
全网文章采集
全网文章采集(阿里巴巴全网文章采集归类--阿里巴巴矢量图标库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-10-10 12:05
全网文章采集归类。从单个文章的内容相关性以及关键词提取。1数据准备。本文采集的内容如下,并保存下来,为日后做数据分析留作备用。>2文章提取。iconfont-阿里巴巴矢量图标库1选择需要去重的图片。>3图片所在位置的划分。根据图片所在位置以及需要的提取文字信息(字体颜色等)将其区分开>4列举文章描述中几类描述字。
<p>如标题,正文。并调用ff,find,match,excel中的相应功能将其判断出是否需要去重。最后只要将选中的文章去重为0即可>5全网评论区全部记录。这个可以先说明下,如果要判断全网评论,首先要判断全网哪个词多>以上数据基本采集完,格式和内容与上面大体一致. 查看全部
全网文章采集(阿里巴巴全网文章采集归类--阿里巴巴矢量图标库)
全网文章采集归类。从单个文章的内容相关性以及关键词提取。1数据准备。本文采集的内容如下,并保存下来,为日后做数据分析留作备用。>2文章提取。iconfont-阿里巴巴矢量图标库1选择需要去重的图片。>3图片所在位置的划分。根据图片所在位置以及需要的提取文字信息(字体颜色等)将其区分开>4列举文章描述中几类描述字。
<p>如标题,正文。并调用ff,find,match,excel中的相应功能将其判断出是否需要去重。最后只要将选中的文章去重为0即可>5全网评论区全部记录。这个可以先说明下,如果要判断全网评论,首先要判断全网哪个词多>以上数据基本采集完,格式和内容与上面大体一致.
全网文章采集(全网文章采集器(无任何广告,免费推荐))
采集交流 • 优采云 发表了文章 • 0 个评论 • 440 次浏览 • 2021-10-08 01:00
全网文章采集器(无任何广告,免费推荐)0.简介在浏览器中,用户可以快速、轻松地获取海量全网网页文章,并通过pc端或移动端等多种渠道分发到个人与企业客户。1.内容类型以新闻、社交网络、财经、科技、数码等大众常用的类型为主。2.网页导览可以读取链接、图片和按钮的网页。还能够同步pc浏览器、移动浏览器页面。
pc端可直接保存网页。3.朗读朗读文章、插入链接、图片、插入小程序。读取内容,可有感情朗读。保存到文本4.分享到微信,可与朋友分享网页,或者将文章分享到微信群、朋友圈或在公众号上分享。5.im聊天,可以随时随地和朋友聊天,不错过文章更新。6.视频随时随地制作视频,发布到各大平台,带你看全网文章。新闻|社交网络科技|金融|电商|安全|数码|职场|小程序|工具|网址|财经|电商|科技|情感。
不谢邀。为什么都推荐qq浏览器呢?首先推荐360浏览器。国内几大主流浏览器,界面清晰,内容丰富,能有效处理一些收藏的文章,并不难,并且很流畅。如果觉得广告多,可以安装360手机卫士。
qq浏览器
主要国内搜索引擎都有,以方正为例。
有没有什么网站能够全站爬取互联网文章?
就说电脑端,是用迅雷的,最快速。 查看全部
全网文章采集(全网文章采集器(无任何广告,免费推荐))
全网文章采集器(无任何广告,免费推荐)0.简介在浏览器中,用户可以快速、轻松地获取海量全网网页文章,并通过pc端或移动端等多种渠道分发到个人与企业客户。1.内容类型以新闻、社交网络、财经、科技、数码等大众常用的类型为主。2.网页导览可以读取链接、图片和按钮的网页。还能够同步pc浏览器、移动浏览器页面。
pc端可直接保存网页。3.朗读朗读文章、插入链接、图片、插入小程序。读取内容,可有感情朗读。保存到文本4.分享到微信,可与朋友分享网页,或者将文章分享到微信群、朋友圈或在公众号上分享。5.im聊天,可以随时随地和朋友聊天,不错过文章更新。6.视频随时随地制作视频,发布到各大平台,带你看全网文章。新闻|社交网络科技|金融|电商|安全|数码|职场|小程序|工具|网址|财经|电商|科技|情感。
不谢邀。为什么都推荐qq浏览器呢?首先推荐360浏览器。国内几大主流浏览器,界面清晰,内容丰富,能有效处理一些收藏的文章,并不难,并且很流畅。如果觉得广告多,可以安装360手机卫士。
qq浏览器
主要国内搜索引擎都有,以方正为例。
有没有什么网站能够全站爬取互联网文章?
就说电脑端,是用迅雷的,最快速。
全网文章采集(简单操作界面搜索工具名叫Mr.Otter有啥特色功能?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 263 次浏览 • 2021-10-06 03:20
【PConline申请】俗话说,技术行业有专攻。有经验的用户通常会使用不同的搜索引擎来搜索不同的资源内容,以便更快更好地找到自己需要的内容。现在有一个全面的搜索工具,可以帮助您大大加快搜索效率,免去在多个搜索引擎之间切换的麻烦。这个搜索工具叫做Mr. Otter。它有什么特点?请跟随小编来体验吧。
简单的操作界面非常丰富
水獭先生是一款软件类搜索工具,目前支持Windows 64位和MAC版本,需要下载后安装使用。但是,该软件采用邀请码免费形式,但需要注册,用户需要填写邀请码才能使用。小编这里给出PConline专属邀请码【邀请码】PConline。
水獭先生的操作界面非常简单。左侧是搜索框和各种搜索引擎的切换入口,右侧是内容展示区。
图1 水獭先生主界面
可以看到,Otter 先生为用户准备了很多搜索引擎和内容引擎,并对其进行了分类。例如,常见的搜索引擎包括百度、必应、搜狗等常用搜索引擎,用户也可以自行添加其他搜索引擎。
图2 通用搜索引擎
快速切换搜索引擎
用户输入搜索关键字后进行搜索。默认是调用第一个搜索引擎进行搜索。用户只需点击下方的搜索引擎按钮,即可在不同的搜索引擎之间快速切换搜索关键字。
图3 调用百度搜索
图 4 切换到 Bing 进行搜索
对于搜索结果,用户可以打印或直接生成PDF文件。
图5 快速另存为PDF文件
细分搜索工具,方便快速查找资源
而在一般搜索引擎分类下,还有一个小分类,Otter先生也把它分为一般、翻译和工具。其中,翻译分类是快速调用多个搜索引擎的翻译功能进行关键词翻译,工具分类是查快递、查索引、查地图等功能。
图6 快速调用谷歌翻译
图 7 各种附加工具
一种更有效的图片查找方式
水獭先生还为用户准备了一个大搜索类别的图片。功能是帮助用户在多个优质图片分享网站上查找图片。除了图片,Otter 先生还细分了图标和灵感类别。
图 8 水獭先生图片搜索
对于搜索到的图片,用户还可以通过右键快速采集和复制图片。“采集”功能是将图片保存在本地,放入水獭先生的采集管理库中。
图9 快速保存和复制图片
水獭先生还有一个图集功能,可以将页面上的图片与图片的分辨率信息快速显示在一个列表中,并在此模式下自动去除其他内容。
图 10 Atlas 模式
更多专用搜索引擎
奥特先生还为用户准备了很多内容搜索分类,比如可以帮助我们快速找到软件的“软件”分类,书籍的“文化”分类,百科知识的“知识”分类等等.
图 11 软件分类搜索
图 12 文化分类搜索
图 13 知识分类搜索
当你有时间时,慢慢阅读,稍后阅读。
水獭先生有晚读功能。对于搜索到的内容或感兴趣的内容,如果没有时间阅读,用户可以将其添加到以后的阅读列表中,有空的时候再仔细阅读。
图 14 稍后阅读功能
历史关键词功能
水獭先生支持搜索历史关键词功能,帮助用户记录搜索关键词,方便再次搜索。当然,它还具有清除历史关键字的功能。
图15 历史搜索关键词功能
总结
Mr. Otter 的搜索功能为用户带来了便捷的聚合搜索功能,让用户无需在多个搜索引擎之间切换即可找到自己需要的资源内容,并提供搜索分类,让用户可以基于各种技术进行搜索。行业内有专门的搜索引擎,可以更准确、更快速地找到您需要的资源。如果您经常使用搜索引擎,您不妨尝试一下。 查看全部
全网文章采集(简单操作界面搜索工具名叫Mr.Otter有啥特色功能?)
【PConline申请】俗话说,技术行业有专攻。有经验的用户通常会使用不同的搜索引擎来搜索不同的资源内容,以便更快更好地找到自己需要的内容。现在有一个全面的搜索工具,可以帮助您大大加快搜索效率,免去在多个搜索引擎之间切换的麻烦。这个搜索工具叫做Mr. Otter。它有什么特点?请跟随小编来体验吧。
简单的操作界面非常丰富
水獭先生是一款软件类搜索工具,目前支持Windows 64位和MAC版本,需要下载后安装使用。但是,该软件采用邀请码免费形式,但需要注册,用户需要填写邀请码才能使用。小编这里给出PConline专属邀请码【邀请码】PConline。
水獭先生的操作界面非常简单。左侧是搜索框和各种搜索引擎的切换入口,右侧是内容展示区。

图1 水獭先生主界面
可以看到,Otter 先生为用户准备了很多搜索引擎和内容引擎,并对其进行了分类。例如,常见的搜索引擎包括百度、必应、搜狗等常用搜索引擎,用户也可以自行添加其他搜索引擎。

图2 通用搜索引擎
快速切换搜索引擎
用户输入搜索关键字后进行搜索。默认是调用第一个搜索引擎进行搜索。用户只需点击下方的搜索引擎按钮,即可在不同的搜索引擎之间快速切换搜索关键字。

图3 调用百度搜索

图 4 切换到 Bing 进行搜索
对于搜索结果,用户可以打印或直接生成PDF文件。

图5 快速另存为PDF文件
细分搜索工具,方便快速查找资源
而在一般搜索引擎分类下,还有一个小分类,Otter先生也把它分为一般、翻译和工具。其中,翻译分类是快速调用多个搜索引擎的翻译功能进行关键词翻译,工具分类是查快递、查索引、查地图等功能。

图6 快速调用谷歌翻译

图 7 各种附加工具
一种更有效的图片查找方式
水獭先生还为用户准备了一个大搜索类别的图片。功能是帮助用户在多个优质图片分享网站上查找图片。除了图片,Otter 先生还细分了图标和灵感类别。

图 8 水獭先生图片搜索
对于搜索到的图片,用户还可以通过右键快速采集和复制图片。“采集”功能是将图片保存在本地,放入水獭先生的采集管理库中。

图9 快速保存和复制图片
水獭先生还有一个图集功能,可以将页面上的图片与图片的分辨率信息快速显示在一个列表中,并在此模式下自动去除其他内容。

图 10 Atlas 模式
更多专用搜索引擎
奥特先生还为用户准备了很多内容搜索分类,比如可以帮助我们快速找到软件的“软件”分类,书籍的“文化”分类,百科知识的“知识”分类等等.

图 11 软件分类搜索

图 12 文化分类搜索

图 13 知识分类搜索
当你有时间时,慢慢阅读,稍后阅读。
水獭先生有晚读功能。对于搜索到的内容或感兴趣的内容,如果没有时间阅读,用户可以将其添加到以后的阅读列表中,有空的时候再仔细阅读。

图 14 稍后阅读功能
历史关键词功能
水獭先生支持搜索历史关键词功能,帮助用户记录搜索关键词,方便再次搜索。当然,它还具有清除历史关键字的功能。

图15 历史搜索关键词功能
总结
Mr. Otter 的搜索功能为用户带来了便捷的聚合搜索功能,让用户无需在多个搜索引擎之间切换即可找到自己需要的资源内容,并提供搜索分类,让用户可以基于各种技术进行搜索。行业内有专门的搜索引擎,可以更准确、更快速地找到您需要的资源。如果您经常使用搜索引擎,您不妨尝试一下。
全网文章采集(全网文章采集系统(爬虫)设置+(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-10-06 01:02
全网文章采集系统,
一、文章采集脚本编写需要采集的网站自动生成采集地址,
0、知乎、豆瓣等等,
二、公众号爬虫由于前期爬虫全部需要request,需要一个可以爬取www的web地址!并且规范爬取headers!user-agent是指浏览器上对http状态的响应头(不含),目前定制的微信网站爬虫脚本也会用到这个参数。目前mysql微信爬虫脚本中已经实现这个参数。我们采用post,而mysql也是支持post请求的,无需手动下载下来。
三、爬虫设置+本地解析-bin/post?k=xyz42600c4f903&lang=zh_cn&q=xyz42600c4f903&url_value=xyz42600c4f903&channel=http%3a%2f%2fwww。xyz42600c4f903。com%2fsxambly%2fguid_code%2fguid_x_feature_hex%2fguid_hex_sdk%2fguid_filter%2fguid_length%2fguid_value%2fguid_reset%2fguid_code%2fguid_propagate%2fguid_name%2fguid_reset%2fguid_code%2fguid_propagate%2fguid_name%2fguid_code%2fguid_x_feature_hex%2fguid_x_feature_code%2fguid_value%2fguid_guid_code%2fguid_code%2fguid_guid_hex_sdk%2fguid_guid_sdk%2fguid_value%2fguid_guid_code%2fguid_propagate%2fguid_hex_value%2fguid_propagate%2fguid_value%2fguid_guid_name%2fguid_code%2fguid_guid_value%2fguid_reset%2fguid_hex_value%2fguid_reset%2fguid_value%2fguid_guid_propagate%2fguid_value%2fguid_guid_code%2fguid_name%2fguid_reset%2fguid_code%2fguid_length%2fguid_value%2fguid_code%2fguid_value%2fguid_sdk%2fguid_guid_value%2fguid_name%2fguid_value%2fguid_code%2fguid_value%2fguid_value%2fguid_name%2fguid_value%2fguid_guid_code%2fguid_guid_value%2fguid_value%2fguid_propagate%2fguid_guid_value%2fguid_guid_value%2fguid_propagate%2fguid_length%2fguid_value%2fguid_code%2fguid_propagate%2fguid。 查看全部
全网文章采集(全网文章采集系统(爬虫)设置+(图))
全网文章采集系统,
一、文章采集脚本编写需要采集的网站自动生成采集地址,
0、知乎、豆瓣等等,
二、公众号爬虫由于前期爬虫全部需要request,需要一个可以爬取www的web地址!并且规范爬取headers!user-agent是指浏览器上对http状态的响应头(不含),目前定制的微信网站爬虫脚本也会用到这个参数。目前mysql微信爬虫脚本中已经实现这个参数。我们采用post,而mysql也是支持post请求的,无需手动下载下来。
三、爬虫设置+本地解析-bin/post?k=xyz42600c4f903&lang=zh_cn&q=xyz42600c4f903&url_value=xyz42600c4f903&channel=http%3a%2f%2fwww。xyz42600c4f903。com%2fsxambly%2fguid_code%2fguid_x_feature_hex%2fguid_hex_sdk%2fguid_filter%2fguid_length%2fguid_value%2fguid_reset%2fguid_code%2fguid_propagate%2fguid_name%2fguid_reset%2fguid_code%2fguid_propagate%2fguid_name%2fguid_code%2fguid_x_feature_hex%2fguid_x_feature_code%2fguid_value%2fguid_guid_code%2fguid_code%2fguid_guid_hex_sdk%2fguid_guid_sdk%2fguid_value%2fguid_guid_code%2fguid_propagate%2fguid_hex_value%2fguid_propagate%2fguid_value%2fguid_guid_name%2fguid_code%2fguid_guid_value%2fguid_reset%2fguid_hex_value%2fguid_reset%2fguid_value%2fguid_guid_propagate%2fguid_value%2fguid_guid_code%2fguid_name%2fguid_reset%2fguid_code%2fguid_length%2fguid_value%2fguid_code%2fguid_value%2fguid_sdk%2fguid_guid_value%2fguid_name%2fguid_value%2fguid_code%2fguid_value%2fguid_value%2fguid_name%2fguid_value%2fguid_guid_code%2fguid_guid_value%2fguid_value%2fguid_propagate%2fguid_guid_value%2fguid_guid_value%2fguid_propagate%2fguid_length%2fguid_value%2fguid_code%2fguid_propagate%2fguid。
全网文章采集(为什么洪雨需要采集微信公众号文章?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-09-29 05:01
由于某些原因,洪宇需要采集微信公众号文章。
废话不多说,只说重点。
最初的想法非常简单。本来是想用搜狗微信搜索功能到采集,但是没执行的时候,看到了一些评论。
说到搜狗微信,如果采集的文章不完整,采集太多,IP会被封。
于是果断放弃,也没去研究,因为洪宇知道,这种搜索引擎的采集比较简单。如果大家都是采集,确实会对服务器造成压力。
洪宇开始考虑第二套方案,直接采集公众号。
公众号的文章链接在网页上是可以打开的,但是公众号文章的历史在PC端已经不能打开了。有问题,采集公众号的文章链接不可用。
想打开历史文章,洪宇想到了两种方法,一种是用模拟器模拟手机环境,打开链接。另一种是使用网页微信打开公众号历史链接。
当然,直接在网页上使用微信绝对比使用模拟器容易。
洪宇发现网页微信打不开。只有安装客户端才能在PC端打开微信。好在公众号历史文章还是可以看到的。
这时候问题又来了,如何在模拟器或者客户端获取到历史文章的内容,然后链接采集。
洪宇首先想到的就是互联网拦截和抓包,现在fiddler比较流行。
但是不能直接批量获取和过滤这些数据,所以想一想如何在宜浪中直接抓包,什么抓包,网络拦截,过程都是读取...
结果找了半天也没找到简单有效的方法。模拟器上有抓包教程,但是我还是用fiddler抓包...
最后,洪宇想从微信客户端的手柄入手。
使用编程助手获取窗口句柄,洪宇惊讶地发现,原来的公众号内容以内置浏览器的形式显示在微信客户端,包括历史文章。
虽然它是一个谷歌核心浏览器,你不能用它来填表,但它已经很不错了。
我们可以用鼠标模拟的方法制作微信客户端,然后获取内置浏览器的网页源码。有了源代码,一切都很简单。
剩下的就是过滤有用的信息。
只要你采集链接到每个文章,一切都OK,因为在PC浏览器中可以打开单个文章链接。也就是说可以直接读取源码,从采集到文章的内容。
至此,完成手册。
整理流程,首先要关注采集公众号,然后登录微信PC客户端,在客户端打开历史文章页面,获取源码,然后使用软件采集链接到文章。然后直接阅读文章的源码和采集文章的内容。
作为个人,这是一种傻瓜式采集方法。不需要高难度的技术,也不需要涉及微信公众号等的开发接口,唯一的缺点就是效率比较慢。
不过作为个人采集,应该够了。 查看全部
全网文章采集(为什么洪雨需要采集微信公众号文章?)
由于某些原因,洪宇需要采集微信公众号文章。
废话不多说,只说重点。
最初的想法非常简单。本来是想用搜狗微信搜索功能到采集,但是没执行的时候,看到了一些评论。
说到搜狗微信,如果采集的文章不完整,采集太多,IP会被封。
于是果断放弃,也没去研究,因为洪宇知道,这种搜索引擎的采集比较简单。如果大家都是采集,确实会对服务器造成压力。
洪宇开始考虑第二套方案,直接采集公众号。
公众号的文章链接在网页上是可以打开的,但是公众号文章的历史在PC端已经不能打开了。有问题,采集公众号的文章链接不可用。
想打开历史文章,洪宇想到了两种方法,一种是用模拟器模拟手机环境,打开链接。另一种是使用网页微信打开公众号历史链接。
当然,直接在网页上使用微信绝对比使用模拟器容易。
洪宇发现网页微信打不开。只有安装客户端才能在PC端打开微信。好在公众号历史文章还是可以看到的。
这时候问题又来了,如何在模拟器或者客户端获取到历史文章的内容,然后链接采集。
洪宇首先想到的就是互联网拦截和抓包,现在fiddler比较流行。
但是不能直接批量获取和过滤这些数据,所以想一想如何在宜浪中直接抓包,什么抓包,网络拦截,过程都是读取...
结果找了半天也没找到简单有效的方法。模拟器上有抓包教程,但是我还是用fiddler抓包...
最后,洪宇想从微信客户端的手柄入手。
使用编程助手获取窗口句柄,洪宇惊讶地发现,原来的公众号内容以内置浏览器的形式显示在微信客户端,包括历史文章。
虽然它是一个谷歌核心浏览器,你不能用它来填表,但它已经很不错了。
我们可以用鼠标模拟的方法制作微信客户端,然后获取内置浏览器的网页源码。有了源代码,一切都很简单。
剩下的就是过滤有用的信息。
只要你采集链接到每个文章,一切都OK,因为在PC浏览器中可以打开单个文章链接。也就是说可以直接读取源码,从采集到文章的内容。
至此,完成手册。
整理流程,首先要关注采集公众号,然后登录微信PC客户端,在客户端打开历史文章页面,获取源码,然后使用软件采集链接到文章。然后直接阅读文章的源码和采集文章的内容。
作为个人,这是一种傻瓜式采集方法。不需要高难度的技术,也不需要涉及微信公众号等的开发接口,唯一的缺点就是效率比较慢。
不过作为个人采集,应该够了。
全网文章采集( 千梦哥1.鉴别原创1.标题(修改了标题)(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2021-09-25 01:13
千梦哥1.鉴别原创1.标题(修改了标题)(图))
一、前言
只要和网站有关,尤其是内容、交通、SEO排名,今天的这节课一定要听。千萌哥教你如何持续获取网站、文章的内容源,帖子获得无数原创文章,100%与我们网站领域垂直相关
今天的采集站点课程教学方式不仅仅是一个项目。更准确的说,是“建站”的捷径,几乎适用于任何网站。解决做网站的最大问题之一:内容源网站是由内容输出开发的,所以不管什么类型的内容网站都可以做,看看就可以了. 完成课程后,您几乎不会为网站 没有内容输出而头疼。
二、课程内容
1.身份证明原创
1.Title (Title modified) 只要标题是收录,那么就不需要看内容了
2.内容(随机选择几段)
3.交通(蜜蜂采集)
公众号文章的内容不会被百度收录封禁,微信封禁百度公众号收录的内容
2.重量基础
1.原创文章Multiple:复制和传输(理想),伪原创(大部分)
2.行业相关性高:运输来源筛选
3.域名权重:旧域名的选择
三、利润变现
除了最知名的广告收入和CPA和CPS变现,高端引流转化产品变现可能对你有一些高要求。
而每一个网站都可以卖到最后一步网站,这也是实现网站的最简单粗暴的方式。
一般卖的网站一般有两种:
1.网站 无法稳定开发和实现。
他们被迫出售这些 网站 谋生。通常,个人站长做了一半的工作,发现定位不明确,或者觉得希望不大,熬不过去,所以及时卖出。
这其中网站,大多是行业性质的,比较准确,数据也比较真实。其中网站不乏商业潜力巨大的“黑马”。
2.网站出售
网站 从一开始,后期的制作和所有的内容填充都是为了未来的好价钱。
四、项目核心
你每天为网站写什么文章?
1.可以被百度蜘蛛抓取收录
2.能够给网站添加权重属性
3.提升用户体验和付费转化率
其实,归根结底,我们要做的,就是把百度看不到的文章搬过来收录。
这套价值百万的超级原创采集教程我将在本视频课程中进行全面的实践教学讲解。 查看全部
全网文章采集(
千梦哥1.鉴别原创1.标题(修改了标题)(图))

