
优采集平台
优采集平台( 如何利用云优CMS插件让网站快速收录关键词排名-所有网站通用 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-03-12 20:00
如何利用云优CMS插件让网站快速收录关键词排名-所有网站通用
)
云游cms插件-云游cms采集发布模块
SEO技术分享2022-02-18
如何使用云游cms插件使网站快速收录关键词排名-所有网站通用。有无数种方法可以进行 SEO 优化。网站做生意最重要的是SEO优化,做SEO优化最重要的是关键词优化。网站收录不稳定,网站的排名上下波动。也是常见的SEO优化问题,很可能会影响关键词的排名。如何解决这个问题呢?让seo技术小编给大家分享一些内容。
(1)网站重量
之所以把网站的权重放在合适的位置,是因为收录会影响网站的权重。尤其是收录那种突如其来的跌落变化,想必已经找到了跌落的权利。我们也可以根据网站其他数据分析得出相关结论。
(2)文章质量
影响收录 的第二大因素是文章 的质量。这篇原创 文章的收录 速度与伪原创 和采集 文章的速度有很大不同。如果内容是纯 采集 收录 会发生波动。因此,我们需要每天至少坚持伪原创原创,虽然不是每篇文章都有价值,但至少由于原创,百度可以稳定进行网站< @网站 @收录。这是一种快速管理网站的方法。
云游cms插件-支持所有网站使用
1、通过云游cms插件采集,根据关键词采集文章填写内容。(云游cms插件也配置了关键词采集功能)
2、自动过滤其他网站促销信息/支持其他网站信息替换
3、支持多种采集来源采集(涵盖所有行业新闻来源,海量内容库,采集新内容)
4、支持图片本地化或其他平台存储
5、自动批量挂机采集,无缝对接各大cms发布者,采集伪原创并自动发布推送到搜索引擎
这款云游cms插件工具还配备了很多SEO功能,不仅通过云游cms插件实现采集伪原创的发布,还有很多SEO功能。可以提高关键词的密度,提高页面原创的度数,增加用户体验,实现优质内容。
1、标题前缀和后缀设置(标题的区别更好收录)
2、内容关键词插入(合理增加关键词密度)
3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后,主动向搜索引擎推送文章,保证新链接能被搜索引擎及时推送收录)
5、随机点赞-随机阅读-随机作者(增加页面度数原创)
6、内容与标题一致(使内容与标题一致)
7、自动内链(发布任务时会在文章的内容中自动生成内链,帮助引导页面蜘蛛抓取,提高页面权限)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期抓取网页的习惯,从而提升网站的收录)
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
1、批量监控不同cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Cyclone, 站群 、PB、Apple、搜外、云游cms等各大cms工具,可同时管理和批量发布)
2、设置批量发布次数(可以设置发布间隔/单日总发布次数)
3、不同关键词文章可设置发布不同栏目
4、伪原创保留字(当文章原创未被伪原创使用时设置核心字)
5、软件直接监控是否已发布、即将发布、是否为伪原创、发布状态、网址、节目、发布时间等。
6、每日蜘蛛、收录、网站权重可以通过软件直接查看
(3)空间连通性
当你查询收录或相关域时,百度会给出空间连通率的数据,从中可以看出空间或服务器的稳定性。如果空间响应速度慢或者出现宕机,收录的音量自然会上下波动。
(4)网站 被挂或被解析
一般解析,查询收录应该不带3w,现在可以带3w,所以这种情况可以忽略。如果 网站 被暂停,肯定会将收入减少到 0。
(5)网站修订
网站改版自然会影响到收录,毕竟对于蜘蛛来说,如果改版太强的话,会被认为是新站,就算进入了巡检期,那布局比较多有利于网站的优化。网站结构是影响排名的一个非常重要的因素。网站结构不合理会不利于百度蜘蛛的爬取。可能有一些 网站
2、网站 内容更少,更新频率更低
网站除了公司简介和提供的服务之外,几乎没有什么新闻和实际内容。通过查看新闻发布时间,我们发现更新频率不仅很低,而且没有规律性。有很多文章在短时间内发表,但不是很长时间。
3、网站刷流量
网站这几年刷流量这个方法比较有效,但是因为百度这两年根据我们的关键词排名站长“量身定做”了应急算法,这个方法难度很大要想有效,当然不能排除一些高手开发的排名软件确实有这种效果。即便是前几年,“刮排名”的方法虽然奏效,但只要不小心被百度“盯上”,那网站就被认为是掉进了深渊,绝不会恢复了。
4、导出链接太多,有降级站点
通过友好的链接检查工具,发现本站的出口链接有30多个,而且都是单向链接。链接列表中还有几个快照极慢的新站收录。估计之前技术人员也不想建站,干脆把它当作资源。太多的外链会分散网站的权重和PR值,这比交换不合理的链接还要糟糕。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天为你展示各种SEO经验,打通你的二线任命和主管!
查看全部
优采集平台(
如何利用云优CMS插件让网站快速收录关键词排名-所有网站通用
)
云游cms插件-云游cms采集发布模块
SEO技术分享2022-02-18
如何使用云游cms插件使网站快速收录关键词排名-所有网站通用。有无数种方法可以进行 SEO 优化。网站做生意最重要的是SEO优化,做SEO优化最重要的是关键词优化。网站收录不稳定,网站的排名上下波动。也是常见的SEO优化问题,很可能会影响关键词的排名。如何解决这个问题呢?让seo技术小编给大家分享一些内容。
(1)网站重量
之所以把网站的权重放在合适的位置,是因为收录会影响网站的权重。尤其是收录那种突如其来的跌落变化,想必已经找到了跌落的权利。我们也可以根据网站其他数据分析得出相关结论。
(2)文章质量
影响收录 的第二大因素是文章 的质量。这篇原创 文章的收录 速度与伪原创 和采集 文章的速度有很大不同。如果内容是纯 采集 收录 会发生波动。因此,我们需要每天至少坚持伪原创原创,虽然不是每篇文章都有价值,但至少由于原创,百度可以稳定进行网站< @网站 @收录。这是一种快速管理网站的方法。
云游cms插件-支持所有网站使用
1、通过云游cms插件采集,根据关键词采集文章填写内容。(云游cms插件也配置了关键词采集功能)
2、自动过滤其他网站促销信息/支持其他网站信息替换
3、支持多种采集来源采集(涵盖所有行业新闻来源,海量内容库,采集新内容)
4、支持图片本地化或其他平台存储
5、自动批量挂机采集,无缝对接各大cms发布者,采集伪原创并自动发布推送到搜索引擎
这款云游cms插件工具还配备了很多SEO功能,不仅通过云游cms插件实现采集伪原创的发布,还有很多SEO功能。可以提高关键词的密度,提高页面原创的度数,增加用户体验,实现优质内容。
1、标题前缀和后缀设置(标题的区别更好收录)
2、内容关键词插入(合理增加关键词密度)
3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后,主动向搜索引擎推送文章,保证新链接能被搜索引擎及时推送收录)
5、随机点赞-随机阅读-随机作者(增加页面度数原创)
6、内容与标题一致(使内容与标题一致)
7、自动内链(发布任务时会在文章的内容中自动生成内链,帮助引导页面蜘蛛抓取,提高页面权限)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期抓取网页的习惯,从而提升网站的收录)
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
1、批量监控不同cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Cyclone, 站群 、PB、Apple、搜外、云游cms等各大cms工具,可同时管理和批量发布)
2、设置批量发布次数(可以设置发布间隔/单日总发布次数)
3、不同关键词文章可设置发布不同栏目
4、伪原创保留字(当文章原创未被伪原创使用时设置核心字)
5、软件直接监控是否已发布、即将发布、是否为伪原创、发布状态、网址、节目、发布时间等。
6、每日蜘蛛、收录、网站权重可以通过软件直接查看
(3)空间连通性
当你查询收录或相关域时,百度会给出空间连通率的数据,从中可以看出空间或服务器的稳定性。如果空间响应速度慢或者出现宕机,收录的音量自然会上下波动。
(4)网站 被挂或被解析
一般解析,查询收录应该不带3w,现在可以带3w,所以这种情况可以忽略。如果 网站 被暂停,肯定会将收入减少到 0。
(5)网站修订
网站改版自然会影响到收录,毕竟对于蜘蛛来说,如果改版太强的话,会被认为是新站,就算进入了巡检期,那布局比较多有利于网站的优化。网站结构是影响排名的一个非常重要的因素。网站结构不合理会不利于百度蜘蛛的爬取。可能有一些 网站
2、网站 内容更少,更新频率更低
网站除了公司简介和提供的服务之外,几乎没有什么新闻和实际内容。通过查看新闻发布时间,我们发现更新频率不仅很低,而且没有规律性。有很多文章在短时间内发表,但不是很长时间。
3、网站刷流量
网站这几年刷流量这个方法比较有效,但是因为百度这两年根据我们的关键词排名站长“量身定做”了应急算法,这个方法难度很大要想有效,当然不能排除一些高手开发的排名软件确实有这种效果。即便是前几年,“刮排名”的方法虽然奏效,但只要不小心被百度“盯上”,那网站就被认为是掉进了深渊,绝不会恢复了。
4、导出链接太多,有降级站点
通过友好的链接检查工具,发现本站的出口链接有30多个,而且都是单向链接。链接列表中还有几个快照极慢的新站收录。估计之前技术人员也不想建站,干脆把它当作资源。太多的外链会分散网站的权重和PR值,这比交换不合理的链接还要糟糕。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天为你展示各种SEO经验,打通你的二线任命和主管!
优采集平台(优采吧——自采自引的模式是什么)
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2022-03-12 07:05
优采集平台在成立之初便提出要以“优势有优采”为宗旨,企业可以使用我们平台进行营销、运营活动、数据分析等一体化工作,
现在优采取的是自采自引的模式。自采自引意思就是平台自己生产、采集客户需要的数据源,商家在开通会员后,相关数据源就可以得到采集,这样平台也可以为商家解决数据泄露的问题。
我以前在优采取做过,
进去就可以实现大数据分析,并且数据全部公开透明。
优采源于整合原生态资源,
优采吧,你可以考虑下,我同学在优采做过,讲的挺好的,帮他解决了优质原材料,数据全面共享和费用透明吧,
感觉优采采集不仅优,而且好,我用他们采集时没有一个靠谱的后台,查看不到订单,采集数据功能太差,有了优采之后很多都能采集,
优采吧,实现商品源采集,提供产品信息分析,客户数据库。
优采是什么,
推荐一个,聚达网,在朋友圈有推广,效果也还不错,这个应该是目前体验最好的,还提供免费的试用。还有广告精准营销之类的,总之一家人都有份。应该是目前业内最完善,体验最好的了。
优采吧可以搜优采源,好像是个新站吧,还可以去站看看, 查看全部
优采集平台(优采吧——自采自引的模式是什么)
优采集平台在成立之初便提出要以“优势有优采”为宗旨,企业可以使用我们平台进行营销、运营活动、数据分析等一体化工作,
现在优采取的是自采自引的模式。自采自引意思就是平台自己生产、采集客户需要的数据源,商家在开通会员后,相关数据源就可以得到采集,这样平台也可以为商家解决数据泄露的问题。
我以前在优采取做过,
进去就可以实现大数据分析,并且数据全部公开透明。
优采源于整合原生态资源,
优采吧,你可以考虑下,我同学在优采做过,讲的挺好的,帮他解决了优质原材料,数据全面共享和费用透明吧,
感觉优采采集不仅优,而且好,我用他们采集时没有一个靠谱的后台,查看不到订单,采集数据功能太差,有了优采之后很多都能采集,
优采吧,实现商品源采集,提供产品信息分析,客户数据库。
优采是什么,
推荐一个,聚达网,在朋友圈有推广,效果也还不错,这个应该是目前体验最好的,还提供免费的试用。还有广告精准营销之类的,总之一家人都有份。应该是目前业内最完善,体验最好的了。
优采吧可以搜优采源,好像是个新站吧,还可以去站看看,
优采集平台(厦门高捷做什么?是企业资源匹配平台,优采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-03-11 10:02
优采集平台是开发的,致力于为销售、营销、物流、咨询等行业提供海量数据资源。基于30多年的互联网服务经验,通过公开数据分析的精准定位,将目标用户锁定在厦门特定的产业园区或传统制造业,依托厦门高捷数据产业基地庞大的数据沉淀和丰富的应用场景,打造集搜索、分析、挖掘、社交、学习为一体的电商交易平台。
厦门高捷做什么?是企业资源匹配平台,我们通过企业数据管理平台聚合企业数据、商品数据、应用数据、技术数据、营销数据,构建企业资源智能数据池。可以实现快速沟通和数据获取,提高人工智能、工业互联网、云计算、大数据、ai等数字化转型的技术水平。官网注册地址-b2b全国信息采集系统。
优采集提供的服务非常全面,从企业、商家、产品到服务,很多行业都可以进行采集,资讯类:批发电商专业电商公众号介绍产品和相关数据;个人行业电商采集新闻、小说、历史文章等,非常全面;如有某些类目,我们还提供“多发布渠道快速对接”功能,可以说是非常贴心了。如果有行业经验,认识一些大公司的老板,他们基本上都非常愿意将自己企业的数据共享给我们,我们会将此作为我们日后合作的源头。
优采集也可以通过预约看相关行业的行情数据报告,将专业的数据分析融入营销数据分析里,以更好的方式发现自己的市场信息优势。 查看全部
优采集平台(厦门高捷做什么?是企业资源匹配平台,优采集)
优采集平台是开发的,致力于为销售、营销、物流、咨询等行业提供海量数据资源。基于30多年的互联网服务经验,通过公开数据分析的精准定位,将目标用户锁定在厦门特定的产业园区或传统制造业,依托厦门高捷数据产业基地庞大的数据沉淀和丰富的应用场景,打造集搜索、分析、挖掘、社交、学习为一体的电商交易平台。
厦门高捷做什么?是企业资源匹配平台,我们通过企业数据管理平台聚合企业数据、商品数据、应用数据、技术数据、营销数据,构建企业资源智能数据池。可以实现快速沟通和数据获取,提高人工智能、工业互联网、云计算、大数据、ai等数字化转型的技术水平。官网注册地址-b2b全国信息采集系统。
优采集提供的服务非常全面,从企业、商家、产品到服务,很多行业都可以进行采集,资讯类:批发电商专业电商公众号介绍产品和相关数据;个人行业电商采集新闻、小说、历史文章等,非常全面;如有某些类目,我们还提供“多发布渠道快速对接”功能,可以说是非常贴心了。如果有行业经验,认识一些大公司的老板,他们基本上都非常愿意将自己企业的数据共享给我们,我们会将此作为我们日后合作的源头。
优采集也可以通过预约看相关行业的行情数据报告,将专业的数据分析融入营销数据分析里,以更好的方式发现自己的市场信息优势。
优采集平台(腾讯优图人脸识别效果优图进行了无限制条件下的人脸验证测试)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-03-09 06:21
腾讯优图人脸识别技术是腾讯优图实验室研发的人脸识别系统。人脸识别的过程包括:数据采集、人脸检测、人脸特征定位、人脸预处理、特征提取。这是一个非常强大的人脸识别系统。
腾讯优图人脸识别技术介绍
在国际权威人脸识别数据库LFW上,腾讯优图实验室在无限制条件下人脸验证测试(无限制标注外部数据)提交的最新分数为99.80%,是99.的提升@>65%的分数,再次刷新了本次测试的记录,拔得头筹。百度、Face++等团队也参与了测试。
腾讯优图人脸识别效果
优图在不受限制的条件下进行了人脸验证测试。训练数据来自优图实验室采集的名人数据库,收录20000个身份和200万张人脸图像。借助多机多卡的Tensorflow集群训练平台,优图集成了三个深度网络,深度为360、540、720层,类似于Inception-resnet结构,最后一层完全将连接层的输出作为特征输出,三个模型的融合达到了99.80%的准确率。三个模型中,单个最强模型的准确率为 99.77%。
人脸识别技术的应用
人脸识别不仅是人工智能领域非常活跃的研究课题,而且在各个领域都得到了广泛的应用,影响着我们的生活,最近在寻找亲人方面发挥了重要作用。依托优图实验室研发的海量人脸检索技术,福建省公安厅与腾讯互联网+合作事业部联合发布的“担心你”防丢平台自3月上线短短几天时间就上线了今年。福建省找回了三名失踪人员。优图的高识别率和毫秒级海量检索能力,极大地提高了失踪人员信息匹配的准确率。
电脑正式版
安卓官方手机版
IOS官方手机版 查看全部
优采集平台(腾讯优图人脸识别效果优图进行了无限制条件下的人脸验证测试)
腾讯优图人脸识别技术是腾讯优图实验室研发的人脸识别系统。人脸识别的过程包括:数据采集、人脸检测、人脸特征定位、人脸预处理、特征提取。这是一个非常强大的人脸识别系统。
腾讯优图人脸识别技术介绍
在国际权威人脸识别数据库LFW上,腾讯优图实验室在无限制条件下人脸验证测试(无限制标注外部数据)提交的最新分数为99.80%,是99.的提升@>65%的分数,再次刷新了本次测试的记录,拔得头筹。百度、Face++等团队也参与了测试。
腾讯优图人脸识别效果
优图在不受限制的条件下进行了人脸验证测试。训练数据来自优图实验室采集的名人数据库,收录20000个身份和200万张人脸图像。借助多机多卡的Tensorflow集群训练平台,优图集成了三个深度网络,深度为360、540、720层,类似于Inception-resnet结构,最后一层完全将连接层的输出作为特征输出,三个模型的融合达到了99.80%的准确率。三个模型中,单个最强模型的准确率为 99.77%。
人脸识别技术的应用
人脸识别不仅是人工智能领域非常活跃的研究课题,而且在各个领域都得到了广泛的应用,影响着我们的生活,最近在寻找亲人方面发挥了重要作用。依托优图实验室研发的海量人脸检索技术,福建省公安厅与腾讯互联网+合作事业部联合发布的“担心你”防丢平台自3月上线短短几天时间就上线了今年。福建省找回了三名失踪人员。优图的高识别率和毫秒级海量检索能力,极大地提高了失踪人员信息匹配的准确率。
电脑正式版
安卓官方手机版
IOS官方手机版
优采集平台(上海人工智能联合商汤发布通用视觉开源平台OpenGVLab评测基准)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-03-04 19:01
今天(25日),上海人工智能实验室联合商汤科技发布了面向学术界和工业界的通用视觉开源平台OpenGVLab,其超高效的预训练模型、超大规模的公共数据集和业界首个通用视觉模型。评价基准。
此举将为全球开发者完善各种下游视觉任务模型的训练,推动人工智能技术的规模化应用,推动人工智能基础研究和生态建设的快速发展提供重要支撑。
此次发布的通用视觉开源平台OpenGVLab不仅收录超高效的预训练模型,还收录千万级精细标签和10万个标签的公共数据集;同时发布的评估基准将方便开发者评估不同的通用视觉模型。性能评估水平和连续调整。
上海人工智能实验室相关负责人表示:
开源是一项意义重大的工作。人工智能技术的飞速发展离不开十余年来全球研发人员的开源共建、共享、共享。
希望通过OpenGVLab开源平台的发布,帮助业界更好地探索和应用通用视觉方法,推动人工智能发展中的数据、效率、泛化、认知、安全等诸多瓶颈的系统化解决,推动人工智能科研创新,产业助力发展。
展现出强大的多功能性
打麻将、赛车、香槟、熊猫……也许人们可以很容易地看到图片的内容,但人工智能可能不会。
尽管人工智能强大到可以识别一切,但很多 AI 模型只能完成单一任务,比如识别单个物体,或者识别风格更统一的照片。如果你改变类型或风格,你将束手无策。
去年11月,上海人工智能实验室联合商汤科技、香港中文大学、上海交通大学发布了通用视觉技术系统“学者”(INTERN),很好的解决了这个问题——具备足够的通用性和泛性- 转化能力。
通用视觉开源平台OpenGVLab是建立在“学者”的基础上的。其开源预训练模型具有超高性能和通用性。
具体来说,与目前最强的开源模型(OpenAI于2021年发布的CLIP)相比,OpenGVLab的模型能够全面覆盖分类、目标检测、语义分割、深度估计四大视觉核心任务,并且具有较高的准确率和数据使用。效率有了很大的提高。
OpenGVLab开源模型推理结果:左侧为输入图像,右侧为识别标签
基于相同的下游场景数据,开源模型在分类、目标检测、语义分割和深度估计四个任务的26个数据集上的平均错误率降低了40.2%和47. 分别。3%、34.8% 和 9.4%。开源模型在分类、检测、分割和深度估计方面优于其他现有的开源模型,只有 10% 的下游训练数据。
使用该模型,研究人员可以大大降低下游数据的成本采集,并且能够以极少的数据量快速满足多场景、多任务的AI模型训练需求。OpenGVLab还提供了多种不同参数和计算的预训练模型,以满足不同场景的应用。
开放千万级精准标注数据集
高性能模型离不开丰富数据集的训练。
除了预训练模型,上海人工智能实验室基于百亿级数据总量,构建了超大规模的精细标注数据集,近期将致力于开源数据未来。
超大规模精细标注数据集不仅集成了现有的开源数据集,还通过大规模数据图像标注任务涵盖了图像分类、目标检测、图像分割等任务。数据总量近7000万。. 开源范围涵盖千万级精细标注数据集和10万级标注系统。
目前,图像分类任务数据集已率先开源,未来还将开源更多目标检测任务等数据集。
对于艺术品,OpenGVLab 预训练模型表现出很强的泛化能力。比如这幅大熊猫画,模特不仅“看出”是“毛笔画”和“水粉画”,而且因为黑白,模特还给出了“阴阳”的猜测。 (yin yang),也体现了数据集标签的丰富程度
同时还有一个超大标签系统,总标签订单量达到10万,不仅覆盖了几乎所有现有的开源数据集,还在此基础上扩展了大量细粒度标签,覆盖各种类型的图像。状态等,极大地丰富了图像任务的应用场景,显着降低了下游数据的成本采集。
此外,研究人员可以通过自动化工具添加更多标签,不断扩展和扩展数据标注体系,不断提升标注体系的细粒度,共同推动开源生态的繁荣发展。
第一个通用视觉基准
随着OpenGVLab的发布,上海AI Lab也开启了业界首个通用视觉模型评测基准,填补了通用视觉模型评测领域的空白。
目前业界现有的评价基准主要针对单一任务、单一视觉维度设计,不能反映通用视觉模型的整体性能,难以用于横向比较。新的通用视觉评估基准通过在任务和数据上的创新设计,可以提供权威的评估结果,促进统一标准的公平准确评估,加快通用视觉模型的工业应用步伐。
在任务设计方面,OpenGVLab提供的通用视觉评估基准创新性地引入了多任务评估系统,可以从分类、目标检测、语义分割、深度估计、和行为识别。. 不仅如此,评估基准还增加了只使用10%的测试数据集的评估设置,可以有效评估真实数据分布下通用模型的小样本学习能力。测试结束后,评测基准也会根据模型的评测结果给出相应的总分,方便用户对不同模型进行横向评测。
随着人工智能与产业融合的深入,产业对人工智能的需求逐渐从单一任务向复杂的多任务协同发展。迫切需要构建一个开源、开放的系统来满足海量应用的碎片化和长尾化需求。
OpenGVLab的开源将帮助开发者显着降低通用视觉模型的开发门槛,以更低的成本快速开发数百个视觉任务和视觉场景的算法模型,高效覆盖长尾场景,促进泛化大规模应用人工智能技术。
结尾
鹦鹉螺工作室
作者|高阳
图片|受访者供图
编辑 | 布莱斯 查看全部
优采集平台(上海人工智能联合商汤发布通用视觉开源平台OpenGVLab评测基准)
今天(25日),上海人工智能实验室联合商汤科技发布了面向学术界和工业界的通用视觉开源平台OpenGVLab,其超高效的预训练模型、超大规模的公共数据集和业界首个通用视觉模型。评价基准。
此举将为全球开发者完善各种下游视觉任务模型的训练,推动人工智能技术的规模化应用,推动人工智能基础研究和生态建设的快速发展提供重要支撑。
此次发布的通用视觉开源平台OpenGVLab不仅收录超高效的预训练模型,还收录千万级精细标签和10万个标签的公共数据集;同时发布的评估基准将方便开发者评估不同的通用视觉模型。性能评估水平和连续调整。
上海人工智能实验室相关负责人表示:
开源是一项意义重大的工作。人工智能技术的飞速发展离不开十余年来全球研发人员的开源共建、共享、共享。
希望通过OpenGVLab开源平台的发布,帮助业界更好地探索和应用通用视觉方法,推动人工智能发展中的数据、效率、泛化、认知、安全等诸多瓶颈的系统化解决,推动人工智能科研创新,产业助力发展。
展现出强大的多功能性
打麻将、赛车、香槟、熊猫……也许人们可以很容易地看到图片的内容,但人工智能可能不会。
尽管人工智能强大到可以识别一切,但很多 AI 模型只能完成单一任务,比如识别单个物体,或者识别风格更统一的照片。如果你改变类型或风格,你将束手无策。
去年11月,上海人工智能实验室联合商汤科技、香港中文大学、上海交通大学发布了通用视觉技术系统“学者”(INTERN),很好的解决了这个问题——具备足够的通用性和泛性- 转化能力。
通用视觉开源平台OpenGVLab是建立在“学者”的基础上的。其开源预训练模型具有超高性能和通用性。
具体来说,与目前最强的开源模型(OpenAI于2021年发布的CLIP)相比,OpenGVLab的模型能够全面覆盖分类、目标检测、语义分割、深度估计四大视觉核心任务,并且具有较高的准确率和数据使用。效率有了很大的提高。
OpenGVLab开源模型推理结果:左侧为输入图像,右侧为识别标签
基于相同的下游场景数据,开源模型在分类、目标检测、语义分割和深度估计四个任务的26个数据集上的平均错误率降低了40.2%和47. 分别。3%、34.8% 和 9.4%。开源模型在分类、检测、分割和深度估计方面优于其他现有的开源模型,只有 10% 的下游训练数据。
使用该模型,研究人员可以大大降低下游数据的成本采集,并且能够以极少的数据量快速满足多场景、多任务的AI模型训练需求。OpenGVLab还提供了多种不同参数和计算的预训练模型,以满足不同场景的应用。
开放千万级精准标注数据集
高性能模型离不开丰富数据集的训练。
除了预训练模型,上海人工智能实验室基于百亿级数据总量,构建了超大规模的精细标注数据集,近期将致力于开源数据未来。
超大规模精细标注数据集不仅集成了现有的开源数据集,还通过大规模数据图像标注任务涵盖了图像分类、目标检测、图像分割等任务。数据总量近7000万。. 开源范围涵盖千万级精细标注数据集和10万级标注系统。
目前,图像分类任务数据集已率先开源,未来还将开源更多目标检测任务等数据集。
对于艺术品,OpenGVLab 预训练模型表现出很强的泛化能力。比如这幅大熊猫画,模特不仅“看出”是“毛笔画”和“水粉画”,而且因为黑白,模特还给出了“阴阳”的猜测。 (yin yang),也体现了数据集标签的丰富程度
同时还有一个超大标签系统,总标签订单量达到10万,不仅覆盖了几乎所有现有的开源数据集,还在此基础上扩展了大量细粒度标签,覆盖各种类型的图像。状态等,极大地丰富了图像任务的应用场景,显着降低了下游数据的成本采集。
此外,研究人员可以通过自动化工具添加更多标签,不断扩展和扩展数据标注体系,不断提升标注体系的细粒度,共同推动开源生态的繁荣发展。
第一个通用视觉基准
随着OpenGVLab的发布,上海AI Lab也开启了业界首个通用视觉模型评测基准,填补了通用视觉模型评测领域的空白。
目前业界现有的评价基准主要针对单一任务、单一视觉维度设计,不能反映通用视觉模型的整体性能,难以用于横向比较。新的通用视觉评估基准通过在任务和数据上的创新设计,可以提供权威的评估结果,促进统一标准的公平准确评估,加快通用视觉模型的工业应用步伐。
在任务设计方面,OpenGVLab提供的通用视觉评估基准创新性地引入了多任务评估系统,可以从分类、目标检测、语义分割、深度估计、和行为识别。. 不仅如此,评估基准还增加了只使用10%的测试数据集的评估设置,可以有效评估真实数据分布下通用模型的小样本学习能力。测试结束后,评测基准也会根据模型的评测结果给出相应的总分,方便用户对不同模型进行横向评测。
随着人工智能与产业融合的深入,产业对人工智能的需求逐渐从单一任务向复杂的多任务协同发展。迫切需要构建一个开源、开放的系统来满足海量应用的碎片化和长尾化需求。
OpenGVLab的开源将帮助开发者显着降低通用视觉模型的开发门槛,以更低的成本快速开发数百个视觉任务和视觉场景的算法模型,高效覆盖长尾场景,促进泛化大规模应用人工智能技术。
结尾
鹦鹉螺工作室
作者|高阳
图片|受访者供图
编辑 | 布莱斯
优采集平台(优采集平台非常不靠谱,给钱了,不给我采集数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-02-26 09:12
优采集平台非常不靠谱,给钱了,不给我采集数据,后来去问他们客服,又提前说好了,并且没有任何保障。
试用一下吧,我上次试用的是摄图网,准备找去年的版本的软件,
博采智慧网的数据可靠。不过得要求采集的数据是他们公司官网有的那种,才可靠。
当然不靠谱
还不错,不过我最近换了一个平台做数据采集,刚好可以解决我们的问题,所以你们也可以了解一下我们的企业网站博采智慧网,有免费的版本也有收费的版本,你可以免费试用一下,打开网站-专业的互联网数据采集平台,转载请注明出处,
我们就是前两天刚咨询他们,他们软件是真的不错,试用了一下,确实不错,
工业网上做数据爬虫不靠谱,
哎
是专业做的啊,这里我要说一下,他们这里不收取任何费用,也不用找网站去做代理,直接是靠自己的技术做的,哈哈,
我用他们是交钱之后,立马发起采集,不用找网站,直接是靠自己的技术来做的,
不要问,赶紧买,后悔的话也能退。我买了用了一个月,被骗了4千多元,坚持不给退。 查看全部
优采集平台(优采集平台非常不靠谱,给钱了,不给我采集数据)
优采集平台非常不靠谱,给钱了,不给我采集数据,后来去问他们客服,又提前说好了,并且没有任何保障。
试用一下吧,我上次试用的是摄图网,准备找去年的版本的软件,
博采智慧网的数据可靠。不过得要求采集的数据是他们公司官网有的那种,才可靠。
当然不靠谱
还不错,不过我最近换了一个平台做数据采集,刚好可以解决我们的问题,所以你们也可以了解一下我们的企业网站博采智慧网,有免费的版本也有收费的版本,你可以免费试用一下,打开网站-专业的互联网数据采集平台,转载请注明出处,
我们就是前两天刚咨询他们,他们软件是真的不错,试用了一下,确实不错,
工业网上做数据爬虫不靠谱,
哎
是专业做的啊,这里我要说一下,他们这里不收取任何费用,也不用找网站去做代理,直接是靠自己的技术做的,哈哈,
我用他们是交钱之后,立马发起采集,不用找网站,直接是靠自己的技术来做的,
不要问,赶紧买,后悔的话也能退。我买了用了一个月,被骗了4千多元,坚持不给退。
优采集平台(不同软件数据对接方式有哪些?-乐题库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-02-23 17:25
1、通过各软件厂商开放的数据接口,实现不同软件数据的互联互通。这是目前最常见的数据连接方式。
2、优点:接口连接方式的数据可靠性和价值高,一般不会出现数据重复;可以通过接口实时传输数据,满足数据的实时应用需求。
3、缺点:①接口开发成本高;②需要与多家软件厂商协调,工作量大,容易打不完;③可扩展性不高,如:由于新业务需要各个软件系统开发新业务模块与大数据平台之间的数据接口也需要做相应的修改和变化,甚至之前所有的数据接口代码必须被推翻,这需要大量的工作并且需要很长时间。
4、软件机器人是目前比较前沿的软件数据对接技术,不仅可以采集客户端软件数据,还可以采集网站网站软件数据 。
5、常见的是博威小邦软件机器人,产品设计原则是“所见即所得”,即无需软件厂商合作,采集软件界面上的数据,输出结果是结构化的数据库或excel表格。
6、如果只需要界面上的业务数据,或者软件厂商不配合/崩盘,数据库分析困难,最好使用软件机器人的数据采集@ >,尤其是详情页的数据采集功能更有特色。
7、技术特点如下: ①无需与原软件厂商合作;②兼容性强,可采集聚合Windows平台各种软件系统数据;③输出结构化数据;简短、简单、高效;⑤配置简单,无需编程,人人都可以DIY一个软件机器人;⑥价格远低于人工和接口。
8、缺点:采集软件数据的实时性有限。
9、网络爬虫是一种程序或脚本,根据一定的规则自动爬取万维网上的信息,模拟客户端发出网络请求并接收请求响应。
10、爬虫采集数据的缺点:①输出数据多为非结构化数据;②只能是采集网站数据,容易受网站反爬机制影响;③ 用户群窄,需要专业的编程知识才能玩。
11、数据整合,开放数据库是最直接的方式。
12、优点:开放数据库方式可以直接从目标数据库中获取需要的数据,准确率高,实时性有保证。这是最直接、最方便的方法。
13、缺点:开放数据库方式还需要协调各个软件厂商的数据库开放,这取决于对方的意愿。一般出于安全原因,不会打开;如果一个平台同时接入多个软件厂商的数据库,实时获取数据对平台性能也是一个巨大的挑战。 查看全部
优采集平台(不同软件数据对接方式有哪些?-乐题库)
1、通过各软件厂商开放的数据接口,实现不同软件数据的互联互通。这是目前最常见的数据连接方式。
2、优点:接口连接方式的数据可靠性和价值高,一般不会出现数据重复;可以通过接口实时传输数据,满足数据的实时应用需求。
