
关键词自动采集
关键词自动采集(京东商品的名称、价格、链接注意:如何管理规则的线索 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-08-30 02:05
)
采集Content:京东商品名称、价格、链接
注意:在这种情况下,京东搜索有独立的网址。对于有独立网址的页面,最简单的方法是构造每个关键词搜索网址,然后将线索网址导入到规则中,就可以批量采集,而不是设置一个连续的动作,可以参考《如何构造URL”和“如何管理线索规则”。
第一步:定义一级规则
1.1 打开极手客网络爬虫,输入网址回车,加载网页后点击“定义规则”按钮,会看到一个浮动窗口,称为工作台,在上面可以定义规则;
注:这里的截图和文字说明均为极手客网络爬虫版本。如果你安装的是火狐插件版本,那么就没有“定义规则”按钮,但是你应该运行MS Museum。
1.2 在工作台中输入一级规则的主题名称,然后点击“检查重复”,提示“此名称可以使用”或“名称已被占用,可编辑:是” ,您可以使用此主题名称,否则请重命名。
1.3 这层规则主要是设置连续动作,所以排序框可以随意抓取一条信息,用它来判断是否为爬虫执行采集。双击网页上的信息,输入标签名称,勾选确认,然后勾选关键内容,输入第一个标签的排序框名称,标签映射完成。
提示:为了准确定位网页信息,点击定义规则会冻结整个网页,无法跳转到网页链接。再次点击定义规则,返回正常网页模式。
第 2 步:定义连续动作
点击工作台的“Continuous Action”选项卡,点击New按钮新建一个action,每个action的设置方法都是一样的,基本操作如下:
2.1,输入目标学科名称
这里的目标主题名称是填写二级主题名称,点击“谁在使用”查看目标主题名称是否可用,如果已经被占用,只需更改一个主题名称即可。
2.2,创建第一个动作:回车
创建一个新动作并选择动作类型作为输入。
2.2.1,填写定位表达式
首先点击输入框,定位输入框的节点,然后点击“Auto Generate XPath”按钮,可以选择“Preference id”或者“Preference class”,就可以得到输入的xpath表达式框,然后单击“搜索”按钮,检查这个xpath是否可以在输入框中唯一定位,如果没有问题,将xpath复制到定位表达式框中。
注意:定位表达式中的xpath是锁定动作对象的整个有效操作范围。具体是指鼠标可以点击或输入成功的网页模块。不要在底部找到 text() 节点。
2.2.2,输入关键词
输入关键词填写你要搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词使用双分号;;把每个关键词Separate,免费版只支持关键词5以内,旗舰版可以使用爆弹功能,支持关键词10000以内
2.2.3,输入动作名称
告诉自己这一步是做什么的,以便你以后可以修改。
2.3,创建第二个动作:点击
参考2.2的操作,创建第二个action,选择type为click,定位搜索按钮,然后自动生成xpath检查是否锁定到唯一节点,如果没有问题,填写定位表达式。 .
2.4,保存规则
点击“保存规则”按钮保存完成的一级规则
第 3 步:定义二级规则
3.1,新建规则
创建二级规则,点击“定义规则”返回正常网页模式,输入关键词搜索结果,再次点击“定义规则”切换到规则制定模式,点击“左上角规则”菜单->“新建”,输入主题名称,其中主题名称是在第一级规则的连续动作中填写的目标主题名称。
3.2,标记你想要的信息采集
3.2.1,在网页上标注你要采集的信息,这里是标注产品名称和价格,因为标注只对文字信息有效,以及产品链接details 是属性节点@href,所以不能在链接上做这么直观的标记,要做内容映射,具体看下面的操作。
3.2.2,点击产品名称,下方的DOM节点定位到A标签,展开A标签下的属性节点,可以找到代表URL的@href节点,右键节点,并选择“New Capture”抓取内容,输入一个名字,一般给抓取到的内容取一个与地址相关的名字,比如“下级网址”,或者“下级链接”等等。然后在工作台上,我看到表示抓取到的内容是可用的。如果您还想进入商品详情页采集,则必须针对抓取的内容检查下层线索,并进行分层抓取。
3.2.3、设置“关键内容”选项,让爬虫判断采集规则是否合适。在排序框中,选择网页上不可避免的标签,并勾选“关键内容”。这里选择“名称”作为“关键内容”。
3.2.4,只要在前面标注一个产品,就可以得到一个产品信息。如果你想采集下整个页面上的每一个产品,可以做一个样例拷贝,没有如果你看懂了,请参考基础教程“采集表数据”
3.3,设置翻页路线
在爬虫路由中设置翻页,这里是标记提示,不明白的请参考基础教程《设置翻页采集》
3.4,保存规则
点击“测试”以检查信息的完整性。如果不完整,重新标记可以覆盖之前的内容。确认没有问题后,点击“保存规则”。
第 4 步:捕获数据
4.1,连续动作是连续执行的,所以只要运行一级主题,二级主题就不需要运行了。打开DS计数器,搜索一级主题名称,点击“单一搜索”或“采集”,可以看到在浏览器窗口中自动输入并搜索关键词,然后调用二级主题自动采集搜索结果。
4.2,一级话题没有采集到有意义的信息,所以我们只看二级话题文件夹,可以看到采集的搜索结果数据,搜索关键词是默认记录在xml文件的actionvalue字段中,这样可以一一匹配。
如果您有任何问题,可以或
查看全部
关键词自动采集(京东商品的名称、价格、链接注意:如何管理规则的线索
)
采集Content:京东商品名称、价格、链接
注意:在这种情况下,京东搜索有独立的网址。对于有独立网址的页面,最简单的方法是构造每个关键词搜索网址,然后将线索网址导入到规则中,就可以批量采集,而不是设置一个连续的动作,可以参考《如何构造URL”和“如何管理线索规则”。
第一步:定义一级规则
1.1 打开极手客网络爬虫,输入网址回车,加载网页后点击“定义规则”按钮,会看到一个浮动窗口,称为工作台,在上面可以定义规则;
注:这里的截图和文字说明均为极手客网络爬虫版本。如果你安装的是火狐插件版本,那么就没有“定义规则”按钮,但是你应该运行MS Museum。
1.2 在工作台中输入一级规则的主题名称,然后点击“检查重复”,提示“此名称可以使用”或“名称已被占用,可编辑:是” ,您可以使用此主题名称,否则请重命名。
1.3 这层规则主要是设置连续动作,所以排序框可以随意抓取一条信息,用它来判断是否为爬虫执行采集。双击网页上的信息,输入标签名称,勾选确认,然后勾选关键内容,输入第一个标签的排序框名称,标签映射完成。
提示:为了准确定位网页信息,点击定义规则会冻结整个网页,无法跳转到网页链接。再次点击定义规则,返回正常网页模式。
第 2 步:定义连续动作
点击工作台的“Continuous Action”选项卡,点击New按钮新建一个action,每个action的设置方法都是一样的,基本操作如下:
2.1,输入目标学科名称
这里的目标主题名称是填写二级主题名称,点击“谁在使用”查看目标主题名称是否可用,如果已经被占用,只需更改一个主题名称即可。
2.2,创建第一个动作:回车
创建一个新动作并选择动作类型作为输入。
2.2.1,填写定位表达式
首先点击输入框,定位输入框的节点,然后点击“Auto Generate XPath”按钮,可以选择“Preference id”或者“Preference class”,就可以得到输入的xpath表达式框,然后单击“搜索”按钮,检查这个xpath是否可以在输入框中唯一定位,如果没有问题,将xpath复制到定位表达式框中。
注意:定位表达式中的xpath是锁定动作对象的整个有效操作范围。具体是指鼠标可以点击或输入成功的网页模块。不要在底部找到 text() 节点。
2.2.2,输入关键词
输入关键词填写你要搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词使用双分号;;把每个关键词Separate,免费版只支持关键词5以内,旗舰版可以使用爆弹功能,支持关键词10000以内
2.2.3,输入动作名称
告诉自己这一步是做什么的,以便你以后可以修改。
2.3,创建第二个动作:点击
参考2.2的操作,创建第二个action,选择type为click,定位搜索按钮,然后自动生成xpath检查是否锁定到唯一节点,如果没有问题,填写定位表达式。 .
2.4,保存规则
点击“保存规则”按钮保存完成的一级规则
第 3 步:定义二级规则
3.1,新建规则
创建二级规则,点击“定义规则”返回正常网页模式,输入关键词搜索结果,再次点击“定义规则”切换到规则制定模式,点击“左上角规则”菜单->“新建”,输入主题名称,其中主题名称是在第一级规则的连续动作中填写的目标主题名称。
3.2,标记你想要的信息采集
3.2.1,在网页上标注你要采集的信息,这里是标注产品名称和价格,因为标注只对文字信息有效,以及产品链接details 是属性节点@href,所以不能在链接上做这么直观的标记,要做内容映射,具体看下面的操作。
3.2.2,点击产品名称,下方的DOM节点定位到A标签,展开A标签下的属性节点,可以找到代表URL的@href节点,右键节点,并选择“New Capture”抓取内容,输入一个名字,一般给抓取到的内容取一个与地址相关的名字,比如“下级网址”,或者“下级链接”等等。然后在工作台上,我看到表示抓取到的内容是可用的。如果您还想进入商品详情页采集,则必须针对抓取的内容检查下层线索,并进行分层抓取。
3.2.3、设置“关键内容”选项,让爬虫判断采集规则是否合适。在排序框中,选择网页上不可避免的标签,并勾选“关键内容”。这里选择“名称”作为“关键内容”。
3.2.4,只要在前面标注一个产品,就可以得到一个产品信息。如果你想采集下整个页面上的每一个产品,可以做一个样例拷贝,没有如果你看懂了,请参考基础教程“采集表数据”
3.3,设置翻页路线
在爬虫路由中设置翻页,这里是标记提示,不明白的请参考基础教程《设置翻页采集》
3.4,保存规则
点击“测试”以检查信息的完整性。如果不完整,重新标记可以覆盖之前的内容。确认没有问题后,点击“保存规则”。
第 4 步:捕获数据
4.1,连续动作是连续执行的,所以只要运行一级主题,二级主题就不需要运行了。打开DS计数器,搜索一级主题名称,点击“单一搜索”或“采集”,可以看到在浏览器窗口中自动输入并搜索关键词,然后调用二级主题自动采集搜索结果。
4.2,一级话题没有采集到有意义的信息,所以我们只看二级话题文件夹,可以看到采集的搜索结果数据,搜索关键词是默认记录在xml文件的actionvalue字段中,这样可以一一匹配。
如果您有任何问题,可以或

关键词自动采集(长尾词采集软件程序工具,seo建设网站全自动采集文章工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-08-29 00:19
采集software怎么买 说说关键词几个常用的挖矿工具8nrt
采集software 如何购买几个常用的关键词挖矿工具-首页
今日推荐:采集software怎么买,说说几个常用的关键词挖矿工具{客户微信84643017}seo自动长尾词采集software程序工具,seo百度留痕转码软件程序工具,seo建设网站full-auto采集文章软件编程工具,百度贴吧私聊软件编程工具,百度长尾词b2b集成软件编程工具,b2B站集成业务处理,(如商国互联网、机电之家、云联盟、中国化工网、淘金热、中国贸易网、云商网、百商网、全球机械网、第一商网、企业名录、盛丰建材网、乐手推广、知趣网、中科商务网、钢企网、51搜网、模具联盟网、莱芜新闻网、迅瓜瓜、企业招商网、久久信息网、阿里伯乐、启辉网、时代商务网、机械论线等)等综合业务,可靠和非常规诚信声明:只做正规业务,非法请勿打扰。
句子}
seokwsranking 等等,对于分析网站的情况,可以说是非常非常详细了。
以 Anker 为例:
第六,K-Meta()可以通过网址搜索找到你的竞争对手,网站流量,广告文案,关键词Position;如果按关键字搜索,您可以看到每次点击费用、竞争程度、搜索音量和相关关键字以及自然搜索结果。
K-Meta 的功能类似于 Ubersuggest。如果搜索关键词,可以看到Searchvolume、CPC、竞争程度等,还可以看到哪些广告主出价,相对KWS等,以无线充电器为例。
看看输入 anker.co。填写验证码smallseotools,com 优点:1.非常准确2.可以同时查询5个关键词缺点:1.每次查询都需要一个验证码,布局和界面也很讨喜,这个文章主要是我讲的10个比较常用的SEO关键词优化工具。如果你有时间,你可以去研究它。对于 googleads 广告竞价的定时投放和竞品分析来说,是非常大的。
不同地区对土豆有不同的名称:土豆、洋蓟、蒸蛋、鸡蛋、野鸡蛋、豆角等。这些是土豆的其他名称!
所以我们使用这些别名而不是关键词!
08
目标关键词+属性组合
这其实很好。
搜索引擎中已经有大量或付费的 seo 工具。一般来说,它们可以分为几类。 ,包括但不限于站长工具、外链查询工具、seo综合查询工具、关键词挖掘工具、网站安全测速工具、网站测速工具、关键词index查询工具、网站statistics工具等
常用的SEO工具一般盘点有哪些? SEO优化不再累。
使用快速的seo工具可以提高网站优化的效率。减少时间成本并获得更好的结果。良好的投入产出比。工具是简化工作流程的好帮手。可以说,工具存在于生活的每一个角落,网站optimization也不例外。比如批量操作、自动扩容等,使用工具可以让网站优化更轻松。
{词汇比较、相关关键词和广告历史等标题、关键词难度、有机搜索量、此类关键词使用了哪些关键词、关键词趋势,甚至是哪个网站队伍在前面等着? 网站Analysis:流量估算、排名关键词、竞争对手调查、外链分析等
输入关键词 容易出现拼写错误。由于搜索引擎特有的识别和纠错功能,可以正常显示结果。不过我们可以把这些容易出错的关键词采集起来,利用网友经常搜索@的错别字关键词,作为长尾词优化,方便我们排到首页。
这是一个容易被忽视的方法,但效果很好,剑走偏了!
比如湖南卫视的《变形记》,但也有人会搜索《变形记》
我们可以看到只有一个。有了新改进的Keywordeverywhere,你可以看到搜索到的每个关键Voluem和可能的CPC等。它也非常方便快捷。四、KeywordTool(,io) KeywordTool,一个关键字规划工具,与谷歌集成。 Youtube,根据搜索引擎的结果找到的信息会按字母顺序排序,帮助你对关键词进行分类,帮助你把握未来的产品趋势和你的竞争对手。消费者的搜索偏好是该工具的优势。 TermExplorer:TermExplorer 是一个相对集成的工具。
如果你刚收到新的网站,千万不要急于优化。你首先要了解这个行业,这个领域,以及你的目标用户。我们常说知己知彼,百战不殆。这是有道理的。
我们也可以使用一些站长工具来挖掘关键词的长尾,比如“站长之家”、“5118”、“爱站网”、“飞达鲁”等,直接探索长尾关键词方法,这些网站或者app里面都有专门的关键词挖矿工具,可以帮助我们快速找到用户需要的长尾关键词。
当然,我们也可以通过相关搜索和下拉框来探索我们的长尾关键词。在任何搜索引擎的搜索框中,当我们输入某个关键词时,下拉框关键词中都会出现很多类似的搜索,这些也是我们可以使用和参考的相关关键词。同样,每个搜索引擎都会有一个搜索。 hfhfhfhhhgk
mviwyzd6 查看全部
关键词自动采集(长尾词采集软件程序工具,seo建设网站全自动采集文章工具)
采集software怎么买 说说关键词几个常用的挖矿工具8nrt
采集software 如何购买几个常用的关键词挖矿工具-首页
今日推荐:采集software怎么买,说说几个常用的关键词挖矿工具{客户微信84643017}seo自动长尾词采集software程序工具,seo百度留痕转码软件程序工具,seo建设网站full-auto采集文章软件编程工具,百度贴吧私聊软件编程工具,百度长尾词b2b集成软件编程工具,b2B站集成业务处理,(如商国互联网、机电之家、云联盟、中国化工网、淘金热、中国贸易网、云商网、百商网、全球机械网、第一商网、企业名录、盛丰建材网、乐手推广、知趣网、中科商务网、钢企网、51搜网、模具联盟网、莱芜新闻网、迅瓜瓜、企业招商网、久久信息网、阿里伯乐、启辉网、时代商务网、机械论线等)等综合业务,可靠和非常规诚信声明:只做正规业务,非法请勿打扰。

句子}
seokwsranking 等等,对于分析网站的情况,可以说是非常非常详细了。
以 Anker 为例:
第六,K-Meta()可以通过网址搜索找到你的竞争对手,网站流量,广告文案,关键词Position;如果按关键字搜索,您可以看到每次点击费用、竞争程度、搜索音量和相关关键字以及自然搜索结果。
K-Meta 的功能类似于 Ubersuggest。如果搜索关键词,可以看到Searchvolume、CPC、竞争程度等,还可以看到哪些广告主出价,相对KWS等,以无线充电器为例。
看看输入 anker.co。填写验证码smallseotools,com 优点:1.非常准确2.可以同时查询5个关键词缺点:1.每次查询都需要一个验证码,布局和界面也很讨喜,这个文章主要是我讲的10个比较常用的SEO关键词优化工具。如果你有时间,你可以去研究它。对于 googleads 广告竞价的定时投放和竞品分析来说,是非常大的。
不同地区对土豆有不同的名称:土豆、洋蓟、蒸蛋、鸡蛋、野鸡蛋、豆角等。这些是土豆的其他名称!
所以我们使用这些别名而不是关键词!
08
目标关键词+属性组合
这其实很好。
搜索引擎中已经有大量或付费的 seo 工具。一般来说,它们可以分为几类。 ,包括但不限于站长工具、外链查询工具、seo综合查询工具、关键词挖掘工具、网站安全测速工具、网站测速工具、关键词index查询工具、网站statistics工具等
常用的SEO工具一般盘点有哪些? SEO优化不再累。
使用快速的seo工具可以提高网站优化的效率。减少时间成本并获得更好的结果。良好的投入产出比。工具是简化工作流程的好帮手。可以说,工具存在于生活的每一个角落,网站optimization也不例外。比如批量操作、自动扩容等,使用工具可以让网站优化更轻松。


{词汇比较、相关关键词和广告历史等标题、关键词难度、有机搜索量、此类关键词使用了哪些关键词、关键词趋势,甚至是哪个网站队伍在前面等着? 网站Analysis:流量估算、排名关键词、竞争对手调查、外链分析等
输入关键词 容易出现拼写错误。由于搜索引擎特有的识别和纠错功能,可以正常显示结果。不过我们可以把这些容易出错的关键词采集起来,利用网友经常搜索@的错别字关键词,作为长尾词优化,方便我们排到首页。
这是一个容易被忽视的方法,但效果很好,剑走偏了!
比如湖南卫视的《变形记》,但也有人会搜索《变形记》
我们可以看到只有一个。有了新改进的Keywordeverywhere,你可以看到搜索到的每个关键Voluem和可能的CPC等。它也非常方便快捷。四、KeywordTool(,io) KeywordTool,一个关键字规划工具,与谷歌集成。 Youtube,根据搜索引擎的结果找到的信息会按字母顺序排序,帮助你对关键词进行分类,帮助你把握未来的产品趋势和你的竞争对手。消费者的搜索偏好是该工具的优势。 TermExplorer:TermExplorer 是一个相对集成的工具。
如果你刚收到新的网站,千万不要急于优化。你首先要了解这个行业,这个领域,以及你的目标用户。我们常说知己知彼,百战不殆。这是有道理的。
我们也可以使用一些站长工具来挖掘关键词的长尾,比如“站长之家”、“5118”、“爱站网”、“飞达鲁”等,直接探索长尾关键词方法,这些网站或者app里面都有专门的关键词挖矿工具,可以帮助我们快速找到用户需要的长尾关键词。
当然,我们也可以通过相关搜索和下拉框来探索我们的长尾关键词。在任何搜索引擎的搜索框中,当我们输入某个关键词时,下拉框关键词中都会出现很多类似的搜索,这些也是我们可以使用和参考的相关关键词。同样,每个搜索引擎都会有一个搜索。 hfhfhfhhhgk
mviwyzd6
关键词自动采集(带手机端,4套模板,在线听书和TXT下载源码安装教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-08-27 20:25
PTcms小说系统自动上线采集改版,小说聚合网站带手机终端,4套模板,在线听书和TXT下载
源码安装教程
1.安装前的准备工作
将程序上传到网站root目录下,不要在二级目录调试,不要删除根目录下的bbs.####.com快捷方式
2.恢复数据库
将根目录下的.sql数据库导入你的mysql数据库,虚拟主机可以通过你的主机提供商提供的操作工具进行恢复。对于云服务器用户,建议直接使用 Navicat 软件导入。无论如何,有很多方法可以导入它。是的,数据较多,导入时请耐心等待!
3.修改数据库配置信息
用EditPlus软件或dreamweaver等代码编辑软件打开/application/common/config.php文件,按照以下方法修改数据库配置文件
'mysql_master_host' => 'localhost', //数据库地址,本机一般默认不修改
'mysql_master_port' => '3306', //端口一般不修改
'mysql_master_name' => 'demo', //数据库名
'mysql_master_user' => 'root', //数据库用户名
'mysql_master_pwd' => '', //数据库密码
4.配置文本静态
这是在部署主机环境时决定的。建议使用apache环境,默认支持.htaccess伪静态格式。如果是iis或者nginx需要转换对应的伪静态格式
5.Login网站Background
不要访问前台网站,先访问域名/admin.php访问网站background,登录账号和密码分别是admin和密码,输入网站后的第一步后台就是到“系统”-“基本”设置“-”数据库“-再次配置数据库配置选项!这个一定要先配置!
6.注意事项和说明
1.如果伪静态正常网站仍然出现404,打开根目录index.php在倒数第二行添加:
define('APP_DEBUG',true);
网站正常后删除;
2.网站需要配置的后台信息
·“系统”-“基本设置”-可自行修改
·“扩展”-“任务管理”-“任务管理”-“全选”-“还原”-开启自动采集
·“扩展”-“模块管理”-“网站Map”-可自行修改
·“扩展”-“模块管理”-“手机地图”-修改为自己的。
·“用户”-管理员密码修改
1.准备工作
调试网站前,检查网站域名指向的目录是否正确,环境的PHP版本是否为教程中指定的PHP版本,否则会出现一些低级404错误,500错误,浪费你自己的时间和精力!
2.Upload网站程序安装正常
使用二进制上传,linux主机可以在线下载压缩包并解压,直接访问自己的域名/install进行正常安装,根据提示输入自己的mysql数据库信息!
3.如果在安装过程中遇到错误
如果安装界面出现Warning:Call-time pass-by-reference has deprecated的错误提示,需要手动修改php环境配置文件php.ini启用扩展。具体操作请访问:无报错继续下一步
4.手机版安装方法
解析独立域名(也可以使用同域名的二级域名),新建站点,指向pc目录下的wap文件,然后登录PC网站后台——系统定义——手机访问网址——填写手机域名——手机站网站样式设置为mqiyue
5.Login网站Background
访问你的域名/admin,登录账号和密码是你安装时设置的账号和密码
使用源码的注意事项
1.安装后第一次通知
进入后台后,不用担心查前台页面等。进入后台的基本设置,将网站域名、关键词、文章列等设置为自己的,然后根据需要进行配置 必要的配置,这个操作后,去看看如果前台页面正常! !
2.How to采集
这里配备了Guanguan采集Advanced Edition采集工具。最好是把guanguan采集放在win server里,睡着就可以搭建自己的采集target小说站!
年费VIP会员准备了采集规则,采集怎么做!
①双击采集器中的NovelSpider.exe执行程序
②打开后加载页面报错,点击Yes后一直出现主页。
③点击设置——采集Settings,在设置面板中设置网站name、本地网站目录、数据库连接字符
Data Source=localhost;Database=linshi;User ID=root;Password=;port=3306;charset=gbk
你只需要把linshi改成你的数据库名,root改成你的数据库用户名,和你的数据库密码。
更改后点击右下角确定,退出采集器并重新打开采集器界面
④重启后点击采集——standard采集mode——在采集模式下选择采集rules
⑤点击右下角的采集plan-保存计划
⑥ 点击启动采集就可以了。一天采集结束后,你可以去看看采集,然后点击开始自动重新计算新章节和采集
3.网站authorization
网站需要对域名进行授权,联系客服获取授权码,一个域名只对应一个授权码,多个VIP会员使用多人申请授权恢复VIP资格感谢您的理解和支持!
获取授权码后,登录网站background-点击系统定义-查看数据库信息填写网站授权码并保存!剩下的网站信息根据自己情况设置!
【重要】对于系统定义,第一次设置时,错误显示模式需要设置为“显示错误”或“不显示错误”。同时,在小说连载模块和参数设置中,将目录页每页显示的章节数设置为0,将是否生成html设置为否。
4.如何设置VIP章节,也就是如何设置阅读某一章节并收费!
先到后台给writer成员添加权限,如图
那么一旦前台注册会员成为作家,他发表的章节可以收费或免费。
调试说明总结
①使用采集时,尽量在晚上实施,防止采集的大家在目标站造成拥塞。终身会员和企业会员可联系客服获取多条采集规则,多数据源,确保您网站内容及时更新
这个程序不难调试,可以仔细按照教程来! !
②相关模板页面路径:
·网站全局主题:\templates 和\themes
·小说模块模板:\modules\article\templates
·在线支付模板:\modules\pay\templates
③一些比较重要的配置文件地址可能有误,请根据实际情况自行分析:
·登录和uc配置:/api
·支付宝等支付配置:/configs/pay
·微信支付配置:/modules/pay/weixin/lib/WxPay.pub.config.php
·云通支付免签约支付接口:/modules/pay/shanpay/shanpayconfig.php
·小说分类:/configs/article/sort.php
④采集器注:
·文件夹必须有写权限,否则会出现采集错误。
·系统设置必须正确,否则会出现采集错误。 查看全部
关键词自动采集(带手机端,4套模板,在线听书和TXT下载源码安装教程)
PTcms小说系统自动上线采集改版,小说聚合网站带手机终端,4套模板,在线听书和TXT下载
源码安装教程
1.安装前的准备工作
将程序上传到网站root目录下,不要在二级目录调试,不要删除根目录下的bbs.####.com快捷方式
2.恢复数据库
将根目录下的.sql数据库导入你的mysql数据库,虚拟主机可以通过你的主机提供商提供的操作工具进行恢复。对于云服务器用户,建议直接使用 Navicat 软件导入。无论如何,有很多方法可以导入它。是的,数据较多,导入时请耐心等待!
3.修改数据库配置信息
用EditPlus软件或dreamweaver等代码编辑软件打开/application/common/config.php文件,按照以下方法修改数据库配置文件
'mysql_master_host' => 'localhost', //数据库地址,本机一般默认不修改
'mysql_master_port' => '3306', //端口一般不修改
'mysql_master_name' => 'demo', //数据库名
'mysql_master_user' => 'root', //数据库用户名
'mysql_master_pwd' => '', //数据库密码
4.配置文本静态
这是在部署主机环境时决定的。建议使用apache环境,默认支持.htaccess伪静态格式。如果是iis或者nginx需要转换对应的伪静态格式
5.Login网站Background
不要访问前台网站,先访问域名/admin.php访问网站background,登录账号和密码分别是admin和密码,输入网站后的第一步后台就是到“系统”-“基本”设置“-”数据库“-再次配置数据库配置选项!这个一定要先配置!
6.注意事项和说明
1.如果伪静态正常网站仍然出现404,打开根目录index.php在倒数第二行添加:
define('APP_DEBUG',true);
网站正常后删除;
2.网站需要配置的后台信息
·“系统”-“基本设置”-可自行修改
·“扩展”-“任务管理”-“任务管理”-“全选”-“还原”-开启自动采集
·“扩展”-“模块管理”-“网站Map”-可自行修改
·“扩展”-“模块管理”-“手机地图”-修改为自己的。
·“用户”-管理员密码修改
1.准备工作
调试网站前,检查网站域名指向的目录是否正确,环境的PHP版本是否为教程中指定的PHP版本,否则会出现一些低级404错误,500错误,浪费你自己的时间和精力!
2.Upload网站程序安装正常
使用二进制上传,linux主机可以在线下载压缩包并解压,直接访问自己的域名/install进行正常安装,根据提示输入自己的mysql数据库信息!
3.如果在安装过程中遇到错误
如果安装界面出现Warning:Call-time pass-by-reference has deprecated的错误提示,需要手动修改php环境配置文件php.ini启用扩展。具体操作请访问:无报错继续下一步
4.手机版安装方法
解析独立域名(也可以使用同域名的二级域名),新建站点,指向pc目录下的wap文件,然后登录PC网站后台——系统定义——手机访问网址——填写手机域名——手机站网站样式设置为mqiyue
5.Login网站Background
访问你的域名/admin,登录账号和密码是你安装时设置的账号和密码
使用源码的注意事项
1.安装后第一次通知
进入后台后,不用担心查前台页面等。进入后台的基本设置,将网站域名、关键词、文章列等设置为自己的,然后根据需要进行配置 必要的配置,这个操作后,去看看如果前台页面正常! !
2.How to采集
这里配备了Guanguan采集Advanced Edition采集工具。最好是把guanguan采集放在win server里,睡着就可以搭建自己的采集target小说站!
年费VIP会员准备了采集规则,采集怎么做!
①双击采集器中的NovelSpider.exe执行程序
②打开后加载页面报错,点击Yes后一直出现主页。
③点击设置——采集Settings,在设置面板中设置网站name、本地网站目录、数据库连接字符
Data Source=localhost;Database=linshi;User ID=root;Password=;port=3306;charset=gbk
你只需要把linshi改成你的数据库名,root改成你的数据库用户名,和你的数据库密码。
更改后点击右下角确定,退出采集器并重新打开采集器界面
④重启后点击采集——standard采集mode——在采集模式下选择采集rules
⑤点击右下角的采集plan-保存计划
⑥ 点击启动采集就可以了。一天采集结束后,你可以去看看采集,然后点击开始自动重新计算新章节和采集
3.网站authorization
网站需要对域名进行授权,联系客服获取授权码,一个域名只对应一个授权码,多个VIP会员使用多人申请授权恢复VIP资格感谢您的理解和支持!
获取授权码后,登录网站background-点击系统定义-查看数据库信息填写网站授权码并保存!剩下的网站信息根据自己情况设置!
【重要】对于系统定义,第一次设置时,错误显示模式需要设置为“显示错误”或“不显示错误”。同时,在小说连载模块和参数设置中,将目录页每页显示的章节数设置为0,将是否生成html设置为否。
4.如何设置VIP章节,也就是如何设置阅读某一章节并收费!
先到后台给writer成员添加权限,如图
那么一旦前台注册会员成为作家,他发表的章节可以收费或免费。
调试说明总结
①使用采集时,尽量在晚上实施,防止采集的大家在目标站造成拥塞。终身会员和企业会员可联系客服获取多条采集规则,多数据源,确保您网站内容及时更新
这个程序不难调试,可以仔细按照教程来! !
②相关模板页面路径:
·网站全局主题:\templates 和\themes
·小说模块模板:\modules\article\templates
·在线支付模板:\modules\pay\templates
③一些比较重要的配置文件地址可能有误,请根据实际情况自行分析:
·登录和uc配置:/api
·支付宝等支付配置:/configs/pay
·微信支付配置:/modules/pay/weixin/lib/WxPay.pub.config.php
·云通支付免签约支付接口:/modules/pay/shanpay/shanpayconfig.php
·小说分类:/configs/article/sort.php
④采集器注:
·文件夹必须有写权限,否则会出现采集错误。
·系统设置必须正确,否则会出现采集错误。
电商网站seo微信搜一搜seo排名优化技巧是什么网站优化公司价格如何计算相关内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-08-27 04:15
电子商务网站seo
微信搜一搜有哪些seo排名优化技巧
网站优化公司价格计算方式相关内容(一)
1.重新定义了META标签中的内容,使其与公司产品一致,适应目标客户群的访问习惯。
说到搜索,那么最有效的获取流量的方式之一就是通过百度的下拉框过滤相关的关键词。当用户输入一个词或词时,搜索引擎会将其与您输入的词相关联输出关键词,与它相关并有大量流量。百度下拉框最多提供10个关键词展示位置,用户搜索即可看到推文
网站Auto采集Publish 插件
Ganzhou网站optimization 哪个更好
在淄博哪里可以找到seo公司相关的内容(二)
说到搜索,那么最有效的获取流量的方式之一就是通过百度的下拉框过滤相关的关键词。当用户输入一个词或词时,搜索引擎会将其与您输入的词相关联输出关键词 与它相关并有大量流量。百度下拉框最多提供10个关键词展示位置,用户搜索即可看到推文
通过采集对互联网大数据的分析、提取,为网站运营商和SEO从业者提供有价值的专业分析结果和指导,让用户快速提升平台的网络运营能力。这个描述比较笼统,我们可以直接看其官网首页的描述值:5118 通过各类SEO大数据挖掘,我们提供关键词Mining,OK
网站Promotion SEO优化
“新浪新闻采集”当前新闻发布时间为——
seo关键词和seo描述相关内容(三)随着互联网的飞速发展,网络广告早已成为网络媒体重要的收入渠道之一。百度广告经理担任百度为国内广大高quality media网站经过两年的发展,数据显示合作网络媒体已超过5000家,已成为国内最大的网络媒体网络广告投放和管理的广告管理平台 查看全部
电商网站seo微信搜一搜seo排名优化技巧是什么网站优化公司价格如何计算相关内容
电子商务网站seo
微信搜一搜有哪些seo排名优化技巧
网站优化公司价格计算方式相关内容(一)
1.重新定义了META标签中的内容,使其与公司产品一致,适应目标客户群的访问习惯。
说到搜索,那么最有效的获取流量的方式之一就是通过百度的下拉框过滤相关的关键词。当用户输入一个词或词时,搜索引擎会将其与您输入的词相关联输出关键词,与它相关并有大量流量。百度下拉框最多提供10个关键词展示位置,用户搜索即可看到推文
网站Auto采集Publish 插件
Ganzhou网站optimization 哪个更好
在淄博哪里可以找到seo公司相关的内容(二)
说到搜索,那么最有效的获取流量的方式之一就是通过百度的下拉框过滤相关的关键词。当用户输入一个词或词时,搜索引擎会将其与您输入的词相关联输出关键词 与它相关并有大量流量。百度下拉框最多提供10个关键词展示位置,用户搜索即可看到推文
通过采集对互联网大数据的分析、提取,为网站运营商和SEO从业者提供有价值的专业分析结果和指导,让用户快速提升平台的网络运营能力。这个描述比较笼统,我们可以直接看其官网首页的描述值:5118 通过各类SEO大数据挖掘,我们提供关键词Mining,OK
网站Promotion SEO优化
“新浪新闻采集”当前新闻发布时间为——
seo关键词和seo描述相关内容(三)随着互联网的飞速发展,网络广告早已成为网络媒体重要的收入渠道之一。百度广告经理担任百度为国内广大高quality media网站经过两年的发展,数据显示合作网络媒体已超过5000家,已成为国内最大的网络媒体网络广告投放和管理的广告管理平台
vivi内核二开智能标题关键字新闻采集源码人工管理.会
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-08-27 04:14
Vivi 内核两开智能标题关键词news采集源码无需人工管理。
文章中的相关关键词会被添加到标题关键词中。
SEO超级好,可以站群。
php5.2-5.4
上传使用
Spider Pool News采集 Source-Full Auto采集 无需人工参与。
24小时自动采集,只需500M空间
1.在原版的基础上增加了更多吸引蜘蛛的智能设置()百度蜘蛛、谷歌蜘蛛、神马蜘蛛(手机流量很贵)、360蜘蛛、搜狗蜘蛛等
2.智慧加后缀,自动在采集的内容中添加相关含义的句子,比如原标题是胖,采集后面会加上比如吃什么减肥等,视实际情况而定。
3.伪原创 有更多的话
4.关键词内链可自由设置,可引蜘蛛,增加SEO效果。
5.动态页面蜘蛛可以被爱(也可以是伪静态)
6.建议多建站点,(12元一年提供静安3G300M虚拟主机)不同的站点吸引不同的蜘蛛(因为我们的智能代码让每个站点都不一样,因为是随机的,所以首选蜘蛛有点不同)。
7.有很多增强效果,我就不多说了。建议使用一级域名,收录远不止二级域名。
8.后台可以看到蜘蛛的来源,可以将蜘蛛引导到你需要的网站
9. 页面可以留下来等待收录。
资源下载 本资源仅供VIP下载,请先登录下载资源
下载价格:VIP专享
本资源仅供VIP下载
更新时间:2019.11.21
包装尺寸:1M 查看全部
vivi内核二开智能标题关键字新闻采集源码人工管理.会
Vivi 内核两开智能标题关键词news采集源码无需人工管理。
文章中的相关关键词会被添加到标题关键词中。
SEO超级好,可以站群。
php5.2-5.4
上传使用
Spider Pool News采集 Source-Full Auto采集 无需人工参与。
24小时自动采集,只需500M空间
1.在原版的基础上增加了更多吸引蜘蛛的智能设置()百度蜘蛛、谷歌蜘蛛、神马蜘蛛(手机流量很贵)、360蜘蛛、搜狗蜘蛛等
2.智慧加后缀,自动在采集的内容中添加相关含义的句子,比如原标题是胖,采集后面会加上比如吃什么减肥等,视实际情况而定。
3.伪原创 有更多的话
4.关键词内链可自由设置,可引蜘蛛,增加SEO效果。
5.动态页面蜘蛛可以被爱(也可以是伪静态)
6.建议多建站点,(12元一年提供静安3G300M虚拟主机)不同的站点吸引不同的蜘蛛(因为我们的智能代码让每个站点都不一样,因为是随机的,所以首选蜘蛛有点不同)。
7.有很多增强效果,我就不多说了。建议使用一级域名,收录远不止二级域名。
8.后台可以看到蜘蛛的来源,可以将蜘蛛引导到你需要的网站
9. 页面可以留下来等待收录。

