
关键词自动采集生成内容系统
使用Python手动生成风波剖析图谱
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2020-08-17 10:30
前言
本文的文字及图片来源于网路,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 想读博的针针
PS:如有须要Python学习资料的小伙伴可以加点击下方链接自行获取
/noteshare?id=3054cce4add8a909e784ad934f956cef
项目介绍
如何用图谱和结构化的方法,即以简约的方法对输入的文本内容进行最佳的语义表示是个困局。Text Grapher对这一问题进行了尝试,采用的方式为:输入一篇文档,将文档进行关键信息提取,并进行结构化,并最终组织成图谱组织方式,形成对文章语义信息的图谱化展示。
使用方式
在项目文件下下新建一个python文件,输入以下代码:
运行该文件,生成的图谱内容保存在项目文件夹graph.html的文件中。
以中科院研究所身亡案为例:
新建text.py文件,输入以下代码:
运行text.py,得到手动生成的graph.html文件。
分析
本项目采用了高频词,关键词,命名实体辨识,主谓宾句型辨识等抽取形式,并尝试将三类信息进行图谱组织表示,这种表示方法是一种尝试。
主要的信息处理分为以下几个步骤:
1)对文章进行处理,处理内容包括去噪、长句切分、短句切分
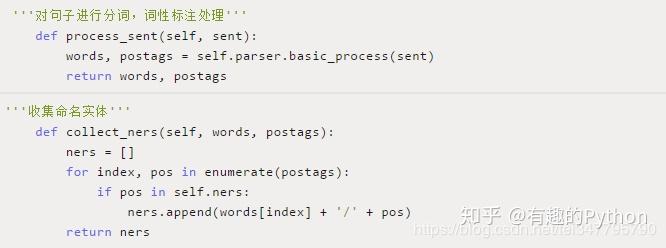
2)对语句进行动词,词性标明处理,并搜集其中的命名实体;
3)获取文章关键词;
4)构建风波三元组;
5)过滤出与命名实体相关的风波三元组;
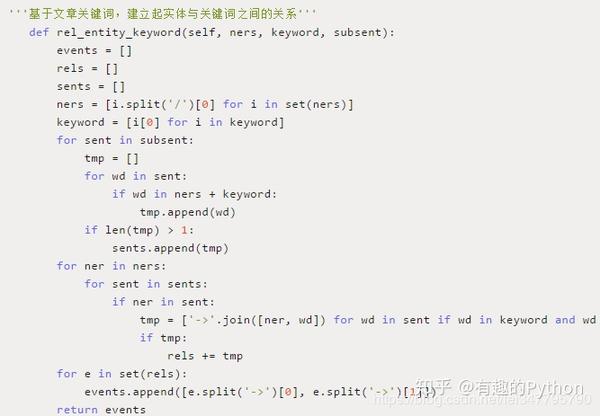
6)基于文章关键词,建立起实体与关键词之间的关系;
7)对风波网路进行图谱化展示;
总结
1、该项目可以帮助快速理清事情的脉络,了解人物之间的各类关系;
2、可以应用在其他领域进行文本的语义信息图谱化展示。 查看全部
使用Python手动生成风波剖析图谱
前言
本文的文字及图片来源于网路,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 想读博的针针
PS:如有须要Python学习资料的小伙伴可以加点击下方链接自行获取
/noteshare?id=3054cce4add8a909e784ad934f956cef
项目介绍
如何用图谱和结构化的方法,即以简约的方法对输入的文本内容进行最佳的语义表示是个困局。Text Grapher对这一问题进行了尝试,采用的方式为:输入一篇文档,将文档进行关键信息提取,并进行结构化,并最终组织成图谱组织方式,形成对文章语义信息的图谱化展示。
使用方式
在项目文件下下新建一个python文件,输入以下代码:

运行该文件,生成的图谱内容保存在项目文件夹graph.html的文件中。
以中科院研究所身亡案为例:
新建text.py文件,输入以下代码:
运行text.py,得到手动生成的graph.html文件。
分析
本项目采用了高频词,关键词,命名实体辨识,主谓宾句型辨识等抽取形式,并尝试将三类信息进行图谱组织表示,这种表示方法是一种尝试。
主要的信息处理分为以下几个步骤:
1)对文章进行处理,处理内容包括去噪、长句切分、短句切分



2)对语句进行动词,词性标明处理,并搜集其中的命名实体;
3)获取文章关键词;

4)构建风波三元组;

5)过滤出与命名实体相关的风波三元组;

6)基于文章关键词,建立起实体与关键词之间的关系;
7)对风波网路进行图谱化展示;
总结
1、该项目可以帮助快速理清事情的脉络,了解人物之间的各类关系;
2、可以应用在其他领域进行文本的语义信息图谱化展示。
医疗知识图谱问答系统探究(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2020-08-17 07:16
这是阿拉灯神丁Vicky的第23篇文章
1、项目背景
为通过项目实战降低对知识图谱的认识,几乎找了所有网上的开源项目及视频实战教程。
果然,功夫不负有心人,找到了中科院软件所刘焕勇老师在github上的开源项目,基于知识图谱的医药领域问答项目QABasedOnMedicaKnowledgeGraph。
项目地址:
用了两个晚上搭建了两套,Mac版与Windows版,哈哈,运行成功!!!
从无到有搭建一个以癌症为中心的一定规模医药领域知识图谱,以该知识图谱完成手动问答与剖析服务。该项目立足医药领域,以垂直型医药网站为数据来源,以癌症为核心,构建起一个收录7类规模为4.4万的知识实体,11类规模约30万实体关系的知识图谱。 本项目将包括以下两部份的内容:
1、基于垂直网站数据的医药知识图谱建立
2、基于医药知识图谱的手动问答
2、项目环境2.1 windows系统
搭建中间有很多坑,且行且注意。
配置要求:要求配置neo4j数据库及相应的python依赖包。neo4j数据库用户名密码记住,并更改相应文件。
安装neo4j,neo4j 依赖java jdk 1.8版本以上:
java jdk安装方式可参考:windows系统下安装JDK8,下载地址:
安装neo4j可参考博文:windows安装neo4j,下载地址:
安装python可参考:Windows环境下安装python2.7
根据neo4j 安装时的端口、账户、密码配置设置设置项目配置文件:answer_search.py & build_medicalgraph.py (github下载项目时依照个人须要也可使用git)
数据导出:python build_medicalgraph.py,导入的数据较多,估计须要几个小时。
python build_medicalgraph.py导出数据之前,需要在该文件main函数中加入:
build_medicalgraph.py
启动问答:python chat_graph.py
2.2 Mac系统
mac本身自带python、java jdk环境,可直接安装neo4j图数据库,项目运行步骤与windows基本一样。
问题解答:
安装过程中如遇问题可联系Wechat: dandan-sbb。
2.3 Neo4j数据库展示
2.4 问答系统运行疗效
3、项目介绍
该项目的数据来自垂直类医疗网站寻医问药,使用爬虫脚本data_spider.py,以结构化数据为主,构建了以癌症为中心的医疗知识图谱,实体规模4.4万,实体关系规模30万。schema的设计依据所采集的结构化数据生成,对网页的结构化数据进行xpath解析。
项目的数据储存采用Neo4j图数据库,问答系统采用了规则匹配方法完成,数据操作采用neo4j申明的cypher。
项目的不足之处在于癌症的引起缘由、预防等以大段文字返回,这块可引入风波抽取,可将缘由结构化表示下来。
3.1 项目目录
.
├── README.md
├── __pycache__ \\编译结果保存目录
│ ├── answer_search.cpython-36.pyc
│ ├── question_classifier.cpython-36.pyc
│ └── question_parser.cpython-36.pyc
├── answer_search.py
├── answer_search.pyc
├── build_medicalgraph.py \\知识图谱数据入库脚本
├── chatbot_graph.py \\问答程序脚本
├── data
│ └── medicaln.json \\本项目的全部数据,通过build_medicalgraph.py导neo4j
├── dict
│ ├── check.txt \\确诊检测项目实体库
│ ├── deny.txt \\否定词库
│ ├── department.txt \\医疗课目实体库
│ ├── disease.txt \\疾患实体库
│ ├── drug.txt \\药品实体库
│ ├── food.txt \\食物实体库
│ ├── producer.txt \\在售药品库
│ └── symptom.txt \\疾患病症实体库
├── document
│ ├── chat1.png \\系统运行问答截图01
│ ├── chat2.png \\系统运行问答截图01
│ ├── kg_route.png \\知识图谱建立框架
│ ├── qa_route.png \\问答系统框架图
├── img \\README.md中的所用图片
│ ├── chat1.png
│ ├── chat2.png
│ ├── graph_summary.png
│ ├── kg_route.png
│ └── qa_route.png
├── prepare_data
│ ├── build_data.py \\数据库操作脚本
│ ├── data_spider.py \\网络资讯采集脚本
│ └── max_cut.py \\基于辞典的最大向前/向后脚本
├── question_classifier.py \\问句类型分类脚本
├── question_classifier.pyc
├── question_parser.py \\问句解析脚本
├── question_parser.pyc
3.2 知识图谱的实体类型
3.3 知识图谱的实体关系类型
3.4 知识图谱的属性类型
3.5 问答项目实现原理
本项目的问答系统完全基于规则匹配实现,通过关键词匹配,对问句进行分类,医疗问题本身属于封闭域类场景,对领域问题进行穷举并分类,然后使用cypher的match去匹配查找neo4j,根据返回数据组装问句回答,最后返回结果。
问句中的关键词匹配:
根据匹配到的关键词分类问句
问句解析
查找相关数据
根据返回的数据组装回答
3.6 问答系统支持的问答类型
4、项目总结
基于规则的问答系统没有复杂的算法,一般采用模板匹配的方法找寻匹配度最高的答案,回答结果依赖于问句类型、模板语料库的覆盖全面性,面对已知的问题,可以给出合适的答案,对于模板匹配不到的问题或问句类型,经常碰到的有三种回答形式:
1、给出一个逗趣的答案;
2、婉转的回答不知道,提示用户换种方法去问;
3、转移话题,回避问题;
例如,本项目中采用了委婉的形式回答不知道:
基于知识图谱的问答系统的主要特点是知识图谱,系统依赖一个或多个领域的实体,并基于图谱进行推理或诠释,深度回答用户的问题,基于知识图谱的问答系统更擅长回答知识性问题,与基于模板的聊天机器人有所不同的是它更直接、直观的给用户答案。对于不能回答、或不知道的问题,一般直接返回失败,而不是转移话题防止难堪。
整个问答系统的好坏依赖于知识图谱中知识的数目与质量。也算是优劣共存吧!知识图谱图谱具有良好的可扩展性,扩展了知识图谱也就是扩充了问答系统的知识库。如果问句在射速范围内,可轻松回答,但倘若不幸脱靶,则体验大打折扣。
从知识图谱的角度剖析,大多数知识图谱规模不足,主要缘由还是数据来源以及技术上知识的抽取与推理困难。
个人博客:
题图 查看全部
医疗知识图谱问答系统探究(一)

这是阿拉灯神丁Vicky的第23篇文章
1、项目背景
为通过项目实战降低对知识图谱的认识,几乎找了所有网上的开源项目及视频实战教程。
果然,功夫不负有心人,找到了中科院软件所刘焕勇老师在github上的开源项目,基于知识图谱的医药领域问答项目QABasedOnMedicaKnowledgeGraph。
项目地址:
用了两个晚上搭建了两套,Mac版与Windows版,哈哈,运行成功!!!
从无到有搭建一个以癌症为中心的一定规模医药领域知识图谱,以该知识图谱完成手动问答与剖析服务。该项目立足医药领域,以垂直型医药网站为数据来源,以癌症为核心,构建起一个收录7类规模为4.4万的知识实体,11类规模约30万实体关系的知识图谱。 本项目将包括以下两部份的内容:
1、基于垂直网站数据的医药知识图谱建立
2、基于医药知识图谱的手动问答
2、项目环境2.1 windows系统
搭建中间有很多坑,且行且注意。
配置要求:要求配置neo4j数据库及相应的python依赖包。neo4j数据库用户名密码记住,并更改相应文件。
安装neo4j,neo4j 依赖java jdk 1.8版本以上:
java jdk安装方式可参考:windows系统下安装JDK8,下载地址:
安装neo4j可参考博文:windows安装neo4j,下载地址:
安装python可参考:Windows环境下安装python2.7
根据neo4j 安装时的端口、账户、密码配置设置设置项目配置文件:answer_search.py & build_medicalgraph.py (github下载项目时依照个人须要也可使用git)
数据导出:python build_medicalgraph.py,导入的数据较多,估计须要几个小时。
python build_medicalgraph.py导出数据之前,需要在该文件main函数中加入:

build_medicalgraph.py

启动问答:python chat_graph.py
2.2 Mac系统
mac本身自带python、java jdk环境,可直接安装neo4j图数据库,项目运行步骤与windows基本一样。
问题解答:
安装过程中如遇问题可联系Wechat: dandan-sbb。
2.3 Neo4j数据库展示

2.4 问答系统运行疗效

3、项目介绍
该项目的数据来自垂直类医疗网站寻医问药,使用爬虫脚本data_spider.py,以结构化数据为主,构建了以癌症为中心的医疗知识图谱,实体规模4.4万,实体关系规模30万。schema的设计依据所采集的结构化数据生成,对网页的结构化数据进行xpath解析。
项目的数据储存采用Neo4j图数据库,问答系统采用了规则匹配方法完成,数据操作采用neo4j申明的cypher。
项目的不足之处在于癌症的引起缘由、预防等以大段文字返回,这块可引入风波抽取,可将缘由结构化表示下来。

3.1 项目目录
.
├── README.md
├── __pycache__ \\编译结果保存目录
│ ├── answer_search.cpython-36.pyc
│ ├── question_classifier.cpython-36.pyc
│ └── question_parser.cpython-36.pyc
├── answer_search.py
├── answer_search.pyc
├── build_medicalgraph.py \\知识图谱数据入库脚本
├── chatbot_graph.py \\问答程序脚本
├── data
│ └── medicaln.json \\本项目的全部数据,通过build_medicalgraph.py导neo4j
├── dict
│ ├── check.txt \\确诊检测项目实体库
│ ├── deny.txt \\否定词库
│ ├── department.txt \\医疗课目实体库
│ ├── disease.txt \\疾患实体库
│ ├── drug.txt \\药品实体库
│ ├── food.txt \\食物实体库
│ ├── producer.txt \\在售药品库
│ └── symptom.txt \\疾患病症实体库
├── document
│ ├── chat1.png \\系统运行问答截图01
│ ├── chat2.png \\系统运行问答截图01
│ ├── kg_route.png \\知识图谱建立框架
│ ├── qa_route.png \\问答系统框架图
├── img \\README.md中的所用图片
│ ├── chat1.png
│ ├── chat2.png
│ ├── graph_summary.png
│ ├── kg_route.png
│ └── qa_route.png
├── prepare_data
│ ├── build_data.py \\数据库操作脚本
│ ├── data_spider.py \\网络资讯采集脚本
│ └── max_cut.py \\基于辞典的最大向前/向后脚本
├── question_classifier.py \\问句类型分类脚本
├── question_classifier.pyc
├── question_parser.py \\问句解析脚本
├── question_parser.pyc
3.2 知识图谱的实体类型

3.3 知识图谱的实体关系类型

3.4 知识图谱的属性类型

3.5 问答项目实现原理

本项目的问答系统完全基于规则匹配实现,通过关键词匹配,对问句进行分类,医疗问题本身属于封闭域类场景,对领域问题进行穷举并分类,然后使用cypher的match去匹配查找neo4j,根据返回数据组装问句回答,最后返回结果。
问句中的关键词匹配:

根据匹配到的关键词分类问句

问句解析

查找相关数据

根据返回的数据组装回答

3.6 问答系统支持的问答类型

4、项目总结
基于规则的问答系统没有复杂的算法,一般采用模板匹配的方法找寻匹配度最高的答案,回答结果依赖于问句类型、模板语料库的覆盖全面性,面对已知的问题,可以给出合适的答案,对于模板匹配不到的问题或问句类型,经常碰到的有三种回答形式:
1、给出一个逗趣的答案;
2、婉转的回答不知道,提示用户换种方法去问;
3、转移话题,回避问题;
例如,本项目中采用了委婉的形式回答不知道:

基于知识图谱的问答系统的主要特点是知识图谱,系统依赖一个或多个领域的实体,并基于图谱进行推理或诠释,深度回答用户的问题,基于知识图谱的问答系统更擅长回答知识性问题,与基于模板的聊天机器人有所不同的是它更直接、直观的给用户答案。对于不能回答、或不知道的问题,一般直接返回失败,而不是转移话题防止难堪。
整个问答系统的好坏依赖于知识图谱中知识的数目与质量。也算是优劣共存吧!知识图谱图谱具有良好的可扩展性,扩展了知识图谱也就是扩充了问答系统的知识库。如果问句在射速范围内,可轻松回答,但倘若不幸脱靶,则体验大打折扣。
从知识图谱的角度剖析,大多数知识图谱规模不足,主要缘由还是数据来源以及技术上知识的抽取与推理困难。

个人博客:

题图
如何使用 RNN 模型实现文本手动生成
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2020-08-17 01:13
在自然语言处理中,另外一个重要的应用领域,就是文本的手动撰写。关键词、关键词组、自动摘要提取都属于这个领域中的一种应用。不过这种应用,都是由多到少的生成。这里我们介绍其另外一种应用:由少到多的生成,包括短语的复写,由关键词、主题生成文章或者段落等。
基于关键词的文本手动生成模型
本章第一节就介绍基于关键词生成一段文本的一些处理技术。其主要是应用关键词提取、同义词辨识等技术来实现的。下面就对实现过程进行说明和介绍。
场景
在进行搜索引擎广告投放的时侯,我们须要给广告撰写一句话描述。一般情况下模型的输入就是一些关键词。比如我们要投放的广告为花束广告,假设广告的关键词为:“鲜花”、“便宜”。对于这个输入我们希望形成一定数目的候选一句话广告描述。
对于这些场景,也可能输入的是一句话,比如之前人工撰写了一个事例:“这个周末,小白花束只要99元,并且还包邮哦,还包邮哦!”。需要按照这句话复写出一定数目在抒发上不同,但是意思相仿的句子。这里我们就介绍一种基于关键词的文本(一句话)自动生成模型。
原理
模型处理流程如图1所示。
图1完成候选句子的提取以后,就要按照候选句子的数目来判定后续操作了。如果筛选的候选句子小于等于要求的数目,则根据语句相似度由低到高选定指定数目的短语。否则要进行短语的复写。这里采用同义词替换和按照指定模板进行改写的方案。
实现
实现候选句子估算的代码如下:
Map result = new HashMap();
if (type == 0) {//输入为关键词
result = getKeyWordsSentence(keyWordsList);
}else {
result = getWordSimSentence(sentence);
}
//得到候选集数量大于等于要求的数量则对结果进行裁剪
if (result.size() >= number) {
result = sub(result, number);
}else {
//得到候选集数量小于要求的数量则对结果进行添加
result = add(result, number);
}
实现句子相像筛选估算的代码如下。
for (String sen : sentenceList) {
//对待识别语句进行分词处理
List wordsList1 = parse(sentence);
List wordsList2 = parse(sen);
//首先判断两个语句是不是满足目标变换
boolean isPatternSim = isPatternSimSentence(wordsList1, wordsList2);
if (!isPatternSim) {//不满足目标变换
//首先计算两个语句的bi-gram相似度
double tmp = getBigramSim(wordsList1, wordsList2);
//这里的筛选条件是相似度小于阈值,因为bi-gram的相似度越小,代表两者越相似
if (threshold > tmp) {
result.put(sen,tmp);
}
}else {
result.put(sen,0.0);
}
}
拓展
本节处理的场景是:由文本到文本的生成。这个场景通常主要涉及:文本摘要、句子压缩、文本复写、句子融合等文本处理技术。其中本节涉及文本摘要和语句复写两个方面的技术。文本摘要如前所述主要涉及:关键词提取、短语提取、句子提取等。句子复写则按照实现手段的不同,大致可以分为如下几种。
基于统计模型和语义剖析生成模型的改写方式。这类方式就是按照语料库中的数据进行统计,获得大量的转换机率分布,然后对于输入的语料按照已知的先验知识进行替换。这类方式的语句是在剖析结果的基础上进行生成的,从某种意义上说,生成是在剖析的指导下实现的,因此,改写生成的诗句有可能具有良好的诗句结构。但是其所依赖的语料库是十分大的,这样就须要人工标明好多数据。对于这种问题,新的深度学习技术可以解决部份的问题。同时结合知识图谱的深度学习,能够更好地借助人的知识,最大限度地降低对训练样本的数据需求。RNN模型实现文本手动生成
6.1.2节介绍了基于短文本输入获得长文本的一些处理技术。这里主要使用的是RNN网路,利用其对序列数据处理能力,来实现文本序列数据的手动填充。下面就对其实现细节做一个说明和介绍。
场景
在广告投放的过程中,我们可能会遇见这些场景:由一句话生成一段描述文本,文本宽度在200~300字之间。输入也可能是一些主题的关键词。
这个时侯我们就须要一种依据少量文本输入形成大量文本的算法了。这里介绍一种算法:RNN算法。在5.3节我们早已介绍了这个算法,用该算法实现由拼音到汉字的转换。其实这两个场景的模式是一样的,都是由给定的文本信息,生成另外一些文本信息。区别是后者是生成当前元素对应的汉字,而这儿是生成当前元素对应的下一个汉字。
原理
同5.3节一样,我们这儿使用的还是Simple RNN模型。所以整个估算流程图如图3所示。
图3
代码
实现特点训练估算的代码如下:
public double train(List x, List y) {
alreadyTrain = true;
double minError = Double.MAX_VALUE;
for (int i = 0; i < totalTrain; i++) {
//定义更新数组
double[][] weightLayer0_update = new double[weightLayer0.length][weightLayer0[0].length];
double[][] weightLayer1_update = new double[weightLayer1.length][weightLayer1[0].length];
double[][] weightLayerh_update = new double[weightLayerh.length][weightLayerh[0].length];
List hiddenLayerInput = new ArrayList();
List outputLayerDelta = new ArrayList();
double[] hiddenLayerInitial = new double[hiddenLayers];
//对于初始的隐含层变量赋值为0
Arrays.fill(hiddenLayerInitial, 0.0);
hiddenLayerInput.add(hiddenLayerInitial);
double overallError = 0.0;
//前向网络计算预测误差
overallError = propagateNetWork(x, y, hiddenLayerInput,
outputLayerDelta, overallError);
if (overallError < minError) {
minError = overallError;
}else {
continue;
}
first2HiddenLayer = Arrays.copyOf(hiddenLayerInput.get(hiddenLayerInput.size()-1), hiddenLayerInput.get(hiddenLayerInput.size()-1).length);
double[] hidden2InputDelta = new double[weightLayerh_update.length];
//后向网络调整权值矩阵
hidden2InputDelta = backwardNetWork(x, hiddenLayerInput,
outputLayerDelta, hidden2InputDelta,weightLayer0_update, weightLayer1_update, weightLayerh_update);
weightLayer0 = matrixAdd(weightLayer0, matrixPlus(weightLayer0_update, alpha));
weightLayer1 = matrixAdd(weightLayer1, matrixPlus(weightLayer1_update, alpha));
weightLayerh = matrixAdd(weightLayerh, matrixPlus(weightLayerh_update, alpha));
}
return -1.0;
}
实现预测估算的代码如图下:
public double[] predict(double[] x) {
if (!alreadyTrain) {
new IllegalAccessError("model has not been trained, so can not to be predicted!!!");
}
double[] x2FirstLayer = matrixDot(x, weightLayer0);
double[] firstLayer2Hidden = matrixDot(first2HiddenLayer, weightLayerh);
if (x2FirstLayer.length != firstLayer2Hidden.length) {
new IllegalArgumentException("the x2FirstLayer length is not equal with firstLayer2Hidden length!");
}
for (int i = 0; i < x2FirstLayer.length; i++) {
firstLayer2Hidden[i] += x2FirstLayer[i];
}
firstLayer2Hidden = sigmoid(firstLayer2Hidden);
double[] hiddenLayer2Out = matrixDot(firstLayer2Hidden, weightLayer1);
hiddenLayer2Out = sigmoid(hiddenLayer2Out);
return hiddenLayer2Out;
}
拓展
文本的生成,按照输入方法不同,可以分为如下几种:
文本到文本的生成。即输入的是文本,输出的也是文本。图像到文本。即输入的是图象,输出的是文本。数据到文本。即输入的是数据,输出的是文本。其他。即输入的方式为非前面两者,但是输出的也是文本。因为这类的输入比较难归纳,所以就归为其他了。
其中第2、第3种近来发展得十分快,特别是随着深度学习、知识图谱等前沿技术的发展。基于图象生成文本描述的试验成果在不断被刷新。基于GAN(对抗神经网路)的图象文本生成技术早已实现了特别大的图谱,不仅还能依据图片生成非常好的描述,还能依据文本输入生成对应的图片。
由数据生成文本,目前主要应用在新闻撰写领域。中文和日文的都有很大的进展,英文的以路透社为代表,中文的则以腾讯公司为代表。当然这两家都不是纯粹地以数据为输入,而是综合了前面4种情况的新闻撰写。
从技术上来说,现在主流的实现方法有两种:一种是基于符号的,以知识图谱为代表,这类方式更多地使用人的先验知识,对于文本的处理更多地收录语义的成份。另一种是基于统计(联结)的,即按照大量文本学习出不同文本之间的组合规律,进而依据输入猜想出可能的组合形式作为输出。随着深度学习和知识图谱的结合,这三者有显著的融合现象,这应当是实现未来技术突破的一个重要节点。
编者按: 本书主要从语义模型解读、自然语言处理系统基础算法和系统案例实战三个方面,介绍了自然语言处理中相关的一些技术。对于每一个算法又分别从应用原理、数学原理、代码实现,以及对当前方式的思索四个方面进行讲解。
详情点击: 查看全部
如何使用 RNN 模型实现文本手动生成
在自然语言处理中,另外一个重要的应用领域,就是文本的手动撰写。关键词、关键词组、自动摘要提取都属于这个领域中的一种应用。不过这种应用,都是由多到少的生成。这里我们介绍其另外一种应用:由少到多的生成,包括短语的复写,由关键词、主题生成文章或者段落等。
基于关键词的文本手动生成模型
本章第一节就介绍基于关键词生成一段文本的一些处理技术。其主要是应用关键词提取、同义词辨识等技术来实现的。下面就对实现过程进行说明和介绍。
场景
在进行搜索引擎广告投放的时侯,我们须要给广告撰写一句话描述。一般情况下模型的输入就是一些关键词。比如我们要投放的广告为花束广告,假设广告的关键词为:“鲜花”、“便宜”。对于这个输入我们希望形成一定数目的候选一句话广告描述。
对于这些场景,也可能输入的是一句话,比如之前人工撰写了一个事例:“这个周末,小白花束只要99元,并且还包邮哦,还包邮哦!”。需要按照这句话复写出一定数目在抒发上不同,但是意思相仿的句子。这里我们就介绍一种基于关键词的文本(一句话)自动生成模型。
原理
模型处理流程如图1所示。
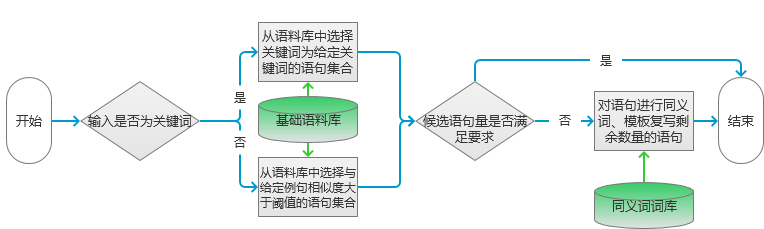
图1完成候选句子的提取以后,就要按照候选句子的数目来判定后续操作了。如果筛选的候选句子小于等于要求的数目,则根据语句相似度由低到高选定指定数目的短语。否则要进行短语的复写。这里采用同义词替换和按照指定模板进行改写的方案。
实现
实现候选句子估算的代码如下:
Map result = new HashMap();
if (type == 0) {//输入为关键词
result = getKeyWordsSentence(keyWordsList);
}else {
result = getWordSimSentence(sentence);
}
//得到候选集数量大于等于要求的数量则对结果进行裁剪
if (result.size() >= number) {
result = sub(result, number);
}else {
//得到候选集数量小于要求的数量则对结果进行添加
result = add(result, number);
}
实现句子相像筛选估算的代码如下。
for (String sen : sentenceList) {
//对待识别语句进行分词处理
List wordsList1 = parse(sentence);
List wordsList2 = parse(sen);
//首先判断两个语句是不是满足目标变换
boolean isPatternSim = isPatternSimSentence(wordsList1, wordsList2);
if (!isPatternSim) {//不满足目标变换
//首先计算两个语句的bi-gram相似度
double tmp = getBigramSim(wordsList1, wordsList2);
//这里的筛选条件是相似度小于阈值,因为bi-gram的相似度越小,代表两者越相似
if (threshold > tmp) {
result.put(sen,tmp);
}
}else {
result.put(sen,0.0);
}
}
拓展
本节处理的场景是:由文本到文本的生成。这个场景通常主要涉及:文本摘要、句子压缩、文本复写、句子融合等文本处理技术。其中本节涉及文本摘要和语句复写两个方面的技术。文本摘要如前所述主要涉及:关键词提取、短语提取、句子提取等。句子复写则按照实现手段的不同,大致可以分为如下几种。
基于统计模型和语义剖析生成模型的改写方式。这类方式就是按照语料库中的数据进行统计,获得大量的转换机率分布,然后对于输入的语料按照已知的先验知识进行替换。这类方式的语句是在剖析结果的基础上进行生成的,从某种意义上说,生成是在剖析的指导下实现的,因此,改写生成的诗句有可能具有良好的诗句结构。但是其所依赖的语料库是十分大的,这样就须要人工标明好多数据。对于这种问题,新的深度学习技术可以解决部份的问题。同时结合知识图谱的深度学习,能够更好地借助人的知识,最大限度地降低对训练样本的数据需求。RNN模型实现文本手动生成
6.1.2节介绍了基于短文本输入获得长文本的一些处理技术。这里主要使用的是RNN网路,利用其对序列数据处理能力,来实现文本序列数据的手动填充。下面就对其实现细节做一个说明和介绍。
场景
在广告投放的过程中,我们可能会遇见这些场景:由一句话生成一段描述文本,文本宽度在200~300字之间。输入也可能是一些主题的关键词。
这个时侯我们就须要一种依据少量文本输入形成大量文本的算法了。这里介绍一种算法:RNN算法。在5.3节我们早已介绍了这个算法,用该算法实现由拼音到汉字的转换。其实这两个场景的模式是一样的,都是由给定的文本信息,生成另外一些文本信息。区别是后者是生成当前元素对应的汉字,而这儿是生成当前元素对应的下一个汉字。
原理
同5.3节一样,我们这儿使用的还是Simple RNN模型。所以整个估算流程图如图3所示。
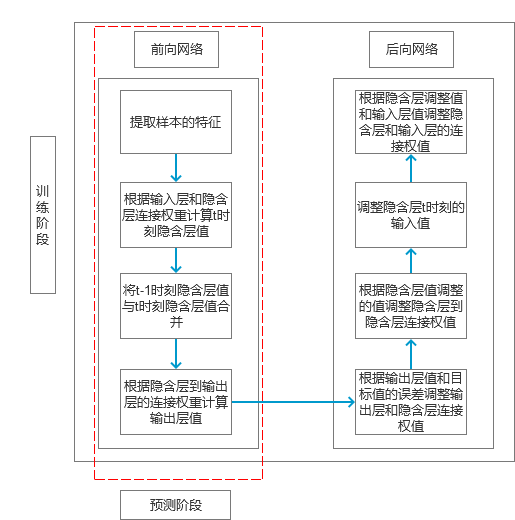
图3
代码
实现特点训练估算的代码如下:
public double train(List x, List y) {
alreadyTrain = true;
double minError = Double.MAX_VALUE;
for (int i = 0; i < totalTrain; i++) {
//定义更新数组
double[][] weightLayer0_update = new double[weightLayer0.length][weightLayer0[0].length];
double[][] weightLayer1_update = new double[weightLayer1.length][weightLayer1[0].length];
double[][] weightLayerh_update = new double[weightLayerh.length][weightLayerh[0].length];
List hiddenLayerInput = new ArrayList();
List outputLayerDelta = new ArrayList();
double[] hiddenLayerInitial = new double[hiddenLayers];
//对于初始的隐含层变量赋值为0
Arrays.fill(hiddenLayerInitial, 0.0);
hiddenLayerInput.add(hiddenLayerInitial);
double overallError = 0.0;
//前向网络计算预测误差
overallError = propagateNetWork(x, y, hiddenLayerInput,
outputLayerDelta, overallError);
if (overallError < minError) {
minError = overallError;
}else {
continue;
}
first2HiddenLayer = Arrays.copyOf(hiddenLayerInput.get(hiddenLayerInput.size()-1), hiddenLayerInput.get(hiddenLayerInput.size()-1).length);
double[] hidden2InputDelta = new double[weightLayerh_update.length];
//后向网络调整权值矩阵
hidden2InputDelta = backwardNetWork(x, hiddenLayerInput,
outputLayerDelta, hidden2InputDelta,weightLayer0_update, weightLayer1_update, weightLayerh_update);
weightLayer0 = matrixAdd(weightLayer0, matrixPlus(weightLayer0_update, alpha));
weightLayer1 = matrixAdd(weightLayer1, matrixPlus(weightLayer1_update, alpha));
weightLayerh = matrixAdd(weightLayerh, matrixPlus(weightLayerh_update, alpha));
}
return -1.0;
}
实现预测估算的代码如图下:
public double[] predict(double[] x) {
if (!alreadyTrain) {
new IllegalAccessError("model has not been trained, so can not to be predicted!!!");
}
double[] x2FirstLayer = matrixDot(x, weightLayer0);
double[] firstLayer2Hidden = matrixDot(first2HiddenLayer, weightLayerh);
if (x2FirstLayer.length != firstLayer2Hidden.length) {
new IllegalArgumentException("the x2FirstLayer length is not equal with firstLayer2Hidden length!");
}
for (int i = 0; i < x2FirstLayer.length; i++) {
firstLayer2Hidden[i] += x2FirstLayer[i];
}
firstLayer2Hidden = sigmoid(firstLayer2Hidden);
double[] hiddenLayer2Out = matrixDot(firstLayer2Hidden, weightLayer1);
hiddenLayer2Out = sigmoid(hiddenLayer2Out);
return hiddenLayer2Out;
}
拓展
文本的生成,按照输入方法不同,可以分为如下几种:
文本到文本的生成。即输入的是文本,输出的也是文本。图像到文本。即输入的是图象,输出的是文本。数据到文本。即输入的是数据,输出的是文本。其他。即输入的方式为非前面两者,但是输出的也是文本。因为这类的输入比较难归纳,所以就归为其他了。
其中第2、第3种近来发展得十分快,特别是随着深度学习、知识图谱等前沿技术的发展。基于图象生成文本描述的试验成果在不断被刷新。基于GAN(对抗神经网路)的图象文本生成技术早已实现了特别大的图谱,不仅还能依据图片生成非常好的描述,还能依据文本输入生成对应的图片。
由数据生成文本,目前主要应用在新闻撰写领域。中文和日文的都有很大的进展,英文的以路透社为代表,中文的则以腾讯公司为代表。当然这两家都不是纯粹地以数据为输入,而是综合了前面4种情况的新闻撰写。
从技术上来说,现在主流的实现方法有两种:一种是基于符号的,以知识图谱为代表,这类方式更多地使用人的先验知识,对于文本的处理更多地收录语义的成份。另一种是基于统计(联结)的,即按照大量文本学习出不同文本之间的组合规律,进而依据输入猜想出可能的组合形式作为输出。随着深度学习和知识图谱的结合,这三者有显著的融合现象,这应当是实现未来技术突破的一个重要节点。
编者按: 本书主要从语义模型解读、自然语言处理系统基础算法和系统案例实战三个方面,介绍了自然语言处理中相关的一些技术。对于每一个算法又分别从应用原理、数学原理、代码实现,以及对当前方式的思索四个方面进行讲解。
详情点击:
seo关键词生成系统一套全手动快速生成网站(htm)的程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 501 次浏览 • 2020-08-16 19:58
演示站点
前言:让网站产生大流量,赚美金,赚广告费!
seo关键词生成系统 600一套 购买QQ联系:
一套全手动快速生成网站(htm)的程序' />
一套全手动快速生成网站(htm)的程序.它能按照您提供的关键词,从搜索引擎中提取大量相关关键词,再依照关键词从网路中抓取到优质的相关内容,并按照设定好的网页模板快速生成内容网站及大量网站.再把网站供搜索引擎收录,从而获得巨大流量.本软件既能"一键式"全手动快速生成网站,也能按照你的优化要求自动调整,做到了灵活多元化,以适应搜索引擎对不同关键词的优化要求.
软件特色:
以热门搜索词为title关键词,排名靠前,针对性强
定向抓取优质内容,不再是空壳网站抓取和生成网站速度超快,数分钟可生成几千htm
主要特征与功能:
使用多线程下载,采用了智能换网址补抓网页机制,采集率高达99%。
采集内容经多方优化,内容优质。注:优化处理不断升级中
自定义标签即抓取到更优质的内容!增加定义栏目,可无限降低栏目,向正规站靠拢!
重要功能:增加更新功能,支持每日更新记录,方便快捷的更新,更有利于搜索引擎收录和提升权重!
选择生成对象是文件或目录。文件名或目录名,可使用ID号,数字,字母+数字,随机字母。 查看全部
seo关键词生成系统一套全手动快速生成网站(htm)的程序
演示站点
前言:让网站产生大流量,赚美金,赚广告费!
seo关键词生成系统 600一套 购买QQ联系:
一套全手动快速生成网站(htm)的程序' />
一套全手动快速生成网站(htm)的程序.它能按照您提供的关键词,从搜索引擎中提取大量相关关键词,再依照关键词从网路中抓取到优质的相关内容,并按照设定好的网页模板快速生成内容网站及大量网站.再把网站供搜索引擎收录,从而获得巨大流量.本软件既能"一键式"全手动快速生成网站,也能按照你的优化要求自动调整,做到了灵活多元化,以适应搜索引擎对不同关键词的优化要求.
软件特色:
以热门搜索词为title关键词,排名靠前,针对性强
定向抓取优质内容,不再是空壳网站抓取和生成网站速度超快,数分钟可生成几千htm
主要特征与功能:
使用多线程下载,采用了智能换网址补抓网页机制,采集率高达99%。
采集内容经多方优化,内容优质。注:优化处理不断升级中
自定义标签即抓取到更优质的内容!增加定义栏目,可无限降低栏目,向正规站靠拢!
重要功能:增加更新功能,支持每日更新记录,方便快捷的更新,更有利于搜索引擎收录和提升权重!
选择生成对象是文件或目录。文件名或目录名,可使用ID号,数字,字母+数字,随机字母。
做SEO重复的内容与采集站会遭到搜索引擎惩罚吗
采集交流 • 优采云 发表了文章 • 0 个评论 • 307 次浏览 • 2020-08-15 02:03
查找引擎到底会不会奖惩搜集的内容要需求阐述的是内容重复与站点搜集,由于这两点是有定差别的。就当时来讲,查找引擎关于重复内容到是没有太冲击现象。那么你也就能这样了解,查找引擎通常关于重复的内容是不会进行奖惩的。
许多网站优化界的人士在做网站剖析的时分还会考虑站点的重复系数的问题,一般还会经过一些站长辅助工具来大概核算一下原文链接。
咱们共同含混的就是文章别被人剽窃后竟然排行比自己的还要高,对此百度也曾视图处理这等相像的问题。在当时的测验阶段里,咱们才能在逾刚才推出的熊掌号上面看出一些新的期望。渠道晋级后有权限的站长才能够在熊掌号的维护伞下递交原创内容,其间一个亮点就是文章的发布时刻简直才能确切到秒来核算。
具有原创维护的站点,提交链接一旦被审读经过。那么在移动端的手机查找上都会加注原创标签,这样一来你的原创文章天然都会比转载的要好的多。 查看全部
重复的节选别人的内容都是SEO职业一向比较注重的大问题,那么重复的内容终究会不会受到查找引擎的奖惩呢?其实这种一向都是优化师们经常在一起评论的话题了,这一段百度对搜集网站进行了大批量的K站。可是仍然有许多同学的站点排行始终挺好,面临如此对的搜集内容,查找引擎又是如何进行差别的呢?下面和北京百度霸屏推广公司一起来瞧瞧具体情况

查找引擎到底会不会奖惩搜集的内容要需求阐述的是内容重复与站点搜集,由于这两点是有定差别的。就当时来讲,查找引擎关于重复内容到是没有太冲击现象。那么你也就能这样了解,查找引擎通常关于重复的内容是不会进行奖惩的。
许多网站优化界的人士在做网站剖析的时分还会考虑站点的重复系数的问题,一般还会经过一些站长辅助工具来大概核算一下原文链接。

