
内容采集
SEO如何成为采集站| SEO如何处理采集内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 350 次浏览 • 2020-08-07 17:21
p>
设置一些主题,直接获取各种大型平台的搜索结果. 什么是大平台?大量内容集中的地方: 各种搜索引擎,各种门户网站,头条,微信微博,优酷土豆等.
如何捕获采集的内容?
许多浏览器插件,例如Evernote,具有许多类似于“只看文字”的功能. 单击以仅显示当前网页的文本信息. 许多人已经将此类算法移植到python,php,搜索诸如java之类的编程语言.
如何处理采集的内容?
两个连续的过程:
原创内容的处理
百度专利说,除了基于文本判断内容相似度之外,搜索引擎还将判断html的dom节点的位置和顺序. 如果两个网页的html结构相似,则也可以将其视为重复内容.
因此,采集的内容不能直接使用,并且源代码必须清除. 每个人都有不同的方式,个人通常会执行以下操作:
html清洁
a = re.sub(r'','',content).strip()
b = re.sub(r']*?>','<p>',a)
newcontent = re.sub(r'alt="[^"]*?"','alt="%s"' % title,b).lower()
已删除的汉字数
text = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,::。?、~@#¥%……&*()“”《》]+".decode("utf8"), "".decode("utf8"),newcontent)
text2 = re.sub(']*?>','',text) words_number = len(text2)
删除垃圾邮件
例如“ XXX Net Editor: XXX”,电子邮件地址等.
整理处理后的内容
实际上,就行形式的更改而言,我之前写过一篇有关“组织内容”的几种方法的文章,请参阅: [SEO]如何反转网站内容?
微信公众号: 流量贩子
GoGo的官方帐户
Knowledge Planet(稍后将发布,例如一段可以编写色情句子的Python代码~~~)
GoGo的知识星球 查看全部
对于那些没有正式站的人,还有很多选择. 您可以使用带点的内容来抓取内容,并且内容量很大,因此无需限制某些工作站的抓取. 有人称它为泛采集.
p>
设置一些主题,直接获取各种大型平台的搜索结果. 什么是大平台?大量内容集中的地方: 各种搜索引擎,各种门户网站,头条,微信微博,优酷土豆等.
如何捕获采集的内容?
许多浏览器插件,例如Evernote,具有许多类似于“只看文字”的功能. 单击以仅显示当前网页的文本信息. 许多人已经将此类算法移植到python,php,搜索诸如java之类的编程语言.
如何处理采集的内容?
两个连续的过程:
原创内容的处理
百度专利说,除了基于文本判断内容相似度之外,搜索引擎还将判断html的dom节点的位置和顺序. 如果两个网页的html结构相似,则也可以将其视为重复内容.
因此,采集的内容不能直接使用,并且源代码必须清除. 每个人都有不同的方式,个人通常会执行以下操作:
html清洁
a = re.sub(r'','',content).strip()
b = re.sub(r']*?>','<p>',a)
newcontent = re.sub(r'alt="[^"]*?"','alt="%s"' % title,b).lower()
已删除的汉字数
text = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,::。?、~@#¥%……&*()“”《》]+".decode("utf8"), "".decode("utf8"),newcontent)
text2 = re.sub(']*?>','',text) words_number = len(text2)
删除垃圾邮件
例如“ XXX Net Editor: XXX”,电子邮件地址等.
整理处理后的内容
实际上,就行形式的更改而言,我之前写过一篇有关“组织内容”的几种方法的文章,请参阅: [SEO]如何反转网站内容?
微信公众号: 流量贩子

GoGo的官方帐户
Knowledge Planet(稍后将发布,例如一段可以编写色情句子的Python代码~~~)
GoGo的知识星球
webscraper for mac破解版(mac网站内容采集工具)v4.4
采集交流 • 优采云 发表了文章 • 0 个评论 • 318 次浏览 • 2020-08-07 17:10
软件安装教程
1. 打开从该站点下载的图像包,然后将“ webscraper.app”拖到“应用程序”中.
2. 等待软件安装完成,您可以在应用程序中打开软件,安装正在破解,您可以单击菜单栏顶部的软件徽标,选择“关于网页抓取器”,可以看到以下图片,这表示该软件已经过放心使用,请放心使用.
提醒: 此软件是破解版,请不要轻易升级,以免破解失败.
软件功能
首先,从动态网页中提取数据
使用WebScraper,您可以构建一个站点地图,该站点地图将导航该站点并提取数据. Web Scraper使用不同的类型选择器,将在网站上导航并提取多种类型的数据,包括文本,表格,图像,链接等.
第二,专门为现代网络构建
与其他仅从HTML Web提取数据的抓取工具不同,Scraper还可以提取使用JavaScript动态加载或生成的数据. Web抓取工具可以:
1. 等待动态数据加载到页面上.
2. 单击分页按钮以通过AJAX加载数据.
3. 单击该按钮以加载更多数据.
4. 向下滚动页面以加载更多数据.
三,以CSV格式导出数据或将其存储在CouchDB中
站点地图的构建,数据提取和导出均在浏览器中完成. 搜寻网站后,您可以CSV格式下载数据. 对于高级用例,您可能希望尝试将数据保存到CouchDB. 查看全部
适用于Mac的webscraper版本是适用于macOS的网站内容采集工具. 它使用Integrity v8引擎快速扫描网站. 您只需要指定需要采集的网站地址以及需要采集哪些内容来提取数据(当前)(以CSV或JSON格式输出),然后将图像下载到该文件夹中即可. 用户可以选择要从网页中提取的信息类型: URL,标题,描述,与不同类型或ID相关的内容,标题,页面内容的各种格式(纯文本,HTML或Markdown)以及上次修改日期等;您还可以选择输出文件格式(CSV或JSON),决定合并空格,并在文件超过特定大小时设置警报. 如果选择使用CSV格式,则可以选择何时在列周围使用引号,并用引号替换引号或行. 分隔符类型. 这次,我们为您带来了适用于Mac的webscraper破解版,该版本不受功能和时间限制. 您可以轻松使用该软件的所有功能. 有关详细的安装教程,请参阅以下内容. 欢迎朋友下载免费体验.

软件安装教程
1. 打开从该站点下载的图像包,然后将“ webscraper.app”拖到“应用程序”中.

2. 等待软件安装完成,您可以在应用程序中打开软件,安装正在破解,您可以单击菜单栏顶部的软件徽标,选择“关于网页抓取器”,可以看到以下图片,这表示该软件已经过放心使用,请放心使用.

提醒: 此软件是破解版,请不要轻易升级,以免破解失败.
软件功能
首先,从动态网页中提取数据
使用WebScraper,您可以构建一个站点地图,该站点地图将导航该站点并提取数据. Web Scraper使用不同的类型选择器,将在网站上导航并提取多种类型的数据,包括文本,表格,图像,链接等.
第二,专门为现代网络构建
与其他仅从HTML Web提取数据的抓取工具不同,Scraper还可以提取使用JavaScript动态加载或生成的数据. Web抓取工具可以:
1. 等待动态数据加载到页面上.
2. 单击分页按钮以通过AJAX加载数据.
3. 单击该按钮以加载更多数据.
4. 向下滚动页面以加载更多数据.
三,以CSV格式导出数据或将其存储在CouchDB中
站点地图的构建,数据提取和导出均在浏览器中完成. 搜寻网站后,您可以CSV格式下载数据. 对于高级用例,您可能希望尝试将数据保存到CouchDB.
PHPCMS采集模块
采集交流 • 优采云 发表了文章 • 0 个评论 • 307 次浏览 • 2020-08-07 16:48
操作名称
说明
详细的采集过程
没有
其他功能说明
没有
描述: 文章采集功能是通过程序远程获取目标网页的内容,并在进行本地规则分析处理后将其存储在服务器的数据库中.
文章采集系统颠覆了传统的采集方式和过程,将采集规则与采集界面分开,规则设置更加简单. 只有具有基本技术知识的人员才需要设置相关规则. 编辑人员不需要了解太多详细的技术规则,只需选择要采集的文章列表,就可以像发布文章一样轻松地完成数据采集操作.
首先,采集过程很简单,分三个步骤:
1. 添加采集点并填写采集规则.
2. 采集网址和内容
3. 将内容发布到指定的列
以Sina News()的集合为例,并介绍详细过程.
示例说明:
目标: 将新浪新闻采集到V9系统的国际新闻专栏中.
目标网址:
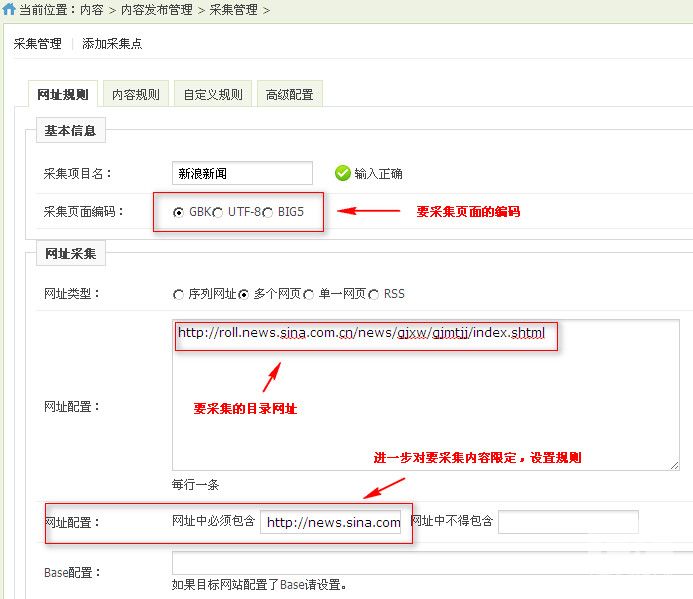
1. 添加采集点1.1 URL规则配置
添加采集点URL规则配置图1
检查要采集的目标URL的源代码,并找到要采集的URL的起点和终点(这两个点在整个源代码中必须是唯一的). 进一步缩小集合URL的搜索范围.
添加采集点URL规则配置图2
测试您的URL采集规则是否正确,如下图所示
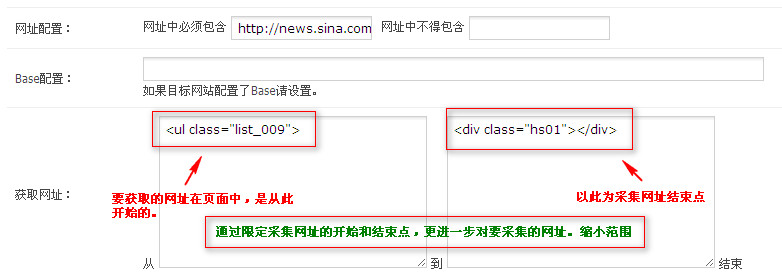
1.2内容规则配置
内容规则在这里看起来很复杂,但实际上非常简单. 为了便于说明,我们仅采集两个字段: 标题和内容. 集合网址:
内容采集规则,请打开此网站,然后右键单击页面的空白区域->查看源文件以搜索内容的标题和起始边界.
标题采集配置:
从网页上获取标题并删除不必要的字符. 如下图所示
内容采集配置:
新浪新闻的最后一页,新闻内容收录在两者之间,并且这两个节点在整个页面的源代码中都是唯一的. 因此,您可以将内容作为规则. 并过滤内容. 如下图所示
1.3自定义规则
1.4高级配置
您可以设置是否将图片下载到服务器,是否打印水印和其他配置.
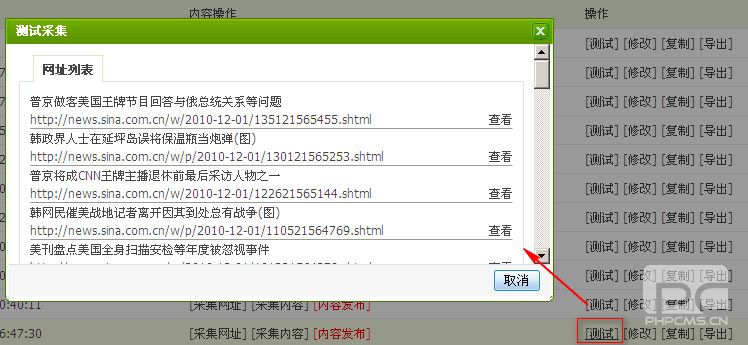
2. 采集网址和内容
设置采集规则后,可以采集网站,然后可以采集内容.
3. 将内容发布到指定的列
选择要导入的列
设置采集的内容和数据库字段之间的对应关系. 提交数据存储,在此期间请耐心等待,完成后它将自动重定向. 到目前为止,一个简单的采集过程就完成了.
其他更多功能,期待您的发现. 查看全部
模块的常用操作
操作名称
说明
详细的采集过程
没有
其他功能说明
没有
描述: 文章采集功能是通过程序远程获取目标网页的内容,并在进行本地规则分析处理后将其存储在服务器的数据库中.
文章采集系统颠覆了传统的采集方式和过程,将采集规则与采集界面分开,规则设置更加简单. 只有具有基本技术知识的人员才需要设置相关规则. 编辑人员不需要了解太多详细的技术规则,只需选择要采集的文章列表,就可以像发布文章一样轻松地完成数据采集操作.
首先,采集过程很简单,分三个步骤:
1. 添加采集点并填写采集规则.
2. 采集网址和内容
3. 将内容发布到指定的列
以Sina News()的集合为例,并介绍详细过程.
示例说明:
目标: 将新浪新闻采集到V9系统的国际新闻专栏中.
目标网址:
1. 添加采集点1.1 URL规则配置
添加采集点URL规则配置图1
检查要采集的目标URL的源代码,并找到要采集的URL的起点和终点(这两个点在整个源代码中必须是唯一的). 进一步缩小集合URL的搜索范围.
添加采集点URL规则配置图2
测试您的URL采集规则是否正确,如下图所示
1.2内容规则配置
内容规则在这里看起来很复杂,但实际上非常简单. 为了便于说明,我们仅采集两个字段: 标题和内容. 集合网址:
内容采集规则,请打开此网站,然后右键单击页面的空白区域->查看源文件以搜索内容的标题和起始边界.
标题采集配置:
从网页上获取标题并删除不必要的字符. 如下图所示

内容采集配置:
新浪新闻的最后一页,新闻内容收录在两者之间,并且这两个节点在整个页面的源代码中都是唯一的. 因此,您可以将内容作为规则. 并过滤内容. 如下图所示

1.3自定义规则
1.4高级配置
您可以设置是否将图片下载到服务器,是否打印水印和其他配置.

2. 采集网址和内容
设置采集规则后,可以采集网站,然后可以采集内容.

3. 将内容发布到指定的列
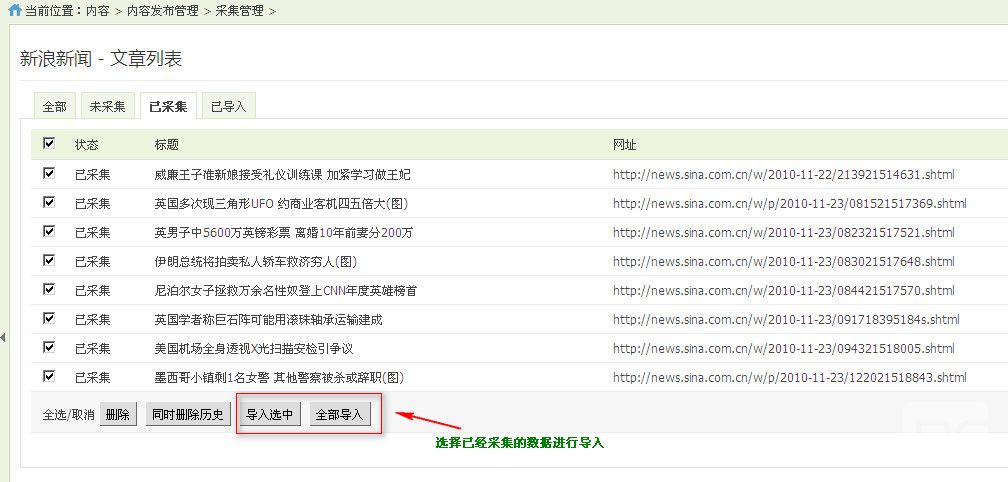
选择要导入的列

设置采集的内容和数据库字段之间的对应关系. 提交数据存储,在此期间请耐心等待,完成后它将自动重定向. 到目前为止,一个简单的采集过程就完成了.
其他更多功能,期待您的发现.
优采云采集了网站体验以及如何防止其被采集的提示!
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-08-07 16:47
1. 谈论优采云采集器的起源
优采云: 我们的采集器从2005年底开始就有这个想法. 那时,与所有人(个人网站管理员)一样,添加,管理和维护网站非常困难,而且开始时联系以修改,复制和发布文章. 然后Dede发现他有一个外部c#采集器. 我不知道还有多少人记得. 我的想法基本上是从这个绝望的人中学到的. 我什么都不知道后来我学习了php和.net. 因此,只要每个人都感兴趣,就可以克服技术问题. 到目前为止,该采集集只能替代网站站长的部分手动操作. 我们不建议大规模创建垃圾场(完整地采集和复制他人的站点),因此我们当前的软件具有越来越多的功能,但是新用户将不会使用它.
Souwainet:
我们现在有一群非常忠实的成员,他们依靠采集器来更新他们的网站. 快速采集的时代和百度搜索带来的巨大流量已经过去. 网站管理员仍然需要注意内容. 注意采集器采集的数据. 早期阶段只能用作数据填充,可以稍大一些. 但是经过很长一段时间,我们的目标是将垃圾数据变成高质量的商品,否则不会持续很长时间
第二,采集网站的经验
优采云: 我们现在正在更新此采集器,我们已经在数据采集方面积累了一些经验,并添加了更多功能以适应新的采集形式
1. 不要使用其他人经常使用的网站
2. 不要使用太容易挑选的网站
3. 一次不要采集太多,一定要注意后处理(稍后详细介绍)
4. 做好关键字和标签的采集和分析
5. 您自己的网站必须具有自己的定位,并且不得使用与您自己的网站无关的内容
6. 采集还应该是连续的,经常更新的,并且我们还具有自动采集功能,但是仍然建议您也手动参与一些审核,或者定期且无序发布
在后处理中,我们必须尝试使搜索引擎无法看到这两篇文章是相同的. 应该有很多SEO大师,所以我不会很丑. 让我谈谈我们现在正在实现的功能. 您可以将它们混合使用以实现伪原创内容更改:
1. 给出标题. 内容细分
2. 使用同义词和类似词来替换,排除敏感词,不同标签之间的数据融合,例如标题内容之间的数据相互替换
3. 在文章中添加摘要
4. 生成文章标题等的拼音地址.
5. 采集其他一些编码网站,我们可以从简体到繁体,也可以采集中文网站并将其翻译成英文(尽管是相对垃圾,但应视为原创)
我们还发现,难于采集的网站的总体内容质量通常非常好. 实际上,采集有时是一件很有趣的事情,您需要学习一些与采集有关的知识.
三,关于反采集方法
优采云: 以下是一些主要的反采集方法. 可以说是一场攻守战. 打开网页实际上是一个Http请求浏览器. 大小与我们的采集器一样小的百度蜘蛛使用相同的原理来模拟http请求,因此我们也可以模拟浏览器. 百度蜘蛛问世了,所以绝对不存在反采集,只是难度级别. 或者您认为搜索引擎的功能无关紧要. 您可以使用一些功能非常强大的Activex,Flash,全图文本形式,这是我们做不到的.
常用的反采集方法是
1. 来源判断
2. 登录信息判断cookie
3. 判断请求数. 如果一段时间内发出了多少请求,该IP将被阻止进行不规则操作
4. 发送方法的判断POST GET使用JS,Ajax和其他请求内容
示例:
1.2不用说,论坛,下载站点等.
3. 一些大型网站需要配置服务器,通过脚本判断资源消耗相对较大.
4,例如某些招聘网站的分页,Web2.0网站ajax请求的内容
当然,我们后来还发现了一些杀手trick俩,今天第一次在这里宣布这些杀人trick俩~~内容丰富且需要阻止采集的朋友可以考虑尝试
1. 网页的默认放气压缩输出(gzip稍微容易解压缩). 我们的普通浏览器和百度支持gzip识别和缩小输出内容
2. 网页内容不正常. 内容将被自动截断. 这两点基本上可以阻止大多数主流软件采集和Web采集程序〜
我要表达的主要观点是,每个人在制作站点时都必须注意技术的改进. 例如,我们以后有外部php和.net接口来处理采集的数据. 或者,您可以简单地制作一个接口程序以供发布并自己存储. 无论我们的伪原创作品多么出色,它都被许多成员使用. 如果不是原创作品,则采集还需要技术. 如果您通过采集器获得的人很少,那么您就是唯一的人. 查看全部
优采云采集了网站体验以及如何防止其被采集的提示!
1. 谈论优采云采集器的起源
优采云: 我们的采集器从2005年底开始就有这个想法. 那时,与所有人(个人网站管理员)一样,添加,管理和维护网站非常困难,而且开始时联系以修改,复制和发布文章. 然后Dede发现他有一个外部c#采集器. 我不知道还有多少人记得. 我的想法基本上是从这个绝望的人中学到的. 我什么都不知道后来我学习了php和.net. 因此,只要每个人都感兴趣,就可以克服技术问题. 到目前为止,该采集集只能替代网站站长的部分手动操作. 我们不建议大规模创建垃圾场(完整地采集和复制他人的站点),因此我们当前的软件具有越来越多的功能,但是新用户将不会使用它.