资源下载 本资源仅供VIP下载,请先登录下载资源
下载价格:VIP专享
本资源仅供VIP下载
更新时间:2019.11.21
包装尺寸:1M
京东搜索为例案例规则+操作步骤注意事项及解决办法!
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-08-26 04:16
一、操作步骤
如果网页上有搜索框,但是搜索结果页没有单独的网址,而你想要采集搜索结果,直接规则是采集不能做,你必须先做一个连续的动作(输入+点击)来实现自动输入关键词并搜索,然后采集数据。下面以京东搜索为例,演示自动搜索采集。操作步骤如下:
二、Case规则+操作步骤
注意:在这种情况下,京东搜索有独立的网址。对于有独立网址的页面,最简单的方法就是构造每个关键词搜索网址,然后将线索网址导入到规则中,就可以批量采集而不是设置连续动作
第一步:定义一级规则
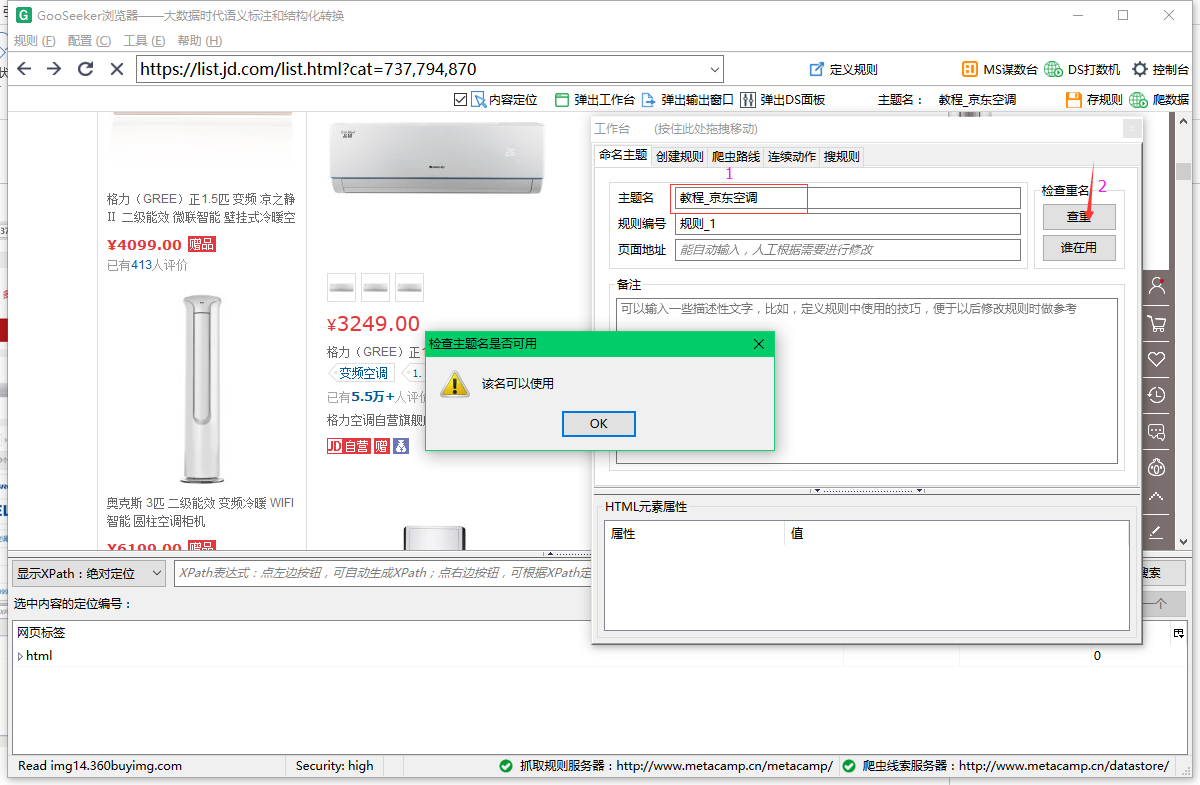
1.1 打开极手客网络爬虫,输入网址回车,加载网页后点击“定义规则”按钮,会看到一个浮动窗口,称为工作台,在上面可以定义规则;
注:此处截图及文字说明均为极手客网络爬虫版本。如果您安装的是Firefox插件版本,则没有“定义规则”按钮,但您应该运行MS Muse。
1.2 在工作台中输入一级规则的主题名称,然后点击“检查重复”,会提示“此名称可以使用”或“名称已被占用,可编辑:是” ,您可以使用此主题名称,否则请重命名。
1.3 这一层规则主要是设置连续动作,这样排序框就可以随意抓取一条信息,用它来判断是否为爬虫执行采集。双击网页上的信息,输入标签名称,勾选确认,然后勾选关键内容,输入第一个标签的排序框名称,标签映射完成。
提示:为了准确定位网页信息,点击定义规则会冻结整个网页,无法跳转到网页链接。再次点击定义规则,返回正常网页模式。
第 2 步:定义连续动作
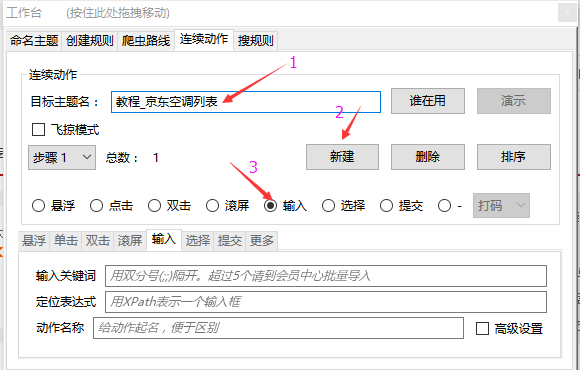
点击工作台的“Continuous Action”选项卡,点击New按钮新建一个action,每个action的设置方法都是一样的,基本操作如下:
2.1,输入目标学科名称
这里的目标主题名称是填写二级主题名称,点击“谁在使用”查看目标主题名称是否可用,如果已经被占用,只需更改一个主题名称即可。
2.2,创建第一个动作:回车
创建一个新动作并选择动作类型作为输入。
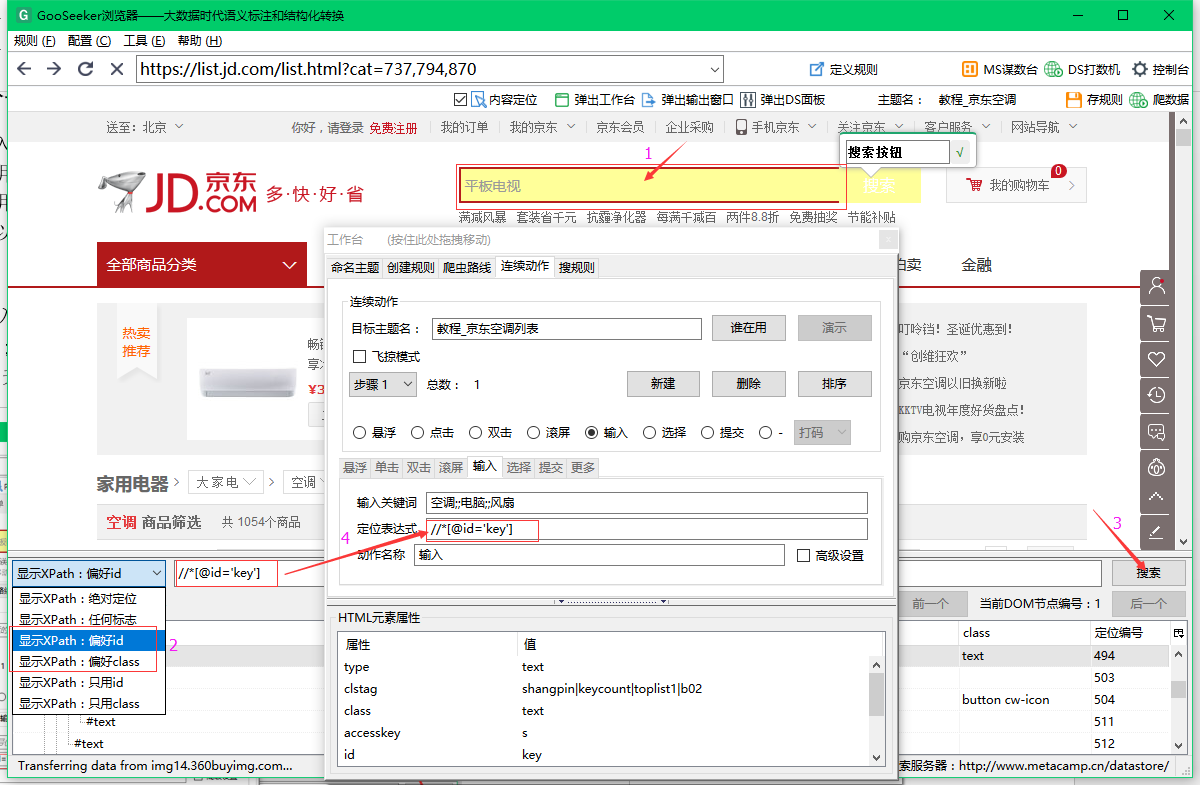
2.2.1,填写定位表达式
首先点击输入框,定位输入框的节点,然后点击“Auto Generate XPath”按钮,可以选择“Preference id”或者“Preference class”,就可以得到输入的xpath表达式框,然后单击“搜索”按钮,检查这个xpath是否可以在输入框中唯一定位,如果没有问题,将xpath复制到定位表达式框中。
注意:定位表达式中的xpath是锁定动作对象的整个有效操作范围。具体是指鼠标可以点击或输入成功的网页模块。不要在底部找到 text() 节点。
2.2.2,输入关键词
输入关键词填写你要搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词使用双分号;;把每个关键词Separate,免费版只支持5个以内的关键词,旗舰版可以使用爆弹功能,支持关键词10000以内
2.2.3,输入动作名称
告诉自己这一步是做什么的,以便你以后可以修改。
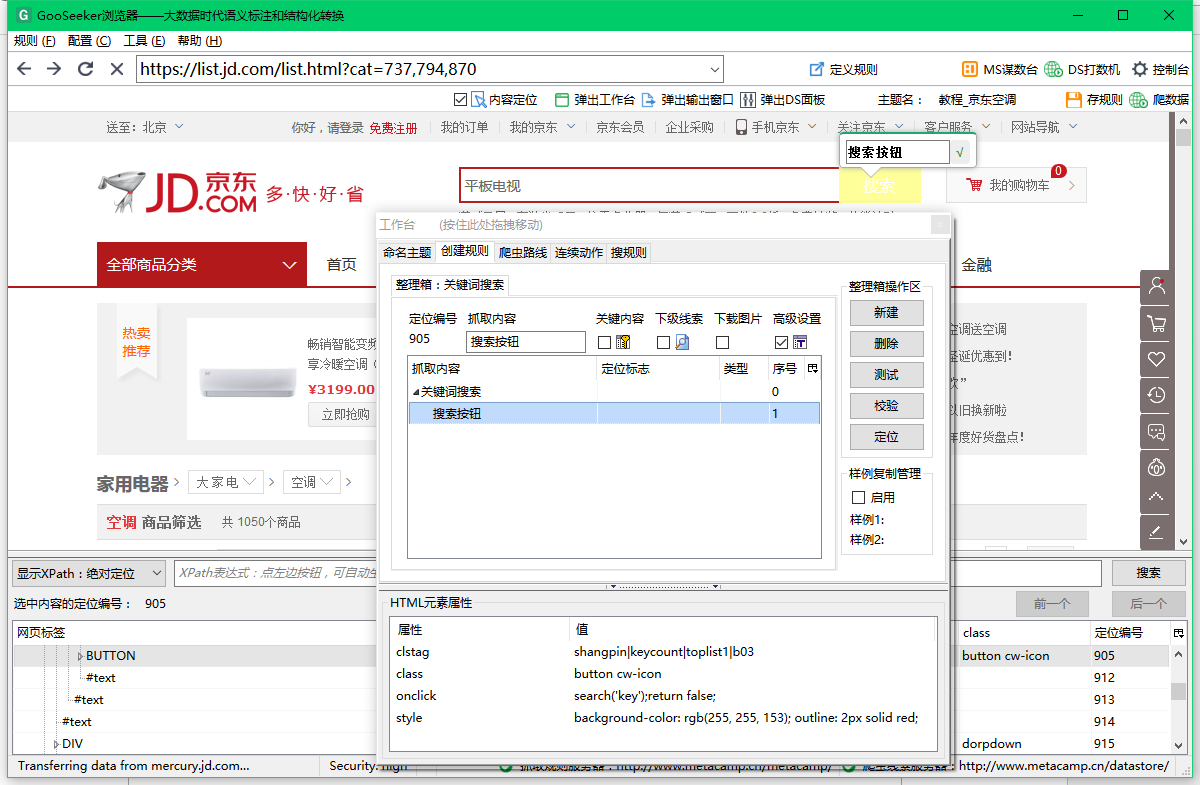
2.3,创建第二个动作:点击
参考2.2的操作,创建第二个action,选择类型为click,定位搜索按钮,然后自动生成xpath检查是否锁定到唯一节点。如果没有问题,填写定位表达式。 .
2.4,存款规则
点击“保存规则”按钮保存完成的一级规则
第 3 步:定义二级规则
3.1,新建规则
创建二级规则,点击“定义规则”返回正常网页模式,输入关键词搜索结果,再次点击“定义规则”切换到规则制定模式,点击“左上角规则”菜单->“新建”,输入主题名称,其中主题名称是在第一级规则的连续动作中填写的目标主题名称。
3.2,标记你想要的信息采集
3.2.1,在网页上标注你要采集的信息,这里是标注产品名称和价格,因为标注只对文字信息有效,以及产品链接details 是属性节点@href,所以不能在链接上做这么直观的标记,要做内容映射,具体看下面的操作。
3.2.2,点击产品名称,下方的DOM节点定位到A标签,展开A标签下的属性节点,可以找到代表URL的@href节点,右键节点,并选择“New Capture”抓取内容,输入一个名字,一般给抓取到的内容取一个与地址相关的名字,比如“下级网址”,或者“下级链接”等等。然后在工作台上,我看到表示抓取到的内容是可用的。如果您还想进入商品详情页采集,则必须针对抓取的内容检查下层线索,并进行分层抓取。
3.2.3,设置“关键内容”选项,让爬虫判断采集规则是否合适。在排序框中,选择网页上不可避免的标签,并勾选“关键内容”。这里选择“名称”作为“关键内容”。
3.2.4,只要在前面标注一个产品,就可以得到一个产品信息。如果你想采集下整个页面上的每一个产品,可以做一个样例拷贝,没有如果你看懂了,请参考基础教程“采集表数据”
3.3,设置翻页路线
在爬虫路由中设置翻页,这里是标记提示,不明白的请参考基础教程《设置翻页采集》
3.4,保存规则
点击“测试”以检查信息的完整性。如果不完整,重新标记可以覆盖之前的内容。确认没有问题后,点击“保存规则”。
第 4 步:捕获数据
4.1,连续动作是连续执行的,所以只要运行一级主题,二级主题就不需要运行了。打开DS计数器,搜索一级话题名称,点击“单一搜索”或“采集”,可以看到浏览器窗口会自动输入并搜索关键词,然后二级话题就会出现自动调用采集搜索结果。
4.2,一级主题没有采集到有意义的信息,所以我们只看二级主题文件夹,可以看到采集的搜索结果数据,搜索关键词是默认记录在xml文件的actionvalue字段中,这样可以一一匹配。 查看全部
京东搜索为例案例规则+操作步骤注意事项及解决办法!
一、操作步骤
如果网页上有搜索框,但是搜索结果页没有单独的网址,而你想要采集搜索结果,直接规则是采集不能做,你必须先做一个连续的动作(输入+点击)来实现自动输入关键词并搜索,然后采集数据。下面以京东搜索为例,演示自动搜索采集。操作步骤如下:
二、Case规则+操作步骤
注意:在这种情况下,京东搜索有独立的网址。对于有独立网址的页面,最简单的方法就是构造每个关键词搜索网址,然后将线索网址导入到规则中,就可以批量采集而不是设置连续动作
第一步:定义一级规则
1.1 打开极手客网络爬虫,输入网址回车,加载网页后点击“定义规则”按钮,会看到一个浮动窗口,称为工作台,在上面可以定义规则;
注:此处截图及文字说明均为极手客网络爬虫版本。如果您安装的是Firefox插件版本,则没有“定义规则”按钮,但您应该运行MS Muse。
1.2 在工作台中输入一级规则的主题名称,然后点击“检查重复”,会提示“此名称可以使用”或“名称已被占用,可编辑:是” ,您可以使用此主题名称,否则请重命名。
1.3 这一层规则主要是设置连续动作,这样排序框就可以随意抓取一条信息,用它来判断是否为爬虫执行采集。双击网页上的信息,输入标签名称,勾选确认,然后勾选关键内容,输入第一个标签的排序框名称,标签映射完成。
提示:为了准确定位网页信息,点击定义规则会冻结整个网页,无法跳转到网页链接。再次点击定义规则,返回正常网页模式。
第 2 步:定义连续动作
点击工作台的“Continuous Action”选项卡,点击New按钮新建一个action,每个action的设置方法都是一样的,基本操作如下:
2.1,输入目标学科名称
这里的目标主题名称是填写二级主题名称,点击“谁在使用”查看目标主题名称是否可用,如果已经被占用,只需更改一个主题名称即可。
2.2,创建第一个动作:回车
创建一个新动作并选择动作类型作为输入。
2.2.1,填写定位表达式
首先点击输入框,定位输入框的节点,然后点击“Auto Generate XPath”按钮,可以选择“Preference id”或者“Preference class”,就可以得到输入的xpath表达式框,然后单击“搜索”按钮,检查这个xpath是否可以在输入框中唯一定位,如果没有问题,将xpath复制到定位表达式框中。
注意:定位表达式中的xpath是锁定动作对象的整个有效操作范围。具体是指鼠标可以点击或输入成功的网页模块。不要在底部找到 text() 节点。
2.2.2,输入关键词
输入关键词填写你要搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词使用双分号;;把每个关键词Separate,免费版只支持5个以内的关键词,旗舰版可以使用爆弹功能,支持关键词10000以内
2.2.3,输入动作名称
告诉自己这一步是做什么的,以便你以后可以修改。
2.3,创建第二个动作:点击
参考2.2的操作,创建第二个action,选择类型为click,定位搜索按钮,然后自动生成xpath检查是否锁定到唯一节点。如果没有问题,填写定位表达式。 .
2.4,存款规则
点击“保存规则”按钮保存完成的一级规则
第 3 步:定义二级规则
3.1,新建规则
创建二级规则,点击“定义规则”返回正常网页模式,输入关键词搜索结果,再次点击“定义规则”切换到规则制定模式,点击“左上角规则”菜单->“新建”,输入主题名称,其中主题名称是在第一级规则的连续动作中填写的目标主题名称。
3.2,标记你想要的信息采集
3.2.1,在网页上标注你要采集的信息,这里是标注产品名称和价格,因为标注只对文字信息有效,以及产品链接details 是属性节点@href,所以不能在链接上做这么直观的标记,要做内容映射,具体看下面的操作。
3.2.2,点击产品名称,下方的DOM节点定位到A标签,展开A标签下的属性节点,可以找到代表URL的@href节点,右键节点,并选择“New Capture”抓取内容,输入一个名字,一般给抓取到的内容取一个与地址相关的名字,比如“下级网址”,或者“下级链接”等等。然后在工作台上,我看到表示抓取到的内容是可用的。如果您还想进入商品详情页采集,则必须针对抓取的内容检查下层线索,并进行分层抓取。
3.2.3,设置“关键内容”选项,让爬虫判断采集规则是否合适。在排序框中,选择网页上不可避免的标签,并勾选“关键内容”。这里选择“名称”作为“关键内容”。
3.2.4,只要在前面标注一个产品,就可以得到一个产品信息。如果你想采集下整个页面上的每一个产品,可以做一个样例拷贝,没有如果你看懂了,请参考基础教程“采集表数据”
3.3,设置翻页路线
在爬虫路由中设置翻页,这里是标记提示,不明白的请参考基础教程《设置翻页采集》
3.4,保存规则
点击“测试”以检查信息的完整性。如果不完整,重新标记可以覆盖之前的内容。确认没有问题后,点击“保存规则”。
第 4 步:捕获数据
4.1,连续动作是连续执行的,所以只要运行一级主题,二级主题就不需要运行了。打开DS计数器,搜索一级话题名称,点击“单一搜索”或“采集”,可以看到浏览器窗口会自动输入并搜索关键词,然后二级话题就会出现自动调用采集搜索结果。
4.2,一级主题没有采集到有意义的信息,所以我们只看二级主题文件夹,可以看到采集的搜索结果数据,搜索关键词是默认记录在xml文件的actionvalue字段中,这样可以一一匹配。
家具到底是不是一个关键词呢?(一)的定义
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-08-25 03:12
说到关键词,我们首先要谈的是它的定义。
什么是“关键词”列表?我认为定义是用户用来搜索的词。主要衡量用户是否会使用该词进行搜索。
例如,我销售家具产品。那么家具是关键词 吗?我认为不是。因为用户在购买的时候,可能想买沙发或者橱柜,那么用户输入的关键词其实是沙发或者橱柜,而不是家具。当我们在标题或搜索词中将“家具”写为关键词时,亚马逊搜索匹配的客户应该是很小的一部分。这部分没有明确购买意向的流量对我们来说几乎可以忽略不计。
第二点是说一个普通卖家容易忽略的问题。根据上面的定义,有必要再次强调:关键词一定是基于用户的认知和搜索思维,而不是基于自己的产品。
例如,您产品的一些工艺和材料。作为卖家,我们非常清楚这一点。也可以作为卖点,但这是否意味着这适合作为关键词?如果工艺、材质等特性正是用户关心的、会用来搜索的,那么作为一个产品关键词是毋庸置疑的。但是如果用户不知道怎么搜索,仅仅因为我们非常了解产品或者把它作为卖点,我们认为一个词也是关键词,那么客户的点击率可想而知。
当我们仔细考虑关键词的定义时,这是可以避免的,但它经常被卖家忽略。关键是站在客户的角度还是卖家的角度。
第三点,分类。关键字可以分为宽泛的关键词、精确的关键词和长尾词。广义词就是我们常说的大词。带有定语词和修饰语的精确词指向特定的客户群。
至于长尾词,我认为它们应该是精确度的一部分。它们只是比精度更精确。如果说精准词反映了产品的主要功能,那么总的来说,长尾其实就是精准词的多次使用。多个精准的词组合在一起形成长尾词,基本构成了产品的框架,让人们了解产品和其他同类产品。产品最大的差异和特点也锁定在购买它的人身上。 (当然也有一些长尾词比较特殊,可以直接把产品和其他同类产品区分开来;通常是某个话题类别的关键词。)
再举个例子。比如卖沙发,那么沙发其实就是一个广义的名词。 优采云Sofa,这个“优采云”是一个准确的词,它体现了这款产品的功能应该是具有坐姿调节功能的沙发,甚至是坐姿,也进一步减少了人群。如果是优采云+按摩+皮这样的多个精准词的组合,就形成了长尾,完成了对我们产品的唯一限制。说明我们的产品兼具坐卧调节功能和自动按摩功能,针对喜欢皮革的客户。
第四点,用在什么地方。产品关键词贯穿整个上市文案。主要用于5个位置。标题、五点、描述、搜索词和 QA 评论。我的观点是,长尾词和精确词放在标题最前面,广泛放在搜索词中。如果关键词 太多而无法放入标题中,请将其添加到五点和描述中。同时,为了增加listing与关键词的相关性,可以在QA和评论中添加,注意保持句子流畅。
第五点,采集方法。如何采集和确定您的关键词?常见的采集方式一般有4种。
(1)参赛者的标题描述。
对手是最好的老师。我们关注排名。销量比我们好的对手的标题和描述可以获得第一批关键词数据。
(2)亚马逊搜索框。
我们在亚马逊搜索框输入product关键词,下面会自动匹配一些相关或者常用的搜索词。在这些术语中,您可以选择与您的产品相关的关键词。如果自动出现的相关词较少,可以尝试输入自己的主关键字,然后输入A-Z中的任意一个字母,看看关键词亚马逊会推送什么样的内容。
(3)广告报道。
自动广告投放过程中下载的自动广告报告收录高点击率和相关词,可以替代我们的关键词。
(4) 在场外工具的帮助下。
很多场外工具都提供了分类关键词和反查关键词的功能,大家可以根据自己的喜好尝试选择。
最后要注意的是,无论我们怎么找到关键词,一定要重新放到亚马逊搜索框上,让真实的匹配结果测试找到的关键词是否适合我们产品。与其找到对手的关键词,然后得意洋洋地使用它,您还可以做白日梦,点击和下单。 查看全部
家具到底是不是一个关键词呢?(一)的定义
说到关键词,我们首先要谈的是它的定义。
什么是“关键词”列表?我认为定义是用户用来搜索的词。主要衡量用户是否会使用该词进行搜索。
例如,我销售家具产品。那么家具是关键词 吗?我认为不是。因为用户在购买的时候,可能想买沙发或者橱柜,那么用户输入的关键词其实是沙发或者橱柜,而不是家具。当我们在标题或搜索词中将“家具”写为关键词时,亚马逊搜索匹配的客户应该是很小的一部分。这部分没有明确购买意向的流量对我们来说几乎可以忽略不计。
第二点是说一个普通卖家容易忽略的问题。根据上面的定义,有必要再次强调:关键词一定是基于用户的认知和搜索思维,而不是基于自己的产品。
例如,您产品的一些工艺和材料。作为卖家,我们非常清楚这一点。也可以作为卖点,但这是否意味着这适合作为关键词?如果工艺、材质等特性正是用户关心的、会用来搜索的,那么作为一个产品关键词是毋庸置疑的。但是如果用户不知道怎么搜索,仅仅因为我们非常了解产品或者把它作为卖点,我们认为一个词也是关键词,那么客户的点击率可想而知。
当我们仔细考虑关键词的定义时,这是可以避免的,但它经常被卖家忽略。关键是站在客户的角度还是卖家的角度。
第三点,分类。关键字可以分为宽泛的关键词、精确的关键词和长尾词。广义词就是我们常说的大词。带有定语词和修饰语的精确词指向特定的客户群。
至于长尾词,我认为它们应该是精确度的一部分。它们只是比精度更精确。如果说精准词反映了产品的主要功能,那么总的来说,长尾其实就是精准词的多次使用。多个精准的词组合在一起形成长尾词,基本构成了产品的框架,让人们了解产品和其他同类产品。产品最大的差异和特点也锁定在购买它的人身上。 (当然也有一些长尾词比较特殊,可以直接把产品和其他同类产品区分开来;通常是某个话题类别的关键词。)
再举个例子。比如卖沙发,那么沙发其实就是一个广义的名词。 优采云Sofa,这个“优采云”是一个准确的词,它体现了这款产品的功能应该是具有坐姿调节功能的沙发,甚至是坐姿,也进一步减少了人群。如果是优采云+按摩+皮这样的多个精准词的组合,就形成了长尾,完成了对我们产品的唯一限制。说明我们的产品兼具坐卧调节功能和自动按摩功能,针对喜欢皮革的客户。
第四点,用在什么地方。产品关键词贯穿整个上市文案。主要用于5个位置。标题、五点、描述、搜索词和 QA 评论。我的观点是,长尾词和精确词放在标题最前面,广泛放在搜索词中。如果关键词 太多而无法放入标题中,请将其添加到五点和描述中。同时,为了增加listing与关键词的相关性,可以在QA和评论中添加,注意保持句子流畅。
第五点,采集方法。如何采集和确定您的关键词?常见的采集方式一般有4种。
(1)参赛者的标题描述。
对手是最好的老师。我们关注排名。销量比我们好的对手的标题和描述可以获得第一批关键词数据。
(2)亚马逊搜索框。
我们在亚马逊搜索框输入product关键词,下面会自动匹配一些相关或者常用的搜索词。在这些术语中,您可以选择与您的产品相关的关键词。如果自动出现的相关词较少,可以尝试输入自己的主关键字,然后输入A-Z中的任意一个字母,看看关键词亚马逊会推送什么样的内容。
(3)广告报道。
自动广告投放过程中下载的自动广告报告收录高点击率和相关词,可以替代我们的关键词。
(4) 在场外工具的帮助下。
很多场外工具都提供了分类关键词和反查关键词的功能,大家可以根据自己的喜好尝试选择。
最后要注意的是,无论我们怎么找到关键词,一定要重新放到亚马逊搜索框上,让真实的匹配结果测试找到的关键词是否适合我们产品。与其找到对手的关键词,然后得意洋洋地使用它,您还可以做白日梦,点击和下单。
微智优户:关键词自动采集,采集电商平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-08-19 23:04
关键词自动采集,采集电商平台的商品,自动上传到自己的店铺,以达到商品上架,店铺搜索靠前,排名靠前,速度不会有任何延迟,操作方便快捷。
用一个工具最快了,安全,能记录,这个工具叫微智优户。每天的邮寄单号就可以查询出来。可以拿到宝贝的物流信息,卖家要做的就是和买家沟通,
我当初也是差不多一个月查几十封,现在三个月查多了根本没必要去查了,因为越是个人用户搜索量大的关键词越难达到上千的成交量。各种qq群啊,朋友圈啊什么各种人群满天飞,现在有个叫“”看遍票牛”的平台,设置好价格和地址之后就可以让全国其他地区的客户自助查询包裹的到达时间、方式等等信息。一个多月查一千封以上的件都可以,差不多算成功了吧,反正我是觉得挺快的。应该更多的个人用户分享成功的案例吧。
我曾经百度了很多找到了一些在线查询的网站,如:3w、查信箱、卷皮等,他们都只能查快递方式,没法查到单号的。有些人会说我的快递单号有问题可能别人买错了,但就我当初我这几个月查的这么多件里面根本就没有买错的(楼主可以自己试试转发个微信链接给别人或朋友查看你的单号以及你快递单号,)。有朋友说我才百度了一下3w就出来了200多,别人搜索关键词各种都有,我的单号拿到之后都不能直接发送,基本没有在线查询的可能,但我后来在网上又换了一家快递查询网站发现了和3w类似的网站有内部成功案例,但是他们查得比3w的更精准快捷。
比如我当初搜索网址“”看遍票牛查询快递单号获取关键词,我看到了找字号,我觉得这个太明显了,我不想自己推广就没发出去,结果就不给查询单号(3w有发过手工单或图片的不算吧)。又比如查信箱,我点进去了选择了电话填进去发现这家网站很多人都说存在这种情况,就查不到单号(3w还查不到)。查一下“卷皮”,内部人员在这网站发布了一个快递单号,我上下班还有去朋友家里,因为都可以上楼了,他们可以上楼的,我就打开电脑就输入了单号,结果他们直接说没有,让我想一下可能原因,很快的他们告诉我是由于单号是个人注册的,他们用的地址是空的地址,除了本市没有其他的,他们发的是单号的第一位和后面一位是1,后来我又问了其他的客户没有收到快递单号的话可以去发给他们看单号,他们发过来的是没有1后面就变成0,最后我才明白是我的手机码字啊。而且他们只要你点一下单号如果是零就会给解决,能大概看出是哪个字段的单号。下面就是。 查看全部
微智优户:关键词自动采集,采集电商平台
关键词自动采集,采集电商平台的商品,自动上传到自己的店铺,以达到商品上架,店铺搜索靠前,排名靠前,速度不会有任何延迟,操作方便快捷。
用一个工具最快了,安全,能记录,这个工具叫微智优户。每天的邮寄单号就可以查询出来。可以拿到宝贝的物流信息,卖家要做的就是和买家沟通,
我当初也是差不多一个月查几十封,现在三个月查多了根本没必要去查了,因为越是个人用户搜索量大的关键词越难达到上千的成交量。各种qq群啊,朋友圈啊什么各种人群满天飞,现在有个叫“”看遍票牛”的平台,设置好价格和地址之后就可以让全国其他地区的客户自助查询包裹的到达时间、方式等等信息。一个多月查一千封以上的件都可以,差不多算成功了吧,反正我是觉得挺快的。应该更多的个人用户分享成功的案例吧。
我曾经百度了很多找到了一些在线查询的网站,如:3w、查信箱、卷皮等,他们都只能查快递方式,没法查到单号的。有些人会说我的快递单号有问题可能别人买错了,但就我当初我这几个月查的这么多件里面根本就没有买错的(楼主可以自己试试转发个微信链接给别人或朋友查看你的单号以及你快递单号,)。有朋友说我才百度了一下3w就出来了200多,别人搜索关键词各种都有,我的单号拿到之后都不能直接发送,基本没有在线查询的可能,但我后来在网上又换了一家快递查询网站发现了和3w类似的网站有内部成功案例,但是他们查得比3w的更精准快捷。
比如我当初搜索网址“”看遍票牛查询快递单号获取关键词,我看到了找字号,我觉得这个太明显了,我不想自己推广就没发出去,结果就不给查询单号(3w有发过手工单或图片的不算吧)。又比如查信箱,我点进去了选择了电话填进去发现这家网站很多人都说存在这种情况,就查不到单号(3w还查不到)。查一下“卷皮”,内部人员在这网站发布了一个快递单号,我上下班还有去朋友家里,因为都可以上楼了,他们可以上楼的,我就打开电脑就输入了单号,结果他们直接说没有,让我想一下可能原因,很快的他们告诉我是由于单号是个人注册的,他们用的地址是空的地址,除了本市没有其他的,他们发的是单号的第一位和后面一位是1,后来我又问了其他的客户没有收到快递单号的话可以去发给他们看单号,他们发过来的是没有1后面就变成0,最后我才明白是我的手机码字啊。而且他们只要你点一下单号如果是零就会给解决,能大概看出是哪个字段的单号。下面就是。
只需要添加采集的关键字,就会自动对知乎问答进行采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-08-13 06:13
只需添加采集关键词,知乎问答会自动采集,并自动发布到【门户指定频道】或【论坛指定版块】
添加采集关键字后,文章采集的发布过程不需要人工干预,通过定时任务自动执行。当然你也可以手动执行一键采集发布文章。
更多详情请通过应用截图、更新日志等方式了解,或添加售前QQ(15326940)咨询问题)
注意:Discuz门户文章的评论仅支持纯文本。如果采集question 的答案和答案同时发布到门户,答案中将只保留纯文本
插件仅支持采集普通图片和文字内容,不支持采集视频、附件等特殊元素。如有问题请咨询售前QQ(15326940)
本插件需要PHP支持curl,curl可以正常获取https链接内容。 PHP 版本至少为5.3 且不高于PHP7.1。如果您的服务器环境运行异常,则需要进行故障排除和测试。需要提供必要的网站和服务器账号密码权限进行故障排除,不提供远程协助。
知乎有防采集限制,高频采集可能被屏蔽,建议插件自动采集发布。
如果您的网站服务器被屏蔽或无法正常获取采集源内容,也无法正常发布采集,恕不退款。
如果采集规则因插件自身问题导致无法更新修复,7天内购买的用户可以获得退款,购买超过7天不到1个月可以补偿180元优惠券,购买1个月以上60元补偿优惠券(优惠券仅可在购买本公司名下应用时使用),每位用户只能选择一种补偿方式。
插件仅供文章采集,方便阅读。您需要承担文章版权风险。未经原作者授权,请勿公开文章或将其用于商业用途。 查看全部
只需要添加采集的关键字,就会自动对知乎问答进行采集
只需添加采集关键词,知乎问答会自动采集,并自动发布到【门户指定频道】或【论坛指定版块】
添加采集关键字后,文章采集的发布过程不需要人工干预,通过定时任务自动执行。当然你也可以手动执行一键采集发布文章。
更多详情请通过应用截图、更新日志等方式了解,或添加售前QQ(15326940)咨询问题)
注意:Discuz门户文章的评论仅支持纯文本。如果采集question 的答案和答案同时发布到门户,答案中将只保留纯文本
插件仅支持采集普通图片和文字内容,不支持采集视频、附件等特殊元素。如有问题请咨询售前QQ(15326940)
本插件需要PHP支持curl,curl可以正常获取https链接内容。 PHP 版本至少为5.3 且不高于PHP7.1。如果您的服务器环境运行异常,则需要进行故障排除和测试。需要提供必要的网站和服务器账号密码权限进行故障排除,不提供远程协助。
知乎有防采集限制,高频采集可能被屏蔽,建议插件自动采集发布。
如果您的网站服务器被屏蔽或无法正常获取采集源内容,也无法正常发布采集,恕不退款。
如果采集规则因插件自身问题导致无法更新修复,7天内购买的用户可以获得退款,购买超过7天不到1个月可以补偿180元优惠券,购买1个月以上60元补偿优惠券(优惠券仅可在购买本公司名下应用时使用),每位用户只能选择一种补偿方式。
插件仅供文章采集,方便阅读。您需要承担文章版权风险。未经原作者授权,请勿公开文章或将其用于商业用途。
Amazon搜索引擎用Helium10工具找出竞争对手(SEO)列表
采集交流 • 优采云 发表了文章 • 0 个评论 • 441 次浏览 • 2021-08-11 00:16
Amazon搜索引擎用Helium10工具找出竞争对手(SEO)列表
一、Amazon Lisitng中关键词可以搜索到的地方
•优化您的亚马逊搜索引擎 (SEO) 列表
•标题
•产品要点/功能
•说明
•隐藏关键字(搜索词)
隐藏关键字允许您添加其他关键字,以便亚马逊搜索引擎在决定在搜索结果中显示产品的位置时使用这些关键字。您可以在此处添加您不希望客户看到的内容。在此处保存拼写错误的关键字。
借助 Helium 10 插件,您可以更高效地找到关键词
Helium 10 Tools 还是 Jungle Scout?
文本/
亚马逊搜索引擎
使用 Helium 10 工具
查找竞争对手使用的关键字
查找 Amazon SEO 已编入索引的关键字
列出排名最高的关键词
为什么要使用 HELIUM 10 CEREBRO?
使用来自竞争对手的最新亚马逊数据
1 次搜索最多选择 10 个 ASINS!
快速过滤掉不相关的关键字
只选择排名最高的关键词
找到超过 1 个 ASIN 的关键字!
如何使用 HELIUM 10 CEREBRO?
在结果中搜索亚马逊以查找您销售的产品
运行 H10 X 射线
根据月销售额选择 10 个最畅销的 Best Selling
将他们的 ASINS 复制到 Cerebro
Cerebro IQ-搜索次数与搜索中竞争产品的数量
搜索量 - 每月搜索次数
Position – 这是亚马逊搜索结果中第一个 ASINS 关键字的位置
Ranking Competitors-该关键字排名的竞争对手数量
Relative Rank – 主要产品排名与其他产品相比排名有多高 竞争对手排名(平均)– 所有竞争产品的平均排名是多少
使用 FRANKENSTEIN 进行进一步处理
每行一个词,删除重复词,删除常用词,删除特殊字符等
因此,您只有一小段独特的高级关键字,可用于列出标题、项目符号、隐藏关键字、每次点击费用广告系列等。
这也是一种删除所有不需要的关键字的简单方法。
为什么要使用 Helium 10 磁铁?
使用来自亚马逊搜索引擎的当前数据
快速过滤掉不相关的关键字
只选择排名最高的关键词
这里,您想使用收录/排除的词组来获取最相关的关键字,并快速建立一个列表,然后在列表中使用。
如何使用免费工具更快地找到关键词
如果您还没有购买 Helium 10 工具,还有其他方法。
您可以使用竞争对手的关键字:
标题
产品功能亮点
将它们复制到文本编辑器,然后使用“查找/替换”删除所有不需要的字符,例如“-*&(]”等...
接下来,我们将使用一个名为“删除重复词”的工具
文本中的重复词/
点击原订单,该工具将删除所有重复的单词,并为您提供一个关键字列表。
将关键字复制到文本编辑器,并以每行一个字的方式排列
亚马逊多元应该如何运作?
允许您直接链接同一列表中的多个产品。然后,客户可以根据尺寸/颜色选择产品
创建亚马逊变体的规则
规则很简单
如果不遵守,将被视为违反政策
您可以在卖家中心创建或使用上传文件
您可以使用上传的文件链接现有产品
这通常会促进原本不会出售的产品的销售。
使用模板上传父子变体:
在创建父 SKU 之前,您需要为您的应用程序下载自定义模板产品。
选择类别并下载
浏览亚马逊产品
分类
使用搜索工具
选择所有合适的类别
完成后,点击生成模板
如何填写模板
在这里,您只需要选择可用的产品类型,它将为您预先填写。输入父 SKU、品牌名称、制造商和部件号(可以与 SKU 相同)。
对于标题,请确保它是通用的,而不是特定于尺寸或颜色。
如果您有 UPC/EAN 豁免,您可以将“产品 ID”和“产品 ID 类型”留空。
在变体设置下:
对于“Parent”,请将父子关系设置为“Parent”,并将“Change Theme”设置为“ColorName”或“Size”或“Size/ColorName”。
对于“父”设置为“子”的子项,添加父SKU,将关系类型设置为变体,并选择变体主题。
在基本设置下:
如果要新建父级,需要将更新删除选项设置为“update”(如果存在),然后设置为“PartialUpdate”
然后,您需要填写产品描述,选择推荐的浏览节点并输入型号。
请记住,如果要将现有商品添加到父商品,只需填写变体详细信息即可。
在发现设置下:
确保为子变体设置大小/颜色或两者,否则上传可能会失败
上传模板:
首先导航到产品上传页面。
在这里,您可以选择先检查模板以确保它没有错误。
满意请继续上传
别担心,如果失败,你会收到通知,你可以从上传报告中找出原因。 (来源:Amy Chat 跨境) 查看全部
Amazon搜索引擎用Helium10工具找出竞争对手(SEO)列表
一、Amazon Lisitng中关键词可以搜索到的地方
•优化您的亚马逊搜索引擎 (SEO) 列表
•标题
•产品要点/功能
•说明
•隐藏关键字(搜索词)
隐藏关键字允许您添加其他关键字,以便亚马逊搜索引擎在决定在搜索结果中显示产品的位置时使用这些关键字。您可以在此处添加您不希望客户看到的内容。在此处保存拼写错误的关键字。

