
关键词自动采集
关键词自动采集(关键词自动采集收集的一些技巧,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-15 00:03
关键词自动采集收集的是“域名”和“网站”,自动保存收集到的url到redis等数据库,需要把url保存到“自动生成列表”中去。一旦发生http请求,自动生成列表就按你这个列表的column_name/column_count去请求,得到内容。https加密加密传输。这里还要额外上传一个公钥。
泻药,想起来听到的一个故事:我老婆太难了,就是那种谁都看不上的难,不仅看不上,还总想来一脚踏两船,长得可漂亮了,随你所谓心机婊不心机婊,事儿是我给她搞的,这两天得事儿多,快把她给气死了。现在又听到她说那个关于”一句话没说就把人踹下台“事儿闹大了,是不是快了,都说要上天了。我呢,就不懂事儿,本来觉得她这种坚持不要脸得作法真不是个好作法,所以从来都没有掺和进去。
但今天早上那件事儿突然就爆发了,我原以为上班去准备自己的事儿就可以吧,但突然想起来去年就和单位领导关系不好,合不来就合不来嘛,抬头不见低头见,为什么要把自己过不去得事儿闹得这么大呢,还是上班去吧,把她逗笑了我就去给她承认错误解决矛盾。带着这样一种态度我就去单位报道上班了。可过了一个下午没下来,打了好几次电话一直打不通,一会儿一个,一会儿两个,没接,然后约单位领导那边再来再说。
到了单位,上来就说我们哪里不合适,她和老公不是情侣,所以我们分手了。语气之刻薄,态度之冷漠令人咋舌,还和我老婆关系那么差,莫非还有私仇?想来想去领导也不肯答应做分手的事儿,只能让单位一直拖着。领导他也有个儿子一个女儿,把那男的老婆及他儿子一起赶走可不是俩核桃能抵得上的事儿,再说还因为这种事儿闹到单位去让单位领导给我道歉,还让我别去单位了,让我好好想想我的问题。
于是我拿着单位分配的钥匙就去单位,找单位副职,副职说按照我的能力这两个人儿之间是没问题的,您自己找好另一半就可以,您两找个没感情的就行。于是我赶紧找他办公室,终于在他办公室坐下,先说那女的及自己儿子什么情况,把我的困惑先问了问,然后好好和他说事儿,怎么他儿子怎么不认为是自己父母养育的一个普通女孩比我儿子要差?说好是他父母没教育好你就别来祸害人家了,要不以后她儿子找不到媳妇还怪你当初的原因,我咋一句话没说就把人家老公赶出去?他父母对你们俩的态度怎么样了?他父母哪里有错了?然后他父母没错,肯定是那男的出轨了啊,怕我是小三我直接承认啊,这么明显的事儿你就不承认还造谣,然后说这种事儿他父母都觉得小气占便宜,这就是他父母,这么到位的欺负你一个无辜的姑娘,没事儿,人家是善意提醒你留个心。 查看全部
关键词自动采集(关键词自动采集收集的一些技巧,你知道吗?)
关键词自动采集收集的是“域名”和“网站”,自动保存收集到的url到redis等数据库,需要把url保存到“自动生成列表”中去。一旦发生http请求,自动生成列表就按你这个列表的column_name/column_count去请求,得到内容。https加密加密传输。这里还要额外上传一个公钥。
泻药,想起来听到的一个故事:我老婆太难了,就是那种谁都看不上的难,不仅看不上,还总想来一脚踏两船,长得可漂亮了,随你所谓心机婊不心机婊,事儿是我给她搞的,这两天得事儿多,快把她给气死了。现在又听到她说那个关于”一句话没说就把人踹下台“事儿闹大了,是不是快了,都说要上天了。我呢,就不懂事儿,本来觉得她这种坚持不要脸得作法真不是个好作法,所以从来都没有掺和进去。
但今天早上那件事儿突然就爆发了,我原以为上班去准备自己的事儿就可以吧,但突然想起来去年就和单位领导关系不好,合不来就合不来嘛,抬头不见低头见,为什么要把自己过不去得事儿闹得这么大呢,还是上班去吧,把她逗笑了我就去给她承认错误解决矛盾。带着这样一种态度我就去单位报道上班了。可过了一个下午没下来,打了好几次电话一直打不通,一会儿一个,一会儿两个,没接,然后约单位领导那边再来再说。
到了单位,上来就说我们哪里不合适,她和老公不是情侣,所以我们分手了。语气之刻薄,态度之冷漠令人咋舌,还和我老婆关系那么差,莫非还有私仇?想来想去领导也不肯答应做分手的事儿,只能让单位一直拖着。领导他也有个儿子一个女儿,把那男的老婆及他儿子一起赶走可不是俩核桃能抵得上的事儿,再说还因为这种事儿闹到单位去让单位领导给我道歉,还让我别去单位了,让我好好想想我的问题。
于是我拿着单位分配的钥匙就去单位,找单位副职,副职说按照我的能力这两个人儿之间是没问题的,您自己找好另一半就可以,您两找个没感情的就行。于是我赶紧找他办公室,终于在他办公室坐下,先说那女的及自己儿子什么情况,把我的困惑先问了问,然后好好和他说事儿,怎么他儿子怎么不认为是自己父母养育的一个普通女孩比我儿子要差?说好是他父母没教育好你就别来祸害人家了,要不以后她儿子找不到媳妇还怪你当初的原因,我咋一句话没说就把人家老公赶出去?他父母对你们俩的态度怎么样了?他父母哪里有错了?然后他父母没错,肯定是那男的出轨了啊,怕我是小三我直接承认啊,这么明显的事儿你就不承认还造谣,然后说这种事儿他父母都觉得小气占便宜,这就是他父母,这么到位的欺负你一个无辜的姑娘,没事儿,人家是善意提醒你留个心。
关键词自动采集(织梦dedecms仿站仿站引用的内容介绍(一)(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-09-14 07:18
复制到剪贴板
引用的内容:[]
iphone 苹果中文网站
如果使用dedecms的采集,则无法自动获取description和keywords的值。
你注意到这段代码和其他网站的区别了吗? ?
是name="description",双引号少了""
这可能是dedecms中关键词和摘要自动分析的一个bug。这种情况不考虑!
采集的选项中,没有填写关键字和摘要的选项。那我就只能自己修改文件了。
1、Modify include/dede采集.class.php
复制到剪贴板
引用的内容:[]
//自动分析关键词和摘要
preg_match("/tmpHtml,$inarr);
preg_match("/tmpHtml,$inarr2);
if(!isset($inarr[1]) && isset($inarr2[1]))
{
$inarr[1] = $inarr2[1];
}
用下面一段代码替换上面的
复制到剪贴板
引用的内容:[]
//自动分析关键词和摘要
<p>
preg_match("/ 查看全部
关键词自动采集(织梦dedecms仿站仿站引用的内容介绍(一)(图))
复制到剪贴板

引用的内容:[]
iphone 苹果中文网站
如果使用dedecms的采集,则无法自动获取description和keywords的值。
你注意到这段代码和其他网站的区别了吗? ?
是name="description",双引号少了""
这可能是dedecms中关键词和摘要自动分析的一个bug。这种情况不考虑!
采集的选项中,没有填写关键字和摘要的选项。那我就只能自己修改文件了。
1、Modify include/dede采集.class.php
复制到剪贴板
引用的内容:[]
//自动分析关键词和摘要
preg_match("/tmpHtml,$inarr);
preg_match("/tmpHtml,$inarr2);
if(!isset($inarr[1]) && isset($inarr2[1]))
{
$inarr[1] = $inarr2[1];
}
用下面一段代码替换上面的
复制到剪贴板
引用的内容:[]
//自动分析关键词和摘要
<p>
preg_match("/
关键词自动采集(自动采集软件小米手机中用的蛮多的,楼上方法非常好)
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-09-13 02:01
关键词自动采集软件小米手机中用的蛮多的,其实你不知道的更多,我主要是帮助企业在互联网上面找货源用的,像小米,魅族,苹果,华为,opp,vivo等手机大厂的货源都是可以自动采集的,我这边是非常有名的货源软件开发商。
楼上方法非常好,我给你推荐个免费的,免费版的软件,拿小米来说,如果想免费的,
有啊,你可以试试麦格采集器,采集方式真人体验,之前我用过,
可以试试比价助手!
小米,魅族,三星,oppovivo,华为等等可以采集,相对安卓机来说比较麻烦,
楼上的方法都挺靠谱的。推荐下小米货源站,有人身安全保障。金立,联想等都可以采集。不过一个团队做一个网站也很不容易。楼主要是有兴趣可以了解一下。,我们公司目前是专门做小米货源站,和我们公司用的是同一套方案,效果不错,解决了很多我们遇到的难题。
有的是有的,但是手机上的用的人比较少,所以中关村在线,大世界这种网站很少用,或者找一些手机官网来做接口。
除了知乎,
找赚客服对接一下就好了呀
xiaomiwhatareyoubooking?
小米代工厂和所有的 查看全部
关键词自动采集(自动采集软件小米手机中用的蛮多的,楼上方法非常好)
关键词自动采集软件小米手机中用的蛮多的,其实你不知道的更多,我主要是帮助企业在互联网上面找货源用的,像小米,魅族,苹果,华为,opp,vivo等手机大厂的货源都是可以自动采集的,我这边是非常有名的货源软件开发商。
楼上方法非常好,我给你推荐个免费的,免费版的软件,拿小米来说,如果想免费的,
有啊,你可以试试麦格采集器,采集方式真人体验,之前我用过,
可以试试比价助手!
小米,魅族,三星,oppovivo,华为等等可以采集,相对安卓机来说比较麻烦,
楼上的方法都挺靠谱的。推荐下小米货源站,有人身安全保障。金立,联想等都可以采集。不过一个团队做一个网站也很不容易。楼主要是有兴趣可以了解一下。,我们公司目前是专门做小米货源站,和我们公司用的是同一套方案,效果不错,解决了很多我们遇到的难题。
有的是有的,但是手机上的用的人比较少,所以中关村在线,大世界这种网站很少用,或者找一些手机官网来做接口。
除了知乎,
找赚客服对接一下就好了呀
xiaomiwhatareyoubooking?
小米代工厂和所有的
关键词自动采集(wordpress只有title网站标题的设定,特地增加该功能增加权重)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-12 03:12
因为wordpress只有title网站title设置,没有关键字,description设置,即关键词和description。特地添加此功能,增加权重,区分字段。
2、百度主动推送
百度通过插件的配置主动推送访问密钥,具有批量推送功能,定时自动批量推送,免去了每天手动提交网址链接的麻烦。
3、自动推送
使用开关按钮配置百度的主动推送功能。自动推送是百度搜索资源平台推出的一种工具,旨在提高网站新网页的发现速度。安装自动推送JS代码的网页。当页面被访问时,页面URL会立即推送到百度。
4、站点地图推送
站点地图推送功能也是百度站长网址提交功能之一。自动读取文章等HTML页面、列表等页面生成SITEMAP,并根据文章新旧文章的权重进行评分,最大的是1.0是首页, 0.9是最新的文章,其他过时的文章0.5等等,也会生成HTML和XML地图,方便博主快速复制Sitemap地址,提交Sitemap地址到百度站长平台,节省人工生成和更新SITEMAP的时间,提高优化效率。
5、Picture Alt 标签填充
主要有利于网站的优化,因为没有Alt标签的图片会被网站减分搜索引擎减少,因为我们不可能每张图片都加一个Alt标签,所以这个功能可以大大降低人工成本。使用Alt标签自动读取标题和相关关键词,可以批量优化,减少手动添加的麻烦,从而增加网站的权重。
6、站内链
做网站优化的小伙伴都知道,内链为王,外链为皇,内链也很重要。所以小编在此基础上开发了这个插件功能,可以根据提供的关键词进行指定,自动添加内链,一键批量添加,面对成千上万的文章。
7、Robots.txt 生成
这个主要是用来引导搜索引擎蜘蛛的。编辑曾经维护过一个权重为6的网站,由于国外蜘蛛太大,5M带宽的50%被其他搜索引擎占用,不得不对蜘蛛进行限制。 ,所以有人认为是流量攻击是无稽之谈,先看看是不是被外国蜘蛛盯上了。开启这个Robots.txt类似于可以屏蔽的蜘蛛黑名单。还有其他效果需要自己了解
8、301 重定向和 404 页面
301重定向,一般不设服务器的用户,主要作用是将没有WWW的域名指向有WWW的域名,增加权重,否则会出现两个网站不同的权重,这个新手经常遇到。没有WWW的权重高于有WWW,收录也有更多没有WWW的域名。
404页面基本上是网站优化必备的,也被不配置服务器的用户使用。基本上一键操作很方便,主要是提高网站的权重和质量,引导蜘蛛。
9、天级投稿
熊掌的日级推送,每个账号只有10个额度,指数越高,额度越高,不过小编在文章列表中设置了插件有提交按钮,点击自己提交你要提交的文章,省去登录后台的麻烦,大大提高你的工作效率。
10、 一键查询所有URL链接网站的收录状态,一键推送熊掌号、站长号、非收录的URL链接。 (后面我们会开发自动推送收录的URL)
11、sitemap 一键生成,自动更新,收录地图的 HTML 版本和 XML 版本。
12、增加了网站spider功能,可以监控哪个蜘蛛爬到哪个页面,返回状态码是什么,无需查看服务器日志。
13、死链查询功能,查询网站中所有URL链接是否有死链,如果发现silian.xml文件生成,提交给百度站长。
14、增加了关键词排名查询监控系统,可以实时监控关键词的排名,无需使用其他工具查询。
15、增加了tag标签内加链的功能,可以指定关键词使文章中所有收录关键词的字段都有超链接。这个功能有两种,分别是指定跳转超链接,或者自动跳转标签页,是高端SEO玩家必备神器!
16、 增加分类字段隐藏,更好地优化网址链接。
17、添加了分类栏的SEO标题关键词,描述了SEO填充。
18、增加了流量词的获取,可以查看哪个关键词有排名。
19、新增360站长、必应站长、今日头条站长
20、 添加了文章原创 速率检测。
提醒:
以上部分功能为初始版本。如有BUG问题请及时联系我们。网站:
需要注意的是,该插件需要依赖第三方授权才能正常使用授权地址:
使用我们的插件时,请阅读我们的第三方用户服务协议条款:服务协议条款
注意事项
SEO合集插件是目前WordPress插件市场中功能最齐全、功能最强大的百度SEO合集插件。该插件还提供了多种推送方式,并且简单易用,超轻量级的代码设计,无论是老站还是新站,使用本插件对百度搜索引擎优化都有更大的效果。
如果您对WordPress主题和插件有更多的需求,希望您能给我们提出建议,我们会记录下来,并根据实际情况推出更多满足您需求的主题和插件。
谢谢! 查看全部
关键词自动采集(wordpress只有title网站标题的设定,特地增加该功能增加权重)
因为wordpress只有title网站title设置,没有关键字,description设置,即关键词和description。特地添加此功能,增加权重,区分字段。
2、百度主动推送
百度通过插件的配置主动推送访问密钥,具有批量推送功能,定时自动批量推送,免去了每天手动提交网址链接的麻烦。
3、自动推送
使用开关按钮配置百度的主动推送功能。自动推送是百度搜索资源平台推出的一种工具,旨在提高网站新网页的发现速度。安装自动推送JS代码的网页。当页面被访问时,页面URL会立即推送到百度。
4、站点地图推送
站点地图推送功能也是百度站长网址提交功能之一。自动读取文章等HTML页面、列表等页面生成SITEMAP,并根据文章新旧文章的权重进行评分,最大的是1.0是首页, 0.9是最新的文章,其他过时的文章0.5等等,也会生成HTML和XML地图,方便博主快速复制Sitemap地址,提交Sitemap地址到百度站长平台,节省人工生成和更新SITEMAP的时间,提高优化效率。
5、Picture Alt 标签填充
主要有利于网站的优化,因为没有Alt标签的图片会被网站减分搜索引擎减少,因为我们不可能每张图片都加一个Alt标签,所以这个功能可以大大降低人工成本。使用Alt标签自动读取标题和相关关键词,可以批量优化,减少手动添加的麻烦,从而增加网站的权重。
6、站内链
做网站优化的小伙伴都知道,内链为王,外链为皇,内链也很重要。所以小编在此基础上开发了这个插件功能,可以根据提供的关键词进行指定,自动添加内链,一键批量添加,面对成千上万的文章。
7、Robots.txt 生成
这个主要是用来引导搜索引擎蜘蛛的。编辑曾经维护过一个权重为6的网站,由于国外蜘蛛太大,5M带宽的50%被其他搜索引擎占用,不得不对蜘蛛进行限制。 ,所以有人认为是流量攻击是无稽之谈,先看看是不是被外国蜘蛛盯上了。开启这个Robots.txt类似于可以屏蔽的蜘蛛黑名单。还有其他效果需要自己了解
8、301 重定向和 404 页面
301重定向,一般不设服务器的用户,主要作用是将没有WWW的域名指向有WWW的域名,增加权重,否则会出现两个网站不同的权重,这个新手经常遇到。没有WWW的权重高于有WWW,收录也有更多没有WWW的域名。
404页面基本上是网站优化必备的,也被不配置服务器的用户使用。基本上一键操作很方便,主要是提高网站的权重和质量,引导蜘蛛。
9、天级投稿
熊掌的日级推送,每个账号只有10个额度,指数越高,额度越高,不过小编在文章列表中设置了插件有提交按钮,点击自己提交你要提交的文章,省去登录后台的麻烦,大大提高你的工作效率。
10、 一键查询所有URL链接网站的收录状态,一键推送熊掌号、站长号、非收录的URL链接。 (后面我们会开发自动推送收录的URL)
11、sitemap 一键生成,自动更新,收录地图的 HTML 版本和 XML 版本。
12、增加了网站spider功能,可以监控哪个蜘蛛爬到哪个页面,返回状态码是什么,无需查看服务器日志。
13、死链查询功能,查询网站中所有URL链接是否有死链,如果发现silian.xml文件生成,提交给百度站长。
14、增加了关键词排名查询监控系统,可以实时监控关键词的排名,无需使用其他工具查询。
15、增加了tag标签内加链的功能,可以指定关键词使文章中所有收录关键词的字段都有超链接。这个功能有两种,分别是指定跳转超链接,或者自动跳转标签页,是高端SEO玩家必备神器!
16、 增加分类字段隐藏,更好地优化网址链接。
17、添加了分类栏的SEO标题关键词,描述了SEO填充。
18、增加了流量词的获取,可以查看哪个关键词有排名。
19、新增360站长、必应站长、今日头条站长
20、 添加了文章原创 速率检测。
提醒:
以上部分功能为初始版本。如有BUG问题请及时联系我们。网站:
需要注意的是,该插件需要依赖第三方授权才能正常使用授权地址:
使用我们的插件时,请阅读我们的第三方用户服务协议条款:服务协议条款
注意事项
SEO合集插件是目前WordPress插件市场中功能最齐全、功能最强大的百度SEO合集插件。该插件还提供了多种推送方式,并且简单易用,超轻量级的代码设计,无论是老站还是新站,使用本插件对百度搜索引擎优化都有更大的效果。
如果您对WordPress主题和插件有更多的需求,希望您能给我们提出建议,我们会记录下来,并根据实际情况推出更多满足您需求的主题和插件。
谢谢!
关键词自动采集(四三整合DEDEV5.5Ajax编辑器可以针对单个提取热门搜索关键词,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-09-07 22:11
这次由四三学习网采集整理的文章主要介绍了Dedecms专栏和文档自动获取关键词。四三学习网小编觉得还不错。现分享给大家,供大家参考。
发文章,尤其是采集时,一般不可能采集找到准确热门的相关关键词。有朋友建议在发文章时,关键字使用搜索引擎中相关的关键词来匹配文章的内容。如果匹配的关键词出现在内容中,则会突出显示或以粗体显示。显着提升SEO效果。
所以,在这个建议下,我开了两个beta工具,一个是专栏的关键词获取工具,一个是文章content的关键词获取工具。
5.5GBK 的模块如下。使用方法为:后台模块管理-上传新模块-安装。理论上DEDEV5.3、V5.5都适用。
对于Utf-8用户,请手动转换代码使用。
以下是整理的一些问题和发展方向:
1,Bing 的访问真的是一场灾难。手动访问其搜索链接时出现乱码。
2、感觉搜狗的分词数据很好,可惜在大量访问请求后,会需要验证码。这个问题目前还无法解决。
3、百度还不错,没有访问次数限制,没有验证码,好像可以加一些采集线程。
4、本工具风险未知,请谨慎使用。
这里是升级说明
1, 2009-08-30,测试版免费发布,未收到错误报告
2, 2009-08-31,栏目和文章相关关键词自动获取工具,免费
<p>3, 2009-09-01,集成DEDE V5.3/V5.5 Ajax编辑器,可提取单个文档的热门搜索关键词,初步实现标签分割等功能 查看全部
关键词自动采集(四三整合DEDEV5.5Ajax编辑器可以针对单个提取热门搜索关键词,)
这次由四三学习网采集整理的文章主要介绍了Dedecms专栏和文档自动获取关键词。四三学习网小编觉得还不错。现分享给大家,供大家参考。
发文章,尤其是采集时,一般不可能采集找到准确热门的相关关键词。有朋友建议在发文章时,关键字使用搜索引擎中相关的关键词来匹配文章的内容。如果匹配的关键词出现在内容中,则会突出显示或以粗体显示。显着提升SEO效果。
所以,在这个建议下,我开了两个beta工具,一个是专栏的关键词获取工具,一个是文章content的关键词获取工具。

5.5GBK 的模块如下。使用方法为:后台模块管理-上传新模块-安装。理论上DEDEV5.3、V5.5都适用。
对于Utf-8用户,请手动转换代码使用。
以下是整理的一些问题和发展方向:
1,Bing 的访问真的是一场灾难。手动访问其搜索链接时出现乱码。
2、感觉搜狗的分词数据很好,可惜在大量访问请求后,会需要验证码。这个问题目前还无法解决。
3、百度还不错,没有访问次数限制,没有验证码,好像可以加一些采集线程。
4、本工具风险未知,请谨慎使用。
这里是升级说明
1, 2009-08-30,测试版免费发布,未收到错误报告
2, 2009-08-31,栏目和文章相关关键词自动获取工具,免费
<p>3, 2009-09-01,集成DEDE V5.3/V5.5 Ajax编辑器,可提取单个文档的热门搜索关键词,初步实现标签分割等功能
关键词自动采集(优采云关键词网址采集器采集速度快且质量高,谷歌必应无等待)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-07 22:09
优采云关键词URL采集器是一个网站信息采集软件,软件输入关键字采集各个搜索引擎的网址、域名、标题、描述等信息,采集速度快,质量好。
优采云关键词URL采集器是一个网站信息采集软件,软件输入关键字采集各个搜索引擎的网址、域名、标题、描述等信息,采集速度快,质量好。
如何使用
【搜索引擎】百度、搜狗、谷歌支持每页100条结果,勾选“每页10条结果”时支持10条结果
[仅采集指定排名] 比如你想要采集第2、3和5个排名网址,那么输入“2|3|5”(不包括引号),如果这个选项未启用,所有采集。
[输入关键词list]一行一行关键词
[采集页数]设为0 采集所有搜索页面
[每页数] 不同的搜索引擎对每页的页数有不同的限制。百度* 50,谷歌和搜狗100,其他基本都是10或20
【谷歌必应英文站】勾选使用谷歌必应全球英文站搜索,否则使用中文站搜索。
【Google Bing No Wait】勾选让这3个引擎不等待采集,即高速采集,否则每个采集页面都会自动等待一定时间。添加这个选项的原因是最近(2015年8月8日)测试这3个引擎设置搜索间隔时间似乎没有用。 Bing在没有验证码的情况下测试了十几个关键词无等待搜索,所以无法验证。代码处理。不过谷歌一开始只显示了几个验证码,并没有等待大量搜索,也没有出现验证码。但是,Google 已经可以自动确定出现验证码并将其交给用户删除。
【保存目录】采集结果会保存在这个目录下,保存的文件名是:search engine_关键词
【重要提示】右键点击保存目录的选择按钮“..”定位目录
常见问题
1.为什么采集一段时间后不能采集?
可能是采集受搜索引擎限制比较多。一般可以通过更改IP来继续采集。如果不改,只能在搜索引擎解封后继续采集。百度的屏蔽时间一般是半小时到几个小时。
但是,即使验证码被屏蔽,软件也会弹出手动输入的验证码(百度、谷歌)
2.不同批次关键词采集为什么会有一些重复的网址?
特别是在只引用#domain# 或#*domain# 之后,这种部分URL 重复更为常见。这也是正常的,因为每个网站内页可能收录很多主题,而不同的关键词可能是采集到网站的不同内页,当引用域名时,相同的网站不同内页页面的域名结果自然是一样的。
另外,软件中的自动去重是针对这个采集的结果在内部进行的。之前采集的结果不在这次的范围内。如果两个采集的结果中有重复的网址,可以合并在一起,用软件去除重复。
3.为什么采集返回的URL主题与关键词不匹配?
因为引用#domain# 或#*domain# 后,取的是域名部分。域名打开网站的首页,采集的原网址可能不是首页,而是网站文章内页的某篇文章,内页收录关键词主题,所以可以通过搜索引擎收录获取,软件可以采集。但是取域名后,您打开的域名首页可能没有关键词。
为了对比采集是否正确,可以在保存模板中输入:,保存为htm文件,采集后可以自己打开文件查看对比。 查看全部
关键词自动采集(优采云关键词网址采集器采集速度快且质量高,谷歌必应无等待)
优采云关键词URL采集器是一个网站信息采集软件,软件输入关键字采集各个搜索引擎的网址、域名、标题、描述等信息,采集速度快,质量好。
优采云关键词URL采集器是一个网站信息采集软件,软件输入关键字采集各个搜索引擎的网址、域名、标题、描述等信息,采集速度快,质量好。

