。建议将滚动间隔设置的大一些。滚动的次数应该取决于我们滚动加载我们需要的所有数据的次数。建议准备一两次。滚动方法是看页面滚动时是否能顺利加载所有数据,或者是否需要一次滚动一屏。一般来说,一次滚动一屏更好,但更耗时。滚动屏幕取决于屏幕大小,云抓图默认为全屏。
3)文章图文集
文章中文字和图片的采集方式有两种。
方法一:设置判断条件,分别采集文字和图片。
采集 示例:腾讯新闻图片文字采集
方法二:先采集全文,再采集图片。
Sample采集:UC 标题图片采集
3、课程目的
这一步采集图片网址在上面的图片采集教程中有详细介绍,不再赘述。本文将重点介绍图片采集的技术和注意事项。
4、图片URL采集process
以下是具体操作步骤的演示。以百度图片的URL采集为例,抓取图片的URL。不同的网站picture URL会遇到不同的情况,请灵活处理。
选择图片,全选,采集以下图片地址
(2)开始采集查看结果。采集图片网址。
具体流程参考:瀑布图采集,以百度图为例,步骤1-4。
5、图片批量导出操作步骤
经过以上操作,我们就得到了采集的图片地址。接下来我们使用章鱼图片批量下载工具将图片下载并保存到本地电脑的图片网址。
1)Download八达通图片批量下载工具,双击文件中的mydownloader.app.exe打开软件。
2)打开文件菜单,选择从Excel导入(目前只支持Excel格式的文件)
3)设置
选择Excel文件:导入需要下载图片地址的Excel文件
Excel表名:对应数据表的名称
文件URL列名:表中对应URL的列名
保存文件夹名称:Excel 需要一个单独的列来列出要保存到此文件夹的图像的路径。在上面的例子中,我们在excel中添加了一个名为“picturesavefolder”的列,该列中的数据为“d:baidupicture采集”,然后“d:baidupicture采集”成为保存图片的路径(其他盘可以自定义存储,文件夹名称可自定义修改;“d:\”需输入英文)。 查看全部
利用采集器 采集的平台(UC头图像采集的应用方法及解决办法(一))
注意:根据网页的加载情况设置滚动条的数量和滚动间隔。如果向下滚动,页面信息会加载缓慢。建议将滚动间隔设置的大一些。滚动的次数应该取决于我们滚动加载我们需要的所有数据的次数。建议准备一两次。滚动方法是看页面滚动时是否能顺利加载所有数据,或者是否需要一次滚动一屏。一般来说,一次滚动一屏更好,但更耗时。滚动屏幕取决于屏幕大小,云抓图默认为全屏。
3)文章图文集
文章中文字和图片的采集方式有两种。
方法一:设置判断条件,分别采集文字和图片。
采集 示例:腾讯新闻图片文字采集
方法二:先采集全文,再采集图片。
Sample采集:UC 标题图片采集
3、课程目的
这一步采集图片网址在上面的图片采集教程中有详细介绍,不再赘述。本文将重点介绍图片采集的技术和注意事项。
4、图片URL采集process
以下是具体操作步骤的演示。以百度图片的URL采集为例,抓取图片的URL。不同的网站picture URL会遇到不同的情况,请灵活处理。
选择图片,全选,采集以下图片地址
(2)开始采集查看结果。采集图片网址。
具体流程参考:瀑布图采集,以百度图为例,步骤1-4。
5、图片批量导出操作步骤
经过以上操作,我们就得到了采集的图片地址。接下来我们使用章鱼图片批量下载工具将图片下载并保存到本地电脑的图片网址。
1)Download八达通图片批量下载工具,双击文件中的mydownloader.app.exe打开软件。
2)打开文件菜单,选择从Excel导入(目前只支持Excel格式的文件)
3)设置
选择Excel文件:导入需要下载图片地址的Excel文件
Excel表名:对应数据表的名称
文件URL列名:表中对应URL的列名
保存文件夹名称:Excel 需要一个单独的列来列出要保存到此文件夹的图像的路径。在上面的例子中,我们在excel中添加了一个名为“picturesavefolder”的列,该列中的数据为“d:baidupicture采集”,然后“d:baidupicture采集”成为保存图片的路径(其他盘可以自定义存储,文件夹名称可自定义修改;“d:\”需输入英文)。
利用采集器 采集的平台(企业在数据采集、数据分析过程中遇到的7大难点 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-08-30 05:08
)
在这个数字世界中,每分钟都会产生大量数据。数据已成为新时代企业发展的必要因素。如今,企业产生的数据量正以每年 40% 到 60% 的速度增长。如何有效解决全链条的数据采集和数据分析,已经成为每个业务经理的首要问题。
下面将告诉你企业在数据采集和数据分析过程中遇到的7大难点!
Data采集数据需求调查
明确过程中数据采集的需求,就是确定我们的采集场景和需要的采集字段,既简化了采集工作的复杂性,又节省了采集的工作量!
数据清洗
数据清理——重新检查和验证采集的数据的过程,目的是去除重复信息,纠正现有错误,并提供数据一致性。如果没有这一步,我们会增加数据采集的存储空间,同时也会降低数据的有效价值!
数据合并
数据合并——以统一标准化的格式展示清洗后的数据源。缺少这一步会导致数据存储过程中的格式杂乱无章,不便于分析人员使用!
任务调度
任务调度是data采集系统的重要组成部分——它可以设置各个爬虫程序的定时启停时间,查看抓取的信息记录。任务调度环节的缺失将直接影响其时效性。
搜索引擎系统
搜索引擎系统可以通过条件+关键字组合查询采集数据库中的数据,无论采集的数量有多大,一个好的搜索引擎系统都会帮助分析师检索他们想要使用的数据在最快的时间内。缩短数据分析时间,提高整体工作效率!
数据分析
数据分析是指用适当的统计分析方法对采集到的大量数据进行分析,提取有用信息,形成结论,并对数据进行详细研究和概括的过程。这个过程也是质量管理体系的一个支持过程。在实践中,数据分析可以帮助企业做出商业判断,从而采取适当的行动,帮助企业赢得商机。
数据可视化展示
数据可视化主要使用图形、图像处理、计算机视觉和用户界面,通过显示三维图形或动画来直观地解释数据。可视化展示,让更多人能够清晰直观地分辨数据分析的结果,提升用户体验!
总结
数据采集和数据分析是很专业的东西。如果不是特别大的企业,就没有必要投入太多的财力和时间来搭建自己的数据采集和分析系统。由于缺乏专业性,采集的数据分析结果并不能指导公司做出正确的商业判断,最终不得不尝试。
天马科技自主研发的DYSON Smart采集系统是一个强大的大数据采集、分析和可视化平台。采用天马科技自主研发的TMF框架为主体架构,支持运营智能发展。用户通过一系列分析选项来使用采集的数据,以发现复杂的联系并探索其数据中的各种关系,包括图形可视化、全文多面搜索、动态直方图、交互式地理空间视图和实时共享协作工作区。探测码 戴森智能采集系统可以专业地捕捉、处理、分析和挖掘互联网数据。并灵活快速地抓取网络上分散的信息,通过智能数据中心提供存储和计算,利用网络应用服务器和开放平台服务器进行大数据存储、管理和挖掘服务,并调整平台服务器的中心帮助企业实现大数据。智能分析,准确挖掘出所需数据。并已应用于金融机构、电子商务、新闻媒体和旅游行业。
功能亮点
查看全部
利用采集器 采集的平台(企业在数据采集、数据分析过程中遇到的7大难点
)
在这个数字世界中,每分钟都会产生大量数据。数据已成为新时代企业发展的必要因素。如今,企业产生的数据量正以每年 40% 到 60% 的速度增长。如何有效解决全链条的数据采集和数据分析,已经成为每个业务经理的首要问题。
下面将告诉你企业在数据采集和数据分析过程中遇到的7大难点!
Data采集数据需求调查
明确过程中数据采集的需求,就是确定我们的采集场景和需要的采集字段,既简化了采集工作的复杂性,又节省了采集的工作量!
数据清洗
数据清理——重新检查和验证采集的数据的过程,目的是去除重复信息,纠正现有错误,并提供数据一致性。如果没有这一步,我们会增加数据采集的存储空间,同时也会降低数据的有效价值!
数据合并
数据合并——以统一标准化的格式展示清洗后的数据源。缺少这一步会导致数据存储过程中的格式杂乱无章,不便于分析人员使用!
任务调度
任务调度是data采集系统的重要组成部分——它可以设置各个爬虫程序的定时启停时间,查看抓取的信息记录。任务调度环节的缺失将直接影响其时效性。
搜索引擎系统
搜索引擎系统可以通过条件+关键字组合查询采集数据库中的数据,无论采集的数量有多大,一个好的搜索引擎系统都会帮助分析师检索他们想要使用的数据在最快的时间内。缩短数据分析时间,提高整体工作效率!
数据分析
数据分析是指用适当的统计分析方法对采集到的大量数据进行分析,提取有用信息,形成结论,并对数据进行详细研究和概括的过程。这个过程也是质量管理体系的一个支持过程。在实践中,数据分析可以帮助企业做出商业判断,从而采取适当的行动,帮助企业赢得商机。
数据可视化展示
数据可视化主要使用图形、图像处理、计算机视觉和用户界面,通过显示三维图形或动画来直观地解释数据。可视化展示,让更多人能够清晰直观地分辨数据分析的结果,提升用户体验!
总结
数据采集和数据分析是很专业的东西。如果不是特别大的企业,就没有必要投入太多的财力和时间来搭建自己的数据采集和分析系统。由于缺乏专业性,采集的数据分析结果并不能指导公司做出正确的商业判断,最终不得不尝试。
天马科技自主研发的DYSON Smart采集系统是一个强大的大数据采集、分析和可视化平台。采用天马科技自主研发的TMF框架为主体架构,支持运营智能发展。用户通过一系列分析选项来使用采集的数据,以发现复杂的联系并探索其数据中的各种关系,包括图形可视化、全文多面搜索、动态直方图、交互式地理空间视图和实时共享协作工作区。探测码 戴森智能采集系统可以专业地捕捉、处理、分析和挖掘互联网数据。并灵活快速地抓取网络上分散的信息,通过智能数据中心提供存储和计算,利用网络应用服务器和开放平台服务器进行大数据存储、管理和挖掘服务,并调整平台服务器的中心帮助企业实现大数据。智能分析,准确挖掘出所需数据。并已应用于金融机构、电子商务、新闻媒体和旅游行业。
功能亮点
利用采集器 采集的平台(百度的开发者平台你是指webapp还是网页app?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-08-28 14:09
利用采集器采集的平台,下面是我已经采集好的功能区域app采集app采集共分为几大块业务区域,涉及到一些手机各方面的全网通,全屏等app的内容信息获取,就是目前一些app的信息采集,也是现在app的用户量的直接体现!一键生成采集app如果需要进行app的采集,一般都是采集一些app中的某个版块中的app功能信息,就需要一键生成app。
shortcut采集这种采集方式因为适用性更广,所以目前也是一种新的采集方式。采集的app区域基本都是包含着各个版块的,一般这种采集方式很适合第三方应用!对于业务进行个性化定制的比较多!来自一家专业的采集平台山火采集,转载请告知!!!。
百度的开发者平台
你是指webapp还是网页app呢?webapp的话:appstore+各大厂商自家的平台(最常见的就是三方的,app推广平台),ios的话appstore+各大厂商自家的平台。网页app的话:一般很多第三方app采集平台都是这种模式,小平台类似于易观,腾讯应用宝,app115,515等。
不止是app,任何网站都可以找到,可以关注我的微信公众号,专门做app收集网站做app和seo必不可少的一个服务,
91query网就是最好的app采集平台,
我用过的app分析平台:【app分析工具appspot】【appstore图片分析】【appxi安卓】【ios工具】【广告投放工具】【app注册平台】【app评论工具】 查看全部
利用采集器 采集的平台(百度的开发者平台你是指webapp还是网页app?)
利用采集器采集的平台,下面是我已经采集好的功能区域app采集app采集共分为几大块业务区域,涉及到一些手机各方面的全网通,全屏等app的内容信息获取,就是目前一些app的信息采集,也是现在app的用户量的直接体现!一键生成采集app如果需要进行app的采集,一般都是采集一些app中的某个版块中的app功能信息,就需要一键生成app。
shortcut采集这种采集方式因为适用性更广,所以目前也是一种新的采集方式。采集的app区域基本都是包含着各个版块的,一般这种采集方式很适合第三方应用!对于业务进行个性化定制的比较多!来自一家专业的采集平台山火采集,转载请告知!!!。
百度的开发者平台
你是指webapp还是网页app呢?webapp的话:appstore+各大厂商自家的平台(最常见的就是三方的,app推广平台),ios的话appstore+各大厂商自家的平台。网页app的话:一般很多第三方app采集平台都是这种模式,小平台类似于易观,腾讯应用宝,app115,515等。
不止是app,任何网站都可以找到,可以关注我的微信公众号,专门做app收集网站做app和seo必不可少的一个服务,
91query网就是最好的app采集平台,
我用过的app分析平台:【app分析工具appspot】【appstore图片分析】【appxi安卓】【ios工具】【广告投放工具】【app注册平台】【app评论工具】
为何探码Dyson选择定制采集服务科技(组图)!
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-08-19 05:03
随着大数据的发展,传统的采集工具已经难以满足用户的需求。首先,传统的采集工具在日常实用工具中无法照顾到用户的使用习惯,用户需要花费大量时间来熟悉工具。其次,传统的采集工具无法满足不同用户的需求,导致采集来满足不同的结果。数据采集的定制更符合时代发展趋势!
为什么戴森选择定制采集service
作为成都一家专门从事该行业的大数据公司,我们发现他们对采集的要求很难统一,而且用户在前期与客户沟通的过程中,使用软件的习惯非常难阶段。方面也不同。很难创造一个大家都非常满意的采集工具。市面上没有大家喜欢的采集工具吧?所以我们选择使用自主研发的Dyson采集系统为我们的客户做专业的采集定制。
什么是定制采集
数据定制是指根据用户的需求,根据互联网上的海量数据信息,对特定数据进行采集过滤、清洗、计算和处理输出数据结果的过程称为数据定制。让客户对工具的需求转变为与技术人员面对面的交流。以下是戴森采集为国内知名国企打造的投融资并购平台,告诉你定制采集!