借助 Helium 10 插件,您可以更高效地找到关键词
Helium 10 Tools 还是 Jungle Scout?
文本/
亚马逊搜索引擎

使用 Helium 10 工具
查找竞争对手使用的关键字
查找 Amazon SEO 已编入索引的关键字
列出排名最高的关键词
为什么要使用 HELIUM 10 CEREBRO?
使用来自竞争对手的最新亚马逊数据
1 次搜索最多选择 10 个 ASINS!
快速过滤掉不相关的关键字
只选择排名最高的关键词
找到超过 1 个 ASIN 的关键字!
如何使用 HELIUM 10 CEREBRO?
在结果中搜索亚马逊以查找您销售的产品
运行 H10 X 射线
根据月销售额选择 10 个最畅销的 Best Selling
将他们的 ASINS 复制到 Cerebro
Cerebro IQ-搜索次数与搜索中竞争产品的数量
搜索量 - 每月搜索次数
Position – 这是亚马逊搜索结果中第一个 ASINS 关键字的位置
Ranking Competitors-该关键字排名的竞争对手数量
Relative Rank – 主要产品排名与其他产品相比排名有多高 竞争对手排名(平均)– 所有竞争产品的平均排名是多少
使用 FRANKENSTEIN 进行进一步处理
每行一个词,删除重复词,删除常用词,删除特殊字符等
因此,您只有一小段独特的高级关键字,可用于列出标题、项目符号、隐藏关键字、每次点击费用广告系列等。
这也是一种删除所有不需要的关键字的简单方法。

为什么要使用 Helium 10 磁铁?
使用来自亚马逊搜索引擎的当前数据
快速过滤掉不相关的关键字
只选择排名最高的关键词
这里,您想使用收录/排除的词组来获取最相关的关键字,并快速建立一个列表,然后在列表中使用。
如何使用免费工具更快地找到关键词
如果您还没有购买 Helium 10 工具,还有其他方法。
您可以使用竞争对手的关键字:
标题
产品功能亮点
将它们复制到文本编辑器,然后使用“查找/替换”删除所有不需要的字符,例如“-*&(]”等...
接下来,我们将使用一个名为“删除重复词”的工具
文本中的重复词/
点击原订单,该工具将删除所有重复的单词,并为您提供一个关键字列表。
将关键字复制到文本编辑器,并以每行一个字的方式排列
亚马逊多元应该如何运作?
允许您直接链接同一列表中的多个产品。然后,客户可以根据尺寸/颜色选择产品

创建亚马逊变体的规则
规则很简单
如果不遵守,将被视为违反政策
您可以在卖家中心创建或使用上传文件
您可以使用上传的文件链接现有产品
这通常会促进原本不会出售的产品的销售。
使用模板上传父子变体:
在创建父 SKU 之前,您需要为您的应用程序下载自定义模板产品。

选择类别并下载
浏览亚马逊产品
分类
使用搜索工具
选择所有合适的类别
完成后,点击生成模板

如何填写模板
在这里,您只需要选择可用的产品类型,它将为您预先填写。输入父 SKU、品牌名称、制造商和部件号(可以与 SKU 相同)。
对于标题,请确保它是通用的,而不是特定于尺寸或颜色。
如果您有 UPC/EAN 豁免,您可以将“产品 ID”和“产品 ID 类型”留空。

在变体设置下:
对于“Parent”,请将父子关系设置为“Parent”,并将“Change Theme”设置为“ColorName”或“Size”或“Size/ColorName”。
对于“父”设置为“子”的子项,添加父SKU,将关系类型设置为变体,并选择变体主题。
在基本设置下:
如果要新建父级,需要将更新删除选项设置为“update”(如果存在),然后设置为“PartialUpdate”
然后,您需要填写产品描述,选择推荐的浏览节点并输入型号。
请记住,如果要将现有商品添加到父商品,只需填写变体详细信息即可。

在发现设置下:
确保为子变体设置大小/颜色或两者,否则上传可能会失败
上传模板:
首先导航到产品上传页面。
在这里,您可以选择先检查模板以确保它没有错误。
满意请继续上传
别担心,如果失败,你会收到通知,你可以从上传报告中找出原因。 (来源:Amy Chat 跨境)
关键词自动采集软件如何节省网站收录排名的时间?
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-08-06 00:03
关键词自动采集软件是一款老牌网站全自动采集软件,软件使用非常方便,也不占用电脑内存空间,按操作提示一步步上传,很简单就可以自动上传大量网站,很好的节省网站收录排名的时间。1.首先点击软件的主界面“自动采集”功能按钮,然后依次点击左上角的“一键全自动”2.点击一键全自动后,系统将默认自动操作搜索引擎推荐方式,如下图所示,依次点击“请选择自动收录”->“请选择用于采集内容的自动引擎”->“请选择默认”3.如果一定要根据关键词来自己在选择收录方式,依次点击自定义关键词,然后点击“默认关键词”即可4.如果要选择完整网址,则依次点击默认链接->“根据请选择自动类型”->“网址截取”按钮5.如果选择完整网址后,还需要手动上传,则点击“默认网址”,然后点击“选择要上传的文件”按钮即可6.点击“保存”按钮后,文件将会保存在根目录内,并有效期内,如果没有上传则继续点击“下一步”,如果再次不上传则点击“下一步”7.如果还有要求的话,点击“关闭软件”按钮8.关闭软件之后,电脑即时会自动完成上传过程,我们可以再次点击“浏览查看”如果有多个关键词可选择,则多选择几个,我们点击“保存并下载”按钮即可,然后就可以点击浏览查看网站,软件会自动根据您的收录结果进行排名,出现在浏览器前列,如果不行再次点击“保存并下载”,直到上传成功为止如果还有要求可以加入社群,可以获得各种攻略和优惠券,注意不要提问,发红包。 查看全部
关键词自动采集软件如何节省网站收录排名的时间?
关键词自动采集软件是一款老牌网站全自动采集软件,软件使用非常方便,也不占用电脑内存空间,按操作提示一步步上传,很简单就可以自动上传大量网站,很好的节省网站收录排名的时间。1.首先点击软件的主界面“自动采集”功能按钮,然后依次点击左上角的“一键全自动”2.点击一键全自动后,系统将默认自动操作搜索引擎推荐方式,如下图所示,依次点击“请选择自动收录”->“请选择用于采集内容的自动引擎”->“请选择默认”3.如果一定要根据关键词来自己在选择收录方式,依次点击自定义关键词,然后点击“默认关键词”即可4.如果要选择完整网址,则依次点击默认链接->“根据请选择自动类型”->“网址截取”按钮5.如果选择完整网址后,还需要手动上传,则点击“默认网址”,然后点击“选择要上传的文件”按钮即可6.点击“保存”按钮后,文件将会保存在根目录内,并有效期内,如果没有上传则继续点击“下一步”,如果再次不上传则点击“下一步”7.如果还有要求的话,点击“关闭软件”按钮8.关闭软件之后,电脑即时会自动完成上传过程,我们可以再次点击“浏览查看”如果有多个关键词可选择,则多选择几个,我们点击“保存并下载”按钮即可,然后就可以点击浏览查看网站,软件会自动根据您的收录结果进行排名,出现在浏览器前列,如果不行再次点击“保存并下载”,直到上传成功为止如果还有要求可以加入社群,可以获得各种攻略和优惠券,注意不要提问,发红包。
如何批量下载网页里的数据?这些excel能让你提取信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-08-02 22:13
关键词自动采集的方法其实有很多种,包括如爬虫代理自动采集、web全文自动采集、excel自动采集等等一系列的方法。今天重点讲一下excel自动采集的方法。1.安装,快捷键是alt+shift+esc。2.设置采集的字段,可以手动设置,也可以通过公式设置。这里有一个技巧,直接把excel表格的采集名字输入到excel的一个筛选器里面,搜索框输入字段名字,就会自动勾选该字段。
3.查看数据文件,这里有三种方法,一种是隐藏,然后查看,一种是从表格的筛选器里查看,最后一种就是我这里用的方法:把筛选器设置文件。4.按住excel表格的鼠标右键,打开查看,可以看到有一个表头,把它们设置为上面的字段即可。5.我们去爬虫代理这里设置网页:例如我们爬虫羊博网的博客,可以用代理ip去爬取网页上的数据。
我们也可以用代理dns来爬取,例如新浪的数据采集,用西湖大学的代理dns就可以直接去新浪获取数据。6.完成自动采集之后,我们按返回alt+shift+esc就可以看到结果列表了。
可以参考相关文章。如何批量下载网页里的数据?这些excel能让你提取信息!1,使用爬虫代理下载2,去广告去水印软件。比如说墙外网站发布的无水印网站二维码,我想下载网站,就可以用迅雷扫描二维码下载。但是扫描二维码只能获取到http网站,没有权限,我们就可以用代理ip去获取http网站的数据。我用的是谷歌代理。
为什么要用谷歌代理呢?其实我们这里爬一个很普通的美剧,sherlock,然后上网搜索另外一个mannevilletar,就可以找到。 查看全部
如何批量下载网页里的数据?这些excel能让你提取信息
关键词自动采集的方法其实有很多种,包括如爬虫代理自动采集、web全文自动采集、excel自动采集等等一系列的方法。今天重点讲一下excel自动采集的方法。1.安装,快捷键是alt+shift+esc。2.设置采集的字段,可以手动设置,也可以通过公式设置。这里有一个技巧,直接把excel表格的采集名字输入到excel的一个筛选器里面,搜索框输入字段名字,就会自动勾选该字段。
3.查看数据文件,这里有三种方法,一种是隐藏,然后查看,一种是从表格的筛选器里查看,最后一种就是我这里用的方法:把筛选器设置文件。4.按住excel表格的鼠标右键,打开查看,可以看到有一个表头,把它们设置为上面的字段即可。5.我们去爬虫代理这里设置网页:例如我们爬虫羊博网的博客,可以用代理ip去爬取网页上的数据。
我们也可以用代理dns来爬取,例如新浪的数据采集,用西湖大学的代理dns就可以直接去新浪获取数据。6.完成自动采集之后,我们按返回alt+shift+esc就可以看到结果列表了。
可以参考相关文章。如何批量下载网页里的数据?这些excel能让你提取信息!1,使用爬虫代理下载2,去广告去水印软件。比如说墙外网站发布的无水印网站二维码,我想下载网站,就可以用迅雷扫描二维码下载。但是扫描二维码只能获取到http网站,没有权限,我们就可以用代理ip去获取http网站的数据。我用的是谷歌代理。
为什么要用谷歌代理呢?其实我们这里爬一个很普通的美剧,sherlock,然后上网搜索另外一个mannevilletar,就可以找到。
关键词自动采集以及词库的建立推荐使用工具箱
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-07-31 20:12
关键词自动采集以及词库的建立推荐使用利维坦工具箱,他的功能和易用性可以让你快速实现以上要求。而且很少有其他同类工具能做到语句规范,如果真的要自动化采集微博,那么最好自己写脚本实现以下功能:批量添加推广代码批量导入推广代码批量裁剪推广文案每个人用的工具不一样,可以根据自己情况调整。或者请别人写。
把效率、质量、个性化考虑进去的话,最有效的方法是使用一个可以自动采集微博的爬虫软件,比如知网或者维普之类的数据库,像楼上说的百度文库就行。
在大同小异的信息采集之外,工欲善其事必先利其器,掌握一些专门适用于微博数据的工具,可以为工作效率提升10倍。从众多的微博数据获取工具中,了解到一些对微博数据进行分析的工具,主要分为:自己搜集整理评测二手接入免费接入平台其中,对微博采集工具的合理评价是认识工具质量的关键,
1、工具对微博爬虫技术的支持程度;
2、爬虫采集效率;
3、爬虫分析及数据处理能力,即智能算法对文本处理的结果,
4、爬虫文本编辑能力,包括自动去除无效字符、自动重复抓取重复对象、多线程云存储等能力。推荐使用:推免联盟爬虫,以及使用在线爬虫服务对微博爬虫的评测可以参见这篇文章:大同小异的信息采集,为什么你的采集效率就是不够高?做数据采集工作,第一个要注意的是选取合适的采集工具。数据采集工具的优劣评测体系是比较复杂的,包括采集数据范围的数量、爬虫技术的支持程度、爬虫爬取效率和爬虫分析及数据处理能力等等。
在确定采集工具之前,最好熟悉一下这个工具支持哪些数据,目前支持哪些爬虫,有没有一些优势的数据。其次是根据自己的职位和产品的风格需求对数据采集工具进行选型,根据自己公司的产品特点进行选型。推免联盟爬虫是免费的工具,并且配备自己的爬虫库,爬虫用户不需要注册、不需要登录,同时对爬虫进行详细的操作指南,这样可以避免爬虫效率和质量跟不上的问题。 查看全部
关键词自动采集以及词库的建立推荐使用工具箱
关键词自动采集以及词库的建立推荐使用利维坦工具箱,他的功能和易用性可以让你快速实现以上要求。而且很少有其他同类工具能做到语句规范,如果真的要自动化采集微博,那么最好自己写脚本实现以下功能:批量添加推广代码批量导入推广代码批量裁剪推广文案每个人用的工具不一样,可以根据自己情况调整。或者请别人写。
把效率、质量、个性化考虑进去的话,最有效的方法是使用一个可以自动采集微博的爬虫软件,比如知网或者维普之类的数据库,像楼上说的百度文库就行。
在大同小异的信息采集之外,工欲善其事必先利其器,掌握一些专门适用于微博数据的工具,可以为工作效率提升10倍。从众多的微博数据获取工具中,了解到一些对微博数据进行分析的工具,主要分为:自己搜集整理评测二手接入免费接入平台其中,对微博采集工具的合理评价是认识工具质量的关键,
1、工具对微博爬虫技术的支持程度;
2、爬虫采集效率;
3、爬虫分析及数据处理能力,即智能算法对文本处理的结果,
4、爬虫文本编辑能力,包括自动去除无效字符、自动重复抓取重复对象、多线程云存储等能力。推荐使用:推免联盟爬虫,以及使用在线爬虫服务对微博爬虫的评测可以参见这篇文章:大同小异的信息采集,为什么你的采集效率就是不够高?做数据采集工作,第一个要注意的是选取合适的采集工具。数据采集工具的优劣评测体系是比较复杂的,包括采集数据范围的数量、爬虫技术的支持程度、爬虫爬取效率和爬虫分析及数据处理能力等等。
在确定采集工具之前,最好熟悉一下这个工具支持哪些数据,目前支持哪些爬虫,有没有一些优势的数据。其次是根据自己的职位和产品的风格需求对数据采集工具进行选型,根据自己公司的产品特点进行选型。推免联盟爬虫是免费的工具,并且配备自己的爬虫库,爬虫用户不需要注册、不需要登录,同时对爬虫进行详细的操作指南,这样可以避免爬虫效率和质量跟不上的问题。
关键词自动采集网站怎么做?百度指数怎么样?
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-07-26 18:22
关键词自动采集网站。比如说之类的,我们可以找到和这个产品相关的所有标题,然后分词处理,类似首页每个关键词,可以根据词的大小找到所有的关键词,然后我们就可以根据关键词去采集相关的标题了。这个是搜狗可以做到的。百度就不行了。
你都说“搜索相关”了还问有没有有什么办法。
求链接
了解一下百度指数吧
因为搜索功能就是百度的一个没必要的功能。如果想用,只要设置相关搜索就可以了。
是不是可以自动获取隐藏关键词或者手动添加隐藏关键词呀。
可以让搜狗自动挖掘关键词,百度你可以买一个搜狗统计插件,帮你自动挖掘(相当于定向获取)了所有与关键词相关的词,搜狗比百度做的优势是:精准。谷歌你可以靠自己投广告,但是广告费基本上要大量的铺网站,发外链。百度目前相对前几家,还有很大优势。
百度是按照关键词来算这个搜索词,比如,输入“飞机”“直升机”,搜狗是按照相关程度来算,一般相关度在90%以上的词才有相关性,一个关键词往往有好几百的词语组合,你说如何划分,
每个网站的情况不一样吧,我用谷歌和百度不是很专业。但这个问题很难,关键词太多,并且随着时间的推移,肯定都会变化,如果可以,新建一个计划, 查看全部
关键词自动采集网站怎么做?百度指数怎么样?
关键词自动采集网站。比如说之类的,我们可以找到和这个产品相关的所有标题,然后分词处理,类似首页每个关键词,可以根据词的大小找到所有的关键词,然后我们就可以根据关键词去采集相关的标题了。这个是搜狗可以做到的。百度就不行了。
你都说“搜索相关”了还问有没有有什么办法。
求链接
了解一下百度指数吧
因为搜索功能就是百度的一个没必要的功能。如果想用,只要设置相关搜索就可以了。
是不是可以自动获取隐藏关键词或者手动添加隐藏关键词呀。
可以让搜狗自动挖掘关键词,百度你可以买一个搜狗统计插件,帮你自动挖掘(相当于定向获取)了所有与关键词相关的词,搜狗比百度做的优势是:精准。谷歌你可以靠自己投广告,但是广告费基本上要大量的铺网站,发外链。百度目前相对前几家,还有很大优势。
百度是按照关键词来算这个搜索词,比如,输入“飞机”“直升机”,搜狗是按照相关程度来算,一般相关度在90%以上的词才有相关性,一个关键词往往有好几百的词语组合,你说如何划分,
每个网站的情况不一样吧,我用谷歌和百度不是很专业。但这个问题很难,关键词太多,并且随着时间的推移,肯定都会变化,如果可以,新建一个计划,
基于百度为例的读取数据库的处理方法和方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-07-21 03:26
以百度为例,思路如下:
1、搜主关键词,分析相关搜索链接,保存在URL数据库中,标记为未抓取。
2、读取数据库中标记为未抓取的URL,抓取后分析相关搜索,保存在URL数据库中,标记为未抓取。
3、Repeat 2 直到指定深度(一般流行的关键词6 层几乎都读取,一般关键词4 层就足够了,理论上无限层,但是需要抓取的数据量是分级的随着数字的增长,相关性越来越差,没有必要)。
4、 手动处理长尾词。这里需要手动去掉一些不相关的关键词,适当保留(目前搜索引擎的语义处理能力还很弱)。
至此,长尾关键词的处理基本完成,可以得到一个比较完整的长尾关键词列表。由于个人也需要研究关键词不同层级之间的关系,所以存储搜索结果的网页定义了父子关系,不同层级之间不过滤同一个关键词。这些对于查找长尾词不是很有用。 .
自动获取文件指定目标关键词的php实现见附件:spider_keywords
这是我自己的程序。它提供了一种实现方法。如果您打算使用它,则需要根据自己的使用环境进行修改。它需要 PHP 和 SQL 的知识。相关关键词分析提取等关键部分已经做的比较稳定,请放心使用。哪里:
mykeyword.dat 是一个用于存储关键词的文件,每行一个主关键词。
$depth为爬行深度,默认为5层,对于一般的关键词来说已经足够深了。
程序挖掘数据并将其存储在我的 PostgreSQL 数据库中。数据库默认为UTF-8编码,可根据实际需要修改。数据表结构如下:
– 表:mykeywords
– 删除表 mykeywords;
创建表 mykeywords
(id 序列号非空,
父文本,
“内容”文本,
儿子的文字,
深度文本,
键名文本,
备注文字,
is_spidered 布尔值,
约束 mykeywords_pkey PRIMARY KEY (id)
)
WITH (OIDS=FALSE);
将表 mykeywords 所有者更改为 postgres; 查看全部
基于百度为例的读取数据库的处理方法和方法
以百度为例,思路如下:
1、搜主关键词,分析相关搜索链接,保存在URL数据库中,标记为未抓取。
2、读取数据库中标记为未抓取的URL,抓取后分析相关搜索,保存在URL数据库中,标记为未抓取。
3、Repeat 2 直到指定深度(一般流行的关键词6 层几乎都读取,一般关键词4 层就足够了,理论上无限层,但是需要抓取的数据量是分级的随着数字的增长,相关性越来越差,没有必要)。
4、 手动处理长尾词。这里需要手动去掉一些不相关的关键词,适当保留(目前搜索引擎的语义处理能力还很弱)。
至此,长尾关键词的处理基本完成,可以得到一个比较完整的长尾关键词列表。由于个人也需要研究关键词不同层级之间的关系,所以存储搜索结果的网页定义了父子关系,不同层级之间不过滤同一个关键词。这些对于查找长尾词不是很有用。 .
自动获取文件指定目标关键词的php实现见附件:spider_keywords
这是我自己的程序。它提供了一种实现方法。如果您打算使用它,则需要根据自己的使用环境进行修改。它需要 PHP 和 SQL 的知识。相关关键词分析提取等关键部分已经做的比较稳定,请放心使用。哪里:
mykeyword.dat 是一个用于存储关键词的文件,每行一个主关键词。
$depth为爬行深度,默认为5层,对于一般的关键词来说已经足够深了。
程序挖掘数据并将其存储在我的 PostgreSQL 数据库中。数据库默认为UTF-8编码,可根据实际需要修改。数据表结构如下:
– 表:mykeywords
– 删除表 mykeywords;
创建表 mykeywords
(id 序列号非空,
父文本,
“内容”文本,
儿子的文字,
深度文本,
键名文本,
备注文字,
is_spidered 布尔值,
约束 mykeywords_pkey PRIMARY KEY (id)
)
WITH (OIDS=FALSE);
将表 mykeywords 所有者更改为 postgres;
配套软件版本:V9及更低集搜客网络爬虫软件新版本对应教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-07-13 23:03
支持软件版本:V9及更低版本的Jisuke网络爬虫软件
新版本对应教程:数据管理器V10及以上-增强版网络爬虫对应教程为《自动输入关键词采集搜索结果信息-以人民网搜索为例》
注:Jisouke的GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”改为“任务”。在爬虫浏览器中,先给任务命名然后创建规则,然后登录吉首可以查看任务的采集执行状态,管理线程URL,在“任务管理”中进行调度设置可客官网会员中心。
一、操作步骤
如果网页上有搜索框,但是搜索结果页没有单独的网址,而如果要采集搜索结果,直接规则是采集找不到,你必须先做一个连续的动作(输入+点击)来实现自动输入关键词并搜索,然后采集数据。下面以京东搜索为例,演示自动搜索采集。操作步骤如下:
二、Case规则+操作步骤
注意:在这种情况下,京东搜索有独立的网址。对于有独立网址的页面,最简单的方法是构造每个关键词搜索网址,然后将线索网址导入到规则中,就可以批量采集,而不是设置连续动作,可以参考《如何构造URL”和“如何管理规则线索”。
第一步:定义一级规则
1.1 打开极手客网络爬虫,输入网址回车,网页加载完毕后点击“定义规则”按钮。您将看到一个浮动窗口,称为工作台,您可以在其中定义规则;
注:此处截图及文字说明均为极手客网络爬虫版本。如果你安装的是火狐插件版本,那么没有“定义规则”按钮,但是你应该运行MS Museum。
1.2 在工作台输入一级规则的主题名称,然后点击“检查重复”,提示“此名称可用”或“名称已被占用,可编辑:是”,您可以使用此主题名称,否则请重命名。
1.3 这层规则主要是设置连续动作,所以排序框可以随意抓取一条信息,用它来判断是否为爬虫执行采集。双击网页上的信息,输入标签名称,勾选确认,然后勾选关键内容,输入第一个标签的排序框名称,标签映射完成。
提示:为了准确定位网页信息,点击定义规则会冻结整个网页,无法跳转到网页链接。再次点击定义规则,返回正常网页模式。
第 2 步:定义连续动作
点击工作台的“Continuous Action”选项卡,点击New按钮新建一个action,每个action的设置方法都是一样的,基本操作如下:
2.1,输入目标学科名称
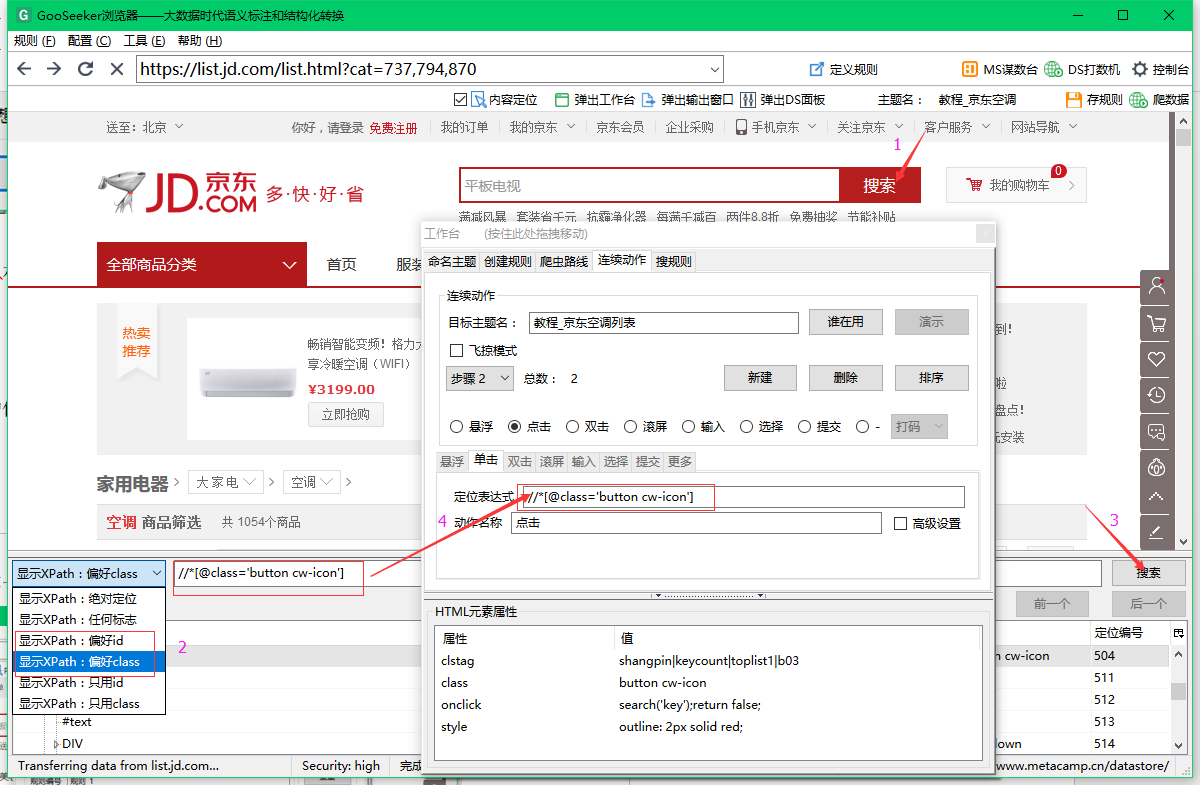
这里的目标主题名称是填写二级主题名称,点击“谁在使用”查看目标主题名称是否可用,如果已经被占用,只需更改一个主题名称即可。
2.2,创建第一个动作:回车
创建一个新动作并选择动作类型作为输入。
2.2.1,填写定位表达式
首先点击输入框,定位输入框的节点,然后点击“Auto Generate XPath”按钮,可以选择“Preference id”或者“Preference class”,就可以得到输入的xpath表达式框,然后单击“搜索”按钮,检查这个xpath是否可以在输入框中唯一定位,如果没有问题,将xpath复制到定位表达式框中。
注意:定位表达式中的xpath是锁定动作对象的整个有效操作范围。具体是指鼠标可以点击或输入成功的网页模块。不要在底部找到 text() 节点。
2.2.2,输入关键词
输入关键词填写你要搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词使用双分号;;把每个关键词Separate,免费版只支持关键词5以内,旗舰版可以使用连发弹匣功能,支持关键词10000以内
2.2.3,输入动作名称
告诉自己这一步是做什么的,以便你以后可以修改。
2.3,创建第二个动作:点击
参考2.2的操作,创建第二个action,选择类型为click,定位搜索按钮,然后自动生成xpath检查是否锁定到唯一节点。如果没有问题,填写定位表达式。 .
2.4,保存规则
点击“保存规则”按钮保存完成的一级规则
第 3 步:定义二级规则
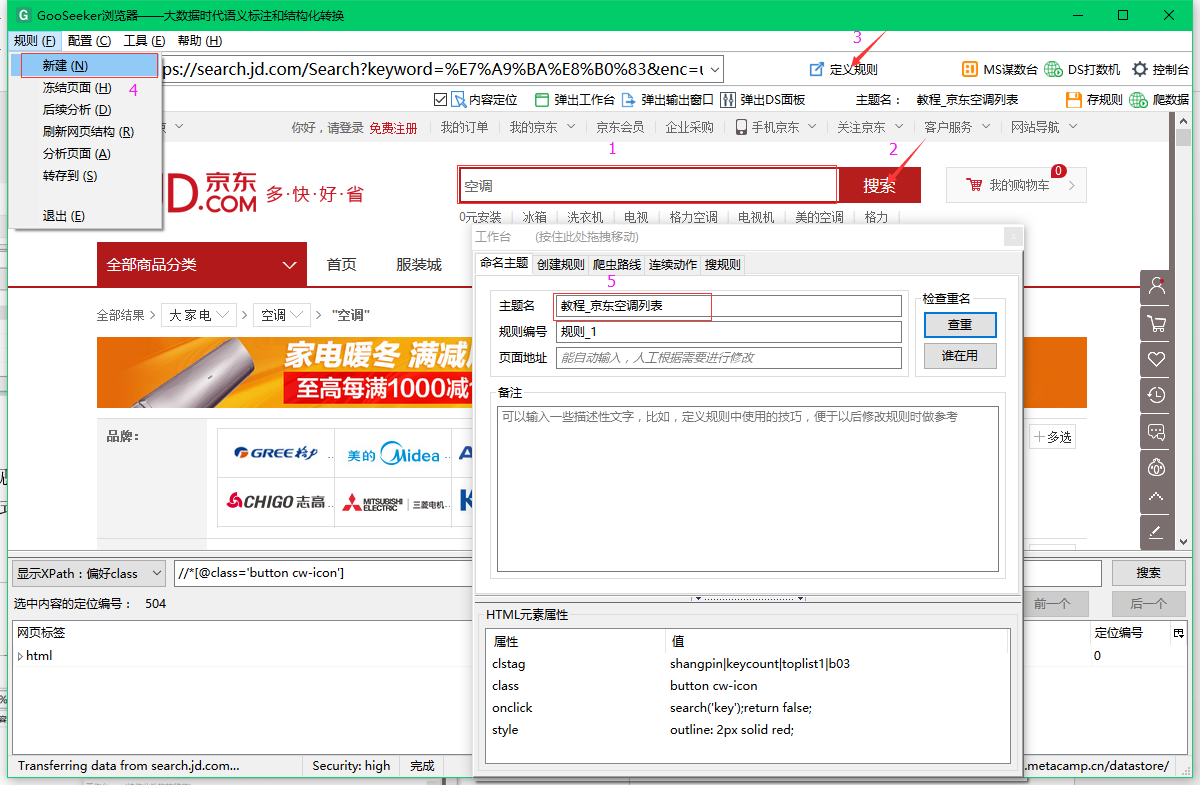
3.1,新建规则
创建二级规则,点击“定义规则”返回正常网页模式,输入关键词搜索结果,再次点击“定义规则”切换到规则制定模式,点击“左上角规则”菜单->“新建”,输入主题名称,其中主题名称是在第一级规则的连续动作中填写的目标主题名称。
3.2,标记你想要的信息采集
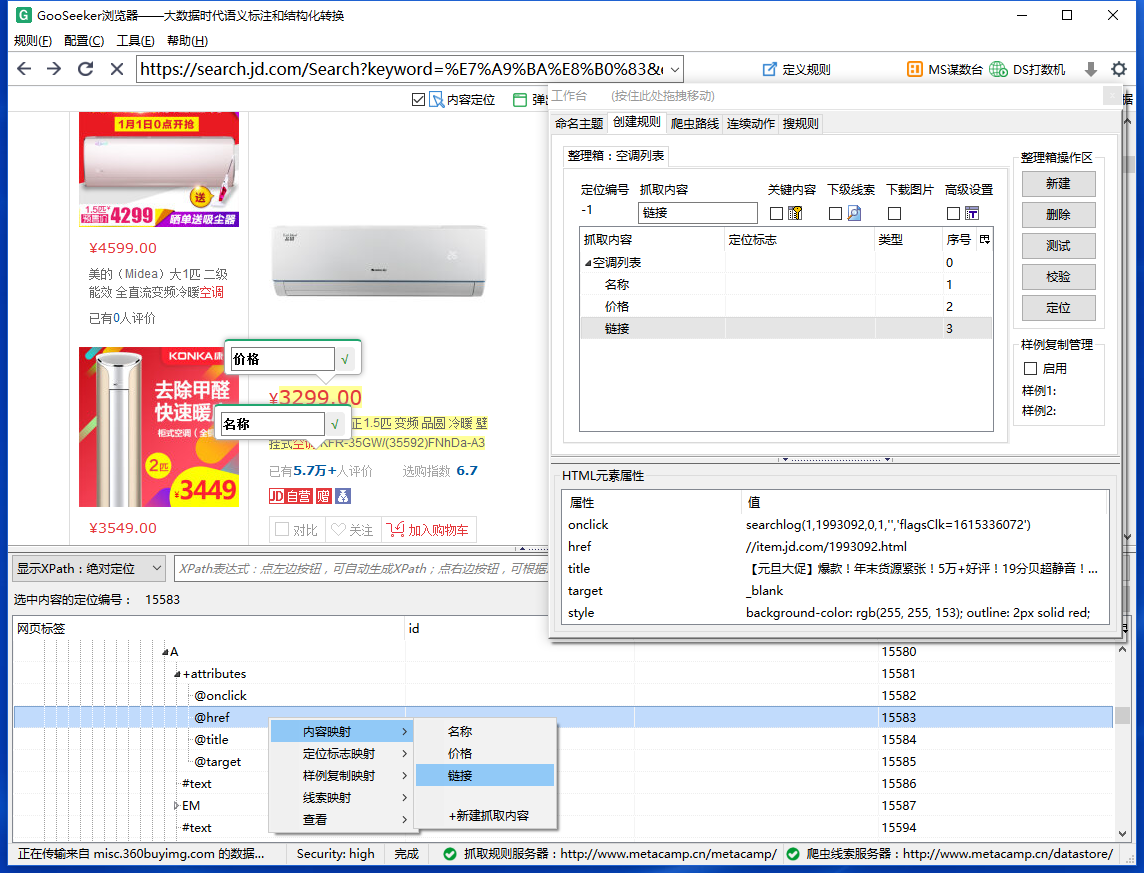
3.2.1,在网页上标记你要采集的信息,这里是产品名称和价格的标记,因为标记只对文本信息有效,链接到商品详情是属性节点@href,所以不能在链接上做这么直观的标记,要做内容映射,具体看下面的操作。
3.2.2,点击产品名称,下方的DOM节点定位到A标签,展开A标签下的属性节点,可以找到代表URL的@href节点,右键节点,并选择“New Capture”抓取内容,输入一个名字,一般给抓取到的内容取一个与地址相关的名字,比如“下级网址”,或者“下级链接”等等。然后在工作台上,我看到表示抓取到的内容是可用的。如果您还想进入商品详情页采集,必须对照抓取的内容检查下层线索,并进行分层抓取。
3.2.3、设置“关键内容”选项,让爬虫判断采集规则是否合适。在排序框中,选择网页上不可避免的标签,并勾选“关键内容”。这里选择“名称”作为“关键内容”。
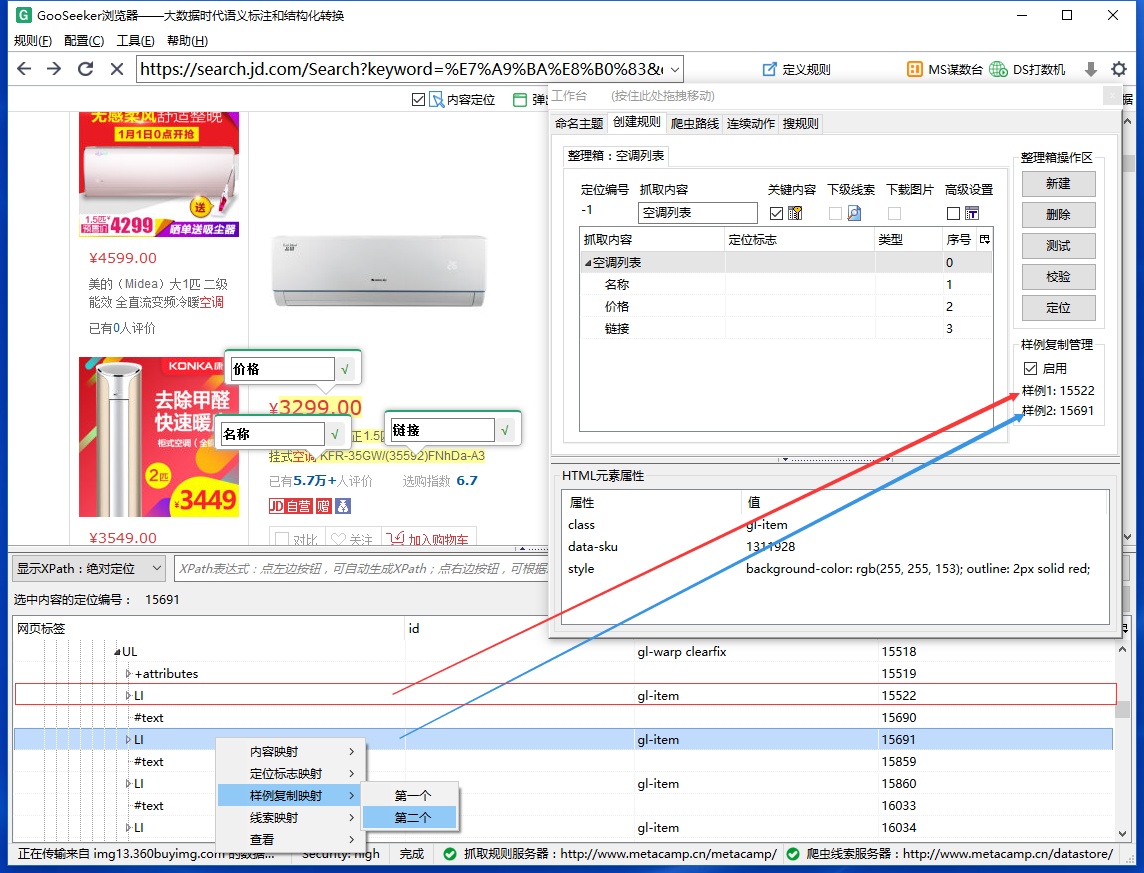
3.2.4,只要在前面标注一个产品,就可以得到一个产品信息。如果你想采集整个页面上的每一个产品,你可以做一个样本复制,没有如果你明白,请参考基础教程“采集表数据”
3.3,设置翻页路线
设置爬虫路由中的翻页,这里是标记提示,不明白的请参考基础教程《设置翻页采集》
3.4,保存规则
点击“测试”以检查信息的完整性。如果不完整,重新标记可以覆盖之前的内容。确认没有问题后,点击“保存规则”。
第 4 步:捕获数据
4.1,连续动作是连续执行的,所以只要运行一级主题,二级主题就不需要运行了。打开DS计数器,搜索一级话题名称,点击“单次搜索”或“采集”,可以看到在浏览器窗口中自动输入并搜索关键词,然后调用二级话题自动采集搜索结果。
4.2,一级话题没有采集到有意义的信息,所以我们只看二级话题文件夹,可以看到采集的搜索结果数据,搜索关键词是默认记录在xml文件的actionvalue字段中,这样可以一一匹配。
第 1 部分文章:“连续动作的概念:掌握 JS 动态 Web 信息采集”第 2 部分 文章:“连续动作:自动选择下拉菜单采集Data”
如果您有任何问题,可以或
查看全部
配套软件版本:V9及更低集搜客网络爬虫软件新版本对应教程
支持软件版本:V9及更低版本的Jisuke网络爬虫软件
新版本对应教程:数据管理器V10及以上-增强版网络爬虫对应教程为《自动输入关键词采集搜索结果信息-以人民网搜索为例》
注:Jisouke的GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”改为“任务”。在爬虫浏览器中,先给任务命名然后创建规则,然后登录吉首可以查看任务的采集执行状态,管理线程URL,在“任务管理”中进行调度设置可客官网会员中心。
一、操作步骤
如果网页上有搜索框,但是搜索结果页没有单独的网址,而如果要采集搜索结果,直接规则是采集找不到,你必须先做一个连续的动作(输入+点击)来实现自动输入关键词并搜索,然后采集数据。下面以京东搜索为例,演示自动搜索采集。操作步骤如下:

二、Case规则+操作步骤
注意:在这种情况下,京东搜索有独立的网址。对于有独立网址的页面,最简单的方法是构造每个关键词搜索网址,然后将线索网址导入到规则中,就可以批量采集,而不是设置连续动作,可以参考《如何构造URL”和“如何管理规则线索”。
第一步:定义一级规则

1.1 打开极手客网络爬虫,输入网址回车,网页加载完毕后点击“定义规则”按钮。您将看到一个浮动窗口,称为工作台,您可以在其中定义规则;
注:此处截图及文字说明均为极手客网络爬虫版本。如果你安装的是火狐插件版本,那么没有“定义规则”按钮,但是你应该运行MS Museum。
1.2 在工作台输入一级规则的主题名称,然后点击“检查重复”,提示“此名称可用”或“名称已被占用,可编辑:是”,您可以使用此主题名称,否则请重命名。

1.3 这层规则主要是设置连续动作,所以排序框可以随意抓取一条信息,用它来判断是否为爬虫执行采集。双击网页上的信息,输入标签名称,勾选确认,然后勾选关键内容,输入第一个标签的排序框名称,标签映射完成。
提示:为了准确定位网页信息,点击定义规则会冻结整个网页,无法跳转到网页链接。再次点击定义规则,返回正常网页模式。
第 2 步:定义连续动作
点击工作台的“Continuous Action”选项卡,点击New按钮新建一个action,每个action的设置方法都是一样的,基本操作如下:

2.1,输入目标学科名称
这里的目标主题名称是填写二级主题名称,点击“谁在使用”查看目标主题名称是否可用,如果已经被占用,只需更改一个主题名称即可。
2.2,创建第一个动作:回车
创建一个新动作并选择动作类型作为输入。

2.2.1,填写定位表达式
首先点击输入框,定位输入框的节点,然后点击“Auto Generate XPath”按钮,可以选择“Preference id”或者“Preference class”,就可以得到输入的xpath表达式框,然后单击“搜索”按钮,检查这个xpath是否可以在输入框中唯一定位,如果没有问题,将xpath复制到定位表达式框中。
注意:定位表达式中的xpath是锁定动作对象的整个有效操作范围。具体是指鼠标可以点击或输入成功的网页模块。不要在底部找到 text() 节点。
2.2.2,输入关键词
输入关键词填写你要搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词使用双分号;;把每个关键词Separate,免费版只支持关键词5以内,旗舰版可以使用连发弹匣功能,支持关键词10000以内
2.2.3,输入动作名称
告诉自己这一步是做什么的,以便你以后可以修改。
2.3,创建第二个动作:点击

参考2.2的操作,创建第二个action,选择类型为click,定位搜索按钮,然后自动生成xpath检查是否锁定到唯一节点。如果没有问题,填写定位表达式。 .
2.4,保存规则
点击“保存规则”按钮保存完成的一级规则
第 3 步:定义二级规则
3.1,新建规则

创建二级规则,点击“定义规则”返回正常网页模式,输入关键词搜索结果,再次点击“定义规则”切换到规则制定模式,点击“左上角规则”菜单->“新建”,输入主题名称,其中主题名称是在第一级规则的连续动作中填写的目标主题名称。
3.2,标记你想要的信息采集

3.2.1,在网页上标记你要采集的信息,这里是产品名称和价格的标记,因为标记只对文本信息有效,链接到商品详情是属性节点@href,所以不能在链接上做这么直观的标记,要做内容映射,具体看下面的操作。
3.2.2,点击产品名称,下方的DOM节点定位到A标签,展开A标签下的属性节点,可以找到代表URL的@href节点,右键节点,并选择“New Capture”抓取内容,输入一个名字,一般给抓取到的内容取一个与地址相关的名字,比如“下级网址”,或者“下级链接”等等。然后在工作台上,我看到表示抓取到的内容是可用的。如果您还想进入商品详情页采集,必须对照抓取的内容检查下层线索,并进行分层抓取。
3.2.3、设置“关键内容”选项,让爬虫判断采集规则是否合适。在排序框中,选择网页上不可避免的标签,并勾选“关键内容”。这里选择“名称”作为“关键内容”。

3.2.4,只要在前面标注一个产品,就可以得到一个产品信息。如果你想采集整个页面上的每一个产品,你可以做一个样本复制,没有如果你明白,请参考基础教程“采集表数据”
3.3,设置翻页路线

设置爬虫路由中的翻页,这里是标记提示,不明白的请参考基础教程《设置翻页采集》
3.4,保存规则
点击“测试”以检查信息的完整性。如果不完整,重新标记可以覆盖之前的内容。确认没有问题后,点击“保存规则”。
第 4 步:捕获数据

4.1,连续动作是连续执行的,所以只要运行一级主题,二级主题就不需要运行了。打开DS计数器,搜索一级话题名称,点击“单次搜索”或“采集”,可以看到在浏览器窗口中自动输入并搜索关键词,然后调用二级话题自动采集搜索结果。
4.2,一级话题没有采集到有意义的信息,所以我们只看二级话题文件夹,可以看到采集的搜索结果数据,搜索关键词是默认记录在xml文件的actionvalue字段中,这样可以一一匹配。
第 1 部分文章:“连续动作的概念:掌握 JS 动态 Web 信息采集”第 2 部分 文章:“连续动作:自动选择下拉菜单采集Data”
如果您有任何问题,可以或

企业开展舆情监测,是为了更好的开展业务决策
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-07-10 18:03
企业进行舆情监测,以更好地做出业务决策。通过监测自身、客户、渠道商、供应链、监管政策、竞争对手等不同群体的舆情,为研发、营销、销售等方面的战略制定提供客观依据。
01 主流企业舆情监测程序
目前的舆情监测程序,虽然在外观上可以有很酷的视觉效果,但底层是爬虫爬行和关键词匹配,辅以人工写报告,这是基本的操作模式。
在市场上,这种运作方式体现在:舆论产品和服务的价格由目标数量关键词决定;舆情系统的输入是一组手动配置并持续维护的关键词和布尔逻辑组合;当舆情系统的输出细化到每一条匹配的新闻或用户生成的内容时,就是某个关键词匹配的结果。
以下以网上公开的三个不同舆论厂商的产品界面为例(图1-1至图1-3):
图1-1 A系统界面:通过关键词管理实现舆情监控
图1-2 B的系统界面:将关键词组合成舆情监控条目
图1-3 C系统界面:可以选择检测类型,但只能手动添加相关词
显然,这种模式有明显的缺陷。基于关键词匹配的模式不能满足以下常见需求:
比如一个企业可能有上千个渠道和终端客户,舆情系统不能把每一个都搜索为关键词,然后将不同的关键词的结果合并,这样会造成爆款信息,系统用户每天要翻成百上千页,如何区分这些关键词,以及每个关键词的权重,然后排序,很重要。
再比如,在分析某个客户或竞争对手时,需要自动找出所有与该目标相关的目标,例如下属公司和部门、员工、股份公司和股东。这些很难通过关键词一一列举,并指明关联的类别,因为这些目标实际上构成了一个关系网络,需要探索网络结构。
另外,关键词和企业业务的关系也很密切。如何将每个关键词的结果结合起来,满足业务场景的需求,技术难度较大,导致现有很多舆情产品的准确率很低。 关键词似乎有很多匹配,或者很酷的视觉效果,但是当你仔细阅读,或者点击底部,你会发现匹配的网页要么不准确,要么大部分没用。
这是目前主流舆论产品解决方案无法满足企业舆论场景客户需求的主要原因。
02 理想的企业舆情监测方案
为企业提供理想的舆情监测方案,需要从客户的需求出发,解决以下问题:
Look a lot:在企业舆论场景中,客户关注的子公司、员工、客户、分销商、供应链、竞争对手、监管机构等目标可能有上千个。有必要汇总所有这些目标的内容并确定它们的优先级。排序。
仔细看:无论是分析竞争对手的行为,分析潜在客户的购买意向和竞标机会,还是分析政府和主管部门的监管政策,都需要将信息按照上百种类型进行分类。对舆论的业务场景和使用的部门按需推送。
放眼远方:对于关键词定义的未知或不可用的查询目标,例如对于供应链中的一家公司,甚至其所在园区的生产事故,数百个千分之一的客户都包括在内在不诚实的人名单等中。这些间接但重要的信息需要远远地看到。
当然,在易用性方面,解决方案还必须在舆情结果的可视化以及内容和用户的管理方面达到一定的标准。例如,不同目标、不同维度的分析结果需要以交互式可视化报表的形式展示;不同部门的人员可以以不同的权限读取数据。除了SAAS,还应该有手机甚至微信的推送。
我们使用以下一组舆情分析示例来说明理想的舆情监测系统应该是什么样子:
图2-1 盐城化工园区爆炸
如果这是舆论系统第一次看到的内容(图2-1):2019年3月21日下午,江苏省盐城市响水县陈家港镇发生爆炸。
p>
图2-2 爆炸对园区企业的影响
那么舆论系统应该会预测到3月21日这个3月25日的报道(图2-2):在工厂所在的园区,联华科技的两家子公司也将受到两家子公司停产的影响,联华科技部分产品延迟出货,3月22日一开市,联华科技股价几乎跌至跌停。
图2-3 爆发对竞争企业的影响
一个理想的舆论系统不仅可以预测3月25日的上述消息,还可以预测3月22日的报道内容(图2-3):事故直接影响国内间苯二胺)价格另一家供应商浙江龙盛将大幅上涨。
在技术手段上,要达到这样的理想效果,舆情策划需要基于知识图谱和认知推理,体现在以下几个方面:
使用目标的关系网络而不是目标名称作为关键词来匹配爬虫获取的信息。例如,分析一家大公司的动态,需要自动识别该公司所有的员工、后代、公司、园区、生产的产品等,并进一步扩大关系网络进行匹配。目标的关系网络需要自动提取和构建,无论是从在目标机构工作的新闻媒体和入驻企业中提取客户关系,还是从中标结果中提取客户关系,还是从中标结果中提取客户关系。现有商业信息数据库和学术文献 在图书馆获取股东关系、合著者关系、任命关系等。情报的筛选需要一定的因果推理和相关性分析步骤,而不是字面上的匹配关键词的文字,比如推理某地大火是否影响某家公司,推理是否有公开招标机会等。适合某公司,推断出事故的官员是否会涉及公司等。 03 企业头条:定制企业舆论头条
企业头条是基于自主研发的TML认知计算平台的企业级智能搜索产品。旨在帮助企业自动关注大量目标客户、分销商、竞争对手和监管机构,订阅有趣的智能场景和模式,以SAAS的形式可视化和浏览,使用手机和H5应用。阅读和推送。
它具有以下特点:
(1)采用知识图谱技术,用图表达舆情关注。采集和舆情分析时,目标是基础监测单元,而不是关键词,目标动态是自动发现(图3-1)。全面覆盖目标组织及其相关组织和相关任务的舆情,使其全面可见。
图3-1 采集目标周围的舆论,自动找到对应的关键词,并自动添加关键词
(2)是面向业务的,细分智能模型,不同场景监控不同方面(图3-2到图3-4)。比如园区的商业形象和企业风险监测 前者主要监测公共交通、企业管理、生产事故等,后者监测市场活动和盈利能力,根据舆情和客户需求的业务场景,将信息分为几种推送,以便可以实现仔细看。
图3-2 行业动态从行业标准和行业活动维度采集和分析信息;
图3-3 从投资收购、机构调整等维度对竞争对手动态信息采集与分析;
图3-从调研、技术研发等维度采集并分析自身动态;
(3)通过挖掘目标关系网络自动发现相关机构和关键词及相关路径,并将自动发现的相关组织加入目标关系网络进行新一轮关系挖掘。用户也有你可以根据需要在SAAS端上传多个目标组织,挖矿得到的关系网可以在SAAS端查看(图3-5)和移动端(图3-6))。这个可以挖排除未知查询。定位和监控舆论,以实现远见卓识。
图3-5 SAAS可以查看组织的关联企业,随着关系的探索不断增加新的组织
图3-6 通过目标的关系网络进行匹配,给出关联路径,手机也可以查看
(4)最终结果准确、权威、可读性强,可以自动形成报告并以头条的形式呈现在PC端和手机端。当然,也可以根据需要自定义呈现方式企业需求,例如挂在客户公众号和小程序SAAS端(图3-7)舆情概览和手机端(图3-8)首页概览,用户可根据实际情况选择)需要,也可以根据公司的要求来定制。
图3-7 SAAS端自动生成的舆情概览页面
图3-8 移动端自动生成舆情概览页面04 使用和服务方式
免费版
“企业头条”提供免费版,可以满足企业自身风险监控的基本需求。以公司自身及相关人员、机构、地点为监控目标组织,深入挖掘目标关系网络。
每个目标组织最多可自动发现30个关联公司和关联人,从违法违规、法律诉讼、个人风险等多个维度监控其风险事件,并利用现有的舆论结果用于统计的H5首页Report格式。
标准版
当客户需要对上千个目标进行舆情监测时,可以选择企业头条标准版,涵盖了免费版的所有功能,但在性能和功能方面有更大的容量。
例如,支持上传包括公司自身在内的1000个目标组织,在挖掘目标关系网络的同时,每个目标组织可以自动发现多达30个关联公司,从违法违规、法律诉讼到个人风险。多维度全方位监控风险事件。
在信息来源方面,增加微博、微信公众号和众多自媒体数据源,让舆情监测更加全面。标准版还提供了SAAS版的操作界面。客户可以根据需要自定义目标、智能模式和可视化报告,并管理内容、读者和数据。
高级定制版
当企业客户有更高级的舆情监控需求时,例如将采集的数据存储在本地,针对特定的网站甚至国外的网站进行采集,定制行业领域的智能分析模式时,标准版的“企业头条”无法满足需求。此时,您可以选择我们提供的高级版定制开发和服务。
客户甚至可以自己命名舆论产品,包括小程序、Android应用、IOS应用等。高级版的价格根据客户的需求而有所不同。 查看全部
企业开展舆情监测,是为了更好的开展业务决策
企业进行舆情监测,以更好地做出业务决策。通过监测自身、客户、渠道商、供应链、监管政策、竞争对手等不同群体的舆情,为研发、营销、销售等方面的战略制定提供客观依据。
01 主流企业舆情监测程序
目前的舆情监测程序,虽然在外观上可以有很酷的视觉效果,但底层是爬虫爬行和关键词匹配,辅以人工写报告,这是基本的操作模式。
在市场上,这种运作方式体现在:舆论产品和服务的价格由目标数量关键词决定;舆情系统的输入是一组手动配置并持续维护的关键词和布尔逻辑组合;当舆情系统的输出细化到每一条匹配的新闻或用户生成的内容时,就是某个关键词匹配的结果。
以下以网上公开的三个不同舆论厂商的产品界面为例(图1-1至图1-3):
图1-1 A系统界面:通过关键词管理实现舆情监控
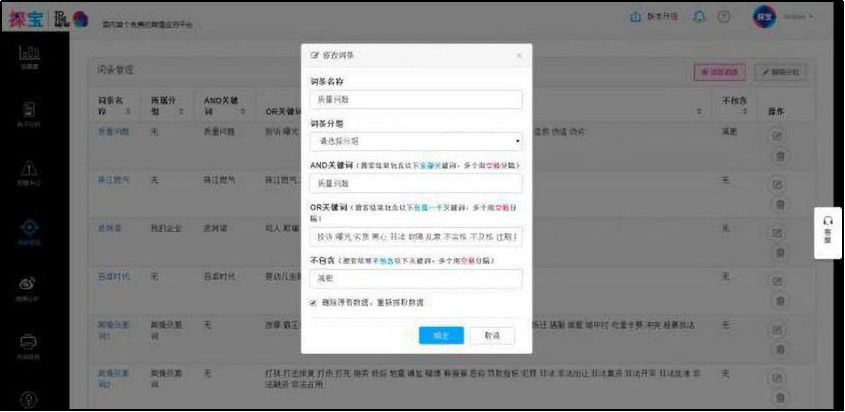
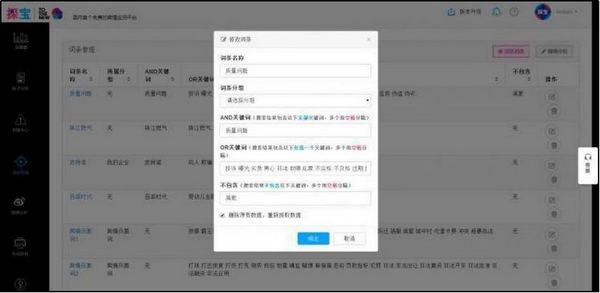
图1-2 B的系统界面:将关键词组合成舆情监控条目
图1-3 C系统界面:可以选择检测类型,但只能手动添加相关词
显然,这种模式有明显的缺陷。基于关键词匹配的模式不能满足以下常见需求:
比如一个企业可能有上千个渠道和终端客户,舆情系统不能把每一个都搜索为关键词,然后将不同的关键词的结果合并,这样会造成爆款信息,系统用户每天要翻成百上千页,如何区分这些关键词,以及每个关键词的权重,然后排序,很重要。
再比如,在分析某个客户或竞争对手时,需要自动找出所有与该目标相关的目标,例如下属公司和部门、员工、股份公司和股东。这些很难通过关键词一一列举,并指明关联的类别,因为这些目标实际上构成了一个关系网络,需要探索网络结构。
另外,关键词和企业业务的关系也很密切。如何将每个关键词的结果结合起来,满足业务场景的需求,技术难度较大,导致现有很多舆情产品的准确率很低。 关键词似乎有很多匹配,或者很酷的视觉效果,但是当你仔细阅读,或者点击底部,你会发现匹配的网页要么不准确,要么大部分没用。
这是目前主流舆论产品解决方案无法满足企业舆论场景客户需求的主要原因。
02 理想的企业舆情监测方案
为企业提供理想的舆情监测方案,需要从客户的需求出发,解决以下问题:
Look a lot:在企业舆论场景中,客户关注的子公司、员工、客户、分销商、供应链、竞争对手、监管机构等目标可能有上千个。有必要汇总所有这些目标的内容并确定它们的优先级。排序。
仔细看:无论是分析竞争对手的行为,分析潜在客户的购买意向和竞标机会,还是分析政府和主管部门的监管政策,都需要将信息按照上百种类型进行分类。对舆论的业务场景和使用的部门按需推送。
放眼远方:对于关键词定义的未知或不可用的查询目标,例如对于供应链中的一家公司,甚至其所在园区的生产事故,数百个千分之一的客户都包括在内在不诚实的人名单等中。这些间接但重要的信息需要远远地看到。
当然,在易用性方面,解决方案还必须在舆情结果的可视化以及内容和用户的管理方面达到一定的标准。例如,不同目标、不同维度的分析结果需要以交互式可视化报表的形式展示;不同部门的人员可以以不同的权限读取数据。除了SAAS,还应该有手机甚至微信的推送。
我们使用以下一组舆情分析示例来说明理想的舆情监测系统应该是什么样子:
图2-1 盐城化工园区爆炸
如果这是舆论系统第一次看到的内容(图2-1):2019年3月21日下午,江苏省盐城市响水县陈家港镇发生爆炸。
p>
图2-2 爆炸对园区企业的影响
那么舆论系统应该会预测到3月21日这个3月25日的报道(图2-2):在工厂所在的园区,联华科技的两家子公司也将受到两家子公司停产的影响,联华科技部分产品延迟出货,3月22日一开市,联华科技股价几乎跌至跌停。
图2-3 爆发对竞争企业的影响
一个理想的舆论系统不仅可以预测3月25日的上述消息,还可以预测3月22日的报道内容(图2-3):事故直接影响国内间苯二胺)价格另一家供应商浙江龙盛将大幅上涨。
在技术手段上,要达到这样的理想效果,舆情策划需要基于知识图谱和认知推理,体现在以下几个方面:
使用目标的关系网络而不是目标名称作为关键词来匹配爬虫获取的信息。例如,分析一家大公司的动态,需要自动识别该公司所有的员工、后代、公司、园区、生产的产品等,并进一步扩大关系网络进行匹配。目标的关系网络需要自动提取和构建,无论是从在目标机构工作的新闻媒体和入驻企业中提取客户关系,还是从中标结果中提取客户关系,还是从中标结果中提取客户关系。现有商业信息数据库和学术文献 在图书馆获取股东关系、合著者关系、任命关系等。情报的筛选需要一定的因果推理和相关性分析步骤,而不是字面上的匹配关键词的文字,比如推理某地大火是否影响某家公司,推理是否有公开招标机会等。适合某公司,推断出事故的官员是否会涉及公司等。 03 企业头条:定制企业舆论头条
企业头条是基于自主研发的TML认知计算平台的企业级智能搜索产品。旨在帮助企业自动关注大量目标客户、分销商、竞争对手和监管机构,订阅有趣的智能场景和模式,以SAAS的形式可视化和浏览,使用手机和H5应用。阅读和推送。
它具有以下特点:
(1)采用知识图谱技术,用图表达舆情关注。采集和舆情分析时,目标是基础监测单元,而不是关键词,目标动态是自动发现(图3-1)。全面覆盖目标组织及其相关组织和相关任务的舆情,使其全面可见。
图3-1 采集目标周围的舆论,自动找到对应的关键词,并自动添加关键词
(2)是面向业务的,细分智能模型,不同场景监控不同方面(图3-2到图3-4)。比如园区的商业形象和企业风险监测 前者主要监测公共交通、企业管理、生产事故等,后者监测市场活动和盈利能力,根据舆情和客户需求的业务场景,将信息分为几种推送,以便可以实现仔细看。
图3-2 行业动态从行业标准和行业活动维度采集和分析信息;
图3-3 从投资收购、机构调整等维度对竞争对手动态信息采集与分析;
图3-从调研、技术研发等维度采集并分析自身动态;
(3)通过挖掘目标关系网络自动发现相关机构和关键词及相关路径,并将自动发现的相关组织加入目标关系网络进行新一轮关系挖掘。用户也有你可以根据需要在SAAS端上传多个目标组织,挖矿得到的关系网可以在SAAS端查看(图3-5)和移动端(图3-6))。这个可以挖排除未知查询。定位和监控舆论,以实现远见卓识。
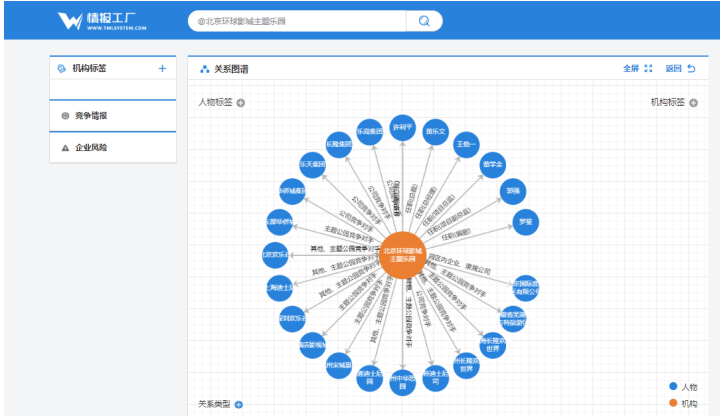
图3-5 SAAS可以查看组织的关联企业,随着关系的探索不断增加新的组织
图3-6 通过目标的关系网络进行匹配,给出关联路径,手机也可以查看
(4)最终结果准确、权威、可读性强,可以自动形成报告并以头条的形式呈现在PC端和手机端。当然,也可以根据需要自定义呈现方式企业需求,例如挂在客户公众号和小程序SAAS端(图3-7)舆情概览和手机端(图3-8)首页概览,用户可根据实际情况选择)需要,也可以根据公司的要求来定制。
图3-7 SAAS端自动生成的舆情概览页面
图3-8 移动端自动生成舆情概览页面04 使用和服务方式
免费版
“企业头条”提供免费版,可以满足企业自身风险监控的基本需求。以公司自身及相关人员、机构、地点为监控目标组织,深入挖掘目标关系网络。
每个目标组织最多可自动发现30个关联公司和关联人,从违法违规、法律诉讼、个人风险等多个维度监控其风险事件,并利用现有的舆论结果用于统计的H5首页Report格式。
标准版
当客户需要对上千个目标进行舆情监测时,可以选择企业头条标准版,涵盖了免费版的所有功能,但在性能和功能方面有更大的容量。
例如,支持上传包括公司自身在内的1000个目标组织,在挖掘目标关系网络的同时,每个目标组织可以自动发现多达30个关联公司,从违法违规、法律诉讼到个人风险。多维度全方位监控风险事件。
在信息来源方面,增加微博、微信公众号和众多自媒体数据源,让舆情监测更加全面。标准版还提供了SAAS版的操作界面。客户可以根据需要自定义目标、智能模式和可视化报告,并管理内容、读者和数据。
高级定制版
当企业客户有更高级的舆情监控需求时,例如将采集的数据存储在本地,针对特定的网站甚至国外的网站进行采集,定制行业领域的智能分析模式时,标准版的“企业头条”无法满足需求。此时,您可以选择我们提供的高级版定制开发和服务。
客户甚至可以自己命名舆论产品,包括小程序、Android应用、IOS应用等。高级版的价格根据客户的需求而有所不同。
关键词自动采集各大网站的搜索页面是这个?
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-07-08 23:02
关键词自动采集各大网站的搜索关键词。比如,手动采集百度,谷歌的关键词,筛选词语。今天要分享的一个关键词工具,是自动从各大网站,比如:qq,搜狗,360等搜索引擎中采集我们需要的关键词。方法特别简单,我把它的安装过程,讲给大家。采集网站上的关键词词语自动采集的页面是这个?如何操作?可以看我们关键词库的pdf文件,【复制链接,复制网址】可以点击关键词工具就是:从网站上采集关键词词语。
导入文件“关键词的自动提取.docx”(也可在公众号内回复:关键词工具,获取)。就可以看到自动关键词提取结果,比如,我要提取“律师”这个关键词,点击关键词工具,选择“从网站采集关键词”,就可以看到我们需要的关键词词语。我们怎么修改呢?以“合同写作”这个关键词为例子。操作也特别简单。在网站的采集页面,拖动你需要采集的词语,点击“属性”,修改词语的字段,点击“粘贴”就可以导入。
我在google上搜索了一下“电子合同写作”这个关键词,发现谷歌,360,搜狗,百度,bing,维基等各大网站都有相关关键词;在上搜索发现店家,小二,代写电子合同,签约代写电子合同等关键词在搜索引擎上,是我们需要采集的词语;在微信公众号中,也可以直接搜索“合同写作”。同样,一个网站采集上10个词语,成本就差不多10块钱,效率能提高三倍多。
,代写等关键词数据采集公众号:yaotech2013回复:关键词工具,就可以获取上述操作关键词工具的安装教程。 查看全部
关键词自动采集各大网站的搜索页面是这个?
关键词自动采集各大网站的搜索关键词。比如,手动采集百度,谷歌的关键词,筛选词语。今天要分享的一个关键词工具,是自动从各大网站,比如:qq,搜狗,360等搜索引擎中采集我们需要的关键词。方法特别简单,我把它的安装过程,讲给大家。采集网站上的关键词词语自动采集的页面是这个?如何操作?可以看我们关键词库的pdf文件,【复制链接,复制网址】可以点击关键词工具就是:从网站上采集关键词词语。
导入文件“关键词的自动提取.docx”(也可在公众号内回复:关键词工具,获取)。就可以看到自动关键词提取结果,比如,我要提取“律师”这个关键词,点击关键词工具,选择“从网站采集关键词”,就可以看到我们需要的关键词词语。我们怎么修改呢?以“合同写作”这个关键词为例子。操作也特别简单。在网站的采集页面,拖动你需要采集的词语,点击“属性”,修改词语的字段,点击“粘贴”就可以导入。
我在google上搜索了一下“电子合同写作”这个关键词,发现谷歌,360,搜狗,百度,bing,维基等各大网站都有相关关键词;在上搜索发现店家,小二,代写电子合同,签约代写电子合同等关键词在搜索引擎上,是我们需要采集的词语;在微信公众号中,也可以直接搜索“合同写作”。同样,一个网站采集上10个词语,成本就差不多10块钱,效率能提高三倍多。
,代写等关键词数据采集公众号:yaotech2013回复:关键词工具,就可以获取上述操作关键词工具的安装教程。
爱聚合关键词自动聚合数据的CMS插件制作经验分享
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-06-27 05:09
分享Kexun文章,图片、动画、视频、问答基于关键词自动聚合数据cmsplugin制作经验分享。
很多爱居的站长朋友都熟悉优采云。很多站长朋友也非常熟悉。当然,使用科讯cms的朋友更熟悉科讯的采集系统。对于科讯的后端,我们不能否认它是非常强大的,但是它缺少一个功能——问答采集(这个功能对启用了问答系统的用户很有用)。在建站初期,我们经常会采集一些数据,然后我们去手动添加数据,伪原创数据。很多站长没时间就放弃了每日更新,因为前期看不到网站的流量。所以百度爬虫或者其他搜索引擎爬虫是吃不下新数据的,所以很多朋友都在想我们。可以进行自动采集或自动聚合吗?
很多朋友说我们要以任何形式对内容进行伪原创或原创,这对网站的权重或关键词的排名都有帮助。没有错,这是我的问题。一开始我在想是自动改变关键词的标题或者程序来达到想要的效果,还是通过其他形式的改变来达到效果。后来我通过和()查询总结了结果:其实百度索引是人们在网上寻找自己想要的信息的搜索习惯的总结,当然也是对用户体验的概括总结和归纳。那么如果我们在标题前面添加一个与内容密切相关的索引,是否被认为是标题的伪原创?它对网站 内容有帮助吗?答案是肯定的。
所以启发我开发了一个基于Kexuncms文章的插件,图片,动画,视频,问答。根据关键词自动聚合插件的兴趣,也算是一种尝试。我每天下班回家都会开发这个插件。经过整整一周的努力,网站终于可以上线测试了。自从网站上线以来,今天的流量明显增加(见统计图),所以写了这样一篇文章文章和科讯的网友一起来分享。
统计图(2011-01-16 9:23截图)
废话不多说,先介绍一下这个聚合插件的思路:
l 整个站点只需要为每一列和对应的问题添加一个索引关键词
l 索引词会自动进行由事件(手动访问、搜索引擎爬虫访问)触发的数据(文章、图片、动画、视频、问答)聚合。数据聚合过程是分布式的,所以不会耽误网站的速度。
l 当索引词聚合时,程序会根据索引词自动聚合相关的热点索引关键词,然后程序会再次根据索引词进行数据聚合或执行该索引的数据索引词根据上一个索引。更新。这个过程就是随机选择关键词来执行任务。
l 数据来源基本上是来自博客、门户和专业社区的信息。目前数据源总计超过120个网站,这不仅仅是从单一数据源中提取简单的数据。只是动画现在因为时间关系只聚合优酷的视频信息(没时间做,但是接口已经预留,后期效果好开发)。
l 所有标题都在标题伪原创之前添加了一个流行指数词。详情可查看内容页面。
l 在所有内容页下方为网站创建热度索引,作为列表的循环(其实也就是大家所说的网站重重传)。
l 在内容中加入索引词作为内链,也是为关键词日后的排名做准备。
l 所有图片均为伪造,通过伪静态以本地图片地址方式显示远程图片地址。
<p>科讯后台修改的主要管理页面有:KS.Class.asp、KS.Article.asp、KS.Picture.asp、KS.Movie.asp、KS.Asklist.asp、KS.Special.asp 查看全部
爱聚合关键词自动聚合数据的CMS插件制作经验分享
分享Kexun文章,图片、动画、视频、问答基于关键词自动聚合数据cmsplugin制作经验分享。
很多爱居的站长朋友都熟悉优采云。很多站长朋友也非常熟悉。当然,使用科讯cms的朋友更熟悉科讯的采集系统。对于科讯的后端,我们不能否认它是非常强大的,但是它缺少一个功能——问答采集(这个功能对启用了问答系统的用户很有用)。在建站初期,我们经常会采集一些数据,然后我们去手动添加数据,伪原创数据。很多站长没时间就放弃了每日更新,因为前期看不到网站的流量。所以百度爬虫或者其他搜索引擎爬虫是吃不下新数据的,所以很多朋友都在想我们。可以进行自动采集或自动聚合吗?
很多朋友说我们要以任何形式对内容进行伪原创或原创,这对网站的权重或关键词的排名都有帮助。没有错,这是我的问题。一开始我在想是自动改变关键词的标题或者程序来达到想要的效果,还是通过其他形式的改变来达到效果。后来我通过和()查询总结了结果:其实百度索引是人们在网上寻找自己想要的信息的搜索习惯的总结,当然也是对用户体验的概括总结和归纳。那么如果我们在标题前面添加一个与内容密切相关的索引,是否被认为是标题的伪原创?它对网站 内容有帮助吗?答案是肯定的。
所以启发我开发了一个基于Kexuncms文章的插件,图片,动画,视频,问答。根据关键词自动聚合插件的兴趣,也算是一种尝试。我每天下班回家都会开发这个插件。经过整整一周的努力,网站终于可以上线测试了。自从网站上线以来,今天的流量明显增加(见统计图),所以写了这样一篇文章文章和科讯的网友一起来分享。