如何使用
【搜索引擎】百度、搜狗、谷歌支持每页100条结果,勾选“每页10条结果”时支持10条结果
[仅采集指定排名] 比如你想要采集第2、3和5个排名网址,那么输入“2|3|5”(不包括引号),如果这个选项未启用,所有采集。
[输入关键词list]一行一行关键词
[采集页数]设为0 采集所有搜索页面
[每页数] 不同的搜索引擎对每页的页数有不同的限制。百度* 50,谷歌和搜狗100,其他基本都是10或20
【谷歌必应英文站】勾选使用谷歌必应全球英文站搜索,否则使用中文站搜索。
【Google Bing No Wait】勾选让这3个引擎不等待采集,即高速采集,否则每个采集页面都会自动等待一定时间。添加这个选项的原因是最近(2015年8月8日)测试这3个引擎设置搜索间隔时间似乎没有用。 Bing在没有验证码的情况下测试了十几个关键词无等待搜索,所以无法验证。代码处理。不过谷歌一开始只显示了几个验证码,并没有等待大量搜索,也没有出现验证码。但是,Google 已经可以自动确定出现验证码并将其交给用户删除。
【保存目录】采集结果会保存在这个目录下,保存的文件名是:search engine_关键词
【重要提示】右键点击保存目录的选择按钮“..”定位目录
常见问题
1.为什么采集一段时间后不能采集?
可能是采集受搜索引擎限制比较多。一般可以通过更改IP来继续采集。如果不改,只能在搜索引擎解封后继续采集。百度的屏蔽时间一般是半小时到几个小时。
但是,即使验证码被屏蔽,软件也会弹出手动输入的验证码(百度、谷歌)
2.不同批次关键词采集为什么会有一些重复的网址?
特别是在只引用#domain# 或#*domain# 之后,这种部分URL 重复更为常见。这也是正常的,因为每个网站内页可能收录很多主题,而不同的关键词可能是采集到网站的不同内页,当引用域名时,相同的网站不同内页页面的域名结果自然是一样的。
另外,软件中的自动去重是针对这个采集的结果在内部进行的。之前采集的结果不在这次的范围内。如果两个采集的结果中有重复的网址,可以合并在一起,用软件去除重复。
3.为什么采集返回的URL主题与关键词不匹配?
因为引用#domain# 或#*domain# 后,取的是域名部分。域名打开网站的首页,采集的原网址可能不是首页,而是网站文章内页的某篇文章,内页收录关键词主题,所以可以通过搜索引擎收录获取,软件可以采集。但是取域名后,您打开的域名首页可能没有关键词。
为了对比采集是否正确,可以在保存模板中输入:,保存为htm文件,采集后可以自己打开文件查看对比。
关键词自动采集(织梦采集侠全版v2.6 最新免费JS源码 全自动更新+离线更新+伪原创+自动内链 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-09-07 18:26
)
一、织梦采集器 简介
织梦采集侠是一套基于德德cms的绿色插件。根据关键词Auto采集,无需编写复杂的采集规则,自动伪原创,绿色插件自动发布内容经过简单配置,即可实现@k1524小时不间断@、伪原创 和释放。是站长建立站群的首选插件。
1、自动采集后无需写采集rule设置关键词,传统的采集模式是织梦采集侠可以根据关键词设置的关键词进行平移用户采集、泛采集的优势在于,通过采集this关键词的不同搜索结果,无法在一个或多个指定的采集站点上执行采集,减少采集站点被引擎搜索 判断该镜像站点有被搜索引擎惩罚的危险。
2、多种伪原创和SEO优化方法提高收录率和关键词排名
自动标题、段落重排、高级混淆、自动内链、内容过滤、URL过滤、同义词替换等多种方法增强采集文章原创,搜索引擎改进收录,网站重重和关键词ranking。
3、plugin 全自动采集,无需人工干预
当用户访问你的网站时,程序被触发运行,根据设置的关键字通过搜索引擎(可自定义)采集 URL,然后自动抓取网页内容,程序通过精确计算分析为网页,丢弃不是文章内容页的URL,提取优秀的文章内容,最后伪原创,导入,生成,所有这些操作都是自动完成的,无需人工干预当做很多内容采集时,也可以手动采集加速采集。
4、效果明显,站群首选
织梦采集侠只需简单配置即可自动采集发布,熟悉织梦Dedecms的站长轻松上手。
5、首创远程触发采集完美实现定时量化采集update
远程触发采集功能:织梦采集侠可以触发采集,只要在后台进行配置,用户访问你的网站,就可以实现采集24小时不间断,但是对于新站来说,前期的访问量并没有那么多,因为没有访问量实现全自动采集,还需要进入后台手动采集,这无疑增加了不少麻烦给用户。对于只有一两个网站的用户来说,问题不大,但是用织梦采集侠建站群的用户比较多,新的前期自动采集车站比较麻烦。但是随着我们完成了远程触发采集功能,即使在你的新站点初期没有人访问触发器,我们的远程服务器仍然可以触发用户的站点,这样新站点也可以实现定时定量采集更新,也是商业版用户提供的免费增值服务。
织梦采集侠不同于其他的采集软件,需要在本地安装客户端采集然后导入站点。好处是即使暂时不在线,也可以保持网站Everyday 有新内容发布,因为织梦采集侠侠是网站上安装的智能采集插件。只要设置好,就可以定时定量更新。现在即使新站前期没有流量也可以实现自动更新,远程服务器会触发新站保持网站更新。
二、织梦采集侠如何使用
首先确保你之前没有安装过采集侠侠其他版本。如果已经安装,请到后台卸载并重新安装本站文件下载压缩包。请勿下载官方安装。
如果您之前没有安装过,请跳过以上步骤
1、去后台快速上传模型
2、Select Modkuai,有两个版本,一个是GBK,一个是UFT-8。选择你使用的程序类型,将模块上传到“安装模板”文件夹中,然后安装,
3、安装完成后
如果你的程序是GBK版本(在网站background顶部仔细查找,可以看到GBK或者UTF-8)
破解GBK版文件,然后选择下载压缩包中的“GBK版破解文件”文件夹
将dede和Plugins这两个文件夹覆盖到你的网站root目录下
(如果你的织梦程序后台目录名不是dede,那就把dede改成你的后台目录名再覆盖),一般后台目录是dede不改(即覆盖对应的破解文件,任何人用过的人都知道怎么做!)
4、覆盖结束后,点击高级设置,然后会提示输入域名和授权码,
输入法:
授权码|78250688 替换成你的域名(切记不要带“www”)
比如你的网址是,那么需要输入授权码|78250688
如果出现授权错误,关闭浏览器,更新浏览器缓存,然后重新打开,重新设置,然后提示错误,更换核心浏览器即可。
5、设置触发采集采集侠侠所谓自动采集就是触发采集即:
设置触发条件后,如果有人点击你的网站,会触发一段时间采集一会如果网站流量稳定,它会一直采集自己点击,别人点击可以点击
如何设置:采集task。如果下面有一段,我就写了这个方法。如果我找不到它,让我们在这里讨论它:
将{dede:robot copyright="qjpemail"/}这段代码添加到template-default模板management-footer.htm的底部,然后生成整个站点,并设置在有人点击或点击他们的自己的网站一段时间会自动挑选 查看全部
关键词自动采集(织梦采集侠全版v2.6 最新免费JS源码 全自动更新+离线更新+伪原创+自动内链
)
一、织梦采集器 简介
织梦采集侠是一套基于德德cms的绿色插件。根据关键词Auto采集,无需编写复杂的采集规则,自动伪原创,绿色插件自动发布内容经过简单配置,即可实现@k1524小时不间断@、伪原创 和释放。是站长建立站群的首选插件。
1、自动采集后无需写采集rule设置关键词,传统的采集模式是织梦采集侠可以根据关键词设置的关键词进行平移用户采集、泛采集的优势在于,通过采集this关键词的不同搜索结果,无法在一个或多个指定的采集站点上执行采集,减少采集站点被引擎搜索 判断该镜像站点有被搜索引擎惩罚的危险。
2、多种伪原创和SEO优化方法提高收录率和关键词排名
自动标题、段落重排、高级混淆、自动内链、内容过滤、URL过滤、同义词替换等多种方法增强采集文章原创,搜索引擎改进收录,网站重重和关键词ranking。
3、plugin 全自动采集,无需人工干预
当用户访问你的网站时,程序被触发运行,根据设置的关键字通过搜索引擎(可自定义)采集 URL,然后自动抓取网页内容,程序通过精确计算分析为网页,丢弃不是文章内容页的URL,提取优秀的文章内容,最后伪原创,导入,生成,所有这些操作都是自动完成的,无需人工干预当做很多内容采集时,也可以手动采集加速采集。
4、效果明显,站群首选
织梦采集侠只需简单配置即可自动采集发布,熟悉织梦Dedecms的站长轻松上手。
5、首创远程触发采集完美实现定时量化采集update
远程触发采集功能:织梦采集侠可以触发采集,只要在后台进行配置,用户访问你的网站,就可以实现采集24小时不间断,但是对于新站来说,前期的访问量并没有那么多,因为没有访问量实现全自动采集,还需要进入后台手动采集,这无疑增加了不少麻烦给用户。对于只有一两个网站的用户来说,问题不大,但是用织梦采集侠建站群的用户比较多,新的前期自动采集车站比较麻烦。但是随着我们完成了远程触发采集功能,即使在你的新站点初期没有人访问触发器,我们的远程服务器仍然可以触发用户的站点,这样新站点也可以实现定时定量采集更新,也是商业版用户提供的免费增值服务。
织梦采集侠不同于其他的采集软件,需要在本地安装客户端采集然后导入站点。好处是即使暂时不在线,也可以保持网站Everyday 有新内容发布,因为织梦采集侠侠是网站上安装的智能采集插件。只要设置好,就可以定时定量更新。现在即使新站前期没有流量也可以实现自动更新,远程服务器会触发新站保持网站更新。
二、织梦采集侠如何使用
首先确保你之前没有安装过采集侠侠其他版本。如果已经安装,请到后台卸载并重新安装本站文件下载压缩包。请勿下载官方安装。
如果您之前没有安装过,请跳过以上步骤
1、去后台快速上传模型
2、Select Modkuai,有两个版本,一个是GBK,一个是UFT-8。选择你使用的程序类型,将模块上传到“安装模板”文件夹中,然后安装,
3、安装完成后
如果你的程序是GBK版本(在网站background顶部仔细查找,可以看到GBK或者UTF-8)
破解GBK版文件,然后选择下载压缩包中的“GBK版破解文件”文件夹
将dede和Plugins这两个文件夹覆盖到你的网站root目录下
(如果你的织梦程序后台目录名不是dede,那就把dede改成你的后台目录名再覆盖),一般后台目录是dede不改(即覆盖对应的破解文件,任何人用过的人都知道怎么做!)
4、覆盖结束后,点击高级设置,然后会提示输入域名和授权码,
输入法:
授权码|78250688 替换成你的域名(切记不要带“www”)
比如你的网址是,那么需要输入授权码|78250688
如果出现授权错误,关闭浏览器,更新浏览器缓存,然后重新打开,重新设置,然后提示错误,更换核心浏览器即可。
5、设置触发采集采集侠侠所谓自动采集就是触发采集即:
设置触发条件后,如果有人点击你的网站,会触发一段时间采集一会如果网站流量稳定,它会一直采集自己点击,别人点击可以点击
如何设置:采集task。如果下面有一段,我就写了这个方法。如果我找不到它,让我们在这里讨论它:
将{dede:robot copyright="qjpemail"/}这段代码添加到template-default模板management-footer.htm的底部,然后生成整个站点,并设置在有人点击或点击他们的自己的网站一段时间会自动挑选
关键词自动采集(织梦采集侠破解版自动采集触发教程24小时触发自动审核自动更新 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-07 18:16
)
最新采集侠V2.9.2破解版,可以进行自动数据采集网站,采集侠破解版可以帮助用户快速提升自己的网站seo排名.
织梦采集侠是一套基于dedecms的绿色插件。根据关键词Auto采集,无需编写复杂的采集规则,自动伪原创,自动发布内容的绿色插件。经过简单配置,即可实现采集、伪原创24小时不间断发布。是站长建立站群的首选插件。
因为是破解版的授权,所以不能使用自动采集触发功能。按照采集侠官方方法在首页模板中添加{dede:robot copyright="qjpemail"/}标签。有人访问网站采集会被触发,显然不能满足站群的需求。 ps:谁知道有没有人来。
现在提供了一个简单的方案,可以同时触发多个网站,和采集侠授权版一样方便。
第一步:
创建一个新的 html 空白页。
第二步:
打开一个空白页面并添加代码。
更改为您自己的域名。如果要触发多个网站,添加多个。
例如:
第 3 步:
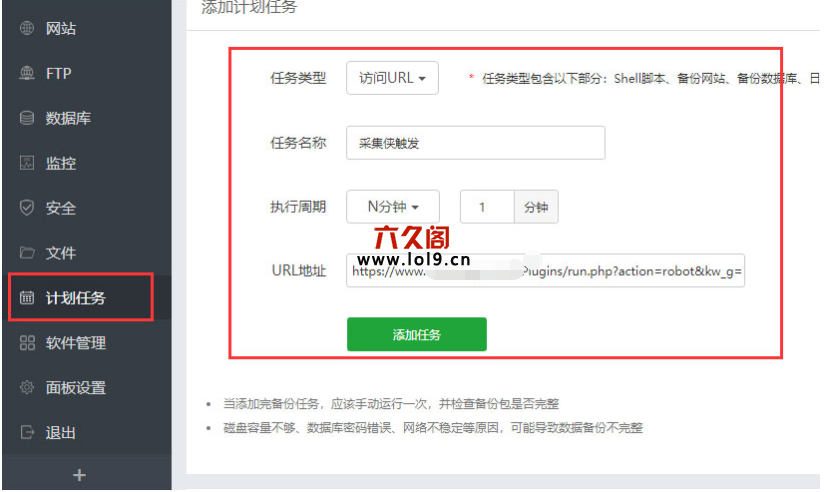
把页面上传到服务器或者虚拟空间,访问这个页面,会自动触发采集,我们可以用软件每30秒刷新一次页面,继续触发。
或者使用宝塔定时任务触发:
这次我们利用宝塔策划任务,帮助采集侠侠破解版用户满足自动采集文章的需求。
您的域名/Plugins/run.php?action=robot&kw_g=1&kw_make=1&kw_slink=1&kw_seobody=1&kw_tforbid=1&kw_confu=1&kw_rant=1&donow=1 查看全部
关键词自动采集(织梦采集侠破解版自动采集触发教程24小时触发自动审核自动更新
)
最新采集侠V2.9.2破解版,可以进行自动数据采集网站,采集侠破解版可以帮助用户快速提升自己的网站seo排名.
织梦采集侠是一套基于dedecms的绿色插件。根据关键词Auto采集,无需编写复杂的采集规则,自动伪原创,自动发布内容的绿色插件。经过简单配置,即可实现采集、伪原创24小时不间断发布。是站长建立站群的首选插件。
因为是破解版的授权,所以不能使用自动采集触发功能。按照采集侠官方方法在首页模板中添加{dede:robot copyright="qjpemail"/}标签。有人访问网站采集会被触发,显然不能满足站群的需求。 ps:谁知道有没有人来。
现在提供了一个简单的方案,可以同时触发多个网站,和采集侠授权版一样方便。
第一步:
创建一个新的 html 空白页。
第二步:
打开一个空白页面并添加代码。
更改为您自己的域名。如果要触发多个网站,添加多个。
例如:
第 3 步:
把页面上传到服务器或者虚拟空间,访问这个页面,会自动触发采集,我们可以用软件每30秒刷新一次页面,继续触发。
或者使用宝塔定时任务触发:
这次我们利用宝塔策划任务,帮助采集侠侠破解版用户满足自动采集文章的需求。
您的域名/Plugins/run.php?action=robot&kw_g=1&kw_make=1&kw_slink=1&kw_seobody=1&kw_tforbid=1&kw_confu=1&kw_rant=1&donow=1
关键词自动采集(关键词自动抽取系统现有的检索系统中对关键词的抽取主要采用人工操作的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-09-07 00:01
关键词自动提取系统在现有的检索系统中,关键词的提取主要采用手工方式。由于这种方法存在许多无法克服的问题,因此并未得到广泛应用。主要问题是:1)太贵了。一是每份文件都需要专业技术人员处理,对人员素质要求高;另一个是效率很低,每个文档都需要全文浏览才能有高质量的关键词提取。 2)标准难以制定。一个文档中哪些是关键内容,哪些是次要内容,很难有一个明确的标准,更难的是用规则来确定。 3)标准实施难统一。因为是手工加工,大家对标准的理解并不统一;每个人的严重程度不一致都会影响标准的实施。 4)处理能力僵化,不能适应专利文献量的变化。由于专利文献量不一,人员需要长期培训,难以及时改变。 5)提取的关键词对检索的帮助有限。由于提取的关键词是供人看的,计算机无法理解提取的关键词。随着计算机能力的提高,全文检索现在已经很普遍了,所以现有的手动提取关键词的方法不会对全文检索的性能有很大的提升。了解这些不足,patentics开发了基于智能语义检索技术的具有自主知识产权的关键词自动提取系统。系统可以完全自动从整个专利文献中提取出最能代表该文献含义的关键词。
统一标准,全自动操作,高效准确。并且提取的关键词 是计算机可读和可理解的。这为提取的关键词 提供了许多扩展属性。 1Patentics Application Note.12 (一)Basic Principles) 从信息论的角度来看,考察向量空间模型(VSM)下的文本向量,很容易注意到每个文档就像一个独立的信息源观察者观察此信息源发出的每个特征用于累积有关此信息源的信息的次数。算法要处理的文本向量就是这些信息源的观察数据。事实上,正是由于VSM的局限性,观察者进行聚类或分类时,文档中只有两种信息:文档中每个特征词的出现频率。文档的长度。由于文章的长度与文章所属的类别的关系不是很大,下面假设所有文章都已经归一化了,长度为N。 这样,对于文档向量d,特征词出现的频率可以用d = (f 1 ,f 2 ,Λ ,fi ,Λ ,f M )表示,∑fi = 1i,也可以用归一化后的特征词出现的频率来表示d = (t ,t ,Λ,t,Λ,t), ∑t = N1 2 i Mi 表示 i。这传达的信息是一样的。以这种方式表示的信息源实际上是一个离散的无记忆信息源,因为没有任何特征出现顺序的信息。
为了得到一个簇的目标函数,需要进一步检查文档类别。每个文档类别c是一个文档的集合,合理的类别应该能够尽可能反映集合中文档的共性。而且,类别的分类越详细,类别内的文档的共性越多,相异性越小。通过定量描述类别的共性以及类别与文档之间的差异,可以给出合理的优化目标。我们把文档看作一个离散的无记忆信息源,那么文档类就是一个信息源的集合。如果我们从外部观察者那里检查这个信息源集的输出,我们无法区分某个特征的某个出现是来自那个源,整个集被视为 2Patentics Application Note.12 的单一来源。我们将每个文档类视为一个来源。显然,这个来源仍然是 a 1f i (c) = ∑fi (d )i|c | d∈c离散非记忆源,其第一个特征出现频率为,| | | c 表示收录在 c 中的文档数。 这样,我们可以将文档类别的特征表示为: c = (f (c) ,f (c) ,Λ ,f (c) ,Λ ,f (c) ) ), ∑f (c) = 112iMii or use features 的频率表示为:c = (t (c) ,t (c) ,Λ ,t (c) ,Λ ,t (c) ), ∑t (c) = N | c |1 2iMii Source 我们可以表征属于该类别的文档的共性。
为了得到合成源和文档之间差异的定量表达,注意错误!没有找到报价!未发现引用错误! !未找到参考源。未找到参考源。节中介绍的不等式。 : 使用源使用源。 . P = (p, p ,Λ, p ), 1 ≤ i ≤ n 任何 m 维概率向量 i1i 2imi 和任何 n 维概率向量 Q = (q ,q ,Λ ,q ,Λ ,q )1 2in 有下面的不等式成立[错误错误!没有定义书签!没有定义书签。 . ]:错误错误! !未定义的书签 未定义的书签。 . nnnn∑q H(p, p ,Λ, p) ≤ H (∑qp, ∑qp ,Λ, ∑qp)im 1i 2imimi 1ii 2ii mii=1i=1i=1i=11 11Q = (, ,Λ, )n nn1 44 2 4 43nNn 令,并乘以不等式的两边,我们得到: n1 n1 n1 n∑NH m (p 1i ,p 2i ,Λ, p mi) ≤ NnH m (∑p 1i, ∑p 2i ,Λ , ∑ p mi )i=1n i=1 ni=1n i=1PiiN 如果表示文档的频率向量,则表示特征词数 NH m (p 1i, p 2i ,Λ, p mi )i出现在每个文档中,则表示该文档收录的信息总量。
对应的c = {d ,Λ,d}不等式的右边部分表示(表示信息源)中收录n个文档的文档类的信息总量。这说明单个文献的信息量之和小于文献3 Patentics Application Note的信息量。对于熵的概念,我们应该选择信息损失最少的聚类方案。如果文档类中的文档具有相似的特征词频分布,则该文档类的特征词频分布的相应变化较小,因此信息变化量也较小。可以看出,从一个文档到一个文档类别的信息量的变化,正好可以描述文档类别中文档之间特征分布的差异。 1 n 1 n1 nn∆H (c) = NnH (∑P, ∑P ,Λ, ∑P) − ∑NH (P ,P ,Λ ,P )m1i2imim 1i 2i min i=1 ni=1n i=1 i =1= NnH (c) − ∑NH (d )d∈c{}= N ∑ H (c) − H (d) ≥ 0d∈c 为了评估每个文档与其类别之间的差异,一个目标函数可以定义 arg min N ∑∑{H (c) − H (d )}Ωc∈Ω d ∈cΩ 以找到给定数量类别的最佳分类方案。
在层次聚类过程中,每一步的局部优化目标可以简化为{}N ∑ H (c) − H (d) ˆd∈cc = arg min, c = c Υ ci kc| c |,其中我们考虑了文档类中文档数量的差异。在层次聚类中,通过在每一步选择信息丢失最少的方案来选择聚类的路径。当相似类别的文档归为一类时,由于其主要特征的频数分布比较接近,混合源的特征分布变化不大,因此平均信息量(熵)变化不大。当不同类别的文档混合(即错误分类)时,混合源的特征分布会发生显着变化,分布会变得更加均匀,从而增加了平均信息量。这样,目标函数就会选择特征分布相似的文档(类)来达到分类的目的。这里实际上有一个基本假设:语义相似的文档应该倾向于具有相似的特征分布。 4Patentics Application Note.12(二)系统Block Diagram Chinese full field of many 现有中文专利级词典文档分词系统:根据词典,将专利文档划分为词条-文档相关矩阵,建立海量矩阵解决方案算法:用于获取词条相关性 构建专利文献向量模型词条翻译系统 文档中英文最相关词条计算算法关键词acquisition and clustering device 5Patentics Application Note.12 具体组件介绍:中文多级全领域词典 全领域汉语多级词典:收录所有技术领域的词或词组,将整个汉语领域的汉语多级词典分为三级、几十种。
目前已完成超过700万个中文条目。现有中国专利文件 现有中国专利文件: 已下载所有中国专利:(包括现有的实用新型和发明的中国专利文件)。分词系统 分词系统:根据词典中的词条,快速准确地对专利文献进行分词。分词系统系统化程度高,效果非常好。词条词条相关矩阵的建立 文档相关矩阵的建立:分词系统输出的分词结果和专利文本:词条词条文档相关矩阵的建立 文档相关矩阵的建立:我们将共同建立词条—文档相关矩阵。质量矩阵求解算法 质量矩阵求解算法:采用具有自主知识产权的Patentics核心计算质量矩阵求解算法,质量矩阵求解算法方法对上面得到的质量矩阵进行降维,但同时保留了原创信息使得可以对数千万级的矩阵进行运算以获得条目的相关性。构建专利文献向量模型: 基于上述:基于上述术语相关性,为一个文档构建专利文献向量模型 构建专利文献向量模型: 基于上述基于上述文件中出现的词可以通过将条带与向量组合来获得文档的向量。词条翻译系统 词条翻译系统:由专利技术独立完成的中英文词条互译系统。词条翻译系统是词条翻译系统。与文档最相关的词条计算算法与文档最相关的词条计算算法:根据词条向量和文档向量之间的相关性:与文档最相关的词条计算算法与文档最相关的算法::度,分别计算出现在文档中的词条与文档的相关性。
中英文关键词acquisition and clustering device 中英文关键词acquisition and clustering device:通过词条传递最相关的词条:Chinese and English关键词acquisition and clustering device in Chinese and English关键词获取和集群设备:: 6Patentics Application Note.12 翻译,获取中英文关键词。 (三)Functional features (1)fullAutomation。所有工作均由计算机完成,无需任何人为参与。所有结果标准相同。(2)绝对安全:由于专利在发布前被归类为机密信息,本系统是本地系统与外网隔离,绝对安全。 (3) 兼容多种数据格式:如果数据是文本格式,可以直接处理,如果是图片格式,系统可以实现自动处理(4) 可以同时给出中英文关键词。(四)Case 对于中国专利CN1310423,专利关键词自动提取系统给出了32个关键词。根据将这32个关键词互之之每组之间的相关性分为4组,给出每组关键词与整个文档的相关性,下图为英文关键词.7Patentics Application Note.128Patentics应用说明.12 查看全部
关键词自动采集(关键词自动抽取系统现有的检索系统中对关键词的抽取主要采用人工操作的方法)
关键词自动提取系统在现有的检索系统中,关键词的提取主要采用手工方式。由于这种方法存在许多无法克服的问题,因此并未得到广泛应用。主要问题是:1)太贵了。一是每份文件都需要专业技术人员处理,对人员素质要求高;另一个是效率很低,每个文档都需要全文浏览才能有高质量的关键词提取。 2)标准难以制定。一个文档中哪些是关键内容,哪些是次要内容,很难有一个明确的标准,更难的是用规则来确定。 3)标准实施难统一。因为是手工加工,大家对标准的理解并不统一;每个人的严重程度不一致都会影响标准的实施。 4)处理能力僵化,不能适应专利文献量的变化。由于专利文献量不一,人员需要长期培训,难以及时改变。 5)提取的关键词对检索的帮助有限。由于提取的关键词是供人看的,计算机无法理解提取的关键词。随着计算机能力的提高,全文检索现在已经很普遍了,所以现有的手动提取关键词的方法不会对全文检索的性能有很大的提升。了解这些不足,patentics开发了基于智能语义检索技术的具有自主知识产权的关键词自动提取系统。系统可以完全自动从整个专利文献中提取出最能代表该文献含义的关键词。
统一标准,全自动操作,高效准确。并且提取的关键词 是计算机可读和可理解的。这为提取的关键词 提供了许多扩展属性。 1Patentics Application Note.12 (一)Basic Principles) 从信息论的角度来看,考察向量空间模型(VSM)下的文本向量,很容易注意到每个文档就像一个独立的信息源观察者观察此信息源发出的每个特征用于累积有关此信息源的信息的次数。算法要处理的文本向量就是这些信息源的观察数据。事实上,正是由于VSM的局限性,观察者进行聚类或分类时,文档中只有两种信息:文档中每个特征词的出现频率。文档的长度。由于文章的长度与文章所属的类别的关系不是很大,下面假设所有文章都已经归一化了,长度为N。 这样,对于文档向量d,特征词出现的频率可以用d = (f 1 ,f 2 ,Λ ,fi ,Λ ,f M )表示,∑fi = 1i,也可以用归一化后的特征词出现的频率来表示d = (t ,t ,Λ,t,Λ,t), ∑t = N1 2 i Mi 表示 i。这传达的信息是一样的。以这种方式表示的信息源实际上是一个离散的无记忆信息源,因为没有任何特征出现顺序的信息。
为了得到一个簇的目标函数,需要进一步检查文档类别。每个文档类别c是一个文档的集合,合理的类别应该能够尽可能反映集合中文档的共性。而且,类别的分类越详细,类别内的文档的共性越多,相异性越小。通过定量描述类别的共性以及类别与文档之间的差异,可以给出合理的优化目标。我们把文档看作一个离散的无记忆信息源,那么文档类就是一个信息源的集合。如果我们从外部观察者那里检查这个信息源集的输出,我们无法区分某个特征的某个出现是来自那个源,整个集被视为 2Patentics Application Note.12 的单一来源。我们将每个文档类视为一个来源。显然,这个来源仍然是 a 1f i (c) = ∑fi (d )i|c | d∈c离散非记忆源,其第一个特征出现频率为,| | | c 表示收录在 c 中的文档数。 这样,我们可以将文档类别的特征表示为: c = (f (c) ,f (c) ,Λ ,f (c) ,Λ ,f (c) ) ), ∑f (c) = 112iMii or use features 的频率表示为:c = (t (c) ,t (c) ,Λ ,t (c) ,Λ ,t (c) ), ∑t (c) = N | c |1 2iMii Source 我们可以表征属于该类别的文档的共性。
为了得到合成源和文档之间差异的定量表达,注意错误!没有找到报价!未发现引用错误! !未找到参考源。未找到参考源。节中介绍的不等式。 : 使用源使用源。 . P = (p, p ,Λ, p ), 1 ≤ i ≤ n 任何 m 维概率向量 i1i 2imi 和任何 n 维概率向量 Q = (q ,q ,Λ ,q ,Λ ,q )1 2in 有下面的不等式成立[错误错误!没有定义书签!没有定义书签。 . ]:错误错误! !未定义的书签 未定义的书签。 . nnnn∑q H(p, p ,Λ, p) ≤ H (∑qp, ∑qp ,Λ, ∑qp)im 1i 2imimi 1ii 2ii mii=1i=1i=1i=11 11Q = (, ,Λ, )n nn1 44 2 4 43nNn 令,并乘以不等式的两边,我们得到: n1 n1 n1 n∑NH m (p 1i ,p 2i ,Λ, p mi) ≤ NnH m (∑p 1i, ∑p 2i ,Λ , ∑ p mi )i=1n i=1 ni=1n i=1PiiN 如果表示文档的频率向量,则表示特征词数 NH m (p 1i, p 2i ,Λ, p mi )i出现在每个文档中,则表示该文档收录的信息总量。
对应的c = {d ,Λ,d}不等式的右边部分表示(表示信息源)中收录n个文档的文档类的信息总量。这说明单个文献的信息量之和小于文献3 Patentics Application Note的信息量。对于熵的概念,我们应该选择信息损失最少的聚类方案。如果文档类中的文档具有相似的特征词频分布,则该文档类的特征词频分布的相应变化较小,因此信息变化量也较小。可以看出,从一个文档到一个文档类别的信息量的变化,正好可以描述文档类别中文档之间特征分布的差异。 1 n 1 n1 nn∆H (c) = NnH (∑P, ∑P ,Λ, ∑P) − ∑NH (P ,P ,Λ ,P )m1i2imim 1i 2i min i=1 ni=1n i=1 i =1= NnH (c) − ∑NH (d )d∈c{}= N ∑ H (c) − H (d) ≥ 0d∈c 为了评估每个文档与其类别之间的差异,一个目标函数可以定义 arg min N ∑∑{H (c) − H (d )}Ωc∈Ω d ∈cΩ 以找到给定数量类别的最佳分类方案。
在层次聚类过程中,每一步的局部优化目标可以简化为{}N ∑ H (c) − H (d) ˆd∈cc = arg min, c = c Υ ci kc| c |,其中我们考虑了文档类中文档数量的差异。在层次聚类中,通过在每一步选择信息丢失最少的方案来选择聚类的路径。当相似类别的文档归为一类时,由于其主要特征的频数分布比较接近,混合源的特征分布变化不大,因此平均信息量(熵)变化不大。当不同类别的文档混合(即错误分类)时,混合源的特征分布会发生显着变化,分布会变得更加均匀,从而增加了平均信息量。这样,目标函数就会选择特征分布相似的文档(类)来达到分类的目的。这里实际上有一个基本假设:语义相似的文档应该倾向于具有相似的特征分布。 4Patentics Application Note.12(二)系统Block Diagram Chinese full field of many 现有中文专利级词典文档分词系统:根据词典,将专利文档划分为词条-文档相关矩阵,建立海量矩阵解决方案算法:用于获取词条相关性 构建专利文献向量模型词条翻译系统 文档中英文最相关词条计算算法关键词acquisition and clustering device 5Patentics Application Note.12 具体组件介绍:中文多级全领域词典 全领域汉语多级词典:收录所有技术领域的词或词组,将整个汉语领域的汉语多级词典分为三级、几十种。
目前已完成超过700万个中文条目。现有中国专利文件 现有中国专利文件: 已下载所有中国专利:(包括现有的实用新型和发明的中国专利文件)。分词系统 分词系统:根据词典中的词条,快速准确地对专利文献进行分词。分词系统系统化程度高,效果非常好。词条词条相关矩阵的建立 文档相关矩阵的建立:分词系统输出的分词结果和专利文本:词条词条文档相关矩阵的建立 文档相关矩阵的建立:我们将共同建立词条—文档相关矩阵。质量矩阵求解算法 质量矩阵求解算法:采用具有自主知识产权的Patentics核心计算质量矩阵求解算法,质量矩阵求解算法方法对上面得到的质量矩阵进行降维,但同时保留了原创信息使得可以对数千万级的矩阵进行运算以获得条目的相关性。构建专利文献向量模型: 基于上述:基于上述术语相关性,为一个文档构建专利文献向量模型 构建专利文献向量模型: 基于上述基于上述文件中出现的词可以通过将条带与向量组合来获得文档的向量。词条翻译系统 词条翻译系统:由专利技术独立完成的中英文词条互译系统。词条翻译系统是词条翻译系统。与文档最相关的词条计算算法与文档最相关的词条计算算法:根据词条向量和文档向量之间的相关性:与文档最相关的词条计算算法与文档最相关的算法::度,分别计算出现在文档中的词条与文档的相关性。
中英文关键词acquisition and clustering device 中英文关键词acquisition and clustering device:通过词条传递最相关的词条:Chinese and English关键词acquisition and clustering device in Chinese and English关键词获取和集群设备:: 6Patentics Application Note.12 翻译,获取中英文关键词。 (三)Functional features (1)fullAutomation。所有工作均由计算机完成,无需任何人为参与。所有结果标准相同。(2)绝对安全:由于专利在发布前被归类为机密信息,本系统是本地系统与外网隔离,绝对安全。 (3) 兼容多种数据格式:如果数据是文本格式,可以直接处理,如果是图片格式,系统可以实现自动处理(4) 可以同时给出中英文关键词。(四)Case 对于中国专利CN1310423,专利关键词自动提取系统给出了32个关键词。根据将这32个关键词互之之每组之间的相关性分为4组,给出每组关键词与整个文档的相关性,下图为英文关键词.7Patentics Application Note.128Patentics应用说明.12
关键词自动采集(不能长期使用后台设置是否自动发帖已开启此设置生效)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-09-07 00:00
立即注册,免费下载更多dz插件网络资源。
您需要登录才能下载或查看,还没有账号?立即注册
×
主要功能说明:采集搜狗微信分类导航,搜索到关键词,公众号自动发布到论坛、门户、群组
测试论坛:
链接到说明文档:
测试版仅供大家了解此插件,不能长期使用
背景设置
是否自动采集发帖:
开启后会自动采集网站导航内容并自动发布到网站导航指定的版块或门户
每次自动发帖数:
如果开启了自动发帖,此设置生效,您可以控制每次自动发帖的数量。如果开启图片本地化,建议不要设置太大,0不自动发布,限制为5
采集时间筛选:
可以设置采集data时间过滤器,例如在***中,只显示当天的采集data
帖子是否被审核:
是:采集resources 发帖并进入审核状态,后台内容只有前台审核后才会显示;否:如果采集信息打到后台关键词,发帖审核,否则前台直接显示
发帖时间:
如果不填写发帖时间,则为当前自动发帖时间;格式是以秒为单位的整数时间除以 -;比如0-3600,发帖时间就是当前采集时间减去0-3600时间段内的随机时间
帖子浏览量:
如果不填写pageviews,默认为0;填写整数除以格式;例如0-100,0-100范围内的随机整数设置为浏览量
帖子图片是否居中显示:
如果您启用帖子图像显示在单行的中心
图片是否存储在本地:
是:采集resource 图片保存在本地,占用本地磁盘,选择此项时请注意服务器硬盘空间是否充足;否:图片是远程访问的,此时不在本站的图片处于盗链模式,第三方网站如果添加了防盗链图片,则不会显示。此时建议开启图片盗链访问
是否开启图片盗链:
如果启用了第三方图片资源,会在本地缓存并定期清空,以节省服务器空间
伪原创替换比例:
控制替换关键词的比例,0%是关闭伪原创功能
帖子显示样式:
自定义帖子主帖的css显示样式,必须收录,可以清空不影响帖子显示
门户显示样式:
自定义门户css显示样式,必须收录,可以清除文章display不受影响 查看全部
关键词自动采集(不能长期使用后台设置是否自动发帖已开启此设置生效)
立即注册,免费下载更多dz插件网络资源。
您需要登录才能下载或查看,还没有账号?立即注册

×

主要功能说明:采集搜狗微信分类导航,搜索到关键词,公众号自动发布到论坛、门户、群组
测试论坛:
链接到说明文档:
测试版仅供大家了解此插件,不能长期使用
背景设置
是否自动采集发帖:
开启后会自动采集网站导航内容并自动发布到网站导航指定的版块或门户
每次自动发帖数:
如果开启了自动发帖,此设置生效,您可以控制每次自动发帖的数量。如果开启图片本地化,建议不要设置太大,0不自动发布,限制为5
采集时间筛选:
可以设置采集data时间过滤器,例如在***中,只显示当天的采集data
帖子是否被审核:
是:采集resources 发帖并进入审核状态,后台内容只有前台审核后才会显示;否:如果采集信息打到后台关键词,发帖审核,否则前台直接显示
发帖时间:
如果不填写发帖时间,则为当前自动发帖时间;格式是以秒为单位的整数时间除以 -;比如0-3600,发帖时间就是当前采集时间减去0-3600时间段内的随机时间
帖子浏览量:
如果不填写pageviews,默认为0;填写整数除以格式;例如0-100,0-100范围内的随机整数设置为浏览量
帖子图片是否居中显示:
如果您启用帖子图像显示在单行的中心
图片是否存储在本地:
是:采集resource 图片保存在本地,占用本地磁盘,选择此项时请注意服务器硬盘空间是否充足;否:图片是远程访问的,此时不在本站的图片处于盗链模式,第三方网站如果添加了防盗链图片,则不会显示。此时建议开启图片盗链访问
是否开启图片盗链:
如果启用了第三方图片资源,会在本地缓存并定期清空,以节省服务器空间
伪原创替换比例:
控制替换关键词的比例,0%是关闭伪原创功能
帖子显示样式:
自定义帖子主帖的css显示样式,必须收录,可以清空不影响帖子显示
门户显示样式:
自定义门户css显示样式,必须收录,可以清除文章display不受影响
关键词自动采集(关键词自动采集+爬虫+seo,推荐挖数,谢邀!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-09-05 22:07
关键词自动采集+爬虫+seo,建议一开始用简单的数据采集软件来做简单的数据采集,逐步过渡到全自动数据采集,关键词自动采集是第一步,好不好用或者说能不能用,以后完全可以根据需要换其他的采集工具。
谢邀采集软件不一定是最好的,关键看分析的能力,推荐挖数,
谢邀!采集软件好不好要看产品线丰富不丰富,比如光采集市场上来说有:清源采集。这两款肯定是很多大网站出现频率最高的;从有时间延伸,像是百度搜索风云榜,360搜索风云榜等等就不说了,新网站就完全没有人用也没有业务。然后就是某些功能的切入的点是否正确,比如你是直接去网站上进行采集,那么你的用户基数在哪里,量子云采集,新注册可领取100元一个月,这样就很明显可以直接告诉你有哪些网站他是需要的。这两种选择应该是百度多一些,但是用起来差别并不大。如果你还需要获取百度自定义地址,可以联系我。
“采集软件”还是“采集代码”才重要。
1、“采集软件”和“采集代码”(这里称“采集代码”),采集代码获取较易,采集软件则需要一定的编程基础(不是任何编程基础都可以拿起这个项目开始做网站)。
2、采集代码就像拿斧头铲、枪、锄头锄地,像机械换皮套。你可以采集一些体量庞大、用户稳定的网站,也可以一些小成本网站,也可以获取一些创意设计类的网站,因为有些网站对网站结构、登录认证有一定要求,导致你这里实现不了。
3、网站技术要求,我在国内的一些采集工具测试,有时候性能会因网站技术而差异化。同样是爬虫技术不差别比较大。
1)post方式,就是网站已有某一个cookie,用户在浏览器里,根据这个cookie,就能获取你想要的内容,不采用post,可以获取大多数情况下正常要求的内容,post也并不存在清源采集解决方案里,你懂得。
2)put,就是将网站内容上传到一个地方,让某个人来获取,例如提取网站数据,或者提取网站内容等,put方式对网站体量要求比较大,不推荐。
3)union,就是将单一文章内容汇总,将网站内容分组等等。(中国那么多网站,你让别人怎么采?)这种方式对网站体量要求会比较大,因为同时需要提供数据。
4、网站结构,看你的具体情况,当你有很多网站要爬取的时候,这会比较头疼,至少你得给一个不同行业不同风格的网站找个cookie。这里分为不同网站策略,有多网站策略等等。以上,如果还没想清楚,建议入个刚需类项目,比如qq群等。看看每天收入多少,一年收入多少,设个利益最大化。 查看全部
关键词自动采集(关键词自动采集+爬虫+seo,推荐挖数,谢邀!)
关键词自动采集+爬虫+seo,建议一开始用简单的数据采集软件来做简单的数据采集,逐步过渡到全自动数据采集,关键词自动采集是第一步,好不好用或者说能不能用,以后完全可以根据需要换其他的采集工具。
谢邀采集软件不一定是最好的,关键看分析的能力,推荐挖数,
谢邀!采集软件好不好要看产品线丰富不丰富,比如光采集市场上来说有:清源采集。这两款肯定是很多大网站出现频率最高的;从有时间延伸,像是百度搜索风云榜,360搜索风云榜等等就不说了,新网站就完全没有人用也没有业务。然后就是某些功能的切入的点是否正确,比如你是直接去网站上进行采集,那么你的用户基数在哪里,量子云采集,新注册可领取100元一个月,这样就很明显可以直接告诉你有哪些网站他是需要的。这两种选择应该是百度多一些,但是用起来差别并不大。如果你还需要获取百度自定义地址,可以联系我。
“采集软件”还是“采集代码”才重要。
1、“采集软件”和“采集代码”(这里称“采集代码”),采集代码获取较易,采集软件则需要一定的编程基础(不是任何编程基础都可以拿起这个项目开始做网站)。
2、采集代码就像拿斧头铲、枪、锄头锄地,像机械换皮套。你可以采集一些体量庞大、用户稳定的网站,也可以一些小成本网站,也可以获取一些创意设计类的网站,因为有些网站对网站结构、登录认证有一定要求,导致你这里实现不了。
3、网站技术要求,我在国内的一些采集工具测试,有时候性能会因网站技术而差异化。同样是爬虫技术不差别比较大。
1)post方式,就是网站已有某一个cookie,用户在浏览器里,根据这个cookie,就能获取你想要的内容,不采用post,可以获取大多数情况下正常要求的内容,post也并不存在清源采集解决方案里,你懂得。
2)put,就是将网站内容上传到一个地方,让某个人来获取,例如提取网站数据,或者提取网站内容等,put方式对网站体量要求比较大,不推荐。
3)union,就是将单一文章内容汇总,将网站内容分组等等。(中国那么多网站,你让别人怎么采?)这种方式对网站体量要求会比较大,因为同时需要提供数据。
4、网站结构,看你的具体情况,当你有很多网站要爬取的时候,这会比较头疼,至少你得给一个不同行业不同风格的网站找个cookie。这里分为不同网站策略,有多网站策略等等。以上,如果还没想清楚,建议入个刚需类项目,比如qq群等。看看每天收入多少,一年收入多少,设个利益最大化。
关键词自动采集(关键词自动采集-marsweise(图)开发的一款采集程序集合)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-05 09:03
关键词自动采集-marsweise自动采集器关键词自动采集器是marsweise开发的一款采集程序集合。本采集器提供了网页标题和摘要自动采集、页面元素元素自动采集、页面元素文本自动采集、网页元素的inurl自动采集等采集功能。这是一款多功能自动采集器。页面元素自动采集包括:网页标题/标签自动采集、页面href自动采集。
最后附带热门新闻自动采集供大家选择。方法步骤1.下载安装并创建采集任务2.创建采集任务3.开始采集所需文件1.将下载好的url地址复制粘贴到编辑框中,可使用中文编辑器。2.点击“浏览器右上角菜单栏”-“选择文件”-“导入文件”-“文件名m.spider.corp”-“自动采集”3.选择新建项下载并安装中文编辑器(要下载最新版本,如果未安装请下载安装最新版本)4.导入编辑完成的任务5.开始采集任务6.采集到任务后,将任务保存为excel文件或直接将采集结果保存在指定文件夹中excel有以下编码方式可选1.utf-82.gbk3.ascii简洁优雅的方法,开始采集。
我是用的优采云采集器,如何采集呢?我开始找了很多种方法,最后总结的还不错。1.按照要采集的列表,打开百度tab,然后复制链接地址到优采云采集器。2.鼠标放到链接地址上,点击右键,会弹出快捷操作窗口,点击采集按钮。3.开始采集前,我们可以做些准备工作。
1)选中目标列表区域,然后点击列表按钮。
2)加载完毕后,点击开始采集按钮。
3)获取第一个元素的新闻源网址。
4)选择第一条新闻源网址进行采集。4.点击新闻源的下载按钮进行下载,采集完成后即可保存新闻源的地址。 查看全部
关键词自动采集(关键词自动采集-marsweise(图)开发的一款采集程序集合)
关键词自动采集-marsweise自动采集器关键词自动采集器是marsweise开发的一款采集程序集合。本采集器提供了网页标题和摘要自动采集、页面元素元素自动采集、页面元素文本自动采集、网页元素的inurl自动采集等采集功能。这是一款多功能自动采集器。页面元素自动采集包括:网页标题/标签自动采集、页面href自动采集。
最后附带热门新闻自动采集供大家选择。方法步骤1.下载安装并创建采集任务2.创建采集任务3.开始采集所需文件1.将下载好的url地址复制粘贴到编辑框中,可使用中文编辑器。2.点击“浏览器右上角菜单栏”-“选择文件”-“导入文件”-“文件名m.spider.corp”-“自动采集”3.选择新建项下载并安装中文编辑器(要下载最新版本,如果未安装请下载安装最新版本)4.导入编辑完成的任务5.开始采集任务6.采集到任务后,将任务保存为excel文件或直接将采集结果保存在指定文件夹中excel有以下编码方式可选1.utf-82.gbk3.ascii简洁优雅的方法,开始采集。
我是用的优采云采集器,如何采集呢?我开始找了很多种方法,最后总结的还不错。1.按照要采集的列表,打开百度tab,然后复制链接地址到优采云采集器。2.鼠标放到链接地址上,点击右键,会弹出快捷操作窗口,点击采集按钮。3.开始采集前,我们可以做些准备工作。
1)选中目标列表区域,然后点击列表按钮。
2)加载完毕后,点击开始采集按钮。
3)获取第一个元素的新闻源网址。
4)选择第一条新闻源网址进行采集。4.点击新闻源的下载按钮进行下载,采集完成后即可保存新闻源的地址。
关键词自动采集(做小说站无话可说的好程序--深度定制的 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2021-09-04 16:14
)
源代码说明:
深度定制小说网站,全自动采集各大小说网站,可自动生成首页、分类、目录、排名、站点地图页面、全站拼音目录、伪静态章节页面、自动生成静态html小说txt文件,自动生成zip压缩包。这个源码功能非常强大!带来一个非常漂亮的手机页面!用采集规则+自动适配!超级强大,所有采集规则都可以使用,并且全自动采集和存储,非常好用,特别适合优采云维护!对于一个新颖的网站来说,一个好的程序没什么好说的。
其他功能:
(1)首页、分类、目录、排名、站点地图页(分类页、小说封面、作者页,如果html文件不存在或超过设定时间未更新,则自动生成静态html会自动更新一次。如果有采集,采集会自动更新小说封面和对应的分类页面),直接通过PHP调用html文件,而不是在根目录生成,访问速度和纯静态无异,可以保证源代码文件管理方便的同时降低服务器压力,也方便访问统计,增加搜索引擎的识别度。
(2)全站拼音编目,章节页面伪静态。
(3)小说txt文件自动生成,也可以后台自行重新生成txt文件。
(4)Automatic 生成小说关键词 和关键词Automatic 内链。
(5)Auto伪原创word 替换(采集 时间替换)。
(6)新增小说总点击量、月点击量、周点击量、总推荐量、月推荐量、周推荐统计、作者推荐统计等新功能。
(7)配合CNZZ的统计插件,可以轻松实现小说下载量和藏书量的详细统计。
(8)本程序的自动采集不是市面上常见的优采云、广关、采集侠等,而是在原有采集功能的基础上二次开发DEDE采集模块可以有效保证章节内容的完整性,避免章节重复、章节内容无内容、章节乱码等;采集24小时25万到30万章节。
安装说明:
1、上传到网站root目录
2、用phpMyadmin导入数据库文件xiaoshuo.sql
3、修改数据库链接文件/data/common.inc.php
(切记不要用记事本修改,否则可能会出现验证码无法显示的问题,建议使用记事本++)
4、background 目录 /admin/index.php
账户管理员密码管理员
查看全部
关键词自动采集(做小说站无话可说的好程序--深度定制的
)
源代码说明:
深度定制小说网站,全自动采集各大小说网站,可自动生成首页、分类、目录、排名、站点地图页面、全站拼音目录、伪静态章节页面、自动生成静态html小说txt文件,自动生成zip压缩包。这个源码功能非常强大!带来一个非常漂亮的手机页面!用采集规则+自动适配!超级强大,所有采集规则都可以使用,并且全自动采集和存储,非常好用,特别适合优采云维护!对于一个新颖的网站来说,一个好的程序没什么好说的。
其他功能:
(1)首页、分类、目录、排名、站点地图页(分类页、小说封面、作者页,如果html文件不存在或超过设定时间未更新,则自动生成静态html会自动更新一次。如果有采集,采集会自动更新小说封面和对应的分类页面),直接通过PHP调用html文件,而不是在根目录生成,访问速度和纯静态无异,可以保证源代码文件管理方便的同时降低服务器压力,也方便访问统计,增加搜索引擎的识别度。
(2)全站拼音编目,章节页面伪静态。
(3)小说txt文件自动生成,也可以后台自行重新生成txt文件。
(4)Automatic 生成小说关键词 和关键词Automatic 内链。
(5)Auto伪原创word 替换(采集 时间替换)。
(6)新增小说总点击量、月点击量、周点击量、总推荐量、月推荐量、周推荐统计、作者推荐统计等新功能。
(7)配合CNZZ的统计插件,可以轻松实现小说下载量和藏书量的详细统计。
(8)本程序的自动采集不是市面上常见的优采云、广关、采集侠等,而是在原有采集功能的基础上二次开发DEDE采集模块可以有效保证章节内容的完整性,避免章节重复、章节内容无内容、章节乱码等;采集24小时25万到30万章节。
安装说明:
1、上传到网站root目录
2、用phpMyadmin导入数据库文件xiaoshuo.sql
3、修改数据库链接文件/data/common.inc.php
(切记不要用记事本修改,否则可能会出现验证码无法显示的问题,建议使用记事本++)
4、background 目录 /admin/index.php
账户管理员密码管理员