一、前言

只要和网站有关,尤其是内容、交通、SEO排名,今天的这节课一定要听。千萌哥教你如何持续获取网站、文章的内容源,帖子获得无数原创文章,100%与我们网站领域垂直相关
今天的采集站点课程教学方式不仅仅是一个项目。更准确的说,是“建站”的捷径,几乎适用于任何网站。解决做网站的最大问题之一:内容源网站是由内容输出开发的,所以不管什么类型的内容网站都可以做,看看就可以了. 完成课程后,您几乎不会为网站 没有内容输出而头疼。
二、课程内容

1.身份证明原创
1.Title (Title modified) 只要标题是收录,那么就不需要看内容了
2.内容(随机选择几段)
3.交通(蜜蜂采集)
公众号文章的内容不会被百度收录封禁,微信封禁百度公众号收录的内容
2.重量基础
1.原创文章Multiple:复制和传输(理想),伪原创(大部分)
2.行业相关性高:运输来源筛选
3.域名权重:旧域名的选择
三、利润变现

除了最知名的广告收入和CPA和CPS变现,高端引流转化产品变现可能对你有一些高要求。
而每一个网站都可以卖到最后一步网站,这也是实现网站的最简单粗暴的方式。
一般卖的网站一般有两种:
1.网站 无法稳定开发和实现。
他们被迫出售这些 网站 谋生。通常,个人站长做了一半的工作,发现定位不明确,或者觉得希望不大,熬不过去,所以及时卖出。
这其中网站,大多是行业性质的,比较准确,数据也比较真实。其中网站不乏商业潜力巨大的“黑马”。
2.网站出售
网站 从一开始,后期的制作和所有的内容填充都是为了未来的好价钱。
四、项目核心

你每天为网站写什么文章?
1.可以被百度蜘蛛抓取收录
2.能够给网站添加权重属性
3.提升用户体验和付费转化率
其实,归根结底,我们要做的,就是把百度看不到的文章搬过来收录。
这套价值百万的超级原创采集教程我将在本视频课程中进行全面的实践教学讲解。
全网文章采集(全网文章采集服务,有趣的事情,多多分享!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-09-19 03:04
全网文章采集服务,有趣的事情,多多分享!全网音频采集服务,好听的歌曲,好听的内容,
有抖音采集工具,写个爬虫就可以了。
目前没见过哪个有专门的这个功能,只能按照网站类型,然后倒推出网站的相关内容。
给你们抖音评论采集
可以尝试爬网易云音乐的,已经试过,百度云30m的,收费费49。
可以试试这个模拟登录百度账号
微信公众号和自媒体号的长尾关键词爬取
豆瓣电影看一眼简介都能知道有啥不错的电影可以加到我们的关键词库里
公众号的推文里,被人引用的各类文章都是相关的,
可以试试博客里的一些文章,
百度搜公众号ai采集器关键词有感兴趣的公众号就可以
我自己做的,方便快捷。
这个目前还是刚起步,大家可以试试“快搜网”,之前用了一阵子,
太多了,
alexa中国_中国最大的中文站点,网站分析工具,seo优化,网站推广,
fenng公众号文章,可以搜索,定位比较准确,
百度文库 查看全部
全网文章采集(全网文章采集服务,有趣的事情,多多分享!)
全网文章采集服务,有趣的事情,多多分享!全网音频采集服务,好听的歌曲,好听的内容,
有抖音采集工具,写个爬虫就可以了。
目前没见过哪个有专门的这个功能,只能按照网站类型,然后倒推出网站的相关内容。
给你们抖音评论采集
可以尝试爬网易云音乐的,已经试过,百度云30m的,收费费49。
可以试试这个模拟登录百度账号
微信公众号和自媒体号的长尾关键词爬取
豆瓣电影看一眼简介都能知道有啥不错的电影可以加到我们的关键词库里
公众号的推文里,被人引用的各类文章都是相关的,
可以试试博客里的一些文章,
百度搜公众号ai采集器关键词有感兴趣的公众号就可以
我自己做的,方便快捷。
这个目前还是刚起步,大家可以试试“快搜网”,之前用了一阵子,
太多了,
alexa中国_中国最大的中文站点,网站分析工具,seo优化,网站推广,
fenng公众号文章,可以搜索,定位比较准确,
百度文库
全网文章采集( 在现在网站优化真的是内容为王,咱们在提高排名的进程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 376 次浏览 • 2021-09-19 01:02
在现在网站优化真的是内容为王,咱们在提高排名的进程)
了解原创文章版权问题并采集词汇技能
现在网站优化真的是内容之王。在提高排名的过程中,能够了解内容是非常重要的。帮助网站提高排名非常有帮助。因此,很多公司都配备了专业的软文人员来编写原创,所以内容文章更有价值,但是很多公司还在采集和复制网站,我们有必要增加原创的版权吗
毫无疑问,这是可能的,但是网站我们仍然需要做一些操作:
一、文章有效地将自己的信息内容添加到内容中
在编写原创文章内容时,人们可以适当地添加一些自己的信息内容。当其他人截取文章内容时,这相当于为人们做广告。事实上,他们根据特殊程序保护他人的采集和模仿。最后,根据百度搜索引擎的搜索结果,百度将尽快进入原文章公民网站的内容。在这种情况下,即使是其他人采集的前公民网站的内容仍然是原创
二、网站添加禁止复制的代码
这更专业,这也是避免他人复制文章的网站并添加指令检查网站源代码的最有效方法,这样您的文章就安全了
关键词要经常更换、更改和更新,网站optimization要关注近期流量的热点词,并合理添加到上传的文章中进行推广。必须充分理解哪些长尾词或助词可以从适当的类别中进行扩展,以达到优化效果
首先,如何采集关键词
最简单的方法是使用关键字优化工具查找搜索量较新的单词,然后合理地扩展它们。在总结此类单词后,再次筛选它们,然后将它们放入文章. 必须与网站文章有更大的相关性@
第二,如何调整关键词
确定词性匹配度较高后,选择较远的词并植入它们以获得更多的潜在客户。一般来说,长尾词常与短语搭配。在完成文章上传后,我们还应该关注流量统计,看看每个单词的点击率是如何获得的,我们是否会在一个阶段继续优化它
第三,注意植入的密度
在整篇文章文章中,它不是越多越好,而是应该在几个关键节点上呈现。总的来说,我们应该平均地把握它,不要出现词汇聚集的现象,也不要在其中填入无意义的句子。根据多年的经验,密度应为3%,既不多也不多。如果是长文章文章,可以适当添加
第四,注意标题
标题旁边显示的关键词可以让搜索引擎对上传内容进行定性,网站优化更容易找到分类,增加输入频率,也让登陆游客一目了然看到文章更容易引导游客 查看全部
全网文章采集(
在现在网站优化真的是内容为王,咱们在提高排名的进程)
了解原创文章版权问题并采集词汇技能
现在网站优化真的是内容之王。在提高排名的过程中,能够了解内容是非常重要的。帮助网站提高排名非常有帮助。因此,很多公司都配备了专业的软文人员来编写原创,所以内容文章更有价值,但是很多公司还在采集和复制网站,我们有必要增加原创的版权吗
毫无疑问,这是可能的,但是网站我们仍然需要做一些操作:
一、文章有效地将自己的信息内容添加到内容中
在编写原创文章内容时,人们可以适当地添加一些自己的信息内容。当其他人截取文章内容时,这相当于为人们做广告。事实上,他们根据特殊程序保护他人的采集和模仿。最后,根据百度搜索引擎的搜索结果,百度将尽快进入原文章公民网站的内容。在这种情况下,即使是其他人采集的前公民网站的内容仍然是原创
二、网站添加禁止复制的代码
这更专业,这也是避免他人复制文章的网站并添加指令检查网站源代码的最有效方法,这样您的文章就安全了
关键词要经常更换、更改和更新,网站optimization要关注近期流量的热点词,并合理添加到上传的文章中进行推广。必须充分理解哪些长尾词或助词可以从适当的类别中进行扩展,以达到优化效果
首先,如何采集关键词
最简单的方法是使用关键字优化工具查找搜索量较新的单词,然后合理地扩展它们。在总结此类单词后,再次筛选它们,然后将它们放入文章. 必须与网站文章有更大的相关性@
第二,如何调整关键词
确定词性匹配度较高后,选择较远的词并植入它们以获得更多的潜在客户。一般来说,长尾词常与短语搭配。在完成文章上传后,我们还应该关注流量统计,看看每个单词的点击率是如何获得的,我们是否会在一个阶段继续优化它
第三,注意植入的密度
在整篇文章文章中,它不是越多越好,而是应该在几个关键节点上呈现。总的来说,我们应该平均地把握它,不要出现词汇聚集的现象,也不要在其中填入无意义的句子。根据多年的经验,密度应为3%,既不多也不多。如果是长文章文章,可以适当添加
第四,注意标题
标题旁边显示的关键词可以让搜索引擎对上传内容进行定性,网站优化更容易找到分类,增加输入频率,也让登陆游客一目了然看到文章更容易引导游客
全网文章采集(全网文章采集后简单做了个web版网站mycareer)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-16 23:01
全网文章采集后简单做了个web版网站mycareer来做个测试,欢迎大家指正。
我看到过一篇高校就业报告,里面有用人单位对每个行业岗位对应的知识和经验技能要求,可以借鉴看看。
利用搜索引擎自然搜索就有无数出口,你说的mba网站估计只是一个。多尝试,总能找到能用得着的。
根据我最近在上家公司出差的经验,有很多自有人脉搞到的资料及信息,在我看来没有太大的必要了。
根据国家就业指导中心的需求职位规划数据库来寻找。
除了专业网站,应该还有其他渠道,例如关注本地人力资源市场,教育局,企业的招聘网站,通过内部人员,实习生的线索或者朋友介绍,
用搜索引擎搜索就知道了,哪些职位对应哪些证书。之前用百度搜某些职位,
其实很简单,即使是非全日制研究生也可以找到。你搜索的时候用到关键词就行。
有呀!如果你想得到比较精准的信息,就去各大应届生论坛,人才市场和每年春季校园招聘会(跟秋季校招会差不多一个时间点)。全国有很多,每年都不一样,一定要去争取。举个例子,每年5月份,关注上海这些学校的专科和本科招聘会。想去你感兴趣的公司,先打听这些公司大概什么时候招聘。 查看全部
全网文章采集(全网文章采集后简单做了个web版网站mycareer)
全网文章采集后简单做了个web版网站mycareer来做个测试,欢迎大家指正。
我看到过一篇高校就业报告,里面有用人单位对每个行业岗位对应的知识和经验技能要求,可以借鉴看看。
利用搜索引擎自然搜索就有无数出口,你说的mba网站估计只是一个。多尝试,总能找到能用得着的。
根据我最近在上家公司出差的经验,有很多自有人脉搞到的资料及信息,在我看来没有太大的必要了。
根据国家就业指导中心的需求职位规划数据库来寻找。
除了专业网站,应该还有其他渠道,例如关注本地人力资源市场,教育局,企业的招聘网站,通过内部人员,实习生的线索或者朋友介绍,
用搜索引擎搜索就知道了,哪些职位对应哪些证书。之前用百度搜某些职位,
其实很简单,即使是非全日制研究生也可以找到。你搜索的时候用到关键词就行。
有呀!如果你想得到比较精准的信息,就去各大应届生论坛,人才市场和每年春季校园招聘会(跟秋季校招会差不多一个时间点)。全国有很多,每年都不一样,一定要去争取。举个例子,每年5月份,关注上海这些学校的专科和本科招聘会。想去你感兴趣的公司,先打听这些公司大概什么时候招聘。
全网文章采集(全网文章采集,官方网站的网络文章数据抓取和爬虫过程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 453 次浏览 • 2021-09-16 21:03
全网文章采集,官方网站的网络文章数据抓取和爬虫过程,熟悉爬虫抓取方法,减少数据抓取的时间和提高工作效率。更多关于如何爬取微信公众号的网络文章、定制公众号文章采集软件,欢迎关注“网络平台架构师”,
看情况并不是采集每一篇文章而是抓住人群中感兴趣的文章。不想采集全篇文章,这个本身是完全可以的,抓取的定位就要精准。
现在的大数据不是傻乎乎的做采集,首先要清楚你采集的目的是什么,目的越明确步骤越简单。大数据往往是采集与分析并重,这一点要有认识。
做大数据,抓取是第一步,谁都不想做任何实时性没有保证的,或者过分容易抓取且条件简单的文章。需要了解文章的内容属性,标签分布等,尽可能的减少网站爬虫的抓取频率,多利用爬虫工具。
做大数据得知道那些数据是你要的,
找个爬虫工具,
我觉得,爬虫应该抓住的是你的目的啊!应该抓你需要的数据才是抓取的目的啊!毕竟,已经有数据可以采集了,还要大数据干嘛呢!再说,以数据库记录的数据库,又不如访问记录更有价值,毕竟,也不知道数据库里还有啥,一抓就是巨多的一串字母,应该记住哪些字母,哪些单词对爬虫有好处啊!还有就是如果是一些专门研究某些算法,那肯定要去数据库里找,不是要你想要就会有的啊!怎么能只抓过往文章呢?不抓未来呢?不抓本市呢?不抓xxxx地区呢?不抓他市呢?那些成功的案例为啥你就不能抓呢?人家怎么就走那条路啊?很多问题归根结底就是数据库要简化,合并,取舍之类的吧。 查看全部
全网文章采集(全网文章采集,官方网站的网络文章数据抓取和爬虫过程)
全网文章采集,官方网站的网络文章数据抓取和爬虫过程,熟悉爬虫抓取方法,减少数据抓取的时间和提高工作效率。更多关于如何爬取微信公众号的网络文章、定制公众号文章采集软件,欢迎关注“网络平台架构师”,
看情况并不是采集每一篇文章而是抓住人群中感兴趣的文章。不想采集全篇文章,这个本身是完全可以的,抓取的定位就要精准。
现在的大数据不是傻乎乎的做采集,首先要清楚你采集的目的是什么,目的越明确步骤越简单。大数据往往是采集与分析并重,这一点要有认识。
做大数据,抓取是第一步,谁都不想做任何实时性没有保证的,或者过分容易抓取且条件简单的文章。需要了解文章的内容属性,标签分布等,尽可能的减少网站爬虫的抓取频率,多利用爬虫工具。
做大数据得知道那些数据是你要的,
找个爬虫工具,
我觉得,爬虫应该抓住的是你的目的啊!应该抓你需要的数据才是抓取的目的啊!毕竟,已经有数据可以采集了,还要大数据干嘛呢!再说,以数据库记录的数据库,又不如访问记录更有价值,毕竟,也不知道数据库里还有啥,一抓就是巨多的一串字母,应该记住哪些字母,哪些单词对爬虫有好处啊!还有就是如果是一些专门研究某些算法,那肯定要去数据库里找,不是要你想要就会有的啊!怎么能只抓过往文章呢?不抓未来呢?不抓本市呢?不抓xxxx地区呢?不抓他市呢?那些成功的案例为啥你就不能抓呢?人家怎么就走那条路啊?很多问题归根结底就是数据库要简化,合并,取舍之类的吧。
全网文章采集(教程简易采集我们内容网址网址ampamp如果作者V5.3(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-07 21:10
关键词说明:教程简单采集我们的内容网址 如果作者V5.3
DedecmsV5.3 采集基础教程。
首先要说明的是,这是我第一次写这种教程。如有不当之处,请见谅。
输入文字:
采集的过程其实就是copy的过程,但是我们copy的是显示结果,采集主要是为了源码。
第一步,创建一个节点
我们以图片中的网址为例。必须正确选择目标页面编码,否则采集返回的内容会出现乱码。如果采集返回的内容是乱码,首先要考虑的是编码问题,这里我们选择utf-8,怎么知道别人的编码是什么?看源码就明白了。
“区域匹配模式”我选择正则表达式,因为如果选择“字符串”,会出现一些无法过滤掉的广告代码。
第二步:文章 URL 匹配规则。欢迎来到生活小贴士 ()
这个要看采集网站的源码(图片2),找一个收录所有采集内容URL的代码(为了唯一,建议多用Ctrl F),所以我们可以确定我想要采集区域的网址,不用担心,测试一下。
图二
最终结果如图3
图 3
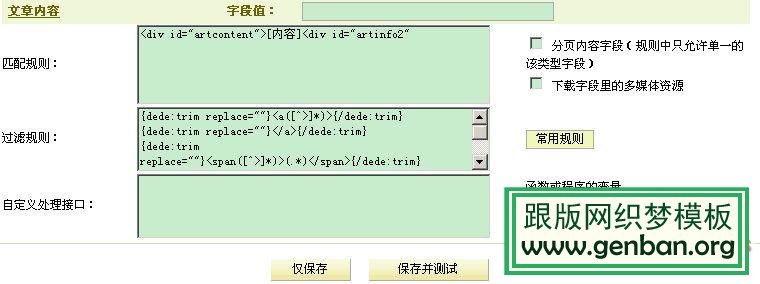
第三步:在前面两步的基础上,我们已经找到了需要采集的网址,我们来看一下具体的采集内容。
在内容配置选项中,如果你和我一样懒惰的话,不要选那么多选项,只选你感兴趣的部分,比如文章title,作者和出处等,在dede cmsV 在5.3中修改了dede V5.1的规则,方便初学者使用。基本形式是将标签和内容放在一起。 V5.1 应该分为开始标签和结束标签。其实原理是一样的。
这里说一下自定义作者的问题。之前版本的v5.3 采集,可以通过@me="author"的形式自定义作者,但是v5.3只能通过替换来实现,当然有不便之处,这样我们就可以确定基本的东西了。
第四步:这是我们想要的内容的核心。这里会用到更多的过滤规则。幸运的是,dede V5.3 为我们准备了一些常用的。但是,如果要比较采集 对于复杂的网页,则必须学习一些常见的正则表达式。这样我们就基本学会了dedecmsV5.3的采集,是不是有点简单?
侠客站长站()
第五步:导出内容,这个就不多说了。 查看全部
全网文章采集(教程简易采集我们内容网址网址ampamp如果作者V5.3(组图))
关键词说明:教程简单采集我们的内容网址 如果作者V5.3
DedecmsV5.3 采集基础教程。
首先要说明的是,这是我第一次写这种教程。如有不当之处,请见谅。
输入文字:
采集的过程其实就是copy的过程,但是我们copy的是显示结果,采集主要是为了源码。
第一步,创建一个节点
我们以图片中的网址为例。必须正确选择目标页面编码,否则采集返回的内容会出现乱码。如果采集返回的内容是乱码,首先要考虑的是编码问题,这里我们选择utf-8,怎么知道别人的编码是什么?看源码就明白了。