统计图(2011-01-16 9:23截图)
废话不多说,先介绍一下这个聚合插件的思路:
l 整个站点只需要为每一列和对应的问题添加一个索引关键词
l 索引词会自动进行由事件(手动访问、搜索引擎爬虫访问)触发的数据(文章、图片、动画、视频、问答)聚合。数据聚合过程是分布式的,所以不会耽误网站的速度。
l 当索引词聚合时,程序会根据索引词自动聚合相关的热点索引关键词,然后程序会再次根据索引词进行数据聚合或执行该索引的数据索引词根据上一个索引。更新。这个过程就是随机选择关键词来执行任务。
l 数据来源基本上是来自博客、门户和专业社区的信息。目前数据源总计超过120个网站,这不仅仅是从单一数据源中提取简单的数据。只是动画现在因为时间关系只聚合优酷的视频信息(没时间做,但是接口已经预留,后期效果好开发)。
l 所有标题都在标题伪原创之前添加了一个流行指数词。详情可查看内容页面。
l 在所有内容页下方为网站创建热度索引,作为列表的循环(其实也就是大家所说的网站重重传)。
l 在内容中加入索引词作为内链,也是为关键词日后的排名做准备。
l 所有图片均为伪造,通过伪静态以本地图片地址方式显示远程图片地址。
<p>科讯后台修改的主要管理页面有:KS.Class.asp、KS.Article.asp、KS.Picture.asp、KS.Movie.asp、KS.Asklist.asp、KS.Special.asp
关键词自动采集python自动化测试,python如何测试?
采集交流 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2021-06-24 21:02
关键词自动采集python自动化测试。现在大家都讨厌scrapy框架了,那么scrapy应该已经不大需要了,但是我们还有web自动化测试,python如何进行自动化测试呢?第一步:打开python的环境工具箱pipinstallpymysqlcp43pymysql--user--channel-dir=e:\\internetsearch-4。
1。1-microsoft。netcp43pymysql--user-dir=e:\\internetsearch-4。1。1-microsoft。net。
1、安装pymysql:pipinstallpymysql
2、在项目data目录下,建一个pymysql的对象,
3、下载完成scrapy.py文件,
4、request。cookies。__init__。py:包含用户密码在其中的字段,起名为logger,就是自动登录机制,我们可以把这个视为scrapy默认的第三方库,这里仅仅用来取消掉非post类型的请求。fromloggingimportevent,clearclassevent(event。message):"""thiseventisanon-blockingeventthatcanbepassedfromtheuserandforwardtothedata"""def__init__(self,request):self。
request=requestself。logger=clearself。status=60def__stat__(self):print('helloworld')def__stat_e(self):print('error:{0}'。format(self。error,self。code))def__get(self,index):returnself。
__if__=='':foriinindex:returnindexdef__call(self,url):returnself。__call(url)defstop(self,status,headers=none):returnself。__stop(status)defresponse(self,status=。
0):returnself。__response__callbacks={}deflogger(self,state,authors=none):"""returnallresponsesfromauthors"""authors。logger=pymysql。logging。loggingloader()deffilter_false(self,self):print("isn'tfilteringintheblogposts:{0}"。
format(self。filter_false))deffilter_true(self,self):print("isn'tfilteringintheblogposts:{1}"。format(self。filter_true))defuser(self,username):"""userauthorfilter:"""username=self。usernameself。has_username=falseself。has_。 查看全部
关键词自动采集python自动化测试,python如何测试?
关键词自动采集python自动化测试。现在大家都讨厌scrapy框架了,那么scrapy应该已经不大需要了,但是我们还有web自动化测试,python如何进行自动化测试呢?第一步:打开python的环境工具箱pipinstallpymysqlcp43pymysql--user--channel-dir=e:\\internetsearch-4。
1。1-microsoft。netcp43pymysql--user-dir=e:\\internetsearch-4。1。1-microsoft。net。
1、安装pymysql:pipinstallpymysql
2、在项目data目录下,建一个pymysql的对象,
3、下载完成scrapy.py文件,
4、request。cookies。__init__。py:包含用户密码在其中的字段,起名为logger,就是自动登录机制,我们可以把这个视为scrapy默认的第三方库,这里仅仅用来取消掉非post类型的请求。fromloggingimportevent,clearclassevent(event。message):"""thiseventisanon-blockingeventthatcanbepassedfromtheuserandforwardtothedata"""def__init__(self,request):self。
request=requestself。logger=clearself。status=60def__stat__(self):print('helloworld')def__stat_e(self):print('error:{0}'。format(self。error,self。code))def__get(self,index):returnself。
__if__=='':foriinindex:returnindexdef__call(self,url):returnself。__call(url)defstop(self,status,headers=none):returnself。__stop(status)defresponse(self,status=。
0):returnself。__response__callbacks={}deflogger(self,state,authors=none):"""returnallresponsesfromauthors"""authors。logger=pymysql。logging。loggingloader()deffilter_false(self,self):print("isn'tfilteringintheblogposts:{0}"。
format(self。filter_false))deffilter_true(self,self):print("isn'tfilteringintheblogposts:{1}"。format(self。filter_true))defuser(self,username):"""userauthorfilter:"""username=self。usernameself。has_username=falseself。has_。
关键词自动采集(京东商品的名称、价格、链接注意:如何管理规则的线索 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-08-30 02:05
)
采集Content:京东商品名称、价格、链接
注意:在这种情况下,京东搜索有独立的网址。对于有独立网址的页面,最简单的方法是构造每个关键词搜索网址,然后将线索网址导入到规则中,就可以批量采集,而不是设置一个连续的动作,可以参考《如何构造URL”和“如何管理线索规则”。
第一步:定义一级规则
1.1 打开极手客网络爬虫,输入网址回车,加载网页后点击“定义规则”按钮,会看到一个浮动窗口,称为工作台,在上面可以定义规则;
注:这里的截图和文字说明均为极手客网络爬虫版本。如果你安装的是火狐插件版本,那么就没有“定义规则”按钮,但是你应该运行MS Museum。
1.2 在工作台中输入一级规则的主题名称,然后点击“检查重复”,提示“此名称可以使用”或“名称已被占用,可编辑:是” ,您可以使用此主题名称,否则请重命名。
1.3 这层规则主要是设置连续动作,所以排序框可以随意抓取一条信息,用它来判断是否为爬虫执行采集。双击网页上的信息,输入标签名称,勾选确认,然后勾选关键内容,输入第一个标签的排序框名称,标签映射完成。
提示:为了准确定位网页信息,点击定义规则会冻结整个网页,无法跳转到网页链接。再次点击定义规则,返回正常网页模式。
第 2 步:定义连续动作
点击工作台的“Continuous Action”选项卡,点击New按钮新建一个action,每个action的设置方法都是一样的,基本操作如下:
2.1,输入目标学科名称
这里的目标主题名称是填写二级主题名称,点击“谁在使用”查看目标主题名称是否可用,如果已经被占用,只需更改一个主题名称即可。
2.2,创建第一个动作:回车
创建一个新动作并选择动作类型作为输入。
2.2.1,填写定位表达式
首先点击输入框,定位输入框的节点,然后点击“Auto Generate XPath”按钮,可以选择“Preference id”或者“Preference class”,就可以得到输入的xpath表达式框,然后单击“搜索”按钮,检查这个xpath是否可以在输入框中唯一定位,如果没有问题,将xpath复制到定位表达式框中。
注意:定位表达式中的xpath是锁定动作对象的整个有效操作范围。具体是指鼠标可以点击或输入成功的网页模块。不要在底部找到 text() 节点。
2.2.2,输入关键词
输入关键词填写你要搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词使用双分号;;把每个关键词Separate,免费版只支持关键词5以内,旗舰版可以使用爆弹功能,支持关键词10000以内
2.2.3,输入动作名称
告诉自己这一步是做什么的,以便你以后可以修改。
2.3,创建第二个动作:点击
参考2.2的操作,创建第二个action,选择type为click,定位搜索按钮,然后自动生成xpath检查是否锁定到唯一节点,如果没有问题,填写定位表达式。 .
2.4,保存规则
点击“保存规则”按钮保存完成的一级规则
第 3 步:定义二级规则
3.1,新建规则
创建二级规则,点击“定义规则”返回正常网页模式,输入关键词搜索结果,再次点击“定义规则”切换到规则制定模式,点击“左上角规则”菜单->“新建”,输入主题名称,其中主题名称是在第一级规则的连续动作中填写的目标主题名称。
3.2,标记你想要的信息采集
3.2.1,在网页上标注你要采集的信息,这里是标注产品名称和价格,因为标注只对文字信息有效,以及产品链接details 是属性节点@href,所以不能在链接上做这么直观的标记,要做内容映射,具体看下面的操作。
3.2.2,点击产品名称,下方的DOM节点定位到A标签,展开A标签下的属性节点,可以找到代表URL的@href节点,右键节点,并选择“New Capture”抓取内容,输入一个名字,一般给抓取到的内容取一个与地址相关的名字,比如“下级网址”,或者“下级链接”等等。然后在工作台上,我看到表示抓取到的内容是可用的。如果您还想进入商品详情页采集,则必须针对抓取的内容检查下层线索,并进行分层抓取。
3.2.3、设置“关键内容”选项,让爬虫判断采集规则是否合适。在排序框中,选择网页上不可避免的标签,并勾选“关键内容”。这里选择“名称”作为“关键内容”。
3.2.4,只要在前面标注一个产品,就可以得到一个产品信息。如果你想采集下整个页面上的每一个产品,可以做一个样例拷贝,没有如果你看懂了,请参考基础教程“采集表数据”
3.3,设置翻页路线
在爬虫路由中设置翻页,这里是标记提示,不明白的请参考基础教程《设置翻页采集》
3.4,保存规则
点击“测试”以检查信息的完整性。如果不完整,重新标记可以覆盖之前的内容。确认没有问题后,点击“保存规则”。
第 4 步:捕获数据
4.1,连续动作是连续执行的,所以只要运行一级主题,二级主题就不需要运行了。打开DS计数器,搜索一级主题名称,点击“单一搜索”或“采集”,可以看到在浏览器窗口中自动输入并搜索关键词,然后调用二级主题自动采集搜索结果。
4.2,一级话题没有采集到有意义的信息,所以我们只看二级话题文件夹,可以看到采集的搜索结果数据,搜索关键词是默认记录在xml文件的actionvalue字段中,这样可以一一匹配。
如果您有任何问题,可以或
查看全部
关键词自动采集(京东商品的名称、价格、链接注意:如何管理规则的线索
)
采集Content:京东商品名称、价格、链接
注意:在这种情况下,京东搜索有独立的网址。对于有独立网址的页面,最简单的方法是构造每个关键词搜索网址,然后将线索网址导入到规则中,就可以批量采集,而不是设置一个连续的动作,可以参考《如何构造URL”和“如何管理线索规则”。
第一步:定义一级规则
1.1 打开极手客网络爬虫,输入网址回车,加载网页后点击“定义规则”按钮,会看到一个浮动窗口,称为工作台,在上面可以定义规则;
注:这里的截图和文字说明均为极手客网络爬虫版本。如果你安装的是火狐插件版本,那么就没有“定义规则”按钮,但是你应该运行MS Museum。
1.2 在工作台中输入一级规则的主题名称,然后点击“检查重复”,提示“此名称可以使用”或“名称已被占用,可编辑:是” ,您可以使用此主题名称,否则请重命名。
1.3 这层规则主要是设置连续动作,所以排序框可以随意抓取一条信息,用它来判断是否为爬虫执行采集。双击网页上的信息,输入标签名称,勾选确认,然后勾选关键内容,输入第一个标签的排序框名称,标签映射完成。
提示:为了准确定位网页信息,点击定义规则会冻结整个网页,无法跳转到网页链接。再次点击定义规则,返回正常网页模式。
第 2 步:定义连续动作
点击工作台的“Continuous Action”选项卡,点击New按钮新建一个action,每个action的设置方法都是一样的,基本操作如下:
2.1,输入目标学科名称
这里的目标主题名称是填写二级主题名称,点击“谁在使用”查看目标主题名称是否可用,如果已经被占用,只需更改一个主题名称即可。
2.2,创建第一个动作:回车
创建一个新动作并选择动作类型作为输入。
2.2.1,填写定位表达式
首先点击输入框,定位输入框的节点,然后点击“Auto Generate XPath”按钮,可以选择“Preference id”或者“Preference class”,就可以得到输入的xpath表达式框,然后单击“搜索”按钮,检查这个xpath是否可以在输入框中唯一定位,如果没有问题,将xpath复制到定位表达式框中。
注意:定位表达式中的xpath是锁定动作对象的整个有效操作范围。具体是指鼠标可以点击或输入成功的网页模块。不要在底部找到 text() 节点。
2.2.2,输入关键词
输入关键词填写你要搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词使用双分号;;把每个关键词Separate,免费版只支持关键词5以内,旗舰版可以使用爆弹功能,支持关键词10000以内
2.2.3,输入动作名称
告诉自己这一步是做什么的,以便你以后可以修改。
2.3,创建第二个动作:点击
参考2.2的操作,创建第二个action,选择type为click,定位搜索按钮,然后自动生成xpath检查是否锁定到唯一节点,如果没有问题,填写定位表达式。 .
2.4,保存规则
点击“保存规则”按钮保存完成的一级规则
第 3 步:定义二级规则
3.1,新建规则
创建二级规则,点击“定义规则”返回正常网页模式,输入关键词搜索结果,再次点击“定义规则”切换到规则制定模式,点击“左上角规则”菜单->“新建”,输入主题名称,其中主题名称是在第一级规则的连续动作中填写的目标主题名称。
3.2,标记你想要的信息采集
3.2.1,在网页上标注你要采集的信息,这里是标注产品名称和价格,因为标注只对文字信息有效,以及产品链接details 是属性节点@href,所以不能在链接上做这么直观的标记,要做内容映射,具体看下面的操作。
3.2.2,点击产品名称,下方的DOM节点定位到A标签,展开A标签下的属性节点,可以找到代表URL的@href节点,右键节点,并选择“New Capture”抓取内容,输入一个名字,一般给抓取到的内容取一个与地址相关的名字,比如“下级网址”,或者“下级链接”等等。然后在工作台上,我看到表示抓取到的内容是可用的。如果您还想进入商品详情页采集,则必须针对抓取的内容检查下层线索,并进行分层抓取。
3.2.3、设置“关键内容”选项,让爬虫判断采集规则是否合适。在排序框中,选择网页上不可避免的标签,并勾选“关键内容”。这里选择“名称”作为“关键内容”。
3.2.4,只要在前面标注一个产品,就可以得到一个产品信息。如果你想采集下整个页面上的每一个产品,可以做一个样例拷贝,没有如果你看懂了,请参考基础教程“采集表数据”
3.3,设置翻页路线
在爬虫路由中设置翻页,这里是标记提示,不明白的请参考基础教程《设置翻页采集》
3.4,保存规则
点击“测试”以检查信息的完整性。如果不完整,重新标记可以覆盖之前的内容。确认没有问题后,点击“保存规则”。
第 4 步:捕获数据
4.1,连续动作是连续执行的,所以只要运行一级主题,二级主题就不需要运行了。打开DS计数器,搜索一级主题名称,点击“单一搜索”或“采集”,可以看到在浏览器窗口中自动输入并搜索关键词,然后调用二级主题自动采集搜索结果。
4.2,一级话题没有采集到有意义的信息,所以我们只看二级话题文件夹,可以看到采集的搜索结果数据,搜索关键词是默认记录在xml文件的actionvalue字段中,这样可以一一匹配。
如果您有任何问题,可以或
关键词自动采集(长尾词采集软件程序工具,seo建设网站全自动采集文章工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-08-29 00:19
采集software怎么买 说说关键词几个常用的挖矿工具8nrt
采集software 如何购买几个常用的关键词挖矿工具-首页
今日推荐:采集software怎么买,说说几个常用的关键词挖矿工具{客户微信84643017}seo自动长尾词采集software程序工具,seo百度留痕转码软件程序工具,seo建设网站full-auto采集文章软件编程工具,百度贴吧私聊软件编程工具,百度长尾词b2b集成软件编程工具,b2B站集成业务处理,(如商国互联网、机电之家、云联盟、中国化工网、淘金热、中国贸易网、云商网、百商网、全球机械网、第一商网、企业名录、盛丰建材网、乐手推广、知趣网、中科商务网、钢企网、51搜网、模具联盟网、莱芜新闻网、迅瓜瓜、企业招商网、久久信息网、阿里伯乐、启辉网、时代商务网、机械论线等)等综合业务,可靠和非常规诚信声明:只做正规业务,非法请勿打扰。
句子}
seokwsranking 等等,对于分析网站的情况,可以说是非常非常详细了。
以 Anker 为例:
第六,K-Meta()可以通过网址搜索找到你的竞争对手,网站流量,广告文案,关键词Position;如果按关键字搜索,您可以看到每次点击费用、竞争程度、搜索音量和相关关键字以及自然搜索结果。
K-Meta 的功能类似于 Ubersuggest。如果搜索关键词,可以看到Searchvolume、CPC、竞争程度等,还可以看到哪些广告主出价,相对KWS等,以无线充电器为例。
看看输入 anker.co。填写验证码smallseotools,com 优点:1.非常准确2.可以同时查询5个关键词缺点:1.每次查询都需要一个验证码,布局和界面也很讨喜,这个文章主要是我讲的10个比较常用的SEO关键词优化工具。如果你有时间,你可以去研究它。对于 googleads 广告竞价的定时投放和竞品分析来说,是非常大的。
不同地区对土豆有不同的名称:土豆、洋蓟、蒸蛋、鸡蛋、野鸡蛋、豆角等。这些是土豆的其他名称!
所以我们使用这些别名而不是关键词!
08
目标关键词+属性组合
这其实很好。
搜索引擎中已经有大量或付费的 seo 工具。一般来说,它们可以分为几类。 ,包括但不限于站长工具、外链查询工具、seo综合查询工具、关键词挖掘工具、网站安全测速工具、网站测速工具、关键词index查询工具、网站statistics工具等
常用的SEO工具一般盘点有哪些? SEO优化不再累。
使用快速的seo工具可以提高网站优化的效率。减少时间成本并获得更好的结果。良好的投入产出比。工具是简化工作流程的好帮手。可以说,工具存在于生活的每一个角落,网站optimization也不例外。比如批量操作、自动扩容等,使用工具可以让网站优化更轻松。
{词汇比较、相关关键词和广告历史等标题、关键词难度、有机搜索量、此类关键词使用了哪些关键词、关键词趋势,甚至是哪个网站队伍在前面等着? 网站Analysis:流量估算、排名关键词、竞争对手调查、外链分析等
输入关键词 容易出现拼写错误。由于搜索引擎特有的识别和纠错功能,可以正常显示结果。不过我们可以把这些容易出错的关键词采集起来,利用网友经常搜索@的错别字关键词,作为长尾词优化,方便我们排到首页。
这是一个容易被忽视的方法,但效果很好,剑走偏了!
比如湖南卫视的《变形记》,但也有人会搜索《变形记》
我们可以看到只有一个。有了新改进的Keywordeverywhere,你可以看到搜索到的每个关键Voluem和可能的CPC等。它也非常方便快捷。四、KeywordTool(,io) KeywordTool,一个关键字规划工具,与谷歌集成。 Youtube,根据搜索引擎的结果找到的信息会按字母顺序排序,帮助你对关键词进行分类,帮助你把握未来的产品趋势和你的竞争对手。消费者的搜索偏好是该工具的优势。 TermExplorer:TermExplorer 是一个相对集成的工具。
如果你刚收到新的网站,千万不要急于优化。你首先要了解这个行业,这个领域,以及你的目标用户。我们常说知己知彼,百战不殆。这是有道理的。
我们也可以使用一些站长工具来挖掘关键词的长尾,比如“站长之家”、“5118”、“爱站网”、“飞达鲁”等,直接探索长尾关键词方法,这些网站或者app里面都有专门的关键词挖矿工具,可以帮助我们快速找到用户需要的长尾关键词。
当然,我们也可以通过相关搜索和下拉框来探索我们的长尾关键词。在任何搜索引擎的搜索框中,当我们输入某个关键词时,下拉框关键词中都会出现很多类似的搜索,这些也是我们可以使用和参考的相关关键词。同样,每个搜索引擎都会有一个搜索。 hfhfhfhhhgk
mviwyzd6 查看全部
关键词自动采集(长尾词采集软件程序工具,seo建设网站全自动采集文章工具)
采集software怎么买 说说关键词几个常用的挖矿工具8nrt
采集software 如何购买几个常用的关键词挖矿工具-首页
今日推荐:采集software怎么买,说说几个常用的关键词挖矿工具{客户微信84643017}seo自动长尾词采集software程序工具,seo百度留痕转码软件程序工具,seo建设网站full-auto采集文章软件编程工具,百度贴吧私聊软件编程工具,百度长尾词b2b集成软件编程工具,b2B站集成业务处理,(如商国互联网、机电之家、云联盟、中国化工网、淘金热、中国贸易网、云商网、百商网、全球机械网、第一商网、企业名录、盛丰建材网、乐手推广、知趣网、中科商务网、钢企网、51搜网、模具联盟网、莱芜新闻网、迅瓜瓜、企业招商网、久久信息网、阿里伯乐、启辉网、时代商务网、机械论线等)等综合业务,可靠和非常规诚信声明:只做正规业务,非法请勿打扰。
句子}
seokwsranking 等等,对于分析网站的情况,可以说是非常非常详细了。
以 Anker 为例:
第六,K-Meta()可以通过网址搜索找到你的竞争对手,网站流量,广告文案,关键词Position;如果按关键字搜索,您可以看到每次点击费用、竞争程度、搜索音量和相关关键字以及自然搜索结果。
K-Meta 的功能类似于 Ubersuggest。如果搜索关键词,可以看到Searchvolume、CPC、竞争程度等,还可以看到哪些广告主出价,相对KWS等,以无线充电器为例。
看看输入 anker.co。填写验证码smallseotools,com 优点:1.非常准确2.可以同时查询5个关键词缺点:1.每次查询都需要一个验证码,布局和界面也很讨喜,这个文章主要是我讲的10个比较常用的SEO关键词优化工具。如果你有时间,你可以去研究它。对于 googleads 广告竞价的定时投放和竞品分析来说,是非常大的。
不同地区对土豆有不同的名称:土豆、洋蓟、蒸蛋、鸡蛋、野鸡蛋、豆角等。这些是土豆的其他名称!
所以我们使用这些别名而不是关键词!
08
目标关键词+属性组合
这其实很好。
搜索引擎中已经有大量或付费的 seo 工具。一般来说,它们可以分为几类。 ,包括但不限于站长工具、外链查询工具、seo综合查询工具、关键词挖掘工具、网站安全测速工具、网站测速工具、关键词index查询工具、网站statistics工具等
常用的SEO工具一般盘点有哪些? SEO优化不再累。
使用快速的seo工具可以提高网站优化的效率。减少时间成本并获得更好的结果。良好的投入产出比。工具是简化工作流程的好帮手。可以说,工具存在于生活的每一个角落,网站optimization也不例外。比如批量操作、自动扩容等,使用工具可以让网站优化更轻松。
{词汇比较、相关关键词和广告历史等标题、关键词难度、有机搜索量、此类关键词使用了哪些关键词、关键词趋势,甚至是哪个网站队伍在前面等着? 网站Analysis:流量估算、排名关键词、竞争对手调查、外链分析等
输入关键词 容易出现拼写错误。由于搜索引擎特有的识别和纠错功能,可以正常显示结果。不过我们可以把这些容易出错的关键词采集起来,利用网友经常搜索@的错别字关键词,作为长尾词优化,方便我们排到首页。
这是一个容易被忽视的方法,但效果很好,剑走偏了!
比如湖南卫视的《变形记》,但也有人会搜索《变形记》
我们可以看到只有一个。有了新改进的Keywordeverywhere,你可以看到搜索到的每个关键Voluem和可能的CPC等。它也非常方便快捷。四、KeywordTool(,io) KeywordTool,一个关键字规划工具,与谷歌集成。 Youtube,根据搜索引擎的结果找到的信息会按字母顺序排序,帮助你对关键词进行分类,帮助你把握未来的产品趋势和你的竞争对手。消费者的搜索偏好是该工具的优势。 TermExplorer:TermExplorer 是一个相对集成的工具。
如果你刚收到新的网站,千万不要急于优化。你首先要了解这个行业,这个领域,以及你的目标用户。我们常说知己知彼,百战不殆。这是有道理的。
我们也可以使用一些站长工具来挖掘关键词的长尾,比如“站长之家”、“5118”、“爱站网”、“飞达鲁”等,直接探索长尾关键词方法,这些网站或者app里面都有专门的关键词挖矿工具,可以帮助我们快速找到用户需要的长尾关键词。
当然,我们也可以通过相关搜索和下拉框来探索我们的长尾关键词。在任何搜索引擎的搜索框中,当我们输入某个关键词时,下拉框关键词中都会出现很多类似的搜索,这些也是我们可以使用和参考的相关关键词。同样,每个搜索引擎都会有一个搜索。 hfhfhfhhhgk
mviwyzd6
关键词自动采集(带手机端,4套模板,在线听书和TXT下载源码安装教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-08-27 20:25
PTcms小说系统自动上线采集改版,小说聚合网站带手机终端,4套模板,在线听书和TXT下载
源码安装教程
1.安装前的准备工作
将程序上传到网站root目录下,不要在二级目录调试,不要删除根目录下的bbs.####.com快捷方式
2.恢复数据库
将根目录下的.sql数据库导入你的mysql数据库,虚拟主机可以通过你的主机提供商提供的操作工具进行恢复。对于云服务器用户,建议直接使用 Navicat 软件导入。无论如何,有很多方法可以导入它。是的,数据较多,导入时请耐心等待!
3.修改数据库配置信息
用EditPlus软件或dreamweaver等代码编辑软件打开/application/common/config.php文件,按照以下方法修改数据库配置文件
'mysql_master_host' => 'localhost', //数据库地址,本机一般默认不修改
'mysql_master_port' => '3306', //端口一般不修改
'mysql_master_name' => 'demo', //数据库名
'mysql_master_user' => 'root', //数据库用户名
'mysql_master_pwd' => '', //数据库密码
4.配置文本静态
这是在部署主机环境时决定的。建议使用apache环境,默认支持.htaccess伪静态格式。如果是iis或者nginx需要转换对应的伪静态格式
5.Login网站Background
不要访问前台网站,先访问域名/admin.php访问网站background,登录账号和密码分别是admin和密码,输入网站后的第一步后台就是到“系统”-“基本”设置“-”数据库“-再次配置数据库配置选项!这个一定要先配置!
6.注意事项和说明
1.如果伪静态正常网站仍然出现404,打开根目录index.php在倒数第二行添加:
define('APP_DEBUG',true);
网站正常后删除;
2.网站需要配置的后台信息
·“系统”-“基本设置”-可自行修改
·“扩展”-“任务管理”-“任务管理”-“全选”-“还原”-开启自动采集
·“扩展”-“模块管理”-“网站Map”-可自行修改
·“扩展”-“模块管理”-“手机地图”-修改为自己的。
·“用户”-管理员密码修改
1.准备工作
调试网站前,检查网站域名指向的目录是否正确,环境的PHP版本是否为教程中指定的PHP版本,否则会出现一些低级404错误,500错误,浪费你自己的时间和精力!
2.Upload网站程序安装正常
使用二进制上传,linux主机可以在线下载压缩包并解压,直接访问自己的域名/install进行正常安装,根据提示输入自己的mysql数据库信息!
3.如果在安装过程中遇到错误
如果安装界面出现Warning:Call-time pass-by-reference has deprecated的错误提示,需要手动修改php环境配置文件php.ini启用扩展。具体操作请访问:无报错继续下一步
4.手机版安装方法
解析独立域名(也可以使用同域名的二级域名),新建站点,指向pc目录下的wap文件,然后登录PC网站后台——系统定义——手机访问网址——填写手机域名——手机站网站样式设置为mqiyue
5.Login网站Background
访问你的域名/admin,登录账号和密码是你安装时设置的账号和密码
使用源码的注意事项
1.安装后第一次通知
进入后台后,不用担心查前台页面等。进入后台的基本设置,将网站域名、关键词、文章列等设置为自己的,然后根据需要进行配置 必要的配置,这个操作后,去看看如果前台页面正常! !
2.How to采集
这里配备了Guanguan采集Advanced Edition采集工具。最好是把guanguan采集放在win server里,睡着就可以搭建自己的采集target小说站!
年费VIP会员准备了采集规则,采集怎么做!
①双击采集器中的NovelSpider.exe执行程序
②打开后加载页面报错,点击Yes后一直出现主页。
③点击设置——采集Settings,在设置面板中设置网站name、本地网站目录、数据库连接字符
Data Source=localhost;Database=linshi;User ID=root;Password=;port=3306;charset=gbk
你只需要把linshi改成你的数据库名,root改成你的数据库用户名,和你的数据库密码。
更改后点击右下角确定,退出采集器并重新打开采集器界面
④重启后点击采集——standard采集mode——在采集模式下选择采集rules
⑤点击右下角的采集plan-保存计划
⑥ 点击启动采集就可以了。一天采集结束后,你可以去看看采集,然后点击开始自动重新计算新章节和采集
3.网站authorization
网站需要对域名进行授权,联系客服获取授权码,一个域名只对应一个授权码,多个VIP会员使用多人申请授权恢复VIP资格感谢您的理解和支持!
获取授权码后,登录网站background-点击系统定义-查看数据库信息填写网站授权码并保存!剩下的网站信息根据自己情况设置!
【重要】对于系统定义,第一次设置时,错误显示模式需要设置为“显示错误”或“不显示错误”。同时,在小说连载模块和参数设置中,将目录页每页显示的章节数设置为0,将是否生成html设置为否。
4.如何设置VIP章节,也就是如何设置阅读某一章节并收费!
先到后台给writer成员添加权限,如图
那么一旦前台注册会员成为作家,他发表的章节可以收费或免费。
调试说明总结
①使用采集时,尽量在晚上实施,防止采集的大家在目标站造成拥塞。终身会员和企业会员可联系客服获取多条采集规则,多数据源,确保您网站内容及时更新
这个程序不难调试,可以仔细按照教程来! !
②相关模板页面路径:
·网站全局主题:\templates 和\themes
·小说模块模板:\modules\article\templates
·在线支付模板:\modules\pay\templates
③一些比较重要的配置文件地址可能有误,请根据实际情况自行分析:
·登录和uc配置:/api
·支付宝等支付配置:/configs/pay
·微信支付配置:/modules/pay/weixin/lib/WxPay.pub.config.php
·云通支付免签约支付接口:/modules/pay/shanpay/shanpayconfig.php
·小说分类:/configs/article/sort.php
④采集器注:
·文件夹必须有写权限,否则会出现采集错误。
·系统设置必须正确,否则会出现采集错误。 查看全部
关键词自动采集(带手机端,4套模板,在线听书和TXT下载源码安装教程)
PTcms小说系统自动上线采集改版,小说聚合网站带手机终端,4套模板,在线听书和TXT下载
源码安装教程
1.安装前的准备工作
将程序上传到网站root目录下,不要在二级目录调试,不要删除根目录下的bbs.####.com快捷方式
2.恢复数据库
将根目录下的.sql数据库导入你的mysql数据库,虚拟主机可以通过你的主机提供商提供的操作工具进行恢复。对于云服务器用户,建议直接使用 Navicat 软件导入。无论如何,有很多方法可以导入它。是的,数据较多,导入时请耐心等待!
3.修改数据库配置信息
用EditPlus软件或dreamweaver等代码编辑软件打开/application/common/config.php文件,按照以下方法修改数据库配置文件
'mysql_master_host' => 'localhost', //数据库地址,本机一般默认不修改
'mysql_master_port' => '3306', //端口一般不修改
'mysql_master_name' => 'demo', //数据库名
