
关键词自动采集生成内容系统
易淘站群管理系统特点及特点分析-乐题库
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-06-27 05:10
易淘站群管理系统特点及特点分析-乐题库
所有版本,支持网站,傻瓜式操作,采集自动更新,无需写采集规则,长尾关键词采集,新数据采集,数据发布,可用永久免费升级,包括vps在内的任何电脑都可以挂采集发布,可以同时开多个账号使用。
所有版本,支持网站,傻瓜式操作,采集自动更新,无需写采集规则,长尾关键词采集,新数据采集,数据发布,可用 永久免费升级,任何含有vps的电脑都可以使用挂机采集发布,可以开多个账号同时使用,不绑定机器硬件,无需购买加密狗,支持发布数据到各种流行的cms,也有独立的网站程序自定义发布界面。
Easy Tao站群管理系统特点:
1、整站全自动采集自动更新关键词和爬取频率设置后,系统会自动生成相关关键词和自动采集并生成相关文章,真正全自动聚合! 关键词系统爬虫会智能采集相对原创性别和相对较新的文章,保证文章质量。最重要的采集是pan采集,不需要写任何采集规则。你只需添加几个关键词,告诉系统你的网站定位,剩下的让系统自动完成。
2、制易淘站群建站数量管理系统本身就是一个免费的采集自动更新站群软件。无需花一分钱,即可使用功能强大的站群 软件。这个系统最大的特点就是网站的数量,和夏克、艾聚等限制网站数量的系统有很大的不同。你只需要一套。只要你有能量,你就可以做出无数的改变。输入网站。
3、强的伪原创Function Easy Amoy站群 系统可以在不影响原文可读性的情况下自动采集根据系统原文自动执行伪原创。这个系统是独一无二的文章的同义词和反义词引擎可以适当改变文章的语义,并使用独特的算法进行控制,让每一个文章都接近原创文章,而这一切由系统智能自动完成,无需人工。干预。
4、strong 抓取准确率 Yitao站群系统是泛抓取pan采集系统,不能局限于网站不限域名抓取相关文章,不是您需要定制的任意爬取策略和采集规则,系统会爬取与集合关键词最相关的原创文章,捕获的文章正确率可接受。达到90%以上,瞬间就能产生上千个原创性文章。
5 自定义关键词、链接、html代码可以随意插入到发布的内容中。支持内部锚链接。 关键词内锚文本网站随机插入到文章内容中。可设置链接环,实现单站定时定量发布。支持单站一键直接采集发布支持英文数据采集和发布new网站更新完成后自动提取文章标题和连接插入全局链接库进行插入集成 自动update可以设置一次更新网站会自动关闭增加周期站群Update:根据设置,站群24hours可以轮流更新采集post 查看全部
易淘站群管理系统特点及特点分析-乐题库

所有版本,支持网站,傻瓜式操作,采集自动更新,无需写采集规则,长尾关键词采集,新数据采集,数据发布,可用永久免费升级,包括vps在内的任何电脑都可以挂采集发布,可以同时开多个账号使用。
所有版本,支持网站,傻瓜式操作,采集自动更新,无需写采集规则,长尾关键词采集,新数据采集,数据发布,可用 永久免费升级,任何含有vps的电脑都可以使用挂机采集发布,可以开多个账号同时使用,不绑定机器硬件,无需购买加密狗,支持发布数据到各种流行的cms,也有独立的网站程序自定义发布界面。
Easy Tao站群管理系统特点:
1、整站全自动采集自动更新关键词和爬取频率设置后,系统会自动生成相关关键词和自动采集并生成相关文章,真正全自动聚合! 关键词系统爬虫会智能采集相对原创性别和相对较新的文章,保证文章质量。最重要的采集是pan采集,不需要写任何采集规则。你只需添加几个关键词,告诉系统你的网站定位,剩下的让系统自动完成。
2、制易淘站群建站数量管理系统本身就是一个免费的采集自动更新站群软件。无需花一分钱,即可使用功能强大的站群 软件。这个系统最大的特点就是网站的数量,和夏克、艾聚等限制网站数量的系统有很大的不同。你只需要一套。只要你有能量,你就可以做出无数的改变。输入网站。
3、强的伪原创Function Easy Amoy站群 系统可以在不影响原文可读性的情况下自动采集根据系统原文自动执行伪原创。这个系统是独一无二的文章的同义词和反义词引擎可以适当改变文章的语义,并使用独特的算法进行控制,让每一个文章都接近原创文章,而这一切由系统智能自动完成,无需人工。干预。
4、strong 抓取准确率 Yitao站群系统是泛抓取pan采集系统,不能局限于网站不限域名抓取相关文章,不是您需要定制的任意爬取策略和采集规则,系统会爬取与集合关键词最相关的原创文章,捕获的文章正确率可接受。达到90%以上,瞬间就能产生上千个原创性文章。
5 自定义关键词、链接、html代码可以随意插入到发布的内容中。支持内部锚链接。 关键词内锚文本网站随机插入到文章内容中。可设置链接环,实现单站定时定量发布。支持单站一键直接采集发布支持英文数据采集和发布new网站更新完成后自动提取文章标题和连接插入全局链接库进行插入集成 自动update可以设置一次更新网站会自动关闭增加周期站群Update:根据设置,站群24hours可以轮流更新采集post
自然语言处理中比较难的一个任务-序文本摘要
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-06-22 18:28
转载
前言
文本摘要是自然语言处理中相对困难的任务。别说用机器做总结,就连人类在做总结的时候都需要有很强的语言阅读理解和概括能力。新闻摘要要求编辑从新闻事件中提取最关键的信息点,重新组织语言来撰写摘要;论文摘要要求作者从全文中提取核心工作,然后用更精炼的语言撰写摘要;总结一篇性论文需要作者通读N篇相关主题的论文,用最通俗的语言写出每个文章的贡献和创新,比较每个文章方法的优缺点。自动摘要本质上做的一件事是信息过滤。从某种意义上说,它类似于推荐系统的功能。它旨在让人们更快地找到感兴趣的事物,但它使用了不同的方法。 .
问题描述
文本摘要问题根据文档数量可以分为单文档摘要和多文档摘要。根据实现方式,可分为抽取式和抽象式。抽象问题的特点是输出文本比输入文本少很多,但收录了很多有效信息。感觉有点像主成分分析(PCA),它的功能有点像推荐系统,都是为了解决信息过载的问题。目前,大多数应用系统都是提取式的。这种方法比较简单,但是问题很多。原因很简单,只需要从原文中找出比较重要的句子就可以组成输出。系统只需要使用模型。选择信息量大的句子,按照自然顺序组合起来,形成摘要。但是,很难保证摘要的连贯性和一致性。例如,当一个句子收录代词时,仅仅通过连接它是不可能知道代词所指代词的,这会导致结果不佳。在研究中,随着nlp中的深度学习技术,尤其是seq2seq+attention模型的“横行”,大家将抽象抽象的研究提升到了一个层次,提出了copy机制等机制来解决seq2seq模型中的OOV问题。
本文讨论了使用 abstractive 解决句子级文本摘要问题。问题的定义比较简单。输入为长度为M的文本序列,输出为长度为N的文本序列,其中M> >N,输出文本的含义与输入文本的含义基本相同。输入可能是一个句子或多个句子,输出都是一个句子或多个句子。
语料库
这里的语料分为两种,一种是用于训练深度学习模型的大型语料库,一种是用于参与评价的小型语料库。
1、DUC
这个网站 提供了一个文本摘要竞赛。 2001年到2007年是网站,2008年改为网站TAC。这是一场正式的比赛,各大文本摘要系统都会在这里展开较量,相互较量。这里提供的数据集都是用来评估模型的小数据集。
2、Gigaword
语料库非常大。大约有 950w 个 news文章。数据集以标题为摘要,即输出文本,以第一句为输入,即输入文本。属于单句摘要数据集。
3、CNN/每日邮报
这个语料库是我们在机器阅读理解中使用的语料库,这个数据集是一个多句摘要。
4、Large Scale Chinese Short Text Summarization Dataset (LCSTS)[6]
这是一个中文短文本摘要数据集。数据采集自新浪微博给学习中文文摘的童鞋们带来了好处。
型号
本文提到的模型都是抽象的seq2seq模型。最早在nlp中使用seq2seq+attention模型解决问题是在机器翻译领域。现在这个方法已经席卷了很多领域的排名。
seq2seq的模型一般有如下结构[1]:
编码器部分使用单层或多层 rnn/lstm/gru 对输入进行编码,解码器部分是用于生成摘要的语言模型。这种生成问题可以简化为解决条件概率问题 p(word|context)。在上下文条件下,计算词汇表中每个词的概率值,将概率最高的词作为生成词,依次生成摘要中的所有词。这里的关键是如何表示上下文。每个模型之间最大的区别在于上下文的不同。这里的上下文可能只是编码器的表示,也可能是注意力和编码器的表示。解码器部分通常由波束搜索算法生成。
1、复杂注意力模型[1]
模型中的注意力权重通过将编码器中每个词的最后一个隐藏层的表示与当前解码器中最新词的最后一个隐藏层的表示相乘,然后进行归一化来表示。
2、简单注意力模型[1]
该模型将每个词最后一层隐藏层中编码器部分的表示分为两个块,一个小块用于计算注意力权重,另一个大块用作编码器。该模型将最后一个隐藏层细分为不同的功能。
3、Attention-Based Summarization(ABS)[2]
该模型使用三种不同的编码器,包括:词袋编码器、卷积编码器和基于注意力的编码器。 Rush 属于HarvardNLP 小组。这个群体的特点是他们喜欢用CNN来做nlp任务。在这个模型中,我们看到了不同的编码器,从非常简单的词袋模型到 CNN,再到基于注意力的模型,而不是千篇一律的 rnn、lstm 和 gru。解码器部分使用了一个非常简单的NNLM,即Bengio[10]在2003年提出的前馈神经网络语言模型。该模型是后续神经网络语言模型研究的基石,也是后续词研究的基础嵌入。了基。基础。可以说这个模型用最简单的encoder和decoder来做seq2seq,是一个非常好的尝试。
4、ABS+[2]
Rush 在提出纯数据驱动模型 ABS 之后,又提出了抽象与抽取相结合的模型。在ABS模型的基础上,增加了特征函数,修改了score函数,得到了更好的ABS+。模型。
5、Recurrent Attentive Summarizer(RAS)[3]
这个模型是由 Rush 的学生提出的。输入中每个词的最终embedding是每个词的embedding和每个词位置的embedding之和。经过一层卷积,得到聚合向量:
根据聚合向量计算上下文(编码器输出):
权重的计算公式如下:
解码器部分使用RNNLM生成。 RNNLM是基于Bengio提出的NNLM的改进模型,也是主流的语言模型。
6、big-words-lvt2k-1sent 模型[4]
该模型将大词汇量技巧 (LVT) 技术引入到文本摘要问题中。在该方法中,每个minibatch中解码器的词汇以编码器的词汇为准,解码器词汇中的词由一定数量的高频词组成。该模型的思想侧重于解决由于解码器词汇量大而导致的softmax层的计算瓶颈。该模型非常适合解决文本摘要的问题,因为摘要中的很多词都来自原文。
7、words-lvt2k-2sent-hieratt 模型[4]
这样的问题在文字摘要中经常遇到。一些关键词 很少出现但非常重要。由于该模型基于词嵌入,对低频词不友好,本文提出了一种decoder/pointer机制来解决这个问题。模型中的解码器有一个开关。如果开关状态是打开发电机,则产生一个字;如果关闭,则解码器生成一个指向原创单词位置的指针,然后将其复制到摘要中。指针机制在求解低频词时更加鲁棒,因为它使用编码器中低频词的隐藏层表示作为输入,是一种上下文敏感的表示,但只是一个词向量。这种指针机制与下一篇文章中的复制机制非常相似。
8、feats-lvt2k-2sent-ptr 模型[4]
数据集中的原文一般都很长。原文中的关键词和关键句对于形成总结非常重要。该模型使用了两个双向RNN来捕捉这两个层次的重要性,一个是word-level,一个是sentence-level,模型在两个层次上都使用了attention,权重如下:
9、COPYNET[8]
编码器采用双向RNN模型,输出一个隐藏层表示的矩阵M作为解码器的输入。解码器部分与传统的Seq2Seq有以下三个部分不同:
预测:生成词有两种模式,一种是生成模式,一种是复制模式,生成模型是两种模式结合的概率模型。
状态更新:使用t-1时刻的预测词来更新t时刻的状态。 COPYNET不仅是词向量,还利用了M矩阵中特定位置的隐藏状态。
读取M:COPYNET也会有选择地读取M矩阵来获取混合内容和位置的信息。
这个模型的想法与第七个模型的想法非常相似。因为很好地处理了OOV问题,所以效果非常好。
10、MRT+NHG[7]
该模型的特殊之处在于它使用最小风险训练训练数据,而不是传统的 MLE(最大似然估计)。将评价指标纳入优化目标,对评价指标进行更直接的优化。效果不错。
结果
评价指标是否科学可行,直接影响一个研究领域的研究水平。目前,文本摘要任务中最常用的评估方法是 ROUGE(Recall-Oriented Understudy for Gisting Evaluation)。 ROUGE 的灵感来自 BLEU,一种机器翻译的自动评估方法,不同之处在于它使用召回率作为指标。基本思想是利用模型生成的摘要和参考摘要的n元组贡献统计量作为判断依据。
在中文数据集LCSTS上进行评估,结果如下:
无论是中文数据集还是英文数据集,最好的结果都来自Model 10[7],而且这个模型只是使用了最常见的seq2seq+attention模型,没有使用效果更好的副本。机制或指针机制。
思考
自动摘要是我关注的第一个nlp字段。前期有很多相关的论文,各方面都学习了,也有一些比较浅薄的想法。现在我总结一下。
1、为什么MRT文章文章的结果比其他各种模型好?因为它直接在待优化的目标中收录了ROUGE指标,而不是像其他模型一样使用传统的MLE,传统的目标评估你的生产质量如何,但它与我们最终的评估指标ROUGE不一样。没有直接关系。所以,如果改变一个优化目标,直接针对评价指标进行优化,效果会非常好。这不仅出现在自动摘要中,我记得在机器人相关论文和机器阅读理解相关论文中也出现过,只是具体评价指标不同。这是非常有启发性的。如果用copy机制解决文章[7]中的OOV问题,会不会有更惊人的结果?我们拭目以待。
2、OOV(词汇量不足)问题。归根结底,文本摘要是一个语言生成问题。只要涉及到生成问题,就难免会遇到OOV问题,因为不可能把词表中的所有词都放在来计算概率。可行的方法是使用Choose topn高频词形成词汇表。 文章[4] 和 [8] 都采用了类似的想法,将原创文本从输入复制到输出,而不是仅仅生成它。这里需要设置一个门来判断单词是复制的还是生成的。显然,加入复制机制的模型将在很大程度上解决OOV问题,并将显着提高评估结果。这个想法不仅适用于抽象问题,也适用于所有生成问题,例如机器人。
3、关于评价指标的问题。一个评价指标的科学与否,直接影响到该领域的发展水平,我们不说人工评价,只说自动评价。 ROUGE 指标由 Lin 在 2003 年提出 [9]。 13年后,仍然没有更合适的评价体系来取代它。 ROUGE评价过于死板,只能评价输出和目标之间的一些表面信息,不涉及语义层面的东西。能否提出更高层次的评价体系,从语义层面评价摘要?影响。其实技术问题不大,因为计算两个文本序列之间的相似度有无数种解决方案,比如有监督的、无监督的、半监督的等等。期待新的摘要效果评价体系,相信新的评价体系必将推动自动摘要领域的发展。
4、关于数据集的问题。 LCSTS数据集的构建为中文文本摘要的研究奠定了基础,将极大地推动中文领域自动摘要的发展。当今互联网上最不可缺少的就是数据,大量的非结构化数据。然而,如何构建高质量的语料库是一个难题。如何避免使用过多的人工方法来保证质量,如何使用自动化的方法来提高语料库的质量是一个难题。因此,如果能提出新的思路来构建自动抽象语料库,将是非常有意义的。
参考资料
[1] 使用循环神经网络生成新闻标题
[2] 抽象句摘要的神经注意力模型
[3] 基于注意力循环神经网络的抽象句子摘要
[4] 使用序列到序列 RNN 及其他方法的抽象文本摘要
[5] AttSum:Focusing and Summarization with Neural Attention的联合学习
[6] LCSTS:大规模中文短文本摘要数据集
[7] 最小风险训练的神经标题生成
[8] 在序列到序列学习训练中加入复制机制
[9] 使用 N-gram 共现统计自动评估摘要
[10] 神经概率语言模型 查看全部
自然语言处理中比较难的一个任务-序文本摘要
转载
前言
文本摘要是自然语言处理中相对困难的任务。别说用机器做总结,就连人类在做总结的时候都需要有很强的语言阅读理解和概括能力。新闻摘要要求编辑从新闻事件中提取最关键的信息点,重新组织语言来撰写摘要;论文摘要要求作者从全文中提取核心工作,然后用更精炼的语言撰写摘要;总结一篇性论文需要作者通读N篇相关主题的论文,用最通俗的语言写出每个文章的贡献和创新,比较每个文章方法的优缺点。自动摘要本质上做的一件事是信息过滤。从某种意义上说,它类似于推荐系统的功能。它旨在让人们更快地找到感兴趣的事物,但它使用了不同的方法。 .
问题描述
文本摘要问题根据文档数量可以分为单文档摘要和多文档摘要。根据实现方式,可分为抽取式和抽象式。抽象问题的特点是输出文本比输入文本少很多,但收录了很多有效信息。感觉有点像主成分分析(PCA),它的功能有点像推荐系统,都是为了解决信息过载的问题。目前,大多数应用系统都是提取式的。这种方法比较简单,但是问题很多。原因很简单,只需要从原文中找出比较重要的句子就可以组成输出。系统只需要使用模型。选择信息量大的句子,按照自然顺序组合起来,形成摘要。但是,很难保证摘要的连贯性和一致性。例如,当一个句子收录代词时,仅仅通过连接它是不可能知道代词所指代词的,这会导致结果不佳。在研究中,随着nlp中的深度学习技术,尤其是seq2seq+attention模型的“横行”,大家将抽象抽象的研究提升到了一个层次,提出了copy机制等机制来解决seq2seq模型中的OOV问题。
本文讨论了使用 abstractive 解决句子级文本摘要问题。问题的定义比较简单。输入为长度为M的文本序列,输出为长度为N的文本序列,其中M> >N,输出文本的含义与输入文本的含义基本相同。输入可能是一个句子或多个句子,输出都是一个句子或多个句子。
语料库
这里的语料分为两种,一种是用于训练深度学习模型的大型语料库,一种是用于参与评价的小型语料库。
1、DUC
这个网站 提供了一个文本摘要竞赛。 2001年到2007年是网站,2008年改为网站TAC。这是一场正式的比赛,各大文本摘要系统都会在这里展开较量,相互较量。这里提供的数据集都是用来评估模型的小数据集。
2、Gigaword
语料库非常大。大约有 950w 个 news文章。数据集以标题为摘要,即输出文本,以第一句为输入,即输入文本。属于单句摘要数据集。
3、CNN/每日邮报
这个语料库是我们在机器阅读理解中使用的语料库,这个数据集是一个多句摘要。
4、Large Scale Chinese Short Text Summarization Dataset (LCSTS)[6]
这是一个中文短文本摘要数据集。数据采集自新浪微博给学习中文文摘的童鞋们带来了好处。
型号
本文提到的模型都是抽象的seq2seq模型。最早在nlp中使用seq2seq+attention模型解决问题是在机器翻译领域。现在这个方法已经席卷了很多领域的排名。
seq2seq的模型一般有如下结构[1]:

编码器部分使用单层或多层 rnn/lstm/gru 对输入进行编码,解码器部分是用于生成摘要的语言模型。这种生成问题可以简化为解决条件概率问题 p(word|context)。在上下文条件下,计算词汇表中每个词的概率值,将概率最高的词作为生成词,依次生成摘要中的所有词。这里的关键是如何表示上下文。每个模型之间最大的区别在于上下文的不同。这里的上下文可能只是编码器的表示,也可能是注意力和编码器的表示。解码器部分通常由波束搜索算法生成。
1、复杂注意力模型[1]
模型中的注意力权重通过将编码器中每个词的最后一个隐藏层的表示与当前解码器中最新词的最后一个隐藏层的表示相乘,然后进行归一化来表示。
2、简单注意力模型[1]
该模型将每个词最后一层隐藏层中编码器部分的表示分为两个块,一个小块用于计算注意力权重,另一个大块用作编码器。该模型将最后一个隐藏层细分为不同的功能。
3、Attention-Based Summarization(ABS)[2]
该模型使用三种不同的编码器,包括:词袋编码器、卷积编码器和基于注意力的编码器。 Rush 属于HarvardNLP 小组。这个群体的特点是他们喜欢用CNN来做nlp任务。在这个模型中,我们看到了不同的编码器,从非常简单的词袋模型到 CNN,再到基于注意力的模型,而不是千篇一律的 rnn、lstm 和 gru。解码器部分使用了一个非常简单的NNLM,即Bengio[10]在2003年提出的前馈神经网络语言模型。该模型是后续神经网络语言模型研究的基石,也是后续词研究的基础嵌入。了基。基础。可以说这个模型用最简单的encoder和decoder来做seq2seq,是一个非常好的尝试。
4、ABS+[2]
Rush 在提出纯数据驱动模型 ABS 之后,又提出了抽象与抽取相结合的模型。在ABS模型的基础上,增加了特征函数,修改了score函数,得到了更好的ABS+。模型。
5、Recurrent Attentive Summarizer(RAS)[3]
这个模型是由 Rush 的学生提出的。输入中每个词的最终embedding是每个词的embedding和每个词位置的embedding之和。经过一层卷积,得到聚合向量:
根据聚合向量计算上下文(编码器输出):
权重的计算公式如下:
解码器部分使用RNNLM生成。 RNNLM是基于Bengio提出的NNLM的改进模型,也是主流的语言模型。
6、big-words-lvt2k-1sent 模型[4]
该模型将大词汇量技巧 (LVT) 技术引入到文本摘要问题中。在该方法中,每个minibatch中解码器的词汇以编码器的词汇为准,解码器词汇中的词由一定数量的高频词组成。该模型的思想侧重于解决由于解码器词汇量大而导致的softmax层的计算瓶颈。该模型非常适合解决文本摘要的问题,因为摘要中的很多词都来自原文。
7、words-lvt2k-2sent-hieratt 模型[4]
这样的问题在文字摘要中经常遇到。一些关键词 很少出现但非常重要。由于该模型基于词嵌入,对低频词不友好,本文提出了一种decoder/pointer机制来解决这个问题。模型中的解码器有一个开关。如果开关状态是打开发电机,则产生一个字;如果关闭,则解码器生成一个指向原创单词位置的指针,然后将其复制到摘要中。指针机制在求解低频词时更加鲁棒,因为它使用编码器中低频词的隐藏层表示作为输入,是一种上下文敏感的表示,但只是一个词向量。这种指针机制与下一篇文章中的复制机制非常相似。
8、feats-lvt2k-2sent-ptr 模型[4]
数据集中的原文一般都很长。原文中的关键词和关键句对于形成总结非常重要。该模型使用了两个双向RNN来捕捉这两个层次的重要性,一个是word-level,一个是sentence-level,模型在两个层次上都使用了attention,权重如下:
9、COPYNET[8]
编码器采用双向RNN模型,输出一个隐藏层表示的矩阵M作为解码器的输入。解码器部分与传统的Seq2Seq有以下三个部分不同:
预测:生成词有两种模式,一种是生成模式,一种是复制模式,生成模型是两种模式结合的概率模型。
状态更新:使用t-1时刻的预测词来更新t时刻的状态。 COPYNET不仅是词向量,还利用了M矩阵中特定位置的隐藏状态。
读取M:COPYNET也会有选择地读取M矩阵来获取混合内容和位置的信息。
这个模型的想法与第七个模型的想法非常相似。因为很好地处理了OOV问题,所以效果非常好。
10、MRT+NHG[7]
该模型的特殊之处在于它使用最小风险训练训练数据,而不是传统的 MLE(最大似然估计)。将评价指标纳入优化目标,对评价指标进行更直接的优化。效果不错。
结果
评价指标是否科学可行,直接影响一个研究领域的研究水平。目前,文本摘要任务中最常用的评估方法是 ROUGE(Recall-Oriented Understudy for Gisting Evaluation)。 ROUGE 的灵感来自 BLEU,一种机器翻译的自动评估方法,不同之处在于它使用召回率作为指标。基本思想是利用模型生成的摘要和参考摘要的n元组贡献统计量作为判断依据。
在中文数据集LCSTS上进行评估,结果如下:
无论是中文数据集还是英文数据集,最好的结果都来自Model 10[7],而且这个模型只是使用了最常见的seq2seq+attention模型,没有使用效果更好的副本。机制或指针机制。
思考
自动摘要是我关注的第一个nlp字段。前期有很多相关的论文,各方面都学习了,也有一些比较浅薄的想法。现在我总结一下。
1、为什么MRT文章文章的结果比其他各种模型好?因为它直接在待优化的目标中收录了ROUGE指标,而不是像其他模型一样使用传统的MLE,传统的目标评估你的生产质量如何,但它与我们最终的评估指标ROUGE不一样。没有直接关系。所以,如果改变一个优化目标,直接针对评价指标进行优化,效果会非常好。这不仅出现在自动摘要中,我记得在机器人相关论文和机器阅读理解相关论文中也出现过,只是具体评价指标不同。这是非常有启发性的。如果用copy机制解决文章[7]中的OOV问题,会不会有更惊人的结果?我们拭目以待。
2、OOV(词汇量不足)问题。归根结底,文本摘要是一个语言生成问题。只要涉及到生成问题,就难免会遇到OOV问题,因为不可能把词表中的所有词都放在来计算概率。可行的方法是使用Choose topn高频词形成词汇表。 文章[4] 和 [8] 都采用了类似的想法,将原创文本从输入复制到输出,而不是仅仅生成它。这里需要设置一个门来判断单词是复制的还是生成的。显然,加入复制机制的模型将在很大程度上解决OOV问题,并将显着提高评估结果。这个想法不仅适用于抽象问题,也适用于所有生成问题,例如机器人。
3、关于评价指标的问题。一个评价指标的科学与否,直接影响到该领域的发展水平,我们不说人工评价,只说自动评价。 ROUGE 指标由 Lin 在 2003 年提出 [9]。 13年后,仍然没有更合适的评价体系来取代它。 ROUGE评价过于死板,只能评价输出和目标之间的一些表面信息,不涉及语义层面的东西。能否提出更高层次的评价体系,从语义层面评价摘要?影响。其实技术问题不大,因为计算两个文本序列之间的相似度有无数种解决方案,比如有监督的、无监督的、半监督的等等。期待新的摘要效果评价体系,相信新的评价体系必将推动自动摘要领域的发展。
4、关于数据集的问题。 LCSTS数据集的构建为中文文本摘要的研究奠定了基础,将极大地推动中文领域自动摘要的发展。当今互联网上最不可缺少的就是数据,大量的非结构化数据。然而,如何构建高质量的语料库是一个难题。如何避免使用过多的人工方法来保证质量,如何使用自动化的方法来提高语料库的质量是一个难题。因此,如果能提出新的思路来构建自动抽象语料库,将是非常有意义的。
参考资料
[1] 使用循环神经网络生成新闻标题
[2] 抽象句摘要的神经注意力模型
[3] 基于注意力循环神经网络的抽象句子摘要
[4] 使用序列到序列 RNN 及其他方法的抽象文本摘要
[5] AttSum:Focusing and Summarization with Neural Attention的联合学习
[6] LCSTS:大规模中文短文本摘要数据集
[7] 最小风险训练的神经标题生成
[8] 在序列到序列学习训练中加入复制机制
[9] 使用 N-gram 共现统计自动评估摘要
[10] 神经概率语言模型
文本摘要技术在图书情报领域,IBM计算机科学家H.P.Luhn
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-06-07 19:30
文本摘要的应用
文本摘要的应用、文档自动索引、新闻信息服务、信息检索等
是图书情报领域的主要研究内容。一般索引包括关键词标引、主题词索引和摘要索引。以前是人做的,现在机器自动做,会节省很多人力。
新闻服务商提供新闻信息时,无论是提供单条新闻还是聚合新闻,用户有时不想看全文,或者看很多相关新闻,又想看摘要,所以有些网站 大会提供的新闻摘要将显示在news网站上。有一个叫Summly的应用,原名Trimit,是一款运行在iOS上的新闻阅读应用。它是由英国天才尼克·达洛伊西奥 (Nick D'Aloisio) 在 15 岁时创作的。该应用程序可以使用全文语义分析算法将整个新闻浓缩成一个新闻摘要,标题清晰,几句话。用户只需不到一分钟就能了解新闻中最关键的信息。该申请于2018年获得雅虎批准,以3000万美元收购。
信息检索是用户查询和获取信息的主要方式,是查找信息的方法和手段。输入相关的关键词,就会得到相关的网页,
信息检索中的典型应用搜索。打开搜索引擎,输入search关键词,就会返回搜索结果。网页会显示多个满足关键词条件的信息结果,每个结果会显示结果信息片段,这个信息结果片段会收录搜索关键词,这也是网页内容中最重要的部分,对原文的总结。这是一个特殊的摘要,内容应该与关键词有关。很多年前,就有专门研究这个领域的人。由于技术成熟,现在学习的人越来越少。
文本摘要技术
在图书馆和信息领域,IBM 计算机科学家 H.P.卢恩于1958年发表了《文学文摘的自动创建》,一篇关于文学文摘自动创建的论文。本文提出文章中最重要的句子是关键词最多的句子,关键词是出现次数最多的词。他的总结是将最重要的句子组合在一起。从本文开始到现在,人们研究文本自动摘要的历史已有 60 多年,并取得了一些进展,但仍不尽如人意。
目前在实现自动文本摘要方面还存在很大的困难:
第一:写摘要是一项非常聪明的工作,所以聪明的任务是免费的。假设有一个任务,需要 10 人或更多人根据同一个长文档写一个摘要。很可能大家都会写一个总结。他们不一样,但每个人写的摘要可能还可以。这种没有统一标准、玩起来比较自由的工作,其实机器很难做到。这个任务本质上是机器的搜索问题。你提供的信息越多,组合就越多,搜索空间就越大,结果越不可控。相反,信息越少,搜索空间越小,机器做起来就越容易。
自然语言处理中的机器翻译工作比自动文本摘要更容易。机器翻译的任务是给出源语言的句子,机器翻译后得到目标语言的句子。这个任务有很强的约束,要求前后语言的语义报告一致,甚至每个词都可以匹配。这种约束强的任务会比较容易做。
第二:机器写的摘要与专家写的摘要不同
在写摘要之前,人们已经在脑海中对文章内容的内容和意义有了很好的理解和体验,然后再写摘要形成摘要。写好摘要后,可以展开为文章,如果有摘要,就会有文章。机器写summary的时候,需要先文章再生成summary。这将挑战机器自动生成摘要。
自动汇总代表系统
是一个简单的系统,主要通过句子抽取来实现。 NewsInEssence 是一个应用于新闻领域的摘要系统。提供news文章topic聚类(Topic Clustering)、实时搜索、文章summary和用户交互(User Interaction)等功能。
Newsblaster 是美国哥伦比亚大学开发的多文档抽象系统,采用文本聚类作为预处理过程,在处理每天发生的重要新闻后生成简明摘要,如文本聚类、信息融合和文本一代。这项工作稍微复杂一些。句子可以调整,任何句子都可以断开和重新组合。从而会出现句子不一致、标点符号缺失等问题。
总长度
自动文本摘要的长度是实际应用场景中的一个重要问题。会影响用户的阅读体验,以及系统能否在文本长度上有效表达文章内容。 ,
《摘要特刊介绍》一书的作者拉德夫认为,摘要是“从一个或多个文本中提取的一段文本,其中收录原文中的重要信息,其长度不超过比或远远少于原文的一半”。
生成的摘要的长度可以由用户根据需要指定。可以根据摘要与原文的比例,如10%或20%,也可以根据摘要的字数或字节数,100字,250个汉字等,可以根据关于用户的定义或句子的数量,无论是三句还是五句。
在实践中,也有人在研究自动计算合适的摘要长度。其实没有很好的答案,因为自动文本摘要的长度与用户的需求有关。它可以很长也可以很短。如果你需要一台机器预测摘要的长度实际上是非常困难的。在实际应用中,模型是自动汇总的,生成的汇总有长有短。其他阈值参数将在模型运行之前设置。本质上是将汇总长度参数改为设置其他阈值参数,长度成为其他受控参数。我们知道一个意思可以有多种表达方式,表达的句子有很多种,虽然都表达相同的意思,所以自动生成的摘要的内容也可能有多种结果,结果可以是长的,也可以是长的。短,所以预测生成摘要的长度是困难的。
多样化的总结任务