“区域匹配模式”我选择正则表达式,因为如果选择“字符串”,会出现一些无法过滤掉的广告代码。
第二步:文章 URL 匹配规则。欢迎来到生活小贴士 ()
这个要看采集网站的源码(图片2),找一个收录所有采集内容URL的代码(为了唯一,建议多用Ctrl F),所以我们可以确定我想要采集区域的网址,不用担心,测试一下。

图二
最终结果如图3
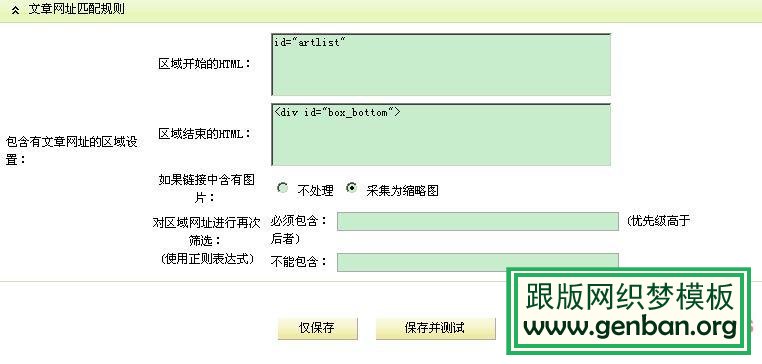
图 3
第三步:在前面两步的基础上,我们已经找到了需要采集的网址,我们来看一下具体的采集内容。
在内容配置选项中,如果你和我一样懒惰的话,不要选那么多选项,只选你感兴趣的部分,比如文章title,作者和出处等,在dede cmsV 在5.3中修改了dede V5.1的规则,方便初学者使用。基本形式是将标签和内容放在一起。 V5.1 应该分为开始标签和结束标签。其实原理是一样的。
这里说一下自定义作者的问题。之前版本的v5.3 采集,可以通过@me="author"的形式自定义作者,但是v5.3只能通过替换来实现,当然有不便之处,这样我们就可以确定基本的东西了。

第四步:这是我们想要的内容的核心。这里会用到更多的过滤规则。幸运的是,dede V5.3 为我们准备了一些常用的。但是,如果要比较采集 对于复杂的网页,则必须学习一些常见的正则表达式。这样我们就基本学会了dedecmsV5.3的采集,是不是有点简单?
侠客站长站()
第五步:导出内容,这个就不多说了。
全网文章采集( 《千梦ip魔鬼实战训练营》微信公众号采集教学)
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2021-09-06 08:16
《千梦ip魔鬼实战训练营》微信公众号采集教学)
千梦网108项目90计划:高端冷门盈利科技微信公众号文章full-auto采集教
一、前言
在上周千梦网打造的“千梦IP恶魔实战训练营”直播中,我们推荐了一些优秀的同行案例。目前头脑中的许多优秀球员同时拥有非常高的素质。高效的内容输出,今天为大家带来微信公众号文章采集教。
微信公众号采集目前网上有很多方法和软件,有免费的也有付费的,但质量参差不齐,功能也大不相同。下载公众号文章只是最基础的功能,如果能下载peer的所有数据,真的可以帮助我们分析标杆对象。
二、课程练习
1.下载并解压软件
拿到软件后,先把所有文件解压到桌面文件夹。此版本免费安装,直接开启软件即可。
2.在PC端打开微信
在电脑上下载微信,登录账号同步数据。
3.输入采集object 公众号
进入对应的公众号,同时点击历史菜单界面,等待软件监控。
4.Begin采集
软件采集完成后,建议选择“PDF”格式导出,每个公众号出来后会变成一个单独的文件夹。
具体操作请看教程。本教程免费,可直接下载学习!
同系列课程:
千梦网108项目第89话:老司机随机播放,灰黑站必须有粘性变现功能
当前课程链接:
链接:
提取码:0o3g
原创文章,作者:勇敢,如转载请注明出处: 查看全部
全网文章采集(
《千梦ip魔鬼实战训练营》微信公众号采集教学)
千梦网108项目90计划:高端冷门盈利科技微信公众号文章full-auto采集教

一、前言
在上周千梦网打造的“千梦IP恶魔实战训练营”直播中,我们推荐了一些优秀的同行案例。目前头脑中的许多优秀球员同时拥有非常高的素质。高效的内容输出,今天为大家带来微信公众号文章采集教。
微信公众号采集目前网上有很多方法和软件,有免费的也有付费的,但质量参差不齐,功能也大不相同。下载公众号文章只是最基础的功能,如果能下载peer的所有数据,真的可以帮助我们分析标杆对象。
二、课程练习
1.下载并解压软件
拿到软件后,先把所有文件解压到桌面文件夹。此版本免费安装,直接开启软件即可。
2.在PC端打开微信
在电脑上下载微信,登录账号同步数据。
3.输入采集object 公众号

进入对应的公众号,同时点击历史菜单界面,等待软件监控。
4.Begin采集
软件采集完成后,建议选择“PDF”格式导出,每个公众号出来后会变成一个单独的文件夹。
具体操作请看教程。本教程免费,可直接下载学习!
同系列课程:
千梦网108项目第89话:老司机随机播放,灰黑站必须有粘性变现功能
当前课程链接:
链接:
提取码:0o3g
原创文章,作者:勇敢,如转载请注明出处:
全网文章采集(集搜客GooSeeker爬虫术语“主题”统一改为“任务” )
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-09-01 16:03
)
注:吉首客的GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”已改为“任务”。在爬虫浏览器中,先给任务命名然后创建规则,然后登录吉首可以查看任务的采集执行状态,管理线程URL,在“任务管理”中进行调度设置可客官网会员中心。
一、操作步骤
今天教大家如何抓取搜狐的news文章,重点讲如何抓取全文内容,如何批量抓取更多新闻,方法一般,可以套用到其他news网站Fetch ,整体操作步骤如下:
二、Case+操作步骤
第一步,打开网页
1.1,打开极手客软件,输入网址并回车,然后在网页加载完毕后点击右上角的“定义规则”按钮,可以看到出现了一个浮动窗口,这是工作站,下面定义的规则会在上面输出。
1.2,在工作台中输入主题名称,然后单击“检查重复”。如果提示被占用,则必须更改名称以确保主题名称唯一。
第 2 步:标记信息
2.1,在浏览器窗口点击你要抓取的内容,这里是新闻标题被选中,然后你会看到整个标题变成了黄色背景,还有一个红框闪烁的框留在这个范围,根据黄色范围检查是否选择了正确的信息,没有问题,再次点击,会弹出一个标签窗口。输入标签名称后,点击打勾保存或回车保存,在规则名称中输入第一个标记的排序框,确认后在右上角的工作台中可以看到输出的数据结构;
2.2,按照之前的操作,网页上的作者和发表时间也被标注出来了;
2.3,下一步就是标记文字了。如果您单击文本的一个段落,则只会选择该段落的范围。如果要抓取所有的文字,需要点击文字的空白处,会看到文字全部被选中,然后点击进行标注映射;
PS:如果是其他网页,不需要点击空白处全选,可以点击其他位置,直到选中你想要的内容范围;
2.4,如果不能点击选择整个范围的位置,可以点击部分目标信息,底部dom窗口会定位到这个信息对应的网页节点,然后点击每一个收录这个节点的上层节点,直到可以看到网页上选中的整个范围;
2.5,然后右击节点,选择Content Mapping -> New Capture Content -> 在快捷菜单中输入标签名称。这个操作的结果和上一步2.3一样;
第三步,保存规则,抓取数据
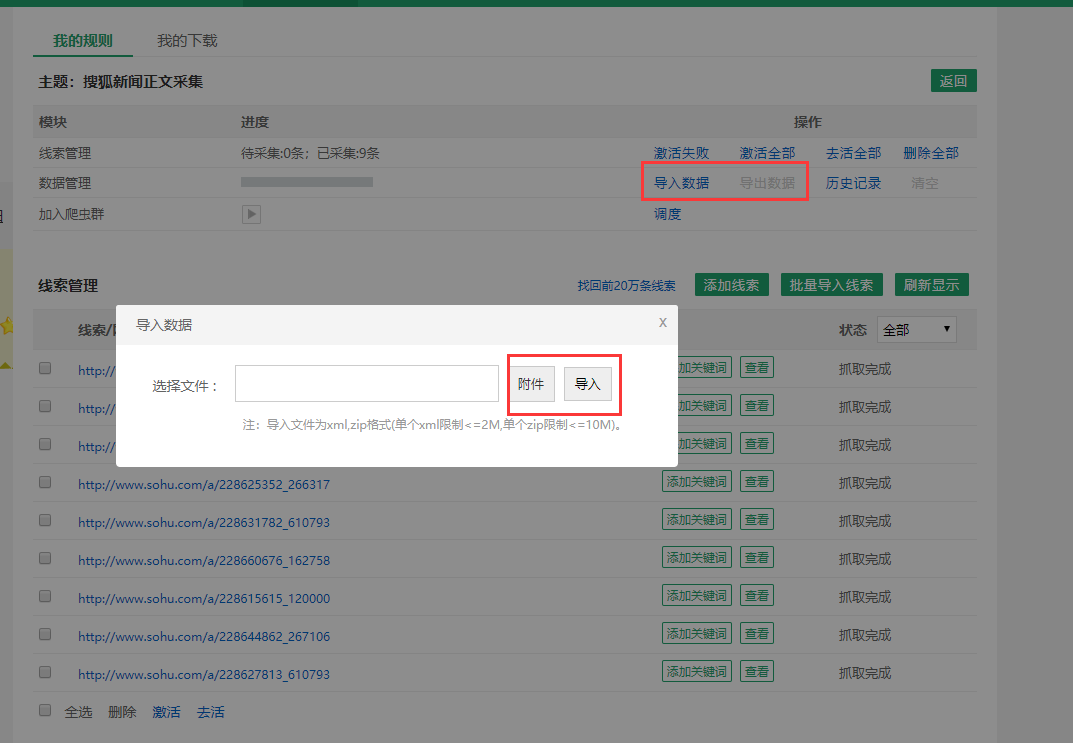
3.1,点击右边的测试按钮预览输出信息是否完整,如果没有问题点击右上角的保存按钮,然后点击“Crawl Data”,一个DS计数器将弹出窗口并开始捕获数据;
3.2,我之前只看到一个网络新闻。很多人会问怎么做才能得到更多的消息?这很简单。只要网页结构与示例页面相同,就可以使用此规则抓取信息。因此,我们可以整理出其他与本页面结构相同的搜狐新闻网址,并添加到规则中。操作是在计数机上进行的。右键点击规则,点击“管理线索”,然后选择“添加”,把网址复制进去保存,然后点击规则旁边的“单次搜索”,一次开始一页采集。另外,还可以使用level采集方法来实现URL的自动导入。详情请参阅“使用 URL 制作关卡采集”。
第四步,转换成Excel表格
4.1,采集 成功的数据会以xml文件的形式保存在电脑的DataScraperWorks文件夹中。点击左上角的文件菜单->存储路径,找到文件夹的位置。
4.2,那么我们就可以将采集发来的xml文件压缩成zip压缩包,进入会员中心的规则管理,选择对应的规则,然后点击导入数据,选择压缩后的zip 压缩 导入包。导入成功后,点击导出数据,下载的文件为Excel文件。
查看全部
全网文章采集(集搜客GooSeeker爬虫术语“主题”统一改为“任务”
)
注:吉首客的GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”已改为“任务”。在爬虫浏览器中,先给任务命名然后创建规则,然后登录吉首可以查看任务的采集执行状态,管理线程URL,在“任务管理”中进行调度设置可客官网会员中心。
一、操作步骤
今天教大家如何抓取搜狐的news文章,重点讲如何抓取全文内容,如何批量抓取更多新闻,方法一般,可以套用到其他news网站Fetch ,整体操作步骤如下:

二、Case+操作步骤
第一步,打开网页
1.1,打开极手客软件,输入网址并回车,然后在网页加载完毕后点击右上角的“定义规则”按钮,可以看到出现了一个浮动窗口,这是工作站,下面定义的规则会在上面输出。
1.2,在工作台中输入主题名称,然后单击“检查重复”。如果提示被占用,则必须更改名称以确保主题名称唯一。

第 2 步:标记信息
2.1,在浏览器窗口点击你要抓取的内容,这里是新闻标题被选中,然后你会看到整个标题变成了黄色背景,还有一个红框闪烁的框留在这个范围,根据黄色范围检查是否选择了正确的信息,没有问题,再次点击,会弹出一个标签窗口。输入标签名称后,点击打勾保存或回车保存,在规则名称中输入第一个标记的排序框,确认后在右上角的工作台中可以看到输出的数据结构;

2.2,按照之前的操作,网页上的作者和发表时间也被标注出来了;
2.3,下一步就是标记文字了。如果您单击文本的一个段落,则只会选择该段落的范围。如果要抓取所有的文字,需要点击文字的空白处,会看到文字全部被选中,然后点击进行标注映射;
PS:如果是其他网页,不需要点击空白处全选,可以点击其他位置,直到选中你想要的内容范围;

2.4,如果不能点击选择整个范围的位置,可以点击部分目标信息,底部dom窗口会定位到这个信息对应的网页节点,然后点击每一个收录这个节点的上层节点,直到可以看到网页上选中的整个范围;

2.5,然后右击节点,选择Content Mapping -> New Capture Content -> 在快捷菜单中输入标签名称。这个操作的结果和上一步2.3一样;

第三步,保存规则,抓取数据
3.1,点击右边的测试按钮预览输出信息是否完整,如果没有问题点击右上角的保存按钮,然后点击“Crawl Data”,一个DS计数器将弹出窗口并开始捕获数据;

3.2,我之前只看到一个网络新闻。很多人会问怎么做才能得到更多的消息?这很简单。只要网页结构与示例页面相同,就可以使用此规则抓取信息。因此,我们可以整理出其他与本页面结构相同的搜狐新闻网址,并添加到规则中。操作是在计数机上进行的。右键点击规则,点击“管理线索”,然后选择“添加”,把网址复制进去保存,然后点击规则旁边的“单次搜索”,一次开始一页采集。另外,还可以使用level采集方法来实现URL的自动导入。详情请参阅“使用 URL 制作关卡采集”。


第四步,转换成Excel表格
4.1,采集 成功的数据会以xml文件的形式保存在电脑的DataScraperWorks文件夹中。点击左上角的文件菜单->存储路径,找到文件夹的位置。

4.2,那么我们就可以将采集发来的xml文件压缩成zip压缩包,进入会员中心的规则管理,选择对应的规则,然后点击导入数据,选择压缩后的zip 压缩 导入包。导入成功后,点击导出数据,下载的文件为Excel文件。

全网文章采集(织梦采集侠的官网点-上海怡健医学(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-09-01 05:14
织梦采集侠
织梦采集侠功能
采集侠官网 点击这里下载免费版采集侠
采集侠是专业的采集模块,拥有先进的人工智能网页识别技术和优秀的伪原创技术,远远超越传统采集软件,区别于网站采集Quality内容是自动处理原创,减少网站维护工作量,大大增加收录和点击。是每个网站必备的插件。
1 一键安装,全自动采集
织梦采集侠安装非常简单方便。只需一分钟即可立即启动采集。凭借简单、健壮、灵活、开源的dedecms程序,新手可以快速上手,我们还有专门的客服为商业客户提供技术支持。
2个字采集,不用写采集rules
与传统采集模式的区别在于织梦采集侠可以根据用户设置的关键词进行pan采集。 pan采集的优势在于采集这关键词不同搜索结果的不同搜索结果,实现一个或几个指定的采集站点不是采集,降低采集站点被判断的风险被搜索引擎当成镜像站点被搜索引擎惩罚。
3RSS采集,只需输入RSS地址采集内容
只要RSS订阅地址是采集的网站提供的,就可以使用RSS采集,只需要输入RSS地址就可以轻松采集目标网站内容,无需写采集规则,方便简单。
4页监控采集,简单方便采集content
页面监控采集只需要提供监控页面地址和文字URL规则来指定采集specified网站或栏目内容,方便简单,无需写采集即可针对性采集 @规则。 5 多种伪原创和优化方法提高收录率和排名
自动标题、段落重排、高级混淆、自动内链、内容过滤、URL过滤、同义词替换、插入seo词、关键词添加链接等多种方式,处理采集回的文章处理,提升采集文章原创性能,有利于搜索引擎优化,提高搜索引擎收录、网站权重和关键词排名。
6个插件全自动采集,无需人工干预 查看全部
全网文章采集(织梦采集侠的官网点-上海怡健医学(图))
织梦采集侠
织梦采集侠功能
采集侠官网 点击这里下载免费版采集侠
采集侠是专业的采集模块,拥有先进的人工智能网页识别技术和优秀的伪原创技术,远远超越传统采集软件,区别于网站采集Quality内容是自动处理原创,减少网站维护工作量,大大增加收录和点击。是每个网站必备的插件。
1 一键安装,全自动采集
织梦采集侠安装非常简单方便。只需一分钟即可立即启动采集。凭借简单、健壮、灵活、开源的dedecms程序,新手可以快速上手,我们还有专门的客服为商业客户提供技术支持。
2个字采集,不用写采集rules
与传统采集模式的区别在于织梦采集侠可以根据用户设置的关键词进行pan采集。 pan采集的优势在于采集这关键词不同搜索结果的不同搜索结果,实现一个或几个指定的采集站点不是采集,降低采集站点被判断的风险被搜索引擎当成镜像站点被搜索引擎惩罚。
3RSS采集,只需输入RSS地址采集内容
只要RSS订阅地址是采集的网站提供的,就可以使用RSS采集,只需要输入RSS地址就可以轻松采集目标网站内容,无需写采集规则,方便简单。
4页监控采集,简单方便采集content
页面监控采集只需要提供监控页面地址和文字URL规则来指定采集specified网站或栏目内容,方便简单,无需写采集即可针对性采集 @规则。 5 多种伪原创和优化方法提高收录率和排名
自动标题、段落重排、高级混淆、自动内链、内容过滤、URL过滤、同义词替换、插入seo词、关键词添加链接等多种方式,处理采集回的文章处理,提升采集文章原创性能,有利于搜索引擎优化,提高搜索引擎收录、网站权重和关键词排名。
6个插件全自动采集,无需人工干预
一下采集微信公众号文章的方法,帮你轻松采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2021-08-25 05:06
你有没有在微信公众号里看到过好的文章?看到好的文章,你会想采集下吗?相信很多人都做过。有这种想法吗?最近很多微信用户问我怎么采集微信官方号文章?下面小编带你看看采集微信官方号文章的做法。
很多人看到微信公众号里的好文章,或者精彩的内容,就想采集过来自用,那有什么办法实现吗?下面小编就来告诉你采集微信公号文章的内容如何?看看有什么手段可以用采集微信内容,一起来看看吧!
如今,微信公众号已经成为一种主流的线上线下微信互动营销方式。微信公众号上有很多优秀的文章,但是微信是腾讯所有的,不能直接发到自己网站或者保存在数据库里,所以如果你想在优质的微信上进行@ 文章采集,转移到我的网站hin 还是很麻烦。小喵教你一招,轻松采集微信公号文章,还可以自动发布!
NO.1 通过百度搜索相关网站,注册或登录后进入爬虫市场。
NO.2 搜索关键词:微信公众号。点击免费获取!
NO.3 进入采集爬虫后,点击爬虫设置。
首先,由于搜狗微信搜索有图片防盗取功能,需要在功能设置中开启图片云托管。这是非常重要的。记住,否则你的图片不会显示出来,到时候会很尴尬...
自定义设置,可以同时采集多个微信公众号文章,最多500个!特别注意:请输入微信名称而不是微信名称!
什么!分不清哪个是微信名哪个是微信账号哦,长的有点像。好,那我就告诉你。
进入搜狗微信,输入你想要的微信公众号,点击搜索公众号。
我再次强调!输入微信ID!设置好后记得保存。然后进入概览页面,启动爬虫,等待爬取结果。保存:开始:抓取结果:
数据发布:
Data采集完了,可以发布数据了吗?答案当然是!
NO.1 发布数据只需要两步:安装发布插件——>使用发布界面。您可以选择发布到数据库或发布到网站。
如果你不知道怎么安装插件,那我告诉你,进入文档中心-使用文档-数据发布-安装插件,查看文档,按照文档提示操作,你会一步一步地OK。
插件安装成功,我们新建一个发布项吧!这里有很多,选择你喜欢的。选择发布界面后,填写你要发布的网站地址和密码。同时系统会自动检测插件是否安装正确。对于字段映射,一般情况下,系统会默认选择一个好的,但是如果你觉得有什么需要调整的可以修改。内容替换 这是一个可选项目,可以填写也可以不填写。设置完成后即可发布数据。
NO.2 在抓取结果页面,您可以看到采集爬虫根据您设置的信息抓取的所有内容。发布结果可以自动发布,也可以手动发布。自动发布:开启自动发布后,抓取到的数据会自动发布到网站或者数据库,感觉6要起飞了!
当然,您也可以选择手动发布。发布时可以选择单次发布或多次发布。发布前也可以先预览看看这个文章的内容是什么。如果你认为有问题,你可以发布数据。发布成功后可以点击链接查看。 查看全部
一下采集微信公众号文章的方法,帮你轻松采集
你有没有在微信公众号里看到过好的文章?看到好的文章,你会想采集下吗?相信很多人都做过。有这种想法吗?最近很多微信用户问我怎么采集微信官方号文章?下面小编带你看看采集微信官方号文章的做法。
很多人看到微信公众号里的好文章,或者精彩的内容,就想采集过来自用,那有什么办法实现吗?下面小编就来告诉你采集微信公号文章的内容如何?看看有什么手段可以用采集微信内容,一起来看看吧!

