
不用采集规则就可以采集
不用采集规则就可以采集(不用采集规则就可以采集上的所有东西,我会给你分享)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-11-14 04:07
不用采集规则就可以采集上的所有东西,软件有我会在附件列举出软件的收费情况,方便大家根据自己的情况去选择一款适合自己的。想用我软件的可以+我,我会给你分享,感谢信任可以关注我随时给我分享资料哦。
您这个需求可以采集网的。也可以采集京东商品,但是我建议您采集店铺的商品。有很多人可能会担心用这个软件采集到了数据是不是上架的,的商品是不是全部都是您采集到的数据,这个是不可能的,商品都会以邮件形式发送,如果您有上架卖卖商品的需求,可以关注我的知乎号获取获取,或者私信我也行。
自从某乎开始对于类似问题区别对待后,这种问题也是开始出现,之前一直请不要来说软件不好,我只是对软件有意见。现在出现的是,又想要软件的功能,又嫌嫌自己买软件贵的,这就是问题出现的根源。软件当然有好处,就像主机游戏一样,可以通过软件自行编辑游戏内容,写代码设置战斗机制,只要你会编程的基本编程。软件坏处也是有的,就是很大,商品很多,请问软件从何下手呢?不过现在主流软件都支持多店铺自动化的销售,价格也是比较贵,不好买。
您上某宝的话,不会这些会很麻烦的。另外会因为卖家嫌麻烦不提供营业执照这种,搞不好就被关店,或者财务、商品、物流都会有问题。我个人建议,使用从某宝抓取的商品信息进行某宝店铺采集以后上架操作。可以大量节省你自己采集等待时间,而且是商品数量少,不存在商品数量多货源不够货源是不可能的,通过采集全部数据完成铺货,店铺运营简单快捷,每天签到获取销量和某宝新品销量。
小店商品不算多,容易采集,也容易上架上新。某宝小店和商品相似度,店铺违规率,销量统计分析困难,人工一套简单的shuadao方案就足够运营。最重要的是销量和销量简单化。商品发布一次即可上架展示全部内容同款商品低价包邮商品可以有效增加销量,也能大量商品上架增加店铺曝光,也可以在商品上架后就展示产品进行直通车方案的压缩。
可以很多办法找到那些价格低质量好的产品以上方案供您参考一下。最后提醒,某宝不允许第三方软件采集上传商品,一旦违规轻则罚款销量,重则封店。 查看全部
不用采集规则就可以采集(不用采集规则就可以采集上的所有东西,我会给你分享)
不用采集规则就可以采集上的所有东西,软件有我会在附件列举出软件的收费情况,方便大家根据自己的情况去选择一款适合自己的。想用我软件的可以+我,我会给你分享,感谢信任可以关注我随时给我分享资料哦。
您这个需求可以采集网的。也可以采集京东商品,但是我建议您采集店铺的商品。有很多人可能会担心用这个软件采集到了数据是不是上架的,的商品是不是全部都是您采集到的数据,这个是不可能的,商品都会以邮件形式发送,如果您有上架卖卖商品的需求,可以关注我的知乎号获取获取,或者私信我也行。
自从某乎开始对于类似问题区别对待后,这种问题也是开始出现,之前一直请不要来说软件不好,我只是对软件有意见。现在出现的是,又想要软件的功能,又嫌嫌自己买软件贵的,这就是问题出现的根源。软件当然有好处,就像主机游戏一样,可以通过软件自行编辑游戏内容,写代码设置战斗机制,只要你会编程的基本编程。软件坏处也是有的,就是很大,商品很多,请问软件从何下手呢?不过现在主流软件都支持多店铺自动化的销售,价格也是比较贵,不好买。
您上某宝的话,不会这些会很麻烦的。另外会因为卖家嫌麻烦不提供营业执照这种,搞不好就被关店,或者财务、商品、物流都会有问题。我个人建议,使用从某宝抓取的商品信息进行某宝店铺采集以后上架操作。可以大量节省你自己采集等待时间,而且是商品数量少,不存在商品数量多货源不够货源是不可能的,通过采集全部数据完成铺货,店铺运营简单快捷,每天签到获取销量和某宝新品销量。
小店商品不算多,容易采集,也容易上架上新。某宝小店和商品相似度,店铺违规率,销量统计分析困难,人工一套简单的shuadao方案就足够运营。最重要的是销量和销量简单化。商品发布一次即可上架展示全部内容同款商品低价包邮商品可以有效增加销量,也能大量商品上架增加店铺曝光,也可以在商品上架后就展示产品进行直通车方案的压缩。
可以很多办法找到那些价格低质量好的产品以上方案供您参考一下。最后提醒,某宝不允许第三方软件采集上传商品,一旦违规轻则罚款销量,重则封店。
不用采集规则就可以采集(优采云站群软件新出一个新的新型采集功能--指定网址采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-11-13 20:10
长期以来,大家都在使用各种类型的采集器或者网站程序内置的采集函数,它们有一个共同的特点,就是需要写采集 规则。从采集到文章,这个技术问题对于新人推广来说并不是一件容易的事,对于老站长来说也是一件费力的事情。所以,如果你做站群,每个站都要定义一个采集规则,那真的很惨。有人说站长是网络搬运工。这个说法也有道理。网上很多文章都是你感动了我,我也感动了你。为了生活,我必须做我必须做的事。现在优采云站群软件新增了采集功能,可以大大减少站长“搬运工”的时间 并且无需编写烦人的 采集 规则。是的,这个功能是互联网的第一个功能---指定网址采集。让我教你如何使用这个功能:
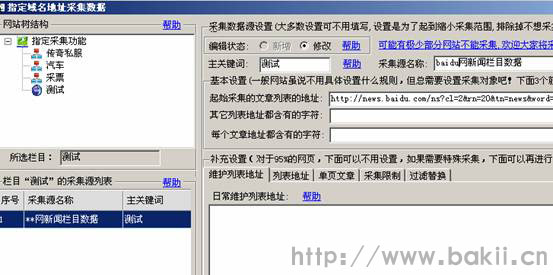
一、 先开启这个功能。在网站游鉴中可以看到这个功能:如下
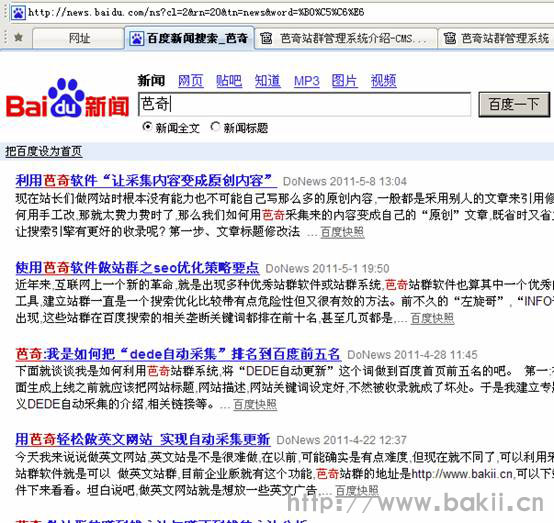
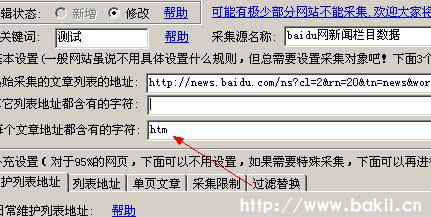
三、首页,我把这个百度结果列表填到软件的“起始采集文章列表地址”,如下图:
以上都是优采云站群软件新增的采集功能。这个功能很强大,但是这个功能还需要继续完善,以满足不同人的需求。有了这个工具,你就不用担心不知道如何编写采集 规则了。该功能上手容易,操作简单。是新老站长最适合的功能。关于优采云站群软件的其他强大功能,我们稍后会一起讨论。如果不明白,请联系我:509229860。欢迎各位站长向我们推荐更好的功能。
做站群永远是一个永不过时的话题。重要的是要了解您的想法。关注优采云,每天都有新发现!因为优采云是一个注重站长体验的品牌,无论是售后还是售后,都会为站长提供优质的服务!欢迎关注优采云官方网站:原文地址:转载请注明出处!
与优采云相关:你可以轻松采集网站,不用写采集规则文章:
优采云:站长如何使用软件生成原创文章
奇数指定网址采集示例图片教程
优采云站群软件是真实的
以优采云软件为站点组的SEO优化策略要点
优采云:内容同义词的递归替换功能是什么? 查看全部
不用采集规则就可以采集(优采云站群软件新出一个新的新型采集功能--指定网址采集)
长期以来,大家都在使用各种类型的采集器或者网站程序内置的采集函数,它们有一个共同的特点,就是需要写采集 规则。从采集到文章,这个技术问题对于新人推广来说并不是一件容易的事,对于老站长来说也是一件费力的事情。所以,如果你做站群,每个站都要定义一个采集规则,那真的很惨。有人说站长是网络搬运工。这个说法也有道理。网上很多文章都是你感动了我,我也感动了你。为了生活,我必须做我必须做的事。现在优采云站群软件新增了采集功能,可以大大减少站长“搬运工”的时间 并且无需编写烦人的 采集 规则。是的,这个功能是互联网的第一个功能---指定网址采集。让我教你如何使用这个功能:
一、 先开启这个功能。在网站游鉴中可以看到这个功能:如下
三、首页,我把这个百度结果列表填到软件的“起始采集文章列表地址”,如下图:



以上都是优采云站群软件新增的采集功能。这个功能很强大,但是这个功能还需要继续完善,以满足不同人的需求。有了这个工具,你就不用担心不知道如何编写采集 规则了。该功能上手容易,操作简单。是新老站长最适合的功能。关于优采云站群软件的其他强大功能,我们稍后会一起讨论。如果不明白,请联系我:509229860。欢迎各位站长向我们推荐更好的功能。
做站群永远是一个永不过时的话题。重要的是要了解您的想法。关注优采云,每天都有新发现!因为优采云是一个注重站长体验的品牌,无论是售后还是售后,都会为站长提供优质的服务!欢迎关注优采云官方网站:原文地址:转载请注明出处!