对于传统的新闻摘要任务
请看上一篇:
飘哥:自然语言处理自动文本摘要技术系列(一)信息摘要概述
请看其他系列自然语言处理文章:
飘哥:自然语言学习的表征学习与知识获取(一)disnotation
飘哥:自然语言学习的表征学习与知识获取(二)word2vec
飘哥:自然语言学习的表征学习与知识获取(三)知识图谱
飘哥:自然语言学习的表征学习与知识获取(四)TransE
飘哥:自然语言系列学习的表征学习与知识获取(五)融合文本与知识,使用cnn方法进行关系抽取
飘哥:自然语言学习的表征学习与知识获取(六)fusion entity description Knowledge representation and fusion entity description knowledge representation)
Piaoge:自然语言学习的表征学习和知识获取(七)Relation Extraction Using Relation Paths
飘哥:自然语言系列学习的表征学习和知识获取(八)Using remote supervisor and multi-instance关系抽取
查看全部
文本摘要技术在图书情报领域,IBM计算机科学家H.P.Luhn
文本摘要的应用
文本摘要的应用、文档自动索引、新闻信息服务、信息检索等
是图书情报领域的主要研究内容。一般索引包括关键词标引、主题词索引和摘要索引。以前是人做的,现在机器自动做,会节省很多人力。
新闻服务商提供新闻信息时,无论是提供单条新闻还是聚合新闻,用户有时不想看全文,或者看很多相关新闻,又想看摘要,所以有些网站 大会提供的新闻摘要将显示在news网站上。有一个叫Summly的应用,原名Trimit,是一款运行在iOS上的新闻阅读应用。它是由英国天才尼克·达洛伊西奥 (Nick D'Aloisio) 在 15 岁时创作的。该应用程序可以使用全文语义分析算法将整个新闻浓缩成一个新闻摘要,标题清晰,几句话。用户只需不到一分钟就能了解新闻中最关键的信息。该申请于2018年获得雅虎批准,以3000万美元收购。
信息检索是用户查询和获取信息的主要方式,是查找信息的方法和手段。输入相关的关键词,就会得到相关的网页,
信息检索中的典型应用搜索。打开搜索引擎,输入search关键词,就会返回搜索结果。网页会显示多个满足关键词条件的信息结果,每个结果会显示结果信息片段,这个信息结果片段会收录搜索关键词,这也是网页内容中最重要的部分,对原文的总结。这是一个特殊的摘要,内容应该与关键词有关。很多年前,就有专门研究这个领域的人。由于技术成熟,现在学习的人越来越少。
文本摘要技术
在图书馆和信息领域,IBM 计算机科学家 H.P.卢恩于1958年发表了《文学文摘的自动创建》,一篇关于文学文摘自动创建的论文。本文提出文章中最重要的句子是关键词最多的句子,关键词是出现次数最多的词。他的总结是将最重要的句子组合在一起。从本文开始到现在,人们研究文本自动摘要的历史已有 60 多年,并取得了一些进展,但仍不尽如人意。
目前在实现自动文本摘要方面还存在很大的困难:
第一:写摘要是一项非常聪明的工作,所以聪明的任务是免费的。假设有一个任务,需要 10 人或更多人根据同一个长文档写一个摘要。很可能大家都会写一个总结。他们不一样,但每个人写的摘要可能还可以。这种没有统一标准、玩起来比较自由的工作,其实机器很难做到。这个任务本质上是机器的搜索问题。你提供的信息越多,组合就越多,搜索空间就越大,结果越不可控。相反,信息越少,搜索空间越小,机器做起来就越容易。
自然语言处理中的机器翻译工作比自动文本摘要更容易。机器翻译的任务是给出源语言的句子,机器翻译后得到目标语言的句子。这个任务有很强的约束,要求前后语言的语义报告一致,甚至每个词都可以匹配。这种约束强的任务会比较容易做。
第二:机器写的摘要与专家写的摘要不同
在写摘要之前,人们已经在脑海中对文章内容的内容和意义有了很好的理解和体验,然后再写摘要形成摘要。写好摘要后,可以展开为文章,如果有摘要,就会有文章。机器写summary的时候,需要先文章再生成summary。这将挑战机器自动生成摘要。
自动汇总代表系统
是一个简单的系统,主要通过句子抽取来实现。 NewsInEssence 是一个应用于新闻领域的摘要系统。提供news文章topic聚类(Topic Clustering)、实时搜索、文章summary和用户交互(User Interaction)等功能。
Newsblaster 是美国哥伦比亚大学开发的多文档抽象系统,采用文本聚类作为预处理过程,在处理每天发生的重要新闻后生成简明摘要,如文本聚类、信息融合和文本一代。这项工作稍微复杂一些。句子可以调整,任何句子都可以断开和重新组合。从而会出现句子不一致、标点符号缺失等问题。
总长度
自动文本摘要的长度是实际应用场景中的一个重要问题。会影响用户的阅读体验,以及系统能否在文本长度上有效表达文章内容。 ,
《摘要特刊介绍》一书的作者拉德夫认为,摘要是“从一个或多个文本中提取的一段文本,其中收录原文中的重要信息,其长度不超过比或远远少于原文的一半”。
生成的摘要的长度可以由用户根据需要指定。可以根据摘要与原文的比例,如10%或20%,也可以根据摘要的字数或字节数,100字,250个汉字等,可以根据关于用户的定义或句子的数量,无论是三句还是五句。
在实践中,也有人在研究自动计算合适的摘要长度。其实没有很好的答案,因为自动文本摘要的长度与用户的需求有关。它可以很长也可以很短。如果你需要一台机器预测摘要的长度实际上是非常困难的。在实际应用中,模型是自动汇总的,生成的汇总有长有短。其他阈值参数将在模型运行之前设置。本质上是将汇总长度参数改为设置其他阈值参数,长度成为其他受控参数。我们知道一个意思可以有多种表达方式,表达的句子有很多种,虽然都表达相同的意思,所以自动生成的摘要的内容也可能有多种结果,结果可以是长的,也可以是长的。短,所以预测生成摘要的长度是困难的。
多样化的总结任务
对于传统的新闻摘要任务
请看上一篇:
飘哥:自然语言处理自动文本摘要技术系列(一)信息摘要概述

请看其他系列自然语言处理文章:
飘哥:自然语言学习的表征学习与知识获取(一)disnotation

飘哥:自然语言学习的表征学习与知识获取(二)word2vec
飘哥:自然语言学习的表征学习与知识获取(三)知识图谱

飘哥:自然语言学习的表征学习与知识获取(四)TransE
飘哥:自然语言系列学习的表征学习与知识获取(五)融合文本与知识,使用cnn方法进行关系抽取

飘哥:自然语言学习的表征学习与知识获取(六)fusion entity description Knowledge representation and fusion entity description knowledge representation)

Piaoge:自然语言学习的表征学习和知识获取(七)Relation Extraction Using Relation Paths

飘哥:自然语言系列学习的表征学习和知识获取(八)Using remote supervisor and multi-instance关系抽取

深度定制的小说站,全自动采集各大小说站
采集交流 • 优采云 发表了文章 • 0 个评论 • 552 次浏览 • 2021-05-29 19:06
源代码说明:
深度定制小说站,全自动【k15】各类站,可自动生成首页、分类、目录、排名、站点地图页面、全站拼音目录、伪静态章节页面、自动生成静态html小说txt文件,自动生成zip压缩包。这个源码功能非常强大!带来一个非常漂亮的手机页面!使用采集规则+自动调整!超级强大,可以使用所有采集规则,并且全自动采集和存储,非常易于使用,特别适合优采云维护!对于一个新颖的网站来说,一个好的程序没什么好说的。
其他功能:
(1) 自动生成首页、分类、目录、排名、站点地图页(分类页、小说封面、作者页,如果html文件不存在或超过设定时间未更新,则自动生成静态html)会自动更新一次,如果有采集,在采集时会自动更新小说封面和对应的分类页面,html文件直接通过PHP调用,而不是在根目录生成。访问速度与纯静态无异,可以保证,源代码文件管理很方便,同时减轻了服务器压力,还方便了访问统计信息并提高了搜索引擎的识别率。
(2)全站拼音目录,章节页面伪静态。
(3)自动生成小说txt文件,也可以后台自己重新生成txt文件。
([4)自动生成新颖的关键词和关键词自动内部链接。
(5) 自动 伪原创 词替换(在 采集 处替换)。
(6)新增小说总点击、月点击、周点击、总推荐、月推荐、周推荐统计、作者推荐统计等新功能。
(7)通过CNZZ的统计插件,方便实现小说下载量和藏书量的详细统计。
(8)这个程序的自动采集在市场上并不常见优采云、广管、采集等,而是在DEDE原有的采集功能的基础上二次开发的采集模块可以有效地确保章节内容的完整性,避免章节重复,章节内容无内容,章节乱码等;一天24小时采集可以达到250,000至300,000个章节。
安装说明:
1、上传到网站根目录
2、用phpMyadmin导入数据库文件xiaoshuo.sql
3、 修改数据库链接文件/data/common.inc.php
(切记不要用记事本修改,否则可能会出现验证码无法显示的问题,建议使用记事本++)
4、后台目录/admin/index.php
账户管理员密码管理员
点击下载—注意:当您点击下载按钮时,将计算一次下载,因此请勿随意点击。 —【下载权限】:青铜会员—
如果你觉得我的文章对你有用,欢迎打赏。您的支持将鼓励我继续创作!
奖励支持 查看全部
深度定制的小说站,全自动采集各大小说站
源代码说明:
深度定制小说站,全自动【k15】各类站,可自动生成首页、分类、目录、排名、站点地图页面、全站拼音目录、伪静态章节页面、自动生成静态html小说txt文件,自动生成zip压缩包。这个源码功能非常强大!带来一个非常漂亮的手机页面!使用采集规则+自动调整!超级强大,可以使用所有采集规则,并且全自动采集和存储,非常易于使用,特别适合优采云维护!对于一个新颖的网站来说,一个好的程序没什么好说的。


其他功能:
(1) 自动生成首页、分类、目录、排名、站点地图页(分类页、小说封面、作者页,如果html文件不存在或超过设定时间未更新,则自动生成静态html)会自动更新一次,如果有采集,在采集时会自动更新小说封面和对应的分类页面,html文件直接通过PHP调用,而不是在根目录生成。访问速度与纯静态无异,可以保证,源代码文件管理很方便,同时减轻了服务器压力,还方便了访问统计信息并提高了搜索引擎的识别率。
(2)全站拼音目录,章节页面伪静态。
(3)自动生成小说txt文件,也可以后台自己重新生成txt文件。
([4)自动生成新颖的关键词和关键词自动内部链接。
(5) 自动 伪原创 词替换(在 采集 处替换)。
(6)新增小说总点击、月点击、周点击、总推荐、月推荐、周推荐统计、作者推荐统计等新功能。
(7)通过CNZZ的统计插件,方便实现小说下载量和藏书量的详细统计。
(8)这个程序的自动采集在市场上并不常见优采云、广管、采集等,而是在DEDE原有的采集功能的基础上二次开发的采集模块可以有效地确保章节内容的完整性,避免章节重复,章节内容无内容,章节乱码等;一天24小时采集可以达到250,000至300,000个章节。
安装说明:
1、上传到网站根目录
2、用phpMyadmin导入数据库文件xiaoshuo.sql
3、 修改数据库链接文件/data/common.inc.php
(切记不要用记事本修改,否则可能会出现验证码无法显示的问题,建议使用记事本++)
4、后台目录/admin/index.php
账户管理员密码管理员
点击下载—注意:当您点击下载按钮时,将计算一次下载,因此请勿随意点击。 —【下载权限】:青铜会员—
如果你觉得我的文章对你有用,欢迎打赏。您的支持将鼓励我继续创作!
奖励支持
关键词自动采集生成内容系统,如果你的核心内容是文字内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2021-05-25 18:04
关键词自动采集生成内容系统,如果你的核心内容是文字内容,这一点非常重要,保持抓取状态,生成全站链接。如果想采集网页,可以采集你想抓取的网页,如果全站抓取不了,点击对应搜索引擎框下方的自动生成链接。无论你是想抓取所有网页,还是抓取某些网页,只要保持抓取状态就可以。google有代理连接、百度会有代理连接、微博会有代理连接,而对于想采集的网页或发送的链接,也可以抓取,和人工连接没区别。
这里提一个别的选择,利用cookie,cookie可以存储搜索引擎抓取你的网页或发送的链接。具体操作如下:获取采集地址地址请放在心里先百度:console.log("xxx")进入console.log("xxx")查看console.log("xxx")打印aspx网页上的httpurl打印python程序,获取httpurl代码如下fromurllibimportrequesthttp=request.urlopen('')req=request.urlopen('').read()response=urllib.urlencode(req)response.encoding='utf-8'cookie=cookie(req,response.state,req.state_default)javascript代码:添加获取url的cookiehttp=request.urlopen('').read()withopen('xxx.html','w')asf:f.write(cookie)此外,还可以有其他方法:有没有获取网页的方法,不在本文提供中欢迎留言提问!!本文由我平凡的日常小技巧拼凑而成,不甚精彩,请大家酌情观看哈!!。 查看全部
关键词自动采集生成内容系统,如果你的核心内容是文字内容
关键词自动采集生成内容系统,如果你的核心内容是文字内容,这一点非常重要,保持抓取状态,生成全站链接。如果想采集网页,可以采集你想抓取的网页,如果全站抓取不了,点击对应搜索引擎框下方的自动生成链接。无论你是想抓取所有网页,还是抓取某些网页,只要保持抓取状态就可以。google有代理连接、百度会有代理连接、微博会有代理连接,而对于想采集的网页或发送的链接,也可以抓取,和人工连接没区别。
这里提一个别的选择,利用cookie,cookie可以存储搜索引擎抓取你的网页或发送的链接。具体操作如下:获取采集地址地址请放在心里先百度:console.log("xxx")进入console.log("xxx")查看console.log("xxx")打印aspx网页上的httpurl打印python程序,获取httpurl代码如下fromurllibimportrequesthttp=request.urlopen('')req=request.urlopen('').read()response=urllib.urlencode(req)response.encoding='utf-8'cookie=cookie(req,response.state,req.state_default)javascript代码:添加获取url的cookiehttp=request.urlopen('').read()withopen('xxx.html','w')asf:f.write(cookie)此外,还可以有其他方法:有没有获取网页的方法,不在本文提供中欢迎留言提问!!本文由我平凡的日常小技巧拼凑而成,不甚精彩,请大家酌情观看哈!!。
百度和谷歌等搜索引擎的全文提取原理是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-05-23 01:04
关键词自动采集生成内容系统开源、自动构造标题、内容、文章地址、内容描述、文章排名;
二、自动完成文章分类、选题、关键词选取、重点摘要、二级标题、百度首页创建,
三、自动发布的同时进行内容的识别、搜索量推荐,
百度全文提取是自动提取网站全文内容的技术实现方案,利用自动文章提取技术把网站的所有带有搜索关键词的文章自动提取出来。
0、知乎等多个搜索引擎都有广泛的应用。原理百度和谷歌等搜索引擎的全文提取原理是:不同的搜索引擎对互联网上的网页内容就提取出了不同的文字标签或是文字链接。任何一篇文章不仅要标题好,而且在首页或者其他页面文章链接文章标题的页面即为标题页,会加上网站全称,这个页面只允许谷歌搜索引擎抓取。百度会抓取网站中的整篇文章,包括标题和正文,然后把文章内容抓取出来,计算其长度,再统计互联网上不同网站文章的完整度,根据互联网的完整度计算标题重复率,比如网站中有10篇文章内容完全相同,但是这些文章在互联网上没有存在完整度的这么高,即互联网上没有完整度的这么高,那么百度会把这10篇文章抓取出来计算重复率。
所以这个工作会花掉整整3个小时的时间,才能把文章提取出来。而谷歌提取的这些网站的标题是非常短的,标题基本只有1个字。比如把网站放在美国ucsi机场里面的网站全名是:ucsi-https。所以标题非常短的文章百度也基本上看不到。而基于nodejs的workerman框架提供了这种能力。框架提供的自动文章提取接口非常简单:接口定义:functionself.filenames(pageid){returnnewfunction(ext,extension){returnextension.alias(pageid);}};vartemplate=newworkerman.filenames(pageid);vartmplate=newworkerman.filenames(pageid);varcrawlinger=newworkerman.filenames(pageid);crawlinger.setobjecturl({templateurl:templateurl,crawlingurl:crawlinger});crawlinger.setdata({location:'https'});workerman框架提供的方法实现全文提取原理比较复杂,有兴趣的可以参考:。 查看全部
百度和谷歌等搜索引擎的全文提取原理是什么?
关键词自动采集生成内容系统开源、自动构造标题、内容、文章地址、内容描述、文章排名;
二、自动完成文章分类、选题、关键词选取、重点摘要、二级标题、百度首页创建,
三、自动发布的同时进行内容的识别、搜索量推荐,
百度全文提取是自动提取网站全文内容的技术实现方案,利用自动文章提取技术把网站的所有带有搜索关键词的文章自动提取出来。
0、知乎等多个搜索引擎都有广泛的应用。原理百度和谷歌等搜索引擎的全文提取原理是:不同的搜索引擎对互联网上的网页内容就提取出了不同的文字标签或是文字链接。任何一篇文章不仅要标题好,而且在首页或者其他页面文章链接文章标题的页面即为标题页,会加上网站全称,这个页面只允许谷歌搜索引擎抓取。百度会抓取网站中的整篇文章,包括标题和正文,然后把文章内容抓取出来,计算其长度,再统计互联网上不同网站文章的完整度,根据互联网的完整度计算标题重复率,比如网站中有10篇文章内容完全相同,但是这些文章在互联网上没有存在完整度的这么高,即互联网上没有完整度的这么高,那么百度会把这10篇文章抓取出来计算重复率。
所以这个工作会花掉整整3个小时的时间,才能把文章提取出来。而谷歌提取的这些网站的标题是非常短的,标题基本只有1个字。比如把网站放在美国ucsi机场里面的网站全名是:ucsi-https。所以标题非常短的文章百度也基本上看不到。而基于nodejs的workerman框架提供了这种能力。框架提供的自动文章提取接口非常简单:接口定义:functionself.filenames(pageid){returnnewfunction(ext,extension){returnextension.alias(pageid);}};vartemplate=newworkerman.filenames(pageid);vartmplate=newworkerman.filenames(pageid);varcrawlinger=newworkerman.filenames(pageid);crawlinger.setobjecturl({templateurl:templateurl,crawlingurl:crawlinger});crawlinger.setdata({location:'https'});workerman框架提供的方法实现全文提取原理比较复杂,有兴趣的可以参考:。
关键词自动采集生成内容系统智能网页爬虫内容数据库
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-05-06 22:06
关键词自动采集生成内容系统智能网页爬虫内容数据库计算单元网页地址格式化字体排版打印消耗电力视频从一开始的先录视频后写代码,学习成本是有点大,
提示框里写需要提交的信息,大概扫一下,把课件提交上去。
直接把视频链接转成一个base64文件,然后上传到浏览器就可以缓存,这样就可以直接看了。
百度一下,就有。网址=../config.phpecho('yourhomeforexample...')这个很多其他公司的教程都有。最简单就是上站长平台申请开通免费的。可以在一定程度上提高视频获取成功率。之后可以想办法利用爬虫技术。理论上都是存在可行性的。
用arpa,
我把我们的uml前端用前端页面设计界面/参考文献
1、教程网站上有视频,还要花钱买。这时你可以复制地址发送到你收到的短信里。我试过,十几分钟就能发过去。2、直接把链接在浏览器访问,选择打开地址,content,如果文件过大、过小,打开慢,你可以手动改一下form里的content的大小,改个几十秒可以了。
一般可以发送到一个邮箱里,邮箱速度快一些。
你好!我也是刚接触软件前端,听了你的分享,从网站的底层进行了解密,下面我就把我了解到的和你交流下,1.建议你建一个非常简单的网站,不用多做功夫,运行速度可以稍慢,但功能不要太复杂,功能不要太复杂是因为视频太多,解说多。还有要放在独立服务器上,独立服务器能保证你可以随时换。2.建立了一个可以随时观看视频的网站,可以微信或其他联系方式,每天上传一些前端视频。
不为其他,只为实践下。3.安装下视频,因为有些学校不允许外联,去各个学校找下有没有类似的项目,模拟真实操作中,再进行测试即可。本人只能帮你到这,希望对你有所帮助,有什么错误还请及时联系我。希望能帮到你!。 查看全部
关键词自动采集生成内容系统智能网页爬虫内容数据库
关键词自动采集生成内容系统智能网页爬虫内容数据库计算单元网页地址格式化字体排版打印消耗电力视频从一开始的先录视频后写代码,学习成本是有点大,
提示框里写需要提交的信息,大概扫一下,把课件提交上去。
直接把视频链接转成一个base64文件,然后上传到浏览器就可以缓存,这样就可以直接看了。
百度一下,就有。网址=../config.phpecho('yourhomeforexample...')这个很多其他公司的教程都有。最简单就是上站长平台申请开通免费的。可以在一定程度上提高视频获取成功率。之后可以想办法利用爬虫技术。理论上都是存在可行性的。
用arpa,
我把我们的uml前端用前端页面设计界面/参考文献
1、教程网站上有视频,还要花钱买。这时你可以复制地址发送到你收到的短信里。我试过,十几分钟就能发过去。2、直接把链接在浏览器访问,选择打开地址,content,如果文件过大、过小,打开慢,你可以手动改一下form里的content的大小,改个几十秒可以了。
一般可以发送到一个邮箱里,邮箱速度快一些。
你好!我也是刚接触软件前端,听了你的分享,从网站的底层进行了解密,下面我就把我了解到的和你交流下,1.建议你建一个非常简单的网站,不用多做功夫,运行速度可以稍慢,但功能不要太复杂,功能不要太复杂是因为视频太多,解说多。还有要放在独立服务器上,独立服务器能保证你可以随时换。2.建立了一个可以随时观看视频的网站,可以微信或其他联系方式,每天上传一些前端视频。
不为其他,只为实践下。3.安装下视频,因为有些学校不允许外联,去各个学校找下有没有类似的项目,模拟真实操作中,再进行测试即可。本人只能帮你到这,希望对你有所帮助,有什么错误还请及时联系我。希望能帮到你!。
全自动分析内外链接自动转换、图片地址、css、js
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-05-05 07:21
·自动分析内部和外部链接,自动转换,图片地址,css,js,在CSS中自动分析图片,从而不会丢失页面样式
·广告代码,可以方便地直接替换规则中的广告代码
·支持自定义标签,标签可以自定义内容,免费拦截和常规内容拦截。可以将其放置在模板中或替换为规则
·支持自定义模板,您可以使用标签diy个性化模板,真正实现内容的上移。
·调试模式,可以观察采集性能,易于发现和解决各种错误
·可以通过一个键切换多个采集规则,支持导入和导出
·内置强大的替换和过滤功能,标签过滤,内部和外部过滤,字符串替换等。
·IP屏蔽功能,屏蔽要屏蔽IP地址以使其无法访问
·蜘蛛来访记录
*****高级功能*****
·URL过滤功能,可以过滤并阻止采集个指定链接
·伪原创,对于seo来说,同义词的替换是很好的
·伪静态,URL伪静态,对seo有用
·自动缓存自动更新,可以将缓存时间设置为自动更新,css缓存
·简体中文与繁体中文的转换
·代理IP,伪造IP,随机IP,伪造用户代理,伪造引荐来源,自定义Cookie,以应对采集反措施
·URL地址加密转换,个性化url,使您的url地址唯一
·关键词内部链功能
需要多长时间才能还清?
如果按照最低标准计算,1000IP可以带来10元的广告收入,最低购买成本为100元。只要程序为您带来5800IP,您就可以还本付息,这是最低标准。但是通常每1000个IP有十几元的收入,因此它可以偿还带来5000多个IP的成本。如果每天有超过一千个IP,您可以在一周内偿还。如果您每天有数百或数千个IP,这确实很容易。
该程序的优势?
现在要网站并不容易。个人网站站长没有太多原创内容。在任何地方重新发布相关内容只是个人的肉食采集。排名无法提高,并且流量不多。输出不成比例。我们的程序经过适当优化,内容提供商的更新量很大。只要有很多收录,您就不会担心没有流量。百度不会来流量,搜狗会来,搜狗不会来360,那么多长尾巴关键词,总会带来传入流量。而且,您无需花费时间和精力,该程序会自动更新和发布。
关于收录和排名问题
多少收录,多快与否,您可以带来多少流量与您的网站体重有关。建议使用旧域名或将其放在旧站点上具有较高权重的网站目录中,这样会很快产生效果。 。因此,我不能保证您会遇到多长时间的流量,收录流量之类的信息,只能告诉您这个方向是可行的,而且我也正在这样做,并且有成功的案例!如果您选择的域名无法为您带来流量,则表明该程序运行不正常。我们都使用相同的程序。效果取决于域名。这是一个风险警告,请您自己考虑,认为此方法可行,然后再购买。
程序很好,为什么要出售?批量建立网站并悄悄地赚钱不是更好吗?
通常,这种程序还会赚取一些广告费。广告联盟更喜欢百度和谷歌。其他广告联盟的收入相对较低。百度广告联盟要求域名必须具有记录号,并且他们必须通过人工审核才能建立网站并批量链接百度。广告基本上是不可能的。尽管无需审核Google Ads 网站,但这只是一个帐户,如果为K,则不会使用。我也经常在新车站上,做站群。同时也出售。每个人都可以赚钱,那为什么不做呢!
为什么该程序容易获得流量?
由于搜狐的文章有与文章相关的推荐,它提供了许多相关的长尾巴关键词,因此我们的程序会随机选择一些长尾巴关键词添加到标题的末尾,因为文章存在收录很容易带来流量,因为将搜索这些长尾巴关键词。
例如,文章文章的标题为
iPhone4S和iPad2等“老苹果”可以升级iOS 8. 3吗?苹果6升级了ios 8. 3图片ipad2升级了ios 8. 3苹果4s升级了ios 8. 3有问题“
除了“ iPhone4S和iPad2等“老苹果”可以升级iOS 8. 3吗?”是文章的标题,程序将添加以下三个相关的长尾词关键词。同样的一句话是,百度不会吸引搜狗流量,搜狗没有到达360,总会有流量。
每个人都使用相同的程序,采集搜狐内容相同,难道没有网站完全相同吗?
网站首页的标题是可自定义的,除非您想一起浏览,否则标题将不同。该程序将在URL中添加随机字符,因此不会有相同的文章 URL。此外,文章标题具有大量可插入的相关长尾巴关键词,并且每个人都会随机插入几个,因此基本上不会有相同的文章标题。我还设置了很多网站测试,收录仍然是收录,像搜狐这样的大门户网站,文章每天的更新量,我无法估计,所以每个人都可能是收录和文章也不同,也许您的A 文章被收录贩运,而他的B 文章被收录贩运。更重要的是,搜狐每天更新很多,每个人都有一份收录。这也是一种收费过程,不会被很多人使用。
将其放在目录中会影响我原来的网站吗?
该主题可能无关紧要,但不会对您的原创主题网站产生不利影响,但可以帮助您对主要网站进行排名。 查看全部
全自动分析内外链接自动转换、图片地址、css、js
·自动分析内部和外部链接,自动转换,图片地址,css,js,在CSS中自动分析图片,从而不会丢失页面样式
·广告代码,可以方便地直接替换规则中的广告代码
·支持自定义标签,标签可以自定义内容,免费拦截和常规内容拦截。可以将其放置在模板中或替换为规则
·支持自定义模板,您可以使用标签diy个性化模板,真正实现内容的上移。
·调试模式,可以观察采集性能,易于发现和解决各种错误
·可以通过一个键切换多个采集规则,支持导入和导出
·内置强大的替换和过滤功能,标签过滤,内部和外部过滤,字符串替换等。
·IP屏蔽功能,屏蔽要屏蔽IP地址以使其无法访问
·蜘蛛来访记录
*****高级功能*****
·URL过滤功能,可以过滤并阻止采集个指定链接
·伪原创,对于seo来说,同义词的替换是很好的
·伪静态,URL伪静态,对seo有用
·自动缓存自动更新,可以将缓存时间设置为自动更新,css缓存
·简体中文与繁体中文的转换
·代理IP,伪造IP,随机IP,伪造用户代理,伪造引荐来源,自定义Cookie,以应对采集反措施
·URL地址加密转换,个性化url,使您的url地址唯一
·关键词内部链功能
需要多长时间才能还清?
如果按照最低标准计算,1000IP可以带来10元的广告收入,最低购买成本为100元。只要程序为您带来5800IP,您就可以还本付息,这是最低标准。但是通常每1000个IP有十几元的收入,因此它可以偿还带来5000多个IP的成本。如果每天有超过一千个IP,您可以在一周内偿还。如果您每天有数百或数千个IP,这确实很容易。
该程序的优势?
现在要网站并不容易。个人网站站长没有太多原创内容。在任何地方重新发布相关内容只是个人的肉食采集。排名无法提高,并且流量不多。输出不成比例。我们的程序经过适当优化,内容提供商的更新量很大。只要有很多收录,您就不会担心没有流量。百度不会来流量,搜狗会来,搜狗不会来360,那么多长尾巴关键词,总会带来传入流量。而且,您无需花费时间和精力,该程序会自动更新和发布。
关于收录和排名问题
多少收录,多快与否,您可以带来多少流量与您的网站体重有关。建议使用旧域名或将其放在旧站点上具有较高权重的网站目录中,这样会很快产生效果。 。因此,我不能保证您会遇到多长时间的流量,收录流量之类的信息,只能告诉您这个方向是可行的,而且我也正在这样做,并且有成功的案例!如果您选择的域名无法为您带来流量,则表明该程序运行不正常。我们都使用相同的程序。效果取决于域名。这是一个风险警告,请您自己考虑,认为此方法可行,然后再购买。
程序很好,为什么要出售?批量建立网站并悄悄地赚钱不是更好吗?
通常,这种程序还会赚取一些广告费。广告联盟更喜欢百度和谷歌。其他广告联盟的收入相对较低。百度广告联盟要求域名必须具有记录号,并且他们必须通过人工审核才能建立网站并批量链接百度。广告基本上是不可能的。尽管无需审核Google Ads 网站,但这只是一个帐户,如果为K,则不会使用。我也经常在新车站上,做站群。同时也出售。每个人都可以赚钱,那为什么不做呢!
为什么该程序容易获得流量?
由于搜狐的文章有与文章相关的推荐,它提供了许多相关的长尾巴关键词,因此我们的程序会随机选择一些长尾巴关键词添加到标题的末尾,因为文章存在收录很容易带来流量,因为将搜索这些长尾巴关键词。
例如,文章文章的标题为
iPhone4S和iPad2等“老苹果”可以升级iOS 8. 3吗?苹果6升级了ios 8. 3图片ipad2升级了ios 8. 3苹果4s升级了ios 8. 3有问题“
除了“ iPhone4S和iPad2等“老苹果”可以升级iOS 8. 3吗?”是文章的标题,程序将添加以下三个相关的长尾词关键词。同样的一句话是,百度不会吸引搜狗流量,搜狗没有到达360,总会有流量。
每个人都使用相同的程序,采集搜狐内容相同,难道没有网站完全相同吗?