Souwainet:
我们现在有一群非常忠实的成员,他们依靠采集器来更新他们的网站. 快速采集的时代和百度搜索带来的巨大流量已经过去. 网站管理员仍然需要注意内容. 注意采集器采集的数据. 早期阶段只能用作数据填充,可以稍大一些. 但是经过很长一段时间,我们的目标是将垃圾数据变成高质量的商品,否则不会持续很长时间
第二,采集网站的经验
优采云: 我们现在正在更新此采集器,我们已经在数据采集方面积累了一些经验,并添加了更多功能以适应新的采集形式
1. 不要使用其他人经常使用的网站
2. 不要使用太容易挑选的网站
3. 一次不要采集太多,一定要注意后处理(稍后详细介绍)
4. 做好关键字和标签的采集和分析
5. 您自己的网站必须具有自己的定位,并且不得使用与您自己的网站无关的内容
6. 采集还应该是连续的,经常更新的,并且我们还具有自动采集功能,但是仍然建议您也手动参与一些审核,或者定期且无序发布
在后处理中,我们必须尝试使搜索引擎无法看到这两篇文章是相同的. 应该有很多SEO大师,所以我不会很丑. 让我谈谈我们现在正在实现的功能. 您可以将它们混合使用以实现伪原创内容更改:
1. 给出标题. 内容细分
2. 使用同义词和类似词来替换,排除敏感词,不同标签之间的数据融合,例如标题内容之间的数据相互替换
3. 在文章中添加摘要
4. 生成文章标题等的拼音地址.
5. 采集其他一些编码网站,我们可以从简体到繁体,也可以采集中文网站并将其翻译成英文(尽管是相对垃圾,但应视为原创)
我们还发现,难于采集的网站的总体内容质量通常非常好. 实际上,采集有时是一件很有趣的事情,您需要学习一些与采集有关的知识.
三,关于反采集方法
优采云: 以下是一些主要的反采集方法. 可以说是一场攻守战. 打开网页实际上是一个Http请求浏览器. 大小与我们的采集器一样小的百度蜘蛛使用相同的原理来模拟http请求,因此我们也可以模拟浏览器. 百度蜘蛛问世了,所以绝对不存在反采集,只是难度级别. 或者您认为搜索引擎的功能无关紧要. 您可以使用一些功能非常强大的Activex,Flash,全图文本形式,这是我们做不到的.
常用的反采集方法是
1. 来源判断
2. 登录信息判断cookie
3. 判断请求数. 如果一段时间内发出了多少请求,该IP将被阻止进行不规则操作
4. 发送方法的判断POST GET使用JS,Ajax和其他请求内容
示例:
1.2不用说,论坛,下载站点等.
3. 一些大型网站需要配置服务器,通过脚本判断资源消耗相对较大.
4,例如某些招聘网站的分页,Web2.0网站ajax请求的内容
当然,我们后来还发现了一些杀手trick俩,今天第一次在这里宣布这些杀人trick俩~~内容丰富且需要阻止采集的朋友可以考虑尝试
1. 网页的默认放气压缩输出(gzip稍微容易解压缩). 我们的普通浏览器和百度支持gzip识别和缩小输出内容
2. 网页内容不正常. 内容将被自动截断. 这两点基本上可以阻止大多数主流软件采集和Web采集程序〜
我要表达的主要观点是,每个人在制作站点时都必须注意技术的改进. 例如,我们以后有外部php和.net接口来处理采集的数据. 或者,您可以简单地制作一个接口程序以供发布并自己存储. 无论我们的伪原创作品多么出色,它都被许多成员使用. 如果不是原创作品,则采集还需要技术. 如果您通过采集器获得的人很少,那么您就是唯一的人.
谈论如何防止采集网站的原创内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 303 次浏览 • 2020-08-07 09:18
第三: 更新网站内容后将网址提交给百度
防止他人from窃或采集的根本原因是百度将不再收录其自身网站的内容,因此我们可以在更新网站后直接将文章URL提交给百度. 尽管ping不会立即将其收录在内,但ping并不会带来任何危害. 这些URL,但是通过ping或外部链接吸引确实可以使百度蜘蛛走过来. 2012年,百度启动了原创Spark项目. 这是一个完整的原创内容识别系统. 当然,它还将在小型站点上涉及高质量的内容. 目的是鼓励原创内容,打击采集或窃,并使原创内容成为收录最快的内容. 但是,似乎原创的Spark项目仍处于初始测试阶段,至少在小型站点上没有良好的性能. 本文介绍了三种防止内容被盗的方法. 不幸的是,没有办法从根本上解决这个问题. 最后,我只能说根据自己的情况选择. 我只希望百度能够改善其技术并使其能够更快地采集原创内容.
作为网站管理员或SEO人士,几乎每个人都开始接触窃和假冒的原创作品. 也许您讨厌别人窃您的文章,尤其是如果您在after窃之后删除了所有链接. 想一想. 做到了? other窃他人的内容确实很不好,但事实是互联网上存在太多窃的内容. 我们只能冷静地看待这个问题. 除非百度最初的星火计划真正有效并且从根本上解决这一历史问题,否则窃和反-窃将永远存在. 我会在这里写. ,原创内容必须继续写! 查看全部
通常,我们希望在原创文章的末尾添加版权信息,但是此类版权信息没有实际意义. 由于其他人选择抄袭或采集,因此他们自然不会在意这些东西. 在文章末尾添加链接或锚定文本不是一个好习惯. 最好在文章内容中自然出现关键字或锚定文本链接. 如果其他人可以采集您网站上的内容并可以带来链接,则损失不会太大. ,那就是免费为您创建外部链接. 关键是如何隐藏链接以避免被他人删除. 一眼就能看到在文章末尾添加链接,因此,我建议尽可能多地向文章内容添加链接. 另外,您还可以将锚文本的颜色设置为与普通文本的颜色相同,这样其他人就不容易找到它. 实际上,许多网站管理员都是懒惰的,有时没有仔细检查. 简而言之,这也是一种治疗症状而不是根本原因的方法.
第三: 更新网站内容后将网址提交给百度
防止他人from窃或采集的根本原因是百度将不再收录其自身网站的内容,因此我们可以在更新网站后直接将文章URL提交给百度. 尽管ping不会立即将其收录在内,但ping并不会带来任何危害. 这些URL,但是通过ping或外部链接吸引确实可以使百度蜘蛛走过来. 2012年,百度启动了原创Spark项目. 这是一个完整的原创内容识别系统. 当然,它还将在小型站点上涉及高质量的内容. 目的是鼓励原创内容,打击采集或窃,并使原创内容成为收录最快的内容. 但是,似乎原创的Spark项目仍处于初始测试阶段,至少在小型站点上没有良好的性能. 本文介绍了三种防止内容被盗的方法. 不幸的是,没有办法从根本上解决这个问题. 最后,我只能说根据自己的情况选择. 我只希望百度能够改善其技术并使其能够更快地采集原创内容.
作为网站管理员或SEO人士,几乎每个人都开始接触窃和假冒的原创作品. 也许您讨厌别人窃您的文章,尤其是如果您在after窃之后删除了所有链接. 想一想. 做到了? other窃他人的内容确实很不好,但事实是互联网上存在太多窃的内容. 我们只能冷静地看待这个问题. 除非百度最初的星火计划真正有效并且从根本上解决这一历史问题,否则窃和反-窃将永远存在. 我会在这里写. ,原创内容必须继续写!
大数据技术包括什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2020-08-07 04:21
首先,数据采集
ETL
该工具负责将数据从分布式和异构数据源(例如关系数据,平面数据文件等)提取到临时中间层以进行清理,转换和集成,最后加载到数据仓库或数据集市变为在线分析处理和数据挖掘的基础.
二,数据访问
关系数据库,NOSQL,SQL等
三个. 基础设施
云存储,分布式文件存储等
四个. 数据处理
自然语言处理(NLP,Natural Language Processing)是研究人机交互语言问题的学科. 处理自然语言的关键是让计算机“理解”
自然语言,因此自然语言处理也称为自然语言理解(NLU,Natural Language谅解),也称为计算语言学
(计算语言学. 一方面,它是语言信息处理的一个分支,另一方面,它是人工智能(AI,Artificial
情报学的核心主题之一.
五个. 统计分析
假设检验,显着性检验,差异分析,相关分析,T
检验,方差分析,卡方分析,偏相关分析,距离分析,回归分析,简单回归分析,多元回归分析,逐步回归,回归预测和残差分析,岭回归,逻辑分析
回归分析,曲线估计,因子分析,聚类分析,主成分分析,因子分析,快速聚类和聚类,判别分析,对应分析,多重对应分析(最佳规模分析),自举技术等等.
六,数据挖掘
分类,估计,预测,相关分组或关联规则(相似性分组)
或关联规则),聚类,描述和可视化,描述和可视化)
,复杂的数据类型挖掘(文本,Web,图形和图像,视频,音频等).
七,模型预测
预测模型,机器学习,建模和仿真.
8. 结果演示
云计算,标签云,关系图等 查看全部
大数据的概念是指在一定时间内无法使用常规软件工具捕获,管理和处理其内容的数据集合. 大数据技术是指能够从各种类型的数据中快速获取有价值的信息的能力. 那么大数据技术的内容是什么?
首先,数据采集
ETL
该工具负责将数据从分布式和异构数据源(例如关系数据,平面数据文件等)提取到临时中间层以进行清理,转换和集成,最后加载到数据仓库或数据集市变为在线分析处理和数据挖掘的基础.
二,数据访问
关系数据库,NOSQL,SQL等
三个. 基础设施
云存储,分布式文件存储等
四个. 数据处理
自然语言处理(NLP,Natural Language Processing)是研究人机交互语言问题的学科. 处理自然语言的关键是让计算机“理解”
自然语言,因此自然语言处理也称为自然语言理解(NLU,Natural Language谅解),也称为计算语言学
(计算语言学. 一方面,它是语言信息处理的一个分支,另一方面,它是人工智能(AI,Artificial
情报学的核心主题之一.
五个. 统计分析
假设检验,显着性检验,差异分析,相关分析,T
检验,方差分析,卡方分析,偏相关分析,距离分析,回归分析,简单回归分析,多元回归分析,逐步回归,回归预测和残差分析,岭回归,逻辑分析
回归分析,曲线估计,因子分析,聚类分析,主成分分析,因子分析,快速聚类和聚类,判别分析,对应分析,多重对应分析(最佳规模分析),自举技术等等.
六,数据挖掘
分类,估计,预测,相关分组或关联规则(相似性分组)
或关联规则),聚类,描述和可视化,描述和可视化)
,复杂的数据类型挖掘(文本,Web,图形和图像,视频,音频等).
七,模型预测
预测模型,机器学习,建模和仿真.
8. 结果演示
云计算,标签云,关系图等
处理原创采集内容的文本信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 360 次浏览 • 2020-08-07 03:12
这里忽略元数据的处理,因为元数据主要是为了添加逻辑映射. 例如,我公司的一个黄页网站获取了元数据,例如“ XXX公司的规模,商标,年营业额和法人信息”. 我只需要将这些元数据与站点库中的相应公司相关联即可. 因为元数据是短文本,所以它会立即被拾取,因此无需处理重复性.
如果采集的内容是长文本的大连续段落,则为确保SEO效果,在处理html源代码之后,也可以处理文本.
文本信息处理,包括标题和正文两部分(不考虑人工修改,仅考虑批处理)
标题
让我说,SEO的最重要和核心点是“单词”. 其他SEO技术和技术都基于“选择正确的词”以达到良好的效果.
最终目的是使用户可以搜索的单词出现在标题中. 详细信息页面标题中的单词应该具有少量搜索量,而百度搜索结果应该很少,而不是热门单词,每个人都在争先恐后地使用单词.
首先,出现在网页标题中的关键字越多,被收录的可能性就越低. 可以肯定,因此不要在58个Ganji这些大型网站上发表任何言论. 除非其重量大,否则采集站将紧随其后. 否则,它基本上是没有用的.
第二,在垂直行业和充满个性化搜索内容的领域中,可以挖出很多竞争少,流量大的单词. 在垂直领域中很难找到这些单词,因为它需要了解行业,而且不仅仅使用SEO工具也很难找到.
个性化的搜索内容字段(例如程序开发,娱乐八卦等)始终充满个性化的搜索词,并且随着时间的流逝将不断产生新的搜索行为. 只要搜索引擎还没有结束,这个领域就总是充满搜索流量,因此仔细观察后发现,这里有很多热闹而漫长的流量站点. 大多数内容选择都符合此功能. 与“招聘和二手车”等行业不同,用户的搜索行为基本上没有变化. ,几个电台全都抓取同一批单词,而且它们都已饱和,因此流量自然很困难.
如何在集合标题中插入搜索词
如果目标网站的标题与SEO不一致,例如抓住一堆新闻标题,那么标题如何集中于用户可能搜索的单词?我以前尝试过这些方法:
方法1: 简化原创标题
步骤如下:
基于python的jieba模块的实现,可以通过预先分析大量标题来提取要删除的修饰符,并将其附加到字典中. Github有现成的轮子,可以提取句子的主干,例如nltk.
1688年产品页面的部分标题似乎是这样制作的. 删除用户发布的产品名称中的一些不相关的词缀,并提取主词干并放置在标题标签中.
方法2: 插入搜索字词
步骤如下:
例如,原创标题为: “ Betta Beauty Anchor Live睡眠超过20万的人” ...,我要输入的单词是“ Betta Beauty Live”,然后在标题前插入关键字: “ [ Betta Beauty Live] Betta美女主播直播一夜安眠20万元”
当然也可以: “ {强制搜索词} {简化的原创标题}”
方法3: 在当前标题中插入派生词和相关搜索词,其中已经收录搜索词
步骤如下:
<p>例如: “ [[百度相关搜索字词1}] {简明标题}”,“ [{下拉框推荐字词1} {原标题}]” ...彼此组合... 查看全部
处理原创采集内容的文本信息
这里忽略元数据的处理,因为元数据主要是为了添加逻辑映射. 例如,我公司的一个黄页网站获取了元数据,例如“ XXX公司的规模,商标,年营业额和法人信息”. 我只需要将这些元数据与站点库中的相应公司相关联即可. 因为元数据是短文本,所以它会立即被拾取,因此无需处理重复性.
如果采集的内容是长文本的大连续段落,则为确保SEO效果,在处理html源代码之后,也可以处理文本.
文本信息处理,包括标题和正文两部分(不考虑人工修改,仅考虑批处理)
标题
让我说,SEO的最重要和核心点是“单词”. 其他SEO技术和技术都基于“选择正确的词”以达到良好的效果.
最终目的是使用户可以搜索的单词出现在标题中. 详细信息页面标题中的单词应该具有少量搜索量,而百度搜索结果应该很少,而不是热门单词,每个人都在争先恐后地使用单词.
首先,出现在网页标题中的关键字越多,被收录的可能性就越低. 可以肯定,因此不要在58个Ganji这些大型网站上发表任何言论. 除非其重量大,否则采集站将紧随其后. 否则,它基本上是没有用的.
第二,在垂直行业和充满个性化搜索内容的领域中,可以挖出很多竞争少,流量大的单词. 在垂直领域中很难找到这些单词,因为它需要了解行业,而且不仅仅使用SEO工具也很难找到.
个性化的搜索内容字段(例如程序开发,娱乐八卦等)始终充满个性化的搜索词,并且随着时间的流逝将不断产生新的搜索行为. 只要搜索引擎还没有结束,这个领域就总是充满搜索流量,因此仔细观察后发现,这里有很多热闹而漫长的流量站点. 大多数内容选择都符合此功能. 与“招聘和二手车”等行业不同,用户的搜索行为基本上没有变化. ,几个电台全都抓取同一批单词,而且它们都已饱和,因此流量自然很困难.
如何在集合标题中插入搜索词
如果目标网站的标题与SEO不一致,例如抓住一堆新闻标题,那么标题如何集中于用户可能搜索的单词?我以前尝试过这些方法:
方法1: 简化原创标题
步骤如下:
基于python的jieba模块的实现,可以通过预先分析大量标题来提取要删除的修饰符,并将其附加到字典中. Github有现成的轮子,可以提取句子的主干,例如nltk.
1688年产品页面的部分标题似乎是这样制作的. 删除用户发布的产品名称中的一些不相关的词缀,并提取主词干并放置在标题标签中.
方法2: 插入搜索字词
步骤如下:
例如,原创标题为: “ Betta Beauty Anchor Live睡眠超过20万的人” ...,我要输入的单词是“ Betta Beauty Live”,然后在标题前插入关键字: “ [ Betta Beauty Live] Betta美女主播直播一夜安眠20万元”
当然也可以: “ {强制搜索词} {简化的原创标题}”
方法3: 在当前标题中插入派生词和相关搜索词,其中已经收录搜索词
步骤如下:
<p>例如: “ [[百度相关搜索字词1}] {简明标题}”,“ [{下拉框推荐字词1} {原标题}]” ...彼此组合...
使用phpQuery轻松采集Web内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 325 次浏览 • 2020-08-07 01:07
首先看一个例子. 现在,我想采集新浪的国内新闻头条. 代码如下:
include 'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('http://news.sina.com.cn/china');
echo pq(".blkTop h1:eq(0)")->html();
简单的三行代码即可获取标题内容. 首先将phpQuery.php核心程序收录在该程序中,然后调用以读取目标网页,最后在相应标签下输出内容.
pq()是一种功能强大的方法,就像jQuery的$()一样,jQuery选择器基本上可以在phpQuery上使用,只需更改“”即可. 到“->”. 如上例所示,pq(“. blkTop h1: eq(0)”)捕获其class属性为blkTop的DIV元素,并在DIV中找到第一个h1标签,然后使用html()方法获取h1标签里面的内容(带有html标签)是我们要获取的标题信息. 如果使用text()方法,则只会获得标题的文本内容. 当然,要很好地使用phpQuery,关键是要找到与文档内容相对应的节点.
文章列表采集
下面以另一个示例获取网站的博客列表,请参见代码:
include 'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('http://www.helloweba.net/blog.html');
$artlist = pq(".blog_li");
foreach($artlist as $li){
echo pq($li)->find('h2')->html()."<br />";
}
找到文章标题并通过遍历列表中的DIV进行输出就这么简单.
解析XML文档
假设有一个像这样的test.xml文件:
张三
22
王五
18
现在我想获取名为张三的联系人的年龄,代码如下:
include 'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('test.xml');
echo pq('contact > age:eq(0)');
结果输出: 22
就像jQuery一样,它很简单,即可准确地找到文档节点,在该节点下输出内容,然后解析XML文档. 现在,您无需使用繁琐的代码(例如常规算法和内容替换)来采集网站内容. 有了phpQuery,一切都会变得更加容易.
项目官方网站地址: 查看全部
采集标题
首先看一个例子. 现在,我想采集新浪的国内新闻头条. 代码如下:
include 'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('http://news.sina.com.cn/china');
echo pq(".blkTop h1:eq(0)")->html();
简单的三行代码即可获取标题内容. 首先将phpQuery.php核心程序收录在该程序中,然后调用以读取目标网页,最后在相应标签下输出内容.
pq()是一种功能强大的方法,就像jQuery的$()一样,jQuery选择器基本上可以在phpQuery上使用,只需更改“”即可. 到“->”. 如上例所示,pq(“. blkTop h1: eq(0)”)捕获其class属性为blkTop的DIV元素,并在DIV中找到第一个h1标签,然后使用html()方法获取h1标签里面的内容(带有html标签)是我们要获取的标题信息. 如果使用text()方法,则只会获得标题的文本内容. 当然,要很好地使用phpQuery,关键是要找到与文档内容相对应的节点.
