
云端内容采集
云端内容采集(本文主题商品分析,竞品分析店铺蜂鸟采集数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-04-05 23:23
采集功能] 准确的采集目标上的数据网站,包括变体、属性、图片等采集。完整的产品信息导出。一键翻译采集的产品信息可以翻译成任意语言(54种语言)。产品认领可以直接将采集的数据向ActNeed平台授权的店铺进行认领。【蜂鸟优势采集】采集全网数据,以全网数据为计算基石,对数据进行多维数据分析和多维分析,为用户提供最有价值的数据。帮助用户更轻松地从平台获取数据。
本文题目为商品分析、竞品分析、店铺数据分析、蜂鸟采集、数据采集、跨境电商数据、数据分析、跨境电商数据存储, 数据分析。
蜂鸟采集是一个跨境电商数据采集平台,智能化采集,云存储,将平台数据变成自己的产品库。
【蜂鸟功能采集】
精度采集
目标网站上的数据,包括变体、属性、图片等,完全是采集。
一键式采集
小白神器,只要用鼠标点击产品,就可以自动完成采集。
轻松出口
您可以自己设置导出字段以完全导出产品信息。
一键翻译
采集的产品信息可以翻译成任何语言(54种语言)
产品声明
采集的数据可以直接到ActNeed平台授权的商店领取。
【蜂鸟的优势采集】
采集全网数据
以全网数据为计算基石,确保不遗漏重要数据。
多维数据分析
多维度分析数据,为用户提供最有价值的数据。
全方位数据查询
全方位的查询方式,帮助用户更轻松地从平台获取数据。
快速的产品索赔和出口
可以在任何地方快速声明、导出和使用产品数据。
实时跟踪数据变化
实时跟踪确保用户关心的所有数据始终是最新的。
电商运营商将为您更新最实用的电商工具、产品分析、竞品分析、店铺数据分析。更多电商资讯和行业动态,记得关注电商运营商!同时也欢迎大家推荐。 查看全部
云端内容采集(本文主题商品分析,竞品分析店铺蜂鸟采集数据)
采集功能] 准确的采集目标上的数据网站,包括变体、属性、图片等采集。完整的产品信息导出。一键翻译采集的产品信息可以翻译成任意语言(54种语言)。产品认领可以直接将采集的数据向ActNeed平台授权的店铺进行认领。【蜂鸟优势采集】采集全网数据,以全网数据为计算基石,对数据进行多维数据分析和多维分析,为用户提供最有价值的数据。帮助用户更轻松地从平台获取数据。

本文题目为商品分析、竞品分析、店铺数据分析、蜂鸟采集、数据采集、跨境电商数据、数据分析、跨境电商数据存储, 数据分析。
蜂鸟采集是一个跨境电商数据采集平台,智能化采集,云存储,将平台数据变成自己的产品库。
【蜂鸟功能采集】
精度采集
目标网站上的数据,包括变体、属性、图片等,完全是采集。
一键式采集
小白神器,只要用鼠标点击产品,就可以自动完成采集。
轻松出口
您可以自己设置导出字段以完全导出产品信息。
一键翻译
采集的产品信息可以翻译成任何语言(54种语言)
产品声明
采集的数据可以直接到ActNeed平台授权的商店领取。
【蜂鸟的优势采集】
采集全网数据
以全网数据为计算基石,确保不遗漏重要数据。
多维数据分析
多维度分析数据,为用户提供最有价值的数据。
全方位数据查询
全方位的查询方式,帮助用户更轻松地从平台获取数据。
快速的产品索赔和出口
可以在任何地方快速声明、导出和使用产品数据。
实时跟踪数据变化
实时跟踪确保用户关心的所有数据始终是最新的。
电商运营商将为您更新最实用的电商工具、产品分析、竞品分析、店铺数据分析。更多电商资讯和行业动态,记得关注电商运营商!同时也欢迎大家推荐。
云端内容采集(大连云沃做在线娱乐的大连海天科技(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-04-04 00:04
云端内容采集到互联网基础设施(),再由此落地到各个垂直行业(此处为汽车制造业),实现各应用场景内容的快速获取。
xp就不说了,大连tsdk做android的,阿里的开发者服务也很强。做android最好还是找海尔啊,大连湾那边。
大连云沃做在线娱乐的
大连海天科技
据说大连华采也很不错
大连云沃大连云沃是一家专注于成套应用系统建设的服务商。基于行业互联网应用平台服务,实现丰富的自助化在线应用解决方案,大连云沃受到众多客户的青睐,客户遍布全国各地的212家知名企业以及政府机构和国有企业。ps:之前同事推荐我用过,
多年来为多个项目公司、行业提供基于局域网或广域网环境下的在线娱乐内容采集、上传、处理、传输、展示及精准广告投放服务,从而实现了企业在互联网时代的营销与广告转型。
对啊网,
都快2020年了,
挺不错的
大连云沃算吗,去年我见过他们家有用过,还有开放平台,
有说华采,应该算是对啊,基于行业互联网应用平台服务, 查看全部
云端内容采集(大连云沃做在线娱乐的大连海天科技(组图))
云端内容采集到互联网基础设施(),再由此落地到各个垂直行业(此处为汽车制造业),实现各应用场景内容的快速获取。
xp就不说了,大连tsdk做android的,阿里的开发者服务也很强。做android最好还是找海尔啊,大连湾那边。
大连云沃做在线娱乐的
大连海天科技
据说大连华采也很不错
大连云沃大连云沃是一家专注于成套应用系统建设的服务商。基于行业互联网应用平台服务,实现丰富的自助化在线应用解决方案,大连云沃受到众多客户的青睐,客户遍布全国各地的212家知名企业以及政府机构和国有企业。ps:之前同事推荐我用过,
多年来为多个项目公司、行业提供基于局域网或广域网环境下的在线娱乐内容采集、上传、处理、传输、展示及精准广告投放服务,从而实现了企业在互联网时代的营销与广告转型。
对啊网,
都快2020年了,
挺不错的
大连云沃算吗,去年我见过他们家有用过,还有开放平台,
有说华采,应该算是对啊,基于行业互联网应用平台服务,
云端内容采集(云端服务器设备采集的注意事项有哪些呢??)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-04-02 09:06
云端内容采集主要分为两部分,一是基于云端服务器设备采集来的数据流,二是本地电脑采集来的文件。这里重点讲一下云端服务器设备采集的注意事项。
1、采集数据文件加密,特别是各类数据流敏感数据。
2、关于后端数据处理服务,由于云端采集对后端处理服务的要求较高,大大的超出一般企业现有的服务水平,建议对云端数据流数据进行开发和二次开发。
3、采集的前端设备要针对各类采集主题专门设计,采集的后端处理服务也是专门设计,避免开发繁琐。根据题主提问,云端采集数据流平台已完成,
参见百度经验里的一篇文章,
有云服务器可以实现一个小网站的采集,一般应该没有大客户,这个不好做,
云端采集目前是技术层面,需要服务器作为支撑,在门户网站是个趋势。
涉及数据采集的话最好用本地网站采集,因为数据的准确率不高。一定是涉及到数据请求的话不要用云服务器。云服务器多一个是其资金,二是其系统的限制。
还是用本地的web服务器吧,这个最好能够用国内的公司,阿里云、腾讯云和浪潮云就行。现在这方面的技术也非常成熟了,不是特别难找。 查看全部
云端内容采集(云端服务器设备采集的注意事项有哪些呢??)
云端内容采集主要分为两部分,一是基于云端服务器设备采集来的数据流,二是本地电脑采集来的文件。这里重点讲一下云端服务器设备采集的注意事项。
1、采集数据文件加密,特别是各类数据流敏感数据。
2、关于后端数据处理服务,由于云端采集对后端处理服务的要求较高,大大的超出一般企业现有的服务水平,建议对云端数据流数据进行开发和二次开发。
3、采集的前端设备要针对各类采集主题专门设计,采集的后端处理服务也是专门设计,避免开发繁琐。根据题主提问,云端采集数据流平台已完成,
参见百度经验里的一篇文章,
有云服务器可以实现一个小网站的采集,一般应该没有大客户,这个不好做,
云端采集目前是技术层面,需要服务器作为支撑,在门户网站是个趋势。
涉及数据采集的话最好用本地网站采集,因为数据的准确率不高。一定是涉及到数据请求的话不要用云服务器。云服务器多一个是其资金,二是其系统的限制。
还是用本地的web服务器吧,这个最好能够用国内的公司,阿里云、腾讯云和浪潮云就行。现在这方面的技术也非常成熟了,不是特别难找。
云端内容采集(优采云采集过程中常出现的问题以及解决方法本教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2022-03-27 23:24
优采云采集过程中常见问题及解决方法
本教程主要讲如果您在使用优采云采集时遇到一些问题,如何快速找出错误,解决错误或如何理解错误,以及与客服沟通的更好方法。
优采云采集器主要通过技术定位和模拟用户对网页的浏览操作来采集数据。用户无需了解网页架构、数据采集原理等技能。采集器 可以形成一个 优采云 可以理解并且可以循环工作的采集 进程。
如果出现采集模式不符合要求的情况,排查后有更详细的教程。
采集过程中的错误可以分为五个方面,分别是网页问题、规则问题、定位模拟问题、采集器问题、云端问题。当采集出现异常时,请按照以下步骤排查错误,查找问题类型:
1、 手动执行规则:打开界面右上角的流程图,用鼠标点击流程图中的规则,从上到下,每次点击下一步,都会有对应的响应,没有响应的步骤是一个问题。步。
当心:
1)点击提取循环中的元素手动选择循环中第一个以外的内容,防止循环失效,只点击提取循环中的第一个元素
2)所有规则在每一步之后执行,然后再执行下一步。网页未完全加载,即浏览器上的圆圈等待图标消失时,观察网页内容是否已完全加载。如果满载可以自行取消
加载,然后配置规则。
2、执行单机采集,查看采集的结果中没有收到采集数据的项目。
注意:最好将当前的URL添加到规则中,这样如果数据中有不是采集的项,可以复制URL在浏览器中打开查看原因并确定错误。
可能出现的症状描述如下,供您参考:
1、对手动步骤没有响应
有两种可能的现象:
1)步骤未正确执行
原因:规则问题、采集器问题、定位模拟问题
解决方案:
您可以执行故障排除,删除此步骤,然后重新添加。如果仍然无法执行,则排除规则问题。你可以:
在浏览器中打开网页进行操作,如果在浏览器中可以执行一些滚动或点击翻页,而在采集器中却不能执行,那就是采集器的问题,原因是采集器 内置浏览器是火狐,可能是内置的浏览器版本在后续版本中发生了变化,导致浏览器中可以实现的功能无法在采集器中执行@> 内置浏览器。此类网页中的数据,智能采集翻页或滚动之前的数据。
排除采集器问题和规则问题后,可以尝试在页面上重新添加步骤,布局与制定规则时相同。如果可以在这样的页面上执行,但在某些页面上不能执行,那就是定位模拟。这个问题在时间跨度较大的网站中经常存在,因为网站的布局
如果发生变化,采集器 定位所需的 XPath 将发生变化。请参考XPath章节修改规则或咨询客服。建议向客服说明网站网址及错误原因,以便客服提供解决方案。
优采云采集器故障排除 - 图 1
2)循环中的点击或采集只有在点击第一个内容时才会发生,第二个内容还是采集到第一个内容
原因:规则问题,定位模拟问题
解决方案:
检查循环中的第一项是否勾选点击当前循环中设置的元素
如果勾选还是不能,可以:如果循环中还有其他循环,先参考问题1的动画去掉里面的内容,删除有问题的循环,再重新设置,如果去掉的规则有不自动复位需要手动复位。如果可以使用循环,则排除问题。如果不是,那就是定位模拟的问题。你可以:
勾选循环中提取数据的自定义数据字段,勾选自定义定位元素方法,看里面是否有相对的Xpath路径,如果没有,删除该字段,勾选外部高级选项中的使用循环,添加再次,再次尝试,如果有反应,问题就解决了,如果还是不行,可以:
参考Xpath章节修改网页的Xpath或咨询客服。建议向客服说明网站网址及错误原因,以便客服提供解决方案。
优采云采集器故障排除 - 图 2
2、单机采集无法采集数据
有4个可能的原因:
1)单机操作规则,数据采集前会显示采集Complete
这种现象分为3种情况
①打开网页后会直接显示采集完成
原因:网页问题,第一个网页加载太慢,优采云会等待一段时间,如果过了一定时间仍然加载,优采云会跳过这一步,后续步骤认为内容尚未加载。如果没有数据,优采云 将结束任务,导致 采集 没有数据。
解决方法:增加网页的超时时间,或者在设置下一步执行之前等待,让网页有足够的时间加载。
优采云采集器故障排除 - 图 3
优采云采集器故障排除 - 图 4
②网页一直在加载
原因:网页问题,有些网页加载很慢。采集 的所需数据未出现。
解决方法:如果当前步骤是打开网页,可以延长网页的超时时间。如果是点击元素步骤,并且要加载采集的数据,可以在点击元素步骤中设置ajax延迟。点击后,新数据加载完毕,网页URL不变,是ajax链接。
优采云采集器故障排除 - 图 5
③网页没有进入采集页面
原因:这个问题经常出现在点击元素步骤。当某些网页收录ajax链接时,根据点击位置来判断是否需要设置。如果不设置,单机采集,采集无数据时,总是卡在上一步。网页异步加载时,如果不设置Ajax延迟,一般不会正确执行操作,导致规则无法进行下一步,无法提取数据。
解决方法:在相应的步骤中设置ajax延迟,一般为2-3S。如果网页加载时间较长,可以适当增加延迟时间。点击元素,循环下一页,将鼠标移到元素上,这三步都有ajax设置
2)单机运行规则无法正常执行
原因:规则问题或定位模拟问题
解决方案:
首先判断ajax是否需要设置,是否设置正确,如果不是ajax问题,可以:
删除问题步骤并重新设置。如果问题解决了,那就是规则问题。如果问题没有解决,那就是定位仿真问题。你可以:
参考Xpath章节修改网页的Xpath或咨询客服。建议向客服说明网站网址及错误原因,以便客服提供解决方案。
3)单机操作规则,第一页或第一页数据正常,后面不能执行
原因:规则问题 - 循环部分出现问题
解决方法:参考第二个内容的手动执行。
4)单机操作规则,数据采集缺失或错误
这种现象分为5种情况:
①部分字段没有数据
原因:网页中的数据为空,模拟定位问题
解决方案:
查看没有字段的链接并使用浏览器打开它们。如果没有字段,则没有问题。如果浏览器打开内容,这是一个模拟定位问题。你可以:
参考Xpath章节修改网页的Xpath或咨询客服。建议向客服说明网站网址及错误原因,以便客服提供解决方案。
②采集数据个数不对
原因:规则问题 - 循环部分出现问题
解决方法:参考手动执行第二个内容
③采集数据乱七八糟,没有对应的信息
原因:规则问题——提取步骤太多,页面加载时间过长,如果设置ajax忽略加载,可能会由于内容未加载或加载不完整而导致部分提取步骤多的错误。
解决方案:将规则分为两个步骤。如果采集评论网页数据,第一步是采集当前页面信息和评论页面的URL,第二步是循环URL采集评论数据,和然后将数据导出到excel和数据库中进行匹配处理。
④ 字段出现在不同位置
原因:网页问题 - Xpath 更改
解决方法:参考Xpath章节修改网页的Xpath或咨询客服。
服务描述网站URL及错误原因,以便客服给出解决方案。
⑤数据重复
原因:网页问题——Xpath定位问题,问题主要出现在翻页时,比如只循环一两页,或者最后一页的下一页按钮仍然可以点击。
解决方法:参考Xpath章节修改网页的Xpath或咨询客服。建议向客服说明网站网址和错误原因,以便客服给出解决方案。
3、独立采集普通,云采集无数据
这种现象分为4种情况:
1)网页问题 - IP 阻塞的原因
原因:大部分网站优采云有IP屏蔽措施都可以解决,很少有网站采取极其严格的IP屏蔽措施,会导致云采集采集@ > 无可用数据。
解决方案:
如果是单机采集,可以使用代理IP功能。详见代理IP教程。
如果是云采集,可以为任务分配到多个节点,可以让多个节点空闲,避免同一个云采集同IP上的任务。
2)云问题-云服务器带宽小
原因:云端带宽小,导致本地网站打开慢,在云端打开时间较长。一旦超时,将无法打开网站或无法加载数据,导致跳过此步骤。
解决方法:将打开URL的超时时间或下次执行前的等待时间设置长一些。
3)规则问题 - 增量采集
原因:规则设置了增量采集,增量采集根据URL判断采集是否已经通过。部分网页使用增量采集,会导致增量判断错误,跳过。这页纸。
解决方法:关闭增量采集。
4)规则问题-禁止浏览器加载图片和云采集不要拆分任务
原因:很少有网页不能勾选禁止浏览器加载图片和云采集不要拆分任务解决方法:取消勾选相关选项。
如有更多问题,请在官网或客服反馈,感谢您的支持。
相关 采集 教程:
天猫商品信息采集
美团商业资讯采集
市场招聘信息采集
优采云——70万用户选择的网页数据采集器。
1、操作简单,任何人都可以使用:无需技术背景,只需要互联网采集。完成流程可视化,点击鼠标完成操作,2分钟快速上手。
2、功能强大,任意网站可选:点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据,都可以通过简单的设置进行设置< @采集。
3、云采集,你也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。
4、功能免费+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。 查看全部
云端内容采集(优采云采集过程中常出现的问题以及解决方法本教程)
优采云采集过程中常见问题及解决方法
本教程主要讲如果您在使用优采云采集时遇到一些问题,如何快速找出错误,解决错误或如何理解错误,以及与客服沟通的更好方法。
优采云采集器主要通过技术定位和模拟用户对网页的浏览操作来采集数据。用户无需了解网页架构、数据采集原理等技能。采集器 可以形成一个 优采云 可以理解并且可以循环工作的采集 进程。
如果出现采集模式不符合要求的情况,排查后有更详细的教程。
采集过程中的错误可以分为五个方面,分别是网页问题、规则问题、定位模拟问题、采集器问题、云端问题。当采集出现异常时,请按照以下步骤排查错误,查找问题类型:
1、 手动执行规则:打开界面右上角的流程图,用鼠标点击流程图中的规则,从上到下,每次点击下一步,都会有对应的响应,没有响应的步骤是一个问题。步。
当心:
1)点击提取循环中的元素手动选择循环中第一个以外的内容,防止循环失效,只点击提取循环中的第一个元素
2)所有规则在每一步之后执行,然后再执行下一步。网页未完全加载,即浏览器上的圆圈等待图标消失时,观察网页内容是否已完全加载。如果满载可以自行取消
加载,然后配置规则。
2、执行单机采集,查看采集的结果中没有收到采集数据的项目。
注意:最好将当前的URL添加到规则中,这样如果数据中有不是采集的项,可以复制URL在浏览器中打开查看原因并确定错误。
可能出现的症状描述如下,供您参考:
1、对手动步骤没有响应
有两种可能的现象:
1)步骤未正确执行
原因:规则问题、采集器问题、定位模拟问题
解决方案:
您可以执行故障排除,删除此步骤,然后重新添加。如果仍然无法执行,则排除规则问题。你可以:
在浏览器中打开网页进行操作,如果在浏览器中可以执行一些滚动或点击翻页,而在采集器中却不能执行,那就是采集器的问题,原因是采集器 内置浏览器是火狐,可能是内置的浏览器版本在后续版本中发生了变化,导致浏览器中可以实现的功能无法在采集器中执行@> 内置浏览器。此类网页中的数据,智能采集翻页或滚动之前的数据。
排除采集器问题和规则问题后,可以尝试在页面上重新添加步骤,布局与制定规则时相同。如果可以在这样的页面上执行,但在某些页面上不能执行,那就是定位模拟。这个问题在时间跨度较大的网站中经常存在,因为网站的布局
如果发生变化,采集器 定位所需的 XPath 将发生变化。请参考XPath章节修改规则或咨询客服。建议向客服说明网站网址及错误原因,以便客服提供解决方案。
优采云采集器故障排除 - 图 1
2)循环中的点击或采集只有在点击第一个内容时才会发生,第二个内容还是采集到第一个内容
原因:规则问题,定位模拟问题
解决方案:
检查循环中的第一项是否勾选点击当前循环中设置的元素
如果勾选还是不能,可以:如果循环中还有其他循环,先参考问题1的动画去掉里面的内容,删除有问题的循环,再重新设置,如果去掉的规则有不自动复位需要手动复位。如果可以使用循环,则排除问题。如果不是,那就是定位模拟的问题。你可以:
勾选循环中提取数据的自定义数据字段,勾选自定义定位元素方法,看里面是否有相对的Xpath路径,如果没有,删除该字段,勾选外部高级选项中的使用循环,添加再次,再次尝试,如果有反应,问题就解决了,如果还是不行,可以:
参考Xpath章节修改网页的Xpath或咨询客服。建议向客服说明网站网址及错误原因,以便客服提供解决方案。
优采云采集器故障排除 - 图 2
2、单机采集无法采集数据
有4个可能的原因:
1)单机操作规则,数据采集前会显示采集Complete
这种现象分为3种情况
①打开网页后会直接显示采集完成
原因:网页问题,第一个网页加载太慢,优采云会等待一段时间,如果过了一定时间仍然加载,优采云会跳过这一步,后续步骤认为内容尚未加载。如果没有数据,优采云 将结束任务,导致 采集 没有数据。
解决方法:增加网页的超时时间,或者在设置下一步执行之前等待,让网页有足够的时间加载。
优采云采集器故障排除 - 图 3
优采云采集器故障排除 - 图 4
②网页一直在加载
原因:网页问题,有些网页加载很慢。采集 的所需数据未出现。
解决方法:如果当前步骤是打开网页,可以延长网页的超时时间。如果是点击元素步骤,并且要加载采集的数据,可以在点击元素步骤中设置ajax延迟。点击后,新数据加载完毕,网页URL不变,是ajax链接。
优采云采集器故障排除 - 图 5
③网页没有进入采集页面
原因:这个问题经常出现在点击元素步骤。当某些网页收录ajax链接时,根据点击位置来判断是否需要设置。如果不设置,单机采集,采集无数据时,总是卡在上一步。网页异步加载时,如果不设置Ajax延迟,一般不会正确执行操作,导致规则无法进行下一步,无法提取数据。
解决方法:在相应的步骤中设置ajax延迟,一般为2-3S。如果网页加载时间较长,可以适当增加延迟时间。点击元素,循环下一页,将鼠标移到元素上,这三步都有ajax设置
2)单机运行规则无法正常执行
原因:规则问题或定位模拟问题
解决方案:
首先判断ajax是否需要设置,是否设置正确,如果不是ajax问题,可以:
删除问题步骤并重新设置。如果问题解决了,那就是规则问题。如果问题没有解决,那就是定位仿真问题。你可以:
参考Xpath章节修改网页的Xpath或咨询客服。建议向客服说明网站网址及错误原因,以便客服提供解决方案。
3)单机操作规则,第一页或第一页数据正常,后面不能执行
原因:规则问题 - 循环部分出现问题
解决方法:参考第二个内容的手动执行。
4)单机操作规则,数据采集缺失或错误
这种现象分为5种情况:
①部分字段没有数据
原因:网页中的数据为空,模拟定位问题
解决方案:
查看没有字段的链接并使用浏览器打开它们。如果没有字段,则没有问题。如果浏览器打开内容,这是一个模拟定位问题。你可以:
参考Xpath章节修改网页的Xpath或咨询客服。建议向客服说明网站网址及错误原因,以便客服提供解决方案。
②采集数据个数不对
原因:规则问题 - 循环部分出现问题
解决方法:参考手动执行第二个内容
③采集数据乱七八糟,没有对应的信息
原因:规则问题——提取步骤太多,页面加载时间过长,如果设置ajax忽略加载,可能会由于内容未加载或加载不完整而导致部分提取步骤多的错误。
解决方案:将规则分为两个步骤。如果采集评论网页数据,第一步是采集当前页面信息和评论页面的URL,第二步是循环URL采集评论数据,和然后将数据导出到excel和数据库中进行匹配处理。
④ 字段出现在不同位置
原因:网页问题 - Xpath 更改
解决方法:参考Xpath章节修改网页的Xpath或咨询客服。
服务描述网站URL及错误原因,以便客服给出解决方案。
⑤数据重复
原因:网页问题——Xpath定位问题,问题主要出现在翻页时,比如只循环一两页,或者最后一页的下一页按钮仍然可以点击。
解决方法:参考Xpath章节修改网页的Xpath或咨询客服。建议向客服说明网站网址和错误原因,以便客服给出解决方案。
3、独立采集普通,云采集无数据
这种现象分为4种情况:
1)网页问题 - IP 阻塞的原因
原因:大部分网站优采云有IP屏蔽措施都可以解决,很少有网站采取极其严格的IP屏蔽措施,会导致云采集采集@ > 无可用数据。
解决方案:
如果是单机采集,可以使用代理IP功能。详见代理IP教程。
如果是云采集,可以为任务分配到多个节点,可以让多个节点空闲,避免同一个云采集同IP上的任务。
2)云问题-云服务器带宽小
原因:云端带宽小,导致本地网站打开慢,在云端打开时间较长。一旦超时,将无法打开网站或无法加载数据,导致跳过此步骤。
解决方法:将打开URL的超时时间或下次执行前的等待时间设置长一些。
3)规则问题 - 增量采集
原因:规则设置了增量采集,增量采集根据URL判断采集是否已经通过。部分网页使用增量采集,会导致增量判断错误,跳过。这页纸。
解决方法:关闭增量采集。
4)规则问题-禁止浏览器加载图片和云采集不要拆分任务
原因:很少有网页不能勾选禁止浏览器加载图片和云采集不要拆分任务解决方法:取消勾选相关选项。
如有更多问题,请在官网或客服反馈,感谢您的支持。
相关 采集 教程:
天猫商品信息采集
美团商业资讯采集
市场招聘信息采集
优采云——70万用户选择的网页数据采集器。
1、操作简单,任何人都可以使用:无需技术背景,只需要互联网采集。完成流程可视化,点击鼠标完成操作,2分钟快速上手。
2、功能强大,任意网站可选:点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据,都可以通过简单的设置进行设置< @采集。
3、云采集,你也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。
4、功能免费+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。
云端内容采集(如何采集云+云编辑,企业云端内容采集系统?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-03-26 22:06
云端内容采集系统:站长工具:采集云+云采集+云编辑。一键投稿:/z/index.html?uk=126044552&href=http%3a%2f%%2f21%2fd%2fpc%2f9.index%2findex%2f%2f2%2f876582%2f%2f8%2f554941%2f5%2f8%2f8%2f8%2f75426%2f5%2f5%2f64605%2f%2f%2f3%2f63707%2f%2f5%2f8%2f71606%2f%2f%2f5%2f91176%2f%2f%2f64607%2f%2f%2f%2f5%2f634410%2f%2f5%2f12214%2f%2f5%2f4%2f8%2f2%2f2%2f3%2f62684%2f%2f4%2f4%2f6%2f4%2f3%2f7%2f25347%2f%2f3%2f66302%2f5%2f6%2f7%2f5%2f4%2f5%2f2&from=timeline&isappinstalled=0&uid=957385569&vid=641347864。
推荐app采集助手采集个人以及机构,网站以及企业的各种采集产品的各种应用。更重要的是采集app里面的各种资源,每天都有资源更新,不需要再注册来着,省事省时。 查看全部
云端内容采集(如何采集云+云编辑,企业云端内容采集系统?)