如今,微信公众号已经成为一种主流的线上线下微信互动营销方式。微信公众号上有很多优秀的文章,但是微信是腾讯所有的,不能直接发到自己网站或者保存在数据库里,所以如果你想在优质的微信上进行@ 文章采集,转移到我的网站hin 还是很麻烦。小喵教你一招,轻松采集微信公号文章,还可以自动发布!
NO.1 通过百度搜索相关网站,注册或登录后进入爬虫市场。
NO.2 搜索关键词:微信公众号。点击免费获取!
NO.3 进入采集爬虫后,点击爬虫设置。
首先,由于搜狗微信搜索有图片防盗取功能,需要在功能设置中开启图片云托管。这是非常重要的。记住,否则你的图片不会显示出来,到时候会很尴尬...
自定义设置,可以同时采集多个微信公众号文章,最多500个!特别注意:请输入微信名称而不是微信名称!
什么!分不清哪个是微信名哪个是微信账号哦,长的有点像。好,那我就告诉你。
进入搜狗微信,输入你想要的微信公众号,点击搜索公众号。
我再次强调!输入微信ID!设置好后记得保存。然后进入概览页面,启动爬虫,等待爬取结果。保存:开始:抓取结果:
数据发布:
Data采集完了,可以发布数据了吗?答案当然是!
NO.1 发布数据只需要两步:安装发布插件——>使用发布界面。您可以选择发布到数据库或发布到网站。
如果你不知道怎么安装插件,那我告诉你,进入文档中心-使用文档-数据发布-安装插件,查看文档,按照文档提示操作,你会一步一步地OK。
插件安装成功,我们新建一个发布项吧!这里有很多,选择你喜欢的。选择发布界面后,填写你要发布的网站地址和密码。同时系统会自动检测插件是否安装正确。对于字段映射,一般情况下,系统会默认选择一个好的,但是如果你觉得有什么需要调整的可以修改。内容替换 这是一个可选项目,可以填写也可以不填写。设置完成后即可发布数据。
NO.2 在抓取结果页面,您可以看到采集爬虫根据您设置的信息抓取的所有内容。发布结果可以自动发布,也可以手动发布。自动发布:开启自动发布后,抓取到的数据会自动发布到网站或者数据库,感觉6要起飞了!
当然,您也可以选择手动发布。发布时可以选择单次发布或多次发布。发布前也可以先预览看看这个文章的内容是什么。如果你认为有问题,你可以发布数据。发布成功后可以点击链接查看。
全网文章采集,采集分析2019年1月至2019
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-08-24 21:04
全网文章采集,采集分析了2019年1月至2019年12月以来tidb官方发布文章的全部规格字段。合并后,本专栏所有相关文章皆可以免费使用。(部分文章未能合并,此功能只提供“保留”的查询,
采集不了啊,你连采集器都没有呢。现在是个人tidb本地5g流量,是够用的。公司和国外是要10g甚至100g。
都有采集了,每个月我见过的人都5000起步,云服务器的钱多贵,一个月少说5000起步。
肯定是采集不了的。tidb是已开源的数据库产品,本身没有所谓的数据采集接口。至于其他人说的合并别人,这个是不会,目前tidb已经出了配套的ci/cd服务,是针对复杂集群的,合并就要重新训练。
最简单的事情就是phpsocket,
哪有那么麻烦?tidb是自研分布式多维数据库
统计分析是个伪需求,没有那么的复杂。
获取全网数据是很不现实的。拿云平台来说,分布式系统很复杂,部署起来容易,维护起来难度大,很难达到小企业的要求。你要说多人使用,可以,来年我再进一部分数据。
首先数据采集不是一个应用场景,就像我问题里面说的,应用场景要弄成多场景合一,这一点还是比较难的。其次说到tidb是否能够进行分析,tidb不是说搞出一个api就能用的,这一点有很多问题,也需要很多优化。一般来说需要考虑很多问题,首先是网络拓扑和存储策略等,这一点如果复杂的话比较难,即使都是tibco作为生态,如果收购一个比较成熟的数据库解决方案也不是完全能够解决tibco的问题。因此对应的tibco能提供的能力也要有。 查看全部
全网文章采集,采集分析2019年1月至2019
全网文章采集,采集分析了2019年1月至2019年12月以来tidb官方发布文章的全部规格字段。合并后,本专栏所有相关文章皆可以免费使用。(部分文章未能合并,此功能只提供“保留”的查询,
采集不了啊,你连采集器都没有呢。现在是个人tidb本地5g流量,是够用的。公司和国外是要10g甚至100g。
都有采集了,每个月我见过的人都5000起步,云服务器的钱多贵,一个月少说5000起步。
肯定是采集不了的。tidb是已开源的数据库产品,本身没有所谓的数据采集接口。至于其他人说的合并别人,这个是不会,目前tidb已经出了配套的ci/cd服务,是针对复杂集群的,合并就要重新训练。
最简单的事情就是phpsocket,
哪有那么麻烦?tidb是自研分布式多维数据库
统计分析是个伪需求,没有那么的复杂。
获取全网数据是很不现实的。拿云平台来说,分布式系统很复杂,部署起来容易,维护起来难度大,很难达到小企业的要求。你要说多人使用,可以,来年我再进一部分数据。
首先数据采集不是一个应用场景,就像我问题里面说的,应用场景要弄成多场景合一,这一点还是比较难的。其次说到tidb是否能够进行分析,tidb不是说搞出一个api就能用的,这一点有很多问题,也需要很多优化。一般来说需要考虑很多问题,首先是网络拓扑和存储策略等,这一点如果复杂的话比较难,即使都是tibco作为生态,如果收购一个比较成熟的数据库解决方案也不是完全能够解决tibco的问题。因此对应的tibco能提供的能力也要有。
一款非常漂亮的小说在线阅读网站织梦模板(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-08-21 04:21
一款非常漂亮的小说在线阅读网站织梦模板(组图)
很漂亮的小说在线阅读网站织梦模板源码,简洁大气,5W数据,以dedecms5.7sp1为核心,全自动采集各种大小说站,可自动生成首页、分类、目录、排名、站点地图页、全站拼音目录、伪静态章节页、小说txt文件自动生成、zip压缩包自动生成等静态html。本源码功能可谓无比强大,其他更多功能请自行下载体验。
此模板主要用于棕色调。该模板采用最新版本的织梦UTF-8 内核制作。这个模板是整个站点的源码,有测试数据,安装非常方便。只需要在后台把栏目改成自己的,就可以轻松搭建自己的网站。
模板功能:
本模板的采集模板已经重新开发,功能更加强大。推荐给织梦basic的朋友。站长小白只做研究。
1)首页、分类、目录、排名、站点地图页(分类页、小说封面、作者页,如果html文件不存在或超过设定时间未更新,则自动生成静态html自动更新一次。如果有采集,采集会自动更新小说封面和对应的分类页面),直接通过PHP调用html文件,而不是在根目录生成,访问速度无区别于纯静态,源代码可以保证文件管理方便的同时降低服务器压力,还可以方便的访问统计,增加搜索引擎的识别度。
(2)全站拼音编目,章节页面伪静态。
(3)小说txt文件自动生成,也可以后台自行重新生成txt文件。
(4)自动生成小说关键词和关键词自动内链。
(5)Auto伪原创word 替换(采集 时间替换)。
(6)新增小说总点击量、月点击量、周点击量、总推荐量、月推荐量、周推荐统计、作者推荐统计等新功能。
(7)配合CNZZ的统计插件,可以轻松实现小说下载量和藏书量的详细统计。
环境语言:PHP5.2/5.3/5.4/5.5+MYSQL5+伪静态
编码类型:GBK
由于源码修改优化,不自动升级。一般没有BUG就不需要升级。 查看全部
一款非常漂亮的小说在线阅读网站织梦模板(组图)





很漂亮的小说在线阅读网站织梦模板源码,简洁大气,5W数据,以dedecms5.7sp1为核心,全自动采集各种大小说站,可自动生成首页、分类、目录、排名、站点地图页、全站拼音目录、伪静态章节页、小说txt文件自动生成、zip压缩包自动生成等静态html。本源码功能可谓无比强大,其他更多功能请自行下载体验。
此模板主要用于棕色调。该模板采用最新版本的织梦UTF-8 内核制作。这个模板是整个站点的源码,有测试数据,安装非常方便。只需要在后台把栏目改成自己的,就可以轻松搭建自己的网站。
模板功能:
本模板的采集模板已经重新开发,功能更加强大。推荐给织梦basic的朋友。站长小白只做研究。
1)首页、分类、目录、排名、站点地图页(分类页、小说封面、作者页,如果html文件不存在或超过设定时间未更新,则自动生成静态html自动更新一次。如果有采集,采集会自动更新小说封面和对应的分类页面),直接通过PHP调用html文件,而不是在根目录生成,访问速度无区别于纯静态,源代码可以保证文件管理方便的同时降低服务器压力,还可以方便的访问统计,增加搜索引擎的识别度。
(2)全站拼音编目,章节页面伪静态。
(3)小说txt文件自动生成,也可以后台自行重新生成txt文件。
(4)自动生成小说关键词和关键词自动内链。
(5)Auto伪原创word 替换(采集 时间替换)。
(6)新增小说总点击量、月点击量、周点击量、总推荐量、月推荐量、周推荐统计、作者推荐统计等新功能。
(7)配合CNZZ的统计插件,可以轻松实现小说下载量和藏书量的详细统计。
环境语言:PHP5.2/5.3/5.4/5.5+MYSQL5+伪静态
编码类型:GBK
由于源码修改优化,不自动升级。一般没有BUG就不需要升级。
免费自学学习网模板文章资讯作文整站源码手机同步生成+安装教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-08-20 20:22
2021帝国cms7.5免费自学学习网模板文章资讯作文全站源码手机同步生成+安装教程+采集
———————————————————————————————————
PC/电脑版演示地址:查看演示
WAP/手机版演示地址:查看演示(请使用手机访问)
———————————————————————————————————
源代码是EmpirecmsUTF8版本。如需GBK版本请自行转码!
模板简洁大方,访问快捷,移动端优化美观用户体验。
适用于文章资讯中小学生的知识点总结、试题、练习题、考试资料、论文、学习方法和技巧等!
所有功能后台管理,已预留广告位(如需添加广告位请联系店主添加)。
模板使用标签灵活调用,采集精选优质源站,模板精美同时兼顾SEO搜索引擎优化。全站静态生成有利于收录和关键词布局和内容页面优化!
功能列表:
1、内置ITAG插件,标签可以拼音,标签分类可用,功能更强大,更容易生成词库。 (标签链接样式可选择ID或拼音)
2、内置百度推送插件,实时数据推送到步行搜索引擎。
3、带优采云采集规则,可以自己采集海量数据,全自动无人值守采集。
4、built-in网站map 站点地图插件
本产品是整个站点的源代码,不仅是模板,还有演示站点的所有数据。
详情请看演示网站,更直观。
注意:演示站机器配置低,有延迟是正常的。这与模板程序无关。
———————————————————————————————————————
●帝国cms7.5UTF-8
●系统开源,域名不限。
●同步生成WAP移动终端简单实用。
●大约 330MB 大小
●简单的安装方法,详细的安装教程。
●TAG标签聚合
资源下载本资源下载价格为99金币,请先登录 查看全部
免费自学学习网模板文章资讯作文整站源码手机同步生成+安装教程
2021帝国cms7.5免费自学学习网模板文章资讯作文全站源码手机同步生成+安装教程+采集
———————————————————————————————————
PC/电脑版演示地址:查看演示
WAP/手机版演示地址:查看演示(请使用手机访问)
———————————————————————————————————
源代码是EmpirecmsUTF8版本。如需GBK版本请自行转码!
模板简洁大方,访问快捷,移动端优化美观用户体验。
适用于文章资讯中小学生的知识点总结、试题、练习题、考试资料、论文、学习方法和技巧等!
所有功能后台管理,已预留广告位(如需添加广告位请联系店主添加)。
模板使用标签灵活调用,采集精选优质源站,模板精美同时兼顾SEO搜索引擎优化。全站静态生成有利于收录和关键词布局和内容页面优化!
功能列表:
1、内置ITAG插件,标签可以拼音,标签分类可用,功能更强大,更容易生成词库。 (标签链接样式可选择ID或拼音)
2、内置百度推送插件,实时数据推送到步行搜索引擎。
3、带优采云采集规则,可以自己采集海量数据,全自动无人值守采集。
4、built-in网站map 站点地图插件
本产品是整个站点的源代码,不仅是模板,还有演示站点的所有数据。
详情请看演示网站,更直观。
注意:演示站机器配置低,有延迟是正常的。这与模板程序无关。
———————————————————————————————————————
●帝国cms7.5UTF-8
●系统开源,域名不限。
●同步生成WAP移动终端简单实用。
●大约 330MB 大小
●简单的安装方法,详细的安装教程。
●TAG标签聚合
 http://www.hanjutt.com/wp-cont ... 0.jpg 265w, http://www.hanjutt.com/wp-cont ... 0.jpg 768w" />
http://www.hanjutt.com/wp-cont ... 0.jpg 265w, http://www.hanjutt.com/wp-cont ... 0.jpg 768w" /> http://www.hanjutt.com/wp-cont ... 4.jpg 300w, http://www.hanjutt.com/wp-cont ... 2.jpg 1024w, http://www.hanjutt.com/wp-cont ... 7.jpg 768w" />
http://www.hanjutt.com/wp-cont ... 4.jpg 300w, http://www.hanjutt.com/wp-cont ... 2.jpg 1024w, http://www.hanjutt.com/wp-cont ... 7.jpg 768w" /> http://www.hanjutt.com/wp-cont ... 0.jpg 260w, http://www.hanjutt.com/wp-cont ... 6.jpg 768w" />
http://www.hanjutt.com/wp-cont ... 0.jpg 260w, http://www.hanjutt.com/wp-cont ... 6.jpg 768w" /> http://www.hanjutt.com/wp-cont ... 9.jpg 300w, http://www.hanjutt.com/wp-cont ... 6.jpg 768w" />
http://www.hanjutt.com/wp-cont ... 9.jpg 300w, http://www.hanjutt.com/wp-cont ... 6.jpg 768w" /> http://www.hanjutt.com/wp-cont ... 5.jpg 300w, http://www.hanjutt.com/wp-cont ... 6.jpg 768w" />
http://www.hanjutt.com/wp-cont ... 5.jpg 300w, http://www.hanjutt.com/wp-cont ... 6.jpg 768w" /> http://www.hanjutt.com/wp-cont ... 0.jpg 229w" />
http://www.hanjutt.com/wp-cont ... 0.jpg 229w" /> http://www.hanjutt.com/wp-cont ... 0.jpg 248w" />
http://www.hanjutt.com/wp-cont ... 0.jpg 248w" /> http://www.hanjutt.com/wp-cont ... 0.jpg 254w" />
http://www.hanjutt.com/wp-cont ... 0.jpg 254w" />资源下载本资源下载价格为99金币,请先登录
Excel教程Excel函数Excel透视表Excel电子表格Excel基础入门到精通
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-08-20 05:15
Excel教程Excel函数Excel透视表Excel电子表格Excel基础入门到精通
Python爬虫采集今日热榜数据:聚合全网热榜
时间:2020-03-19
本文章为大家介绍Python爬虫采集今日热榜数据:聚合全网热榜,主要包括Python爬虫采集今日热榜数据:聚合用例、应用技巧、基础知识全网热点榜要点总结及注意事项有一定参考价值,有需要的朋友可以参考。
主要使用request库和beautifulSoup库抓取今日热点数据。
具体代码实现:
1 import requests
2 from bs4 import BeautifulSoup
3 import time
4 import pandas
5 import re
6
7 def get_html(url):
8 headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'}
9 resp = requests.get(url, headers=headers)
10 return resp.text
11
12
13 def get_data(html):
14 soup = BeautifulSoup(html, 'html.parser')
15 nodes = soup.find_all('div', class_='cc-cd')
16 return nodes
17
18
19 def get_node_data(df, nodes):
20 now = int(time.time())
21 for node in nodes:
22 source = node.find('div', class_='cc-cd-lb').text.strip()
23 messages = node.find('div', class_='cc-cd-cb-l nano-content').find_all('a')
24 for message in messages:
25 content = message.find('span', class_='t').text.strip()
26 if source == '微信':
27 reg = '「.+?」(.+)'
28 content = re.findall(reg, content)[0]
29
30 if df.empty or df[df.content == content].empty:
31 data = {
32 'content': [content],
33 'url': [message['href']],
34 'source': [source],
35 'start_time': [now],
36 'end_time': [now]
37 }
38
39 item = pandas.DataFrame(data)
40 df = pandas.concat([df, item], ignore_index=True)
41
42 else:
43 index = df[df.content == content].index[0]
44 df.at[index, 'end_time'] = now
45
46 return df
47
48
49 url = 'https://tophub.today'
50 html = get_html(url)
51 data = get_data(html)
52 res = pandas.read_excel('今日热榜.xlsx')
53 res = get_node_data(res, data)
54 res.to_excel('今日热榜.xlsx') 查看全部
Excel教程Excel函数Excel透视表Excel电子表格Excel基础入门到精通
Python爬虫采集今日热榜数据:聚合全网热榜
时间:2020-03-19
本文章为大家介绍Python爬虫采集今日热榜数据:聚合全网热榜,主要包括Python爬虫采集今日热榜数据:聚合用例、应用技巧、基础知识全网热点榜要点总结及注意事项有一定参考价值,有需要的朋友可以参考。
主要使用request库和beautifulSoup库抓取今日热点数据。
具体代码实现:
1 import requests
2 from bs4 import BeautifulSoup
3 import time
4 import pandas
5 import re
6
7 def get_html(url):
8 headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'}
9 resp = requests.get(url, headers=headers)
10 return resp.text
11
12
13 def get_data(html):
14 soup = BeautifulSoup(html, 'html.parser')
15 nodes = soup.find_all('div', class_='cc-cd')
16 return nodes
17
18
19 def get_node_data(df, nodes):
20 now = int(time.time())
21 for node in nodes:
22 source = node.find('div', class_='cc-cd-lb').text.strip()
23 messages = node.find('div', class_='cc-cd-cb-l nano-content').find_all('a')
24 for message in messages:
25 content = message.find('span', class_='t').text.strip()
26 if source == '微信':
27 reg = '「.+?」(.+)'
28 content = re.findall(reg, content)[0]
29
30 if df.empty or df[df.content == content].empty:
31 data = {
32 'content': [content],
33 'url': [message['href']],
34 'source': [source],
35 'start_time': [now],
36 'end_time': [now]
37 }
38
39 item = pandas.DataFrame(data)
40 df = pandas.concat([df, item], ignore_index=True)
41
42 else:
43 index = df[df.content == content].index[0]
44 df.at[index, 'end_time'] = now
45
46 return df
47
48
49 url = 'https://tophub.today'
50 html = get_html(url)
51 data = get_data(html)
52 res = pandas.read_excel('今日热榜.xlsx')
53 res = get_node_data(res, data)
54 res.to_excel('今日热榜.xlsx')
软件特点优采云软件首创的智能提取网页正文算法(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-08-15 07:00
软件特点优采云软件首创的智能提取网页正文算法(组图)
优采云·新闻源文章采集器(SMnewsbot)——第一个提取文本的智能算法;准确采集新闻源,泛网;多语言翻译伪原创
本软件是一款只需要输入关键词采集百度、谷歌、搜搜等各大搜索引擎新闻源和泛网互联网文章软件(更多介绍...)的软件。
优采云software 是首创的独家智能算法,可以准确提取网页正文部分并保存为文章。
支持对标签、链接、邮件等进行格式化处理,还有插入关键词的功能,可以识别旁边插入的标签或者标点符号,可以识别英文空格的插入。
更多文章transfer 翻译功能,即文章可以从一种语言如中文转为英文或日文等另一种语言,再由英文或日文转回中文。这是一个翻译周期。您可以将翻译周期设置为循环多次(翻译次数)。
采集文章+翻译伪原创可以满足站长和各领域朋友对文章的需求。
一些公关处理和信息研究公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而优采云的软件也是一个信息采集系统功能和市场上昂贵的软件有相似之处,但价格只有几百元,你会知道如何尝试性价比。
软件功能
优采云Software 首个智能提取网页正文的算法
百度新闻、谷歌新闻和搜搜新闻强聚合
不时更新的新闻资源取之不尽
多语言翻译伪原创。你,输入关键词
受影响区域
1、按关键词采集 Internet文章翻译伪原创,站长朋友的首选。
2、适用于信息公关公司采集过滤提炼信息资料(上万专业公司的软件,我的几百块钱) 查看全部
软件特点优采云软件首创的智能提取网页正文算法(组图)