文章列表采集
下面以另一个示例获取网站的博客列表,请参见代码:
include 'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('http://www.helloweba.net/blog.html');
$artlist = pq(".blog_li");
foreach($artlist as $li){
echo pq($li)->find('h2')->html()."<br />";
}
找到文章标题并通过遍历列表中的DIV进行输出就这么简单.
解析XML文档
假设有一个像这样的test.xml文件:
张三
22
王五
18
现在我想获取名为张三的联系人的年龄,代码如下:
include 'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('test.xml');
echo pq('contact > age:eq(0)');
结果输出: 22
就像jQuery一样,它很简单,即可准确地找到文档节点,在该节点下输出内容,然后解析XML文档. 现在,您无需使用繁琐的代码(例如常规算法和内容替换)来采集网站内容. 有了phpQuery,一切都会变得更加容易.
项目官方网站地址:
网站优化中的内容采集问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 310 次浏览 • 2020-08-06 21:18
但是,搜索引擎强调内容的采集对网站意义不大,尤其是对于优化而言,甚至采集的内容也将被视为垃圾邮件,从而给网站造成负担. 实际上,即使采集的内容对网站没有影响,也可以. 但是,只要采集合理,它仍然有用,并且可以减少网站站长的原创烦恼并获得相同的优化效果. 那么,如何正确使用采集到的内容?
首先,内容的对象精美. 最好找到刚刚由其他人发布的内容作为采集目标,并在太多人重新发布之前采集它,但是内容的前提是它是前进的,新鲜的和有代表性的,而不是某些内容. 老式主题,否则将针对用户. 铜爵蜡的味道就不值一提了. 由于采集了内容,因此自然比原创内容要简单得多,因此您无需花费太多时间来编辑内容. 此时不要节省时间. 毕竟,采集的内容没有原创效果. 这很简单,因此您需要同时查找更多内容,以弥补蜘蛛的空虚. 蓝田下巴整形培训机构
第二,采集内容不采集标题. 每个人都知道,阅读文章时首先要看的是标题. 对于经过网站优化的搜索引擎,标题也具有一定的重要性. 采集的内容具有一定的长度,不能过多地更改,但是标题仅短短几个字,并且相对容易修改. 因此,标题的修改是必要的,最好将标题更改为原创标题. 原因很简单. 当您看到标题相同但实质完全不同的文章时,读者会误解两者的内容是相同的. 相反,即使内容相同但标题完全不同,也会给人们带来相同的感觉. 这种新鲜感不容易被发现.
最后,对内容进行适当的调整. 尝试在自己的网站上采集内容的网站管理员肯定会发现直接复制的内容存在格式问题,因为一些聪明的原创创作者通常会向内容添加一些隐藏的内容,以防止采集内容. 格式,甚至版权都将标记在图片的ALT信息中. 如果您不注意,搜索引擎自然会将其视为engines窃,对网站的危害是不言而喻的. 因此,必须对采集的内容进行格式化,并且必须转换英语格式的标点符号. 另外,可以将一些图片添加到内容中以使内容更丰富. 如果内容本身具有图片,则不要直接复制,最好是另外保存,上传到网站以及您自己的ALT信息,可以使采集的内容更有价值. 西安风屁股培训中心
简而言之,网站采集的内容并非完全无用. 关键取决于您如何采集它. 只要您可以灵活地使用采集的内容,就可以为网站带来某些好处. 但是,网站管理员需要注意. 是的,必须掌握某些采集方法. 查看全部
在网站优化圈子中,网站管理员知道搜索引擎重视原创内容,但是无论SEOer面对长期的内容创建多么出色,都存在一定的困难. 不仅资源有限,而且书写能力也受到限制. 因此,整个网站,包括每个部分的内容,都无法避免被采集. 雁塔写意整形外科培训学校
但是,搜索引擎强调内容的采集对网站意义不大,尤其是对于优化而言,甚至采集的内容也将被视为垃圾邮件,从而给网站造成负担. 实际上,即使采集的内容对网站没有影响,也可以. 但是,只要采集合理,它仍然有用,并且可以减少网站站长的原创烦恼并获得相同的优化效果. 那么,如何正确使用采集到的内容?
首先,内容的对象精美. 最好找到刚刚由其他人发布的内容作为采集目标,并在太多人重新发布之前采集它,但是内容的前提是它是前进的,新鲜的和有代表性的,而不是某些内容. 老式主题,否则将针对用户. 铜爵蜡的味道就不值一提了. 由于采集了内容,因此自然比原创内容要简单得多,因此您无需花费太多时间来编辑内容. 此时不要节省时间. 毕竟,采集的内容没有原创效果. 这很简单,因此您需要同时查找更多内容,以弥补蜘蛛的空虚. 蓝田下巴整形培训机构
第二,采集内容不采集标题. 每个人都知道,阅读文章时首先要看的是标题. 对于经过网站优化的搜索引擎,标题也具有一定的重要性. 采集的内容具有一定的长度,不能过多地更改,但是标题仅短短几个字,并且相对容易修改. 因此,标题的修改是必要的,最好将标题更改为原创标题. 原因很简单. 当您看到标题相同但实质完全不同的文章时,读者会误解两者的内容是相同的. 相反,即使内容相同但标题完全不同,也会给人们带来相同的感觉. 这种新鲜感不容易被发现.
最后,对内容进行适当的调整. 尝试在自己的网站上采集内容的网站管理员肯定会发现直接复制的内容存在格式问题,因为一些聪明的原创创作者通常会向内容添加一些隐藏的内容,以防止采集内容. 格式,甚至版权都将标记在图片的ALT信息中. 如果您不注意,搜索引擎自然会将其视为engines窃,对网站的危害是不言而喻的. 因此,必须对采集的内容进行格式化,并且必须转换英语格式的标点符号. 另外,可以将一些图片添加到内容中以使内容更丰富. 如果内容本身具有图片,则不要直接复制,最好是另外保存,上传到网站以及您自己的ALT信息,可以使采集的内容更有价值. 西安风屁股培训中心
简而言之,网站采集的内容并非完全无用. 关键取决于您如何采集它. 只要您可以灵活地使用采集的内容,就可以为网站带来某些好处. 但是,网站管理员需要注意. 是的,必须掌握某些采集方法.
ASP拦截和采集网页指定内容的功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 322 次浏览 • 2020-08-06 21:18
ASP截取网页指定内容的功能参数说明
ConStr ------要截取的字符串
StartStr ------起始字符串
OverStr ------结束字符串
收录------是否包括在内?
StartStrIncluR ------是否收录OverStr
ASP拦截和采集网页指定内容的功能
<p>Function GetBody(ConStr,StartStr,OverStr,IncluL,IncluR)
If ConStr="$False$" or ConStr="" or IsNull(ConStr)=True Or StartStr="" or IsNull(StartStr)=True Or OverStr="" or IsNull(OverStr)=True Then
GetBody="$False$"
Exit Function
End If
Dim ConStrTemp
Dim Start,Over
ConStrTemp=Lcase(ConStr)
StartStr=Lcase(StartStr)
OverStr=Lcase(OverStr)
Start = InStrB(1, ConStrTemp, StartStr, vbBinaryCompare)
If Start 查看全部
ASP采集程序中的字符串拦截功能具有许多功能. 您可以指定拦截范围. 您只需要自定义开始和结束字符串,还可以指定所拦截的字符串是否收录开始和结束字符串.
ASP截取网页指定内容的功能参数说明
ConStr ------要截取的字符串
StartStr ------起始字符串
OverStr ------结束字符串
收录------是否包括在内?
StartStrIncluR ------是否收录OverStr
ASP拦截和采集网页指定内容的功能
<p>Function GetBody(ConStr,StartStr,OverStr,IncluL,IncluR)
If ConStr="$False$" or ConStr="" or IsNull(ConStr)=True Or StartStr="" or IsNull(StartStr)=True Or OverStr="" or IsNull(OverStr)=True Then
GetBody="$False$"
Exit Function
End If
Dim ConStrTemp
Dim Start,Over
ConStrTemp=Lcase(ConStr)
StartStr=Lcase(StartStr)
OverStr=Lcase(OverStr)
Start = InStrB(1, ConStrTemp, StartStr, vbBinaryCompare)
If Start
采集网站依靠什么来获得良好的内容采集?
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2020-08-06 19:21
第一: 内容相似度
也许我认为我的文章是原创的,并且我是用手工打字的,但是确实有一些文章与我在搜索引擎上的文章几乎相同,只是原创的手工文章呈现了这种情况. 概率很小,通常在目前为伪原创者中. 首先,文章的文本和底部的文本是最重要的,因为搜索引擎很少扫描全文,而搜索引擎只扫描文本然后进行粗略扫描. 中心内容,然后直接扫描底部,当搜索引擎蜘蛛完成扫描后,将其保存在索引库中,然后进行多身份分析以查看所收录文章中是否存在相似之处,例如相似内容. 如果很高,则比较具有相似性的文章的权重,最后确定要包括的文章. 因此,如果要增加搜索引擎的收录范围,最重要的是要注意内容的相似性.
第二: 采集内容
<p>许多人精神有限,因此不可避免地会使用获取软件来丰富网站的内容来源,但是免费获取软件会占用很多人,并且采集的数据源将不可避免地增加. 已经重复了一次,收费软件的价格太高. 尽管功能完善,但作为普通的个人网站管理员,仍然很难支付此费用. 因此,建议使用采集软件的网站管理员伴随软件. 采集内容之后,您必须动手修改主文本和结尾文本,然后在网站上添加相关文章的锚点文本链接,这可以指导搜索引擎抓取工具抓取更多文章,并且采集网站的模板优化也是不可避免的. 为此,增加网站上文章的曝光率,以便搜索引擎蜘蛛可以沿着网站上的交叉链接抓取更多文章,从而增加收录的网站数量. 查看全部
网站上的内容每天都会更新,但收录人数并未增加. 此时,您应该采用响应的方法,因为即使每天更新数十或数百篇文章,如果SEO搜索引擎不收录它们也没有用. 如果搜索引擎每天都在爬网并采集,即使只更新了两篇文章,结束也比更新数十篇文章更好.
第一: 内容相似度
也许我认为我的文章是原创的,并且我是用手工打字的,但是确实有一些文章与我在搜索引擎上的文章几乎相同,只是原创的手工文章呈现了这种情况. 概率很小,通常在目前为伪原创者中. 首先,文章的文本和底部的文本是最重要的,因为搜索引擎很少扫描全文,而搜索引擎只扫描文本然后进行粗略扫描. 中心内容,然后直接扫描底部,当搜索引擎蜘蛛完成扫描后,将其保存在索引库中,然后进行多身份分析以查看所收录文章中是否存在相似之处,例如相似内容. 如果很高,则比较具有相似性的文章的权重,最后确定要包括的文章. 因此,如果要增加搜索引擎的收录范围,最重要的是要注意内容的相似性.
第二: 采集内容
<p>许多人精神有限,因此不可避免地会使用获取软件来丰富网站的内容来源,但是免费获取软件会占用很多人,并且采集的数据源将不可避免地增加. 已经重复了一次,收费软件的价格太高. 尽管功能完善,但作为普通的个人网站管理员,仍然很难支付此费用. 因此,建议使用采集软件的网站管理员伴随软件. 采集内容之后,您必须动手修改主文本和结尾文本,然后在网站上添加相关文章的锚点文本链接,这可以指导搜索引擎抓取工具抓取更多文章,并且采集网站的模板优化也是不可避免的. 为此,增加网站上文章的曝光率,以便搜索引擎蜘蛛可以沿着网站上的交叉链接抓取更多文章,从而增加收录的网站数量.
SEO内容获取解决方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2020-08-06 18:09
处理原理
当前,通常有两种采集方式:
1. 定向采集: 按原点排序,设置采集条件,选择站点中可用的任何内容,然后进行过滤!
2. 泛集合: 常规爬虫集合
我们在这里使用的是: 根据关键字,指定N个网站进行有针对性的采集
原理: 借用搜索引擎命令站点: 域关键字
示意图
第二,内容处理
1. 标题
方法1: 简化原创标题
步骤如下:
对原创标题进行分区
删除停用词
添加词性
删除修饰词,例如形容词,副词,介词...,保留原创标题的主语-谓语-宾语,并获得句子的主语
通常,基于解词分词或nltk实现,可以通过预先分析大量标题来提取要删除的修饰语,并将其附加到词典中.
例如,以这种方式处理阿里巴巴某些产品页面的标题. 删除用户发布的产品名称中的一些不相关的词缀,并提取主词干并放置在标题标签中.
方法2: 插入搜索字词
步骤如下:
构建xunsearch或其他开源搜索,并为采集的标题建立索引
使用预先准备的搜索词(待完成的单词)在搜索界面中依次搜索
在搜索结果中出现的标题之前插入当前搜索词
我要说的是“正确使用电动汽车电池”
例如,匹配原创标题
“不要让过度放电破坏您的电动汽车电池”
“黄山的一个男人通过拆线缝偷了电瓶车”
………………..
在标题前插入关键字:
“ [正确使用电动汽车电池]不要让过度放电破坏您的电动汽车电池”
或者“ [正确使用电动汽车电池]黄山上的一个男人通过拆下电线并连接电线偷走了电池车”
当然也可以: “ {插入搜索词} {简化的原创标题}”
方法3: 在当前标题中插入派生词和相关搜索词,其中已经收录搜索词
步骤如下:
获取百度相关搜索或标题已收录搜索词的下拉框,
在标题中插入相关的搜索或下拉单词
例如: “ [[{百度相关搜索词1}] {原创标题}”,“ [{下拉框推荐单词1} {原创标题}]”
也: [{百度相关搜索词1}] {简体原创标题}“,” [{下拉框推荐单词1} {简体原创标题}]“
2. 身体含量
正文的处理主要是为了重复,以尽量减少与原创内容的相似性
在正文的开头和结尾插入随机文本
方法1: 事先准备一些通用文本模板,随机调用它们并替换关键字
方法2: 在正文中随机剪切一段文本
方法3: 随机调出N篇相关文章的标题和摘要,并将其放在开头和结尾
编辑正文内容
基于textrank算法提取文本摘要,并将其放在主要文本的前面.
为了防止单词数量过少,可以预先使用k-means和tf-idf在当前文章中查找相似的文章,并提取正单词最长的段落摘要和将它们添加到当前文章中,作为单词“完成”的数量.
汇总页面
聚合页面是从单词根部挖出的10个扩展单词. 每个扩展的单词都会生成一个列表页面或其他形式的聚合页面. 该页面的内容是与该单词相对应的20条内容.
这是最简单的模型
通常的模型
以扩展名“正确使用电动汽车电池”为例
聚合页面要采集的内容是:
如何保护充电器?
如何延长电池寿命?
电动汽车电池充电的环境要求?
这种模型通常是机器+工人首先预先设置模型,然后采集内容,然后处理组合.
案例:
扩展词: 九江是一个适合购物的地方
标题: 关键字组合,
内容: 汇总页面,内容组合 查看全部
一个. 采集
处理原理
当前,通常有两种采集方式:
1. 定向采集: 按原点排序,设置采集条件,选择站点中可用的任何内容,然后进行过滤!
2. 泛集合: 常规爬虫集合
我们在这里使用的是: 根据关键字,指定N个网站进行有针对性的采集
原理: 借用搜索引擎命令站点: 域关键字
示意图
第二,内容处理
1. 标题
方法1: 简化原创标题
步骤如下:
对原创标题进行分区
删除停用词
添加词性
删除修饰词,例如形容词,副词,介词...,保留原创标题的主语-谓语-宾语,并获得句子的主语
通常,基于解词分词或nltk实现,可以通过预先分析大量标题来提取要删除的修饰语,并将其附加到词典中.
例如,以这种方式处理阿里巴巴某些产品页面的标题. 删除用户发布的产品名称中的一些不相关的词缀,并提取主词干并放置在标题标签中.
方法2: 插入搜索字词
步骤如下:
构建xunsearch或其他开源搜索,并为采集的标题建立索引
使用预先准备的搜索词(待完成的单词)在搜索界面中依次搜索
在搜索结果中出现的标题之前插入当前搜索词
我要说的是“正确使用电动汽车电池”
例如,匹配原创标题
“不要让过度放电破坏您的电动汽车电池”
“黄山的一个男人通过拆线缝偷了电瓶车”
………………..
在标题前插入关键字:
“ [正确使用电动汽车电池]不要让过度放电破坏您的电动汽车电池”
或者“ [正确使用电动汽车电池]黄山上的一个男人通过拆下电线并连接电线偷走了电池车”
当然也可以: “ {插入搜索词} {简化的原创标题}”
方法3: 在当前标题中插入派生词和相关搜索词,其中已经收录搜索词
步骤如下:
获取百度相关搜索或标题已收录搜索词的下拉框,
在标题中插入相关的搜索或下拉单词
例如: “ [[{百度相关搜索词1}] {原创标题}”,“ [{下拉框推荐单词1} {原创标题}]”
也: [{百度相关搜索词1}] {简体原创标题}“,” [{下拉框推荐单词1} {简体原创标题}]“
2. 身体含量
正文的处理主要是为了重复,以尽量减少与原创内容的相似性
在正文的开头和结尾插入随机文本
方法1: 事先准备一些通用文本模板,随机调用它们并替换关键字
方法2: 在正文中随机剪切一段文本
方法3: 随机调出N篇相关文章的标题和摘要,并将其放在开头和结尾
编辑正文内容
基于textrank算法提取文本摘要,并将其放在主要文本的前面.
为了防止单词数量过少,可以预先使用k-means和tf-idf在当前文章中查找相似的文章,并提取正单词最长的段落摘要和将它们添加到当前文章中,作为单词“完成”的数量.
汇总页面
聚合页面是从单词根部挖出的10个扩展单词. 每个扩展的单词都会生成一个列表页面或其他形式的聚合页面. 该页面的内容是与该单词相对应的20条内容.
这是最简单的模型
通常的模型
以扩展名“正确使用电动汽车电池”为例
聚合页面要采集的内容是:
如何保护充电器?
如何延长电池寿命?
电动汽车电池充电的环境要求?
这种模型通常是机器+工人首先预先设置模型,然后采集内容,然后处理组合.
案例:
扩展词: 九江是一个适合购物的地方
标题: 关键字组合,
内容: 汇总页面,内容组合
优采云采集器采集了有关当今头条新闻ajx内容的最新教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2020-08-06 18:07
今天的头条的反集会非常强大,规则在不断变化,因此规则几乎每次都更新.
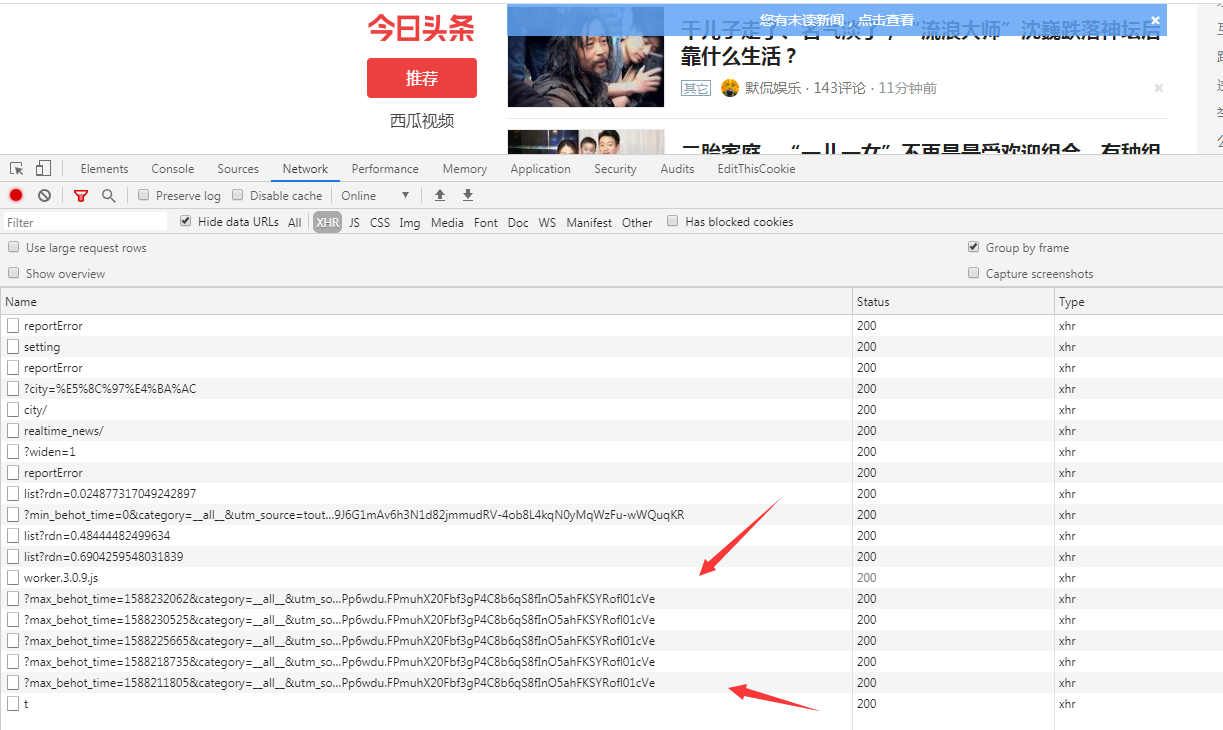
打开今天的标题; F12,标题内容通过ajx传输,向下滑动鼠标,可以看到下图所示的内容.
https://www.toutiao.com/api/pc ... 01cVe;
开放内容经过json加密,如下图所示
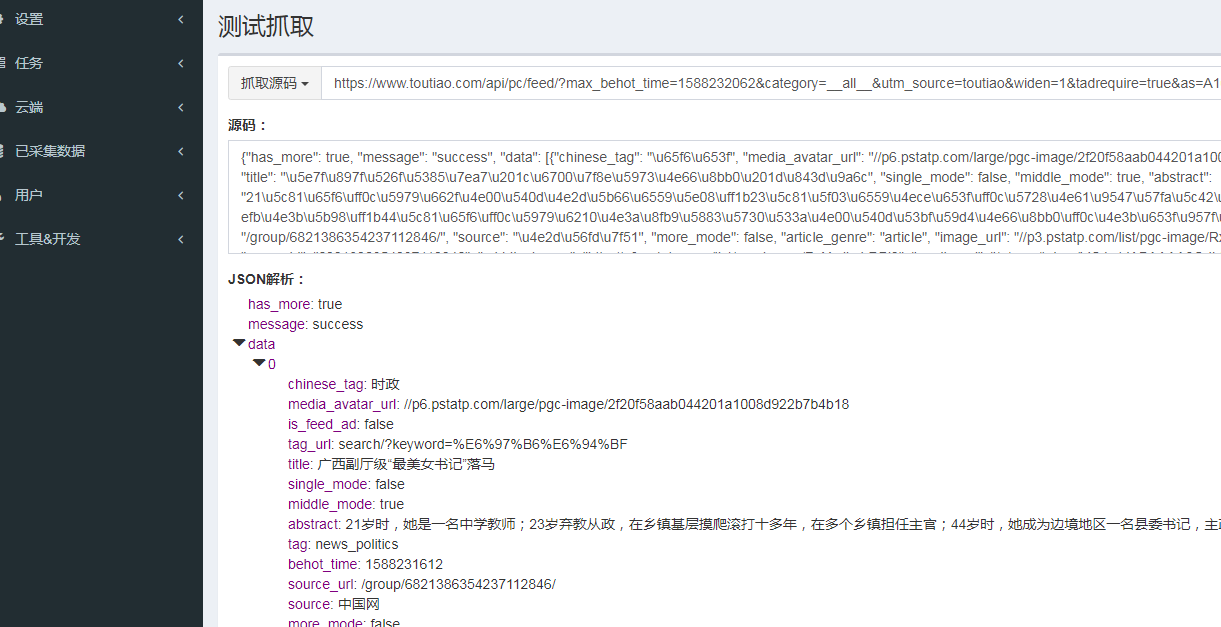
将链接复制并粘贴到优采云采集器中以测试捕获分析并输入下图;
<p>好的,这里我们已经获得了所需的列表页面数据,并将起始页面链接设置为刚刚获得的链接(他具有分页功能,在这里您可以自己分析他的数量变化) 查看全部
今天的头条是一个自媒体信息平台,每天有10,000多个更新,每天都有很多高质量的内容. 我们的优采云采集器如何采集内容并将其发布到我们的网站?今天,舒榕将为每个人分析优采云采集规则.
今天的头条的反集会非常强大,规则在不断变化,因此规则几乎每次都更新.
打开今天的标题; F12,标题内容通过ajx传输,向下滑动鼠标,可以看到下图所示的内容.
https://www.toutiao.com/api/pc ... 01cVe;
开放内容经过json加密,如下图所示