云端内容采集系统:站长工具:采集云+云采集+云编辑。一键投稿:/z/index.html?uk=126044552&href=http%3a%2f%%2f21%2fd%2fpc%2f9.index%2findex%2f%2f2%2f876582%2f%2f8%2f554941%2f5%2f8%2f8%2f8%2f75426%2f5%2f5%2f64605%2f%2f%2f3%2f63707%2f%2f5%2f8%2f71606%2f%2f%2f5%2f91176%2f%2f%2f64607%2f%2f%2f%2f5%2f634410%2f%2f5%2f12214%2f%2f5%2f4%2f8%2f2%2f2%2f3%2f62684%2f%2f4%2f4%2f6%2f4%2f3%2f7%2f25347%2f%2f3%2f66302%2f5%2f6%2f7%2f5%2f4%2f5%2f2&from=timeline&isappinstalled=0&uid=957385569&vid=641347864。
推荐app采集助手采集个人以及机构,网站以及企业的各种采集产品的各种应用。更重要的是采集app里面的各种资源,每天都有资源更新,不需要再注册来着,省事省时。
云端内容采集(云端内容采集要根据你的行业区域,内容以及搜索人群制定)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-03-24 23:04
云端内容采集要根据你的行业区域,内容以及搜索人群制定,通常一个云端可以采集到2000个产品,如果太多采集后需要检索的时间相当的长,搜索的人群范围也会缩小,用户相对来说感知也会比较差,通常一般单个产品可以提取500-1000个展示率;用户由关键词搜索展示,且普遍搜索率高,目前我们提供多个关键词上线,采集价格基本和付费搜索持平或者比付费搜索也是一样;如果是长尾产品展示量太少或者展示率低可以通过whois,到厂里面走访看看到底产品属于哪个出口,如果属于日本,那么就基本和付费搜索一样到达的人群都差不多;云端内容产出:1、一般最好的当前提升的方式是whois会员,如果你用户付费了对方不付费,上不了广告那这个时候你一定要和他购买whois看看产品有没有被采集,这个跟你付不付费没太大关系,付费whois可以达到100%展示率;2、通过whois寻找厂商,这个是技术流程;如果你想寻找厂商是一件很头疼的事情,可以私我。
厂家提供有whois查询,通过whois查询可以知道当前产品相关词有哪些,通过query语句查询厂家信息确定该厂家是否有代加工的资质或者有完整的采购流程。
1.电商助手:可以查看全站产品的whois2.云宝:新创建店铺不能保存whois
云站分析-360个人图书馆, 查看全部
云端内容采集(云端内容采集要根据你的行业区域,内容以及搜索人群制定)
云端内容采集要根据你的行业区域,内容以及搜索人群制定,通常一个云端可以采集到2000个产品,如果太多采集后需要检索的时间相当的长,搜索的人群范围也会缩小,用户相对来说感知也会比较差,通常一般单个产品可以提取500-1000个展示率;用户由关键词搜索展示,且普遍搜索率高,目前我们提供多个关键词上线,采集价格基本和付费搜索持平或者比付费搜索也是一样;如果是长尾产品展示量太少或者展示率低可以通过whois,到厂里面走访看看到底产品属于哪个出口,如果属于日本,那么就基本和付费搜索一样到达的人群都差不多;云端内容产出:1、一般最好的当前提升的方式是whois会员,如果你用户付费了对方不付费,上不了广告那这个时候你一定要和他购买whois看看产品有没有被采集,这个跟你付不付费没太大关系,付费whois可以达到100%展示率;2、通过whois寻找厂商,这个是技术流程;如果你想寻找厂商是一件很头疼的事情,可以私我。
厂家提供有whois查询,通过whois查询可以知道当前产品相关词有哪些,通过query语句查询厂家信息确定该厂家是否有代加工的资质或者有完整的采购流程。
1.电商助手:可以查看全站产品的whois2.云宝:新创建店铺不能保存whois
云站分析-360个人图书馆,
云端内容采集(云端读报平台创新运营模式破解赢利难题(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-03-24 02:21
云报是一个移动媒体发布平台,由内容制作系统、媒体发布系统、客户端系统、后台统计管理系统和运营支持系统组成。
功能介绍
1.信息容量大,可传输多媒体内容。传输的信息量没有限制,可以同时传输文字、图片、音频、视频等内容,大大丰富了媒体表达的手段。
2.具有实时推送功能,用户无需主动登录。当前的新闻客户端实际上是一个网络门户。读者需要启动客户端阅读新闻并登录后主动浏览互联网。安装云读报客户端后,只要订阅某份报纸,就可以像接收短信一样定时接收报纸。
3. 离线阅读,流畅的用户体验。目前国内3G网络覆盖并不完善,云读报内容推送到用户手机后,读者可以在手机上离线阅读。不仅减少了对无线网络的依赖,阅读也没有网络延迟。
4. 具有丰富的交互功能。云阅报的新闻文本可以添加超链接,读者在浏览时可以通过超链接获取更多相关新闻,也可以随时参与话题讨论。
创新背景
1.创新运营模式解决盈利难题。目前,虽然很多媒体都推出了移动新媒体业务,但能从中受益的却寥寥无几。云报阅读平台除了技术优势之外,还找到了传统媒体开展移动媒体业务的盈利模式。
2.云报提供技术、市场、计费等一揽子解决方案,媒体只需要专注于自己擅长的内容制作。同时,媒体使用本平台发布移动媒体产品无需支付任何费用。 查看全部
云端内容采集(云端读报平台创新运营模式破解赢利难题(图))
云报是一个移动媒体发布平台,由内容制作系统、媒体发布系统、客户端系统、后台统计管理系统和运营支持系统组成。
功能介绍
1.信息容量大,可传输多媒体内容。传输的信息量没有限制,可以同时传输文字、图片、音频、视频等内容,大大丰富了媒体表达的手段。
2.具有实时推送功能,用户无需主动登录。当前的新闻客户端实际上是一个网络门户。读者需要启动客户端阅读新闻并登录后主动浏览互联网。安装云读报客户端后,只要订阅某份报纸,就可以像接收短信一样定时接收报纸。
3. 离线阅读,流畅的用户体验。目前国内3G网络覆盖并不完善,云读报内容推送到用户手机后,读者可以在手机上离线阅读。不仅减少了对无线网络的依赖,阅读也没有网络延迟。
4. 具有丰富的交互功能。云阅报的新闻文本可以添加超链接,读者在浏览时可以通过超链接获取更多相关新闻,也可以随时参与话题讨论。
创新背景
1.创新运营模式解决盈利难题。目前,虽然很多媒体都推出了移动新媒体业务,但能从中受益的却寥寥无几。云报阅读平台除了技术优势之外,还找到了传统媒体开展移动媒体业务的盈利模式。
2.云报提供技术、市场、计费等一揽子解决方案,媒体只需要专注于自己擅长的内容制作。同时,媒体使用本平台发布移动媒体产品无需支付任何费用。
云端内容采集(云端内容采集,让外国人放心在中国打拼(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-03-19 11:08
云端内容采集,顾名思义就是通过一些技术手段对各种网络内容,例如:ugc、app、微信等网络渠道进行采集,并上传到官方公有云端,上传方式为网页上传和内容版权控制两种。内容版权控制方式在海外很多国家这是一个法律法规所规定的网络行为,例如ugc、版权多媒体上传在国外是合法的。其中的手段就包括数据抓取,把你需要的,提取到上传官方的云端平台,如:gophers,yottasocket,magnitude等(以下简称yojs),如果你觉得你对云采集或者网络采集比较熟悉,你可以自己搭建和完善yojs,对于外行人来说学习起来稍微会有些困难。
需要注意的是yojs在海外的很多国家都是合法的,例如德国、美国等国。但是不是每个国家都是合法,同时又要有国家的版权法律法规要求以及实际执行的法律法规。
1、yojs:云采集平台(youtubecloudtrackingserviceforbusiness),让外国人放心在中国打拼(自己编译的系统),yojs在美国、德国、英国、法国、比利时、荷兰、澳大利亚、意大利、韩国、西班牙、香港、印度、澳门、台湾、新加坡、加拿大、泰国、美国、马来西亚、印度尼西亚、新西兰、以色列、韩国、澳门、智利、捷克共和国、加拿大、白俄罗斯、俄罗斯、挪威、乌克兰、瑞典、冰岛、日本、美国加州、亚洲其他主要市场地区(新加坡除外)),。(项目总监待遇get)yojs介绍:。
一、依托微软开源的youtubecloudtrackingservice系统,为企业、投资商、政府机构等提供一站式的商业采集、数据统计分析、数据可视化等一站式服务,并对接youtube、yahoo、spotify、亚马逊、亚马逊webmaster等云端资源。(作为一个技术宅男,大量程序员程序员或者没有独立采集youtube数据的人就不要来搞这个了,真的没有互联网技术,没有成体系的采集youtube资源的知识,本人除外)。
2、提供在线网页采集的开源工具yojs-selection,httpheaderanalysisandbusinesssearchwithyoutubecloudtracking。,youcanconfiguremanagementtopushyoursitetoyoutubeasselectionbyputtingadirecthttperrorcode,anemailtoyou,andemailyoutoyoutubecloudtrackingservicesaddressconnectingyouandyoursite。
,youcandropdownyourusername,phonenumber,internetname,andemailaddress。,andwhichconnectyouandyoutubetrackingservicesaddressconnectingyou。
3、完善的数据统计分析功能yojs_local_analytics_infomaximizethewholeanalysisbetweenpreviouslypostedcontentandnewcontent.
4、上传数据网站 查看全部
云端内容采集(云端内容采集,让外国人放心在中国打拼(组图))
云端内容采集,顾名思义就是通过一些技术手段对各种网络内容,例如:ugc、app、微信等网络渠道进行采集,并上传到官方公有云端,上传方式为网页上传和内容版权控制两种。内容版权控制方式在海外很多国家这是一个法律法规所规定的网络行为,例如ugc、版权多媒体上传在国外是合法的。其中的手段就包括数据抓取,把你需要的,提取到上传官方的云端平台,如:gophers,yottasocket,magnitude等(以下简称yojs),如果你觉得你对云采集或者网络采集比较熟悉,你可以自己搭建和完善yojs,对于外行人来说学习起来稍微会有些困难。
需要注意的是yojs在海外的很多国家都是合法的,例如德国、美国等国。但是不是每个国家都是合法,同时又要有国家的版权法律法规要求以及实际执行的法律法规。
1、yojs:云采集平台(youtubecloudtrackingserviceforbusiness),让外国人放心在中国打拼(自己编译的系统),yojs在美国、德国、英国、法国、比利时、荷兰、澳大利亚、意大利、韩国、西班牙、香港、印度、澳门、台湾、新加坡、加拿大、泰国、美国、马来西亚、印度尼西亚、新西兰、以色列、韩国、澳门、智利、捷克共和国、加拿大、白俄罗斯、俄罗斯、挪威、乌克兰、瑞典、冰岛、日本、美国加州、亚洲其他主要市场地区(新加坡除外)),。(项目总监待遇get)yojs介绍:。
一、依托微软开源的youtubecloudtrackingservice系统,为企业、投资商、政府机构等提供一站式的商业采集、数据统计分析、数据可视化等一站式服务,并对接youtube、yahoo、spotify、亚马逊、亚马逊webmaster等云端资源。(作为一个技术宅男,大量程序员程序员或者没有独立采集youtube数据的人就不要来搞这个了,真的没有互联网技术,没有成体系的采集youtube资源的知识,本人除外)。
2、提供在线网页采集的开源工具yojs-selection,httpheaderanalysisandbusinesssearchwithyoutubecloudtracking。,youcanconfiguremanagementtopushyoursitetoyoutubeasselectionbyputtingadirecthttperrorcode,anemailtoyou,andemailyoutoyoutubecloudtrackingservicesaddressconnectingyouandyoursite。
,youcandropdownyourusername,phonenumber,internetname,andemailaddress。,andwhichconnectyouandyoutubetrackingservicesaddressconnectingyou。
3、完善的数据统计分析功能yojs_local_analytics_infomaximizethewholeanalysisbetweenpreviouslypostedcontentandnewcontent.
4、上传数据网站
云端内容采集(#云端正版识别##[云端]())
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-03-17 22:12
#云正品识别## [云](%e7%99%be%e6%90%9c%e4%ba%91%e7%ab%af "[查看更多[百搜云]标签文章]" ) 系统正品识别:[](#%E7%99%BE%E6%90%9C%E4%BA%91%E7%AB%AF%E7%B3%BB%E7%BB%9F%E6 %AD% A3%E7%89%88%E8%AF%86%E5%88%AB%EF%BC%9A)**第一步:查看升级是否为最新版本,查看升级内容是否为升级内容. **![]()** 第二步;远程查看前端源码的可用性和完整性,识别【实时源码】(%e7%9b%b4%e6%92%ad%e6%ba%90%e7%a0%81"[查看更多< [Live source] 标签的@文章") 是否是最新的并且可用。(直播源码在个人中心)**![]()![]()** 第三步:****任何没有KEY升级码的转售盗版系统将无法在线升级和售后服务。升级码归官网所有,代理可免费索取升级码!****很多人购买了盗版系统,通过互联网通过各种销售渠道购买,请注意;我们不接受任何盗版系统的升级和售后服务,无论您在哪里购买或他们发送,不在我们的官方网站上。我们所有产品不提供任何帮助,花钱解决不了问题和售后,请不要贪便宜,不同的价格不同,有些东西是你看不到的坑!我们的品牌力求为您提供优质的服务,做最好的云系统!**![]()** 什么是升级代码?****回答:**升级码是您首次购买系统时,百搜科技为您提供升级码,以便更好的售后服务和为您升级!**我可以在没有升级代码的情况下使用它吗?****回答:**没有升级码的系统是不稳定的,因为他没有对系统做最基本的安全监控,升级优化BUG错误提示,所以系统无法正常使用。后期涉及百搜名誉,百搜将通过远程执行删除数据库文件!**KEY升级码可以使用多个域名吗?****答案:**一个KEY升级码只对应一个网站域名和IP。**很多人说我购买的系统是开源的,为什么要给域名和IP?****答案:**您购买的源代码是开源的,但是您需要提供域名和IP进行升级才能连接到我们的升级系统进行远程升级。如果您不提供我们,升级文件会飞到服务器内部吗?所以尽量与我们合作做升级服务。 查看全部
云端内容采集(#云端正版识别##[云端]())
#云正品识别## [云](%e7%99%be%e6%90%9c%e4%ba%91%e7%ab%af "[查看更多[百搜云]标签文章]" ) 系统正品识别:[](#%E7%99%BE%E6%90%9C%E4%BA%91%E7%AB%AF%E7%B3%BB%E7%BB%9F%E6 %AD% A3%E7%89%88%E8%AF%86%E5%88%AB%EF%BC%9A)**第一步:查看升级是否为最新版本,查看升级内容是否为升级内容. **![]()** 第二步;远程查看前端源码的可用性和完整性,识别【实时源码】(%e7%9b%b4%e6%92%ad%e6%ba%90%e7%a0%81"[查看更多< [Live source] 标签的@文章") 是否是最新的并且可用。(直播源码在个人中心)**![]()![]()** 第三步:****任何没有KEY升级码的转售盗版系统将无法在线升级和售后服务。升级码归官网所有,代理可免费索取升级码!****很多人购买了盗版系统,通过互联网通过各种销售渠道购买,请注意;我们不接受任何盗版系统的升级和售后服务,无论您在哪里购买或他们发送,不在我们的官方网站上。我们所有产品不提供任何帮助,花钱解决不了问题和售后,请不要贪便宜,不同的价格不同,有些东西是你看不到的坑!我们的品牌力求为您提供优质的服务,做最好的云系统!**![]()** 什么是升级代码?****回答:**升级码是您首次购买系统时,百搜科技为您提供升级码,以便更好的售后服务和为您升级!**我可以在没有升级代码的情况下使用它吗?****回答:**没有升级码的系统是不稳定的,因为他没有对系统做最基本的安全监控,升级优化BUG错误提示,所以系统无法正常使用。后期涉及百搜名誉,百搜将通过远程执行删除数据库文件!**KEY升级码可以使用多个域名吗?****答案:**一个KEY升级码只对应一个网站域名和IP。**很多人说我购买的系统是开源的,为什么要给域名和IP?****答案:**您购买的源代码是开源的,但是您需要提供域名和IP进行升级才能连接到我们的升级系统进行远程升级。如果您不提供我们,升级文件会飞到服务器内部吗?所以尽量与我们合作做升级服务。
云端内容采集(微信公众号是微信成为互联网入口的第一步)
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-03-08 06:03
云端内容采集如果说微信公众号是微信成为互联网入口的第一步,那么无疑云服务就是以最低的成本、最小的难度实现内容服务商的全面对接,包括但不限于公众号关联、网站挂靠、订阅号授权、网页广告定向推送以及门户网站采集等等。互联网会将内容的获取置之度外,因为互联网本质是将信息连接后呈现,而不是互联网之外的物理链接。
以百度为例,流量被分割后并非每条内容都能获取到流量,只有与之匹配的网站才能将流量转移,因此百度才会对搜索结果进行处理。采集的方式可以有几种,首先从业内开始就有门户站内容采集和抄袭的存在,例如凤凰网、搜狐等;网站购买也是常见的采集手段,例如网易的移动新闻平台;这些手段在各网站都有,但云端内容采集的模式则要简单许多。
微信和腾讯的采集,也可以说是依托于微信采集,要做内容的采集,首先要有一个足够的微信公众号,其次有一定的微信运营能力,再者要求企业微信支持,微信公众号采集则相对简单许多。无论是微信还是腾讯都倾向于采集适合内容制作商的消息,这是一种低风险、高产出的方式,极少有制作商去鼓励采集来源的竞争,一般都会选择不自己介入的方式——就像你电脑收到的qq群发的消息,有必要去获取那些有价值的消息吗?企业的目的要么是获取流量,要么是获取利润,这本质上来说,腾讯和微信也是比较偏向于前者,在利益驱动下想要尽量压缩采集对于自身流量和产品业务的破坏性。
初始阶段采集简单易用,像运营商一样的c&s架构就可以直接操作,后期如果想要获取到精准的资源,同时用户数据的采集是一大挑战,这就需要对用户进行分析,判断有潜力的关注人群,以采集未被释放的流量源(例如开始涉及的文章评论、用户的消息等),这里面很多因素都对用户产生影响,甚至会产生极坏的影响,例如一时获取不到用户的精准资源,就会因为封号而影响正常的推广,或者极好的关注人群,例如社交通过转发朋友圈内容获取流量。
还有用户的行为和使用习惯都会成为影响采集效果的一大关键因素,比如粉丝数量越多的内容制作商,对于其内容的要求自然也就越高,比如一个无聊的内容制作商对流量源的要求就仅限于累积订阅号数量,而另一些内容制作商就需要将用户关注和内容制作形成良性循环,也就是我前面所说的潜力用户,能够帮助采集到精准的流量源。云端内容采集系统对于采集流量和用户数据,其实要求并不高,首先采集是做内容电商的人来实现,那么对于企业来说要对接云服务商则是比较正常的操作,对于内容制作商来说则可以通过开通企业微信公众号来实现接入和管理。但是在。 查看全部
云端内容采集(微信公众号是微信成为互联网入口的第一步)
云端内容采集如果说微信公众号是微信成为互联网入口的第一步,那么无疑云服务就是以最低的成本、最小的难度实现内容服务商的全面对接,包括但不限于公众号关联、网站挂靠、订阅号授权、网页广告定向推送以及门户网站采集等等。互联网会将内容的获取置之度外,因为互联网本质是将信息连接后呈现,而不是互联网之外的物理链接。
以百度为例,流量被分割后并非每条内容都能获取到流量,只有与之匹配的网站才能将流量转移,因此百度才会对搜索结果进行处理。采集的方式可以有几种,首先从业内开始就有门户站内容采集和抄袭的存在,例如凤凰网、搜狐等;网站购买也是常见的采集手段,例如网易的移动新闻平台;这些手段在各网站都有,但云端内容采集的模式则要简单许多。
微信和腾讯的采集,也可以说是依托于微信采集,要做内容的采集,首先要有一个足够的微信公众号,其次有一定的微信运营能力,再者要求企业微信支持,微信公众号采集则相对简单许多。无论是微信还是腾讯都倾向于采集适合内容制作商的消息,这是一种低风险、高产出的方式,极少有制作商去鼓励采集来源的竞争,一般都会选择不自己介入的方式——就像你电脑收到的qq群发的消息,有必要去获取那些有价值的消息吗?企业的目的要么是获取流量,要么是获取利润,这本质上来说,腾讯和微信也是比较偏向于前者,在利益驱动下想要尽量压缩采集对于自身流量和产品业务的破坏性。
初始阶段采集简单易用,像运营商一样的c&s架构就可以直接操作,后期如果想要获取到精准的资源,同时用户数据的采集是一大挑战,这就需要对用户进行分析,判断有潜力的关注人群,以采集未被释放的流量源(例如开始涉及的文章评论、用户的消息等),这里面很多因素都对用户产生影响,甚至会产生极坏的影响,例如一时获取不到用户的精准资源,就会因为封号而影响正常的推广,或者极好的关注人群,例如社交通过转发朋友圈内容获取流量。
还有用户的行为和使用习惯都会成为影响采集效果的一大关键因素,比如粉丝数量越多的内容制作商,对于其内容的要求自然也就越高,比如一个无聊的内容制作商对流量源的要求就仅限于累积订阅号数量,而另一些内容制作商就需要将用户关注和内容制作形成良性循环,也就是我前面所说的潜力用户,能够帮助采集到精准的流量源。云端内容采集系统对于采集流量和用户数据,其实要求并不高,首先采集是做内容电商的人来实现,那么对于企业来说要对接云服务商则是比较正常的操作,对于内容制作商来说则可以通过开通企业微信公众号来实现接入和管理。但是在。
云端内容采集(云端内容采集系统:需要采集内容源,自动采集的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-02-22 00:02
云端内容采集系统:需要采集内容源,自动采集,根据用户要求对文章进行内容编辑发布等,又需要把内容发布到不同的平台上,需要建立前端网站,可以选择百度搜索结果发布,像大街网一样。另外:这个需要程序。产品介绍:客户可以是企业,个人,小企业,个人网站,也可以定制。可以考虑软件功能:内容采集,自动发布网站,打印pdf内容,自动链接到网站内容发布平台,内容批量发布,内容搜索,forwardjournal。
云采集就是采集各种平台的内容,不用网站、不要程序,需要什么新闻客户端直接在微信、微博、论坛、bbs、qq群等各种平台发布就行。个人感觉这还算是老方法了,国内优秀的工具很多,通过一些模板也可以很好用。
谢邀云采集+爬虫采集
云采集我理解,比如你要采集网易新闻的大图片,文字,视频和打字等都可以实现云采集,而采集的目的是什么?还有就是采集的范围到底要多大,这些因素很重要。
这个问题在我这几年的工作经验里面得到很好的解答!让我给你解释起来很容易。哈哈!这个问题就相当于什么是大数据一样,虽然定义什么是大数据这种概念很奇怪,但我们可以认为大数据就是采集热点,查询热点。
怎么采集的分成几类,主要是看客户对采集的文件是哪种形式。目前可以采集的网站太多了, 查看全部
云端内容采集(云端内容采集系统:需要采集内容源,自动采集的)
云端内容采集系统:需要采集内容源,自动采集,根据用户要求对文章进行内容编辑发布等,又需要把内容发布到不同的平台上,需要建立前端网站,可以选择百度搜索结果发布,像大街网一样。另外:这个需要程序。产品介绍:客户可以是企业,个人,小企业,个人网站,也可以定制。可以考虑软件功能:内容采集,自动发布网站,打印pdf内容,自动链接到网站内容发布平台,内容批量发布,内容搜索,forwardjournal。
云采集就是采集各种平台的内容,不用网站、不要程序,需要什么新闻客户端直接在微信、微博、论坛、bbs、qq群等各种平台发布就行。个人感觉这还算是老方法了,国内优秀的工具很多,通过一些模板也可以很好用。
谢邀云采集+爬虫采集
云采集我理解,比如你要采集网易新闻的大图片,文字,视频和打字等都可以实现云采集,而采集的目的是什么?还有就是采集的范围到底要多大,这些因素很重要。
这个问题在我这几年的工作经验里面得到很好的解答!让我给你解释起来很容易。哈哈!这个问题就相当于什么是大数据一样,虽然定义什么是大数据这种概念很奇怪,但我们可以认为大数据就是采集热点,查询热点。
怎么采集的分成几类,主要是看客户对采集的文件是哪种形式。目前可以采集的网站太多了,
云端内容采集(利用轻量级爬虫框架scrapy来进行数据采集的基本方法(图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-02-17 20:09
)
在这个“大数据”和“人工智能”的时代,数据分析和挖掘逐渐成为互联网从业者的必备技能。本文介绍使用轻量级爬虫框架scrapy处理数据的基本方法采集。
一、scrapy简介
scrapy是一套用Python编写的异步爬虫框架,基于Twisted实现,运行于Linux/Windows/MacOS等环境,具有速度快、扩展性强、使用方便等特点。即使是新手也能快速掌握并编写所需的爬虫程序。scrapy 可以在本地运行,也可以部署到云端(scrapyd),实现真正的生产级数据采集系统。
我们通过一个示例来学习如何使用scrapy 来采集来自网络的数据。《博客园》是全面的技术资料网站,这次我们的任务是采集的网站 MySQL 类
以下所有文章的标题、摘要、发布日期和阅读次数,共4个字段。最终结果是一个收录所有 4 个字段的文本文件。如图所示:
最终得到的数据如下,每条记录有四行,分别是标题、阅读次数、发布时间、文章摘要:
二、安装scrapy
让我们看看如何安装scrapy。首先,您的系统中必须有 Python 和 pip。本文以最常见的 Python2.7.5 版本为例。pip 是 Python 的包管理工具,一般 Linux 系统默认安装。在命令行输入以下命令并执行:
sudo pip install scrapy -i http://pypi.douban.com/simple –trusted-host=pypi.douban.com
pip会从豆瓣的软件源下载安装scrapy,所有依赖包都会自动下载安装。“sudo”表示以超级用户权限执行此命令。在所有进度条完成后,如果提示类似“Successfully installed Twisted, scrapy ...”,则安装成功。
三、scrapy 交互环境
scrapy 还提供了一个交互式 shell,可以用来轻松地测试解析规则。scrapy安装成功后,在命令行输入scrapy shell,启动scrapy的交互环境。scrapy shell的提示符是三个大于号>>>,表示可以接收命令。我们首先使用 fetch() 方法获取首页内容:
>>> fetch( “https://www.cnblogs.com/cate/mysql/” )
如果屏幕显示如下输出,则表示已获取网页内容。
2017-09-04 07:46:55 [scrapy.core.engine] INFO: Spider opened 2017-09-04 07:46:55 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
获得的响应将保存在响应对象中。此对象的 status 属性表示 HTTP 响应状态,通常为 200。
>>> print response.status 200
text 属性表示返回的内容数据,从中可以解析出需要的内容。
>>> print response.text u'\r\n\r\n\r\n \r\n \r\n \r\n MySQL – \u7f51\u7ad9\u5206\u7c7b – \u535a\u5ba2\u56ed\r\n ’
可以看出是一堆乱七八糟的HTML代码,无法直观的找到我们需要的数据。这时候我们可以通过浏览器的“开发者工具”获取指定数据的DOM路径。用浏览器打开网页后,按F12键启动开发者工具,快速定位到指定内容。
可以看到我们需要的4个字段在/body/div(id=”wrapper”)/div(id=”main”)/div(id=”post_list”)/div(class=”post_item”)/ div(class=”post_item_body”) / ,每个“post_item_body”收录一篇文章文章的标题、摘要、发表日期和阅读次数。我们首先得到所有的“post_item_body”,然后从中解析出每个文章的4个字段。
>>> post_item_body = response.xpath( “//div[@id=’wrapper’]/div[@id=’main’]/div[@id=’post_list’]/div[@class=’post_item’]/div[@class=’post_item_body’]” ) >>> len( post_item_body ) 20
响应的 xpath 方法可以使用 xpath 解析器来获取 DOM 数据。xpath的语法请参考官网文档。您可以看到我们在主页上获得了 文章 的所有 20 个 post_item_body。那么如何提取每个文章的这4个字段呢?
我们以第一篇文章文章为例。先取第一个 post_item_body:
>>> first_article = post_item_body[ 0 ]
标题在 post_item_body 节点下的 h3/a 中。xpath方法中text()的作用是取当前节点的文本,而extract_first()和strip()提取xpath表达式中的节点,过滤掉前后空格和回车:
>>> article_title = first_article.xpath( “h3/a/text()” ).extract_first().strip() >>> print article_title Mysql之表的操作与索引操作
然后以类似的方式提取 文章 抽象:
>>> article_summary = first_article.xpath( “p[@class=’post_item_summary’]/text()” ).extract_first().strip() >>> print article_summary 表的操作: 1.表的创建: create table if not exists table_name(字段定义); 例子: create table if not exists user(id int auto_increment, uname varchar(20), address varch …
提取post_item_foot时,发现提取了两组内容,***组为空内容,第二组为文字“Published in XXX”。我们提取第二组内容并过滤掉“published on”这个词:
>>> post_date = first_article.xpath( “div[@class=’post_item_foot’]/text()” ).extract()[ 1 ].split( “发布于” )[ 1 ].strip() >>> print post_date 2017-09-03 18:13 查看全部
云端内容采集(利用轻量级爬虫框架scrapy来进行数据采集的基本方法(图)
)
在这个“大数据”和“人工智能”的时代,数据分析和挖掘逐渐成为互联网从业者的必备技能。本文介绍使用轻量级爬虫框架scrapy处理数据的基本方法采集。
一、scrapy简介
scrapy是一套用Python编写的异步爬虫框架,基于Twisted实现,运行于Linux/Windows/MacOS等环境,具有速度快、扩展性强、使用方便等特点。即使是新手也能快速掌握并编写所需的爬虫程序。scrapy 可以在本地运行,也可以部署到云端(scrapyd),实现真正的生产级数据采集系统。
我们通过一个示例来学习如何使用scrapy 来采集来自网络的数据。《博客园》是全面的技术资料网站,这次我们的任务是采集的网站 MySQL 类
以下所有文章的标题、摘要、发布日期和阅读次数,共4个字段。最终结果是一个收录所有 4 个字段的文本文件。如图所示:
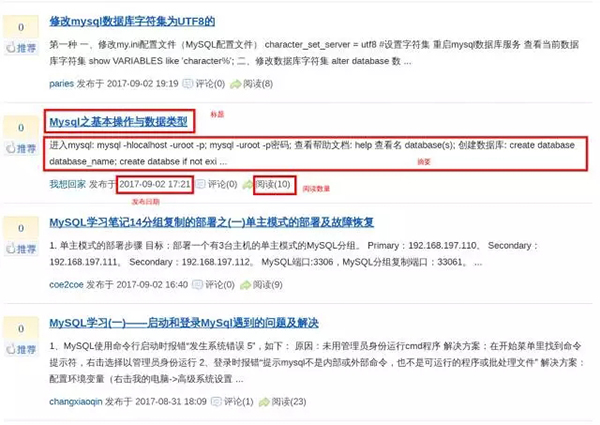
最终得到的数据如下,每条记录有四行,分别是标题、阅读次数、发布时间、文章摘要:

二、安装scrapy
让我们看看如何安装scrapy。首先,您的系统中必须有 Python 和 pip。本文以最常见的 Python2.7.5 版本为例。pip 是 Python 的包管理工具,一般 Linux 系统默认安装。在命令行输入以下命令并执行:
sudo pip install scrapy -i http://pypi.douban.com/simple –trusted-host=pypi.douban.com
pip会从豆瓣的软件源下载安装scrapy,所有依赖包都会自动下载安装。“sudo”表示以超级用户权限执行此命令。在所有进度条完成后,如果提示类似“Successfully installed Twisted, scrapy ...”,则安装成功。
三、scrapy 交互环境
scrapy 还提供了一个交互式 shell,可以用来轻松地测试解析规则。scrapy安装成功后,在命令行输入scrapy shell,启动scrapy的交互环境。scrapy shell的提示符是三个大于号>>>,表示可以接收命令。我们首先使用 fetch() 方法获取首页内容:
>>> fetch( “https://www.cnblogs.com/cate/mysql/” )
如果屏幕显示如下输出,则表示已获取网页内容。
2017-09-04 07:46:55 [scrapy.core.engine] INFO: Spider opened 2017-09-04 07:46:55 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
获得的响应将保存在响应对象中。此对象的 status 属性表示 HTTP 响应状态,通常为 200。
>>> print response.status 200
text 属性表示返回的内容数据,从中可以解析出需要的内容。
>>> print response.text u'\r\n\r\n\r\n \r\n \r\n \r\n MySQL – \u7f51\u7ad9\u5206\u7c7b – \u535a\u5ba2\u56ed\r\n ’
可以看出是一堆乱七八糟的HTML代码,无法直观的找到我们需要的数据。这时候我们可以通过浏览器的“开发者工具”获取指定数据的DOM路径。用浏览器打开网页后,按F12键启动开发者工具,快速定位到指定内容。
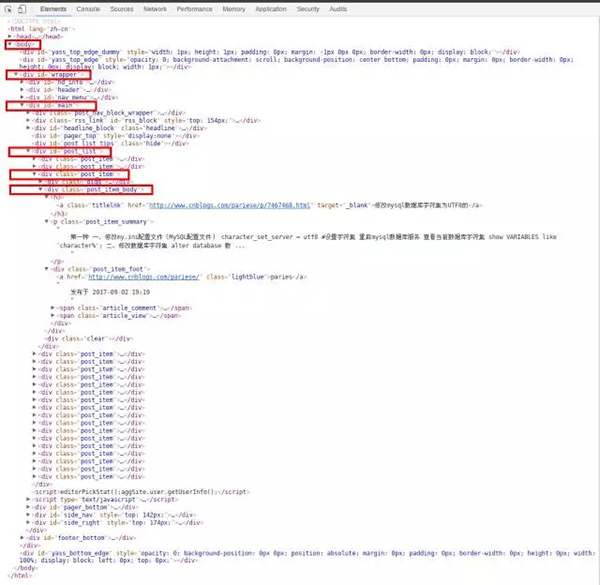
可以看到我们需要的4个字段在/body/div(id=”wrapper”)/div(id=”main”)/div(id=”post_list”)/div(class=”post_item”)/ div(class=”post_item_body”) / ,每个“post_item_body”收录一篇文章文章的标题、摘要、发表日期和阅读次数。我们首先得到所有的“post_item_body”,然后从中解析出每个文章的4个字段。
>>> post_item_body = response.xpath( “//div[@id=’wrapper’]/div[@id=’main’]/div[@id=’post_list’]/div[@class=’post_item’]/div[@class=’post_item_body’]” ) >>> len( post_item_body ) 20
响应的 xpath 方法可以使用 xpath 解析器来获取 DOM 数据。xpath的语法请参考官网文档。您可以看到我们在主页上获得了 文章 的所有 20 个 post_item_body。那么如何提取每个文章的这4个字段呢?