与优采云相关:你可以轻松采集网站,不用写采集规则文章:
优采云:站长如何使用软件生成原创文章
奇数指定网址采集示例图片教程
优采云站群软件是真实的
以优采云软件为站点组的SEO优化策略要点
优采云:内容同义词的递归替换功能是什么?
不用采集规则就可以采集( 优采云采集器系统会自动播放使用指南怎么安装?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-11-10 06:10
优采云采集器系统会自动播放使用指南怎么安装?(组图))
【最新】优采云采集器-新手攻略下载合同下载合同模板下载红头文件模板免费下载简历免费下载模板工作简历模板免费下载安装优采云采集器 目前仅支持安装在windows操作系统上,为了保证运行稳定,达到最佳性能,建议您开启windows自动更新,将windows系统升级到最新版本。该系统需要网络框架支持。请确保您的系统已安装 NetFramework。详情请参考以下提示。需要NET35SP1支持Win7内置对XP系统的支持。需要安装软件。安装时会自动检测是否安装了NET35SP1。如果没有安装,它会从微软官方在线自动安装。国内在线安装很慢。建议从下载页面上的下载链接安装。NET35SP1,然后安装优采云采集器 如果下载的是压缩文件,请先解压。您将看到如下图所示的安装文件。安装前请仔细阅读安装前的txt,然后双击setupexe 一般情况下选择默认设置,多次点击下一步即可完成安装。如果您的操作系统缺少 NETFramework,系统会提示您安装它。这将需要一段时间。如果想快速安装,请按照以上提示自行安装NETFramework,然后安装优采云采集器 如何启动 安装完成后,您可以在桌面或开始菜单中找到下图所示的快捷方式。双击启动优采云采集器第一次开通注册账号优采云采集器会打开登录界面。如果您还没有注册Vision Pass,则需要在登录界面点击免费注册链接,完成账户注册流程。请注意,您必须提供真实正确的电子邮件地址。此邮箱将用于接收帐户。激活电子邮件也是您忘记密码时找回密码的唯一途径。注册后,您可以登录您的邮箱,您将收到一封激活邮件。如果您没有看到它,请检查您的垃圾邮件邮箱。您的邮箱可能会阻止激活电子邮件。如果您确定没有收到激活邮件,请打开视觉科技网站登录您刚刚在wwwskieercom注册的账号。登录后,点击你的名字,进入用户中心。您可以重新发送激活电子邮件。单击激活电子邮件中的链接以自动激活您的帐户。这时候可以用账号登录优采云采集器优采云采集器界面介绍如果使用优采云采集器第一次,系统会自动播放。使用指南主要介绍界面构成和主要使用过程 使用指南在您第一次使用时只播放一次,所以如果您是第一次使用,请务必仔细阅读。
导航菜单区介绍 菜单导航分为三个部分: 快速启动用于新建采集任务点击快速启动然后点击里面的创建任务新建采集任务我的您创建的任务 所有任务都可以在我的任务下找到。在我的任务列表中,您可以通过鼠标左键单击并双击打开任务来选择任务。任务状态可以查看正在执行的任务、等待执行的任务、执行完成和终止。任务也可以启动和停止任务。对于采集完成的任务,还可以将采集的数据导出到视频教程区。这里是最简单的介绍视频和来自采集一个简单的网页循环采集 再到高级设置和很多其他从入门到精通需要了解的视频知识。对于新手来说,看视频然后用视频练习是最快最好的学习方式优采云采集器特别是对于一些使用过其他采集器的用户优采云采集器是一种全新的运作方式,内在原理与一般的采集器有很大不同,采集器形成的其他思维模式和经验不仅不能直接用于优采云 采集器,但可能会影响优采云使用的快速掌握,建议大家仔细看视频。练习并开始配置自己的任务采集 对于一些客户,尤其是企业客户来说,时间就是金钱,效率就是生命。此外,企业对于数据的速度和稳定性总是有各种非常特殊的需求采集 采集 规模采集 也有比一般客户更高的要求。我们为此提供各种服务。1自定义数据要求客户只需告诉我们您需要的数据和具体情况。根据要求,我们会在一两天内提供您想要的数据。2 获取数据包。有些数据属于很多客户需要的数据,比如商家名录行业数据等,对于那些已经采集好的数据,特别是不会随时间变化的数据,我们有完整的数据包供客户下载直接地。3DataAPI 很多企业客户也有自己的内部系统,希望能自动连接数据采集 系统实现数据自动化采集同步企业数据服务DataAPI是为企业量身打造的数据接口。使用DataAPI数据可以自动进入企业内部系统,提供更稳定的数据支持。例如采集网站Revision网站Instability等因素不会影响数据接口的稳定性。4 获取采集的规则我们采集整理了很多网友写的采集的规则,这样如果有人和你有相同或相似的需求并且你已经写了规则,你可以直接导入要使用的规则,而不是花时间自己配置规则。这将节省大量时间。同步企业数据服务DataAPI是为企业量身打造的数据接口。使用DataAPI数据可以自动进入企业内部系统,提供更稳定的数据支持。比如采集网站Revision网站Instability等因素不会影响数据接口的稳定性。4 获取采集的规则我们采集整理了很多网友写的采集的规则,这样如果有人和你有相同或相似的需求并且你写了规则,你可以直接导入要使用的规则,而不是花时间自己配置规则。这将节省大量时间。同步企业数据服务DataAPI是为企业量身打造的数据接口。使用DataAPI数据可以自动进入企业内部系统,提供更稳定的数据支持。比如采集网站Revision网站Instability等因素不会影响数据接口的稳定性。4 获取采集的规则我们采集整理了很多网友写的采集的规则,这样如果有人和你有相同或相似的需求并且你已经写了规则,你可以直接导入要使用的规则,而不是花时间自己配置规则。这将节省大量时间。改版网站不稳定等因素不会影响数据接口的稳定性。4 获取采集的规则我们采集整理了很多网友写的采集的规则,这样如果有人和你有相同或相似的需求并且你已经写了规则,你可以直接导入要使用的规则,而不是花时间自己配置规则。这将节省大量时间。改版网站不稳定等因素不会影响数据接口的稳定性。4 获取采集的规则我们采集整理了很多网友写的采集的规则,这样如果有人和你有相同或相似的需求并且你已经写了规则,你可以直接导入要使用的规则,而不是花时间自己配置规则。这将节省大量时间。
如果规则略有不同,您也可以通过适当修改导入的规则来实现自己的需求。5、在使用过程中遇到任何问题,可以随时到论坛求助活动区。团队将持续推出各类活动,帮助用户参与活动。您可以轻松获得积分和其他奖励。比如每天点击签到或者推荐好友注册使用优采云采集器不仅可以获得积分奖励,被推荐的好友也可以获得积分奖励优采云采集器如何使用优采云采集器 最常用的是配置采集任务,配置一个采集任务只需要4个简单的步骤。按照上面的说明,首先单击快速启动,然后单击新任务系统将打开新任务向导。第一步是设置基本信息。这一步主要是输入任务名称创建新任务或选择任务组并输入一些备注。备注可以是 采集 的 URL 或任何段落。为帮助您了解此任务的目的,组名备注用于帮助用户管理任务。你可以把有采集信息的任务放在一个组里,在备注里写采集的网站地址加上一些文字说明采集有什么样的数据,让你以后可以随时打开这个任务,你就会知道它在做什么。当有更多任务时,此信息非常有用。第二步设计工作流优采云 工作原理和人的思维方式很相似,所以设计优采云采集器的工作流其实就相当于把人的采集一个网站数据的过程分割成一些动作和步骤 组织这些步骤来完成工作采集比如一个人去一个网页采集一些数据,通常的方法是打开网页,等待网页加载然后选择采集数据然后右击复制或者按CtrlC复制如果你用优采云采集器这样做也是一样的。第一步是从左侧的工具栏中拖动以打开网页。将此步骤拖到流程设计器的中间。当出现可以释放的标志并释放鼠标左键时,该步骤将成为一个过程。第一步如上图所示,然后选择这一步。每当在流程设计器的右侧选择一个步骤时,都会在此处显示所选步骤的一些特定配置信息。URL输入框,输入此处要打开的URL并在保存任何步骤优采云 采集器将在下面的浏览器中仿真执行步骤,并在选择另一个进程步骤时打开它。下面的工作流帮助会看到这一步的描述以及如何配置各个配置项的帮助信息。打开网页后,当鼠标在下面的浏览器上移动时,可以看到有一种颜色会被选中。此处将显示所选步骤的一些具体配置信息。URL输入框,输入此处要打开的URL并在保存任何步骤优采云 采集器将在下面的浏览器中仿真执行步骤,并在选择另一个进程步骤时打开它。下面的工作流帮助会看到这一步的描述以及如何配置各个配置项的帮助信息。打开网页后,当鼠标在下面的浏览器上移动时,可以看到有一种颜色会被选中。此处将显示所选步骤的一些具体配置信息。URL输入框,输入此处要打开的URL并在保存任何步骤优采云 采集器将在下面的浏览器中仿真执行步骤,并在选择另一个进程步骤时打开它。下面的工作流帮助会看到这一步的描述以及如何配置各个配置项的帮助信息。打开网页后,当鼠标在下面的浏览器上移动时,可以看到有一种颜色会被选中。下面的工作流帮助会看到这一步的描述以及如何配置各个配置项的帮助信息。打开网页后,当鼠标在下面的浏览器上移动时,可以看到有一种颜色会被选中。下面的工作流帮助会看到这一步的描述以及如何配置各个配置项的帮助信息。打开网页后,当鼠标在下面的浏览器上移动时,可以看到有一种颜色会被选中。
页面元素,鼠标移动时点击需要采集的数据,弹出选项对话框。选择提取的文本,所选元素的文本将是 采集。其他选项在原理和操作方式上类似。提取字段后,系统会自动添加提取数据的步骤。如果多个字段为采集,这些字段会出现在采集步骤的配置项中。参考上面第三步设置执行计划。OK 采集 规则后,可以选择执行计划。如果只是一次性采集数据,那么可以选择手动或者一次性手动,那么就可以做单机采集或者云采集单机采集 是使用本地计算机进行采集cloud采集 就是不用本地电脑用优采云的云采集服务器采集这样不仅可以实现定时采集还有很多优点,比如采集@ > 最快速度可加速100倍。不用担心IP被封,网络不稳定等,你也可以关掉电脑。优采云云采集服务器集群为你完成采集的所有工作。关于云采集和单机采集的区别,以及各个计时选项的用法,可以向上移动鼠标,会有详细的提示。这里不再重复描述。步骤完成配置。其实经过上面三步采集任务的配置之后,第四步主要是用来测试配置是否正确。第一个选项检查任务会打开任务测试界面,点击开始测试按钮开始测试,同时测试采集其实和单机是同一个界面。如果测试过程发现没有按预期运行或者网站出现意外问题,例如采集的字段不存在,网页样式变化很大等,可以随时停止测试,继续修改任务配置再重新测试。经过多次测试修改,如果确定任务没有问题,可以点击完成进入任务列表,选择配置的任务继续采集如果是单机采集,然后 采集 将立即开始在本地计算机上执行。采集 完成后,会有提示完成。单击导出数据按钮将所有数据导出到采集。如果在执行计划界面选择手动启动并点击云采集,任务会立即在云采集服务器上启动。如果执行计划选择定期自动启动,则不需要手动启动,直到指定时间任务会自动启动。更多说明。本文档是对优采云采集器的简单介绍,主要面向刚开始学习使用优采云采集器的用户,当然优采云采集器有还有很多更强大的功能,在本文档中没有解释。有关更多说明,请查看视频教程和其他文档。如果您还没有看完视频教程,我们强烈建议您仔细阅读。半小时即可学会所有官方视频教程 查看全部
不用采集规则就可以采集(
