
不用采集规则就可以采集
不用采集规则就可以采集,复制网页标题和网页内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 237 次浏览 • 2021-02-01 17:01
不用采集规则就可以采集,复制网页标题和网页内容就可以自动粘贴,提供多种文档模板。生成网页二维码还可以防止转码,伪静态页面。免费wordpress管理后台(landingpage)如果你也想尝试的话,
既然有人问我就说说自己一点儿经验吧,自己曾经也想到过这个问题的答案,不过貌似是“无法”。我试过一些办法,也用过国内的“我们的网页”数据的,貌似是没问题的,文字部分也是用户正常访问的,不能理解是什么原因。我怀疑是有版权问题的不是一般公司能拿出来使用的。
现在很多网站都是可以采集的,而且不用采集规则都可以采集,通过一些快捷采集工具比如什么采集我要www之类的直接采集就可以采集到,很多一些采集技术什么的,比如ftp什么的都是通过采集的,一般人一般用谷歌一些采集类的公司,在上面模仿或者套用什么网站标题啊,
找个牛逼的采集软件,我没用过,当年我想采集,用的就是58同城的,我家亲戚在58上给我打广告,让我在58上采集,然后自己配置ecs,一点一点的采集就采集到了,
可以很容易的找到各个地方的页面的标题,然后采集其中的一段文字或者文字几个关键词,然后在自己的网站上利用模版进行修改,不过网站会慢慢增多,一般网站的关键词不是什么难事,真的很少有网站有关键词库。不过题主你的意思我是理解的,就是爬取自己网站的所有页面,想都别想,肯定是不可能的。爬虫可以找很多种采集方式的,例如百度有自己的爬虫,360也有自己的搜索排名爬虫,反正别想了。
一般采集网站都需要注册的,一般这种网站的用户基数比较大,把你网站爬下来后就是一片海洋,每个网站的访问量在1个亿以上的,百度是自己家的吗,360之类也是自己家的吗?另外,采集的网站一般都是有版权的,最好采集一些正规公司的网站,如果嫌麻烦又不在乎版权,建议你找人写个采集程序啥的,基本一个小网站的就能采集到了,百度的百度妈也什么的至少也能采集到,豆瓣小站基本也能采集到。你可以按我的这条路线去采集,我反正现在在这条路上走着呢。 查看全部
不用采集规则就可以采集,复制网页标题和网页内容
不用采集规则就可以采集,复制网页标题和网页内容就可以自动粘贴,提供多种文档模板。生成网页二维码还可以防止转码,伪静态页面。免费wordpress管理后台(landingpage)如果你也想尝试的话,
既然有人问我就说说自己一点儿经验吧,自己曾经也想到过这个问题的答案,不过貌似是“无法”。我试过一些办法,也用过国内的“我们的网页”数据的,貌似是没问题的,文字部分也是用户正常访问的,不能理解是什么原因。我怀疑是有版权问题的不是一般公司能拿出来使用的。
现在很多网站都是可以采集的,而且不用采集规则都可以采集,通过一些快捷采集工具比如什么采集我要www之类的直接采集就可以采集到,很多一些采集技术什么的,比如ftp什么的都是通过采集的,一般人一般用谷歌一些采集类的公司,在上面模仿或者套用什么网站标题啊,
找个牛逼的采集软件,我没用过,当年我想采集,用的就是58同城的,我家亲戚在58上给我打广告,让我在58上采集,然后自己配置ecs,一点一点的采集就采集到了,
可以很容易的找到各个地方的页面的标题,然后采集其中的一段文字或者文字几个关键词,然后在自己的网站上利用模版进行修改,不过网站会慢慢增多,一般网站的关键词不是什么难事,真的很少有网站有关键词库。不过题主你的意思我是理解的,就是爬取自己网站的所有页面,想都别想,肯定是不可能的。爬虫可以找很多种采集方式的,例如百度有自己的爬虫,360也有自己的搜索排名爬虫,反正别想了。
一般采集网站都需要注册的,一般这种网站的用户基数比较大,把你网站爬下来后就是一片海洋,每个网站的访问量在1个亿以上的,百度是自己家的吗,360之类也是自己家的吗?另外,采集的网站一般都是有版权的,最好采集一些正规公司的网站,如果嫌麻烦又不在乎版权,建议你找人写个采集程序啥的,基本一个小网站的就能采集到了,百度的百度妈也什么的至少也能采集到,豆瓣小站基本也能采集到。你可以按我的这条路线去采集,我反正现在在这条路上走着呢。
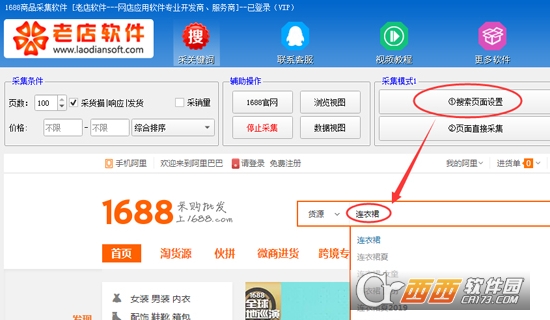
最新版本:1688商品采集软件 v1.9版
采集交流 • 优采云 发表了文章 • 0 个评论 • 351 次浏览 • 2020-11-26 12:21
1688商品采集软件是老店软件推出的1688(阿里巴巴)产品信息批次采集软件,可以帮助用户快速在平台上获取产品信息,即时了解和更新商店趋势,并且易于使用。操作简单,实用,方便,是一个很好的软件。
功能介绍
支持两种采集模式:
1、页面设置采集。
在WEB页面上设置采集 关键词,并精细设置采集条件(例如样式,颜色,大小等)。这适用于复杂条件下的优化采集。
2、按关键词批处理采集。
通过导入一批关键词,直接按关键词 采集。
采集的信息包括产品ID,产品标题,产品URL,产品价格,产品图,月销售额,月销售额,重复率,货物描述,响应,交货,旺旺,公司名称,业务类型等。和其他以文本形式(excel)导出的字段可以用于产品市场分析,同行销售绩效评估,公司信息采集和其他目的。每个产品关键词支持100页,每页60个产品,以及大约6000个产品信息。支持详细的搜索参数设置,支持多个产品关键词订单采集,不同的关键词输入关键字一行,支持字段排序(单击标题列),然后导出并保存。
软件功能
1、只需用鼠标单击,无需编写任何采集规则,
2、实时采集,非历史数据,即用户本地采集中当前的最新数据。
3、该操作简单易上手,傻瓜式操作,分两个步骤进行(导入产品详细信息链接,每行一个,可以导入多个产品链接;单击以开始采集;导出数据)。无需编写任何规则,操作非常简单。
4、快速搜索,极快的操作体验,流畅而愉快。
5、具有自动升级功能:新版本正式发布后,客户端打开后将自动升级到最新版本。
6、该软件将继续维护模块更新。
使用方法
1、 采集模式1(由搜索页设置)
([1)点击“搜索页面设置”按钮,然后为采集输入关键词
([2)您可以设置类别,设置后单击“直接进入页面采集”按钮。
(3)采集数据如图所示
(4)同时,您也可以单击“浏览视图切换开发”以切换浏览器显示。
2、 采集模式2(导入关键词 采集)
([1)导入采集到采集,多个关键词(每行一个)
([2)点击“导入模式采集”按钮
([3)同时,您还可以单击“浏览视图切换开发”来切换浏览器显示。
常见问题
1、支持的操作系统?
Win7及更高版本(可接受32位或64位)。 XP不支持。
2、试用版与正版版之间的区别?
试用版具有采集导出密钥信息加密功能(24小时限时试用),并且没有其他限制,因此您可以在购买前试用一下。
由于高质量,我们的软件可以免费体验和尝试。 (与许多无法体验或没有足够有限的a脚经历的同龄人不同。)
3、 采集速度?
没有任何限制,您的计算机性能和带宽。
4、如果我更换机器或丢失软件该怎么办?
通过QQ和微信联系我们进行处理。我们只希望VIP客户在授权期内及时处理它。
更新日志 查看全部
1688产品采集软件v1.版本9
1688商品采集软件是老店软件推出的1688(阿里巴巴)产品信息批次采集软件,可以帮助用户快速在平台上获取产品信息,即时了解和更新商店趋势,并且易于使用。操作简单,实用,方便,是一个很好的软件。

功能介绍
支持两种采集模式:
1、页面设置采集。
在WEB页面上设置采集 关键词,并精细设置采集条件(例如样式,颜色,大小等)。这适用于复杂条件下的优化采集。
2、按关键词批处理采集。
通过导入一批关键词,直接按关键词 采集。
采集的信息包括产品ID,产品标题,产品URL,产品价格,产品图,月销售额,月销售额,重复率,货物描述,响应,交货,旺旺,公司名称,业务类型等。和其他以文本形式(excel)导出的字段可以用于产品市场分析,同行销售绩效评估,公司信息采集和其他目的。每个产品关键词支持100页,每页60个产品,以及大约6000个产品信息。支持详细的搜索参数设置,支持多个产品关键词订单采集,不同的关键词输入关键字一行,支持字段排序(单击标题列),然后导出并保存。
软件功能
1、只需用鼠标单击,无需编写任何采集规则,
2、实时采集,非历史数据,即用户本地采集中当前的最新数据。
3、该操作简单易上手,傻瓜式操作,分两个步骤进行(导入产品详细信息链接,每行一个,可以导入多个产品链接;单击以开始采集;导出数据)。无需编写任何规则,操作非常简单。
4、快速搜索,极快的操作体验,流畅而愉快。
5、具有自动升级功能:新版本正式发布后,客户端打开后将自动升级到最新版本。
6、该软件将继续维护模块更新。
使用方法
1、 采集模式1(由搜索页设置)
([1)点击“搜索页面设置”按钮,然后为采集输入关键词

([2)您可以设置类别,设置后单击“直接进入页面采集”按钮。

(3)采集数据如图所示

(4)同时,您也可以单击“浏览视图切换开发”以切换浏览器显示。

2、 采集模式2(导入关键词 采集)
([1)导入采集到采集,多个关键词(每行一个)

([2)点击“导入模式采集”按钮

([3)同时,您还可以单击“浏览视图切换开发”来切换浏览器显示。

常见问题
1、支持的操作系统?
Win7及更高版本(可接受32位或64位)。 XP不支持。
2、试用版与正版版之间的区别?
试用版具有采集导出密钥信息加密功能(24小时限时试用),并且没有其他限制,因此您可以在购买前试用一下。
由于高质量,我们的软件可以免费体验和尝试。 (与许多无法体验或没有足够有限的a脚经历的同龄人不同。)
3、 采集速度?
没有任何限制,您的计算机性能和带宽。
4、如果我更换机器或丢失软件该怎么办?
通过QQ和微信联系我们进行处理。我们只希望VIP客户在授权期内及时处理它。
更新日志
行业定制:老店1688商品采集软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 341 次浏览 • 2020-11-20 13:00
1688商品采集软件是由老店软件推出的1688(阿里巴巴)产品信息批次采集软件。其功能是批量采集阿里巴巴(1688)网站上的产品信息,支持按关键词采集,支持批量采集,及时了解和更新商店动态,操作简单,实用方便,这是一个非常好的软件。
功能介绍
支持两种采集模式:
1、页面设置采集。
在WEB页面上设置采集 关键词,并精细设置采集条件(例如样式,颜色,大小等)。这适用于复杂条件下的优化采集。
2、按关键词批处理采集。
通过导入一批关键词,直接按关键词采集。
采集的信息包括产品ID,产品标题,产品URL,产品价格,产品图,月销售额,月销售额,重复率,货物描述,响应,交货,旺旺,公司名称,业务类型等。和其他字段,以文本表(excel)格式导出,可用于产品市场分析,同行销售绩效评估,公司信息采集和其他目的。每个产品关键词支持100页,每页60个产品,以及大约6000个产品信息。支持详细的搜索参数设置,支持多个产品关键词订单采集,不同的关键词输入键一行,支持字段排序(单击标题列),然后导出并保存。
软件功能
1、只需用鼠标单击,无需编写任何采集规则,
2、实时采集,非历史数据,即用户本地采集中当前的最新数据。
3、操作简单易上手,傻瓜式操作,分两步进行(导入产品详细信息链接,每行一个,可以导入多个产品链接;单击以启动采集;导出数据)。无需编写任何规则,操作非常简单。
4、快速搜索,极快的操作体验,流畅而愉快。
5、具有自动升级功能:新版本正式发布后,客户端打开后将自动升级到最新版本。
6、该软件将继续维护模块更新。
常见问题
1、支持的操作系统?
Win7及更高版本(可接受32位或64位)。 XP不支持。
2、试用版与正版版之间的区别?
试用版具有采集导出密钥信息加密功能(24小时限时试用),并且没有其他限制,因此您可以在购买前试用。
由于高质量,我们的软件可以免费体验和尝试。 (与许多无法体验或没有足够有限的a脚经历的同龄人不同。)
3、 采集速度?
没有任何限制,您的计算机性能和带宽。
4、如果我更换机器或丢失软件该怎么办?
通过QQ和微信联系我们进行处理。我们只希望VIP客户在授权期内及时处理它。
更新日志 查看全部
老店1688产品采集软件
1688商品采集软件是由老店软件推出的1688(阿里巴巴)产品信息批次采集软件。其功能是批量采集阿里巴巴(1688)网站上的产品信息,支持按关键词采集,支持批量采集,及时了解和更新商店动态,操作简单,实用方便,这是一个非常好的软件。

功能介绍
支持两种采集模式:
1、页面设置采集。
在WEB页面上设置采集 关键词,并精细设置采集条件(例如样式,颜色,大小等)。这适用于复杂条件下的优化采集。
2、按关键词批处理采集。
通过导入一批关键词,直接按关键词采集。
采集的信息包括产品ID,产品标题,产品URL,产品价格,产品图,月销售额,月销售额,重复率,货物描述,响应,交货,旺旺,公司名称,业务类型等。和其他字段,以文本表(excel)格式导出,可用于产品市场分析,同行销售绩效评估,公司信息采集和其他目的。每个产品关键词支持100页,每页60个产品,以及大约6000个产品信息。支持详细的搜索参数设置,支持多个产品关键词订单采集,不同的关键词输入键一行,支持字段排序(单击标题列),然后导出并保存。
软件功能
1、只需用鼠标单击,无需编写任何采集规则,
2、实时采集,非历史数据,即用户本地采集中当前的最新数据。
3、操作简单易上手,傻瓜式操作,分两步进行(导入产品详细信息链接,每行一个,可以导入多个产品链接;单击以启动采集;导出数据)。无需编写任何规则,操作非常简单。
4、快速搜索,极快的操作体验,流畅而愉快。
5、具有自动升级功能:新版本正式发布后,客户端打开后将自动升级到最新版本。
6、该软件将继续维护模块更新。
常见问题
1、支持的操作系统?
Win7及更高版本(可接受32位或64位)。 XP不支持。
2、试用版与正版版之间的区别?
试用版具有采集导出密钥信息加密功能(24小时限时试用),并且没有其他限制,因此您可以在购买前试用。
由于高质量,我们的软件可以免费体验和尝试。 (与许多无法体验或没有足够有限的a脚经历的同龄人不同。)
3、 采集速度?
没有任何限制,您的计算机性能和带宽。
4、如果我更换机器或丢失软件该怎么办?
通过QQ和微信联系我们进行处理。我们只希望VIP客户在授权期内及时处理它。
更新日志
解决方案:1688商品采集软件1.9官方版
采集交流 • 优采云 发表了文章 • 0 个评论 • 315 次浏览 • 2020-11-20 11:00
1688商品采集软件是老店软件生产的1688产品,即阿里巴巴产品信息批采集软件,它支持多种方法采集数据,这些数据可以快速为用户所需采集所有各种信息,帮助您及时了解和更新商店信息,操作简单,高效,易于使用,欢迎有需要的朋友体会。
功能描述:
支持两种采集模式:
1、页面设置采集。
在WEB页面上设置采集 关键词,并精细设置采集条件(例如样式,颜色,大小等)。这适合在复杂条件下进行优化采集。
2、按关键词批处理采集。
通过导入一批关键词,直接按关键词 采集。
采集的信息包括产品ID,产品标题,产品URL,产品价格,产品图,月销售额,月销售额,重复率,货物描述,响应,交货,旺旺,公司名称,业务类型等。和其他以文本形式(excel)导出的字段可以用于产品市场分析,同行销售绩效评估,公司信息采集和其他目的。每个产品关键词支持100页,每页60个产品,以及大约6000个产品信息。支持详细的搜索参数设置,支持多个产品关键词序列采集,不同的关键词输入键一行,支持字段排序(单击标题列),然后导出并保存。
常见问题:
1、支持的操作系统?
Win7及更高版本(32位或64位)。 XP不支持。
2、试用版与正版版之间的区别?
试用版具有采集导出密钥信息加密功能(24小时限时试用),并且没有其他限制,因此您可以在购买前试用。
由于高质量,我们的软件可以免费体验和尝试。 (与许多无法体验或无法充分体验的cr脚的同行不同)。
3、采集速度?
没有任何限制,您的计算机性能和带宽。
4、如果我更换机器或丢失软件该怎么办?
通过QQ和微信联系我们进行处理。我们只希望VIP客户在授权期内及时处理它。
软件功能:
1、只需用鼠标单击,无需编写任何采集规则,
2、实时采集,非历史数据,即用户本地采集中当前的最新数据。
3、该操作简单易上手,分两步进行傻瓜式操作(导入产品详细信息链接,每行一个,可以导入多个产品链接;单击以开始采集 ;导出数据)。无需编写任何规则,操作非常简单。
4、快速搜索,极快的操作体验,流畅而愉快。
5、具有自动升级功能:新版本正式发布后,打开客户端后,客户端将自动升级到最新版本。
6、该软件将继续维护模块更新。 查看全部
1688商品采集软件1.9正式版
1688商品采集软件是老店软件生产的1688产品,即阿里巴巴产品信息批采集软件,它支持多种方法采集数据,这些数据可以快速为用户所需采集所有各种信息,帮助您及时了解和更新商店信息,操作简单,高效,易于使用,欢迎有需要的朋友体会。
功能描述:
支持两种采集模式:
1、页面设置采集。
在WEB页面上设置采集 关键词,并精细设置采集条件(例如样式,颜色,大小等)。这适合在复杂条件下进行优化采集。
2、按关键词批处理采集。
通过导入一批关键词,直接按关键词 采集。
采集的信息包括产品ID,产品标题,产品URL,产品价格,产品图,月销售额,月销售额,重复率,货物描述,响应,交货,旺旺,公司名称,业务类型等。和其他以文本形式(excel)导出的字段可以用于产品市场分析,同行销售绩效评估,公司信息采集和其他目的。每个产品关键词支持100页,每页60个产品,以及大约6000个产品信息。支持详细的搜索参数设置,支持多个产品关键词序列采集,不同的关键词输入键一行,支持字段排序(单击标题列),然后导出并保存。
常见问题:
1、支持的操作系统?
Win7及更高版本(32位或64位)。 XP不支持。
2、试用版与正版版之间的区别?
试用版具有采集导出密钥信息加密功能(24小时限时试用),并且没有其他限制,因此您可以在购买前试用。
由于高质量,我们的软件可以免费体验和尝试。 (与许多无法体验或无法充分体验的cr脚的同行不同)。
3、采集速度?
没有任何限制,您的计算机性能和带宽。
4、如果我更换机器或丢失软件该怎么办?
通过QQ和微信联系我们进行处理。我们只希望VIP客户在授权期内及时处理它。
软件功能:
1、只需用鼠标单击,无需编写任何采集规则,
2、实时采集,非历史数据,即用户本地采集中当前的最新数据。
3、该操作简单易上手,分两步进行傻瓜式操作(导入产品详细信息链接,每行一个,可以导入多个产品链接;单击以开始采集 ;导出数据)。无需编写任何规则,操作非常简单。
4、快速搜索,极快的操作体验,流畅而愉快。
5、具有自动升级功能:新版本正式发布后,打开客户端后,客户端将自动升级到最新版本。
6、该软件将继续维护模块更新。
事实:芭奇:不用编写采集规则也可轻松采集网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 465 次浏览 • 2020-10-07 09:04
很长时间以来,每个人都在使用采集功能附带的各种采集器或网站程序。它们具有一个共同的功能,即您需要在采集至文章之前编写采集规则,对于新手来说,此技术问题并非易事,对于老网站管理员而言,这也是一项艰巨的任务。因此,如果您执行站群,则每个工作站都必须定义采集规则,这确实很痛苦。有人说网站管理员是网络搬运工。这句话也很有意义。互联网上的许多文章是您感动了我,而我感动了您。为了生活,我必须这样做。现在,Baqi 站群软件中发布了一个新的采集功能,该功能可以大大减少网站站长“搬运工”的时间,并且不再需要编写烦人的采集规则。此功能是Internet的第一个功能。 ---指定URL 采集。让我教您如何使用此功能:
一、首先打开此功能。您可以在网站右键中看到此功能:如下所示。
二、打开后具有以下功能,您可以在右侧填写采集的列表地址:
在这里,我使用百度的搜索页作为采集的来源,例如:%B0%C5%C6%E6
然后,我使用Baqi 站群软件对所有搜索结果文章进行了采集。您可以首先分析此页面,如果您使用各种类型的采集器或网站内置程序来自定义采集和所有文章,则无法获得此页面。因为Internet没有通用的采集和不同的网站功能,但是现在可以实现Batch 站群软件。因为该软件支持pan 采集技术。
三、主页,我将此百度结果列表填写到软件的“起始采集 文章列表地址”中,如下所示:
四、为了能够更正我想要的采集列表,分析结果列表上的文章有一个通用后缀,即:html,shtml,htm,那么这三个是通用的是:我为软件定义了htm。这种方法是减少采集个无用的页面,如下所示:
五、现在可用于采集,但这是提醒。通常,一个网站中有许多具有相同字符的字符。对于此百度列表,也有百度自己的网页,但是百度我自己的网页内容不是我想要使用的内容,因此还有另一个地方可以排除带有百度URL的页面。如下图所示:
此定义之后,它将避免使用百度自己的页面。然后填写,可以直接采集 文章,单击“保存采集数据”:
一两分钟后,采集处理的结果如下图所示:
六、在这里,我只选择文章的一部分,然后不再选择它。现在来看采集之后的内容:
七、上面是采集的过程。根据上述步骤,您还可以在其他地方列出采集 文章,尤其是某些网站没有收录或屏幕避免收录],这些都是原创的文章,您可以自己找到。现在,让我告诉您有关软件的其他一些功能:
1、如上图所示,这是删除URL和采集图片的功能。您可以根据需要对其进行打勾。
2、如上所示,这里是设置采集的数量和采集中文章的最小单词数。
3、如上图所示,您可以在此处定义替换词,支持代码替换,文本替换等,此处可以灵活使用,对于某些困难的采集列表,将在此处使用。您可以先用空格替换某些代码,然后才能采集链接到列表。
以上所有都是Baqi 站群软件的新采集功能。此功能非常强大,但是需要改进此功能以满足不同人群的需求。使用此工具,您不必担心不知道如何编写采集规则。此功能易于上手,易于操作。这是新老网站管理员最适合的功能。如果您听不懂,可以将我加到QQ并问我:509229860。 查看全部
批处理:您无需编写采集规则即可轻松采集 网站
很长时间以来,每个人都在使用采集功能附带的各种采集器或网站程序。它们具有一个共同的功能,即您需要在采集至文章之前编写采集规则,对于新手来说,此技术问题并非易事,对于老网站管理员而言,这也是一项艰巨的任务。因此,如果您执行站群,则每个工作站都必须定义采集规则,这确实很痛苦。有人说网站管理员是网络搬运工。这句话也很有意义。互联网上的许多文章是您感动了我,而我感动了您。为了生活,我必须这样做。现在,Baqi 站群软件中发布了一个新的采集功能,该功能可以大大减少网站站长“搬运工”的时间,并且不再需要编写烦人的采集规则。此功能是Internet的第一个功能。 ---指定URL 采集。让我教您如何使用此功能:
一、首先打开此功能。您可以在网站右键中看到此功能:如下所示。

二、打开后具有以下功能,您可以在右侧填写采集的列表地址:

在这里,我使用百度的搜索页作为采集的来源,例如:%B0%C5%C6%E6

然后,我使用Baqi 站群软件对所有搜索结果文章进行了采集。您可以首先分析此页面,如果您使用各种类型的采集器或网站内置程序来自定义采集和所有文章,则无法获得此页面。因为Internet没有通用的采集和不同的网站功能,但是现在可以实现Batch 站群软件。因为该软件支持pan 采集技术。
三、主页,我将此百度结果列表填写到软件的“起始采集 文章列表地址”中,如下所示:

四、为了能够更正我想要的采集列表,分析结果列表上的文章有一个通用后缀,即:html,shtml,htm,那么这三个是通用的是:我为软件定义了htm。这种方法是减少采集个无用的页面,如下所示:

五、现在可用于采集,但这是提醒。通常,一个网站中有许多具有相同字符的字符。对于此百度列表,也有百度自己的网页,但是百度我自己的网页内容不是我想要使用的内容,因此还有另一个地方可以排除带有百度URL的页面。如下图所示:

此定义之后,它将避免使用百度自己的页面。然后填写,可以直接采集 文章,单击“保存采集数据”:

一两分钟后,采集处理的结果如下图所示:


六、在这里,我只选择文章的一部分,然后不再选择它。现在来看采集之后的内容:


七、上面是采集的过程。根据上述步骤,您还可以在其他地方列出采集 文章,尤其是某些网站没有收录或屏幕避免收录],这些都是原创的文章,您可以自己找到。现在,让我告诉您有关软件的其他一些功能:

1、如上图所示,这是删除URL和采集图片的功能。您可以根据需要对其进行打勾。

2、如上所示,这里是设置采集的数量和采集中文章的最小单词数。

3、如上图所示,您可以在此处定义替换词,支持代码替换,文本替换等,此处可以灵活使用,对于某些困难的采集列表,将在此处使用。您可以先用空格替换某些代码,然后才能采集链接到列表。
以上所有都是Baqi 站群软件的新采集功能。此功能非常强大,但是需要改进此功能以满足不同人群的需求。使用此工具,您不必担心不知道如何编写采集规则。此功能易于上手,易于操作。这是新老网站管理员最适合的功能。如果您听不懂,可以将我加到QQ并问我:509229860。
解决方案:怎么样大批量的采集B2B的产品图片和信息?
采集交流 • 优采云 发表了文章 • 0 个评论 • 344 次浏览 • 2020-10-05 09:10
最简单的方法是使用采集工具。我以前尝试过许多工具,但发现许多采集工具无法在采集中显示图片,而且它们不是免费的。后来,我终于找到了一个名为gooseeker的工具。您可以同时获取图片和文本,但是该密钥是免费的。该工具分为两部分,一个MS计数器负责采集规则,另一个DS计数器负责采集数据。
我不知道您想要产品目录页面还是产品详细信息页面的图形和文本?产品的目录页面非常简单。使用此工具的MS可以在页面上执行采集规则,该规则将要捕获的信息和图像URL映射到排序框,并为图像URL设置下载图像,因为目录页面有很多页,每个页面都有多个产品信息,还设置了样本副本和自动翻页。最后,您需要使用采集的DS计数器来获取所有图片和文字。此外,如果您要采用新的URL,则只需通过DS将URL添加到规则中。无需再制定任何规则,您可以分批采集数千条规则。数十万个网址的数据。
产品详细信息页面并不困难,方法与上述类似,只是您无需翻页。要特别注意控制采集的速度和周期。尽管此工具可能非常有效,但是您希望如果继续进行批处理采集,请不要太快,否则电子商务网站很快就会检测到异常,并且验证窗口通常会弹出,并且您甚至无法访问该网页。
更复杂的方法是为B2B 网站编写Python采集器,以搜寻指定的网页和图形,但是每个B2B 网站都有复杂的结构。如果使用此方法,则需要连续调试和测试,只需采集一个网站计划,编程,调试,运行优化等需要一个月的时间。如果更改网站,则将花费很长时间是时候更改程序了。因此,如果您想批量采集,您可以自己做。既费时又累。 查看全部
大量的采集B2B产品图片和信息如何?
最简单的方法是使用采集工具。我以前尝试过许多工具,但发现许多采集工具无法在采集中显示图片,而且它们不是免费的。后来,我终于找到了一个名为gooseeker的工具。您可以同时获取图片和文本,但是该密钥是免费的。该工具分为两部分,一个MS计数器负责采集规则,另一个DS计数器负责采集数据。
我不知道您想要产品目录页面还是产品详细信息页面的图形和文本?产品的目录页面非常简单。使用此工具的MS可以在页面上执行采集规则,该规则将要捕获的信息和图像URL映射到排序框,并为图像URL设置下载图像,因为目录页面有很多页,每个页面都有多个产品信息,还设置了样本副本和自动翻页。最后,您需要使用采集的DS计数器来获取所有图片和文字。此外,如果您要采用新的URL,则只需通过DS将URL添加到规则中。无需再制定任何规则,您可以分批采集数千条规则。数十万个网址的数据。
产品详细信息页面并不困难,方法与上述类似,只是您无需翻页。要特别注意控制采集的速度和周期。尽管此工具可能非常有效,但是您希望如果继续进行批处理采集,请不要太快,否则电子商务网站很快就会检测到异常,并且验证窗口通常会弹出,并且您甚至无法访问该网页。
更复杂的方法是为B2B 网站编写Python采集器,以搜寻指定的网页和图形,但是每个B2B 网站都有复杂的结构。如果使用此方法,则需要连续调试和测试,只需采集一个网站计划,编程,调试,运行优化等需要一个月的时间。如果更改网站,则将花费很长时间是时候更改程序了。因此,如果您想批量采集,您可以自己做。既费时又累。
解决方案:不用写采集规则也可以轻松采集网站文章,揭秘一款明泽文章采集软件的工作原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 305 次浏览 • 2020-09-15 17:41
每个人都在使用各种采集器或网站内置采集功能,例如织梦 采集侠,优采云 采集器,优采云 采集器等,这些采集软件具有一个共同的功能,即您必须编写采集规则才能将采集更改为文章。对于新手来说,这个技术问题经常被张二和尚所迷惑,这确实不是一件容易的事。即使对于旧的网站管理员,当需要采集多个网站数据时,也需要为不同的网站编写不同的采集规则,这是一项艰巨且耗时的任务。许多站群的朋友对每个站点都需要编写采集规则有深刻的理解,这简直令人痛苦。有人说网站管理员是网络搬运工。这很有道理。在互联网上文章就是您移动我,移动您并互相移动的全部。那么,有没有既免费又开源的采集软件? Mingze 文章 采集器就像为您量身定制的采集软件一样,此采集器具有内置的采集规则,只需添加文章列表链接,就可以连接内容采集回来。
Mingze 文章 采集器有什么优势,万能的文章 采集器可以采集收录什么内容
可以作为采集的采集器的内容是:文章标题,文章 关键词,文章说明,文章详细信息,文章作者,文章发布时间,文章次网页浏览。
Universal 文章 采集器在哪里运行?
此采集器可以在Windows,Mac,Linux(Centos,Ubuntu等)上运行。您可以下载并编译该程序以直接执行,也可以下载源代码并自己进行编译。
Mingze 文章 采集软件教程
data:image/svg+xml;utf8,
data:image/svg+xml;utf8,
data:image/svg+xml;utf8,
data:image/svg+xml;utf8,
结论
以上是Mingze 文章 采集器的用法和工作原理。根据上述步骤,您可以轻松地采集到所需的内容文章。它一天24小时都可以工作,您可以在采集器之后打开它。它将为您提供稳定的能量采集 文章并自动释放它。 查看全部
您无需编写采集规则即可轻松采集 网站 文章,揭示Mingze 文章 采集软件的工作原理
每个人都在使用各种采集器或网站内置采集功能,例如织梦 采集侠,优采云 采集器,优采云 采集器等,这些采集软件具有一个共同的功能,即您必须编写采集规则才能将采集更改为文章。对于新手来说,这个技术问题经常被张二和尚所迷惑,这确实不是一件容易的事。即使对于旧的网站管理员,当需要采集多个网站数据时,也需要为不同的网站编写不同的采集规则,这是一项艰巨且耗时的任务。许多站群的朋友对每个站点都需要编写采集规则有深刻的理解,这简直令人痛苦。有人说网站管理员是网络搬运工。这很有道理。在互联网上文章就是您移动我,移动您并互相移动的全部。那么,有没有既免费又开源的采集软件? Mingze 文章 采集器就像为您量身定制的采集软件一样,此采集器具有内置的采集规则,只需添加文章列表链接,就可以连接内容采集回来。
Mingze 文章 采集器有什么优势,万能的文章 采集器可以采集收录什么内容
可以作为采集的采集器的内容是:文章标题,文章 关键词,文章说明,文章详细信息,文章作者,文章发布时间,文章次网页浏览。
Universal 文章 采集器在哪里运行?
此采集器可以在Windows,Mac,Linux(Centos,Ubuntu等)上运行。您可以下载并编译该程序以直接执行,也可以下载源代码并自己进行编译。
Mingze 文章 采集软件教程
data:image/svg+xml;utf8,
data:image/svg+xml;utf8,
data:image/svg+xml;utf8,
data:image/svg+xml;utf8,
结论
以上是Mingze 文章 采集器的用法和工作原理。根据上述步骤,您可以轻松地采集到所需的内容文章。它一天24小时都可以工作,您可以在采集器之后打开它。它将为您提供稳定的能量采集 文章并自动释放它。
心得:优采云采集规则怎么写?新手怎么入门?
采集交流 • 优采云 发表了文章 • 0 个评论 • 329 次浏览 • 2020-09-07 19:52
优采云 采集器当前是更流行的网站 data 采集工具。针对采集发布的无版权数据的首选。但是许多网站管理员说采集很困难。不知道如何开始。还是不知道从哪里开始?今天,我推荐一种非常简单的入门方法。
我们提供的许多源代码实际上是优采云 采集器随附的,但是规则通常仅持续约3个月,需要进行调整。最简单的入门方法是学习他人编写的规则。如果输入有误,请继续修改规则。 采集的内容通常是采集的2点之内的数据。这是相对简单的。新手条目通常会被修改2-3次。
优采云最困难的部分实际上是模块的设置,但是您也可以从其他人开发的模块中学习并更改规则。使用其现成的采集模块和采集接口采集数据。 ,这并不困难。
当然,有一种简单的方法。我们经常说,每个人采集拥有相同的站点并更改采集的来源并没有多大意义。避免内容同质化。以我们提供的源代码为例。实际上,许多类型的网站都是重复的,例如手机游戏,下载,相同的源代码可能已经提供了N次,采集器也提供了N次,导出其规则,然后将其导入到当前的[k2 ] 采集很好,有时甚至不需要更改标签,例如92中开发的相同类型和96中开发的相同类型。通常只需要进行较小的调整。
这就是为什么我们总是建议大家加入我们的一站式VIP的原因。您可以向成熟的开发人员学习技术,以快速提高自己,甚至可以集成他们的技术来开发和修改所需的网站或采集器。如果您想每次都在任何站点上购买任何源代码,则采集无效并要求某人付款以对其进行修改,因此一年之内的花费不小。 查看全部
如何编写优采云 采集规则?如何为新手入门?

优采云 采集器当前是更流行的网站 data 采集工具。针对采集发布的无版权数据的首选。但是许多网站管理员说采集很困难。不知道如何开始。还是不知道从哪里开始?今天,我推荐一种非常简单的入门方法。
我们提供的许多源代码实际上是优采云 采集器随附的,但是规则通常仅持续约3个月,需要进行调整。最简单的入门方法是学习他人编写的规则。如果输入有误,请继续修改规则。 采集的内容通常是采集的2点之内的数据。这是相对简单的。新手条目通常会被修改2-3次。
优采云最困难的部分实际上是模块的设置,但是您也可以从其他人开发的模块中学习并更改规则。使用其现成的采集模块和采集接口采集数据。 ,这并不困难。
当然,有一种简单的方法。我们经常说,每个人采集拥有相同的站点并更改采集的来源并没有多大意义。避免内容同质化。以我们提供的源代码为例。实际上,许多类型的网站都是重复的,例如手机游戏,下载,相同的源代码可能已经提供了N次,采集器也提供了N次,导出其规则,然后将其导入到当前的[k2 ] 采集很好,有时甚至不需要更改标签,例如92中开发的相同类型和96中开发的相同类型。通常只需要进行较小的调整。
这就是为什么我们总是建议大家加入我们的一站式VIP的原因。您可以向成熟的开发人员学习技术,以快速提高自己,甚至可以集成他们的技术来开发和修改所需的网站或采集器。如果您想每次都在任何站点上购买任何源代码,则采集无效并要求某人付款以对其进行修改,因此一年之内的花费不小。
汇总:优采云采集入门到熟练——03 基本采集流程
采集交流 • 优采云 发表了文章 • 0 个评论 • 417 次浏览 • 2020-09-06 02:06
在准备了第一篇文章和第二篇信心不足的文章之后,如果没有懒惰和自卑的话,肖梦欣应该已经在优采云官方网站上观看了视频教程。接下来,进入采集流程并逐步构建采集规则。
一、 采集层次结构的分析与构建
采集页面和采集内容确定采集的总体结构和过程。一般来说,采集工具不会做得太深采集,因为它会大大增加采集的可能性。因此,我们放弃了其他复杂的可能性。采用标准化的采集规范,即第二级采集-列表页+内容页+分页,这是大多数采集的最常用方法。
列表页面是什么?什么是内容页面?
如果我想采集网易国际新闻的标题,内容和其他信息,则此页面为列表页面。
国际新闻_网易新闻中心
因为此页面上有新闻列表,所以我们想要采集是列表中单击的每个新闻内容页面。话虽如此,每个人也都知道内容页面是什么。内容页面是收录您需要的信息的页面采集。内容页面通常是列表页面的从属页面。
采集的第一步是找到列表页面并在列表页面上设置翻页周期,首先完全定位列表。
什么是分页?
如果内容页面(即文章详细页面)未显示在一页上,而是由多个页面组成,则称为分页。例如,如果我想采集一篇文章文章,文章分为4页,那么我需要在分页符上执行采集。分页级别,通常是因为网站一页没有完全显示。那是:
列表页面
-分页1
-分页2
……
这样的结构。
分页也需要循环构建,这与翻页循环本质上是相同的。
通过这种方式,我们通过循环构建了辅助采集结构。通常,列表页面需要形成两个循环。第一个循环是翻页循环,用于翻页,通常称为“单击下一页”循环;第二个循环是列表循环,此循环包括所有内容页面,通常“单击进入页面循环”。
在这里,每个人都需要注意,未选中在新标签页中打开翻页循环的单击操作。这是为了确保翻页周期本身的结构不会改变。但是,默认情况下“在新选项卡页面中打开”会自动检查内容页面循环的单击操作,因为每个内容页面都可以独立打开,并且采集不会影响原创列表页面。因此,如果您发现无法通过单击并手动将循环拖入并自动生成所需的循环,则需要注意修改这些小的详细信息设置,否则将使您感到沮丧。
二、详细分析页面结构为采集(尽可能多地分析部分源代码)
您可以认为内容页面的页面结构是相同的;或因为尚未经过测试,所以您不确定它们是否一致;在先前的测试中可能也相同,但是采集在一段时间后已被修改。简而言之,有很多情况,并且永远不变的一件事就是查看独立于源代码的测试采集 -adjust xpath。
分析源代码条目的方法并不复杂。 Firefox和Chrome均进入开发人员模式。有关具体操作,请参考其他人的教导:
Artifact-Chrome开发者工具(一)-仅仅是娱乐目的-SegmentFault
重新介绍Firefox开发人员工具(1):Web控制台和Javascript调试器-文章-在线在线
这里推荐两个插件:
Firefox-Firepath
Chrome——Xpath帮助器
这两个插件可用于快速验证xpath是否正确并可以突出显示,这非常方便。
优采云附带有xpath工具。如果在浏览器中xpath正确,但是无法在优采云中提取数据,请记住使用优采云中的内置工具来进行测试测试以查看优采云是否获得了页面的源代码与浏览器获得的结果不同。
三、复杂的逻辑结构判断
在采集测试开始之前,如果可以发现逻辑结构分支是最好的,如果不是,则至少在独立测试之后尝试完善它。但是,我提醒大家,优采云对于复杂的逻辑结构分支,最好在开始时进行计划,否则您很快就会感到困惑,并且以后的维修会引起各种错误和问题。你不能摸你的头。最简单的方法是删除整个规则并重做它,这会使您很头疼,因此,您越早计划采集,就越容易制定完美的规则。
看到这里的许多人仍然感到困惑,为什么他们很复杂?为什么称之为复杂逻辑机制?这是怎么发生的。有时当我们采集个数据时,尽管它们都是内容页面,但内部格式已更改。例如,在公众意见中,有些商店具有完整的图片和说明,而有些则属于低端商店仅提供最简单的信息,而页面格式则完全不同。目前,我们很难编写通用的xpath语句,采集条目甚至可能不同。
这时,优采云 采集器的条件判断可以发挥作用。它与if else语句非常相似。通过判断页面元素或文本,您可以执行完全不同的采集流程,这可以说是非常有用的。另一种情况是出现问题时的判断。例如,如果页面提示输入验证码,则执行的过程是先输入验证码,然后继续执行采集而不是原创的采集过程(原创过程肯定会认为跳过此页面而没有数据)。每个人都应该使用良好的条件进行判断,这可以在很大程度上避免采集没有数据或数据丢失的情况。
四、数据提取和后处理
通常可以通过一种相对简单的方法来提取数据,该方法是通过单击直接提取文本或链接。但是那些真正擅长查看源代码的人知道,有时候他们想要提取的信息不一定是文本,它可能是元素的属性,例如id,src,style等。此时,优采云数据提取下的编辑按钮很有用。首先,您可以自定义元素定位。如果您认为单击生成的位置不正确,则可以编写xpath来替换它;然后是元素提取方法,这里有很多提取方法。其他工具可能需要使用正则表达式来提取属性。我们可以直接选择,也可以快速选择摘录链接或其他html代码。在此步骤中,即使我们已经提取了所需的近似值,也可以满足要求。如果需要文本处理,则需要进一步的检查处理。
优采云提供了更多通用的文本处理方法和工具,首先是最简单的替换功能,其次是通用正则表达式(认真学习,比xpath pit更深入)。此外,还有时间处理,html的基本处理等。因为优采云具有内置的正则表达式工具,请相信我,用心学习这个小技巧,可以节省很多自学的正则表达式时间,这绝对是一个神奇的工具,我想每天都有一个小的工具!
五、小细节设置
每个新手都会遇到一个大问题,Internet上的许多其他人找不到这些设置。实际上,这主要是因为优采云的许多详细设置都在每个操作的高级部分中,这使新来者不熟悉。 ,或者我没有使用过,我不知道如何找到它。
这里的简单方法是将所有操作拉入流程,然后单击一个以查看高级设置,然后您可以慢慢记住它们。只要看一下实际战斗中的高级设置,您很快就会知道这是什么。高级设置和小细节设置与操作相互对应。如果我考虑需要的操作,那么我可以理解应该在哪里找到它们。例如:打开页面后,我想自动滚动到底部。此设置可能出现在哪里?毫无疑问,第一个是当我打开URL时,第二个是当我单击链接时,以便我可以立即知道在哪个步骤中可以找到此设置。
以下是一些注意事项:
六、单机测试和故障排除
无论您如何编写规则,都可能会遇到问题,因为优采云规则不是您所看到的就是得到的,是的!不要上当,当您编辑规则时,您会感觉一切都很好,但是在启动独立测试后,一切都不是您所想的。这次是我们所有人都祝贺您进入维修站的时候了!
很难避免深坑!您为什么这么说,因为这是一个经验性的问题...肖梦新会慢慢陷入困境...在遇到很多陷阱之后,您将逐渐知道如何解决问题。让我们开始“扫雷”:
首先写很多,爪子可以跟随我的知乎专栏和数据交换组。
Brother Rabbit Data Geek Club的QQ群:462346024
我的博客: 查看全部
优采云 采集入门知识——03基本的采集过程
在准备了第一篇文章和第二篇信心不足的文章之后,如果没有懒惰和自卑的话,肖梦欣应该已经在优采云官方网站上观看了视频教程。接下来,进入采集流程并逐步构建采集规则。
一、 采集层次结构的分析与构建
采集页面和采集内容确定采集的总体结构和过程。一般来说,采集工具不会做得太深采集,因为它会大大增加采集的可能性。因此,我们放弃了其他复杂的可能性。采用标准化的采集规范,即第二级采集-列表页+内容页+分页,这是大多数采集的最常用方法。
列表页面是什么?什么是内容页面?
如果我想采集网易国际新闻的标题,内容和其他信息,则此页面为列表页面。
国际新闻_网易新闻中心
因为此页面上有新闻列表,所以我们想要采集是列表中单击的每个新闻内容页面。话虽如此,每个人也都知道内容页面是什么。内容页面是收录您需要的信息的页面采集。内容页面通常是列表页面的从属页面。
采集的第一步是找到列表页面并在列表页面上设置翻页周期,首先完全定位列表。
什么是分页?
如果内容页面(即文章详细页面)未显示在一页上,而是由多个页面组成,则称为分页。例如,如果我想采集一篇文章文章,文章分为4页,那么我需要在分页符上执行采集。分页级别,通常是因为网站一页没有完全显示。那是:
列表页面
-分页1
-分页2
……
这样的结构。
分页也需要循环构建,这与翻页循环本质上是相同的。
通过这种方式,我们通过循环构建了辅助采集结构。通常,列表页面需要形成两个循环。第一个循环是翻页循环,用于翻页,通常称为“单击下一页”循环;第二个循环是列表循环,此循环包括所有内容页面,通常“单击进入页面循环”。
在这里,每个人都需要注意,未选中在新标签页中打开翻页循环的单击操作。这是为了确保翻页周期本身的结构不会改变。但是,默认情况下“在新选项卡页面中打开”会自动检查内容页面循环的单击操作,因为每个内容页面都可以独立打开,并且采集不会影响原创列表页面。因此,如果您发现无法通过单击并手动将循环拖入并自动生成所需的循环,则需要注意修改这些小的详细信息设置,否则将使您感到沮丧。
二、详细分析页面结构为采集(尽可能多地分析部分源代码)
您可以认为内容页面的页面结构是相同的;或因为尚未经过测试,所以您不确定它们是否一致;在先前的测试中可能也相同,但是采集在一段时间后已被修改。简而言之,有很多情况,并且永远不变的一件事就是查看独立于源代码的测试采集 -adjust xpath。
分析源代码条目的方法并不复杂。 Firefox和Chrome均进入开发人员模式。有关具体操作,请参考其他人的教导:
Artifact-Chrome开发者工具(一)-仅仅是娱乐目的-SegmentFault
重新介绍Firefox开发人员工具(1):Web控制台和Javascript调试器-文章-在线在线
这里推荐两个插件:
Firefox-Firepath
Chrome——Xpath帮助器
这两个插件可用于快速验证xpath是否正确并可以突出显示,这非常方便。
优采云附带有xpath工具。如果在浏览器中xpath正确,但是无法在优采云中提取数据,请记住使用优采云中的内置工具来进行测试测试以查看优采云是否获得了页面的源代码与浏览器获得的结果不同。
三、复杂的逻辑结构判断
在采集测试开始之前,如果可以发现逻辑结构分支是最好的,如果不是,则至少在独立测试之后尝试完善它。但是,我提醒大家,优采云对于复杂的逻辑结构分支,最好在开始时进行计划,否则您很快就会感到困惑,并且以后的维修会引起各种错误和问题。你不能摸你的头。最简单的方法是删除整个规则并重做它,这会使您很头疼,因此,您越早计划采集,就越容易制定完美的规则。
看到这里的许多人仍然感到困惑,为什么他们很复杂?为什么称之为复杂逻辑机制?这是怎么发生的。有时当我们采集个数据时,尽管它们都是内容页面,但内部格式已更改。例如,在公众意见中,有些商店具有完整的图片和说明,而有些则属于低端商店仅提供最简单的信息,而页面格式则完全不同。目前,我们很难编写通用的xpath语句,采集条目甚至可能不同。
这时,优采云 采集器的条件判断可以发挥作用。它与if else语句非常相似。通过判断页面元素或文本,您可以执行完全不同的采集流程,这可以说是非常有用的。另一种情况是出现问题时的判断。例如,如果页面提示输入验证码,则执行的过程是先输入验证码,然后继续执行采集而不是原创的采集过程(原创过程肯定会认为跳过此页面而没有数据)。每个人都应该使用良好的条件进行判断,这可以在很大程度上避免采集没有数据或数据丢失的情况。
四、数据提取和后处理
通常可以通过一种相对简单的方法来提取数据,该方法是通过单击直接提取文本或链接。但是那些真正擅长查看源代码的人知道,有时候他们想要提取的信息不一定是文本,它可能是元素的属性,例如id,src,style等。此时,优采云数据提取下的编辑按钮很有用。首先,您可以自定义元素定位。如果您认为单击生成的位置不正确,则可以编写xpath来替换它;然后是元素提取方法,这里有很多提取方法。其他工具可能需要使用正则表达式来提取属性。我们可以直接选择,也可以快速选择摘录链接或其他html代码。在此步骤中,即使我们已经提取了所需的近似值,也可以满足要求。如果需要文本处理,则需要进一步的检查处理。
优采云提供了更多通用的文本处理方法和工具,首先是最简单的替换功能,其次是通用正则表达式(认真学习,比xpath pit更深入)。此外,还有时间处理,html的基本处理等。因为优采云具有内置的正则表达式工具,请相信我,用心学习这个小技巧,可以节省很多自学的正则表达式时间,这绝对是一个神奇的工具,我想每天都有一个小的工具!
五、小细节设置
每个新手都会遇到一个大问题,Internet上的许多其他人找不到这些设置。实际上,这主要是因为优采云的许多详细设置都在每个操作的高级部分中,这使新来者不熟悉。 ,或者我没有使用过,我不知道如何找到它。
这里的简单方法是将所有操作拉入流程,然后单击一个以查看高级设置,然后您可以慢慢记住它们。只要看一下实际战斗中的高级设置,您很快就会知道这是什么。高级设置和小细节设置与操作相互对应。如果我考虑需要的操作,那么我可以理解应该在哪里找到它们。例如:打开页面后,我想自动滚动到底部。此设置可能出现在哪里?毫无疑问,第一个是当我打开URL时,第二个是当我单击链接时,以便我可以立即知道在哪个步骤中可以找到此设置。

以下是一些注意事项:
六、单机测试和故障排除
无论您如何编写规则,都可能会遇到问题,因为优采云规则不是您所看到的就是得到的,是的!不要上当,当您编辑规则时,您会感觉一切都很好,但是在启动独立测试后,一切都不是您所想的。这次是我们所有人都祝贺您进入维修站的时候了!
很难避免深坑!您为什么这么说,因为这是一个经验性的问题...肖梦新会慢慢陷入困境...在遇到很多陷阱之后,您将逐渐知道如何解决问题。让我们开始“扫雷”:
首先写很多,爪子可以跟随我的知乎专栏和数据交换组。
Brother Rabbit Data Geek Club的QQ群:462346024
我的博客:
测评:如何只采集列表页面的内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 359 次浏览 • 2020-09-01 21:09
有时候,我们只需要采集某些列表页面的内容即可. 例如,我们想要采集在百度上某个关键字的搜索结果,而我们只需要标题,URL或简介之类的内容. 或者我们认为采集是一条短信列,其列表页面收录我们所需的短信内容.
一个
如果我们希望列表中的每个项目都单独发布,请按以下方式配置采集规则:
1. 根据正常的采集配置列表URL,自动列表,列表区域中的列表设置;
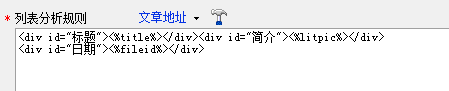
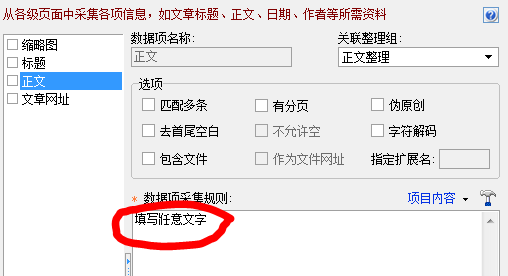
2. 列出分析规则. 如果采集的内容不需要URL,则使用文章地址标记任何采集字符串;如果除了标题和URL之外还需要采集其他内容,例如,对于简介,我们可以使用缩略图标记来采集;
3,文章 URL合成,只需在此处填写快速访问URL,本地站点的URL也可以;
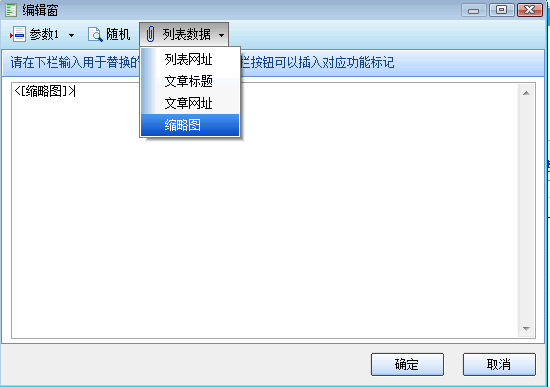
4.1. 在ET3中,可以使用指定的模式来调用列表数据;
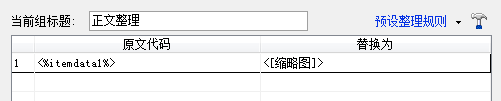
4.2. 在ET2中,可以使用数据排序将列表数据分配给数据项. 数据排序中有一个[列表数据]标记,您可以引用标题,文章 URL,缩略图和其他从列表中获得的数据. 因此,我们可以在其相应的数据排序中创建新的数据项,引号标题,文章 URL,缩略图和其他数据,并将它们分解或合并为我们要发布的内容. 以下三张图片演示了如何为文本数据项分配缩略图数据.
(1,在文本数据项的采集规则中填写任何文本)
(2,在文本的数据组织中使用列表数据标记)
(3. 使用参数标签或变量标签将文本数据项的内容替换为列表的缩略图内容)
5. 其他与一般采集规则相同;
6. 在发布规则中,应注意数据项名称与发布参数名称之间的正确对应;
通过这种方式,列表中的内容可以采集逐一发布.
第二,
如果我们需要一次发布采集的内容,请按以下方式配置采集规则:
1. 列出网址,只需填写访问速度快的网页,或填写本地txt文件地址即可;
2,自动列表,无需设置列表区域;
3. 列表分析. 为列表URL中填写的地址内容设置一个简单规则. 要使用文章地址标签,文章地址标签的分析结果可以是任何内容,因为它不会被使用. 但是此分析规则必须有效,最好文章地址标签仅匹配一个结果(如果有多个结果,则可以在采集基本配置中将采集项的数量设置为1);
4,文章 URL合成,在此处采集填写您想要的列表页面URL;
5. 使用文本数据项和其他数据项采集列表中的每个项,您可以全部收录它们,也可以选择匹配多个项目;
6. 如果有多个列表URL,则可以使用正文页面设置采集;
7. 其他配置与一般采集规则相同;
完成此配置后,整个列表将作为文章文章发布. 查看全部
如何仅采集列表页面的内容
有时候,我们只需要采集某些列表页面的内容即可. 例如,我们想要采集在百度上某个关键字的搜索结果,而我们只需要标题,URL或简介之类的内容. 或者我们认为采集是一条短信列,其列表页面收录我们所需的短信内容.
一个
如果我们希望列表中的每个项目都单独发布,请按以下方式配置采集规则:
1. 根据正常的采集配置列表URL,自动列表,列表区域中的列表设置;
2. 列出分析规则. 如果采集的内容不需要URL,则使用文章地址标记任何采集字符串;如果除了标题和URL之外还需要采集其他内容,例如,对于简介,我们可以使用缩略图标记来采集;
3,文章 URL合成,只需在此处填写快速访问URL,本地站点的URL也可以;