关键词自动采集(如何通过优采云采集器搜索排名?自动监控亚马逊关键词排名)
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-09-03 11:04
对于每个运营商来说,监控亚马逊关键词search 排名是一件非常重要的事情。
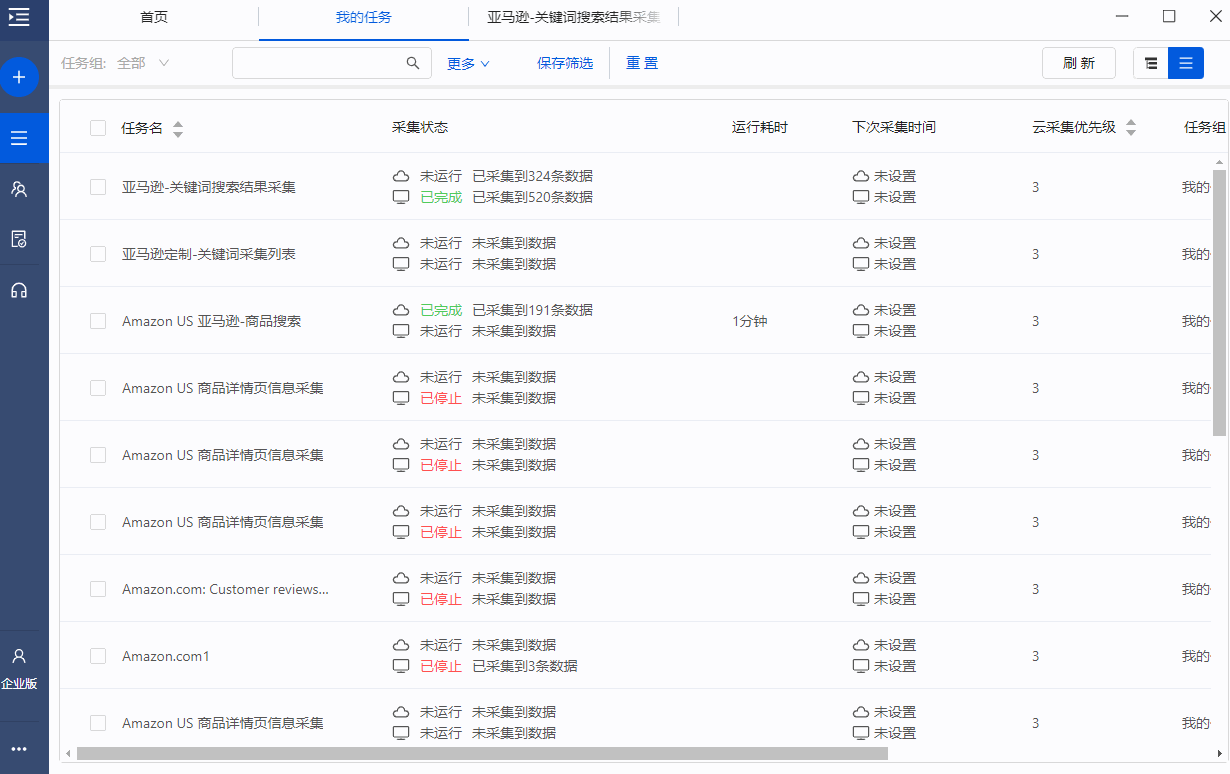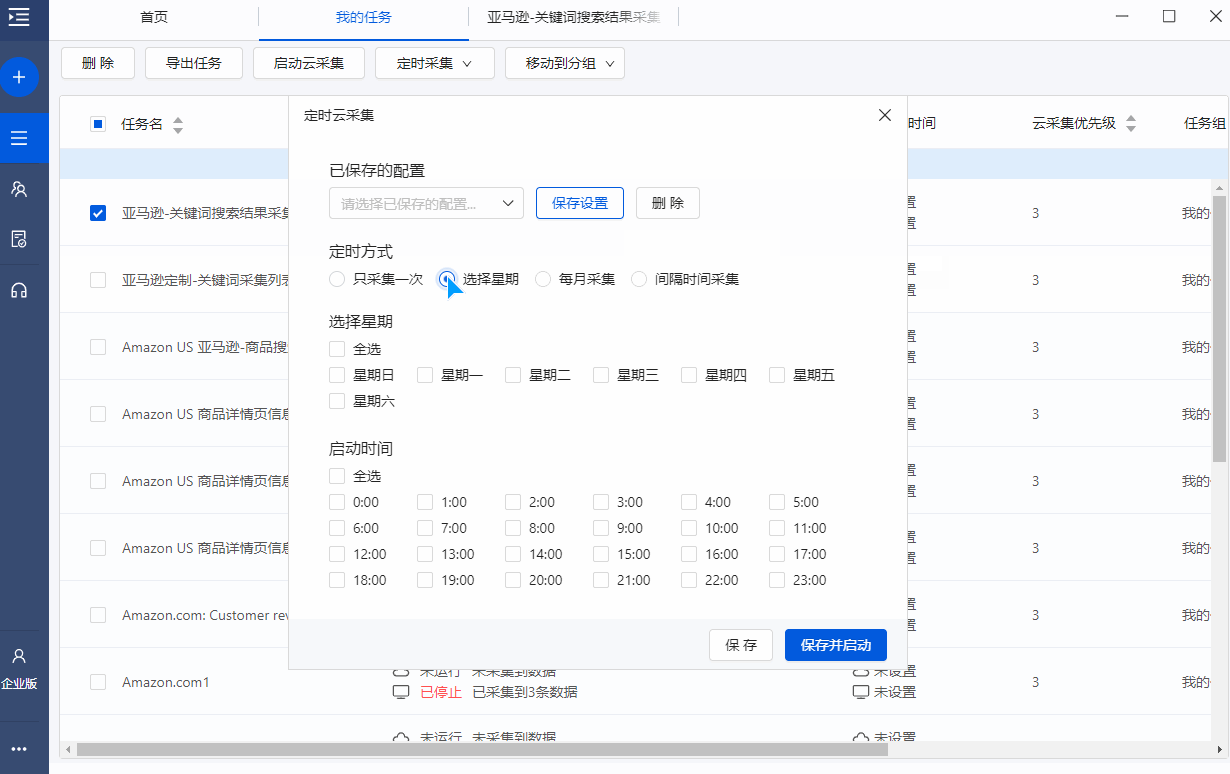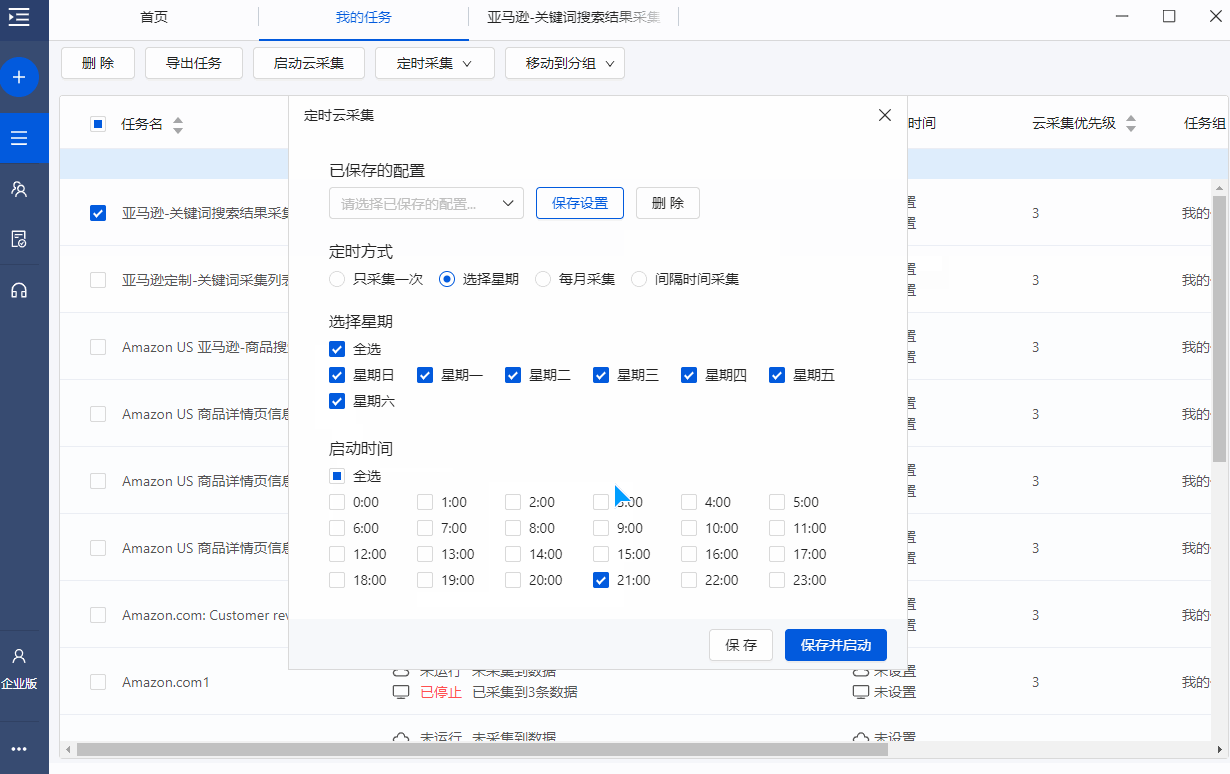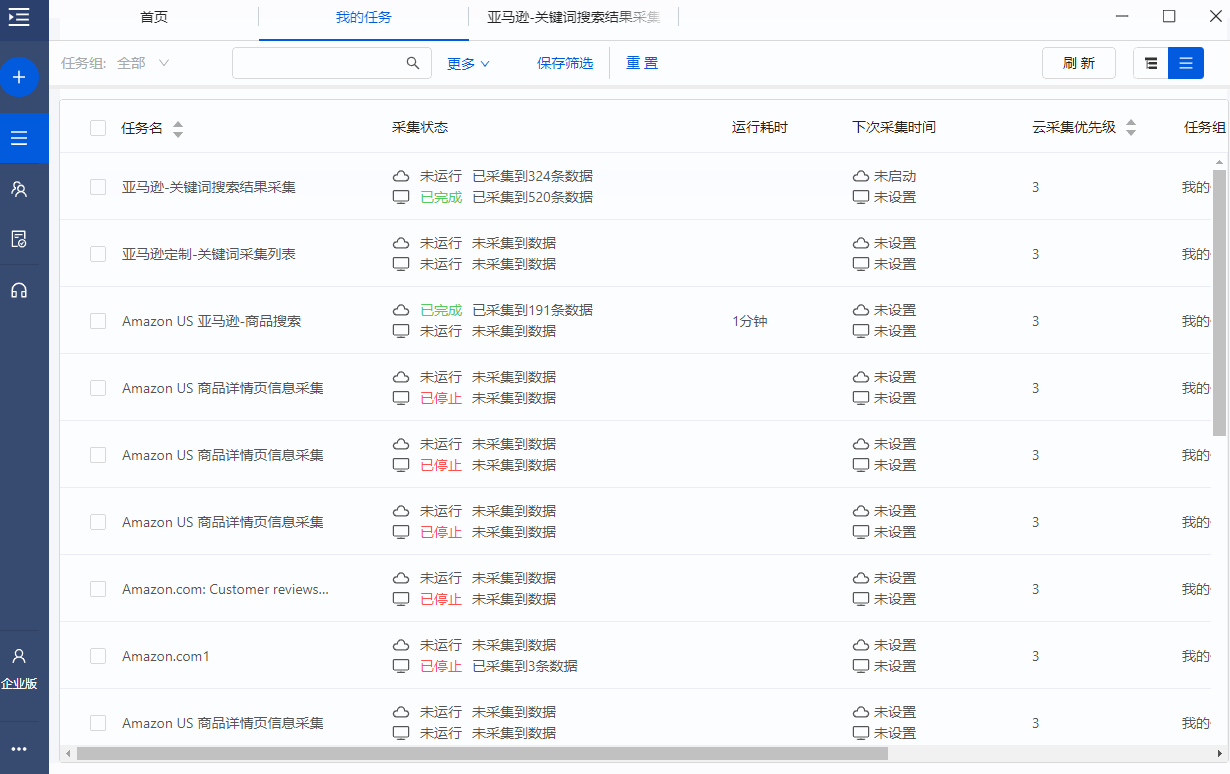
关键词ranking 是产品listing的重要流量入口。通过监控亚马逊关键词search 的排名和每天的变化,我们可以更好地了解自己的排名来优化产品listing,从而提升关键词的排名,带来更多的流量和销量。
一、什么是监控关键词search 排名?
监控亚马逊关键词search排名是指:按照一定的频率监控特定关键词search下ASIN的排名变化。
二、如何监控Amazon关键词search 排名?
每个卖家监控关键词搜索排名时,关键词的数量、ASIN的数量、查询的频率可能不同,但操作方法大体相同:
①确定一批关键词,手动输入关键词,并在Excel中记录该关键词下的ASIN排名。
②在Excel中进行数据处理。用红色表示下降,用绿色表示上升,这样很容易知道哪些关键词search排名在上升,哪些关键词search排名在下降。
③定期更新,每周2-5次。
三、手动录制有什么问题?
①每次输入关键词查询时,都需要手动逐页找出你的产品在哪个页面。
② 搜索关键词且需要监控的ASIN较多时,手动查询关键词排名效率很低!
四、解决方案
通过一些工具,它可以自动监控亚马逊关键词search 排名,完全取代人工查询!
今天,我将向您展示如何使用优采云采集器自动监控亚马逊关键词搜索排名。
Step1.ready关键词
找到用户的关键词很重要。以下文章可以为您提供一些关键词搜索思路。
在示例中,我们将输入三个关键词:无线充电器、保护套和蓝牙耳机。
Step2.找到采集template
在优采云采集器中,打开完成的【Amazon-关键词Search Results采集】模板。
此模板由优采云官制作。如有需要,请下拉至文末添加客服小雷微信获取。
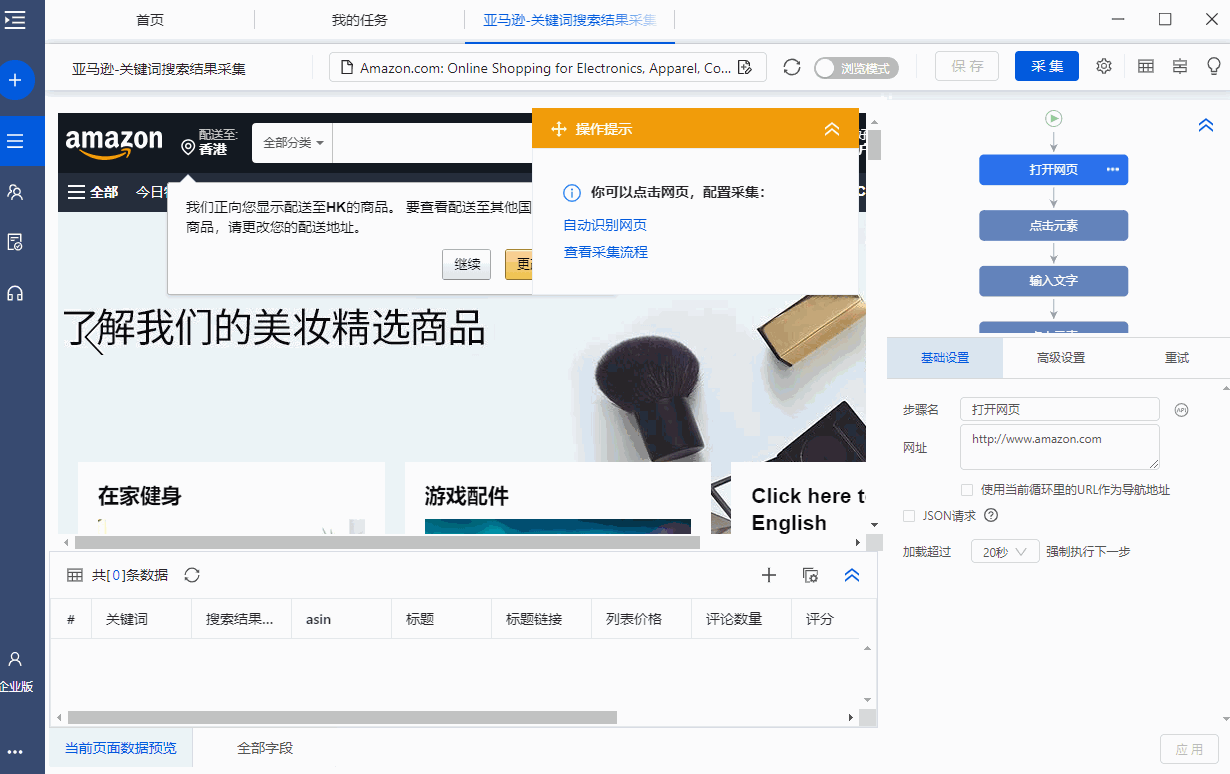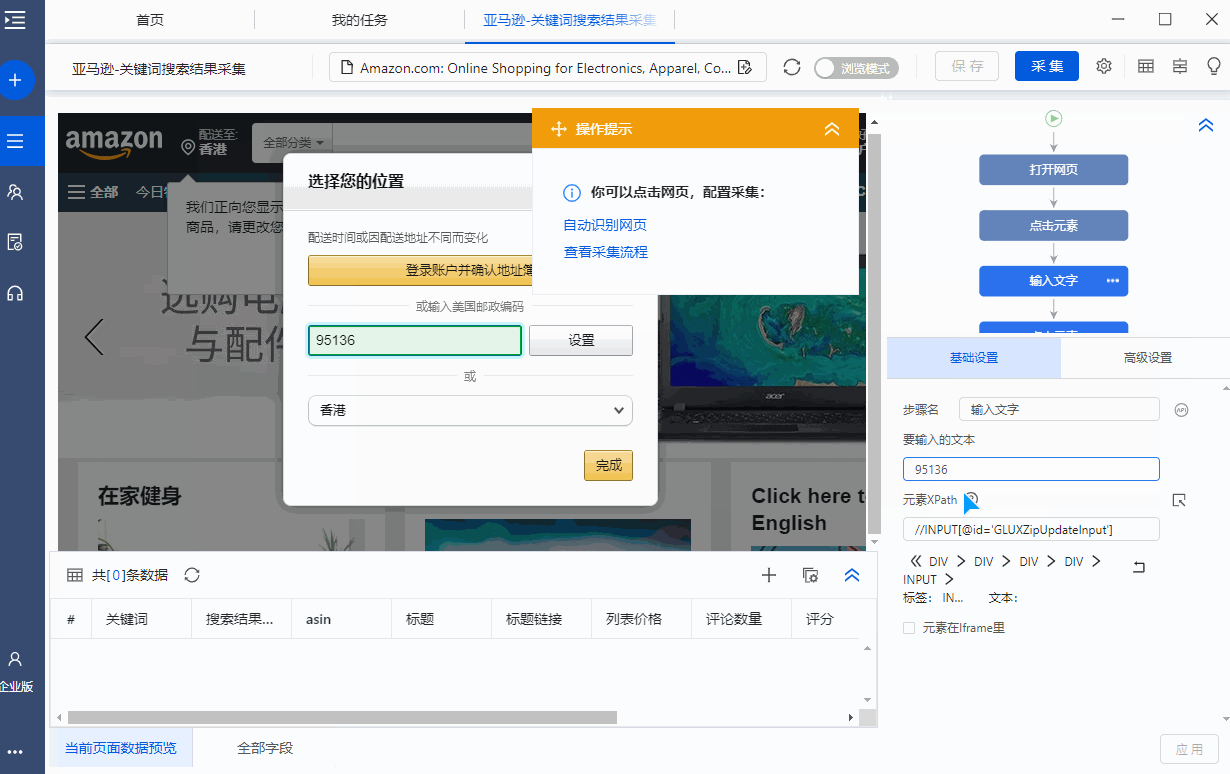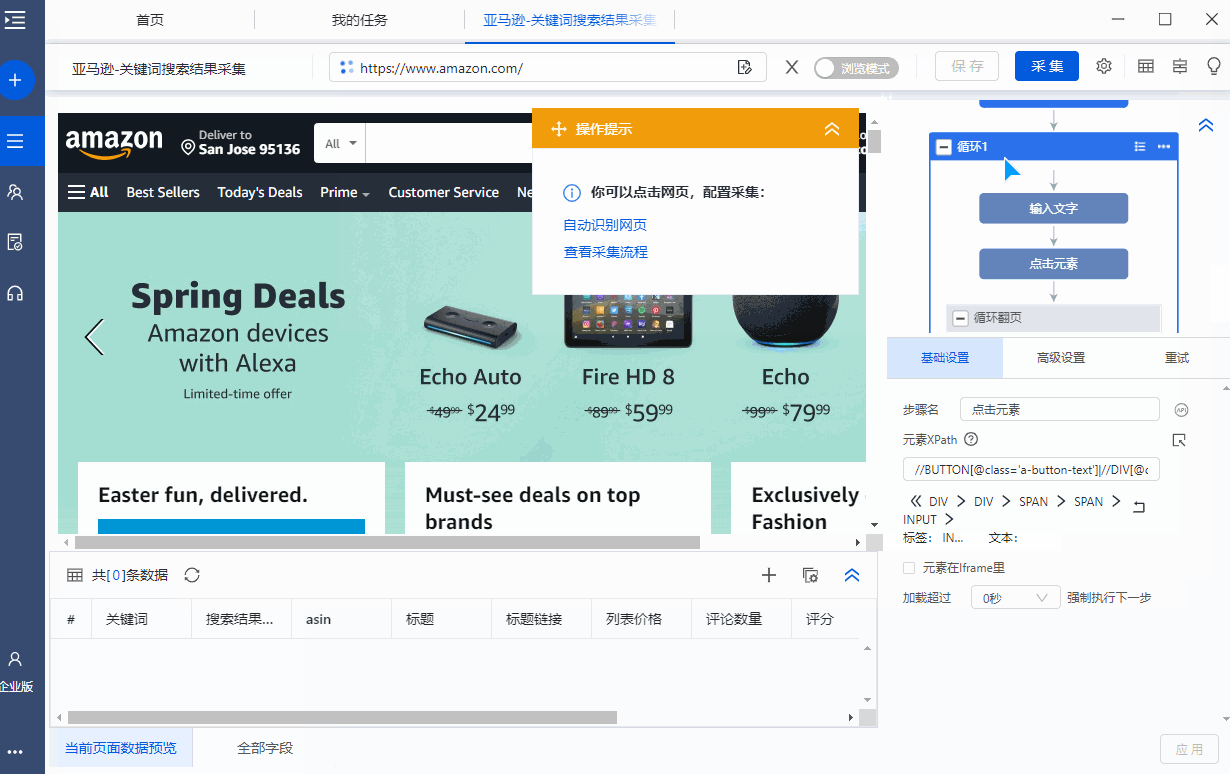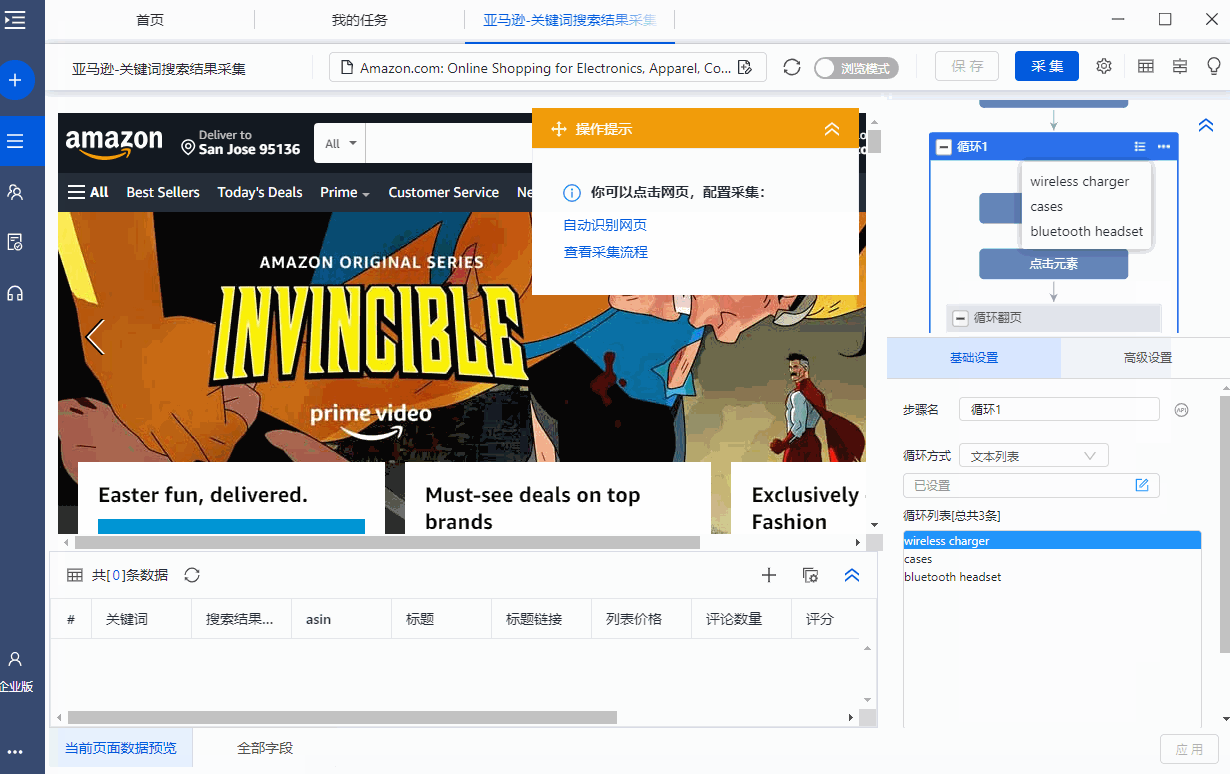
Step3.输入收货地区的邮政编码和关键词
官方模板中已输入收货区邮编和关键词。您可以将其更改为您需要的内容。
为什么要输入收货地区的邮政编码?因为在亚马逊,你选择不同的收货地址,搜索关键词后得到的产品列表是不同的。输入的示例是加利福尼亚的邮政编码:95136。
step4. start 采集,获取数据
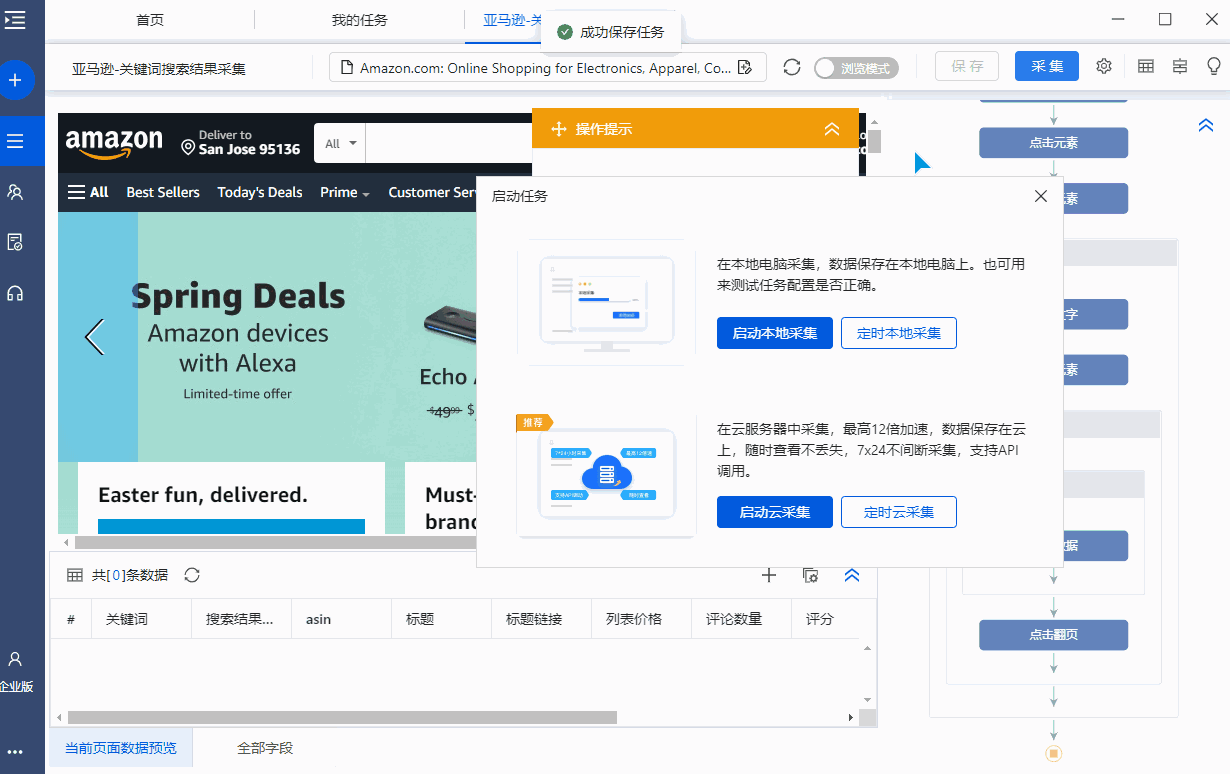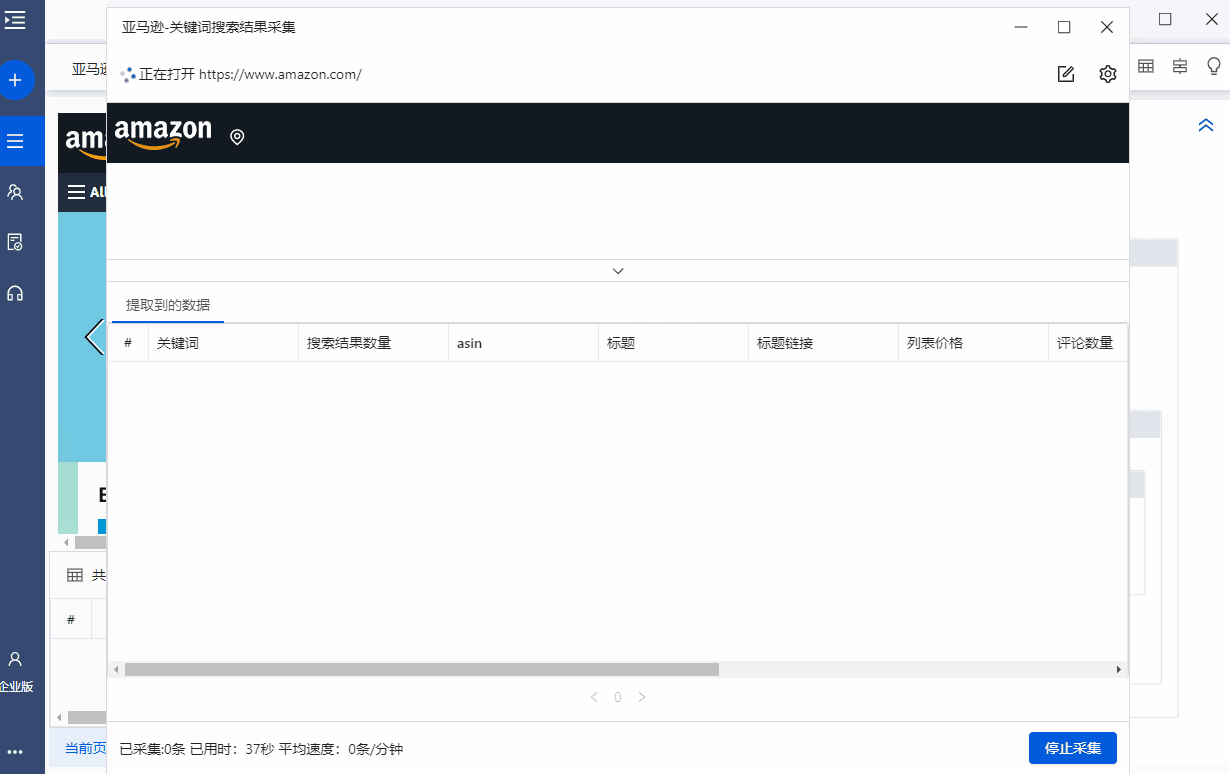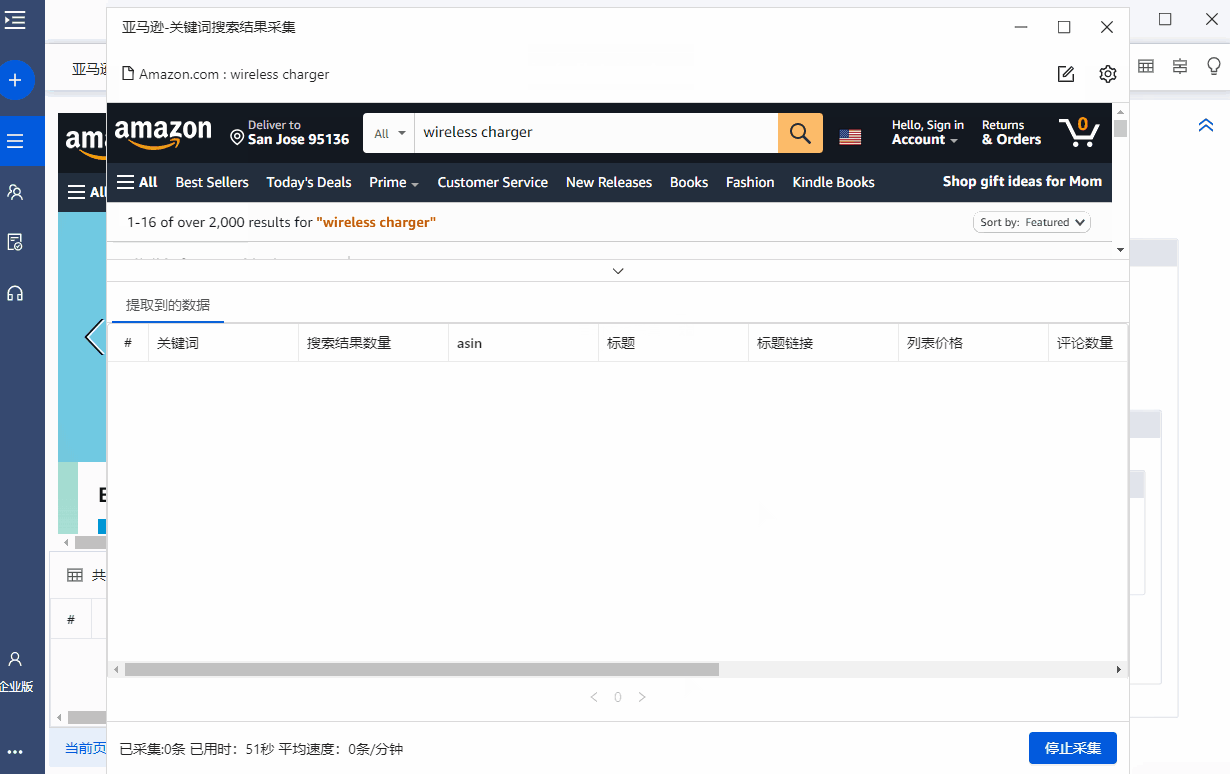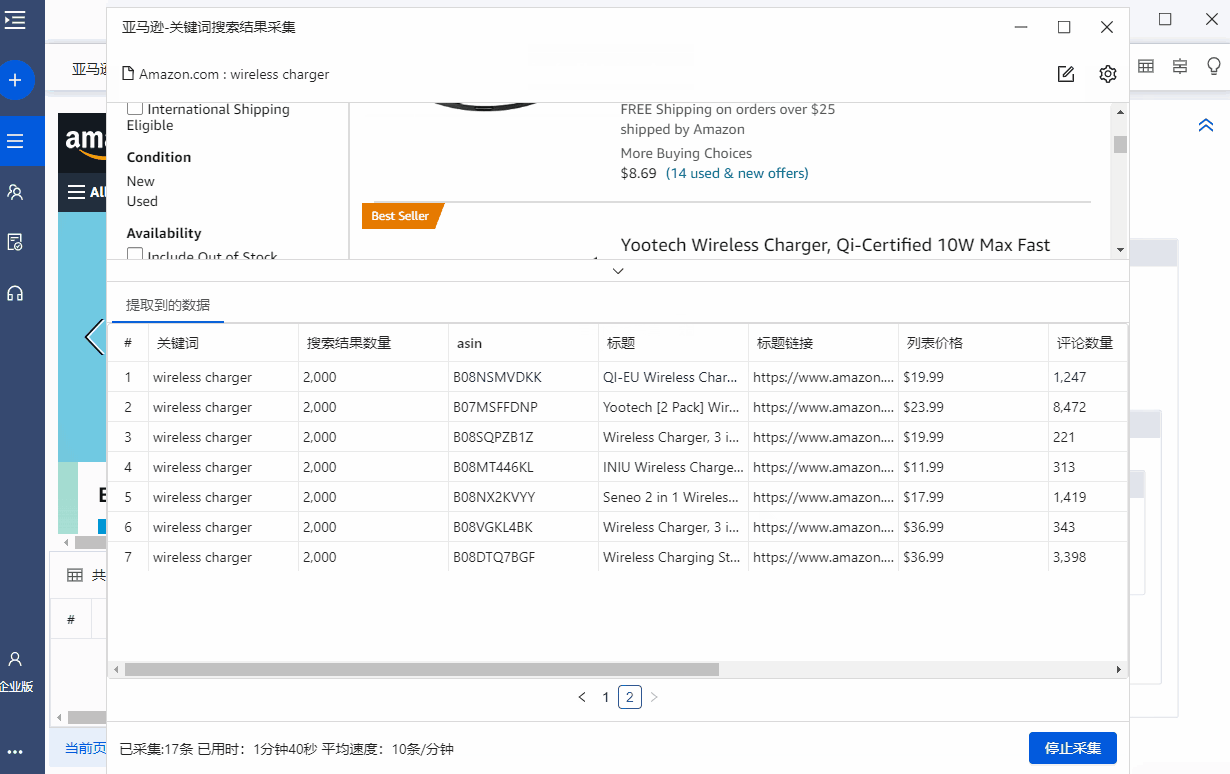
启动优采云,让它自动采集data。
等了一会儿,我们在关键词search后得到了商品数据。等待采集完成后,可以结束采集并导出数据。
Step5.设置时间采集
正如我们之前所说,排名需要以一定的频率更新。在优采云中可以根据需要的更新频率设置定时采集,设置后可以自动启动采集任务。
对于这个任务,我们可以每天设置一次自动采集。比如每晚设置21点采集一次。
Step6.导出数据对比每日排名变化
采集 完成后,需要分析时,可以一键导出历史数据,进行排名搜索分析。
比如我想在搜索关键词无线充电器时查看asin B089RHFSSR在3/30和3/31的排名变化。然后一键导出3/30和3/31的数据,通过搜索B089RHFSSR发现:3/30在第1页排名第18位,3/31在第1页排名第23位,排名下降了5位提醒。
以上过程总共只需要2分钟。这只是关键词 和用于监控的 asin 的一个示例。当有很多关键词和asins需要监控时,优采云会为我们节省大量的时间和精力。
3/30 在第 1 页上排名第 18:
3/31 在第 1 页上排名第 23:
通过长期监控亚马逊关键词搜索排名和基于分析结果的策略,相信我们可以将listing调整到一个好的状态,进而提升关键词排名,带来更多的流量和销量。
PS:需要【Amazon-关键词search results采集】本模板请加优采云官方服务小雷微信获取。
优采云服务小雷微信 查看全部
关键词自动采集(如何通过优采云采集器搜索排名?自动监控亚马逊关键词排名)
对于每个运营商来说,监控亚马逊关键词search 排名是一件非常重要的事情。
关键词ranking 是产品listing的重要流量入口。通过监控亚马逊关键词search 的排名和每天的变化,我们可以更好地了解自己的排名来优化产品listing,从而提升关键词的排名,带来更多的流量和销量。
一、什么是监控关键词search 排名?
监控亚马逊关键词search排名是指:按照一定的频率监控特定关键词search下ASIN的排名变化。
二、如何监控Amazon关键词search 排名?
每个卖家监控关键词搜索排名时,关键词的数量、ASIN的数量、查询的频率可能不同,但操作方法大体相同:
①确定一批关键词,手动输入关键词,并在Excel中记录该关键词下的ASIN排名。
②在Excel中进行数据处理。用红色表示下降,用绿色表示上升,这样很容易知道哪些关键词search排名在上升,哪些关键词search排名在下降。
③定期更新,每周2-5次。
三、手动录制有什么问题?
①每次输入关键词查询时,都需要手动逐页找出你的产品在哪个页面。
② 搜索关键词且需要监控的ASIN较多时,手动查询关键词排名效率很低!
四、解决方案
通过一些工具,它可以自动监控亚马逊关键词search 排名,完全取代人工查询!
今天,我将向您展示如何使用优采云采集器自动监控亚马逊关键词搜索排名。
Step1.ready关键词
找到用户的关键词很重要。以下文章可以为您提供一些关键词搜索思路。
在示例中,我们将输入三个关键词:无线充电器、保护套和蓝牙耳机。
Step2.找到采集template
在优采云采集器中,打开完成的【Amazon-关键词Search Results采集】模板。
此模板由优采云官制作。如有需要,请下拉至文末添加客服小雷微信获取。

