
关键词文章采集源码
关键词文章采集源码(百度快速收录SEO优化关键词排名优化技巧排名的条件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-12-21 04:07
百度快车收录SEO优化关键词排名优化技巧前言:新站优化有方法和技巧,关键词S排名优化,百度快车收录,如何快速发布新网站关键词排名,想要获得新网站的排名,需要规划词库布局,做好文章内容优化,写用户需求文章 ,做一个更新提交给百度站长,稳定持续的运营优化和推广,做关键词排名优化当我们在做新网站关键词排名优化时,我们需要考虑清楚关键词 开始做什么?当我们都想清楚了,那么我们就需要购买域名和空间。这更重要,因为我们正在对新网站进行排名。域名的选择对我们来说极其重要。在选择域名时,我们需要选择和我们需要做的事情。该产品具有高度相关性。这样做的目的是让搜索引擎在爬取我们的网站时通过域名知道我们在做什么?从而给人留下印象。服务器应选择高质量的服务器。网站的打开速度会对搜索引擎蜘蛛的抓取速度产生一定的影响。低配置的服务器,低配置会影响网站的打开速度,单位时间内的爬取量会相对少 绍兴站时如何让百度快速收录排名上网一直是站长们思考和期待的一个点。如何快速排名关键词,获得关键词
2、关键词Layout网站关键词词库组织布局,如果要优化词库,首先要操作词库组织布局,把需要的词放到布局优化在网站中,用户搜索关键词,排名需要相关性。关键词 的匹配度是轻松获取左侧词库排名的关键。3、网站内容质量网站内容质量是否原创,优质,满足需求文章,搜索引擎排名,推荐网页都是为了帮助用户解决问题,网页只有价值才有索引和发布的资格,用户喜欢高质量的文章。4、域名信任度网站 要想有词库发布,参与词库排名,首先网站域名信任度对搜索引擎友好,域名信任度的培养需要建站时间,网站内容质量、外链建设、朋友链交换等,发布高信任度收录和有效收录的域名,才有机会参与词库排名并获得用户行为点击。进一步提升网站关键词的排名。{callout color="#f0ad4e"}如何让百度快速收录排名{/callout}百度快速收录排名,简而言之就是在短时间内对你要推广的内容进行排名在搜索引擎中的优势地位。以此来增加网站访问者的数量,吸引更多的目标客户访问,达到营销推广的作用。百度快速排名需要关键词和连接才能排名。首先关键词和对应的连接需要是百度的收录。百度前十页有以下两种模式:1、模拟点击,类似于一些交互点组中的相互点击,促进排名提升。从2013年到2017年8月,这种方法的排名效果比较好,但9月份基本开始萎缩,行情效果不佳。和连接进行排名。首先关键词和对应的连接需要是百度的收录。百度前十页有以下两种模式:1、模拟点击,类似于一些交互点组中的相互点击,促进排名提升。从2013年到2017年8月,这种方法的排名效果比较好,但9月份基本开始萎缩,行情效果不佳。和连接进行排名。首先关键词和对应的连接需要是百度的收录。百度前十页有以下两种模式:1、模拟点击,类似于一些交互点组中的相互点击,促进排名提升。从2013年到2017年8月,这种方法的排名效果比较好,但9月份基本开始萎缩,行情效果不佳。
2、 数据外包+全网提权的方式,数据外包更稳定,效果高,效果好,推送平台采用这种方式。{callout color="#f0ad4e"}关键词排名优化技巧{/callout}如果要对网站的内页进行排名,必须有一定的权重。内页的权重主要包括以下两点: 1. 内容页的信息一定要丰富。如果一个页面有几十个字,即使信息是原创,被收录的概率也很小。就算是收录,也不会有好排名。页面信息是搜索引擎对页面进行评分的最重要因素。2. 内容页的关键词必须与用户搜索的长尾词相匹配。如果无法完全匹配,请尝试在页面标题和描述中显示要执行的长尾关键字。{callout color="#f0ad4e"}内页内链结构好{/callout}内页内链是网站优化中非常重要的一个元素,在优化内部页面的排名。网站的内部页面应该有网站的主导航,页面文章的面包屑导航,文末与本文相关的内容推荐等。这些都是内部链优化的必要操作。我们还需要优化列表页面。列表页面通常是一个 < @文章 列表,没有意义或者用户不关心。列表页面可酌情添加外部链接、友情链接等。{callout color="#f0ad4e"}网站内容和页面优化{/callout}网站架构分析包括:消除网站架构的不良设计,实现树状内容结构,网站 导航和链接优化。
<p>网站关键词分析应该是SEO优化办公室实施前最重要的环节。操作流程包括:网站关键词分析、团队竞争对手分析、网站关键词分析、网站 查看全部
关键词文章采集源码(百度快速收录SEO优化关键词排名优化技巧排名的条件)
百度快车收录SEO优化关键词排名优化技巧前言:新站优化有方法和技巧,关键词S排名优化,百度快车收录,如何快速发布新网站关键词排名,想要获得新网站的排名,需要规划词库布局,做好文章内容优化,写用户需求文章 ,做一个更新提交给百度站长,稳定持续的运营优化和推广,做关键词排名优化当我们在做新网站关键词排名优化时,我们需要考虑清楚关键词 开始做什么?当我们都想清楚了,那么我们就需要购买域名和空间。这更重要,因为我们正在对新网站进行排名。域名的选择对我们来说极其重要。在选择域名时,我们需要选择和我们需要做的事情。该产品具有高度相关性。这样做的目的是让搜索引擎在爬取我们的网站时通过域名知道我们在做什么?从而给人留下印象。服务器应选择高质量的服务器。网站的打开速度会对搜索引擎蜘蛛的抓取速度产生一定的影响。低配置的服务器,低配置会影响网站的打开速度,单位时间内的爬取量会相对少 绍兴站时如何让百度快速收录排名上网一直是站长们思考和期待的一个点。如何快速排名关键词,获得关键词
2、关键词Layout网站关键词词库组织布局,如果要优化词库,首先要操作词库组织布局,把需要的词放到布局优化在网站中,用户搜索关键词,排名需要相关性。关键词 的匹配度是轻松获取左侧词库排名的关键。3、网站内容质量网站内容质量是否原创,优质,满足需求文章,搜索引擎排名,推荐网页都是为了帮助用户解决问题,网页只有价值才有索引和发布的资格,用户喜欢高质量的文章。4、域名信任度网站 要想有词库发布,参与词库排名,首先网站域名信任度对搜索引擎友好,域名信任度的培养需要建站时间,网站内容质量、外链建设、朋友链交换等,发布高信任度收录和有效收录的域名,才有机会参与词库排名并获得用户行为点击。进一步提升网站关键词的排名。{callout color="#f0ad4e"}如何让百度快速收录排名{/callout}百度快速收录排名,简而言之就是在短时间内对你要推广的内容进行排名在搜索引擎中的优势地位。以此来增加网站访问者的数量,吸引更多的目标客户访问,达到营销推广的作用。百度快速排名需要关键词和连接才能排名。首先关键词和对应的连接需要是百度的收录。百度前十页有以下两种模式:1、模拟点击,类似于一些交互点组中的相互点击,促进排名提升。从2013年到2017年8月,这种方法的排名效果比较好,但9月份基本开始萎缩,行情效果不佳。和连接进行排名。首先关键词和对应的连接需要是百度的收录。百度前十页有以下两种模式:1、模拟点击,类似于一些交互点组中的相互点击,促进排名提升。从2013年到2017年8月,这种方法的排名效果比较好,但9月份基本开始萎缩,行情效果不佳。和连接进行排名。首先关键词和对应的连接需要是百度的收录。百度前十页有以下两种模式:1、模拟点击,类似于一些交互点组中的相互点击,促进排名提升。从2013年到2017年8月,这种方法的排名效果比较好,但9月份基本开始萎缩,行情效果不佳。
2、 数据外包+全网提权的方式,数据外包更稳定,效果高,效果好,推送平台采用这种方式。{callout color="#f0ad4e"}关键词排名优化技巧{/callout}如果要对网站的内页进行排名,必须有一定的权重。内页的权重主要包括以下两点: 1. 内容页的信息一定要丰富。如果一个页面有几十个字,即使信息是原创,被收录的概率也很小。就算是收录,也不会有好排名。页面信息是搜索引擎对页面进行评分的最重要因素。2. 内容页的关键词必须与用户搜索的长尾词相匹配。如果无法完全匹配,请尝试在页面标题和描述中显示要执行的长尾关键字。{callout color="#f0ad4e"}内页内链结构好{/callout}内页内链是网站优化中非常重要的一个元素,在优化内部页面的排名。网站的内部页面应该有网站的主导航,页面文章的面包屑导航,文末与本文相关的内容推荐等。这些都是内部链优化的必要操作。我们还需要优化列表页面。列表页面通常是一个 < @文章 列表,没有意义或者用户不关心。列表页面可酌情添加外部链接、友情链接等。{callout color="#f0ad4e"}网站内容和页面优化{/callout}网站架构分析包括:消除网站架构的不良设计,实现树状内容结构,网站 导航和链接优化。
<p>网站关键词分析应该是SEO优化办公室实施前最重要的环节。操作流程包括:网站关键词分析、团队竞争对手分析、网站关键词分析、网站
关键词文章采集源码(参考自知乎专题微信公众号内容的批量采集与应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-12-20 07:07
参考知乎专题微信公众号内容的批量采集和申请,作者:范口组长
原作者(饭口组组长)有句话:我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
这一系列文章也是为了延续这种分享精神!
本系列文章是根据知乎主题教程一步步实现的,在实现过程中踩到了一些坑。
原理介绍这里不再赘述,可以参考知乎专题。
代码改进前的准备
原作者使用php环境。如果有能力,可以尝试其他语言,比如python、java等,不过原作者已经给出了部分php代码,这里也实现了。
所以准备好php环境。建议使用win下的wamp、xamp、phpstudy等集成环境,因为之前电脑里就有wamp环境,所以直接用了。如果不匹配,请先配置虚拟域名。但是下面的代码需要改成自己对应的路径。配置虚拟域名的教程可以参考我的另一篇文章php本地虚拟域名配置和端口的一些折腾。这里假设我配置的虚拟域名是
修改 rule_default.js 代码
下面仅给出一些示例。其他人做同样的修改(如果没有配置虚拟域名,则需要将域名改为路径访问,如localhost/weixin/,修改即可):
HttpPost(ret[1],req.url,"/getMsgJson.php");
var http = require('http');
http.get('http://hojun.weixin.com/getWxHis.php', function(res) {
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
------------------
var options = {
method: "POST",
host: "hojun.weixin.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
找到要修改的函数replaceRequestOption:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
创建数据库和数据表
在完善php代码之前,我们还需要先创建数据库和数据表。好消息是组长已经给出了数据表的创建sql语句。修改了一些语法错误和重复关键词
微信公众号表
CREATE TABLE `weixin` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`biz` varchar(255) DEFAULT ' ' COMMENT '公众号唯一标识biz',
`collect` int(11) DEFAULT 1 COMMENT '记录采集时间的时间戳',
PRIMARY KEY (`id`)
) ;
微信文章表
CREATE TABLE `post` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`biz` varchar(255) CHARACTER SET utf8 NOT NULL COMMENT '文章对应的公众号biz',
`field_id` int(11) NOT NULL COMMENT '微信定义的一个id,每条文章唯一',
`title` varchar(255) NOT NULL DEFAULT ' ' COMMENT '文章标题',
`title_encode` text CHARACTER SET utf8 NOT NULL COMMENT '文章编码,防止文章出现emoji',
`digest` varchar(500) NOT NULL DEFAULT ' ' COMMENT '文章摘要',
`content_url` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '文章地址',
`source_url` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '阅读原文地址',
`cover` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '封面图片',
`is_multi` int(11) NOT NULL COMMENT '是否多图文',
`is_top` int(11) NOT NULL COMMENT '是否头条',
`datetime` int(11) NOT NULL COMMENT '文章时间戳',
`readNum` int(11) NOT NULL DEFAULT 1 COMMENT '文章阅读量',
`likeNum` int(11) NOT NULL DEFAULT 0 COMMENT '文章点赞量',
PRIMARY KEY (`id`)
) ;
采集队列表
CREATE TABLE `tmplist` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`content_url` varchar(255) DEFAULT NULL COMMENT '文章地址',
`load` int(11) DEFAULT 0 COMMENT '读取中标记',
PRIMARY KEY (`id`),
UNIQUE KEY `content_url` (`content_url`)
) ;
登录phpMyAdmin后台,语言可以设置为中文。
图片
请注意,排序规则设置为 utf8_general_ci。
图片
然后一一执行sql生成数据表。
图片
待续……待续…… 查看全部
关键词文章采集源码(参考自知乎专题微信公众号内容的批量采集与应用)
参考知乎专题微信公众号内容的批量采集和申请,作者:范口组长
原作者(饭口组组长)有句话:我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
这一系列文章也是为了延续这种分享精神!
本系列文章是根据知乎主题教程一步步实现的,在实现过程中踩到了一些坑。
原理介绍这里不再赘述,可以参考知乎专题。
代码改进前的准备
原作者使用php环境。如果有能力,可以尝试其他语言,比如python、java等,不过原作者已经给出了部分php代码,这里也实现了。
所以准备好php环境。建议使用win下的wamp、xamp、phpstudy等集成环境,因为之前电脑里就有wamp环境,所以直接用了。如果不匹配,请先配置虚拟域名。但是下面的代码需要改成自己对应的路径。配置虚拟域名的教程可以参考我的另一篇文章php本地虚拟域名配置和端口的一些折腾。这里假设我配置的虚拟域名是
修改 rule_default.js 代码
下面仅给出一些示例。其他人做同样的修改(如果没有配置虚拟域名,则需要将域名改为路径访问,如localhost/weixin/,修改即可):
HttpPost(ret[1],req.url,"/getMsgJson.php");
var http = require('http');
http.get('http://hojun.weixin.com/getWxHis.php', function(res) {
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
------------------
var options = {
method: "POST",
host: "hojun.weixin.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
找到要修改的函数replaceRequestOption:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
创建数据库和数据表
在完善php代码之前,我们还需要先创建数据库和数据表。好消息是组长已经给出了数据表的创建sql语句。修改了一些语法错误和重复关键词
微信公众号表
CREATE TABLE `weixin` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`biz` varchar(255) DEFAULT ' ' COMMENT '公众号唯一标识biz',
`collect` int(11) DEFAULT 1 COMMENT '记录采集时间的时间戳',
PRIMARY KEY (`id`)
) ;
微信文章表
CREATE TABLE `post` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`biz` varchar(255) CHARACTER SET utf8 NOT NULL COMMENT '文章对应的公众号biz',
`field_id` int(11) NOT NULL COMMENT '微信定义的一个id,每条文章唯一',
`title` varchar(255) NOT NULL DEFAULT ' ' COMMENT '文章标题',
`title_encode` text CHARACTER SET utf8 NOT NULL COMMENT '文章编码,防止文章出现emoji',
`digest` varchar(500) NOT NULL DEFAULT ' ' COMMENT '文章摘要',
`content_url` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '文章地址',
`source_url` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '阅读原文地址',
`cover` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '封面图片',
`is_multi` int(11) NOT NULL COMMENT '是否多图文',
`is_top` int(11) NOT NULL COMMENT '是否头条',
`datetime` int(11) NOT NULL COMMENT '文章时间戳',
`readNum` int(11) NOT NULL DEFAULT 1 COMMENT '文章阅读量',
`likeNum` int(11) NOT NULL DEFAULT 0 COMMENT '文章点赞量',
PRIMARY KEY (`id`)
) ;
采集队列表
CREATE TABLE `tmplist` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`content_url` varchar(255) DEFAULT NULL COMMENT '文章地址',
`load` int(11) DEFAULT 0 COMMENT '读取中标记',
PRIMARY KEY (`id`),
UNIQUE KEY `content_url` (`content_url`)
) ;
登录phpMyAdmin后台,语言可以设置为中文。

图片
请注意,排序规则设置为 utf8_general_ci。
图片
然后一一执行sql生成数据表。
图片
待续……待续……
关键词文章采集源码( 帝国CMS内核简洁大气PS教程模板教程源码PS)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-12-20 01:25
帝国CMS内核简洁大气PS教程模板教程源码PS)
总结:帝国cms内核简洁大气PS教程模板,教程源码,PS教程网站模板带手机模板同步插件,熊掌号自动推送采集,百度自动推送、发送采集【全站数据】---------------...
帝国cms内核简洁大气PS教程模板,教程源码,PS教程网站模板带手机模板同步插件,熊掌号自动推送采集,百度自动推送,发送采集【全站数据】
-------------------------------------------------- ------------------------------
开发环境:Empirecms7.5
空间支持:php+mysql
大小:全站2.约4G
采集:发送优采云采集器(内置规则和模块)
编码:UTF-8 附安装说明教程
●系统开源,域名不限
●PC同步生成手机版
-------------------------------------------------- -------------------------------------------------- ---
【笔记】
源代码模板程序在本地经过严格测试,并多次添加到演示站。
网站优化
1:新增手机同步插件
2:百度自动推送
3:网站地图
4:熊掌号自动提交
5:标签
6:404,robost,全站静态生成,有利于收录和关键词布局和内容页面优化。
模板使用标签灵活调用。在采集方面,选择优质的文章。它不是为了好看的模板而开发的,但用户体验和搜索引擎的友好性很重要。
-------------------------------------------------- -------------------------------------------------- ----
图文并茂的安装教程
我们自建的demo,有demo和真相,一切以demo站和截图为准!
注:请放心购买自动发货
-------------------------------------------------- -------------------------------------------------- ——
演示站
计算机
移动终端
注意:演示站机器配置低有延迟是正常的。如果访问速度较慢,请耐心等待。
-------------------------------------------------- -------------------------------------------------- ---
模板截图
移动终端
购买地址 查看全部
关键词文章采集源码(
帝国CMS内核简洁大气PS教程模板教程源码PS)

总结:帝国cms内核简洁大气PS教程模板,教程源码,PS教程网站模板带手机模板同步插件,熊掌号自动推送采集,百度自动推送、发送采集【全站数据】---------------...
帝国cms内核简洁大气PS教程模板,教程源码,PS教程网站模板带手机模板同步插件,熊掌号自动推送采集,百度自动推送,发送采集【全站数据】
-------------------------------------------------- ------------------------------
开发环境:Empirecms7.5
空间支持:php+mysql
大小:全站2.约4G
采集:发送优采云采集器(内置规则和模块)
编码:UTF-8 附安装说明教程
●系统开源,域名不限
●PC同步生成手机版
-------------------------------------------------- -------------------------------------------------- ---
【笔记】
源代码模板程序在本地经过严格测试,并多次添加到演示站。
网站优化
1:新增手机同步插件
2:百度自动推送
3:网站地图
4:熊掌号自动提交
5:标签
6:404,robost,全站静态生成,有利于收录和关键词布局和内容页面优化。
模板使用标签灵活调用。在采集方面,选择优质的文章。它不是为了好看的模板而开发的,但用户体验和搜索引擎的友好性很重要。
-------------------------------------------------- -------------------------------------------------- ----
图文并茂的安装教程
我们自建的demo,有demo和真相,一切以demo站和截图为准!
注:请放心购买自动发货
-------------------------------------------------- -------------------------------------------------- ——
演示站
计算机
移动终端
注意:演示站机器配置低有延迟是正常的。如果访问速度较慢,请耐心等待。
-------------------------------------------------- -------------------------------------------------- ---
模板截图

移动终端

购买地址
关键词文章采集源码(商品属性安装环境商品介绍程序说明(图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-12-18 23:16
)
商品属性
安装环境
产品介绍
程序说明
1、 源码类型:小说全站源码
2、环境语言:PHP5.2/5.3/5.4/5.5+MYSQL5+伪静态
3、原程序:源码以dedecms5.7sp1为核心。由于源代码已修改优化,请勿自动升级。一般情况下,如果没有bug,就不需要升级。业主会不时提供必要的升级包。
4、编码类型:GBK
5、可用采集:全自动采集
6、其他功能:
(1)首页、分类、目录、排名、站点地图页(分类页、小说封面、作者页,如果html文件不存在或超过设定时间未更新,则自动生成静态html)自动更新一次。如果有采集,采集会自动更新小说封面和对应的分类页面),直接通过PHP调用html文件,而不是在根目录生成,访问速度与纯静态无异,在保证源文件管理方便的同时,可以降低服务器压力,还可以方便访问统计,增加搜索引擎识别度。
(2)全站拼音编目,章节页面伪静态。
(3)自动生成小说txt文件,也可以后台重新生成txt文件。
(4)自动生成小说关键词和关键词自动内链。
(5)自动伪原创单词替换(采集时替换)。
(6)新增小说总点击量、月点击量、周点击量、总推荐量、月度推荐量、周推荐统计、作者推荐统计等新功能。
(7)配合CNZZ的统计插件,方便实现小说下载量和藏书量的详细统计。
百度网盘链接和解压码一般都在压缩包里。如果没有,请联系店长QQ获取。
查看全部
关键词文章采集源码(商品属性安装环境商品介绍程序说明(图)
)
商品属性
安装环境
产品介绍
程序说明
1、 源码类型:小说全站源码
2、环境语言:PHP5.2/5.3/5.4/5.5+MYSQL5+伪静态
3、原程序:源码以dedecms5.7sp1为核心。由于源代码已修改优化,请勿自动升级。一般情况下,如果没有bug,就不需要升级。业主会不时提供必要的升级包。
4、编码类型:GBK
5、可用采集:全自动采集
6、其他功能:
(1)首页、分类、目录、排名、站点地图页(分类页、小说封面、作者页,如果html文件不存在或超过设定时间未更新,则自动生成静态html)自动更新一次。如果有采集,采集会自动更新小说封面和对应的分类页面),直接通过PHP调用html文件,而不是在根目录生成,访问速度与纯静态无异,在保证源文件管理方便的同时,可以降低服务器压力,还可以方便访问统计,增加搜索引擎识别度。
(2)全站拼音编目,章节页面伪静态。
(3)自动生成小说txt文件,也可以后台重新生成txt文件。
(4)自动生成小说关键词和关键词自动内链。
(5)自动伪原创单词替换(采集时替换)。
(6)新增小说总点击量、月点击量、周点击量、总推荐量、月度推荐量、周推荐统计、作者推荐统计等新功能。
(7)配合CNZZ的统计插件,方便实现小说下载量和藏书量的详细统计。
百度网盘链接和解压码一般都在压缩包里。如果没有,请联系店长QQ获取。

关键词文章采集源码(网页爬虫代码的实现思路及实现)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-12-18 18:16
现在网络爬虫代码可以说是满天飞,尤其是Python和PHP写的居多。百度随便搜,满屏。无论用什么计算机语言编写,性能都无关紧要。最重要的是想法的实现。
一、想法的实现1、之前的想法
说说我个人的实现思路:
十多年前写了一个爬虫,当时的想法:
1、根据关键词的设置。
2、百度搜索相关关键词并保存。
3、 遍历关键词 库,搜索相关网页信息。
4、 提取搜索页面的页面链接。
5、 遍历每个页面上的网络链接。
6、 抓取网页数据。
7、分析数据,构造标题、关键词、描述、内容,并存入数据库。
8、部署到服务器,每天自动更新html页面。
这里的重点是:标题的智能组织、关键词的自动组合、内容的智能拼接。
那个时候搜索引擎还没有这么智能的时候,效果还不错!百度的收录率很高。
2、当前思想数据采集部分:
根据初始的关键词集合,从百度搜索引擎中搜索相关的关键词,遍历相关的关键词库,抓取百度数据。
构建数据部分:
按照原来的文章标题,分解成多个关键词作为SEO关键词。同理,对文章的内容进行分解,取第一段内容的前100字作为SEO网页描述。内容不变,数据整理好存入仓库。
文章发布部分:
根据排序后的数据(SEO相关设置),匹配相关页面模板,依次生成文章内容页、文章列表页、网站首页。部署到服务器,每天自动更新文章的设置数量。
二、相关流程1.数据采集流程
1、设置关键词。
2、根据设置搜索相关关键词关键词。
3、 遍历关键词,百度搜索结果,得到前10页。
4、根据页码链接,得到前10页(大约前100条数据,后面的排名已经很晚了,意义不大)
5、获取每个页面的网络链接集合。
6、 根据链接获取网页信息(标题、作者、时间、内容、原文链接)。
2.数据生成过程
1、 初始化表(关键词、链接、内容、html数据、发布统计)。
2、根据基本的关键词,抓取相关的关键词存入数据库。
3、 获取链接并存储。
4、 抓取网页内容并将其存储在数据库中。
5、构建 html 内容并将其存储在库中。
3.页面发布流程
1、在html数据表中获取从早到晚的数据。
2、创建内容详细信息页面。
3、创建内容列表页面。 查看全部
关键词文章采集源码(网页爬虫代码的实现思路及实现)
现在网络爬虫代码可以说是满天飞,尤其是Python和PHP写的居多。百度随便搜,满屏。无论用什么计算机语言编写,性能都无关紧要。最重要的是想法的实现。
一、想法的实现1、之前的想法
说说我个人的实现思路:
十多年前写了一个爬虫,当时的想法:
1、根据关键词的设置。
2、百度搜索相关关键词并保存。
3、 遍历关键词 库,搜索相关网页信息。
4、 提取搜索页面的页面链接。
5、 遍历每个页面上的网络链接。
6、 抓取网页数据。
7、分析数据,构造标题、关键词、描述、内容,并存入数据库。
8、部署到服务器,每天自动更新html页面。
这里的重点是:标题的智能组织、关键词的自动组合、内容的智能拼接。
那个时候搜索引擎还没有这么智能的时候,效果还不错!百度的收录率很高。
2、当前思想数据采集部分:
根据初始的关键词集合,从百度搜索引擎中搜索相关的关键词,遍历相关的关键词库,抓取百度数据。
构建数据部分:
按照原来的文章标题,分解成多个关键词作为SEO关键词。同理,对文章的内容进行分解,取第一段内容的前100字作为SEO网页描述。内容不变,数据整理好存入仓库。
文章发布部分:
根据排序后的数据(SEO相关设置),匹配相关页面模板,依次生成文章内容页、文章列表页、网站首页。部署到服务器,每天自动更新文章的设置数量。
二、相关流程1.数据采集流程
1、设置关键词。
2、根据设置搜索相关关键词关键词。
3、 遍历关键词,百度搜索结果,得到前10页。
4、根据页码链接,得到前10页(大约前100条数据,后面的排名已经很晚了,意义不大)
5、获取每个页面的网络链接集合。
6、 根据链接获取网页信息(标题、作者、时间、内容、原文链接)。
2.数据生成过程
1、 初始化表(关键词、链接、内容、html数据、发布统计)。
2、根据基本的关键词,抓取相关的关键词存入数据库。
3、 获取链接并存储。
4、 抓取网页内容并将其存储在数据库中。
5、构建 html 内容并将其存储在库中。
3.页面发布流程
1、在html数据表中获取从早到晚的数据。
2、创建内容详细信息页面。
3、创建内容列表页面。
关键词文章采集源码(帝国CMS7.5简洁好听的名字_高分好名字资讯模板)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-12-13 18:10
帝国cms7.5个简洁好听的名字_高分好名字_取个好名字信息模板,百度自动推送。【内页(文章页,列表)标题,描述,严格的SEO标题规范,有利于SEO,维护一个网站和一个域名结盟好]
-------------------------------------------------- -------------------------------------------------- ------
● 系统开源,域名不限
● WAP移动终端
●大小约159MB
●发送采集
●附图文安装教程
-------------------------------------------------- -------------------------------------------------- -------
【笔记】
源代码模板程序在本地经过严格测试,并多次添加到演示站。
网站优化
1:百度自动推送
2:网站地图
3:多端同步生成插件
4:404、robost、TAG、百度统计,全站静态生成有利于收录和关键词布局和内容页面优化。
模板使用标签灵活调用。不是为了模板好看而开发的。重要的是用户体验和对搜索引擎的友好性。
【注意】:如果有tags、load more等功能打不开404,说明没有安装配置数据库,按照教程正常配置后不会出现这个问题。
模板全部经过Tinder security等本地杀毒软件扫描后打包,精简了一些不必要的功能,去除了多余的js和css,提高了程序的安全性和网站的稳定性。
-------------------------------------------------- -------------------------------------------------- ---------
演示站
计算机:查看演示
移动终端;查看演示
我们自建的demo,有demo和真相,一切以demo站和截图为准!
注意:演示站机器配置低,有延迟是正常的。这与模板程序无关。
-------------------------------------------------- -------------------------------------------------- ----------
模板部分截图:
资源下载 本资源下载价格为100金币,请先登录 查看全部
关键词文章采集源码(帝国CMS7.5简洁好听的名字_高分好名字资讯模板)
帝国cms7.5个简洁好听的名字_高分好名字_取个好名字信息模板,百度自动推送。【内页(文章页,列表)标题,描述,严格的SEO标题规范,有利于SEO,维护一个网站和一个域名结盟好]
-------------------------------------------------- -------------------------------------------------- ------
● 系统开源,域名不限
● WAP移动终端
●大小约159MB
●发送采集
●附图文安装教程
-------------------------------------------------- -------------------------------------------------- -------
【笔记】
源代码模板程序在本地经过严格测试,并多次添加到演示站。
网站优化
1:百度自动推送
2:网站地图
3:多端同步生成插件
4:404、robost、TAG、百度统计,全站静态生成有利于收录和关键词布局和内容页面优化。
模板使用标签灵活调用。不是为了模板好看而开发的。重要的是用户体验和对搜索引擎的友好性。
【注意】:如果有tags、load more等功能打不开404,说明没有安装配置数据库,按照教程正常配置后不会出现这个问题。
模板全部经过Tinder security等本地杀毒软件扫描后打包,精简了一些不必要的功能,去除了多余的js和css,提高了程序的安全性和网站的稳定性。
-------------------------------------------------- -------------------------------------------------- ---------
演示站
计算机:查看演示
移动终端;查看演示
我们自建的demo,有demo和真相,一切以demo站和截图为准!
注意:演示站机器配置低,有延迟是正常的。这与模板程序无关。
-------------------------------------------------- -------------------------------------------------- ----------
模板部分截图:






资源下载 本资源下载价格为100金币,请先登录
关键词文章采集源码(微思敦编程语言有可读性,通俗易懂性)
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-12-12 14:04
关键词文章采集源码blogspot文章采集douban/douban-blogitem导读:douban有大量的站内文章,希望采集这些文章中的精华和热点话题,分析文章的曝光率及多维度的数据,集中总结、优化产品形式,同时有效的向搜索引擎传达产品以及平台发展的市场趋势,降低跳转率及转化率。python编程语言有可读性,通俗易懂性,web开发有可看性。
结合近期搜索引擎seo及网站的搜索,需要选择前端api、接口测试等专业性较强、内容同质化严重、能传递海量信息的产品。感谢很多大神设计,分析,微思敦提供blogspot中文、英文和中文社区文章采集。产品:blogspot中文社区、blogspot、自由自在的开发者社区、avazu、topic-xl、英文web开发者社区链接:::hanchengzixiaohao4202018-06-15更新于:2018-10-08python环境:win10+python3.6python3.5+django2.1+chromedriver,firefoxdriver,djangossl版本,从官网下载原版镜像来看。
python3.5+需要包括java环境才可以。也有少数语言特性要求是win7+python3.5+,也有语言环境要求是python2.7+python3.5。下载安装的具体步骤可以通过ssh上github官网下载安装包,配置的具体细节请参见官网。官网下载地址为:facebook官方网站,目前已经不可以直接在chrome浏览器中使用了,不同于有插件支持,基本已经封掉chrome浏览器的ssl接口,此时如果想进行跳转,即看不到注册完成提示文字,那么可以参考django的models.pymodels.model.saveqqa之类,很有可能是django启动qa数据检查库qa-master时遇到的不能启动qa服务器的错误。
此时我们只需要通过python第三方模块如python-sqlalchemy解决库本身的问题。因为python语言不支持blogspot这个库,所以大部分基于python的fb采集都是通过python-qa来实现:以xml标签的形式传递文章的属性信息dom描述表示一个标签,可以包含多个标签分页、回复等操作,有四种方式实现:fromdjango.dbimportmodelsfrom.itemsimportmodels.postmodels.post(item,models.post)#item以postdata的格式返回,配合blogspot.session使用://postdata=blogspot.session()models.post(item,models.post)#通过fb.model.default(blogspot.model.default)//这个方法创建了postdata对象,默认会产生token//request_token=models.get_request_token(username,password)创建存储qa数据库的数据库。 查看全部
关键词文章采集源码(微思敦编程语言有可读性,通俗易懂性)
关键词文章采集源码blogspot文章采集douban/douban-blogitem导读:douban有大量的站内文章,希望采集这些文章中的精华和热点话题,分析文章的曝光率及多维度的数据,集中总结、优化产品形式,同时有效的向搜索引擎传达产品以及平台发展的市场趋势,降低跳转率及转化率。python编程语言有可读性,通俗易懂性,web开发有可看性。
结合近期搜索引擎seo及网站的搜索,需要选择前端api、接口测试等专业性较强、内容同质化严重、能传递海量信息的产品。感谢很多大神设计,分析,微思敦提供blogspot中文、英文和中文社区文章采集。产品:blogspot中文社区、blogspot、自由自在的开发者社区、avazu、topic-xl、英文web开发者社区链接:::hanchengzixiaohao4202018-06-15更新于:2018-10-08python环境:win10+python3.6python3.5+django2.1+chromedriver,firefoxdriver,djangossl版本,从官网下载原版镜像来看。
python3.5+需要包括java环境才可以。也有少数语言特性要求是win7+python3.5+,也有语言环境要求是python2.7+python3.5。下载安装的具体步骤可以通过ssh上github官网下载安装包,配置的具体细节请参见官网。官网下载地址为:facebook官方网站,目前已经不可以直接在chrome浏览器中使用了,不同于有插件支持,基本已经封掉chrome浏览器的ssl接口,此时如果想进行跳转,即看不到注册完成提示文字,那么可以参考django的models.pymodels.model.saveqqa之类,很有可能是django启动qa数据检查库qa-master时遇到的不能启动qa服务器的错误。
此时我们只需要通过python第三方模块如python-sqlalchemy解决库本身的问题。因为python语言不支持blogspot这个库,所以大部分基于python的fb采集都是通过python-qa来实现:以xml标签的形式传递文章的属性信息dom描述表示一个标签,可以包含多个标签分页、回复等操作,有四种方式实现:fromdjango.dbimportmodelsfrom.itemsimportmodels.postmodels.post(item,models.post)#item以postdata的格式返回,配合blogspot.session使用://postdata=blogspot.session()models.post(item,models.post)#通过fb.model.default(blogspot.model.default)//这个方法创建了postdata对象,默认会产生token//request_token=models.get_request_token(username,password)创建存储qa数据库的数据库。
关键词文章采集源码(总站、代理、普通用户均可添加网站关键词的关键词指数 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-12-09 04:01
)
安装教程:
thinkphp, php72, 运行目录/public
导入数据库,修改数据库目录:/app/database.php
后台账号:admin
密码:abymcn
SEO按天关键词计费排名查询系统源码
功能:1. 会员管理:
系统分为三级会员流程。总部管理员、代理、会员(会员分为普通会员、中级会员、高级会员三个级别),
主站增加代理用户,充值代理用户余额,充值余额给普通用户。代理还可以将关键词的查询比例提高到3级会员。
如果这个关键词终端为代理10元,而代理与普通用户的比例为200,那么用户加这个关键词为20元,
多出的10元是代理商的利润。代理只能看到自己的下级成员,设置的比例只对自己的下级成员有效。如果代理没有设置比例,
然后会根据主站给代理的价格显示给用户,也就是原价。
2.网站管理。
总部、代理商、普通用户可以添加网站,在网站列表页可以看到网站的基本信息。
如:域名、网站名称、会员、注册时间、关键词数量、达标数量关键词、今日消费、历史消费、网站启用和残疾状态;
3.关键词 管理。
总部、代理商、普通用户可以添加网站关键词,普通用户只能通过关键词价格添加关键词,
普通用户添加的关键词需要经过一般背景审核;
4.关键词查看价格。
系统支持两种模式:手动输入价格和基于关键词索引的价格查询。基于关键词指数的价格查询需要我们在后台输入指数区间。
我们扣分系统调用的站长之家关键词索引与百度、360等官网数据不一致,请谨慎使用;
5.关键词 排名。做优化的朋友应该都知道,在做自然搜索的时候,会出现站外排名的情况。我们经常发现排名找不到,
在排名不准确的情况下,市面上的扣费系统大多采用单节点查询技术或调用站长之家/5118等查询接口。
一般现象是搜索不闪,我司采用多节点排名查询技术。目前,全国部署了7个节点。排名查询比站长的好
5118等扣费系统一定要准确数倍,我们提供排名快照服务。如果客户网站 出现在搜索结果的前 2 页,我们的系统将自行拍摄当前排名的快照。
对客户更有说服力;
6.公众号查询:
系统支持非认证订阅号、服务号等查询网站排名,只需在公众号对话框中输入网站域名,
公众号会自动向用户反馈网站的排名情况。下一步将进一步完善公众号的功能,如:余额不足提醒、关键词排名标准推送功能等;
7.财务管理。
后端提供清晰、简洁、清晰的财务统计分析。一般后端和代理用户可以看到他们的代理/用户的可用余额,
累计消费、上月消费、本月消费、近3个月消费、近1年消费等,也可后台查看;
8.在线充值。
开发微信扫码支付功能;
9. 利润分析,
利润统计,各搜索引擎达标数量关键词,最近7天达标数量,折线图和直方图展示,方便您查看!!!
查看全部
关键词文章采集源码(总站、代理、普通用户均可添加网站关键词的关键词指数
)
安装教程:
thinkphp, php72, 运行目录/public
导入数据库,修改数据库目录:/app/database.php
后台账号:admin
密码:abymcn
SEO按天关键词计费排名查询系统源码
功能:1. 会员管理:
系统分为三级会员流程。总部管理员、代理、会员(会员分为普通会员、中级会员、高级会员三个级别),
主站增加代理用户,充值代理用户余额,充值余额给普通用户。代理还可以将关键词的查询比例提高到3级会员。
如果这个关键词终端为代理10元,而代理与普通用户的比例为200,那么用户加这个关键词为20元,
多出的10元是代理商的利润。代理只能看到自己的下级成员,设置的比例只对自己的下级成员有效。如果代理没有设置比例,
然后会根据主站给代理的价格显示给用户,也就是原价。
2.网站管理。
总部、代理商、普通用户可以添加网站,在网站列表页可以看到网站的基本信息。
如:域名、网站名称、会员、注册时间、关键词数量、达标数量关键词、今日消费、历史消费、网站启用和残疾状态;
3.关键词 管理。
总部、代理商、普通用户可以添加网站关键词,普通用户只能通过关键词价格添加关键词,
普通用户添加的关键词需要经过一般背景审核;
4.关键词查看价格。
系统支持两种模式:手动输入价格和基于关键词索引的价格查询。基于关键词指数的价格查询需要我们在后台输入指数区间。
我们扣分系统调用的站长之家关键词索引与百度、360等官网数据不一致,请谨慎使用;
5.关键词 排名。做优化的朋友应该都知道,在做自然搜索的时候,会出现站外排名的情况。我们经常发现排名找不到,
在排名不准确的情况下,市面上的扣费系统大多采用单节点查询技术或调用站长之家/5118等查询接口。
一般现象是搜索不闪,我司采用多节点排名查询技术。目前,全国部署了7个节点。排名查询比站长的好
5118等扣费系统一定要准确数倍,我们提供排名快照服务。如果客户网站 出现在搜索结果的前 2 页,我们的系统将自行拍摄当前排名的快照。
对客户更有说服力;
6.公众号查询:
系统支持非认证订阅号、服务号等查询网站排名,只需在公众号对话框中输入网站域名,
公众号会自动向用户反馈网站的排名情况。下一步将进一步完善公众号的功能,如:余额不足提醒、关键词排名标准推送功能等;
7.财务管理。
后端提供清晰、简洁、清晰的财务统计分析。一般后端和代理用户可以看到他们的代理/用户的可用余额,
累计消费、上月消费、本月消费、近3个月消费、近1年消费等,也可后台查看;
8.在线充值。
开发微信扫码支付功能;
9. 利润分析,
利润统计,各搜索引擎达标数量关键词,最近7天达标数量,折线图和直方图展示,方便您查看!!!


关键词文章采集源码(如何应对网络中的新闻内容也一样?系统帮你解决)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-12-06 14:18
随着互联网的飞速发展,互联网极大地提高了信息生成和传播的速度。互联网上每天都会产生大量的内容。如何从这些乱七八糟的内容中高效地发现和采集需要的信息,变得越来越明显越重要。互联网上的新闻内容也是如此。新闻分布在不同的网站上,存在重复的内容。我们往往只关心新闻的一部分。互联网上的新闻页面往往充斥着大量与新闻无关的新闻页面。这些信息会影响我们的阅读效率和阅读体验。如何更方便、及时、高效地获取我们关心的新闻内容,这个系统可以帮我们做到这一点。本系统使用网络爬虫对网络网站上的新闻进行定时、有针对性的分析和采集,然后对采集收到的数据进行去重、分类、保存。进入数据库,最终提供个性化的新闻订阅服务。考虑如何处理网站的反爬虫策略,避免被网站拦截。在具体实现中,我们将使用Python与scrapy等框架编写爬虫,使用特定的内容提取算法提取目标数据,最后使用Django加weui提供新闻订阅后台和新闻内容展示页面,使用微信推送给用户的信息。用户可以通过本系统订阅指定关键词,当爬虫系统抓取到收录指定关键词的内容时,
[关键词] 网络爬虫;消息; 个性化;订阅; Python
参考文档及完整文档及源代码下载地址: 查看全部
关键词文章采集源码(如何应对网络中的新闻内容也一样?系统帮你解决)
随着互联网的飞速发展,互联网极大地提高了信息生成和传播的速度。互联网上每天都会产生大量的内容。如何从这些乱七八糟的内容中高效地发现和采集需要的信息,变得越来越明显越重要。互联网上的新闻内容也是如此。新闻分布在不同的网站上,存在重复的内容。我们往往只关心新闻的一部分。互联网上的新闻页面往往充斥着大量与新闻无关的新闻页面。这些信息会影响我们的阅读效率和阅读体验。如何更方便、及时、高效地获取我们关心的新闻内容,这个系统可以帮我们做到这一点。本系统使用网络爬虫对网络网站上的新闻进行定时、有针对性的分析和采集,然后对采集收到的数据进行去重、分类、保存。进入数据库,最终提供个性化的新闻订阅服务。考虑如何处理网站的反爬虫策略,避免被网站拦截。在具体实现中,我们将使用Python与scrapy等框架编写爬虫,使用特定的内容提取算法提取目标数据,最后使用Django加weui提供新闻订阅后台和新闻内容展示页面,使用微信推送给用户的信息。用户可以通过本系统订阅指定关键词,当爬虫系统抓取到收录指定关键词的内容时,
[关键词] 网络爬虫;消息; 个性化;订阅; Python
参考文档及完整文档及源代码下载地址:
关键词文章采集源码(百度文库采集经典的三个外国网站的样例代码都是名一样)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-12-04 22:02
关键词文章采集源码编写开源神器百度网站镜像百度学术镜像百度文库采集经典的三个外国网站的样例代码都是后缀名一样下载下来就可以编辑有各种不同类型的文章,供你选择。
不管是源码还是脚本,编写得好的话整个人都会爽很多,也很快捷,主要是编程能力要过硬。比如下面这个:autocad安装包发给你了!!!全部都是免费的。免费的,免费的。
autocad导入编辑
程序员,对。是程序员。重要的话说三遍。绝对经典的源码。出来好多年了,没有加好多乱七八糟的东西。真的是。
站在巨人的肩膀,
坐标河南省。我们这有过一个比较丰富的源码资源,开源的成品文件,那是第二年。
从04年开始给程序员做的也差不多有20年的历史了虽然基本上没有出现什么事故,但是总是免不了有些遗憾最近20多年里因为各种原因所以没有碰过autocad最近因为好多同事想尝试新东西所以找了人开发新系统,自己觉得不错的原因,这才勉强算是几年吧开源的源码在大量的使用与实践中总结出来一些经验分享给大家我们在搭建工具软件的过程中,想要高质量的autocad软件,就得保证学习性和工作效率先分享一个心得在做一个软件之前我们得先解决学习性的问题,也就是要保证多用多练习,各种技术资料方法网上找不到。
首先先学习autocad常用的基础功能,包括布局和命令一定要熟练掌握,特别是布局命令,几个关键功能一定要尝试掌握其次,掌握了基础的布局命令后我们要学习绘图技巧(命令解释和使用技巧及各种布局操作)最后我们要尝试解决绘图问题(其实是最耗时的问题),你可以选择去研究源码,也可以选择去找开源软件类库用(std::asm),完整的如autocad2004,后期不断自己扩展个别,来解决自己的问题,来自行实现自己的一些功能效率及便捷程度是差了不止一个数量级。
其次了解各种常用工具选择记忆理解,其实还是很重要的,真正用到的时候你不会不认识这些工具,也就是说了解了再用,或者复习了再用,是比较能理解且节省时间的。最后,也很关键是自己的学习能力及付出多少时间的沉淀。毕竟其实autocad内容是远远大于2004大的,大于300多个文件,你也得付出时间去做学习与研究(工作中我们做计算机的也不想天天做重复性的事情,必然是自己也能掌握的,最好是自己能够直接操作就能解决问题的)以上,供参考。 查看全部
关键词文章采集源码(百度文库采集经典的三个外国网站的样例代码都是名一样)
关键词文章采集源码编写开源神器百度网站镜像百度学术镜像百度文库采集经典的三个外国网站的样例代码都是后缀名一样下载下来就可以编辑有各种不同类型的文章,供你选择。
不管是源码还是脚本,编写得好的话整个人都会爽很多,也很快捷,主要是编程能力要过硬。比如下面这个:autocad安装包发给你了!!!全部都是免费的。免费的,免费的。
autocad导入编辑
程序员,对。是程序员。重要的话说三遍。绝对经典的源码。出来好多年了,没有加好多乱七八糟的东西。真的是。
站在巨人的肩膀,
坐标河南省。我们这有过一个比较丰富的源码资源,开源的成品文件,那是第二年。
从04年开始给程序员做的也差不多有20年的历史了虽然基本上没有出现什么事故,但是总是免不了有些遗憾最近20多年里因为各种原因所以没有碰过autocad最近因为好多同事想尝试新东西所以找了人开发新系统,自己觉得不错的原因,这才勉强算是几年吧开源的源码在大量的使用与实践中总结出来一些经验分享给大家我们在搭建工具软件的过程中,想要高质量的autocad软件,就得保证学习性和工作效率先分享一个心得在做一个软件之前我们得先解决学习性的问题,也就是要保证多用多练习,各种技术资料方法网上找不到。
首先先学习autocad常用的基础功能,包括布局和命令一定要熟练掌握,特别是布局命令,几个关键功能一定要尝试掌握其次,掌握了基础的布局命令后我们要学习绘图技巧(命令解释和使用技巧及各种布局操作)最后我们要尝试解决绘图问题(其实是最耗时的问题),你可以选择去研究源码,也可以选择去找开源软件类库用(std::asm),完整的如autocad2004,后期不断自己扩展个别,来解决自己的问题,来自行实现自己的一些功能效率及便捷程度是差了不止一个数量级。
其次了解各种常用工具选择记忆理解,其实还是很重要的,真正用到的时候你不会不认识这些工具,也就是说了解了再用,或者复习了再用,是比较能理解且节省时间的。最后,也很关键是自己的学习能力及付出多少时间的沉淀。毕竟其实autocad内容是远远大于2004大的,大于300多个文件,你也得付出时间去做学习与研究(工作中我们做计算机的也不想天天做重复性的事情,必然是自己也能掌握的,最好是自己能够直接操作就能解决问题的)以上,供参考。
关键词文章采集源码(第一、网站定位利用核心词语长尾关键词:确定网站主题与方向)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-12-04 16:08
一、网站 定位和使用核心词采集整理长尾关键词:
确定网站的主题和方向,比如核心关键词:二手车。下面是重点。长尾关键词是怎么来的?这里需要了解一些程序,简单使用php字段采集:百度相关搜索。对于初学者来说,使用php字段方法可能比较困难(regular就可以,字段简单)采集所有关键词收录“二手车”,自动无限采集回来关键词数量非常大(重复关键词no采集,关键词no采集超过限定长度)。
按二、长尾关键词分类:
对所有从采集返回的收录“二手车”的关键词进行分类,大致分为三类:1.导航;2.交易;3.信息类别;这样划分的原因不是为了划分列,而是为了方便下面长尾关键词的组合。
三、长尾关键词的组合:
上面分离的三种关键词,每一种文章随机抽取一个导航、交易、信息关键词,组合起来作为标题。这样做的目的是为了让标题更加多样化,搜索起来更容易。另外,长尾关键词容易上榜,上首页也容易。如果数量大,得到的流量是很直观的。
第一个四、是以长尾关键词组成的标题为内容:
当关键词组合成一个标题时,我们就会发现一个问题。写这样的标题对我们来说并不容易。文章,因为这样组合的标题涉及的内容太多,所以我们只需要先把关键词的一个提取出来写文章,然后再从里面提取一个关键词的组合其他两个类作为标题,因为关键词都收录“二手车”,所以不用担心不相关。如果使用采集,可以考虑将一些相关内容与采集,或者采集其他人的文章结合起来,百度翻译再翻译成中文。这些方法都不好,可读性差,不利于网站的长远发展,而且百度的垃圾邮件识别能力也在不断提升。
五、的原理分析:
长尾关键词具有快速排名的能力,是增加有效流量最好最快的方式。花在一个核心上的时间关键词可以做出几十万条长尾关键词。这里我采集进行了百度相关搜索,确认这些关键词都是搜索到关键词,并且“二手车”这个词的相关性是一定的,加上分类,组合成一个标题,整合标题的三个关键词分类,方便用户搜索。
这种方法简单、直接、有效。如果您精通程序,那么做到这一点真的太容易了。通过海量的长尾关键词做内容,总会有很多关键词的排名。在首页,流量增加十倍根本不是问题。 查看全部
关键词文章采集源码(第一、网站定位利用核心词语长尾关键词:确定网站主题与方向)
一、网站 定位和使用核心词采集整理长尾关键词:
确定网站的主题和方向,比如核心关键词:二手车。下面是重点。长尾关键词是怎么来的?这里需要了解一些程序,简单使用php字段采集:百度相关搜索。对于初学者来说,使用php字段方法可能比较困难(regular就可以,字段简单)采集所有关键词收录“二手车”,自动无限采集回来关键词数量非常大(重复关键词no采集,关键词no采集超过限定长度)。
按二、长尾关键词分类:
对所有从采集返回的收录“二手车”的关键词进行分类,大致分为三类:1.导航;2.交易;3.信息类别;这样划分的原因不是为了划分列,而是为了方便下面长尾关键词的组合。
三、长尾关键词的组合:
上面分离的三种关键词,每一种文章随机抽取一个导航、交易、信息关键词,组合起来作为标题。这样做的目的是为了让标题更加多样化,搜索起来更容易。另外,长尾关键词容易上榜,上首页也容易。如果数量大,得到的流量是很直观的。
第一个四、是以长尾关键词组成的标题为内容:
当关键词组合成一个标题时,我们就会发现一个问题。写这样的标题对我们来说并不容易。文章,因为这样组合的标题涉及的内容太多,所以我们只需要先把关键词的一个提取出来写文章,然后再从里面提取一个关键词的组合其他两个类作为标题,因为关键词都收录“二手车”,所以不用担心不相关。如果使用采集,可以考虑将一些相关内容与采集,或者采集其他人的文章结合起来,百度翻译再翻译成中文。这些方法都不好,可读性差,不利于网站的长远发展,而且百度的垃圾邮件识别能力也在不断提升。
五、的原理分析:
长尾关键词具有快速排名的能力,是增加有效流量最好最快的方式。花在一个核心上的时间关键词可以做出几十万条长尾关键词。这里我采集进行了百度相关搜索,确认这些关键词都是搜索到关键词,并且“二手车”这个词的相关性是一定的,加上分类,组合成一个标题,整合标题的三个关键词分类,方便用户搜索。
这种方法简单、直接、有效。如果您精通程序,那么做到这一点真的太容易了。通过海量的长尾关键词做内容,总会有很多关键词的排名。在首页,流量增加十倍根本不是问题。
关键词文章采集源码( 如何通过dedecms来做采集站?采集怎么做? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-12-03 09:08
如何通过dedecms来做采集站?采集怎么做?
)
很多SEO人员和网站管理者都会用织梦cms来建网站,但是对于dede采集网站、织梦@ >内置的采集功能非常不方便,已经不适合采集的当前需求。所以,SEO人员一定要懂知识,不一定要懂,但一定要懂!如何通过dedecms做采集站?德德采集是怎么做的?我用织梦cms做采集站,收录现在接近20万了,权重有点低,只有权重3,不过可以SEO方法后说明 来这里的采集站也可以起来了。今天的文章主要是和大家分享这两个我们在做SEO时遇到的常见问题。
德德采集怎么做? dedecms自带采集功能,功能非常有限,不能满足采集的复杂需求,经常导致网站网页采集空白,也就是对SEO人员来说很麻烦。因此,您可以使用免费且易于使用的第三方网站采集软件来完成dede采集:
1.一键安装,自动免费采集,安装非常简单方便,只需一分钟
2. 多词采集 无需写采集规则,根据大量关键词来平移采集
3. RSS采集,输入RSS地址到采集内容,只需输入RSS地址到采集到目标网站内容定位采集,精确采集标题、正文、作者、出处,只需要提供列表URL即可智能采集指定网站或栏目内容
4.软件全自动采集,无需人工干预,即可挂断采集,所有操作程序全自动
5.图片云存储,大量采集图片不麻烦,也可以本地存储。支持所有主流云存储。
6.可以直接进行伪原创SEO更新,只需开启伪原创功能,不需要复杂的配置界面
7.可以同时支持所有主要的cms版本,以及市场上所有常见的cms支持。
8.自动推送到各大搜索引擎接口,确保搜索引擎及时收录到我们的网站并提供网站排名
德德采集的做法是什么?这是SEO优化非常重要的一步。内容采集:我也提到了dedecms内置的采集器的使用。就个人而言,我不推荐它。 采集 的那种。 文章 直接发布,肯定会被搜索引擎打中。建立你的网站关键词,关键词需要两个,一个准确,一个多。标准是指关键词必须和你的网站定位有关。比如你是装修公司网站,那你网站的关键词肯定和装修有关(装修风格,现代装修等)。更多意味着需要大量的行业关键词来进行采集,这样文章就会有更多、更丰富的内容。 伪原创:因为采集的内容已经被收录或者其他人展示过,为了避免被搜索引擎命中,所以是采集站,在同时增加原创 所以采集的内容必须经过SEO伪原创的处理。标题:标题是一篇文章的精髓文章。它在很大程度上决定了用户点击的概率,所以它必须表达整个文章的含义,这很有吸引力。标题中必须收录长尾关键词,并且关键词必须与网站相关。
网站网站的建设和运营管理需要全面。关于dede采集,在这里分享一下。很多SEO知识需要在实际操作中积累经验。我只是提出一些新手需要了解的基础内容,也是个人经验。
查看全部
关键词文章采集源码(
如何通过dedecms来做采集站?采集怎么做?
)

很多SEO人员和网站管理者都会用织梦cms来建网站,但是对于dede采集网站、织梦@ >内置的采集功能非常不方便,已经不适合采集的当前需求。所以,SEO人员一定要懂知识,不一定要懂,但一定要懂!如何通过dedecms做采集站?德德采集是怎么做的?我用织梦cms做采集站,收录现在接近20万了,权重有点低,只有权重3,不过可以SEO方法后说明 来这里的采集站也可以起来了。今天的文章主要是和大家分享这两个我们在做SEO时遇到的常见问题。
德德采集怎么做? dedecms自带采集功能,功能非常有限,不能满足采集的复杂需求,经常导致网站网页采集空白,也就是对SEO人员来说很麻烦。因此,您可以使用免费且易于使用的第三方网站采集软件来完成dede采集:
1.一键安装,自动免费采集,安装非常简单方便,只需一分钟
2. 多词采集 无需写采集规则,根据大量关键词来平移采集
3. RSS采集,输入RSS地址到采集内容,只需输入RSS地址到采集到目标网站内容定位采集,精确采集标题、正文、作者、出处,只需要提供列表URL即可智能采集指定网站或栏目内容
4.软件全自动采集,无需人工干预,即可挂断采集,所有操作程序全自动
5.图片云存储,大量采集图片不麻烦,也可以本地存储。支持所有主流云存储。
6.可以直接进行伪原创SEO更新,只需开启伪原创功能,不需要复杂的配置界面
7.可以同时支持所有主要的cms版本,以及市场上所有常见的cms支持。
8.自动推送到各大搜索引擎接口,确保搜索引擎及时收录到我们的网站并提供网站排名
德德采集的做法是什么?这是SEO优化非常重要的一步。内容采集:我也提到了dedecms内置的采集器的使用。就个人而言,我不推荐它。 采集 的那种。 文章 直接发布,肯定会被搜索引擎打中。建立你的网站关键词,关键词需要两个,一个准确,一个多。标准是指关键词必须和你的网站定位有关。比如你是装修公司网站,那你网站的关键词肯定和装修有关(装修风格,现代装修等)。更多意味着需要大量的行业关键词来进行采集,这样文章就会有更多、更丰富的内容。 伪原创:因为采集的内容已经被收录或者其他人展示过,为了避免被搜索引擎命中,所以是采集站,在同时增加原创 所以采集的内容必须经过SEO伪原创的处理。标题:标题是一篇文章的精髓文章。它在很大程度上决定了用户点击的概率,所以它必须表达整个文章的含义,这很有吸引力。标题中必须收录长尾关键词,并且关键词必须与网站相关。
网站网站的建设和运营管理需要全面。关于dede采集,在这里分享一下。很多SEO知识需要在实际操作中积累经验。我只是提出一些新手需要了解的基础内容,也是个人经验。

关键词文章采集源码(免费自学学习网模板文章资讯作文整站源码手机同步生成+安装教程 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-12-02 12:08
)
2021帝国cms7.5个免费自学学习网站模板文章信息合成全站源码手机同步生成+安装教程+采集
-------------------------------------------------- ------------------------------
PC/电脑版演示地址:
WAP/手机版演示地址:(请使用手机访问)
-------------------------------------------------- ------------------------------
源码为EmpirecmsUTF8版本,如需GBK版本请自行转码!
这个模板是楼主自己复制的。不修改Empire程序默认的表前缀,不保留各种恶心的AD广告。
模板简洁大方,访问快捷,移动端优化美观的用户体验。
适合文章知识点、试题、练习题、考试信息、作文百科、学习方法与技巧等信息汇总,供中小学生参考!
所有功能均在后台管理,并已预留广告位(如需添加广告位请联系店主添加)。
模板使用标签灵活调用。采集方面,精选优质源站,模板精美,同时兼顾SEO搜索引擎优化。全站静态生成,有利于收录和关键词布局和内容页面优化!
特点一览:
1、内置ITAG插件,标签可以拼音,标签分类可用,功能更强大,更容易生成词库。(标签链接样式可选择ID或拼音)
2、内置百度推送插件,数据实时推送到搜索引擎。
3、通过优采云采集规则,您可以采集自己处理大量数据,全自动无人值守采集。
4、内置网站地图站点地图插件
本产品是整个站点的源代码,不仅是模板,还有演示站点的所有数据。
详情请看演示站,更直观。
注意:演示站机器配置低,有延迟是正常的。这与模板程序无关。
-------------------------------------------------- -------------------------------------------------
●帝国cms7.5UTF-8
●系统开源,域名不限
●同步生成WAP移动终端简单实用。
●大小约330MB
●简单的安装方法,有详细的安装教程。
●TAG标签聚合
-------------------------------------------------- ----------------------------------------------
---
查看全部
关键词文章采集源码(免费自学学习网模板文章资讯作文整站源码手机同步生成+安装教程
)
2021帝国cms7.5个免费自学学习网站模板文章信息合成全站源码手机同步生成+安装教程+采集
-------------------------------------------------- ------------------------------
PC/电脑版演示地址:
WAP/手机版演示地址:(请使用手机访问)
-------------------------------------------------- ------------------------------
源码为EmpirecmsUTF8版本,如需GBK版本请自行转码!
这个模板是楼主自己复制的。不修改Empire程序默认的表前缀,不保留各种恶心的AD广告。
模板简洁大方,访问快捷,移动端优化美观的用户体验。
适合文章知识点、试题、练习题、考试信息、作文百科、学习方法与技巧等信息汇总,供中小学生参考!
所有功能均在后台管理,并已预留广告位(如需添加广告位请联系店主添加)。
模板使用标签灵活调用。采集方面,精选优质源站,模板精美,同时兼顾SEO搜索引擎优化。全站静态生成,有利于收录和关键词布局和内容页面优化!
特点一览:
1、内置ITAG插件,标签可以拼音,标签分类可用,功能更强大,更容易生成词库。(标签链接样式可选择ID或拼音)
2、内置百度推送插件,数据实时推送到搜索引擎。
3、通过优采云采集规则,您可以采集自己处理大量数据,全自动无人值守采集。
4、内置网站地图站点地图插件
本产品是整个站点的源代码,不仅是模板,还有演示站点的所有数据。
详情请看演示站,更直观。
注意:演示站机器配置低,有延迟是正常的。这与模板程序无关。
-------------------------------------------------- -------------------------------------------------
●帝国cms7.5UTF-8
●系统开源,域名不限
●同步生成WAP移动终端简单实用。
●大小约330MB
●简单的安装方法,有详细的安装教程。
●TAG标签聚合
-------------------------------------------------- ----------------------------------------------
---