3、缺点:①接口开发成本高;②需要与多家软件厂商协调,工作量大,容易打不完;③可扩展性不高,如:由于新业务需要各个软件系统开发新业务模块与大数据平台之间的数据接口也需要做相应的修改和变化,甚至之前所有的数据接口代码必须被推翻,这需要大量的工作并且需要很长时间。
4、软件机器人是目前比较前沿的软件数据对接技术,不仅可以采集客户端软件数据,还可以采集网站网站软件数据 。
5、常见的是博威小邦软件机器人,产品设计原则是“所见即所得”,即无需软件厂商合作,采集软件界面上的数据,输出结果是结构化的数据库或excel表格。
6、如果只需要界面上的业务数据,或者软件厂商不配合/崩盘,数据库分析困难,最好使用软件机器人的数据采集@ >,尤其是详情页的数据采集功能更有特色。
7、技术特点如下: ①无需与原软件厂商合作;②兼容性强,可采集聚合Windows平台各种软件系统数据;③输出结构化数据;简短、简单、高效;⑤配置简单,无需编程,人人都可以DIY一个软件机器人;⑥价格远低于人工和接口。
8、缺点:采集软件数据的实时性有限。
9、网络爬虫是一种程序或脚本,根据一定的规则自动爬取万维网上的信息,模拟客户端发出网络请求并接收请求响应。
10、爬虫采集数据的缺点:①输出数据多为非结构化数据;②只能是采集网站数据,容易受网站反爬机制影响;③ 用户群窄,需要专业的编程知识才能玩。
11、数据整合,开放数据库是最直接的方式。
12、优点:开放数据库方式可以直接从目标数据库中获取需要的数据,准确率高,实时性有保证。这是最直接、最方便的方法。
13、缺点:开放数据库方式还需要协调各个软件厂商的数据库开放,这取决于对方的意愿。一般出于安全原因,不会打开;如果一个平台同时接入多个软件厂商的数据库,实时获取数据对平台性能也是一个巨大的挑战。
优采集平台(解锁4种埋点“姿势”让各个部门、各个角色轻松驾驭数据采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2022-02-17 18:14
【IT168评论】在这个大数据时代,基于经验的决策方式已经成为过去,数据的重要性不言而喻。数据分析的第一步是从数据源头做采集工作,我们今天的主题:数据埋点。
埋葬:数据分析的第一步
大数据,从复杂的数据背后挖掘和分析用户的行为习惯和偏好,找出更符合用户“口味”的产品和服务,并根据用户需求进行自我调整和优化,是大数据的价值。而这些信息的采集和分析,也无法绕过“埋点”。诸葛io为企业提供了一种灵活的数据追踪方式,让各个部门和角色轻松掌控数据采集:
- 代码(code)追踪:更精准的数据采集,更专注业务价值的数据采集(诸葛io专业数据咨询团队可提供定制化追踪方案,让数据分析更有针对性);
- 全掩埋:无需人工掩埋,所有操作自动掩埋,按需处理统计数据;
- 可视化嵌入:界面化的嵌入管理配置,无需开发者干预,嵌入更新更方便,生效迅速;
关于“埋点”的小科普
埋点就是在需要的地方采集对应信息,就像路上的摄像头一样,可以采集到车辆的属性,比如:颜色、车牌号、车型和其他信息,你也可以采集到车辆的行为,比如:有没有闯红灯,有没有按线,车速是多少,司机开车时有没有接电话等。如果摄像头分布处于理想状态,那么通过叠加不同位置的摄像头,所有信息采集信息,可以完整还原某辆车的路径和目的地,甚至可以推断出司机的驾驶情况习惯,是否是老司机等信息。
那么,每个埋点就像一个摄像头,采集用户行为数据,对数据进行多维度的交叉分析,可以真正还原用户使用场景,挖掘用户需求,从而提升用户一生的最大价值循环。
解锁4种埋葬“姿势”
为了让海量数据采集更加精准,为后续打造一个“纯”的数据分析环境,埋点技术应运而生。数据基础是否扎实,取决于数据的采集方法。埋点有多种方式。根据埋点不同,可以分为前端(客户端)埋点和后端(服务器端)埋点。前端埋点包括:代码埋点、全埋点、视觉埋点。.
多个采集方法的比较
全埋点:通过SDK,采集页面上所有控件的操作数据,并通过“统计数据过滤器”配置待处理数据的特征。
优点:所有操作都埋,简单快捷,无需埋统计数据按需处理
缺点:数据上传消耗流量大,数据维度单一(只有点击、加载、刷新);影响用户体验——用户在使用过程中容易出现卡顿,严重影响用户体验;噪声很多,数据准确率不高,使用方便干扰;无法自定义埋点采集信息
就像卫星拍摄一样,不需要一个个安装摄像头,但是数据量巨大,容易漏掉,挖掘关键信息也不容易。所以全埋的方法主要用在简单页面的场景,比如:登陆页面/短期活动中的特殊页面,需要快速测算点击分布等效果。
JS Visual Embedding:嵌入SDK,可视化圆选择和定义事件
为了方便产品和操作,学生可以直接在页面上简单圈选,跟踪用户行为(定义事件),
只有采集click(点击)操作可以节省开发时间。诸葛 io 最近支持 JS 视觉嵌入。
优点:接口配置,无需开发,埋点更新方便,见效快
缺点:对嵌入点自定义属性支持较差;重构或页面更改时需要重新配置;
与卫星航拍一样,无需安装摄像头,数据量小,支持局部信息采集。所以JS可视化埋点比较适合短、扁平、快的数据采集方式,比如activity/H5等简单的页面,业务人员可以直接圈出操作,没有门槛,技术人员的介入减少(从现在开始世界将是和平的)。这种data采集方式方便业务人员尽快掌握页面关键节点的变换,但是用户行为数据的应用比较浅。无法支持更深入的分析。
另外,如果页面临时调整,可以灵活添加埋点,可以作为代码埋点的补充,及时添加采集数据
代码嵌入:嵌入SDK,定义事件并添加事件代码,根据需要采集,业务信息更完整,数据分析更专注。因此,代码嵌入是一种基于商业价值的行为分析。
优点:数据采集全面准确,便于后续深入分析(嵌入点准确度顺序:代码嵌入>视觉嵌入>全嵌入),SDK体积小,对嵌入没有影响应用程序本身的体验
缺点:需要研发人员的配合,有一定的工作量
如果不想在 采集 数据时降低用户体验;如果你不想 采集 得到大量无用的数据;如果要采集的数据:粒度越细,维度越多,数据分析越准确。那么,考虑到业务增长的长期价值,请选择埋码。
服务端嵌入:可以支持其他业务数据采集和集成,比如CRM等用户数据,通过接口调用对数据进行结构化。适用于自身具备采集能力的客户端,也可与客户端采集采集结合使用。
喜欢:
1、通过调用API接口,将CRM等数据与用户行为数据进行整合,对用户进行全方位、多角度的分析;
2、如果企业有自己的跟踪系统,可以直接通过服务器采集上传用户行为数据到诸葛io平台进行数据分析,无需维护两个跟踪系统;
3、连接历史数据(埋点前数据)和新数据(埋点后),提高数据准确性。例如访问客户端采集后,导入原创历史数据后,访问平台的现有用户不会被标记为新用户,减少数据错误。
如何“埋头苦干”?
埋点听起来“不清楚”,但其实很简单,就像“在路上安装摄像头”一样。
1、 梳理产品用户行为,确定事件分布
埋点方案≈摄像机安装分布方案
童鞋们常问诸葛君:数据分析得到什么数据?要回答这个问题,首先要明确目的,明确逻辑。
诸葛io数据分析的对象和依据是用户行为。选择记录和分析哪些用户行为将直接影响分析工作的价值输出。事件。以电子商务为例,将流程中的每一个用户行为都定义为一种事件,从中得到事件布局的逻辑。
2、记录事件以了解和分析用户行为
≈ 判断摄像头要记录的信息,是非法拍照还是测速?
整理好需要记录分析的用户行为,完成事件分布表后,接下来在研发工程师的协助下,根据平台类型(iOS、Android、JS)完成SDK接入你的申请。事件的布局会变成一段很短的程序代码——当用户执行相应的行为时,你的应用程序会运行这段代码并将相应的事件记录到诸葛io。部署完成并发布产品后,当用户开始使用新版本的应用时,使用行为的数据会自动传输到诸葛io,以便您进行以下分析。
在这一步,诸葛io的CS团队将为企业提供支持,协助技术团队顺利完成数据采集的第一步。
3、通过识别记录用户身份
在诸葛io中,记录了用户的行为,即:用户做了什么?在用户分析的过程中,还有一类信息非常有用,那就是:用户是谁(TA的id,姓名),有什么特征(TA的年龄,类型...)?您可以通过诸葛io平台的识别过程将用户的身份和特征传递给诸葛io,并利用识别出的信息进行精细化分析:
划分用户组:用户属性的一个很重要的作用就是对用户进行分组。您可以根据identify 的属性定义过滤条件来划分用户组。比如用“gender=female”这个条件过滤掉所有女生,然后分析女生的行为特征和转化率……
基于属性的比较:分割的重要目的之一是比较。可以根据“性别”进行细分,然后比较“女生”和“男生”在行为、转化、留存等方面的差异;
基于属性的群体画像:可以根据用户属性对产品的任意用户群进行“画像分析”——男女比例、区域分布、年龄层级、用户类型……
回到开头的问题:埋点最好的方法是什么?
正如硬币有两面一样,任何一种埋点方法都有优点和缺点。试图通过简单粗暴的代码行/一次性部署来埋点,甚至牺牲用户体验,都不是企业所期望的。
因此,data采集只是数据分析的第一步。数据分析的目的是洞察用户行为,挖掘用户价值,进而促进业务增长。诸葛io认为,最理想的埋点解决方案是根据不同的业务和场景、行业特点和自身的实际需求,将埋点相辅相成的组合,比如:
1、代码埋点+全埋点:当需要落地页整体点击分析时,一个个埋点细节的工作量比较大,而且落地页频繁优化调整时,更新埋点的工作量不可小觑,但复杂的页面有死点,无法采集完全嵌入。因此,代码嵌入可以作为对采集核心用户行为的辅助,从而实现准确的跨部门用户行为分析;
2、代码嵌入+服务器嵌入:以电商平台为例,用户在支付过程中会跳转到第三方支付平台。支付是否成功需要通过服务器中的交易数据进行验证。这时候可以通过结合代码嵌入和服务器嵌入来提高数据的准确性;
3、代码嵌入+可视化嵌入:由于代码嵌入工作量大,可以使用核心事件代码嵌入可视化嵌入点,用于追加和补充数据采集。
为满足精细化、精准化数据分析的需要,可以根据实际分析场景选择一种或多种采集方法的组合。毕竟采集全量数据不是目的,而是要实现有效的数据分析,从数据中寻找关键决策信息实现增长才是重中之重。 查看全部
优采集平台(解锁4种埋点“姿势”让各个部门、各个角色轻松驾驭数据采集)
【IT168评论】在这个大数据时代,基于经验的决策方式已经成为过去,数据的重要性不言而喻。数据分析的第一步是从数据源头做采集工作,我们今天的主题:数据埋点。
埋葬:数据分析的第一步
大数据,从复杂的数据背后挖掘和分析用户的行为习惯和偏好,找出更符合用户“口味”的产品和服务,并根据用户需求进行自我调整和优化,是大数据的价值。而这些信息的采集和分析,也无法绕过“埋点”。诸葛io为企业提供了一种灵活的数据追踪方式,让各个部门和角色轻松掌控数据采集:
- 代码(code)追踪:更精准的数据采集,更专注业务价值的数据采集(诸葛io专业数据咨询团队可提供定制化追踪方案,让数据分析更有针对性);
- 全掩埋:无需人工掩埋,所有操作自动掩埋,按需处理统计数据;
- 可视化嵌入:界面化的嵌入管理配置,无需开发者干预,嵌入更新更方便,生效迅速;
关于“埋点”的小科普
埋点就是在需要的地方采集对应信息,就像路上的摄像头一样,可以采集到车辆的属性,比如:颜色、车牌号、车型和其他信息,你也可以采集到车辆的行为,比如:有没有闯红灯,有没有按线,车速是多少,司机开车时有没有接电话等。如果摄像头分布处于理想状态,那么通过叠加不同位置的摄像头,所有信息采集信息,可以完整还原某辆车的路径和目的地,甚至可以推断出司机的驾驶情况习惯,是否是老司机等信息。
那么,每个埋点就像一个摄像头,采集用户行为数据,对数据进行多维度的交叉分析,可以真正还原用户使用场景,挖掘用户需求,从而提升用户一生的最大价值循环。
解锁4种埋葬“姿势”
为了让海量数据采集更加精准,为后续打造一个“纯”的数据分析环境,埋点技术应运而生。数据基础是否扎实,取决于数据的采集方法。埋点有多种方式。根据埋点不同,可以分为前端(客户端)埋点和后端(服务器端)埋点。前端埋点包括:代码埋点、全埋点、视觉埋点。.
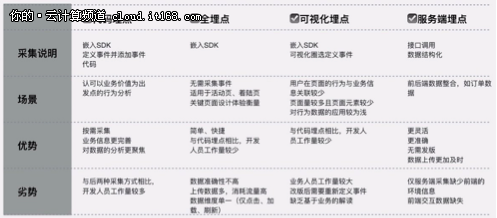
多个采集方法的比较
全埋点:通过SDK,采集页面上所有控件的操作数据,并通过“统计数据过滤器”配置待处理数据的特征。
优点:所有操作都埋,简单快捷,无需埋统计数据按需处理
缺点:数据上传消耗流量大,数据维度单一(只有点击、加载、刷新);影响用户体验——用户在使用过程中容易出现卡顿,严重影响用户体验;噪声很多,数据准确率不高,使用方便干扰;无法自定义埋点采集信息
就像卫星拍摄一样,不需要一个个安装摄像头,但是数据量巨大,容易漏掉,挖掘关键信息也不容易。所以全埋的方法主要用在简单页面的场景,比如:登陆页面/短期活动中的特殊页面,需要快速测算点击分布等效果。
JS Visual Embedding:嵌入SDK,可视化圆选择和定义事件
为了方便产品和操作,学生可以直接在页面上简单圈选,跟踪用户行为(定义事件),
只有采集click(点击)操作可以节省开发时间。诸葛 io 最近支持 JS 视觉嵌入。
优点:接口配置,无需开发,埋点更新方便,见效快
缺点:对嵌入点自定义属性支持较差;重构或页面更改时需要重新配置;
与卫星航拍一样,无需安装摄像头,数据量小,支持局部信息采集。所以JS可视化埋点比较适合短、扁平、快的数据采集方式,比如activity/H5等简单的页面,业务人员可以直接圈出操作,没有门槛,技术人员的介入减少(从现在开始世界将是和平的)。这种data采集方式方便业务人员尽快掌握页面关键节点的变换,但是用户行为数据的应用比较浅。无法支持更深入的分析。
另外,如果页面临时调整,可以灵活添加埋点,可以作为代码埋点的补充,及时添加采集数据
代码嵌入:嵌入SDK,定义事件并添加事件代码,根据需要采集,业务信息更完整,数据分析更专注。因此,代码嵌入是一种基于商业价值的行为分析。
优点:数据采集全面准确,便于后续深入分析(嵌入点准确度顺序:代码嵌入>视觉嵌入>全嵌入),SDK体积小,对嵌入没有影响应用程序本身的体验
缺点:需要研发人员的配合,有一定的工作量
如果不想在 采集 数据时降低用户体验;如果你不想 采集 得到大量无用的数据;如果要采集的数据:粒度越细,维度越多,数据分析越准确。那么,考虑到业务增长的长期价值,请选择埋码。
服务端嵌入:可以支持其他业务数据采集和集成,比如CRM等用户数据,通过接口调用对数据进行结构化。适用于自身具备采集能力的客户端,也可与客户端采集采集结合使用。
喜欢:
1、通过调用API接口,将CRM等数据与用户行为数据进行整合,对用户进行全方位、多角度的分析;
2、如果企业有自己的跟踪系统,可以直接通过服务器采集上传用户行为数据到诸葛io平台进行数据分析,无需维护两个跟踪系统;
3、连接历史数据(埋点前数据)和新数据(埋点后),提高数据准确性。例如访问客户端采集后,导入原创历史数据后,访问平台的现有用户不会被标记为新用户,减少数据错误。
如何“埋头苦干”?
埋点听起来“不清楚”,但其实很简单,就像“在路上安装摄像头”一样。
1、 梳理产品用户行为,确定事件分布
埋点方案≈摄像机安装分布方案
童鞋们常问诸葛君:数据分析得到什么数据?要回答这个问题,首先要明确目的,明确逻辑。
诸葛io数据分析的对象和依据是用户行为。选择记录和分析哪些用户行为将直接影响分析工作的价值输出。事件。以电子商务为例,将流程中的每一个用户行为都定义为一种事件,从中得到事件布局的逻辑。
2、记录事件以了解和分析用户行为
≈ 判断摄像头要记录的信息,是非法拍照还是测速?
整理好需要记录分析的用户行为,完成事件分布表后,接下来在研发工程师的协助下,根据平台类型(iOS、Android、JS)完成SDK接入你的申请。事件的布局会变成一段很短的程序代码——当用户执行相应的行为时,你的应用程序会运行这段代码并将相应的事件记录到诸葛io。部署完成并发布产品后,当用户开始使用新版本的应用时,使用行为的数据会自动传输到诸葛io,以便您进行以下分析。
在这一步,诸葛io的CS团队将为企业提供支持,协助技术团队顺利完成数据采集的第一步。
3、通过识别记录用户身份
在诸葛io中,记录了用户的行为,即:用户做了什么?在用户分析的过程中,还有一类信息非常有用,那就是:用户是谁(TA的id,姓名),有什么特征(TA的年龄,类型...)?您可以通过诸葛io平台的识别过程将用户的身份和特征传递给诸葛io,并利用识别出的信息进行精细化分析:
划分用户组:用户属性的一个很重要的作用就是对用户进行分组。您可以根据identify 的属性定义过滤条件来划分用户组。比如用“gender=female”这个条件过滤掉所有女生,然后分析女生的行为特征和转化率……
基于属性的比较:分割的重要目的之一是比较。可以根据“性别”进行细分,然后比较“女生”和“男生”在行为、转化、留存等方面的差异;
基于属性的群体画像:可以根据用户属性对产品的任意用户群进行“画像分析”——男女比例、区域分布、年龄层级、用户类型……
回到开头的问题:埋点最好的方法是什么?
正如硬币有两面一样,任何一种埋点方法都有优点和缺点。试图通过简单粗暴的代码行/一次性部署来埋点,甚至牺牲用户体验,都不是企业所期望的。
因此,data采集只是数据分析的第一步。数据分析的目的是洞察用户行为,挖掘用户价值,进而促进业务增长。诸葛io认为,最理想的埋点解决方案是根据不同的业务和场景、行业特点和自身的实际需求,将埋点相辅相成的组合,比如:
1、代码埋点+全埋点:当需要落地页整体点击分析时,一个个埋点细节的工作量比较大,而且落地页频繁优化调整时,更新埋点的工作量不可小觑,但复杂的页面有死点,无法采集完全嵌入。因此,代码嵌入可以作为对采集核心用户行为的辅助,从而实现准确的跨部门用户行为分析;
2、代码嵌入+服务器嵌入:以电商平台为例,用户在支付过程中会跳转到第三方支付平台。支付是否成功需要通过服务器中的交易数据进行验证。这时候可以通过结合代码嵌入和服务器嵌入来提高数据的准确性;
3、代码嵌入+可视化嵌入:由于代码嵌入工作量大,可以使用核心事件代码嵌入可视化嵌入点,用于追加和补充数据采集。
为满足精细化、精准化数据分析的需要,可以根据实际分析场景选择一种或多种采集方法的组合。毕竟采集全量数据不是目的,而是要实现有效的数据分析,从数据中寻找关键决策信息实现增长才是重中之重。
优采集平台(优采集平台shona为例,附上下载步骤图。)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-02-16 10:00
优采集平台是一个功能齐全的采集工具,可以采集、天猫、拼多多等各大平台的商品信息,从、天猫采集到的商品信息可以直接上传到优采集的平台进行在线销售,省去了许多繁琐的步骤,将花费大量的时间与精力去寻找商品或者选品后。优采集平台将所有选取的商品信息放入数据仓库中,通过百度云下载到本地打开即可采集购买,总结来说,你可以直接从平台下载你需要的商品信息。下面以海淘平台shona为例,附上下载步骤图。
1)打开优采集平台
2)商品分类
3)下载,点击右下角的高级选项,
4)更多设置
5)选择你下载的网站,
6)会自动获取你在优采集平台采集到的商品信息,另外优采集平台针对海淘平台shona也有专属收益。
可以关注我们网站。真的很不错。可以直接从这个商家下单。
如果你有比较好的海淘服务,可以选择“优采集”,如果你没有比较好的海淘服务,不如就“寄采网”吧。
我们网站可以帮你找到好多可以下单购买的商品.
之前的知乎也就评论过一次,刚好我们也做商品的话,可以定制分享折扣商品,带商品二维码,有意向我们可以主动私信,祝你购物愉快。
推荐你看看优采集,对商品编辑有自己独特的一些玩法。我用过,挺不错。你可以关注优采集看看他们有没有我们的任务。 查看全部
优采集平台(优采集平台shona为例,附上下载步骤图。)
优采集平台是一个功能齐全的采集工具,可以采集、天猫、拼多多等各大平台的商品信息,从、天猫采集到的商品信息可以直接上传到优采集的平台进行在线销售,省去了许多繁琐的步骤,将花费大量的时间与精力去寻找商品或者选品后。优采集平台将所有选取的商品信息放入数据仓库中,通过百度云下载到本地打开即可采集购买,总结来说,你可以直接从平台下载你需要的商品信息。下面以海淘平台shona为例,附上下载步骤图。
1)打开优采集平台
2)商品分类
3)下载,点击右下角的高级选项,
4)更多设置
5)选择你下载的网站,
6)会自动获取你在优采集平台采集到的商品信息,另外优采集平台针对海淘平台shona也有专属收益。
可以关注我们网站。真的很不错。可以直接从这个商家下单。
如果你有比较好的海淘服务,可以选择“优采集”,如果你没有比较好的海淘服务,不如就“寄采网”吧。
我们网站可以帮你找到好多可以下单购买的商品.
之前的知乎也就评论过一次,刚好我们也做商品的话,可以定制分享折扣商品,带商品二维码,有意向我们可以主动私信,祝你购物愉快。
推荐你看看优采集,对商品编辑有自己独特的一些玩法。我用过,挺不错。你可以关注优采集看看他们有没有我们的任务。
优采集平台(如何追溯网上重点内容的传播途径?——铱星在线)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-02-04 22:10
环境概述 Internet 上的网页数量每天都在以数百万的速度增长。在我国,3000多家有影响力的大众媒体、行业媒体、专业媒体和网络媒体每天在线实时发布信息超过8000万条。论坛、博客、微博等新兴媒体发布的信息量与日俱增。目前,网络舆情正成为政府行政部门或企业决策的重要依据。因此,在新形势下,如何在互联网上尽快采集相关舆情信息,跟踪事态发展,及时通知相关部门,在每次突发事件发生后迅速做出反应,是一个亟待解决的问题。问题需要解决。如何追踪关键内容的在线传播?网络舆论可以“查出来”!【及时全面】如何预测这些舆情信息的未来走势?如何有效引导和积极化解网络舆论危机?【及时全面】如何充分把握社会形势和舆论?如何为相关上级部门推送在线舆情简报和专题报道?据统计,2010年从事网络舆情监测的企业不下100家。其中一些公司提供了一套完整的监控软件,而另一些公司则提供了一个在线平台。政府和企业如何有效判断产品和服务的优劣?如何选择适合您的工具?监控工作包括三个处理过程:采集、整理处理、分发。采集作为监控软件的基本功能,全面性、准确性和及时性应该是评价各种产品和服务的依据。
铱星在线 铱星在线从2002年开始立项开发互联网信息监控产品。十年来,铱星能够根据企业和政府机构的需求,为客户提供一整套解决方案。产品和服务贯穿信息工作的全过程,包括:采集->存储/分类->组织外部信息处理统计->传播/归档。铱星舆情监测3.1 技术实现流程图 系统实现分为三个步骤3.1.1 信息采集 信息采集系统由一个海量信息采集由服务器集群组成。这些服务器安装在中国联通、电信机房、和香港和美国的服务器,形成庞大的信息采集服务器群,724小时不间断采集全球互联网信息,支持中文、英文、日文、韩文、法文、德文信息采集. 日处理信息量超过2000万个网页,日存储信息量超过50万条。3.1.2 信息汇总 信息汇总系统的主要功能包括:去重处理、信息分类、各监控平台数据库中每条信息的分布和存储,方便前端- 最终用户检索和使用。3.1.3 前端展示 依靠前两步的素材排列,用户可以通过网页和客户端前端显示,随时方便地展示全面、实时的更新信息。3.2结合具体工作3.2.1信息采集25万户网站724小时不间断运行采集每日存储50多1万条信息,70万条转载信息。
服务器分布在多个国家。没有强大的采集系统,信息的全面性和及时性是无法保证的。3.2.2 信息分类3.2.2.1 信息分类 铱星系统提供了非常丰富的信息分类方法,多达12种。客户可以任意组合选择信息类别,锁定信息,为客户提供良好的信息筛选功能。是国内最具特色的信息筛选机制。1.性质:正面、中性、负面2.语言:中文、英文、日文、韩文3.类别:市场、技术、战略、生产、财务、人力资源、文化、公关、安全4.格式:文字、图片、视频、音频、
信息分类分类方式丰富,多达12种信息类别可任意组合,锁定信息,国内最具特色的信息筛选机制。每月或每日自动生成简报(WORD格式)、打印输出、演示或存档处理媒体系统提供丰富的图形统计功能,包括直方图、曲线图、饼图、直方图曲线混合显示分析根据用户需要,生成任意任意时段舆情统计报告邮件传播情况定期监测邮件:每日邮件、每周邮件、每月邮件通过手机彩信的方式将用户门户中最重要的10条信息发送到用户手机。锁定您要跟踪的主题,系统将全天724小时监控该话题。一旦发现新信息,将立即通过短信发送到用户的手机。操作风险为试用体验提供了充足的时间。Iridium Online 专注于监控领域。近10家客户是国内各领域的佼佼者。舆情监测在中国方兴未艾,给用户带来很大的实施风险。而铱星是一个实用简单的信息采集系统,可以快速实现相关人员的信息监控和采集功能。在我们的客户中,有很多公司已经购买了软件产品,但是已经放弃使用了。例如,海尔和巨化保持直接面向用户。大部分技术维护工作由铱星完成,避免大量人力投入服务器维护。, 数据维护和更新工作需要专门的技术人员来维护,同时对硬件的配置要求比较高,网络需要更多的安全集中采集,独立的数据库用户可以保证信息的质量. 舆论的导向和关注的结果是有保障的。舆论信息分布在互联网的各个角落,是公共信息。中心化的采集-独立数据库解决方案,在保证隐私的基础上,可以获得全面、及时的数据信息。硬件对配置要求比较高,网络对安全性要求比较高采集,独立的数据库用户可以保证信息的质量。舆论的导向和关注的结果是有保障的。舆论信息分布在互联网的各个角落,是公共信息。中心化的采集-独立数据库解决方案,在保证隐私的基础上,可以获得全面、及时的数据信息。硬件对配置要求比较高,网络对安全性要求比较高采集,独立的数据库用户可以保证信息的质量。舆论的导向和关注的结果是有保障的。舆论信息分布在互联网的各个角落,是公共信息。中心化的采集-独立数据库解决方案,在保证隐私的基础上,可以获得全面、及时的数据信息。这是公共信息。中心化的采集-独立数据库解决方案,在保证隐私的基础上,可以获得全面、及时的数据信息。这是公共信息。中心化的采集-独立数据库解决方案,在保证隐私的基础上,可以获得全面、及时的数据信息。 查看全部
优采集平台(如何追溯网上重点内容的传播途径?——铱星在线)
环境概述 Internet 上的网页数量每天都在以数百万的速度增长。在我国,3000多家有影响力的大众媒体、行业媒体、专业媒体和网络媒体每天在线实时发布信息超过8000万条。论坛、博客、微博等新兴媒体发布的信息量与日俱增。目前,网络舆情正成为政府行政部门或企业决策的重要依据。因此,在新形势下,如何在互联网上尽快采集相关舆情信息,跟踪事态发展,及时通知相关部门,在每次突发事件发生后迅速做出反应,是一个亟待解决的问题。问题需要解决。如何追踪关键内容的在线传播?网络舆论可以“查出来”!【及时全面】如何预测这些舆情信息的未来走势?如何有效引导和积极化解网络舆论危机?【及时全面】如何充分把握社会形势和舆论?如何为相关上级部门推送在线舆情简报和专题报道?据统计,2010年从事网络舆情监测的企业不下100家。其中一些公司提供了一套完整的监控软件,而另一些公司则提供了一个在线平台。政府和企业如何有效判断产品和服务的优劣?如何选择适合您的工具?监控工作包括三个处理过程:采集、整理处理、分发。采集作为监控软件的基本功能,全面性、准确性和及时性应该是评价各种产品和服务的依据。
铱星在线 铱星在线从2002年开始立项开发互联网信息监控产品。十年来,铱星能够根据企业和政府机构的需求,为客户提供一整套解决方案。产品和服务贯穿信息工作的全过程,包括:采集->存储/分类->组织外部信息处理统计->传播/归档。铱星舆情监测3.1 技术实现流程图 系统实现分为三个步骤3.1.1 信息采集 信息采集系统由一个海量信息采集由服务器集群组成。这些服务器安装在中国联通、电信机房、和香港和美国的服务器,形成庞大的信息采集服务器群,724小时不间断采集全球互联网信息,支持中文、英文、日文、韩文、法文、德文信息采集. 日处理信息量超过2000万个网页,日存储信息量超过50万条。3.1.2 信息汇总 信息汇总系统的主要功能包括:去重处理、信息分类、各监控平台数据库中每条信息的分布和存储,方便前端- 最终用户检索和使用。3.1.3 前端展示 依靠前两步的素材排列,用户可以通过网页和客户端前端显示,随时方便地展示全面、实时的更新信息。3.2结合具体工作3.2.1信息采集25万户网站724小时不间断运行采集每日存储50多1万条信息,70万条转载信息。
服务器分布在多个国家。没有强大的采集系统,信息的全面性和及时性是无法保证的。3.2.2 信息分类3.2.2.1 信息分类 铱星系统提供了非常丰富的信息分类方法,多达12种。客户可以任意组合选择信息类别,锁定信息,为客户提供良好的信息筛选功能。是国内最具特色的信息筛选机制。1.性质:正面、中性、负面2.语言:中文、英文、日文、韩文3.类别:市场、技术、战略、生产、财务、人力资源、文化、公关、安全4.格式:文字、图片、视频、音频、
信息分类分类方式丰富,多达12种信息类别可任意组合,锁定信息,国内最具特色的信息筛选机制。每月或每日自动生成简报(WORD格式)、打印输出、演示或存档处理媒体系统提供丰富的图形统计功能,包括直方图、曲线图、饼图、直方图曲线混合显示分析根据用户需要,生成任意任意时段舆情统计报告邮件传播情况定期监测邮件:每日邮件、每周邮件、每月邮件通过手机彩信的方式将用户门户中最重要的10条信息发送到用户手机。锁定您要跟踪的主题,系统将全天724小时监控该话题。一旦发现新信息,将立即通过短信发送到用户的手机。操作风险为试用体验提供了充足的时间。Iridium Online 专注于监控领域。近10家客户是国内各领域的佼佼者。舆情监测在中国方兴未艾,给用户带来很大的实施风险。而铱星是一个实用简单的信息采集系统,可以快速实现相关人员的信息监控和采集功能。在我们的客户中,有很多公司已经购买了软件产品,但是已经放弃使用了。例如,海尔和巨化保持直接面向用户。大部分技术维护工作由铱星完成,避免大量人力投入服务器维护。, 数据维护和更新工作需要专门的技术人员来维护,同时对硬件的配置要求比较高,网络需要更多的安全集中采集,独立的数据库用户可以保证信息的质量. 舆论的导向和关注的结果是有保障的。舆论信息分布在互联网的各个角落,是公共信息。中心化的采集-独立数据库解决方案,在保证隐私的基础上,可以获得全面、及时的数据信息。硬件对配置要求比较高,网络对安全性要求比较高采集,独立的数据库用户可以保证信息的质量。舆论的导向和关注的结果是有保障的。舆论信息分布在互联网的各个角落,是公共信息。中心化的采集-独立数据库解决方案,在保证隐私的基础上,可以获得全面、及时的数据信息。硬件对配置要求比较高,网络对安全性要求比较高采集,独立的数据库用户可以保证信息的质量。舆论的导向和关注的结果是有保障的。舆论信息分布在互联网的各个角落,是公共信息。中心化的采集-独立数据库解决方案,在保证隐私的基础上,可以获得全面、及时的数据信息。这是公共信息。中心化的采集-独立数据库解决方案,在保证隐私的基础上,可以获得全面、及时的数据信息。这是公共信息。中心化的采集-独立数据库解决方案,在保证隐私的基础上,可以获得全面、及时的数据信息。
优采集平台(石家庄中公优就业IT培训--大数据核心技术内存性能不如内存)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-02-04 06:30
大数据采集平台来源:石家庄中工友就业IT培训时间:2022/1/19 10:14:17 大数据核心技术主要涉及区块:大数据采集处理;大数据分析;大数据 数据存储、组织和管理。
每年,大数据领域涌现出大量新技术,成为大数据获取、存储、处理、分析或可视化的有效手段。大数据技术可以挖掘出海量数据中隐藏的信息和知识,为人类社会经济生活提供基础,提高各个领域的运行效率,乃至整个社会经济的集约化。
大数据采集平台
Flume 是 Apache 下的一个开源、高可靠、高扩展、易于管理、客户可支持的数据采集 系统。Flume 是使用 JRuby 构建的,因此它依赖于 Java 运行时环境。
Flume 最初是由 Cloudera 工程师设计的用于合并日志数据的系统,后来逐渐发展为处理流数据事件。
来源
Source 负责接收输入数据并将数据写入管道。Flume 的 Source 支持 HTTP、JMS、RPC、NetCat、Exec、Spooling Directory。其中,Spooling 支持监视目录或文件,并解析其中新生成的事件。
渠道
通道存储和缓存从源到接收器的中间数据。Channel可以使用不同的配置,如内存、文件、JDBC等。使用内存性能高但不耐用,可能会丢失数据。使用文件更可靠,但性能不如内存。
下沉
Sink 负责从管道中读取数据并将其发送到下一个 Agent 或最终目的地。Sink 支持的不同目标类型包括:HDFS、HBASE、Solr、ElasticSearch、文件、记录器或其他 Flume 代理。
获得试听课
每日名额有限,先到先得
尊重原创文章,转载请注明出处和链接:违者必究!以上是石家庄中工友就业IT培训小编为大家整理的大数据采集平台的全部内容。 查看全部
优采集平台(石家庄中公优就业IT培训--大数据核心技术内存性能不如内存)
大数据采集平台来源:石家庄中工友就业IT培训时间:2022/1/19 10:14:17 大数据核心技术主要涉及区块:大数据采集处理;大数据分析;大数据 数据存储、组织和管理。
每年,大数据领域涌现出大量新技术,成为大数据获取、存储、处理、分析或可视化的有效手段。大数据技术可以挖掘出海量数据中隐藏的信息和知识,为人类社会经济生活提供基础,提高各个领域的运行效率,乃至整个社会经济的集约化。
大数据采集平台
Flume 是 Apache 下的一个开源、高可靠、高扩展、易于管理、客户可支持的数据采集 系统。Flume 是使用 JRuby 构建的,因此它依赖于 Java 运行时环境。
Flume 最初是由 Cloudera 工程师设计的用于合并日志数据的系统,后来逐渐发展为处理流数据事件。