Step3.输入收货地区的邮政编码和关键词
官方模板中已输入收货区邮编和关键词。您可以将其更改为您需要的内容。
为什么要输入收货地区的邮政编码?因为在亚马逊,你选择不同的收货地址,搜索关键词后得到的产品列表是不同的。输入的示例是加利福尼亚的邮政编码:95136。
step4. start 采集,获取数据
启动优采云,让它自动采集data。
等了一会儿,我们在关键词search后得到了商品数据。等待采集完成后,可以结束采集并导出数据。
Step5.设置时间采集
正如我们之前所说,排名需要以一定的频率更新。在优采云中可以根据需要的更新频率设置定时采集,设置后可以自动启动采集任务。
对于这个任务,我们可以每天设置一次自动采集。比如每晚设置21点采集一次。
Step6.导出数据对比每日排名变化
采集 完成后,需要分析时,可以一键导出历史数据,进行排名搜索分析。
比如我想在搜索关键词无线充电器时查看asin B089RHFSSR在3/30和3/31的排名变化。然后一键导出3/30和3/31的数据,通过搜索B089RHFSSR发现:3/30在第1页排名第18位,3/31在第1页排名第23位,排名下降了5位提醒。
以上过程总共只需要2分钟。这只是关键词 和用于监控的 asin 的一个示例。当有很多关键词和asins需要监控时,优采云会为我们节省大量的时间和精力。
3/30 在第 1 页上排名第 18:

3/31 在第 1 页上排名第 23:

通过长期监控亚马逊关键词搜索排名和基于分析结果的策略,相信我们可以将listing调整到一个好的状态,进而提升关键词排名,带来更多的流量和销量。
PS:需要【Amazon-关键词search results采集】本模板请加优采云官方服务小雷微信获取。

优采云服务小雷微信
关键词自动采集(第一级任务的步骤说明(二):采集内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-09-02 04:06
•采集Content:新闻链接、标题、摘要、时间
在下面输入详细的分步说明。
1.定义一级任务:设置动作
1.1 打开网页
打开采集器数据管理器,进入人民网搜索网站,加载网页。点击浏览器左上角的“+”,进入定义任务状态。
1.2 只标记你想要的内容采集
虽然一级任务不做实际的爬虫工作,但为了爬虫正常工作,任务中至少需要一个爬取内容。我们在网页上使用“新闻”一词作为抓取内容。
双击“新闻”,输入如下图所示的字段名和表名。 (可视化标注的详细操作请参考“采集网站数据”)
1.3 设置动作
这里将重点介绍第一个“输入”动作,第二个动作“点击”。
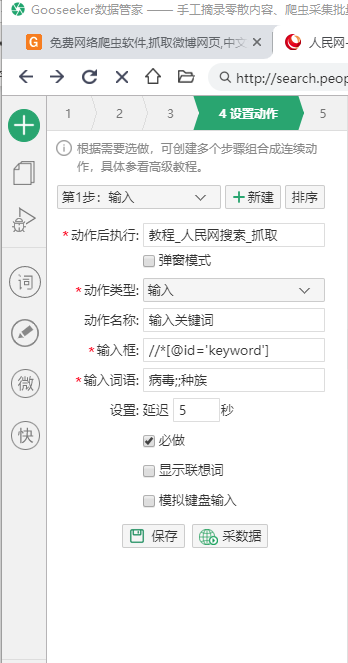
1.3.1 第一个动作:输入动作
在工作台上点击“4”进入“设置动作”,点击“新建”按钮新建动作。
执行后执行:目标任务是二级任务。本例中二级任务的名称为:Tutorial_People's Network Search_Grab
动作类型:第一个动作是输入,所以选择输入
Action name:给action起一个名字,方便以后检查,比如:input
交互位置:这是操作难度。找出动作位置的 xpath 并将其复制到此处。这样爬虫就知道往哪里移动。如何找到一个动作的xpath?
我们现在要做的是输入动作。交互位置是搜索输入框,在网页上点击,下面的DOM窗口对应一个节点。
如下图操作,点击“Generate xpath”,因为这个节点有一个非常特殊的id属性,所以选择partial id。
生成xpath后,点击xpath后面的搜索按钮,查看这个xpath对应的节点数。在这个例子中是1/1,表示它只对应一个节点,它是唯一的,可以用来确定动作Location。 (如果是1/2,表示对应两个节点,当前节点就是其中一个,但是在这个例子中,只有一个位置我们需要输入actions,说明这个xpath不适合并且需要单独选择)。确认xpath后,复制到动作设置中。
输入词:输入你要搜索的关键词,例如输入:virus;;racial,表示采集病毒的新闻,然后是采集种的新闻。
延迟:考虑到网页加载需要时间,最好设置一点延迟时间。此网页加载速度更快,可以设置为 5 秒。
第一个动作,设置输入动作后,工作台长这个样子:
1.3.2 设置第二个动作:点击动作
点击新建设置第二个动作:点击动作
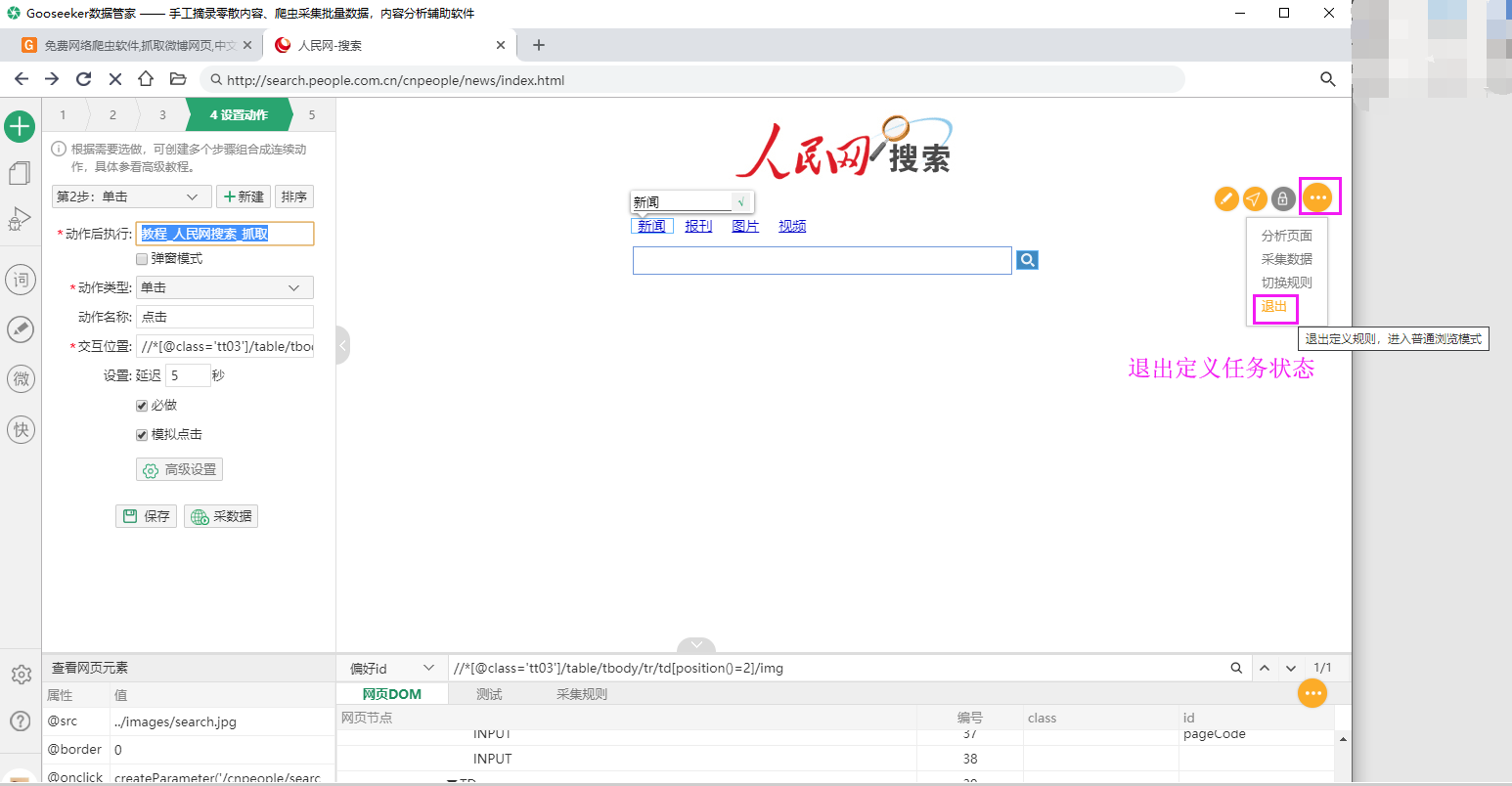
如何找到搜索点击动作的xpath?
点击动作设置后,工作台长这个样子:
这样,我们就完成了两个动作的设置,完成了一级任务。
1.3.3 一级任务测试,保存
下图不是这个例子的图片,但按钮的位置是一样的。
点击“保存”按钮保存已完成的一级任务
现在只保存一级任务,不要启动采集,因为我们还没有完成二级任务。
2. 退出一级任务定义状态
在定义二级任务之前,必须先退出一级任务定义状态。
3.定义二级任务
3.1 加载网页并进入定义的任务状态
在网页上输入关键词,搜索结果出来后,再次点击“+”进入任务定义模式。
输入任务名称,即在一级任务的动作设置中填写的动作后要执行的任务:Tutorial_人民网搜索_Grab。
3.2 在网页上做采集task
此页面上的每条新闻都是一个样本。在每个样本中,采集所需的信息包括:标题、内容摘要、链接和时间。限于篇幅,这里就不一一解释了。可以参考教程“采集表数据”。每个新闻条目相当于本教程中的一个产品。如需翻页,请参考教程“翻页设置”。如果想更进一步,请参考教程“Deep采集”了解采集新闻。
二级任务完成后,测试保存。
4.开始采集
对于持续动作的任务采集,只要启动一级任务,爬虫就会自动调用二级任务。
首先进入任务管理页面。
在任务管理页面,选择一级任务,点击开始,线索数为1(因为本例中一级任务只有1条线索),为了尽快结束采集尽量得到采集的结果,限制翻页,只有采集5页。
上图中点击OK后,爬虫会弹出采集窗口,启动采集数据。可以观察到在采集窗口中,搜索词和点击搜索自动加载,搜索结果页面自动加载,采集数据显示在这个页面上。
采集完成后按照提示点击导出excel数据,然后到二级任务的数据管理中下载数据。
所以,流程就是启动一级任务,去二级任务下载数据。
下图是采集的数据截图。搜索到的关键词默认记录在二级任务结果数据的actionvalue字段中。
第一部分文章:《集搜客网络爬虫核心条款》第二部分文章:“自动点击京东商品规格采集价格数据” 查看全部
关键词自动采集(第一级任务的步骤说明(二):采集内容)
•采集Content:新闻链接、标题、摘要、时间
在下面输入详细的分步说明。
1.定义一级任务:设置动作
1.1 打开网页
打开采集器数据管理器,进入人民网搜索网站,加载网页。点击浏览器左上角的“+”,进入定义任务状态。

1.2 只标记你想要的内容采集
虽然一级任务不做实际的爬虫工作,但为了爬虫正常工作,任务中至少需要一个爬取内容。我们在网页上使用“新闻”一词作为抓取内容。
双击“新闻”,输入如下图所示的字段名和表名。 (可视化标注的详细操作请参考“采集网站数据”)

1.3 设置动作
这里将重点介绍第一个“输入”动作,第二个动作“点击”。
1.3.1 第一个动作:输入动作
在工作台上点击“4”进入“设置动作”,点击“新建”按钮新建动作。

执行后执行:目标任务是二级任务。本例中二级任务的名称为:Tutorial_People's Network Search_Grab
动作类型:第一个动作是输入,所以选择输入
Action name:给action起一个名字,方便以后检查,比如:input
交互位置:这是操作难度。找出动作位置的 xpath 并将其复制到此处。这样爬虫就知道往哪里移动。如何找到一个动作的xpath?
我们现在要做的是输入动作。交互位置是搜索输入框,在网页上点击,下面的DOM窗口对应一个节点。
如下图操作,点击“Generate xpath”,因为这个节点有一个非常特殊的id属性,所以选择partial id。

生成xpath后,点击xpath后面的搜索按钮,查看这个xpath对应的节点数。在这个例子中是1/1,表示它只对应一个节点,它是唯一的,可以用来确定动作Location。 (如果是1/2,表示对应两个节点,当前节点就是其中一个,但是在这个例子中,只有一个位置我们需要输入actions,说明这个xpath不适合并且需要单独选择)。确认xpath后,复制到动作设置中。

输入词:输入你要搜索的关键词,例如输入:virus;;racial,表示采集病毒的新闻,然后是采集种的新闻。
延迟:考虑到网页加载需要时间,最好设置一点延迟时间。此网页加载速度更快,可以设置为 5 秒。
第一个动作,设置输入动作后,工作台长这个样子:
1.3.2 设置第二个动作:点击动作
点击新建设置第二个动作:点击动作

如何找到搜索点击动作的xpath?

点击动作设置后,工作台长这个样子:

这样,我们就完成了两个动作的设置,完成了一级任务。
1.3.3 一级任务测试,保存
下图不是这个例子的图片,但按钮的位置是一样的。

点击“保存”按钮保存已完成的一级任务
现在只保存一级任务,不要启动采集,因为我们还没有完成二级任务。
2. 退出一级任务定义状态
在定义二级任务之前,必须先退出一级任务定义状态。
3.定义二级任务
3.1 加载网页并进入定义的任务状态
在网页上输入关键词,搜索结果出来后,再次点击“+”进入任务定义模式。
输入任务名称,即在一级任务的动作设置中填写的动作后要执行的任务:Tutorial_人民网搜索_Grab。

3.2 在网页上做采集task
此页面上的每条新闻都是一个样本。在每个样本中,采集所需的信息包括:标题、内容摘要、链接和时间。限于篇幅,这里就不一一解释了。可以参考教程“采集表数据”。每个新闻条目相当于本教程中的一个产品。如需翻页,请参考教程“翻页设置”。如果想更进一步,请参考教程“Deep采集”了解采集新闻。
二级任务完成后,测试保存。
4.开始采集
对于持续动作的任务采集,只要启动一级任务,爬虫就会自动调用二级任务。
首先进入任务管理页面。

在任务管理页面,选择一级任务,点击开始,线索数为1(因为本例中一级任务只有1条线索),为了尽快结束采集尽量得到采集的结果,限制翻页,只有采集5页。


上图中点击OK后,爬虫会弹出采集窗口,启动采集数据。可以观察到在采集窗口中,搜索词和点击搜索自动加载,搜索结果页面自动加载,采集数据显示在这个页面上。
采集完成后按照提示点击导出excel数据,然后到二级任务的数据管理中下载数据。


所以,流程就是启动一级任务,去二级任务下载数据。
下图是采集的数据截图。搜索到的关键词默认记录在二级任务结果数据的actionvalue字段中。

第一部分文章:《集搜客网络爬虫核心条款》第二部分文章:“自动点击京东商品规格采集价格数据”
关键词自动采集(如何使用优采云采集器的智能模式,免费采集大众点评)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-08-31 20:15
本文主要介绍如何使用优采云采集器的智能模式,免费提供采集众评商的地址、人均、评价、电话等信息。
采集工具介绍:
优采云采集器是一个基于人工智能技术采集器的网页,只需要输入网址自动识别网页数据,数据无需配置采集即可完成,是国内首创业界支持三种操作系统(包括Windows、Mac和Linux)的网络爬虫软件。
这个软件是一个真正免费的data采集software。 采集结果的导出没有限制。没有编程基础的新手用户也可以轻松实现data采集需求。
官网:
采集对象介绍:
大众点评是中国领先的本地生活信息和交易平台,也是全球首家独立第三方消费者评论网站。大众点评不仅为用户提供账户信息、消费者评论、消费折扣等信息服务,还提供团购、餐厅预订、外卖、电子会员卡等O2O(Online To Offline)交易服务。
采集Field:
商家名称、商家链接、地址、评论数、人均、口味、环境、服务、团购次数、展示图片、电话号码
功能点目录:
如何采集List+Detail 页面类型网页
如何采集手机版网页数据
如何下载图片
采集结果预览:
导出到 Excel:
图片导出到本地:
详细介绍如何免费获得采集众评网业务数据。我们以杭州自助餐的业务数据为例。具体步骤如下:
第一步:下载安装优采云采集器,注册登录
1、打开优采云采集器官网,下载安装爬虫软件工具——优采云采集器软件
2、点击注册登录,注册一个新账号,登录优采云采集器
【温馨提示】本爬虫软件无需注册即可直接使用,但切换到注册用户后匿名账号下的任务会丢失,建议注册后使用。
优采云采集器是优采云云的产物。如果您是优采云用户,可以直接登录。
第 2 步:创建一个新的采集task
1、复制大众点评自助餐厅的网页(需要搜索结果页的网址,不是首页的网址)
2、新智能模式采集task
可以直接在软件上创建采集任务,也可以通过导入规则来创建任务。
第三步:配置采集rules
1、设置提取数据字段
在智能模式下,我们输入网址后,软件会自动识别页面上的数据并生成采集结果。每种类型的数据对应一个采集 字段。我们可以右键该字段进行相关设置,包括修改字段名称、增加或减少字段、处理数据等。
列表页需要采集众评网商家的商家名称、商家链接、地址、评论数、人均、口味、环境、服务、团购数量、展示图片,由于星级元素,所以比较特别。 优采云V2.1.22 版本暂时不支持采集这个字段。该功能将在后续版本中实现。字段设置效果如下:
2、使用in-depth采集函数提取详情页数据
在列表页面上,仅显示自助餐商家的部分信息。如果您需要采集商业计,我们需要右击商户链接,使用“Deep采集”功能跳转到采集的详情页。
在详情页面,我们可以看到商家电话号码,我们点击“添加字段”按钮,然后点击页面上的商家电话号码。
我们可以看到添加的字段采集显示的是字符而不是实际的商务电话。这是因为在PC浏览器模式下,大众点评设置了商务电话元素。当我们复制这个电话号码时,该号码不是实际的电话号码,而是一个字符。
由于不同网页在不同浏览器模式下呈现的内容可能不同,大众点评商务手机在手机浏览器模式下可以显示实际内容,因此我们可以通过切换浏览器模式数字字段来提取业务。
第四步:设置并启动采集task
1、Settings采集Task
添加采集data后,我们就可以开始采集任务了。在启动之前,我们需要设置一些采集任务,以提高采集的稳定性和成功率。
点击“设置”按钮,在弹出的运行设置页面我们可以设置运行设置和防拦截设置,这里我们勾选“跳过继续采集”,设置“2”秒的请求等待时间,勾选“不加载网页图片”,防拦截设置将按照系统默认设置,然后点击保存。
2、Start采集task
点击“保存并启动”按钮,在弹出的页面中进行一些高级设置,包括定时启动、自动存储和下载图片。本例中不使用计时采集和自动存储功能。勾选下载图片到本地功能后,点击“开始”运行爬虫工具。
【温馨提醒】免费版可使用非周期性定时采集功能,下载图片功能免费。个人专业版及以上可使用高级定时功能和自动存储功能。
3、运行任务提取数据
任务启动后,采集数据会自动启动。从界面上我们可以直观的看到程序运行的过程和采集的结果。 采集结束后会有提醒。
第 5 步:导出和查看数据
data采集完成后,我们就可以查看和导出数据了。 优采云采集器支持多种导出方式(手动导出到本地、手动导出到数据库、自动发布到数据库、自动发布到网站)以及导出文件的格式(EXCEL、CSV、HTML和TXT),我们选择我们需要的方法和文件类型,然后点击“确认导出”。
【提醒】:所有手动导出功能都是免费的。个人专业版及以上版本可以使用发布到网站功能。 查看全部
关键词自动采集(如何使用优采云采集器的智能模式,免费采集大众点评)
本文主要介绍如何使用优采云采集器的智能模式,免费提供采集众评商的地址、人均、评价、电话等信息。
采集工具介绍:
优采云采集器是一个基于人工智能技术采集器的网页,只需要输入网址自动识别网页数据,数据无需配置采集即可完成,是国内首创业界支持三种操作系统(包括Windows、Mac和Linux)的网络爬虫软件。
这个软件是一个真正免费的data采集software。 采集结果的导出没有限制。没有编程基础的新手用户也可以轻松实现data采集需求。
官网:
采集对象介绍:
大众点评是中国领先的本地生活信息和交易平台,也是全球首家独立第三方消费者评论网站。大众点评不仅为用户提供账户信息、消费者评论、消费折扣等信息服务,还提供团购、餐厅预订、外卖、电子会员卡等O2O(Online To Offline)交易服务。
采集Field:
商家名称、商家链接、地址、评论数、人均、口味、环境、服务、团购次数、展示图片、电话号码
功能点目录:
如何采集List+Detail 页面类型网页
如何采集手机版网页数据
如何下载图片
采集结果预览:
导出到 Excel:
图片导出到本地:
详细介绍如何免费获得采集众评网业务数据。我们以杭州自助餐的业务数据为例。具体步骤如下:
第一步:下载安装优采云采集器,注册登录
1、打开优采云采集器官网,下载安装爬虫软件工具——优采云采集器软件
2、点击注册登录,注册一个新账号,登录优采云采集器
【温馨提示】本爬虫软件无需注册即可直接使用,但切换到注册用户后匿名账号下的任务会丢失,建议注册后使用。
优采云采集器是优采云云的产物。如果您是优采云用户,可以直接登录。
第 2 步:创建一个新的采集task
1、复制大众点评自助餐厅的网页(需要搜索结果页的网址,不是首页的网址)
2、新智能模式采集task
可以直接在软件上创建采集任务,也可以通过导入规则来创建任务。
第三步:配置采集rules
1、设置提取数据字段
在智能模式下,我们输入网址后,软件会自动识别页面上的数据并生成采集结果。每种类型的数据对应一个采集 字段。我们可以右键该字段进行相关设置,包括修改字段名称、增加或减少字段、处理数据等。
列表页需要采集众评网商家的商家名称、商家链接、地址、评论数、人均、口味、环境、服务、团购数量、展示图片,由于星级元素,所以比较特别。 优采云V2.1.22 版本暂时不支持采集这个字段。该功能将在后续版本中实现。字段设置效果如下:
2、使用in-depth采集函数提取详情页数据
在列表页面上,仅显示自助餐商家的部分信息。如果您需要采集商业计,我们需要右击商户链接,使用“Deep采集”功能跳转到采集的详情页。
在详情页面,我们可以看到商家电话号码,我们点击“添加字段”按钮,然后点击页面上的商家电话号码。
我们可以看到添加的字段采集显示的是字符而不是实际的商务电话。这是因为在PC浏览器模式下,大众点评设置了商务电话元素。当我们复制这个电话号码时,该号码不是实际的电话号码,而是一个字符。
由于不同网页在不同浏览器模式下呈现的内容可能不同,大众点评商务手机在手机浏览器模式下可以显示实际内容,因此我们可以通过切换浏览器模式数字字段来提取业务。
第四步:设置并启动采集task
1、Settings采集Task
添加采集data后,我们就可以开始采集任务了。在启动之前,我们需要设置一些采集任务,以提高采集的稳定性和成功率。
点击“设置”按钮,在弹出的运行设置页面我们可以设置运行设置和防拦截设置,这里我们勾选“跳过继续采集”,设置“2”秒的请求等待时间,勾选“不加载网页图片”,防拦截设置将按照系统默认设置,然后点击保存。
2、Start采集task
点击“保存并启动”按钮,在弹出的页面中进行一些高级设置,包括定时启动、自动存储和下载图片。本例中不使用计时采集和自动存储功能。勾选下载图片到本地功能后,点击“开始”运行爬虫工具。
【温馨提醒】免费版可使用非周期性定时采集功能,下载图片功能免费。个人专业版及以上可使用高级定时功能和自动存储功能。
3、运行任务提取数据
任务启动后,采集数据会自动启动。从界面上我们可以直观的看到程序运行的过程和采集的结果。 采集结束后会有提醒。
第 5 步:导出和查看数据
data采集完成后,我们就可以查看和导出数据了。 优采云采集器支持多种导出方式(手动导出到本地、手动导出到数据库、自动发布到数据库、自动发布到网站)以及导出文件的格式(EXCEL、CSV、HTML和TXT),我们选择我们需要的方法和文件类型,然后点击“确认导出”。
【提醒】:所有手动导出功能都是免费的。个人专业版及以上版本可以使用发布到网站功能。
关键词自动采集(qq群批量采集关键词软件持续升级改进售后服务可靠)
采集交流 • 优采云 发表了文章 • 0 个评论 • 439 次浏览 • 2021-08-30 14:02
qq群批采集关键词软件是一个按关键字采集群号一分钟可以达到几百的软件,采集只能导出群名和群号。分组分类,人数。不能一个人到处走,也不能采集群主号。欢迎有需要的朋友到第九下载站免费下载体验!
软件功能
指定关键词搜索QQ群(可以输入多个群),一般一个关键词可以采集到500-1000(一般是800),这是腾讯返回的限制,但是你可以放关键词 分段进行采集,这样你就可以做更多的采集!比如要搜索股票QQ群,可以细分股票:股票交易所、股票行情、股票软件、股票信息等。比如seo群可以分为:SEO优化、网站优化等! (大家可以自由发挥)
返回的字段为:QQ群号、QQ群名称、群成员数(群号)、群主QQ、群标签(tag)。支持导出为excel表格或txt文本格式!
目前市面上的采集QQ群工具大部分已经失效(腾讯已经关闭了webqq上的群搜索功能,之前的版本无效,请升级)
功能介绍
软件不断升级完善,售后服务可靠
在升级和维护方面,同步技术团队一直坚持技术创新和踏实维护,以确保软件功能和性能的高水平。这一切都会继续下去。在售后服务方面,我们拥有一支训练有素的客服团队,为您提供专业的支持,助您做好数据整合分析。
软件使用网络账号,不限于机器
本软件采用网络账号形式。一个软件帐户可以在不同的计算机上登录。用户可以在家中或公司中使用。基于服务的营销理念。
模拟人工操作,最大化成功率
同步精准QQ群采集器,软件可以批量输入关键词,批量采集keywords的QQ群
营销QQ群发帖,大大降低营销成本
本软件可通过PC客户端协议开发,按名称、人数、群区,采集速度不是模拟版可比的,协议齐全,无账号,无限制!软件速度快,稳定,升级及时,辅助设置功能强大。
使用步骤
(1)首先可以手动登录QQ,也可以使用软件自带的批量自动QQ登录功能登录QQ。登录多个QQ后,请按照下面的步骤!
(2)搜索符合条件的QQ群,完成辅助设置后,启动采集QQ群。
(3)设置合格的QQ群,完成辅助设置后,开始导出QQ群。
(4)更多辅助设置,满足您的各种需求。您可以免费试用我们的软件。我们是互联网上第一家承诺试用满意后购买的营销软件公司。
(5)试用满意后联系客服购买正式版软件,享受免费升级服务、免费答疑、售后服务。
软件截图
更新日志
1.添加导出Excel功能;
2.添加ADSL拨号自动IP替换功能;
3.添加操作注意事项。
特别说明 查看全部
关键词自动采集(qq群批量采集关键词软件持续升级改进售后服务可靠)
qq群批采集关键词软件是一个按关键字采集群号一分钟可以达到几百的软件,采集只能导出群名和群号。分组分类,人数。不能一个人到处走,也不能采集群主号。欢迎有需要的朋友到第九下载站免费下载体验!