关键词文章采集源码(仓库源码采集源码分享(1)_社会万象_光明网)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-12-02 11:08
关键词文章采集源码分享:仓库源码controls。pypathmap。py。1。安装neo4j包需要先安装pipinstallneo4j2。初始化neo4j数据库启动neo4j服务,并从服务器下载源码。dmg文件。jar下载地址:,将下载好的。jar文件解压,双击。py安装成功后的。dmg路径(注意能解压,安装成功后不能解压)。
/neo4j_config。py:/client/hostname/client/bin/neo4j_config。py#代码修改自官方文档create_table_filenamename(request。url,create_table_filenamename(request。url,set_create_table_filename('user','person')))#(user)对应的是用户或者一个表(table)参数request。
url必须为。/client/url/create_table_filename(request。url,set_create_table_file('user','person'))#(table)对应的是数据库名参数set_create_table_file('family','user')#(person)对应的是姓名(必须为字符串类型)参数create_table_filename设置默认采用了bash环境安装,如果是python环境需要pipinstallneo4j2。
数据库增加字段,添加表名名称和表名字段名字段名字段数据库名名称字段名称字段数据库名名字段数据库名参数(family)字段名参数set_database('user')exportdbnameexporttablename启动neo4j服务#检查export的启动neo4jconfigserver:friend@localhostpassword:localhost#启动成功configserver:friend@localhostpassword:localhost#停止启动neo4jserver:friend@localhostpassword:localhost#configserver:friend@localhostpassword:localhost#启动服务neo4jconfigserver:friend@localhostpassword:localhost#启动服务neo4jconfigserver:friend@localhostpassword:localhost#停止服务neo4jconfigserver:friend@localhostpassword:localhost#修改neo4j文件路径。
/neo4j_config。py修改文件路径/user/neo4j/bin/neo4j。write修改为/user/neo4j/bin/neo4j。write3。neo4j定义对象查询语句“从文档中查询json/java/jsp等格式类似的所有类型对象”1。定义json/java对象1。1定义一个json对象(要注意定义的时候类型一定要合法)2。
定义java对象定义代码#注意:java对象可以是定义在python模块下的,例如python2。x,python3。x这是通用的,需要用python2。x用gensim模块或者python1。x用python。2中的json模块3。命名。 查看全部
关键词文章采集源码(仓库源码采集源码分享(1)_社会万象_光明网)
关键词文章采集源码分享:仓库源码controls。pypathmap。py。1。安装neo4j包需要先安装pipinstallneo4j2。初始化neo4j数据库启动neo4j服务,并从服务器下载源码。dmg文件。jar下载地址:,将下载好的。jar文件解压,双击。py安装成功后的。dmg路径(注意能解压,安装成功后不能解压)。
/neo4j_config。py:/client/hostname/client/bin/neo4j_config。py#代码修改自官方文档create_table_filenamename(request。url,create_table_filenamename(request。url,set_create_table_filename('user','person')))#(user)对应的是用户或者一个表(table)参数request。
url必须为。/client/url/create_table_filename(request。url,set_create_table_file('user','person'))#(table)对应的是数据库名参数set_create_table_file('family','user')#(person)对应的是姓名(必须为字符串类型)参数create_table_filename设置默认采用了bash环境安装,如果是python环境需要pipinstallneo4j2。
数据库增加字段,添加表名名称和表名字段名字段名字段数据库名名称字段名称字段数据库名名字段数据库名参数(family)字段名参数set_database('user')exportdbnameexporttablename启动neo4j服务#检查export的启动neo4jconfigserver:friend@localhostpassword:localhost#启动成功configserver:friend@localhostpassword:localhost#停止启动neo4jserver:friend@localhostpassword:localhost#configserver:friend@localhostpassword:localhost#启动服务neo4jconfigserver:friend@localhostpassword:localhost#启动服务neo4jconfigserver:friend@localhostpassword:localhost#停止服务neo4jconfigserver:friend@localhostpassword:localhost#修改neo4j文件路径。
/neo4j_config。py修改文件路径/user/neo4j/bin/neo4j。write修改为/user/neo4j/bin/neo4j。write3。neo4j定义对象查询语句“从文档中查询json/java/jsp等格式类似的所有类型对象”1。定义json/java对象1。1定义一个json对象(要注意定义的时候类型一定要合法)2。
定义java对象定义代码#注意:java对象可以是定义在python模块下的,例如python2。x,python3。x这是通用的,需要用python2。x用gensim模块或者python1。x用python。2中的json模块3。命名。
关键词文章采集源码(免费下载分享源码搜索引擎异步加载功能源码(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-12-01 04:03
关键词文章采集源码api文章抓取常用源码源码下载skd源码,获取全网skd源码全网分享免费下载分享源码搜索引擎异步加载功能源码热点爬取,爬虫工程师必备对象模型,给源码加一个属性可以快速的进行某个对象类型变量存取,这样可以提高开发效率接口和框架快速学习不会的依赖的源码可以参考网页底部关于文章内容下载的方式ps:源码下载后可以公众号后台自助获取源码以下是个人简介和以后的学习计划源码下载。
基于chromeextension推出的非主流网站抓取web综合排名第7,
python里面的selenium+ie/firefox以及其他的浏览器类。
django啊,毕竟是封装了其他mvc框架的http服务器.虽然有些不完美,毕竟和springmvc这种大厂相比,毕竟django是开源的.除此之外还有一个叫做bootstrap的bs框架封装了一个mvc模型.
gayhub
之前写过的一篇文章可以看下-10-webfiledownloading-part-1
web.py
楼上说的是我以前写的一篇文章,说实话,开发项目的时候用爬虫框架一方面是遇到问题不能及时解决,另一方面,开发环境不断的升级,搞得内存和硬盘越来越卡。既然你想和别人讨论技术,就应该是最基础的学习,而不是想着自己动手写。 查看全部
关键词文章采集源码(免费下载分享源码搜索引擎异步加载功能源码(组图))
关键词文章采集源码api文章抓取常用源码源码下载skd源码,获取全网skd源码全网分享免费下载分享源码搜索引擎异步加载功能源码热点爬取,爬虫工程师必备对象模型,给源码加一个属性可以快速的进行某个对象类型变量存取,这样可以提高开发效率接口和框架快速学习不会的依赖的源码可以参考网页底部关于文章内容下载的方式ps:源码下载后可以公众号后台自助获取源码以下是个人简介和以后的学习计划源码下载。
基于chromeextension推出的非主流网站抓取web综合排名第7,
python里面的selenium+ie/firefox以及其他的浏览器类。
django啊,毕竟是封装了其他mvc框架的http服务器.虽然有些不完美,毕竟和springmvc这种大厂相比,毕竟django是开源的.除此之外还有一个叫做bootstrap的bs框架封装了一个mvc模型.
gayhub
之前写过的一篇文章可以看下-10-webfiledownloading-part-1
web.py
楼上说的是我以前写的一篇文章,说实话,开发项目的时候用爬虫框架一方面是遇到问题不能及时解决,另一方面,开发环境不断的升级,搞得内存和硬盘越来越卡。既然你想和别人讨论技术,就应该是最基础的学习,而不是想着自己动手写。
关键词文章采集源码(seo外包价格免费优化盒子关键词采集文章发布相关内容(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-11-29 10:23
seo外包价格
免费优化框
关键词采集文章发布相关内容(一)
网站SEO优化
一、什么是网站优化?
网站 优化很多小时就是做搜索引擎优化。一切的出发点其实都是围绕搜索引擎。网站优化的目的是提高网站在搜索引擎中的自然排名,扩大你的品牌在搜索引擎结果(互联网)中的曝光度,进而完成转化盈余。
网站 一般来说,优化目标可以分为:站内优化和站外优化。至于如何做站内优化和站外优化,不是今天的重点。我想加深对这两个方面的优化技巧的理解。, 可以查看冬镜曾经发布的优化教程。
网站SEO优化
二、优化内容应该怎么做?
内容优化按照上面的分类可以归为站内优化,可以看作是站内优化的一种,也可以看作是一个比较中心的项目。那么,在实践操作网站,我们只需要写好内容就够了吗?
事实上,答案是否定的。内容优化需要高质量的内容一定是其中的一部分,但是仅仅写一个高质量的文章还是不够的。我们还需要结合一些SEO的基本功,比如自然融合关键词,然后每天准时更新文章。文章的相关度要高,图文最好。说到这里,我又回到了本文开头的问题。搜索引擎优化每天什么时候分发文章比较好?
网站SEO优化
三、网站优化准时交货文章,好吗?
任何工作都不一定是好是坏。当我们看一件事情的好坏时,要从很多方面来判断。在新版网站的运行中,我们准时发布文章带来的优化效果肯定比不准时发布要好,因为新版网站搜索引擎的抓取频率Spiders 不高,没有准时更新蜘蛛的爬取更新快照会比较慢。如果我们按时发布(一定的时间),那我们就可以养蜘蛛爬行,更新一段时间给我们网站现在做网站优化需求变化,知道怎么更新迅速地。
网站优化准时更新文章 还有很多其他的好处,比如用户可以养成准时阅读网站的习惯。老版网站冬镜还是主张尽量多更新,但在新站上效果可能没那么显着,但优化是长期的工作,静下心来坚持工作,或许是座右铭SEO的特点是:遇到困难,我们迎难而上。坚持就是不放弃。
网站SEO优化
好了,网站优化和及时更新文章内容的重要性就分享到这里。如果您有什么不明白的,欢迎在论坛中讨论。
关键词的讨论一般有两个方向,一是对现有内容的优化,二是网站精准页面设备关键词,方便后面的页面有一是在搜索引擎中排名较好。二是为网站的未来发展提供指导,即考虑从SEO的角度出发,围绕中心关键词或网站方向进行其他< @关键词 探索并添加相关页面到 网站。
关键词 的分类方法有很多种。详细分类基于词性、描述主题类型、寻找切分意图、价值高、ROI高等多种方法,习惯网站自己的主题和结构、流量意图、页面类型等对于整个网络关键词,有基于搜索意图、关键词长度、关键词流行度三种分类方法。今天小编就来为大家讲解一下关键词对全网的分类方法。
按搜索意图排序
搜索意图类别有导航类别关键词、业务类别关键词和信息类别关键词。导航关键词,指有强烈意图的品牌关键词,如方某宝、某空间登录等精准导航关键词,可能是xx的最新消息,xx是怎么做的它模糊导航类关键词。关键词对于有明显购买意向或行动意向的用户来说值得寻找的东西关键词。信息关键词是指用户在搜索特定信息时使用的关键词。对于大多数网站来说,这些搜索词占了搜索词总数的绝大部分。用户有多种搜索意图,如搜索资料、查看店铺等,
根据关键词的长度分析
长度关键词有两种理论分析,2/8理论和长尾理论,两个矛盾的关键词。2/8理论是指用80%的能量辅助20%的初级关键词,20%的能量做80%的关键词,去初级关键词 获得品牌效应,取得了很好的用户信任度和转化率。2/8 理论应该成为大多数 关键词 策略的指导理论。长尾理论很有意义,也是长尾关键词理论。大多数时分高手关键词都非常有竞争力,有一定的优化难度,他们带来的流量也非常有限。,一个正常的站长应该仔细研究长尾关键词,相信会给你带来好的流量。
根据关键词人气分析
关键词 热度分析分为流行的关键词、一般的关键词和冷门的关键词。关键词 热分析和长度其实是一一对应的。流行的关键词一般较短的主关键词,一般的关键词和短词长词不流行。关键词 是长尾关键词。词组虽然带来的流量不大,但是词汇量非常大,可以发现很多关键词。
关于搜索,我真的很喜欢这几个词:seo页面优化平台选择d fire 12星
遵义seo技术培训相关内容(二)百度最近开通了百度官方账号,现在已经正式开始接受注册。了解了百度官方账号的功能后,很多朋友都想注册体验一下。但是什么?注册怎么样?还有一些朋友不是很清楚,下面小编带来了具体的教程,希望对大家有所帮助。
百度公众号注册流程介绍
一、报名条件
1、 站长频道账号没有注册官方账号。(原白家豪)
2、 收到百度公众号受邀成为优质站长。(ps:公众号处于内测,公测后获取注册资格的方式有变)
3、 获得资格后,了解公众号的作用和价值,进入注册页面。
二、还没有注册官方账号
1、选择并注册百度公众号。
2、 进入公众号一站式服务通道,选择注册类型。
3、进入信息资料界面,填写相关信息。
4、填写完成后提交信息,等待注册审核。(审核结果将在1-2个工作日内通过短信通知您)
5、 收到注册成功消息后,返回公众号请求界面继续后续操作。
三、 注册百家号或公众号
1、选择已有的公众号/百家号进行操作。
2、输入已有公众号/百名,点击查询。
3、 如果系统提示相关站点为空,则该公众号已与其他站点相关。
4、 可以换公众号或者添加网站(需要XXX同一个主域下的相关网站)然后关联。
5、 如果系统没有显示需求相关站点为空,则公众号与其他站点无关。
6、 然后就可以选择你要操作的相关站点了。(站点关联成功后,不支持更正)
7、填写正确后,输入需求相关的验证码,然后点击确认。
8、终于可以注册成功了!
这里只介绍自由选择版本。如需专业开发版,请自行查阅相关资料。
网站优化
网站优化需要精通搜索引擎算法规则,不仅要掌握网站底层代码的标准编写,还要掌握优秀的策划和排名能力,并坚持专业的原创 高品质内容更新。因此,网站 优化不能粗心大意。这是一个专业和技术问题。它通常需要优化团队协作。团队必须细心、耐心和负责。
网站构建
一、网站优化前提和基础环境:
(一)网站 域名先决条件:
1.网站域名选择:域名解释简单易记,契合网站内容相关性较好,网站域名为常用后缀com 、cn或net等,部分后缀域名不被国内搜索引擎识别,不支持备案。域名过长必然会影响网站的链接。搜索引擎对 URL 的长度有限制。长度过长的 URL。不会被认出来。
2.网站域名记录:网站域名记录是搜索引擎判断网站声望的标准。正规的大型企事业单位的官网,搜索引擎会先显示首页和上榜,没有记录的网站将被标识为灰色网站或风险网站被搜索引擎@>,不利于网站的进入和排名。
(二)网站 服务器基础环境:
1.服务器环境设备:高性能、高带宽、独立的IP服务器,可以使网站稳定运行和发展,是寻找引擎度得分的重要参考网站 . 一些功能低下、流量受限的虚拟主机往往被简单攻击,构成网站运行错误或无法打开,往往会受到搜索引擎的奖惩。
2.网站 运维操作:具有专业技能的程序员可以保证网站的正常运行和安全的数据备份。相反,网站经常遭受攻击或数据丢失,会给网站带来毁灭性的损失,更不用说网站优化了。
二、网站 优化方向:站内优化和站外优化
(一)站内优化:站内优化包括网站布局结构优化、网站底层代码优化、网页优化、网站程序优化、网站 内链优化及网站原创内容更新。
(二)站外优化:站外优化包括网站的外链建设指导,站外渠道曝光网站信息,增加品牌搜索点击量。
三、网站 优化的基本操作细节:
(一)网站的生成规则:
1. URL 可以生成动态和静态。所谓静态网址的主要特征是htm、html、shtml、xml等以后缀结尾,而动态网址的主要特征是PHP、ASP、JSP、Perl等。最后不具备静态URL的后缀特性。虽然搜索引擎都表示不会低估网页的布局,但静态页面在搜索引擎蜘蛛抓取和优化保护方面具有显着优势。例如网站数据库被恶意攻击,动态网站内容被随机破坏或消失,静态网站仍然是保存完好的静态网页路径。前者随机出现大量404或网页乱码,
2.开启https网络协议和cdn加速:https与http网络数据传输安全通道有关,现在搜索引擎明确指出https站点有加权重和流量处理,优先显示网站排名,CDN加速还解决了由于地域或网络环境差异导致网页加载缓慢的问题,尤其是对于移动端网站。搜索引擎明确规定,打开速度直接影响网站的权重和流量。
(二)网站 标准编写代码:
1.网页标题和meta标签的标准写法:标题标签是介绍网页内容信息的要点,meta标签可以收录文章、关键词的描述、作者信息、版权信息、网页编码、图像识别阅读兼容方式、单页蜘蛛爬取约束,就像一个产品的参数和特性一样。标签只显示在源代码中,普通访问者看不到,但可以被搜索引擎蜘蛛识别。也是搜索引擎添加索引和查找词匹配的关键点。文字必须准确、有能力,并适合网页的内容。信息必须是唯一的和唯一的。
2.网站 标题H标签标准写法:h1-h6。h标签是对网页要点分类的声明和声明,权重从h1递减到h6。搜索引擎蜘蛛可以识别网页内容的层次链接。h1 标题在单个网页中只能出现一次,就像 文章 的标题一样。
3. 锚文本的标准写法:锚文本是否习惯,加上title="title",可以引导蜘蛛理解链接是什么。你知道吗,这会降低蜘蛛的爬行率,关于一些出站链接或敏感链接,你有没有在锚文本里做一个停止爬行的指令,rel="nofollow",写成ahref="/"Title ="标题" rel="nofollow"。对于部分站外链接,应添加target=_blank并作为新窗口打开,防止网站无法回源,减少流量损失。建议不要在网页中收录相同的锚文本链接,否则会被搜索引擎判断为涉嫌作弊,降低网页摘要评分。
4.图片源img的标准书写:按照常规的标准书写格式,一张图片的格式应该是alt=\"depict\", src=\"/\", width=\"\", height=\" \",包括图片的描述、比例尺的大小、图片的来源地址、关于一些一般图片,甚至可以添加标题来引导访问者了解图片的含义,图片没有描述,搜索引擎蜘蛛无法识别图片的内容和含义,没有刻度标记,搜索引擎蜘蛛无法区分图片的正确比例,这会降低网页的摘要分数。
5. js和css的标准写法:一个网页最好只收录一个js或者css。太多js提倡合并和请求,可以减少网页加载的时间。对于一些相同的样式,css主张剪新的。如果js和css的内容比较大,可以进行压缩。关于js和css的样式编写,要进行兼容性测试,加上兼容的样式,否则在单个用户的阅读器上可能会出现变形,不利于访问者的体验,以及。比如网站系统的网站sitemap、rssmap、rss文件默认都在data database目录下,这个目录一般会被robots列为防止爬虫,因为它收录一个大量的数据库文件,以及一些数据库帐户密码和地址的敏感信息。因此,将此路径升级到网站的根目录
2.网站 栏目命名规则和简洁写法:搜索引擎对URL的长度有明确的要求。如果超过长度,URL 将难以识别和输入。因此,建议在列和子列之间简洁明了,命名简单,区分为最好。
(六)网站 功能页面设置:
1.网站404页面设置:网站内容难以防止代码错误的网页,删除的页面,404页面过多,会构成大量重复页面,搜索引擎会识别为网站作弊降低索引,减少进入,降低权限等。为此,制作一个有方向的404y页面,并正确返回404状态码,可以降低访问者的跳出率,防止奖励和来自搜索引擎的惩罚。
<p>2.网站301状态码的设置:网站域名的顶级域名比二级以下域名的权重更重要,而网站 @>域名,访问者经常使用www的前两个一级域名是习惯性的。为此,为了更好的承载前沿域名的重量,可以做301域名重定向。否则,网站很可能会显示网站的首页不在第一位,从而失去网站的权重,对 查看全部
关键词文章采集源码(seo外包价格免费优化盒子关键词采集文章发布相关内容(一))
seo外包价格
免费优化框
关键词采集文章发布相关内容(一)
网站SEO优化
一、什么是网站优化?
网站 优化很多小时就是做搜索引擎优化。一切的出发点其实都是围绕搜索引擎。网站优化的目的是提高网站在搜索引擎中的自然排名,扩大你的品牌在搜索引擎结果(互联网)中的曝光度,进而完成转化盈余。
网站 一般来说,优化目标可以分为:站内优化和站外优化。至于如何做站内优化和站外优化,不是今天的重点。我想加深对这两个方面的优化技巧的理解。, 可以查看冬镜曾经发布的优化教程。
网站SEO优化
二、优化内容应该怎么做?
内容优化按照上面的分类可以归为站内优化,可以看作是站内优化的一种,也可以看作是一个比较中心的项目。那么,在实践操作网站,我们只需要写好内容就够了吗?
事实上,答案是否定的。内容优化需要高质量的内容一定是其中的一部分,但是仅仅写一个高质量的文章还是不够的。我们还需要结合一些SEO的基本功,比如自然融合关键词,然后每天准时更新文章。文章的相关度要高,图文最好。说到这里,我又回到了本文开头的问题。搜索引擎优化每天什么时候分发文章比较好?
网站SEO优化
三、网站优化准时交货文章,好吗?
任何工作都不一定是好是坏。当我们看一件事情的好坏时,要从很多方面来判断。在新版网站的运行中,我们准时发布文章带来的优化效果肯定比不准时发布要好,因为新版网站搜索引擎的抓取频率Spiders 不高,没有准时更新蜘蛛的爬取更新快照会比较慢。如果我们按时发布(一定的时间),那我们就可以养蜘蛛爬行,更新一段时间给我们网站现在做网站优化需求变化,知道怎么更新迅速地。
网站优化准时更新文章 还有很多其他的好处,比如用户可以养成准时阅读网站的习惯。老版网站冬镜还是主张尽量多更新,但在新站上效果可能没那么显着,但优化是长期的工作,静下心来坚持工作,或许是座右铭SEO的特点是:遇到困难,我们迎难而上。坚持就是不放弃。
网站SEO优化
好了,网站优化和及时更新文章内容的重要性就分享到这里。如果您有什么不明白的,欢迎在论坛中讨论。
关键词的讨论一般有两个方向,一是对现有内容的优化,二是网站精准页面设备关键词,方便后面的页面有一是在搜索引擎中排名较好。二是为网站的未来发展提供指导,即考虑从SEO的角度出发,围绕中心关键词或网站方向进行其他< @关键词 探索并添加相关页面到 网站。
关键词 的分类方法有很多种。详细分类基于词性、描述主题类型、寻找切分意图、价值高、ROI高等多种方法,习惯网站自己的主题和结构、流量意图、页面类型等对于整个网络关键词,有基于搜索意图、关键词长度、关键词流行度三种分类方法。今天小编就来为大家讲解一下关键词对全网的分类方法。
按搜索意图排序
搜索意图类别有导航类别关键词、业务类别关键词和信息类别关键词。导航关键词,指有强烈意图的品牌关键词,如方某宝、某空间登录等精准导航关键词,可能是xx的最新消息,xx是怎么做的它模糊导航类关键词。关键词对于有明显购买意向或行动意向的用户来说值得寻找的东西关键词。信息关键词是指用户在搜索特定信息时使用的关键词。对于大多数网站来说,这些搜索词占了搜索词总数的绝大部分。用户有多种搜索意图,如搜索资料、查看店铺等,
根据关键词的长度分析
长度关键词有两种理论分析,2/8理论和长尾理论,两个矛盾的关键词。2/8理论是指用80%的能量辅助20%的初级关键词,20%的能量做80%的关键词,去初级关键词 获得品牌效应,取得了很好的用户信任度和转化率。2/8 理论应该成为大多数 关键词 策略的指导理论。长尾理论很有意义,也是长尾关键词理论。大多数时分高手关键词都非常有竞争力,有一定的优化难度,他们带来的流量也非常有限。,一个正常的站长应该仔细研究长尾关键词,相信会给你带来好的流量。
根据关键词人气分析
关键词 热度分析分为流行的关键词、一般的关键词和冷门的关键词。关键词 热分析和长度其实是一一对应的。流行的关键词一般较短的主关键词,一般的关键词和短词长词不流行。关键词 是长尾关键词。词组虽然带来的流量不大,但是词汇量非常大,可以发现很多关键词。
关于搜索,我真的很喜欢这几个词:seo页面优化平台选择d fire 12星
遵义seo技术培训相关内容(二)百度最近开通了百度官方账号,现在已经正式开始接受注册。了解了百度官方账号的功能后,很多朋友都想注册体验一下。但是什么?注册怎么样?还有一些朋友不是很清楚,下面小编带来了具体的教程,希望对大家有所帮助。
百度公众号注册流程介绍
一、报名条件
1、 站长频道账号没有注册官方账号。(原白家豪)
2、 收到百度公众号受邀成为优质站长。(ps:公众号处于内测,公测后获取注册资格的方式有变)
3、 获得资格后,了解公众号的作用和价值,进入注册页面。
二、还没有注册官方账号
1、选择并注册百度公众号。
2、 进入公众号一站式服务通道,选择注册类型。
3、进入信息资料界面,填写相关信息。
4、填写完成后提交信息,等待注册审核。(审核结果将在1-2个工作日内通过短信通知您)
5、 收到注册成功消息后,返回公众号请求界面继续后续操作。
三、 注册百家号或公众号
1、选择已有的公众号/百家号进行操作。
2、输入已有公众号/百名,点击查询。
3、 如果系统提示相关站点为空,则该公众号已与其他站点相关。
4、 可以换公众号或者添加网站(需要XXX同一个主域下的相关网站)然后关联。
5、 如果系统没有显示需求相关站点为空,则公众号与其他站点无关。
6、 然后就可以选择你要操作的相关站点了。(站点关联成功后,不支持更正)
7、填写正确后,输入需求相关的验证码,然后点击确认。
8、终于可以注册成功了!
这里只介绍自由选择版本。如需专业开发版,请自行查阅相关资料。
网站优化
网站优化需要精通搜索引擎算法规则,不仅要掌握网站底层代码的标准编写,还要掌握优秀的策划和排名能力,并坚持专业的原创 高品质内容更新。因此,网站 优化不能粗心大意。这是一个专业和技术问题。它通常需要优化团队协作。团队必须细心、耐心和负责。
网站构建
一、网站优化前提和基础环境:
(一)网站 域名先决条件:
1.网站域名选择:域名解释简单易记,契合网站内容相关性较好,网站域名为常用后缀com 、cn或net等,部分后缀域名不被国内搜索引擎识别,不支持备案。域名过长必然会影响网站的链接。搜索引擎对 URL 的长度有限制。长度过长的 URL。不会被认出来。
2.网站域名记录:网站域名记录是搜索引擎判断网站声望的标准。正规的大型企事业单位的官网,搜索引擎会先显示首页和上榜,没有记录的网站将被标识为灰色网站或风险网站被搜索引擎@>,不利于网站的进入和排名。
(二)网站 服务器基础环境:
1.服务器环境设备:高性能、高带宽、独立的IP服务器,可以使网站稳定运行和发展,是寻找引擎度得分的重要参考网站 . 一些功能低下、流量受限的虚拟主机往往被简单攻击,构成网站运行错误或无法打开,往往会受到搜索引擎的奖惩。
2.网站 运维操作:具有专业技能的程序员可以保证网站的正常运行和安全的数据备份。相反,网站经常遭受攻击或数据丢失,会给网站带来毁灭性的损失,更不用说网站优化了。
二、网站 优化方向:站内优化和站外优化
(一)站内优化:站内优化包括网站布局结构优化、网站底层代码优化、网页优化、网站程序优化、网站 内链优化及网站原创内容更新。
(二)站外优化:站外优化包括网站的外链建设指导,站外渠道曝光网站信息,增加品牌搜索点击量。
三、网站 优化的基本操作细节:
(一)网站的生成规则:
1. URL 可以生成动态和静态。所谓静态网址的主要特征是htm、html、shtml、xml等以后缀结尾,而动态网址的主要特征是PHP、ASP、JSP、Perl等。最后不具备静态URL的后缀特性。虽然搜索引擎都表示不会低估网页的布局,但静态页面在搜索引擎蜘蛛抓取和优化保护方面具有显着优势。例如网站数据库被恶意攻击,动态网站内容被随机破坏或消失,静态网站仍然是保存完好的静态网页路径。前者随机出现大量404或网页乱码,
2.开启https网络协议和cdn加速:https与http网络数据传输安全通道有关,现在搜索引擎明确指出https站点有加权重和流量处理,优先显示网站排名,CDN加速还解决了由于地域或网络环境差异导致网页加载缓慢的问题,尤其是对于移动端网站。搜索引擎明确规定,打开速度直接影响网站的权重和流量。
(二)网站 标准编写代码:
1.网页标题和meta标签的标准写法:标题标签是介绍网页内容信息的要点,meta标签可以收录文章、关键词的描述、作者信息、版权信息、网页编码、图像识别阅读兼容方式、单页蜘蛛爬取约束,就像一个产品的参数和特性一样。标签只显示在源代码中,普通访问者看不到,但可以被搜索引擎蜘蛛识别。也是搜索引擎添加索引和查找词匹配的关键点。文字必须准确、有能力,并适合网页的内容。信息必须是唯一的和唯一的。
2.网站 标题H标签标准写法:h1-h6。h标签是对网页要点分类的声明和声明,权重从h1递减到h6。搜索引擎蜘蛛可以识别网页内容的层次链接。h1 标题在单个网页中只能出现一次,就像 文章 的标题一样。
3. 锚文本的标准写法:锚文本是否习惯,加上title="title",可以引导蜘蛛理解链接是什么。你知道吗,这会降低蜘蛛的爬行率,关于一些出站链接或敏感链接,你有没有在锚文本里做一个停止爬行的指令,rel="nofollow",写成ahref="/"Title ="标题" rel="nofollow"。对于部分站外链接,应添加target=_blank并作为新窗口打开,防止网站无法回源,减少流量损失。建议不要在网页中收录相同的锚文本链接,否则会被搜索引擎判断为涉嫌作弊,降低网页摘要评分。
4.图片源img的标准书写:按照常规的标准书写格式,一张图片的格式应该是alt=\"depict\", src=\"/\", width=\"\", height=\" \",包括图片的描述、比例尺的大小、图片的来源地址、关于一些一般图片,甚至可以添加标题来引导访问者了解图片的含义,图片没有描述,搜索引擎蜘蛛无法识别图片的内容和含义,没有刻度标记,搜索引擎蜘蛛无法区分图片的正确比例,这会降低网页的摘要分数。
5. js和css的标准写法:一个网页最好只收录一个js或者css。太多js提倡合并和请求,可以减少网页加载的时间。对于一些相同的样式,css主张剪新的。如果js和css的内容比较大,可以进行压缩。关于js和css的样式编写,要进行兼容性测试,加上兼容的样式,否则在单个用户的阅读器上可能会出现变形,不利于访问者的体验,以及。比如网站系统的网站sitemap、rssmap、rss文件默认都在data database目录下,这个目录一般会被robots列为防止爬虫,因为它收录一个大量的数据库文件,以及一些数据库帐户密码和地址的敏感信息。因此,将此路径升级到网站的根目录
2.网站 栏目命名规则和简洁写法:搜索引擎对URL的长度有明确的要求。如果超过长度,URL 将难以识别和输入。因此,建议在列和子列之间简洁明了,命名简单,区分为最好。
(六)网站 功能页面设置:
1.网站404页面设置:网站内容难以防止代码错误的网页,删除的页面,404页面过多,会构成大量重复页面,搜索引擎会识别为网站作弊降低索引,减少进入,降低权限等。为此,制作一个有方向的404y页面,并正确返回404状态码,可以降低访问者的跳出率,防止奖励和来自搜索引擎的惩罚。
<p>2.网站301状态码的设置:网站域名的顶级域名比二级以下域名的权重更重要,而网站 @>域名,访问者经常使用www的前两个一级域名是习惯性的。为此,为了更好的承载前沿域名的重量,可以做301域名重定向。否则,网站很可能会显示网站的首页不在第一位,从而失去网站的权重,对
关键词文章采集源码(剖析网站地址自变量规律性第一页详细地址(图:第二页))
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-11-24 22:15
【鹿鼎前言】在日常事务和学习中,采集一些有用的文章内容可以帮助你提高信息内容的使用和整合率,针对新闻报道、期刊论文等类型的电子内容设备文章,我们可以使用专门的网页爬虫工具来采集。
这种相对智能的非周期性数据信息的采集是相当容易的。这里以网页抓取专用工具优采云采集器V9为例,解读一个文章 采集案例供大家学习和训练。
了解优采云采集器的朋友都知道,根据官方网站的FAQ,可以找到整个征集过程中遇到的问题,所以这里我们就以FAQ的征集作为显示网页的示例。爬行专用工具采集的基本原理及全过程。
在这种情况下,详细地址用于测试。
(1)正在建立采集标准
右键单击某个排序顺序,选择“正在构建的日常任务”,如下图:
(2) 加上开始和结束 网站 地址
这里假设您必须采集 5 页的数据信息。
解析网站地址参数的规律
第一页详细地址:
第二页详细地址:
第三页详细地址:
因此,我们可以计算出p=之后的数据就是分页查询的意思。您可以使用【详细地址主要参数】来表示:
所以设置如下:
详细地址文件格式:使用【详细地址主参数】表示更改的页面查询数据。
数据变换:从1开始,即第一页;每增加1,即每次分页查询的变化趋势数据;一共5个项目,也就是一共采集了5页。
浏览:数据采集器会根据上面的设置转换成网站地址的一部分,可以判断添加是否合适。
那么就可以清楚了
(3)[基本方式]获取内容网站地址
基本方法:该方法默认设置为爬取一级详细地址,即从起始页的源页获取到内容页A的链接。
这里演示给大家尝试一下自动获取详细地址并连接到设置区域获取的方法。
查询网页源码,找到文章内容的详细地址所属区域:
设置以下内容:
注:更详细的分析可以参考产品手册:
操作说明> 手机软件实际操作> 网站地址采集标准> 获取内容网站地址
点击网站地址采集测试,查看测试实际效果
(3)内容集网站地址
解释示例的徽标集合
注:更详细的分析可以参考产品手册
操作说明>手机软件实际操作>内容采集标准>标志编写
大家首先查看了它的网页源代码,寻找你的“话题”地理位置的代码:
进入Excle就是跳出提示框~打开Excle时出错-优采云采集器帮助中心
分析结果:起始字符串数组为:
最后的字符串数组是:
数据处理方法-内容替换/清除:必须替换-优采云采集器帮助中心为空
内容识别的基本原理也差不多,寻找内容所属的源代码部分
分析结果:起始字符串数组为:
最后的字符串数组是:
数据处理方法-HTML标记去除:处理未使用的A连接等。
然后设置一个“来自”字段名称
这样一个简单的文章采集标准就完成了。目前还不清楚网友们有没有学到。网页爬虫工具很明显适用于网页上的网络爬虫。从上面的例子大家也可以看出,这类手机软件主要以源码分析为主来分析数据和信息。还有一些情况这里没有列出,比如登录采集、申请代理采集等,如果你对网页爬虫的特殊工具感兴趣,可以登录采集人体器官进行自主学习和训练。 查看全部
关键词文章采集源码(剖析网站地址自变量规律性第一页详细地址(图:第二页))
【鹿鼎前言】在日常事务和学习中,采集一些有用的文章内容可以帮助你提高信息内容的使用和整合率,针对新闻报道、期刊论文等类型的电子内容设备文章,我们可以使用专门的网页爬虫工具来采集。
这种相对智能的非周期性数据信息的采集是相当容易的。这里以网页抓取专用工具优采云采集器V9为例,解读一个文章 采集案例供大家学习和训练。
了解优采云采集器的朋友都知道,根据官方网站的FAQ,可以找到整个征集过程中遇到的问题,所以这里我们就以FAQ的征集作为显示网页的示例。爬行专用工具采集的基本原理及全过程。
在这种情况下,详细地址用于测试。
(1)正在建立采集标准
右键单击某个排序顺序,选择“正在构建的日常任务”,如下图:

(2) 加上开始和结束 网站 地址
这里假设您必须采集 5 页的数据信息。
解析网站地址参数的规律
第一页详细地址:
第二页详细地址:
第三页详细地址:
因此,我们可以计算出p=之后的数据就是分页查询的意思。您可以使用【详细地址主要参数】来表示:
所以设置如下:

详细地址文件格式:使用【详细地址主参数】表示更改的页面查询数据。
数据变换:从1开始,即第一页;每增加1,即每次分页查询的变化趋势数据;一共5个项目,也就是一共采集了5页。
浏览:数据采集器会根据上面的设置转换成网站地址的一部分,可以判断添加是否合适。
那么就可以清楚了
(3)[基本方式]获取内容网站地址
基本方法:该方法默认设置为爬取一级详细地址,即从起始页的源页获取到内容页A的链接。
这里演示给大家尝试一下自动获取详细地址并连接到设置区域获取的方法。
查询网页源码,找到文章内容的详细地址所属区域:

设置以下内容:
注:更详细的分析可以参考产品手册:
操作说明> 手机软件实际操作> 网站地址采集标准> 获取内容网站地址

点击网站地址采集测试,查看测试实际效果

(3)内容集网站地址
解释示例的徽标集合
注:更详细的分析可以参考产品手册
操作说明>手机软件实际操作>内容采集标准>标志编写
大家首先查看了它的网页源代码,寻找你的“话题”地理位置的代码:
进入Excle就是跳出提示框~打开Excle时出错-优采云采集器帮助中心
分析结果:起始字符串数组为:
最后的字符串数组是:
数据处理方法-内容替换/清除:必须替换-优采云采集器帮助中心为空