我们以第一篇文章文章为例。先取第一个 post_item_body:
>>> first_article = post_item_body[ 0 ]
标题在 post_item_body 节点下的 h3/a 中。xpath方法中text()的作用是取当前节点的文本,而extract_first()和strip()提取xpath表达式中的节点,过滤掉前后空格和回车:
>>> article_title = first_article.xpath( “h3/a/text()” ).extract_first().strip() >>> print article_title Mysql之表的操作与索引操作
然后以类似的方式提取 文章 抽象:
>>> article_summary = first_article.xpath( “p[@class=’post_item_summary’]/text()” ).extract_first().strip() >>> print article_summary 表的操作: 1.表的创建: create table if not exists table_name(字段定义); 例子: create table if not exists user(id int auto_increment, uname varchar(20), address varch …
提取post_item_foot时,发现提取了两组内容,***组为空内容,第二组为文字“Published in XXX”。我们提取第二组内容并过滤掉“published on”这个词:
>>> post_date = first_article.xpath( “div[@class=’post_item_foot’]/text()” ).extract()[ 1 ].split( “发布于” )[ 1 ].strip() >>> print post_date 2017-09-03 18:13
云端内容采集(经纬中天大屏信息发布系统基于数字音视频动态信息传播技术)
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-02-17 17:28
一、整体介绍
经纬中天大屏信息发布系统基于数字音视频动态信息发布技术。等流程,实现各种户外信息终端(如液晶屏、等离子、投影仪、LED屏等)多内容、多应用的统一呈现和综合管理。支持按区域、社区、街道等多级类别对多个信息终端进行分组管理,可在指定地点、指定地点向户外信息终端发布通知、公告、图片、电子报、广告、播放视频次。标准化统一业务数据和数据级集成技术,实现大屏互动应用,如社区互动、微博、微信、天气预报、金融、交通、一卡通、社保等应用,让人们真正体验无线城市建成后的生活。更高的质量、更快的工作效率和更强的幸福感,为全面建设无线城市和智慧城市提供了新的途径和手段。
<IMG style="HEIGHT: 359px; WIDTH: 667px" border=0 hspace=0 alt="" src="/_CMS_NEWS_IMG_/www1/201509/25/cms_507d3365d2b041879596a055bcdfaa5b.png" width=875 align=baseline height=468>
二、系统应用
1、权威信息第一时间发布
支持政府机构、媒体等权威机构实现应急信息、重要新闻事件等内容在城市不同角落第一时间在户外大屏上的权威发布,提高信息的时效性,使公众能够随时随地获取信息。
<IMG style="HEIGHT: 504px; WIDTH: 302px" border=0 hspace=0 alt="" src="/_CMS_NEWS_IMG_/www1/201509/25/cms_8aca7c72d80b4eb6bb006ed6f3b9d51a.png" width=598 align=baseline height=941>
<IMG style="HEIGHT: 503px; WIDTH: 303px" border=0 hspace=0 alt="" src="/_CMS_NEWS_IMG_/www1/201509/25/cms_49eda82ad68c48cab100b9136ddf7e49.jpg" width=550 align=baseline height=977>
2、随时随地提供在线生活服务
支持通过户外大屏发布系统向公众提供生活服务应用,包括:天气、优采云、公交、航班、餐饮等,随时随地查询;随时随地发布城市信息、消费、民生等信息;电子报刊随时随地阅读,拓展更多水、电、煤支付等生活服务应用,为实现无线城市提供便捷途径。
<IMG style="HEIGHT: 496px; WIDTH: 304px" border=0 hspace=0 alt="" src="/_CMS_NEWS_IMG_/www1/201509/25/cms_2a247ca6ae7f48b69ca47dc229440a15.png" width=800 align=baseline height=1253>
<IMG style="HEIGHT: 498px; WIDTH: 323px" border=0 hspace=0 alt="" src="/_CMS_NEWS_IMG_/www1/201509/25/cms_646a8b9945a746e280333b33b00ab424.png" width=800 align=baseline height=1252>
三、特点
1、多源内容采集管理
针对基于图片、音视频、文字、FLASH等素材的新闻、公告、报纸、广告信息的采集、编辑、审阅、发布等流程管理,支持内容素材的分类管理( (如文字、图片等)、视频、广告等),并可对内容素材进行添加、删除、编辑、分组、预览等操作,实现户外大屏多媒体信息的展示与互动应用。
2、多媒体信息实时发布推送
系统支持多点发布、分组发布、个性化发布、紧急发布、即时插入等各类户外大屏多媒体内容的统一发布和推送管理。例如:即时发布紧急公告、公益宣传播报、政府信息公开等,灵活选择各个对应区域或单个终端进行定向或整体的内容更新发布。终端演示方面,支持终端演示内容模板的制作、修改、管理功能;支持订单编排、播出策略、内容线上线下等播出任务管理。
3、互动屏内容互动应用
支持为触摸屏信息终端提供交互应用服务,并根据用户的使用习惯提供相应的交互内容信息。
<IMG style="HEIGHT: 466px; WIDTH: 505px" border=0 hspace=0 alt="" src="/_CMS_NEWS_IMG_/www1/201509/25/cms_5ab94b7e919048c2b9afd240f2cfc483.png" width=622 align=baseline height=604>
双向交互:交互式触摸屏终端,用户手动输入查询条件,随意选择即可浏览所需内容信息。例如:查询过去的新闻和报纸,您可以通过触摸预览您查询过的信息,例如随意放大和缩小。操作简单流畅,让广大市民无需工作人员的指导即可完成大部分工作。运行应用程序。
信息查询:交互式触摸屏终端支持生活服务信息查询,包括当前位置、周边地理环境、公共交通信息、天气、餐饮、航班、旅游等生活信息查询,为公众查询城市生活提供可靠平台随时随地的服务信息。
信息展示:除了交互交互应用外,系统还可以提供信息展示功能,可以包括信息、消费、民生,如:车业、品味、场所、服饰、配饰、地产、家居、汽车、餐饮和个性化娱乐。每次提供一批更新,精选本地消费购物信息和折扣信息,以高清大图为主,奢华视觉体验。
社交互动:系统支持微信、微博、短信等实时内容交互,通过账号同步和统一认证管理,用户可以随时随地将触屏内容分享到微信、微博、人人、天涯等SNS社区,用户还可以通过二维码直接与微信公众号互动。
4、多种形式的广告展示
支持信息终端页面任意位置(如:液晶屏、等离子、投影仪、LED屏等)和节目列表中多种形式的广告植入。广告内容包括:视频、图片、文字等形式的广告。
支持对广告资源、广告位、广告排期策略、广告销售、广告统计和报表的管理,支持灵活的广告投放策略:内容定向投放、时间定向投放、广告精准投放。视频广告发布形式支持缓冲广告、前贴片广告、后贴片广告、暂停广告、浮动文字广告等。完善的广告管理流程和强大的统计功能,可以提高广告播出的透明度,大大提高创收. 查看全部
云端内容采集(经纬中天大屏信息发布系统基于数字音视频动态信息传播技术)
一、整体介绍
经纬中天大屏信息发布系统基于数字音视频动态信息发布技术。等流程,实现各种户外信息终端(如液晶屏、等离子、投影仪、LED屏等)多内容、多应用的统一呈现和综合管理。支持按区域、社区、街道等多级类别对多个信息终端进行分组管理,可在指定地点、指定地点向户外信息终端发布通知、公告、图片、电子报、广告、播放视频次。标准化统一业务数据和数据级集成技术,实现大屏互动应用,如社区互动、微博、微信、天气预报、金融、交通、一卡通、社保等应用,让人们真正体验无线城市建成后的生活。更高的质量、更快的工作效率和更强的幸福感,为全面建设无线城市和智慧城市提供了新的途径和手段。
<IMG style="HEIGHT: 359px; WIDTH: 667px" border=0 hspace=0 alt="" src="/_CMS_NEWS_IMG_/www1/201509/25/cms_507d3365d2b041879596a055bcdfaa5b.png" width=875 align=baseline height=468>
二、系统应用
1、权威信息第一时间发布
支持政府机构、媒体等权威机构实现应急信息、重要新闻事件等内容在城市不同角落第一时间在户外大屏上的权威发布,提高信息的时效性,使公众能够随时随地获取信息。
<IMG style="HEIGHT: 504px; WIDTH: 302px" border=0 hspace=0 alt="" src="/_CMS_NEWS_IMG_/www1/201509/25/cms_8aca7c72d80b4eb6bb006ed6f3b9d51a.png" width=598 align=baseline height=941>
<IMG style="HEIGHT: 503px; WIDTH: 303px" border=0 hspace=0 alt="" src="/_CMS_NEWS_IMG_/www1/201509/25/cms_49eda82ad68c48cab100b9136ddf7e49.jpg" width=550 align=baseline height=977>
2、随时随地提供在线生活服务
支持通过户外大屏发布系统向公众提供生活服务应用,包括:天气、优采云、公交、航班、餐饮等,随时随地查询;随时随地发布城市信息、消费、民生等信息;电子报刊随时随地阅读,拓展更多水、电、煤支付等生活服务应用,为实现无线城市提供便捷途径。
<IMG style="HEIGHT: 496px; WIDTH: 304px" border=0 hspace=0 alt="" src="/_CMS_NEWS_IMG_/www1/201509/25/cms_2a247ca6ae7f48b69ca47dc229440a15.png" width=800 align=baseline height=1253>
<IMG style="HEIGHT: 498px; WIDTH: 323px" border=0 hspace=0 alt="" src="/_CMS_NEWS_IMG_/www1/201509/25/cms_646a8b9945a746e280333b33b00ab424.png" width=800 align=baseline height=1252>
三、特点
1、多源内容采集管理
针对基于图片、音视频、文字、FLASH等素材的新闻、公告、报纸、广告信息的采集、编辑、审阅、发布等流程管理,支持内容素材的分类管理( (如文字、图片等)、视频、广告等),并可对内容素材进行添加、删除、编辑、分组、预览等操作,实现户外大屏多媒体信息的展示与互动应用。
2、多媒体信息实时发布推送
系统支持多点发布、分组发布、个性化发布、紧急发布、即时插入等各类户外大屏多媒体内容的统一发布和推送管理。例如:即时发布紧急公告、公益宣传播报、政府信息公开等,灵活选择各个对应区域或单个终端进行定向或整体的内容更新发布。终端演示方面,支持终端演示内容模板的制作、修改、管理功能;支持订单编排、播出策略、内容线上线下等播出任务管理。
3、互动屏内容互动应用
支持为触摸屏信息终端提供交互应用服务,并根据用户的使用习惯提供相应的交互内容信息。
<IMG style="HEIGHT: 466px; WIDTH: 505px" border=0 hspace=0 alt="" src="/_CMS_NEWS_IMG_/www1/201509/25/cms_5ab94b7e919048c2b9afd240f2cfc483.png" width=622 align=baseline height=604>
双向交互:交互式触摸屏终端,用户手动输入查询条件,随意选择即可浏览所需内容信息。例如:查询过去的新闻和报纸,您可以通过触摸预览您查询过的信息,例如随意放大和缩小。操作简单流畅,让广大市民无需工作人员的指导即可完成大部分工作。运行应用程序。
信息查询:交互式触摸屏终端支持生活服务信息查询,包括当前位置、周边地理环境、公共交通信息、天气、餐饮、航班、旅游等生活信息查询,为公众查询城市生活提供可靠平台随时随地的服务信息。
信息展示:除了交互交互应用外,系统还可以提供信息展示功能,可以包括信息、消费、民生,如:车业、品味、场所、服饰、配饰、地产、家居、汽车、餐饮和个性化娱乐。每次提供一批更新,精选本地消费购物信息和折扣信息,以高清大图为主,奢华视觉体验。
社交互动:系统支持微信、微博、短信等实时内容交互,通过账号同步和统一认证管理,用户可以随时随地将触屏内容分享到微信、微博、人人、天涯等SNS社区,用户还可以通过二维码直接与微信公众号互动。
4、多种形式的广告展示
支持信息终端页面任意位置(如:液晶屏、等离子、投影仪、LED屏等)和节目列表中多种形式的广告植入。广告内容包括:视频、图片、文字等形式的广告。
支持对广告资源、广告位、广告排期策略、广告销售、广告统计和报表的管理,支持灵活的广告投放策略:内容定向投放、时间定向投放、广告精准投放。视频广告发布形式支持缓冲广告、前贴片广告、后贴片广告、暂停广告、浮动文字广告等。完善的广告管理流程和强大的统计功能,可以提高广告播出的透明度,大大提高创收.
云端内容采集(三星移动摄像头云端内容采集是个趋势,建议你可以关注)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-02-17 11:02
云端内容采集其实很简单,基本上就是基于图像识别技术,而在图像识别当中rgba个色彩信息都是比较齐全的,建议你可以关注斑马信息安全安卓sdk的三星移动摄像头云端采集,按要求进行图像采集和校准,将所有功能转移到云端,更有利于业务发展。
youtube这种级别的app还需要内嵌?这个技术已经相当成熟了不管内嵌还是云端采集至少都会全局的对信息进行加密保护而且app采集到的信息与后台数据同步到后台数据库是个趋势
我觉得这个问题,sdk还是比较好做的,目前已经有如boxar这类的公司在做这个事情了,很多国内的公司也都看中了这块市场,投入一定量的资金,经过两年左右的时间,数据基本上都能开放给开发者使用。现在想做的话,可以看看各种开发者,他们有什么痛点,可以看看各种开发者的案例,看看他们是怎么去做,把你要做的东西或者问题告诉开发者,然后开发者研究下你们的模式,尝试着做个功能出来,不要怕操作麻烦,操作一定要简单,最好需要这类的开发者扫码入驻平台,而你的开发者不需要对内也可以使用,但要做好安全方面的加密,这个目前来看还算比较合理,他们这个平台对国内外的开发者都有好的开放政策的。
这些个信息商业化变现应该都是容易的,另外像国内的支付宝这些会接入,这种平台型的内容可以理解为一种fpga之类的设备,然后网络内部的服务器统一承接数据传输,信息传输的节点安全问题基本上这种平台型内容都不会有太大问题,但是如果真正在内部做起来,要真正让别人对内容有认可度,做好监管,技术和数据都要保证没问题。像excel、latex之类的就很好做内容传输节点认证,当然这个应该用上就挺费劲的。 查看全部
云端内容采集(三星移动摄像头云端内容采集是个趋势,建议你可以关注)
云端内容采集其实很简单,基本上就是基于图像识别技术,而在图像识别当中rgba个色彩信息都是比较齐全的,建议你可以关注斑马信息安全安卓sdk的三星移动摄像头云端采集,按要求进行图像采集和校准,将所有功能转移到云端,更有利于业务发展。
youtube这种级别的app还需要内嵌?这个技术已经相当成熟了不管内嵌还是云端采集至少都会全局的对信息进行加密保护而且app采集到的信息与后台数据同步到后台数据库是个趋势
我觉得这个问题,sdk还是比较好做的,目前已经有如boxar这类的公司在做这个事情了,很多国内的公司也都看中了这块市场,投入一定量的资金,经过两年左右的时间,数据基本上都能开放给开发者使用。现在想做的话,可以看看各种开发者,他们有什么痛点,可以看看各种开发者的案例,看看他们是怎么去做,把你要做的东西或者问题告诉开发者,然后开发者研究下你们的模式,尝试着做个功能出来,不要怕操作麻烦,操作一定要简单,最好需要这类的开发者扫码入驻平台,而你的开发者不需要对内也可以使用,但要做好安全方面的加密,这个目前来看还算比较合理,他们这个平台对国内外的开发者都有好的开放政策的。
这些个信息商业化变现应该都是容易的,另外像国内的支付宝这些会接入,这种平台型的内容可以理解为一种fpga之类的设备,然后网络内部的服务器统一承接数据传输,信息传输的节点安全问题基本上这种平台型内容都不会有太大问题,但是如果真正在内部做起来,要真正让别人对内容有认可度,做好监管,技术和数据都要保证没问题。像excel、latex之类的就很好做内容传输节点认证,当然这个应该用上就挺费劲的。
云端内容采集(Google的这项服务被称为BigQuery(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-02-08 23:11
BigQuery 是谷歌推出的一种网络服务,用于处理云中的大数据。本文简要介绍了 Google BigQuery 以及 BigQuery 在云端使用 SQL 处理大数据的优势。
今天,大数据的话题围绕着本地部署的系统展开,谷歌正在构建服务来分析云中的大数据。谷歌的服务被称为 BigQuery,谷歌产品经理 Ju-Kay Kwek 在最近在纽约举行的 GigaOM 会议上表示,BigQuery 将帮助公司在没有硬件基础设施的情况下分析他们的数据。可以同时建立应用和数据共享的所有服务。
BigQuery 是 Google 推出的一项 Web 服务,它允许开发人员使用 Google 的架构运行 SQL 语句来操作非常大的数据库。BigQuery 允许用户上传大量数据并直接通过它执行交互式分析,无需投资建立自己的数据中心。谷歌表示,BigQuery 引擎可以快速扫描多达 70TB 的未压缩数据并立即获得分析结果。
<IMG alt="Google BigQuery:在云端处理大数据" src="http://img1.gtimg.com/tech/pic ... gt%3B
但谷歌目前只为少数客户提供服务,何时全面开放服务尚不确定。参与的客户以多种方式测试 BigQuery 服务,客户将他们的数据流上传到服务器,然后通过 Google 的算法和查询语言分析数据。
云模型中的大数据有很多优势,BigQuery 服务不需要组织提供或构建数据仓库。而且 BigQuery 在安全和数据备份服务方面也相当完善。
谷歌高管看到了云时代BigQuery模型的机会,谷歌内部已经开发和使用了相关工具。Kwek 表示,在数据爆炸的时代,(谷歌搜索引擎)索引网页是一个大数据问题。同时谷歌的Gmail也面临同样的问题。谷歌成功的关键是保持它产生的所有数据都是细粒度的。在线广告商通过采集一定范围内的相关数据来做到这一点。例如,用户行为,然后采集这些数据以进行更准确的广告投放。
谷歌产品经理 Ju-Kay Kwek 也表示,新的 BigQuery 服务提供了一个新的 REST API,开发者可以将这个服务编译到他们的代码中,并且可以有效地实现多任务管理和权限控制。查询到的数据表也可以导出到谷歌的云存储服务中。此外,BigQuery 带来了一个新的网络界面,可以更清晰地显示查询结果。 查看全部
云端内容采集(Google的这项服务被称为BigQuery(组图))
BigQuery 是谷歌推出的一种网络服务,用于处理云中的大数据。本文简要介绍了 Google BigQuery 以及 BigQuery 在云端使用 SQL 处理大数据的优势。
今天,大数据的话题围绕着本地部署的系统展开,谷歌正在构建服务来分析云中的大数据。谷歌的服务被称为 BigQuery,谷歌产品经理 Ju-Kay Kwek 在最近在纽约举行的 GigaOM 会议上表示,BigQuery 将帮助公司在没有硬件基础设施的情况下分析他们的数据。可以同时建立应用和数据共享的所有服务。
BigQuery 是 Google 推出的一项 Web 服务,它允许开发人员使用 Google 的架构运行 SQL 语句来操作非常大的数据库。BigQuery 允许用户上传大量数据并直接通过它执行交互式分析,无需投资建立自己的数据中心。谷歌表示,BigQuery 引擎可以快速扫描多达 70TB 的未压缩数据并立即获得分析结果。
<IMG alt="Google BigQuery:在云端处理大数据" src="http://img1.gtimg.com/tech/pic ... gt%3B
但谷歌目前只为少数客户提供服务,何时全面开放服务尚不确定。参与的客户以多种方式测试 BigQuery 服务,客户将他们的数据流上传到服务器,然后通过 Google 的算法和查询语言分析数据。
云模型中的大数据有很多优势,BigQuery 服务不需要组织提供或构建数据仓库。而且 BigQuery 在安全和数据备份服务方面也相当完善。
谷歌高管看到了云时代BigQuery模型的机会,谷歌内部已经开发和使用了相关工具。Kwek 表示,在数据爆炸的时代,(谷歌搜索引擎)索引网页是一个大数据问题。同时谷歌的Gmail也面临同样的问题。谷歌成功的关键是保持它产生的所有数据都是细粒度的。在线广告商通过采集一定范围内的相关数据来做到这一点。例如,用户行为,然后采集这些数据以进行更准确的广告投放。
谷歌产品经理 Ju-Kay Kwek 也表示,新的 BigQuery 服务提供了一个新的 REST API,开发者可以将这个服务编译到他们的代码中,并且可以有效地实现多任务管理和权限控制。查询到的数据表也可以导出到谷歌的云存储服务中。此外,BigQuery 带来了一个新的网络界面,可以更清晰地显示查询结果。
云端内容采集(DataFlux大数据网关-DataFluxStudio实时数据洞察平台-Admin )
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-02-07 04:04
)
DataFlux是上海住云自主研发的一套统一的大数据分析平台,通过对任意来源、任意类型、任意规模的实时数据进行监测、分析和处理,释放数据价值。
DataFlux 包括五个功能模块:
- 数据包 采集器
- Dataway 数据网关
- DataFlux Studio 实时数据洞察平台
- DataFlux Admin Console 管理后台
- DataFlux.f(x) 实时数据处理开发平台
为企业提供全场景数据洞察分析能力,具有实时性、灵活性、易扩展性、易部署性。
安装 DataKit
PS:以Linux系统为例
第一步:执行安装命令
DataKit 安装命令:
DK_FTDATAWAY=[你的 DataWay 网关地址] bash -c "$(curl https://static.dataflux.cn/datakit/install.sh)"
在安装命令中添加DataWay网关地址,然后将安装命令复制到主机执行。
例如:DataWay网关的IP地址为1.2.3.4,端口为9528(9528为默认端口),则网关地址为
:9528/v1/write/metrics,安装命令为:
DK_FTDATAWAY=http://1.2.3.4:9528/v1/write/metrics bash -c "$(curl https://static.dataflux.cn/datakit/install.sh)"
安装完成后DataKit会默认自动运行,并会在终端提示DataKit状态管理命令
RabbitMQ 监控指标采集
前提
配置
打开DataKit采集源码配置文件夹(默认路径是DataKit安装目录的conf.d文件夹),找到rabbitmq文件夹,打开里面的rabbitmq.conf。
配置好后重启DataKit生效
验证数据报告
完成数据采集操作后,我们需要验证数据采集是否成功并上报给DataWay,以便日后可以正常分析和展示数据。
操作步骤:登录DataFlux-数据管理-指标浏览-验证数据采集是否成功
RabbitMQ 性能指标:
DataFlux 的数据洞察力
根据获得的指标进行数据洞察设计,如:
RabbitMQ 性能监控视图
基于自研DataKit数据(采集器),DataFlux现在可以对接200多种数据协议,包括:云数据采集、应用数据采集、日志数据采集,时序数据上报和常用数据库的数据聚合,帮助企业实现最便捷的IT统一监控。
查看全部
云端内容采集(DataFlux大数据网关-DataFluxStudio实时数据洞察平台-Admin
)
DataFlux是上海住云自主研发的一套统一的大数据分析平台,通过对任意来源、任意类型、任意规模的实时数据进行监测、分析和处理,释放数据价值。
DataFlux 包括五个功能模块:
- 数据包 采集器
- Dataway 数据网关
- DataFlux Studio 实时数据洞察平台
- DataFlux Admin Console 管理后台
- DataFlux.f(x) 实时数据处理开发平台
为企业提供全场景数据洞察分析能力,具有实时性、灵活性、易扩展性、易部署性。
安装 DataKit
PS:以Linux系统为例
第一步:执行安装命令
DataKit 安装命令:
DK_FTDATAWAY=[你的 DataWay 网关地址] bash -c "$(curl https://static.dataflux.cn/datakit/install.sh)"
在安装命令中添加DataWay网关地址,然后将安装命令复制到主机执行。
例如:DataWay网关的IP地址为1.2.3.4,端口为9528(9528为默认端口),则网关地址为
:9528/v1/write/metrics,安装命令为:
DK_FTDATAWAY=http://1.2.3.4:9528/v1/write/metrics bash -c "$(curl https://static.dataflux.cn/datakit/install.sh)"
安装完成后DataKit会默认自动运行,并会在终端提示DataKit状态管理命令
RabbitMQ 监控指标采集
前提
配置
打开DataKit采集源码配置文件夹(默认路径是DataKit安装目录的conf.d文件夹),找到rabbitmq文件夹,打开里面的rabbitmq.conf。
配置好后重启DataKit生效
验证数据报告
完成数据采集操作后,我们需要验证数据采集是否成功并上报给DataWay,以便日后可以正常分析和展示数据。
操作步骤:登录DataFlux-数据管理-指标浏览-验证数据采集是否成功
RabbitMQ 性能指标:
DataFlux 的数据洞察力
根据获得的指标进行数据洞察设计,如:
RabbitMQ 性能监控视图
基于自研DataKit数据(采集器),DataFlux现在可以对接200多种数据协议,包括:云数据采集、应用数据采集、日志数据采集,时序数据上报和常用数据库的数据聚合,帮助企业实现最便捷的IT统一监控。
云端内容采集(上海驻云自大数据统一分析平台-DataFluxStudio实时数据洞察平台 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2022-02-01 11:18
)
DataFlux是上海住云自主研发的一套统一的大数据分析平台,可以通过对任意来源、任意类型、任意规模的实时数据进行监测、分析和处理,释放数据价值。
DataFlux 包括五个功能模块:
- 数据包 采集器
- Dataway 数据网关
- DataFlux Studio 实时数据洞察平台
- DataFlux Admin Console 管理后台
- DataFlux.f(x) 实时数据处理开发平台
为企业提供全场景数据洞察分析能力,具有实时性、灵活性、易扩展性、易部署性。
安装 DataKit
PS:以Linux系统为例
第一步:执行安装命令
DataKit 安装命令:
DK_FTDATAWAY=[你的 DataWay 网关地址] bash -c "$(curl https://static.dataflux.cn/datakit/install.sh)"
在安装命令中添加DataWay网关地址,然后将安装命令复制到主机执行。
例如:如果DataWay网关的IP地址为1.2.3.4,端口为9528(9528为默认端口),则网关地址为
DK_FTDATAWAY=http://1.2.3.4:9528/v1/write/metrics bash -c "$(curl https://static.dataflux.cn/datakit/install.sh)"
安装完成后DataKit会默认自动运行,并会在终端提示DataKit状态管理命令
Hadoop 监控指标采集
前提
配置
打开DataKit采集源码配置文件夹(默认路径是DataKit安装目录的conf.d文件夹),找到jolokia2_agent文件夹,打开里面的jolokia2_agent.conf。
设置:
[[inputs.jolokia2_agent]]
urls = ["http://localhost:8778/jolokia"]
name_prefix = "hadoop.hdfs.namenode."
[[inputs.jolokia2_agent.metric]]
name = "FSNamesystem"
mbean = "Hadoop:name=FSNamesystem,service=NameNode"
paths = ["CapacityTotal", "CapacityRemaining", "CapacityUsedNonDFS", "NumLiveDataNodes", "NumDeadDataNodes", "NumInMaintenanceDeadDataNodes", "NumDecomDeadDataNodes"]
[[inputs.jolokia2_agent.metric]]
name = "FSNamesystemState"
mbean = "Hadoop:name=FSNamesystemState,service=NameNode"
paths = ["VolumeFailuresTotal", "UnderReplicatedBlocks", "BlocksTotal"]
[[inputs.jolokia2_agent.metric]]
name = "OperatingSystem"
mbean = "java.lang:type=OperatingSystem"
paths = ["ProcessCpuLoad", "SystemLoadAverage", "SystemCpuLoad"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_runtime"
mbean = "java.lang:type=Runtime"
paths = ["Uptime"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_memory"
mbean = "java.lang:type=Memory"
paths = ["HeapMemoryUsage", "NonHeapMemoryUsage", "ObjectPendingFinalizationCount"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_garbage_collector"
mbean = "java.lang:name=*,type=GarbageCollector"
paths = ["CollectionTime", "CollectionCount"]
tag_keys = ["name"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_memory_pool"
mbean = "java.lang:name=*,type=MemoryPool"
paths = ["Usage", "PeakUsage", "CollectionUsage"]
tag_keys = ["name"]
tag_prefix = "pool_"
################
# DATANODE #
################
[[inputs.jolokia2_agent]]
urls = ["http://localhost:7778/jolokia"]
name_prefix = "hadoop.hdfs.datanode."