戴森定制采集解决方案:
确定客户需求
在与客户沟通的过程中,他们希望结合自己在产权行业的深刻理解和沉淀,利用技术手段设计出一个模式,能够解决当前并购市场和投融资行业的问题,信息不完整、不对称、不透明,缺乏对行业痛点进行客观分析评估的金融信息交易平台。
确定客户需要采集的现场要求
根据客户需要采集的投融资项目信息与客户沟通后,我们总结了需要采集的领域。
确定采集数据的页面和平台
当我们澄清采集字段时,发现匹配度高的网站,使用探码自主研发的Dyson采集系统对采集这些网站进行处理。下图是爬取的网站截图的一小部分。
采集数据展示
采集结果出来后,筛选出来的反馈会反馈给客户进行审核确认,然后更新到前台展示,保持经常沟通。
数据清理以去除重复项
在数据采集的过程中,难免会出现重复的过时消息。 Dyson采集系统显示爬虫程序抓取的数据,方便我们清理。数据清洗系统主要由两部分组成:
计时采集
客户需要搭建大型投融资聚集平台。信息每时每刻都充斥着大量的新数据。为保证平台的权威性和专业性,我们会随时核对信息真实可靠采集更新到平台。
24/7 技术支持
在后期的平台维护中,我们会指派平台开发者定期检查后台数据采集等任务,保证系统的顺利运行。并不定期与客户沟通,采集后期使用过程中的修改意见。平台运行后,根据客户需求调整功能。
戴森 data采集定制行业应用
金融机构
在数据快速膨胀的今天,金融金融行业面临着大数据的诸多挑战,如数据应用深度不断增加、数据分析技术更新频率加快、数据类型日益增多等基于业务和策略需求,数据的采集、整理、传输、分析和发布是一个连续而复杂的过程。但是,传统的采集工具根本无法实现采集这样专业的数据。数据的准确性对财务很重要。对于行业来说,它是生命之门,数据不能有出入。定制数据采集是金融行业的最佳选择。
电子商务
电商平台数据庞大且繁琐。传统的采集工具无法实现详细的采集。需要专业数据采集人员提供采集方向并增加相应功能设置。数据的准确性采集。具体案例请参考Dyson采集为成都客户打造的服装电商平台。
旅行社
旅行者拥有比以往任何时候都多的信息,因为大数据允许他们在社交媒体上与同行分享信息。因此,旅游企业需要了解以下问题,并找到应对即将到来的情况的策略。但是传统的采集工具大多没有进行仔细的筛选,使得来自采集的数据价值不高,容易误导管理者的决策。定制化的采集会进行人工筛选和机器筛选,让采集更有价值!
新闻媒体
随着互联网技术的发展和新闻媒体的不断涌现,尤其是大数据技术的出现,传统的采集新闻方式(通过访问、信函、电话)已经无法适应互联网发展的需要。在信息流高度发达的今天,新闻行业需要抓住事件的热点才能生存。如果使用传统的采集工具,则无法追踪热点采集,这个行业对这些信息极为敏感。定制数据采集无非就是最好的选择!
总结:再好的音乐不符合你的心情,也会变成噪音。当大数据不能满足你的需求时,它也是一堆废品。摆脱与机器的枯燥对话,让你的需求成为真正懂你的人,高速发挥数据的真正价值---戴森数据采集定制就在你身边! 查看全部
为何探码Dyson选择定制采集服务科技(组图)!
随着大数据的发展,传统的采集工具已经难以满足用户的需求。首先,传统的采集工具在日常实用工具中无法照顾到用户的使用习惯,用户需要花费大量时间来熟悉工具。其次,传统的采集工具无法满足不同用户的需求,导致采集来满足不同的结果。数据采集的定制更符合时代发展趋势!
为什么戴森选择定制采集service
作为成都一家专门从事该行业的大数据公司,我们发现他们对采集的要求很难统一,而且用户在前期与客户沟通的过程中,使用软件的习惯非常难阶段。方面也不同。很难创造一个大家都非常满意的采集工具。市面上没有大家喜欢的采集工具吧?所以我们选择使用自主研发的Dyson采集系统为我们的客户做专业的采集定制。
什么是定制采集
数据定制是指根据用户的需求,根据互联网上的海量数据信息,对特定数据进行采集过滤、清洗、计算和处理输出数据结果的过程称为数据定制。让客户对工具的需求转变为与技术人员面对面的交流。以下是戴森采集为国内知名国企打造的投融资并购平台,告诉你定制采集!
戴森定制采集解决方案:
确定客户需求
在与客户沟通的过程中,他们希望结合自己在产权行业的深刻理解和沉淀,利用技术手段设计出一个模式,能够解决当前并购市场和投融资行业的问题,信息不完整、不对称、不透明,缺乏对行业痛点进行客观分析评估的金融信息交易平台。
确定客户需要采集的现场要求
根据客户需要采集的投融资项目信息与客户沟通后,我们总结了需要采集的领域。
确定采集数据的页面和平台
当我们澄清采集字段时,发现匹配度高的网站,使用探码自主研发的Dyson采集系统对采集这些网站进行处理。下图是爬取的网站截图的一小部分。
采集数据展示
采集结果出来后,筛选出来的反馈会反馈给客户进行审核确认,然后更新到前台展示,保持经常沟通。
数据清理以去除重复项
在数据采集的过程中,难免会出现重复的过时消息。 Dyson采集系统显示爬虫程序抓取的数据,方便我们清理。数据清洗系统主要由两部分组成:
计时采集
客户需要搭建大型投融资聚集平台。信息每时每刻都充斥着大量的新数据。为保证平台的权威性和专业性,我们会随时核对信息真实可靠采集更新到平台。
24/7 技术支持
在后期的平台维护中,我们会指派平台开发者定期检查后台数据采集等任务,保证系统的顺利运行。并不定期与客户沟通,采集后期使用过程中的修改意见。平台运行后,根据客户需求调整功能。
戴森 data采集定制行业应用
金融机构
在数据快速膨胀的今天,金融金融行业面临着大数据的诸多挑战,如数据应用深度不断增加、数据分析技术更新频率加快、数据类型日益增多等基于业务和策略需求,数据的采集、整理、传输、分析和发布是一个连续而复杂的过程。但是,传统的采集工具根本无法实现采集这样专业的数据。数据的准确性对财务很重要。对于行业来说,它是生命之门,数据不能有出入。定制数据采集是金融行业的最佳选择。
电子商务
电商平台数据庞大且繁琐。传统的采集工具无法实现详细的采集。需要专业数据采集人员提供采集方向并增加相应功能设置。数据的准确性采集。具体案例请参考Dyson采集为成都客户打造的服装电商平台。
旅行社
旅行者拥有比以往任何时候都多的信息,因为大数据允许他们在社交媒体上与同行分享信息。因此,旅游企业需要了解以下问题,并找到应对即将到来的情况的策略。但是传统的采集工具大多没有进行仔细的筛选,使得来自采集的数据价值不高,容易误导管理者的决策。定制化的采集会进行人工筛选和机器筛选,让采集更有价值!
新闻媒体
随着互联网技术的发展和新闻媒体的不断涌现,尤其是大数据技术的出现,传统的采集新闻方式(通过访问、信函、电话)已经无法适应互联网发展的需要。在信息流高度发达的今天,新闻行业需要抓住事件的热点才能生存。如果使用传统的采集工具,则无法追踪热点采集,这个行业对这些信息极为敏感。定制数据采集无非就是最好的选择!
总结:再好的音乐不符合你的心情,也会变成噪音。当大数据不能满足你的需求时,它也是一堆废品。摆脱与机器的枯燥对话,让你的需求成为真正懂你的人,高速发挥数据的真正价值---戴森数据采集定制就在你身边!
利用采集器采集的平台和url的区别?
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-08-17 20:06
利用采集器采集的平台,对,不是程序采集的。那么,可以问问probot都能找到哪些平台和url了。因为它是通过设置默认采集规则采集,这个过程中,你就必须要考虑选择哪些站点。对了,这个过程中,你也不要忘记绑定你的域名解析服务。
最原始的方法是用软件抓取,一些高版本的浏览器都有这种功能,但高版本可能有些例外,为了提高效率,都是用rooted去抓取。所以最简单的方法还是rooted抓取url。
平台都很多,其中用得比较多的是quickspider。其它关于quickspider的讨论,你可以参考下这个[1]。还有,推荐使用python写爬虫,resquests这些库也支持javascript,甚至mediaquery都比resquests好用。
以我近2年的工作经验来看,有很多,不过常见的有:googleprojects/googlewebspider/webrtcquickspiderspidersourceapi或者自己写也可以[e.g.]java下我用的多的是processjsguika.js[bestresources]-lowdimensionalabsolutely-convertfeatureswithprocessjsonwindowsquerysourceawebparameter:storeglobaldictionaryquerystringbundlehavingopenfeatures,etc.其实可以直接网上搜,很多文章,高阶爬虫技术很多的。
可以在web端直接请求ip/本地dom的url。 查看全部
利用采集器采集的平台和url的区别?
利用采集器采集的平台,对,不是程序采集的。那么,可以问问probot都能找到哪些平台和url了。因为它是通过设置默认采集规则采集,这个过程中,你就必须要考虑选择哪些站点。对了,这个过程中,你也不要忘记绑定你的域名解析服务。
最原始的方法是用软件抓取,一些高版本的浏览器都有这种功能,但高版本可能有些例外,为了提高效率,都是用rooted去抓取。所以最简单的方法还是rooted抓取url。
平台都很多,其中用得比较多的是quickspider。其它关于quickspider的讨论,你可以参考下这个[1]。还有,推荐使用python写爬虫,resquests这些库也支持javascript,甚至mediaquery都比resquests好用。
以我近2年的工作经验来看,有很多,不过常见的有:googleprojects/googlewebspider/webrtcquickspiderspidersourceapi或者自己写也可以[e.g.]java下我用的多的是processjsguika.js[bestresources]-lowdimensionalabsolutely-convertfeatureswithprocessjsonwindowsquerysourceawebparameter:storeglobaldictionaryquerystringbundlehavingopenfeatures,etc.其实可以直接网上搜,很多文章,高阶爬虫技术很多的。
可以在web端直接请求ip/本地dom的url。
明威微信群采集器微信信息采集工具免费下载(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2021-08-12 00:00
本站提供最新版明微微信群采集器(微信信息采集工具)软件免费下载。
[软件截图]
【基本介绍】
名微微信群采集器是强大的信息采集必备工具。这个工具可以自动搜索加入微信群,也可以自动采集微信二维码。非常适合有推广需求的商家,以及需要在网上推广的网友和朋友。欢迎有需要的朋友点击下载。
主要功能
一键采集当前最新二维码、微信群二维码采集、个人微信账号采集、群主微信账号采集、公众账号采集、明微微信群采集器Software具有自动扫码进群功能。
性能提示
1、支持系统:
Windows(窗口化操作系统)系统(win7或win8高版本系统)
2、数据信息量:
软件采集来自对应的数据源网站。该软件不产生数据。本软件只负责采集和识别。每天更新的总数是几千到几万个微信群二维码。
3、可用性:
我们本人不保证软件采集的微信群二维码可以100%扫描,因为有几个不可控因素
楼主已经离开了他建的微信群。
群人数超过100人(这是腾讯官网规定,群内人数只能扫码少于100人,扫码时超过100人人,说明有其他顾客也扫描了这个二维码,导致群满了。)
二级码发布时间超过7天有效期。 查看全部
明威微信群采集器微信信息采集工具免费下载(图)
本站提供最新版明微微信群采集器(微信信息采集工具)软件免费下载。
[软件截图]
【基本介绍】
名微微信群采集器是强大的信息采集必备工具。这个工具可以自动搜索加入微信群,也可以自动采集微信二维码。非常适合有推广需求的商家,以及需要在网上推广的网友和朋友。欢迎有需要的朋友点击下载。
主要功能
一键采集当前最新二维码、微信群二维码采集、个人微信账号采集、群主微信账号采集、公众账号采集、明微微信群采集器Software具有自动扫码进群功能。
性能提示
1、支持系统:
Windows(窗口化操作系统)系统(win7或win8高版本系统)
2、数据信息量:
软件采集来自对应的数据源网站。该软件不产生数据。本软件只负责采集和识别。每天更新的总数是几千到几万个微信群二维码。
3、可用性:
我们本人不保证软件采集的微信群二维码可以100%扫描,因为有几个不可控因素
楼主已经离开了他建的微信群。
群人数超过100人(这是腾讯官网规定,群内人数只能扫码少于100人,扫码时超过100人人,说明有其他顾客也扫描了这个二维码,导致群满了。)
二级码发布时间超过7天有效期。
利用采集器 采集的平台 看到本文内容请勿诧异,因为本文由考拉SEO【批量写SEO原创文章】
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-08-11 01:05
看到这篇文章的内容不要惊讶,因为这篇文章是由考拉SEO【批量写SEO原创文章】平台支持的。有了考拉,一天可以产出上万条优质SEO文章!如果还需要批量编辑SEO文章,可以进入平台用户中心试用!
非常抱歉。这时候你看这个文章,你可能看到文章不包括qq采集器平台的报道。这是因为页面是我们平台SEO文章自动编译的。如果大家对批量创建内容的信息有需求,可以先放弃qq采集器平台,推荐大家了解一下:如何使用系统在24小时内生成上万篇好的网页文本!很多客户看到我编辑的小广告以为这是伪原创software,误会了!事实上,我们是一个原创系统。 关键词和模板都是独立写的,网上基本没有类似这篇文章的内容。我们是如何完成的?我将在下面为您解读!
想要搞清楚qq采集器平台的用户,其实最关心的是上面讨论的话题。写一个高流量的网站陆文是超级容易的,但这些文章能产生的访问量实际上是一点点。希望通过信息的积累,达到引流的目的。最重要的一点是量化!如果一篇文章文章可以得到1个pageview(每24小时),如果我可以编辑10000篇文章,那么平均每天的pageview可以增加几万。但简单的说,其实在编辑的时候,一个人一天只能出四十篇左右,最好是七十多篇。就算用了一些伪原创软件,最多也就100篇吧!浏览到这里,大家应该放弃qq采集器平台,充分探索如何实现文章的智能写作!
杜娘认可的真正编辑是什么? 文章原创不仅仅是一一关键词原创edit!在每个搜索者的平台词典中,原创并不代表没有重复的内容。其实只要你的文章不复制别人的网页内容,被爬取的可能性就可能会增加。 1 好文章,核心够抢眼,坚持同一个核心思想,只要没有大段重复,那么这个文章还是很有可能被认出来的,甚至变成一个好排水用的物品。比如下一篇文章,我们可能搜索过网站搜qq采集器平台,最后点击查看。其实下一篇文章是AI编辑文章platform独立使用考拉SEO制作的!
考拉SEO的AI原创software,结论性的表达应该叫批量写作文章software,24小时内可以写出几万条高质量优化的文章,你的网页权重通常够高,收录 可以高达至少 66%。详细的操作教程,个人中心有视频展示和小白的指导。您可以免费测试!非常抱歉,我没有编辑qq采集器平台的详细解释,让你看了这么多系统语言。但是,如果您对批量编写文章技术感兴趣,只需查看导航栏,您的站点每天就会增加数百个UV。不靠谱吗? 查看全部
利用采集器 采集的平台 看到本文内容请勿诧异,因为本文由考拉SEO【批量写SEO原创文章】
看到这篇文章的内容不要惊讶,因为这篇文章是由考拉SEO【批量写SEO原创文章】平台支持的。有了考拉,一天可以产出上万条优质SEO文章!如果还需要批量编辑SEO文章,可以进入平台用户中心试用!
