
不用采集规则就可以采集
不用采集规则就可以采集(最近PTCMS火爆全网了,PTCMS源码下载地址:全新开发 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-08-29 18:08
)
近期PTcms火爆全网,PTcms源码下载地址:
说说PTcms的搭建教程。
功能介绍:
新开发,新UI,增加原创专区,新闻发布,书单发布,采集日志,百度推送,神马推送,推送日志功能。
前端高仿起点小说网站,自适应模板,可分手机域名。
后端是用LAYUI新开发的。
以下为施工内容:
一、服务器环境要求
推荐Linux环境,也支持win,但是我没有去测试和构建,按照下面的教程自己测试。下面是我要搭建的环境。
nginx1.15 MySQL5.5 php7.3
安装php扩展fileinfo memcached swoole4
删除php7.3禁用功能中的shell exec
二、Configuration Swoole
1、在/www/server/文件中创建一个ptcms文件夹,将License和loader73.so上传到ptcms
2、打开php7.3(也叫php.ini)的配置文件,拉到最下面,添加下面两行代码,保存重启php,如果报错,检查以上步骤如有错误!
extension= /www/server/ptcms/loader73.so swoole_license_files= /www/server/ptcms/license
三、Configuration网站Settings,
1、click网站——点击站点名称或设置
2、Set网站运行目录公开
3、设置伪静态规则
一定是下面的伪静态规则
if (!-e $request_filename) { rewrite ^/(.*) /index.php?s=$1 last; }
四、运行安装
直接访问域名报错,需要域名/install.php
以下是访问域名/install.php后的正确页面,按照提示安装即可,选择memcached
安装完成后,进入网站配置。后台功能设置就不介绍了。我只会解释如何启动自动采集
五、Configuration采集
1、点击采集管理——规则管理,进入采集规则管理页面
2、在给任务添加规则之前,建议先进行测试,测试规则是否可用
3、然后添加到任务区
4、点击任务管理——采集任务监控页面,看到主线进程状态failed,时间也是1970,说明你没有配置cron所以主进程没有运行
My 已激活,所以显示正常。如果您的显示器无法作为主进程运行,请执行以下操作。
说说配置cron启动主进程以及如何启动
1、首先我们可以使用SHH链接工具,或者直接连接宝塔的SHH也是可以的
2、进入shh连接页面,需要登录连接服务器,输入如下代码,进入网站目录,看我下面截图
cd /www/wwwroot/网站根目录名称
然后,输入以下代码启动主进程任务。我已经开始了,所以这是正常的。一开始就是下图的样子
/www/server/php/73/bin/php kx cron:check
现在我们回到后台刷新下一页,可以再次看到进程采集,点击开启自动刷新,会自动刷新页面
好的,基本安装和设置到此结束。现在来说说列表采集settings分页和后台设置分页采集。
分页规则应使用 [page] 设置进行分页
设置列表时选择前台或后台离线,前台浏览器不能关闭,可以关闭浏览器和电脑。
起始页可以从任何页开始,前提是目标站点有此页,结束页相同,且必须等于或大于起始页。
查看全部
不用采集规则就可以采集(最近PTCMS火爆全网了,PTCMS源码下载地址:全新开发
)
近期PTcms火爆全网,PTcms源码下载地址:
说说PTcms的搭建教程。
功能介绍:
新开发,新UI,增加原创专区,新闻发布,书单发布,采集日志,百度推送,神马推送,推送日志功能。
前端高仿起点小说网站,自适应模板,可分手机域名。
后端是用LAYUI新开发的。
以下为施工内容:
一、服务器环境要求
推荐Linux环境,也支持win,但是我没有去测试和构建,按照下面的教程自己测试。下面是我要搭建的环境。
nginx1.15 MySQL5.5 php7.3
安装php扩展fileinfo memcached swoole4


删除php7.3禁用功能中的shell exec

二、Configuration Swoole
1、在/www/server/文件中创建一个ptcms文件夹,将License和loader73.so上传到ptcms

2、打开php7.3(也叫php.ini)的配置文件,拉到最下面,添加下面两行代码,保存重启php,如果报错,检查以上步骤如有错误!
extension= /www/server/ptcms/loader73.so swoole_license_files= /www/server/ptcms/license

三、Configuration网站Settings,
1、click网站——点击站点名称或设置

2、Set网站运行目录公开
3、设置伪静态规则
一定是下面的伪静态规则
if (!-e $request_filename) { rewrite ^/(.*) /index.php?s=$1 last; }
四、运行安装
直接访问域名报错,需要域名/install.php
以下是访问域名/install.php后的正确页面,按照提示安装即可,选择memcached
安装完成后,进入网站配置。后台功能设置就不介绍了。我只会解释如何启动自动采集
五、Configuration采集
1、点击采集管理——规则管理,进入采集规则管理页面
2、在给任务添加规则之前,建议先进行测试,测试规则是否可用
3、然后添加到任务区
4、点击任务管理——采集任务监控页面,看到主线进程状态failed,时间也是1970,说明你没有配置cron所以主进程没有运行

My 已激活,所以显示正常。如果您的显示器无法作为主进程运行,请执行以下操作。
说说配置cron启动主进程以及如何启动
1、首先我们可以使用SHH链接工具,或者直接连接宝塔的SHH也是可以的

2、进入shh连接页面,需要登录连接服务器,输入如下代码,进入网站目录,看我下面截图
cd /www/wwwroot/网站根目录名称
然后,输入以下代码启动主进程任务。我已经开始了,所以这是正常的。一开始就是下图的样子
/www/server/php/73/bin/php kx cron:check
现在我们回到后台刷新下一页,可以再次看到进程采集,点击开启自动刷新,会自动刷新页面

好的,基本安装和设置到此结束。现在来说说列表采集settings分页和后台设置分页采集。
分页规则应使用 [page] 设置进行分页
设置列表时选择前台或后台离线,前台浏览器不能关闭,可以关闭浏览器和电脑。
起始页可以从任何页开始,前提是目标站点有此页,结束页相同,且必须等于或大于起始页。
不用采集规则就可以采集(非DMA模式转换模式的方法,你get到了吗? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-08-29 15:10
)
一、Non-DMA 模式(传输)
说明:这个是我第一次做的时候百度出来的。我不是自己做的。因为觉得很有用,所以存起来供学习之用。原文链接:,我会在下面的第二部分添加我自己的DMA模式的方法。 .
Stm32 ADC的转换方式还是非常灵活强大的。有许多类型的模式。当许多人在没有仔细阅读参考手册的情况下使用它时,这也会导致混淆。不知道用什么方式来实现我想要的功能。网上也可以查到很多资料,但大部分都是针对旧版标准库的。昨天帮客户解决了这个问题,只是做个总结:使用stm32cubeMX配置生成多通道采集的例子。
软件:STM32Cumebx MDK
硬件:eemaker板(基于stm32F103c8)
在百度上搜索ADC多通道采集,大部分都是基于dma模式的。我说的是使用非 dma 方法。首先,有几个概念需要澄清:
扫描模式(如果要采集multi-channel 必须开启):就是一次转换选中的通道,例如ch0、ch1、ch4、ch5都开启。 Ch0 转换后,会自动转换通道 0、1、4、5,直到转换完成。但这种连续性并不是不能中断。这就引入了一种非连续模式,可以说是对扫描模式的补充。可对0、1、4、5四个通道进行分组,可分为0、1组和4、5组,每个通道也可配置为一组。这样每组转化都需要触发一次。
Stm32 ADC 的单模式和连续模式。两种模式的概念是对应的。这里的单一模式不是指一个通道。假设您同时打开四个通道 ch0、ch1、ch4 和 ch5。在单模转换模式下,这四个通道采集会停在一侧。连续模式下,四个通道转换后循环,然后从ch0开始。
还有规则组和注入组的概念。因为我在这个例子中只使用了规则组,所以我不会介绍这两个概念。如果你想弄清楚,请参阅手册。
进入下面的主题并配置stm32cubeMX。
先开启几个通道,我设置为0、1、4、5.
然后我们需要配置ADC参数:
目前,经过我的测试,如果要使用非dma和中断模式,只有这样配置才能正确进行多通道转换:扫描模式+单次转换模式+非连续转换模式(每个非连续组一个通道) .
在此模式下配置分析。配置多通道时必须开启扫描模式。 stm32cubeMX 也是默认设置,只能启用。在单次转换模式下,我不需要不断去每个通道值采集,而是在四个通道采集完成后停止。不连续的配置是这里的关键。不连续模式允许将扫描的四个通道分为四组。 stm32cubeMX参数中的Discontinous Conversions的数量就是配置不连续组,每组有几个通道。此处必须配置为1(否则在获取广告值时,只能读取每个不连续组的最后一个通道)。
生成mdk项目代码。此时还没有完成,但是已经实现了ADC的初始化。你需要采集自己写四个频道值得的功能。以下是我的主函数的while循环:
<p>for(i=1;i 查看全部
不用采集规则就可以采集(非DMA模式转换模式的方法,你get到了吗?
)
一、Non-DMA 模式(传输)
说明:这个是我第一次做的时候百度出来的。我不是自己做的。因为觉得很有用,所以存起来供学习之用。原文链接:,我会在下面的第二部分添加我自己的DMA模式的方法。 .
Stm32 ADC的转换方式还是非常灵活强大的。有许多类型的模式。当许多人在没有仔细阅读参考手册的情况下使用它时,这也会导致混淆。不知道用什么方式来实现我想要的功能。网上也可以查到很多资料,但大部分都是针对旧版标准库的。昨天帮客户解决了这个问题,只是做个总结:使用stm32cubeMX配置生成多通道采集的例子。
软件:STM32Cumebx MDK
硬件:eemaker板(基于stm32F103c8)
在百度上搜索ADC多通道采集,大部分都是基于dma模式的。我说的是使用非 dma 方法。首先,有几个概念需要澄清:
扫描模式(如果要采集multi-channel 必须开启):就是一次转换选中的通道,例如ch0、ch1、ch4、ch5都开启。 Ch0 转换后,会自动转换通道 0、1、4、5,直到转换完成。但这种连续性并不是不能中断。这就引入了一种非连续模式,可以说是对扫描模式的补充。可对0、1、4、5四个通道进行分组,可分为0、1组和4、5组,每个通道也可配置为一组。这样每组转化都需要触发一次。
Stm32 ADC 的单模式和连续模式。两种模式的概念是对应的。这里的单一模式不是指一个通道。假设您同时打开四个通道 ch0、ch1、ch4 和 ch5。在单模转换模式下,这四个通道采集会停在一侧。连续模式下,四个通道转换后循环,然后从ch0开始。
还有规则组和注入组的概念。因为我在这个例子中只使用了规则组,所以我不会介绍这两个概念。如果你想弄清楚,请参阅手册。
进入下面的主题并配置stm32cubeMX。

先开启几个通道,我设置为0、1、4、5.
然后我们需要配置ADC参数:

目前,经过我的测试,如果要使用非dma和中断模式,只有这样配置才能正确进行多通道转换:扫描模式+单次转换模式+非连续转换模式(每个非连续组一个通道) .
在此模式下配置分析。配置多通道时必须开启扫描模式。 stm32cubeMX 也是默认设置,只能启用。在单次转换模式下,我不需要不断去每个通道值采集,而是在四个通道采集完成后停止。不连续的配置是这里的关键。不连续模式允许将扫描的四个通道分为四组。 stm32cubeMX参数中的Discontinous Conversions的数量就是配置不连续组,每组有几个通道。此处必须配置为1(否则在获取广告值时,只能读取每个不连续组的最后一个通道)。
生成mdk项目代码。此时还没有完成,但是已经实现了ADC的初始化。你需要采集自己写四个频道值得的功能。以下是我的主函数的while循环:
<p>for(i=1;i
不用采集规则就可以采集(统计某博主某一年内发布的全部微博,并计算转评赞总数)
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2021-08-29 11:08
我只是想统计某个博主在某一年发布的所有微博,并统计了转发和点赞的总数。这么简单的任务。没想到折腾了这么久。
首先是微博数据提供的支付功能。且不说支付,只能算近一年,不能任意规定时间段。比如2020.4.11这一天,只能统计2019.@。对于4.11~2020.4.11的数据,不是每年都要等过年了才算去年的数据吗? ? ?
于是我找到了微博API(),发现很难用。不知道是不是只有我。毕竟我只用过百度和高德的API,经验不够。先创建应用,找了好久才找到入口。它不在[我的应用程序]中,而是在主页上看起来像广告的按钮中。 API接口部分提供的基础公共信息需要授权,OAuth2.0授权因不明原因失败。官方渠道好像无法获取数据,只能自己爬了。
爬虫坑似乎迟早要被填满。我还没有学过,也没有使用过。找了几段别人的代码,改了微博ID后,访问不了。不知道企业微博是否受到保护。 .
最后不得不用优采云采集器来爬取数据。软件虽然好用,但还是费了一番周折才弄明白里面的各种设置。经过无数次的零采集和不完整的数据,最终的设置可能是不必要的,但是这组设置确实可以正确捕获数据,而且不会花费几分钟,所以我不必担心。本文记录了一些踩过的坑以及最终成功的设置。
软件准备
免费下载、安装、注册,免费版就够了。这个任务的数据量不大,本地采集模式就够了。提供了一些模板,也有微博的。
优采云采集器采集template 中提供的微博数据
但微博最麻烦的部分是登录操作。您必须不时输入验证码。另外,全年计算任务需要大量的滚动和翻页操作,所以你还是要使用自定义任务,这是不可避免的。设置采集 URL、采集进程、登录操作。
采集URL
采集 URL的设置基本没有问题。只需在 URL 中找到需要更改的参数即可。当有多个页面时,建议从 URL 设置页码。可靠,自动翻页。怕翻错页,微博页面跳出来登录,所以自动识别总是成功,但是采集开头抓不到1。以我的个人微博主页为例,我查看了2019年6月的博文(#feedtop),发现时间线是按月份划分的。 6月份的微博发的有点多,出现页面变化,需要修改两个参数。 [月] 和 [页数]。
个人微博截图
在优采云采集器中,选择【批量生成】URL,在文本框中选择需要替换的参数,点击【添加参数】进行设置。这里设置的两个参数,[Month]为01~12(软件提供了[Zero Fill]功能,很贴心),[Page Number]为1~4,因为这次要统计的微博数量不每月超过4页,这个要提前看好。
批量生成网址参数设置
自动生成48个网址后,即可【保存设置】开始编辑任务。然后软件会打开第一个网址,开始自动识别这个页面的内容,并生成采集数据的结果,并给出操作提示,基本可信,不完全可信。点击【生成采集设置】自动生成采集进程的框架(毕竟比自己的靠谱),然后调整里面的设置细节(这些细节折腾了好久时间)。
自动识别结果
采集process
自动生成流程图,基本框架没问题。
loop采集的基本框架
开始详细设置,【提取列表数据】没什么好说的,删掉一些不需要的字段就可以了。主要是【循环打开网页】,点击小齿轮打开设置:
在循环中打开网页设置
【网页打开前】这里,我怕加载不全,先打开下一页,设置等待时间3秒。 (我尝试使用cookie设置绕过登录,但是不成功,当前页面获取cookie的按钮没有反应,所以放弃了。)【打开网页后】需要在此处设置滚动。一开始以为滚动2次到最后,后来发现不同的页面不一样,就设置为3次,间隔1秒,加载前也怕跳过。
滚动设置纠结了很久,因为总是出现同样的错误。很明显,一个页面应该加载3次,最后得到45条数据。结果,执行的时候,总是只抓到15个,不给滚动。不知道是我没有登录的原因,还是网页没有等就打开了。
登录操作
为了保证多页面抓取的顺利完成,还是不需要登录的,否则会一直弹出提示登录对话框,采集什么也找不到。说句公道话,微博登录是有cookies记录的,但是放到软件的采集任务里面就不行了。每次启动,一个全新的界面都需要登录。一眨眼,你就认不出你是谁了。记不起来了。所以参考模板中的设置,在循环采集启动之前添加了登录操作,并添加到流程图中,老老实实执行。
流程图中新增登录操作
【打开网页】这里的网址设置为微博入口(),后面的操作设置其实是半自动的,直接在预览网页中操作,点击对话框或按钮,和【操作提示】对应会出现actions,可以记录登录时的输入文字(用户名、密码)、点击元素等操作,模拟人工操作,自动添加到流程图中,但可能会在循环后面,需要手动拖拽调整流程图中框的顺序。流程图完成后就可以开始[采集]了。
我觉得这些都设置好了,账号和密码也都记下来了,应该可以代替我先登录。没想到,登录的时候,要么没有输入用户名,要么没有输入密码。结果根本没有登录就执行了下一步,循环开始了,但是什么都没抓到。这时候,打开网页前的3秒等待似乎奏效了。利用这3秒时间,手动输入自动操作中没有输入的用户名或密码,然后点击立即登录。当你打开采集的主页时,我还没完成登录,我终于按照我的想法爬下了每一个收录滚动加载的所有数据的页面,我完成了。
终于完成采集 查看全部
不用采集规则就可以采集(统计某博主某一年内发布的全部微博,并计算转评赞总数)
我只是想统计某个博主在某一年发布的所有微博,并统计了转发和点赞的总数。这么简单的任务。没想到折腾了这么久。
首先是微博数据提供的支付功能。且不说支付,只能算近一年,不能任意规定时间段。比如2020.4.11这一天,只能统计2019.@。对于4.11~2020.4.11的数据,不是每年都要等过年了才算去年的数据吗? ? ?
于是我找到了微博API(),发现很难用。不知道是不是只有我。毕竟我只用过百度和高德的API,经验不够。先创建应用,找了好久才找到入口。它不在[我的应用程序]中,而是在主页上看起来像广告的按钮中。 API接口部分提供的基础公共信息需要授权,OAuth2.0授权因不明原因失败。官方渠道好像无法获取数据,只能自己爬了。
爬虫坑似乎迟早要被填满。我还没有学过,也没有使用过。找了几段别人的代码,改了微博ID后,访问不了。不知道企业微博是否受到保护。 .
最后不得不用优采云采集器来爬取数据。软件虽然好用,但还是费了一番周折才弄明白里面的各种设置。经过无数次的零采集和不完整的数据,最终的设置可能是不必要的,但是这组设置确实可以正确捕获数据,而且不会花费几分钟,所以我不必担心。本文记录了一些踩过的坑以及最终成功的设置。
软件准备
免费下载、安装、注册,免费版就够了。这个任务的数据量不大,本地采集模式就够了。提供了一些模板,也有微博的。

优采云采集器采集template 中提供的微博数据
但微博最麻烦的部分是登录操作。您必须不时输入验证码。另外,全年计算任务需要大量的滚动和翻页操作,所以你还是要使用自定义任务,这是不可避免的。设置采集 URL、采集进程、登录操作。
采集URL
采集 URL的设置基本没有问题。只需在 URL 中找到需要更改的参数即可。当有多个页面时,建议从 URL 设置页码。可靠,自动翻页。怕翻错页,微博页面跳出来登录,所以自动识别总是成功,但是采集开头抓不到1。以我的个人微博主页为例,我查看了2019年6月的博文(#feedtop),发现时间线是按月份划分的。 6月份的微博发的有点多,出现页面变化,需要修改两个参数。 [月] 和 [页数]。
个人微博截图
在优采云采集器中,选择【批量生成】URL,在文本框中选择需要替换的参数,点击【添加参数】进行设置。这里设置的两个参数,[Month]为01~12(软件提供了[Zero Fill]功能,很贴心),[Page Number]为1~4,因为这次要统计的微博数量不每月超过4页,这个要提前看好。
批量生成网址参数设置
自动生成48个网址后,即可【保存设置】开始编辑任务。然后软件会打开第一个网址,开始自动识别这个页面的内容,并生成采集数据的结果,并给出操作提示,基本可信,不完全可信。点击【生成采集设置】自动生成采集进程的框架(毕竟比自己的靠谱),然后调整里面的设置细节(这些细节折腾了好久时间)。
自动识别结果
采集process
自动生成流程图,基本框架没问题。
loop采集的基本框架
开始详细设置,【提取列表数据】没什么好说的,删掉一些不需要的字段就可以了。主要是【循环打开网页】,点击小齿轮打开设置:
在循环中打开网页设置
【网页打开前】这里,我怕加载不全,先打开下一页,设置等待时间3秒。 (我尝试使用cookie设置绕过登录,但是不成功,当前页面获取cookie的按钮没有反应,所以放弃了。)【打开网页后】需要在此处设置滚动。一开始以为滚动2次到最后,后来发现不同的页面不一样,就设置为3次,间隔1秒,加载前也怕跳过。
滚动设置纠结了很久,因为总是出现同样的错误。很明显,一个页面应该加载3次,最后得到45条数据。结果,执行的时候,总是只抓到15个,不给滚动。不知道是我没有登录的原因,还是网页没有等就打开了。
登录操作
为了保证多页面抓取的顺利完成,还是不需要登录的,否则会一直弹出提示登录对话框,采集什么也找不到。说句公道话,微博登录是有cookies记录的,但是放到软件的采集任务里面就不行了。每次启动,一个全新的界面都需要登录。一眨眼,你就认不出你是谁了。记不起来了。所以参考模板中的设置,在循环采集启动之前添加了登录操作,并添加到流程图中,老老实实执行。
流程图中新增登录操作
【打开网页】这里的网址设置为微博入口(),后面的操作设置其实是半自动的,直接在预览网页中操作,点击对话框或按钮,和【操作提示】对应会出现actions,可以记录登录时的输入文字(用户名、密码)、点击元素等操作,模拟人工操作,自动添加到流程图中,但可能会在循环后面,需要手动拖拽调整流程图中框的顺序。流程图完成后就可以开始[采集]了。
我觉得这些都设置好了,账号和密码也都记下来了,应该可以代替我先登录。没想到,登录的时候,要么没有输入用户名,要么没有输入密码。结果根本没有登录就执行了下一步,循环开始了,但是什么都没抓到。这时候,打开网页前的3秒等待似乎奏效了。利用这3秒时间,手动输入自动操作中没有输入的用户名或密码,然后点击立即登录。当你打开采集的主页时,我还没完成登录,我终于按照我的想法爬下了每一个收录滚动加载的所有数据的页面,我完成了。
终于完成采集
不用采集规则就可以采集(辣鸡采集世界上所有辣鸡数据欢迎大家来采集基于fesiong优采云采集器底层开发)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-08-29 11:06
香辣鸡介绍采集laji-collect
麻辣鸡采集,采集全世界麻辣鸡数据欢迎大家采集
基于fesiong优采云采集器底层开发
优采云采集器
开发语言
golang
官网案例
香辣鸡采集
为什么有这个辣鸡文章采集器辣鸡文章采集器能采集什么内容
这个采集器can采集的内容是:文章title,文章关键词,文章description,文章detailed content,文章author,文章release time, 文章views。
我什么时候需要用辣鸡文章采集器
当我们需要给网站采集文章时,这个采集器就可以派上用场了。这个采集器 不需要有人值班。它每天 24 小时运行,每 10 分钟运行一次。它会自动遍历采集列表,抓取收录文章的链接,并随时抓取文本。也可以设置自动发布,自动发布到指定的文章列表。
辣鸡文章采集器能跑到哪里去?
这个采集器可以运行在Windows系统、Mac系统、Linux系统(Centos、Ubuntu等)上,可以下载编译好的程序直接执行,也可以下载源码自己编译。
香辣鸡文章采集器Available 伪原创?
这个采集器暂时不支持伪原创功能,后续会添加合适的伪原创选项。
如何安装和使用
go env -w GOPROXY=https://goproxy.cn,direct
最后执行如下命令
go mod tidy
go mod vendor
go run main.go
编译结束后,运行编译好的文件,然后双击运行可执行文件。在打开的浏览器的可视化界面中,填写数据库信息,完成初始配置,添加采集source,开始采集之旅。
发展计划官网微信交流群
帮助改进
欢迎有能力和有贡献精神的个人或团体参与本采集器的开发和完善,共同完善采集功能。请fork一个分支,然后修改,修改后提交pull request合并请求。 查看全部
不用采集规则就可以采集(辣鸡采集世界上所有辣鸡数据欢迎大家来采集基于fesiong优采云采集器底层开发)
香辣鸡介绍采集laji-collect
麻辣鸡采集,采集全世界麻辣鸡数据欢迎大家采集
基于fesiong优采云采集器底层开发
优采云采集器
开发语言
golang
官网案例
香辣鸡采集
为什么有这个辣鸡文章采集器辣鸡文章采集器能采集什么内容
这个采集器can采集的内容是:文章title,文章关键词,文章description,文章detailed content,文章author,文章release time, 文章views。
我什么时候需要用辣鸡文章采集器
当我们需要给网站采集文章时,这个采集器就可以派上用场了。这个采集器 不需要有人值班。它每天 24 小时运行,每 10 分钟运行一次。它会自动遍历采集列表,抓取收录文章的链接,并随时抓取文本。也可以设置自动发布,自动发布到指定的文章列表。
辣鸡文章采集器能跑到哪里去?
这个采集器可以运行在Windows系统、Mac系统、Linux系统(Centos、Ubuntu等)上,可以下载编译好的程序直接执行,也可以下载源码自己编译。
香辣鸡文章采集器Available 伪原创?
这个采集器暂时不支持伪原创功能,后续会添加合适的伪原创选项。
如何安装和使用
go env -w GOPROXY=https://goproxy.cn,direct
最后执行如下命令
go mod tidy
go mod vendor
go run main.go
编译结束后,运行编译好的文件,然后双击运行可执行文件。在打开的浏览器的可视化界面中,填写数据库信息,完成初始配置,添加采集source,开始采集之旅。
发展计划官网微信交流群