咱们共同含混的就是文章别被人剽窃后竟然排行比自己的还要高,对此百度也曾视图处理这等相像的问题。在当时的测验阶段里,咱们才能在逾刚才推出的熊掌号上面看出一些新的期望。渠道晋级后有权限的站长才能够在熊掌号的维护伞下递交原创内容,其间一个亮点就是文章的发布时刻简直才能确切到秒来核算。
具有原创维护的站点,提交链接一旦被审读经过。那么在移动端的手机查找上都会加注原创标签,这样一来你的原创文章天然都会比转载的要好的多。
网站搜索引擎优化六步骤
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2020-08-13 19:46
总的说来,对图片的优化还是应当尽量降低大图片以及缩小图片的加载时间。alt属性中的文字对搜索引擎来说,其重要性比正文内容的文字要低。
四、网页代码的优化(主要是javascript)
正常情况下,网页尽量以作为代码的开始端。但我们好多的网页是采用javascript技术的,往往在页面一开始就堆积大量java代码,以至于meta及关键字迟迟不能出现,被推至页面中上部,对搜索引擎太不友好。有两个建议:
1、将脚本移至页面顶部
大部分的java代码都可以移到页面结束标签之上,而不影响网站功能。这样才能一开始突出关键词,并推动页面加载时间。
2、将javascript脚本放在.js文件中。
这样.js脚本就可以被缓存出来,访问同样调用这个javascript的页面的时侯才会提升网页的访问速率。
五、防止因优化过度被判定为作弊
(编辑在发布信息时要防止的问题)
做优化必须了解基本的作弊手段,否则都会让辛苦付之东流:
1、关键字拼凑:
为了降低关键词的出现次数,故意在网页代码中,如在meta、title、注释、图片alt以及url地址等地方重复添加同一个关键词。(一定要时刻把握关键字的密度要求)
2、虚假关键词(不相关的关键字):
通过在meta中设置与网站内容无关的关键词,比如在title中设置了热门关键词,希望使用户按照此步入网站。同样的情况也包括链接关键词与实际内容不符的情况。
3、隐形文本/链接:
为了降低关键词的出现频次,故意在网页中放一段与背景颜色相同的、收录好多关键字的文本。访客看不到,搜索引擎却能找到。类似方式还包括使用超大号文字等手段。隐形链接是在隐型文本的基础上在其它页面添加指向目标优化页的行为。
六、新版上线后的注意事项
1.保留原有的网页命名/pr值:
保留原有网页,即使网页的结构和内容被修改,搜索引擎蜘蛛还是可以按"原街"找到页面。这种方法能使蜘蛛更快的重新收录原页面中的新内容,也保护了原有的排行及页面的pr值。当然,如果有些页面不合理的,不适宜搜索引擎的可以删除,对于这些收录现今每晚能带来稳定流量的关键字页面,可以将其保留。
2.sitemaps更新:
能使搜索引擎更好、更快的收录新站,建议构建sitemaps,告诉搜索引擎我的网站在改变,牵引搜索蜘蛛去收录新的页面。
3.避免站点内容的冲突:
因为新改版以后不可能很快就有很多新的内容,所以网站的内容还是仿效旧版本的内容,这样对搜索引擎是不友好的,另外加上新、旧网站的网站结构不一样,搜索引擎有可能要花更多的时间来观察、分析目前的网站情况。所以应当处理好新、旧站之间的链接、内容的关联性,避免出现过多内容重复。
4.及时检测网站友情链接,以避免链接到的页面因作弊被惩罚。
自助建站网站建设域名申请虚拟主机广州域名注册佛山域名注册广州域名注册广州域名注册
与网站搜索引擎优化六步骤相关文章:
·长沙网站优化-如何递交目录
·谈谈网站优化及网路推广工程中的工作流程问题
·企业网站优化策略
·长沙推广武汉推广网站长沙网路推广武汉网站推
·我要做网站,长沙我要做网站,长沙网站设计南京
·平民网站排名优化和基于用户体验的网站建设
本文标题:网站搜索引擎优化六步骤
本文地址: 查看全部
3、在图片下方或后面降低如"更多某甲"链接,收录关键词。
总的说来,对图片的优化还是应当尽量降低大图片以及缩小图片的加载时间。alt属性中的文字对搜索引擎来说,其重要性比正文内容的文字要低。
四、网页代码的优化(主要是javascript)
正常情况下,网页尽量以作为代码的开始端。但我们好多的网页是采用javascript技术的,往往在页面一开始就堆积大量java代码,以至于meta及关键字迟迟不能出现,被推至页面中上部,对搜索引擎太不友好。有两个建议:
1、将脚本移至页面顶部
大部分的java代码都可以移到页面结束标签之上,而不影响网站功能。这样才能一开始突出关键词,并推动页面加载时间。
2、将javascript脚本放在.js文件中。
这样.js脚本就可以被缓存出来,访问同样调用这个javascript的页面的时侯才会提升网页的访问速率。
五、防止因优化过度被判定为作弊
(编辑在发布信息时要防止的问题)
做优化必须了解基本的作弊手段,否则都会让辛苦付之东流:
1、关键字拼凑:
为了降低关键词的出现次数,故意在网页代码中,如在meta、title、注释、图片alt以及url地址等地方重复添加同一个关键词。(一定要时刻把握关键字的密度要求)
2、虚假关键词(不相关的关键字):
通过在meta中设置与网站内容无关的关键词,比如在title中设置了热门关键词,希望使用户按照此步入网站。同样的情况也包括链接关键词与实际内容不符的情况。
3、隐形文本/链接:
为了降低关键词的出现频次,故意在网页中放一段与背景颜色相同的、收录好多关键字的文本。访客看不到,搜索引擎却能找到。类似方式还包括使用超大号文字等手段。隐形链接是在隐型文本的基础上在其它页面添加指向目标优化页的行为。
六、新版上线后的注意事项
1.保留原有的网页命名/pr值:
保留原有网页,即使网页的结构和内容被修改,搜索引擎蜘蛛还是可以按"原街"找到页面。这种方法能使蜘蛛更快的重新收录原页面中的新内容,也保护了原有的排行及页面的pr值。当然,如果有些页面不合理的,不适宜搜索引擎的可以删除,对于这些收录现今每晚能带来稳定流量的关键字页面,可以将其保留。
2.sitemaps更新:
能使搜索引擎更好、更快的收录新站,建议构建sitemaps,告诉搜索引擎我的网站在改变,牵引搜索蜘蛛去收录新的页面。
3.避免站点内容的冲突:
因为新改版以后不可能很快就有很多新的内容,所以网站的内容还是仿效旧版本的内容,这样对搜索引擎是不友好的,另外加上新、旧网站的网站结构不一样,搜索引擎有可能要花更多的时间来观察、分析目前的网站情况。所以应当处理好新、旧站之间的链接、内容的关联性,避免出现过多内容重复。
4.及时检测网站友情链接,以避免链接到的页面因作弊被惩罚。
自助建站网站建设域名申请虚拟主机广州域名注册佛山域名注册广州域名注册广州域名注册
与网站搜索引擎优化六步骤相关文章:
·长沙网站优化-如何递交目录
·谈谈网站优化及网路推广工程中的工作流程问题
·企业网站优化策略
·长沙推广武汉推广网站长沙网路推广武汉网站推
·我要做网站,长沙我要做网站,长沙网站设计南京
·平民网站排名优化和基于用户体验的网站建设
本文标题:网站搜索引擎优化六步骤
本文地址:
网站优化想省心,得使“站群优化系统”来做!
采集交流 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2020-08-12 18:35
站群优化系统“慧营销”为你网站优化!
站群优化系统仍然是好多企业选择的网站优化方案,因为不需要聘请专业的优化专业员对其网站进行优化,站群优化系统对其网站进行优化,完全可以做到智能优化和手动优化,日常人工优化网站的工作,站群优化系统“慧营销”都能智能帮我们完成,省心又省时。
站群优化系统“慧营销”拥有的功能!
1、智能采集+更新
站群优化系统“慧营销”,可以做到手动采集内容,然后在通过自己的词库对其内容进行智能洗白加伪原创,再手动为你更新到网站。
2、裂变式分站
“慧营销”可以在短时间内,为我们生成上百上千个城市分站,全程智能生成不需要任何自动设置,为你获取到更多的排行和流量的入口。
3、智能快速上排行
站群优化系统“慧营销”采用智能造词、智能替换,系统智能生产出大量的行业相关“关键词”,以实现搜索霸屏疗效,帮你扩张关键词,获取到更多的关键词首页排行。
站群优化系统优化网站省心省力,想要晓得更多关于站群优化系统资讯,访问“慧营销”专区网址,免费发放试用版: 查看全部
搭建完成的网站,在往前一定要对网站进行优化工作的,但好多的人对网站的优化工作都不是太擅长,不知该怎么去对网站开展优化,其实在优化网站是有两个种方法,一种是专业的SEO优化专员对其网站进行优化,另一种就是运用站群优化系统对其网站进行智能优化,其实前者站群优化系统,更适宜不会网站优化的人去使用,把网站优化的工作交给站群优化系统,它也一样可以为我们把网站优化做的更好!

站群优化系统“慧营销”为你网站优化!
站群优化系统仍然是好多企业选择的网站优化方案,因为不需要聘请专业的优化专业员对其网站进行优化,站群优化系统对其网站进行优化,完全可以做到智能优化和手动优化,日常人工优化网站的工作,站群优化系统“慧营销”都能智能帮我们完成,省心又省时。
站群优化系统“慧营销”拥有的功能!
1、智能采集+更新
站群优化系统“慧营销”,可以做到手动采集内容,然后在通过自己的词库对其内容进行智能洗白加伪原创,再手动为你更新到网站。
2、裂变式分站
“慧营销”可以在短时间内,为我们生成上百上千个城市分站,全程智能生成不需要任何自动设置,为你获取到更多的排行和流量的入口。
3、智能快速上排行
站群优化系统“慧营销”采用智能造词、智能替换,系统智能生产出大量的行业相关“关键词”,以实现搜索霸屏疗效,帮你扩张关键词,获取到更多的关键词首页排行。

站群优化系统优化网站省心省力,想要晓得更多关于站群优化系统资讯,访问“慧营销”专区网址,免费发放试用版:
亚马逊关键词挖掘工具有什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2020-08-12 12:48
名称:Keyword Tool Dominator
/
价格:$69.99
支持的亚马逊站点:US, EU, UK
功能特点:该工具是一个Chrome插件,这是一个非常有影响力的长尾关键词研究工具。能手动从amamzon、google、bing、youtube抓取到自己数据库。
排名:4
名称:Google Keyword Planner
价格:免费
支持的亚马逊站点:US, GE, ES, FR, UK…
功能特点:可能是目前最好的关键词研究工具。谷歌官方出品,做亚马逊的店家也可以参考。
排名:5
名称:Merchant Words
网址:/
价格:$60/月
支持的亚马逊站点:US, IT, FR, CA…
功能特点:大名鼎鼎的,Merchant Words,帮助店家找到非常的关键词及熟语。
排名:6
名称:KeywordInspector
/
价格:$39.95/月
支持的亚马逊站点:US, UK
功能特点:提供的Reverse ASIN Tool 和 KeywordTrend tool 工具能帮买家提高在亚马逊上的竞争力。
排名:7
名称:AmaSuite
网址:/
价格:$97
支持的亚马逊站点:US, CA, UK, DE, IT, FR…
功能特点:AmaSuite是一个强悍的mac和pc客户端软件。强力推荐给每一个想做好亚马逊SEO的店家。
排名:8
名称:AMZ One
网址:/
价格:提供免费版本
支持的亚马逊站点:US, RU
功能特点:类似关键词排行跟踪、销量跟踪的功能,使得对于希望找寻中级关键词研究工具的人来说特别有用,此工具不适宜菜鸟。
排名:9
名称:AMZ Space
网址:amz.space (网址真奇怪)
价格:提供1个月免费
支持的亚马逊站点:UK, FR, DE, IT, ES…
功能特点:该工具能提供的功能有:计算收益、自动发送电邮给消费者、跟踪高排行的关键词。使用该工具须要有一定的SEO:基础。
排名:10
名称:AMZ Tracker
网址:/
价格:$33 /月起
支持的亚马逊站点:JP, BR, FR, DE, ES, US, IN…
功能特点:AMZ Tracker是一款高效但高昂的关键词工具。通过Amazon SEO功能你可以提高关键词排行、通过Keyword Suggester 功能你可以找寻到新的关键词。
排名:11
名称:Helium 10
网址:/
价格:提供免费版本
支持的亚马逊站点:US, UK, DE…
功能特点:诸如Frankenstein Keyword Processor和Magnet Amazon Keyword research tool 这样的功能使 Helium 10成为最出色的SEO专业工具。
排名:12
名称:Scientific Seller
网址:/
价格:免费
支持的亚马逊站点:US, BR, JP, CA…
功能特点:不象其它的关键词剖析工具又快又高效,Scientific Seller容许平缓却十分严谨,一个关键词查询可以持续数小时。
排名:13
名称:Scope
网址:/scope/
价格:提供免费版本
支持的亚马逊站点:US
功能特点:该工具能对销量最好的产品进行监控、罗列关键词排行。你不需要成为一个专家也能通过Scope做好关键词和亚马:逊产品研究。
排名:14
名称:Keyword Keg
网址:/
价格:$8/月起
支持的亚马逊站点:US, UK, CA, NZ…
功能特点:Keyword Keg 共享来自于Yahoo, Google, Bing or Yandex.等平台的数据。它的定价计划为亚马逊的买家提供了不同数目的选择。
排名:15
名称:Keyword Eye
网址:/
价格:$35/月起
支持的亚马逊站点:US, UK…
功能特点:超过5万名用户和超过100万的关键字建议充分说明了Keyword Eye的实力。这个工具将使您了解您须要晓得的关于顾客需求的所有信息。
排名:16
名称:AMZ Sistrix
/amazon/keywords/country/us
价格:免费
支持的亚马逊站点:DE, UK, US, ES
功能特点:简单的输入一个关键词,剩下的交给AMZ Sistrix吧。
排名:17
名称:Kparser
网址:/
价格:提供免费版本
支持的亚马逊站点:US, AR, BR, DK, UK…
功能特点:通过Kparser,你可以在微软、Amazon、eBay或Bing上为您的产品找到最好的关键字,并通过几个简单的步骤发觉长尾关键字。
排名:18
名称:SEO Chat
网址: (似乎挂了)
价格:提供免费版本
支持的亚马逊站点:US, UK…
功能特点:大名鼎鼎的SEO Chat,是一个你可以找到所有的信息和工具的专业搜索引擎优化网站。
排名:19
名称:Asin key
网址:/
价格:$19.99/月起
支持的亚马逊站点:US, UK, DE, FR…
功能特点:Amazon SEO, Amazon Keyword, and Keyword Rankings tools:要求使用者有知识储备,所以不适宜没有经验的用户。
排名:20
名称:Seo Stack
网址:/
价格:30天免费试用:
支持的亚马逊站点:US, UK…
功能特点:该工具能轻松生成关键词、获得关键词建议、关键词竞争程度剖析。
跨境电商软件工具 查看全部
排名:3
名称:Keyword Tool Dominator
/
价格:$69.99
支持的亚马逊站点:US, EU, UK
功能特点:该工具是一个Chrome插件,这是一个非常有影响力的长尾关键词研究工具。能手动从amamzon、google、bing、youtube抓取到自己数据库。
排名:4
名称:Google Keyword Planner
价格:免费
支持的亚马逊站点:US, GE, ES, FR, UK…
功能特点:可能是目前最好的关键词研究工具。谷歌官方出品,做亚马逊的店家也可以参考。
排名:5
名称:Merchant Words
网址:/
价格:$60/月
支持的亚马逊站点:US, IT, FR, CA…
功能特点:大名鼎鼎的,Merchant Words,帮助店家找到非常的关键词及熟语。
排名:6
名称:KeywordInspector
/
价格:$39.95/月
支持的亚马逊站点:US, UK
功能特点:提供的Reverse ASIN Tool 和 KeywordTrend tool 工具能帮买家提高在亚马逊上的竞争力。
排名:7
名称:AmaSuite
网址:/
价格:$97
支持的亚马逊站点:US, CA, UK, DE, IT, FR…
功能特点:AmaSuite是一个强悍的mac和pc客户端软件。强力推荐给每一个想做好亚马逊SEO的店家。
排名:8
名称:AMZ One
网址:/
价格:提供免费版本
支持的亚马逊站点:US, RU
功能特点:类似关键词排行跟踪、销量跟踪的功能,使得对于希望找寻中级关键词研究工具的人来说特别有用,此工具不适宜菜鸟。
排名:9
名称:AMZ Space
网址:amz.space (网址真奇怪)
价格:提供1个月免费
支持的亚马逊站点:UK, FR, DE, IT, ES…
功能特点:该工具能提供的功能有:计算收益、自动发送电邮给消费者、跟踪高排行的关键词。使用该工具须要有一定的SEO:基础。
排名:10
名称:AMZ Tracker
网址:/
价格:$33 /月起
支持的亚马逊站点:JP, BR, FR, DE, ES, US, IN…
功能特点:AMZ Tracker是一款高效但高昂的关键词工具。通过Amazon SEO功能你可以提高关键词排行、通过Keyword Suggester 功能你可以找寻到新的关键词。
排名:11
名称:Helium 10
网址:/
价格:提供免费版本
支持的亚马逊站点:US, UK, DE…
功能特点:诸如Frankenstein Keyword Processor和Magnet Amazon Keyword research tool 这样的功能使 Helium 10成为最出色的SEO专业工具。
排名:12
名称:Scientific Seller
网址:/
价格:免费
支持的亚马逊站点:US, BR, JP, CA…
功能特点:不象其它的关键词剖析工具又快又高效,Scientific Seller容许平缓却十分严谨,一个关键词查询可以持续数小时。
排名:13
名称:Scope
网址:/scope/
价格:提供免费版本
支持的亚马逊站点:US
功能特点:该工具能对销量最好的产品进行监控、罗列关键词排行。你不需要成为一个专家也能通过Scope做好关键词和亚马:逊产品研究。
排名:14
名称:Keyword Keg
网址:/
价格:$8/月起
支持的亚马逊站点:US, UK, CA, NZ…
功能特点:Keyword Keg 共享来自于Yahoo, Google, Bing or Yandex.等平台的数据。它的定价计划为亚马逊的买家提供了不同数目的选择。
排名:15
名称:Keyword Eye
网址:/
价格:$35/月起
支持的亚马逊站点:US, UK…
功能特点:超过5万名用户和超过100万的关键字建议充分说明了Keyword Eye的实力。这个工具将使您了解您须要晓得的关于顾客需求的所有信息。
排名:16
名称:AMZ Sistrix
/amazon/keywords/country/us
价格:免费
支持的亚马逊站点:DE, UK, US, ES
功能特点:简单的输入一个关键词,剩下的交给AMZ Sistrix吧。
排名:17
名称:Kparser
网址:/
价格:提供免费版本
支持的亚马逊站点:US, AR, BR, DK, UK…
功能特点:通过Kparser,你可以在微软、Amazon、eBay或Bing上为您的产品找到最好的关键字,并通过几个简单的步骤发觉长尾关键字。
排名:18
名称:SEO Chat
网址: (似乎挂了)
价格:提供免费版本
支持的亚马逊站点:US, UK…
功能特点:大名鼎鼎的SEO Chat,是一个你可以找到所有的信息和工具的专业搜索引擎优化网站。
排名:19
名称:Asin key
网址:/
价格:$19.99/月起
支持的亚马逊站点:US, UK, DE, FR…
功能特点:Amazon SEO, Amazon Keyword, and Keyword Rankings tools:要求使用者有知识储备,所以不适宜没有经验的用户。
排名:20
名称:Seo Stack
网址:/
价格:30天免费试用:
支持的亚马逊站点:US, UK…
功能特点:该工具能轻松生成关键词、获得关键词建议、关键词竞争程度剖析。
跨境电商软件工具
输入关键词手动生成文章高阶的SEO查询
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2020-08-12 07:11
4、快速收录上线对SEO意味着哪些?快速收录上线站点管理一方面是便捷百度开发人员维护调试,统一化管理,另一方面也便捷的用户,这样不用多个后台去递交(以前自动递交须要到站点管理,天级递交须要到联通专区后台)。快速收录功能上线也就代表联通专区距离彻底下线也不远了,或者就是这几天了。
5、网站蜘蛛池作用剖析大量降低外链,会被搜索引擎判断为作弊(大机率是过度优化);
6、主动推送链接:更新sitemap地图,提交给搜索引擎,在百度资源验证网站,安装手动推送代码,加页面的抓取收录。
7、seo搜索引擎收录原理,走进百度收录的背后
8、如果把一个网站页面组成的页面看做是一个有向图,从指定的页面出发,沿着页面中的链接,按照某种特定的策略对网站中的页面进行遍历。不停地从URL列表中移出早已访问的URL,并储存原创页面,同时提取原创页面中的URL的信息:再将URL分为域名及内部URL两大类,同时判定URL是否被访问过,将未访问过的URL加入URL列表中。递归地扫描URL列表,直至用尽所有URL资源为止。经过这种工作,搜索引擎就可以构建庞大的域名列表、页面URL列表并存储足够多的原创页面。
—————————————————————————————–
问:黑帽seo是哪些意思?
答:黑帽SEO是借助和放大搜索引擎的策略缺陷(实际上完美的系统是不存在的)获取更多用户访问量,而这种更多的访问量,是以伤害用户体验为代价的SEO行为。
问:网页标题与描述写多少字合适?
答:网站title标题搜索引擎在搜索结果中只能展示63个字节,后边都省略了;网页标题通常建议不超过32个汉字,描述Description不要超过72个汉字。
问:网站服务器空间买多大适宜?
答:根据网站规模和要提供的服务来决定选择订购何种空间(服务器),选择有实力的正规空间商,根据用户群分布选择接入商,保证用户的访问速率和稳定性。 查看全部
3、外部链接建设;网站的外部链接做好了才能促使排行的提高,但是发外链不是一件容易的事,尤其是优质的外链少之又少,这个在工作的过程中一定要仔细筛选。
4、快速收录上线对SEO意味着哪些?快速收录上线站点管理一方面是便捷百度开发人员维护调试,统一化管理,另一方面也便捷的用户,这样不用多个后台去递交(以前自动递交须要到站点管理,天级递交须要到联通专区后台)。快速收录功能上线也就代表联通专区距离彻底下线也不远了,或者就是这几天了。
5、网站蜘蛛池作用剖析大量降低外链,会被搜索引擎判断为作弊(大机率是过度优化);
6、主动推送链接:更新sitemap地图,提交给搜索引擎,在百度资源验证网站,安装手动推送代码,加页面的抓取收录。
7、seo搜索引擎收录原理,走进百度收录的背后
8、如果把一个网站页面组成的页面看做是一个有向图,从指定的页面出发,沿着页面中的链接,按照某种特定的策略对网站中的页面进行遍历。不停地从URL列表中移出早已访问的URL,并储存原创页面,同时提取原创页面中的URL的信息:再将URL分为域名及内部URL两大类,同时判定URL是否被访问过,将未访问过的URL加入URL列表中。递归地扫描URL列表,直至用尽所有URL资源为止。经过这种工作,搜索引擎就可以构建庞大的域名列表、页面URL列表并存储足够多的原创页面。
—————————————————————————————–
问:黑帽seo是哪些意思?
答:黑帽SEO是借助和放大搜索引擎的策略缺陷(实际上完美的系统是不存在的)获取更多用户访问量,而这种更多的访问量,是以伤害用户体验为代价的SEO行为。
问:网页标题与描述写多少字合适?
答:网站title标题搜索引擎在搜索结果中只能展示63个字节,后边都省略了;网页标题通常建议不超过32个汉字,描述Description不要超过72个汉字。
问:网站服务器空间买多大适宜?
答:根据网站规模和要提供的服务来决定选择订购何种空间(服务器),选择有实力的正规空间商,根据用户群分布选择接入商,保证用户的访问速率和稳定性。
在线客服系统怎样实现手动生成数据统计的功能 - 快商通
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2020-08-12 06:38
高点击、高转化是所有网路推广人员梦寐以求的状态。但好多情况下,广告会带来一定的垃圾流量,比如因为关键词的广泛匹配,或者投放渠道可能不是产品目标人群等。
第一步、我们要注意时刻检测流量质量,从客服系统的数据中剖析缘由。
比如:根据剖析不同时段、日期的流量趋势变化形态,通过客服系统详尽了解网站流量的累计过程,从而摸透访客的访问规律,流量变动规律和缘由、网站的发展状况等。
[数据统计]-[流量剖析]-[按时间段剖析]
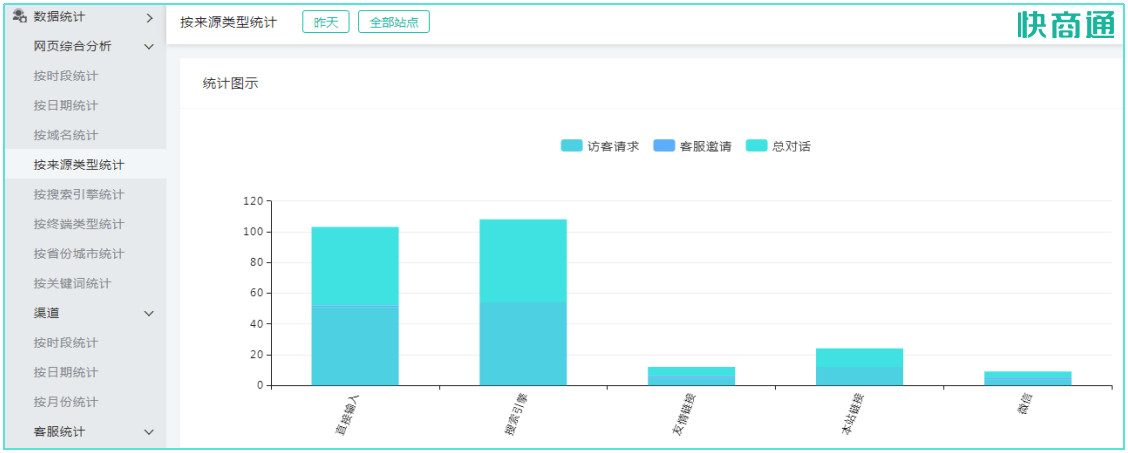
或按照剖析在线客服系统不同来源项(搜索引擎、友情链接、来源类型、终端类型)引入流量的情况,分析不同来源的流量数目和质量,进而合理优化和选择推广渠道
[数据统计]-[流量剖析]-[按来源类型剖析]
综合多维度、多指标的流量数据剖析,有助于观察不同的流量变化趋势,分析流量质量,并作为调整广告投放策略的根据。
[数据统计]-[流量剖析]-[按时段](可自定义显示列)
[数据统计]-[流量剖析]-[近7天渠道趋势]
通常我们拿来判定页面的流量质量低的指标收录:低PV数、低平均访问页数、高跳出率、低平均访问时长等。遇到低质量流量形成的情况,需要先排查以下这三点:
一、渠道引流上呈现的关键词创意与落地页是否匹配;
二、投放的渠道和投放关键词是否是目标用户活跃的范围和兴趣点,即投放是否精准;
三、落地页出错以及其他诱因(收录但不限于网站打开速率慢、页面错误过期,跳转出错等)。
这里有一个十分重要的指标:[关键词]。结合关键词流量与对话两个维度的数据,集中投放带来高对话量(有效流量)的关键词,控制高消费低对话量(无效流量)的关键词消费。
[数据统计]-[流量剖析]-[按关键词统计]
关键词代表着用户的需求,是sem推广投放的核心。那么选择什么样的关键词就变得至关重要。
例如品牌词的意向高转化率高而且流量小,产品词的流量大点击率高而且竞争激烈。每类词都各有特征,需要适当的进行搭配能够达到最好的引流疗效。
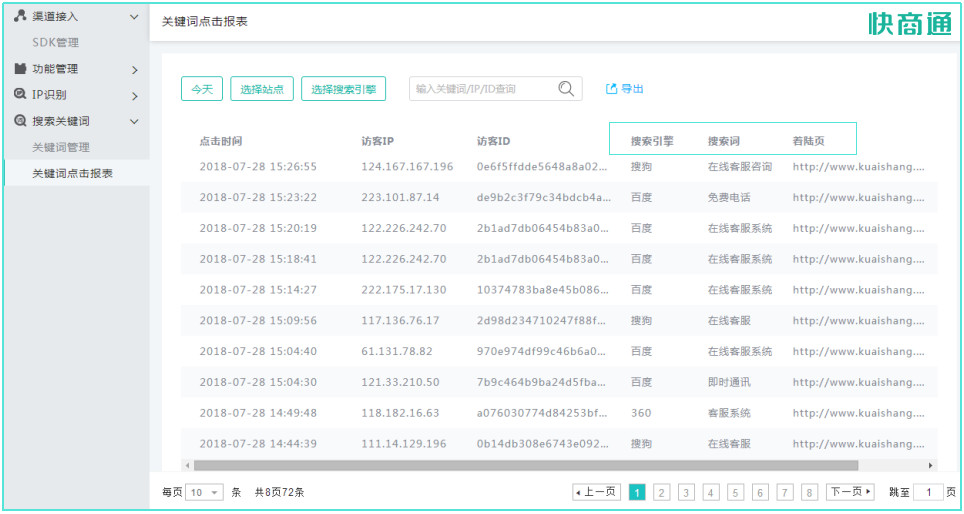
因此,在合理安排关键词策略时,可以结合在线客服系统提供的访客搜索词到着陆页的浏览轨迹来看
[设置中心]-[搜索关键词]-[关键词点击报表]
因为访客一般会选择各网站比价钱和口碑,确认完信息然后认为xx可能更适宜,直接搜索xx品牌,点击品牌词步入网站咨询。这个过程中,访客完成从产品词到品牌词的点击轨迹,产品词对品牌词形成了间接转化贡献。
通过在线客服系统剖析访客浏览轨迹,可以剖析产品词投放对品牌词形成的影响,特别在费用控制时,有效评估品牌市流量的变化和目标设定。
另外,如果一个看着意向度很高的词转化率低到使你大跌眼镜,那么该关掉一些引流的工具就关掉,该收缩匹配方法就要及时的收。
优化着陆页
在碎片化和用户注意力难以捉摸的明天,着陆页的选择对于企业网路营销起着至关重要的作用。推广竞价的目的是把目标顾客带到我们的网站上来,着陆页承载的是消费者对你网站和业务的第一印象。
[数据统计]-[关键词分析]-[跳出率]
持续进行帐户优化的同时,我们除了可以通过关键词跳出率的高低来评判流量是否精准,还可以评判网站页面质量是否优质。
当关键词跳出率偏低的时侯,要考虑到是否是着陆页质量影响流量转化疗效。理想的着陆页应当具备以下要素:
一、内容相关性:合理搭配关键词、方便快速找到想了解的相关内容,内容有价值、没有过多的广告;
二、访客体验感:网站加载速率快、收录清晰的导航栏、页面设计美观、内容精简且富于创意、扬长避短;
三、交互能力:与访客产生共同利益点、突出指出“点击原因”、引导咨询、能够即时有在线沟通(咨询窗口合理)。
还可以结合[访问轨迹]、[对话网址]、[对话历史]等数据,观察网站不同页面形成对话量的情况,分析才能形成对话的优质页面并做相应的关键词推广和布局调整,减少访客抵达优质内容页的路径,缩短转化流程
[查看历史]-[访客历史对话]
根据不同目标受众,可以“投其所好”的设置不同的关键词着陆页。比如,根据不同的产品设计不同风格的网站,多个网站同时进行引流;或依据企业营销计划,在重点活动期间更换不同设计的在线客服系统着陆页。
快商通免费提供10+套风格式样:
[生成代码]-自定义款式、风格券
这里须要注意的是,不管是优先推广那个网页,都须要在全站提供方便的咨询入口。根据不同的网页设计风格,灵活搭配咨询入口、邀请框、浮动图标款式(并注意它们的统一)等,吸引访客点击咨询。
企业通过推广获得流量——从流量中获得咨询——从咨询中获得线索——从线索中获得订单,当我们步入网路营销漏斗的最后一环,有效沟通就是成交的关键,也是网路营销疗效的首要标准,而对话数目又是对话质量的前提。
随着互联网时代的发展,客服中心正在从“成本中心”走向“利润中心”,越来越得到企业的注重:
一方面,在线客服通过网站建立访客与企业内部即时交流的平台,是第一时间为访客提供服务、解决问题的人;另一方面,通过与顾客沟通交流,无形之中实现品牌的输出,也是网路营销重要目标。
总结:
提升网站对话量涉及到多个环节,我们除了须要具备流量控制、流量质量剖析、页面前往剖析、页面承载剖析、页面转化剖析等多种能力,还须要为前往网站的访客构建有效的沟通渠道,提供引导性的高质量服务。 查看全部
很多企业喜欢通过在线客服系统来捕捉访客行为喜好等数据来进行剖析,但大多客服系统并没有手动统计的功能,需要客服人员额外花精力一条一条的进行统计,效率和准确率都太低,今天给你们介绍一下快商通在线客服系统按照24个用户维度手动生成数据统计的功能。
高点击、高转化是所有网路推广人员梦寐以求的状态。但好多情况下,广告会带来一定的垃圾流量,比如因为关键词的广泛匹配,或者投放渠道可能不是产品目标人群等。
第一步、我们要注意时刻检测流量质量,从客服系统的数据中剖析缘由。
比如:根据剖析不同时段、日期的流量趋势变化形态,通过客服系统详尽了解网站流量的累计过程,从而摸透访客的访问规律,流量变动规律和缘由、网站的发展状况等。

[数据统计]-[流量剖析]-[按时间段剖析]
或按照剖析在线客服系统不同来源项(搜索引擎、友情链接、来源类型、终端类型)引入流量的情况,分析不同来源的流量数目和质量,进而合理优化和选择推广渠道
[数据统计]-[流量剖析]-[按来源类型剖析]
综合多维度、多指标的流量数据剖析,有助于观察不同的流量变化趋势,分析流量质量,并作为调整广告投放策略的根据。

[数据统计]-[流量剖析]-[按时段](可自定义显示列)

[数据统计]-[流量剖析]-[近7天渠道趋势]
通常我们拿来判定页面的流量质量低的指标收录:低PV数、低平均访问页数、高跳出率、低平均访问时长等。遇到低质量流量形成的情况,需要先排查以下这三点:
一、渠道引流上呈现的关键词创意与落地页是否匹配;
二、投放的渠道和投放关键词是否是目标用户活跃的范围和兴趣点,即投放是否精准;
三、落地页出错以及其他诱因(收录但不限于网站打开速率慢、页面错误过期,跳转出错等)。
这里有一个十分重要的指标:[关键词]。结合关键词流量与对话两个维度的数据,集中投放带来高对话量(有效流量)的关键词,控制高消费低对话量(无效流量)的关键词消费。

[数据统计]-[流量剖析]-[按关键词统计]
关键词代表着用户的需求,是sem推广投放的核心。那么选择什么样的关键词就变得至关重要。
例如品牌词的意向高转化率高而且流量小,产品词的流量大点击率高而且竞争激烈。每类词都各有特征,需要适当的进行搭配能够达到最好的引流疗效。
因此,在合理安排关键词策略时,可以结合在线客服系统提供的访客搜索词到着陆页的浏览轨迹来看
[设置中心]-[搜索关键词]-[关键词点击报表]
因为访客一般会选择各网站比价钱和口碑,确认完信息然后认为xx可能更适宜,直接搜索xx品牌,点击品牌词步入网站咨询。这个过程中,访客完成从产品词到品牌词的点击轨迹,产品词对品牌词形成了间接转化贡献。
通过在线客服系统剖析访客浏览轨迹,可以剖析产品词投放对品牌词形成的影响,特别在费用控制时,有效评估品牌市流量的变化和目标设定。
另外,如果一个看着意向度很高的词转化率低到使你大跌眼镜,那么该关掉一些引流的工具就关掉,该收缩匹配方法就要及时的收。
优化着陆页
在碎片化和用户注意力难以捉摸的明天,着陆页的选择对于企业网路营销起着至关重要的作用。推广竞价的目的是把目标顾客带到我们的网站上来,着陆页承载的是消费者对你网站和业务的第一印象。

[数据统计]-[关键词分析]-[跳出率]
持续进行帐户优化的同时,我们除了可以通过关键词跳出率的高低来评判流量是否精准,还可以评判网站页面质量是否优质。
当关键词跳出率偏低的时侯,要考虑到是否是着陆页质量影响流量转化疗效。理想的着陆页应当具备以下要素:
一、内容相关性:合理搭配关键词、方便快速找到想了解的相关内容,内容有价值、没有过多的广告;
二、访客体验感:网站加载速率快、收录清晰的导航栏、页面设计美观、内容精简且富于创意、扬长避短;
三、交互能力:与访客产生共同利益点、突出指出“点击原因”、引导咨询、能够即时有在线沟通(咨询窗口合理)。
还可以结合[访问轨迹]、[对话网址]、[对话历史]等数据,观察网站不同页面形成对话量的情况,分析才能形成对话的优质页面并做相应的关键词推广和布局调整,减少访客抵达优质内容页的路径,缩短转化流程

[查看历史]-[访客历史对话]
根据不同目标受众,可以“投其所好”的设置不同的关键词着陆页。比如,根据不同的产品设计不同风格的网站,多个网站同时进行引流;或依据企业营销计划,在重点活动期间更换不同设计的在线客服系统着陆页。

快商通免费提供10+套风格式样:
[生成代码]-自定义款式、风格券
这里须要注意的是,不管是优先推广那个网页,都须要在全站提供方便的咨询入口。根据不同的网页设计风格,灵活搭配咨询入口、邀请框、浮动图标款式(并注意它们的统一)等,吸引访客点击咨询。
企业通过推广获得流量——从流量中获得咨询——从咨询中获得线索——从线索中获得订单,当我们步入网路营销漏斗的最后一环,有效沟通就是成交的关键,也是网路营销疗效的首要标准,而对话数目又是对话质量的前提。
随着互联网时代的发展,客服中心正在从“成本中心”走向“利润中心”,越来越得到企业的注重:
一方面,在线客服通过网站建立访客与企业内部即时交流的平台,是第一时间为访客提供服务、解决问题的人;另一方面,通过与顾客沟通交流,无形之中实现品牌的输出,也是网路营销重要目标。
总结:
提升网站对话量涉及到多个环节,我们除了须要具备流量控制、流量质量剖析、页面前往剖析、页面承载剖析、页面转化剖析等多种能力,还须要为前往网站的访客构建有效的沟通渠道,提供引导性的高质量服务。
如何按照文本内容手动生成关键词或标签?
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2020-08-12 06:38
1. 基于统计的tf * idf
2. 基于pagerank的textrank算法
但是完全依赖于上述算法,会有一些问题:
1. 新词问题: 如一些网路新词(怒怼、种草、多闪、4AM)由于早期切词错误,会导致本身切块,从而难以召回结果,此时,采用PMI,左右熵来辅助做一个新词发觉,进而补充词库极其重要
2. 实体问题:一些实体词,天然就应当被当作关键词抽取下来(如描述姚明的文章,那么姚明是一个人名,这个人名是一个PER,是一个实体),采用ontonotes 或者是CTB等公开数据集,顺便再加点当前自有的语料训练一个序列标明的模型就变得很重要了
3. 相关性问题:因为抽取得到的关键词,需要和当前的文本足够相关,如果轻率采用TF*IDF或则TextRank,其实难以解决好多的相关性的case(传统搜索引擎的相关性算法采用TFIDF来做,而不融入一些别的算法,会导致一些case搞不定),举个反例(美的,这个term即是一个实体,又是一个形容词,TF*IDF值也比较高,对于一个不是描述空调或则家用电器的文章,抽取得到美的这个是不make sense的),因此,我们须要有一个相关性模型(融合好多的特点来对抽取的词和当前文章做相关性估算并排序,筛选top K 作为关键词)
至于上述所说的通过 “范式” 来推演得到 “数据库”,这个就弄成了另一个层面的东西了,想要做的好,需要有如下几个步骤:
1. 有一个分类体系,就是见到当前这篇文章,可以把当前文章可以分为 哪一类 ,科技类/数据库,但是本身这些概念性的东西比较多,也比较泛
2. 人工建立一套标签体系,采用类似于embedding的思路,只要出现范式就把其归到数据库一类,因为embedding中,范式和数据库足够逾,另外也须要用一些知识图谱中的数据,辅助减少一些badcase
3. 另外,用一些topic model的形式,来做向下聚合也会有一定的疗效 查看全部
纵观目前业界流行的关键词抽取方式,基本的逻辑逃脱不了二种:
1. 基于统计的tf * idf
2. 基于pagerank的textrank算法
但是完全依赖于上述算法,会有一些问题:
1. 新词问题: 如一些网路新词(怒怼、种草、多闪、4AM)由于早期切词错误,会导致本身切块,从而难以召回结果,此时,采用PMI,左右熵来辅助做一个新词发觉,进而补充词库极其重要
2. 实体问题:一些实体词,天然就应当被当作关键词抽取下来(如描述姚明的文章,那么姚明是一个人名,这个人名是一个PER,是一个实体),采用ontonotes 或者是CTB等公开数据集,顺便再加点当前自有的语料训练一个序列标明的模型就变得很重要了
3. 相关性问题:因为抽取得到的关键词,需要和当前的文本足够相关,如果轻率采用TF*IDF或则TextRank,其实难以解决好多的相关性的case(传统搜索引擎的相关性算法采用TFIDF来做,而不融入一些别的算法,会导致一些case搞不定),举个反例(美的,这个term即是一个实体,又是一个形容词,TF*IDF值也比较高,对于一个不是描述空调或则家用电器的文章,抽取得到美的这个是不make sense的),因此,我们须要有一个相关性模型(融合好多的特点来对抽取的词和当前文章做相关性估算并排序,筛选top K 作为关键词)
至于上述所说的通过 “范式” 来推演得到 “数据库”,这个就弄成了另一个层面的东西了,想要做的好,需要有如下几个步骤:
1. 有一个分类体系,就是见到当前这篇文章,可以把当前文章可以分为 哪一类 ,科技类/数据库,但是本身这些概念性的东西比较多,也比较泛
2. 人工建立一套标签体系,采用类似于embedding的思路,只要出现范式就把其归到数据库一类,因为embedding中,范式和数据库足够逾,另外也须要用一些知识图谱中的数据,辅助减少一些badcase
3. 另外,用一些topic model的形式,来做向下聚合也会有一定的疗效
江阴SEO:哪些优化方法会被百度认定作弊?
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2020-08-12 00:12
1、复制站点或网页
常见的站点属于镜像站点,通过复制站点和页面的内容并将其分成不同的域名和服务器,它误导搜索引擎多次索引同一个站点或同一个页面。目前,许多搜索引擎都配备了就能测量镜像站点的适当过滤系统。一旦找到镜像站点,源站点和镜像站点都将从索引数据库中删掉。
2、采集内容
目前,许多网站没有精力去写文章来丰富网站的内容,但她们只能搜集文章,但她们希望对搜集到的文章进行二次编辑,并降低一些看法。
3、欺骗性重定向
用户登入也页面,快速转入内容完全不同的页面。另一种重定向行为是欺骗性的,如果用户宣称早已联通到新域名之下,并且用户通过单击新域名的链接来直接访问该站点,并且用户步入后才发觉该链接是会员链接。
4、使用免费cdn技术
许多人说cdn可以推动网站的访问速率,有利于用户体验。然而,免费的cdn有时不稳定,有些地区不能打开网站。只要网站的速率依然可以接受,不要使用免费的cdn。如果有必要,建议做付费cdn。
5、误导性或重复性关键词
(1)误导性关键词
页面使用与该页面无关的欺骗流行关键字来吸引访问该主题的用户和流量。这种做法严重影响了搜索引擎提供结果的相关性和客观性,严重影响了用户体验完全误导用户的行为。这种做法被搜索引擎深恶痛绝。
(2)重复性关键词
这样的作弊技术是我们常常讨论的关键词堆积现象,利用搜索引擎在网页正文的标题中找出关键词的高度,强行重复关键词。 其他方式还包括在HTML元标签上堆积大量关键字,或者使用多个关键字元标签来提升关键字的相关性。这种误导技术很容易被搜索引擎察觉并遭到相应的惩罚。
6、关键词拼凑
这是一个老话题,也是常见的SEO优化作弊方式之一。您可以在短期获取关键字列表,但潜在风险特别高。一旦你被判作弊,准备工作都会枉费。适当的关键字密度有利于关键字排序的推广,但过量的关键字被堆积,这是太危险的。
7、购买友情链接
现在外链的释放越来越困难。很多网站管理员只能选购一些友情链接,但是她们在订购时应当注意上传链接的频度。例如,如果你一次订购50个链接,而对方一次添加你的网站,那么朋友链的忽然降低就不正常了。
优化网站需要一步步来,用白帽SEO优化的方法做,网站内部基础,布局,关键词等,也要确保用户体验,让网站排名提高,不要去碰触搜索引擎底线。 查看全部
网络营销兴起的年代企业纷纷做起加入队列,行业间竞争不断扩大,很多企业SEO优化的知识量不够深,导致网站关键词排行提高很难,安耐不住孤寂做起快排,要知道搜索引擎不断做调整,一旦判断是作弊,那么网站轻则降权重则K站。
1、复制站点或网页
常见的站点属于镜像站点,通过复制站点和页面的内容并将其分成不同的域名和服务器,它误导搜索引擎多次索引同一个站点或同一个页面。目前,许多搜索引擎都配备了就能测量镜像站点的适当过滤系统。一旦找到镜像站点,源站点和镜像站点都将从索引数据库中删掉。