优采云·新闻源文章采集器(SMnewsbot)——第一个提取文本的智能算法;准确采集新闻源,泛网;多语言翻译伪原创
本软件是一款只需要输入关键词采集百度、谷歌、搜搜等各大搜索引擎新闻源和泛网互联网文章软件(更多介绍...)的软件。
优采云software 是首创的独家智能算法,可以准确提取网页正文部分并保存为文章。
支持对标签、链接、邮件等进行格式化处理,还有插入关键词的功能,可以识别旁边插入的标签或者标点符号,可以识别英文空格的插入。
更多文章transfer 翻译功能,即文章可以从一种语言如中文转为英文或日文等另一种语言,再由英文或日文转回中文。这是一个翻译周期。您可以将翻译周期设置为循环多次(翻译次数)。
采集文章+翻译伪原创可以满足站长和各领域朋友对文章的需求。
一些公关处理和信息研究公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而优采云的软件也是一个信息采集系统功能和市场上昂贵的软件有相似之处,但价格只有几百元,你会知道如何尝试性价比。
软件功能
优采云Software 首个智能提取网页正文的算法
百度新闻、谷歌新闻和搜搜新闻强聚合
不时更新的新闻资源取之不尽
多语言翻译伪原创。你,输入关键词
受影响区域
1、按关键词采集 Internet文章翻译伪原创,站长朋友的首选。
2、适用于信息公关公司采集过滤提炼信息资料(上万专业公司的软件,我的几百块钱)
全网文章采集(阿里巴巴全网文章采集归类--阿里巴巴矢量图标库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-10-10 12:05
全网文章采集归类。从单个文章的内容相关性以及关键词提取。1数据准备。本文采集的内容如下,并保存下来,为日后做数据分析留作备用。>2文章提取。iconfont-阿里巴巴矢量图标库1选择需要去重的图片。>3图片所在位置的划分。根据图片所在位置以及需要的提取文字信息(字体颜色等)将其区分开>4列举文章描述中几类描述字。
<p>如标题,正文。并调用ff,find,match,excel中的相应功能将其判断出是否需要去重。最后只要将选中的文章去重为0即可>5全网评论区全部记录。这个可以先说明下,如果要判断全网评论,首先要判断全网哪个词多>以上数据基本采集完,格式和内容与上面大体一致. 查看全部
全网文章采集(阿里巴巴全网文章采集归类--阿里巴巴矢量图标库)
全网文章采集归类。从单个文章的内容相关性以及关键词提取。1数据准备。本文采集的内容如下,并保存下来,为日后做数据分析留作备用。>2文章提取。iconfont-阿里巴巴矢量图标库1选择需要去重的图片。>3图片所在位置的划分。根据图片所在位置以及需要的提取文字信息(字体颜色等)将其区分开>4列举文章描述中几类描述字。
<p>如标题,正文。并调用ff,find,match,excel中的相应功能将其判断出是否需要去重。最后只要将选中的文章去重为0即可>5全网评论区全部记录。这个可以先说明下,如果要判断全网评论,首先要判断全网哪个词多>以上数据基本采集完,格式和内容与上面大体一致.
全网文章采集(全网文章采集器(无任何广告,免费推荐))
采集交流 • 优采云 发表了文章 • 0 个评论 • 440 次浏览 • 2021-10-08 01:00
全网文章采集器(无任何广告,免费推荐)0.简介在浏览器中,用户可以快速、轻松地获取海量全网网页文章,并通过pc端或移动端等多种渠道分发到个人与企业客户。1.内容类型以新闻、社交网络、财经、科技、数码等大众常用的类型为主。2.网页导览可以读取链接、图片和按钮的网页。还能够同步pc浏览器、移动浏览器页面。
pc端可直接保存网页。3.朗读朗读文章、插入链接、图片、插入小程序。读取内容,可有感情朗读。保存到文本4.分享到微信,可与朋友分享网页,或者将文章分享到微信群、朋友圈或在公众号上分享。5.im聊天,可以随时随地和朋友聊天,不错过文章更新。6.视频随时随地制作视频,发布到各大平台,带你看全网文章。新闻|社交网络科技|金融|电商|安全|数码|职场|小程序|工具|网址|财经|电商|科技|情感。
不谢邀。为什么都推荐qq浏览器呢?首先推荐360浏览器。国内几大主流浏览器,界面清晰,内容丰富,能有效处理一些收藏的文章,并不难,并且很流畅。如果觉得广告多,可以安装360手机卫士。
qq浏览器
主要国内搜索引擎都有,以方正为例。
有没有什么网站能够全站爬取互联网文章?
就说电脑端,是用迅雷的,最快速。 查看全部
全网文章采集(全网文章采集器(无任何广告,免费推荐))
全网文章采集器(无任何广告,免费推荐)0.简介在浏览器中,用户可以快速、轻松地获取海量全网网页文章,并通过pc端或移动端等多种渠道分发到个人与企业客户。1.内容类型以新闻、社交网络、财经、科技、数码等大众常用的类型为主。2.网页导览可以读取链接、图片和按钮的网页。还能够同步pc浏览器、移动浏览器页面。
pc端可直接保存网页。3.朗读朗读文章、插入链接、图片、插入小程序。读取内容,可有感情朗读。保存到文本4.分享到微信,可与朋友分享网页,或者将文章分享到微信群、朋友圈或在公众号上分享。5.im聊天,可以随时随地和朋友聊天,不错过文章更新。6.视频随时随地制作视频,发布到各大平台,带你看全网文章。新闻|社交网络科技|金融|电商|安全|数码|职场|小程序|工具|网址|财经|电商|科技|情感。
不谢邀。为什么都推荐qq浏览器呢?首先推荐360浏览器。国内几大主流浏览器,界面清晰,内容丰富,能有效处理一些收藏的文章,并不难,并且很流畅。如果觉得广告多,可以安装360手机卫士。
qq浏览器
主要国内搜索引擎都有,以方正为例。
有没有什么网站能够全站爬取互联网文章?
就说电脑端,是用迅雷的,最快速。
全网文章采集(简单操作界面搜索工具名叫Mr.Otter有啥特色功能?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 263 次浏览 • 2021-10-06 03:20
【PConline申请】俗话说,技术行业有专攻。有经验的用户通常会使用不同的搜索引擎来搜索不同的资源内容,以便更快更好地找到自己需要的内容。现在有一个全面的搜索工具,可以帮助您大大加快搜索效率,免去在多个搜索引擎之间切换的麻烦。这个搜索工具叫做Mr. Otter。它有什么特点?请跟随小编来体验吧。
简单的操作界面非常丰富
水獭先生是一款软件类搜索工具,目前支持Windows 64位和MAC版本,需要下载后安装使用。但是,该软件采用邀请码免费形式,但需要注册,用户需要填写邀请码才能使用。小编这里给出PConline专属邀请码【邀请码】PConline。
水獭先生的操作界面非常简单。左侧是搜索框和各种搜索引擎的切换入口,右侧是内容展示区。
图1 水獭先生主界面
可以看到,Otter 先生为用户准备了很多搜索引擎和内容引擎,并对其进行了分类。例如,常见的搜索引擎包括百度、必应、搜狗等常用搜索引擎,用户也可以自行添加其他搜索引擎。
图2 通用搜索引擎
快速切换搜索引擎
用户输入搜索关键字后进行搜索。默认是调用第一个搜索引擎进行搜索。用户只需点击下方的搜索引擎按钮,即可在不同的搜索引擎之间快速切换搜索关键字。
图3 调用百度搜索
图 4 切换到 Bing 进行搜索
对于搜索结果,用户可以打印或直接生成PDF文件。
图5 快速另存为PDF文件
细分搜索工具,方便快速查找资源
而在一般搜索引擎分类下,还有一个小分类,Otter先生也把它分为一般、翻译和工具。其中,翻译分类是快速调用多个搜索引擎的翻译功能进行关键词翻译,工具分类是查快递、查索引、查地图等功能。
图6 快速调用谷歌翻译
图 7 各种附加工具
一种更有效的图片查找方式
水獭先生还为用户准备了一个大搜索类别的图片。功能是帮助用户在多个优质图片分享网站上查找图片。除了图片,Otter 先生还细分了图标和灵感类别。
图 8 水獭先生图片搜索
对于搜索到的图片,用户还可以通过右键快速采集和复制图片。“采集”功能是将图片保存在本地,放入水獭先生的采集管理库中。
图9 快速保存和复制图片
水獭先生还有一个图集功能,可以将页面上的图片与图片的分辨率信息快速显示在一个列表中,并在此模式下自动去除其他内容。
图 10 Atlas 模式
更多专用搜索引擎
奥特先生还为用户准备了很多内容搜索分类,比如可以帮助我们快速找到软件的“软件”分类,书籍的“文化”分类,百科知识的“知识”分类等等.
图 11 软件分类搜索
图 12 文化分类搜索
图 13 知识分类搜索
当你有时间时,慢慢阅读,稍后阅读。
水獭先生有晚读功能。对于搜索到的内容或感兴趣的内容,如果没有时间阅读,用户可以将其添加到以后的阅读列表中,有空的时候再仔细阅读。
图 14 稍后阅读功能
历史关键词功能
水獭先生支持搜索历史关键词功能,帮助用户记录搜索关键词,方便再次搜索。当然,它还具有清除历史关键字的功能。
图15 历史搜索关键词功能
总结
Mr. Otter 的搜索功能为用户带来了便捷的聚合搜索功能,让用户无需在多个搜索引擎之间切换即可找到自己需要的资源内容,并提供搜索分类,让用户可以基于各种技术进行搜索。行业内有专门的搜索引擎,可以更准确、更快速地找到您需要的资源。如果您经常使用搜索引擎,您不妨尝试一下。 查看全部
全网文章采集(简单操作界面搜索工具名叫Mr.Otter有啥特色功能?)
【PConline申请】俗话说,技术行业有专攻。有经验的用户通常会使用不同的搜索引擎来搜索不同的资源内容,以便更快更好地找到自己需要的内容。现在有一个全面的搜索工具,可以帮助您大大加快搜索效率,免去在多个搜索引擎之间切换的麻烦。这个搜索工具叫做Mr. Otter。它有什么特点?请跟随小编来体验吧。
简单的操作界面非常丰富
水獭先生是一款软件类搜索工具,目前支持Windows 64位和MAC版本,需要下载后安装使用。但是,该软件采用邀请码免费形式,但需要注册,用户需要填写邀请码才能使用。小编这里给出PConline专属邀请码【邀请码】PConline。
水獭先生的操作界面非常简单。左侧是搜索框和各种搜索引擎的切换入口,右侧是内容展示区。
图1 水獭先生主界面
可以看到,Otter 先生为用户准备了很多搜索引擎和内容引擎,并对其进行了分类。例如,常见的搜索引擎包括百度、必应、搜狗等常用搜索引擎,用户也可以自行添加其他搜索引擎。
图2 通用搜索引擎
快速切换搜索引擎
用户输入搜索关键字后进行搜索。默认是调用第一个搜索引擎进行搜索。用户只需点击下方的搜索引擎按钮,即可在不同的搜索引擎之间快速切换搜索关键字。
图3 调用百度搜索
图 4 切换到 Bing 进行搜索
对于搜索结果,用户可以打印或直接生成PDF文件。
图5 快速另存为PDF文件
细分搜索工具,方便快速查找资源
而在一般搜索引擎分类下,还有一个小分类,Otter先生也把它分为一般、翻译和工具。其中,翻译分类是快速调用多个搜索引擎的翻译功能进行关键词翻译,工具分类是查快递、查索引、查地图等功能。
图6 快速调用谷歌翻译
图 7 各种附加工具
一种更有效的图片查找方式
水獭先生还为用户准备了一个大搜索类别的图片。功能是帮助用户在多个优质图片分享网站上查找图片。除了图片,Otter 先生还细分了图标和灵感类别。
图 8 水獭先生图片搜索
对于搜索到的图片,用户还可以通过右键快速采集和复制图片。“采集”功能是将图片保存在本地,放入水獭先生的采集管理库中。
图9 快速保存和复制图片
水獭先生还有一个图集功能,可以将页面上的图片与图片的分辨率信息快速显示在一个列表中,并在此模式下自动去除其他内容。
图 10 Atlas 模式
更多专用搜索引擎
奥特先生还为用户准备了很多内容搜索分类,比如可以帮助我们快速找到软件的“软件”分类,书籍的“文化”分类,百科知识的“知识”分类等等.
图 11 软件分类搜索
图 12 文化分类搜索
图 13 知识分类搜索
当你有时间时,慢慢阅读,稍后阅读。
水獭先生有晚读功能。对于搜索到的内容或感兴趣的内容,如果没有时间阅读,用户可以将其添加到以后的阅读列表中,有空的时候再仔细阅读。
图 14 稍后阅读功能
历史关键词功能
水獭先生支持搜索历史关键词功能,帮助用户记录搜索关键词,方便再次搜索。当然,它还具有清除历史关键字的功能。
图15 历史搜索关键词功能
总结
Mr. Otter 的搜索功能为用户带来了便捷的聚合搜索功能,让用户无需在多个搜索引擎之间切换即可找到自己需要的资源内容,并提供搜索分类,让用户可以基于各种技术进行搜索。行业内有专门的搜索引擎,可以更准确、更快速地找到您需要的资源。如果您经常使用搜索引擎,您不妨尝试一下。
全网文章采集(全网文章采集系统(爬虫)设置+(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-10-06 01:02
全网文章采集系统,
一、文章采集脚本编写需要采集的网站自动生成采集地址,
0、知乎、豆瓣等等,
二、公众号爬虫由于前期爬虫全部需要request,需要一个可以爬取www的web地址!并且规范爬取headers!user-agent是指浏览器上对http状态的响应头(不含),目前定制的微信网站爬虫脚本也会用到这个参数。目前mysql微信爬虫脚本中已经实现这个参数。我们采用post,而mysql也是支持post请求的,无需手动下载下来。
三、爬虫设置+本地解析-bin/post?k=xyz42600c4f903&lang=zh_cn&q=xyz42600c4f903&url_value=xyz42600c4f903&channel=http%3a%2f%2fwww。xyz42600c4f903。com%2fsxambly%2fguid_code%2fguid_x_feature_hex%2fguid_hex_sdk%2fguid_filter%2fguid_length%2fguid_value%2fguid_reset%2fguid_code%2fguid_propagate%2fguid_name%2fguid_reset%2fguid_code%2fguid_propagate%2fguid_name%2fguid_code%2fguid_x_feature_hex%2fguid_x_feature_code%2fguid_value%2fguid_guid_code%2fguid_code%2fguid_guid_hex_sdk%2fguid_guid_sdk%2fguid_value%2fguid_guid_code%2fguid_propagate%2fguid_hex_value%2fguid_propagate%2fguid_value%2fguid_guid_name%2fguid_code%2fguid_guid_value%2fguid_reset%2fguid_hex_value%2fguid_reset%2fguid_value%2fguid_guid_propagate%2fguid_value%2fguid_guid_code%2fguid_name%2fguid_reset%2fguid_code%2fguid_length%2fguid_value%2fguid_code%2fguid_value%2fguid_sdk%2fguid_guid_value%2fguid_name%2fguid_value%2fguid_code%2fguid_value%2fguid_value%2fguid_name%2fguid_value%2fguid_guid_code%2fguid_guid_value%2fguid_value%2fguid_propagate%2fguid_guid_value%2fguid_guid_value%2fguid_propagate%2fguid_length%2fguid_value%2fguid_code%2fguid_propagate%2fguid。 查看全部
全网文章采集(全网文章采集系统(爬虫)设置+(图))
全网文章采集系统,
一、文章采集脚本编写需要采集的网站自动生成采集地址,
0、知乎、豆瓣等等,
二、公众号爬虫由于前期爬虫全部需要request,需要一个可以爬取www的web地址!并且规范爬取headers!user-agent是指浏览器上对http状态的响应头(不含),目前定制的微信网站爬虫脚本也会用到这个参数。目前mysql微信爬虫脚本中已经实现这个参数。我们采用post,而mysql也是支持post请求的,无需手动下载下来。
三、爬虫设置+本地解析-bin/post?k=xyz42600c4f903&lang=zh_cn&q=xyz42600c4f903&url_value=xyz42600c4f903&channel=http%3a%2f%2fwww。xyz42600c4f903。com%2fsxambly%2fguid_code%2fguid_x_feature_hex%2fguid_hex_sdk%2fguid_filter%2fguid_length%2fguid_value%2fguid_reset%2fguid_code%2fguid_propagate%2fguid_name%2fguid_reset%2fguid_code%2fguid_propagate%2fguid_name%2fguid_code%2fguid_x_feature_hex%2fguid_x_feature_code%2fguid_value%2fguid_guid_code%2fguid_code%2fguid_guid_hex_sdk%2fguid_guid_sdk%2fguid_value%2fguid_guid_code%2fguid_propagate%2fguid_hex_value%2fguid_propagate%2fguid_value%2fguid_guid_name%2fguid_code%2fguid_guid_value%2fguid_reset%2fguid_hex_value%2fguid_reset%2fguid_value%2fguid_guid_propagate%2fguid_value%2fguid_guid_code%2fguid_name%2fguid_reset%2fguid_code%2fguid_length%2fguid_value%2fguid_code%2fguid_value%2fguid_sdk%2fguid_guid_value%2fguid_name%2fguid_value%2fguid_code%2fguid_value%2fguid_value%2fguid_name%2fguid_value%2fguid_guid_code%2fguid_guid_value%2fguid_value%2fguid_propagate%2fguid_guid_value%2fguid_guid_value%2fguid_propagate%2fguid_length%2fguid_value%2fguid_code%2fguid_propagate%2fguid。
全网文章采集(为什么洪雨需要采集微信公众号文章?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-09-29 05:01
由于某些原因,洪宇需要采集微信公众号文章。
废话不多说,只说重点。
最初的想法非常简单。本来是想用搜狗微信搜索功能到采集,但是没执行的时候,看到了一些评论。
说到搜狗微信,如果采集的文章不完整,采集太多,IP会被封。
于是果断放弃,也没去研究,因为洪宇知道,这种搜索引擎的采集比较简单。如果大家都是采集,确实会对服务器造成压力。
洪宇开始考虑第二套方案,直接采集公众号。
公众号的文章链接在网页上是可以打开的,但是公众号文章的历史在PC端已经不能打开了。有问题,采集公众号的文章链接不可用。
想打开历史文章,洪宇想到了两种方法,一种是用模拟器模拟手机环境,打开链接。另一种是使用网页微信打开公众号历史链接。
当然,直接在网页上使用微信绝对比使用模拟器容易。
洪宇发现网页微信打不开。只有安装客户端才能在PC端打开微信。好在公众号历史文章还是可以看到的。
这时候问题又来了,如何在模拟器或者客户端获取到历史文章的内容,然后链接采集。
洪宇首先想到的就是互联网拦截和抓包,现在fiddler比较流行。
但是不能直接批量获取和过滤这些数据,所以想一想如何在宜浪中直接抓包,什么抓包,网络拦截,过程都是读取...
结果找了半天也没找到简单有效的方法。模拟器上有抓包教程,但是我还是用fiddler抓包...
最后,洪宇想从微信客户端的手柄入手。
使用编程助手获取窗口句柄,洪宇惊讶地发现,原来的公众号内容以内置浏览器的形式显示在微信客户端,包括历史文章。
虽然它是一个谷歌核心浏览器,你不能用它来填表,但它已经很不错了。
我们可以用鼠标模拟的方法制作微信客户端,然后获取内置浏览器的网页源码。有了源代码,一切都很简单。
剩下的就是过滤有用的信息。
只要你采集链接到每个文章,一切都OK,因为在PC浏览器中可以打开单个文章链接。也就是说可以直接读取源码,从采集到文章的内容。
至此,完成手册。
整理流程,首先要关注采集公众号,然后登录微信PC客户端,在客户端打开历史文章页面,获取源码,然后使用软件采集链接到文章。然后直接阅读文章的源码和采集文章的内容。
作为个人,这是一种傻瓜式采集方法。不需要高难度的技术,也不需要涉及微信公众号等的开发接口,唯一的缺点就是效率比较慢。
不过作为个人采集,应该够了。 查看全部
全网文章采集(为什么洪雨需要采集微信公众号文章?)
由于某些原因,洪宇需要采集微信公众号文章。
废话不多说,只说重点。
最初的想法非常简单。本来是想用搜狗微信搜索功能到采集,但是没执行的时候,看到了一些评论。