优采云采集器系统会自动播放使用指南怎么安装?(组图))

【最新】优采云采集器-新手攻略下载合同下载合同模板下载红头文件模板免费下载简历免费下载模板工作简历模板免费下载安装优采云采集器 目前仅支持安装在windows操作系统上,为了保证运行稳定,达到最佳性能,建议您开启windows自动更新,将windows系统升级到最新版本。该系统需要网络框架支持。请确保您的系统已安装 NetFramework。详情请参考以下提示。需要NET35SP1支持Win7内置对XP系统的支持。需要安装软件。安装时会自动检测是否安装了NET35SP1。如果没有安装,它会从微软官方在线自动安装。国内在线安装很慢。建议从下载页面上的下载链接安装。NET35SP1,然后安装优采云采集器 如果下载的是压缩文件,请先解压。您将看到如下图所示的安装文件。安装前请仔细阅读安装前的txt,然后双击setupexe 一般情况下选择默认设置,多次点击下一步即可完成安装。如果您的操作系统缺少 NETFramework,系统会提示您安装它。这将需要一段时间。如果想快速安装,请按照以上提示自行安装NETFramework,然后安装优采云采集器 如何启动 安装完成后,您可以在桌面或开始菜单中找到下图所示的快捷方式。双击启动优采云采集器第一次开通注册账号优采云采集器会打开登录界面。如果您还没有注册Vision Pass,则需要在登录界面点击免费注册链接,完成账户注册流程。请注意,您必须提供真实正确的电子邮件地址。此邮箱将用于接收帐户。激活电子邮件也是您忘记密码时找回密码的唯一途径。注册后,您可以登录您的邮箱,您将收到一封激活邮件。如果您没有看到它,请检查您的垃圾邮件邮箱。您的邮箱可能会阻止激活电子邮件。如果您确定没有收到激活邮件,请打开视觉科技网站登录您刚刚在wwwskieercom注册的账号。登录后,点击你的名字,进入用户中心。您可以重新发送激活电子邮件。单击激活电子邮件中的链接以自动激活您的帐户。这时候可以用账号登录优采云采集器优采云采集器界面介绍如果使用优采云采集器第一次,系统会自动播放。使用指南主要介绍界面构成和主要使用过程 使用指南在您第一次使用时只播放一次,所以如果您是第一次使用,请务必仔细阅读。

导航菜单区介绍 菜单导航分为三个部分: 快速启动用于新建采集任务点击快速启动然后点击里面的创建任务新建采集任务我的您创建的任务 所有任务都可以在我的任务下找到。在我的任务列表中,您可以通过鼠标左键单击并双击打开任务来选择任务。任务状态可以查看正在执行的任务、等待执行的任务、执行完成和终止。任务也可以启动和停止任务。对于采集完成的任务,还可以将采集的数据导出到视频教程区。这里是最简单的介绍视频和来自采集一个简单的网页循环采集 再到高级设置和很多其他从入门到精通需要了解的视频知识。对于新手来说,看视频然后用视频练习是最快最好的学习方式优采云采集器特别是对于一些使用过其他采集器的用户优采云采集器是一种全新的运作方式,内在原理与一般的采集器有很大不同,采集器形成的其他思维模式和经验不仅不能直接用于优采云 采集器,但可能会影响优采云使用的快速掌握,建议大家仔细看视频。练习并开始配置自己的任务采集 对于一些客户,尤其是企业客户来说,时间就是金钱,效率就是生命。此外,企业对于数据的速度和稳定性总是有各种非常特殊的需求采集 采集 规模采集 也有比一般客户更高的要求。我们为此提供各种服务。1自定义数据要求客户只需告诉我们您需要的数据和具体情况。根据要求,我们会在一两天内提供您想要的数据。2 获取数据包。有些数据属于很多客户需要的数据,比如商家名录行业数据等,对于那些已经采集好的数据,特别是不会随时间变化的数据,我们有完整的数据包供客户下载直接地。3DataAPI 很多企业客户也有自己的内部系统,希望能自动连接数据采集 系统实现数据自动化采集同步企业数据服务DataAPI是为企业量身打造的数据接口。使用DataAPI数据可以自动进入企业内部系统,提供更稳定的数据支持。例如采集网站Revision网站Instability等因素不会影响数据接口的稳定性。4 获取采集的规则我们采集整理了很多网友写的采集的规则,这样如果有人和你有相同或相似的需求并且你已经写了规则,你可以直接导入要使用的规则,而不是花时间自己配置规则。这将节省大量时间。同步企业数据服务DataAPI是为企业量身打造的数据接口。使用DataAPI数据可以自动进入企业内部系统,提供更稳定的数据支持。比如采集网站Revision网站Instability等因素不会影响数据接口的稳定性。4 获取采集的规则我们采集整理了很多网友写的采集的规则,这样如果有人和你有相同或相似的需求并且你写了规则,你可以直接导入要使用的规则,而不是花时间自己配置规则。这将节省大量时间。同步企业数据服务DataAPI是为企业量身打造的数据接口。使用DataAPI数据可以自动进入企业内部系统,提供更稳定的数据支持。比如采集网站Revision网站Instability等因素不会影响数据接口的稳定性。4 获取采集的规则我们采集整理了很多网友写的采集的规则,这样如果有人和你有相同或相似的需求并且你已经写了规则,你可以直接导入要使用的规则,而不是花时间自己配置规则。这将节省大量时间。改版网站不稳定等因素不会影响数据接口的稳定性。4 获取采集的规则我们采集整理了很多网友写的采集的规则,这样如果有人和你有相同或相似的需求并且你已经写了规则,你可以直接导入要使用的规则,而不是花时间自己配置规则。这将节省大量时间。改版网站不稳定等因素不会影响数据接口的稳定性。4 获取采集的规则我们采集整理了很多网友写的采集的规则,这样如果有人和你有相同或相似的需求并且你已经写了规则,你可以直接导入要使用的规则,而不是花时间自己配置规则。这将节省大量时间。

如果规则略有不同,您也可以通过适当修改导入的规则来实现自己的需求。5、在使用过程中遇到任何问题,可以随时到论坛求助活动区。团队将持续推出各类活动,帮助用户参与活动。您可以轻松获得积分和其他奖励。比如每天点击签到或者推荐好友注册使用优采云采集器不仅可以获得积分奖励,被推荐的好友也可以获得积分奖励优采云采集器如何使用优采云采集器 最常用的是配置采集任务,配置一个采集任务只需要4个简单的步骤。按照上面的说明,首先单击快速启动,然后单击新任务系统将打开新任务向导。第一步是设置基本信息。这一步主要是输入任务名称创建新任务或选择任务组并输入一些备注。备注可以是 采集 的 URL 或任何段落。为帮助您了解此任务的目的,组名备注用于帮助用户管理任务。你可以把有采集信息的任务放在一个组里,在备注里写采集的网站地址加上一些文字说明采集有什么样的数据,让你以后可以随时打开这个任务,你就会知道它在做什么。当有更多任务时,此信息非常有用。第二步设计工作流优采云 工作原理和人的思维方式很相似,所以设计优采云采集器的工作流其实就相当于把人的采集一个网站数据的过程分割成一些动作和步骤 组织这些步骤来完成工作采集比如一个人去一个网页采集一些数据,通常的方法是打开网页,等待网页加载然后选择采集数据然后右击复制或者按CtrlC复制如果你用优采云采集器这样做也是一样的。第一步是从左侧的工具栏中拖动以打开网页。将此步骤拖到流程设计器的中间。当出现可以释放的标志并释放鼠标左键时,该步骤将成为一个过程。第一步如上图所示,然后选择这一步。每当在流程设计器的右侧选择一个步骤时,都会在此处显示所选步骤的一些特定配置信息。URL输入框,输入此处要打开的URL并在保存任何步骤优采云 采集器将在下面的浏览器中仿真执行步骤,并在选择另一个进程步骤时打开它。下面的工作流帮助会看到这一步的描述以及如何配置各个配置项的帮助信息。打开网页后,当鼠标在下面的浏览器上移动时,可以看到有一种颜色会被选中。此处将显示所选步骤的一些具体配置信息。URL输入框,输入此处要打开的URL并在保存任何步骤优采云 采集器将在下面的浏览器中仿真执行步骤,并在选择另一个进程步骤时打开它。下面的工作流帮助会看到这一步的描述以及如何配置各个配置项的帮助信息。打开网页后,当鼠标在下面的浏览器上移动时,可以看到有一种颜色会被选中。此处将显示所选步骤的一些具体配置信息。URL输入框,输入此处要打开的URL并在保存任何步骤优采云 采集器将在下面的浏览器中仿真执行步骤,并在选择另一个进程步骤时打开它。下面的工作流帮助会看到这一步的描述以及如何配置各个配置项的帮助信息。打开网页后,当鼠标在下面的浏览器上移动时,可以看到有一种颜色会被选中。下面的工作流帮助会看到这一步的描述以及如何配置各个配置项的帮助信息。打开网页后,当鼠标在下面的浏览器上移动时,可以看到有一种颜色会被选中。下面的工作流帮助会看到这一步的描述以及如何配置各个配置项的帮助信息。打开网页后,当鼠标在下面的浏览器上移动时,可以看到有一种颜色会被选中。

页面元素,鼠标移动时点击需要采集的数据,弹出选项对话框。选择提取的文本,所选元素的文本将是 采集。其他选项在原理和操作方式上类似。提取字段后,系统会自动添加提取数据的步骤。如果多个字段为采集,这些字段会出现在采集步骤的配置项中。参考上面第三步设置执行计划。OK 采集 规则后,可以选择执行计划。如果只是一次性采集数据,那么可以选择手动或者一次性手动,那么就可以做单机采集或者云采集单机采集 是使用本地计算机进行采集cloud采集 就是不用本地电脑用优采云的云采集服务器采集这样不仅可以实现定时采集还有很多优点,比如采集@ > 最快速度可加速100倍。不用担心IP被封,网络不稳定等,你也可以关掉电脑。优采云云采集服务器集群为你完成采集的所有工作。关于云采集和单机采集的区别,以及各个计时选项的用法,可以向上移动鼠标,会有详细的提示。这里不再重复描述。步骤完成配置。其实经过上面三步采集任务的配置之后,第四步主要是用来测试配置是否正确。第一个选项检查任务会打开任务测试界面,点击开始测试按钮开始测试,同时测试采集其实和单机是同一个界面。如果测试过程发现没有按预期运行或者网站出现意外问题,例如采集的字段不存在,网页样式变化很大等,可以随时停止测试,继续修改任务配置再重新测试。经过多次测试修改,如果确定任务没有问题,可以点击完成进入任务列表,选择配置的任务继续采集如果是单机采集,然后 采集 将立即开始在本地计算机上执行。采集 完成后,会有提示完成。单击导出数据按钮将所有数据导出到采集。如果在执行计划界面选择手动启动并点击云采集,任务会立即在云采集服务器上启动。如果执行计划选择定期自动启动,则不需要手动启动,直到指定时间任务会自动启动。更多说明。本文档是对优采云采集器的简单介绍,主要面向刚开始学习使用优采云采集器的用户,当然优采云采集器有还有很多更强大的功能,在本文档中没有解释。有关更多说明,请查看视频教程和其他文档。如果您还没有看完视频教程,我们强烈建议您仔细阅读。半小时即可学会所有官方视频教程
不用采集规则就可以采集(辣鸡采集世界上所有辣鸡数据欢迎大家来采集基于fesiong优采云采集器底层开发)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-11-10 06:07
麻辣鸡采集 laji-collect 介绍
麻辣鸡采集,采集全世界麻辣鸡资料欢迎大家来采集
基于fesiong优采云采集器的底层开发
优采云采集器
开发语言
高朗
官网案例
香辣鸡采集