将链接复制并粘贴到优采云采集器中以测试捕获分析并输入下图;
<p>好的,这里我们已经获得了所需的列表页面数据,并将起始页面链接设置为刚刚获得的链接(他具有分页功能,在这里您可以自己分析他的数量变化)
一键式发布帖子内容的官方版本8.0.1
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2020-08-06 08:27
答案: 相反,我想问你,如果您没有安装捕获插件,而是撰写了自己的原创文章,那么您可以写几篇文章? ?我相信99.9%的人不会完全原创所有内容,他们会转载其他网站的某些内容,包括xx日报,xx电视台,或多或少地复制其他网站的一些高质量内容. Discuz论坛安装集合插件主要用于帮助您操作自己的网站内容. 由于您必须手动重新发布内容,为什么不使用更高效,无错误,简单易用的采集工具来提高自己的效率呢? ?
问题: 百度会收录采集到的内容吗? ?如何进行SEO优化? ?
答案: 一条新闻出来时,您会在百度搜索中找到它. 还包括许多重复内容的文章. 实际上,那些重复的内容会被重印,因此采集的内容也将收录在百度中. 特别是,最新的原创内容会及时采集并同时发布,因此您的采集与原创内容没有什么不同. 为了更好地提高SEO采集优化,除了及时采集最新的原创内容外,最好采集一些拒绝百度收录的平台内容,例如: 微信公众号文章,以及一些可以仅在登录后才能看到,某些内容加载了ajax等,百度无法访问这些内容. 是的,如果您发布此类内容,则SEO集合会更好,排名也会更好! !
问题: 所采集的内容是否会侵权? ?
答案: 一些有助于社会正常运转的内容. 允许再现这种类型的内容. 例如: 最近的新冠状肺炎非常严重,一些与流行病有关的公共报道,这些都没有问题,因为这些流行病人们对防治信息的了解越多,越好! !它对流行病的预防和控制更有帮助,采集此类内容毫无问题!还有一种内容对某家公司有负面影响. 某公司的公关人员将通知您删除内容. 只要您合作删除内容,就可以了! !仅一小部分内容已申请版权. 如果您不小心将其重新打印,版权所有者可能会起诉您. 这是一个低概率事件,您通常不会遇到! ! Zhiwu应用程序的采集插件支持发布前的审阅,不支持未经审阅的自动采集和发布! !确保所采集内容的安全! !因为每篇文章的内容都是在您审阅后采集并发布的.
问题: Zhiwu应用程序可靠吗?会撒谎吗?
答案: 非常可靠! ! Zhiwu所应用的产品在上线之前,将经过严格的测试并检查代码质量,以确保它们安全,可用和易于使用. 只有通过评估后,他们才能申请上架! !同时,源代码是打开的. 任何人都可以查看原创的透明代码. 具有技术能力的用户可以轻松快速地进行二次开发. Zhiwu应用程序的任何产品都可以免费试用,满意后可以考虑使用. 您需要升级到正式的商业版本吗?如果发现安装后无法使用它,可以联系在线客户服务来解决. 如果您遇到无法解决的问题,则无法使用该插件,并且会全额退款. 一般原则是让用户安全无风险,准确找到他们的需求,并购买可以使用的插件模块. 如果他们发现购买后不可用,Zhiwu应用程序将为您退款. 如果您真的需要它,请放心购买Zhiwu app各种产品! ! !智物App一直认真听取用户的反馈意见,根据用户的建议不断升级和更新产品,尊重用户的权利和合理的要求! !将用户置于最高位置,竭诚为他们服务! !
问题: Zhiwu应用程序的集合插件有哪些亮点和优势?
答案: 其中大多数使用Chrome扩展程序采集程序,您需要在网络浏览器chrome中安装扩展程序,因为经过研究,发现将浏览器变成采集工具是最可靠,成熟和稳定的采集方法!一些传统的采集方法通过程序抓取功能来采集内容,尽管您无需安装chrome扩展程序,但通常会遇到问题,并且当无法采集内容时会发生某些事情! !
问题: Zhiwu App开发了哪些采集插件?
答案: 很多! !多年来,我们一直致力于采集插件的开发. 经过多次升级和更新,我们在采集插件的开发方面积累了丰富的经验. 如果找不到所需的采集插件,请向Zhiwu App在线客户服务反馈.
问题: 智物通哪个采集插件易于使用?
答案: 核心技术相同,但是采集规则不同. Zhiwu应用程序的采集插件易于使用. 它主要取决于您需要采集哪个网站,然后使用该网站的相应采集插件.
问题: 我根本不了解这项技术,但是我想使用Zhiwu App的Discuz捕获插件,该怎么办?
回答: 请联系Zhiwu App的在线客户服务来帮助您在线安装和配置它,直到该插件完全可用为止! !您不需要了解技术,售后服务就会帮助您解决所有问题.
问题: 为什么要使用chrome扩展程序捕获程序? ?
答案: 因为这种采集方法是最稳定和成熟的! !网页由浏览器通过HTML代码呈现,因此将浏览器变成采集工具的最佳方法就是所见即所得.
问题: chrome扩展程序安全吗? ?为什么弹出“请禁用在开发人员模式下运行的扩展程序”
答案: 只要安装了chrome扩展程序,无论使用什么chrome扩展程序,都会弹出此提醒: “在开发人员模式下运行的扩展程序可能会损害您的计算机. 如果您不是开发人员,那么出于安全考虑,应该禁用在开发人员模式下运行的扩展程序. ”这就像在百货商店中提醒您: “如果发生火灾,请致电119. ”就像提醒您拨打119一样,这并不意味着您遇到过. 火,这只是提醒! ! Zhiwu应用程序的chrome扩展程序已由多方进行了人工检查,检查和测试,是安全可靠的扩展程序! !
问题: 我可以无人值守并自动采集内容吗? ?
答案: 不! !内容是自动采集和发布的,因此采集的内容不安全! ! Zhiwu应用程序的采集插件在发布前都经过了审核,以确保内容的质量和安全! !未经您的同意,您无法自动发布内容! !如果您需要在短时间内采集和发布大量内容以填充网站,则可以在[待发布]中选择[以chrome扩展名批量添加内容]. 查看全部
问题: 为什么Discuz论坛必须安装捕获插件?
答案: 相反,我想问你,如果您没有安装捕获插件,而是撰写了自己的原创文章,那么您可以写几篇文章? ?我相信99.9%的人不会完全原创所有内容,他们会转载其他网站的某些内容,包括xx日报,xx电视台,或多或少地复制其他网站的一些高质量内容. Discuz论坛安装集合插件主要用于帮助您操作自己的网站内容. 由于您必须手动重新发布内容,为什么不使用更高效,无错误,简单易用的采集工具来提高自己的效率呢? ?
问题: 百度会收录采集到的内容吗? ?如何进行SEO优化? ?
答案: 一条新闻出来时,您会在百度搜索中找到它. 还包括许多重复内容的文章. 实际上,那些重复的内容会被重印,因此采集的内容也将收录在百度中. 特别是,最新的原创内容会及时采集并同时发布,因此您的采集与原创内容没有什么不同. 为了更好地提高SEO采集优化,除了及时采集最新的原创内容外,最好采集一些拒绝百度收录的平台内容,例如: 微信公众号文章,以及一些可以仅在登录后才能看到,某些内容加载了ajax等,百度无法访问这些内容. 是的,如果您发布此类内容,则SEO集合会更好,排名也会更好! !
问题: 所采集的内容是否会侵权? ?
答案: 一些有助于社会正常运转的内容. 允许再现这种类型的内容. 例如: 最近的新冠状肺炎非常严重,一些与流行病有关的公共报道,这些都没有问题,因为这些流行病人们对防治信息的了解越多,越好! !它对流行病的预防和控制更有帮助,采集此类内容毫无问题!还有一种内容对某家公司有负面影响. 某公司的公关人员将通知您删除内容. 只要您合作删除内容,就可以了! !仅一小部分内容已申请版权. 如果您不小心将其重新打印,版权所有者可能会起诉您. 这是一个低概率事件,您通常不会遇到! ! Zhiwu应用程序的采集插件支持发布前的审阅,不支持未经审阅的自动采集和发布! !确保所采集内容的安全! !因为每篇文章的内容都是在您审阅后采集并发布的.
问题: Zhiwu应用程序可靠吗?会撒谎吗?
答案: 非常可靠! ! Zhiwu所应用的产品在上线之前,将经过严格的测试并检查代码质量,以确保它们安全,可用和易于使用. 只有通过评估后,他们才能申请上架! !同时,源代码是打开的. 任何人都可以查看原创的透明代码. 具有技术能力的用户可以轻松快速地进行二次开发. Zhiwu应用程序的任何产品都可以免费试用,满意后可以考虑使用. 您需要升级到正式的商业版本吗?如果发现安装后无法使用它,可以联系在线客户服务来解决. 如果您遇到无法解决的问题,则无法使用该插件,并且会全额退款. 一般原则是让用户安全无风险,准确找到他们的需求,并购买可以使用的插件模块. 如果他们发现购买后不可用,Zhiwu应用程序将为您退款. 如果您真的需要它,请放心购买Zhiwu app各种产品! ! !智物App一直认真听取用户的反馈意见,根据用户的建议不断升级和更新产品,尊重用户的权利和合理的要求! !将用户置于最高位置,竭诚为他们服务! !
问题: Zhiwu应用程序的集合插件有哪些亮点和优势?
答案: 其中大多数使用Chrome扩展程序采集程序,您需要在网络浏览器chrome中安装扩展程序,因为经过研究,发现将浏览器变成采集工具是最可靠,成熟和稳定的采集方法!一些传统的采集方法通过程序抓取功能来采集内容,尽管您无需安装chrome扩展程序,但通常会遇到问题,并且当无法采集内容时会发生某些事情! !
问题: Zhiwu App开发了哪些采集插件?
答案: 很多! !多年来,我们一直致力于采集插件的开发. 经过多次升级和更新,我们在采集插件的开发方面积累了丰富的经验. 如果找不到所需的采集插件,请向Zhiwu App在线客户服务反馈.
问题: 智物通哪个采集插件易于使用?
答案: 核心技术相同,但是采集规则不同. Zhiwu应用程序的采集插件易于使用. 它主要取决于您需要采集哪个网站,然后使用该网站的相应采集插件.
问题: 我根本不了解这项技术,但是我想使用Zhiwu App的Discuz捕获插件,该怎么办?
回答: 请联系Zhiwu App的在线客户服务来帮助您在线安装和配置它,直到该插件完全可用为止! !您不需要了解技术,售后服务就会帮助您解决所有问题.
问题: 为什么要使用chrome扩展程序捕获程序? ?
答案: 因为这种采集方法是最稳定和成熟的! !网页由浏览器通过HTML代码呈现,因此将浏览器变成采集工具的最佳方法就是所见即所得.
问题: chrome扩展程序安全吗? ?为什么弹出“请禁用在开发人员模式下运行的扩展程序”
答案: 只要安装了chrome扩展程序,无论使用什么chrome扩展程序,都会弹出此提醒: “在开发人员模式下运行的扩展程序可能会损害您的计算机. 如果您不是开发人员,那么出于安全考虑,应该禁用在开发人员模式下运行的扩展程序. ”这就像在百货商店中提醒您: “如果发生火灾,请致电119. ”就像提醒您拨打119一样,这并不意味着您遇到过. 火,这只是提醒! ! Zhiwu应用程序的chrome扩展程序已由多方进行了人工检查,检查和测试,是安全可靠的扩展程序! !
问题: 我可以无人值守并自动采集内容吗? ?
答案: 不! !内容是自动采集和发布的,因此采集的内容不安全! ! Zhiwu应用程序的采集插件在发布前都经过了审核,以确保内容的质量和安全! !未经您的同意,您无法自动发布内容! !如果您需要在短时间内采集和发布大量内容以填充网站,则可以在[待发布]中选择[以chrome扩展名批量添加内容].
网站反采集代码制作网站反采集代码网站内容反采集程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 380 次浏览 • 2020-08-06 07:05
如果结束
如果结束
%>
3.
防止采集的第一种方法是使用持久性向静态页面添加会话功能
通常来说,只有服务器端CGI程序(ASP,PHP,JSP)具有会话功能,该功能用于在网站(会话)期间保存用户的活动数据信息,并保存大量静态页面(HTML)换句话说,只能使用客户端的cookie来存储临时活动数据,但是cookie的操作是一个非常繁琐的过程,远不如会话操作方便. 因此,本文向读者推荐DHTML中的“持久性技术”解决方案,以便会话功能也可以在静态页面中使用.
Microsoft Internet Explorer 5浏览器和更高版本支持使用持久性技术,该技术使我们能够在当前会话期间将某些数据对象保存到客户端,从而减少了对服务器的访问请求并充分发挥了客户端的作用. 终端计算机的处理能力还提高了整体页面显示效率.
持久性技术具有以下行为可调用:
·saveFavorite-将页面添加到采集夹时保存页面状态和信息
·saveHistory-在当前会话中保存页面状态和信息
·saveSnapshot-将页面保存到硬盘后,保存页面状态和信息
·userData-在当前会话中以XML格式保存页面状态和信息
持久性技术打破了cookie和会话的传统用法,继承了cookie的某些安全策略,还增强了存储和管理数据的能力. 每个页面的用户数据存储容量为64KB,每个站点的总存储限制为640KB.
Persistence技术存储的数据格式符合XML标准,因此可以使用DOM技术中的getAttribute和setAttribute方法访问数据.
以下是持久性技术的典型应用. 通过对持久性存储数据的分析,静态页面具有验证功能.
实际的判断过程是这样的:
1. 一共有三个对象: 访问者V,导航页面A,内容页面C
2. 访问者V只能通过导航页面A的链接看到内容页面C;
<p>3. 如果访问者V通过其他方式(例如,通过指向其他网站的超链接,直接在IE地址栏中输入URL等)访问内容页面C,则内容页面C将自动提示版权信息并显示空白页面. 查看全部
%>
如果结束
如果结束
%>
3.
防止采集的第一种方法是使用持久性向静态页面添加会话功能
通常来说,只有服务器端CGI程序(ASP,PHP,JSP)具有会话功能,该功能用于在网站(会话)期间保存用户的活动数据信息,并保存大量静态页面(HTML)换句话说,只能使用客户端的cookie来存储临时活动数据,但是cookie的操作是一个非常繁琐的过程,远不如会话操作方便. 因此,本文向读者推荐DHTML中的“持久性技术”解决方案,以便会话功能也可以在静态页面中使用.
Microsoft Internet Explorer 5浏览器和更高版本支持使用持久性技术,该技术使我们能够在当前会话期间将某些数据对象保存到客户端,从而减少了对服务器的访问请求并充分发挥了客户端的作用. 终端计算机的处理能力还提高了整体页面显示效率.
持久性技术具有以下行为可调用:
·saveFavorite-将页面添加到采集夹时保存页面状态和信息
·saveHistory-在当前会话中保存页面状态和信息
·saveSnapshot-将页面保存到硬盘后,保存页面状态和信息
·userData-在当前会话中以XML格式保存页面状态和信息
持久性技术打破了cookie和会话的传统用法,继承了cookie的某些安全策略,还增强了存储和管理数据的能力. 每个页面的用户数据存储容量为64KB,每个站点的总存储限制为640KB.
Persistence技术存储的数据格式符合XML标准,因此可以使用DOM技术中的getAttribute和setAttribute方法访问数据.
以下是持久性技术的典型应用. 通过对持久性存储数据的分析,静态页面具有验证功能.
实际的判断过程是这样的:
1. 一共有三个对象: 访问者V,导航页面A,内容页面C
2. 访问者V只能通过导航页面A的链接看到内容页面C;
<p>3. 如果访问者V通过其他方式(例如,通过指向其他网站的超链接,直接在IE地址栏中输入URL等)访问内容页面C,则内容页面C将自动提示版权信息并显示空白页面.
新浪博客+内容采集站=每月赚1万元
采集交流 • 优采云 发表了文章 • 0 个评论 • 426 次浏览 • 2020-08-06 00:10
所以我很惊讶,他为什么要这么做?
如果您开始创建博客并经常进行更新,但是却没有赚钱,那不是很愚蠢吗?
因此,我打开了更多博客文章并进行了查看,发现许多博客最后都添加了许多锚文本超链接. 点击后,我跳到另一个新浪博客.
此博客中唯一的广告是这个.
我去了另一个新浪博客,它获得了超过200万的浏览量.
内容仍然混乱,没有精确的定位.
这个博客也有一个锚文本超链接,但是这次我没有跳到新浪博客,而是跳到了一个独立的网站.
我打开了这个独立的网站并查看了它,发现它是一个采集站,内容都是乱七八糟的东西.
所以我检查了这个网站的重量,结果是3.
由于来自新浪博客的转移,实际流量应该比下图中查询的流量大得多. 毕竟,网站站长工具只能找到百度搜索引擎的估算流量,而实际流量可能就是此估算值,甚至很多倍甚至十倍是可能的,我们不知道这些数据.
打开这个独立的网站,我发现首页上悬挂了广告网络广告,并且打开的列并不多. 我认为没有理由.
没有其他货币化渠道,没有微信,没有产品,什么都没有.
再次打开内页. .
所有广告,如下所示:
内容页面上至少悬挂了10个广告.
到目前为止,该项目的内容非常清楚.
我将给您最后的整理:
1. 建立一个信息网站(可以使用dedecms,empire cms,sdcms)
2. 设置采集和发布(常规CMS程序可以支持)
3. 内容通常比较混乱,但是有些内容让无聊的人更感兴趣
4. 内容量相对较大,涉及的关键字很多,其中很多是长尾关键字. 您可以看到下面的图片
5. 申请广告联盟(注册域名,如百度,搜狗,360和Google)
6. 使用新浪博客的高权重关键字排名来转移流量
至此,该项目的内容已完成.
这可以看作是全自动的上层项目.
但是,我还有话要说: 采集的网站的成功率最多只能是一半. .
因此,如果执行此操作,可能会失败,但是幸运的是,没有费用. 200元就足够了: 域名50,空间50,采集和发布插件100,如果您不知道如何建立网站,则需要再花200元在淘宝上建立一个站点.
网上赚钱是一个不断反复试验的过程,在不断的实际战斗中经验会不断增长.
关注疯狂团队(),关注更多精彩内容,微信/ QQ: 543890,公共帐户: 疯狂团队俱乐部,bfclub. 查看全部
但是因为这种博客没有有意义的内容,也没有精确的定位,所以没有广告.
所以我很惊讶,他为什么要这么做?
如果您开始创建博客并经常进行更新,但是却没有赚钱,那不是很愚蠢吗?
因此,我打开了更多博客文章并进行了查看,发现许多博客最后都添加了许多锚文本超链接. 点击后,我跳到另一个新浪博客.
此博客中唯一的广告是这个.