说到搜狗微信,如果采集的文章不完整,采集太多,IP会被封。
于是果断放弃,也没去研究,因为洪宇知道,这种搜索引擎的采集比较简单。如果大家都是采集,确实会对服务器造成压力。
洪宇开始考虑第二套方案,直接采集公众号。
公众号的文章链接在网页上是可以打开的,但是公众号文章的历史在PC端已经不能打开了。有问题,采集公众号的文章链接不可用。
想打开历史文章,洪宇想到了两种方法,一种是用模拟器模拟手机环境,打开链接。另一种是使用网页微信打开公众号历史链接。
当然,直接在网页上使用微信绝对比使用模拟器容易。
洪宇发现网页微信打不开。只有安装客户端才能在PC端打开微信。好在公众号历史文章还是可以看到的。
这时候问题又来了,如何在模拟器或者客户端获取到历史文章的内容,然后链接采集。
洪宇首先想到的就是互联网拦截和抓包,现在fiddler比较流行。
但是不能直接批量获取和过滤这些数据,所以想一想如何在宜浪中直接抓包,什么抓包,网络拦截,过程都是读取...
结果找了半天也没找到简单有效的方法。模拟器上有抓包教程,但是我还是用fiddler抓包...
最后,洪宇想从微信客户端的手柄入手。
使用编程助手获取窗口句柄,洪宇惊讶地发现,原来的公众号内容以内置浏览器的形式显示在微信客户端,包括历史文章。
虽然它是一个谷歌核心浏览器,你不能用它来填表,但它已经很不错了。
我们可以用鼠标模拟的方法制作微信客户端,然后获取内置浏览器的网页源码。有了源代码,一切都很简单。
剩下的就是过滤有用的信息。
只要你采集链接到每个文章,一切都OK,因为在PC浏览器中可以打开单个文章链接。也就是说可以直接读取源码,从采集到文章的内容。
至此,完成手册。
整理流程,首先要关注采集公众号,然后登录微信PC客户端,在客户端打开历史文章页面,获取源码,然后使用软件采集链接到文章。然后直接阅读文章的源码和采集文章的内容。
作为个人,这是一种傻瓜式采集方法。不需要高难度的技术,也不需要涉及微信公众号等的开发接口,唯一的缺点就是效率比较慢。
不过作为个人采集,应该够了。
全网文章采集( 千梦哥1.鉴别原创1.标题(修改了标题)(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2021-09-25 01:13
千梦哥1.鉴别原创1.标题(修改了标题)(图))
一、前言
只要和网站有关,尤其是内容、交通、SEO排名,今天的这节课一定要听。千萌哥教你如何持续获取网站、文章的内容源,帖子获得无数原创文章,100%与我们网站领域垂直相关
今天的采集站点课程教学方式不仅仅是一个项目。更准确的说,是“建站”的捷径,几乎适用于任何网站。解决做网站的最大问题之一:内容源网站是由内容输出开发的,所以不管什么类型的内容网站都可以做,看看就可以了. 完成课程后,您几乎不会为网站 没有内容输出而头疼。
二、课程内容
1.身份证明原创
1.Title (Title modified) 只要标题是收录,那么就不需要看内容了
2.内容(随机选择几段)
3.交通(蜜蜂采集)
公众号文章的内容不会被百度收录封禁,微信封禁百度公众号收录的内容
2.重量基础
1.原创文章Multiple:复制和传输(理想),伪原创(大部分)
2.行业相关性高:运输来源筛选
3.域名权重:旧域名的选择
三、利润变现
除了最知名的广告收入和CPA和CPS变现,高端引流转化产品变现可能对你有一些高要求。
而每一个网站都可以卖到最后一步网站,这也是实现网站的最简单粗暴的方式。
一般卖的网站一般有两种:
1.网站 无法稳定开发和实现。
他们被迫出售这些 网站 谋生。通常,个人站长做了一半的工作,发现定位不明确,或者觉得希望不大,熬不过去,所以及时卖出。
这其中网站,大多是行业性质的,比较准确,数据也比较真实。其中网站不乏商业潜力巨大的“黑马”。
2.网站出售
网站 从一开始,后期的制作和所有的内容填充都是为了未来的好价钱。
四、项目核心
你每天为网站写什么文章?
1.可以被百度蜘蛛抓取收录
2.能够给网站添加权重属性
3.提升用户体验和付费转化率
其实,归根结底,我们要做的,就是把百度看不到的文章搬过来收录。
这套价值百万的超级原创采集教程我将在本视频课程中进行全面的实践教学讲解。 查看全部
全网文章采集(
千梦哥1.鉴别原创1.标题(修改了标题)(图))
一、前言
只要和网站有关,尤其是内容、交通、SEO排名,今天的这节课一定要听。千萌哥教你如何持续获取网站、文章的内容源,帖子获得无数原创文章,100%与我们网站领域垂直相关
今天的采集站点课程教学方式不仅仅是一个项目。更准确的说,是“建站”的捷径,几乎适用于任何网站。解决做网站的最大问题之一:内容源网站是由内容输出开发的,所以不管什么类型的内容网站都可以做,看看就可以了. 完成课程后,您几乎不会为网站 没有内容输出而头疼。
二、课程内容
1.身份证明原创
1.Title (Title modified) 只要标题是收录,那么就不需要看内容了
2.内容(随机选择几段)
3.交通(蜜蜂采集)
公众号文章的内容不会被百度收录封禁,微信封禁百度公众号收录的内容
2.重量基础
1.原创文章Multiple:复制和传输(理想),伪原创(大部分)
2.行业相关性高:运输来源筛选
3.域名权重:旧域名的选择
三、利润变现
除了最知名的广告收入和CPA和CPS变现,高端引流转化产品变现可能对你有一些高要求。
而每一个网站都可以卖到最后一步网站,这也是实现网站的最简单粗暴的方式。
一般卖的网站一般有两种:
1.网站 无法稳定开发和实现。
他们被迫出售这些 网站 谋生。通常,个人站长做了一半的工作,发现定位不明确,或者觉得希望不大,熬不过去,所以及时卖出。
这其中网站,大多是行业性质的,比较准确,数据也比较真实。其中网站不乏商业潜力巨大的“黑马”。
2.网站出售
网站 从一开始,后期的制作和所有的内容填充都是为了未来的好价钱。
四、项目核心
你每天为网站写什么文章?
1.可以被百度蜘蛛抓取收录
2.能够给网站添加权重属性
3.提升用户体验和付费转化率
其实,归根结底,我们要做的,就是把百度看不到的文章搬过来收录。
这套价值百万的超级原创采集教程我将在本视频课程中进行全面的实践教学讲解。
全网文章采集(全网文章采集服务,有趣的事情,多多分享!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-09-19 03:04
全网文章采集服务,有趣的事情,多多分享!全网音频采集服务,好听的歌曲,好听的内容,
有抖音采集工具,写个爬虫就可以了。
目前没见过哪个有专门的这个功能,只能按照网站类型,然后倒推出网站的相关内容。
给你们抖音评论采集
可以尝试爬网易云音乐的,已经试过,百度云30m的,收费费49。
可以试试这个模拟登录百度账号
微信公众号和自媒体号的长尾关键词爬取
豆瓣电影看一眼简介都能知道有啥不错的电影可以加到我们的关键词库里
公众号的推文里,被人引用的各类文章都是相关的,
可以试试博客里的一些文章,
百度搜公众号ai采集器关键词有感兴趣的公众号就可以
我自己做的,方便快捷。
这个目前还是刚起步,大家可以试试“快搜网”,之前用了一阵子,
太多了,
alexa中国_中国最大的中文站点,网站分析工具,seo优化,网站推广,
fenng公众号文章,可以搜索,定位比较准确,
百度文库 查看全部
全网文章采集(全网文章采集服务,有趣的事情,多多分享!)
全网文章采集服务,有趣的事情,多多分享!全网音频采集服务,好听的歌曲,好听的内容,
有抖音采集工具,写个爬虫就可以了。
目前没见过哪个有专门的这个功能,只能按照网站类型,然后倒推出网站的相关内容。
给你们抖音评论采集
可以尝试爬网易云音乐的,已经试过,百度云30m的,收费费49。
可以试试这个模拟登录百度账号
微信公众号和自媒体号的长尾关键词爬取
豆瓣电影看一眼简介都能知道有啥不错的电影可以加到我们的关键词库里
公众号的推文里,被人引用的各类文章都是相关的,
可以试试博客里的一些文章,
百度搜公众号ai采集器关键词有感兴趣的公众号就可以
我自己做的,方便快捷。
这个目前还是刚起步,大家可以试试“快搜网”,之前用了一阵子,
太多了,
alexa中国_中国最大的中文站点,网站分析工具,seo优化,网站推广,
fenng公众号文章,可以搜索,定位比较准确,
百度文库
全网文章采集( 在现在网站优化真的是内容为王,咱们在提高排名的进程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 376 次浏览 • 2021-09-19 01:02
在现在网站优化真的是内容为王,咱们在提高排名的进程)
了解原创文章版权问题并采集词汇技能
现在网站优化真的是内容之王。在提高排名的过程中,能够了解内容是非常重要的。帮助网站提高排名非常有帮助。因此,很多公司都配备了专业的软文人员来编写原创,所以内容文章更有价值,但是很多公司还在采集和复制网站,我们有必要增加原创的版权吗
毫无疑问,这是可能的,但是网站我们仍然需要做一些操作:
一、文章有效地将自己的信息内容添加到内容中
在编写原创文章内容时,人们可以适当地添加一些自己的信息内容。当其他人截取文章内容时,这相当于为人们做广告。事实上,他们根据特殊程序保护他人的采集和模仿。最后,根据百度搜索引擎的搜索结果,百度将尽快进入原文章公民网站的内容。在这种情况下,即使是其他人采集的前公民网站的内容仍然是原创
二、网站添加禁止复制的代码
这更专业,这也是避免他人复制文章的网站并添加指令检查网站源代码的最有效方法,这样您的文章就安全了
关键词要经常更换、更改和更新,网站optimization要关注近期流量的热点词,并合理添加到上传的文章中进行推广。必须充分理解哪些长尾词或助词可以从适当的类别中进行扩展,以达到优化效果
首先,如何采集关键词
最简单的方法是使用关键字优化工具查找搜索量较新的单词,然后合理地扩展它们。在总结此类单词后,再次筛选它们,然后将它们放入文章. 必须与网站文章有更大的相关性@
第二,如何调整关键词
确定词性匹配度较高后,选择较远的词并植入它们以获得更多的潜在客户。一般来说,长尾词常与短语搭配。在完成文章上传后,我们还应该关注流量统计,看看每个单词的点击率是如何获得的,我们是否会在一个阶段继续优化它
第三,注意植入的密度
在整篇文章文章中,它不是越多越好,而是应该在几个关键节点上呈现。总的来说,我们应该平均地把握它,不要出现词汇聚集的现象,也不要在其中填入无意义的句子。根据多年的经验,密度应为3%,既不多也不多。如果是长文章文章,可以适当添加
第四,注意标题
标题旁边显示的关键词可以让搜索引擎对上传内容进行定性,网站优化更容易找到分类,增加输入频率,也让登陆游客一目了然看到文章更容易引导游客 查看全部
全网文章采集(
在现在网站优化真的是内容为王,咱们在提高排名的进程)
了解原创文章版权问题并采集词汇技能
现在网站优化真的是内容之王。在提高排名的过程中,能够了解内容是非常重要的。帮助网站提高排名非常有帮助。因此,很多公司都配备了专业的软文人员来编写原创,所以内容文章更有价值,但是很多公司还在采集和复制网站,我们有必要增加原创的版权吗
毫无疑问,这是可能的,但是网站我们仍然需要做一些操作:
一、文章有效地将自己的信息内容添加到内容中
在编写原创文章内容时,人们可以适当地添加一些自己的信息内容。当其他人截取文章内容时,这相当于为人们做广告。事实上,他们根据特殊程序保护他人的采集和模仿。最后,根据百度搜索引擎的搜索结果,百度将尽快进入原文章公民网站的内容。在这种情况下,即使是其他人采集的前公民网站的内容仍然是原创
二、网站添加禁止复制的代码
这更专业,这也是避免他人复制文章的网站并添加指令检查网站源代码的最有效方法,这样您的文章就安全了
关键词要经常更换、更改和更新,网站optimization要关注近期流量的热点词,并合理添加到上传的文章中进行推广。必须充分理解哪些长尾词或助词可以从适当的类别中进行扩展,以达到优化效果
首先,如何采集关键词
最简单的方法是使用关键字优化工具查找搜索量较新的单词,然后合理地扩展它们。在总结此类单词后,再次筛选它们,然后将它们放入文章. 必须与网站文章有更大的相关性@
第二,如何调整关键词
确定词性匹配度较高后,选择较远的词并植入它们以获得更多的潜在客户。一般来说,长尾词常与短语搭配。在完成文章上传后,我们还应该关注流量统计,看看每个单词的点击率是如何获得的,我们是否会在一个阶段继续优化它
第三,注意植入的密度
在整篇文章文章中,它不是越多越好,而是应该在几个关键节点上呈现。总的来说,我们应该平均地把握它,不要出现词汇聚集的现象,也不要在其中填入无意义的句子。根据多年的经验,密度应为3%,既不多也不多。如果是长文章文章,可以适当添加
第四,注意标题
标题旁边显示的关键词可以让搜索引擎对上传内容进行定性,网站优化更容易找到分类,增加输入频率,也让登陆游客一目了然看到文章更容易引导游客
全网文章采集(全网文章采集后简单做了个web版网站mycareer)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-16 23:01
全网文章采集后简单做了个web版网站mycareer来做个测试,欢迎大家指正。
我看到过一篇高校就业报告,里面有用人单位对每个行业岗位对应的知识和经验技能要求,可以借鉴看看。
利用搜索引擎自然搜索就有无数出口,你说的mba网站估计只是一个。多尝试,总能找到能用得着的。
根据我最近在上家公司出差的经验,有很多自有人脉搞到的资料及信息,在我看来没有太大的必要了。
根据国家就业指导中心的需求职位规划数据库来寻找。
除了专业网站,应该还有其他渠道,例如关注本地人力资源市场,教育局,企业的招聘网站,通过内部人员,实习生的线索或者朋友介绍,
用搜索引擎搜索就知道了,哪些职位对应哪些证书。之前用百度搜某些职位,
其实很简单,即使是非全日制研究生也可以找到。你搜索的时候用到关键词就行。
有呀!如果你想得到比较精准的信息,就去各大应届生论坛,人才市场和每年春季校园招聘会(跟秋季校招会差不多一个时间点)。全国有很多,每年都不一样,一定要去争取。举个例子,每年5月份,关注上海这些学校的专科和本科招聘会。想去你感兴趣的公司,先打听这些公司大概什么时候招聘。 查看全部
全网文章采集(全网文章采集后简单做了个web版网站mycareer)
全网文章采集后简单做了个web版网站mycareer来做个测试,欢迎大家指正。
我看到过一篇高校就业报告,里面有用人单位对每个行业岗位对应的知识和经验技能要求,可以借鉴看看。
利用搜索引擎自然搜索就有无数出口,你说的mba网站估计只是一个。多尝试,总能找到能用得着的。
根据我最近在上家公司出差的经验,有很多自有人脉搞到的资料及信息,在我看来没有太大的必要了。
根据国家就业指导中心的需求职位规划数据库来寻找。
除了专业网站,应该还有其他渠道,例如关注本地人力资源市场,教育局,企业的招聘网站,通过内部人员,实习生的线索或者朋友介绍,
用搜索引擎搜索就知道了,哪些职位对应哪些证书。之前用百度搜某些职位,
其实很简单,即使是非全日制研究生也可以找到。你搜索的时候用到关键词就行。
有呀!如果你想得到比较精准的信息,就去各大应届生论坛,人才市场和每年春季校园招聘会(跟秋季校招会差不多一个时间点)。全国有很多,每年都不一样,一定要去争取。举个例子,每年5月份,关注上海这些学校的专科和本科招聘会。想去你感兴趣的公司,先打听这些公司大概什么时候招聘。
全网文章采集(全网文章采集,官方网站的网络文章数据抓取和爬虫过程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 453 次浏览 • 2021-09-16 21:03
全网文章采集,官方网站的网络文章数据抓取和爬虫过程,熟悉爬虫抓取方法,减少数据抓取的时间和提高工作效率。更多关于如何爬取微信公众号的网络文章、定制公众号文章采集软件,欢迎关注“网络平台架构师”,
看情况并不是采集每一篇文章而是抓住人群中感兴趣的文章。不想采集全篇文章,这个本身是完全可以的,抓取的定位就要精准。
现在的大数据不是傻乎乎的做采集,首先要清楚你采集的目的是什么,目的越明确步骤越简单。大数据往往是采集与分析并重,这一点要有认识。
做大数据,抓取是第一步,谁都不想做任何实时性没有保证的,或者过分容易抓取且条件简单的文章。需要了解文章的内容属性,标签分布等,尽可能的减少网站爬虫的抓取频率,多利用爬虫工具。
做大数据得知道那些数据是你要的,
找个爬虫工具,
我觉得,爬虫应该抓住的是你的目的啊!应该抓你需要的数据才是抓取的目的啊!毕竟,已经有数据可以采集了,还要大数据干嘛呢!再说,以数据库记录的数据库,又不如访问记录更有价值,毕竟,也不知道数据库里还有啥,一抓就是巨多的一串字母,应该记住哪些字母,哪些单词对爬虫有好处啊!还有就是如果是一些专门研究某些算法,那肯定要去数据库里找,不是要你想要就会有的啊!怎么能只抓过往文章呢?不抓未来呢?不抓本市呢?不抓xxxx地区呢?不抓他市呢?那些成功的案例为啥你就不能抓呢?人家怎么就走那条路啊?很多问题归根结底就是数据库要简化,合并,取舍之类的吧。 查看全部
全网文章采集(全网文章采集,官方网站的网络文章数据抓取和爬虫过程)
全网文章采集,官方网站的网络文章数据抓取和爬虫过程,熟悉爬虫抓取方法,减少数据抓取的时间和提高工作效率。更多关于如何爬取微信公众号的网络文章、定制公众号文章采集软件,欢迎关注“网络平台架构师”,
看情况并不是采集每一篇文章而是抓住人群中感兴趣的文章。不想采集全篇文章,这个本身是完全可以的,抓取的定位就要精准。
现在的大数据不是傻乎乎的做采集,首先要清楚你采集的目的是什么,目的越明确步骤越简单。大数据往往是采集与分析并重,这一点要有认识。
做大数据,抓取是第一步,谁都不想做任何实时性没有保证的,或者过分容易抓取且条件简单的文章。需要了解文章的内容属性,标签分布等,尽可能的减少网站爬虫的抓取频率,多利用爬虫工具。
做大数据得知道那些数据是你要的,
找个爬虫工具,
我觉得,爬虫应该抓住的是你的目的啊!应该抓你需要的数据才是抓取的目的啊!毕竟,已经有数据可以采集了,还要大数据干嘛呢!再说,以数据库记录的数据库,又不如访问记录更有价值,毕竟,也不知道数据库里还有啥,一抓就是巨多的一串字母,应该记住哪些字母,哪些单词对爬虫有好处啊!还有就是如果是一些专门研究某些算法,那肯定要去数据库里找,不是要你想要就会有的啊!怎么能只抓过往文章呢?不抓未来呢?不抓本市呢?不抓xxxx地区呢?不抓他市呢?那些成功的案例为啥你就不能抓呢?人家怎么就走那条路啊?很多问题归根结底就是数据库要简化,合并,取舍之类的吧。
全网文章采集(教程简易采集我们内容网址网址ampamp如果作者V5.3(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-07 21:10
关键词说明:教程简单采集我们的内容网址 如果作者V5.3
DedecmsV5.3 采集基础教程。
首先要说明的是,这是我第一次写这种教程。如有不当之处,请见谅。
输入文字:
采集的过程其实就是copy的过程,但是我们copy的是显示结果,采集主要是为了源码。
第一步,创建一个节点
我们以图片中的网址为例。必须正确选择目标页面编码,否则采集返回的内容会出现乱码。如果采集返回的内容是乱码,首先要考虑的是编码问题,这里我们选择utf-8,怎么知道别人的编码是什么?看源码就明白了。
“区域匹配模式”我选择正则表达式,因为如果选择“字符串”,会出现一些无法过滤掉的广告代码。
第二步:文章 URL 匹配规则。欢迎来到生活小贴士 ()
这个要看采集网站的源码(图片2),找一个收录所有采集内容URL的代码(为了唯一,建议多用Ctrl F),所以我们可以确定我想要采集区域的网址,不用担心,测试一下。
图二
最终结果如图3
图 3
第三步:在前面两步的基础上,我们已经找到了需要采集的网址,我们来看一下具体的采集内容。
在内容配置选项中,如果你和我一样懒惰的话,不要选那么多选项,只选你感兴趣的部分,比如文章title,作者和出处等,在dede cmsV 在5.3中修改了dede V5.1的规则,方便初学者使用。基本形式是将标签和内容放在一起。 V5.1 应该分为开始标签和结束标签。其实原理是一样的。
这里说一下自定义作者的问题。之前版本的v5.3 采集,可以通过@me="author"的形式自定义作者,但是v5.3只能通过替换来实现,当然有不便之处,这样我们就可以确定基本的东西了。
第四步:这是我们想要的内容的核心。这里会用到更多的过滤规则。幸运的是,dede V5.3 为我们准备了一些常用的。但是,如果要比较采集 对于复杂的网页,则必须学习一些常见的正则表达式。这样我们就基本学会了dedecmsV5.3的采集,是不是有点简单?
侠客站长站()
第五步:导出内容,这个就不多说了。 查看全部
全网文章采集(教程简易采集我们内容网址网址ampamp如果作者V5.3(组图))
关键词说明:教程简单采集我们的内容网址 如果作者V5.3
DedecmsV5.3 采集基础教程。
首先要说明的是,这是我第一次写这种教程。如有不当之处,请见谅。
输入文字:
采集的过程其实就是copy的过程,但是我们copy的是显示结果,采集主要是为了源码。
第一步,创建一个节点
我们以图片中的网址为例。必须正确选择目标页面编码,否则采集返回的内容会出现乱码。如果采集返回的内容是乱码,首先要考虑的是编码问题,这里我们选择utf-8,怎么知道别人的编码是什么?看源码就明白了。
“区域匹配模式”我选择正则表达式,因为如果选择“字符串”,会出现一些无法过滤掉的广告代码。
第二步:文章 URL 匹配规则。欢迎来到生活小贴士 ()