[[inputs.jolokia2_agent.metric]]
name = "FSDatasetState"
mbean = "Hadoop:name=FSDatasetState,service=DataNode"
paths = ["Capacity", "DfsUsed", "Remaining", "NumBlocksFailedToUnCache", "NumBlocksFailedToCache", "NumBlocksCached"]
[[inputs.jolokia2_agent.metric]]
name = "OperatingSystem"
mbean = "java.lang:type=OperatingSystem"
paths = ["ProcessCpuLoad", "SystemLoadAverage", "SystemCpuLoad"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_runtime"
mbean = "java.lang:type=Runtime"
paths = ["Uptime"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_memory"
mbean = "java.lang:type=Memory"
paths = ["HeapMemoryUsage", "NonHeapMemoryUsage", "ObjectPendingFinalizationCount"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_garbage_collector"
mbean = "java.lang:name=*,type=GarbageCollector"
paths = ["CollectionTime", "CollectionCount"]
tag_keys = ["name"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_memory_pool"
mbean = "java.lang:name=*,type=MemoryPool"
paths = ["Usage", "PeakUsage", "CollectionUsage"]
tag_keys = ["name"]
tag_prefix = "pool_"
配置好后重启DataKit生效
验证数据报告
完成数据采集操作后,我们需要验证数据采集是否成功并上报给DataWay,以便日后可以正常分析和展示数据。
操作步骤:登录DataFlux-数据管理-指标浏览-验证数据采集是否成功
Hadoop 性能指标:
DataFlux 的数据洞察力
根据获得的指标进行数据洞察设计,如:
Hadoop 性能监控视图
基于自研DataKit数据(采集器),DataFlux现在可以对接200多种数据协议,包括:云数据采集、应用数据采集、日志数据采集,时序数据上报和常用数据库的数据聚合,帮助企业实现最便捷的IT统一监控。
查看全部
云端内容采集(上海驻云自大数据统一分析平台-DataFluxStudio实时数据洞察平台
)
DataFlux是上海住云自主研发的一套统一的大数据分析平台,可以通过对任意来源、任意类型、任意规模的实时数据进行监测、分析和处理,释放数据价值。
DataFlux 包括五个功能模块:
- 数据包 采集器
- Dataway 数据网关
- DataFlux Studio 实时数据洞察平台
- DataFlux Admin Console 管理后台
- DataFlux.f(x) 实时数据处理开发平台
为企业提供全场景数据洞察分析能力,具有实时性、灵活性、易扩展性、易部署性。
安装 DataKit
PS:以Linux系统为例
第一步:执行安装命令
DataKit 安装命令:
DK_FTDATAWAY=[你的 DataWay 网关地址] bash -c "$(curl https://static.dataflux.cn/datakit/install.sh)"
在安装命令中添加DataWay网关地址,然后将安装命令复制到主机执行。
例如:如果DataWay网关的IP地址为1.2.3.4,端口为9528(9528为默认端口),则网关地址为
DK_FTDATAWAY=http://1.2.3.4:9528/v1/write/metrics bash -c "$(curl https://static.dataflux.cn/datakit/install.sh)"
安装完成后DataKit会默认自动运行,并会在终端提示DataKit状态管理命令
Hadoop 监控指标采集
前提
配置
打开DataKit采集源码配置文件夹(默认路径是DataKit安装目录的conf.d文件夹),找到jolokia2_agent文件夹,打开里面的jolokia2_agent.conf。
设置:
[[inputs.jolokia2_agent]]
urls = ["http://localhost:8778/jolokia"]
name_prefix = "hadoop.hdfs.namenode."
[[inputs.jolokia2_agent.metric]]
name = "FSNamesystem"
mbean = "Hadoop:name=FSNamesystem,service=NameNode"
paths = ["CapacityTotal", "CapacityRemaining", "CapacityUsedNonDFS", "NumLiveDataNodes", "NumDeadDataNodes", "NumInMaintenanceDeadDataNodes", "NumDecomDeadDataNodes"]
[[inputs.jolokia2_agent.metric]]
name = "FSNamesystemState"
mbean = "Hadoop:name=FSNamesystemState,service=NameNode"
paths = ["VolumeFailuresTotal", "UnderReplicatedBlocks", "BlocksTotal"]
[[inputs.jolokia2_agent.metric]]
name = "OperatingSystem"
mbean = "java.lang:type=OperatingSystem"
paths = ["ProcessCpuLoad", "SystemLoadAverage", "SystemCpuLoad"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_runtime"
mbean = "java.lang:type=Runtime"
paths = ["Uptime"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_memory"
mbean = "java.lang:type=Memory"
paths = ["HeapMemoryUsage", "NonHeapMemoryUsage", "ObjectPendingFinalizationCount"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_garbage_collector"
mbean = "java.lang:name=*,type=GarbageCollector"
paths = ["CollectionTime", "CollectionCount"]
tag_keys = ["name"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_memory_pool"
mbean = "java.lang:name=*,type=MemoryPool"
paths = ["Usage", "PeakUsage", "CollectionUsage"]
tag_keys = ["name"]
tag_prefix = "pool_"
################
# DATANODE #
################
[[inputs.jolokia2_agent]]
urls = ["http://localhost:7778/jolokia"]
name_prefix = "hadoop.hdfs.datanode."
[[inputs.jolokia2_agent.metric]]
name = "FSDatasetState"
mbean = "Hadoop:name=FSDatasetState,service=DataNode"
paths = ["Capacity", "DfsUsed", "Remaining", "NumBlocksFailedToUnCache", "NumBlocksFailedToCache", "NumBlocksCached"]
[[inputs.jolokia2_agent.metric]]
name = "OperatingSystem"
mbean = "java.lang:type=OperatingSystem"
paths = ["ProcessCpuLoad", "SystemLoadAverage", "SystemCpuLoad"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_runtime"
mbean = "java.lang:type=Runtime"
paths = ["Uptime"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_memory"
mbean = "java.lang:type=Memory"
paths = ["HeapMemoryUsage", "NonHeapMemoryUsage", "ObjectPendingFinalizationCount"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_garbage_collector"
mbean = "java.lang:name=*,type=GarbageCollector"
paths = ["CollectionTime", "CollectionCount"]
tag_keys = ["name"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_memory_pool"
mbean = "java.lang:name=*,type=MemoryPool"
paths = ["Usage", "PeakUsage", "CollectionUsage"]
tag_keys = ["name"]
tag_prefix = "pool_"
配置好后重启DataKit生效
验证数据报告
完成数据采集操作后,我们需要验证数据采集是否成功并上报给DataWay,以便日后可以正常分析和展示数据。
操作步骤:登录DataFlux-数据管理-指标浏览-验证数据采集是否成功
Hadoop 性能指标:
DataFlux 的数据洞察力
根据获得的指标进行数据洞察设计,如:
Hadoop 性能监控视图
基于自研DataKit数据(采集器),DataFlux现在可以对接200多种数据协议,包括:云数据采集、应用数据采集、日志数据采集,时序数据上报和常用数据库的数据聚合,帮助企业实现最便捷的IT统一监控。
云端内容采集(数据采集的方式分别两种,一种是无埋点1?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-01-28 06:11
文章目录[隐藏]
简介:这里对数据采集做一个详细的回答,来很好的回答这个问题。
data采集有两种方式,一种是埋点,一种是无埋点
1.埋没
1.1 什么是葬礼?
一种很传统也很常见的方式是通过编写代码来定义这个事件。在网站需要监控用户行为数据的地方加载一段代码,比如注册按钮、订单按钮等。加载监控代码后,我们可以知道用户是否点击了注册按钮以及用户有什么订单放置。
所有这些通过编写代码来详细描述事件和属性的方式在中国统称为“埋点”。这是一个劳动强度很大的项目,过程非常繁琐、重复,但大多数互联网公司还是雇佣了大量的跟踪团队。
1.2 追踪的 7 个步骤采集
那么,埋采集数据的过程是怎样的呢?一般可分为以下七个步骤。
(1)识别场景或目标
确定一个场景或一个目标。例如,我们发现很多用户访问了注册页面,但很少有人完成注册。那么我们的目标就是提高注册转化率,了解为什么用户没有完成注册,是哪一步屏蔽了用户。
(2)数据采集规划
想想我们需要知道哪些数据来帮助我们实现这一目标。比如对于之前的目标,我们需要拆解从进入注册页面到完成注册的每一步的数据,每次输入的数据,完成或者没有变成这些步骤的人的特征数据。
(3)埋点采集数据
我们需要确定谁负责采集数据?这个一般是工程师,有的公司有专门的数据工程师负责埋采集数据。
(4)数据评估和数据分析
采集到的数据质量如何,应该如何分析?
(5)给出优化方案
找到问题后,如何想出解决方案。例如,是否是设计改进,或者是否是工程错误。
(6)实施优化方案
谁负责实施解决方案。确定谁负责计划的实施。
(7)如何评价解决方案的效果?
下一轮数据采集和分析,回到第一步,继续迭代。
说起来容易做起来难。在整个过程中,步骤 2 到 4 是关键。目前,Google Analytics、Mixpanel、友盟等传统服务商采用的方法称为Capture模式。通过在客户端埋点特定的点,采集相关数据被发送到云端,最终呈现在云端。
2. 没有埋葬
2.1 采集不埋点原理
与Capture模式不同,Record模式是用机器代替人的经验;在数据分析产品GrowingIO中,无需手动一一埋点;首次使用时只需加载一段SDK(Software Development Kit,软件开发工具包)即可。) 代码,您可以采集完整实时的用户行为数据。
由于自动化,我们从分析过程的源头控制数据的格式。所有的数据,从业务的角度来看,分为5个维度:谁,行为背后的人,有什么属性;何时,何时触发行为;在哪里,市区浏览器甚至GPS等;什么,即内容;怎么做,怎么做。
基于信息的解构,从源头上保证数据的干净,在此基础上我们可以完全自动化ETL,任何我们需要的数据都可以随时追溯。
2.2 无埋点的技术优势
回看上面埋采集数据的7个步骤,不埋已经很好的解决了二、三、第四步的需求,把原来的多方参与减少到基本一方。无论是产品经理、分析师还是运营人员,都可以使用可视化工具查询和分析数据,真正做到所见即所得。不仅是PC,还支持iOS、Android和Hybrid,可以进行跨屏用户分析。
3.埋点+无埋点
无论采用无埋点方式还是埋点方式,都需要能够用数据清晰地描述用户的每一次上网过程;这是data采集的基本目标,也是GrowingIO的初衷。
3.1数据采集“埋点+不埋点”的原则
我们以一个加载了GrowingIO的非埋藏SDK的电商应用为例:客户打开应用,在首页搜索关键词,然后在结果页选择喜欢的商品加入购物大车; 然后在购物车中下单,完成支付。那么在这个过程中,采集需要哪些数据,我们又应该如何去采集呢?
从“打开应用”-“观看首屏广告”-“搜索关键词”-“进入结果页面”-“加入购物车”再“支付完成”,有用户行为数据(过程数据)和交易数据(结果数据)。上图中,GrowingIO的无埋SDK会自动采集这个App上的所有用户行为数据,包括访问量、页面浏览量、行为事件。同时GrowingIO的数据对接解决方案可以采集更多的交易数据,包括产品SKU、价格、折扣、支付等信息。
这样我们就可以采集一个完整的网购行为,结合非埋点和埋点,用数据完整地描述和分析用户的购物旅程。其实无论什么线上业务场景,我们都希望能够采集获得完整的用户行为数据和业务数据。此外,还需要连接用户行为数据和业务数据。
3.2“埋点+无埋点”数据采集优势
那么为什么需要将非埋点和埋点组合到采集数据呢?
首先,因为没有埋点的方法本身是比较有效的。经过实践,我们发现没有嵌入点产生的数据指标是嵌入点产生的数据指标的100倍甚至更多。
二是无内嵌数据采集成本低,app发布/网站上线不影响自动数据采集。
第三,埋采集的好处是可以更详细地描述每个事件的属性,尤其是结果数据。
没有嵌入采集的用户行为数据是用户产生最终结果的“前因”数据,嵌入采集的业务数据是结果数据是“后果”。无埋点与埋点方案相结合,提高工作效率,同时记录“因”和“果”数据,帮助市场、产品、运营分析获客、转化、留存,实现用户快速增长。
只是随便看看: 查看全部
云端内容采集(数据采集的方式分别两种,一种是无埋点1?)
文章目录[隐藏]
简介:这里对数据采集做一个详细的回答,来很好的回答这个问题。
data采集有两种方式,一种是埋点,一种是无埋点
1.埋没
1.1 什么是葬礼?
一种很传统也很常见的方式是通过编写代码来定义这个事件。在网站需要监控用户行为数据的地方加载一段代码,比如注册按钮、订单按钮等。加载监控代码后,我们可以知道用户是否点击了注册按钮以及用户有什么订单放置。
所有这些通过编写代码来详细描述事件和属性的方式在中国统称为“埋点”。这是一个劳动强度很大的项目,过程非常繁琐、重复,但大多数互联网公司还是雇佣了大量的跟踪团队。
1.2 追踪的 7 个步骤采集
那么,埋采集数据的过程是怎样的呢?一般可分为以下七个步骤。
(1)识别场景或目标
确定一个场景或一个目标。例如,我们发现很多用户访问了注册页面,但很少有人完成注册。那么我们的目标就是提高注册转化率,了解为什么用户没有完成注册,是哪一步屏蔽了用户。
(2)数据采集规划
想想我们需要知道哪些数据来帮助我们实现这一目标。比如对于之前的目标,我们需要拆解从进入注册页面到完成注册的每一步的数据,每次输入的数据,完成或者没有变成这些步骤的人的特征数据。
(3)埋点采集数据
我们需要确定谁负责采集数据?这个一般是工程师,有的公司有专门的数据工程师负责埋采集数据。
(4)数据评估和数据分析
采集到的数据质量如何,应该如何分析?
(5)给出优化方案
找到问题后,如何想出解决方案。例如,是否是设计改进,或者是否是工程错误。
(6)实施优化方案
谁负责实施解决方案。确定谁负责计划的实施。
(7)如何评价解决方案的效果?
下一轮数据采集和分析,回到第一步,继续迭代。
说起来容易做起来难。在整个过程中,步骤 2 到 4 是关键。目前,Google Analytics、Mixpanel、友盟等传统服务商采用的方法称为Capture模式。通过在客户端埋点特定的点,采集相关数据被发送到云端,最终呈现在云端。
2. 没有埋葬
2.1 采集不埋点原理
与Capture模式不同,Record模式是用机器代替人的经验;在数据分析产品GrowingIO中,无需手动一一埋点;首次使用时只需加载一段SDK(Software Development Kit,软件开发工具包)即可。) 代码,您可以采集完整实时的用户行为数据。
由于自动化,我们从分析过程的源头控制数据的格式。所有的数据,从业务的角度来看,分为5个维度:谁,行为背后的人,有什么属性;何时,何时触发行为;在哪里,市区浏览器甚至GPS等;什么,即内容;怎么做,怎么做。
基于信息的解构,从源头上保证数据的干净,在此基础上我们可以完全自动化ETL,任何我们需要的数据都可以随时追溯。
2.2 无埋点的技术优势
回看上面埋采集数据的7个步骤,不埋已经很好的解决了二、三、第四步的需求,把原来的多方参与减少到基本一方。无论是产品经理、分析师还是运营人员,都可以使用可视化工具查询和分析数据,真正做到所见即所得。不仅是PC,还支持iOS、Android和Hybrid,可以进行跨屏用户分析。
3.埋点+无埋点
无论采用无埋点方式还是埋点方式,都需要能够用数据清晰地描述用户的每一次上网过程;这是data采集的基本目标,也是GrowingIO的初衷。
3.1数据采集“埋点+不埋点”的原则
我们以一个加载了GrowingIO的非埋藏SDK的电商应用为例:客户打开应用,在首页搜索关键词,然后在结果页选择喜欢的商品加入购物大车; 然后在购物车中下单,完成支付。那么在这个过程中,采集需要哪些数据,我们又应该如何去采集呢?
从“打开应用”-“观看首屏广告”-“搜索关键词”-“进入结果页面”-“加入购物车”再“支付完成”,有用户行为数据(过程数据)和交易数据(结果数据)。上图中,GrowingIO的无埋SDK会自动采集这个App上的所有用户行为数据,包括访问量、页面浏览量、行为事件。同时GrowingIO的数据对接解决方案可以采集更多的交易数据,包括产品SKU、价格、折扣、支付等信息。
这样我们就可以采集一个完整的网购行为,结合非埋点和埋点,用数据完整地描述和分析用户的购物旅程。其实无论什么线上业务场景,我们都希望能够采集获得完整的用户行为数据和业务数据。此外,还需要连接用户行为数据和业务数据。
3.2“埋点+无埋点”数据采集优势
那么为什么需要将非埋点和埋点组合到采集数据呢?
首先,因为没有埋点的方法本身是比较有效的。经过实践,我们发现没有嵌入点产生的数据指标是嵌入点产生的数据指标的100倍甚至更多。
二是无内嵌数据采集成本低,app发布/网站上线不影响自动数据采集。
第三,埋采集的好处是可以更详细地描述每个事件的属性,尤其是结果数据。
没有嵌入采集的用户行为数据是用户产生最终结果的“前因”数据,嵌入采集的业务数据是结果数据是“后果”。无埋点与埋点方案相结合,提高工作效率,同时记录“因”和“果”数据,帮助市场、产品、运营分析获客、转化、留存,实现用户快速增长。
只是随便看看:
云端内容采集(所述服务器端基于每日更新的网络疫情数据构建地理信息疫情地图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-01-26 04:13
技术领域
本发明涉及疫情防控领域,具体涉及一种基于云端的疫情发布及自动轨迹采集系统。
背景技术
随着疫情防控工作的推进,国内疫情得到有效控制,学校将欢迎全国各地学子返校。由于学校无法及时准确获取学生信息,影响学校疫情防控工作和学生健康安全。挑战。
发明内容
本发明的目的是针对现有技术的不足,提供一种基于云端的疫情发布和轨迹自动采集系统,通过用户手机位置获取用户的具体位置,利用网络疫情数据构建地理信息。疫情地图结合地理信息分析方法,为加强学校疫情防控提供疫情防控措施。
本发明解决的技术问题可以通过以下技术方案来实现:一种基于云端的疫情发布和轨迹自动采集系统,包括服务器和与服务器连接的客户端;服务器根据网络疫情数据构建疫情地图;客户端根据手机定位获取用户位置信息,生成用户运动轨迹;将用户运动轨迹上传至服务器,并与服务器存储的疫情图进行对比,若用户的运动轨迹与疫情图重叠,则会发出警告信息。
进一步地,该系统具有返校登记模块、打卡报告模块和位置风险模块;用户通过客户端填写学号、姓名、院校,服务器接收用户信息并保存在服务器端数据库中;返校注册模块用于客户端向服务器发送返校申请。返校申请包括用户的位置信息。服务器根据用户所在位置和疫情地图信息判断是否存在疫情风险,反馈是否同意返校;打卡上报模块用于客户端定期向服务器发送当前用户位置信息,服务器生成用户' s 根据用户位置信息的运动轨迹;位置风险模块用于客户端向服务器发送疫情风险查询请求,疫情风险查询请求中收录当前用户位置信息,服务器将接收到的当前用户位置信息反馈给周边疫情信息。
进一步地,服务器端根据每日更新的网络疫情数据构建疫情地图。
进一步地,客户端根据设定的采集时间周期性地采集用户位置信息,并根据用户位置信息生成用户运动轨迹。
与现有技术相比,本发明的有益效果是: 1.基于手机定位技术,通过用户上传位置信息,解决了定位用户位置的问题。
2.利用网络疫情数据,构建地理信息疫情地图,解决了疫情数据不可见的问题,更容易判断疫区。
3.通过结合用户位置信息和地理信息疫情地图,展示用户运动轨迹的疫情信息,解决用户不了解事件周边疫情的问题。信息上传到学校数据库,也方便学校疫情管理。
图纸说明
如图。附图说明图1是本发明的系统结构示意图。
如图。图2为本发明的返校注册示意图。
如图。图3为本发明的上报功能示意图。
如图。图4为本发明的用户运动轨迹示意图。
详细说明
为使本发明实现的技术手段、创造性特征、实现目的和效果易于理解,下面结合具体实施例对本发明作进一步说明。
参考图。如图1所示,根据本发明的一种基于云端的疫情发布与轨迹自动采集系统,其特征在于:包括服务器端和与服务器端通信的客户端。服务器端根据网络疫情数据构建疫情地图;客户端根据手机定位获取用户位置信息,生成用户移动轨迹;将用户运动轨迹上传至服务器,并与服务器中存储的疫情图进行比较,如果用户的运动轨迹与疫情图重叠,则会发出警告信息。
系统具有返校登记模块、打卡报告模块和位置风险模块;用户通过客户端填写学号、姓名、院校,服务器接收用户信息并保存在服务器端数据库中;返校注册 客户端通过该模块向服务器发送返校申请。返校申请中收录用户的位置信息。服务器根据用户所在位置和疫情地图信息判断是否存在疫情风险,反馈是否同意返校;打孔卡被举报。该模块用于客户端定期向服务器发送当前用户位置信息,服务器根据用户位置信息生成用户运动轨迹;位置风险模块用于客户端向服务器发送疫情风险查询请求,疫情风险查询请求中收录当前用户位置信息,服务器将接收到的当前用户位置信息反馈给周边疫情信息。
实施例本发明涉及一种基于云的疫情发布和轨迹自动采集系统。系统数据源包括用户上传和网络疫情数据两部分,如图1所示。1.
用户上传个人位置信息并按日期保存。流行病地图是根据网络流行病数据构建的。结合用户的位置信息和构建的疫情地图,将围绕用户表现轨迹的相关疫情信息展示在地图上。打卡功能可以有效节省人力成本,补充和提高学校的疫情防控工作。通过及时发布疫情信息和学生信息打卡功能,结合国家公布的疫情数据和在校学生上报的疫情信息,进行地理信息的空间分析。开展学校疫情分析,有效保障学生健康安全。
具体说明如下:(1)利用上海报名、打卡举报和位置风险功能,上传管理用户位置,了解用户是否经过疫区,为学校防疫提供便利防控管理,如图2所示。
其中,上海报名功能为学生向上海提交申请,打卡报告功能为学生轻松打卡定位,定位风险功能显示风险区域。
(2)在程序中,如图3所示,我们使用用户在程序中填写以下内容:学号、姓名、学院,然后将上面得到的数据保存到后台保存数据库了解用户采集间隔的位置信息用于描述用户的大致运动轨迹。
(3)用户上传个人位置信息,并按日期保存。疫情地图由网络疫情数据构建,结合用户位置信息和构建的疫情地图,围绕用户表现轨迹的相关疫情信息如图4所示,通过用户日常位置签到功能,补充和完善学校的疫情防控工作,有效保障学生的健康安全。
以上已经对本发明的基本原理和主要特征以及本发明的优点进行了展示和描述。
本领域技术人员应当理解,本发明不受上述实施例的限制,上述实施例中的描述和说明仅用于说明本发明的原理。在不脱离本发明的精神和范围的情况下,本发明将有各种变化和变型,均落入要求保护的发明范围内。
本发明要求保护的范围由所附权利要求及其等同物限定。
扩张 查看全部
云端内容采集(所述服务器端基于每日更新的网络疫情数据构建地理信息疫情地图)
技术领域
本发明涉及疫情防控领域,具体涉及一种基于云端的疫情发布及自动轨迹采集系统。
背景技术
随着疫情防控工作的推进,国内疫情得到有效控制,学校将欢迎全国各地学子返校。由于学校无法及时准确获取学生信息,影响学校疫情防控工作和学生健康安全。挑战。
发明内容
本发明的目的是针对现有技术的不足,提供一种基于云端的疫情发布和轨迹自动采集系统,通过用户手机位置获取用户的具体位置,利用网络疫情数据构建地理信息。疫情地图结合地理信息分析方法,为加强学校疫情防控提供疫情防控措施。
本发明解决的技术问题可以通过以下技术方案来实现:一种基于云端的疫情发布和轨迹自动采集系统,包括服务器和与服务器连接的客户端;服务器根据网络疫情数据构建疫情地图;客户端根据手机定位获取用户位置信息,生成用户运动轨迹;将用户运动轨迹上传至服务器,并与服务器存储的疫情图进行对比,若用户的运动轨迹与疫情图重叠,则会发出警告信息。
进一步地,该系统具有返校登记模块、打卡报告模块和位置风险模块;用户通过客户端填写学号、姓名、院校,服务器接收用户信息并保存在服务器端数据库中;返校注册模块用于客户端向服务器发送返校申请。返校申请包括用户的位置信息。服务器根据用户所在位置和疫情地图信息判断是否存在疫情风险,反馈是否同意返校;打卡上报模块用于客户端定期向服务器发送当前用户位置信息,服务器生成用户' s 根据用户位置信息的运动轨迹;位置风险模块用于客户端向服务器发送疫情风险查询请求,疫情风险查询请求中收录当前用户位置信息,服务器将接收到的当前用户位置信息反馈给周边疫情信息。
进一步地,服务器端根据每日更新的网络疫情数据构建疫情地图。
进一步地,客户端根据设定的采集时间周期性地采集用户位置信息,并根据用户位置信息生成用户运动轨迹。
与现有技术相比,本发明的有益效果是: 1.基于手机定位技术,通过用户上传位置信息,解决了定位用户位置的问题。
2.利用网络疫情数据,构建地理信息疫情地图,解决了疫情数据不可见的问题,更容易判断疫区。
3.通过结合用户位置信息和地理信息疫情地图,展示用户运动轨迹的疫情信息,解决用户不了解事件周边疫情的问题。信息上传到学校数据库,也方便学校疫情管理。
图纸说明
如图。附图说明图1是本发明的系统结构示意图。
如图。图2为本发明的返校注册示意图。
如图。图3为本发明的上报功能示意图。
如图。图4为本发明的用户运动轨迹示意图。
详细说明
为使本发明实现的技术手段、创造性特征、实现目的和效果易于理解,下面结合具体实施例对本发明作进一步说明。
参考图。如图1所示,根据本发明的一种基于云端的疫情发布与轨迹自动采集系统,其特征在于:包括服务器端和与服务器端通信的客户端。服务器端根据网络疫情数据构建疫情地图;客户端根据手机定位获取用户位置信息,生成用户移动轨迹;将用户运动轨迹上传至服务器,并与服务器中存储的疫情图进行比较,如果用户的运动轨迹与疫情图重叠,则会发出警告信息。
系统具有返校登记模块、打卡报告模块和位置风险模块;用户通过客户端填写学号、姓名、院校,服务器接收用户信息并保存在服务器端数据库中;返校注册 客户端通过该模块向服务器发送返校申请。返校申请中收录用户的位置信息。服务器根据用户所在位置和疫情地图信息判断是否存在疫情风险,反馈是否同意返校;打孔卡被举报。该模块用于客户端定期向服务器发送当前用户位置信息,服务器根据用户位置信息生成用户运动轨迹;位置风险模块用于客户端向服务器发送疫情风险查询请求,疫情风险查询请求中收录当前用户位置信息,服务器将接收到的当前用户位置信息反馈给周边疫情信息。
实施例本发明涉及一种基于云的疫情发布和轨迹自动采集系统。系统数据源包括用户上传和网络疫情数据两部分,如图1所示。1.