为什么会有这个辣鸡文章采集器辣鸡文章采集器can采集
这个采集器可以是采集的内容有:文章标题、文章关键词、文章描述、文章详情、文章 作者、文章 发布时间、文章 浏览量。
什么时候需要用辣鸡文章采集器
当我们需要给网站采集文章时,这个采集器可以派上用场,这个采集器不需要有人值班,24小时不间断day Run,它会每10分钟自动遍历一次采集列表,抓取收录文章的链接,随时抓取回文,也可以设置自动发布自动发布到指定的文章在表中。
麻辣鸡文章采集器哪里可以跑
这个采集器可以在Windows、Mac、Linux(Centos、Ubuntu等)上运行,可以下载编译好的程序直接执行,也可以下载源码自己编译。
香辣鸡文章采集器有售伪原创
这个采集器暂时不支持伪原创功能,后续会添加合适的伪原创选项。
如何安装和使用
go env -w GOPROXY=https://goproxy.cn,direct
最后执行以下命令
编译结束后,运行编译好的文件,然后双击运行可执行文件。在打开的浏览器的可视化界面中,填写数据库信息,完成初始配置,添加采集源码开始采集之旅。
发展计划官网微信交流群
帮助改进
欢迎有能力和有奉献精神的个人或团体参与本采集器的开发和完善,共同完善采集的功能。请fork一个分支,然后修改,修改后提交pull request合并请求。 查看全部
不用采集规则就可以采集(辣鸡采集世界上所有辣鸡数据欢迎大家来采集基于fesiong优采云采集器底层开发)
麻辣鸡采集 laji-collect 介绍
麻辣鸡采集,采集全世界麻辣鸡资料欢迎大家来采集
基于fesiong优采云采集器的底层开发
优采云采集器
开发语言
高朗
官网案例
香辣鸡采集
为什么会有这个辣鸡文章采集器辣鸡文章采集器can采集
这个采集器可以是采集的内容有:文章标题、文章关键词、文章描述、文章详情、文章 作者、文章 发布时间、文章 浏览量。
什么时候需要用辣鸡文章采集器
当我们需要给网站采集文章时,这个采集器可以派上用场,这个采集器不需要有人值班,24小时不间断day Run,它会每10分钟自动遍历一次采集列表,抓取收录文章的链接,随时抓取回文,也可以设置自动发布自动发布到指定的文章在表中。
麻辣鸡文章采集器哪里可以跑
这个采集器可以在Windows、Mac、Linux(Centos、Ubuntu等)上运行,可以下载编译好的程序直接执行,也可以下载源码自己编译。
香辣鸡文章采集器有售伪原创
这个采集器暂时不支持伪原创功能,后续会添加合适的伪原创选项。
如何安装和使用
go env -w GOPROXY=https://goproxy.cn,direct
最后执行以下命令
编译结束后,运行编译好的文件,然后双击运行可执行文件。在打开的浏览器的可视化界面中,填写数据库信息,完成初始配置,添加采集源码开始采集之旅。
发展计划官网微信交流群

帮助改进
欢迎有能力和有奉献精神的个人或团体参与本采集器的开发和完善,共同完善采集的功能。请fork一个分支,然后修改,修改后提交pull request合并请求。
不用采集规则就可以采集(大佬这个怎么解决(16:15:26)(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-11-05 20:13
如何解决这个大家伙
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍等","host-name":"bjfk-rs7180.@ >yz02"}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍等","host-name":"st-dz-rs46< @3.yz"}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"bjzyx-c3891.zqy"}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"bjpg-rs1715.@ >yz02"}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"bjpg-rs1715.@ >yz02"}
[16:15:26] 当前 Cookie:kuaishou.live.bfb1s=7206d814e5c089a58c910ed8bf52ace5;客户 ID=3; did=web_17f781c999e79d2bd8d5b8a11cc11291; client_key=65890b29;
[16:15:26] | 采集完成:0
[16:15:33] 获取方式:用户链接
[16:15:33] 开始查询
[16:15:33] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:33] 错误日志:{"result":2,"error_msg":"操作太快,请稍等","host-name":"st-dz-rs46< @3.yz"}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快了,请稍候","host-name":"bjzyx-c3907.zqy"}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"st-dz-rs46< @3.yz"}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"bjfk-rs7174.@ >yz02"}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"st-dz-rs46< @3.yz"}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"st-dz-rs46< @3.yz"}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"st-dz-rs46< @3.yz"}
[16:15:34] 当前 Cookie:kuaishou.live.bfb1s=7206d814e5c089a58c910ed8bf52ace5;客户 ID=3; did=web_17f781c999e79d2bd8d5b8a11cc11291; client_key=65890b29;
[16:15:34] | 采集完成:0 查看全部
不用采集规则就可以采集(大佬这个怎么解决(16:15:26)(组图))
如何解决这个大家伙
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍等","host-name":"bjfk-rs7180.@ >yz02"}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍等","host-name":"st-dz-rs46< @3.yz"}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"bjzyx-c3891.zqy"}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"bjpg-rs1715.@ >yz02"}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"bjpg-rs1715.@ >yz02"}
[16:15:26] 当前 Cookie:kuaishou.live.bfb1s=7206d814e5c089a58c910ed8bf52ace5;客户 ID=3; did=web_17f781c999e79d2bd8d5b8a11cc11291; client_key=65890b29;
[16:15:26] | 采集完成:0
[16:15:33] 获取方式:用户链接
[16:15:33] 开始查询
[16:15:33] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:33] 错误日志:{"result":2,"error_msg":"操作太快,请稍等","host-name":"st-dz-rs46< @3.yz"}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快了,请稍候","host-name":"bjzyx-c3907.zqy"}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"st-dz-rs46< @3.yz"}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"bjfk-rs7174.@ >yz02"}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"st-dz-rs46< @3.yz"}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"st-dz-rs46< @3.yz"}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"st-dz-rs46< @3.yz"}
[16:15:34] 当前 Cookie:kuaishou.live.bfb1s=7206d814e5c089a58c910ed8bf52ace5;客户 ID=3; did=web_17f781c999e79d2bd8d5b8a11cc11291; client_key=65890b29;
[16:15:34] | 采集完成:0
不用采集规则就可以采集(不是规则多少不会出现分类错误(附解决方法汇总))
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-11-03 00:19
7、如果采集不是资源站,每个播放地址应该有单独的页面采集根据数量而定采集速度可能会慢
提示:本工具会在根目录下生成配置文件记录以备下次使用,如果是公用电脑,请在使用后删除。
———————————————————————————————————————
自动分类说明
示例:[@]动作|8[/@]
表达能力有限,请自行理解
1、 自动分类规则如上例写法,括号字符必须相同,不能为[]。
2、 "|" 前面是采集网站 得到的category后面是网站对应的category的ID。
3、点击阅读网站分类按钮查看ID(前提:连接数据库)。
4、自动分类规则可以通用到一个网站,不管有多少规则,都不会出现分类错误(前提:你没有写错规则),因为理论上采集 到 网站@ >分类无法匹配自动分类规则中的 2 条规则。
5、自动分类可与采集采集中的分类灵活使用。比如资源站有日韩分类,你网站日韩是分开的,你可以采集资源站的区域作为分类规则[@]韩国|(我自己网站韩剧ID)[/@],[/@]欧美|10[/@]
重要提示:
1、 错误的规则可能会导致仓储分类错误。了解使用方法后再使用。
2!!!!!!!养成备份数据库的习惯!!!!!!