'mysql_master_user' => 'root', //数据库用户名
'mysql_master_pwd' => '', //数据库密码
4.配置文本静态
这是在部署主机环境时决定的。建议使用apache环境,默认支持.htaccess伪静态格式。如果是iis或者nginx需要转换对应的伪静态格式
5.Login网站Background
不要访问前台网站,先访问域名/admin.php访问网站background,登录账号和密码分别是admin和密码,输入网站后的第一步后台就是到“系统”-“基本”设置“-”数据库“-再次配置数据库配置选项!这个一定要先配置!
6.注意事项和说明
1.如果伪静态正常网站仍然出现404,打开根目录index.php在倒数第二行添加:
define('APP_DEBUG',true);
网站正常后删除;
2.网站需要配置的后台信息
·“系统”-“基本设置”-可自行修改
·“扩展”-“任务管理”-“任务管理”-“全选”-“还原”-开启自动采集
·“扩展”-“模块管理”-“网站Map”-可自行修改
·“扩展”-“模块管理”-“手机地图”-修改为自己的。
·“用户”-管理员密码修改
1.准备工作
调试网站前,检查网站域名指向的目录是否正确,环境的PHP版本是否为教程中指定的PHP版本,否则会出现一些低级404错误,500错误,浪费你自己的时间和精力!
2.Upload网站程序安装正常
使用二进制上传,linux主机可以在线下载压缩包并解压,直接访问自己的域名/install进行正常安装,根据提示输入自己的mysql数据库信息!
3.如果在安装过程中遇到错误
如果安装界面出现Warning:Call-time pass-by-reference has deprecated的错误提示,需要手动修改php环境配置文件php.ini启用扩展。具体操作请访问:无报错继续下一步
4.手机版安装方法
解析独立域名(也可以使用同域名的二级域名),新建站点,指向pc目录下的wap文件,然后登录PC网站后台——系统定义——手机访问网址——填写手机域名——手机站网站样式设置为mqiyue
5.Login网站Background
访问你的域名/admin,登录账号和密码是你安装时设置的账号和密码
使用源码的注意事项
1.安装后第一次通知
进入后台后,不用担心查前台页面等。进入后台的基本设置,将网站域名、关键词、文章列等设置为自己的,然后根据需要进行配置 必要的配置,这个操作后,去看看如果前台页面正常! !
2.How to采集
这里配备了Guanguan采集Advanced Edition采集工具。最好是把guanguan采集放在win server里,睡着就可以搭建自己的采集target小说站!
年费VIP会员准备了采集规则,采集怎么做!
①双击采集器中的NovelSpider.exe执行程序
②打开后加载页面报错,点击Yes后一直出现主页。
③点击设置——采集Settings,在设置面板中设置网站name、本地网站目录、数据库连接字符
Data Source=localhost;Database=linshi;User ID=root;Password=;port=3306;charset=gbk
你只需要把linshi改成你的数据库名,root改成你的数据库用户名,和你的数据库密码。
更改后点击右下角确定,退出采集器并重新打开采集器界面
④重启后点击采集——standard采集mode——在采集模式下选择采集rules
⑤点击右下角的采集plan-保存计划
⑥ 点击启动采集就可以了。一天采集结束后,你可以去看看采集,然后点击开始自动重新计算新章节和采集
3.网站authorization
网站需要对域名进行授权,联系客服获取授权码,一个域名只对应一个授权码,多个VIP会员使用多人申请授权恢复VIP资格感谢您的理解和支持!
获取授权码后,登录网站background-点击系统定义-查看数据库信息填写网站授权码并保存!剩下的网站信息根据自己情况设置!
【重要】对于系统定义,第一次设置时,错误显示模式需要设置为“显示错误”或“不显示错误”。同时,在小说连载模块和参数设置中,将目录页每页显示的章节数设置为0,将是否生成html设置为否。
4.如何设置VIP章节,也就是如何设置阅读某一章节并收费!
先到后台给writer成员添加权限,如图
那么一旦前台注册会员成为作家,他发表的章节可以收费或免费。
调试说明总结
①使用采集时,尽量在晚上实施,防止采集的大家在目标站造成拥塞。终身会员和企业会员可联系客服获取多条采集规则,多数据源,确保您网站内容及时更新
这个程序不难调试,可以仔细按照教程来! !
②相关模板页面路径:
·网站全局主题:\templates 和\themes
·小说模块模板:\modules\article\templates
·在线支付模板:\modules\pay\templates
③一些比较重要的配置文件地址可能有误,请根据实际情况自行分析:
·登录和uc配置:/api
·支付宝等支付配置:/configs/pay
·微信支付配置:/modules/pay/weixin/lib/WxPay.pub.config.php
·云通支付免签约支付接口:/modules/pay/shanpay/shanpayconfig.php
·小说分类:/configs/article/sort.php
④采集器注:
·文件夹必须有写权限,否则会出现采集错误。
·系统设置必须正确,否则会出现采集错误。
电商网站seo微信搜一搜seo排名优化技巧是什么网站优化公司价格如何计算相关内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-08-27 04:15
电子商务网站seo
微信搜一搜有哪些seo排名优化技巧
网站优化公司价格计算方式相关内容(一)
1.重新定义了META标签中的内容,使其与公司产品一致,适应目标客户群的访问习惯。
说到搜索,那么最有效的获取流量的方式之一就是通过百度的下拉框过滤相关的关键词。当用户输入一个词或词时,搜索引擎会将其与您输入的词相关联输出关键词,与它相关并有大量流量。百度下拉框最多提供10个关键词展示位置,用户搜索即可看到推文
网站Auto采集Publish 插件
Ganzhou网站optimization 哪个更好
在淄博哪里可以找到seo公司相关的内容(二)
说到搜索,那么最有效的获取流量的方式之一就是通过百度的下拉框过滤相关的关键词。当用户输入一个词或词时,搜索引擎会将其与您输入的词相关联输出关键词 与它相关并有大量流量。百度下拉框最多提供10个关键词展示位置,用户搜索即可看到推文
通过采集对互联网大数据的分析、提取,为网站运营商和SEO从业者提供有价值的专业分析结果和指导,让用户快速提升平台的网络运营能力。这个描述比较笼统,我们可以直接看其官网首页的描述值:5118 通过各类SEO大数据挖掘,我们提供关键词Mining,OK
网站Promotion SEO优化
“新浪新闻采集”当前新闻发布时间为——
seo关键词和seo描述相关内容(三)随着互联网的飞速发展,网络广告早已成为网络媒体重要的收入渠道之一。百度广告经理担任百度为国内广大高quality media网站经过两年的发展,数据显示合作网络媒体已超过5000家,已成为国内最大的网络媒体网络广告投放和管理的广告管理平台 查看全部
电商网站seo微信搜一搜seo排名优化技巧是什么网站优化公司价格如何计算相关内容
电子商务网站seo
微信搜一搜有哪些seo排名优化技巧
网站优化公司价格计算方式相关内容(一)
1.重新定义了META标签中的内容,使其与公司产品一致,适应目标客户群的访问习惯。
说到搜索,那么最有效的获取流量的方式之一就是通过百度的下拉框过滤相关的关键词。当用户输入一个词或词时,搜索引擎会将其与您输入的词相关联输出关键词,与它相关并有大量流量。百度下拉框最多提供10个关键词展示位置,用户搜索即可看到推文
网站Auto采集Publish 插件
Ganzhou网站optimization 哪个更好
在淄博哪里可以找到seo公司相关的内容(二)
说到搜索,那么最有效的获取流量的方式之一就是通过百度的下拉框过滤相关的关键词。当用户输入一个词或词时,搜索引擎会将其与您输入的词相关联输出关键词 与它相关并有大量流量。百度下拉框最多提供10个关键词展示位置,用户搜索即可看到推文
通过采集对互联网大数据的分析、提取,为网站运营商和SEO从业者提供有价值的专业分析结果和指导,让用户快速提升平台的网络运营能力。这个描述比较笼统,我们可以直接看其官网首页的描述值:5118 通过各类SEO大数据挖掘,我们提供关键词Mining,OK
网站Promotion SEO优化
“新浪新闻采集”当前新闻发布时间为——
seo关键词和seo描述相关内容(三)随着互联网的飞速发展,网络广告早已成为网络媒体重要的收入渠道之一。百度广告经理担任百度为国内广大高quality media网站经过两年的发展,数据显示合作网络媒体已超过5000家,已成为国内最大的网络媒体网络广告投放和管理的广告管理平台
vivi内核二开智能标题关键字新闻采集源码人工管理.会
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-08-27 04:14
Vivi 内核两开智能标题关键词news采集源码无需人工管理。
文章中的相关关键词会被添加到标题关键词中。
SEO超级好,可以站群。
php5.2-5.4
上传使用
Spider Pool News采集 Source-Full Auto采集 无需人工参与。
24小时自动采集,只需500M空间
1.在原版的基础上增加了更多吸引蜘蛛的智能设置()百度蜘蛛、谷歌蜘蛛、神马蜘蛛(手机流量很贵)、360蜘蛛、搜狗蜘蛛等
2.智慧加后缀,自动在采集的内容中添加相关含义的句子,比如原标题是胖,采集后面会加上比如吃什么减肥等,视实际情况而定。
3.伪原创 有更多的话
4.关键词内链可自由设置,可引蜘蛛,增加SEO效果。
5.动态页面蜘蛛可以被爱(也可以是伪静态)
6.建议多建站点,(12元一年提供静安3G300M虚拟主机)不同的站点吸引不同的蜘蛛(因为我们的智能代码让每个站点都不一样,因为是随机的,所以首选蜘蛛有点不同)。
7.有很多增强效果,我就不多说了。建议使用一级域名,收录远不止二级域名。
8.后台可以看到蜘蛛的来源,可以将蜘蛛引导到你需要的网站
9. 页面可以留下来等待收录。
资源下载 本资源仅供VIP下载,请先登录下载资源
下载价格:VIP专享
本资源仅供VIP下载
更新时间:2019.11.21
包装尺寸:1M 查看全部
vivi内核二开智能标题关键字新闻采集源码人工管理.会
Vivi 内核两开智能标题关键词news采集源码无需人工管理。
文章中的相关关键词会被添加到标题关键词中。
SEO超级好,可以站群。
php5.2-5.4
上传使用
Spider Pool News采集 Source-Full Auto采集 无需人工参与。
24小时自动采集,只需500M空间
1.在原版的基础上增加了更多吸引蜘蛛的智能设置()百度蜘蛛、谷歌蜘蛛、神马蜘蛛(手机流量很贵)、360蜘蛛、搜狗蜘蛛等
2.智慧加后缀,自动在采集的内容中添加相关含义的句子,比如原标题是胖,采集后面会加上比如吃什么减肥等,视实际情况而定。
3.伪原创 有更多的话
4.关键词内链可自由设置,可引蜘蛛,增加SEO效果。
5.动态页面蜘蛛可以被爱(也可以是伪静态)
6.建议多建站点,(12元一年提供静安3G300M虚拟主机)不同的站点吸引不同的蜘蛛(因为我们的智能代码让每个站点都不一样,因为是随机的,所以首选蜘蛛有点不同)。
7.有很多增强效果,我就不多说了。建议使用一级域名,收录远不止二级域名。
8.后台可以看到蜘蛛的来源,可以将蜘蛛引导到你需要的网站
9. 页面可以留下来等待收录。
资源下载 本资源仅供VIP下载,请先登录下载资源
下载价格:VIP专享
本资源仅供VIP下载
更新时间:2019.11.21
包装尺寸:1M
京东搜索为例案例规则+操作步骤注意事项及解决办法!
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-08-26 04:16
一、操作步骤
如果网页上有搜索框,但是搜索结果页没有单独的网址,而你想要采集搜索结果,直接规则是采集不能做,你必须先做一个连续的动作(输入+点击)来实现自动输入关键词并搜索,然后采集数据。下面以京东搜索为例,演示自动搜索采集。操作步骤如下:
二、Case规则+操作步骤
注意:在这种情况下,京东搜索有独立的网址。对于有独立网址的页面,最简单的方法就是构造每个关键词搜索网址,然后将线索网址导入到规则中,就可以批量采集而不是设置连续动作
第一步:定义一级规则
1.1 打开极手客网络爬虫,输入网址回车,加载网页后点击“定义规则”按钮,会看到一个浮动窗口,称为工作台,在上面可以定义规则;
注:此处截图及文字说明均为极手客网络爬虫版本。如果您安装的是Firefox插件版本,则没有“定义规则”按钮,但您应该运行MS Muse。
1.2 在工作台中输入一级规则的主题名称,然后点击“检查重复”,会提示“此名称可以使用”或“名称已被占用,可编辑:是” ,您可以使用此主题名称,否则请重命名。
1.3 这一层规则主要是设置连续动作,这样排序框就可以随意抓取一条信息,用它来判断是否为爬虫执行采集。双击网页上的信息,输入标签名称,勾选确认,然后勾选关键内容,输入第一个标签的排序框名称,标签映射完成。
提示:为了准确定位网页信息,点击定义规则会冻结整个网页,无法跳转到网页链接。再次点击定义规则,返回正常网页模式。
第 2 步:定义连续动作
点击工作台的“Continuous Action”选项卡,点击New按钮新建一个action,每个action的设置方法都是一样的,基本操作如下:
2.1,输入目标学科名称
这里的目标主题名称是填写二级主题名称,点击“谁在使用”查看目标主题名称是否可用,如果已经被占用,只需更改一个主题名称即可。
2.2,创建第一个动作:回车
创建一个新动作并选择动作类型作为输入。
2.2.1,填写定位表达式
首先点击输入框,定位输入框的节点,然后点击“Auto Generate XPath”按钮,可以选择“Preference id”或者“Preference class”,就可以得到输入的xpath表达式框,然后单击“搜索”按钮,检查这个xpath是否可以在输入框中唯一定位,如果没有问题,将xpath复制到定位表达式框中。
注意:定位表达式中的xpath是锁定动作对象的整个有效操作范围。具体是指鼠标可以点击或输入成功的网页模块。不要在底部找到 text() 节点。
2.2.2,输入关键词
输入关键词填写你要搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词使用双分号;;把每个关键词Separate,免费版只支持5个以内的关键词,旗舰版可以使用爆弹功能,支持关键词10000以内
2.2.3,输入动作名称
告诉自己这一步是做什么的,以便你以后可以修改。
2.3,创建第二个动作:点击
参考2.2的操作,创建第二个action,选择类型为click,定位搜索按钮,然后自动生成xpath检查是否锁定到唯一节点。如果没有问题,填写定位表达式。 .
2.4,存款规则
点击“保存规则”按钮保存完成的一级规则
第 3 步:定义二级规则
3.1,新建规则
创建二级规则,点击“定义规则”返回正常网页模式,输入关键词搜索结果,再次点击“定义规则”切换到规则制定模式,点击“左上角规则”菜单->“新建”,输入主题名称,其中主题名称是在第一级规则的连续动作中填写的目标主题名称。
3.2,标记你想要的信息采集
3.2.1,在网页上标注你要采集的信息,这里是标注产品名称和价格,因为标注只对文字信息有效,以及产品链接details 是属性节点@href,所以不能在链接上做这么直观的标记,要做内容映射,具体看下面的操作。
3.2.2,点击产品名称,下方的DOM节点定位到A标签,展开A标签下的属性节点,可以找到代表URL的@href节点,右键节点,并选择“New Capture”抓取内容,输入一个名字,一般给抓取到的内容取一个与地址相关的名字,比如“下级网址”,或者“下级链接”等等。然后在工作台上,我看到表示抓取到的内容是可用的。如果您还想进入商品详情页采集,则必须针对抓取的内容检查下层线索,并进行分层抓取。
3.2.3,设置“关键内容”选项,让爬虫判断采集规则是否合适。在排序框中,选择网页上不可避免的标签,并勾选“关键内容”。这里选择“名称”作为“关键内容”。
3.2.4,只要在前面标注一个产品,就可以得到一个产品信息。如果你想采集下整个页面上的每一个产品,可以做一个样例拷贝,没有如果你看懂了,请参考基础教程“采集表数据”
3.3,设置翻页路线
在爬虫路由中设置翻页,这里是标记提示,不明白的请参考基础教程《设置翻页采集》
3.4,保存规则
点击“测试”以检查信息的完整性。如果不完整,重新标记可以覆盖之前的内容。确认没有问题后,点击“保存规则”。
第 4 步:捕获数据
4.1,连续动作是连续执行的,所以只要运行一级主题,二级主题就不需要运行了。打开DS计数器,搜索一级话题名称,点击“单一搜索”或“采集”,可以看到浏览器窗口会自动输入并搜索关键词,然后二级话题就会出现自动调用采集搜索结果。
4.2,一级主题没有采集到有意义的信息,所以我们只看二级主题文件夹,可以看到采集的搜索结果数据,搜索关键词是默认记录在xml文件的actionvalue字段中,这样可以一一匹配。 查看全部
京东搜索为例案例规则+操作步骤注意事项及解决办法!
一、操作步骤
如果网页上有搜索框,但是搜索结果页没有单独的网址,而你想要采集搜索结果,直接规则是采集不能做,你必须先做一个连续的动作(输入+点击)来实现自动输入关键词并搜索,然后采集数据。下面以京东搜索为例,演示自动搜索采集。操作步骤如下:
二、Case规则+操作步骤
注意:在这种情况下,京东搜索有独立的网址。对于有独立网址的页面,最简单的方法就是构造每个关键词搜索网址,然后将线索网址导入到规则中,就可以批量采集而不是设置连续动作
第一步:定义一级规则
1.1 打开极手客网络爬虫,输入网址回车,加载网页后点击“定义规则”按钮,会看到一个浮动窗口,称为工作台,在上面可以定义规则;
注:此处截图及文字说明均为极手客网络爬虫版本。如果您安装的是Firefox插件版本,则没有“定义规则”按钮,但您应该运行MS Muse。
1.2 在工作台中输入一级规则的主题名称,然后点击“检查重复”,会提示“此名称可以使用”或“名称已被占用,可编辑:是” ,您可以使用此主题名称,否则请重命名。
1.3 这一层规则主要是设置连续动作,这样排序框就可以随意抓取一条信息,用它来判断是否为爬虫执行采集。双击网页上的信息,输入标签名称,勾选确认,然后勾选关键内容,输入第一个标签的排序框名称,标签映射完成。
提示:为了准确定位网页信息,点击定义规则会冻结整个网页,无法跳转到网页链接。再次点击定义规则,返回正常网页模式。
第 2 步:定义连续动作
点击工作台的“Continuous Action”选项卡,点击New按钮新建一个action,每个action的设置方法都是一样的,基本操作如下:
2.1,输入目标学科名称
这里的目标主题名称是填写二级主题名称,点击“谁在使用”查看目标主题名称是否可用,如果已经被占用,只需更改一个主题名称即可。
2.2,创建第一个动作:回车
创建一个新动作并选择动作类型作为输入。
2.2.1,填写定位表达式
首先点击输入框,定位输入框的节点,然后点击“Auto Generate XPath”按钮,可以选择“Preference id”或者“Preference class”,就可以得到输入的xpath表达式框,然后单击“搜索”按钮,检查这个xpath是否可以在输入框中唯一定位,如果没有问题,将xpath复制到定位表达式框中。
注意:定位表达式中的xpath是锁定动作对象的整个有效操作范围。具体是指鼠标可以点击或输入成功的网页模块。不要在底部找到 text() 节点。
2.2.2,输入关键词
输入关键词填写你要搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词使用双分号;;把每个关键词Separate,免费版只支持5个以内的关键词,旗舰版可以使用爆弹功能,支持关键词10000以内
2.2.3,输入动作名称
告诉自己这一步是做什么的,以便你以后可以修改。
2.3,创建第二个动作:点击
参考2.2的操作,创建第二个action,选择类型为click,定位搜索按钮,然后自动生成xpath检查是否锁定到唯一节点。如果没有问题,填写定位表达式。 .
2.4,存款规则
点击“保存规则”按钮保存完成的一级规则
第 3 步:定义二级规则
3.1,新建规则
创建二级规则,点击“定义规则”返回正常网页模式,输入关键词搜索结果,再次点击“定义规则”切换到规则制定模式,点击“左上角规则”菜单->“新建”,输入主题名称,其中主题名称是在第一级规则的连续动作中填写的目标主题名称。
3.2,标记你想要的信息采集
3.2.1,在网页上标注你要采集的信息,这里是标注产品名称和价格,因为标注只对文字信息有效,以及产品链接details 是属性节点@href,所以不能在链接上做这么直观的标记,要做内容映射,具体看下面的操作。
3.2.2,点击产品名称,下方的DOM节点定位到A标签,展开A标签下的属性节点,可以找到代表URL的@href节点,右键节点,并选择“New Capture”抓取内容,输入一个名字,一般给抓取到的内容取一个与地址相关的名字,比如“下级网址”,或者“下级链接”等等。然后在工作台上,我看到表示抓取到的内容是可用的。如果您还想进入商品详情页采集,则必须针对抓取的内容检查下层线索,并进行分层抓取。
3.2.3,设置“关键内容”选项,让爬虫判断采集规则是否合适。在排序框中,选择网页上不可避免的标签,并勾选“关键内容”。这里选择“名称”作为“关键内容”。
3.2.4,只要在前面标注一个产品,就可以得到一个产品信息。如果你想采集下整个页面上的每一个产品,可以做一个样例拷贝,没有如果你看懂了,请参考基础教程“采集表数据”
3.3,设置翻页路线
在爬虫路由中设置翻页,这里是标记提示,不明白的请参考基础教程《设置翻页采集》
3.4,保存规则
点击“测试”以检查信息的完整性。如果不完整,重新标记可以覆盖之前的内容。确认没有问题后,点击“保存规则”。
第 4 步:捕获数据
4.1,连续动作是连续执行的,所以只要运行一级主题,二级主题就不需要运行了。打开DS计数器,搜索一级话题名称,点击“单一搜索”或“采集”,可以看到浏览器窗口会自动输入并搜索关键词,然后二级话题就会出现自动调用采集搜索结果。
4.2,一级主题没有采集到有意义的信息,所以我们只看二级主题文件夹,可以看到采集的搜索结果数据,搜索关键词是默认记录在xml文件的actionvalue字段中,这样可以一一匹配。
家具到底是不是一个关键词呢?(一)的定义
采集交流 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-08-25 03:12
说到关键词,我们首先要谈的是它的定义。
什么是“关键词”列表?我认为定义是用户用来搜索的词。主要衡量用户是否会使用该词进行搜索。
例如,我销售家具产品。那么家具是关键词 吗?我认为不是。因为用户在购买的时候,可能想买沙发或者橱柜,那么用户输入的关键词其实是沙发或者橱柜,而不是家具。当我们在标题或搜索词中将“家具”写为关键词时,亚马逊搜索匹配的客户应该是很小的一部分。这部分没有明确购买意向的流量对我们来说几乎可以忽略不计。
第二点是说一个普通卖家容易忽略的问题。根据上面的定义,有必要再次强调:关键词一定是基于用户的认知和搜索思维,而不是基于自己的产品。
例如,您产品的一些工艺和材料。作为卖家,我们非常清楚这一点。也可以作为卖点,但这是否意味着这适合作为关键词?如果工艺、材质等特性正是用户关心的、会用来搜索的,那么作为一个产品关键词是毋庸置疑的。但是如果用户不知道怎么搜索,仅仅因为我们非常了解产品或者把它作为卖点,我们认为一个词也是关键词,那么客户的点击率可想而知。
当我们仔细考虑关键词的定义时,这是可以避免的,但它经常被卖家忽略。关键是站在客户的角度还是卖家的角度。
第三点,分类。关键字可以分为宽泛的关键词、精确的关键词和长尾词。广义词就是我们常说的大词。带有定语词和修饰语的精确词指向特定的客户群。
至于长尾词,我认为它们应该是精确度的一部分。它们只是比精度更精确。如果说精准词反映了产品的主要功能,那么总的来说,长尾其实就是精准词的多次使用。多个精准的词组合在一起形成长尾词,基本构成了产品的框架,让人们了解产品和其他同类产品。产品最大的差异和特点也锁定在购买它的人身上。 (当然也有一些长尾词比较特殊,可以直接把产品和其他同类产品区分开来;通常是某个话题类别的关键词。)
再举个例子。比如卖沙发,那么沙发其实就是一个广义的名词。 优采云Sofa,这个“优采云”是一个准确的词,它体现了这款产品的功能应该是具有坐姿调节功能的沙发,甚至是坐姿,也进一步减少了人群。如果是优采云+按摩+皮这样的多个精准词的组合,就形成了长尾,完成了对我们产品的唯一限制。说明我们的产品兼具坐卧调节功能和自动按摩功能,针对喜欢皮革的客户。
第四点,用在什么地方。产品关键词贯穿整个上市文案。主要用于5个位置。标题、五点、描述、搜索词和 QA 评论。我的观点是,长尾词和精确词放在标题最前面,广泛放在搜索词中。如果关键词 太多而无法放入标题中,请将其添加到五点和描述中。同时,为了增加listing与关键词的相关性,可以在QA和评论中添加,注意保持句子流畅。
第五点,采集方法。如何采集和确定您的关键词?常见的采集方式一般有4种。
(1)参赛者的标题描述。
对手是最好的老师。我们关注排名。销量比我们好的对手的标题和描述可以获得第一批关键词数据。
(2)亚马逊搜索框。
我们在亚马逊搜索框输入product关键词,下面会自动匹配一些相关或者常用的搜索词。在这些术语中,您可以选择与您的产品相关的关键词。如果自动出现的相关词较少,可以尝试输入自己的主关键字,然后输入A-Z中的任意一个字母,看看关键词亚马逊会推送什么样的内容。
(3)广告报道。
自动广告投放过程中下载的自动广告报告收录高点击率和相关词,可以替代我们的关键词。
(4) 在场外工具的帮助下。
很多场外工具都提供了分类关键词和反查关键词的功能,大家可以根据自己的喜好尝试选择。
最后要注意的是,无论我们怎么找到关键词,一定要重新放到亚马逊搜索框上,让真实的匹配结果测试找到的关键词是否适合我们产品。与其找到对手的关键词,然后得意洋洋地使用它,您还可以做白日梦,点击和下单。 查看全部
家具到底是不是一个关键词呢?(一)的定义
说到关键词,我们首先要谈的是它的定义。
什么是“关键词”列表?我认为定义是用户用来搜索的词。主要衡量用户是否会使用该词进行搜索。
例如,我销售家具产品。那么家具是关键词 吗?我认为不是。因为用户在购买的时候,可能想买沙发或者橱柜,那么用户输入的关键词其实是沙发或者橱柜,而不是家具。当我们在标题或搜索词中将“家具”写为关键词时,亚马逊搜索匹配的客户应该是很小的一部分。这部分没有明确购买意向的流量对我们来说几乎可以忽略不计。
第二点是说一个普通卖家容易忽略的问题。根据上面的定义,有必要再次强调:关键词一定是基于用户的认知和搜索思维,而不是基于自己的产品。
例如,您产品的一些工艺和材料。作为卖家,我们非常清楚这一点。也可以作为卖点,但这是否意味着这适合作为关键词?如果工艺、材质等特性正是用户关心的、会用来搜索的,那么作为一个产品关键词是毋庸置疑的。但是如果用户不知道怎么搜索,仅仅因为我们非常了解产品或者把它作为卖点,我们认为一个词也是关键词,那么客户的点击率可想而知。
当我们仔细考虑关键词的定义时,这是可以避免的,但它经常被卖家忽略。关键是站在客户的角度还是卖家的角度。
第三点,分类。关键字可以分为宽泛的关键词、精确的关键词和长尾词。广义词就是我们常说的大词。带有定语词和修饰语的精确词指向特定的客户群。
至于长尾词,我认为它们应该是精确度的一部分。它们只是比精度更精确。如果说精准词反映了产品的主要功能,那么总的来说,长尾其实就是精准词的多次使用。多个精准的词组合在一起形成长尾词,基本构成了产品的框架,让人们了解产品和其他同类产品。产品最大的差异和特点也锁定在购买它的人身上。 (当然也有一些长尾词比较特殊,可以直接把产品和其他同类产品区分开来;通常是某个话题类别的关键词。)
再举个例子。比如卖沙发,那么沙发其实就是一个广义的名词。 优采云Sofa,这个“优采云”是一个准确的词,它体现了这款产品的功能应该是具有坐姿调节功能的沙发,甚至是坐姿,也进一步减少了人群。如果是优采云+按摩+皮这样的多个精准词的组合,就形成了长尾,完成了对我们产品的唯一限制。说明我们的产品兼具坐卧调节功能和自动按摩功能,针对喜欢皮革的客户。
第四点,用在什么地方。产品关键词贯穿整个上市文案。主要用于5个位置。标题、五点、描述、搜索词和 QA 评论。我的观点是,长尾词和精确词放在标题最前面,广泛放在搜索词中。如果关键词 太多而无法放入标题中,请将其添加到五点和描述中。同时,为了增加listing与关键词的相关性,可以在QA和评论中添加,注意保持句子流畅。
第五点,采集方法。如何采集和确定您的关键词?常见的采集方式一般有4种。
(1)参赛者的标题描述。
对手是最好的老师。我们关注排名。销量比我们好的对手的标题和描述可以获得第一批关键词数据。
(2)亚马逊搜索框。
我们在亚马逊搜索框输入product关键词,下面会自动匹配一些相关或者常用的搜索词。在这些术语中,您可以选择与您的产品相关的关键词。如果自动出现的相关词较少,可以尝试输入自己的主关键字,然后输入A-Z中的任意一个字母,看看关键词亚马逊会推送什么样的内容。
(3)广告报道。
自动广告投放过程中下载的自动广告报告收录高点击率和相关词,可以替代我们的关键词。
(4) 在场外工具的帮助下。
很多场外工具都提供了分类关键词和反查关键词的功能,大家可以根据自己的喜好尝试选择。
最后要注意的是,无论我们怎么找到关键词,一定要重新放到亚马逊搜索框上,让真实的匹配结果测试找到的关键词是否适合我们产品。与其找到对手的关键词,然后得意洋洋地使用它,您还可以做白日梦,点击和下单。
微智优户:关键词自动采集,采集电商平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-08-19 23:04
关键词自动采集,采集电商平台的商品,自动上传到自己的店铺,以达到商品上架,店铺搜索靠前,排名靠前,速度不会有任何延迟,操作方便快捷。
用一个工具最快了,安全,能记录,这个工具叫微智优户。每天的邮寄单号就可以查询出来。可以拿到宝贝的物流信息,卖家要做的就是和买家沟通,
我当初也是差不多一个月查几十封,现在三个月查多了根本没必要去查了,因为越是个人用户搜索量大的关键词越难达到上千的成交量。各种qq群啊,朋友圈啊什么各种人群满天飞,现在有个叫“”看遍票牛”的平台,设置好价格和地址之后就可以让全国其他地区的客户自助查询包裹的到达时间、方式等等信息。一个多月查一千封以上的件都可以,差不多算成功了吧,反正我是觉得挺快的。应该更多的个人用户分享成功的案例吧。
我曾经百度了很多找到了一些在线查询的网站,如:3w、查信箱、卷皮等,他们都只能查快递方式,没法查到单号的。有些人会说我的快递单号有问题可能别人买错了,但就我当初我这几个月查的这么多件里面根本就没有买错的(楼主可以自己试试转发个微信链接给别人或朋友查看你的单号以及你快递单号,)。有朋友说我才百度了一下3w就出来了200多,别人搜索关键词各种都有,我的单号拿到之后都不能直接发送,基本没有在线查询的可能,但我后来在网上又换了一家快递查询网站发现了和3w类似的网站有内部成功案例,但是他们查得比3w的更精准快捷。
比如我当初搜索网址“”看遍票牛查询快递单号获取关键词,我看到了找字号,我觉得这个太明显了,我不想自己推广就没发出去,结果就不给查询单号(3w有发过手工单或图片的不算吧)。又比如查信箱,我点进去了选择了电话填进去发现这家网站很多人都说存在这种情况,就查不到单号(3w还查不到)。查一下“卷皮”,内部人员在这网站发布了一个快递单号,我上下班还有去朋友家里,因为都可以上楼了,他们可以上楼的,我就打开电脑就输入了单号,结果他们直接说没有,让我想一下可能原因,很快的他们告诉我是由于单号是个人注册的,他们用的地址是空的地址,除了本市没有其他的,他们发的是单号的第一位和后面一位是1,后来我又问了其他的客户没有收到快递单号的话可以去发给他们看单号,他们发过来的是没有1后面就变成0,最后我才明白是我的手机码字啊。而且他们只要你点一下单号如果是零就会给解决,能大概看出是哪个字段的单号。下面就是。 查看全部
微智优户:关键词自动采集,采集电商平台
关键词自动采集,采集电商平台的商品,自动上传到自己的店铺,以达到商品上架,店铺搜索靠前,排名靠前,速度不会有任何延迟,操作方便快捷。
用一个工具最快了,安全,能记录,这个工具叫微智优户。每天的邮寄单号就可以查询出来。可以拿到宝贝的物流信息,卖家要做的就是和买家沟通,
我当初也是差不多一个月查几十封,现在三个月查多了根本没必要去查了,因为越是个人用户搜索量大的关键词越难达到上千的成交量。各种qq群啊,朋友圈啊什么各种人群满天飞,现在有个叫“”看遍票牛”的平台,设置好价格和地址之后就可以让全国其他地区的客户自助查询包裹的到达时间、方式等等信息。一个多月查一千封以上的件都可以,差不多算成功了吧,反正我是觉得挺快的。应该更多的个人用户分享成功的案例吧。
我曾经百度了很多找到了一些在线查询的网站,如:3w、查信箱、卷皮等,他们都只能查快递方式,没法查到单号的。有些人会说我的快递单号有问题可能别人买错了,但就我当初我这几个月查的这么多件里面根本就没有买错的(楼主可以自己试试转发个微信链接给别人或朋友查看你的单号以及你快递单号,)。有朋友说我才百度了一下3w就出来了200多,别人搜索关键词各种都有,我的单号拿到之后都不能直接发送,基本没有在线查询的可能,但我后来在网上又换了一家快递查询网站发现了和3w类似的网站有内部成功案例,但是他们查得比3w的更精准快捷。
比如我当初搜索网址“”看遍票牛查询快递单号获取关键词,我看到了找字号,我觉得这个太明显了,我不想自己推广就没发出去,结果就不给查询单号(3w有发过手工单或图片的不算吧)。又比如查信箱,我点进去了选择了电话填进去发现这家网站很多人都说存在这种情况,就查不到单号(3w还查不到)。查一下“卷皮”,内部人员在这网站发布了一个快递单号,我上下班还有去朋友家里,因为都可以上楼了,他们可以上楼的,我就打开电脑就输入了单号,结果他们直接说没有,让我想一下可能原因,很快的他们告诉我是由于单号是个人注册的,他们用的地址是空的地址,除了本市没有其他的,他们发的是单号的第一位和后面一位是1,后来我又问了其他的客户没有收到快递单号的话可以去发给他们看单号,他们发过来的是没有1后面就变成0,最后我才明白是我的手机码字啊。而且他们只要你点一下单号如果是零就会给解决,能大概看出是哪个字段的单号。下面就是。
只需要添加采集的关键字,就会自动对知乎问答进行采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-08-13 06:13
只需添加采集关键词,知乎问答会自动采集,并自动发布到【门户指定频道】或【论坛指定版块】
添加采集关键字后,文章采集的发布过程不需要人工干预,通过定时任务自动执行。当然你也可以手动执行一键采集发布文章。
更多详情请通过应用截图、更新日志等方式了解,或添加售前QQ(15326940)咨询问题)
注意:Discuz门户文章的评论仅支持纯文本。如果采集question 的答案和答案同时发布到门户,答案中将只保留纯文本
插件仅支持采集普通图片和文字内容,不支持采集视频、附件等特殊元素。如有问题请咨询售前QQ(15326940)
本插件需要PHP支持curl,curl可以正常获取https链接内容。 PHP 版本至少为5.3 且不高于PHP7.1。如果您的服务器环境运行异常,则需要进行故障排除和测试。需要提供必要的网站和服务器账号密码权限进行故障排除,不提供远程协助。
知乎有防采集限制,高频采集可能被屏蔽,建议插件自动采集发布。
如果您的网站服务器被屏蔽或无法正常获取采集源内容,也无法正常发布采集,恕不退款。