4.1. 在ET3中,可以使用指定的模式来调用列表数据;
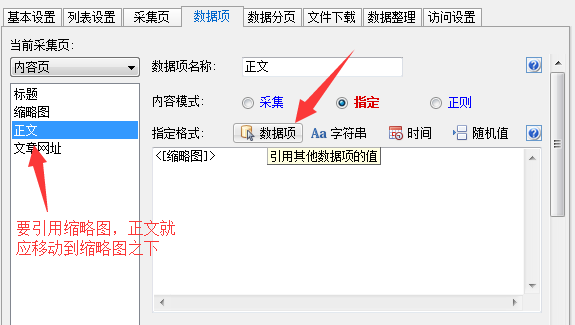
4.2. 在ET2中,可以使用数据排序将列表数据分配给数据项. 数据排序中有一个[列表数据]标记,您可以引用标题,文章 URL,缩略图和其他从列表中获得的数据. 因此,我们可以在其相应的数据排序中创建新的数据项,引号标题,文章 URL,缩略图和其他数据,并将它们分解或合并为我们要发布的内容. 以下三张图片演示了如何为文本数据项分配缩略图数据.
(1,在文本数据项的采集规则中填写任何文本)
(2,在文本的数据组织中使用列表数据标记)
(3. 使用参数标签或变量标签将文本数据项的内容替换为列表的缩略图内容)
5. 其他与一般采集规则相同;
6. 在发布规则中,应注意数据项名称与发布参数名称之间的正确对应;
通过这种方式,列表中的内容可以采集逐一发布.
第二,
如果我们需要一次发布采集的内容,请按以下方式配置采集规则:
1. 列出网址,只需填写访问速度快的网页,或填写本地txt文件地址即可;
2,自动列表,无需设置列表区域;
3. 列表分析. 为列表URL中填写的地址内容设置一个简单规则. 要使用文章地址标签,文章地址标签的分析结果可以是任何内容,因为它不会被使用. 但是此分析规则必须有效,最好文章地址标签仅匹配一个结果(如果有多个结果,则可以在采集基本配置中将采集项的数量设置为1);
4,文章 URL合成,在此处采集填写您想要的列表页面URL;
5. 使用文本数据项和其他数据项采集列表中的每个项,您可以全部收录它们,也可以选择匹配多个项目;
6. 如果有多个列表URL,则可以使用正文页面设置采集;
7. 其他配置与一般采集规则相同;
完成此配置后,整个列表将作为文章文章发布.
解决方案:文章批量采集生成 伪原创工具 中英日文自动很长时间版软件ArticleSea 杭
采集交流 • 优采云 发表了文章 • 0 个评论 • 433 次浏览 • 2020-09-01 20:46
拍照时请离开您的邮箱,信息将自动发送到您的邮箱进行下载!拍照后,它将自动将指向百度网络磁盘的链接发送到您的电子邮件! 文章 采集,支持中文,英文,日文,法文,德文和其他语言采集,还可以自定义采集的来源,自动学习采集规则,采集一般需要两个或三个小时,成千上万的文章很快就无法下载采集,因此采集请耐心等待,晚上将其放置在采集很好,第二天就可以了. ·自动降噪和乱码,变得干净整洁文章. 中文伪原创是句子库混合生成模式: 不直接使用伪原创,而是使用句子库生成+页面优化+批处理插入,不要打开软件并直接使用软件的伪原创功能,然后说那里没效果,谁介意呢. ·批处理页面优化. 文章 采集生成
拍照时请离开您的邮箱,信息将自动发送到您的邮箱进行下载!拍照后,它将自动将指向百度网络磁盘的链接发送到您的电子邮件! 文章 采集,支持中文,英文,日文,法文,德文和其他语言采集,还可以自定义采集的来源,自动学习采集规则,采集一般需要两个或三个小时,成千上万的文章很快就无法下载采集,因此采集请耐心等待,晚上将其放置在采集很好,第二天就可以了. ·自动降噪和乱码,变得干净整洁文章. 中文伪原创是句子库混合生成模式: 不直接使用伪原创,而是使用句子库生成+页面优化+批处理插入,不要打开软件并直接使用软件的伪原创功能,然后说那里没效果,谁介意呢. ·批处理页面优化. 拍照时请离开邮箱,信息将自动发送到邮箱进行下载!
拍照后,它将自动将指向百度网络磁盘的链接发送到您的电子邮件中!
文章 采集,支持中文,英文,日文,法文,德文和其他语言采集,还可以自定义采集的来源,并自动学习采集规则(不喜欢其他采集软件需要自己编写规则,只需直接输入关键字采集),采集通常需要两三个小时,成千上万的文章文章无法快速下载采集,因此[k1 ]请耐心等待,将其放在晚上采集很好,第二天就可以了
·自动去噪和乱码,变得新鲜干净文章.
·支持多个关键字,考虑输入一百个关键字并在一夜之间选择它们,多少个采集将是文章?
·支持线程设置,只要将计算机配置为具有较高的互联网速度,就可以设置任意多个线程!
·支持代理设置.
·一键生成长尾单词库,标题库,段落库,单句库,双句库和三句库.
拍照时请留下您的电子邮件,该信息将自动发送到您的电子邮件中以供下载!拍照后,它将自动将指向百度网络磁盘的链接发送到您的电子邮件! 文章 采集,支持中文,英文,日文,法文,德文和其他语言采集,还可以自定义采集的来源,自动学习采集规则,采集一般需要两个或三个小时,成千上万的文章很快就无法下载采集,因此采集请耐心等待,晚上将其放置在采集很好,第二天就可以了. ·自动降噪和乱码,变得干净整洁文章. 中文伪原创是句子库混合生成模式: 不直接使用伪原创,而是使用句子库生成+页面优化+批处理插入,不要打开软件并直接使用软件的伪原创功能,然后说那里没效果,谁介意呢. ·Batch ON PAGE优化.
·使用语料库生成大量的文章.
中文伪原创是句子库混合生成模式: 使用句子库生成(文章段落句子拆分和重组)+页面优化(关键字插入和粗体显示,添加图片等)+批处理插入(锚文本)插入,关键字替换),不能直接伪原创,不要打开软件,然后直接使用软件的伪原创功能,然后说没有任何效果,请介意,
·伪原创: 功能强大的词库,伪原创快速且可读性强.
·伪原创: 支持SPIN.
·伪原创: 支持的标题是否为伪原创.
·伪原创: 支持不同的伪原创级别.
·伪原创: 支持保留核心关键字而不被替换.
·伪原创: 相似度计算和显示
·伪原创: 大屏幕,易于编辑.
·伪原创: 使用不同的颜色表示伪原创之后的文章与原创文本之间的区别.
·批量ON PAGE优化. 查看全部
文章批处理采集生成伪原创工具中文,英文和日文自动长时间版本软件ArticleSea Hang
拍照时请离开您的邮箱,信息将自动发送到您的邮箱进行下载!拍照后,它将自动将指向百度网络磁盘的链接发送到您的电子邮件! 文章 采集,支持中文,英文,日文,法文,德文和其他语言采集,还可以自定义采集的来源,自动学习采集规则,采集一般需要两个或三个小时,成千上万的文章很快就无法下载采集,因此采集请耐心等待,晚上将其放置在采集很好,第二天就可以了. ·自动降噪和乱码,变得干净整洁文章. 中文伪原创是句子库混合生成模式: 不直接使用伪原创,而是使用句子库生成+页面优化+批处理插入,不要打开软件并直接使用软件的伪原创功能,然后说那里没效果,谁介意呢. ·批处理页面优化. 文章 采集生成
拍照时请离开您的邮箱,信息将自动发送到您的邮箱进行下载!拍照后,它将自动将指向百度网络磁盘的链接发送到您的电子邮件! 文章 采集,支持中文,英文,日文,法文,德文和其他语言采集,还可以自定义采集的来源,自动学习采集规则,采集一般需要两个或三个小时,成千上万的文章很快就无法下载采集,因此采集请耐心等待,晚上将其放置在采集很好,第二天就可以了. ·自动降噪和乱码,变得干净整洁文章. 中文伪原创是句子库混合生成模式: 不直接使用伪原创,而是使用句子库生成+页面优化+批处理插入,不要打开软件并直接使用软件的伪原创功能,然后说那里没效果,谁介意呢. ·批处理页面优化. 拍照时请离开邮箱,信息将自动发送到邮箱进行下载!
拍照后,它将自动将指向百度网络磁盘的链接发送到您的电子邮件中!
文章 采集,支持中文,英文,日文,法文,德文和其他语言采集,还可以自定义采集的来源,并自动学习采集规则(不喜欢其他采集软件需要自己编写规则,只需直接输入关键字采集),采集通常需要两三个小时,成千上万的文章文章无法快速下载采集,因此[k1 ]请耐心等待,将其放在晚上采集很好,第二天就可以了
·自动去噪和乱码,变得新鲜干净文章.
·支持多个关键字,考虑输入一百个关键字并在一夜之间选择它们,多少个采集将是文章?
·支持线程设置,只要将计算机配置为具有较高的互联网速度,就可以设置任意多个线程!
·支持代理设置.
·一键生成长尾单词库,标题库,段落库,单句库,双句库和三句库.
拍照时请留下您的电子邮件,该信息将自动发送到您的电子邮件中以供下载!拍照后,它将自动将指向百度网络磁盘的链接发送到您的电子邮件! 文章 采集,支持中文,英文,日文,法文,德文和其他语言采集,还可以自定义采集的来源,自动学习采集规则,采集一般需要两个或三个小时,成千上万的文章很快就无法下载采集,因此采集请耐心等待,晚上将其放置在采集很好,第二天就可以了. ·自动降噪和乱码,变得干净整洁文章. 中文伪原创是句子库混合生成模式: 不直接使用伪原创,而是使用句子库生成+页面优化+批处理插入,不要打开软件并直接使用软件的伪原创功能,然后说那里没效果,谁介意呢. ·Batch ON PAGE优化.
·使用语料库生成大量的文章.
中文伪原创是句子库混合生成模式: 使用句子库生成(文章段落句子拆分和重组)+页面优化(关键字插入和粗体显示,添加图片等)+批处理插入(锚文本)插入,关键字替换),不能直接伪原创,不要打开软件,然后直接使用软件的伪原创功能,然后说没有任何效果,请介意,
·伪原创: 功能强大的词库,伪原创快速且可读性强.
·伪原创: 支持SPIN.
·伪原创: 支持的标题是否为伪原创.
·伪原创: 支持不同的伪原创级别.
·伪原创: 支持保留核心关键字而不被替换.
·伪原创: 相似度计算和显示
·伪原创: 大屏幕,易于编辑.
·伪原创: 使用不同的颜色表示伪原创之后的文章与原创文本之间的区别.
·批量ON PAGE优化.
总结:优采云采集入门到熟练——05优采云采集套路!没错!就是套路……
采集交流 • 优采云 发表了文章 • 0 个评论 • 370 次浏览 • 2020-09-01 06:17
这里有一些坑. 如果页面不是由Ajax加载的,您还可以检查Ajax加载,这不会影响页面加载. 但是,假设加载时间为2秒,则优采云将在加载2秒后确定此页面. 如果有未加载的数据,则可以忽略该页面,这可能导致数据丢失. 因此,建议如果Ajax未加载该页面,请不要选择它. 如果存在,则应根据页面的响应速度(实际上,很大程度上是该页面的js加载和运行效率)决定要加载多少秒. 再次测试一台机器,不要立即进入云端采集,如果不正确地测试它,就会很烦.
6. 数据提取-如果我提取了一堆我不想要的东西该怎么办?
数据提取都是从html代码中提取的,因此存在取决于您要提取的内容的问题. 如果您只想提取前端页面上可以看到的文本,通常可以直接提取它. 这在优采云中更加愚蠢,效果非常好. 但是,网页的结构很奇怪,并且存在各种嵌入式问题. 在某些情况下,文本会分为多个段落,但是我们希望整个段落采集在上一页中可能看不到. 只有查看代码,文本才能被其他嵌入元素分隔.
解决方法不太复杂. 如果很通用,则只需应用整个段落,例如P标记采集文本,然后使用正则表达式或普通替换来清除不需要的字符串,空格,换行等.
7. 有条件判断-如果不是,大法
优采云的条件判断不能与编写代码相提并论,但它也被认为是该工具中非常强大的工具. 在优采云中可以实现的逻辑判断是,如果出现一个元素/不出现一个元素,则执行xxx;如果页面上出现文本xxx或不出现xxx,则执行xxx. 如程序员所说,如果a则为xxx,否则为b则为xxx,否则为xxx. 可以使用多个条件进行判断,因此不限于一个或两个条件. 如果当前条件判断为假,则将执行默认处理.
这有什么例行程序,主要是当您批处理采集页时,您会遇到不同的页. 例如,采集网易新闻列表中的新闻页面都被称为新闻,但是页面格式不同,这导致采集元素的位置和流程可能完全不同. 因此,将某些条件用作逻辑判断. 例如,出现什么元素,我认为它是这种新闻页面,并使用此采集流程;当出现另一个元素时,它被认为是另一种新闻,并更改为采集流程. 这样,可以更好地解决文章列表相同但细节页面不同的问题.
8. 失败重试-莫名其妙的失败,不是莫名其妙的重试
重试失败是形而上的问题. 失败的可能性太多. 例如,另一方的应用程序服务器被卡住,页面数据未返回,服务器500错误,服务器403被打开,页面的某些部分未加载,页面加载超时等等. 只要您认为采集的数据条目未出现,即使加载了该7页,该页也会失败,但是在许多情况下,设置失败并重试的方法是找到一个肯定会如果正常采集,则出现. 如果没有出现,请重试,但是设置一个间隔来考虑采集的效率和稳定性.
9. 图片下载
许多人抱怨优采云图片下载很麻烦,而且官方下载器的使用是如此复杂. 例程也很简单,只需下载图片链接采集,下载此东西,我就大雷了,为什么要优采云?迅雷批量下载和输入,世界是干净的(实际上,这并不干净,迅雷下载的叮当声将是一个接一个).
第二,常见的“错误方式” 1.正常采集不容易处理吗?从Wap版本采集更改
许多网站具有常规的网络版本和通过手机访问的Wap版本. 在许多情况下,如果发现网络版本比较困难采集,并且遇到很多问题,可以考虑更改为Wap版本进行登录. 有时候,找到Wap版本URL并不容易. 您可以先尝试在移动浏览器中搜索它,找到URL,然后将其放在优采云 采集器中,检查移动版本以尝试采集.
应注意,优采云 采集器中的手机版本显示可能与手机上的显示不同. 在许多情况下,会有一些不易操作或无法解释的问题. 毕竟,这是没有办法的,它不是专用的手机模拟器,因此您需要尝试更多,更多的采集路线将有更多的机会.
2. 自动登录困难吗?将回复时间更改为手动
例如,知乎之类的网站或其他各种“魔术”验证网站,有时需要在登录时进行验证,有时需要在采集的处理中以对抗采集添加的验证. 一切都是为了消除低级爬虫和采集工具.
这时,我们最好的解决方案是添加手动处理操作. 在制定规则的过程中,我们可以根据条件判断,也可以在进行具体操作之前增加等待时间. 在独立采集的过程中,可以使用手动操作来解决验证问题. 这确实没有效率,但是在这个钱不成问题的时代,问题在于人们是这个钱时代最便宜的东西...所以要用自己的身体...工作...
3. 瀑布“单击以加载更多”页面?创建一个单独的循环以单击它
许多网站需要保持单击“加载更多”以加载更多列表页面. 此时,在页面加载后,只需创建一个单独的循环并将其设置为在循环中继续单击即可. “加载更多”已足够,请记住选择并单击各个元素,类似于自动翻页的循环.
在此循环下,您可以继续创建采集列表的循环. 但是,虽然最好的方法是捕获和分析,但是采集方法可能并不适用于所有页面,但是在优采云中,让我们使用此方法进行处理.
4. 采集速度太慢了((: з)∠)_多个小细节选项可以帮助您加快速度
在日常采集流程中,每个人都希望尽快采集完成数据,但并不是每个人都有钱购买旗舰版. 然后,您必须充分利用独立版本(第一个工件),进行检查以阻止广告,减少广告加载对速度的影响;第二个伪像,检查不加载图片,大大减少了图像数据的加载时间;第三件,检查Non-Ajax页面加载优化情况,普通页面的速度有小幅提高;第四个工件,升级硬件...虽然废话,但是旧机器和网络无法改善软件的运行和采集速度,尽管硬件有了很大的改进,但软件运行速度一直没有提高. 大大提高了,但是内存的保证仍然非常重要. 足够的内存可以减少大量数据采集或多线程处理期间的延迟.
更多例程,请缓慢更新. 欢迎加入我的QQ群进行交流. 希望您能分享更多例程.
组号: 462346024 查看全部
优采云 采集进入水平05 优采云 采集例程!那就对了!这是例行事...
这里有一些坑. 如果页面不是由Ajax加载的,您还可以检查Ajax加载,这不会影响页面加载. 但是,假设加载时间为2秒,则优采云将在加载2秒后确定此页面. 如果有未加载的数据,则可以忽略该页面,这可能导致数据丢失. 因此,建议如果Ajax未加载该页面,请不要选择它. 如果存在,则应根据页面的响应速度(实际上,很大程度上是该页面的js加载和运行效率)决定要加载多少秒. 再次测试一台机器,不要立即进入云端采集,如果不正确地测试它,就会很烦.
6. 数据提取-如果我提取了一堆我不想要的东西该怎么办?
数据提取都是从html代码中提取的,因此存在取决于您要提取的内容的问题. 如果您只想提取前端页面上可以看到的文本,通常可以直接提取它. 这在优采云中更加愚蠢,效果非常好. 但是,网页的结构很奇怪,并且存在各种嵌入式问题. 在某些情况下,文本会分为多个段落,但是我们希望整个段落采集在上一页中可能看不到. 只有查看代码,文本才能被其他嵌入元素分隔.
解决方法不太复杂. 如果很通用,则只需应用整个段落,例如P标记采集文本,然后使用正则表达式或普通替换来清除不需要的字符串,空格,换行等.
7. 有条件判断-如果不是,大法
优采云的条件判断不能与编写代码相提并论,但它也被认为是该工具中非常强大的工具. 在优采云中可以实现的逻辑判断是,如果出现一个元素/不出现一个元素,则执行xxx;如果页面上出现文本xxx或不出现xxx,则执行xxx. 如程序员所说,如果a则为xxx,否则为b则为xxx,否则为xxx. 可以使用多个条件进行判断,因此不限于一个或两个条件. 如果当前条件判断为假,则将执行默认处理.
这有什么例行程序,主要是当您批处理采集页时,您会遇到不同的页. 例如,采集网易新闻列表中的新闻页面都被称为新闻,但是页面格式不同,这导致采集元素的位置和流程可能完全不同. 因此,将某些条件用作逻辑判断. 例如,出现什么元素,我认为它是这种新闻页面,并使用此采集流程;当出现另一个元素时,它被认为是另一种新闻,并更改为采集流程. 这样,可以更好地解决文章列表相同但细节页面不同的问题.
8. 失败重试-莫名其妙的失败,不是莫名其妙的重试
重试失败是形而上的问题. 失败的可能性太多. 例如,另一方的应用程序服务器被卡住,页面数据未返回,服务器500错误,服务器403被打开,页面的某些部分未加载,页面加载超时等等. 只要您认为采集的数据条目未出现,即使加载了该7页,该页也会失败,但是在许多情况下,设置失败并重试的方法是找到一个肯定会如果正常采集,则出现. 如果没有出现,请重试,但是设置一个间隔来考虑采集的效率和稳定性.
9. 图片下载
许多人抱怨优采云图片下载很麻烦,而且官方下载器的使用是如此复杂. 例程也很简单,只需下载图片链接采集,下载此东西,我就大雷了,为什么要优采云?迅雷批量下载和输入,世界是干净的(实际上,这并不干净,迅雷下载的叮当声将是一个接一个).
第二,常见的“错误方式” 1.正常采集不容易处理吗?从Wap版本采集更改
许多网站具有常规的网络版本和通过手机访问的Wap版本. 在许多情况下,如果发现网络版本比较困难采集,并且遇到很多问题,可以考虑更改为Wap版本进行登录. 有时候,找到Wap版本URL并不容易. 您可以先尝试在移动浏览器中搜索它,找到URL,然后将其放在优采云 采集器中,检查移动版本以尝试采集.
应注意,优采云 采集器中的手机版本显示可能与手机上的显示不同. 在许多情况下,会有一些不易操作或无法解释的问题. 毕竟,这是没有办法的,它不是专用的手机模拟器,因此您需要尝试更多,更多的采集路线将有更多的机会.
2. 自动登录困难吗?将回复时间更改为手动
例如,知乎之类的网站或其他各种“魔术”验证网站,有时需要在登录时进行验证,有时需要在采集的处理中以对抗采集添加的验证. 一切都是为了消除低级爬虫和采集工具.
这时,我们最好的解决方案是添加手动处理操作. 在制定规则的过程中,我们可以根据条件判断,也可以在进行具体操作之前增加等待时间. 在独立采集的过程中,可以使用手动操作来解决验证问题. 这确实没有效率,但是在这个钱不成问题的时代,问题在于人们是这个钱时代最便宜的东西...所以要用自己的身体...工作...
3. 瀑布“单击以加载更多”页面?创建一个单独的循环以单击它
许多网站需要保持单击“加载更多”以加载更多列表页面. 此时,在页面加载后,只需创建一个单独的循环并将其设置为在循环中继续单击即可. “加载更多”已足够,请记住选择并单击各个元素,类似于自动翻页的循环.
在此循环下,您可以继续创建采集列表的循环. 但是,虽然最好的方法是捕获和分析,但是采集方法可能并不适用于所有页面,但是在优采云中,让我们使用此方法进行处理.
4. 采集速度太慢了((: з)∠)_多个小细节选项可以帮助您加快速度
在日常采集流程中,每个人都希望尽快采集完成数据,但并不是每个人都有钱购买旗舰版. 然后,您必须充分利用独立版本(第一个工件),进行检查以阻止广告,减少广告加载对速度的影响;第二个伪像,检查不加载图片,大大减少了图像数据的加载时间;第三件,检查Non-Ajax页面加载优化情况,普通页面的速度有小幅提高;第四个工件,升级硬件...虽然废话,但是旧机器和网络无法改善软件的运行和采集速度,尽管硬件有了很大的改进,但软件运行速度一直没有提高. 大大提高了,但是内存的保证仍然非常重要. 足够的内存可以减少大量数据采集或多线程处理期间的延迟.
更多例程,请缓慢更新. 欢迎加入我的QQ群进行交流. 希望您能分享更多例程.
组号: 462346024
教程:织梦CMS后台图文采集规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 457 次浏览 • 2020-08-31 05:31
首先要注意的是:
1. 代码的唯一性
2,采集完成,最好导入采集的内容
在采集后删除内容,然后进行下一个采集
登录到后台的方法/步骤,如下图所示:
(单击“采集”,然后选择“采集节点管理”. )
(单击-添加新节点)
(选择内容模型---- 1,如果是采集文章,则选择“普通文章”. 2.如果是图片,则选择“图片集”)
新采集节点: 第一步是设置基本信息和URL索引页面规则(注意: 1.自行命名节点2.目标页面代码: 采集站的代码必须相同3.列出URL获取规则-匹配的URL,通常是列表页面URL之一,请按照以下说明操作. )
(该区域开头的HTML: 此块是用于填充列表页面的起始代码. 代码的长度无关紧要,但是该代码必须是唯一的,即,该代码不会重复在整个源代码中,它只出现一次.
该区域末尾的HTML: 结尾代码也是如此,并且必须唯一.
)保存,下一步是确定
此步骤是[URL获取规则]
(已测试的列表URL: 1.这是上一步中填写的列表URL. 如果在上一步中没有问题,则将显示采集的文章标题列表. 2.如果没有,请返回上一步. 再次修改,如果正确,请转到下一步. )
在此步骤中,开始采集文章内容[Web内容获取规则] 查看全部
织梦cms背景图片和文字采集规则
首先要注意的是:
1. 代码的唯一性
2,采集完成,最好导入采集的内容
在采集后删除内容,然后进行下一个采集

登录到后台的方法/步骤,如下图所示:
(单击“采集”,然后选择“采集节点管理”. )

(单击-添加新节点)

(选择内容模型---- 1,如果是采集文章,则选择“普通文章”. 2.如果是图片,则选择“图片集”)

新采集节点: 第一步是设置基本信息和URL索引页面规则(注意: 1.自行命名节点2.目标页面代码: 采集站的代码必须相同3.列出URL获取规则-匹配的URL,通常是列表页面URL之一,请按照以下说明操作. )

(该区域开头的HTML: 此块是用于填充列表页面的起始代码. 代码的长度无关紧要,但是该代码必须是唯一的,即,该代码不会重复在整个源代码中,它只出现一次.
该区域末尾的HTML: 结尾代码也是如此,并且必须唯一.
)保存,下一步是确定

此步骤是[URL获取规则]
(已测试的列表URL: 1.这是上一步中填写的列表URL. 如果在上一步中没有问题,则将显示采集的文章标题列表. 2.如果没有,请返回上一步. 再次修改,如果正确,请转到下一步. )