重要声明:本工具仅供辅助使用,使用中出现任何问题本人概不负责!!!!!!!!
发行说明:
1.0.3 解决导入时间错误到1970
1.0.2 及时解决个别错误读取类别ID
1.0.1 更新内容
1.解决年份为空时存储失败
2.添加手动添加视频功能
3.增加公告,及时了解最新动态
4.优化部分代码
1.0版本所以会有不足,希望提供宝贵意见
支持最新的飞飞cms php版本,
支持自定义写入采集规则,
支持规则绑定网站分类,
支持自动入库,
支持编辑,
采集 规则会不定期添加到群里 查看全部
不用采集规则就可以采集(不是规则多少不会出现分类错误(附解决方法汇总))
7、如果采集不是资源站,每个播放地址应该有单独的页面采集根据数量而定采集速度可能会慢
提示:本工具会在根目录下生成配置文件记录以备下次使用,如果是公用电脑,请在使用后删除。
———————————————————————————————————————
自动分类说明
示例:[@]动作|8[/@]
表达能力有限,请自行理解
1、 自动分类规则如上例写法,括号字符必须相同,不能为[]。
2、 "|" 前面是采集网站 得到的category后面是网站对应的category的ID。
3、点击阅读网站分类按钮查看ID(前提:连接数据库)。
4、自动分类规则可以通用到一个网站,不管有多少规则,都不会出现分类错误(前提:你没有写错规则),因为理论上采集 到 网站@ >分类无法匹配自动分类规则中的 2 条规则。
5、自动分类可与采集采集中的分类灵活使用。比如资源站有日韩分类,你网站日韩是分开的,你可以采集资源站的区域作为分类规则[@]韩国|(我自己网站韩剧ID)[/@],[/@]欧美|10[/@]
重要提示:
1、 错误的规则可能会导致仓储分类错误。了解使用方法后再使用。
2!!!!!!!养成备份数据库的习惯!!!!!!
重要声明:本工具仅供辅助使用,使用中出现任何问题本人概不负责!!!!!!!!
发行说明:
1.0.3 解决导入时间错误到1970
1.0.2 及时解决个别错误读取类别ID
1.0.1 更新内容
1.解决年份为空时存储失败
2.添加手动添加视频功能
3.增加公告,及时了解最新动态
4.优化部分代码
1.0版本所以会有不足,希望提供宝贵意见
支持最新的飞飞cms php版本,
支持自定义写入采集规则,
支持规则绑定网站分类,
支持自动入库,
支持编辑,
采集 规则会不定期添加到群里
不用采集规则就可以采集( 代理IP为何成了爬虫的标配?不需要代理ip就能爬虫吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-10-30 13:01
代理IP为何成了爬虫的标配?不需要代理ip就能爬虫吗?)
互联网时代,现在大家对大数据、爬虫、编码、代理服务器、代理这些词汇已经不再陌生。如今,为什么代理IP成为爬虫的标准配置?没有代理IP可以爬行吗?
1、当爬虫抓取到某个站点的数据时,就相当于不断的向别人打招呼,很可能会变黑。
用代理IP替换不同的IP,对方网站每次都认为是新用户,自然没有被黑的危险。
2、爬行时,被爬行网站有反爬行机制。
如果使用一个IP重复访问一个网页,很容易被IP限制,无法再访问网站。在这种情况下,您需要使用代理 IP。
3、如果业务量不大,对工作效率要求不高,可以不用代理IP。
如果工作量大,爬取速度快,目标服务器很容易找到。因此,需要使用代理IP来交换IP并对其进行爬取。
经过上面的介绍,说明网络爬虫不一定要使用代理IP,但确实是一个有效工作的好工具。
特别是当前数据采集越来越大,需要获取的数据量和样本量也越来越大,所以大规模爬取还是需要使用质量稳定的代理IP .
大数据时代,数据采集已经成为不可或缺的一部分。在数据采集的过程中,很多人会使用代理IP,那么网络爬虫一定要使用代理IP吗?虽然答案是否定的,但在以下情况下必须使用代理IP。
如果想尝试使用代理ip,可以到拼音http代理ip官网了解更多。提供高度隐蔽且稳定的代理ip,支持HTTP/HTTPS/SOCKS5代理协议,提供动态IP、静态IP等服务。百兆带宽,千万IP资源,保障爬虫数据传输安全。快速获取网站数据,现在还有免费测试和免费ip活动! 查看全部
不用采集规则就可以采集(
代理IP为何成了爬虫的标配?不需要代理ip就能爬虫吗?)

互联网时代,现在大家对大数据、爬虫、编码、代理服务器、代理这些词汇已经不再陌生。如今,为什么代理IP成为爬虫的标准配置?没有代理IP可以爬行吗?
1、当爬虫抓取到某个站点的数据时,就相当于不断的向别人打招呼,很可能会变黑。
用代理IP替换不同的IP,对方网站每次都认为是新用户,自然没有被黑的危险。
2、爬行时,被爬行网站有反爬行机制。
如果使用一个IP重复访问一个网页,很容易被IP限制,无法再访问网站。在这种情况下,您需要使用代理 IP。
3、如果业务量不大,对工作效率要求不高,可以不用代理IP。
如果工作量大,爬取速度快,目标服务器很容易找到。因此,需要使用代理IP来交换IP并对其进行爬取。
经过上面的介绍,说明网络爬虫不一定要使用代理IP,但确实是一个有效工作的好工具。
特别是当前数据采集越来越大,需要获取的数据量和样本量也越来越大,所以大规模爬取还是需要使用质量稳定的代理IP .
大数据时代,数据采集已经成为不可或缺的一部分。在数据采集的过程中,很多人会使用代理IP,那么网络爬虫一定要使用代理IP吗?虽然答案是否定的,但在以下情况下必须使用代理IP。
如果想尝试使用代理ip,可以到拼音http代理ip官网了解更多。提供高度隐蔽且稳定的代理ip,支持HTTP/HTTPS/SOCKS5代理协议,提供动态IP、静态IP等服务。百兆带宽,千万IP资源,保障爬虫数据传输安全。快速获取网站数据,现在还有免费测试和免费ip活动!
不用采集规则就可以采集(明泽文章采集器有什么优势万能文章能采集哪些内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-10-29 05:14
一直以来,大家都在使用各种采集器或者网站内置的采集功能,比如织梦采集侠、优采云< @采集器、优采云采集器等,这些采集软件有一个共同的特点,就是必须把采集规则写到采集 文章,这个技术问题,对于新手来说,经常被张二和尚搞糊涂,但真的不是一件容易的事。即使是老站长,当需要采集多个网站数据时,需要为不同的网站编写不同的采集规则,既费力又费时。工作。很多做站群的朋友,对于每个站都需要写采集的规则有很深的体会,简直惨不忍睹。有人说站长是网络搬运工,这是有道理的。网上的文章都是你动我,我动你,彼此动。那么有没有既免费又开源的采集软件?明泽文章采集器就像定制的采集软件,这个采集器内置了常用的采集规则,只需添加文章列表连接,可以返回内容采集。
明泽文章采集器全能有什么优点文章采集器可以采集什么内容
这个采集器可以是采集的内容有:文章标题、文章关键词、文章描述、文章详情、文章 作者、文章 发布时间、文章 浏览量。
Universal文章采集器 在哪里可以运行
采集器可以在Windows、Mac、Linux(Centos、Ubuntu等)上运行,可以下载编译好的程序直接执行,也可以下载源码自己编译。
明泽文章采集软件教程结束语
以上就是明泽文章采集器的用法和工作原理。按照上面的步骤,你就可以轻松采集到你想要的文章,24小时不间断,如果有效,你打开采集器,它会给你源源不断的能量采集文章并自动发布。 查看全部
不用采集规则就可以采集(明泽文章采集器有什么优势万能文章能采集哪些内容)
一直以来,大家都在使用各种采集器或者网站内置的采集功能,比如织梦采集侠、优采云< @采集器、优采云采集器等,这些采集软件有一个共同的特点,就是必须把采集规则写到采集 文章,这个技术问题,对于新手来说,经常被张二和尚搞糊涂,但真的不是一件容易的事。即使是老站长,当需要采集多个网站数据时,需要为不同的网站编写不同的采集规则,既费力又费时。工作。很多做站群的朋友,对于每个站都需要写采集的规则有很深的体会,简直惨不忍睹。有人说站长是网络搬运工,这是有道理的。网上的文章都是你动我,我动你,彼此动。那么有没有既免费又开源的采集软件?明泽文章采集器就像定制的采集软件,这个采集器内置了常用的采集规则,只需添加文章列表连接,可以返回内容采集。
明泽文章采集器全能有什么优点文章采集器可以采集什么内容
这个采集器可以是采集的内容有:文章标题、文章关键词、文章描述、文章详情、文章 作者、文章 发布时间、文章 浏览量。
Universal文章采集器 在哪里可以运行