我去了另一个新浪博客,它获得了超过200万的浏览量.
内容仍然混乱,没有精确的定位.
这个博客也有一个锚文本超链接,但是这次我没有跳到新浪博客,而是跳到了一个独立的网站.

我打开了这个独立的网站并查看了它,发现它是一个采集站,内容都是乱七八糟的东西.

所以我检查了这个网站的重量,结果是3.
由于来自新浪博客的转移,实际流量应该比下图中查询的流量大得多. 毕竟,网站站长工具只能找到百度搜索引擎的估算流量,而实际流量可能就是此估算值,甚至很多倍甚至十倍是可能的,我们不知道这些数据.

打开这个独立的网站,我发现首页上悬挂了广告网络广告,并且打开的列并不多. 我认为没有理由.
没有其他货币化渠道,没有微信,没有产品,什么都没有.
再次打开内页. .
所有广告,如下所示:
内容页面上至少悬挂了10个广告.


到目前为止,该项目的内容非常清楚.
我将给您最后的整理:
1. 建立一个信息网站(可以使用dedecms,empire cms,sdcms)
2. 设置采集和发布(常规CMS程序可以支持)
3. 内容通常比较混乱,但是有些内容让无聊的人更感兴趣
4. 内容量相对较大,涉及的关键字很多,其中很多是长尾关键字. 您可以看到下面的图片

5. 申请广告联盟(注册域名,如百度,搜狗,360和Google)
6. 使用新浪博客的高权重关键字排名来转移流量
至此,该项目的内容已完成.
这可以看作是全自动的上层项目.
但是,我还有话要说: 采集的网站的成功率最多只能是一半. .
因此,如果执行此操作,可能会失败,但是幸运的是,没有费用. 200元就足够了: 域名50,空间50,采集和发布插件100,如果您不知道如何建立网站,则需要再花200元在淘宝上建立一个站点.
网上赚钱是一个不断反复试验的过程,在不断的实际战斗中经验会不断增长.
关注疯狂团队(),关注更多精彩内容,微信/ QQ: 543890,公共帐户: 疯狂团队俱乐部,bfclub.
SEO如何处理采集的内容(5)
采集交流 • 优采云 发表了文章 • 0 个评论 • 355 次浏览 • 2020-08-05 12:53
文本提取
在[SEO如何处理集合内容①]的“泛集合”部分中,提到了文本提取,有些人仍然说他们不知道该怎么做.
这个东西可以在Internet上开源. 在Google搜索“ {programming language}文本提取算法”时,可以找到很多解决方案,例如: 可读性,Boilerpipe,Diffbot ...大多数算法已经打包. 您可以直接使用它,而无需自己编写. 我们在做网站,而不是技术网站. 如果您有现成的车轮,就可以.
所以有些人还有另一个问题: 我应该使用哪个?
否否,这不是在考虑轮子. 首先,不可能每种算法都提取所有网页. 其次,有不止一种算法.
这很简单. 算法不会提取当前网页的正文. 它很容易处理. 无需做任何其他事情. 只需切出算法,然后重试即可. 如果此方法不起作用,请更改另一种. 如果网页正常,可以提取文字. 除非此页面模板凌乱且收录所有内容(例如网站首页),否则没有明显的主要内容块,这是另一回事.
因此,如果在平移采集过程中需要提取链接的文本,则最好首先过滤主页URL.
如果您需要纠结使用哪一个,请参阅: / blog / 2011/06/09 / evaluating-text-extraction-algorithms /
重复数据删除
另一个问题,如果我采集重复的内容该怎么办?
这种炉渣以前使用过两种方法.
第一种类型:
首先,我们定义了有效内容需要满足的指标,例如,单词数必须大于150个单词才能被视为有效内容,而删除少于150个单词将不会存储在数据库. 然后,大于150个单词的内容通常具有超过4个标点符号.
XXXXXXX,XXXXXXXXX。XXX:“XXXXXX,XXXXXXXXXXXX。XXXXXX,XXXXXXXXXX,XXXXXXXX,XXXXXX。XXX?”
XXXX,XXXXXXX。XXXXXXX;XXXX;XXXXXXXX;XXXXXX,XXXXXXXXXX,XXXXXXXX,XXXXXX - XXX!
因此,对于每篇文章,从第二个标点符号开始,连续提取两个标点符号之间的文本,并且单词数大于7,直到提取了三个文本段.
然后将这三个文本段合并为一个,删除该文本段的重复项,并仅保留一个. 因为基本上重复了具有相同文本段的三个连续文章,并且它们被完全重复,所以它们不会更改.
第二种
使用现成的文本重复数据删除算法,还在Google搜索中使用一堆现成的解决方案,例如simhash,Shingling ...
首先清理所有捕获的文本,删除不相关的词,例如停用词,辅助词(不起作用...)等,然后使用上述解决方案计算相似的文档.
哪个更好?渣all都是中等的,我认为没有什么好用的,但是都可以使用. .
但是有一个问题. 一旦大量的文章(例如数以百万计的文章)变大,程序就会运行缓慢,并且CPU会被大量消耗. 我该怎么办? ?
所以我遵循第一种方法的思想,而不是分析全文,而是直接找到每篇文章的最长n个句子,再次进行哈希签名,然后使用上述现成的算法要运行,n通常需要3. 不仅运行速度快得多,而且找到相似文章的最终效果似乎比以前要好.
================================================ ====
知识星球->将来会有好处,例如一段可以编写色情句子的Python代码
微信公众号---->右下角
查看全部
背景中还有很多问题,本文是对其中两个问题的解答
文本提取
在[SEO如何处理集合内容①]的“泛集合”部分中,提到了文本提取,有些人仍然说他们不知道该怎么做.
这个东西可以在Internet上开源. 在Google搜索“ {programming language}文本提取算法”时,可以找到很多解决方案,例如: 可读性,Boilerpipe,Diffbot ...大多数算法已经打包. 您可以直接使用它,而无需自己编写. 我们在做网站,而不是技术网站. 如果您有现成的车轮,就可以.
所以有些人还有另一个问题: 我应该使用哪个?
否否,这不是在考虑轮子. 首先,不可能每种算法都提取所有网页. 其次,有不止一种算法.
这很简单. 算法不会提取当前网页的正文. 它很容易处理. 无需做任何其他事情. 只需切出算法,然后重试即可. 如果此方法不起作用,请更改另一种. 如果网页正常,可以提取文字. 除非此页面模板凌乱且收录所有内容(例如网站首页),否则没有明显的主要内容块,这是另一回事.
因此,如果在平移采集过程中需要提取链接的文本,则最好首先过滤主页URL.
如果您需要纠结使用哪一个,请参阅: / blog / 2011/06/09 / evaluating-text-extraction-algorithms /
重复数据删除
另一个问题,如果我采集重复的内容该怎么办?
这种炉渣以前使用过两种方法.
第一种类型:
首先,我们定义了有效内容需要满足的指标,例如,单词数必须大于150个单词才能被视为有效内容,而删除少于150个单词将不会存储在数据库. 然后,大于150个单词的内容通常具有超过4个标点符号.
XXXXXXX,XXXXXXXXX。XXX:“XXXXXX,XXXXXXXXXXXX。XXXXXX,XXXXXXXXXX,XXXXXXXX,XXXXXX。XXX?”
XXXX,XXXXXXX。XXXXXXX;XXXX;XXXXXXXX;XXXXXX,XXXXXXXXXX,XXXXXXXX,XXXXXX - XXX!
因此,对于每篇文章,从第二个标点符号开始,连续提取两个标点符号之间的文本,并且单词数大于7,直到提取了三个文本段.
然后将这三个文本段合并为一个,删除该文本段的重复项,并仅保留一个. 因为基本上重复了具有相同文本段的三个连续文章,并且它们被完全重复,所以它们不会更改.
第二种
使用现成的文本重复数据删除算法,还在Google搜索中使用一堆现成的解决方案,例如simhash,Shingling ...
首先清理所有捕获的文本,删除不相关的词,例如停用词,辅助词(不起作用...)等,然后使用上述解决方案计算相似的文档.
哪个更好?渣all都是中等的,我认为没有什么好用的,但是都可以使用. .
但是有一个问题. 一旦大量的文章(例如数以百万计的文章)变大,程序就会运行缓慢,并且CPU会被大量消耗. 我该怎么办? ?
所以我遵循第一种方法的思想,而不是分析全文,而是直接找到每篇文章的最长n个句子,再次进行哈希签名,然后使用上述现成的算法要运行,n通常需要3. 不仅运行速度快得多,而且找到相似文章的最终效果似乎比以前要好.
================================================ ====
知识星球->将来会有好处,例如一段可以编写色情句子的Python代码
微信公众号---->右下角