如果采集规则因插件自身问题导致无法更新修复,7天内购买的用户可以获得退款,购买超过7天不到1个月可以补偿180元优惠券,购买1个月以上60元补偿优惠券(优惠券仅可在购买本公司名下应用时使用),每位用户只能选择一种补偿方式。
插件仅供文章采集,方便阅读。您需要承担文章版权风险。未经原作者授权,请勿公开文章或将其用于商业用途。 查看全部
只需要添加采集的关键字,就会自动对知乎问答进行采集
只需添加采集关键词,知乎问答会自动采集,并自动发布到【门户指定频道】或【论坛指定版块】
添加采集关键字后,文章采集的发布过程不需要人工干预,通过定时任务自动执行。当然你也可以手动执行一键采集发布文章。
更多详情请通过应用截图、更新日志等方式了解,或添加售前QQ(15326940)咨询问题)
注意:Discuz门户文章的评论仅支持纯文本。如果采集question 的答案和答案同时发布到门户,答案中将只保留纯文本
插件仅支持采集普通图片和文字内容,不支持采集视频、附件等特殊元素。如有问题请咨询售前QQ(15326940)
本插件需要PHP支持curl,curl可以正常获取https链接内容。 PHP 版本至少为5.3 且不高于PHP7.1。如果您的服务器环境运行异常,则需要进行故障排除和测试。需要提供必要的网站和服务器账号密码权限进行故障排除,不提供远程协助。
知乎有防采集限制,高频采集可能被屏蔽,建议插件自动采集发布。
如果您的网站服务器被屏蔽或无法正常获取采集源内容,也无法正常发布采集,恕不退款。
如果采集规则因插件自身问题导致无法更新修复,7天内购买的用户可以获得退款,购买超过7天不到1个月可以补偿180元优惠券,购买1个月以上60元补偿优惠券(优惠券仅可在购买本公司名下应用时使用),每位用户只能选择一种补偿方式。
插件仅供文章采集,方便阅读。您需要承担文章版权风险。未经原作者授权,请勿公开文章或将其用于商业用途。
Amazon搜索引擎用Helium10工具找出竞争对手(SEO)列表
采集交流 • 优采云 发表了文章 • 0 个评论 • 441 次浏览 • 2021-08-11 00:16
Amazon搜索引擎用Helium10工具找出竞争对手(SEO)列表
一、Amazon Lisitng中关键词可以搜索到的地方
•优化您的亚马逊搜索引擎 (SEO) 列表
•标题
•产品要点/功能
•说明
•隐藏关键字(搜索词)
隐藏关键字允许您添加其他关键字,以便亚马逊搜索引擎在决定在搜索结果中显示产品的位置时使用这些关键字。您可以在此处添加您不希望客户看到的内容。在此处保存拼写错误的关键字。
借助 Helium 10 插件,您可以更高效地找到关键词
Helium 10 Tools 还是 Jungle Scout?
文本/
亚马逊搜索引擎
使用 Helium 10 工具
查找竞争对手使用的关键字
查找 Amazon SEO 已编入索引的关键字
列出排名最高的关键词
为什么要使用 HELIUM 10 CEREBRO?
使用来自竞争对手的最新亚马逊数据
1 次搜索最多选择 10 个 ASINS!
快速过滤掉不相关的关键字
只选择排名最高的关键词
找到超过 1 个 ASIN 的关键字!
如何使用 HELIUM 10 CEREBRO?
在结果中搜索亚马逊以查找您销售的产品
运行 H10 X 射线
根据月销售额选择 10 个最畅销的 Best Selling
将他们的 ASINS 复制到 Cerebro
Cerebro IQ-搜索次数与搜索中竞争产品的数量
搜索量 - 每月搜索次数
Position – 这是亚马逊搜索结果中第一个 ASINS 关键字的位置
Ranking Competitors-该关键字排名的竞争对手数量
Relative Rank – 主要产品排名与其他产品相比排名有多高 竞争对手排名(平均)– 所有竞争产品的平均排名是多少
使用 FRANKENSTEIN 进行进一步处理
每行一个词,删除重复词,删除常用词,删除特殊字符等
因此,您只有一小段独特的高级关键字,可用于列出标题、项目符号、隐藏关键字、每次点击费用广告系列等。
这也是一种删除所有不需要的关键字的简单方法。
为什么要使用 Helium 10 磁铁?
使用来自亚马逊搜索引擎的当前数据
快速过滤掉不相关的关键字
只选择排名最高的关键词
这里,您想使用收录/排除的词组来获取最相关的关键字,并快速建立一个列表,然后在列表中使用。
如何使用免费工具更快地找到关键词
如果您还没有购买 Helium 10 工具,还有其他方法。
您可以使用竞争对手的关键字:
标题
产品功能亮点
将它们复制到文本编辑器,然后使用“查找/替换”删除所有不需要的字符,例如“-*&(]”等...
接下来,我们将使用一个名为“删除重复词”的工具
文本中的重复词/
点击原订单,该工具将删除所有重复的单词,并为您提供一个关键字列表。
将关键字复制到文本编辑器,并以每行一个字的方式排列
亚马逊多元应该如何运作?
允许您直接链接同一列表中的多个产品。然后,客户可以根据尺寸/颜色选择产品
创建亚马逊变体的规则
规则很简单
如果不遵守,将被视为违反政策
您可以在卖家中心创建或使用上传文件
您可以使用上传的文件链接现有产品
这通常会促进原本不会出售的产品的销售。
使用模板上传父子变体:
在创建父 SKU 之前,您需要为您的应用程序下载自定义模板产品。
选择类别并下载
浏览亚马逊产品
分类
使用搜索工具
选择所有合适的类别
完成后,点击生成模板
如何填写模板
在这里,您只需要选择可用的产品类型,它将为您预先填写。输入父 SKU、品牌名称、制造商和部件号(可以与 SKU 相同)。
对于标题,请确保它是通用的,而不是特定于尺寸或颜色。
如果您有 UPC/EAN 豁免,您可以将“产品 ID”和“产品 ID 类型”留空。
在变体设置下:
对于“Parent”,请将父子关系设置为“Parent”,并将“Change Theme”设置为“ColorName”或“Size”或“Size/ColorName”。
对于“父”设置为“子”的子项,添加父SKU,将关系类型设置为变体,并选择变体主题。
在基本设置下:
如果要新建父级,需要将更新删除选项设置为“update”(如果存在),然后设置为“PartialUpdate”
然后,您需要填写产品描述,选择推荐的浏览节点并输入型号。
请记住,如果要将现有商品添加到父商品,只需填写变体详细信息即可。
在发现设置下:
确保为子变体设置大小/颜色或两者,否则上传可能会失败
上传模板:
首先导航到产品上传页面。
在这里,您可以选择先检查模板以确保它没有错误。
满意请继续上传
别担心,如果失败,你会收到通知,你可以从上传报告中找出原因。 (来源:Amy Chat 跨境) 查看全部
Amazon搜索引擎用Helium10工具找出竞争对手(SEO)列表
一、Amazon Lisitng中关键词可以搜索到的地方
•优化您的亚马逊搜索引擎 (SEO) 列表
•标题
•产品要点/功能
•说明
•隐藏关键字(搜索词)
隐藏关键字允许您添加其他关键字,以便亚马逊搜索引擎在决定在搜索结果中显示产品的位置时使用这些关键字。您可以在此处添加您不希望客户看到的内容。在此处保存拼写错误的关键字。
借助 Helium 10 插件,您可以更高效地找到关键词
Helium 10 Tools 还是 Jungle Scout?
文本/
亚马逊搜索引擎
使用 Helium 10 工具
查找竞争对手使用的关键字
查找 Amazon SEO 已编入索引的关键字
列出排名最高的关键词
为什么要使用 HELIUM 10 CEREBRO?
使用来自竞争对手的最新亚马逊数据
1 次搜索最多选择 10 个 ASINS!
快速过滤掉不相关的关键字
只选择排名最高的关键词
找到超过 1 个 ASIN 的关键字!
如何使用 HELIUM 10 CEREBRO?
在结果中搜索亚马逊以查找您销售的产品
运行 H10 X 射线
根据月销售额选择 10 个最畅销的 Best Selling
将他们的 ASINS 复制到 Cerebro
Cerebro IQ-搜索次数与搜索中竞争产品的数量
搜索量 - 每月搜索次数
Position – 这是亚马逊搜索结果中第一个 ASINS 关键字的位置
Ranking Competitors-该关键字排名的竞争对手数量
Relative Rank – 主要产品排名与其他产品相比排名有多高 竞争对手排名(平均)– 所有竞争产品的平均排名是多少
使用 FRANKENSTEIN 进行进一步处理
每行一个词,删除重复词,删除常用词,删除特殊字符等
因此,您只有一小段独特的高级关键字,可用于列出标题、项目符号、隐藏关键字、每次点击费用广告系列等。
这也是一种删除所有不需要的关键字的简单方法。
为什么要使用 Helium 10 磁铁?
使用来自亚马逊搜索引擎的当前数据
快速过滤掉不相关的关键字
只选择排名最高的关键词
这里,您想使用收录/排除的词组来获取最相关的关键字,并快速建立一个列表,然后在列表中使用。
如何使用免费工具更快地找到关键词
如果您还没有购买 Helium 10 工具,还有其他方法。
您可以使用竞争对手的关键字:
标题
产品功能亮点
将它们复制到文本编辑器,然后使用“查找/替换”删除所有不需要的字符,例如“-*&(]”等...
接下来,我们将使用一个名为“删除重复词”的工具
文本中的重复词/
点击原订单,该工具将删除所有重复的单词,并为您提供一个关键字列表。
将关键字复制到文本编辑器,并以每行一个字的方式排列
亚马逊多元应该如何运作?
允许您直接链接同一列表中的多个产品。然后,客户可以根据尺寸/颜色选择产品
创建亚马逊变体的规则
规则很简单
如果不遵守,将被视为违反政策
您可以在卖家中心创建或使用上传文件
您可以使用上传的文件链接现有产品
这通常会促进原本不会出售的产品的销售。
使用模板上传父子变体:
在创建父 SKU 之前,您需要为您的应用程序下载自定义模板产品。
选择类别并下载
浏览亚马逊产品
分类
使用搜索工具
选择所有合适的类别
完成后,点击生成模板
如何填写模板
在这里,您只需要选择可用的产品类型,它将为您预先填写。输入父 SKU、品牌名称、制造商和部件号(可以与 SKU 相同)。
对于标题,请确保它是通用的,而不是特定于尺寸或颜色。
如果您有 UPC/EAN 豁免,您可以将“产品 ID”和“产品 ID 类型”留空。
在变体设置下:
对于“Parent”,请将父子关系设置为“Parent”,并将“Change Theme”设置为“ColorName”或“Size”或“Size/ColorName”。
对于“父”设置为“子”的子项,添加父SKU,将关系类型设置为变体,并选择变体主题。
在基本设置下:
如果要新建父级,需要将更新删除选项设置为“update”(如果存在),然后设置为“PartialUpdate”
然后,您需要填写产品描述,选择推荐的浏览节点并输入型号。
请记住,如果要将现有商品添加到父商品,只需填写变体详细信息即可。
在发现设置下:
确保为子变体设置大小/颜色或两者,否则上传可能会失败
上传模板:
首先导航到产品上传页面。
在这里,您可以选择先检查模板以确保它没有错误。
满意请继续上传
别担心,如果失败,你会收到通知,你可以从上传报告中找出原因。 (来源:Amy Chat 跨境)
关键词自动采集软件如何节省网站收录排名的时间?
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-08-06 00:03
关键词自动采集软件是一款老牌网站全自动采集软件,软件使用非常方便,也不占用电脑内存空间,按操作提示一步步上传,很简单就可以自动上传大量网站,很好的节省网站收录排名的时间。1.首先点击软件的主界面“自动采集”功能按钮,然后依次点击左上角的“一键全自动”2.点击一键全自动后,系统将默认自动操作搜索引擎推荐方式,如下图所示,依次点击“请选择自动收录”->“请选择用于采集内容的自动引擎”->“请选择默认”3.如果一定要根据关键词来自己在选择收录方式,依次点击自定义关键词,然后点击“默认关键词”即可4.如果要选择完整网址,则依次点击默认链接->“根据请选择自动类型”->“网址截取”按钮5.如果选择完整网址后,还需要手动上传,则点击“默认网址”,然后点击“选择要上传的文件”按钮即可6.点击“保存”按钮后,文件将会保存在根目录内,并有效期内,如果没有上传则继续点击“下一步”,如果再次不上传则点击“下一步”7.如果还有要求的话,点击“关闭软件”按钮8.关闭软件之后,电脑即时会自动完成上传过程,我们可以再次点击“浏览查看”如果有多个关键词可选择,则多选择几个,我们点击“保存并下载”按钮即可,然后就可以点击浏览查看网站,软件会自动根据您的收录结果进行排名,出现在浏览器前列,如果不行再次点击“保存并下载”,直到上传成功为止如果还有要求可以加入社群,可以获得各种攻略和优惠券,注意不要提问,发红包。 查看全部
关键词自动采集软件如何节省网站收录排名的时间?
关键词自动采集软件是一款老牌网站全自动采集软件,软件使用非常方便,也不占用电脑内存空间,按操作提示一步步上传,很简单就可以自动上传大量网站,很好的节省网站收录排名的时间。1.首先点击软件的主界面“自动采集”功能按钮,然后依次点击左上角的“一键全自动”2.点击一键全自动后,系统将默认自动操作搜索引擎推荐方式,如下图所示,依次点击“请选择自动收录”->“请选择用于采集内容的自动引擎”->“请选择默认”3.如果一定要根据关键词来自己在选择收录方式,依次点击自定义关键词,然后点击“默认关键词”即可4.如果要选择完整网址,则依次点击默认链接->“根据请选择自动类型”->“网址截取”按钮5.如果选择完整网址后,还需要手动上传,则点击“默认网址”,然后点击“选择要上传的文件”按钮即可6.点击“保存”按钮后,文件将会保存在根目录内,并有效期内,如果没有上传则继续点击“下一步”,如果再次不上传则点击“下一步”7.如果还有要求的话,点击“关闭软件”按钮8.关闭软件之后,电脑即时会自动完成上传过程,我们可以再次点击“浏览查看”如果有多个关键词可选择,则多选择几个,我们点击“保存并下载”按钮即可,然后就可以点击浏览查看网站,软件会自动根据您的收录结果进行排名,出现在浏览器前列,如果不行再次点击“保存并下载”,直到上传成功为止如果还有要求可以加入社群,可以获得各种攻略和优惠券,注意不要提问,发红包。
如何批量下载网页里的数据?这些excel能让你提取信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-08-02 22:13
关键词自动采集的方法其实有很多种,包括如爬虫代理自动采集、web全文自动采集、excel自动采集等等一系列的方法。今天重点讲一下excel自动采集的方法。1.安装,快捷键是alt+shift+esc。2.设置采集的字段,可以手动设置,也可以通过公式设置。这里有一个技巧,直接把excel表格的采集名字输入到excel的一个筛选器里面,搜索框输入字段名字,就会自动勾选该字段。
3.查看数据文件,这里有三种方法,一种是隐藏,然后查看,一种是从表格的筛选器里查看,最后一种就是我这里用的方法:把筛选器设置文件。4.按住excel表格的鼠标右键,打开查看,可以看到有一个表头,把它们设置为上面的字段即可。5.我们去爬虫代理这里设置网页:例如我们爬虫羊博网的博客,可以用代理ip去爬取网页上的数据。
我们也可以用代理dns来爬取,例如新浪的数据采集,用西湖大学的代理dns就可以直接去新浪获取数据。6.完成自动采集之后,我们按返回alt+shift+esc就可以看到结果列表了。
可以参考相关文章。如何批量下载网页里的数据?这些excel能让你提取信息!1,使用爬虫代理下载2,去广告去水印软件。比如说墙外网站发布的无水印网站二维码,我想下载网站,就可以用迅雷扫描二维码下载。但是扫描二维码只能获取到http网站,没有权限,我们就可以用代理ip去获取http网站的数据。我用的是谷歌代理。
为什么要用谷歌代理呢?其实我们这里爬一个很普通的美剧,sherlock,然后上网搜索另外一个mannevilletar,就可以找到。 查看全部
如何批量下载网页里的数据?这些excel能让你提取信息
关键词自动采集的方法其实有很多种,包括如爬虫代理自动采集、web全文自动采集、excel自动采集等等一系列的方法。今天重点讲一下excel自动采集的方法。1.安装,快捷键是alt+shift+esc。2.设置采集的字段,可以手动设置,也可以通过公式设置。这里有一个技巧,直接把excel表格的采集名字输入到excel的一个筛选器里面,搜索框输入字段名字,就会自动勾选该字段。
3.查看数据文件,这里有三种方法,一种是隐藏,然后查看,一种是从表格的筛选器里查看,最后一种就是我这里用的方法:把筛选器设置文件。4.按住excel表格的鼠标右键,打开查看,可以看到有一个表头,把它们设置为上面的字段即可。5.我们去爬虫代理这里设置网页:例如我们爬虫羊博网的博客,可以用代理ip去爬取网页上的数据。
我们也可以用代理dns来爬取,例如新浪的数据采集,用西湖大学的代理dns就可以直接去新浪获取数据。6.完成自动采集之后,我们按返回alt+shift+esc就可以看到结果列表了。
可以参考相关文章。如何批量下载网页里的数据?这些excel能让你提取信息!1,使用爬虫代理下载2,去广告去水印软件。比如说墙外网站发布的无水印网站二维码,我想下载网站,就可以用迅雷扫描二维码下载。但是扫描二维码只能获取到http网站,没有权限,我们就可以用代理ip去获取http网站的数据。我用的是谷歌代理。
为什么要用谷歌代理呢?其实我们这里爬一个很普通的美剧,sherlock,然后上网搜索另外一个mannevilletar,就可以找到。
关键词自动采集以及词库的建立推荐使用工具箱
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-07-31 20:12
关键词自动采集以及词库的建立推荐使用利维坦工具箱,他的功能和易用性可以让你快速实现以上要求。而且很少有其他同类工具能做到语句规范,如果真的要自动化采集微博,那么最好自己写脚本实现以下功能:批量添加推广代码批量导入推广代码批量裁剪推广文案每个人用的工具不一样,可以根据自己情况调整。或者请别人写。
把效率、质量、个性化考虑进去的话,最有效的方法是使用一个可以自动采集微博的爬虫软件,比如知网或者维普之类的数据库,像楼上说的百度文库就行。
在大同小异的信息采集之外,工欲善其事必先利其器,掌握一些专门适用于微博数据的工具,可以为工作效率提升10倍。从众多的微博数据获取工具中,了解到一些对微博数据进行分析的工具,主要分为:自己搜集整理评测二手接入免费接入平台其中,对微博采集工具的合理评价是认识工具质量的关键,
1、工具对微博爬虫技术的支持程度;
2、爬虫采集效率;
3、爬虫分析及数据处理能力,即智能算法对文本处理的结果,
4、爬虫文本编辑能力,包括自动去除无效字符、自动重复抓取重复对象、多线程云存储等能力。推荐使用:推免联盟爬虫,以及使用在线爬虫服务对微博爬虫的评测可以参见这篇文章:大同小异的信息采集,为什么你的采集效率就是不够高?做数据采集工作,第一个要注意的是选取合适的采集工具。数据采集工具的优劣评测体系是比较复杂的,包括采集数据范围的数量、爬虫技术的支持程度、爬虫爬取效率和爬虫分析及数据处理能力等等。
在确定采集工具之前,最好熟悉一下这个工具支持哪些数据,目前支持哪些爬虫,有没有一些优势的数据。其次是根据自己的职位和产品的风格需求对数据采集工具进行选型,根据自己公司的产品特点进行选型。推免联盟爬虫是免费的工具,并且配备自己的爬虫库,爬虫用户不需要注册、不需要登录,同时对爬虫进行详细的操作指南,这样可以避免爬虫效率和质量跟不上的问题。 查看全部
关键词自动采集以及词库的建立推荐使用工具箱
关键词自动采集以及词库的建立推荐使用利维坦工具箱,他的功能和易用性可以让你快速实现以上要求。而且很少有其他同类工具能做到语句规范,如果真的要自动化采集微博,那么最好自己写脚本实现以下功能:批量添加推广代码批量导入推广代码批量裁剪推广文案每个人用的工具不一样,可以根据自己情况调整。或者请别人写。
把效率、质量、个性化考虑进去的话,最有效的方法是使用一个可以自动采集微博的爬虫软件,比如知网或者维普之类的数据库,像楼上说的百度文库就行。
在大同小异的信息采集之外,工欲善其事必先利其器,掌握一些专门适用于微博数据的工具,可以为工作效率提升10倍。从众多的微博数据获取工具中,了解到一些对微博数据进行分析的工具,主要分为:自己搜集整理评测二手接入免费接入平台其中,对微博采集工具的合理评价是认识工具质量的关键,
1、工具对微博爬虫技术的支持程度;
2、爬虫采集效率;
3、爬虫分析及数据处理能力,即智能算法对文本处理的结果,
4、爬虫文本编辑能力,包括自动去除无效字符、自动重复抓取重复对象、多线程云存储等能力。推荐使用:推免联盟爬虫,以及使用在线爬虫服务对微博爬虫的评测可以参见这篇文章:大同小异的信息采集,为什么你的采集效率就是不够高?做数据采集工作,第一个要注意的是选取合适的采集工具。数据采集工具的优劣评测体系是比较复杂的,包括采集数据范围的数量、爬虫技术的支持程度、爬虫爬取效率和爬虫分析及数据处理能力等等。
在确定采集工具之前,最好熟悉一下这个工具支持哪些数据,目前支持哪些爬虫,有没有一些优势的数据。其次是根据自己的职位和产品的风格需求对数据采集工具进行选型,根据自己公司的产品特点进行选型。推免联盟爬虫是免费的工具,并且配备自己的爬虫库,爬虫用户不需要注册、不需要登录,同时对爬虫进行详细的操作指南,这样可以避免爬虫效率和质量跟不上的问题。
关键词自动采集网站怎么做?百度指数怎么样?
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-07-26 18:22
关键词自动采集网站。比如说之类的,我们可以找到和这个产品相关的所有标题,然后分词处理,类似首页每个关键词,可以根据词的大小找到所有的关键词,然后我们就可以根据关键词去采集相关的标题了。这个是搜狗可以做到的。百度就不行了。
你都说“搜索相关”了还问有没有有什么办法。
求链接
了解一下百度指数吧
因为搜索功能就是百度的一个没必要的功能。如果想用,只要设置相关搜索就可以了。
是不是可以自动获取隐藏关键词或者手动添加隐藏关键词呀。
可以让搜狗自动挖掘关键词,百度你可以买一个搜狗统计插件,帮你自动挖掘(相当于定向获取)了所有与关键词相关的词,搜狗比百度做的优势是:精准。谷歌你可以靠自己投广告,但是广告费基本上要大量的铺网站,发外链。百度目前相对前几家,还有很大优势。
百度是按照关键词来算这个搜索词,比如,输入“飞机”“直升机”,搜狗是按照相关程度来算,一般相关度在90%以上的词才有相关性,一个关键词往往有好几百的词语组合,你说如何划分,
每个网站的情况不一样吧,我用谷歌和百度不是很专业。但这个问题很难,关键词太多,并且随着时间的推移,肯定都会变化,如果可以,新建一个计划, 查看全部
关键词自动采集网站怎么做?百度指数怎么样?
关键词自动采集网站。比如说之类的,我们可以找到和这个产品相关的所有标题,然后分词处理,类似首页每个关键词,可以根据词的大小找到所有的关键词,然后我们就可以根据关键词去采集相关的标题了。这个是搜狗可以做到的。百度就不行了。
你都说“搜索相关”了还问有没有有什么办法。
求链接
了解一下百度指数吧
因为搜索功能就是百度的一个没必要的功能。如果想用,只要设置相关搜索就可以了。
是不是可以自动获取隐藏关键词或者手动添加隐藏关键词呀。
可以让搜狗自动挖掘关键词,百度你可以买一个搜狗统计插件,帮你自动挖掘(相当于定向获取)了所有与关键词相关的词,搜狗比百度做的优势是:精准。谷歌你可以靠自己投广告,但是广告费基本上要大量的铺网站,发外链。百度目前相对前几家,还有很大优势。
百度是按照关键词来算这个搜索词,比如,输入“飞机”“直升机”,搜狗是按照相关程度来算,一般相关度在90%以上的词才有相关性,一个关键词往往有好几百的词语组合,你说如何划分,
每个网站的情况不一样吧,我用谷歌和百度不是很专业。但这个问题很难,关键词太多,并且随着时间的推移,肯定都会变化,如果可以,新建一个计划,
基于百度为例的读取数据库的处理方法和方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-07-21 03:26
以百度为例,思路如下:
1、搜主关键词,分析相关搜索链接,保存在URL数据库中,标记为未抓取。
2、读取数据库中标记为未抓取的URL,抓取后分析相关搜索,保存在URL数据库中,标记为未抓取。
3、Repeat 2 直到指定深度(一般流行的关键词6 层几乎都读取,一般关键词4 层就足够了,理论上无限层,但是需要抓取的数据量是分级的随着数字的增长,相关性越来越差,没有必要)。
4、 手动处理长尾词。这里需要手动去掉一些不相关的关键词,适当保留(目前搜索引擎的语义处理能力还很弱)。
至此,长尾关键词的处理基本完成,可以得到一个比较完整的长尾关键词列表。由于个人也需要研究关键词不同层级之间的关系,所以存储搜索结果的网页定义了父子关系,不同层级之间不过滤同一个关键词。这些对于查找长尾词不是很有用。 .
自动获取文件指定目标关键词的php实现见附件:spider_keywords
这是我自己的程序。它提供了一种实现方法。如果您打算使用它,则需要根据自己的使用环境进行修改。它需要 PHP 和 SQL 的知识。相关关键词分析提取等关键部分已经做的比较稳定,请放心使用。哪里:
mykeyword.dat 是一个用于存储关键词的文件,每行一个主关键词。
$depth为爬行深度,默认为5层,对于一般的关键词来说已经足够深了。
程序挖掘数据并将其存储在我的 PostgreSQL 数据库中。数据库默认为UTF-8编码,可根据实际需要修改。数据表结构如下:
– 表:mykeywords
– 删除表 mykeywords;
创建表 mykeywords
(id 序列号非空,
父文本,
“内容”文本,
儿子的文字,
深度文本,
键名文本,
备注文字,
is_spidered 布尔值,
约束 mykeywords_pkey PRIMARY KEY (id)
)
WITH (OIDS=FALSE);
将表 mykeywords 所有者更改为 postgres; 查看全部
基于百度为例的读取数据库的处理方法和方法
以百度为例,思路如下:
1、搜主关键词,分析相关搜索链接,保存在URL数据库中,标记为未抓取。
2、读取数据库中标记为未抓取的URL,抓取后分析相关搜索,保存在URL数据库中,标记为未抓取。
3、Repeat 2 直到指定深度(一般流行的关键词6 层几乎都读取,一般关键词4 层就足够了,理论上无限层,但是需要抓取的数据量是分级的随着数字的增长,相关性越来越差,没有必要)。
4、 手动处理长尾词。这里需要手动去掉一些不相关的关键词,适当保留(目前搜索引擎的语义处理能力还很弱)。
至此,长尾关键词的处理基本完成,可以得到一个比较完整的长尾关键词列表。由于个人也需要研究关键词不同层级之间的关系,所以存储搜索结果的网页定义了父子关系,不同层级之间不过滤同一个关键词。这些对于查找长尾词不是很有用。 .
自动获取文件指定目标关键词的php实现见附件:spider_keywords
这是我自己的程序。它提供了一种实现方法。如果您打算使用它,则需要根据自己的使用环境进行修改。它需要 PHP 和 SQL 的知识。相关关键词分析提取等关键部分已经做的比较稳定,请放心使用。哪里:
mykeyword.dat 是一个用于存储关键词的文件,每行一个主关键词。
$depth为爬行深度,默认为5层,对于一般的关键词来说已经足够深了。
程序挖掘数据并将其存储在我的 PostgreSQL 数据库中。数据库默认为UTF-8编码,可根据实际需要修改。数据表结构如下:
– 表:mykeywords
– 删除表 mykeywords;
创建表 mykeywords
(id 序列号非空,
父文本,
“内容”文本,
儿子的文字,
深度文本,
键名文本,
备注文字,
is_spidered 布尔值,
约束 mykeywords_pkey PRIMARY KEY (id)
)
WITH (OIDS=FALSE);
将表 mykeywords 所有者更改为 postgres;
配套软件版本:V9及更低集搜客网络爬虫软件新版本对应教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-07-13 23:03
支持软件版本:V9及更低版本的Jisuke网络爬虫软件
新版本对应教程:数据管理器V10及以上-增强版网络爬虫对应教程为《自动输入关键词采集搜索结果信息-以人民网搜索为例》
注:Jisouke的GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”改为“任务”。在爬虫浏览器中,先给任务命名然后创建规则,然后登录吉首可以查看任务的采集执行状态,管理线程URL,在“任务管理”中进行调度设置可客官网会员中心。
一、操作步骤
如果网页上有搜索框,但是搜索结果页没有单独的网址,而如果要采集搜索结果,直接规则是采集找不到,你必须先做一个连续的动作(输入+点击)来实现自动输入关键词并搜索,然后采集数据。下面以京东搜索为例,演示自动搜索采集。操作步骤如下:
二、Case规则+操作步骤
注意:在这种情况下,京东搜索有独立的网址。对于有独立网址的页面,最简单的方法是构造每个关键词搜索网址,然后将线索网址导入到规则中,就可以批量采集,而不是设置连续动作,可以参考《如何构造URL”和“如何管理规则线索”。
第一步:定义一级规则
1.1 打开极手客网络爬虫,输入网址回车,网页加载完毕后点击“定义规则”按钮。您将看到一个浮动窗口,称为工作台,您可以在其中定义规则;
注:此处截图及文字说明均为极手客网络爬虫版本。如果你安装的是火狐插件版本,那么没有“定义规则”按钮,但是你应该运行MS Museum。
1.2 在工作台输入一级规则的主题名称,然后点击“检查重复”,提示“此名称可用”或“名称已被占用,可编辑:是”,您可以使用此主题名称,否则请重命名。
1.3 这层规则主要是设置连续动作,所以排序框可以随意抓取一条信息,用它来判断是否为爬虫执行采集。双击网页上的信息,输入标签名称,勾选确认,然后勾选关键内容,输入第一个标签的排序框名称,标签映射完成。
提示:为了准确定位网页信息,点击定义规则会冻结整个网页,无法跳转到网页链接。再次点击定义规则,返回正常网页模式。
第 2 步:定义连续动作
点击工作台的“Continuous Action”选项卡,点击New按钮新建一个action,每个action的设置方法都是一样的,基本操作如下:
2.1,输入目标学科名称
这里的目标主题名称是填写二级主题名称,点击“谁在使用”查看目标主题名称是否可用,如果已经被占用,只需更改一个主题名称即可。
2.2,创建第一个动作:回车
创建一个新动作并选择动作类型作为输入。
2.2.1,填写定位表达式
首先点击输入框,定位输入框的节点,然后点击“Auto Generate XPath”按钮,可以选择“Preference id”或者“Preference class”,就可以得到输入的xpath表达式框,然后单击“搜索”按钮,检查这个xpath是否可以在输入框中唯一定位,如果没有问题,将xpath复制到定位表达式框中。
注意:定位表达式中的xpath是锁定动作对象的整个有效操作范围。具体是指鼠标可以点击或输入成功的网页模块。不要在底部找到 text() 节点。
2.2.2,输入关键词
输入关键词填写你要搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词使用双分号;;把每个关键词Separate,免费版只支持关键词5以内,旗舰版可以使用连发弹匣功能,支持关键词10000以内
2.2.3,输入动作名称
告诉自己这一步是做什么的,以便你以后可以修改。
2.3,创建第二个动作:点击
参考2.2的操作,创建第二个action,选择类型为click,定位搜索按钮,然后自动生成xpath检查是否锁定到唯一节点。如果没有问题,填写定位表达式。 .
2.4,保存规则
点击“保存规则”按钮保存完成的一级规则
第 3 步:定义二级规则
3.1,新建规则
创建二级规则,点击“定义规则”返回正常网页模式,输入关键词搜索结果,再次点击“定义规则”切换到规则制定模式,点击“左上角规则”菜单->“新建”,输入主题名称,其中主题名称是在第一级规则的连续动作中填写的目标主题名称。
3.2,标记你想要的信息采集
3.2.1,在网页上标记你要采集的信息,这里是产品名称和价格的标记,因为标记只对文本信息有效,链接到商品详情是属性节点@href,所以不能在链接上做这么直观的标记,要做内容映射,具体看下面的操作。
3.2.2,点击产品名称,下方的DOM节点定位到A标签,展开A标签下的属性节点,可以找到代表URL的@href节点,右键节点,并选择“New Capture”抓取内容,输入一个名字,一般给抓取到的内容取一个与地址相关的名字,比如“下级网址”,或者“下级链接”等等。然后在工作台上,我看到表示抓取到的内容是可用的。如果您还想进入商品详情页采集,必须对照抓取的内容检查下层线索,并进行分层抓取。
3.2.3、设置“关键内容”选项,让爬虫判断采集规则是否合适。在排序框中,选择网页上不可避免的标签,并勾选“关键内容”。这里选择“名称”作为“关键内容”。
3.2.4,只要在前面标注一个产品,就可以得到一个产品信息。如果你想采集整个页面上的每一个产品,你可以做一个样本复制,没有如果你明白,请参考基础教程“采集表数据”
3.3,设置翻页路线
设置爬虫路由中的翻页,这里是标记提示,不明白的请参考基础教程《设置翻页采集》
3.4,保存规则
点击“测试”以检查信息的完整性。如果不完整,重新标记可以覆盖之前的内容。确认没有问题后,点击“保存规则”。
第 4 步:捕获数据
4.1,连续动作是连续执行的,所以只要运行一级主题,二级主题就不需要运行了。打开DS计数器,搜索一级话题名称,点击“单次搜索”或“采集”,可以看到在浏览器窗口中自动输入并搜索关键词,然后调用二级话题自动采集搜索结果。
4.2,一级话题没有采集到有意义的信息,所以我们只看二级话题文件夹,可以看到采集的搜索结果数据,搜索关键词是默认记录在xml文件的actionvalue字段中,这样可以一一匹配。
第 1 部分文章:“连续动作的概念:掌握 JS 动态 Web 信息采集”第 2 部分 文章:“连续动作:自动选择下拉菜单采集Data”
如果您有任何问题,可以或
查看全部
配套软件版本:V9及更低集搜客网络爬虫软件新版本对应教程
支持软件版本:V9及更低版本的Jisuke网络爬虫软件
新版本对应教程:数据管理器V10及以上-增强版网络爬虫对应教程为《自动输入关键词采集搜索结果信息-以人民网搜索为例》
注:Jisouke的GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”改为“任务”。在爬虫浏览器中,先给任务命名然后创建规则,然后登录吉首可以查看任务的采集执行状态,管理线程URL,在“任务管理”中进行调度设置可客官网会员中心。
一、操作步骤
如果网页上有搜索框,但是搜索结果页没有单独的网址,而如果要采集搜索结果,直接规则是采集找不到,你必须先做一个连续的动作(输入+点击)来实现自动输入关键词并搜索,然后采集数据。下面以京东搜索为例,演示自动搜索采集。操作步骤如下:
二、Case规则+操作步骤
注意:在这种情况下,京东搜索有独立的网址。对于有独立网址的页面,最简单的方法是构造每个关键词搜索网址,然后将线索网址导入到规则中,就可以批量采集,而不是设置连续动作,可以参考《如何构造URL”和“如何管理规则线索”。
第一步:定义一级规则
1.1 打开极手客网络爬虫,输入网址回车,网页加载完毕后点击“定义规则”按钮。您将看到一个浮动窗口,称为工作台,您可以在其中定义规则;
注:此处截图及文字说明均为极手客网络爬虫版本。如果你安装的是火狐插件版本,那么没有“定义规则”按钮,但是你应该运行MS Museum。
1.2 在工作台输入一级规则的主题名称,然后点击“检查重复”,提示“此名称可用”或“名称已被占用,可编辑:是”,您可以使用此主题名称,否则请重命名。
1.3 这层规则主要是设置连续动作,所以排序框可以随意抓取一条信息,用它来判断是否为爬虫执行采集。双击网页上的信息,输入标签名称,勾选确认,然后勾选关键内容,输入第一个标签的排序框名称,标签映射完成。