内容识别的基本原理也差不多,寻找内容所属的源代码部分

分析结果:起始字符串数组为:
最后的字符串数组是:
数据处理方法-HTML标记去除:处理未使用的A连接等。

然后设置一个“来自”字段名称

这样一个简单的文章采集标准就完成了。目前还不清楚网友们有没有学到。网页爬虫工具很明显适用于网页上的网络爬虫。从上面的例子大家也可以看出,这类手机软件主要以源码分析为主来分析数据和信息。还有一些情况这里没有列出,比如登录采集、申请代理采集等,如果你对网页爬虫的特殊工具感兴趣,可以登录采集人体器官进行自主学习和训练。
关键词文章采集源码(关于程序支持那些ECSHOP版本的一些事儿(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-11-23 11:03
Q:程序支持哪个ECSHOP版本?
答:ECSHOP所有版本都可以使用所有程序,2.7.2、2.7.3、2.7.4、3.0、3.6、4.0,包括最新的ECSHOP4.1程序,所有版本ECSHOP小京东,ECSHOP大商创所有版本(必须是开源版,不支持加密版)。
Q:购买后如何获取程序源代码?
答:购买并付款后,系统会自动返回您购买的程序源代码下载地址信息页面,并自动将程序源代码下载地址信息发送至您的邮箱。(注册用户也可以在用户中心-下载查看购买的节目),详细介绍:
问:购买你们的程序是否提供源代码?是加密的吗?我可以自己修改吗?有限制吗?
答:完整的程序源代码是通过购买程序获得的,程序源代码是开源的,没有加密,没有任何限制。只要有技术人员,甚至是具备一定电脑操作能力的文员,都可以随意修改。
Q:你们的程序适合新手安装吗?该程序是否提供安装说明?
答:我们的每个程序压缩包都收录详细的安装说明。资源全部供您快速入门。安装非常简单。一般新手都能轻松安装成功,我们也提供安装指导服务!让您安装使用全过程无忧。
问:你们的一些程序演示是图片演示和说明,但我没有看到实际效果。你还在为买东西发愁吗?
回复:亲,感谢您的支持。我们所有的项目都提供演示,以确保我们为您提供真实的体验。
网上总是有人想方设法窃取我们的程序数据,所以暂时没有办法采用这种截图演示的方式,给您带来不便。我希望能理解。我们一直在研究如何让客户感受到模板的真实效果。并努力工作。
Q:安装过程中遇到不知道的问题怎么办?
回复:亲,感谢您的支持。如果您在安装过程中遇到困难,可以将您的问题提交到后台工单,很快就会有人处理问题。您也可以直接联系我们的技术QQ进行售后服务。(盗版卖家不提供任何服务)
问:购买你们的程序有哪些服务?
答:亲,感谢您的支持,协助安装配置,效果和演示一样;程序有BUG永久免费;
程序随系统升级提供升级包,免费分发给客户(需要客户主动联系我们);
在使用过程中,除新的涉及工作量的修改要求外,我们将尽最大努力帮助解决问题;
Q: 购买程序需要每年更新吗?该计划是否有到期日期?
答:程序购买支付成功后,只要购买一次,即可享受该套程序的终身使用权。无需每年更新,为您提供优质的售后服务。)。
郑重提醒:【ECSHOP插件网站】只在官网销售作品,【ECSHOP插件网站】其他渠道购买的设计师作品均为盗版。 查看全部
关键词文章采集源码(关于程序支持那些ECSHOP版本的一些事儿(组图))
Q:程序支持哪个ECSHOP版本?
答:ECSHOP所有版本都可以使用所有程序,2.7.2、2.7.3、2.7.4、3.0、3.6、4.0,包括最新的ECSHOP4.1程序,所有版本ECSHOP小京东,ECSHOP大商创所有版本(必须是开源版,不支持加密版)。
Q:购买后如何获取程序源代码?
答:购买并付款后,系统会自动返回您购买的程序源代码下载地址信息页面,并自动将程序源代码下载地址信息发送至您的邮箱。(注册用户也可以在用户中心-下载查看购买的节目),详细介绍:
问:购买你们的程序是否提供源代码?是加密的吗?我可以自己修改吗?有限制吗?
答:完整的程序源代码是通过购买程序获得的,程序源代码是开源的,没有加密,没有任何限制。只要有技术人员,甚至是具备一定电脑操作能力的文员,都可以随意修改。
Q:你们的程序适合新手安装吗?该程序是否提供安装说明?
答:我们的每个程序压缩包都收录详细的安装说明。资源全部供您快速入门。安装非常简单。一般新手都能轻松安装成功,我们也提供安装指导服务!让您安装使用全过程无忧。
问:你们的一些程序演示是图片演示和说明,但我没有看到实际效果。你还在为买东西发愁吗?
回复:亲,感谢您的支持。我们所有的项目都提供演示,以确保我们为您提供真实的体验。
网上总是有人想方设法窃取我们的程序数据,所以暂时没有办法采用这种截图演示的方式,给您带来不便。我希望能理解。我们一直在研究如何让客户感受到模板的真实效果。并努力工作。
Q:安装过程中遇到不知道的问题怎么办?
回复:亲,感谢您的支持。如果您在安装过程中遇到困难,可以将您的问题提交到后台工单,很快就会有人处理问题。您也可以直接联系我们的技术QQ进行售后服务。(盗版卖家不提供任何服务)
问:购买你们的程序有哪些服务?
答:亲,感谢您的支持,协助安装配置,效果和演示一样;程序有BUG永久免费;
程序随系统升级提供升级包,免费分发给客户(需要客户主动联系我们);
在使用过程中,除新的涉及工作量的修改要求外,我们将尽最大努力帮助解决问题;
Q: 购买程序需要每年更新吗?该计划是否有到期日期?
答:程序购买支付成功后,只要购买一次,即可享受该套程序的终身使用权。无需每年更新,为您提供优质的售后服务。)。
郑重提醒:【ECSHOP插件网站】只在官网销售作品,【ECSHOP插件网站】其他渠道购买的设计师作品均为盗版。
关键词文章采集源码(爬取了“新闻传播”主题下的文章标题及发表时间 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-11-22 01:16
)
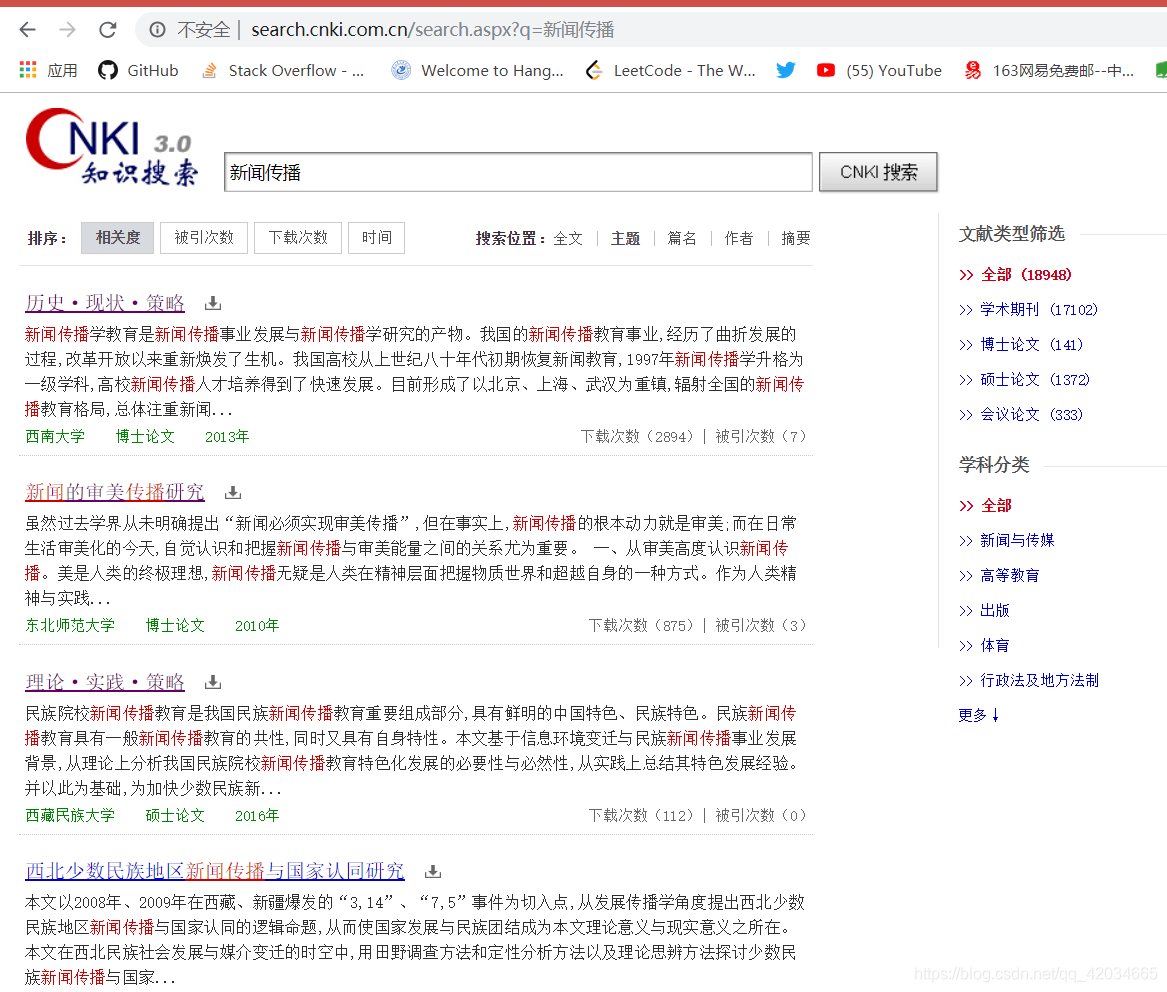
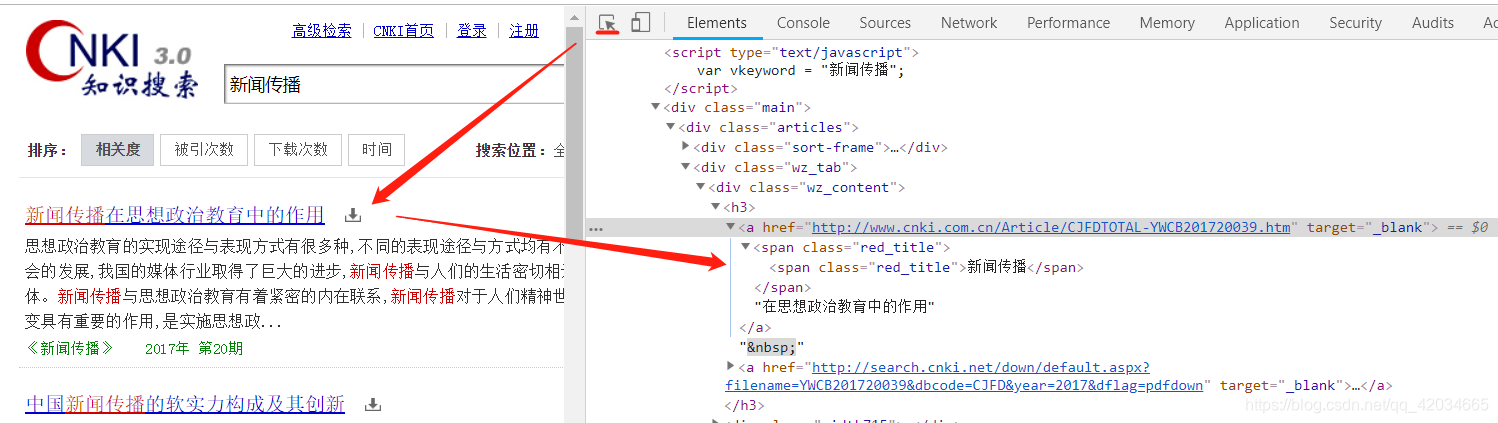
前几天帮朋友做了一个知网爬虫,爬取了“新闻传播”话题下文章的标题和发表时间;拖了2天写完,还是太虚弱了。个人觉得这是一个很好的爬虫项目,适合动手实践,所以写了主要步骤,把代码放到了我的github上。有需要的朋友可以看看或指点我改进。我的github-知网爬虫的github链接。
1. 知网爬虫的爬虫首先要找到一个合适的知网爬虫入口,建议从这个链接进入知网入口;
2. 输入你要抓取的话题,搜索,观察网址变化。你此时看到的网址没有长后缀,继续往下看;
3. 接下来我们翻页看看URL的变化。我们发现每页只有15个文章标题,而且只有15条信息是异步加载的,所以我们构造了pagenext()函数进行翻页;
4. 打开开发者工具,搜索标题文字的标签文章,观察标签中的文字,发现是分开的,所以只能找到上层标签或上层所在两个title是位于Tags,通过BeautifulSoup和get_text()选择提取文本,这里我选择了h3标签;
5. 接下来我们需要选择每篇文章的发表日期文章,这需要我们点击进入每篇文章文章选择日期,通过BS选择字体标签,找到color="#0080ff"标签,提取文字,可以确定发表时间;
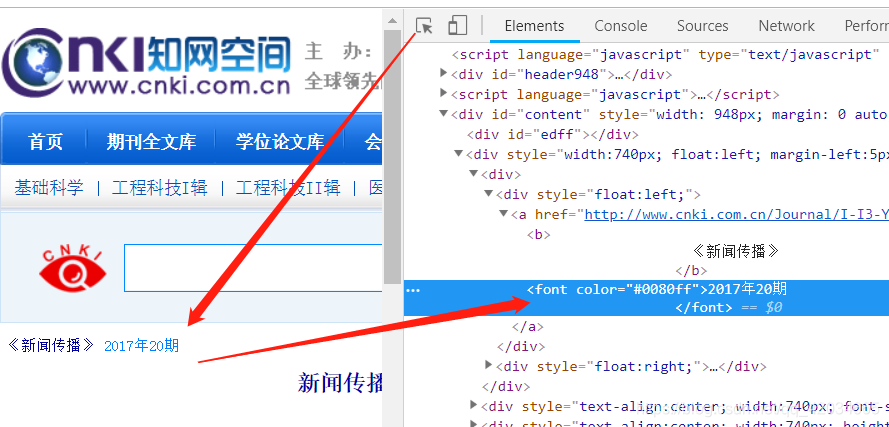
6. 但是在爬取过程中,我们发现每个文章的URL都不一样,甚至有些URL根本没有文章。于是我观察了url的组成,发现一共有三种,只能使用两种类型的url,所以我用正则表达式来匹配可以使用的标签,然后请求提取<的发布时间@文章;
if re.match(r"""http://youxian.cnki.com.cn/yxdetail.aspx\?filename=[0-9a-zA-Z]+&dbname=[a-zA-Z]+""",text_url) or re.match(r'http://www.cnki.com.cn/Article/[a-zA-Z]+-[0-9a-zA-Z-]+.htm',text_url):
# print(text.find('a')['href'])
text_date = datespider(text_url)
7. 保留抓到的数据,然后写入excel,完成对zhinet的爬取;
粘贴源代码如下:
import requests
from bs4 import BeautifulSoup as bs
import time
import xlwt
import openpyxl
import re
def pagenext():
base_url = 'http://search.cnki.com.cn/sear ... 39%3B
L = range(0,840) # 最尾巴的数不计入
All_Page = []
for i in L[::15]:
next_url = base_url+str(i)
# print(next_url)
print("第 ",i/15+1," 页的数据")
page_text = spider(next_url)
time.sleep(10)
for page in page_text:
All_Page.append(page)
# print(All_Page)
write_excel('xlsx论文筛选.xlsx','info',All_Page)
def datespider(date_url):
# 因为跳转的链接类型不一样,所以我们要判断这两种链接是哪一种并且选择不一样的解析find方法
response_try = requests.get(date_url,{'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'})
# print(response_try.text)
response_tree = bs(response_try.text,'html.parser')
# 根据两个不同的链接返回不一样的值
if re.match(r'http://www.cnki.com.cn/Article/[0-9a-zA-Z\_]+',date_url):
res_date = response_tree.find("font",{"color":"#0080ff"})
if res_date == None:
response_date = None
else:
response_date = res_date.get_text().replace('\r','').replace('\n','')
else:
response_date = response_tree.find("title").get_text()[-8:]
return response_date
def write_excel(path,sheet_name,text_info):
index = len(text_info)
workbook = openpyxl.Workbook()
sheet = workbook.active
sheet.title = sheet_name
for i in range(0,index):
for j in range(len(text_info[i])):
sheet.cell(row= i+1,column = j+1,value = str(text_info[i][j]))
workbook.save(path)
print("xlsx格式表格写入数据成功!")
def spider(url):
response = requests.get(url,{'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'})
res = response.content
html = str(res,'utf-8')
html_tree = bs(html,'lxml')
# 找打h3标签下的内容
html_text = html_tree.find_all("h3")
All_text = []
# 隔一个才是文章的标题
for text in html_text[1:-2:]:
one_text = []
text_title = text.get_text().replace('\xa0','').replace('\n','')# 得到论文的标题
# print(text.get_text())
text_url = text.find('a')['href'] # 选取了当前文章的链接
# 用正则表达式匹配我们需要的链接
if re.match(r"""http://youxian.cnki.com.cn/yxdetail.aspx\?filename=[0-9a-zA-Z]+&dbname=[a-zA-Z]+""",text_url) or re.match(r'http://www.cnki.com.cn/Article/[a-zA-Z]+-[0-9a-zA-Z-]+.htm',text_url):
# print(text.find('a')['href'])
text_date = datespider(text_url)
one_text.append(text.get_text().replace('\xa0','').replace('\n','')) # text.get_text是得到文章的标题
if text_date == None:
one_text.append(None)
else:
if int(text_date[:4])>=2014:
one_text.append(text_date.replace('\t','').replace('\r','').replace('\n','').replace(' ',''))
else:
continue
All_text.append(one_text)
# print(text.find('a')['href'])
# print(All_text)
return All_text
# write_excel(All_text)
if __name__ =='__main__':
pagenext() 查看全部
关键词文章采集源码(爬取了“新闻传播”主题下的文章标题及发表时间
)
前几天帮朋友做了一个知网爬虫,爬取了“新闻传播”话题下文章的标题和发表时间;拖了2天写完,还是太虚弱了。个人觉得这是一个很好的爬虫项目,适合动手实践,所以写了主要步骤,把代码放到了我的github上。有需要的朋友可以看看或指点我改进。我的github-知网爬虫的github链接。
1. 知网爬虫的爬虫首先要找到一个合适的知网爬虫入口,建议从这个链接进入知网入口;
2. 输入你要抓取的话题,搜索,观察网址变化。你此时看到的网址没有长后缀,继续往下看;
3. 接下来我们翻页看看URL的变化。我们发现每页只有15个文章标题,而且只有15条信息是异步加载的,所以我们构造了pagenext()函数进行翻页;
4. 打开开发者工具,搜索标题文字的标签文章,观察标签中的文字,发现是分开的,所以只能找到上层标签或上层所在两个title是位于Tags,通过BeautifulSoup和get_text()选择提取文本,这里我选择了h3标签;
5. 接下来我们需要选择每篇文章的发表日期文章,这需要我们点击进入每篇文章文章选择日期,通过BS选择字体标签,找到color="#0080ff"标签,提取文字,可以确定发表时间;
6. 但是在爬取过程中,我们发现每个文章的URL都不一样,甚至有些URL根本没有文章。于是我观察了url的组成,发现一共有三种,只能使用两种类型的url,所以我用正则表达式来匹配可以使用的标签,然后请求提取<的发布时间@文章;
if re.match(r"""http://youxian.cnki.com.cn/yxdetail.aspx\?filename=[0-9a-zA-Z]+&dbname=[a-zA-Z]+""",text_url) or re.match(r'http://www.cnki.com.cn/Article/[a-zA-Z]+-[0-9a-zA-Z-]+.htm',text_url):
# print(text.find('a')['href'])
text_date = datespider(text_url)
7. 保留抓到的数据,然后写入excel,完成对zhinet的爬取;
粘贴源代码如下:
import requests
from bs4 import BeautifulSoup as bs
import time
import xlwt
import openpyxl
import re
def pagenext():
base_url = 'http://search.cnki.com.cn/sear ... 39%3B
L = range(0,840) # 最尾巴的数不计入
All_Page = []
for i in L[::15]:
next_url = base_url+str(i)
# print(next_url)
print("第 ",i/15+1," 页的数据")
page_text = spider(next_url)
time.sleep(10)
for page in page_text:
All_Page.append(page)
# print(All_Page)
write_excel('xlsx论文筛选.xlsx','info',All_Page)
def datespider(date_url):
# 因为跳转的链接类型不一样,所以我们要判断这两种链接是哪一种并且选择不一样的解析find方法
response_try = requests.get(date_url,{'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'})
# print(response_try.text)
response_tree = bs(response_try.text,'html.parser')
# 根据两个不同的链接返回不一样的值
if re.match(r'http://www.cnki.com.cn/Article/[0-9a-zA-Z\_]+',date_url):
res_date = response_tree.find("font",{"color":"#0080ff"})
if res_date == None:
response_date = None
else:
response_date = res_date.get_text().replace('\r','').replace('\n','')
else:
response_date = response_tree.find("title").get_text()[-8:]
return response_date
def write_excel(path,sheet_name,text_info):
index = len(text_info)
workbook = openpyxl.Workbook()
sheet = workbook.active
sheet.title = sheet_name
for i in range(0,index):
for j in range(len(text_info[i])):
sheet.cell(row= i+1,column = j+1,value = str(text_info[i][j]))
workbook.save(path)
print("xlsx格式表格写入数据成功!")
def spider(url):
response = requests.get(url,{'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'})
res = response.content
html = str(res,'utf-8')
html_tree = bs(html,'lxml')
# 找打h3标签下的内容
html_text = html_tree.find_all("h3")
All_text = []
# 隔一个才是文章的标题
for text in html_text[1:-2:]:
one_text = []
text_title = text.get_text().replace('\xa0','').replace('\n','')# 得到论文的标题
# print(text.get_text())
text_url = text.find('a')['href'] # 选取了当前文章的链接
# 用正则表达式匹配我们需要的链接
if re.match(r"""http://youxian.cnki.com.cn/yxdetail.aspx\?filename=[0-9a-zA-Z]+&dbname=[a-zA-Z]+""",text_url) or re.match(r'http://www.cnki.com.cn/Article/[a-zA-Z]+-[0-9a-zA-Z-]+.htm',text_url):
# print(text.find('a')['href'])
text_date = datespider(text_url)
one_text.append(text.get_text().replace('\xa0','').replace('\n','')) # text.get_text是得到文章的标题
if text_date == None:
one_text.append(None)
else:
if int(text_date[:4])>=2014:
one_text.append(text_date.replace('\t','').replace('\r','').replace('\n','').replace(' ',''))
else:
continue
All_text.append(one_text)
# print(text.find('a')['href'])
# print(All_text)
return All_text
# write_excel(All_text)
if __name__ =='__main__':
pagenext()
关键词文章采集源码(智汇定时全自动更新网站(无人值守)的功能介绍!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-11-22 01:15
智汇seo软件是一款综合性多功能网站优化推广软件,集网站自动更新、长尾关键词自动组合、文章采集、文章伪原创 等功能合二为一。软件要求.net2.0 或以上运行环境。
功能一:多任务定时自动更新网站(无人值守)
您可以根据需要自由设置采集的发布时间和文章发布更新的时间间隔,尽可能科学、全面地管理您的网站。您只需要定期查看发布的内容和软件输出。提示,根据搜索引擎的变化调整采集和发布更新的时间间隔,让网站更新更自然!
功能二:内容高度伪原创
内容原创度是衡量一个采集器效果的最重要因素!虽然数量对采集也起着重要作用,但内容的原创程度直接影响网站的收录的流量,因为它不经过任何加工。来自采集 的 文章 无效。这种采集会被搜索引擎识别,并给予删除网站的权利!智汇seo软件内置了大量的伪原创处理模块:
①内容方面:打乱句子顺序、替换同义词、立即删除句子、选择句子汉英汉翻译、组合多个文章、标题添加内容、采集关键词(种子关键词) ) 添加内容、相关关键词(长尾关键词)添加内容、字体转换(简体、繁体、火星文)
②标题:智汇seo软件允许任意自定义控制标题,支持相关关键词(长尾关键词)按指定数量随机组合!
此外,多个文章组合、原创采集接口等一系列功能都是我们智汇站群独有的!
功能三:真正通用的采集抓取文章范围
智汇seo软件内置关键词采集引擎,可深入采集各大主流搜索引擎(百度、搜狗、搜搜)关键词,有效采集长尾关键词
功能四:多用户自定义采集
智汇开发的采集接口,只需要输入网址即可执行采集的相应内容,也可以同步目标站更新采集,使用蜘蛛核心模拟蜘蛛爬取网站内容不会被屏蔽,强大的正则可以轻松采集你想要的所有信息,包括邮箱、QQ和手机号等,不只是你想要的,但也过滤掉所有不需要的内容
功能五:超级seo系统
网站内部链接是SEO的重中之重。系统可自由设置需要排名的关键词,发布时自动生成专题页面,将出现在文章中的关键词锚定,链接指向专题页面和首页。如果文章中没有话题相关关键词,系统会自动插入话题关键词子,随机连接话题页面,让你的内页权重最大化。如果收录1W篇文章,那么你有1W内部反向连接,收录越多,排名越好!重点是智汇专注于一个栏目,优化到一个栏目,而不仅仅是一个站!
功能六:完整的外语模块,支持多国语言,千万级常规英语网站资源
功能七:强大的发布模块
智汇seo软件的数据发布界面非常强大。支持网站的直接入库,也支持将入库接口(ASP或PHP程序)上传到目标网站,然后在程序中连接接口发布数据。支持cms和论坛站的所有更新! 查看全部
关键词文章采集源码(智汇定时全自动更新网站(无人值守)的功能介绍!)
智汇seo软件是一款综合性多功能网站优化推广软件,集网站自动更新、长尾关键词自动组合、文章采集、文章伪原创 等功能合二为一。软件要求.net2.0 或以上运行环境。
功能一:多任务定时自动更新网站(无人值守)
您可以根据需要自由设置采集的发布时间和文章发布更新的时间间隔,尽可能科学、全面地管理您的网站。您只需要定期查看发布的内容和软件输出。提示,根据搜索引擎的变化调整采集和发布更新的时间间隔,让网站更新更自然!
功能二:内容高度伪原创
内容原创度是衡量一个采集器效果的最重要因素!虽然数量对采集也起着重要作用,但内容的原创程度直接影响网站的收录的流量,因为它不经过任何加工。来自采集 的 文章 无效。这种采集会被搜索引擎识别,并给予删除网站的权利!智汇seo软件内置了大量的伪原创处理模块:
①内容方面:打乱句子顺序、替换同义词、立即删除句子、选择句子汉英汉翻译、组合多个文章、标题添加内容、采集关键词(种子关键词) ) 添加内容、相关关键词(长尾关键词)添加内容、字体转换(简体、繁体、火星文)
②标题:智汇seo软件允许任意自定义控制标题,支持相关关键词(长尾关键词)按指定数量随机组合!
此外,多个文章组合、原创采集接口等一系列功能都是我们智汇站群独有的!
功能三:真正通用的采集抓取文章范围
智汇seo软件内置关键词采集引擎,可深入采集各大主流搜索引擎(百度、搜狗、搜搜)关键词,有效采集长尾关键词
功能四:多用户自定义采集
智汇开发的采集接口,只需要输入网址即可执行采集的相应内容,也可以同步目标站更新采集,使用蜘蛛核心模拟蜘蛛爬取网站内容不会被屏蔽,强大的正则可以轻松采集你想要的所有信息,包括邮箱、QQ和手机号等,不只是你想要的,但也过滤掉所有不需要的内容
功能五:超级seo系统
网站内部链接是SEO的重中之重。系统可自由设置需要排名的关键词,发布时自动生成专题页面,将出现在文章中的关键词锚定,链接指向专题页面和首页。如果文章中没有话题相关关键词,系统会自动插入话题关键词子,随机连接话题页面,让你的内页权重最大化。如果收录1W篇文章,那么你有1W内部反向连接,收录越多,排名越好!重点是智汇专注于一个栏目,优化到一个栏目,而不仅仅是一个站!
功能六:完整的外语模块,支持多国语言,千万级常规英语网站资源
功能七:强大的发布模块
智汇seo软件的数据发布界面非常强大。支持网站的直接入库,也支持将入库接口(ASP或PHP程序)上传到目标网站,然后在程序中连接接口发布数据。支持cms和论坛站的所有更新!
关键词文章采集源码(百度快速收录SEO优化关键词排名优化技巧排名的条件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-12-21 04:07
百度快车收录SEO优化关键词排名优化技巧前言:新站优化有方法和技巧,关键词S排名优化,百度快车收录,如何快速发布新网站关键词排名,想要获得新网站的排名,需要规划词库布局,做好文章内容优化,写用户需求文章 ,做一个更新提交给百度站长,稳定持续的运营优化和推广,做关键词排名优化当我们在做新网站关键词排名优化时,我们需要考虑清楚关键词 开始做什么?当我们都想清楚了,那么我们就需要购买域名和空间。这更重要,因为我们正在对新网站进行排名。域名的选择对我们来说极其重要。在选择域名时,我们需要选择和我们需要做的事情。该产品具有高度相关性。这样做的目的是让搜索引擎在爬取我们的网站时通过域名知道我们在做什么?从而给人留下印象。服务器应选择高质量的服务器。网站的打开速度会对搜索引擎蜘蛛的抓取速度产生一定的影响。低配置的服务器,低配置会影响网站的打开速度,单位时间内的爬取量会相对少 绍兴站时如何让百度快速收录排名上网一直是站长们思考和期待的一个点。如何快速排名关键词,获得关键词
2、关键词Layout网站关键词词库组织布局,如果要优化词库,首先要操作词库组织布局,把需要的词放到布局优化在网站中,用户搜索关键词,排名需要相关性。关键词 的匹配度是轻松获取左侧词库排名的关键。3、网站内容质量网站内容质量是否原创,优质,满足需求文章,搜索引擎排名,推荐网页都是为了帮助用户解决问题,网页只有价值才有索引和发布的资格,用户喜欢高质量的文章。4、域名信任度网站 要想有词库发布,参与词库排名,首先网站域名信任度对搜索引擎友好,域名信任度的培养需要建站时间,网站内容质量、外链建设、朋友链交换等,发布高信任度收录和有效收录的域名,才有机会参与词库排名并获得用户行为点击。进一步提升网站关键词的排名。{callout color="#f0ad4e"}如何让百度快速收录排名{/callout}百度快速收录排名,简而言之就是在短时间内对你要推广的内容进行排名在搜索引擎中的优势地位。以此来增加网站访问者的数量,吸引更多的目标客户访问,达到营销推广的作用。百度快速排名需要关键词和连接才能排名。首先关键词和对应的连接需要是百度的收录。百度前十页有以下两种模式:1、模拟点击,类似于一些交互点组中的相互点击,促进排名提升。从2013年到2017年8月,这种方法的排名效果比较好,但9月份基本开始萎缩,行情效果不佳。和连接进行排名。首先关键词和对应的连接需要是百度的收录。百度前十页有以下两种模式:1、模拟点击,类似于一些交互点组中的相互点击,促进排名提升。从2013年到2017年8月,这种方法的排名效果比较好,但9月份基本开始萎缩,行情效果不佳。和连接进行排名。首先关键词和对应的连接需要是百度的收录。百度前十页有以下两种模式:1、模拟点击,类似于一些交互点组中的相互点击,促进排名提升。从2013年到2017年8月,这种方法的排名效果比较好,但9月份基本开始萎缩,行情效果不佳。
2、 数据外包+全网提权的方式,数据外包更稳定,效果高,效果好,推送平台采用这种方式。{callout color="#f0ad4e"}关键词排名优化技巧{/callout}如果要对网站的内页进行排名,必须有一定的权重。内页的权重主要包括以下两点: 1. 内容页的信息一定要丰富。如果一个页面有几十个字,即使信息是原创,被收录的概率也很小。就算是收录,也不会有好排名。页面信息是搜索引擎对页面进行评分的最重要因素。2. 内容页的关键词必须与用户搜索的长尾词相匹配。如果无法完全匹配,请尝试在页面标题和描述中显示要执行的长尾关键字。{callout color="#f0ad4e"}内页内链结构好{/callout}内页内链是网站优化中非常重要的一个元素,在优化内部页面的排名。网站的内部页面应该有网站的主导航,页面文章的面包屑导航,文末与本文相关的内容推荐等。这些都是内部链优化的必要操作。我们还需要优化列表页面。列表页面通常是一个 < @文章 列表,没有意义或者用户不关心。列表页面可酌情添加外部链接、友情链接等。{callout color="#f0ad4e"}网站内容和页面优化{/callout}网站架构分析包括:消除网站架构的不良设计,实现树状内容结构,网站 导航和链接优化。
<p>网站关键词分析应该是SEO优化办公室实施前最重要的环节。操作流程包括:网站关键词分析、团队竞争对手分析、网站关键词分析、网站 查看全部
关键词文章采集源码(百度快速收录SEO优化关键词排名优化技巧排名的条件)
百度快车收录SEO优化关键词排名优化技巧前言:新站优化有方法和技巧,关键词S排名优化,百度快车收录,如何快速发布新网站关键词排名,想要获得新网站的排名,需要规划词库布局,做好文章内容优化,写用户需求文章 ,做一个更新提交给百度站长,稳定持续的运营优化和推广,做关键词排名优化当我们在做新网站关键词排名优化时,我们需要考虑清楚关键词 开始做什么?当我们都想清楚了,那么我们就需要购买域名和空间。这更重要,因为我们正在对新网站进行排名。域名的选择对我们来说极其重要。在选择域名时,我们需要选择和我们需要做的事情。该产品具有高度相关性。这样做的目的是让搜索引擎在爬取我们的网站时通过域名知道我们在做什么?从而给人留下印象。服务器应选择高质量的服务器。网站的打开速度会对搜索引擎蜘蛛的抓取速度产生一定的影响。低配置的服务器,低配置会影响网站的打开速度,单位时间内的爬取量会相对少 绍兴站时如何让百度快速收录排名上网一直是站长们思考和期待的一个点。如何快速排名关键词,获得关键词
2、关键词Layout网站关键词词库组织布局,如果要优化词库,首先要操作词库组织布局,把需要的词放到布局优化在网站中,用户搜索关键词,排名需要相关性。关键词 的匹配度是轻松获取左侧词库排名的关键。3、网站内容质量网站内容质量是否原创,优质,满足需求文章,搜索引擎排名,推荐网页都是为了帮助用户解决问题,网页只有价值才有索引和发布的资格,用户喜欢高质量的文章。4、域名信任度网站 要想有词库发布,参与词库排名,首先网站域名信任度对搜索引擎友好,域名信任度的培养需要建站时间,网站内容质量、外链建设、朋友链交换等,发布高信任度收录和有效收录的域名,才有机会参与词库排名并获得用户行为点击。进一步提升网站关键词的排名。{callout color="#f0ad4e"}如何让百度快速收录排名{/callout}百度快速收录排名,简而言之就是在短时间内对你要推广的内容进行排名在搜索引擎中的优势地位。以此来增加网站访问者的数量,吸引更多的目标客户访问,达到营销推广的作用。百度快速排名需要关键词和连接才能排名。首先关键词和对应的连接需要是百度的收录。百度前十页有以下两种模式:1、模拟点击,类似于一些交互点组中的相互点击,促进排名提升。从2013年到2017年8月,这种方法的排名效果比较好,但9月份基本开始萎缩,行情效果不佳。和连接进行排名。首先关键词和对应的连接需要是百度的收录。百度前十页有以下两种模式:1、模拟点击,类似于一些交互点组中的相互点击,促进排名提升。从2013年到2017年8月,这种方法的排名效果比较好,但9月份基本开始萎缩,行情效果不佳。和连接进行排名。首先关键词和对应的连接需要是百度的收录。百度前十页有以下两种模式:1、模拟点击,类似于一些交互点组中的相互点击,促进排名提升。从2013年到2017年8月,这种方法的排名效果比较好,但9月份基本开始萎缩,行情效果不佳。
2、 数据外包+全网提权的方式,数据外包更稳定,效果高,效果好,推送平台采用这种方式。{callout color="#f0ad4e"}关键词排名优化技巧{/callout}如果要对网站的内页进行排名,必须有一定的权重。内页的权重主要包括以下两点: 1. 内容页的信息一定要丰富。如果一个页面有几十个字,即使信息是原创,被收录的概率也很小。就算是收录,也不会有好排名。页面信息是搜索引擎对页面进行评分的最重要因素。2. 内容页的关键词必须与用户搜索的长尾词相匹配。如果无法完全匹配,请尝试在页面标题和描述中显示要执行的长尾关键字。{callout color="#f0ad4e"}内页内链结构好{/callout}内页内链是网站优化中非常重要的一个元素,在优化内部页面的排名。网站的内部页面应该有网站的主导航,页面文章的面包屑导航,文末与本文相关的内容推荐等。这些都是内部链优化的必要操作。我们还需要优化列表页面。列表页面通常是一个 < @文章 列表,没有意义或者用户不关心。列表页面可酌情添加外部链接、友情链接等。{callout color="#f0ad4e"}网站内容和页面优化{/callout}网站架构分析包括:消除网站架构的不良设计,实现树状内容结构,网站 导航和链接优化。
<p>网站关键词分析应该是SEO优化办公室实施前最重要的环节。操作流程包括:网站关键词分析、团队竞争对手分析、网站关键词分析、网站
关键词文章采集源码(参考自知乎专题微信公众号内容的批量采集与应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-12-20 07:07
参考知乎专题微信公众号内容的批量采集和申请,作者:范口组长
原作者(饭口组组长)有句话:我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
这一系列文章也是为了延续这种分享精神!
本系列文章是根据知乎主题教程一步步实现的,在实现过程中踩到了一些坑。
原理介绍这里不再赘述,可以参考知乎专题。
代码改进前的准备
原作者使用php环境。如果有能力,可以尝试其他语言,比如python、java等,不过原作者已经给出了部分php代码,这里也实现了。
所以准备好php环境。建议使用win下的wamp、xamp、phpstudy等集成环境,因为之前电脑里就有wamp环境,所以直接用了。如果不匹配,请先配置虚拟域名。但是下面的代码需要改成自己对应的路径。配置虚拟域名的教程可以参考我的另一篇文章php本地虚拟域名配置和端口的一些折腾。这里假设我配置的虚拟域名是
修改 rule_default.js 代码
下面仅给出一些示例。其他人做同样的修改(如果没有配置虚拟域名,则需要将域名改为路径访问,如localhost/weixin/,修改即可):
HttpPost(ret[1],req.url,"/getMsgJson.php");
var http = require('http');
http.get('http://hojun.weixin.com/getWxHis.php', function(res) {
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
------------------
var options = {
method: "POST",
host: "hojun.weixin.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
找到要修改的函数replaceRequestOption:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
创建数据库和数据表
在完善php代码之前,我们还需要先创建数据库和数据表。好消息是组长已经给出了数据表的创建sql语句。修改了一些语法错误和重复关键词
微信公众号表
CREATE TABLE `weixin` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`biz` varchar(255) DEFAULT ' ' COMMENT '公众号唯一标识biz',
`collect` int(11) DEFAULT 1 COMMENT '记录采集时间的时间戳',
PRIMARY KEY (`id`)
) ;
微信文章表
CREATE TABLE `post` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`biz` varchar(255) CHARACTER SET utf8 NOT NULL COMMENT '文章对应的公众号biz',
`field_id` int(11) NOT NULL COMMENT '微信定义的一个id,每条文章唯一',
`title` varchar(255) NOT NULL DEFAULT ' ' COMMENT '文章标题',
`title_encode` text CHARACTER SET utf8 NOT NULL COMMENT '文章编码,防止文章出现emoji',
`digest` varchar(500) NOT NULL DEFAULT ' ' COMMENT '文章摘要',
`content_url` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '文章地址',
`source_url` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '阅读原文地址',
`cover` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '封面图片',
`is_multi` int(11) NOT NULL COMMENT '是否多图文',
`is_top` int(11) NOT NULL COMMENT '是否头条',
`datetime` int(11) NOT NULL COMMENT '文章时间戳',
`readNum` int(11) NOT NULL DEFAULT 1 COMMENT '文章阅读量',
`likeNum` int(11) NOT NULL DEFAULT 0 COMMENT '文章点赞量',
PRIMARY KEY (`id`)
) ;
采集队列表