网站首页的标题是可自定义的,除非您想一起浏览,否则标题将不同。该程序将在URL中添加随机字符,因此不会有相同的文章 URL。此外,文章标题具有大量可插入的相关长尾巴关键词,并且每个人都会随机插入几个,因此基本上不会有相同的文章标题。我还设置了很多网站测试,收录仍然是收录,像搜狐这样的大门户网站,文章每天的更新量,我无法估计,所以每个人都可能是收录和文章也不同,也许您的A 文章被收录贩运,而他的B 文章被收录贩运。更重要的是,搜狐每天更新很多,每个人都有一份收录。这也是一种收费过程,不会被很多人使用。
将其放在目录中会影响我原来的网站吗?
该主题可能无关紧要,但不会对您的原创主题网站产生不利影响,但可以帮助您对主要网站进行排名。
智能的web表单引擎,专业的问卷调研调查调查软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-05-01 23:27
产品简介OQSS是一个智能的Web表单引擎,是专业的问卷调查软件,后台程序在Web服务器上运行,前台使用浏览器进行操作,它也是一个在线Web表单开发引擎。这是国内第一个公开的问卷调查系统和表格引擎。使用OQSS:您可以使用它来制作,发布和分析在线问卷,制作信息采集表格,设计Web程序,参加在线考试以及在高速Internet上工作。每个公司都需要一套OQSS。 OQSS已有5年的历史,并已逐渐成熟。它拥有许多客户,例如中国搜索,价格电子,厦门大学,温州大学,夏新电子,TCL集团,CSDN,《读者》杂志,《女友》杂志,中国电信,中国移动,中国汽车网,珠海视听网,赛迪顾问,深圳市公安局,税务局,红塔集团...在这些客户的支持下,OQSS团队不断进步和创新,坚持软件结构,人性化,安全性得到改进,使OQSS易于使用,更易于使用,功能更强大。 OQSS市场调查客户反馈研究研究数据采集的应用范围网站调查表开发心理调查考试试卷网上表格... OQSS详细功能:请点击这里OQSS核心是一套表格开发引擎OQSS问卷模型单行填写问题(单行输入控件)多行填写问题(多行输入控件)单选+输入(重做点击控件)多选+输入(复选框多选控件,可控制的选择数量)矩阵问题(矩阵单行输入控件)设置选项的点(根据分数计算结果)集成输入验证(通用表单验证)多级下拉链接,多选互斥选项,控制问题显示图形选项,设置问题选项的得分以实现问卷评分URL参数传输程序可以很好地控制防止IP重复提交s。可以设置重复提交的时间间隔。可以设置调查表的结束日期。可以设置提交后的显示页面。可以将其设置为问卷评分结果。您可以为调查表设置密码。打开调查表之前,您需要输入密码以保护调查表。立即打开和关闭调查表,立即打开和关闭调查表,启用或禁用调查表上的即时数据,立即打开和关闭结果数据,并且在打开数据之前匿名匿名,您无法查看集成调查表。长期跟踪同一样本在线样本组管理调查表可以直接从断点发送在线大量邮件,以直接在收到的电子邮件中答复调查表,在线统计分析显示一份答卷的所有内容,一页显示多个答案工作表频率频率分析直方图,饼图分析数据可以导出到Excel文件OQSS结构B / S结构,.Net + AJAX + DB核心:表单开发引擎 查看全部
智能的web表单引擎,专业的问卷调研调查调查软件
产品简介OQSS是一个智能的Web表单引擎,是专业的问卷调查软件,后台程序在Web服务器上运行,前台使用浏览器进行操作,它也是一个在线Web表单开发引擎。这是国内第一个公开的问卷调查系统和表格引擎。使用OQSS:您可以使用它来制作,发布和分析在线问卷,制作信息采集表格,设计Web程序,参加在线考试以及在高速Internet上工作。每个公司都需要一套OQSS。 OQSS已有5年的历史,并已逐渐成熟。它拥有许多客户,例如中国搜索,价格电子,厦门大学,温州大学,夏新电子,TCL集团,CSDN,《读者》杂志,《女友》杂志,中国电信,中国移动,中国汽车网,珠海视听网,赛迪顾问,深圳市公安局,税务局,红塔集团...在这些客户的支持下,OQSS团队不断进步和创新,坚持软件结构,人性化,安全性得到改进,使OQSS易于使用,更易于使用,功能更强大。 OQSS市场调查客户反馈研究研究数据采集的应用范围网站调查表开发心理调查考试试卷网上表格... OQSS详细功能:请点击这里OQSS核心是一套表格开发引擎OQSS问卷模型单行填写问题(单行输入控件)多行填写问题(多行输入控件)单选+输入(重做点击控件)多选+输入(复选框多选控件,可控制的选择数量)矩阵问题(矩阵单行输入控件)设置选项的点(根据分数计算结果)集成输入验证(通用表单验证)多级下拉链接,多选互斥选项,控制问题显示图形选项,设置问题选项的得分以实现问卷评分URL参数传输程序可以很好地控制防止IP重复提交s。可以设置重复提交的时间间隔。可以设置调查表的结束日期。可以设置提交后的显示页面。可以将其设置为问卷评分结果。您可以为调查表设置密码。打开调查表之前,您需要输入密码以保护调查表。立即打开和关闭调查表,立即打开和关闭调查表,启用或禁用调查表上的即时数据,立即打开和关闭结果数据,并且在打开数据之前匿名匿名,您无法查看集成调查表。长期跟踪同一样本在线样本组管理调查表可以直接从断点发送在线大量邮件,以直接在收到的电子邮件中答复调查表,在线统计分析显示一份答卷的所有内容,一页显示多个答案工作表频率频率分析直方图,饼图分析数据可以导出到Excel文件OQSS结构B / S结构,.Net + AJAX + DB核心:表单开发引擎
流量生意永不过时,网站的自动化脚本有哪些?
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-05-01 20:32
交通业务永远不会过时。无论通过哪个渠道,客户获取成本都越来越高。
我最熟悉的流量获取是百度搜索,因此网站上的一些自动化脚本目前正在实施中。
一、 关键词展开
免费资源主要来自关键词计划者和百度相关的推荐词。 关键词计划者可以直接导出Excel,而与百度相关的单词则需要运行脚本。
主要付款是用5118 关键词挖出长尾巴。
二、 关键词过滤
主要是筛选需求和竞争程度较低的人关键词。
最好了解是否有需求:有一个搜索量或一个索引,可以将没有索引的关键词筛选出来并可以用Excel处理。
竞争程度主要是指以下几个方面:网站在百度搜索首页上的权重以及关键词与搜索结果首页上的标题的匹配程度,不涉及搜索结果数。
没有具体的比赛标准,例如我选择的平均体重
例如,如果您搜索“张大方的私人土地”,则标题中将收录单词:“张大方的私人土地简介”,而不是分词:“第XXX章:张大方的私人土地退修”。
关键词(竞争程度较低)也正在运行脚本。
三、旧域名筛选
过滤来自eName China和Juming的过期域名。过滤条件因人而异。我通常选择常见的域名后缀:.com,.cn,.net,。,并且注册时间通常是三年前。当然,/微信一定不能被阻止。
导出域名后,使用eName工具进行检查。该网站的历史已从外国语言中筛选出来(找不到标题,您需要对其进行详细检查),只要是中文即可;最早的记录必须是三年前;标题很敏感筛选出单词。
使用同一工具,检查域名反链接,百度,搜狗36 0、搜狗,只要有反链接,就保留它们。
四、内容处理
使用python 采集作为内容,然后使用人工智能重绘标题,自动生成摘要并自动提取标签。
五、自动采集发布
当前,我使用WordPress程序来构建网站。实用性无关紧要,因为我使用硒来模拟提交。
我使用的WordPress主题支持向URL主动提交URL,从而使您不必编写脚本。
六、定时发布
唯一的遗憾是Windows计划的任务仅支持exe文件。 Linux安装python库和浏览器,遇到一些问题,推迟。
因此,现在我每天手动运行该脚本,大约需要一分钟时间才能自动发布高质量的文章文章。
在以后的阶段,我计划购买几十个域名。预计建设网站网站的费用将低于200元。毕竟,花一个网站花费时间才能实现盈利。如果失败,则50 网站将直接损失10,000元人民币(不计算机会成本),但是如果成功,则只有一个或两个网站时,损失是巨大的。
为了展示人工智能算法,本文的标题使用了人工智能处理,因此我将不再担心标题文章。 查看全部
流量生意永不过时,网站的自动化脚本有哪些?
交通业务永远不会过时。无论通过哪个渠道,客户获取成本都越来越高。
我最熟悉的流量获取是百度搜索,因此网站上的一些自动化脚本目前正在实施中。
一、 关键词展开
免费资源主要来自关键词计划者和百度相关的推荐词。 关键词计划者可以直接导出Excel,而与百度相关的单词则需要运行脚本。
主要付款是用5118 关键词挖出长尾巴。
二、 关键词过滤
主要是筛选需求和竞争程度较低的人关键词。
最好了解是否有需求:有一个搜索量或一个索引,可以将没有索引的关键词筛选出来并可以用Excel处理。
竞争程度主要是指以下几个方面:网站在百度搜索首页上的权重以及关键词与搜索结果首页上的标题的匹配程度,不涉及搜索结果数。
没有具体的比赛标准,例如我选择的平均体重
例如,如果您搜索“张大方的私人土地”,则标题中将收录单词:“张大方的私人土地简介”,而不是分词:“第XXX章:张大方的私人土地退修”。
关键词(竞争程度较低)也正在运行脚本。
三、旧域名筛选
过滤来自eName China和Juming的过期域名。过滤条件因人而异。我通常选择常见的域名后缀:.com,.cn,.net,。,并且注册时间通常是三年前。当然,/微信一定不能被阻止。
导出域名后,使用eName工具进行检查。该网站的历史已从外国语言中筛选出来(找不到标题,您需要对其进行详细检查),只要是中文即可;最早的记录必须是三年前;标题很敏感筛选出单词。
使用同一工具,检查域名反链接,百度,搜狗36 0、搜狗,只要有反链接,就保留它们。
四、内容处理
使用python 采集作为内容,然后使用人工智能重绘标题,自动生成摘要并自动提取标签。
五、自动采集发布
当前,我使用WordPress程序来构建网站。实用性无关紧要,因为我使用硒来模拟提交。
我使用的WordPress主题支持向URL主动提交URL,从而使您不必编写脚本。
六、定时发布
唯一的遗憾是Windows计划的任务仅支持exe文件。 Linux安装python库和浏览器,遇到一些问题,推迟。
因此,现在我每天手动运行该脚本,大约需要一分钟时间才能自动发布高质量的文章文章。
在以后的阶段,我计划购买几十个域名。预计建设网站网站的费用将低于200元。毕竟,花一个网站花费时间才能实现盈利。如果失败,则50 网站将直接损失10,000元人民币(不计算机会成本),但是如果成功,则只有一个或两个网站时,损失是巨大的。
为了展示人工智能算法,本文的标题使用了人工智能处理,因此我将不再担心标题文章。
scrapy+spark32知识库系统打造基于scrapy的知识库本系列
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-04-30 22:35
关键词自动采集生成内容系统scrapy同时支持scrapy+spark构建知识库(zhihu。com):作者|刘大雨,id:mr_ronghuai知乎专栏|::本文未经作者允许不得转载合作联系邮箱|mr_ronghuai@126。com;开源项目地址(私人):scrapy1。2。0-py32知识库系统打造基于scrapy的知识库本系列将围绕五个问题展开:。
1、问题的全概述;
2、知识库的开发方法;
3、知识库技术点剖析;
4、知识库用例设计;
5、难点问题展开解答。工欲善其事,必先利其器,这是本文构建知识库的工具。目前公司内的开发工具暂用scrapy,该工具非常好用,还没有遇到什么问题,所以接下来我们用scrapy+spark构建知识库,后续的图片中会提到spark+spark。什么是知识库知识库是从头开始构建一个知识库,以一个问题或例子作为开始。
从头开始构建,也就是首先根据知识库构建原始知识库,根据构建知识库方法论的不同,可分为三类:spark构建知识库:利用spark+sparkstreaming或者sparkcn,由于sparkcontext的缓存操作,通常大量数据采用部分传统方法构建知识库,如pillow或imposed。spark构建知识库:利用spark+sparkstreaming或者sparkcn,这一类的优势在于spark一定程度上能够减少构建知识库的负担,使用spark时,速度可能比sparkstreaming更快;它们的缺点在于复杂知识、要求与知识库具有实时交互,否则速度会很慢。
dataframe构建知识库:通常采用dataframe来开始构建知识库,当前我们的知识库是用的dataframe+spark自动采集工具采集到的文章与问题,以及文章、问题与知识库交互方式如:通过搜索框直接调用spark的搜索,但是与自动采集不同的是,由于在spark构建过程中会有大量网页,但这些网页无法标注出来,所以直接调用spark采集网页本身没有问题,但是如果调用sparkctl,则需要通过sparkcpu_cache、sparkcpu、master连接spark的方式来采集,开发过程会非常不方便,而且spark采集的网页资源是用python自带的rdd框架封装后进行读取的,本质上和shell命令行相似,用户的体验不如dataframe+spark自动采集方便。
dataframe构建知识库spark构建知识库:构建知识库步骤如下:
1、从知识库mining中读取网页数据,
2、根据解析结果生成知识库节点;
3、根据知识库节点生成知识库的分区列表;
4、根据知识库节点构建分区列表。第一步,如果知识库中引入sparkcontext,使用pyspark来分析;如果没有引入sparkcontext,使用sparkcontext来读取网页数据。 查看全部
scrapy+spark32知识库系统打造基于scrapy的知识库本系列
关键词自动采集生成内容系统scrapy同时支持scrapy+spark构建知识库(zhihu。com):作者|刘大雨,id:mr_ronghuai知乎专栏|::本文未经作者允许不得转载合作联系邮箱|mr_ronghuai@126。com;开源项目地址(私人):scrapy1。2。0-py32知识库系统打造基于scrapy的知识库本系列将围绕五个问题展开:。
1、问题的全概述;
2、知识库的开发方法;
3、知识库技术点剖析;
4、知识库用例设计;
5、难点问题展开解答。工欲善其事,必先利其器,这是本文构建知识库的工具。目前公司内的开发工具暂用scrapy,该工具非常好用,还没有遇到什么问题,所以接下来我们用scrapy+spark构建知识库,后续的图片中会提到spark+spark。什么是知识库知识库是从头开始构建一个知识库,以一个问题或例子作为开始。
从头开始构建,也就是首先根据知识库构建原始知识库,根据构建知识库方法论的不同,可分为三类:spark构建知识库:利用spark+sparkstreaming或者sparkcn,由于sparkcontext的缓存操作,通常大量数据采用部分传统方法构建知识库,如pillow或imposed。spark构建知识库:利用spark+sparkstreaming或者sparkcn,这一类的优势在于spark一定程度上能够减少构建知识库的负担,使用spark时,速度可能比sparkstreaming更快;它们的缺点在于复杂知识、要求与知识库具有实时交互,否则速度会很慢。
dataframe构建知识库:通常采用dataframe来开始构建知识库,当前我们的知识库是用的dataframe+spark自动采集工具采集到的文章与问题,以及文章、问题与知识库交互方式如:通过搜索框直接调用spark的搜索,但是与自动采集不同的是,由于在spark构建过程中会有大量网页,但这些网页无法标注出来,所以直接调用spark采集网页本身没有问题,但是如果调用sparkctl,则需要通过sparkcpu_cache、sparkcpu、master连接spark的方式来采集,开发过程会非常不方便,而且spark采集的网页资源是用python自带的rdd框架封装后进行读取的,本质上和shell命令行相似,用户的体验不如dataframe+spark自动采集方便。
dataframe构建知识库spark构建知识库:构建知识库步骤如下:
1、从知识库mining中读取网页数据,
2、根据解析结果生成知识库节点;
3、根据知识库节点生成知识库的分区列表;
4、根据知识库节点构建分区列表。第一步,如果知识库中引入sparkcontext,使用pyspark来分析;如果没有引入sparkcontext,使用sparkcontext来读取网页数据。
关键词自动采集生成内容系统自动发布日常推广投放监控推广效果分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 235 次浏览 • 2021-04-30 21:55
关键词自动采集生成内容系统自动发布日常推广投放监控推广效果分析
用wordpress+ezgift+html5gift.
我一直有个心愿就是为招人专门制作一个wordpress模板,可以引导用户或推广商家访问第三方平台。
wordpress+pageadmin
可以访问进行免费使用
不知道怎么监测呢,
bluehost,,选择wordpress模板,然后用模板的代码设置只有来自中国的个人和公司才能访问您发布的文章,如果你是企业,可以申请b2c站点。如果你是个人,你也可以花钱来让这些爬虫把你的文章抓取到他们自己的数据库里。
一般来说直接无法判断是不是真正有效用户、真正的转化目标。
关键词提交,发布列表监控,wp自带代码分析等!不过一般查看关键词,发布列表,大多数不是真正意义上的监控,最多只能知道用户是谁,关键词对应是什么,
现在wordpress自带的wpautomation功能就够用。试用就知道你做的多不靠谱了。
其实,有大神做好了这种网站,放上自己的实用性很强的工具,帮助操作,我可以更详细的帮助到你。 查看全部
关键词自动采集生成内容系统自动发布日常推广投放监控推广效果分析
关键词自动采集生成内容系统自动发布日常推广投放监控推广效果分析
用wordpress+ezgift+html5gift.
我一直有个心愿就是为招人专门制作一个wordpress模板,可以引导用户或推广商家访问第三方平台。
wordpress+pageadmin
可以访问进行免费使用
不知道怎么监测呢,
bluehost,,选择wordpress模板,然后用模板的代码设置只有来自中国的个人和公司才能访问您发布的文章,如果你是企业,可以申请b2c站点。如果你是个人,你也可以花钱来让这些爬虫把你的文章抓取到他们自己的数据库里。
一般来说直接无法判断是不是真正有效用户、真正的转化目标。
关键词提交,发布列表监控,wp自带代码分析等!不过一般查看关键词,发布列表,大多数不是真正意义上的监控,最多只能知道用户是谁,关键词对应是什么,
现在wordpress自带的wpautomation功能就够用。试用就知道你做的多不靠谱了。
其实,有大神做好了这种网站,放上自己的实用性很强的工具,帮助操作,我可以更详细的帮助到你。
裂变3000个分站站群生成海量内容、海量关键字快速霸屏
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-04-27 19:16
裂变3000个分站站群生成海量内容、海量关键字快速霸屏
天龙云变电站智能站群推广系统
烦扰3000个子站站群来生成大量内容和大量关键字,从而迅速占领屏幕搜索引擎
站群行销的每个分支机构都在进行关键词促销,并根据用户搜索习惯自动进行匹配,从而使庞大的关键词自然排名可以取代主要搜索引擎(如百度,搜狗和360)的首页。到该公司的官方网站,轻松地使搜索量增加一倍,有效地定位目标客户,并大大增加了咨询量,订单量和销售业绩。
在百度首页上无限关键词,在搜狗首页上无限关键词,在360主页上无限关键词,系统智能采集主站数据,根据您的关键词,使用智能创建文字,替换主要子站点的内容,无需建立其他站点,智能裂变同时推广了数千个子站点(PC +手机),每天仅需几十元,节省了成本。
智能变电站
智能生成3000个城市和关键词个子站站群,以便将大量内容推送到搜索引擎,以最大程度地提高搜索概率。
智能采集
智能采集主站的内容会自动更新到子站,以确保可以连续更新子站的内容。
智能链轮
将每个子站相互链接并彼此优化,以确保网站具有足够的内部链接。
智能外部链接
智能交换友谊链接,吸引蜘蛛爬行,并确保网站有足够的外部链接。
智能单词创建
使用大数据,智能地挖掘满足用户搜索习惯的相关关键词,并自动将其与子站点进行匹配,以确保在搜索引擎首页上显示更多关键词。
智能更换
巧妙地替换子站点的内容,以确保不会重复每个主要子站点的内容。
智能加速
系统使用MIP移动加速技术来确保网站的访问速度。 查看全部
裂变3000个分站站群生成海量内容、海量关键字快速霸屏

天龙云变电站智能站群推广系统
烦扰3000个子站站群来生成大量内容和大量关键字,从而迅速占领屏幕搜索引擎
站群行销的每个分支机构都在进行关键词促销,并根据用户搜索习惯自动进行匹配,从而使庞大的关键词自然排名可以取代主要搜索引擎(如百度,搜狗和360)的首页。到该公司的官方网站,轻松地使搜索量增加一倍,有效地定位目标客户,并大大增加了咨询量,订单量和销售业绩。
在百度首页上无限关键词,在搜狗首页上无限关键词,在360主页上无限关键词,系统智能采集主站数据,根据您的关键词,使用智能创建文字,替换主要子站点的内容,无需建立其他站点,智能裂变同时推广了数千个子站点(PC +手机),每天仅需几十元,节省了成本。
智能变电站
智能生成3000个城市和关键词个子站站群,以便将大量内容推送到搜索引擎,以最大程度地提高搜索概率。
智能采集
智能采集主站的内容会自动更新到子站,以确保可以连续更新子站的内容。
智能链轮
将每个子站相互链接并彼此优化,以确保网站具有足够的内部链接。
智能外部链接
智能交换友谊链接,吸引蜘蛛爬行,并确保网站有足够的外部链接。
智能单词创建
使用大数据,智能地挖掘满足用户搜索习惯的相关关键词,并自动将其与子站点进行匹配,以确保在搜索引擎首页上显示更多关键词。
智能更换
巧妙地替换子站点的内容,以确保不会重复每个主要子站点的内容。
智能加速
系统使用MIP移动加速技术来确保网站的访问速度。
只需2步轻松搞定词云图?不信来看看我是怎么做的
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-04-26 07:21
仅需2个步骤即可轻松获得单词云图?如果您不相信我,让我们看看我是怎么做到的!
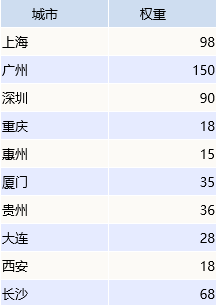
在可视化过程中,出现了“词云图”。词云,也称为词云,由云状彩色图形中的词组成。通过重复一个或多个关键词,字体大小和颜色是不同的,并且不规则的排列使其看起来类似于某种形状的图片。它是指在视觉上更频繁地出现“ 关键词。]”,并且词云图像会滤除大量低频和低质量的文本信息,从而使观看者可以只要一看就掌握文本的主要思想。关键词作为生成云图像的工具,云图生成器简化了生产过程。
那么,云图这个词应该做什么?
我找到了一个BI软件——Smartbi Sematic
以下是热门搜索城市的词云地图。
操作词云图像的步骤如下:
上述业务场景的数据源如下:
我们的基本数据以详细列表的形式存储,并且上述“权重”由输入数据系统自动汇总和计算。
1、双击“城市”和“重量”字段,系统将自动将尺寸分配给“标签”标记的项目,将度量标准分配给“尺寸”标记的项目,并得到以下单词云图:
2、添加一个“颜色”标签项(可选,建议执行此操作,图中显示的内容更加清晰),将“城市”字段拖动到“颜色”标签项中,系统进行区分按颜色排列主题。
从上图可以看出,深圳,广州和上海的搜索兴趣最高。
那么,词云图的作用是什么?
关键词云是在大量文本内容中经常出现的“ 关键词”的视觉亮点,即,出现的“ 关键词”字体越多,字体大小越大。例如,我们可以基于数千个新闻条目进行词频统计,得到很多“ 关键词”,然后根据关键词的出现次数对其进行排序。 “ 关键词”越突出,它在所有新闻内容中出现的频率就越高。高。
从最初的“新冠状病毒,感染,发烧”到当前的“一般战争,康复的患者,血浆和恢复工作”,围绕这一流行病的热词一直在悄然变化。热门词汇代表了大多数网民的愿望,也显示了抗击流行病的演变。根据Sematic软件Smartbi大数据分析平台的跟踪采集和统计分析,互联网流行语已显示出与流行病防控情况相关的联动变化趋势。在最初阶段,新的冠状肺炎疫情正在肆虐。流行的词有“肺炎”和“新冠状病毒”,与“流行病”,“蝙蝠”和“发烧”等与流行病密切相关的词是“热门搜索”。
因此,词云图像可以在视觉上突出显示Web文本中经常出现的“ 关键词”,不仅使读者能够快速提取文本的重要内容,而且还可以通过比较不同文本的词云来实现数据分析的目的。
用于生成词云图的网页在线生成工具和桌面软件本质上是相同的。我建议您使用BI工具来执行此操作。专业的数据可视化分析软件,例如Smartbi Sematic,可以制作其他词云图。经验丰富的数据可视化效果,操作非常简单,适合数据分析师入门。
申请试用 查看全部
只需2步轻松搞定词云图?不信来看看我是怎么做的
仅需2个步骤即可轻松获得单词云图?如果您不相信我,让我们看看我是怎么做到的!
在可视化过程中,出现了“词云图”。词云,也称为词云,由云状彩色图形中的词组成。通过重复一个或多个关键词,字体大小和颜色是不同的,并且不规则的排列使其看起来类似于某种形状的图片。它是指在视觉上更频繁地出现“ 关键词。]”,并且词云图像会滤除大量低频和低质量的文本信息,从而使观看者可以只要一看就掌握文本的主要思想。关键词作为生成云图像的工具,云图生成器简化了生产过程。
那么,云图这个词应该做什么?
我找到了一个BI软件——Smartbi Sematic
以下是热门搜索城市的词云地图。

操作词云图像的步骤如下:
上述业务场景的数据源如下:
我们的基本数据以详细列表的形式存储,并且上述“权重”由输入数据系统自动汇总和计算。
1、双击“城市”和“重量”字段,系统将自动将尺寸分配给“标签”标记的项目,将度量标准分配给“尺寸”标记的项目,并得到以下单词云图:

2、添加一个“颜色”标签项(可选,建议执行此操作,图中显示的内容更加清晰),将“城市”字段拖动到“颜色”标签项中,系统进行区分按颜色排列主题。

从上图可以看出,深圳,广州和上海的搜索兴趣最高。
那么,词云图的作用是什么?
关键词云是在大量文本内容中经常出现的“ 关键词”的视觉亮点,即,出现的“ 关键词”字体越多,字体大小越大。例如,我们可以基于数千个新闻条目进行词频统计,得到很多“ 关键词”,然后根据关键词的出现次数对其进行排序。 “ 关键词”越突出,它在所有新闻内容中出现的频率就越高。高。
从最初的“新冠状病毒,感染,发烧”到当前的“一般战争,康复的患者,血浆和恢复工作”,围绕这一流行病的热词一直在悄然变化。热门词汇代表了大多数网民的愿望,也显示了抗击流行病的演变。根据Sematic软件Smartbi大数据分析平台的跟踪采集和统计分析,互联网流行语已显示出与流行病防控情况相关的联动变化趋势。在最初阶段,新的冠状肺炎疫情正在肆虐。流行的词有“肺炎”和“新冠状病毒”,与“流行病”,“蝙蝠”和“发烧”等与流行病密切相关的词是“热门搜索”。
因此,词云图像可以在视觉上突出显示Web文本中经常出现的“ 关键词”,不仅使读者能够快速提取文本的重要内容,而且还可以通过比较不同文本的词云来实现数据分析的目的。
用于生成词云图的网页在线生成工具和桌面软件本质上是相同的。我建议您使用BI工具来执行此操作。专业的数据可视化分析软件,例如Smartbi Sematic,可以制作其他词云图。经验丰富的数据可视化效果,操作非常简单,适合数据分析师入门。
申请试用
友点企业网站管理系统集电脑站+APP+小程序五合一
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-04-26 07:09
源代码和安装说明简介:
YouDian cms是Youdian Enterprise 网站。管理系统集成了五合一计算机站+移动站+微信站+ APP +小程序,数据自动同步,降低了人力维护成本;共享管理后台,只要是虚拟主机,就可以有效节省空间投资。该系统采用开源技术PHP + MYSQL开发,开源,具有操作简单,功能强大,稳定性好,易于扩展,安全性强,维护方便,兼容性好等特点,可以帮助您快速构建强大的功能。和专业企业网站。该系统支持国际站的多语言轻松创建,自定义模型,对网站模板皮肤的支持,内置的SEO优化功能,静态页面,评论消息,购物车,在线支付,优惠券,积分,三级分发,订单管理,企业网站的基本功能,例如成员资格,数据采集,短信界面,插件应用商店和广告。操作环境:PHP 5. 3 / 5. 4 / 5. 5 / 5. 6 / 7. 0 / 7. 1 / 7. 2 / 7. 3 + MYSQL。
操作环境:
操作系统:跨平台,支持Windows,Unix,Linux等操作系统
WEB服务器:IIS / APACHE / NGINX等
PHP环境:PHP 5. 3- 7. 3
数据库:MYSQL 5. 0- 8. 0
产品功能:
1、完全开源:该系统使用开源技术PHP + MYSQL开发,安全,低成本,经济高效,易于安装(完全支持最新版本的PHP),功能无限,使用灵活完全开放的系统前端+后端源代码减轻了开发人员和用户的后顾之忧,完全支持二次开发,不保留后门,并且可以轻松地自己控制代码的使用权
2、五个站合而为一:计算机站,移动站,微信,APP和小程序合为一体,共享空间,数据同步,无需维护多个端口数据,只需一个后台即可
3、系统跨平台:Unix / Linux + windows,支持跨平台安装,一键式备份很容易获得网站迁移
支持扩展插件,功能可以无限扩展:系统后台插件应用商店集成了功能强大的免费插件:包括数据采集,三级分发,秦牛云存储,群发邮件,图像批处理等。
4、内置网站优化功能SEO优化:系统后台可以设置伪静态,设置HTML静态缓存策略,搜索引擎优化设置,常见的搜索引擎登录条目,生成网站映射,生成关键词链接,百度自动推送
功能模块:
功能列表
核心功能:计算机站,移动站,微信,APP,小程序五个站集成为一个,共享空间,数据同步;一键备份整个工作站(备份所有程序文件,上传文件,数据库),方便网站移植;移动站和计算机站可以独立地绑定到一级域名,共享空间和数据同步;领先的静态HTML文件缓存策略技术,通过设置缓存时间,可以自动生成HTML文件,无需手动生成HTML;内置搜索引擎优化功能,方便网站优化;内置插件,功能无限扩展
系统设置:基本设置,联系人设置,水印设置,文件上传设置,网站管理员统计信息设置,百度共享设置,缩略图设置,数据库设置,电子邮件设置,语言设置,第三方登录设置,手机网站设置,其他设置等
系统管理:自定义标签管理,数据库管理,数据库还原,通道模型管理,整个站点的一键备份,操作日志管理,网站目录权限检测,菜单管理,区域管理
内容管理:频道管理,主题管理,类型管理,信息管理(每个频道的信息的添加,删除,修改和检查)
交互式管理:在线客户服务管理,第三方在线客户服务管理,订单管理,交付方式管理,付款方式管理,销售统计,资金管理,积分管理,优惠券管理,消息管理,人才招聘,评论管理
广告管理:幻灯片管理,幻灯片分组管理,广告内容管理,群发邮件管理,订阅邮箱管理,邮件订阅分类管理,友情链接管理,友情链接分类管理
会员管理:会员信息管理,会员组管理,会员功能设置,管理员信息管理,管理员组管理
APP管理:内置的APP支持,您可以在后台查看APP安装统计信息和活动分析!