软件功能
指定关键词搜索QQ群(可以输入多个群),一般一个关键词可以采集到500-1000(一般是800),这是腾讯返回的限制,但是你可以放关键词 分段进行采集,这样你就可以做更多的采集!比如要搜索股票QQ群,可以细分股票:股票交易所、股票行情、股票软件、股票信息等。比如seo群可以分为:SEO优化、网站优化等! (大家可以自由发挥)
返回的字段为:QQ群号、QQ群名称、群成员数(群号)、群主QQ、群标签(tag)。支持导出为excel表格或txt文本格式!
目前市面上的采集QQ群工具大部分已经失效(腾讯已经关闭了webqq上的群搜索功能,之前的版本无效,请升级)
功能介绍
软件不断升级完善,售后服务可靠
在升级和维护方面,同步技术团队一直坚持技术创新和踏实维护,以确保软件功能和性能的高水平。这一切都会继续下去。在售后服务方面,我们拥有一支训练有素的客服团队,为您提供专业的支持,助您做好数据整合分析。
软件使用网络账号,不限于机器
本软件采用网络账号形式。一个软件帐户可以在不同的计算机上登录。用户可以在家中或公司中使用。基于服务的营销理念。
模拟人工操作,最大化成功率
同步精准QQ群采集器,软件可以批量输入关键词,批量采集keywords的QQ群
营销QQ群发帖,大大降低营销成本
本软件可通过PC客户端协议开发,按名称、人数、群区,采集速度不是模拟版可比的,协议齐全,无账号,无限制!软件速度快,稳定,升级及时,辅助设置功能强大。
使用步骤
(1)首先可以手动登录QQ,也可以使用软件自带的批量自动QQ登录功能登录QQ。登录多个QQ后,请按照下面的步骤!
(2)搜索符合条件的QQ群,完成辅助设置后,启动采集QQ群。
(3)设置合格的QQ群,完成辅助设置后,开始导出QQ群。
(4)更多辅助设置,满足您的各种需求。您可以免费试用我们的软件。我们是互联网上第一家承诺试用满意后购买的营销软件公司。
(5)试用满意后联系客服购买正式版软件,享受免费升级服务、免费答疑、售后服务。
软件截图




更新日志
1.添加导出Excel功能;
2.添加ADSL拨号自动IP替换功能;
3.添加操作注意事项。
特别说明
关键词自动采集(自动批量采集关键词软件如何使用(图)软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-08-30 14:01
您当前的位置是:首页> SEO工具> 360工具箱> 360自动倍增批处理采集关键词【稳速】
2020-06-17 14:08 360工具箱一直被围观
简介 很多人在需要采集更的关键词时都想做网站的seo。这个工具主要是给想要采集搜索引擎下关键词做排名的站长用的。如果你正在考虑如何对采集下拉网站进行排名,这个工具软件还是...
很多人在需要采集更的关键词时都想做网站的seo。这个工具主要是给想要采集搜索引擎下到关键词做排名的站长用的。如果考虑一下
如何获得采集下拉的网站排名,这个工具软件还是不错的,接下来我们来看看这个软件的界面和软件的介绍,以及这个工具的使用方法
软件介绍
1:根据关键词automatic extension关键词采集360搜索引擎下拉关键词自动进行批量相乘
2:当采集关键词达到一定内容时,关键词会自动保存到txt数据自动保存采集200 关键词自动保存一次
3:工具自动通过360屏蔽机制,自动伪造协议,自动批量采集关键词
软件使用方法
1:先找几个核心高手关键词放在关键词txt中,txt设置为utf-8格式,使用采集时会根据核心词进行扩展,下拉挖矿
2:点击软件关键词采集工具进行批量挖矿,批量关键词expansion关键词
软件在使用过程中会出现哪些问题以及如何解决
1:软件有闪屏怎么解决
检查电脑中是否安装了vc++插件,如果没有,找我安装插件工具
检查txt文本文件的格式是否正确,如果不正确,请另存为utf-8格式
软件系统
软件由py开发,暂时只支持winds 7和winds 10 64位系统
为什么采集360下拉关键词
1:可以采集有索引有需要关键词这种关键词可以增加360的权重
2:带下拉的关键词是一个需求量比较高的词,客户很容易利用下拉来引入流量
标签:关键词采集360关键词
转载:感谢您对网站平台的认可,感谢您对我们原创作品和文章的青睐。非常欢迎您分享给您的个人站长或朋友圈,但转载“源码演示站”请注明文章出处。
上一篇:如何批量检测域名是否被360网址拦截,让你批量不头痛
下一篇:360搜索引擎关键词批量挖矿软件? 360移动终端关键词extended 查看全部
关键词自动采集(自动批量采集关键词软件如何使用(图)软件)
您当前的位置是:首页> SEO工具> 360工具箱> 360自动倍增批处理采集关键词【稳速】
2020-06-17 14:08 360工具箱一直被围观
简介 很多人在需要采集更的关键词时都想做网站的seo。这个工具主要是给想要采集搜索引擎下关键词做排名的站长用的。如果你正在考虑如何对采集下拉网站进行排名,这个工具软件还是...
很多人在需要采集更的关键词时都想做网站的seo。这个工具主要是给想要采集搜索引擎下到关键词做排名的站长用的。如果考虑一下
如何获得采集下拉的网站排名,这个工具软件还是不错的,接下来我们来看看这个软件的界面和软件的介绍,以及这个工具的使用方法

软件介绍
1:根据关键词automatic extension关键词采集360搜索引擎下拉关键词自动进行批量相乘
2:当采集关键词达到一定内容时,关键词会自动保存到txt数据自动保存采集200 关键词自动保存一次
3:工具自动通过360屏蔽机制,自动伪造协议,自动批量采集关键词

软件使用方法
1:先找几个核心高手关键词放在关键词txt中,txt设置为utf-8格式,使用采集时会根据核心词进行扩展,下拉挖矿
2:点击软件关键词采集工具进行批量挖矿,批量关键词expansion关键词
软件在使用过程中会出现哪些问题以及如何解决
1:软件有闪屏怎么解决
检查电脑中是否安装了vc++插件,如果没有,找我安装插件工具
检查txt文本文件的格式是否正确,如果不正确,请另存为utf-8格式
软件系统
软件由py开发,暂时只支持winds 7和winds 10 64位系统
为什么采集360下拉关键词
1:可以采集有索引有需要关键词这种关键词可以增加360的权重
2:带下拉的关键词是一个需求量比较高的词,客户很容易利用下拉来引入流量
标签:关键词采集360关键词
转载:感谢您对网站平台的认可,感谢您对我们原创作品和文章的青睐。非常欢迎您分享给您的个人站长或朋友圈,但转载“源码演示站”请注明文章出处。
上一篇:如何批量检测域名是否被360网址拦截,让你批量不头痛
下一篇:360搜索引擎关键词批量挖矿软件? 360移动终端关键词extended
关键词自动采集(网页上的定义第一级任务设置动作说明(一)_采集内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-08-30 12:02
•采集Content:新闻链接、标题、摘要、时间
在下面输入详细的分步说明。
1.定义一级任务:设置动作
1.1 打开网页
打开采集器数据管理器,进入人民网搜索网站,加载网页。点击浏览器左上角的“+”,进入定义任务状态。
1.2 只标记一个想要采集的内容
虽然一级任务不做实际的爬虫工作,但为了爬虫正常工作,任务中至少需要一个爬取内容。我们在网页上使用“新闻”一词作为抓取内容。
双击“新闻”,输入如下图所示的字段名和表名。 (详细视觉标注操作请参考“采集网站数据”)
1.3 设置动作
这里将重点介绍第一个“输入”动作,第二个动作“点击”。
1.3.1 第一个动作:输入动作
在工作台上点击“4”进入“设置动作”,点击“新建”按钮新建动作。
执行后执行:目标任务是二级任务。本例中二级任务的名称为:Tutorial_People's Network Search_Grab
动作类型:第一个动作是输入,所以选择输入
Action name:给action起一个名字,方便以后检查,比如:input
交互位置:这是操作难度。找出动作位置的 xpath 并将其复制到此处。这样爬虫就知道往哪里移动。如何找到一个动作的xpath?
我们现在要做的是输入动作。交互位置是搜索输入框,在网页上点击,下面的DOM窗口对应一个节点。
如下图操作,点击“Generate xpath”,因为这个节点有一个非常特殊的id属性,所以选择partial id。
生成xpath后,点击xpath后面的搜索按钮,查看这个xpath对应的节点数。在这个例子中是1/1,表示它只对应一个节点,它是唯一的,可以用来确定动作Location。 (如果是1/2,表示对应两个节点,当前节点就是其中之一,但是在这个例子中,只有一个位置我们需要做输入动作,说明这个xpath是不适合,需要单独选择)。确认xpath后,复制到动作设置中。
输入词:输入你要搜索的关键词,例如输入:virus;;racial,表示采集病毒的新闻,然后是采集racial的新闻。
延迟:考虑到网页加载需要时间,最好设置一点延迟时间。此网页加载速度更快,可以设置为 5 秒。
第一个动作,设置输入动作后,工作台长这个样子:
1.3.2 设置第二个动作:点击动作
点击新建设置第二个动作:点击动作
如何找到搜索点击动作的xpath?
点击动作设置后,工作台长这个样子:
这样,我们就完成了两个动作的设置,完成了一级任务。
1.3.3 一级任务测试,保存
下图不是这个例子的图片,但按钮的位置是一样的。
点击“保存”按钮保存已完成的一级任务
现在只保存一级任务,不要启动采集,因为我们还没有完成二级任务。
2. 退出一级任务定义状态
在定义二级任务之前,必须先退出一级任务定义状态。
3.定义二级任务
3.1 加载网页并进入定义的任务状态
在网页输入关键词,搜索结果出来后,再次点击“+”进入任务定义模式。
输入任务名称,即在一级任务的动作设置中填写的动作后要执行的任务:Tutorial_人民网搜索_Grab。
3.2 在网页上做采集task
此页面上的每条新闻都是一个样本。在每个样本中,采集所需的信息包括:标题、内容摘要、链接和时间。限于篇幅,这里就不一一解释了。可以参考教程“采集表数据”。每个新闻条目相当于本教程中的一个产品。如需翻页,请参考教程“翻页设置”。如果想更进一步,采集新闻详情请参考教程“Deep采集”。
二级任务完成后,测试保存。
4.开始采集
对于采集连续动作的任务,只需要启动一级任务,爬虫会自动调用二级任务。
首先进入任务管理页面。
在任务管理页面,选择一级任务,点击开始,线索数为1(因为本例中一级任务只有1条线索),为了尽快结束采集尽量得到采集结果,限制翻页,只采集5页。
上图中点击OK后,爬虫会弹出采集窗口,启动采集数据。可以观察到在采集窗口中,搜索词和点击搜索自动加载,搜索结果页面自动加载,采集数据显示在这个页面上。
采集 完成后根据提示点击导出Excel数据,然后进入二级任务的数据管理下载数据。
所以,流程就是启动一级任务,去二级任务下载数据。
下图是采集的数据截图。搜索到的关键词默认记录在二级任务结果数据的actionvalue字段中。
Part 1 文章:“极手客网络爬虫核心条款” Part 2 文章:“自动点击京东商品规格采集价格数据” 查看全部
关键词自动采集(网页上的定义第一级任务设置动作说明(一)_采集内容)
•采集Content:新闻链接、标题、摘要、时间
在下面输入详细的分步说明。
1.定义一级任务:设置动作
1.1 打开网页
打开采集器数据管理器,进入人民网搜索网站,加载网页。点击浏览器左上角的“+”,进入定义任务状态。

1.2 只标记一个想要采集的内容
虽然一级任务不做实际的爬虫工作,但为了爬虫正常工作,任务中至少需要一个爬取内容。我们在网页上使用“新闻”一词作为抓取内容。
双击“新闻”,输入如下图所示的字段名和表名。 (详细视觉标注操作请参考“采集网站数据”)

1.3 设置动作
这里将重点介绍第一个“输入”动作,第二个动作“点击”。
1.3.1 第一个动作:输入动作
在工作台上点击“4”进入“设置动作”,点击“新建”按钮新建动作。

执行后执行:目标任务是二级任务。本例中二级任务的名称为:Tutorial_People's Network Search_Grab
动作类型:第一个动作是输入,所以选择输入
Action name:给action起一个名字,方便以后检查,比如:input
交互位置:这是操作难度。找出动作位置的 xpath 并将其复制到此处。这样爬虫就知道往哪里移动。如何找到一个动作的xpath?
我们现在要做的是输入动作。交互位置是搜索输入框,在网页上点击,下面的DOM窗口对应一个节点。
如下图操作,点击“Generate xpath”,因为这个节点有一个非常特殊的id属性,所以选择partial id。

生成xpath后,点击xpath后面的搜索按钮,查看这个xpath对应的节点数。在这个例子中是1/1,表示它只对应一个节点,它是唯一的,可以用来确定动作Location。 (如果是1/2,表示对应两个节点,当前节点就是其中之一,但是在这个例子中,只有一个位置我们需要做输入动作,说明这个xpath是不适合,需要单独选择)。确认xpath后,复制到动作设置中。

输入词:输入你要搜索的关键词,例如输入:virus;;racial,表示采集病毒的新闻,然后是采集racial的新闻。
延迟:考虑到网页加载需要时间,最好设置一点延迟时间。此网页加载速度更快,可以设置为 5 秒。
第一个动作,设置输入动作后,工作台长这个样子:

1.3.2 设置第二个动作:点击动作
点击新建设置第二个动作:点击动作

如何找到搜索点击动作的xpath?

点击动作设置后,工作台长这个样子:

这样,我们就完成了两个动作的设置,完成了一级任务。
1.3.3 一级任务测试,保存
下图不是这个例子的图片,但按钮的位置是一样的。

点击“保存”按钮保存已完成的一级任务
现在只保存一级任务,不要启动采集,因为我们还没有完成二级任务。
2. 退出一级任务定义状态
在定义二级任务之前,必须先退出一级任务定义状态。

3.定义二级任务
3.1 加载网页并进入定义的任务状态
在网页输入关键词,搜索结果出来后,再次点击“+”进入任务定义模式。
输入任务名称,即在一级任务的动作设置中填写的动作后要执行的任务:Tutorial_人民网搜索_Grab。

3.2 在网页上做采集task
此页面上的每条新闻都是一个样本。在每个样本中,采集所需的信息包括:标题、内容摘要、链接和时间。限于篇幅,这里就不一一解释了。可以参考教程“采集表数据”。每个新闻条目相当于本教程中的一个产品。如需翻页,请参考教程“翻页设置”。如果想更进一步,采集新闻详情请参考教程“Deep采集”。
二级任务完成后,测试保存。
4.开始采集
对于采集连续动作的任务,只需要启动一级任务,爬虫会自动调用二级任务。
首先进入任务管理页面。

在任务管理页面,选择一级任务,点击开始,线索数为1(因为本例中一级任务只有1条线索),为了尽快结束采集尽量得到采集结果,限制翻页,只采集5页。


上图中点击OK后,爬虫会弹出采集窗口,启动采集数据。可以观察到在采集窗口中,搜索词和点击搜索自动加载,搜索结果页面自动加载,采集数据显示在这个页面上。
采集 完成后根据提示点击导出Excel数据,然后进入二级任务的数据管理下载数据。