浅谈手机APP的内容采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 335 次浏览 • 2020-08-04 15:02
网站端的采集相对好做,至少从功能上讲是这样,功能是指将数据采集下来的能力,但是从性能上讲,网终端的采集也并不简单。为什么网站端实现数据采集功能相对容易呢内容采集,是因为网站内容我们是通过浏览器看的,而浏览器是一个公共的标准的平台,也就是说客户端没有发布内容企业自己的东西,有的仅仅是内容。那么我们就可以模拟浏览器进行肆无忌惮的采集,因为服务器没办法辨认出客户端是真正的浏览器访问还是采集网络爬虫。
如果在手机APP情况就完全不一样了,因为手机APP是企业自己发布的,所有的功能都是自己的,我们企业想避免采集就很容易了,在手机APP端加密,或做数据校准,在服务器端收到数据后最揭密或数据验证,网络爬虫很难象网站采集那样模拟访问了,使用旧的采集方案内容采集,除非破解APP加密算法或校准算法,否则无解。
是不是手机APP就不能采集了呢,当然不是,还好我们找出了采集手机APP的方案 查看全部
当前工作中遇见一些顾客要求采集手机APP上面的内容,随着移动端的盛行,这方面的需求会越来越多,在当前的互联网环境下,移动端越来越受重视,从内容上才能看下来,移动端内容愈发丰富,体验更好,网站端内容就没有这么丰富了,从这个角度能看出通配符的趋势。
网站端的采集相对好做,至少从功能上讲是这样,功能是指将数据采集下来的能力,但是从性能上讲,网终端的采集也并不简单。为什么网站端实现数据采集功能相对容易呢内容采集,是因为网站内容我们是通过浏览器看的,而浏览器是一个公共的标准的平台,也就是说客户端没有发布内容企业自己的东西,有的仅仅是内容。那么我们就可以模拟浏览器进行肆无忌惮的采集,因为服务器没办法辨认出客户端是真正的浏览器访问还是采集网络爬虫。
如果在手机APP情况就完全不一样了,因为手机APP是企业自己发布的,所有的功能都是自己的,我们企业想避免采集就很容易了,在手机APP端加密,或做数据校准,在服务器端收到数据后最揭密或数据验证,网络爬虫很难象网站采集那样模拟访问了,使用旧的采集方案内容采集,除非破解APP加密算法或校准算法,否则无解。
是不是手机APP就不能采集了呢,当然不是,还好我们找出了采集手机APP的方案
SEO如何成为采集站| SEO如何处理采集内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 350 次浏览 • 2020-08-07 17:21
p>
设置一些主题,直接获取各种大型平台的搜索结果. 什么是大平台?大量内容集中的地方: 各种搜索引擎,各种门户网站,头条,微信微博,优酷土豆等.
如何捕获采集的内容?
许多浏览器插件,例如Evernote,具有许多类似于“只看文字”的功能. 单击以仅显示当前网页的文本信息. 许多人已经将此类算法移植到python,php,搜索诸如java之类的编程语言.
如何处理采集的内容?
两个连续的过程:
原创内容的处理
百度专利说,除了基于文本判断内容相似度之外,搜索引擎还将判断html的dom节点的位置和顺序. 如果两个网页的html结构相似,则也可以将其视为重复内容.
因此,采集的内容不能直接使用,并且源代码必须清除. 每个人都有不同的方式,个人通常会执行以下操作:
html清洁
a = re.sub(r'','',content).strip()
b = re.sub(r']*?>','<p>',a)
newcontent = re.sub(r'alt="[^"]*?"','alt="%s"' % title,b).lower()
已删除的汉字数
text = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,::。?、~@#¥%……&*()“”《》]+".decode("utf8"), "".decode("utf8"),newcontent)
text2 = re.sub(']*?>','',text) words_number = len(text2)
删除垃圾邮件
例如“ XXX Net Editor: XXX”,电子邮件地址等.
整理处理后的内容
实际上,就行形式的更改而言,我之前写过一篇有关“组织内容”的几种方法的文章,请参阅: [SEO]如何反转网站内容?
微信公众号: 流量贩子
GoGo的官方帐户
Knowledge Planet(稍后将发布,例如一段可以编写色情句子的Python代码~~~)
GoGo的知识星球 查看全部
对于那些没有正式站的人,还有很多选择. 您可以使用带点的内容来抓取内容,并且内容量很大,因此无需限制某些工作站的抓取. 有人称它为泛采集.
p>
设置一些主题,直接获取各种大型平台的搜索结果. 什么是大平台?大量内容集中的地方: 各种搜索引擎,各种门户网站,头条,微信微博,优酷土豆等.
如何捕获采集的内容?
许多浏览器插件,例如Evernote,具有许多类似于“只看文字”的功能. 单击以仅显示当前网页的文本信息. 许多人已经将此类算法移植到python,php,搜索诸如java之类的编程语言.
如何处理采集的内容?
两个连续的过程:
原创内容的处理
百度专利说,除了基于文本判断内容相似度之外,搜索引擎还将判断html的dom节点的位置和顺序. 如果两个网页的html结构相似,则也可以将其视为重复内容.
因此,采集的内容不能直接使用,并且源代码必须清除. 每个人都有不同的方式,个人通常会执行以下操作:
html清洁
a = re.sub(r'','',content).strip()
b = re.sub(r']*?>','<p>',a)
newcontent = re.sub(r'alt="[^"]*?"','alt="%s"' % title,b).lower()
已删除的汉字数
text = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,::。?、~@#¥%……&*()“”《》]+".decode("utf8"), "".decode("utf8"),newcontent)
text2 = re.sub(']*?>','',text) words_number = len(text2)
删除垃圾邮件
例如“ XXX Net Editor: XXX”,电子邮件地址等.
整理处理后的内容
实际上,就行形式的更改而言,我之前写过一篇有关“组织内容”的几种方法的文章,请参阅: [SEO]如何反转网站内容?
微信公众号: 流量贩子
GoGo的官方帐户
Knowledge Planet(稍后将发布,例如一段可以编写色情句子的Python代码~~~)
GoGo的知识星球
webscraper for mac破解版(mac网站内容采集工具)v4.4
采集交流 • 优采云 发表了文章 • 0 个评论 • 318 次浏览 • 2020-08-07 17:10
软件安装教程
1. 打开从该站点下载的图像包,然后将“ webscraper.app”拖到“应用程序”中.
2. 等待软件安装完成,您可以在应用程序中打开软件,安装正在破解,您可以单击菜单栏顶部的软件徽标,选择“关于网页抓取器”,可以看到以下图片,这表示该软件已经过放心使用,请放心使用.
提醒: 此软件是破解版,请不要轻易升级,以免破解失败.
软件功能
首先,从动态网页中提取数据
使用WebScraper,您可以构建一个站点地图,该站点地图将导航该站点并提取数据. Web Scraper使用不同的类型选择器,将在网站上导航并提取多种类型的数据,包括文本,表格,图像,链接等.
第二,专门为现代网络构建
与其他仅从HTML Web提取数据的抓取工具不同,Scraper还可以提取使用JavaScript动态加载或生成的数据. Web抓取工具可以:
1. 等待动态数据加载到页面上.
2. 单击分页按钮以通过AJAX加载数据.
3. 单击该按钮以加载更多数据.
4. 向下滚动页面以加载更多数据.
三,以CSV格式导出数据或将其存储在CouchDB中
站点地图的构建,数据提取和导出均在浏览器中完成. 搜寻网站后,您可以CSV格式下载数据. 对于高级用例,您可能希望尝试将数据保存到CouchDB. 查看全部
适用于Mac的webscraper版本是适用于macOS的网站内容采集工具. 它使用Integrity v8引擎快速扫描网站. 您只需要指定需要采集的网站地址以及需要采集哪些内容来提取数据(当前)(以CSV或JSON格式输出),然后将图像下载到该文件夹中即可. 用户可以选择要从网页中提取的信息类型: URL,标题,描述,与不同类型或ID相关的内容,标题,页面内容的各种格式(纯文本,HTML或Markdown)以及上次修改日期等;您还可以选择输出文件格式(CSV或JSON),决定合并空格,并在文件超过特定大小时设置警报. 如果选择使用CSV格式,则可以选择何时在列周围使用引号,并用引号替换引号或行. 分隔符类型. 这次,我们为您带来了适用于Mac的webscraper破解版,该版本不受功能和时间限制. 您可以轻松使用该软件的所有功能. 有关详细的安装教程,请参阅以下内容. 欢迎朋友下载免费体验.
软件安装教程
1. 打开从该站点下载的图像包,然后将“ webscraper.app”拖到“应用程序”中.
2. 等待软件安装完成,您可以在应用程序中打开软件,安装正在破解,您可以单击菜单栏顶部的软件徽标,选择“关于网页抓取器”,可以看到以下图片,这表示该软件已经过放心使用,请放心使用.
提醒: 此软件是破解版,请不要轻易升级,以免破解失败.
软件功能
首先,从动态网页中提取数据
使用WebScraper,您可以构建一个站点地图,该站点地图将导航该站点并提取数据. Web Scraper使用不同的类型选择器,将在网站上导航并提取多种类型的数据,包括文本,表格,图像,链接等.
第二,专门为现代网络构建
与其他仅从HTML Web提取数据的抓取工具不同,Scraper还可以提取使用JavaScript动态加载或生成的数据. Web抓取工具可以:
1. 等待动态数据加载到页面上.
2. 单击分页按钮以通过AJAX加载数据.
3. 单击该按钮以加载更多数据.
4. 向下滚动页面以加载更多数据.
三,以CSV格式导出数据或将其存储在CouchDB中
站点地图的构建,数据提取和导出均在浏览器中完成. 搜寻网站后,您可以CSV格式下载数据. 对于高级用例,您可能希望尝试将数据保存到CouchDB.
PHPCMS采集模块
采集交流 • 优采云 发表了文章 • 0 个评论 • 307 次浏览 • 2020-08-07 16:48
操作名称
说明
详细的采集过程
没有
其他功能说明
没有
描述: 文章采集功能是通过程序远程获取目标网页的内容,并在进行本地规则分析处理后将其存储在服务器的数据库中.
文章采集系统颠覆了传统的采集方式和过程,将采集规则与采集界面分开,规则设置更加简单. 只有具有基本技术知识的人员才需要设置相关规则. 编辑人员不需要了解太多详细的技术规则,只需选择要采集的文章列表,就可以像发布文章一样轻松地完成数据采集操作.
首先,采集过程很简单,分三个步骤:
1. 添加采集点并填写采集规则.
2. 采集网址和内容
3. 将内容发布到指定的列
以Sina News()的集合为例,并介绍详细过程.
示例说明:
目标: 将新浪新闻采集到V9系统的国际新闻专栏中.
目标网址:
1. 添加采集点1.1 URL规则配置
添加采集点URL规则配置图1
检查要采集的目标URL的源代码,并找到要采集的URL的起点和终点(这两个点在整个源代码中必须是唯一的). 进一步缩小集合URL的搜索范围.
添加采集点URL规则配置图2
测试您的URL采集规则是否正确,如下图所示
1.2内容规则配置
内容规则在这里看起来很复杂,但实际上非常简单. 为了便于说明,我们仅采集两个字段: 标题和内容. 集合网址:
内容采集规则,请打开此网站,然后右键单击页面的空白区域->查看源文件以搜索内容的标题和起始边界.
标题采集配置:
从网页上获取标题并删除不必要的字符. 如下图所示
内容采集配置:
新浪新闻的最后一页,新闻内容收录在两者之间,并且这两个节点在整个页面的源代码中都是唯一的. 因此,您可以将内容作为规则. 并过滤内容. 如下图所示
1.3自定义规则
1.4高级配置
您可以设置是否将图片下载到服务器,是否打印水印和其他配置.
2. 采集网址和内容
设置采集规则后,可以采集网站,然后可以采集内容.
3. 将内容发布到指定的列
选择要导入的列
设置采集的内容和数据库字段之间的对应关系. 提交数据存储,在此期间请耐心等待,完成后它将自动重定向. 到目前为止,一个简单的采集过程就完成了.
其他更多功能,期待您的发现. 查看全部
模块的常用操作
操作名称
说明
详细的采集过程
没有
其他功能说明
没有
描述: 文章采集功能是通过程序远程获取目标网页的内容,并在进行本地规则分析处理后将其存储在服务器的数据库中.
文章采集系统颠覆了传统的采集方式和过程,将采集规则与采集界面分开,规则设置更加简单. 只有具有基本技术知识的人员才需要设置相关规则. 编辑人员不需要了解太多详细的技术规则,只需选择要采集的文章列表,就可以像发布文章一样轻松地完成数据采集操作.
首先,采集过程很简单,分三个步骤:
1. 添加采集点并填写采集规则.
2. 采集网址和内容
3. 将内容发布到指定的列
以Sina News()的集合为例,并介绍详细过程.
示例说明:
目标: 将新浪新闻采集到V9系统的国际新闻专栏中.
目标网址:
1. 添加采集点1.1 URL规则配置
添加采集点URL规则配置图1
检查要采集的目标URL的源代码,并找到要采集的URL的起点和终点(这两个点在整个源代码中必须是唯一的). 进一步缩小集合URL的搜索范围.
添加采集点URL规则配置图2
测试您的URL采集规则是否正确,如下图所示
1.2内容规则配置
内容规则在这里看起来很复杂,但实际上非常简单. 为了便于说明,我们仅采集两个字段: 标题和内容. 集合网址:
内容采集规则,请打开此网站,然后右键单击页面的空白区域->查看源文件以搜索内容的标题和起始边界.
标题采集配置:
从网页上获取标题并删除不必要的字符. 如下图所示
内容采集配置:
新浪新闻的最后一页,新闻内容收录在两者之间,并且这两个节点在整个页面的源代码中都是唯一的. 因此,您可以将内容作为规则. 并过滤内容. 如下图所示
1.3自定义规则
1.4高级配置
您可以设置是否将图片下载到服务器,是否打印水印和其他配置.
2. 采集网址和内容
设置采集规则后,可以采集网站,然后可以采集内容.
3. 将内容发布到指定的列
选择要导入的列
设置采集的内容和数据库字段之间的对应关系. 提交数据存储,在此期间请耐心等待,完成后它将自动重定向. 到目前为止,一个简单的采集过程就完成了.
其他更多功能,期待您的发现.
优采云采集了网站体验以及如何防止其被采集的提示!
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-08-07 16:47
1. 谈论优采云采集器的起源
优采云: 我们的采集器从2005年底开始就有这个想法. 那时,与所有人(个人网站管理员)一样,添加,管理和维护网站非常困难,而且开始时联系以修改,复制和发布文章. 然后Dede发现他有一个外部c#采集器. 我不知道还有多少人记得. 我的想法基本上是从这个绝望的人中学到的. 我什么都不知道后来我学习了php和.net. 因此,只要每个人都感兴趣,就可以克服技术问题. 到目前为止,该采集集只能替代网站站长的部分手动操作. 我们不建议大规模创建垃圾场(完整地采集和复制他人的站点),因此我们当前的软件具有越来越多的功能,但是新用户将不会使用它.
Souwainet:
我们现在有一群非常忠实的成员,他们依靠采集器来更新他们的网站. 快速采集的时代和百度搜索带来的巨大流量已经过去. 网站管理员仍然需要注意内容. 注意采集器采集的数据. 早期阶段只能用作数据填充,可以稍大一些. 但是经过很长一段时间,我们的目标是将垃圾数据变成高质量的商品,否则不会持续很长时间
第二,采集网站的经验
优采云: 我们现在正在更新此采集器,我们已经在数据采集方面积累了一些经验,并添加了更多功能以适应新的采集形式
1. 不要使用其他人经常使用的网站
2. 不要使用太容易挑选的网站
3. 一次不要采集太多,一定要注意后处理(稍后详细介绍)
4. 做好关键字和标签的采集和分析
5. 您自己的网站必须具有自己的定位,并且不得使用与您自己的网站无关的内容
6. 采集还应该是连续的,经常更新的,并且我们还具有自动采集功能,但是仍然建议您也手动参与一些审核,或者定期且无序发布
在后处理中,我们必须尝试使搜索引擎无法看到这两篇文章是相同的. 应该有很多SEO大师,所以我不会很丑. 让我谈谈我们现在正在实现的功能. 您可以将它们混合使用以实现伪原创内容更改:
1. 给出标题. 内容细分
2. 使用同义词和类似词来替换,排除敏感词,不同标签之间的数据融合,例如标题内容之间的数据相互替换
3. 在文章中添加摘要
4. 生成文章标题等的拼音地址.
5. 采集其他一些编码网站,我们可以从简体到繁体,也可以采集中文网站并将其翻译成英文(尽管是相对垃圾,但应视为原创)
我们还发现,难于采集的网站的总体内容质量通常非常好. 实际上,采集有时是一件很有趣的事情,您需要学习一些与采集有关的知识.
三,关于反采集方法
优采云: 以下是一些主要的反采集方法. 可以说是一场攻守战. 打开网页实际上是一个Http请求浏览器. 大小与我们的采集器一样小的百度蜘蛛使用相同的原理来模拟http请求,因此我们也可以模拟浏览器. 百度蜘蛛问世了,所以绝对不存在反采集,只是难度级别. 或者您认为搜索引擎的功能无关紧要. 您可以使用一些功能非常强大的Activex,Flash,全图文本形式,这是我们做不到的.
常用的反采集方法是
1. 来源判断
2. 登录信息判断cookie
3. 判断请求数. 如果一段时间内发出了多少请求,该IP将被阻止进行不规则操作
4. 发送方法的判断POST GET使用JS,Ajax和其他请求内容
示例:
1.2不用说,论坛,下载站点等.
3. 一些大型网站需要配置服务器,通过脚本判断资源消耗相对较大.
4,例如某些招聘网站的分页,Web2.0网站ajax请求的内容
当然,我们后来还发现了一些杀手trick俩,今天第一次在这里宣布这些杀人trick俩~~内容丰富且需要阻止采集的朋友可以考虑尝试
1. 网页的默认放气压缩输出(gzip稍微容易解压缩). 我们的普通浏览器和百度支持gzip识别和缩小输出内容
2. 网页内容不正常. 内容将被自动截断. 这两点基本上可以阻止大多数主流软件采集和Web采集程序〜
我要表达的主要观点是,每个人在制作站点时都必须注意技术的改进. 例如,我们以后有外部php和.net接口来处理采集的数据. 或者,您可以简单地制作一个接口程序以供发布并自己存储. 无论我们的伪原创作品多么出色,它都被许多成员使用. 如果不是原创作品,则采集还需要技术. 如果您通过采集器获得的人很少,那么您就是唯一的人. 查看全部
优采云采集了网站体验以及如何防止其被采集的提示!
1. 谈论优采云采集器的起源
优采云: 我们的采集器从2005年底开始就有这个想法. 那时,与所有人(个人网站管理员)一样,添加,管理和维护网站非常困难,而且开始时联系以修改,复制和发布文章. 然后Dede发现他有一个外部c#采集器. 我不知道还有多少人记得. 我的想法基本上是从这个绝望的人中学到的. 我什么都不知道后来我学习了php和.net. 因此,只要每个人都感兴趣,就可以克服技术问题. 到目前为止,该采集集只能替代网站站长的部分手动操作. 我们不建议大规模创建垃圾场(完整地采集和复制他人的站点),因此我们当前的软件具有越来越多的功能,但是新用户将不会使用它.
Souwainet:
我们现在有一群非常忠实的成员,他们依靠采集器来更新他们的网站. 快速采集的时代和百度搜索带来的巨大流量已经过去. 网站管理员仍然需要注意内容. 注意采集器采集的数据. 早期阶段只能用作数据填充,可以稍大一些. 但是经过很长一段时间,我们的目标是将垃圾数据变成高质量的商品,否则不会持续很长时间
第二,采集网站的经验
优采云: 我们现在正在更新此采集器,我们已经在数据采集方面积累了一些经验,并添加了更多功能以适应新的采集形式
1. 不要使用其他人经常使用的网站
2. 不要使用太容易挑选的网站
3. 一次不要采集太多,一定要注意后处理(稍后详细介绍)
4. 做好关键字和标签的采集和分析
5. 您自己的网站必须具有自己的定位,并且不得使用与您自己的网站无关的内容
6. 采集还应该是连续的,经常更新的,并且我们还具有自动采集功能,但是仍然建议您也手动参与一些审核,或者定期且无序发布
在后处理中,我们必须尝试使搜索引擎无法看到这两篇文章是相同的. 应该有很多SEO大师,所以我不会很丑. 让我谈谈我们现在正在实现的功能. 您可以将它们混合使用以实现伪原创内容更改:
1. 给出标题. 内容细分
2. 使用同义词和类似词来替换,排除敏感词,不同标签之间的数据融合,例如标题内容之间的数据相互替换
3. 在文章中添加摘要
4. 生成文章标题等的拼音地址.
5. 采集其他一些编码网站,我们可以从简体到繁体,也可以采集中文网站并将其翻译成英文(尽管是相对垃圾,但应视为原创)
我们还发现,难于采集的网站的总体内容质量通常非常好. 实际上,采集有时是一件很有趣的事情,您需要学习一些与采集有关的知识.
三,关于反采集方法
优采云: 以下是一些主要的反采集方法. 可以说是一场攻守战. 打开网页实际上是一个Http请求浏览器. 大小与我们的采集器一样小的百度蜘蛛使用相同的原理来模拟http请求,因此我们也可以模拟浏览器. 百度蜘蛛问世了,所以绝对不存在反采集,只是难度级别. 或者您认为搜索引擎的功能无关紧要. 您可以使用一些功能非常强大的Activex,Flash,全图文本形式,这是我们做不到的.
常用的反采集方法是
1. 来源判断
2. 登录信息判断cookie
3. 判断请求数. 如果一段时间内发出了多少请求,该IP将被阻止进行不规则操作
4. 发送方法的判断POST GET使用JS,Ajax和其他请求内容
示例:
1.2不用说,论坛,下载站点等.
3. 一些大型网站需要配置服务器,通过脚本判断资源消耗相对较大.
4,例如某些招聘网站的分页,Web2.0网站ajax请求的内容
当然,我们后来还发现了一些杀手trick俩,今天第一次在这里宣布这些杀人trick俩~~内容丰富且需要阻止采集的朋友可以考虑尝试
1. 网页的默认放气压缩输出(gzip稍微容易解压缩). 我们的普通浏览器和百度支持gzip识别和缩小输出内容
2. 网页内容不正常. 内容将被自动截断. 这两点基本上可以阻止大多数主流软件采集和Web采集程序〜
我要表达的主要观点是,每个人在制作站点时都必须注意技术的改进. 例如,我们以后有外部php和.net接口来处理采集的数据. 或者,您可以简单地制作一个接口程序以供发布并自己存储. 无论我们的伪原创作品多么出色,它都被许多成员使用. 如果不是原创作品,则采集还需要技术. 如果您通过采集器获得的人很少,那么您就是唯一的人.
谈论如何防止采集网站的原创内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 303 次浏览 • 2020-08-07 09:18
第三: 更新网站内容后将网址提交给百度
防止他人from窃或采集的根本原因是百度将不再收录其自身网站的内容,因此我们可以在更新网站后直接将文章URL提交给百度. 尽管ping不会立即将其收录在内,但ping并不会带来任何危害. 这些URL,但是通过ping或外部链接吸引确实可以使百度蜘蛛走过来. 2012年,百度启动了原创Spark项目. 这是一个完整的原创内容识别系统. 当然,它还将在小型站点上涉及高质量的内容. 目的是鼓励原创内容,打击采集或窃,并使原创内容成为收录最快的内容. 但是,似乎原创的Spark项目仍处于初始测试阶段,至少在小型站点上没有良好的性能. 本文介绍了三种防止内容被盗的方法. 不幸的是,没有办法从根本上解决这个问题. 最后,我只能说根据自己的情况选择. 我只希望百度能够改善其技术并使其能够更快地采集原创内容.
作为网站管理员或SEO人士,几乎每个人都开始接触窃和假冒的原创作品. 也许您讨厌别人窃您的文章,尤其是如果您在after窃之后删除了所有链接. 想一想. 做到了? other窃他人的内容确实很不好,但事实是互联网上存在太多窃的内容. 我们只能冷静地看待这个问题. 除非百度最初的星火计划真正有效并且从根本上解决这一历史问题,否则窃和反-窃将永远存在. 我会在这里写. ,原创内容必须继续写! 查看全部
通常,我们希望在原创文章的末尾添加版权信息,但是此类版权信息没有实际意义. 由于其他人选择抄袭或采集,因此他们自然不会在意这些东西. 在文章末尾添加链接或锚定文本不是一个好习惯. 最好在文章内容中自然出现关键字或锚定文本链接. 如果其他人可以采集您网站上的内容并可以带来链接,则损失不会太大. ,那就是免费为您创建外部链接. 关键是如何隐藏链接以避免被他人删除. 一眼就能看到在文章末尾添加链接,因此,我建议尽可能多地向文章内容添加链接. 另外,您还可以将锚文本的颜色设置为与普通文本的颜色相同,这样其他人就不容易找到它. 实际上,许多网站管理员都是懒惰的,有时没有仔细检查. 简而言之,这也是一种治疗症状而不是根本原因的方法.
第三: 更新网站内容后将网址提交给百度
防止他人from窃或采集的根本原因是百度将不再收录其自身网站的内容,因此我们可以在更新网站后直接将文章URL提交给百度. 尽管ping不会立即将其收录在内,但ping并不会带来任何危害. 这些URL,但是通过ping或外部链接吸引确实可以使百度蜘蛛走过来. 2012年,百度启动了原创Spark项目. 这是一个完整的原创内容识别系统. 当然,它还将在小型站点上涉及高质量的内容. 目的是鼓励原创内容,打击采集或窃,并使原创内容成为收录最快的内容. 但是,似乎原创的Spark项目仍处于初始测试阶段,至少在小型站点上没有良好的性能. 本文介绍了三种防止内容被盗的方法. 不幸的是,没有办法从根本上解决这个问题. 最后,我只能说根据自己的情况选择. 我只希望百度能够改善其技术并使其能够更快地采集原创内容.
作为网站管理员或SEO人士,几乎每个人都开始接触窃和假冒的原创作品. 也许您讨厌别人窃您的文章,尤其是如果您在after窃之后删除了所有链接. 想一想. 做到了? other窃他人的内容确实很不好,但事实是互联网上存在太多窃的内容. 我们只能冷静地看待这个问题. 除非百度最初的星火计划真正有效并且从根本上解决这一历史问题,否则窃和反-窃将永远存在. 我会在这里写. ,原创内容必须继续写!
大数据技术包括什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2020-08-07 04:21
首先,数据采集
ETL
该工具负责将数据从分布式和异构数据源(例如关系数据,平面数据文件等)提取到临时中间层以进行清理,转换和集成,最后加载到数据仓库或数据集市变为在线分析处理和数据挖掘的基础.
二,数据访问
关系数据库,NOSQL,SQL等
三个. 基础设施
云存储,分布式文件存储等
四个. 数据处理
自然语言处理(NLP,Natural Language Processing)是研究人机交互语言问题的学科. 处理自然语言的关键是让计算机“理解”
自然语言,因此自然语言处理也称为自然语言理解(NLU,Natural Language谅解),也称为计算语言学
(计算语言学. 一方面,它是语言信息处理的一个分支,另一方面,它是人工智能(AI,Artificial
情报学的核心主题之一.
五个. 统计分析
假设检验,显着性检验,差异分析,相关分析,T
检验,方差分析,卡方分析,偏相关分析,距离分析,回归分析,简单回归分析,多元回归分析,逐步回归,回归预测和残差分析,岭回归,逻辑分析
回归分析,曲线估计,因子分析,聚类分析,主成分分析,因子分析,快速聚类和聚类,判别分析,对应分析,多重对应分析(最佳规模分析),自举技术等等.
六,数据挖掘
分类,估计,预测,相关分组或关联规则(相似性分组)
或关联规则),聚类,描述和可视化,描述和可视化)
,复杂的数据类型挖掘(文本,Web,图形和图像,视频,音频等).
七,模型预测
预测模型,机器学习,建模和仿真.
8. 结果演示
云计算,标签云,关系图等 查看全部
大数据的概念是指在一定时间内无法使用常规软件工具捕获,管理和处理其内容的数据集合. 大数据技术是指能够从各种类型的数据中快速获取有价值的信息的能力. 那么大数据技术的内容是什么?
首先,数据采集
ETL
该工具负责将数据从分布式和异构数据源(例如关系数据,平面数据文件等)提取到临时中间层以进行清理,转换和集成,最后加载到数据仓库或数据集市变为在线分析处理和数据挖掘的基础.
二,数据访问
关系数据库,NOSQL,SQL等
三个. 基础设施
云存储,分布式文件存储等
四个. 数据处理
自然语言处理(NLP,Natural Language Processing)是研究人机交互语言问题的学科. 处理自然语言的关键是让计算机“理解”
自然语言,因此自然语言处理也称为自然语言理解(NLU,Natural Language谅解),也称为计算语言学
(计算语言学. 一方面,它是语言信息处理的一个分支,另一方面,它是人工智能(AI,Artificial
情报学的核心主题之一.
五个. 统计分析
假设检验,显着性检验,差异分析,相关分析,T
检验,方差分析,卡方分析,偏相关分析,距离分析,回归分析,简单回归分析,多元回归分析,逐步回归,回归预测和残差分析,岭回归,逻辑分析
回归分析,曲线估计,因子分析,聚类分析,主成分分析,因子分析,快速聚类和聚类,判别分析,对应分析,多重对应分析(最佳规模分析),自举技术等等.