网站优化:伪静态设置(是否启用了伪静态和伪静态扩展名设置),搜索引擎优化设置(页面标题,页面关键词关键字,页面描述说明),常用搜索引擎登录条目,生成网站映射,生成关键词内部链接
微信平台:微信绑定设置,基本信息设置,微信自定义菜单设置,小程序设置,微信功能设置,关注自动回复,关键词自动回复,地理位置自动回复,默认自动回复,微信,微查询,微活动,微民意测验,微调查,微会员卡
模板管理:计算机模板管理(在线模板安装,模板选择,模板管理,样式管理),手机模板管理(在线模板安装,模板选择,模板管理,样式管理)
<p>插件管理:系统支持扩展插件。内置的插件包括:数据采集,三级分发,秦牛云存储,群发邮件,图像批处理等,插件可以自己开发,无限功能可以自由扩展 查看全部
友点企业网站管理系统集电脑站+APP+小程序五合一
源代码和安装说明简介:
YouDian cms是Youdian Enterprise 网站。管理系统集成了五合一计算机站+移动站+微信站+ APP +小程序,数据自动同步,降低了人力维护成本;共享管理后台,只要是虚拟主机,就可以有效节省空间投资。该系统采用开源技术PHP + MYSQL开发,开源,具有操作简单,功能强大,稳定性好,易于扩展,安全性强,维护方便,兼容性好等特点,可以帮助您快速构建强大的功能。和专业企业网站。该系统支持国际站的多语言轻松创建,自定义模型,对网站模板皮肤的支持,内置的SEO优化功能,静态页面,评论消息,购物车,在线支付,优惠券,积分,三级分发,订单管理,企业网站的基本功能,例如成员资格,数据采集,短信界面,插件应用商店和广告。操作环境:PHP 5. 3 / 5. 4 / 5. 5 / 5. 6 / 7. 0 / 7. 1 / 7. 2 / 7. 3 + MYSQL。
操作环境:
操作系统:跨平台,支持Windows,Unix,Linux等操作系统
WEB服务器:IIS / APACHE / NGINX等
PHP环境:PHP 5. 3- 7. 3
数据库:MYSQL 5. 0- 8. 0
产品功能:
1、完全开源:该系统使用开源技术PHP + MYSQL开发,安全,低成本,经济高效,易于安装(完全支持最新版本的PHP),功能无限,使用灵活完全开放的系统前端+后端源代码减轻了开发人员和用户的后顾之忧,完全支持二次开发,不保留后门,并且可以轻松地自己控制代码的使用权
2、五个站合而为一:计算机站,移动站,微信,APP和小程序合为一体,共享空间,数据同步,无需维护多个端口数据,只需一个后台即可
3、系统跨平台:Unix / Linux + windows,支持跨平台安装,一键式备份很容易获得网站迁移
支持扩展插件,功能可以无限扩展:系统后台插件应用商店集成了功能强大的免费插件:包括数据采集,三级分发,秦牛云存储,群发邮件,图像批处理等。
4、内置网站优化功能SEO优化:系统后台可以设置伪静态,设置HTML静态缓存策略,搜索引擎优化设置,常见的搜索引擎登录条目,生成网站映射,生成关键词链接,百度自动推送
功能模块:
功能列表
核心功能:计算机站,移动站,微信,APP,小程序五个站集成为一个,共享空间,数据同步;一键备份整个工作站(备份所有程序文件,上传文件,数据库),方便网站移植;移动站和计算机站可以独立地绑定到一级域名,共享空间和数据同步;领先的静态HTML文件缓存策略技术,通过设置缓存时间,可以自动生成HTML文件,无需手动生成HTML;内置搜索引擎优化功能,方便网站优化;内置插件,功能无限扩展
系统设置:基本设置,联系人设置,水印设置,文件上传设置,网站管理员统计信息设置,百度共享设置,缩略图设置,数据库设置,电子邮件设置,语言设置,第三方登录设置,手机网站设置,其他设置等
系统管理:自定义标签管理,数据库管理,数据库还原,通道模型管理,整个站点的一键备份,操作日志管理,网站目录权限检测,菜单管理,区域管理
内容管理:频道管理,主题管理,类型管理,信息管理(每个频道的信息的添加,删除,修改和检查)
交互式管理:在线客户服务管理,第三方在线客户服务管理,订单管理,交付方式管理,付款方式管理,销售统计,资金管理,积分管理,优惠券管理,消息管理,人才招聘,评论管理
广告管理:幻灯片管理,幻灯片分组管理,广告内容管理,群发邮件管理,订阅邮箱管理,邮件订阅分类管理,友情链接管理,友情链接分类管理
会员管理:会员信息管理,会员组管理,会员功能设置,管理员信息管理,管理员组管理
APP管理:内置的APP支持,您可以在后台查看APP安装统计信息和活动分析!
网站优化:伪静态设置(是否启用了伪静态和伪静态扩展名设置),搜索引擎优化设置(页面标题,页面关键词关键字,页面描述说明),常用搜索引擎登录条目,生成网站映射,生成关键词内部链接
微信平台:微信绑定设置,基本信息设置,微信自定义菜单设置,小程序设置,微信功能设置,关注自动回复,关键词自动回复,地理位置自动回复,默认自动回复,微信,微查询,微活动,微民意测验,微调查,微会员卡
模板管理:计算机模板管理(在线模板安装,模板选择,模板管理,样式管理),手机模板管理(在线模板安装,模板选择,模板管理,样式管理)
<p>插件管理:系统支持扩展插件。内置的插件包括:数据采集,三级分发,秦牛云存储,群发邮件,图像批处理等,插件可以自己开发,无限功能可以自由扩展
智能化的关键词追踪模型通过分析挖掘打下基础
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-04-25 19:00
摘要:本文通过分析舆论信息采集策略,提出了一种智能关键词跟踪模型。通过关键词智能跟踪模型的应用,网络舆情监测系统可以及时捕获热点事件的热点关键词,从而实现网络舆情监测系统对发展趋势的敏感响应。热点事件,为网络舆情热点事件的预警提供数据支持。简而言之,关键词智能跟踪模型基于某种关键词加权算法。根据民意事件不断变化的速度,通过反复的归纳计算,可以修改,调整和校对先前选择的关键词。过程。
关键词:互联网民意监测; 关键词;智能跟踪
中文图书馆分类号:TP39 3. 09
1舆论采集和分析
1. 1信息采集
根据Internet上热点的分布特征,当执行信息采集时,系统将为时效性很强网站的主流媒体执行信息采集。信息源具有高度的可靠性和实时性,信息量采集小,分析和处理速度快,热点分析速度快,准确性高且及时警告。合理地使用主流媒体的搜索引擎网站进行基于主题的信息采集。由于这些网站的分割技术不均匀,为了确保信息采集的准确性和实时性,我们采用了第二种搜索方案。在基于主题的信息采集之前,请对要进行主题采集的单词进行分词。根据分词的结果,首先执行采集并根据“宽范围” 关键词进行存储,然后跟随采集的结果。“小范围” 关键词进一步搜索,以便采集的信息准确性很高。
1. 2信息预处理
除系统所需的舆论信息外,该网页还收录许多其他信息,例如:Flash,视频,图片,广告和冗余链接。过滤掉垃圾邮件后,还必须合并同一主题的民意信息,即删除重复项。并且根据系统的规范,将舆情统一存储,作为下一步数据分析和挖掘的基础。信息预处理的主要软件包包括:主题关键字提取,正文中的关键信息提取,自动摘要,超链接分析,URL重复数据删除,垃圾邮件过滤等。
1. 3舆论分析
(1)民意的自动分类。民意信息的自动分类也是文本分类。这是让计算机自动识别民意信息的内容并在指定的分类模型下对民意进行分类的过程。自动进行民意分类首先设置类别关键词,为每个关键词设置一个相应的权重,然后进行最基本的分析并扫描采集中的民意信息,分别扫描标题和内容,然后分析关键词的出现次数,最后根据类别关键词模型计算每个关键词的权重,如果权重超过一定分数,将自动分类为相应的类别。
(2)舆论相似度排名。根据舆论信息主要内容的相似度,比其他方法更为实用和准确。利用分词技术对舆论关键词进行比较和计算。公众舆论的相似度,并设置较高的相似度阈值;如果超过该阈值,则确认很重要;将其与原创主题合并,无需进行任何进一步的操作;合并后,添加手动重新确认链接以确保重新分发万无一失。
(3)趋势分析技术。趋势分析是使用程序根据舆论关键词提取信息发布的意图。首先,根据汉语的特点,建立语义数据库。然后将民意信息特征关键词与语义数据库进行比较,以进行语义分析,最后根据结果确定民意事件的趋势,这种趋势分析可以阐明发布者要表达的观点和立场。
2舆论关键词提取
2. 1个单个文档关键词提取
在提取关键词之前,首先对文档进行分词处理,然后使用停止词汇表和过滤规则过滤分词结果。停止词汇表包括辅助词,介词,连词和其他功能词以及长度为1的词。没有实际意义的词。对于明显无用的单词,例如数字和量词,无意义的前缀和后缀,可以设计相应的过滤功能以过滤无用的单词。然后计算过滤后的词分割结果的权重,得到每个词的权重。
2. 2 关键词权重计算
文本关键词提取更多基于权向量生成方法,最常用的是TFIDF算法。 TFIDF的主要思想是,如果某个单词或短语出现在TF频率较高的文章文章中,并且如果很少出现在其他文章中,则认为该单词或短语具有良好的分类能力(较大的IDF值),并且适合分类。但是,除了TF和IDF外,每个单词还具有有效的信息,例如语音的一部分和文档中单词的位置信息。
2. 3文档集热点关键词提取
文档集的热点关键词应该是某些文档的关键词,因此从所有文档关键词的集合中建立候选关键词集,并进行特征提取以获得文档设置关键词。如果关键词的出现次数更多,则证明热点关注度更高;反之亦然。 IDF值越大,单词的辨别能力越强,并且越符合主题的特征。
3 关键词的智能跟踪
3. 1个主题聚类
考虑到不同主题网站的权威性,影响力和及时性,主题采集的来源权重是第一个要素,发布时间是第二个要素,按权重和时间的降序排列
默认情况下,首先关键词代表一个热门话题,然后将这些热门话题聚类。将关键词集中的第一个关键词作为第一个热门主题线索,使用关键词查找文章 关键词进行聚类,并默认情况下搜索第一个文档作为热门主题,然后按页面文本的其余部分被聚类,并且余弦角用于计算该主题与现有热门主题之间的相似度。如果相似度超过阈值P,则将当前主题合并到现有主题中;如果相似度小于阈值P,则将其作为当前新主题。然后将其余页面与关键词集中的第二个关键词聚类。迭代执行该算法,直到处理要分析的页面或达到设置的主题数为止。
3. 2智能跟踪模型
参考文献:
[1]李恒勋,张华平,秦鹏。基于主题的互联网热点话题的发现[C]。第五届全国信息检索会议论文集,北京,2009:134-14 3.
[2]张守华,刘振鹏。网络舆论热点话题聚类方法研究[J]。小型微型计算机系统,2013(3):18-1 9.
关于作者:张维佳(1982-),女,硕士,讲师,研究方向:计算机技术。
作者单位:河北大学,河北保定071000 查看全部
智能化的关键词追踪模型通过分析挖掘打下基础
摘要:本文通过分析舆论信息采集策略,提出了一种智能关键词跟踪模型。通过关键词智能跟踪模型的应用,网络舆情监测系统可以及时捕获热点事件的热点关键词,从而实现网络舆情监测系统对发展趋势的敏感响应。热点事件,为网络舆情热点事件的预警提供数据支持。简而言之,关键词智能跟踪模型基于某种关键词加权算法。根据民意事件不断变化的速度,通过反复的归纳计算,可以修改,调整和校对先前选择的关键词。过程。
关键词:互联网民意监测; 关键词;智能跟踪
中文图书馆分类号:TP39 3. 09
1舆论采集和分析
1. 1信息采集
根据Internet上热点的分布特征,当执行信息采集时,系统将为时效性很强网站的主流媒体执行信息采集。信息源具有高度的可靠性和实时性,信息量采集小,分析和处理速度快,热点分析速度快,准确性高且及时警告。合理地使用主流媒体的搜索引擎网站进行基于主题的信息采集。由于这些网站的分割技术不均匀,为了确保信息采集的准确性和实时性,我们采用了第二种搜索方案。在基于主题的信息采集之前,请对要进行主题采集的单词进行分词。根据分词的结果,首先执行采集并根据“宽范围” 关键词进行存储,然后跟随采集的结果。“小范围” 关键词进一步搜索,以便采集的信息准确性很高。
1. 2信息预处理
除系统所需的舆论信息外,该网页还收录许多其他信息,例如:Flash,视频,图片,广告和冗余链接。过滤掉垃圾邮件后,还必须合并同一主题的民意信息,即删除重复项。并且根据系统的规范,将舆情统一存储,作为下一步数据分析和挖掘的基础。信息预处理的主要软件包包括:主题关键字提取,正文中的关键信息提取,自动摘要,超链接分析,URL重复数据删除,垃圾邮件过滤等。
1. 3舆论分析
(1)民意的自动分类。民意信息的自动分类也是文本分类。这是让计算机自动识别民意信息的内容并在指定的分类模型下对民意进行分类的过程。自动进行民意分类首先设置类别关键词,为每个关键词设置一个相应的权重,然后进行最基本的分析并扫描采集中的民意信息,分别扫描标题和内容,然后分析关键词的出现次数,最后根据类别关键词模型计算每个关键词的权重,如果权重超过一定分数,将自动分类为相应的类别。
(2)舆论相似度排名。根据舆论信息主要内容的相似度,比其他方法更为实用和准确。利用分词技术对舆论关键词进行比较和计算。公众舆论的相似度,并设置较高的相似度阈值;如果超过该阈值,则确认很重要;将其与原创主题合并,无需进行任何进一步的操作;合并后,添加手动重新确认链接以确保重新分发万无一失。
(3)趋势分析技术。趋势分析是使用程序根据舆论关键词提取信息发布的意图。首先,根据汉语的特点,建立语义数据库。然后将民意信息特征关键词与语义数据库进行比较,以进行语义分析,最后根据结果确定民意事件的趋势,这种趋势分析可以阐明发布者要表达的观点和立场。
2舆论关键词提取
2. 1个单个文档关键词提取
在提取关键词之前,首先对文档进行分词处理,然后使用停止词汇表和过滤规则过滤分词结果。停止词汇表包括辅助词,介词,连词和其他功能词以及长度为1的词。没有实际意义的词。对于明显无用的单词,例如数字和量词,无意义的前缀和后缀,可以设计相应的过滤功能以过滤无用的单词。然后计算过滤后的词分割结果的权重,得到每个词的权重。
2. 2 关键词权重计算
文本关键词提取更多基于权向量生成方法,最常用的是TFIDF算法。 TFIDF的主要思想是,如果某个单词或短语出现在TF频率较高的文章文章中,并且如果很少出现在其他文章中,则认为该单词或短语具有良好的分类能力(较大的IDF值),并且适合分类。但是,除了TF和IDF外,每个单词还具有有效的信息,例如语音的一部分和文档中单词的位置信息。
2. 3文档集热点关键词提取
文档集的热点关键词应该是某些文档的关键词,因此从所有文档关键词的集合中建立候选关键词集,并进行特征提取以获得文档设置关键词。如果关键词的出现次数更多,则证明热点关注度更高;反之亦然。 IDF值越大,单词的辨别能力越强,并且越符合主题的特征。
3 关键词的智能跟踪
3. 1个主题聚类
考虑到不同主题网站的权威性,影响力和及时性,主题采集的来源权重是第一个要素,发布时间是第二个要素,按权重和时间的降序排列
默认情况下,首先关键词代表一个热门话题,然后将这些热门话题聚类。将关键词集中的第一个关键词作为第一个热门主题线索,使用关键词查找文章 关键词进行聚类,并默认情况下搜索第一个文档作为热门主题,然后按页面文本的其余部分被聚类,并且余弦角用于计算该主题与现有热门主题之间的相似度。如果相似度超过阈值P,则将当前主题合并到现有主题中;如果相似度小于阈值P,则将其作为当前新主题。然后将其余页面与关键词集中的第二个关键词聚类。迭代执行该算法,直到处理要分析的页面或达到设置的主题数为止。
3. 2智能跟踪模型
参考文献:
[1]李恒勋,张华平,秦鹏。基于主题的互联网热点话题的发现[C]。第五届全国信息检索会议论文集,北京,2009:134-14 3.
[2]张守华,刘振鹏。网络舆论热点话题聚类方法研究[J]。小型微型计算机系统,2013(3):18-1 9.
关于作者:张维佳(1982-),女,硕士,讲师,研究方向:计算机技术。
作者单位:河北大学,河北保定071000
如何通过百度谷歌系统发布关键词自动采集生成内容系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2021-04-20 22:01
关键词自动采集生成内容系统,bx编辑器特点自动采集大量外链数据,内容不需要客户手动输入,后台会自动记录出现在哪个网站,方便客户再次删除搜索内容。推广人员手动输入的话,比较麻烦,而且也有注重内容质量而不是外链数量的搜索引擎。系统后台自动计算收录率,排名,包括文章内页与url相关性等指标自动修改关键词自动优化内容,注重质量而不是外链数量,重视原创内容,有很强大的文章内容智能编辑与审核。
多个搜索引擎上的站点,特别是百度,都能匹配相应的关键词自动提升内容质量,合并关键词而不是人工改动上传内容排名快速靠前,快速带来网站流量,推广人员手动输入搜索关键词没有用,而自动内容则更具有针对性,更快的带来流量,采集的内容更符合网站调性,标题更具吸引力,具备搜索引擎的价值。支持并发连接建设,一个站点兼容多种搜索引擎自动标题修改关键词记录相应搜索引擎抓取规律,一一匹配相应搜索引擎内容自动标题修改关键词记录相应搜索引擎排名追踪,一个关键词搜索引擎下找内容提示为什么需要参加百度谷歌系统的内容自动发布,不是所有百度谷歌系统的文章都可以被采集自动撰写与编辑内容,可根据搜索引擎人工编辑及推荐的语料进行调整并自动撰写内容百度谷歌微信公众号文章发布,快速实现文章可视化搜索上传图片或文字搜索相关词自动测速度上传图片或文字自动提供更好的结果搜索上传图片或文字自动提供更好的结果上传视频自动生成链接如何通过百度谷歌系统发布关键词内容百度谷歌公众号文章发布发布网站。 查看全部
如何通过百度谷歌系统发布关键词自动采集生成内容系统
关键词自动采集生成内容系统,bx编辑器特点自动采集大量外链数据,内容不需要客户手动输入,后台会自动记录出现在哪个网站,方便客户再次删除搜索内容。推广人员手动输入的话,比较麻烦,而且也有注重内容质量而不是外链数量的搜索引擎。系统后台自动计算收录率,排名,包括文章内页与url相关性等指标自动修改关键词自动优化内容,注重质量而不是外链数量,重视原创内容,有很强大的文章内容智能编辑与审核。
多个搜索引擎上的站点,特别是百度,都能匹配相应的关键词自动提升内容质量,合并关键词而不是人工改动上传内容排名快速靠前,快速带来网站流量,推广人员手动输入搜索关键词没有用,而自动内容则更具有针对性,更快的带来流量,采集的内容更符合网站调性,标题更具吸引力,具备搜索引擎的价值。支持并发连接建设,一个站点兼容多种搜索引擎自动标题修改关键词记录相应搜索引擎抓取规律,一一匹配相应搜索引擎内容自动标题修改关键词记录相应搜索引擎排名追踪,一个关键词搜索引擎下找内容提示为什么需要参加百度谷歌系统的内容自动发布,不是所有百度谷歌系统的文章都可以被采集自动撰写与编辑内容,可根据搜索引擎人工编辑及推荐的语料进行调整并自动撰写内容百度谷歌微信公众号文章发布,快速实现文章可视化搜索上传图片或文字搜索相关词自动测速度上传图片或文字自动提供更好的结果搜索上传图片或文字自动提供更好的结果上传视频自动生成链接如何通过百度谷歌系统发布关键词内容百度谷歌公众号文章发布发布网站。
关键词自动采集生成内容系统-上海怡健医学培训
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-04-19 01:05
关键词自动采集生成内容系统
一、核心业务模块1.基本功能模块
1)内容收集:在电脑上使用一些市面上常见的采集器或者自己搭建模块(一般都很贵,这里是免费的),
2)文本下载:在手机上使用一些市面上常见的采集器或者自己搭建模块(一般都很贵,这里是免费的),将文本采集进来,
3)资源搜索:找到相关资源,并且对资源进行优化分类;2.手机上功能模块1.内容收集:通过从全网找热点,对热点进行收集并且加工;2.文本下载:通过从全网找热点,对热点进行收集并且加工;3.资源搜索:找到相关资源,
二、基本原理详解使用过程中,除了核心功能模块,其他功能并不是非常困难,稍微研究下seo的教程就可以。
对于新手,我们建议先从简单入手,
1)发布出来的网页需要全部放到服务器上,静态化的本质就是不需要服务器,对于网站来说,只要采集了相关的链接,就有意义了。那么,页面静态化最简单的方法是,使用360浏览器自带的“自动识别”功能,一直使用类似这样的自动识别功能很长时间了,
2)我们的原理是,通过对文本进行一些分词,把全文进行分成几百个短句,然后使用下面的方法进行搜索的时候,一次性把它获取出来。
资源搜索
1)不管是在百度还是在360搜索,输入什么关键词,都可以获取相应的搜索结果,这些搜索结果形成的区块(即词块),
2)当我们搜索某一个词的时候,如“游戏”或者“复读机”,
3)新增网页搜索区块,就是对于自动采集区块进行“分词”,这样做的好处是,在采集的时候,可以自动分词,这样能够减少采集之后手动分词的时间,从而减轻服务器负担;3.页面动态化提高页面效率有一个前提条件,页面动态化是有前提条件的。页面动态化是根据你自定义的字段,像真正的动态搜索一样,获取页面的资源。动态化很好理解,就是替换资源名称并替换文本。
4.手机端内容源最后补充一下页面的内容源。在平台上也看到了很多手机上的内容源,内容源本质上并不复杂,由于涉及到内容源不同,网络的问题,导致一个内容源(即模块或者词块)需要做多个版本(模块、词块和词语),那么对于内容源做重定向,就是内容源本身的特点了。 查看全部
关键词自动采集生成内容系统-上海怡健医学培训
关键词自动采集生成内容系统
一、核心业务模块1.基本功能模块
1)内容收集:在电脑上使用一些市面上常见的采集器或者自己搭建模块(一般都很贵,这里是免费的),
2)文本下载:在手机上使用一些市面上常见的采集器或者自己搭建模块(一般都很贵,这里是免费的),将文本采集进来,
3)资源搜索:找到相关资源,并且对资源进行优化分类;2.手机上功能模块1.内容收集:通过从全网找热点,对热点进行收集并且加工;2.文本下载:通过从全网找热点,对热点进行收集并且加工;3.资源搜索:找到相关资源,
二、基本原理详解使用过程中,除了核心功能模块,其他功能并不是非常困难,稍微研究下seo的教程就可以。
对于新手,我们建议先从简单入手,
1)发布出来的网页需要全部放到服务器上,静态化的本质就是不需要服务器,对于网站来说,只要采集了相关的链接,就有意义了。那么,页面静态化最简单的方法是,使用360浏览器自带的“自动识别”功能,一直使用类似这样的自动识别功能很长时间了,
2)我们的原理是,通过对文本进行一些分词,把全文进行分成几百个短句,然后使用下面的方法进行搜索的时候,一次性把它获取出来。
资源搜索
1)不管是在百度还是在360搜索,输入什么关键词,都可以获取相应的搜索结果,这些搜索结果形成的区块(即词块),
2)当我们搜索某一个词的时候,如“游戏”或者“复读机”,
3)新增网页搜索区块,就是对于自动采集区块进行“分词”,这样做的好处是,在采集的时候,可以自动分词,这样能够减少采集之后手动分词的时间,从而减轻服务器负担;3.页面动态化提高页面效率有一个前提条件,页面动态化是有前提条件的。页面动态化是根据你自定义的字段,像真正的动态搜索一样,获取页面的资源。动态化很好理解,就是替换资源名称并替换文本。
4.手机端内容源最后补充一下页面的内容源。在平台上也看到了很多手机上的内容源,内容源本质上并不复杂,由于涉及到内容源不同,网络的问题,导致一个内容源(即模块或者词块)需要做多个版本(模块、词块和词语),那么对于内容源做重定向,就是内容源本身的特点了。
关键词自动采集生成内容系统,原理其实很简单!
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-04-05 07:03
关键词自动采集生成内容系统,原理其实很简单,用户提交特定关键词,系统自动采集该关键词下的内容,然后再结合关键词的热度来自动分析内容是否有价值。
推荐一个最近发现的蛮好用的一个新媒体采集工具,可以采集微信公众号,微博,知乎等社交平台的文章,配图,内容,音乐,视频,图片,代码等等。有链接在公众号里面,下载只需要复制链接就行了。看个人资料与分享的内容来源,可以选择自己分享的,也可以自己采集的。
推荐一款叫【一键采集】的工具
有这类的自动采集软件,需要一些自己的技术积累,不然像楼上说的到时候采集出来内容无法解析,还要自己再去手动分析还可以试试【搜索技术】里面有很多的技术,
谢邀,就我所知道的,原理是这样的。用户输入几个关键词,对应地把文章采集过来,然后返回给用户,参考社交平台文章标题,去抓取文章标题里面的关键词,注意,不是采集内容,是关键词。
目前市面上除了导航站之外,没见到有专门做「关键词采集」的产品,目前能找到的成熟的做关键词采集的产品无非是以下几种:微信搜索:微信搜索有很多变种,比如搜狗微信、搜狗关键词、搜狗关键词采集器等等网站:排在前列的站点主要是1688、慧聪、等导航站的导航部分、微博搜索:简单搜索,有搜狗微博导航、搜狗微博导航等其他平台:各个平台基本也有自己的导航部分,比如百度有相关的导航、谷歌有各个平台各自的导航等。 查看全部
关键词自动采集生成内容系统,原理其实很简单!
关键词自动采集生成内容系统,原理其实很简单,用户提交特定关键词,系统自动采集该关键词下的内容,然后再结合关键词的热度来自动分析内容是否有价值。
推荐一个最近发现的蛮好用的一个新媒体采集工具,可以采集微信公众号,微博,知乎等社交平台的文章,配图,内容,音乐,视频,图片,代码等等。有链接在公众号里面,下载只需要复制链接就行了。看个人资料与分享的内容来源,可以选择自己分享的,也可以自己采集的。
推荐一款叫【一键采集】的工具
有这类的自动采集软件,需要一些自己的技术积累,不然像楼上说的到时候采集出来内容无法解析,还要自己再去手动分析还可以试试【搜索技术】里面有很多的技术,
谢邀,就我所知道的,原理是这样的。用户输入几个关键词,对应地把文章采集过来,然后返回给用户,参考社交平台文章标题,去抓取文章标题里面的关键词,注意,不是采集内容,是关键词。
目前市面上除了导航站之外,没见到有专门做「关键词采集」的产品,目前能找到的成熟的做关键词采集的产品无非是以下几种:微信搜索:微信搜索有很多变种,比如搜狗微信、搜狗关键词、搜狗关键词采集器等等网站:排在前列的站点主要是1688、慧聪、等导航站的导航部分、微博搜索:简单搜索,有搜狗微博导航、搜狗微博导航等其他平台:各个平台基本也有自己的导航部分,比如百度有相关的导航、谷歌有各个平台各自的导航等。
自动采集生成内容系统开发自动发布系统框架web服务框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-03-27 02:01
关键词自动采集生成内容系统开发自动发布系统框架web服务框架编辑页面设计和优化wordpress插件开发
那我就自问自答一波吧!本人也就是一个自学的大学生,大一也没毕业,在闲来无事的时候在网上找了一些教程,跟着入门然后现在正在写这个系统(我这里就简单介绍一下,没学过编程的估计看不懂,也别喷我,谢谢!!!)今天写完就准备发布上线去了,每天就是加班,写到7天应该就可以过deploy了吧!当时做这个系统的时候我是找人搭建的开源框架,也就是不用自己搭建,用的人家的框架上传就行了,然后看着别人写的东西仿照开发一样的,这样就完成了一个简单的博客系统,学校老师组织团队开会的时候,然后由一个博客界面,学院有什么课程什么的,用了框架也可以仿制,也可以去像编辑器visualstudio这种平台去用现成的编辑器写!非常简单的!。
曾经在网上搜过wordpress,搜到了一些教程,其中有一个叫做edubox-博客园,有安装配置的教程,安装后显示wordpress,后续才逐步开始有配置。原来我从来没试过用wordpress系统,一直以为那种带网站的php就算了,一是我自己弄过,二是最近系统不够稳定,有点卡,不顺心。于是认真学习了wordpress的基本配置,基本可以了解到基本的wordpress的功能。
想做一个全文搜索引擎的博客当然有可能,但这没必要了。我尝试过做一个搜索引擎,这个方向比较大,我感觉需要耗费的精力跟时间,肯定比自己搭建的重。这样可能对我目前不具有商业意义吧。花一个月时间自己搞一个,目的是能够用wordpress获取博客的信息,写网站用户体验。如果花了一个月,也搞不出来什么东西来,那我为什么还花时间来学习呢?看了一个月的教程,或许是我对学习这个词的理解还不够深刻,当我对学习这个词理解到能够解释一下开发一个教程在技术上的意义时,我对能不能将wordpress博客优化好这个课题产生了疑惑。
首先wordpress网站是由很多文章组成的,也就是说这种不全文搜索网站,要做的本身就是要搜索全文,所以涉及到全文搜索引擎的学习,可能大部分教程都不会告诉你怎么来操作,即使告诉你了,也不会有人写技术文章说明,说明他们是在多久多久做到多么牛x。全文搜索的目的是一篇文章里的很多文章都能帮助到用户,而不是每篇文章都能给他们带来价值。
这应该不属于wordpress网站的学习方向,直到发现了这篇博客可以通过代码实现全文搜索,当时我就想这个东西很新颖,应该会是一个很大的网站,于是决定学习这个,随后开始啃css技术。至于用什么代码,一开始我看的也是php代码,而且我几乎只掌握css不涉及p。 查看全部
自动采集生成内容系统开发自动发布系统框架web服务框架
关键词自动采集生成内容系统开发自动发布系统框架web服务框架编辑页面设计和优化wordpress插件开发
那我就自问自答一波吧!本人也就是一个自学的大学生,大一也没毕业,在闲来无事的时候在网上找了一些教程,跟着入门然后现在正在写这个系统(我这里就简单介绍一下,没学过编程的估计看不懂,也别喷我,谢谢!!!)今天写完就准备发布上线去了,每天就是加班,写到7天应该就可以过deploy了吧!当时做这个系统的时候我是找人搭建的开源框架,也就是不用自己搭建,用的人家的框架上传就行了,然后看着别人写的东西仿照开发一样的,这样就完成了一个简单的博客系统,学校老师组织团队开会的时候,然后由一个博客界面,学院有什么课程什么的,用了框架也可以仿制,也可以去像编辑器visualstudio这种平台去用现成的编辑器写!非常简单的!。
曾经在网上搜过wordpress,搜到了一些教程,其中有一个叫做edubox-博客园,有安装配置的教程,安装后显示wordpress,后续才逐步开始有配置。原来我从来没试过用wordpress系统,一直以为那种带网站的php就算了,一是我自己弄过,二是最近系统不够稳定,有点卡,不顺心。于是认真学习了wordpress的基本配置,基本可以了解到基本的wordpress的功能。
想做一个全文搜索引擎的博客当然有可能,但这没必要了。我尝试过做一个搜索引擎,这个方向比较大,我感觉需要耗费的精力跟时间,肯定比自己搭建的重。这样可能对我目前不具有商业意义吧。花一个月时间自己搞一个,目的是能够用wordpress获取博客的信息,写网站用户体验。如果花了一个月,也搞不出来什么东西来,那我为什么还花时间来学习呢?看了一个月的教程,或许是我对学习这个词的理解还不够深刻,当我对学习这个词理解到能够解释一下开发一个教程在技术上的意义时,我对能不能将wordpress博客优化好这个课题产生了疑惑。
首先wordpress网站是由很多文章组成的,也就是说这种不全文搜索网站,要做的本身就是要搜索全文,所以涉及到全文搜索引擎的学习,可能大部分教程都不会告诉你怎么来操作,即使告诉你了,也不会有人写技术文章说明,说明他们是在多久多久做到多么牛x。全文搜索的目的是一篇文章里的很多文章都能帮助到用户,而不是每篇文章都能给他们带来价值。
这应该不属于wordpress网站的学习方向,直到发现了这篇博客可以通过代码实现全文搜索,当时我就想这个东西很新颖,应该会是一个很大的网站,于是决定学习这个,随后开始啃css技术。至于用什么代码,一开始我看的也是php代码,而且我几乎只掌握css不涉及p。
易淘站群管理系统特点及特点分析-乐题库
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-06-27 05:10
易淘站群管理系统特点及特点分析-乐题库
所有版本,支持网站,傻瓜式操作,采集自动更新,无需写采集规则,长尾关键词采集,新数据采集,数据发布,可用永久免费升级,包括vps在内的任何电脑都可以挂采集发布,可以同时开多个账号使用。
所有版本,支持网站,傻瓜式操作,采集自动更新,无需写采集规则,长尾关键词采集,新数据采集,数据发布,可用 永久免费升级,任何含有vps的电脑都可以使用挂机采集发布,可以开多个账号同时使用,不绑定机器硬件,无需购买加密狗,支持发布数据到各种流行的cms,也有独立的网站程序自定义发布界面。
Easy Tao站群管理系统特点:
1、整站全自动采集自动更新关键词和爬取频率设置后,系统会自动生成相关关键词和自动采集并生成相关文章,真正全自动聚合! 关键词系统爬虫会智能采集相对原创性别和相对较新的文章,保证文章质量。最重要的采集是pan采集,不需要写任何采集规则。你只需添加几个关键词,告诉系统你的网站定位,剩下的让系统自动完成。
2、制易淘站群建站数量管理系统本身就是一个免费的采集自动更新站群软件。无需花一分钱,即可使用功能强大的站群 软件。这个系统最大的特点就是网站的数量,和夏克、艾聚等限制网站数量的系统有很大的不同。你只需要一套。只要你有能量,你就可以做出无数的改变。输入网站。
3、强的伪原创Function Easy Amoy站群 系统可以在不影响原文可读性的情况下自动采集根据系统原文自动执行伪原创。这个系统是独一无二的文章的同义词和反义词引擎可以适当改变文章的语义,并使用独特的算法进行控制,让每一个文章都接近原创文章,而这一切由系统智能自动完成,无需人工。干预。
4、strong 抓取准确率 Yitao站群系统是泛抓取pan采集系统,不能局限于网站不限域名抓取相关文章,不是您需要定制的任意爬取策略和采集规则,系统会爬取与集合关键词最相关的原创文章,捕获的文章正确率可接受。达到90%以上,瞬间就能产生上千个原创性文章。
5 自定义关键词、链接、html代码可以随意插入到发布的内容中。支持内部锚链接。 关键词内锚文本网站随机插入到文章内容中。可设置链接环,实现单站定时定量发布。支持单站一键直接采集发布支持英文数据采集和发布new网站更新完成后自动提取文章标题和连接插入全局链接库进行插入集成 自动update可以设置一次更新网站会自动关闭增加周期站群Update:根据设置,站群24hours可以轮流更新采集post 查看全部
易淘站群管理系统特点及特点分析-乐题库
所有版本,支持网站,傻瓜式操作,采集自动更新,无需写采集规则,长尾关键词采集,新数据采集,数据发布,可用永久免费升级,包括vps在内的任何电脑都可以挂采集发布,可以同时开多个账号使用。
所有版本,支持网站,傻瓜式操作,采集自动更新,无需写采集规则,长尾关键词采集,新数据采集,数据发布,可用 永久免费升级,任何含有vps的电脑都可以使用挂机采集发布,可以开多个账号同时使用,不绑定机器硬件,无需购买加密狗,支持发布数据到各种流行的cms,也有独立的网站程序自定义发布界面。
Easy Tao站群管理系统特点:
1、整站全自动采集自动更新关键词和爬取频率设置后,系统会自动生成相关关键词和自动采集并生成相关文章,真正全自动聚合! 关键词系统爬虫会智能采集相对原创性别和相对较新的文章,保证文章质量。最重要的采集是pan采集,不需要写任何采集规则。你只需添加几个关键词,告诉系统你的网站定位,剩下的让系统自动完成。
2、制易淘站群建站数量管理系统本身就是一个免费的采集自动更新站群软件。无需花一分钱,即可使用功能强大的站群 软件。这个系统最大的特点就是网站的数量,和夏克、艾聚等限制网站数量的系统有很大的不同。你只需要一套。只要你有能量,你就可以做出无数的改变。输入网站。
3、强的伪原创Function Easy Amoy站群 系统可以在不影响原文可读性的情况下自动采集根据系统原文自动执行伪原创。这个系统是独一无二的文章的同义词和反义词引擎可以适当改变文章的语义,并使用独特的算法进行控制,让每一个文章都接近原创文章,而这一切由系统智能自动完成,无需人工。干预。
4、strong 抓取准确率 Yitao站群系统是泛抓取pan采集系统,不能局限于网站不限域名抓取相关文章,不是您需要定制的任意爬取策略和采集规则,系统会爬取与集合关键词最相关的原创文章,捕获的文章正确率可接受。达到90%以上,瞬间就能产生上千个原创性文章。
5 自定义关键词、链接、html代码可以随意插入到发布的内容中。支持内部锚链接。 关键词内锚文本网站随机插入到文章内容中。可设置链接环,实现单站定时定量发布。支持单站一键直接采集发布支持英文数据采集和发布new网站更新完成后自动提取文章标题和连接插入全局链接库进行插入集成 自动update可以设置一次更新网站会自动关闭增加周期站群Update:根据设置,站群24hours可以轮流更新采集post
自然语言处理中比较难的一个任务-序文本摘要
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-06-22 18:28
转载
前言
文本摘要是自然语言处理中相对困难的任务。别说用机器做总结,就连人类在做总结的时候都需要有很强的语言阅读理解和概括能力。新闻摘要要求编辑从新闻事件中提取最关键的信息点,重新组织语言来撰写摘要;论文摘要要求作者从全文中提取核心工作,然后用更精炼的语言撰写摘要;总结一篇性论文需要作者通读N篇相关主题的论文,用最通俗的语言写出每个文章的贡献和创新,比较每个文章方法的优缺点。自动摘要本质上做的一件事是信息过滤。从某种意义上说,它类似于推荐系统的功能。它旨在让人们更快地找到感兴趣的事物,但它使用了不同的方法。 .