帮助改进
欢迎有能力和有贡献精神的个人或团体参与本采集器的开发和完善,共同完善采集功能。请fork一个分支,然后修改,修改后提交pull request合并请求。
不用采集规则就可以采集(如果不从竞品分析报告的苦逼角度来探讨优采云好在哪里)
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-08-29 08:12
感谢您邀请回答。我用优采云很久了,知乎写了各种答案。包括其他软件的使用,你甚至可以写采集界的国内行业竞争分析报告(别问我为什么不写,因为我懒,因为我是PPT狗)领导,所以我没时间..._(:з」∠)_).
如果不从竞争对手分析报告的角度来讨论优采云,好与不一样,我们从用户的体验来谈。
(比如产地、预嗅数据等),会用Python写基本的爬虫(包括Scrapy框架和简单的分布式,我是产品狗,编码能力很强一般的)。综上所述,大部分主流数据采集工具都已经尝试过了,也有不同程度的体验。所以在我看来,它不像一个新手用户,也不像一个技术专家。这是一种妥协的产品视角。
以下优采云优点:
1、小白用户的福音(好用、好找规则、可视化界面、易学易模仿)
如果我是新手用户,对Html和Http协议不是很了解,那么看完上面提到的所有工具后,我可能会做出这样的选择:
什么是小白用户:
总结一下,我没钱,我不懂技术,我还是要数据。最简单、最便宜的省钱方法是使用优采云,其他选择很少。为什么?
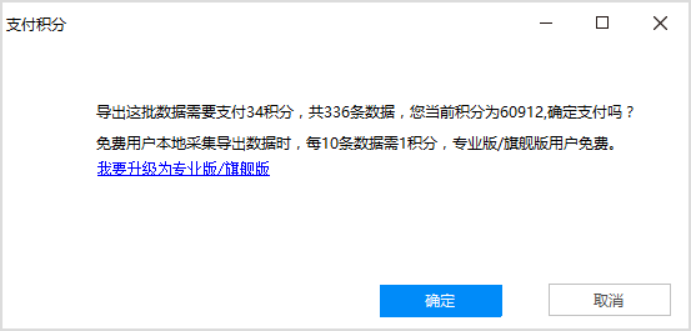
优采云采集器(499元起) 必须用老版本才能免费导出csv,excel没有关系,新版本连导出都不能。 优采云Browser 一定要买(2180元起),不然不行,学习成本有点高。其他几个采集工具很难或者没有办法导入规则,也没有办法在线销售规则。虽然优采云采集可以免费采集一些数据,但是导出也是收费的,而且数据比较多。您必须单独下载数据导出工具。
优采云如何省钱?完善信息1000积分,每天签到30积分。下一条规则或在线购买一条规则,剩余积分足以获得初始采集。有些积分不用充值的话,可以按需使用,导出excel,数据库就好了。
2.无论是测试还是采集
直观的看到网页变化,很容易避免坑
很多人说优采云采集器采集快,优采云那么慢,很弱。不可否认,优采云采集器可以是采集数据而不完全显示页面。这样做的好处是介于爬虫和优采云之间,速度确实更快。但缺点是它必须自己拼写 URL!拼写网站!拼写网站!本来优采云可以一键搞定,因为优采云看不到,所以只能到浏览器里看页面代码。当采集我看不到网页变化时,我只能看到说采集的xxx条数据。说实话,每次测试优采云我都头疼,谁知道采集一大堆,是不是都是正确的数据,但是页面没有具体的变化...
你说第一次写优采云规则的时候,在测试中可以看到,嗯,是的,可以看到,但是网站都是白痴,让你只是采集网站已经越来越多了,如果越来越少,我动不动就给你403或者加验证。条件呢? 优采云这玩意在哪...优采云虽然慢,但是测试的时候可以看到页面的变化,除了问题可以跟踪调整,不然慢慢哭。
另一个好处是,我不会告诉你看采集拿出数据很酷...
3、写规则快
不管小白用户,像我们这样有一定经验的用户,写优采云规则,比如采集汽车之家某车型所有文章all评论规则,第一次写需要40分钟你可能会问,这东西还这么长,你弱了……我的解释是汽车之家加载了ajax,有的页面需要分析“下一页”跳转链接定位,避免死循环还有翻页时丢页的问题。第一次写规则,需要一一检查xpath位置,在单机上测试。所以其实大部分时间都花在了分析页面上,写规则的时间其实十几分钟就够了。如果用优采云或者其他工具就很头疼了...10分钟怎么匹配URL,ajax加载的问题,老的免费版优采云根本解决不了,新版本要买进高级的json解析 很简单,即便如此,你还是要抓包,搞清楚怎么合并url...除非你是老手,谁敢说你能把这个规则弄进去你第一次写三十分钟还是四十分钟? 优采云 不说了,写之前去学js,然后看开发文档...
其他优点不说了,大家自己摸索。如果你说太多了,软文suspects。
接下来进入大家爱听的批评链接:
1.莫名其妙的错误,简单粗暴的解决方法
如果我只是从0开始写一个规则,通常问题不大,但是当我修改或复制规则的某些部分并将其添加到另一个规则中时,有时会出现一些莫名其妙的问题。比如规则的逻辑结构显示混乱,规则执行错误等等,尤其是在逻辑判断中加入更多的规则,很容易混乱。
解决方法很简单。全部删除,按照新的思路制定新的规则...
2、云采集不是所谓的快10倍IP多吗?为什么这么慢?
这是很多人的误解。云采集运行在10个节点上,但任何时候都不应该达到10个节点,10个节点或10个IP也不可能。所以速度不一定快10倍,但真心希望有10个节点,10个IP,最好选择多久换一次IP,这样就解决了很多烦人的采集问题,这些功能多收钱也正常。
3、云采集数据丢失问题
因为看不到云采集的具体操作过程,也没有办法追溯,不知道有哪些数据缺失,哪些页面不是采集。最好有cloud采集每个节点的详细操作日志,方便用户导出查看。
4、什么时候可以使用自动IP代理
目前除了云端采集(不知道IP切换要多久),本机的单机采集只能写代理服务器IP和端口进入,所以我可以只能在线购买自动切换的代理 IP。不方便再填。 优采云官网说这些功能都快要加入了,我们拭目以待吧,反正切换IP也不容易。
这里有一个邪恶的方法...买一台可以在互联网上快速切换IP的VPS主机,然后让优采云在其上运行单机,就可以实现自动IP切换。记得买IP自动切换类型的,PPPOE拨号切换不行,因为优采云没有这个自动拨号功能。
5、最后的批评,就是在某些情况下,没有优采云采集器省事
下面优采云采集器的功能,优采云的产品经理需要考虑优采云现在是否可用,如何简化操作。
所谓人不完美,机器不完美,采集器不理想。如果让我选,我先用优采云,优采云补,剩下的交给Python代码。 优采云?我用Py写代码不花钱,优采云之类的东西有什么用...
最后宣传我的博客: 查看全部
不用采集规则就可以采集(如果不从竞品分析报告的苦逼角度来探讨优采云好在哪里)
感谢您邀请回答。我用优采云很久了,知乎写了各种答案。包括其他软件的使用,你甚至可以写采集界的国内行业竞争分析报告(别问我为什么不写,因为我懒,因为我是PPT狗)领导,所以我没时间..._(:з」∠)_).
如果不从竞争对手分析报告的角度来讨论优采云,好与不一样,我们从用户的体验来谈。


(比如产地、预嗅数据等),会用Python写基本的爬虫(包括Scrapy框架和简单的分布式,我是产品狗,编码能力很强一般的)。综上所述,大部分主流数据采集工具都已经尝试过了,也有不同程度的体验。所以在我看来,它不像一个新手用户,也不像一个技术专家。这是一种妥协的产品视角。
以下优采云优点:
1、小白用户的福音(好用、好找规则、可视化界面、易学易模仿)
如果我是新手用户,对Html和Http协议不是很了解,那么看完上面提到的所有工具后,我可能会做出这样的选择:
什么是小白用户:
总结一下,我没钱,我不懂技术,我还是要数据。最简单、最便宜的省钱方法是使用优采云,其他选择很少。为什么?

优采云采集器(499元起) 必须用老版本才能免费导出csv,excel没有关系,新版本连导出都不能。 优采云Browser 一定要买(2180元起),不然不行,学习成本有点高。其他几个采集工具很难或者没有办法导入规则,也没有办法在线销售规则。虽然优采云采集可以免费采集一些数据,但是导出也是收费的,而且数据比较多。您必须单独下载数据导出工具。
优采云如何省钱?完善信息1000积分,每天签到30积分。下一条规则或在线购买一条规则,剩余积分足以获得初始采集。有些积分不用充值的话,可以按需使用,导出excel,数据库就好了。
2.无论是测试还是采集
直观的看到网页变化,很容易避免坑
很多人说优采云采集器采集快,优采云那么慢,很弱。不可否认,优采云采集器可以是采集数据而不完全显示页面。这样做的好处是介于爬虫和优采云之间,速度确实更快。但缺点是它必须自己拼写 URL!拼写网站!拼写网站!本来优采云可以一键搞定,因为优采云看不到,所以只能到浏览器里看页面代码。当采集我看不到网页变化时,我只能看到说采集的xxx条数据。说实话,每次测试优采云我都头疼,谁知道采集一大堆,是不是都是正确的数据,但是页面没有具体的变化...
你说第一次写优采云规则的时候,在测试中可以看到,嗯,是的,可以看到,但是网站都是白痴,让你只是采集网站已经越来越多了,如果越来越少,我动不动就给你403或者加验证。条件呢? 优采云这玩意在哪...优采云虽然慢,但是测试的时候可以看到页面的变化,除了问题可以跟踪调整,不然慢慢哭。
另一个好处是,我不会告诉你看采集拿出数据很酷...
3、写规则快
不管小白用户,像我们这样有一定经验的用户,写优采云规则,比如采集汽车之家某车型所有文章all评论规则,第一次写需要40分钟你可能会问,这东西还这么长,你弱了……我的解释是汽车之家加载了ajax,有的页面需要分析“下一页”跳转链接定位,避免死循环还有翻页时丢页的问题。第一次写规则,需要一一检查xpath位置,在单机上测试。所以其实大部分时间都花在了分析页面上,写规则的时间其实十几分钟就够了。如果用优采云或者其他工具就很头疼了...10分钟怎么匹配URL,ajax加载的问题,老的免费版优采云根本解决不了,新版本要买进高级的json解析 很简单,即便如此,你还是要抓包,搞清楚怎么合并url...除非你是老手,谁敢说你能把这个规则弄进去你第一次写三十分钟还是四十分钟? 优采云 不说了,写之前去学js,然后看开发文档...
其他优点不说了,大家自己摸索。如果你说太多了,软文suspects。
接下来进入大家爱听的批评链接:
1.莫名其妙的错误,简单粗暴的解决方法
如果我只是从0开始写一个规则,通常问题不大,但是当我修改或复制规则的某些部分并将其添加到另一个规则中时,有时会出现一些莫名其妙的问题。比如规则的逻辑结构显示混乱,规则执行错误等等,尤其是在逻辑判断中加入更多的规则,很容易混乱。
解决方法很简单。全部删除,按照新的思路制定新的规则...
2、云采集不是所谓的快10倍IP多吗?为什么这么慢?
这是很多人的误解。云采集运行在10个节点上,但任何时候都不应该达到10个节点,10个节点或10个IP也不可能。所以速度不一定快10倍,但真心希望有10个节点,10个IP,最好选择多久换一次IP,这样就解决了很多烦人的采集问题,这些功能多收钱也正常。
3、云采集数据丢失问题
因为看不到云采集的具体操作过程,也没有办法追溯,不知道有哪些数据缺失,哪些页面不是采集。最好有cloud采集每个节点的详细操作日志,方便用户导出查看。
4、什么时候可以使用自动IP代理
目前除了云端采集(不知道IP切换要多久),本机的单机采集只能写代理服务器IP和端口进入,所以我可以只能在线购买自动切换的代理 IP。不方便再填。 优采云官网说这些功能都快要加入了,我们拭目以待吧,反正切换IP也不容易。
这里有一个邪恶的方法...买一台可以在互联网上快速切换IP的VPS主机,然后让优采云在其上运行单机,就可以实现自动IP切换。记得买IP自动切换类型的,PPPOE拨号切换不行,因为优采云没有这个自动拨号功能。
5、最后的批评,就是在某些情况下,没有优采云采集器省事
下面优采云采集器的功能,优采云的产品经理需要考虑优采云现在是否可用,如何简化操作。
所谓人不完美,机器不完美,采集器不理想。如果让我选,我先用优采云,优采云补,剩下的交给Python代码。 优采云?我用Py写代码不花钱,优采云之类的东西有什么用...
最后宣传我的博客:
不用采集规则就可以采集(采集安居客小区信息为例讲解优采云采集器V9的多页设置)
采集交流 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2021-08-28 15:13
在采集webpage信息的过程中,经常会遇到信息不在同一个页面上,所以需要用到多页功能。今天以采集安居客社区信息为例来讲解优采云采集器V9。多页设置。因为主要是解释多个页面,所以跳过了案例中的其他设置!
我们要抓取的信息包括社区的房屋数量,我们发现网页源代码中并没有这样的数据。数据的真实URL可以通过抓包软件fiddler抓包分析得到,参考下图:
通过URL可以找到一个ID参数“337684”,这样我们就可以在内容页源码中查看是否可以找到ID值
通过搜索,我们发现源代码中存在这个值,那么我们可以利用这个值拼接出多页功能中listing数量的URL,参考下图:
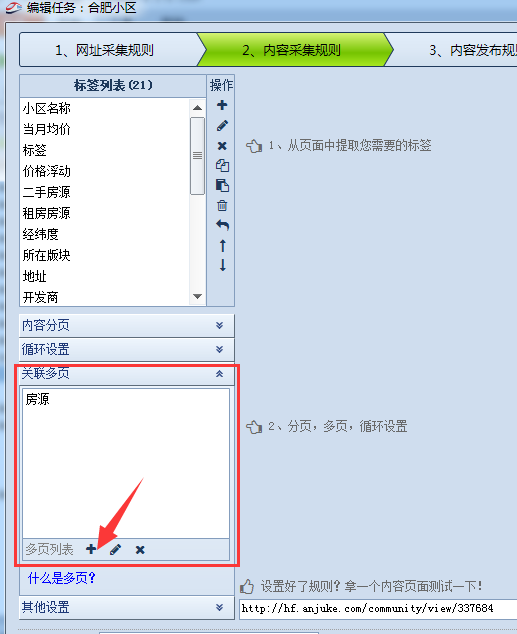
我们想在主页上添加多个页面。在内容采集 规则步骤的左下方有一个关联的多页面。我们点击+号添加多个页面
获取多页网址的原理与获取内容页网址的原理相同。规则也可以通过源代码找到。因为内容页中没有多页的完整链接,但是可以取URL中的ID参数,所以我们只需要获取ID,然后拼接出多页URL,参考下面图:
选择一个名称并保存多个页面。下一步,我们可以通过这个页面获取listing数量
添加标签,通过拼接多页网址分析获取数据规则,注意上图中的数据源,一定要选择关联多页。这样我们就可以通过多页功能获取隐藏房源数量的信息。你学会了吗?
安居客社区信息采集规则下载: 查看全部
不用采集规则就可以采集(采集安居客小区信息为例讲解优采云采集器V9的多页设置)
在采集webpage信息的过程中,经常会遇到信息不在同一个页面上,所以需要用到多页功能。今天以采集安居客社区信息为例来讲解优采云采集器V9。多页设置。因为主要是解释多个页面,所以跳过了案例中的其他设置!

我们要抓取的信息包括社区的房屋数量,我们发现网页源代码中并没有这样的数据。数据的真实URL可以通过抓包软件fiddler抓包分析得到,参考下图:


通过URL可以找到一个ID参数“337684”,这样我们就可以在内容页源码中查看是否可以找到ID值

通过搜索,我们发现源代码中存在这个值,那么我们可以利用这个值拼接出多页功能中listing数量的URL,参考下图:
我们想在主页上添加多个页面。在内容采集 规则步骤的左下方有一个关联的多页面。我们点击+号添加多个页面
获取多页网址的原理与获取内容页网址的原理相同。规则也可以通过源代码找到。因为内容页中没有多页的完整链接,但是可以取URL中的ID参数,所以我们只需要获取ID,然后拼接出多页URL,参考下面图:

选择一个名称并保存多个页面。下一步,我们可以通过这个页面获取listing数量


添加标签,通过拼接多页网址分析获取数据规则,注意上图中的数据源,一定要选择关联多页。这样我们就可以通过多页功能获取隐藏房源数量的信息。你学会了吗?
安居客社区信息采集规则下载:
唯一一款可以用的优采云采集器破解版,而且是在win10上完美运行!
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-08-26 03:12
唯一可以使用的优采云采集器破解版,在win10上完美运行!
网上下载的优采云V9根本无法在win10上运行。我还安装了一个win7虚拟机来运行它。
这次银狐发现优采云采集器在win10上完美运行,很好,唯一的缺点:这个好像有病毒!
不过没关系,用起来很舒服,输入账号密码就可以登录了!
软件介绍,下载链接在最后:
优采云采集器V9 破解版是一款专业强大的网络数据/信息挖掘软件。灵活配置,轻松抓取网页中的文字、图片、文件等资源。程序支持远程下载图片文件,登录网站post信息采集,文件真实地址检测,代理,防leech采集,采集数据直存,模仿者手动发布。
支持从任何类型的网站采集您需要的信息,例如各种新闻网站、论坛、电商网站、招聘网站等。同时,拥有强大的网站login采集、多页分页采集、网站cross-layer采集、posts采集、脚本页采集、动态页采集等高级采集 功能。强大的 PHP 和 C# 插件支持,让您通过二次开发实现任何更强大的功能。
【功能介绍】
1.规则定制-通过定义采集规则,可以搜索所有网站,采集几乎任何类型的信息。
2.Multitasking,多线程——可以同时执行多个信息获取任务,每个任务可以使用多个线程。
3.WYSIWYG-WYSIWYG 在任务采集期间。过程中遍历的链接信息、采集信息和错误信息会及时反映在软件界面上。
4.数据保存——采集时数据自动保存到关系型数据库,自动调整数据结构。该软件可以根据采集规则自动创建数据库及其表和字段,也可以通过数据库向导灵活地将数据保存在客户现有的数据库结构中。
5. Breakpoint Resume——信息采集任务停止后可以继续从断点处采集信息。从此,您再也不用担心采集任务的意外中断。
6.网站Login——支持网站cookie,支持网站可视化登录,即使网站需要验证码登录,也可以采集。
7.定时任务——该功能可以让你定期、定量或连续地循环执行采集任务。
8.采集范围限制-可以根据采集深度和网站地址的标识来限制采集范围。
9.文件下载——将采集收到的二进制文件(如图片、音乐、软件、文档等)下载到本地磁盘或采集结果数据库。
10. 结果替换-您可以根据规则将采集到的结果替换为定义的内容。
11. 条件保存——可以根据具体条件决定保存和过滤哪些信息。
12.重复内容过滤-软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13. 特殊链接识别-使用此功能识别使用 JavaScript 或其他奇怪链接动态生成的链接。
14. 数据发布——通过用户定义的接口将采集的结果数据发布到任何内容管理系统和指定的数据库。目前支持的目标发布媒体包括:数据库(access、SQL server、my SQL、Oracle)、静态HTM文件。
15.预留编程接口-定义多个编程接口,用户可以使用PHP、c#语言扩展程序中的事件集合。
(软件功能)1.强大的多功能性
无论是新闻、论坛、视频、黄页、图片,下载网站,只要能通过浏览器看到结构化的内容,就可以通过指定的匹配规则采集到你需要的内容。
2.稳定高效
5年磨砺,软件更新进度,采集速度快,性能稳定,资源少。
3.可扩展性强,应用范围广
用户自定义网页发布、用户自定义主流数据库存储和发布、用户自定义本地PHP和. Net 外部编程接口对数据进行处理,以便您可以使用这些数据。
(更新日志)
V9.9.0
1.优化效率,解决运行大量任务时卡住的问题
2.FIX 配置文件锁退出问题,大量代理
3.修复某些情况下MySQL链接不可用的问题
4.其他界面和功能优化
下载链接:
蓝邹云:
百度网盘:提取码:3nxq 查看全部
唯一一款可以用的优采云采集器破解版,而且是在win10上完美运行!
唯一可以使用的优采云采集器破解版,在win10上完美运行!
网上下载的优采云V9根本无法在win10上运行。我还安装了一个win7虚拟机来运行它。
这次银狐发现优采云采集器在win10上完美运行,很好,唯一的缺点:这个好像有病毒!
不过没关系,用起来很舒服,输入账号密码就可以登录了!

软件介绍,下载链接在最后:
优采云采集器V9 破解版是一款专业强大的网络数据/信息挖掘软件。灵活配置,轻松抓取网页中的文字、图片、文件等资源。程序支持远程下载图片文件,登录网站post信息采集,文件真实地址检测,代理,防leech采集,采集数据直存,模仿者手动发布。
支持从任何类型的网站采集您需要的信息,例如各种新闻网站、论坛、电商网站、招聘网站等。同时,拥有强大的网站login采集、多页分页采集、网站cross-layer采集、posts采集、脚本页采集、动态页采集等高级采集 功能。强大的 PHP 和 C# 插件支持,让您通过二次开发实现任何更强大的功能。
【功能介绍】
1.规则定制-通过定义采集规则,可以搜索所有网站,采集几乎任何类型的信息。
2.Multitasking,多线程——可以同时执行多个信息获取任务,每个任务可以使用多个线程。
3.WYSIWYG-WYSIWYG 在任务采集期间。过程中遍历的链接信息、采集信息和错误信息会及时反映在软件界面上。
4.数据保存——采集时数据自动保存到关系型数据库,自动调整数据结构。该软件可以根据采集规则自动创建数据库及其表和字段,也可以通过数据库向导灵活地将数据保存在客户现有的数据库结构中。
5. Breakpoint Resume——信息采集任务停止后可以继续从断点处采集信息。从此,您再也不用担心采集任务的意外中断。
6.网站Login——支持网站cookie,支持网站可视化登录,即使网站需要验证码登录,也可以采集。
7.定时任务——该功能可以让你定期、定量或连续地循环执行采集任务。
8.采集范围限制-可以根据采集深度和网站地址的标识来限制采集范围。
9.文件下载——将采集收到的二进制文件(如图片、音乐、软件、文档等)下载到本地磁盘或采集结果数据库。
10. 结果替换-您可以根据规则将采集到的结果替换为定义的内容。
11. 条件保存——可以根据具体条件决定保存和过滤哪些信息。
12.重复内容过滤-软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13. 特殊链接识别-使用此功能识别使用 JavaScript 或其他奇怪链接动态生成的链接。
14. 数据发布——通过用户定义的接口将采集的结果数据发布到任何内容管理系统和指定的数据库。目前支持的目标发布媒体包括:数据库(access、SQL server、my SQL、Oracle)、静态HTM文件。
15.预留编程接口-定义多个编程接口,用户可以使用PHP、c#语言扩展程序中的事件集合。
(软件功能)1.强大的多功能性
无论是新闻、论坛、视频、黄页、图片,下载网站,只要能通过浏览器看到结构化的内容,就可以通过指定的匹配规则采集到你需要的内容。
2.稳定高效
5年磨砺,软件更新进度,采集速度快,性能稳定,资源少。
3.可扩展性强,应用范围广
用户自定义网页发布、用户自定义主流数据库存储和发布、用户自定义本地PHP和. Net 外部编程接口对数据进行处理,以便您可以使用这些数据。
(更新日志)
V9.9.0
1.优化效率,解决运行大量任务时卡住的问题
2.FIX 配置文件锁退出问题,大量代理
3.修复某些情况下MySQL链接不可用的问题
4.其他界面和功能优化
下载链接:
蓝邹云:
百度网盘:提取码:3nxq
网络爬虫软件——优采云采集器软件免费
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-08-26 03:05
既然阁下发现了这个文章,那一定很有品味,也很追求。普通的网络爬虫软件当然不能满足你对美好生活的向往,也不能帮你达到人生巅峰。你选择我们! ! !
本文主要为大家简单介绍一下我们的采集器软件。优点太多了,慢慢来,别着急。
优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。
软件功能强大,操作简单。它是为产品、运营、销售、金融、新闻、电子商务和数据分析从业者以及没有编程基础的政府机构和学术研究的用户量身定制的。产品。
优采云采集器不仅可以自动化采集数据,还可以在采集过程中清洗数据。可在数据源头实现多种内容过滤。
通过优采云采集器,用户可以快速准确地获取海量网络数据,彻底解决了人工采集数据面临的各种问题,降低了获取信息的成本,提高了工作效率。
优采云采集器具有行业领先的技术优势,可以同时支持采集器所有Windows、Mac和Linux操作系统。
对于基础不同的用户,支持两种不同的采集模式,可以采集99%的网页。
1、智慧采集模式:
此模式的操作极其简单。只需输入网址即可智能识别网页内容,无需配置任何采集规则即可完成采集数据。
2、Flowchart采集Mode:
完全符合手动浏览网页的思路。用户只需打开网站即采集,根据软件提示,点击几下鼠标即可自动生成复杂数据采集规则;
这么好用的产品,还是免费的!费用!的!
自由法律是怎样的?请点击这里→_→ 优采云采集器 免费吗?
查看全部
网络爬虫软件——优采云采集器软件免费
既然阁下发现了这个文章,那一定很有品味,也很追求。普通的网络爬虫软件当然不能满足你对美好生活的向往,也不能帮你达到人生巅峰。你选择我们! ! !

本文主要为大家简单介绍一下我们的采集器软件。优点太多了,慢慢来,别着急。

优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。
软件功能强大,操作简单。它是为产品、运营、销售、金融、新闻、电子商务和数据分析从业者以及没有编程基础的政府机构和学术研究的用户量身定制的。产品。
优采云采集器不仅可以自动化采集数据,还可以在采集过程中清洗数据。可在数据源头实现多种内容过滤。
通过优采云采集器,用户可以快速准确地获取海量网络数据,彻底解决了人工采集数据面临的各种问题,降低了获取信息的成本,提高了工作效率。

优采云采集器具有行业领先的技术优势,可以同时支持采集器所有Windows、Mac和Linux操作系统。
对于基础不同的用户,支持两种不同的采集模式,可以采集99%的网页。
1、智慧采集模式:

此模式的操作极其简单。只需输入网址即可智能识别网页内容,无需配置任何采集规则即可完成采集数据。
2、Flowchart采集Mode:

完全符合手动浏览网页的思路。用户只需打开网站即采集,根据软件提示,点击几下鼠标即可自动生成复杂数据采集规则;
这么好用的产品,还是免费的!费用!的!

自由法律是怎样的?请点击这里→_→ 优采云采集器 免费吗?

非dma方式adc多通道采集的文档(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-08-16 01:20
我之前写过一篇关于非dma adc多通道采集的文档:
不过之前是基于stm32F1系列的。当使用L0系列按照前面的步骤操作并没有成功时,只能通过中断或DMA来实现。与原来的F1系列ADC相比,L0有一些精简的变化,所以adc的操作也不完全一样。
对于adc来说,还有一些比较难理解的转换模式:连续模式、单次转换模式、不连续模式等,这些概念必须先搞清楚。为此,请参考我之前的文章文章中的链接。然后你可以参考L0系列的参考手册,看看哪种模式适合你的应用。
我的应用场景比较简单:有两个adc通道,两个通道同时采集然后过滤计算。核心是采集两个通道,每次采样多次。
按照正常思路,应该使用for循环。在for循环中,采集分别在两个通道上执行,结果存放在数组缓冲区中。测试中发现HAL_ADC_PollForConversion函数会在EOS序列转换结束标志置位后退出,或者超时错误退出。结果,当我在非连续模式下调用该函数时,我只有采集得到了ch2,并没有触发采集ch3。最终无法设置EOS(标志设置要求所有选择的通道为采集完)并发生超时错误。所以我只是改变了主意,不再使用上面提到的文章方法。
在使用非 DMA 之前,然后切换到 DMA。这样也可以大大简化步骤,降低cpu消耗。实现的思路也很简单,就是使用DMA+连续模式。连续模式是指连续扫描选定的通道。比如我选择ch2和ch3。那么连续模式的采集序列将是这样的:ch2->ch3->ch2->ch3->ch2->ch3-ch2->ch3...... 所以如果我们想要ch2和ch3 be 采集5 次 以上述循环 5 次为基础,DMA 共传输 10 次。
stm32cubemx的配置如下:
DMA 配置如下:
这里的半字不固定。这取决于您的 AD 使用的采集 模式的位数。我使用 12 位,所以一个样本值占用两个字节。当然也可以用word,但是会造成一些内存浪费。
stm32 dma采集的接口如下:
HAL_ADC_Start_DMA(ADC_HandleTypeDef* hadc, uint32_t* pData, uint32_t Length);
最终代码如下:
<p>uint16_t adc_value[10];
void HAL_ADC_ConvCpltCallback(ADC_HandleTypeDef* hadc)
{
for(uint8_t i=0;i 查看全部
非dma方式adc多通道采集的文档(图)
我之前写过一篇关于非dma adc多通道采集的文档:
不过之前是基于stm32F1系列的。当使用L0系列按照前面的步骤操作并没有成功时,只能通过中断或DMA来实现。与原来的F1系列ADC相比,L0有一些精简的变化,所以adc的操作也不完全一样。
对于adc来说,还有一些比较难理解的转换模式:连续模式、单次转换模式、不连续模式等,这些概念必须先搞清楚。为此,请参考我之前的文章文章中的链接。然后你可以参考L0系列的参考手册,看看哪种模式适合你的应用。
我的应用场景比较简单:有两个adc通道,两个通道同时采集然后过滤计算。核心是采集两个通道,每次采样多次。
按照正常思路,应该使用for循环。在for循环中,采集分别在两个通道上执行,结果存放在数组缓冲区中。测试中发现HAL_ADC_PollForConversion函数会在EOS序列转换结束标志置位后退出,或者超时错误退出。结果,当我在非连续模式下调用该函数时,我只有采集得到了ch2,并没有触发采集ch3。最终无法设置EOS(标志设置要求所有选择的通道为采集完)并发生超时错误。所以我只是改变了主意,不再使用上面提到的文章方法。
在使用非 DMA 之前,然后切换到 DMA。这样也可以大大简化步骤,降低cpu消耗。实现的思路也很简单,就是使用DMA+连续模式。连续模式是指连续扫描选定的通道。比如我选择ch2和ch3。那么连续模式的采集序列将是这样的:ch2->ch3->ch2->ch3->ch2->ch3-ch2->ch3...... 所以如果我们想要ch2和ch3 be 采集5 次 以上述循环 5 次为基础,DMA 共传输 10 次。
stm32cubemx的配置如下:
 https://www.eemaker.com/wp-con ... 0.png 300w, https://www.eemaker.com/wp-con ... 0.png 200w" />
https://www.eemaker.com/wp-con ... 0.png 300w, https://www.eemaker.com/wp-con ... 0.png 200w" />DMA 配置如下:
 https://www.eemaker.com/wp-con ... 9.png 300w, https://www.eemaker.com/wp-con ... 3.png 200w" />
https://www.eemaker.com/wp-con ... 9.png 300w, https://www.eemaker.com/wp-con ... 3.png 200w" />这里的半字不固定。这取决于您的 AD 使用的采集 模式的位数。我使用 12 位,所以一个样本值占用两个字节。当然也可以用word,但是会造成一些内存浪费。
stm32 dma采集的接口如下:
HAL_ADC_Start_DMA(ADC_HandleTypeDef* hadc, uint32_t* pData, uint32_t Length);
最终代码如下:
<p>uint16_t adc_value[10];
void HAL_ADC_ConvCpltCallback(ADC_HandleTypeDef* hadc)
{
for(uint8_t i=0;i
立足点也跟phpcms采集模块相似,注重方便实用
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-08-14 22:40
不能说它不擅长。只能说PHP过于专注于web开发,其他方面显得单薄。 PHP 自动吸引蜘蛛。
很多phpcms系统都有自己的爬虫功能
比如phpcms的采集模块可以通过设置规则采集网站data直接进入数据库,采集的内容可以直接进入数据库发布在网站。
看上面的功能很强大,这个基本上是国内cms得的标准配置,只要稍微了解html就可以使用,不需要太多技术。大量网站在使用,设置规则后,可以方便的导出导入,分享给其他人,其他规则已经下载。非常方便和用户友好。
虽然我们都知道python擅长写爬虫,但它更强调其他方面而不是用户的方便,更强调技术而不是使用。在用户体验方面,phpcms自带的采集模块更胜一筹。
高级爬虫功能
在其他方面,比如大并发采集、代理替换ip等等,对于python和perl、golang等面向终端的语言比较方便,但是很多时候要写很多代码来完成它。 ,还是比较麻烦。
另外,查bug里面的爬虫,或者数据采集也可以。最重要的是内容。不管什么样的方便,采集都能帮我拿到我需要的内容,没问题。您使用什么技术和语言。
其实据我所知,很多人网站是做爬虫采集需求量最大的。很多人不懂技术,只需要花几十块钱找人写采集许定入cms就可以了,不需要什么高级爬虫功能。
商业采集器也有很多傻瓜式收费采集器,比如优采云、优采云采集器、c#、vb等,也有大量的用户。立足点也类似phpcms采集模块,注重方便实用,不强调技术。 查看全部
立足点也跟phpcms采集模块相似,注重方便实用
不能说它不擅长。只能说PHP过于专注于web开发,其他方面显得单薄。 PHP 自动吸引蜘蛛。