用户上传个人位置信息并按日期保存。流行病地图是根据网络流行病数据构建的。结合用户的位置信息和构建的疫情地图,将围绕用户表现轨迹的相关疫情信息展示在地图上。打卡功能可以有效节省人力成本,补充和提高学校的疫情防控工作。通过及时发布疫情信息和学生信息打卡功能,结合国家公布的疫情数据和在校学生上报的疫情信息,进行地理信息的空间分析。开展学校疫情分析,有效保障学生健康安全。
具体说明如下:(1)利用上海报名、打卡举报和位置风险功能,上传管理用户位置,了解用户是否经过疫区,为学校防疫提供便利防控管理,如图2所示。
其中,上海报名功能为学生向上海提交申请,打卡报告功能为学生轻松打卡定位,定位风险功能显示风险区域。
(2)在程序中,如图3所示,我们使用用户在程序中填写以下内容:学号、姓名、学院,然后将上面得到的数据保存到后台保存数据库了解用户采集间隔的位置信息用于描述用户的大致运动轨迹。
(3)用户上传个人位置信息,并按日期保存。疫情地图由网络疫情数据构建,结合用户位置信息和构建的疫情地图,围绕用户表现轨迹的相关疫情信息如图4所示,通过用户日常位置签到功能,补充和完善学校的疫情防控工作,有效保障学生的健康安全。
以上已经对本发明的基本原理和主要特征以及本发明的优点进行了展示和描述。
本领域技术人员应当理解,本发明不受上述实施例的限制,上述实施例中的描述和说明仅用于说明本发明的原理。在不脱离本发明的精神和范围的情况下,本发明将有各种变化和变型,均落入要求保护的发明范围内。
本发明要求保护的范围由所附权利要求及其等同物限定。
扩张
云端内容采集(云端内容采集、自动化定时推送,可以试试中青云)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-20 05:01
云端内容采集、自动化定时推送。可以用apilink的。还是非常强大的。
刚刚在线实验了一下,如果要在app端使用,则需要使用网页版,app有代码调用,网页版的可以使用apilink可以定时推送文章的。
在移动端需要定时在特定时间推送,把关键词做app变量,定时推送或是本地推送。
可以根据用户自身需求定制推送内容。
还是要看用户的定制需求,要根据用户自身的需求进行个性化定制,才能满足用户的需求。比如:用户是企业、用户是宝妈,需要每天都能及时的了解企业、宝妈的生活情况;又或者是有个人需求的用户,希望定制用户自身喜欢的内容,方便用户收藏、转发。
谢邀定制语言应该是比较难的,但是可以定制事件主题的日期,推送时间,推送频率,推送内容和定时推送有共同的点。相对于定制语言,定制定时推送更简单一些,重点是方便定制和组合。
ezhelper,简单有效率
小猿搜题君,
可以试试中青云。不需要任何编程基础,没有门槛,我用他的可视化demo做的。有时候按照自己的需求不定期组合推送,从而提高数据的增长速度。比如,他能实现推送到:公众号文章、企业文章、h5页面、app版本、app活动,甚至是刷机包里的。可以根据自己的需求定制。 查看全部
云端内容采集(云端内容采集、自动化定时推送,可以试试中青云)
云端内容采集、自动化定时推送。可以用apilink的。还是非常强大的。
刚刚在线实验了一下,如果要在app端使用,则需要使用网页版,app有代码调用,网页版的可以使用apilink可以定时推送文章的。
在移动端需要定时在特定时间推送,把关键词做app变量,定时推送或是本地推送。
可以根据用户自身需求定制推送内容。
还是要看用户的定制需求,要根据用户自身的需求进行个性化定制,才能满足用户的需求。比如:用户是企业、用户是宝妈,需要每天都能及时的了解企业、宝妈的生活情况;又或者是有个人需求的用户,希望定制用户自身喜欢的内容,方便用户收藏、转发。
谢邀定制语言应该是比较难的,但是可以定制事件主题的日期,推送时间,推送频率,推送内容和定时推送有共同的点。相对于定制语言,定制定时推送更简单一些,重点是方便定制和组合。
ezhelper,简单有效率
小猿搜题君,
可以试试中青云。不需要任何编程基础,没有门槛,我用他的可视化demo做的。有时候按照自己的需求不定期组合推送,从而提高数据的增长速度。比如,他能实现推送到:公众号文章、企业文章、h5页面、app版本、app活动,甚至是刷机包里的。可以根据自己的需求定制。
云端内容采集(本文主题商品分析,竞品分析店铺蜂鸟采集数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-04-05 23:23
采集功能] 准确的采集目标上的数据网站,包括变体、属性、图片等采集。完整的产品信息导出。一键翻译采集的产品信息可以翻译成任意语言(54种语言)。产品认领可以直接将采集的数据向ActNeed平台授权的店铺进行认领。【蜂鸟优势采集】采集全网数据,以全网数据为计算基石,对数据进行多维数据分析和多维分析,为用户提供最有价值的数据。帮助用户更轻松地从平台获取数据。
本文题目为商品分析、竞品分析、店铺数据分析、蜂鸟采集、数据采集、跨境电商数据、数据分析、跨境电商数据存储, 数据分析。
蜂鸟采集是一个跨境电商数据采集平台,智能化采集,云存储,将平台数据变成自己的产品库。
【蜂鸟功能采集】
精度采集
目标网站上的数据,包括变体、属性、图片等,完全是采集。
一键式采集
小白神器,只要用鼠标点击产品,就可以自动完成采集。
轻松出口
您可以自己设置导出字段以完全导出产品信息。
一键翻译
采集的产品信息可以翻译成任何语言(54种语言)
产品声明
采集的数据可以直接到ActNeed平台授权的商店领取。
【蜂鸟的优势采集】
采集全网数据
以全网数据为计算基石,确保不遗漏重要数据。
多维数据分析
多维度分析数据,为用户提供最有价值的数据。
全方位数据查询
全方位的查询方式,帮助用户更轻松地从平台获取数据。
快速的产品索赔和出口
可以在任何地方快速声明、导出和使用产品数据。
实时跟踪数据变化
实时跟踪确保用户关心的所有数据始终是最新的。
电商运营商将为您更新最实用的电商工具、产品分析、竞品分析、店铺数据分析。更多电商资讯和行业动态,记得关注电商运营商!同时也欢迎大家推荐。 查看全部
云端内容采集(本文主题商品分析,竞品分析店铺蜂鸟采集数据)
采集功能] 准确的采集目标上的数据网站,包括变体、属性、图片等采集。完整的产品信息导出。一键翻译采集的产品信息可以翻译成任意语言(54种语言)。产品认领可以直接将采集的数据向ActNeed平台授权的店铺进行认领。【蜂鸟优势采集】采集全网数据,以全网数据为计算基石,对数据进行多维数据分析和多维分析,为用户提供最有价值的数据。帮助用户更轻松地从平台获取数据。
本文题目为商品分析、竞品分析、店铺数据分析、蜂鸟采集、数据采集、跨境电商数据、数据分析、跨境电商数据存储, 数据分析。
蜂鸟采集是一个跨境电商数据采集平台,智能化采集,云存储,将平台数据变成自己的产品库。
【蜂鸟功能采集】
精度采集
目标网站上的数据,包括变体、属性、图片等,完全是采集。
一键式采集
小白神器,只要用鼠标点击产品,就可以自动完成采集。
轻松出口
您可以自己设置导出字段以完全导出产品信息。
一键翻译
采集的产品信息可以翻译成任何语言(54种语言)
产品声明
采集的数据可以直接到ActNeed平台授权的商店领取。
【蜂鸟的优势采集】
采集全网数据
以全网数据为计算基石,确保不遗漏重要数据。
多维数据分析
多维度分析数据,为用户提供最有价值的数据。
全方位数据查询
全方位的查询方式,帮助用户更轻松地从平台获取数据。
快速的产品索赔和出口
可以在任何地方快速声明、导出和使用产品数据。
实时跟踪数据变化
实时跟踪确保用户关心的所有数据始终是最新的。
电商运营商将为您更新最实用的电商工具、产品分析、竞品分析、店铺数据分析。更多电商资讯和行业动态,记得关注电商运营商!同时也欢迎大家推荐。
云端内容采集(大连云沃做在线娱乐的大连海天科技(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-04-04 00:04
云端内容采集到互联网基础设施(),再由此落地到各个垂直行业(此处为汽车制造业),实现各应用场景内容的快速获取。
xp就不说了,大连tsdk做android的,阿里的开发者服务也很强。做android最好还是找海尔啊,大连湾那边。
大连云沃做在线娱乐的
大连海天科技
据说大连华采也很不错
大连云沃大连云沃是一家专注于成套应用系统建设的服务商。基于行业互联网应用平台服务,实现丰富的自助化在线应用解决方案,大连云沃受到众多客户的青睐,客户遍布全国各地的212家知名企业以及政府机构和国有企业。ps:之前同事推荐我用过,
多年来为多个项目公司、行业提供基于局域网或广域网环境下的在线娱乐内容采集、上传、处理、传输、展示及精准广告投放服务,从而实现了企业在互联网时代的营销与广告转型。
对啊网,
都快2020年了,
挺不错的
大连云沃算吗,去年我见过他们家有用过,还有开放平台,
有说华采,应该算是对啊,基于行业互联网应用平台服务, 查看全部
云端内容采集(大连云沃做在线娱乐的大连海天科技(组图))
云端内容采集到互联网基础设施(),再由此落地到各个垂直行业(此处为汽车制造业),实现各应用场景内容的快速获取。
xp就不说了,大连tsdk做android的,阿里的开发者服务也很强。做android最好还是找海尔啊,大连湾那边。
大连云沃做在线娱乐的
大连海天科技
据说大连华采也很不错
大连云沃大连云沃是一家专注于成套应用系统建设的服务商。基于行业互联网应用平台服务,实现丰富的自助化在线应用解决方案,大连云沃受到众多客户的青睐,客户遍布全国各地的212家知名企业以及政府机构和国有企业。ps:之前同事推荐我用过,
多年来为多个项目公司、行业提供基于局域网或广域网环境下的在线娱乐内容采集、上传、处理、传输、展示及精准广告投放服务,从而实现了企业在互联网时代的营销与广告转型。
对啊网,
都快2020年了,
挺不错的
大连云沃算吗,去年我见过他们家有用过,还有开放平台,
有说华采,应该算是对啊,基于行业互联网应用平台服务,
云端内容采集(云端服务器设备采集的注意事项有哪些呢??)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-04-02 09:06
云端内容采集主要分为两部分,一是基于云端服务器设备采集来的数据流,二是本地电脑采集来的文件。这里重点讲一下云端服务器设备采集的注意事项。
1、采集数据文件加密,特别是各类数据流敏感数据。
2、关于后端数据处理服务,由于云端采集对后端处理服务的要求较高,大大的超出一般企业现有的服务水平,建议对云端数据流数据进行开发和二次开发。
3、采集的前端设备要针对各类采集主题专门设计,采集的后端处理服务也是专门设计,避免开发繁琐。根据题主提问,云端采集数据流平台已完成,
参见百度经验里的一篇文章,
有云服务器可以实现一个小网站的采集,一般应该没有大客户,这个不好做,
云端采集目前是技术层面,需要服务器作为支撑,在门户网站是个趋势。
涉及数据采集的话最好用本地网站采集,因为数据的准确率不高。一定是涉及到数据请求的话不要用云服务器。云服务器多一个是其资金,二是其系统的限制。
还是用本地的web服务器吧,这个最好能够用国内的公司,阿里云、腾讯云和浪潮云就行。现在这方面的技术也非常成熟了,不是特别难找。 查看全部
云端内容采集(云端服务器设备采集的注意事项有哪些呢??)
云端内容采集主要分为两部分,一是基于云端服务器设备采集来的数据流,二是本地电脑采集来的文件。这里重点讲一下云端服务器设备采集的注意事项。
1、采集数据文件加密,特别是各类数据流敏感数据。
2、关于后端数据处理服务,由于云端采集对后端处理服务的要求较高,大大的超出一般企业现有的服务水平,建议对云端数据流数据进行开发和二次开发。
3、采集的前端设备要针对各类采集主题专门设计,采集的后端处理服务也是专门设计,避免开发繁琐。根据题主提问,云端采集数据流平台已完成,
参见百度经验里的一篇文章,
有云服务器可以实现一个小网站的采集,一般应该没有大客户,这个不好做,
云端采集目前是技术层面,需要服务器作为支撑,在门户网站是个趋势。
涉及数据采集的话最好用本地网站采集,因为数据的准确率不高。一定是涉及到数据请求的话不要用云服务器。云服务器多一个是其资金,二是其系统的限制。
还是用本地的web服务器吧,这个最好能够用国内的公司,阿里云、腾讯云和浪潮云就行。现在这方面的技术也非常成熟了,不是特别难找。
云端内容采集(优采云采集过程中常出现的问题以及解决方法本教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2022-03-27 23:24
优采云采集过程中常见问题及解决方法
本教程主要讲如果您在使用优采云采集时遇到一些问题,如何快速找出错误,解决错误或如何理解错误,以及与客服沟通的更好方法。
优采云采集器主要通过技术定位和模拟用户对网页的浏览操作来采集数据。用户无需了解网页架构、数据采集原理等技能。采集器 可以形成一个 优采云 可以理解并且可以循环工作的采集 进程。
如果出现采集模式不符合要求的情况,排查后有更详细的教程。
采集过程中的错误可以分为五个方面,分别是网页问题、规则问题、定位模拟问题、采集器问题、云端问题。当采集出现异常时,请按照以下步骤排查错误,查找问题类型:
1、 手动执行规则:打开界面右上角的流程图,用鼠标点击流程图中的规则,从上到下,每次点击下一步,都会有对应的响应,没有响应的步骤是一个问题。步。
当心:
1)点击提取循环中的元素手动选择循环中第一个以外的内容,防止循环失效,只点击提取循环中的第一个元素
2)所有规则在每一步之后执行,然后再执行下一步。网页未完全加载,即浏览器上的圆圈等待图标消失时,观察网页内容是否已完全加载。如果满载可以自行取消
加载,然后配置规则。
2、执行单机采集,查看采集的结果中没有收到采集数据的项目。
注意:最好将当前的URL添加到规则中,这样如果数据中有不是采集的项,可以复制URL在浏览器中打开查看原因并确定错误。
可能出现的症状描述如下,供您参考:
1、对手动步骤没有响应
有两种可能的现象:
1)步骤未正确执行
原因:规则问题、采集器问题、定位模拟问题
解决方案:
您可以执行故障排除,删除此步骤,然后重新添加。如果仍然无法执行,则排除规则问题。你可以:
在浏览器中打开网页进行操作,如果在浏览器中可以执行一些滚动或点击翻页,而在采集器中却不能执行,那就是采集器的问题,原因是采集器 内置浏览器是火狐,可能是内置的浏览器版本在后续版本中发生了变化,导致浏览器中可以实现的功能无法在采集器中执行@> 内置浏览器。此类网页中的数据,智能采集翻页或滚动之前的数据。
排除采集器问题和规则问题后,可以尝试在页面上重新添加步骤,布局与制定规则时相同。如果可以在这样的页面上执行,但在某些页面上不能执行,那就是定位模拟。这个问题在时间跨度较大的网站中经常存在,因为网站的布局
如果发生变化,采集器 定位所需的 XPath 将发生变化。请参考XPath章节修改规则或咨询客服。建议向客服说明网站网址及错误原因,以便客服提供解决方案。
优采云采集器故障排除 - 图 1
2)循环中的点击或采集只有在点击第一个内容时才会发生,第二个内容还是采集到第一个内容
原因:规则问题,定位模拟问题
解决方案:
检查循环中的第一项是否勾选点击当前循环中设置的元素
如果勾选还是不能,可以:如果循环中还有其他循环,先参考问题1的动画去掉里面的内容,删除有问题的循环,再重新设置,如果去掉的规则有不自动复位需要手动复位。如果可以使用循环,则排除问题。如果不是,那就是定位模拟的问题。你可以:
勾选循环中提取数据的自定义数据字段,勾选自定义定位元素方法,看里面是否有相对的Xpath路径,如果没有,删除该字段,勾选外部高级选项中的使用循环,添加再次,再次尝试,如果有反应,问题就解决了,如果还是不行,可以:
参考Xpath章节修改网页的Xpath或咨询客服。建议向客服说明网站网址及错误原因,以便客服提供解决方案。
优采云采集器故障排除 - 图 2
2、单机采集无法采集数据
有4个可能的原因:
1)单机操作规则,数据采集前会显示采集Complete
这种现象分为3种情况
①打开网页后会直接显示采集完成
原因:网页问题,第一个网页加载太慢,优采云会等待一段时间,如果过了一定时间仍然加载,优采云会跳过这一步,后续步骤认为内容尚未加载。如果没有数据,优采云 将结束任务,导致 采集 没有数据。
解决方法:增加网页的超时时间,或者在设置下一步执行之前等待,让网页有足够的时间加载。
优采云采集器故障排除 - 图 3
优采云采集器故障排除 - 图 4
②网页一直在加载
原因:网页问题,有些网页加载很慢。采集 的所需数据未出现。
解决方法:如果当前步骤是打开网页,可以延长网页的超时时间。如果是点击元素步骤,并且要加载采集的数据,可以在点击元素步骤中设置ajax延迟。点击后,新数据加载完毕,网页URL不变,是ajax链接。
优采云采集器故障排除 - 图 5
③网页没有进入采集页面
原因:这个问题经常出现在点击元素步骤。当某些网页收录ajax链接时,根据点击位置来判断是否需要设置。如果不设置,单机采集,采集无数据时,总是卡在上一步。网页异步加载时,如果不设置Ajax延迟,一般不会正确执行操作,导致规则无法进行下一步,无法提取数据。
解决方法:在相应的步骤中设置ajax延迟,一般为2-3S。如果网页加载时间较长,可以适当增加延迟时间。点击元素,循环下一页,将鼠标移到元素上,这三步都有ajax设置
2)单机运行规则无法正常执行
原因:规则问题或定位模拟问题
解决方案:
首先判断ajax是否需要设置,是否设置正确,如果不是ajax问题,可以:
删除问题步骤并重新设置。如果问题解决了,那就是规则问题。如果问题没有解决,那就是定位仿真问题。你可以:
参考Xpath章节修改网页的Xpath或咨询客服。建议向客服说明网站网址及错误原因,以便客服提供解决方案。
3)单机操作规则,第一页或第一页数据正常,后面不能执行
原因:规则问题 - 循环部分出现问题
解决方法:参考第二个内容的手动执行。
4)单机操作规则,数据采集缺失或错误
这种现象分为5种情况:
①部分字段没有数据
原因:网页中的数据为空,模拟定位问题
解决方案:
查看没有字段的链接并使用浏览器打开它们。如果没有字段,则没有问题。如果浏览器打开内容,这是一个模拟定位问题。你可以:
参考Xpath章节修改网页的Xpath或咨询客服。建议向客服说明网站网址及错误原因,以便客服提供解决方案。
②采集数据个数不对
原因:规则问题 - 循环部分出现问题
解决方法:参考手动执行第二个内容
③采集数据乱七八糟,没有对应的信息
原因:规则问题——提取步骤太多,页面加载时间过长,如果设置ajax忽略加载,可能会由于内容未加载或加载不完整而导致部分提取步骤多的错误。
解决方案:将规则分为两个步骤。如果采集评论网页数据,第一步是采集当前页面信息和评论页面的URL,第二步是循环URL采集评论数据,和然后将数据导出到excel和数据库中进行匹配处理。
④ 字段出现在不同位置
原因:网页问题 - Xpath 更改
解决方法:参考Xpath章节修改网页的Xpath或咨询客服。
服务描述网站URL及错误原因,以便客服给出解决方案。
⑤数据重复
原因:网页问题——Xpath定位问题,问题主要出现在翻页时,比如只循环一两页,或者最后一页的下一页按钮仍然可以点击。
解决方法:参考Xpath章节修改网页的Xpath或咨询客服。建议向客服说明网站网址和错误原因,以便客服给出解决方案。
3、独立采集普通,云采集无数据
这种现象分为4种情况:
1)网页问题 - IP 阻塞的原因
原因:大部分网站优采云有IP屏蔽措施都可以解决,很少有网站采取极其严格的IP屏蔽措施,会导致云采集采集@ > 无可用数据。
解决方案:
如果是单机采集,可以使用代理IP功能。详见代理IP教程。
如果是云采集,可以为任务分配到多个节点,可以让多个节点空闲,避免同一个云采集同IP上的任务。
2)云问题-云服务器带宽小
原因:云端带宽小,导致本地网站打开慢,在云端打开时间较长。一旦超时,将无法打开网站或无法加载数据,导致跳过此步骤。
解决方法:将打开URL的超时时间或下次执行前的等待时间设置长一些。
3)规则问题 - 增量采集
原因:规则设置了增量采集,增量采集根据URL判断采集是否已经通过。部分网页使用增量采集,会导致增量判断错误,跳过。这页纸。
解决方法:关闭增量采集。
4)规则问题-禁止浏览器加载图片和云采集不要拆分任务
原因:很少有网页不能勾选禁止浏览器加载图片和云采集不要拆分任务解决方法:取消勾选相关选项。
如有更多问题,请在官网或客服反馈,感谢您的支持。
相关 采集 教程:
天猫商品信息采集
美团商业资讯采集
市场招聘信息采集
优采云——70万用户选择的网页数据采集器。
1、操作简单,任何人都可以使用:无需技术背景,只需要互联网采集。完成流程可视化,点击鼠标完成操作,2分钟快速上手。
2、功能强大,任意网站可选:点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据,都可以通过简单的设置进行设置< @采集。
3、云采集,你也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。
4、功能免费+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。 查看全部
云端内容采集(优采云采集过程中常出现的问题以及解决方法本教程)
优采云采集过程中常见问题及解决方法
本教程主要讲如果您在使用优采云采集时遇到一些问题,如何快速找出错误,解决错误或如何理解错误,以及与客服沟通的更好方法。
优采云采集器主要通过技术定位和模拟用户对网页的浏览操作来采集数据。用户无需了解网页架构、数据采集原理等技能。采集器 可以形成一个 优采云 可以理解并且可以循环工作的采集 进程。
如果出现采集模式不符合要求的情况,排查后有更详细的教程。
采集过程中的错误可以分为五个方面,分别是网页问题、规则问题、定位模拟问题、采集器问题、云端问题。当采集出现异常时,请按照以下步骤排查错误,查找问题类型:
1、 手动执行规则:打开界面右上角的流程图,用鼠标点击流程图中的规则,从上到下,每次点击下一步,都会有对应的响应,没有响应的步骤是一个问题。步。
当心:
1)点击提取循环中的元素手动选择循环中第一个以外的内容,防止循环失效,只点击提取循环中的第一个元素
2)所有规则在每一步之后执行,然后再执行下一步。网页未完全加载,即浏览器上的圆圈等待图标消失时,观察网页内容是否已完全加载。如果满载可以自行取消
加载,然后配置规则。
2、执行单机采集,查看采集的结果中没有收到采集数据的项目。
注意:最好将当前的URL添加到规则中,这样如果数据中有不是采集的项,可以复制URL在浏览器中打开查看原因并确定错误。
可能出现的症状描述如下,供您参考:
1、对手动步骤没有响应
有两种可能的现象:
1)步骤未正确执行
原因:规则问题、采集器问题、定位模拟问题
解决方案:
您可以执行故障排除,删除此步骤,然后重新添加。如果仍然无法执行,则排除规则问题。你可以:
在浏览器中打开网页进行操作,如果在浏览器中可以执行一些滚动或点击翻页,而在采集器中却不能执行,那就是采集器的问题,原因是采集器 内置浏览器是火狐,可能是内置的浏览器版本在后续版本中发生了变化,导致浏览器中可以实现的功能无法在采集器中执行@> 内置浏览器。此类网页中的数据,智能采集翻页或滚动之前的数据。
排除采集器问题和规则问题后,可以尝试在页面上重新添加步骤,布局与制定规则时相同。如果可以在这样的页面上执行,但在某些页面上不能执行,那就是定位模拟。这个问题在时间跨度较大的网站中经常存在,因为网站的布局
如果发生变化,采集器 定位所需的 XPath 将发生变化。请参考XPath章节修改规则或咨询客服。建议向客服说明网站网址及错误原因,以便客服提供解决方案。
优采云采集器故障排除 - 图 1
2)循环中的点击或采集只有在点击第一个内容时才会发生,第二个内容还是采集到第一个内容
原因:规则问题,定位模拟问题
解决方案:
检查循环中的第一项是否勾选点击当前循环中设置的元素
如果勾选还是不能,可以:如果循环中还有其他循环,先参考问题1的动画去掉里面的内容,删除有问题的循环,再重新设置,如果去掉的规则有不自动复位需要手动复位。如果可以使用循环,则排除问题。如果不是,那就是定位模拟的问题。你可以:
勾选循环中提取数据的自定义数据字段,勾选自定义定位元素方法,看里面是否有相对的Xpath路径,如果没有,删除该字段,勾选外部高级选项中的使用循环,添加再次,再次尝试,如果有反应,问题就解决了,如果还是不行,可以:
参考Xpath章节修改网页的Xpath或咨询客服。建议向客服说明网站网址及错误原因,以便客服提供解决方案。
优采云采集器故障排除 - 图 2
2、单机采集无法采集数据
有4个可能的原因:
1)单机操作规则,数据采集前会显示采集Complete
这种现象分为3种情况
①打开网页后会直接显示采集完成
原因:网页问题,第一个网页加载太慢,优采云会等待一段时间,如果过了一定时间仍然加载,优采云会跳过这一步,后续步骤认为内容尚未加载。如果没有数据,优采云 将结束任务,导致 采集 没有数据。
解决方法:增加网页的超时时间,或者在设置下一步执行之前等待,让网页有足够的时间加载。
优采云采集器故障排除 - 图 3
优采云采集器故障排除 - 图 4
②网页一直在加载
原因:网页问题,有些网页加载很慢。采集 的所需数据未出现。
解决方法:如果当前步骤是打开网页,可以延长网页的超时时间。如果是点击元素步骤,并且要加载采集的数据,可以在点击元素步骤中设置ajax延迟。点击后,新数据加载完毕,网页URL不变,是ajax链接。
优采云采集器故障排除 - 图 5
③网页没有进入采集页面
原因:这个问题经常出现在点击元素步骤。当某些网页收录ajax链接时,根据点击位置来判断是否需要设置。如果不设置,单机采集,采集无数据时,总是卡在上一步。网页异步加载时,如果不设置Ajax延迟,一般不会正确执行操作,导致规则无法进行下一步,无法提取数据。
解决方法:在相应的步骤中设置ajax延迟,一般为2-3S。如果网页加载时间较长,可以适当增加延迟时间。点击元素,循环下一页,将鼠标移到元素上,这三步都有ajax设置
2)单机运行规则无法正常执行
原因:规则问题或定位模拟问题
解决方案:
首先判断ajax是否需要设置,是否设置正确,如果不是ajax问题,可以:
删除问题步骤并重新设置。如果问题解决了,那就是规则问题。如果问题没有解决,那就是定位仿真问题。你可以:
参考Xpath章节修改网页的Xpath或咨询客服。建议向客服说明网站网址及错误原因,以便客服提供解决方案。
3)单机操作规则,第一页或第一页数据正常,后面不能执行
原因:规则问题 - 循环部分出现问题
解决方法:参考第二个内容的手动执行。
4)单机操作规则,数据采集缺失或错误
这种现象分为5种情况:
①部分字段没有数据
原因:网页中的数据为空,模拟定位问题
解决方案:
查看没有字段的链接并使用浏览器打开它们。如果没有字段,则没有问题。如果浏览器打开内容,这是一个模拟定位问题。你可以:
参考Xpath章节修改网页的Xpath或咨询客服。建议向客服说明网站网址及错误原因,以便客服提供解决方案。
②采集数据个数不对
原因:规则问题 - 循环部分出现问题
解决方法:参考手动执行第二个内容
③采集数据乱七八糟,没有对应的信息
原因:规则问题——提取步骤太多,页面加载时间过长,如果设置ajax忽略加载,可能会由于内容未加载或加载不完整而导致部分提取步骤多的错误。
解决方案:将规则分为两个步骤。如果采集评论网页数据,第一步是采集当前页面信息和评论页面的URL,第二步是循环URL采集评论数据,和然后将数据导出到excel和数据库中进行匹配处理。
④ 字段出现在不同位置
原因:网页问题 - Xpath 更改
解决方法:参考Xpath章节修改网页的Xpath或咨询客服。
服务描述网站URL及错误原因,以便客服给出解决方案。
⑤数据重复
原因:网页问题——Xpath定位问题,问题主要出现在翻页时,比如只循环一两页,或者最后一页的下一页按钮仍然可以点击。
解决方法:参考Xpath章节修改网页的Xpath或咨询客服。建议向客服说明网站网址和错误原因,以便客服给出解决方案。
3、独立采集普通,云采集无数据
这种现象分为4种情况:
1)网页问题 - IP 阻塞的原因
原因:大部分网站优采云有IP屏蔽措施都可以解决,很少有网站采取极其严格的IP屏蔽措施,会导致云采集采集@ > 无可用数据。
解决方案:
如果是单机采集,可以使用代理IP功能。详见代理IP教程。
如果是云采集,可以为任务分配到多个节点,可以让多个节点空闲,避免同一个云采集同IP上的任务。
2)云问题-云服务器带宽小
原因:云端带宽小,导致本地网站打开慢,在云端打开时间较长。一旦超时,将无法打开网站或无法加载数据,导致跳过此步骤。
解决方法:将打开URL的超时时间或下次执行前的等待时间设置长一些。
3)规则问题 - 增量采集
原因:规则设置了增量采集,增量采集根据URL判断采集是否已经通过。部分网页使用增量采集,会导致增量判断错误,跳过。这页纸。
解决方法:关闭增量采集。
4)规则问题-禁止浏览器加载图片和云采集不要拆分任务
原因:很少有网页不能勾选禁止浏览器加载图片和云采集不要拆分任务解决方法:取消勾选相关选项。
如有更多问题,请在官网或客服反馈,感谢您的支持。
相关 采集 教程:
天猫商品信息采集
美团商业资讯采集
市场招聘信息采集
优采云——70万用户选择的网页数据采集器。
1、操作简单,任何人都可以使用:无需技术背景,只需要互联网采集。完成流程可视化,点击鼠标完成操作,2分钟快速上手。
2、功能强大,任意网站可选:点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据,都可以通过简单的设置进行设置< @采集。
3、云采集,你也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。
4、功能免费+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。
云端内容采集(如何采集云+云编辑,企业云端内容采集系统?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-03-26 22:06
云端内容采集系统:站长工具:采集云+云采集+云编辑。一键投稿:/z/index.html?uk=126044552&href=http%3a%2f%%2f21%2fd%2fpc%2f9.index%2findex%2f%2f2%2f876582%2f%2f8%2f554941%2f5%2f8%2f8%2f8%2f75426%2f5%2f5%2f64605%2f%2f%2f3%2f63707%2f%2f5%2f8%2f71606%2f%2f%2f5%2f91176%2f%2f%2f64607%2f%2f%2f%2f5%2f634410%2f%2f5%2f12214%2f%2f5%2f4%2f8%2f2%2f2%2f3%2f62684%2f%2f4%2f4%2f6%2f4%2f3%2f7%2f25347%2f%2f3%2f66302%2f5%2f6%2f7%2f5%2f4%2f5%2f2&from=timeline&isappinstalled=0&uid=957385569&vid=641347864。
推荐app采集助手采集个人以及机构,网站以及企业的各种采集产品的各种应用。更重要的是采集app里面的各种资源,每天都有资源更新,不需要再注册来着,省事省时。 查看全部
云端内容采集(如何采集云+云编辑,企业云端内容采集系统?)