CREATE TABLE `tmplist` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`content_url` varchar(255) DEFAULT NULL COMMENT '文章地址',
`load` int(11) DEFAULT 0 COMMENT '读取中标记',
PRIMARY KEY (`id`),
UNIQUE KEY `content_url` (`content_url`)
) ;
登录phpMyAdmin后台,语言可以设置为中文。
图片
请注意,排序规则设置为 utf8_general_ci。
图片
然后一一执行sql生成数据表。
图片
待续……待续…… 查看全部
关键词文章采集源码(参考自知乎专题微信公众号内容的批量采集与应用)
参考知乎专题微信公众号内容的批量采集和申请,作者:范口组长
原作者(饭口组组长)有句话:我的方法来自于很多同事的分享精神,所以我会延续这种精神,分享我的成果。
这一系列文章也是为了延续这种分享精神!
本系列文章是根据知乎主题教程一步步实现的,在实现过程中踩到了一些坑。
原理介绍这里不再赘述,可以参考知乎专题。
代码改进前的准备
原作者使用php环境。如果有能力,可以尝试其他语言,比如python、java等,不过原作者已经给出了部分php代码,这里也实现了。
所以准备好php环境。建议使用win下的wamp、xamp、phpstudy等集成环境,因为之前电脑里就有wamp环境,所以直接用了。如果不匹配,请先配置虚拟域名。但是下面的代码需要改成自己对应的路径。配置虚拟域名的教程可以参考我的另一篇文章php本地虚拟域名配置和端口的一些折腾。这里假设我配置的虚拟域名是
修改 rule_default.js 代码
下面仅给出一些示例。其他人做同样的修改(如果没有配置虚拟域名,则需要将域名改为路径访问,如localhost/weixin/,修改即可):
HttpPost(ret[1],req.url,"/getMsgJson.php");
var http = require('http');
http.get('http://hojun.weixin.com/getWxHis.php', function(res) {
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
------------------
var options = {
method: "POST",
host: "hojun.weixin.com",//注意没有http://,这是服务器的域名。
port: 80,
path: path,//接收程序的路径和文件名
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": content.length
}
};
找到要修改的函数replaceRequestOption:
replaceRequestOption : function(req,option){
var newOption = option;
if(/google/i.test(newOption.headers.host)){
newOption.hostname = "www.baidu.com";
newOption.port = "80";
}
return newOption;
},
创建数据库和数据表
在完善php代码之前,我们还需要先创建数据库和数据表。好消息是组长已经给出了数据表的创建sql语句。修改了一些语法错误和重复关键词
微信公众号表
CREATE TABLE `weixin` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`biz` varchar(255) DEFAULT ' ' COMMENT '公众号唯一标识biz',
`collect` int(11) DEFAULT 1 COMMENT '记录采集时间的时间戳',
PRIMARY KEY (`id`)
) ;
微信文章表
CREATE TABLE `post` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`biz` varchar(255) CHARACTER SET utf8 NOT NULL COMMENT '文章对应的公众号biz',
`field_id` int(11) NOT NULL COMMENT '微信定义的一个id,每条文章唯一',
`title` varchar(255) NOT NULL DEFAULT ' ' COMMENT '文章标题',
`title_encode` text CHARACTER SET utf8 NOT NULL COMMENT '文章编码,防止文章出现emoji',
`digest` varchar(500) NOT NULL DEFAULT ' ' COMMENT '文章摘要',
`content_url` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '文章地址',
`source_url` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '阅读原文地址',
`cover` varchar(500) CHARACTER SET utf8 NOT NULL COMMENT '封面图片',
`is_multi` int(11) NOT NULL COMMENT '是否多图文',
`is_top` int(11) NOT NULL COMMENT '是否头条',
`datetime` int(11) NOT NULL COMMENT '文章时间戳',
`readNum` int(11) NOT NULL DEFAULT 1 COMMENT '文章阅读量',
`likeNum` int(11) NOT NULL DEFAULT 0 COMMENT '文章点赞量',
PRIMARY KEY (`id`)
) ;
采集队列表
CREATE TABLE `tmplist` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`content_url` varchar(255) DEFAULT NULL COMMENT '文章地址',
`load` int(11) DEFAULT 0 COMMENT '读取中标记',
PRIMARY KEY (`id`),
UNIQUE KEY `content_url` (`content_url`)
) ;
登录phpMyAdmin后台,语言可以设置为中文。
图片
请注意,排序规则设置为 utf8_general_ci。
图片
然后一一执行sql生成数据表。
图片
待续……待续……
关键词文章采集源码( 帝国CMS内核简洁大气PS教程模板教程源码PS)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-12-20 01:25
帝国CMS内核简洁大气PS教程模板教程源码PS)
总结:帝国cms内核简洁大气PS教程模板,教程源码,PS教程网站模板带手机模板同步插件,熊掌号自动推送采集,百度自动推送、发送采集【全站数据】---------------...
帝国cms内核简洁大气PS教程模板,教程源码,PS教程网站模板带手机模板同步插件,熊掌号自动推送采集,百度自动推送,发送采集【全站数据】
-------------------------------------------------- ------------------------------
开发环境:Empirecms7.5
空间支持:php+mysql
大小:全站2.约4G
采集:发送优采云采集器(内置规则和模块)
编码:UTF-8 附安装说明教程
●系统开源,域名不限
●PC同步生成手机版
-------------------------------------------------- -------------------------------------------------- ---
【笔记】
源代码模板程序在本地经过严格测试,并多次添加到演示站。
网站优化
1:新增手机同步插件
2:百度自动推送
3:网站地图
4:熊掌号自动提交
5:标签
6:404,robost,全站静态生成,有利于收录和关键词布局和内容页面优化。
模板使用标签灵活调用。在采集方面,选择优质的文章。它不是为了好看的模板而开发的,但用户体验和搜索引擎的友好性很重要。
-------------------------------------------------- -------------------------------------------------- ----
图文并茂的安装教程
我们自建的demo,有demo和真相,一切以demo站和截图为准!
注:请放心购买自动发货
-------------------------------------------------- -------------------------------------------------- ——
演示站
计算机
移动终端
注意:演示站机器配置低有延迟是正常的。如果访问速度较慢,请耐心等待。
-------------------------------------------------- -------------------------------------------------- ---
模板截图
移动终端
购买地址 查看全部
关键词文章采集源码(
帝国CMS内核简洁大气PS教程模板教程源码PS)
总结:帝国cms内核简洁大气PS教程模板,教程源码,PS教程网站模板带手机模板同步插件,熊掌号自动推送采集,百度自动推送、发送采集【全站数据】---------------...
帝国cms内核简洁大气PS教程模板,教程源码,PS教程网站模板带手机模板同步插件,熊掌号自动推送采集,百度自动推送,发送采集【全站数据】
-------------------------------------------------- ------------------------------
开发环境:Empirecms7.5
空间支持:php+mysql
大小:全站2.约4G
采集:发送优采云采集器(内置规则和模块)
编码:UTF-8 附安装说明教程
●系统开源,域名不限
●PC同步生成手机版
-------------------------------------------------- -------------------------------------------------- ---
【笔记】
源代码模板程序在本地经过严格测试,并多次添加到演示站。
网站优化
1:新增手机同步插件
2:百度自动推送
3:网站地图
4:熊掌号自动提交
5:标签
6:404,robost,全站静态生成,有利于收录和关键词布局和内容页面优化。
模板使用标签灵活调用。在采集方面,选择优质的文章。它不是为了好看的模板而开发的,但用户体验和搜索引擎的友好性很重要。
-------------------------------------------------- -------------------------------------------------- ----
图文并茂的安装教程
我们自建的demo,有demo和真相,一切以demo站和截图为准!
注:请放心购买自动发货
-------------------------------------------------- -------------------------------------------------- ——
演示站
计算机
移动终端
注意:演示站机器配置低有延迟是正常的。如果访问速度较慢,请耐心等待。
-------------------------------------------------- -------------------------------------------------- ---
模板截图
移动终端
购买地址
关键词文章采集源码(商品属性安装环境商品介绍程序说明(图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-12-18 23:16
)
商品属性
安装环境
产品介绍
程序说明
1、 源码类型:小说全站源码
2、环境语言:PHP5.2/5.3/5.4/5.5+MYSQL5+伪静态
3、原程序:源码以dedecms5.7sp1为核心。由于源代码已修改优化,请勿自动升级。一般情况下,如果没有bug,就不需要升级。业主会不时提供必要的升级包。
4、编码类型:GBK
5、可用采集:全自动采集
6、其他功能:
(1)首页、分类、目录、排名、站点地图页(分类页、小说封面、作者页,如果html文件不存在或超过设定时间未更新,则自动生成静态html)自动更新一次。如果有采集,采集会自动更新小说封面和对应的分类页面),直接通过PHP调用html文件,而不是在根目录生成,访问速度与纯静态无异,在保证源文件管理方便的同时,可以降低服务器压力,还可以方便访问统计,增加搜索引擎识别度。
(2)全站拼音编目,章节页面伪静态。
(3)自动生成小说txt文件,也可以后台重新生成txt文件。
(4)自动生成小说关键词和关键词自动内链。
(5)自动伪原创单词替换(采集时替换)。
(6)新增小说总点击量、月点击量、周点击量、总推荐量、月度推荐量、周推荐统计、作者推荐统计等新功能。
(7)配合CNZZ的统计插件,方便实现小说下载量和藏书量的详细统计。
百度网盘链接和解压码一般都在压缩包里。如果没有,请联系店长QQ获取。
查看全部
关键词文章采集源码(商品属性安装环境商品介绍程序说明(图)
)
商品属性
安装环境
产品介绍
程序说明
1、 源码类型:小说全站源码
2、环境语言:PHP5.2/5.3/5.4/5.5+MYSQL5+伪静态
3、原程序:源码以dedecms5.7sp1为核心。由于源代码已修改优化,请勿自动升级。一般情况下,如果没有bug,就不需要升级。业主会不时提供必要的升级包。
4、编码类型:GBK
5、可用采集:全自动采集
6、其他功能:
(1)首页、分类、目录、排名、站点地图页(分类页、小说封面、作者页,如果html文件不存在或超过设定时间未更新,则自动生成静态html)自动更新一次。如果有采集,采集会自动更新小说封面和对应的分类页面),直接通过PHP调用html文件,而不是在根目录生成,访问速度与纯静态无异,在保证源文件管理方便的同时,可以降低服务器压力,还可以方便访问统计,增加搜索引擎识别度。
(2)全站拼音编目,章节页面伪静态。
(3)自动生成小说txt文件,也可以后台重新生成txt文件。
(4)自动生成小说关键词和关键词自动内链。
(5)自动伪原创单词替换(采集时替换)。
(6)新增小说总点击量、月点击量、周点击量、总推荐量、月度推荐量、周推荐统计、作者推荐统计等新功能。
(7)配合CNZZ的统计插件,方便实现小说下载量和藏书量的详细统计。
百度网盘链接和解压码一般都在压缩包里。如果没有,请联系店长QQ获取。
关键词文章采集源码(网页爬虫代码的实现思路及实现)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-12-18 18:16
现在网络爬虫代码可以说是满天飞,尤其是Python和PHP写的居多。百度随便搜,满屏。无论用什么计算机语言编写,性能都无关紧要。最重要的是想法的实现。
一、想法的实现1、之前的想法
说说我个人的实现思路:
十多年前写了一个爬虫,当时的想法:
1、根据关键词的设置。
2、百度搜索相关关键词并保存。
3、 遍历关键词 库,搜索相关网页信息。
4、 提取搜索页面的页面链接。
5、 遍历每个页面上的网络链接。
6、 抓取网页数据。
7、分析数据,构造标题、关键词、描述、内容,并存入数据库。
8、部署到服务器,每天自动更新html页面。
这里的重点是:标题的智能组织、关键词的自动组合、内容的智能拼接。
那个时候搜索引擎还没有这么智能的时候,效果还不错!百度的收录率很高。
2、当前思想数据采集部分:
根据初始的关键词集合,从百度搜索引擎中搜索相关的关键词,遍历相关的关键词库,抓取百度数据。
构建数据部分:
按照原来的文章标题,分解成多个关键词作为SEO关键词。同理,对文章的内容进行分解,取第一段内容的前100字作为SEO网页描述。内容不变,数据整理好存入仓库。
文章发布部分:
根据排序后的数据(SEO相关设置),匹配相关页面模板,依次生成文章内容页、文章列表页、网站首页。部署到服务器,每天自动更新文章的设置数量。
二、相关流程1.数据采集流程
1、设置关键词。
2、根据设置搜索相关关键词关键词。
3、 遍历关键词,百度搜索结果,得到前10页。
4、根据页码链接,得到前10页(大约前100条数据,后面的排名已经很晚了,意义不大)
5、获取每个页面的网络链接集合。
6、 根据链接获取网页信息(标题、作者、时间、内容、原文链接)。
2.数据生成过程
1、 初始化表(关键词、链接、内容、html数据、发布统计)。
2、根据基本的关键词,抓取相关的关键词存入数据库。
3、 获取链接并存储。
4、 抓取网页内容并将其存储在数据库中。
5、构建 html 内容并将其存储在库中。
3.页面发布流程
1、在html数据表中获取从早到晚的数据。
2、创建内容详细信息页面。
3、创建内容列表页面。 查看全部
关键词文章采集源码(网页爬虫代码的实现思路及实现)
现在网络爬虫代码可以说是满天飞,尤其是Python和PHP写的居多。百度随便搜,满屏。无论用什么计算机语言编写,性能都无关紧要。最重要的是想法的实现。
一、想法的实现1、之前的想法
说说我个人的实现思路:
十多年前写了一个爬虫,当时的想法:
1、根据关键词的设置。
2、百度搜索相关关键词并保存。
3、 遍历关键词 库,搜索相关网页信息。
4、 提取搜索页面的页面链接。
5、 遍历每个页面上的网络链接。
6、 抓取网页数据。
7、分析数据,构造标题、关键词、描述、内容,并存入数据库。
8、部署到服务器,每天自动更新html页面。
这里的重点是:标题的智能组织、关键词的自动组合、内容的智能拼接。
那个时候搜索引擎还没有这么智能的时候,效果还不错!百度的收录率很高。
2、当前思想数据采集部分:
根据初始的关键词集合,从百度搜索引擎中搜索相关的关键词,遍历相关的关键词库,抓取百度数据。
构建数据部分:
按照原来的文章标题,分解成多个关键词作为SEO关键词。同理,对文章的内容进行分解,取第一段内容的前100字作为SEO网页描述。内容不变,数据整理好存入仓库。
文章发布部分:
根据排序后的数据(SEO相关设置),匹配相关页面模板,依次生成文章内容页、文章列表页、网站首页。部署到服务器,每天自动更新文章的设置数量。
二、相关流程1.数据采集流程
1、设置关键词。
2、根据设置搜索相关关键词关键词。
3、 遍历关键词,百度搜索结果,得到前10页。
4、根据页码链接,得到前10页(大约前100条数据,后面的排名已经很晚了,意义不大)
5、获取每个页面的网络链接集合。
6、 根据链接获取网页信息(标题、作者、时间、内容、原文链接)。
2.数据生成过程
1、 初始化表(关键词、链接、内容、html数据、发布统计)。
2、根据基本的关键词,抓取相关的关键词存入数据库。
3、 获取链接并存储。
4、 抓取网页内容并将其存储在数据库中。
5、构建 html 内容并将其存储在库中。
3.页面发布流程
1、在html数据表中获取从早到晚的数据。
2、创建内容详细信息页面。
3、创建内容列表页面。
关键词文章采集源码(帝国CMS7.5简洁好听的名字_高分好名字资讯模板)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-12-13 18:10
帝国cms7.5个简洁好听的名字_高分好名字_取个好名字信息模板,百度自动推送。【内页(文章页,列表)标题,描述,严格的SEO标题规范,有利于SEO,维护一个网站和一个域名结盟好]
-------------------------------------------------- -------------------------------------------------- ------
● 系统开源,域名不限
● WAP移动终端
●大小约159MB
●发送采集
●附图文安装教程
-------------------------------------------------- -------------------------------------------------- -------
【笔记】
源代码模板程序在本地经过严格测试,并多次添加到演示站。
网站优化
1:百度自动推送
2:网站地图
3:多端同步生成插件
4:404、robost、TAG、百度统计,全站静态生成有利于收录和关键词布局和内容页面优化。
模板使用标签灵活调用。不是为了模板好看而开发的。重要的是用户体验和对搜索引擎的友好性。
【注意】:如果有tags、load more等功能打不开404,说明没有安装配置数据库,按照教程正常配置后不会出现这个问题。
模板全部经过Tinder security等本地杀毒软件扫描后打包,精简了一些不必要的功能,去除了多余的js和css,提高了程序的安全性和网站的稳定性。
-------------------------------------------------- -------------------------------------------------- ---------
演示站
计算机:查看演示
移动终端;查看演示
我们自建的demo,有demo和真相,一切以demo站和截图为准!
注意:演示站机器配置低,有延迟是正常的。这与模板程序无关。
-------------------------------------------------- -------------------------------------------------- ----------
模板部分截图:
资源下载 本资源下载价格为100金币,请先登录 查看全部
关键词文章采集源码(帝国CMS7.5简洁好听的名字_高分好名字资讯模板)
帝国cms7.5个简洁好听的名字_高分好名字_取个好名字信息模板,百度自动推送。【内页(文章页,列表)标题,描述,严格的SEO标题规范,有利于SEO,维护一个网站和一个域名结盟好]
-------------------------------------------------- -------------------------------------------------- ------
● 系统开源,域名不限
● WAP移动终端
●大小约159MB
●发送采集
●附图文安装教程
-------------------------------------------------- -------------------------------------------------- -------
【笔记】
源代码模板程序在本地经过严格测试,并多次添加到演示站。
网站优化
1:百度自动推送
2:网站地图
3:多端同步生成插件
4:404、robost、TAG、百度统计,全站静态生成有利于收录和关键词布局和内容页面优化。
模板使用标签灵活调用。不是为了模板好看而开发的。重要的是用户体验和对搜索引擎的友好性。
【注意】:如果有tags、load more等功能打不开404,说明没有安装配置数据库,按照教程正常配置后不会出现这个问题。
模板全部经过Tinder security等本地杀毒软件扫描后打包,精简了一些不必要的功能,去除了多余的js和css,提高了程序的安全性和网站的稳定性。
-------------------------------------------------- -------------------------------------------------- ---------
演示站
计算机:查看演示
移动终端;查看演示
我们自建的demo,有demo和真相,一切以demo站和截图为准!
注意:演示站机器配置低,有延迟是正常的。这与模板程序无关。
-------------------------------------------------- -------------------------------------------------- ----------
模板部分截图:
资源下载 本资源下载价格为100金币,请先登录
关键词文章采集源码(微思敦编程语言有可读性,通俗易懂性)
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-12-12 14:04
关键词文章采集源码blogspot文章采集douban/douban-blogitem导读:douban有大量的站内文章,希望采集这些文章中的精华和热点话题,分析文章的曝光率及多维度的数据,集中总结、优化产品形式,同时有效的向搜索引擎传达产品以及平台发展的市场趋势,降低跳转率及转化率。python编程语言有可读性,通俗易懂性,web开发有可看性。
结合近期搜索引擎seo及网站的搜索,需要选择前端api、接口测试等专业性较强、内容同质化严重、能传递海量信息的产品。感谢很多大神设计,分析,微思敦提供blogspot中文、英文和中文社区文章采集。产品:blogspot中文社区、blogspot、自由自在的开发者社区、avazu、topic-xl、英文web开发者社区链接:::hanchengzixiaohao4202018-06-15更新于:2018-10-08python环境:win10+python3.6python3.5+django2.1+chromedriver,firefoxdriver,djangossl版本,从官网下载原版镜像来看。
python3.5+需要包括java环境才可以。也有少数语言特性要求是win7+python3.5+,也有语言环境要求是python2.7+python3.5。下载安装的具体步骤可以通过ssh上github官网下载安装包,配置的具体细节请参见官网。官网下载地址为:facebook官方网站,目前已经不可以直接在chrome浏览器中使用了,不同于有插件支持,基本已经封掉chrome浏览器的ssl接口,此时如果想进行跳转,即看不到注册完成提示文字,那么可以参考django的models.pymodels.model.saveqqa之类,很有可能是django启动qa数据检查库qa-master时遇到的不能启动qa服务器的错误。
此时我们只需要通过python第三方模块如python-sqlalchemy解决库本身的问题。因为python语言不支持blogspot这个库,所以大部分基于python的fb采集都是通过python-qa来实现:以xml标签的形式传递文章的属性信息dom描述表示一个标签,可以包含多个标签分页、回复等操作,有四种方式实现:fromdjango.dbimportmodelsfrom.itemsimportmodels.postmodels.post(item,models.post)#item以postdata的格式返回,配合blogspot.session使用://postdata=blogspot.session()models.post(item,models.post)#通过fb.model.default(blogspot.model.default)//这个方法创建了postdata对象,默认会产生token//request_token=models.get_request_token(username,password)创建存储qa数据库的数据库。 查看全部
关键词文章采集源码(微思敦编程语言有可读性,通俗易懂性)
关键词文章采集源码blogspot文章采集douban/douban-blogitem导读:douban有大量的站内文章,希望采集这些文章中的精华和热点话题,分析文章的曝光率及多维度的数据,集中总结、优化产品形式,同时有效的向搜索引擎传达产品以及平台发展的市场趋势,降低跳转率及转化率。python编程语言有可读性,通俗易懂性,web开发有可看性。
结合近期搜索引擎seo及网站的搜索,需要选择前端api、接口测试等专业性较强、内容同质化严重、能传递海量信息的产品。感谢很多大神设计,分析,微思敦提供blogspot中文、英文和中文社区文章采集。产品:blogspot中文社区、blogspot、自由自在的开发者社区、avazu、topic-xl、英文web开发者社区链接:::hanchengzixiaohao4202018-06-15更新于:2018-10-08python环境:win10+python3.6python3.5+django2.1+chromedriver,firefoxdriver,djangossl版本,从官网下载原版镜像来看。
python3.5+需要包括java环境才可以。也有少数语言特性要求是win7+python3.5+,也有语言环境要求是python2.7+python3.5。下载安装的具体步骤可以通过ssh上github官网下载安装包,配置的具体细节请参见官网。官网下载地址为:facebook官方网站,目前已经不可以直接在chrome浏览器中使用了,不同于有插件支持,基本已经封掉chrome浏览器的ssl接口,此时如果想进行跳转,即看不到注册完成提示文字,那么可以参考django的models.pymodels.model.saveqqa之类,很有可能是django启动qa数据检查库qa-master时遇到的不能启动qa服务器的错误。
此时我们只需要通过python第三方模块如python-sqlalchemy解决库本身的问题。因为python语言不支持blogspot这个库,所以大部分基于python的fb采集都是通过python-qa来实现:以xml标签的形式传递文章的属性信息dom描述表示一个标签,可以包含多个标签分页、回复等操作,有四种方式实现:fromdjango.dbimportmodelsfrom.itemsimportmodels.postmodels.post(item,models.post)#item以postdata的格式返回,配合blogspot.session使用://postdata=blogspot.session()models.post(item,models.post)#通过fb.model.default(blogspot.model.default)//这个方法创建了postdata对象,默认会产生token//request_token=models.get_request_token(username,password)创建存储qa数据库的数据库。
关键词文章采集源码(总站、代理、普通用户均可添加网站关键词的关键词指数 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-12-09 04:01
)
安装教程:
thinkphp, php72, 运行目录/public
导入数据库,修改数据库目录:/app/database.php
后台账号:admin
密码:abymcn
SEO按天关键词计费排名查询系统源码
功能:1. 会员管理:
系统分为三级会员流程。总部管理员、代理、会员(会员分为普通会员、中级会员、高级会员三个级别),
主站增加代理用户,充值代理用户余额,充值余额给普通用户。代理还可以将关键词的查询比例提高到3级会员。
如果这个关键词终端为代理10元,而代理与普通用户的比例为200,那么用户加这个关键词为20元,
多出的10元是代理商的利润。代理只能看到自己的下级成员,设置的比例只对自己的下级成员有效。如果代理没有设置比例,
然后会根据主站给代理的价格显示给用户,也就是原价。
2.网站管理。
总部、代理商、普通用户可以添加网站,在网站列表页可以看到网站的基本信息。
如:域名、网站名称、会员、注册时间、关键词数量、达标数量关键词、今日消费、历史消费、网站启用和残疾状态;
3.关键词 管理。
总部、代理商、普通用户可以添加网站关键词,普通用户只能通过关键词价格添加关键词,
普通用户添加的关键词需要经过一般背景审核;
4.关键词查看价格。
系统支持两种模式:手动输入价格和基于关键词索引的价格查询。基于关键词指数的价格查询需要我们在后台输入指数区间。
我们扣分系统调用的站长之家关键词索引与百度、360等官网数据不一致,请谨慎使用;
5.关键词 排名。做优化的朋友应该都知道,在做自然搜索的时候,会出现站外排名的情况。我们经常发现排名找不到,
在排名不准确的情况下,市面上的扣费系统大多采用单节点查询技术或调用站长之家/5118等查询接口。
一般现象是搜索不闪,我司采用多节点排名查询技术。目前,全国部署了7个节点。排名查询比站长的好
5118等扣费系统一定要准确数倍,我们提供排名快照服务。如果客户网站 出现在搜索结果的前 2 页,我们的系统将自行拍摄当前排名的快照。
对客户更有说服力;
6.公众号查询:
系统支持非认证订阅号、服务号等查询网站排名,只需在公众号对话框中输入网站域名,
公众号会自动向用户反馈网站的排名情况。下一步将进一步完善公众号的功能,如:余额不足提醒、关键词排名标准推送功能等;
7.财务管理。
后端提供清晰、简洁、清晰的财务统计分析。一般后端和代理用户可以看到他们的代理/用户的可用余额,
累计消费、上月消费、本月消费、近3个月消费、近1年消费等,也可后台查看;
8.在线充值。
开发微信扫码支付功能;
9. 利润分析,
利润统计,各搜索引擎达标数量关键词,最近7天达标数量,折线图和直方图展示,方便您查看!!!
查看全部
关键词文章采集源码(总站、代理、普通用户均可添加网站关键词的关键词指数
)
安装教程:
thinkphp, php72, 运行目录/public
导入数据库,修改数据库目录:/app/database.php
后台账号:admin
密码:abymcn
SEO按天关键词计费排名查询系统源码
功能:1. 会员管理:
系统分为三级会员流程。总部管理员、代理、会员(会员分为普通会员、中级会员、高级会员三个级别),
主站增加代理用户,充值代理用户余额,充值余额给普通用户。代理还可以将关键词的查询比例提高到3级会员。
如果这个关键词终端为代理10元,而代理与普通用户的比例为200,那么用户加这个关键词为20元,
多出的10元是代理商的利润。代理只能看到自己的下级成员,设置的比例只对自己的下级成员有效。如果代理没有设置比例,
然后会根据主站给代理的价格显示给用户,也就是原价。
2.网站管理。
总部、代理商、普通用户可以添加网站,在网站列表页可以看到网站的基本信息。
如:域名、网站名称、会员、注册时间、关键词数量、达标数量关键词、今日消费、历史消费、网站启用和残疾状态;
3.关键词 管理。
总部、代理商、普通用户可以添加网站关键词,普通用户只能通过关键词价格添加关键词,
普通用户添加的关键词需要经过一般背景审核;
4.关键词查看价格。
系统支持两种模式:手动输入价格和基于关键词索引的价格查询。基于关键词指数的价格查询需要我们在后台输入指数区间。
我们扣分系统调用的站长之家关键词索引与百度、360等官网数据不一致,请谨慎使用;
5.关键词 排名。做优化的朋友应该都知道,在做自然搜索的时候,会出现站外排名的情况。我们经常发现排名找不到,
在排名不准确的情况下,市面上的扣费系统大多采用单节点查询技术或调用站长之家/5118等查询接口。
一般现象是搜索不闪,我司采用多节点排名查询技术。目前,全国部署了7个节点。排名查询比站长的好
5118等扣费系统一定要准确数倍,我们提供排名快照服务。如果客户网站 出现在搜索结果的前 2 页,我们的系统将自行拍摄当前排名的快照。
对客户更有说服力;
6.公众号查询:
系统支持非认证订阅号、服务号等查询网站排名,只需在公众号对话框中输入网站域名,
公众号会自动向用户反馈网站的排名情况。下一步将进一步完善公众号的功能,如:余额不足提醒、关键词排名标准推送功能等;
7.财务管理。
后端提供清晰、简洁、清晰的财务统计分析。一般后端和代理用户可以看到他们的代理/用户的可用余额,
累计消费、上月消费、本月消费、近3个月消费、近1年消费等,也可后台查看;
8.在线充值。
开发微信扫码支付功能;
9. 利润分析,
利润统计,各搜索引擎达标数量关键词,最近7天达标数量,折线图和直方图展示,方便您查看!!!
关键词文章采集源码(如何应对网络中的新闻内容也一样?系统帮你解决)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-12-06 14:18
随着互联网的飞速发展,互联网极大地提高了信息生成和传播的速度。互联网上每天都会产生大量的内容。如何从这些乱七八糟的内容中高效地发现和采集需要的信息,变得越来越明显越重要。互联网上的新闻内容也是如此。新闻分布在不同的网站上,存在重复的内容。我们往往只关心新闻的一部分。互联网上的新闻页面往往充斥着大量与新闻无关的新闻页面。这些信息会影响我们的阅读效率和阅读体验。如何更方便、及时、高效地获取我们关心的新闻内容,这个系统可以帮我们做到这一点。本系统使用网络爬虫对网络网站上的新闻进行定时、有针对性的分析和采集,然后对采集收到的数据进行去重、分类、保存。进入数据库,最终提供个性化的新闻订阅服务。考虑如何处理网站的反爬虫策略,避免被网站拦截。在具体实现中,我们将使用Python与scrapy等框架编写爬虫,使用特定的内容提取算法提取目标数据,最后使用Django加weui提供新闻订阅后台和新闻内容展示页面,使用微信推送给用户的信息。用户可以通过本系统订阅指定关键词,当爬虫系统抓取到收录指定关键词的内容时,
[关键词] 网络爬虫;消息; 个性化;订阅; Python
参考文档及完整文档及源代码下载地址: 查看全部
关键词文章采集源码(如何应对网络中的新闻内容也一样?系统帮你解决)
随着互联网的飞速发展,互联网极大地提高了信息生成和传播的速度。互联网上每天都会产生大量的内容。如何从这些乱七八糟的内容中高效地发现和采集需要的信息,变得越来越明显越重要。互联网上的新闻内容也是如此。新闻分布在不同的网站上,存在重复的内容。我们往往只关心新闻的一部分。互联网上的新闻页面往往充斥着大量与新闻无关的新闻页面。这些信息会影响我们的阅读效率和阅读体验。如何更方便、及时、高效地获取我们关心的新闻内容,这个系统可以帮我们做到这一点。本系统使用网络爬虫对网络网站上的新闻进行定时、有针对性的分析和采集,然后对采集收到的数据进行去重、分类、保存。进入数据库,最终提供个性化的新闻订阅服务。考虑如何处理网站的反爬虫策略,避免被网站拦截。在具体实现中,我们将使用Python与scrapy等框架编写爬虫,使用特定的内容提取算法提取目标数据,最后使用Django加weui提供新闻订阅后台和新闻内容展示页面,使用微信推送给用户的信息。用户可以通过本系统订阅指定关键词,当爬虫系统抓取到收录指定关键词的内容时,
[关键词] 网络爬虫;消息; 个性化;订阅; Python
参考文档及完整文档及源代码下载地址:
关键词文章采集源码(百度文库采集经典的三个外国网站的样例代码都是名一样)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-12-04 22:02
关键词文章采集源码编写开源神器百度网站镜像百度学术镜像百度文库采集经典的三个外国网站的样例代码都是后缀名一样下载下来就可以编辑有各种不同类型的文章,供你选择。
不管是源码还是脚本,编写得好的话整个人都会爽很多,也很快捷,主要是编程能力要过硬。比如下面这个:autocad安装包发给你了!!!全部都是免费的。免费的,免费的。
autocad导入编辑
程序员,对。是程序员。重要的话说三遍。绝对经典的源码。出来好多年了,没有加好多乱七八糟的东西。真的是。
站在巨人的肩膀,
坐标河南省。我们这有过一个比较丰富的源码资源,开源的成品文件,那是第二年。
从04年开始给程序员做的也差不多有20年的历史了虽然基本上没有出现什么事故,但是总是免不了有些遗憾最近20多年里因为各种原因所以没有碰过autocad最近因为好多同事想尝试新东西所以找了人开发新系统,自己觉得不错的原因,这才勉强算是几年吧开源的源码在大量的使用与实践中总结出来一些经验分享给大家我们在搭建工具软件的过程中,想要高质量的autocad软件,就得保证学习性和工作效率先分享一个心得在做一个软件之前我们得先解决学习性的问题,也就是要保证多用多练习,各种技术资料方法网上找不到。
首先先学习autocad常用的基础功能,包括布局和命令一定要熟练掌握,特别是布局命令,几个关键功能一定要尝试掌握其次,掌握了基础的布局命令后我们要学习绘图技巧(命令解释和使用技巧及各种布局操作)最后我们要尝试解决绘图问题(其实是最耗时的问题),你可以选择去研究源码,也可以选择去找开源软件类库用(std::asm),完整的如autocad2004,后期不断自己扩展个别,来解决自己的问题,来自行实现自己的一些功能效率及便捷程度是差了不止一个数量级。
其次了解各种常用工具选择记忆理解,其实还是很重要的,真正用到的时候你不会不认识这些工具,也就是说了解了再用,或者复习了再用,是比较能理解且节省时间的。最后,也很关键是自己的学习能力及付出多少时间的沉淀。毕竟其实autocad内容是远远大于2004大的,大于300多个文件,你也得付出时间去做学习与研究(工作中我们做计算机的也不想天天做重复性的事情,必然是自己也能掌握的,最好是自己能够直接操作就能解决问题的)以上,供参考。 查看全部