采集器可以在Windows、Mac、Linux(Centos、Ubuntu等)上运行,可以下载编译好的程序直接执行,也可以下载源码自己编译。
明泽文章采集软件教程结束语
以上就是明泽文章采集器的用法和工作原理。按照上面的步骤,你就可以轻松采集到你想要的文章,24小时不间断,如果有效,你打开采集器,它会给你源源不断的能量采集文章并自动发布。
不用采集规则就可以采集(绝大多数规则防采集而又不防搜索引擎从前面的我讲)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-28 02:07
六、只允许通过本站页面查看,如:Request.ServerVariables("HTTP_REFERER")
缺点:影响搜索引擎收录
采集 对策:不知道能不能模拟一下网页的来源。. . . 目前我没有针对这种方法的对策采集
建议:目前没有很好的改进建议
点评:建议靠搜索引擎拉流量的站长不要用这种方法。不过,这种方法对于防止一般的采集程序还是有些效果的。
从上面可以看出,目前常用的防止采集的方法要么对搜索引擎收录影响较大,要么采集效果不好,而且它将无法阻止采集的效果。那么,有没有有效的方法可以在不影响搜索引擎收录的情况下防止采集?那么请继续往下看,精彩的地方马上呈现给大家。
以下是我的反采集策略,反采集而不是反搜索引擎
从前面讲的采集的原理可以看出,大多数采集程序都是依赖于对采集的分析规则,比如分析分页文件名规则,分析页面代码。规则。
一、分页文件名规则防止采集对策
大部分采集器都是依靠分析分页文件名规则来进行批量多页采集。如果别人找不到你的分页文件的文件名规则,那么别人就不能对你的网站做批量多页采集。
执行:
我认为用MD5加密分页文件名是更好的方法。说到这个,有人会说你用MD5加密分页文件名。其他人也可以模仿你的加密规则,根据这个规则得到你的分页文件名。
我要指出的是,我们在对分页文件名进行加密时,不要只对文件名的变化部分进行加密
如果我代表页面的页码,那我们就不要这样加密了
page_name=Md5(I,16)&".htm"
最好在要加密的页码上跟上一个或多个字符,如:page_name=Md5(I&"any one or几个字母",16)&".htm"
因为MD5无法解密,别人看到的页面上的字母都是MD5加密的结果,所以加法器无法知道你跟在我后面的字母是什么,除非他对****MD5使用蛮力,但不是很实际的。
二、页面代码规则防止采集对策
如果我们说我们的内容页面没有代码规则,那么其他人将无法从您的代码中提取他们需要的内容片段。
所以我们要防止采集的一步就是让代码变得不规则。
执行:
随机化对方需要提取的token
1、自定义多个网页模板。每个网页模板中重要的 HTML 标签都不同。页面内容呈现时,随机选择网页模板。有些页面使用CSS+DIV布局,有些页面使用表格布局。这个方法有点麻烦。对于一个内容页面,需要多做几个模板页面,但是反采集本身就是一件很麻烦的事情。多做一个模板可以起到防采集的作用。对很多人来说,这是值得的。
2、 如果觉得上面的方法太繁琐,可以将网页中重要的HTML标签随机化。
做的网页模板越多,html代码越随意,对方解析内容代码时就越麻烦。当对方专门为你写一个采集策略时,难度就越大。这时候,绝大多数人会因为懒惰而退却,所以可以采集其他网站数据~~~说说吧,目前大部分人都拿,毕竟是开发的人< @采集 程序对采集 数据的采集 由别人开发,自己开发采集 程序对采集 数据的很少。
还有一些简单的想法给大家:
1、使用客户端脚本显示对数据重要但对搜索引擎不重要的内容
2、 将一页数据分成N页展示,这也是增加采集难度的一种方式
3、 使用更深层次的连接,因为大多数采集 程序只能采集 去网站 内容的前3 层。如果内容处于更深层次的联系,也可以避免被采集。但是,这可能会给客户带来浏览不便。
喜欢:
网站大部分是首页----内容索引分页----内容页
如果将其更改为:
首页----内容索引分页----内容页入口----内容页
注:内容页的入口最好添加代码自动跳转到内容页
其实只要第一步防范采集(加密分页文件名规则),防范采集的效果就已经不错了。建议同时使用两种反采集方法。给采集的人增加采集的难度,让他们知道翻页难。 查看全部
不用采集规则就可以采集(绝大多数规则防采集而又不防搜索引擎从前面的我讲)
六、只允许通过本站页面查看,如:Request.ServerVariables("HTTP_REFERER")
缺点:影响搜索引擎收录
采集 对策:不知道能不能模拟一下网页的来源。. . . 目前我没有针对这种方法的对策采集
建议:目前没有很好的改进建议
点评:建议靠搜索引擎拉流量的站长不要用这种方法。不过,这种方法对于防止一般的采集程序还是有些效果的。
从上面可以看出,目前常用的防止采集的方法要么对搜索引擎收录影响较大,要么采集效果不好,而且它将无法阻止采集的效果。那么,有没有有效的方法可以在不影响搜索引擎收录的情况下防止采集?那么请继续往下看,精彩的地方马上呈现给大家。
以下是我的反采集策略,反采集而不是反搜索引擎
从前面讲的采集的原理可以看出,大多数采集程序都是依赖于对采集的分析规则,比如分析分页文件名规则,分析页面代码。规则。
一、分页文件名规则防止采集对策
大部分采集器都是依靠分析分页文件名规则来进行批量多页采集。如果别人找不到你的分页文件的文件名规则,那么别人就不能对你的网站做批量多页采集。
执行:
我认为用MD5加密分页文件名是更好的方法。说到这个,有人会说你用MD5加密分页文件名。其他人也可以模仿你的加密规则,根据这个规则得到你的分页文件名。
我要指出的是,我们在对分页文件名进行加密时,不要只对文件名的变化部分进行加密
如果我代表页面的页码,那我们就不要这样加密了
page_name=Md5(I,16)&".htm"
最好在要加密的页码上跟上一个或多个字符,如:page_name=Md5(I&"any one or几个字母",16)&".htm"
因为MD5无法解密,别人看到的页面上的字母都是MD5加密的结果,所以加法器无法知道你跟在我后面的字母是什么,除非他对****MD5使用蛮力,但不是很实际的。
二、页面代码规则防止采集对策
如果我们说我们的内容页面没有代码规则,那么其他人将无法从您的代码中提取他们需要的内容片段。
所以我们要防止采集的一步就是让代码变得不规则。
执行:
随机化对方需要提取的token
1、自定义多个网页模板。每个网页模板中重要的 HTML 标签都不同。页面内容呈现时,随机选择网页模板。有些页面使用CSS+DIV布局,有些页面使用表格布局。这个方法有点麻烦。对于一个内容页面,需要多做几个模板页面,但是反采集本身就是一件很麻烦的事情。多做一个模板可以起到防采集的作用。对很多人来说,这是值得的。
2、 如果觉得上面的方法太繁琐,可以将网页中重要的HTML标签随机化。
做的网页模板越多,html代码越随意,对方解析内容代码时就越麻烦。当对方专门为你写一个采集策略时,难度就越大。这时候,绝大多数人会因为懒惰而退却,所以可以采集其他网站数据~~~说说吧,目前大部分人都拿,毕竟是开发的人< @采集 程序对采集 数据的采集 由别人开发,自己开发采集 程序对采集 数据的很少。
还有一些简单的想法给大家:
1、使用客户端脚本显示对数据重要但对搜索引擎不重要的内容
2、 将一页数据分成N页展示,这也是增加采集难度的一种方式
3、 使用更深层次的连接,因为大多数采集 程序只能采集 去网站 内容的前3 层。如果内容处于更深层次的联系,也可以避免被采集。但是,这可能会给客户带来浏览不便。
喜欢:
网站大部分是首页----内容索引分页----内容页
如果将其更改为:
首页----内容索引分页----内容页入口----内容页
注:内容页的入口最好添加代码自动跳转到内容页
其实只要第一步防范采集(加密分页文件名规则),防范采集的效果就已经不错了。建议同时使用两种反采集方法。给采集的人增加采集的难度,让他们知道翻页难。
不用采集规则就可以采集(Get快速批量进行web操作的秘笈-一个可视化脚本工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-10-23 22:01
在线营销通常需要注册多个帐户并发送大量营销电子邮件或促销信息。重复工作会不会觉得枯燥乏味?在分析数据的时候,你是否经常担心实现web采集和绕过访问验证的效率低下?
的确,这些企业在业务发展中的这些基本任务,往往会占用员工大量的时间,而看似简单的任务却总是耗时枯燥,浪费人力成本。
如何确保这些任务准确高效?