非常抱歉。这时候你看这个文章,你可能看到文章不包括qq采集器平台的报道。这是因为页面是我们平台SEO文章自动编译的。如果大家对批量创建内容的信息有需求,可以先放弃qq采集器平台,推荐大家了解一下:如何使用系统在24小时内生成上万篇好的网页文本!很多客户看到我编辑的小广告以为这是伪原创software,误会了!事实上,我们是一个原创系统。 关键词和模板都是独立写的,网上基本没有类似这篇文章的内容。我们是如何完成的?我将在下面为您解读!
想要搞清楚qq采集器平台的用户,其实最关心的是上面讨论的话题。写一个高流量的网站陆文是超级容易的,但这些文章能产生的访问量实际上是一点点。希望通过信息的积累,达到引流的目的。最重要的一点是量化!如果一篇文章文章可以得到1个pageview(每24小时),如果我可以编辑10000篇文章,那么平均每天的pageview可以增加几万。但简单的说,其实在编辑的时候,一个人一天只能出四十篇左右,最好是七十多篇。就算用了一些伪原创软件,最多也就100篇吧!浏览到这里,大家应该放弃qq采集器平台,充分探索如何实现文章的智能写作!
杜娘认可的真正编辑是什么? 文章原创不仅仅是一一关键词原创edit!在每个搜索者的平台词典中,原创并不代表没有重复的内容。其实只要你的文章不复制别人的网页内容,被爬取的可能性就可能会增加。 1 好文章,核心够抢眼,坚持同一个核心思想,只要没有大段重复,那么这个文章还是很有可能被认出来的,甚至变成一个好排水用的物品。比如下一篇文章,我们可能搜索过网站搜qq采集器平台,最后点击查看。其实下一篇文章是AI编辑文章platform独立使用考拉SEO制作的!
考拉SEO的AI原创software,结论性的表达应该叫批量写作文章software,24小时内可以写出几万条高质量优化的文章,你的网页权重通常够高,收录 可以高达至少 66%。详细的操作教程,个人中心有视频展示和小白的指导。您可以免费测试!非常抱歉,我没有编辑qq采集器平台的详细解释,让你看了这么多系统语言。但是,如果您对批量编写文章技术感兴趣,只需查看导航栏,您的站点每天就会增加数百个UV。不靠谱吗?
如何利用采集器采集的平台的url下载采集文件目录
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-08-06 18:01
利用采集器采集的平台的url,下载采集的文件,然后去放置java后台的目录找下,index目录一般就是本地文件目录。建议你自己先动手,最起码了解一下采集器,或者多问问牛人。
应该是那个excel下面的“simulation”文件夹,本地的应该也是那个project,可以自己建一个脚本,把url抓过来,然后直接放到java脚本里。
lz学学爬虫吧。简单来说就是selenium。
前端爬虫发,后端app的话,
需要读懂中cookie的实现原理,把url的httpget拿过来,然后做一个简单的模拟登录,然后直接把获取的信息放到爬虫里面去,你得说清楚,
你好,这是java后端基础中的模拟登录功能,自己封装一个小功能用于管理和统计:然后集中挂机工作,每天登录过的url,更新的url,需要的工具,都记录进行统计吧。
不考虑学习的可能。如果是要爬取手机号码码段的话就不需要爬取相关的固定url,如果觉得手机号难道就是空格?那是没有抓到核心需求,那么可以做个模拟登录的功能,获取账号密码为核心如果有变量需要填写,可以参考requests或aiohttp的define方法方法。前端可以用jquery来实现。有些技术在学习中可能比实际工作需要多一些,但是一旦掌握,非常有用,做项目就可以解决。比如前端中的ajax的使用。 查看全部
如何利用采集器采集的平台的url下载采集文件目录
利用采集器采集的平台的url,下载采集的文件,然后去放置java后台的目录找下,index目录一般就是本地文件目录。建议你自己先动手,最起码了解一下采集器,或者多问问牛人。
应该是那个excel下面的“simulation”文件夹,本地的应该也是那个project,可以自己建一个脚本,把url抓过来,然后直接放到java脚本里。
lz学学爬虫吧。简单来说就是selenium。
前端爬虫发,后端app的话,
需要读懂中cookie的实现原理,把url的httpget拿过来,然后做一个简单的模拟登录,然后直接把获取的信息放到爬虫里面去,你得说清楚,
你好,这是java后端基础中的模拟登录功能,自己封装一个小功能用于管理和统计:然后集中挂机工作,每天登录过的url,更新的url,需要的工具,都记录进行统计吧。
不考虑学习的可能。如果是要爬取手机号码码段的话就不需要爬取相关的固定url,如果觉得手机号难道就是空格?那是没有抓到核心需求,那么可以做个模拟登录的功能,获取账号密码为核心如果有变量需要填写,可以参考requests或aiohttp的define方法方法。前端可以用jquery来实现。有些技术在学习中可能比实际工作需要多一些,但是一旦掌握,非常有用,做项目就可以解决。比如前端中的ajax的使用。
本发明提供一种基于云平台的网站信息采集系统(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-08-03 01:24
本发明提供一种基于云平台的网站信息采集系统(图)
本发明涉及信息采集领域,尤其涉及一种基于云平台的网站信息采集系统。
背景技术:
在现有技术中,对网站信息的获取一般是通过爬虫技术来实现的。但是为了防止爬虫的访问连接占用正常的访问带宽,很多网站都设置了反爬虫机制。如果使用单个客户端爬取网站的信息,很容易被反爬虫机制识别,导致网站的信息采集失败。
技术实现要素:
针对上述问题,本发明的目的在于提供一种基于云平台的网站信息采集系统。
本发明提供了一种基于云平台的网站信息采集系统,包括任务管理模块、代理服务模块和数据管理模块;
任务管理模块用于生成网站信息采集任务,并将网站信息采集任务发送给代理服务模块;
代理服务模块用于通过代理服务器处理网站信息采集任务,生成爬虫任务,利用代理服务器实现爬虫任务获取网站数据;
p>
数据管理模块用于将网站数据存储到云计算存储服务器,并对存储在云计算存储服务器中的网站数据进行管理。
优选地,任务管理模块包括权限控制单元和任务管理单元;
权限控制单元用于验证使用任务管理单元的人的身份,判断此人是否有使用任务管理单元的权限,如果有,则将任务开放给此人的权限管理单元,否则禁止该人使用任务管理单元;
任务管理单元用于为通过身份验证的人员新建网站信息采集任务。
最好也使用任务管理单元来管理现有的网站信息采集任务,具体包括:
删除现有网站信息采集任务,修改现有网站信息采集任务。
优选地,网站信息采集任务包括需要信息采集的网站的URL,需要信息采集的网站的登录信息,以及代理服务器Identity的使用用公钥加密的验证信息进行身份验证。
优选地,代理服务器在处理网站信息采集任务并生成爬虫任务之前,还包括:
使用与身份验证公钥对应的身份验证私钥对身份验证信息进行解密,得到身份验证识别码;
将身份验证信息中收录的身份验证识别码与代理服务器中预先存储的身份验证识别码进行比较,判断两者是否一致。执行处理并生成爬虫任务。如果不是,则不处理网站信息采集任务。
优选地,基于网站信息采集任务生成爬虫任务包括:
使用代理服务器访问网站,下载网站对应的网页数据;
判断网页数据中是否存在统一资源定位器,如果有,获取每个统一资源定位器对应的URL,并根据该URL生成爬虫任务。
优选地,爬虫任务包括统一资源定位器对应的网址和从统一资源定位器对应的网址下载数据的时间间隔。
优选地,数据管理模块包括设置在云计算服务器上的数据管理单元和存储单元;
数据管理单元用于将网站数据存存到存储单元;
存储单元用于存储网站数据。
与现有技术相比,本发明的优点是:
本发明通过代理服务器为目标网站获取网站信息,从而实现网站中数据的下载。由于采用代理方式,本应用中用于实现任务管理模块的客户端不会受到网站反爬虫机制的影响,可以灵活地为网站信息的采集使用不同的代理服务器,有效提高网站信息采集的成功率。
图纸说明
以下结合附图对本发明作进一步说明,但附图中的实施例并不构成对本发明的任何限制。对于本领域普通技术人员来说,在没有创造性劳动的情况下,也可以使用下面的图纸获取其他图纸。
图1为本发明基于云平台的网站信息采集系统的一个示例性实施例示意图。
具体实现方法
下面详细描述本发明的实施例。实施例的示例在附图中示出,其中相同或相似的附图标记表示相同或相似的元件或具有相同或相似功能的元件。以下结合附图所描述的实施例仅为示例性的,仅用以解释本发明,而不能理解为对本发明的限制。
如图1所示实施例所示,本发明提供了一种基于云平台的网站信息采集系统,包括任务管理模块、代理服务模块和数据管理模块;
任务管理模块用于生成网站信息采集任务,并将网站信息采集任务发送给代理服务模块;
代理服务模块用于通过代理服务器处理网站信息采集任务,生成爬虫任务,利用代理服务器实现爬虫任务获取网站数据;
p>
数据管理模块用于将网站数据存储到云计算存储服务器,并对存储在云计算存储服务器中的网站数据进行管理。
网站信息采集任务管理和网站信息采集任务管理的分离,有利于灵活选择不同的代理服务器来执行网站信息采集任务,避免后单客户端被反爬虫机制识别,影响网页下载效率。
在一个实施例中,任务管理模块包括权限控制单元和任务管理单元;
权限控制单元用于验证使用任务管理单元的人的身份,判断此人是否有使用任务管理单元的权限,如果有,则将任务开放给此人的权限管理单元,否则禁止该人使用任务管理单元;
任务管理单元用于为通过身份验证的人员新建网站信息采集任务。
在一实施例中,任务管理模块包括输入单元和判断单元;
输入单元用于人员输入任务管理单元的账号和密码;
判断单元用于判断使用账号和使用密码是否正确,如果正确,则判断此人有权限使用任务管理单元;如果不是,则判断该人没有使用任务管理单元的权利。任务管理单元的权限。
在另一个实施例中,任务管理模块包括拍照单元、图像处理单元和权限判断单元;
拍摄单元用于获取人脸图像;
图像处理单元用于对人脸图像进行图像识别处理,得到人脸图像中收录的特征信息;
权限判断单元用于将图像处理单元获取的特征信息与任务管理模块中预存的所有具有使用任务管理单元权限的人的面部图像的特征信息进行匹配,如果如果匹配成功,则确定此人具有使用任务管理单元的权限;如果匹配失败,则确定此人没有使用任务管理单元的权限。
在一个实施例中,对人脸图像进行图像识别处理以获得人脸图像中收录的特征信息包括:
对人脸图像进行灰度处理,得到灰度图像;
计算人脸图像的差异度,得到差异图像;
对灰度图像进行边缘检测,得到边缘图像;
对灰度图像进行降噪处理,得到降噪图像;
对降噪图像进行图像分割处理,得到前景图像;
根据差分图像、前景图像和边缘图像生成目标图像;
使用预设的特征信息采集算法获取目标图像中收录的特征信息。
在本发明上述实施例中,通过差分图像、前景图像和边缘图像生成目标图像,然后提取目标图像中收录的特征信息,极大地提高了特征信息的准确性。现有技术中,一般在对灰度图像进行去噪后,直接提取去噪后图像的特征信息。但是,由于降噪是减少图像中有效信息的过程,因此得到的特征信息不够准确。在本应用中,从目标图像中提取特征信息,可以有效地获取准确的特征信息。可以将差异图像中收录的像素之间的差异信息、边缘图像中收录的边缘信息以及前景信息体现在目标图像中,从而实现对降噪图像中丢失的特征信息的补偿。
在一个实施例中,计算人脸图像的差异度以获得差异图像包括:
将人脸图像转换到lab颜色空间,得到lab颜色空间中人脸图像对应的l分量图像、a分量图像和b分量图像;
分别获取人脸图像中每个像素的差分参数:
式中,csn(nod)表示人脸图像中像素nod的差分参数,nodu表示nod的d×d邻域内所有像素的集合,nodu表示nodu w1、的元素@w2、w3代表预设的尺度参数,w1+w2+w3=1,l(nod)和l(nodu)分别代表l分量图像中nod和nodu的像素值,a(nod)和a (nodu)表示a分量图像中nod和nodu的像素值,b(nod)和b(nodu)分别表示b分量图像中nod和nodu的像素值,numnodu表示总和nodu中收录的元素个数;
获取l分量图像中像素值的中值对应的像素点,将像素点标记为mxn;
通过以下方法获取差异图像:
将l分量图像中的像素点保存到集合dlul中,对于dlul中的像素点dlu,通过下式计算差分图像中的像素值:
式中,xc(dlu)代表差异图像中dlu的像素值,csn(dlu)和csn(mxn)分别代表dlu和mxn的差异程度参数,l(mxn)代表mxn l 分量图像的像素值;
计算差分图像中dlul中每个像素的像素值,得到差分图像。
在本发明的上述实施例中,在获取差异图像时,首先将人脸图像转换为lab色彩空间,然后根据其中的三个变量计算每个像素的差异度参数lab 颜色空间,然后从 l 计算差异度参数 在分量图像中,选择一个像素作为参考像素,针对不同的像素计算差异图像中不同像素的像素值,有利于全面获取像素间的差异信息,同时避免光线的影响。差异度参数与计算时的邻域像素有关。差异度参数由邻域像素点与当前正在计算的像素点在三个分量中的差异的加权值得到,有利于差异度参数充分反映当前的进展情况。计算出的像素与相邻像素之间的差异。在选择参考像素时,选择l分量图像中像素值的中值对应的像素作为参考像素。这种设置方法有助于避免错误地将噪声的像素值用作参考像素值。 , 有利于获得准确的差分图像。
在一个实施例中,对灰度图像进行边缘检测得到边缘图像包括:
使用sobel边缘检测算法对灰度图像进行边缘检测,得到边缘图像。
在一个实施例中,对灰度图像进行降噪处理得到降噪图像包括:
对灰度图像进行小波分解处理,得到小波高频系数和小波低频系数;
对小波高频系数中的像素进行如下处理:
式中,tsl(p)表示小波高频系数中位置p对应的像素的像素值,btsl(p)表示上述对tsl(p)的处理结果; vb和vc代表预先设置的处理阈值,sh代表判断操作,如果tsl(p)大于预设阈值tp,则sh[tsl(p)]的值为1.2,如果tsl (p) 小于等于预设阈值 tp ,则 sh[tsl(p)] 的值为1.05,
对小波高频系数中的所有像素进行上述处理,得到第一处理系数;
对小波低频系数中的像素进行如下处理:
式中,tlluq表示小波低频系数中位置q对应的像素点k×k邻域内的像素集合,lon(q,u)表示位置q对应的像素点小波低频系数中像素点u与tlluq收录的像素点u之间的直线距离,tll(u)表示低频小波系数图像中u的像素值,btll(q)表示小波低频系数中位置q对应的像素使用上式点处理的结果; tll(q)表示小波低频系数中q位置对应的像素点的像素值;
公式中ntlluq表示tlluq中收录的像素总数;
对小波低频系数中的所有像素进行上述处理,得到第二处理系数;
对第一处理系数和第二处理系数进行小波重构,得到降噪图像。
在本发明的上述实施例中,在进行降噪处理时,将灰度图像分解为小波高频系数和小波低频系数,然后小波高频系数和小波分别对低频系数进行处理,对处理后的小波高频系数和小波低频系数进行重构,得到去噪图像。有利于在保持图像边缘信息等特征信息的同时实现准确的降噪处理。现有技术中,例如使用高斯函数进行降噪时,像素点会变得模糊,像素之间的差异会变小,从而导致细节信息丢失。这个应用程序能够很好地避免这个问题。本应用在处理小波高频系数时,采用了改进的处理功能。通过处理阈值与当前处理像素的像素值之间的关系,对当前处理的像素自适应选择不同的处理函数处理,有助于提高小波高频系数的处理精度。此外,该应用程序还处理小波低频系数。在处理中,低频小波系数中的像素与其邻域内的像素之间的线性距离和像素值的差异就是低频小波系数中的当前处理。像素提供准确的处理结果。因此,有效提高了降噪的准确性,提高了本发明采集系统的安全性。
在一个实施例中,对降噪图像进行图像分割处理得到前景图像包括:
使用otsu算法对去噪后的图像进行图像分割处理,得到所有前景像素的集合fru1;
用下面的方法对fru1中的像素进行过滤,得到集合fru2:
<p>对于 fru1 中的像素 fru,计算 fru 和参考像素 stad 之间的距离 dist(fru,stad)。如果dist(fru,stad)小于预设的距离阈值,则下一步判断fru,如果dist(fru,stad)大于或等于预设的距离阈值,则从fru1中删除fru; 查看全部
本发明提供一种基于云平台的网站信息采集系统(图)
本发明涉及信息采集领域,尤其涉及一种基于云平台的网站信息采集系统。
背景技术:
在现有技术中,对网站信息的获取一般是通过爬虫技术来实现的。但是为了防止爬虫的访问连接占用正常的访问带宽,很多网站都设置了反爬虫机制。如果使用单个客户端爬取网站的信息,很容易被反爬虫机制识别,导致网站的信息采集失败。