问题描述
文本摘要问题根据文档数量可以分为单文档摘要和多文档摘要。根据实现方式,可分为抽取式和抽象式。抽象问题的特点是输出文本比输入文本少很多,但收录了很多有效信息。感觉有点像主成分分析(PCA),它的功能有点像推荐系统,都是为了解决信息过载的问题。目前,大多数应用系统都是提取式的。这种方法比较简单,但是问题很多。原因很简单,只需要从原文中找出比较重要的句子就可以组成输出。系统只需要使用模型。选择信息量大的句子,按照自然顺序组合起来,形成摘要。但是,很难保证摘要的连贯性和一致性。例如,当一个句子收录代词时,仅仅通过连接它是不可能知道代词所指代词的,这会导致结果不佳。在研究中,随着nlp中的深度学习技术,尤其是seq2seq+attention模型的“横行”,大家将抽象抽象的研究提升到了一个层次,提出了copy机制等机制来解决seq2seq模型中的OOV问题。
本文讨论了使用 abstractive 解决句子级文本摘要问题。问题的定义比较简单。输入为长度为M的文本序列,输出为长度为N的文本序列,其中M> >N,输出文本的含义与输入文本的含义基本相同。输入可能是一个句子或多个句子,输出都是一个句子或多个句子。
语料库
这里的语料分为两种,一种是用于训练深度学习模型的大型语料库,一种是用于参与评价的小型语料库。
1、DUC
这个网站 提供了一个文本摘要竞赛。 2001年到2007年是网站,2008年改为网站TAC。这是一场正式的比赛,各大文本摘要系统都会在这里展开较量,相互较量。这里提供的数据集都是用来评估模型的小数据集。
2、Gigaword
语料库非常大。大约有 950w 个 news文章。数据集以标题为摘要,即输出文本,以第一句为输入,即输入文本。属于单句摘要数据集。
3、CNN/每日邮报
这个语料库是我们在机器阅读理解中使用的语料库,这个数据集是一个多句摘要。
4、Large Scale Chinese Short Text Summarization Dataset (LCSTS)[6]
这是一个中文短文本摘要数据集。数据采集自新浪微博给学习中文文摘的童鞋们带来了好处。
型号
本文提到的模型都是抽象的seq2seq模型。最早在nlp中使用seq2seq+attention模型解决问题是在机器翻译领域。现在这个方法已经席卷了很多领域的排名。
seq2seq的模型一般有如下结构[1]:
编码器部分使用单层或多层 rnn/lstm/gru 对输入进行编码,解码器部分是用于生成摘要的语言模型。这种生成问题可以简化为解决条件概率问题 p(word|context)。在上下文条件下,计算词汇表中每个词的概率值,将概率最高的词作为生成词,依次生成摘要中的所有词。这里的关键是如何表示上下文。每个模型之间最大的区别在于上下文的不同。这里的上下文可能只是编码器的表示,也可能是注意力和编码器的表示。解码器部分通常由波束搜索算法生成。
1、复杂注意力模型[1]
模型中的注意力权重通过将编码器中每个词的最后一个隐藏层的表示与当前解码器中最新词的最后一个隐藏层的表示相乘,然后进行归一化来表示。
2、简单注意力模型[1]
该模型将每个词最后一层隐藏层中编码器部分的表示分为两个块,一个小块用于计算注意力权重,另一个大块用作编码器。该模型将最后一个隐藏层细分为不同的功能。
3、Attention-Based Summarization(ABS)[2]
该模型使用三种不同的编码器,包括:词袋编码器、卷积编码器和基于注意力的编码器。 Rush 属于HarvardNLP 小组。这个群体的特点是他们喜欢用CNN来做nlp任务。在这个模型中,我们看到了不同的编码器,从非常简单的词袋模型到 CNN,再到基于注意力的模型,而不是千篇一律的 rnn、lstm 和 gru。解码器部分使用了一个非常简单的NNLM,即Bengio[10]在2003年提出的前馈神经网络语言模型。该模型是后续神经网络语言模型研究的基石,也是后续词研究的基础嵌入。了基。基础。可以说这个模型用最简单的encoder和decoder来做seq2seq,是一个非常好的尝试。
4、ABS+[2]
Rush 在提出纯数据驱动模型 ABS 之后,又提出了抽象与抽取相结合的模型。在ABS模型的基础上,增加了特征函数,修改了score函数,得到了更好的ABS+。模型。
5、Recurrent Attentive Summarizer(RAS)[3]
这个模型是由 Rush 的学生提出的。输入中每个词的最终embedding是每个词的embedding和每个词位置的embedding之和。经过一层卷积,得到聚合向量:
根据聚合向量计算上下文(编码器输出):
权重的计算公式如下:
解码器部分使用RNNLM生成。 RNNLM是基于Bengio提出的NNLM的改进模型,也是主流的语言模型。
6、big-words-lvt2k-1sent 模型[4]
该模型将大词汇量技巧 (LVT) 技术引入到文本摘要问题中。在该方法中,每个minibatch中解码器的词汇以编码器的词汇为准,解码器词汇中的词由一定数量的高频词组成。该模型的思想侧重于解决由于解码器词汇量大而导致的softmax层的计算瓶颈。该模型非常适合解决文本摘要的问题,因为摘要中的很多词都来自原文。
7、words-lvt2k-2sent-hieratt 模型[4]
这样的问题在文字摘要中经常遇到。一些关键词 很少出现但非常重要。由于该模型基于词嵌入,对低频词不友好,本文提出了一种decoder/pointer机制来解决这个问题。模型中的解码器有一个开关。如果开关状态是打开发电机,则产生一个字;如果关闭,则解码器生成一个指向原创单词位置的指针,然后将其复制到摘要中。指针机制在求解低频词时更加鲁棒,因为它使用编码器中低频词的隐藏层表示作为输入,是一种上下文敏感的表示,但只是一个词向量。这种指针机制与下一篇文章中的复制机制非常相似。
8、feats-lvt2k-2sent-ptr 模型[4]
数据集中的原文一般都很长。原文中的关键词和关键句对于形成总结非常重要。该模型使用了两个双向RNN来捕捉这两个层次的重要性,一个是word-level,一个是sentence-level,模型在两个层次上都使用了attention,权重如下:
9、COPYNET[8]
编码器采用双向RNN模型,输出一个隐藏层表示的矩阵M作为解码器的输入。解码器部分与传统的Seq2Seq有以下三个部分不同:
预测:生成词有两种模式,一种是生成模式,一种是复制模式,生成模型是两种模式结合的概率模型。
状态更新:使用t-1时刻的预测词来更新t时刻的状态。 COPYNET不仅是词向量,还利用了M矩阵中特定位置的隐藏状态。
读取M:COPYNET也会有选择地读取M矩阵来获取混合内容和位置的信息。
这个模型的想法与第七个模型的想法非常相似。因为很好地处理了OOV问题,所以效果非常好。
10、MRT+NHG[7]
该模型的特殊之处在于它使用最小风险训练训练数据,而不是传统的 MLE(最大似然估计)。将评价指标纳入优化目标,对评价指标进行更直接的优化。效果不错。
结果
评价指标是否科学可行,直接影响一个研究领域的研究水平。目前,文本摘要任务中最常用的评估方法是 ROUGE(Recall-Oriented Understudy for Gisting Evaluation)。 ROUGE 的灵感来自 BLEU,一种机器翻译的自动评估方法,不同之处在于它使用召回率作为指标。基本思想是利用模型生成的摘要和参考摘要的n元组贡献统计量作为判断依据。
在中文数据集LCSTS上进行评估,结果如下:
无论是中文数据集还是英文数据集,最好的结果都来自Model 10[7],而且这个模型只是使用了最常见的seq2seq+attention模型,没有使用效果更好的副本。机制或指针机制。
思考
自动摘要是我关注的第一个nlp字段。前期有很多相关的论文,各方面都学习了,也有一些比较浅薄的想法。现在我总结一下。
1、为什么MRT文章文章的结果比其他各种模型好?因为它直接在待优化的目标中收录了ROUGE指标,而不是像其他模型一样使用传统的MLE,传统的目标评估你的生产质量如何,但它与我们最终的评估指标ROUGE不一样。没有直接关系。所以,如果改变一个优化目标,直接针对评价指标进行优化,效果会非常好。这不仅出现在自动摘要中,我记得在机器人相关论文和机器阅读理解相关论文中也出现过,只是具体评价指标不同。这是非常有启发性的。如果用copy机制解决文章[7]中的OOV问题,会不会有更惊人的结果?我们拭目以待。
2、OOV(词汇量不足)问题。归根结底,文本摘要是一个语言生成问题。只要涉及到生成问题,就难免会遇到OOV问题,因为不可能把词表中的所有词都放在来计算概率。可行的方法是使用Choose topn高频词形成词汇表。 文章[4] 和 [8] 都采用了类似的想法,将原创文本从输入复制到输出,而不是仅仅生成它。这里需要设置一个门来判断单词是复制的还是生成的。显然,加入复制机制的模型将在很大程度上解决OOV问题,并将显着提高评估结果。这个想法不仅适用于抽象问题,也适用于所有生成问题,例如机器人。
3、关于评价指标的问题。一个评价指标的科学与否,直接影响到该领域的发展水平,我们不说人工评价,只说自动评价。 ROUGE 指标由 Lin 在 2003 年提出 [9]。 13年后,仍然没有更合适的评价体系来取代它。 ROUGE评价过于死板,只能评价输出和目标之间的一些表面信息,不涉及语义层面的东西。能否提出更高层次的评价体系,从语义层面评价摘要?影响。其实技术问题不大,因为计算两个文本序列之间的相似度有无数种解决方案,比如有监督的、无监督的、半监督的等等。期待新的摘要效果评价体系,相信新的评价体系必将推动自动摘要领域的发展。
4、关于数据集的问题。 LCSTS数据集的构建为中文文本摘要的研究奠定了基础,将极大地推动中文领域自动摘要的发展。当今互联网上最不可缺少的就是数据,大量的非结构化数据。然而,如何构建高质量的语料库是一个难题。如何避免使用过多的人工方法来保证质量,如何使用自动化的方法来提高语料库的质量是一个难题。因此,如果能提出新的思路来构建自动抽象语料库,将是非常有意义的。
参考资料
[1] 使用循环神经网络生成新闻标题
[2] 抽象句摘要的神经注意力模型
[3] 基于注意力循环神经网络的抽象句子摘要
[4] 使用序列到序列 RNN 及其他方法的抽象文本摘要
[5] AttSum:Focusing and Summarization with Neural Attention的联合学习
[6] LCSTS:大规模中文短文本摘要数据集
[7] 最小风险训练的神经标题生成
[8] 在序列到序列学习训练中加入复制机制
[9] 使用 N-gram 共现统计自动评估摘要
[10] 神经概率语言模型 查看全部
自然语言处理中比较难的一个任务-序文本摘要
转载
前言
文本摘要是自然语言处理中相对困难的任务。别说用机器做总结,就连人类在做总结的时候都需要有很强的语言阅读理解和概括能力。新闻摘要要求编辑从新闻事件中提取最关键的信息点,重新组织语言来撰写摘要;论文摘要要求作者从全文中提取核心工作,然后用更精炼的语言撰写摘要;总结一篇性论文需要作者通读N篇相关主题的论文,用最通俗的语言写出每个文章的贡献和创新,比较每个文章方法的优缺点。自动摘要本质上做的一件事是信息过滤。从某种意义上说,它类似于推荐系统的功能。它旨在让人们更快地找到感兴趣的事物,但它使用了不同的方法。 .
问题描述
文本摘要问题根据文档数量可以分为单文档摘要和多文档摘要。根据实现方式,可分为抽取式和抽象式。抽象问题的特点是输出文本比输入文本少很多,但收录了很多有效信息。感觉有点像主成分分析(PCA),它的功能有点像推荐系统,都是为了解决信息过载的问题。目前,大多数应用系统都是提取式的。这种方法比较简单,但是问题很多。原因很简单,只需要从原文中找出比较重要的句子就可以组成输出。系统只需要使用模型。选择信息量大的句子,按照自然顺序组合起来,形成摘要。但是,很难保证摘要的连贯性和一致性。例如,当一个句子收录代词时,仅仅通过连接它是不可能知道代词所指代词的,这会导致结果不佳。在研究中,随着nlp中的深度学习技术,尤其是seq2seq+attention模型的“横行”,大家将抽象抽象的研究提升到了一个层次,提出了copy机制等机制来解决seq2seq模型中的OOV问题。
本文讨论了使用 abstractive 解决句子级文本摘要问题。问题的定义比较简单。输入为长度为M的文本序列,输出为长度为N的文本序列,其中M> >N,输出文本的含义与输入文本的含义基本相同。输入可能是一个句子或多个句子,输出都是一个句子或多个句子。
语料库
这里的语料分为两种,一种是用于训练深度学习模型的大型语料库,一种是用于参与评价的小型语料库。
1、DUC
这个网站 提供了一个文本摘要竞赛。 2001年到2007年是网站,2008年改为网站TAC。这是一场正式的比赛,各大文本摘要系统都会在这里展开较量,相互较量。这里提供的数据集都是用来评估模型的小数据集。
2、Gigaword
语料库非常大。大约有 950w 个 news文章。数据集以标题为摘要,即输出文本,以第一句为输入,即输入文本。属于单句摘要数据集。
3、CNN/每日邮报
这个语料库是我们在机器阅读理解中使用的语料库,这个数据集是一个多句摘要。
4、Large Scale Chinese Short Text Summarization Dataset (LCSTS)[6]
这是一个中文短文本摘要数据集。数据采集自新浪微博给学习中文文摘的童鞋们带来了好处。
型号
本文提到的模型都是抽象的seq2seq模型。最早在nlp中使用seq2seq+attention模型解决问题是在机器翻译领域。现在这个方法已经席卷了很多领域的排名。
seq2seq的模型一般有如下结构[1]:
编码器部分使用单层或多层 rnn/lstm/gru 对输入进行编码,解码器部分是用于生成摘要的语言模型。这种生成问题可以简化为解决条件概率问题 p(word|context)。在上下文条件下,计算词汇表中每个词的概率值,将概率最高的词作为生成词,依次生成摘要中的所有词。这里的关键是如何表示上下文。每个模型之间最大的区别在于上下文的不同。这里的上下文可能只是编码器的表示,也可能是注意力和编码器的表示。解码器部分通常由波束搜索算法生成。
1、复杂注意力模型[1]
模型中的注意力权重通过将编码器中每个词的最后一个隐藏层的表示与当前解码器中最新词的最后一个隐藏层的表示相乘,然后进行归一化来表示。
2、简单注意力模型[1]
该模型将每个词最后一层隐藏层中编码器部分的表示分为两个块,一个小块用于计算注意力权重,另一个大块用作编码器。该模型将最后一个隐藏层细分为不同的功能。
3、Attention-Based Summarization(ABS)[2]
该模型使用三种不同的编码器,包括:词袋编码器、卷积编码器和基于注意力的编码器。 Rush 属于HarvardNLP 小组。这个群体的特点是他们喜欢用CNN来做nlp任务。在这个模型中,我们看到了不同的编码器,从非常简单的词袋模型到 CNN,再到基于注意力的模型,而不是千篇一律的 rnn、lstm 和 gru。解码器部分使用了一个非常简单的NNLM,即Bengio[10]在2003年提出的前馈神经网络语言模型。该模型是后续神经网络语言模型研究的基石,也是后续词研究的基础嵌入。了基。基础。可以说这个模型用最简单的encoder和decoder来做seq2seq,是一个非常好的尝试。
4、ABS+[2]
Rush 在提出纯数据驱动模型 ABS 之后,又提出了抽象与抽取相结合的模型。在ABS模型的基础上,增加了特征函数,修改了score函数,得到了更好的ABS+。模型。
5、Recurrent Attentive Summarizer(RAS)[3]
这个模型是由 Rush 的学生提出的。输入中每个词的最终embedding是每个词的embedding和每个词位置的embedding之和。经过一层卷积,得到聚合向量:
根据聚合向量计算上下文(编码器输出):
权重的计算公式如下:
解码器部分使用RNNLM生成。 RNNLM是基于Bengio提出的NNLM的改进模型,也是主流的语言模型。
6、big-words-lvt2k-1sent 模型[4]
该模型将大词汇量技巧 (LVT) 技术引入到文本摘要问题中。在该方法中,每个minibatch中解码器的词汇以编码器的词汇为准,解码器词汇中的词由一定数量的高频词组成。该模型的思想侧重于解决由于解码器词汇量大而导致的softmax层的计算瓶颈。该模型非常适合解决文本摘要的问题,因为摘要中的很多词都来自原文。
7、words-lvt2k-2sent-hieratt 模型[4]
这样的问题在文字摘要中经常遇到。一些关键词 很少出现但非常重要。由于该模型基于词嵌入,对低频词不友好,本文提出了一种decoder/pointer机制来解决这个问题。模型中的解码器有一个开关。如果开关状态是打开发电机,则产生一个字;如果关闭,则解码器生成一个指向原创单词位置的指针,然后将其复制到摘要中。指针机制在求解低频词时更加鲁棒,因为它使用编码器中低频词的隐藏层表示作为输入,是一种上下文敏感的表示,但只是一个词向量。这种指针机制与下一篇文章中的复制机制非常相似。
8、feats-lvt2k-2sent-ptr 模型[4]
数据集中的原文一般都很长。原文中的关键词和关键句对于形成总结非常重要。该模型使用了两个双向RNN来捕捉这两个层次的重要性,一个是word-level,一个是sentence-level,模型在两个层次上都使用了attention,权重如下:
9、COPYNET[8]
编码器采用双向RNN模型,输出一个隐藏层表示的矩阵M作为解码器的输入。解码器部分与传统的Seq2Seq有以下三个部分不同:
预测:生成词有两种模式,一种是生成模式,一种是复制模式,生成模型是两种模式结合的概率模型。
状态更新:使用t-1时刻的预测词来更新t时刻的状态。 COPYNET不仅是词向量,还利用了M矩阵中特定位置的隐藏状态。
读取M:COPYNET也会有选择地读取M矩阵来获取混合内容和位置的信息。
这个模型的想法与第七个模型的想法非常相似。因为很好地处理了OOV问题,所以效果非常好。
10、MRT+NHG[7]
该模型的特殊之处在于它使用最小风险训练训练数据,而不是传统的 MLE(最大似然估计)。将评价指标纳入优化目标,对评价指标进行更直接的优化。效果不错。
结果
评价指标是否科学可行,直接影响一个研究领域的研究水平。目前,文本摘要任务中最常用的评估方法是 ROUGE(Recall-Oriented Understudy for Gisting Evaluation)。 ROUGE 的灵感来自 BLEU,一种机器翻译的自动评估方法,不同之处在于它使用召回率作为指标。基本思想是利用模型生成的摘要和参考摘要的n元组贡献统计量作为判断依据。
在中文数据集LCSTS上进行评估,结果如下:
无论是中文数据集还是英文数据集,最好的结果都来自Model 10[7],而且这个模型只是使用了最常见的seq2seq+attention模型,没有使用效果更好的副本。机制或指针机制。
思考
自动摘要是我关注的第一个nlp字段。前期有很多相关的论文,各方面都学习了,也有一些比较浅薄的想法。现在我总结一下。
1、为什么MRT文章文章的结果比其他各种模型好?因为它直接在待优化的目标中收录了ROUGE指标,而不是像其他模型一样使用传统的MLE,传统的目标评估你的生产质量如何,但它与我们最终的评估指标ROUGE不一样。没有直接关系。所以,如果改变一个优化目标,直接针对评价指标进行优化,效果会非常好。这不仅出现在自动摘要中,我记得在机器人相关论文和机器阅读理解相关论文中也出现过,只是具体评价指标不同。这是非常有启发性的。如果用copy机制解决文章[7]中的OOV问题,会不会有更惊人的结果?我们拭目以待。
2、OOV(词汇量不足)问题。归根结底,文本摘要是一个语言生成问题。只要涉及到生成问题,就难免会遇到OOV问题,因为不可能把词表中的所有词都放在来计算概率。可行的方法是使用Choose topn高频词形成词汇表。 文章[4] 和 [8] 都采用了类似的想法,将原创文本从输入复制到输出,而不是仅仅生成它。这里需要设置一个门来判断单词是复制的还是生成的。显然,加入复制机制的模型将在很大程度上解决OOV问题,并将显着提高评估结果。这个想法不仅适用于抽象问题,也适用于所有生成问题,例如机器人。
3、关于评价指标的问题。一个评价指标的科学与否,直接影响到该领域的发展水平,我们不说人工评价,只说自动评价。 ROUGE 指标由 Lin 在 2003 年提出 [9]。 13年后,仍然没有更合适的评价体系来取代它。 ROUGE评价过于死板,只能评价输出和目标之间的一些表面信息,不涉及语义层面的东西。能否提出更高层次的评价体系,从语义层面评价摘要?影响。其实技术问题不大,因为计算两个文本序列之间的相似度有无数种解决方案,比如有监督的、无监督的、半监督的等等。期待新的摘要效果评价体系,相信新的评价体系必将推动自动摘要领域的发展。
4、关于数据集的问题。 LCSTS数据集的构建为中文文本摘要的研究奠定了基础,将极大地推动中文领域自动摘要的发展。当今互联网上最不可缺少的就是数据,大量的非结构化数据。然而,如何构建高质量的语料库是一个难题。如何避免使用过多的人工方法来保证质量,如何使用自动化的方法来提高语料库的质量是一个难题。因此,如果能提出新的思路来构建自动抽象语料库,将是非常有意义的。
参考资料
[1] 使用循环神经网络生成新闻标题
[2] 抽象句摘要的神经注意力模型
[3] 基于注意力循环神经网络的抽象句子摘要
[4] 使用序列到序列 RNN 及其他方法的抽象文本摘要
[5] AttSum:Focusing and Summarization with Neural Attention的联合学习
[6] LCSTS:大规模中文短文本摘要数据集
[7] 最小风险训练的神经标题生成
[8] 在序列到序列学习训练中加入复制机制
[9] 使用 N-gram 共现统计自动评估摘要
[10] 神经概率语言模型
文本摘要技术在图书情报领域,IBM计算机科学家H.P.Luhn
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-06-07 19:30
文本摘要的应用
文本摘要的应用、文档自动索引、新闻信息服务、信息检索等
是图书情报领域的主要研究内容。一般索引包括关键词标引、主题词索引和摘要索引。以前是人做的,现在机器自动做,会节省很多人力。
新闻服务商提供新闻信息时,无论是提供单条新闻还是聚合新闻,用户有时不想看全文,或者看很多相关新闻,又想看摘要,所以有些网站 大会提供的新闻摘要将显示在news网站上。有一个叫Summly的应用,原名Trimit,是一款运行在iOS上的新闻阅读应用。它是由英国天才尼克·达洛伊西奥 (Nick D'Aloisio) 在 15 岁时创作的。该应用程序可以使用全文语义分析算法将整个新闻浓缩成一个新闻摘要,标题清晰,几句话。用户只需不到一分钟就能了解新闻中最关键的信息。该申请于2018年获得雅虎批准,以3000万美元收购。
信息检索是用户查询和获取信息的主要方式,是查找信息的方法和手段。输入相关的关键词,就会得到相关的网页,
信息检索中的典型应用搜索。打开搜索引擎,输入search关键词,就会返回搜索结果。网页会显示多个满足关键词条件的信息结果,每个结果会显示结果信息片段,这个信息结果片段会收录搜索关键词,这也是网页内容中最重要的部分,对原文的总结。这是一个特殊的摘要,内容应该与关键词有关。很多年前,就有专门研究这个领域的人。由于技术成熟,现在学习的人越来越少。
文本摘要技术
在图书馆和信息领域,IBM 计算机科学家 H.P.卢恩于1958年发表了《文学文摘的自动创建》,一篇关于文学文摘自动创建的论文。本文提出文章中最重要的句子是关键词最多的句子,关键词是出现次数最多的词。他的总结是将最重要的句子组合在一起。从本文开始到现在,人们研究文本自动摘要的历史已有 60 多年,并取得了一些进展,但仍不尽如人意。
目前在实现自动文本摘要方面还存在很大的困难:
第一:写摘要是一项非常聪明的工作,所以聪明的任务是免费的。假设有一个任务,需要 10 人或更多人根据同一个长文档写一个摘要。很可能大家都会写一个总结。他们不一样,但每个人写的摘要可能还可以。这种没有统一标准、玩起来比较自由的工作,其实机器很难做到。这个任务本质上是机器的搜索问题。你提供的信息越多,组合就越多,搜索空间就越大,结果越不可控。相反,信息越少,搜索空间越小,机器做起来就越容易。
自然语言处理中的机器翻译工作比自动文本摘要更容易。机器翻译的任务是给出源语言的句子,机器翻译后得到目标语言的句子。这个任务有很强的约束,要求前后语言的语义报告一致,甚至每个词都可以匹配。这种约束强的任务会比较容易做。
第二:机器写的摘要与专家写的摘要不同
在写摘要之前,人们已经在脑海中对文章内容的内容和意义有了很好的理解和体验,然后再写摘要形成摘要。写好摘要后,可以展开为文章,如果有摘要,就会有文章。机器写summary的时候,需要先文章再生成summary。这将挑战机器自动生成摘要。
自动汇总代表系统
是一个简单的系统,主要通过句子抽取来实现。 NewsInEssence 是一个应用于新闻领域的摘要系统。提供news文章topic聚类(Topic Clustering)、实时搜索、文章summary和用户交互(User Interaction)等功能。
Newsblaster 是美国哥伦比亚大学开发的多文档抽象系统,采用文本聚类作为预处理过程,在处理每天发生的重要新闻后生成简明摘要,如文本聚类、信息融合和文本一代。这项工作稍微复杂一些。句子可以调整,任何句子都可以断开和重新组合。从而会出现句子不一致、标点符号缺失等问题。
总长度
自动文本摘要的长度是实际应用场景中的一个重要问题。会影响用户的阅读体验,以及系统能否在文本长度上有效表达文章内容。 ,
《摘要特刊介绍》一书的作者拉德夫认为,摘要是“从一个或多个文本中提取的一段文本,其中收录原文中的重要信息,其长度不超过比或远远少于原文的一半”。
生成的摘要的长度可以由用户根据需要指定。可以根据摘要与原文的比例,如10%或20%,也可以根据摘要的字数或字节数,100字,250个汉字等,可以根据关于用户的定义或句子的数量,无论是三句还是五句。
在实践中,也有人在研究自动计算合适的摘要长度。其实没有很好的答案,因为自动文本摘要的长度与用户的需求有关。它可以很长也可以很短。如果你需要一台机器预测摘要的长度实际上是非常困难的。在实际应用中,模型是自动汇总的,生成的汇总有长有短。其他阈值参数将在模型运行之前设置。本质上是将汇总长度参数改为设置其他阈值参数,长度成为其他受控参数。我们知道一个意思可以有多种表达方式,表达的句子有很多种,虽然都表达相同的意思,所以自动生成的摘要的内容也可能有多种结果,结果可以是长的,也可以是长的。短,所以预测生成摘要的长度是困难的。
多样化的总结任务
对于传统的新闻摘要任务
请看上一篇:
飘哥:自然语言处理自动文本摘要技术系列(一)信息摘要概述
请看其他系列自然语言处理文章:
飘哥:自然语言学习的表征学习与知识获取(一)disnotation
飘哥:自然语言学习的表征学习与知识获取(二)word2vec
飘哥:自然语言学习的表征学习与知识获取(三)知识图谱
飘哥:自然语言学习的表征学习与知识获取(四)TransE
飘哥:自然语言系列学习的表征学习与知识获取(五)融合文本与知识,使用cnn方法进行关系抽取
飘哥:自然语言学习的表征学习与知识获取(六)fusion entity description Knowledge representation and fusion entity description knowledge representation)
Piaoge:自然语言学习的表征学习和知识获取(七)Relation Extraction Using Relation Paths
飘哥:自然语言系列学习的表征学习和知识获取(八)Using remote supervisor and multi-instance关系抽取
查看全部
文本摘要技术在图书情报领域,IBM计算机科学家H.P.Luhn
文本摘要的应用
文本摘要的应用、文档自动索引、新闻信息服务、信息检索等
是图书情报领域的主要研究内容。一般索引包括关键词标引、主题词索引和摘要索引。以前是人做的,现在机器自动做,会节省很多人力。
新闻服务商提供新闻信息时,无论是提供单条新闻还是聚合新闻,用户有时不想看全文,或者看很多相关新闻,又想看摘要,所以有些网站 大会提供的新闻摘要将显示在news网站上。有一个叫Summly的应用,原名Trimit,是一款运行在iOS上的新闻阅读应用。它是由英国天才尼克·达洛伊西奥 (Nick D'Aloisio) 在 15 岁时创作的。该应用程序可以使用全文语义分析算法将整个新闻浓缩成一个新闻摘要,标题清晰,几句话。用户只需不到一分钟就能了解新闻中最关键的信息。该申请于2018年获得雅虎批准,以3000万美元收购。
信息检索是用户查询和获取信息的主要方式,是查找信息的方法和手段。输入相关的关键词,就会得到相关的网页,
信息检索中的典型应用搜索。打开搜索引擎,输入search关键词,就会返回搜索结果。网页会显示多个满足关键词条件的信息结果,每个结果会显示结果信息片段,这个信息结果片段会收录搜索关键词,这也是网页内容中最重要的部分,对原文的总结。这是一个特殊的摘要,内容应该与关键词有关。很多年前,就有专门研究这个领域的人。由于技术成熟,现在学习的人越来越少。
文本摘要技术
在图书馆和信息领域,IBM 计算机科学家 H.P.卢恩于1958年发表了《文学文摘的自动创建》,一篇关于文学文摘自动创建的论文。本文提出文章中最重要的句子是关键词最多的句子,关键词是出现次数最多的词。他的总结是将最重要的句子组合在一起。从本文开始到现在,人们研究文本自动摘要的历史已有 60 多年,并取得了一些进展,但仍不尽如人意。