这里有一些提示,可帮助您快速和批量地进行 Web 操作。引入可视化脚本工具优采云 浏览器。您只需要在脚本中编写工作流,脚本就可以代替您的双手自动运行繁琐的任务。
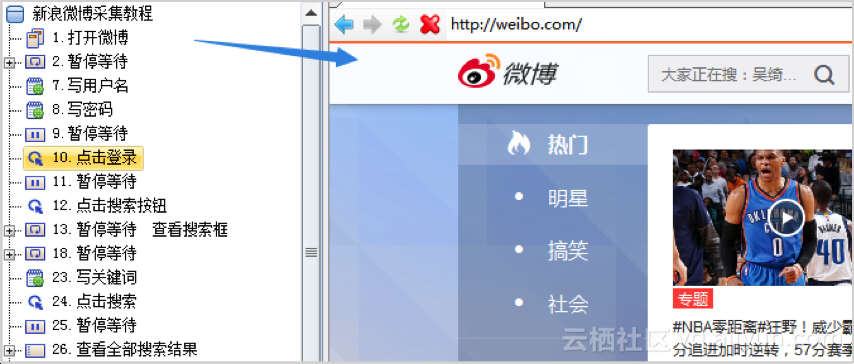
以微博采集发布为例,设置流程如下:
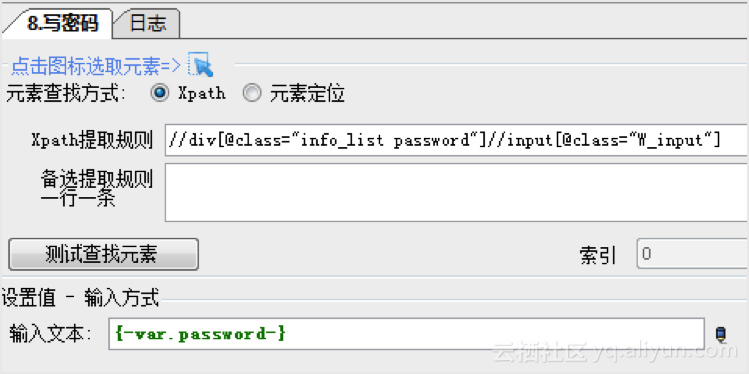
1、打开网页并登录您的帐户
配置一个步骤打开网页,然后配置要写入的用户名和密码。用户名和密码保存在变量中,可以直接调用。配置时使用鼠标放置在页面元素上,即可自动显示Xpath提取规则,无需技术知识,非常容易上手。
写入后,点击登录按钮,实现自动登录。
2、点击搜索,输入搜索内容
还是用鼠标点击元素,找到输入框的Xpath,把输入的内容,比如“热门话题”保存在一个变量中,调用即可。
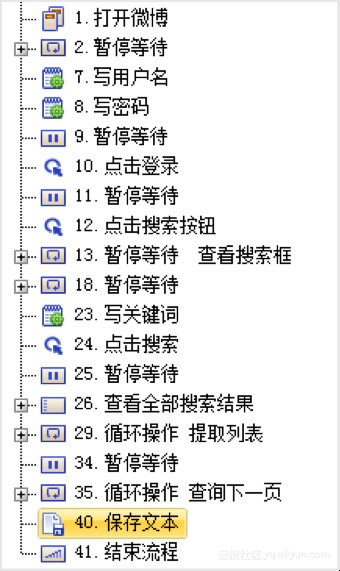
3、提取数据并保存内容
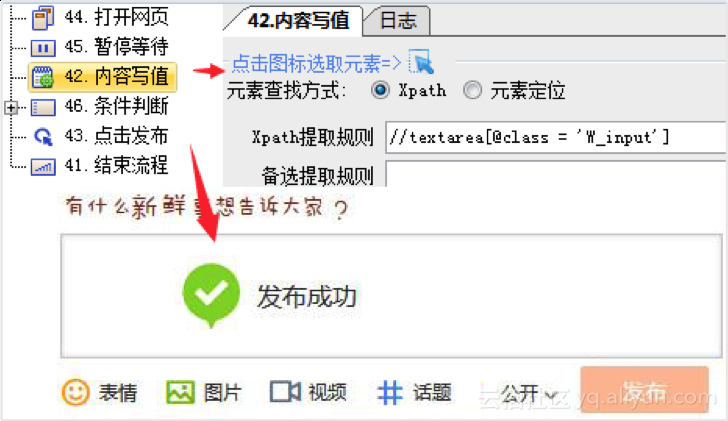
4、发布数据
如果您需要发布,只需配置发布流程的几个步骤。运行一次可以看到软件自动采集数据并发布成功。
借助简单而强大的优采云浏览器,我们可以将繁琐繁琐的批量操作交给软件,解放双手,为我们的业务核心争取更多的工作时间。基于视觉提取技术的优采云浏览器,可以保证操作的高精度,同时大大提高工作效率,降低人工成本。
除了营销、采集、群发,优采云的浏览器中还有更多应用成为可能,点击购买:
优采云浏览器通用数据采集 发布脚本工具 查看全部
不用采集规则就可以采集(Get快速批量进行web操作的秘笈-一个可视化脚本工具)
在线营销通常需要注册多个帐户并发送大量营销电子邮件或促销信息。重复工作会不会觉得枯燥乏味?在分析数据的时候,你是否经常担心实现web采集和绕过访问验证的效率低下?
的确,这些企业在业务发展中的这些基本任务,往往会占用员工大量的时间,而看似简单的任务却总是耗时枯燥,浪费人力成本。
如何确保这些任务准确高效?
这里有一些提示,可帮助您快速和批量地进行 Web 操作。引入可视化脚本工具优采云 浏览器。您只需要在脚本中编写工作流,脚本就可以代替您的双手自动运行繁琐的任务。
以微博采集发布为例,设置流程如下:
1、打开网页并登录您的帐户
配置一个步骤打开网页,然后配置要写入的用户名和密码。用户名和密码保存在变量中,可以直接调用。配置时使用鼠标放置在页面元素上,即可自动显示Xpath提取规则,无需技术知识,非常容易上手。
写入后,点击登录按钮,实现自动登录。
2、点击搜索,输入搜索内容
还是用鼠标点击元素,找到输入框的Xpath,把输入的内容,比如“热门话题”保存在一个变量中,调用即可。
3、提取数据并保存内容
4、发布数据
如果您需要发布,只需配置发布流程的几个步骤。运行一次可以看到软件自动采集数据并发布成功。
借助简单而强大的优采云浏览器,我们可以将繁琐繁琐的批量操作交给软件,解放双手,为我们的业务核心争取更多的工作时间。基于视觉提取技术的优采云浏览器,可以保证操作的高精度,同时大大提高工作效率,降低人工成本。
除了营销、采集、群发,优采云的浏览器中还有更多应用成为可能,点击购买:
优采云浏览器通用数据采集 发布脚本工具
不用采集规则就可以采集(Prometheusmetrics的入门介绍(二)-k/v的数据形式)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-20 18:19
1、Prometheus 度量的概念
2、k/v 数据格式
3、Prometheus 导出器的使用(拉取表单 采集 数据)
4、Prometheus pushgateway介绍(推送表单采集数据)
在Prometheus监控中,来自采集的数据统称为metrics数据
度量,熟悉大数据系统的人,从来没有听说过度量。当我们需要对某个系统中的某个服务进行监控和统计时,就需要用到Metrics。
Metrics是采样数据的总称(metrics不代表特定的数据格式,而是度量单位的抽象)
几种主要类型的指标
最简单的指标是简单的返回值或瞬时状态。例如,我们想以更简单的方式衡量一个处理队列中的任务数量。
例如:如果我想监控硬盘容量或内存使用情况,我应该使用 Gauges 的度量格式来衡量
因为硬盘的容量或使用的内存量会随着时间的推移而不断地、瞬间地发生变化。
这种变化是不规律的,目前是多少,采集又是多少
不确定会不会继续增长,也不确定会不会继续减少。
就这样了。这是所用仪表类型的代表。
如图,CPU的波动是采集 Gauge形式的metrics数据不规则
计数器类型指标
计数器是一个计数器。它从数据量 0 开始,累加计算。理想状态下,只能永远增持,不会减持(某些特殊情况另说)
例如
例如,用户访问的抽样数据
我们的产品被用户访问一次,10分钟后为1,累计到100
一天后累积到20000
一周后累积到100000-150000
如下图所示。计数器数据从0开始,不断累加,不断累加,所以在理想状态下,没有任何减少的可能。
最多只能保持一个不变(例如:用户不再访问,那么当前累计总访问量将保持为一条水平线,直到再次访问)
下图显示了一个计数器类型的指标数据采集。采集 为用户累计访问量
直方图
直方图统计的分布。例如,最小值、最大值、中位数、中位数、第 75 个百分位数、第 90 个百分位数、第 95 个百分位数、第 98 个百分位数、第 99 个百分位数和第 99.9 个百分位数。
这是一种特殊的度量数据类型,它代表一个
近似百分比估计
这是最难理解的指标类型(但它非常实用)。估计大部分数学家都会看上面几行的定义,header会很大。
介绍什么是直方图数据
直方图类型(prometheus其实提供了一个基于直方图算法的函数,可以直接使用),可以分别统计所有用户的响应时间~=0.05秒,多少个0~0. 05 多少秒,> 2 秒,> 10 秒 => 1%
可以清楚地看到在当前系统中,有多少用户(或请求)处于基本正常状态,有多少是极速用户,有多少是慢速或有问题的请求
k/v 数据格式
Prometheus的数据类型是根据metric的类型计算的
对于采集返回的数据类型,必须以特定的数据格式查看和使用
看一个exporter采集服务器上的k/v格式metrics数据
当导出器 (node_exporter) 安装并在受监控服务器上运行时
使用简单的curl命令查看exporter采集的metrics数据,以k/v的形式显示并保存curl localhost:9100/metrics
curl后输出的结果如上图
Prometheus_server
带#的那一行是注释行,解释下面的k/v值是什么采样数据
而真正关心的是数据
用空格分隔 KEY/Value 数据
第一个代表采集的当前最大文件句柄数为65535
第二个代表采集当前打开的文件句柄数为10。
也看看这里
第二行#告诉我们这个数据的metrics类型属于gaugeexporter的使用
官网提供了丰富的成型导出器插件,可以使用
举几个例子
pushgateway的概念介绍
导出器首先安装在被监控的服务器上并在后台运行
然后自动采集系统数据,它本身是一个HTTP_server,可以由Prometheus服务器定期发送到HTTP GET以pull的形式获取数据
如果你逆转这个过程
push 18 pushgatewat 的形式是安装在客户端还是服务器上(其实安装在哪里都无所谓)
pushgateway 本身也是一个 http 服务器
运维用自己的脚本抓取自己想要的监控数据,然后push到pushgateway再pushgateway到prometheus服务器是反向的被动模式
已经有了node_exporter采集这么强大的pull形式,为什么还需要pushgateway形式呢?