技术实现要素:
针对上述问题,本发明的目的在于提供一种基于云平台的网站信息采集系统。
本发明提供了一种基于云平台的网站信息采集系统,包括任务管理模块、代理服务模块和数据管理模块;
任务管理模块用于生成网站信息采集任务,并将网站信息采集任务发送给代理服务模块;
代理服务模块用于通过代理服务器处理网站信息采集任务,生成爬虫任务,利用代理服务器实现爬虫任务获取网站数据;
p>
数据管理模块用于将网站数据存储到云计算存储服务器,并对存储在云计算存储服务器中的网站数据进行管理。
优选地,任务管理模块包括权限控制单元和任务管理单元;
权限控制单元用于验证使用任务管理单元的人的身份,判断此人是否有使用任务管理单元的权限,如果有,则将任务开放给此人的权限管理单元,否则禁止该人使用任务管理单元;
任务管理单元用于为通过身份验证的人员新建网站信息采集任务。
最好也使用任务管理单元来管理现有的网站信息采集任务,具体包括:
删除现有网站信息采集任务,修改现有网站信息采集任务。
优选地,网站信息采集任务包括需要信息采集的网站的URL,需要信息采集的网站的登录信息,以及代理服务器Identity的使用用公钥加密的验证信息进行身份验证。
优选地,代理服务器在处理网站信息采集任务并生成爬虫任务之前,还包括:
使用与身份验证公钥对应的身份验证私钥对身份验证信息进行解密,得到身份验证识别码;
将身份验证信息中收录的身份验证识别码与代理服务器中预先存储的身份验证识别码进行比较,判断两者是否一致。执行处理并生成爬虫任务。如果不是,则不处理网站信息采集任务。
优选地,基于网站信息采集任务生成爬虫任务包括:
使用代理服务器访问网站,下载网站对应的网页数据;
判断网页数据中是否存在统一资源定位器,如果有,获取每个统一资源定位器对应的URL,并根据该URL生成爬虫任务。
优选地,爬虫任务包括统一资源定位器对应的网址和从统一资源定位器对应的网址下载数据的时间间隔。
优选地,数据管理模块包括设置在云计算服务器上的数据管理单元和存储单元;
数据管理单元用于将网站数据存存到存储单元;
存储单元用于存储网站数据。
与现有技术相比,本发明的优点是:
本发明通过代理服务器为目标网站获取网站信息,从而实现网站中数据的下载。由于采用代理方式,本应用中用于实现任务管理模块的客户端不会受到网站反爬虫机制的影响,可以灵活地为网站信息的采集使用不同的代理服务器,有效提高网站信息采集的成功率。
图纸说明
以下结合附图对本发明作进一步说明,但附图中的实施例并不构成对本发明的任何限制。对于本领域普通技术人员来说,在没有创造性劳动的情况下,也可以使用下面的图纸获取其他图纸。
图1为本发明基于云平台的网站信息采集系统的一个示例性实施例示意图。
具体实现方法
下面详细描述本发明的实施例。实施例的示例在附图中示出,其中相同或相似的附图标记表示相同或相似的元件或具有相同或相似功能的元件。以下结合附图所描述的实施例仅为示例性的,仅用以解释本发明,而不能理解为对本发明的限制。
如图1所示实施例所示,本发明提供了一种基于云平台的网站信息采集系统,包括任务管理模块、代理服务模块和数据管理模块;
任务管理模块用于生成网站信息采集任务,并将网站信息采集任务发送给代理服务模块;
代理服务模块用于通过代理服务器处理网站信息采集任务,生成爬虫任务,利用代理服务器实现爬虫任务获取网站数据;
p>
数据管理模块用于将网站数据存储到云计算存储服务器,并对存储在云计算存储服务器中的网站数据进行管理。
网站信息采集任务管理和网站信息采集任务管理的分离,有利于灵活选择不同的代理服务器来执行网站信息采集任务,避免后单客户端被反爬虫机制识别,影响网页下载效率。
在一个实施例中,任务管理模块包括权限控制单元和任务管理单元;
权限控制单元用于验证使用任务管理单元的人的身份,判断此人是否有使用任务管理单元的权限,如果有,则将任务开放给此人的权限管理单元,否则禁止该人使用任务管理单元;
任务管理单元用于为通过身份验证的人员新建网站信息采集任务。
在一实施例中,任务管理模块包括输入单元和判断单元;
输入单元用于人员输入任务管理单元的账号和密码;
判断单元用于判断使用账号和使用密码是否正确,如果正确,则判断此人有权限使用任务管理单元;如果不是,则判断该人没有使用任务管理单元的权利。任务管理单元的权限。
在另一个实施例中,任务管理模块包括拍照单元、图像处理单元和权限判断单元;
拍摄单元用于获取人脸图像;
图像处理单元用于对人脸图像进行图像识别处理,得到人脸图像中收录的特征信息;
权限判断单元用于将图像处理单元获取的特征信息与任务管理模块中预存的所有具有使用任务管理单元权限的人的面部图像的特征信息进行匹配,如果如果匹配成功,则确定此人具有使用任务管理单元的权限;如果匹配失败,则确定此人没有使用任务管理单元的权限。
在一个实施例中,对人脸图像进行图像识别处理以获得人脸图像中收录的特征信息包括:
对人脸图像进行灰度处理,得到灰度图像;
计算人脸图像的差异度,得到差异图像;
对灰度图像进行边缘检测,得到边缘图像;
对灰度图像进行降噪处理,得到降噪图像;
对降噪图像进行图像分割处理,得到前景图像;
根据差分图像、前景图像和边缘图像生成目标图像;
使用预设的特征信息采集算法获取目标图像中收录的特征信息。
在本发明上述实施例中,通过差分图像、前景图像和边缘图像生成目标图像,然后提取目标图像中收录的特征信息,极大地提高了特征信息的准确性。现有技术中,一般在对灰度图像进行去噪后,直接提取去噪后图像的特征信息。但是,由于降噪是减少图像中有效信息的过程,因此得到的特征信息不够准确。在本应用中,从目标图像中提取特征信息,可以有效地获取准确的特征信息。可以将差异图像中收录的像素之间的差异信息、边缘图像中收录的边缘信息以及前景信息体现在目标图像中,从而实现对降噪图像中丢失的特征信息的补偿。
在一个实施例中,计算人脸图像的差异度以获得差异图像包括:
将人脸图像转换到lab颜色空间,得到lab颜色空间中人脸图像对应的l分量图像、a分量图像和b分量图像;
分别获取人脸图像中每个像素的差分参数:
式中,csn(nod)表示人脸图像中像素nod的差分参数,nodu表示nod的d×d邻域内所有像素的集合,nodu表示nodu w1、的元素@w2、w3代表预设的尺度参数,w1+w2+w3=1,l(nod)和l(nodu)分别代表l分量图像中nod和nodu的像素值,a(nod)和a (nodu)表示a分量图像中nod和nodu的像素值,b(nod)和b(nodu)分别表示b分量图像中nod和nodu的像素值,numnodu表示总和nodu中收录的元素个数;
获取l分量图像中像素值的中值对应的像素点,将像素点标记为mxn;
通过以下方法获取差异图像:
将l分量图像中的像素点保存到集合dlul中,对于dlul中的像素点dlu,通过下式计算差分图像中的像素值:
式中,xc(dlu)代表差异图像中dlu的像素值,csn(dlu)和csn(mxn)分别代表dlu和mxn的差异程度参数,l(mxn)代表mxn l 分量图像的像素值;
计算差分图像中dlul中每个像素的像素值,得到差分图像。
在本发明的上述实施例中,在获取差异图像时,首先将人脸图像转换为lab色彩空间,然后根据其中的三个变量计算每个像素的差异度参数lab 颜色空间,然后从 l 计算差异度参数 在分量图像中,选择一个像素作为参考像素,针对不同的像素计算差异图像中不同像素的像素值,有利于全面获取像素间的差异信息,同时避免光线的影响。差异度参数与计算时的邻域像素有关。差异度参数由邻域像素点与当前正在计算的像素点在三个分量中的差异的加权值得到,有利于差异度参数充分反映当前的进展情况。计算出的像素与相邻像素之间的差异。在选择参考像素时,选择l分量图像中像素值的中值对应的像素作为参考像素。这种设置方法有助于避免错误地将噪声的像素值用作参考像素值。 , 有利于获得准确的差分图像。
在一个实施例中,对灰度图像进行边缘检测得到边缘图像包括:
使用sobel边缘检测算法对灰度图像进行边缘检测,得到边缘图像。
在一个实施例中,对灰度图像进行降噪处理得到降噪图像包括:
对灰度图像进行小波分解处理,得到小波高频系数和小波低频系数;
对小波高频系数中的像素进行如下处理:
式中,tsl(p)表示小波高频系数中位置p对应的像素的像素值,btsl(p)表示上述对tsl(p)的处理结果; vb和vc代表预先设置的处理阈值,sh代表判断操作,如果tsl(p)大于预设阈值tp,则sh[tsl(p)]的值为1.2,如果tsl (p) 小于等于预设阈值 tp ,则 sh[tsl(p)] 的值为1.05,
对小波高频系数中的所有像素进行上述处理,得到第一处理系数;
对小波低频系数中的像素进行如下处理:
式中,tlluq表示小波低频系数中位置q对应的像素点k×k邻域内的像素集合,lon(q,u)表示位置q对应的像素点小波低频系数中像素点u与tlluq收录的像素点u之间的直线距离,tll(u)表示低频小波系数图像中u的像素值,btll(q)表示小波低频系数中位置q对应的像素使用上式点处理的结果; tll(q)表示小波低频系数中q位置对应的像素点的像素值;
公式中ntlluq表示tlluq中收录的像素总数;
对小波低频系数中的所有像素进行上述处理,得到第二处理系数;
对第一处理系数和第二处理系数进行小波重构,得到降噪图像。
在本发明的上述实施例中,在进行降噪处理时,将灰度图像分解为小波高频系数和小波低频系数,然后小波高频系数和小波分别对低频系数进行处理,对处理后的小波高频系数和小波低频系数进行重构,得到去噪图像。有利于在保持图像边缘信息等特征信息的同时实现准确的降噪处理。现有技术中,例如使用高斯函数进行降噪时,像素点会变得模糊,像素之间的差异会变小,从而导致细节信息丢失。这个应用程序能够很好地避免这个问题。本应用在处理小波高频系数时,采用了改进的处理功能。通过处理阈值与当前处理像素的像素值之间的关系,对当前处理的像素自适应选择不同的处理函数处理,有助于提高小波高频系数的处理精度。此外,该应用程序还处理小波低频系数。在处理中,低频小波系数中的像素与其邻域内的像素之间的线性距离和像素值的差异就是低频小波系数中的当前处理。像素提供准确的处理结果。因此,有效提高了降噪的准确性,提高了本发明采集系统的安全性。
在一个实施例中,对降噪图像进行图像分割处理得到前景图像包括:
使用otsu算法对去噪后的图像进行图像分割处理,得到所有前景像素的集合fru1;
用下面的方法对fru1中的像素进行过滤,得到集合fru2:
<p>对于 fru1 中的像素 fru,计算 fru 和参考像素 stad 之间的距离 dist(fru,stad)。如果dist(fru,stad)小于预设的距离阈值,则下一步判断fru,如果dist(fru,stad)大于或等于预设的距离阈值,则从fru1中删除fru;
优采云采集器mac版优质采集软件推荐(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 241 次浏览 • 2021-08-03 01:17
优采云采集器苹果电脑版是一款非常优质的采集软件,涵盖了多种功能,采集传输很专业,值得信赖,可以打开直接学习,还犹豫什么,快来为有需要的用户体验吧。
优采云采集器mac 亮点
监控竞争对手的最新信息,包括商品价格和库存;
财务数据,如季报、年报、财报,包括最新的每日净值自动采集;
各大新闻门户网站实时监控,自动更新上传最新消息;
监控各大社交网络网站、博客,自动获取企业产品相关评论;
优采云采集器软件说明
自定义采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax、页面滚动、条件判断等。此类功能支持不同网页结构的复杂网站采集,满足多种采集应用场景。
云采集
云采集,5000多台云服务器支持,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活适配业务场景,助您提升采集效率,并保证数据的及时性。
方便的定时功能
只需简单几步,点击设置即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集。同时自由设置多个任务,根据需要进行多种选择时间组合,灵活部署自己的采集任务。
模板采集
模板采集模式内置了数百个主流网站数据源,如京东、天猫、大众点评等流行的采集网站。只需参考模板设置参数即可快速获取网站。 @公共数据。
Smart采集
采集可根据网站的不同提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助采集整个流程实现数据的完整性和稳定性。
多级采集
众多主流新闻和电商网站,收录一级商品列表页、二级商品详情页、三级评论详情页;不管网站有多少层,优采云所有采集数据都可以无限,满足采集各种业务需求。
api接口
通过优采云api,您可以轻松获取采集接收到的优采云任务信息和数据,灵活调度任务,如远程控制任务启停,高效实现数据采集和归档。基于强大的api系统,还可以与公司内部各种管理平台无缝对接,实现各种业务自动化。
正式版的优点
满足多种业务场景
适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等各种职业。
舆论监测
全方位监控公众信息,抢先掌握舆情动态。
产品研发
大力支持用户研究,准确获取用户反馈和偏好
风险预测
高效信息采集和数据清洗,及时应对系统风险
市场分析
获取用户真实行为数据,全面掌握客户真实需求
更新日志
修复偶尔卡住的问题
修复验证码识别失败问题,提高识别率
修复循环中的字段不能设置为XPath拼接的问题
修复无法保存数据提取步骤的触发器的问题
修复数据预览二级面板无法应用和保存的问题
修复循环中某些步骤无法设置XPath拼接的问题 查看全部
优采云采集器mac版优质采集软件推荐(组图)
优采云采集器苹果电脑版是一款非常优质的采集软件,涵盖了多种功能,采集传输很专业,值得信赖,可以打开直接学习,还犹豫什么,快来为有需要的用户体验吧。
优采云采集器mac 亮点
监控竞争对手的最新信息,包括商品价格和库存;
财务数据,如季报、年报、财报,包括最新的每日净值自动采集;
各大新闻门户网站实时监控,自动更新上传最新消息;
监控各大社交网络网站、博客,自动获取企业产品相关评论;
优采云采集器软件说明
自定义采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax、页面滚动、条件判断等。此类功能支持不同网页结构的复杂网站采集,满足多种采集应用场景。
云采集
云采集,5000多台云服务器支持,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活适配业务场景,助您提升采集效率,并保证数据的及时性。
方便的定时功能
只需简单几步,点击设置即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集。同时自由设置多个任务,根据需要进行多种选择时间组合,灵活部署自己的采集任务。
模板采集
模板采集模式内置了数百个主流网站数据源,如京东、天猫、大众点评等流行的采集网站。只需参考模板设置参数即可快速获取网站。 @公共数据。
Smart采集
采集可根据网站的不同提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助采集整个流程实现数据的完整性和稳定性。
多级采集
众多主流新闻和电商网站,收录一级商品列表页、二级商品详情页、三级评论详情页;不管网站有多少层,优采云所有采集数据都可以无限,满足采集各种业务需求。
api接口
通过优采云api,您可以轻松获取采集接收到的优采云任务信息和数据,灵活调度任务,如远程控制任务启停,高效实现数据采集和归档。基于强大的api系统,还可以与公司内部各种管理平台无缝对接,实现各种业务自动化。
正式版的优点
满足多种业务场景
适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等各种职业。
舆论监测
全方位监控公众信息,抢先掌握舆情动态。
产品研发
大力支持用户研究,准确获取用户反馈和偏好
风险预测
高效信息采集和数据清洗,及时应对系统风险
市场分析
获取用户真实行为数据,全面掌握客户真实需求
更新日志
修复偶尔卡住的问题
修复验证码识别失败问题,提高识别率
修复循环中的字段不能设置为XPath拼接的问题
修复无法保存数据提取步骤的触发器的问题
修复数据预览二级面板无法应用和保存的问题
修复循环中某些步骤无法设置XPath拼接的问题
网络爬虫软件,瑞雪采集云,还是有一些特点?