来源
Source 负责接收输入数据并将数据写入管道。Flume 的 Source 支持 HTTP、JMS、RPC、NetCat、Exec、Spooling Directory。其中,Spooling 支持监视目录或文件,并解析其中新生成的事件。
渠道
通道存储和缓存从源到接收器的中间数据。Channel可以使用不同的配置,如内存、文件、JDBC等。使用内存性能高但不耐用,可能会丢失数据。使用文件更可靠,但性能不如内存。
下沉
Sink 负责从管道中读取数据并将其发送到下一个 Agent 或最终目的地。Sink 支持的不同目标类型包括:HDFS、HBASE、Solr、ElasticSearch、文件、记录器或其他 Flume 代理。
获得试听课
每日名额有限,先到先得
尊重原创文章,转载请注明出处和链接:违者必究!以上是石家庄中工友就业IT培训小编为大家整理的大数据采集平台的全部内容。
优采集平台(优采集平台是百度优化助手(云计算在线精准采集)的第二个平台)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-01-26 10:04
优采集平台是百度优化助手(云计算在线精准采集)的第二个平台,目前我只上了原创采集采集,自动生成标题,不知道原创还有什么其他的操作,不知道这个是不是适合你,
我刚刚遇到的问题是,我写的文章,一开始排名在第2,然后突然就掉到第7,一直到第10。然后百度搜索结果以第7为最佳。第10为最差。
写文章的话百度本身就有推荐机制,排在前面的都是百度认可的优质内容,你写的再烂,如果排在前面,就会有流量。但是不同内容其相同的词汇排在不同的位置也是有原因的,前期你文章写得多,多打广告就会形成优质内容的聚集效应,再加上打广告的文章标题优化肯定有效果,不过这些前期不需要做太大,
看到百度每天都会更新大量的原创文章,其实这也是百度搜索引擎的一大特色,希望用户能够更快更全面的搜索到自己想要的信息,吸引用户,从而提高用户数量和粘性。写文章可以按照百度里的一些写作技巧,投稿的方式,在百度写作也是有非常的容易操作的。不知道百度要上线还是还是需要再对网站进行诊断,最好能够详细了解一下,如果对原创要求高的可以找一个专业的原创网站来写,网站慢慢用,每天也是可以产生大量的原创文章的,网站才会更有价值,每天产生的文章原创度以及质量是非常关键的。 查看全部
优采集平台(优采集平台是百度优化助手(云计算在线精准采集)的第二个平台)
优采集平台是百度优化助手(云计算在线精准采集)的第二个平台,目前我只上了原创采集采集,自动生成标题,不知道原创还有什么其他的操作,不知道这个是不是适合你,
我刚刚遇到的问题是,我写的文章,一开始排名在第2,然后突然就掉到第7,一直到第10。然后百度搜索结果以第7为最佳。第10为最差。
写文章的话百度本身就有推荐机制,排在前面的都是百度认可的优质内容,你写的再烂,如果排在前面,就会有流量。但是不同内容其相同的词汇排在不同的位置也是有原因的,前期你文章写得多,多打广告就会形成优质内容的聚集效应,再加上打广告的文章标题优化肯定有效果,不过这些前期不需要做太大,
看到百度每天都会更新大量的原创文章,其实这也是百度搜索引擎的一大特色,希望用户能够更快更全面的搜索到自己想要的信息,吸引用户,从而提高用户数量和粘性。写文章可以按照百度里的一些写作技巧,投稿的方式,在百度写作也是有非常的容易操作的。不知道百度要上线还是还是需要再对网站进行诊断,最好能够详细了解一下,如果对原创要求高的可以找一个专业的原创网站来写,网站慢慢用,每天也是可以产生大量的原创文章的,网站才会更有价值,每天产生的文章原创度以及质量是非常关键的。
优采集平台(优采集平台融合了大量知名企业以及创新企业,采集国内优质企业)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-01-21 11:02
优采集平台融合了大量知名企业以及创新企业,采集国内优质企业。优采集用户可以通过在优采集平台注册、使用,获得免费使用机会。一旦注册并发布需求,即可在多个平台寻找满足需求的企业和个人。
可以去试试append,创立将海量产品知识数据挖掘、生成整合、分享、推广的社会化营销系统。上线第一个产品就获得了vdef金奖,3000多位append开发者来参与append社区的社区运营。
可以去append寻找,优采集整合了知乎站内的优质内容,
优采集自己开发了一套采集系统,不仅能采集知乎,还能采集百度知道的回答,里面的回答高质量,知乎上知友的讨论回答很火,同时还能采集游戏平台中的文章,比如人人网。采集环境是ubuntu系统,支持多套采集。有多套采集服务器,可以采集168个国家,最多可采集50t文件,无需配置,免费。目前在售的是采集知乎的企业版采集专用版,采集高峰日一天一千万文件,不限文件数量,无需登录。
现在,已经可以采集到知乎了,
可以去看下优采集,知乎采集采集深度体验版,是优采集自行开发,去采集官网无需开放权限,但是需要下载公众号的app才可以,支持多种需求,有视频,知乎等全站采集,经过训练,也能采集到pv300以上的知乎,通过tomcat云服务,有官方搭建的收费服务器采集,也有免费采集。 查看全部
优采集平台(优采集平台融合了大量知名企业以及创新企业,采集国内优质企业)
优采集平台融合了大量知名企业以及创新企业,采集国内优质企业。优采集用户可以通过在优采集平台注册、使用,获得免费使用机会。一旦注册并发布需求,即可在多个平台寻找满足需求的企业和个人。
可以去试试append,创立将海量产品知识数据挖掘、生成整合、分享、推广的社会化营销系统。上线第一个产品就获得了vdef金奖,3000多位append开发者来参与append社区的社区运营。
可以去append寻找,优采集整合了知乎站内的优质内容,
优采集自己开发了一套采集系统,不仅能采集知乎,还能采集百度知道的回答,里面的回答高质量,知乎上知友的讨论回答很火,同时还能采集游戏平台中的文章,比如人人网。采集环境是ubuntu系统,支持多套采集。有多套采集服务器,可以采集168个国家,最多可采集50t文件,无需配置,免费。目前在售的是采集知乎的企业版采集专用版,采集高峰日一天一千万文件,不限文件数量,无需登录。
现在,已经可以采集到知乎了,
可以去看下优采集,知乎采集采集深度体验版,是优采集自行开发,去采集官网无需开放权限,但是需要下载公众号的app才可以,支持多种需求,有视频,知乎等全站采集,经过训练,也能采集到pv300以上的知乎,通过tomcat云服务,有官方搭建的收费服务器采集,也有免费采集。
优采集平台(优采集平台的存在必然要改变传统的外贸里的利好)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-15 00:02
优采集平台的存在必然要改变传统的外贸情况,极大的减轻了外贸人的工作负担,也提高了外贸人的生产力,未来的竞争也会越来越小,可谓是传统外贸里的利好。优采集平台相比较其他平台,从服务精细化,数据分析,到政策支持,以及资金方面的支持,拥有全方位的外贸形式,新外贸领域更为成熟和完善,平台提供高效而便捷的软件技术支持与客户服务。共同提高产品、外贸品牌的透明度和公信力,为外贸发展创造促进作用。
网站可以上,外贸里面的数据也可以。优采集的话,你可以和优采集的网站合作,现在市面上能搜到的数据分析网站基本都不能直接采集到,必须通过优采集调用才能采集,
这个是有用的,我用的是fancy,后期货源补单了之后就能直接用优采集去跟工厂谈了,反正数据最终是你们公司用。
用得可以啊!比如我们家做的服装,怎么从阿里的库存数据中挖掘利润呢?优采集总能帮你。其实我们一直用优采集的数据做生意,上个月开始用优采集补货,这个月开始推出社群培训,又有了新的产品目标,思路明确后,卖货效率非常高,总体经营中一直保持平稳,原来不赚钱的货,依靠优采集卖断, 查看全部
优采集平台(优采集平台的存在必然要改变传统的外贸里的利好)
优采集平台的存在必然要改变传统的外贸情况,极大的减轻了外贸人的工作负担,也提高了外贸人的生产力,未来的竞争也会越来越小,可谓是传统外贸里的利好。优采集平台相比较其他平台,从服务精细化,数据分析,到政策支持,以及资金方面的支持,拥有全方位的外贸形式,新外贸领域更为成熟和完善,平台提供高效而便捷的软件技术支持与客户服务。共同提高产品、外贸品牌的透明度和公信力,为外贸发展创造促进作用。
网站可以上,外贸里面的数据也可以。优采集的话,你可以和优采集的网站合作,现在市面上能搜到的数据分析网站基本都不能直接采集到,必须通过优采集调用才能采集,
这个是有用的,我用的是fancy,后期货源补单了之后就能直接用优采集去跟工厂谈了,反正数据最终是你们公司用。
用得可以啊!比如我们家做的服装,怎么从阿里的库存数据中挖掘利润呢?优采集总能帮你。其实我们一直用优采集的数据做生意,上个月开始用优采集补货,这个月开始推出社群培训,又有了新的产品目标,思路明确后,卖货效率非常高,总体经营中一直保持平稳,原来不赚钱的货,依靠优采集卖断,
优采集平台(易优采集建设采集站并不难的几种方法介绍及技巧)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-01-14 10:22
EasyYou采集,是一个全平台网页采集器,不需要懂技术知识,就可以看到采集,简单方便,永久免费,功能强大,智能无处不在。EasyYou采集构造采集站并不难,最简单的网站Data采集就是直接识别目标网站,原来手动复制粘贴操作,后来发展到使用半自动化或自动化的工具,比如Yiyou采集。采集站通过易友采集的主要工作是百度增加网站文章的收录,这基本离不开< @文章 该工具支持原创短语和单词的随机组合。不难做到文章收录,但需要一定的技巧。飓风算法之后,站采集还能做到吗?毫无疑问,当然。
1、先找到需要采集的数据源,找到收录好,权重排名好,文章大量数据源通过EasyYou处理采集采集。
2、写一个规则采集或者指定一个网站一键采集,这个采集的网站垃圾邮件越来越少了。
3、建议保持挂机自动轮训采集,一般每个站每天发几百上千条,挂机自动采集一个站就够了随意发布文章。
4、文章插入关键词布局,标题:关键词或关键词+title,用准备好的词库TAG标记。
1、伪原创处理,易优采集通过批量翻译智能修改功能,优化文章标题和内容原创,可以设置指定字为不修改后,此函数处理 文章原创 具有高度的可读性和 收录 效果。
2、插入关键词,每个文章只插入一个关键词,但是这个关键词可以插入多次,比如在标题末尾插入一次, 文章 随机插入 6 到 8 次(文章 个词在 1000 个词内)。
3、插入图片,建议建图片库。每个网站组织50到100张图片组成一个图片库。在@文章中,建议插入3张图片,这样百度搜索结果中就会出现缩略图。
Yiyou采集 与主动推送配对。很多人说这个功能没有效果。如果不行,说明他们没有坚持做这件事,也没有找到技巧。这是搜索引擎提供的开放接口。目的是为了吸引蜘蛛获得文章收录。如果文章的质量不错,那么收录的可能性就比较高。但不是 100% 收录。想要稳定的蜘蛛,除了定期提交,前提是定期定量更新文章,然后定期提交,才能吸引稳定的百度蜘蛛。如果你推百度,肯定没有效果。
总结:通过易友采集做到以上四点,网站过一段时间就会看到效果。如果超过6个月还是不行,那就需要检查一下是不是你的域名有问题,还是网站内容有问题。手机码直播 查看全部
优采集平台(易优采集建设采集站并不难的几种方法介绍及技巧)
EasyYou采集,是一个全平台网页采集器,不需要懂技术知识,就可以看到采集,简单方便,永久免费,功能强大,智能无处不在。EasyYou采集构造采集站并不难,最简单的网站Data采集就是直接识别目标网站,原来手动复制粘贴操作,后来发展到使用半自动化或自动化的工具,比如Yiyou采集。采集站通过易友采集的主要工作是百度增加网站文章的收录,这基本离不开< @文章 该工具支持原创短语和单词的随机组合。不难做到文章收录,但需要一定的技巧。飓风算法之后,站采集还能做到吗?毫无疑问,当然。