2、采集内容
目前,许多网站没有精力去写文章来丰富网站的内容,但她们只能搜集文章,但她们希望对搜集到的文章进行二次编辑,并降低一些看法。
3、欺骗性重定向
用户登入也页面,快速转入内容完全不同的页面。另一种重定向行为是欺骗性的,如果用户宣称早已联通到新域名之下,并且用户通过单击新域名的链接来直接访问该站点,并且用户步入后才发觉该链接是会员链接。
4、使用免费cdn技术
许多人说cdn可以推动网站的访问速率,有利于用户体验。然而,免费的cdn有时不稳定,有些地区不能打开网站。只要网站的速率依然可以接受,不要使用免费的cdn。如果有必要,建议做付费cdn。
5、误导性或重复性关键词
(1)误导性关键词
页面使用与该页面无关的欺骗流行关键字来吸引访问该主题的用户和流量。这种做法严重影响了搜索引擎提供结果的相关性和客观性,严重影响了用户体验完全误导用户的行为。这种做法被搜索引擎深恶痛绝。
(2)重复性关键词
这样的作弊技术是我们常常讨论的关键词堆积现象,利用搜索引擎在网页正文的标题中找出关键词的高度,强行重复关键词。 其他方式还包括在HTML元标签上堆积大量关键字,或者使用多个关键字元标签来提升关键字的相关性。这种误导技术很容易被搜索引擎察觉并遭到相应的惩罚。

6、关键词拼凑
这是一个老话题,也是常见的SEO优化作弊方式之一。您可以在短期获取关键字列表,但潜在风险特别高。一旦你被判作弊,准备工作都会枉费。适当的关键字密度有利于关键字排序的推广,但过量的关键字被堆积,这是太危险的。
7、购买友情链接
现在外链的释放越来越困难。很多网站管理员只能选购一些友情链接,但是她们在订购时应当注意上传链接的频度。例如,如果你一次订购50个链接,而对方一次添加你的网站,那么朋友链的忽然降低就不正常了。
优化网站需要一步步来,用白帽SEO优化的方法做,网站内部基础,布局,关键词等,也要确保用户体验,让网站排名提高,不要去碰触搜索引擎底线。
网站建设被K网站如何快速恢复收录和排行
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2020-08-12 00:02
六、关键词密度过大
网站不能堆积关键词,刚刚开始有可能你的网站会有排行,但是十分容易被惩罚的。谨慎慎重
七、网站频繁改动
网站频繁改动,这而且SEO的三忌,就像有个SEO优化老师给我说,网站刚刚开始不要想着模板是不是好看,不重要,只要网站排名起来了,有一定的流量了,这时候就有必要该网站的模板,因为这个时侯你的网站每天都有一定的人群浏览,为了用户体验你也得把网站模板改的好一点。
八、网站描文本内容单一
比方说你的网站所有网站描文本都只做一个关键词,这个被发觉后,就会被觉得是机器操作的都会被惩罚。
九、网站服务器不稳定
网站服务器的环境不稳定,会导致网站有时候进的去网站有时候进不去网站,导致用户体验特别不好。
根据以上列出的网站被K缘由,从缘由中入手判定网站是否具备着恢复的可能性,骏 域网路优化常规化的K站大多数采集、垃圾外链、关键词优化过度、关键词密度、网站频繁改动等系列缘由,使用原创稳定更新方式通常三个月即可实现重新收录和重新排行。被K网站恢复方式除此之外,网站优化能够够通过文章优化、外链优化、百度站长申述等普通的形式解决。
1、页面链接过多,一般一个页面上的链接不能超过五十个,这是得到好多站长的肯定认可的,太多的外链导入会使自己的网站权重增加,还有就是文章的内链通常维持在三个以内。
2、文章的原创度,切忌盲目复制他人的内容,及时没有过多的时间来做原创内容,也要对复制的文章进行一定地更改。
3、网站上切莫不要有违规、违反中国法律的内容,这样难以使百度收录。
4、在帖吧以及百度知道上四处留下自己网站的痕迹会提高被百度K的可能性,凡事都要有个度,适量即可,新站通常都是先耐心等待收录,收录以后再做适当的推广。
5、整站都是他人网站的内容。我想大多数的搜索引擎都不喜欢重复喝一样的东西,做网站就是要持之以恒,坚持原创,这样就能赢得搜索引擎的偏爱。
6、使用手动跳转的页面,很有可能被百度K掉。
7、过度的优化。还是那句话,凡事都要有个度,如果你对网站进行大量的优化,却引起使用户有不良的体验,那么被百度K也是迟早的事情,做好用户体验也是提高权重的一大关键。
8、切忌与一些垃圾站交换友情链接,对自己网站的不良影响甚大。
9、定时检测站上的友情链接,对一些深受百度惩罚以及被K的链接要及时除去,还有防止站上死链的出现,同样要及时除去。
网站建设过程中防止不了会形成一定违背搜索引擎的手段,在seoer的眼里,能够作为提升网站价值的方式都是值得借助和使用的办法,比如锚文本和内链,其不仅仅只是为了给搜索引擎来抓取,更是为现代网站用户提供便捷。深圳网站建设公司觉得:如果在网站建设期倒霉了,网站被K惩罚了,这个时侯不用惊慌,分析下你的网站最近都做哪些操作了,修改哪些了之后指定相关方案更改过来,在继续发布优质文章,发布好外链。还有可以关注下搜索引擎是否算法调整造成刺伤,端正态度,继续优化好网站。 查看全部
首页优化过度,会导致网站权重非常分散,导致网站排名上不去,或者被搜索引擎惩罚。
六、关键词密度过大
网站不能堆积关键词,刚刚开始有可能你的网站会有排行,但是十分容易被惩罚的。谨慎慎重
七、网站频繁改动
网站频繁改动,这而且SEO的三忌,就像有个SEO优化老师给我说,网站刚刚开始不要想着模板是不是好看,不重要,只要网站排名起来了,有一定的流量了,这时候就有必要该网站的模板,因为这个时侯你的网站每天都有一定的人群浏览,为了用户体验你也得把网站模板改的好一点。
八、网站描文本内容单一
比方说你的网站所有网站描文本都只做一个关键词,这个被发觉后,就会被觉得是机器操作的都会被惩罚。
九、网站服务器不稳定
网站服务器的环境不稳定,会导致网站有时候进的去网站有时候进不去网站,导致用户体验特别不好。
根据以上列出的网站被K缘由,从缘由中入手判定网站是否具备着恢复的可能性,骏 域网路优化常规化的K站大多数采集、垃圾外链、关键词优化过度、关键词密度、网站频繁改动等系列缘由,使用原创稳定更新方式通常三个月即可实现重新收录和重新排行。被K网站恢复方式除此之外,网站优化能够够通过文章优化、外链优化、百度站长申述等普通的形式解决。
1、页面链接过多,一般一个页面上的链接不能超过五十个,这是得到好多站长的肯定认可的,太多的外链导入会使自己的网站权重增加,还有就是文章的内链通常维持在三个以内。
2、文章的原创度,切忌盲目复制他人的内容,及时没有过多的时间来做原创内容,也要对复制的文章进行一定地更改。
3、网站上切莫不要有违规、违反中国法律的内容,这样难以使百度收录。
4、在帖吧以及百度知道上四处留下自己网站的痕迹会提高被百度K的可能性,凡事都要有个度,适量即可,新站通常都是先耐心等待收录,收录以后再做适当的推广。
5、整站都是他人网站的内容。我想大多数的搜索引擎都不喜欢重复喝一样的东西,做网站就是要持之以恒,坚持原创,这样就能赢得搜索引擎的偏爱。
6、使用手动跳转的页面,很有可能被百度K掉。
7、过度的优化。还是那句话,凡事都要有个度,如果你对网站进行大量的优化,却引起使用户有不良的体验,那么被百度K也是迟早的事情,做好用户体验也是提高权重的一大关键。
8、切忌与一些垃圾站交换友情链接,对自己网站的不良影响甚大。
9、定时检测站上的友情链接,对一些深受百度惩罚以及被K的链接要及时除去,还有防止站上死链的出现,同样要及时除去。
网站建设过程中防止不了会形成一定违背搜索引擎的手段,在seoer的眼里,能够作为提升网站价值的方式都是值得借助和使用的办法,比如锚文本和内链,其不仅仅只是为了给搜索引擎来抓取,更是为现代网站用户提供便捷。深圳网站建设公司觉得:如果在网站建设期倒霉了,网站被K惩罚了,这个时侯不用惊慌,分析下你的网站最近都做哪些操作了,修改哪些了之后指定相关方案更改过来,在继续发布优质文章,发布好外链。还有可以关注下搜索引擎是否算法调整造成刺伤,端正态度,继续优化好网站。
Links Auto Replacer 自动给文章的关键词添加链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2020-08-11 13:12
总所周知,网站内链(指网站内部的相关信息相互联接)是十分重要的,不仅针对于SEO优化,对于用户的访问也是十分有利的,你可以将文章中出现的一些关键添加上联接,这样那些重要的信息就能否被用户点击所看见,增强网站内容的黏性,让用户才能更容易的找到你的内容。
如果我们自动进行关键词的链接添加,这无疑是一个十分繁杂的工作,因此我们在此介绍一款插件,这款插件才能手动的给你的文章出现的关键添加指定的链接。
之前我们有介绍一款wordpress插件: WP Keyword Link ,但经过用户的反馈其实早已不能再使用了,因此我们这儿再介绍一款插件:Links Auto Replacer 可以在最新版本的wordpress上继续使用。
Links Auto Replacer 自动给文章的关键词添加链接
市面上有不少的wordpress插件可以做到添加关键词的功能,但好多的插件并不才能支持英文,因此我们所介绍的这款插件是可以支持英文的。
插件可以自定义关键词,你可以统计你的文章内所出现的关键词数目,并经过筛选重要的关键词和她们所须要去的介绍页面,在插件中设置好,这样插件都会手动将你的网站文章扫描,检测出关键词并添加链接。
插件安装,在wordpress后台--插件--安装插件处搜索Links Auto Replacer,或者在我们的云盘下载汉化版本(网络整理)
安装启用以后,进入手动联接选项,可以查看早已创建的手动联接,也可以新建一个手动联接:
由于早已有了英文版本,因此这款wordpress插件十分简单能够够设置好了。
设置好了以后,文章中所出现的关键词就能否被手动添加上联接了。
希望这款插件才能帮助到你建设好你的wordpress网站内链。 查看全部
wordpress网站内链的建设
总所周知,网站内链(指网站内部的相关信息相互联接)是十分重要的,不仅针对于SEO优化,对于用户的访问也是十分有利的,你可以将文章中出现的一些关键添加上联接,这样那些重要的信息就能否被用户点击所看见,增强网站内容的黏性,让用户才能更容易的找到你的内容。
如果我们自动进行关键词的链接添加,这无疑是一个十分繁杂的工作,因此我们在此介绍一款插件,这款插件才能手动的给你的文章出现的关键添加指定的链接。
之前我们有介绍一款wordpress插件: WP Keyword Link ,但经过用户的反馈其实早已不能再使用了,因此我们这儿再介绍一款插件:Links Auto Replacer 可以在最新版本的wordpress上继续使用。
Links Auto Replacer 自动给文章的关键词添加链接
市面上有不少的wordpress插件可以做到添加关键词的功能,但好多的插件并不才能支持英文,因此我们所介绍的这款插件是可以支持英文的。
插件可以自定义关键词,你可以统计你的文章内所出现的关键词数目,并经过筛选重要的关键词和她们所须要去的介绍页面,在插件中设置好,这样插件都会手动将你的网站文章扫描,检测出关键词并添加链接。
插件安装,在wordpress后台--插件--安装插件处搜索Links Auto Replacer,或者在我们的云盘下载汉化版本(网络整理)
安装启用以后,进入手动联接选项,可以查看早已创建的手动联接,也可以新建一个手动联接:
由于早已有了英文版本,因此这款wordpress插件十分简单能够够设置好了。
设置好了以后,文章中所出现的关键词就能否被手动添加上联接了。
希望这款插件才能帮助到你建设好你的wordpress网站内链。
芭奇站群管理系统下载 18.11.13 绿色版
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2020-08-11 13:11
芭奇站群管理系统无需绑定笔记本或IP,不限网站数量,可以24小时挂机采集维护,让站长可以太轻松就管理上百个网站。软件奇特的内容抓取引擎,能及时确切的抓取互联网上比较新的内容,配合外置的文章伪原创功能,能大大降低网站的收录,为站长带来更多流量!
核心功能
无限制降低域名、网站,中文站群采集,英文站群采集,指定网址采集,自定义发布插口,自定义生成原创文章,长尾关键词采集,相关图片采集,全局SEO链轮,文章自动加入内链,随机提取内容作为标题,不同内容段落互换,随机插入指定关键字,定时发布文章,自动内容伪原创,分组参数设置,分组链接库互链,全手动监控挂机采集发布,自动更新网站首页栏目内页静态化等等。
使用说明
值守手动重启站群会手动在system用户下手动启动挂机,
实现真正的无人值守挂机
3,完善站群挂机监控器的部份功能,新增家用笔记本开机
自启动与服务器vps开机启动的分辨
更新日志
1、增加指定采集指定IE的功能(分组参数1.4.4)
2、增加指定域名3个屏蔽错误功能(勾选会手动保存),用于前台采集的网站规则
3、增加至尊版的标题与内容转换为unicode功能
4、增加至尊版的内容前后可插入大量自定义HTML随机标签功能
5、增加单站图片库与单站视频库
6、增加至尊版多线程挂机同机敌视功能,防止同一台服务器网站同时发布
7、增加至尊版单文章重组合的伪原创比率控制,可控制文章部份可读性
8、优化栏目文章库受损手动创建功能
9、修复指定采集图片过滤数字的BUG
10、修复批量导入TXT后没有清空内容设已发布的BUG
11、修复4.1四个插口批量多站执行的BUG
12、修复文本工具提示异常的BUG
13、增加文件工具多路径定义,实现多模板克隆批量建站
14、增加文本工具删掉含XX关键字所在行的功能
15、优化分组和子分组归属网站问题
16,指定域名列表地址与内容地址手动辨识的过滤替换支持键值星号
17,修复所有导出富含单引号的失败问题
18,修复超级伪原创只勾选标题伪原创后内容为空的问题
19、其他部分小功能细节优化修补等
文件信息
文件大小:4427776 字节
文件说明:启动程序
文件版本:1.0.0.0
MD5:612233482D1D53299BAF680EA3EBE975
SHA1:2438CB4B1DEACFE1FC174FFE80640B4BEAB8C758
CRC32:5D63A2A1
官方网站:
相关搜索:站群 查看全部
芭奇站群管理系统是一套仅需输入关键词,即可采集到比较新相关内容,并手动SEO发布到指定网站的多任务站群管理系统,可24小时不间断的全手动维护数百个网站。芭奇站群管理系统能按照设置的关键词手动抓取各大搜索引擎的相关搜索词以及相关长尾词,然后依照衍生出的词来抓取大量的比较新数据,完全摈弃普通采集软件所需的冗长规则订制,实现一键采集一键发布。

芭奇站群管理系统无需绑定笔记本或IP,不限网站数量,可以24小时挂机采集维护,让站长可以太轻松就管理上百个网站。软件奇特的内容抓取引擎,能及时确切的抓取互联网上比较新的内容,配合外置的文章伪原创功能,能大大降低网站的收录,为站长带来更多流量!