六,数据挖掘
分类,估计,预测,相关分组或关联规则(相似性分组)
或关联规则),聚类,描述和可视化,描述和可视化)
,复杂的数据类型挖掘(文本,Web,图形和图像,视频,音频等).
七,模型预测
预测模型,机器学习,建模和仿真.
8. 结果演示
云计算,标签云,关系图等
处理原创采集内容的文本信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 360 次浏览 • 2020-08-07 03:12
这里忽略元数据的处理,因为元数据主要是为了添加逻辑映射. 例如,我公司的一个黄页网站获取了元数据,例如“ XXX公司的规模,商标,年营业额和法人信息”. 我只需要将这些元数据与站点库中的相应公司相关联即可. 因为元数据是短文本,所以它会立即被拾取,因此无需处理重复性.
如果采集的内容是长文本的大连续段落,则为确保SEO效果,在处理html源代码之后,也可以处理文本.
文本信息处理,包括标题和正文两部分(不考虑人工修改,仅考虑批处理)
标题
让我说,SEO的最重要和核心点是“单词”. 其他SEO技术和技术都基于“选择正确的词”以达到良好的效果.
最终目的是使用户可以搜索的单词出现在标题中. 详细信息页面标题中的单词应该具有少量搜索量,而百度搜索结果应该很少,而不是热门单词,每个人都在争先恐后地使用单词.
首先,出现在网页标题中的关键字越多,被收录的可能性就越低. 可以肯定,因此不要在58个Ganji这些大型网站上发表任何言论. 除非其重量大,否则采集站将紧随其后. 否则,它基本上是没有用的.
第二,在垂直行业和充满个性化搜索内容的领域中,可以挖出很多竞争少,流量大的单词. 在垂直领域中很难找到这些单词,因为它需要了解行业,而且不仅仅使用SEO工具也很难找到.
个性化的搜索内容字段(例如程序开发,娱乐八卦等)始终充满个性化的搜索词,并且随着时间的流逝将不断产生新的搜索行为. 只要搜索引擎还没有结束,这个领域就总是充满搜索流量,因此仔细观察后发现,这里有很多热闹而漫长的流量站点. 大多数内容选择都符合此功能. 与“招聘和二手车”等行业不同,用户的搜索行为基本上没有变化. ,几个电台全都抓取同一批单词,而且它们都已饱和,因此流量自然很困难.
如何在集合标题中插入搜索词
如果目标网站的标题与SEO不一致,例如抓住一堆新闻标题,那么标题如何集中于用户可能搜索的单词?我以前尝试过这些方法:
方法1: 简化原创标题
步骤如下:
基于python的jieba模块的实现,可以通过预先分析大量标题来提取要删除的修饰符,并将其附加到字典中. Github有现成的轮子,可以提取句子的主干,例如nltk.
1688年产品页面的部分标题似乎是这样制作的. 删除用户发布的产品名称中的一些不相关的词缀,并提取主词干并放置在标题标签中.
方法2: 插入搜索字词
步骤如下:
例如,原创标题为: “ Betta Beauty Anchor Live睡眠超过20万的人” ...,我要输入的单词是“ Betta Beauty Live”,然后在标题前插入关键字: “ [ Betta Beauty Live] Betta美女主播直播一夜安眠20万元”
当然也可以: “ {强制搜索词} {简化的原创标题}”
方法3: 在当前标题中插入派生词和相关搜索词,其中已经收录搜索词
步骤如下:
<p>例如: “ [[百度相关搜索字词1}] {简明标题}”,“ [{下拉框推荐字词1} {原标题}]” ...彼此组合... 查看全部
处理原创采集内容的文本信息
这里忽略元数据的处理,因为元数据主要是为了添加逻辑映射. 例如,我公司的一个黄页网站获取了元数据,例如“ XXX公司的规模,商标,年营业额和法人信息”. 我只需要将这些元数据与站点库中的相应公司相关联即可. 因为元数据是短文本,所以它会立即被拾取,因此无需处理重复性.
如果采集的内容是长文本的大连续段落,则为确保SEO效果,在处理html源代码之后,也可以处理文本.
文本信息处理,包括标题和正文两部分(不考虑人工修改,仅考虑批处理)
标题
让我说,SEO的最重要和核心点是“单词”. 其他SEO技术和技术都基于“选择正确的词”以达到良好的效果.
最终目的是使用户可以搜索的单词出现在标题中. 详细信息页面标题中的单词应该具有少量搜索量,而百度搜索结果应该很少,而不是热门单词,每个人都在争先恐后地使用单词.
首先,出现在网页标题中的关键字越多,被收录的可能性就越低. 可以肯定,因此不要在58个Ganji这些大型网站上发表任何言论. 除非其重量大,否则采集站将紧随其后. 否则,它基本上是没有用的.
第二,在垂直行业和充满个性化搜索内容的领域中,可以挖出很多竞争少,流量大的单词. 在垂直领域中很难找到这些单词,因为它需要了解行业,而且不仅仅使用SEO工具也很难找到.
个性化的搜索内容字段(例如程序开发,娱乐八卦等)始终充满个性化的搜索词,并且随着时间的流逝将不断产生新的搜索行为. 只要搜索引擎还没有结束,这个领域就总是充满搜索流量,因此仔细观察后发现,这里有很多热闹而漫长的流量站点. 大多数内容选择都符合此功能. 与“招聘和二手车”等行业不同,用户的搜索行为基本上没有变化. ,几个电台全都抓取同一批单词,而且它们都已饱和,因此流量自然很困难.
如何在集合标题中插入搜索词
如果目标网站的标题与SEO不一致,例如抓住一堆新闻标题,那么标题如何集中于用户可能搜索的单词?我以前尝试过这些方法:
方法1: 简化原创标题
步骤如下:
基于python的jieba模块的实现,可以通过预先分析大量标题来提取要删除的修饰符,并将其附加到字典中. Github有现成的轮子,可以提取句子的主干,例如nltk.
1688年产品页面的部分标题似乎是这样制作的. 删除用户发布的产品名称中的一些不相关的词缀,并提取主词干并放置在标题标签中.
方法2: 插入搜索字词
步骤如下:
例如,原创标题为: “ Betta Beauty Anchor Live睡眠超过20万的人” ...,我要输入的单词是“ Betta Beauty Live”,然后在标题前插入关键字: “ [ Betta Beauty Live] Betta美女主播直播一夜安眠20万元”
当然也可以: “ {强制搜索词} {简化的原创标题}”
方法3: 在当前标题中插入派生词和相关搜索词,其中已经收录搜索词
步骤如下:
<p>例如: “ [[百度相关搜索字词1}] {简明标题}”,“ [{下拉框推荐字词1} {原标题}]” ...彼此组合...
使用phpQuery轻松采集Web内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 325 次浏览 • 2020-08-07 01:07
首先看一个例子. 现在,我想采集新浪的国内新闻头条. 代码如下:
include 'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('http://news.sina.com.cn/china');
echo pq(".blkTop h1:eq(0)")->html();
简单的三行代码即可获取标题内容. 首先将phpQuery.php核心程序收录在该程序中,然后调用以读取目标网页,最后在相应标签下输出内容.
pq()是一种功能强大的方法,就像jQuery的$()一样,jQuery选择器基本上可以在phpQuery上使用,只需更改“”即可. 到“->”. 如上例所示,pq(“. blkTop h1: eq(0)”)捕获其class属性为blkTop的DIV元素,并在DIV中找到第一个h1标签,然后使用html()方法获取h1标签里面的内容(带有html标签)是我们要获取的标题信息. 如果使用text()方法,则只会获得标题的文本内容. 当然,要很好地使用phpQuery,关键是要找到与文档内容相对应的节点.
文章列表采集
下面以另一个示例获取网站的博客列表,请参见代码:
include 'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('http://www.helloweba.net/blog.html');
$artlist = pq(".blog_li");
foreach($artlist as $li){
echo pq($li)->find('h2')->html()."<br />";
}
找到文章标题并通过遍历列表中的DIV进行输出就这么简单.
解析XML文档
假设有一个像这样的test.xml文件:
张三
22
王五
18
现在我想获取名为张三的联系人的年龄,代码如下:
include 'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('test.xml');
echo pq('contact > age:eq(0)');
结果输出: 22
就像jQuery一样,它很简单,即可准确地找到文档节点,在该节点下输出内容,然后解析XML文档. 现在,您无需使用繁琐的代码(例如常规算法和内容替换)来采集网站内容. 有了phpQuery,一切都会变得更加容易.
项目官方网站地址: 查看全部
采集标题
首先看一个例子. 现在,我想采集新浪的国内新闻头条. 代码如下:
include 'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('http://news.sina.com.cn/china');
echo pq(".blkTop h1:eq(0)")->html();
简单的三行代码即可获取标题内容. 首先将phpQuery.php核心程序收录在该程序中,然后调用以读取目标网页,最后在相应标签下输出内容.
pq()是一种功能强大的方法,就像jQuery的$()一样,jQuery选择器基本上可以在phpQuery上使用,只需更改“”即可. 到“->”. 如上例所示,pq(“. blkTop h1: eq(0)”)捕获其class属性为blkTop的DIV元素,并在DIV中找到第一个h1标签,然后使用html()方法获取h1标签里面的内容(带有html标签)是我们要获取的标题信息. 如果使用text()方法,则只会获得标题的文本内容. 当然,要很好地使用phpQuery,关键是要找到与文档内容相对应的节点.
文章列表采集
下面以另一个示例获取网站的博客列表,请参见代码:
include 'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('http://www.helloweba.net/blog.html');
$artlist = pq(".blog_li");
foreach($artlist as $li){
echo pq($li)->find('h2')->html()."<br />";
}
找到文章标题并通过遍历列表中的DIV进行输出就这么简单.
解析XML文档
假设有一个像这样的test.xml文件:
张三
22
王五
18
现在我想获取名为张三的联系人的年龄,代码如下:
include 'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('test.xml');
echo pq('contact > age:eq(0)');
结果输出: 22
就像jQuery一样,它很简单,即可准确地找到文档节点,在该节点下输出内容,然后解析XML文档. 现在,您无需使用繁琐的代码(例如常规算法和内容替换)来采集网站内容. 有了phpQuery,一切都会变得更加容易.
项目官方网站地址:
网站优化中的内容采集问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 310 次浏览 • 2020-08-06 21:18
但是,搜索引擎强调内容的采集对网站意义不大,尤其是对于优化而言,甚至采集的内容也将被视为垃圾邮件,从而给网站造成负担. 实际上,即使采集的内容对网站没有影响,也可以. 但是,只要采集合理,它仍然有用,并且可以减少网站站长的原创烦恼并获得相同的优化效果. 那么,如何正确使用采集到的内容?
首先,内容的对象精美. 最好找到刚刚由其他人发布的内容作为采集目标,并在太多人重新发布之前采集它,但是内容的前提是它是前进的,新鲜的和有代表性的,而不是某些内容. 老式主题,否则将针对用户. 铜爵蜡的味道就不值一提了. 由于采集了内容,因此自然比原创内容要简单得多,因此您无需花费太多时间来编辑内容. 此时不要节省时间. 毕竟,采集的内容没有原创效果. 这很简单,因此您需要同时查找更多内容,以弥补蜘蛛的空虚. 蓝田下巴整形培训机构
第二,采集内容不采集标题. 每个人都知道,阅读文章时首先要看的是标题. 对于经过网站优化的搜索引擎,标题也具有一定的重要性. 采集的内容具有一定的长度,不能过多地更改,但是标题仅短短几个字,并且相对容易修改. 因此,标题的修改是必要的,最好将标题更改为原创标题. 原因很简单. 当您看到标题相同但实质完全不同的文章时,读者会误解两者的内容是相同的. 相反,即使内容相同但标题完全不同,也会给人们带来相同的感觉. 这种新鲜感不容易被发现.
最后,对内容进行适当的调整. 尝试在自己的网站上采集内容的网站管理员肯定会发现直接复制的内容存在格式问题,因为一些聪明的原创创作者通常会向内容添加一些隐藏的内容,以防止采集内容. 格式,甚至版权都将标记在图片的ALT信息中. 如果您不注意,搜索引擎自然会将其视为engines窃,对网站的危害是不言而喻的. 因此,必须对采集的内容进行格式化,并且必须转换英语格式的标点符号. 另外,可以将一些图片添加到内容中以使内容更丰富. 如果内容本身具有图片,则不要直接复制,最好是另外保存,上传到网站以及您自己的ALT信息,可以使采集的内容更有价值. 西安风屁股培训中心
简而言之,网站采集的内容并非完全无用. 关键取决于您如何采集它. 只要您可以灵活地使用采集的内容,就可以为网站带来某些好处. 但是,网站管理员需要注意. 是的,必须掌握某些采集方法. 查看全部
在网站优化圈子中,网站管理员知道搜索引擎重视原创内容,但是无论SEOer面对长期的内容创建多么出色,都存在一定的困难. 不仅资源有限,而且书写能力也受到限制. 因此,整个网站,包括每个部分的内容,都无法避免被采集. 雁塔写意整形外科培训学校
但是,搜索引擎强调内容的采集对网站意义不大,尤其是对于优化而言,甚至采集的内容也将被视为垃圾邮件,从而给网站造成负担. 实际上,即使采集的内容对网站没有影响,也可以. 但是,只要采集合理,它仍然有用,并且可以减少网站站长的原创烦恼并获得相同的优化效果. 那么,如何正确使用采集到的内容?
首先,内容的对象精美. 最好找到刚刚由其他人发布的内容作为采集目标,并在太多人重新发布之前采集它,但是内容的前提是它是前进的,新鲜的和有代表性的,而不是某些内容. 老式主题,否则将针对用户. 铜爵蜡的味道就不值一提了. 由于采集了内容,因此自然比原创内容要简单得多,因此您无需花费太多时间来编辑内容. 此时不要节省时间. 毕竟,采集的内容没有原创效果. 这很简单,因此您需要同时查找更多内容,以弥补蜘蛛的空虚. 蓝田下巴整形培训机构
第二,采集内容不采集标题. 每个人都知道,阅读文章时首先要看的是标题. 对于经过网站优化的搜索引擎,标题也具有一定的重要性. 采集的内容具有一定的长度,不能过多地更改,但是标题仅短短几个字,并且相对容易修改. 因此,标题的修改是必要的,最好将标题更改为原创标题. 原因很简单. 当您看到标题相同但实质完全不同的文章时,读者会误解两者的内容是相同的. 相反,即使内容相同但标题完全不同,也会给人们带来相同的感觉. 这种新鲜感不容易被发现.
最后,对内容进行适当的调整. 尝试在自己的网站上采集内容的网站管理员肯定会发现直接复制的内容存在格式问题,因为一些聪明的原创创作者通常会向内容添加一些隐藏的内容,以防止采集内容. 格式,甚至版权都将标记在图片的ALT信息中. 如果您不注意,搜索引擎自然会将其视为engines窃,对网站的危害是不言而喻的. 因此,必须对采集的内容进行格式化,并且必须转换英语格式的标点符号. 另外,可以将一些图片添加到内容中以使内容更丰富. 如果内容本身具有图片,则不要直接复制,最好是另外保存,上传到网站以及您自己的ALT信息,可以使采集的内容更有价值. 西安风屁股培训中心
简而言之,网站采集的内容并非完全无用. 关键取决于您如何采集它. 只要您可以灵活地使用采集的内容,就可以为网站带来某些好处. 但是,网站管理员需要注意. 是的,必须掌握某些采集方法.
ASP拦截和采集网页指定内容的功能
采集交流 • 优采云 发表了文章 • 0 个评论 • 322 次浏览 • 2020-08-06 21:18
ASP截取网页指定内容的功能参数说明
ConStr ------要截取的字符串
StartStr ------起始字符串
OverStr ------结束字符串
收录------是否包括在内?
StartStrIncluR ------是否收录OverStr
ASP拦截和采集网页指定内容的功能
<p>Function GetBody(ConStr,StartStr,OverStr,IncluL,IncluR)
If ConStr="$False$" or ConStr="" or IsNull(ConStr)=True Or StartStr="" or IsNull(StartStr)=True Or OverStr="" or IsNull(OverStr)=True Then
GetBody="$False$"
Exit Function
End If
Dim ConStrTemp
Dim Start,Over
ConStrTemp=Lcase(ConStr)
StartStr=Lcase(StartStr)
OverStr=Lcase(OverStr)
Start = InStrB(1, ConStrTemp, StartStr, vbBinaryCompare)
If Start 查看全部
ASP采集程序中的字符串拦截功能具有许多功能. 您可以指定拦截范围. 您只需要自定义开始和结束字符串,还可以指定所拦截的字符串是否收录开始和结束字符串.
ASP截取网页指定内容的功能参数说明
ConStr ------要截取的字符串
StartStr ------起始字符串
OverStr ------结束字符串
收录------是否包括在内?
StartStrIncluR ------是否收录OverStr
ASP拦截和采集网页指定内容的功能
<p>Function GetBody(ConStr,StartStr,OverStr,IncluL,IncluR)
If ConStr="$False$" or ConStr="" or IsNull(ConStr)=True Or StartStr="" or IsNull(StartStr)=True Or OverStr="" or IsNull(OverStr)=True Then
GetBody="$False$"
Exit Function
End If
Dim ConStrTemp
Dim Start,Over
ConStrTemp=Lcase(ConStr)
StartStr=Lcase(StartStr)
OverStr=Lcase(OverStr)
Start = InStrB(1, ConStrTemp, StartStr, vbBinaryCompare)
If Start
采集网站依靠什么来获得良好的内容采集?
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2020-08-06 19:21
第一: 内容相似度
也许我认为我的文章是原创的,并且我是用手工打字的,但是确实有一些文章与我在搜索引擎上的文章几乎相同,只是原创的手工文章呈现了这种情况. 概率很小,通常在目前为伪原创者中. 首先,文章的文本和底部的文本是最重要的,因为搜索引擎很少扫描全文,而搜索引擎只扫描文本然后进行粗略扫描. 中心内容,然后直接扫描底部,当搜索引擎蜘蛛完成扫描后,将其保存在索引库中,然后进行多身份分析以查看所收录文章中是否存在相似之处,例如相似内容. 如果很高,则比较具有相似性的文章的权重,最后确定要包括的文章. 因此,如果要增加搜索引擎的收录范围,最重要的是要注意内容的相似性.
第二: 采集内容
<p>许多人精神有限,因此不可避免地会使用获取软件来丰富网站的内容来源,但是免费获取软件会占用很多人,并且采集的数据源将不可避免地增加. 已经重复了一次,收费软件的价格太高. 尽管功能完善,但作为普通的个人网站管理员,仍然很难支付此费用. 因此,建议使用采集软件的网站管理员伴随软件. 采集内容之后,您必须动手修改主文本和结尾文本,然后在网站上添加相关文章的锚点文本链接,这可以指导搜索引擎抓取工具抓取更多文章,并且采集网站的模板优化也是不可避免的. 为此,增加网站上文章的曝光率,以便搜索引擎蜘蛛可以沿着网站上的交叉链接抓取更多文章,从而增加收录的网站数量. 查看全部
网站上的内容每天都会更新,但收录人数并未增加. 此时,您应该采用响应的方法,因为即使每天更新数十或数百篇文章,如果SEO搜索引擎不收录它们也没有用. 如果搜索引擎每天都在爬网并采集,即使只更新了两篇文章,结束也比更新数十篇文章更好.
第一: 内容相似度
也许我认为我的文章是原创的,并且我是用手工打字的,但是确实有一些文章与我在搜索引擎上的文章几乎相同,只是原创的手工文章呈现了这种情况. 概率很小,通常在目前为伪原创者中. 首先,文章的文本和底部的文本是最重要的,因为搜索引擎很少扫描全文,而搜索引擎只扫描文本然后进行粗略扫描. 中心内容,然后直接扫描底部,当搜索引擎蜘蛛完成扫描后,将其保存在索引库中,然后进行多身份分析以查看所收录文章中是否存在相似之处,例如相似内容. 如果很高,则比较具有相似性的文章的权重,最后确定要包括的文章. 因此,如果要增加搜索引擎的收录范围,最重要的是要注意内容的相似性.
第二: 采集内容
<p>许多人精神有限,因此不可避免地会使用获取软件来丰富网站的内容来源,但是免费获取软件会占用很多人,并且采集的数据源将不可避免地增加. 已经重复了一次,收费软件的价格太高. 尽管功能完善,但作为普通的个人网站管理员,仍然很难支付此费用. 因此,建议使用采集软件的网站管理员伴随软件. 采集内容之后,您必须动手修改主文本和结尾文本,然后在网站上添加相关文章的锚点文本链接,这可以指导搜索引擎抓取工具抓取更多文章,并且采集网站的模板优化也是不可避免的. 为此,增加网站上文章的曝光率,以便搜索引擎蜘蛛可以沿着网站上的交叉链接抓取更多文章,从而增加收录的网站数量.
SEO内容获取解决方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2020-08-06 18:09
处理原理
当前,通常有两种采集方式:
1. 定向采集: 按原点排序,设置采集条件,选择站点中可用的任何内容,然后进行过滤!
2. 泛集合: 常规爬虫集合
我们在这里使用的是: 根据关键字,指定N个网站进行有针对性的采集
原理: 借用搜索引擎命令站点: 域关键字
示意图
第二,内容处理
1. 标题
方法1: 简化原创标题
步骤如下:
对原创标题进行分区
删除停用词
添加词性
删除修饰词,例如形容词,副词,介词...,保留原创标题的主语-谓语-宾语,并获得句子的主语
通常,基于解词分词或nltk实现,可以通过预先分析大量标题来提取要删除的修饰语,并将其附加到词典中.
例如,以这种方式处理阿里巴巴某些产品页面的标题. 删除用户发布的产品名称中的一些不相关的词缀,并提取主词干并放置在标题标签中.
方法2: 插入搜索字词
步骤如下:
构建xunsearch或其他开源搜索,并为采集的标题建立索引
使用预先准备的搜索词(待完成的单词)在搜索界面中依次搜索
在搜索结果中出现的标题之前插入当前搜索词
我要说的是“正确使用电动汽车电池”
例如,匹配原创标题
“不要让过度放电破坏您的电动汽车电池”
“黄山的一个男人通过拆线缝偷了电瓶车”
………………..
在标题前插入关键字:
“ [正确使用电动汽车电池]不要让过度放电破坏您的电动汽车电池”
或者“ [正确使用电动汽车电池]黄山上的一个男人通过拆下电线并连接电线偷走了电池车”
当然也可以: “ {插入搜索词} {简化的原创标题}”
方法3: 在当前标题中插入派生词和相关搜索词,其中已经收录搜索词
步骤如下:
获取百度相关搜索或标题已收录搜索词的下拉框,
在标题中插入相关的搜索或下拉单词
例如: “ [[{百度相关搜索词1}] {原创标题}”,“ [{下拉框推荐单词1} {原创标题}]”
也: [{百度相关搜索词1}] {简体原创标题}“,” [{下拉框推荐单词1} {简体原创标题}]“
2. 身体含量
正文的处理主要是为了重复,以尽量减少与原创内容的相似性
在正文的开头和结尾插入随机文本
方法1: 事先准备一些通用文本模板,随机调用它们并替换关键字
方法2: 在正文中随机剪切一段文本
方法3: 随机调出N篇相关文章的标题和摘要,并将其放在开头和结尾
编辑正文内容
基于textrank算法提取文本摘要,并将其放在主要文本的前面.
为了防止单词数量过少,可以预先使用k-means和tf-idf在当前文章中查找相似的文章,并提取正单词最长的段落摘要和将它们添加到当前文章中,作为单词“完成”的数量.
汇总页面
聚合页面是从单词根部挖出的10个扩展单词. 每个扩展的单词都会生成一个列表页面或其他形式的聚合页面. 该页面的内容是与该单词相对应的20条内容.
这是最简单的模型
通常的模型
以扩展名“正确使用电动汽车电池”为例
聚合页面要采集的内容是:
如何保护充电器?
如何延长电池寿命?
电动汽车电池充电的环境要求?
这种模型通常是机器+工人首先预先设置模型,然后采集内容,然后处理组合.
案例:
扩展词: 九江是一个适合购物的地方
标题: 关键字组合,
内容: 汇总页面,内容组合 查看全部
一个. 采集
处理原理
当前,通常有两种采集方式:
1. 定向采集: 按原点排序,设置采集条件,选择站点中可用的任何内容,然后进行过滤!
2. 泛集合: 常规爬虫集合
我们在这里使用的是: 根据关键字,指定N个网站进行有针对性的采集
原理: 借用搜索引擎命令站点: 域关键字
示意图
第二,内容处理
1. 标题
方法1: 简化原创标题
步骤如下:
对原创标题进行分区
删除停用词
添加词性
删除修饰词,例如形容词,副词,介词...,保留原创标题的主语-谓语-宾语,并获得句子的主语
通常,基于解词分词或nltk实现,可以通过预先分析大量标题来提取要删除的修饰语,并将其附加到词典中.
例如,以这种方式处理阿里巴巴某些产品页面的标题. 删除用户发布的产品名称中的一些不相关的词缀,并提取主词干并放置在标题标签中.
方法2: 插入搜索字词
步骤如下:
构建xunsearch或其他开源搜索,并为采集的标题建立索引
使用预先准备的搜索词(待完成的单词)在搜索界面中依次搜索
在搜索结果中出现的标题之前插入当前搜索词
我要说的是“正确使用电动汽车电池”
例如,匹配原创标题
“不要让过度放电破坏您的电动汽车电池”
“黄山的一个男人通过拆线缝偷了电瓶车”
………………..
在标题前插入关键字:
“ [正确使用电动汽车电池]不要让过度放电破坏您的电动汽车电池”
或者“ [正确使用电动汽车电池]黄山上的一个男人通过拆下电线并连接电线偷走了电池车”
当然也可以: “ {插入搜索词} {简化的原创标题}”
方法3: 在当前标题中插入派生词和相关搜索词,其中已经收录搜索词
步骤如下:
获取百度相关搜索或标题已收录搜索词的下拉框,
在标题中插入相关的搜索或下拉单词
例如: “ [[{百度相关搜索词1}] {原创标题}”,“ [{下拉框推荐单词1} {原创标题}]”
也: [{百度相关搜索词1}] {简体原创标题}“,” [{下拉框推荐单词1} {简体原创标题}]“
2. 身体含量
正文的处理主要是为了重复,以尽量减少与原创内容的相似性
在正文的开头和结尾插入随机文本
方法1: 事先准备一些通用文本模板,随机调用它们并替换关键字
方法2: 在正文中随机剪切一段文本
方法3: 随机调出N篇相关文章的标题和摘要,并将其放在开头和结尾
编辑正文内容
基于textrank算法提取文本摘要,并将其放在主要文本的前面.
为了防止单词数量过少,可以预先使用k-means和tf-idf在当前文章中查找相似的文章,并提取正单词最长的段落摘要和将它们添加到当前文章中,作为单词“完成”的数量.
汇总页面
聚合页面是从单词根部挖出的10个扩展单词. 每个扩展的单词都会生成一个列表页面或其他形式的聚合页面. 该页面的内容是与该单词相对应的20条内容.
这是最简单的模型
通常的模型
以扩展名“正确使用电动汽车电池”为例
聚合页面要采集的内容是:
如何保护充电器?
如何延长电池寿命?
电动汽车电池充电的环境要求?
这种模型通常是机器+工人首先预先设置模型,然后采集内容,然后处理组合.
案例:
扩展词: 九江是一个适合购物的地方
标题: 关键字组合,
内容: 汇总页面,内容组合
优采云采集器采集了有关当今头条新闻ajx内容的最新教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2020-08-06 18:07
今天的头条的反集会非常强大,规则在不断变化,因此规则几乎每次都更新.
打开今天的标题; F12,标题内容通过ajx传输,向下滑动鼠标,可以看到下图所示的内容.
https://www.toutiao.com/api/pc ... 01cVe;
开放内容经过json加密,如下图所示
将链接复制并粘贴到优采云采集器中以测试捕获分析并输入下图;
<p>好的,这里我们已经获得了所需的列表页面数据,并将起始页面链接设置为刚刚获得的链接(他具有分页功能,在这里您可以自己分析他的数量变化) 查看全部