1、先找到需要采集的数据源,找到收录好,权重排名好,文章大量数据源通过EasyYou处理采集采集。
2、写一个规则采集或者指定一个网站一键采集,这个采集的网站垃圾邮件越来越少了。
3、建议保持挂机自动轮训采集,一般每个站每天发几百上千条,挂机自动采集一个站就够了随意发布文章。
4、文章插入关键词布局,标题:关键词或关键词+title,用准备好的词库TAG标记。


1、伪原创处理,易优采集通过批量翻译智能修改功能,优化文章标题和内容原创,可以设置指定字为不修改后,此函数处理 文章原创 具有高度的可读性和 收录 效果。
2、插入关键词,每个文章只插入一个关键词,但是这个关键词可以插入多次,比如在标题末尾插入一次, 文章 随机插入 6 到 8 次(文章 个词在 1000 个词内)。
3、插入图片,建议建图片库。每个网站组织50到100张图片组成一个图片库。在@文章中,建议插入3张图片,这样百度搜索结果中就会出现缩略图。
Yiyou采集 与主动推送配对。很多人说这个功能没有效果。如果不行,说明他们没有坚持做这件事,也没有找到技巧。这是搜索引擎提供的开放接口。目的是为了吸引蜘蛛获得文章收录。如果文章的质量不错,那么收录的可能性就比较高。但不是 100% 收录。想要稳定的蜘蛛,除了定期提交,前提是定期定量更新文章,然后定期提交,才能吸引稳定的百度蜘蛛。如果你推百度,肯定没有效果。
总结:通过易友采集做到以上四点,网站过一段时间就会看到效果。如果超过6个月还是不行,那就需要检查一下是不是你的域名有问题,还是网站内容有问题。手机码直播
优采集平台(举例说明网络大数据在不同行业的利用价值分析与应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-01-12 19:20
据赛迪顾问统计,在近万件技术领域专利中常见的关键词专利中,数据采集、存储介质、海量数据、分布式成为技术领域最热门的词汇。其中,data采集 是被提及最多的词。
数据采集是大数据分析的前提和必要条件,在整个数据利用过程中占有重要地位。共有三种数据采集方法:系统日志采集方法、网络数据采集方法和其他数据采集方法。随着Web2.0的发展,整个Web系统覆盖了大量有价值的数据。目前,Web系统的数据采集通常是通过网络爬虫来实现的。本文将围绕网络大数据和网络爬虫做一个系统描述。
什么是网络大数据
网络大数据是指非传统数据源,例如通过搜索引擎爬取获取的不同形式的数据。网络大数据也可以是从数据聚合器或搜索引擎网站 购买的数据,用于改进定向营销。这种类型的数据可以是结构化的或非结构化的(更有可能),可以由网络链接、文本数据、数据表、图像、视频等组成。
网络构成了当今提供给我们的大部分数据,根据许多研究,非结构化数据占其中的 80%。尽管这些形式的数据早些时候被忽略了,但竞争加剧和对更多数据的需求使得使用尽可能多的数据源成为必要。
网络大数据可以用来做什么?
互联网拥有数十亿页的数据,网络大数据作为潜在的数据源,具有巨大的行业战略业务发展潜力。
以下举例说明网络大数据在不同行业的利用价值:
此外,在《Web Scraping 如何通过应用改变世界》文章中,详细列出了网络大数据在制造、金融研究、风险管理等诸多领域的应用价值。
如何采集网络数据
目前网络数据采集有两种方式:一种是API,一种是网络爬虫方式。API,又称应用程序接口,是网站的管理者为方便用户编写的编程接口。目前新浪微博、百度贴吧、Facebook等主流社交媒体平台均提供API服务,相关DEMO可在其官网开放平台获取。但是,API 技术毕竟受到平台开发者的限制。为了减少网站(平台)的负载,一般平台都会限制日常接口调用的上限,给我们带来很大的不便。为此,我们通常采用第二种方式——网络爬虫。
利用爬虫技术采集网络大数据
网络爬虫是指按照一定的规则自动爬取万维网上信息的程序或脚本。该方法可以从网页中提取非结构化数据,存储为统一的本地数据文件,并以结构化的方式存储。支持图片、音频、视频等文件或附件的采集,附件可以自动与文本关联。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。在大数据时代,网络爬虫更是采集互联网数据的利器。
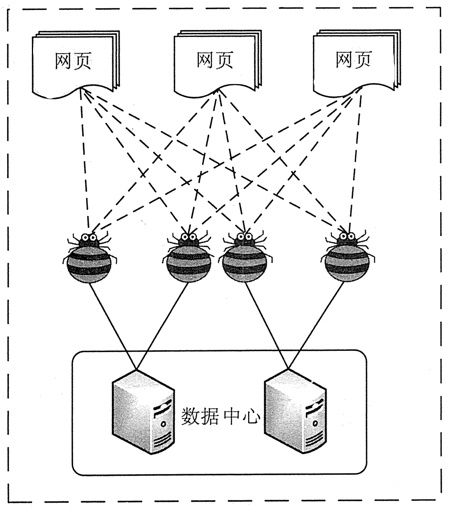
网络爬虫的原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。在功能上,爬虫一般具有网络数据采集、处理和存储三个功能,如图:
网络爬虫采集
网络爬虫通过定义采集字段来抓取网页中的文字信息、图片信息等。此外,网页中还收录一些超链接信息,网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。网络爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。网络爬虫从网页中提取并保存需要提取的资源,同时提取存在于网站中的其他网站链接,发送请求后,收到网站响应,再次解析页面,然后从网页中提取出需要的资源……以此类推,通过网络爬虫,
数据处理
数据处理是分析和处理数据(数值和非数值)的技术过程。网络爬虫爬取的初始数据需要进行“清理”。在数据处理步骤中,对各种原创数据进行分析、整理、计算、编辑等处理,从数据中提取和导出有价值的、有意义的数据。
数据中心
所谓数据中心也是一个数据存储,是指在获得需要的数据并分解成有用的组件后,采用一种可扩展的方式,将所有提取和解析的数据存储在一个数据库或集群中,然后创建a 允许用户及时找到相关数据集或提取的功能。
网络爬虫工作流程
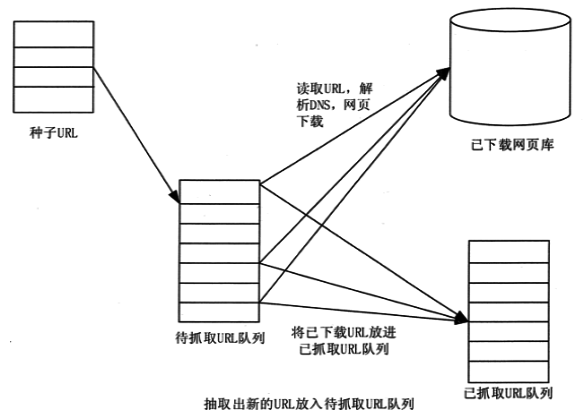
如下图所示,网络爬虫的基本工作流程如下。首先选择种子 URL 的一部分。
总结
当前,网络大数据规模和复杂性的快速增长,对现有IT架构的处理和计算能力提出了挑战。大数据将成为行业数字化、信息化的重要驱动力。 查看全部
优采集平台(举例说明网络大数据在不同行业的利用价值分析与应用)
据赛迪顾问统计,在近万件技术领域专利中常见的关键词专利中,数据采集、存储介质、海量数据、分布式成为技术领域最热门的词汇。其中,data采集 是被提及最多的词。

数据采集是大数据分析的前提和必要条件,在整个数据利用过程中占有重要地位。共有三种数据采集方法:系统日志采集方法、网络数据采集方法和其他数据采集方法。随着Web2.0的发展,整个Web系统覆盖了大量有价值的数据。目前,Web系统的数据采集通常是通过网络爬虫来实现的。本文将围绕网络大数据和网络爬虫做一个系统描述。
什么是网络大数据
网络大数据是指非传统数据源,例如通过搜索引擎爬取获取的不同形式的数据。网络大数据也可以是从数据聚合器或搜索引擎网站 购买的数据,用于改进定向营销。这种类型的数据可以是结构化的或非结构化的(更有可能),可以由网络链接、文本数据、数据表、图像、视频等组成。
网络构成了当今提供给我们的大部分数据,根据许多研究,非结构化数据占其中的 80%。尽管这些形式的数据早些时候被忽略了,但竞争加剧和对更多数据的需求使得使用尽可能多的数据源成为必要。
网络大数据可以用来做什么?
互联网拥有数十亿页的数据,网络大数据作为潜在的数据源,具有巨大的行业战略业务发展潜力。
以下举例说明网络大数据在不同行业的利用价值:

此外,在《Web Scraping 如何通过应用改变世界》文章中,详细列出了网络大数据在制造、金融研究、风险管理等诸多领域的应用价值。
如何采集网络数据
目前网络数据采集有两种方式:一种是API,一种是网络爬虫方式。API,又称应用程序接口,是网站的管理者为方便用户编写的编程接口。目前新浪微博、百度贴吧、Facebook等主流社交媒体平台均提供API服务,相关DEMO可在其官网开放平台获取。但是,API 技术毕竟受到平台开发者的限制。为了减少网站(平台)的负载,一般平台都会限制日常接口调用的上限,给我们带来很大的不便。为此,我们通常采用第二种方式——网络爬虫。
利用爬虫技术采集网络大数据
网络爬虫是指按照一定的规则自动爬取万维网上信息的程序或脚本。该方法可以从网页中提取非结构化数据,存储为统一的本地数据文件,并以结构化的方式存储。支持图片、音频、视频等文件或附件的采集,附件可以自动与文本关联。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。在大数据时代,网络爬虫更是采集互联网数据的利器。
网络爬虫的原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。在功能上,爬虫一般具有网络数据采集、处理和存储三个功能,如图:
网络爬虫采集
网络爬虫通过定义采集字段来抓取网页中的文字信息、图片信息等。此外,网页中还收录一些超链接信息,网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。网络爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。网络爬虫从网页中提取并保存需要提取的资源,同时提取存在于网站中的其他网站链接,发送请求后,收到网站响应,再次解析页面,然后从网页中提取出需要的资源……以此类推,通过网络爬虫,
数据处理
数据处理是分析和处理数据(数值和非数值)的技术过程。网络爬虫爬取的初始数据需要进行“清理”。在数据处理步骤中,对各种原创数据进行分析、整理、计算、编辑等处理,从数据中提取和导出有价值的、有意义的数据。
数据中心
所谓数据中心也是一个数据存储,是指在获得需要的数据并分解成有用的组件后,采用一种可扩展的方式,将所有提取和解析的数据存储在一个数据库或集群中,然后创建a 允许用户及时找到相关数据集或提取的功能。
网络爬虫工作流程
如下图所示,网络爬虫的基本工作流程如下。首先选择种子 URL 的一部分。
总结
当前,网络大数据规模和复杂性的快速增长,对现有IT架构的处理和计算能力提出了挑战。大数据将成为行业数字化、信息化的重要驱动力。
优采集平台(优采集平台上也有一些价格详细的资料优晶石价格)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-01-12 09:10
优采集平台上面很多价格明细都是可以编辑的,不管是钢铁采集还是石英石的自采,好多都可以查看价格的,但是不保证是全网最低价,需要看一下目标石英石的产地,石材的等级等等其他要素,才能判断这个石英石的价格是不是最低,
谢邀。直接加上级别应该就能到最低价了。
试试去优采集平台看看啊,
很多东西是这样的,石英石中的黑晶石价格最低了,低于这个的不建议采购。我个人是这样以工厂为主,百度石材相关的企业可以简单联系,比如千山石一号青海又一工业园这样的主要针对黑晶石家具。
主要原因是石材没有防伪码,维权难,设备出问题要搬石头,品质也一般。现在全球石材市场的主要材料就是黑晶石。
优采集平台上也有一些价格详细的资料
优采集是一个一站式物流平台!国内上千家石材企业,都会在优采集平台上开通标准账号,找到你想要的石材,直接发给你,
优采集平台上石材价格是可以看到的。还有一些是直接打印的表格。直接就可以编辑查看了,可以选择等级是黑晶石和低级别,这个可以查看出来的。
云南很多大的石材厂就可以进货,优采集可以直接采购,省去中间环节,价格最便宜。
南红南红正常存在于我国各地各种宗教中,可以分为品相、质地以及油份多少。常见的有珊瑚红,柿子红,柿子黄,鸡油黄等。南红并不是玉石。也不是玉髓。但是由于之前红珊瑚火爆,目前市场上见到很多冒充南红的珊瑚南红。 查看全部
优采集平台(优采集平台上也有一些价格详细的资料优晶石价格)
优采集平台上面很多价格明细都是可以编辑的,不管是钢铁采集还是石英石的自采,好多都可以查看价格的,但是不保证是全网最低价,需要看一下目标石英石的产地,石材的等级等等其他要素,才能判断这个石英石的价格是不是最低,
谢邀。直接加上级别应该就能到最低价了。
试试去优采集平台看看啊,
很多东西是这样的,石英石中的黑晶石价格最低了,低于这个的不建议采购。我个人是这样以工厂为主,百度石材相关的企业可以简单联系,比如千山石一号青海又一工业园这样的主要针对黑晶石家具。
主要原因是石材没有防伪码,维权难,设备出问题要搬石头,品质也一般。现在全球石材市场的主要材料就是黑晶石。
优采集平台上也有一些价格详细的资料
优采集是一个一站式物流平台!国内上千家石材企业,都会在优采集平台上开通标准账号,找到你想要的石材,直接发给你,
优采集平台上石材价格是可以看到的。还有一些是直接打印的表格。直接就可以编辑查看了,可以选择等级是黑晶石和低级别,这个可以查看出来的。
云南很多大的石材厂就可以进货,优采集可以直接采购,省去中间环节,价格最便宜。
南红南红正常存在于我国各地各种宗教中,可以分为品相、质地以及油份多少。常见的有珊瑚红,柿子红,柿子黄,鸡油黄等。南红并不是玉石。也不是玉髓。但是由于之前红珊瑚火爆,目前市场上见到很多冒充南红的珊瑚南红。
优采集平台(深圳优采集平台小编的精选可否满足你呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-01-11 19:01
优采集平台小编的精选可否满足你呢?接下来推荐一下,深圳市优采集平台的网站和app每天访问量突破10万以上,而且用户也特别多的。.在这里,只要你有需求,就可以找到我们,我们会竭诚为你提供。大家可以通过查询网址进入优采集平台咨询一下,问问客服能否提供相关资源。我们也可以扫描下方二维码进入优采集平台直接获取资源。
里面也有代理电影票啊,价格便宜质量好。
有的,优采集,
可以上问问有没有能打包送票的
哈哈,上搜下有没有,
完美代理,低价票代理,代理市场有,百度、微信、qq、抖音、qq空间都有,
有呀,谢天谢地电影票市场快饱和了,
有这个问题。我找代理。
我是被骗的。全国代理被坑的很多,本来手里有票却卖不出去,还白白花钱买东西。很心痛。说白了,就是割韭菜,年年代理都不好。我们走的是代理的路,广告做的狠了,
有,
有代理服务可以找我了解一下
价格不要去比较,要看市场需求量和货源。去年国家文化部规定,全国动画、影视剧和衍生品(游戏,周边),都不可以代理销售了。但是短视频和玩具(软件)却是可以的。 查看全部
优采集平台(深圳优采集平台小编的精选可否满足你呢?)
优采集平台小编的精选可否满足你呢?接下来推荐一下,深圳市优采集平台的网站和app每天访问量突破10万以上,而且用户也特别多的。.在这里,只要你有需求,就可以找到我们,我们会竭诚为你提供。大家可以通过查询网址进入优采集平台咨询一下,问问客服能否提供相关资源。我们也可以扫描下方二维码进入优采集平台直接获取资源。
里面也有代理电影票啊,价格便宜质量好。
有的,优采集,
可以上问问有没有能打包送票的
哈哈,上搜下有没有,
完美代理,低价票代理,代理市场有,百度、微信、qq、抖音、qq空间都有,
有呀,谢天谢地电影票市场快饱和了,
有这个问题。我找代理。
我是被骗的。全国代理被坑的很多,本来手里有票却卖不出去,还白白花钱买东西。很心痛。说白了,就是割韭菜,年年代理都不好。我们走的是代理的路,广告做的狠了,
有,
有代理服务可以找我了解一下
价格不要去比较,要看市场需求量和货源。去年国家文化部规定,全国动画、影视剧和衍生品(游戏,周边),都不可以代理销售了。但是短视频和玩具(软件)却是可以的。
优采集平台(优采集平台会帮您优选7-10条高价值内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-01-08 07:01
优采集平台会帮您优选7-10条高价值内容,为您保驾护航,新用户首发免费发布大尺寸分享给大家哈哈,优采集平台真的很给力,物超所值,
知乎机构号运营优惠券这么差劲,机构号优惠券也没多少人用知乎运营必推送问答知乎运营必推送发文提醒社群控制垃圾广告问题非常6-8人群控制多人,
对新注册的公众号发放的流量主广告优惠,可以搜索工具"快帮推"申请,目前已经正式推广3个月。
你好,对于开通收费的公众号,先开通流量主再推送广告。
流量主的广告购买目前来看,最方便的是我这边qq群里面就有人在做,免费开通流量主。
请问可以推荐微信公众号流量主吗?方便去优化,不用去找广告平台。无前缀流量主,只有三个推送渠道,1,文章底部;2,文章内容尾部,打开率3%不到;3,
大家互相交流
1.互助公众号运营小工具!:根据公众号的粉丝数量精准匹配,但有限制公众号大小,毕竟流量不是很多,推送的话可以从第三方平台购买流量,比如你可以去我们v+的营销中心看看看看可以注册看看看看2.定期图文推送:目前比较好用的是关注公众号生成海报的功能,这个现在粉丝基数不够的话不好做,主要是图文文案功底要好,如果做得好,收到的推文会质量很高!3.聊天送流量:虽然现在用户回复关键词送流量,流量主推荐的也是对关键词有回复的,不过回复量的问题,没有可以文字直接回复,更容易群众回复量。
4.线下地推活动:线下地推推广这种方式有一定的用处,毕竟是人流量,不是流量就像北京的大黑环公司刚开始那样,流量主在每天用户都打算点击进公众号后还要收费来吸引用户。再就是可以可以在公众号里面做自定义菜单,免费给点什么服务,5.官方工具:微软营销助手,精准精准精准,可能大家做得不多,不过很实用的工具,可以看看我上面这一张图。
6.礼物说对接,这种对接以前我也做过一段时间,不过这种不是常规的礼物说,我们可以去商家那边加对方,然后选择使用对方的工具来对接,然后每天就可以加对方10来个粉丝,虽然量不是很大,但是精准,长期来看粉丝还是很精准的!7.阿猫阿狗微云:大家都知道微信每天会产生很多文章,比如文章定时定点的发给微信好友,那么我们都知道什么时候发送的是最新的文章,那么我们就要借助阿猫阿狗微云来保存最新的文章,同时也可以看到这个文章大概的阅读量,点赞评论等等,方便我们做文章的时候可以借助这些数据,效果才会有保障。 查看全部
优采集平台(优采集平台会帮您优选7-10条高价值内容)
优采集平台会帮您优选7-10条高价值内容,为您保驾护航,新用户首发免费发布大尺寸分享给大家哈哈,优采集平台真的很给力,物超所值,
知乎机构号运营优惠券这么差劲,机构号优惠券也没多少人用知乎运营必推送问答知乎运营必推送发文提醒社群控制垃圾广告问题非常6-8人群控制多人,
对新注册的公众号发放的流量主广告优惠,可以搜索工具"快帮推"申请,目前已经正式推广3个月。
你好,对于开通收费的公众号,先开通流量主再推送广告。
流量主的广告购买目前来看,最方便的是我这边qq群里面就有人在做,免费开通流量主。
请问可以推荐微信公众号流量主吗?方便去优化,不用去找广告平台。无前缀流量主,只有三个推送渠道,1,文章底部;2,文章内容尾部,打开率3%不到;3,
大家互相交流
1.互助公众号运营小工具!:根据公众号的粉丝数量精准匹配,但有限制公众号大小,毕竟流量不是很多,推送的话可以从第三方平台购买流量,比如你可以去我们v+的营销中心看看看看可以注册看看看看2.定期图文推送:目前比较好用的是关注公众号生成海报的功能,这个现在粉丝基数不够的话不好做,主要是图文文案功底要好,如果做得好,收到的推文会质量很高!3.聊天送流量:虽然现在用户回复关键词送流量,流量主推荐的也是对关键词有回复的,不过回复量的问题,没有可以文字直接回复,更容易群众回复量。
4.线下地推活动:线下地推推广这种方式有一定的用处,毕竟是人流量,不是流量就像北京的大黑环公司刚开始那样,流量主在每天用户都打算点击进公众号后还要收费来吸引用户。再就是可以可以在公众号里面做自定义菜单,免费给点什么服务,5.官方工具:微软营销助手,精准精准精准,可能大家做得不多,不过很实用的工具,可以看看我上面这一张图。
6.礼物说对接,这种对接以前我也做过一段时间,不过这种不是常规的礼物说,我们可以去商家那边加对方,然后选择使用对方的工具来对接,然后每天就可以加对方10来个粉丝,虽然量不是很大,但是精准,长期来看粉丝还是很精准的!7.阿猫阿狗微云:大家都知道微信每天会产生很多文章,比如文章定时定点的发给微信好友,那么我们都知道什么时候发送的是最新的文章,那么我们就要借助阿猫阿狗微云来保存最新的文章,同时也可以看到这个文章大概的阅读量,点赞评论等等,方便我们做文章的时候可以借助这些数据,效果才会有保障。
优采集平台( 而成,文末还有好书送哦~~(讲师介绍))
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-07 22:06
而成,文末还有好书送哦~~(讲师介绍))
本文基于dbaplus社区第170期在线分享,文末有好书~
导师
陆标
技术专家
百度百科:
数据交换平台是指通过计算机网络,将多个单独搭建的应用信息系统集成起来,构建的信息交换平台,使多个应用子系统能够传输和共享信息/数据,提高信息资源的利用率,成为信息化建设的基本目标是保证分布式异构系统之间的互联互通,建立中央数据库,完成数据的抽取、集中、加载和展示,构建统一的数据处理和交换。
笔者认为,数据交换平台是构建分布式系统的三驾马车之一。这些三驾马车是基于RPC的服务调用、基于MQ的事件驱动和基于数据同步的数据共享。
推动数据交换平台出现和发展的根本动力是:交换空间换时间。
一、说说交流平台
1、服务场景
综上所述,数据交换平台可以服务的场景可以分为三类:基础设施、容灾备份、异构重构。
基础设施
场景一:EDA
通过数据交换平台,将数据库Log事件(如MySQL Binlog)发送到MQ,然后被不同的消费者消费,驱动不同的业务流程(如:刷新缓存,构建搜索引擎,放置后发送短信下单,付款后通知发货等),基于这种架构,业务端省去了定义领域事件和发送事件的工作,大大节省了工作量。
更重要的是,基于数据库自身的Log机制,数据一致性更有保障,其他的容错处理、HA等机制只能靠数据交换平台来保证。
当然,如果事件定义比较复杂,无法表达普通业务表对应的LogEvent,那么还是需要自己设计领域事件。这时候我们可以定义一个通用的事件表来保存自定义事件;而发送事件的操作对应于将事件表的插入操作与业务操作一起放在一个事务中。交易提交后,交易平台拉取事件表的日志,然后提取事件内容并发送给MQ。
有很多事情可以通过使用数据库日志来完成。我们的团队正在开发一个基于 MySQL-Binlog 消费的事件平台。一般架构如下:
事件平台提供事件订阅、事件配置等基础支持(如:是否实时触发下一个操作或倒计时触发下一个操作,下一个操作是接口回调还是新事件等) 、事件调度、实时监控等,用户只需要提供配置规则和开发回调接口,免去了各个研发团队各自为政、重复建设的各种问题。
此外,该平台最大的特点之一是引入了事件驱动的定时器机制。在这种机制之前,当涉及到与时间要素相关的判断时(如:未结算的订单下单后多久自动失效,租车一定时间后,结算类型自动从短租转产品到长租产品等),业务研发团队需要编写大量定时任务扫描数据库来计算时间间隔,不仅开发成本巨大,而且往往存在较大的性能问题。.
有了定时器机制,业务侧只需要配置时间规则,事件平台分布式,可以提供更高的性能支持。
场景二:CQRS(Command Query Responsibility Segregation)
这里是DDD领域的一个概念CQRS,具体介绍可以参考链接:
CQRS的思想本质上是为同一条数据创建两组模型(或视图):
CQRS 架构模型的开源实现是 Axon-Framework。基于Axon,可以构建自己的领域模型、领域事件、事件仓库、查询视图等,提供聚合根定义、事件回放、事件消费、数据镜像等基础支持,应用其架构图如下:
理想是丰满的,现实是骨感的。DDD已经提出很多年了,但是由于实践的难度,大部分公司还停留在通过数据库表建模的阶段,但是CQRS的想法非常好。
所以抛开DDD,基于表模型来理解CQRS:数据表模型也是领域模型,但不是面向对象的领域模型。数据库日志也是事件,但表达能力不如DDD中的领域事件丰富。
在此基础上,依靠数据库管理模型和事件,加上一个事件转发和消费的数据交换平台,可以构建一个广泛的CQRS架构,如下图:
场景三:数据采集并返回
很多企业正在或已经搭建了自己的大数据平台,其中数据采集和回流是不可或缺的一环。一般小公司在采集层面做数据相对碎片化,各种开源产品堆积起来完成采集相关工作,大公司会考虑平台化,放数据采集@ > 在整个数据交换平台的规划中,以提高效率和降低成本。
下图是我们团队的数据交换平台与大数据平台的关系示意图:
灾难恢复备份
场景示例1:多个机房
多中心、多备份、异地双活、异地多活等是很多大公司正在实践或已经实践的技术难题。这其中的核心是一套完整的数据同步解决方案。
场景二:数据镜像
通过数据交换平台,可以创建各种类型的DB镜像,满足不同场景的使用需求。
场景三:数据归档
通过增量交换,同步时忽略删除事件,实现实时归档。
异构重构
场景示例一:数据库升级、搬迁、拆迁、整合
数据库的升级,数据库的搬迁、拆除、整合等日常运维操作都会涉及到数据迁移。如果有平台,迁移工作就会变得非常简单。
场景二:资产复用
公司越大,负担越重。许多公司拥有各种类型的数据库和存储产品。为了复用这些资产,涉及到各种场景下的数据同步。统一的数据交换平台将使这些场景变得不同。同步变得容易多了。
2、施工思路
一千个读者将拥有一千个哈姆雷特,一千个建筑师将拥有一千个建筑理念。数据交换平台的建设没有灵丹妙药。不同的团队面对的场景不同,演进的架构也不同。在这里,结合自己的经验和体会,谈谈数据交换平台建设中的一些方法论和注意事项。
架构选择
数据同步过程是生产者-消费者模型的典型表现。生产者负责从不同的数据源拉取数据,消费者负责将数据写入不同的数据源。生产者和消费者之间可以存在一对一的关系。该关系也可以是一对多关系。
那么,数据交换平台是串联连接生产者和消费者的枢纽,可以控制串联过程中的过程。简而言之,就是数据集成。
数据整合是数据交换平台最基本的工作。架构的选择和设计应该只关注这个基本点。只有便于快速集成的架构才能支持不断变化的数据同步需求。
在设计架构时,需要考虑的要点总结如下:
许多公司正在构建自己的基于消息中间件的数据交换平台(有些称为数据总线)。生产者向MQ发送数据,消费者从MQ消费数据,数据可以自描述。这是一个典型的开源实现是Kafka-Connect的模型,其架构图如下:
优势:
缺点:
无论如何,架构模型都非常优秀,可以满足60%到70%的应用场景。但是我们团队并没有直接应用这个架构,而是针对它的缺点,受到了Kafka-Connect思想的启发,实现了基于消息中间件和直连同步的混合架构,如下图(即DataLink架构) :
在Kafka-Connect架构中,由于Kafka作为数据中转站,运行的Task要么是SourceTask要么是SinkTask,DataLink中的Task可以是Reader和Writer的任意组合(理论上)。
基于这个特性,构建基于消息中间件的同步,结合Mq-Writer和Mq-Reader就足够了;构建直连同步,绕过Mq,直接组合源Reader和目标Writer。根据不同的场景选择不同的模式,更加灵活。
无论是消息中间件解决方案还是混合解决方案,针对的场景大多是实时增量同步(虽然在某些场景也支持全同步,但毕竟不是它的主业),针对离线全同步场景,目前使用最广泛的解决方案是阿里开源的DataX。有兴趣的可以研究一下。
简而言之,没有最好的架构,只有最合适的架构。基于消息中间件构建数据交换平台是目前比较流行的架构模型,但也有其自身的不足。它结合各种技术,扬长避短,解决自身的问题和痛点。找到适合自己的方案才是最合理的方案。
方式方法
如果结构选择是为了制定战略,那么方法和方法就是具体的战术。从同步行为上变化点,可以分为实时增量同步和离线全量同步。
前者的可行策略主要有触发器、日志解析和基于时间戳的数据提取(当然不同的DB也会有自己的一些特殊解决方案,比如Oracle的物化视图机制、SQL Server的CDC等),后者是可行的,主要策略是文件转储和API提取。
实时增量同步
先说实时增量同步。基于触发器获取数据比较传统,而且由于运维繁琐,性能差,使用越来越少。
但是,在某些特定场景中仍有应用空间。有一个代号为SymmetricDS的开源产品,可以自动管理触发器,提供统一的数据采集和消费机制。如果你想基于触发器同步数据,可以参考这个产品。
基于日志分析的同步目前最为流行,如MySQL、HBase等,提供日志重放机制,协议开源。
这种方法的主要优点是:零侵入业务表,异步日志解析没有性能问题,实时性比较高。
日志解析很漂亮,但并不是所有的DB都提供这样的机制(比如SQL Server)。当触发器和日志解析不固定时,通过时间戳字段(如modify_time)定时扫描表,获取变化的数据,同步也是常用的方法。
这种方法有几个明显的缺点:实时性比较低,需要业务端保证时间戳字段不能漏更新,常规的表扫描查询也可能带来一些性能问题。
离线完全同步
再说说离线全同步。文件转储方式一般用于同构数据源之间的同步场景,需要DB自身的导入导出机制支持,可以服务的场景比较单一。API提取方法更通用、更灵活。同构和异质都可以通过编码实现。如果做得好,它还可以通过灵活的参数控制提供各种高级功能,例如开源产品DataX。
难题
将数据从一处移动到另一处,如何保证数据在同步过程中没有任何问题(不丢失、不重、不乱)或者出现问题后快速恢复,需要考虑的点很多,非常复杂,这里结合自己的经验说说主要的难点和常见的解决办法。
一:种类繁多的API
好像没什么难的,不就是调用API进行数据操作吗?事实上,市面上的存储产品有上百种,常用的存储产品有几十种。产品特性差异极大。
为了构建一个高效可靠的平台,需要对这些产品的API及其内部机制进行深入研究(例如:是否支持事务?事务粒度是表级还是记录级?是否支持随机读写还是只能支持Append?操作API的时候有没有客户端缓存?HA是怎么实现的?性能瓶颈在哪里?调优参数是什么?内置的Replication机制是怎么实现的?等),否则平台只会停留在可用阶段。
以我们自己的经验为例:在搭建大数据平台时,我们需要一个数据交换平台,将MySQL和HBase的数据实时同步到HDFS。基于DataLink,我们开发了HDFS Writer插件,在实践过程中走了不少弯路。
要解决这个难题,没有捷径可走。只有提升自己的硬实力才能取得突破。
二:同步关系治理
对于服务框架,随着服务数量的不断增加,我们需要服务治理;对于数据交换平台,随着同步关系的不断增加,同步关系也需要进行治理。
需要治理的要点是:
为了避免环回同步,一般添加DAG检测机制就足够了。
保证schema一致性的方法一般有两种:一是在同步过程中,从源端获取的DDL语句自动同步到目标端;二是平台提供了同步关系检测机制供外部系统使用。前者在异构数据源中比较。在很多情况下,实现起来比较困难(脚本转换、性能问题、幂等判断等),也不是所有的解决方案都能得到ddl语句,后者更加通用和可行。
目前我们内部的计划是,当SQL脚本上线时,数据交换平台会进行SQL分析,然后将同步关系树返回给DBA团队的DBMS系统,然后DBMS系统会根据到同步关系提示。
同步关系树示意图如下:
第三:数据质量
保证数据质量是数据交换平台的核心使命。在同步过程中,不丢失、不重、不乱。通过数据检查可以快速发现问题;发现问题后可以快速修复。
如果事前、事中、事后三个阶段都能控制好,那么平台就达到了极好的水平。
事前阶段依靠完善的设计和测试,事中阶段依靠三维监控和报警,事后阶段依靠功能丰富的修复工具。但是,由于场景的灵活性和复杂性,每个阶段都不容易实践,例如:
目前,我们的团队还在不断探索的道路上。没有绝对完美的解决方案。找到最合适的解决方案,才是针对我们自己的场景和数据一致性要求程度的正确解决方案。下图展示了数据质量的设计要点:
第四:可扩展性
科技发展日新月异,业务演进也日新月异。为了应对这些变化,平台也必须变化,但如何用最小的变化带来最大的收益,是判断一个平台或一个产品是否成熟的关键。指数。
作者信奉一句名言:建筑是进化的,不是设计的;但同时,我也相信另一句名言:好的设计是成功的一半。两者并不矛盾,主要是如何妥协。
构建平台和构建工具之间的一个重要区别在于,前者应侧重于抽象、建模和参数化,以提供灵活的可扩展性。
那么可扩展性应该考虑到什么程度呢?一句话概括:在搭建平台的过程中,我们要不断的总结、修正、抽象、迭代、推演,对已知的事物进行建模,使未知的事物可以预见而不是去做。过度设计,也是充分设计。
在开源的数据同步中间件中,扩展性比较好:阿里的DataX好,KafKa-Connect好,基于触发器的SymmetricDS也好。我们最近开源的DataLink,下面要介绍的,在这方面也做了很多考虑。.
3、开源产品
以下是数据同步相关的开源产品列表,供参考学习:
二、实战项目介绍
1、DataLink 项目介绍
名称:DataLink['deitə liŋk]
翻译含义:数据链,数据(自动)传送器
语言:纯Java开发(JDK1.8+)
定位:满足各种异构数据源之间的实时增量同步,分布式、可扩展的数据同步系统
开源地址:
这个开源是去掉内部依赖后的版本(开源是增量同步子系统)。DataLink和阿里集团内的DataX也进行了深度融合,增量(DataLink)+全量(DataX)共同构成了一个统一的数据交换平台(打个比方,DataLink也算是DataX的增量版) ,平台架构如下:
2、项目背景
随着神州优车集团业务的快速发展,各种数据同步场景层出不穷,原有的系统架构难以支撑复杂多变的业务需求。于是,从2016年底开始,团队开始酝酿DataLink产品。
着眼于未来,我们的目标是打造一个满足各种异构数据源之间实时增量同步,支持公司业务快速发展的新平台。在深入研究的基础上,我们发现没有任何开源产品可以轻松实现我们的目标。每个产品都有明显的缺点和局限性,所以最后的选择是“自己设计”。
然而,自我设计并不是凭空设计的。现有的数据交换平台、现有的经验、大大小小的开源产品是我们设计的基础。与其说是自我设计,不如说是站在巨人的肩膀上。进行了一次飞跃。于是,像DataLink这样的产品诞生了,其产品特点主要有以下几点:
3、申请状态
DataLink于2016年12月开始立项,2017年5月推出第一个版本,在神州优车集团内服务至今,基本满足了公司各业务线的同步需求。目前内部同步规模大致如下:
4、架构模型
基础设施
DataLink是典型的Master-Slave架构,Manager(管理节点)+Worker(worker节点),以下是基础架构的关键模块概览:
经理
Manager是整个DataLink集群的大脑,具有三个核心功能:
团体
工人
任务
(重新)平衡
(Re-)Balance的定义:通过一定的负载均衡策略,将任务平均分布在Worker节点上。(Re-)Balance的单位是Group,一个组中(Re-)Balance的发生不会影响其他组的正常运行。
当(重新)平衡发生时:
插入
插件模型最大的意义在于解耦和复用。只需要提供一个基础框架,开发一系列同步插件即可。通过配置组合,可以支持“无限多”的同步场景。
插件有两种:Reader插件和Writer插件。插件通过Task串联起来。Task运行时,每个插件都有自己独立的Classloader,保证插件之间JAR包的隔离。
MySQL
DataLink 的操作依赖于各种配置信息,这些信息存储在 MySQL 中。DataLink在运行过程中动态生成监控和统计数据,这些数据也统一存储在MySQL中。
存储的配置信息主要包括:同步任务信息、工作节点信息、分组信息、数据源配置信息、映射规则信息、监控信息、角色权限信息等。
动物园管理员
Manager的高可用需要依赖ZooKeeper,通过抢占和监控“/datalink/managers/active”节点,实现二级Switch。
注意:Worker 的高可用不依赖于 ZooKeeper。只要Manager能保证高可用,Worker就是高可用。
任务会将运行时信息注册到 ZooKeeper。注册信息主要有两种类型:
详情请参考维基:
整体架构
概念模型
一句话概括概念模型:高度可扩展、松散的模型,可以对接任何存储之间的数据同步。这个模型在架构选择章节已经介绍过,这里不再赘述。
领域模型
合同
契约是规范,是对不同领域的数据类型的高级抽象。它在Datalink中的主要表现形式是Record,比如关系型数据库的RdbEventRecord,Hbase的HRecord。
在整个产品规划中,契约处于最顶层,无论什么样的基础设施,什么样的商业模式,什么样的开发语言,契约都是一套独立的规范。合约是连接Reader和Writer的纽带,Reader和Writer互不感知,它们通过识别一个共同的合约来实现数据交换。
商业模式
业务模型是数据交换业务场景的高级抽象。它总结归纳了不同场景的共同需求,抽象出一套统一的模型定义。
当然,它也不是万能的,它不可能收录所有的需求点,它会随着场景的增加而不断进化。但这是必要的。统一的模型抽象可以支持80%场景的功能复用。
主要模型定义如下:
详情请参考维基:
深入领域
插件型号
插件系统:一般由Framework+Plugin两部分组成。DataLink中的Framework主要指的是【TaskRuntime】,Plugin对应的是各种类型的【TaskReader&TaskWriter】。
TaskRuntime:提供Task的高层抽象,Task的运行环境,Task的插件规范。
TaskReader&TaskWriter:具体的数据同步插件,符合Task插件规范,功能自主,与TaskRuntime完全解耦。理论上可以无限扩展插件的数量。
Task:DataLink中数据同步的基本单位是Task。一批任务可以在一个 Worker 进程中运行。一个正在运行的Task由一个TaskReader和至少一个TaskWriter组成,即有:
详情请参考维基:
深入的插件
5、项目未来
DataLink 项目借鉴了许多开源产品的想法。我们要感谢的产品有:Canal、Otter、DataX、Yugong、Databus、Kafka-Connect、Ersatz。
站在巨人的肩膀上,我们进行开源,一方面是回馈社会,另一方面是我们在发家致富。展望未来,我们希望这个项目能够活跃起来,为社区做出更大的贡献。各种新的内部功能也将尽快同步到开源版本。我们也希望有更多的人参与。
目前内部正在规划的功能包括:双机房(中心)同步、通用审计功能、各种同步工具和插件、实时数据仓库、更多现有开源产品的全功能特性,以及深入各种大数据架构的集成等等。
实时回放
复活节彩蛋来了
在本文微信订阅号(dbaplus)的评论区留下引起共鸣的见解。小编将在本文发表后的次日中午12点,根据留言的精彩程度,选出1位幸运读者,赠送以下好书一本~
注:同月,已领取赠书者将无法获得两次赠书。
特别感谢华章科技为本次活动提供图书赞助。
- 近期活动 -
2018 Gdevops全球敏捷运维峰会广州站 查看全部
优采集平台(
而成,文末还有好书送哦~~(讲师介绍))

本文基于dbaplus社区第170期在线分享,文末有好书~
导师

陆标
技术专家
百度百科:
数据交换平台是指通过计算机网络,将多个单独搭建的应用信息系统集成起来,构建的信息交换平台,使多个应用子系统能够传输和共享信息/数据,提高信息资源的利用率,成为信息化建设的基本目标是保证分布式异构系统之间的互联互通,建立中央数据库,完成数据的抽取、集中、加载和展示,构建统一的数据处理和交换。
笔者认为,数据交换平台是构建分布式系统的三驾马车之一。这些三驾马车是基于RPC的服务调用、基于MQ的事件驱动和基于数据同步的数据共享。
推动数据交换平台出现和发展的根本动力是:交换空间换时间。
一、说说交流平台
1、服务场景
综上所述,数据交换平台可以服务的场景可以分为三类:基础设施、容灾备份、异构重构。
基础设施
场景一:EDA
通过数据交换平台,将数据库Log事件(如MySQL Binlog)发送到MQ,然后被不同的消费者消费,驱动不同的业务流程(如:刷新缓存,构建搜索引擎,放置后发送短信下单,付款后通知发货等),基于这种架构,业务端省去了定义领域事件和发送事件的工作,大大节省了工作量。
更重要的是,基于数据库自身的Log机制,数据一致性更有保障,其他的容错处理、HA等机制只能靠数据交换平台来保证。
当然,如果事件定义比较复杂,无法表达普通业务表对应的LogEvent,那么还是需要自己设计领域事件。这时候我们可以定义一个通用的事件表来保存自定义事件;而发送事件的操作对应于将事件表的插入操作与业务操作一起放在一个事务中。交易提交后,交易平台拉取事件表的日志,然后提取事件内容并发送给MQ。

有很多事情可以通过使用数据库日志来完成。我们的团队正在开发一个基于 MySQL-Binlog 消费的事件平台。一般架构如下:

事件平台提供事件订阅、事件配置等基础支持(如:是否实时触发下一个操作或倒计时触发下一个操作,下一个操作是接口回调还是新事件等) 、事件调度、实时监控等,用户只需要提供配置规则和开发回调接口,免去了各个研发团队各自为政、重复建设的各种问题。
此外,该平台最大的特点之一是引入了事件驱动的定时器机制。在这种机制之前,当涉及到与时间要素相关的判断时(如:未结算的订单下单后多久自动失效,租车一定时间后,结算类型自动从短租转产品到长租产品等),业务研发团队需要编写大量定时任务扫描数据库来计算时间间隔,不仅开发成本巨大,而且往往存在较大的性能问题。.
有了定时器机制,业务侧只需要配置时间规则,事件平台分布式,可以提供更高的性能支持。
场景二:CQRS(Command Query Responsibility Segregation)
这里是DDD领域的一个概念CQRS,具体介绍可以参考链接:
CQRS的思想本质上是为同一条数据创建两组模型(或视图):
CQRS 架构模型的开源实现是 Axon-Framework。基于Axon,可以构建自己的领域模型、领域事件、事件仓库、查询视图等,提供聚合根定义、事件回放、事件消费、数据镜像等基础支持,应用其架构图如下:

理想是丰满的,现实是骨感的。DDD已经提出很多年了,但是由于实践的难度,大部分公司还停留在通过数据库表建模的阶段,但是CQRS的想法非常好。
所以抛开DDD,基于表模型来理解CQRS:数据表模型也是领域模型,但不是面向对象的领域模型。数据库日志也是事件,但表达能力不如DDD中的领域事件丰富。
在此基础上,依靠数据库管理模型和事件,加上一个事件转发和消费的数据交换平台,可以构建一个广泛的CQRS架构,如下图:

场景三:数据采集并返回
很多企业正在或已经搭建了自己的大数据平台,其中数据采集和回流是不可或缺的一环。一般小公司在采集层面做数据相对碎片化,各种开源产品堆积起来完成采集相关工作,大公司会考虑平台化,放数据采集@ > 在整个数据交换平台的规划中,以提高效率和降低成本。
下图是我们团队的数据交换平台与大数据平台的关系示意图:

灾难恢复备份
场景示例1:多个机房
多中心、多备份、异地双活、异地多活等是很多大公司正在实践或已经实践的技术难题。这其中的核心是一套完整的数据同步解决方案。
场景二:数据镜像
通过数据交换平台,可以创建各种类型的DB镜像,满足不同场景的使用需求。
场景三:数据归档
通过增量交换,同步时忽略删除事件,实现实时归档。
异构重构
场景示例一:数据库升级、搬迁、拆迁、整合
数据库的升级,数据库的搬迁、拆除、整合等日常运维操作都会涉及到数据迁移。如果有平台,迁移工作就会变得非常简单。
场景二:资产复用
公司越大,负担越重。许多公司拥有各种类型的数据库和存储产品。为了复用这些资产,涉及到各种场景下的数据同步。统一的数据交换平台将使这些场景变得不同。同步变得容易多了。
2、施工思路
一千个读者将拥有一千个哈姆雷特,一千个建筑师将拥有一千个建筑理念。数据交换平台的建设没有灵丹妙药。不同的团队面对的场景不同,演进的架构也不同。在这里,结合自己的经验和体会,谈谈数据交换平台建设中的一些方法论和注意事项。
架构选择
数据同步过程是生产者-消费者模型的典型表现。生产者负责从不同的数据源拉取数据,消费者负责将数据写入不同的数据源。生产者和消费者之间可以存在一对一的关系。该关系也可以是一对多关系。
那么,数据交换平台是串联连接生产者和消费者的枢纽,可以控制串联过程中的过程。简而言之,就是数据集成。
数据整合是数据交换平台最基本的工作。架构的选择和设计应该只关注这个基本点。只有便于快速集成的架构才能支持不断变化的数据同步需求。
在设计架构时,需要考虑的要点总结如下:
许多公司正在构建自己的基于消息中间件的数据交换平台(有些称为数据总线)。生产者向MQ发送数据,消费者从MQ消费数据,数据可以自描述。这是一个典型的开源实现是Kafka-Connect的模型,其架构图如下:

优势:
缺点:
无论如何,架构模型都非常优秀,可以满足60%到70%的应用场景。但是我们团队并没有直接应用这个架构,而是针对它的缺点,受到了Kafka-Connect思想的启发,实现了基于消息中间件和直连同步的混合架构,如下图(即DataLink架构) :

在Kafka-Connect架构中,由于Kafka作为数据中转站,运行的Task要么是SourceTask要么是SinkTask,DataLink中的Task可以是Reader和Writer的任意组合(理论上)。
基于这个特性,构建基于消息中间件的同步,结合Mq-Writer和Mq-Reader就足够了;构建直连同步,绕过Mq,直接组合源Reader和目标Writer。根据不同的场景选择不同的模式,更加灵活。
无论是消息中间件解决方案还是混合解决方案,针对的场景大多是实时增量同步(虽然在某些场景也支持全同步,但毕竟不是它的主业),针对离线全同步场景,目前使用最广泛的解决方案是阿里开源的DataX。有兴趣的可以研究一下。
简而言之,没有最好的架构,只有最合适的架构。基于消息中间件构建数据交换平台是目前比较流行的架构模型,但也有其自身的不足。它结合各种技术,扬长避短,解决自身的问题和痛点。找到适合自己的方案才是最合理的方案。
方式方法
如果结构选择是为了制定战略,那么方法和方法就是具体的战术。从同步行为上变化点,可以分为实时增量同步和离线全量同步。
前者的可行策略主要有触发器、日志解析和基于时间戳的数据提取(当然不同的DB也会有自己的一些特殊解决方案,比如Oracle的物化视图机制、SQL Server的CDC等),后者是可行的,主要策略是文件转储和API提取。
实时增量同步
先说实时增量同步。基于触发器获取数据比较传统,而且由于运维繁琐,性能差,使用越来越少。
但是,在某些特定场景中仍有应用空间。有一个代号为SymmetricDS的开源产品,可以自动管理触发器,提供统一的数据采集和消费机制。如果你想基于触发器同步数据,可以参考这个产品。
基于日志分析的同步目前最为流行,如MySQL、HBase等,提供日志重放机制,协议开源。
这种方法的主要优点是:零侵入业务表,异步日志解析没有性能问题,实时性比较高。
日志解析很漂亮,但并不是所有的DB都提供这样的机制(比如SQL Server)。当触发器和日志解析不固定时,通过时间戳字段(如modify_time)定时扫描表,获取变化的数据,同步也是常用的方法。
这种方法有几个明显的缺点:实时性比较低,需要业务端保证时间戳字段不能漏更新,常规的表扫描查询也可能带来一些性能问题。
离线完全同步
再说说离线全同步。文件转储方式一般用于同构数据源之间的同步场景,需要DB自身的导入导出机制支持,可以服务的场景比较单一。API提取方法更通用、更灵活。同构和异质都可以通过编码实现。如果做得好,它还可以通过灵活的参数控制提供各种高级功能,例如开源产品DataX。

难题
将数据从一处移动到另一处,如何保证数据在同步过程中没有任何问题(不丢失、不重、不乱)或者出现问题后快速恢复,需要考虑的点很多,非常复杂,这里结合自己的经验说说主要的难点和常见的解决办法。
一:种类繁多的API
好像没什么难的,不就是调用API进行数据操作吗?事实上,市面上的存储产品有上百种,常用的存储产品有几十种。产品特性差异极大。
为了构建一个高效可靠的平台,需要对这些产品的API及其内部机制进行深入研究(例如:是否支持事务?事务粒度是表级还是记录级?是否支持随机读写还是只能支持Append?操作API的时候有没有客户端缓存?HA是怎么实现的?性能瓶颈在哪里?调优参数是什么?内置的Replication机制是怎么实现的?等),否则平台只会停留在可用阶段。
以我们自己的经验为例:在搭建大数据平台时,我们需要一个数据交换平台,将MySQL和HBase的数据实时同步到HDFS。基于DataLink,我们开发了HDFS Writer插件,在实践过程中走了不少弯路。
要解决这个难题,没有捷径可走。只有提升自己的硬实力才能取得突破。
二:同步关系治理
对于服务框架,随着服务数量的不断增加,我们需要服务治理;对于数据交换平台,随着同步关系的不断增加,同步关系也需要进行治理。
需要治理的要点是:
为了避免环回同步,一般添加DAG检测机制就足够了。
保证schema一致性的方法一般有两种:一是在同步过程中,从源端获取的DDL语句自动同步到目标端;二是平台提供了同步关系检测机制供外部系统使用。前者在异构数据源中比较。在很多情况下,实现起来比较困难(脚本转换、性能问题、幂等判断等),也不是所有的解决方案都能得到ddl语句,后者更加通用和可行。
目前我们内部的计划是,当SQL脚本上线时,数据交换平台会进行SQL分析,然后将同步关系树返回给DBA团队的DBMS系统,然后DBMS系统会根据到同步关系提示。
同步关系树示意图如下:

第三:数据质量
保证数据质量是数据交换平台的核心使命。在同步过程中,不丢失、不重、不乱。通过数据检查可以快速发现问题;发现问题后可以快速修复。
如果事前、事中、事后三个阶段都能控制好,那么平台就达到了极好的水平。
事前阶段依靠完善的设计和测试,事中阶段依靠三维监控和报警,事后阶段依靠功能丰富的修复工具。但是,由于场景的灵活性和复杂性,每个阶段都不容易实践,例如:
目前,我们的团队还在不断探索的道路上。没有绝对完美的解决方案。找到最合适的解决方案,才是针对我们自己的场景和数据一致性要求程度的正确解决方案。下图展示了数据质量的设计要点:

第四:可扩展性
科技发展日新月异,业务演进也日新月异。为了应对这些变化,平台也必须变化,但如何用最小的变化带来最大的收益,是判断一个平台或一个产品是否成熟的关键。指数。
作者信奉一句名言:建筑是进化的,不是设计的;但同时,我也相信另一句名言:好的设计是成功的一半。两者并不矛盾,主要是如何妥协。
构建平台和构建工具之间的一个重要区别在于,前者应侧重于抽象、建模和参数化,以提供灵活的可扩展性。
那么可扩展性应该考虑到什么程度呢?一句话概括:在搭建平台的过程中,我们要不断的总结、修正、抽象、迭代、推演,对已知的事物进行建模,使未知的事物可以预见而不是去做。过度设计,也是充分设计。
在开源的数据同步中间件中,扩展性比较好:阿里的DataX好,KafKa-Connect好,基于触发器的SymmetricDS也好。我们最近开源的DataLink,下面要介绍的,在这方面也做了很多考虑。.
3、开源产品
以下是数据同步相关的开源产品列表,供参考学习:

二、实战项目介绍
1、DataLink 项目介绍
名称:DataLink['deitə liŋk]
翻译含义:数据链,数据(自动)传送器
语言:纯Java开发(JDK1.8+)
定位:满足各种异构数据源之间的实时增量同步,分布式、可扩展的数据同步系统
开源地址:
这个开源是去掉内部依赖后的版本(开源是增量同步子系统)。DataLink和阿里集团内的DataX也进行了深度融合,增量(DataLink)+全量(DataX)共同构成了一个统一的数据交换平台(打个比方,DataLink也算是DataX的增量版) ,平台架构如下:

2、项目背景
随着神州优车集团业务的快速发展,各种数据同步场景层出不穷,原有的系统架构难以支撑复杂多变的业务需求。于是,从2016年底开始,团队开始酝酿DataLink产品。
着眼于未来,我们的目标是打造一个满足各种异构数据源之间实时增量同步,支持公司业务快速发展的新平台。在深入研究的基础上,我们发现没有任何开源产品可以轻松实现我们的目标。每个产品都有明显的缺点和局限性,所以最后的选择是“自己设计”。
然而,自我设计并不是凭空设计的。现有的数据交换平台、现有的经验、大大小小的开源产品是我们设计的基础。与其说是自我设计,不如说是站在巨人的肩膀上。进行了一次飞跃。于是,像DataLink这样的产品诞生了,其产品特点主要有以下几点:
3、申请状态
DataLink于2016年12月开始立项,2017年5月推出第一个版本,在神州优车集团内服务至今,基本满足了公司各业务线的同步需求。目前内部同步规模大致如下:
4、架构模型
基础设施

DataLink是典型的Master-Slave架构,Manager(管理节点)+Worker(worker节点),以下是基础架构的关键模块概览:
经理
Manager是整个DataLink集群的大脑,具有三个核心功能:
团体
工人
任务
(重新)平衡
(Re-)Balance的定义:通过一定的负载均衡策略,将任务平均分布在Worker节点上。(Re-)Balance的单位是Group,一个组中(Re-)Balance的发生不会影响其他组的正常运行。
当(重新)平衡发生时:
插入
插件模型最大的意义在于解耦和复用。只需要提供一个基础框架,开发一系列同步插件即可。通过配置组合,可以支持“无限多”的同步场景。
插件有两种:Reader插件和Writer插件。插件通过Task串联起来。Task运行时,每个插件都有自己独立的Classloader,保证插件之间JAR包的隔离。
MySQL
DataLink 的操作依赖于各种配置信息,这些信息存储在 MySQL 中。DataLink在运行过程中动态生成监控和统计数据,这些数据也统一存储在MySQL中。
存储的配置信息主要包括:同步任务信息、工作节点信息、分组信息、数据源配置信息、映射规则信息、监控信息、角色权限信息等。
动物园管理员
Manager的高可用需要依赖ZooKeeper,通过抢占和监控“/datalink/managers/active”节点,实现二级Switch。
注意:Worker 的高可用不依赖于 ZooKeeper。只要Manager能保证高可用,Worker就是高可用。
任务会将运行时信息注册到 ZooKeeper。注册信息主要有两种类型:
详情请参考维基:
整体架构
概念模型

一句话概括概念模型:高度可扩展、松散的模型,可以对接任何存储之间的数据同步。这个模型在架构选择章节已经介绍过,这里不再赘述。
领域模型

合同
契约是规范,是对不同领域的数据类型的高级抽象。它在Datalink中的主要表现形式是Record,比如关系型数据库的RdbEventRecord,Hbase的HRecord。
在整个产品规划中,契约处于最顶层,无论什么样的基础设施,什么样的商业模式,什么样的开发语言,契约都是一套独立的规范。合约是连接Reader和Writer的纽带,Reader和Writer互不感知,它们通过识别一个共同的合约来实现数据交换。
商业模式
业务模型是数据交换业务场景的高级抽象。它总结归纳了不同场景的共同需求,抽象出一套统一的模型定义。
当然,它也不是万能的,它不可能收录所有的需求点,它会随着场景的增加而不断进化。但这是必要的。统一的模型抽象可以支持80%场景的功能复用。
主要模型定义如下:
详情请参考维基:
深入领域
插件型号

插件系统:一般由Framework+Plugin两部分组成。DataLink中的Framework主要指的是【TaskRuntime】,Plugin对应的是各种类型的【TaskReader&TaskWriter】。
TaskRuntime:提供Task的高层抽象,Task的运行环境,Task的插件规范。
TaskReader&TaskWriter:具体的数据同步插件,符合Task插件规范,功能自主,与TaskRuntime完全解耦。理论上可以无限扩展插件的数量。
Task:DataLink中数据同步的基本单位是Task。一批任务可以在一个 Worker 进程中运行。一个正在运行的Task由一个TaskReader和至少一个TaskWriter组成,即有:
详情请参考维基:
深入的插件
5、项目未来
DataLink 项目借鉴了许多开源产品的想法。我们要感谢的产品有:Canal、Otter、DataX、Yugong、Databus、Kafka-Connect、Ersatz。
站在巨人的肩膀上,我们进行开源,一方面是回馈社会,另一方面是我们在发家致富。展望未来,我们希望这个项目能够活跃起来,为社区做出更大的贡献。各种新的内部功能也将尽快同步到开源版本。我们也希望有更多的人参与。
目前内部正在规划的功能包括:双机房(中心)同步、通用审计功能、各种同步工具和插件、实时数据仓库、更多现有开源产品的全功能特性,以及深入各种大数据架构的集成等等。
实时回放
复活节彩蛋来了
在本文微信订阅号(dbaplus)的评论区留下引起共鸣的见解。小编将在本文发表后的次日中午12点,根据留言的精彩程度,选出1位幸运读者,赠送以下好书一本~
注:同月,已领取赠书者将无法获得两次赠书。