核心功能
无限制降低域名、网站,中文站群采集,英文站群采集,指定网址采集,自定义发布插口,自定义生成原创文章,长尾关键词采集,相关图片采集,全局SEO链轮,文章自动加入内链,随机提取内容作为标题,不同内容段落互换,随机插入指定关键字,定时发布文章,自动内容伪原创,分组参数设置,分组链接库互链,全手动监控挂机采集发布,自动更新网站首页栏目内页静态化等等。
使用说明
值守手动重启站群会手动在system用户下手动启动挂机,
实现真正的无人值守挂机
3,完善站群挂机监控器的部份功能,新增家用笔记本开机
自启动与服务器vps开机启动的分辨
更新日志
1、增加指定采集指定IE的功能(分组参数1.4.4)
2、增加指定域名3个屏蔽错误功能(勾选会手动保存),用于前台采集的网站规则
3、增加至尊版的标题与内容转换为unicode功能
4、增加至尊版的内容前后可插入大量自定义HTML随机标签功能
5、增加单站图片库与单站视频库
6、增加至尊版多线程挂机同机敌视功能,防止同一台服务器网站同时发布
7、增加至尊版单文章重组合的伪原创比率控制,可控制文章部份可读性
8、优化栏目文章库受损手动创建功能
9、修复指定采集图片过滤数字的BUG
10、修复批量导入TXT后没有清空内容设已发布的BUG
11、修复4.1四个插口批量多站执行的BUG
12、修复文本工具提示异常的BUG
13、增加文件工具多路径定义,实现多模板克隆批量建站
14、增加文本工具删掉含XX关键字所在行的功能
15、优化分组和子分组归属网站问题
16,指定域名列表地址与内容地址手动辨识的过滤替换支持键值星号
17,修复所有导出富含单引号的失败问题
18,修复超级伪原创只勾选标题伪原创后内容为空的问题
19、其他部分小功能细节优化修补等
文件信息
文件大小:4427776 字节
文件说明:启动程序
文件版本:1.0.0.0
MD5:612233482D1D53299BAF680EA3EBE975
SHA1:2438CB4B1DEACFE1FC174FFE80640B4BEAB8C758
CRC32:5D63A2A1
官方网站:
相关搜索:站群
怎么抓取亚马逊关键词:亚马逊关键词是怎样做
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2020-08-10 23:58
好的标题直接才能在搜索排序中获得好的位置。到底是用长关键字还是用短关键字,用冒号分隔还是用空格分隔。search term 就是一个搜索引擎的关键字抓取的地方,当然是关键字越多越好,至于关键字长短倒不是很重要,但是要注意重复的关键字出现,那会被觉得是关键字作弊2,用冒号属于精准定位,用户搜索的时侯只有符号之间的关键是是有效的,只有用户输入全部的时侯才能搜索到,如果用户输入phone case katoon,那就可能搜不到了,如果用空格表示模糊搜索,关键字的任意组合都可能被搜索到,用户搜索phone case katoon或则katoon,则会被亚马逊搜索到。三.再来说一下找关键词的方式:1、使用微软关键词规划词,建议广告单词时微软会给到你精准的推荐2、在亚马逊前台搜索栏:输入关键词会出现下拉菜单。大家是如何爬取亚马逊(美国)的数据做第一个规则把商品列表的网址全爬出来,并且设置层级规则,把网址手动导出到第二个规则那儿,然后选择其中一个网址,打开做第二个规则。 查看全部
亚马逊关键词是怎样做亚马逊的流量来源见右图。要做好流量,只有做好各个细分的内容之后谈谈亚马逊关键字设置1.亚马逊关键字分两大块,一块是标题,这是最最重要的关键字,设置标题关键字的时侯最好的方式是品牌+ 名称+重要属性1,3+相关名称 +功能+参数好的标题直接才能在搜索排序中获得好的位置。到底是用长关键字还是用短关键字,用冒号分隔还是用空格分隔。search term 就是一个搜索引擎的关键字抓取的地方,当然是关键字越多越好,至于关键字长短倒不是很重要,但是要注意重复的关键字出现,那会被觉得是关键字作弊其次,用冒号属于精准定位,用户搜索的时侯只有符号之间的关键是是有效的,只有用户输入全部的时侯才能搜索到,如果用户输入phone case katoon,那就可能搜不到了。如何通过亚马逊前后台获取关键词?不同的人有不同的方式寻找关键词,而用第三方工具查找的关键词不是非常的全面,其实直接通过前台和后台也是可以获取关键词的,基本不会偏离系统的算法,获取的关键词对前期编辑listing和后期优化listing、广告都是够用了!亚马逊关键词选定工具有什么?紫鸟数据魔方官网—百度搜索:是Amazon数据剖析最好的关键词挖掘工具,挖掘出亚马逊当前最热搜关键词,为买家提供最及时确切的热搜关键词,紫鸟数据亚马逊产品剖析:是经过数万买家常年使用并一致推荐的亚马逊产品剖析工具,能全面展示剖析产品当前价钱、Rank、评论数和预估销售量等核心数据,紫鸟数据亚马逊热销排行榜:如何用python爬虫抓取亚马逊美国站关键词排行选择合适的关键词,确认用户搜索次数达到一定的数量级。找到搜索次数比较多,才能在一定的预算和周期下取得较好的疗效。亚马逊采集关键词?关键词采集商家是如何做到的?根据自己的产品信息和特征,选择合适的关键词,确认用户搜索次数达到一定的数量级。作为亚马逊买家,找到搜索次数比较多,同时难度不太大的关键词,才能在一定的预算和周期下取得较好的疗效。同时有效借助整合营销,结合社交媒体充分爆光商店信息和产品优势,争取获得更广的爆光和更多的点击。亚马逊产品关键词如何找一.亚马逊关键字分两大块,一块是标题,这是最最重要的关键字,设置标题关键字的时侯最好的方式是:品牌+ 名称+重要属性1,3+相关名称 +功能+参数
好的标题直接才能在搜索排序中获得好的位置。到底是用长关键字还是用短关键字,用冒号分隔还是用空格分隔。search term 就是一个搜索引擎的关键字抓取的地方,当然是关键字越多越好,至于关键字长短倒不是很重要,但是要注意重复的关键字出现,那会被觉得是关键字作弊2,用冒号属于精准定位,用户搜索的时侯只有符号之间的关键是是有效的,只有用户输入全部的时侯才能搜索到,如果用户输入phone case katoon,那就可能搜不到了,如果用空格表示模糊搜索,关键字的任意组合都可能被搜索到,用户搜索phone case katoon或则katoon,则会被亚马逊搜索到。三.再来说一下找关键词的方式:1、使用微软关键词规划词,建议广告单词时微软会给到你精准的推荐2、在亚马逊前台搜索栏:输入关键词会出现下拉菜单。大家是如何爬取亚马逊(美国)的数据做第一个规则把商品列表的网址全爬出来,并且设置层级规则,把网址手动导出到第二个规则那儿,然后选择其中一个网址,打开做第二个规则。
信息门户网站自动生成系统的研究.pdf
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2020-08-10 20:00
摘要随着信息技术的不断发展,特别是/应用的普及,网上信息呈指数级下降。如何高效的借助和检索这种海量的信息,成为一个极为重要的问题,信息门户网站很好的解决了这个问题。它一般为用户提供对互联网上信息的密集访问方法,通过将来自不同信息源的同类信息集中在一个网站上,帮助用户通过统一的入口访问来自不同网站的信息,而无需挨个去访问单独的网站。信息门户网站极大的促进了互联网的发展,成为网路发展史上的一座罩程碑,因而对信息门户网站的研究具有重要的理论意义和实用价值。信息门户网站不仅仅是一个网站,更是一个知识和信息的“集中营”,因而本文从后台信息资源的组织和整合以及前台网站的设计和建设这两个方面着手进行研究,将本系统主要分为三个模块:用户界面、客户端模块和服务器端模块。用户界面即前台的信息门户网站,它具有动态生成的功能,提供给用户动态交互的操作;客户端模块主要实现信息的过滤,它还能对用户输入的自然语言句子进行语义辨识让之成为计算机才能检索的关键词对;服务器端模块主要实现对力.维网北京量信息的智能检索。本文首先研究和讨论了基于自然语言的语义剖析方式,对汉语的自动分词方式进行了侧重讨论和剖析,并给出了一种基于反向最大匹配法的动词方式在本系统中的应用展望,提出动词的关键还须要一个完整合理的动词辞典。其次研究和讨论了万维网上的智能检索技术,针对当前万维网上的信息检索的若干缺陷提出了客户端和服务器端处理技术,并结合软件和数据库系统设计开发了一套后台的智能枪索软件系统,它通过对网页采集工具所搜集到的网页进行智能分类和检索,实验证明,该系统具有一定的智能性。最后从网站的设计和建设方面介绍了基于疟编程语言的信息门户网站设计的关键技术技巧并给出了具体的设计步骤和实现。关键词:语义剖析,分词,智能检索,门户网站武汉理工大学硕士学位论文
,甀舶琤.武汉理笱妒垦宦畚甀琱”.也.,瓾..“甌,:’琧..甀’
甀.武汉理笱妒垦宦畚甅:..瓵,,,
第一章总论课题选题的目的和意义众所周知,互联网的诞生是世纪信息技术的一座壮歌,它以前主要是科研人员进行学术交流的场所。近年来随着商业、娱乐和教育的加入,互联网开始弄成无所不包的“信息集散地”,许多有价值的科研信息逐步“淹没”在其他信息构成的“汪洋大海”中。当科研人员和普通的用户发觉找寻须要的有用信息越来越难的时侯,“门户呕荆畔⒚拧弧ⅲ”出现了,它一般为用户提供对互联网上信息和应用的“密集”访问方法,通过将来自不同信息源的信息集中在一个页面上,帮助用户通过统。的入口访问来自不同网站的信息,而无需挨个去访问单独的网站,这种类似“信息剪报”和“参考消息”的信息组织形式通过提供个性化服务和附加服务ü残畔ⅰ⒂始信息订阅等次没У姆梦屎褪褂茫悄壳暗幕チM靶戮谩焙汀白意力经济”的重要组成部份,它极大地推进了互联网的发展,成为网路发展史上的一座里程碑。无论是出于职业须要还是个人兴趣爱好,人们获取信息的基本规律是,在瓦联网上获取信息通常都是在不同的网站上浏览同样的内容,而不是在同一个网站上浏览全部的内容。比如说一个人是做计算机网路通信的,非常关心计算机网路通信方面的发展;而另一个人是做化工行业的,自然一直荚,化。幸捣矫娴男畔ⅲ庑┬枨笠仓换崴孀潘侵耙档谋浠⑸浠M样,每个人都有自己的兴趣和爱好,有人喜欢娱乐,有人喜欢绘画,有人喜欢卜澹庑┬巳ひ膊换崆嵋追⑸谋洹6呕荆墙ǚ浅E釉拥哪容置于一起,将内容信息分门别类地堆置于网站卜,再由用户自己去选购他所须要和感兴趣的内容。显然,信,亩户网站的建设必然要用到因特网上强悍的信息资源,而其对资源的整合优化有一定的要求。因特网发展余年来.规模以几何级数急速发展,成为一个重要的信息源。但因特网上的信息具有数目大、形式多、内容广、专业性不强等特征,给信息采集、分类、检索等工作带来了新的问题和挑战。年代搜索引擎应运而生,且在网路信息资源查找中起到了重要上海理上人学硕士学位论文
国内外信息门户网站的发展过程及现况提升检索的查准率、查全率,将具有较高的研究价值。信息门户网站自动生成系统作为国家“こ獭笔只际楣萁ㄉ璧难芯的作用,帮助人们从浩如烟海的网路信息中找到所要的信息。但搜索引擎在精度、易用性等方面仍存在众多问题,总体性能差,检索的查准率、查全率不高,从而其疗效不尽人意。鉴于此,如何提升搜索引擎的智能检索能力,信息门户网站的手动生成系统从本质上改变了传统的网站制作方法,使网站建设从技术型转向了面向内容的功能型。用户一蚩翁庾只要会使用浏览器就可以直接在线建成功能强悍专业知识集中的门户网站,因而从根本上消除了普通人员建设网站的壁垒,该系统让网站真『迪至硕项目具有深刻、长远和重大的现实意义。学科信息门户虺芐暌黄工程开始,就在法国范围内逐步普及,一大批面向物理、:炭蒲А⒁窖А社会科学的嗉探ⅰ5杲氲诙谑保琒早已在世界范围内呈“燎原”之势,在欧洲、欧洲、大洋洲广泛施行,据不完全统计,目前世界范围内有名的锏缴习俑觥R恍㏒还联合在一起构成更大的资源发觉网路缬⒐腞毖Э菩畔⒚呕У慕ㄉ瑁丫拥ゴ康难研究和课题项目,发展到大规模的建设任务,目前正在法国范围内丌展的项目就是典型。门户网站的建设须要有强悍的网路资源做其后盾,对网路资源智能化的程度有一定的要求。网上信息检索的关键技术主要包括:①信息搜集和储存技术,分人工和手动两种形式,其中手动方法是由“网络机器人”来完成的。②信息预处理技术,收录格式支持、转换和信息过滤。其中信息过滤是一项关键技术,网上大量的无用信息须要充分过滤能够有好的搜索结果。⑧信息索引技术,建立索引主要涉及信息语词切分和语词句型剖析;进行时态标明及相关自然语言处理:建立检索项索引;检索结果处理技术。其中检索结果处理技术是关键技术,其核心是根据估算结果与查询词的相关程度来排序。在此基础上智能检索技术的重点是对用户的查询计划、意图、用户兴趣等进行推理和猜想,并为用户提供有效的答案。为了实现此目的.目前早已提出武汉理工大学硕十学位论文 查看全部
文档介绍:
摘要随着信息技术的不断发展,特别是/应用的普及,网上信息呈指数级下降。如何高效的借助和检索这种海量的信息,成为一个极为重要的问题,信息门户网站很好的解决了这个问题。它一般为用户提供对互联网上信息的密集访问方法,通过将来自不同信息源的同类信息集中在一个网站上,帮助用户通过统一的入口访问来自不同网站的信息,而无需挨个去访问单独的网站。信息门户网站极大的促进了互联网的发展,成为网路发展史上的一座罩程碑,因而对信息门户网站的研究具有重要的理论意义和实用价值。信息门户网站不仅仅是一个网站,更是一个知识和信息的“集中营”,因而本文从后台信息资源的组织和整合以及前台网站的设计和建设这两个方面着手进行研究,将本系统主要分为三个模块:用户界面、客户端模块和服务器端模块。用户界面即前台的信息门户网站,它具有动态生成的功能,提供给用户动态交互的操作;客户端模块主要实现信息的过滤,它还能对用户输入的自然语言句子进行语义辨识让之成为计算机才能检索的关键词对;服务器端模块主要实现对力.维网北京量信息的智能检索。本文首先研究和讨论了基于自然语言的语义剖析方式,对汉语的自动分词方式进行了侧重讨论和剖析,并给出了一种基于反向最大匹配法的动词方式在本系统中的应用展望,提出动词的关键还须要一个完整合理的动词辞典。其次研究和讨论了万维网上的智能检索技术,针对当前万维网上的信息检索的若干缺陷提出了客户端和服务器端处理技术,并结合软件和数据库系统设计开发了一套后台的智能枪索软件系统,它通过对网页采集工具所搜集到的网页进行智能分类和检索,实验证明,该系统具有一定的智能性。最后从网站的设计和建设方面介绍了基于疟编程语言的信息门户网站设计的关键技术技巧并给出了具体的设计步骤和实现。关键词:语义剖析,分词,智能检索,门户网站武汉理工大学硕士学位论文
,甀舶琤.武汉理笱妒垦宦畚甀琱”.也.,瓾..“甌,:’琧..甀’
甀.武汉理笱妒垦宦畚甅:..瓵,,,
第一章总论课题选题的目的和意义众所周知,互联网的诞生是世纪信息技术的一座壮歌,它以前主要是科研人员进行学术交流的场所。近年来随着商业、娱乐和教育的加入,互联网开始弄成无所不包的“信息集散地”,许多有价值的科研信息逐步“淹没”在其他信息构成的“汪洋大海”中。当科研人员和普通的用户发觉找寻须要的有用信息越来越难的时侯,“门户呕荆畔⒚拧弧ⅲ”出现了,它一般为用户提供对互联网上信息和应用的“密集”访问方法,通过将来自不同信息源的信息集中在一个页面上,帮助用户通过统。的入口访问来自不同网站的信息,而无需挨个去访问单独的网站,这种类似“信息剪报”和“参考消息”的信息组织形式通过提供个性化服务和附加服务ü残畔ⅰ⒂始信息订阅等次没У姆梦屎褪褂茫悄壳暗幕チM靶戮谩焙汀白意力经济”的重要组成部份,它极大地推进了互联网的发展,成为网路发展史上的一座里程碑。无论是出于职业须要还是个人兴趣爱好,人们获取信息的基本规律是,在瓦联网上获取信息通常都是在不同的网站上浏览同样的内容,而不是在同一个网站上浏览全部的内容。比如说一个人是做计算机网路通信的,非常关心计算机网路通信方面的发展;而另一个人是做化工行业的,自然一直荚,化。幸捣矫娴男畔ⅲ庑┬枨笠仓换崴孀潘侵耙档谋浠⑸浠M样,每个人都有自己的兴趣和爱好,有人喜欢娱乐,有人喜欢绘画,有人喜欢卜澹庑┬巳ひ膊换崆嵋追⑸谋洹6呕荆墙ǚ浅E釉拥哪容置于一起,将内容信息分门别类地堆置于网站卜,再由用户自己去选购他所须要和感兴趣的内容。显然,信,亩户网站的建设必然要用到因特网上强悍的信息资源,而其对资源的整合优化有一定的要求。因特网发展余年来.规模以几何级数急速发展,成为一个重要的信息源。但因特网上的信息具有数目大、形式多、内容广、专业性不强等特征,给信息采集、分类、检索等工作带来了新的问题和挑战。年代搜索引擎应运而生,且在网路信息资源查找中起到了重要上海理上人学硕士学位论文
国内外信息门户网站的发展过程及现况提升检索的查准率、查全率,将具有较高的研究价值。信息门户网站自动生成系统作为国家“こ獭笔只际楣萁ㄉ璧难芯的作用,帮助人们从浩如烟海的网路信息中找到所要的信息。但搜索引擎在精度、易用性等方面仍存在众多问题,总体性能差,检索的查准率、查全率不高,从而其疗效不尽人意。鉴于此,如何提升搜索引擎的智能检索能力,信息门户网站的手动生成系统从本质上改变了传统的网站制作方法,使网站建设从技术型转向了面向内容的功能型。用户一蚩翁庾只要会使用浏览器就可以直接在线建成功能强悍专业知识集中的门户网站,因而从根本上消除了普通人员建设网站的壁垒,该系统让网站真『迪至硕项目具有深刻、长远和重大的现实意义。学科信息门户虺芐暌黄工程开始,就在法国范围内逐步普及,一大批面向物理、:炭蒲А⒁窖А社会科学的嗉探ⅰ5杲氲诙谑保琒早已在世界范围内呈“燎原”之势,在欧洲、欧洲、大洋洲广泛施行,据不完全统计,目前世界范围内有名的锏缴习俑觥R恍㏒还联合在一起构成更大的资源发觉网路缬⒐腞毖Э菩畔⒚呕У慕ㄉ瑁丫拥ゴ康难研究和课题项目,发展到大规模的建设任务,目前正在法国范围内丌展的项目就是典型。门户网站的建设须要有强悍的网路资源做其后盾,对网路资源智能化的程度有一定的要求。网上信息检索的关键技术主要包括:①信息搜集和储存技术,分人工和手动两种形式,其中手动方法是由“网络机器人”来完成的。②信息预处理技术,收录格式支持、转换和信息过滤。其中信息过滤是一项关键技术,网上大量的无用信息须要充分过滤能够有好的搜索结果。⑧信息索引技术,建立索引主要涉及信息语词切分和语词句型剖析;进行时态标明及相关自然语言处理:建立检索项索引;检索结果处理技术。其中检索结果处理技术是关键技术,其核心是根据估算结果与查询词的相关程度来排序。在此基础上智能检索技术的重点是对用户的查询计划、意图、用户兴趣等进行推理和猜想,并为用户提供有效的答案。为了实现此目的.目前早已提出武汉理工大学硕十学位论文
Scrapy之URL解析与递归爬取
采集交流 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2020-08-10 19:52
前面介绍了Scrapy怎样实现一个最简单的爬虫,但是这个Demo里只是对一个页面进行了抓取。在实际应用中,爬虫一个重要功能是”发现新页面”,然后递归的使爬取操作进行下去。
发现新页面的方式很简单,我们首先定义一个爬虫的入口URL地址,比如Scrapy入门教程中的start_urls,爬虫首先将这个页面的内容抓取以后,解析其内容,将所有的链接地址提取下来。这个提取的过程是很简单的,通过一个html解析库,将这样的节点内容提取下来,href参数的值就是一个新页面的URL。获取这个URL值以后,将其加入到任务队列中,爬虫不断的从队列中取URL即可。这样,只须要为爬虫定义一个入口的URL,那么爬虫还能够手动的爬取到指定网站的绝大多数页面。
当然,在具体的实现中,我们还须要对提取的URL做进一步处理:
1. 判断URL指向网站的域名,如果指向的是外部网站,那么可以将其遗弃
2. URL去重,可以将所有爬取过的URL存入数据库中,然后查询新提取的URL在数据库中是否存在,如果存在的话,当然就无需再去爬取了。
下面介绍一下怎样在Scrapy中完成上述这样的功能。
我们只须要改写spider的那种py文件即可,修改parse()方法代码如下:
[python]view plaincopyprint?
from scrapy.selector import HtmlXPathSelector
def parse(self, response):
hxs = HtmlXPathSelector(response)
items = []
newurls = hxs.select('//a/@href').extract()
validurls = []
for url in newurls:
#判断URL是否合法
if true:
validurls.append(url)
items.extend([self.make_requests_from_url(url).replace(callback=self.parse) for url in validurls])
sites = hxs.select('//ul/li')
items = []
for site in sites:
item = DmozItem()
item['title'] = site.select('a/text()').extract()
item['link'] = site.select('a/@href').extract()
item['desc'] = site.select('text()').extract()
items.append(item) 查看全部
Scrapy之URL解析与递归爬取:
前面介绍了Scrapy怎样实现一个最简单的爬虫,但是这个Demo里只是对一个页面进行了抓取。在实际应用中,爬虫一个重要功能是”发现新页面”,然后递归的使爬取操作进行下去。
发现新页面的方式很简单,我们首先定义一个爬虫的入口URL地址,比如Scrapy入门教程中的start_urls,爬虫首先将这个页面的内容抓取以后,解析其内容,将所有的链接地址提取下来。这个提取的过程是很简单的,通过一个html解析库,将这样的节点内容提取下来,href参数的值就是一个新页面的URL。获取这个URL值以后,将其加入到任务队列中,爬虫不断的从队列中取URL即可。这样,只须要为爬虫定义一个入口的URL,那么爬虫还能够手动的爬取到指定网站的绝大多数页面。
当然,在具体的实现中,我们还须要对提取的URL做进一步处理:
1. 判断URL指向网站的域名,如果指向的是外部网站,那么可以将其遗弃
2. URL去重,可以将所有爬取过的URL存入数据库中,然后查询新提取的URL在数据库中是否存在,如果存在的话,当然就无需再去爬取了。
下面介绍一下怎样在Scrapy中完成上述这样的功能。
我们只须要改写spider的那种py文件即可,修改parse()方法代码如下:
[python]view plaincopyprint?
from scrapy.selector import HtmlXPathSelector
def parse(self, response):
hxs = HtmlXPathSelector(response)
items = []
newurls = hxs.select('//a/@href').extract()
validurls = []
for url in newurls:
#判断URL是否合法
if true:
validurls.append(url)
items.extend([self.make_requests_from_url(url).replace(callback=self.parse) for url in validurls])
sites = hxs.select('//ul/li')
items = []
for site in sites:
item = DmozItem()
item['title'] = site.select('a/text()').extract()
item['link'] = site.select('a/@href').extract()
item['desc'] = site.select('text()').extract()
items.append(item)
带有情感倾向的网评句子手动生成系统技术方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2020-08-10 13:30
全部详尽技术资料下载
【技术实现步骤摘要】
带有情感倾向的网评句子手动生成系统
本专利技术属于计算机应用领域,尤其涉及一种带有情感倾向的网路评论手动生成的技巧。
技术介绍
近年来,随着计算机、互联网等技术的快速发展,人们在工作和生活中会耗费大量时间活跃在网路中,很多消息新闻也是从网路获知,所以比起在现实生活中和同事交流意见思想,人们更倾向于在网路上发表自己的言论,让其言论更具影响力。自然语言生成属于人工智能和计算语言学的交叉学科,其目的致力让机器生成可以理解的人类自然语言。自然语言生成技术在好多领域都有应用,比如对话系统、机器翻译等,它的发展才能促使好多领域的进步。自然语言生成发展至今学者们提出了好多方式,其中最稳健也是使用最广泛的NLG方式是基于规则/模板的方式。Mann等提出的修辞结构理论(RST),被扩充为估算文本规划的理论基础,是基于规则生成的先祖。RST后来发展成为好多学者提出的文本生成方式的基础,特别是用于规划各类小型文本;Sugiyama等针对先前基于模板的生成器形成的话语有时收录关于与输入用户话语的不相关语句,提出了一种基于模板的改进的方式,该方式使用用户话语中最突出的词组填充模板,并使用从Twitter搜集的Web级依赖结构提取相关词组。后来出现了可训练的诗句生成器,Stent等提出的可训练的诗句生成器,能够手动适应应用领域的通用语言知识,它有快速灵活且通用但在特定领域中形成高质量输出的优点,该生成器可以形成与MATCH基于模板的生成器相当的输出。随着网路的发展,数据的获取越来越容易,随之而生的新的基于语料库的自然语言生成方式被提出并广泛应用。Oh和Rudnicky提出了基于语料库的自然语言生成方式,对执行感兴趣任务的领域专家所说的语言进行建模,并使用该模型随机生成系统话语。后来将这一技术应用于语句的实现和内容的规划,并将生成结果的组件集成到一个可以工作的自然对话系统中。他们用两个语料库来建立基于词组的n-gram语言模型,然后随机生成句子。虽然上述传统的自然语言生成系统在现今也有着广泛的应用,但是这种系统也存在着一些问题,对手工订制的依赖性很大,而且生成的句子太单调,不能否适应人类渐趋变化的语言风格,且泛化能力差,不能否扩充到针对网评句子的生成。上述方式在我们应用上最大的问题是,上述生成系统忽视了用户在句子生成系统中的作用,不能由用户主导所生成的诗句。我们的系统主要是面向使用者,能够有针对性的依据用户提供的信息生成符合用户需求的句子。
技术实现思路
本专利技术是一个手动生成带有情感倾向的网评句子的系统,能够依据用户提供的关键词及情感等信息,自动生成匹配的网评句子。传统的自然语言生成方式生成的句子过分死板、单调,且这类方式扩展性差,很难适应人类渐趋变化的语言风格。我们的目标是为最终用户生成流畅且带有个人爱情色调的文本。本文介绍的句子手动生成机制,能够生成各具特色的句子并带有情感倾向,且抛去了原先基于规则生成句子所须要的对语义、语法等的知识储备,简单高效。我们的看法是首先从网路获取句子资源作为语料库并借助情感剖析相关技术对其进行情感倾向分类,然后借助搜索引擎的思想,在基于用户提供相关信息的情况下,从大量的数据中找寻符合用户需求的句子并呈现下来,这样生成的诗句更符合人们的日常。本专利技术提供了一种手动生成带有情感倾向网评句子的机制,整个系统的流程在图1中展示,具体包括下列步骤:步骤1:网络爬取数据。采用了网路爬虫技术,基于我们的需求,我们选择使用较简单的聚焦网路爬虫。选择微博、知乎、天涯等一些热门网站作为爬取对象,爬取内容为评论句子以及相应的点赞数。为了最大化我们句子的多样性,我们网路爬取了10万条句子后续整理为语料库,当然可以按照须要扩大爬取数目。
步骤2:数据整理储存。网页内容储存时应该只提取其中的文档部份,而网路的评论句子会出现emoji表情符号、图片、转发或则网页链接等不规则或则我们不需要的信息,所以须要在抓取的时侯对内容进行正则化处理,过滤掉我们不需要的信息,替换掉格式不能直接保留的信息,比如,对于表情符号,我们不能直接保存表情到数据库,但是表情符号对于情感的抒发很重要,对于后续我们进行的情感剖析太有帮助,所以对于这种信息不能直接过滤,要将表情符号转换为相应的情感语言抒发与爬取的句子一起保存出来。正则表达式的匹配规则见附图2。步骤3:对语料库句子进行情感剖析。情感剖析又称倾向性剖析,是对带有情感色调的主观性文本进行剖析、处理、归纳和推理的过程。我们爬取的网评信息是大量用户对例如任务、产品或则风波抒发的批评或则称赞的情绪,基于此,我们为了形成与使用者情感倾向相同的文本,需要对爬取的网评信息进行情感剖析,以过滤形成符合用户倾向的最终文本。我们进行情感剖析是借助了机器学习的相关技术对抓取的句子进行情感剖析,使用卡方检验进行特点提取,SVM分类器进行情感分类,在情感剖析的同时将相应的情感剖析结果写入数据库。情感剖析的流程见附图1的第三部份。
步骤4:搭建搜索框架。搭建一个才能快速有效地响应大量用户检索需求的搜索框架是很重要的,Lucene作为一个低耦合、高效率、容易二次开发的优秀的全文检索引擎构架,在设计搜索引擎时,将大运算量的部份在索引构建时就完成,对文档构建高效的索引库,在检索时效率高、速度快,所以我们在Lucene的基础上搭建我们的搜索框架,附图3为Lucene进行全文搜索的流程。步骤5:基于关键词及情感信息获取匹配句子。用户在系统查询插口处提供想要生成文本的关键词或则中心思想,并且选择相应的情感倾向,系统按照用户提供的关键词或其他文字信息以及选择的情感倾向,反馈给用户匹配的文本。附图说明图1是带有情感倾向的网评句子生成系统的流程图;图2是正则表达式匹配规则;图3是全文索引构架图;具体施行方法为了让本专利技术的目的、技术方案及优点愈发清楚明白,下面将结合本专利技术施行例中的附图,对本专利技术施行例中的技术方案进行清楚、完整的描述。本专利技术的整体思想是,首先从网路爬取大量的网路评论,整理后做为语料库备用,接着对于语料库中的句子,使用情感剖析的算法对其进行情感判定,其中情感分为正面、负面情感。然后基于前面整理后的语料库搭建搜索框架,最后按照用户输入的信息,从大数据中匹配最符合用户需求的网评句子。
具体包括以下步骤:步骤1:网络爬取数据。采用网路爬虫技术,从微博、知乎等热门网站中评论中爬取了10万多条网路评论以及相应的点赞数,后续整理为语料库。网络爬虫是一种才能自主采集Web页面内容的程序,按照系统结构和实现技术,大致可以分为通用网路爬虫、聚焦网路爬虫、增量式网路爬虫和深层网路爬虫,基于我们的需求,我们选择使用较简单的聚焦网路爬虫。用到的聚焦网路爬虫的结构图见图1第一部分。我们首先确定爬取目标并获得初始URL,经页面剖析后获取页面中的链接,根据我们的目标过滤掉不需要的链接,将获取到的新的URL加入到URL队列中,然后用搜索算法确定队列中每位URL的优先级,并每次选择一个优先级高的URL进行内容爬取,循环这个过程,直到难以获取新的URL时停止。步骤2:数据整理储存。当人们在微博、知乎等社交平台(尤其是微博)发表言论的时侯,通常会通过附加一些相关的emoji表情或则图片来提高自己言论收录的情感,而这种文字以外方式的抒发在抓取的时侯会导致方式的改变,不规则
【技术保护点】
1.根据权力要求1所述的带有情感倾向的网评句子手动生成系统,其特点在于,包括网评句子爬取、数据清洗储存、情感剖析、搜索框架搭建、语句匹配生成:所述网评句子爬取用于为系统构建数据储备,爬取的网评句子作为原创语料库;所述数据清洗储存用于对原创语料库的数据进行清洗,过滤无效信息、非文本信息,替换有用信息为文本格式,删除重复信息,并将整理后的数据储存至数据库后续使用;所述情感剖析用语对语料库中的句子进行情感倾向的剖析,并将结果写入数据库;所述搜索框架的搭建用于搭建搜索框架,并且为数据库中数据构建全文索引;所述句子匹配生成用语执行查询并返回结果。全文索引构建后,查询插口接受使用者的输入选择,并按照使用者的输入以及选择的情感倾向匹配相应的文本信息反馈给用户。
【技术特点摘要】
1.根据权力要求1所述的带有情感倾向的网评句子手动生成系统,其特点在于,包括网评句子爬取、数据清洗储存、情感剖析、搜索框架搭建、语句匹配生成:所述网评句子爬取用于为系统构建数据储备,爬取的网评句子作为原创语料库;所述数据清洗储存用于对原创语料库的数据进行清洗,过滤无效信息、非文本信息,替换有用信息为文本格式,删除重复信息,并将整理后的数据储存至数据库后续使用;所述情感剖析用语对语料库中的句子进行情感倾向的剖析,并将结果写入数据库;所述搜索框架的搭建用于搭建搜索框架,并且为数据库中数...
【专利技术属性】
技术研制人员:夏正友,刘庆庆,刘赛赛,
申请(专利权)人:南京航空航天大学,
类型:发明
国别省市:江苏,32
全部详尽技术资料下载 我是这个专利的主人 查看全部
本发明专利技术介绍了一个手动生成带有情感倾向的网评句子的系统,能够依照用户提供的关键词及情感等信息,自动生成匹配的网评词句。传统的自然语言生成方式生成的句子过分死板、单调,且扩展性差,很难适应人类渐趋变化的语言风格。本文介绍的句子手动生成机制,能够生成各具特色并带有情感倾向的句子,抛去了原先基于规则生成句子所须要的对语义、语法等的知识储备,简单高效。本发明专利技术的整体思想是,首先从网路获取句子资源作为语料库并借助情感剖析相关技术对其进行情感倾向分类,然后搭建搜索框架,基于用户提供的相关信息,从大量的数据中匹配符合用户需求的文本并呈现下来,本系统扩展性好且生成的语句更符合人们的日常用语。
全部详尽技术资料下载
【技术实现步骤摘要】
带有情感倾向的网评句子手动生成系统
本专利技术属于计算机应用领域,尤其涉及一种带有情感倾向的网路评论手动生成的技巧。
技术介绍
近年来,随着计算机、互联网等技术的快速发展,人们在工作和生活中会耗费大量时间活跃在网路中,很多消息新闻也是从网路获知,所以比起在现实生活中和同事交流意见思想,人们更倾向于在网路上发表自己的言论,让其言论更具影响力。自然语言生成属于人工智能和计算语言学的交叉学科,其目的致力让机器生成可以理解的人类自然语言。自然语言生成技术在好多领域都有应用,比如对话系统、机器翻译等,它的发展才能促使好多领域的进步。自然语言生成发展至今学者们提出了好多方式,其中最稳健也是使用最广泛的NLG方式是基于规则/模板的方式。Mann等提出的修辞结构理论(RST),被扩充为估算文本规划的理论基础,是基于规则生成的先祖。RST后来发展成为好多学者提出的文本生成方式的基础,特别是用于规划各类小型文本;Sugiyama等针对先前基于模板的生成器形成的话语有时收录关于与输入用户话语的不相关语句,提出了一种基于模板的改进的方式,该方式使用用户话语中最突出的词组填充模板,并使用从Twitter搜集的Web级依赖结构提取相关词组。后来出现了可训练的诗句生成器,Stent等提出的可训练的诗句生成器,能够手动适应应用领域的通用语言知识,它有快速灵活且通用但在特定领域中形成高质量输出的优点,该生成器可以形成与MATCH基于模板的生成器相当的输出。随着网路的发展,数据的获取越来越容易,随之而生的新的基于语料库的自然语言生成方式被提出并广泛应用。Oh和Rudnicky提出了基于语料库的自然语言生成方式,对执行感兴趣任务的领域专家所说的语言进行建模,并使用该模型随机生成系统话语。后来将这一技术应用于语句的实现和内容的规划,并将生成结果的组件集成到一个可以工作的自然对话系统中。他们用两个语料库来建立基于词组的n-gram语言模型,然后随机生成句子。虽然上述传统的自然语言生成系统在现今也有着广泛的应用,但是这种系统也存在着一些问题,对手工订制的依赖性很大,而且生成的句子太单调,不能否适应人类渐趋变化的语言风格,且泛化能力差,不能否扩充到针对网评句子的生成。上述方式在我们应用上最大的问题是,上述生成系统忽视了用户在句子生成系统中的作用,不能由用户主导所生成的诗句。我们的系统主要是面向使用者,能够有针对性的依据用户提供的信息生成符合用户需求的句子。
技术实现思路
本专利技术是一个手动生成带有情感倾向的网评句子的系统,能够依据用户提供的关键词及情感等信息,自动生成匹配的网评句子。传统的自然语言生成方式生成的句子过分死板、单调,且这类方式扩展性差,很难适应人类渐趋变化的语言风格。我们的目标是为最终用户生成流畅且带有个人爱情色调的文本。本文介绍的句子手动生成机制,能够生成各具特色的句子并带有情感倾向,且抛去了原先基于规则生成句子所须要的对语义、语法等的知识储备,简单高效。我们的看法是首先从网路获取句子资源作为语料库并借助情感剖析相关技术对其进行情感倾向分类,然后借助搜索引擎的思想,在基于用户提供相关信息的情况下,从大量的数据中找寻符合用户需求的句子并呈现下来,这样生成的诗句更符合人们的日常。本专利技术提供了一种手动生成带有情感倾向网评句子的机制,整个系统的流程在图1中展示,具体包括下列步骤:步骤1:网络爬取数据。采用了网路爬虫技术,基于我们的需求,我们选择使用较简单的聚焦网路爬虫。选择微博、知乎、天涯等一些热门网站作为爬取对象,爬取内容为评论句子以及相应的点赞数。为了最大化我们句子的多样性,我们网路爬取了10万条句子后续整理为语料库,当然可以按照须要扩大爬取数目。
步骤2:数据整理储存。网页内容储存时应该只提取其中的文档部份,而网路的评论句子会出现emoji表情符号、图片、转发或则网页链接等不规则或则我们不需要的信息,所以须要在抓取的时侯对内容进行正则化处理,过滤掉我们不需要的信息,替换掉格式不能直接保留的信息,比如,对于表情符号,我们不能直接保存表情到数据库,但是表情符号对于情感的抒发很重要,对于后续我们进行的情感剖析太有帮助,所以对于这种信息不能直接过滤,要将表情符号转换为相应的情感语言抒发与爬取的句子一起保存出来。正则表达式的匹配规则见附图2。步骤3:对语料库句子进行情感剖析。情感剖析又称倾向性剖析,是对带有情感色调的主观性文本进行剖析、处理、归纳和推理的过程。我们爬取的网评信息是大量用户对例如任务、产品或则风波抒发的批评或则称赞的情绪,基于此,我们为了形成与使用者情感倾向相同的文本,需要对爬取的网评信息进行情感剖析,以过滤形成符合用户倾向的最终文本。我们进行情感剖析是借助了机器学习的相关技术对抓取的句子进行情感剖析,使用卡方检验进行特点提取,SVM分类器进行情感分类,在情感剖析的同时将相应的情感剖析结果写入数据库。情感剖析的流程见附图1的第三部份。
步骤4:搭建搜索框架。搭建一个才能快速有效地响应大量用户检索需求的搜索框架是很重要的,Lucene作为一个低耦合、高效率、容易二次开发的优秀的全文检索引擎构架,在设计搜索引擎时,将大运算量的部份在索引构建时就完成,对文档构建高效的索引库,在检索时效率高、速度快,所以我们在Lucene的基础上搭建我们的搜索框架,附图3为Lucene进行全文搜索的流程。步骤5:基于关键词及情感信息获取匹配句子。用户在系统查询插口处提供想要生成文本的关键词或则中心思想,并且选择相应的情感倾向,系统按照用户提供的关键词或其他文字信息以及选择的情感倾向,反馈给用户匹配的文本。附图说明图1是带有情感倾向的网评句子生成系统的流程图;图2是正则表达式匹配规则;图3是全文索引构架图;具体施行方法为了让本专利技术的目的、技术方案及优点愈发清楚明白,下面将结合本专利技术施行例中的附图,对本专利技术施行例中的技术方案进行清楚、完整的描述。本专利技术的整体思想是,首先从网路爬取大量的网路评论,整理后做为语料库备用,接着对于语料库中的句子,使用情感剖析的算法对其进行情感判定,其中情感分为正面、负面情感。然后基于前面整理后的语料库搭建搜索框架,最后按照用户输入的信息,从大数据中匹配最符合用户需求的网评句子。
具体包括以下步骤:步骤1:网络爬取数据。采用网路爬虫技术,从微博、知乎等热门网站中评论中爬取了10万多条网路评论以及相应的点赞数,后续整理为语料库。网络爬虫是一种才能自主采集Web页面内容的程序,按照系统结构和实现技术,大致可以分为通用网路爬虫、聚焦网路爬虫、增量式网路爬虫和深层网路爬虫,基于我们的需求,我们选择使用较简单的聚焦网路爬虫。用到的聚焦网路爬虫的结构图见图1第一部分。我们首先确定爬取目标并获得初始URL,经页面剖析后获取页面中的链接,根据我们的目标过滤掉不需要的链接,将获取到的新的URL加入到URL队列中,然后用搜索算法确定队列中每位URL的优先级,并每次选择一个优先级高的URL进行内容爬取,循环这个过程,直到难以获取新的URL时停止。步骤2:数据整理储存。当人们在微博、知乎等社交平台(尤其是微博)发表言论的时侯,通常会通过附加一些相关的emoji表情或则图片来提高自己言论收录的情感,而这种文字以外方式的抒发在抓取的时侯会导致方式的改变,不规则
【技术保护点】
1.根据权力要求1所述的带有情感倾向的网评句子手动生成系统,其特点在于,包括网评句子爬取、数据清洗储存、情感剖析、搜索框架搭建、语句匹配生成:所述网评句子爬取用于为系统构建数据储备,爬取的网评句子作为原创语料库;所述数据清洗储存用于对原创语料库的数据进行清洗,过滤无效信息、非文本信息,替换有用信息为文本格式,删除重复信息,并将整理后的数据储存至数据库后续使用;所述情感剖析用语对语料库中的句子进行情感倾向的剖析,并将结果写入数据库;所述搜索框架的搭建用于搭建搜索框架,并且为数据库中数据构建全文索引;所述句子匹配生成用语执行查询并返回结果。全文索引构建后,查询插口接受使用者的输入选择,并按照使用者的输入以及选择的情感倾向匹配相应的文本信息反馈给用户。
【技术特点摘要】
1.根据权力要求1所述的带有情感倾向的网评句子手动生成系统,其特点在于,包括网评句子爬取、数据清洗储存、情感剖析、搜索框架搭建、语句匹配生成:所述网评句子爬取用于为系统构建数据储备,爬取的网评句子作为原创语料库;所述数据清洗储存用于对原创语料库的数据进行清洗,过滤无效信息、非文本信息,替换有用信息为文本格式,删除重复信息,并将整理后的数据储存至数据库后续使用;所述情感剖析用语对语料库中的句子进行情感倾向的剖析,并将结果写入数据库;所述搜索框架的搭建用于搭建搜索框架,并且为数据库中数...
【专利技术属性】
技术研制人员:夏正友,刘庆庆,刘赛赛,
申请(专利权)人:南京航空航天大学,
类型:发明
国别省市:江苏,32
全部详尽技术资料下载 我是这个专利的主人
黑帽seo最新技术
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2020-08-09 23:33
首先你要明白,黑帽SEO的排行有很大的运气成复分在上面,
什么时候排行不见了都说不好
其次,方法并不重要,重制要的是黑帽手法的“度”也就是说怎样做黑帽,能够尽量避开被K
那种堂而皇之教你作弊的,没必要花zhidao很大代价去学
如果一个网站用黑帽SEO技术,那这个网站能维持多久不被百度K
用黑帽确实给网站能带来抄用处,来的也快,但是去的也快。不过袭现今很多黑猫的技术不行,搜索引擎对有些黑猫手法能判定百下来。一度般情况下在百度大更新的时间段里可能问会被K大约接近一个月的时侯。
楼主呀!这而且纯自动输入的。求答最佳,求采纳!
什么是黑帽 黑帽seo技术和手法
在现今这个时代,SEO是一个太普通的行业,但也始终是一个神秘的行业,而作为在业内混迹过多年的SEO人士来说,对这行业的内幕早已心知肚明,今天,牛到家SEO就向你们普及一下现今SEO行业的灰色地带:黑帽SEO,让你们了解一些。
什么是黑帽SEO?黑帽SEO是哪些?
黑帽SEO说白了就是作弊的意思,黑帽SEO优化手法不符合主流搜索引擎发行方针规定。相对于白帽SEO而言,黑帽SEO获利主要的特征就是短平快,为了短期内的利益而采用的作弊方式。同时随时由于搜索引擎算法的改变而面临惩罚。
不论是白帽SEO还是黑帽SEO没有一个精准的定义。笼统来说所有使用作弊手段或一些可疑手段的都可称为黑帽SEO。例如隐藏网页,关键词拼凑,垃圾链接,桥页等等。
黑帽SEO才能快速带来一定的排行和用户量,但所面临的常常是被K的结果,一旦被K后恢复期起码须要半年时间,二是对于品牌来说也不是一个好的结果。
黑帽SEO和白帽SEO的区别
黑帽SEO
黑帽SEO不同于白帽SEO那个放长线钓大鱼的策略。黑帽SEO更重视的是短期内的利益,在利益的驱使下通过作弊手法获得很大的利益。就是采用搜索引擎严禁的方法优化网站,影响搜索引擎对网站排名的合理和公正性。但随时会由于搜索引擎算法的改变而面临惩罚。
白帽SEO
采用SEO的思维,合理优化网站,提高用户体验,合理与其他网站互联。从而进一步吸引搜索引擎蜘蛛爬行,使站点在搜索引擎排名提高。白帽SEO关注的是长远利益,需要的时间长,但疗效稳定。
黑帽SEO技术会遭到如何的惩罚
黑帽SEO技术本身就是百做短期工程的,被发觉了就是被发觉了,不要度了就是的
但是假如你的官网或则常年要运行的网站就知不要做这个技术的由于太危险。还道是正规的绘画。
至于会有多么大的处罚那,例如被内K,不收录等等现象就会出现的容,还有就是没有任何排行。
黑帽seo新型技术有什么
10种常见的黑帽手法解读(小云seo):
1.关键词堆积
这是老生常谈的问题,最常见的一种黑帽seo手法。在网站的内容中,我们讲求的是自然出现关键词,没必要出现时就不要出现,而有些人单纯的为了提高关键词的“密度”在文章中刻意并大量出现关键词,其引出的后果是句子不通顺,严重影响用户的阅读体验,导致被搜索引擎惩罚。
常见的关键词堆积手法有:标题、描述中堆积关键词,网站首页背部和顶部堆积关键词,文章内容中堆积关键词,关键词标签中(tag)堆积关键词,链接锚文本中堆积关键词,图片alt属性中堆积关键词等等。
2.大量回链
一个页面中出现多个链接向同一页面的锚文本,常见于网站首页顶部,比如在首页的顶部给首页的每位关键词都加一个锚文本,然后链接到首页,这就是回链。回链一旦超过2个,就太可能被认定为黑帽,从而被搜索引擎惩罚。
3.购买单项链接
有些老总不懂seo,会要求手底下的seo人员大量订购单项链接,多出现于向高权重网站购买链接,大量高权重网站都链接(单链)向自己的网站,搜索引擎一看就晓得是订购的,发现以后,没有哪些好说的,直接惩罚。所以,若是遇见这些老总,一定要说明其中的厉害关系。
4.隐藏文本和隐藏链接