提示:为了准确定位网页信息,点击定义规则会冻结整个网页,无法跳转到网页链接。再次点击定义规则,返回正常网页模式。
第 2 步:定义连续动作
点击工作台的“Continuous Action”选项卡,点击New按钮新建一个action,每个action的设置方法都是一样的,基本操作如下:
2.1,输入目标学科名称
这里的目标主题名称是填写二级主题名称,点击“谁在使用”查看目标主题名称是否可用,如果已经被占用,只需更改一个主题名称即可。
2.2,创建第一个动作:回车
创建一个新动作并选择动作类型作为输入。
2.2.1,填写定位表达式
首先点击输入框,定位输入框的节点,然后点击“Auto Generate XPath”按钮,可以选择“Preference id”或者“Preference class”,就可以得到输入的xpath表达式框,然后单击“搜索”按钮,检查这个xpath是否可以在输入框中唯一定位,如果没有问题,将xpath复制到定位表达式框中。
注意:定位表达式中的xpath是锁定动作对象的整个有效操作范围。具体是指鼠标可以点击或输入成功的网页模块。不要在底部找到 text() 节点。
2.2.2,输入关键词
输入关键词填写你要搜索的关键词,可以输入一个关键词,也可以输入多个关键词,输入多个关键词使用双分号;;把每个关键词Separate,免费版只支持关键词5以内,旗舰版可以使用连发弹匣功能,支持关键词10000以内
2.2.3,输入动作名称
告诉自己这一步是做什么的,以便你以后可以修改。
2.3,创建第二个动作:点击
参考2.2的操作,创建第二个action,选择类型为click,定位搜索按钮,然后自动生成xpath检查是否锁定到唯一节点。如果没有问题,填写定位表达式。 .
2.4,保存规则
点击“保存规则”按钮保存完成的一级规则
第 3 步:定义二级规则
3.1,新建规则
创建二级规则,点击“定义规则”返回正常网页模式,输入关键词搜索结果,再次点击“定义规则”切换到规则制定模式,点击“左上角规则”菜单->“新建”,输入主题名称,其中主题名称是在第一级规则的连续动作中填写的目标主题名称。
3.2,标记你想要的信息采集
3.2.1,在网页上标记你要采集的信息,这里是产品名称和价格的标记,因为标记只对文本信息有效,链接到商品详情是属性节点@href,所以不能在链接上做这么直观的标记,要做内容映射,具体看下面的操作。
3.2.2,点击产品名称,下方的DOM节点定位到A标签,展开A标签下的属性节点,可以找到代表URL的@href节点,右键节点,并选择“New Capture”抓取内容,输入一个名字,一般给抓取到的内容取一个与地址相关的名字,比如“下级网址”,或者“下级链接”等等。然后在工作台上,我看到表示抓取到的内容是可用的。如果您还想进入商品详情页采集,必须对照抓取的内容检查下层线索,并进行分层抓取。
3.2.3、设置“关键内容”选项,让爬虫判断采集规则是否合适。在排序框中,选择网页上不可避免的标签,并勾选“关键内容”。这里选择“名称”作为“关键内容”。
3.2.4,只要在前面标注一个产品,就可以得到一个产品信息。如果你想采集整个页面上的每一个产品,你可以做一个样本复制,没有如果你明白,请参考基础教程“采集表数据”
3.3,设置翻页路线
设置爬虫路由中的翻页,这里是标记提示,不明白的请参考基础教程《设置翻页采集》
3.4,保存规则
点击“测试”以检查信息的完整性。如果不完整,重新标记可以覆盖之前的内容。确认没有问题后,点击“保存规则”。
第 4 步:捕获数据
4.1,连续动作是连续执行的,所以只要运行一级主题,二级主题就不需要运行了。打开DS计数器,搜索一级话题名称,点击“单次搜索”或“采集”,可以看到在浏览器窗口中自动输入并搜索关键词,然后调用二级话题自动采集搜索结果。
4.2,一级话题没有采集到有意义的信息,所以我们只看二级话题文件夹,可以看到采集的搜索结果数据,搜索关键词是默认记录在xml文件的actionvalue字段中,这样可以一一匹配。
第 1 部分文章:“连续动作的概念:掌握 JS 动态 Web 信息采集”第 2 部分 文章:“连续动作:自动选择下拉菜单采集Data”
如果您有任何问题,可以或
企业开展舆情监测,是为了更好的开展业务决策
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-07-10 18:03
企业进行舆情监测,以更好地做出业务决策。通过监测自身、客户、渠道商、供应链、监管政策、竞争对手等不同群体的舆情,为研发、营销、销售等方面的战略制定提供客观依据。
01 主流企业舆情监测程序
目前的舆情监测程序,虽然在外观上可以有很酷的视觉效果,但底层是爬虫爬行和关键词匹配,辅以人工写报告,这是基本的操作模式。
在市场上,这种运作方式体现在:舆论产品和服务的价格由目标数量关键词决定;舆情系统的输入是一组手动配置并持续维护的关键词和布尔逻辑组合;当舆情系统的输出细化到每一条匹配的新闻或用户生成的内容时,就是某个关键词匹配的结果。
以下以网上公开的三个不同舆论厂商的产品界面为例(图1-1至图1-3):
图1-1 A系统界面:通过关键词管理实现舆情监控
图1-2 B的系统界面:将关键词组合成舆情监控条目
图1-3 C系统界面:可以选择检测类型,但只能手动添加相关词
显然,这种模式有明显的缺陷。基于关键词匹配的模式不能满足以下常见需求:
比如一个企业可能有上千个渠道和终端客户,舆情系统不能把每一个都搜索为关键词,然后将不同的关键词的结果合并,这样会造成爆款信息,系统用户每天要翻成百上千页,如何区分这些关键词,以及每个关键词的权重,然后排序,很重要。
再比如,在分析某个客户或竞争对手时,需要自动找出所有与该目标相关的目标,例如下属公司和部门、员工、股份公司和股东。这些很难通过关键词一一列举,并指明关联的类别,因为这些目标实际上构成了一个关系网络,需要探索网络结构。
另外,关键词和企业业务的关系也很密切。如何将每个关键词的结果结合起来,满足业务场景的需求,技术难度较大,导致现有很多舆情产品的准确率很低。 关键词似乎有很多匹配,或者很酷的视觉效果,但是当你仔细阅读,或者点击底部,你会发现匹配的网页要么不准确,要么大部分没用。
这是目前主流舆论产品解决方案无法满足企业舆论场景客户需求的主要原因。
02 理想的企业舆情监测方案
为企业提供理想的舆情监测方案,需要从客户的需求出发,解决以下问题:
Look a lot:在企业舆论场景中,客户关注的子公司、员工、客户、分销商、供应链、竞争对手、监管机构等目标可能有上千个。有必要汇总所有这些目标的内容并确定它们的优先级。排序。
仔细看:无论是分析竞争对手的行为,分析潜在客户的购买意向和竞标机会,还是分析政府和主管部门的监管政策,都需要将信息按照上百种类型进行分类。对舆论的业务场景和使用的部门按需推送。
放眼远方:对于关键词定义的未知或不可用的查询目标,例如对于供应链中的一家公司,甚至其所在园区的生产事故,数百个千分之一的客户都包括在内在不诚实的人名单等中。这些间接但重要的信息需要远远地看到。
当然,在易用性方面,解决方案还必须在舆情结果的可视化以及内容和用户的管理方面达到一定的标准。例如,不同目标、不同维度的分析结果需要以交互式可视化报表的形式展示;不同部门的人员可以以不同的权限读取数据。除了SAAS,还应该有手机甚至微信的推送。
我们使用以下一组舆情分析示例来说明理想的舆情监测系统应该是什么样子:
图2-1 盐城化工园区爆炸
如果这是舆论系统第一次看到的内容(图2-1):2019年3月21日下午,江苏省盐城市响水县陈家港镇发生爆炸。
p>
图2-2 爆炸对园区企业的影响
那么舆论系统应该会预测到3月21日这个3月25日的报道(图2-2):在工厂所在的园区,联华科技的两家子公司也将受到两家子公司停产的影响,联华科技部分产品延迟出货,3月22日一开市,联华科技股价几乎跌至跌停。
图2-3 爆发对竞争企业的影响
一个理想的舆论系统不仅可以预测3月25日的上述消息,还可以预测3月22日的报道内容(图2-3):事故直接影响国内间苯二胺)价格另一家供应商浙江龙盛将大幅上涨。
在技术手段上,要达到这样的理想效果,舆情策划需要基于知识图谱和认知推理,体现在以下几个方面:
使用目标的关系网络而不是目标名称作为关键词来匹配爬虫获取的信息。例如,分析一家大公司的动态,需要自动识别该公司所有的员工、后代、公司、园区、生产的产品等,并进一步扩大关系网络进行匹配。目标的关系网络需要自动提取和构建,无论是从在目标机构工作的新闻媒体和入驻企业中提取客户关系,还是从中标结果中提取客户关系,还是从中标结果中提取客户关系。现有商业信息数据库和学术文献 在图书馆获取股东关系、合著者关系、任命关系等。情报的筛选需要一定的因果推理和相关性分析步骤,而不是字面上的匹配关键词的文字,比如推理某地大火是否影响某家公司,推理是否有公开招标机会等。适合某公司,推断出事故的官员是否会涉及公司等。 03 企业头条:定制企业舆论头条
企业头条是基于自主研发的TML认知计算平台的企业级智能搜索产品。旨在帮助企业自动关注大量目标客户、分销商、竞争对手和监管机构,订阅有趣的智能场景和模式,以SAAS的形式可视化和浏览,使用手机和H5应用。阅读和推送。
它具有以下特点:
(1)采用知识图谱技术,用图表达舆情关注。采集和舆情分析时,目标是基础监测单元,而不是关键词,目标动态是自动发现(图3-1)。全面覆盖目标组织及其相关组织和相关任务的舆情,使其全面可见。
图3-1 采集目标周围的舆论,自动找到对应的关键词,并自动添加关键词
(2)是面向业务的,细分智能模型,不同场景监控不同方面(图3-2到图3-4)。比如园区的商业形象和企业风险监测 前者主要监测公共交通、企业管理、生产事故等,后者监测市场活动和盈利能力,根据舆情和客户需求的业务场景,将信息分为几种推送,以便可以实现仔细看。
图3-2 行业动态从行业标准和行业活动维度采集和分析信息;
图3-3 从投资收购、机构调整等维度对竞争对手动态信息采集与分析;
图3-从调研、技术研发等维度采集并分析自身动态;
(3)通过挖掘目标关系网络自动发现相关机构和关键词及相关路径,并将自动发现的相关组织加入目标关系网络进行新一轮关系挖掘。用户也有你可以根据需要在SAAS端上传多个目标组织,挖矿得到的关系网可以在SAAS端查看(图3-5)和移动端(图3-6))。这个可以挖排除未知查询。定位和监控舆论,以实现远见卓识。
图3-5 SAAS可以查看组织的关联企业,随着关系的探索不断增加新的组织
图3-6 通过目标的关系网络进行匹配,给出关联路径,手机也可以查看
(4)最终结果准确、权威、可读性强,可以自动形成报告并以头条的形式呈现在PC端和手机端。当然,也可以根据需要自定义呈现方式企业需求,例如挂在客户公众号和小程序SAAS端(图3-7)舆情概览和手机端(图3-8)首页概览,用户可根据实际情况选择)需要,也可以根据公司的要求来定制。
图3-7 SAAS端自动生成的舆情概览页面
图3-8 移动端自动生成舆情概览页面04 使用和服务方式
免费版
“企业头条”提供免费版,可以满足企业自身风险监控的基本需求。以公司自身及相关人员、机构、地点为监控目标组织,深入挖掘目标关系网络。
每个目标组织最多可自动发现30个关联公司和关联人,从违法违规、法律诉讼、个人风险等多个维度监控其风险事件,并利用现有的舆论结果用于统计的H5首页Report格式。
标准版
当客户需要对上千个目标进行舆情监测时,可以选择企业头条标准版,涵盖了免费版的所有功能,但在性能和功能方面有更大的容量。
例如,支持上传包括公司自身在内的1000个目标组织,在挖掘目标关系网络的同时,每个目标组织可以自动发现多达30个关联公司,从违法违规、法律诉讼到个人风险。多维度全方位监控风险事件。
在信息来源方面,增加微博、微信公众号和众多自媒体数据源,让舆情监测更加全面。标准版还提供了SAAS版的操作界面。客户可以根据需要自定义目标、智能模式和可视化报告,并管理内容、读者和数据。
高级定制版
当企业客户有更高级的舆情监控需求时,例如将采集的数据存储在本地,针对特定的网站甚至国外的网站进行采集,定制行业领域的智能分析模式时,标准版的“企业头条”无法满足需求。此时,您可以选择我们提供的高级版定制开发和服务。
客户甚至可以自己命名舆论产品,包括小程序、Android应用、IOS应用等。高级版的价格根据客户的需求而有所不同。 查看全部
企业开展舆情监测,是为了更好的开展业务决策
企业进行舆情监测,以更好地做出业务决策。通过监测自身、客户、渠道商、供应链、监管政策、竞争对手等不同群体的舆情,为研发、营销、销售等方面的战略制定提供客观依据。
01 主流企业舆情监测程序
目前的舆情监测程序,虽然在外观上可以有很酷的视觉效果,但底层是爬虫爬行和关键词匹配,辅以人工写报告,这是基本的操作模式。
在市场上,这种运作方式体现在:舆论产品和服务的价格由目标数量关键词决定;舆情系统的输入是一组手动配置并持续维护的关键词和布尔逻辑组合;当舆情系统的输出细化到每一条匹配的新闻或用户生成的内容时,就是某个关键词匹配的结果。
以下以网上公开的三个不同舆论厂商的产品界面为例(图1-1至图1-3):
图1-1 A系统界面:通过关键词管理实现舆情监控
图1-2 B的系统界面:将关键词组合成舆情监控条目
图1-3 C系统界面:可以选择检测类型,但只能手动添加相关词
显然,这种模式有明显的缺陷。基于关键词匹配的模式不能满足以下常见需求:
比如一个企业可能有上千个渠道和终端客户,舆情系统不能把每一个都搜索为关键词,然后将不同的关键词的结果合并,这样会造成爆款信息,系统用户每天要翻成百上千页,如何区分这些关键词,以及每个关键词的权重,然后排序,很重要。
再比如,在分析某个客户或竞争对手时,需要自动找出所有与该目标相关的目标,例如下属公司和部门、员工、股份公司和股东。这些很难通过关键词一一列举,并指明关联的类别,因为这些目标实际上构成了一个关系网络,需要探索网络结构。
另外,关键词和企业业务的关系也很密切。如何将每个关键词的结果结合起来,满足业务场景的需求,技术难度较大,导致现有很多舆情产品的准确率很低。 关键词似乎有很多匹配,或者很酷的视觉效果,但是当你仔细阅读,或者点击底部,你会发现匹配的网页要么不准确,要么大部分没用。
这是目前主流舆论产品解决方案无法满足企业舆论场景客户需求的主要原因。
02 理想的企业舆情监测方案
为企业提供理想的舆情监测方案,需要从客户的需求出发,解决以下问题:
Look a lot:在企业舆论场景中,客户关注的子公司、员工、客户、分销商、供应链、竞争对手、监管机构等目标可能有上千个。有必要汇总所有这些目标的内容并确定它们的优先级。排序。
仔细看:无论是分析竞争对手的行为,分析潜在客户的购买意向和竞标机会,还是分析政府和主管部门的监管政策,都需要将信息按照上百种类型进行分类。对舆论的业务场景和使用的部门按需推送。
放眼远方:对于关键词定义的未知或不可用的查询目标,例如对于供应链中的一家公司,甚至其所在园区的生产事故,数百个千分之一的客户都包括在内在不诚实的人名单等中。这些间接但重要的信息需要远远地看到。
当然,在易用性方面,解决方案还必须在舆情结果的可视化以及内容和用户的管理方面达到一定的标准。例如,不同目标、不同维度的分析结果需要以交互式可视化报表的形式展示;不同部门的人员可以以不同的权限读取数据。除了SAAS,还应该有手机甚至微信的推送。
我们使用以下一组舆情分析示例来说明理想的舆情监测系统应该是什么样子:
图2-1 盐城化工园区爆炸
如果这是舆论系统第一次看到的内容(图2-1):2019年3月21日下午,江苏省盐城市响水县陈家港镇发生爆炸。
p>
图2-2 爆炸对园区企业的影响
那么舆论系统应该会预测到3月21日这个3月25日的报道(图2-2):在工厂所在的园区,联华科技的两家子公司也将受到两家子公司停产的影响,联华科技部分产品延迟出货,3月22日一开市,联华科技股价几乎跌至跌停。
图2-3 爆发对竞争企业的影响
一个理想的舆论系统不仅可以预测3月25日的上述消息,还可以预测3月22日的报道内容(图2-3):事故直接影响国内间苯二胺)价格另一家供应商浙江龙盛将大幅上涨。
在技术手段上,要达到这样的理想效果,舆情策划需要基于知识图谱和认知推理,体现在以下几个方面:
使用目标的关系网络而不是目标名称作为关键词来匹配爬虫获取的信息。例如,分析一家大公司的动态,需要自动识别该公司所有的员工、后代、公司、园区、生产的产品等,并进一步扩大关系网络进行匹配。目标的关系网络需要自动提取和构建,无论是从在目标机构工作的新闻媒体和入驻企业中提取客户关系,还是从中标结果中提取客户关系,还是从中标结果中提取客户关系。现有商业信息数据库和学术文献 在图书馆获取股东关系、合著者关系、任命关系等。情报的筛选需要一定的因果推理和相关性分析步骤,而不是字面上的匹配关键词的文字,比如推理某地大火是否影响某家公司,推理是否有公开招标机会等。适合某公司,推断出事故的官员是否会涉及公司等。 03 企业头条:定制企业舆论头条
企业头条是基于自主研发的TML认知计算平台的企业级智能搜索产品。旨在帮助企业自动关注大量目标客户、分销商、竞争对手和监管机构,订阅有趣的智能场景和模式,以SAAS的形式可视化和浏览,使用手机和H5应用。阅读和推送。
它具有以下特点:
(1)采用知识图谱技术,用图表达舆情关注。采集和舆情分析时,目标是基础监测单元,而不是关键词,目标动态是自动发现(图3-1)。全面覆盖目标组织及其相关组织和相关任务的舆情,使其全面可见。
图3-1 采集目标周围的舆论,自动找到对应的关键词,并自动添加关键词
(2)是面向业务的,细分智能模型,不同场景监控不同方面(图3-2到图3-4)。比如园区的商业形象和企业风险监测 前者主要监测公共交通、企业管理、生产事故等,后者监测市场活动和盈利能力,根据舆情和客户需求的业务场景,将信息分为几种推送,以便可以实现仔细看。
图3-2 行业动态从行业标准和行业活动维度采集和分析信息;
图3-3 从投资收购、机构调整等维度对竞争对手动态信息采集与分析;
图3-从调研、技术研发等维度采集并分析自身动态;
(3)通过挖掘目标关系网络自动发现相关机构和关键词及相关路径,并将自动发现的相关组织加入目标关系网络进行新一轮关系挖掘。用户也有你可以根据需要在SAAS端上传多个目标组织,挖矿得到的关系网可以在SAAS端查看(图3-5)和移动端(图3-6))。这个可以挖排除未知查询。定位和监控舆论,以实现远见卓识。
图3-5 SAAS可以查看组织的关联企业,随着关系的探索不断增加新的组织
图3-6 通过目标的关系网络进行匹配,给出关联路径,手机也可以查看
(4)最终结果准确、权威、可读性强,可以自动形成报告并以头条的形式呈现在PC端和手机端。当然,也可以根据需要自定义呈现方式企业需求,例如挂在客户公众号和小程序SAAS端(图3-7)舆情概览和手机端(图3-8)首页概览,用户可根据实际情况选择)需要,也可以根据公司的要求来定制。
图3-7 SAAS端自动生成的舆情概览页面
图3-8 移动端自动生成舆情概览页面04 使用和服务方式
免费版
“企业头条”提供免费版,可以满足企业自身风险监控的基本需求。以公司自身及相关人员、机构、地点为监控目标组织,深入挖掘目标关系网络。
每个目标组织最多可自动发现30个关联公司和关联人,从违法违规、法律诉讼、个人风险等多个维度监控其风险事件,并利用现有的舆论结果用于统计的H5首页Report格式。
标准版
当客户需要对上千个目标进行舆情监测时,可以选择企业头条标准版,涵盖了免费版的所有功能,但在性能和功能方面有更大的容量。
例如,支持上传包括公司自身在内的1000个目标组织,在挖掘目标关系网络的同时,每个目标组织可以自动发现多达30个关联公司,从违法违规、法律诉讼到个人风险。多维度全方位监控风险事件。
在信息来源方面,增加微博、微信公众号和众多自媒体数据源,让舆情监测更加全面。标准版还提供了SAAS版的操作界面。客户可以根据需要自定义目标、智能模式和可视化报告,并管理内容、读者和数据。
高级定制版
当企业客户有更高级的舆情监控需求时,例如将采集的数据存储在本地,针对特定的网站甚至国外的网站进行采集,定制行业领域的智能分析模式时,标准版的“企业头条”无法满足需求。此时,您可以选择我们提供的高级版定制开发和服务。
客户甚至可以自己命名舆论产品,包括小程序、Android应用、IOS应用等。高级版的价格根据客户的需求而有所不同。
关键词自动采集各大网站的搜索页面是这个?
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-07-08 23:02
关键词自动采集各大网站的搜索关键词。比如,手动采集百度,谷歌的关键词,筛选词语。今天要分享的一个关键词工具,是自动从各大网站,比如:qq,搜狗,360等搜索引擎中采集我们需要的关键词。方法特别简单,我把它的安装过程,讲给大家。采集网站上的关键词词语自动采集的页面是这个?如何操作?可以看我们关键词库的pdf文件,【复制链接,复制网址】可以点击关键词工具就是:从网站上采集关键词词语。
导入文件“关键词的自动提取.docx”(也可在公众号内回复:关键词工具,获取)。就可以看到自动关键词提取结果,比如,我要提取“律师”这个关键词,点击关键词工具,选择“从网站采集关键词”,就可以看到我们需要的关键词词语。我们怎么修改呢?以“合同写作”这个关键词为例子。操作也特别简单。在网站的采集页面,拖动你需要采集的词语,点击“属性”,修改词语的字段,点击“粘贴”就可以导入。
我在google上搜索了一下“电子合同写作”这个关键词,发现谷歌,360,搜狗,百度,bing,维基等各大网站都有相关关键词;在上搜索发现店家,小二,代写电子合同,签约代写电子合同等关键词在搜索引擎上,是我们需要采集的词语;在微信公众号中,也可以直接搜索“合同写作”。同样,一个网站采集上10个词语,成本就差不多10块钱,效率能提高三倍多。
,代写等关键词数据采集公众号:yaotech2013回复:关键词工具,就可以获取上述操作关键词工具的安装教程。 查看全部
关键词自动采集各大网站的搜索页面是这个?
关键词自动采集各大网站的搜索关键词。比如,手动采集百度,谷歌的关键词,筛选词语。今天要分享的一个关键词工具,是自动从各大网站,比如:qq,搜狗,360等搜索引擎中采集我们需要的关键词。方法特别简单,我把它的安装过程,讲给大家。采集网站上的关键词词语自动采集的页面是这个?如何操作?可以看我们关键词库的pdf文件,【复制链接,复制网址】可以点击关键词工具就是:从网站上采集关键词词语。
导入文件“关键词的自动提取.docx”(也可在公众号内回复:关键词工具,获取)。就可以看到自动关键词提取结果,比如,我要提取“律师”这个关键词,点击关键词工具,选择“从网站采集关键词”,就可以看到我们需要的关键词词语。我们怎么修改呢?以“合同写作”这个关键词为例子。操作也特别简单。在网站的采集页面,拖动你需要采集的词语,点击“属性”,修改词语的字段,点击“粘贴”就可以导入。
我在google上搜索了一下“电子合同写作”这个关键词,发现谷歌,360,搜狗,百度,bing,维基等各大网站都有相关关键词;在上搜索发现店家,小二,代写电子合同,签约代写电子合同等关键词在搜索引擎上,是我们需要采集的词语;在微信公众号中,也可以直接搜索“合同写作”。同样,一个网站采集上10个词语,成本就差不多10块钱,效率能提高三倍多。
,代写等关键词数据采集公众号:yaotech2013回复:关键词工具,就可以获取上述操作关键词工具的安装教程。
爱聚合关键词自动聚合数据的CMS插件制作经验分享
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-06-27 05:09
分享Kexun文章,图片、动画、视频、问答基于关键词自动聚合数据cmsplugin制作经验分享。
很多爱居的站长朋友都熟悉优采云。很多站长朋友也非常熟悉。当然,使用科讯cms的朋友更熟悉科讯的采集系统。对于科讯的后端,我们不能否认它是非常强大的,但是它缺少一个功能——问答采集(这个功能对启用了问答系统的用户很有用)。在建站初期,我们经常会采集一些数据,然后我们去手动添加数据,伪原创数据。很多站长没时间就放弃了每日更新,因为前期看不到网站的流量。所以百度爬虫或者其他搜索引擎爬虫是吃不下新数据的,所以很多朋友都在想我们。可以进行自动采集或自动聚合吗?
很多朋友说我们要以任何形式对内容进行伪原创或原创,这对网站的权重或关键词的排名都有帮助。没有错,这是我的问题。一开始我在想是自动改变关键词的标题或者程序来达到想要的效果,还是通过其他形式的改变来达到效果。后来我通过和()查询总结了结果:其实百度索引是人们在网上寻找自己想要的信息的搜索习惯的总结,当然也是对用户体验的概括总结和归纳。那么如果我们在标题前面添加一个与内容密切相关的索引,是否被认为是标题的伪原创?它对网站 内容有帮助吗?答案是肯定的。
所以启发我开发了一个基于Kexuncms文章的插件,图片,动画,视频,问答。根据关键词自动聚合插件的兴趣,也算是一种尝试。我每天下班回家都会开发这个插件。经过整整一周的努力,网站终于可以上线测试了。自从网站上线以来,今天的流量明显增加(见统计图),所以写了这样一篇文章文章和科讯的网友一起来分享。
统计图(2011-01-16 9:23截图)
废话不多说,先介绍一下这个聚合插件的思路:
l 整个站点只需要为每一列和对应的问题添加一个索引关键词
l 索引词会自动进行由事件(手动访问、搜索引擎爬虫访问)触发的数据(文章、图片、动画、视频、问答)聚合。数据聚合过程是分布式的,所以不会耽误网站的速度。
l 当索引词聚合时,程序会根据索引词自动聚合相关的热点索引关键词,然后程序会再次根据索引词进行数据聚合或执行该索引的数据索引词根据上一个索引。更新。这个过程就是随机选择关键词来执行任务。
l 数据来源基本上是来自博客、门户和专业社区的信息。目前数据源总计超过120个网站,这不仅仅是从单一数据源中提取简单的数据。只是动画现在因为时间关系只聚合优酷的视频信息(没时间做,但是接口已经预留,后期效果好开发)。
l 所有标题都在标题伪原创之前添加了一个流行指数词。详情可查看内容页面。
l 在所有内容页下方为网站创建热度索引,作为列表的循环(其实也就是大家所说的网站重重传)。
l 在内容中加入索引词作为内链,也是为关键词日后的排名做准备。
l 所有图片均为伪造,通过伪静态以本地图片地址方式显示远程图片地址。
<p>科讯后台修改的主要管理页面有:KS.Class.asp、KS.Article.asp、KS.Picture.asp、KS.Movie.asp、KS.Asklist.asp、KS.Special.asp 查看全部
爱聚合关键词自动聚合数据的CMS插件制作经验分享
分享Kexun文章,图片、动画、视频、问答基于关键词自动聚合数据cmsplugin制作经验分享。
很多爱居的站长朋友都熟悉优采云。很多站长朋友也非常熟悉。当然,使用科讯cms的朋友更熟悉科讯的采集系统。对于科讯的后端,我们不能否认它是非常强大的,但是它缺少一个功能——问答采集(这个功能对启用了问答系统的用户很有用)。在建站初期,我们经常会采集一些数据,然后我们去手动添加数据,伪原创数据。很多站长没时间就放弃了每日更新,因为前期看不到网站的流量。所以百度爬虫或者其他搜索引擎爬虫是吃不下新数据的,所以很多朋友都在想我们。可以进行自动采集或自动聚合吗?
很多朋友说我们要以任何形式对内容进行伪原创或原创,这对网站的权重或关键词的排名都有帮助。没有错,这是我的问题。一开始我在想是自动改变关键词的标题或者程序来达到想要的效果,还是通过其他形式的改变来达到效果。后来我通过和()查询总结了结果:其实百度索引是人们在网上寻找自己想要的信息的搜索习惯的总结,当然也是对用户体验的概括总结和归纳。那么如果我们在标题前面添加一个与内容密切相关的索引,是否被认为是标题的伪原创?它对网站 内容有帮助吗?答案是肯定的。
所以启发我开发了一个基于Kexuncms文章的插件,图片,动画,视频,问答。根据关键词自动聚合插件的兴趣,也算是一种尝试。我每天下班回家都会开发这个插件。经过整整一周的努力,网站终于可以上线测试了。自从网站上线以来,今天的流量明显增加(见统计图),所以写了这样一篇文章文章和科讯的网友一起来分享。
统计图(2011-01-16 9:23截图)
废话不多说,先介绍一下这个聚合插件的思路:
l 整个站点只需要为每一列和对应的问题添加一个索引关键词
l 索引词会自动进行由事件(手动访问、搜索引擎爬虫访问)触发的数据(文章、图片、动画、视频、问答)聚合。数据聚合过程是分布式的,所以不会耽误网站的速度。
l 当索引词聚合时,程序会根据索引词自动聚合相关的热点索引关键词,然后程序会再次根据索引词进行数据聚合或执行该索引的数据索引词根据上一个索引。更新。这个过程就是随机选择关键词来执行任务。
l 数据来源基本上是来自博客、门户和专业社区的信息。目前数据源总计超过120个网站,这不仅仅是从单一数据源中提取简单的数据。只是动画现在因为时间关系只聚合优酷的视频信息(没时间做,但是接口已经预留,后期效果好开发)。
l 所有标题都在标题伪原创之前添加了一个流行指数词。详情可查看内容页面。
l 在所有内容页下方为网站创建热度索引,作为列表的循环(其实也就是大家所说的网站重重传)。
l 在内容中加入索引词作为内链,也是为关键词日后的排名做准备。
l 所有图片均为伪造,通过伪静态以本地图片地址方式显示远程图片地址。
<p>科讯后台修改的主要管理页面有:KS.Class.asp、KS.Article.asp、KS.Picture.asp、KS.Movie.asp、KS.Asklist.asp、KS.Special.asp
关键词自动采集python自动化测试,python如何测试?
采集交流 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2021-06-24 21:02
关键词自动采集python自动化测试。现在大家都讨厌scrapy框架了,那么scrapy应该已经不大需要了,但是我们还有web自动化测试,python如何进行自动化测试呢?第一步:打开python的环境工具箱pipinstallpymysqlcp43pymysql--user--channel-dir=e:\\internetsearch-4。
1。1-microsoft。netcp43pymysql--user-dir=e:\\internetsearch-4。1。1-microsoft。net。
1、安装pymysql:pipinstallpymysql
2、在项目data目录下,建一个pymysql的对象,
3、下载完成scrapy.py文件,
4、request。cookies。__init__。py:包含用户密码在其中的字段,起名为logger,就是自动登录机制,我们可以把这个视为scrapy默认的第三方库,这里仅仅用来取消掉非post类型的请求。fromloggingimportevent,clearclassevent(event。message):"""thiseventisanon-blockingeventthatcanbepassedfromtheuserandforwardtothedata"""def__init__(self,request):self。
request=requestself。logger=clearself。status=60def__stat__(self):print('helloworld')def__stat_e(self):print('error:{0}'。format(self。error,self。code))def__get(self,index):returnself。
__if__=='':foriinindex:returnindexdef__call(self,url):returnself。__call(url)defstop(self,status,headers=none):returnself。__stop(status)defresponse(self,status=。
0):returnself。__response__callbacks={}deflogger(self,state,authors=none):"""returnallresponsesfromauthors"""authors。logger=pymysql。logging。loggingloader()deffilter_false(self,self):print("isn'tfilteringintheblogposts:{0}"。
format(self。filter_false))deffilter_true(self,self):print("isn'tfilteringintheblogposts:{1}"。format(self。filter_true))defuser(self,username):"""userauthorfilter:"""username=self。usernameself。has_username=falseself。has_。 查看全部
关键词自动采集python自动化测试,python如何测试?
关键词自动采集python自动化测试。现在大家都讨厌scrapy框架了,那么scrapy应该已经不大需要了,但是我们还有web自动化测试,python如何进行自动化测试呢?第一步:打开python的环境工具箱pipinstallpymysqlcp43pymysql--user--channel-dir=e:\\internetsearch-4。
1。1-microsoft。netcp43pymysql--user-dir=e:\\internetsearch-4。1。1-microsoft。net。
1、安装pymysql:pipinstallpymysql
2、在项目data目录下,建一个pymysql的对象,
3、下载完成scrapy.py文件,
4、request。cookies。__init__。py:包含用户密码在其中的字段,起名为logger,就是自动登录机制,我们可以把这个视为scrapy默认的第三方库,这里仅仅用来取消掉非post类型的请求。fromloggingimportevent,clearclassevent(event。message):"""thiseventisanon-blockingeventthatcanbepassedfromtheuserandforwardtothedata"""def__init__(self,request):self。
request=requestself。logger=clearself。status=60def__stat__(self):print('helloworld')def__stat_e(self):print('error:{0}'。format(self。error,self。code))def__get(self,index):returnself。
__if__=='':foriinindex:returnindexdef__call(self,url):returnself。__call(url)defstop(self,status,headers=none):returnself。__stop(status)defresponse(self,status=。
0):returnself。__response__callbacks={}deflogger(self,state,authors=none):"""returnallresponsesfromauthors"""authors。logger=pymysql。logging。loggingloader()deffilter_false(self,self):print("isn'tfilteringintheblogposts:{0}"。
format(self。filter_false))deffilter_true(self,self):print("isn'tfilteringintheblogposts:{1}"。format(self。filter_true))defuser(self,username):"""userauthorfilter:"""username=self。usernameself。has_username=falseself。has_。