云端内容采集系统:站长工具:采集云+云采集+云编辑。一键投稿:/z/index.html?uk=126044552&href=http%3a%2f%%2f21%2fd%2fpc%2f9.index%2findex%2f%2f2%2f876582%2f%2f8%2f554941%2f5%2f8%2f8%2f8%2f75426%2f5%2f5%2f64605%2f%2f%2f3%2f63707%2f%2f5%2f8%2f71606%2f%2f%2f5%2f91176%2f%2f%2f64607%2f%2f%2f%2f5%2f634410%2f%2f5%2f12214%2f%2f5%2f4%2f8%2f2%2f2%2f3%2f62684%2f%2f4%2f4%2f6%2f4%2f3%2f7%2f25347%2f%2f3%2f66302%2f5%2f6%2f7%2f5%2f4%2f5%2f2&from=timeline&isappinstalled=0&uid=957385569&vid=641347864。
推荐app采集助手采集个人以及机构,网站以及企业的各种采集产品的各种应用。更重要的是采集app里面的各种资源,每天都有资源更新,不需要再注册来着,省事省时。
云端内容采集(云端内容采集要根据你的行业区域,内容以及搜索人群制定)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-03-24 23:04
云端内容采集要根据你的行业区域,内容以及搜索人群制定,通常一个云端可以采集到2000个产品,如果太多采集后需要检索的时间相当的长,搜索的人群范围也会缩小,用户相对来说感知也会比较差,通常一般单个产品可以提取500-1000个展示率;用户由关键词搜索展示,且普遍搜索率高,目前我们提供多个关键词上线,采集价格基本和付费搜索持平或者比付费搜索也是一样;如果是长尾产品展示量太少或者展示率低可以通过whois,到厂里面走访看看到底产品属于哪个出口,如果属于日本,那么就基本和付费搜索一样到达的人群都差不多;云端内容产出:1、一般最好的当前提升的方式是whois会员,如果你用户付费了对方不付费,上不了广告那这个时候你一定要和他购买whois看看产品有没有被采集,这个跟你付不付费没太大关系,付费whois可以达到100%展示率;2、通过whois寻找厂商,这个是技术流程;如果你想寻找厂商是一件很头疼的事情,可以私我。
厂家提供有whois查询,通过whois查询可以知道当前产品相关词有哪些,通过query语句查询厂家信息确定该厂家是否有代加工的资质或者有完整的采购流程。
1.电商助手:可以查看全站产品的whois2.云宝:新创建店铺不能保存whois
云站分析-360个人图书馆, 查看全部
云端内容采集(云端内容采集要根据你的行业区域,内容以及搜索人群制定)
云端内容采集要根据你的行业区域,内容以及搜索人群制定,通常一个云端可以采集到2000个产品,如果太多采集后需要检索的时间相当的长,搜索的人群范围也会缩小,用户相对来说感知也会比较差,通常一般单个产品可以提取500-1000个展示率;用户由关键词搜索展示,且普遍搜索率高,目前我们提供多个关键词上线,采集价格基本和付费搜索持平或者比付费搜索也是一样;如果是长尾产品展示量太少或者展示率低可以通过whois,到厂里面走访看看到底产品属于哪个出口,如果属于日本,那么就基本和付费搜索一样到达的人群都差不多;云端内容产出:1、一般最好的当前提升的方式是whois会员,如果你用户付费了对方不付费,上不了广告那这个时候你一定要和他购买whois看看产品有没有被采集,这个跟你付不付费没太大关系,付费whois可以达到100%展示率;2、通过whois寻找厂商,这个是技术流程;如果你想寻找厂商是一件很头疼的事情,可以私我。
厂家提供有whois查询,通过whois查询可以知道当前产品相关词有哪些,通过query语句查询厂家信息确定该厂家是否有代加工的资质或者有完整的采购流程。
1.电商助手:可以查看全站产品的whois2.云宝:新创建店铺不能保存whois
云站分析-360个人图书馆,
云端内容采集(云端读报平台创新运营模式破解赢利难题(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-03-24 02:21
云报是一个移动媒体发布平台,由内容制作系统、媒体发布系统、客户端系统、后台统计管理系统和运营支持系统组成。
功能介绍
1.信息容量大,可传输多媒体内容。传输的信息量没有限制,可以同时传输文字、图片、音频、视频等内容,大大丰富了媒体表达的手段。
2.具有实时推送功能,用户无需主动登录。当前的新闻客户端实际上是一个网络门户。读者需要启动客户端阅读新闻并登录后主动浏览互联网。安装云读报客户端后,只要订阅某份报纸,就可以像接收短信一样定时接收报纸。
3. 离线阅读,流畅的用户体验。目前国内3G网络覆盖并不完善,云读报内容推送到用户手机后,读者可以在手机上离线阅读。不仅减少了对无线网络的依赖,阅读也没有网络延迟。
4. 具有丰富的交互功能。云阅报的新闻文本可以添加超链接,读者在浏览时可以通过超链接获取更多相关新闻,也可以随时参与话题讨论。
创新背景
1.创新运营模式解决盈利难题。目前,虽然很多媒体都推出了移动新媒体业务,但能从中受益的却寥寥无几。云报阅读平台除了技术优势之外,还找到了传统媒体开展移动媒体业务的盈利模式。
2.云报提供技术、市场、计费等一揽子解决方案,媒体只需要专注于自己擅长的内容制作。同时,媒体使用本平台发布移动媒体产品无需支付任何费用。 查看全部
云端内容采集(云端读报平台创新运营模式破解赢利难题(图))
云报是一个移动媒体发布平台,由内容制作系统、媒体发布系统、客户端系统、后台统计管理系统和运营支持系统组成。
功能介绍
1.信息容量大,可传输多媒体内容。传输的信息量没有限制,可以同时传输文字、图片、音频、视频等内容,大大丰富了媒体表达的手段。
2.具有实时推送功能,用户无需主动登录。当前的新闻客户端实际上是一个网络门户。读者需要启动客户端阅读新闻并登录后主动浏览互联网。安装云读报客户端后,只要订阅某份报纸,就可以像接收短信一样定时接收报纸。
3. 离线阅读,流畅的用户体验。目前国内3G网络覆盖并不完善,云读报内容推送到用户手机后,读者可以在手机上离线阅读。不仅减少了对无线网络的依赖,阅读也没有网络延迟。
4. 具有丰富的交互功能。云阅报的新闻文本可以添加超链接,读者在浏览时可以通过超链接获取更多相关新闻,也可以随时参与话题讨论。
创新背景
1.创新运营模式解决盈利难题。目前,虽然很多媒体都推出了移动新媒体业务,但能从中受益的却寥寥无几。云报阅读平台除了技术优势之外,还找到了传统媒体开展移动媒体业务的盈利模式。
2.云报提供技术、市场、计费等一揽子解决方案,媒体只需要专注于自己擅长的内容制作。同时,媒体使用本平台发布移动媒体产品无需支付任何费用。
云端内容采集(云端内容采集,让外国人放心在中国打拼(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-03-19 11:08
云端内容采集,顾名思义就是通过一些技术手段对各种网络内容,例如:ugc、app、微信等网络渠道进行采集,并上传到官方公有云端,上传方式为网页上传和内容版权控制两种。内容版权控制方式在海外很多国家这是一个法律法规所规定的网络行为,例如ugc、版权多媒体上传在国外是合法的。其中的手段就包括数据抓取,把你需要的,提取到上传官方的云端平台,如:gophers,yottasocket,magnitude等(以下简称yojs),如果你觉得你对云采集或者网络采集比较熟悉,你可以自己搭建和完善yojs,对于外行人来说学习起来稍微会有些困难。
需要注意的是yojs在海外的很多国家都是合法的,例如德国、美国等国。但是不是每个国家都是合法,同时又要有国家的版权法律法规要求以及实际执行的法律法规。
1、yojs:云采集平台(youtubecloudtrackingserviceforbusiness),让外国人放心在中国打拼(自己编译的系统),yojs在美国、德国、英国、法国、比利时、荷兰、澳大利亚、意大利、韩国、西班牙、香港、印度、澳门、台湾、新加坡、加拿大、泰国、美国、马来西亚、印度尼西亚、新西兰、以色列、韩国、澳门、智利、捷克共和国、加拿大、白俄罗斯、俄罗斯、挪威、乌克兰、瑞典、冰岛、日本、美国加州、亚洲其他主要市场地区(新加坡除外)),。(项目总监待遇get)yojs介绍:。
一、依托微软开源的youtubecloudtrackingservice系统,为企业、投资商、政府机构等提供一站式的商业采集、数据统计分析、数据可视化等一站式服务,并对接youtube、yahoo、spotify、亚马逊、亚马逊webmaster等云端资源。(作为一个技术宅男,大量程序员程序员或者没有独立采集youtube数据的人就不要来搞这个了,真的没有互联网技术,没有成体系的采集youtube资源的知识,本人除外)。
2、提供在线网页采集的开源工具yojs-selection,httpheaderanalysisandbusinesssearchwithyoutubecloudtracking。,youcanconfiguremanagementtopushyoursitetoyoutubeasselectionbyputtingadirecthttperrorcode,anemailtoyou,andemailyoutoyoutubecloudtrackingservicesaddressconnectingyouandyoursite。
,youcandropdownyourusername,phonenumber,internetname,andemailaddress。,andwhichconnectyouandyoutubetrackingservicesaddressconnectingyou。
3、完善的数据统计分析功能yojs_local_analytics_infomaximizethewholeanalysisbetweenpreviouslypostedcontentandnewcontent.
4、上传数据网站 查看全部
云端内容采集(云端内容采集,让外国人放心在中国打拼(组图))
云端内容采集,顾名思义就是通过一些技术手段对各种网络内容,例如:ugc、app、微信等网络渠道进行采集,并上传到官方公有云端,上传方式为网页上传和内容版权控制两种。内容版权控制方式在海外很多国家这是一个法律法规所规定的网络行为,例如ugc、版权多媒体上传在国外是合法的。其中的手段就包括数据抓取,把你需要的,提取到上传官方的云端平台,如:gophers,yottasocket,magnitude等(以下简称yojs),如果你觉得你对云采集或者网络采集比较熟悉,你可以自己搭建和完善yojs,对于外行人来说学习起来稍微会有些困难。
需要注意的是yojs在海外的很多国家都是合法的,例如德国、美国等国。但是不是每个国家都是合法,同时又要有国家的版权法律法规要求以及实际执行的法律法规。
1、yojs:云采集平台(youtubecloudtrackingserviceforbusiness),让外国人放心在中国打拼(自己编译的系统),yojs在美国、德国、英国、法国、比利时、荷兰、澳大利亚、意大利、韩国、西班牙、香港、印度、澳门、台湾、新加坡、加拿大、泰国、美国、马来西亚、印度尼西亚、新西兰、以色列、韩国、澳门、智利、捷克共和国、加拿大、白俄罗斯、俄罗斯、挪威、乌克兰、瑞典、冰岛、日本、美国加州、亚洲其他主要市场地区(新加坡除外)),。(项目总监待遇get)yojs介绍:。
一、依托微软开源的youtubecloudtrackingservice系统,为企业、投资商、政府机构等提供一站式的商业采集、数据统计分析、数据可视化等一站式服务,并对接youtube、yahoo、spotify、亚马逊、亚马逊webmaster等云端资源。(作为一个技术宅男,大量程序员程序员或者没有独立采集youtube数据的人就不要来搞这个了,真的没有互联网技术,没有成体系的采集youtube资源的知识,本人除外)。
2、提供在线网页采集的开源工具yojs-selection,httpheaderanalysisandbusinesssearchwithyoutubecloudtracking。,youcanconfiguremanagementtopushyoursitetoyoutubeasselectionbyputtingadirecthttperrorcode,anemailtoyou,andemailyoutoyoutubecloudtrackingservicesaddressconnectingyouandyoursite。
,youcandropdownyourusername,phonenumber,internetname,andemailaddress。,andwhichconnectyouandyoutubetrackingservicesaddressconnectingyou。
3、完善的数据统计分析功能yojs_local_analytics_infomaximizethewholeanalysisbetweenpreviouslypostedcontentandnewcontent.
4、上传数据网站
云端内容采集(#云端正版识别##[云端]())
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-03-17 22:12
#云正品识别## [云](%e7%99%be%e6%90%9c%e4%ba%91%e7%ab%af "[查看更多[百搜云]标签文章]" ) 系统正品识别:[](#%E7%99%BE%E6%90%9C%E4%BA%91%E7%AB%AF%E7%B3%BB%E7%BB%9F%E6 %AD% A3%E7%89%88%E8%AF%86%E5%88%AB%EF%BC%9A)**第一步:查看升级是否为最新版本,查看升级内容是否为升级内容. **![]()** 第二步;远程查看前端源码的可用性和完整性,识别【实时源码】(%e7%9b%b4%e6%92%ad%e6%ba%90%e7%a0%81"[查看更多< [Live source] 标签的@文章") 是否是最新的并且可用。(直播源码在个人中心)**![]()![]()** 第三步:****任何没有KEY升级码的转售盗版系统将无法在线升级和售后服务。升级码归官网所有,代理可免费索取升级码!****很多人购买了盗版系统,通过互联网通过各种销售渠道购买,请注意;我们不接受任何盗版系统的升级和售后服务,无论您在哪里购买或他们发送,不在我们的官方网站上。我们所有产品不提供任何帮助,花钱解决不了问题和售后,请不要贪便宜,不同的价格不同,有些东西是你看不到的坑!我们的品牌力求为您提供优质的服务,做最好的云系统!**![]()** 什么是升级代码?****回答:**升级码是您首次购买系统时,百搜科技为您提供升级码,以便更好的售后服务和为您升级!**我可以在没有升级代码的情况下使用它吗?****回答:**没有升级码的系统是不稳定的,因为他没有对系统做最基本的安全监控,升级优化BUG错误提示,所以系统无法正常使用。后期涉及百搜名誉,百搜将通过远程执行删除数据库文件!**KEY升级码可以使用多个域名吗?****答案:**一个KEY升级码只对应一个网站域名和IP。**很多人说我购买的系统是开源的,为什么要给域名和IP?****答案:**您购买的源代码是开源的,但是您需要提供域名和IP进行升级才能连接到我们的升级系统进行远程升级。如果您不提供我们,升级文件会飞到服务器内部吗?所以尽量与我们合作做升级服务。 查看全部
云端内容采集(#云端正版识别##[云端]())
#云正品识别## [云](%e7%99%be%e6%90%9c%e4%ba%91%e7%ab%af "[查看更多[百搜云]标签文章]" ) 系统正品识别:[](#%E7%99%BE%E6%90%9C%E4%BA%91%E7%AB%AF%E7%B3%BB%E7%BB%9F%E6 %AD% A3%E7%89%88%E8%AF%86%E5%88%AB%EF%BC%9A)**第一步:查看升级是否为最新版本,查看升级内容是否为升级内容. **![]()** 第二步;远程查看前端源码的可用性和完整性,识别【实时源码】(%e7%9b%b4%e6%92%ad%e6%ba%90%e7%a0%81"[查看更多< [Live source] 标签的@文章") 是否是最新的并且可用。(直播源码在个人中心)**![]()![]()** 第三步:****任何没有KEY升级码的转售盗版系统将无法在线升级和售后服务。升级码归官网所有,代理可免费索取升级码!****很多人购买了盗版系统,通过互联网通过各种销售渠道购买,请注意;我们不接受任何盗版系统的升级和售后服务,无论您在哪里购买或他们发送,不在我们的官方网站上。我们所有产品不提供任何帮助,花钱解决不了问题和售后,请不要贪便宜,不同的价格不同,有些东西是你看不到的坑!我们的品牌力求为您提供优质的服务,做最好的云系统!**![]()** 什么是升级代码?****回答:**升级码是您首次购买系统时,百搜科技为您提供升级码,以便更好的售后服务和为您升级!**我可以在没有升级代码的情况下使用它吗?****回答:**没有升级码的系统是不稳定的,因为他没有对系统做最基本的安全监控,升级优化BUG错误提示,所以系统无法正常使用。后期涉及百搜名誉,百搜将通过远程执行删除数据库文件!**KEY升级码可以使用多个域名吗?****答案:**一个KEY升级码只对应一个网站域名和IP。**很多人说我购买的系统是开源的,为什么要给域名和IP?****答案:**您购买的源代码是开源的,但是您需要提供域名和IP进行升级才能连接到我们的升级系统进行远程升级。如果您不提供我们,升级文件会飞到服务器内部吗?所以尽量与我们合作做升级服务。
云端内容采集(微信公众号是微信成为互联网入口的第一步)
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-03-08 06:03
云端内容采集如果说微信公众号是微信成为互联网入口的第一步,那么无疑云服务就是以最低的成本、最小的难度实现内容服务商的全面对接,包括但不限于公众号关联、网站挂靠、订阅号授权、网页广告定向推送以及门户网站采集等等。互联网会将内容的获取置之度外,因为互联网本质是将信息连接后呈现,而不是互联网之外的物理链接。
以百度为例,流量被分割后并非每条内容都能获取到流量,只有与之匹配的网站才能将流量转移,因此百度才会对搜索结果进行处理。采集的方式可以有几种,首先从业内开始就有门户站内容采集和抄袭的存在,例如凤凰网、搜狐等;网站购买也是常见的采集手段,例如网易的移动新闻平台;这些手段在各网站都有,但云端内容采集的模式则要简单许多。
微信和腾讯的采集,也可以说是依托于微信采集,要做内容的采集,首先要有一个足够的微信公众号,其次有一定的微信运营能力,再者要求企业微信支持,微信公众号采集则相对简单许多。无论是微信还是腾讯都倾向于采集适合内容制作商的消息,这是一种低风险、高产出的方式,极少有制作商去鼓励采集来源的竞争,一般都会选择不自己介入的方式——就像你电脑收到的qq群发的消息,有必要去获取那些有价值的消息吗?企业的目的要么是获取流量,要么是获取利润,这本质上来说,腾讯和微信也是比较偏向于前者,在利益驱动下想要尽量压缩采集对于自身流量和产品业务的破坏性。
初始阶段采集简单易用,像运营商一样的c&s架构就可以直接操作,后期如果想要获取到精准的资源,同时用户数据的采集是一大挑战,这就需要对用户进行分析,判断有潜力的关注人群,以采集未被释放的流量源(例如开始涉及的文章评论、用户的消息等),这里面很多因素都对用户产生影响,甚至会产生极坏的影响,例如一时获取不到用户的精准资源,就会因为封号而影响正常的推广,或者极好的关注人群,例如社交通过转发朋友圈内容获取流量。
还有用户的行为和使用习惯都会成为影响采集效果的一大关键因素,比如粉丝数量越多的内容制作商,对于其内容的要求自然也就越高,比如一个无聊的内容制作商对流量源的要求就仅限于累积订阅号数量,而另一些内容制作商就需要将用户关注和内容制作形成良性循环,也就是我前面所说的潜力用户,能够帮助采集到精准的流量源。云端内容采集系统对于采集流量和用户数据,其实要求并不高,首先采集是做内容电商的人来实现,那么对于企业来说要对接云服务商则是比较正常的操作,对于内容制作商来说则可以通过开通企业微信公众号来实现接入和管理。但是在。 查看全部
云端内容采集(微信公众号是微信成为互联网入口的第一步)
云端内容采集如果说微信公众号是微信成为互联网入口的第一步,那么无疑云服务就是以最低的成本、最小的难度实现内容服务商的全面对接,包括但不限于公众号关联、网站挂靠、订阅号授权、网页广告定向推送以及门户网站采集等等。互联网会将内容的获取置之度外,因为互联网本质是将信息连接后呈现,而不是互联网之外的物理链接。
以百度为例,流量被分割后并非每条内容都能获取到流量,只有与之匹配的网站才能将流量转移,因此百度才会对搜索结果进行处理。采集的方式可以有几种,首先从业内开始就有门户站内容采集和抄袭的存在,例如凤凰网、搜狐等;网站购买也是常见的采集手段,例如网易的移动新闻平台;这些手段在各网站都有,但云端内容采集的模式则要简单许多。
微信和腾讯的采集,也可以说是依托于微信采集,要做内容的采集,首先要有一个足够的微信公众号,其次有一定的微信运营能力,再者要求企业微信支持,微信公众号采集则相对简单许多。无论是微信还是腾讯都倾向于采集适合内容制作商的消息,这是一种低风险、高产出的方式,极少有制作商去鼓励采集来源的竞争,一般都会选择不自己介入的方式——就像你电脑收到的qq群发的消息,有必要去获取那些有价值的消息吗?企业的目的要么是获取流量,要么是获取利润,这本质上来说,腾讯和微信也是比较偏向于前者,在利益驱动下想要尽量压缩采集对于自身流量和产品业务的破坏性。
初始阶段采集简单易用,像运营商一样的c&s架构就可以直接操作,后期如果想要获取到精准的资源,同时用户数据的采集是一大挑战,这就需要对用户进行分析,判断有潜力的关注人群,以采集未被释放的流量源(例如开始涉及的文章评论、用户的消息等),这里面很多因素都对用户产生影响,甚至会产生极坏的影响,例如一时获取不到用户的精准资源,就会因为封号而影响正常的推广,或者极好的关注人群,例如社交通过转发朋友圈内容获取流量。
还有用户的行为和使用习惯都会成为影响采集效果的一大关键因素,比如粉丝数量越多的内容制作商,对于其内容的要求自然也就越高,比如一个无聊的内容制作商对流量源的要求就仅限于累积订阅号数量,而另一些内容制作商就需要将用户关注和内容制作形成良性循环,也就是我前面所说的潜力用户,能够帮助采集到精准的流量源。云端内容采集系统对于采集流量和用户数据,其实要求并不高,首先采集是做内容电商的人来实现,那么对于企业来说要对接云服务商则是比较正常的操作,对于内容制作商来说则可以通过开通企业微信公众号来实现接入和管理。但是在。
云端内容采集(云端内容采集系统:需要采集内容源,自动采集的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-02-22 00:02
云端内容采集系统:需要采集内容源,自动采集,根据用户要求对文章进行内容编辑发布等,又需要把内容发布到不同的平台上,需要建立前端网站,可以选择百度搜索结果发布,像大街网一样。另外:这个需要程序。产品介绍:客户可以是企业,个人,小企业,个人网站,也可以定制。可以考虑软件功能:内容采集,自动发布网站,打印pdf内容,自动链接到网站内容发布平台,内容批量发布,内容搜索,forwardjournal。
云采集就是采集各种平台的内容,不用网站、不要程序,需要什么新闻客户端直接在微信、微博、论坛、bbs、qq群等各种平台发布就行。个人感觉这还算是老方法了,国内优秀的工具很多,通过一些模板也可以很好用。
谢邀云采集+爬虫采集
云采集我理解,比如你要采集网易新闻的大图片,文字,视频和打字等都可以实现云采集,而采集的目的是什么?还有就是采集的范围到底要多大,这些因素很重要。
这个问题在我这几年的工作经验里面得到很好的解答!让我给你解释起来很容易。哈哈!这个问题就相当于什么是大数据一样,虽然定义什么是大数据这种概念很奇怪,但我们可以认为大数据就是采集热点,查询热点。
怎么采集的分成几类,主要是看客户对采集的文件是哪种形式。目前可以采集的网站太多了, 查看全部
云端内容采集(云端内容采集系统:需要采集内容源,自动采集的)
云端内容采集系统:需要采集内容源,自动采集,根据用户要求对文章进行内容编辑发布等,又需要把内容发布到不同的平台上,需要建立前端网站,可以选择百度搜索结果发布,像大街网一样。另外:这个需要程序。产品介绍:客户可以是企业,个人,小企业,个人网站,也可以定制。可以考虑软件功能:内容采集,自动发布网站,打印pdf内容,自动链接到网站内容发布平台,内容批量发布,内容搜索,forwardjournal。
云采集就是采集各种平台的内容,不用网站、不要程序,需要什么新闻客户端直接在微信、微博、论坛、bbs、qq群等各种平台发布就行。个人感觉这还算是老方法了,国内优秀的工具很多,通过一些模板也可以很好用。
谢邀云采集+爬虫采集
云采集我理解,比如你要采集网易新闻的大图片,文字,视频和打字等都可以实现云采集,而采集的目的是什么?还有就是采集的范围到底要多大,这些因素很重要。
这个问题在我这几年的工作经验里面得到很好的解答!让我给你解释起来很容易。哈哈!这个问题就相当于什么是大数据一样,虽然定义什么是大数据这种概念很奇怪,但我们可以认为大数据就是采集热点,查询热点。
怎么采集的分成几类,主要是看客户对采集的文件是哪种形式。目前可以采集的网站太多了,
云端内容采集(利用轻量级爬虫框架scrapy来进行数据采集的基本方法(图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-02-17 20:09
)
在这个“大数据”和“人工智能”的时代,数据分析和挖掘逐渐成为互联网从业者的必备技能。本文介绍使用轻量级爬虫框架scrapy处理数据的基本方法采集。
一、scrapy简介
scrapy是一套用Python编写的异步爬虫框架,基于Twisted实现,运行于Linux/Windows/MacOS等环境,具有速度快、扩展性强、使用方便等特点。即使是新手也能快速掌握并编写所需的爬虫程序。scrapy 可以在本地运行,也可以部署到云端(scrapyd),实现真正的生产级数据采集系统。
我们通过一个示例来学习如何使用scrapy 来采集来自网络的数据。《博客园》是全面的技术资料网站,这次我们的任务是采集的网站 MySQL 类
以下所有文章的标题、摘要、发布日期和阅读次数,共4个字段。最终结果是一个收录所有 4 个字段的文本文件。如图所示:
最终得到的数据如下,每条记录有四行,分别是标题、阅读次数、发布时间、文章摘要:
二、安装scrapy
让我们看看如何安装scrapy。首先,您的系统中必须有 Python 和 pip。本文以最常见的 Python2.7.5 版本为例。pip 是 Python 的包管理工具,一般 Linux 系统默认安装。在命令行输入以下命令并执行:
sudo pip install scrapy -i http://pypi.douban.com/simple –trusted-host=pypi.douban.com
pip会从豆瓣的软件源下载安装scrapy,所有依赖包都会自动下载安装。“sudo”表示以超级用户权限执行此命令。在所有进度条完成后,如果提示类似“Successfully installed Twisted, scrapy ...”,则安装成功。
三、scrapy 交互环境
scrapy 还提供了一个交互式 shell,可以用来轻松地测试解析规则。scrapy安装成功后,在命令行输入scrapy shell,启动scrapy的交互环境。scrapy shell的提示符是三个大于号>>>,表示可以接收命令。我们首先使用 fetch() 方法获取首页内容:
>>> fetch( “https://www.cnblogs.com/cate/mysql/” )
如果屏幕显示如下输出,则表示已获取网页内容。
2017-09-04 07:46:55 [scrapy.core.engine] INFO: Spider opened 2017-09-04 07:46:55 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
获得的响应将保存在响应对象中。此对象的 status 属性表示 HTTP 响应状态,通常为 200。
>>> print response.status 200
text 属性表示返回的内容数据,从中可以解析出需要的内容。
>>> print response.text u'\r\n\r\n\r\n \r\n \r\n \r\n MySQL – \u7f51\u7ad9\u5206\u7c7b – \u535a\u5ba2\u56ed\r\n ’
可以看出是一堆乱七八糟的HTML代码,无法直观的找到我们需要的数据。这时候我们可以通过浏览器的“开发者工具”获取指定数据的DOM路径。用浏览器打开网页后,按F12键启动开发者工具,快速定位到指定内容。
可以看到我们需要的4个字段在/body/div(id=”wrapper”)/div(id=”main”)/div(id=”post_list”)/div(class=”post_item”)/ div(class=”post_item_body”) / ,每个“post_item_body”收录一篇文章文章的标题、摘要、发表日期和阅读次数。我们首先得到所有的“post_item_body”,然后从中解析出每个文章的4个字段。
>>> post_item_body = response.xpath( “//div[@id=’wrapper’]/div[@id=’main’]/div[@id=’post_list’]/div[@class=’post_item’]/div[@class=’post_item_body’]” ) >>> len( post_item_body ) 20
响应的 xpath 方法可以使用 xpath 解析器来获取 DOM 数据。xpath的语法请参考官网文档。您可以看到我们在主页上获得了 文章 的所有 20 个 post_item_body。那么如何提取每个文章的这4个字段呢?
我们以第一篇文章文章为例。先取第一个 post_item_body:
>>> first_article = post_item_body[ 0 ]
标题在 post_item_body 节点下的 h3/a 中。xpath方法中text()的作用是取当前节点的文本,而extract_first()和strip()提取xpath表达式中的节点,过滤掉前后空格和回车:
>>> article_title = first_article.xpath( “h3/a/text()” ).extract_first().strip() >>> print article_title Mysql之表的操作与索引操作
然后以类似的方式提取 文章 抽象:
>>> article_summary = first_article.xpath( “p[@class=’post_item_summary’]/text()” ).extract_first().strip() >>> print article_summary 表的操作: 1.表的创建: create table if not exists table_name(字段定义); 例子: create table if not exists user(id int auto_increment, uname varchar(20), address varch …
提取post_item_foot时,发现提取了两组内容,***组为空内容,第二组为文字“Published in XXX”。我们提取第二组内容并过滤掉“published on”这个词:
>>> post_date = first_article.xpath( “div[@class=’post_item_foot’]/text()” ).extract()[ 1 ].split( “发布于” )[ 1 ].strip() >>> print post_date 2017-09-03 18:13 查看全部
云端内容采集(利用轻量级爬虫框架scrapy来进行数据采集的基本方法(图)
)
在这个“大数据”和“人工智能”的时代,数据分析和挖掘逐渐成为互联网从业者的必备技能。本文介绍使用轻量级爬虫框架scrapy处理数据的基本方法采集。
一、scrapy简介
scrapy是一套用Python编写的异步爬虫框架,基于Twisted实现,运行于Linux/Windows/MacOS等环境,具有速度快、扩展性强、使用方便等特点。即使是新手也能快速掌握并编写所需的爬虫程序。scrapy 可以在本地运行,也可以部署到云端(scrapyd),实现真正的生产级数据采集系统。
我们通过一个示例来学习如何使用scrapy 来采集来自网络的数据。《博客园》是全面的技术资料网站,这次我们的任务是采集的网站 MySQL 类
以下所有文章的标题、摘要、发布日期和阅读次数,共4个字段。最终结果是一个收录所有 4 个字段的文本文件。如图所示:
最终得到的数据如下,每条记录有四行,分别是标题、阅读次数、发布时间、文章摘要:
二、安装scrapy
让我们看看如何安装scrapy。首先,您的系统中必须有 Python 和 pip。本文以最常见的 Python2.7.5 版本为例。pip 是 Python 的包管理工具,一般 Linux 系统默认安装。在命令行输入以下命令并执行:
sudo pip install scrapy -i http://pypi.douban.com/simple –trusted-host=pypi.douban.com
pip会从豆瓣的软件源下载安装scrapy,所有依赖包都会自动下载安装。“sudo”表示以超级用户权限执行此命令。在所有进度条完成后,如果提示类似“Successfully installed Twisted, scrapy ...”,则安装成功。
三、scrapy 交互环境
scrapy 还提供了一个交互式 shell,可以用来轻松地测试解析规则。scrapy安装成功后,在命令行输入scrapy shell,启动scrapy的交互环境。scrapy shell的提示符是三个大于号>>>,表示可以接收命令。我们首先使用 fetch() 方法获取首页内容:
>>> fetch( “https://www.cnblogs.com/cate/mysql/” )
如果屏幕显示如下输出,则表示已获取网页内容。
2017-09-04 07:46:55 [scrapy.core.engine] INFO: Spider opened 2017-09-04 07:46:55 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
获得的响应将保存在响应对象中。此对象的 status 属性表示 HTTP 响应状态,通常为 200。
>>> print response.status 200
text 属性表示返回的内容数据,从中可以解析出需要的内容。
>>> print response.text u'\r\n\r\n\r\n \r\n \r\n \r\n MySQL – \u7f51\u7ad9\u5206\u7c7b – \u535a\u5ba2\u56ed\r\n ’
可以看出是一堆乱七八糟的HTML代码,无法直观的找到我们需要的数据。这时候我们可以通过浏览器的“开发者工具”获取指定数据的DOM路径。用浏览器打开网页后,按F12键启动开发者工具,快速定位到指定内容。
可以看到我们需要的4个字段在/body/div(id=”wrapper”)/div(id=”main”)/div(id=”post_list”)/div(class=”post_item”)/ div(class=”post_item_body”) / ,每个“post_item_body”收录一篇文章文章的标题、摘要、发表日期和阅读次数。我们首先得到所有的“post_item_body”,然后从中解析出每个文章的4个字段。
>>> post_item_body = response.xpath( “//div[@id=’wrapper’]/div[@id=’main’]/div[@id=’post_list’]/div[@class=’post_item’]/div[@class=’post_item_body’]” ) >>> len( post_item_body ) 20
响应的 xpath 方法可以使用 xpath 解析器来获取 DOM 数据。xpath的语法请参考官网文档。您可以看到我们在主页上获得了 文章 的所有 20 个 post_item_body。那么如何提取每个文章的这4个字段呢?