从字面上也能看出这三者的意思,就是通过某种手段把文字或则链接弄的只有搜索引擎能看到,用户是看不见的。这种黑帽手法一般是将文字或则链接的颜色设置成和背景相仿或一样,亦或则是将文字或则链接设置的特别小,比如1px,这时肉眼就很难发觉,而这些疗效的实现一般是css(样式)文件实现的。
隐藏链接有两种可能,一种是自己隐藏的链接,第二种是网站被黑了,被植入了大量的黑链,所以,这就要求我们常常检测网页源代码,检查源代码中是否存在被植入的黑链。
5.链轮的实现
所谓的导轮,也常被称为站群,是指通过大量网站来实现互相之间的链接,链轮可以有多组,每组轴套中都有1个主网站和多个次网站,次网站之间依次给下一个网站做单项链接,形成一个闭合的圈,然后,这些次网站再分别给主网站做一个单项链接。
链轮是一个比较高档的黑帽seo技术,不是这么容易实现的,需要手上有很多资源。
6.外链群发
最常见的,如博客群发、评论群发等。多是通过群发软件来实现的,如博客群发软件、顶贴机等,通过这些方法做的外链都是垃圾外链,如今百度对垃圾外链查的特别严格,这种黑帽手法对网站百害而无一利。
7.网页绑架
现如今,网页绑架十分普遍,多见于一些医疗站,大家都晓得医疗行业十分暴利,很多医疗公司都太乐意做这方面的绑架,因为获利十分多,即使被搜索引擎发觉后惩罚了,他们仍然可以继续做其他站点的绑架,反正也是稳赚不陪。
常见的绑架行为有百度快照绑架和pr胁持。百度快照绑架指的是:当你搜索一个网站的关键词时,如果该网站被绑架了,当你点击的时侯,会手动跳转到另外一个网站,通常会跳转到赌博这种违规行业的网站中,而直接输入网站一般是不会跳转的,还是原先的正常的网站。
PR劫持指的是:通过seo站长工具查询到一些高权重的网站,然后将自己的网站301或则302重定向到这个高权重的网站上,等PR值更新时,就会显示和高权重网站一样的PR值。
8.购买目录
这种黑帽手法,去年太常见,也是医疗行业比较多。通过订购别的高权重网站(新闻源网站)的目录,来填充自己的内容,高权重网站很容易排行,目录排行很快就起来了。然而,这种黑帽手法却严重影响了用户体验,进来以后不是用户想要听到的内容,所以百度在今年对这一黑帽手法严打的力度很大。
9.桥页
所谓的桥页,是指借助工具手动生成大量收录不同关键词的网页,然后做跳转到主页,或者在桥页上放置一个主页的链接,不手动跳转。其目的是想通过大量桥页在搜索引擎中获得排行,桥页的特征是文字太混乱,因为都是由工具生成的。
10.域名轰炸
域名轰炸指的是:注册多个域名,每个域名对应的网站内容极少,然后将这种网站链到主站,以提升主站的权重。这是一种十分显著的黑帽seo手法,被K的机率相当高。
值得一提的是,如果各个域名有对应自己的独立网站,且内容丰富,则不属于域名轰炸。
好歆传媒为您解答黑帽SEO是做网路优化不可取的方式,在这里写下这种方式并不是使你们用黑帽SEO的方式去对搜索引擎优化,而是告诉你们黑帽的方式有什么,避免之后自己出现此类情况还不清楚。
●运用大量关键词
各种可能出现关键词的地方加上关键词。比如:关键词标签、页面内部链接、表格、网页的titile等等,你想到的想不到的地方就会出现关键词。所以我们在做关键词的时侯在合适的地方可以加,但是不该出现的地方最好不要出现,避免被误认为黑帽SEO。
●隐藏文字和链接
一般隐藏文字和链接用户在页面上是看不到的,但是用户看不到搜索引擎可以啊,所以那些字都是专门为搜索引擎设计的,最常用的一些隐藏文字的手段就是字的颜色与背景色相同或则十分接近通常看不下来,还有就是用图片将文字遮住等等。
这种隐藏链接的方式是自己网站指向自己的网站,还有就是黑入其他人的网站,这是十分明晰的黑帽SEO作弊的方式。
●用权重高的网站
网站的权重对于网站的排行是十分重要的,所以好多黑帽SEO都会用这种权重高的网站做链接,导出链接传递权重,关键词的排行会迅速提高,这中不符合搜索引擎优化手段的方式只会获得短期的排行,持续疗效不会长久,但是这正满足了短期须要的人的需求。
●关键词的替换
因为搜索引擎通常不会很快将页面删掉,所以这个页面都会有一定的作用,关键词的替换就是借助早已发过的文章,并且文章排名比较靠前,然后将这篇文章进行修改,替换成相仿的比较热门的词。
●利用站群
站群就是养资源,自己有一定数目的网站的时侯,对于友情链接和外链就比较好操作,一般站群定义比较难,几十个网站推一个网站还可以,但是数目太多的网站很容易被觉得是黑帽SEO。
●网站间的互相链接
这样的网站就是为了友情链接存在的,全部链接到其他网站,还有其他网站链接回去,这些网站之间互相链接。
以上是黑帽SEO时常运用的手段,做网路优化的一定要注意以上几点做到回避那些问题,避免最终网站被封。
黑帽seo快速排行技术须要具备什么技术
一、黑帽SEO与白帽SEO的区别
黑帽SEO:所有不符合搜索引擎优化规范的作弊方式都属于黑帽SEO;
白帽SEO:所有符合用户体验及搜索引擎规范的优化方式都属于白帽SEO;
二、黑帽SEO技术的特点
1、锚文本轰炸
一个页面并没有相关的内容,但是有大量的锚文本指向这个页面。比如知名的“谷歌炸弹”,大量的波兰公民在她们能控制的页面上用“miserablefailure”(惨败)加超链接指向布什在白宫网站的个人主页,两个月后微软上搜索“miserablefailure”的时侯布什在白宫的个人主页就升到了搜索结果的第一位。事实上布什的个人主页并没有关于“miserablefailure”的相关内容。
2、网站内容采集
用一些程序在网路上手动搜集一些文字,经过简单的程序手动处理过后发布网站上(采集站),用户体验极差,但是因为页面诸多加上搜索引擎算法不是非常完美,经常会有网页有排行,进而带来流量,然后用户点击她们放置的广告,从而获取利益,实际上没有给用户带来有用的价值。
3、群发作弊
用软件把自己的链接发布到一些网站上,短时间内获得大量的外链。如今外链对于SEO的作用越来越小,这个技巧在现在的SEO中也不会有很大作用。
4、挂马
为了达到某种目的,通过一些手段,进入一个网站且在该网站上安装了木马程序,不但该网站被提权,更重要是该网站的用户她们的笔记本也有中毒的危险,导致网站的用户体验极差。
5、网站黑链
简单理解就是不正当的链接,用户通常看不到,但是搜索引擎可以看见的链接。一般是网站后台被入侵,挂上了对方网站的链接,这些链接似乎从页面上看不下来,但是搜索引擎是可以抓取的,网站被挂黑链是我们做SEO时常常会碰到的情况,网站被挂黑链如何办?如果你的网站被挂了黑链,崔鹏瀚SEO的网站内有比较好的处理方式,不妨去看一下。
6、其它黑帽SEO技术
一些行之有效的黑帽SEO常常是一些技术高人所为,但是这些手段她们通常是不敢公布的,因为小范围的作弊搜索引擎通常不会调整算法,但是影响扩大以后那就另当别论了。
总结:黑帽SEO属于SEO作弊,这种行为一旦被搜索引擎发觉将给网站带来灭顶之灾。崔鹏瀚建议,如果你准备好好优化一个网站并通过网站来赢利,那么请记住,在任何时侯都不要使用黑帽SEO方式,这样对网站百害无一利。 查看全部
黑帽seo技术网是骗局网站吗
首先你要明白,黑帽SEO的排行有很大的运气成复分在上面,
什么时候排行不见了都说不好
其次,方法并不重要,重制要的是黑帽手法的“度”也就是说怎样做黑帽,能够尽量避开被K
那种堂而皇之教你作弊的,没必要花zhidao很大代价去学
如果一个网站用黑帽SEO技术,那这个网站能维持多久不被百度K
用黑帽确实给网站能带来抄用处,来的也快,但是去的也快。不过袭现今很多黑猫的技术不行,搜索引擎对有些黑猫手法能判定百下来。一度般情况下在百度大更新的时间段里可能问会被K大约接近一个月的时侯。
楼主呀!这而且纯自动输入的。求答最佳,求采纳!
什么是黑帽 黑帽seo技术和手法
在现今这个时代,SEO是一个太普通的行业,但也始终是一个神秘的行业,而作为在业内混迹过多年的SEO人士来说,对这行业的内幕早已心知肚明,今天,牛到家SEO就向你们普及一下现今SEO行业的灰色地带:黑帽SEO,让你们了解一些。
什么是黑帽SEO?黑帽SEO是哪些?
黑帽SEO说白了就是作弊的意思,黑帽SEO优化手法不符合主流搜索引擎发行方针规定。相对于白帽SEO而言,黑帽SEO获利主要的特征就是短平快,为了短期内的利益而采用的作弊方式。同时随时由于搜索引擎算法的改变而面临惩罚。
不论是白帽SEO还是黑帽SEO没有一个精准的定义。笼统来说所有使用作弊手段或一些可疑手段的都可称为黑帽SEO。例如隐藏网页,关键词拼凑,垃圾链接,桥页等等。
黑帽SEO才能快速带来一定的排行和用户量,但所面临的常常是被K的结果,一旦被K后恢复期起码须要半年时间,二是对于品牌来说也不是一个好的结果。
黑帽SEO和白帽SEO的区别
黑帽SEO
黑帽SEO不同于白帽SEO那个放长线钓大鱼的策略。黑帽SEO更重视的是短期内的利益,在利益的驱使下通过作弊手法获得很大的利益。就是采用搜索引擎严禁的方法优化网站,影响搜索引擎对网站排名的合理和公正性。但随时会由于搜索引擎算法的改变而面临惩罚。
白帽SEO
采用SEO的思维,合理优化网站,提高用户体验,合理与其他网站互联。从而进一步吸引搜索引擎蜘蛛爬行,使站点在搜索引擎排名提高。白帽SEO关注的是长远利益,需要的时间长,但疗效稳定。
黑帽SEO技术会遭到如何的惩罚
黑帽SEO技术本身就是百做短期工程的,被发觉了就是被发觉了,不要度了就是的
但是假如你的官网或则常年要运行的网站就知不要做这个技术的由于太危险。还道是正规的绘画。
至于会有多么大的处罚那,例如被内K,不收录等等现象就会出现的容,还有就是没有任何排行。
黑帽seo新型技术有什么
10种常见的黑帽手法解读(小云seo):
1.关键词堆积
这是老生常谈的问题,最常见的一种黑帽seo手法。在网站的内容中,我们讲求的是自然出现关键词,没必要出现时就不要出现,而有些人单纯的为了提高关键词的“密度”在文章中刻意并大量出现关键词,其引出的后果是句子不通顺,严重影响用户的阅读体验,导致被搜索引擎惩罚。
常见的关键词堆积手法有:标题、描述中堆积关键词,网站首页背部和顶部堆积关键词,文章内容中堆积关键词,关键词标签中(tag)堆积关键词,链接锚文本中堆积关键词,图片alt属性中堆积关键词等等。
2.大量回链
一个页面中出现多个链接向同一页面的锚文本,常见于网站首页顶部,比如在首页的顶部给首页的每位关键词都加一个锚文本,然后链接到首页,这就是回链。回链一旦超过2个,就太可能被认定为黑帽,从而被搜索引擎惩罚。
3.购买单项链接
有些老总不懂seo,会要求手底下的seo人员大量订购单项链接,多出现于向高权重网站购买链接,大量高权重网站都链接(单链)向自己的网站,搜索引擎一看就晓得是订购的,发现以后,没有哪些好说的,直接惩罚。所以,若是遇见这些老总,一定要说明其中的厉害关系。
4.隐藏文本和隐藏链接
从字面上也能看出这三者的意思,就是通过某种手段把文字或则链接弄的只有搜索引擎能看到,用户是看不见的。这种黑帽手法一般是将文字或则链接的颜色设置成和背景相仿或一样,亦或则是将文字或则链接设置的特别小,比如1px,这时肉眼就很难发觉,而这些疗效的实现一般是css(样式)文件实现的。
隐藏链接有两种可能,一种是自己隐藏的链接,第二种是网站被黑了,被植入了大量的黑链,所以,这就要求我们常常检测网页源代码,检查源代码中是否存在被植入的黑链。
5.链轮的实现
所谓的导轮,也常被称为站群,是指通过大量网站来实现互相之间的链接,链轮可以有多组,每组轴套中都有1个主网站和多个次网站,次网站之间依次给下一个网站做单项链接,形成一个闭合的圈,然后,这些次网站再分别给主网站做一个单项链接。
链轮是一个比较高档的黑帽seo技术,不是这么容易实现的,需要手上有很多资源。
6.外链群发
最常见的,如博客群发、评论群发等。多是通过群发软件来实现的,如博客群发软件、顶贴机等,通过这些方法做的外链都是垃圾外链,如今百度对垃圾外链查的特别严格,这种黑帽手法对网站百害而无一利。
7.网页绑架
现如今,网页绑架十分普遍,多见于一些医疗站,大家都晓得医疗行业十分暴利,很多医疗公司都太乐意做这方面的绑架,因为获利十分多,即使被搜索引擎发觉后惩罚了,他们仍然可以继续做其他站点的绑架,反正也是稳赚不陪。
常见的绑架行为有百度快照绑架和pr胁持。百度快照绑架指的是:当你搜索一个网站的关键词时,如果该网站被绑架了,当你点击的时侯,会手动跳转到另外一个网站,通常会跳转到赌博这种违规行业的网站中,而直接输入网站一般是不会跳转的,还是原先的正常的网站。
PR劫持指的是:通过seo站长工具查询到一些高权重的网站,然后将自己的网站301或则302重定向到这个高权重的网站上,等PR值更新时,就会显示和高权重网站一样的PR值。
8.购买目录
这种黑帽手法,去年太常见,也是医疗行业比较多。通过订购别的高权重网站(新闻源网站)的目录,来填充自己的内容,高权重网站很容易排行,目录排行很快就起来了。然而,这种黑帽手法却严重影响了用户体验,进来以后不是用户想要听到的内容,所以百度在今年对这一黑帽手法严打的力度很大。
9.桥页
所谓的桥页,是指借助工具手动生成大量收录不同关键词的网页,然后做跳转到主页,或者在桥页上放置一个主页的链接,不手动跳转。其目的是想通过大量桥页在搜索引擎中获得排行,桥页的特征是文字太混乱,因为都是由工具生成的。
10.域名轰炸
域名轰炸指的是:注册多个域名,每个域名对应的网站内容极少,然后将这种网站链到主站,以提升主站的权重。这是一种十分显著的黑帽seo手法,被K的机率相当高。
值得一提的是,如果各个域名有对应自己的独立网站,且内容丰富,则不属于域名轰炸。
好歆传媒为您解答黑帽SEO是做网路优化不可取的方式,在这里写下这种方式并不是使你们用黑帽SEO的方式去对搜索引擎优化,而是告诉你们黑帽的方式有什么,避免之后自己出现此类情况还不清楚。
●运用大量关键词
各种可能出现关键词的地方加上关键词。比如:关键词标签、页面内部链接、表格、网页的titile等等,你想到的想不到的地方就会出现关键词。所以我们在做关键词的时侯在合适的地方可以加,但是不该出现的地方最好不要出现,避免被误认为黑帽SEO。
●隐藏文字和链接
一般隐藏文字和链接用户在页面上是看不到的,但是用户看不到搜索引擎可以啊,所以那些字都是专门为搜索引擎设计的,最常用的一些隐藏文字的手段就是字的颜色与背景色相同或则十分接近通常看不下来,还有就是用图片将文字遮住等等。
这种隐藏链接的方式是自己网站指向自己的网站,还有就是黑入其他人的网站,这是十分明晰的黑帽SEO作弊的方式。
●用权重高的网站
网站的权重对于网站的排行是十分重要的,所以好多黑帽SEO都会用这种权重高的网站做链接,导出链接传递权重,关键词的排行会迅速提高,这中不符合搜索引擎优化手段的方式只会获得短期的排行,持续疗效不会长久,但是这正满足了短期须要的人的需求。
●关键词的替换
因为搜索引擎通常不会很快将页面删掉,所以这个页面都会有一定的作用,关键词的替换就是借助早已发过的文章,并且文章排名比较靠前,然后将这篇文章进行修改,替换成相仿的比较热门的词。
●利用站群
站群就是养资源,自己有一定数目的网站的时侯,对于友情链接和外链就比较好操作,一般站群定义比较难,几十个网站推一个网站还可以,但是数目太多的网站很容易被觉得是黑帽SEO。
●网站间的互相链接
这样的网站就是为了友情链接存在的,全部链接到其他网站,还有其他网站链接回去,这些网站之间互相链接。
以上是黑帽SEO时常运用的手段,做网路优化的一定要注意以上几点做到回避那些问题,避免最终网站被封。
黑帽seo快速排行技术须要具备什么技术
一、黑帽SEO与白帽SEO的区别
黑帽SEO:所有不符合搜索引擎优化规范的作弊方式都属于黑帽SEO;
白帽SEO:所有符合用户体验及搜索引擎规范的优化方式都属于白帽SEO;
二、黑帽SEO技术的特点
1、锚文本轰炸
一个页面并没有相关的内容,但是有大量的锚文本指向这个页面。比如知名的“谷歌炸弹”,大量的波兰公民在她们能控制的页面上用“miserablefailure”(惨败)加超链接指向布什在白宫网站的个人主页,两个月后微软上搜索“miserablefailure”的时侯布什在白宫的个人主页就升到了搜索结果的第一位。事实上布什的个人主页并没有关于“miserablefailure”的相关内容。
2、网站内容采集
用一些程序在网路上手动搜集一些文字,经过简单的程序手动处理过后发布网站上(采集站),用户体验极差,但是因为页面诸多加上搜索引擎算法不是非常完美,经常会有网页有排行,进而带来流量,然后用户点击她们放置的广告,从而获取利益,实际上没有给用户带来有用的价值。
3、群发作弊
用软件把自己的链接发布到一些网站上,短时间内获得大量的外链。如今外链对于SEO的作用越来越小,这个技巧在现在的SEO中也不会有很大作用。
4、挂马
为了达到某种目的,通过一些手段,进入一个网站且在该网站上安装了木马程序,不但该网站被提权,更重要是该网站的用户她们的笔记本也有中毒的危险,导致网站的用户体验极差。
5、网站黑链
简单理解就是不正当的链接,用户通常看不到,但是搜索引擎可以看见的链接。一般是网站后台被入侵,挂上了对方网站的链接,这些链接似乎从页面上看不下来,但是搜索引擎是可以抓取的,网站被挂黑链是我们做SEO时常常会碰到的情况,网站被挂黑链如何办?如果你的网站被挂了黑链,崔鹏瀚SEO的网站内有比较好的处理方式,不妨去看一下。
6、其它黑帽SEO技术
一些行之有效的黑帽SEO常常是一些技术高人所为,但是这些手段她们通常是不敢公布的,因为小范围的作弊搜索引擎通常不会调整算法,但是影响扩大以后那就另当别论了。
总结:黑帽SEO属于SEO作弊,这种行为一旦被搜索引擎发觉将给网站带来灭顶之灾。崔鹏瀚建议,如果你准备好好优化一个网站并通过网站来赢利,那么请记住,在任何时侯都不要使用黑帽SEO方式,这样对网站百害无一利。
使用Python手动生成风波剖析图谱
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2020-08-17 10:30
前言
本文的文字及图片来源于网路,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 想读博的针针
PS:如有须要Python学习资料的小伙伴可以加点击下方链接自行获取
/noteshare?id=3054cce4add8a909e784ad934f956cef
项目介绍
如何用图谱和结构化的方法,即以简约的方法对输入的文本内容进行最佳的语义表示是个困局。Text Grapher对这一问题进行了尝试,采用的方式为:输入一篇文档,将文档进行关键信息提取,并进行结构化,并最终组织成图谱组织方式,形成对文章语义信息的图谱化展示。
使用方式
在项目文件下下新建一个python文件,输入以下代码:
运行该文件,生成的图谱内容保存在项目文件夹graph.html的文件中。
以中科院研究所身亡案为例:
新建text.py文件,输入以下代码:
运行text.py,得到手动生成的graph.html文件。
分析
本项目采用了高频词,关键词,命名实体辨识,主谓宾句型辨识等抽取形式,并尝试将三类信息进行图谱组织表示,这种表示方法是一种尝试。
主要的信息处理分为以下几个步骤:
1)对文章进行处理,处理内容包括去噪、长句切分、短句切分
2)对语句进行动词,词性标明处理,并搜集其中的命名实体;
3)获取文章关键词;
4)构建风波三元组;
5)过滤出与命名实体相关的风波三元组;
6)基于文章关键词,建立起实体与关键词之间的关系;
7)对风波网路进行图谱化展示;
总结
1、该项目可以帮助快速理清事情的脉络,了解人物之间的各类关系;
2、可以应用在其他领域进行文本的语义信息图谱化展示。 查看全部
使用Python手动生成风波剖析图谱
前言
本文的文字及图片来源于网路,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 想读博的针针
PS:如有须要Python学习资料的小伙伴可以加点击下方链接自行获取
/noteshare?id=3054cce4add8a909e784ad934f956cef
项目介绍
如何用图谱和结构化的方法,即以简约的方法对输入的文本内容进行最佳的语义表示是个困局。Text Grapher对这一问题进行了尝试,采用的方式为:输入一篇文档,将文档进行关键信息提取,并进行结构化,并最终组织成图谱组织方式,形成对文章语义信息的图谱化展示。
使用方式
在项目文件下下新建一个python文件,输入以下代码:
运行该文件,生成的图谱内容保存在项目文件夹graph.html的文件中。
以中科院研究所身亡案为例:
新建text.py文件,输入以下代码:
运行text.py,得到手动生成的graph.html文件。
分析
本项目采用了高频词,关键词,命名实体辨识,主谓宾句型辨识等抽取形式,并尝试将三类信息进行图谱组织表示,这种表示方法是一种尝试。
主要的信息处理分为以下几个步骤:
1)对文章进行处理,处理内容包括去噪、长句切分、短句切分
2)对语句进行动词,词性标明处理,并搜集其中的命名实体;
3)获取文章关键词;
4)构建风波三元组;
5)过滤出与命名实体相关的风波三元组;
6)基于文章关键词,建立起实体与关键词之间的关系;
7)对风波网路进行图谱化展示;
总结
1、该项目可以帮助快速理清事情的脉络,了解人物之间的各类关系;
2、可以应用在其他领域进行文本的语义信息图谱化展示。
医疗知识图谱问答系统探究(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2020-08-17 07:16
这是阿拉灯神丁Vicky的第23篇文章
1、项目背景
为通过项目实战降低对知识图谱的认识,几乎找了所有网上的开源项目及视频实战教程。
果然,功夫不负有心人,找到了中科院软件所刘焕勇老师在github上的开源项目,基于知识图谱的医药领域问答项目QABasedOnMedicaKnowledgeGraph。
项目地址:
用了两个晚上搭建了两套,Mac版与Windows版,哈哈,运行成功!!!
从无到有搭建一个以癌症为中心的一定规模医药领域知识图谱,以该知识图谱完成手动问答与剖析服务。该项目立足医药领域,以垂直型医药网站为数据来源,以癌症为核心,构建起一个收录7类规模为4.4万的知识实体,11类规模约30万实体关系的知识图谱。 本项目将包括以下两部份的内容:
1、基于垂直网站数据的医药知识图谱建立
2、基于医药知识图谱的手动问答
2、项目环境2.1 windows系统
搭建中间有很多坑,且行且注意。
配置要求:要求配置neo4j数据库及相应的python依赖包。neo4j数据库用户名密码记住,并更改相应文件。
安装neo4j,neo4j 依赖java jdk 1.8版本以上:
java jdk安装方式可参考:windows系统下安装JDK8,下载地址:
安装neo4j可参考博文:windows安装neo4j,下载地址:
安装python可参考:Windows环境下安装python2.7
根据neo4j 安装时的端口、账户、密码配置设置设置项目配置文件:answer_search.py & build_medicalgraph.py (github下载项目时依照个人须要也可使用git)
数据导出:python build_medicalgraph.py,导入的数据较多,估计须要几个小时。
python build_medicalgraph.py导出数据之前,需要在该文件main函数中加入:
build_medicalgraph.py
启动问答:python chat_graph.py
2.2 Mac系统
mac本身自带python、java jdk环境,可直接安装neo4j图数据库,项目运行步骤与windows基本一样。
问题解答:
安装过程中如遇问题可联系Wechat: dandan-sbb。
2.3 Neo4j数据库展示
2.4 问答系统运行疗效
3、项目介绍
该项目的数据来自垂直类医疗网站寻医问药,使用爬虫脚本data_spider.py,以结构化数据为主,构建了以癌症为中心的医疗知识图谱,实体规模4.4万,实体关系规模30万。schema的设计依据所采集的结构化数据生成,对网页的结构化数据进行xpath解析。
项目的数据储存采用Neo4j图数据库,问答系统采用了规则匹配方法完成,数据操作采用neo4j申明的cypher。
项目的不足之处在于癌症的引起缘由、预防等以大段文字返回,这块可引入风波抽取,可将缘由结构化表示下来。
3.1 项目目录
.
├── README.md
├── __pycache__ \\编译结果保存目录
│ ├── answer_search.cpython-36.pyc
│ ├── question_classifier.cpython-36.pyc
│ └── question_parser.cpython-36.pyc
├── answer_search.py
├── answer_search.pyc
├── build_medicalgraph.py \\知识图谱数据入库脚本
├── chatbot_graph.py \\问答程序脚本
├── data
│ └── medicaln.json \\本项目的全部数据,通过build_medicalgraph.py导neo4j
├── dict
│ ├── check.txt \\确诊检测项目实体库
│ ├── deny.txt \\否定词库
│ ├── department.txt \\医疗课目实体库
│ ├── disease.txt \\疾患实体库
│ ├── drug.txt \\药品实体库
│ ├── food.txt \\食物实体库
│ ├── producer.txt \\在售药品库
│ └── symptom.txt \\疾患病症实体库
├── document
│ ├── chat1.png \\系统运行问答截图01
│ ├── chat2.png \\系统运行问答截图01
│ ├── kg_route.png \\知识图谱建立框架
│ ├── qa_route.png \\问答系统框架图
├── img \\README.md中的所用图片
│ ├── chat1.png
│ ├── chat2.png
│ ├── graph_summary.png
│ ├── kg_route.png
│ └── qa_route.png
├── prepare_data
│ ├── build_data.py \\数据库操作脚本
│ ├── data_spider.py \\网络资讯采集脚本
│ └── max_cut.py \\基于辞典的最大向前/向后脚本
├── question_classifier.py \\问句类型分类脚本
├── question_classifier.pyc
├── question_parser.py \\问句解析脚本
├── question_parser.pyc
3.2 知识图谱的实体类型
3.3 知识图谱的实体关系类型
3.4 知识图谱的属性类型
3.5 问答项目实现原理
本项目的问答系统完全基于规则匹配实现,通过关键词匹配,对问句进行分类,医疗问题本身属于封闭域类场景,对领域问题进行穷举并分类,然后使用cypher的match去匹配查找neo4j,根据返回数据组装问句回答,最后返回结果。
问句中的关键词匹配:
根据匹配到的关键词分类问句
问句解析
查找相关数据
根据返回的数据组装回答
3.6 问答系统支持的问答类型
4、项目总结
基于规则的问答系统没有复杂的算法,一般采用模板匹配的方法找寻匹配度最高的答案,回答结果依赖于问句类型、模板语料库的覆盖全面性,面对已知的问题,可以给出合适的答案,对于模板匹配不到的问题或问句类型,经常碰到的有三种回答形式:
1、给出一个逗趣的答案;
2、婉转的回答不知道,提示用户换种方法去问;
3、转移话题,回避问题;
例如,本项目中采用了委婉的形式回答不知道:
基于知识图谱的问答系统的主要特点是知识图谱,系统依赖一个或多个领域的实体,并基于图谱进行推理或诠释,深度回答用户的问题,基于知识图谱的问答系统更擅长回答知识性问题,与基于模板的聊天机器人有所不同的是它更直接、直观的给用户答案。对于不能回答、或不知道的问题,一般直接返回失败,而不是转移话题防止难堪。
整个问答系统的好坏依赖于知识图谱中知识的数目与质量。也算是优劣共存吧!知识图谱图谱具有良好的可扩展性,扩展了知识图谱也就是扩充了问答系统的知识库。如果问句在射速范围内,可轻松回答,但倘若不幸脱靶,则体验大打折扣。
从知识图谱的角度剖析,大多数知识图谱规模不足,主要缘由还是数据来源以及技术上知识的抽取与推理困难。
个人博客:
题图 查看全部
医疗知识图谱问答系统探究(一)
这是阿拉灯神丁Vicky的第23篇文章
1、项目背景
为通过项目实战降低对知识图谱的认识,几乎找了所有网上的开源项目及视频实战教程。
果然,功夫不负有心人,找到了中科院软件所刘焕勇老师在github上的开源项目,基于知识图谱的医药领域问答项目QABasedOnMedicaKnowledgeGraph。
项目地址:
用了两个晚上搭建了两套,Mac版与Windows版,哈哈,运行成功!!!
从无到有搭建一个以癌症为中心的一定规模医药领域知识图谱,以该知识图谱完成手动问答与剖析服务。该项目立足医药领域,以垂直型医药网站为数据来源,以癌症为核心,构建起一个收录7类规模为4.4万的知识实体,11类规模约30万实体关系的知识图谱。 本项目将包括以下两部份的内容:
1、基于垂直网站数据的医药知识图谱建立
2、基于医药知识图谱的手动问答
2、项目环境2.1 windows系统
搭建中间有很多坑,且行且注意。
配置要求:要求配置neo4j数据库及相应的python依赖包。neo4j数据库用户名密码记住,并更改相应文件。
安装neo4j,neo4j 依赖java jdk 1.8版本以上:
java jdk安装方式可参考:windows系统下安装JDK8,下载地址:
安装neo4j可参考博文:windows安装neo4j,下载地址:
安装python可参考:Windows环境下安装python2.7
根据neo4j 安装时的端口、账户、密码配置设置设置项目配置文件:answer_search.py & build_medicalgraph.py (github下载项目时依照个人须要也可使用git)
数据导出:python build_medicalgraph.py,导入的数据较多,估计须要几个小时。
python build_medicalgraph.py导出数据之前,需要在该文件main函数中加入:
build_medicalgraph.py
启动问答:python chat_graph.py
2.2 Mac系统
mac本身自带python、java jdk环境,可直接安装neo4j图数据库,项目运行步骤与windows基本一样。
问题解答:
安装过程中如遇问题可联系Wechat: dandan-sbb。
2.3 Neo4j数据库展示
2.4 问答系统运行疗效
3、项目介绍
该项目的数据来自垂直类医疗网站寻医问药,使用爬虫脚本data_spider.py,以结构化数据为主,构建了以癌症为中心的医疗知识图谱,实体规模4.4万,实体关系规模30万。schema的设计依据所采集的结构化数据生成,对网页的结构化数据进行xpath解析。
项目的数据储存采用Neo4j图数据库,问答系统采用了规则匹配方法完成,数据操作采用neo4j申明的cypher。
项目的不足之处在于癌症的引起缘由、预防等以大段文字返回,这块可引入风波抽取,可将缘由结构化表示下来。
3.1 项目目录
.
├── README.md
├── __pycache__ \\编译结果保存目录
│ ├── answer_search.cpython-36.pyc
│ ├── question_classifier.cpython-36.pyc
│ └── question_parser.cpython-36.pyc
├── answer_search.py
├── answer_search.pyc
├── build_medicalgraph.py \\知识图谱数据入库脚本
├── chatbot_graph.py \\问答程序脚本
├── data
│ └── medicaln.json \\本项目的全部数据,通过build_medicalgraph.py导neo4j
├── dict
│ ├── check.txt \\确诊检测项目实体库
│ ├── deny.txt \\否定词库
│ ├── department.txt \\医疗课目实体库
│ ├── disease.txt \\疾患实体库
│ ├── drug.txt \\药品实体库
│ ├── food.txt \\食物实体库
│ ├── producer.txt \\在售药品库
│ └── symptom.txt \\疾患病症实体库
├── document
│ ├── chat1.png \\系统运行问答截图01
│ ├── chat2.png \\系统运行问答截图01
│ ├── kg_route.png \\知识图谱建立框架
│ ├── qa_route.png \\问答系统框架图
├── img \\README.md中的所用图片
│ ├── chat1.png
│ ├── chat2.png
│ ├── graph_summary.png
│ ├── kg_route.png
│ └── qa_route.png
├── prepare_data
│ ├── build_data.py \\数据库操作脚本
│ ├── data_spider.py \\网络资讯采集脚本
│ └── max_cut.py \\基于辞典的最大向前/向后脚本
├── question_classifier.py \\问句类型分类脚本
├── question_classifier.pyc
├── question_parser.py \\问句解析脚本
├── question_parser.pyc
3.2 知识图谱的实体类型
3.3 知识图谱的实体关系类型
3.4 知识图谱的属性类型
3.5 问答项目实现原理
本项目的问答系统完全基于规则匹配实现,通过关键词匹配,对问句进行分类,医疗问题本身属于封闭域类场景,对领域问题进行穷举并分类,然后使用cypher的match去匹配查找neo4j,根据返回数据组装问句回答,最后返回结果。
问句中的关键词匹配:
根据匹配到的关键词分类问句
问句解析
查找相关数据
根据返回的数据组装回答
3.6 问答系统支持的问答类型
4、项目总结
基于规则的问答系统没有复杂的算法,一般采用模板匹配的方法找寻匹配度最高的答案,回答结果依赖于问句类型、模板语料库的覆盖全面性,面对已知的问题,可以给出合适的答案,对于模板匹配不到的问题或问句类型,经常碰到的有三种回答形式:
1、给出一个逗趣的答案;
2、婉转的回答不知道,提示用户换种方法去问;
3、转移话题,回避问题;
例如,本项目中采用了委婉的形式回答不知道:
基于知识图谱的问答系统的主要特点是知识图谱,系统依赖一个或多个领域的实体,并基于图谱进行推理或诠释,深度回答用户的问题,基于知识图谱的问答系统更擅长回答知识性问题,与基于模板的聊天机器人有所不同的是它更直接、直观的给用户答案。对于不能回答、或不知道的问题,一般直接返回失败,而不是转移话题防止难堪。
整个问答系统的好坏依赖于知识图谱中知识的数目与质量。也算是优劣共存吧!知识图谱图谱具有良好的可扩展性,扩展了知识图谱也就是扩充了问答系统的知识库。如果问句在射速范围内,可轻松回答,但倘若不幸脱靶,则体验大打折扣。
从知识图谱的角度剖析,大多数知识图谱规模不足,主要缘由还是数据来源以及技术上知识的抽取与推理困难。
个人博客:
题图
如何使用 RNN 模型实现文本手动生成
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2020-08-17 01:13
在自然语言处理中,另外一个重要的应用领域,就是文本的手动撰写。关键词、关键词组、自动摘要提取都属于这个领域中的一种应用。不过这种应用,都是由多到少的生成。这里我们介绍其另外一种应用:由少到多的生成,包括短语的复写,由关键词、主题生成文章或者段落等。
基于关键词的文本手动生成模型
本章第一节就介绍基于关键词生成一段文本的一些处理技术。其主要是应用关键词提取、同义词辨识等技术来实现的。下面就对实现过程进行说明和介绍。
场景
在进行搜索引擎广告投放的时侯,我们须要给广告撰写一句话描述。一般情况下模型的输入就是一些关键词。比如我们要投放的广告为花束广告,假设广告的关键词为:“鲜花”、“便宜”。对于这个输入我们希望形成一定数目的候选一句话广告描述。
对于这些场景,也可能输入的是一句话,比如之前人工撰写了一个事例:“这个周末,小白花束只要99元,并且还包邮哦,还包邮哦!”。需要按照这句话复写出一定数目在抒发上不同,但是意思相仿的句子。这里我们就介绍一种基于关键词的文本(一句话)自动生成模型。
原理
模型处理流程如图1所示。
图1完成候选句子的提取以后,就要按照候选句子的数目来判定后续操作了。如果筛选的候选句子小于等于要求的数目,则根据语句相似度由低到高选定指定数目的短语。否则要进行短语的复写。这里采用同义词替换和按照指定模板进行改写的方案。
实现
实现候选句子估算的代码如下:
Map result = new HashMap();
if (type == 0) {//输入为关键词
result = getKeyWordsSentence(keyWordsList);
}else {
result = getWordSimSentence(sentence);
}
//得到候选集数量大于等于要求的数量则对结果进行裁剪
if (result.size() >= number) {
result = sub(result, number);
}else {
//得到候选集数量小于要求的数量则对结果进行添加
result = add(result, number);
}
实现句子相像筛选估算的代码如下。
for (String sen : sentenceList) {
//对待识别语句进行分词处理
List wordsList1 = parse(sentence);
List wordsList2 = parse(sen);
//首先判断两个语句是不是满足目标变换
boolean isPatternSim = isPatternSimSentence(wordsList1, wordsList2);
if (!isPatternSim) {//不满足目标变换
//首先计算两个语句的bi-gram相似度
double tmp = getBigramSim(wordsList1, wordsList2);
//这里的筛选条件是相似度小于阈值,因为bi-gram的相似度越小,代表两者越相似
if (threshold > tmp) {
result.put(sen,tmp);
}
}else {
result.put(sen,0.0);
}
}
拓展
本节处理的场景是:由文本到文本的生成。这个场景通常主要涉及:文本摘要、句子压缩、文本复写、句子融合等文本处理技术。其中本节涉及文本摘要和语句复写两个方面的技术。文本摘要如前所述主要涉及:关键词提取、短语提取、句子提取等。句子复写则按照实现手段的不同,大致可以分为如下几种。
基于统计模型和语义剖析生成模型的改写方式。这类方式就是按照语料库中的数据进行统计,获得大量的转换机率分布,然后对于输入的语料按照已知的先验知识进行替换。这类方式的语句是在剖析结果的基础上进行生成的,从某种意义上说,生成是在剖析的指导下实现的,因此,改写生成的诗句有可能具有良好的诗句结构。但是其所依赖的语料库是十分大的,这样就须要人工标明好多数据。对于这种问题,新的深度学习技术可以解决部份的问题。同时结合知识图谱的深度学习,能够更好地借助人的知识,最大限度地降低对训练样本的数据需求。RNN模型实现文本手动生成
6.1.2节介绍了基于短文本输入获得长文本的一些处理技术。这里主要使用的是RNN网路,利用其对序列数据处理能力,来实现文本序列数据的手动填充。下面就对其实现细节做一个说明和介绍。
场景
在广告投放的过程中,我们可能会遇见这些场景:由一句话生成一段描述文本,文本宽度在200~300字之间。输入也可能是一些主题的关键词。
这个时侯我们就须要一种依据少量文本输入形成大量文本的算法了。这里介绍一种算法:RNN算法。在5.3节我们早已介绍了这个算法,用该算法实现由拼音到汉字的转换。其实这两个场景的模式是一样的,都是由给定的文本信息,生成另外一些文本信息。区别是后者是生成当前元素对应的汉字,而这儿是生成当前元素对应的下一个汉字。
原理
同5.3节一样,我们这儿使用的还是Simple RNN模型。所以整个估算流程图如图3所示。
图3
代码
实现特点训练估算的代码如下:
public double train(List x, List y) {
alreadyTrain = true;
double minError = Double.MAX_VALUE;
for (int i = 0; i < totalTrain; i++) {
//定义更新数组
double[][] weightLayer0_update = new double[weightLayer0.length][weightLayer0[0].length];
double[][] weightLayer1_update = new double[weightLayer1.length][weightLayer1[0].length];
double[][] weightLayerh_update = new double[weightLayerh.length][weightLayerh[0].length];
List hiddenLayerInput = new ArrayList();
List outputLayerDelta = new ArrayList();
double[] hiddenLayerInitial = new double[hiddenLayers];
//对于初始的隐含层变量赋值为0
Arrays.fill(hiddenLayerInitial, 0.0);
hiddenLayerInput.add(hiddenLayerInitial);
double overallError = 0.0;
//前向网络计算预测误差
overallError = propagateNetWork(x, y, hiddenLayerInput,
outputLayerDelta, overallError);
if (overallError < minError) {
minError = overallError;
}else {
continue;
}
first2HiddenLayer = Arrays.copyOf(hiddenLayerInput.get(hiddenLayerInput.size()-1), hiddenLayerInput.get(hiddenLayerInput.size()-1).length);
double[] hidden2InputDelta = new double[weightLayerh_update.length];
//后向网络调整权值矩阵
hidden2InputDelta = backwardNetWork(x, hiddenLayerInput,
outputLayerDelta, hidden2InputDelta,weightLayer0_update, weightLayer1_update, weightLayerh_update);
weightLayer0 = matrixAdd(weightLayer0, matrixPlus(weightLayer0_update, alpha));
weightLayer1 = matrixAdd(weightLayer1, matrixPlus(weightLayer1_update, alpha));
weightLayerh = matrixAdd(weightLayerh, matrixPlus(weightLayerh_update, alpha));
}
return -1.0;
}
实现预测估算的代码如图下:
public double[] predict(double[] x) {
if (!alreadyTrain) {
new IllegalAccessError("model has not been trained, so can not to be predicted!!!");
}
double[] x2FirstLayer = matrixDot(x, weightLayer0);
double[] firstLayer2Hidden = matrixDot(first2HiddenLayer, weightLayerh);
if (x2FirstLayer.length != firstLayer2Hidden.length) {
new IllegalArgumentException("the x2FirstLayer length is not equal with firstLayer2Hidden length!");
}
for (int i = 0; i < x2FirstLayer.length; i++) {
firstLayer2Hidden[i] += x2FirstLayer[i];
}
firstLayer2Hidden = sigmoid(firstLayer2Hidden);
double[] hiddenLayer2Out = matrixDot(firstLayer2Hidden, weightLayer1);
hiddenLayer2Out = sigmoid(hiddenLayer2Out);
return hiddenLayer2Out;
}
拓展
文本的生成,按照输入方法不同,可以分为如下几种:
文本到文本的生成。即输入的是文本,输出的也是文本。图像到文本。即输入的是图象,输出的是文本。数据到文本。即输入的是数据,输出的是文本。其他。即输入的方式为非前面两者,但是输出的也是文本。因为这类的输入比较难归纳,所以就归为其他了。