今天的头条是一个自媒体信息平台,每天有10,000多个更新,每天都有很多高质量的内容. 我们的优采云采集器如何采集内容并将其发布到我们的网站?今天,舒榕将为每个人分析优采云采集规则.
今天的头条的反集会非常强大,规则在不断变化,因此规则几乎每次都更新.
打开今天的标题; F12,标题内容通过ajx传输,向下滑动鼠标,可以看到下图所示的内容.
https://www.toutiao.com/api/pc ... 01cVe;
开放内容经过json加密,如下图所示
将链接复制并粘贴到优采云采集器中以测试捕获分析并输入下图;
<p>好的,这里我们已经获得了所需的列表页面数据,并将起始页面链接设置为刚刚获得的链接(他具有分页功能,在这里您可以自己分析他的数量变化)
一键式发布帖子内容的官方版本8.0.1
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2020-08-06 08:27
答案: 相反,我想问你,如果您没有安装捕获插件,而是撰写了自己的原创文章,那么您可以写几篇文章? ?我相信99.9%的人不会完全原创所有内容,他们会转载其他网站的某些内容,包括xx日报,xx电视台,或多或少地复制其他网站的一些高质量内容. Discuz论坛安装集合插件主要用于帮助您操作自己的网站内容. 由于您必须手动重新发布内容,为什么不使用更高效,无错误,简单易用的采集工具来提高自己的效率呢? ?
问题: 百度会收录采集到的内容吗? ?如何进行SEO优化? ?
答案: 一条新闻出来时,您会在百度搜索中找到它. 还包括许多重复内容的文章. 实际上,那些重复的内容会被重印,因此采集的内容也将收录在百度中. 特别是,最新的原创内容会及时采集并同时发布,因此您的采集与原创内容没有什么不同. 为了更好地提高SEO采集优化,除了及时采集最新的原创内容外,最好采集一些拒绝百度收录的平台内容,例如: 微信公众号文章,以及一些可以仅在登录后才能看到,某些内容加载了ajax等,百度无法访问这些内容. 是的,如果您发布此类内容,则SEO集合会更好,排名也会更好! !
问题: 所采集的内容是否会侵权? ?
答案: 一些有助于社会正常运转的内容. 允许再现这种类型的内容. 例如: 最近的新冠状肺炎非常严重,一些与流行病有关的公共报道,这些都没有问题,因为这些流行病人们对防治信息的了解越多,越好! !它对流行病的预防和控制更有帮助,采集此类内容毫无问题!还有一种内容对某家公司有负面影响. 某公司的公关人员将通知您删除内容. 只要您合作删除内容,就可以了! !仅一小部分内容已申请版权. 如果您不小心将其重新打印,版权所有者可能会起诉您. 这是一个低概率事件,您通常不会遇到! ! Zhiwu应用程序的采集插件支持发布前的审阅,不支持未经审阅的自动采集和发布! !确保所采集内容的安全! !因为每篇文章的内容都是在您审阅后采集并发布的.
问题: Zhiwu应用程序可靠吗?会撒谎吗?
答案: 非常可靠! ! Zhiwu所应用的产品在上线之前,将经过严格的测试并检查代码质量,以确保它们安全,可用和易于使用. 只有通过评估后,他们才能申请上架! !同时,源代码是打开的. 任何人都可以查看原创的透明代码. 具有技术能力的用户可以轻松快速地进行二次开发. Zhiwu应用程序的任何产品都可以免费试用,满意后可以考虑使用. 您需要升级到正式的商业版本吗?如果发现安装后无法使用它,可以联系在线客户服务来解决. 如果您遇到无法解决的问题,则无法使用该插件,并且会全额退款. 一般原则是让用户安全无风险,准确找到他们的需求,并购买可以使用的插件模块. 如果他们发现购买后不可用,Zhiwu应用程序将为您退款. 如果您真的需要它,请放心购买Zhiwu app各种产品! ! !智物App一直认真听取用户的反馈意见,根据用户的建议不断升级和更新产品,尊重用户的权利和合理的要求! !将用户置于最高位置,竭诚为他们服务! !
问题: Zhiwu应用程序的集合插件有哪些亮点和优势?
答案: 其中大多数使用Chrome扩展程序采集程序,您需要在网络浏览器chrome中安装扩展程序,因为经过研究,发现将浏览器变成采集工具是最可靠,成熟和稳定的采集方法!一些传统的采集方法通过程序抓取功能来采集内容,尽管您无需安装chrome扩展程序,但通常会遇到问题,并且当无法采集内容时会发生某些事情! !
问题: Zhiwu App开发了哪些采集插件?
答案: 很多! !多年来,我们一直致力于采集插件的开发. 经过多次升级和更新,我们在采集插件的开发方面积累了丰富的经验. 如果找不到所需的采集插件,请向Zhiwu App在线客户服务反馈.
问题: 智物通哪个采集插件易于使用?
答案: 核心技术相同,但是采集规则不同. Zhiwu应用程序的采集插件易于使用. 它主要取决于您需要采集哪个网站,然后使用该网站的相应采集插件.
问题: 我根本不了解这项技术,但是我想使用Zhiwu App的Discuz捕获插件,该怎么办?
回答: 请联系Zhiwu App的在线客户服务来帮助您在线安装和配置它,直到该插件完全可用为止! !您不需要了解技术,售后服务就会帮助您解决所有问题.
问题: 为什么要使用chrome扩展程序捕获程序? ?
答案: 因为这种采集方法是最稳定和成熟的! !网页由浏览器通过HTML代码呈现,因此将浏览器变成采集工具的最佳方法就是所见即所得.
问题: chrome扩展程序安全吗? ?为什么弹出“请禁用在开发人员模式下运行的扩展程序”
答案: 只要安装了chrome扩展程序,无论使用什么chrome扩展程序,都会弹出此提醒: “在开发人员模式下运行的扩展程序可能会损害您的计算机. 如果您不是开发人员,那么出于安全考虑,应该禁用在开发人员模式下运行的扩展程序. ”这就像在百货商店中提醒您: “如果发生火灾,请致电119. ”就像提醒您拨打119一样,这并不意味着您遇到过. 火,这只是提醒! ! Zhiwu应用程序的chrome扩展程序已由多方进行了人工检查,检查和测试,是安全可靠的扩展程序! !
问题: 我可以无人值守并自动采集内容吗? ?
答案: 不! !内容是自动采集和发布的,因此采集的内容不安全! ! Zhiwu应用程序的采集插件在发布前都经过了审核,以确保内容的质量和安全! !未经您的同意,您无法自动发布内容! !如果您需要在短时间内采集和发布大量内容以填充网站,则可以在[待发布]中选择[以chrome扩展名批量添加内容]. 查看全部
问题: 为什么Discuz论坛必须安装捕获插件?
答案: 相反,我想问你,如果您没有安装捕获插件,而是撰写了自己的原创文章,那么您可以写几篇文章? ?我相信99.9%的人不会完全原创所有内容,他们会转载其他网站的某些内容,包括xx日报,xx电视台,或多或少地复制其他网站的一些高质量内容. Discuz论坛安装集合插件主要用于帮助您操作自己的网站内容. 由于您必须手动重新发布内容,为什么不使用更高效,无错误,简单易用的采集工具来提高自己的效率呢? ?
问题: 百度会收录采集到的内容吗? ?如何进行SEO优化? ?
答案: 一条新闻出来时,您会在百度搜索中找到它. 还包括许多重复内容的文章. 实际上,那些重复的内容会被重印,因此采集的内容也将收录在百度中. 特别是,最新的原创内容会及时采集并同时发布,因此您的采集与原创内容没有什么不同. 为了更好地提高SEO采集优化,除了及时采集最新的原创内容外,最好采集一些拒绝百度收录的平台内容,例如: 微信公众号文章,以及一些可以仅在登录后才能看到,某些内容加载了ajax等,百度无法访问这些内容. 是的,如果您发布此类内容,则SEO集合会更好,排名也会更好! !
问题: 所采集的内容是否会侵权? ?
答案: 一些有助于社会正常运转的内容. 允许再现这种类型的内容. 例如: 最近的新冠状肺炎非常严重,一些与流行病有关的公共报道,这些都没有问题,因为这些流行病人们对防治信息的了解越多,越好! !它对流行病的预防和控制更有帮助,采集此类内容毫无问题!还有一种内容对某家公司有负面影响. 某公司的公关人员将通知您删除内容. 只要您合作删除内容,就可以了! !仅一小部分内容已申请版权. 如果您不小心将其重新打印,版权所有者可能会起诉您. 这是一个低概率事件,您通常不会遇到! ! Zhiwu应用程序的采集插件支持发布前的审阅,不支持未经审阅的自动采集和发布! !确保所采集内容的安全! !因为每篇文章的内容都是在您审阅后采集并发布的.
问题: Zhiwu应用程序可靠吗?会撒谎吗?
答案: 非常可靠! ! Zhiwu所应用的产品在上线之前,将经过严格的测试并检查代码质量,以确保它们安全,可用和易于使用. 只有通过评估后,他们才能申请上架! !同时,源代码是打开的. 任何人都可以查看原创的透明代码. 具有技术能力的用户可以轻松快速地进行二次开发. Zhiwu应用程序的任何产品都可以免费试用,满意后可以考虑使用. 您需要升级到正式的商业版本吗?如果发现安装后无法使用它,可以联系在线客户服务来解决. 如果您遇到无法解决的问题,则无法使用该插件,并且会全额退款. 一般原则是让用户安全无风险,准确找到他们的需求,并购买可以使用的插件模块. 如果他们发现购买后不可用,Zhiwu应用程序将为您退款. 如果您真的需要它,请放心购买Zhiwu app各种产品! ! !智物App一直认真听取用户的反馈意见,根据用户的建议不断升级和更新产品,尊重用户的权利和合理的要求! !将用户置于最高位置,竭诚为他们服务! !
问题: Zhiwu应用程序的集合插件有哪些亮点和优势?
答案: 其中大多数使用Chrome扩展程序采集程序,您需要在网络浏览器chrome中安装扩展程序,因为经过研究,发现将浏览器变成采集工具是最可靠,成熟和稳定的采集方法!一些传统的采集方法通过程序抓取功能来采集内容,尽管您无需安装chrome扩展程序,但通常会遇到问题,并且当无法采集内容时会发生某些事情! !
问题: Zhiwu App开发了哪些采集插件?
答案: 很多! !多年来,我们一直致力于采集插件的开发. 经过多次升级和更新,我们在采集插件的开发方面积累了丰富的经验. 如果找不到所需的采集插件,请向Zhiwu App在线客户服务反馈.
问题: 智物通哪个采集插件易于使用?
答案: 核心技术相同,但是采集规则不同. Zhiwu应用程序的采集插件易于使用. 它主要取决于您需要采集哪个网站,然后使用该网站的相应采集插件.
问题: 我根本不了解这项技术,但是我想使用Zhiwu App的Discuz捕获插件,该怎么办?
回答: 请联系Zhiwu App的在线客户服务来帮助您在线安装和配置它,直到该插件完全可用为止! !您不需要了解技术,售后服务就会帮助您解决所有问题.
问题: 为什么要使用chrome扩展程序捕获程序? ?
答案: 因为这种采集方法是最稳定和成熟的! !网页由浏览器通过HTML代码呈现,因此将浏览器变成采集工具的最佳方法就是所见即所得.
问题: chrome扩展程序安全吗? ?为什么弹出“请禁用在开发人员模式下运行的扩展程序”
答案: 只要安装了chrome扩展程序,无论使用什么chrome扩展程序,都会弹出此提醒: “在开发人员模式下运行的扩展程序可能会损害您的计算机. 如果您不是开发人员,那么出于安全考虑,应该禁用在开发人员模式下运行的扩展程序. ”这就像在百货商店中提醒您: “如果发生火灾,请致电119. ”就像提醒您拨打119一样,这并不意味着您遇到过. 火,这只是提醒! ! Zhiwu应用程序的chrome扩展程序已由多方进行了人工检查,检查和测试,是安全可靠的扩展程序! !
问题: 我可以无人值守并自动采集内容吗? ?
答案: 不! !内容是自动采集和发布的,因此采集的内容不安全! ! Zhiwu应用程序的采集插件在发布前都经过了审核,以确保内容的质量和安全! !未经您的同意,您无法自动发布内容! !如果您需要在短时间内采集和发布大量内容以填充网站,则可以在[待发布]中选择[以chrome扩展名批量添加内容].
网站反采集代码制作网站反采集代码网站内容反采集程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 380 次浏览 • 2020-08-06 07:05
如果结束
如果结束
%>
3.
防止采集的第一种方法是使用持久性向静态页面添加会话功能
通常来说,只有服务器端CGI程序(ASP,PHP,JSP)具有会话功能,该功能用于在网站(会话)期间保存用户的活动数据信息,并保存大量静态页面(HTML)换句话说,只能使用客户端的cookie来存储临时活动数据,但是cookie的操作是一个非常繁琐的过程,远不如会话操作方便. 因此,本文向读者推荐DHTML中的“持久性技术”解决方案,以便会话功能也可以在静态页面中使用.
Microsoft Internet Explorer 5浏览器和更高版本支持使用持久性技术,该技术使我们能够在当前会话期间将某些数据对象保存到客户端,从而减少了对服务器的访问请求并充分发挥了客户端的作用. 终端计算机的处理能力还提高了整体页面显示效率.
持久性技术具有以下行为可调用:
·saveFavorite-将页面添加到采集夹时保存页面状态和信息
·saveHistory-在当前会话中保存页面状态和信息
·saveSnapshot-将页面保存到硬盘后,保存页面状态和信息
·userData-在当前会话中以XML格式保存页面状态和信息
持久性技术打破了cookie和会话的传统用法,继承了cookie的某些安全策略,还增强了存储和管理数据的能力. 每个页面的用户数据存储容量为64KB,每个站点的总存储限制为640KB.
Persistence技术存储的数据格式符合XML标准,因此可以使用DOM技术中的getAttribute和setAttribute方法访问数据.
以下是持久性技术的典型应用. 通过对持久性存储数据的分析,静态页面具有验证功能.
实际的判断过程是这样的:
1. 一共有三个对象: 访问者V,导航页面A,内容页面C
2. 访问者V只能通过导航页面A的链接看到内容页面C;
<p>3. 如果访问者V通过其他方式(例如,通过指向其他网站的超链接,直接在IE地址栏中输入URL等)访问内容页面C,则内容页面C将自动提示版权信息并显示空白页面. 查看全部
%>
如果结束
如果结束
%>
3.
防止采集的第一种方法是使用持久性向静态页面添加会话功能
通常来说,只有服务器端CGI程序(ASP,PHP,JSP)具有会话功能,该功能用于在网站(会话)期间保存用户的活动数据信息,并保存大量静态页面(HTML)换句话说,只能使用客户端的cookie来存储临时活动数据,但是cookie的操作是一个非常繁琐的过程,远不如会话操作方便. 因此,本文向读者推荐DHTML中的“持久性技术”解决方案,以便会话功能也可以在静态页面中使用.
Microsoft Internet Explorer 5浏览器和更高版本支持使用持久性技术,该技术使我们能够在当前会话期间将某些数据对象保存到客户端,从而减少了对服务器的访问请求并充分发挥了客户端的作用. 终端计算机的处理能力还提高了整体页面显示效率.
持久性技术具有以下行为可调用:
·saveFavorite-将页面添加到采集夹时保存页面状态和信息
·saveHistory-在当前会话中保存页面状态和信息
·saveSnapshot-将页面保存到硬盘后,保存页面状态和信息
·userData-在当前会话中以XML格式保存页面状态和信息
持久性技术打破了cookie和会话的传统用法,继承了cookie的某些安全策略,还增强了存储和管理数据的能力. 每个页面的用户数据存储容量为64KB,每个站点的总存储限制为640KB.
Persistence技术存储的数据格式符合XML标准,因此可以使用DOM技术中的getAttribute和setAttribute方法访问数据.
以下是持久性技术的典型应用. 通过对持久性存储数据的分析,静态页面具有验证功能.
实际的判断过程是这样的:
1. 一共有三个对象: 访问者V,导航页面A,内容页面C
2. 访问者V只能通过导航页面A的链接看到内容页面C;
<p>3. 如果访问者V通过其他方式(例如,通过指向其他网站的超链接,直接在IE地址栏中输入URL等)访问内容页面C,则内容页面C将自动提示版权信息并显示空白页面.
新浪博客+内容采集站=每月赚1万元
采集交流 • 优采云 发表了文章 • 0 个评论 • 426 次浏览 • 2020-08-06 00:10
所以我很惊讶,他为什么要这么做?
如果您开始创建博客并经常进行更新,但是却没有赚钱,那不是很愚蠢吗?
因此,我打开了更多博客文章并进行了查看,发现许多博客最后都添加了许多锚文本超链接. 点击后,我跳到另一个新浪博客.
此博客中唯一的广告是这个.
我去了另一个新浪博客,它获得了超过200万的浏览量.
内容仍然混乱,没有精确的定位.
这个博客也有一个锚文本超链接,但是这次我没有跳到新浪博客,而是跳到了一个独立的网站.
我打开了这个独立的网站并查看了它,发现它是一个采集站,内容都是乱七八糟的东西.
所以我检查了这个网站的重量,结果是3.
由于来自新浪博客的转移,实际流量应该比下图中查询的流量大得多. 毕竟,网站站长工具只能找到百度搜索引擎的估算流量,而实际流量可能就是此估算值,甚至很多倍甚至十倍是可能的,我们不知道这些数据.
打开这个独立的网站,我发现首页上悬挂了广告网络广告,并且打开的列并不多. 我认为没有理由.
没有其他货币化渠道,没有微信,没有产品,什么都没有.
再次打开内页. .
所有广告,如下所示:
内容页面上至少悬挂了10个广告.
到目前为止,该项目的内容非常清楚.
我将给您最后的整理:
1. 建立一个信息网站(可以使用dedecms,empire cms,sdcms)
2. 设置采集和发布(常规CMS程序可以支持)
3. 内容通常比较混乱,但是有些内容让无聊的人更感兴趣
4. 内容量相对较大,涉及的关键字很多,其中很多是长尾关键字. 您可以看到下面的图片
5. 申请广告联盟(注册域名,如百度,搜狗,360和Google)
6. 使用新浪博客的高权重关键字排名来转移流量
至此,该项目的内容已完成.
这可以看作是全自动的上层项目.
但是,我还有话要说: 采集的网站的成功率最多只能是一半. .
因此,如果执行此操作,可能会失败,但是幸运的是,没有费用. 200元就足够了: 域名50,空间50,采集和发布插件100,如果您不知道如何建立网站,则需要再花200元在淘宝上建立一个站点.
网上赚钱是一个不断反复试验的过程,在不断的实际战斗中经验会不断增长.
关注疯狂团队(),关注更多精彩内容,微信/ QQ: 543890,公共帐户: 疯狂团队俱乐部,bfclub. 查看全部
但是因为这种博客没有有意义的内容,也没有精确的定位,所以没有广告.
所以我很惊讶,他为什么要这么做?
如果您开始创建博客并经常进行更新,但是却没有赚钱,那不是很愚蠢吗?
因此,我打开了更多博客文章并进行了查看,发现许多博客最后都添加了许多锚文本超链接. 点击后,我跳到另一个新浪博客.
此博客中唯一的广告是这个.
我去了另一个新浪博客,它获得了超过200万的浏览量.
内容仍然混乱,没有精确的定位.
这个博客也有一个锚文本超链接,但是这次我没有跳到新浪博客,而是跳到了一个独立的网站.
我打开了这个独立的网站并查看了它,发现它是一个采集站,内容都是乱七八糟的东西.
所以我检查了这个网站的重量,结果是3.
由于来自新浪博客的转移,实际流量应该比下图中查询的流量大得多. 毕竟,网站站长工具只能找到百度搜索引擎的估算流量,而实际流量可能就是此估算值,甚至很多倍甚至十倍是可能的,我们不知道这些数据.
打开这个独立的网站,我发现首页上悬挂了广告网络广告,并且打开的列并不多. 我认为没有理由.
没有其他货币化渠道,没有微信,没有产品,什么都没有.
再次打开内页. .
所有广告,如下所示:
内容页面上至少悬挂了10个广告.
到目前为止,该项目的内容非常清楚.
我将给您最后的整理:
1. 建立一个信息网站(可以使用dedecms,empire cms,sdcms)
2. 设置采集和发布(常规CMS程序可以支持)
3. 内容通常比较混乱,但是有些内容让无聊的人更感兴趣
4. 内容量相对较大,涉及的关键字很多,其中很多是长尾关键字. 您可以看到下面的图片
5. 申请广告联盟(注册域名,如百度,搜狗,360和Google)
6. 使用新浪博客的高权重关键字排名来转移流量
至此,该项目的内容已完成.
这可以看作是全自动的上层项目.
但是,我还有话要说: 采集的网站的成功率最多只能是一半. .
因此,如果执行此操作,可能会失败,但是幸运的是,没有费用. 200元就足够了: 域名50,空间50,采集和发布插件100,如果您不知道如何建立网站,则需要再花200元在淘宝上建立一个站点.
网上赚钱是一个不断反复试验的过程,在不断的实际战斗中经验会不断增长.
关注疯狂团队(),关注更多精彩内容,微信/ QQ: 543890,公共帐户: 疯狂团队俱乐部,bfclub.
SEO如何处理采集的内容(5)
采集交流 • 优采云 发表了文章 • 0 个评论 • 355 次浏览 • 2020-08-05 12:53
文本提取
在[SEO如何处理集合内容①]的“泛集合”部分中,提到了文本提取,有些人仍然说他们不知道该怎么做.
这个东西可以在Internet上开源. 在Google搜索“ {programming language}文本提取算法”时,可以找到很多解决方案,例如: 可读性,Boilerpipe,Diffbot ...大多数算法已经打包. 您可以直接使用它,而无需自己编写. 我们在做网站,而不是技术网站. 如果您有现成的车轮,就可以.
所以有些人还有另一个问题: 我应该使用哪个?
否否,这不是在考虑轮子. 首先,不可能每种算法都提取所有网页. 其次,有不止一种算法.
这很简单. 算法不会提取当前网页的正文. 它很容易处理. 无需做任何其他事情. 只需切出算法,然后重试即可. 如果此方法不起作用,请更改另一种. 如果网页正常,可以提取文字. 除非此页面模板凌乱且收录所有内容(例如网站首页),否则没有明显的主要内容块,这是另一回事.
因此,如果在平移采集过程中需要提取链接的文本,则最好首先过滤主页URL.
如果您需要纠结使用哪一个,请参阅: / blog / 2011/06/09 / evaluating-text-extraction-algorithms /
重复数据删除
另一个问题,如果我采集重复的内容该怎么办?
这种炉渣以前使用过两种方法.
第一种类型:
首先,我们定义了有效内容需要满足的指标,例如,单词数必须大于150个单词才能被视为有效内容,而删除少于150个单词将不会存储在数据库. 然后,大于150个单词的内容通常具有超过4个标点符号.
XXXXXXX,XXXXXXXXX。XXX:“XXXXXX,XXXXXXXXXXXX。XXXXXX,XXXXXXXXXX,XXXXXXXX,XXXXXX。XXX?”
XXXX,XXXXXXX。XXXXXXX;XXXX;XXXXXXXX;XXXXXX,XXXXXXXXXX,XXXXXXXX,XXXXXX - XXX!
因此,对于每篇文章,从第二个标点符号开始,连续提取两个标点符号之间的文本,并且单词数大于7,直到提取了三个文本段.
然后将这三个文本段合并为一个,删除该文本段的重复项,并仅保留一个. 因为基本上重复了具有相同文本段的三个连续文章,并且它们被完全重复,所以它们不会更改.
第二种
使用现成的文本重复数据删除算法,还在Google搜索中使用一堆现成的解决方案,例如simhash,Shingling ...
首先清理所有捕获的文本,删除不相关的词,例如停用词,辅助词(不起作用...)等,然后使用上述解决方案计算相似的文档.
哪个更好?渣all都是中等的,我认为没有什么好用的,但是都可以使用. .
但是有一个问题. 一旦大量的文章(例如数以百万计的文章)变大,程序就会运行缓慢,并且CPU会被大量消耗. 我该怎么办? ?
所以我遵循第一种方法的思想,而不是分析全文,而是直接找到每篇文章的最长n个句子,再次进行哈希签名,然后使用上述现成的算法要运行,n通常需要3. 不仅运行速度快得多,而且找到相似文章的最终效果似乎比以前要好.
================================================ ====
知识星球->将来会有好处,例如一段可以编写色情句子的Python代码
微信公众号---->右下角
查看全部
背景中还有很多问题,本文是对其中两个问题的解答
文本提取
在[SEO如何处理集合内容①]的“泛集合”部分中,提到了文本提取,有些人仍然说他们不知道该怎么做.
这个东西可以在Internet上开源. 在Google搜索“ {programming language}文本提取算法”时,可以找到很多解决方案,例如: 可读性,Boilerpipe,Diffbot ...大多数算法已经打包. 您可以直接使用它,而无需自己编写. 我们在做网站,而不是技术网站. 如果您有现成的车轮,就可以.
所以有些人还有另一个问题: 我应该使用哪个?
否否,这不是在考虑轮子. 首先,不可能每种算法都提取所有网页. 其次,有不止一种算法.
这很简单. 算法不会提取当前网页的正文. 它很容易处理. 无需做任何其他事情. 只需切出算法,然后重试即可. 如果此方法不起作用,请更改另一种. 如果网页正常,可以提取文字. 除非此页面模板凌乱且收录所有内容(例如网站首页),否则没有明显的主要内容块,这是另一回事.
因此,如果在平移采集过程中需要提取链接的文本,则最好首先过滤主页URL.
如果您需要纠结使用哪一个,请参阅: / blog / 2011/06/09 / evaluating-text-extraction-algorithms /
重复数据删除
另一个问题,如果我采集重复的内容该怎么办?
这种炉渣以前使用过两种方法.
第一种类型:
首先,我们定义了有效内容需要满足的指标,例如,单词数必须大于150个单词才能被视为有效内容,而删除少于150个单词将不会存储在数据库. 然后,大于150个单词的内容通常具有超过4个标点符号.
XXXXXXX,XXXXXXXXX。XXX:“XXXXXX,XXXXXXXXXXXX。XXXXXX,XXXXXXXXXX,XXXXXXXX,XXXXXX。XXX?”
XXXX,XXXXXXX。XXXXXXX;XXXX;XXXXXXXX;XXXXXX,XXXXXXXXXX,XXXXXXXX,XXXXXX - XXX!
因此,对于每篇文章,从第二个标点符号开始,连续提取两个标点符号之间的文本,并且单词数大于7,直到提取了三个文本段.
然后将这三个文本段合并为一个,删除该文本段的重复项,并仅保留一个. 因为基本上重复了具有相同文本段的三个连续文章,并且它们被完全重复,所以它们不会更改.
第二种
使用现成的文本重复数据删除算法,还在Google搜索中使用一堆现成的解决方案,例如simhash,Shingling ...
首先清理所有捕获的文本,删除不相关的词,例如停用词,辅助词(不起作用...)等,然后使用上述解决方案计算相似的文档.
哪个更好?渣all都是中等的,我认为没有什么好用的,但是都可以使用. .
但是有一个问题. 一旦大量的文章(例如数以百万计的文章)变大,程序就会运行缓慢,并且CPU会被大量消耗. 我该怎么办? ?
所以我遵循第一种方法的思想,而不是分析全文,而是直接找到每篇文章的最长n个句子,再次进行哈希签名,然后使用上述现成的算法要运行,n通常需要3. 不仅运行速度快得多,而且找到相似文章的最终效果似乎比以前要好.
================================================ ====
知识星球->将来会有好处,例如一段可以编写色情句子的Python代码
微信公众号---->右下角
浅谈手机APP的内容采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 335 次浏览 • 2020-08-04 15:02
网站端的采集相对好做,至少从功能上讲是这样,功能是指将数据采集下来的能力,但是从性能上讲,网终端的采集也并不简单。为什么网站端实现数据采集功能相对容易呢内容采集,是因为网站内容我们是通过浏览器看的,而浏览器是一个公共的标准的平台,也就是说客户端没有发布内容企业自己的东西,有的仅仅是内容。那么我们就可以模拟浏览器进行肆无忌惮的采集,因为服务器没办法辨认出客户端是真正的浏览器访问还是采集网络爬虫。
如果在手机APP情况就完全不一样了,因为手机APP是企业自己发布的,所有的功能都是自己的,我们企业想避免采集就很容易了,在手机APP端加密,或做数据校准,在服务器端收到数据后最揭密或数据验证,网络爬虫很难象网站采集那样模拟访问了,使用旧的采集方案内容采集,除非破解APP加密算法或校准算法,否则无解。
是不是手机APP就不能采集了呢,当然不是,还好我们找出了采集手机APP的方案 查看全部
当前工作中遇见一些顾客要求采集手机APP上面的内容,随着移动端的盛行,这方面的需求会越来越多,在当前的互联网环境下,移动端越来越受重视,从内容上才能看下来,移动端内容愈发丰富,体验更好,网站端内容就没有这么丰富了,从这个角度能看出通配符的趋势。
网站端的采集相对好做,至少从功能上讲是这样,功能是指将数据采集下来的能力,但是从性能上讲,网终端的采集也并不简单。为什么网站端实现数据采集功能相对容易呢内容采集,是因为网站内容我们是通过浏览器看的,而浏览器是一个公共的标准的平台,也就是说客户端没有发布内容企业自己的东西,有的仅仅是内容。那么我们就可以模拟浏览器进行肆无忌惮的采集,因为服务器没办法辨认出客户端是真正的浏览器访问还是采集网络爬虫。
如果在手机APP情况就完全不一样了,因为手机APP是企业自己发布的,所有的功能都是自己的,我们企业想避免采集就很容易了,在手机APP端加密,或做数据校准,在服务器端收到数据后最揭密或数据验证,网络爬虫很难象网站采集那样模拟访问了,使用旧的采集方案内容采集,除非破解APP加密算法或校准算法,否则无解。
是不是手机APP就不能采集了呢,当然不是,还好我们找出了采集手机APP的方案

