全网文章采集(教程简易采集我们内容网址网址ampamp如果作者V5.3(组图))
优采云 发布时间: 2021-09-07 21:10全网文章采集(教程简易采集我们内容网址网址ampamp如果作者V5.3(组图))
关键词说明:教程简单采集我们的内容网址 如果作者V5.3
DedecmsV5.3 采集基础教程。
首先要说明的是,这是我第一次写这种教程。如有不当之处,请见谅。
输入文字:
采集的过程其实就是copy的过程,但是我们copy的是显示结果,采集主要是为了源码。
第一步,创建一个节点
我们以图片中的网址为例。必须正确选择目标页面编码,否则采集返回的内容会出现乱码。如果采集返回的内容是乱码,首先要考虑的是编码问题,这里我们选择utf-8,怎么知道别人的编码是什么?看源码就明白了。
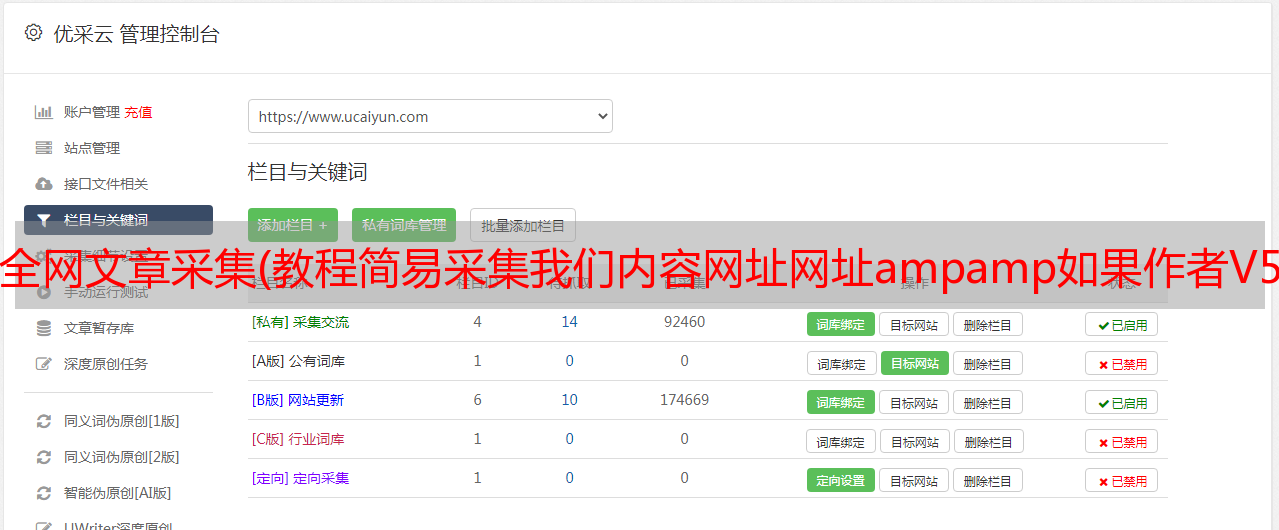
“区域匹配模式”我选择正则表达式,因为如果选择“字符串”,会出现一些无法过滤掉的广告代码。
第二步:文章 URL 匹配规则。欢迎来到生活小贴士 ()
这个要看采集网站的源码(图片2),找一个收录所有采集内容URL的代码(为了唯一,建议多用Ctrl F),所以我们可以确定我想要采集区域的网址,不用担心,测试一下。