目前在实现自动文本摘要方面还存在很大的困难:
第一:写摘要是一项非常聪明的工作,所以聪明的任务是免费的。假设有一个任务,需要 10 人或更多人根据同一个长文档写一个摘要。很可能大家都会写一个总结。他们不一样,但每个人写的摘要可能还可以。这种没有统一标准、玩起来比较自由的工作,其实机器很难做到。这个任务本质上是机器的搜索问题。你提供的信息越多,组合就越多,搜索空间就越大,结果越不可控。相反,信息越少,搜索空间越小,机器做起来就越容易。
自然语言处理中的机器翻译工作比自动文本摘要更容易。机器翻译的任务是给出源语言的句子,机器翻译后得到目标语言的句子。这个任务有很强的约束,要求前后语言的语义报告一致,甚至每个词都可以匹配。这种约束强的任务会比较容易做。
第二:机器写的摘要与专家写的摘要不同
在写摘要之前,人们已经在脑海中对文章内容的内容和意义有了很好的理解和体验,然后再写摘要形成摘要。写好摘要后,可以展开为文章,如果有摘要,就会有文章。机器写summary的时候,需要先文章再生成summary。这将挑战机器自动生成摘要。
自动汇总代表系统
是一个简单的系统,主要通过句子抽取来实现。 NewsInEssence 是一个应用于新闻领域的摘要系统。提供news文章topic聚类(Topic Clustering)、实时搜索、文章summary和用户交互(User Interaction)等功能。
Newsblaster 是美国哥伦比亚大学开发的多文档抽象系统,采用文本聚类作为预处理过程,在处理每天发生的重要新闻后生成简明摘要,如文本聚类、信息融合和文本一代。这项工作稍微复杂一些。句子可以调整,任何句子都可以断开和重新组合。从而会出现句子不一致、标点符号缺失等问题。
总长度
自动文本摘要的长度是实际应用场景中的一个重要问题。会影响用户的阅读体验,以及系统能否在文本长度上有效表达文章内容。 ,
《摘要特刊介绍》一书的作者拉德夫认为,摘要是“从一个或多个文本中提取的一段文本,其中收录原文中的重要信息,其长度不超过比或远远少于原文的一半”。
生成的摘要的长度可以由用户根据需要指定。可以根据摘要与原文的比例,如10%或20%,也可以根据摘要的字数或字节数,100字,250个汉字等,可以根据关于用户的定义或句子的数量,无论是三句还是五句。
在实践中,也有人在研究自动计算合适的摘要长度。其实没有很好的答案,因为自动文本摘要的长度与用户的需求有关。它可以很长也可以很短。如果你需要一台机器预测摘要的长度实际上是非常困难的。在实际应用中,模型是自动汇总的,生成的汇总有长有短。其他阈值参数将在模型运行之前设置。本质上是将汇总长度参数改为设置其他阈值参数,长度成为其他受控参数。我们知道一个意思可以有多种表达方式,表达的句子有很多种,虽然都表达相同的意思,所以自动生成的摘要的内容也可能有多种结果,结果可以是长的,也可以是长的。短,所以预测生成摘要的长度是困难的。
多样化的总结任务
对于传统的新闻摘要任务
请看上一篇:
飘哥:自然语言处理自动文本摘要技术系列(一)信息摘要概述
请看其他系列自然语言处理文章:
飘哥:自然语言学习的表征学习与知识获取(一)disnotation
飘哥:自然语言学习的表征学习与知识获取(二)word2vec
飘哥:自然语言学习的表征学习与知识获取(三)知识图谱
飘哥:自然语言学习的表征学习与知识获取(四)TransE
飘哥:自然语言系列学习的表征学习与知识获取(五)融合文本与知识,使用cnn方法进行关系抽取
飘哥:自然语言学习的表征学习与知识获取(六)fusion entity description Knowledge representation and fusion entity description knowledge representation)
Piaoge:自然语言学习的表征学习和知识获取(七)Relation Extraction Using Relation Paths
飘哥:自然语言系列学习的表征学习和知识获取(八)Using remote supervisor and multi-instance关系抽取
深度定制的小说站,全自动采集各大小说站
采集交流 • 优采云 发表了文章 • 0 个评论 • 552 次浏览 • 2021-05-29 19:06
源代码说明:
深度定制小说站,全自动【k15】各类站,可自动生成首页、分类、目录、排名、站点地图页面、全站拼音目录、伪静态章节页面、自动生成静态html小说txt文件,自动生成zip压缩包。这个源码功能非常强大!带来一个非常漂亮的手机页面!使用采集规则+自动调整!超级强大,可以使用所有采集规则,并且全自动采集和存储,非常易于使用,特别适合优采云维护!对于一个新颖的网站来说,一个好的程序没什么好说的。
其他功能:
(1) 自动生成首页、分类、目录、排名、站点地图页(分类页、小说封面、作者页,如果html文件不存在或超过设定时间未更新,则自动生成静态html)会自动更新一次,如果有采集,在采集时会自动更新小说封面和对应的分类页面,html文件直接通过PHP调用,而不是在根目录生成。访问速度与纯静态无异,可以保证,源代码文件管理很方便,同时减轻了服务器压力,还方便了访问统计信息并提高了搜索引擎的识别率。
(2)全站拼音目录,章节页面伪静态。
(3)自动生成小说txt文件,也可以后台自己重新生成txt文件。
([4)自动生成新颖的关键词和关键词自动内部链接。
(5) 自动 伪原创 词替换(在 采集 处替换)。
(6)新增小说总点击、月点击、周点击、总推荐、月推荐、周推荐统计、作者推荐统计等新功能。
(7)通过CNZZ的统计插件,方便实现小说下载量和藏书量的详细统计。
(8)这个程序的自动采集在市场上并不常见优采云、广管、采集等,而是在DEDE原有的采集功能的基础上二次开发的采集模块可以有效地确保章节内容的完整性,避免章节重复,章节内容无内容,章节乱码等;一天24小时采集可以达到250,000至300,000个章节。
安装说明:
1、上传到网站根目录
2、用phpMyadmin导入数据库文件xiaoshuo.sql
3、 修改数据库链接文件/data/common.inc.php
(切记不要用记事本修改,否则可能会出现验证码无法显示的问题,建议使用记事本++)
4、后台目录/admin/index.php
账户管理员密码管理员
点击下载—注意:当您点击下载按钮时,将计算一次下载,因此请勿随意点击。 —【下载权限】:青铜会员—
如果你觉得我的文章对你有用,欢迎打赏。您的支持将鼓励我继续创作!
奖励支持 查看全部
深度定制的小说站,全自动采集各大小说站
源代码说明:
深度定制小说站,全自动【k15】各类站,可自动生成首页、分类、目录、排名、站点地图页面、全站拼音目录、伪静态章节页面、自动生成静态html小说txt文件,自动生成zip压缩包。这个源码功能非常强大!带来一个非常漂亮的手机页面!使用采集规则+自动调整!超级强大,可以使用所有采集规则,并且全自动采集和存储,非常易于使用,特别适合优采云维护!对于一个新颖的网站来说,一个好的程序没什么好说的。
其他功能:
(1) 自动生成首页、分类、目录、排名、站点地图页(分类页、小说封面、作者页,如果html文件不存在或超过设定时间未更新,则自动生成静态html)会自动更新一次,如果有采集,在采集时会自动更新小说封面和对应的分类页面,html文件直接通过PHP调用,而不是在根目录生成。访问速度与纯静态无异,可以保证,源代码文件管理很方便,同时减轻了服务器压力,还方便了访问统计信息并提高了搜索引擎的识别率。
(2)全站拼音目录,章节页面伪静态。
(3)自动生成小说txt文件,也可以后台自己重新生成txt文件。
([4)自动生成新颖的关键词和关键词自动内部链接。
(5) 自动 伪原创 词替换(在 采集 处替换)。
(6)新增小说总点击、月点击、周点击、总推荐、月推荐、周推荐统计、作者推荐统计等新功能。
(7)通过CNZZ的统计插件,方便实现小说下载量和藏书量的详细统计。
(8)这个程序的自动采集在市场上并不常见优采云、广管、采集等,而是在DEDE原有的采集功能的基础上二次开发的采集模块可以有效地确保章节内容的完整性,避免章节重复,章节内容无内容,章节乱码等;一天24小时采集可以达到250,000至300,000个章节。
安装说明:
1、上传到网站根目录
2、用phpMyadmin导入数据库文件xiaoshuo.sql
3、 修改数据库链接文件/data/common.inc.php
(切记不要用记事本修改,否则可能会出现验证码无法显示的问题,建议使用记事本++)
4、后台目录/admin/index.php
账户管理员密码管理员
点击下载—注意:当您点击下载按钮时,将计算一次下载,因此请勿随意点击。 —【下载权限】:青铜会员—
如果你觉得我的文章对你有用,欢迎打赏。您的支持将鼓励我继续创作!
奖励支持
关键词自动采集生成内容系统,如果你的核心内容是文字内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2021-05-25 18:04
关键词自动采集生成内容系统,如果你的核心内容是文字内容,这一点非常重要,保持抓取状态,生成全站链接。如果想采集网页,可以采集你想抓取的网页,如果全站抓取不了,点击对应搜索引擎框下方的自动生成链接。无论你是想抓取所有网页,还是抓取某些网页,只要保持抓取状态就可以。google有代理连接、百度会有代理连接、微博会有代理连接,而对于想采集的网页或发送的链接,也可以抓取,和人工连接没区别。
这里提一个别的选择,利用cookie,cookie可以存储搜索引擎抓取你的网页或发送的链接。具体操作如下:获取采集地址地址请放在心里先百度:console.log("xxx")进入console.log("xxx")查看console.log("xxx")打印aspx网页上的httpurl打印python程序,获取httpurl代码如下fromurllibimportrequesthttp=request.urlopen('')req=request.urlopen('').read()response=urllib.urlencode(req)response.encoding='utf-8'cookie=cookie(req,response.state,req.state_default)javascript代码:添加获取url的cookiehttp=request.urlopen('').read()withopen('xxx.html','w')asf:f.write(cookie)此外,还可以有其他方法:有没有获取网页的方法,不在本文提供中欢迎留言提问!!本文由我平凡的日常小技巧拼凑而成,不甚精彩,请大家酌情观看哈!!。 查看全部
关键词自动采集生成内容系统,如果你的核心内容是文字内容
关键词自动采集生成内容系统,如果你的核心内容是文字内容,这一点非常重要,保持抓取状态,生成全站链接。如果想采集网页,可以采集你想抓取的网页,如果全站抓取不了,点击对应搜索引擎框下方的自动生成链接。无论你是想抓取所有网页,还是抓取某些网页,只要保持抓取状态就可以。google有代理连接、百度会有代理连接、微博会有代理连接,而对于想采集的网页或发送的链接,也可以抓取,和人工连接没区别。
这里提一个别的选择,利用cookie,cookie可以存储搜索引擎抓取你的网页或发送的链接。具体操作如下:获取采集地址地址请放在心里先百度:console.log("xxx")进入console.log("xxx")查看console.log("xxx")打印aspx网页上的httpurl打印python程序,获取httpurl代码如下fromurllibimportrequesthttp=request.urlopen('')req=request.urlopen('').read()response=urllib.urlencode(req)response.encoding='utf-8'cookie=cookie(req,response.state,req.state_default)javascript代码:添加获取url的cookiehttp=request.urlopen('').read()withopen('xxx.html','w')asf:f.write(cookie)此外,还可以有其他方法:有没有获取网页的方法,不在本文提供中欢迎留言提问!!本文由我平凡的日常小技巧拼凑而成,不甚精彩,请大家酌情观看哈!!。
百度和谷歌等搜索引擎的全文提取原理是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-05-23 01:04
关键词自动采集生成内容系统开源、自动构造标题、内容、文章地址、内容描述、文章排名;
二、自动完成文章分类、选题、关键词选取、重点摘要、二级标题、百度首页创建,
三、自动发布的同时进行内容的识别、搜索量推荐,
百度全文提取是自动提取网站全文内容的技术实现方案,利用自动文章提取技术把网站的所有带有搜索关键词的文章自动提取出来。
0、知乎等多个搜索引擎都有广泛的应用。原理百度和谷歌等搜索引擎的全文提取原理是:不同的搜索引擎对互联网上的网页内容就提取出了不同的文字标签或是文字链接。任何一篇文章不仅要标题好,而且在首页或者其他页面文章链接文章标题的页面即为标题页,会加上网站全称,这个页面只允许谷歌搜索引擎抓取。百度会抓取网站中的整篇文章,包括标题和正文,然后把文章内容抓取出来,计算其长度,再统计互联网上不同网站文章的完整度,根据互联网的完整度计算标题重复率,比如网站中有10篇文章内容完全相同,但是这些文章在互联网上没有存在完整度的这么高,即互联网上没有完整度的这么高,那么百度会把这10篇文章抓取出来计算重复率。
所以这个工作会花掉整整3个小时的时间,才能把文章提取出来。而谷歌提取的这些网站的标题是非常短的,标题基本只有1个字。比如把网站放在美国ucsi机场里面的网站全名是:ucsi-https。所以标题非常短的文章百度也基本上看不到。而基于nodejs的workerman框架提供了这种能力。框架提供的自动文章提取接口非常简单:接口定义:functionself.filenames(pageid){returnnewfunction(ext,extension){returnextension.alias(pageid);}};vartemplate=newworkerman.filenames(pageid);vartmplate=newworkerman.filenames(pageid);varcrawlinger=newworkerman.filenames(pageid);crawlinger.setobjecturl({templateurl:templateurl,crawlingurl:crawlinger});crawlinger.setdata({location:'https'});workerman框架提供的方法实现全文提取原理比较复杂,有兴趣的可以参考:。 查看全部
百度和谷歌等搜索引擎的全文提取原理是什么?
关键词自动采集生成内容系统开源、自动构造标题、内容、文章地址、内容描述、文章排名;
二、自动完成文章分类、选题、关键词选取、重点摘要、二级标题、百度首页创建,
三、自动发布的同时进行内容的识别、搜索量推荐,
百度全文提取是自动提取网站全文内容的技术实现方案,利用自动文章提取技术把网站的所有带有搜索关键词的文章自动提取出来。
0、知乎等多个搜索引擎都有广泛的应用。原理百度和谷歌等搜索引擎的全文提取原理是:不同的搜索引擎对互联网上的网页内容就提取出了不同的文字标签或是文字链接。任何一篇文章不仅要标题好,而且在首页或者其他页面文章链接文章标题的页面即为标题页,会加上网站全称,这个页面只允许谷歌搜索引擎抓取。百度会抓取网站中的整篇文章,包括标题和正文,然后把文章内容抓取出来,计算其长度,再统计互联网上不同网站文章的完整度,根据互联网的完整度计算标题重复率,比如网站中有10篇文章内容完全相同,但是这些文章在互联网上没有存在完整度的这么高,即互联网上没有完整度的这么高,那么百度会把这10篇文章抓取出来计算重复率。
所以这个工作会花掉整整3个小时的时间,才能把文章提取出来。而谷歌提取的这些网站的标题是非常短的,标题基本只有1个字。比如把网站放在美国ucsi机场里面的网站全名是:ucsi-https。所以标题非常短的文章百度也基本上看不到。而基于nodejs的workerman框架提供了这种能力。框架提供的自动文章提取接口非常简单:接口定义:functionself.filenames(pageid){returnnewfunction(ext,extension){returnextension.alias(pageid);}};vartemplate=newworkerman.filenames(pageid);vartmplate=newworkerman.filenames(pageid);varcrawlinger=newworkerman.filenames(pageid);crawlinger.setobjecturl({templateurl:templateurl,crawlingurl:crawlinger});crawlinger.setdata({location:'https'});workerman框架提供的方法实现全文提取原理比较复杂,有兴趣的可以参考:。
关键词自动采集生成内容系统智能网页爬虫内容数据库
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-05-06 22:06
关键词自动采集生成内容系统智能网页爬虫内容数据库计算单元网页地址格式化字体排版打印消耗电力视频从一开始的先录视频后写代码,学习成本是有点大,
提示框里写需要提交的信息,大概扫一下,把课件提交上去。
直接把视频链接转成一个base64文件,然后上传到浏览器就可以缓存,这样就可以直接看了。
百度一下,就有。网址=../config.phpecho('yourhomeforexample...')这个很多其他公司的教程都有。最简单就是上站长平台申请开通免费的。可以在一定程度上提高视频获取成功率。之后可以想办法利用爬虫技术。理论上都是存在可行性的。
用arpa,
我把我们的uml前端用前端页面设计界面/参考文献
1、教程网站上有视频,还要花钱买。这时你可以复制地址发送到你收到的短信里。我试过,十几分钟就能发过去。2、直接把链接在浏览器访问,选择打开地址,content,如果文件过大、过小,打开慢,你可以手动改一下form里的content的大小,改个几十秒可以了。
一般可以发送到一个邮箱里,邮箱速度快一些。
你好!我也是刚接触软件前端,听了你的分享,从网站的底层进行了解密,下面我就把我了解到的和你交流下,1.建议你建一个非常简单的网站,不用多做功夫,运行速度可以稍慢,但功能不要太复杂,功能不要太复杂是因为视频太多,解说多。还有要放在独立服务器上,独立服务器能保证你可以随时换。2.建立了一个可以随时观看视频的网站,可以微信或其他联系方式,每天上传一些前端视频。
不为其他,只为实践下。3.安装下视频,因为有些学校不允许外联,去各个学校找下有没有类似的项目,模拟真实操作中,再进行测试即可。本人只能帮你到这,希望对你有所帮助,有什么错误还请及时联系我。希望能帮到你!。 查看全部
关键词自动采集生成内容系统智能网页爬虫内容数据库
关键词自动采集生成内容系统智能网页爬虫内容数据库计算单元网页地址格式化字体排版打印消耗电力视频从一开始的先录视频后写代码,学习成本是有点大,
提示框里写需要提交的信息,大概扫一下,把课件提交上去。
直接把视频链接转成一个base64文件,然后上传到浏览器就可以缓存,这样就可以直接看了。
百度一下,就有。网址=../config.phpecho('yourhomeforexample...')这个很多其他公司的教程都有。最简单就是上站长平台申请开通免费的。可以在一定程度上提高视频获取成功率。之后可以想办法利用爬虫技术。理论上都是存在可行性的。
用arpa,
我把我们的uml前端用前端页面设计界面/参考文献
1、教程网站上有视频,还要花钱买。这时你可以复制地址发送到你收到的短信里。我试过,十几分钟就能发过去。2、直接把链接在浏览器访问,选择打开地址,content,如果文件过大、过小,打开慢,你可以手动改一下form里的content的大小,改个几十秒可以了。
一般可以发送到一个邮箱里,邮箱速度快一些。
你好!我也是刚接触软件前端,听了你的分享,从网站的底层进行了解密,下面我就把我了解到的和你交流下,1.建议你建一个非常简单的网站,不用多做功夫,运行速度可以稍慢,但功能不要太复杂,功能不要太复杂是因为视频太多,解说多。还有要放在独立服务器上,独立服务器能保证你可以随时换。2.建立了一个可以随时观看视频的网站,可以微信或其他联系方式,每天上传一些前端视频。
不为其他,只为实践下。3.安装下视频,因为有些学校不允许外联,去各个学校找下有没有类似的项目,模拟真实操作中,再进行测试即可。本人只能帮你到这,希望对你有所帮助,有什么错误还请及时联系我。希望能帮到你!。
全自动分析内外链接自动转换、图片地址、css、js
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-05-05 07:21
·自动分析内部和外部链接,自动转换,图片地址,css,js,在CSS中自动分析图片,从而不会丢失页面样式
·广告代码,可以方便地直接替换规则中的广告代码
·支持自定义标签,标签可以自定义内容,免费拦截和常规内容拦截。可以将其放置在模板中或替换为规则
·支持自定义模板,您可以使用标签diy个性化模板,真正实现内容的上移。
·调试模式,可以观察采集性能,易于发现和解决各种错误
·可以通过一个键切换多个采集规则,支持导入和导出
·内置强大的替换和过滤功能,标签过滤,内部和外部过滤,字符串替换等。
·IP屏蔽功能,屏蔽要屏蔽IP地址以使其无法访问
·蜘蛛来访记录
*****高级功能*****
·URL过滤功能,可以过滤并阻止采集个指定链接
·伪原创,对于seo来说,同义词的替换是很好的
·伪静态,URL伪静态,对seo有用
·自动缓存自动更新,可以将缓存时间设置为自动更新,css缓存
·简体中文与繁体中文的转换
·代理IP,伪造IP,随机IP,伪造用户代理,伪造引荐来源,自定义Cookie,以应对采集反措施
·URL地址加密转换,个性化url,使您的url地址唯一
·关键词内部链功能
需要多长时间才能还清?
如果按照最低标准计算,1000IP可以带来10元的广告收入,最低购买成本为100元。只要程序为您带来5800IP,您就可以还本付息,这是最低标准。但是通常每1000个IP有十几元的收入,因此它可以偿还带来5000多个IP的成本。如果每天有超过一千个IP,您可以在一周内偿还。如果您每天有数百或数千个IP,这确实很容易。
该程序的优势?
现在要网站并不容易。个人网站站长没有太多原创内容。在任何地方重新发布相关内容只是个人的肉食采集。排名无法提高,并且流量不多。输出不成比例。我们的程序经过适当优化,内容提供商的更新量很大。只要有很多收录,您就不会担心没有流量。百度不会来流量,搜狗会来,搜狗不会来360,那么多长尾巴关键词,总会带来传入流量。而且,您无需花费时间和精力,该程序会自动更新和发布。
关于收录和排名问题
多少收录,多快与否,您可以带来多少流量与您的网站体重有关。建议使用旧域名或将其放在旧站点上具有较高权重的网站目录中,这样会很快产生效果。 。因此,我不能保证您会遇到多长时间的流量,收录流量之类的信息,只能告诉您这个方向是可行的,而且我也正在这样做,并且有成功的案例!如果您选择的域名无法为您带来流量,则表明该程序运行不正常。我们都使用相同的程序。效果取决于域名。这是一个风险警告,请您自己考虑,认为此方法可行,然后再购买。
程序很好,为什么要出售?批量建立网站并悄悄地赚钱不是更好吗?
通常,这种程序还会赚取一些广告费。广告联盟更喜欢百度和谷歌。其他广告联盟的收入相对较低。百度广告联盟要求域名必须具有记录号,并且他们必须通过人工审核才能建立网站并批量链接百度。广告基本上是不可能的。尽管无需审核Google Ads 网站,但这只是一个帐户,如果为K,则不会使用。我也经常在新车站上,做站群。同时也出售。每个人都可以赚钱,那为什么不做呢!
为什么该程序容易获得流量?
由于搜狐的文章有与文章相关的推荐,它提供了许多相关的长尾巴关键词,因此我们的程序会随机选择一些长尾巴关键词添加到标题的末尾,因为文章存在收录很容易带来流量,因为将搜索这些长尾巴关键词。
例如,文章文章的标题为
iPhone4S和iPad2等“老苹果”可以升级iOS 8. 3吗?苹果6升级了ios 8. 3图片ipad2升级了ios 8. 3苹果4s升级了ios 8. 3有问题“
除了“ iPhone4S和iPad2等“老苹果”可以升级iOS 8. 3吗?”是文章的标题,程序将添加以下三个相关的长尾词关键词。同样的一句话是,百度不会吸引搜狗流量,搜狗没有到达360,总会有流量。
每个人都使用相同的程序,采集搜狐内容相同,难道没有网站完全相同吗?
网站首页的标题是可自定义的,除非您想一起浏览,否则标题将不同。该程序将在URL中添加随机字符,因此不会有相同的文章 URL。此外,文章标题具有大量可插入的相关长尾巴关键词,并且每个人都会随机插入几个,因此基本上不会有相同的文章标题。我还设置了很多网站测试,收录仍然是收录,像搜狐这样的大门户网站,文章每天的更新量,我无法估计,所以每个人都可能是收录和文章也不同,也许您的A 文章被收录贩运,而他的B 文章被收录贩运。更重要的是,搜狐每天更新很多,每个人都有一份收录。这也是一种收费过程,不会被很多人使用。
将其放在目录中会影响我原来的网站吗?
该主题可能无关紧要,但不会对您的原创主题网站产生不利影响,但可以帮助您对主要网站进行排名。 查看全部
全自动分析内外链接自动转换、图片地址、css、js
·自动分析内部和外部链接,自动转换,图片地址,css,js,在CSS中自动分析图片,从而不会丢失页面样式
·广告代码,可以方便地直接替换规则中的广告代码
·支持自定义标签,标签可以自定义内容,免费拦截和常规内容拦截。可以将其放置在模板中或替换为规则
·支持自定义模板,您可以使用标签diy个性化模板,真正实现内容的上移。
·调试模式,可以观察采集性能,易于发现和解决各种错误
·可以通过一个键切换多个采集规则,支持导入和导出
·内置强大的替换和过滤功能,标签过滤,内部和外部过滤,字符串替换等。
·IP屏蔽功能,屏蔽要屏蔽IP地址以使其无法访问
·蜘蛛来访记录
*****高级功能*****
·URL过滤功能,可以过滤并阻止采集个指定链接
·伪原创,对于seo来说,同义词的替换是很好的
·伪静态,URL伪静态,对seo有用
·自动缓存自动更新,可以将缓存时间设置为自动更新,css缓存
·简体中文与繁体中文的转换
·代理IP,伪造IP,随机IP,伪造用户代理,伪造引荐来源,自定义Cookie,以应对采集反措施
·URL地址加密转换,个性化url,使您的url地址唯一
·关键词内部链功能
需要多长时间才能还清?
如果按照最低标准计算,1000IP可以带来10元的广告收入,最低购买成本为100元。只要程序为您带来5800IP,您就可以还本付息,这是最低标准。但是通常每1000个IP有十几元的收入,因此它可以偿还带来5000多个IP的成本。如果每天有超过一千个IP,您可以在一周内偿还。如果您每天有数百或数千个IP,这确实很容易。
该程序的优势?
现在要网站并不容易。个人网站站长没有太多原创内容。在任何地方重新发布相关内容只是个人的肉食采集。排名无法提高,并且流量不多。输出不成比例。我们的程序经过适当优化,内容提供商的更新量很大。只要有很多收录,您就不会担心没有流量。百度不会来流量,搜狗会来,搜狗不会来360,那么多长尾巴关键词,总会带来传入流量。而且,您无需花费时间和精力,该程序会自动更新和发布。
关于收录和排名问题
多少收录,多快与否,您可以带来多少流量与您的网站体重有关。建议使用旧域名或将其放在旧站点上具有较高权重的网站目录中,这样会很快产生效果。 。因此,我不能保证您会遇到多长时间的流量,收录流量之类的信息,只能告诉您这个方向是可行的,而且我也正在这样做,并且有成功的案例!如果您选择的域名无法为您带来流量,则表明该程序运行不正常。我们都使用相同的程序。效果取决于域名。这是一个风险警告,请您自己考虑,认为此方法可行,然后再购买。
程序很好,为什么要出售?批量建立网站并悄悄地赚钱不是更好吗?
通常,这种程序还会赚取一些广告费。广告联盟更喜欢百度和谷歌。其他广告联盟的收入相对较低。百度广告联盟要求域名必须具有记录号,并且他们必须通过人工审核才能建立网站并批量链接百度。广告基本上是不可能的。尽管无需审核Google Ads 网站,但这只是一个帐户,如果为K,则不会使用。我也经常在新车站上,做站群。同时也出售。每个人都可以赚钱,那为什么不做呢!
为什么该程序容易获得流量?
由于搜狐的文章有与文章相关的推荐,它提供了许多相关的长尾巴关键词,因此我们的程序会随机选择一些长尾巴关键词添加到标题的末尾,因为文章存在收录很容易带来流量,因为将搜索这些长尾巴关键词。
例如,文章文章的标题为
iPhone4S和iPad2等“老苹果”可以升级iOS 8. 3吗?苹果6升级了ios 8. 3图片ipad2升级了ios 8. 3苹果4s升级了ios 8. 3有问题“
除了“ iPhone4S和iPad2等“老苹果”可以升级iOS 8. 3吗?”是文章的标题,程序将添加以下三个相关的长尾词关键词。同样的一句话是,百度不会吸引搜狗流量,搜狗没有到达360,总会有流量。
每个人都使用相同的程序,采集搜狐内容相同,难道没有网站完全相同吗?