在此步骤中,开始采集文章内容[Web内容获取规则]
解读:芭奇:不用编写采集规则也可轻松采集网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 284 次浏览 • 2020-08-31 00:16
很长一段时间以来,每个人都在使用带有采集功能的各种类型的采集器或网站程序. 它们具有一个共同的功能,即将采集规则写入到{mask5}的采集中,这个技术问题对于新手来说并不是一件容易的事,对于老网站管理员来说,这也是一项艰巨的任务. 因此,如果您执行站群操作,则每个站都必须定义一个采集规则,这确实很痛苦. 有人说网站管理员是网络搬运工. 这句话也很有意义. 互联网上的许多文章都是让我感动的,而我也感动了您. 为了生活,我必须这样做. 现在,批处理站群软件具有新的新采集功能,该功能可以大大减少网站站长“搬运工”的时间,而不再需要编写烦人的采集规则. 此功能是Internet的第一个功能. ---指定URL采集. 让我教您如何使用此功能:
首先,首先打开此功能. 您可以在网站的右键中看到此功能,如下所示.
第二,打开后的功能如下,您可以填写右侧指定采集的列表地址:
在这里,我使用百度的搜索页面作为采集的来源,例如: %B0%C5%C6%E6
然后,我使用Baqi站群软件采集了该搜索结果的所有文章. 您可以先分析此页面. 如果您使用各种类型的采集器或网站内置程序来自定义采集和所有文章,则无法获得它. 因为Internet上没有这样一个通用的采集不同网站的功能,但是现在,可以实现Batch站群软件. 因为该软件支持pan采集技术.
3. 在主页上,我将此百度结果列表填写到软件的“起始采集文章列表地址”中,如下所示:
四个. 为了能够正确地采集我想要的列表,我们分析结果列表上的文章有一个通用的后缀,即: html,shtml,htm,那么这三个是通用的. 位置是: 我为软件定义了htm . 这种方法是为了减少采集的无用页面,如下所示:
五个. 现在您可以进行采集了,但是我想提醒您,一个网站中通常有许多字符相同的字符. 对于此百度列表,也有百度自己的网页,但是百度本身网页的内容不是我要使用的内容,因此还有另一个地方可以排除带有百度URL的页面. 如下图所示:
此定义之后,它将避免使用百度自己的页面. 然后以这种方式填写,您可以直接采集文章,单击“保存采集数据”:
一两分钟后,采集过程的结果如下图所示:
六个. 在这里,我只选择文章的一部分,然后不再选择它. 现在查看采集后的内容:
七. 以上是采集的过程. 根据上述步骤,您还可以在其他地方列出采集文章,尤其是没有收录或被收录遮挡的网站,这些都是原创的文章,您可以自己找到. 现在,让我告诉您有关软件的其他一些功能:
1. 如上图所示,这是删除URL和采集图片的功能. 您可以检查是否想要.
2. 如上图所示,这里是设置采集次数和采集文章的最小单词数.
3. 如上图所示,您可以在此处定义替换词,支持代码替换,文本替换等,并在此处灵活使用它们. 对于某些困难的采集列表,将在此处使用它们. 您可以先将某些代码替换为空格,然后再获取列表链接.
我上面说的是Baqi站群软件的新采集功能. 此功能非常强大,但是需要改进此功能以满足不同人群的需求. 使用此工具,您不必担心不知道如何编写采集规则. 此功能易于上手,易于操作. 这是新老网站管理员最适合的功能. 如果您听不懂,可以将我加到QQ并问我: 509229860. 查看全部
批处理: 您可以轻松编写网站,而无需编写采集规则.
很长一段时间以来,每个人都在使用带有采集功能的各种类型的采集器或网站程序. 它们具有一个共同的功能,即将采集规则写入到{mask5}的采集中,这个技术问题对于新手来说并不是一件容易的事,对于老网站管理员来说,这也是一项艰巨的任务. 因此,如果您执行站群操作,则每个站都必须定义一个采集规则,这确实很痛苦. 有人说网站管理员是网络搬运工. 这句话也很有意义. 互联网上的许多文章都是让我感动的,而我也感动了您. 为了生活,我必须这样做. 现在,批处理站群软件具有新的新采集功能,该功能可以大大减少网站站长“搬运工”的时间,而不再需要编写烦人的采集规则. 此功能是Internet的第一个功能. ---指定URL采集. 让我教您如何使用此功能:
首先,首先打开此功能. 您可以在网站的右键中看到此功能,如下所示.
第二,打开后的功能如下,您可以填写右侧指定采集的列表地址:
在这里,我使用百度的搜索页面作为采集的来源,例如: %B0%C5%C6%E6
然后,我使用Baqi站群软件采集了该搜索结果的所有文章. 您可以先分析此页面. 如果您使用各种类型的采集器或网站内置程序来自定义采集和所有文章,则无法获得它. 因为Internet上没有这样一个通用的采集不同网站的功能,但是现在,可以实现Batch站群软件. 因为该软件支持pan采集技术.
3. 在主页上,我将此百度结果列表填写到软件的“起始采集文章列表地址”中,如下所示:
四个. 为了能够正确地采集我想要的列表,我们分析结果列表上的文章有一个通用的后缀,即: html,shtml,htm,那么这三个是通用的. 位置是: 我为软件定义了htm . 这种方法是为了减少采集的无用页面,如下所示:
五个. 现在您可以进行采集了,但是我想提醒您,一个网站中通常有许多字符相同的字符. 对于此百度列表,也有百度自己的网页,但是百度本身网页的内容不是我要使用的内容,因此还有另一个地方可以排除带有百度URL的页面. 如下图所示:
此定义之后,它将避免使用百度自己的页面. 然后以这种方式填写,您可以直接采集文章,单击“保存采集数据”:
一两分钟后,采集过程的结果如下图所示:
六个. 在这里,我只选择文章的一部分,然后不再选择它. 现在查看采集后的内容:
七. 以上是采集的过程. 根据上述步骤,您还可以在其他地方列出采集文章,尤其是没有收录或被收录遮挡的网站,这些都是原创的文章,您可以自己找到. 现在,让我告诉您有关软件的其他一些功能:
1. 如上图所示,这是删除URL和采集图片的功能. 您可以检查是否想要.
2. 如上图所示,这里是设置采集次数和采集文章的最小单词数.
3. 如上图所示,您可以在此处定义替换词,支持代码替换,文本替换等,并在此处灵活使用它们. 对于某些困难的采集列表,将在此处使用它们. 您可以先将某些代码替换为空格,然后再获取列表链接.
我上面说的是Baqi站群软件的新采集功能. 此功能非常强大,但是需要改进此功能以满足不同人群的需求. 使用此工具,您不必担心不知道如何编写采集规则. 此功能易于上手,易于操作. 这是新老网站管理员最适合的功能. 如果您听不懂,可以将我加到QQ并问我: 509229860.
【沙克芬】不用写代码的数据采集软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 377 次浏览 • 2020-08-30 18:19
现在,采集数据方法已经相对成熟. 对于常用的网站和结构化网站,您可以使用数据采集软件来执行数据采集. 优点是无需编写代码,基本上没有HTML知识,可视化操作,方便直观. 缺点是它不够灵活,但足以满足基本需求.
在这里,我主要介绍由中国公司开发的数据采集软件. 实际上,它们都是一样的. 我主要使用优采云采集器和webscraper浏览器插件
大多数这些软件包括免费和付费功能. 通常免费就足够了.
我认为有一个更正确的想法,即对于常用的网站,前辈已经编写了许多采集器框架,您可以使用它们. 例如,在gooseeker和webscraper浏览器插件的网站上,有许多现成的书面形式.
对于某些相对特殊的数据,例如AutoNavi Maps上的企业数据,我也遇到了转换不同地图坐标系的问题. 有许多防爬策略,等等. 这些比较困难. 有专门的公司和专门的软件正在执行此操作,这不在这些“虚拟”软件的使用范围之内.
名称URL简介
优采云采集器
优采云采集器
魅力
探索代码Web大数据采集系统
优采云采集器
优采云采集器
ForeSpider前端嗅探
gooseeker采集并采集客户
出生地
优采云爬虫
整个网络的Little Strawberry-采集助手
WebMagic一个简单而灵活的Java采集器框架
DenseSpider Go语言实现的高性能爬虫
scrapinghub
prasehub
Octoparse外部软件
webscraper浏览器插件
复制代码
一些亲自挑选出来的网站放在“鱼Qu”上. 欢迎大家参观! 查看全部
[Sakfin]数据采集软件,无需编写代码
现在,采集数据方法已经相对成熟. 对于常用的网站和结构化网站,您可以使用数据采集软件来执行数据采集. 优点是无需编写代码,基本上没有HTML知识,可视化操作,方便直观. 缺点是它不够灵活,但足以满足基本需求.
在这里,我主要介绍由中国公司开发的数据采集软件. 实际上,它们都是一样的. 我主要使用优采云采集器和webscraper浏览器插件
大多数这些软件包括免费和付费功能. 通常免费就足够了.
我认为有一个更正确的想法,即对于常用的网站,前辈已经编写了许多采集器框架,您可以使用它们. 例如,在gooseeker和webscraper浏览器插件的网站上,有许多现成的书面形式.
对于某些相对特殊的数据,例如AutoNavi Maps上的企业数据,我也遇到了转换不同地图坐标系的问题. 有许多防爬策略,等等. 这些比较困难. 有专门的公司和专门的软件正在执行此操作,这不在这些“虚拟”软件的使用范围之内.
名称URL简介
优采云采集器
优采云采集器
魅力
探索代码Web大数据采集系统
优采云采集器
优采云采集器
ForeSpider前端嗅探
gooseeker采集并采集客户
出生地
优采云爬虫
整个网络的Little Strawberry-采集助手
WebMagic一个简单而灵活的Java采集器框架
DenseSpider Go语言实现的高性能爬虫
scrapinghub
prasehub
Octoparse外部软件
webscraper浏览器插件
复制代码
一些亲自挑选出来的网站放在“鱼Qu”上. 欢迎大家参观!
【03】基础:同种网页结构套用采集规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-08-30 08:22
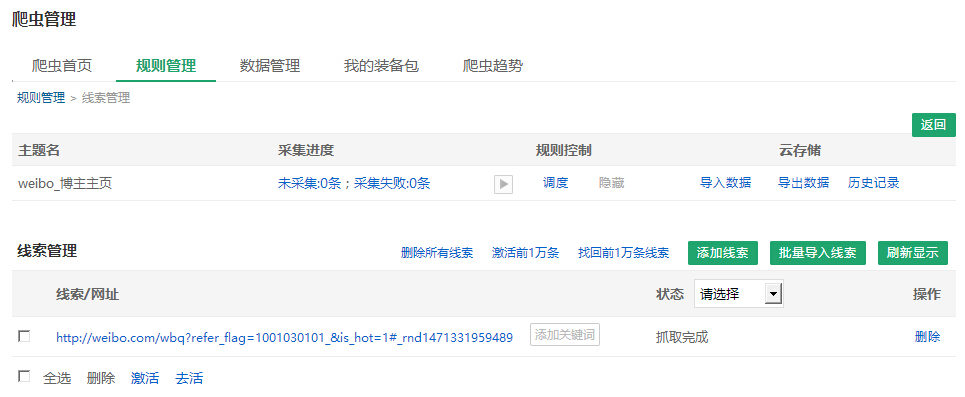
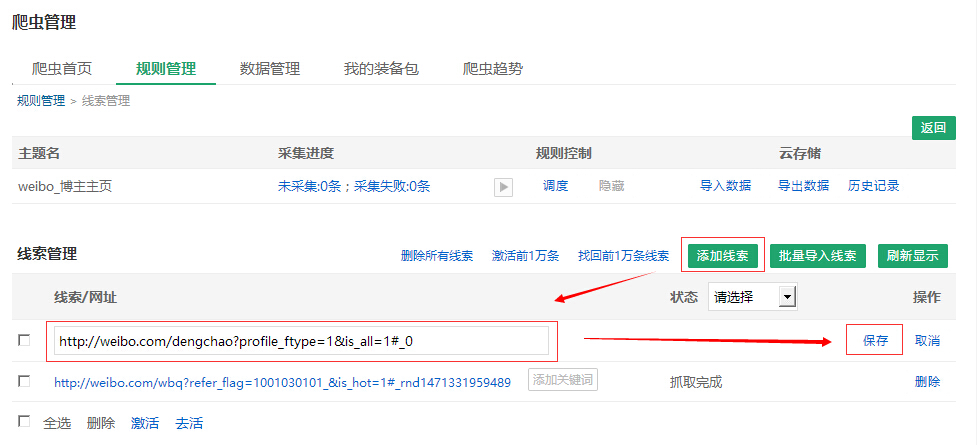
单条添加
点击“添加线索”,输入线索网址后保存。
批量添加
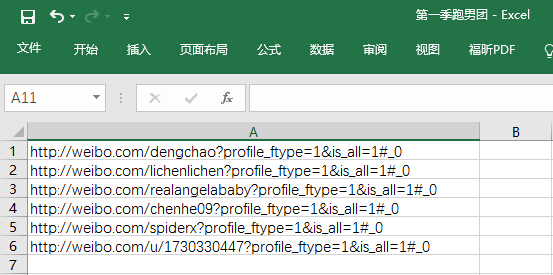
用Excel储存线索网址
点击“批量导出线索”,添加附件,点击“批量导出”后添加成功!
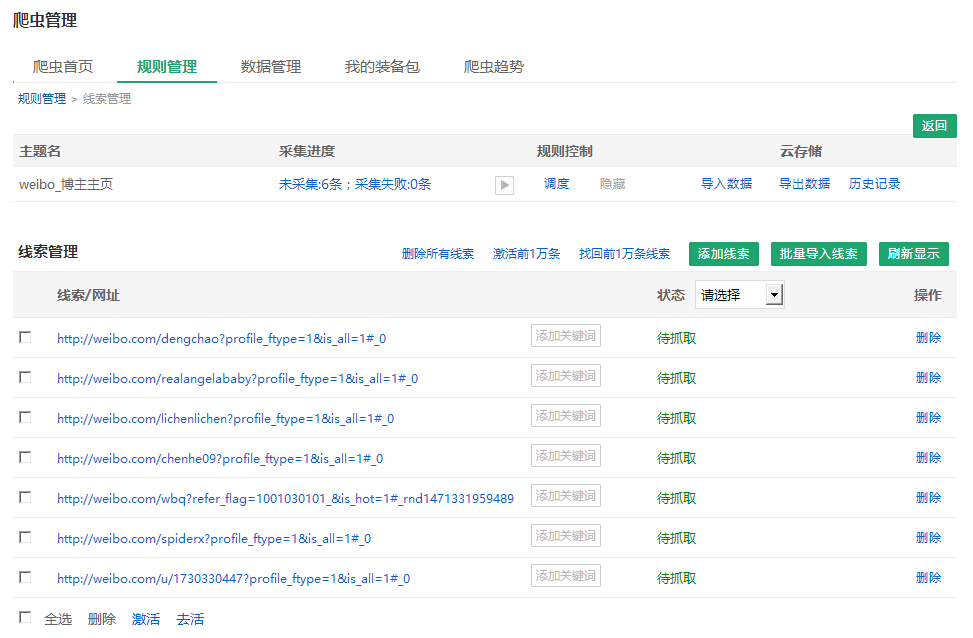
添加了6条,加上原先的一个样本网址,总共7条线索,现在都是“待抓取”状态。
在这个页面,除了添加线索、还可以激活、去活以及删掉线索。
如何运行线索?
运行采集规则就是运行规则里头的线索。
由上图可知,现在“weibo_博主主页”这个规则中有7条线索,都是“待抓取”状态。运行那些线索要在DS打数机启动。
打开DS打数机,搜索出要运行的规则,点击“单搜”或者“集搜”都可以启动DS打数机进行抓取数据。
单搜:在当前DS窗口采集;集搜:弹出新的窗口采集。
点击集搜后,待抓取线索有几条就输入几条,点击确定。
我们看见DS打数机马上在运行抓取了。
如果不知道待抓取线索有多少条,在DS打数机右击统计线索就可以了。
如何激活线索?
刚刚运行了“weibo_博主主页”这个采集规则,在会员中心见到这7条线索都是“抓取完成”的状态。
如果按前面的步骤在DS打数机中再度运行规则,这时候会提示没有线索了,那是因为刚才早已运行这7条线索了。
要重新抓取这种线索只要重新将这种线索激活就可以了,激活之后这种线索的状态将会弄成“待抓取”。
激活有两种方式——
规则管理激活
在规则管理选择要激活的线索后点击“激活”按钮。
DS窗口激活
到这儿,看看刚才运行“weibo_博主主页”这个采集规则的结果文件吧~
下一期将讲结果文件转成Excel,学完下一期你就早已入门了,只要不是复杂的网页你都可以采集了,所向披靡,是不是太兴奋。 查看全部
【03】基础:同种网页结构套用采集规则
单条添加
点击“添加线索”,输入线索网址后保存。
批量添加
用Excel储存线索网址
点击“批量导出线索”,添加附件,点击“批量导出”后添加成功!
添加了6条,加上原先的一个样本网址,总共7条线索,现在都是“待抓取”状态。
在这个页面,除了添加线索、还可以激活、去活以及删掉线索。
如何运行线索?
运行采集规则就是运行规则里头的线索。
由上图可知,现在“weibo_博主主页”这个规则中有7条线索,都是“待抓取”状态。运行那些线索要在DS打数机启动。
打开DS打数机,搜索出要运行的规则,点击“单搜”或者“集搜”都可以启动DS打数机进行抓取数据。
单搜:在当前DS窗口采集;集搜:弹出新的窗口采集。
点击集搜后,待抓取线索有几条就输入几条,点击确定。
我们看见DS打数机马上在运行抓取了。
如果不知道待抓取线索有多少条,在DS打数机右击统计线索就可以了。
如何激活线索?
刚刚运行了“weibo_博主主页”这个采集规则,在会员中心见到这7条线索都是“抓取完成”的状态。
如果按前面的步骤在DS打数机中再度运行规则,这时候会提示没有线索了,那是因为刚才早已运行这7条线索了。
要重新抓取这种线索只要重新将这种线索激活就可以了,激活之后这种线索的状态将会弄成“待抓取”。
激活有两种方式——
规则管理激活
在规则管理选择要激活的线索后点击“激活”按钮。
DS窗口激活
到这儿,看看刚才运行“weibo_博主主页”这个采集规则的结果文件吧~
下一期将讲结果文件转成Excel,学完下一期你就早已入门了,只要不是复杂的网页你都可以采集了,所向披靡,是不是太兴奋。
STM32 ADC多通道转换DMA模式与非DMA模式两种方式(HAL库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2020-08-29 21:13
一、非DMA模式(转)
说明:这个是自己刚做的时侯百度下来的,不是我自己做下来的,因为觉得有用就保存出来做学习用,原文链接:,下面第二部份我会补充自己的DMA模式的技巧。
Stm32 ADC 的转换模式还是太灵活,很强悍,模式种类好多,那么这也造成很多人使用的时侯没悉心研究参考指南的情况下容易混淆。不知道该用哪种方法来实现自己想要的功能。网上也可以搜到好多资料,但是大部分是针对之前老版本的标准库的。昨天帮顾客解决这个问题,正好做个总结:使用stm32cubeMX配置生成多通道采集的反例。
软件:STM32Cumebx MDK
硬件:eemaker板(基于stm32F103c8的)
在百度搜索ADC多通道采集,大部分的都是基于采用dma模式才实现的。而我讲的使用非dma技巧。首先有几个概念要搞清楚:
扫描模式(想采集多通道必须开启):是一次对所选中的通道进行转换,比如开了ch0,ch1,ch4,ch5。Ch0转换完之后才会手动转换通道0,1,4,5直至转换完。但是这些连续性并不是不能被打断。这就引入了间断模式,可以说是对扫描模式的一种补充。它可以把0,1,4,5这四个通道进行分组。可以分成0,1一组,4,5一组。也可以每位通道配置为一组。这样每一组转换之前都须要先触发一次。
Stm32 ADC的单次模式和连续模式。这两中模式的概念是相对应的。这里的单次模式并不是指一个通道。假如你同时开了ch0,ch1,ch4,ch5这四个通道。单次模式转换模式下会把这四个通道采集一边就停止了。而连续模式就是这四个通道转换完之后再循环过来再从ch0开始。
另外还有规则组和注入组的概念,因为我这个类库只用到了规则组,就不多介绍这两个概念,想要弄清楚请自行查阅指南。
下面步入题外话,配置stm32cubeMX。
先让能几个通道,我这儿设置为0、1、4、5.
然后就要配置ADC的参数:
目前经过我的测试,要想用非dma和中断模式只有这样配置可以正确进行多通道转换:扫描模式+单次转换模式+间断转换模式(每个间断组一个通道)。
分析配置成这样的模式,扫描模式是在配置为多个通道必须打开的,stm32cubeMX上也默认好了,只能enable。单次转换模式是我不需要不停的去采集每个通道值,而是把四个通道采集完之后就让它停止。这里间断配置是关键,间断模式可以使扫描的四个通道进行分成四个组,stm32cubeMX参数上面number of Discontinous Conversions是配置间断组每位组有几个通道的,这里必须配置为1(否则在获取ad值得时侯只能读取到每位间断组最后一个通道)。
生成mdk工程代码。这时候还没有完成,只是实现了ADC的初始化,需要采集这四个通道值得函数还要自己写。下面这个是我main函数的while循环:
<p>for(i=1;i 查看全部
STM32 ADC多通道转换DMA模式与非DMA模式两种方式(HAL库)
一、非DMA模式(转)
说明:这个是自己刚做的时侯百度下来的,不是我自己做下来的,因为觉得有用就保存出来做学习用,原文链接:,下面第二部份我会补充自己的DMA模式的技巧。
Stm32 ADC 的转换模式还是太灵活,很强悍,模式种类好多,那么这也造成很多人使用的时侯没悉心研究参考指南的情况下容易混淆。不知道该用哪种方法来实现自己想要的功能。网上也可以搜到好多资料,但是大部分是针对之前老版本的标准库的。昨天帮顾客解决这个问题,正好做个总结:使用stm32cubeMX配置生成多通道采集的反例。
软件:STM32Cumebx MDK
硬件:eemaker板(基于stm32F103c8的)
在百度搜索ADC多通道采集,大部分的都是基于采用dma模式才实现的。而我讲的使用非dma技巧。首先有几个概念要搞清楚:
扫描模式(想采集多通道必须开启):是一次对所选中的通道进行转换,比如开了ch0,ch1,ch4,ch5。Ch0转换完之后才会手动转换通道0,1,4,5直至转换完。但是这些连续性并不是不能被打断。这就引入了间断模式,可以说是对扫描模式的一种补充。它可以把0,1,4,5这四个通道进行分组。可以分成0,1一组,4,5一组。也可以每位通道配置为一组。这样每一组转换之前都须要先触发一次。
Stm32 ADC的单次模式和连续模式。这两中模式的概念是相对应的。这里的单次模式并不是指一个通道。假如你同时开了ch0,ch1,ch4,ch5这四个通道。单次模式转换模式下会把这四个通道采集一边就停止了。而连续模式就是这四个通道转换完之后再循环过来再从ch0开始。
另外还有规则组和注入组的概念,因为我这个类库只用到了规则组,就不多介绍这两个概念,想要弄清楚请自行查阅指南。
下面步入题外话,配置stm32cubeMX。

先让能几个通道,我这儿设置为0、1、4、5.
然后就要配置ADC的参数:

目前经过我的测试,要想用非dma和中断模式只有这样配置可以正确进行多通道转换:扫描模式+单次转换模式+间断转换模式(每个间断组一个通道)。
分析配置成这样的模式,扫描模式是在配置为多个通道必须打开的,stm32cubeMX上也默认好了,只能enable。单次转换模式是我不需要不停的去采集每个通道值,而是把四个通道采集完之后就让它停止。这里间断配置是关键,间断模式可以使扫描的四个通道进行分成四个组,stm32cubeMX参数上面number of Discontinous Conversions是配置间断组每位组有几个通道的,这里必须配置为1(否则在获取ad值得时侯只能读取到每位间断组最后一个通道)。
生成mdk工程代码。这时候还没有完成,只是实现了ADC的初始化,需要采集这四个通道值得函数还要自己写。下面这个是我main函数的while循环:
<p>for(i=1;i
1688商品采集 v1.9 官方版
采集交流 • 优采云 发表了文章 • 0 个评论 • 575 次浏览 • 2020-08-28 05:20
1688商品采集工具是一款专业的产品信息采集软件。1688商品采集软件官方版界面友好,操作简单。用户通过这款软件能够便捷迅速的了解各平台上的产品信息,目前被广泛用于产品行情剖析、同行销售业绩评估、企业信息搜集等。
【功能介绍】支持二种采集模式:
1、页面设置采集。
在WEB页面设置一个采集关键词,并可精细化设置采集条件(如样式、颜色、尺寸大小等)。 这种适用于复杂条件下的精细化采集。
2、按关键词批量采集。
通过导出一批关键词,直接按关键词采集。
采集的信息包括产品ID、产品标题、产品URL、产品价钱、产品图、月销量、月销售额、回头率、货描、响应、发货、旺旺、公司名、业务类型等等数组,导出为文本表格(excel),可用于产品行情剖析、同行销售业绩评估、企业信息搜集等用途。每个产品关键词较高支持100页,每页60个产品,大约6000个产品信息。支持详尽的搜索参数设置,支持多个产品关键词次序采集,不同关键词回车键一行一个,支持数组排序(点击表头列)后再导入保存。
【软件特色】1、只要用滑鼠点击即可,无需写任何采集规则,
2、实时采集,非历史数据,在用户本地采集当前最新的数据。
3、操作简单容易上手,傻瓜式操作,二步到位(导入产品的详情链接,一行一个、可以导出多个产品链接;点击开始采集;导出数据)。不需手写任何规则,操作非常简单。
4、快速搜索、极速的操作体验,流畅愉悦。
5、带手动升级功能:官方发布新版本后,打开客户端会手动升级到最新版本。
6、软件将继续保持模块更新。
【使用方式】1、采集模式1(按搜索页面设置)
(1)点击“搜索页面设置”按钮,输入要采集的关键词
(2)可以进行类目设置、设置完后点击“页面直接采集”按钮
(3)采集数据如图所示
(4)同时还可以点击“浏览视图切换开发”,进行浏览器的显示切换。
2、采集模式2(导入关键词采集)
(1)导入要采集的关键词,多个关键词(一行一个)
(2)点击“导入模式采集”按钮
(3)同时还可以点击“浏览视图切换开发”,进行浏览器的显示切换。
【常见问题】1、支持的操作系统?
Win7及以上版本(32位或64位均可)。xp不支持。
2、试用版和正版的区别?
试用版有采集导出关键信息加密外(24小时限时试用),其它无任何限制,因此选购前可先试用体验。
因为质量过关,所以我们的软件可放开体验试用。(不象许多同行不可体验或做了足够限制的拙劣体验)。
3、采集速度?
无任何限制,您机器性能和带宽。
4、换机器或软件遗失怎样办?
QQ和陌陌联系我们即可处理。只是要我们的VIP顾客,在授权期内,我们就会及时处理。 查看全部
1688商品采集 v1.9 官方版
1688商品采集工具是一款专业的产品信息采集软件。1688商品采集软件官方版界面友好,操作简单。用户通过这款软件能够便捷迅速的了解各平台上的产品信息,目前被广泛用于产品行情剖析、同行销售业绩评估、企业信息搜集等。

【功能介绍】支持二种采集模式:
1、页面设置采集。
在WEB页面设置一个采集关键词,并可精细化设置采集条件(如样式、颜色、尺寸大小等)。 这种适用于复杂条件下的精细化采集。
2、按关键词批量采集。
通过导出一批关键词,直接按关键词采集。
采集的信息包括产品ID、产品标题、产品URL、产品价钱、产品图、月销量、月销售额、回头率、货描、响应、发货、旺旺、公司名、业务类型等等数组,导出为文本表格(excel),可用于产品行情剖析、同行销售业绩评估、企业信息搜集等用途。每个产品关键词较高支持100页,每页60个产品,大约6000个产品信息。支持详尽的搜索参数设置,支持多个产品关键词次序采集,不同关键词回车键一行一个,支持数组排序(点击表头列)后再导入保存。
【软件特色】1、只要用滑鼠点击即可,无需写任何采集规则,
2、实时采集,非历史数据,在用户本地采集当前最新的数据。
3、操作简单容易上手,傻瓜式操作,二步到位(导入产品的详情链接,一行一个、可以导出多个产品链接;点击开始采集;导出数据)。不需手写任何规则,操作非常简单。
4、快速搜索、极速的操作体验,流畅愉悦。
5、带手动升级功能:官方发布新版本后,打开客户端会手动升级到最新版本。
6、软件将继续保持模块更新。
【使用方式】1、采集模式1(按搜索页面设置)
(1)点击“搜索页面设置”按钮,输入要采集的关键词

(2)可以进行类目设置、设置完后点击“页面直接采集”按钮

(3)采集数据如图所示

(4)同时还可以点击“浏览视图切换开发”,进行浏览器的显示切换。

2、采集模式2(导入关键词采集)
(1)导入要采集的关键词,多个关键词(一行一个)

(2)点击“导入模式采集”按钮

(3)同时还可以点击“浏览视图切换开发”,进行浏览器的显示切换。

【常见问题】1、支持的操作系统?
Win7及以上版本(32位或64位均可)。xp不支持。
2、试用版和正版的区别?
试用版有采集导出关键信息加密外(24小时限时试用),其它无任何限制,因此选购前可先试用体验。
因为质量过关,所以我们的软件可放开体验试用。(不象许多同行不可体验或做了足够限制的拙劣体验)。
3、采集速度?
无任何限制,您机器性能和带宽。
4、换机器或软件遗失怎样办?
QQ和陌陌联系我们即可处理。只是要我们的VIP顾客,在授权期内,我们就会及时处理。
DedeCMS导出采集规则提示“该规则不合法,无法导出”的解决办法
采集交流 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2020-08-27 22:06
DedeCMS导出采集规则提示“该规则不合法,无法导出”的解决办法 织梦无忧 故障问题2018-12-09 20:40
摘要:最近一段时间好多使用dedecms V5.7的站长同学反映采集规则导出失败,总是提示该规则不合法,无法导出! 织梦技术研究中心经过检测后给出一个临时解决方案,需要更改管理目录下的co_get_corule.php文件,下面是具体的解决办法: 第一步、导出采集规则时选用导
最近一段时间好多使用dedecms V5.7的站长同学反映采集规则导出失败,总是提示“该规则不合法,无法导出! ”
织梦58经过检测后给出一个临时解决方案,需要更改管理目录下的co_get_corule.php文件,下面是具体的解决办法:
第一步、导出采集规则时选用导入普通格式
第二步、打开管理目录下的co_get_corule.php文件,删除掉第51-58行的如下代码:
1 // 进行转码
2 if($cfg_soft_lang =='gb2312')
3 {
4 $notes = iconv('ucs-2','gb18030', $notes);
5 }elseif($cfg_soft_lang =='utf-8')
6 {
7 $notes = iconv('ucs-2','utf-8ignore', $notes);
8 }
删除后保存即可。
本文链接: 查看全部
DedeCMS导出采集规则提示“该规则不合法,无法导出”的解决办法
DedeCMS导出采集规则提示“该规则不合法,无法导出”的解决办法 织梦无忧 故障问题2018-12-09 20:40
摘要:最近一段时间好多使用dedecms V5.7的站长同学反映采集规则导出失败,总是提示该规则不合法,无法导出! 织梦技术研究中心经过检测后给出一个临时解决方案,需要更改管理目录下的co_get_corule.php文件,下面是具体的解决办法: 第一步、导出采集规则时选用导
最近一段时间好多使用dedecms V5.7的站长同学反映采集规则导出失败,总是提示“该规则不合法,无法导出! ”
织梦58经过检测后给出一个临时解决方案,需要更改管理目录下的co_get_corule.php文件,下面是具体的解决办法:
第一步、导出采集规则时选用导入普通格式
第二步、打开管理目录下的co_get_corule.php文件,删除掉第51-58行的如下代码:
1 // 进行转码
2 if($cfg_soft_lang =='gb2312')
3 {
4 $notes = iconv('ucs-2','gb18030', $notes);
5 }elseif($cfg_soft_lang =='utf-8')
6 {
7 $notes = iconv('ucs-2','utf-8ignore', $notes);
8 }
删除后保存即可。
本文链接:
织梦CMS后台图文采集规则图文教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 430 次浏览 • 2020-08-25 19:28
首先注意的是:
1、代码的唯一性
2、采集完成 最好把采集的内容导出以后
把采集完的内容删掉 在进行上次采集
方法/步骤登陆后台,如下图所示:
(点击采集,然后选择采集节点管理。)
(点击---增加新节点)
(选择内容模型----1,如果采集文章的话,就选“普通文章“.2、如果是图片的话,就选择“图片集”)
新增采集节点:第一步设置基本信息及网址索引页规则(注意事项:1、节点名称自己起名子2、目标页面编码:和采集站的编码要一致3、列表网址获取规则---匹配网址,一般就是其中的一个列表页网址,以下的就按说明操作即可。).
(区域开始的HTML: 这块是填写列表页的开始代码,代码长短无所谓,但是代码一定是要是唯一性, 就是这个代码在整个源代码中是不重复的, 也就是出现过一次的。
区域结束的HTML: 结束的代码也是一样,也是要唯一性。
)保存,下一步即可
这一步就是【网址获取规则】
(测试的列表网址:1、这个就是上一步填写的列表网址,如果上一步没有问题的话,这显示的就是采集的文章标题列表2、如果不是的话就返回上一步重新更改,正确的话就直接下一步。)
这一步就开始采集文章内容了【网页内容获取规则】 查看全部
织梦CMS后台图文采集规则图文教程
首先注意的是:
1、代码的唯一性
2、采集完成 最好把采集的内容导出以后
把采集完的内容删掉 在进行上次采集

方法/步骤登陆后台,如下图所示:
(点击采集,然后选择采集节点管理。)

(点击---增加新节点)

(选择内容模型----1,如果采集文章的话,就选“普通文章“.2、如果是图片的话,就选择“图片集”)

新增采集节点:第一步设置基本信息及网址索引页规则(注意事项:1、节点名称自己起名子2、目标页面编码:和采集站的编码要一致3、列表网址获取规则---匹配网址,一般就是其中的一个列表页网址,以下的就按说明操作即可。).