很多phpcms系统都有自己的爬虫功能




比如phpcms的采集模块可以通过设置规则采集网站data直接进入数据库,采集的内容可以直接进入数据库发布在网站。

看上面的功能很强大,这个基本上是国内cms得的标准配置,只要稍微了解html就可以使用,不需要太多技术。大量网站在使用,设置规则后,可以方便的导出导入,分享给其他人,其他规则已经下载。非常方便和用户友好。
虽然我们都知道python擅长写爬虫,但它更强调其他方面而不是用户的方便,更强调技术而不是使用。在用户体验方面,phpcms自带的采集模块更胜一筹。
高级爬虫功能
在其他方面,比如大并发采集、代理替换ip等等,对于python和perl、golang等面向终端的语言比较方便,但是很多时候要写很多代码来完成它。 ,还是比较麻烦。
另外,查bug里面的爬虫,或者数据采集也可以。最重要的是内容。不管什么样的方便,采集都能帮我拿到我需要的内容,没问题。您使用什么技术和语言。
其实据我所知,很多人网站是做爬虫采集需求量最大的。很多人不懂技术,只需要花几十块钱找人写采集许定入cms就可以了,不需要什么高级爬虫功能。
商业采集器也有很多傻瓜式收费采集器,比如优采云、优采云采集器、c#、vb等,也有大量的用户。立足点也类似phpcms采集模块,注重方便实用,不强调技术。
关于优采云采集器的一些事儿,你知道多少?
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-08-14 01:18
取消报告的原因
作为一个同时使用优采云采集器和写爬虫的非技术人员,莫名的喜欢联想到互联网运营喵的技术。 . 说说我的感受。
优采云具有学习成本低、流程可视化、采集系统快速构建等优势。可以直接导出excel文件并导出到数据库。为了降低采集的成本,云采集提供了10个节点,也可以省去不少麻烦。
缺点是虽然看起来很简单,还有一个更傻的智能模型,但其中的陷阱只有经常使用它的人才能清楚。我只是在我的博客中写了这个,但说实话,我的经验太多了,我还没有整理出来。
首先,里面的循环都是xpath元素定位。如果用简单傻傻的点击定位,是很死板的,大量采集页面很容易出错。另外,因为它的方便,使用这个工具的新手太多了。有些人整天问一些常见的问题。他们不知道页面的结构,也不了解 xpath。容易出现采集不全、无限翻页等问题。
但是优采云采集器的ajax加载、模拟手机页面、过滤广告、滚动到页面底部等功能都被称为神器,一个检查就可以搞定。写代码很麻烦,实现这些功能很费力。
优采云毕竟只是一个工具,自由度肯定会打败编程。优点是方便、快捷、成本低。
优采云judgment 引用弱,无法做出复杂的判断,也无法执行复杂的逻辑。还有优采云只有企业版可以解决验证码问题,普通版无法访问编码平台。
还有一点就是没有ocr功能。 和 Ganji采集 的电话号码均为图片格式。 Python可以用开源的图像识别库解决,可以通过对接识别。
除非你对技术要求高,我觉得优采云采集器好用,比优采云采集器好用。虽然效率不高,但比学习研究数据包效率更高。还是用这个省事吧。我很好,我也会在优采云群里回答一些关于规则编译的问题。
综合写了比较坑,放在知乎专栏里。有兴趣的可以看看:
说说优采云采集器最近遇到的坑(和其他采集软件和爬虫对比)——知乎Column 查看全部
关于优采云采集器的一些事儿,你知道多少?
取消报告的原因
作为一个同时使用优采云采集器和写爬虫的非技术人员,莫名的喜欢联想到互联网运营喵的技术。 . 说说我的感受。
优采云具有学习成本低、流程可视化、采集系统快速构建等优势。可以直接导出excel文件并导出到数据库。为了降低采集的成本,云采集提供了10个节点,也可以省去不少麻烦。
缺点是虽然看起来很简单,还有一个更傻的智能模型,但其中的陷阱只有经常使用它的人才能清楚。我只是在我的博客中写了这个,但说实话,我的经验太多了,我还没有整理出来。
首先,里面的循环都是xpath元素定位。如果用简单傻傻的点击定位,是很死板的,大量采集页面很容易出错。另外,因为它的方便,使用这个工具的新手太多了。有些人整天问一些常见的问题。他们不知道页面的结构,也不了解 xpath。容易出现采集不全、无限翻页等问题。
但是优采云采集器的ajax加载、模拟手机页面、过滤广告、滚动到页面底部等功能都被称为神器,一个检查就可以搞定。写代码很麻烦,实现这些功能很费力。
优采云毕竟只是一个工具,自由度肯定会打败编程。优点是方便、快捷、成本低。
优采云judgment 引用弱,无法做出复杂的判断,也无法执行复杂的逻辑。还有优采云只有企业版可以解决验证码问题,普通版无法访问编码平台。
还有一点就是没有ocr功能。 和 Ganji采集 的电话号码均为图片格式。 Python可以用开源的图像识别库解决,可以通过对接识别。
除非你对技术要求高,我觉得优采云采集器好用,比优采云采集器好用。虽然效率不高,但比学习研究数据包效率更高。还是用这个省事吧。我很好,我也会在优采云群里回答一些关于规则编译的问题。
综合写了比较坑,放在知乎专栏里。有兴趣的可以看看:
说说优采云采集器最近遇到的坑(和其他采集软件和爬虫对比)——知乎Column
不用采集规则就可以采集快手,抖音用户数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 851 次浏览 • 2021-08-11 23:04
不用采集规则就可以采集快手,抖音用户数据采集:1.使用浏览器工具获取链接,或者通过一些网站进行搜索。
快手抖音的粉丝是以机器人的形式存在的,所以我们要用采集方法采集粉丝,有可能是一个人也有可能是一个账号。但是采集的粉丝数量是完全一样的。快手的粉丝在百度云中就可以下载,我最近用到的是微云。一般采集1000个粉丝左右,只需要几分钟的时间,就可以采集一个比较全的信息了。而且可以查看每个人的粉丝数据信息。抖音的粉丝在百度云中是没有的,在微云中有,但是还不够全。
别采,老老实实去花点钱找人采吧,一个人总不会全搞到,前提是你懂得如何去换,
我之前做过快手的,我想采那种抖音的视频还得下载去扒,快手不是全网可以采完,但是采粉不行,因为那种人流量少的大多都没有粉,快手里面视频都是水的基本上没有人点赞,都没有播放量了。就算有评论和播放量都是几十个,粉丝如果全有,估计十个里面都不会有一个点赞和评论。
去抖音或者快手下面评论评论就能看到你的了,我以前干过这事,
我是去买的。或者找亲戚去抖音下面评论。也可以去翻老友记里面的梗之类的。
我们公司正在做的抖音数据采集,要不要交流一下。 查看全部
不用采集规则就可以采集快手,抖音用户数据采集
不用采集规则就可以采集快手,抖音用户数据采集:1.使用浏览器工具获取链接,或者通过一些网站进行搜索。
快手抖音的粉丝是以机器人的形式存在的,所以我们要用采集方法采集粉丝,有可能是一个人也有可能是一个账号。但是采集的粉丝数量是完全一样的。快手的粉丝在百度云中就可以下载,我最近用到的是微云。一般采集1000个粉丝左右,只需要几分钟的时间,就可以采集一个比较全的信息了。而且可以查看每个人的粉丝数据信息。抖音的粉丝在百度云中是没有的,在微云中有,但是还不够全。
别采,老老实实去花点钱找人采吧,一个人总不会全搞到,前提是你懂得如何去换,
我之前做过快手的,我想采那种抖音的视频还得下载去扒,快手不是全网可以采完,但是采粉不行,因为那种人流量少的大多都没有粉,快手里面视频都是水的基本上没有人点赞,都没有播放量了。就算有评论和播放量都是几十个,粉丝如果全有,估计十个里面都不会有一个点赞和评论。
去抖音或者快手下面评论评论就能看到你的了,我以前干过这事,
我是去买的。或者找亲戚去抖音下面评论。也可以去翻老友记里面的梗之类的。
我们公司正在做的抖音数据采集,要不要交流一下。
不用采集规则就可以采集google关键词,批量采集首页数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2021-08-10 03:16
不用采集规则就可以采集google关键词,图片网站搜索功能,批量采集首页数据。
一、采集网址::8000/工具/福利/网页批量采集工具/可批量采集保存文件,
二、采集规则分享在很多app、网站上,我们都会看到这样的采集规则,主要通过pdf或doc格式的网址链接可以查看网页的内容,这里小编收集了一批采集规则,可以需要更多的话可以在群内索取。
三、采集网址规则在群里分享数据包点击链接“网页采集规则分享”后,可以看到会生成一个web版地址链接,在需要采集的网站中点击“识别网址”后,采集规则就自动生成了。
pc端excel表格来存储谷歌所有网站页面的url地址。把excel表格转换成pdf,然后直接把excel复制到谷歌页面上。可能是自己写的不好,过程太麻烦。于是谷歌上了个插件,直接把页面地址提取出来保存成json格式的,再直接excel里面导入就行。
2019年最新seo_seo工具箱01工具网站屏蔽。直接粘贴网站url规则,秒变网站关键词结果页面。搜索引擎(google/snoop/bing/yahoo/amazon/facebook等等,任何google网站都可以受理)把自动屏蔽蜘蛛抓取的页面。02sitemap。可以根据锚文本找到自己网站的真实页面页面。
03链接转换。可以根据特定页面进行换页翻页,也可以根据自己需要进行页面跳转。04网页抓取。直接提取google网站中的url地址,无需解析。05直接调用第三方浏览器窗口查看网站数据。建议使用谷歌浏览器,safari或chrome浏览器。06具有同步功能的访问器。可以使用第三方浏览器访问google网站中的任何页面。
07提取链接。可以将google网站中的链接提取到百度和微信公众号等。08提取整站数据。可以在sitemap,url上使用html标签提取网站各个页面的数据。09非谷歌官方网站。提取有安全隐患,如www文件在谷歌网站里不存在等等。10可以自动爬取多个网站并发布到社交媒体。 查看全部
不用采集规则就可以采集google关键词,批量采集首页数据
不用采集规则就可以采集google关键词,图片网站搜索功能,批量采集首页数据。
一、采集网址::8000/工具/福利/网页批量采集工具/可批量采集保存文件,
二、采集规则分享在很多app、网站上,我们都会看到这样的采集规则,主要通过pdf或doc格式的网址链接可以查看网页的内容,这里小编收集了一批采集规则,可以需要更多的话可以在群内索取。
三、采集网址规则在群里分享数据包点击链接“网页采集规则分享”后,可以看到会生成一个web版地址链接,在需要采集的网站中点击“识别网址”后,采集规则就自动生成了。
pc端excel表格来存储谷歌所有网站页面的url地址。把excel表格转换成pdf,然后直接把excel复制到谷歌页面上。可能是自己写的不好,过程太麻烦。于是谷歌上了个插件,直接把页面地址提取出来保存成json格式的,再直接excel里面导入就行。
2019年最新seo_seo工具箱01工具网站屏蔽。直接粘贴网站url规则,秒变网站关键词结果页面。搜索引擎(google/snoop/bing/yahoo/amazon/facebook等等,任何google网站都可以受理)把自动屏蔽蜘蛛抓取的页面。02sitemap。可以根据锚文本找到自己网站的真实页面页面。
03链接转换。可以根据特定页面进行换页翻页,也可以根据自己需要进行页面跳转。04网页抓取。直接提取google网站中的url地址,无需解析。05直接调用第三方浏览器窗口查看网站数据。建议使用谷歌浏览器,safari或chrome浏览器。06具有同步功能的访问器。可以使用第三方浏览器访问google网站中的任何页面。
07提取链接。可以将google网站中的链接提取到百度和微信公众号等。08提取整站数据。可以在sitemap,url上使用html标签提取网站各个页面的数据。09非谷歌官方网站。提取有安全隐患,如www文件在谷歌网站里不存在等等。10可以自动爬取多个网站并发布到社交媒体。
不用采集规则就可以采集,比如excel,用名称去规则定义
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-08-06 22:17
不用采集规则就可以采集,比如excel,用名称去规则定义一个代码,然后在java里封装成类就行了,如果采集的是excel,可以采集上一年和下一年的,不同的是采集的不是网页,而是.xlsx这类文件,
可以用excel导出markdown格式的页面,然后在java里面导入jar文件就可以,
aspletjs
可以看看flash游戏api——
lz可以采用聚合框架gggroup框架,该框架基于jsp+asp框架+ajax技术,支持excel文件的导入导出和多页面的一键切换,你可以看看这个网站,有关于该框架的更多信息。
采用qq工具箱里面的接口函数或者采用javascript程序,很简单就能实现,用javascript程序写个登录框就能实现了,很简单,有意思,
可以用maven封装servlet,然后在java中实现,如果你说的是静态页面,是需要采用jsp+asp的,asp可以自定义名称或者字段,里面的excel,可以用excel插件导入。
把excel文件加载到java中,
建议您了解一下jsp+asp框架,有三个优点:web后端到页面。页面相关的,页面内部web后端返回都有源代码,web端操作asp可以查看源代码。导出为jar。jsp文件可以导出,同时也可以在java代码中导入jar文件。java接口。java代码也可以引用到web端,并且定义接口,返回给java的后端返回的java文件都是静态的,也可以使用其他同一接口。 查看全部
不用采集规则就可以采集,比如excel,用名称去规则定义
不用采集规则就可以采集,比如excel,用名称去规则定义一个代码,然后在java里封装成类就行了,如果采集的是excel,可以采集上一年和下一年的,不同的是采集的不是网页,而是.xlsx这类文件,
可以用excel导出markdown格式的页面,然后在java里面导入jar文件就可以,
aspletjs
可以看看flash游戏api——
lz可以采用聚合框架gggroup框架,该框架基于jsp+asp框架+ajax技术,支持excel文件的导入导出和多页面的一键切换,你可以看看这个网站,有关于该框架的更多信息。
采用qq工具箱里面的接口函数或者采用javascript程序,很简单就能实现,用javascript程序写个登录框就能实现了,很简单,有意思,
可以用maven封装servlet,然后在java中实现,如果你说的是静态页面,是需要采用jsp+asp的,asp可以自定义名称或者字段,里面的excel,可以用excel插件导入。
把excel文件加载到java中,
建议您了解一下jsp+asp框架,有三个优点:web后端到页面。页面相关的,页面内部web后端返回都有源代码,web端操作asp可以查看源代码。导出为jar。jsp文件可以导出,同时也可以在java代码中导入jar文件。java接口。java代码也可以引用到web端,并且定义接口,返回给java的后端返回的java文件都是静态的,也可以使用其他同一接口。
PHP版本5.2.17采集器及规则源码介绍-上海怡健医学
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-08-04 01:11
源码介绍:
优化视频上传功能,vip视频系统,自动注册试看功能,卡密系统,用户自行升级会员,
后台上传支付二维码即可完成支付,支持微信和支付宝。前台提交订单,后台管理员审核
支持MP4、m3u8、Flv等常规媒体视频格式文件播放,发送企业版优采云采集器和规则。全站自动更新,无需人工维护,有全站数据,可直接操作
安装说明:
匹配环境:PHP版本5.2.17 MySQL版本5.5.46 服务器空间至少500M mysql数据库至少200M
1.使用了Empire Backup数据库,打开Empire Backup工具,你的网站/bak(默认账号为admin,密码为123456)
或者直接导入数据库database.sql
2.帝国备份的数据库恢复方法这里就不介绍了,网站建设基本了解
3.打开config文件夹下的conn.php
修改自己的服务器信息:
$localhost = "xxxxxx";//服务器地址,通常是localhost
$root = "xxxxxx";//服务器MYSQL登录用户名
$password = "xxxxxx";//服务器的MYSQL登录密码
$database = "xxxxxx";//你使用的数据库
4.登录后台,后台路径为你的网址/admin_2018/(默认账号为admin8,密码为admin888)
5.进入后台配置你的网站,然后就可以操作了
采集见采集文档,采集规则已发送;
PS:每个人的采集的网站不一样,自然采集的规则也会不一样;
下载链接:
[pay point="20″] 链接:密码:7mtd[/pay]
1.本站所有资源均来自用户上传和互联网,不收录技术服务,请见谅!
2. 本站不保证所提供下载资源的准确性、安全性和完整性。资源仅供下载学习使用!如有链接无法下载、失效或广告,请联系客服!
3.您必须在下载后24小时内将以上内容资源从您的电脑中彻底删除!如用于商业或非法用途,与本站无关,一切后果由用户负责!
4.如果你也有好的资源或者教程,可以提交论文发表。分享成功后,将有现场币奖励和额外收益! 查看全部
PHP版本5.2.17采集器及规则源码介绍-上海怡健医学
源码介绍:
优化视频上传功能,vip视频系统,自动注册试看功能,卡密系统,用户自行升级会员,
后台上传支付二维码即可完成支付,支持微信和支付宝。前台提交订单,后台管理员审核
支持MP4、m3u8、Flv等常规媒体视频格式文件播放,发送企业版优采云采集器和规则。全站自动更新,无需人工维护,有全站数据,可直接操作