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-07-31 04:17
我知道一个网络爬虫软件,瑞雪采集云,还是有一些特点的:
Ruixue采集云是一个PaaS在线开发平台。与图形化配置的爬虫客户端工具相比,瑞雪采集云提供了通用的采集能力,可以满足企业客户数据采集业务的长期需求。
主要特点如下:
(一)一站式通用能力集成,成倍提升开发效率。平台封装了丰富的通用功能,开发者无需关心Ajax和Cookie等底层细节。他们只需要使用平台封装API,将主要的Focus放在业务上,提供10倍的工作效率。
(二)开发自由度高,支持复杂网站的采集。支持Java/Python编写应用插件,具有高级语言的高自由度,可以处理复杂的网站 采集. 平台提供 业界首个基于Web浏览器的在线开发环境,无需任何客户端安装,提高了客户内部应用源代码的共享。
(三)分布式任务调度机制,并发采集效率高。采集工作分解成多个采集程序,一个大任务拆解成大量小任务在不同的程序中执行,然后分发到大量爬虫机器集群进行分布式并发执行,保证系统达到最高的采集效率。
(四)强大的任务管理机制,保证数据完整性。平台具有强大的任务状态机制,支持任务重传,支持使用结束码管理不同的任务结束状态,选择不同的后续处理根据具体情况,保证目标数据不遗漏,保证最终目标数据的完整性。
(五)学习时间短,可以支撑业务的快速发展。平台提供了丰富的在线帮助文档,开发者可以在一小时内快速掌握平台的基本使用。当有是新数据采集需求,新开发者可以立即学会开发采集爬虫程序,快速对应相关业务的发展。
(六)支持私有化部署,保障数据安全。支持平台所有模块私有化部署,让客户拥有瑞雪采集云平台的所有能力,保证应用插件的绝对性客户开发的代码和目标数据安全。 查看全部
网络爬虫软件,瑞雪采集云,还是有一些特点?
我知道一个网络爬虫软件,瑞雪采集云,还是有一些特点的:
Ruixue采集云是一个PaaS在线开发平台。与图形化配置的爬虫客户端工具相比,瑞雪采集云提供了通用的采集能力,可以满足企业客户数据采集业务的长期需求。
主要特点如下:
(一)一站式通用能力集成,成倍提升开发效率。平台封装了丰富的通用功能,开发者无需关心Ajax和Cookie等底层细节。他们只需要使用平台封装API,将主要的Focus放在业务上,提供10倍的工作效率。
(二)开发自由度高,支持复杂网站的采集。支持Java/Python编写应用插件,具有高级语言的高自由度,可以处理复杂的网站 采集. 平台提供 业界首个基于Web浏览器的在线开发环境,无需任何客户端安装,提高了客户内部应用源代码的共享。
(三)分布式任务调度机制,并发采集效率高。采集工作分解成多个采集程序,一个大任务拆解成大量小任务在不同的程序中执行,然后分发到大量爬虫机器集群进行分布式并发执行,保证系统达到最高的采集效率。
(四)强大的任务管理机制,保证数据完整性。平台具有强大的任务状态机制,支持任务重传,支持使用结束码管理不同的任务结束状态,选择不同的后续处理根据具体情况,保证目标数据不遗漏,保证最终目标数据的完整性。
(五)学习时间短,可以支撑业务的快速发展。平台提供了丰富的在线帮助文档,开发者可以在一小时内快速掌握平台的基本使用。当有是新数据采集需求,新开发者可以立即学会开发采集爬虫程序,快速对应相关业务的发展。
(六)支持私有化部署,保障数据安全。支持平台所有模块私有化部署,让客户拥有瑞雪采集云平台的所有能力,保证应用插件的绝对性客户开发的代码和目标数据安全。
推荐采集器蝉大师的“图片采集工具”,给几点小建议
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-07-29 20:02
利用采集器采集的平台有很多,推荐采集器蝉大师的“图片采集工具”,将图片中的内容采集下来保存在excel里,还可以对图片数据进行其他操作,是个不错的采集器。具体步骤:找到他们家的“图片采集工具”1,启动选择需要采集的链接或页面,上传图片选择需要采集的页面,上传图片,识别后点击下载;2,上传图片上传图片成功后,点击采集按钮,进行采集。
3,图片数据可以进行下载保存使用4,图片修改设置图片修改设置,设置采集的图片名称及url,采集完成后点击下载,生成pdf文件对源数据进行修改,进行生成doc或者docx等其他格式的文件,重新上传即可。以上。采集工具的链接和介绍都有了,希望能帮到你。
给几点小建议吧!工具类不管是影视、音乐、电商、还是小游戏、都有各种数据源,可以找数据源进行,按照需求采集,下载即可,
现在三无产品比较多,如果不想用第三方采集器,
用平台代码采集,
爬虫也好,去除水印也好,阿里站长平台都有固定的套路,自己写也能爬到目标网站,但是固定的模板就限制太多了,
第一个叫捕手采集器,是一款专业的视频采集,拼多多采集,猫扑,58同城等等,还可以发布求助信息。第二个叫乐采网,收录地方门户网站的视频、音乐等内容,还能进行ppt配图等。第三个叫采集狗,专业的网络爬虫,可以抓到各种地方的内容。现在公众号评论中百分之八十都能采到!以上都是我们公司对接过的平台,楼主可以看看。这是一些网上比较出名的平台,可以去看看。 查看全部
推荐采集器蝉大师的“图片采集工具”,给几点小建议
利用采集器采集的平台有很多,推荐采集器蝉大师的“图片采集工具”,将图片中的内容采集下来保存在excel里,还可以对图片数据进行其他操作,是个不错的采集器。具体步骤:找到他们家的“图片采集工具”1,启动选择需要采集的链接或页面,上传图片选择需要采集的页面,上传图片,识别后点击下载;2,上传图片上传图片成功后,点击采集按钮,进行采集。
3,图片数据可以进行下载保存使用4,图片修改设置图片修改设置,设置采集的图片名称及url,采集完成后点击下载,生成pdf文件对源数据进行修改,进行生成doc或者docx等其他格式的文件,重新上传即可。以上。采集工具的链接和介绍都有了,希望能帮到你。
给几点小建议吧!工具类不管是影视、音乐、电商、还是小游戏、都有各种数据源,可以找数据源进行,按照需求采集,下载即可,
现在三无产品比较多,如果不想用第三方采集器,
用平台代码采集,
爬虫也好,去除水印也好,阿里站长平台都有固定的套路,自己写也能爬到目标网站,但是固定的模板就限制太多了,
第一个叫捕手采集器,是一款专业的视频采集,拼多多采集,猫扑,58同城等等,还可以发布求助信息。第二个叫乐采网,收录地方门户网站的视频、音乐等内容,还能进行ppt配图等。第三个叫采集狗,专业的网络爬虫,可以抓到各种地方的内容。现在公众号评论中百分之八十都能采到!以上都是我们公司对接过的平台,楼主可以看看。这是一些网上比较出名的平台,可以去看看。
网页中“右键点击”——查看源码(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 342 次浏览 • 2021-07-29 07:53
网页中“右键点击”——查看源码(图)
我们可以用这个作为内容开始的标志,但这并不完美。请自行打开几个内容页面,页面中“右键”-“查看源代码”,然后比较代码,提取相同的部分,我用
作为内容开始的标志。
接下来看内容结束标记,如下两张图所示:
以下是根据us采集设置的规则返回的内容
一般来说采集返回的内容从头到尾都会收录必须排除的内容、广告或链接。这里我们需要排除的内容是“相关话题>>>第六届金鹰电视艺术节”。排除的方法是找到对应的代码,将代码完整复制到内容排除窗口中,修改后的部分用“(*)”代替。因为这是整个站点的规则,所以你必须多找几个类别。比如现在的163娱乐还包括“名人|图片|电影|电视|音乐|论坛|专题|名人专访”等等,这里我只摘录“明星、图片、电影”作为列子给大家讲解。寻找其他类别只是为了使规则具有普遍性和完善性。如果您只需要一个类别,例如“图片”,那么您可以直接制定此规则。
这个页面正好有分页,所以顺便说一下下一页和下一页的设置。他这边的“上一页”和“下一页”是用图片链接的,所以不要复制图片的名称(右键点击对应图片查看属性,复制图片名称)复制到对应的代码框。是的,详细看图:
在这个提示下,要排除任何内容,只需要找到对应的代码,复制到代码排除窗口中,将变量部分替换为“(*)”即可。既然他这边没有广告,就算把整个站点的规则都做完了,点击保存进入单任务制作。嗯,全站的规则就讲这两个标签,其他的根据需要按照上面的步骤添加。记住,永远不要改变。其他问题请到优采云采集器论坛:讨论。
二、以下解释单任务规则的产生:
1、content 的制作规则,很多人可能不明白优采云采集器好在哪,我现在说的绝对是优采云的独到之处(至少到目前为止,我不知道以后有没有人有同样的功能!)
优采云采集器不需要通过URL规则直接进入内容采集,所以可以根据网站的难度决定采集是否选择目标源,而是等URL@之后采集发现网站你不能选或者不值得你浪费时间(之前的时间没用!)。
优采云v3.0 最大的功能之一就是可以继承网站的规则。只要你之前制定的规则是通用的,你就不需要为后面的所有任务制定内容采集规则。由于我们之前制定的采集规则是通用的,这里不需要解释规则,直接继承站点,如图:
2、URL采集规则制作
步骤:“新建”-“新建任务”,其他操作如下:
要制定规则,您需要善于发现常规事物。此时采集没问题。我们要这里采集例子的地址
本板仅以采集第1-3页为例。我们发现每个叶子的URL开头都收录“过去的娱乐热点”,结尾是“Page 1 2...”,所以请将html源代码中的相应代码复制到特定区域采集范围内,另外,URL必须收录“/06/”,这样URL采集就完成了(简单,自己试试),如下图:
3、posting 方法。发布方式有5种,这里以最常用的“在线发布”为例。
选择要在线发布的web到网站,点击“定义全局发布方式”,然后按照系统提示的步骤操作: 选择发布模块——“填写网站/cms根地址——》使用优采云内置浏览器登录——》登录后关闭内置浏览器——》刷新列表——》测试模块,测试成功——》保存配置——》保存任务——》发布下图高亮部分就是你要操作的步骤,从左到右,从上到下:
以下是我采集测试到本地论坛采集的两张截图:
查看全部
网页中“右键点击”——查看源码(图)
我们可以用这个作为内容开始的标志,但这并不完美。请自行打开几个内容页面,页面中“右键”-“查看源代码”,然后比较代码,提取相同的部分,我用
作为内容开始的标志。
接下来看内容结束标记,如下两张图所示:
以下是根据us采集设置的规则返回的内容
一般来说采集返回的内容从头到尾都会收录必须排除的内容、广告或链接。这里我们需要排除的内容是“相关话题>>>第六届金鹰电视艺术节”。排除的方法是找到对应的代码,将代码完整复制到内容排除窗口中,修改后的部分用“(*)”代替。因为这是整个站点的规则,所以你必须多找几个类别。比如现在的163娱乐还包括“名人|图片|电影|电视|音乐|论坛|专题|名人专访”等等,这里我只摘录“明星、图片、电影”作为列子给大家讲解。寻找其他类别只是为了使规则具有普遍性和完善性。如果您只需要一个类别,例如“图片”,那么您可以直接制定此规则。
这个页面正好有分页,所以顺便说一下下一页和下一页的设置。他这边的“上一页”和“下一页”是用图片链接的,所以不要复制图片的名称(右键点击对应图片查看属性,复制图片名称)复制到对应的代码框。是的,详细看图:
在这个提示下,要排除任何内容,只需要找到对应的代码,复制到代码排除窗口中,将变量部分替换为“(*)”即可。既然他这边没有广告,就算把整个站点的规则都做完了,点击保存进入单任务制作。嗯,全站的规则就讲这两个标签,其他的根据需要按照上面的步骤添加。记住,永远不要改变。其他问题请到优采云采集器论坛:讨论。
二、以下解释单任务规则的产生:
1、content 的制作规则,很多人可能不明白优采云采集器好在哪,我现在说的绝对是优采云的独到之处(至少到目前为止,我不知道以后有没有人有同样的功能!)