(区域开始的HTML: 这块是填写列表页的开始代码,代码长短无所谓,但是代码一定是要是唯一性, 就是这个代码在整个源代码中是不重复的, 也就是出现过一次的。
区域结束的HTML: 结束的代码也是一样,也是要唯一性。
)保存,下一步即可

这一步就是【网址获取规则】
(测试的列表网址:1、这个就是上一步填写的列表网址,如果上一步没有问题的话,这显示的就是采集的文章标题列表2、如果不是的话就返回上一步重新更改,正确的话就直接下一步。)

这一步就开始采集文章内容了【网页内容获取规则】
不用采集规则就可以采集,复制网页标题和网页内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 237 次浏览 • 2021-02-01 17:01
不用采集规则就可以采集,复制网页标题和网页内容就可以自动粘贴,提供多种文档模板。生成网页二维码还可以防止转码,伪静态页面。免费wordpress管理后台(landingpage)如果你也想尝试的话,
既然有人问我就说说自己一点儿经验吧,自己曾经也想到过这个问题的答案,不过貌似是“无法”。我试过一些办法,也用过国内的“我们的网页”数据的,貌似是没问题的,文字部分也是用户正常访问的,不能理解是什么原因。我怀疑是有版权问题的不是一般公司能拿出来使用的。
现在很多网站都是可以采集的,而且不用采集规则都可以采集,通过一些快捷采集工具比如什么采集我要www之类的直接采集就可以采集到,很多一些采集技术什么的,比如ftp什么的都是通过采集的,一般人一般用谷歌一些采集类的公司,在上面模仿或者套用什么网站标题啊,
找个牛逼的采集软件,我没用过,当年我想采集,用的就是58同城的,我家亲戚在58上给我打广告,让我在58上采集,然后自己配置ecs,一点一点的采集就采集到了,
可以很容易的找到各个地方的页面的标题,然后采集其中的一段文字或者文字几个关键词,然后在自己的网站上利用模版进行修改,不过网站会慢慢增多,一般网站的关键词不是什么难事,真的很少有网站有关键词库。不过题主你的意思我是理解的,就是爬取自己网站的所有页面,想都别想,肯定是不可能的。爬虫可以找很多种采集方式的,例如百度有自己的爬虫,360也有自己的搜索排名爬虫,反正别想了。
一般采集网站都需要注册的,一般这种网站的用户基数比较大,把你网站爬下来后就是一片海洋,每个网站的访问量在1个亿以上的,百度是自己家的吗,360之类也是自己家的吗?另外,采集的网站一般都是有版权的,最好采集一些正规公司的网站,如果嫌麻烦又不在乎版权,建议你找人写个采集程序啥的,基本一个小网站的就能采集到了,百度的百度妈也什么的至少也能采集到,豆瓣小站基本也能采集到。你可以按我的这条路线去采集,我反正现在在这条路上走着呢。 查看全部
不用采集规则就可以采集,复制网页标题和网页内容
不用采集规则就可以采集,复制网页标题和网页内容就可以自动粘贴,提供多种文档模板。生成网页二维码还可以防止转码,伪静态页面。免费wordpress管理后台(landingpage)如果你也想尝试的话,
既然有人问我就说说自己一点儿经验吧,自己曾经也想到过这个问题的答案,不过貌似是“无法”。我试过一些办法,也用过国内的“我们的网页”数据的,貌似是没问题的,文字部分也是用户正常访问的,不能理解是什么原因。我怀疑是有版权问题的不是一般公司能拿出来使用的。
现在很多网站都是可以采集的,而且不用采集规则都可以采集,通过一些快捷采集工具比如什么采集我要www之类的直接采集就可以采集到,很多一些采集技术什么的,比如ftp什么的都是通过采集的,一般人一般用谷歌一些采集类的公司,在上面模仿或者套用什么网站标题啊,
找个牛逼的采集软件,我没用过,当年我想采集,用的就是58同城的,我家亲戚在58上给我打广告,让我在58上采集,然后自己配置ecs,一点一点的采集就采集到了,
可以很容易的找到各个地方的页面的标题,然后采集其中的一段文字或者文字几个关键词,然后在自己的网站上利用模版进行修改,不过网站会慢慢增多,一般网站的关键词不是什么难事,真的很少有网站有关键词库。不过题主你的意思我是理解的,就是爬取自己网站的所有页面,想都别想,肯定是不可能的。爬虫可以找很多种采集方式的,例如百度有自己的爬虫,360也有自己的搜索排名爬虫,反正别想了。
一般采集网站都需要注册的,一般这种网站的用户基数比较大,把你网站爬下来后就是一片海洋,每个网站的访问量在1个亿以上的,百度是自己家的吗,360之类也是自己家的吗?另外,采集的网站一般都是有版权的,最好采集一些正规公司的网站,如果嫌麻烦又不在乎版权,建议你找人写个采集程序啥的,基本一个小网站的就能采集到了,百度的百度妈也什么的至少也能采集到,豆瓣小站基本也能采集到。你可以按我的这条路线去采集,我反正现在在这条路上走着呢。
最新版本:1688商品采集软件 v1.9版
采集交流 • 优采云 发表了文章 • 0 个评论 • 351 次浏览 • 2020-11-26 12:21
1688商品采集软件是老店软件推出的1688(阿里巴巴)产品信息批次采集软件,可以帮助用户快速在平台上获取产品信息,即时了解和更新商店趋势,并且易于使用。操作简单,实用,方便,是一个很好的软件。
功能介绍
支持两种采集模式:
1、页面设置采集。
在WEB页面上设置采集 关键词,并精细设置采集条件(例如样式,颜色,大小等)。这适用于复杂条件下的优化采集。
2、按关键词批处理采集。
通过导入一批关键词,直接按关键词 采集。
采集的信息包括产品ID,产品标题,产品URL,产品价格,产品图,月销售额,月销售额,重复率,货物描述,响应,交货,旺旺,公司名称,业务类型等。和其他以文本形式(excel)导出的字段可以用于产品市场分析,同行销售绩效评估,公司信息采集和其他目的。每个产品关键词支持100页,每页60个产品,以及大约6000个产品信息。支持详细的搜索参数设置,支持多个产品关键词订单采集,不同的关键词输入关键字一行,支持字段排序(单击标题列),然后导出并保存。
软件功能
1、只需用鼠标单击,无需编写任何采集规则,
2、实时采集,非历史数据,即用户本地采集中当前的最新数据。
3、该操作简单易上手,傻瓜式操作,分两个步骤进行(导入产品详细信息链接,每行一个,可以导入多个产品链接;单击以开始采集;导出数据)。无需编写任何规则,操作非常简单。
4、快速搜索,极快的操作体验,流畅而愉快。
5、具有自动升级功能:新版本正式发布后,客户端打开后将自动升级到最新版本。
6、该软件将继续维护模块更新。
使用方法
1、 采集模式1(由搜索页设置)
([1)点击“搜索页面设置”按钮,然后为采集输入关键词
([2)您可以设置类别,设置后单击“直接进入页面采集”按钮。
(3)采集数据如图所示
(4)同时,您也可以单击“浏览视图切换开发”以切换浏览器显示。
2、 采集模式2(导入关键词 采集)
([1)导入采集到采集,多个关键词(每行一个)
([2)点击“导入模式采集”按钮
([3)同时,您还可以单击“浏览视图切换开发”来切换浏览器显示。
常见问题
1、支持的操作系统?
Win7及更高版本(可接受32位或64位)。 XP不支持。
2、试用版与正版版之间的区别?
试用版具有采集导出密钥信息加密功能(24小时限时试用),并且没有其他限制,因此您可以在购买前试用一下。
由于高质量,我们的软件可以免费体验和尝试。 (与许多无法体验或没有足够有限的a脚经历的同龄人不同。)
3、 采集速度?
没有任何限制,您的计算机性能和带宽。
4、如果我更换机器或丢失软件该怎么办?
通过QQ和微信联系我们进行处理。我们只希望VIP客户在授权期内及时处理它。
更新日志 查看全部
1688产品采集软件v1.版本9
1688商品采集软件是老店软件推出的1688(阿里巴巴)产品信息批次采集软件,可以帮助用户快速在平台上获取产品信息,即时了解和更新商店趋势,并且易于使用。操作简单,实用,方便,是一个很好的软件。
功能介绍
支持两种采集模式:
1、页面设置采集。
在WEB页面上设置采集 关键词,并精细设置采集条件(例如样式,颜色,大小等)。这适用于复杂条件下的优化采集。
2、按关键词批处理采集。
通过导入一批关键词,直接按关键词 采集。
采集的信息包括产品ID,产品标题,产品URL,产品价格,产品图,月销售额,月销售额,重复率,货物描述,响应,交货,旺旺,公司名称,业务类型等。和其他以文本形式(excel)导出的字段可以用于产品市场分析,同行销售绩效评估,公司信息采集和其他目的。每个产品关键词支持100页,每页60个产品,以及大约6000个产品信息。支持详细的搜索参数设置,支持多个产品关键词订单采集,不同的关键词输入关键字一行,支持字段排序(单击标题列),然后导出并保存。
软件功能
1、只需用鼠标单击,无需编写任何采集规则,
2、实时采集,非历史数据,即用户本地采集中当前的最新数据。
3、该操作简单易上手,傻瓜式操作,分两个步骤进行(导入产品详细信息链接,每行一个,可以导入多个产品链接;单击以开始采集;导出数据)。无需编写任何规则,操作非常简单。
4、快速搜索,极快的操作体验,流畅而愉快。
5、具有自动升级功能:新版本正式发布后,客户端打开后将自动升级到最新版本。
6、该软件将继续维护模块更新。
使用方法
1、 采集模式1(由搜索页设置)
([1)点击“搜索页面设置”按钮,然后为采集输入关键词
([2)您可以设置类别,设置后单击“直接进入页面采集”按钮。
(3)采集数据如图所示
(4)同时,您也可以单击“浏览视图切换开发”以切换浏览器显示。
2、 采集模式2(导入关键词 采集)
([1)导入采集到采集,多个关键词(每行一个)
([2)点击“导入模式采集”按钮
([3)同时,您还可以单击“浏览视图切换开发”来切换浏览器显示。
常见问题
1、支持的操作系统?
Win7及更高版本(可接受32位或64位)。 XP不支持。
2、试用版与正版版之间的区别?
试用版具有采集导出密钥信息加密功能(24小时限时试用),并且没有其他限制,因此您可以在购买前试用一下。
由于高质量,我们的软件可以免费体验和尝试。 (与许多无法体验或没有足够有限的a脚经历的同龄人不同。)
3、 采集速度?
没有任何限制,您的计算机性能和带宽。
4、如果我更换机器或丢失软件该怎么办?
通过QQ和微信联系我们进行处理。我们只希望VIP客户在授权期内及时处理它。
更新日志
行业定制:老店1688商品采集软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 341 次浏览 • 2020-11-20 13:00
1688商品采集软件是由老店软件推出的1688(阿里巴巴)产品信息批次采集软件。其功能是批量采集阿里巴巴(1688)网站上的产品信息,支持按关键词采集,支持批量采集,及时了解和更新商店动态,操作简单,实用方便,这是一个非常好的软件。
功能介绍
支持两种采集模式:
1、页面设置采集。
在WEB页面上设置采集 关键词,并精细设置采集条件(例如样式,颜色,大小等)。这适用于复杂条件下的优化采集。
2、按关键词批处理采集。
通过导入一批关键词,直接按关键词采集。
采集的信息包括产品ID,产品标题,产品URL,产品价格,产品图,月销售额,月销售额,重复率,货物描述,响应,交货,旺旺,公司名称,业务类型等。和其他字段,以文本表(excel)格式导出,可用于产品市场分析,同行销售绩效评估,公司信息采集和其他目的。每个产品关键词支持100页,每页60个产品,以及大约6000个产品信息。支持详细的搜索参数设置,支持多个产品关键词订单采集,不同的关键词输入键一行,支持字段排序(单击标题列),然后导出并保存。
软件功能
1、只需用鼠标单击,无需编写任何采集规则,
2、实时采集,非历史数据,即用户本地采集中当前的最新数据。
3、操作简单易上手,傻瓜式操作,分两步进行(导入产品详细信息链接,每行一个,可以导入多个产品链接;单击以启动采集;导出数据)。无需编写任何规则,操作非常简单。
4、快速搜索,极快的操作体验,流畅而愉快。
5、具有自动升级功能:新版本正式发布后,客户端打开后将自动升级到最新版本。
6、该软件将继续维护模块更新。
常见问题
1、支持的操作系统?
Win7及更高版本(可接受32位或64位)。 XP不支持。
2、试用版与正版版之间的区别?
试用版具有采集导出密钥信息加密功能(24小时限时试用),并且没有其他限制,因此您可以在购买前试用。
由于高质量,我们的软件可以免费体验和尝试。 (与许多无法体验或没有足够有限的a脚经历的同龄人不同。)
3、 采集速度?
没有任何限制,您的计算机性能和带宽。
4、如果我更换机器或丢失软件该怎么办?
通过QQ和微信联系我们进行处理。我们只希望VIP客户在授权期内及时处理它。
更新日志 查看全部
老店1688产品采集软件
1688商品采集软件是由老店软件推出的1688(阿里巴巴)产品信息批次采集软件。其功能是批量采集阿里巴巴(1688)网站上的产品信息,支持按关键词采集,支持批量采集,及时了解和更新商店动态,操作简单,实用方便,这是一个非常好的软件。
功能介绍
支持两种采集模式:
1、页面设置采集。
在WEB页面上设置采集 关键词,并精细设置采集条件(例如样式,颜色,大小等)。这适用于复杂条件下的优化采集。
2、按关键词批处理采集。
通过导入一批关键词,直接按关键词采集。
采集的信息包括产品ID,产品标题,产品URL,产品价格,产品图,月销售额,月销售额,重复率,货物描述,响应,交货,旺旺,公司名称,业务类型等。和其他字段,以文本表(excel)格式导出,可用于产品市场分析,同行销售绩效评估,公司信息采集和其他目的。每个产品关键词支持100页,每页60个产品,以及大约6000个产品信息。支持详细的搜索参数设置,支持多个产品关键词订单采集,不同的关键词输入键一行,支持字段排序(单击标题列),然后导出并保存。
软件功能
1、只需用鼠标单击,无需编写任何采集规则,
2、实时采集,非历史数据,即用户本地采集中当前的最新数据。
3、操作简单易上手,傻瓜式操作,分两步进行(导入产品详细信息链接,每行一个,可以导入多个产品链接;单击以启动采集;导出数据)。无需编写任何规则,操作非常简单。
4、快速搜索,极快的操作体验,流畅而愉快。
5、具有自动升级功能:新版本正式发布后,客户端打开后将自动升级到最新版本。
6、该软件将继续维护模块更新。
常见问题
1、支持的操作系统?
Win7及更高版本(可接受32位或64位)。 XP不支持。
2、试用版与正版版之间的区别?
试用版具有采集导出密钥信息加密功能(24小时限时试用),并且没有其他限制,因此您可以在购买前试用。
由于高质量,我们的软件可以免费体验和尝试。 (与许多无法体验或没有足够有限的a脚经历的同龄人不同。)
3、 采集速度?
没有任何限制,您的计算机性能和带宽。
4、如果我更换机器或丢失软件该怎么办?
通过QQ和微信联系我们进行处理。我们只希望VIP客户在授权期内及时处理它。
更新日志
解决方案:1688商品采集软件1.9官方版
采集交流 • 优采云 发表了文章 • 0 个评论 • 315 次浏览 • 2020-11-20 11:00
1688商品采集软件是老店软件生产的1688产品,即阿里巴巴产品信息批采集软件,它支持多种方法采集数据,这些数据可以快速为用户所需采集所有各种信息,帮助您及时了解和更新商店信息,操作简单,高效,易于使用,欢迎有需要的朋友体会。
功能描述:
支持两种采集模式:
1、页面设置采集。
在WEB页面上设置采集 关键词,并精细设置采集条件(例如样式,颜色,大小等)。这适合在复杂条件下进行优化采集。
2、按关键词批处理采集。
通过导入一批关键词,直接按关键词 采集。
采集的信息包括产品ID,产品标题,产品URL,产品价格,产品图,月销售额,月销售额,重复率,货物描述,响应,交货,旺旺,公司名称,业务类型等。和其他以文本形式(excel)导出的字段可以用于产品市场分析,同行销售绩效评估,公司信息采集和其他目的。每个产品关键词支持100页,每页60个产品,以及大约6000个产品信息。支持详细的搜索参数设置,支持多个产品关键词序列采集,不同的关键词输入键一行,支持字段排序(单击标题列),然后导出并保存。
常见问题:
1、支持的操作系统?
Win7及更高版本(32位或64位)。 XP不支持。
2、试用版与正版版之间的区别?
试用版具有采集导出密钥信息加密功能(24小时限时试用),并且没有其他限制,因此您可以在购买前试用。
由于高质量,我们的软件可以免费体验和尝试。 (与许多无法体验或无法充分体验的cr脚的同行不同)。
3、采集速度?
没有任何限制,您的计算机性能和带宽。
4、如果我更换机器或丢失软件该怎么办?
通过QQ和微信联系我们进行处理。我们只希望VIP客户在授权期内及时处理它。
软件功能:
1、只需用鼠标单击,无需编写任何采集规则,
2、实时采集,非历史数据,即用户本地采集中当前的最新数据。
3、该操作简单易上手,分两步进行傻瓜式操作(导入产品详细信息链接,每行一个,可以导入多个产品链接;单击以开始采集 ;导出数据)。无需编写任何规则,操作非常简单。
4、快速搜索,极快的操作体验,流畅而愉快。
5、具有自动升级功能:新版本正式发布后,打开客户端后,客户端将自动升级到最新版本。
6、该软件将继续维护模块更新。 查看全部
1688商品采集软件1.9正式版
1688商品采集软件是老店软件生产的1688产品,即阿里巴巴产品信息批采集软件,它支持多种方法采集数据,这些数据可以快速为用户所需采集所有各种信息,帮助您及时了解和更新商店信息,操作简单,高效,易于使用,欢迎有需要的朋友体会。
功能描述:
支持两种采集模式:
1、页面设置采集。
在WEB页面上设置采集 关键词,并精细设置采集条件(例如样式,颜色,大小等)。这适合在复杂条件下进行优化采集。
2、按关键词批处理采集。
通过导入一批关键词,直接按关键词 采集。
采集的信息包括产品ID,产品标题,产品URL,产品价格,产品图,月销售额,月销售额,重复率,货物描述,响应,交货,旺旺,公司名称,业务类型等。和其他以文本形式(excel)导出的字段可以用于产品市场分析,同行销售绩效评估,公司信息采集和其他目的。每个产品关键词支持100页,每页60个产品,以及大约6000个产品信息。支持详细的搜索参数设置,支持多个产品关键词序列采集,不同的关键词输入键一行,支持字段排序(单击标题列),然后导出并保存。
常见问题:
1、支持的操作系统?
Win7及更高版本(32位或64位)。 XP不支持。
2、试用版与正版版之间的区别?
试用版具有采集导出密钥信息加密功能(24小时限时试用),并且没有其他限制,因此您可以在购买前试用。
由于高质量,我们的软件可以免费体验和尝试。 (与许多无法体验或无法充分体验的cr脚的同行不同)。
3、采集速度?
没有任何限制,您的计算机性能和带宽。
4、如果我更换机器或丢失软件该怎么办?
通过QQ和微信联系我们进行处理。我们只希望VIP客户在授权期内及时处理它。
软件功能:
1、只需用鼠标单击,无需编写任何采集规则,
2、实时采集,非历史数据,即用户本地采集中当前的最新数据。
3、该操作简单易上手,分两步进行傻瓜式操作(导入产品详细信息链接,每行一个,可以导入多个产品链接;单击以开始采集 ;导出数据)。无需编写任何规则,操作非常简单。
4、快速搜索,极快的操作体验,流畅而愉快。
5、具有自动升级功能:新版本正式发布后,打开客户端后,客户端将自动升级到最新版本。
6、该软件将继续维护模块更新。
事实:芭奇:不用编写采集规则也可轻松采集网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 465 次浏览 • 2020-10-07 09:04
很长时间以来,每个人都在使用采集功能附带的各种采集器或网站程序。它们具有一个共同的功能,即您需要在采集至文章之前编写采集规则,对于新手来说,此技术问题并非易事,对于老网站管理员而言,这也是一项艰巨的任务。因此,如果您执行站群,则每个工作站都必须定义采集规则,这确实很痛苦。有人说网站管理员是网络搬运工。这句话也很有意义。互联网上的许多文章是您感动了我,而我感动了您。为了生活,我必须这样做。现在,Baqi 站群软件中发布了一个新的采集功能,该功能可以大大减少网站站长“搬运工”的时间,并且不再需要编写烦人的采集规则。此功能是Internet的第一个功能。 ---指定URL 采集。让我教您如何使用此功能:
一、首先打开此功能。您可以在网站右键中看到此功能:如下所示。
二、打开后具有以下功能,您可以在右侧填写采集的列表地址:
在这里,我使用百度的搜索页作为采集的来源,例如:%B0%C5%C6%E6
然后,我使用Baqi 站群软件对所有搜索结果文章进行了采集。您可以首先分析此页面,如果您使用各种类型的采集器或网站内置程序来自定义采集和所有文章,则无法获得此页面。因为Internet没有通用的采集和不同的网站功能,但是现在可以实现Batch 站群软件。因为该软件支持pan 采集技术。
三、主页,我将此百度结果列表填写到软件的“起始采集 文章列表地址”中,如下所示:
四、为了能够更正我想要的采集列表,分析结果列表上的文章有一个通用后缀,即:html,shtml,htm,那么这三个是通用的是:我为软件定义了htm。这种方法是减少采集个无用的页面,如下所示:
五、现在可用于采集,但这是提醒。通常,一个网站中有许多具有相同字符的字符。对于此百度列表,也有百度自己的网页,但是百度我自己的网页内容不是我想要使用的内容,因此还有另一个地方可以排除带有百度URL的页面。如下图所示:
此定义之后,它将避免使用百度自己的页面。然后填写,可以直接采集 文章,单击“保存采集数据”:
一两分钟后,采集处理的结果如下图所示:
六、在这里,我只选择文章的一部分,然后不再选择它。现在来看采集之后的内容:
七、上面是采集的过程。根据上述步骤,您还可以在其他地方列出采集 文章,尤其是某些网站没有收录或屏幕避免收录],这些都是原创的文章,您可以自己找到。现在,让我告诉您有关软件的其他一些功能:
1、如上图所示,这是删除URL和采集图片的功能。您可以根据需要对其进行打勾。
2、如上所示,这里是设置采集的数量和采集中文章的最小单词数。
3、如上图所示,您可以在此处定义替换词,支持代码替换,文本替换等,此处可以灵活使用,对于某些困难的采集列表,将在此处使用。您可以先用空格替换某些代码,然后才能采集链接到列表。
以上所有都是Baqi 站群软件的新采集功能。此功能非常强大,但是需要改进此功能以满足不同人群的需求。使用此工具,您不必担心不知道如何编写采集规则。此功能易于上手,易于操作。这是新老网站管理员最适合的功能。如果您听不懂,可以将我加到QQ并问我:509229860。 查看全部
批处理:您无需编写采集规则即可轻松采集 网站
很长时间以来,每个人都在使用采集功能附带的各种采集器或网站程序。它们具有一个共同的功能,即您需要在采集至文章之前编写采集规则,对于新手来说,此技术问题并非易事,对于老网站管理员而言,这也是一项艰巨的任务。因此,如果您执行站群,则每个工作站都必须定义采集规则,这确实很痛苦。有人说网站管理员是网络搬运工。这句话也很有意义。互联网上的许多文章是您感动了我,而我感动了您。为了生活,我必须这样做。现在,Baqi 站群软件中发布了一个新的采集功能,该功能可以大大减少网站站长“搬运工”的时间,并且不再需要编写烦人的采集规则。此功能是Internet的第一个功能。 ---指定URL 采集。让我教您如何使用此功能:
一、首先打开此功能。您可以在网站右键中看到此功能:如下所示。
二、打开后具有以下功能,您可以在右侧填写采集的列表地址:
在这里,我使用百度的搜索页作为采集的来源,例如:%B0%C5%C6%E6
然后,我使用Baqi 站群软件对所有搜索结果文章进行了采集。您可以首先分析此页面,如果您使用各种类型的采集器或网站内置程序来自定义采集和所有文章,则无法获得此页面。因为Internet没有通用的采集和不同的网站功能,但是现在可以实现Batch 站群软件。因为该软件支持pan 采集技术。
三、主页,我将此百度结果列表填写到软件的“起始采集 文章列表地址”中,如下所示:
四、为了能够更正我想要的采集列表,分析结果列表上的文章有一个通用后缀,即:html,shtml,htm,那么这三个是通用的是:我为软件定义了htm。这种方法是减少采集个无用的页面,如下所示:
五、现在可用于采集,但这是提醒。通常,一个网站中有许多具有相同字符的字符。对于此百度列表,也有百度自己的网页,但是百度我自己的网页内容不是我想要使用的内容,因此还有另一个地方可以排除带有百度URL的页面。如下图所示:
此定义之后,它将避免使用百度自己的页面。然后填写,可以直接采集 文章,单击“保存采集数据”:
一两分钟后,采集处理的结果如下图所示:
六、在这里,我只选择文章的一部分,然后不再选择它。现在来看采集之后的内容:
七、上面是采集的过程。根据上述步骤,您还可以在其他地方列出采集 文章,尤其是某些网站没有收录或屏幕避免收录],这些都是原创的文章,您可以自己找到。现在,让我告诉您有关软件的其他一些功能:
1、如上图所示,这是删除URL和采集图片的功能。您可以根据需要对其进行打勾。
2、如上所示,这里是设置采集的数量和采集中文章的最小单词数。
3、如上图所示,您可以在此处定义替换词,支持代码替换,文本替换等,此处可以灵活使用,对于某些困难的采集列表,将在此处使用。您可以先用空格替换某些代码,然后才能采集链接到列表。
以上所有都是Baqi 站群软件的新采集功能。此功能非常强大,但是需要改进此功能以满足不同人群的需求。使用此工具,您不必担心不知道如何编写采集规则。此功能易于上手,易于操作。这是新老网站管理员最适合的功能。如果您听不懂,可以将我加到QQ并问我:509229860。
解决方案:怎么样大批量的采集B2B的产品图片和信息?
采集交流 • 优采云 发表了文章 • 0 个评论 • 344 次浏览 • 2020-10-05 09:10
最简单的方法是使用采集工具。我以前尝试过许多工具,但发现许多采集工具无法在采集中显示图片,而且它们不是免费的。后来,我终于找到了一个名为gooseeker的工具。您可以同时获取图片和文本,但是该密钥是免费的。该工具分为两部分,一个MS计数器负责采集规则,另一个DS计数器负责采集数据。
我不知道您想要产品目录页面还是产品详细信息页面的图形和文本?产品的目录页面非常简单。使用此工具的MS可以在页面上执行采集规则,该规则将要捕获的信息和图像URL映射到排序框,并为图像URL设置下载图像,因为目录页面有很多页,每个页面都有多个产品信息,还设置了样本副本和自动翻页。最后,您需要使用采集的DS计数器来获取所有图片和文字。此外,如果您要采用新的URL,则只需通过DS将URL添加到规则中。无需再制定任何规则,您可以分批采集数千条规则。数十万个网址的数据。