安装说明:
匹配环境:PHP版本5.2.17 MySQL版本5.5.46 服务器空间至少500M mysql数据库至少200M
1.使用了Empire Backup数据库,打开Empire Backup工具,你的网站/bak(默认账号为admin,密码为123456)
或者直接导入数据库database.sql
2.帝国备份的数据库恢复方法这里就不介绍了,网站建设基本了解
3.打开config文件夹下的conn.php
修改自己的服务器信息:
$localhost = "xxxxxx";//服务器地址,通常是localhost
$root = "xxxxxx";//服务器MYSQL登录用户名
$password = "xxxxxx";//服务器的MYSQL登录密码
$database = "xxxxxx";//你使用的数据库
4.登录后台,后台路径为你的网址/admin_2018/(默认账号为admin8,密码为admin888)
5.进入后台配置你的网站,然后就可以操作了
采集见采集文档,采集规则已发送;
PS:每个人的采集的网站不一样,自然采集的规则也会不一样;
下载链接:
[pay point="20″] 链接:密码:7mtd[/pay]
1.本站所有资源均来自用户上传和互联网,不收录技术服务,请见谅!
2. 本站不保证所提供下载资源的准确性、安全性和完整性。资源仅供下载学习使用!如有链接无法下载、失效或广告,请联系客服!
3.您必须在下载后24小时内将以上内容资源从您的电脑中彻底删除!如用于商业或非法用途,与本站无关,一切后果由用户负责!
4.如果你也有好的资源或者教程,可以提交论文发表。分享成功后,将有现场币奖励和额外收益!
V9及更低集搜客网络爬虫软件新版本对应教程
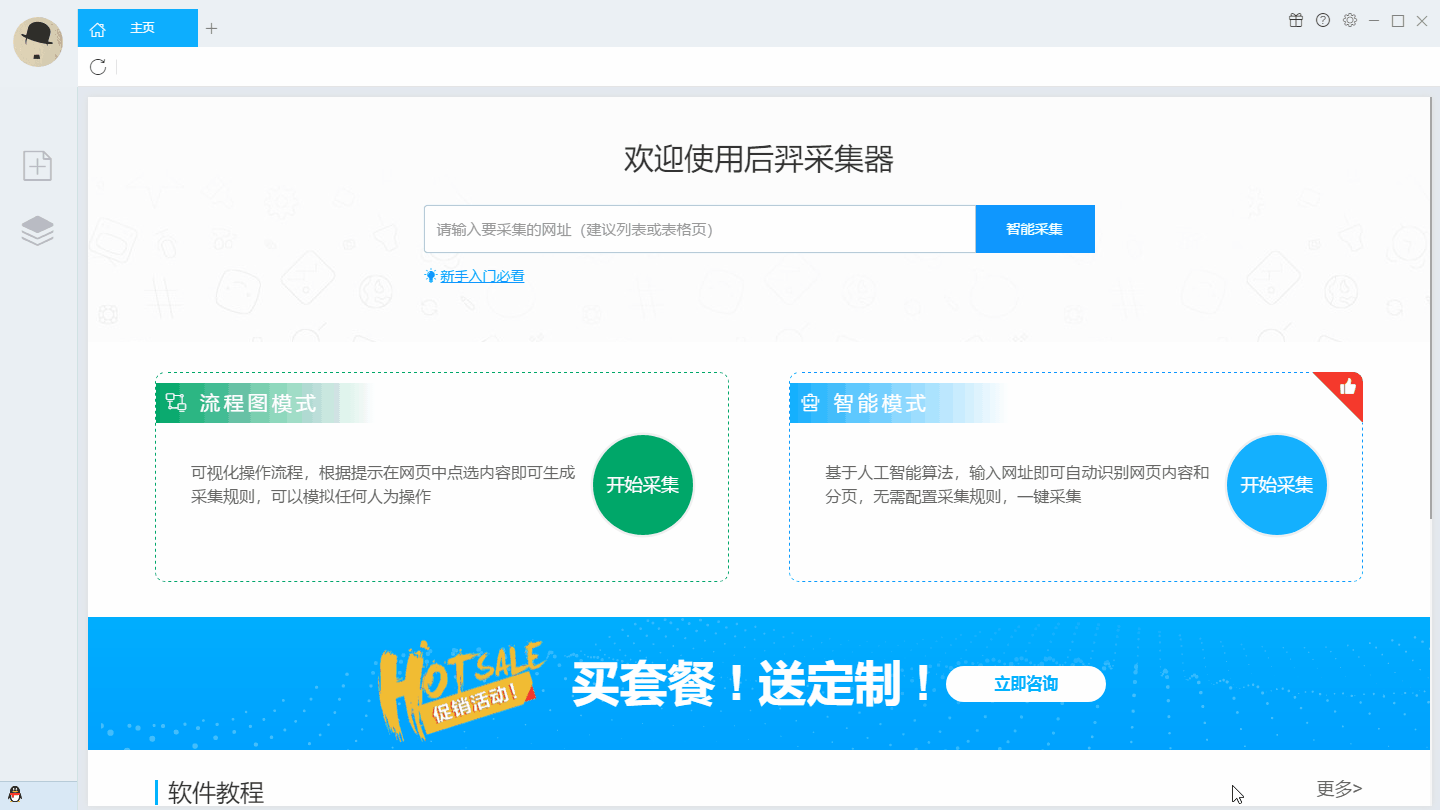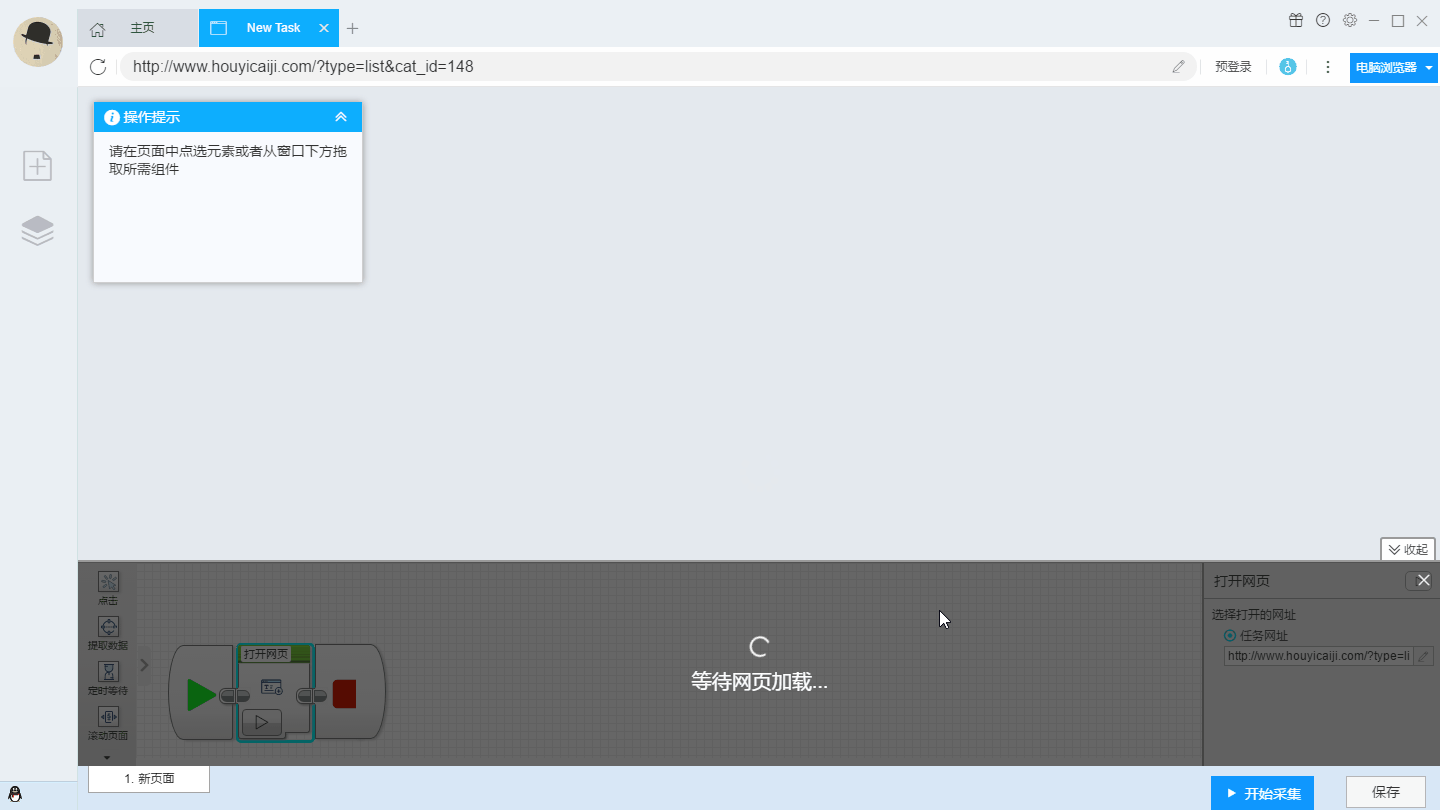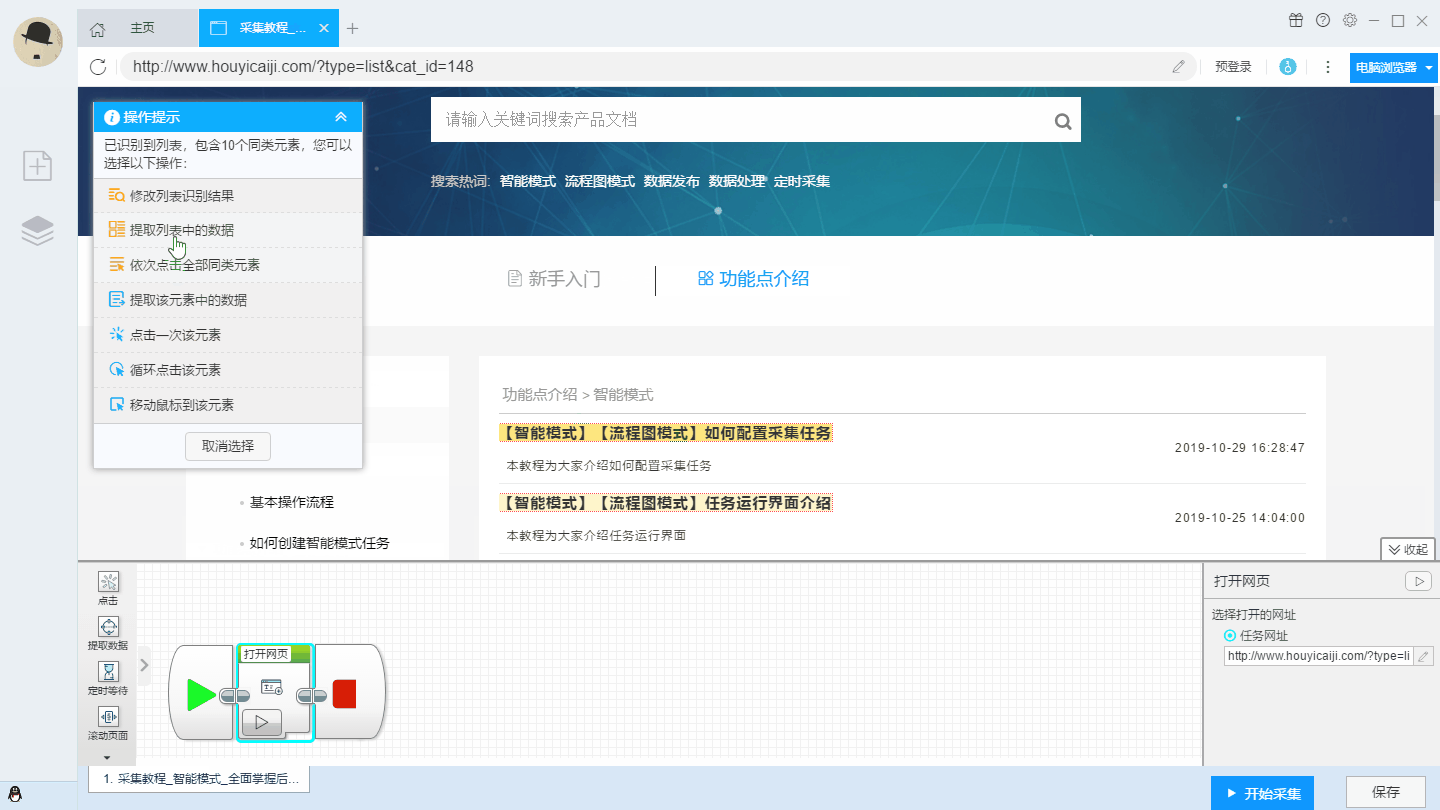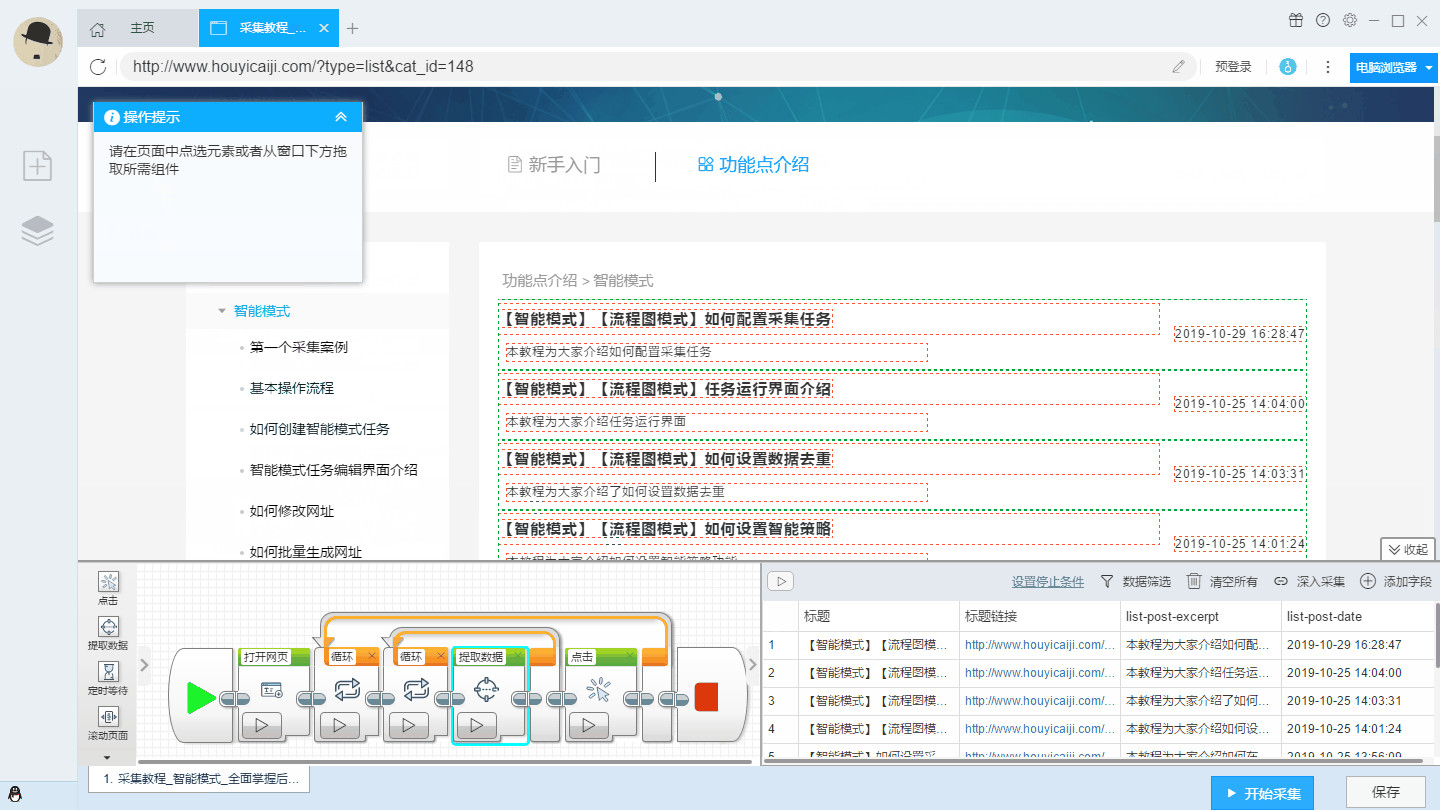
采集交流 • 优采云 发表了文章 • 0 个评论 • 242 次浏览 • 2021-08-01 07:28
支持软件版本:V9及以下吉首网络爬虫软件
新版本对应教程:V10及更高版本Data Manager-Enhanced Web Crawler对应教程为“Web Crawler采集表数据”
注:Jisouke的GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”改为“任务”。在爬虫浏览器中,先给任务命名然后创建规则,然后登录吉首可以查看任务的采集执行状态,管理线程URL,在“任务管理”中进行调度设置可客官网会员中心。
一、操作步骤(看视频)
当你列出采集时,你可以看到多条结构相同的信息。我们称一条信息为样本。例如,表中的每一行都是一个样本。比如京东搜索列表中的每一行A产品也是一个例子。如果您有一个收录两个以上示例的列表页面,请复制示例以获取整个列表采集。以下京东列表页面为案例,操作步骤如下:
二、Case规则+操作步骤
第一步:打开网页
1.1,打开GS爬虫浏览器,输入上面的示例网址回车,网页加载完毕后,点击网址输入栏后面的“定义规则”按钮,可以看到一个浮动窗口显示出来,称为工作站,在其上定义规则;
1.2,在工作台输入主题名称,点击“检查重复”查看名称是否被占用。
第 2 步:标记信息
2.1,在浏览器窗口双击你想要的内容采集,在弹出的窗口中输入标签名称,勾选确认或回车完成一次标注操作。必须为第一个标签输入整理箱的名称。这也是建立标签和网页信息映射关系的过程。
2.2,重复上一步标记其他信息。
第 3 步:复制样本
3.1,点击第一个示例中的任意内容,可以看到在下面的DOM窗口中,光标自动定位到一个节点,右键点击这个节点,选择示例复制映射→第一个Piece。
3.2,然后,单击第二个示例中的任何内容。同理,在下面的DOM窗口中,光标自动定位到一个节点,右键单击该节点,选择Sample Copy Map→Second Piece。
这完成了示例副本映射。
注意:有时候sample的copy操作没有报错,但是经过测试,只有采集拿到了一条数据。大部分问题在于整理箱的定位。排序框默认定位方式为“Partial ID”,但京东listing网页排序框的定位方式一般选择“绝对定位”。
第 4 步:保存规则并捕获数据
4.1,规则测试成功后,点击“保存规则”;
4.2,点击“抓取数据”,会弹出DS计数器,开始抓取数据。
4.3,采集 成功的数据会以xml文件的形式保存在DataScraperWorks文件夹中。详情请参考文章“查看数据结果”。
第1部分文章:“采集网页数据”第2部分文章:“翻页采集”
如果您有任何问题,可以或
查看全部
V9及更低集搜客网络爬虫软件新版本对应教程
支持软件版本:V9及以下吉首网络爬虫软件
新版本对应教程:V10及更高版本Data Manager-Enhanced Web Crawler对应教程为“Web Crawler采集表数据”
注:Jisouke的GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”改为“任务”。在爬虫浏览器中,先给任务命名然后创建规则,然后登录吉首可以查看任务的采集执行状态,管理线程URL,在“任务管理”中进行调度设置可客官网会员中心。
一、操作步骤(看视频)
当你列出采集时,你可以看到多条结构相同的信息。我们称一条信息为样本。例如,表中的每一行都是一个样本。比如京东搜索列表中的每一行A产品也是一个例子。如果您有一个收录两个以上示例的列表页面,请复制示例以获取整个列表采集。以下京东列表页面为案例,操作步骤如下:

二、Case规则+操作步骤
第一步:打开网页
1.1,打开GS爬虫浏览器,输入上面的示例网址回车,网页加载完毕后,点击网址输入栏后面的“定义规则”按钮,可以看到一个浮动窗口显示出来,称为工作站,在其上定义规则;
1.2,在工作台输入主题名称,点击“检查重复”查看名称是否被占用。

第 2 步:标记信息
2.1,在浏览器窗口双击你想要的内容采集,在弹出的窗口中输入标签名称,勾选确认或回车完成一次标注操作。必须为第一个标签输入整理箱的名称。这也是建立标签和网页信息映射关系的过程。
2.2,重复上一步标记其他信息。

第 3 步:复制样本
3.1,点击第一个示例中的任意内容,可以看到在下面的DOM窗口中,光标自动定位到一个节点,右键点击这个节点,选择示例复制映射→第一个Piece。

3.2,然后,单击第二个示例中的任何内容。同理,在下面的DOM窗口中,光标自动定位到一个节点,右键单击该节点,选择Sample Copy Map→Second Piece。

这完成了示例副本映射。
注意:有时候sample的copy操作没有报错,但是经过测试,只有采集拿到了一条数据。大部分问题在于整理箱的定位。排序框默认定位方式为“Partial ID”,但京东listing网页排序框的定位方式一般选择“绝对定位”。

第 4 步:保存规则并捕获数据
4.1,规则测试成功后,点击“保存规则”;
4.2,点击“抓取数据”,会弹出DS计数器,开始抓取数据。
4.3,采集 成功的数据会以xml文件的形式保存在DataScraperWorks文件夹中。详情请参考文章“查看数据结果”。

第1部分文章:“采集网页数据”第2部分文章:“翻页采集”
如果您有任何问题,可以或

大数据、大影响、国际发展新的可能性》
采集交流 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-08-01 03:08
2008 年 9 月 4 日,英国《自然》杂志出版了名为《大数据》的专辑,首次提出了大数据的概念。讨论了充分利用海量数据的最新策略。 2011、2012达沃斯世界经济论坛将大数据作为专题讨论的主题之一,发布了《大数据,大影响:国际发展的新可能性》等系列报告。
自 2011 年以来,中国成立了大数据委员会,研究大数据中的科学和工程问题。科技部《中国云技术发展“十二五”专项规划》、工信部《物联网“十二五”发展规划》等均支持大数据技术作为业内普遍认为,2013年是中国“大数据元年”。
根据IDC的估算,数据以每年50%的速度增长,这意味着每两年翻一番(大数据摩尔定律),大量新数据源的出现导致了结构化和半结构化数据的爆发式增长,意味着近两年人类产生的数据量相当于之前产生的数据总量。预计到2020年,全球数据总量将达到35亿GB。与2010年相比,数据量将增加近30倍。这不是一个简单的增加数据的问题,而是一个全新的问题。
随着大数据时代的到来,我们要处理的数据量过大、增长过快,业务需求和竞争压力对数据处理的实时性和有效性提出了更高的要求。传统的常规技术手段根本无法应对。
大数据的特点具有数据量大、类型多样、价值密度低、速度快、效率高等特点。面对大数据的新特性,现有的技术架构和路线已经无法高效处理如此海量的数据。 ,而对于相关机构来说,如果采集的输入不能及时处理,反馈有效信息,那将是不值得的。可以说,大数据时代对人类的数据掌控能力提出了新的挑战,也为人们获得更深入、全面的洞察提供了前所未有的空间和潜力。
大数据蕴含巨大价值,对我们的工作和生活产生重大影响。如何快速有效地获取这些数据来为我们服务是一个大问题。有问题,自然会有能解决问题的人。为了解决这个问题,优采云工程师团队经过不断的探索和研发,终于开发出了一款基于人工智能技术的网络爬虫软件。只需输入网址。网页数据自动识别,数据无需配置采集即可完成,是业界首款支持三种操作系统(包括Windows、Mac和Linux)的采集软件。同时,这是一款真正免费的数据采集软件。 采集结果的导出没有限制。没有编程基础的新手用户也能轻松实现数据采集需求。
我们以杭州同城58套二手房为例,介绍如何使用软件采集二房房房信息及中介联系电话。
首先复制需要采集的URL。注意需要复制结果页的网址,而不是搜索页的网址,然后在软件中输入网址即可创建智能采集任务。
接下来我们对智能识别的字段进行处理,我们可以修改字段名称,添加或删除字段等
由于listing页面只显示了部分信息,如果需要listing的具体描述,需要右键listing链接使用“deep采集”功能,跳转到listing页面采集 的详细信息页面。
设置采集字段后,我们点击“保存并启动”按钮运行爬虫工具。
提取数据后,我们就可以导出数据了。软件提供多种导出方式,供我们自由选择。
我们导出一张excel2007表,可以看到数据还是很齐全的,可以直接使用这个数据,也可以在此基础上处理数据。
查看全部
大数据、大影响、国际发展新的可能性》
2008 年 9 月 4 日,英国《自然》杂志出版了名为《大数据》的专辑,首次提出了大数据的概念。讨论了充分利用海量数据的最新策略。 2011、2012达沃斯世界经济论坛将大数据作为专题讨论的主题之一,发布了《大数据,大影响:国际发展的新可能性》等系列报告。
自 2011 年以来,中国成立了大数据委员会,研究大数据中的科学和工程问题。科技部《中国云技术发展“十二五”专项规划》、工信部《物联网“十二五”发展规划》等均支持大数据技术作为业内普遍认为,2013年是中国“大数据元年”。
根据IDC的估算,数据以每年50%的速度增长,这意味着每两年翻一番(大数据摩尔定律),大量新数据源的出现导致了结构化和半结构化数据的爆发式增长,意味着近两年人类产生的数据量相当于之前产生的数据总量。预计到2020年,全球数据总量将达到35亿GB。与2010年相比,数据量将增加近30倍。这不是一个简单的增加数据的问题,而是一个全新的问题。
随着大数据时代的到来,我们要处理的数据量过大、增长过快,业务需求和竞争压力对数据处理的实时性和有效性提出了更高的要求。传统的常规技术手段根本无法应对。
大数据的特点具有数据量大、类型多样、价值密度低、速度快、效率高等特点。面对大数据的新特性,现有的技术架构和路线已经无法高效处理如此海量的数据。 ,而对于相关机构来说,如果采集的输入不能及时处理,反馈有效信息,那将是不值得的。可以说,大数据时代对人类的数据掌控能力提出了新的挑战,也为人们获得更深入、全面的洞察提供了前所未有的空间和潜力。
大数据蕴含巨大价值,对我们的工作和生活产生重大影响。如何快速有效地获取这些数据来为我们服务是一个大问题。有问题,自然会有能解决问题的人。为了解决这个问题,优采云工程师团队经过不断的探索和研发,终于开发出了一款基于人工智能技术的网络爬虫软件。只需输入网址。网页数据自动识别,数据无需配置采集即可完成,是业界首款支持三种操作系统(包括Windows、Mac和Linux)的采集软件。同时,这是一款真正免费的数据采集软件。 采集结果的导出没有限制。没有编程基础的新手用户也能轻松实现数据采集需求。
我们以杭州同城58套二手房为例,介绍如何使用软件采集二房房房信息及中介联系电话。
首先复制需要采集的URL。注意需要复制结果页的网址,而不是搜索页的网址,然后在软件中输入网址即可创建智能采集任务。

接下来我们对智能识别的字段进行处理,我们可以修改字段名称,添加或删除字段等

由于listing页面只显示了部分信息,如果需要listing的具体描述,需要右键listing链接使用“deep采集”功能,跳转到listing页面采集 的详细信息页面。

设置采集字段后,我们点击“保存并启动”按钮运行爬虫工具。
提取数据后,我们就可以导出数据了。软件提供多种导出方式,供我们自由选择。
我们导出一张excel2007表,可以看到数据还是很齐全的,可以直接使用这个数据,也可以在此基础上处理数据。
XPath入门教程:优采云采集数据常见使用场景工具
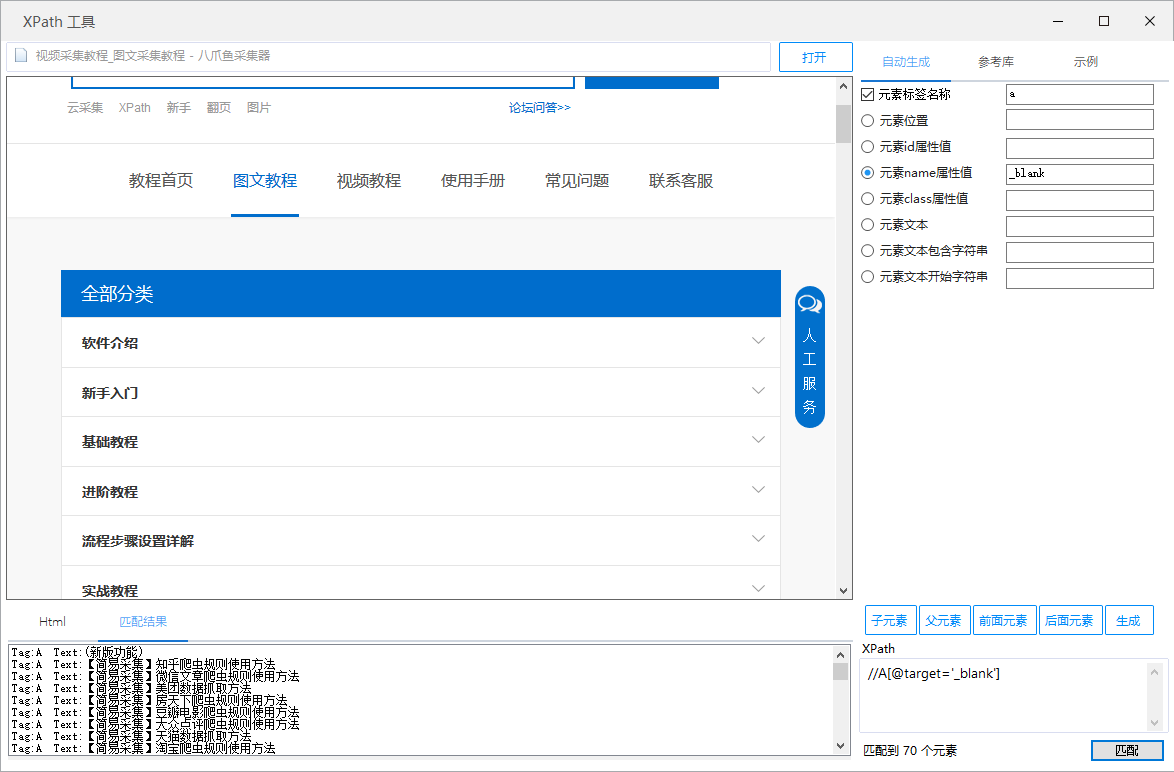
采集交流 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2021-07-31 19:42
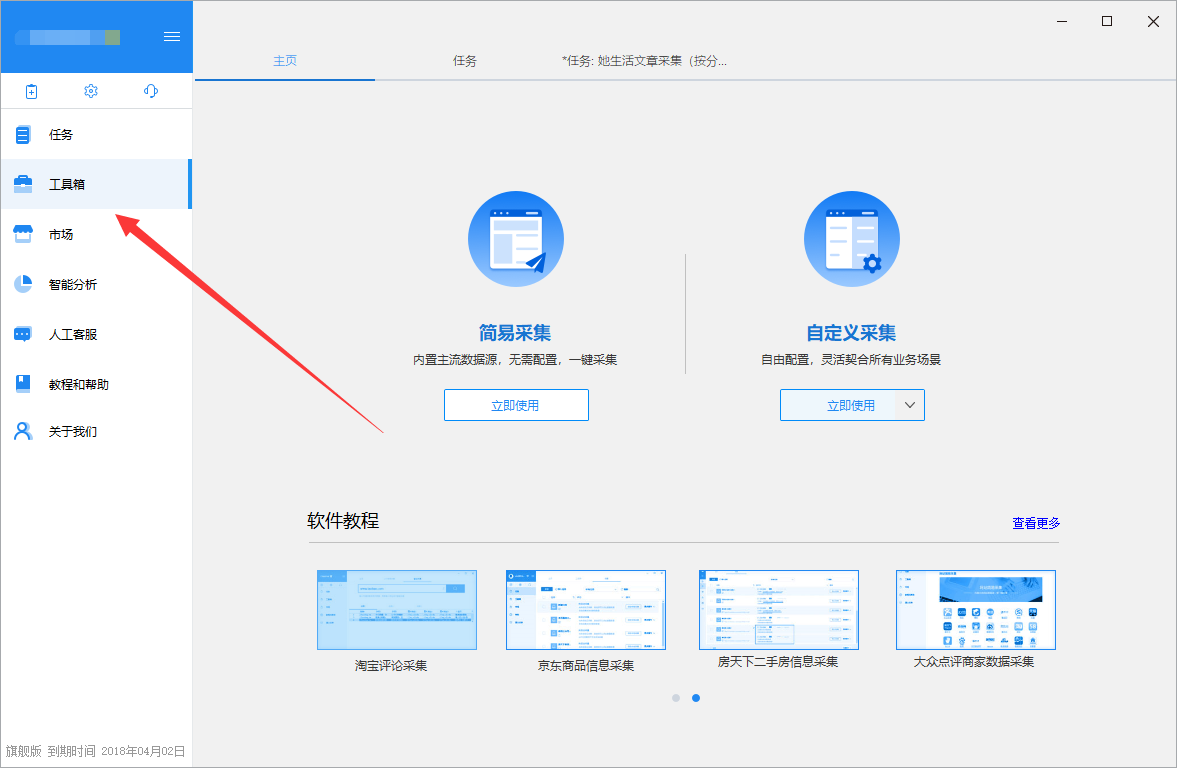
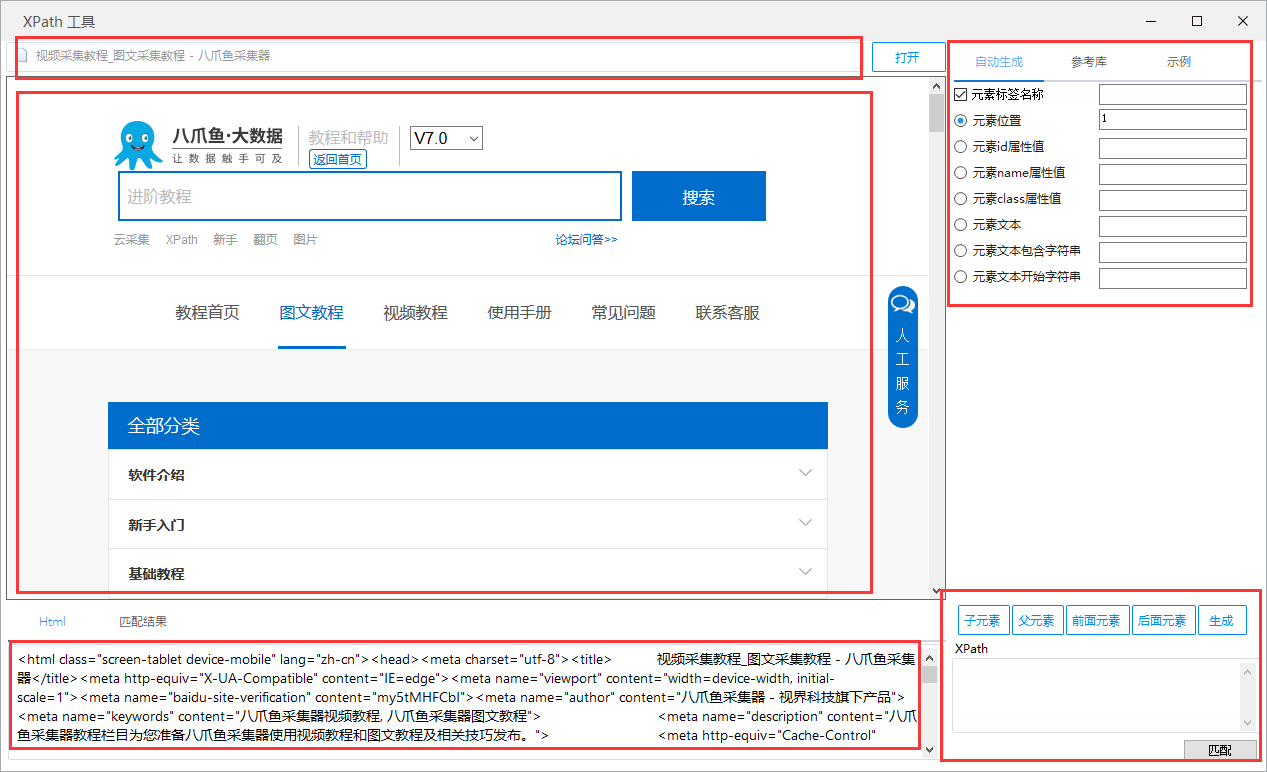
一、常见使用场景
优采云采集数据在日常使用中,偶尔会出现一些特殊情况。比如某个采集步骤由于网页或者优采云识别问题导致定位有偏差,导致自动生成的XPath有问题,采集出错了。这时候就需要手工编写XPath来定位我们要设置的步骤,而优采云内置了XPath工具,可以帮你写一些简单的XPath定位(除了打开网页的步骤) ,没有XPath工具,其他步骤都可以)。
二、XPath 工具位置
XPath 工具可以在两个地方打开。
一个入口是:登录后可以直接在软件首页的工具箱中打开。
另一个入口是:流程中步骤的“自定义”按钮,点击进入
点击“自定义”按钮后,点击“不懂XPath,试试XPath工具”
三、XPath 工具界面介绍
打开XPath工具,工具界面主要分为五个部分:
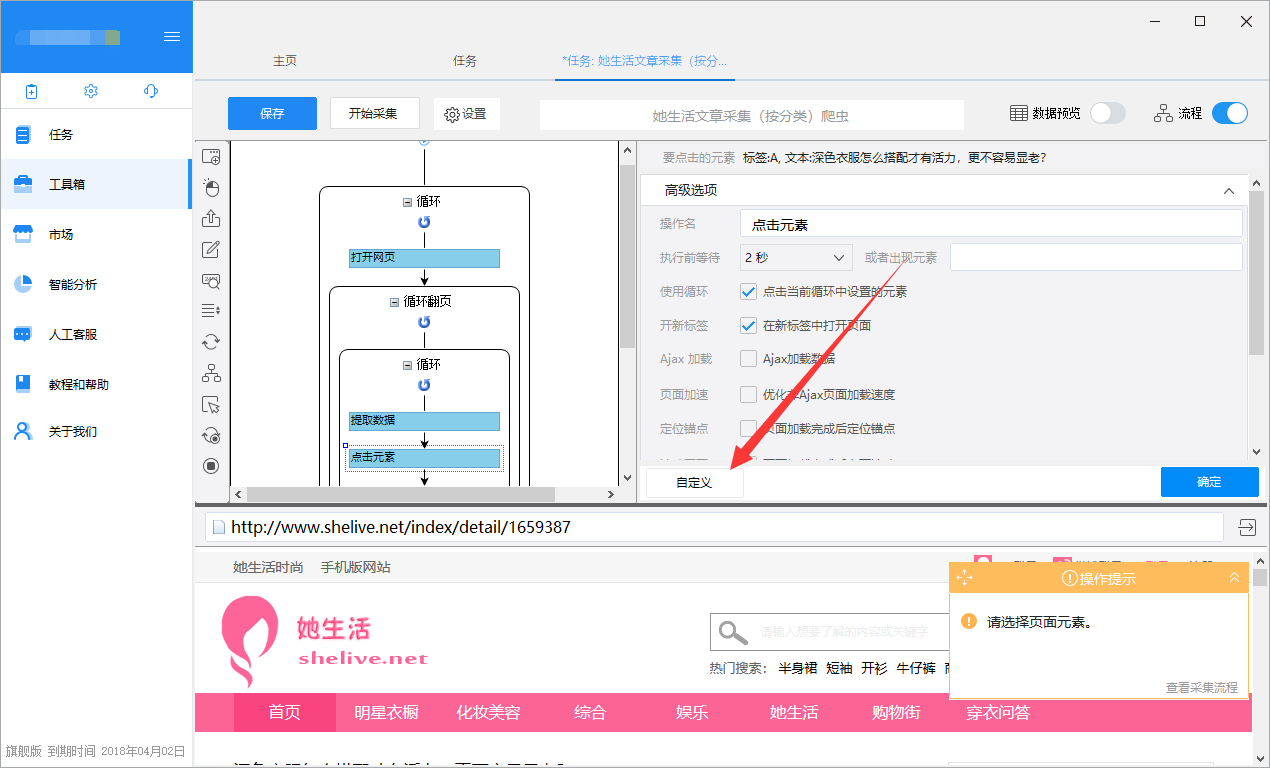
左上角是填写网址
左中是浏览器
左下为页面的HTML源代码(由于XPath工具源代码层次不清,建议使用火狐插件Firebug和FirePath查看源代码。火狐版54或更早版本支持这两个插件,Chrome浏览器有一个类似的插件XPath Helper。以下是XPath的入门教程,新用户请稍后学习:)
右上角是定位参数(工具会根据你填写的参数生成XPath)
右下方是点击Generate as required后匹配的XPath
1、来看看定位参数
1)Element 标签名:火狐中所有蓝色字体为元素标签名,如下:span、a、h、br等,具体参数名请到火狐查看代码行您要定位的前标签是什么?就写在这里吧。您可以在 Firefox 中清楚地看到它:
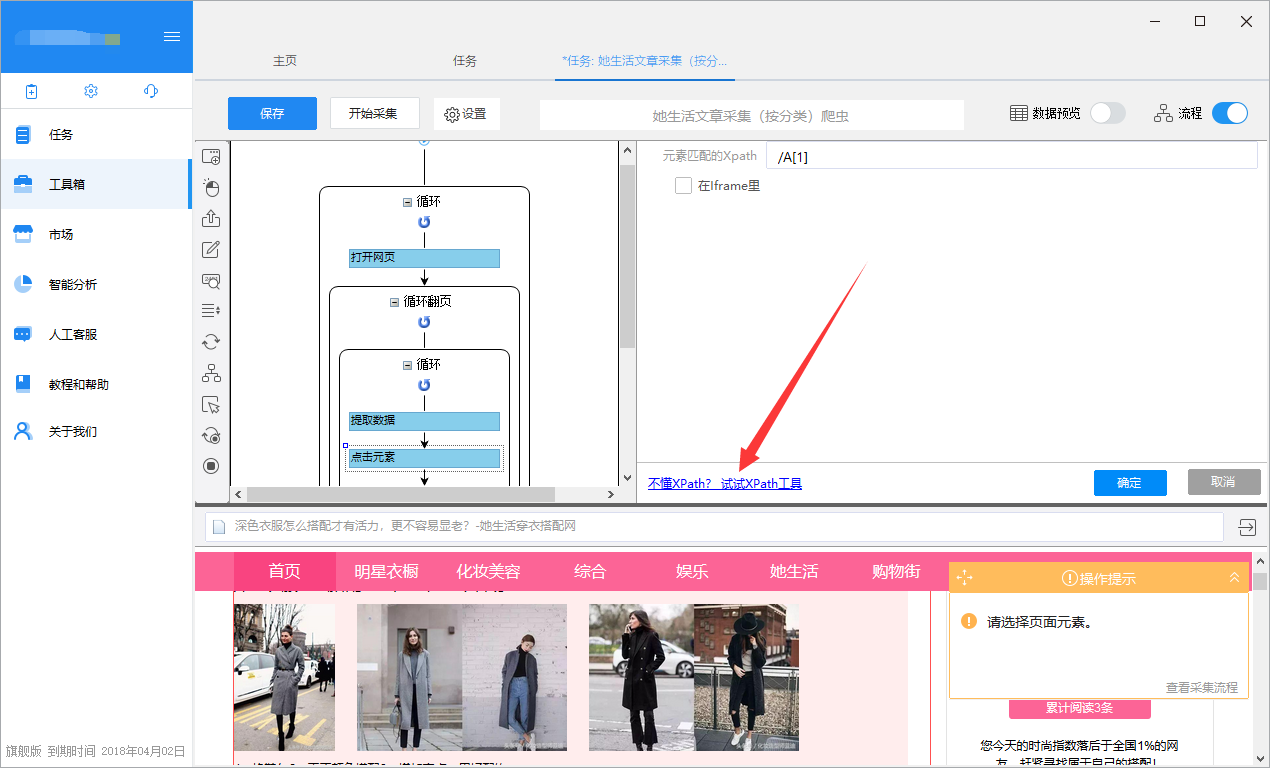
2)元素位置:默认填1。这个位置意味着第一。一般用的比较少,因为Firefox中自动生成的XPath很多都用到了位置定位。最好使用 Firefox 来使用它。快速生成;
3)Element ID属性值、元素名称属性值、元素类属性值:属性值是一行源码中尖括号括起来的参数,会有很多,这里的三个属性值大多数网页通用的属性值只有三种,但是也可以改变它们,例如:
a 标签下有 class、href 和 target 三个属性。如果要通过属性类定位,只需将class=后面引号内的参数复制粘贴到网格中,点击生成,就会自动生成类属性值定位的XPath路径。
如果你要定位的属性不是这三个,比如target,也可以直接把target=后面引号中的属性值复制进去,放到一个属性中。
此时,没有匹配项。需要将生成的XPath中的属性改为target,也就是将图中@和=之间的属性改为:
<p>4)Element text: Firefox 中全黑字体。一般会显示在网页上,我们可以直接看到字体。如果要填这个框,必须填满整个文本,少一个空格标点,全角和半角不一致会导致定位失败,但是如果是纯文本就可以了; 查看全部
XPath入门教程:优采云采集数据常见使用场景工具
一、常见使用场景
优采云采集数据在日常使用中,偶尔会出现一些特殊情况。比如某个采集步骤由于网页或者优采云识别问题导致定位有偏差,导致自动生成的XPath有问题,采集出错了。这时候就需要手工编写XPath来定位我们要设置的步骤,而优采云内置了XPath工具,可以帮你写一些简单的XPath定位(除了打开网页的步骤) ,没有XPath工具,其他步骤都可以)。
二、XPath 工具位置
XPath 工具可以在两个地方打开。
一个入口是:登录后可以直接在软件首页的工具箱中打开。