优采云采集器不需要通过URL规则直接进入内容采集,所以可以根据网站的难度决定采集是否选择目标源,而是等URL@之后采集发现网站你不能选或者不值得你浪费时间(之前的时间没用!)。
优采云v3.0 最大的功能之一就是可以继承网站的规则。只要你之前制定的规则是通用的,你就不需要为后面的所有任务制定内容采集规则。由于我们之前制定的采集规则是通用的,这里不需要解释规则,直接继承站点,如图:
2、URL采集规则制作
步骤:“新建”-“新建任务”,其他操作如下:
要制定规则,您需要善于发现常规事物。此时采集没问题。我们要这里采集例子的地址
本板仅以采集第1-3页为例。我们发现每个叶子的URL开头都收录“过去的娱乐热点”,结尾是“Page 1 2...”,所以请将html源代码中的相应代码复制到特定区域采集范围内,另外,URL必须收录“/06/”,这样URL采集就完成了(简单,自己试试),如下图:
3、posting 方法。发布方式有5种,这里以最常用的“在线发布”为例。
选择要在线发布的web到网站,点击“定义全局发布方式”,然后按照系统提示的步骤操作: 选择发布模块——“填写网站/cms根地址——》使用优采云内置浏览器登录——》登录后关闭内置浏览器——》刷新列表——》测试模块,测试成功——》保存配置——》保存任务——》发布下图高亮部分就是你要操作的步骤,从左到右,从上到下:
以下是我采集测试到本地论坛采集的两张截图:
让数据触手可及2017年04月
采集交流 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-07-27 04:38
让数据触手可及2017年4月优采云采集器销售客服部一、优采云简介二、采集器作文三、简例四、基本简介五、采集Instance目录浏览器优采云采集器,是一种模拟人访问网页文档的互联网数据采集器。通过设计流程操作,采集可以自动化实现网页数据的快速采集集成,完成用户数据采集的目的。原理:1.imperson 浏览网页2.通过设计过程操作完成采集Automation 优采云principle 通常,我们将一个采集任务称为一个规则。规则是优采云采集器的核心组件。我们按照规则来划分章鱼的构成,可以分为以下几种:一、Task List:Task List是指优采云采集器中的已编辑任务,已编辑的任务可以直接从等待状态二、任务规则:任务规则是指根据特定网页以及人们使用浏览器访问网页的过程开发的自动化任务程序,一般来说,类似网站的类型对应于一个任务规则三、task状态:1)task生命周期:可执行状态、等待状态、运行状态、完成状态、停止状态2)运行状态:1)local采集况、云采集State 优采云采集器构成一、打开网页:打开网页,一般指的是我们想要的采集数据的网站,就像我们平时浏览这个网站需要输入相同的网址数据信息二、循环翻页:循环翻页是指当我们需要快速采集整合时,需要实现翻页c周。循环翻页的本质是单个元素。 Cycle 三、Extracting data 正式采集Step 四、 点击元素 循环本身没有任何执行操作。如果要循环翻页,则需要一个click元素来生成与循环的联动。流程简单设计实例一、Settings 基本信息:此处用于填写规则名称和规则备注二、设计工作流:此处用于设计任务规则的自动化流程步骤,例如:which web页面要打开的任务和步骤这些都是在设计工作流中完成的。设计工作流是任务规则的核心步骤三、设置执行计划:这里可以设置任务规则的相关选项,例如:禁止浏览器加载图片,云采集不拆分任务,启动增加采集等四、task启动选择:如果规则写得正确,这里可以启动一个任务规则的生命周期,此时,如果编辑正确,任务应该在可执行文件中状态。流程设计步骤介绍:优采云采集器一共11个流程设计操作,分为基本步骤和高级步骤,分为以下几个: 基本步骤:基本步骤本身比较多应用流程设计操作 一般来说,这些步骤对于用采集实现网页数据的快速排序是必不可少的。基本步骤如下:1)打开网页2)点击元素3)环4)提取数据到高级步骤:除了基本步骤,我们还需要使用以下操作来辅助完成我们的数据采集。例如:有时我们的采集数据需要在采集之前输入文字,高级步骤如下:1)input文字Word2)身份验证码3)toggle下拉选项4)judgment conditions 5)将鼠标移到元素6)end cycle7)end 工艺流程设计步骤优采云,工艺操作由基本信息决定 由两部分组成,带有高级选项一、基本信息:基本信息信息一般会显示操作过程的基本信息,例如:打开一个网页会显示你打开的网页的网址,点击一个元素会显示你点击的元素的文字等。二、Advanced options:高级选项,可以为辅助规则的正确有效执行设置一些额外的选项设置,例如:执行前等待、iframe中的元素等高级选项的基本信息和简单示例 查看全部
让数据触手可及2017年04月
让数据触手可及2017年4月优采云采集器销售客服部一、优采云简介二、采集器作文三、简例四、基本简介五、采集Instance目录浏览器优采云采集器,是一种模拟人访问网页文档的互联网数据采集器。通过设计流程操作,采集可以自动化实现网页数据的快速采集集成,完成用户数据采集的目的。原理:1.imperson 浏览网页2.通过设计过程操作完成采集Automation 优采云principle 通常,我们将一个采集任务称为一个规则。规则是优采云采集器的核心组件。我们按照规则来划分章鱼的构成,可以分为以下几种:一、Task List:Task List是指优采云采集器中的已编辑任务,已编辑的任务可以直接从等待状态二、任务规则:任务规则是指根据特定网页以及人们使用浏览器访问网页的过程开发的自动化任务程序,一般来说,类似网站的类型对应于一个任务规则三、task状态:1)task生命周期:可执行状态、等待状态、运行状态、完成状态、停止状态2)运行状态:1)local采集况、云采集State 优采云采集器构成一、打开网页:打开网页,一般指的是我们想要的采集数据的网站,就像我们平时浏览这个网站需要输入相同的网址数据信息二、循环翻页:循环翻页是指当我们需要快速采集整合时,需要实现翻页c周。循环翻页的本质是单个元素。 Cycle 三、Extracting data 正式采集Step 四、 点击元素 循环本身没有任何执行操作。如果要循环翻页,则需要一个click元素来生成与循环的联动。流程简单设计实例一、Settings 基本信息:此处用于填写规则名称和规则备注二、设计工作流:此处用于设计任务规则的自动化流程步骤,例如:which web页面要打开的任务和步骤这些都是在设计工作流中完成的。设计工作流是任务规则的核心步骤三、设置执行计划:这里可以设置任务规则的相关选项,例如:禁止浏览器加载图片,云采集不拆分任务,启动增加采集等四、task启动选择:如果规则写得正确,这里可以启动一个任务规则的生命周期,此时,如果编辑正确,任务应该在可执行文件中状态。流程设计步骤介绍:优采云采集器一共11个流程设计操作,分为基本步骤和高级步骤,分为以下几个: 基本步骤:基本步骤本身比较多应用流程设计操作 一般来说,这些步骤对于用采集实现网页数据的快速排序是必不可少的。基本步骤如下:1)打开网页2)点击元素3)环4)提取数据到高级步骤:除了基本步骤,我们还需要使用以下操作来辅助完成我们的数据采集。例如:有时我们的采集数据需要在采集之前输入文字,高级步骤如下:1)input文字Word2)身份验证码3)toggle下拉选项4)judgment conditions 5)将鼠标移到元素6)end cycle7)end 工艺流程设计步骤优采云,工艺操作由基本信息决定 由两部分组成,带有高级选项一、基本信息:基本信息信息一般会显示操作过程的基本信息,例如:打开一个网页会显示你打开的网页的网址,点击一个元素会显示你点击的元素的文字等。二、Advanced options:高级选项,可以为辅助规则的正确有效执行设置一些额外的选项设置,例如:执行前等待、iframe中的元素等高级选项的基本信息和简单示例
利用网页采集技术消除“信息孤岛”,搭建内部新闻平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-07-25 07:23
利用webpage采集technology搭建内部新闻平台,医务人员可以通过信息系统的内部网络及时了解国内外新闻动态。 关键词网页采集内网新闻cms简介 我院信息系统网络与公网均采取了严格的物理隔离措施,内外网之间的数据访问通过一个网守实现。医院在内网上建立了内部网站,用于发布医院新闻、通知等信息。信息系统用户只能浏览网站提供的内部新闻,不能浏览公网信息。随着医院的不断发展和互联网的普及,临床工作人员通过网络渴望通过信息系统网络了解他们关心的国家的时事、新闻、政策和法规。利用信息技术消除“信息孤岛”,为临床医生和医院管理人员提供更多的服务选项来实现上述功能。有两种方案: 方案一:利用现有的网守将公网地址映射到内网,解决用户浏览新闻的问题。方案二:在外网搭建自己的新闻平台,及时发布新闻信息,通过看门人将网站映射到内网。方案一实现起来比较简单,只需要简单的配置就可以实现上述功能,但是也有缺点。主要原因是一旦将公网网站上的内容映射到内网,用户就可以浏览网站中的所有信息。部分娱乐信息和无关信息无法屏蔽,浏览无法控制,故未采用该方案。方案二需要自己搭建新闻平台,实现起来比方案一复杂,但是可以对新闻信息进行管理,避免一些不相关的信息,所以采用了第二套方案。
按照第二个方案,问题是依靠人力逐条复制录入新闻,必然造成资源的巨大浪费。因此,可以考虑使用网页信息采集技术来实现新闻信息的批量获取和发布。网页信息采集技术是通过分析网页的HTML代码,获取网络中的超链接信息,采用广度优先搜索算法和增量存储算法,实现自动连续分析链接、抓取文件、处理和处理的过程。保存数据。具体实现过程如下:3.1 cms选型cms是Content Management System的缩写,意思是“内容管理系统”。它有很多优秀的基于模板的设计,可以加快网站的开发速度,降低开发成本。为了节省投资,比较了比较流行的“empirecms”、“PHPcms”、“织梦cms”等免费的cms。感觉织梦cms好用。模板很多,尤其是后端的网页采集模块,最终选择了织梦内容管理系统(以下简称Dedecms)。 3.2 搭建服务器环境,作者使用Windows2003 Server IIS+PHP+ MySQL模型搭建。 PHP 是超文本预处理器的缩写。 PHP 是一种 HTML 嵌入语言,一种嵌入在服务器端执行的 HTML 文档中的脚本语言。语言风格与语言相似,应用广泛。
现在PHP部署很简单,下载5.4.0版本安装包安装即可。 MySQL 是一个小型的关系型数据库管理系统。由于其体积小、速度快、总拥有成本低,尤其是其开源特性,很多网站选择了MySQL作为网站数据库。下载并安装 MySQL Installer 5.5.21 版本进行安装。为了保证数据库的安全,在MySQL安装过程中要注意设置root用户密码。如果忘记设置,可以在系统安装后使用mysqladmin命令设置密码。安装完成后,测试PHP和MySQL服务是否正常。 3.3 MySQL 数据库管理,可以使用 PhpMyAdmin 或 Navicat MySQL。 PhpMyAdmin 的缺点是必须安装在Web 服务器中,如果没有适当的访问权限,其他用户可能会损坏SQL 数据。 Navicat MySQL 是一个强大的 MySQL 数据库服务器管理和开发工具。它可以与任何3.21或更高版本的MySQL一起工作,并支持大多数最新的MySQL特性,包括触发器、存储过程、函数、事件、视图、管理用户等。它不仅对专业开发人员来说是一项非常前沿的技术,而且对于新手来说也很容易学习和使用。因为是本地服务器,综合考虑,安装了Navicat MySQL,用于MySQL数据库管理。
3.4 安装Dedecms并下载“Dedecms V5.7”版本。按照网站提供的教程进行安装,安装过程中注意以下问题。 3.4.1 数据,模板,上传,一个或html目录,设置读写,非执行权限; 3.4.2 不需要设置topic,建议删除special目录,需要能生成HTML后,删除special/index.php,设置该目录为可读写和不可执行的权限; 3.4.3 include、member、plus、后台管理目录设置为可执行脚本,可读,但不可写(如果安装了附加模块,book、ask、company、group目录为也以同样的方式设置)。 3.4.4 安装完成后,删除安装目录。 3.5 设置网站列,根据自己的需要设置不同的网站列。作者开设人民网、健康日报、地方报等栏目。 3.6 网页采集的实现是本方案的核心部分。 dedecms自带的网络采集模块也可以实现网页自动采集,但是采集比较瘦,不能同时采集和发布多个网站,需要登录网站后台操作,操作过程繁琐,需要找一套可以实现自动批量采集的软件。目前采集software的在线数据主要包括以下几类:“优采云”、“网络矿工”、“优讯软件”、“网络神才”、“一菜”、“优采云”、“三人行”“等等。