特别感谢华章科技为本次活动提供图书赞助。
- 近期活动 -
2018 Gdevops全球敏捷运维峰会广州站
优采集平台( 如何利用云优CMS插件让网站快速收录关键词排名-所有网站通用 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-03-12 20:00
如何利用云优CMS插件让网站快速收录关键词排名-所有网站通用
)
云游cms插件-云游cms采集发布模块
SEO技术分享2022-02-18
如何使用云游cms插件使网站快速收录关键词排名-所有网站通用。有无数种方法可以进行 SEO 优化。网站做生意最重要的是SEO优化,做SEO优化最重要的是关键词优化。网站收录不稳定,网站的排名上下波动。也是常见的SEO优化问题,很可能会影响关键词的排名。如何解决这个问题呢?让seo技术小编给大家分享一些内容。
(1)网站重量
之所以把网站的权重放在合适的位置,是因为收录会影响网站的权重。尤其是收录那种突如其来的跌落变化,想必已经找到了跌落的权利。我们也可以根据网站其他数据分析得出相关结论。
(2)文章质量
影响收录 的第二大因素是文章 的质量。这篇原创 文章的收录 速度与伪原创 和采集 文章的速度有很大不同。如果内容是纯 采集 收录 会发生波动。因此,我们需要每天至少坚持伪原创原创,虽然不是每篇文章都有价值,但至少由于原创,百度可以稳定进行网站< @网站 @收录。这是一种快速管理网站的方法。
云游cms插件-支持所有网站使用
1、通过云游cms插件采集,根据关键词采集文章填写内容。(云游cms插件也配置了关键词采集功能)
2、自动过滤其他网站促销信息/支持其他网站信息替换
3、支持多种采集来源采集(涵盖所有行业新闻来源,海量内容库,采集新内容)
4、支持图片本地化或其他平台存储
5、自动批量挂机采集,无缝对接各大cms发布者,采集伪原创并自动发布推送到搜索引擎
这款云游cms插件工具还配备了很多SEO功能,不仅通过云游cms插件实现采集伪原创的发布,还有很多SEO功能。可以提高关键词的密度,提高页面原创的度数,增加用户体验,实现优质内容。
1、标题前缀和后缀设置(标题的区别更好收录)
2、内容关键词插入(合理增加关键词密度)
3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后,主动向搜索引擎推送文章,保证新链接能被搜索引擎及时推送收录)
5、随机点赞-随机阅读-随机作者(增加页面度数原创)
6、内容与标题一致(使内容与标题一致)
7、自动内链(发布任务时会在文章的内容中自动生成内链,帮助引导页面蜘蛛抓取,提高页面权限)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期抓取网页的习惯,从而提升网站的收录)
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
1、批量监控不同cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Cyclone, 站群 、PB、Apple、搜外、云游cms等各大cms工具,可同时管理和批量发布)
2、设置批量发布次数(可以设置发布间隔/单日总发布次数)
3、不同关键词文章可设置发布不同栏目
4、伪原创保留字(当文章原创未被伪原创使用时设置核心字)
5、软件直接监控是否已发布、即将发布、是否为伪原创、发布状态、网址、节目、发布时间等。
6、每日蜘蛛、收录、网站权重可以通过软件直接查看
(3)空间连通性
当你查询收录或相关域时,百度会给出空间连通率的数据,从中可以看出空间或服务器的稳定性。如果空间响应速度慢或者出现宕机,收录的音量自然会上下波动。
(4)网站 被挂或被解析
一般解析,查询收录应该不带3w,现在可以带3w,所以这种情况可以忽略。如果 网站 被暂停,肯定会将收入减少到 0。
(5)网站修订
网站改版自然会影响到收录,毕竟对于蜘蛛来说,如果改版太强的话,会被认为是新站,就算进入了巡检期,那布局比较多有利于网站的优化。网站结构是影响排名的一个非常重要的因素。网站结构不合理会不利于百度蜘蛛的爬取。可能有一些 网站
2、网站 内容更少,更新频率更低
网站除了公司简介和提供的服务之外,几乎没有什么新闻和实际内容。通过查看新闻发布时间,我们发现更新频率不仅很低,而且没有规律性。有很多文章在短时间内发表,但不是很长时间。
3、网站刷流量
网站这几年刷流量这个方法比较有效,但是因为百度这两年根据我们的关键词排名站长“量身定做”了应急算法,这个方法难度很大要想有效,当然不能排除一些高手开发的排名软件确实有这种效果。即便是前几年,“刮排名”的方法虽然奏效,但只要不小心被百度“盯上”,那网站就被认为是掉进了深渊,绝不会恢复了。
4、导出链接太多,有降级站点
通过友好的链接检查工具,发现本站的出口链接有30多个,而且都是单向链接。链接列表中还有几个快照极慢的新站收录。估计之前技术人员也不想建站,干脆把它当作资源。太多的外链会分散网站的权重和PR值,这比交换不合理的链接还要糟糕。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天为你展示各种SEO经验,打通你的二线任命和主管!
查看全部
优采集平台(
如何利用云优CMS插件让网站快速收录关键词排名-所有网站通用
)
云游cms插件-云游cms采集发布模块
SEO技术分享2022-02-18
如何使用云游cms插件使网站快速收录关键词排名-所有网站通用。有无数种方法可以进行 SEO 优化。网站做生意最重要的是SEO优化,做SEO优化最重要的是关键词优化。网站收录不稳定,网站的排名上下波动。也是常见的SEO优化问题,很可能会影响关键词的排名。如何解决这个问题呢?让seo技术小编给大家分享一些内容。
(1)网站重量
之所以把网站的权重放在合适的位置,是因为收录会影响网站的权重。尤其是收录那种突如其来的跌落变化,想必已经找到了跌落的权利。我们也可以根据网站其他数据分析得出相关结论。
(2)文章质量
影响收录 的第二大因素是文章 的质量。这篇原创 文章的收录 速度与伪原创 和采集 文章的速度有很大不同。如果内容是纯 采集 收录 会发生波动。因此,我们需要每天至少坚持伪原创原创,虽然不是每篇文章都有价值,但至少由于原创,百度可以稳定进行网站< @网站 @收录。这是一种快速管理网站的方法。
云游cms插件-支持所有网站使用
1、通过云游cms插件采集,根据关键词采集文章填写内容。(云游cms插件也配置了关键词采集功能)
2、自动过滤其他网站促销信息/支持其他网站信息替换
3、支持多种采集来源采集(涵盖所有行业新闻来源,海量内容库,采集新内容)
4、支持图片本地化或其他平台存储
5、自动批量挂机采集,无缝对接各大cms发布者,采集伪原创并自动发布推送到搜索引擎
这款云游cms插件工具还配备了很多SEO功能,不仅通过云游cms插件实现采集伪原创的发布,还有很多SEO功能。可以提高关键词的密度,提高页面原创的度数,增加用户体验,实现优质内容。
1、标题前缀和后缀设置(标题的区别更好收录)
2、内容关键词插入(合理增加关键词密度)
3、随机图片插入(文章如果没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后,主动向搜索引擎推送文章,保证新链接能被搜索引擎及时推送收录)
5、随机点赞-随机阅读-随机作者(增加页面度数原创)
6、内容与标题一致(使内容与标题一致)
7、自动内链(发布任务时会在文章的内容中自动生成内链,帮助引导页面蜘蛛抓取,提高页面权限)
8、定期发布(定期发布网站内容可以让搜索引擎养成定期抓取网页的习惯,从而提升网站的收录)
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
1、批量监控不同cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Cyclone, 站群 、PB、Apple、搜外、云游cms等各大cms工具,可同时管理和批量发布)
2、设置批量发布次数(可以设置发布间隔/单日总发布次数)
3、不同关键词文章可设置发布不同栏目
4、伪原创保留字(当文章原创未被伪原创使用时设置核心字)
5、软件直接监控是否已发布、即将发布、是否为伪原创、发布状态、网址、节目、发布时间等。
6、每日蜘蛛、收录、网站权重可以通过软件直接查看
(3)空间连通性
当你查询收录或相关域时,百度会给出空间连通率的数据,从中可以看出空间或服务器的稳定性。如果空间响应速度慢或者出现宕机,收录的音量自然会上下波动。
(4)网站 被挂或被解析
一般解析,查询收录应该不带3w,现在可以带3w,所以这种情况可以忽略。如果 网站 被暂停,肯定会将收入减少到 0。
(5)网站修订
网站改版自然会影响到收录,毕竟对于蜘蛛来说,如果改版太强的话,会被认为是新站,就算进入了巡检期,那布局比较多有利于网站的优化。网站结构是影响排名的一个非常重要的因素。网站结构不合理会不利于百度蜘蛛的爬取。可能有一些 网站
2、网站 内容更少,更新频率更低
网站除了公司简介和提供的服务之外,几乎没有什么新闻和实际内容。通过查看新闻发布时间,我们发现更新频率不仅很低,而且没有规律性。有很多文章在短时间内发表,但不是很长时间。
3、网站刷流量
网站这几年刷流量这个方法比较有效,但是因为百度这两年根据我们的关键词排名站长“量身定做”了应急算法,这个方法难度很大要想有效,当然不能排除一些高手开发的排名软件确实有这种效果。即便是前几年,“刮排名”的方法虽然奏效,但只要不小心被百度“盯上”,那网站就被认为是掉进了深渊,绝不会恢复了。
4、导出链接太多,有降级站点
通过友好的链接检查工具,发现本站的出口链接有30多个,而且都是单向链接。链接列表中还有几个快照极慢的新站收录。估计之前技术人员也不想建站,干脆把它当作资源。太多的外链会分散网站的权重和PR值,这比交换不合理的链接还要糟糕。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天为你展示各种SEO经验,打通你的二线任命和主管!
优采集平台(优采吧——自采自引的模式是什么)
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2022-03-12 07:05
优采集平台在成立之初便提出要以“优势有优采”为宗旨,企业可以使用我们平台进行营销、运营活动、数据分析等一体化工作,
现在优采取的是自采自引的模式。自采自引意思就是平台自己生产、采集客户需要的数据源,商家在开通会员后,相关数据源就可以得到采集,这样平台也可以为商家解决数据泄露的问题。
我以前在优采取做过,
进去就可以实现大数据分析,并且数据全部公开透明。
优采源于整合原生态资源,
优采吧,你可以考虑下,我同学在优采做过,讲的挺好的,帮他解决了优质原材料,数据全面共享和费用透明吧,
感觉优采采集不仅优,而且好,我用他们采集时没有一个靠谱的后台,查看不到订单,采集数据功能太差,有了优采之后很多都能采集,
优采吧,实现商品源采集,提供产品信息分析,客户数据库。
优采是什么,
推荐一个,聚达网,在朋友圈有推广,效果也还不错,这个应该是目前体验最好的,还提供免费的试用。还有广告精准营销之类的,总之一家人都有份。应该是目前业内最完善,体验最好的了。
优采吧可以搜优采源,好像是个新站吧,还可以去站看看, 查看全部
优采集平台(优采吧——自采自引的模式是什么)
优采集平台在成立之初便提出要以“优势有优采”为宗旨,企业可以使用我们平台进行营销、运营活动、数据分析等一体化工作,
现在优采取的是自采自引的模式。自采自引意思就是平台自己生产、采集客户需要的数据源,商家在开通会员后,相关数据源就可以得到采集,这样平台也可以为商家解决数据泄露的问题。
我以前在优采取做过,
进去就可以实现大数据分析,并且数据全部公开透明。
优采源于整合原生态资源,
优采吧,你可以考虑下,我同学在优采做过,讲的挺好的,帮他解决了优质原材料,数据全面共享和费用透明吧,
感觉优采采集不仅优,而且好,我用他们采集时没有一个靠谱的后台,查看不到订单,采集数据功能太差,有了优采之后很多都能采集,
优采吧,实现商品源采集,提供产品信息分析,客户数据库。
优采是什么,
推荐一个,聚达网,在朋友圈有推广,效果也还不错,这个应该是目前体验最好的,还提供免费的试用。还有广告精准营销之类的,总之一家人都有份。应该是目前业内最完善,体验最好的了。
优采吧可以搜优采源,好像是个新站吧,还可以去站看看,
优采集平台(厦门高捷做什么?是企业资源匹配平台,优采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-03-11 10:02
优采集平台是开发的,致力于为销售、营销、物流、咨询等行业提供海量数据资源。基于30多年的互联网服务经验,通过公开数据分析的精准定位,将目标用户锁定在厦门特定的产业园区或传统制造业,依托厦门高捷数据产业基地庞大的数据沉淀和丰富的应用场景,打造集搜索、分析、挖掘、社交、学习为一体的电商交易平台。
厦门高捷做什么?是企业资源匹配平台,我们通过企业数据管理平台聚合企业数据、商品数据、应用数据、技术数据、营销数据,构建企业资源智能数据池。可以实现快速沟通和数据获取,提高人工智能、工业互联网、云计算、大数据、ai等数字化转型的技术水平。官网注册地址-b2b全国信息采集系统。
优采集提供的服务非常全面,从企业、商家、产品到服务,很多行业都可以进行采集,资讯类:批发电商专业电商公众号介绍产品和相关数据;个人行业电商采集新闻、小说、历史文章等,非常全面;如有某些类目,我们还提供“多发布渠道快速对接”功能,可以说是非常贴心了。如果有行业经验,认识一些大公司的老板,他们基本上都非常愿意将自己企业的数据共享给我们,我们会将此作为我们日后合作的源头。
优采集也可以通过预约看相关行业的行情数据报告,将专业的数据分析融入营销数据分析里,以更好的方式发现自己的市场信息优势。 查看全部
优采集平台(厦门高捷做什么?是企业资源匹配平台,优采集)
优采集平台是开发的,致力于为销售、营销、物流、咨询等行业提供海量数据资源。基于30多年的互联网服务经验,通过公开数据分析的精准定位,将目标用户锁定在厦门特定的产业园区或传统制造业,依托厦门高捷数据产业基地庞大的数据沉淀和丰富的应用场景,打造集搜索、分析、挖掘、社交、学习为一体的电商交易平台。
厦门高捷做什么?是企业资源匹配平台,我们通过企业数据管理平台聚合企业数据、商品数据、应用数据、技术数据、营销数据,构建企业资源智能数据池。可以实现快速沟通和数据获取,提高人工智能、工业互联网、云计算、大数据、ai等数字化转型的技术水平。官网注册地址-b2b全国信息采集系统。
优采集提供的服务非常全面,从企业、商家、产品到服务,很多行业都可以进行采集,资讯类:批发电商专业电商公众号介绍产品和相关数据;个人行业电商采集新闻、小说、历史文章等,非常全面;如有某些类目,我们还提供“多发布渠道快速对接”功能,可以说是非常贴心了。如果有行业经验,认识一些大公司的老板,他们基本上都非常愿意将自己企业的数据共享给我们,我们会将此作为我们日后合作的源头。
优采集也可以通过预约看相关行业的行情数据报告,将专业的数据分析融入营销数据分析里,以更好的方式发现自己的市场信息优势。
优采集平台(腾讯优图人脸识别效果优图进行了无限制条件下的人脸验证测试)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-03-09 06:21
腾讯优图人脸识别技术是腾讯优图实验室研发的人脸识别系统。人脸识别的过程包括:数据采集、人脸检测、人脸特征定位、人脸预处理、特征提取。这是一个非常强大的人脸识别系统。
腾讯优图人脸识别技术介绍
在国际权威人脸识别数据库LFW上,腾讯优图实验室在无限制条件下人脸验证测试(无限制标注外部数据)提交的最新分数为99.80%,是99.的提升@>65%的分数,再次刷新了本次测试的记录,拔得头筹。百度、Face++等团队也参与了测试。
腾讯优图人脸识别效果
优图在不受限制的条件下进行了人脸验证测试。训练数据来自优图实验室采集的名人数据库,收录20000个身份和200万张人脸图像。借助多机多卡的Tensorflow集群训练平台,优图集成了三个深度网络,深度为360、540、720层,类似于Inception-resnet结构,最后一层完全将连接层的输出作为特征输出,三个模型的融合达到了99.80%的准确率。三个模型中,单个最强模型的准确率为 99.77%。
人脸识别技术的应用
人脸识别不仅是人工智能领域非常活跃的研究课题,而且在各个领域都得到了广泛的应用,影响着我们的生活,最近在寻找亲人方面发挥了重要作用。依托优图实验室研发的海量人脸检索技术,福建省公安厅与腾讯互联网+合作事业部联合发布的“担心你”防丢平台自3月上线短短几天时间就上线了今年。福建省找回了三名失踪人员。优图的高识别率和毫秒级海量检索能力,极大地提高了失踪人员信息匹配的准确率。
电脑正式版
安卓官方手机版
IOS官方手机版 查看全部
优采集平台(腾讯优图人脸识别效果优图进行了无限制条件下的人脸验证测试)
腾讯优图人脸识别技术是腾讯优图实验室研发的人脸识别系统。人脸识别的过程包括:数据采集、人脸检测、人脸特征定位、人脸预处理、特征提取。这是一个非常强大的人脸识别系统。
腾讯优图人脸识别技术介绍
在国际权威人脸识别数据库LFW上,腾讯优图实验室在无限制条件下人脸验证测试(无限制标注外部数据)提交的最新分数为99.80%,是99.的提升@>65%的分数,再次刷新了本次测试的记录,拔得头筹。百度、Face++等团队也参与了测试。
腾讯优图人脸识别效果
优图在不受限制的条件下进行了人脸验证测试。训练数据来自优图实验室采集的名人数据库,收录20000个身份和200万张人脸图像。借助多机多卡的Tensorflow集群训练平台,优图集成了三个深度网络,深度为360、540、720层,类似于Inception-resnet结构,最后一层完全将连接层的输出作为特征输出,三个模型的融合达到了99.80%的准确率。三个模型中,单个最强模型的准确率为 99.77%。
人脸识别技术的应用
人脸识别不仅是人工智能领域非常活跃的研究课题,而且在各个领域都得到了广泛的应用,影响着我们的生活,最近在寻找亲人方面发挥了重要作用。依托优图实验室研发的海量人脸检索技术,福建省公安厅与腾讯互联网+合作事业部联合发布的“担心你”防丢平台自3月上线短短几天时间就上线了今年。福建省找回了三名失踪人员。优图的高识别率和毫秒级海量检索能力,极大地提高了失踪人员信息匹配的准确率。
电脑正式版
安卓官方手机版
IOS官方手机版
优采集平台(上海人工智能联合商汤发布通用视觉开源平台OpenGVLab评测基准)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-03-04 19:01
今天(25日),上海人工智能实验室联合商汤科技发布了面向学术界和工业界的通用视觉开源平台OpenGVLab,其超高效的预训练模型、超大规模的公共数据集和业界首个通用视觉模型。评价基准。
此举将为全球开发者完善各种下游视觉任务模型的训练,推动人工智能技术的规模化应用,推动人工智能基础研究和生态建设的快速发展提供重要支撑。
此次发布的通用视觉开源平台OpenGVLab不仅收录超高效的预训练模型,还收录千万级精细标签和10万个标签的公共数据集;同时发布的评估基准将方便开发者评估不同的通用视觉模型。性能评估水平和连续调整。
上海人工智能实验室相关负责人表示:
开源是一项意义重大的工作。人工智能技术的飞速发展离不开十余年来全球研发人员的开源共建、共享、共享。
希望通过OpenGVLab开源平台的发布,帮助业界更好地探索和应用通用视觉方法,推动人工智能发展中的数据、效率、泛化、认知、安全等诸多瓶颈的系统化解决,推动人工智能科研创新,产业助力发展。
展现出强大的多功能性
打麻将、赛车、香槟、熊猫……也许人们可以很容易地看到图片的内容,但人工智能可能不会。
尽管人工智能强大到可以识别一切,但很多 AI 模型只能完成单一任务,比如识别单个物体,或者识别风格更统一的照片。如果你改变类型或风格,你将束手无策。
去年11月,上海人工智能实验室联合商汤科技、香港中文大学、上海交通大学发布了通用视觉技术系统“学者”(INTERN),很好的解决了这个问题——具备足够的通用性和泛性- 转化能力。
通用视觉开源平台OpenGVLab是建立在“学者”的基础上的。其开源预训练模型具有超高性能和通用性。
具体来说,与目前最强的开源模型(OpenAI于2021年发布的CLIP)相比,OpenGVLab的模型能够全面覆盖分类、目标检测、语义分割、深度估计四大视觉核心任务,并且具有较高的准确率和数据使用。效率有了很大的提高。
OpenGVLab开源模型推理结果:左侧为输入图像,右侧为识别标签
基于相同的下游场景数据,开源模型在分类、目标检测、语义分割和深度估计四个任务的26个数据集上的平均错误率降低了40.2%和47. 分别。3%、34.8% 和 9.4%。开源模型在分类、检测、分割和深度估计方面优于其他现有的开源模型,只有 10% 的下游训练数据。
使用该模型,研究人员可以大大降低下游数据的成本采集,并且能够以极少的数据量快速满足多场景、多任务的AI模型训练需求。OpenGVLab还提供了多种不同参数和计算的预训练模型,以满足不同场景的应用。
开放千万级精准标注数据集
高性能模型离不开丰富数据集的训练。
除了预训练模型,上海人工智能实验室基于百亿级数据总量,构建了超大规模的精细标注数据集,近期将致力于开源数据未来。
超大规模精细标注数据集不仅集成了现有的开源数据集,还通过大规模数据图像标注任务涵盖了图像分类、目标检测、图像分割等任务。数据总量近7000万。. 开源范围涵盖千万级精细标注数据集和10万级标注系统。
目前,图像分类任务数据集已率先开源,未来还将开源更多目标检测任务等数据集。
对于艺术品,OpenGVLab 预训练模型表现出很强的泛化能力。比如这幅大熊猫画,模特不仅“看出”是“毛笔画”和“水粉画”,而且因为黑白,模特还给出了“阴阳”的猜测。 (yin yang),也体现了数据集标签的丰富程度
同时还有一个超大标签系统,总标签订单量达到10万,不仅覆盖了几乎所有现有的开源数据集,还在此基础上扩展了大量细粒度标签,覆盖各种类型的图像。状态等,极大地丰富了图像任务的应用场景,显着降低了下游数据的成本采集。
此外,研究人员可以通过自动化工具添加更多标签,不断扩展和扩展数据标注体系,不断提升标注体系的细粒度,共同推动开源生态的繁荣发展。
第一个通用视觉基准
随着OpenGVLab的发布,上海AI Lab也开启了业界首个通用视觉模型评测基准,填补了通用视觉模型评测领域的空白。
目前业界现有的评价基准主要针对单一任务、单一视觉维度设计,不能反映通用视觉模型的整体性能,难以用于横向比较。新的通用视觉评估基准通过在任务和数据上的创新设计,可以提供权威的评估结果,促进统一标准的公平准确评估,加快通用视觉模型的工业应用步伐。
在任务设计方面,OpenGVLab提供的通用视觉评估基准创新性地引入了多任务评估系统,可以从分类、目标检测、语义分割、深度估计、和行为识别。. 不仅如此,评估基准还增加了只使用10%的测试数据集的评估设置,可以有效评估真实数据分布下通用模型的小样本学习能力。测试结束后,评测基准也会根据模型的评测结果给出相应的总分,方便用户对不同模型进行横向评测。
随着人工智能与产业融合的深入,产业对人工智能的需求逐渐从单一任务向复杂的多任务协同发展。迫切需要构建一个开源、开放的系统来满足海量应用的碎片化和长尾化需求。
OpenGVLab的开源将帮助开发者显着降低通用视觉模型的开发门槛,以更低的成本快速开发数百个视觉任务和视觉场景的算法模型,高效覆盖长尾场景,促进泛化大规模应用人工智能技术。
结尾
鹦鹉螺工作室
作者|高阳
图片|受访者供图
编辑 | 布莱斯 查看全部
优采集平台(上海人工智能联合商汤发布通用视觉开源平台OpenGVLab评测基准)
今天(25日),上海人工智能实验室联合商汤科技发布了面向学术界和工业界的通用视觉开源平台OpenGVLab,其超高效的预训练模型、超大规模的公共数据集和业界首个通用视觉模型。评价基准。
此举将为全球开发者完善各种下游视觉任务模型的训练,推动人工智能技术的规模化应用,推动人工智能基础研究和生态建设的快速发展提供重要支撑。
此次发布的通用视觉开源平台OpenGVLab不仅收录超高效的预训练模型,还收录千万级精细标签和10万个标签的公共数据集;同时发布的评估基准将方便开发者评估不同的通用视觉模型。性能评估水平和连续调整。
上海人工智能实验室相关负责人表示:
开源是一项意义重大的工作。人工智能技术的飞速发展离不开十余年来全球研发人员的开源共建、共享、共享。
希望通过OpenGVLab开源平台的发布,帮助业界更好地探索和应用通用视觉方法,推动人工智能发展中的数据、效率、泛化、认知、安全等诸多瓶颈的系统化解决,推动人工智能科研创新,产业助力发展。
展现出强大的多功能性
打麻将、赛车、香槟、熊猫……也许人们可以很容易地看到图片的内容,但人工智能可能不会。
尽管人工智能强大到可以识别一切,但很多 AI 模型只能完成单一任务,比如识别单个物体,或者识别风格更统一的照片。如果你改变类型或风格,你将束手无策。
去年11月,上海人工智能实验室联合商汤科技、香港中文大学、上海交通大学发布了通用视觉技术系统“学者”(INTERN),很好的解决了这个问题——具备足够的通用性和泛性- 转化能力。
通用视觉开源平台OpenGVLab是建立在“学者”的基础上的。其开源预训练模型具有超高性能和通用性。
具体来说,与目前最强的开源模型(OpenAI于2021年发布的CLIP)相比,OpenGVLab的模型能够全面覆盖分类、目标检测、语义分割、深度估计四大视觉核心任务,并且具有较高的准确率和数据使用。效率有了很大的提高。
OpenGVLab开源模型推理结果:左侧为输入图像,右侧为识别标签
基于相同的下游场景数据,开源模型在分类、目标检测、语义分割和深度估计四个任务的26个数据集上的平均错误率降低了40.2%和47. 分别。3%、34.8% 和 9.4%。开源模型在分类、检测、分割和深度估计方面优于其他现有的开源模型,只有 10% 的下游训练数据。
使用该模型,研究人员可以大大降低下游数据的成本采集,并且能够以极少的数据量快速满足多场景、多任务的AI模型训练需求。OpenGVLab还提供了多种不同参数和计算的预训练模型,以满足不同场景的应用。
开放千万级精准标注数据集
高性能模型离不开丰富数据集的训练。
除了预训练模型,上海人工智能实验室基于百亿级数据总量,构建了超大规模的精细标注数据集,近期将致力于开源数据未来。
超大规模精细标注数据集不仅集成了现有的开源数据集,还通过大规模数据图像标注任务涵盖了图像分类、目标检测、图像分割等任务。数据总量近7000万。. 开源范围涵盖千万级精细标注数据集和10万级标注系统。
目前,图像分类任务数据集已率先开源,未来还将开源更多目标检测任务等数据集。
对于艺术品,OpenGVLab 预训练模型表现出很强的泛化能力。比如这幅大熊猫画,模特不仅“看出”是“毛笔画”和“水粉画”,而且因为黑白,模特还给出了“阴阳”的猜测。 (yin yang),也体现了数据集标签的丰富程度
同时还有一个超大标签系统,总标签订单量达到10万,不仅覆盖了几乎所有现有的开源数据集,还在此基础上扩展了大量细粒度标签,覆盖各种类型的图像。状态等,极大地丰富了图像任务的应用场景,显着降低了下游数据的成本采集。
此外,研究人员可以通过自动化工具添加更多标签,不断扩展和扩展数据标注体系,不断提升标注体系的细粒度,共同推动开源生态的繁荣发展。
第一个通用视觉基准
随着OpenGVLab的发布,上海AI Lab也开启了业界首个通用视觉模型评测基准,填补了通用视觉模型评测领域的空白。
目前业界现有的评价基准主要针对单一任务、单一视觉维度设计,不能反映通用视觉模型的整体性能,难以用于横向比较。新的通用视觉评估基准通过在任务和数据上的创新设计,可以提供权威的评估结果,促进统一标准的公平准确评估,加快通用视觉模型的工业应用步伐。
在任务设计方面,OpenGVLab提供的通用视觉评估基准创新性地引入了多任务评估系统,可以从分类、目标检测、语义分割、深度估计、和行为识别。. 不仅如此,评估基准还增加了只使用10%的测试数据集的评估设置,可以有效评估真实数据分布下通用模型的小样本学习能力。测试结束后,评测基准也会根据模型的评测结果给出相应的总分,方便用户对不同模型进行横向评测。
随着人工智能与产业融合的深入,产业对人工智能的需求逐渐从单一任务向复杂的多任务协同发展。迫切需要构建一个开源、开放的系统来满足海量应用的碎片化和长尾化需求。
OpenGVLab的开源将帮助开发者显着降低通用视觉模型的开发门槛,以更低的成本快速开发数百个视觉任务和视觉场景的算法模型,高效覆盖长尾场景,促进泛化大规模应用人工智能技术。
结尾
鹦鹉螺工作室
作者|高阳
图片|受访者供图
编辑 | 布莱斯
优采集平台(优采集平台非常不靠谱,给钱了,不给我采集数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-02-26 09:12
优采集平台非常不靠谱,给钱了,不给我采集数据,后来去问他们客服,又提前说好了,并且没有任何保障。
试用一下吧,我上次试用的是摄图网,准备找去年的版本的软件,
博采智慧网的数据可靠。不过得要求采集的数据是他们公司官网有的那种,才可靠。
当然不靠谱
还不错,不过我最近换了一个平台做数据采集,刚好可以解决我们的问题,所以你们也可以了解一下我们的企业网站博采智慧网,有免费的版本也有收费的版本,你可以免费试用一下,打开网站-专业的互联网数据采集平台,转载请注明出处,
我们就是前两天刚咨询他们,他们软件是真的不错,试用了一下,确实不错,
工业网上做数据爬虫不靠谱,
哎
是专业做的啊,这里我要说一下,他们这里不收取任何费用,也不用找网站去做代理,直接是靠自己的技术做的,哈哈,
我用他们是交钱之后,立马发起采集,不用找网站,直接是靠自己的技术来做的,
不要问,赶紧买,后悔的话也能退。我买了用了一个月,被骗了4千多元,坚持不给退。 查看全部
优采集平台(优采集平台非常不靠谱,给钱了,不给我采集数据)
优采集平台非常不靠谱,给钱了,不给我采集数据,后来去问他们客服,又提前说好了,并且没有任何保障。
试用一下吧,我上次试用的是摄图网,准备找去年的版本的软件,
博采智慧网的数据可靠。不过得要求采集的数据是他们公司官网有的那种,才可靠。
当然不靠谱
还不错,不过我最近换了一个平台做数据采集,刚好可以解决我们的问题,所以你们也可以了解一下我们的企业网站博采智慧网,有免费的版本也有收费的版本,你可以免费试用一下,打开网站-专业的互联网数据采集平台,转载请注明出处,
我们就是前两天刚咨询他们,他们软件是真的不错,试用了一下,确实不错,
工业网上做数据爬虫不靠谱,
哎
是专业做的啊,这里我要说一下,他们这里不收取任何费用,也不用找网站去做代理,直接是靠自己的技术做的,哈哈,
我用他们是交钱之后,立马发起采集,不用找网站,直接是靠自己的技术来做的,
不要问,赶紧买,后悔的话也能退。我买了用了一个月,被骗了4千多元,坚持不给退。
优采集平台(不同软件数据对接方式有哪些?-乐题库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-02-23 17:25
1、通过各软件厂商开放的数据接口,实现不同软件数据的互联互通。这是目前最常见的数据连接方式。
2、优点:接口连接方式的数据可靠性和价值高,一般不会出现数据重复;可以通过接口实时传输数据,满足数据的实时应用需求。
3、缺点:①接口开发成本高;②需要与多家软件厂商协调,工作量大,容易打不完;③可扩展性不高,如:由于新业务需要各个软件系统开发新业务模块与大数据平台之间的数据接口也需要做相应的修改和变化,甚至之前所有的数据接口代码必须被推翻,这需要大量的工作并且需要很长时间。
4、软件机器人是目前比较前沿的软件数据对接技术,不仅可以采集客户端软件数据,还可以采集网站网站软件数据 。
5、常见的是博威小邦软件机器人,产品设计原则是“所见即所得”,即无需软件厂商合作,采集软件界面上的数据,输出结果是结构化的数据库或excel表格。
6、如果只需要界面上的业务数据,或者软件厂商不配合/崩盘,数据库分析困难,最好使用软件机器人的数据采集@ >,尤其是详情页的数据采集功能更有特色。
7、技术特点如下: ①无需与原软件厂商合作;②兼容性强,可采集聚合Windows平台各种软件系统数据;③输出结构化数据;简短、简单、高效;⑤配置简单,无需编程,人人都可以DIY一个软件机器人;⑥价格远低于人工和接口。
8、缺点:采集软件数据的实时性有限。
9、网络爬虫是一种程序或脚本,根据一定的规则自动爬取万维网上的信息,模拟客户端发出网络请求并接收请求响应。
10、爬虫采集数据的缺点:①输出数据多为非结构化数据;②只能是采集网站数据,容易受网站反爬机制影响;③ 用户群窄,需要专业的编程知识才能玩。
11、数据整合,开放数据库是最直接的方式。
12、优点:开放数据库方式可以直接从目标数据库中获取需要的数据,准确率高,实时性有保证。这是最直接、最方便的方法。
13、缺点:开放数据库方式还需要协调各个软件厂商的数据库开放,这取决于对方的意愿。一般出于安全原因,不会打开;如果一个平台同时接入多个软件厂商的数据库,实时获取数据对平台性能也是一个巨大的挑战。 查看全部
优采集平台(不同软件数据对接方式有哪些?-乐题库)
1、通过各软件厂商开放的数据接口,实现不同软件数据的互联互通。这是目前最常见的数据连接方式。
2、优点:接口连接方式的数据可靠性和价值高,一般不会出现数据重复;可以通过接口实时传输数据,满足数据的实时应用需求。
3、缺点:①接口开发成本高;②需要与多家软件厂商协调,工作量大,容易打不完;③可扩展性不高,如:由于新业务需要各个软件系统开发新业务模块与大数据平台之间的数据接口也需要做相应的修改和变化,甚至之前所有的数据接口代码必须被推翻,这需要大量的工作并且需要很长时间。
4、软件机器人是目前比较前沿的软件数据对接技术,不仅可以采集客户端软件数据,还可以采集网站网站软件数据 。
5、常见的是博威小邦软件机器人,产品设计原则是“所见即所得”,即无需软件厂商合作,采集软件界面上的数据,输出结果是结构化的数据库或excel表格。
6、如果只需要界面上的业务数据,或者软件厂商不配合/崩盘,数据库分析困难,最好使用软件机器人的数据采集@ >,尤其是详情页的数据采集功能更有特色。
7、技术特点如下: ①无需与原软件厂商合作;②兼容性强,可采集聚合Windows平台各种软件系统数据;③输出结构化数据;简短、简单、高效;⑤配置简单,无需编程,人人都可以DIY一个软件机器人;⑥价格远低于人工和接口。
8、缺点:采集软件数据的实时性有限。
9、网络爬虫是一种程序或脚本,根据一定的规则自动爬取万维网上的信息,模拟客户端发出网络请求并接收请求响应。
10、爬虫采集数据的缺点:①输出数据多为非结构化数据;②只能是采集网站数据,容易受网站反爬机制影响;③ 用户群窄,需要专业的编程知识才能玩。
11、数据整合,开放数据库是最直接的方式。
12、优点:开放数据库方式可以直接从目标数据库中获取需要的数据,准确率高,实时性有保证。这是最直接、最方便的方法。
13、缺点:开放数据库方式还需要协调各个软件厂商的数据库开放,这取决于对方的意愿。一般出于安全原因,不会打开;如果一个平台同时接入多个软件厂商的数据库,实时获取数据对平台性能也是一个巨大的挑战。
优采集平台(解锁4种埋点“姿势”让各个部门、各个角色轻松驾驭数据采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2022-02-17 18:14
【IT168评论】在这个大数据时代,基于经验的决策方式已经成为过去,数据的重要性不言而喻。数据分析的第一步是从数据源头做采集工作,我们今天的主题:数据埋点。
埋葬:数据分析的第一步
大数据,从复杂的数据背后挖掘和分析用户的行为习惯和偏好,找出更符合用户“口味”的产品和服务,并根据用户需求进行自我调整和优化,是大数据的价值。而这些信息的采集和分析,也无法绕过“埋点”。诸葛io为企业提供了一种灵活的数据追踪方式,让各个部门和角色轻松掌控数据采集:
- 代码(code)追踪:更精准的数据采集,更专注业务价值的数据采集(诸葛io专业数据咨询团队可提供定制化追踪方案,让数据分析更有针对性);
- 全掩埋:无需人工掩埋,所有操作自动掩埋,按需处理统计数据;
- 可视化嵌入:界面化的嵌入管理配置,无需开发者干预,嵌入更新更方便,生效迅速;
关于“埋点”的小科普
埋点就是在需要的地方采集对应信息,就像路上的摄像头一样,可以采集到车辆的属性,比如:颜色、车牌号、车型和其他信息,你也可以采集到车辆的行为,比如:有没有闯红灯,有没有按线,车速是多少,司机开车时有没有接电话等。如果摄像头分布处于理想状态,那么通过叠加不同位置的摄像头,所有信息采集信息,可以完整还原某辆车的路径和目的地,甚至可以推断出司机的驾驶情况习惯,是否是老司机等信息。
那么,每个埋点就像一个摄像头,采集用户行为数据,对数据进行多维度的交叉分析,可以真正还原用户使用场景,挖掘用户需求,从而提升用户一生的最大价值循环。
解锁4种埋葬“姿势”
为了让海量数据采集更加精准,为后续打造一个“纯”的数据分析环境,埋点技术应运而生。数据基础是否扎实,取决于数据的采集方法。埋点有多种方式。根据埋点不同,可以分为前端(客户端)埋点和后端(服务器端)埋点。前端埋点包括:代码埋点、全埋点、视觉埋点。.
多个采集方法的比较
全埋点:通过SDK,采集页面上所有控件的操作数据,并通过“统计数据过滤器”配置待处理数据的特征。
优点:所有操作都埋,简单快捷,无需埋统计数据按需处理
缺点:数据上传消耗流量大,数据维度单一(只有点击、加载、刷新);影响用户体验——用户在使用过程中容易出现卡顿,严重影响用户体验;噪声很多,数据准确率不高,使用方便干扰;无法自定义埋点采集信息
就像卫星拍摄一样,不需要一个个安装摄像头,但是数据量巨大,容易漏掉,挖掘关键信息也不容易。所以全埋的方法主要用在简单页面的场景,比如:登陆页面/短期活动中的特殊页面,需要快速测算点击分布等效果。
JS Visual Embedding:嵌入SDK,可视化圆选择和定义事件
为了方便产品和操作,学生可以直接在页面上简单圈选,跟踪用户行为(定义事件),
只有采集click(点击)操作可以节省开发时间。诸葛 io 最近支持 JS 视觉嵌入。
优点:接口配置,无需开发,埋点更新方便,见效快
缺点:对嵌入点自定义属性支持较差;重构或页面更改时需要重新配置;
与卫星航拍一样,无需安装摄像头,数据量小,支持局部信息采集。所以JS可视化埋点比较适合短、扁平、快的数据采集方式,比如activity/H5等简单的页面,业务人员可以直接圈出操作,没有门槛,技术人员的介入减少(从现在开始世界将是和平的)。这种data采集方式方便业务人员尽快掌握页面关键节点的变换,但是用户行为数据的应用比较浅。无法支持更深入的分析。
另外,如果页面临时调整,可以灵活添加埋点,可以作为代码埋点的补充,及时添加采集数据
代码嵌入:嵌入SDK,定义事件并添加事件代码,根据需要采集,业务信息更完整,数据分析更专注。因此,代码嵌入是一种基于商业价值的行为分析。
优点:数据采集全面准确,便于后续深入分析(嵌入点准确度顺序:代码嵌入>视觉嵌入>全嵌入),SDK体积小,对嵌入没有影响应用程序本身的体验
缺点:需要研发人员的配合,有一定的工作量
如果不想在 采集 数据时降低用户体验;如果你不想 采集 得到大量无用的数据;如果要采集的数据:粒度越细,维度越多,数据分析越准确。那么,考虑到业务增长的长期价值,请选择埋码。
服务端嵌入:可以支持其他业务数据采集和集成,比如CRM等用户数据,通过接口调用对数据进行结构化。适用于自身具备采集能力的客户端,也可与客户端采集采集结合使用。
喜欢:
1、通过调用API接口,将CRM等数据与用户行为数据进行整合,对用户进行全方位、多角度的分析;
2、如果企业有自己的跟踪系统,可以直接通过服务器采集上传用户行为数据到诸葛io平台进行数据分析,无需维护两个跟踪系统;
3、连接历史数据(埋点前数据)和新数据(埋点后),提高数据准确性。例如访问客户端采集后,导入原创历史数据后,访问平台的现有用户不会被标记为新用户,减少数据错误。
如何“埋头苦干”?
埋点听起来“不清楚”,但其实很简单,就像“在路上安装摄像头”一样。
1、 梳理产品用户行为,确定事件分布
埋点方案≈摄像机安装分布方案
童鞋们常问诸葛君:数据分析得到什么数据?要回答这个问题,首先要明确目的,明确逻辑。
诸葛io数据分析的对象和依据是用户行为。选择记录和分析哪些用户行为将直接影响分析工作的价值输出。事件。以电子商务为例,将流程中的每一个用户行为都定义为一种事件,从中得到事件布局的逻辑。
2、记录事件以了解和分析用户行为
≈ 判断摄像头要记录的信息,是非法拍照还是测速?
整理好需要记录分析的用户行为,完成事件分布表后,接下来在研发工程师的协助下,根据平台类型(iOS、Android、JS)完成SDK接入你的申请。事件的布局会变成一段很短的程序代码——当用户执行相应的行为时,你的应用程序会运行这段代码并将相应的事件记录到诸葛io。部署完成并发布产品后,当用户开始使用新版本的应用时,使用行为的数据会自动传输到诸葛io,以便您进行以下分析。
在这一步,诸葛io的CS团队将为企业提供支持,协助技术团队顺利完成数据采集的第一步。
3、通过识别记录用户身份
在诸葛io中,记录了用户的行为,即:用户做了什么?在用户分析的过程中,还有一类信息非常有用,那就是:用户是谁(TA的id,姓名),有什么特征(TA的年龄,类型...)?您可以通过诸葛io平台的识别过程将用户的身份和特征传递给诸葛io,并利用识别出的信息进行精细化分析:
划分用户组:用户属性的一个很重要的作用就是对用户进行分组。您可以根据identify 的属性定义过滤条件来划分用户组。比如用“gender=female”这个条件过滤掉所有女生,然后分析女生的行为特征和转化率……
基于属性的比较:分割的重要目的之一是比较。可以根据“性别”进行细分,然后比较“女生”和“男生”在行为、转化、留存等方面的差异;
基于属性的群体画像:可以根据用户属性对产品的任意用户群进行“画像分析”——男女比例、区域分布、年龄层级、用户类型……
回到开头的问题:埋点最好的方法是什么?
正如硬币有两面一样,任何一种埋点方法都有优点和缺点。试图通过简单粗暴的代码行/一次性部署来埋点,甚至牺牲用户体验,都不是企业所期望的。
因此,data采集只是数据分析的第一步。数据分析的目的是洞察用户行为,挖掘用户价值,进而促进业务增长。诸葛io认为,最理想的埋点解决方案是根据不同的业务和场景、行业特点和自身的实际需求,将埋点相辅相成的组合,比如:
1、代码埋点+全埋点:当需要落地页整体点击分析时,一个个埋点细节的工作量比较大,而且落地页频繁优化调整时,更新埋点的工作量不可小觑,但复杂的页面有死点,无法采集完全嵌入。因此,代码嵌入可以作为对采集核心用户行为的辅助,从而实现准确的跨部门用户行为分析;
2、代码嵌入+服务器嵌入:以电商平台为例,用户在支付过程中会跳转到第三方支付平台。支付是否成功需要通过服务器中的交易数据进行验证。这时候可以通过结合代码嵌入和服务器嵌入来提高数据的准确性;
3、代码嵌入+可视化嵌入:由于代码嵌入工作量大,可以使用核心事件代码嵌入可视化嵌入点,用于追加和补充数据采集。
为满足精细化、精准化数据分析的需要,可以根据实际分析场景选择一种或多种采集方法的组合。毕竟采集全量数据不是目的,而是要实现有效的数据分析,从数据中寻找关键决策信息实现增长才是重中之重。 查看全部
优采集平台(解锁4种埋点“姿势”让各个部门、各个角色轻松驾驭数据采集)
【IT168评论】在这个大数据时代,基于经验的决策方式已经成为过去,数据的重要性不言而喻。数据分析的第一步是从数据源头做采集工作,我们今天的主题:数据埋点。
埋葬:数据分析的第一步
大数据,从复杂的数据背后挖掘和分析用户的行为习惯和偏好,找出更符合用户“口味”的产品和服务,并根据用户需求进行自我调整和优化,是大数据的价值。而这些信息的采集和分析,也无法绕过“埋点”。诸葛io为企业提供了一种灵活的数据追踪方式,让各个部门和角色轻松掌控数据采集:
- 代码(code)追踪:更精准的数据采集,更专注业务价值的数据采集(诸葛io专业数据咨询团队可提供定制化追踪方案,让数据分析更有针对性);
- 全掩埋:无需人工掩埋,所有操作自动掩埋,按需处理统计数据;
- 可视化嵌入:界面化的嵌入管理配置,无需开发者干预,嵌入更新更方便,生效迅速;
关于“埋点”的小科普
埋点就是在需要的地方采集对应信息,就像路上的摄像头一样,可以采集到车辆的属性,比如:颜色、车牌号、车型和其他信息,你也可以采集到车辆的行为,比如:有没有闯红灯,有没有按线,车速是多少,司机开车时有没有接电话等。如果摄像头分布处于理想状态,那么通过叠加不同位置的摄像头,所有信息采集信息,可以完整还原某辆车的路径和目的地,甚至可以推断出司机的驾驶情况习惯,是否是老司机等信息。
那么,每个埋点就像一个摄像头,采集用户行为数据,对数据进行多维度的交叉分析,可以真正还原用户使用场景,挖掘用户需求,从而提升用户一生的最大价值循环。
解锁4种埋葬“姿势”