产品详细信息页面并不困难,方法与上述类似,只是您无需翻页。要特别注意控制采集的速度和周期。尽管此工具可能非常有效,但是您希望如果继续进行批处理采集,请不要太快,否则电子商务网站很快就会检测到异常,并且验证窗口通常会弹出,并且您甚至无法访问该网页。
更复杂的方法是为B2B 网站编写Python采集器,以搜寻指定的网页和图形,但是每个B2B 网站都有复杂的结构。如果使用此方法,则需要连续调试和测试,只需采集一个网站计划,编程,调试,运行优化等需要一个月的时间。如果更改网站,则将花费很长时间是时候更改程序了。因此,如果您想批量采集,您可以自己做。既费时又累。 查看全部
大量的采集B2B产品图片和信息如何?
最简单的方法是使用采集工具。我以前尝试过许多工具,但发现许多采集工具无法在采集中显示图片,而且它们不是免费的。后来,我终于找到了一个名为gooseeker的工具。您可以同时获取图片和文本,但是该密钥是免费的。该工具分为两部分,一个MS计数器负责采集规则,另一个DS计数器负责采集数据。
我不知道您想要产品目录页面还是产品详细信息页面的图形和文本?产品的目录页面非常简单。使用此工具的MS可以在页面上执行采集规则,该规则将要捕获的信息和图像URL映射到排序框,并为图像URL设置下载图像,因为目录页面有很多页,每个页面都有多个产品信息,还设置了样本副本和自动翻页。最后,您需要使用采集的DS计数器来获取所有图片和文字。此外,如果您要采用新的URL,则只需通过DS将URL添加到规则中。无需再制定任何规则,您可以分批采集数千条规则。数十万个网址的数据。
产品详细信息页面并不困难,方法与上述类似,只是您无需翻页。要特别注意控制采集的速度和周期。尽管此工具可能非常有效,但是您希望如果继续进行批处理采集,请不要太快,否则电子商务网站很快就会检测到异常,并且验证窗口通常会弹出,并且您甚至无法访问该网页。
更复杂的方法是为B2B 网站编写Python采集器,以搜寻指定的网页和图形,但是每个B2B 网站都有复杂的结构。如果使用此方法,则需要连续调试和测试,只需采集一个网站计划,编程,调试,运行优化等需要一个月的时间。如果更改网站,则将花费很长时间是时候更改程序了。因此,如果您想批量采集,您可以自己做。既费时又累。
解决方案:不用写采集规则也可以轻松采集网站文章,揭秘一款明泽文章采集软件的工作原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 305 次浏览 • 2020-09-15 17:41
每个人都在使用各种采集器或网站内置采集功能,例如织梦 采集侠,优采云 采集器,优采云 采集器等,这些采集软件具有一个共同的功能,即您必须编写采集规则才能将采集更改为文章。对于新手来说,这个技术问题经常被张二和尚所迷惑,这确实不是一件容易的事。即使对于旧的网站管理员,当需要采集多个网站数据时,也需要为不同的网站编写不同的采集规则,这是一项艰巨且耗时的任务。许多站群的朋友对每个站点都需要编写采集规则有深刻的理解,这简直令人痛苦。有人说网站管理员是网络搬运工。这很有道理。在互联网上文章就是您移动我,移动您并互相移动的全部。那么,有没有既免费又开源的采集软件? Mingze 文章 采集器就像为您量身定制的采集软件一样,此采集器具有内置的采集规则,只需添加文章列表链接,就可以连接内容采集回来。
Mingze 文章 采集器有什么优势,万能的文章 采集器可以采集收录什么内容
可以作为采集的采集器的内容是:文章标题,文章 关键词,文章说明,文章详细信息,文章作者,文章发布时间,文章次网页浏览。
Universal 文章 采集器在哪里运行?
此采集器可以在Windows,Mac,Linux(Centos,Ubuntu等)上运行。您可以下载并编译该程序以直接执行,也可以下载源代码并自己进行编译。
Mingze 文章 采集软件教程
data:image/svg+xml;utf8,
data:image/svg+xml;utf8,
data:image/svg+xml;utf8,
data:image/svg+xml;utf8,
结论
以上是Mingze 文章 采集器的用法和工作原理。根据上述步骤,您可以轻松地采集到所需的内容文章。它一天24小时都可以工作,您可以在采集器之后打开它。它将为您提供稳定的能量采集 文章并自动释放它。 查看全部
您无需编写采集规则即可轻松采集 网站 文章,揭示Mingze 文章 采集软件的工作原理
每个人都在使用各种采集器或网站内置采集功能,例如织梦 采集侠,优采云 采集器,优采云 采集器等,这些采集软件具有一个共同的功能,即您必须编写采集规则才能将采集更改为文章。对于新手来说,这个技术问题经常被张二和尚所迷惑,这确实不是一件容易的事。即使对于旧的网站管理员,当需要采集多个网站数据时,也需要为不同的网站编写不同的采集规则,这是一项艰巨且耗时的任务。许多站群的朋友对每个站点都需要编写采集规则有深刻的理解,这简直令人痛苦。有人说网站管理员是网络搬运工。这很有道理。在互联网上文章就是您移动我,移动您并互相移动的全部。那么,有没有既免费又开源的采集软件? Mingze 文章 采集器就像为您量身定制的采集软件一样,此采集器具有内置的采集规则,只需添加文章列表链接,就可以连接内容采集回来。
Mingze 文章 采集器有什么优势,万能的文章 采集器可以采集收录什么内容
可以作为采集的采集器的内容是:文章标题,文章 关键词,文章说明,文章详细信息,文章作者,文章发布时间,文章次网页浏览。
Universal 文章 采集器在哪里运行?
此采集器可以在Windows,Mac,Linux(Centos,Ubuntu等)上运行。您可以下载并编译该程序以直接执行,也可以下载源代码并自己进行编译。
Mingze 文章 采集软件教程
data:image/svg+xml;utf8,
data:image/svg+xml;utf8,
data:image/svg+xml;utf8,
data:image/svg+xml;utf8,
结论
以上是Mingze 文章 采集器的用法和工作原理。根据上述步骤,您可以轻松地采集到所需的内容文章。它一天24小时都可以工作,您可以在采集器之后打开它。它将为您提供稳定的能量采集 文章并自动释放它。
心得:优采云采集规则怎么写?新手怎么入门?
采集交流 • 优采云 发表了文章 • 0 个评论 • 329 次浏览 • 2020-09-07 19:52
优采云 采集器当前是更流行的网站 data 采集工具。针对采集发布的无版权数据的首选。但是许多网站管理员说采集很困难。不知道如何开始。还是不知道从哪里开始?今天,我推荐一种非常简单的入门方法。
我们提供的许多源代码实际上是优采云 采集器随附的,但是规则通常仅持续约3个月,需要进行调整。最简单的入门方法是学习他人编写的规则。如果输入有误,请继续修改规则。 采集的内容通常是采集的2点之内的数据。这是相对简单的。新手条目通常会被修改2-3次。
优采云最困难的部分实际上是模块的设置,但是您也可以从其他人开发的模块中学习并更改规则。使用其现成的采集模块和采集接口采集数据。 ,这并不困难。
当然,有一种简单的方法。我们经常说,每个人采集拥有相同的站点并更改采集的来源并没有多大意义。避免内容同质化。以我们提供的源代码为例。实际上,许多类型的网站都是重复的,例如手机游戏,下载,相同的源代码可能已经提供了N次,采集器也提供了N次,导出其规则,然后将其导入到当前的[k2 ] 采集很好,有时甚至不需要更改标签,例如92中开发的相同类型和96中开发的相同类型。通常只需要进行较小的调整。
这就是为什么我们总是建议大家加入我们的一站式VIP的原因。您可以向成熟的开发人员学习技术,以快速提高自己,甚至可以集成他们的技术来开发和修改所需的网站或采集器。如果您想每次都在任何站点上购买任何源代码,则采集无效并要求某人付款以对其进行修改,因此一年之内的花费不小。 查看全部
如何编写优采云 采集规则?如何为新手入门?
优采云 采集器当前是更流行的网站 data 采集工具。针对采集发布的无版权数据的首选。但是许多网站管理员说采集很困难。不知道如何开始。还是不知道从哪里开始?今天,我推荐一种非常简单的入门方法。
我们提供的许多源代码实际上是优采云 采集器随附的,但是规则通常仅持续约3个月,需要进行调整。最简单的入门方法是学习他人编写的规则。如果输入有误,请继续修改规则。 采集的内容通常是采集的2点之内的数据。这是相对简单的。新手条目通常会被修改2-3次。
优采云最困难的部分实际上是模块的设置,但是您也可以从其他人开发的模块中学习并更改规则。使用其现成的采集模块和采集接口采集数据。 ,这并不困难。
当然,有一种简单的方法。我们经常说,每个人采集拥有相同的站点并更改采集的来源并没有多大意义。避免内容同质化。以我们提供的源代码为例。实际上,许多类型的网站都是重复的,例如手机游戏,下载,相同的源代码可能已经提供了N次,采集器也提供了N次,导出其规则,然后将其导入到当前的[k2 ] 采集很好,有时甚至不需要更改标签,例如92中开发的相同类型和96中开发的相同类型。通常只需要进行较小的调整。
这就是为什么我们总是建议大家加入我们的一站式VIP的原因。您可以向成熟的开发人员学习技术,以快速提高自己,甚至可以集成他们的技术来开发和修改所需的网站或采集器。如果您想每次都在任何站点上购买任何源代码,则采集无效并要求某人付款以对其进行修改,因此一年之内的花费不小。
汇总:优采云采集入门到熟练——03 基本采集流程
采集交流 • 优采云 发表了文章 • 0 个评论 • 417 次浏览 • 2020-09-06 02:06
在准备了第一篇文章和第二篇信心不足的文章之后,如果没有懒惰和自卑的话,肖梦欣应该已经在优采云官方网站上观看了视频教程。接下来,进入采集流程并逐步构建采集规则。
一、 采集层次结构的分析与构建
采集页面和采集内容确定采集的总体结构和过程。一般来说,采集工具不会做得太深采集,因为它会大大增加采集的可能性。因此,我们放弃了其他复杂的可能性。采用标准化的采集规范,即第二级采集-列表页+内容页+分页,这是大多数采集的最常用方法。
列表页面是什么?什么是内容页面?
如果我想采集网易国际新闻的标题,内容和其他信息,则此页面为列表页面。
国际新闻_网易新闻中心
因为此页面上有新闻列表,所以我们想要采集是列表中单击的每个新闻内容页面。话虽如此,每个人也都知道内容页面是什么。内容页面是收录您需要的信息的页面采集。内容页面通常是列表页面的从属页面。
采集的第一步是找到列表页面并在列表页面上设置翻页周期,首先完全定位列表。
什么是分页?
如果内容页面(即文章详细页面)未显示在一页上,而是由多个页面组成,则称为分页。例如,如果我想采集一篇文章文章,文章分为4页,那么我需要在分页符上执行采集。分页级别,通常是因为网站一页没有完全显示。那是:
列表页面
-分页1
-分页2
……
这样的结构。
分页也需要循环构建,这与翻页循环本质上是相同的。
通过这种方式,我们通过循环构建了辅助采集结构。通常,列表页面需要形成两个循环。第一个循环是翻页循环,用于翻页,通常称为“单击下一页”循环;第二个循环是列表循环,此循环包括所有内容页面,通常“单击进入页面循环”。
在这里,每个人都需要注意,未选中在新标签页中打开翻页循环的单击操作。这是为了确保翻页周期本身的结构不会改变。但是,默认情况下“在新选项卡页面中打开”会自动检查内容页面循环的单击操作,因为每个内容页面都可以独立打开,并且采集不会影响原创列表页面。因此,如果您发现无法通过单击并手动将循环拖入并自动生成所需的循环,则需要注意修改这些小的详细信息设置,否则将使您感到沮丧。
二、详细分析页面结构为采集(尽可能多地分析部分源代码)
您可以认为内容页面的页面结构是相同的;或因为尚未经过测试,所以您不确定它们是否一致;在先前的测试中可能也相同,但是采集在一段时间后已被修改。简而言之,有很多情况,并且永远不变的一件事就是查看独立于源代码的测试采集 -adjust xpath。
分析源代码条目的方法并不复杂。 Firefox和Chrome均进入开发人员模式。有关具体操作,请参考其他人的教导:
Artifact-Chrome开发者工具(一)-仅仅是娱乐目的-SegmentFault
重新介绍Firefox开发人员工具(1):Web控制台和Javascript调试器-文章-在线在线
这里推荐两个插件:
Firefox-Firepath
Chrome——Xpath帮助器
这两个插件可用于快速验证xpath是否正确并可以突出显示,这非常方便。
优采云附带有xpath工具。如果在浏览器中xpath正确,但是无法在优采云中提取数据,请记住使用优采云中的内置工具来进行测试测试以查看优采云是否获得了页面的源代码与浏览器获得的结果不同。
三、复杂的逻辑结构判断
在采集测试开始之前,如果可以发现逻辑结构分支是最好的,如果不是,则至少在独立测试之后尝试完善它。但是,我提醒大家,优采云对于复杂的逻辑结构分支,最好在开始时进行计划,否则您很快就会感到困惑,并且以后的维修会引起各种错误和问题。你不能摸你的头。最简单的方法是删除整个规则并重做它,这会使您很头疼,因此,您越早计划采集,就越容易制定完美的规则。
看到这里的许多人仍然感到困惑,为什么他们很复杂?为什么称之为复杂逻辑机制?这是怎么发生的。有时当我们采集个数据时,尽管它们都是内容页面,但内部格式已更改。例如,在公众意见中,有些商店具有完整的图片和说明,而有些则属于低端商店仅提供最简单的信息,而页面格式则完全不同。目前,我们很难编写通用的xpath语句,采集条目甚至可能不同。
这时,优采云 采集器的条件判断可以发挥作用。它与if else语句非常相似。通过判断页面元素或文本,您可以执行完全不同的采集流程,这可以说是非常有用的。另一种情况是出现问题时的判断。例如,如果页面提示输入验证码,则执行的过程是先输入验证码,然后继续执行采集而不是原创的采集过程(原创过程肯定会认为跳过此页面而没有数据)。每个人都应该使用良好的条件进行判断,这可以在很大程度上避免采集没有数据或数据丢失的情况。
四、数据提取和后处理
通常可以通过一种相对简单的方法来提取数据,该方法是通过单击直接提取文本或链接。但是那些真正擅长查看源代码的人知道,有时候他们想要提取的信息不一定是文本,它可能是元素的属性,例如id,src,style等。此时,优采云数据提取下的编辑按钮很有用。首先,您可以自定义元素定位。如果您认为单击生成的位置不正确,则可以编写xpath来替换它;然后是元素提取方法,这里有很多提取方法。其他工具可能需要使用正则表达式来提取属性。我们可以直接选择,也可以快速选择摘录链接或其他html代码。在此步骤中,即使我们已经提取了所需的近似值,也可以满足要求。如果需要文本处理,则需要进一步的检查处理。
优采云提供了更多通用的文本处理方法和工具,首先是最简单的替换功能,其次是通用正则表达式(认真学习,比xpath pit更深入)。此外,还有时间处理,html的基本处理等。因为优采云具有内置的正则表达式工具,请相信我,用心学习这个小技巧,可以节省很多自学的正则表达式时间,这绝对是一个神奇的工具,我想每天都有一个小的工具!
五、小细节设置
每个新手都会遇到一个大问题,Internet上的许多其他人找不到这些设置。实际上,这主要是因为优采云的许多详细设置都在每个操作的高级部分中,这使新来者不熟悉。 ,或者我没有使用过,我不知道如何找到它。
这里的简单方法是将所有操作拉入流程,然后单击一个以查看高级设置,然后您可以慢慢记住它们。只要看一下实际战斗中的高级设置,您很快就会知道这是什么。高级设置和小细节设置与操作相互对应。如果我考虑需要的操作,那么我可以理解应该在哪里找到它们。例如:打开页面后,我想自动滚动到底部。此设置可能出现在哪里?毫无疑问,第一个是当我打开URL时,第二个是当我单击链接时,以便我可以立即知道在哪个步骤中可以找到此设置。
以下是一些注意事项:
六、单机测试和故障排除
无论您如何编写规则,都可能会遇到问题,因为优采云规则不是您所看到的就是得到的,是的!不要上当,当您编辑规则时,您会感觉一切都很好,但是在启动独立测试后,一切都不是您所想的。这次是我们所有人都祝贺您进入维修站的时候了!
很难避免深坑!您为什么这么说,因为这是一个经验性的问题...肖梦新会慢慢陷入困境...在遇到很多陷阱之后,您将逐渐知道如何解决问题。让我们开始“扫雷”:
首先写很多,爪子可以跟随我的知乎专栏和数据交换组。
Brother Rabbit Data Geek Club的QQ群:462346024
我的博客: 查看全部
优采云 采集入门知识——03基本的采集过程
在准备了第一篇文章和第二篇信心不足的文章之后,如果没有懒惰和自卑的话,肖梦欣应该已经在优采云官方网站上观看了视频教程。接下来,进入采集流程并逐步构建采集规则。
一、 采集层次结构的分析与构建
采集页面和采集内容确定采集的总体结构和过程。一般来说,采集工具不会做得太深采集,因为它会大大增加采集的可能性。因此,我们放弃了其他复杂的可能性。采用标准化的采集规范,即第二级采集-列表页+内容页+分页,这是大多数采集的最常用方法。
列表页面是什么?什么是内容页面?
如果我想采集网易国际新闻的标题,内容和其他信息,则此页面为列表页面。
国际新闻_网易新闻中心
因为此页面上有新闻列表,所以我们想要采集是列表中单击的每个新闻内容页面。话虽如此,每个人也都知道内容页面是什么。内容页面是收录您需要的信息的页面采集。内容页面通常是列表页面的从属页面。
采集的第一步是找到列表页面并在列表页面上设置翻页周期,首先完全定位列表。
什么是分页?
如果内容页面(即文章详细页面)未显示在一页上,而是由多个页面组成,则称为分页。例如,如果我想采集一篇文章文章,文章分为4页,那么我需要在分页符上执行采集。分页级别,通常是因为网站一页没有完全显示。那是:
列表页面
-分页1
-分页2
……
这样的结构。
分页也需要循环构建,这与翻页循环本质上是相同的。
通过这种方式,我们通过循环构建了辅助采集结构。通常,列表页面需要形成两个循环。第一个循环是翻页循环,用于翻页,通常称为“单击下一页”循环;第二个循环是列表循环,此循环包括所有内容页面,通常“单击进入页面循环”。
在这里,每个人都需要注意,未选中在新标签页中打开翻页循环的单击操作。这是为了确保翻页周期本身的结构不会改变。但是,默认情况下“在新选项卡页面中打开”会自动检查内容页面循环的单击操作,因为每个内容页面都可以独立打开,并且采集不会影响原创列表页面。因此,如果您发现无法通过单击并手动将循环拖入并自动生成所需的循环,则需要注意修改这些小的详细信息设置,否则将使您感到沮丧。
二、详细分析页面结构为采集(尽可能多地分析部分源代码)
您可以认为内容页面的页面结构是相同的;或因为尚未经过测试,所以您不确定它们是否一致;在先前的测试中可能也相同,但是采集在一段时间后已被修改。简而言之,有很多情况,并且永远不变的一件事就是查看独立于源代码的测试采集 -adjust xpath。
分析源代码条目的方法并不复杂。 Firefox和Chrome均进入开发人员模式。有关具体操作,请参考其他人的教导:
Artifact-Chrome开发者工具(一)-仅仅是娱乐目的-SegmentFault
重新介绍Firefox开发人员工具(1):Web控制台和Javascript调试器-文章-在线在线
这里推荐两个插件:
Firefox-Firepath
Chrome——Xpath帮助器
这两个插件可用于快速验证xpath是否正确并可以突出显示,这非常方便。
优采云附带有xpath工具。如果在浏览器中xpath正确,但是无法在优采云中提取数据,请记住使用优采云中的内置工具来进行测试测试以查看优采云是否获得了页面的源代码与浏览器获得的结果不同。
三、复杂的逻辑结构判断
在采集测试开始之前,如果可以发现逻辑结构分支是最好的,如果不是,则至少在独立测试之后尝试完善它。但是,我提醒大家,优采云对于复杂的逻辑结构分支,最好在开始时进行计划,否则您很快就会感到困惑,并且以后的维修会引起各种错误和问题。你不能摸你的头。最简单的方法是删除整个规则并重做它,这会使您很头疼,因此,您越早计划采集,就越容易制定完美的规则。
看到这里的许多人仍然感到困惑,为什么他们很复杂?为什么称之为复杂逻辑机制?这是怎么发生的。有时当我们采集个数据时,尽管它们都是内容页面,但内部格式已更改。例如,在公众意见中,有些商店具有完整的图片和说明,而有些则属于低端商店仅提供最简单的信息,而页面格式则完全不同。目前,我们很难编写通用的xpath语句,采集条目甚至可能不同。
这时,优采云 采集器的条件判断可以发挥作用。它与if else语句非常相似。通过判断页面元素或文本,您可以执行完全不同的采集流程,这可以说是非常有用的。另一种情况是出现问题时的判断。例如,如果页面提示输入验证码,则执行的过程是先输入验证码,然后继续执行采集而不是原创的采集过程(原创过程肯定会认为跳过此页面而没有数据)。每个人都应该使用良好的条件进行判断,这可以在很大程度上避免采集没有数据或数据丢失的情况。
四、数据提取和后处理
通常可以通过一种相对简单的方法来提取数据,该方法是通过单击直接提取文本或链接。但是那些真正擅长查看源代码的人知道,有时候他们想要提取的信息不一定是文本,它可能是元素的属性,例如id,src,style等。此时,优采云数据提取下的编辑按钮很有用。首先,您可以自定义元素定位。如果您认为单击生成的位置不正确,则可以编写xpath来替换它;然后是元素提取方法,这里有很多提取方法。其他工具可能需要使用正则表达式来提取属性。我们可以直接选择,也可以快速选择摘录链接或其他html代码。在此步骤中,即使我们已经提取了所需的近似值,也可以满足要求。如果需要文本处理,则需要进一步的检查处理。
优采云提供了更多通用的文本处理方法和工具,首先是最简单的替换功能,其次是通用正则表达式(认真学习,比xpath pit更深入)。此外,还有时间处理,html的基本处理等。因为优采云具有内置的正则表达式工具,请相信我,用心学习这个小技巧,可以节省很多自学的正则表达式时间,这绝对是一个神奇的工具,我想每天都有一个小的工具!
五、小细节设置
每个新手都会遇到一个大问题,Internet上的许多其他人找不到这些设置。实际上,这主要是因为优采云的许多详细设置都在每个操作的高级部分中,这使新来者不熟悉。 ,或者我没有使用过,我不知道如何找到它。
这里的简单方法是将所有操作拉入流程,然后单击一个以查看高级设置,然后您可以慢慢记住它们。只要看一下实际战斗中的高级设置,您很快就会知道这是什么。高级设置和小细节设置与操作相互对应。如果我考虑需要的操作,那么我可以理解应该在哪里找到它们。例如:打开页面后,我想自动滚动到底部。此设置可能出现在哪里?毫无疑问,第一个是当我打开URL时,第二个是当我单击链接时,以便我可以立即知道在哪个步骤中可以找到此设置。
以下是一些注意事项:
六、单机测试和故障排除
无论您如何编写规则,都可能会遇到问题,因为优采云规则不是您所看到的就是得到的,是的!不要上当,当您编辑规则时,您会感觉一切都很好,但是在启动独立测试后,一切都不是您所想的。这次是我们所有人都祝贺您进入维修站的时候了!
很难避免深坑!您为什么这么说,因为这是一个经验性的问题...肖梦新会慢慢陷入困境...在遇到很多陷阱之后,您将逐渐知道如何解决问题。让我们开始“扫雷”:
首先写很多,爪子可以跟随我的知乎专栏和数据交换组。
Brother Rabbit Data Geek Club的QQ群:462346024
我的博客:
测评:如何只采集列表页面的内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 359 次浏览 • 2020-09-01 21:09
有时候,我们只需要采集某些列表页面的内容即可. 例如,我们想要采集在百度上某个关键字的搜索结果,而我们只需要标题,URL或简介之类的内容. 或者我们认为采集是一条短信列,其列表页面收录我们所需的短信内容.
一个
如果我们希望列表中的每个项目都单独发布,请按以下方式配置采集规则:
1. 根据正常的采集配置列表URL,自动列表,列表区域中的列表设置;
2. 列出分析规则. 如果采集的内容不需要URL,则使用文章地址标记任何采集字符串;如果除了标题和URL之外还需要采集其他内容,例如,对于简介,我们可以使用缩略图标记来采集;
3,文章 URL合成,只需在此处填写快速访问URL,本地站点的URL也可以;
4.1. 在ET3中,可以使用指定的模式来调用列表数据;
4.2. 在ET2中,可以使用数据排序将列表数据分配给数据项. 数据排序中有一个[列表数据]标记,您可以引用标题,文章 URL,缩略图和其他从列表中获得的数据. 因此,我们可以在其相应的数据排序中创建新的数据项,引号标题,文章 URL,缩略图和其他数据,并将它们分解或合并为我们要发布的内容. 以下三张图片演示了如何为文本数据项分配缩略图数据.
(1,在文本数据项的采集规则中填写任何文本)
(2,在文本的数据组织中使用列表数据标记)
(3. 使用参数标签或变量标签将文本数据项的内容替换为列表的缩略图内容)
5. 其他与一般采集规则相同;
6. 在发布规则中,应注意数据项名称与发布参数名称之间的正确对应;
通过这种方式,列表中的内容可以采集逐一发布.
第二,
如果我们需要一次发布采集的内容,请按以下方式配置采集规则:
1. 列出网址,只需填写访问速度快的网页,或填写本地txt文件地址即可;
2,自动列表,无需设置列表区域;
3. 列表分析. 为列表URL中填写的地址内容设置一个简单规则. 要使用文章地址标签,文章地址标签的分析结果可以是任何内容,因为它不会被使用. 但是此分析规则必须有效,最好文章地址标签仅匹配一个结果(如果有多个结果,则可以在采集基本配置中将采集项的数量设置为1);
4,文章 URL合成,在此处采集填写您想要的列表页面URL;
5. 使用文本数据项和其他数据项采集列表中的每个项,您可以全部收录它们,也可以选择匹配多个项目;
6. 如果有多个列表URL,则可以使用正文页面设置采集;
7. 其他配置与一般采集规则相同;
完成此配置后,整个列表将作为文章文章发布. 查看全部
如何仅采集列表页面的内容
有时候,我们只需要采集某些列表页面的内容即可. 例如,我们想要采集在百度上某个关键字的搜索结果,而我们只需要标题,URL或简介之类的内容. 或者我们认为采集是一条短信列,其列表页面收录我们所需的短信内容.
一个
如果我们希望列表中的每个项目都单独发布,请按以下方式配置采集规则:
1. 根据正常的采集配置列表URL,自动列表,列表区域中的列表设置;
2. 列出分析规则. 如果采集的内容不需要URL,则使用文章地址标记任何采集字符串;如果除了标题和URL之外还需要采集其他内容,例如,对于简介,我们可以使用缩略图标记来采集;
3,文章 URL合成,只需在此处填写快速访问URL,本地站点的URL也可以;
4.1. 在ET3中,可以使用指定的模式来调用列表数据;