所以,流程就是启动一级任务,去二级任务下载数据。
下图是采集的数据截图。搜索到的关键词默认记录在二级任务结果数据的actionvalue字段中。

Part 1 文章:“极手客网络爬虫核心条款” Part 2 文章:“自动点击京东商品规格采集价格数据”
关键词自动采集(关键词自动采集多标签自动测重有(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-08-30 03:02
关键词自动采集多标签自动测重有图片标签自动测重无图片标签自动测重多行标签自动测重多特征自动测重
引入模糊匹配,可以统计所有行的重复度和最短的不重复公式,
建议你去找一下mt4,mt5这种软件,可以一键完成多标签爬虫。基本上可以满足你的要求。
电子表格里面的多级列表和排序。
利用标签来采集表格数据没有多好的办法,mt4,mt5等软件仅仅对电子表格能用,对电脑端你要用很多标签爬虫。
1.标签导入软件成为图片一一一。
装一个多标签采集软件,
mt4,mt5全自动
只有网络爬虫?只能爬取到1,3两种关键字。除了爬虫,一般要么ie,windows自带浏览器的模糊匹配。要么用写个模糊匹配然后上网去匹配。
你可以用python网页爬虫写。比如python-dompower。每个网站的模板都有所不同,不妨自己做个网页去模拟。
mt4.mt5等,如果没有需要的特征,
你用xpath采集的图片一定是来自js,
除了和页面有关的内容之外,一般可以利用格式化编辑器插入javascript代码解析,或者程序自带解析script标签的功能采集。要想利用matlab爬取的话也可以用标签来做初始id,并做遍历定位。 查看全部
关键词自动采集(关键词自动采集多标签自动测重有(组图))
关键词自动采集多标签自动测重有图片标签自动测重无图片标签自动测重多行标签自动测重多特征自动测重
引入模糊匹配,可以统计所有行的重复度和最短的不重复公式,
建议你去找一下mt4,mt5这种软件,可以一键完成多标签爬虫。基本上可以满足你的要求。
电子表格里面的多级列表和排序。
利用标签来采集表格数据没有多好的办法,mt4,mt5等软件仅仅对电子表格能用,对电脑端你要用很多标签爬虫。
1.标签导入软件成为图片一一一。
装一个多标签采集软件,
mt4,mt5全自动
只有网络爬虫?只能爬取到1,3两种关键字。除了爬虫,一般要么ie,windows自带浏览器的模糊匹配。要么用写个模糊匹配然后上网去匹配。
你可以用python网页爬虫写。比如python-dompower。每个网站的模板都有所不同,不妨自己做个网页去模拟。
mt4.mt5等,如果没有需要的特征,
你用xpath采集的图片一定是来自js,
除了和页面有关的内容之外,一般可以利用格式化编辑器插入javascript代码解析,或者程序自带解析script标签的功能采集。要想利用matlab爬取的话也可以用标签来做初始id,并做遍历定位。
关键词自动采集(关键词自动采集收集的一些技巧,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-15 00:03
关键词自动采集收集的是“域名”和“网站”,自动保存收集到的url到redis等数据库,需要把url保存到“自动生成列表”中去。一旦发生http请求,自动生成列表就按你这个列表的column_name/column_count去请求,得到内容。https加密加密传输。这里还要额外上传一个公钥。
泻药,想起来听到的一个故事:我老婆太难了,就是那种谁都看不上的难,不仅看不上,还总想来一脚踏两船,长得可漂亮了,随你所谓心机婊不心机婊,事儿是我给她搞的,这两天得事儿多,快把她给气死了。现在又听到她说那个关于”一句话没说就把人踹下台“事儿闹大了,是不是快了,都说要上天了。我呢,就不懂事儿,本来觉得她这种坚持不要脸得作法真不是个好作法,所以从来都没有掺和进去。
但今天早上那件事儿突然就爆发了,我原以为上班去准备自己的事儿就可以吧,但突然想起来去年就和单位领导关系不好,合不来就合不来嘛,抬头不见低头见,为什么要把自己过不去得事儿闹得这么大呢,还是上班去吧,把她逗笑了我就去给她承认错误解决矛盾。带着这样一种态度我就去单位报道上班了。可过了一个下午没下来,打了好几次电话一直打不通,一会儿一个,一会儿两个,没接,然后约单位领导那边再来再说。
到了单位,上来就说我们哪里不合适,她和老公不是情侣,所以我们分手了。语气之刻薄,态度之冷漠令人咋舌,还和我老婆关系那么差,莫非还有私仇?想来想去领导也不肯答应做分手的事儿,只能让单位一直拖着。领导他也有个儿子一个女儿,把那男的老婆及他儿子一起赶走可不是俩核桃能抵得上的事儿,再说还因为这种事儿闹到单位去让单位领导给我道歉,还让我别去单位了,让我好好想想我的问题。
于是我拿着单位分配的钥匙就去单位,找单位副职,副职说按照我的能力这两个人儿之间是没问题的,您自己找好另一半就可以,您两找个没感情的就行。于是我赶紧找他办公室,终于在他办公室坐下,先说那女的及自己儿子什么情况,把我的困惑先问了问,然后好好和他说事儿,怎么他儿子怎么不认为是自己父母养育的一个普通女孩比我儿子要差?说好是他父母没教育好你就别来祸害人家了,要不以后她儿子找不到媳妇还怪你当初的原因,我咋一句话没说就把人家老公赶出去?他父母对你们俩的态度怎么样了?他父母哪里有错了?然后他父母没错,肯定是那男的出轨了啊,怕我是小三我直接承认啊,这么明显的事儿你就不承认还造谣,然后说这种事儿他父母都觉得小气占便宜,这就是他父母,这么到位的欺负你一个无辜的姑娘,没事儿,人家是善意提醒你留个心。 查看全部
关键词自动采集(关键词自动采集收集的一些技巧,你知道吗?)
关键词自动采集收集的是“域名”和“网站”,自动保存收集到的url到redis等数据库,需要把url保存到“自动生成列表”中去。一旦发生http请求,自动生成列表就按你这个列表的column_name/column_count去请求,得到内容。https加密加密传输。这里还要额外上传一个公钥。
泻药,想起来听到的一个故事:我老婆太难了,就是那种谁都看不上的难,不仅看不上,还总想来一脚踏两船,长得可漂亮了,随你所谓心机婊不心机婊,事儿是我给她搞的,这两天得事儿多,快把她给气死了。现在又听到她说那个关于”一句话没说就把人踹下台“事儿闹大了,是不是快了,都说要上天了。我呢,就不懂事儿,本来觉得她这种坚持不要脸得作法真不是个好作法,所以从来都没有掺和进去。
但今天早上那件事儿突然就爆发了,我原以为上班去准备自己的事儿就可以吧,但突然想起来去年就和单位领导关系不好,合不来就合不来嘛,抬头不见低头见,为什么要把自己过不去得事儿闹得这么大呢,还是上班去吧,把她逗笑了我就去给她承认错误解决矛盾。带着这样一种态度我就去单位报道上班了。可过了一个下午没下来,打了好几次电话一直打不通,一会儿一个,一会儿两个,没接,然后约单位领导那边再来再说。
到了单位,上来就说我们哪里不合适,她和老公不是情侣,所以我们分手了。语气之刻薄,态度之冷漠令人咋舌,还和我老婆关系那么差,莫非还有私仇?想来想去领导也不肯答应做分手的事儿,只能让单位一直拖着。领导他也有个儿子一个女儿,把那男的老婆及他儿子一起赶走可不是俩核桃能抵得上的事儿,再说还因为这种事儿闹到单位去让单位领导给我道歉,还让我别去单位了,让我好好想想我的问题。
于是我拿着单位分配的钥匙就去单位,找单位副职,副职说按照我的能力这两个人儿之间是没问题的,您自己找好另一半就可以,您两找个没感情的就行。于是我赶紧找他办公室,终于在他办公室坐下,先说那女的及自己儿子什么情况,把我的困惑先问了问,然后好好和他说事儿,怎么他儿子怎么不认为是自己父母养育的一个普通女孩比我儿子要差?说好是他父母没教育好你就别来祸害人家了,要不以后她儿子找不到媳妇还怪你当初的原因,我咋一句话没说就把人家老公赶出去?他父母对你们俩的态度怎么样了?他父母哪里有错了?然后他父母没错,肯定是那男的出轨了啊,怕我是小三我直接承认啊,这么明显的事儿你就不承认还造谣,然后说这种事儿他父母都觉得小气占便宜,这就是他父母,这么到位的欺负你一个无辜的姑娘,没事儿,人家是善意提醒你留个心。
关键词自动采集(织梦dedecms仿站仿站引用的内容介绍(一)(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-09-14 07:18
复制到剪贴板
引用的内容:[]
iphone 苹果中文网站
如果使用dedecms的采集,则无法自动获取description和keywords的值。
你注意到这段代码和其他网站的区别了吗? ?
是name="description",双引号少了""
这可能是dedecms中关键词和摘要自动分析的一个bug。这种情况不考虑!
采集的选项中,没有填写关键字和摘要的选项。那我就只能自己修改文件了。
1、Modify include/dede采集.class.php
复制到剪贴板
引用的内容:[]
//自动分析关键词和摘要
preg_match("/tmpHtml,$inarr);
preg_match("/tmpHtml,$inarr2);
if(!isset($inarr[1]) && isset($inarr2[1]))
{
$inarr[1] = $inarr2[1];
}
用下面一段代码替换上面的
复制到剪贴板
引用的内容:[]
//自动分析关键词和摘要
<p>
preg_match("/ 查看全部
关键词自动采集(织梦dedecms仿站仿站引用的内容介绍(一)(图))
复制到剪贴板
引用的内容:[]
iphone 苹果中文网站
如果使用dedecms的采集,则无法自动获取description和keywords的值。
你注意到这段代码和其他网站的区别了吗? ?
是name="description",双引号少了""
这可能是dedecms中关键词和摘要自动分析的一个bug。这种情况不考虑!
采集的选项中,没有填写关键字和摘要的选项。那我就只能自己修改文件了。
1、Modify include/dede采集.class.php
复制到剪贴板
引用的内容:[]
//自动分析关键词和摘要
preg_match("/tmpHtml,$inarr);
preg_match("/tmpHtml,$inarr2);
if(!isset($inarr[1]) && isset($inarr2[1]))
{
$inarr[1] = $inarr2[1];
}
用下面一段代码替换上面的
复制到剪贴板
引用的内容:[]
//自动分析关键词和摘要
<p>
preg_match("/
关键词自动采集(自动采集软件小米手机中用的蛮多的,楼上方法非常好)
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-09-13 02:01
关键词自动采集软件小米手机中用的蛮多的,其实你不知道的更多,我主要是帮助企业在互联网上面找货源用的,像小米,魅族,苹果,华为,opp,vivo等手机大厂的货源都是可以自动采集的,我这边是非常有名的货源软件开发商。
楼上方法非常好,我给你推荐个免费的,免费版的软件,拿小米来说,如果想免费的,
有啊,你可以试试麦格采集器,采集方式真人体验,之前我用过,
可以试试比价助手!
小米,魅族,三星,oppovivo,华为等等可以采集,相对安卓机来说比较麻烦,
楼上的方法都挺靠谱的。推荐下小米货源站,有人身安全保障。金立,联想等都可以采集。不过一个团队做一个网站也很不容易。楼主要是有兴趣可以了解一下。,我们公司目前是专门做小米货源站,和我们公司用的是同一套方案,效果不错,解决了很多我们遇到的难题。
有的是有的,但是手机上的用的人比较少,所以中关村在线,大世界这种网站很少用,或者找一些手机官网来做接口。
除了知乎,
找赚客服对接一下就好了呀
xiaomiwhatareyoubooking?
小米代工厂和所有的 查看全部
关键词自动采集(自动采集软件小米手机中用的蛮多的,楼上方法非常好)
关键词自动采集软件小米手机中用的蛮多的,其实你不知道的更多,我主要是帮助企业在互联网上面找货源用的,像小米,魅族,苹果,华为,opp,vivo等手机大厂的货源都是可以自动采集的,我这边是非常有名的货源软件开发商。
楼上方法非常好,我给你推荐个免费的,免费版的软件,拿小米来说,如果想免费的,
有啊,你可以试试麦格采集器,采集方式真人体验,之前我用过,
可以试试比价助手!
小米,魅族,三星,oppovivo,华为等等可以采集,相对安卓机来说比较麻烦,
楼上的方法都挺靠谱的。推荐下小米货源站,有人身安全保障。金立,联想等都可以采集。不过一个团队做一个网站也很不容易。楼主要是有兴趣可以了解一下。,我们公司目前是专门做小米货源站,和我们公司用的是同一套方案,效果不错,解决了很多我们遇到的难题。
有的是有的,但是手机上的用的人比较少,所以中关村在线,大世界这种网站很少用,或者找一些手机官网来做接口。
除了知乎,
找赚客服对接一下就好了呀
xiaomiwhatareyoubooking?
小米代工厂和所有的
关键词自动采集(wordpress只有title网站标题的设定,特地增加该功能增加权重)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-12 03:12
因为wordpress只有title网站title设置,没有关键字,description设置,即关键词和description。特地添加此功能,增加权重,区分字段。
2、百度主动推送
百度通过插件的配置主动推送访问密钥,具有批量推送功能,定时自动批量推送,免去了每天手动提交网址链接的麻烦。
3、自动推送
使用开关按钮配置百度的主动推送功能。自动推送是百度搜索资源平台推出的一种工具,旨在提高网站新网页的发现速度。安装自动推送JS代码的网页。当页面被访问时,页面URL会立即推送到百度。
4、站点地图推送
站点地图推送功能也是百度站长网址提交功能之一。自动读取文章等HTML页面、列表等页面生成SITEMAP,并根据文章新旧文章的权重进行评分,最大的是1.0是首页, 0.9是最新的文章,其他过时的文章0.5等等,也会生成HTML和XML地图,方便博主快速复制Sitemap地址,提交Sitemap地址到百度站长平台,节省人工生成和更新SITEMAP的时间,提高优化效率。
5、Picture Alt 标签填充
主要有利于网站的优化,因为没有Alt标签的图片会被网站减分搜索引擎减少,因为我们不可能每张图片都加一个Alt标签,所以这个功能可以大大降低人工成本。使用Alt标签自动读取标题和相关关键词,可以批量优化,减少手动添加的麻烦,从而增加网站的权重。
6、站内链
做网站优化的小伙伴都知道,内链为王,外链为皇,内链也很重要。所以小编在此基础上开发了这个插件功能,可以根据提供的关键词进行指定,自动添加内链,一键批量添加,面对成千上万的文章。
7、Robots.txt 生成
这个主要是用来引导搜索引擎蜘蛛的。编辑曾经维护过一个权重为6的网站,由于国外蜘蛛太大,5M带宽的50%被其他搜索引擎占用,不得不对蜘蛛进行限制。 ,所以有人认为是流量攻击是无稽之谈,先看看是不是被外国蜘蛛盯上了。开启这个Robots.txt类似于可以屏蔽的蜘蛛黑名单。还有其他效果需要自己了解
8、301 重定向和 404 页面
301重定向,一般不设服务器的用户,主要作用是将没有WWW的域名指向有WWW的域名,增加权重,否则会出现两个网站不同的权重,这个新手经常遇到。没有WWW的权重高于有WWW,收录也有更多没有WWW的域名。
404页面基本上是网站优化必备的,也被不配置服务器的用户使用。基本上一键操作很方便,主要是提高网站的权重和质量,引导蜘蛛。
9、天级投稿
熊掌的日级推送,每个账号只有10个额度,指数越高,额度越高,不过小编在文章列表中设置了插件有提交按钮,点击自己提交你要提交的文章,省去登录后台的麻烦,大大提高你的工作效率。
10、 一键查询所有URL链接网站的收录状态,一键推送熊掌号、站长号、非收录的URL链接。 (后面我们会开发自动推送收录的URL)
11、sitemap 一键生成,自动更新,收录地图的 HTML 版本和 XML 版本。
12、增加了网站spider功能,可以监控哪个蜘蛛爬到哪个页面,返回状态码是什么,无需查看服务器日志。
13、死链查询功能,查询网站中所有URL链接是否有死链,如果发现silian.xml文件生成,提交给百度站长。
14、增加了关键词排名查询监控系统,可以实时监控关键词的排名,无需使用其他工具查询。
15、增加了tag标签内加链的功能,可以指定关键词使文章中所有收录关键词的字段都有超链接。这个功能有两种,分别是指定跳转超链接,或者自动跳转标签页,是高端SEO玩家必备神器!
16、 增加分类字段隐藏,更好地优化网址链接。
17、添加了分类栏的SEO标题关键词,描述了SEO填充。
18、增加了流量词的获取,可以查看哪个关键词有排名。
19、新增360站长、必应站长、今日头条站长
20、 添加了文章原创 速率检测。
提醒:
以上部分功能为初始版本。如有BUG问题请及时联系我们。网站:
需要注意的是,该插件需要依赖第三方授权才能正常使用授权地址:
使用我们的插件时,请阅读我们的第三方用户服务协议条款:服务协议条款
注意事项
SEO合集插件是目前WordPress插件市场中功能最齐全、功能最强大的百度SEO合集插件。该插件还提供了多种推送方式,并且简单易用,超轻量级的代码设计,无论是老站还是新站,使用本插件对百度搜索引擎优化都有更大的效果。
如果您对WordPress主题和插件有更多的需求,希望您能给我们提出建议,我们会记录下来,并根据实际情况推出更多满足您需求的主题和插件。
谢谢! 查看全部
关键词自动采集(wordpress只有title网站标题的设定,特地增加该功能增加权重)
因为wordpress只有title网站title设置,没有关键字,description设置,即关键词和description。特地添加此功能,增加权重,区分字段。
2、百度主动推送
百度通过插件的配置主动推送访问密钥,具有批量推送功能,定时自动批量推送,免去了每天手动提交网址链接的麻烦。
3、自动推送
使用开关按钮配置百度的主动推送功能。自动推送是百度搜索资源平台推出的一种工具,旨在提高网站新网页的发现速度。安装自动推送JS代码的网页。当页面被访问时,页面URL会立即推送到百度。
4、站点地图推送
站点地图推送功能也是百度站长网址提交功能之一。自动读取文章等HTML页面、列表等页面生成SITEMAP,并根据文章新旧文章的权重进行评分,最大的是1.0是首页, 0.9是最新的文章,其他过时的文章0.5等等,也会生成HTML和XML地图,方便博主快速复制Sitemap地址,提交Sitemap地址到百度站长平台,节省人工生成和更新SITEMAP的时间,提高优化效率。
5、Picture Alt 标签填充
主要有利于网站的优化,因为没有Alt标签的图片会被网站减分搜索引擎减少,因为我们不可能每张图片都加一个Alt标签,所以这个功能可以大大降低人工成本。使用Alt标签自动读取标题和相关关键词,可以批量优化,减少手动添加的麻烦,从而增加网站的权重。
6、站内链
做网站优化的小伙伴都知道,内链为王,外链为皇,内链也很重要。所以小编在此基础上开发了这个插件功能,可以根据提供的关键词进行指定,自动添加内链,一键批量添加,面对成千上万的文章。
7、Robots.txt 生成
这个主要是用来引导搜索引擎蜘蛛的。编辑曾经维护过一个权重为6的网站,由于国外蜘蛛太大,5M带宽的50%被其他搜索引擎占用,不得不对蜘蛛进行限制。 ,所以有人认为是流量攻击是无稽之谈,先看看是不是被外国蜘蛛盯上了。开启这个Robots.txt类似于可以屏蔽的蜘蛛黑名单。还有其他效果需要自己了解
8、301 重定向和 404 页面
301重定向,一般不设服务器的用户,主要作用是将没有WWW的域名指向有WWW的域名,增加权重,否则会出现两个网站不同的权重,这个新手经常遇到。没有WWW的权重高于有WWW,收录也有更多没有WWW的域名。
404页面基本上是网站优化必备的,也被不配置服务器的用户使用。基本上一键操作很方便,主要是提高网站的权重和质量,引导蜘蛛。
9、天级投稿
熊掌的日级推送,每个账号只有10个额度,指数越高,额度越高,不过小编在文章列表中设置了插件有提交按钮,点击自己提交你要提交的文章,省去登录后台的麻烦,大大提高你的工作效率。
10、 一键查询所有URL链接网站的收录状态,一键推送熊掌号、站长号、非收录的URL链接。 (后面我们会开发自动推送收录的URL)
11、sitemap 一键生成,自动更新,收录地图的 HTML 版本和 XML 版本。
12、增加了网站spider功能,可以监控哪个蜘蛛爬到哪个页面,返回状态码是什么,无需查看服务器日志。
13、死链查询功能,查询网站中所有URL链接是否有死链,如果发现silian.xml文件生成,提交给百度站长。
14、增加了关键词排名查询监控系统,可以实时监控关键词的排名,无需使用其他工具查询。
15、增加了tag标签内加链的功能,可以指定关键词使文章中所有收录关键词的字段都有超链接。这个功能有两种,分别是指定跳转超链接,或者自动跳转标签页,是高端SEO玩家必备神器!
16、 增加分类字段隐藏,更好地优化网址链接。
17、添加了分类栏的SEO标题关键词,描述了SEO填充。
18、增加了流量词的获取,可以查看哪个关键词有排名。
19、新增360站长、必应站长、今日头条站长
20、 添加了文章原创 速率检测。
提醒:
以上部分功能为初始版本。如有BUG问题请及时联系我们。网站:
需要注意的是,该插件需要依赖第三方授权才能正常使用授权地址:
使用我们的插件时,请阅读我们的第三方用户服务协议条款:服务协议条款
注意事项
SEO合集插件是目前WordPress插件市场中功能最齐全、功能最强大的百度SEO合集插件。该插件还提供了多种推送方式,并且简单易用,超轻量级的代码设计,无论是老站还是新站,使用本插件对百度搜索引擎优化都有更大的效果。
如果您对WordPress主题和插件有更多的需求,希望您能给我们提出建议,我们会记录下来,并根据实际情况推出更多满足您需求的主题和插件。
谢谢!
关键词自动采集(四三整合DEDEV5.5Ajax编辑器可以针对单个提取热门搜索关键词,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-09-07 22:11
这次由四三学习网采集整理的文章主要介绍了Dedecms专栏和文档自动获取关键词。四三学习网小编觉得还不错。现分享给大家,供大家参考。
发文章,尤其是采集时,一般不可能采集找到准确热门的相关关键词。有朋友建议在发文章时,关键字使用搜索引擎中相关的关键词来匹配文章的内容。如果匹配的关键词出现在内容中,则会突出显示或以粗体显示。显着提升SEO效果。
所以,在这个建议下,我开了两个beta工具,一个是专栏的关键词获取工具,一个是文章content的关键词获取工具。
5.5GBK 的模块如下。使用方法为:后台模块管理-上传新模块-安装。理论上DEDEV5.3、V5.5都适用。
对于Utf-8用户,请手动转换代码使用。
以下是整理的一些问题和发展方向:
1,Bing 的访问真的是一场灾难。手动访问其搜索链接时出现乱码。
2、感觉搜狗的分词数据很好,可惜在大量访问请求后,会需要验证码。这个问题目前还无法解决。
3、百度还不错,没有访问次数限制,没有验证码,好像可以加一些采集线程。
4、本工具风险未知,请谨慎使用。
这里是升级说明
1, 2009-08-30,测试版免费发布,未收到错误报告
2, 2009-08-31,栏目和文章相关关键词自动获取工具,免费
<p>3, 2009-09-01,集成DEDE V5.3/V5.5 Ajax编辑器,可提取单个文档的热门搜索关键词,初步实现标签分割等功能 查看全部
关键词自动采集(四三整合DEDEV5.5Ajax编辑器可以针对单个提取热门搜索关键词,)
这次由四三学习网采集整理的文章主要介绍了Dedecms专栏和文档自动获取关键词。四三学习网小编觉得还不错。现分享给大家,供大家参考。
发文章,尤其是采集时,一般不可能采集找到准确热门的相关关键词。有朋友建议在发文章时,关键字使用搜索引擎中相关的关键词来匹配文章的内容。如果匹配的关键词出现在内容中,则会突出显示或以粗体显示。显着提升SEO效果。
所以,在这个建议下,我开了两个beta工具,一个是专栏的关键词获取工具,一个是文章content的关键词获取工具。
5.5GBK 的模块如下。使用方法为:后台模块管理-上传新模块-安装。理论上DEDEV5.3、V5.5都适用。
对于Utf-8用户,请手动转换代码使用。
以下是整理的一些问题和发展方向:
1,Bing 的访问真的是一场灾难。手动访问其搜索链接时出现乱码。
2、感觉搜狗的分词数据很好,可惜在大量访问请求后,会需要验证码。这个问题目前还无法解决。
3、百度还不错,没有访问次数限制,没有验证码,好像可以加一些采集线程。
4、本工具风险未知,请谨慎使用。
这里是升级说明
1, 2009-08-30,测试版免费发布,未收到错误报告
2, 2009-08-31,栏目和文章相关关键词自动获取工具,免费
<p>3, 2009-09-01,集成DEDE V5.3/V5.5 Ajax编辑器,可提取单个文档的热门搜索关键词,初步实现标签分割等功能
关键词自动采集(优采云关键词网址采集器采集速度快且质量高,谷歌必应无等待)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-07 22:09
优采云关键词URL采集器是一个网站信息采集软件,软件输入关键字采集各个搜索引擎的网址、域名、标题、描述等信息,采集速度快,质量好。
优采云关键词URL采集器是一个网站信息采集软件,软件输入关键字采集各个搜索引擎的网址、域名、标题、描述等信息,采集速度快,质量好。
如何使用
【搜索引擎】百度、搜狗、谷歌支持每页100条结果,勾选“每页10条结果”时支持10条结果
[仅采集指定排名] 比如你想要采集第2、3和5个排名网址,那么输入“2|3|5”(不包括引号),如果这个选项未启用,所有采集。
[输入关键词list]一行一行关键词
[采集页数]设为0 采集所有搜索页面
[每页数] 不同的搜索引擎对每页的页数有不同的限制。百度* 50,谷歌和搜狗100,其他基本都是10或20
【谷歌必应英文站】勾选使用谷歌必应全球英文站搜索,否则使用中文站搜索。
【Google Bing No Wait】勾选让这3个引擎不等待采集,即高速采集,否则每个采集页面都会自动等待一定时间。添加这个选项的原因是最近(2015年8月8日)测试这3个引擎设置搜索间隔时间似乎没有用。 Bing在没有验证码的情况下测试了十几个关键词无等待搜索,所以无法验证。代码处理。不过谷歌一开始只显示了几个验证码,并没有等待大量搜索,也没有出现验证码。但是,Google 已经可以自动确定出现验证码并将其交给用户删除。
【保存目录】采集结果会保存在这个目录下,保存的文件名是:search engine_关键词
【重要提示】右键点击保存目录的选择按钮“..”定位目录
常见问题
1.为什么采集一段时间后不能采集?
可能是采集受搜索引擎限制比较多。一般可以通过更改IP来继续采集。如果不改,只能在搜索引擎解封后继续采集。百度的屏蔽时间一般是半小时到几个小时。
但是,即使验证码被屏蔽,软件也会弹出手动输入的验证码(百度、谷歌)
2.不同批次关键词采集为什么会有一些重复的网址?
特别是在只引用#domain# 或#*domain# 之后,这种部分URL 重复更为常见。这也是正常的,因为每个网站内页可能收录很多主题,而不同的关键词可能是采集到网站的不同内页,当引用域名时,相同的网站不同内页页面的域名结果自然是一样的。
另外,软件中的自动去重是针对这个采集的结果在内部进行的。之前采集的结果不在这次的范围内。如果两个采集的结果中有重复的网址,可以合并在一起,用软件去除重复。
3.为什么采集返回的URL主题与关键词不匹配?
因为引用#domain# 或#*domain# 后,取的是域名部分。域名打开网站的首页,采集的原网址可能不是首页,而是网站文章内页的某篇文章,内页收录关键词主题,所以可以通过搜索引擎收录获取,软件可以采集。但是取域名后,您打开的域名首页可能没有关键词。
为了对比采集是否正确,可以在保存模板中输入:,保存为htm文件,采集后可以自己打开文件查看对比。 查看全部
关键词自动采集(优采云关键词网址采集器采集速度快且质量高,谷歌必应无等待)
优采云关键词URL采集器是一个网站信息采集软件,软件输入关键字采集各个搜索引擎的网址、域名、标题、描述等信息,采集速度快,质量好。
优采云关键词URL采集器是一个网站信息采集软件,软件输入关键字采集各个搜索引擎的网址、域名、标题、描述等信息,采集速度快,质量好。
如何使用
【搜索引擎】百度、搜狗、谷歌支持每页100条结果,勾选“每页10条结果”时支持10条结果
[仅采集指定排名] 比如你想要采集第2、3和5个排名网址,那么输入“2|3|5”(不包括引号),如果这个选项未启用,所有采集。
[输入关键词list]一行一行关键词
[采集页数]设为0 采集所有搜索页面
[每页数] 不同的搜索引擎对每页的页数有不同的限制。百度* 50,谷歌和搜狗100,其他基本都是10或20
【谷歌必应英文站】勾选使用谷歌必应全球英文站搜索,否则使用中文站搜索。
【Google Bing No Wait】勾选让这3个引擎不等待采集,即高速采集,否则每个采集页面都会自动等待一定时间。添加这个选项的原因是最近(2015年8月8日)测试这3个引擎设置搜索间隔时间似乎没有用。 Bing在没有验证码的情况下测试了十几个关键词无等待搜索,所以无法验证。代码处理。不过谷歌一开始只显示了几个验证码,并没有等待大量搜索,也没有出现验证码。但是,Google 已经可以自动确定出现验证码并将其交给用户删除。
【保存目录】采集结果会保存在这个目录下,保存的文件名是:search engine_关键词
【重要提示】右键点击保存目录的选择按钮“..”定位目录
常见问题
1.为什么采集一段时间后不能采集?
可能是采集受搜索引擎限制比较多。一般可以通过更改IP来继续采集。如果不改,只能在搜索引擎解封后继续采集。百度的屏蔽时间一般是半小时到几个小时。
但是,即使验证码被屏蔽,软件也会弹出手动输入的验证码(百度、谷歌)
2.不同批次关键词采集为什么会有一些重复的网址?
特别是在只引用#domain# 或#*domain# 之后,这种部分URL 重复更为常见。这也是正常的,因为每个网站内页可能收录很多主题,而不同的关键词可能是采集到网站的不同内页,当引用域名时,相同的网站不同内页页面的域名结果自然是一样的。
另外,软件中的自动去重是针对这个采集的结果在内部进行的。之前采集的结果不在这次的范围内。如果两个采集的结果中有重复的网址,可以合并在一起,用软件去除重复。
3.为什么采集返回的URL主题与关键词不匹配?
因为引用#domain# 或#*domain# 后,取的是域名部分。域名打开网站的首页,采集的原网址可能不是首页,而是网站文章内页的某篇文章,内页收录关键词主题,所以可以通过搜索引擎收录获取,软件可以采集。但是取域名后,您打开的域名首页可能没有关键词。
为了对比采集是否正确,可以在保存模板中输入:,保存为htm文件,采集后可以自己打开文件查看对比。
关键词自动采集(织梦采集侠全版v2.6 最新免费JS源码 全自动更新+离线更新+伪原创+自动内链 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-09-07 18:26
)
一、织梦采集器 简介
织梦采集侠是一套基于德德cms的绿色插件。根据关键词Auto采集,无需编写复杂的采集规则,自动伪原创,绿色插件自动发布内容经过简单配置,即可实现@k1524小时不间断@、伪原创 和释放。是站长建立站群的首选插件。
1、自动采集后无需写采集rule设置关键词,传统的采集模式是织梦采集侠可以根据关键词设置的关键词进行平移用户采集、泛采集的优势在于,通过采集this关键词的不同搜索结果,无法在一个或多个指定的采集站点上执行采集,减少采集站点被引擎搜索 判断该镜像站点有被搜索引擎惩罚的危险。
2、多种伪原创和SEO优化方法提高收录率和关键词排名
自动标题、段落重排、高级混淆、自动内链、内容过滤、URL过滤、同义词替换等多种方法增强采集文章原创,搜索引擎改进收录,网站重重和关键词ranking。
3、plugin 全自动采集,无需人工干预
当用户访问你的网站时,程序被触发运行,根据设置的关键字通过搜索引擎(可自定义)采集 URL,然后自动抓取网页内容,程序通过精确计算分析为网页,丢弃不是文章内容页的URL,提取优秀的文章内容,最后伪原创,导入,生成,所有这些操作都是自动完成的,无需人工干预当做很多内容采集时,也可以手动采集加速采集。
4、效果明显,站群首选
织梦采集侠只需简单配置即可自动采集发布,熟悉织梦Dedecms的站长轻松上手。
5、首创远程触发采集完美实现定时量化采集update
远程触发采集功能:织梦采集侠可以触发采集,只要在后台进行配置,用户访问你的网站,就可以实现采集24小时不间断,但是对于新站来说,前期的访问量并没有那么多,因为没有访问量实现全自动采集,还需要进入后台手动采集,这无疑增加了不少麻烦给用户。对于只有一两个网站的用户来说,问题不大,但是用织梦采集侠建站群的用户比较多,新的前期自动采集车站比较麻烦。但是随着我们完成了远程触发采集功能,即使在你的新站点初期没有人访问触发器,我们的远程服务器仍然可以触发用户的站点,这样新站点也可以实现定时定量采集更新,也是商业版用户提供的免费增值服务。
织梦采集侠不同于其他的采集软件,需要在本地安装客户端采集然后导入站点。好处是即使暂时不在线,也可以保持网站Everyday 有新内容发布,因为织梦采集侠侠是网站上安装的智能采集插件。只要设置好,就可以定时定量更新。现在即使新站前期没有流量也可以实现自动更新,远程服务器会触发新站保持网站更新。
二、织梦采集侠如何使用
首先确保你之前没有安装过采集侠侠其他版本。如果已经安装,请到后台卸载并重新安装本站文件下载压缩包。请勿下载官方安装。
如果您之前没有安装过,请跳过以上步骤
1、去后台快速上传模型
2、Select Modkuai,有两个版本,一个是GBK,一个是UFT-8。选择你使用的程序类型,将模块上传到“安装模板”文件夹中,然后安装,
3、安装完成后
如果你的程序是GBK版本(在网站background顶部仔细查找,可以看到GBK或者UTF-8)
破解GBK版文件,然后选择下载压缩包中的“GBK版破解文件”文件夹
将dede和Plugins这两个文件夹覆盖到你的网站root目录下
(如果你的织梦程序后台目录名不是dede,那就把dede改成你的后台目录名再覆盖),一般后台目录是dede不改(即覆盖对应的破解文件,任何人用过的人都知道怎么做!)
4、覆盖结束后,点击高级设置,然后会提示输入域名和授权码,
输入法:
授权码|78250688 替换成你的域名(切记不要带“www”)
比如你的网址是,那么需要输入授权码|78250688
如果出现授权错误,关闭浏览器,更新浏览器缓存,然后重新打开,重新设置,然后提示错误,更换核心浏览器即可。
5、设置触发采集采集侠侠所谓自动采集就是触发采集即:
设置触发条件后,如果有人点击你的网站,会触发一段时间采集一会如果网站流量稳定,它会一直采集自己点击,别人点击可以点击
如何设置:采集task。如果下面有一段,我就写了这个方法。如果我找不到它,让我们在这里讨论它:
将{dede:robot copyright="qjpemail"/}这段代码添加到template-default模板management-footer.htm的底部,然后生成整个站点,并设置在有人点击或点击他们的自己的网站一段时间会自动挑选 查看全部
关键词自动采集(织梦采集侠全版v2.6 最新免费JS源码 全自动更新+离线更新+伪原创+自动内链
)
一、织梦采集器 简介
织梦采集侠是一套基于德德cms的绿色插件。根据关键词Auto采集,无需编写复杂的采集规则,自动伪原创,绿色插件自动发布内容经过简单配置,即可实现@k1524小时不间断@、伪原创 和释放。是站长建立站群的首选插件。
1、自动采集后无需写采集rule设置关键词,传统的采集模式是织梦采集侠可以根据关键词设置的关键词进行平移用户采集、泛采集的优势在于,通过采集this关键词的不同搜索结果,无法在一个或多个指定的采集站点上执行采集,减少采集站点被引擎搜索 判断该镜像站点有被搜索引擎惩罚的危险。
2、多种伪原创和SEO优化方法提高收录率和关键词排名
自动标题、段落重排、高级混淆、自动内链、内容过滤、URL过滤、同义词替换等多种方法增强采集文章原创,搜索引擎改进收录,网站重重和关键词ranking。
3、plugin 全自动采集,无需人工干预
当用户访问你的网站时,程序被触发运行,根据设置的关键字通过搜索引擎(可自定义)采集 URL,然后自动抓取网页内容,程序通过精确计算分析为网页,丢弃不是文章内容页的URL,提取优秀的文章内容,最后伪原创,导入,生成,所有这些操作都是自动完成的,无需人工干预当做很多内容采集时,也可以手动采集加速采集。
4、效果明显,站群首选
织梦采集侠只需简单配置即可自动采集发布,熟悉织梦Dedecms的站长轻松上手。
5、首创远程触发采集完美实现定时量化采集update
远程触发采集功能:织梦采集侠可以触发采集,只要在后台进行配置,用户访问你的网站,就可以实现采集24小时不间断,但是对于新站来说,前期的访问量并没有那么多,因为没有访问量实现全自动采集,还需要进入后台手动采集,这无疑增加了不少麻烦给用户。对于只有一两个网站的用户来说,问题不大,但是用织梦采集侠建站群的用户比较多,新的前期自动采集车站比较麻烦。但是随着我们完成了远程触发采集功能,即使在你的新站点初期没有人访问触发器,我们的远程服务器仍然可以触发用户的站点,这样新站点也可以实现定时定量采集更新,也是商业版用户提供的免费增值服务。
织梦采集侠不同于其他的采集软件,需要在本地安装客户端采集然后导入站点。好处是即使暂时不在线,也可以保持网站Everyday 有新内容发布,因为织梦采集侠侠是网站上安装的智能采集插件。只要设置好,就可以定时定量更新。现在即使新站前期没有流量也可以实现自动更新,远程服务器会触发新站保持网站更新。
二、织梦采集侠如何使用
首先确保你之前没有安装过采集侠侠其他版本。如果已经安装,请到后台卸载并重新安装本站文件下载压缩包。请勿下载官方安装。
如果您之前没有安装过,请跳过以上步骤
1、去后台快速上传模型
2、Select Modkuai,有两个版本,一个是GBK,一个是UFT-8。选择你使用的程序类型,将模块上传到“安装模板”文件夹中,然后安装,
3、安装完成后
如果你的程序是GBK版本(在网站background顶部仔细查找,可以看到GBK或者UTF-8)
破解GBK版文件,然后选择下载压缩包中的“GBK版破解文件”文件夹
将dede和Plugins这两个文件夹覆盖到你的网站root目录下
(如果你的织梦程序后台目录名不是dede,那就把dede改成你的后台目录名再覆盖),一般后台目录是dede不改(即覆盖对应的破解文件,任何人用过的人都知道怎么做!)
4、覆盖结束后,点击高级设置,然后会提示输入域名和授权码,
输入法:
授权码|78250688 替换成你的域名(切记不要带“www”)
比如你的网址是,那么需要输入授权码|78250688
如果出现授权错误,关闭浏览器,更新浏览器缓存,然后重新打开,重新设置,然后提示错误,更换核心浏览器即可。
5、设置触发采集采集侠侠所谓自动采集就是触发采集即:
设置触发条件后,如果有人点击你的网站,会触发一段时间采集一会如果网站流量稳定,它会一直采集自己点击,别人点击可以点击
如何设置:采集task。如果下面有一段,我就写了这个方法。如果我找不到它,让我们在这里讨论它:
将{dede:robot copyright="qjpemail"/}这段代码添加到template-default模板management-footer.htm的底部,然后生成整个站点,并设置在有人点击或点击他们的自己的网站一段时间会自动挑选
关键词自动采集(织梦采集侠破解版自动采集触发教程24小时触发自动审核自动更新 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-07 18:16
)
最新采集侠V2.9.2破解版,可以进行自动数据采集网站,采集侠破解版可以帮助用户快速提升自己的网站seo排名.
织梦采集侠是一套基于dedecms的绿色插件。根据关键词Auto采集,无需编写复杂的采集规则,自动伪原创,自动发布内容的绿色插件。经过简单配置,即可实现采集、伪原创24小时不间断发布。是站长建立站群的首选插件。
因为是破解版的授权,所以不能使用自动采集触发功能。按照采集侠官方方法在首页模板中添加{dede:robot copyright="qjpemail"/}标签。有人访问网站采集会被触发,显然不能满足站群的需求。 ps:谁知道有没有人来。
现在提供了一个简单的方案,可以同时触发多个网站,和采集侠授权版一样方便。
第一步:
创建一个新的 html 空白页。
第二步:
打开一个空白页面并添加代码。
更改为您自己的域名。如果要触发多个网站,添加多个。
例如:
第 3 步:
把页面上传到服务器或者虚拟空间,访问这个页面,会自动触发采集,我们可以用软件每30秒刷新一次页面,继续触发。
或者使用宝塔定时任务触发:
这次我们利用宝塔策划任务,帮助采集侠侠破解版用户满足自动采集文章的需求。
您的域名/Plugins/run.php?action=robot&kw_g=1&kw_make=1&kw_slink=1&kw_seobody=1&kw_tforbid=1&kw_confu=1&kw_rant=1&donow=1 查看全部
关键词自动采集(织梦采集侠破解版自动采集触发教程24小时触发自动审核自动更新
)
最新采集侠V2.9.2破解版,可以进行自动数据采集网站,采集侠破解版可以帮助用户快速提升自己的网站seo排名.
织梦采集侠是一套基于dedecms的绿色插件。根据关键词Auto采集,无需编写复杂的采集规则,自动伪原创,自动发布内容的绿色插件。经过简单配置,即可实现采集、伪原创24小时不间断发布。是站长建立站群的首选插件。