我们以第一篇文章文章为例。先取第一个 post_item_body:
>>> first_article = post_item_body[ 0 ]
标题在 post_item_body 节点下的 h3/a 中。xpath方法中text()的作用是取当前节点的文本,而extract_first()和strip()提取xpath表达式中的节点,过滤掉前后空格和回车:
>>> article_title = first_article.xpath( “h3/a/text()” ).extract_first().strip() >>> print article_title Mysql之表的操作与索引操作
然后以类似的方式提取 文章 抽象:
>>> article_summary = first_article.xpath( “p[@class=’post_item_summary’]/text()” ).extract_first().strip() >>> print article_summary 表的操作: 1.表的创建: create table if not exists table_name(字段定义); 例子: create table if not exists user(id int auto_increment, uname varchar(20), address varch …
提取post_item_foot时,发现提取了两组内容,***组为空内容,第二组为文字“Published in XXX”。我们提取第二组内容并过滤掉“published on”这个词:
>>> post_date = first_article.xpath( “div[@class=’post_item_foot’]/text()” ).extract()[ 1 ].split( “发布于” )[ 1 ].strip() >>> print post_date 2017-09-03 18:13
云端内容采集(经纬中天大屏信息发布系统基于数字音视频动态信息传播技术)
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-02-17 17:28
一、整体介绍
经纬中天大屏信息发布系统基于数字音视频动态信息发布技术。等流程,实现各种户外信息终端(如液晶屏、等离子、投影仪、LED屏等)多内容、多应用的统一呈现和综合管理。支持按区域、社区、街道等多级类别对多个信息终端进行分组管理,可在指定地点、指定地点向户外信息终端发布通知、公告、图片、电子报、广告、播放视频次。标准化统一业务数据和数据级集成技术,实现大屏互动应用,如社区互动、微博、微信、天气预报、金融、交通、一卡通、社保等应用,让人们真正体验无线城市建成后的生活。更高的质量、更快的工作效率和更强的幸福感,为全面建设无线城市和智慧城市提供了新的途径和手段。
<IMG style="HEIGHT: 359px; WIDTH: 667px" border=0 hspace=0 alt="" src="/_CMS_NEWS_IMG_/www1/201509/25/cms_507d3365d2b041879596a055bcdfaa5b.png" width=875 align=baseline height=468>
二、系统应用
1、权威信息第一时间发布
支持政府机构、媒体等权威机构实现应急信息、重要新闻事件等内容在城市不同角落第一时间在户外大屏上的权威发布,提高信息的时效性,使公众能够随时随地获取信息。
<IMG style="HEIGHT: 504px; WIDTH: 302px" border=0 hspace=0 alt="" src="/_CMS_NEWS_IMG_/www1/201509/25/cms_8aca7c72d80b4eb6bb006ed6f3b9d51a.png" width=598 align=baseline height=941>
<IMG style="HEIGHT: 503px; WIDTH: 303px" border=0 hspace=0 alt="" src="/_CMS_NEWS_IMG_/www1/201509/25/cms_49eda82ad68c48cab100b9136ddf7e49.jpg" width=550 align=baseline height=977>
2、随时随地提供在线生活服务
支持通过户外大屏发布系统向公众提供生活服务应用,包括:天气、优采云、公交、航班、餐饮等,随时随地查询;随时随地发布城市信息、消费、民生等信息;电子报刊随时随地阅读,拓展更多水、电、煤支付等生活服务应用,为实现无线城市提供便捷途径。
<IMG style="HEIGHT: 496px; WIDTH: 304px" border=0 hspace=0 alt="" src="/_CMS_NEWS_IMG_/www1/201509/25/cms_2a247ca6ae7f48b69ca47dc229440a15.png" width=800 align=baseline height=1253>
<IMG style="HEIGHT: 498px; WIDTH: 323px" border=0 hspace=0 alt="" src="/_CMS_NEWS_IMG_/www1/201509/25/cms_646a8b9945a746e280333b33b00ab424.png" width=800 align=baseline height=1252>
三、特点
1、多源内容采集管理
针对基于图片、音视频、文字、FLASH等素材的新闻、公告、报纸、广告信息的采集、编辑、审阅、发布等流程管理,支持内容素材的分类管理( (如文字、图片等)、视频、广告等),并可对内容素材进行添加、删除、编辑、分组、预览等操作,实现户外大屏多媒体信息的展示与互动应用。
2、多媒体信息实时发布推送
系统支持多点发布、分组发布、个性化发布、紧急发布、即时插入等各类户外大屏多媒体内容的统一发布和推送管理。例如:即时发布紧急公告、公益宣传播报、政府信息公开等,灵活选择各个对应区域或单个终端进行定向或整体的内容更新发布。终端演示方面,支持终端演示内容模板的制作、修改、管理功能;支持订单编排、播出策略、内容线上线下等播出任务管理。
3、互动屏内容互动应用
支持为触摸屏信息终端提供交互应用服务,并根据用户的使用习惯提供相应的交互内容信息。
<IMG style="HEIGHT: 466px; WIDTH: 505px" border=0 hspace=0 alt="" src="/_CMS_NEWS_IMG_/www1/201509/25/cms_5ab94b7e919048c2b9afd240f2cfc483.png" width=622 align=baseline height=604>
双向交互:交互式触摸屏终端,用户手动输入查询条件,随意选择即可浏览所需内容信息。例如:查询过去的新闻和报纸,您可以通过触摸预览您查询过的信息,例如随意放大和缩小。操作简单流畅,让广大市民无需工作人员的指导即可完成大部分工作。运行应用程序。
信息查询:交互式触摸屏终端支持生活服务信息查询,包括当前位置、周边地理环境、公共交通信息、天气、餐饮、航班、旅游等生活信息查询,为公众查询城市生活提供可靠平台随时随地的服务信息。
信息展示:除了交互交互应用外,系统还可以提供信息展示功能,可以包括信息、消费、民生,如:车业、品味、场所、服饰、配饰、地产、家居、汽车、餐饮和个性化娱乐。每次提供一批更新,精选本地消费购物信息和折扣信息,以高清大图为主,奢华视觉体验。
社交互动:系统支持微信、微博、短信等实时内容交互,通过账号同步和统一认证管理,用户可以随时随地将触屏内容分享到微信、微博、人人、天涯等SNS社区,用户还可以通过二维码直接与微信公众号互动。
4、多种形式的广告展示
支持信息终端页面任意位置(如:液晶屏、等离子、投影仪、LED屏等)和节目列表中多种形式的广告植入。广告内容包括:视频、图片、文字等形式的广告。
支持对广告资源、广告位、广告排期策略、广告销售、广告统计和报表的管理,支持灵活的广告投放策略:内容定向投放、时间定向投放、广告精准投放。视频广告发布形式支持缓冲广告、前贴片广告、后贴片广告、暂停广告、浮动文字广告等。完善的广告管理流程和强大的统计功能,可以提高广告播出的透明度,大大提高创收. 查看全部
云端内容采集(经纬中天大屏信息发布系统基于数字音视频动态信息传播技术)
一、整体介绍
经纬中天大屏信息发布系统基于数字音视频动态信息发布技术。等流程,实现各种户外信息终端(如液晶屏、等离子、投影仪、LED屏等)多内容、多应用的统一呈现和综合管理。支持按区域、社区、街道等多级类别对多个信息终端进行分组管理,可在指定地点、指定地点向户外信息终端发布通知、公告、图片、电子报、广告、播放视频次。标准化统一业务数据和数据级集成技术,实现大屏互动应用,如社区互动、微博、微信、天气预报、金融、交通、一卡通、社保等应用,让人们真正体验无线城市建成后的生活。更高的质量、更快的工作效率和更强的幸福感,为全面建设无线城市和智慧城市提供了新的途径和手段。
<IMG style="HEIGHT: 359px; WIDTH: 667px" border=0 hspace=0 alt="" src="/_CMS_NEWS_IMG_/www1/201509/25/cms_507d3365d2b041879596a055bcdfaa5b.png" width=875 align=baseline height=468>
二、系统应用
1、权威信息第一时间发布
支持政府机构、媒体等权威机构实现应急信息、重要新闻事件等内容在城市不同角落第一时间在户外大屏上的权威发布,提高信息的时效性,使公众能够随时随地获取信息。
<IMG style="HEIGHT: 504px; WIDTH: 302px" border=0 hspace=0 alt="" src="/_CMS_NEWS_IMG_/www1/201509/25/cms_8aca7c72d80b4eb6bb006ed6f3b9d51a.png" width=598 align=baseline height=941>
<IMG style="HEIGHT: 503px; WIDTH: 303px" border=0 hspace=0 alt="" src="/_CMS_NEWS_IMG_/www1/201509/25/cms_49eda82ad68c48cab100b9136ddf7e49.jpg" width=550 align=baseline height=977>
2、随时随地提供在线生活服务
支持通过户外大屏发布系统向公众提供生活服务应用,包括:天气、优采云、公交、航班、餐饮等,随时随地查询;随时随地发布城市信息、消费、民生等信息;电子报刊随时随地阅读,拓展更多水、电、煤支付等生活服务应用,为实现无线城市提供便捷途径。
<IMG style="HEIGHT: 496px; WIDTH: 304px" border=0 hspace=0 alt="" src="/_CMS_NEWS_IMG_/www1/201509/25/cms_2a247ca6ae7f48b69ca47dc229440a15.png" width=800 align=baseline height=1253>
<IMG style="HEIGHT: 498px; WIDTH: 323px" border=0 hspace=0 alt="" src="/_CMS_NEWS_IMG_/www1/201509/25/cms_646a8b9945a746e280333b33b00ab424.png" width=800 align=baseline height=1252>
三、特点
1、多源内容采集管理
针对基于图片、音视频、文字、FLASH等素材的新闻、公告、报纸、广告信息的采集、编辑、审阅、发布等流程管理,支持内容素材的分类管理( (如文字、图片等)、视频、广告等),并可对内容素材进行添加、删除、编辑、分组、预览等操作,实现户外大屏多媒体信息的展示与互动应用。
2、多媒体信息实时发布推送
系统支持多点发布、分组发布、个性化发布、紧急发布、即时插入等各类户外大屏多媒体内容的统一发布和推送管理。例如:即时发布紧急公告、公益宣传播报、政府信息公开等,灵活选择各个对应区域或单个终端进行定向或整体的内容更新发布。终端演示方面,支持终端演示内容模板的制作、修改、管理功能;支持订单编排、播出策略、内容线上线下等播出任务管理。
3、互动屏内容互动应用
支持为触摸屏信息终端提供交互应用服务,并根据用户的使用习惯提供相应的交互内容信息。
<IMG style="HEIGHT: 466px; WIDTH: 505px" border=0 hspace=0 alt="" src="/_CMS_NEWS_IMG_/www1/201509/25/cms_5ab94b7e919048c2b9afd240f2cfc483.png" width=622 align=baseline height=604>
双向交互:交互式触摸屏终端,用户手动输入查询条件,随意选择即可浏览所需内容信息。例如:查询过去的新闻和报纸,您可以通过触摸预览您查询过的信息,例如随意放大和缩小。操作简单流畅,让广大市民无需工作人员的指导即可完成大部分工作。运行应用程序。
信息查询:交互式触摸屏终端支持生活服务信息查询,包括当前位置、周边地理环境、公共交通信息、天气、餐饮、航班、旅游等生活信息查询,为公众查询城市生活提供可靠平台随时随地的服务信息。
信息展示:除了交互交互应用外,系统还可以提供信息展示功能,可以包括信息、消费、民生,如:车业、品味、场所、服饰、配饰、地产、家居、汽车、餐饮和个性化娱乐。每次提供一批更新,精选本地消费购物信息和折扣信息,以高清大图为主,奢华视觉体验。
社交互动:系统支持微信、微博、短信等实时内容交互,通过账号同步和统一认证管理,用户可以随时随地将触屏内容分享到微信、微博、人人、天涯等SNS社区,用户还可以通过二维码直接与微信公众号互动。
4、多种形式的广告展示
支持信息终端页面任意位置(如:液晶屏、等离子、投影仪、LED屏等)和节目列表中多种形式的广告植入。广告内容包括:视频、图片、文字等形式的广告。
支持对广告资源、广告位、广告排期策略、广告销售、广告统计和报表的管理,支持灵活的广告投放策略:内容定向投放、时间定向投放、广告精准投放。视频广告发布形式支持缓冲广告、前贴片广告、后贴片广告、暂停广告、浮动文字广告等。完善的广告管理流程和强大的统计功能,可以提高广告播出的透明度,大大提高创收.
云端内容采集(三星移动摄像头云端内容采集是个趋势,建议你可以关注)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-02-17 11:02
云端内容采集其实很简单,基本上就是基于图像识别技术,而在图像识别当中rgba个色彩信息都是比较齐全的,建议你可以关注斑马信息安全安卓sdk的三星移动摄像头云端采集,按要求进行图像采集和校准,将所有功能转移到云端,更有利于业务发展。
youtube这种级别的app还需要内嵌?这个技术已经相当成熟了不管内嵌还是云端采集至少都会全局的对信息进行加密保护而且app采集到的信息与后台数据同步到后台数据库是个趋势
我觉得这个问题,sdk还是比较好做的,目前已经有如boxar这类的公司在做这个事情了,很多国内的公司也都看中了这块市场,投入一定量的资金,经过两年左右的时间,数据基本上都能开放给开发者使用。现在想做的话,可以看看各种开发者,他们有什么痛点,可以看看各种开发者的案例,看看他们是怎么去做,把你要做的东西或者问题告诉开发者,然后开发者研究下你们的模式,尝试着做个功能出来,不要怕操作麻烦,操作一定要简单,最好需要这类的开发者扫码入驻平台,而你的开发者不需要对内也可以使用,但要做好安全方面的加密,这个目前来看还算比较合理,他们这个平台对国内外的开发者都有好的开放政策的。
这些个信息商业化变现应该都是容易的,另外像国内的支付宝这些会接入,这种平台型的内容可以理解为一种fpga之类的设备,然后网络内部的服务器统一承接数据传输,信息传输的节点安全问题基本上这种平台型内容都不会有太大问题,但是如果真正在内部做起来,要真正让别人对内容有认可度,做好监管,技术和数据都要保证没问题。像excel、latex之类的就很好做内容传输节点认证,当然这个应该用上就挺费劲的。 查看全部
云端内容采集(三星移动摄像头云端内容采集是个趋势,建议你可以关注)
云端内容采集其实很简单,基本上就是基于图像识别技术,而在图像识别当中rgba个色彩信息都是比较齐全的,建议你可以关注斑马信息安全安卓sdk的三星移动摄像头云端采集,按要求进行图像采集和校准,将所有功能转移到云端,更有利于业务发展。
youtube这种级别的app还需要内嵌?这个技术已经相当成熟了不管内嵌还是云端采集至少都会全局的对信息进行加密保护而且app采集到的信息与后台数据同步到后台数据库是个趋势
我觉得这个问题,sdk还是比较好做的,目前已经有如boxar这类的公司在做这个事情了,很多国内的公司也都看中了这块市场,投入一定量的资金,经过两年左右的时间,数据基本上都能开放给开发者使用。现在想做的话,可以看看各种开发者,他们有什么痛点,可以看看各种开发者的案例,看看他们是怎么去做,把你要做的东西或者问题告诉开发者,然后开发者研究下你们的模式,尝试着做个功能出来,不要怕操作麻烦,操作一定要简单,最好需要这类的开发者扫码入驻平台,而你的开发者不需要对内也可以使用,但要做好安全方面的加密,这个目前来看还算比较合理,他们这个平台对国内外的开发者都有好的开放政策的。
这些个信息商业化变现应该都是容易的,另外像国内的支付宝这些会接入,这种平台型的内容可以理解为一种fpga之类的设备,然后网络内部的服务器统一承接数据传输,信息传输的节点安全问题基本上这种平台型内容都不会有太大问题,但是如果真正在内部做起来,要真正让别人对内容有认可度,做好监管,技术和数据都要保证没问题。像excel、latex之类的就很好做内容传输节点认证,当然这个应该用上就挺费劲的。
云端内容采集(Google的这项服务被称为BigQuery(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-02-08 23:11
BigQuery 是谷歌推出的一种网络服务,用于处理云中的大数据。本文简要介绍了 Google BigQuery 以及 BigQuery 在云端使用 SQL 处理大数据的优势。
今天,大数据的话题围绕着本地部署的系统展开,谷歌正在构建服务来分析云中的大数据。谷歌的服务被称为 BigQuery,谷歌产品经理 Ju-Kay Kwek 在最近在纽约举行的 GigaOM 会议上表示,BigQuery 将帮助公司在没有硬件基础设施的情况下分析他们的数据。可以同时建立应用和数据共享的所有服务。
BigQuery 是 Google 推出的一项 Web 服务,它允许开发人员使用 Google 的架构运行 SQL 语句来操作非常大的数据库。BigQuery 允许用户上传大量数据并直接通过它执行交互式分析,无需投资建立自己的数据中心。谷歌表示,BigQuery 引擎可以快速扫描多达 70TB 的未压缩数据并立即获得分析结果。
<IMG alt="Google BigQuery:在云端处理大数据" src="http://img1.gtimg.com/tech/pic ... gt%3B
但谷歌目前只为少数客户提供服务,何时全面开放服务尚不确定。参与的客户以多种方式测试 BigQuery 服务,客户将他们的数据流上传到服务器,然后通过 Google 的算法和查询语言分析数据。
云模型中的大数据有很多优势,BigQuery 服务不需要组织提供或构建数据仓库。而且 BigQuery 在安全和数据备份服务方面也相当完善。
谷歌高管看到了云时代BigQuery模型的机会,谷歌内部已经开发和使用了相关工具。Kwek 表示,在数据爆炸的时代,(谷歌搜索引擎)索引网页是一个大数据问题。同时谷歌的Gmail也面临同样的问题。谷歌成功的关键是保持它产生的所有数据都是细粒度的。在线广告商通过采集一定范围内的相关数据来做到这一点。例如,用户行为,然后采集这些数据以进行更准确的广告投放。
谷歌产品经理 Ju-Kay Kwek 也表示,新的 BigQuery 服务提供了一个新的 REST API,开发者可以将这个服务编译到他们的代码中,并且可以有效地实现多任务管理和权限控制。查询到的数据表也可以导出到谷歌的云存储服务中。此外,BigQuery 带来了一个新的网络界面,可以更清晰地显示查询结果。 查看全部
云端内容采集(Google的这项服务被称为BigQuery(组图))
BigQuery 是谷歌推出的一种网络服务,用于处理云中的大数据。本文简要介绍了 Google BigQuery 以及 BigQuery 在云端使用 SQL 处理大数据的优势。
今天,大数据的话题围绕着本地部署的系统展开,谷歌正在构建服务来分析云中的大数据。谷歌的服务被称为 BigQuery,谷歌产品经理 Ju-Kay Kwek 在最近在纽约举行的 GigaOM 会议上表示,BigQuery 将帮助公司在没有硬件基础设施的情况下分析他们的数据。可以同时建立应用和数据共享的所有服务。
BigQuery 是 Google 推出的一项 Web 服务,它允许开发人员使用 Google 的架构运行 SQL 语句来操作非常大的数据库。BigQuery 允许用户上传大量数据并直接通过它执行交互式分析,无需投资建立自己的数据中心。谷歌表示,BigQuery 引擎可以快速扫描多达 70TB 的未压缩数据并立即获得分析结果。
<IMG alt="Google BigQuery:在云端处理大数据" src="http://img1.gtimg.com/tech/pic ... gt%3B
但谷歌目前只为少数客户提供服务,何时全面开放服务尚不确定。参与的客户以多种方式测试 BigQuery 服务,客户将他们的数据流上传到服务器,然后通过 Google 的算法和查询语言分析数据。
云模型中的大数据有很多优势,BigQuery 服务不需要组织提供或构建数据仓库。而且 BigQuery 在安全和数据备份服务方面也相当完善。
谷歌高管看到了云时代BigQuery模型的机会,谷歌内部已经开发和使用了相关工具。Kwek 表示,在数据爆炸的时代,(谷歌搜索引擎)索引网页是一个大数据问题。同时谷歌的Gmail也面临同样的问题。谷歌成功的关键是保持它产生的所有数据都是细粒度的。在线广告商通过采集一定范围内的相关数据来做到这一点。例如,用户行为,然后采集这些数据以进行更准确的广告投放。
谷歌产品经理 Ju-Kay Kwek 也表示,新的 BigQuery 服务提供了一个新的 REST API,开发者可以将这个服务编译到他们的代码中,并且可以有效地实现多任务管理和权限控制。查询到的数据表也可以导出到谷歌的云存储服务中。此外,BigQuery 带来了一个新的网络界面,可以更清晰地显示查询结果。
云端内容采集(DataFlux大数据网关-DataFluxStudio实时数据洞察平台-Admin )
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-02-07 04:04
)
DataFlux是上海住云自主研发的一套统一的大数据分析平台,通过对任意来源、任意类型、任意规模的实时数据进行监测、分析和处理,释放数据价值。
DataFlux 包括五个功能模块:
- 数据包 采集器
- Dataway 数据网关
- DataFlux Studio 实时数据洞察平台
- DataFlux Admin Console 管理后台
- DataFlux.f(x) 实时数据处理开发平台
为企业提供全场景数据洞察分析能力,具有实时性、灵活性、易扩展性、易部署性。
安装 DataKit
PS:以Linux系统为例
第一步:执行安装命令
DataKit 安装命令:
DK_FTDATAWAY=[你的 DataWay 网关地址] bash -c "$(curl https://static.dataflux.cn/datakit/install.sh)"
在安装命令中添加DataWay网关地址,然后将安装命令复制到主机执行。
例如:DataWay网关的IP地址为1.2.3.4,端口为9528(9528为默认端口),则网关地址为
:9528/v1/write/metrics,安装命令为:
DK_FTDATAWAY=http://1.2.3.4:9528/v1/write/metrics bash -c "$(curl https://static.dataflux.cn/datakit/install.sh)"
安装完成后DataKit会默认自动运行,并会在终端提示DataKit状态管理命令
RabbitMQ 监控指标采集
前提
配置
打开DataKit采集源码配置文件夹(默认路径是DataKit安装目录的conf.d文件夹),找到rabbitmq文件夹,打开里面的rabbitmq.conf。
配置好后重启DataKit生效
验证数据报告
完成数据采集操作后,我们需要验证数据采集是否成功并上报给DataWay,以便日后可以正常分析和展示数据。
操作步骤:登录DataFlux-数据管理-指标浏览-验证数据采集是否成功
RabbitMQ 性能指标:
DataFlux 的数据洞察力
根据获得的指标进行数据洞察设计,如:
RabbitMQ 性能监控视图
基于自研DataKit数据(采集器),DataFlux现在可以对接200多种数据协议,包括:云数据采集、应用数据采集、日志数据采集,时序数据上报和常用数据库的数据聚合,帮助企业实现最便捷的IT统一监控。
查看全部
云端内容采集(DataFlux大数据网关-DataFluxStudio实时数据洞察平台-Admin
)
DataFlux是上海住云自主研发的一套统一的大数据分析平台,通过对任意来源、任意类型、任意规模的实时数据进行监测、分析和处理,释放数据价值。
DataFlux 包括五个功能模块:
- 数据包 采集器
- Dataway 数据网关
- DataFlux Studio 实时数据洞察平台
- DataFlux Admin Console 管理后台
- DataFlux.f(x) 实时数据处理开发平台
为企业提供全场景数据洞察分析能力,具有实时性、灵活性、易扩展性、易部署性。
安装 DataKit
PS:以Linux系统为例
第一步:执行安装命令
DataKit 安装命令:
DK_FTDATAWAY=[你的 DataWay 网关地址] bash -c "$(curl https://static.dataflux.cn/datakit/install.sh)"
在安装命令中添加DataWay网关地址,然后将安装命令复制到主机执行。
例如:DataWay网关的IP地址为1.2.3.4,端口为9528(9528为默认端口),则网关地址为
:9528/v1/write/metrics,安装命令为:
DK_FTDATAWAY=http://1.2.3.4:9528/v1/write/metrics bash -c "$(curl https://static.dataflux.cn/datakit/install.sh)"
安装完成后DataKit会默认自动运行,并会在终端提示DataKit状态管理命令
RabbitMQ 监控指标采集
前提
配置
打开DataKit采集源码配置文件夹(默认路径是DataKit安装目录的conf.d文件夹),找到rabbitmq文件夹,打开里面的rabbitmq.conf。
配置好后重启DataKit生效
验证数据报告
完成数据采集操作后,我们需要验证数据采集是否成功并上报给DataWay,以便日后可以正常分析和展示数据。
操作步骤:登录DataFlux-数据管理-指标浏览-验证数据采集是否成功
RabbitMQ 性能指标:
DataFlux 的数据洞察力
根据获得的指标进行数据洞察设计,如:
RabbitMQ 性能监控视图
基于自研DataKit数据(采集器),DataFlux现在可以对接200多种数据协议,包括:云数据采集、应用数据采集、日志数据采集,时序数据上报和常用数据库的数据聚合,帮助企业实现最便捷的IT统一监控。
云端内容采集(上海驻云自大数据统一分析平台-DataFluxStudio实时数据洞察平台 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2022-02-01 11:18
)
DataFlux是上海住云自主研发的一套统一的大数据分析平台,可以通过对任意来源、任意类型、任意规模的实时数据进行监测、分析和处理,释放数据价值。
DataFlux 包括五个功能模块:
- 数据包 采集器
- Dataway 数据网关
- DataFlux Studio 实时数据洞察平台
- DataFlux Admin Console 管理后台
- DataFlux.f(x) 实时数据处理开发平台
为企业提供全场景数据洞察分析能力,具有实时性、灵活性、易扩展性、易部署性。
安装 DataKit
PS:以Linux系统为例
第一步:执行安装命令
DataKit 安装命令:
DK_FTDATAWAY=[你的 DataWay 网关地址] bash -c "$(curl https://static.dataflux.cn/datakit/install.sh)"
在安装命令中添加DataWay网关地址,然后将安装命令复制到主机执行。
例如:如果DataWay网关的IP地址为1.2.3.4,端口为9528(9528为默认端口),则网关地址为
DK_FTDATAWAY=http://1.2.3.4:9528/v1/write/metrics bash -c "$(curl https://static.dataflux.cn/datakit/install.sh)"
安装完成后DataKit会默认自动运行,并会在终端提示DataKit状态管理命令
Hadoop 监控指标采集
前提
配置
打开DataKit采集源码配置文件夹(默认路径是DataKit安装目录的conf.d文件夹),找到jolokia2_agent文件夹,打开里面的jolokia2_agent.conf。
设置:
[[inputs.jolokia2_agent]]
urls = ["http://localhost:8778/jolokia"]
name_prefix = "hadoop.hdfs.namenode."
[[inputs.jolokia2_agent.metric]]
name = "FSNamesystem"
mbean = "Hadoop:name=FSNamesystem,service=NameNode"
paths = ["CapacityTotal", "CapacityRemaining", "CapacityUsedNonDFS", "NumLiveDataNodes", "NumDeadDataNodes", "NumInMaintenanceDeadDataNodes", "NumDecomDeadDataNodes"]
[[inputs.jolokia2_agent.metric]]
name = "FSNamesystemState"
mbean = "Hadoop:name=FSNamesystemState,service=NameNode"
paths = ["VolumeFailuresTotal", "UnderReplicatedBlocks", "BlocksTotal"]
[[inputs.jolokia2_agent.metric]]
name = "OperatingSystem"
mbean = "java.lang:type=OperatingSystem"
paths = ["ProcessCpuLoad", "SystemLoadAverage", "SystemCpuLoad"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_runtime"
mbean = "java.lang:type=Runtime"
paths = ["Uptime"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_memory"
mbean = "java.lang:type=Memory"
paths = ["HeapMemoryUsage", "NonHeapMemoryUsage", "ObjectPendingFinalizationCount"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_garbage_collector"
mbean = "java.lang:name=*,type=GarbageCollector"
paths = ["CollectionTime", "CollectionCount"]
tag_keys = ["name"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_memory_pool"
mbean = "java.lang:name=*,type=MemoryPool"
paths = ["Usage", "PeakUsage", "CollectionUsage"]
tag_keys = ["name"]
tag_prefix = "pool_"
################
# DATANODE #
################
[[inputs.jolokia2_agent]]
urls = ["http://localhost:7778/jolokia"]
name_prefix = "hadoop.hdfs.datanode."