4.2. 在ET2中,可以使用数据排序将列表数据分配给数据项. 数据排序中有一个[列表数据]标记,您可以引用标题,文章 URL,缩略图和其他从列表中获得的数据. 因此,我们可以在其相应的数据排序中创建新的数据项,引号标题,文章 URL,缩略图和其他数据,并将它们分解或合并为我们要发布的内容. 以下三张图片演示了如何为文本数据项分配缩略图数据.
(1,在文本数据项的采集规则中填写任何文本)
(2,在文本的数据组织中使用列表数据标记)
(3. 使用参数标签或变量标签将文本数据项的内容替换为列表的缩略图内容)
5. 其他与一般采集规则相同;
6. 在发布规则中,应注意数据项名称与发布参数名称之间的正确对应;
通过这种方式,列表中的内容可以采集逐一发布.
第二,
如果我们需要一次发布采集的内容,请按以下方式配置采集规则:
1. 列出网址,只需填写访问速度快的网页,或填写本地txt文件地址即可;
2,自动列表,无需设置列表区域;
3. 列表分析. 为列表URL中填写的地址内容设置一个简单规则. 要使用文章地址标签,文章地址标签的分析结果可以是任何内容,因为它不会被使用. 但是此分析规则必须有效,最好文章地址标签仅匹配一个结果(如果有多个结果,则可以在采集基本配置中将采集项的数量设置为1);
4,文章 URL合成,在此处采集填写您想要的列表页面URL;
5. 使用文本数据项和其他数据项采集列表中的每个项,您可以全部收录它们,也可以选择匹配多个项目;
6. 如果有多个列表URL,则可以使用正文页面设置采集;
7. 其他配置与一般采集规则相同;
完成此配置后,整个列表将作为文章文章发布.
解决方案:文章批量采集生成 伪原创工具 中英日文自动很长时间版软件ArticleSea 杭
采集交流 • 优采云 发表了文章 • 0 个评论 • 433 次浏览 • 2020-09-01 20:46
拍照时请离开您的邮箱,信息将自动发送到您的邮箱进行下载!拍照后,它将自动将指向百度网络磁盘的链接发送到您的电子邮件! 文章 采集,支持中文,英文,日文,法文,德文和其他语言采集,还可以自定义采集的来源,自动学习采集规则,采集一般需要两个或三个小时,成千上万的文章很快就无法下载采集,因此采集请耐心等待,晚上将其放置在采集很好,第二天就可以了. ·自动降噪和乱码,变得干净整洁文章. 中文伪原创是句子库混合生成模式: 不直接使用伪原创,而是使用句子库生成+页面优化+批处理插入,不要打开软件并直接使用软件的伪原创功能,然后说那里没效果,谁介意呢. ·批处理页面优化. 文章 采集生成
拍照时请离开您的邮箱,信息将自动发送到您的邮箱进行下载!拍照后,它将自动将指向百度网络磁盘的链接发送到您的电子邮件! 文章 采集,支持中文,英文,日文,法文,德文和其他语言采集,还可以自定义采集的来源,自动学习采集规则,采集一般需要两个或三个小时,成千上万的文章很快就无法下载采集,因此采集请耐心等待,晚上将其放置在采集很好,第二天就可以了. ·自动降噪和乱码,变得干净整洁文章. 中文伪原创是句子库混合生成模式: 不直接使用伪原创,而是使用句子库生成+页面优化+批处理插入,不要打开软件并直接使用软件的伪原创功能,然后说那里没效果,谁介意呢. ·批处理页面优化. 拍照时请离开邮箱,信息将自动发送到邮箱进行下载!
拍照后,它将自动将指向百度网络磁盘的链接发送到您的电子邮件中!
文章 采集,支持中文,英文,日文,法文,德文和其他语言采集,还可以自定义采集的来源,并自动学习采集规则(不喜欢其他采集软件需要自己编写规则,只需直接输入关键字采集),采集通常需要两三个小时,成千上万的文章文章无法快速下载采集,因此[k1 ]请耐心等待,将其放在晚上采集很好,第二天就可以了
·自动去噪和乱码,变得新鲜干净文章.
·支持多个关键字,考虑输入一百个关键字并在一夜之间选择它们,多少个采集将是文章?
·支持线程设置,只要将计算机配置为具有较高的互联网速度,就可以设置任意多个线程!
·支持代理设置.
·一键生成长尾单词库,标题库,段落库,单句库,双句库和三句库.
拍照时请留下您的电子邮件,该信息将自动发送到您的电子邮件中以供下载!拍照后,它将自动将指向百度网络磁盘的链接发送到您的电子邮件! 文章 采集,支持中文,英文,日文,法文,德文和其他语言采集,还可以自定义采集的来源,自动学习采集规则,采集一般需要两个或三个小时,成千上万的文章很快就无法下载采集,因此采集请耐心等待,晚上将其放置在采集很好,第二天就可以了. ·自动降噪和乱码,变得干净整洁文章. 中文伪原创是句子库混合生成模式: 不直接使用伪原创,而是使用句子库生成+页面优化+批处理插入,不要打开软件并直接使用软件的伪原创功能,然后说那里没效果,谁介意呢. ·Batch ON PAGE优化.
·使用语料库生成大量的文章.
中文伪原创是句子库混合生成模式: 使用句子库生成(文章段落句子拆分和重组)+页面优化(关键字插入和粗体显示,添加图片等)+批处理插入(锚文本)插入,关键字替换),不能直接伪原创,不要打开软件,然后直接使用软件的伪原创功能,然后说没有任何效果,请介意,
·伪原创: 功能强大的词库,伪原创快速且可读性强.
·伪原创: 支持SPIN.
·伪原创: 支持的标题是否为伪原创.
·伪原创: 支持不同的伪原创级别.
·伪原创: 支持保留核心关键字而不被替换.
·伪原创: 相似度计算和显示
·伪原创: 大屏幕,易于编辑.
·伪原创: 使用不同的颜色表示伪原创之后的文章与原创文本之间的区别.
·批量ON PAGE优化. 查看全部
文章批处理采集生成伪原创工具中文,英文和日文自动长时间版本软件ArticleSea Hang
拍照时请离开您的邮箱,信息将自动发送到您的邮箱进行下载!拍照后,它将自动将指向百度网络磁盘的链接发送到您的电子邮件! 文章 采集,支持中文,英文,日文,法文,德文和其他语言采集,还可以自定义采集的来源,自动学习采集规则,采集一般需要两个或三个小时,成千上万的文章很快就无法下载采集,因此采集请耐心等待,晚上将其放置在采集很好,第二天就可以了. ·自动降噪和乱码,变得干净整洁文章. 中文伪原创是句子库混合生成模式: 不直接使用伪原创,而是使用句子库生成+页面优化+批处理插入,不要打开软件并直接使用软件的伪原创功能,然后说那里没效果,谁介意呢. ·批处理页面优化. 文章 采集生成
拍照时请离开您的邮箱,信息将自动发送到您的邮箱进行下载!拍照后,它将自动将指向百度网络磁盘的链接发送到您的电子邮件! 文章 采集,支持中文,英文,日文,法文,德文和其他语言采集,还可以自定义采集的来源,自动学习采集规则,采集一般需要两个或三个小时,成千上万的文章很快就无法下载采集,因此采集请耐心等待,晚上将其放置在采集很好,第二天就可以了. ·自动降噪和乱码,变得干净整洁文章. 中文伪原创是句子库混合生成模式: 不直接使用伪原创,而是使用句子库生成+页面优化+批处理插入,不要打开软件并直接使用软件的伪原创功能,然后说那里没效果,谁介意呢. ·批处理页面优化. 拍照时请离开邮箱,信息将自动发送到邮箱进行下载!
拍照后,它将自动将指向百度网络磁盘的链接发送到您的电子邮件中!
文章 采集,支持中文,英文,日文,法文,德文和其他语言采集,还可以自定义采集的来源,并自动学习采集规则(不喜欢其他采集软件需要自己编写规则,只需直接输入关键字采集),采集通常需要两三个小时,成千上万的文章文章无法快速下载采集,因此[k1 ]请耐心等待,将其放在晚上采集很好,第二天就可以了
·自动去噪和乱码,变得新鲜干净文章.
·支持多个关键字,考虑输入一百个关键字并在一夜之间选择它们,多少个采集将是文章?
·支持线程设置,只要将计算机配置为具有较高的互联网速度,就可以设置任意多个线程!
·支持代理设置.
·一键生成长尾单词库,标题库,段落库,单句库,双句库和三句库.
拍照时请留下您的电子邮件,该信息将自动发送到您的电子邮件中以供下载!拍照后,它将自动将指向百度网络磁盘的链接发送到您的电子邮件! 文章 采集,支持中文,英文,日文,法文,德文和其他语言采集,还可以自定义采集的来源,自动学习采集规则,采集一般需要两个或三个小时,成千上万的文章很快就无法下载采集,因此采集请耐心等待,晚上将其放置在采集很好,第二天就可以了. ·自动降噪和乱码,变得干净整洁文章. 中文伪原创是句子库混合生成模式: 不直接使用伪原创,而是使用句子库生成+页面优化+批处理插入,不要打开软件并直接使用软件的伪原创功能,然后说那里没效果,谁介意呢. ·Batch ON PAGE优化.
·使用语料库生成大量的文章.
中文伪原创是句子库混合生成模式: 使用句子库生成(文章段落句子拆分和重组)+页面优化(关键字插入和粗体显示,添加图片等)+批处理插入(锚文本)插入,关键字替换),不能直接伪原创,不要打开软件,然后直接使用软件的伪原创功能,然后说没有任何效果,请介意,
·伪原创: 功能强大的词库,伪原创快速且可读性强.
·伪原创: 支持SPIN.
·伪原创: 支持的标题是否为伪原创.
·伪原创: 支持不同的伪原创级别.
·伪原创: 支持保留核心关键字而不被替换.
·伪原创: 相似度计算和显示
·伪原创: 大屏幕,易于编辑.
·伪原创: 使用不同的颜色表示伪原创之后的文章与原创文本之间的区别.
·批量ON PAGE优化.
总结:优采云采集入门到熟练——05优采云采集套路!没错!就是套路……
采集交流 • 优采云 发表了文章 • 0 个评论 • 370 次浏览 • 2020-09-01 06:17
这里有一些坑. 如果页面不是由Ajax加载的,您还可以检查Ajax加载,这不会影响页面加载. 但是,假设加载时间为2秒,则优采云将在加载2秒后确定此页面. 如果有未加载的数据,则可以忽略该页面,这可能导致数据丢失. 因此,建议如果Ajax未加载该页面,请不要选择它. 如果存在,则应根据页面的响应速度(实际上,很大程度上是该页面的js加载和运行效率)决定要加载多少秒. 再次测试一台机器,不要立即进入云端采集,如果不正确地测试它,就会很烦.
6. 数据提取-如果我提取了一堆我不想要的东西该怎么办?
数据提取都是从html代码中提取的,因此存在取决于您要提取的内容的问题. 如果您只想提取前端页面上可以看到的文本,通常可以直接提取它. 这在优采云中更加愚蠢,效果非常好. 但是,网页的结构很奇怪,并且存在各种嵌入式问题. 在某些情况下,文本会分为多个段落,但是我们希望整个段落采集在上一页中可能看不到. 只有查看代码,文本才能被其他嵌入元素分隔.
解决方法不太复杂. 如果很通用,则只需应用整个段落,例如P标记采集文本,然后使用正则表达式或普通替换来清除不需要的字符串,空格,换行等.
7. 有条件判断-如果不是,大法
优采云的条件判断不能与编写代码相提并论,但它也被认为是该工具中非常强大的工具. 在优采云中可以实现的逻辑判断是,如果出现一个元素/不出现一个元素,则执行xxx;如果页面上出现文本xxx或不出现xxx,则执行xxx. 如程序员所说,如果a则为xxx,否则为b则为xxx,否则为xxx. 可以使用多个条件进行判断,因此不限于一个或两个条件. 如果当前条件判断为假,则将执行默认处理.
这有什么例行程序,主要是当您批处理采集页时,您会遇到不同的页. 例如,采集网易新闻列表中的新闻页面都被称为新闻,但是页面格式不同,这导致采集元素的位置和流程可能完全不同. 因此,将某些条件用作逻辑判断. 例如,出现什么元素,我认为它是这种新闻页面,并使用此采集流程;当出现另一个元素时,它被认为是另一种新闻,并更改为采集流程. 这样,可以更好地解决文章列表相同但细节页面不同的问题.
8. 失败重试-莫名其妙的失败,不是莫名其妙的重试
重试失败是形而上的问题. 失败的可能性太多. 例如,另一方的应用程序服务器被卡住,页面数据未返回,服务器500错误,服务器403被打开,页面的某些部分未加载,页面加载超时等等. 只要您认为采集的数据条目未出现,即使加载了该7页,该页也会失败,但是在许多情况下,设置失败并重试的方法是找到一个肯定会如果正常采集,则出现. 如果没有出现,请重试,但是设置一个间隔来考虑采集的效率和稳定性.
9. 图片下载
许多人抱怨优采云图片下载很麻烦,而且官方下载器的使用是如此复杂. 例程也很简单,只需下载图片链接采集,下载此东西,我就大雷了,为什么要优采云?迅雷批量下载和输入,世界是干净的(实际上,这并不干净,迅雷下载的叮当声将是一个接一个).
第二,常见的“错误方式” 1.正常采集不容易处理吗?从Wap版本采集更改
许多网站具有常规的网络版本和通过手机访问的Wap版本. 在许多情况下,如果发现网络版本比较困难采集,并且遇到很多问题,可以考虑更改为Wap版本进行登录. 有时候,找到Wap版本URL并不容易. 您可以先尝试在移动浏览器中搜索它,找到URL,然后将其放在优采云 采集器中,检查移动版本以尝试采集.
应注意,优采云 采集器中的手机版本显示可能与手机上的显示不同. 在许多情况下,会有一些不易操作或无法解释的问题. 毕竟,这是没有办法的,它不是专用的手机模拟器,因此您需要尝试更多,更多的采集路线将有更多的机会.
2. 自动登录困难吗?将回复时间更改为手动
例如,知乎之类的网站或其他各种“魔术”验证网站,有时需要在登录时进行验证,有时需要在采集的处理中以对抗采集添加的验证. 一切都是为了消除低级爬虫和采集工具.
这时,我们最好的解决方案是添加手动处理操作. 在制定规则的过程中,我们可以根据条件判断,也可以在进行具体操作之前增加等待时间. 在独立采集的过程中,可以使用手动操作来解决验证问题. 这确实没有效率,但是在这个钱不成问题的时代,问题在于人们是这个钱时代最便宜的东西...所以要用自己的身体...工作...
3. 瀑布“单击以加载更多”页面?创建一个单独的循环以单击它
许多网站需要保持单击“加载更多”以加载更多列表页面. 此时,在页面加载后,只需创建一个单独的循环并将其设置为在循环中继续单击即可. “加载更多”已足够,请记住选择并单击各个元素,类似于自动翻页的循环.
在此循环下,您可以继续创建采集列表的循环. 但是,虽然最好的方法是捕获和分析,但是采集方法可能并不适用于所有页面,但是在优采云中,让我们使用此方法进行处理.
4. 采集速度太慢了((: з)∠)_多个小细节选项可以帮助您加快速度
在日常采集流程中,每个人都希望尽快采集完成数据,但并不是每个人都有钱购买旗舰版. 然后,您必须充分利用独立版本(第一个工件),进行检查以阻止广告,减少广告加载对速度的影响;第二个伪像,检查不加载图片,大大减少了图像数据的加载时间;第三件,检查Non-Ajax页面加载优化情况,普通页面的速度有小幅提高;第四个工件,升级硬件...虽然废话,但是旧机器和网络无法改善软件的运行和采集速度,尽管硬件有了很大的改进,但软件运行速度一直没有提高. 大大提高了,但是内存的保证仍然非常重要. 足够的内存可以减少大量数据采集或多线程处理期间的延迟.
更多例程,请缓慢更新. 欢迎加入我的QQ群进行交流. 希望您能分享更多例程.
组号: 462346024 查看全部
优采云 采集进入水平05 优采云 采集例程!那就对了!这是例行事...
这里有一些坑. 如果页面不是由Ajax加载的,您还可以检查Ajax加载,这不会影响页面加载. 但是,假设加载时间为2秒,则优采云将在加载2秒后确定此页面. 如果有未加载的数据,则可以忽略该页面,这可能导致数据丢失. 因此,建议如果Ajax未加载该页面,请不要选择它. 如果存在,则应根据页面的响应速度(实际上,很大程度上是该页面的js加载和运行效率)决定要加载多少秒. 再次测试一台机器,不要立即进入云端采集,如果不正确地测试它,就会很烦.
6. 数据提取-如果我提取了一堆我不想要的东西该怎么办?
数据提取都是从html代码中提取的,因此存在取决于您要提取的内容的问题. 如果您只想提取前端页面上可以看到的文本,通常可以直接提取它. 这在优采云中更加愚蠢,效果非常好. 但是,网页的结构很奇怪,并且存在各种嵌入式问题. 在某些情况下,文本会分为多个段落,但是我们希望整个段落采集在上一页中可能看不到. 只有查看代码,文本才能被其他嵌入元素分隔.
解决方法不太复杂. 如果很通用,则只需应用整个段落,例如P标记采集文本,然后使用正则表达式或普通替换来清除不需要的字符串,空格,换行等.
7. 有条件判断-如果不是,大法
优采云的条件判断不能与编写代码相提并论,但它也被认为是该工具中非常强大的工具. 在优采云中可以实现的逻辑判断是,如果出现一个元素/不出现一个元素,则执行xxx;如果页面上出现文本xxx或不出现xxx,则执行xxx. 如程序员所说,如果a则为xxx,否则为b则为xxx,否则为xxx. 可以使用多个条件进行判断,因此不限于一个或两个条件. 如果当前条件判断为假,则将执行默认处理.
这有什么例行程序,主要是当您批处理采集页时,您会遇到不同的页. 例如,采集网易新闻列表中的新闻页面都被称为新闻,但是页面格式不同,这导致采集元素的位置和流程可能完全不同. 因此,将某些条件用作逻辑判断. 例如,出现什么元素,我认为它是这种新闻页面,并使用此采集流程;当出现另一个元素时,它被认为是另一种新闻,并更改为采集流程. 这样,可以更好地解决文章列表相同但细节页面不同的问题.
8. 失败重试-莫名其妙的失败,不是莫名其妙的重试
重试失败是形而上的问题. 失败的可能性太多. 例如,另一方的应用程序服务器被卡住,页面数据未返回,服务器500错误,服务器403被打开,页面的某些部分未加载,页面加载超时等等. 只要您认为采集的数据条目未出现,即使加载了该7页,该页也会失败,但是在许多情况下,设置失败并重试的方法是找到一个肯定会如果正常采集,则出现. 如果没有出现,请重试,但是设置一个间隔来考虑采集的效率和稳定性.
9. 图片下载
许多人抱怨优采云图片下载很麻烦,而且官方下载器的使用是如此复杂. 例程也很简单,只需下载图片链接采集,下载此东西,我就大雷了,为什么要优采云?迅雷批量下载和输入,世界是干净的(实际上,这并不干净,迅雷下载的叮当声将是一个接一个).
第二,常见的“错误方式” 1.正常采集不容易处理吗?从Wap版本采集更改
许多网站具有常规的网络版本和通过手机访问的Wap版本. 在许多情况下,如果发现网络版本比较困难采集,并且遇到很多问题,可以考虑更改为Wap版本进行登录. 有时候,找到Wap版本URL并不容易. 您可以先尝试在移动浏览器中搜索它,找到URL,然后将其放在优采云 采集器中,检查移动版本以尝试采集.
应注意,优采云 采集器中的手机版本显示可能与手机上的显示不同. 在许多情况下,会有一些不易操作或无法解释的问题. 毕竟,这是没有办法的,它不是专用的手机模拟器,因此您需要尝试更多,更多的采集路线将有更多的机会.
2. 自动登录困难吗?将回复时间更改为手动
例如,知乎之类的网站或其他各种“魔术”验证网站,有时需要在登录时进行验证,有时需要在采集的处理中以对抗采集添加的验证. 一切都是为了消除低级爬虫和采集工具.
这时,我们最好的解决方案是添加手动处理操作. 在制定规则的过程中,我们可以根据条件判断,也可以在进行具体操作之前增加等待时间. 在独立采集的过程中,可以使用手动操作来解决验证问题. 这确实没有效率,但是在这个钱不成问题的时代,问题在于人们是这个钱时代最便宜的东西...所以要用自己的身体...工作...
3. 瀑布“单击以加载更多”页面?创建一个单独的循环以单击它
许多网站需要保持单击“加载更多”以加载更多列表页面. 此时,在页面加载后,只需创建一个单独的循环并将其设置为在循环中继续单击即可. “加载更多”已足够,请记住选择并单击各个元素,类似于自动翻页的循环.
在此循环下,您可以继续创建采集列表的循环. 但是,虽然最好的方法是捕获和分析,但是采集方法可能并不适用于所有页面,但是在优采云中,让我们使用此方法进行处理.
4. 采集速度太慢了((: з)∠)_多个小细节选项可以帮助您加快速度
在日常采集流程中,每个人都希望尽快采集完成数据,但并不是每个人都有钱购买旗舰版. 然后,您必须充分利用独立版本(第一个工件),进行检查以阻止广告,减少广告加载对速度的影响;第二个伪像,检查不加载图片,大大减少了图像数据的加载时间;第三件,检查Non-Ajax页面加载优化情况,普通页面的速度有小幅提高;第四个工件,升级硬件...虽然废话,但是旧机器和网络无法改善软件的运行和采集速度,尽管硬件有了很大的改进,但软件运行速度一直没有提高. 大大提高了,但是内存的保证仍然非常重要. 足够的内存可以减少大量数据采集或多线程处理期间的延迟.
更多例程,请缓慢更新. 欢迎加入我的QQ群进行交流. 希望您能分享更多例程.
组号: 462346024
教程:织梦CMS后台图文采集规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 457 次浏览 • 2020-08-31 05:31
首先要注意的是:
1. 代码的唯一性
2,采集完成,最好导入采集的内容
在采集后删除内容,然后进行下一个采集
登录到后台的方法/步骤,如下图所示:
(单击“采集”,然后选择“采集节点管理”. )
(单击-添加新节点)
(选择内容模型---- 1,如果是采集文章,则选择“普通文章”. 2.如果是图片,则选择“图片集”)
新采集节点: 第一步是设置基本信息和URL索引页面规则(注意: 1.自行命名节点2.目标页面代码: 采集站的代码必须相同3.列出URL获取规则-匹配的URL,通常是列表页面URL之一,请按照以下说明操作. )
(该区域开头的HTML: 此块是用于填充列表页面的起始代码. 代码的长度无关紧要,但是该代码必须是唯一的,即,该代码不会重复在整个源代码中,它只出现一次.
该区域末尾的HTML: 结尾代码也是如此,并且必须唯一.
)保存,下一步是确定
此步骤是[URL获取规则]
(已测试的列表URL: 1.这是上一步中填写的列表URL. 如果在上一步中没有问题,则将显示采集的文章标题列表. 2.如果没有,请返回上一步. 再次修改,如果正确,请转到下一步. )
在此步骤中,开始采集文章内容[Web内容获取规则] 查看全部
织梦cms背景图片和文字采集规则
首先要注意的是:
1. 代码的唯一性
2,采集完成,最好导入采集的内容
在采集后删除内容,然后进行下一个采集
登录到后台的方法/步骤,如下图所示:
(单击“采集”,然后选择“采集节点管理”. )
(单击-添加新节点)
(选择内容模型---- 1,如果是采集文章,则选择“普通文章”. 2.如果是图片,则选择“图片集”)
新采集节点: 第一步是设置基本信息和URL索引页面规则(注意: 1.自行命名节点2.目标页面代码: 采集站的代码必须相同3.列出URL获取规则-匹配的URL,通常是列表页面URL之一,请按照以下说明操作. )
(该区域开头的HTML: 此块是用于填充列表页面的起始代码. 代码的长度无关紧要,但是该代码必须是唯一的,即,该代码不会重复在整个源代码中,它只出现一次.
该区域末尾的HTML: 结尾代码也是如此,并且必须唯一.
)保存,下一步是确定
此步骤是[URL获取规则]
(已测试的列表URL: 1.这是上一步中填写的列表URL. 如果在上一步中没有问题,则将显示采集的文章标题列表. 2.如果没有,请返回上一步. 再次修改,如果正确,请转到下一步. )
在此步骤中,开始采集文章内容[Web内容获取规则]
解读:芭奇:不用编写采集规则也可轻松采集网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 284 次浏览 • 2020-08-31 00:16
很长一段时间以来,每个人都在使用带有采集功能的各种类型的采集器或网站程序. 它们具有一个共同的功能,即将采集规则写入到{mask5}的采集中,这个技术问题对于新手来说并不是一件容易的事,对于老网站管理员来说,这也是一项艰巨的任务. 因此,如果您执行站群操作,则每个站都必须定义一个采集规则,这确实很痛苦. 有人说网站管理员是网络搬运工. 这句话也很有意义. 互联网上的许多文章都是让我感动的,而我也感动了您. 为了生活,我必须这样做. 现在,批处理站群软件具有新的新采集功能,该功能可以大大减少网站站长“搬运工”的时间,而不再需要编写烦人的采集规则. 此功能是Internet的第一个功能. ---指定URL采集. 让我教您如何使用此功能:
首先,首先打开此功能. 您可以在网站的右键中看到此功能,如下所示.
第二,打开后的功能如下,您可以填写右侧指定采集的列表地址:
在这里,我使用百度的搜索页面作为采集的来源,例如: %B0%C5%C6%E6
然后,我使用Baqi站群软件采集了该搜索结果的所有文章. 您可以先分析此页面. 如果您使用各种类型的采集器或网站内置程序来自定义采集和所有文章,则无法获得它. 因为Internet上没有这样一个通用的采集不同网站的功能,但是现在,可以实现Batch站群软件. 因为该软件支持pan采集技术.
3. 在主页上,我将此百度结果列表填写到软件的“起始采集文章列表地址”中,如下所示:
四个. 为了能够正确地采集我想要的列表,我们分析结果列表上的文章有一个通用的后缀,即: html,shtml,htm,那么这三个是通用的. 位置是: 我为软件定义了htm . 这种方法是为了减少采集的无用页面,如下所示:
五个. 现在您可以进行采集了,但是我想提醒您,一个网站中通常有许多字符相同的字符. 对于此百度列表,也有百度自己的网页,但是百度本身网页的内容不是我要使用的内容,因此还有另一个地方可以排除带有百度URL的页面. 如下图所示:
此定义之后,它将避免使用百度自己的页面. 然后以这种方式填写,您可以直接采集文章,单击“保存采集数据”:
一两分钟后,采集过程的结果如下图所示:
六个. 在这里,我只选择文章的一部分,然后不再选择它. 现在查看采集后的内容:
七. 以上是采集的过程. 根据上述步骤,您还可以在其他地方列出采集文章,尤其是没有收录或被收录遮挡的网站,这些都是原创的文章,您可以自己找到. 现在,让我告诉您有关软件的其他一些功能:
1. 如上图所示,这是删除URL和采集图片的功能. 您可以检查是否想要.
2. 如上图所示,这里是设置采集次数和采集文章的最小单词数.
3. 如上图所示,您可以在此处定义替换词,支持代码替换,文本替换等,并在此处灵活使用它们. 对于某些困难的采集列表,将在此处使用它们. 您可以先将某些代码替换为空格,然后再获取列表链接.
我上面说的是Baqi站群软件的新采集功能. 此功能非常强大,但是需要改进此功能以满足不同人群的需求. 使用此工具,您不必担心不知道如何编写采集规则. 此功能易于上手,易于操作. 这是新老网站管理员最适合的功能. 如果您听不懂,可以将我加到QQ并问我: 509229860. 查看全部
批处理: 您可以轻松编写网站,而无需编写采集规则.