另一个入口是:流程中步骤的“自定义”按钮,点击进入
点击“自定义”按钮后,点击“不懂XPath,试试XPath工具”
三、XPath 工具界面介绍
打开XPath工具,工具界面主要分为五个部分:
左上角是填写网址
左中是浏览器
左下为页面的HTML源代码(由于XPath工具源代码层次不清,建议使用火狐插件Firebug和FirePath查看源代码。火狐版54或更早版本支持这两个插件,Chrome浏览器有一个类似的插件XPath Helper。以下是XPath的入门教程,新用户请稍后学习:)
右上角是定位参数(工具会根据你填写的参数生成XPath)
右下方是点击Generate as required后匹配的XPath
1、来看看定位参数

1)Element 标签名:火狐中所有蓝色字体为元素标签名,如下:span、a、h、br等,具体参数名请到火狐查看代码行您要定位的前标签是什么?就写在这里吧。您可以在 Firefox 中清楚地看到它:
2)元素位置:默认填1。这个位置意味着第一。一般用的比较少,因为Firefox中自动生成的XPath很多都用到了位置定位。最好使用 Firefox 来使用它。快速生成;
3)Element ID属性值、元素名称属性值、元素类属性值:属性值是一行源码中尖括号括起来的参数,会有很多,这里的三个属性值大多数网页通用的属性值只有三种,但是也可以改变它们,例如:

a 标签下有 class、href 和 target 三个属性。如果要通过属性类定位,只需将class=后面引号内的参数复制粘贴到网格中,点击生成,就会自动生成类属性值定位的XPath路径。
如果你要定位的属性不是这三个,比如target,也可以直接把target=后面引号中的属性值复制进去,放到一个属性中。
此时,没有匹配项。需要将生成的XPath中的属性改为target,也就是将图中@和=之间的属性改为:
<p>4)Element text: Firefox 中全黑字体。一般会显示在网页上,我们可以直接看到字体。如果要填这个框,必须填满整个文本,少一个空格标点,全角和半角不一致会导致定位失败,但是如果是纯文本就可以了;
不用采集规则,就可以采集公众号文章。。
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-07-30 22:05
不用采集规则就可以采集公众号文章。本篇教程需要三个软件,这些软件我都有,欢迎大家找我要,有的一起打包给大家,支持三个人吧(百度云盘)(网盘)链接:提取码:hdqq也可以关注本专栏,查看往期视频。
参考:文章采集软件你有哪些值得推荐的采集软件?如果有问题,欢迎私信交流。
目前我用的比较多的有微信公众号采集器,可以采集微信公众号文章、微信图文等,个人觉得效果还不错。
可以采集公众号:1718黄金眼,不知道可不可以采集,可以看下。
多种方式,遇到热点问题,可以参考头条公众号热点资讯,每天更新,一目了然,还可以根据自己的话题选择内容。
微信公众号:1718黄金眼是做公众号的可以有上述客服帮忙找投稿的地方(不能是的。
没有,因为那是传统的投放投放是有投放要求的,我不是投放专家也没做过数据投放,所以没法回答你真正能投放的地方,但是可以说几点通用的方法微信朋友圈:假如一个粉丝给你个小福利,只要你能够这么操作,再加上你的微信朋友圈是公开发布,而不是单独给某个个人投放,一般投放效果不会太差。发帖或者公众号文章链接:这个方法通常是做公众号内容时用得上,假如你以前没怎么关注过公众号的话,最好了解下每天发的微信推送的领域,或者顺藤摸瓜一下你将发现更多原创的微信推送,经常有投放人员将对某个领域的微信内容做了一些内容,其他领域的也将照样投放。
其他大众类:这些大众类投放可以在平时中去投放,例如自己是个餐馆的可以投放一些火锅呀,自助餐之类的食物,而且是带图文链接的,或者你写这个公众号有情趣用品的话可以写一些跟情趣相关的内容。 查看全部
不用采集规则,就可以采集公众号文章。。
不用采集规则就可以采集公众号文章。本篇教程需要三个软件,这些软件我都有,欢迎大家找我要,有的一起打包给大家,支持三个人吧(百度云盘)(网盘)链接:提取码:hdqq也可以关注本专栏,查看往期视频。
参考:文章采集软件你有哪些值得推荐的采集软件?如果有问题,欢迎私信交流。
目前我用的比较多的有微信公众号采集器,可以采集微信公众号文章、微信图文等,个人觉得效果还不错。
可以采集公众号:1718黄金眼,不知道可不可以采集,可以看下。
多种方式,遇到热点问题,可以参考头条公众号热点资讯,每天更新,一目了然,还可以根据自己的话题选择内容。
微信公众号:1718黄金眼是做公众号的可以有上述客服帮忙找投稿的地方(不能是的。
没有,因为那是传统的投放投放是有投放要求的,我不是投放专家也没做过数据投放,所以没法回答你真正能投放的地方,但是可以说几点通用的方法微信朋友圈:假如一个粉丝给你个小福利,只要你能够这么操作,再加上你的微信朋友圈是公开发布,而不是单独给某个个人投放,一般投放效果不会太差。发帖或者公众号文章链接:这个方法通常是做公众号内容时用得上,假如你以前没怎么关注过公众号的话,最好了解下每天发的微信推送的领域,或者顺藤摸瓜一下你将发现更多原创的微信推送,经常有投放人员将对某个领域的微信内容做了一些内容,其他领域的也将照样投放。
其他大众类:这些大众类投放可以在平时中去投放,例如自己是个餐馆的可以投放一些火锅呀,自助餐之类的食物,而且是带图文链接的,或者你写这个公众号有情趣用品的话可以写一些跟情趣相关的内容。
mobipai注册了名下的亚马逊仓库资源多想想为什么要赚钱
采集交流 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-07-28 18:24
不用采集规则就可以采集的流量,成本可控。平台的现有资源还是很好的。通过多组合点位的打磨,后期将很快将游戏引入appstore。没有资源之前,关注各组合点位的流量利用率,单纯考虑盈利的话,需要通过实战总结出一套合理的获取资源的方法。
mobipai注册了名下的亚马逊仓库资源
多想想为什么要赚钱?赚钱本身就是一个很好的事情。
当然是每次销售出去的数据,效果和同比就可以赚钱,不用天天想着花钱。
如果先不用精心布局好,
先明确需求,再想好卖什么产品,再根据这个产品找流量平台。
可以看看一款软件,叫卖客,那个是游戏版本的,但是质量不错。
想想。你可以在哪里流量?网站?app?还是微信?搜索一下。用网站的话,你是用了哪些付费流量?是竞价的?是官方内置的。微信公众号?官方的?那么用什么搜索?关键词在哪里搜。好了现在把问题说的细一点。然后,你可以用哪些手段?可以用价格手段和广告手段。很多手段。说白了,其实就是花钱呗,广告不好做,那么就做竞价。竞价赚不了钱,那么用低价做多销量也是可以赚钱的。回答好累。
游戏是什么?盈利方式具体想好了吗?
小游戏都有积分商城的,那么它能存在的几率就大一些。平台是一方面,要吸引用户才是一定要做的。 查看全部
mobipai注册了名下的亚马逊仓库资源多想想为什么要赚钱
不用采集规则就可以采集的流量,成本可控。平台的现有资源还是很好的。通过多组合点位的打磨,后期将很快将游戏引入appstore。没有资源之前,关注各组合点位的流量利用率,单纯考虑盈利的话,需要通过实战总结出一套合理的获取资源的方法。
mobipai注册了名下的亚马逊仓库资源
多想想为什么要赚钱?赚钱本身就是一个很好的事情。
当然是每次销售出去的数据,效果和同比就可以赚钱,不用天天想着花钱。
如果先不用精心布局好,
先明确需求,再想好卖什么产品,再根据这个产品找流量平台。
可以看看一款软件,叫卖客,那个是游戏版本的,但是质量不错。
想想。你可以在哪里流量?网站?app?还是微信?搜索一下。用网站的话,你是用了哪些付费流量?是竞价的?是官方内置的。微信公众号?官方的?那么用什么搜索?关键词在哪里搜。好了现在把问题说的细一点。然后,你可以用哪些手段?可以用价格手段和广告手段。很多手段。说白了,其实就是花钱呗,广告不好做,那么就做竞价。竞价赚不了钱,那么用低价做多销量也是可以赚钱的。回答好累。
游戏是什么?盈利方式具体想好了吗?
小游戏都有积分商城的,那么它能存在的几率就大一些。平台是一方面,要吸引用户才是一定要做的。
不用采集规则就可以采集(最近PTCMS火爆全网了,PTCMS源码下载地址:全新开发 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-08-29 18:08
)
近期PTcms火爆全网,PTcms源码下载地址:
说说PTcms的搭建教程。
功能介绍:
新开发,新UI,增加原创专区,新闻发布,书单发布,采集日志,百度推送,神马推送,推送日志功能。
前端高仿起点小说网站,自适应模板,可分手机域名。
后端是用LAYUI新开发的。
以下为施工内容:
一、服务器环境要求
推荐Linux环境,也支持win,但是我没有去测试和构建,按照下面的教程自己测试。下面是我要搭建的环境。
nginx1.15 MySQL5.5 php7.3
安装php扩展fileinfo memcached swoole4
删除php7.3禁用功能中的shell exec
二、Configuration Swoole
1、在/www/server/文件中创建一个ptcms文件夹,将License和loader73.so上传到ptcms
2、打开php7.3(也叫php.ini)的配置文件,拉到最下面,添加下面两行代码,保存重启php,如果报错,检查以上步骤如有错误!
extension= /www/server/ptcms/loader73.so swoole_license_files= /www/server/ptcms/license
三、Configuration网站Settings,
1、click网站——点击站点名称或设置
2、Set网站运行目录公开
3、设置伪静态规则
一定是下面的伪静态规则
if (!-e $request_filename) { rewrite ^/(.*) /index.php?s=$1 last; }
四、运行安装
直接访问域名报错,需要域名/install.php
以下是访问域名/install.php后的正确页面,按照提示安装即可,选择memcached
安装完成后,进入网站配置。后台功能设置就不介绍了。我只会解释如何启动自动采集
五、Configuration采集
1、点击采集管理——规则管理,进入采集规则管理页面
2、在给任务添加规则之前,建议先进行测试,测试规则是否可用
3、然后添加到任务区
4、点击任务管理——采集任务监控页面,看到主线进程状态failed,时间也是1970,说明你没有配置cron所以主进程没有运行
My 已激活,所以显示正常。如果您的显示器无法作为主进程运行,请执行以下操作。
说说配置cron启动主进程以及如何启动
1、首先我们可以使用SHH链接工具,或者直接连接宝塔的SHH也是可以的
2、进入shh连接页面,需要登录连接服务器,输入如下代码,进入网站目录,看我下面截图
cd /www/wwwroot/网站根目录名称
然后,输入以下代码启动主进程任务。我已经开始了,所以这是正常的。一开始就是下图的样子
/www/server/php/73/bin/php kx cron:check
现在我们回到后台刷新下一页,可以再次看到进程采集,点击开启自动刷新,会自动刷新页面
好的,基本安装和设置到此结束。现在来说说列表采集settings分页和后台设置分页采集。
分页规则应使用 [page] 设置进行分页
设置列表时选择前台或后台离线,前台浏览器不能关闭,可以关闭浏览器和电脑。
起始页可以从任何页开始,前提是目标站点有此页,结束页相同,且必须等于或大于起始页。
查看全部
不用采集规则就可以采集(最近PTCMS火爆全网了,PTCMS源码下载地址:全新开发
)
近期PTcms火爆全网,PTcms源码下载地址:
说说PTcms的搭建教程。
功能介绍:
新开发,新UI,增加原创专区,新闻发布,书单发布,采集日志,百度推送,神马推送,推送日志功能。
前端高仿起点小说网站,自适应模板,可分手机域名。
后端是用LAYUI新开发的。
以下为施工内容:
一、服务器环境要求
推荐Linux环境,也支持win,但是我没有去测试和构建,按照下面的教程自己测试。下面是我要搭建的环境。
nginx1.15 MySQL5.5 php7.3
安装php扩展fileinfo memcached swoole4
删除php7.3禁用功能中的shell exec
二、Configuration Swoole
1、在/www/server/文件中创建一个ptcms文件夹,将License和loader73.so上传到ptcms
2、打开php7.3(也叫php.ini)的配置文件,拉到最下面,添加下面两行代码,保存重启php,如果报错,检查以上步骤如有错误!
extension= /www/server/ptcms/loader73.so swoole_license_files= /www/server/ptcms/license
三、Configuration网站Settings,
1、click网站——点击站点名称或设置
2、Set网站运行目录公开
3、设置伪静态规则
一定是下面的伪静态规则
if (!-e $request_filename) { rewrite ^/(.*) /index.php?s=$1 last; }
四、运行安装
直接访问域名报错,需要域名/install.php
以下是访问域名/install.php后的正确页面,按照提示安装即可,选择memcached
安装完成后,进入网站配置。后台功能设置就不介绍了。我只会解释如何启动自动采集
五、Configuration采集
1、点击采集管理——规则管理,进入采集规则管理页面
2、在给任务添加规则之前,建议先进行测试,测试规则是否可用
3、然后添加到任务区
4、点击任务管理——采集任务监控页面,看到主线进程状态failed,时间也是1970,说明你没有配置cron所以主进程没有运行
My 已激活,所以显示正常。如果您的显示器无法作为主进程运行,请执行以下操作。
说说配置cron启动主进程以及如何启动
1、首先我们可以使用SHH链接工具,或者直接连接宝塔的SHH也是可以的
2、进入shh连接页面,需要登录连接服务器,输入如下代码,进入网站目录,看我下面截图
cd /www/wwwroot/网站根目录名称
然后,输入以下代码启动主进程任务。我已经开始了,所以这是正常的。一开始就是下图的样子
/www/server/php/73/bin/php kx cron:check
现在我们回到后台刷新下一页,可以再次看到进程采集,点击开启自动刷新,会自动刷新页面
好的,基本安装和设置到此结束。现在来说说列表采集settings分页和后台设置分页采集。
分页规则应使用 [page] 设置进行分页
设置列表时选择前台或后台离线,前台浏览器不能关闭,可以关闭浏览器和电脑。
起始页可以从任何页开始,前提是目标站点有此页,结束页相同,且必须等于或大于起始页。
不用采集规则就可以采集(非DMA模式转换模式的方法,你get到了吗? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-08-29 15:10
)
一、Non-DMA 模式(传输)
说明:这个是我第一次做的时候百度出来的。我不是自己做的。因为觉得很有用,所以存起来供学习之用。原文链接:,我会在下面的第二部分添加我自己的DMA模式的方法。 .
Stm32 ADC的转换方式还是非常灵活强大的。有许多类型的模式。当许多人在没有仔细阅读参考手册的情况下使用它时,这也会导致混淆。不知道用什么方式来实现我想要的功能。网上也可以查到很多资料,但大部分都是针对旧版标准库的。昨天帮客户解决了这个问题,只是做个总结:使用stm32cubeMX配置生成多通道采集的例子。
软件:STM32Cumebx MDK
硬件:eemaker板(基于stm32F103c8)
在百度上搜索ADC多通道采集,大部分都是基于dma模式的。我说的是使用非 dma 方法。首先,有几个概念需要澄清:
扫描模式(如果要采集multi-channel 必须开启):就是一次转换选中的通道,例如ch0、ch1、ch4、ch5都开启。 Ch0 转换后,会自动转换通道 0、1、4、5,直到转换完成。但这种连续性并不是不能中断。这就引入了一种非连续模式,可以说是对扫描模式的补充。可对0、1、4、5四个通道进行分组,可分为0、1组和4、5组,每个通道也可配置为一组。这样每组转化都需要触发一次。
Stm32 ADC 的单模式和连续模式。两种模式的概念是对应的。这里的单一模式不是指一个通道。假设您同时打开四个通道 ch0、ch1、ch4 和 ch5。在单模转换模式下,这四个通道采集会停在一侧。连续模式下,四个通道转换后循环,然后从ch0开始。
还有规则组和注入组的概念。因为我在这个例子中只使用了规则组,所以我不会介绍这两个概念。如果你想弄清楚,请参阅手册。
进入下面的主题并配置stm32cubeMX。
先开启几个通道,我设置为0、1、4、5.
然后我们需要配置ADC参数:
目前,经过我的测试,如果要使用非dma和中断模式,只有这样配置才能正确进行多通道转换:扫描模式+单次转换模式+非连续转换模式(每个非连续组一个通道) .
在此模式下配置分析。配置多通道时必须开启扫描模式。 stm32cubeMX 也是默认设置,只能启用。在单次转换模式下,我不需要不断去每个通道值采集,而是在四个通道采集完成后停止。不连续的配置是这里的关键。不连续模式允许将扫描的四个通道分为四组。 stm32cubeMX参数中的Discontinous Conversions的数量就是配置不连续组,每组有几个通道。此处必须配置为1(否则在获取广告值时,只能读取每个不连续组的最后一个通道)。
生成mdk项目代码。此时还没有完成,但是已经实现了ADC的初始化。你需要采集自己写四个频道值得的功能。以下是我的主函数的while循环:
<p>for(i=1;i 查看全部
不用采集规则就可以采集(非DMA模式转换模式的方法,你get到了吗?
)
一、Non-DMA 模式(传输)
说明:这个是我第一次做的时候百度出来的。我不是自己做的。因为觉得很有用,所以存起来供学习之用。原文链接:,我会在下面的第二部分添加我自己的DMA模式的方法。 .
Stm32 ADC的转换方式还是非常灵活强大的。有许多类型的模式。当许多人在没有仔细阅读参考手册的情况下使用它时,这也会导致混淆。不知道用什么方式来实现我想要的功能。网上也可以查到很多资料,但大部分都是针对旧版标准库的。昨天帮客户解决了这个问题,只是做个总结:使用stm32cubeMX配置生成多通道采集的例子。
软件:STM32Cumebx MDK
硬件:eemaker板(基于stm32F103c8)
在百度上搜索ADC多通道采集,大部分都是基于dma模式的。我说的是使用非 dma 方法。首先,有几个概念需要澄清:
扫描模式(如果要采集multi-channel 必须开启):就是一次转换选中的通道,例如ch0、ch1、ch4、ch5都开启。 Ch0 转换后,会自动转换通道 0、1、4、5,直到转换完成。但这种连续性并不是不能中断。这就引入了一种非连续模式,可以说是对扫描模式的补充。可对0、1、4、5四个通道进行分组,可分为0、1组和4、5组,每个通道也可配置为一组。这样每组转化都需要触发一次。
Stm32 ADC 的单模式和连续模式。两种模式的概念是对应的。这里的单一模式不是指一个通道。假设您同时打开四个通道 ch0、ch1、ch4 和 ch5。在单模转换模式下,这四个通道采集会停在一侧。连续模式下,四个通道转换后循环,然后从ch0开始。
还有规则组和注入组的概念。因为我在这个例子中只使用了规则组,所以我不会介绍这两个概念。如果你想弄清楚,请参阅手册。
进入下面的主题并配置stm32cubeMX。
先开启几个通道,我设置为0、1、4、5.
然后我们需要配置ADC参数:
目前,经过我的测试,如果要使用非dma和中断模式,只有这样配置才能正确进行多通道转换:扫描模式+单次转换模式+非连续转换模式(每个非连续组一个通道) .
在此模式下配置分析。配置多通道时必须开启扫描模式。 stm32cubeMX 也是默认设置,只能启用。在单次转换模式下,我不需要不断去每个通道值采集,而是在四个通道采集完成后停止。不连续的配置是这里的关键。不连续模式允许将扫描的四个通道分为四组。 stm32cubeMX参数中的Discontinous Conversions的数量就是配置不连续组,每组有几个通道。此处必须配置为1(否则在获取广告值时,只能读取每个不连续组的最后一个通道)。
生成mdk项目代码。此时还没有完成,但是已经实现了ADC的初始化。你需要采集自己写四个频道值得的功能。以下是我的主函数的while循环:
<p>for(i=1;i
不用采集规则就可以采集(统计某博主某一年内发布的全部微博,并计算转评赞总数)
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2021-08-29 11:08
我只是想统计某个博主在某一年发布的所有微博,并统计了转发和点赞的总数。这么简单的任务。没想到折腾了这么久。
首先是微博数据提供的支付功能。且不说支付,只能算近一年,不能任意规定时间段。比如2020.4.11这一天,只能统计2019.@。对于4.11~2020.4.11的数据,不是每年都要等过年了才算去年的数据吗? ? ?
于是我找到了微博API(),发现很难用。不知道是不是只有我。毕竟我只用过百度和高德的API,经验不够。先创建应用,找了好久才找到入口。它不在[我的应用程序]中,而是在主页上看起来像广告的按钮中。 API接口部分提供的基础公共信息需要授权,OAuth2.0授权因不明原因失败。官方渠道好像无法获取数据,只能自己爬了。
爬虫坑似乎迟早要被填满。我还没有学过,也没有使用过。找了几段别人的代码,改了微博ID后,访问不了。不知道企业微博是否受到保护。 .
最后不得不用优采云采集器来爬取数据。软件虽然好用,但还是费了一番周折才弄明白里面的各种设置。经过无数次的零采集和不完整的数据,最终的设置可能是不必要的,但是这组设置确实可以正确捕获数据,而且不会花费几分钟,所以我不必担心。本文记录了一些踩过的坑以及最终成功的设置。
软件准备
免费下载、安装、注册,免费版就够了。这个任务的数据量不大,本地采集模式就够了。提供了一些模板,也有微博的。
优采云采集器采集template 中提供的微博数据
但微博最麻烦的部分是登录操作。您必须不时输入验证码。另外,全年计算任务需要大量的滚动和翻页操作,所以你还是要使用自定义任务,这是不可避免的。设置采集 URL、采集进程、登录操作。
采集URL
采集 URL的设置基本没有问题。只需在 URL 中找到需要更改的参数即可。当有多个页面时,建议从 URL 设置页码。可靠,自动翻页。怕翻错页,微博页面跳出来登录,所以自动识别总是成功,但是采集开头抓不到1。以我的个人微博主页为例,我查看了2019年6月的博文(#feedtop),发现时间线是按月份划分的。 6月份的微博发的有点多,出现页面变化,需要修改两个参数。 [月] 和 [页数]。
个人微博截图
在优采云采集器中,选择【批量生成】URL,在文本框中选择需要替换的参数,点击【添加参数】进行设置。这里设置的两个参数,[Month]为01~12(软件提供了[Zero Fill]功能,很贴心),[Page Number]为1~4,因为这次要统计的微博数量不每月超过4页,这个要提前看好。
批量生成网址参数设置
自动生成48个网址后,即可【保存设置】开始编辑任务。然后软件会打开第一个网址,开始自动识别这个页面的内容,并生成采集数据的结果,并给出操作提示,基本可信,不完全可信。点击【生成采集设置】自动生成采集进程的框架(毕竟比自己的靠谱),然后调整里面的设置细节(这些细节折腾了好久时间)。
自动识别结果
采集process
自动生成流程图,基本框架没问题。
loop采集的基本框架
开始详细设置,【提取列表数据】没什么好说的,删掉一些不需要的字段就可以了。主要是【循环打开网页】,点击小齿轮打开设置:
在循环中打开网页设置
【网页打开前】这里,我怕加载不全,先打开下一页,设置等待时间3秒。 (我尝试使用cookie设置绕过登录,但是不成功,当前页面获取cookie的按钮没有反应,所以放弃了。)【打开网页后】需要在此处设置滚动。一开始以为滚动2次到最后,后来发现不同的页面不一样,就设置为3次,间隔1秒,加载前也怕跳过。
滚动设置纠结了很久,因为总是出现同样的错误。很明显,一个页面应该加载3次,最后得到45条数据。结果,执行的时候,总是只抓到15个,不给滚动。不知道是我没有登录的原因,还是网页没有等就打开了。
登录操作
为了保证多页面抓取的顺利完成,还是不需要登录的,否则会一直弹出提示登录对话框,采集什么也找不到。说句公道话,微博登录是有cookies记录的,但是放到软件的采集任务里面就不行了。每次启动,一个全新的界面都需要登录。一眨眼,你就认不出你是谁了。记不起来了。所以参考模板中的设置,在循环采集启动之前添加了登录操作,并添加到流程图中,老老实实执行。
流程图中新增登录操作
【打开网页】这里的网址设置为微博入口(),后面的操作设置其实是半自动的,直接在预览网页中操作,点击对话框或按钮,和【操作提示】对应会出现actions,可以记录登录时的输入文字(用户名、密码)、点击元素等操作,模拟人工操作,自动添加到流程图中,但可能会在循环后面,需要手动拖拽调整流程图中框的顺序。流程图完成后就可以开始[采集]了。
我觉得这些都设置好了,账号和密码也都记下来了,应该可以代替我先登录。没想到,登录的时候,要么没有输入用户名,要么没有输入密码。结果根本没有登录就执行了下一步,循环开始了,但是什么都没抓到。这时候,打开网页前的3秒等待似乎奏效了。利用这3秒时间,手动输入自动操作中没有输入的用户名或密码,然后点击立即登录。当你打开采集的主页时,我还没完成登录,我终于按照我的想法爬下了每一个收录滚动加载的所有数据的页面,我完成了。
终于完成采集 查看全部
不用采集规则就可以采集(统计某博主某一年内发布的全部微博,并计算转评赞总数)
我只是想统计某个博主在某一年发布的所有微博,并统计了转发和点赞的总数。这么简单的任务。没想到折腾了这么久。
首先是微博数据提供的支付功能。且不说支付,只能算近一年,不能任意规定时间段。比如2020.4.11这一天,只能统计2019.@。对于4.11~2020.4.11的数据,不是每年都要等过年了才算去年的数据吗? ? ?
于是我找到了微博API(),发现很难用。不知道是不是只有我。毕竟我只用过百度和高德的API,经验不够。先创建应用,找了好久才找到入口。它不在[我的应用程序]中,而是在主页上看起来像广告的按钮中。 API接口部分提供的基础公共信息需要授权,OAuth2.0授权因不明原因失败。官方渠道好像无法获取数据,只能自己爬了。
爬虫坑似乎迟早要被填满。我还没有学过,也没有使用过。找了几段别人的代码,改了微博ID后,访问不了。不知道企业微博是否受到保护。 .
最后不得不用优采云采集器来爬取数据。软件虽然好用,但还是费了一番周折才弄明白里面的各种设置。经过无数次的零采集和不完整的数据,最终的设置可能是不必要的,但是这组设置确实可以正确捕获数据,而且不会花费几分钟,所以我不必担心。本文记录了一些踩过的坑以及最终成功的设置。
软件准备
免费下载、安装、注册,免费版就够了。这个任务的数据量不大,本地采集模式就够了。提供了一些模板,也有微博的。
优采云采集器采集template 中提供的微博数据
但微博最麻烦的部分是登录操作。您必须不时输入验证码。另外,全年计算任务需要大量的滚动和翻页操作,所以你还是要使用自定义任务,这是不可避免的。设置采集 URL、采集进程、登录操作。
采集URL
采集 URL的设置基本没有问题。只需在 URL 中找到需要更改的参数即可。当有多个页面时,建议从 URL 设置页码。可靠,自动翻页。怕翻错页,微博页面跳出来登录,所以自动识别总是成功,但是采集开头抓不到1。以我的个人微博主页为例,我查看了2019年6月的博文(#feedtop),发现时间线是按月份划分的。 6月份的微博发的有点多,出现页面变化,需要修改两个参数。 [月] 和 [页数]。
个人微博截图
在优采云采集器中,选择【批量生成】URL,在文本框中选择需要替换的参数,点击【添加参数】进行设置。这里设置的两个参数,[Month]为01~12(软件提供了[Zero Fill]功能,很贴心),[Page Number]为1~4,因为这次要统计的微博数量不每月超过4页,这个要提前看好。
批量生成网址参数设置
自动生成48个网址后,即可【保存设置】开始编辑任务。然后软件会打开第一个网址,开始自动识别这个页面的内容,并生成采集数据的结果,并给出操作提示,基本可信,不完全可信。点击【生成采集设置】自动生成采集进程的框架(毕竟比自己的靠谱),然后调整里面的设置细节(这些细节折腾了好久时间)。
自动识别结果
采集process
自动生成流程图,基本框架没问题。
loop采集的基本框架
开始详细设置,【提取列表数据】没什么好说的,删掉一些不需要的字段就可以了。主要是【循环打开网页】,点击小齿轮打开设置:
在循环中打开网页设置
【网页打开前】这里,我怕加载不全,先打开下一页,设置等待时间3秒。 (我尝试使用cookie设置绕过登录,但是不成功,当前页面获取cookie的按钮没有反应,所以放弃了。)【打开网页后】需要在此处设置滚动。一开始以为滚动2次到最后,后来发现不同的页面不一样,就设置为3次,间隔1秒,加载前也怕跳过。
滚动设置纠结了很久,因为总是出现同样的错误。很明显,一个页面应该加载3次,最后得到45条数据。结果,执行的时候,总是只抓到15个,不给滚动。不知道是我没有登录的原因,还是网页没有等就打开了。
登录操作
为了保证多页面抓取的顺利完成,还是不需要登录的,否则会一直弹出提示登录对话框,采集什么也找不到。说句公道话,微博登录是有cookies记录的,但是放到软件的采集任务里面就不行了。每次启动,一个全新的界面都需要登录。一眨眼,你就认不出你是谁了。记不起来了。所以参考模板中的设置,在循环采集启动之前添加了登录操作,并添加到流程图中,老老实实执行。
流程图中新增登录操作
【打开网页】这里的网址设置为微博入口(),后面的操作设置其实是半自动的,直接在预览网页中操作,点击对话框或按钮,和【操作提示】对应会出现actions,可以记录登录时的输入文字(用户名、密码)、点击元素等操作,模拟人工操作,自动添加到流程图中,但可能会在循环后面,需要手动拖拽调整流程图中框的顺序。流程图完成后就可以开始[采集]了。
我觉得这些都设置好了,账号和密码也都记下来了,应该可以代替我先登录。没想到,登录的时候,要么没有输入用户名,要么没有输入密码。结果根本没有登录就执行了下一步,循环开始了,但是什么都没抓到。这时候,打开网页前的3秒等待似乎奏效了。利用这3秒时间,手动输入自动操作中没有输入的用户名或密码,然后点击立即登录。当你打开采集的主页时,我还没完成登录,我终于按照我的想法爬下了每一个收录滚动加载的所有数据的页面,我完成了。
终于完成采集
不用采集规则就可以采集(辣鸡采集世界上所有辣鸡数据欢迎大家来采集基于fesiong优采云采集器底层开发)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-08-29 11:06
香辣鸡介绍采集laji-collect
麻辣鸡采集,采集全世界麻辣鸡数据欢迎大家采集
基于fesiong优采云采集器底层开发
优采云采集器
开发语言
golang
官网案例
香辣鸡采集
为什么有这个辣鸡文章采集器辣鸡文章采集器能采集什么内容
这个采集器can采集的内容是:文章title,文章关键词,文章description,文章detailed content,文章author,文章release time, 文章views。
我什么时候需要用辣鸡文章采集器
当我们需要给网站采集文章时,这个采集器就可以派上用场了。这个采集器 不需要有人值班。它每天 24 小时运行,每 10 分钟运行一次。它会自动遍历采集列表,抓取收录文章的链接,并随时抓取文本。也可以设置自动发布,自动发布到指定的文章列表。
辣鸡文章采集器能跑到哪里去?
这个采集器可以运行在Windows系统、Mac系统、Linux系统(Centos、Ubuntu等)上,可以下载编译好的程序直接执行,也可以下载源码自己编译。
香辣鸡文章采集器Available 伪原创?
这个采集器暂时不支持伪原创功能,后续会添加合适的伪原创选项。
如何安装和使用
go env -w GOPROXY=https://goproxy.cn,direct
最后执行如下命令
go mod tidy
go mod vendor
go run main.go
编译结束后,运行编译好的文件,然后双击运行可执行文件。在打开的浏览器的可视化界面中,填写数据库信息,完成初始配置,添加采集source,开始采集之旅。
发展计划官网微信交流群
帮助改进
欢迎有能力和有贡献精神的个人或团体参与本采集器的开发和完善,共同完善采集功能。请fork一个分支,然后修改,修改后提交pull request合并请求。 查看全部
不用采集规则就可以采集(辣鸡采集世界上所有辣鸡数据欢迎大家来采集基于fesiong优采云采集器底层开发)
香辣鸡介绍采集laji-collect
麻辣鸡采集,采集全世界麻辣鸡数据欢迎大家采集
基于fesiong优采云采集器底层开发
优采云采集器
开发语言
golang
官网案例
香辣鸡采集
为什么有这个辣鸡文章采集器辣鸡文章采集器能采集什么内容
这个采集器can采集的内容是:文章title,文章关键词,文章description,文章detailed content,文章author,文章release time, 文章views。
我什么时候需要用辣鸡文章采集器
当我们需要给网站采集文章时,这个采集器就可以派上用场了。这个采集器 不需要有人值班。它每天 24 小时运行,每 10 分钟运行一次。它会自动遍历采集列表,抓取收录文章的链接,并随时抓取文本。也可以设置自动发布,自动发布到指定的文章列表。
辣鸡文章采集器能跑到哪里去?
这个采集器可以运行在Windows系统、Mac系统、Linux系统(Centos、Ubuntu等)上,可以下载编译好的程序直接执行,也可以下载源码自己编译。
香辣鸡文章采集器Available 伪原创?
这个采集器暂时不支持伪原创功能,后续会添加合适的伪原创选项。
如何安装和使用
go env -w GOPROXY=https://goproxy.cn,direct
最后执行如下命令
go mod tidy
go mod vendor
go run main.go
编译结束后,运行编译好的文件,然后双击运行可执行文件。在打开的浏览器的可视化界面中,填写数据库信息,完成初始配置,添加采集source,开始采集之旅。
发展计划官网微信交流群
帮助改进
欢迎有能力和有贡献精神的个人或团体参与本采集器的开发和完善,共同完善采集功能。请fork一个分支,然后修改,修改后提交pull request合并请求。
不用采集规则就可以采集(如果不从竞品分析报告的苦逼角度来探讨优采云好在哪里)
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-08-29 08:12
感谢您邀请回答。我用优采云很久了,知乎写了各种答案。包括其他软件的使用,你甚至可以写采集界的国内行业竞争分析报告(别问我为什么不写,因为我懒,因为我是PPT狗)领导,所以我没时间..._(:з」∠)_).
如果不从竞争对手分析报告的角度来讨论优采云,好与不一样,我们从用户的体验来谈。
(比如产地、预嗅数据等),会用Python写基本的爬虫(包括Scrapy框架和简单的分布式,我是产品狗,编码能力很强一般的)。综上所述,大部分主流数据采集工具都已经尝试过了,也有不同程度的体验。所以在我看来,它不像一个新手用户,也不像一个技术专家。这是一种妥协的产品视角。
以下优采云优点:
1、小白用户的福音(好用、好找规则、可视化界面、易学易模仿)
如果我是新手用户,对Html和Http协议不是很了解,那么看完上面提到的所有工具后,我可能会做出这样的选择:
什么是小白用户:
总结一下,我没钱,我不懂技术,我还是要数据。最简单、最便宜的省钱方法是使用优采云,其他选择很少。为什么?
优采云采集器(499元起) 必须用老版本才能免费导出csv,excel没有关系,新版本连导出都不能。 优采云Browser 一定要买(2180元起),不然不行,学习成本有点高。其他几个采集工具很难或者没有办法导入规则,也没有办法在线销售规则。虽然优采云采集可以免费采集一些数据,但是导出也是收费的,而且数据比较多。您必须单独下载数据导出工具。
优采云如何省钱?完善信息1000积分,每天签到30积分。下一条规则或在线购买一条规则,剩余积分足以获得初始采集。有些积分不用充值的话,可以按需使用,导出excel,数据库就好了。
2.无论是测试还是采集
直观的看到网页变化,很容易避免坑
很多人说优采云采集器采集快,优采云那么慢,很弱。不可否认,优采云采集器可以是采集数据而不完全显示页面。这样做的好处是介于爬虫和优采云之间,速度确实更快。但缺点是它必须自己拼写 URL!拼写网站!拼写网站!本来优采云可以一键搞定,因为优采云看不到,所以只能到浏览器里看页面代码。当采集我看不到网页变化时,我只能看到说采集的xxx条数据。说实话,每次测试优采云我都头疼,谁知道采集一大堆,是不是都是正确的数据,但是页面没有具体的变化...