关键词文章采集源码(百度文库采集经典的三个外国网站的样例代码都是名一样)
关键词文章采集源码编写开源神器百度网站镜像百度学术镜像百度文库采集经典的三个外国网站的样例代码都是后缀名一样下载下来就可以编辑有各种不同类型的文章,供你选择。
不管是源码还是脚本,编写得好的话整个人都会爽很多,也很快捷,主要是编程能力要过硬。比如下面这个:autocad安装包发给你了!!!全部都是免费的。免费的,免费的。
autocad导入编辑
程序员,对。是程序员。重要的话说三遍。绝对经典的源码。出来好多年了,没有加好多乱七八糟的东西。真的是。
站在巨人的肩膀,
坐标河南省。我们这有过一个比较丰富的源码资源,开源的成品文件,那是第二年。
从04年开始给程序员做的也差不多有20年的历史了虽然基本上没有出现什么事故,但是总是免不了有些遗憾最近20多年里因为各种原因所以没有碰过autocad最近因为好多同事想尝试新东西所以找了人开发新系统,自己觉得不错的原因,这才勉强算是几年吧开源的源码在大量的使用与实践中总结出来一些经验分享给大家我们在搭建工具软件的过程中,想要高质量的autocad软件,就得保证学习性和工作效率先分享一个心得在做一个软件之前我们得先解决学习性的问题,也就是要保证多用多练习,各种技术资料方法网上找不到。
首先先学习autocad常用的基础功能,包括布局和命令一定要熟练掌握,特别是布局命令,几个关键功能一定要尝试掌握其次,掌握了基础的布局命令后我们要学习绘图技巧(命令解释和使用技巧及各种布局操作)最后我们要尝试解决绘图问题(其实是最耗时的问题),你可以选择去研究源码,也可以选择去找开源软件类库用(std::asm),完整的如autocad2004,后期不断自己扩展个别,来解决自己的问题,来自行实现自己的一些功能效率及便捷程度是差了不止一个数量级。
其次了解各种常用工具选择记忆理解,其实还是很重要的,真正用到的时候你不会不认识这些工具,也就是说了解了再用,或者复习了再用,是比较能理解且节省时间的。最后,也很关键是自己的学习能力及付出多少时间的沉淀。毕竟其实autocad内容是远远大于2004大的,大于300多个文件,你也得付出时间去做学习与研究(工作中我们做计算机的也不想天天做重复性的事情,必然是自己也能掌握的,最好是自己能够直接操作就能解决问题的)以上,供参考。
关键词文章采集源码(第一、网站定位利用核心词语长尾关键词:确定网站主题与方向)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-12-04 16:08
一、网站 定位和使用核心词采集整理长尾关键词:
确定网站的主题和方向,比如核心关键词:二手车。下面是重点。长尾关键词是怎么来的?这里需要了解一些程序,简单使用php字段采集:百度相关搜索。对于初学者来说,使用php字段方法可能比较困难(regular就可以,字段简单)采集所有关键词收录“二手车”,自动无限采集回来关键词数量非常大(重复关键词no采集,关键词no采集超过限定长度)。
按二、长尾关键词分类:
对所有从采集返回的收录“二手车”的关键词进行分类,大致分为三类:1.导航;2.交易;3.信息类别;这样划分的原因不是为了划分列,而是为了方便下面长尾关键词的组合。
三、长尾关键词的组合:
上面分离的三种关键词,每一种文章随机抽取一个导航、交易、信息关键词,组合起来作为标题。这样做的目的是为了让标题更加多样化,搜索起来更容易。另外,长尾关键词容易上榜,上首页也容易。如果数量大,得到的流量是很直观的。
第一个四、是以长尾关键词组成的标题为内容:
当关键词组合成一个标题时,我们就会发现一个问题。写这样的标题对我们来说并不容易。文章,因为这样组合的标题涉及的内容太多,所以我们只需要先把关键词的一个提取出来写文章,然后再从里面提取一个关键词的组合其他两个类作为标题,因为关键词都收录“二手车”,所以不用担心不相关。如果使用采集,可以考虑将一些相关内容与采集,或者采集其他人的文章结合起来,百度翻译再翻译成中文。这些方法都不好,可读性差,不利于网站的长远发展,而且百度的垃圾邮件识别能力也在不断提升。
五、的原理分析:
长尾关键词具有快速排名的能力,是增加有效流量最好最快的方式。花在一个核心上的时间关键词可以做出几十万条长尾关键词。这里我采集进行了百度相关搜索,确认这些关键词都是搜索到关键词,并且“二手车”这个词的相关性是一定的,加上分类,组合成一个标题,整合标题的三个关键词分类,方便用户搜索。
这种方法简单、直接、有效。如果您精通程序,那么做到这一点真的太容易了。通过海量的长尾关键词做内容,总会有很多关键词的排名。在首页,流量增加十倍根本不是问题。 查看全部
关键词文章采集源码(第一、网站定位利用核心词语长尾关键词:确定网站主题与方向)
一、网站 定位和使用核心词采集整理长尾关键词:
确定网站的主题和方向,比如核心关键词:二手车。下面是重点。长尾关键词是怎么来的?这里需要了解一些程序,简单使用php字段采集:百度相关搜索。对于初学者来说,使用php字段方法可能比较困难(regular就可以,字段简单)采集所有关键词收录“二手车”,自动无限采集回来关键词数量非常大(重复关键词no采集,关键词no采集超过限定长度)。
按二、长尾关键词分类:
对所有从采集返回的收录“二手车”的关键词进行分类,大致分为三类:1.导航;2.交易;3.信息类别;这样划分的原因不是为了划分列,而是为了方便下面长尾关键词的组合。
三、长尾关键词的组合:
上面分离的三种关键词,每一种文章随机抽取一个导航、交易、信息关键词,组合起来作为标题。这样做的目的是为了让标题更加多样化,搜索起来更容易。另外,长尾关键词容易上榜,上首页也容易。如果数量大,得到的流量是很直观的。
第一个四、是以长尾关键词组成的标题为内容:
当关键词组合成一个标题时,我们就会发现一个问题。写这样的标题对我们来说并不容易。文章,因为这样组合的标题涉及的内容太多,所以我们只需要先把关键词的一个提取出来写文章,然后再从里面提取一个关键词的组合其他两个类作为标题,因为关键词都收录“二手车”,所以不用担心不相关。如果使用采集,可以考虑将一些相关内容与采集,或者采集其他人的文章结合起来,百度翻译再翻译成中文。这些方法都不好,可读性差,不利于网站的长远发展,而且百度的垃圾邮件识别能力也在不断提升。
五、的原理分析:
长尾关键词具有快速排名的能力,是增加有效流量最好最快的方式。花在一个核心上的时间关键词可以做出几十万条长尾关键词。这里我采集进行了百度相关搜索,确认这些关键词都是搜索到关键词,并且“二手车”这个词的相关性是一定的,加上分类,组合成一个标题,整合标题的三个关键词分类,方便用户搜索。
这种方法简单、直接、有效。如果您精通程序,那么做到这一点真的太容易了。通过海量的长尾关键词做内容,总会有很多关键词的排名。在首页,流量增加十倍根本不是问题。
关键词文章采集源码( 如何通过dedecms来做采集站?采集怎么做? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-12-03 09:08
如何通过dedecms来做采集站?采集怎么做?
)
很多SEO人员和网站管理者都会用织梦cms来建网站,但是对于dede采集网站、织梦@ >内置的采集功能非常不方便,已经不适合采集的当前需求。所以,SEO人员一定要懂知识,不一定要懂,但一定要懂!如何通过dedecms做采集站?德德采集是怎么做的?我用织梦cms做采集站,收录现在接近20万了,权重有点低,只有权重3,不过可以SEO方法后说明 来这里的采集站也可以起来了。今天的文章主要是和大家分享这两个我们在做SEO时遇到的常见问题。
德德采集怎么做? dedecms自带采集功能,功能非常有限,不能满足采集的复杂需求,经常导致网站网页采集空白,也就是对SEO人员来说很麻烦。因此,您可以使用免费且易于使用的第三方网站采集软件来完成dede采集:
1.一键安装,自动免费采集,安装非常简单方便,只需一分钟
2. 多词采集 无需写采集规则,根据大量关键词来平移采集
3. RSS采集,输入RSS地址到采集内容,只需输入RSS地址到采集到目标网站内容定位采集,精确采集标题、正文、作者、出处,只需要提供列表URL即可智能采集指定网站或栏目内容
4.软件全自动采集,无需人工干预,即可挂断采集,所有操作程序全自动
5.图片云存储,大量采集图片不麻烦,也可以本地存储。支持所有主流云存储。
6.可以直接进行伪原创SEO更新,只需开启伪原创功能,不需要复杂的配置界面
7.可以同时支持所有主要的cms版本,以及市场上所有常见的cms支持。
8.自动推送到各大搜索引擎接口,确保搜索引擎及时收录到我们的网站并提供网站排名
德德采集的做法是什么?这是SEO优化非常重要的一步。内容采集:我也提到了dedecms内置的采集器的使用。就个人而言,我不推荐它。 采集 的那种。 文章 直接发布,肯定会被搜索引擎打中。建立你的网站关键词,关键词需要两个,一个准确,一个多。标准是指关键词必须和你的网站定位有关。比如你是装修公司网站,那你网站的关键词肯定和装修有关(装修风格,现代装修等)。更多意味着需要大量的行业关键词来进行采集,这样文章就会有更多、更丰富的内容。 伪原创:因为采集的内容已经被收录或者其他人展示过,为了避免被搜索引擎命中,所以是采集站,在同时增加原创 所以采集的内容必须经过SEO伪原创的处理。标题:标题是一篇文章的精髓文章。它在很大程度上决定了用户点击的概率,所以它必须表达整个文章的含义,这很有吸引力。标题中必须收录长尾关键词,并且关键词必须与网站相关。
网站网站的建设和运营管理需要全面。关于dede采集,在这里分享一下。很多SEO知识需要在实际操作中积累经验。我只是提出一些新手需要了解的基础内容,也是个人经验。
查看全部
关键词文章采集源码(
如何通过dedecms来做采集站?采集怎么做?
)
很多SEO人员和网站管理者都会用织梦cms来建网站,但是对于dede采集网站、织梦@ >内置的采集功能非常不方便,已经不适合采集的当前需求。所以,SEO人员一定要懂知识,不一定要懂,但一定要懂!如何通过dedecms做采集站?德德采集是怎么做的?我用织梦cms做采集站,收录现在接近20万了,权重有点低,只有权重3,不过可以SEO方法后说明 来这里的采集站也可以起来了。今天的文章主要是和大家分享这两个我们在做SEO时遇到的常见问题。
德德采集怎么做? dedecms自带采集功能,功能非常有限,不能满足采集的复杂需求,经常导致网站网页采集空白,也就是对SEO人员来说很麻烦。因此,您可以使用免费且易于使用的第三方网站采集软件来完成dede采集:
1.一键安装,自动免费采集,安装非常简单方便,只需一分钟
2. 多词采集 无需写采集规则,根据大量关键词来平移采集
3. RSS采集,输入RSS地址到采集内容,只需输入RSS地址到采集到目标网站内容定位采集,精确采集标题、正文、作者、出处,只需要提供列表URL即可智能采集指定网站或栏目内容
4.软件全自动采集,无需人工干预,即可挂断采集,所有操作程序全自动
5.图片云存储,大量采集图片不麻烦,也可以本地存储。支持所有主流云存储。
6.可以直接进行伪原创SEO更新,只需开启伪原创功能,不需要复杂的配置界面
7.可以同时支持所有主要的cms版本,以及市场上所有常见的cms支持。
8.自动推送到各大搜索引擎接口,确保搜索引擎及时收录到我们的网站并提供网站排名
德德采集的做法是什么?这是SEO优化非常重要的一步。内容采集:我也提到了dedecms内置的采集器的使用。就个人而言,我不推荐它。 采集 的那种。 文章 直接发布,肯定会被搜索引擎打中。建立你的网站关键词,关键词需要两个,一个准确,一个多。标准是指关键词必须和你的网站定位有关。比如你是装修公司网站,那你网站的关键词肯定和装修有关(装修风格,现代装修等)。更多意味着需要大量的行业关键词来进行采集,这样文章就会有更多、更丰富的内容。 伪原创:因为采集的内容已经被收录或者其他人展示过,为了避免被搜索引擎命中,所以是采集站,在同时增加原创 所以采集的内容必须经过SEO伪原创的处理。标题:标题是一篇文章的精髓文章。它在很大程度上决定了用户点击的概率,所以它必须表达整个文章的含义,这很有吸引力。标题中必须收录长尾关键词,并且关键词必须与网站相关。
网站网站的建设和运营管理需要全面。关于dede采集,在这里分享一下。很多SEO知识需要在实际操作中积累经验。我只是提出一些新手需要了解的基础内容,也是个人经验。
关键词文章采集源码(免费自学学习网模板文章资讯作文整站源码手机同步生成+安装教程 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-12-02 12:08
)
2021帝国cms7.5个免费自学学习网站模板文章信息合成全站源码手机同步生成+安装教程+采集
-------------------------------------------------- ------------------------------
PC/电脑版演示地址:
WAP/手机版演示地址:(请使用手机访问)
-------------------------------------------------- ------------------------------
源码为EmpirecmsUTF8版本,如需GBK版本请自行转码!
这个模板是楼主自己复制的。不修改Empire程序默认的表前缀,不保留各种恶心的AD广告。
模板简洁大方,访问快捷,移动端优化美观的用户体验。
适合文章知识点、试题、练习题、考试信息、作文百科、学习方法与技巧等信息汇总,供中小学生参考!
所有功能均在后台管理,并已预留广告位(如需添加广告位请联系店主添加)。
模板使用标签灵活调用。采集方面,精选优质源站,模板精美,同时兼顾SEO搜索引擎优化。全站静态生成,有利于收录和关键词布局和内容页面优化!
特点一览:
1、内置ITAG插件,标签可以拼音,标签分类可用,功能更强大,更容易生成词库。(标签链接样式可选择ID或拼音)
2、内置百度推送插件,数据实时推送到搜索引擎。
3、通过优采云采集规则,您可以采集自己处理大量数据,全自动无人值守采集。
4、内置网站地图站点地图插件
本产品是整个站点的源代码,不仅是模板,还有演示站点的所有数据。
详情请看演示站,更直观。
注意:演示站机器配置低,有延迟是正常的。这与模板程序无关。
-------------------------------------------------- -------------------------------------------------
●帝国cms7.5UTF-8
●系统开源,域名不限
●同步生成WAP移动终端简单实用。
●大小约330MB
●简单的安装方法,有详细的安装教程。
●TAG标签聚合
-------------------------------------------------- ----------------------------------------------
---
查看全部
关键词文章采集源码(免费自学学习网模板文章资讯作文整站源码手机同步生成+安装教程
)
2021帝国cms7.5个免费自学学习网站模板文章信息合成全站源码手机同步生成+安装教程+采集
-------------------------------------------------- ------------------------------
PC/电脑版演示地址:
WAP/手机版演示地址:(请使用手机访问)
-------------------------------------------------- ------------------------------
源码为EmpirecmsUTF8版本,如需GBK版本请自行转码!
这个模板是楼主自己复制的。不修改Empire程序默认的表前缀,不保留各种恶心的AD广告。
模板简洁大方,访问快捷,移动端优化美观的用户体验。
适合文章知识点、试题、练习题、考试信息、作文百科、学习方法与技巧等信息汇总,供中小学生参考!
所有功能均在后台管理,并已预留广告位(如需添加广告位请联系店主添加)。
模板使用标签灵活调用。采集方面,精选优质源站,模板精美,同时兼顾SEO搜索引擎优化。全站静态生成,有利于收录和关键词布局和内容页面优化!
特点一览:
1、内置ITAG插件,标签可以拼音,标签分类可用,功能更强大,更容易生成词库。(标签链接样式可选择ID或拼音)
2、内置百度推送插件,数据实时推送到搜索引擎。
3、通过优采云采集规则,您可以采集自己处理大量数据,全自动无人值守采集。
4、内置网站地图站点地图插件
本产品是整个站点的源代码,不仅是模板,还有演示站点的所有数据。
详情请看演示站,更直观。
注意:演示站机器配置低,有延迟是正常的。这与模板程序无关。
-------------------------------------------------- -------------------------------------------------
●帝国cms7.5UTF-8
●系统开源,域名不限
●同步生成WAP移动终端简单实用。
●大小约330MB
●简单的安装方法,有详细的安装教程。
●TAG标签聚合
-------------------------------------------------- ----------------------------------------------
---
关键词文章采集源码(仓库源码采集源码分享(1)_社会万象_光明网)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-12-02 11:08
关键词文章采集源码分享:仓库源码controls。pypathmap。py。1。安装neo4j包需要先安装pipinstallneo4j2。初始化neo4j数据库启动neo4j服务,并从服务器下载源码。dmg文件。jar下载地址:,将下载好的。jar文件解压,双击。py安装成功后的。dmg路径(注意能解压,安装成功后不能解压)。
/neo4j_config。py:/client/hostname/client/bin/neo4j_config。py#代码修改自官方文档create_table_filenamename(request。url,create_table_filenamename(request。url,set_create_table_filename('user','person')))#(user)对应的是用户或者一个表(table)参数request。
url必须为。/client/url/create_table_filename(request。url,set_create_table_file('user','person'))#(table)对应的是数据库名参数set_create_table_file('family','user')#(person)对应的是姓名(必须为字符串类型)参数create_table_filename设置默认采用了bash环境安装,如果是python环境需要pipinstallneo4j2。
数据库增加字段,添加表名名称和表名字段名字段名字段数据库名名称字段名称字段数据库名名字段数据库名参数(family)字段名参数set_database('user')exportdbnameexporttablename启动neo4j服务#检查export的启动neo4jconfigserver:friend@localhostpassword:localhost#启动成功configserver:friend@localhostpassword:localhost#停止启动neo4jserver:friend@localhostpassword:localhost#configserver:friend@localhostpassword:localhost#启动服务neo4jconfigserver:friend@localhostpassword:localhost#启动服务neo4jconfigserver:friend@localhostpassword:localhost#停止服务neo4jconfigserver:friend@localhostpassword:localhost#修改neo4j文件路径。
/neo4j_config。py修改文件路径/user/neo4j/bin/neo4j。write修改为/user/neo4j/bin/neo4j。write3。neo4j定义对象查询语句“从文档中查询json/java/jsp等格式类似的所有类型对象”1。定义json/java对象1。1定义一个json对象(要注意定义的时候类型一定要合法)2。
定义java对象定义代码#注意:java对象可以是定义在python模块下的,例如python2。x,python3。x这是通用的,需要用python2。x用gensim模块或者python1。x用python。2中的json模块3。命名。 查看全部
关键词文章采集源码(仓库源码采集源码分享(1)_社会万象_光明网)
关键词文章采集源码分享:仓库源码controls。pypathmap。py。1。安装neo4j包需要先安装pipinstallneo4j2。初始化neo4j数据库启动neo4j服务,并从服务器下载源码。dmg文件。jar下载地址:,将下载好的。jar文件解压,双击。py安装成功后的。dmg路径(注意能解压,安装成功后不能解压)。
/neo4j_config。py:/client/hostname/client/bin/neo4j_config。py#代码修改自官方文档create_table_filenamename(request。url,create_table_filenamename(request。url,set_create_table_filename('user','person')))#(user)对应的是用户或者一个表(table)参数request。
url必须为。/client/url/create_table_filename(request。url,set_create_table_file('user','person'))#(table)对应的是数据库名参数set_create_table_file('family','user')#(person)对应的是姓名(必须为字符串类型)参数create_table_filename设置默认采用了bash环境安装,如果是python环境需要pipinstallneo4j2。
数据库增加字段,添加表名名称和表名字段名字段名字段数据库名名称字段名称字段数据库名名字段数据库名参数(family)字段名参数set_database('user')exportdbnameexporttablename启动neo4j服务#检查export的启动neo4jconfigserver:friend@localhostpassword:localhost#启动成功configserver:friend@localhostpassword:localhost#停止启动neo4jserver:friend@localhostpassword:localhost#configserver:friend@localhostpassword:localhost#启动服务neo4jconfigserver:friend@localhostpassword:localhost#启动服务neo4jconfigserver:friend@localhostpassword:localhost#停止服务neo4jconfigserver:friend@localhostpassword:localhost#修改neo4j文件路径。
/neo4j_config。py修改文件路径/user/neo4j/bin/neo4j。write修改为/user/neo4j/bin/neo4j。write3。neo4j定义对象查询语句“从文档中查询json/java/jsp等格式类似的所有类型对象”1。定义json/java对象1。1定义一个json对象(要注意定义的时候类型一定要合法)2。
定义java对象定义代码#注意:java对象可以是定义在python模块下的,例如python2。x,python3。x这是通用的,需要用python2。x用gensim模块或者python1。x用python。2中的json模块3。命名。
关键词文章采集源码(免费下载分享源码搜索引擎异步加载功能源码(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-12-01 04:03
关键词文章采集源码api文章抓取常用源码源码下载skd源码,获取全网skd源码全网分享免费下载分享源码搜索引擎异步加载功能源码热点爬取,爬虫工程师必备对象模型,给源码加一个属性可以快速的进行某个对象类型变量存取,这样可以提高开发效率接口和框架快速学习不会的依赖的源码可以参考网页底部关于文章内容下载的方式ps:源码下载后可以公众号后台自助获取源码以下是个人简介和以后的学习计划源码下载。
基于chromeextension推出的非主流网站抓取web综合排名第7,
python里面的selenium+ie/firefox以及其他的浏览器类。
django啊,毕竟是封装了其他mvc框架的http服务器.虽然有些不完美,毕竟和springmvc这种大厂相比,毕竟django是开源的.除此之外还有一个叫做bootstrap的bs框架封装了一个mvc模型.
gayhub
之前写过的一篇文章可以看下-10-webfiledownloading-part-1
web.py
楼上说的是我以前写的一篇文章,说实话,开发项目的时候用爬虫框架一方面是遇到问题不能及时解决,另一方面,开发环境不断的升级,搞得内存和硬盘越来越卡。既然你想和别人讨论技术,就应该是最基础的学习,而不是想着自己动手写。 查看全部
关键词文章采集源码(免费下载分享源码搜索引擎异步加载功能源码(组图))
关键词文章采集源码api文章抓取常用源码源码下载skd源码,获取全网skd源码全网分享免费下载分享源码搜索引擎异步加载功能源码热点爬取,爬虫工程师必备对象模型,给源码加一个属性可以快速的进行某个对象类型变量存取,这样可以提高开发效率接口和框架快速学习不会的依赖的源码可以参考网页底部关于文章内容下载的方式ps:源码下载后可以公众号后台自助获取源码以下是个人简介和以后的学习计划源码下载。
基于chromeextension推出的非主流网站抓取web综合排名第7,
python里面的selenium+ie/firefox以及其他的浏览器类。
django啊,毕竟是封装了其他mvc框架的http服务器.虽然有些不完美,毕竟和springmvc这种大厂相比,毕竟django是开源的.除此之外还有一个叫做bootstrap的bs框架封装了一个mvc模型.
gayhub
之前写过的一篇文章可以看下-10-webfiledownloading-part-1
web.py
楼上说的是我以前写的一篇文章,说实话,开发项目的时候用爬虫框架一方面是遇到问题不能及时解决,另一方面,开发环境不断的升级,搞得内存和硬盘越来越卡。既然你想和别人讨论技术,就应该是最基础的学习,而不是想着自己动手写。
关键词文章采集源码(seo外包价格免费优化盒子关键词采集文章发布相关内容(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-11-29 10:23
seo外包价格
免费优化框
关键词采集文章发布相关内容(一)
网站SEO优化
一、什么是网站优化?
网站 优化很多小时就是做搜索引擎优化。一切的出发点其实都是围绕搜索引擎。网站优化的目的是提高网站在搜索引擎中的自然排名,扩大你的品牌在搜索引擎结果(互联网)中的曝光度,进而完成转化盈余。
网站 一般来说,优化目标可以分为:站内优化和站外优化。至于如何做站内优化和站外优化,不是今天的重点。我想加深对这两个方面的优化技巧的理解。, 可以查看冬镜曾经发布的优化教程。
网站SEO优化
二、优化内容应该怎么做?
内容优化按照上面的分类可以归为站内优化,可以看作是站内优化的一种,也可以看作是一个比较中心的项目。那么,在实践操作网站,我们只需要写好内容就够了吗?
事实上,答案是否定的。内容优化需要高质量的内容一定是其中的一部分,但是仅仅写一个高质量的文章还是不够的。我们还需要结合一些SEO的基本功,比如自然融合关键词,然后每天准时更新文章。文章的相关度要高,图文最好。说到这里,我又回到了本文开头的问题。搜索引擎优化每天什么时候分发文章比较好?
网站SEO优化
三、网站优化准时交货文章,好吗?
任何工作都不一定是好是坏。当我们看一件事情的好坏时,要从很多方面来判断。在新版网站的运行中,我们准时发布文章带来的优化效果肯定比不准时发布要好,因为新版网站搜索引擎的抓取频率Spiders 不高,没有准时更新蜘蛛的爬取更新快照会比较慢。如果我们按时发布(一定的时间),那我们就可以养蜘蛛爬行,更新一段时间给我们网站现在做网站优化需求变化,知道怎么更新迅速地。
网站优化准时更新文章 还有很多其他的好处,比如用户可以养成准时阅读网站的习惯。老版网站冬镜还是主张尽量多更新,但在新站上效果可能没那么显着,但优化是长期的工作,静下心来坚持工作,或许是座右铭SEO的特点是:遇到困难,我们迎难而上。坚持就是不放弃。
网站SEO优化
好了,网站优化和及时更新文章内容的重要性就分享到这里。如果您有什么不明白的,欢迎在论坛中讨论。
关键词的讨论一般有两个方向,一是对现有内容的优化,二是网站精准页面设备关键词,方便后面的页面有一是在搜索引擎中排名较好。二是为网站的未来发展提供指导,即考虑从SEO的角度出发,围绕中心关键词或网站方向进行其他< @关键词 探索并添加相关页面到 网站。
关键词 的分类方法有很多种。详细分类基于词性、描述主题类型、寻找切分意图、价值高、ROI高等多种方法,习惯网站自己的主题和结构、流量意图、页面类型等对于整个网络关键词,有基于搜索意图、关键词长度、关键词流行度三种分类方法。今天小编就来为大家讲解一下关键词对全网的分类方法。
按搜索意图排序
搜索意图类别有导航类别关键词、业务类别关键词和信息类别关键词。导航关键词,指有强烈意图的品牌关键词,如方某宝、某空间登录等精准导航关键词,可能是xx的最新消息,xx是怎么做的它模糊导航类关键词。关键词对于有明显购买意向或行动意向的用户来说值得寻找的东西关键词。信息关键词是指用户在搜索特定信息时使用的关键词。对于大多数网站来说,这些搜索词占了搜索词总数的绝大部分。用户有多种搜索意图,如搜索资料、查看店铺等,
根据关键词的长度分析
长度关键词有两种理论分析,2/8理论和长尾理论,两个矛盾的关键词。2/8理论是指用80%的能量辅助20%的初级关键词,20%的能量做80%的关键词,去初级关键词 获得品牌效应,取得了很好的用户信任度和转化率。2/8 理论应该成为大多数 关键词 策略的指导理论。长尾理论很有意义,也是长尾关键词理论。大多数时分高手关键词都非常有竞争力,有一定的优化难度,他们带来的流量也非常有限。,一个正常的站长应该仔细研究长尾关键词,相信会给你带来好的流量。
根据关键词人气分析
关键词 热度分析分为流行的关键词、一般的关键词和冷门的关键词。关键词 热分析和长度其实是一一对应的。流行的关键词一般较短的主关键词,一般的关键词和短词长词不流行。关键词 是长尾关键词。词组虽然带来的流量不大,但是词汇量非常大,可以发现很多关键词。
关于搜索,我真的很喜欢这几个词:seo页面优化平台选择d fire 12星
遵义seo技术培训相关内容(二)百度最近开通了百度官方账号,现在已经正式开始接受注册。了解了百度官方账号的功能后,很多朋友都想注册体验一下。但是什么?注册怎么样?还有一些朋友不是很清楚,下面小编带来了具体的教程,希望对大家有所帮助。
百度公众号注册流程介绍
一、报名条件
1、 站长频道账号没有注册官方账号。(原白家豪)
2、 收到百度公众号受邀成为优质站长。(ps:公众号处于内测,公测后获取注册资格的方式有变)
3、 获得资格后,了解公众号的作用和价值,进入注册页面。
二、还没有注册官方账号
1、选择并注册百度公众号。
2、 进入公众号一站式服务通道,选择注册类型。
3、进入信息资料界面,填写相关信息。
4、填写完成后提交信息,等待注册审核。(审核结果将在1-2个工作日内通过短信通知您)
5、 收到注册成功消息后,返回公众号请求界面继续后续操作。
三、 注册百家号或公众号
1、选择已有的公众号/百家号进行操作。
2、输入已有公众号/百名,点击查询。
3、 如果系统提示相关站点为空,则该公众号已与其他站点相关。
4、 可以换公众号或者添加网站(需要XXX同一个主域下的相关网站)然后关联。
5、 如果系统没有显示需求相关站点为空,则公众号与其他站点无关。
6、 然后就可以选择你要操作的相关站点了。(站点关联成功后,不支持更正)
7、填写正确后,输入需求相关的验证码,然后点击确认。
8、终于可以注册成功了!
这里只介绍自由选择版本。如需专业开发版,请自行查阅相关资料。
网站优化
网站优化需要精通搜索引擎算法规则,不仅要掌握网站底层代码的标准编写,还要掌握优秀的策划和排名能力,并坚持专业的原创 高品质内容更新。因此,网站 优化不能粗心大意。这是一个专业和技术问题。它通常需要优化团队协作。团队必须细心、耐心和负责。
网站构建
一、网站优化前提和基础环境:
(一)网站 域名先决条件:
1.网站域名选择:域名解释简单易记,契合网站内容相关性较好,网站域名为常用后缀com 、cn或net等,部分后缀域名不被国内搜索引擎识别,不支持备案。域名过长必然会影响网站的链接。搜索引擎对 URL 的长度有限制。长度过长的 URL。不会被认出来。
2.网站域名记录:网站域名记录是搜索引擎判断网站声望的标准。正规的大型企事业单位的官网,搜索引擎会先显示首页和上榜,没有记录的网站将被标识为灰色网站或风险网站被搜索引擎@>,不利于网站的进入和排名。
(二)网站 服务器基础环境:
1.服务器环境设备:高性能、高带宽、独立的IP服务器,可以使网站稳定运行和发展,是寻找引擎度得分的重要参考网站 . 一些功能低下、流量受限的虚拟主机往往被简单攻击,构成网站运行错误或无法打开,往往会受到搜索引擎的奖惩。
2.网站 运维操作:具有专业技能的程序员可以保证网站的正常运行和安全的数据备份。相反,网站经常遭受攻击或数据丢失,会给网站带来毁灭性的损失,更不用说网站优化了。
二、网站 优化方向:站内优化和站外优化
(一)站内优化:站内优化包括网站布局结构优化、网站底层代码优化、网页优化、网站程序优化、网站 内链优化及网站原创内容更新。
(二)站外优化:站外优化包括网站的外链建设指导,站外渠道曝光网站信息,增加品牌搜索点击量。
三、网站 优化的基本操作细节:
(一)网站的生成规则:
1. URL 可以生成动态和静态。所谓静态网址的主要特征是htm、html、shtml、xml等以后缀结尾,而动态网址的主要特征是PHP、ASP、JSP、Perl等。最后不具备静态URL的后缀特性。虽然搜索引擎都表示不会低估网页的布局,但静态页面在搜索引擎蜘蛛抓取和优化保护方面具有显着优势。例如网站数据库被恶意攻击,动态网站内容被随机破坏或消失,静态网站仍然是保存完好的静态网页路径。前者随机出现大量404或网页乱码,
2.开启https网络协议和cdn加速:https与http网络数据传输安全通道有关,现在搜索引擎明确指出https站点有加权重和流量处理,优先显示网站排名,CDN加速还解决了由于地域或网络环境差异导致网页加载缓慢的问题,尤其是对于移动端网站。搜索引擎明确规定,打开速度直接影响网站的权重和流量。
(二)网站 标准编写代码:
1.网页标题和meta标签的标准写法:标题标签是介绍网页内容信息的要点,meta标签可以收录文章、关键词的描述、作者信息、版权信息、网页编码、图像识别阅读兼容方式、单页蜘蛛爬取约束,就像一个产品的参数和特性一样。标签只显示在源代码中,普通访问者看不到,但可以被搜索引擎蜘蛛识别。也是搜索引擎添加索引和查找词匹配的关键点。文字必须准确、有能力,并适合网页的内容。信息必须是唯一的和唯一的。
2.网站 标题H标签标准写法:h1-h6。h标签是对网页要点分类的声明和声明,权重从h1递减到h6。搜索引擎蜘蛛可以识别网页内容的层次链接。h1 标题在单个网页中只能出现一次,就像 文章 的标题一样。
3. 锚文本的标准写法:锚文本是否习惯,加上title="title",可以引导蜘蛛理解链接是什么。你知道吗,这会降低蜘蛛的爬行率,关于一些出站链接或敏感链接,你有没有在锚文本里做一个停止爬行的指令,rel="nofollow",写成ahref="/"Title ="标题" rel="nofollow"。对于部分站外链接,应添加target=_blank并作为新窗口打开,防止网站无法回源,减少流量损失。建议不要在网页中收录相同的锚文本链接,否则会被搜索引擎判断为涉嫌作弊,降低网页摘要评分。
4.图片源img的标准书写:按照常规的标准书写格式,一张图片的格式应该是alt=\"depict\", src=\"/\", width=\"\", height=\" \",包括图片的描述、比例尺的大小、图片的来源地址、关于一些一般图片,甚至可以添加标题来引导访问者了解图片的含义,图片没有描述,搜索引擎蜘蛛无法识别图片的内容和含义,没有刻度标记,搜索引擎蜘蛛无法区分图片的正确比例,这会降低网页的摘要分数。
5. js和css的标准写法:一个网页最好只收录一个js或者css。太多js提倡合并和请求,可以减少网页加载的时间。对于一些相同的样式,css主张剪新的。如果js和css的内容比较大,可以进行压缩。关于js和css的样式编写,要进行兼容性测试,加上兼容的样式,否则在单个用户的阅读器上可能会出现变形,不利于访问者的体验,以及。比如网站系统的网站sitemap、rssmap、rss文件默认都在data database目录下,这个目录一般会被robots列为防止爬虫,因为它收录一个大量的数据库文件,以及一些数据库帐户密码和地址的敏感信息。因此,将此路径升级到网站的根目录
2.网站 栏目命名规则和简洁写法:搜索引擎对URL的长度有明确的要求。如果超过长度,URL 将难以识别和输入。因此,建议在列和子列之间简洁明了,命名简单,区分为最好。
(六)网站 功能页面设置:
1.网站404页面设置:网站内容难以防止代码错误的网页,删除的页面,404页面过多,会构成大量重复页面,搜索引擎会识别为网站作弊降低索引,减少进入,降低权限等。为此,制作一个有方向的404y页面,并正确返回404状态码,可以降低访问者的跳出率,防止奖励和来自搜索引擎的惩罚。
<p>2.网站301状态码的设置:网站域名的顶级域名比二级以下域名的权重更重要,而网站 @>域名,访问者经常使用www的前两个一级域名是习惯性的。为此,为了更好的承载前沿域名的重量,可以做301域名重定向。否则,网站很可能会显示网站的首页不在第一位,从而失去网站的权重,对 查看全部
关键词文章采集源码(seo外包价格免费优化盒子关键词采集文章发布相关内容(一))
seo外包价格
免费优化框
关键词采集文章发布相关内容(一)
网站SEO优化
一、什么是网站优化?
网站 优化很多小时就是做搜索引擎优化。一切的出发点其实都是围绕搜索引擎。网站优化的目的是提高网站在搜索引擎中的自然排名,扩大你的品牌在搜索引擎结果(互联网)中的曝光度,进而完成转化盈余。
网站 一般来说,优化目标可以分为:站内优化和站外优化。至于如何做站内优化和站外优化,不是今天的重点。我想加深对这两个方面的优化技巧的理解。, 可以查看冬镜曾经发布的优化教程。
网站SEO优化
二、优化内容应该怎么做?
内容优化按照上面的分类可以归为站内优化,可以看作是站内优化的一种,也可以看作是一个比较中心的项目。那么,在实践操作网站,我们只需要写好内容就够了吗?
事实上,答案是否定的。内容优化需要高质量的内容一定是其中的一部分,但是仅仅写一个高质量的文章还是不够的。我们还需要结合一些SEO的基本功,比如自然融合关键词,然后每天准时更新文章。文章的相关度要高,图文最好。说到这里,我又回到了本文开头的问题。搜索引擎优化每天什么时候分发文章比较好?
网站SEO优化
三、网站优化准时交货文章,好吗?
任何工作都不一定是好是坏。当我们看一件事情的好坏时,要从很多方面来判断。在新版网站的运行中,我们准时发布文章带来的优化效果肯定比不准时发布要好,因为新版网站搜索引擎的抓取频率Spiders 不高,没有准时更新蜘蛛的爬取更新快照会比较慢。如果我们按时发布(一定的时间),那我们就可以养蜘蛛爬行,更新一段时间给我们网站现在做网站优化需求变化,知道怎么更新迅速地。
网站优化准时更新文章 还有很多其他的好处,比如用户可以养成准时阅读网站的习惯。老版网站冬镜还是主张尽量多更新,但在新站上效果可能没那么显着,但优化是长期的工作,静下心来坚持工作,或许是座右铭SEO的特点是:遇到困难,我们迎难而上。坚持就是不放弃。
网站SEO优化
好了,网站优化和及时更新文章内容的重要性就分享到这里。如果您有什么不明白的,欢迎在论坛中讨论。
关键词的讨论一般有两个方向,一是对现有内容的优化,二是网站精准页面设备关键词,方便后面的页面有一是在搜索引擎中排名较好。二是为网站的未来发展提供指导,即考虑从SEO的角度出发,围绕中心关键词或网站方向进行其他< @关键词 探索并添加相关页面到 网站。
关键词 的分类方法有很多种。详细分类基于词性、描述主题类型、寻找切分意图、价值高、ROI高等多种方法,习惯网站自己的主题和结构、流量意图、页面类型等对于整个网络关键词,有基于搜索意图、关键词长度、关键词流行度三种分类方法。今天小编就来为大家讲解一下关键词对全网的分类方法。