为了让海量数据采集更加精准,为后续打造一个“纯”的数据分析环境,埋点技术应运而生。数据基础是否扎实,取决于数据的采集方法。埋点有多种方式。根据埋点不同,可以分为前端(客户端)埋点和后端(服务器端)埋点。前端埋点包括:代码埋点、全埋点、视觉埋点。.
多个采集方法的比较
全埋点:通过SDK,采集页面上所有控件的操作数据,并通过“统计数据过滤器”配置待处理数据的特征。
优点:所有操作都埋,简单快捷,无需埋统计数据按需处理
缺点:数据上传消耗流量大,数据维度单一(只有点击、加载、刷新);影响用户体验——用户在使用过程中容易出现卡顿,严重影响用户体验;噪声很多,数据准确率不高,使用方便干扰;无法自定义埋点采集信息
就像卫星拍摄一样,不需要一个个安装摄像头,但是数据量巨大,容易漏掉,挖掘关键信息也不容易。所以全埋的方法主要用在简单页面的场景,比如:登陆页面/短期活动中的特殊页面,需要快速测算点击分布等效果。
JS Visual Embedding:嵌入SDK,可视化圆选择和定义事件
为了方便产品和操作,学生可以直接在页面上简单圈选,跟踪用户行为(定义事件),
只有采集click(点击)操作可以节省开发时间。诸葛 io 最近支持 JS 视觉嵌入。
优点:接口配置,无需开发,埋点更新方便,见效快
缺点:对嵌入点自定义属性支持较差;重构或页面更改时需要重新配置;
与卫星航拍一样,无需安装摄像头,数据量小,支持局部信息采集。所以JS可视化埋点比较适合短、扁平、快的数据采集方式,比如activity/H5等简单的页面,业务人员可以直接圈出操作,没有门槛,技术人员的介入减少(从现在开始世界将是和平的)。这种data采集方式方便业务人员尽快掌握页面关键节点的变换,但是用户行为数据的应用比较浅。无法支持更深入的分析。
另外,如果页面临时调整,可以灵活添加埋点,可以作为代码埋点的补充,及时添加采集数据
代码嵌入:嵌入SDK,定义事件并添加事件代码,根据需要采集,业务信息更完整,数据分析更专注。因此,代码嵌入是一种基于商业价值的行为分析。
优点:数据采集全面准确,便于后续深入分析(嵌入点准确度顺序:代码嵌入>视觉嵌入>全嵌入),SDK体积小,对嵌入没有影响应用程序本身的体验
缺点:需要研发人员的配合,有一定的工作量
如果不想在 采集 数据时降低用户体验;如果你不想 采集 得到大量无用的数据;如果要采集的数据:粒度越细,维度越多,数据分析越准确。那么,考虑到业务增长的长期价值,请选择埋码。
服务端嵌入:可以支持其他业务数据采集和集成,比如CRM等用户数据,通过接口调用对数据进行结构化。适用于自身具备采集能力的客户端,也可与客户端采集采集结合使用。
喜欢:
1、通过调用API接口,将CRM等数据与用户行为数据进行整合,对用户进行全方位、多角度的分析;
2、如果企业有自己的跟踪系统,可以直接通过服务器采集上传用户行为数据到诸葛io平台进行数据分析,无需维护两个跟踪系统;
3、连接历史数据(埋点前数据)和新数据(埋点后),提高数据准确性。例如访问客户端采集后,导入原创历史数据后,访问平台的现有用户不会被标记为新用户,减少数据错误。
如何“埋头苦干”?
埋点听起来“不清楚”,但其实很简单,就像“在路上安装摄像头”一样。
1、 梳理产品用户行为,确定事件分布
埋点方案≈摄像机安装分布方案
童鞋们常问诸葛君:数据分析得到什么数据?要回答这个问题,首先要明确目的,明确逻辑。
诸葛io数据分析的对象和依据是用户行为。选择记录和分析哪些用户行为将直接影响分析工作的价值输出。事件。以电子商务为例,将流程中的每一个用户行为都定义为一种事件,从中得到事件布局的逻辑。
2、记录事件以了解和分析用户行为
≈ 判断摄像头要记录的信息,是非法拍照还是测速?
整理好需要记录分析的用户行为,完成事件分布表后,接下来在研发工程师的协助下,根据平台类型(iOS、Android、JS)完成SDK接入你的申请。事件的布局会变成一段很短的程序代码——当用户执行相应的行为时,你的应用程序会运行这段代码并将相应的事件记录到诸葛io。部署完成并发布产品后,当用户开始使用新版本的应用时,使用行为的数据会自动传输到诸葛io,以便您进行以下分析。
在这一步,诸葛io的CS团队将为企业提供支持,协助技术团队顺利完成数据采集的第一步。
3、通过识别记录用户身份
在诸葛io中,记录了用户的行为,即:用户做了什么?在用户分析的过程中,还有一类信息非常有用,那就是:用户是谁(TA的id,姓名),有什么特征(TA的年龄,类型...)?您可以通过诸葛io平台的识别过程将用户的身份和特征传递给诸葛io,并利用识别出的信息进行精细化分析:
划分用户组:用户属性的一个很重要的作用就是对用户进行分组。您可以根据identify 的属性定义过滤条件来划分用户组。比如用“gender=female”这个条件过滤掉所有女生,然后分析女生的行为特征和转化率……
基于属性的比较:分割的重要目的之一是比较。可以根据“性别”进行细分,然后比较“女生”和“男生”在行为、转化、留存等方面的差异;
基于属性的群体画像:可以根据用户属性对产品的任意用户群进行“画像分析”——男女比例、区域分布、年龄层级、用户类型……
回到开头的问题:埋点最好的方法是什么?
正如硬币有两面一样,任何一种埋点方法都有优点和缺点。试图通过简单粗暴的代码行/一次性部署来埋点,甚至牺牲用户体验,都不是企业所期望的。
因此,data采集只是数据分析的第一步。数据分析的目的是洞察用户行为,挖掘用户价值,进而促进业务增长。诸葛io认为,最理想的埋点解决方案是根据不同的业务和场景、行业特点和自身的实际需求,将埋点相辅相成的组合,比如:
1、代码埋点+全埋点:当需要落地页整体点击分析时,一个个埋点细节的工作量比较大,而且落地页频繁优化调整时,更新埋点的工作量不可小觑,但复杂的页面有死点,无法采集完全嵌入。因此,代码嵌入可以作为对采集核心用户行为的辅助,从而实现准确的跨部门用户行为分析;
2、代码嵌入+服务器嵌入:以电商平台为例,用户在支付过程中会跳转到第三方支付平台。支付是否成功需要通过服务器中的交易数据进行验证。这时候可以通过结合代码嵌入和服务器嵌入来提高数据的准确性;
3、代码嵌入+可视化嵌入:由于代码嵌入工作量大,可以使用核心事件代码嵌入可视化嵌入点,用于追加和补充数据采集。
为满足精细化、精准化数据分析的需要,可以根据实际分析场景选择一种或多种采集方法的组合。毕竟采集全量数据不是目的,而是要实现有效的数据分析,从数据中寻找关键决策信息实现增长才是重中之重。
优采集平台(优采集平台shona为例,附上下载步骤图。)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-02-16 10:00
优采集平台是一个功能齐全的采集工具,可以采集、天猫、拼多多等各大平台的商品信息,从、天猫采集到的商品信息可以直接上传到优采集的平台进行在线销售,省去了许多繁琐的步骤,将花费大量的时间与精力去寻找商品或者选品后。优采集平台将所有选取的商品信息放入数据仓库中,通过百度云下载到本地打开即可采集购买,总结来说,你可以直接从平台下载你需要的商品信息。下面以海淘平台shona为例,附上下载步骤图。
1)打开优采集平台
2)商品分类
3)下载,点击右下角的高级选项,
4)更多设置
5)选择你下载的网站,
6)会自动获取你在优采集平台采集到的商品信息,另外优采集平台针对海淘平台shona也有专属收益。
可以关注我们网站。真的很不错。可以直接从这个商家下单。
如果你有比较好的海淘服务,可以选择“优采集”,如果你没有比较好的海淘服务,不如就“寄采网”吧。
我们网站可以帮你找到好多可以下单购买的商品.
之前的知乎也就评论过一次,刚好我们也做商品的话,可以定制分享折扣商品,带商品二维码,有意向我们可以主动私信,祝你购物愉快。
推荐你看看优采集,对商品编辑有自己独特的一些玩法。我用过,挺不错。你可以关注优采集看看他们有没有我们的任务。 查看全部
优采集平台(优采集平台shona为例,附上下载步骤图。)
优采集平台是一个功能齐全的采集工具,可以采集、天猫、拼多多等各大平台的商品信息,从、天猫采集到的商品信息可以直接上传到优采集的平台进行在线销售,省去了许多繁琐的步骤,将花费大量的时间与精力去寻找商品或者选品后。优采集平台将所有选取的商品信息放入数据仓库中,通过百度云下载到本地打开即可采集购买,总结来说,你可以直接从平台下载你需要的商品信息。下面以海淘平台shona为例,附上下载步骤图。
1)打开优采集平台
2)商品分类
3)下载,点击右下角的高级选项,
4)更多设置
5)选择你下载的网站,
6)会自动获取你在优采集平台采集到的商品信息,另外优采集平台针对海淘平台shona也有专属收益。
可以关注我们网站。真的很不错。可以直接从这个商家下单。
如果你有比较好的海淘服务,可以选择“优采集”,如果你没有比较好的海淘服务,不如就“寄采网”吧。
我们网站可以帮你找到好多可以下单购买的商品.
之前的知乎也就评论过一次,刚好我们也做商品的话,可以定制分享折扣商品,带商品二维码,有意向我们可以主动私信,祝你购物愉快。
推荐你看看优采集,对商品编辑有自己独特的一些玩法。我用过,挺不错。你可以关注优采集看看他们有没有我们的任务。
优采集平台(如何追溯网上重点内容的传播途径?——铱星在线)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-02-04 22:10
环境概述 Internet 上的网页数量每天都在以数百万的速度增长。在我国,3000多家有影响力的大众媒体、行业媒体、专业媒体和网络媒体每天在线实时发布信息超过8000万条。论坛、博客、微博等新兴媒体发布的信息量与日俱增。目前,网络舆情正成为政府行政部门或企业决策的重要依据。因此,在新形势下,如何在互联网上尽快采集相关舆情信息,跟踪事态发展,及时通知相关部门,在每次突发事件发生后迅速做出反应,是一个亟待解决的问题。问题需要解决。如何追踪关键内容的在线传播?网络舆论可以“查出来”!【及时全面】如何预测这些舆情信息的未来走势?如何有效引导和积极化解网络舆论危机?【及时全面】如何充分把握社会形势和舆论?如何为相关上级部门推送在线舆情简报和专题报道?据统计,2010年从事网络舆情监测的企业不下100家。其中一些公司提供了一套完整的监控软件,而另一些公司则提供了一个在线平台。政府和企业如何有效判断产品和服务的优劣?如何选择适合您的工具?监控工作包括三个处理过程:采集、整理处理、分发。采集作为监控软件的基本功能,全面性、准确性和及时性应该是评价各种产品和服务的依据。
铱星在线 铱星在线从2002年开始立项开发互联网信息监控产品。十年来,铱星能够根据企业和政府机构的需求,为客户提供一整套解决方案。产品和服务贯穿信息工作的全过程,包括:采集->存储/分类->组织外部信息处理统计->传播/归档。铱星舆情监测3.1 技术实现流程图 系统实现分为三个步骤3.1.1 信息采集 信息采集系统由一个海量信息采集由服务器集群组成。这些服务器安装在中国联通、电信机房、和香港和美国的服务器,形成庞大的信息采集服务器群,724小时不间断采集全球互联网信息,支持中文、英文、日文、韩文、法文、德文信息采集. 日处理信息量超过2000万个网页,日存储信息量超过50万条。3.1.2 信息汇总 信息汇总系统的主要功能包括:去重处理、信息分类、各监控平台数据库中每条信息的分布和存储,方便前端- 最终用户检索和使用。3.1.3 前端展示 依靠前两步的素材排列,用户可以通过网页和客户端前端显示,随时方便地展示全面、实时的更新信息。3.2结合具体工作3.2.1信息采集25万户网站724小时不间断运行采集每日存储50多1万条信息,70万条转载信息。
服务器分布在多个国家。没有强大的采集系统,信息的全面性和及时性是无法保证的。3.2.2 信息分类3.2.2.1 信息分类 铱星系统提供了非常丰富的信息分类方法,多达12种。客户可以任意组合选择信息类别,锁定信息,为客户提供良好的信息筛选功能。是国内最具特色的信息筛选机制。1.性质:正面、中性、负面2.语言:中文、英文、日文、韩文3.类别:市场、技术、战略、生产、财务、人力资源、文化、公关、安全4.格式:文字、图片、视频、音频、
信息分类分类方式丰富,多达12种信息类别可任意组合,锁定信息,国内最具特色的信息筛选机制。每月或每日自动生成简报(WORD格式)、打印输出、演示或存档处理媒体系统提供丰富的图形统计功能,包括直方图、曲线图、饼图、直方图曲线混合显示分析根据用户需要,生成任意任意时段舆情统计报告邮件传播情况定期监测邮件:每日邮件、每周邮件、每月邮件通过手机彩信的方式将用户门户中最重要的10条信息发送到用户手机。锁定您要跟踪的主题,系统将全天724小时监控该话题。一旦发现新信息,将立即通过短信发送到用户的手机。操作风险为试用体验提供了充足的时间。Iridium Online 专注于监控领域。近10家客户是国内各领域的佼佼者。舆情监测在中国方兴未艾,给用户带来很大的实施风险。而铱星是一个实用简单的信息采集系统,可以快速实现相关人员的信息监控和采集功能。在我们的客户中,有很多公司已经购买了软件产品,但是已经放弃使用了。例如,海尔和巨化保持直接面向用户。大部分技术维护工作由铱星完成,避免大量人力投入服务器维护。, 数据维护和更新工作需要专门的技术人员来维护,同时对硬件的配置要求比较高,网络需要更多的安全集中采集,独立的数据库用户可以保证信息的质量. 舆论的导向和关注的结果是有保障的。舆论信息分布在互联网的各个角落,是公共信息。中心化的采集-独立数据库解决方案,在保证隐私的基础上,可以获得全面、及时的数据信息。硬件对配置要求比较高,网络对安全性要求比较高采集,独立的数据库用户可以保证信息的质量。舆论的导向和关注的结果是有保障的。舆论信息分布在互联网的各个角落,是公共信息。中心化的采集-独立数据库解决方案,在保证隐私的基础上,可以获得全面、及时的数据信息。硬件对配置要求比较高,网络对安全性要求比较高采集,独立的数据库用户可以保证信息的质量。舆论的导向和关注的结果是有保障的。舆论信息分布在互联网的各个角落,是公共信息。中心化的采集-独立数据库解决方案,在保证隐私的基础上,可以获得全面、及时的数据信息。这是公共信息。中心化的采集-独立数据库解决方案,在保证隐私的基础上,可以获得全面、及时的数据信息。这是公共信息。中心化的采集-独立数据库解决方案,在保证隐私的基础上,可以获得全面、及时的数据信息。 查看全部
优采集平台(如何追溯网上重点内容的传播途径?——铱星在线)
环境概述 Internet 上的网页数量每天都在以数百万的速度增长。在我国,3000多家有影响力的大众媒体、行业媒体、专业媒体和网络媒体每天在线实时发布信息超过8000万条。论坛、博客、微博等新兴媒体发布的信息量与日俱增。目前,网络舆情正成为政府行政部门或企业决策的重要依据。因此,在新形势下,如何在互联网上尽快采集相关舆情信息,跟踪事态发展,及时通知相关部门,在每次突发事件发生后迅速做出反应,是一个亟待解决的问题。问题需要解决。如何追踪关键内容的在线传播?网络舆论可以“查出来”!【及时全面】如何预测这些舆情信息的未来走势?如何有效引导和积极化解网络舆论危机?【及时全面】如何充分把握社会形势和舆论?如何为相关上级部门推送在线舆情简报和专题报道?据统计,2010年从事网络舆情监测的企业不下100家。其中一些公司提供了一套完整的监控软件,而另一些公司则提供了一个在线平台。政府和企业如何有效判断产品和服务的优劣?如何选择适合您的工具?监控工作包括三个处理过程:采集、整理处理、分发。采集作为监控软件的基本功能,全面性、准确性和及时性应该是评价各种产品和服务的依据。
铱星在线 铱星在线从2002年开始立项开发互联网信息监控产品。十年来,铱星能够根据企业和政府机构的需求,为客户提供一整套解决方案。产品和服务贯穿信息工作的全过程,包括:采集->存储/分类->组织外部信息处理统计->传播/归档。铱星舆情监测3.1 技术实现流程图 系统实现分为三个步骤3.1.1 信息采集 信息采集系统由一个海量信息采集由服务器集群组成。这些服务器安装在中国联通、电信机房、和香港和美国的服务器,形成庞大的信息采集服务器群,724小时不间断采集全球互联网信息,支持中文、英文、日文、韩文、法文、德文信息采集. 日处理信息量超过2000万个网页,日存储信息量超过50万条。3.1.2 信息汇总 信息汇总系统的主要功能包括:去重处理、信息分类、各监控平台数据库中每条信息的分布和存储,方便前端- 最终用户检索和使用。3.1.3 前端展示 依靠前两步的素材排列,用户可以通过网页和客户端前端显示,随时方便地展示全面、实时的更新信息。3.2结合具体工作3.2.1信息采集25万户网站724小时不间断运行采集每日存储50多1万条信息,70万条转载信息。
服务器分布在多个国家。没有强大的采集系统,信息的全面性和及时性是无法保证的。3.2.2 信息分类3.2.2.1 信息分类 铱星系统提供了非常丰富的信息分类方法,多达12种。客户可以任意组合选择信息类别,锁定信息,为客户提供良好的信息筛选功能。是国内最具特色的信息筛选机制。1.性质:正面、中性、负面2.语言:中文、英文、日文、韩文3.类别:市场、技术、战略、生产、财务、人力资源、文化、公关、安全4.格式:文字、图片、视频、音频、
信息分类分类方式丰富,多达12种信息类别可任意组合,锁定信息,国内最具特色的信息筛选机制。每月或每日自动生成简报(WORD格式)、打印输出、演示或存档处理媒体系统提供丰富的图形统计功能,包括直方图、曲线图、饼图、直方图曲线混合显示分析根据用户需要,生成任意任意时段舆情统计报告邮件传播情况定期监测邮件:每日邮件、每周邮件、每月邮件通过手机彩信的方式将用户门户中最重要的10条信息发送到用户手机。锁定您要跟踪的主题,系统将全天724小时监控该话题。一旦发现新信息,将立即通过短信发送到用户的手机。操作风险为试用体验提供了充足的时间。Iridium Online 专注于监控领域。近10家客户是国内各领域的佼佼者。舆情监测在中国方兴未艾,给用户带来很大的实施风险。而铱星是一个实用简单的信息采集系统,可以快速实现相关人员的信息监控和采集功能。在我们的客户中,有很多公司已经购买了软件产品,但是已经放弃使用了。例如,海尔和巨化保持直接面向用户。大部分技术维护工作由铱星完成,避免大量人力投入服务器维护。, 数据维护和更新工作需要专门的技术人员来维护,同时对硬件的配置要求比较高,网络需要更多的安全集中采集,独立的数据库用户可以保证信息的质量. 舆论的导向和关注的结果是有保障的。舆论信息分布在互联网的各个角落,是公共信息。中心化的采集-独立数据库解决方案,在保证隐私的基础上,可以获得全面、及时的数据信息。硬件对配置要求比较高,网络对安全性要求比较高采集,独立的数据库用户可以保证信息的质量。舆论的导向和关注的结果是有保障的。舆论信息分布在互联网的各个角落,是公共信息。中心化的采集-独立数据库解决方案,在保证隐私的基础上,可以获得全面、及时的数据信息。硬件对配置要求比较高,网络对安全性要求比较高采集,独立的数据库用户可以保证信息的质量。舆论的导向和关注的结果是有保障的。舆论信息分布在互联网的各个角落,是公共信息。中心化的采集-独立数据库解决方案,在保证隐私的基础上,可以获得全面、及时的数据信息。这是公共信息。中心化的采集-独立数据库解决方案,在保证隐私的基础上,可以获得全面、及时的数据信息。这是公共信息。中心化的采集-独立数据库解决方案,在保证隐私的基础上,可以获得全面、及时的数据信息。
优采集平台(石家庄中公优就业IT培训--大数据核心技术内存性能不如内存)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-02-04 06:30
大数据采集平台来源:石家庄中工友就业IT培训时间:2022/1/19 10:14:17 大数据核心技术主要涉及区块:大数据采集处理;大数据分析;大数据 数据存储、组织和管理。
每年,大数据领域涌现出大量新技术,成为大数据获取、存储、处理、分析或可视化的有效手段。大数据技术可以挖掘出海量数据中隐藏的信息和知识,为人类社会经济生活提供基础,提高各个领域的运行效率,乃至整个社会经济的集约化。
大数据采集平台
Flume 是 Apache 下的一个开源、高可靠、高扩展、易于管理、客户可支持的数据采集 系统。Flume 是使用 JRuby 构建的,因此它依赖于 Java 运行时环境。
Flume 最初是由 Cloudera 工程师设计的用于合并日志数据的系统,后来逐渐发展为处理流数据事件。
来源
Source 负责接收输入数据并将数据写入管道。Flume 的 Source 支持 HTTP、JMS、RPC、NetCat、Exec、Spooling Directory。其中,Spooling 支持监视目录或文件,并解析其中新生成的事件。
渠道
通道存储和缓存从源到接收器的中间数据。Channel可以使用不同的配置,如内存、文件、JDBC等。使用内存性能高但不耐用,可能会丢失数据。使用文件更可靠,但性能不如内存。
下沉
Sink 负责从管道中读取数据并将其发送到下一个 Agent 或最终目的地。Sink 支持的不同目标类型包括:HDFS、HBASE、Solr、ElasticSearch、文件、记录器或其他 Flume 代理。
获得试听课
每日名额有限,先到先得
尊重原创文章,转载请注明出处和链接:违者必究!以上是石家庄中工友就业IT培训小编为大家整理的大数据采集平台的全部内容。 查看全部
优采集平台(石家庄中公优就业IT培训--大数据核心技术内存性能不如内存)
大数据采集平台来源:石家庄中工友就业IT培训时间:2022/1/19 10:14:17 大数据核心技术主要涉及区块:大数据采集处理;大数据分析;大数据 数据存储、组织和管理。
每年,大数据领域涌现出大量新技术,成为大数据获取、存储、处理、分析或可视化的有效手段。大数据技术可以挖掘出海量数据中隐藏的信息和知识,为人类社会经济生活提供基础,提高各个领域的运行效率,乃至整个社会经济的集约化。
大数据采集平台
Flume 是 Apache 下的一个开源、高可靠、高扩展、易于管理、客户可支持的数据采集 系统。Flume 是使用 JRuby 构建的,因此它依赖于 Java 运行时环境。
Flume 最初是由 Cloudera 工程师设计的用于合并日志数据的系统,后来逐渐发展为处理流数据事件。
来源
Source 负责接收输入数据并将数据写入管道。Flume 的 Source 支持 HTTP、JMS、RPC、NetCat、Exec、Spooling Directory。其中,Spooling 支持监视目录或文件,并解析其中新生成的事件。
渠道
通道存储和缓存从源到接收器的中间数据。Channel可以使用不同的配置,如内存、文件、JDBC等。使用内存性能高但不耐用,可能会丢失数据。使用文件更可靠,但性能不如内存。
下沉
Sink 负责从管道中读取数据并将其发送到下一个 Agent 或最终目的地。Sink 支持的不同目标类型包括:HDFS、HBASE、Solr、ElasticSearch、文件、记录器或其他 Flume 代理。
获得试听课
每日名额有限,先到先得
尊重原创文章,转载请注明出处和链接:违者必究!以上是石家庄中工友就业IT培训小编为大家整理的大数据采集平台的全部内容。
优采集平台(优采集平台是百度优化助手(云计算在线精准采集)的第二个平台)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-01-26 10:04
优采集平台是百度优化助手(云计算在线精准采集)的第二个平台,目前我只上了原创采集采集,自动生成标题,不知道原创还有什么其他的操作,不知道这个是不是适合你,
我刚刚遇到的问题是,我写的文章,一开始排名在第2,然后突然就掉到第7,一直到第10。然后百度搜索结果以第7为最佳。第10为最差。
写文章的话百度本身就有推荐机制,排在前面的都是百度认可的优质内容,你写的再烂,如果排在前面,就会有流量。但是不同内容其相同的词汇排在不同的位置也是有原因的,前期你文章写得多,多打广告就会形成优质内容的聚集效应,再加上打广告的文章标题优化肯定有效果,不过这些前期不需要做太大,
看到百度每天都会更新大量的原创文章,其实这也是百度搜索引擎的一大特色,希望用户能够更快更全面的搜索到自己想要的信息,吸引用户,从而提高用户数量和粘性。写文章可以按照百度里的一些写作技巧,投稿的方式,在百度写作也是有非常的容易操作的。不知道百度要上线还是还是需要再对网站进行诊断,最好能够详细了解一下,如果对原创要求高的可以找一个专业的原创网站来写,网站慢慢用,每天也是可以产生大量的原创文章的,网站才会更有价值,每天产生的文章原创度以及质量是非常关键的。 查看全部
优采集平台(优采集平台是百度优化助手(云计算在线精准采集)的第二个平台)
优采集平台是百度优化助手(云计算在线精准采集)的第二个平台,目前我只上了原创采集采集,自动生成标题,不知道原创还有什么其他的操作,不知道这个是不是适合你,
我刚刚遇到的问题是,我写的文章,一开始排名在第2,然后突然就掉到第7,一直到第10。然后百度搜索结果以第7为最佳。第10为最差。
写文章的话百度本身就有推荐机制,排在前面的都是百度认可的优质内容,你写的再烂,如果排在前面,就会有流量。但是不同内容其相同的词汇排在不同的位置也是有原因的,前期你文章写得多,多打广告就会形成优质内容的聚集效应,再加上打广告的文章标题优化肯定有效果,不过这些前期不需要做太大,
看到百度每天都会更新大量的原创文章,其实这也是百度搜索引擎的一大特色,希望用户能够更快更全面的搜索到自己想要的信息,吸引用户,从而提高用户数量和粘性。写文章可以按照百度里的一些写作技巧,投稿的方式,在百度写作也是有非常的容易操作的。不知道百度要上线还是还是需要再对网站进行诊断,最好能够详细了解一下,如果对原创要求高的可以找一个专业的原创网站来写,网站慢慢用,每天也是可以产生大量的原创文章的,网站才会更有价值,每天产生的文章原创度以及质量是非常关键的。
优采集平台(优采集平台融合了大量知名企业以及创新企业,采集国内优质企业)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-01-21 11:02
优采集平台融合了大量知名企业以及创新企业,采集国内优质企业。优采集用户可以通过在优采集平台注册、使用,获得免费使用机会。一旦注册并发布需求,即可在多个平台寻找满足需求的企业和个人。
可以去试试append,创立将海量产品知识数据挖掘、生成整合、分享、推广的社会化营销系统。上线第一个产品就获得了vdef金奖,3000多位append开发者来参与append社区的社区运营。
可以去append寻找,优采集整合了知乎站内的优质内容,
优采集自己开发了一套采集系统,不仅能采集知乎,还能采集百度知道的回答,里面的回答高质量,知乎上知友的讨论回答很火,同时还能采集游戏平台中的文章,比如人人网。采集环境是ubuntu系统,支持多套采集。有多套采集服务器,可以采集168个国家,最多可采集50t文件,无需配置,免费。目前在售的是采集知乎的企业版采集专用版,采集高峰日一天一千万文件,不限文件数量,无需登录。
现在,已经可以采集到知乎了,
可以去看下优采集,知乎采集采集深度体验版,是优采集自行开发,去采集官网无需开放权限,但是需要下载公众号的app才可以,支持多种需求,有视频,知乎等全站采集,经过训练,也能采集到pv300以上的知乎,通过tomcat云服务,有官方搭建的收费服务器采集,也有免费采集。 查看全部
优采集平台(优采集平台融合了大量知名企业以及创新企业,采集国内优质企业)
优采集平台融合了大量知名企业以及创新企业,采集国内优质企业。优采集用户可以通过在优采集平台注册、使用,获得免费使用机会。一旦注册并发布需求,即可在多个平台寻找满足需求的企业和个人。
可以去试试append,创立将海量产品知识数据挖掘、生成整合、分享、推广的社会化营销系统。上线第一个产品就获得了vdef金奖,3000多位append开发者来参与append社区的社区运营。
可以去append寻找,优采集整合了知乎站内的优质内容,
优采集自己开发了一套采集系统,不仅能采集知乎,还能采集百度知道的回答,里面的回答高质量,知乎上知友的讨论回答很火,同时还能采集游戏平台中的文章,比如人人网。采集环境是ubuntu系统,支持多套采集。有多套采集服务器,可以采集168个国家,最多可采集50t文件,无需配置,免费。目前在售的是采集知乎的企业版采集专用版,采集高峰日一天一千万文件,不限文件数量,无需登录。
现在,已经可以采集到知乎了,
可以去看下优采集,知乎采集采集深度体验版,是优采集自行开发,去采集官网无需开放权限,但是需要下载公众号的app才可以,支持多种需求,有视频,知乎等全站采集,经过训练,也能采集到pv300以上的知乎,通过tomcat云服务,有官方搭建的收费服务器采集,也有免费采集。
优采集平台(优采集平台的存在必然要改变传统的外贸里的利好)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-15 00:02
优采集平台的存在必然要改变传统的外贸情况,极大的减轻了外贸人的工作负担,也提高了外贸人的生产力,未来的竞争也会越来越小,可谓是传统外贸里的利好。优采集平台相比较其他平台,从服务精细化,数据分析,到政策支持,以及资金方面的支持,拥有全方位的外贸形式,新外贸领域更为成熟和完善,平台提供高效而便捷的软件技术支持与客户服务。共同提高产品、外贸品牌的透明度和公信力,为外贸发展创造促进作用。
网站可以上,外贸里面的数据也可以。优采集的话,你可以和优采集的网站合作,现在市面上能搜到的数据分析网站基本都不能直接采集到,必须通过优采集调用才能采集,
这个是有用的,我用的是fancy,后期货源补单了之后就能直接用优采集去跟工厂谈了,反正数据最终是你们公司用。
用得可以啊!比如我们家做的服装,怎么从阿里的库存数据中挖掘利润呢?优采集总能帮你。其实我们一直用优采集的数据做生意,上个月开始用优采集补货,这个月开始推出社群培训,又有了新的产品目标,思路明确后,卖货效率非常高,总体经营中一直保持平稳,原来不赚钱的货,依靠优采集卖断, 查看全部
优采集平台(优采集平台的存在必然要改变传统的外贸里的利好)
优采集平台的存在必然要改变传统的外贸情况,极大的减轻了外贸人的工作负担,也提高了外贸人的生产力,未来的竞争也会越来越小,可谓是传统外贸里的利好。优采集平台相比较其他平台,从服务精细化,数据分析,到政策支持,以及资金方面的支持,拥有全方位的外贸形式,新外贸领域更为成熟和完善,平台提供高效而便捷的软件技术支持与客户服务。共同提高产品、外贸品牌的透明度和公信力,为外贸发展创造促进作用。
网站可以上,外贸里面的数据也可以。优采集的话,你可以和优采集的网站合作,现在市面上能搜到的数据分析网站基本都不能直接采集到,必须通过优采集调用才能采集,
这个是有用的,我用的是fancy,后期货源补单了之后就能直接用优采集去跟工厂谈了,反正数据最终是你们公司用。
用得可以啊!比如我们家做的服装,怎么从阿里的库存数据中挖掘利润呢?优采集总能帮你。其实我们一直用优采集的数据做生意,上个月开始用优采集补货,这个月开始推出社群培训,又有了新的产品目标,思路明确后,卖货效率非常高,总体经营中一直保持平稳,原来不赚钱的货,依靠优采集卖断,
优采集平台(易优采集建设采集站并不难的几种方法介绍及技巧)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-01-14 10:22
EasyYou采集,是一个全平台网页采集器,不需要懂技术知识,就可以看到采集,简单方便,永久免费,功能强大,智能无处不在。EasyYou采集构造采集站并不难,最简单的网站Data采集就是直接识别目标网站,原来手动复制粘贴操作,后来发展到使用半自动化或自动化的工具,比如Yiyou采集。采集站通过易友采集的主要工作是百度增加网站文章的收录,这基本离不开< @文章 该工具支持原创短语和单词的随机组合。不难做到文章收录,但需要一定的技巧。飓风算法之后,站采集还能做到吗?毫无疑问,当然。
1、先找到需要采集的数据源,找到收录好,权重排名好,文章大量数据源通过EasyYou处理采集采集。
2、写一个规则采集或者指定一个网站一键采集,这个采集的网站垃圾邮件越来越少了。
3、建议保持挂机自动轮训采集,一般每个站每天发几百上千条,挂机自动采集一个站就够了随意发布文章。
4、文章插入关键词布局,标题:关键词或关键词+title,用准备好的词库TAG标记。
1、伪原创处理,易优采集通过批量翻译智能修改功能,优化文章标题和内容原创,可以设置指定字为不修改后,此函数处理 文章原创 具有高度的可读性和 收录 效果。
2、插入关键词,每个文章只插入一个关键词,但是这个关键词可以插入多次,比如在标题末尾插入一次, 文章 随机插入 6 到 8 次(文章 个词在 1000 个词内)。
3、插入图片,建议建图片库。每个网站组织50到100张图片组成一个图片库。在@文章中,建议插入3张图片,这样百度搜索结果中就会出现缩略图。
Yiyou采集 与主动推送配对。很多人说这个功能没有效果。如果不行,说明他们没有坚持做这件事,也没有找到技巧。这是搜索引擎提供的开放接口。目的是为了吸引蜘蛛获得文章收录。如果文章的质量不错,那么收录的可能性就比较高。但不是 100% 收录。想要稳定的蜘蛛,除了定期提交,前提是定期定量更新文章,然后定期提交,才能吸引稳定的百度蜘蛛。如果你推百度,肯定没有效果。
总结:通过易友采集做到以上四点,网站过一段时间就会看到效果。如果超过6个月还是不行,那就需要检查一下是不是你的域名有问题,还是网站内容有问题。手机码直播 查看全部
优采集平台(易优采集建设采集站并不难的几种方法介绍及技巧)
EasyYou采集,是一个全平台网页采集器,不需要懂技术知识,就可以看到采集,简单方便,永久免费,功能强大,智能无处不在。EasyYou采集构造采集站并不难,最简单的网站Data采集就是直接识别目标网站,原来手动复制粘贴操作,后来发展到使用半自动化或自动化的工具,比如Yiyou采集。采集站通过易友采集的主要工作是百度增加网站文章的收录,这基本离不开< @文章 该工具支持原创短语和单词的随机组合。不难做到文章收录,但需要一定的技巧。飓风算法之后,站采集还能做到吗?毫无疑问,当然。
1、先找到需要采集的数据源,找到收录好,权重排名好,文章大量数据源通过EasyYou处理采集采集。
2、写一个规则采集或者指定一个网站一键采集,这个采集的网站垃圾邮件越来越少了。
3、建议保持挂机自动轮训采集,一般每个站每天发几百上千条,挂机自动采集一个站就够了随意发布文章。
4、文章插入关键词布局,标题:关键词或关键词+title,用准备好的词库TAG标记。
1、伪原创处理,易优采集通过批量翻译智能修改功能,优化文章标题和内容原创,可以设置指定字为不修改后,此函数处理 文章原创 具有高度的可读性和 收录 效果。
2、插入关键词,每个文章只插入一个关键词,但是这个关键词可以插入多次,比如在标题末尾插入一次, 文章 随机插入 6 到 8 次(文章 个词在 1000 个词内)。
3、插入图片,建议建图片库。每个网站组织50到100张图片组成一个图片库。在@文章中,建议插入3张图片,这样百度搜索结果中就会出现缩略图。
Yiyou采集 与主动推送配对。很多人说这个功能没有效果。如果不行,说明他们没有坚持做这件事,也没有找到技巧。这是搜索引擎提供的开放接口。目的是为了吸引蜘蛛获得文章收录。如果文章的质量不错,那么收录的可能性就比较高。但不是 100% 收录。想要稳定的蜘蛛,除了定期提交,前提是定期定量更新文章,然后定期提交,才能吸引稳定的百度蜘蛛。如果你推百度,肯定没有效果。
总结:通过易友采集做到以上四点,网站过一段时间就会看到效果。如果超过6个月还是不行,那就需要检查一下是不是你的域名有问题,还是网站内容有问题。手机码直播
优采集平台(举例说明网络大数据在不同行业的利用价值分析与应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-01-12 19:20
据赛迪顾问统计,在近万件技术领域专利中常见的关键词专利中,数据采集、存储介质、海量数据、分布式成为技术领域最热门的词汇。其中,data采集 是被提及最多的词。
数据采集是大数据分析的前提和必要条件,在整个数据利用过程中占有重要地位。共有三种数据采集方法:系统日志采集方法、网络数据采集方法和其他数据采集方法。随着Web2.0的发展,整个Web系统覆盖了大量有价值的数据。目前,Web系统的数据采集通常是通过网络爬虫来实现的。本文将围绕网络大数据和网络爬虫做一个系统描述。
什么是网络大数据
网络大数据是指非传统数据源,例如通过搜索引擎爬取获取的不同形式的数据。网络大数据也可以是从数据聚合器或搜索引擎网站 购买的数据,用于改进定向营销。这种类型的数据可以是结构化的或非结构化的(更有可能),可以由网络链接、文本数据、数据表、图像、视频等组成。
网络构成了当今提供给我们的大部分数据,根据许多研究,非结构化数据占其中的 80%。尽管这些形式的数据早些时候被忽略了,但竞争加剧和对更多数据的需求使得使用尽可能多的数据源成为必要。
网络大数据可以用来做什么?
互联网拥有数十亿页的数据,网络大数据作为潜在的数据源,具有巨大的行业战略业务发展潜力。
以下举例说明网络大数据在不同行业的利用价值:
此外,在《Web Scraping 如何通过应用改变世界》文章中,详细列出了网络大数据在制造、金融研究、风险管理等诸多领域的应用价值。
如何采集网络数据
目前网络数据采集有两种方式:一种是API,一种是网络爬虫方式。API,又称应用程序接口,是网站的管理者为方便用户编写的编程接口。目前新浪微博、百度贴吧、Facebook等主流社交媒体平台均提供API服务,相关DEMO可在其官网开放平台获取。但是,API 技术毕竟受到平台开发者的限制。为了减少网站(平台)的负载,一般平台都会限制日常接口调用的上限,给我们带来很大的不便。为此,我们通常采用第二种方式——网络爬虫。
利用爬虫技术采集网络大数据
网络爬虫是指按照一定的规则自动爬取万维网上信息的程序或脚本。该方法可以从网页中提取非结构化数据,存储为统一的本地数据文件,并以结构化的方式存储。支持图片、音频、视频等文件或附件的采集,附件可以自动与文本关联。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。在大数据时代,网络爬虫更是采集互联网数据的利器。
网络爬虫的原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。在功能上,爬虫一般具有网络数据采集、处理和存储三个功能,如图:
网络爬虫采集
网络爬虫通过定义采集字段来抓取网页中的文字信息、图片信息等。此外,网页中还收录一些超链接信息,网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。网络爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。网络爬虫从网页中提取并保存需要提取的资源,同时提取存在于网站中的其他网站链接,发送请求后,收到网站响应,再次解析页面,然后从网页中提取出需要的资源……以此类推,通过网络爬虫,
数据处理
数据处理是分析和处理数据(数值和非数值)的技术过程。网络爬虫爬取的初始数据需要进行“清理”。在数据处理步骤中,对各种原创数据进行分析、整理、计算、编辑等处理,从数据中提取和导出有价值的、有意义的数据。
数据中心
所谓数据中心也是一个数据存储,是指在获得需要的数据并分解成有用的组件后,采用一种可扩展的方式,将所有提取和解析的数据存储在一个数据库或集群中,然后创建a 允许用户及时找到相关数据集或提取的功能。
网络爬虫工作流程
如下图所示,网络爬虫的基本工作流程如下。首先选择种子 URL 的一部分。
总结
当前,网络大数据规模和复杂性的快速增长,对现有IT架构的处理和计算能力提出了挑战。大数据将成为行业数字化、信息化的重要驱动力。 查看全部
优采集平台(举例说明网络大数据在不同行业的利用价值分析与应用)
据赛迪顾问统计,在近万件技术领域专利中常见的关键词专利中,数据采集、存储介质、海量数据、分布式成为技术领域最热门的词汇。其中,data采集 是被提及最多的词。
数据采集是大数据分析的前提和必要条件,在整个数据利用过程中占有重要地位。共有三种数据采集方法:系统日志采集方法、网络数据采集方法和其他数据采集方法。随着Web2.0的发展,整个Web系统覆盖了大量有价值的数据。目前,Web系统的数据采集通常是通过网络爬虫来实现的。本文将围绕网络大数据和网络爬虫做一个系统描述。
什么是网络大数据
网络大数据是指非传统数据源,例如通过搜索引擎爬取获取的不同形式的数据。网络大数据也可以是从数据聚合器或搜索引擎网站 购买的数据,用于改进定向营销。这种类型的数据可以是结构化的或非结构化的(更有可能),可以由网络链接、文本数据、数据表、图像、视频等组成。
网络构成了当今提供给我们的大部分数据,根据许多研究,非结构化数据占其中的 80%。尽管这些形式的数据早些时候被忽略了,但竞争加剧和对更多数据的需求使得使用尽可能多的数据源成为必要。
网络大数据可以用来做什么?
互联网拥有数十亿页的数据,网络大数据作为潜在的数据源,具有巨大的行业战略业务发展潜力。
以下举例说明网络大数据在不同行业的利用价值:
此外,在《Web Scraping 如何通过应用改变世界》文章中,详细列出了网络大数据在制造、金融研究、风险管理等诸多领域的应用价值。
如何采集网络数据
目前网络数据采集有两种方式:一种是API,一种是网络爬虫方式。API,又称应用程序接口,是网站的管理者为方便用户编写的编程接口。目前新浪微博、百度贴吧、Facebook等主流社交媒体平台均提供API服务,相关DEMO可在其官网开放平台获取。但是,API 技术毕竟受到平台开发者的限制。为了减少网站(平台)的负载,一般平台都会限制日常接口调用的上限,给我们带来很大的不便。为此,我们通常采用第二种方式——网络爬虫。
利用爬虫技术采集网络大数据
网络爬虫是指按照一定的规则自动爬取万维网上信息的程序或脚本。该方法可以从网页中提取非结构化数据,存储为统一的本地数据文件,并以结构化的方式存储。支持图片、音频、视频等文件或附件的采集,附件可以自动与文本关联。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。在大数据时代,网络爬虫更是采集互联网数据的利器。
网络爬虫的原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。在功能上,爬虫一般具有网络数据采集、处理和存储三个功能,如图:
网络爬虫采集
网络爬虫通过定义采集字段来抓取网页中的文字信息、图片信息等。此外,网页中还收录一些超链接信息,网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。网络爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。网络爬虫从网页中提取并保存需要提取的资源,同时提取存在于网站中的其他网站链接,发送请求后,收到网站响应,再次解析页面,然后从网页中提取出需要的资源……以此类推,通过网络爬虫,
数据处理
数据处理是分析和处理数据(数值和非数值)的技术过程。网络爬虫爬取的初始数据需要进行“清理”。在数据处理步骤中,对各种原创数据进行分析、整理、计算、编辑等处理,从数据中提取和导出有价值的、有意义的数据。
数据中心
所谓数据中心也是一个数据存储,是指在获得需要的数据并分解成有用的组件后,采用一种可扩展的方式,将所有提取和解析的数据存储在一个数据库或集群中,然后创建a 允许用户及时找到相关数据集或提取的功能。
网络爬虫工作流程
如下图所示,网络爬虫的基本工作流程如下。首先选择种子 URL 的一部分。
总结
当前,网络大数据规模和复杂性的快速增长,对现有IT架构的处理和计算能力提出了挑战。大数据将成为行业数字化、信息化的重要驱动力。
优采集平台(优采集平台上也有一些价格详细的资料优晶石价格)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-01-12 09:10
优采集平台上面很多价格明细都是可以编辑的,不管是钢铁采集还是石英石的自采,好多都可以查看价格的,但是不保证是全网最低价,需要看一下目标石英石的产地,石材的等级等等其他要素,才能判断这个石英石的价格是不是最低,
谢邀。直接加上级别应该就能到最低价了。
试试去优采集平台看看啊,
很多东西是这样的,石英石中的黑晶石价格最低了,低于这个的不建议采购。我个人是这样以工厂为主,百度石材相关的企业可以简单联系,比如千山石一号青海又一工业园这样的主要针对黑晶石家具。
主要原因是石材没有防伪码,维权难,设备出问题要搬石头,品质也一般。现在全球石材市场的主要材料就是黑晶石。
优采集平台上也有一些价格详细的资料
优采集是一个一站式物流平台!国内上千家石材企业,都会在优采集平台上开通标准账号,找到你想要的石材,直接发给你,
优采集平台上石材价格是可以看到的。还有一些是直接打印的表格。直接就可以编辑查看了,可以选择等级是黑晶石和低级别,这个可以查看出来的。
云南很多大的石材厂就可以进货,优采集可以直接采购,省去中间环节,价格最便宜。
南红南红正常存在于我国各地各种宗教中,可以分为品相、质地以及油份多少。常见的有珊瑚红,柿子红,柿子黄,鸡油黄等。南红并不是玉石。也不是玉髓。但是由于之前红珊瑚火爆,目前市场上见到很多冒充南红的珊瑚南红。 查看全部
优采集平台(优采集平台上也有一些价格详细的资料优晶石价格)