你说第一次写优采云规则的时候,在测试中可以看到,嗯,是的,可以看到,但是网站都是白痴,让你只是采集网站已经越来越多了,如果越来越少,我动不动就给你403或者加验证。条件呢? 优采云这玩意在哪...优采云虽然慢,但是测试的时候可以看到页面的变化,除了问题可以跟踪调整,不然慢慢哭。
另一个好处是,我不会告诉你看采集拿出数据很酷...
3、写规则快
不管小白用户,像我们这样有一定经验的用户,写优采云规则,比如采集汽车之家某车型所有文章all评论规则,第一次写需要40分钟你可能会问,这东西还这么长,你弱了……我的解释是汽车之家加载了ajax,有的页面需要分析“下一页”跳转链接定位,避免死循环还有翻页时丢页的问题。第一次写规则,需要一一检查xpath位置,在单机上测试。所以其实大部分时间都花在了分析页面上,写规则的时间其实十几分钟就够了。如果用优采云或者其他工具就很头疼了...10分钟怎么匹配URL,ajax加载的问题,老的免费版优采云根本解决不了,新版本要买进高级的json解析 很简单,即便如此,你还是要抓包,搞清楚怎么合并url...除非你是老手,谁敢说你能把这个规则弄进去你第一次写三十分钟还是四十分钟? 优采云 不说了,写之前去学js,然后看开发文档...
其他优点不说了,大家自己摸索。如果你说太多了,软文suspects。
接下来进入大家爱听的批评链接:
1.莫名其妙的错误,简单粗暴的解决方法
如果我只是从0开始写一个规则,通常问题不大,但是当我修改或复制规则的某些部分并将其添加到另一个规则中时,有时会出现一些莫名其妙的问题。比如规则的逻辑结构显示混乱,规则执行错误等等,尤其是在逻辑判断中加入更多的规则,很容易混乱。
解决方法很简单。全部删除,按照新的思路制定新的规则...
2、云采集不是所谓的快10倍IP多吗?为什么这么慢?
这是很多人的误解。云采集运行在10个节点上,但任何时候都不应该达到10个节点,10个节点或10个IP也不可能。所以速度不一定快10倍,但真心希望有10个节点,10个IP,最好选择多久换一次IP,这样就解决了很多烦人的采集问题,这些功能多收钱也正常。
3、云采集数据丢失问题
因为看不到云采集的具体操作过程,也没有办法追溯,不知道有哪些数据缺失,哪些页面不是采集。最好有cloud采集每个节点的详细操作日志,方便用户导出查看。
4、什么时候可以使用自动IP代理
目前除了云端采集(不知道IP切换要多久),本机的单机采集只能写代理服务器IP和端口进入,所以我可以只能在线购买自动切换的代理 IP。不方便再填。 优采云官网说这些功能都快要加入了,我们拭目以待吧,反正切换IP也不容易。
这里有一个邪恶的方法...买一台可以在互联网上快速切换IP的VPS主机,然后让优采云在其上运行单机,就可以实现自动IP切换。记得买IP自动切换类型的,PPPOE拨号切换不行,因为优采云没有这个自动拨号功能。
5、最后的批评,就是在某些情况下,没有优采云采集器省事
下面优采云采集器的功能,优采云的产品经理需要考虑优采云现在是否可用,如何简化操作。
所谓人不完美,机器不完美,采集器不理想。如果让我选,我先用优采云,优采云补,剩下的交给Python代码。 优采云?我用Py写代码不花钱,优采云之类的东西有什么用...
最后宣传我的博客: 查看全部
不用采集规则就可以采集(如果不从竞品分析报告的苦逼角度来探讨优采云好在哪里)
感谢您邀请回答。我用优采云很久了,知乎写了各种答案。包括其他软件的使用,你甚至可以写采集界的国内行业竞争分析报告(别问我为什么不写,因为我懒,因为我是PPT狗)领导,所以我没时间..._(:з」∠)_).
如果不从竞争对手分析报告的角度来讨论优采云,好与不一样,我们从用户的体验来谈。
(比如产地、预嗅数据等),会用Python写基本的爬虫(包括Scrapy框架和简单的分布式,我是产品狗,编码能力很强一般的)。综上所述,大部分主流数据采集工具都已经尝试过了,也有不同程度的体验。所以在我看来,它不像一个新手用户,也不像一个技术专家。这是一种妥协的产品视角。
以下优采云优点:
1、小白用户的福音(好用、好找规则、可视化界面、易学易模仿)
如果我是新手用户,对Html和Http协议不是很了解,那么看完上面提到的所有工具后,我可能会做出这样的选择:
什么是小白用户:
总结一下,我没钱,我不懂技术,我还是要数据。最简单、最便宜的省钱方法是使用优采云,其他选择很少。为什么?
优采云采集器(499元起) 必须用老版本才能免费导出csv,excel没有关系,新版本连导出都不能。 优采云Browser 一定要买(2180元起),不然不行,学习成本有点高。其他几个采集工具很难或者没有办法导入规则,也没有办法在线销售规则。虽然优采云采集可以免费采集一些数据,但是导出也是收费的,而且数据比较多。您必须单独下载数据导出工具。
优采云如何省钱?完善信息1000积分,每天签到30积分。下一条规则或在线购买一条规则,剩余积分足以获得初始采集。有些积分不用充值的话,可以按需使用,导出excel,数据库就好了。
2.无论是测试还是采集
直观的看到网页变化,很容易避免坑
很多人说优采云采集器采集快,优采云那么慢,很弱。不可否认,优采云采集器可以是采集数据而不完全显示页面。这样做的好处是介于爬虫和优采云之间,速度确实更快。但缺点是它必须自己拼写 URL!拼写网站!拼写网站!本来优采云可以一键搞定,因为优采云看不到,所以只能到浏览器里看页面代码。当采集我看不到网页变化时,我只能看到说采集的xxx条数据。说实话,每次测试优采云我都头疼,谁知道采集一大堆,是不是都是正确的数据,但是页面没有具体的变化...
你说第一次写优采云规则的时候,在测试中可以看到,嗯,是的,可以看到,但是网站都是白痴,让你只是采集网站已经越来越多了,如果越来越少,我动不动就给你403或者加验证。条件呢? 优采云这玩意在哪...优采云虽然慢,但是测试的时候可以看到页面的变化,除了问题可以跟踪调整,不然慢慢哭。
另一个好处是,我不会告诉你看采集拿出数据很酷...
3、写规则快
不管小白用户,像我们这样有一定经验的用户,写优采云规则,比如采集汽车之家某车型所有文章all评论规则,第一次写需要40分钟你可能会问,这东西还这么长,你弱了……我的解释是汽车之家加载了ajax,有的页面需要分析“下一页”跳转链接定位,避免死循环还有翻页时丢页的问题。第一次写规则,需要一一检查xpath位置,在单机上测试。所以其实大部分时间都花在了分析页面上,写规则的时间其实十几分钟就够了。如果用优采云或者其他工具就很头疼了...10分钟怎么匹配URL,ajax加载的问题,老的免费版优采云根本解决不了,新版本要买进高级的json解析 很简单,即便如此,你还是要抓包,搞清楚怎么合并url...除非你是老手,谁敢说你能把这个规则弄进去你第一次写三十分钟还是四十分钟? 优采云 不说了,写之前去学js,然后看开发文档...
其他优点不说了,大家自己摸索。如果你说太多了,软文suspects。
接下来进入大家爱听的批评链接:
1.莫名其妙的错误,简单粗暴的解决方法
如果我只是从0开始写一个规则,通常问题不大,但是当我修改或复制规则的某些部分并将其添加到另一个规则中时,有时会出现一些莫名其妙的问题。比如规则的逻辑结构显示混乱,规则执行错误等等,尤其是在逻辑判断中加入更多的规则,很容易混乱。
解决方法很简单。全部删除,按照新的思路制定新的规则...
2、云采集不是所谓的快10倍IP多吗?为什么这么慢?
这是很多人的误解。云采集运行在10个节点上,但任何时候都不应该达到10个节点,10个节点或10个IP也不可能。所以速度不一定快10倍,但真心希望有10个节点,10个IP,最好选择多久换一次IP,这样就解决了很多烦人的采集问题,这些功能多收钱也正常。
3、云采集数据丢失问题
因为看不到云采集的具体操作过程,也没有办法追溯,不知道有哪些数据缺失,哪些页面不是采集。最好有cloud采集每个节点的详细操作日志,方便用户导出查看。
4、什么时候可以使用自动IP代理
目前除了云端采集(不知道IP切换要多久),本机的单机采集只能写代理服务器IP和端口进入,所以我可以只能在线购买自动切换的代理 IP。不方便再填。 优采云官网说这些功能都快要加入了,我们拭目以待吧,反正切换IP也不容易。
这里有一个邪恶的方法...买一台可以在互联网上快速切换IP的VPS主机,然后让优采云在其上运行单机,就可以实现自动IP切换。记得买IP自动切换类型的,PPPOE拨号切换不行,因为优采云没有这个自动拨号功能。
5、最后的批评,就是在某些情况下,没有优采云采集器省事
下面优采云采集器的功能,优采云的产品经理需要考虑优采云现在是否可用,如何简化操作。
所谓人不完美,机器不完美,采集器不理想。如果让我选,我先用优采云,优采云补,剩下的交给Python代码。 优采云?我用Py写代码不花钱,优采云之类的东西有什么用...
最后宣传我的博客:
不用采集规则就可以采集(采集安居客小区信息为例讲解优采云采集器V9的多页设置)
采集交流 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2021-08-28 15:13
在采集webpage信息的过程中,经常会遇到信息不在同一个页面上,所以需要用到多页功能。今天以采集安居客社区信息为例来讲解优采云采集器V9。多页设置。因为主要是解释多个页面,所以跳过了案例中的其他设置!
我们要抓取的信息包括社区的房屋数量,我们发现网页源代码中并没有这样的数据。数据的真实URL可以通过抓包软件fiddler抓包分析得到,参考下图:
通过URL可以找到一个ID参数“337684”,这样我们就可以在内容页源码中查看是否可以找到ID值
通过搜索,我们发现源代码中存在这个值,那么我们可以利用这个值拼接出多页功能中listing数量的URL,参考下图:
我们想在主页上添加多个页面。在内容采集 规则步骤的左下方有一个关联的多页面。我们点击+号添加多个页面
获取多页网址的原理与获取内容页网址的原理相同。规则也可以通过源代码找到。因为内容页中没有多页的完整链接,但是可以取URL中的ID参数,所以我们只需要获取ID,然后拼接出多页URL,参考下面图:
选择一个名称并保存多个页面。下一步,我们可以通过这个页面获取listing数量
添加标签,通过拼接多页网址分析获取数据规则,注意上图中的数据源,一定要选择关联多页。这样我们就可以通过多页功能获取隐藏房源数量的信息。你学会了吗?
安居客社区信息采集规则下载: 查看全部
不用采集规则就可以采集(采集安居客小区信息为例讲解优采云采集器V9的多页设置)
在采集webpage信息的过程中,经常会遇到信息不在同一个页面上,所以需要用到多页功能。今天以采集安居客社区信息为例来讲解优采云采集器V9。多页设置。因为主要是解释多个页面,所以跳过了案例中的其他设置!
我们要抓取的信息包括社区的房屋数量,我们发现网页源代码中并没有这样的数据。数据的真实URL可以通过抓包软件fiddler抓包分析得到,参考下图:
通过URL可以找到一个ID参数“337684”,这样我们就可以在内容页源码中查看是否可以找到ID值
通过搜索,我们发现源代码中存在这个值,那么我们可以利用这个值拼接出多页功能中listing数量的URL,参考下图:
我们想在主页上添加多个页面。在内容采集 规则步骤的左下方有一个关联的多页面。我们点击+号添加多个页面
获取多页网址的原理与获取内容页网址的原理相同。规则也可以通过源代码找到。因为内容页中没有多页的完整链接,但是可以取URL中的ID参数,所以我们只需要获取ID,然后拼接出多页URL,参考下面图:
选择一个名称并保存多个页面。下一步,我们可以通过这个页面获取listing数量
添加标签,通过拼接多页网址分析获取数据规则,注意上图中的数据源,一定要选择关联多页。这样我们就可以通过多页功能获取隐藏房源数量的信息。你学会了吗?
安居客社区信息采集规则下载:
唯一一款可以用的优采云采集器破解版,而且是在win10上完美运行!
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-08-26 03:12
唯一可以使用的优采云采集器破解版,在win10上完美运行!
网上下载的优采云V9根本无法在win10上运行。我还安装了一个win7虚拟机来运行它。
这次银狐发现优采云采集器在win10上完美运行,很好,唯一的缺点:这个好像有病毒!
不过没关系,用起来很舒服,输入账号密码就可以登录了!
软件介绍,下载链接在最后:
优采云采集器V9 破解版是一款专业强大的网络数据/信息挖掘软件。灵活配置,轻松抓取网页中的文字、图片、文件等资源。程序支持远程下载图片文件,登录网站post信息采集,文件真实地址检测,代理,防leech采集,采集数据直存,模仿者手动发布。
支持从任何类型的网站采集您需要的信息,例如各种新闻网站、论坛、电商网站、招聘网站等。同时,拥有强大的网站login采集、多页分页采集、网站cross-layer采集、posts采集、脚本页采集、动态页采集等高级采集 功能。强大的 PHP 和 C# 插件支持,让您通过二次开发实现任何更强大的功能。
【功能介绍】
1.规则定制-通过定义采集规则,可以搜索所有网站,采集几乎任何类型的信息。
2.Multitasking,多线程——可以同时执行多个信息获取任务,每个任务可以使用多个线程。
3.WYSIWYG-WYSIWYG 在任务采集期间。过程中遍历的链接信息、采集信息和错误信息会及时反映在软件界面上。
4.数据保存——采集时数据自动保存到关系型数据库,自动调整数据结构。该软件可以根据采集规则自动创建数据库及其表和字段,也可以通过数据库向导灵活地将数据保存在客户现有的数据库结构中。
5. Breakpoint Resume——信息采集任务停止后可以继续从断点处采集信息。从此,您再也不用担心采集任务的意外中断。
6.网站Login——支持网站cookie,支持网站可视化登录,即使网站需要验证码登录,也可以采集。
7.定时任务——该功能可以让你定期、定量或连续地循环执行采集任务。
8.采集范围限制-可以根据采集深度和网站地址的标识来限制采集范围。
9.文件下载——将采集收到的二进制文件(如图片、音乐、软件、文档等)下载到本地磁盘或采集结果数据库。
10. 结果替换-您可以根据规则将采集到的结果替换为定义的内容。
11. 条件保存——可以根据具体条件决定保存和过滤哪些信息。
12.重复内容过滤-软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13. 特殊链接识别-使用此功能识别使用 JavaScript 或其他奇怪链接动态生成的链接。
14. 数据发布——通过用户定义的接口将采集的结果数据发布到任何内容管理系统和指定的数据库。目前支持的目标发布媒体包括:数据库(access、SQL server、my SQL、Oracle)、静态HTM文件。
15.预留编程接口-定义多个编程接口,用户可以使用PHP、c#语言扩展程序中的事件集合。
(软件功能)1.强大的多功能性
无论是新闻、论坛、视频、黄页、图片,下载网站,只要能通过浏览器看到结构化的内容,就可以通过指定的匹配规则采集到你需要的内容。
2.稳定高效
5年磨砺,软件更新进度,采集速度快,性能稳定,资源少。
3.可扩展性强,应用范围广
用户自定义网页发布、用户自定义主流数据库存储和发布、用户自定义本地PHP和. Net 外部编程接口对数据进行处理,以便您可以使用这些数据。
(更新日志)
V9.9.0
1.优化效率,解决运行大量任务时卡住的问题
2.FIX 配置文件锁退出问题,大量代理
3.修复某些情况下MySQL链接不可用的问题
4.其他界面和功能优化
下载链接:
蓝邹云:
百度网盘:提取码:3nxq 查看全部
唯一一款可以用的优采云采集器破解版,而且是在win10上完美运行!
唯一可以使用的优采云采集器破解版,在win10上完美运行!
网上下载的优采云V9根本无法在win10上运行。我还安装了一个win7虚拟机来运行它。
这次银狐发现优采云采集器在win10上完美运行,很好,唯一的缺点:这个好像有病毒!
不过没关系,用起来很舒服,输入账号密码就可以登录了!
软件介绍,下载链接在最后:
优采云采集器V9 破解版是一款专业强大的网络数据/信息挖掘软件。灵活配置,轻松抓取网页中的文字、图片、文件等资源。程序支持远程下载图片文件,登录网站post信息采集,文件真实地址检测,代理,防leech采集,采集数据直存,模仿者手动发布。
支持从任何类型的网站采集您需要的信息,例如各种新闻网站、论坛、电商网站、招聘网站等。同时,拥有强大的网站login采集、多页分页采集、网站cross-layer采集、posts采集、脚本页采集、动态页采集等高级采集 功能。强大的 PHP 和 C# 插件支持,让您通过二次开发实现任何更强大的功能。
【功能介绍】
1.规则定制-通过定义采集规则,可以搜索所有网站,采集几乎任何类型的信息。
2.Multitasking,多线程——可以同时执行多个信息获取任务,每个任务可以使用多个线程。
3.WYSIWYG-WYSIWYG 在任务采集期间。过程中遍历的链接信息、采集信息和错误信息会及时反映在软件界面上。
4.数据保存——采集时数据自动保存到关系型数据库,自动调整数据结构。该软件可以根据采集规则自动创建数据库及其表和字段,也可以通过数据库向导灵活地将数据保存在客户现有的数据库结构中。
5. Breakpoint Resume——信息采集任务停止后可以继续从断点处采集信息。从此,您再也不用担心采集任务的意外中断。
6.网站Login——支持网站cookie,支持网站可视化登录,即使网站需要验证码登录,也可以采集。
7.定时任务——该功能可以让你定期、定量或连续地循环执行采集任务。
8.采集范围限制-可以根据采集深度和网站地址的标识来限制采集范围。
9.文件下载——将采集收到的二进制文件(如图片、音乐、软件、文档等)下载到本地磁盘或采集结果数据库。
10. 结果替换-您可以根据规则将采集到的结果替换为定义的内容。
11. 条件保存——可以根据具体条件决定保存和过滤哪些信息。
12.重复内容过滤-软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13. 特殊链接识别-使用此功能识别使用 JavaScript 或其他奇怪链接动态生成的链接。
14. 数据发布——通过用户定义的接口将采集的结果数据发布到任何内容管理系统和指定的数据库。目前支持的目标发布媒体包括:数据库(access、SQL server、my SQL、Oracle)、静态HTM文件。
15.预留编程接口-定义多个编程接口,用户可以使用PHP、c#语言扩展程序中的事件集合。
(软件功能)1.强大的多功能性
无论是新闻、论坛、视频、黄页、图片,下载网站,只要能通过浏览器看到结构化的内容,就可以通过指定的匹配规则采集到你需要的内容。
2.稳定高效
5年磨砺,软件更新进度,采集速度快,性能稳定,资源少。
3.可扩展性强,应用范围广
用户自定义网页发布、用户自定义主流数据库存储和发布、用户自定义本地PHP和. Net 外部编程接口对数据进行处理,以便您可以使用这些数据。
(更新日志)
V9.9.0
1.优化效率,解决运行大量任务时卡住的问题
2.FIX 配置文件锁退出问题,大量代理
3.修复某些情况下MySQL链接不可用的问题
4.其他界面和功能优化
下载链接:
蓝邹云:
百度网盘:提取码:3nxq
网络爬虫软件——优采云采集器软件免费
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-08-26 03:05
既然阁下发现了这个文章,那一定很有品味,也很追求。普通的网络爬虫软件当然不能满足你对美好生活的向往,也不能帮你达到人生巅峰。你选择我们! ! !
本文主要为大家简单介绍一下我们的采集器软件。优点太多了,慢慢来,别着急。
优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。
软件功能强大,操作简单。它是为产品、运营、销售、金融、新闻、电子商务和数据分析从业者以及没有编程基础的政府机构和学术研究的用户量身定制的。产品。
优采云采集器不仅可以自动化采集数据,还可以在采集过程中清洗数据。可在数据源头实现多种内容过滤。
通过优采云采集器,用户可以快速准确地获取海量网络数据,彻底解决了人工采集数据面临的各种问题,降低了获取信息的成本,提高了工作效率。
优采云采集器具有行业领先的技术优势,可以同时支持采集器所有Windows、Mac和Linux操作系统。
对于基础不同的用户,支持两种不同的采集模式,可以采集99%的网页。
1、智慧采集模式:
此模式的操作极其简单。只需输入网址即可智能识别网页内容,无需配置任何采集规则即可完成采集数据。
2、Flowchart采集Mode:
完全符合手动浏览网页的思路。用户只需打开网站即采集,根据软件提示,点击几下鼠标即可自动生成复杂数据采集规则;
这么好用的产品,还是免费的!费用!的!
自由法律是怎样的?请点击这里→_→ 优采云采集器 免费吗?
查看全部
网络爬虫软件——优采云采集器软件免费
既然阁下发现了这个文章,那一定很有品味,也很追求。普通的网络爬虫软件当然不能满足你对美好生活的向往,也不能帮你达到人生巅峰。你选择我们! ! !
本文主要为大家简单介绍一下我们的采集器软件。优点太多了,慢慢来,别着急。
优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。
软件功能强大,操作简单。它是为产品、运营、销售、金融、新闻、电子商务和数据分析从业者以及没有编程基础的政府机构和学术研究的用户量身定制的。产品。
优采云采集器不仅可以自动化采集数据,还可以在采集过程中清洗数据。可在数据源头实现多种内容过滤。
通过优采云采集器,用户可以快速准确地获取海量网络数据,彻底解决了人工采集数据面临的各种问题,降低了获取信息的成本,提高了工作效率。
优采云采集器具有行业领先的技术优势,可以同时支持采集器所有Windows、Mac和Linux操作系统。
对于基础不同的用户,支持两种不同的采集模式,可以采集99%的网页。
1、智慧采集模式:
此模式的操作极其简单。只需输入网址即可智能识别网页内容,无需配置任何采集规则即可完成采集数据。
2、Flowchart采集Mode:
完全符合手动浏览网页的思路。用户只需打开网站即采集,根据软件提示,点击几下鼠标即可自动生成复杂数据采集规则;
这么好用的产品,还是免费的!费用!的!
自由法律是怎样的?请点击这里→_→ 优采云采集器 免费吗?
非dma方式adc多通道采集的文档(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-08-16 01:20
我之前写过一篇关于非dma adc多通道采集的文档:
不过之前是基于stm32F1系列的。当使用L0系列按照前面的步骤操作并没有成功时,只能通过中断或DMA来实现。与原来的F1系列ADC相比,L0有一些精简的变化,所以adc的操作也不完全一样。
对于adc来说,还有一些比较难理解的转换模式:连续模式、单次转换模式、不连续模式等,这些概念必须先搞清楚。为此,请参考我之前的文章文章中的链接。然后你可以参考L0系列的参考手册,看看哪种模式适合你的应用。
我的应用场景比较简单:有两个adc通道,两个通道同时采集然后过滤计算。核心是采集两个通道,每次采样多次。
按照正常思路,应该使用for循环。在for循环中,采集分别在两个通道上执行,结果存放在数组缓冲区中。测试中发现HAL_ADC_PollForConversion函数会在EOS序列转换结束标志置位后退出,或者超时错误退出。结果,当我在非连续模式下调用该函数时,我只有采集得到了ch2,并没有触发采集ch3。最终无法设置EOS(标志设置要求所有选择的通道为采集完)并发生超时错误。所以我只是改变了主意,不再使用上面提到的文章方法。
在使用非 DMA 之前,然后切换到 DMA。这样也可以大大简化步骤,降低cpu消耗。实现的思路也很简单,就是使用DMA+连续模式。连续模式是指连续扫描选定的通道。比如我选择ch2和ch3。那么连续模式的采集序列将是这样的:ch2->ch3->ch2->ch3->ch2->ch3-ch2->ch3...... 所以如果我们想要ch2和ch3 be 采集5 次 以上述循环 5 次为基础,DMA 共传输 10 次。
stm32cubemx的配置如下:
DMA 配置如下:
这里的半字不固定。这取决于您的 AD 使用的采集 模式的位数。我使用 12 位,所以一个样本值占用两个字节。当然也可以用word,但是会造成一些内存浪费。
stm32 dma采集的接口如下:
HAL_ADC_Start_DMA(ADC_HandleTypeDef* hadc, uint32_t* pData, uint32_t Length);
最终代码如下:
<p>uint16_t adc_value[10];
void HAL_ADC_ConvCpltCallback(ADC_HandleTypeDef* hadc)
{
for(uint8_t i=0;i 查看全部
非dma方式adc多通道采集的文档(图)
我之前写过一篇关于非dma adc多通道采集的文档:
不过之前是基于stm32F1系列的。当使用L0系列按照前面的步骤操作并没有成功时,只能通过中断或DMA来实现。与原来的F1系列ADC相比,L0有一些精简的变化,所以adc的操作也不完全一样。
对于adc来说,还有一些比较难理解的转换模式:连续模式、单次转换模式、不连续模式等,这些概念必须先搞清楚。为此,请参考我之前的文章文章中的链接。然后你可以参考L0系列的参考手册,看看哪种模式适合你的应用。
我的应用场景比较简单:有两个adc通道,两个通道同时采集然后过滤计算。核心是采集两个通道,每次采样多次。
按照正常思路,应该使用for循环。在for循环中,采集分别在两个通道上执行,结果存放在数组缓冲区中。测试中发现HAL_ADC_PollForConversion函数会在EOS序列转换结束标志置位后退出,或者超时错误退出。结果,当我在非连续模式下调用该函数时,我只有采集得到了ch2,并没有触发采集ch3。最终无法设置EOS(标志设置要求所有选择的通道为采集完)并发生超时错误。所以我只是改变了主意,不再使用上面提到的文章方法。
在使用非 DMA 之前,然后切换到 DMA。这样也可以大大简化步骤,降低cpu消耗。实现的思路也很简单,就是使用DMA+连续模式。连续模式是指连续扫描选定的通道。比如我选择ch2和ch3。那么连续模式的采集序列将是这样的:ch2->ch3->ch2->ch3->ch2->ch3-ch2->ch3...... 所以如果我们想要ch2和ch3 be 采集5 次 以上述循环 5 次为基础,DMA 共传输 10 次。
stm32cubemx的配置如下:
https://www.eemaker.com/wp-con ... 0.png 300w, https://www.eemaker.com/wp-con ... 0.png 200w" />DMA 配置如下:
https://www.eemaker.com/wp-con ... 9.png 300w, https://www.eemaker.com/wp-con ... 3.png 200w" />这里的半字不固定。这取决于您的 AD 使用的采集 模式的位数。我使用 12 位,所以一个样本值占用两个字节。当然也可以用word,但是会造成一些内存浪费。
stm32 dma采集的接口如下:
HAL_ADC_Start_DMA(ADC_HandleTypeDef* hadc, uint32_t* pData, uint32_t Length);
最终代码如下:
<p>uint16_t adc_value[10];
void HAL_ADC_ConvCpltCallback(ADC_HandleTypeDef* hadc)
{
for(uint8_t i=0;i
立足点也跟phpcms采集模块相似,注重方便实用
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-08-14 22:40
不能说它不擅长。只能说PHP过于专注于web开发,其他方面显得单薄。 PHP 自动吸引蜘蛛。
很多phpcms系统都有自己的爬虫功能
比如phpcms的采集模块可以通过设置规则采集网站data直接进入数据库,采集的内容可以直接进入数据库发布在网站。
看上面的功能很强大,这个基本上是国内cms得的标准配置,只要稍微了解html就可以使用,不需要太多技术。大量网站在使用,设置规则后,可以方便的导出导入,分享给其他人,其他规则已经下载。非常方便和用户友好。
虽然我们都知道python擅长写爬虫,但它更强调其他方面而不是用户的方便,更强调技术而不是使用。在用户体验方面,phpcms自带的采集模块更胜一筹。
高级爬虫功能
在其他方面,比如大并发采集、代理替换ip等等,对于python和perl、golang等面向终端的语言比较方便,但是很多时候要写很多代码来完成它。 ,还是比较麻烦。
另外,查bug里面的爬虫,或者数据采集也可以。最重要的是内容。不管什么样的方便,采集都能帮我拿到我需要的内容,没问题。您使用什么技术和语言。
其实据我所知,很多人网站是做爬虫采集需求量最大的。很多人不懂技术,只需要花几十块钱找人写采集许定入cms就可以了,不需要什么高级爬虫功能。
商业采集器也有很多傻瓜式收费采集器,比如优采云、优采云采集器、c#、vb等,也有大量的用户。立足点也类似phpcms采集模块,注重方便实用,不强调技术。 查看全部
立足点也跟phpcms采集模块相似,注重方便实用
不能说它不擅长。只能说PHP过于专注于web开发,其他方面显得单薄。 PHP 自动吸引蜘蛛。
很多phpcms系统都有自己的爬虫功能
比如phpcms的采集模块可以通过设置规则采集网站data直接进入数据库,采集的内容可以直接进入数据库发布在网站。
看上面的功能很强大,这个基本上是国内cms得的标准配置,只要稍微了解html就可以使用,不需要太多技术。大量网站在使用,设置规则后,可以方便的导出导入,分享给其他人,其他规则已经下载。非常方便和用户友好。
虽然我们都知道python擅长写爬虫,但它更强调其他方面而不是用户的方便,更强调技术而不是使用。在用户体验方面,phpcms自带的采集模块更胜一筹。
高级爬虫功能
在其他方面,比如大并发采集、代理替换ip等等,对于python和perl、golang等面向终端的语言比较方便,但是很多时候要写很多代码来完成它。 ,还是比较麻烦。
另外,查bug里面的爬虫,或者数据采集也可以。最重要的是内容。不管什么样的方便,采集都能帮我拿到我需要的内容,没问题。您使用什么技术和语言。
其实据我所知,很多人网站是做爬虫采集需求量最大的。很多人不懂技术,只需要花几十块钱找人写采集许定入cms就可以了,不需要什么高级爬虫功能。
商业采集器也有很多傻瓜式收费采集器,比如优采云、优采云采集器、c#、vb等,也有大量的用户。立足点也类似phpcms采集模块,注重方便实用,不强调技术。
关于优采云采集器的一些事儿,你知道多少?
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-08-14 01:18
取消报告的原因
作为一个同时使用优采云采集器和写爬虫的非技术人员,莫名的喜欢联想到互联网运营喵的技术。 . 说说我的感受。
优采云具有学习成本低、流程可视化、采集系统快速构建等优势。可以直接导出excel文件并导出到数据库。为了降低采集的成本,云采集提供了10个节点,也可以省去不少麻烦。
缺点是虽然看起来很简单,还有一个更傻的智能模型,但其中的陷阱只有经常使用它的人才能清楚。我只是在我的博客中写了这个,但说实话,我的经验太多了,我还没有整理出来。
首先,里面的循环都是xpath元素定位。如果用简单傻傻的点击定位,是很死板的,大量采集页面很容易出错。另外,因为它的方便,使用这个工具的新手太多了。有些人整天问一些常见的问题。他们不知道页面的结构,也不了解 xpath。容易出现采集不全、无限翻页等问题。
但是优采云采集器的ajax加载、模拟手机页面、过滤广告、滚动到页面底部等功能都被称为神器,一个检查就可以搞定。写代码很麻烦,实现这些功能很费力。
优采云毕竟只是一个工具,自由度肯定会打败编程。优点是方便、快捷、成本低。
优采云judgment 引用弱,无法做出复杂的判断,也无法执行复杂的逻辑。还有优采云只有企业版可以解决验证码问题,普通版无法访问编码平台。
还有一点就是没有ocr功能。 和 Ganji采集 的电话号码均为图片格式。 Python可以用开源的图像识别库解决,可以通过对接识别。
除非你对技术要求高,我觉得优采云采集器好用,比优采云采集器好用。虽然效率不高,但比学习研究数据包效率更高。还是用这个省事吧。我很好,我也会在优采云群里回答一些关于规则编译的问题。
综合写了比较坑,放在知乎专栏里。有兴趣的可以看看:
说说优采云采集器最近遇到的坑(和其他采集软件和爬虫对比)——知乎Column 查看全部
关于优采云采集器的一些事儿,你知道多少?
取消报告的原因
作为一个同时使用优采云采集器和写爬虫的非技术人员,莫名的喜欢联想到互联网运营喵的技术。 . 说说我的感受。
优采云具有学习成本低、流程可视化、采集系统快速构建等优势。可以直接导出excel文件并导出到数据库。为了降低采集的成本,云采集提供了10个节点,也可以省去不少麻烦。
缺点是虽然看起来很简单,还有一个更傻的智能模型,但其中的陷阱只有经常使用它的人才能清楚。我只是在我的博客中写了这个,但说实话,我的经验太多了,我还没有整理出来。
首先,里面的循环都是xpath元素定位。如果用简单傻傻的点击定位,是很死板的,大量采集页面很容易出错。另外,因为它的方便,使用这个工具的新手太多了。有些人整天问一些常见的问题。他们不知道页面的结构,也不了解 xpath。容易出现采集不全、无限翻页等问题。
但是优采云采集器的ajax加载、模拟手机页面、过滤广告、滚动到页面底部等功能都被称为神器,一个检查就可以搞定。写代码很麻烦,实现这些功能很费力。
优采云毕竟只是一个工具,自由度肯定会打败编程。优点是方便、快捷、成本低。
优采云judgment 引用弱,无法做出复杂的判断,也无法执行复杂的逻辑。还有优采云只有企业版可以解决验证码问题,普通版无法访问编码平台。
还有一点就是没有ocr功能。 和 Ganji采集 的电话号码均为图片格式。 Python可以用开源的图像识别库解决,可以通过对接识别。
除非你对技术要求高,我觉得优采云采集器好用,比优采云采集器好用。虽然效率不高,但比学习研究数据包效率更高。还是用这个省事吧。我很好,我也会在优采云群里回答一些关于规则编译的问题。
综合写了比较坑,放在知乎专栏里。有兴趣的可以看看:
说说优采云采集器最近遇到的坑(和其他采集软件和爬虫对比)——知乎Column
不用采集规则就可以采集快手,抖音用户数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 851 次浏览 • 2021-08-11 23:04
不用采集规则就可以采集快手,抖音用户数据采集:1.使用浏览器工具获取链接,或者通过一些网站进行搜索。
快手抖音的粉丝是以机器人的形式存在的,所以我们要用采集方法采集粉丝,有可能是一个人也有可能是一个账号。但是采集的粉丝数量是完全一样的。快手的粉丝在百度云中就可以下载,我最近用到的是微云。一般采集1000个粉丝左右,只需要几分钟的时间,就可以采集一个比较全的信息了。而且可以查看每个人的粉丝数据信息。抖音的粉丝在百度云中是没有的,在微云中有,但是还不够全。
别采,老老实实去花点钱找人采吧,一个人总不会全搞到,前提是你懂得如何去换,
我之前做过快手的,我想采那种抖音的视频还得下载去扒,快手不是全网可以采完,但是采粉不行,因为那种人流量少的大多都没有粉,快手里面视频都是水的基本上没有人点赞,都没有播放量了。就算有评论和播放量都是几十个,粉丝如果全有,估计十个里面都不会有一个点赞和评论。
去抖音或者快手下面评论评论就能看到你的了,我以前干过这事,
我是去买的。或者找亲戚去抖音下面评论。也可以去翻老友记里面的梗之类的。
我们公司正在做的抖音数据采集,要不要交流一下。 查看全部
不用采集规则就可以采集快手,抖音用户数据采集