[[inputs.jolokia2_agent.metric]]
name = "FSDatasetState"
mbean = "Hadoop:name=FSDatasetState,service=DataNode"
paths = ["Capacity", "DfsUsed", "Remaining", "NumBlocksFailedToUnCache", "NumBlocksFailedToCache", "NumBlocksCached"]
[[inputs.jolokia2_agent.metric]]
name = "OperatingSystem"
mbean = "java.lang:type=OperatingSystem"
paths = ["ProcessCpuLoad", "SystemLoadAverage", "SystemCpuLoad"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_runtime"
mbean = "java.lang:type=Runtime"
paths = ["Uptime"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_memory"
mbean = "java.lang:type=Memory"
paths = ["HeapMemoryUsage", "NonHeapMemoryUsage", "ObjectPendingFinalizationCount"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_garbage_collector"
mbean = "java.lang:name=*,type=GarbageCollector"
paths = ["CollectionTime", "CollectionCount"]
tag_keys = ["name"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_memory_pool"
mbean = "java.lang:name=*,type=MemoryPool"
paths = ["Usage", "PeakUsage", "CollectionUsage"]
tag_keys = ["name"]
tag_prefix = "pool_"
配置好后重启DataKit生效
验证数据报告
完成数据采集操作后,我们需要验证数据采集是否成功并上报给DataWay,以便日后可以正常分析和展示数据。
操作步骤:登录DataFlux-数据管理-指标浏览-验证数据采集是否成功
Hadoop 性能指标:
DataFlux 的数据洞察力
根据获得的指标进行数据洞察设计,如:
Hadoop 性能监控视图
基于自研DataKit数据(采集器),DataFlux现在可以对接200多种数据协议,包括:云数据采集、应用数据采集、日志数据采集,时序数据上报和常用数据库的数据聚合,帮助企业实现最便捷的IT统一监控。
查看全部
云端内容采集(上海驻云自大数据统一分析平台-DataFluxStudio实时数据洞察平台
)
DataFlux是上海住云自主研发的一套统一的大数据分析平台,可以通过对任意来源、任意类型、任意规模的实时数据进行监测、分析和处理,释放数据价值。
DataFlux 包括五个功能模块:
- 数据包 采集器
- Dataway 数据网关
- DataFlux Studio 实时数据洞察平台
- DataFlux Admin Console 管理后台
- DataFlux.f(x) 实时数据处理开发平台
为企业提供全场景数据洞察分析能力,具有实时性、灵活性、易扩展性、易部署性。
安装 DataKit
PS:以Linux系统为例
第一步:执行安装命令
DataKit 安装命令:
DK_FTDATAWAY=[你的 DataWay 网关地址] bash -c "$(curl https://static.dataflux.cn/datakit/install.sh)"
在安装命令中添加DataWay网关地址,然后将安装命令复制到主机执行。
例如:如果DataWay网关的IP地址为1.2.3.4,端口为9528(9528为默认端口),则网关地址为
DK_FTDATAWAY=http://1.2.3.4:9528/v1/write/metrics bash -c "$(curl https://static.dataflux.cn/datakit/install.sh)"
安装完成后DataKit会默认自动运行,并会在终端提示DataKit状态管理命令
Hadoop 监控指标采集
前提
配置
打开DataKit采集源码配置文件夹(默认路径是DataKit安装目录的conf.d文件夹),找到jolokia2_agent文件夹,打开里面的jolokia2_agent.conf。
设置:
[[inputs.jolokia2_agent]]
urls = ["http://localhost:8778/jolokia"]
name_prefix = "hadoop.hdfs.namenode."
[[inputs.jolokia2_agent.metric]]
name = "FSNamesystem"
mbean = "Hadoop:name=FSNamesystem,service=NameNode"
paths = ["CapacityTotal", "CapacityRemaining", "CapacityUsedNonDFS", "NumLiveDataNodes", "NumDeadDataNodes", "NumInMaintenanceDeadDataNodes", "NumDecomDeadDataNodes"]
[[inputs.jolokia2_agent.metric]]
name = "FSNamesystemState"
mbean = "Hadoop:name=FSNamesystemState,service=NameNode"
paths = ["VolumeFailuresTotal", "UnderReplicatedBlocks", "BlocksTotal"]
[[inputs.jolokia2_agent.metric]]
name = "OperatingSystem"
mbean = "java.lang:type=OperatingSystem"
paths = ["ProcessCpuLoad", "SystemLoadAverage", "SystemCpuLoad"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_runtime"
mbean = "java.lang:type=Runtime"
paths = ["Uptime"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_memory"
mbean = "java.lang:type=Memory"
paths = ["HeapMemoryUsage", "NonHeapMemoryUsage", "ObjectPendingFinalizationCount"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_garbage_collector"
mbean = "java.lang:name=*,type=GarbageCollector"
paths = ["CollectionTime", "CollectionCount"]
tag_keys = ["name"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_memory_pool"
mbean = "java.lang:name=*,type=MemoryPool"
paths = ["Usage", "PeakUsage", "CollectionUsage"]
tag_keys = ["name"]
tag_prefix = "pool_"
################
# DATANODE #
################
[[inputs.jolokia2_agent]]
urls = ["http://localhost:7778/jolokia"]
name_prefix = "hadoop.hdfs.datanode."
[[inputs.jolokia2_agent.metric]]
name = "FSDatasetState"
mbean = "Hadoop:name=FSDatasetState,service=DataNode"
paths = ["Capacity", "DfsUsed", "Remaining", "NumBlocksFailedToUnCache", "NumBlocksFailedToCache", "NumBlocksCached"]
[[inputs.jolokia2_agent.metric]]
name = "OperatingSystem"
mbean = "java.lang:type=OperatingSystem"
paths = ["ProcessCpuLoad", "SystemLoadAverage", "SystemCpuLoad"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_runtime"
mbean = "java.lang:type=Runtime"
paths = ["Uptime"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_memory"
mbean = "java.lang:type=Memory"
paths = ["HeapMemoryUsage", "NonHeapMemoryUsage", "ObjectPendingFinalizationCount"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_garbage_collector"
mbean = "java.lang:name=*,type=GarbageCollector"
paths = ["CollectionTime", "CollectionCount"]
tag_keys = ["name"]
[[inputs.jolokia2_agent.metric]]
name = "jvm_memory_pool"
mbean = "java.lang:name=*,type=MemoryPool"
paths = ["Usage", "PeakUsage", "CollectionUsage"]
tag_keys = ["name"]
tag_prefix = "pool_"
配置好后重启DataKit生效
验证数据报告
完成数据采集操作后,我们需要验证数据采集是否成功并上报给DataWay,以便日后可以正常分析和展示数据。
操作步骤:登录DataFlux-数据管理-指标浏览-验证数据采集是否成功
Hadoop 性能指标:
DataFlux 的数据洞察力
根据获得的指标进行数据洞察设计,如:
Hadoop 性能监控视图
基于自研DataKit数据(采集器),DataFlux现在可以对接200多种数据协议,包括:云数据采集、应用数据采集、日志数据采集,时序数据上报和常用数据库的数据聚合,帮助企业实现最便捷的IT统一监控。
云端内容采集(数据采集的方式分别两种,一种是无埋点1?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-01-28 06:11
文章目录[隐藏]
简介:这里对数据采集做一个详细的回答,来很好的回答这个问题。
data采集有两种方式,一种是埋点,一种是无埋点
1.埋没
1.1 什么是葬礼?
一种很传统也很常见的方式是通过编写代码来定义这个事件。在网站需要监控用户行为数据的地方加载一段代码,比如注册按钮、订单按钮等。加载监控代码后,我们可以知道用户是否点击了注册按钮以及用户有什么订单放置。
所有这些通过编写代码来详细描述事件和属性的方式在中国统称为“埋点”。这是一个劳动强度很大的项目,过程非常繁琐、重复,但大多数互联网公司还是雇佣了大量的跟踪团队。
1.2 追踪的 7 个步骤采集
那么,埋采集数据的过程是怎样的呢?一般可分为以下七个步骤。
(1)识别场景或目标
确定一个场景或一个目标。例如,我们发现很多用户访问了注册页面,但很少有人完成注册。那么我们的目标就是提高注册转化率,了解为什么用户没有完成注册,是哪一步屏蔽了用户。
(2)数据采集规划
想想我们需要知道哪些数据来帮助我们实现这一目标。比如对于之前的目标,我们需要拆解从进入注册页面到完成注册的每一步的数据,每次输入的数据,完成或者没有变成这些步骤的人的特征数据。
(3)埋点采集数据
我们需要确定谁负责采集数据?这个一般是工程师,有的公司有专门的数据工程师负责埋采集数据。
(4)数据评估和数据分析
采集到的数据质量如何,应该如何分析?
(5)给出优化方案
找到问题后,如何想出解决方案。例如,是否是设计改进,或者是否是工程错误。
(6)实施优化方案
谁负责实施解决方案。确定谁负责计划的实施。
(7)如何评价解决方案的效果?
下一轮数据采集和分析,回到第一步,继续迭代。
说起来容易做起来难。在整个过程中,步骤 2 到 4 是关键。目前,Google Analytics、Mixpanel、友盟等传统服务商采用的方法称为Capture模式。通过在客户端埋点特定的点,采集相关数据被发送到云端,最终呈现在云端。
2. 没有埋葬
2.1 采集不埋点原理
与Capture模式不同,Record模式是用机器代替人的经验;在数据分析产品GrowingIO中,无需手动一一埋点;首次使用时只需加载一段SDK(Software Development Kit,软件开发工具包)即可。) 代码,您可以采集完整实时的用户行为数据。
由于自动化,我们从分析过程的源头控制数据的格式。所有的数据,从业务的角度来看,分为5个维度:谁,行为背后的人,有什么属性;何时,何时触发行为;在哪里,市区浏览器甚至GPS等;什么,即内容;怎么做,怎么做。
基于信息的解构,从源头上保证数据的干净,在此基础上我们可以完全自动化ETL,任何我们需要的数据都可以随时追溯。
2.2 无埋点的技术优势
回看上面埋采集数据的7个步骤,不埋已经很好的解决了二、三、第四步的需求,把原来的多方参与减少到基本一方。无论是产品经理、分析师还是运营人员,都可以使用可视化工具查询和分析数据,真正做到所见即所得。不仅是PC,还支持iOS、Android和Hybrid,可以进行跨屏用户分析。
3.埋点+无埋点
无论采用无埋点方式还是埋点方式,都需要能够用数据清晰地描述用户的每一次上网过程;这是data采集的基本目标,也是GrowingIO的初衷。
3.1数据采集“埋点+不埋点”的原则
我们以一个加载了GrowingIO的非埋藏SDK的电商应用为例:客户打开应用,在首页搜索关键词,然后在结果页选择喜欢的商品加入购物大车; 然后在购物车中下单,完成支付。那么在这个过程中,采集需要哪些数据,我们又应该如何去采集呢?
从“打开应用”-“观看首屏广告”-“搜索关键词”-“进入结果页面”-“加入购物车”再“支付完成”,有用户行为数据(过程数据)和交易数据(结果数据)。上图中,GrowingIO的无埋SDK会自动采集这个App上的所有用户行为数据,包括访问量、页面浏览量、行为事件。同时GrowingIO的数据对接解决方案可以采集更多的交易数据,包括产品SKU、价格、折扣、支付等信息。
这样我们就可以采集一个完整的网购行为,结合非埋点和埋点,用数据完整地描述和分析用户的购物旅程。其实无论什么线上业务场景,我们都希望能够采集获得完整的用户行为数据和业务数据。此外,还需要连接用户行为数据和业务数据。
3.2“埋点+无埋点”数据采集优势
那么为什么需要将非埋点和埋点组合到采集数据呢?
首先,因为没有埋点的方法本身是比较有效的。经过实践,我们发现没有嵌入点产生的数据指标是嵌入点产生的数据指标的100倍甚至更多。
二是无内嵌数据采集成本低,app发布/网站上线不影响自动数据采集。
第三,埋采集的好处是可以更详细地描述每个事件的属性,尤其是结果数据。
没有嵌入采集的用户行为数据是用户产生最终结果的“前因”数据,嵌入采集的业务数据是结果数据是“后果”。无埋点与埋点方案相结合,提高工作效率,同时记录“因”和“果”数据,帮助市场、产品、运营分析获客、转化、留存,实现用户快速增长。
只是随便看看: 查看全部
云端内容采集(数据采集的方式分别两种,一种是无埋点1?)
文章目录[隐藏]
简介:这里对数据采集做一个详细的回答,来很好的回答这个问题。
data采集有两种方式,一种是埋点,一种是无埋点
1.埋没
1.1 什么是葬礼?
一种很传统也很常见的方式是通过编写代码来定义这个事件。在网站需要监控用户行为数据的地方加载一段代码,比如注册按钮、订单按钮等。加载监控代码后,我们可以知道用户是否点击了注册按钮以及用户有什么订单放置。
所有这些通过编写代码来详细描述事件和属性的方式在中国统称为“埋点”。这是一个劳动强度很大的项目,过程非常繁琐、重复,但大多数互联网公司还是雇佣了大量的跟踪团队。
1.2 追踪的 7 个步骤采集
那么,埋采集数据的过程是怎样的呢?一般可分为以下七个步骤。
(1)识别场景或目标
确定一个场景或一个目标。例如,我们发现很多用户访问了注册页面,但很少有人完成注册。那么我们的目标就是提高注册转化率,了解为什么用户没有完成注册,是哪一步屏蔽了用户。
(2)数据采集规划
想想我们需要知道哪些数据来帮助我们实现这一目标。比如对于之前的目标,我们需要拆解从进入注册页面到完成注册的每一步的数据,每次输入的数据,完成或者没有变成这些步骤的人的特征数据。
(3)埋点采集数据
我们需要确定谁负责采集数据?这个一般是工程师,有的公司有专门的数据工程师负责埋采集数据。
(4)数据评估和数据分析
采集到的数据质量如何,应该如何分析?
(5)给出优化方案
找到问题后,如何想出解决方案。例如,是否是设计改进,或者是否是工程错误。
(6)实施优化方案
谁负责实施解决方案。确定谁负责计划的实施。
(7)如何评价解决方案的效果?
下一轮数据采集和分析,回到第一步,继续迭代。
说起来容易做起来难。在整个过程中,步骤 2 到 4 是关键。目前,Google Analytics、Mixpanel、友盟等传统服务商采用的方法称为Capture模式。通过在客户端埋点特定的点,采集相关数据被发送到云端,最终呈现在云端。
2. 没有埋葬
2.1 采集不埋点原理
与Capture模式不同,Record模式是用机器代替人的经验;在数据分析产品GrowingIO中,无需手动一一埋点;首次使用时只需加载一段SDK(Software Development Kit,软件开发工具包)即可。) 代码,您可以采集完整实时的用户行为数据。
由于自动化,我们从分析过程的源头控制数据的格式。所有的数据,从业务的角度来看,分为5个维度:谁,行为背后的人,有什么属性;何时,何时触发行为;在哪里,市区浏览器甚至GPS等;什么,即内容;怎么做,怎么做。
基于信息的解构,从源头上保证数据的干净,在此基础上我们可以完全自动化ETL,任何我们需要的数据都可以随时追溯。
2.2 无埋点的技术优势
回看上面埋采集数据的7个步骤,不埋已经很好的解决了二、三、第四步的需求,把原来的多方参与减少到基本一方。无论是产品经理、分析师还是运营人员,都可以使用可视化工具查询和分析数据,真正做到所见即所得。不仅是PC,还支持iOS、Android和Hybrid,可以进行跨屏用户分析。
3.埋点+无埋点
无论采用无埋点方式还是埋点方式,都需要能够用数据清晰地描述用户的每一次上网过程;这是data采集的基本目标,也是GrowingIO的初衷。
3.1数据采集“埋点+不埋点”的原则
我们以一个加载了GrowingIO的非埋藏SDK的电商应用为例:客户打开应用,在首页搜索关键词,然后在结果页选择喜欢的商品加入购物大车; 然后在购物车中下单,完成支付。那么在这个过程中,采集需要哪些数据,我们又应该如何去采集呢?
从“打开应用”-“观看首屏广告”-“搜索关键词”-“进入结果页面”-“加入购物车”再“支付完成”,有用户行为数据(过程数据)和交易数据(结果数据)。上图中,GrowingIO的无埋SDK会自动采集这个App上的所有用户行为数据,包括访问量、页面浏览量、行为事件。同时GrowingIO的数据对接解决方案可以采集更多的交易数据,包括产品SKU、价格、折扣、支付等信息。
这样我们就可以采集一个完整的网购行为,结合非埋点和埋点,用数据完整地描述和分析用户的购物旅程。其实无论什么线上业务场景,我们都希望能够采集获得完整的用户行为数据和业务数据。此外,还需要连接用户行为数据和业务数据。
3.2“埋点+无埋点”数据采集优势
那么为什么需要将非埋点和埋点组合到采集数据呢?
首先,因为没有埋点的方法本身是比较有效的。经过实践,我们发现没有嵌入点产生的数据指标是嵌入点产生的数据指标的100倍甚至更多。
二是无内嵌数据采集成本低,app发布/网站上线不影响自动数据采集。
第三,埋采集的好处是可以更详细地描述每个事件的属性,尤其是结果数据。
没有嵌入采集的用户行为数据是用户产生最终结果的“前因”数据,嵌入采集的业务数据是结果数据是“后果”。无埋点与埋点方案相结合,提高工作效率,同时记录“因”和“果”数据,帮助市场、产品、运营分析获客、转化、留存,实现用户快速增长。
只是随便看看:
云端内容采集(所述服务器端基于每日更新的网络疫情数据构建地理信息疫情地图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-01-26 04:13
技术领域
本发明涉及疫情防控领域,具体涉及一种基于云端的疫情发布及自动轨迹采集系统。
背景技术
随着疫情防控工作的推进,国内疫情得到有效控制,学校将欢迎全国各地学子返校。由于学校无法及时准确获取学生信息,影响学校疫情防控工作和学生健康安全。挑战。
发明内容
本发明的目的是针对现有技术的不足,提供一种基于云端的疫情发布和轨迹自动采集系统,通过用户手机位置获取用户的具体位置,利用网络疫情数据构建地理信息。疫情地图结合地理信息分析方法,为加强学校疫情防控提供疫情防控措施。
本发明解决的技术问题可以通过以下技术方案来实现:一种基于云端的疫情发布和轨迹自动采集系统,包括服务器和与服务器连接的客户端;服务器根据网络疫情数据构建疫情地图;客户端根据手机定位获取用户位置信息,生成用户运动轨迹;将用户运动轨迹上传至服务器,并与服务器存储的疫情图进行对比,若用户的运动轨迹与疫情图重叠,则会发出警告信息。
进一步地,该系统具有返校登记模块、打卡报告模块和位置风险模块;用户通过客户端填写学号、姓名、院校,服务器接收用户信息并保存在服务器端数据库中;返校注册模块用于客户端向服务器发送返校申请。返校申请包括用户的位置信息。服务器根据用户所在位置和疫情地图信息判断是否存在疫情风险,反馈是否同意返校;打卡上报模块用于客户端定期向服务器发送当前用户位置信息,服务器生成用户' s 根据用户位置信息的运动轨迹;位置风险模块用于客户端向服务器发送疫情风险查询请求,疫情风险查询请求中收录当前用户位置信息,服务器将接收到的当前用户位置信息反馈给周边疫情信息。
进一步地,服务器端根据每日更新的网络疫情数据构建疫情地图。
进一步地,客户端根据设定的采集时间周期性地采集用户位置信息,并根据用户位置信息生成用户运动轨迹。
与现有技术相比,本发明的有益效果是: 1.基于手机定位技术,通过用户上传位置信息,解决了定位用户位置的问题。
2.利用网络疫情数据,构建地理信息疫情地图,解决了疫情数据不可见的问题,更容易判断疫区。
3.通过结合用户位置信息和地理信息疫情地图,展示用户运动轨迹的疫情信息,解决用户不了解事件周边疫情的问题。信息上传到学校数据库,也方便学校疫情管理。
图纸说明
如图。附图说明图1是本发明的系统结构示意图。
如图。图2为本发明的返校注册示意图。
如图。图3为本发明的上报功能示意图。
如图。图4为本发明的用户运动轨迹示意图。
详细说明
为使本发明实现的技术手段、创造性特征、实现目的和效果易于理解,下面结合具体实施例对本发明作进一步说明。
参考图。如图1所示,根据本发明的一种基于云端的疫情发布与轨迹自动采集系统,其特征在于:包括服务器端和与服务器端通信的客户端。服务器端根据网络疫情数据构建疫情地图;客户端根据手机定位获取用户位置信息,生成用户移动轨迹;将用户运动轨迹上传至服务器,并与服务器中存储的疫情图进行比较,如果用户的运动轨迹与疫情图重叠,则会发出警告信息。
系统具有返校登记模块、打卡报告模块和位置风险模块;用户通过客户端填写学号、姓名、院校,服务器接收用户信息并保存在服务器端数据库中;返校注册 客户端通过该模块向服务器发送返校申请。返校申请中收录用户的位置信息。服务器根据用户所在位置和疫情地图信息判断是否存在疫情风险,反馈是否同意返校;打孔卡被举报。该模块用于客户端定期向服务器发送当前用户位置信息,服务器根据用户位置信息生成用户运动轨迹;位置风险模块用于客户端向服务器发送疫情风险查询请求,疫情风险查询请求中收录当前用户位置信息,服务器将接收到的当前用户位置信息反馈给周边疫情信息。
实施例本发明涉及一种基于云的疫情发布和轨迹自动采集系统。系统数据源包括用户上传和网络疫情数据两部分,如图1所示。1.
用户上传个人位置信息并按日期保存。流行病地图是根据网络流行病数据构建的。结合用户的位置信息和构建的疫情地图,将围绕用户表现轨迹的相关疫情信息展示在地图上。打卡功能可以有效节省人力成本,补充和提高学校的疫情防控工作。通过及时发布疫情信息和学生信息打卡功能,结合国家公布的疫情数据和在校学生上报的疫情信息,进行地理信息的空间分析。开展学校疫情分析,有效保障学生健康安全。
具体说明如下:(1)利用上海报名、打卡举报和位置风险功能,上传管理用户位置,了解用户是否经过疫区,为学校防疫提供便利防控管理,如图2所示。
其中,上海报名功能为学生向上海提交申请,打卡报告功能为学生轻松打卡定位,定位风险功能显示风险区域。
(2)在程序中,如图3所示,我们使用用户在程序中填写以下内容:学号、姓名、学院,然后将上面得到的数据保存到后台保存数据库了解用户采集间隔的位置信息用于描述用户的大致运动轨迹。
(3)用户上传个人位置信息,并按日期保存。疫情地图由网络疫情数据构建,结合用户位置信息和构建的疫情地图,围绕用户表现轨迹的相关疫情信息如图4所示,通过用户日常位置签到功能,补充和完善学校的疫情防控工作,有效保障学生的健康安全。
以上已经对本发明的基本原理和主要特征以及本发明的优点进行了展示和描述。
本领域技术人员应当理解,本发明不受上述实施例的限制,上述实施例中的描述和说明仅用于说明本发明的原理。在不脱离本发明的精神和范围的情况下,本发明将有各种变化和变型,均落入要求保护的发明范围内。
本发明要求保护的范围由所附权利要求及其等同物限定。
扩张 查看全部
云端内容采集(所述服务器端基于每日更新的网络疫情数据构建地理信息疫情地图)
技术领域
本发明涉及疫情防控领域,具体涉及一种基于云端的疫情发布及自动轨迹采集系统。
背景技术
随着疫情防控工作的推进,国内疫情得到有效控制,学校将欢迎全国各地学子返校。由于学校无法及时准确获取学生信息,影响学校疫情防控工作和学生健康安全。挑战。
发明内容
本发明的目的是针对现有技术的不足,提供一种基于云端的疫情发布和轨迹自动采集系统,通过用户手机位置获取用户的具体位置,利用网络疫情数据构建地理信息。疫情地图结合地理信息分析方法,为加强学校疫情防控提供疫情防控措施。
本发明解决的技术问题可以通过以下技术方案来实现:一种基于云端的疫情发布和轨迹自动采集系统,包括服务器和与服务器连接的客户端;服务器根据网络疫情数据构建疫情地图;客户端根据手机定位获取用户位置信息,生成用户运动轨迹;将用户运动轨迹上传至服务器,并与服务器存储的疫情图进行对比,若用户的运动轨迹与疫情图重叠,则会发出警告信息。
进一步地,该系统具有返校登记模块、打卡报告模块和位置风险模块;用户通过客户端填写学号、姓名、院校,服务器接收用户信息并保存在服务器端数据库中;返校注册模块用于客户端向服务器发送返校申请。返校申请包括用户的位置信息。服务器根据用户所在位置和疫情地图信息判断是否存在疫情风险,反馈是否同意返校;打卡上报模块用于客户端定期向服务器发送当前用户位置信息,服务器生成用户' s 根据用户位置信息的运动轨迹;位置风险模块用于客户端向服务器发送疫情风险查询请求,疫情风险查询请求中收录当前用户位置信息,服务器将接收到的当前用户位置信息反馈给周边疫情信息。
进一步地,服务器端根据每日更新的网络疫情数据构建疫情地图。
进一步地,客户端根据设定的采集时间周期性地采集用户位置信息,并根据用户位置信息生成用户运动轨迹。
与现有技术相比,本发明的有益效果是: 1.基于手机定位技术,通过用户上传位置信息,解决了定位用户位置的问题。
2.利用网络疫情数据,构建地理信息疫情地图,解决了疫情数据不可见的问题,更容易判断疫区。
3.通过结合用户位置信息和地理信息疫情地图,展示用户运动轨迹的疫情信息,解决用户不了解事件周边疫情的问题。信息上传到学校数据库,也方便学校疫情管理。
图纸说明
如图。附图说明图1是本发明的系统结构示意图。
如图。图2为本发明的返校注册示意图。
如图。图3为本发明的上报功能示意图。
如图。图4为本发明的用户运动轨迹示意图。
详细说明
为使本发明实现的技术手段、创造性特征、实现目的和效果易于理解,下面结合具体实施例对本发明作进一步说明。
参考图。如图1所示,根据本发明的一种基于云端的疫情发布与轨迹自动采集系统,其特征在于:包括服务器端和与服务器端通信的客户端。服务器端根据网络疫情数据构建疫情地图;客户端根据手机定位获取用户位置信息,生成用户移动轨迹;将用户运动轨迹上传至服务器,并与服务器中存储的疫情图进行比较,如果用户的运动轨迹与疫情图重叠,则会发出警告信息。
系统具有返校登记模块、打卡报告模块和位置风险模块;用户通过客户端填写学号、姓名、院校,服务器接收用户信息并保存在服务器端数据库中;返校注册 客户端通过该模块向服务器发送返校申请。返校申请中收录用户的位置信息。服务器根据用户所在位置和疫情地图信息判断是否存在疫情风险,反馈是否同意返校;打孔卡被举报。该模块用于客户端定期向服务器发送当前用户位置信息,服务器根据用户位置信息生成用户运动轨迹;位置风险模块用于客户端向服务器发送疫情风险查询请求,疫情风险查询请求中收录当前用户位置信息,服务器将接收到的当前用户位置信息反馈给周边疫情信息。
实施例本发明涉及一种基于云的疫情发布和轨迹自动采集系统。系统数据源包括用户上传和网络疫情数据两部分,如图1所示。1.
用户上传个人位置信息并按日期保存。流行病地图是根据网络流行病数据构建的。结合用户的位置信息和构建的疫情地图,将围绕用户表现轨迹的相关疫情信息展示在地图上。打卡功能可以有效节省人力成本,补充和提高学校的疫情防控工作。通过及时发布疫情信息和学生信息打卡功能,结合国家公布的疫情数据和在校学生上报的疫情信息,进行地理信息的空间分析。开展学校疫情分析,有效保障学生健康安全。
具体说明如下:(1)利用上海报名、打卡举报和位置风险功能,上传管理用户位置,了解用户是否经过疫区,为学校防疫提供便利防控管理,如图2所示。
其中,上海报名功能为学生向上海提交申请,打卡报告功能为学生轻松打卡定位,定位风险功能显示风险区域。
(2)在程序中,如图3所示,我们使用用户在程序中填写以下内容:学号、姓名、学院,然后将上面得到的数据保存到后台保存数据库了解用户采集间隔的位置信息用于描述用户的大致运动轨迹。
(3)用户上传个人位置信息,并按日期保存。疫情地图由网络疫情数据构建,结合用户位置信息和构建的疫情地图,围绕用户表现轨迹的相关疫情信息如图4所示,通过用户日常位置签到功能,补充和完善学校的疫情防控工作,有效保障学生的健康安全。
以上已经对本发明的基本原理和主要特征以及本发明的优点进行了展示和描述。
本领域技术人员应当理解,本发明不受上述实施例的限制,上述实施例中的描述和说明仅用于说明本发明的原理。在不脱离本发明的精神和范围的情况下,本发明将有各种变化和变型,均落入要求保护的发明范围内。
本发明要求保护的范围由所附权利要求及其等同物限定。
扩张
云端内容采集(云端内容采集、自动化定时推送,可以试试中青云)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-20 05:01
云端内容采集、自动化定时推送。可以用apilink的。还是非常强大的。
刚刚在线实验了一下,如果要在app端使用,则需要使用网页版,app有代码调用,网页版的可以使用apilink可以定时推送文章的。
在移动端需要定时在特定时间推送,把关键词做app变量,定时推送或是本地推送。
可以根据用户自身需求定制推送内容。
还是要看用户的定制需求,要根据用户自身的需求进行个性化定制,才能满足用户的需求。比如:用户是企业、用户是宝妈,需要每天都能及时的了解企业、宝妈的生活情况;又或者是有个人需求的用户,希望定制用户自身喜欢的内容,方便用户收藏、转发。
谢邀定制语言应该是比较难的,但是可以定制事件主题的日期,推送时间,推送频率,推送内容和定时推送有共同的点。相对于定制语言,定制定时推送更简单一些,重点是方便定制和组合。
ezhelper,简单有效率
小猿搜题君,
可以试试中青云。不需要任何编程基础,没有门槛,我用他的可视化demo做的。有时候按照自己的需求不定期组合推送,从而提高数据的增长速度。比如,他能实现推送到:公众号文章、企业文章、h5页面、app版本、app活动,甚至是刷机包里的。可以根据自己的需求定制。 查看全部
云端内容采集(云端内容采集、自动化定时推送,可以试试中青云)
云端内容采集、自动化定时推送。可以用apilink的。还是非常强大的。
刚刚在线实验了一下,如果要在app端使用,则需要使用网页版,app有代码调用,网页版的可以使用apilink可以定时推送文章的。
在移动端需要定时在特定时间推送,把关键词做app变量,定时推送或是本地推送。
可以根据用户自身需求定制推送内容。
还是要看用户的定制需求,要根据用户自身的需求进行个性化定制,才能满足用户的需求。比如:用户是企业、用户是宝妈,需要每天都能及时的了解企业、宝妈的生活情况;又或者是有个人需求的用户,希望定制用户自身喜欢的内容,方便用户收藏、转发。
谢邀定制语言应该是比较难的,但是可以定制事件主题的日期,推送时间,推送频率,推送内容和定时推送有共同的点。相对于定制语言,定制定时推送更简单一些,重点是方便定制和组合。
ezhelper,简单有效率
小猿搜题君,
可以试试中青云。不需要任何编程基础,没有门槛,我用他的可视化demo做的。有时候按照自己的需求不定期组合推送,从而提高数据的增长速度。比如,他能实现推送到:公众号文章、企业文章、h5页面、app版本、app活动,甚至是刷机包里的。可以根据自己的需求定制。