以上都是付费软件。有免费试用版,但有功能限制。因为采集大部分是纯静态页面,数据结构简单,尝试了很多采集软件后,最终选择了“优采云采集器V7免费版”。 “优采云采集器V7”自带“Dedecms5.7”版本的Web发布模块,无需编写发布接口代码。直接运行“优采云采集器”,在任务栏中添加需要采集网页的任务,编辑采集网址规则,采集内容规则,发布内容设置等,实现网页批量自动化页采集 和批量发布。在实际操作中,需要注意以下几个方面: 3.6.1 在采集中,涉及到如何采集将远程图片发布到本地服务器。在采集content规则中选择“把相对地址作为绝对地址完成”,因为Dedecms本身有下载远程图片和资源的模块,可以自动下载远程图片。由于免费版的使用和限制,笔者在这里走了很多弯路。 3.6.2 由于采集数量众多,难免出现文章重复。 “Dedecms”提供的重复文档检测功能可以批量删除重复文档。 3.6.3 可以通过优采云采集器批量发布文章。当你还需要登录后台点时,使用易鉴更新网站功能,更新网页链接。 3.6.4 编辑采集规则时,应用过滤功能过滤和调整冗余代码。讨论通过以上方式搭建的医院新闻平台,可以及时批量更新网站,网络信息采集在信息采集,在资源整合方面节省了大量的人力和资金。
但是,一些网站采取了阻止采集的措施,无法采集数据。另外,由于全部使用免费软件,目前只实现了图片的自动发布,没有更好的发布附件的方式,需要进一步改进。参考文献 校园网新闻及其管理[J].计算机知识与技术(学术交流),2007,05:1191-1197 李强。院内网站建设的一些经验与建议[J].现代医院管理,2011,41(2):66-68 查看全部
利用网页采集技术消除“信息孤岛”,搭建内部新闻平台
利用webpage采集technology搭建内部新闻平台,医务人员可以通过信息系统的内部网络及时了解国内外新闻动态。 关键词网页采集内网新闻cms简介 我院信息系统网络与公网均采取了严格的物理隔离措施,内外网之间的数据访问通过一个网守实现。医院在内网上建立了内部网站,用于发布医院新闻、通知等信息。信息系统用户只能浏览网站提供的内部新闻,不能浏览公网信息。随着医院的不断发展和互联网的普及,临床工作人员通过网络渴望通过信息系统网络了解他们关心的国家的时事、新闻、政策和法规。利用信息技术消除“信息孤岛”,为临床医生和医院管理人员提供更多的服务选项来实现上述功能。有两种方案: 方案一:利用现有的网守将公网地址映射到内网,解决用户浏览新闻的问题。方案二:在外网搭建自己的新闻平台,及时发布新闻信息,通过看门人将网站映射到内网。方案一实现起来比较简单,只需要简单的配置就可以实现上述功能,但是也有缺点。主要原因是一旦将公网网站上的内容映射到内网,用户就可以浏览网站中的所有信息。部分娱乐信息和无关信息无法屏蔽,浏览无法控制,故未采用该方案。方案二需要自己搭建新闻平台,实现起来比方案一复杂,但是可以对新闻信息进行管理,避免一些不相关的信息,所以采用了第二套方案。
按照第二个方案,问题是依靠人力逐条复制录入新闻,必然造成资源的巨大浪费。因此,可以考虑使用网页信息采集技术来实现新闻信息的批量获取和发布。网页信息采集技术是通过分析网页的HTML代码,获取网络中的超链接信息,采用广度优先搜索算法和增量存储算法,实现自动连续分析链接、抓取文件、处理和处理的过程。保存数据。具体实现过程如下:3.1 cms选型cms是Content Management System的缩写,意思是“内容管理系统”。它有很多优秀的基于模板的设计,可以加快网站的开发速度,降低开发成本。为了节省投资,比较了比较流行的“empirecms”、“PHPcms”、“织梦cms”等免费的cms。感觉织梦cms好用。模板很多,尤其是后端的网页采集模块,最终选择了织梦内容管理系统(以下简称Dedecms)。 3.2 搭建服务器环境,作者使用Windows2003 Server IIS+PHP+ MySQL模型搭建。 PHP 是超文本预处理器的缩写。 PHP 是一种 HTML 嵌入语言,一种嵌入在服务器端执行的 HTML 文档中的脚本语言。语言风格与语言相似,应用广泛。
现在PHP部署很简单,下载5.4.0版本安装包安装即可。 MySQL 是一个小型的关系型数据库管理系统。由于其体积小、速度快、总拥有成本低,尤其是其开源特性,很多网站选择了MySQL作为网站数据库。下载并安装 MySQL Installer 5.5.21 版本进行安装。为了保证数据库的安全,在MySQL安装过程中要注意设置root用户密码。如果忘记设置,可以在系统安装后使用mysqladmin命令设置密码。安装完成后,测试PHP和MySQL服务是否正常。 3.3 MySQL 数据库管理,可以使用 PhpMyAdmin 或 Navicat MySQL。 PhpMyAdmin 的缺点是必须安装在Web 服务器中,如果没有适当的访问权限,其他用户可能会损坏SQL 数据。 Navicat MySQL 是一个强大的 MySQL 数据库服务器管理和开发工具。它可以与任何3.21或更高版本的MySQL一起工作,并支持大多数最新的MySQL特性,包括触发器、存储过程、函数、事件、视图、管理用户等。它不仅对专业开发人员来说是一项非常前沿的技术,而且对于新手来说也很容易学习和使用。因为是本地服务器,综合考虑,安装了Navicat MySQL,用于MySQL数据库管理。
3.4 安装Dedecms并下载“Dedecms V5.7”版本。按照网站提供的教程进行安装,安装过程中注意以下问题。 3.4.1 数据,模板,上传,一个或html目录,设置读写,非执行权限; 3.4.2 不需要设置topic,建议删除special目录,需要能生成HTML后,删除special/index.php,设置该目录为可读写和不可执行的权限; 3.4.3 include、member、plus、后台管理目录设置为可执行脚本,可读,但不可写(如果安装了附加模块,book、ask、company、group目录为也以同样的方式设置)。 3.4.4 安装完成后,删除安装目录。 3.5 设置网站列,根据自己的需要设置不同的网站列。作者开设人民网、健康日报、地方报等栏目。 3.6 网页采集的实现是本方案的核心部分。 dedecms自带的网络采集模块也可以实现网页自动采集,但是采集比较瘦,不能同时采集和发布多个网站,需要登录网站后台操作,操作过程繁琐,需要找一套可以实现自动批量采集的软件。目前采集software的在线数据主要包括以下几类:“优采云”、“网络矿工”、“优讯软件”、“网络神才”、“一菜”、“优采云”、“三人行”“等等。
以上都是付费软件。有免费试用版,但有功能限制。因为采集大部分是纯静态页面,数据结构简单,尝试了很多采集软件后,最终选择了“优采云采集器V7免费版”。 “优采云采集器V7”自带“Dedecms5.7”版本的Web发布模块,无需编写发布接口代码。直接运行“优采云采集器”,在任务栏中添加需要采集网页的任务,编辑采集网址规则,采集内容规则,发布内容设置等,实现网页批量自动化页采集 和批量发布。在实际操作中,需要注意以下几个方面: 3.6.1 在采集中,涉及到如何采集将远程图片发布到本地服务器。在采集content规则中选择“把相对地址作为绝对地址完成”,因为Dedecms本身有下载远程图片和资源的模块,可以自动下载远程图片。由于免费版的使用和限制,笔者在这里走了很多弯路。 3.6.2 由于采集数量众多,难免出现文章重复。 “Dedecms”提供的重复文档检测功能可以批量删除重复文档。 3.6.3 可以通过优采云采集器批量发布文章。当你还需要登录后台点时,使用易鉴更新网站功能,更新网页链接。 3.6.4 编辑采集规则时,应用过滤功能过滤和调整冗余代码。讨论通过以上方式搭建的医院新闻平台,可以及时批量更新网站,网络信息采集在信息采集,在资源整合方面节省了大量的人力和资金。
但是,一些网站采取了阻止采集的措施,无法采集数据。另外,由于全部使用免费软件,目前只实现了图片的自动发布,没有更好的发布附件的方式,需要进一步改进。参考文献 校园网新闻及其管理[J].计算机知识与技术(学术交流),2007,05:1191-1197 李强。院内网站建设的一些经验与建议[J].现代医院管理,2011,41(2):66-68
利用采集器 采集的平台 最新最全的学术论文期刊文献年终总结(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-07-24 03:26
利用网页信息采集技术搭建医院内网新闻平台-精美素材本文档格式为WORD,感谢阅读。最新最全的学术论文、期刊、文献、年终总结、年终报告、工作总结、个人总述职报告、实习报告、单位总结总结:利用网页采集技术搭建内部新闻平台,医务人员可以通过信息系统内部网络及时了解国内外新闻动态关键词:webpage采集;内网新闻; cmsG640 文件标识码:A 1674-9324 (2013)51-0198-02 一、 简介 采用严格的物理隔离措施,通过一个看门人实现内外网的数据访问。医院建立了内部网络网站发布医院新闻、通知等信息 信息系统用户只能浏览内部网站提供的医院新闻无法浏览公共网络信息 随着医院的不断发展和随着互联网的普及,临床工作人员通过网络渴望通过信息系统网络了解自己关心的国家的时事、新闻、政策法规。临床医生和医院管理者。二、方案选择实现上述功能,有如下两种方案: 方案一:使用exis ting gatekeeper 映射公网地址 去内网解决用户浏览新闻的问题。方案二:在外网搭建自己的新闻平台,及时发布新闻信息,通过看门人将网站映射到内网。
方案一实现起来比较简单,只需要简单的配置就可以实现上述功能,但是也有弊端。主要原因是一旦公网网站内容映射到内网,用户就可以浏览所有网站信息,对于一些娱乐信息和无关信息无法屏蔽,浏览无法控制,所以该计划未获通过。第二套方案需要建立自己的新闻平台,实施起来比第一套方案复杂,但是可以对新闻信息进行管理,避免一些不相关的信息,所以采用了第二套方案。按照第二个方案,问题是依靠人力逐条复制录入新闻,必然造成资源的极大浪费。因此,可以考虑使用网络信息采集技术来实现新闻信息的批量获取和发布。网页信息采集技术是通过分析网页的HTML代码,获取网络中的超链接信息,采用广度优先搜索算法和增量存储算法,实现自动连续分析链接、抓取文件、处理和处理的过程。保存数据。 三、的具体实现过程如下: 1.cms选择:cms由Content Management System编写,意为“内容管理系统”。它有很多优秀的基于模板的设计,可以加快网站Speed的开发速度,降低开发成本。为了节省投资,比较了比较流行的“empirecms”、“PHPcms”、“织梦cms”等免费的cms。感觉织梦cms好用。模板很多,尤其是后端的网页采集模块,最终选择了织梦内容管理系统(以下简称Dedecms)。
2.搭建服务器环境,作者使用Windows2003 Server IIS+PHP+ MySQL模型搭建。 PHP是Hypertext Preprocessor的缩写,英文超文本预处理语言。 PHP 是一种 HTML 嵌入语言,一种嵌入在服务器端执行的 HTML 文档中的脚本语言。语言风格与C语言相似,应用广泛。现在 PHP 管理非常简单。直接从下载5.4.0版本安装包后,安装。 MySQL 是一个小型的关系型数据库管理系统。由于其体积小、速度快、总拥有成本低,尤其是其开源特性,很多网站选择了MySQL作为网站数据库。从 下载并安装 MySQL Installer 5.5.21 版本进行安装。为了保证数据库的安全,在MySQL安装过程中要注意设置root用户密码。如果忘记设置,可以在系统安装后使用mysqladmin命令设置密码。安装完成后,测试PHP和MySQL服务是否正常。 3.MySQL 数据库管理,可以使用PhpMyAdmin 或Navicat MySQL。 PhpMyAdmin的缺点是必须安装在Web服务器上,如果没有适当的访问权限,其他用户可能会损坏SQL数据。
Navicat MySQL 是一个强大的 MySQL 数据库服务器管理和开发工具。它可以与任何3.21或以上版本的MySQL一起工作,并支持大多数最新的MySQL特性,包括触发器、存储过程、函数、事件、视图、用户管理等。它不仅对专业开发人员来说是一项非常前沿的技术,而且对于新手来说也很容易学习和使用。因为是本地服务器,综合考虑后安装了Navicat MySQL,用于MySQL数据库管理。 4.安装Dedecms,从下载“DedecmsV5.7”版本。按照网站提供的教程安装,安装过程中注意以下问题:(1)data,templates,uploads,a或html目录,设置读写,非执行权限。(2)不需要设置专题,建议删除专题目录,生成HTML后需要能删除special/index.php,然后将该目录设置为可读写,不可执行权限。(3)include、member、plus、后台管理目录设置为可执行脚本,可读不可写(如果安装了附加模块,book、ask、company、group目录也同样设置) .