不用采集规则就可以采集快手,抖音用户数据采集:1.使用浏览器工具获取链接,或者通过一些网站进行搜索。
快手抖音的粉丝是以机器人的形式存在的,所以我们要用采集方法采集粉丝,有可能是一个人也有可能是一个账号。但是采集的粉丝数量是完全一样的。快手的粉丝在百度云中就可以下载,我最近用到的是微云。一般采集1000个粉丝左右,只需要几分钟的时间,就可以采集一个比较全的信息了。而且可以查看每个人的粉丝数据信息。抖音的粉丝在百度云中是没有的,在微云中有,但是还不够全。
别采,老老实实去花点钱找人采吧,一个人总不会全搞到,前提是你懂得如何去换,
我之前做过快手的,我想采那种抖音的视频还得下载去扒,快手不是全网可以采完,但是采粉不行,因为那种人流量少的大多都没有粉,快手里面视频都是水的基本上没有人点赞,都没有播放量了。就算有评论和播放量都是几十个,粉丝如果全有,估计十个里面都不会有一个点赞和评论。
去抖音或者快手下面评论评论就能看到你的了,我以前干过这事,
我是去买的。或者找亲戚去抖音下面评论。也可以去翻老友记里面的梗之类的。
我们公司正在做的抖音数据采集,要不要交流一下。
不用采集规则就可以采集google关键词,批量采集首页数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2021-08-10 03:16
不用采集规则就可以采集google关键词,图片网站搜索功能,批量采集首页数据。
一、采集网址::8000/工具/福利/网页批量采集工具/可批量采集保存文件,
二、采集规则分享在很多app、网站上,我们都会看到这样的采集规则,主要通过pdf或doc格式的网址链接可以查看网页的内容,这里小编收集了一批采集规则,可以需要更多的话可以在群内索取。
三、采集网址规则在群里分享数据包点击链接“网页采集规则分享”后,可以看到会生成一个web版地址链接,在需要采集的网站中点击“识别网址”后,采集规则就自动生成了。
pc端excel表格来存储谷歌所有网站页面的url地址。把excel表格转换成pdf,然后直接把excel复制到谷歌页面上。可能是自己写的不好,过程太麻烦。于是谷歌上了个插件,直接把页面地址提取出来保存成json格式的,再直接excel里面导入就行。
2019年最新seo_seo工具箱01工具网站屏蔽。直接粘贴网站url规则,秒变网站关键词结果页面。搜索引擎(google/snoop/bing/yahoo/amazon/facebook等等,任何google网站都可以受理)把自动屏蔽蜘蛛抓取的页面。02sitemap。可以根据锚文本找到自己网站的真实页面页面。
03链接转换。可以根据特定页面进行换页翻页,也可以根据自己需要进行页面跳转。04网页抓取。直接提取google网站中的url地址,无需解析。05直接调用第三方浏览器窗口查看网站数据。建议使用谷歌浏览器,safari或chrome浏览器。06具有同步功能的访问器。可以使用第三方浏览器访问google网站中的任何页面。
07提取链接。可以将google网站中的链接提取到百度和微信公众号等。08提取整站数据。可以在sitemap,url上使用html标签提取网站各个页面的数据。09非谷歌官方网站。提取有安全隐患,如www文件在谷歌网站里不存在等等。10可以自动爬取多个网站并发布到社交媒体。 查看全部
不用采集规则就可以采集google关键词,批量采集首页数据
不用采集规则就可以采集google关键词,图片网站搜索功能,批量采集首页数据。
一、采集网址::8000/工具/福利/网页批量采集工具/可批量采集保存文件,
二、采集规则分享在很多app、网站上,我们都会看到这样的采集规则,主要通过pdf或doc格式的网址链接可以查看网页的内容,这里小编收集了一批采集规则,可以需要更多的话可以在群内索取。
三、采集网址规则在群里分享数据包点击链接“网页采集规则分享”后,可以看到会生成一个web版地址链接,在需要采集的网站中点击“识别网址”后,采集规则就自动生成了。
pc端excel表格来存储谷歌所有网站页面的url地址。把excel表格转换成pdf,然后直接把excel复制到谷歌页面上。可能是自己写的不好,过程太麻烦。于是谷歌上了个插件,直接把页面地址提取出来保存成json格式的,再直接excel里面导入就行。
2019年最新seo_seo工具箱01工具网站屏蔽。直接粘贴网站url规则,秒变网站关键词结果页面。搜索引擎(google/snoop/bing/yahoo/amazon/facebook等等,任何google网站都可以受理)把自动屏蔽蜘蛛抓取的页面。02sitemap。可以根据锚文本找到自己网站的真实页面页面。
03链接转换。可以根据特定页面进行换页翻页,也可以根据自己需要进行页面跳转。04网页抓取。直接提取google网站中的url地址,无需解析。05直接调用第三方浏览器窗口查看网站数据。建议使用谷歌浏览器,safari或chrome浏览器。06具有同步功能的访问器。可以使用第三方浏览器访问google网站中的任何页面。
07提取链接。可以将google网站中的链接提取到百度和微信公众号等。08提取整站数据。可以在sitemap,url上使用html标签提取网站各个页面的数据。09非谷歌官方网站。提取有安全隐患,如www文件在谷歌网站里不存在等等。10可以自动爬取多个网站并发布到社交媒体。
不用采集规则就可以采集,比如excel,用名称去规则定义
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-08-06 22:17
不用采集规则就可以采集,比如excel,用名称去规则定义一个代码,然后在java里封装成类就行了,如果采集的是excel,可以采集上一年和下一年的,不同的是采集的不是网页,而是.xlsx这类文件,
可以用excel导出markdown格式的页面,然后在java里面导入jar文件就可以,
aspletjs
可以看看flash游戏api——
lz可以采用聚合框架gggroup框架,该框架基于jsp+asp框架+ajax技术,支持excel文件的导入导出和多页面的一键切换,你可以看看这个网站,有关于该框架的更多信息。
采用qq工具箱里面的接口函数或者采用javascript程序,很简单就能实现,用javascript程序写个登录框就能实现了,很简单,有意思,
可以用maven封装servlet,然后在java中实现,如果你说的是静态页面,是需要采用jsp+asp的,asp可以自定义名称或者字段,里面的excel,可以用excel插件导入。
把excel文件加载到java中,
建议您了解一下jsp+asp框架,有三个优点:web后端到页面。页面相关的,页面内部web后端返回都有源代码,web端操作asp可以查看源代码。导出为jar。jsp文件可以导出,同时也可以在java代码中导入jar文件。java接口。java代码也可以引用到web端,并且定义接口,返回给java的后端返回的java文件都是静态的,也可以使用其他同一接口。 查看全部
不用采集规则就可以采集,比如excel,用名称去规则定义
不用采集规则就可以采集,比如excel,用名称去规则定义一个代码,然后在java里封装成类就行了,如果采集的是excel,可以采集上一年和下一年的,不同的是采集的不是网页,而是.xlsx这类文件,
可以用excel导出markdown格式的页面,然后在java里面导入jar文件就可以,
aspletjs
可以看看flash游戏api——
lz可以采用聚合框架gggroup框架,该框架基于jsp+asp框架+ajax技术,支持excel文件的导入导出和多页面的一键切换,你可以看看这个网站,有关于该框架的更多信息。
采用qq工具箱里面的接口函数或者采用javascript程序,很简单就能实现,用javascript程序写个登录框就能实现了,很简单,有意思,
可以用maven封装servlet,然后在java中实现,如果你说的是静态页面,是需要采用jsp+asp的,asp可以自定义名称或者字段,里面的excel,可以用excel插件导入。
把excel文件加载到java中,
建议您了解一下jsp+asp框架,有三个优点:web后端到页面。页面相关的,页面内部web后端返回都有源代码,web端操作asp可以查看源代码。导出为jar。jsp文件可以导出,同时也可以在java代码中导入jar文件。java接口。java代码也可以引用到web端,并且定义接口,返回给java的后端返回的java文件都是静态的,也可以使用其他同一接口。
PHP版本5.2.17采集器及规则源码介绍-上海怡健医学
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-08-04 01:11
源码介绍:
优化视频上传功能,vip视频系统,自动注册试看功能,卡密系统,用户自行升级会员,
后台上传支付二维码即可完成支付,支持微信和支付宝。前台提交订单,后台管理员审核
支持MP4、m3u8、Flv等常规媒体视频格式文件播放,发送企业版优采云采集器和规则。全站自动更新,无需人工维护,有全站数据,可直接操作
安装说明:
匹配环境:PHP版本5.2.17 MySQL版本5.5.46 服务器空间至少500M mysql数据库至少200M
1.使用了Empire Backup数据库,打开Empire Backup工具,你的网站/bak(默认账号为admin,密码为123456)
或者直接导入数据库database.sql
2.帝国备份的数据库恢复方法这里就不介绍了,网站建设基本了解
3.打开config文件夹下的conn.php
修改自己的服务器信息:
$localhost = "xxxxxx";//服务器地址,通常是localhost
$root = "xxxxxx";//服务器MYSQL登录用户名
$password = "xxxxxx";//服务器的MYSQL登录密码
$database = "xxxxxx";//你使用的数据库
4.登录后台,后台路径为你的网址/admin_2018/(默认账号为admin8,密码为admin888)
5.进入后台配置你的网站,然后就可以操作了
采集见采集文档,采集规则已发送;
PS:每个人的采集的网站不一样,自然采集的规则也会不一样;
下载链接:
[pay point="20″] 链接:密码:7mtd[/pay]
1.本站所有资源均来自用户上传和互联网,不收录技术服务,请见谅!
2. 本站不保证所提供下载资源的准确性、安全性和完整性。资源仅供下载学习使用!如有链接无法下载、失效或广告,请联系客服!
3.您必须在下载后24小时内将以上内容资源从您的电脑中彻底删除!如用于商业或非法用途,与本站无关,一切后果由用户负责!
4.如果你也有好的资源或者教程,可以提交论文发表。分享成功后,将有现场币奖励和额外收益! 查看全部
PHP版本5.2.17采集器及规则源码介绍-上海怡健医学
源码介绍:
优化视频上传功能,vip视频系统,自动注册试看功能,卡密系统,用户自行升级会员,
后台上传支付二维码即可完成支付,支持微信和支付宝。前台提交订单,后台管理员审核
支持MP4、m3u8、Flv等常规媒体视频格式文件播放,发送企业版优采云采集器和规则。全站自动更新,无需人工维护,有全站数据,可直接操作
安装说明:
匹配环境:PHP版本5.2.17 MySQL版本5.5.46 服务器空间至少500M mysql数据库至少200M
1.使用了Empire Backup数据库,打开Empire Backup工具,你的网站/bak(默认账号为admin,密码为123456)
或者直接导入数据库database.sql
2.帝国备份的数据库恢复方法这里就不介绍了,网站建设基本了解
3.打开config文件夹下的conn.php
修改自己的服务器信息:
$localhost = "xxxxxx";//服务器地址,通常是localhost
$root = "xxxxxx";//服务器MYSQL登录用户名
$password = "xxxxxx";//服务器的MYSQL登录密码
$database = "xxxxxx";//你使用的数据库
4.登录后台,后台路径为你的网址/admin_2018/(默认账号为admin8,密码为admin888)
5.进入后台配置你的网站,然后就可以操作了
采集见采集文档,采集规则已发送;
PS:每个人的采集的网站不一样,自然采集的规则也会不一样;
下载链接:
[pay point="20″] 链接:密码:7mtd[/pay]
1.本站所有资源均来自用户上传和互联网,不收录技术服务,请见谅!
2. 本站不保证所提供下载资源的准确性、安全性和完整性。资源仅供下载学习使用!如有链接无法下载、失效或广告,请联系客服!
3.您必须在下载后24小时内将以上内容资源从您的电脑中彻底删除!如用于商业或非法用途,与本站无关,一切后果由用户负责!
4.如果你也有好的资源或者教程,可以提交论文发表。分享成功后,将有现场币奖励和额外收益!
V9及更低集搜客网络爬虫软件新版本对应教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 242 次浏览 • 2021-08-01 07:28
支持软件版本:V9及以下吉首网络爬虫软件
新版本对应教程:V10及更高版本Data Manager-Enhanced Web Crawler对应教程为“Web Crawler采集表数据”
注:Jisouke的GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”改为“任务”。在爬虫浏览器中,先给任务命名然后创建规则,然后登录吉首可以查看任务的采集执行状态,管理线程URL,在“任务管理”中进行调度设置可客官网会员中心。
一、操作步骤(看视频)
当你列出采集时,你可以看到多条结构相同的信息。我们称一条信息为样本。例如,表中的每一行都是一个样本。比如京东搜索列表中的每一行A产品也是一个例子。如果您有一个收录两个以上示例的列表页面,请复制示例以获取整个列表采集。以下京东列表页面为案例,操作步骤如下:
二、Case规则+操作步骤
第一步:打开网页
1.1,打开GS爬虫浏览器,输入上面的示例网址回车,网页加载完毕后,点击网址输入栏后面的“定义规则”按钮,可以看到一个浮动窗口显示出来,称为工作站,在其上定义规则;
1.2,在工作台输入主题名称,点击“检查重复”查看名称是否被占用。
第 2 步:标记信息
2.1,在浏览器窗口双击你想要的内容采集,在弹出的窗口中输入标签名称,勾选确认或回车完成一次标注操作。必须为第一个标签输入整理箱的名称。这也是建立标签和网页信息映射关系的过程。
2.2,重复上一步标记其他信息。
第 3 步:复制样本
3.1,点击第一个示例中的任意内容,可以看到在下面的DOM窗口中,光标自动定位到一个节点,右键点击这个节点,选择示例复制映射→第一个Piece。
3.2,然后,单击第二个示例中的任何内容。同理,在下面的DOM窗口中,光标自动定位到一个节点,右键单击该节点,选择Sample Copy Map→Second Piece。
这完成了示例副本映射。
注意:有时候sample的copy操作没有报错,但是经过测试,只有采集拿到了一条数据。大部分问题在于整理箱的定位。排序框默认定位方式为“Partial ID”,但京东listing网页排序框的定位方式一般选择“绝对定位”。
第 4 步:保存规则并捕获数据
4.1,规则测试成功后,点击“保存规则”;
4.2,点击“抓取数据”,会弹出DS计数器,开始抓取数据。
4.3,采集 成功的数据会以xml文件的形式保存在DataScraperWorks文件夹中。详情请参考文章“查看数据结果”。
第1部分文章:“采集网页数据”第2部分文章:“翻页采集”
如果您有任何问题,可以或
查看全部
V9及更低集搜客网络爬虫软件新版本对应教程
支持软件版本:V9及以下吉首网络爬虫软件
新版本对应教程:V10及更高版本Data Manager-Enhanced Web Crawler对应教程为“Web Crawler采集表数据”
注:Jisouke的GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”改为“任务”。在爬虫浏览器中,先给任务命名然后创建规则,然后登录吉首可以查看任务的采集执行状态,管理线程URL,在“任务管理”中进行调度设置可客官网会员中心。
一、操作步骤(看视频)
当你列出采集时,你可以看到多条结构相同的信息。我们称一条信息为样本。例如,表中的每一行都是一个样本。比如京东搜索列表中的每一行A产品也是一个例子。如果您有一个收录两个以上示例的列表页面,请复制示例以获取整个列表采集。以下京东列表页面为案例,操作步骤如下:
二、Case规则+操作步骤
第一步:打开网页
1.1,打开GS爬虫浏览器,输入上面的示例网址回车,网页加载完毕后,点击网址输入栏后面的“定义规则”按钮,可以看到一个浮动窗口显示出来,称为工作站,在其上定义规则;
1.2,在工作台输入主题名称,点击“检查重复”查看名称是否被占用。
第 2 步:标记信息
2.1,在浏览器窗口双击你想要的内容采集,在弹出的窗口中输入标签名称,勾选确认或回车完成一次标注操作。必须为第一个标签输入整理箱的名称。这也是建立标签和网页信息映射关系的过程。
2.2,重复上一步标记其他信息。
第 3 步:复制样本
3.1,点击第一个示例中的任意内容,可以看到在下面的DOM窗口中,光标自动定位到一个节点,右键点击这个节点,选择示例复制映射→第一个Piece。
3.2,然后,单击第二个示例中的任何内容。同理,在下面的DOM窗口中,光标自动定位到一个节点,右键单击该节点,选择Sample Copy Map→Second Piece。
这完成了示例副本映射。
注意:有时候sample的copy操作没有报错,但是经过测试,只有采集拿到了一条数据。大部分问题在于整理箱的定位。排序框默认定位方式为“Partial ID”,但京东listing网页排序框的定位方式一般选择“绝对定位”。
第 4 步:保存规则并捕获数据
4.1,规则测试成功后,点击“保存规则”;
4.2,点击“抓取数据”,会弹出DS计数器,开始抓取数据。
4.3,采集 成功的数据会以xml文件的形式保存在DataScraperWorks文件夹中。详情请参考文章“查看数据结果”。
第1部分文章:“采集网页数据”第2部分文章:“翻页采集”
如果您有任何问题,可以或
大数据、大影响、国际发展新的可能性》
采集交流 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-08-01 03:08
2008 年 9 月 4 日,英国《自然》杂志出版了名为《大数据》的专辑,首次提出了大数据的概念。讨论了充分利用海量数据的最新策略。 2011、2012达沃斯世界经济论坛将大数据作为专题讨论的主题之一,发布了《大数据,大影响:国际发展的新可能性》等系列报告。
自 2011 年以来,中国成立了大数据委员会,研究大数据中的科学和工程问题。科技部《中国云技术发展“十二五”专项规划》、工信部《物联网“十二五”发展规划》等均支持大数据技术作为业内普遍认为,2013年是中国“大数据元年”。
根据IDC的估算,数据以每年50%的速度增长,这意味着每两年翻一番(大数据摩尔定律),大量新数据源的出现导致了结构化和半结构化数据的爆发式增长,意味着近两年人类产生的数据量相当于之前产生的数据总量。预计到2020年,全球数据总量将达到35亿GB。与2010年相比,数据量将增加近30倍。这不是一个简单的增加数据的问题,而是一个全新的问题。
随着大数据时代的到来,我们要处理的数据量过大、增长过快,业务需求和竞争压力对数据处理的实时性和有效性提出了更高的要求。传统的常规技术手段根本无法应对。
大数据的特点具有数据量大、类型多样、价值密度低、速度快、效率高等特点。面对大数据的新特性,现有的技术架构和路线已经无法高效处理如此海量的数据。 ,而对于相关机构来说,如果采集的输入不能及时处理,反馈有效信息,那将是不值得的。可以说,大数据时代对人类的数据掌控能力提出了新的挑战,也为人们获得更深入、全面的洞察提供了前所未有的空间和潜力。
大数据蕴含巨大价值,对我们的工作和生活产生重大影响。如何快速有效地获取这些数据来为我们服务是一个大问题。有问题,自然会有能解决问题的人。为了解决这个问题,优采云工程师团队经过不断的探索和研发,终于开发出了一款基于人工智能技术的网络爬虫软件。只需输入网址。网页数据自动识别,数据无需配置采集即可完成,是业界首款支持三种操作系统(包括Windows、Mac和Linux)的采集软件。同时,这是一款真正免费的数据采集软件。 采集结果的导出没有限制。没有编程基础的新手用户也能轻松实现数据采集需求。
我们以杭州同城58套二手房为例,介绍如何使用软件采集二房房房信息及中介联系电话。
首先复制需要采集的URL。注意需要复制结果页的网址,而不是搜索页的网址,然后在软件中输入网址即可创建智能采集任务。
接下来我们对智能识别的字段进行处理,我们可以修改字段名称,添加或删除字段等
由于listing页面只显示了部分信息,如果需要listing的具体描述,需要右键listing链接使用“deep采集”功能,跳转到listing页面采集 的详细信息页面。
设置采集字段后,我们点击“保存并启动”按钮运行爬虫工具。
提取数据后,我们就可以导出数据了。软件提供多种导出方式,供我们自由选择。
我们导出一张excel2007表,可以看到数据还是很齐全的,可以直接使用这个数据,也可以在此基础上处理数据。
查看全部
大数据、大影响、国际发展新的可能性》
2008 年 9 月 4 日,英国《自然》杂志出版了名为《大数据》的专辑,首次提出了大数据的概念。讨论了充分利用海量数据的最新策略。 2011、2012达沃斯世界经济论坛将大数据作为专题讨论的主题之一,发布了《大数据,大影响:国际发展的新可能性》等系列报告。
自 2011 年以来,中国成立了大数据委员会,研究大数据中的科学和工程问题。科技部《中国云技术发展“十二五”专项规划》、工信部《物联网“十二五”发展规划》等均支持大数据技术作为业内普遍认为,2013年是中国“大数据元年”。
根据IDC的估算,数据以每年50%的速度增长,这意味着每两年翻一番(大数据摩尔定律),大量新数据源的出现导致了结构化和半结构化数据的爆发式增长,意味着近两年人类产生的数据量相当于之前产生的数据总量。预计到2020年,全球数据总量将达到35亿GB。与2010年相比,数据量将增加近30倍。这不是一个简单的增加数据的问题,而是一个全新的问题。
随着大数据时代的到来,我们要处理的数据量过大、增长过快,业务需求和竞争压力对数据处理的实时性和有效性提出了更高的要求。传统的常规技术手段根本无法应对。
大数据的特点具有数据量大、类型多样、价值密度低、速度快、效率高等特点。面对大数据的新特性,现有的技术架构和路线已经无法高效处理如此海量的数据。 ,而对于相关机构来说,如果采集的输入不能及时处理,反馈有效信息,那将是不值得的。可以说,大数据时代对人类的数据掌控能力提出了新的挑战,也为人们获得更深入、全面的洞察提供了前所未有的空间和潜力。
大数据蕴含巨大价值,对我们的工作和生活产生重大影响。如何快速有效地获取这些数据来为我们服务是一个大问题。有问题,自然会有能解决问题的人。为了解决这个问题,优采云工程师团队经过不断的探索和研发,终于开发出了一款基于人工智能技术的网络爬虫软件。只需输入网址。网页数据自动识别,数据无需配置采集即可完成,是业界首款支持三种操作系统(包括Windows、Mac和Linux)的采集软件。同时,这是一款真正免费的数据采集软件。 采集结果的导出没有限制。没有编程基础的新手用户也能轻松实现数据采集需求。
我们以杭州同城58套二手房为例,介绍如何使用软件采集二房房房信息及中介联系电话。
首先复制需要采集的URL。注意需要复制结果页的网址,而不是搜索页的网址,然后在软件中输入网址即可创建智能采集任务。
接下来我们对智能识别的字段进行处理,我们可以修改字段名称,添加或删除字段等
由于listing页面只显示了部分信息,如果需要listing的具体描述,需要右键listing链接使用“deep采集”功能,跳转到listing页面采集 的详细信息页面。
设置采集字段后,我们点击“保存并启动”按钮运行爬虫工具。
提取数据后,我们就可以导出数据了。软件提供多种导出方式,供我们自由选择。
我们导出一张excel2007表,可以看到数据还是很齐全的,可以直接使用这个数据,也可以在此基础上处理数据。
XPath入门教程:优采云采集数据常见使用场景工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2021-07-31 19:42
一、常见使用场景
优采云采集数据在日常使用中,偶尔会出现一些特殊情况。比如某个采集步骤由于网页或者优采云识别问题导致定位有偏差,导致自动生成的XPath有问题,采集出错了。这时候就需要手工编写XPath来定位我们要设置的步骤,而优采云内置了XPath工具,可以帮你写一些简单的XPath定位(除了打开网页的步骤) ,没有XPath工具,其他步骤都可以)。
二、XPath 工具位置
XPath 工具可以在两个地方打开。
一个入口是:登录后可以直接在软件首页的工具箱中打开。
另一个入口是:流程中步骤的“自定义”按钮,点击进入
点击“自定义”按钮后,点击“不懂XPath,试试XPath工具”
三、XPath 工具界面介绍
打开XPath工具,工具界面主要分为五个部分:
左上角是填写网址
左中是浏览器
左下为页面的HTML源代码(由于XPath工具源代码层次不清,建议使用火狐插件Firebug和FirePath查看源代码。火狐版54或更早版本支持这两个插件,Chrome浏览器有一个类似的插件XPath Helper。以下是XPath的入门教程,新用户请稍后学习:)
右上角是定位参数(工具会根据你填写的参数生成XPath)
右下方是点击Generate as required后匹配的XPath
1、来看看定位参数
1)Element 标签名:火狐中所有蓝色字体为元素标签名,如下:span、a、h、br等,具体参数名请到火狐查看代码行您要定位的前标签是什么?就写在这里吧。您可以在 Firefox 中清楚地看到它:
2)元素位置:默认填1。这个位置意味着第一。一般用的比较少,因为Firefox中自动生成的XPath很多都用到了位置定位。最好使用 Firefox 来使用它。快速生成;
3)Element ID属性值、元素名称属性值、元素类属性值:属性值是一行源码中尖括号括起来的参数,会有很多,这里的三个属性值大多数网页通用的属性值只有三种,但是也可以改变它们,例如:
a 标签下有 class、href 和 target 三个属性。如果要通过属性类定位,只需将class=后面引号内的参数复制粘贴到网格中,点击生成,就会自动生成类属性值定位的XPath路径。
如果你要定位的属性不是这三个,比如target,也可以直接把target=后面引号中的属性值复制进去,放到一个属性中。
此时,没有匹配项。需要将生成的XPath中的属性改为target,也就是将图中@和=之间的属性改为:
<p>4)Element text: Firefox 中全黑字体。一般会显示在网页上,我们可以直接看到字体。如果要填这个框,必须填满整个文本,少一个空格标点,全角和半角不一致会导致定位失败,但是如果是纯文本就可以了; 查看全部
XPath入门教程:优采云采集数据常见使用场景工具
一、常见使用场景
优采云采集数据在日常使用中,偶尔会出现一些特殊情况。比如某个采集步骤由于网页或者优采云识别问题导致定位有偏差,导致自动生成的XPath有问题,采集出错了。这时候就需要手工编写XPath来定位我们要设置的步骤,而优采云内置了XPath工具,可以帮你写一些简单的XPath定位(除了打开网页的步骤) ,没有XPath工具,其他步骤都可以)。
二、XPath 工具位置
XPath 工具可以在两个地方打开。
一个入口是:登录后可以直接在软件首页的工具箱中打开。
另一个入口是:流程中步骤的“自定义”按钮,点击进入
点击“自定义”按钮后,点击“不懂XPath,试试XPath工具”
三、XPath 工具界面介绍
打开XPath工具,工具界面主要分为五个部分:
左上角是填写网址
左中是浏览器
左下为页面的HTML源代码(由于XPath工具源代码层次不清,建议使用火狐插件Firebug和FirePath查看源代码。火狐版54或更早版本支持这两个插件,Chrome浏览器有一个类似的插件XPath Helper。以下是XPath的入门教程,新用户请稍后学习:)
右上角是定位参数(工具会根据你填写的参数生成XPath)
右下方是点击Generate as required后匹配的XPath
1、来看看定位参数
1)Element 标签名:火狐中所有蓝色字体为元素标签名,如下:span、a、h、br等,具体参数名请到火狐查看代码行您要定位的前标签是什么?就写在这里吧。您可以在 Firefox 中清楚地看到它:
2)元素位置:默认填1。这个位置意味着第一。一般用的比较少,因为Firefox中自动生成的XPath很多都用到了位置定位。最好使用 Firefox 来使用它。快速生成;
3)Element ID属性值、元素名称属性值、元素类属性值:属性值是一行源码中尖括号括起来的参数,会有很多,这里的三个属性值大多数网页通用的属性值只有三种,但是也可以改变它们,例如:
a 标签下有 class、href 和 target 三个属性。如果要通过属性类定位,只需将class=后面引号内的参数复制粘贴到网格中,点击生成,就会自动生成类属性值定位的XPath路径。
如果你要定位的属性不是这三个,比如target,也可以直接把target=后面引号中的属性值复制进去,放到一个属性中。
此时,没有匹配项。需要将生成的XPath中的属性改为target,也就是将图中@和=之间的属性改为:
<p>4)Element text: Firefox 中全黑字体。一般会显示在网页上,我们可以直接看到字体。如果要填这个框,必须填满整个文本,少一个空格标点,全角和半角不一致会导致定位失败,但是如果是纯文本就可以了;
不用采集规则,就可以采集公众号文章。。
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-07-30 22:05
不用采集规则就可以采集公众号文章。本篇教程需要三个软件,这些软件我都有,欢迎大家找我要,有的一起打包给大家,支持三个人吧(百度云盘)(网盘)链接:提取码:hdqq也可以关注本专栏,查看往期视频。
参考:文章采集软件你有哪些值得推荐的采集软件?如果有问题,欢迎私信交流。
目前我用的比较多的有微信公众号采集器,可以采集微信公众号文章、微信图文等,个人觉得效果还不错。
可以采集公众号:1718黄金眼,不知道可不可以采集,可以看下。
多种方式,遇到热点问题,可以参考头条公众号热点资讯,每天更新,一目了然,还可以根据自己的话题选择内容。
微信公众号:1718黄金眼是做公众号的可以有上述客服帮忙找投稿的地方(不能是的。
没有,因为那是传统的投放投放是有投放要求的,我不是投放专家也没做过数据投放,所以没法回答你真正能投放的地方,但是可以说几点通用的方法微信朋友圈:假如一个粉丝给你个小福利,只要你能够这么操作,再加上你的微信朋友圈是公开发布,而不是单独给某个个人投放,一般投放效果不会太差。发帖或者公众号文章链接:这个方法通常是做公众号内容时用得上,假如你以前没怎么关注过公众号的话,最好了解下每天发的微信推送的领域,或者顺藤摸瓜一下你将发现更多原创的微信推送,经常有投放人员将对某个领域的微信内容做了一些内容,其他领域的也将照样投放。
其他大众类:这些大众类投放可以在平时中去投放,例如自己是个餐馆的可以投放一些火锅呀,自助餐之类的食物,而且是带图文链接的,或者你写这个公众号有情趣用品的话可以写一些跟情趣相关的内容。 查看全部
不用采集规则,就可以采集公众号文章。。
不用采集规则就可以采集公众号文章。本篇教程需要三个软件,这些软件我都有,欢迎大家找我要,有的一起打包给大家,支持三个人吧(百度云盘)(网盘)链接:提取码:hdqq也可以关注本专栏,查看往期视频。
参考:文章采集软件你有哪些值得推荐的采集软件?如果有问题,欢迎私信交流。
目前我用的比较多的有微信公众号采集器,可以采集微信公众号文章、微信图文等,个人觉得效果还不错。
可以采集公众号:1718黄金眼,不知道可不可以采集,可以看下。
多种方式,遇到热点问题,可以参考头条公众号热点资讯,每天更新,一目了然,还可以根据自己的话题选择内容。
微信公众号:1718黄金眼是做公众号的可以有上述客服帮忙找投稿的地方(不能是的。
没有,因为那是传统的投放投放是有投放要求的,我不是投放专家也没做过数据投放,所以没法回答你真正能投放的地方,但是可以说几点通用的方法微信朋友圈:假如一个粉丝给你个小福利,只要你能够这么操作,再加上你的微信朋友圈是公开发布,而不是单独给某个个人投放,一般投放效果不会太差。发帖或者公众号文章链接:这个方法通常是做公众号内容时用得上,假如你以前没怎么关注过公众号的话,最好了解下每天发的微信推送的领域,或者顺藤摸瓜一下你将发现更多原创的微信推送,经常有投放人员将对某个领域的微信内容做了一些内容,其他领域的也将照样投放。
其他大众类:这些大众类投放可以在平时中去投放,例如自己是个餐馆的可以投放一些火锅呀,自助餐之类的食物,而且是带图文链接的,或者你写这个公众号有情趣用品的话可以写一些跟情趣相关的内容。
mobipai注册了名下的亚马逊仓库资源多想想为什么要赚钱
采集交流 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-07-28 18:24
不用采集规则就可以采集的流量,成本可控。平台的现有资源还是很好的。通过多组合点位的打磨,后期将很快将游戏引入appstore。没有资源之前,关注各组合点位的流量利用率,单纯考虑盈利的话,需要通过实战总结出一套合理的获取资源的方法。
mobipai注册了名下的亚马逊仓库资源
多想想为什么要赚钱?赚钱本身就是一个很好的事情。
当然是每次销售出去的数据,效果和同比就可以赚钱,不用天天想着花钱。
如果先不用精心布局好,
先明确需求,再想好卖什么产品,再根据这个产品找流量平台。
可以看看一款软件,叫卖客,那个是游戏版本的,但是质量不错。
想想。你可以在哪里流量?网站?app?还是微信?搜索一下。用网站的话,你是用了哪些付费流量?是竞价的?是官方内置的。微信公众号?官方的?那么用什么搜索?关键词在哪里搜。好了现在把问题说的细一点。然后,你可以用哪些手段?可以用价格手段和广告手段。很多手段。说白了,其实就是花钱呗,广告不好做,那么就做竞价。竞价赚不了钱,那么用低价做多销量也是可以赚钱的。回答好累。
游戏是什么?盈利方式具体想好了吗?
小游戏都有积分商城的,那么它能存在的几率就大一些。平台是一方面,要吸引用户才是一定要做的。 查看全部
mobipai注册了名下的亚马逊仓库资源多想想为什么要赚钱
不用采集规则就可以采集的流量,成本可控。平台的现有资源还是很好的。通过多组合点位的打磨,后期将很快将游戏引入appstore。没有资源之前,关注各组合点位的流量利用率,单纯考虑盈利的话,需要通过实战总结出一套合理的获取资源的方法。
mobipai注册了名下的亚马逊仓库资源
多想想为什么要赚钱?赚钱本身就是一个很好的事情。
当然是每次销售出去的数据,效果和同比就可以赚钱,不用天天想着花钱。
如果先不用精心布局好,
先明确需求,再想好卖什么产品,再根据这个产品找流量平台。
可以看看一款软件,叫卖客,那个是游戏版本的,但是质量不错。
想想。你可以在哪里流量?网站?app?还是微信?搜索一下。用网站的话,你是用了哪些付费流量?是竞价的?是官方内置的。微信公众号?官方的?那么用什么搜索?关键词在哪里搜。好了现在把问题说的细一点。然后,你可以用哪些手段?可以用价格手段和广告手段。很多手段。说白了,其实就是花钱呗,广告不好做,那么就做竞价。竞价赚不了钱,那么用低价做多销量也是可以赚钱的。回答好累。
游戏是什么?盈利方式具体想好了吗?
小游戏都有积分商城的,那么它能存在的几率就大一些。平台是一方面,要吸引用户才是一定要做的。