网站首页的标题是可自定义的,除非您想一起浏览,否则标题将不同。该程序将在URL中添加随机字符,因此不会有相同的文章 URL。此外,文章标题具有大量可插入的相关长尾巴关键词,并且每个人都会随机插入几个,因此基本上不会有相同的文章标题。我还设置了很多网站测试,收录仍然是收录,像搜狐这样的大门户网站,文章每天的更新量,我无法估计,所以每个人都可能是收录和文章也不同,也许您的A 文章被收录贩运,而他的B 文章被收录贩运。更重要的是,搜狐每天更新很多,每个人都有一份收录。这也是一种收费过程,不会被很多人使用。
将其放在目录中会影响我原来的网站吗?
该主题可能无关紧要,但不会对您的原创主题网站产生不利影响,但可以帮助您对主要网站进行排名。
智能的web表单引擎,专业的问卷调研调查调查软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-05-01 23:27
产品简介OQSS是一个智能的Web表单引擎,是专业的问卷调查软件,后台程序在Web服务器上运行,前台使用浏览器进行操作,它也是一个在线Web表单开发引擎。这是国内第一个公开的问卷调查系统和表格引擎。使用OQSS:您可以使用它来制作,发布和分析在线问卷,制作信息采集表格,设计Web程序,参加在线考试以及在高速Internet上工作。每个公司都需要一套OQSS。 OQSS已有5年的历史,并已逐渐成熟。它拥有许多客户,例如中国搜索,价格电子,厦门大学,温州大学,夏新电子,TCL集团,CSDN,《读者》杂志,《女友》杂志,中国电信,中国移动,中国汽车网,珠海视听网,赛迪顾问,深圳市公安局,税务局,红塔集团...在这些客户的支持下,OQSS团队不断进步和创新,坚持软件结构,人性化,安全性得到改进,使OQSS易于使用,更易于使用,功能更强大。 OQSS市场调查客户反馈研究研究数据采集的应用范围网站调查表开发心理调查考试试卷网上表格... OQSS详细功能:请点击这里OQSS核心是一套表格开发引擎OQSS问卷模型单行填写问题(单行输入控件)多行填写问题(多行输入控件)单选+输入(重做点击控件)多选+输入(复选框多选控件,可控制的选择数量)矩阵问题(矩阵单行输入控件)设置选项的点(根据分数计算结果)集成输入验证(通用表单验证)多级下拉链接,多选互斥选项,控制问题显示图形选项,设置问题选项的得分以实现问卷评分URL参数传输程序可以很好地控制防止IP重复提交s。可以设置重复提交的时间间隔。可以设置调查表的结束日期。可以设置提交后的显示页面。可以将其设置为问卷评分结果。您可以为调查表设置密码。打开调查表之前,您需要输入密码以保护调查表。立即打开和关闭调查表,立即打开和关闭调查表,启用或禁用调查表上的即时数据,立即打开和关闭结果数据,并且在打开数据之前匿名匿名,您无法查看集成调查表。长期跟踪同一样本在线样本组管理调查表可以直接从断点发送在线大量邮件,以直接在收到的电子邮件中答复调查表,在线统计分析显示一份答卷的所有内容,一页显示多个答案工作表频率频率分析直方图,饼图分析数据可以导出到Excel文件OQSS结构B / S结构,.Net + AJAX + DB核心:表单开发引擎 查看全部
智能的web表单引擎,专业的问卷调研调查调查软件
产品简介OQSS是一个智能的Web表单引擎,是专业的问卷调查软件,后台程序在Web服务器上运行,前台使用浏览器进行操作,它也是一个在线Web表单开发引擎。这是国内第一个公开的问卷调查系统和表格引擎。使用OQSS:您可以使用它来制作,发布和分析在线问卷,制作信息采集表格,设计Web程序,参加在线考试以及在高速Internet上工作。每个公司都需要一套OQSS。 OQSS已有5年的历史,并已逐渐成熟。它拥有许多客户,例如中国搜索,价格电子,厦门大学,温州大学,夏新电子,TCL集团,CSDN,《读者》杂志,《女友》杂志,中国电信,中国移动,中国汽车网,珠海视听网,赛迪顾问,深圳市公安局,税务局,红塔集团...在这些客户的支持下,OQSS团队不断进步和创新,坚持软件结构,人性化,安全性得到改进,使OQSS易于使用,更易于使用,功能更强大。 OQSS市场调查客户反馈研究研究数据采集的应用范围网站调查表开发心理调查考试试卷网上表格... OQSS详细功能:请点击这里OQSS核心是一套表格开发引擎OQSS问卷模型单行填写问题(单行输入控件)多行填写问题(多行输入控件)单选+输入(重做点击控件)多选+输入(复选框多选控件,可控制的选择数量)矩阵问题(矩阵单行输入控件)设置选项的点(根据分数计算结果)集成输入验证(通用表单验证)多级下拉链接,多选互斥选项,控制问题显示图形选项,设置问题选项的得分以实现问卷评分URL参数传输程序可以很好地控制防止IP重复提交s。可以设置重复提交的时间间隔。可以设置调查表的结束日期。可以设置提交后的显示页面。可以将其设置为问卷评分结果。您可以为调查表设置密码。打开调查表之前,您需要输入密码以保护调查表。立即打开和关闭调查表,立即打开和关闭调查表,启用或禁用调查表上的即时数据,立即打开和关闭结果数据,并且在打开数据之前匿名匿名,您无法查看集成调查表。长期跟踪同一样本在线样本组管理调查表可以直接从断点发送在线大量邮件,以直接在收到的电子邮件中答复调查表,在线统计分析显示一份答卷的所有内容,一页显示多个答案工作表频率频率分析直方图,饼图分析数据可以导出到Excel文件OQSS结构B / S结构,.Net + AJAX + DB核心:表单开发引擎
流量生意永不过时,网站的自动化脚本有哪些?
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-05-01 20:32
交通业务永远不会过时。无论通过哪个渠道,客户获取成本都越来越高。
我最熟悉的流量获取是百度搜索,因此网站上的一些自动化脚本目前正在实施中。
一、 关键词展开
免费资源主要来自关键词计划者和百度相关的推荐词。 关键词计划者可以直接导出Excel,而与百度相关的单词则需要运行脚本。
主要付款是用5118 关键词挖出长尾巴。
二、 关键词过滤
主要是筛选需求和竞争程度较低的人关键词。
最好了解是否有需求:有一个搜索量或一个索引,可以将没有索引的关键词筛选出来并可以用Excel处理。
竞争程度主要是指以下几个方面:网站在百度搜索首页上的权重以及关键词与搜索结果首页上的标题的匹配程度,不涉及搜索结果数。
没有具体的比赛标准,例如我选择的平均体重
例如,如果您搜索“张大方的私人土地”,则标题中将收录单词:“张大方的私人土地简介”,而不是分词:“第XXX章:张大方的私人土地退修”。
关键词(竞争程度较低)也正在运行脚本。
三、旧域名筛选
过滤来自eName China和Juming的过期域名。过滤条件因人而异。我通常选择常见的域名后缀:.com,.cn,.net,。,并且注册时间通常是三年前。当然,/微信一定不能被阻止。
导出域名后,使用eName工具进行检查。该网站的历史已从外国语言中筛选出来(找不到标题,您需要对其进行详细检查),只要是中文即可;最早的记录必须是三年前;标题很敏感筛选出单词。
使用同一工具,检查域名反链接,百度,搜狗36 0、搜狗,只要有反链接,就保留它们。
四、内容处理
使用python 采集作为内容,然后使用人工智能重绘标题,自动生成摘要并自动提取标签。
五、自动采集发布
当前,我使用WordPress程序来构建网站。实用性无关紧要,因为我使用硒来模拟提交。
我使用的WordPress主题支持向URL主动提交URL,从而使您不必编写脚本。
六、定时发布
唯一的遗憾是Windows计划的任务仅支持exe文件。 Linux安装python库和浏览器,遇到一些问题,推迟。
因此,现在我每天手动运行该脚本,大约需要一分钟时间才能自动发布高质量的文章文章。
在以后的阶段,我计划购买几十个域名。预计建设网站网站的费用将低于200元。毕竟,花一个网站花费时间才能实现盈利。如果失败,则50 网站将直接损失10,000元人民币(不计算机会成本),但是如果成功,则只有一个或两个网站时,损失是巨大的。
为了展示人工智能算法,本文的标题使用了人工智能处理,因此我将不再担心标题文章。 查看全部
流量生意永不过时,网站的自动化脚本有哪些?
交通业务永远不会过时。无论通过哪个渠道,客户获取成本都越来越高。
我最熟悉的流量获取是百度搜索,因此网站上的一些自动化脚本目前正在实施中。
一、 关键词展开
免费资源主要来自关键词计划者和百度相关的推荐词。 关键词计划者可以直接导出Excel,而与百度相关的单词则需要运行脚本。
主要付款是用5118 关键词挖出长尾巴。
二、 关键词过滤
主要是筛选需求和竞争程度较低的人关键词。
最好了解是否有需求:有一个搜索量或一个索引,可以将没有索引的关键词筛选出来并可以用Excel处理。
竞争程度主要是指以下几个方面:网站在百度搜索首页上的权重以及关键词与搜索结果首页上的标题的匹配程度,不涉及搜索结果数。
没有具体的比赛标准,例如我选择的平均体重
例如,如果您搜索“张大方的私人土地”,则标题中将收录单词:“张大方的私人土地简介”,而不是分词:“第XXX章:张大方的私人土地退修”。
关键词(竞争程度较低)也正在运行脚本。
三、旧域名筛选
过滤来自eName China和Juming的过期域名。过滤条件因人而异。我通常选择常见的域名后缀:.com,.cn,.net,。,并且注册时间通常是三年前。当然,/微信一定不能被阻止。
导出域名后,使用eName工具进行检查。该网站的历史已从外国语言中筛选出来(找不到标题,您需要对其进行详细检查),只要是中文即可;最早的记录必须是三年前;标题很敏感筛选出单词。
使用同一工具,检查域名反链接,百度,搜狗36 0、搜狗,只要有反链接,就保留它们。
四、内容处理
使用python 采集作为内容,然后使用人工智能重绘标题,自动生成摘要并自动提取标签。
五、自动采集发布
当前,我使用WordPress程序来构建网站。实用性无关紧要,因为我使用硒来模拟提交。
我使用的WordPress主题支持向URL主动提交URL,从而使您不必编写脚本。
六、定时发布
唯一的遗憾是Windows计划的任务仅支持exe文件。 Linux安装python库和浏览器,遇到一些问题,推迟。
因此,现在我每天手动运行该脚本,大约需要一分钟时间才能自动发布高质量的文章文章。
在以后的阶段,我计划购买几十个域名。预计建设网站网站的费用将低于200元。毕竟,花一个网站花费时间才能实现盈利。如果失败,则50 网站将直接损失10,000元人民币(不计算机会成本),但是如果成功,则只有一个或两个网站时,损失是巨大的。
为了展示人工智能算法,本文的标题使用了人工智能处理,因此我将不再担心标题文章。
scrapy+spark32知识库系统打造基于scrapy的知识库本系列
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-04-30 22:35
关键词自动采集生成内容系统scrapy同时支持scrapy+spark构建知识库(zhihu。com):作者|刘大雨,id:mr_ronghuai知乎专栏|::本文未经作者允许不得转载合作联系邮箱|mr_ronghuai@126。com;开源项目地址(私人):scrapy1。2。0-py32知识库系统打造基于scrapy的知识库本系列将围绕五个问题展开:。
1、问题的全概述;
2、知识库的开发方法;
3、知识库技术点剖析;
4、知识库用例设计;
5、难点问题展开解答。工欲善其事,必先利其器,这是本文构建知识库的工具。目前公司内的开发工具暂用scrapy,该工具非常好用,还没有遇到什么问题,所以接下来我们用scrapy+spark构建知识库,后续的图片中会提到spark+spark。什么是知识库知识库是从头开始构建一个知识库,以一个问题或例子作为开始。
从头开始构建,也就是首先根据知识库构建原始知识库,根据构建知识库方法论的不同,可分为三类:spark构建知识库:利用spark+sparkstreaming或者sparkcn,由于sparkcontext的缓存操作,通常大量数据采用部分传统方法构建知识库,如pillow或imposed。spark构建知识库:利用spark+sparkstreaming或者sparkcn,这一类的优势在于spark一定程度上能够减少构建知识库的负担,使用spark时,速度可能比sparkstreaming更快;它们的缺点在于复杂知识、要求与知识库具有实时交互,否则速度会很慢。
dataframe构建知识库:通常采用dataframe来开始构建知识库,当前我们的知识库是用的dataframe+spark自动采集工具采集到的文章与问题,以及文章、问题与知识库交互方式如:通过搜索框直接调用spark的搜索,但是与自动采集不同的是,由于在spark构建过程中会有大量网页,但这些网页无法标注出来,所以直接调用spark采集网页本身没有问题,但是如果调用sparkctl,则需要通过sparkcpu_cache、sparkcpu、master连接spark的方式来采集,开发过程会非常不方便,而且spark采集的网页资源是用python自带的rdd框架封装后进行读取的,本质上和shell命令行相似,用户的体验不如dataframe+spark自动采集方便。
dataframe构建知识库spark构建知识库:构建知识库步骤如下:
1、从知识库mining中读取网页数据,
2、根据解析结果生成知识库节点;
3、根据知识库节点生成知识库的分区列表;
4、根据知识库节点构建分区列表。第一步,如果知识库中引入sparkcontext,使用pyspark来分析;如果没有引入sparkcontext,使用sparkcontext来读取网页数据。 查看全部
scrapy+spark32知识库系统打造基于scrapy的知识库本系列
关键词自动采集生成内容系统scrapy同时支持scrapy+spark构建知识库(zhihu。com):作者|刘大雨,id:mr_ronghuai知乎专栏|::本文未经作者允许不得转载合作联系邮箱|mr_ronghuai@126。com;开源项目地址(私人):scrapy1。2。0-py32知识库系统打造基于scrapy的知识库本系列将围绕五个问题展开:。
1、问题的全概述;
2、知识库的开发方法;
3、知识库技术点剖析;
4、知识库用例设计;
5、难点问题展开解答。工欲善其事,必先利其器,这是本文构建知识库的工具。目前公司内的开发工具暂用scrapy,该工具非常好用,还没有遇到什么问题,所以接下来我们用scrapy+spark构建知识库,后续的图片中会提到spark+spark。什么是知识库知识库是从头开始构建一个知识库,以一个问题或例子作为开始。
从头开始构建,也就是首先根据知识库构建原始知识库,根据构建知识库方法论的不同,可分为三类:spark构建知识库:利用spark+sparkstreaming或者sparkcn,由于sparkcontext的缓存操作,通常大量数据采用部分传统方法构建知识库,如pillow或imposed。spark构建知识库:利用spark+sparkstreaming或者sparkcn,这一类的优势在于spark一定程度上能够减少构建知识库的负担,使用spark时,速度可能比sparkstreaming更快;它们的缺点在于复杂知识、要求与知识库具有实时交互,否则速度会很慢。
dataframe构建知识库:通常采用dataframe来开始构建知识库,当前我们的知识库是用的dataframe+spark自动采集工具采集到的文章与问题,以及文章、问题与知识库交互方式如:通过搜索框直接调用spark的搜索,但是与自动采集不同的是,由于在spark构建过程中会有大量网页,但这些网页无法标注出来,所以直接调用spark采集网页本身没有问题,但是如果调用sparkctl,则需要通过sparkcpu_cache、sparkcpu、master连接spark的方式来采集,开发过程会非常不方便,而且spark采集的网页资源是用python自带的rdd框架封装后进行读取的,本质上和shell命令行相似,用户的体验不如dataframe+spark自动采集方便。
dataframe构建知识库spark构建知识库:构建知识库步骤如下:
1、从知识库mining中读取网页数据,
2、根据解析结果生成知识库节点;
3、根据知识库节点生成知识库的分区列表;
4、根据知识库节点构建分区列表。第一步,如果知识库中引入sparkcontext,使用pyspark来分析;如果没有引入sparkcontext,使用sparkcontext来读取网页数据。
关键词自动采集生成内容系统自动发布日常推广投放监控推广效果分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 235 次浏览 • 2021-04-30 21:55
关键词自动采集生成内容系统自动发布日常推广投放监控推广效果分析
用wordpress+ezgift+html5gift.
我一直有个心愿就是为招人专门制作一个wordpress模板,可以引导用户或推广商家访问第三方平台。
wordpress+pageadmin
可以访问进行免费使用
不知道怎么监测呢,
bluehost,,选择wordpress模板,然后用模板的代码设置只有来自中国的个人和公司才能访问您发布的文章,如果你是企业,可以申请b2c站点。如果你是个人,你也可以花钱来让这些爬虫把你的文章抓取到他们自己的数据库里。
一般来说直接无法判断是不是真正有效用户、真正的转化目标。
关键词提交,发布列表监控,wp自带代码分析等!不过一般查看关键词,发布列表,大多数不是真正意义上的监控,最多只能知道用户是谁,关键词对应是什么,
现在wordpress自带的wpautomation功能就够用。试用就知道你做的多不靠谱了。
其实,有大神做好了这种网站,放上自己的实用性很强的工具,帮助操作,我可以更详细的帮助到你。 查看全部
关键词自动采集生成内容系统自动发布日常推广投放监控推广效果分析
关键词自动采集生成内容系统自动发布日常推广投放监控推广效果分析
用wordpress+ezgift+html5gift.
我一直有个心愿就是为招人专门制作一个wordpress模板,可以引导用户或推广商家访问第三方平台。
wordpress+pageadmin
可以访问进行免费使用
不知道怎么监测呢,
bluehost,,选择wordpress模板,然后用模板的代码设置只有来自中国的个人和公司才能访问您发布的文章,如果你是企业,可以申请b2c站点。如果你是个人,你也可以花钱来让这些爬虫把你的文章抓取到他们自己的数据库里。
一般来说直接无法判断是不是真正有效用户、真正的转化目标。
关键词提交,发布列表监控,wp自带代码分析等!不过一般查看关键词,发布列表,大多数不是真正意义上的监控,最多只能知道用户是谁,关键词对应是什么,
现在wordpress自带的wpautomation功能就够用。试用就知道你做的多不靠谱了。
其实,有大神做好了这种网站,放上自己的实用性很强的工具,帮助操作,我可以更详细的帮助到你。
裂变3000个分站站群生成海量内容、海量关键字快速霸屏
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-04-27 19:16
裂变3000个分站站群生成海量内容、海量关键字快速霸屏
天龙云变电站智能站群推广系统
烦扰3000个子站站群来生成大量内容和大量关键字,从而迅速占领屏幕搜索引擎
站群行销的每个分支机构都在进行关键词促销,并根据用户搜索习惯自动进行匹配,从而使庞大的关键词自然排名可以取代主要搜索引擎(如百度,搜狗和360)的首页。到该公司的官方网站,轻松地使搜索量增加一倍,有效地定位目标客户,并大大增加了咨询量,订单量和销售业绩。
在百度首页上无限关键词,在搜狗首页上无限关键词,在360主页上无限关键词,系统智能采集主站数据,根据您的关键词,使用智能创建文字,替换主要子站点的内容,无需建立其他站点,智能裂变同时推广了数千个子站点(PC +手机),每天仅需几十元,节省了成本。
智能变电站
智能生成3000个城市和关键词个子站站群,以便将大量内容推送到搜索引擎,以最大程度地提高搜索概率。
智能采集
智能采集主站的内容会自动更新到子站,以确保可以连续更新子站的内容。
智能链轮
将每个子站相互链接并彼此优化,以确保网站具有足够的内部链接。
智能外部链接
智能交换友谊链接,吸引蜘蛛爬行,并确保网站有足够的外部链接。
智能单词创建
使用大数据,智能地挖掘满足用户搜索习惯的相关关键词,并自动将其与子站点进行匹配,以确保在搜索引擎首页上显示更多关键词。
智能更换
巧妙地替换子站点的内容,以确保不会重复每个主要子站点的内容。
智能加速
系统使用MIP移动加速技术来确保网站的访问速度。 查看全部
裂变3000个分站站群生成海量内容、海量关键字快速霸屏
天龙云变电站智能站群推广系统
烦扰3000个子站站群来生成大量内容和大量关键字,从而迅速占领屏幕搜索引擎
站群行销的每个分支机构都在进行关键词促销,并根据用户搜索习惯自动进行匹配,从而使庞大的关键词自然排名可以取代主要搜索引擎(如百度,搜狗和360)的首页。到该公司的官方网站,轻松地使搜索量增加一倍,有效地定位目标客户,并大大增加了咨询量,订单量和销售业绩。
在百度首页上无限关键词,在搜狗首页上无限关键词,在360主页上无限关键词,系统智能采集主站数据,根据您的关键词,使用智能创建文字,替换主要子站点的内容,无需建立其他站点,智能裂变同时推广了数千个子站点(PC +手机),每天仅需几十元,节省了成本。
智能变电站
智能生成3000个城市和关键词个子站站群,以便将大量内容推送到搜索引擎,以最大程度地提高搜索概率。
智能采集
智能采集主站的内容会自动更新到子站,以确保可以连续更新子站的内容。
智能链轮
将每个子站相互链接并彼此优化,以确保网站具有足够的内部链接。
智能外部链接
智能交换友谊链接,吸引蜘蛛爬行,并确保网站有足够的外部链接。
智能单词创建
使用大数据,智能地挖掘满足用户搜索习惯的相关关键词,并自动将其与子站点进行匹配,以确保在搜索引擎首页上显示更多关键词。
智能更换
巧妙地替换子站点的内容,以确保不会重复每个主要子站点的内容。
智能加速
系统使用MIP移动加速技术来确保网站的访问速度。
只需2步轻松搞定词云图?不信来看看我是怎么做的
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-04-26 07:21
仅需2个步骤即可轻松获得单词云图?如果您不相信我,让我们看看我是怎么做到的!
在可视化过程中,出现了“词云图”。词云,也称为词云,由云状彩色图形中的词组成。通过重复一个或多个关键词,字体大小和颜色是不同的,并且不规则的排列使其看起来类似于某种形状的图片。它是指在视觉上更频繁地出现“ 关键词。]”,并且词云图像会滤除大量低频和低质量的文本信息,从而使观看者可以只要一看就掌握文本的主要思想。关键词作为生成云图像的工具,云图生成器简化了生产过程。
那么,云图这个词应该做什么?
我找到了一个BI软件——Smartbi Sematic
以下是热门搜索城市的词云地图。
操作词云图像的步骤如下:
上述业务场景的数据源如下:
我们的基本数据以详细列表的形式存储,并且上述“权重”由输入数据系统自动汇总和计算。
1、双击“城市”和“重量”字段,系统将自动将尺寸分配给“标签”标记的项目,将度量标准分配给“尺寸”标记的项目,并得到以下单词云图:
2、添加一个“颜色”标签项(可选,建议执行此操作,图中显示的内容更加清晰),将“城市”字段拖动到“颜色”标签项中,系统进行区分按颜色排列主题。
从上图可以看出,深圳,广州和上海的搜索兴趣最高。
那么,词云图的作用是什么?
关键词云是在大量文本内容中经常出现的“ 关键词”的视觉亮点,即,出现的“ 关键词”字体越多,字体大小越大。例如,我们可以基于数千个新闻条目进行词频统计,得到很多“ 关键词”,然后根据关键词的出现次数对其进行排序。 “ 关键词”越突出,它在所有新闻内容中出现的频率就越高。高。
从最初的“新冠状病毒,感染,发烧”到当前的“一般战争,康复的患者,血浆和恢复工作”,围绕这一流行病的热词一直在悄然变化。热门词汇代表了大多数网民的愿望,也显示了抗击流行病的演变。根据Sematic软件Smartbi大数据分析平台的跟踪采集和统计分析,互联网流行语已显示出与流行病防控情况相关的联动变化趋势。在最初阶段,新的冠状肺炎疫情正在肆虐。流行的词有“肺炎”和“新冠状病毒”,与“流行病”,“蝙蝠”和“发烧”等与流行病密切相关的词是“热门搜索”。
因此,词云图像可以在视觉上突出显示Web文本中经常出现的“ 关键词”,不仅使读者能够快速提取文本的重要内容,而且还可以通过比较不同文本的词云来实现数据分析的目的。
用于生成词云图的网页在线生成工具和桌面软件本质上是相同的。我建议您使用BI工具来执行此操作。专业的数据可视化分析软件,例如Smartbi Sematic,可以制作其他词云图。经验丰富的数据可视化效果,操作非常简单,适合数据分析师入门。
申请试用 查看全部
只需2步轻松搞定词云图?不信来看看我是怎么做的
仅需2个步骤即可轻松获得单词云图?如果您不相信我,让我们看看我是怎么做到的!
在可视化过程中,出现了“词云图”。词云,也称为词云,由云状彩色图形中的词组成。通过重复一个或多个关键词,字体大小和颜色是不同的,并且不规则的排列使其看起来类似于某种形状的图片。它是指在视觉上更频繁地出现“ 关键词。]”,并且词云图像会滤除大量低频和低质量的文本信息,从而使观看者可以只要一看就掌握文本的主要思想。关键词作为生成云图像的工具,云图生成器简化了生产过程。
那么,云图这个词应该做什么?
我找到了一个BI软件——Smartbi Sematic
以下是热门搜索城市的词云地图。
操作词云图像的步骤如下:
上述业务场景的数据源如下:
我们的基本数据以详细列表的形式存储,并且上述“权重”由输入数据系统自动汇总和计算。
1、双击“城市”和“重量”字段,系统将自动将尺寸分配给“标签”标记的项目,将度量标准分配给“尺寸”标记的项目,并得到以下单词云图:
2、添加一个“颜色”标签项(可选,建议执行此操作,图中显示的内容更加清晰),将“城市”字段拖动到“颜色”标签项中,系统进行区分按颜色排列主题。
从上图可以看出,深圳,广州和上海的搜索兴趣最高。
那么,词云图的作用是什么?
关键词云是在大量文本内容中经常出现的“ 关键词”的视觉亮点,即,出现的“ 关键词”字体越多,字体大小越大。例如,我们可以基于数千个新闻条目进行词频统计,得到很多“ 关键词”,然后根据关键词的出现次数对其进行排序。 “ 关键词”越突出,它在所有新闻内容中出现的频率就越高。高。
从最初的“新冠状病毒,感染,发烧”到当前的“一般战争,康复的患者,血浆和恢复工作”,围绕这一流行病的热词一直在悄然变化。热门词汇代表了大多数网民的愿望,也显示了抗击流行病的演变。根据Sematic软件Smartbi大数据分析平台的跟踪采集和统计分析,互联网流行语已显示出与流行病防控情况相关的联动变化趋势。在最初阶段,新的冠状肺炎疫情正在肆虐。流行的词有“肺炎”和“新冠状病毒”,与“流行病”,“蝙蝠”和“发烧”等与流行病密切相关的词是“热门搜索”。
因此,词云图像可以在视觉上突出显示Web文本中经常出现的“ 关键词”,不仅使读者能够快速提取文本的重要内容,而且还可以通过比较不同文本的词云来实现数据分析的目的。
用于生成词云图的网页在线生成工具和桌面软件本质上是相同的。我建议您使用BI工具来执行此操作。专业的数据可视化分析软件,例如Smartbi Sematic,可以制作其他词云图。经验丰富的数据可视化效果,操作非常简单,适合数据分析师入门。
申请试用
友点企业网站管理系统集电脑站+APP+小程序五合一
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-04-26 07:09
源代码和安装说明简介:
YouDian cms是Youdian Enterprise 网站。管理系统集成了五合一计算机站+移动站+微信站+ APP +小程序,数据自动同步,降低了人力维护成本;共享管理后台,只要是虚拟主机,就可以有效节省空间投资。该系统采用开源技术PHP + MYSQL开发,开源,具有操作简单,功能强大,稳定性好,易于扩展,安全性强,维护方便,兼容性好等特点,可以帮助您快速构建强大的功能。和专业企业网站。该系统支持国际站的多语言轻松创建,自定义模型,对网站模板皮肤的支持,内置的SEO优化功能,静态页面,评论消息,购物车,在线支付,优惠券,积分,三级分发,订单管理,企业网站的基本功能,例如成员资格,数据采集,短信界面,插件应用商店和广告。操作环境:PHP 5. 3 / 5. 4 / 5. 5 / 5. 6 / 7. 0 / 7. 1 / 7. 2 / 7. 3 + MYSQL。
操作环境:
操作系统:跨平台,支持Windows,Unix,Linux等操作系统
WEB服务器:IIS / APACHE / NGINX等
PHP环境:PHP 5. 3- 7. 3
数据库:MYSQL 5. 0- 8. 0
产品功能:
1、完全开源:该系统使用开源技术PHP + MYSQL开发,安全,低成本,经济高效,易于安装(完全支持最新版本的PHP),功能无限,使用灵活完全开放的系统前端+后端源代码减轻了开发人员和用户的后顾之忧,完全支持二次开发,不保留后门,并且可以轻松地自己控制代码的使用权
2、五个站合而为一:计算机站,移动站,微信,APP和小程序合为一体,共享空间,数据同步,无需维护多个端口数据,只需一个后台即可
3、系统跨平台:Unix / Linux + windows,支持跨平台安装,一键式备份很容易获得网站迁移
支持扩展插件,功能可以无限扩展:系统后台插件应用商店集成了功能强大的免费插件:包括数据采集,三级分发,秦牛云存储,群发邮件,图像批处理等。
4、内置网站优化功能SEO优化:系统后台可以设置伪静态,设置HTML静态缓存策略,搜索引擎优化设置,常见的搜索引擎登录条目,生成网站映射,生成关键词链接,百度自动推送
功能模块:
功能列表
核心功能:计算机站,移动站,微信,APP,小程序五个站集成为一个,共享空间,数据同步;一键备份整个工作站(备份所有程序文件,上传文件,数据库),方便网站移植;移动站和计算机站可以独立地绑定到一级域名,共享空间和数据同步;领先的静态HTML文件缓存策略技术,通过设置缓存时间,可以自动生成HTML文件,无需手动生成HTML;内置搜索引擎优化功能,方便网站优化;内置插件,功能无限扩展
系统设置:基本设置,联系人设置,水印设置,文件上传设置,网站管理员统计信息设置,百度共享设置,缩略图设置,数据库设置,电子邮件设置,语言设置,第三方登录设置,手机网站设置,其他设置等
系统管理:自定义标签管理,数据库管理,数据库还原,通道模型管理,整个站点的一键备份,操作日志管理,网站目录权限检测,菜单管理,区域管理
内容管理:频道管理,主题管理,类型管理,信息管理(每个频道的信息的添加,删除,修改和检查)
交互式管理:在线客户服务管理,第三方在线客户服务管理,订单管理,交付方式管理,付款方式管理,销售统计,资金管理,积分管理,优惠券管理,消息管理,人才招聘,评论管理
广告管理:幻灯片管理,幻灯片分组管理,广告内容管理,群发邮件管理,订阅邮箱管理,邮件订阅分类管理,友情链接管理,友情链接分类管理
会员管理:会员信息管理,会员组管理,会员功能设置,管理员信息管理,管理员组管理
APP管理:内置的APP支持,您可以在后台查看APP安装统计信息和活动分析!