(4)安装完成后删除install目录。5.Set网站column,根据自己的需要设置不同的网站栏目,作者设置人民网、健康报网和本地报纸等栏目6.实现网页采集是本方案最核心的部分,网络采集模块加上Dedecms也可以实现网页自动采集,但采集比较薄不能同时采集。@并发布多个网站,并且需要登录网站后台操作,操作过程繁琐,所以需要找一套可以实现自动批量网站的软件采集.现在采集软件的在线数据主要有以下几种:“优采云”、“网络矿工”、“优讯软件”、“网络神彩”、“一菜”、“优采云”、“三人行”等 以上都是付费软件,有免费版 可以试用,但是功能上有限制。因为采集大部分都是纯静态页面,并且数据结构简单,尝试了很多采集软件后,最终选择了“Train采集器V7免费版”。 “优采云采集器V7”Web发布模块带有“Dedecms5.7”版本,省去编写发布接口代码的需要。直接在任务栏运行“优采云采集器”添加需要采集网页的任务,编辑采集网址规则,采集内容规则,发布内容设置等,实现批量自动采集和批量发布网页。实际操作中要注意几个方面问题:(采集中的1)涉及如何采集将远程图片发布到本地服务器的问题。在采集内容规则中,选择“完成相对地址为绝对地址”,因为Dedecms有下载远程图片和资源的模块,可以自动下载远程图片。
由于使用的是免费版,由于限制,笔者在这里走了很多弯路。 (2)由于采集数量众多,难免会出现重复文章。“Dedecms”提供的重复文档检测功能可以批量删除重复文档。(3)通优采云采集设备可以批量发布文章,当您还需要登录后台时,使用一键更新网站功能更新网页链接。(4)编辑时采集规则,应用过滤功能过滤掉多余的四、讨论通过上述方法搭建的医院新闻平台,可及时批量更新新闻网站,网络信息采集信息采集,资源整合,节省了大量的人力和资金。但是有一些网站采取了防止采集的措施,而且采集数据不可用。另外,因为全部是免费软件,所以只有自动发布图片目前已经实现,没有更好的发布附件的方式,需要进一步改进。文献:[1]郑希敖松,袁继先,徐铭。校园网新闻与管理[J].计算机知识与技术(学术交流),2007,(5).[2]李强.医院内部网站建筑的一些经验与建议[J].现代医院管理,2011,41(2).通讯作者:张伟 阅读相关文献:建筑工程技术专业毕业生与本科生服务驱动型人才培养模式实践结对引领实践成果职业素养教育融入会计教学的研究与实践初探。初中语文自主、合作、探究式学习方法探讨 嵌入式实践教学模式在工商管理本科人才培养中的应用 工业设计基础军品设计课程 学生“画”创情智共生的语文课堂快乐教学——小学情景教学法的创设之道音乐厅数学课堂 如何有效开展小学语文综合实践活动 如何激发初中生思政课学习兴趣 优化活动策略 重视问题 解决试讨论如何培养小学生数学思维和问题意识 利用本地资源诠释智慧课堂 激活小学生数学课堂 具体举措 探索最新、最完整的中学生生活[学术论文][总结报告][演讲][领导讲话] ] [心得] [党建资料] [常用范文] [分析报告] [申请文件] 免费阅读下载 *本文采集于网络,版权归原作者所有。如果您侵犯了您的权利,请留言。我会尽快处理。谢谢。* 查看全部
利用采集器 采集的平台 最新最全的学术论文期刊文献年终总结(组图)
利用网页信息采集技术搭建医院内网新闻平台-精美素材本文档格式为WORD,感谢阅读。最新最全的学术论文、期刊、文献、年终总结、年终报告、工作总结、个人总述职报告、实习报告、单位总结总结:利用网页采集技术搭建内部新闻平台,医务人员可以通过信息系统内部网络及时了解国内外新闻动态关键词:webpage采集;内网新闻; cmsG640 文件标识码:A 1674-9324 (2013)51-0198-02 一、 简介 采用严格的物理隔离措施,通过一个看门人实现内外网的数据访问。医院建立了内部网络网站发布医院新闻、通知等信息 信息系统用户只能浏览内部网站提供的医院新闻无法浏览公共网络信息 随着医院的不断发展和随着互联网的普及,临床工作人员通过网络渴望通过信息系统网络了解自己关心的国家的时事、新闻、政策法规。临床医生和医院管理者。二、方案选择实现上述功能,有如下两种方案: 方案一:使用exis ting gatekeeper 映射公网地址 去内网解决用户浏览新闻的问题。方案二:在外网搭建自己的新闻平台,及时发布新闻信息,通过看门人将网站映射到内网。
方案一实现起来比较简单,只需要简单的配置就可以实现上述功能,但是也有弊端。主要原因是一旦公网网站内容映射到内网,用户就可以浏览所有网站信息,对于一些娱乐信息和无关信息无法屏蔽,浏览无法控制,所以该计划未获通过。第二套方案需要建立自己的新闻平台,实施起来比第一套方案复杂,但是可以对新闻信息进行管理,避免一些不相关的信息,所以采用了第二套方案。按照第二个方案,问题是依靠人力逐条复制录入新闻,必然造成资源的极大浪费。因此,可以考虑使用网络信息采集技术来实现新闻信息的批量获取和发布。网页信息采集技术是通过分析网页的HTML代码,获取网络中的超链接信息,采用广度优先搜索算法和增量存储算法,实现自动连续分析链接、抓取文件、处理和处理的过程。保存数据。 三、的具体实现过程如下: 1.cms选择:cms由Content Management System编写,意为“内容管理系统”。它有很多优秀的基于模板的设计,可以加快网站Speed的开发速度,降低开发成本。为了节省投资,比较了比较流行的“empirecms”、“PHPcms”、“织梦cms”等免费的cms。感觉织梦cms好用。模板很多,尤其是后端的网页采集模块,最终选择了织梦内容管理系统(以下简称Dedecms)。
2.搭建服务器环境,作者使用Windows2003 Server IIS+PHP+ MySQL模型搭建。 PHP是Hypertext Preprocessor的缩写,英文超文本预处理语言。 PHP 是一种 HTML 嵌入语言,一种嵌入在服务器端执行的 HTML 文档中的脚本语言。语言风格与C语言相似,应用广泛。现在 PHP 管理非常简单。直接从下载5.4.0版本安装包后,安装。 MySQL 是一个小型的关系型数据库管理系统。由于其体积小、速度快、总拥有成本低,尤其是其开源特性,很多网站选择了MySQL作为网站数据库。从 下载并安装 MySQL Installer 5.5.21 版本进行安装。为了保证数据库的安全,在MySQL安装过程中要注意设置root用户密码。如果忘记设置,可以在系统安装后使用mysqladmin命令设置密码。安装完成后,测试PHP和MySQL服务是否正常。 3.MySQL 数据库管理,可以使用PhpMyAdmin 或Navicat MySQL。 PhpMyAdmin的缺点是必须安装在Web服务器上,如果没有适当的访问权限,其他用户可能会损坏SQL数据。
Navicat MySQL 是一个强大的 MySQL 数据库服务器管理和开发工具。它可以与任何3.21或以上版本的MySQL一起工作,并支持大多数最新的MySQL特性,包括触发器、存储过程、函数、事件、视图、用户管理等。它不仅对专业开发人员来说是一项非常前沿的技术,而且对于新手来说也很容易学习和使用。因为是本地服务器,综合考虑后安装了Navicat MySQL,用于MySQL数据库管理。 4.安装Dedecms,从下载“DedecmsV5.7”版本。按照网站提供的教程安装,安装过程中注意以下问题:(1)data,templates,uploads,a或html目录,设置读写,非执行权限。(2)不需要设置专题,建议删除专题目录,生成HTML后需要能删除special/index.php,然后将该目录设置为可读写,不可执行权限。(3)include、member、plus、后台管理目录设置为可执行脚本,可读不可写(如果安装了附加模块,book、ask、company、group目录也同样设置) .
(4)安装完成后删除install目录。5.Set网站column,根据自己的需要设置不同的网站栏目,作者设置人民网、健康报网和本地报纸等栏目6.实现网页采集是本方案最核心的部分,网络采集模块加上Dedecms也可以实现网页自动采集,但采集比较薄不能同时采集。@并发布多个网站,并且需要登录网站后台操作,操作过程繁琐,所以需要找一套可以实现自动批量网站的软件采集.现在采集软件的在线数据主要有以下几种:“优采云”、“网络矿工”、“优讯软件”、“网络神彩”、“一菜”、“优采云”、“三人行”等 以上都是付费软件,有免费版 可以试用,但是功能上有限制。因为采集大部分都是纯静态页面,并且数据结构简单,尝试了很多采集软件后,最终选择了“Train采集器V7免费版”。 “优采云采集器V7”Web发布模块带有“Dedecms5.7”版本,省去编写发布接口代码的需要。直接在任务栏运行“优采云采集器”添加需要采集网页的任务,编辑采集网址规则,采集内容规则,发布内容设置等,实现批量自动采集和批量发布网页。实际操作中要注意几个方面问题:(采集中的1)涉及如何采集将远程图片发布到本地服务器的问题。在采集内容规则中,选择“完成相对地址为绝对地址”,因为Dedecms有下载远程图片和资源的模块,可以自动下载远程图片。
由于使用的是免费版,由于限制,笔者在这里走了很多弯路。 (2)由于采集数量众多,难免会出现重复文章。“Dedecms”提供的重复文档检测功能可以批量删除重复文档。(3)通优采云采集设备可以批量发布文章,当您还需要登录后台时,使用一键更新网站功能更新网页链接。(4)编辑时采集规则,应用过滤功能过滤掉多余的四、讨论通过上述方法搭建的医院新闻平台,可及时批量更新新闻网站,网络信息采集信息采集,资源整合,节省了大量的人力和资金。但是有一些网站采取了防止采集的措施,而且采集数据不可用。另外,因为全部是免费软件,所以只有自动发布图片目前已经实现,没有更好的发布附件的方式,需要进一步改进。文献:[1]郑希敖松,袁继先,徐铭。校园网新闻与管理[J].计算机知识与技术(学术交流),2007,(5).[2]李强.医院内部网站建筑的一些经验与建议[J].现代医院管理,2011,41(2).通讯作者:张伟 阅读相关文献:建筑工程技术专业毕业生与本科生服务驱动型人才培养模式实践结对引领实践成果职业素养教育融入会计教学的研究与实践初探。初中语文自主、合作、探究式学习方法探讨 嵌入式实践教学模式在工商管理本科人才培养中的应用 工业设计基础军品设计课程 学生“画”创情智共生的语文课堂快乐教学——小学情景教学法的创设之道音乐厅数学课堂 如何有效开展小学语文综合实践活动 如何激发初中生思政课学习兴趣 优化活动策略 重视问题 解决试讨论如何培养小学生数学思维和问题意识 利用本地资源诠释智慧课堂 激活小学生数学课堂 具体举措 探索最新、最完整的中学生生活[学术论文][总结报告][演讲][领导讲话] ] [心得] [党建资料] [常用范文] [分析报告] [申请文件] 免费阅读下载 *本文采集于网络,版权归原作者所有。如果您侵犯了您的权利,请留言。我会尽快处理。谢谢。*
使用优采云采集器采集大众点评商家的方法采集教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-07-22 01:25
使用优采云采集器采集全球评商数据 本文介绍采集用优采云7.0采集全球评商的方法采集网站:/search/category /7/0 使用功能点:网页列表内容提取相关采集教程:美团商家信息采集黄页88 data采集追集招聘信息采集第一步:/article/javascript:;创建采集任务1)进入主界面选择,选择自定义模式并使用优采云采集器采集众评商数据图12)将以上网址的网址复制粘贴到网站输入中框,点击“保存网址”用优采云采集器采集全球评商数据保存网址后如图23),页面会在优采云采集器打开,红框中的列表是我们需要的信息采集 使用优采云采集器采集全球评商数据 图3 第二步:/article/javascript:; 创建翻页循环找到翻页按钮,设置翻页循环1)页面下拉到底部,找到下一页按钮,点击鼠标,在右侧操作提示框中选择“循环点击下一页”使用优采云采集器采集众评商数据 图4 S第三步:/article/javascript:;商信息采集选择需要采集的字段信息,创建一个采集列表edit采集field name1)如图,移动鼠标选择列表中的商家名称,右击,需要采集的内容会变成绿色 使用优采云采集器采集直播评商数据 图5 注:点击“处理”按钮右上角显示可视化流程图。
2) 移动鼠标选中红框中任意一个文本框后,列表中所有适配的内容都会变成绿色。在右侧操作提示框中勾选提取的字段,删除不需要的字段。然后点击“全选”使用优采云采集器采集k15@众评商数据 图6 注意:当鼠标放在这个字段上时,会出现一个删除图标,点击删除该字段。使用优采云采集器采集全球评商数据图73)点击“采集下数据”使用优采云采集器采集全球评商数据图84)改采集字段名使用优采云采集器采集全球评商数据 图95)点击下方红框中的“保存并启动采集”使用优采云采集器采集众评商数据图106)根据采集的情况选择合适的采集方式。这里选择“启动local采集”使用优采云采集器采集全球评商数据 图11 说明:Local采集 占用采集的当前计算机资源,如果有采集时间要求或当前电脑不能长时间使用采集可以使用cloud采集功能,云端采集在网络采集上进行,没有当前电脑支持,电脑可以关闭,可以设置多个云节点共享任务。 10个节点相当于10台电脑分配任务帮你采集,速度降低到原来速度的十分之一; 采集到达的数据可以在云端保存三个月,随时可以导出。第 4 步:/article/javascript:;数据采集和导出1)采集完成后会弹出提示,选择使用优采云采集器采集全球评商数据图122)导出数据,选择合适的导出方式,使用采集好数据导出优采云采集器采集全球评商数据 图13优采云——70万用户采集器选择的网页数据。
1、操作简单,任何人都可以使用:无需技术背景,可以在网上采集。过程完全可视化,点击鼠标即可完成操作,2分钟即可快速上手。 2、功能强大,任何网站都可以:点击、登录、翻页、识别验证码、瀑布流、异步加载数据页的Ajax脚本,都可以通过简单的设置成为采集 . 3、云采集,可以关闭。 采集任务配置完成后可以关闭采集任务,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。 4、功能免费+增值服务,可根据需要选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。 优采云·云采集服务平台 查看全部
使用优采云采集器采集大众点评商家的方法采集教程
使用优采云采集器采集全球评商数据 本文介绍采集用优采云7.0采集全球评商的方法采集网站:/search/category /7/0 使用功能点:网页列表内容提取相关采集教程:美团商家信息采集黄页88 data采集追集招聘信息采集第一步:/article/javascript:;创建采集任务1)进入主界面选择,选择自定义模式并使用优采云采集器采集众评商数据图12)将以上网址的网址复制粘贴到网站输入中框,点击“保存网址”用优采云采集器采集全球评商数据保存网址后如图23),页面会在优采云采集器打开,红框中的列表是我们需要的信息采集 使用优采云采集器采集全球评商数据 图3 第二步:/article/javascript:; 创建翻页循环找到翻页按钮,设置翻页循环1)页面下拉到底部,找到下一页按钮,点击鼠标,在右侧操作提示框中选择“循环点击下一页”使用优采云采集器采集众评商数据 图4 S第三步:/article/javascript:;商信息采集选择需要采集的字段信息,创建一个采集列表edit采集field name1)如图,移动鼠标选择列表中的商家名称,右击,需要采集的内容会变成绿色 使用优采云采集器采集直播评商数据 图5 注:点击“处理”按钮右上角显示可视化流程图。
2) 移动鼠标选中红框中任意一个文本框后,列表中所有适配的内容都会变成绿色。在右侧操作提示框中勾选提取的字段,删除不需要的字段。然后点击“全选”使用优采云采集器采集k15@众评商数据 图6 注意:当鼠标放在这个字段上时,会出现一个删除图标,点击删除该字段。使用优采云采集器采集全球评商数据图73)点击“采集下数据”使用优采云采集器采集全球评商数据图84)改采集字段名使用优采云采集器采集全球评商数据 图95)点击下方红框中的“保存并启动采集”使用优采云采集器采集众评商数据图106)根据采集的情况选择合适的采集方式。这里选择“启动local采集”使用优采云采集器采集全球评商数据 图11 说明:Local采集 占用采集的当前计算机资源,如果有采集时间要求或当前电脑不能长时间使用采集可以使用cloud采集功能,云端采集在网络采集上进行,没有当前电脑支持,电脑可以关闭,可以设置多个云节点共享任务。 10个节点相当于10台电脑分配任务帮你采集,速度降低到原来速度的十分之一; 采集到达的数据可以在云端保存三个月,随时可以导出。第 4 步:/article/javascript:;数据采集和导出1)采集完成后会弹出提示,选择使用优采云采集器采集全球评商数据图122)导出数据,选择合适的导出方式,使用采集好数据导出优采云采集器采集全球评商数据 图13优采云——70万用户采集器选择的网页数据。
1、操作简单,任何人都可以使用:无需技术背景,可以在网上采集。过程完全可视化,点击鼠标即可完成操作,2分钟即可快速上手。 2、功能强大,任何网站都可以:点击、登录、翻页、识别验证码、瀑布流、异步加载数据页的Ajax脚本,都可以通过简单的设置成为采集 . 3、云采集,可以关闭。 采集任务配置完成后可以关闭采集任务,任务可以在云端执行。庞达云采集集群24*7不间断运行,无需担心IP被封,网络中断。 4、功能免费+增值服务,可根据需要选择。免费版功能齐全,可以满足用户基本的采集需求。同时,还建立了一些增值服务(如私有云),以满足高端付费企业用户的需求。 优采云·云采集服务平台