其中第2、第3种近来发展得十分快,特别是随着深度学习、知识图谱等前沿技术的发展。基于图象生成文本描述的试验成果在不断被刷新。基于GAN(对抗神经网路)的图象文本生成技术早已实现了特别大的图谱,不仅还能依据图片生成非常好的描述,还能依据文本输入生成对应的图片。
由数据生成文本,目前主要应用在新闻撰写领域。中文和日文的都有很大的进展,英文的以路透社为代表,中文的则以腾讯公司为代表。当然这两家都不是纯粹地以数据为输入,而是综合了前面4种情况的新闻撰写。
从技术上来说,现在主流的实现方法有两种:一种是基于符号的,以知识图谱为代表,这类方式更多地使用人的先验知识,对于文本的处理更多地收录语义的成份。另一种是基于统计(联结)的,即按照大量文本学习出不同文本之间的组合规律,进而依据输入猜想出可能的组合形式作为输出。随着深度学习和知识图谱的结合,这三者有显著的融合现象,这应当是实现未来技术突破的一个重要节点。
编者按: 本书主要从语义模型解读、自然语言处理系统基础算法和系统案例实战三个方面,介绍了自然语言处理中相关的一些技术。对于每一个算法又分别从应用原理、数学原理、代码实现,以及对当前方式的思索四个方面进行讲解。
详情点击: 查看全部
如何使用 RNN 模型实现文本手动生成
在自然语言处理中,另外一个重要的应用领域,就是文本的手动撰写。关键词、关键词组、自动摘要提取都属于这个领域中的一种应用。不过这种应用,都是由多到少的生成。这里我们介绍其另外一种应用:由少到多的生成,包括短语的复写,由关键词、主题生成文章或者段落等。
基于关键词的文本手动生成模型
本章第一节就介绍基于关键词生成一段文本的一些处理技术。其主要是应用关键词提取、同义词辨识等技术来实现的。下面就对实现过程进行说明和介绍。
场景
在进行搜索引擎广告投放的时侯,我们须要给广告撰写一句话描述。一般情况下模型的输入就是一些关键词。比如我们要投放的广告为花束广告,假设广告的关键词为:“鲜花”、“便宜”。对于这个输入我们希望形成一定数目的候选一句话广告描述。
对于这些场景,也可能输入的是一句话,比如之前人工撰写了一个事例:“这个周末,小白花束只要99元,并且还包邮哦,还包邮哦!”。需要按照这句话复写出一定数目在抒发上不同,但是意思相仿的句子。这里我们就介绍一种基于关键词的文本(一句话)自动生成模型。
原理
模型处理流程如图1所示。
图1完成候选句子的提取以后,就要按照候选句子的数目来判定后续操作了。如果筛选的候选句子小于等于要求的数目,则根据语句相似度由低到高选定指定数目的短语。否则要进行短语的复写。这里采用同义词替换和按照指定模板进行改写的方案。
实现
实现候选句子估算的代码如下:
Map result = new HashMap();
if (type == 0) {//输入为关键词
result = getKeyWordsSentence(keyWordsList);
}else {
result = getWordSimSentence(sentence);
}
//得到候选集数量大于等于要求的数量则对结果进行裁剪
if (result.size() >= number) {
result = sub(result, number);
}else {
//得到候选集数量小于要求的数量则对结果进行添加
result = add(result, number);
}
实现句子相像筛选估算的代码如下。
for (String sen : sentenceList) {
//对待识别语句进行分词处理
List wordsList1 = parse(sentence);
List wordsList2 = parse(sen);
//首先判断两个语句是不是满足目标变换
boolean isPatternSim = isPatternSimSentence(wordsList1, wordsList2);
if (!isPatternSim) {//不满足目标变换
//首先计算两个语句的bi-gram相似度
double tmp = getBigramSim(wordsList1, wordsList2);
//这里的筛选条件是相似度小于阈值,因为bi-gram的相似度越小,代表两者越相似
if (threshold > tmp) {
result.put(sen,tmp);
}
}else {
result.put(sen,0.0);
}
}
拓展
本节处理的场景是:由文本到文本的生成。这个场景通常主要涉及:文本摘要、句子压缩、文本复写、句子融合等文本处理技术。其中本节涉及文本摘要和语句复写两个方面的技术。文本摘要如前所述主要涉及:关键词提取、短语提取、句子提取等。句子复写则按照实现手段的不同,大致可以分为如下几种。
基于统计模型和语义剖析生成模型的改写方式。这类方式就是按照语料库中的数据进行统计,获得大量的转换机率分布,然后对于输入的语料按照已知的先验知识进行替换。这类方式的语句是在剖析结果的基础上进行生成的,从某种意义上说,生成是在剖析的指导下实现的,因此,改写生成的诗句有可能具有良好的诗句结构。但是其所依赖的语料库是十分大的,这样就须要人工标明好多数据。对于这种问题,新的深度学习技术可以解决部份的问题。同时结合知识图谱的深度学习,能够更好地借助人的知识,最大限度地降低对训练样本的数据需求。RNN模型实现文本手动生成
6.1.2节介绍了基于短文本输入获得长文本的一些处理技术。这里主要使用的是RNN网路,利用其对序列数据处理能力,来实现文本序列数据的手动填充。下面就对其实现细节做一个说明和介绍。
场景
在广告投放的过程中,我们可能会遇见这些场景:由一句话生成一段描述文本,文本宽度在200~300字之间。输入也可能是一些主题的关键词。
这个时侯我们就须要一种依据少量文本输入形成大量文本的算法了。这里介绍一种算法:RNN算法。在5.3节我们早已介绍了这个算法,用该算法实现由拼音到汉字的转换。其实这两个场景的模式是一样的,都是由给定的文本信息,生成另外一些文本信息。区别是后者是生成当前元素对应的汉字,而这儿是生成当前元素对应的下一个汉字。
原理
同5.3节一样,我们这儿使用的还是Simple RNN模型。所以整个估算流程图如图3所示。
图3
代码
实现特点训练估算的代码如下:
public double train(List x, List y) {
alreadyTrain = true;
double minError = Double.MAX_VALUE;
for (int i = 0; i < totalTrain; i++) {
//定义更新数组
double[][] weightLayer0_update = new double[weightLayer0.length][weightLayer0[0].length];
double[][] weightLayer1_update = new double[weightLayer1.length][weightLayer1[0].length];
double[][] weightLayerh_update = new double[weightLayerh.length][weightLayerh[0].length];
List hiddenLayerInput = new ArrayList();
List outputLayerDelta = new ArrayList();
double[] hiddenLayerInitial = new double[hiddenLayers];
//对于初始的隐含层变量赋值为0
Arrays.fill(hiddenLayerInitial, 0.0);
hiddenLayerInput.add(hiddenLayerInitial);
double overallError = 0.0;
//前向网络计算预测误差
overallError = propagateNetWork(x, y, hiddenLayerInput,
outputLayerDelta, overallError);
if (overallError < minError) {
minError = overallError;
}else {
continue;
}
first2HiddenLayer = Arrays.copyOf(hiddenLayerInput.get(hiddenLayerInput.size()-1), hiddenLayerInput.get(hiddenLayerInput.size()-1).length);
double[] hidden2InputDelta = new double[weightLayerh_update.length];
//后向网络调整权值矩阵
hidden2InputDelta = backwardNetWork(x, hiddenLayerInput,
outputLayerDelta, hidden2InputDelta,weightLayer0_update, weightLayer1_update, weightLayerh_update);
weightLayer0 = matrixAdd(weightLayer0, matrixPlus(weightLayer0_update, alpha));
weightLayer1 = matrixAdd(weightLayer1, matrixPlus(weightLayer1_update, alpha));
weightLayerh = matrixAdd(weightLayerh, matrixPlus(weightLayerh_update, alpha));
}
return -1.0;
}
实现预测估算的代码如图下:
public double[] predict(double[] x) {
if (!alreadyTrain) {
new IllegalAccessError("model has not been trained, so can not to be predicted!!!");
}
double[] x2FirstLayer = matrixDot(x, weightLayer0);
double[] firstLayer2Hidden = matrixDot(first2HiddenLayer, weightLayerh);
if (x2FirstLayer.length != firstLayer2Hidden.length) {
new IllegalArgumentException("the x2FirstLayer length is not equal with firstLayer2Hidden length!");
}
for (int i = 0; i < x2FirstLayer.length; i++) {
firstLayer2Hidden[i] += x2FirstLayer[i];
}
firstLayer2Hidden = sigmoid(firstLayer2Hidden);
double[] hiddenLayer2Out = matrixDot(firstLayer2Hidden, weightLayer1);
hiddenLayer2Out = sigmoid(hiddenLayer2Out);
return hiddenLayer2Out;
}
拓展
文本的生成,按照输入方法不同,可以分为如下几种:
文本到文本的生成。即输入的是文本,输出的也是文本。图像到文本。即输入的是图象,输出的是文本。数据到文本。即输入的是数据,输出的是文本。其他。即输入的方式为非前面两者,但是输出的也是文本。因为这类的输入比较难归纳,所以就归为其他了。
其中第2、第3种近来发展得十分快,特别是随着深度学习、知识图谱等前沿技术的发展。基于图象生成文本描述的试验成果在不断被刷新。基于GAN(对抗神经网路)的图象文本生成技术早已实现了特别大的图谱,不仅还能依据图片生成非常好的描述,还能依据文本输入生成对应的图片。
由数据生成文本,目前主要应用在新闻撰写领域。中文和日文的都有很大的进展,英文的以路透社为代表,中文的则以腾讯公司为代表。当然这两家都不是纯粹地以数据为输入,而是综合了前面4种情况的新闻撰写。
从技术上来说,现在主流的实现方法有两种:一种是基于符号的,以知识图谱为代表,这类方式更多地使用人的先验知识,对于文本的处理更多地收录语义的成份。另一种是基于统计(联结)的,即按照大量文本学习出不同文本之间的组合规律,进而依据输入猜想出可能的组合形式作为输出。随着深度学习和知识图谱的结合,这三者有显著的融合现象,这应当是实现未来技术突破的一个重要节点。
编者按: 本书主要从语义模型解读、自然语言处理系统基础算法和系统案例实战三个方面,介绍了自然语言处理中相关的一些技术。对于每一个算法又分别从应用原理、数学原理、代码实现,以及对当前方式的思索四个方面进行讲解。
详情点击:
seo关键词生成系统一套全手动快速生成网站(htm)的程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 501 次浏览 • 2020-08-16 19:58
演示站点
前言:让网站产生大流量,赚美金,赚广告费!
seo关键词生成系统 600一套 购买QQ联系:
一套全手动快速生成网站(htm)的程序' />
一套全手动快速生成网站(htm)的程序.它能按照您提供的关键词,从搜索引擎中提取大量相关关键词,再依照关键词从网路中抓取到优质的相关内容,并按照设定好的网页模板快速生成内容网站及大量网站.再把网站供搜索引擎收录,从而获得巨大流量.本软件既能"一键式"全手动快速生成网站,也能按照你的优化要求自动调整,做到了灵活多元化,以适应搜索引擎对不同关键词的优化要求.
软件特色:
以热门搜索词为title关键词,排名靠前,针对性强
定向抓取优质内容,不再是空壳网站抓取和生成网站速度超快,数分钟可生成几千htm
主要特征与功能:
使用多线程下载,采用了智能换网址补抓网页机制,采集率高达99%。
采集内容经多方优化,内容优质。注:优化处理不断升级中
自定义标签即抓取到更优质的内容!增加定义栏目,可无限降低栏目,向正规站靠拢!
重要功能:增加更新功能,支持每日更新记录,方便快捷的更新,更有利于搜索引擎收录和提升权重!
选择生成对象是文件或目录。文件名或目录名,可使用ID号,数字,字母+数字,随机字母。 查看全部
seo关键词生成系统一套全手动快速生成网站(htm)的程序
演示站点
前言:让网站产生大流量,赚美金,赚广告费!
seo关键词生成系统 600一套 购买QQ联系:
一套全手动快速生成网站(htm)的程序' />
一套全手动快速生成网站(htm)的程序.它能按照您提供的关键词,从搜索引擎中提取大量相关关键词,再依照关键词从网路中抓取到优质的相关内容,并按照设定好的网页模板快速生成内容网站及大量网站.再把网站供搜索引擎收录,从而获得巨大流量.本软件既能"一键式"全手动快速生成网站,也能按照你的优化要求自动调整,做到了灵活多元化,以适应搜索引擎对不同关键词的优化要求.
软件特色:
以热门搜索词为title关键词,排名靠前,针对性强
定向抓取优质内容,不再是空壳网站抓取和生成网站速度超快,数分钟可生成几千htm
主要特征与功能:
使用多线程下载,采用了智能换网址补抓网页机制,采集率高达99%。
采集内容经多方优化,内容优质。注:优化处理不断升级中
自定义标签即抓取到更优质的内容!增加定义栏目,可无限降低栏目,向正规站靠拢!
重要功能:增加更新功能,支持每日更新记录,方便快捷的更新,更有利于搜索引擎收录和提升权重!
选择生成对象是文件或目录。文件名或目录名,可使用ID号,数字,字母+数字,随机字母。
做SEO重复的内容与采集站会遭到搜索引擎惩罚吗
采集交流 • 优采云 发表了文章 • 0 个评论 • 307 次浏览 • 2020-08-15 02:03
查找引擎到底会不会奖惩搜集的内容要需求阐述的是内容重复与站点搜集,由于这两点是有定差别的。就当时来讲,查找引擎关于重复内容到是没有太冲击现象。那么你也就能这样了解,查找引擎通常关于重复的内容是不会进行奖惩的。
许多网站优化界的人士在做网站剖析的时分还会考虑站点的重复系数的问题,一般还会经过一些站长辅助工具来大概核算一下原文链接。
咱们共同含混的就是文章别被人剽窃后竟然排行比自己的还要高,对此百度也曾视图处理这等相像的问题。在当时的测验阶段里,咱们才能在逾刚才推出的熊掌号上面看出一些新的期望。渠道晋级后有权限的站长才能够在熊掌号的维护伞下递交原创内容,其间一个亮点就是文章的发布时刻简直才能确切到秒来核算。
具有原创维护的站点,提交链接一旦被审读经过。那么在移动端的手机查找上都会加注原创标签,这样一来你的原创文章天然都会比转载的要好的多。 查看全部
重复的节选别人的内容都是SEO职业一向比较注重的大问题,那么重复的内容终究会不会受到查找引擎的奖惩呢?其实这种一向都是优化师们经常在一起评论的话题了,这一段百度对搜集网站进行了大批量的K站。可是仍然有许多同学的站点排行始终挺好,面临如此对的搜集内容,查找引擎又是如何进行差别的呢?下面和北京百度霸屏推广公司一起来瞧瞧具体情况
查找引擎到底会不会奖惩搜集的内容要需求阐述的是内容重复与站点搜集,由于这两点是有定差别的。就当时来讲,查找引擎关于重复内容到是没有太冲击现象。那么你也就能这样了解,查找引擎通常关于重复的内容是不会进行奖惩的。
许多网站优化界的人士在做网站剖析的时分还会考虑站点的重复系数的问题,一般还会经过一些站长辅助工具来大概核算一下原文链接。
咱们共同含混的就是文章别被人剽窃后竟然排行比自己的还要高,对此百度也曾视图处理这等相像的问题。在当时的测验阶段里,咱们才能在逾刚才推出的熊掌号上面看出一些新的期望。渠道晋级后有权限的站长才能够在熊掌号的维护伞下递交原创内容,其间一个亮点就是文章的发布时刻简直才能确切到秒来核算。
具有原创维护的站点,提交链接一旦被审读经过。那么在移动端的手机查找上都会加注原创标签,这样一来你的原创文章天然都会比转载的要好的多。
网站搜索引擎优化六步骤
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2020-08-13 19:46
总的说来,对图片的优化还是应当尽量降低大图片以及缩小图片的加载时间。alt属性中的文字对搜索引擎来说,其重要性比正文内容的文字要低。
四、网页代码的优化(主要是javascript)
正常情况下,网页尽量以作为代码的开始端。但我们好多的网页是采用javascript技术的,往往在页面一开始就堆积大量java代码,以至于meta及关键字迟迟不能出现,被推至页面中上部,对搜索引擎太不友好。有两个建议:
1、将脚本移至页面顶部
大部分的java代码都可以移到页面结束标签之上,而不影响网站功能。这样才能一开始突出关键词,并推动页面加载时间。
2、将javascript脚本放在.js文件中。
这样.js脚本就可以被缓存出来,访问同样调用这个javascript的页面的时侯才会提升网页的访问速率。
五、防止因优化过度被判定为作弊
(编辑在发布信息时要防止的问题)
做优化必须了解基本的作弊手段,否则都会让辛苦付之东流:
1、关键字拼凑:
为了降低关键词的出现次数,故意在网页代码中,如在meta、title、注释、图片alt以及url地址等地方重复添加同一个关键词。(一定要时刻把握关键字的密度要求)
2、虚假关键词(不相关的关键字):
通过在meta中设置与网站内容无关的关键词,比如在title中设置了热门关键词,希望使用户按照此步入网站。同样的情况也包括链接关键词与实际内容不符的情况。
3、隐形文本/链接:
为了降低关键词的出现频次,故意在网页中放一段与背景颜色相同的、收录好多关键字的文本。访客看不到,搜索引擎却能找到。类似方式还包括使用超大号文字等手段。隐形链接是在隐型文本的基础上在其它页面添加指向目标优化页的行为。
六、新版上线后的注意事项
1.保留原有的网页命名/pr值:
保留原有网页,即使网页的结构和内容被修改,搜索引擎蜘蛛还是可以按"原街"找到页面。这种方法能使蜘蛛更快的重新收录原页面中的新内容,也保护了原有的排行及页面的pr值。当然,如果有些页面不合理的,不适宜搜索引擎的可以删除,对于这些收录现今每晚能带来稳定流量的关键字页面,可以将其保留。
2.sitemaps更新:
能使搜索引擎更好、更快的收录新站,建议构建sitemaps,告诉搜索引擎我的网站在改变,牵引搜索蜘蛛去收录新的页面。
3.避免站点内容的冲突:
因为新改版以后不可能很快就有很多新的内容,所以网站的内容还是仿效旧版本的内容,这样对搜索引擎是不友好的,另外加上新、旧网站的网站结构不一样,搜索引擎有可能要花更多的时间来观察、分析目前的网站情况。所以应当处理好新、旧站之间的链接、内容的关联性,避免出现过多内容重复。
4.及时检测网站友情链接,以避免链接到的页面因作弊被惩罚。
自助建站网站建设域名申请虚拟主机广州域名注册佛山域名注册广州域名注册广州域名注册
与网站搜索引擎优化六步骤相关文章:
·长沙网站优化-如何递交目录
·谈谈网站优化及网路推广工程中的工作流程问题
·企业网站优化策略
·长沙推广武汉推广网站长沙网路推广武汉网站推
·我要做网站,长沙我要做网站,长沙网站设计南京
·平民网站排名优化和基于用户体验的网站建设
本文标题:网站搜索引擎优化六步骤
本文地址: 查看全部
3、在图片下方或后面降低如"更多某甲"链接,收录关键词。
总的说来,对图片的优化还是应当尽量降低大图片以及缩小图片的加载时间。alt属性中的文字对搜索引擎来说,其重要性比正文内容的文字要低。
四、网页代码的优化(主要是javascript)
正常情况下,网页尽量以作为代码的开始端。但我们好多的网页是采用javascript技术的,往往在页面一开始就堆积大量java代码,以至于meta及关键字迟迟不能出现,被推至页面中上部,对搜索引擎太不友好。有两个建议:
1、将脚本移至页面顶部
大部分的java代码都可以移到页面结束标签之上,而不影响网站功能。这样才能一开始突出关键词,并推动页面加载时间。
2、将javascript脚本放在.js文件中。
这样.js脚本就可以被缓存出来,访问同样调用这个javascript的页面的时侯才会提升网页的访问速率。
五、防止因优化过度被判定为作弊
(编辑在发布信息时要防止的问题)
做优化必须了解基本的作弊手段,否则都会让辛苦付之东流:
1、关键字拼凑:
为了降低关键词的出现次数,故意在网页代码中,如在meta、title、注释、图片alt以及url地址等地方重复添加同一个关键词。(一定要时刻把握关键字的密度要求)
2、虚假关键词(不相关的关键字):
通过在meta中设置与网站内容无关的关键词,比如在title中设置了热门关键词,希望使用户按照此步入网站。同样的情况也包括链接关键词与实际内容不符的情况。
3、隐形文本/链接:
为了降低关键词的出现频次,故意在网页中放一段与背景颜色相同的、收录好多关键字的文本。访客看不到,搜索引擎却能找到。类似方式还包括使用超大号文字等手段。隐形链接是在隐型文本的基础上在其它页面添加指向目标优化页的行为。
六、新版上线后的注意事项
1.保留原有的网页命名/pr值:
保留原有网页,即使网页的结构和内容被修改,搜索引擎蜘蛛还是可以按"原街"找到页面。这种方法能使蜘蛛更快的重新收录原页面中的新内容,也保护了原有的排行及页面的pr值。当然,如果有些页面不合理的,不适宜搜索引擎的可以删除,对于这些收录现今每晚能带来稳定流量的关键字页面,可以将其保留。
2.sitemaps更新:
能使搜索引擎更好、更快的收录新站,建议构建sitemaps,告诉搜索引擎我的网站在改变,牵引搜索蜘蛛去收录新的页面。
3.避免站点内容的冲突:
因为新改版以后不可能很快就有很多新的内容,所以网站的内容还是仿效旧版本的内容,这样对搜索引擎是不友好的,另外加上新、旧网站的网站结构不一样,搜索引擎有可能要花更多的时间来观察、分析目前的网站情况。所以应当处理好新、旧站之间的链接、内容的关联性,避免出现过多内容重复。
4.及时检测网站友情链接,以避免链接到的页面因作弊被惩罚。
自助建站网站建设域名申请虚拟主机广州域名注册佛山域名注册广州域名注册广州域名注册
与网站搜索引擎优化六步骤相关文章:
·长沙网站优化-如何递交目录
·谈谈网站优化及网路推广工程中的工作流程问题
·企业网站优化策略
·长沙推广武汉推广网站长沙网路推广武汉网站推
·我要做网站,长沙我要做网站,长沙网站设计南京
·平民网站排名优化和基于用户体验的网站建设
本文标题:网站搜索引擎优化六步骤
本文地址:
网站优化想省心,得使“站群优化系统”来做!
采集交流 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2020-08-12 18:35
站群优化系统“慧营销”为你网站优化!
站群优化系统仍然是好多企业选择的网站优化方案,因为不需要聘请专业的优化专业员对其网站进行优化,站群优化系统对其网站进行优化,完全可以做到智能优化和手动优化,日常人工优化网站的工作,站群优化系统“慧营销”都能智能帮我们完成,省心又省时。
站群优化系统“慧营销”拥有的功能!
1、智能采集+更新
站群优化系统“慧营销”,可以做到手动采集内容,然后在通过自己的词库对其内容进行智能洗白加伪原创,再手动为你更新到网站。
2、裂变式分站
“慧营销”可以在短时间内,为我们生成上百上千个城市分站,全程智能生成不需要任何自动设置,为你获取到更多的排行和流量的入口。
3、智能快速上排行
站群优化系统“慧营销”采用智能造词、智能替换,系统智能生产出大量的行业相关“关键词”,以实现搜索霸屏疗效,帮你扩张关键词,获取到更多的关键词首页排行。
站群优化系统优化网站省心省力,想要晓得更多关于站群优化系统资讯,访问“慧营销”专区网址,免费发放试用版: 查看全部
搭建完成的网站,在往前一定要对网站进行优化工作的,但好多的人对网站的优化工作都不是太擅长,不知该怎么去对网站开展优化,其实在优化网站是有两个种方法,一种是专业的SEO优化专员对其网站进行优化,另一种就是运用站群优化系统对其网站进行智能优化,其实前者站群优化系统,更适宜不会网站优化的人去使用,把网站优化的工作交给站群优化系统,它也一样可以为我们把网站优化做的更好!
站群优化系统“慧营销”为你网站优化!
站群优化系统仍然是好多企业选择的网站优化方案,因为不需要聘请专业的优化专业员对其网站进行优化,站群优化系统对其网站进行优化,完全可以做到智能优化和手动优化,日常人工优化网站的工作,站群优化系统“慧营销”都能智能帮我们完成,省心又省时。
站群优化系统“慧营销”拥有的功能!
1、智能采集+更新
站群优化系统“慧营销”,可以做到手动采集内容,然后在通过自己的词库对其内容进行智能洗白加伪原创,再手动为你更新到网站。
2、裂变式分站
“慧营销”可以在短时间内,为我们生成上百上千个城市分站,全程智能生成不需要任何自动设置,为你获取到更多的排行和流量的入口。
3、智能快速上排行
站群优化系统“慧营销”采用智能造词、智能替换,系统智能生产出大量的行业相关“关键词”,以实现搜索霸屏疗效,帮你扩张关键词,获取到更多的关键词首页排行。
站群优化系统优化网站省心省力,想要晓得更多关于站群优化系统资讯,访问“慧营销”专区网址,免费发放试用版:
亚马逊关键词挖掘工具有什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2020-08-12 12:48
名称:Keyword Tool Dominator
/
价格:$69.99
支持的亚马逊站点:US, EU, UK
功能特点:该工具是一个Chrome插件,这是一个非常有影响力的长尾关键词研究工具。能手动从amamzon、google、bing、youtube抓取到自己数据库。
排名:4
名称:Google Keyword Planner
价格:免费
支持的亚马逊站点:US, GE, ES, FR, UK…
功能特点:可能是目前最好的关键词研究工具。谷歌官方出品,做亚马逊的店家也可以参考。
排名:5
名称:Merchant Words
网址:/
价格:$60/月
支持的亚马逊站点:US, IT, FR, CA…
功能特点:大名鼎鼎的,Merchant Words,帮助店家找到非常的关键词及熟语。
排名:6
名称:KeywordInspector
/
价格:$39.95/月
支持的亚马逊站点:US, UK
功能特点:提供的Reverse ASIN Tool 和 KeywordTrend tool 工具能帮买家提高在亚马逊上的竞争力。
排名:7
名称:AmaSuite
网址:/
价格:$97
支持的亚马逊站点:US, CA, UK, DE, IT, FR…
功能特点:AmaSuite是一个强悍的mac和pc客户端软件。强力推荐给每一个想做好亚马逊SEO的店家。
排名:8
名称:AMZ One
网址:/
价格:提供免费版本
支持的亚马逊站点:US, RU
功能特点:类似关键词排行跟踪、销量跟踪的功能,使得对于希望找寻中级关键词研究工具的人来说特别有用,此工具不适宜菜鸟。
排名:9
名称:AMZ Space
网址:amz.space (网址真奇怪)
价格:提供1个月免费
支持的亚马逊站点:UK, FR, DE, IT, ES…
功能特点:该工具能提供的功能有:计算收益、自动发送电邮给消费者、跟踪高排行的关键词。使用该工具须要有一定的SEO:基础。
排名:10
名称:AMZ Tracker
网址:/
价格:$33 /月起
支持的亚马逊站点:JP, BR, FR, DE, ES, US, IN…
功能特点:AMZ Tracker是一款高效但高昂的关键词工具。通过Amazon SEO功能你可以提高关键词排行、通过Keyword Suggester 功能你可以找寻到新的关键词。
排名:11
名称:Helium 10
网址:/
价格:提供免费版本
支持的亚马逊站点:US, UK, DE…
功能特点:诸如Frankenstein Keyword Processor和Magnet Amazon Keyword research tool 这样的功能使 Helium 10成为最出色的SEO专业工具。
排名:12
名称:Scientific Seller
网址:/
价格:免费
支持的亚马逊站点:US, BR, JP, CA…
功能特点:不象其它的关键词剖析工具又快又高效,Scientific Seller容许平缓却十分严谨,一个关键词查询可以持续数小时。
排名:13
名称:Scope
网址:/scope/
价格:提供免费版本
支持的亚马逊站点:US
功能特点:该工具能对销量最好的产品进行监控、罗列关键词排行。你不需要成为一个专家也能通过Scope做好关键词和亚马:逊产品研究。
排名:14
名称:Keyword Keg
网址:/
价格:$8/月起
支持的亚马逊站点:US, UK, CA, NZ…
功能特点:Keyword Keg 共享来自于Yahoo, Google, Bing or Yandex.等平台的数据。它的定价计划为亚马逊的买家提供了不同数目的选择。
排名:15
名称:Keyword Eye
网址:/
价格:$35/月起
支持的亚马逊站点:US, UK…
功能特点:超过5万名用户和超过100万的关键字建议充分说明了Keyword Eye的实力。这个工具将使您了解您须要晓得的关于顾客需求的所有信息。
排名:16
名称:AMZ Sistrix
/amazon/keywords/country/us
价格:免费
支持的亚马逊站点:DE, UK, US, ES
功能特点:简单的输入一个关键词,剩下的交给AMZ Sistrix吧。
排名:17
名称:Kparser
网址:/
价格:提供免费版本
支持的亚马逊站点:US, AR, BR, DK, UK…
功能特点:通过Kparser,你可以在微软、Amazon、eBay或Bing上为您的产品找到最好的关键字,并通过几个简单的步骤发觉长尾关键字。
排名:18
名称:SEO Chat
网址: (似乎挂了)
价格:提供免费版本
支持的亚马逊站点:US, UK…
功能特点:大名鼎鼎的SEO Chat,是一个你可以找到所有的信息和工具的专业搜索引擎优化网站。
排名:19
名称:Asin key
网址:/
价格:$19.99/月起
支持的亚马逊站点:US, UK, DE, FR…
功能特点:Amazon SEO, Amazon Keyword, and Keyword Rankings tools:要求使用者有知识储备,所以不适宜没有经验的用户。
排名:20
名称:Seo Stack
网址:/
价格:30天免费试用:
支持的亚马逊站点:US, UK…
功能特点:该工具能轻松生成关键词、获得关键词建议、关键词竞争程度剖析。
跨境电商软件工具 查看全部
排名:3
名称:Keyword Tool Dominator
/
价格:$69.99
支持的亚马逊站点:US, EU, UK
功能特点:该工具是一个Chrome插件,这是一个非常有影响力的长尾关键词研究工具。能手动从amamzon、google、bing、youtube抓取到自己数据库。
排名:4
名称:Google Keyword Planner
价格:免费
支持的亚马逊站点:US, GE, ES, FR, UK…
功能特点:可能是目前最好的关键词研究工具。谷歌官方出品,做亚马逊的店家也可以参考。
排名:5
名称:Merchant Words
网址:/
价格:$60/月
支持的亚马逊站点:US, IT, FR, CA…
功能特点:大名鼎鼎的,Merchant Words,帮助店家找到非常的关键词及熟语。
排名:6
名称:KeywordInspector
/
价格:$39.95/月
支持的亚马逊站点:US, UK
功能特点:提供的Reverse ASIN Tool 和 KeywordTrend tool 工具能帮买家提高在亚马逊上的竞争力。
排名:7
名称:AmaSuite
网址:/
价格:$97
支持的亚马逊站点:US, CA, UK, DE, IT, FR…
功能特点:AmaSuite是一个强悍的mac和pc客户端软件。强力推荐给每一个想做好亚马逊SEO的店家。
排名:8
名称:AMZ One
网址:/
价格:提供免费版本
支持的亚马逊站点:US, RU
功能特点:类似关键词排行跟踪、销量跟踪的功能,使得对于希望找寻中级关键词研究工具的人来说特别有用,此工具不适宜菜鸟。
排名:9
名称:AMZ Space
网址:amz.space (网址真奇怪)
价格:提供1个月免费
支持的亚马逊站点:UK, FR, DE, IT, ES…
功能特点:该工具能提供的功能有:计算收益、自动发送电邮给消费者、跟踪高排行的关键词。使用该工具须要有一定的SEO:基础。
排名:10
名称:AMZ Tracker
网址:/
价格:$33 /月起
支持的亚马逊站点:JP, BR, FR, DE, ES, US, IN…
功能特点:AMZ Tracker是一款高效但高昂的关键词工具。通过Amazon SEO功能你可以提高关键词排行、通过Keyword Suggester 功能你可以找寻到新的关键词。
排名:11
名称:Helium 10
网址:/
价格:提供免费版本
支持的亚马逊站点:US, UK, DE…
功能特点:诸如Frankenstein Keyword Processor和Magnet Amazon Keyword research tool 这样的功能使 Helium 10成为最出色的SEO专业工具。
排名:12
名称:Scientific Seller
网址:/
价格:免费
支持的亚马逊站点:US, BR, JP, CA…
功能特点:不象其它的关键词剖析工具又快又高效,Scientific Seller容许平缓却十分严谨,一个关键词查询可以持续数小时。
排名:13
名称:Scope
网址:/scope/
价格:提供免费版本
支持的亚马逊站点:US
功能特点:该工具能对销量最好的产品进行监控、罗列关键词排行。你不需要成为一个专家也能通过Scope做好关键词和亚马:逊产品研究。
排名:14
名称:Keyword Keg
网址:/
价格:$8/月起
支持的亚马逊站点:US, UK, CA, NZ…
功能特点:Keyword Keg 共享来自于Yahoo, Google, Bing or Yandex.等平台的数据。它的定价计划为亚马逊的买家提供了不同数目的选择。
排名:15
名称:Keyword Eye
网址:/
价格:$35/月起
支持的亚马逊站点:US, UK…
功能特点:超过5万名用户和超过100万的关键字建议充分说明了Keyword Eye的实力。这个工具将使您了解您须要晓得的关于顾客需求的所有信息。
排名:16
名称:AMZ Sistrix
/amazon/keywords/country/us
价格:免费
支持的亚马逊站点:DE, UK, US, ES
功能特点:简单的输入一个关键词,剩下的交给AMZ Sistrix吧。
排名:17
名称:Kparser
网址:/
价格:提供免费版本
支持的亚马逊站点:US, AR, BR, DK, UK…
功能特点:通过Kparser,你可以在微软、Amazon、eBay或Bing上为您的产品找到最好的关键字,并通过几个简单的步骤发觉长尾关键字。
排名:18
名称:SEO Chat
网址: (似乎挂了)
价格:提供免费版本
支持的亚马逊站点:US, UK…
功能特点:大名鼎鼎的SEO Chat,是一个你可以找到所有的信息和工具的专业搜索引擎优化网站。
排名:19
名称:Asin key
网址:/
价格:$19.99/月起
支持的亚马逊站点:US, UK, DE, FR…
功能特点:Amazon SEO, Amazon Keyword, and Keyword Rankings tools:要求使用者有知识储备,所以不适宜没有经验的用户。
排名:20
名称:Seo Stack
网址:/
价格:30天免费试用:
支持的亚马逊站点:US, UK…
功能特点:该工具能轻松生成关键词、获得关键词建议、关键词竞争程度剖析。
跨境电商软件工具
输入关键词手动生成文章高阶的SEO查询
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2020-08-12 07:11
4、快速收录上线对SEO意味着哪些?快速收录上线站点管理一方面是便捷百度开发人员维护调试,统一化管理,另一方面也便捷的用户,这样不用多个后台去递交(以前自动递交须要到站点管理,天级递交须要到联通专区后台)。快速收录功能上线也就代表联通专区距离彻底下线也不远了,或者就是这几天了。
5、网站蜘蛛池作用剖析大量降低外链,会被搜索引擎判断为作弊(大机率是过度优化);
6、主动推送链接:更新sitemap地图,提交给搜索引擎,在百度资源验证网站,安装手动推送代码,加页面的抓取收录。
7、seo搜索引擎收录原理,走进百度收录的背后
8、如果把一个网站页面组成的页面看做是一个有向图,从指定的页面出发,沿着页面中的链接,按照某种特定的策略对网站中的页面进行遍历。不停地从URL列表中移出早已访问的URL,并储存原创页面,同时提取原创页面中的URL的信息:再将URL分为域名及内部URL两大类,同时判定URL是否被访问过,将未访问过的URL加入URL列表中。递归地扫描URL列表,直至用尽所有URL资源为止。经过这种工作,搜索引擎就可以构建庞大的域名列表、页面URL列表并存储足够多的原创页面。
—————————————————————————————–
问:黑帽seo是哪些意思?
答:黑帽SEO是借助和放大搜索引擎的策略缺陷(实际上完美的系统是不存在的)获取更多用户访问量,而这种更多的访问量,是以伤害用户体验为代价的SEO行为。
问:网页标题与描述写多少字合适?
答:网站title标题搜索引擎在搜索结果中只能展示63个字节,后边都省略了;网页标题通常建议不超过32个汉字,描述Description不要超过72个汉字。
问:网站服务器空间买多大适宜?
答:根据网站规模和要提供的服务来决定选择订购何种空间(服务器),选择有实力的正规空间商,根据用户群分布选择接入商,保证用户的访问速率和稳定性。 查看全部
3、外部链接建设;网站的外部链接做好了才能促使排行的提高,但是发外链不是一件容易的事,尤其是优质的外链少之又少,这个在工作的过程中一定要仔细筛选。
4、快速收录上线对SEO意味着哪些?快速收录上线站点管理一方面是便捷百度开发人员维护调试,统一化管理,另一方面也便捷的用户,这样不用多个后台去递交(以前自动递交须要到站点管理,天级递交须要到联通专区后台)。快速收录功能上线也就代表联通专区距离彻底下线也不远了,或者就是这几天了。
5、网站蜘蛛池作用剖析大量降低外链,会被搜索引擎判断为作弊(大机率是过度优化);
6、主动推送链接:更新sitemap地图,提交给搜索引擎,在百度资源验证网站,安装手动推送代码,加页面的抓取收录。
7、seo搜索引擎收录原理,走进百度收录的背后
8、如果把一个网站页面组成的页面看做是一个有向图,从指定的页面出发,沿着页面中的链接,按照某种特定的策略对网站中的页面进行遍历。不停地从URL列表中移出早已访问的URL,并储存原创页面,同时提取原创页面中的URL的信息:再将URL分为域名及内部URL两大类,同时判定URL是否被访问过,将未访问过的URL加入URL列表中。递归地扫描URL列表,直至用尽所有URL资源为止。经过这种工作,搜索引擎就可以构建庞大的域名列表、页面URL列表并存储足够多的原创页面。
—————————————————————————————–
问:黑帽seo是哪些意思?
答:黑帽SEO是借助和放大搜索引擎的策略缺陷(实际上完美的系统是不存在的)获取更多用户访问量,而这种更多的访问量,是以伤害用户体验为代价的SEO行为。
问:网页标题与描述写多少字合适?
答:网站title标题搜索引擎在搜索结果中只能展示63个字节,后边都省略了;网页标题通常建议不超过32个汉字,描述Description不要超过72个汉字。
问:网站服务器空间买多大适宜?
答:根据网站规模和要提供的服务来决定选择订购何种空间(服务器),选择有实力的正规空间商,根据用户群分布选择接入商,保证用户的访问速率和稳定性。
在线客服系统怎样实现手动生成数据统计的功能 - 快商通
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2020-08-12 06:38
高点击、高转化是所有网路推广人员梦寐以求的状态。但好多情况下,广告会带来一定的垃圾流量,比如因为关键词的广泛匹配,或者投放渠道可能不是产品目标人群等。
第一步、我们要注意时刻检测流量质量,从客服系统的数据中剖析缘由。
比如:根据剖析不同时段、日期的流量趋势变化形态,通过客服系统详尽了解网站流量的累计过程,从而摸透访客的访问规律,流量变动规律和缘由、网站的发展状况等。
[数据统计]-[流量剖析]-[按时间段剖析]
或按照剖析在线客服系统不同来源项(搜索引擎、友情链接、来源类型、终端类型)引入流量的情况,分析不同来源的流量数目和质量,进而合理优化和选择推广渠道
[数据统计]-[流量剖析]-[按来源类型剖析]
综合多维度、多指标的流量数据剖析,有助于观察不同的流量变化趋势,分析流量质量,并作为调整广告投放策略的根据。
[数据统计]-[流量剖析]-[按时段](可自定义显示列)
[数据统计]-[流量剖析]-[近7天渠道趋势]
通常我们拿来判定页面的流量质量低的指标收录:低PV数、低平均访问页数、高跳出率、低平均访问时长等。遇到低质量流量形成的情况,需要先排查以下这三点:
一、渠道引流上呈现的关键词创意与落地页是否匹配;
二、投放的渠道和投放关键词是否是目标用户活跃的范围和兴趣点,即投放是否精准;
三、落地页出错以及其他诱因(收录但不限于网站打开速率慢、页面错误过期,跳转出错等)。
这里有一个十分重要的指标:[关键词]。结合关键词流量与对话两个维度的数据,集中投放带来高对话量(有效流量)的关键词,控制高消费低对话量(无效流量)的关键词消费。
[数据统计]-[流量剖析]-[按关键词统计]
关键词代表着用户的需求,是sem推广投放的核心。那么选择什么样的关键词就变得至关重要。
例如品牌词的意向高转化率高而且流量小,产品词的流量大点击率高而且竞争激烈。每类词都各有特征,需要适当的进行搭配能够达到最好的引流疗效。
因此,在合理安排关键词策略时,可以结合在线客服系统提供的访客搜索词到着陆页的浏览轨迹来看
[设置中心]-[搜索关键词]-[关键词点击报表]
因为访客一般会选择各网站比价钱和口碑,确认完信息然后认为xx可能更适宜,直接搜索xx品牌,点击品牌词步入网站咨询。这个过程中,访客完成从产品词到品牌词的点击轨迹,产品词对品牌词形成了间接转化贡献。
通过在线客服系统剖析访客浏览轨迹,可以剖析产品词投放对品牌词形成的影响,特别在费用控制时,有效评估品牌市流量的变化和目标设定。
另外,如果一个看着意向度很高的词转化率低到使你大跌眼镜,那么该关掉一些引流的工具就关掉,该收缩匹配方法就要及时的收。
优化着陆页
在碎片化和用户注意力难以捉摸的明天,着陆页的选择对于企业网路营销起着至关重要的作用。推广竞价的目的是把目标顾客带到我们的网站上来,着陆页承载的是消费者对你网站和业务的第一印象。
[数据统计]-[关键词分析]-[跳出率]
持续进行帐户优化的同时,我们除了可以通过关键词跳出率的高低来评判流量是否精准,还可以评判网站页面质量是否优质。
当关键词跳出率偏低的时侯,要考虑到是否是着陆页质量影响流量转化疗效。理想的着陆页应当具备以下要素:
一、内容相关性:合理搭配关键词、方便快速找到想了解的相关内容,内容有价值、没有过多的广告;
二、访客体验感:网站加载速率快、收录清晰的导航栏、页面设计美观、内容精简且富于创意、扬长避短;
三、交互能力:与访客产生共同利益点、突出指出“点击原因”、引导咨询、能够即时有在线沟通(咨询窗口合理)。
还可以结合[访问轨迹]、[对话网址]、[对话历史]等数据,观察网站不同页面形成对话量的情况,分析才能形成对话的优质页面并做相应的关键词推广和布局调整,减少访客抵达优质内容页的路径,缩短转化流程