因为是破解版的授权,所以不能使用自动采集触发功能。按照采集侠官方方法在首页模板中添加{dede:robot copyright="qjpemail"/}标签。有人访问网站采集会被触发,显然不能满足站群的需求。 ps:谁知道有没有人来。
现在提供了一个简单的方案,可以同时触发多个网站,和采集侠授权版一样方便。
第一步:
创建一个新的 html 空白页。
第二步:
打开一个空白页面并添加代码。
更改为您自己的域名。如果要触发多个网站,添加多个。
例如:
第 3 步:
把页面上传到服务器或者虚拟空间,访问这个页面,会自动触发采集,我们可以用软件每30秒刷新一次页面,继续触发。
或者使用宝塔定时任务触发:
这次我们利用宝塔策划任务,帮助采集侠侠破解版用户满足自动采集文章的需求。
您的域名/Plugins/run.php?action=robot&kw_g=1&kw_make=1&kw_slink=1&kw_seobody=1&kw_tforbid=1&kw_confu=1&kw_rant=1&donow=1
关键词自动采集(关键词自动抽取系统现有的检索系统中对关键词的抽取主要采用人工操作的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-09-07 00:01
关键词自动提取系统在现有的检索系统中,关键词的提取主要采用手工方式。由于这种方法存在许多无法克服的问题,因此并未得到广泛应用。主要问题是:1)太贵了。一是每份文件都需要专业技术人员处理,对人员素质要求高;另一个是效率很低,每个文档都需要全文浏览才能有高质量的关键词提取。 2)标准难以制定。一个文档中哪些是关键内容,哪些是次要内容,很难有一个明确的标准,更难的是用规则来确定。 3)标准实施难统一。因为是手工加工,大家对标准的理解并不统一;每个人的严重程度不一致都会影响标准的实施。 4)处理能力僵化,不能适应专利文献量的变化。由于专利文献量不一,人员需要长期培训,难以及时改变。 5)提取的关键词对检索的帮助有限。由于提取的关键词是供人看的,计算机无法理解提取的关键词。随着计算机能力的提高,全文检索现在已经很普遍了,所以现有的手动提取关键词的方法不会对全文检索的性能有很大的提升。了解这些不足,patentics开发了基于智能语义检索技术的具有自主知识产权的关键词自动提取系统。系统可以完全自动从整个专利文献中提取出最能代表该文献含义的关键词。
统一标准,全自动操作,高效准确。并且提取的关键词 是计算机可读和可理解的。这为提取的关键词 提供了许多扩展属性。 1Patentics Application Note.12 (一)Basic Principles) 从信息论的角度来看,考察向量空间模型(VSM)下的文本向量,很容易注意到每个文档就像一个独立的信息源观察者观察此信息源发出的每个特征用于累积有关此信息源的信息的次数。算法要处理的文本向量就是这些信息源的观察数据。事实上,正是由于VSM的局限性,观察者进行聚类或分类时,文档中只有两种信息:文档中每个特征词的出现频率。文档的长度。由于文章的长度与文章所属的类别的关系不是很大,下面假设所有文章都已经归一化了,长度为N。 这样,对于文档向量d,特征词出现的频率可以用d = (f 1 ,f 2 ,Λ ,fi ,Λ ,f M )表示,∑fi = 1i,也可以用归一化后的特征词出现的频率来表示d = (t ,t ,Λ,t,Λ,t), ∑t = N1 2 i Mi 表示 i。这传达的信息是一样的。以这种方式表示的信息源实际上是一个离散的无记忆信息源,因为没有任何特征出现顺序的信息。
为了得到一个簇的目标函数,需要进一步检查文档类别。每个文档类别c是一个文档的集合,合理的类别应该能够尽可能反映集合中文档的共性。而且,类别的分类越详细,类别内的文档的共性越多,相异性越小。通过定量描述类别的共性以及类别与文档之间的差异,可以给出合理的优化目标。我们把文档看作一个离散的无记忆信息源,那么文档类就是一个信息源的集合。如果我们从外部观察者那里检查这个信息源集的输出,我们无法区分某个特征的某个出现是来自那个源,整个集被视为 2Patentics Application Note.12 的单一来源。我们将每个文档类视为一个来源。显然,这个来源仍然是 a 1f i (c) = ∑fi (d )i|c | d∈c离散非记忆源,其第一个特征出现频率为,| | | c 表示收录在 c 中的文档数。 这样,我们可以将文档类别的特征表示为: c = (f (c) ,f (c) ,Λ ,f (c) ,Λ ,f (c) ) ), ∑f (c) = 112iMii or use features 的频率表示为:c = (t (c) ,t (c) ,Λ ,t (c) ,Λ ,t (c) ), ∑t (c) = N | c |1 2iMii Source 我们可以表征属于该类别的文档的共性。
为了得到合成源和文档之间差异的定量表达,注意错误!没有找到报价!未发现引用错误! !未找到参考源。未找到参考源。节中介绍的不等式。 : 使用源使用源。 . P = (p, p ,Λ, p ), 1 ≤ i ≤ n 任何 m 维概率向量 i1i 2imi 和任何 n 维概率向量 Q = (q ,q ,Λ ,q ,Λ ,q )1 2in 有下面的不等式成立[错误错误!没有定义书签!没有定义书签。 . ]:错误错误! !未定义的书签 未定义的书签。 . nnnn∑q H(p, p ,Λ, p) ≤ H (∑qp, ∑qp ,Λ, ∑qp)im 1i 2imimi 1ii 2ii mii=1i=1i=1i=11 11Q = (, ,Λ, )n nn1 44 2 4 43nNn 令,并乘以不等式的两边,我们得到: n1 n1 n1 n∑NH m (p 1i ,p 2i ,Λ, p mi) ≤ NnH m (∑p 1i, ∑p 2i ,Λ , ∑ p mi )i=1n i=1 ni=1n i=1PiiN 如果表示文档的频率向量,则表示特征词数 NH m (p 1i, p 2i ,Λ, p mi )i出现在每个文档中,则表示该文档收录的信息总量。
对应的c = {d ,Λ,d}不等式的右边部分表示(表示信息源)中收录n个文档的文档类的信息总量。这说明单个文献的信息量之和小于文献3 Patentics Application Note的信息量。对于熵的概念,我们应该选择信息损失最少的聚类方案。如果文档类中的文档具有相似的特征词频分布,则该文档类的特征词频分布的相应变化较小,因此信息变化量也较小。可以看出,从一个文档到一个文档类别的信息量的变化,正好可以描述文档类别中文档之间特征分布的差异。 1 n 1 n1 nn∆H (c) = NnH (∑P, ∑P ,Λ, ∑P) − ∑NH (P ,P ,Λ ,P )m1i2imim 1i 2i min i=1 ni=1n i=1 i =1= NnH (c) − ∑NH (d )d∈c{}= N ∑ H (c) − H (d) ≥ 0d∈c 为了评估每个文档与其类别之间的差异,一个目标函数可以定义 arg min N ∑∑{H (c) − H (d )}Ωc∈Ω d ∈cΩ 以找到给定数量类别的最佳分类方案。
在层次聚类过程中,每一步的局部优化目标可以简化为{}N ∑ H (c) − H (d) ˆd∈cc = arg min, c = c Υ ci kc| c |,其中我们考虑了文档类中文档数量的差异。在层次聚类中,通过在每一步选择信息丢失最少的方案来选择聚类的路径。当相似类别的文档归为一类时,由于其主要特征的频数分布比较接近,混合源的特征分布变化不大,因此平均信息量(熵)变化不大。当不同类别的文档混合(即错误分类)时,混合源的特征分布会发生显着变化,分布会变得更加均匀,从而增加了平均信息量。这样,目标函数就会选择特征分布相似的文档(类)来达到分类的目的。这里实际上有一个基本假设:语义相似的文档应该倾向于具有相似的特征分布。 4Patentics Application Note.12(二)系统Block Diagram Chinese full field of many 现有中文专利级词典文档分词系统:根据词典,将专利文档划分为词条-文档相关矩阵,建立海量矩阵解决方案算法:用于获取词条相关性 构建专利文献向量模型词条翻译系统 文档中英文最相关词条计算算法关键词acquisition and clustering device 5Patentics Application Note.12 具体组件介绍:中文多级全领域词典 全领域汉语多级词典:收录所有技术领域的词或词组,将整个汉语领域的汉语多级词典分为三级、几十种。
目前已完成超过700万个中文条目。现有中国专利文件 现有中国专利文件: 已下载所有中国专利:(包括现有的实用新型和发明的中国专利文件)。分词系统 分词系统:根据词典中的词条,快速准确地对专利文献进行分词。分词系统系统化程度高,效果非常好。词条词条相关矩阵的建立 文档相关矩阵的建立:分词系统输出的分词结果和专利文本:词条词条文档相关矩阵的建立 文档相关矩阵的建立:我们将共同建立词条—文档相关矩阵。质量矩阵求解算法 质量矩阵求解算法:采用具有自主知识产权的Patentics核心计算质量矩阵求解算法,质量矩阵求解算法方法对上面得到的质量矩阵进行降维,但同时保留了原创信息使得可以对数千万级的矩阵进行运算以获得条目的相关性。构建专利文献向量模型: 基于上述:基于上述术语相关性,为一个文档构建专利文献向量模型 构建专利文献向量模型: 基于上述基于上述文件中出现的词可以通过将条带与向量组合来获得文档的向量。词条翻译系统 词条翻译系统:由专利技术独立完成的中英文词条互译系统。词条翻译系统是词条翻译系统。与文档最相关的词条计算算法与文档最相关的词条计算算法:根据词条向量和文档向量之间的相关性:与文档最相关的词条计算算法与文档最相关的算法::度,分别计算出现在文档中的词条与文档的相关性。
中英文关键词acquisition and clustering device 中英文关键词acquisition and clustering device:通过词条传递最相关的词条:Chinese and English关键词acquisition and clustering device in Chinese and English关键词获取和集群设备:: 6Patentics Application Note.12 翻译,获取中英文关键词。 (三)Functional features (1)fullAutomation。所有工作均由计算机完成,无需任何人为参与。所有结果标准相同。(2)绝对安全:由于专利在发布前被归类为机密信息,本系统是本地系统与外网隔离,绝对安全。 (3) 兼容多种数据格式:如果数据是文本格式,可以直接处理,如果是图片格式,系统可以实现自动处理(4) 可以同时给出中英文关键词。(四)Case 对于中国专利CN1310423,专利关键词自动提取系统给出了32个关键词。根据将这32个关键词互之之每组之间的相关性分为4组,给出每组关键词与整个文档的相关性,下图为英文关键词.7Patentics Application Note.128Patentics应用说明.12 查看全部
关键词自动采集(关键词自动抽取系统现有的检索系统中对关键词的抽取主要采用人工操作的方法)
关键词自动提取系统在现有的检索系统中,关键词的提取主要采用手工方式。由于这种方法存在许多无法克服的问题,因此并未得到广泛应用。主要问题是:1)太贵了。一是每份文件都需要专业技术人员处理,对人员素质要求高;另一个是效率很低,每个文档都需要全文浏览才能有高质量的关键词提取。 2)标准难以制定。一个文档中哪些是关键内容,哪些是次要内容,很难有一个明确的标准,更难的是用规则来确定。 3)标准实施难统一。因为是手工加工,大家对标准的理解并不统一;每个人的严重程度不一致都会影响标准的实施。 4)处理能力僵化,不能适应专利文献量的变化。由于专利文献量不一,人员需要长期培训,难以及时改变。 5)提取的关键词对检索的帮助有限。由于提取的关键词是供人看的,计算机无法理解提取的关键词。随着计算机能力的提高,全文检索现在已经很普遍了,所以现有的手动提取关键词的方法不会对全文检索的性能有很大的提升。了解这些不足,patentics开发了基于智能语义检索技术的具有自主知识产权的关键词自动提取系统。系统可以完全自动从整个专利文献中提取出最能代表该文献含义的关键词。
统一标准,全自动操作,高效准确。并且提取的关键词 是计算机可读和可理解的。这为提取的关键词 提供了许多扩展属性。 1Patentics Application Note.12 (一)Basic Principles) 从信息论的角度来看,考察向量空间模型(VSM)下的文本向量,很容易注意到每个文档就像一个独立的信息源观察者观察此信息源发出的每个特征用于累积有关此信息源的信息的次数。算法要处理的文本向量就是这些信息源的观察数据。事实上,正是由于VSM的局限性,观察者进行聚类或分类时,文档中只有两种信息:文档中每个特征词的出现频率。文档的长度。由于文章的长度与文章所属的类别的关系不是很大,下面假设所有文章都已经归一化了,长度为N。 这样,对于文档向量d,特征词出现的频率可以用d = (f 1 ,f 2 ,Λ ,fi ,Λ ,f M )表示,∑fi = 1i,也可以用归一化后的特征词出现的频率来表示d = (t ,t ,Λ,t,Λ,t), ∑t = N1 2 i Mi 表示 i。这传达的信息是一样的。以这种方式表示的信息源实际上是一个离散的无记忆信息源,因为没有任何特征出现顺序的信息。
为了得到一个簇的目标函数,需要进一步检查文档类别。每个文档类别c是一个文档的集合,合理的类别应该能够尽可能反映集合中文档的共性。而且,类别的分类越详细,类别内的文档的共性越多,相异性越小。通过定量描述类别的共性以及类别与文档之间的差异,可以给出合理的优化目标。我们把文档看作一个离散的无记忆信息源,那么文档类就是一个信息源的集合。如果我们从外部观察者那里检查这个信息源集的输出,我们无法区分某个特征的某个出现是来自那个源,整个集被视为 2Patentics Application Note.12 的单一来源。我们将每个文档类视为一个来源。显然,这个来源仍然是 a 1f i (c) = ∑fi (d )i|c | d∈c离散非记忆源,其第一个特征出现频率为,| | | c 表示收录在 c 中的文档数。 这样,我们可以将文档类别的特征表示为: c = (f (c) ,f (c) ,Λ ,f (c) ,Λ ,f (c) ) ), ∑f (c) = 112iMii or use features 的频率表示为:c = (t (c) ,t (c) ,Λ ,t (c) ,Λ ,t (c) ), ∑t (c) = N | c |1 2iMii Source 我们可以表征属于该类别的文档的共性。
为了得到合成源和文档之间差异的定量表达,注意错误!没有找到报价!未发现引用错误! !未找到参考源。未找到参考源。节中介绍的不等式。 : 使用源使用源。 . P = (p, p ,Λ, p ), 1 ≤ i ≤ n 任何 m 维概率向量 i1i 2imi 和任何 n 维概率向量 Q = (q ,q ,Λ ,q ,Λ ,q )1 2in 有下面的不等式成立[错误错误!没有定义书签!没有定义书签。 . ]:错误错误! !未定义的书签 未定义的书签。 . nnnn∑q H(p, p ,Λ, p) ≤ H (∑qp, ∑qp ,Λ, ∑qp)im 1i 2imimi 1ii 2ii mii=1i=1i=1i=11 11Q = (, ,Λ, )n nn1 44 2 4 43nNn 令,并乘以不等式的两边,我们得到: n1 n1 n1 n∑NH m (p 1i ,p 2i ,Λ, p mi) ≤ NnH m (∑p 1i, ∑p 2i ,Λ , ∑ p mi )i=1n i=1 ni=1n i=1PiiN 如果表示文档的频率向量,则表示特征词数 NH m (p 1i, p 2i ,Λ, p mi )i出现在每个文档中,则表示该文档收录的信息总量。
对应的c = {d ,Λ,d}不等式的右边部分表示(表示信息源)中收录n个文档的文档类的信息总量。这说明单个文献的信息量之和小于文献3 Patentics Application Note的信息量。对于熵的概念,我们应该选择信息损失最少的聚类方案。如果文档类中的文档具有相似的特征词频分布,则该文档类的特征词频分布的相应变化较小,因此信息变化量也较小。可以看出,从一个文档到一个文档类别的信息量的变化,正好可以描述文档类别中文档之间特征分布的差异。 1 n 1 n1 nn∆H (c) = NnH (∑P, ∑P ,Λ, ∑P) − ∑NH (P ,P ,Λ ,P )m1i2imim 1i 2i min i=1 ni=1n i=1 i =1= NnH (c) − ∑NH (d )d∈c{}= N ∑ H (c) − H (d) ≥ 0d∈c 为了评估每个文档与其类别之间的差异,一个目标函数可以定义 arg min N ∑∑{H (c) − H (d )}Ωc∈Ω d ∈cΩ 以找到给定数量类别的最佳分类方案。
在层次聚类过程中,每一步的局部优化目标可以简化为{}N ∑ H (c) − H (d) ˆd∈cc = arg min, c = c Υ ci kc| c |,其中我们考虑了文档类中文档数量的差异。在层次聚类中,通过在每一步选择信息丢失最少的方案来选择聚类的路径。当相似类别的文档归为一类时,由于其主要特征的频数分布比较接近,混合源的特征分布变化不大,因此平均信息量(熵)变化不大。当不同类别的文档混合(即错误分类)时,混合源的特征分布会发生显着变化,分布会变得更加均匀,从而增加了平均信息量。这样,目标函数就会选择特征分布相似的文档(类)来达到分类的目的。这里实际上有一个基本假设:语义相似的文档应该倾向于具有相似的特征分布。 4Patentics Application Note.12(二)系统Block Diagram Chinese full field of many 现有中文专利级词典文档分词系统:根据词典,将专利文档划分为词条-文档相关矩阵,建立海量矩阵解决方案算法:用于获取词条相关性 构建专利文献向量模型词条翻译系统 文档中英文最相关词条计算算法关键词acquisition and clustering device 5Patentics Application Note.12 具体组件介绍:中文多级全领域词典 全领域汉语多级词典:收录所有技术领域的词或词组,将整个汉语领域的汉语多级词典分为三级、几十种。
目前已完成超过700万个中文条目。现有中国专利文件 现有中国专利文件: 已下载所有中国专利:(包括现有的实用新型和发明的中国专利文件)。分词系统 分词系统:根据词典中的词条,快速准确地对专利文献进行分词。分词系统系统化程度高,效果非常好。词条词条相关矩阵的建立 文档相关矩阵的建立:分词系统输出的分词结果和专利文本:词条词条文档相关矩阵的建立 文档相关矩阵的建立:我们将共同建立词条—文档相关矩阵。质量矩阵求解算法 质量矩阵求解算法:采用具有自主知识产权的Patentics核心计算质量矩阵求解算法,质量矩阵求解算法方法对上面得到的质量矩阵进行降维,但同时保留了原创信息使得可以对数千万级的矩阵进行运算以获得条目的相关性。构建专利文献向量模型: 基于上述:基于上述术语相关性,为一个文档构建专利文献向量模型 构建专利文献向量模型: 基于上述基于上述文件中出现的词可以通过将条带与向量组合来获得文档的向量。词条翻译系统 词条翻译系统:由专利技术独立完成的中英文词条互译系统。词条翻译系统是词条翻译系统。与文档最相关的词条计算算法与文档最相关的词条计算算法:根据词条向量和文档向量之间的相关性:与文档最相关的词条计算算法与文档最相关的算法::度,分别计算出现在文档中的词条与文档的相关性。
中英文关键词acquisition and clustering device 中英文关键词acquisition and clustering device:通过词条传递最相关的词条:Chinese and English关键词acquisition and clustering device in Chinese and English关键词获取和集群设备:: 6Patentics Application Note.12 翻译,获取中英文关键词。 (三)Functional features (1)fullAutomation。所有工作均由计算机完成,无需任何人为参与。所有结果标准相同。(2)绝对安全:由于专利在发布前被归类为机密信息,本系统是本地系统与外网隔离,绝对安全。 (3) 兼容多种数据格式:如果数据是文本格式,可以直接处理,如果是图片格式,系统可以实现自动处理(4) 可以同时给出中英文关键词。(四)Case 对于中国专利CN1310423,专利关键词自动提取系统给出了32个关键词。根据将这32个关键词互之之每组之间的相关性分为4组,给出每组关键词与整个文档的相关性,下图为英文关键词.7Patentics Application Note.128Patentics应用说明.12
关键词自动采集(不能长期使用后台设置是否自动发帖已开启此设置生效)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-09-07 00:00
立即注册,免费下载更多dz插件网络资源。
您需要登录才能下载或查看,还没有账号?立即注册
×
主要功能说明:采集搜狗微信分类导航,搜索到关键词,公众号自动发布到论坛、门户、群组
测试论坛:
链接到说明文档:
测试版仅供大家了解此插件,不能长期使用
背景设置
是否自动采集发帖:
开启后会自动采集网站导航内容并自动发布到网站导航指定的版块或门户
每次自动发帖数:
如果开启了自动发帖,此设置生效,您可以控制每次自动发帖的数量。如果开启图片本地化,建议不要设置太大,0不自动发布,限制为5
采集时间筛选:
可以设置采集data时间过滤器,例如在***中,只显示当天的采集data
帖子是否被审核:
是:采集resources 发帖并进入审核状态,后台内容只有前台审核后才会显示;否:如果采集信息打到后台关键词,发帖审核,否则前台直接显示
发帖时间:
如果不填写发帖时间,则为当前自动发帖时间;格式是以秒为单位的整数时间除以 -;比如0-3600,发帖时间就是当前采集时间减去0-3600时间段内的随机时间
帖子浏览量:
如果不填写pageviews,默认为0;填写整数除以格式;例如0-100,0-100范围内的随机整数设置为浏览量
帖子图片是否居中显示:
如果您启用帖子图像显示在单行的中心
图片是否存储在本地:
是:采集resource 图片保存在本地,占用本地磁盘,选择此项时请注意服务器硬盘空间是否充足;否:图片是远程访问的,此时不在本站的图片处于盗链模式,第三方网站如果添加了防盗链图片,则不会显示。此时建议开启图片盗链访问
是否开启图片盗链:
如果启用了第三方图片资源,会在本地缓存并定期清空,以节省服务器空间
伪原创替换比例:
控制替换关键词的比例,0%是关闭伪原创功能
帖子显示样式:
自定义帖子主帖的css显示样式,必须收录,可以清空不影响帖子显示
门户显示样式:
自定义门户css显示样式,必须收录,可以清除文章display不受影响 查看全部
关键词自动采集(不能长期使用后台设置是否自动发帖已开启此设置生效)
立即注册,免费下载更多dz插件网络资源。
您需要登录才能下载或查看,还没有账号?立即注册
×
主要功能说明:采集搜狗微信分类导航,搜索到关键词,公众号自动发布到论坛、门户、群组
测试论坛:
链接到说明文档:
测试版仅供大家了解此插件,不能长期使用
背景设置
是否自动采集发帖:
开启后会自动采集网站导航内容并自动发布到网站导航指定的版块或门户
每次自动发帖数:
如果开启了自动发帖,此设置生效,您可以控制每次自动发帖的数量。如果开启图片本地化,建议不要设置太大,0不自动发布,限制为5
采集时间筛选:
可以设置采集data时间过滤器,例如在***中,只显示当天的采集data
帖子是否被审核:
是:采集resources 发帖并进入审核状态,后台内容只有前台审核后才会显示;否:如果采集信息打到后台关键词,发帖审核,否则前台直接显示
发帖时间:
如果不填写发帖时间,则为当前自动发帖时间;格式是以秒为单位的整数时间除以 -;比如0-3600,发帖时间就是当前采集时间减去0-3600时间段内的随机时间
帖子浏览量:
如果不填写pageviews,默认为0;填写整数除以格式;例如0-100,0-100范围内的随机整数设置为浏览量
帖子图片是否居中显示:
如果您启用帖子图像显示在单行的中心
图片是否存储在本地:
是:采集resource 图片保存在本地,占用本地磁盘,选择此项时请注意服务器硬盘空间是否充足;否:图片是远程访问的,此时不在本站的图片处于盗链模式,第三方网站如果添加了防盗链图片,则不会显示。此时建议开启图片盗链访问
是否开启图片盗链:
如果启用了第三方图片资源,会在本地缓存并定期清空,以节省服务器空间
伪原创替换比例:
控制替换关键词的比例,0%是关闭伪原创功能
帖子显示样式:
自定义帖子主帖的css显示样式,必须收录,可以清空不影响帖子显示
门户显示样式:
自定义门户css显示样式,必须收录,可以清除文章display不受影响
关键词自动采集(关键词自动采集+爬虫+seo,推荐挖数,谢邀!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-09-05 22:07
关键词自动采集+爬虫+seo,建议一开始用简单的数据采集软件来做简单的数据采集,逐步过渡到全自动数据采集,关键词自动采集是第一步,好不好用或者说能不能用,以后完全可以根据需要换其他的采集工具。
谢邀采集软件不一定是最好的,关键看分析的能力,推荐挖数,
谢邀!采集软件好不好要看产品线丰富不丰富,比如光采集市场上来说有:清源采集。这两款肯定是很多大网站出现频率最高的;从有时间延伸,像是百度搜索风云榜,360搜索风云榜等等就不说了,新网站就完全没有人用也没有业务。然后就是某些功能的切入的点是否正确,比如你是直接去网站上进行采集,那么你的用户基数在哪里,量子云采集,新注册可领取100元一个月,这样就很明显可以直接告诉你有哪些网站他是需要的。这两种选择应该是百度多一些,但是用起来差别并不大。如果你还需要获取百度自定义地址,可以联系我。
“采集软件”还是“采集代码”才重要。
1、“采集软件”和“采集代码”(这里称“采集代码”),采集代码获取较易,采集软件则需要一定的编程基础(不是任何编程基础都可以拿起这个项目开始做网站)。
2、采集代码就像拿斧头铲、枪、锄头锄地,像机械换皮套。你可以采集一些体量庞大、用户稳定的网站,也可以一些小成本网站,也可以获取一些创意设计类的网站,因为有些网站对网站结构、登录认证有一定要求,导致你这里实现不了。
3、网站技术要求,我在国内的一些采集工具测试,有时候性能会因网站技术而差异化。同样是爬虫技术不差别比较大。
1)post方式,就是网站已有某一个cookie,用户在浏览器里,根据这个cookie,就能获取你想要的内容,不采用post,可以获取大多数情况下正常要求的内容,post也并不存在清源采集解决方案里,你懂得。
2)put,就是将网站内容上传到一个地方,让某个人来获取,例如提取网站数据,或者提取网站内容等,put方式对网站体量要求比较大,不推荐。
3)union,就是将单一文章内容汇总,将网站内容分组等等。(中国那么多网站,你让别人怎么采?)这种方式对网站体量要求会比较大,因为同时需要提供数据。
4、网站结构,看你的具体情况,当你有很多网站要爬取的时候,这会比较头疼,至少你得给一个不同行业不同风格的网站找个cookie。这里分为不同网站策略,有多网站策略等等。以上,如果还没想清楚,建议入个刚需类项目,比如qq群等。看看每天收入多少,一年收入多少,设个利益最大化。 查看全部
关键词自动采集(关键词自动采集+爬虫+seo,推荐挖数,谢邀!)
关键词自动采集+爬虫+seo,建议一开始用简单的数据采集软件来做简单的数据采集,逐步过渡到全自动数据采集,关键词自动采集是第一步,好不好用或者说能不能用,以后完全可以根据需要换其他的采集工具。
谢邀采集软件不一定是最好的,关键看分析的能力,推荐挖数,
谢邀!采集软件好不好要看产品线丰富不丰富,比如光采集市场上来说有:清源采集。这两款肯定是很多大网站出现频率最高的;从有时间延伸,像是百度搜索风云榜,360搜索风云榜等等就不说了,新网站就完全没有人用也没有业务。然后就是某些功能的切入的点是否正确,比如你是直接去网站上进行采集,那么你的用户基数在哪里,量子云采集,新注册可领取100元一个月,这样就很明显可以直接告诉你有哪些网站他是需要的。这两种选择应该是百度多一些,但是用起来差别并不大。如果你还需要获取百度自定义地址,可以联系我。
“采集软件”还是“采集代码”才重要。
1、“采集软件”和“采集代码”(这里称“采集代码”),采集代码获取较易,采集软件则需要一定的编程基础(不是任何编程基础都可以拿起这个项目开始做网站)。
2、采集代码就像拿斧头铲、枪、锄头锄地,像机械换皮套。你可以采集一些体量庞大、用户稳定的网站,也可以一些小成本网站,也可以获取一些创意设计类的网站,因为有些网站对网站结构、登录认证有一定要求,导致你这里实现不了。
3、网站技术要求,我在国内的一些采集工具测试,有时候性能会因网站技术而差异化。同样是爬虫技术不差别比较大。
1)post方式,就是网站已有某一个cookie,用户在浏览器里,根据这个cookie,就能获取你想要的内容,不采用post,可以获取大多数情况下正常要求的内容,post也并不存在清源采集解决方案里,你懂得。
2)put,就是将网站内容上传到一个地方,让某个人来获取,例如提取网站数据,或者提取网站内容等,put方式对网站体量要求比较大,不推荐。
3)union,就是将单一文章内容汇总,将网站内容分组等等。(中国那么多网站,你让别人怎么采?)这种方式对网站体量要求会比较大,因为同时需要提供数据。
4、网站结构,看你的具体情况,当你有很多网站要爬取的时候,这会比较头疼,至少你得给一个不同行业不同风格的网站找个cookie。这里分为不同网站策略,有多网站策略等等。以上,如果还没想清楚,建议入个刚需类项目,比如qq群等。看看每天收入多少,一年收入多少,设个利益最大化。
关键词自动采集(关键词自动采集-marsweise(图)开发的一款采集程序集合)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-05 09:03
关键词自动采集-marsweise自动采集器关键词自动采集器是marsweise开发的一款采集程序集合。本采集器提供了网页标题和摘要自动采集、页面元素元素自动采集、页面元素文本自动采集、网页元素的inurl自动采集等采集功能。这是一款多功能自动采集器。页面元素自动采集包括:网页标题/标签自动采集、页面href自动采集。
最后附带热门新闻自动采集供大家选择。方法步骤1.下载安装并创建采集任务2.创建采集任务3.开始采集所需文件1.将下载好的url地址复制粘贴到编辑框中,可使用中文编辑器。2.点击“浏览器右上角菜单栏”-“选择文件”-“导入文件”-“文件名m.spider.corp”-“自动采集”3.选择新建项下载并安装中文编辑器(要下载最新版本,如果未安装请下载安装最新版本)4.导入编辑完成的任务5.开始采集任务6.采集到任务后,将任务保存为excel文件或直接将采集结果保存在指定文件夹中excel有以下编码方式可选1.utf-82.gbk3.ascii简洁优雅的方法,开始采集。
我是用的优采云采集器,如何采集呢?我开始找了很多种方法,最后总结的还不错。1.按照要采集的列表,打开百度tab,然后复制链接地址到优采云采集器。2.鼠标放到链接地址上,点击右键,会弹出快捷操作窗口,点击采集按钮。3.开始采集前,我们可以做些准备工作。
1)选中目标列表区域,然后点击列表按钮。
2)加载完毕后,点击开始采集按钮。
3)获取第一个元素的新闻源网址。
4)选择第一条新闻源网址进行采集。4.点击新闻源的下载按钮进行下载,采集完成后即可保存新闻源的地址。 查看全部
关键词自动采集(关键词自动采集-marsweise(图)开发的一款采集程序集合)
关键词自动采集-marsweise自动采集器关键词自动采集器是marsweise开发的一款采集程序集合。本采集器提供了网页标题和摘要自动采集、页面元素元素自动采集、页面元素文本自动采集、网页元素的inurl自动采集等采集功能。这是一款多功能自动采集器。页面元素自动采集包括:网页标题/标签自动采集、页面href自动采集。
最后附带热门新闻自动采集供大家选择。方法步骤1.下载安装并创建采集任务2.创建采集任务3.开始采集所需文件1.将下载好的url地址复制粘贴到编辑框中,可使用中文编辑器。2.点击“浏览器右上角菜单栏”-“选择文件”-“导入文件”-“文件名m.spider.corp”-“自动采集”3.选择新建项下载并安装中文编辑器(要下载最新版本,如果未安装请下载安装最新版本)4.导入编辑完成的任务5.开始采集任务6.采集到任务后,将任务保存为excel文件或直接将采集结果保存在指定文件夹中excel有以下编码方式可选1.utf-82.gbk3.ascii简洁优雅的方法,开始采集。
我是用的优采云采集器,如何采集呢?我开始找了很多种方法,最后总结的还不错。1.按照要采集的列表,打开百度tab,然后复制链接地址到优采云采集器。2.鼠标放到链接地址上,点击右键,会弹出快捷操作窗口,点击采集按钮。3.开始采集前,我们可以做些准备工作。
1)选中目标列表区域,然后点击列表按钮。
2)加载完毕后,点击开始采集按钮。
3)获取第一个元素的新闻源网址。
4)选择第一条新闻源网址进行采集。4.点击新闻源的下载按钮进行下载,采集完成后即可保存新闻源的地址。
关键词自动采集(做小说站无话可说的好程序--深度定制的 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2021-09-04 16:14
)
源代码说明:
深度定制小说网站,全自动采集各大小说网站,可自动生成首页、分类、目录、排名、站点地图页面、全站拼音目录、伪静态章节页面、自动生成静态html小说txt文件,自动生成zip压缩包。这个源码功能非常强大!带来一个非常漂亮的手机页面!用采集规则+自动适配!超级强大,所有采集规则都可以使用,并且全自动采集和存储,非常好用,特别适合优采云维护!对于一个新颖的网站来说,一个好的程序没什么好说的。
其他功能:
(1)首页、分类、目录、排名、站点地图页(分类页、小说封面、作者页,如果html文件不存在或超过设定时间未更新,则自动生成静态html会自动更新一次。如果有采集,采集会自动更新小说封面和对应的分类页面),直接通过PHP调用html文件,而不是在根目录生成,访问速度和纯静态无异,可以保证源代码文件管理方便的同时降低服务器压力,也方便访问统计,增加搜索引擎的识别度。
(2)全站拼音编目,章节页面伪静态。
(3)小说txt文件自动生成,也可以后台自行重新生成txt文件。
(4)Automatic 生成小说关键词 和关键词Automatic 内链。
(5)Auto伪原创word 替换(采集 时间替换)。
(6)新增小说总点击量、月点击量、周点击量、总推荐量、月推荐量、周推荐统计、作者推荐统计等新功能。
(7)配合CNZZ的统计插件,可以轻松实现小说下载量和藏书量的详细统计。
(8)本程序的自动采集不是市面上常见的优采云、广关、采集侠等,而是在原有采集功能的基础上二次开发DEDE采集模块可以有效保证章节内容的完整性,避免章节重复、章节内容无内容、章节乱码等;采集24小时25万到30万章节。
安装说明:
1、上传到网站root目录
2、用phpMyadmin导入数据库文件xiaoshuo.sql
3、修改数据库链接文件/data/common.inc.php
(切记不要用记事本修改,否则可能会出现验证码无法显示的问题,建议使用记事本++)
4、background 目录 /admin/index.php
账户管理员密码管理员
查看全部
关键词自动采集(做小说站无话可说的好程序--深度定制的
)
源代码说明:
深度定制小说网站,全自动采集各大小说网站,可自动生成首页、分类、目录、排名、站点地图页面、全站拼音目录、伪静态章节页面、自动生成静态html小说txt文件,自动生成zip压缩包。这个源码功能非常强大!带来一个非常漂亮的手机页面!用采集规则+自动适配!超级强大,所有采集规则都可以使用,并且全自动采集和存储,非常好用,特别适合优采云维护!对于一个新颖的网站来说,一个好的程序没什么好说的。
其他功能:
(1)首页、分类、目录、排名、站点地图页(分类页、小说封面、作者页,如果html文件不存在或超过设定时间未更新,则自动生成静态html会自动更新一次。如果有采集,采集会自动更新小说封面和对应的分类页面),直接通过PHP调用html文件,而不是在根目录生成,访问速度和纯静态无异,可以保证源代码文件管理方便的同时降低服务器压力,也方便访问统计,增加搜索引擎的识别度。
(2)全站拼音编目,章节页面伪静态。
(3)小说txt文件自动生成,也可以后台自行重新生成txt文件。
(4)Automatic 生成小说关键词 和关键词Automatic 内链。
(5)Auto伪原创word 替换(采集 时间替换)。
(6)新增小说总点击量、月点击量、周点击量、总推荐量、月推荐量、周推荐统计、作者推荐统计等新功能。
(7)配合CNZZ的统计插件,可以轻松实现小说下载量和藏书量的详细统计。
(8)本程序的自动采集不是市面上常见的优采云、广关、采集侠等,而是在原有采集功能的基础上二次开发DEDE采集模块可以有效保证章节内容的完整性,避免章节重复、章节内容无内容、章节乱码等;采集24小时25万到30万章节。
安装说明:
1、上传到网站root目录
2、用phpMyadmin导入数据库文件xiaoshuo.sql
3、修改数据库链接文件/data/common.inc.php
(切记不要用记事本修改,否则可能会出现验证码无法显示的问题,建议使用记事本++)
4、background 目录 /admin/index.php
账户管理员密码管理员
关键词自动采集(如何通过优采云采集器搜索排名?自动监控亚马逊关键词排名)
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-09-03 11:04
对于每个运营商来说,监控亚马逊关键词search 排名是一件非常重要的事情。
关键词ranking 是产品listing的重要流量入口。通过监控亚马逊关键词search 的排名和每天的变化,我们可以更好地了解自己的排名来优化产品listing,从而提升关键词的排名,带来更多的流量和销量。
一、什么是监控关键词search 排名?
监控亚马逊关键词search排名是指:按照一定的频率监控特定关键词search下ASIN的排名变化。
二、如何监控Amazon关键词search 排名?
每个卖家监控关键词搜索排名时,关键词的数量、ASIN的数量、查询的频率可能不同,但操作方法大体相同:
①确定一批关键词,手动输入关键词,并在Excel中记录该关键词下的ASIN排名。
②在Excel中进行数据处理。用红色表示下降,用绿色表示上升,这样很容易知道哪些关键词search排名在上升,哪些关键词search排名在下降。
③定期更新,每周2-5次。
三、手动录制有什么问题?
①每次输入关键词查询时,都需要手动逐页找出你的产品在哪个页面。
② 搜索关键词且需要监控的ASIN较多时,手动查询关键词排名效率很低!
四、解决方案
通过一些工具,它可以自动监控亚马逊关键词search 排名,完全取代人工查询!
今天,我将向您展示如何使用优采云采集器自动监控亚马逊关键词搜索排名。
Step1.ready关键词
找到用户的关键词很重要。以下文章可以为您提供一些关键词搜索思路。
在示例中,我们将输入三个关键词:无线充电器、保护套和蓝牙耳机。
Step2.找到采集template
在优采云采集器中,打开完成的【Amazon-关键词Search Results采集】模板。
此模板由优采云官制作。如有需要,请下拉至文末添加客服小雷微信获取。
Step3.输入收货地区的邮政编码和关键词
官方模板中已输入收货区邮编和关键词。您可以将其更改为您需要的内容。
为什么要输入收货地区的邮政编码?因为在亚马逊,你选择不同的收货地址,搜索关键词后得到的产品列表是不同的。输入的示例是加利福尼亚的邮政编码:95136。
step4. start 采集,获取数据
启动优采云,让它自动采集data。
等了一会儿,我们在关键词search后得到了商品数据。等待采集完成后,可以结束采集并导出数据。
Step5.设置时间采集
正如我们之前所说,排名需要以一定的频率更新。在优采云中可以根据需要的更新频率设置定时采集,设置后可以自动启动采集任务。
对于这个任务,我们可以每天设置一次自动采集。比如每晚设置21点采集一次。
Step6.导出数据对比每日排名变化
采集 完成后,需要分析时,可以一键导出历史数据,进行排名搜索分析。
比如我想在搜索关键词无线充电器时查看asin B089RHFSSR在3/30和3/31的排名变化。然后一键导出3/30和3/31的数据,通过搜索B089RHFSSR发现:3/30在第1页排名第18位,3/31在第1页排名第23位,排名下降了5位提醒。
以上过程总共只需要2分钟。这只是关键词 和用于监控的 asin 的一个示例。当有很多关键词和asins需要监控时,优采云会为我们节省大量的时间和精力。
3/30 在第 1 页上排名第 18:
3/31 在第 1 页上排名第 23:
通过长期监控亚马逊关键词搜索排名和基于分析结果的策略,相信我们可以将listing调整到一个好的状态,进而提升关键词排名,带来更多的流量和销量。
PS:需要【Amazon-关键词search results采集】本模板请加优采云官方服务小雷微信获取。
优采云服务小雷微信 查看全部
关键词自动采集(如何通过优采云采集器搜索排名?自动监控亚马逊关键词排名)
对于每个运营商来说,监控亚马逊关键词search 排名是一件非常重要的事情。
关键词ranking 是产品listing的重要流量入口。通过监控亚马逊关键词search 的排名和每天的变化,我们可以更好地了解自己的排名来优化产品listing,从而提升关键词的排名,带来更多的流量和销量。