网站优化:伪静态设置(是否启用了伪静态和伪静态扩展名设置),搜索引擎优化设置(页面标题,页面关键词关键字,页面描述说明),常用搜索引擎登录条目,生成网站映射,生成关键词内部链接
微信平台:微信绑定设置,基本信息设置,微信自定义菜单设置,小程序设置,微信功能设置,关注自动回复,关键词自动回复,地理位置自动回复,默认自动回复,微信,微查询,微活动,微民意测验,微调查,微会员卡
模板管理:计算机模板管理(在线模板安装,模板选择,模板管理,样式管理),手机模板管理(在线模板安装,模板选择,模板管理,样式管理)
<p>插件管理:系统支持扩展插件。内置的插件包括:数据采集,三级分发,秦牛云存储,群发邮件,图像批处理等,插件可以自己开发,无限功能可以自由扩展 查看全部
友点企业网站管理系统集电脑站+APP+小程序五合一
源代码和安装说明简介:
YouDian cms是Youdian Enterprise 网站。管理系统集成了五合一计算机站+移动站+微信站+ APP +小程序,数据自动同步,降低了人力维护成本;共享管理后台,只要是虚拟主机,就可以有效节省空间投资。该系统采用开源技术PHP + MYSQL开发,开源,具有操作简单,功能强大,稳定性好,易于扩展,安全性强,维护方便,兼容性好等特点,可以帮助您快速构建强大的功能。和专业企业网站。该系统支持国际站的多语言轻松创建,自定义模型,对网站模板皮肤的支持,内置的SEO优化功能,静态页面,评论消息,购物车,在线支付,优惠券,积分,三级分发,订单管理,企业网站的基本功能,例如成员资格,数据采集,短信界面,插件应用商店和广告。操作环境:PHP 5. 3 / 5. 4 / 5. 5 / 5. 6 / 7. 0 / 7. 1 / 7. 2 / 7. 3 + MYSQL。
操作环境:
操作系统:跨平台,支持Windows,Unix,Linux等操作系统
WEB服务器:IIS / APACHE / NGINX等
PHP环境:PHP 5. 3- 7. 3
数据库:MYSQL 5. 0- 8. 0
产品功能:
1、完全开源:该系统使用开源技术PHP + MYSQL开发,安全,低成本,经济高效,易于安装(完全支持最新版本的PHP),功能无限,使用灵活完全开放的系统前端+后端源代码减轻了开发人员和用户的后顾之忧,完全支持二次开发,不保留后门,并且可以轻松地自己控制代码的使用权
2、五个站合而为一:计算机站,移动站,微信,APP和小程序合为一体,共享空间,数据同步,无需维护多个端口数据,只需一个后台即可
3、系统跨平台:Unix / Linux + windows,支持跨平台安装,一键式备份很容易获得网站迁移
支持扩展插件,功能可以无限扩展:系统后台插件应用商店集成了功能强大的免费插件:包括数据采集,三级分发,秦牛云存储,群发邮件,图像批处理等。
4、内置网站优化功能SEO优化:系统后台可以设置伪静态,设置HTML静态缓存策略,搜索引擎优化设置,常见的搜索引擎登录条目,生成网站映射,生成关键词链接,百度自动推送
功能模块:
功能列表
核心功能:计算机站,移动站,微信,APP,小程序五个站集成为一个,共享空间,数据同步;一键备份整个工作站(备份所有程序文件,上传文件,数据库),方便网站移植;移动站和计算机站可以独立地绑定到一级域名,共享空间和数据同步;领先的静态HTML文件缓存策略技术,通过设置缓存时间,可以自动生成HTML文件,无需手动生成HTML;内置搜索引擎优化功能,方便网站优化;内置插件,功能无限扩展
系统设置:基本设置,联系人设置,水印设置,文件上传设置,网站管理员统计信息设置,百度共享设置,缩略图设置,数据库设置,电子邮件设置,语言设置,第三方登录设置,手机网站设置,其他设置等
系统管理:自定义标签管理,数据库管理,数据库还原,通道模型管理,整个站点的一键备份,操作日志管理,网站目录权限检测,菜单管理,区域管理
内容管理:频道管理,主题管理,类型管理,信息管理(每个频道的信息的添加,删除,修改和检查)
交互式管理:在线客户服务管理,第三方在线客户服务管理,订单管理,交付方式管理,付款方式管理,销售统计,资金管理,积分管理,优惠券管理,消息管理,人才招聘,评论管理
广告管理:幻灯片管理,幻灯片分组管理,广告内容管理,群发邮件管理,订阅邮箱管理,邮件订阅分类管理,友情链接管理,友情链接分类管理
会员管理:会员信息管理,会员组管理,会员功能设置,管理员信息管理,管理员组管理
APP管理:内置的APP支持,您可以在后台查看APP安装统计信息和活动分析!
网站优化:伪静态设置(是否启用了伪静态和伪静态扩展名设置),搜索引擎优化设置(页面标题,页面关键词关键字,页面描述说明),常用搜索引擎登录条目,生成网站映射,生成关键词内部链接
微信平台:微信绑定设置,基本信息设置,微信自定义菜单设置,小程序设置,微信功能设置,关注自动回复,关键词自动回复,地理位置自动回复,默认自动回复,微信,微查询,微活动,微民意测验,微调查,微会员卡
模板管理:计算机模板管理(在线模板安装,模板选择,模板管理,样式管理),手机模板管理(在线模板安装,模板选择,模板管理,样式管理)
<p>插件管理:系统支持扩展插件。内置的插件包括:数据采集,三级分发,秦牛云存储,群发邮件,图像批处理等,插件可以自己开发,无限功能可以自由扩展
智能化的关键词追踪模型通过分析挖掘打下基础
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-04-25 19:00
摘要:本文通过分析舆论信息采集策略,提出了一种智能关键词跟踪模型。通过关键词智能跟踪模型的应用,网络舆情监测系统可以及时捕获热点事件的热点关键词,从而实现网络舆情监测系统对发展趋势的敏感响应。热点事件,为网络舆情热点事件的预警提供数据支持。简而言之,关键词智能跟踪模型基于某种关键词加权算法。根据民意事件不断变化的速度,通过反复的归纳计算,可以修改,调整和校对先前选择的关键词。过程。
关键词:互联网民意监测; 关键词;智能跟踪
中文图书馆分类号:TP39 3. 09
1舆论采集和分析
1. 1信息采集
根据Internet上热点的分布特征,当执行信息采集时,系统将为时效性很强网站的主流媒体执行信息采集。信息源具有高度的可靠性和实时性,信息量采集小,分析和处理速度快,热点分析速度快,准确性高且及时警告。合理地使用主流媒体的搜索引擎网站进行基于主题的信息采集。由于这些网站的分割技术不均匀,为了确保信息采集的准确性和实时性,我们采用了第二种搜索方案。在基于主题的信息采集之前,请对要进行主题采集的单词进行分词。根据分词的结果,首先执行采集并根据“宽范围” 关键词进行存储,然后跟随采集的结果。“小范围” 关键词进一步搜索,以便采集的信息准确性很高。
1. 2信息预处理
除系统所需的舆论信息外,该网页还收录许多其他信息,例如:Flash,视频,图片,广告和冗余链接。过滤掉垃圾邮件后,还必须合并同一主题的民意信息,即删除重复项。并且根据系统的规范,将舆情统一存储,作为下一步数据分析和挖掘的基础。信息预处理的主要软件包包括:主题关键字提取,正文中的关键信息提取,自动摘要,超链接分析,URL重复数据删除,垃圾邮件过滤等。
1. 3舆论分析
(1)民意的自动分类。民意信息的自动分类也是文本分类。这是让计算机自动识别民意信息的内容并在指定的分类模型下对民意进行分类的过程。自动进行民意分类首先设置类别关键词,为每个关键词设置一个相应的权重,然后进行最基本的分析并扫描采集中的民意信息,分别扫描标题和内容,然后分析关键词的出现次数,最后根据类别关键词模型计算每个关键词的权重,如果权重超过一定分数,将自动分类为相应的类别。
(2)舆论相似度排名。根据舆论信息主要内容的相似度,比其他方法更为实用和准确。利用分词技术对舆论关键词进行比较和计算。公众舆论的相似度,并设置较高的相似度阈值;如果超过该阈值,则确认很重要;将其与原创主题合并,无需进行任何进一步的操作;合并后,添加手动重新确认链接以确保重新分发万无一失。
(3)趋势分析技术。趋势分析是使用程序根据舆论关键词提取信息发布的意图。首先,根据汉语的特点,建立语义数据库。然后将民意信息特征关键词与语义数据库进行比较,以进行语义分析,最后根据结果确定民意事件的趋势,这种趋势分析可以阐明发布者要表达的观点和立场。
2舆论关键词提取
2. 1个单个文档关键词提取
在提取关键词之前,首先对文档进行分词处理,然后使用停止词汇表和过滤规则过滤分词结果。停止词汇表包括辅助词,介词,连词和其他功能词以及长度为1的词。没有实际意义的词。对于明显无用的单词,例如数字和量词,无意义的前缀和后缀,可以设计相应的过滤功能以过滤无用的单词。然后计算过滤后的词分割结果的权重,得到每个词的权重。
2. 2 关键词权重计算
文本关键词提取更多基于权向量生成方法,最常用的是TFIDF算法。 TFIDF的主要思想是,如果某个单词或短语出现在TF频率较高的文章文章中,并且如果很少出现在其他文章中,则认为该单词或短语具有良好的分类能力(较大的IDF值),并且适合分类。但是,除了TF和IDF外,每个单词还具有有效的信息,例如语音的一部分和文档中单词的位置信息。
2. 3文档集热点关键词提取
文档集的热点关键词应该是某些文档的关键词,因此从所有文档关键词的集合中建立候选关键词集,并进行特征提取以获得文档设置关键词。如果关键词的出现次数更多,则证明热点关注度更高;反之亦然。 IDF值越大,单词的辨别能力越强,并且越符合主题的特征。
3 关键词的智能跟踪
3. 1个主题聚类
考虑到不同主题网站的权威性,影响力和及时性,主题采集的来源权重是第一个要素,发布时间是第二个要素,按权重和时间的降序排列
默认情况下,首先关键词代表一个热门话题,然后将这些热门话题聚类。将关键词集中的第一个关键词作为第一个热门主题线索,使用关键词查找文章 关键词进行聚类,并默认情况下搜索第一个文档作为热门主题,然后按页面文本的其余部分被聚类,并且余弦角用于计算该主题与现有热门主题之间的相似度。如果相似度超过阈值P,则将当前主题合并到现有主题中;如果相似度小于阈值P,则将其作为当前新主题。然后将其余页面与关键词集中的第二个关键词聚类。迭代执行该算法,直到处理要分析的页面或达到设置的主题数为止。
3. 2智能跟踪模型
参考文献:
[1]李恒勋,张华平,秦鹏。基于主题的互联网热点话题的发现[C]。第五届全国信息检索会议论文集,北京,2009:134-14 3.
[2]张守华,刘振鹏。网络舆论热点话题聚类方法研究[J]。小型微型计算机系统,2013(3):18-1 9.
关于作者:张维佳(1982-),女,硕士,讲师,研究方向:计算机技术。
作者单位:河北大学,河北保定071000 查看全部
智能化的关键词追踪模型通过分析挖掘打下基础
摘要:本文通过分析舆论信息采集策略,提出了一种智能关键词跟踪模型。通过关键词智能跟踪模型的应用,网络舆情监测系统可以及时捕获热点事件的热点关键词,从而实现网络舆情监测系统对发展趋势的敏感响应。热点事件,为网络舆情热点事件的预警提供数据支持。简而言之,关键词智能跟踪模型基于某种关键词加权算法。根据民意事件不断变化的速度,通过反复的归纳计算,可以修改,调整和校对先前选择的关键词。过程。
关键词:互联网民意监测; 关键词;智能跟踪
中文图书馆分类号:TP39 3. 09
1舆论采集和分析
1. 1信息采集
根据Internet上热点的分布特征,当执行信息采集时,系统将为时效性很强网站的主流媒体执行信息采集。信息源具有高度的可靠性和实时性,信息量采集小,分析和处理速度快,热点分析速度快,准确性高且及时警告。合理地使用主流媒体的搜索引擎网站进行基于主题的信息采集。由于这些网站的分割技术不均匀,为了确保信息采集的准确性和实时性,我们采用了第二种搜索方案。在基于主题的信息采集之前,请对要进行主题采集的单词进行分词。根据分词的结果,首先执行采集并根据“宽范围” 关键词进行存储,然后跟随采集的结果。“小范围” 关键词进一步搜索,以便采集的信息准确性很高。
1. 2信息预处理
除系统所需的舆论信息外,该网页还收录许多其他信息,例如:Flash,视频,图片,广告和冗余链接。过滤掉垃圾邮件后,还必须合并同一主题的民意信息,即删除重复项。并且根据系统的规范,将舆情统一存储,作为下一步数据分析和挖掘的基础。信息预处理的主要软件包包括:主题关键字提取,正文中的关键信息提取,自动摘要,超链接分析,URL重复数据删除,垃圾邮件过滤等。
1. 3舆论分析
(1)民意的自动分类。民意信息的自动分类也是文本分类。这是让计算机自动识别民意信息的内容并在指定的分类模型下对民意进行分类的过程。自动进行民意分类首先设置类别关键词,为每个关键词设置一个相应的权重,然后进行最基本的分析并扫描采集中的民意信息,分别扫描标题和内容,然后分析关键词的出现次数,最后根据类别关键词模型计算每个关键词的权重,如果权重超过一定分数,将自动分类为相应的类别。
(2)舆论相似度排名。根据舆论信息主要内容的相似度,比其他方法更为实用和准确。利用分词技术对舆论关键词进行比较和计算。公众舆论的相似度,并设置较高的相似度阈值;如果超过该阈值,则确认很重要;将其与原创主题合并,无需进行任何进一步的操作;合并后,添加手动重新确认链接以确保重新分发万无一失。
(3)趋势分析技术。趋势分析是使用程序根据舆论关键词提取信息发布的意图。首先,根据汉语的特点,建立语义数据库。然后将民意信息特征关键词与语义数据库进行比较,以进行语义分析,最后根据结果确定民意事件的趋势,这种趋势分析可以阐明发布者要表达的观点和立场。
2舆论关键词提取
2. 1个单个文档关键词提取
在提取关键词之前,首先对文档进行分词处理,然后使用停止词汇表和过滤规则过滤分词结果。停止词汇表包括辅助词,介词,连词和其他功能词以及长度为1的词。没有实际意义的词。对于明显无用的单词,例如数字和量词,无意义的前缀和后缀,可以设计相应的过滤功能以过滤无用的单词。然后计算过滤后的词分割结果的权重,得到每个词的权重。
2. 2 关键词权重计算
文本关键词提取更多基于权向量生成方法,最常用的是TFIDF算法。 TFIDF的主要思想是,如果某个单词或短语出现在TF频率较高的文章文章中,并且如果很少出现在其他文章中,则认为该单词或短语具有良好的分类能力(较大的IDF值),并且适合分类。但是,除了TF和IDF外,每个单词还具有有效的信息,例如语音的一部分和文档中单词的位置信息。
2. 3文档集热点关键词提取
文档集的热点关键词应该是某些文档的关键词,因此从所有文档关键词的集合中建立候选关键词集,并进行特征提取以获得文档设置关键词。如果关键词的出现次数更多,则证明热点关注度更高;反之亦然。 IDF值越大,单词的辨别能力越强,并且越符合主题的特征。
3 关键词的智能跟踪
3. 1个主题聚类
考虑到不同主题网站的权威性,影响力和及时性,主题采集的来源权重是第一个要素,发布时间是第二个要素,按权重和时间的降序排列
默认情况下,首先关键词代表一个热门话题,然后将这些热门话题聚类。将关键词集中的第一个关键词作为第一个热门主题线索,使用关键词查找文章 关键词进行聚类,并默认情况下搜索第一个文档作为热门主题,然后按页面文本的其余部分被聚类,并且余弦角用于计算该主题与现有热门主题之间的相似度。如果相似度超过阈值P,则将当前主题合并到现有主题中;如果相似度小于阈值P,则将其作为当前新主题。然后将其余页面与关键词集中的第二个关键词聚类。迭代执行该算法,直到处理要分析的页面或达到设置的主题数为止。
3. 2智能跟踪模型
参考文献:
[1]李恒勋,张华平,秦鹏。基于主题的互联网热点话题的发现[C]。第五届全国信息检索会议论文集,北京,2009:134-14 3.
[2]张守华,刘振鹏。网络舆论热点话题聚类方法研究[J]。小型微型计算机系统,2013(3):18-1 9.
关于作者:张维佳(1982-),女,硕士,讲师,研究方向:计算机技术。
作者单位:河北大学,河北保定071000
如何通过百度谷歌系统发布关键词自动采集生成内容系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2021-04-20 22:01
关键词自动采集生成内容系统,bx编辑器特点自动采集大量外链数据,内容不需要客户手动输入,后台会自动记录出现在哪个网站,方便客户再次删除搜索内容。推广人员手动输入的话,比较麻烦,而且也有注重内容质量而不是外链数量的搜索引擎。系统后台自动计算收录率,排名,包括文章内页与url相关性等指标自动修改关键词自动优化内容,注重质量而不是外链数量,重视原创内容,有很强大的文章内容智能编辑与审核。
多个搜索引擎上的站点,特别是百度,都能匹配相应的关键词自动提升内容质量,合并关键词而不是人工改动上传内容排名快速靠前,快速带来网站流量,推广人员手动输入搜索关键词没有用,而自动内容则更具有针对性,更快的带来流量,采集的内容更符合网站调性,标题更具吸引力,具备搜索引擎的价值。支持并发连接建设,一个站点兼容多种搜索引擎自动标题修改关键词记录相应搜索引擎抓取规律,一一匹配相应搜索引擎内容自动标题修改关键词记录相应搜索引擎排名追踪,一个关键词搜索引擎下找内容提示为什么需要参加百度谷歌系统的内容自动发布,不是所有百度谷歌系统的文章都可以被采集自动撰写与编辑内容,可根据搜索引擎人工编辑及推荐的语料进行调整并自动撰写内容百度谷歌微信公众号文章发布,快速实现文章可视化搜索上传图片或文字搜索相关词自动测速度上传图片或文字自动提供更好的结果搜索上传图片或文字自动提供更好的结果上传视频自动生成链接如何通过百度谷歌系统发布关键词内容百度谷歌公众号文章发布发布网站。 查看全部
如何通过百度谷歌系统发布关键词自动采集生成内容系统
关键词自动采集生成内容系统,bx编辑器特点自动采集大量外链数据,内容不需要客户手动输入,后台会自动记录出现在哪个网站,方便客户再次删除搜索内容。推广人员手动输入的话,比较麻烦,而且也有注重内容质量而不是外链数量的搜索引擎。系统后台自动计算收录率,排名,包括文章内页与url相关性等指标自动修改关键词自动优化内容,注重质量而不是外链数量,重视原创内容,有很强大的文章内容智能编辑与审核。
多个搜索引擎上的站点,特别是百度,都能匹配相应的关键词自动提升内容质量,合并关键词而不是人工改动上传内容排名快速靠前,快速带来网站流量,推广人员手动输入搜索关键词没有用,而自动内容则更具有针对性,更快的带来流量,采集的内容更符合网站调性,标题更具吸引力,具备搜索引擎的价值。支持并发连接建设,一个站点兼容多种搜索引擎自动标题修改关键词记录相应搜索引擎抓取规律,一一匹配相应搜索引擎内容自动标题修改关键词记录相应搜索引擎排名追踪,一个关键词搜索引擎下找内容提示为什么需要参加百度谷歌系统的内容自动发布,不是所有百度谷歌系统的文章都可以被采集自动撰写与编辑内容,可根据搜索引擎人工编辑及推荐的语料进行调整并自动撰写内容百度谷歌微信公众号文章发布,快速实现文章可视化搜索上传图片或文字搜索相关词自动测速度上传图片或文字自动提供更好的结果搜索上传图片或文字自动提供更好的结果上传视频自动生成链接如何通过百度谷歌系统发布关键词内容百度谷歌公众号文章发布发布网站。
关键词自动采集生成内容系统-上海怡健医学培训
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-04-19 01:05
关键词自动采集生成内容系统
一、核心业务模块1.基本功能模块
1)内容收集:在电脑上使用一些市面上常见的采集器或者自己搭建模块(一般都很贵,这里是免费的),
2)文本下载:在手机上使用一些市面上常见的采集器或者自己搭建模块(一般都很贵,这里是免费的),将文本采集进来,
3)资源搜索:找到相关资源,并且对资源进行优化分类;2.手机上功能模块1.内容收集:通过从全网找热点,对热点进行收集并且加工;2.文本下载:通过从全网找热点,对热点进行收集并且加工;3.资源搜索:找到相关资源,
二、基本原理详解使用过程中,除了核心功能模块,其他功能并不是非常困难,稍微研究下seo的教程就可以。
对于新手,我们建议先从简单入手,
1)发布出来的网页需要全部放到服务器上,静态化的本质就是不需要服务器,对于网站来说,只要采集了相关的链接,就有意义了。那么,页面静态化最简单的方法是,使用360浏览器自带的“自动识别”功能,一直使用类似这样的自动识别功能很长时间了,
2)我们的原理是,通过对文本进行一些分词,把全文进行分成几百个短句,然后使用下面的方法进行搜索的时候,一次性把它获取出来。
资源搜索
1)不管是在百度还是在360搜索,输入什么关键词,都可以获取相应的搜索结果,这些搜索结果形成的区块(即词块),
2)当我们搜索某一个词的时候,如“游戏”或者“复读机”,
3)新增网页搜索区块,就是对于自动采集区块进行“分词”,这样做的好处是,在采集的时候,可以自动分词,这样能够减少采集之后手动分词的时间,从而减轻服务器负担;3.页面动态化提高页面效率有一个前提条件,页面动态化是有前提条件的。页面动态化是根据你自定义的字段,像真正的动态搜索一样,获取页面的资源。动态化很好理解,就是替换资源名称并替换文本。
4.手机端内容源最后补充一下页面的内容源。在平台上也看到了很多手机上的内容源,内容源本质上并不复杂,由于涉及到内容源不同,网络的问题,导致一个内容源(即模块或者词块)需要做多个版本(模块、词块和词语),那么对于内容源做重定向,就是内容源本身的特点了。 查看全部
关键词自动采集生成内容系统-上海怡健医学培训
关键词自动采集生成内容系统
一、核心业务模块1.基本功能模块
1)内容收集:在电脑上使用一些市面上常见的采集器或者自己搭建模块(一般都很贵,这里是免费的),
2)文本下载:在手机上使用一些市面上常见的采集器或者自己搭建模块(一般都很贵,这里是免费的),将文本采集进来,
3)资源搜索:找到相关资源,并且对资源进行优化分类;2.手机上功能模块1.内容收集:通过从全网找热点,对热点进行收集并且加工;2.文本下载:通过从全网找热点,对热点进行收集并且加工;3.资源搜索:找到相关资源,
二、基本原理详解使用过程中,除了核心功能模块,其他功能并不是非常困难,稍微研究下seo的教程就可以。
对于新手,我们建议先从简单入手,
1)发布出来的网页需要全部放到服务器上,静态化的本质就是不需要服务器,对于网站来说,只要采集了相关的链接,就有意义了。那么,页面静态化最简单的方法是,使用360浏览器自带的“自动识别”功能,一直使用类似这样的自动识别功能很长时间了,
2)我们的原理是,通过对文本进行一些分词,把全文进行分成几百个短句,然后使用下面的方法进行搜索的时候,一次性把它获取出来。
资源搜索
1)不管是在百度还是在360搜索,输入什么关键词,都可以获取相应的搜索结果,这些搜索结果形成的区块(即词块),
2)当我们搜索某一个词的时候,如“游戏”或者“复读机”,
3)新增网页搜索区块,就是对于自动采集区块进行“分词”,这样做的好处是,在采集的时候,可以自动分词,这样能够减少采集之后手动分词的时间,从而减轻服务器负担;3.页面动态化提高页面效率有一个前提条件,页面动态化是有前提条件的。页面动态化是根据你自定义的字段,像真正的动态搜索一样,获取页面的资源。动态化很好理解,就是替换资源名称并替换文本。
4.手机端内容源最后补充一下页面的内容源。在平台上也看到了很多手机上的内容源,内容源本质上并不复杂,由于涉及到内容源不同,网络的问题,导致一个内容源(即模块或者词块)需要做多个版本(模块、词块和词语),那么对于内容源做重定向,就是内容源本身的特点了。
关键词自动采集生成内容系统,原理其实很简单!
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-04-05 07:03
关键词自动采集生成内容系统,原理其实很简单,用户提交特定关键词,系统自动采集该关键词下的内容,然后再结合关键词的热度来自动分析内容是否有价值。
推荐一个最近发现的蛮好用的一个新媒体采集工具,可以采集微信公众号,微博,知乎等社交平台的文章,配图,内容,音乐,视频,图片,代码等等。有链接在公众号里面,下载只需要复制链接就行了。看个人资料与分享的内容来源,可以选择自己分享的,也可以自己采集的。
推荐一款叫【一键采集】的工具
有这类的自动采集软件,需要一些自己的技术积累,不然像楼上说的到时候采集出来内容无法解析,还要自己再去手动分析还可以试试【搜索技术】里面有很多的技术,
谢邀,就我所知道的,原理是这样的。用户输入几个关键词,对应地把文章采集过来,然后返回给用户,参考社交平台文章标题,去抓取文章标题里面的关键词,注意,不是采集内容,是关键词。
目前市面上除了导航站之外,没见到有专门做「关键词采集」的产品,目前能找到的成熟的做关键词采集的产品无非是以下几种:微信搜索:微信搜索有很多变种,比如搜狗微信、搜狗关键词、搜狗关键词采集器等等网站:排在前列的站点主要是1688、慧聪、等导航站的导航部分、微博搜索:简单搜索,有搜狗微博导航、搜狗微博导航等其他平台:各个平台基本也有自己的导航部分,比如百度有相关的导航、谷歌有各个平台各自的导航等。 查看全部
关键词自动采集生成内容系统,原理其实很简单!
关键词自动采集生成内容系统,原理其实很简单,用户提交特定关键词,系统自动采集该关键词下的内容,然后再结合关键词的热度来自动分析内容是否有价值。
推荐一个最近发现的蛮好用的一个新媒体采集工具,可以采集微信公众号,微博,知乎等社交平台的文章,配图,内容,音乐,视频,图片,代码等等。有链接在公众号里面,下载只需要复制链接就行了。看个人资料与分享的内容来源,可以选择自己分享的,也可以自己采集的。
推荐一款叫【一键采集】的工具
有这类的自动采集软件,需要一些自己的技术积累,不然像楼上说的到时候采集出来内容无法解析,还要自己再去手动分析还可以试试【搜索技术】里面有很多的技术,
谢邀,就我所知道的,原理是这样的。用户输入几个关键词,对应地把文章采集过来,然后返回给用户,参考社交平台文章标题,去抓取文章标题里面的关键词,注意,不是采集内容,是关键词。
目前市面上除了导航站之外,没见到有专门做「关键词采集」的产品,目前能找到的成熟的做关键词采集的产品无非是以下几种:微信搜索:微信搜索有很多变种,比如搜狗微信、搜狗关键词、搜狗关键词采集器等等网站:排在前列的站点主要是1688、慧聪、等导航站的导航部分、微博搜索:简单搜索,有搜狗微博导航、搜狗微博导航等其他平台:各个平台基本也有自己的导航部分,比如百度有相关的导航、谷歌有各个平台各自的导航等。
自动采集生成内容系统开发自动发布系统框架web服务框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-03-27 02:01
关键词自动采集生成内容系统开发自动发布系统框架web服务框架编辑页面设计和优化wordpress插件开发
那我就自问自答一波吧!本人也就是一个自学的大学生,大一也没毕业,在闲来无事的时候在网上找了一些教程,跟着入门然后现在正在写这个系统(我这里就简单介绍一下,没学过编程的估计看不懂,也别喷我,谢谢!!!)今天写完就准备发布上线去了,每天就是加班,写到7天应该就可以过deploy了吧!当时做这个系统的时候我是找人搭建的开源框架,也就是不用自己搭建,用的人家的框架上传就行了,然后看着别人写的东西仿照开发一样的,这样就完成了一个简单的博客系统,学校老师组织团队开会的时候,然后由一个博客界面,学院有什么课程什么的,用了框架也可以仿制,也可以去像编辑器visualstudio这种平台去用现成的编辑器写!非常简单的!。
曾经在网上搜过wordpress,搜到了一些教程,其中有一个叫做edubox-博客园,有安装配置的教程,安装后显示wordpress,后续才逐步开始有配置。原来我从来没试过用wordpress系统,一直以为那种带网站的php就算了,一是我自己弄过,二是最近系统不够稳定,有点卡,不顺心。于是认真学习了wordpress的基本配置,基本可以了解到基本的wordpress的功能。
想做一个全文搜索引擎的博客当然有可能,但这没必要了。我尝试过做一个搜索引擎,这个方向比较大,我感觉需要耗费的精力跟时间,肯定比自己搭建的重。这样可能对我目前不具有商业意义吧。花一个月时间自己搞一个,目的是能够用wordpress获取博客的信息,写网站用户体验。如果花了一个月,也搞不出来什么东西来,那我为什么还花时间来学习呢?看了一个月的教程,或许是我对学习这个词的理解还不够深刻,当我对学习这个词理解到能够解释一下开发一个教程在技术上的意义时,我对能不能将wordpress博客优化好这个课题产生了疑惑。
首先wordpress网站是由很多文章组成的,也就是说这种不全文搜索网站,要做的本身就是要搜索全文,所以涉及到全文搜索引擎的学习,可能大部分教程都不会告诉你怎么来操作,即使告诉你了,也不会有人写技术文章说明,说明他们是在多久多久做到多么牛x。全文搜索的目的是一篇文章里的很多文章都能帮助到用户,而不是每篇文章都能给他们带来价值。
这应该不属于wordpress网站的学习方向,直到发现了这篇博客可以通过代码实现全文搜索,当时我就想这个东西很新颖,应该会是一个很大的网站,于是决定学习这个,随后开始啃css技术。至于用什么代码,一开始我看的也是php代码,而且我几乎只掌握css不涉及p。 查看全部
自动采集生成内容系统开发自动发布系统框架web服务框架
关键词自动采集生成内容系统开发自动发布系统框架web服务框架编辑页面设计和优化wordpress插件开发
那我就自问自答一波吧!本人也就是一个自学的大学生,大一也没毕业,在闲来无事的时候在网上找了一些教程,跟着入门然后现在正在写这个系统(我这里就简单介绍一下,没学过编程的估计看不懂,也别喷我,谢谢!!!)今天写完就准备发布上线去了,每天就是加班,写到7天应该就可以过deploy了吧!当时做这个系统的时候我是找人搭建的开源框架,也就是不用自己搭建,用的人家的框架上传就行了,然后看着别人写的东西仿照开发一样的,这样就完成了一个简单的博客系统,学校老师组织团队开会的时候,然后由一个博客界面,学院有什么课程什么的,用了框架也可以仿制,也可以去像编辑器visualstudio这种平台去用现成的编辑器写!非常简单的!。
曾经在网上搜过wordpress,搜到了一些教程,其中有一个叫做edubox-博客园,有安装配置的教程,安装后显示wordpress,后续才逐步开始有配置。原来我从来没试过用wordpress系统,一直以为那种带网站的php就算了,一是我自己弄过,二是最近系统不够稳定,有点卡,不顺心。于是认真学习了wordpress的基本配置,基本可以了解到基本的wordpress的功能。
想做一个全文搜索引擎的博客当然有可能,但这没必要了。我尝试过做一个搜索引擎,这个方向比较大,我感觉需要耗费的精力跟时间,肯定比自己搭建的重。这样可能对我目前不具有商业意义吧。花一个月时间自己搞一个,目的是能够用wordpress获取博客的信息,写网站用户体验。如果花了一个月,也搞不出来什么东西来,那我为什么还花时间来学习呢?看了一个月的教程,或许是我对学习这个词的理解还不够深刻,当我对学习这个词理解到能够解释一下开发一个教程在技术上的意义时,我对能不能将wordpress博客优化好这个课题产生了疑惑。
首先wordpress网站是由很多文章组成的,也就是说这种不全文搜索网站,要做的本身就是要搜索全文,所以涉及到全文搜索引擎的学习,可能大部分教程都不会告诉你怎么来操作,即使告诉你了,也不会有人写技术文章说明,说明他们是在多久多久做到多么牛x。全文搜索的目的是一篇文章里的很多文章都能帮助到用户,而不是每篇文章都能给他们带来价值。
这应该不属于wordpress网站的学习方向,直到发现了这篇博客可以通过代码实现全文搜索,当时我就想这个东西很新颖,应该会是一个很大的网站,于是决定学习这个,随后开始啃css技术。至于用什么代码,一开始我看的也是php代码,而且我几乎只掌握css不涉及p。