优采集平台上面很多价格明细都是可以编辑的,不管是钢铁采集还是石英石的自采,好多都可以查看价格的,但是不保证是全网最低价,需要看一下目标石英石的产地,石材的等级等等其他要素,才能判断这个石英石的价格是不是最低,
谢邀。直接加上级别应该就能到最低价了。
试试去优采集平台看看啊,
很多东西是这样的,石英石中的黑晶石价格最低了,低于这个的不建议采购。我个人是这样以工厂为主,百度石材相关的企业可以简单联系,比如千山石一号青海又一工业园这样的主要针对黑晶石家具。
主要原因是石材没有防伪码,维权难,设备出问题要搬石头,品质也一般。现在全球石材市场的主要材料就是黑晶石。
优采集平台上也有一些价格详细的资料
优采集是一个一站式物流平台!国内上千家石材企业,都会在优采集平台上开通标准账号,找到你想要的石材,直接发给你,
优采集平台上石材价格是可以看到的。还有一些是直接打印的表格。直接就可以编辑查看了,可以选择等级是黑晶石和低级别,这个可以查看出来的。
云南很多大的石材厂就可以进货,优采集可以直接采购,省去中间环节,价格最便宜。
南红南红正常存在于我国各地各种宗教中,可以分为品相、质地以及油份多少。常见的有珊瑚红,柿子红,柿子黄,鸡油黄等。南红并不是玉石。也不是玉髓。但是由于之前红珊瑚火爆,目前市场上见到很多冒充南红的珊瑚南红。
优采集平台(深圳优采集平台小编的精选可否满足你呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-01-11 19:01
优采集平台小编的精选可否满足你呢?接下来推荐一下,深圳市优采集平台的网站和app每天访问量突破10万以上,而且用户也特别多的。.在这里,只要你有需求,就可以找到我们,我们会竭诚为你提供。大家可以通过查询网址进入优采集平台咨询一下,问问客服能否提供相关资源。我们也可以扫描下方二维码进入优采集平台直接获取资源。
里面也有代理电影票啊,价格便宜质量好。
有的,优采集,
可以上问问有没有能打包送票的
哈哈,上搜下有没有,
完美代理,低价票代理,代理市场有,百度、微信、qq、抖音、qq空间都有,
有呀,谢天谢地电影票市场快饱和了,
有这个问题。我找代理。
我是被骗的。全国代理被坑的很多,本来手里有票却卖不出去,还白白花钱买东西。很心痛。说白了,就是割韭菜,年年代理都不好。我们走的是代理的路,广告做的狠了,
有,
有代理服务可以找我了解一下
价格不要去比较,要看市场需求量和货源。去年国家文化部规定,全国动画、影视剧和衍生品(游戏,周边),都不可以代理销售了。但是短视频和玩具(软件)却是可以的。 查看全部
优采集平台(深圳优采集平台小编的精选可否满足你呢?)
优采集平台小编的精选可否满足你呢?接下来推荐一下,深圳市优采集平台的网站和app每天访问量突破10万以上,而且用户也特别多的。.在这里,只要你有需求,就可以找到我们,我们会竭诚为你提供。大家可以通过查询网址进入优采集平台咨询一下,问问客服能否提供相关资源。我们也可以扫描下方二维码进入优采集平台直接获取资源。
里面也有代理电影票啊,价格便宜质量好。
有的,优采集,
可以上问问有没有能打包送票的
哈哈,上搜下有没有,
完美代理,低价票代理,代理市场有,百度、微信、qq、抖音、qq空间都有,
有呀,谢天谢地电影票市场快饱和了,
有这个问题。我找代理。
我是被骗的。全国代理被坑的很多,本来手里有票却卖不出去,还白白花钱买东西。很心痛。说白了,就是割韭菜,年年代理都不好。我们走的是代理的路,广告做的狠了,
有,
有代理服务可以找我了解一下
价格不要去比较,要看市场需求量和货源。去年国家文化部规定,全国动画、影视剧和衍生品(游戏,周边),都不可以代理销售了。但是短视频和玩具(软件)却是可以的。
优采集平台(优采集平台会帮您优选7-10条高价值内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-01-08 07:01
优采集平台会帮您优选7-10条高价值内容,为您保驾护航,新用户首发免费发布大尺寸分享给大家哈哈,优采集平台真的很给力,物超所值,
知乎机构号运营优惠券这么差劲,机构号优惠券也没多少人用知乎运营必推送问答知乎运营必推送发文提醒社群控制垃圾广告问题非常6-8人群控制多人,
对新注册的公众号发放的流量主广告优惠,可以搜索工具"快帮推"申请,目前已经正式推广3个月。
你好,对于开通收费的公众号,先开通流量主再推送广告。
流量主的广告购买目前来看,最方便的是我这边qq群里面就有人在做,免费开通流量主。
请问可以推荐微信公众号流量主吗?方便去优化,不用去找广告平台。无前缀流量主,只有三个推送渠道,1,文章底部;2,文章内容尾部,打开率3%不到;3,
大家互相交流
1.互助公众号运营小工具!:根据公众号的粉丝数量精准匹配,但有限制公众号大小,毕竟流量不是很多,推送的话可以从第三方平台购买流量,比如你可以去我们v+的营销中心看看看看可以注册看看看看2.定期图文推送:目前比较好用的是关注公众号生成海报的功能,这个现在粉丝基数不够的话不好做,主要是图文文案功底要好,如果做得好,收到的推文会质量很高!3.聊天送流量:虽然现在用户回复关键词送流量,流量主推荐的也是对关键词有回复的,不过回复量的问题,没有可以文字直接回复,更容易群众回复量。
4.线下地推活动:线下地推推广这种方式有一定的用处,毕竟是人流量,不是流量就像北京的大黑环公司刚开始那样,流量主在每天用户都打算点击进公众号后还要收费来吸引用户。再就是可以可以在公众号里面做自定义菜单,免费给点什么服务,5.官方工具:微软营销助手,精准精准精准,可能大家做得不多,不过很实用的工具,可以看看我上面这一张图。
6.礼物说对接,这种对接以前我也做过一段时间,不过这种不是常规的礼物说,我们可以去商家那边加对方,然后选择使用对方的工具来对接,然后每天就可以加对方10来个粉丝,虽然量不是很大,但是精准,长期来看粉丝还是很精准的!7.阿猫阿狗微云:大家都知道微信每天会产生很多文章,比如文章定时定点的发给微信好友,那么我们都知道什么时候发送的是最新的文章,那么我们就要借助阿猫阿狗微云来保存最新的文章,同时也可以看到这个文章大概的阅读量,点赞评论等等,方便我们做文章的时候可以借助这些数据,效果才会有保障。 查看全部
优采集平台(优采集平台会帮您优选7-10条高价值内容)
优采集平台会帮您优选7-10条高价值内容,为您保驾护航,新用户首发免费发布大尺寸分享给大家哈哈,优采集平台真的很给力,物超所值,
知乎机构号运营优惠券这么差劲,机构号优惠券也没多少人用知乎运营必推送问答知乎运营必推送发文提醒社群控制垃圾广告问题非常6-8人群控制多人,
对新注册的公众号发放的流量主广告优惠,可以搜索工具"快帮推"申请,目前已经正式推广3个月。
你好,对于开通收费的公众号,先开通流量主再推送广告。
流量主的广告购买目前来看,最方便的是我这边qq群里面就有人在做,免费开通流量主。
请问可以推荐微信公众号流量主吗?方便去优化,不用去找广告平台。无前缀流量主,只有三个推送渠道,1,文章底部;2,文章内容尾部,打开率3%不到;3,
大家互相交流
1.互助公众号运营小工具!:根据公众号的粉丝数量精准匹配,但有限制公众号大小,毕竟流量不是很多,推送的话可以从第三方平台购买流量,比如你可以去我们v+的营销中心看看看看可以注册看看看看2.定期图文推送:目前比较好用的是关注公众号生成海报的功能,这个现在粉丝基数不够的话不好做,主要是图文文案功底要好,如果做得好,收到的推文会质量很高!3.聊天送流量:虽然现在用户回复关键词送流量,流量主推荐的也是对关键词有回复的,不过回复量的问题,没有可以文字直接回复,更容易群众回复量。
4.线下地推活动:线下地推推广这种方式有一定的用处,毕竟是人流量,不是流量就像北京的大黑环公司刚开始那样,流量主在每天用户都打算点击进公众号后还要收费来吸引用户。再就是可以可以在公众号里面做自定义菜单,免费给点什么服务,5.官方工具:微软营销助手,精准精准精准,可能大家做得不多,不过很实用的工具,可以看看我上面这一张图。
6.礼物说对接,这种对接以前我也做过一段时间,不过这种不是常规的礼物说,我们可以去商家那边加对方,然后选择使用对方的工具来对接,然后每天就可以加对方10来个粉丝,虽然量不是很大,但是精准,长期来看粉丝还是很精准的!7.阿猫阿狗微云:大家都知道微信每天会产生很多文章,比如文章定时定点的发给微信好友,那么我们都知道什么时候发送的是最新的文章,那么我们就要借助阿猫阿狗微云来保存最新的文章,同时也可以看到这个文章大概的阅读量,点赞评论等等,方便我们做文章的时候可以借助这些数据,效果才会有保障。
优采集平台( 而成,文末还有好书送哦~~(讲师介绍))
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-07 22:06
而成,文末还有好书送哦~~(讲师介绍))
本文基于dbaplus社区第170期在线分享,文末有好书~
导师
陆标
技术专家
百度百科:
数据交换平台是指通过计算机网络,将多个单独搭建的应用信息系统集成起来,构建的信息交换平台,使多个应用子系统能够传输和共享信息/数据,提高信息资源的利用率,成为信息化建设的基本目标是保证分布式异构系统之间的互联互通,建立中央数据库,完成数据的抽取、集中、加载和展示,构建统一的数据处理和交换。
笔者认为,数据交换平台是构建分布式系统的三驾马车之一。这些三驾马车是基于RPC的服务调用、基于MQ的事件驱动和基于数据同步的数据共享。
推动数据交换平台出现和发展的根本动力是:交换空间换时间。
一、说说交流平台
1、服务场景
综上所述,数据交换平台可以服务的场景可以分为三类:基础设施、容灾备份、异构重构。
基础设施
场景一:EDA
通过数据交换平台,将数据库Log事件(如MySQL Binlog)发送到MQ,然后被不同的消费者消费,驱动不同的业务流程(如:刷新缓存,构建搜索引擎,放置后发送短信下单,付款后通知发货等),基于这种架构,业务端省去了定义领域事件和发送事件的工作,大大节省了工作量。
更重要的是,基于数据库自身的Log机制,数据一致性更有保障,其他的容错处理、HA等机制只能靠数据交换平台来保证。
当然,如果事件定义比较复杂,无法表达普通业务表对应的LogEvent,那么还是需要自己设计领域事件。这时候我们可以定义一个通用的事件表来保存自定义事件;而发送事件的操作对应于将事件表的插入操作与业务操作一起放在一个事务中。交易提交后,交易平台拉取事件表的日志,然后提取事件内容并发送给MQ。
有很多事情可以通过使用数据库日志来完成。我们的团队正在开发一个基于 MySQL-Binlog 消费的事件平台。一般架构如下:
事件平台提供事件订阅、事件配置等基础支持(如:是否实时触发下一个操作或倒计时触发下一个操作,下一个操作是接口回调还是新事件等) 、事件调度、实时监控等,用户只需要提供配置规则和开发回调接口,免去了各个研发团队各自为政、重复建设的各种问题。
此外,该平台最大的特点之一是引入了事件驱动的定时器机制。在这种机制之前,当涉及到与时间要素相关的判断时(如:未结算的订单下单后多久自动失效,租车一定时间后,结算类型自动从短租转产品到长租产品等),业务研发团队需要编写大量定时任务扫描数据库来计算时间间隔,不仅开发成本巨大,而且往往存在较大的性能问题。.
有了定时器机制,业务侧只需要配置时间规则,事件平台分布式,可以提供更高的性能支持。
场景二:CQRS(Command Query Responsibility Segregation)
这里是DDD领域的一个概念CQRS,具体介绍可以参考链接:
CQRS的思想本质上是为同一条数据创建两组模型(或视图):
CQRS 架构模型的开源实现是 Axon-Framework。基于Axon,可以构建自己的领域模型、领域事件、事件仓库、查询视图等,提供聚合根定义、事件回放、事件消费、数据镜像等基础支持,应用其架构图如下:
理想是丰满的,现实是骨感的。DDD已经提出很多年了,但是由于实践的难度,大部分公司还停留在通过数据库表建模的阶段,但是CQRS的想法非常好。
所以抛开DDD,基于表模型来理解CQRS:数据表模型也是领域模型,但不是面向对象的领域模型。数据库日志也是事件,但表达能力不如DDD中的领域事件丰富。
在此基础上,依靠数据库管理模型和事件,加上一个事件转发和消费的数据交换平台,可以构建一个广泛的CQRS架构,如下图:
场景三:数据采集并返回
很多企业正在或已经搭建了自己的大数据平台,其中数据采集和回流是不可或缺的一环。一般小公司在采集层面做数据相对碎片化,各种开源产品堆积起来完成采集相关工作,大公司会考虑平台化,放数据采集@ > 在整个数据交换平台的规划中,以提高效率和降低成本。
下图是我们团队的数据交换平台与大数据平台的关系示意图:
灾难恢复备份
场景示例1:多个机房
多中心、多备份、异地双活、异地多活等是很多大公司正在实践或已经实践的技术难题。这其中的核心是一套完整的数据同步解决方案。
场景二:数据镜像
通过数据交换平台,可以创建各种类型的DB镜像,满足不同场景的使用需求。
场景三:数据归档
通过增量交换,同步时忽略删除事件,实现实时归档。
异构重构
场景示例一:数据库升级、搬迁、拆迁、整合
数据库的升级,数据库的搬迁、拆除、整合等日常运维操作都会涉及到数据迁移。如果有平台,迁移工作就会变得非常简单。
场景二:资产复用
公司越大,负担越重。许多公司拥有各种类型的数据库和存储产品。为了复用这些资产,涉及到各种场景下的数据同步。统一的数据交换平台将使这些场景变得不同。同步变得容易多了。
2、施工思路
一千个读者将拥有一千个哈姆雷特,一千个建筑师将拥有一千个建筑理念。数据交换平台的建设没有灵丹妙药。不同的团队面对的场景不同,演进的架构也不同。在这里,结合自己的经验和体会,谈谈数据交换平台建设中的一些方法论和注意事项。
架构选择
数据同步过程是生产者-消费者模型的典型表现。生产者负责从不同的数据源拉取数据,消费者负责将数据写入不同的数据源。生产者和消费者之间可以存在一对一的关系。该关系也可以是一对多关系。
那么,数据交换平台是串联连接生产者和消费者的枢纽,可以控制串联过程中的过程。简而言之,就是数据集成。
数据整合是数据交换平台最基本的工作。架构的选择和设计应该只关注这个基本点。只有便于快速集成的架构才能支持不断变化的数据同步需求。
在设计架构时,需要考虑的要点总结如下:
许多公司正在构建自己的基于消息中间件的数据交换平台(有些称为数据总线)。生产者向MQ发送数据,消费者从MQ消费数据,数据可以自描述。这是一个典型的开源实现是Kafka-Connect的模型,其架构图如下:
优势:
缺点:
无论如何,架构模型都非常优秀,可以满足60%到70%的应用场景。但是我们团队并没有直接应用这个架构,而是针对它的缺点,受到了Kafka-Connect思想的启发,实现了基于消息中间件和直连同步的混合架构,如下图(即DataLink架构) :
在Kafka-Connect架构中,由于Kafka作为数据中转站,运行的Task要么是SourceTask要么是SinkTask,DataLink中的Task可以是Reader和Writer的任意组合(理论上)。
基于这个特性,构建基于消息中间件的同步,结合Mq-Writer和Mq-Reader就足够了;构建直连同步,绕过Mq,直接组合源Reader和目标Writer。根据不同的场景选择不同的模式,更加灵活。
无论是消息中间件解决方案还是混合解决方案,针对的场景大多是实时增量同步(虽然在某些场景也支持全同步,但毕竟不是它的主业),针对离线全同步场景,目前使用最广泛的解决方案是阿里开源的DataX。有兴趣的可以研究一下。
简而言之,没有最好的架构,只有最合适的架构。基于消息中间件构建数据交换平台是目前比较流行的架构模型,但也有其自身的不足。它结合各种技术,扬长避短,解决自身的问题和痛点。找到适合自己的方案才是最合理的方案。
方式方法
如果结构选择是为了制定战略,那么方法和方法就是具体的战术。从同步行为上变化点,可以分为实时增量同步和离线全量同步。
前者的可行策略主要有触发器、日志解析和基于时间戳的数据提取(当然不同的DB也会有自己的一些特殊解决方案,比如Oracle的物化视图机制、SQL Server的CDC等),后者是可行的,主要策略是文件转储和API提取。
实时增量同步
先说实时增量同步。基于触发器获取数据比较传统,而且由于运维繁琐,性能差,使用越来越少。
但是,在某些特定场景中仍有应用空间。有一个代号为SymmetricDS的开源产品,可以自动管理触发器,提供统一的数据采集和消费机制。如果你想基于触发器同步数据,可以参考这个产品。
基于日志分析的同步目前最为流行,如MySQL、HBase等,提供日志重放机制,协议开源。
这种方法的主要优点是:零侵入业务表,异步日志解析没有性能问题,实时性比较高。
日志解析很漂亮,但并不是所有的DB都提供这样的机制(比如SQL Server)。当触发器和日志解析不固定时,通过时间戳字段(如modify_time)定时扫描表,获取变化的数据,同步也是常用的方法。
这种方法有几个明显的缺点:实时性比较低,需要业务端保证时间戳字段不能漏更新,常规的表扫描查询也可能带来一些性能问题。
离线完全同步
再说说离线全同步。文件转储方式一般用于同构数据源之间的同步场景,需要DB自身的导入导出机制支持,可以服务的场景比较单一。API提取方法更通用、更灵活。同构和异质都可以通过编码实现。如果做得好,它还可以通过灵活的参数控制提供各种高级功能,例如开源产品DataX。
难题
将数据从一处移动到另一处,如何保证数据在同步过程中没有任何问题(不丢失、不重、不乱)或者出现问题后快速恢复,需要考虑的点很多,非常复杂,这里结合自己的经验说说主要的难点和常见的解决办法。
一:种类繁多的API
好像没什么难的,不就是调用API进行数据操作吗?事实上,市面上的存储产品有上百种,常用的存储产品有几十种。产品特性差异极大。
为了构建一个高效可靠的平台,需要对这些产品的API及其内部机制进行深入研究(例如:是否支持事务?事务粒度是表级还是记录级?是否支持随机读写还是只能支持Append?操作API的时候有没有客户端缓存?HA是怎么实现的?性能瓶颈在哪里?调优参数是什么?内置的Replication机制是怎么实现的?等),否则平台只会停留在可用阶段。
以我们自己的经验为例:在搭建大数据平台时,我们需要一个数据交换平台,将MySQL和HBase的数据实时同步到HDFS。基于DataLink,我们开发了HDFS Writer插件,在实践过程中走了不少弯路。
要解决这个难题,没有捷径可走。只有提升自己的硬实力才能取得突破。
二:同步关系治理
对于服务框架,随着服务数量的不断增加,我们需要服务治理;对于数据交换平台,随着同步关系的不断增加,同步关系也需要进行治理。
需要治理的要点是:
为了避免环回同步,一般添加DAG检测机制就足够了。
保证schema一致性的方法一般有两种:一是在同步过程中,从源端获取的DDL语句自动同步到目标端;二是平台提供了同步关系检测机制供外部系统使用。前者在异构数据源中比较。在很多情况下,实现起来比较困难(脚本转换、性能问题、幂等判断等),也不是所有的解决方案都能得到ddl语句,后者更加通用和可行。
目前我们内部的计划是,当SQL脚本上线时,数据交换平台会进行SQL分析,然后将同步关系树返回给DBA团队的DBMS系统,然后DBMS系统会根据到同步关系提示。
同步关系树示意图如下:
第三:数据质量
保证数据质量是数据交换平台的核心使命。在同步过程中,不丢失、不重、不乱。通过数据检查可以快速发现问题;发现问题后可以快速修复。
如果事前、事中、事后三个阶段都能控制好,那么平台就达到了极好的水平。
事前阶段依靠完善的设计和测试,事中阶段依靠三维监控和报警,事后阶段依靠功能丰富的修复工具。但是,由于场景的灵活性和复杂性,每个阶段都不容易实践,例如:
目前,我们的团队还在不断探索的道路上。没有绝对完美的解决方案。找到最合适的解决方案,才是针对我们自己的场景和数据一致性要求程度的正确解决方案。下图展示了数据质量的设计要点:
第四:可扩展性
科技发展日新月异,业务演进也日新月异。为了应对这些变化,平台也必须变化,但如何用最小的变化带来最大的收益,是判断一个平台或一个产品是否成熟的关键。指数。
作者信奉一句名言:建筑是进化的,不是设计的;但同时,我也相信另一句名言:好的设计是成功的一半。两者并不矛盾,主要是如何妥协。
构建平台和构建工具之间的一个重要区别在于,前者应侧重于抽象、建模和参数化,以提供灵活的可扩展性。
那么可扩展性应该考虑到什么程度呢?一句话概括:在搭建平台的过程中,我们要不断的总结、修正、抽象、迭代、推演,对已知的事物进行建模,使未知的事物可以预见而不是去做。过度设计,也是充分设计。
在开源的数据同步中间件中,扩展性比较好:阿里的DataX好,KafKa-Connect好,基于触发器的SymmetricDS也好。我们最近开源的DataLink,下面要介绍的,在这方面也做了很多考虑。.
3、开源产品
以下是数据同步相关的开源产品列表,供参考学习:
二、实战项目介绍
1、DataLink 项目介绍
名称:DataLink['deitə liŋk]
翻译含义:数据链,数据(自动)传送器
语言:纯Java开发(JDK1.8+)
定位:满足各种异构数据源之间的实时增量同步,分布式、可扩展的数据同步系统
开源地址:
这个开源是去掉内部依赖后的版本(开源是增量同步子系统)。DataLink和阿里集团内的DataX也进行了深度融合,增量(DataLink)+全量(DataX)共同构成了一个统一的数据交换平台(打个比方,DataLink也算是DataX的增量版) ,平台架构如下:
2、项目背景
随着神州优车集团业务的快速发展,各种数据同步场景层出不穷,原有的系统架构难以支撑复杂多变的业务需求。于是,从2016年底开始,团队开始酝酿DataLink产品。
着眼于未来,我们的目标是打造一个满足各种异构数据源之间实时增量同步,支持公司业务快速发展的新平台。在深入研究的基础上,我们发现没有任何开源产品可以轻松实现我们的目标。每个产品都有明显的缺点和局限性,所以最后的选择是“自己设计”。
然而,自我设计并不是凭空设计的。现有的数据交换平台、现有的经验、大大小小的开源产品是我们设计的基础。与其说是自我设计,不如说是站在巨人的肩膀上。进行了一次飞跃。于是,像DataLink这样的产品诞生了,其产品特点主要有以下几点:
3、申请状态
DataLink于2016年12月开始立项,2017年5月推出第一个版本,在神州优车集团内服务至今,基本满足了公司各业务线的同步需求。目前内部同步规模大致如下:
4、架构模型
基础设施
DataLink是典型的Master-Slave架构,Manager(管理节点)+Worker(worker节点),以下是基础架构的关键模块概览:
经理
Manager是整个DataLink集群的大脑,具有三个核心功能:
团体
工人
任务
(重新)平衡
(Re-)Balance的定义:通过一定的负载均衡策略,将任务平均分布在Worker节点上。(Re-)Balance的单位是Group,一个组中(Re-)Balance的发生不会影响其他组的正常运行。
当(重新)平衡发生时:
插入
插件模型最大的意义在于解耦和复用。只需要提供一个基础框架,开发一系列同步插件即可。通过配置组合,可以支持“无限多”的同步场景。
插件有两种:Reader插件和Writer插件。插件通过Task串联起来。Task运行时,每个插件都有自己独立的Classloader,保证插件之间JAR包的隔离。
MySQL
DataLink 的操作依赖于各种配置信息,这些信息存储在 MySQL 中。DataLink在运行过程中动态生成监控和统计数据,这些数据也统一存储在MySQL中。
存储的配置信息主要包括:同步任务信息、工作节点信息、分组信息、数据源配置信息、映射规则信息、监控信息、角色权限信息等。
动物园管理员
Manager的高可用需要依赖ZooKeeper,通过抢占和监控“/datalink/managers/active”节点,实现二级Switch。
注意:Worker 的高可用不依赖于 ZooKeeper。只要Manager能保证高可用,Worker就是高可用。
任务会将运行时信息注册到 ZooKeeper。注册信息主要有两种类型:
详情请参考维基:
整体架构
概念模型
一句话概括概念模型:高度可扩展、松散的模型,可以对接任何存储之间的数据同步。这个模型在架构选择章节已经介绍过,这里不再赘述。
领域模型
合同
契约是规范,是对不同领域的数据类型的高级抽象。它在Datalink中的主要表现形式是Record,比如关系型数据库的RdbEventRecord,Hbase的HRecord。
在整个产品规划中,契约处于最顶层,无论什么样的基础设施,什么样的商业模式,什么样的开发语言,契约都是一套独立的规范。合约是连接Reader和Writer的纽带,Reader和Writer互不感知,它们通过识别一个共同的合约来实现数据交换。
商业模式
业务模型是数据交换业务场景的高级抽象。它总结归纳了不同场景的共同需求,抽象出一套统一的模型定义。
当然,它也不是万能的,它不可能收录所有的需求点,它会随着场景的增加而不断进化。但这是必要的。统一的模型抽象可以支持80%场景的功能复用。
主要模型定义如下:
详情请参考维基:
深入领域
插件型号
插件系统:一般由Framework+Plugin两部分组成。DataLink中的Framework主要指的是【TaskRuntime】,Plugin对应的是各种类型的【TaskReader&TaskWriter】。
TaskRuntime:提供Task的高层抽象,Task的运行环境,Task的插件规范。
TaskReader&TaskWriter:具体的数据同步插件,符合Task插件规范,功能自主,与TaskRuntime完全解耦。理论上可以无限扩展插件的数量。
Task:DataLink中数据同步的基本单位是Task。一批任务可以在一个 Worker 进程中运行。一个正在运行的Task由一个TaskReader和至少一个TaskWriter组成,即有:
详情请参考维基:
深入的插件
5、项目未来
DataLink 项目借鉴了许多开源产品的想法。我们要感谢的产品有:Canal、Otter、DataX、Yugong、Databus、Kafka-Connect、Ersatz。
站在巨人的肩膀上,我们进行开源,一方面是回馈社会,另一方面是我们在发家致富。展望未来,我们希望这个项目能够活跃起来,为社区做出更大的贡献。各种新的内部功能也将尽快同步到开源版本。我们也希望有更多的人参与。
目前内部正在规划的功能包括:双机房(中心)同步、通用审计功能、各种同步工具和插件、实时数据仓库、更多现有开源产品的全功能特性,以及深入各种大数据架构的集成等等。
实时回放
复活节彩蛋来了
在本文微信订阅号(dbaplus)的评论区留下引起共鸣的见解。小编将在本文发表后的次日中午12点,根据留言的精彩程度,选出1位幸运读者,赠送以下好书一本~
注:同月,已领取赠书者将无法获得两次赠书。
特别感谢华章科技为本次活动提供图书赞助。
- 近期活动 -
2018 Gdevops全球敏捷运维峰会广州站 查看全部
优采集平台(
而成,文末还有好书送哦~~(讲师介绍))
本文基于dbaplus社区第170期在线分享,文末有好书~
导师
陆标
技术专家
百度百科:
数据交换平台是指通过计算机网络,将多个单独搭建的应用信息系统集成起来,构建的信息交换平台,使多个应用子系统能够传输和共享信息/数据,提高信息资源的利用率,成为信息化建设的基本目标是保证分布式异构系统之间的互联互通,建立中央数据库,完成数据的抽取、集中、加载和展示,构建统一的数据处理和交换。
笔者认为,数据交换平台是构建分布式系统的三驾马车之一。这些三驾马车是基于RPC的服务调用、基于MQ的事件驱动和基于数据同步的数据共享。
推动数据交换平台出现和发展的根本动力是:交换空间换时间。
一、说说交流平台
1、服务场景
综上所述,数据交换平台可以服务的场景可以分为三类:基础设施、容灾备份、异构重构。
基础设施
场景一:EDA
通过数据交换平台,将数据库Log事件(如MySQL Binlog)发送到MQ,然后被不同的消费者消费,驱动不同的业务流程(如:刷新缓存,构建搜索引擎,放置后发送短信下单,付款后通知发货等),基于这种架构,业务端省去了定义领域事件和发送事件的工作,大大节省了工作量。
更重要的是,基于数据库自身的Log机制,数据一致性更有保障,其他的容错处理、HA等机制只能靠数据交换平台来保证。
当然,如果事件定义比较复杂,无法表达普通业务表对应的LogEvent,那么还是需要自己设计领域事件。这时候我们可以定义一个通用的事件表来保存自定义事件;而发送事件的操作对应于将事件表的插入操作与业务操作一起放在一个事务中。交易提交后,交易平台拉取事件表的日志,然后提取事件内容并发送给MQ。
有很多事情可以通过使用数据库日志来完成。我们的团队正在开发一个基于 MySQL-Binlog 消费的事件平台。一般架构如下:
事件平台提供事件订阅、事件配置等基础支持(如:是否实时触发下一个操作或倒计时触发下一个操作,下一个操作是接口回调还是新事件等) 、事件调度、实时监控等,用户只需要提供配置规则和开发回调接口,免去了各个研发团队各自为政、重复建设的各种问题。
此外,该平台最大的特点之一是引入了事件驱动的定时器机制。在这种机制之前,当涉及到与时间要素相关的判断时(如:未结算的订单下单后多久自动失效,租车一定时间后,结算类型自动从短租转产品到长租产品等),业务研发团队需要编写大量定时任务扫描数据库来计算时间间隔,不仅开发成本巨大,而且往往存在较大的性能问题。.
有了定时器机制,业务侧只需要配置时间规则,事件平台分布式,可以提供更高的性能支持。
场景二:CQRS(Command Query Responsibility Segregation)
这里是DDD领域的一个概念CQRS,具体介绍可以参考链接:
CQRS的思想本质上是为同一条数据创建两组模型(或视图):
CQRS 架构模型的开源实现是 Axon-Framework。基于Axon,可以构建自己的领域模型、领域事件、事件仓库、查询视图等,提供聚合根定义、事件回放、事件消费、数据镜像等基础支持,应用其架构图如下:
理想是丰满的,现实是骨感的。DDD已经提出很多年了,但是由于实践的难度,大部分公司还停留在通过数据库表建模的阶段,但是CQRS的想法非常好。
所以抛开DDD,基于表模型来理解CQRS:数据表模型也是领域模型,但不是面向对象的领域模型。数据库日志也是事件,但表达能力不如DDD中的领域事件丰富。
在此基础上,依靠数据库管理模型和事件,加上一个事件转发和消费的数据交换平台,可以构建一个广泛的CQRS架构,如下图:
场景三:数据采集并返回
很多企业正在或已经搭建了自己的大数据平台,其中数据采集和回流是不可或缺的一环。一般小公司在采集层面做数据相对碎片化,各种开源产品堆积起来完成采集相关工作,大公司会考虑平台化,放数据采集@ > 在整个数据交换平台的规划中,以提高效率和降低成本。
下图是我们团队的数据交换平台与大数据平台的关系示意图:
灾难恢复备份
场景示例1:多个机房
多中心、多备份、异地双活、异地多活等是很多大公司正在实践或已经实践的技术难题。这其中的核心是一套完整的数据同步解决方案。
场景二:数据镜像
通过数据交换平台,可以创建各种类型的DB镜像,满足不同场景的使用需求。
场景三:数据归档
通过增量交换,同步时忽略删除事件,实现实时归档。
异构重构
场景示例一:数据库升级、搬迁、拆迁、整合
数据库的升级,数据库的搬迁、拆除、整合等日常运维操作都会涉及到数据迁移。如果有平台,迁移工作就会变得非常简单。
场景二:资产复用
公司越大,负担越重。许多公司拥有各种类型的数据库和存储产品。为了复用这些资产,涉及到各种场景下的数据同步。统一的数据交换平台将使这些场景变得不同。同步变得容易多了。
2、施工思路
一千个读者将拥有一千个哈姆雷特,一千个建筑师将拥有一千个建筑理念。数据交换平台的建设没有灵丹妙药。不同的团队面对的场景不同,演进的架构也不同。在这里,结合自己的经验和体会,谈谈数据交换平台建设中的一些方法论和注意事项。
架构选择
数据同步过程是生产者-消费者模型的典型表现。生产者负责从不同的数据源拉取数据,消费者负责将数据写入不同的数据源。生产者和消费者之间可以存在一对一的关系。该关系也可以是一对多关系。
那么,数据交换平台是串联连接生产者和消费者的枢纽,可以控制串联过程中的过程。简而言之,就是数据集成。
数据整合是数据交换平台最基本的工作。架构的选择和设计应该只关注这个基本点。只有便于快速集成的架构才能支持不断变化的数据同步需求。
在设计架构时,需要考虑的要点总结如下:
许多公司正在构建自己的基于消息中间件的数据交换平台(有些称为数据总线)。生产者向MQ发送数据,消费者从MQ消费数据,数据可以自描述。这是一个典型的开源实现是Kafka-Connect的模型,其架构图如下:
优势:
缺点:
无论如何,架构模型都非常优秀,可以满足60%到70%的应用场景。但是我们团队并没有直接应用这个架构,而是针对它的缺点,受到了Kafka-Connect思想的启发,实现了基于消息中间件和直连同步的混合架构,如下图(即DataLink架构) :
在Kafka-Connect架构中,由于Kafka作为数据中转站,运行的Task要么是SourceTask要么是SinkTask,DataLink中的Task可以是Reader和Writer的任意组合(理论上)。
基于这个特性,构建基于消息中间件的同步,结合Mq-Writer和Mq-Reader就足够了;构建直连同步,绕过Mq,直接组合源Reader和目标Writer。根据不同的场景选择不同的模式,更加灵活。
无论是消息中间件解决方案还是混合解决方案,针对的场景大多是实时增量同步(虽然在某些场景也支持全同步,但毕竟不是它的主业),针对离线全同步场景,目前使用最广泛的解决方案是阿里开源的DataX。有兴趣的可以研究一下。
简而言之,没有最好的架构,只有最合适的架构。基于消息中间件构建数据交换平台是目前比较流行的架构模型,但也有其自身的不足。它结合各种技术,扬长避短,解决自身的问题和痛点。找到适合自己的方案才是最合理的方案。
方式方法
如果结构选择是为了制定战略,那么方法和方法就是具体的战术。从同步行为上变化点,可以分为实时增量同步和离线全量同步。
前者的可行策略主要有触发器、日志解析和基于时间戳的数据提取(当然不同的DB也会有自己的一些特殊解决方案,比如Oracle的物化视图机制、SQL Server的CDC等),后者是可行的,主要策略是文件转储和API提取。
实时增量同步
先说实时增量同步。基于触发器获取数据比较传统,而且由于运维繁琐,性能差,使用越来越少。
但是,在某些特定场景中仍有应用空间。有一个代号为SymmetricDS的开源产品,可以自动管理触发器,提供统一的数据采集和消费机制。如果你想基于触发器同步数据,可以参考这个产品。
基于日志分析的同步目前最为流行,如MySQL、HBase等,提供日志重放机制,协议开源。
这种方法的主要优点是:零侵入业务表,异步日志解析没有性能问题,实时性比较高。
日志解析很漂亮,但并不是所有的DB都提供这样的机制(比如SQL Server)。当触发器和日志解析不固定时,通过时间戳字段(如modify_time)定时扫描表,获取变化的数据,同步也是常用的方法。
这种方法有几个明显的缺点:实时性比较低,需要业务端保证时间戳字段不能漏更新,常规的表扫描查询也可能带来一些性能问题。
离线完全同步
再说说离线全同步。文件转储方式一般用于同构数据源之间的同步场景,需要DB自身的导入导出机制支持,可以服务的场景比较单一。API提取方法更通用、更灵活。同构和异质都可以通过编码实现。如果做得好,它还可以通过灵活的参数控制提供各种高级功能,例如开源产品DataX。
难题
将数据从一处移动到另一处,如何保证数据在同步过程中没有任何问题(不丢失、不重、不乱)或者出现问题后快速恢复,需要考虑的点很多,非常复杂,这里结合自己的经验说说主要的难点和常见的解决办法。
一:种类繁多的API
好像没什么难的,不就是调用API进行数据操作吗?事实上,市面上的存储产品有上百种,常用的存储产品有几十种。产品特性差异极大。
为了构建一个高效可靠的平台,需要对这些产品的API及其内部机制进行深入研究(例如:是否支持事务?事务粒度是表级还是记录级?是否支持随机读写还是只能支持Append?操作API的时候有没有客户端缓存?HA是怎么实现的?性能瓶颈在哪里?调优参数是什么?内置的Replication机制是怎么实现的?等),否则平台只会停留在可用阶段。
以我们自己的经验为例:在搭建大数据平台时,我们需要一个数据交换平台,将MySQL和HBase的数据实时同步到HDFS。基于DataLink,我们开发了HDFS Writer插件,在实践过程中走了不少弯路。
要解决这个难题,没有捷径可走。只有提升自己的硬实力才能取得突破。
二:同步关系治理
对于服务框架,随着服务数量的不断增加,我们需要服务治理;对于数据交换平台,随着同步关系的不断增加,同步关系也需要进行治理。
需要治理的要点是:
为了避免环回同步,一般添加DAG检测机制就足够了。
保证schema一致性的方法一般有两种:一是在同步过程中,从源端获取的DDL语句自动同步到目标端;二是平台提供了同步关系检测机制供外部系统使用。前者在异构数据源中比较。在很多情况下,实现起来比较困难(脚本转换、性能问题、幂等判断等),也不是所有的解决方案都能得到ddl语句,后者更加通用和可行。
目前我们内部的计划是,当SQL脚本上线时,数据交换平台会进行SQL分析,然后将同步关系树返回给DBA团队的DBMS系统,然后DBMS系统会根据到同步关系提示。
同步关系树示意图如下:
第三:数据质量
保证数据质量是数据交换平台的核心使命。在同步过程中,不丢失、不重、不乱。通过数据检查可以快速发现问题;发现问题后可以快速修复。
如果事前、事中、事后三个阶段都能控制好,那么平台就达到了极好的水平。
事前阶段依靠完善的设计和测试,事中阶段依靠三维监控和报警,事后阶段依靠功能丰富的修复工具。但是,由于场景的灵活性和复杂性,每个阶段都不容易实践,例如:
目前,我们的团队还在不断探索的道路上。没有绝对完美的解决方案。找到最合适的解决方案,才是针对我们自己的场景和数据一致性要求程度的正确解决方案。下图展示了数据质量的设计要点:
第四:可扩展性
科技发展日新月异,业务演进也日新月异。为了应对这些变化,平台也必须变化,但如何用最小的变化带来最大的收益,是判断一个平台或一个产品是否成熟的关键。指数。
作者信奉一句名言:建筑是进化的,不是设计的;但同时,我也相信另一句名言:好的设计是成功的一半。两者并不矛盾,主要是如何妥协。
构建平台和构建工具之间的一个重要区别在于,前者应侧重于抽象、建模和参数化,以提供灵活的可扩展性。
那么可扩展性应该考虑到什么程度呢?一句话概括:在搭建平台的过程中,我们要不断的总结、修正、抽象、迭代、推演,对已知的事物进行建模,使未知的事物可以预见而不是去做。过度设计,也是充分设计。
在开源的数据同步中间件中,扩展性比较好:阿里的DataX好,KafKa-Connect好,基于触发器的SymmetricDS也好。我们最近开源的DataLink,下面要介绍的,在这方面也做了很多考虑。.
3、开源产品
以下是数据同步相关的开源产品列表,供参考学习:
二、实战项目介绍
1、DataLink 项目介绍
名称:DataLink['deitə liŋk]
翻译含义:数据链,数据(自动)传送器
语言:纯Java开发(JDK1.8+)
定位:满足各种异构数据源之间的实时增量同步,分布式、可扩展的数据同步系统
开源地址:
这个开源是去掉内部依赖后的版本(开源是增量同步子系统)。DataLink和阿里集团内的DataX也进行了深度融合,增量(DataLink)+全量(DataX)共同构成了一个统一的数据交换平台(打个比方,DataLink也算是DataX的增量版) ,平台架构如下:
2、项目背景
随着神州优车集团业务的快速发展,各种数据同步场景层出不穷,原有的系统架构难以支撑复杂多变的业务需求。于是,从2016年底开始,团队开始酝酿DataLink产品。
着眼于未来,我们的目标是打造一个满足各种异构数据源之间实时增量同步,支持公司业务快速发展的新平台。在深入研究的基础上,我们发现没有任何开源产品可以轻松实现我们的目标。每个产品都有明显的缺点和局限性,所以最后的选择是“自己设计”。
然而,自我设计并不是凭空设计的。现有的数据交换平台、现有的经验、大大小小的开源产品是我们设计的基础。与其说是自我设计,不如说是站在巨人的肩膀上。进行了一次飞跃。于是,像DataLink这样的产品诞生了,其产品特点主要有以下几点:
3、申请状态
DataLink于2016年12月开始立项,2017年5月推出第一个版本,在神州优车集团内服务至今,基本满足了公司各业务线的同步需求。目前内部同步规模大致如下:
4、架构模型
基础设施
DataLink是典型的Master-Slave架构,Manager(管理节点)+Worker(worker节点),以下是基础架构的关键模块概览:
经理
Manager是整个DataLink集群的大脑,具有三个核心功能:
团体
工人
任务
(重新)平衡
(Re-)Balance的定义:通过一定的负载均衡策略,将任务平均分布在Worker节点上。(Re-)Balance的单位是Group,一个组中(Re-)Balance的发生不会影响其他组的正常运行。
当(重新)平衡发生时:
插入
插件模型最大的意义在于解耦和复用。只需要提供一个基础框架,开发一系列同步插件即可。通过配置组合,可以支持“无限多”的同步场景。
插件有两种:Reader插件和Writer插件。插件通过Task串联起来。Task运行时,每个插件都有自己独立的Classloader,保证插件之间JAR包的隔离。
MySQL
DataLink 的操作依赖于各种配置信息,这些信息存储在 MySQL 中。DataLink在运行过程中动态生成监控和统计数据,这些数据也统一存储在MySQL中。
存储的配置信息主要包括:同步任务信息、工作节点信息、分组信息、数据源配置信息、映射规则信息、监控信息、角色权限信息等。
动物园管理员
Manager的高可用需要依赖ZooKeeper,通过抢占和监控“/datalink/managers/active”节点,实现二级Switch。
注意:Worker 的高可用不依赖于 ZooKeeper。只要Manager能保证高可用,Worker就是高可用。
任务会将运行时信息注册到 ZooKeeper。注册信息主要有两种类型:
详情请参考维基:
整体架构
概念模型
一句话概括概念模型:高度可扩展、松散的模型,可以对接任何存储之间的数据同步。这个模型在架构选择章节已经介绍过,这里不再赘述。
领域模型
合同
契约是规范,是对不同领域的数据类型的高级抽象。它在Datalink中的主要表现形式是Record,比如关系型数据库的RdbEventRecord,Hbase的HRecord。
在整个产品规划中,契约处于最顶层,无论什么样的基础设施,什么样的商业模式,什么样的开发语言,契约都是一套独立的规范。合约是连接Reader和Writer的纽带,Reader和Writer互不感知,它们通过识别一个共同的合约来实现数据交换。
商业模式
业务模型是数据交换业务场景的高级抽象。它总结归纳了不同场景的共同需求,抽象出一套统一的模型定义。
当然,它也不是万能的,它不可能收录所有的需求点,它会随着场景的增加而不断进化。但这是必要的。统一的模型抽象可以支持80%场景的功能复用。
主要模型定义如下:
详情请参考维基:
深入领域
插件型号
插件系统:一般由Framework+Plugin两部分组成。DataLink中的Framework主要指的是【TaskRuntime】,Plugin对应的是各种类型的【TaskReader&TaskWriter】。
TaskRuntime:提供Task的高层抽象,Task的运行环境,Task的插件规范。
TaskReader&TaskWriter:具体的数据同步插件,符合Task插件规范,功能自主,与TaskRuntime完全解耦。理论上可以无限扩展插件的数量。
Task:DataLink中数据同步的基本单位是Task。一批任务可以在一个 Worker 进程中运行。一个正在运行的Task由一个TaskReader和至少一个TaskWriter组成,即有:
详情请参考维基:
深入的插件
5、项目未来
DataLink 项目借鉴了许多开源产品的想法。我们要感谢的产品有:Canal、Otter、DataX、Yugong、Databus、Kafka-Connect、Ersatz。
站在巨人的肩膀上,我们进行开源,一方面是回馈社会,另一方面是我们在发家致富。展望未来,我们希望这个项目能够活跃起来,为社区做出更大的贡献。各种新的内部功能也将尽快同步到开源版本。我们也希望有更多的人参与。
目前内部正在规划的功能包括:双机房(中心)同步、通用审计功能、各种同步工具和插件、实时数据仓库、更多现有开源产品的全功能特性,以及深入各种大数据架构的集成等等。
实时回放
复活节彩蛋来了
在本文微信订阅号(dbaplus)的评论区留下引起共鸣的见解。小编将在本文发表后的次日中午12点,根据留言的精彩程度,选出1位幸运读者,赠送以下好书一本~
注:同月,已领取赠书者将无法获得两次赠书。
特别感谢华章科技为本次活动提供图书赞助。
- 近期活动 -
2018 Gdevops全球敏捷运维峰会广州站