按搜索意图排序
搜索意图类别有导航类别关键词、业务类别关键词和信息类别关键词。导航关键词,指有强烈意图的品牌关键词,如方某宝、某空间登录等精准导航关键词,可能是xx的最新消息,xx是怎么做的它模糊导航类关键词。关键词对于有明显购买意向或行动意向的用户来说值得寻找的东西关键词。信息关键词是指用户在搜索特定信息时使用的关键词。对于大多数网站来说,这些搜索词占了搜索词总数的绝大部分。用户有多种搜索意图,如搜索资料、查看店铺等,
根据关键词的长度分析
长度关键词有两种理论分析,2/8理论和长尾理论,两个矛盾的关键词。2/8理论是指用80%的能量辅助20%的初级关键词,20%的能量做80%的关键词,去初级关键词 获得品牌效应,取得了很好的用户信任度和转化率。2/8 理论应该成为大多数 关键词 策略的指导理论。长尾理论很有意义,也是长尾关键词理论。大多数时分高手关键词都非常有竞争力,有一定的优化难度,他们带来的流量也非常有限。,一个正常的站长应该仔细研究长尾关键词,相信会给你带来好的流量。
根据关键词人气分析
关键词 热度分析分为流行的关键词、一般的关键词和冷门的关键词。关键词 热分析和长度其实是一一对应的。流行的关键词一般较短的主关键词,一般的关键词和短词长词不流行。关键词 是长尾关键词。词组虽然带来的流量不大,但是词汇量非常大,可以发现很多关键词。
关于搜索,我真的很喜欢这几个词:seo页面优化平台选择d fire 12星
遵义seo技术培训相关内容(二)百度最近开通了百度官方账号,现在已经正式开始接受注册。了解了百度官方账号的功能后,很多朋友都想注册体验一下。但是什么?注册怎么样?还有一些朋友不是很清楚,下面小编带来了具体的教程,希望对大家有所帮助。
百度公众号注册流程介绍
一、报名条件
1、 站长频道账号没有注册官方账号。(原白家豪)
2、 收到百度公众号受邀成为优质站长。(ps:公众号处于内测,公测后获取注册资格的方式有变)
3、 获得资格后,了解公众号的作用和价值,进入注册页面。
二、还没有注册官方账号
1、选择并注册百度公众号。
2、 进入公众号一站式服务通道,选择注册类型。
3、进入信息资料界面,填写相关信息。
4、填写完成后提交信息,等待注册审核。(审核结果将在1-2个工作日内通过短信通知您)
5、 收到注册成功消息后,返回公众号请求界面继续后续操作。
三、 注册百家号或公众号
1、选择已有的公众号/百家号进行操作。
2、输入已有公众号/百名,点击查询。
3、 如果系统提示相关站点为空,则该公众号已与其他站点相关。
4、 可以换公众号或者添加网站(需要XXX同一个主域下的相关网站)然后关联。
5、 如果系统没有显示需求相关站点为空,则公众号与其他站点无关。
6、 然后就可以选择你要操作的相关站点了。(站点关联成功后,不支持更正)
7、填写正确后,输入需求相关的验证码,然后点击确认。
8、终于可以注册成功了!
这里只介绍自由选择版本。如需专业开发版,请自行查阅相关资料。
网站优化
网站优化需要精通搜索引擎算法规则,不仅要掌握网站底层代码的标准编写,还要掌握优秀的策划和排名能力,并坚持专业的原创 高品质内容更新。因此,网站 优化不能粗心大意。这是一个专业和技术问题。它通常需要优化团队协作。团队必须细心、耐心和负责。
网站构建
一、网站优化前提和基础环境:
(一)网站 域名先决条件:
1.网站域名选择:域名解释简单易记,契合网站内容相关性较好,网站域名为常用后缀com 、cn或net等,部分后缀域名不被国内搜索引擎识别,不支持备案。域名过长必然会影响网站的链接。搜索引擎对 URL 的长度有限制。长度过长的 URL。不会被认出来。
2.网站域名记录:网站域名记录是搜索引擎判断网站声望的标准。正规的大型企事业单位的官网,搜索引擎会先显示首页和上榜,没有记录的网站将被标识为灰色网站或风险网站被搜索引擎@>,不利于网站的进入和排名。
(二)网站 服务器基础环境:
1.服务器环境设备:高性能、高带宽、独立的IP服务器,可以使网站稳定运行和发展,是寻找引擎度得分的重要参考网站 . 一些功能低下、流量受限的虚拟主机往往被简单攻击,构成网站运行错误或无法打开,往往会受到搜索引擎的奖惩。
2.网站 运维操作:具有专业技能的程序员可以保证网站的正常运行和安全的数据备份。相反,网站经常遭受攻击或数据丢失,会给网站带来毁灭性的损失,更不用说网站优化了。
二、网站 优化方向:站内优化和站外优化
(一)站内优化:站内优化包括网站布局结构优化、网站底层代码优化、网页优化、网站程序优化、网站 内链优化及网站原创内容更新。
(二)站外优化:站外优化包括网站的外链建设指导,站外渠道曝光网站信息,增加品牌搜索点击量。
三、网站 优化的基本操作细节:
(一)网站的生成规则:
1. URL 可以生成动态和静态。所谓静态网址的主要特征是htm、html、shtml、xml等以后缀结尾,而动态网址的主要特征是PHP、ASP、JSP、Perl等。最后不具备静态URL的后缀特性。虽然搜索引擎都表示不会低估网页的布局,但静态页面在搜索引擎蜘蛛抓取和优化保护方面具有显着优势。例如网站数据库被恶意攻击,动态网站内容被随机破坏或消失,静态网站仍然是保存完好的静态网页路径。前者随机出现大量404或网页乱码,
2.开启https网络协议和cdn加速:https与http网络数据传输安全通道有关,现在搜索引擎明确指出https站点有加权重和流量处理,优先显示网站排名,CDN加速还解决了由于地域或网络环境差异导致网页加载缓慢的问题,尤其是对于移动端网站。搜索引擎明确规定,打开速度直接影响网站的权重和流量。
(二)网站 标准编写代码:
1.网页标题和meta标签的标准写法:标题标签是介绍网页内容信息的要点,meta标签可以收录文章、关键词的描述、作者信息、版权信息、网页编码、图像识别阅读兼容方式、单页蜘蛛爬取约束,就像一个产品的参数和特性一样。标签只显示在源代码中,普通访问者看不到,但可以被搜索引擎蜘蛛识别。也是搜索引擎添加索引和查找词匹配的关键点。文字必须准确、有能力,并适合网页的内容。信息必须是唯一的和唯一的。
2.网站 标题H标签标准写法:h1-h6。h标签是对网页要点分类的声明和声明,权重从h1递减到h6。搜索引擎蜘蛛可以识别网页内容的层次链接。h1 标题在单个网页中只能出现一次,就像 文章 的标题一样。
3. 锚文本的标准写法:锚文本是否习惯,加上title="title",可以引导蜘蛛理解链接是什么。你知道吗,这会降低蜘蛛的爬行率,关于一些出站链接或敏感链接,你有没有在锚文本里做一个停止爬行的指令,rel="nofollow",写成ahref="/"Title ="标题" rel="nofollow"。对于部分站外链接,应添加target=_blank并作为新窗口打开,防止网站无法回源,减少流量损失。建议不要在网页中收录相同的锚文本链接,否则会被搜索引擎判断为涉嫌作弊,降低网页摘要评分。
4.图片源img的标准书写:按照常规的标准书写格式,一张图片的格式应该是alt=\"depict\", src=\"/\", width=\"\", height=\" \",包括图片的描述、比例尺的大小、图片的来源地址、关于一些一般图片,甚至可以添加标题来引导访问者了解图片的含义,图片没有描述,搜索引擎蜘蛛无法识别图片的内容和含义,没有刻度标记,搜索引擎蜘蛛无法区分图片的正确比例,这会降低网页的摘要分数。
5. js和css的标准写法:一个网页最好只收录一个js或者css。太多js提倡合并和请求,可以减少网页加载的时间。对于一些相同的样式,css主张剪新的。如果js和css的内容比较大,可以进行压缩。关于js和css的样式编写,要进行兼容性测试,加上兼容的样式,否则在单个用户的阅读器上可能会出现变形,不利于访问者的体验,以及。比如网站系统的网站sitemap、rssmap、rss文件默认都在data database目录下,这个目录一般会被robots列为防止爬虫,因为它收录一个大量的数据库文件,以及一些数据库帐户密码和地址的敏感信息。因此,将此路径升级到网站的根目录
2.网站 栏目命名规则和简洁写法:搜索引擎对URL的长度有明确的要求。如果超过长度,URL 将难以识别和输入。因此,建议在列和子列之间简洁明了,命名简单,区分为最好。
(六)网站 功能页面设置:
1.网站404页面设置:网站内容难以防止代码错误的网页,删除的页面,404页面过多,会构成大量重复页面,搜索引擎会识别为网站作弊降低索引,减少进入,降低权限等。为此,制作一个有方向的404y页面,并正确返回404状态码,可以降低访问者的跳出率,防止奖励和来自搜索引擎的惩罚。
<p>2.网站301状态码的设置:网站域名的顶级域名比二级以下域名的权重更重要,而网站 @>域名,访问者经常使用www的前两个一级域名是习惯性的。为此,为了更好的承载前沿域名的重量,可以做301域名重定向。否则,网站很可能会显示网站的首页不在第一位,从而失去网站的权重,对
关键词文章采集源码(剖析网站地址自变量规律性第一页详细地址(图:第二页))
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-11-24 22:15
【鹿鼎前言】在日常事务和学习中,采集一些有用的文章内容可以帮助你提高信息内容的使用和整合率,针对新闻报道、期刊论文等类型的电子内容设备文章,我们可以使用专门的网页爬虫工具来采集。
这种相对智能的非周期性数据信息的采集是相当容易的。这里以网页抓取专用工具优采云采集器V9为例,解读一个文章 采集案例供大家学习和训练。
了解优采云采集器的朋友都知道,根据官方网站的FAQ,可以找到整个征集过程中遇到的问题,所以这里我们就以FAQ的征集作为显示网页的示例。爬行专用工具采集的基本原理及全过程。
在这种情况下,详细地址用于测试。
(1)正在建立采集标准
右键单击某个排序顺序,选择“正在构建的日常任务”,如下图:
(2) 加上开始和结束 网站 地址
这里假设您必须采集 5 页的数据信息。
解析网站地址参数的规律
第一页详细地址:
第二页详细地址:
第三页详细地址:
因此,我们可以计算出p=之后的数据就是分页查询的意思。您可以使用【详细地址主要参数】来表示:
所以设置如下:
详细地址文件格式:使用【详细地址主参数】表示更改的页面查询数据。
数据变换:从1开始,即第一页;每增加1,即每次分页查询的变化趋势数据;一共5个项目,也就是一共采集了5页。
浏览:数据采集器会根据上面的设置转换成网站地址的一部分,可以判断添加是否合适。
那么就可以清楚了
(3)[基本方式]获取内容网站地址
基本方法:该方法默认设置为爬取一级详细地址,即从起始页的源页获取到内容页A的链接。
这里演示给大家尝试一下自动获取详细地址并连接到设置区域获取的方法。
查询网页源码,找到文章内容的详细地址所属区域:
设置以下内容:
注:更详细的分析可以参考产品手册:
操作说明> 手机软件实际操作> 网站地址采集标准> 获取内容网站地址
点击网站地址采集测试,查看测试实际效果
(3)内容集网站地址
解释示例的徽标集合
注:更详细的分析可以参考产品手册
操作说明>手机软件实际操作>内容采集标准>标志编写
大家首先查看了它的网页源代码,寻找你的“话题”地理位置的代码:
进入Excle就是跳出提示框~打开Excle时出错-优采云采集器帮助中心
分析结果:起始字符串数组为:
最后的字符串数组是:
数据处理方法-内容替换/清除:必须替换-优采云采集器帮助中心为空
内容识别的基本原理也差不多,寻找内容所属的源代码部分
分析结果:起始字符串数组为:
最后的字符串数组是:
数据处理方法-HTML标记去除:处理未使用的A连接等。
然后设置一个“来自”字段名称
这样一个简单的文章采集标准就完成了。目前还不清楚网友们有没有学到。网页爬虫工具很明显适用于网页上的网络爬虫。从上面的例子大家也可以看出,这类手机软件主要以源码分析为主来分析数据和信息。还有一些情况这里没有列出,比如登录采集、申请代理采集等,如果你对网页爬虫的特殊工具感兴趣,可以登录采集人体器官进行自主学习和训练。 查看全部
关键词文章采集源码(剖析网站地址自变量规律性第一页详细地址(图:第二页))
【鹿鼎前言】在日常事务和学习中,采集一些有用的文章内容可以帮助你提高信息内容的使用和整合率,针对新闻报道、期刊论文等类型的电子内容设备文章,我们可以使用专门的网页爬虫工具来采集。
这种相对智能的非周期性数据信息的采集是相当容易的。这里以网页抓取专用工具优采云采集器V9为例,解读一个文章 采集案例供大家学习和训练。
了解优采云采集器的朋友都知道,根据官方网站的FAQ,可以找到整个征集过程中遇到的问题,所以这里我们就以FAQ的征集作为显示网页的示例。爬行专用工具采集的基本原理及全过程。
在这种情况下,详细地址用于测试。
(1)正在建立采集标准
右键单击某个排序顺序,选择“正在构建的日常任务”,如下图:
(2) 加上开始和结束 网站 地址
这里假设您必须采集 5 页的数据信息。
解析网站地址参数的规律
第一页详细地址:
第二页详细地址:
第三页详细地址:
因此,我们可以计算出p=之后的数据就是分页查询的意思。您可以使用【详细地址主要参数】来表示:
所以设置如下:
详细地址文件格式:使用【详细地址主参数】表示更改的页面查询数据。
数据变换:从1开始,即第一页;每增加1,即每次分页查询的变化趋势数据;一共5个项目,也就是一共采集了5页。
浏览:数据采集器会根据上面的设置转换成网站地址的一部分,可以判断添加是否合适。
那么就可以清楚了
(3)[基本方式]获取内容网站地址
基本方法:该方法默认设置为爬取一级详细地址,即从起始页的源页获取到内容页A的链接。
这里演示给大家尝试一下自动获取详细地址并连接到设置区域获取的方法。
查询网页源码,找到文章内容的详细地址所属区域:
设置以下内容:
注:更详细的分析可以参考产品手册:
操作说明> 手机软件实际操作> 网站地址采集标准> 获取内容网站地址
点击网站地址采集测试,查看测试实际效果
(3)内容集网站地址
解释示例的徽标集合
注:更详细的分析可以参考产品手册
操作说明>手机软件实际操作>内容采集标准>标志编写
大家首先查看了它的网页源代码,寻找你的“话题”地理位置的代码:
进入Excle就是跳出提示框~打开Excle时出错-优采云采集器帮助中心
分析结果:起始字符串数组为:
最后的字符串数组是:
数据处理方法-内容替换/清除:必须替换-优采云采集器帮助中心为空
内容识别的基本原理也差不多,寻找内容所属的源代码部分
分析结果:起始字符串数组为:
最后的字符串数组是:
数据处理方法-HTML标记去除:处理未使用的A连接等。
然后设置一个“来自”字段名称
这样一个简单的文章采集标准就完成了。目前还不清楚网友们有没有学到。网页爬虫工具很明显适用于网页上的网络爬虫。从上面的例子大家也可以看出,这类手机软件主要以源码分析为主来分析数据和信息。还有一些情况这里没有列出,比如登录采集、申请代理采集等,如果你对网页爬虫的特殊工具感兴趣,可以登录采集人体器官进行自主学习和训练。
关键词文章采集源码(关于程序支持那些ECSHOP版本的一些事儿(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-11-23 11:03
Q:程序支持哪个ECSHOP版本?
答:ECSHOP所有版本都可以使用所有程序,2.7.2、2.7.3、2.7.4、3.0、3.6、4.0,包括最新的ECSHOP4.1程序,所有版本ECSHOP小京东,ECSHOP大商创所有版本(必须是开源版,不支持加密版)。
Q:购买后如何获取程序源代码?
答:购买并付款后,系统会自动返回您购买的程序源代码下载地址信息页面,并自动将程序源代码下载地址信息发送至您的邮箱。(注册用户也可以在用户中心-下载查看购买的节目),详细介绍:
问:购买你们的程序是否提供源代码?是加密的吗?我可以自己修改吗?有限制吗?
答:完整的程序源代码是通过购买程序获得的,程序源代码是开源的,没有加密,没有任何限制。只要有技术人员,甚至是具备一定电脑操作能力的文员,都可以随意修改。
Q:你们的程序适合新手安装吗?该程序是否提供安装说明?
答:我们的每个程序压缩包都收录详细的安装说明。资源全部供您快速入门。安装非常简单。一般新手都能轻松安装成功,我们也提供安装指导服务!让您安装使用全过程无忧。
问:你们的一些程序演示是图片演示和说明,但我没有看到实际效果。你还在为买东西发愁吗?
回复:亲,感谢您的支持。我们所有的项目都提供演示,以确保我们为您提供真实的体验。
网上总是有人想方设法窃取我们的程序数据,所以暂时没有办法采用这种截图演示的方式,给您带来不便。我希望能理解。我们一直在研究如何让客户感受到模板的真实效果。并努力工作。
Q:安装过程中遇到不知道的问题怎么办?
回复:亲,感谢您的支持。如果您在安装过程中遇到困难,可以将您的问题提交到后台工单,很快就会有人处理问题。您也可以直接联系我们的技术QQ进行售后服务。(盗版卖家不提供任何服务)
问:购买你们的程序有哪些服务?
答:亲,感谢您的支持,协助安装配置,效果和演示一样;程序有BUG永久免费;
程序随系统升级提供升级包,免费分发给客户(需要客户主动联系我们);
在使用过程中,除新的涉及工作量的修改要求外,我们将尽最大努力帮助解决问题;
Q: 购买程序需要每年更新吗?该计划是否有到期日期?
答:程序购买支付成功后,只要购买一次,即可享受该套程序的终身使用权。无需每年更新,为您提供优质的售后服务。)。
郑重提醒:【ECSHOP插件网站】只在官网销售作品,【ECSHOP插件网站】其他渠道购买的设计师作品均为盗版。 查看全部
关键词文章采集源码(关于程序支持那些ECSHOP版本的一些事儿(组图))
Q:程序支持哪个ECSHOP版本?
答:ECSHOP所有版本都可以使用所有程序,2.7.2、2.7.3、2.7.4、3.0、3.6、4.0,包括最新的ECSHOP4.1程序,所有版本ECSHOP小京东,ECSHOP大商创所有版本(必须是开源版,不支持加密版)。
Q:购买后如何获取程序源代码?
答:购买并付款后,系统会自动返回您购买的程序源代码下载地址信息页面,并自动将程序源代码下载地址信息发送至您的邮箱。(注册用户也可以在用户中心-下载查看购买的节目),详细介绍:
问:购买你们的程序是否提供源代码?是加密的吗?我可以自己修改吗?有限制吗?
答:完整的程序源代码是通过购买程序获得的,程序源代码是开源的,没有加密,没有任何限制。只要有技术人员,甚至是具备一定电脑操作能力的文员,都可以随意修改。
Q:你们的程序适合新手安装吗?该程序是否提供安装说明?
答:我们的每个程序压缩包都收录详细的安装说明。资源全部供您快速入门。安装非常简单。一般新手都能轻松安装成功,我们也提供安装指导服务!让您安装使用全过程无忧。
问:你们的一些程序演示是图片演示和说明,但我没有看到实际效果。你还在为买东西发愁吗?
回复:亲,感谢您的支持。我们所有的项目都提供演示,以确保我们为您提供真实的体验。
网上总是有人想方设法窃取我们的程序数据,所以暂时没有办法采用这种截图演示的方式,给您带来不便。我希望能理解。我们一直在研究如何让客户感受到模板的真实效果。并努力工作。
Q:安装过程中遇到不知道的问题怎么办?
回复:亲,感谢您的支持。如果您在安装过程中遇到困难,可以将您的问题提交到后台工单,很快就会有人处理问题。您也可以直接联系我们的技术QQ进行售后服务。(盗版卖家不提供任何服务)
问:购买你们的程序有哪些服务?
答:亲,感谢您的支持,协助安装配置,效果和演示一样;程序有BUG永久免费;
程序随系统升级提供升级包,免费分发给客户(需要客户主动联系我们);
在使用过程中,除新的涉及工作量的修改要求外,我们将尽最大努力帮助解决问题;
Q: 购买程序需要每年更新吗?该计划是否有到期日期?
答:程序购买支付成功后,只要购买一次,即可享受该套程序的终身使用权。无需每年更新,为您提供优质的售后服务。)。
郑重提醒:【ECSHOP插件网站】只在官网销售作品,【ECSHOP插件网站】其他渠道购买的设计师作品均为盗版。
关键词文章采集源码(爬取了“新闻传播”主题下的文章标题及发表时间 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-11-22 01:16
)
前几天帮朋友做了一个知网爬虫,爬取了“新闻传播”话题下文章的标题和发表时间;拖了2天写完,还是太虚弱了。个人觉得这是一个很好的爬虫项目,适合动手实践,所以写了主要步骤,把代码放到了我的github上。有需要的朋友可以看看或指点我改进。我的github-知网爬虫的github链接。
1. 知网爬虫的爬虫首先要找到一个合适的知网爬虫入口,建议从这个链接进入知网入口;
2. 输入你要抓取的话题,搜索,观察网址变化。你此时看到的网址没有长后缀,继续往下看;
3. 接下来我们翻页看看URL的变化。我们发现每页只有15个文章标题,而且只有15条信息是异步加载的,所以我们构造了pagenext()函数进行翻页;
4. 打开开发者工具,搜索标题文字的标签文章,观察标签中的文字,发现是分开的,所以只能找到上层标签或上层所在两个title是位于Tags,通过BeautifulSoup和get_text()选择提取文本,这里我选择了h3标签;
5. 接下来我们需要选择每篇文章的发表日期文章,这需要我们点击进入每篇文章文章选择日期,通过BS选择字体标签,找到color="#0080ff"标签,提取文字,可以确定发表时间;
6. 但是在爬取过程中,我们发现每个文章的URL都不一样,甚至有些URL根本没有文章。于是我观察了url的组成,发现一共有三种,只能使用两种类型的url,所以我用正则表达式来匹配可以使用的标签,然后请求提取<的发布时间@文章;
if re.match(r"""http://youxian.cnki.com.cn/yxdetail.aspx\?filename=[0-9a-zA-Z]+&dbname=[a-zA-Z]+""",text_url) or re.match(r'http://www.cnki.com.cn/Article/[a-zA-Z]+-[0-9a-zA-Z-]+.htm',text_url):
# print(text.find('a')['href'])
text_date = datespider(text_url)
7. 保留抓到的数据,然后写入excel,完成对zhinet的爬取;
粘贴源代码如下:
import requests
from bs4 import BeautifulSoup as bs
import time
import xlwt
import openpyxl
import re
def pagenext():
base_url = 'http://search.cnki.com.cn/sear ... 39%3B
L = range(0,840) # 最尾巴的数不计入
All_Page = []
for i in L[::15]:
next_url = base_url+str(i)
# print(next_url)
print("第 ",i/15+1," 页的数据")
page_text = spider(next_url)
time.sleep(10)
for page in page_text:
All_Page.append(page)
# print(All_Page)
write_excel('xlsx论文筛选.xlsx','info',All_Page)
def datespider(date_url):
# 因为跳转的链接类型不一样,所以我们要判断这两种链接是哪一种并且选择不一样的解析find方法
response_try = requests.get(date_url,{'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'})
# print(response_try.text)
response_tree = bs(response_try.text,'html.parser')
# 根据两个不同的链接返回不一样的值
if re.match(r'http://www.cnki.com.cn/Article/[0-9a-zA-Z\_]+',date_url):
res_date = response_tree.find("font",{"color":"#0080ff"})
if res_date == None:
response_date = None
else:
response_date = res_date.get_text().replace('\r','').replace('\n','')
else:
response_date = response_tree.find("title").get_text()[-8:]
return response_date
def write_excel(path,sheet_name,text_info):
index = len(text_info)
workbook = openpyxl.Workbook()
sheet = workbook.active
sheet.title = sheet_name
for i in range(0,index):
for j in range(len(text_info[i])):
sheet.cell(row= i+1,column = j+1,value = str(text_info[i][j]))
workbook.save(path)
print("xlsx格式表格写入数据成功!")
def spider(url):
response = requests.get(url,{'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'})
res = response.content
html = str(res,'utf-8')
html_tree = bs(html,'lxml')
# 找打h3标签下的内容
html_text = html_tree.find_all("h3")
All_text = []
# 隔一个才是文章的标题
for text in html_text[1:-2:]:
one_text = []
text_title = text.get_text().replace('\xa0','').replace('\n','')# 得到论文的标题
# print(text.get_text())
text_url = text.find('a')['href'] # 选取了当前文章的链接
# 用正则表达式匹配我们需要的链接
if re.match(r"""http://youxian.cnki.com.cn/yxdetail.aspx\?filename=[0-9a-zA-Z]+&dbname=[a-zA-Z]+""",text_url) or re.match(r'http://www.cnki.com.cn/Article/[a-zA-Z]+-[0-9a-zA-Z-]+.htm',text_url):
# print(text.find('a')['href'])
text_date = datespider(text_url)
one_text.append(text.get_text().replace('\xa0','').replace('\n','')) # text.get_text是得到文章的标题
if text_date == None:
one_text.append(None)
else:
if int(text_date[:4])>=2014:
one_text.append(text_date.replace('\t','').replace('\r','').replace('\n','').replace(' ',''))
else:
continue
All_text.append(one_text)
# print(text.find('a')['href'])
# print(All_text)
return All_text
# write_excel(All_text)
if __name__ =='__main__':
pagenext() 查看全部
关键词文章采集源码(爬取了“新闻传播”主题下的文章标题及发表时间
)
前几天帮朋友做了一个知网爬虫,爬取了“新闻传播”话题下文章的标题和发表时间;拖了2天写完,还是太虚弱了。个人觉得这是一个很好的爬虫项目,适合动手实践,所以写了主要步骤,把代码放到了我的github上。有需要的朋友可以看看或指点我改进。我的github-知网爬虫的github链接。
1. 知网爬虫的爬虫首先要找到一个合适的知网爬虫入口,建议从这个链接进入知网入口;
2. 输入你要抓取的话题,搜索,观察网址变化。你此时看到的网址没有长后缀,继续往下看;
3. 接下来我们翻页看看URL的变化。我们发现每页只有15个文章标题,而且只有15条信息是异步加载的,所以我们构造了pagenext()函数进行翻页;
4. 打开开发者工具,搜索标题文字的标签文章,观察标签中的文字,发现是分开的,所以只能找到上层标签或上层所在两个title是位于Tags,通过BeautifulSoup和get_text()选择提取文本,这里我选择了h3标签;
5. 接下来我们需要选择每篇文章的发表日期文章,这需要我们点击进入每篇文章文章选择日期,通过BS选择字体标签,找到color="#0080ff"标签,提取文字,可以确定发表时间;
6. 但是在爬取过程中,我们发现每个文章的URL都不一样,甚至有些URL根本没有文章。于是我观察了url的组成,发现一共有三种,只能使用两种类型的url,所以我用正则表达式来匹配可以使用的标签,然后请求提取<的发布时间@文章;
if re.match(r"""http://youxian.cnki.com.cn/yxdetail.aspx\?filename=[0-9a-zA-Z]+&dbname=[a-zA-Z]+""",text_url) or re.match(r'http://www.cnki.com.cn/Article/[a-zA-Z]+-[0-9a-zA-Z-]+.htm',text_url):
# print(text.find('a')['href'])
text_date = datespider(text_url)
7. 保留抓到的数据,然后写入excel,完成对zhinet的爬取;
粘贴源代码如下:
import requests
from bs4 import BeautifulSoup as bs
import time
import xlwt
import openpyxl
import re
def pagenext():
base_url = 'http://search.cnki.com.cn/sear ... 39%3B
L = range(0,840) # 最尾巴的数不计入
All_Page = []
for i in L[::15]:
next_url = base_url+str(i)
# print(next_url)
print("第 ",i/15+1," 页的数据")
page_text = spider(next_url)
time.sleep(10)
for page in page_text:
All_Page.append(page)
# print(All_Page)
write_excel('xlsx论文筛选.xlsx','info',All_Page)
def datespider(date_url):
# 因为跳转的链接类型不一样,所以我们要判断这两种链接是哪一种并且选择不一样的解析find方法
response_try = requests.get(date_url,{'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'})
# print(response_try.text)
response_tree = bs(response_try.text,'html.parser')
# 根据两个不同的链接返回不一样的值
if re.match(r'http://www.cnki.com.cn/Article/[0-9a-zA-Z\_]+',date_url):
res_date = response_tree.find("font",{"color":"#0080ff"})
if res_date == None:
response_date = None
else:
response_date = res_date.get_text().replace('\r','').replace('\n','')
else:
response_date = response_tree.find("title").get_text()[-8:]
return response_date
def write_excel(path,sheet_name,text_info):
index = len(text_info)
workbook = openpyxl.Workbook()
sheet = workbook.active
sheet.title = sheet_name
for i in range(0,index):
for j in range(len(text_info[i])):
sheet.cell(row= i+1,column = j+1,value = str(text_info[i][j]))
workbook.save(path)
print("xlsx格式表格写入数据成功!")
def spider(url):
response = requests.get(url,{'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'})
res = response.content
html = str(res,'utf-8')
html_tree = bs(html,'lxml')
# 找打h3标签下的内容
html_text = html_tree.find_all("h3")
All_text = []
# 隔一个才是文章的标题
for text in html_text[1:-2:]:
one_text = []
text_title = text.get_text().replace('\xa0','').replace('\n','')# 得到论文的标题
# print(text.get_text())
text_url = text.find('a')['href'] # 选取了当前文章的链接
# 用正则表达式匹配我们需要的链接
if re.match(r"""http://youxian.cnki.com.cn/yxdetail.aspx\?filename=[0-9a-zA-Z]+&dbname=[a-zA-Z]+""",text_url) or re.match(r'http://www.cnki.com.cn/Article/[a-zA-Z]+-[0-9a-zA-Z-]+.htm',text_url):
# print(text.find('a')['href'])
text_date = datespider(text_url)
one_text.append(text.get_text().replace('\xa0','').replace('\n','')) # text.get_text是得到文章的标题
if text_date == None:
one_text.append(None)
else:
if int(text_date[:4])>=2014:
one_text.append(text_date.replace('\t','').replace('\r','').replace('\n','').replace(' ',''))
else:
continue
All_text.append(one_text)
# print(text.find('a')['href'])
# print(All_text)
return All_text
# write_excel(All_text)
if __name__ =='__main__':
pagenext()
关键词文章采集源码(智汇定时全自动更新网站(无人值守)的功能介绍!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-11-22 01:15
智汇seo软件是一款综合性多功能网站优化推广软件,集网站自动更新、长尾关键词自动组合、文章采集、文章伪原创 等功能合二为一。软件要求.net2.0 或以上运行环境。
功能一:多任务定时自动更新网站(无人值守)
您可以根据需要自由设置采集的发布时间和文章发布更新的时间间隔,尽可能科学、全面地管理您的网站。您只需要定期查看发布的内容和软件输出。提示,根据搜索引擎的变化调整采集和发布更新的时间间隔,让网站更新更自然!
功能二:内容高度伪原创
内容原创度是衡量一个采集器效果的最重要因素!虽然数量对采集也起着重要作用,但内容的原创程度直接影响网站的收录的流量,因为它不经过任何加工。来自采集 的 文章 无效。这种采集会被搜索引擎识别,并给予删除网站的权利!智汇seo软件内置了大量的伪原创处理模块:
①内容方面:打乱句子顺序、替换同义词、立即删除句子、选择句子汉英汉翻译、组合多个文章、标题添加内容、采集关键词(种子关键词) ) 添加内容、相关关键词(长尾关键词)添加内容、字体转换(简体、繁体、火星文)
②标题:智汇seo软件允许任意自定义控制标题,支持相关关键词(长尾关键词)按指定数量随机组合!
此外,多个文章组合、原创采集接口等一系列功能都是我们智汇站群独有的!
功能三:真正通用的采集抓取文章范围
智汇seo软件内置关键词采集引擎,可深入采集各大主流搜索引擎(百度、搜狗、搜搜)关键词,有效采集长尾关键词
功能四:多用户自定义采集
智汇开发的采集接口,只需要输入网址即可执行采集的相应内容,也可以同步目标站更新采集,使用蜘蛛核心模拟蜘蛛爬取网站内容不会被屏蔽,强大的正则可以轻松采集你想要的所有信息,包括邮箱、QQ和手机号等,不只是你想要的,但也过滤掉所有不需要的内容
功能五:超级seo系统
网站内部链接是SEO的重中之重。系统可自由设置需要排名的关键词,发布时自动生成专题页面,将出现在文章中的关键词锚定,链接指向专题页面和首页。如果文章中没有话题相关关键词,系统会自动插入话题关键词子,随机连接话题页面,让你的内页权重最大化。如果收录1W篇文章,那么你有1W内部反向连接,收录越多,排名越好!重点是智汇专注于一个栏目,优化到一个栏目,而不仅仅是一个站!
功能六:完整的外语模块,支持多国语言,千万级常规英语网站资源
功能七:强大的发布模块
智汇seo软件的数据发布界面非常强大。支持网站的直接入库,也支持将入库接口(ASP或PHP程序)上传到目标网站,然后在程序中连接接口发布数据。支持cms和论坛站的所有更新! 查看全部
关键词文章采集源码(智汇定时全自动更新网站(无人值守)的功能介绍!)
智汇seo软件是一款综合性多功能网站优化推广软件,集网站自动更新、长尾关键词自动组合、文章采集、文章伪原创 等功能合二为一。软件要求.net2.0 或以上运行环境。
功能一:多任务定时自动更新网站(无人值守)
您可以根据需要自由设置采集的发布时间和文章发布更新的时间间隔,尽可能科学、全面地管理您的网站。您只需要定期查看发布的内容和软件输出。提示,根据搜索引擎的变化调整采集和发布更新的时间间隔,让网站更新更自然!
功能二:内容高度伪原创
内容原创度是衡量一个采集器效果的最重要因素!虽然数量对采集也起着重要作用,但内容的原创程度直接影响网站的收录的流量,因为它不经过任何加工。来自采集 的 文章 无效。这种采集会被搜索引擎识别,并给予删除网站的权利!智汇seo软件内置了大量的伪原创处理模块:
①内容方面:打乱句子顺序、替换同义词、立即删除句子、选择句子汉英汉翻译、组合多个文章、标题添加内容、采集关键词(种子关键词) ) 添加内容、相关关键词(长尾关键词)添加内容、字体转换(简体、繁体、火星文)
②标题:智汇seo软件允许任意自定义控制标题,支持相关关键词(长尾关键词)按指定数量随机组合!
此外,多个文章组合、原创采集接口等一系列功能都是我们智汇站群独有的!
功能三:真正通用的采集抓取文章范围
智汇seo软件内置关键词采集引擎,可深入采集各大主流搜索引擎(百度、搜狗、搜搜)关键词,有效采集长尾关键词
功能四:多用户自定义采集
智汇开发的采集接口,只需要输入网址即可执行采集的相应内容,也可以同步目标站更新采集,使用蜘蛛核心模拟蜘蛛爬取网站内容不会被屏蔽,强大的正则可以轻松采集你想要的所有信息,包括邮箱、QQ和手机号等,不只是你想要的,但也过滤掉所有不需要的内容
功能五:超级seo系统
网站内部链接是SEO的重中之重。系统可自由设置需要排名的关键词,发布时自动生成专题页面,将出现在文章中的关键词锚定,链接指向专题页面和首页。如果文章中没有话题相关关键词,系统会自动插入话题关键词子,随机连接话题页面,让你的内页权重最大化。如果收录1W篇文章,那么你有1W内部反向连接,收录越多,排名越好!重点是智汇专注于一个栏目,优化到一个栏目,而不仅仅是一个站!
功能六:完整的外语模块,支持多国语言,千万级常规英语网站资源
功能七:强大的发布模块
智汇seo软件的数据发布界面非常强大。支持网站的直接入库,也支持将入库接口(ASP或PHP程序)上传到目标网站,然后在程序中连接接口发布数据。支持cms和论坛站的所有更新!