这个要看采集网站的源码(图片2),找一个收录所有采集内容URL的代码(为了唯一,建议多用Ctrl F),所以我们可以确定我想要采集区域的网址,不用担心,测试一下。
图二
最终结果如图3
图 3
第三步:在前面两步的基础上,我们已经找到了需要采集的网址,我们来看一下具体的采集内容。
在内容配置选项中,如果你和我一样懒惰的话,不要选那么多选项,只选你感兴趣的部分,比如文章title,作者和出处等,在dede cmsV 在5.3中修改了dede V5.1的规则,方便初学者使用。基本形式是将标签和内容放在一起。 V5.1 应该分为开始标签和结束标签。其实原理是一样的。
这里说一下自定义作者的问题。之前版本的v5.3 采集,可以通过@me="author"的形式自定义作者,但是v5.3只能通过替换来实现,当然有不便之处,这样我们就可以确定基本的东西了。
第四步:这是我们想要的内容的核心。这里会用到更多的过滤规则。幸运的是,dede V5.3 为我们准备了一些常用的。但是,如果要比较采集 对于复杂的网页,则必须学习一些常见的正则表达式。这样我们就基本学会了dedecmsV5.3的采集,是不是有点简单?
侠客站长站()
第五步:导出内容,这个就不多说了。
全网文章采集( 《千梦ip魔鬼实战训练营》微信公众号采集教学)
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2021-09-06 08:16
《千梦ip魔鬼实战训练营》微信公众号采集教学)
千梦网108项目90计划:高端冷门盈利科技微信公众号文章full-auto采集教
一、前言
在上周千梦网打造的“千梦IP恶魔实战训练营”直播中,我们推荐了一些优秀的同行案例。目前头脑中的许多优秀球员同时拥有非常高的素质。高效的内容输出,今天为大家带来微信公众号文章采集教。
微信公众号采集目前网上有很多方法和软件,有免费的也有付费的,但质量参差不齐,功能也大不相同。下载公众号文章只是最基础的功能,如果能下载peer的所有数据,真的可以帮助我们分析标杆对象。
二、课程练习
1.下载并解压软件
拿到软件后,先把所有文件解压到桌面文件夹。此版本免费安装,直接开启软件即可。
2.在PC端打开微信
在电脑上下载微信,登录账号同步数据。
3.输入采集object 公众号
进入对应的公众号,同时点击历史菜单界面,等待软件监控。
4.Begin采集
软件采集完成后,建议选择“PDF”格式导出,每个公众号出来后会变成一个单独的文件夹。
具体操作请看教程。本教程免费,可直接下载学习!
同系列课程:
千梦网108项目第89话:老司机随机播放,灰黑站必须有粘性变现功能
当前课程链接:
链接:
提取码:0o3g
原创文章,作者:勇敢,如转载请注明出处: 查看全部
全网文章采集(
《千梦ip魔鬼实战训练营》微信公众号采集教学)
千梦网108项目90计划:高端冷门盈利科技微信公众号文章full-auto采集教
一、前言
在上周千梦网打造的“千梦IP恶魔实战训练营”直播中,我们推荐了一些优秀的同行案例。目前头脑中的许多优秀球员同时拥有非常高的素质。高效的内容输出,今天为大家带来微信公众号文章采集教。
微信公众号采集目前网上有很多方法和软件,有免费的也有付费的,但质量参差不齐,功能也大不相同。下载公众号文章只是最基础的功能,如果能下载peer的所有数据,真的可以帮助我们分析标杆对象。
二、课程练习
1.下载并解压软件
拿到软件后,先把所有文件解压到桌面文件夹。此版本免费安装,直接开启软件即可。
2.在PC端打开微信
在电脑上下载微信,登录账号同步数据。
3.输入采集object 公众号
进入对应的公众号,同时点击历史菜单界面,等待软件监控。
4.Begin采集
软件采集完成后,建议选择“PDF”格式导出,每个公众号出来后会变成一个单独的文件夹。
具体操作请看教程。本教程免费,可直接下载学习!
同系列课程:
千梦网108项目第89话:老司机随机播放,灰黑站必须有粘性变现功能
当前课程链接:
链接:
提取码:0o3g
原创文章,作者:勇敢,如转载请注明出处:
全网文章采集(集搜客GooSeeker爬虫术语“主题”统一改为“任务” )
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-09-01 16:03
)
注:吉首客的GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”已改为“任务”。在爬虫浏览器中,先给任务命名然后创建规则,然后登录吉首可以查看任务的采集执行状态,管理线程URL,在“任务管理”中进行调度设置可客官网会员中心。
一、操作步骤
今天教大家如何抓取搜狐的news文章,重点讲如何抓取全文内容,如何批量抓取更多新闻,方法一般,可以套用到其他news网站Fetch ,整体操作步骤如下:
二、Case+操作步骤
第一步,打开网页
1.1,打开极手客软件,输入网址并回车,然后在网页加载完毕后点击右上角的“定义规则”按钮,可以看到出现了一个浮动窗口,这是工作站,下面定义的规则会在上面输出。
1.2,在工作台中输入主题名称,然后单击“检查重复”。如果提示被占用,则必须更改名称以确保主题名称唯一。
第 2 步:标记信息
2.1,在浏览器窗口点击你要抓取的内容,这里是新闻标题被选中,然后你会看到整个标题变成了黄色背景,还有一个红框闪烁的框留在这个范围,根据黄色范围检查是否选择了正确的信息,没有问题,再次点击,会弹出一个标签窗口。输入标签名称后,点击打勾保存或回车保存,在规则名称中输入第一个标记的排序框,确认后在右上角的工作台中可以看到输出的数据结构;
2.2,按照之前的操作,网页上的作者和发表时间也被标注出来了;
2.3,下一步就是标记文字了。如果您单击文本的一个段落,则只会选择该段落的范围。如果要抓取所有的文字,需要点击文字的空白处,会看到文字全部被选中,然后点击进行标注映射;
PS:如果是其他网页,不需要点击空白处全选,可以点击其他位置,直到选中你想要的内容范围;
2.4,如果不能点击选择整个范围的位置,可以点击部分目标信息,底部dom窗口会定位到这个信息对应的网页节点,然后点击每一个收录这个节点的上层节点,直到可以看到网页上选中的整个范围;
2.5,然后右击节点,选择Content Mapping -> New Capture Content -> 在快捷菜单中输入标签名称。这个操作的结果和上一步2.3一样;
第三步,保存规则,抓取数据
3.1,点击右边的测试按钮预览输出信息是否完整,如果没有问题点击右上角的保存按钮,然后点击“Crawl Data”,一个DS计数器将弹出窗口并开始捕获数据;
3.2,我之前只看到一个网络新闻。很多人会问怎么做才能得到更多的消息?这很简单。只要网页结构与示例页面相同,就可以使用此规则抓取信息。因此,我们可以整理出其他与本页面结构相同的搜狐新闻网址,并添加到规则中。操作是在计数机上进行的。右键点击规则,点击“管理线索”,然后选择“添加”,把网址复制进去保存,然后点击规则旁边的“单次搜索”,一次开始一页采集。另外,还可以使用level采集方法来实现URL的自动导入。详情请参阅“使用 URL 制作关卡采集”。
第四步,转换成Excel表格
4.1,采集 成功的数据会以xml文件的形式保存在电脑的DataScraperWorks文件夹中。点击左上角的文件菜单->存储路径,找到文件夹的位置。
4.2,那么我们就可以将采集发来的xml文件压缩成zip压缩包,进入会员中心的规则管理,选择对应的规则,然后点击导入数据,选择压缩后的zip 压缩 导入包。导入成功后,点击导出数据,下载的文件为Excel文件。
查看全部
全网文章采集(集搜客GooSeeker爬虫术语“主题”统一改为“任务”
)
注:吉首客的GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”已改为“任务”。在爬虫浏览器中,先给任务命名然后创建规则,然后登录吉首可以查看任务的采集执行状态,管理线程URL,在“任务管理”中进行调度设置可客官网会员中心。
一、操作步骤
今天教大家如何抓取搜狐的news文章,重点讲如何抓取全文内容,如何批量抓取更多新闻,方法一般,可以套用到其他news网站Fetch ,整体操作步骤如下:
二、Case+操作步骤
第一步,打开网页
1.1,打开极手客软件,输入网址并回车,然后在网页加载完毕后点击右上角的“定义规则”按钮,可以看到出现了一个浮动窗口,这是工作站,下面定义的规则会在上面输出。
1.2,在工作台中输入主题名称,然后单击“检查重复”。如果提示被占用,则必须更改名称以确保主题名称唯一。
第 2 步:标记信息
2.1,在浏览器窗口点击你要抓取的内容,这里是新闻标题被选中,然后你会看到整个标题变成了黄色背景,还有一个红框闪烁的框留在这个范围,根据黄色范围检查是否选择了正确的信息,没有问题,再次点击,会弹出一个标签窗口。输入标签名称后,点击打勾保存或回车保存,在规则名称中输入第一个标记的排序框,确认后在右上角的工作台中可以看到输出的数据结构;
2.2,按照之前的操作,网页上的作者和发表时间也被标注出来了;
2.3,下一步就是标记文字了。如果您单击文本的一个段落,则只会选择该段落的范围。如果要抓取所有的文字,需要点击文字的空白处,会看到文字全部被选中,然后点击进行标注映射;
PS:如果是其他网页,不需要点击空白处全选,可以点击其他位置,直到选中你想要的内容范围;
2.4,如果不能点击选择整个范围的位置,可以点击部分目标信息,底部dom窗口会定位到这个信息对应的网页节点,然后点击每一个收录这个节点的上层节点,直到可以看到网页上选中的整个范围;
2.5,然后右击节点,选择Content Mapping -> New Capture Content -> 在快捷菜单中输入标签名称。这个操作的结果和上一步2.3一样;
第三步,保存规则,抓取数据
3.1,点击右边的测试按钮预览输出信息是否完整,如果没有问题点击右上角的保存按钮,然后点击“Crawl Data”,一个DS计数器将弹出窗口并开始捕获数据;
3.2,我之前只看到一个网络新闻。很多人会问怎么做才能得到更多的消息?这很简单。只要网页结构与示例页面相同,就可以使用此规则抓取信息。因此,我们可以整理出其他与本页面结构相同的搜狐新闻网址,并添加到规则中。操作是在计数机上进行的。右键点击规则,点击“管理线索”,然后选择“添加”,把网址复制进去保存,然后点击规则旁边的“单次搜索”,一次开始一页采集。另外,还可以使用level采集方法来实现URL的自动导入。详情请参阅“使用 URL 制作关卡采集”。
第四步,转换成Excel表格
4.1,采集 成功的数据会以xml文件的形式保存在电脑的DataScraperWorks文件夹中。点击左上角的文件菜单->存储路径,找到文件夹的位置。
4.2,那么我们就可以将采集发来的xml文件压缩成zip压缩包,进入会员中心的规则管理,选择对应的规则,然后点击导入数据,选择压缩后的zip 压缩 导入包。导入成功后,点击导出数据,下载的文件为Excel文件。
全网文章采集(织梦采集侠的官网点-上海怡健医学(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-09-01 05:14
织梦采集侠
织梦采集侠功能
采集侠官网 点击这里下载免费版采集侠
采集侠是专业的采集模块,拥有先进的人工智能网页识别技术和优秀的伪原创技术,远远超越传统采集软件,区别于网站采集Quality内容是自动处理原创,减少网站维护工作量,大大增加收录和点击。是每个网站必备的插件。
1 一键安装,全自动采集
织梦采集侠安装非常简单方便。只需一分钟即可立即启动采集。凭借简单、健壮、灵活、开源的dedecms程序,新手可以快速上手,我们还有专门的客服为商业客户提供技术支持。
2个字采集,不用写采集rules
与传统采集模式的区别在于织梦采集侠可以根据用户设置的关键词进行pan采集。 pan采集的优势在于采集这关键词不同搜索结果的不同搜索结果,实现一个或几个指定的采集站点不是采集,降低采集站点被判断的风险被搜索引擎当成镜像站点被搜索引擎惩罚。
3RSS采集,只需输入RSS地址采集内容
只要RSS订阅地址是采集的网站提供的,就可以使用RSS采集,只需要输入RSS地址就可以轻松采集目标网站内容,无需写采集规则,方便简单。
4页监控采集,简单方便采集content
页面监控采集只需要提供监控页面地址和文字URL规则来指定采集specified网站或栏目内容,方便简单,无需写采集即可针对性采集 @规则。 5 多种伪原创和优化方法提高收录率和排名
自动标题、段落重排、高级混淆、自动内链、内容过滤、URL过滤、同义词替换、插入seo词、关键词添加链接等多种方式,处理采集回的文章处理,提升采集文章原创性能,有利于搜索引擎优化,提高搜索引擎收录、网站权重和关键词排名。
6个插件全自动采集,无需人工干预 查看全部
全网文章采集(织梦采集侠的官网点-上海怡健医学(图))
织梦采集侠
织梦采集侠功能
采集侠官网 点击这里下载免费版采集侠
采集侠是专业的采集模块,拥有先进的人工智能网页识别技术和优秀的伪原创技术,远远超越传统采集软件,区别于网站采集Quality内容是自动处理原创,减少网站维护工作量,大大增加收录和点击。是每个网站必备的插件。
1 一键安装,全自动采集
织梦采集侠安装非常简单方便。只需一分钟即可立即启动采集。凭借简单、健壮、灵活、开源的dedecms程序,新手可以快速上手,我们还有专门的客服为商业客户提供技术支持。
2个字采集,不用写采集rules
与传统采集模式的区别在于织梦采集侠可以根据用户设置的关键词进行pan采集。 pan采集的优势在于采集这关键词不同搜索结果的不同搜索结果,实现一个或几个指定的采集站点不是采集,降低采集站点被判断的风险被搜索引擎当成镜像站点被搜索引擎惩罚。
3RSS采集,只需输入RSS地址采集内容
只要RSS订阅地址是采集的网站提供的,就可以使用RSS采集,只需要输入RSS地址就可以轻松采集目标网站内容,无需写采集规则,方便简单。
4页监控采集,简单方便采集content
页面监控采集只需要提供监控页面地址和文字URL规则来指定采集specified网站或栏目内容,方便简单,无需写采集即可针对性采集 @规则。 5 多种伪原创和优化方法提高收录率和排名
自动标题、段落重排、高级混淆、自动内链、内容过滤、URL过滤、同义词替换、插入seo词、关键词添加链接等多种方式,处理采集回的文章处理,提升采集文章原创性能,有利于搜索引擎优化,提高搜索引擎收录、网站权重和关键词排名。
6个插件全自动采集,无需人工干预
一下采集微信公众号文章的方法,帮你轻松采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2021-08-25 05:06
你有没有在微信公众号里看到过好的文章?看到好的文章,你会想采集下吗?相信很多人都做过。有这种想法吗?最近很多微信用户问我怎么采集微信官方号文章?下面小编带你看看采集微信官方号文章的做法。
很多人看到微信公众号里的好文章,或者精彩的内容,就想采集过来自用,那有什么办法实现吗?下面小编就来告诉你采集微信公号文章的内容如何?看看有什么手段可以用采集微信内容,一起来看看吧!
如今,微信公众号已经成为一种主流的线上线下微信互动营销方式。微信公众号上有很多优秀的文章,但是微信是腾讯所有的,不能直接发到自己网站或者保存在数据库里,所以如果你想在优质的微信上进行@ 文章采集,转移到我的网站hin 还是很麻烦。小喵教你一招,轻松采集微信公号文章,还可以自动发布!
NO.1 通过百度搜索相关网站,注册或登录后进入爬虫市场。
NO.2 搜索关键词:微信公众号。点击免费获取!
NO.3 进入采集爬虫后,点击爬虫设置。
首先,由于搜狗微信搜索有图片防盗取功能,需要在功能设置中开启图片云托管。这是非常重要的。记住,否则你的图片不会显示出来,到时候会很尴尬...
自定义设置,可以同时采集多个微信公众号文章,最多500个!特别注意:请输入微信名称而不是微信名称!
什么!分不清哪个是微信名哪个是微信账号哦,长的有点像。好,那我就告诉你。
进入搜狗微信,输入你想要的微信公众号,点击搜索公众号。
我再次强调!输入微信ID!设置好后记得保存。然后进入概览页面,启动爬虫,等待爬取结果。保存:开始:抓取结果:
数据发布:
Data采集完了,可以发布数据了吗?答案当然是!
NO.1 发布数据只需要两步:安装发布插件——>使用发布界面。您可以选择发布到数据库或发布到网站。
如果你不知道怎么安装插件,那我告诉你,进入文档中心-使用文档-数据发布-安装插件,查看文档,按照文档提示操作,你会一步一步地OK。
插件安装成功,我们新建一个发布项吧!这里有很多,选择你喜欢的。选择发布界面后,填写你要发布的网站地址和密码。同时系统会自动检测插件是否安装正确。对于字段映射,一般情况下,系统会默认选择一个好的,但是如果你觉得有什么需要调整的可以修改。内容替换 这是一个可选项目,可以填写也可以不填写。设置完成后即可发布数据。
NO.2 在抓取结果页面,您可以看到采集爬虫根据您设置的信息抓取的所有内容。发布结果可以自动发布,也可以手动发布。自动发布:开启自动发布后,抓取到的数据会自动发布到网站或者数据库,感觉6要起飞了!
当然,您也可以选择手动发布。发布时可以选择单次发布或多次发布。发布前也可以先预览看看这个文章的内容是什么。如果你认为有问题,你可以发布数据。发布成功后可以点击链接查看。 查看全部
一下采集微信公众号文章的方法,帮你轻松采集
你有没有在微信公众号里看到过好的文章?看到好的文章,你会想采集下吗?相信很多人都做过。有这种想法吗?最近很多微信用户问我怎么采集微信官方号文章?下面小编带你看看采集微信官方号文章的做法。
很多人看到微信公众号里的好文章,或者精彩的内容,就想采集过来自用,那有什么办法实现吗?下面小编就来告诉你采集微信公号文章的内容如何?看看有什么手段可以用采集微信内容,一起来看看吧!
如今,微信公众号已经成为一种主流的线上线下微信互动营销方式。微信公众号上有很多优秀的文章,但是微信是腾讯所有的,不能直接发到自己网站或者保存在数据库里,所以如果你想在优质的微信上进行@ 文章采集,转移到我的网站hin 还是很麻烦。小喵教你一招,轻松采集微信公号文章,还可以自动发布!
NO.1 通过百度搜索相关网站,注册或登录后进入爬虫市场。
NO.2 搜索关键词:微信公众号。点击免费获取!
NO.3 进入采集爬虫后,点击爬虫设置。
首先,由于搜狗微信搜索有图片防盗取功能,需要在功能设置中开启图片云托管。这是非常重要的。记住,否则你的图片不会显示出来,到时候会很尴尬...
自定义设置,可以同时采集多个微信公众号文章,最多500个!特别注意:请输入微信名称而不是微信名称!
什么!分不清哪个是微信名哪个是微信账号哦,长的有点像。好,那我就告诉你。
进入搜狗微信,输入你想要的微信公众号,点击搜索公众号。
我再次强调!输入微信ID!设置好后记得保存。然后进入概览页面,启动爬虫,等待爬取结果。保存:开始:抓取结果:
数据发布:
Data采集完了,可以发布数据了吗?答案当然是!
NO.1 发布数据只需要两步:安装发布插件——>使用发布界面。您可以选择发布到数据库或发布到网站。
如果你不知道怎么安装插件,那我告诉你,进入文档中心-使用文档-数据发布-安装插件,查看文档,按照文档提示操作,你会一步一步地OK。
插件安装成功,我们新建一个发布项吧!这里有很多,选择你喜欢的。选择发布界面后,填写你要发布的网站地址和密码。同时系统会自动检测插件是否安装正确。对于字段映射,一般情况下,系统会默认选择一个好的,但是如果你觉得有什么需要调整的可以修改。内容替换 这是一个可选项目,可以填写也可以不填写。设置完成后即可发布数据。
NO.2 在抓取结果页面,您可以看到采集爬虫根据您设置的信息抓取的所有内容。发布结果可以自动发布,也可以手动发布。自动发布:开启自动发布后,抓取到的数据会自动发布到网站或者数据库,感觉6要起飞了!
当然,您也可以选择手动发布。发布时可以选择单次发布或多次发布。发布前也可以先预览看看这个文章的内容是什么。如果你认为有问题,你可以发布数据。发布成功后可以点击链接查看。
全网文章采集,采集分析2019年1月至2019
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-08-24 21:04
全网文章采集,采集分析了2019年1月至2019年12月以来tidb官方发布文章的全部规格字段。合并后,本专栏所有相关文章皆可以免费使用。(部分文章未能合并,此功能只提供“保留”的查询,
采集不了啊,你连采集器都没有呢。现在是个人tidb本地5g流量,是够用的。公司和国外是要10g甚至100g。
都有采集了,每个月我见过的人都5000起步,云服务器的钱多贵,一个月少说5000起步。
肯定是采集不了的。tidb是已开源的数据库产品,本身没有所谓的数据采集接口。至于其他人说的合并别人,这个是不会,目前tidb已经出了配套的ci/cd服务,是针对复杂集群的,合并就要重新训练。
最简单的事情就是phpsocket,
哪有那么麻烦?tidb是自研分布式多维数据库
统计分析是个伪需求,没有那么的复杂。
获取全网数据是很不现实的。拿云平台来说,分布式系统很复杂,部署起来容易,维护起来难度大,很难达到小企业的要求。你要说多人使用,可以,来年我再进一部分数据。
首先数据采集不是一个应用场景,就像我问题里面说的,应用场景要弄成多场景合一,这一点还是比较难的。其次说到tidb是否能够进行分析,tidb不是说搞出一个api就能用的,这一点有很多问题,也需要很多优化。一般来说需要考虑很多问题,首先是网络拓扑和存储策略等,这一点如果复杂的话比较难,即使都是tibco作为生态,如果收购一个比较成熟的数据库解决方案也不是完全能够解决tibco的问题。因此对应的tibco能提供的能力也要有。 查看全部