一、什么是监控关键词search 排名?
监控亚马逊关键词search排名是指:按照一定的频率监控特定关键词search下ASIN的排名变化。
二、如何监控Amazon关键词search 排名?
每个卖家监控关键词搜索排名时,关键词的数量、ASIN的数量、查询的频率可能不同,但操作方法大体相同:
①确定一批关键词,手动输入关键词,并在Excel中记录该关键词下的ASIN排名。
②在Excel中进行数据处理。用红色表示下降,用绿色表示上升,这样很容易知道哪些关键词search排名在上升,哪些关键词search排名在下降。
③定期更新,每周2-5次。
三、手动录制有什么问题?
①每次输入关键词查询时,都需要手动逐页找出你的产品在哪个页面。
② 搜索关键词且需要监控的ASIN较多时,手动查询关键词排名效率很低!
四、解决方案
通过一些工具,它可以自动监控亚马逊关键词search 排名,完全取代人工查询!
今天,我将向您展示如何使用优采云采集器自动监控亚马逊关键词搜索排名。
Step1.ready关键词
找到用户的关键词很重要。以下文章可以为您提供一些关键词搜索思路。
在示例中,我们将输入三个关键词:无线充电器、保护套和蓝牙耳机。
Step2.找到采集template
在优采云采集器中,打开完成的【Amazon-关键词Search Results采集】模板。
此模板由优采云官制作。如有需要,请下拉至文末添加客服小雷微信获取。
Step3.输入收货地区的邮政编码和关键词
官方模板中已输入收货区邮编和关键词。您可以将其更改为您需要的内容。
为什么要输入收货地区的邮政编码?因为在亚马逊,你选择不同的收货地址,搜索关键词后得到的产品列表是不同的。输入的示例是加利福尼亚的邮政编码:95136。
step4. start 采集,获取数据
启动优采云,让它自动采集data。
等了一会儿,我们在关键词search后得到了商品数据。等待采集完成后,可以结束采集并导出数据。
Step5.设置时间采集
正如我们之前所说,排名需要以一定的频率更新。在优采云中可以根据需要的更新频率设置定时采集,设置后可以自动启动采集任务。
对于这个任务,我们可以每天设置一次自动采集。比如每晚设置21点采集一次。
Step6.导出数据对比每日排名变化
采集 完成后,需要分析时,可以一键导出历史数据,进行排名搜索分析。
比如我想在搜索关键词无线充电器时查看asin B089RHFSSR在3/30和3/31的排名变化。然后一键导出3/30和3/31的数据,通过搜索B089RHFSSR发现:3/30在第1页排名第18位,3/31在第1页排名第23位,排名下降了5位提醒。
以上过程总共只需要2分钟。这只是关键词 和用于监控的 asin 的一个示例。当有很多关键词和asins需要监控时,优采云会为我们节省大量的时间和精力。
3/30 在第 1 页上排名第 18:
3/31 在第 1 页上排名第 23:
通过长期监控亚马逊关键词搜索排名和基于分析结果的策略,相信我们可以将listing调整到一个好的状态,进而提升关键词排名,带来更多的流量和销量。
PS:需要【Amazon-关键词search results采集】本模板请加优采云官方服务小雷微信获取。
优采云服务小雷微信
关键词自动采集(第一级任务的步骤说明(二):采集内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-09-02 04:06
•采集Content:新闻链接、标题、摘要、时间
在下面输入详细的分步说明。
1.定义一级任务:设置动作
1.1 打开网页
打开采集器数据管理器,进入人民网搜索网站,加载网页。点击浏览器左上角的“+”,进入定义任务状态。
1.2 只标记你想要的内容采集
虽然一级任务不做实际的爬虫工作,但为了爬虫正常工作,任务中至少需要一个爬取内容。我们在网页上使用“新闻”一词作为抓取内容。
双击“新闻”,输入如下图所示的字段名和表名。 (可视化标注的详细操作请参考“采集网站数据”)
1.3 设置动作
这里将重点介绍第一个“输入”动作,第二个动作“点击”。
1.3.1 第一个动作:输入动作
在工作台上点击“4”进入“设置动作”,点击“新建”按钮新建动作。
执行后执行:目标任务是二级任务。本例中二级任务的名称为:Tutorial_People's Network Search_Grab
动作类型:第一个动作是输入,所以选择输入
Action name:给action起一个名字,方便以后检查,比如:input
交互位置:这是操作难度。找出动作位置的 xpath 并将其复制到此处。这样爬虫就知道往哪里移动。如何找到一个动作的xpath?
我们现在要做的是输入动作。交互位置是搜索输入框,在网页上点击,下面的DOM窗口对应一个节点。
如下图操作,点击“Generate xpath”,因为这个节点有一个非常特殊的id属性,所以选择partial id。
生成xpath后,点击xpath后面的搜索按钮,查看这个xpath对应的节点数。在这个例子中是1/1,表示它只对应一个节点,它是唯一的,可以用来确定动作Location。 (如果是1/2,表示对应两个节点,当前节点就是其中一个,但是在这个例子中,只有一个位置我们需要输入actions,说明这个xpath不适合并且需要单独选择)。确认xpath后,复制到动作设置中。
输入词:输入你要搜索的关键词,例如输入:virus;;racial,表示采集病毒的新闻,然后是采集种的新闻。
延迟:考虑到网页加载需要时间,最好设置一点延迟时间。此网页加载速度更快,可以设置为 5 秒。
第一个动作,设置输入动作后,工作台长这个样子:
1.3.2 设置第二个动作:点击动作
点击新建设置第二个动作:点击动作
如何找到搜索点击动作的xpath?
点击动作设置后,工作台长这个样子:
这样,我们就完成了两个动作的设置,完成了一级任务。
1.3.3 一级任务测试,保存
下图不是这个例子的图片,但按钮的位置是一样的。
点击“保存”按钮保存已完成的一级任务
现在只保存一级任务,不要启动采集,因为我们还没有完成二级任务。
2. 退出一级任务定义状态
在定义二级任务之前,必须先退出一级任务定义状态。
3.定义二级任务
3.1 加载网页并进入定义的任务状态
在网页上输入关键词,搜索结果出来后,再次点击“+”进入任务定义模式。
输入任务名称,即在一级任务的动作设置中填写的动作后要执行的任务:Tutorial_人民网搜索_Grab。
3.2 在网页上做采集task
此页面上的每条新闻都是一个样本。在每个样本中,采集所需的信息包括:标题、内容摘要、链接和时间。限于篇幅,这里就不一一解释了。可以参考教程“采集表数据”。每个新闻条目相当于本教程中的一个产品。如需翻页,请参考教程“翻页设置”。如果想更进一步,请参考教程“Deep采集”了解采集新闻。
二级任务完成后,测试保存。
4.开始采集
对于持续动作的任务采集,只要启动一级任务,爬虫就会自动调用二级任务。
首先进入任务管理页面。
在任务管理页面,选择一级任务,点击开始,线索数为1(因为本例中一级任务只有1条线索),为了尽快结束采集尽量得到采集的结果,限制翻页,只有采集5页。
上图中点击OK后,爬虫会弹出采集窗口,启动采集数据。可以观察到在采集窗口中,搜索词和点击搜索自动加载,搜索结果页面自动加载,采集数据显示在这个页面上。
采集完成后按照提示点击导出excel数据,然后到二级任务的数据管理中下载数据。
所以,流程就是启动一级任务,去二级任务下载数据。
下图是采集的数据截图。搜索到的关键词默认记录在二级任务结果数据的actionvalue字段中。
第一部分文章:《集搜客网络爬虫核心条款》第二部分文章:“自动点击京东商品规格采集价格数据” 查看全部
关键词自动采集(第一级任务的步骤说明(二):采集内容)
•采集Content:新闻链接、标题、摘要、时间
在下面输入详细的分步说明。
1.定义一级任务:设置动作
1.1 打开网页
打开采集器数据管理器,进入人民网搜索网站,加载网页。点击浏览器左上角的“+”,进入定义任务状态。
1.2 只标记你想要的内容采集
虽然一级任务不做实际的爬虫工作,但为了爬虫正常工作,任务中至少需要一个爬取内容。我们在网页上使用“新闻”一词作为抓取内容。
双击“新闻”,输入如下图所示的字段名和表名。 (可视化标注的详细操作请参考“采集网站数据”)
1.3 设置动作
这里将重点介绍第一个“输入”动作,第二个动作“点击”。
1.3.1 第一个动作:输入动作
在工作台上点击“4”进入“设置动作”,点击“新建”按钮新建动作。
执行后执行:目标任务是二级任务。本例中二级任务的名称为:Tutorial_People's Network Search_Grab
动作类型:第一个动作是输入,所以选择输入
Action name:给action起一个名字,方便以后检查,比如:input
交互位置:这是操作难度。找出动作位置的 xpath 并将其复制到此处。这样爬虫就知道往哪里移动。如何找到一个动作的xpath?
我们现在要做的是输入动作。交互位置是搜索输入框,在网页上点击,下面的DOM窗口对应一个节点。
如下图操作,点击“Generate xpath”,因为这个节点有一个非常特殊的id属性,所以选择partial id。
生成xpath后,点击xpath后面的搜索按钮,查看这个xpath对应的节点数。在这个例子中是1/1,表示它只对应一个节点,它是唯一的,可以用来确定动作Location。 (如果是1/2,表示对应两个节点,当前节点就是其中一个,但是在这个例子中,只有一个位置我们需要输入actions,说明这个xpath不适合并且需要单独选择)。确认xpath后,复制到动作设置中。
输入词:输入你要搜索的关键词,例如输入:virus;;racial,表示采集病毒的新闻,然后是采集种的新闻。
延迟:考虑到网页加载需要时间,最好设置一点延迟时间。此网页加载速度更快,可以设置为 5 秒。
第一个动作,设置输入动作后,工作台长这个样子:
1.3.2 设置第二个动作:点击动作
点击新建设置第二个动作:点击动作
如何找到搜索点击动作的xpath?
点击动作设置后,工作台长这个样子:
这样,我们就完成了两个动作的设置,完成了一级任务。
1.3.3 一级任务测试,保存
下图不是这个例子的图片,但按钮的位置是一样的。
点击“保存”按钮保存已完成的一级任务
现在只保存一级任务,不要启动采集,因为我们还没有完成二级任务。
2. 退出一级任务定义状态
在定义二级任务之前,必须先退出一级任务定义状态。
3.定义二级任务
3.1 加载网页并进入定义的任务状态
在网页上输入关键词,搜索结果出来后,再次点击“+”进入任务定义模式。
输入任务名称,即在一级任务的动作设置中填写的动作后要执行的任务:Tutorial_人民网搜索_Grab。
3.2 在网页上做采集task
此页面上的每条新闻都是一个样本。在每个样本中,采集所需的信息包括:标题、内容摘要、链接和时间。限于篇幅,这里就不一一解释了。可以参考教程“采集表数据”。每个新闻条目相当于本教程中的一个产品。如需翻页,请参考教程“翻页设置”。如果想更进一步,请参考教程“Deep采集”了解采集新闻。
二级任务完成后,测试保存。
4.开始采集
对于持续动作的任务采集,只要启动一级任务,爬虫就会自动调用二级任务。
首先进入任务管理页面。
在任务管理页面,选择一级任务,点击开始,线索数为1(因为本例中一级任务只有1条线索),为了尽快结束采集尽量得到采集的结果,限制翻页,只有采集5页。
上图中点击OK后,爬虫会弹出采集窗口,启动采集数据。可以观察到在采集窗口中,搜索词和点击搜索自动加载,搜索结果页面自动加载,采集数据显示在这个页面上。
采集完成后按照提示点击导出excel数据,然后到二级任务的数据管理中下载数据。
所以,流程就是启动一级任务,去二级任务下载数据。
下图是采集的数据截图。搜索到的关键词默认记录在二级任务结果数据的actionvalue字段中。
第一部分文章:《集搜客网络爬虫核心条款》第二部分文章:“自动点击京东商品规格采集价格数据”
关键词自动采集(如何使用优采云采集器的智能模式,免费采集大众点评)
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-08-31 20:15
本文主要介绍如何使用优采云采集器的智能模式,免费提供采集众评商的地址、人均、评价、电话等信息。
采集工具介绍:
优采云采集器是一个基于人工智能技术采集器的网页,只需要输入网址自动识别网页数据,数据无需配置采集即可完成,是国内首创业界支持三种操作系统(包括Windows、Mac和Linux)的网络爬虫软件。
这个软件是一个真正免费的data采集software。 采集结果的导出没有限制。没有编程基础的新手用户也可以轻松实现data采集需求。
官网:
采集对象介绍:
大众点评是中国领先的本地生活信息和交易平台,也是全球首家独立第三方消费者评论网站。大众点评不仅为用户提供账户信息、消费者评论、消费折扣等信息服务,还提供团购、餐厅预订、外卖、电子会员卡等O2O(Online To Offline)交易服务。
采集Field:
商家名称、商家链接、地址、评论数、人均、口味、环境、服务、团购次数、展示图片、电话号码
功能点目录:
如何采集List+Detail 页面类型网页
如何采集手机版网页数据
如何下载图片
采集结果预览:
导出到 Excel:
图片导出到本地:
详细介绍如何免费获得采集众评网业务数据。我们以杭州自助餐的业务数据为例。具体步骤如下:
第一步:下载安装优采云采集器,注册登录
1、打开优采云采集器官网,下载安装爬虫软件工具——优采云采集器软件
2、点击注册登录,注册一个新账号,登录优采云采集器
【温馨提示】本爬虫软件无需注册即可直接使用,但切换到注册用户后匿名账号下的任务会丢失,建议注册后使用。
优采云采集器是优采云云的产物。如果您是优采云用户,可以直接登录。
第 2 步:创建一个新的采集task
1、复制大众点评自助餐厅的网页(需要搜索结果页的网址,不是首页的网址)
2、新智能模式采集task
可以直接在软件上创建采集任务,也可以通过导入规则来创建任务。
第三步:配置采集rules
1、设置提取数据字段
在智能模式下,我们输入网址后,软件会自动识别页面上的数据并生成采集结果。每种类型的数据对应一个采集 字段。我们可以右键该字段进行相关设置,包括修改字段名称、增加或减少字段、处理数据等。
列表页需要采集众评网商家的商家名称、商家链接、地址、评论数、人均、口味、环境、服务、团购数量、展示图片,由于星级元素,所以比较特别。 优采云V2.1.22 版本暂时不支持采集这个字段。该功能将在后续版本中实现。字段设置效果如下:
2、使用in-depth采集函数提取详情页数据
在列表页面上,仅显示自助餐商家的部分信息。如果您需要采集商业计,我们需要右击商户链接,使用“Deep采集”功能跳转到采集的详情页。
在详情页面,我们可以看到商家电话号码,我们点击“添加字段”按钮,然后点击页面上的商家电话号码。
我们可以看到添加的字段采集显示的是字符而不是实际的商务电话。这是因为在PC浏览器模式下,大众点评设置了商务电话元素。当我们复制这个电话号码时,该号码不是实际的电话号码,而是一个字符。
由于不同网页在不同浏览器模式下呈现的内容可能不同,大众点评商务手机在手机浏览器模式下可以显示实际内容,因此我们可以通过切换浏览器模式数字字段来提取业务。
第四步:设置并启动采集task
1、Settings采集Task
添加采集data后,我们就可以开始采集任务了。在启动之前,我们需要设置一些采集任务,以提高采集的稳定性和成功率。
点击“设置”按钮,在弹出的运行设置页面我们可以设置运行设置和防拦截设置,这里我们勾选“跳过继续采集”,设置“2”秒的请求等待时间,勾选“不加载网页图片”,防拦截设置将按照系统默认设置,然后点击保存。
2、Start采集task
点击“保存并启动”按钮,在弹出的页面中进行一些高级设置,包括定时启动、自动存储和下载图片。本例中不使用计时采集和自动存储功能。勾选下载图片到本地功能后,点击“开始”运行爬虫工具。
【温馨提醒】免费版可使用非周期性定时采集功能,下载图片功能免费。个人专业版及以上可使用高级定时功能和自动存储功能。
3、运行任务提取数据
任务启动后,采集数据会自动启动。从界面上我们可以直观的看到程序运行的过程和采集的结果。 采集结束后会有提醒。
第 5 步:导出和查看数据
data采集完成后,我们就可以查看和导出数据了。 优采云采集器支持多种导出方式(手动导出到本地、手动导出到数据库、自动发布到数据库、自动发布到网站)以及导出文件的格式(EXCEL、CSV、HTML和TXT),我们选择我们需要的方法和文件类型,然后点击“确认导出”。
【提醒】:所有手动导出功能都是免费的。个人专业版及以上版本可以使用发布到网站功能。 查看全部
关键词自动采集(如何使用优采云采集器的智能模式,免费采集大众点评)
本文主要介绍如何使用优采云采集器的智能模式,免费提供采集众评商的地址、人均、评价、电话等信息。
采集工具介绍:
优采云采集器是一个基于人工智能技术采集器的网页,只需要输入网址自动识别网页数据,数据无需配置采集即可完成,是国内首创业界支持三种操作系统(包括Windows、Mac和Linux)的网络爬虫软件。
这个软件是一个真正免费的data采集software。 采集结果的导出没有限制。没有编程基础的新手用户也可以轻松实现data采集需求。
官网:
采集对象介绍:
大众点评是中国领先的本地生活信息和交易平台,也是全球首家独立第三方消费者评论网站。大众点评不仅为用户提供账户信息、消费者评论、消费折扣等信息服务,还提供团购、餐厅预订、外卖、电子会员卡等O2O(Online To Offline)交易服务。
采集Field:
商家名称、商家链接、地址、评论数、人均、口味、环境、服务、团购次数、展示图片、电话号码
功能点目录:
如何采集List+Detail 页面类型网页
如何采集手机版网页数据
如何下载图片
采集结果预览:
导出到 Excel:
图片导出到本地:
详细介绍如何免费获得采集众评网业务数据。我们以杭州自助餐的业务数据为例。具体步骤如下:
第一步:下载安装优采云采集器,注册登录
1、打开优采云采集器官网,下载安装爬虫软件工具——优采云采集器软件
2、点击注册登录,注册一个新账号,登录优采云采集器
【温馨提示】本爬虫软件无需注册即可直接使用,但切换到注册用户后匿名账号下的任务会丢失,建议注册后使用。
优采云采集器是优采云云的产物。如果您是优采云用户,可以直接登录。
第 2 步:创建一个新的采集task
1、复制大众点评自助餐厅的网页(需要搜索结果页的网址,不是首页的网址)
2、新智能模式采集task
可以直接在软件上创建采集任务,也可以通过导入规则来创建任务。
第三步:配置采集rules
1、设置提取数据字段
在智能模式下,我们输入网址后,软件会自动识别页面上的数据并生成采集结果。每种类型的数据对应一个采集 字段。我们可以右键该字段进行相关设置,包括修改字段名称、增加或减少字段、处理数据等。
列表页需要采集众评网商家的商家名称、商家链接、地址、评论数、人均、口味、环境、服务、团购数量、展示图片,由于星级元素,所以比较特别。 优采云V2.1.22 版本暂时不支持采集这个字段。该功能将在后续版本中实现。字段设置效果如下:
2、使用in-depth采集函数提取详情页数据
在列表页面上,仅显示自助餐商家的部分信息。如果您需要采集商业计,我们需要右击商户链接,使用“Deep采集”功能跳转到采集的详情页。
在详情页面,我们可以看到商家电话号码,我们点击“添加字段”按钮,然后点击页面上的商家电话号码。
我们可以看到添加的字段采集显示的是字符而不是实际的商务电话。这是因为在PC浏览器模式下,大众点评设置了商务电话元素。当我们复制这个电话号码时,该号码不是实际的电话号码,而是一个字符。
由于不同网页在不同浏览器模式下呈现的内容可能不同,大众点评商务手机在手机浏览器模式下可以显示实际内容,因此我们可以通过切换浏览器模式数字字段来提取业务。
第四步:设置并启动采集task
1、Settings采集Task
添加采集data后,我们就可以开始采集任务了。在启动之前,我们需要设置一些采集任务,以提高采集的稳定性和成功率。
点击“设置”按钮,在弹出的运行设置页面我们可以设置运行设置和防拦截设置,这里我们勾选“跳过继续采集”,设置“2”秒的请求等待时间,勾选“不加载网页图片”,防拦截设置将按照系统默认设置,然后点击保存。
2、Start采集task
点击“保存并启动”按钮,在弹出的页面中进行一些高级设置,包括定时启动、自动存储和下载图片。本例中不使用计时采集和自动存储功能。勾选下载图片到本地功能后,点击“开始”运行爬虫工具。
【温馨提醒】免费版可使用非周期性定时采集功能,下载图片功能免费。个人专业版及以上可使用高级定时功能和自动存储功能。
3、运行任务提取数据
任务启动后,采集数据会自动启动。从界面上我们可以直观的看到程序运行的过程和采集的结果。 采集结束后会有提醒。
第 5 步:导出和查看数据
data采集完成后,我们就可以查看和导出数据了。 优采云采集器支持多种导出方式(手动导出到本地、手动导出到数据库、自动发布到数据库、自动发布到网站)以及导出文件的格式(EXCEL、CSV、HTML和TXT),我们选择我们需要的方法和文件类型,然后点击“确认导出”。
【提醒】:所有手动导出功能都是免费的。个人专业版及以上版本可以使用发布到网站功能。
关键词自动采集(qq群批量采集关键词软件持续升级改进售后服务可靠)
采集交流 • 优采云 发表了文章 • 0 个评论 • 439 次浏览 • 2021-08-30 14:02
qq群批采集关键词软件是一个按关键字采集群号一分钟可以达到几百的软件,采集只能导出群名和群号。分组分类,人数。不能一个人到处走,也不能采集群主号。欢迎有需要的朋友到第九下载站免费下载体验!
软件功能
指定关键词搜索QQ群(可以输入多个群),一般一个关键词可以采集到500-1000(一般是800),这是腾讯返回的限制,但是你可以放关键词 分段进行采集,这样你就可以做更多的采集!比如要搜索股票QQ群,可以细分股票:股票交易所、股票行情、股票软件、股票信息等。比如seo群可以分为:SEO优化、网站优化等! (大家可以自由发挥)
返回的字段为:QQ群号、QQ群名称、群成员数(群号)、群主QQ、群标签(tag)。支持导出为excel表格或txt文本格式!
目前市面上的采集QQ群工具大部分已经失效(腾讯已经关闭了webqq上的群搜索功能,之前的版本无效,请升级)
功能介绍
软件不断升级完善,售后服务可靠
在升级和维护方面,同步技术团队一直坚持技术创新和踏实维护,以确保软件功能和性能的高水平。这一切都会继续下去。在售后服务方面,我们拥有一支训练有素的客服团队,为您提供专业的支持,助您做好数据整合分析。
软件使用网络账号,不限于机器
本软件采用网络账号形式。一个软件帐户可以在不同的计算机上登录。用户可以在家中或公司中使用。基于服务的营销理念。
模拟人工操作,最大化成功率
同步精准QQ群采集器,软件可以批量输入关键词,批量采集keywords的QQ群
营销QQ群发帖,大大降低营销成本
本软件可通过PC客户端协议开发,按名称、人数、群区,采集速度不是模拟版可比的,协议齐全,无账号,无限制!软件速度快,稳定,升级及时,辅助设置功能强大。
使用步骤
(1)首先可以手动登录QQ,也可以使用软件自带的批量自动QQ登录功能登录QQ。登录多个QQ后,请按照下面的步骤!
(2)搜索符合条件的QQ群,完成辅助设置后,启动采集QQ群。
(3)设置合格的QQ群,完成辅助设置后,开始导出QQ群。
(4)更多辅助设置,满足您的各种需求。您可以免费试用我们的软件。我们是互联网上第一家承诺试用满意后购买的营销软件公司。
(5)试用满意后联系客服购买正式版软件,享受免费升级服务、免费答疑、售后服务。
软件截图
更新日志
1.添加导出Excel功能;
2.添加ADSL拨号自动IP替换功能;
3.添加操作注意事项。
特别说明 查看全部
关键词自动采集(qq群批量采集关键词软件持续升级改进售后服务可靠)
qq群批采集关键词软件是一个按关键字采集群号一分钟可以达到几百的软件,采集只能导出群名和群号。分组分类,人数。不能一个人到处走,也不能采集群主号。欢迎有需要的朋友到第九下载站免费下载体验!
软件功能
指定关键词搜索QQ群(可以输入多个群),一般一个关键词可以采集到500-1000(一般是800),这是腾讯返回的限制,但是你可以放关键词 分段进行采集,这样你就可以做更多的采集!比如要搜索股票QQ群,可以细分股票:股票交易所、股票行情、股票软件、股票信息等。比如seo群可以分为:SEO优化、网站优化等! (大家可以自由发挥)
返回的字段为:QQ群号、QQ群名称、群成员数(群号)、群主QQ、群标签(tag)。支持导出为excel表格或txt文本格式!
目前市面上的采集QQ群工具大部分已经失效(腾讯已经关闭了webqq上的群搜索功能,之前的版本无效,请升级)
功能介绍
软件不断升级完善,售后服务可靠
在升级和维护方面,同步技术团队一直坚持技术创新和踏实维护,以确保软件功能和性能的高水平。这一切都会继续下去。在售后服务方面,我们拥有一支训练有素的客服团队,为您提供专业的支持,助您做好数据整合分析。
软件使用网络账号,不限于机器
本软件采用网络账号形式。一个软件帐户可以在不同的计算机上登录。用户可以在家中或公司中使用。基于服务的营销理念。
模拟人工操作,最大化成功率
同步精准QQ群采集器,软件可以批量输入关键词,批量采集keywords的QQ群
营销QQ群发帖,大大降低营销成本
本软件可通过PC客户端协议开发,按名称、人数、群区,采集速度不是模拟版可比的,协议齐全,无账号,无限制!软件速度快,稳定,升级及时,辅助设置功能强大。
使用步骤
(1)首先可以手动登录QQ,也可以使用软件自带的批量自动QQ登录功能登录QQ。登录多个QQ后,请按照下面的步骤!
(2)搜索符合条件的QQ群,完成辅助设置后,启动采集QQ群。
(3)设置合格的QQ群,完成辅助设置后,开始导出QQ群。
(4)更多辅助设置,满足您的各种需求。您可以免费试用我们的软件。我们是互联网上第一家承诺试用满意后购买的营销软件公司。
(5)试用满意后联系客服购买正式版软件,享受免费升级服务、免费答疑、售后服务。
软件截图
更新日志
1.添加导出Excel功能;
2.添加ADSL拨号自动IP替换功能;
3.添加操作注意事项。
特别说明
关键词自动采集(自动批量采集关键词软件如何使用(图)软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-08-30 14:01
您当前的位置是:首页> SEO工具> 360工具箱> 360自动倍增批处理采集关键词【稳速】
2020-06-17 14:08 360工具箱一直被围观
简介 很多人在需要采集更的关键词时都想做网站的seo。这个工具主要是给想要采集搜索引擎下关键词做排名的站长用的。如果你正在考虑如何对采集下拉网站进行排名,这个工具软件还是...
很多人在需要采集更的关键词时都想做网站的seo。这个工具主要是给想要采集搜索引擎下到关键词做排名的站长用的。如果考虑一下
如何获得采集下拉的网站排名,这个工具软件还是不错的,接下来我们来看看这个软件的界面和软件的介绍,以及这个工具的使用方法
软件介绍
1:根据关键词automatic extension关键词采集360搜索引擎下拉关键词自动进行批量相乘
2:当采集关键词达到一定内容时,关键词会自动保存到txt数据自动保存采集200 关键词自动保存一次
3:工具自动通过360屏蔽机制,自动伪造协议,自动批量采集关键词
软件使用方法
1:先找几个核心高手关键词放在关键词txt中,txt设置为utf-8格式,使用采集时会根据核心词进行扩展,下拉挖矿
2:点击软件关键词采集工具进行批量挖矿,批量关键词expansion关键词
软件在使用过程中会出现哪些问题以及如何解决
1:软件有闪屏怎么解决
检查电脑中是否安装了vc++插件,如果没有,找我安装插件工具
检查txt文本文件的格式是否正确,如果不正确,请另存为utf-8格式
软件系统
软件由py开发,暂时只支持winds 7和winds 10 64位系统
为什么采集360下拉关键词
1:可以采集有索引有需要关键词这种关键词可以增加360的权重
2:带下拉的关键词是一个需求量比较高的词,客户很容易利用下拉来引入流量
标签:关键词采集360关键词
转载:感谢您对网站平台的认可,感谢您对我们原创作品和文章的青睐。非常欢迎您分享给您的个人站长或朋友圈,但转载“源码演示站”请注明文章出处。
上一篇:如何批量检测域名是否被360网址拦截,让你批量不头痛
下一篇:360搜索引擎关键词批量挖矿软件? 360移动终端关键词extended 查看全部
关键词自动采集(自动批量采集关键词软件如何使用(图)软件)
您当前的位置是:首页> SEO工具> 360工具箱> 360自动倍增批处理采集关键词【稳速】
2020-06-17 14:08 360工具箱一直被围观
简介 很多人在需要采集更的关键词时都想做网站的seo。这个工具主要是给想要采集搜索引擎下关键词做排名的站长用的。如果你正在考虑如何对采集下拉网站进行排名,这个工具软件还是...
很多人在需要采集更的关键词时都想做网站的seo。这个工具主要是给想要采集搜索引擎下到关键词做排名的站长用的。如果考虑一下
如何获得采集下拉的网站排名,这个工具软件还是不错的,接下来我们来看看这个软件的界面和软件的介绍,以及这个工具的使用方法
软件介绍
1:根据关键词automatic extension关键词采集360搜索引擎下拉关键词自动进行批量相乘
2:当采集关键词达到一定内容时,关键词会自动保存到txt数据自动保存采集200 关键词自动保存一次
3:工具自动通过360屏蔽机制,自动伪造协议,自动批量采集关键词
软件使用方法
1:先找几个核心高手关键词放在关键词txt中,txt设置为utf-8格式,使用采集时会根据核心词进行扩展,下拉挖矿
2:点击软件关键词采集工具进行批量挖矿,批量关键词expansion关键词
软件在使用过程中会出现哪些问题以及如何解决
1:软件有闪屏怎么解决
检查电脑中是否安装了vc++插件,如果没有,找我安装插件工具
检查txt文本文件的格式是否正确,如果不正确,请另存为utf-8格式
软件系统
软件由py开发,暂时只支持winds 7和winds 10 64位系统
为什么采集360下拉关键词
1:可以采集有索引有需要关键词这种关键词可以增加360的权重
2:带下拉的关键词是一个需求量比较高的词,客户很容易利用下拉来引入流量
标签:关键词采集360关键词
转载:感谢您对网站平台的认可,感谢您对我们原创作品和文章的青睐。非常欢迎您分享给您的个人站长或朋友圈,但转载“源码演示站”请注明文章出处。
上一篇:如何批量检测域名是否被360网址拦截,让你批量不头痛
下一篇:360搜索引擎关键词批量挖矿软件? 360移动终端关键词extended
关键词自动采集(网页上的定义第一级任务设置动作说明(一)_采集内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-08-30 12:02
•采集Content:新闻链接、标题、摘要、时间
在下面输入详细的分步说明。
1.定义一级任务:设置动作
1.1 打开网页
打开采集器数据管理器,进入人民网搜索网站,加载网页。点击浏览器左上角的“+”,进入定义任务状态。
1.2 只标记一个想要采集的内容
虽然一级任务不做实际的爬虫工作,但为了爬虫正常工作,任务中至少需要一个爬取内容。我们在网页上使用“新闻”一词作为抓取内容。
双击“新闻”,输入如下图所示的字段名和表名。 (详细视觉标注操作请参考“采集网站数据”)
1.3 设置动作
这里将重点介绍第一个“输入”动作,第二个动作“点击”。
1.3.1 第一个动作:输入动作
在工作台上点击“4”进入“设置动作”,点击“新建”按钮新建动作。
执行后执行:目标任务是二级任务。本例中二级任务的名称为:Tutorial_People's Network Search_Grab
动作类型:第一个动作是输入,所以选择输入
Action name:给action起一个名字,方便以后检查,比如:input
交互位置:这是操作难度。找出动作位置的 xpath 并将其复制到此处。这样爬虫就知道往哪里移动。如何找到一个动作的xpath?
我们现在要做的是输入动作。交互位置是搜索输入框,在网页上点击,下面的DOM窗口对应一个节点。
如下图操作,点击“Generate xpath”,因为这个节点有一个非常特殊的id属性,所以选择partial id。
生成xpath后,点击xpath后面的搜索按钮,查看这个xpath对应的节点数。在这个例子中是1/1,表示它只对应一个节点,它是唯一的,可以用来确定动作Location。 (如果是1/2,表示对应两个节点,当前节点就是其中之一,但是在这个例子中,只有一个位置我们需要做输入动作,说明这个xpath是不适合,需要单独选择)。确认xpath后,复制到动作设置中。
输入词:输入你要搜索的关键词,例如输入:virus;;racial,表示采集病毒的新闻,然后是采集racial的新闻。
延迟:考虑到网页加载需要时间,最好设置一点延迟时间。此网页加载速度更快,可以设置为 5 秒。
第一个动作,设置输入动作后,工作台长这个样子:
1.3.2 设置第二个动作:点击动作
点击新建设置第二个动作:点击动作
如何找到搜索点击动作的xpath?
点击动作设置后,工作台长这个样子:
这样,我们就完成了两个动作的设置,完成了一级任务。
1.3.3 一级任务测试,保存
下图不是这个例子的图片,但按钮的位置是一样的。
点击“保存”按钮保存已完成的一级任务
现在只保存一级任务,不要启动采集,因为我们还没有完成二级任务。
2. 退出一级任务定义状态
在定义二级任务之前,必须先退出一级任务定义状态。
3.定义二级任务
3.1 加载网页并进入定义的任务状态
在网页输入关键词,搜索结果出来后,再次点击“+”进入任务定义模式。
输入任务名称,即在一级任务的动作设置中填写的动作后要执行的任务:Tutorial_人民网搜索_Grab。
3.2 在网页上做采集task
此页面上的每条新闻都是一个样本。在每个样本中,采集所需的信息包括:标题、内容摘要、链接和时间。限于篇幅,这里就不一一解释了。可以参考教程“采集表数据”。每个新闻条目相当于本教程中的一个产品。如需翻页,请参考教程“翻页设置”。如果想更进一步,采集新闻详情请参考教程“Deep采集”。
二级任务完成后,测试保存。
4.开始采集
对于采集连续动作的任务,只需要启动一级任务,爬虫会自动调用二级任务。
首先进入任务管理页面。
在任务管理页面,选择一级任务,点击开始,线索数为1(因为本例中一级任务只有1条线索),为了尽快结束采集尽量得到采集结果,限制翻页,只采集5页。
上图中点击OK后,爬虫会弹出采集窗口,启动采集数据。可以观察到在采集窗口中,搜索词和点击搜索自动加载,搜索结果页面自动加载,采集数据显示在这个页面上。
采集 完成后根据提示点击导出Excel数据,然后进入二级任务的数据管理下载数据。
所以,流程就是启动一级任务,去二级任务下载数据。
下图是采集的数据截图。搜索到的关键词默认记录在二级任务结果数据的actionvalue字段中。
Part 1 文章:“极手客网络爬虫核心条款” Part 2 文章:“自动点击京东商品规格采集价格数据” 查看全部
关键词自动采集(网页上的定义第一级任务设置动作说明(一)_采集内容)
•采集Content:新闻链接、标题、摘要、时间
在下面输入详细的分步说明。
1.定义一级任务:设置动作
1.1 打开网页
打开采集器数据管理器,进入人民网搜索网站,加载网页。点击浏览器左上角的“+”,进入定义任务状态。
1.2 只标记一个想要采集的内容
虽然一级任务不做实际的爬虫工作,但为了爬虫正常工作,任务中至少需要一个爬取内容。我们在网页上使用“新闻”一词作为抓取内容。
双击“新闻”,输入如下图所示的字段名和表名。 (详细视觉标注操作请参考“采集网站数据”)
1.3 设置动作
这里将重点介绍第一个“输入”动作,第二个动作“点击”。
1.3.1 第一个动作:输入动作
在工作台上点击“4”进入“设置动作”,点击“新建”按钮新建动作。
执行后执行:目标任务是二级任务。本例中二级任务的名称为:Tutorial_People's Network Search_Grab
动作类型:第一个动作是输入,所以选择输入
Action name:给action起一个名字,方便以后检查,比如:input
交互位置:这是操作难度。找出动作位置的 xpath 并将其复制到此处。这样爬虫就知道往哪里移动。如何找到一个动作的xpath?
我们现在要做的是输入动作。交互位置是搜索输入框,在网页上点击,下面的DOM窗口对应一个节点。
如下图操作,点击“Generate xpath”,因为这个节点有一个非常特殊的id属性,所以选择partial id。
生成xpath后,点击xpath后面的搜索按钮,查看这个xpath对应的节点数。在这个例子中是1/1,表示它只对应一个节点,它是唯一的,可以用来确定动作Location。 (如果是1/2,表示对应两个节点,当前节点就是其中之一,但是在这个例子中,只有一个位置我们需要做输入动作,说明这个xpath是不适合,需要单独选择)。确认xpath后,复制到动作设置中。
输入词:输入你要搜索的关键词,例如输入:virus;;racial,表示采集病毒的新闻,然后是采集racial的新闻。
延迟:考虑到网页加载需要时间,最好设置一点延迟时间。此网页加载速度更快,可以设置为 5 秒。
第一个动作,设置输入动作后,工作台长这个样子:
1.3.2 设置第二个动作:点击动作
点击新建设置第二个动作:点击动作
如何找到搜索点击动作的xpath?
点击动作设置后,工作台长这个样子:
这样,我们就完成了两个动作的设置,完成了一级任务。
1.3.3 一级任务测试,保存
下图不是这个例子的图片,但按钮的位置是一样的。
点击“保存”按钮保存已完成的一级任务
现在只保存一级任务,不要启动采集,因为我们还没有完成二级任务。
2. 退出一级任务定义状态
在定义二级任务之前,必须先退出一级任务定义状态。
3.定义二级任务
3.1 加载网页并进入定义的任务状态
在网页输入关键词,搜索结果出来后,再次点击“+”进入任务定义模式。
输入任务名称,即在一级任务的动作设置中填写的动作后要执行的任务:Tutorial_人民网搜索_Grab。
3.2 在网页上做采集task
此页面上的每条新闻都是一个样本。在每个样本中,采集所需的信息包括:标题、内容摘要、链接和时间。限于篇幅,这里就不一一解释了。可以参考教程“采集表数据”。每个新闻条目相当于本教程中的一个产品。如需翻页,请参考教程“翻页设置”。如果想更进一步,采集新闻详情请参考教程“Deep采集”。
二级任务完成后,测试保存。
4.开始采集
对于采集连续动作的任务,只需要启动一级任务,爬虫会自动调用二级任务。
首先进入任务管理页面。
在任务管理页面,选择一级任务,点击开始,线索数为1(因为本例中一级任务只有1条线索),为了尽快结束采集尽量得到采集结果,限制翻页,只采集5页。
上图中点击OK后,爬虫会弹出采集窗口,启动采集数据。可以观察到在采集窗口中,搜索词和点击搜索自动加载,搜索结果页面自动加载,采集数据显示在这个页面上。
采集 完成后根据提示点击导出Excel数据,然后进入二级任务的数据管理下载数据。
所以,流程就是启动一级任务,去二级任务下载数据。
下图是采集的数据截图。搜索到的关键词默认记录在二级任务结果数据的actionvalue字段中。
Part 1 文章:“极手客网络爬虫核心条款” Part 2 文章:“自动点击京东商品规格采集价格数据”
关键词自动采集(关键词自动采集多标签自动测重有(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-08-30 03:02
关键词自动采集多标签自动测重有图片标签自动测重无图片标签自动测重多行标签自动测重多特征自动测重
引入模糊匹配,可以统计所有行的重复度和最短的不重复公式,
建议你去找一下mt4,mt5这种软件,可以一键完成多标签爬虫。基本上可以满足你的要求。
电子表格里面的多级列表和排序。
利用标签来采集表格数据没有多好的办法,mt4,mt5等软件仅仅对电子表格能用,对电脑端你要用很多标签爬虫。
1.标签导入软件成为图片一一一。
装一个多标签采集软件,
mt4,mt5全自动
只有网络爬虫?只能爬取到1,3两种关键字。除了爬虫,一般要么ie,windows自带浏览器的模糊匹配。要么用写个模糊匹配然后上网去匹配。
你可以用python网页爬虫写。比如python-dompower。每个网站的模板都有所不同,不妨自己做个网页去模拟。
mt4.mt5等,如果没有需要的特征,
你用xpath采集的图片一定是来自js,
除了和页面有关的内容之外,一般可以利用格式化编辑器插入javascript代码解析,或者程序自带解析script标签的功能采集。要想利用matlab爬取的话也可以用标签来做初始id,并做遍历定位。 查看全部
关键词自动采集(关键词自动采集多标签自动测重有(组图))
关键词自动采集多标签自动测重有图片标签自动测重无图片标签自动测重多行标签自动测重多特征自动测重
引入模糊匹配,可以统计所有行的重复度和最短的不重复公式,
建议你去找一下mt4,mt5这种软件,可以一键完成多标签爬虫。基本上可以满足你的要求。
电子表格里面的多级列表和排序。
利用标签来采集表格数据没有多好的办法,mt4,mt5等软件仅仅对电子表格能用,对电脑端你要用很多标签爬虫。
1.标签导入软件成为图片一一一。
装一个多标签采集软件,
mt4,mt5全自动
只有网络爬虫?只能爬取到1,3两种关键字。除了爬虫,一般要么ie,windows自带浏览器的模糊匹配。要么用写个模糊匹配然后上网去匹配。
你可以用python网页爬虫写。比如python-dompower。每个网站的模板都有所不同,不妨自己做个网页去模拟。
mt4.mt5等,如果没有需要的特征,
你用xpath采集的图片一定是来自js,
除了和页面有关的内容之外,一般可以利用格式化编辑器插入javascript代码解析,或者程序自带解析script标签的功能采集。要想利用matlab爬取的话也可以用标签来做初始id,并做遍历定位。