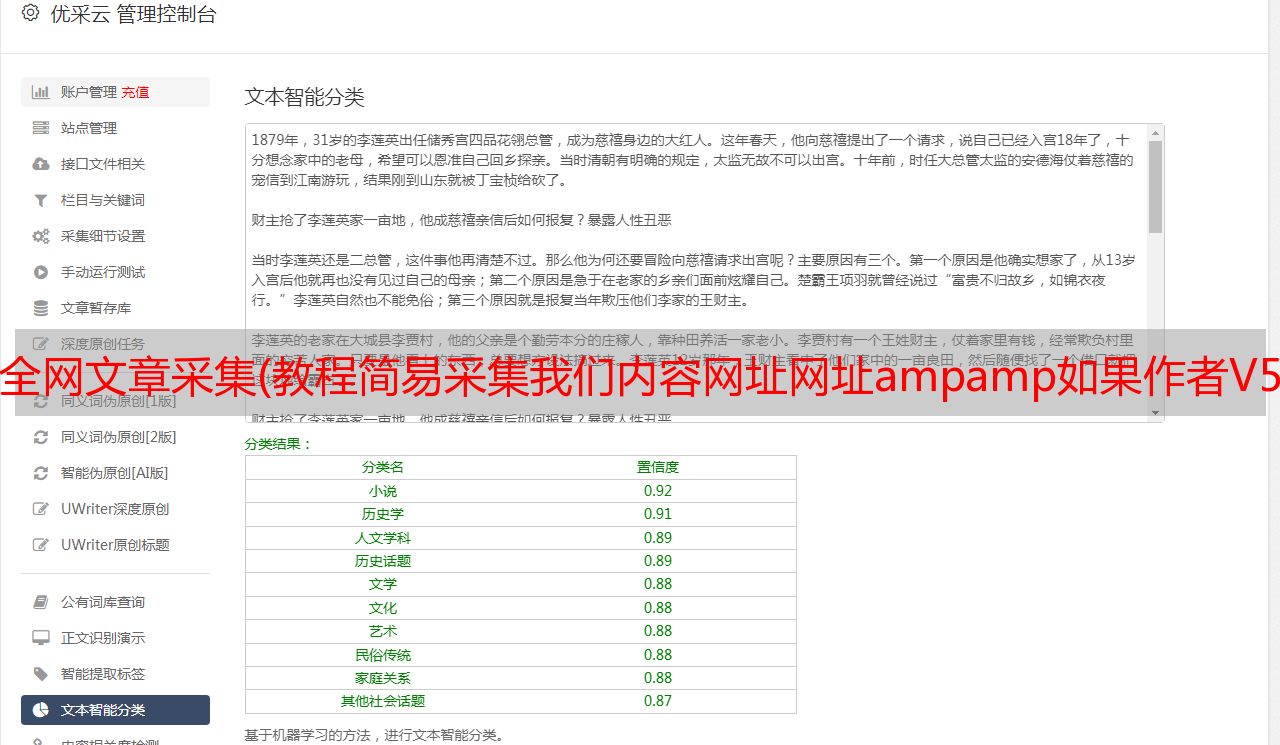
图二
最终结果如图3
图 3
第三步:在前面两步的基础上,我们已经找到了需要采集的网址,我们来看一下具体的采集内容。
在内容配置选项中,如果你和我一样懒惰的话,不要选那么多选项,只选你感兴趣的部分,比如文章title,作者和出处等,在dede cmsV 在5.3中修改了dede V5.1的规则,方便初学者使用。基本形式是将标签和内容放在一起。 V5.1 应该分为开始标签和结束标签。其实原理是一样的。
这里说一下自定义作者的问题。之前版本的v5.3 采集,可以通过@me="author"的形式自定义作者,但是v5.3只能通过替换来实现,当然有不便之处,这样我们就可以确定基本的东西了。
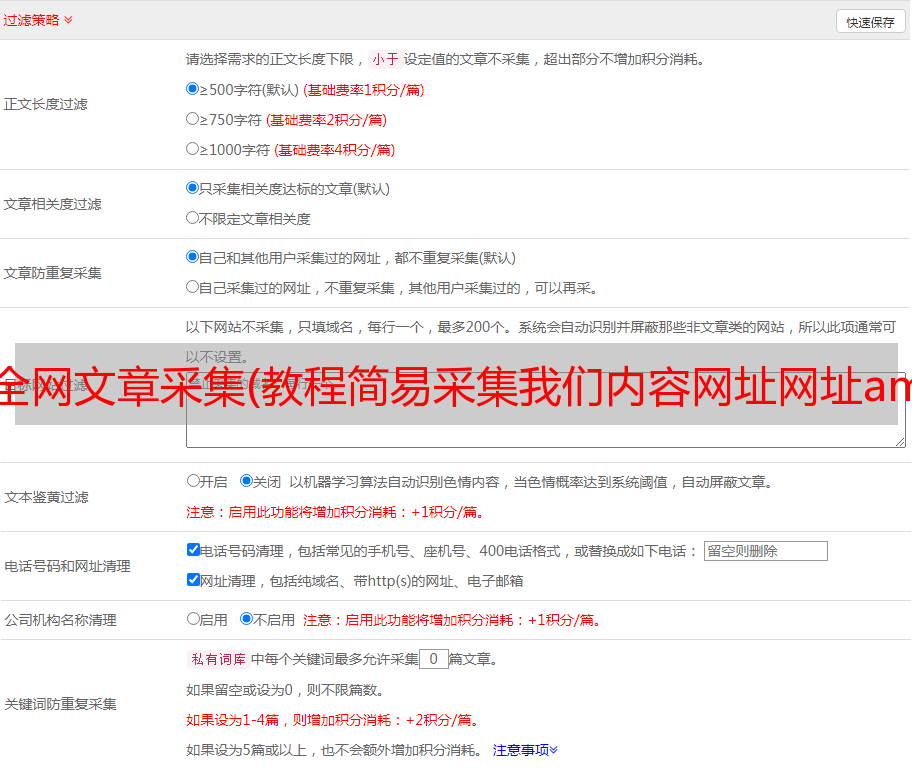
第四步:这是我们想要的内容的核心。这里会用到更多的过滤规则。幸运的是,dede V5.3 为我们准备了一些常用的。但是,如果要比较采集 对于复杂的网页,则必须学习一些常见的正则表达式。这样我们就基本学会了dedecmsV5.3的采集,是不是有点简单?
侠客站长站()
第五步:导出内容,这个就不多说了。