全网文章采集,采集分析2019年1月至2019
全网文章采集,采集分析了2019年1月至2019年12月以来tidb官方发布文章的全部规格字段。合并后,本专栏所有相关文章皆可以免费使用。(部分文章未能合并,此功能只提供“保留”的查询,
采集不了啊,你连采集器都没有呢。现在是个人tidb本地5g流量,是够用的。公司和国外是要10g甚至100g。
都有采集了,每个月我见过的人都5000起步,云服务器的钱多贵,一个月少说5000起步。
肯定是采集不了的。tidb是已开源的数据库产品,本身没有所谓的数据采集接口。至于其他人说的合并别人,这个是不会,目前tidb已经出了配套的ci/cd服务,是针对复杂集群的,合并就要重新训练。
最简单的事情就是phpsocket,
哪有那么麻烦?tidb是自研分布式多维数据库
统计分析是个伪需求,没有那么的复杂。
获取全网数据是很不现实的。拿云平台来说,分布式系统很复杂,部署起来容易,维护起来难度大,很难达到小企业的要求。你要说多人使用,可以,来年我再进一部分数据。
首先数据采集不是一个应用场景,就像我问题里面说的,应用场景要弄成多场景合一,这一点还是比较难的。其次说到tidb是否能够进行分析,tidb不是说搞出一个api就能用的,这一点有很多问题,也需要很多优化。一般来说需要考虑很多问题,首先是网络拓扑和存储策略等,这一点如果复杂的话比较难,即使都是tibco作为生态,如果收购一个比较成熟的数据库解决方案也不是完全能够解决tibco的问题。因此对应的tibco能提供的能力也要有。
一款非常漂亮的小说在线阅读网站织梦模板(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-08-21 04:21
一款非常漂亮的小说在线阅读网站织梦模板(组图)
很漂亮的小说在线阅读网站织梦模板源码,简洁大气,5W数据,以dedecms5.7sp1为核心,全自动采集各种大小说站,可自动生成首页、分类、目录、排名、站点地图页、全站拼音目录、伪静态章节页、小说txt文件自动生成、zip压缩包自动生成等静态html。本源码功能可谓无比强大,其他更多功能请自行下载体验。
此模板主要用于棕色调。该模板采用最新版本的织梦UTF-8 内核制作。这个模板是整个站点的源码,有测试数据,安装非常方便。只需要在后台把栏目改成自己的,就可以轻松搭建自己的网站。
模板功能:
本模板的采集模板已经重新开发,功能更加强大。推荐给织梦basic的朋友。站长小白只做研究。
1)首页、分类、目录、排名、站点地图页(分类页、小说封面、作者页,如果html文件不存在或超过设定时间未更新,则自动生成静态html自动更新一次。如果有采集,采集会自动更新小说封面和对应的分类页面),直接通过PHP调用html文件,而不是在根目录生成,访问速度无区别于纯静态,源代码可以保证文件管理方便的同时降低服务器压力,还可以方便的访问统计,增加搜索引擎的识别度。
(2)全站拼音编目,章节页面伪静态。
(3)小说txt文件自动生成,也可以后台自行重新生成txt文件。
(4)自动生成小说关键词和关键词自动内链。
(5)Auto伪原创word 替换(采集 时间替换)。
(6)新增小说总点击量、月点击量、周点击量、总推荐量、月推荐量、周推荐统计、作者推荐统计等新功能。
(7)配合CNZZ的统计插件,可以轻松实现小说下载量和藏书量的详细统计。
环境语言:PHP5.2/5.3/5.4/5.5+MYSQL5+伪静态
编码类型:GBK
由于源码修改优化,不自动升级。一般没有BUG就不需要升级。 查看全部
一款非常漂亮的小说在线阅读网站织梦模板(组图)
很漂亮的小说在线阅读网站织梦模板源码,简洁大气,5W数据,以dedecms5.7sp1为核心,全自动采集各种大小说站,可自动生成首页、分类、目录、排名、站点地图页、全站拼音目录、伪静态章节页、小说txt文件自动生成、zip压缩包自动生成等静态html。本源码功能可谓无比强大,其他更多功能请自行下载体验。
此模板主要用于棕色调。该模板采用最新版本的织梦UTF-8 内核制作。这个模板是整个站点的源码,有测试数据,安装非常方便。只需要在后台把栏目改成自己的,就可以轻松搭建自己的网站。
模板功能:
本模板的采集模板已经重新开发,功能更加强大。推荐给织梦basic的朋友。站长小白只做研究。
1)首页、分类、目录、排名、站点地图页(分类页、小说封面、作者页,如果html文件不存在或超过设定时间未更新,则自动生成静态html自动更新一次。如果有采集,采集会自动更新小说封面和对应的分类页面),直接通过PHP调用html文件,而不是在根目录生成,访问速度无区别于纯静态,源代码可以保证文件管理方便的同时降低服务器压力,还可以方便的访问统计,增加搜索引擎的识别度。
(2)全站拼音编目,章节页面伪静态。
(3)小说txt文件自动生成,也可以后台自行重新生成txt文件。
(4)自动生成小说关键词和关键词自动内链。
(5)Auto伪原创word 替换(采集 时间替换)。
(6)新增小说总点击量、月点击量、周点击量、总推荐量、月推荐量、周推荐统计、作者推荐统计等新功能。
(7)配合CNZZ的统计插件,可以轻松实现小说下载量和藏书量的详细统计。
环境语言:PHP5.2/5.3/5.4/5.5+MYSQL5+伪静态
编码类型:GBK
由于源码修改优化,不自动升级。一般没有BUG就不需要升级。
免费自学学习网模板文章资讯作文整站源码手机同步生成+安装教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-08-20 20:22
2021帝国cms7.5免费自学学习网模板文章资讯作文全站源码手机同步生成+安装教程+采集
———————————————————————————————————
PC/电脑版演示地址:查看演示
WAP/手机版演示地址:查看演示(请使用手机访问)
———————————————————————————————————
源代码是EmpirecmsUTF8版本。如需GBK版本请自行转码!
模板简洁大方,访问快捷,移动端优化美观用户体验。
适用于文章资讯中小学生的知识点总结、试题、练习题、考试资料、论文、学习方法和技巧等!
所有功能后台管理,已预留广告位(如需添加广告位请联系店主添加)。
模板使用标签灵活调用,采集精选优质源站,模板精美同时兼顾SEO搜索引擎优化。全站静态生成有利于收录和关键词布局和内容页面优化!
功能列表:
1、内置ITAG插件,标签可以拼音,标签分类可用,功能更强大,更容易生成词库。 (标签链接样式可选择ID或拼音)
2、内置百度推送插件,实时数据推送到步行搜索引擎。
3、带优采云采集规则,可以自己采集海量数据,全自动无人值守采集。
4、built-in网站map 站点地图插件
本产品是整个站点的源代码,不仅是模板,还有演示站点的所有数据。
详情请看演示网站,更直观。
注意:演示站机器配置低,有延迟是正常的。这与模板程序无关。
———————————————————————————————————————
●帝国cms7.5UTF-8
●系统开源,域名不限。
●同步生成WAP移动终端简单实用。
●大约 330MB 大小
●简单的安装方法,详细的安装教程。
●TAG标签聚合
资源下载本资源下载价格为99金币,请先登录 查看全部
免费自学学习网模板文章资讯作文整站源码手机同步生成+安装教程
2021帝国cms7.5免费自学学习网模板文章资讯作文全站源码手机同步生成+安装教程+采集
———————————————————————————————————
PC/电脑版演示地址:查看演示
WAP/手机版演示地址:查看演示(请使用手机访问)
———————————————————————————————————
源代码是EmpirecmsUTF8版本。如需GBK版本请自行转码!
模板简洁大方,访问快捷,移动端优化美观用户体验。
适用于文章资讯中小学生的知识点总结、试题、练习题、考试资料、论文、学习方法和技巧等!
所有功能后台管理,已预留广告位(如需添加广告位请联系店主添加)。
模板使用标签灵活调用,采集精选优质源站,模板精美同时兼顾SEO搜索引擎优化。全站静态生成有利于收录和关键词布局和内容页面优化!
功能列表:
1、内置ITAG插件,标签可以拼音,标签分类可用,功能更强大,更容易生成词库。 (标签链接样式可选择ID或拼音)
2、内置百度推送插件,实时数据推送到步行搜索引擎。
3、带优采云采集规则,可以自己采集海量数据,全自动无人值守采集。
4、built-in网站map 站点地图插件
本产品是整个站点的源代码,不仅是模板,还有演示站点的所有数据。
详情请看演示网站,更直观。
注意:演示站机器配置低,有延迟是正常的。这与模板程序无关。
———————————————————————————————————————
●帝国cms7.5UTF-8
●系统开源,域名不限。
●同步生成WAP移动终端简单实用。
●大约 330MB 大小
●简单的安装方法,详细的安装教程。
●TAG标签聚合
http://www.hanjutt.com/wp-cont ... 0.jpg 265w, http://www.hanjutt.com/wp-cont ... 0.jpg 768w" />http://www.hanjutt.com/wp-cont ... 4.jpg 300w, http://www.hanjutt.com/wp-cont ... 2.jpg 1024w, http://www.hanjutt.com/wp-cont ... 7.jpg 768w" />http://www.hanjutt.com/wp-cont ... 0.jpg 260w, http://www.hanjutt.com/wp-cont ... 6.jpg 768w" />http://www.hanjutt.com/wp-cont ... 9.jpg 300w, http://www.hanjutt.com/wp-cont ... 6.jpg 768w" />http://www.hanjutt.com/wp-cont ... 5.jpg 300w, http://www.hanjutt.com/wp-cont ... 6.jpg 768w" />http://www.hanjutt.com/wp-cont ... 0.jpg 229w" />http://www.hanjutt.com/wp-cont ... 0.jpg 248w" />http://www.hanjutt.com/wp-cont ... 0.jpg 254w" />资源下载本资源下载价格为99金币,请先登录
Excel教程Excel函数Excel透视表Excel电子表格Excel基础入门到精通
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-08-20 05:15
Excel教程Excel函数Excel透视表Excel电子表格Excel基础入门到精通
Python爬虫采集今日热榜数据:聚合全网热榜
时间:2020-03-19
本文章为大家介绍Python爬虫采集今日热榜数据:聚合全网热榜,主要包括Python爬虫采集今日热榜数据:聚合用例、应用技巧、基础知识全网热点榜要点总结及注意事项有一定参考价值,有需要的朋友可以参考。
主要使用request库和beautifulSoup库抓取今日热点数据。
具体代码实现:
1 import requests
2 from bs4 import BeautifulSoup
3 import time
4 import pandas
5 import re
6
7 def get_html(url):
8 headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'}
9 resp = requests.get(url, headers=headers)
10 return resp.text
11
12
13 def get_data(html):
14 soup = BeautifulSoup(html, 'html.parser')
15 nodes = soup.find_all('div', class_='cc-cd')
16 return nodes
17
18
19 def get_node_data(df, nodes):
20 now = int(time.time())
21 for node in nodes:
22 source = node.find('div', class_='cc-cd-lb').text.strip()
23 messages = node.find('div', class_='cc-cd-cb-l nano-content').find_all('a')
24 for message in messages:
25 content = message.find('span', class_='t').text.strip()
26 if source == '微信':
27 reg = '「.+?」(.+)'
28 content = re.findall(reg, content)[0]
29
30 if df.empty or df[df.content == content].empty:
31 data = {
32 'content': [content],
33 'url': [message['href']],
34 'source': [source],
35 'start_time': [now],
36 'end_time': [now]
37 }
38
39 item = pandas.DataFrame(data)
40 df = pandas.concat([df, item], ignore_index=True)
41
42 else:
43 index = df[df.content == content].index[0]
44 df.at[index, 'end_time'] = now
45
46 return df
47
48
49 url = 'https://tophub.today'
50 html = get_html(url)
51 data = get_data(html)
52 res = pandas.read_excel('今日热榜.xlsx')
53 res = get_node_data(res, data)
54 res.to_excel('今日热榜.xlsx') 查看全部
Excel教程Excel函数Excel透视表Excel电子表格Excel基础入门到精通
Python爬虫采集今日热榜数据:聚合全网热榜
时间:2020-03-19
本文章为大家介绍Python爬虫采集今日热榜数据:聚合全网热榜,主要包括Python爬虫采集今日热榜数据:聚合用例、应用技巧、基础知识全网热点榜要点总结及注意事项有一定参考价值,有需要的朋友可以参考。
主要使用request库和beautifulSoup库抓取今日热点数据。
具体代码实现:
1 import requests
2 from bs4 import BeautifulSoup
3 import time
4 import pandas
5 import re
6
7 def get_html(url):
8 headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'}
9 resp = requests.get(url, headers=headers)
10 return resp.text
11
12
13 def get_data(html):
14 soup = BeautifulSoup(html, 'html.parser')
15 nodes = soup.find_all('div', class_='cc-cd')
16 return nodes
17
18
19 def get_node_data(df, nodes):
20 now = int(time.time())
21 for node in nodes:
22 source = node.find('div', class_='cc-cd-lb').text.strip()
23 messages = node.find('div', class_='cc-cd-cb-l nano-content').find_all('a')
24 for message in messages:
25 content = message.find('span', class_='t').text.strip()
26 if source == '微信':
27 reg = '「.+?」(.+)'
28 content = re.findall(reg, content)[0]
29
30 if df.empty or df[df.content == content].empty:
31 data = {
32 'content': [content],
33 'url': [message['href']],
34 'source': [source],
35 'start_time': [now],
36 'end_time': [now]
37 }
38
39 item = pandas.DataFrame(data)
40 df = pandas.concat([df, item], ignore_index=True)
41
42 else:
43 index = df[df.content == content].index[0]
44 df.at[index, 'end_time'] = now
45
46 return df
47
48
49 url = 'https://tophub.today'
50 html = get_html(url)
51 data = get_data(html)
52 res = pandas.read_excel('今日热榜.xlsx')
53 res = get_node_data(res, data)
54 res.to_excel('今日热榜.xlsx')
软件特点优采云软件首创的智能提取网页正文算法(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-08-15 07:00
软件特点优采云软件首创的智能提取网页正文算法(组图)
优采云·新闻源文章采集器(SMnewsbot)——第一个提取文本的智能算法;准确采集新闻源,泛网;多语言翻译伪原创
本软件是一款只需要输入关键词采集百度、谷歌、搜搜等各大搜索引擎新闻源和泛网互联网文章软件(更多介绍...)的软件。
优采云software 是首创的独家智能算法,可以准确提取网页正文部分并保存为文章。
支持对标签、链接、邮件等进行格式化处理,还有插入关键词的功能,可以识别旁边插入的标签或者标点符号,可以识别英文空格的插入。
更多文章transfer 翻译功能,即文章可以从一种语言如中文转为英文或日文等另一种语言,再由英文或日文转回中文。这是一个翻译周期。您可以将翻译周期设置为循环多次(翻译次数)。
采集文章+翻译伪原创可以满足站长和各领域朋友对文章的需求。
一些公关处理和信息研究公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而优采云的软件也是一个信息采集系统功能和市场上昂贵的软件有相似之处,但价格只有几百元,你会知道如何尝试性价比。
软件功能
优采云Software 首个智能提取网页正文的算法
百度新闻、谷歌新闻和搜搜新闻强聚合
不时更新的新闻资源取之不尽
多语言翻译伪原创。你,输入关键词
受影响区域
1、按关键词采集 Internet文章翻译伪原创,站长朋友的首选。
2、适用于信息公关公司采集过滤提炼信息资料(上万专业公司的软件,我的几百块钱) 查看全部
软件特点优采云软件首创的智能提取网页正文算法(组图)
优采云·新闻源文章采集器(SMnewsbot)——第一个提取文本的智能算法;准确采集新闻源,泛网;多语言翻译伪原创
本软件是一款只需要输入关键词采集百度、谷歌、搜搜等各大搜索引擎新闻源和泛网互联网文章软件(更多介绍...)的软件。
优采云software 是首创的独家智能算法,可以准确提取网页正文部分并保存为文章。
支持对标签、链接、邮件等进行格式化处理,还有插入关键词的功能,可以识别旁边插入的标签或者标点符号,可以识别英文空格的插入。
更多文章transfer 翻译功能,即文章可以从一种语言如中文转为英文或日文等另一种语言,再由英文或日文转回中文。这是一个翻译周期。您可以将翻译周期设置为循环多次(翻译次数)。
采集文章+翻译伪原创可以满足站长和各领域朋友对文章的需求。
一些公关处理和信息研究公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而优采云的软件也是一个信息采集系统功能和市场上昂贵的软件有相似之处,但价格只有几百元,你会知道如何尝试性价比。
软件功能
优采云Software 首个智能提取网页正文的算法
百度新闻、谷歌新闻和搜搜新闻强聚合
不时更新的新闻资源取之不尽
多语言翻译伪原创。你,输入关键词
受影响区域
1、按关键词采集 Internet文章翻译伪原创,站长朋友的首选。
2、适用于信息公关公司采集过滤提炼信息资料(上万专业公司的软件,我的几百块钱)