[查看历史]-[访客历史对话]
根据不同目标受众,可以“投其所好”的设置不同的关键词着陆页。比如,根据不同的产品设计不同风格的网站,多个网站同时进行引流;或依据企业营销计划,在重点活动期间更换不同设计的在线客服系统着陆页。
快商通免费提供10+套风格式样:
[生成代码]-自定义款式、风格券
这里须要注意的是,不管是优先推广那个网页,都须要在全站提供方便的咨询入口。根据不同的网页设计风格,灵活搭配咨询入口、邀请框、浮动图标款式(并注意它们的统一)等,吸引访客点击咨询。
企业通过推广获得流量——从流量中获得咨询——从咨询中获得线索——从线索中获得订单,当我们步入网路营销漏斗的最后一环,有效沟通就是成交的关键,也是网路营销疗效的首要标准,而对话数目又是对话质量的前提。
随着互联网时代的发展,客服中心正在从“成本中心”走向“利润中心”,越来越得到企业的注重:
一方面,在线客服通过网站建立访客与企业内部即时交流的平台,是第一时间为访客提供服务、解决问题的人;另一方面,通过与顾客沟通交流,无形之中实现品牌的输出,也是网路营销重要目标。
总结:
提升网站对话量涉及到多个环节,我们除了须要具备流量控制、流量质量剖析、页面前往剖析、页面承载剖析、页面转化剖析等多种能力,还须要为前往网站的访客构建有效的沟通渠道,提供引导性的高质量服务。 查看全部
很多企业喜欢通过在线客服系统来捕捉访客行为喜好等数据来进行剖析,但大多客服系统并没有手动统计的功能,需要客服人员额外花精力一条一条的进行统计,效率和准确率都太低,今天给你们介绍一下快商通在线客服系统按照24个用户维度手动生成数据统计的功能。
高点击、高转化是所有网路推广人员梦寐以求的状态。但好多情况下,广告会带来一定的垃圾流量,比如因为关键词的广泛匹配,或者投放渠道可能不是产品目标人群等。
第一步、我们要注意时刻检测流量质量,从客服系统的数据中剖析缘由。
比如:根据剖析不同时段、日期的流量趋势变化形态,通过客服系统详尽了解网站流量的累计过程,从而摸透访客的访问规律,流量变动规律和缘由、网站的发展状况等。
[数据统计]-[流量剖析]-[按时间段剖析]
或按照剖析在线客服系统不同来源项(搜索引擎、友情链接、来源类型、终端类型)引入流量的情况,分析不同来源的流量数目和质量,进而合理优化和选择推广渠道
[数据统计]-[流量剖析]-[按来源类型剖析]
综合多维度、多指标的流量数据剖析,有助于观察不同的流量变化趋势,分析流量质量,并作为调整广告投放策略的根据。
[数据统计]-[流量剖析]-[按时段](可自定义显示列)
[数据统计]-[流量剖析]-[近7天渠道趋势]
通常我们拿来判定页面的流量质量低的指标收录:低PV数、低平均访问页数、高跳出率、低平均访问时长等。遇到低质量流量形成的情况,需要先排查以下这三点:
一、渠道引流上呈现的关键词创意与落地页是否匹配;
二、投放的渠道和投放关键词是否是目标用户活跃的范围和兴趣点,即投放是否精准;
三、落地页出错以及其他诱因(收录但不限于网站打开速率慢、页面错误过期,跳转出错等)。
这里有一个十分重要的指标:[关键词]。结合关键词流量与对话两个维度的数据,集中投放带来高对话量(有效流量)的关键词,控制高消费低对话量(无效流量)的关键词消费。
[数据统计]-[流量剖析]-[按关键词统计]
关键词代表着用户的需求,是sem推广投放的核心。那么选择什么样的关键词就变得至关重要。
例如品牌词的意向高转化率高而且流量小,产品词的流量大点击率高而且竞争激烈。每类词都各有特征,需要适当的进行搭配能够达到最好的引流疗效。
因此,在合理安排关键词策略时,可以结合在线客服系统提供的访客搜索词到着陆页的浏览轨迹来看
[设置中心]-[搜索关键词]-[关键词点击报表]
因为访客一般会选择各网站比价钱和口碑,确认完信息然后认为xx可能更适宜,直接搜索xx品牌,点击品牌词步入网站咨询。这个过程中,访客完成从产品词到品牌词的点击轨迹,产品词对品牌词形成了间接转化贡献。
通过在线客服系统剖析访客浏览轨迹,可以剖析产品词投放对品牌词形成的影响,特别在费用控制时,有效评估品牌市流量的变化和目标设定。
另外,如果一个看着意向度很高的词转化率低到使你大跌眼镜,那么该关掉一些引流的工具就关掉,该收缩匹配方法就要及时的收。
优化着陆页
在碎片化和用户注意力难以捉摸的明天,着陆页的选择对于企业网路营销起着至关重要的作用。推广竞价的目的是把目标顾客带到我们的网站上来,着陆页承载的是消费者对你网站和业务的第一印象。
[数据统计]-[关键词分析]-[跳出率]
持续进行帐户优化的同时,我们除了可以通过关键词跳出率的高低来评判流量是否精准,还可以评判网站页面质量是否优质。
当关键词跳出率偏低的时侯,要考虑到是否是着陆页质量影响流量转化疗效。理想的着陆页应当具备以下要素:
一、内容相关性:合理搭配关键词、方便快速找到想了解的相关内容,内容有价值、没有过多的广告;
二、访客体验感:网站加载速率快、收录清晰的导航栏、页面设计美观、内容精简且富于创意、扬长避短;
三、交互能力:与访客产生共同利益点、突出指出“点击原因”、引导咨询、能够即时有在线沟通(咨询窗口合理)。
还可以结合[访问轨迹]、[对话网址]、[对话历史]等数据,观察网站不同页面形成对话量的情况,分析才能形成对话的优质页面并做相应的关键词推广和布局调整,减少访客抵达优质内容页的路径,缩短转化流程
[查看历史]-[访客历史对话]
根据不同目标受众,可以“投其所好”的设置不同的关键词着陆页。比如,根据不同的产品设计不同风格的网站,多个网站同时进行引流;或依据企业营销计划,在重点活动期间更换不同设计的在线客服系统着陆页。
快商通免费提供10+套风格式样:
[生成代码]-自定义款式、风格券
这里须要注意的是,不管是优先推广那个网页,都须要在全站提供方便的咨询入口。根据不同的网页设计风格,灵活搭配咨询入口、邀请框、浮动图标款式(并注意它们的统一)等,吸引访客点击咨询。
企业通过推广获得流量——从流量中获得咨询——从咨询中获得线索——从线索中获得订单,当我们步入网路营销漏斗的最后一环,有效沟通就是成交的关键,也是网路营销疗效的首要标准,而对话数目又是对话质量的前提。
随着互联网时代的发展,客服中心正在从“成本中心”走向“利润中心”,越来越得到企业的注重:
一方面,在线客服通过网站建立访客与企业内部即时交流的平台,是第一时间为访客提供服务、解决问题的人;另一方面,通过与顾客沟通交流,无形之中实现品牌的输出,也是网路营销重要目标。
总结:
提升网站对话量涉及到多个环节,我们除了须要具备流量控制、流量质量剖析、页面前往剖析、页面承载剖析、页面转化剖析等多种能力,还须要为前往网站的访客构建有效的沟通渠道,提供引导性的高质量服务。
如何按照文本内容手动生成关键词或标签?
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2020-08-12 06:38
1. 基于统计的tf * idf
2. 基于pagerank的textrank算法
但是完全依赖于上述算法,会有一些问题:
1. 新词问题: 如一些网路新词(怒怼、种草、多闪、4AM)由于早期切词错误,会导致本身切块,从而难以召回结果,此时,采用PMI,左右熵来辅助做一个新词发觉,进而补充词库极其重要
2. 实体问题:一些实体词,天然就应当被当作关键词抽取下来(如描述姚明的文章,那么姚明是一个人名,这个人名是一个PER,是一个实体),采用ontonotes 或者是CTB等公开数据集,顺便再加点当前自有的语料训练一个序列标明的模型就变得很重要了
3. 相关性问题:因为抽取得到的关键词,需要和当前的文本足够相关,如果轻率采用TF*IDF或则TextRank,其实难以解决好多的相关性的case(传统搜索引擎的相关性算法采用TFIDF来做,而不融入一些别的算法,会导致一些case搞不定),举个反例(美的,这个term即是一个实体,又是一个形容词,TF*IDF值也比较高,对于一个不是描述空调或则家用电器的文章,抽取得到美的这个是不make sense的),因此,我们须要有一个相关性模型(融合好多的特点来对抽取的词和当前文章做相关性估算并排序,筛选top K 作为关键词)
至于上述所说的通过 “范式” 来推演得到 “数据库”,这个就弄成了另一个层面的东西了,想要做的好,需要有如下几个步骤:
1. 有一个分类体系,就是见到当前这篇文章,可以把当前文章可以分为 哪一类 ,科技类/数据库,但是本身这些概念性的东西比较多,也比较泛
2. 人工建立一套标签体系,采用类似于embedding的思路,只要出现范式就把其归到数据库一类,因为embedding中,范式和数据库足够逾,另外也须要用一些知识图谱中的数据,辅助减少一些badcase
3. 另外,用一些topic model的形式,来做向下聚合也会有一定的疗效 查看全部
纵观目前业界流行的关键词抽取方式,基本的逻辑逃脱不了二种:
1. 基于统计的tf * idf
2. 基于pagerank的textrank算法
但是完全依赖于上述算法,会有一些问题:
1. 新词问题: 如一些网路新词(怒怼、种草、多闪、4AM)由于早期切词错误,会导致本身切块,从而难以召回结果,此时,采用PMI,左右熵来辅助做一个新词发觉,进而补充词库极其重要
2. 实体问题:一些实体词,天然就应当被当作关键词抽取下来(如描述姚明的文章,那么姚明是一个人名,这个人名是一个PER,是一个实体),采用ontonotes 或者是CTB等公开数据集,顺便再加点当前自有的语料训练一个序列标明的模型就变得很重要了
3. 相关性问题:因为抽取得到的关键词,需要和当前的文本足够相关,如果轻率采用TF*IDF或则TextRank,其实难以解决好多的相关性的case(传统搜索引擎的相关性算法采用TFIDF来做,而不融入一些别的算法,会导致一些case搞不定),举个反例(美的,这个term即是一个实体,又是一个形容词,TF*IDF值也比较高,对于一个不是描述空调或则家用电器的文章,抽取得到美的这个是不make sense的),因此,我们须要有一个相关性模型(融合好多的特点来对抽取的词和当前文章做相关性估算并排序,筛选top K 作为关键词)
至于上述所说的通过 “范式” 来推演得到 “数据库”,这个就弄成了另一个层面的东西了,想要做的好,需要有如下几个步骤:
1. 有一个分类体系,就是见到当前这篇文章,可以把当前文章可以分为 哪一类 ,科技类/数据库,但是本身这些概念性的东西比较多,也比较泛
2. 人工建立一套标签体系,采用类似于embedding的思路,只要出现范式就把其归到数据库一类,因为embedding中,范式和数据库足够逾,另外也须要用一些知识图谱中的数据,辅助减少一些badcase
3. 另外,用一些topic model的形式,来做向下聚合也会有一定的疗效
江阴SEO:哪些优化方法会被百度认定作弊?
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2020-08-12 00:12
1、复制站点或网页
常见的站点属于镜像站点,通过复制站点和页面的内容并将其分成不同的域名和服务器,它误导搜索引擎多次索引同一个站点或同一个页面。目前,许多搜索引擎都配备了就能测量镜像站点的适当过滤系统。一旦找到镜像站点,源站点和镜像站点都将从索引数据库中删掉。
2、采集内容
目前,许多网站没有精力去写文章来丰富网站的内容,但她们只能搜集文章,但她们希望对搜集到的文章进行二次编辑,并降低一些看法。
3、欺骗性重定向
用户登入也页面,快速转入内容完全不同的页面。另一种重定向行为是欺骗性的,如果用户宣称早已联通到新域名之下,并且用户通过单击新域名的链接来直接访问该站点,并且用户步入后才发觉该链接是会员链接。
4、使用免费cdn技术
许多人说cdn可以推动网站的访问速率,有利于用户体验。然而,免费的cdn有时不稳定,有些地区不能打开网站。只要网站的速率依然可以接受,不要使用免费的cdn。如果有必要,建议做付费cdn。
5、误导性或重复性关键词
(1)误导性关键词
页面使用与该页面无关的欺骗流行关键字来吸引访问该主题的用户和流量。这种做法严重影响了搜索引擎提供结果的相关性和客观性,严重影响了用户体验完全误导用户的行为。这种做法被搜索引擎深恶痛绝。
(2)重复性关键词
这样的作弊技术是我们常常讨论的关键词堆积现象,利用搜索引擎在网页正文的标题中找出关键词的高度,强行重复关键词。 其他方式还包括在HTML元标签上堆积大量关键字,或者使用多个关键字元标签来提升关键字的相关性。这种误导技术很容易被搜索引擎察觉并遭到相应的惩罚。
6、关键词拼凑
这是一个老话题,也是常见的SEO优化作弊方式之一。您可以在短期获取关键字列表,但潜在风险特别高。一旦你被判作弊,准备工作都会枉费。适当的关键字密度有利于关键字排序的推广,但过量的关键字被堆积,这是太危险的。
7、购买友情链接
现在外链的释放越来越困难。很多网站管理员只能选购一些友情链接,但是她们在订购时应当注意上传链接的频度。例如,如果你一次订购50个链接,而对方一次添加你的网站,那么朋友链的忽然降低就不正常了。
优化网站需要一步步来,用白帽SEO优化的方法做,网站内部基础,布局,关键词等,也要确保用户体验,让网站排名提高,不要去碰触搜索引擎底线。 查看全部
网络营销兴起的年代企业纷纷做起加入队列,行业间竞争不断扩大,很多企业SEO优化的知识量不够深,导致网站关键词排行提高很难,安耐不住孤寂做起快排,要知道搜索引擎不断做调整,一旦判断是作弊,那么网站轻则降权重则K站。
1、复制站点或网页
常见的站点属于镜像站点,通过复制站点和页面的内容并将其分成不同的域名和服务器,它误导搜索引擎多次索引同一个站点或同一个页面。目前,许多搜索引擎都配备了就能测量镜像站点的适当过滤系统。一旦找到镜像站点,源站点和镜像站点都将从索引数据库中删掉。
2、采集内容
目前,许多网站没有精力去写文章来丰富网站的内容,但她们只能搜集文章,但她们希望对搜集到的文章进行二次编辑,并降低一些看法。
3、欺骗性重定向
用户登入也页面,快速转入内容完全不同的页面。另一种重定向行为是欺骗性的,如果用户宣称早已联通到新域名之下,并且用户通过单击新域名的链接来直接访问该站点,并且用户步入后才发觉该链接是会员链接。
4、使用免费cdn技术
许多人说cdn可以推动网站的访问速率,有利于用户体验。然而,免费的cdn有时不稳定,有些地区不能打开网站。只要网站的速率依然可以接受,不要使用免费的cdn。如果有必要,建议做付费cdn。
5、误导性或重复性关键词
(1)误导性关键词
页面使用与该页面无关的欺骗流行关键字来吸引访问该主题的用户和流量。这种做法严重影响了搜索引擎提供结果的相关性和客观性,严重影响了用户体验完全误导用户的行为。这种做法被搜索引擎深恶痛绝。
(2)重复性关键词
这样的作弊技术是我们常常讨论的关键词堆积现象,利用搜索引擎在网页正文的标题中找出关键词的高度,强行重复关键词。 其他方式还包括在HTML元标签上堆积大量关键字,或者使用多个关键字元标签来提升关键字的相关性。这种误导技术很容易被搜索引擎察觉并遭到相应的惩罚。
6、关键词拼凑
这是一个老话题,也是常见的SEO优化作弊方式之一。您可以在短期获取关键字列表,但潜在风险特别高。一旦你被判作弊,准备工作都会枉费。适当的关键字密度有利于关键字排序的推广,但过量的关键字被堆积,这是太危险的。
7、购买友情链接
现在外链的释放越来越困难。很多网站管理员只能选购一些友情链接,但是她们在订购时应当注意上传链接的频度。例如,如果你一次订购50个链接,而对方一次添加你的网站,那么朋友链的忽然降低就不正常了。
优化网站需要一步步来,用白帽SEO优化的方法做,网站内部基础,布局,关键词等,也要确保用户体验,让网站排名提高,不要去碰触搜索引擎底线。
网站建设被K网站如何快速恢复收录和排行
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2020-08-12 00:02
六、关键词密度过大
网站不能堆积关键词,刚刚开始有可能你的网站会有排行,但是十分容易被惩罚的。谨慎慎重
七、网站频繁改动
网站频繁改动,这而且SEO的三忌,就像有个SEO优化老师给我说,网站刚刚开始不要想着模板是不是好看,不重要,只要网站排名起来了,有一定的流量了,这时候就有必要该网站的模板,因为这个时侯你的网站每天都有一定的人群浏览,为了用户体验你也得把网站模板改的好一点。
八、网站描文本内容单一
比方说你的网站所有网站描文本都只做一个关键词,这个被发觉后,就会被觉得是机器操作的都会被惩罚。
九、网站服务器不稳定
网站服务器的环境不稳定,会导致网站有时候进的去网站有时候进不去网站,导致用户体验特别不好。
根据以上列出的网站被K缘由,从缘由中入手判定网站是否具备着恢复的可能性,骏 域网路优化常规化的K站大多数采集、垃圾外链、关键词优化过度、关键词密度、网站频繁改动等系列缘由,使用原创稳定更新方式通常三个月即可实现重新收录和重新排行。被K网站恢复方式除此之外,网站优化能够够通过文章优化、外链优化、百度站长申述等普通的形式解决。
1、页面链接过多,一般一个页面上的链接不能超过五十个,这是得到好多站长的肯定认可的,太多的外链导入会使自己的网站权重增加,还有就是文章的内链通常维持在三个以内。
2、文章的原创度,切忌盲目复制他人的内容,及时没有过多的时间来做原创内容,也要对复制的文章进行一定地更改。
3、网站上切莫不要有违规、违反中国法律的内容,这样难以使百度收录。
4、在帖吧以及百度知道上四处留下自己网站的痕迹会提高被百度K的可能性,凡事都要有个度,适量即可,新站通常都是先耐心等待收录,收录以后再做适当的推广。
5、整站都是他人网站的内容。我想大多数的搜索引擎都不喜欢重复喝一样的东西,做网站就是要持之以恒,坚持原创,这样就能赢得搜索引擎的偏爱。
6、使用手动跳转的页面,很有可能被百度K掉。
7、过度的优化。还是那句话,凡事都要有个度,如果你对网站进行大量的优化,却引起使用户有不良的体验,那么被百度K也是迟早的事情,做好用户体验也是提高权重的一大关键。
8、切忌与一些垃圾站交换友情链接,对自己网站的不良影响甚大。
9、定时检测站上的友情链接,对一些深受百度惩罚以及被K的链接要及时除去,还有防止站上死链的出现,同样要及时除去。
网站建设过程中防止不了会形成一定违背搜索引擎的手段,在seoer的眼里,能够作为提升网站价值的方式都是值得借助和使用的办法,比如锚文本和内链,其不仅仅只是为了给搜索引擎来抓取,更是为现代网站用户提供便捷。深圳网站建设公司觉得:如果在网站建设期倒霉了,网站被K惩罚了,这个时侯不用惊慌,分析下你的网站最近都做哪些操作了,修改哪些了之后指定相关方案更改过来,在继续发布优质文章,发布好外链。还有可以关注下搜索引擎是否算法调整造成刺伤,端正态度,继续优化好网站。 查看全部
首页优化过度,会导致网站权重非常分散,导致网站排名上不去,或者被搜索引擎惩罚。
六、关键词密度过大
网站不能堆积关键词,刚刚开始有可能你的网站会有排行,但是十分容易被惩罚的。谨慎慎重
七、网站频繁改动
网站频繁改动,这而且SEO的三忌,就像有个SEO优化老师给我说,网站刚刚开始不要想着模板是不是好看,不重要,只要网站排名起来了,有一定的流量了,这时候就有必要该网站的模板,因为这个时侯你的网站每天都有一定的人群浏览,为了用户体验你也得把网站模板改的好一点。
八、网站描文本内容单一
比方说你的网站所有网站描文本都只做一个关键词,这个被发觉后,就会被觉得是机器操作的都会被惩罚。
九、网站服务器不稳定
网站服务器的环境不稳定,会导致网站有时候进的去网站有时候进不去网站,导致用户体验特别不好。
根据以上列出的网站被K缘由,从缘由中入手判定网站是否具备着恢复的可能性,骏 域网路优化常规化的K站大多数采集、垃圾外链、关键词优化过度、关键词密度、网站频繁改动等系列缘由,使用原创稳定更新方式通常三个月即可实现重新收录和重新排行。被K网站恢复方式除此之外,网站优化能够够通过文章优化、外链优化、百度站长申述等普通的形式解决。
1、页面链接过多,一般一个页面上的链接不能超过五十个,这是得到好多站长的肯定认可的,太多的外链导入会使自己的网站权重增加,还有就是文章的内链通常维持在三个以内。
2、文章的原创度,切忌盲目复制他人的内容,及时没有过多的时间来做原创内容,也要对复制的文章进行一定地更改。
3、网站上切莫不要有违规、违反中国法律的内容,这样难以使百度收录。
4、在帖吧以及百度知道上四处留下自己网站的痕迹会提高被百度K的可能性,凡事都要有个度,适量即可,新站通常都是先耐心等待收录,收录以后再做适当的推广。
5、整站都是他人网站的内容。我想大多数的搜索引擎都不喜欢重复喝一样的东西,做网站就是要持之以恒,坚持原创,这样就能赢得搜索引擎的偏爱。
6、使用手动跳转的页面,很有可能被百度K掉。
7、过度的优化。还是那句话,凡事都要有个度,如果你对网站进行大量的优化,却引起使用户有不良的体验,那么被百度K也是迟早的事情,做好用户体验也是提高权重的一大关键。
8、切忌与一些垃圾站交换友情链接,对自己网站的不良影响甚大。
9、定时检测站上的友情链接,对一些深受百度惩罚以及被K的链接要及时除去,还有防止站上死链的出现,同样要及时除去。
网站建设过程中防止不了会形成一定违背搜索引擎的手段,在seoer的眼里,能够作为提升网站价值的方式都是值得借助和使用的办法,比如锚文本和内链,其不仅仅只是为了给搜索引擎来抓取,更是为现代网站用户提供便捷。深圳网站建设公司觉得:如果在网站建设期倒霉了,网站被K惩罚了,这个时侯不用惊慌,分析下你的网站最近都做哪些操作了,修改哪些了之后指定相关方案更改过来,在继续发布优质文章,发布好外链。还有可以关注下搜索引擎是否算法调整造成刺伤,端正态度,继续优化好网站。
Links Auto Replacer 自动给文章的关键词添加链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2020-08-11 13:12
总所周知,网站内链(指网站内部的相关信息相互联接)是十分重要的,不仅针对于SEO优化,对于用户的访问也是十分有利的,你可以将文章中出现的一些关键添加上联接,这样那些重要的信息就能否被用户点击所看见,增强网站内容的黏性,让用户才能更容易的找到你的内容。
如果我们自动进行关键词的链接添加,这无疑是一个十分繁杂的工作,因此我们在此介绍一款插件,这款插件才能手动的给你的文章出现的关键添加指定的链接。
之前我们有介绍一款wordpress插件: WP Keyword Link ,但经过用户的反馈其实早已不能再使用了,因此我们这儿再介绍一款插件:Links Auto Replacer 可以在最新版本的wordpress上继续使用。
Links Auto Replacer 自动给文章的关键词添加链接
市面上有不少的wordpress插件可以做到添加关键词的功能,但好多的插件并不才能支持英文,因此我们所介绍的这款插件是可以支持英文的。
插件可以自定义关键词,你可以统计你的文章内所出现的关键词数目,并经过筛选重要的关键词和她们所须要去的介绍页面,在插件中设置好,这样插件都会手动将你的网站文章扫描,检测出关键词并添加链接。
插件安装,在wordpress后台--插件--安装插件处搜索Links Auto Replacer,或者在我们的云盘下载汉化版本(网络整理)
安装启用以后,进入手动联接选项,可以查看早已创建的手动联接,也可以新建一个手动联接:
由于早已有了英文版本,因此这款wordpress插件十分简单能够够设置好了。
设置好了以后,文章中所出现的关键词就能否被手动添加上联接了。
希望这款插件才能帮助到你建设好你的wordpress网站内链。 查看全部
wordpress网站内链的建设
总所周知,网站内链(指网站内部的相关信息相互联接)是十分重要的,不仅针对于SEO优化,对于用户的访问也是十分有利的,你可以将文章中出现的一些关键添加上联接,这样那些重要的信息就能否被用户点击所看见,增强网站内容的黏性,让用户才能更容易的找到你的内容。
如果我们自动进行关键词的链接添加,这无疑是一个十分繁杂的工作,因此我们在此介绍一款插件,这款插件才能手动的给你的文章出现的关键添加指定的链接。
之前我们有介绍一款wordpress插件: WP Keyword Link ,但经过用户的反馈其实早已不能再使用了,因此我们这儿再介绍一款插件:Links Auto Replacer 可以在最新版本的wordpress上继续使用。
Links Auto Replacer 自动给文章的关键词添加链接
市面上有不少的wordpress插件可以做到添加关键词的功能,但好多的插件并不才能支持英文,因此我们所介绍的这款插件是可以支持英文的。
插件可以自定义关键词,你可以统计你的文章内所出现的关键词数目,并经过筛选重要的关键词和她们所须要去的介绍页面,在插件中设置好,这样插件都会手动将你的网站文章扫描,检测出关键词并添加链接。
插件安装,在wordpress后台--插件--安装插件处搜索Links Auto Replacer,或者在我们的云盘下载汉化版本(网络整理)
安装启用以后,进入手动联接选项,可以查看早已创建的手动联接,也可以新建一个手动联接:
由于早已有了英文版本,因此这款wordpress插件十分简单能够够设置好了。
设置好了以后,文章中所出现的关键词就能否被手动添加上联接了。
希望这款插件才能帮助到你建设好你的wordpress网站内链。
芭奇站群管理系统下载 18.11.13 绿色版
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2020-08-11 13:11
芭奇站群管理系统无需绑定笔记本或IP,不限网站数量,可以24小时挂机采集维护,让站长可以太轻松就管理上百个网站。软件奇特的内容抓取引擎,能及时确切的抓取互联网上比较新的内容,配合外置的文章伪原创功能,能大大降低网站的收录,为站长带来更多流量!
核心功能
无限制降低域名、网站,中文站群采集,英文站群采集,指定网址采集,自定义发布插口,自定义生成原创文章,长尾关键词采集,相关图片采集,全局SEO链轮,文章自动加入内链,随机提取内容作为标题,不同内容段落互换,随机插入指定关键字,定时发布文章,自动内容伪原创,分组参数设置,分组链接库互链,全手动监控挂机采集发布,自动更新网站首页栏目内页静态化等等。
使用说明
值守手动重启站群会手动在system用户下手动启动挂机,
实现真正的无人值守挂机
3,完善站群挂机监控器的部份功能,新增家用笔记本开机
自启动与服务器vps开机启动的分辨
更新日志
1、增加指定采集指定IE的功能(分组参数1.4.4)
2、增加指定域名3个屏蔽错误功能(勾选会手动保存),用于前台采集的网站规则
3、增加至尊版的标题与内容转换为unicode功能
4、增加至尊版的内容前后可插入大量自定义HTML随机标签功能
5、增加单站图片库与单站视频库
6、增加至尊版多线程挂机同机敌视功能,防止同一台服务器网站同时发布
7、增加至尊版单文章重组合的伪原创比率控制,可控制文章部份可读性
8、优化栏目文章库受损手动创建功能
9、修复指定采集图片过滤数字的BUG
10、修复批量导入TXT后没有清空内容设已发布的BUG
11、修复4.1四个插口批量多站执行的BUG
12、修复文本工具提示异常的BUG
13、增加文件工具多路径定义,实现多模板克隆批量建站
14、增加文本工具删掉含XX关键字所在行的功能
15、优化分组和子分组归属网站问题
16,指定域名列表地址与内容地址手动辨识的过滤替换支持键值星号
17,修复所有导出富含单引号的失败问题
18,修复超级伪原创只勾选标题伪原创后内容为空的问题
19、其他部分小功能细节优化修补等
文件信息
文件大小:4427776 字节
文件说明:启动程序
文件版本:1.0.0.0
MD5:612233482D1D53299BAF680EA3EBE975
SHA1:2438CB4B1DEACFE1FC174FFE80640B4BEAB8C758
CRC32:5D63A2A1
官方网站:
相关搜索:站群 查看全部
芭奇站群管理系统是一套仅需输入关键词,即可采集到比较新相关内容,并手动SEO发布到指定网站的多任务站群管理系统,可24小时不间断的全手动维护数百个网站。芭奇站群管理系统能按照设置的关键词手动抓取各大搜索引擎的相关搜索词以及相关长尾词,然后依照衍生出的词来抓取大量的比较新数据,完全摈弃普通采集软件所需的冗长规则订制,实现一键采集一键发布。
芭奇站群管理系统无需绑定笔记本或IP,不限网站数量,可以24小时挂机采集维护,让站长可以太轻松就管理上百个网站。软件奇特的内容抓取引擎,能及时确切的抓取互联网上比较新的内容,配合外置的文章伪原创功能,能大大降低网站的收录,为站长带来更多流量!
核心功能
无限制降低域名、网站,中文站群采集,英文站群采集,指定网址采集,自定义发布插口,自定义生成原创文章,长尾关键词采集,相关图片采集,全局SEO链轮,文章自动加入内链,随机提取内容作为标题,不同内容段落互换,随机插入指定关键字,定时发布文章,自动内容伪原创,分组参数设置,分组链接库互链,全手动监控挂机采集发布,自动更新网站首页栏目内页静态化等等。
使用说明
值守手动重启站群会手动在system用户下手动启动挂机,
实现真正的无人值守挂机
3,完善站群挂机监控器的部份功能,新增家用笔记本开机
自启动与服务器vps开机启动的分辨
更新日志
1、增加指定采集指定IE的功能(分组参数1.4.4)
2、增加指定域名3个屏蔽错误功能(勾选会手动保存),用于前台采集的网站规则
3、增加至尊版的标题与内容转换为unicode功能
4、增加至尊版的内容前后可插入大量自定义HTML随机标签功能
5、增加单站图片库与单站视频库
6、增加至尊版多线程挂机同机敌视功能,防止同一台服务器网站同时发布
7、增加至尊版单文章重组合的伪原创比率控制,可控制文章部份可读性
8、优化栏目文章库受损手动创建功能
9、修复指定采集图片过滤数字的BUG
10、修复批量导入TXT后没有清空内容设已发布的BUG
11、修复4.1四个插口批量多站执行的BUG
12、修复文本工具提示异常的BUG
13、增加文件工具多路径定义,实现多模板克隆批量建站
14、增加文本工具删掉含XX关键字所在行的功能
15、优化分组和子分组归属网站问题
16,指定域名列表地址与内容地址手动辨识的过滤替换支持键值星号
17,修复所有导出富含单引号的失败问题
18,修复超级伪原创只勾选标题伪原创后内容为空的问题
19、其他部分小功能细节优化修补等
文件信息
文件大小:4427776 字节
文件说明:启动程序
文件版本:1.0.0.0
MD5:612233482D1D53299BAF680EA3EBE975
SHA1:2438CB4B1DEACFE1FC174FFE80640B4BEAB8C758
CRC32:5D63A2A1
官方网站:
相关搜索:站群
怎么抓取亚马逊关键词:亚马逊关键词是怎样做
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2020-08-10 23:58
好的标题直接才能在搜索排序中获得好的位置。到底是用长关键字还是用短关键字,用冒号分隔还是用空格分隔。search term 就是一个搜索引擎的关键字抓取的地方,当然是关键字越多越好,至于关键字长短倒不是很重要,但是要注意重复的关键字出现,那会被觉得是关键字作弊2,用冒号属于精准定位,用户搜索的时侯只有符号之间的关键是是有效的,只有用户输入全部的时侯才能搜索到,如果用户输入phone case katoon,那就可能搜不到了,如果用空格表示模糊搜索,关键字的任意组合都可能被搜索到,用户搜索phone case katoon或则katoon,则会被亚马逊搜索到。三.再来说一下找关键词的方式:1、使用微软关键词规划词,建议广告单词时微软会给到你精准的推荐2、在亚马逊前台搜索栏:输入关键词会出现下拉菜单。大家是如何爬取亚马逊(美国)的数据做第一个规则把商品列表的网址全爬出来,并且设置层级规则,把网址手动导出到第二个规则那儿,然后选择其中一个网址,打开做第二个规则。 查看全部
亚马逊关键词是怎样做亚马逊的流量来源见右图。要做好流量,只有做好各个细分的内容之后谈谈亚马逊关键字设置1.亚马逊关键字分两大块,一块是标题,这是最最重要的关键字,设置标题关键字的时侯最好的方式是品牌+ 名称+重要属性1,3+相关名称 +功能+参数好的标题直接才能在搜索排序中获得好的位置。到底是用长关键字还是用短关键字,用冒号分隔还是用空格分隔。search term 就是一个搜索引擎的关键字抓取的地方,当然是关键字越多越好,至于关键字长短倒不是很重要,但是要注意重复的关键字出现,那会被觉得是关键字作弊其次,用冒号属于精准定位,用户搜索的时侯只有符号之间的关键是是有效的,只有用户输入全部的时侯才能搜索到,如果用户输入phone case katoon,那就可能搜不到了。如何通过亚马逊前后台获取关键词?不同的人有不同的方式寻找关键词,而用第三方工具查找的关键词不是非常的全面,其实直接通过前台和后台也是可以获取关键词的,基本不会偏离系统的算法,获取的关键词对前期编辑listing和后期优化listing、广告都是够用了!亚马逊关键词选定工具有什么?紫鸟数据魔方官网—百度搜索:是Amazon数据剖析最好的关键词挖掘工具,挖掘出亚马逊当前最热搜关键词,为买家提供最及时确切的热搜关键词,紫鸟数据亚马逊产品剖析:是经过数万买家常年使用并一致推荐的亚马逊产品剖析工具,能全面展示剖析产品当前价钱、Rank、评论数和预估销售量等核心数据,紫鸟数据亚马逊热销排行榜:如何用python爬虫抓取亚马逊美国站关键词排行选择合适的关键词,确认用户搜索次数达到一定的数量级。找到搜索次数比较多,才能在一定的预算和周期下取得较好的疗效。亚马逊采集关键词?关键词采集商家是如何做到的?根据自己的产品信息和特征,选择合适的关键词,确认用户搜索次数达到一定的数量级。作为亚马逊买家,找到搜索次数比较多,同时难度不太大的关键词,才能在一定的预算和周期下取得较好的疗效。同时有效借助整合营销,结合社交媒体充分爆光商店信息和产品优势,争取获得更广的爆光和更多的点击。亚马逊产品关键词如何找一.亚马逊关键字分两大块,一块是标题,这是最最重要的关键字,设置标题关键字的时侯最好的方式是:品牌+ 名称+重要属性1,3+相关名称 +功能+参数
好的标题直接才能在搜索排序中获得好的位置。到底是用长关键字还是用短关键字,用冒号分隔还是用空格分隔。search term 就是一个搜索引擎的关键字抓取的地方,当然是关键字越多越好,至于关键字长短倒不是很重要,但是要注意重复的关键字出现,那会被觉得是关键字作弊2,用冒号属于精准定位,用户搜索的时侯只有符号之间的关键是是有效的,只有用户输入全部的时侯才能搜索到,如果用户输入phone case katoon,那就可能搜不到了,如果用空格表示模糊搜索,关键字的任意组合都可能被搜索到,用户搜索phone case katoon或则katoon,则会被亚马逊搜索到。三.再来说一下找关键词的方式:1、使用微软关键词规划词,建议广告单词时微软会给到你精准的推荐2、在亚马逊前台搜索栏:输入关键词会出现下拉菜单。大家是如何爬取亚马逊(美国)的数据做第一个规则把商品列表的网址全爬出来,并且设置层级规则,把网址手动导出到第二个规则那儿,然后选择其中一个网址,打开做第二个规则。
信息门户网站自动生成系统的研究.pdf
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2020-08-10 20:00
摘要随着信息技术的不断发展,特别是/应用的普及,网上信息呈指数级下降。如何高效的借助和检索这种海量的信息,成为一个极为重要的问题,信息门户网站很好的解决了这个问题。它一般为用户提供对互联网上信息的密集访问方法,通过将来自不同信息源的同类信息集中在一个网站上,帮助用户通过统一的入口访问来自不同网站的信息,而无需挨个去访问单独的网站。信息门户网站极大的促进了互联网的发展,成为网路发展史上的一座罩程碑,因而对信息门户网站的研究具有重要的理论意义和实用价值。信息门户网站不仅仅是一个网站,更是一个知识和信息的“集中营”,因而本文从后台信息资源的组织和整合以及前台网站的设计和建设这两个方面着手进行研究,将本系统主要分为三个模块:用户界面、客户端模块和服务器端模块。用户界面即前台的信息门户网站,它具有动态生成的功能,提供给用户动态交互的操作;客户端模块主要实现信息的过滤,它还能对用户输入的自然语言句子进行语义辨识让之成为计算机才能检索的关键词对;服务器端模块主要实现对力.维网北京量信息的智能检索。本文首先研究和讨论了基于自然语言的语义剖析方式,对汉语的自动分词方式进行了侧重讨论和剖析,并给出了一种基于反向最大匹配法的动词方式在本系统中的应用展望,提出动词的关键还须要一个完整合理的动词辞典。其次研究和讨论了万维网上的智能检索技术,针对当前万维网上的信息检索的若干缺陷提出了客户端和服务器端处理技术,并结合软件和数据库系统设计开发了一套后台的智能枪索软件系统,它通过对网页采集工具所搜集到的网页进行智能分类和检索,实验证明,该系统具有一定的智能性。最后从网站的设计和建设方面介绍了基于疟编程语言的信息门户网站设计的关键技术技巧并给出了具体的设计步骤和实现。关键词:语义剖析,分词,智能检索,门户网站武汉理工大学硕士学位论文
,甀舶琤.武汉理笱妒垦宦畚甀琱”.也.,瓾..“甌,:’琧..甀’
甀.武汉理笱妒垦宦畚甅:..瓵,,,
第一章总论课题选题的目的和意义众所周知,互联网的诞生是世纪信息技术的一座壮歌,它以前主要是科研人员进行学术交流的场所。近年来随着商业、娱乐和教育的加入,互联网开始弄成无所不包的“信息集散地”,许多有价值的科研信息逐步“淹没”在其他信息构成的“汪洋大海”中。当科研人员和普通的用户发觉找寻须要的有用信息越来越难的时侯,“门户呕荆畔⒚拧弧ⅲ”出现了,它一般为用户提供对互联网上信息和应用的“密集”访问方法,通过将来自不同信息源的信息集中在一个页面上,帮助用户通过统。的入口访问来自不同网站的信息,而无需挨个去访问单独的网站,这种类似“信息剪报”和“参考消息”的信息组织形式通过提供个性化服务和附加服务ü残畔ⅰ⒂始信息订阅等次没У姆梦屎褪褂茫悄壳暗幕チM靶戮谩焙汀白意力经济”的重要组成部份,它极大地推进了互联网的发展,成为网路发展史上的一座里程碑。无论是出于职业须要还是个人兴趣爱好,人们获取信息的基本规律是,在瓦联网上获取信息通常都是在不同的网站上浏览同样的内容,而不是在同一个网站上浏览全部的内容。比如说一个人是做计算机网路通信的,非常关心计算机网路通信方面的发展;而另一个人是做化工行业的,自然一直荚,化。幸捣矫娴男畔ⅲ庑┬枨笠仓换崴孀潘侵耙档谋浠⑸浠M样,每个人都有自己的兴趣和爱好,有人喜欢娱乐,有人喜欢绘画,有人喜欢卜澹庑┬巳ひ膊换崆嵋追⑸谋洹6呕荆墙ǚ浅E釉拥哪容置于一起,将内容信息分门别类地堆置于网站卜,再由用户自己去选购他所须要和感兴趣的内容。显然,信,亩户网站的建设必然要用到因特网上强悍的信息资源,而其对资源的整合优化有一定的要求。因特网发展余年来.规模以几何级数急速发展,成为一个重要的信息源。但因特网上的信息具有数目大、形式多、内容广、专业性不强等特征,给信息采集、分类、检索等工作带来了新的问题和挑战。年代搜索引擎应运而生,且在网路信息资源查找中起到了重要上海理上人学硕士学位论文
国内外信息门户网站的发展过程及现况提升检索的查准率、查全率,将具有较高的研究价值。信息门户网站自动生成系统作为国家“こ獭笔只际楣萁ㄉ璧难芯的作用,帮助人们从浩如烟海的网路信息中找到所要的信息。但搜索引擎在精度、易用性等方面仍存在众多问题,总体性能差,检索的查准率、查全率不高,从而其疗效不尽人意。鉴于此,如何提升搜索引擎的智能检索能力,信息门户网站的手动生成系统从本质上改变了传统的网站制作方法,使网站建设从技术型转向了面向内容的功能型。用户一蚩翁庾只要会使用浏览器就可以直接在线建成功能强悍专业知识集中的门户网站,因而从根本上消除了普通人员建设网站的壁垒,该系统让网站真『迪至硕项目具有深刻、长远和重大的现实意义。学科信息门户虺芐暌黄工程开始,就在法国范围内逐步普及,一大批面向物理、:炭蒲А⒁窖А社会科学的嗉探ⅰ5杲氲诙谑保琒早已在世界范围内呈“燎原”之势,在欧洲、欧洲、大洋洲广泛施行,据不完全统计,目前世界范围内有名的锏缴习俑觥R恍㏒还联合在一起构成更大的资源发觉网路缬⒐腞毖Э菩畔⒚呕У慕ㄉ瑁丫拥ゴ康难研究和课题项目,发展到大规模的建设任务,目前正在法国范围内丌展的项目就是典型。门户网站的建设须要有强悍的网路资源做其后盾,对网路资源智能化的程度有一定的要求。网上信息检索的关键技术主要包括:①信息搜集和储存技术,分人工和手动两种形式,其中手动方法是由“网络机器人”来完成的。②信息预处理技术,收录格式支持、转换和信息过滤。其中信息过滤是一项关键技术,网上大量的无用信息须要充分过滤能够有好的搜索结果。⑧信息索引技术,建立索引主要涉及信息语词切分和语词句型剖析;进行时态标明及相关自然语言处理:建立检索项索引;检索结果处理技术。其中检索结果处理技术是关键技术,其核心是根据估算结果与查询词的相关程度来排序。在此基础上智能检索技术的重点是对用户的查询计划、意图、用户兴趣等进行推理和猜想,并为用户提供有效的答案。为了实现此目的.目前早已提出武汉理工大学硕十学位论文 查看全部
文档介绍:
摘要随着信息技术的不断发展,特别是/应用的普及,网上信息呈指数级下降。如何高效的借助和检索这种海量的信息,成为一个极为重要的问题,信息门户网站很好的解决了这个问题。它一般为用户提供对互联网上信息的密集访问方法,通过将来自不同信息源的同类信息集中在一个网站上,帮助用户通过统一的入口访问来自不同网站的信息,而无需挨个去访问单独的网站。信息门户网站极大的促进了互联网的发展,成为网路发展史上的一座罩程碑,因而对信息门户网站的研究具有重要的理论意义和实用价值。信息门户网站不仅仅是一个网站,更是一个知识和信息的“集中营”,因而本文从后台信息资源的组织和整合以及前台网站的设计和建设这两个方面着手进行研究,将本系统主要分为三个模块:用户界面、客户端模块和服务器端模块。用户界面即前台的信息门户网站,它具有动态生成的功能,提供给用户动态交互的操作;客户端模块主要实现信息的过滤,它还能对用户输入的自然语言句子进行语义辨识让之成为计算机才能检索的关键词对;服务器端模块主要实现对力.维网北京量信息的智能检索。本文首先研究和讨论了基于自然语言的语义剖析方式,对汉语的自动分词方式进行了侧重讨论和剖析,并给出了一种基于反向最大匹配法的动词方式在本系统中的应用展望,提出动词的关键还须要一个完整合理的动词辞典。其次研究和讨论了万维网上的智能检索技术,针对当前万维网上的信息检索的若干缺陷提出了客户端和服务器端处理技术,并结合软件和数据库系统设计开发了一套后台的智能枪索软件系统,它通过对网页采集工具所搜集到的网页进行智能分类和检索,实验证明,该系统具有一定的智能性。最后从网站的设计和建设方面介绍了基于疟编程语言的信息门户网站设计的关键技术技巧并给出了具体的设计步骤和实现。关键词:语义剖析,分词,智能检索,门户网站武汉理工大学硕士学位论文
,甀舶琤.武汉理笱妒垦宦畚甀琱”.也.,瓾..“甌,:’琧..甀’
甀.武汉理笱妒垦宦畚甅:..瓵,,,
第一章总论课题选题的目的和意义众所周知,互联网的诞生是世纪信息技术的一座壮歌,它以前主要是科研人员进行学术交流的场所。近年来随着商业、娱乐和教育的加入,互联网开始弄成无所不包的“信息集散地”,许多有价值的科研信息逐步“淹没”在其他信息构成的“汪洋大海”中。当科研人员和普通的用户发觉找寻须要的有用信息越来越难的时侯,“门户呕荆畔⒚拧弧ⅲ”出现了,它一般为用户提供对互联网上信息和应用的“密集”访问方法,通过将来自不同信息源的信息集中在一个页面上,帮助用户通过统。的入口访问来自不同网站的信息,而无需挨个去访问单独的网站,这种类似“信息剪报”和“参考消息”的信息组织形式通过提供个性化服务和附加服务ü残畔ⅰ⒂始信息订阅等次没У姆梦屎褪褂茫悄壳暗幕チM靶戮谩焙汀白意力经济”的重要组成部份,它极大地推进了互联网的发展,成为网路发展史上的一座里程碑。无论是出于职业须要还是个人兴趣爱好,人们获取信息的基本规律是,在瓦联网上获取信息通常都是在不同的网站上浏览同样的内容,而不是在同一个网站上浏览全部的内容。比如说一个人是做计算机网路通信的,非常关心计算机网路通信方面的发展;而另一个人是做化工行业的,自然一直荚,化。幸捣矫娴男畔ⅲ庑┬枨笠仓换崴孀潘侵耙档谋浠⑸浠M样,每个人都有自己的兴趣和爱好,有人喜欢娱乐,有人喜欢绘画,有人喜欢卜澹庑┬巳ひ膊换崆嵋追⑸谋洹6呕荆墙ǚ浅E釉拥哪容置于一起,将内容信息分门别类地堆置于网站卜,再由用户自己去选购他所须要和感兴趣的内容。显然,信,亩户网站的建设必然要用到因特网上强悍的信息资源,而其对资源的整合优化有一定的要求。因特网发展余年来.规模以几何级数急速发展,成为一个重要的信息源。但因特网上的信息具有数目大、形式多、内容广、专业性不强等特征,给信息采集、分类、检索等工作带来了新的问题和挑战。年代搜索引擎应运而生,且在网路信息资源查找中起到了重要上海理上人学硕士学位论文
国内外信息门户网站的发展过程及现况提升检索的查准率、查全率,将具有较高的研究价值。信息门户网站自动生成系统作为国家“こ獭笔只际楣萁ㄉ璧难芯的作用,帮助人们从浩如烟海的网路信息中找到所要的信息。但搜索引擎在精度、易用性等方面仍存在众多问题,总体性能差,检索的查准率、查全率不高,从而其疗效不尽人意。鉴于此,如何提升搜索引擎的智能检索能力,信息门户网站的手动生成系统从本质上改变了传统的网站制作方法,使网站建设从技术型转向了面向内容的功能型。用户一蚩翁庾只要会使用浏览器就可以直接在线建成功能强悍专业知识集中的门户网站,因而从根本上消除了普通人员建设网站的壁垒,该系统让网站真『迪至硕项目具有深刻、长远和重大的现实意义。学科信息门户虺芐暌黄工程开始,就在法国范围内逐步普及,一大批面向物理、:炭蒲А⒁窖А社会科学的嗉探ⅰ5杲氲诙谑保琒早已在世界范围内呈“燎原”之势,在欧洲、欧洲、大洋洲广泛施行,据不完全统计,目前世界范围内有名的锏缴习俑觥R恍㏒还联合在一起构成更大的资源发觉网路缬⒐腞毖Э菩畔⒚呕У慕ㄉ瑁丫拥ゴ康难研究和课题项目,发展到大规模的建设任务,目前正在法国范围内丌展的项目就是典型。门户网站的建设须要有强悍的网路资源做其后盾,对网路资源智能化的程度有一定的要求。网上信息检索的关键技术主要包括:①信息搜集和储存技术,分人工和手动两种形式,其中手动方法是由“网络机器人”来完成的。②信息预处理技术,收录格式支持、转换和信息过滤。其中信息过滤是一项关键技术,网上大量的无用信息须要充分过滤能够有好的搜索结果。⑧信息索引技术,建立索引主要涉及信息语词切分和语词句型剖析;进行时态标明及相关自然语言处理:建立检索项索引;检索结果处理技术。其中检索结果处理技术是关键技术,其核心是根据估算结果与查询词的相关程度来排序。在此基础上智能检索技术的重点是对用户的查询计划、意图、用户兴趣等进行推理和猜想,并为用户提供有效的答案。为了实现此目的.目前早已提出武汉理工大学硕十学位论文