很长一段时间以来,每个人都在使用带有采集功能的各种类型的采集器或网站程序. 它们具有一个共同的功能,即将采集规则写入到{mask5}的采集中,这个技术问题对于新手来说并不是一件容易的事,对于老网站管理员来说,这也是一项艰巨的任务. 因此,如果您执行站群操作,则每个站都必须定义一个采集规则,这确实很痛苦. 有人说网站管理员是网络搬运工. 这句话也很有意义. 互联网上的许多文章都是让我感动的,而我也感动了您. 为了生活,我必须这样做. 现在,批处理站群软件具有新的新采集功能,该功能可以大大减少网站站长“搬运工”的时间,而不再需要编写烦人的采集规则. 此功能是Internet的第一个功能. ---指定URL采集. 让我教您如何使用此功能:
首先,首先打开此功能. 您可以在网站的右键中看到此功能,如下所示.
第二,打开后的功能如下,您可以填写右侧指定采集的列表地址:
在这里,我使用百度的搜索页面作为采集的来源,例如: %B0%C5%C6%E6
然后,我使用Baqi站群软件采集了该搜索结果的所有文章. 您可以先分析此页面. 如果您使用各种类型的采集器或网站内置程序来自定义采集和所有文章,则无法获得它. 因为Internet上没有这样一个通用的采集不同网站的功能,但是现在,可以实现Batch站群软件. 因为该软件支持pan采集技术.
3. 在主页上,我将此百度结果列表填写到软件的“起始采集文章列表地址”中,如下所示:
四个. 为了能够正确地采集我想要的列表,我们分析结果列表上的文章有一个通用的后缀,即: html,shtml,htm,那么这三个是通用的. 位置是: 我为软件定义了htm . 这种方法是为了减少采集的无用页面,如下所示:
五个. 现在您可以进行采集了,但是我想提醒您,一个网站中通常有许多字符相同的字符. 对于此百度列表,也有百度自己的网页,但是百度本身网页的内容不是我要使用的内容,因此还有另一个地方可以排除带有百度URL的页面. 如下图所示:
此定义之后,它将避免使用百度自己的页面. 然后以这种方式填写,您可以直接采集文章,单击“保存采集数据”:
一两分钟后,采集过程的结果如下图所示:
六个. 在这里,我只选择文章的一部分,然后不再选择它. 现在查看采集后的内容:
七. 以上是采集的过程. 根据上述步骤,您还可以在其他地方列出采集文章,尤其是没有收录或被收录遮挡的网站,这些都是原创的文章,您可以自己找到. 现在,让我告诉您有关软件的其他一些功能:
1. 如上图所示,这是删除URL和采集图片的功能. 您可以检查是否想要.
2. 如上图所示,这里是设置采集次数和采集文章的最小单词数.
3. 如上图所示,您可以在此处定义替换词,支持代码替换,文本替换等,并在此处灵活使用它们. 对于某些困难的采集列表,将在此处使用它们. 您可以先将某些代码替换为空格,然后再获取列表链接.
我上面说的是Baqi站群软件的新采集功能. 此功能非常强大,但是需要改进此功能以满足不同人群的需求. 使用此工具,您不必担心不知道如何编写采集规则. 此功能易于上手,易于操作. 这是新老网站管理员最适合的功能. 如果您听不懂,可以将我加到QQ并问我: 509229860.
【沙克芬】不用写代码的数据采集软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 377 次浏览 • 2020-08-30 18:19
现在,采集数据方法已经相对成熟. 对于常用的网站和结构化网站,您可以使用数据采集软件来执行数据采集. 优点是无需编写代码,基本上没有HTML知识,可视化操作,方便直观. 缺点是它不够灵活,但足以满足基本需求.
在这里,我主要介绍由中国公司开发的数据采集软件. 实际上,它们都是一样的. 我主要使用优采云采集器和webscraper浏览器插件
大多数这些软件包括免费和付费功能. 通常免费就足够了.
我认为有一个更正确的想法,即对于常用的网站,前辈已经编写了许多采集器框架,您可以使用它们. 例如,在gooseeker和webscraper浏览器插件的网站上,有许多现成的书面形式.
对于某些相对特殊的数据,例如AutoNavi Maps上的企业数据,我也遇到了转换不同地图坐标系的问题. 有许多防爬策略,等等. 这些比较困难. 有专门的公司和专门的软件正在执行此操作,这不在这些“虚拟”软件的使用范围之内.
名称URL简介
优采云采集器
优采云采集器
魅力
探索代码Web大数据采集系统
优采云采集器
优采云采集器
ForeSpider前端嗅探
gooseeker采集并采集客户
出生地
优采云爬虫
整个网络的Little Strawberry-采集助手
WebMagic一个简单而灵活的Java采集器框架
DenseSpider Go语言实现的高性能爬虫
scrapinghub
prasehub
Octoparse外部软件
webscraper浏览器插件
复制代码
一些亲自挑选出来的网站放在“鱼Qu”上. 欢迎大家参观! 查看全部
[Sakfin]数据采集软件,无需编写代码
现在,采集数据方法已经相对成熟. 对于常用的网站和结构化网站,您可以使用数据采集软件来执行数据采集. 优点是无需编写代码,基本上没有HTML知识,可视化操作,方便直观. 缺点是它不够灵活,但足以满足基本需求.
在这里,我主要介绍由中国公司开发的数据采集软件. 实际上,它们都是一样的. 我主要使用优采云采集器和webscraper浏览器插件
大多数这些软件包括免费和付费功能. 通常免费就足够了.
我认为有一个更正确的想法,即对于常用的网站,前辈已经编写了许多采集器框架,您可以使用它们. 例如,在gooseeker和webscraper浏览器插件的网站上,有许多现成的书面形式.
对于某些相对特殊的数据,例如AutoNavi Maps上的企业数据,我也遇到了转换不同地图坐标系的问题. 有许多防爬策略,等等. 这些比较困难. 有专门的公司和专门的软件正在执行此操作,这不在这些“虚拟”软件的使用范围之内.
名称URL简介
优采云采集器
优采云采集器
魅力
探索代码Web大数据采集系统
优采云采集器
优采云采集器
ForeSpider前端嗅探
gooseeker采集并采集客户
出生地
优采云爬虫
整个网络的Little Strawberry-采集助手
WebMagic一个简单而灵活的Java采集器框架
DenseSpider Go语言实现的高性能爬虫
scrapinghub
prasehub
Octoparse外部软件
webscraper浏览器插件
复制代码
一些亲自挑选出来的网站放在“鱼Qu”上. 欢迎大家参观!
【03】基础:同种网页结构套用采集规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-08-30 08:22
单条添加
点击“添加线索”,输入线索网址后保存。
批量添加
用Excel储存线索网址
点击“批量导出线索”,添加附件,点击“批量导出”后添加成功!
添加了6条,加上原先的一个样本网址,总共7条线索,现在都是“待抓取”状态。
在这个页面,除了添加线索、还可以激活、去活以及删掉线索。
如何运行线索?
运行采集规则就是运行规则里头的线索。
由上图可知,现在“weibo_博主主页”这个规则中有7条线索,都是“待抓取”状态。运行那些线索要在DS打数机启动。
打开DS打数机,搜索出要运行的规则,点击“单搜”或者“集搜”都可以启动DS打数机进行抓取数据。
单搜:在当前DS窗口采集;集搜:弹出新的窗口采集。
点击集搜后,待抓取线索有几条就输入几条,点击确定。
我们看见DS打数机马上在运行抓取了。
如果不知道待抓取线索有多少条,在DS打数机右击统计线索就可以了。
如何激活线索?
刚刚运行了“weibo_博主主页”这个采集规则,在会员中心见到这7条线索都是“抓取完成”的状态。
如果按前面的步骤在DS打数机中再度运行规则,这时候会提示没有线索了,那是因为刚才早已运行这7条线索了。
要重新抓取这种线索只要重新将这种线索激活就可以了,激活之后这种线索的状态将会弄成“待抓取”。
激活有两种方式——
规则管理激活
在规则管理选择要激活的线索后点击“激活”按钮。
DS窗口激活
到这儿,看看刚才运行“weibo_博主主页”这个采集规则的结果文件吧~
下一期将讲结果文件转成Excel,学完下一期你就早已入门了,只要不是复杂的网页你都可以采集了,所向披靡,是不是太兴奋。 查看全部
【03】基础:同种网页结构套用采集规则
单条添加
点击“添加线索”,输入线索网址后保存。
批量添加
用Excel储存线索网址
点击“批量导出线索”,添加附件,点击“批量导出”后添加成功!
添加了6条,加上原先的一个样本网址,总共7条线索,现在都是“待抓取”状态。
在这个页面,除了添加线索、还可以激活、去活以及删掉线索。
如何运行线索?
运行采集规则就是运行规则里头的线索。
由上图可知,现在“weibo_博主主页”这个规则中有7条线索,都是“待抓取”状态。运行那些线索要在DS打数机启动。
打开DS打数机,搜索出要运行的规则,点击“单搜”或者“集搜”都可以启动DS打数机进行抓取数据。
单搜:在当前DS窗口采集;集搜:弹出新的窗口采集。
点击集搜后,待抓取线索有几条就输入几条,点击确定。
我们看见DS打数机马上在运行抓取了。
如果不知道待抓取线索有多少条,在DS打数机右击统计线索就可以了。
如何激活线索?
刚刚运行了“weibo_博主主页”这个采集规则,在会员中心见到这7条线索都是“抓取完成”的状态。
如果按前面的步骤在DS打数机中再度运行规则,这时候会提示没有线索了,那是因为刚才早已运行这7条线索了。
要重新抓取这种线索只要重新将这种线索激活就可以了,激活之后这种线索的状态将会弄成“待抓取”。
激活有两种方式——
规则管理激活
在规则管理选择要激活的线索后点击“激活”按钮。
DS窗口激活
到这儿,看看刚才运行“weibo_博主主页”这个采集规则的结果文件吧~
下一期将讲结果文件转成Excel,学完下一期你就早已入门了,只要不是复杂的网页你都可以采集了,所向披靡,是不是太兴奋。
STM32 ADC多通道转换DMA模式与非DMA模式两种方式(HAL库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2020-08-29 21:13
一、非DMA模式(转)
说明:这个是自己刚做的时侯百度下来的,不是我自己做下来的,因为觉得有用就保存出来做学习用,原文链接:,下面第二部份我会补充自己的DMA模式的技巧。
Stm32 ADC 的转换模式还是太灵活,很强悍,模式种类好多,那么这也造成很多人使用的时侯没悉心研究参考指南的情况下容易混淆。不知道该用哪种方法来实现自己想要的功能。网上也可以搜到好多资料,但是大部分是针对之前老版本的标准库的。昨天帮顾客解决这个问题,正好做个总结:使用stm32cubeMX配置生成多通道采集的反例。
软件:STM32Cumebx MDK
硬件:eemaker板(基于stm32F103c8的)
在百度搜索ADC多通道采集,大部分的都是基于采用dma模式才实现的。而我讲的使用非dma技巧。首先有几个概念要搞清楚:
扫描模式(想采集多通道必须开启):是一次对所选中的通道进行转换,比如开了ch0,ch1,ch4,ch5。Ch0转换完之后才会手动转换通道0,1,4,5直至转换完。但是这些连续性并不是不能被打断。这就引入了间断模式,可以说是对扫描模式的一种补充。它可以把0,1,4,5这四个通道进行分组。可以分成0,1一组,4,5一组。也可以每位通道配置为一组。这样每一组转换之前都须要先触发一次。
Stm32 ADC的单次模式和连续模式。这两中模式的概念是相对应的。这里的单次模式并不是指一个通道。假如你同时开了ch0,ch1,ch4,ch5这四个通道。单次模式转换模式下会把这四个通道采集一边就停止了。而连续模式就是这四个通道转换完之后再循环过来再从ch0开始。
另外还有规则组和注入组的概念,因为我这个类库只用到了规则组,就不多介绍这两个概念,想要弄清楚请自行查阅指南。
下面步入题外话,配置stm32cubeMX。
先让能几个通道,我这儿设置为0、1、4、5.
然后就要配置ADC的参数:
目前经过我的测试,要想用非dma和中断模式只有这样配置可以正确进行多通道转换:扫描模式+单次转换模式+间断转换模式(每个间断组一个通道)。
分析配置成这样的模式,扫描模式是在配置为多个通道必须打开的,stm32cubeMX上也默认好了,只能enable。单次转换模式是我不需要不停的去采集每个通道值,而是把四个通道采集完之后就让它停止。这里间断配置是关键,间断模式可以使扫描的四个通道进行分成四个组,stm32cubeMX参数上面number of Discontinous Conversions是配置间断组每位组有几个通道的,这里必须配置为1(否则在获取ad值得时侯只能读取到每位间断组最后一个通道)。
生成mdk工程代码。这时候还没有完成,只是实现了ADC的初始化,需要采集这四个通道值得函数还要自己写。下面这个是我main函数的while循环:
<p>for(i=1;i 查看全部
STM32 ADC多通道转换DMA模式与非DMA模式两种方式(HAL库)
一、非DMA模式(转)
说明:这个是自己刚做的时侯百度下来的,不是我自己做下来的,因为觉得有用就保存出来做学习用,原文链接:,下面第二部份我会补充自己的DMA模式的技巧。
Stm32 ADC 的转换模式还是太灵活,很强悍,模式种类好多,那么这也造成很多人使用的时侯没悉心研究参考指南的情况下容易混淆。不知道该用哪种方法来实现自己想要的功能。网上也可以搜到好多资料,但是大部分是针对之前老版本的标准库的。昨天帮顾客解决这个问题,正好做个总结:使用stm32cubeMX配置生成多通道采集的反例。
软件:STM32Cumebx MDK
硬件:eemaker板(基于stm32F103c8的)
在百度搜索ADC多通道采集,大部分的都是基于采用dma模式才实现的。而我讲的使用非dma技巧。首先有几个概念要搞清楚:
扫描模式(想采集多通道必须开启):是一次对所选中的通道进行转换,比如开了ch0,ch1,ch4,ch5。Ch0转换完之后才会手动转换通道0,1,4,5直至转换完。但是这些连续性并不是不能被打断。这就引入了间断模式,可以说是对扫描模式的一种补充。它可以把0,1,4,5这四个通道进行分组。可以分成0,1一组,4,5一组。也可以每位通道配置为一组。这样每一组转换之前都须要先触发一次。
Stm32 ADC的单次模式和连续模式。这两中模式的概念是相对应的。这里的单次模式并不是指一个通道。假如你同时开了ch0,ch1,ch4,ch5这四个通道。单次模式转换模式下会把这四个通道采集一边就停止了。而连续模式就是这四个通道转换完之后再循环过来再从ch0开始。
另外还有规则组和注入组的概念,因为我这个类库只用到了规则组,就不多介绍这两个概念,想要弄清楚请自行查阅指南。
下面步入题外话,配置stm32cubeMX。
先让能几个通道,我这儿设置为0、1、4、5.
然后就要配置ADC的参数:
目前经过我的测试,要想用非dma和中断模式只有这样配置可以正确进行多通道转换:扫描模式+单次转换模式+间断转换模式(每个间断组一个通道)。
分析配置成这样的模式,扫描模式是在配置为多个通道必须打开的,stm32cubeMX上也默认好了,只能enable。单次转换模式是我不需要不停的去采集每个通道值,而是把四个通道采集完之后就让它停止。这里间断配置是关键,间断模式可以使扫描的四个通道进行分成四个组,stm32cubeMX参数上面number of Discontinous Conversions是配置间断组每位组有几个通道的,这里必须配置为1(否则在获取ad值得时侯只能读取到每位间断组最后一个通道)。
生成mdk工程代码。这时候还没有完成,只是实现了ADC的初始化,需要采集这四个通道值得函数还要自己写。下面这个是我main函数的while循环:
<p>for(i=1;i
1688商品采集 v1.9 官方版
采集交流 • 优采云 发表了文章 • 0 个评论 • 575 次浏览 • 2020-08-28 05:20
1688商品采集工具是一款专业的产品信息采集软件。1688商品采集软件官方版界面友好,操作简单。用户通过这款软件能够便捷迅速的了解各平台上的产品信息,目前被广泛用于产品行情剖析、同行销售业绩评估、企业信息搜集等。
【功能介绍】支持二种采集模式:
1、页面设置采集。
在WEB页面设置一个采集关键词,并可精细化设置采集条件(如样式、颜色、尺寸大小等)。 这种适用于复杂条件下的精细化采集。
2、按关键词批量采集。
通过导出一批关键词,直接按关键词采集。
采集的信息包括产品ID、产品标题、产品URL、产品价钱、产品图、月销量、月销售额、回头率、货描、响应、发货、旺旺、公司名、业务类型等等数组,导出为文本表格(excel),可用于产品行情剖析、同行销售业绩评估、企业信息搜集等用途。每个产品关键词较高支持100页,每页60个产品,大约6000个产品信息。支持详尽的搜索参数设置,支持多个产品关键词次序采集,不同关键词回车键一行一个,支持数组排序(点击表头列)后再导入保存。
【软件特色】1、只要用滑鼠点击即可,无需写任何采集规则,
2、实时采集,非历史数据,在用户本地采集当前最新的数据。
3、操作简单容易上手,傻瓜式操作,二步到位(导入产品的详情链接,一行一个、可以导出多个产品链接;点击开始采集;导出数据)。不需手写任何规则,操作非常简单。
4、快速搜索、极速的操作体验,流畅愉悦。
5、带手动升级功能:官方发布新版本后,打开客户端会手动升级到最新版本。
6、软件将继续保持模块更新。
【使用方式】1、采集模式1(按搜索页面设置)
(1)点击“搜索页面设置”按钮,输入要采集的关键词
(2)可以进行类目设置、设置完后点击“页面直接采集”按钮
(3)采集数据如图所示
(4)同时还可以点击“浏览视图切换开发”,进行浏览器的显示切换。
2、采集模式2(导入关键词采集)
(1)导入要采集的关键词,多个关键词(一行一个)
(2)点击“导入模式采集”按钮
(3)同时还可以点击“浏览视图切换开发”,进行浏览器的显示切换。
【常见问题】1、支持的操作系统?
Win7及以上版本(32位或64位均可)。xp不支持。
2、试用版和正版的区别?
试用版有采集导出关键信息加密外(24小时限时试用),其它无任何限制,因此选购前可先试用体验。
因为质量过关,所以我们的软件可放开体验试用。(不象许多同行不可体验或做了足够限制的拙劣体验)。
3、采集速度?
无任何限制,您机器性能和带宽。
4、换机器或软件遗失怎样办?
QQ和陌陌联系我们即可处理。只是要我们的VIP顾客,在授权期内,我们就会及时处理。 查看全部
1688商品采集 v1.9 官方版
1688商品采集工具是一款专业的产品信息采集软件。1688商品采集软件官方版界面友好,操作简单。用户通过这款软件能够便捷迅速的了解各平台上的产品信息,目前被广泛用于产品行情剖析、同行销售业绩评估、企业信息搜集等。
【功能介绍】支持二种采集模式:
1、页面设置采集。
在WEB页面设置一个采集关键词,并可精细化设置采集条件(如样式、颜色、尺寸大小等)。 这种适用于复杂条件下的精细化采集。
2、按关键词批量采集。
通过导出一批关键词,直接按关键词采集。
采集的信息包括产品ID、产品标题、产品URL、产品价钱、产品图、月销量、月销售额、回头率、货描、响应、发货、旺旺、公司名、业务类型等等数组,导出为文本表格(excel),可用于产品行情剖析、同行销售业绩评估、企业信息搜集等用途。每个产品关键词较高支持100页,每页60个产品,大约6000个产品信息。支持详尽的搜索参数设置,支持多个产品关键词次序采集,不同关键词回车键一行一个,支持数组排序(点击表头列)后再导入保存。
【软件特色】1、只要用滑鼠点击即可,无需写任何采集规则,
2、实时采集,非历史数据,在用户本地采集当前最新的数据。
3、操作简单容易上手,傻瓜式操作,二步到位(导入产品的详情链接,一行一个、可以导出多个产品链接;点击开始采集;导出数据)。不需手写任何规则,操作非常简单。
4、快速搜索、极速的操作体验,流畅愉悦。
5、带手动升级功能:官方发布新版本后,打开客户端会手动升级到最新版本。
6、软件将继续保持模块更新。
【使用方式】1、采集模式1(按搜索页面设置)
(1)点击“搜索页面设置”按钮,输入要采集的关键词
(2)可以进行类目设置、设置完后点击“页面直接采集”按钮
(3)采集数据如图所示
(4)同时还可以点击“浏览视图切换开发”,进行浏览器的显示切换。
2、采集模式2(导入关键词采集)
(1)导入要采集的关键词,多个关键词(一行一个)
(2)点击“导入模式采集”按钮
(3)同时还可以点击“浏览视图切换开发”,进行浏览器的显示切换。
【常见问题】1、支持的操作系统?
Win7及以上版本(32位或64位均可)。xp不支持。
2、试用版和正版的区别?
试用版有采集导出关键信息加密外(24小时限时试用),其它无任何限制,因此选购前可先试用体验。
因为质量过关,所以我们的软件可放开体验试用。(不象许多同行不可体验或做了足够限制的拙劣体验)。
3、采集速度?
无任何限制,您机器性能和带宽。
4、换机器或软件遗失怎样办?
QQ和陌陌联系我们即可处理。只是要我们的VIP顾客,在授权期内,我们就会及时处理。
DedeCMS导出采集规则提示“该规则不合法,无法导出”的解决办法
采集交流 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2020-08-27 22:06
DedeCMS导出采集规则提示“该规则不合法,无法导出”的解决办法 织梦无忧 故障问题2018-12-09 20:40
摘要:最近一段时间好多使用dedecms V5.7的站长同学反映采集规则导出失败,总是提示该规则不合法,无法导出! 织梦技术研究中心经过检测后给出一个临时解决方案,需要更改管理目录下的co_get_corule.php文件,下面是具体的解决办法: 第一步、导出采集规则时选用导
最近一段时间好多使用dedecms V5.7的站长同学反映采集规则导出失败,总是提示“该规则不合法,无法导出! ”
织梦58经过检测后给出一个临时解决方案,需要更改管理目录下的co_get_corule.php文件,下面是具体的解决办法:
第一步、导出采集规则时选用导入普通格式
第二步、打开管理目录下的co_get_corule.php文件,删除掉第51-58行的如下代码:
1 // 进行转码
2 if($cfg_soft_lang =='gb2312')
3 {
4 $notes = iconv('ucs-2','gb18030', $notes);
5 }elseif($cfg_soft_lang =='utf-8')
6 {
7 $notes = iconv('ucs-2','utf-8ignore', $notes);
8 }
删除后保存即可。
本文链接: 查看全部
DedeCMS导出采集规则提示“该规则不合法,无法导出”的解决办法
DedeCMS导出采集规则提示“该规则不合法,无法导出”的解决办法 织梦无忧 故障问题2018-12-09 20:40
摘要:最近一段时间好多使用dedecms V5.7的站长同学反映采集规则导出失败,总是提示该规则不合法,无法导出! 织梦技术研究中心经过检测后给出一个临时解决方案,需要更改管理目录下的co_get_corule.php文件,下面是具体的解决办法: 第一步、导出采集规则时选用导
最近一段时间好多使用dedecms V5.7的站长同学反映采集规则导出失败,总是提示“该规则不合法,无法导出! ”
织梦58经过检测后给出一个临时解决方案,需要更改管理目录下的co_get_corule.php文件,下面是具体的解决办法:
第一步、导出采集规则时选用导入普通格式
第二步、打开管理目录下的co_get_corule.php文件,删除掉第51-58行的如下代码:
1 // 进行转码
2 if($cfg_soft_lang =='gb2312')
3 {
4 $notes = iconv('ucs-2','gb18030', $notes);
5 }elseif($cfg_soft_lang =='utf-8')
6 {
7 $notes = iconv('ucs-2','utf-8ignore', $notes);
8 }
删除后保存即可。
本文链接:
织梦CMS后台图文采集规则图文教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 430 次浏览 • 2020-08-25 19:28
首先注意的是:
1、代码的唯一性
2、采集完成 最好把采集的内容导出以后
把采集完的内容删掉 在进行上次采集
方法/步骤登陆后台,如下图所示:
(点击采集,然后选择采集节点管理。)
(点击---增加新节点)
(选择内容模型----1,如果采集文章的话,就选“普通文章“.2、如果是图片的话,就选择“图片集”)
新增采集节点:第一步设置基本信息及网址索引页规则(注意事项:1、节点名称自己起名子2、目标页面编码:和采集站的编码要一致3、列表网址获取规则---匹配网址,一般就是其中的一个列表页网址,以下的就按说明操作即可。).
(区域开始的HTML: 这块是填写列表页的开始代码,代码长短无所谓,但是代码一定是要是唯一性, 就是这个代码在整个源代码中是不重复的, 也就是出现过一次的。
区域结束的HTML: 结束的代码也是一样,也是要唯一性。
)保存,下一步即可
这一步就是【网址获取规则】
(测试的列表网址:1、这个就是上一步填写的列表网址,如果上一步没有问题的话,这显示的就是采集的文章标题列表2、如果不是的话就返回上一步重新更改,正确的话就直接下一步。)
这一步就开始采集文章内容了【网页内容获取规则】 查看全部
织梦CMS后台图文采集规则图文教程
首先注意的是:
1、代码的唯一性
2、采集完成 最好把采集的内容导出以后
把采集完的内容删掉 在进行上次采集
方法/步骤登陆后台,如下图所示:
(点击采集,然后选择采集节点管理。)
(点击---增加新节点)
(选择内容模型----1,如果采集文章的话,就选“普通文章“.2、如果是图片的话,就选择“图片集”)
新增采集节点:第一步设置基本信息及网址索引页规则(注意事项:1、节点名称自己起名子2、目标页面编码:和采集站的编码要一致3、列表网址获取规则---匹配网址,一般就是其中的一个列表页网址,以下的就按说明操作即可。).
(区域开始的HTML: 这块是填写列表页的开始代码,代码长短无所谓,但是代码一定是要是唯一性, 就是这个代码在整个源代码中是不重复的, 也就是出现过一次的。
区域结束的HTML: 结束的代码也是一样,也是要唯一性。
)保存,下一步即可
这一步就是【网址获取规则】
(测试的列表网址:1、这个就是上一步填写的列表网址,如果上一步没有问题的话,这显示的就是采集的文章标题列表2、如果不是的话就返回上一步重新更改,正确的话就直接下一步。)
这一步就开始采集文章内容了【网页内容获取规则】