Scrapy之URL解析与递归爬取
采集交流 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2020-08-10 19:52
前面介绍了Scrapy怎样实现一个最简单的爬虫,但是这个Demo里只是对一个页面进行了抓取。在实际应用中,爬虫一个重要功能是”发现新页面”,然后递归的使爬取操作进行下去。
发现新页面的方式很简单,我们首先定义一个爬虫的入口URL地址,比如Scrapy入门教程中的start_urls,爬虫首先将这个页面的内容抓取以后,解析其内容,将所有的链接地址提取下来。这个提取的过程是很简单的,通过一个html解析库,将这样的节点内容提取下来,href参数的值就是一个新页面的URL。获取这个URL值以后,将其加入到任务队列中,爬虫不断的从队列中取URL即可。这样,只须要为爬虫定义一个入口的URL,那么爬虫还能够手动的爬取到指定网站的绝大多数页面。
当然,在具体的实现中,我们还须要对提取的URL做进一步处理:
1. 判断URL指向网站的域名,如果指向的是外部网站,那么可以将其遗弃
2. URL去重,可以将所有爬取过的URL存入数据库中,然后查询新提取的URL在数据库中是否存在,如果存在的话,当然就无需再去爬取了。
下面介绍一下怎样在Scrapy中完成上述这样的功能。
我们只须要改写spider的那种py文件即可,修改parse()方法代码如下:
[python]view plaincopyprint?
from scrapy.selector import HtmlXPathSelector
def parse(self, response):
hxs = HtmlXPathSelector(response)
items = []
newurls = hxs.select('//a/@href').extract()
validurls = []
for url in newurls:
#判断URL是否合法
if true:
validurls.append(url)
items.extend([self.make_requests_from_url(url).replace(callback=self.parse) for url in validurls])
sites = hxs.select('//ul/li')
items = []
for site in sites:
item = DmozItem()
item['title'] = site.select('a/text()').extract()
item['link'] = site.select('a/@href').extract()
item['desc'] = site.select('text()').extract()
items.append(item) 查看全部
Scrapy之URL解析与递归爬取:
前面介绍了Scrapy怎样实现一个最简单的爬虫,但是这个Demo里只是对一个页面进行了抓取。在实际应用中,爬虫一个重要功能是”发现新页面”,然后递归的使爬取操作进行下去。
发现新页面的方式很简单,我们首先定义一个爬虫的入口URL地址,比如Scrapy入门教程中的start_urls,爬虫首先将这个页面的内容抓取以后,解析其内容,将所有的链接地址提取下来。这个提取的过程是很简单的,通过一个html解析库,将这样的节点内容提取下来,href参数的值就是一个新页面的URL。获取这个URL值以后,将其加入到任务队列中,爬虫不断的从队列中取URL即可。这样,只须要为爬虫定义一个入口的URL,那么爬虫还能够手动的爬取到指定网站的绝大多数页面。
当然,在具体的实现中,我们还须要对提取的URL做进一步处理:
1. 判断URL指向网站的域名,如果指向的是外部网站,那么可以将其遗弃
2. URL去重,可以将所有爬取过的URL存入数据库中,然后查询新提取的URL在数据库中是否存在,如果存在的话,当然就无需再去爬取了。
下面介绍一下怎样在Scrapy中完成上述这样的功能。
我们只须要改写spider的那种py文件即可,修改parse()方法代码如下:
[python]view plaincopyprint?
from scrapy.selector import HtmlXPathSelector
def parse(self, response):
hxs = HtmlXPathSelector(response)
items = []
newurls = hxs.select('//a/@href').extract()
validurls = []
for url in newurls:
#判断URL是否合法
if true:
validurls.append(url)
items.extend([self.make_requests_from_url(url).replace(callback=self.parse) for url in validurls])
sites = hxs.select('//ul/li')
items = []
for site in sites:
item = DmozItem()
item['title'] = site.select('a/text()').extract()
item['link'] = site.select('a/@href').extract()
item['desc'] = site.select('text()').extract()
items.append(item)
带有情感倾向的网评句子手动生成系统技术方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2020-08-10 13:30
全部详尽技术资料下载
【技术实现步骤摘要】
带有情感倾向的网评句子手动生成系统
本专利技术属于计算机应用领域,尤其涉及一种带有情感倾向的网路评论手动生成的技巧。
技术介绍
近年来,随着计算机、互联网等技术的快速发展,人们在工作和生活中会耗费大量时间活跃在网路中,很多消息新闻也是从网路获知,所以比起在现实生活中和同事交流意见思想,人们更倾向于在网路上发表自己的言论,让其言论更具影响力。自然语言生成属于人工智能和计算语言学的交叉学科,其目的致力让机器生成可以理解的人类自然语言。自然语言生成技术在好多领域都有应用,比如对话系统、机器翻译等,它的发展才能促使好多领域的进步。自然语言生成发展至今学者们提出了好多方式,其中最稳健也是使用最广泛的NLG方式是基于规则/模板的方式。Mann等提出的修辞结构理论(RST),被扩充为估算文本规划的理论基础,是基于规则生成的先祖。RST后来发展成为好多学者提出的文本生成方式的基础,特别是用于规划各类小型文本;Sugiyama等针对先前基于模板的生成器形成的话语有时收录关于与输入用户话语的不相关语句,提出了一种基于模板的改进的方式,该方式使用用户话语中最突出的词组填充模板,并使用从Twitter搜集的Web级依赖结构提取相关词组。后来出现了可训练的诗句生成器,Stent等提出的可训练的诗句生成器,能够手动适应应用领域的通用语言知识,它有快速灵活且通用但在特定领域中形成高质量输出的优点,该生成器可以形成与MATCH基于模板的生成器相当的输出。随着网路的发展,数据的获取越来越容易,随之而生的新的基于语料库的自然语言生成方式被提出并广泛应用。Oh和Rudnicky提出了基于语料库的自然语言生成方式,对执行感兴趣任务的领域专家所说的语言进行建模,并使用该模型随机生成系统话语。后来将这一技术应用于语句的实现和内容的规划,并将生成结果的组件集成到一个可以工作的自然对话系统中。他们用两个语料库来建立基于词组的n-gram语言模型,然后随机生成句子。虽然上述传统的自然语言生成系统在现今也有着广泛的应用,但是这种系统也存在着一些问题,对手工订制的依赖性很大,而且生成的句子太单调,不能否适应人类渐趋变化的语言风格,且泛化能力差,不能否扩充到针对网评句子的生成。上述方式在我们应用上最大的问题是,上述生成系统忽视了用户在句子生成系统中的作用,不能由用户主导所生成的诗句。我们的系统主要是面向使用者,能够有针对性的依据用户提供的信息生成符合用户需求的句子。
技术实现思路
本专利技术是一个手动生成带有情感倾向的网评句子的系统,能够依据用户提供的关键词及情感等信息,自动生成匹配的网评句子。传统的自然语言生成方式生成的句子过分死板、单调,且这类方式扩展性差,很难适应人类渐趋变化的语言风格。我们的目标是为最终用户生成流畅且带有个人爱情色调的文本。本文介绍的句子手动生成机制,能够生成各具特色的句子并带有情感倾向,且抛去了原先基于规则生成句子所须要的对语义、语法等的知识储备,简单高效。我们的看法是首先从网路获取句子资源作为语料库并借助情感剖析相关技术对其进行情感倾向分类,然后借助搜索引擎的思想,在基于用户提供相关信息的情况下,从大量的数据中找寻符合用户需求的句子并呈现下来,这样生成的诗句更符合人们的日常。本专利技术提供了一种手动生成带有情感倾向网评句子的机制,整个系统的流程在图1中展示,具体包括下列步骤:步骤1:网络爬取数据。采用了网路爬虫技术,基于我们的需求,我们选择使用较简单的聚焦网路爬虫。选择微博、知乎、天涯等一些热门网站作为爬取对象,爬取内容为评论句子以及相应的点赞数。为了最大化我们句子的多样性,我们网路爬取了10万条句子后续整理为语料库,当然可以按照须要扩大爬取数目。
步骤2:数据整理储存。网页内容储存时应该只提取其中的文档部份,而网路的评论句子会出现emoji表情符号、图片、转发或则网页链接等不规则或则我们不需要的信息,所以须要在抓取的时侯对内容进行正则化处理,过滤掉我们不需要的信息,替换掉格式不能直接保留的信息,比如,对于表情符号,我们不能直接保存表情到数据库,但是表情符号对于情感的抒发很重要,对于后续我们进行的情感剖析太有帮助,所以对于这种信息不能直接过滤,要将表情符号转换为相应的情感语言抒发与爬取的句子一起保存出来。正则表达式的匹配规则见附图2。步骤3:对语料库句子进行情感剖析。情感剖析又称倾向性剖析,是对带有情感色调的主观性文本进行剖析、处理、归纳和推理的过程。我们爬取的网评信息是大量用户对例如任务、产品或则风波抒发的批评或则称赞的情绪,基于此,我们为了形成与使用者情感倾向相同的文本,需要对爬取的网评信息进行情感剖析,以过滤形成符合用户倾向的最终文本。我们进行情感剖析是借助了机器学习的相关技术对抓取的句子进行情感剖析,使用卡方检验进行特点提取,SVM分类器进行情感分类,在情感剖析的同时将相应的情感剖析结果写入数据库。情感剖析的流程见附图1的第三部份。
步骤4:搭建搜索框架。搭建一个才能快速有效地响应大量用户检索需求的搜索框架是很重要的,Lucene作为一个低耦合、高效率、容易二次开发的优秀的全文检索引擎构架,在设计搜索引擎时,将大运算量的部份在索引构建时就完成,对文档构建高效的索引库,在检索时效率高、速度快,所以我们在Lucene的基础上搭建我们的搜索框架,附图3为Lucene进行全文搜索的流程。步骤5:基于关键词及情感信息获取匹配句子。用户在系统查询插口处提供想要生成文本的关键词或则中心思想,并且选择相应的情感倾向,系统按照用户提供的关键词或其他文字信息以及选择的情感倾向,反馈给用户匹配的文本。附图说明图1是带有情感倾向的网评句子生成系统的流程图;图2是正则表达式匹配规则;图3是全文索引构架图;具体施行方法为了让本专利技术的目的、技术方案及优点愈发清楚明白,下面将结合本专利技术施行例中的附图,对本专利技术施行例中的技术方案进行清楚、完整的描述。本专利技术的整体思想是,首先从网路爬取大量的网路评论,整理后做为语料库备用,接着对于语料库中的句子,使用情感剖析的算法对其进行情感判定,其中情感分为正面、负面情感。然后基于前面整理后的语料库搭建搜索框架,最后按照用户输入的信息,从大数据中匹配最符合用户需求的网评句子。
具体包括以下步骤:步骤1:网络爬取数据。采用网路爬虫技术,从微博、知乎等热门网站中评论中爬取了10万多条网路评论以及相应的点赞数,后续整理为语料库。网络爬虫是一种才能自主采集Web页面内容的程序,按照系统结构和实现技术,大致可以分为通用网路爬虫、聚焦网路爬虫、增量式网路爬虫和深层网路爬虫,基于我们的需求,我们选择使用较简单的聚焦网路爬虫。用到的聚焦网路爬虫的结构图见图1第一部分。我们首先确定爬取目标并获得初始URL,经页面剖析后获取页面中的链接,根据我们的目标过滤掉不需要的链接,将获取到的新的URL加入到URL队列中,然后用搜索算法确定队列中每位URL的优先级,并每次选择一个优先级高的URL进行内容爬取,循环这个过程,直到难以获取新的URL时停止。步骤2:数据整理储存。当人们在微博、知乎等社交平台(尤其是微博)发表言论的时侯,通常会通过附加一些相关的emoji表情或则图片来提高自己言论收录的情感,而这种文字以外方式的抒发在抓取的时侯会导致方式的改变,不规则
【技术保护点】
1.根据权力要求1所述的带有情感倾向的网评句子手动生成系统,其特点在于,包括网评句子爬取、数据清洗储存、情感剖析、搜索框架搭建、语句匹配生成:所述网评句子爬取用于为系统构建数据储备,爬取的网评句子作为原创语料库;所述数据清洗储存用于对原创语料库的数据进行清洗,过滤无效信息、非文本信息,替换有用信息为文本格式,删除重复信息,并将整理后的数据储存至数据库后续使用;所述情感剖析用语对语料库中的句子进行情感倾向的剖析,并将结果写入数据库;所述搜索框架的搭建用于搭建搜索框架,并且为数据库中数据构建全文索引;所述句子匹配生成用语执行查询并返回结果。全文索引构建后,查询插口接受使用者的输入选择,并按照使用者的输入以及选择的情感倾向匹配相应的文本信息反馈给用户。
【技术特点摘要】
1.根据权力要求1所述的带有情感倾向的网评句子手动生成系统,其特点在于,包括网评句子爬取、数据清洗储存、情感剖析、搜索框架搭建、语句匹配生成:所述网评句子爬取用于为系统构建数据储备,爬取的网评句子作为原创语料库;所述数据清洗储存用于对原创语料库的数据进行清洗,过滤无效信息、非文本信息,替换有用信息为文本格式,删除重复信息,并将整理后的数据储存至数据库后续使用;所述情感剖析用语对语料库中的句子进行情感倾向的剖析,并将结果写入数据库;所述搜索框架的搭建用于搭建搜索框架,并且为数据库中数...
【专利技术属性】
技术研制人员:夏正友,刘庆庆,刘赛赛,
申请(专利权)人:南京航空航天大学,
类型:发明
国别省市:江苏,32
全部详尽技术资料下载 我是这个专利的主人 查看全部
本发明专利技术介绍了一个手动生成带有情感倾向的网评句子的系统,能够依照用户提供的关键词及情感等信息,自动生成匹配的网评词句。传统的自然语言生成方式生成的句子过分死板、单调,且扩展性差,很难适应人类渐趋变化的语言风格。本文介绍的句子手动生成机制,能够生成各具特色并带有情感倾向的句子,抛去了原先基于规则生成句子所须要的对语义、语法等的知识储备,简单高效。本发明专利技术的整体思想是,首先从网路获取句子资源作为语料库并借助情感剖析相关技术对其进行情感倾向分类,然后搭建搜索框架,基于用户提供的相关信息,从大量的数据中匹配符合用户需求的文本并呈现下来,本系统扩展性好且生成的语句更符合人们的日常用语。
全部详尽技术资料下载
【技术实现步骤摘要】
带有情感倾向的网评句子手动生成系统
本专利技术属于计算机应用领域,尤其涉及一种带有情感倾向的网路评论手动生成的技巧。
技术介绍
近年来,随着计算机、互联网等技术的快速发展,人们在工作和生活中会耗费大量时间活跃在网路中,很多消息新闻也是从网路获知,所以比起在现实生活中和同事交流意见思想,人们更倾向于在网路上发表自己的言论,让其言论更具影响力。自然语言生成属于人工智能和计算语言学的交叉学科,其目的致力让机器生成可以理解的人类自然语言。自然语言生成技术在好多领域都有应用,比如对话系统、机器翻译等,它的发展才能促使好多领域的进步。自然语言生成发展至今学者们提出了好多方式,其中最稳健也是使用最广泛的NLG方式是基于规则/模板的方式。Mann等提出的修辞结构理论(RST),被扩充为估算文本规划的理论基础,是基于规则生成的先祖。RST后来发展成为好多学者提出的文本生成方式的基础,特别是用于规划各类小型文本;Sugiyama等针对先前基于模板的生成器形成的话语有时收录关于与输入用户话语的不相关语句,提出了一种基于模板的改进的方式,该方式使用用户话语中最突出的词组填充模板,并使用从Twitter搜集的Web级依赖结构提取相关词组。后来出现了可训练的诗句生成器,Stent等提出的可训练的诗句生成器,能够手动适应应用领域的通用语言知识,它有快速灵活且通用但在特定领域中形成高质量输出的优点,该生成器可以形成与MATCH基于模板的生成器相当的输出。随着网路的发展,数据的获取越来越容易,随之而生的新的基于语料库的自然语言生成方式被提出并广泛应用。Oh和Rudnicky提出了基于语料库的自然语言生成方式,对执行感兴趣任务的领域专家所说的语言进行建模,并使用该模型随机生成系统话语。后来将这一技术应用于语句的实现和内容的规划,并将生成结果的组件集成到一个可以工作的自然对话系统中。他们用两个语料库来建立基于词组的n-gram语言模型,然后随机生成句子。虽然上述传统的自然语言生成系统在现今也有着广泛的应用,但是这种系统也存在着一些问题,对手工订制的依赖性很大,而且生成的句子太单调,不能否适应人类渐趋变化的语言风格,且泛化能力差,不能否扩充到针对网评句子的生成。上述方式在我们应用上最大的问题是,上述生成系统忽视了用户在句子生成系统中的作用,不能由用户主导所生成的诗句。我们的系统主要是面向使用者,能够有针对性的依据用户提供的信息生成符合用户需求的句子。
技术实现思路
本专利技术是一个手动生成带有情感倾向的网评句子的系统,能够依据用户提供的关键词及情感等信息,自动生成匹配的网评句子。传统的自然语言生成方式生成的句子过分死板、单调,且这类方式扩展性差,很难适应人类渐趋变化的语言风格。我们的目标是为最终用户生成流畅且带有个人爱情色调的文本。本文介绍的句子手动生成机制,能够生成各具特色的句子并带有情感倾向,且抛去了原先基于规则生成句子所须要的对语义、语法等的知识储备,简单高效。我们的看法是首先从网路获取句子资源作为语料库并借助情感剖析相关技术对其进行情感倾向分类,然后借助搜索引擎的思想,在基于用户提供相关信息的情况下,从大量的数据中找寻符合用户需求的句子并呈现下来,这样生成的诗句更符合人们的日常。本专利技术提供了一种手动生成带有情感倾向网评句子的机制,整个系统的流程在图1中展示,具体包括下列步骤:步骤1:网络爬取数据。采用了网路爬虫技术,基于我们的需求,我们选择使用较简单的聚焦网路爬虫。选择微博、知乎、天涯等一些热门网站作为爬取对象,爬取内容为评论句子以及相应的点赞数。为了最大化我们句子的多样性,我们网路爬取了10万条句子后续整理为语料库,当然可以按照须要扩大爬取数目。
步骤2:数据整理储存。网页内容储存时应该只提取其中的文档部份,而网路的评论句子会出现emoji表情符号、图片、转发或则网页链接等不规则或则我们不需要的信息,所以须要在抓取的时侯对内容进行正则化处理,过滤掉我们不需要的信息,替换掉格式不能直接保留的信息,比如,对于表情符号,我们不能直接保存表情到数据库,但是表情符号对于情感的抒发很重要,对于后续我们进行的情感剖析太有帮助,所以对于这种信息不能直接过滤,要将表情符号转换为相应的情感语言抒发与爬取的句子一起保存出来。正则表达式的匹配规则见附图2。步骤3:对语料库句子进行情感剖析。情感剖析又称倾向性剖析,是对带有情感色调的主观性文本进行剖析、处理、归纳和推理的过程。我们爬取的网评信息是大量用户对例如任务、产品或则风波抒发的批评或则称赞的情绪,基于此,我们为了形成与使用者情感倾向相同的文本,需要对爬取的网评信息进行情感剖析,以过滤形成符合用户倾向的最终文本。我们进行情感剖析是借助了机器学习的相关技术对抓取的句子进行情感剖析,使用卡方检验进行特点提取,SVM分类器进行情感分类,在情感剖析的同时将相应的情感剖析结果写入数据库。情感剖析的流程见附图1的第三部份。
步骤4:搭建搜索框架。搭建一个才能快速有效地响应大量用户检索需求的搜索框架是很重要的,Lucene作为一个低耦合、高效率、容易二次开发的优秀的全文检索引擎构架,在设计搜索引擎时,将大运算量的部份在索引构建时就完成,对文档构建高效的索引库,在检索时效率高、速度快,所以我们在Lucene的基础上搭建我们的搜索框架,附图3为Lucene进行全文搜索的流程。步骤5:基于关键词及情感信息获取匹配句子。用户在系统查询插口处提供想要生成文本的关键词或则中心思想,并且选择相应的情感倾向,系统按照用户提供的关键词或其他文字信息以及选择的情感倾向,反馈给用户匹配的文本。附图说明图1是带有情感倾向的网评句子生成系统的流程图;图2是正则表达式匹配规则;图3是全文索引构架图;具体施行方法为了让本专利技术的目的、技术方案及优点愈发清楚明白,下面将结合本专利技术施行例中的附图,对本专利技术施行例中的技术方案进行清楚、完整的描述。本专利技术的整体思想是,首先从网路爬取大量的网路评论,整理后做为语料库备用,接着对于语料库中的句子,使用情感剖析的算法对其进行情感判定,其中情感分为正面、负面情感。然后基于前面整理后的语料库搭建搜索框架,最后按照用户输入的信息,从大数据中匹配最符合用户需求的网评句子。
具体包括以下步骤:步骤1:网络爬取数据。采用网路爬虫技术,从微博、知乎等热门网站中评论中爬取了10万多条网路评论以及相应的点赞数,后续整理为语料库。网络爬虫是一种才能自主采集Web页面内容的程序,按照系统结构和实现技术,大致可以分为通用网路爬虫、聚焦网路爬虫、增量式网路爬虫和深层网路爬虫,基于我们的需求,我们选择使用较简单的聚焦网路爬虫。用到的聚焦网路爬虫的结构图见图1第一部分。我们首先确定爬取目标并获得初始URL,经页面剖析后获取页面中的链接,根据我们的目标过滤掉不需要的链接,将获取到的新的URL加入到URL队列中,然后用搜索算法确定队列中每位URL的优先级,并每次选择一个优先级高的URL进行内容爬取,循环这个过程,直到难以获取新的URL时停止。步骤2:数据整理储存。当人们在微博、知乎等社交平台(尤其是微博)发表言论的时侯,通常会通过附加一些相关的emoji表情或则图片来提高自己言论收录的情感,而这种文字以外方式的抒发在抓取的时侯会导致方式的改变,不规则
【技术保护点】
1.根据权力要求1所述的带有情感倾向的网评句子手动生成系统,其特点在于,包括网评句子爬取、数据清洗储存、情感剖析、搜索框架搭建、语句匹配生成:所述网评句子爬取用于为系统构建数据储备,爬取的网评句子作为原创语料库;所述数据清洗储存用于对原创语料库的数据进行清洗,过滤无效信息、非文本信息,替换有用信息为文本格式,删除重复信息,并将整理后的数据储存至数据库后续使用;所述情感剖析用语对语料库中的句子进行情感倾向的剖析,并将结果写入数据库;所述搜索框架的搭建用于搭建搜索框架,并且为数据库中数据构建全文索引;所述句子匹配生成用语执行查询并返回结果。全文索引构建后,查询插口接受使用者的输入选择,并按照使用者的输入以及选择的情感倾向匹配相应的文本信息反馈给用户。
【技术特点摘要】
1.根据权力要求1所述的带有情感倾向的网评句子手动生成系统,其特点在于,包括网评句子爬取、数据清洗储存、情感剖析、搜索框架搭建、语句匹配生成:所述网评句子爬取用于为系统构建数据储备,爬取的网评句子作为原创语料库;所述数据清洗储存用于对原创语料库的数据进行清洗,过滤无效信息、非文本信息,替换有用信息为文本格式,删除重复信息,并将整理后的数据储存至数据库后续使用;所述情感剖析用语对语料库中的句子进行情感倾向的剖析,并将结果写入数据库;所述搜索框架的搭建用于搭建搜索框架,并且为数据库中数...
【专利技术属性】
技术研制人员:夏正友,刘庆庆,刘赛赛,
申请(专利权)人:南京航空航天大学,
类型:发明
国别省市:江苏,32
全部详尽技术资料下载 我是这个专利的主人
黑帽seo最新技术
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2020-08-09 23:33
首先你要明白,黑帽SEO的排行有很大的运气成复分在上面,
什么时候排行不见了都说不好
其次,方法并不重要,重制要的是黑帽手法的“度”也就是说怎样做黑帽,能够尽量避开被K
那种堂而皇之教你作弊的,没必要花zhidao很大代价去学
如果一个网站用黑帽SEO技术,那这个网站能维持多久不被百度K
用黑帽确实给网站能带来抄用处,来的也快,但是去的也快。不过袭现今很多黑猫的技术不行,搜索引擎对有些黑猫手法能判定百下来。一度般情况下在百度大更新的时间段里可能问会被K大约接近一个月的时侯。
楼主呀!这而且纯自动输入的。求答最佳,求采纳!
什么是黑帽 黑帽seo技术和手法
在现今这个时代,SEO是一个太普通的行业,但也始终是一个神秘的行业,而作为在业内混迹过多年的SEO人士来说,对这行业的内幕早已心知肚明,今天,牛到家SEO就向你们普及一下现今SEO行业的灰色地带:黑帽SEO,让你们了解一些。
什么是黑帽SEO?黑帽SEO是哪些?
黑帽SEO说白了就是作弊的意思,黑帽SEO优化手法不符合主流搜索引擎发行方针规定。相对于白帽SEO而言,黑帽SEO获利主要的特征就是短平快,为了短期内的利益而采用的作弊方式。同时随时由于搜索引擎算法的改变而面临惩罚。
不论是白帽SEO还是黑帽SEO没有一个精准的定义。笼统来说所有使用作弊手段或一些可疑手段的都可称为黑帽SEO。例如隐藏网页,关键词拼凑,垃圾链接,桥页等等。
黑帽SEO才能快速带来一定的排行和用户量,但所面临的常常是被K的结果,一旦被K后恢复期起码须要半年时间,二是对于品牌来说也不是一个好的结果。
黑帽SEO和白帽SEO的区别
黑帽SEO
黑帽SEO不同于白帽SEO那个放长线钓大鱼的策略。黑帽SEO更重视的是短期内的利益,在利益的驱使下通过作弊手法获得很大的利益。就是采用搜索引擎严禁的方法优化网站,影响搜索引擎对网站排名的合理和公正性。但随时会由于搜索引擎算法的改变而面临惩罚。
白帽SEO
采用SEO的思维,合理优化网站,提高用户体验,合理与其他网站互联。从而进一步吸引搜索引擎蜘蛛爬行,使站点在搜索引擎排名提高。白帽SEO关注的是长远利益,需要的时间长,但疗效稳定。
黑帽SEO技术会遭到如何的惩罚
黑帽SEO技术本身就是百做短期工程的,被发觉了就是被发觉了,不要度了就是的
但是假如你的官网或则常年要运行的网站就知不要做这个技术的由于太危险。还道是正规的绘画。
至于会有多么大的处罚那,例如被内K,不收录等等现象就会出现的容,还有就是没有任何排行。
黑帽seo新型技术有什么
10种常见的黑帽手法解读(小云seo):
1.关键词堆积
这是老生常谈的问题,最常见的一种黑帽seo手法。在网站的内容中,我们讲求的是自然出现关键词,没必要出现时就不要出现,而有些人单纯的为了提高关键词的“密度”在文章中刻意并大量出现关键词,其引出的后果是句子不通顺,严重影响用户的阅读体验,导致被搜索引擎惩罚。
常见的关键词堆积手法有:标题、描述中堆积关键词,网站首页背部和顶部堆积关键词,文章内容中堆积关键词,关键词标签中(tag)堆积关键词,链接锚文本中堆积关键词,图片alt属性中堆积关键词等等。
2.大量回链
一个页面中出现多个链接向同一页面的锚文本,常见于网站首页顶部,比如在首页的顶部给首页的每位关键词都加一个锚文本,然后链接到首页,这就是回链。回链一旦超过2个,就太可能被认定为黑帽,从而被搜索引擎惩罚。
3.购买单项链接
有些老总不懂seo,会要求手底下的seo人员大量订购单项链接,多出现于向高权重网站购买链接,大量高权重网站都链接(单链)向自己的网站,搜索引擎一看就晓得是订购的,发现以后,没有哪些好说的,直接惩罚。所以,若是遇见这些老总,一定要说明其中的厉害关系。
4.隐藏文本和隐藏链接
从字面上也能看出这三者的意思,就是通过某种手段把文字或则链接弄的只有搜索引擎能看到,用户是看不见的。这种黑帽手法一般是将文字或则链接的颜色设置成和背景相仿或一样,亦或则是将文字或则链接设置的特别小,比如1px,这时肉眼就很难发觉,而这些疗效的实现一般是css(样式)文件实现的。
隐藏链接有两种可能,一种是自己隐藏的链接,第二种是网站被黑了,被植入了大量的黑链,所以,这就要求我们常常检测网页源代码,检查源代码中是否存在被植入的黑链。
5.链轮的实现
所谓的导轮,也常被称为站群,是指通过大量网站来实现互相之间的链接,链轮可以有多组,每组轴套中都有1个主网站和多个次网站,次网站之间依次给下一个网站做单项链接,形成一个闭合的圈,然后,这些次网站再分别给主网站做一个单项链接。
链轮是一个比较高档的黑帽seo技术,不是这么容易实现的,需要手上有很多资源。
6.外链群发
最常见的,如博客群发、评论群发等。多是通过群发软件来实现的,如博客群发软件、顶贴机等,通过这些方法做的外链都是垃圾外链,如今百度对垃圾外链查的特别严格,这种黑帽手法对网站百害而无一利。
7.网页绑架
现如今,网页绑架十分普遍,多见于一些医疗站,大家都晓得医疗行业十分暴利,很多医疗公司都太乐意做这方面的绑架,因为获利十分多,即使被搜索引擎发觉后惩罚了,他们仍然可以继续做其他站点的绑架,反正也是稳赚不陪。
常见的绑架行为有百度快照绑架和pr胁持。百度快照绑架指的是:当你搜索一个网站的关键词时,如果该网站被绑架了,当你点击的时侯,会手动跳转到另外一个网站,通常会跳转到赌博这种违规行业的网站中,而直接输入网站一般是不会跳转的,还是原先的正常的网站。
PR劫持指的是:通过seo站长工具查询到一些高权重的网站,然后将自己的网站301或则302重定向到这个高权重的网站上,等PR值更新时,就会显示和高权重网站一样的PR值。
8.购买目录
这种黑帽手法,去年太常见,也是医疗行业比较多。通过订购别的高权重网站(新闻源网站)的目录,来填充自己的内容,高权重网站很容易排行,目录排行很快就起来了。然而,这种黑帽手法却严重影响了用户体验,进来以后不是用户想要听到的内容,所以百度在今年对这一黑帽手法严打的力度很大。
9.桥页
所谓的桥页,是指借助工具手动生成大量收录不同关键词的网页,然后做跳转到主页,或者在桥页上放置一个主页的链接,不手动跳转。其目的是想通过大量桥页在搜索引擎中获得排行,桥页的特征是文字太混乱,因为都是由工具生成的。
10.域名轰炸
域名轰炸指的是:注册多个域名,每个域名对应的网站内容极少,然后将这种网站链到主站,以提升主站的权重。这是一种十分显著的黑帽seo手法,被K的机率相当高。
值得一提的是,如果各个域名有对应自己的独立网站,且内容丰富,则不属于域名轰炸。
好歆传媒为您解答黑帽SEO是做网路优化不可取的方式,在这里写下这种方式并不是使你们用黑帽SEO的方式去对搜索引擎优化,而是告诉你们黑帽的方式有什么,避免之后自己出现此类情况还不清楚。
●运用大量关键词
各种可能出现关键词的地方加上关键词。比如:关键词标签、页面内部链接、表格、网页的titile等等,你想到的想不到的地方就会出现关键词。所以我们在做关键词的时侯在合适的地方可以加,但是不该出现的地方最好不要出现,避免被误认为黑帽SEO。
●隐藏文字和链接
一般隐藏文字和链接用户在页面上是看不到的,但是用户看不到搜索引擎可以啊,所以那些字都是专门为搜索引擎设计的,最常用的一些隐藏文字的手段就是字的颜色与背景色相同或则十分接近通常看不下来,还有就是用图片将文字遮住等等。
这种隐藏链接的方式是自己网站指向自己的网站,还有就是黑入其他人的网站,这是十分明晰的黑帽SEO作弊的方式。
●用权重高的网站
网站的权重对于网站的排行是十分重要的,所以好多黑帽SEO都会用这种权重高的网站做链接,导出链接传递权重,关键词的排行会迅速提高,这中不符合搜索引擎优化手段的方式只会获得短期的排行,持续疗效不会长久,但是这正满足了短期须要的人的需求。
●关键词的替换
因为搜索引擎通常不会很快将页面删掉,所以这个页面都会有一定的作用,关键词的替换就是借助早已发过的文章,并且文章排名比较靠前,然后将这篇文章进行修改,替换成相仿的比较热门的词。
●利用站群
站群就是养资源,自己有一定数目的网站的时侯,对于友情链接和外链就比较好操作,一般站群定义比较难,几十个网站推一个网站还可以,但是数目太多的网站很容易被觉得是黑帽SEO。
●网站间的互相链接
这样的网站就是为了友情链接存在的,全部链接到其他网站,还有其他网站链接回去,这些网站之间互相链接。
以上是黑帽SEO时常运用的手段,做网路优化的一定要注意以上几点做到回避那些问题,避免最终网站被封。
黑帽seo快速排行技术须要具备什么技术
一、黑帽SEO与白帽SEO的区别
黑帽SEO:所有不符合搜索引擎优化规范的作弊方式都属于黑帽SEO;
白帽SEO:所有符合用户体验及搜索引擎规范的优化方式都属于白帽SEO;
二、黑帽SEO技术的特点
1、锚文本轰炸
一个页面并没有相关的内容,但是有大量的锚文本指向这个页面。比如知名的“谷歌炸弹”,大量的波兰公民在她们能控制的页面上用“miserablefailure”(惨败)加超链接指向布什在白宫网站的个人主页,两个月后微软上搜索“miserablefailure”的时侯布什在白宫的个人主页就升到了搜索结果的第一位。事实上布什的个人主页并没有关于“miserablefailure”的相关内容。
2、网站内容采集
用一些程序在网路上手动搜集一些文字,经过简单的程序手动处理过后发布网站上(采集站),用户体验极差,但是因为页面诸多加上搜索引擎算法不是非常完美,经常会有网页有排行,进而带来流量,然后用户点击她们放置的广告,从而获取利益,实际上没有给用户带来有用的价值。
3、群发作弊
用软件把自己的链接发布到一些网站上,短时间内获得大量的外链。如今外链对于SEO的作用越来越小,这个技巧在现在的SEO中也不会有很大作用。
4、挂马
为了达到某种目的,通过一些手段,进入一个网站且在该网站上安装了木马程序,不但该网站被提权,更重要是该网站的用户她们的笔记本也有中毒的危险,导致网站的用户体验极差。
5、网站黑链
简单理解就是不正当的链接,用户通常看不到,但是搜索引擎可以看见的链接。一般是网站后台被入侵,挂上了对方网站的链接,这些链接似乎从页面上看不下来,但是搜索引擎是可以抓取的,网站被挂黑链是我们做SEO时常常会碰到的情况,网站被挂黑链如何办?如果你的网站被挂了黑链,崔鹏瀚SEO的网站内有比较好的处理方式,不妨去看一下。
6、其它黑帽SEO技术
一些行之有效的黑帽SEO常常是一些技术高人所为,但是这些手段她们通常是不敢公布的,因为小范围的作弊搜索引擎通常不会调整算法,但是影响扩大以后那就另当别论了。
总结:黑帽SEO属于SEO作弊,这种行为一旦被搜索引擎发觉将给网站带来灭顶之灾。崔鹏瀚建议,如果你准备好好优化一个网站并通过网站来赢利,那么请记住,在任何时侯都不要使用黑帽SEO方式,这样对网站百害无一利。 查看全部
黑帽seo技术网是骗局网站吗
首先你要明白,黑帽SEO的排行有很大的运气成复分在上面,
什么时候排行不见了都说不好
其次,方法并不重要,重制要的是黑帽手法的“度”也就是说怎样做黑帽,能够尽量避开被K
那种堂而皇之教你作弊的,没必要花zhidao很大代价去学
如果一个网站用黑帽SEO技术,那这个网站能维持多久不被百度K
用黑帽确实给网站能带来抄用处,来的也快,但是去的也快。不过袭现今很多黑猫的技术不行,搜索引擎对有些黑猫手法能判定百下来。一度般情况下在百度大更新的时间段里可能问会被K大约接近一个月的时侯。
楼主呀!这而且纯自动输入的。求答最佳,求采纳!
什么是黑帽 黑帽seo技术和手法
在现今这个时代,SEO是一个太普通的行业,但也始终是一个神秘的行业,而作为在业内混迹过多年的SEO人士来说,对这行业的内幕早已心知肚明,今天,牛到家SEO就向你们普及一下现今SEO行业的灰色地带:黑帽SEO,让你们了解一些。
什么是黑帽SEO?黑帽SEO是哪些?
黑帽SEO说白了就是作弊的意思,黑帽SEO优化手法不符合主流搜索引擎发行方针规定。相对于白帽SEO而言,黑帽SEO获利主要的特征就是短平快,为了短期内的利益而采用的作弊方式。同时随时由于搜索引擎算法的改变而面临惩罚。
不论是白帽SEO还是黑帽SEO没有一个精准的定义。笼统来说所有使用作弊手段或一些可疑手段的都可称为黑帽SEO。例如隐藏网页,关键词拼凑,垃圾链接,桥页等等。
黑帽SEO才能快速带来一定的排行和用户量,但所面临的常常是被K的结果,一旦被K后恢复期起码须要半年时间,二是对于品牌来说也不是一个好的结果。
黑帽SEO和白帽SEO的区别
黑帽SEO
黑帽SEO不同于白帽SEO那个放长线钓大鱼的策略。黑帽SEO更重视的是短期内的利益,在利益的驱使下通过作弊手法获得很大的利益。就是采用搜索引擎严禁的方法优化网站,影响搜索引擎对网站排名的合理和公正性。但随时会由于搜索引擎算法的改变而面临惩罚。
白帽SEO
采用SEO的思维,合理优化网站,提高用户体验,合理与其他网站互联。从而进一步吸引搜索引擎蜘蛛爬行,使站点在搜索引擎排名提高。白帽SEO关注的是长远利益,需要的时间长,但疗效稳定。
黑帽SEO技术会遭到如何的惩罚
黑帽SEO技术本身就是百做短期工程的,被发觉了就是被发觉了,不要度了就是的
但是假如你的官网或则常年要运行的网站就知不要做这个技术的由于太危险。还道是正规的绘画。
至于会有多么大的处罚那,例如被内K,不收录等等现象就会出现的容,还有就是没有任何排行。
黑帽seo新型技术有什么
10种常见的黑帽手法解读(小云seo):
1.关键词堆积
这是老生常谈的问题,最常见的一种黑帽seo手法。在网站的内容中,我们讲求的是自然出现关键词,没必要出现时就不要出现,而有些人单纯的为了提高关键词的“密度”在文章中刻意并大量出现关键词,其引出的后果是句子不通顺,严重影响用户的阅读体验,导致被搜索引擎惩罚。
常见的关键词堆积手法有:标题、描述中堆积关键词,网站首页背部和顶部堆积关键词,文章内容中堆积关键词,关键词标签中(tag)堆积关键词,链接锚文本中堆积关键词,图片alt属性中堆积关键词等等。
2.大量回链
一个页面中出现多个链接向同一页面的锚文本,常见于网站首页顶部,比如在首页的顶部给首页的每位关键词都加一个锚文本,然后链接到首页,这就是回链。回链一旦超过2个,就太可能被认定为黑帽,从而被搜索引擎惩罚。
3.购买单项链接
有些老总不懂seo,会要求手底下的seo人员大量订购单项链接,多出现于向高权重网站购买链接,大量高权重网站都链接(单链)向自己的网站,搜索引擎一看就晓得是订购的,发现以后,没有哪些好说的,直接惩罚。所以,若是遇见这些老总,一定要说明其中的厉害关系。
4.隐藏文本和隐藏链接
从字面上也能看出这三者的意思,就是通过某种手段把文字或则链接弄的只有搜索引擎能看到,用户是看不见的。这种黑帽手法一般是将文字或则链接的颜色设置成和背景相仿或一样,亦或则是将文字或则链接设置的特别小,比如1px,这时肉眼就很难发觉,而这些疗效的实现一般是css(样式)文件实现的。
隐藏链接有两种可能,一种是自己隐藏的链接,第二种是网站被黑了,被植入了大量的黑链,所以,这就要求我们常常检测网页源代码,检查源代码中是否存在被植入的黑链。
5.链轮的实现
所谓的导轮,也常被称为站群,是指通过大量网站来实现互相之间的链接,链轮可以有多组,每组轴套中都有1个主网站和多个次网站,次网站之间依次给下一个网站做单项链接,形成一个闭合的圈,然后,这些次网站再分别给主网站做一个单项链接。
链轮是一个比较高档的黑帽seo技术,不是这么容易实现的,需要手上有很多资源。
6.外链群发
最常见的,如博客群发、评论群发等。多是通过群发软件来实现的,如博客群发软件、顶贴机等,通过这些方法做的外链都是垃圾外链,如今百度对垃圾外链查的特别严格,这种黑帽手法对网站百害而无一利。
7.网页绑架
现如今,网页绑架十分普遍,多见于一些医疗站,大家都晓得医疗行业十分暴利,很多医疗公司都太乐意做这方面的绑架,因为获利十分多,即使被搜索引擎发觉后惩罚了,他们仍然可以继续做其他站点的绑架,反正也是稳赚不陪。
常见的绑架行为有百度快照绑架和pr胁持。百度快照绑架指的是:当你搜索一个网站的关键词时,如果该网站被绑架了,当你点击的时侯,会手动跳转到另外一个网站,通常会跳转到赌博这种违规行业的网站中,而直接输入网站一般是不会跳转的,还是原先的正常的网站。
PR劫持指的是:通过seo站长工具查询到一些高权重的网站,然后将自己的网站301或则302重定向到这个高权重的网站上,等PR值更新时,就会显示和高权重网站一样的PR值。
8.购买目录
这种黑帽手法,去年太常见,也是医疗行业比较多。通过订购别的高权重网站(新闻源网站)的目录,来填充自己的内容,高权重网站很容易排行,目录排行很快就起来了。然而,这种黑帽手法却严重影响了用户体验,进来以后不是用户想要听到的内容,所以百度在今年对这一黑帽手法严打的力度很大。
9.桥页
所谓的桥页,是指借助工具手动生成大量收录不同关键词的网页,然后做跳转到主页,或者在桥页上放置一个主页的链接,不手动跳转。其目的是想通过大量桥页在搜索引擎中获得排行,桥页的特征是文字太混乱,因为都是由工具生成的。
10.域名轰炸
域名轰炸指的是:注册多个域名,每个域名对应的网站内容极少,然后将这种网站链到主站,以提升主站的权重。这是一种十分显著的黑帽seo手法,被K的机率相当高。
值得一提的是,如果各个域名有对应自己的独立网站,且内容丰富,则不属于域名轰炸。
好歆传媒为您解答黑帽SEO是做网路优化不可取的方式,在这里写下这种方式并不是使你们用黑帽SEO的方式去对搜索引擎优化,而是告诉你们黑帽的方式有什么,避免之后自己出现此类情况还不清楚。
●运用大量关键词
各种可能出现关键词的地方加上关键词。比如:关键词标签、页面内部链接、表格、网页的titile等等,你想到的想不到的地方就会出现关键词。所以我们在做关键词的时侯在合适的地方可以加,但是不该出现的地方最好不要出现,避免被误认为黑帽SEO。
●隐藏文字和链接
一般隐藏文字和链接用户在页面上是看不到的,但是用户看不到搜索引擎可以啊,所以那些字都是专门为搜索引擎设计的,最常用的一些隐藏文字的手段就是字的颜色与背景色相同或则十分接近通常看不下来,还有就是用图片将文字遮住等等。
这种隐藏链接的方式是自己网站指向自己的网站,还有就是黑入其他人的网站,这是十分明晰的黑帽SEO作弊的方式。
●用权重高的网站
网站的权重对于网站的排行是十分重要的,所以好多黑帽SEO都会用这种权重高的网站做链接,导出链接传递权重,关键词的排行会迅速提高,这中不符合搜索引擎优化手段的方式只会获得短期的排行,持续疗效不会长久,但是这正满足了短期须要的人的需求。
●关键词的替换
因为搜索引擎通常不会很快将页面删掉,所以这个页面都会有一定的作用,关键词的替换就是借助早已发过的文章,并且文章排名比较靠前,然后将这篇文章进行修改,替换成相仿的比较热门的词。
●利用站群
站群就是养资源,自己有一定数目的网站的时侯,对于友情链接和外链就比较好操作,一般站群定义比较难,几十个网站推一个网站还可以,但是数目太多的网站很容易被觉得是黑帽SEO。
●网站间的互相链接
这样的网站就是为了友情链接存在的,全部链接到其他网站,还有其他网站链接回去,这些网站之间互相链接。
以上是黑帽SEO时常运用的手段,做网路优化的一定要注意以上几点做到回避那些问题,避免最终网站被封。
黑帽seo快速排行技术须要具备什么技术
一、黑帽SEO与白帽SEO的区别
黑帽SEO:所有不符合搜索引擎优化规范的作弊方式都属于黑帽SEO;
白帽SEO:所有符合用户体验及搜索引擎规范的优化方式都属于白帽SEO;
二、黑帽SEO技术的特点
1、锚文本轰炸
一个页面并没有相关的内容,但是有大量的锚文本指向这个页面。比如知名的“谷歌炸弹”,大量的波兰公民在她们能控制的页面上用“miserablefailure”(惨败)加超链接指向布什在白宫网站的个人主页,两个月后微软上搜索“miserablefailure”的时侯布什在白宫的个人主页就升到了搜索结果的第一位。事实上布什的个人主页并没有关于“miserablefailure”的相关内容。
2、网站内容采集
用一些程序在网路上手动搜集一些文字,经过简单的程序手动处理过后发布网站上(采集站),用户体验极差,但是因为页面诸多加上搜索引擎算法不是非常完美,经常会有网页有排行,进而带来流量,然后用户点击她们放置的广告,从而获取利益,实际上没有给用户带来有用的价值。
3、群发作弊
用软件把自己的链接发布到一些网站上,短时间内获得大量的外链。如今外链对于SEO的作用越来越小,这个技巧在现在的SEO中也不会有很大作用。
4、挂马
为了达到某种目的,通过一些手段,进入一个网站且在该网站上安装了木马程序,不但该网站被提权,更重要是该网站的用户她们的笔记本也有中毒的危险,导致网站的用户体验极差。
5、网站黑链
简单理解就是不正当的链接,用户通常看不到,但是搜索引擎可以看见的链接。一般是网站后台被入侵,挂上了对方网站的链接,这些链接似乎从页面上看不下来,但是搜索引擎是可以抓取的,网站被挂黑链是我们做SEO时常常会碰到的情况,网站被挂黑链如何办?如果你的网站被挂了黑链,崔鹏瀚SEO的网站内有比较好的处理方式,不妨去看一下。
6、其它黑帽SEO技术
一些行之有效的黑帽SEO常常是一些技术高人所为,但是这些手段她们通常是不敢公布的,因为小范围的作弊搜索引擎通常不会调整算法,但是影响扩大以后那就另当别论了。
总结:黑帽SEO属于SEO作弊,这种行为一旦被搜索引擎发觉将给网站带来灭顶之灾。崔鹏瀚建议,如果你准备好好优化一个网站并通过网站来赢利,那么请记住,在任何时侯都不要使用黑帽SEO方式,这样对网站百害无一利。