1、 虽然出口商采集的类型已经很丰富了,但是我们还是需要大量的自制监测数据,不定期的自行定制
2、exporter 由于采集的数据类型比较多,其实很多数据或者大部分数据其实并没有用到我们的监控中。使用pushgateway就是定义一段数据。采集着一节约资源
3、 开发一个新的自定义pushgateway脚本比开发一个全新的exporter更简单、更快捷!!!(exporter的开发需要使用真正的编程语言,shell等快速脚本不行,需要了解很多Prometheus自定义编程格式才能开始做大量工作)
4、虽然exporter已经很丰富了,但是我们需要的采集的形式还有很多,exporter不能提供,或者现有expoter不支持,但是如果用pushgateway的话可以随心所欲 灵活,可以随心所欲,而且非常快 查看全部
不用采集规则就可以采集(Prometheusmetrics的入门介绍(二)-k/v的数据形式)
1、Prometheus 度量的概念
2、k/v 数据格式
3、Prometheus 导出器的使用(拉取表单 采集 数据)
4、Prometheus pushgateway介绍(推送表单采集数据)
在Prometheus监控中,来自采集的数据统称为metrics数据
度量,熟悉大数据系统的人,从来没有听说过度量。当我们需要对某个系统中的某个服务进行监控和统计时,就需要用到Metrics。
Metrics是采样数据的总称(metrics不代表特定的数据格式,而是度量单位的抽象)
几种主要类型的指标
最简单的指标是简单的返回值或瞬时状态。例如,我们想以更简单的方式衡量一个处理队列中的任务数量。
例如:如果我想监控硬盘容量或内存使用情况,我应该使用 Gauges 的度量格式来衡量
因为硬盘的容量或使用的内存量会随着时间的推移而不断地、瞬间地发生变化。
这种变化是不规律的,目前是多少,采集又是多少
不确定会不会继续增长,也不确定会不会继续减少。
就这样了。这是所用仪表类型的代表。
如图,CPU的波动是采集 Gauge形式的metrics数据不规则

计数器类型指标
计数器是一个计数器。它从数据量 0 开始,累加计算。理想状态下,只能永远增持,不会减持(某些特殊情况另说)
例如
例如,用户访问的抽样数据
我们的产品被用户访问一次,10分钟后为1,累计到100
一天后累积到20000
一周后累积到100000-150000
如下图所示。计数器数据从0开始,不断累加,不断累加,所以在理想状态下,没有任何减少的可能。
最多只能保持一个不变(例如:用户不再访问,那么当前累计总访问量将保持为一条水平线,直到再次访问)
下图显示了一个计数器类型的指标数据采集。采集 为用户累计访问量
直方图
直方图统计的分布。例如,最小值、最大值、中位数、中位数、第 75 个百分位数、第 90 个百分位数、第 95 个百分位数、第 98 个百分位数、第 99 个百分位数和第 99.9 个百分位数。
这是一种特殊的度量数据类型,它代表一个
近似百分比估计
这是最难理解的指标类型(但它非常实用)。估计大部分数学家都会看上面几行的定义,header会很大。
介绍什么是直方图数据
直方图类型(prometheus其实提供了一个基于直方图算法的函数,可以直接使用),可以分别统计所有用户的响应时间~=0.05秒,多少个0~0. 05 多少秒,> 2 秒,> 10 秒 => 1%
可以清楚地看到在当前系统中,有多少用户(或请求)处于基本正常状态,有多少是极速用户,有多少是慢速或有问题的请求
k/v 数据格式
Prometheus的数据类型是根据metric的类型计算的
对于采集返回的数据类型,必须以特定的数据格式查看和使用
看一个exporter采集服务器上的k/v格式metrics数据
当导出器 (node_exporter) 安装并在受监控服务器上运行时
使用简单的curl命令查看exporter采集的metrics数据,以k/v的形式显示并保存curl localhost:9100/metrics
curl后输出的结果如上图
Prometheus_server
带#的那一行是注释行,解释下面的k/v值是什么采样数据
而真正关心的是数据
用空格分隔 KEY/Value 数据
第一个代表采集的当前最大文件句柄数为65535
第二个代表采集当前打开的文件句柄数为10。
也看看这里
第二行#告诉我们这个数据的metrics类型属于gaugeexporter的使用
官网提供了丰富的成型导出器插件,可以使用
举几个例子
pushgateway的概念介绍
导出器首先安装在被监控的服务器上并在后台运行
然后自动采集系统数据,它本身是一个HTTP_server,可以由Prometheus服务器定期发送到HTTP GET以pull的形式获取数据
如果你逆转这个过程
push 18 pushgatewat 的形式是安装在客户端还是服务器上(其实安装在哪里都无所谓)
pushgateway 本身也是一个 http 服务器
运维用自己的脚本抓取自己想要的监控数据,然后push到pushgateway再pushgateway到prometheus服务器是反向的被动模式
已经有了node_exporter采集这么强大的pull形式,为什么还需要pushgateway形式呢?
1、 虽然出口商采集的类型已经很丰富了,但是我们还是需要大量的自制监测数据,不定期的自行定制
2、exporter 由于采集的数据类型比较多,其实很多数据或者大部分数据其实并没有用到我们的监控中。使用pushgateway就是定义一段数据。采集着一节约资源
3、 开发一个新的自定义pushgateway脚本比开发一个全新的exporter更简单、更快捷!!!(exporter的开发需要使用真正的编程语言,shell等快速脚本不行,需要了解很多Prometheus自定义编程格式才能开始做大量工作)
4、虽然exporter已经很丰富了,但是我们需要的采集的形式还有很多,exporter不能提供,或者现有expoter不支持,但是如果用pushgateway的话可以随心所欲 灵活,可以随心所欲,而且非常快
不用采集规则就可以采集(机器学习里的获取数据样本数据样本从哪里来?(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-10-19 20:05
一、背景
当前,工业互联网蓬勃发展,企业也在进行数字化、智能化转型。在智能化方面,安防视频监控是最重要的智能化内容。要想实现智能化,需要计算机视觉能力的加持。现阶段,人脸、人体、车辆等相关算法在受限场景(如刺刀)下可以达到商用标准。但是,在智慧社区、智慧园区、工业生产等领域,存在很多碎片化的场景,比如垃圾识别、钓鱼等。检测、广场舞识别、垃圾识别等,这些碎片化场景智能化遇到的最大挑战就是训练数据集的获取。与人脸、人体、车辆首先是政府和公安部门需要的。早年的天网和雪亮项目也积累了大量的视频监控数据,也可以作为AI算法的原材料。但是,在前面提到的碎片化场景中,并没有很好的积累,也没有更好的方法来采集这些数据样本。
二、 数据样本从何而来
机器学习的前提还是需要大量的样本数据。样本数据的获取和标记或多或少需要人工参与。所以,在视觉算法圈里,有句话叫:“人多,智者多”,虽然是个玩笑,但也体现了人工在机器学习中的重要性。下面列出了一些获取数据样本的方法,仅供参考。
1. 手动站点采集
当完全没有数据样本时,可以利用人力资源在真实环境中拍照采集。比如我要识别电动车,那我可以拍遍大街小巷的电动车;想鉴定各种花,也可以去公园拍各种花。手工采集的优点是可以获得比较真实的样本,缺点是劳动强度大,有一定的适用范围。比如一些不正常的识别(火、持刀)不适合这种手动采集的方法。另外,手动字段采集的数据也有限,训练出来的模型泛化能力不强。
2.网上获取的公开数据
互联网上获取的公开数据分为两部分,一是机器学习的公开数据集,二是搜索引擎检索到的结果。更不用说公开的数据集了,大家拿到的都是一样的,没有区别。虽然从搜索引擎找到的图片与真实场景存在一定差距,但仍然可以作为重要的数据源,对模型的训练有积极的帮助。搜索引擎通常会搜索成百上千个样本数据。完成模型训练的初始冷启动并不难。
3.人造场景
对于一些不方便去网站采集的低频或者异常情况,我们可以人为的创建一些场景,然后拍照或者录像记录下来作为数据样本进行标注。比如,要识别不戴安全帽、不穿工作服、打架的行为,就可以人为地“行动”。虽然表现不是那么真实,但总比没有数据要好得多。对于一些成堆的材料和垃圾的识别,手动创建场景非常方便。和上面手工站点采集的缺点一样,人工制造的场景数据也非常有限,训练出来的模型泛化能力不足。
4.现场视频提取
对于一些有现场监控视频的情况,可以从视频中提取数据样本进行后续的标注和训练。这里可能存在一个问题,即当要检测的目标物体或事件只占整个视频的很小一部分时,从中提取有效部分仍然是一项繁重的任务。
5.甲方客户提供数据
在某些情况下,虽然发生异常事件的概率不高,但由于这些异常事件的影响比较大,甲方的客户端已经积累了过去的历史视频数据。这种情况在技术上当然是理想的,但客户通常希望保护他们的数据。通常的处理方式是通过私有化部署,在客户的私有网络中训练,训练出来的模型也是客户自己的产权。乙方通常无权将这些模型用于其他目的(除非有其他合作。条款)。
6.购买第三方数据集
如果其他方法无法获得足够的有效样本,或者获得的样本不能保证训练模型的准确性,那么你也可以找第三方购买特定场景的数据集。这种方法的缺点是要花钱,而且在碎片化方面没有太多的数据积累。
三、机器辅助采样和标记
在实际的ToB/ToG项目中,最常见的场景之一:用户现场部署摄像头,监控视频数据全部可用,需要新的AI模型检测一些异常行为和事件。但是,这种“异常”并不是普遍存在的,与客户自身的业务场景密切相关。例如,城管注重道路占用作业;业主注意抛物线高空和电动车进入电梯;在校园场景中,他们关注校园欺凌和早恋。互联网上没有这些场景的公开数据集,也没有公开的成熟模型。显然,您需要自己重新训练数据。然而,在现有的视频监控视频中,
在正常情况下,监控视频在画面静止时会是静态的,当它处于活动状态时也是如此。静止时只保留选中帧的一张截图,有活动时可以保留选中帧的所有截图。典型的做法是使用运动检测算法进行初步筛选,剔除无用信息。比如要提取垃圾桶是否满的样本数据,只能关注静止图片的瞬间(垃圾桶站不会一直活跃,长期静止图片只需要一张图片);如果要关注投掷垃圾的行为,那么只要有活动时关注屏幕,并通过运动检测的初步筛选,
除了运动检测,还有没有其他方法可以通过机器辅助的方法高效提取这些数据样本?一种思路是手动选择一个小样本集,比如几百个,生成一个小模型,然后通过这个小模型过滤海量的监控视频数据,然后利用选择的样本对模型进行优化,制作模型越来越精确。更精准的模型反过来更高效地提取数据样本,形成增强循环,可以形成手动冷启动加机器辅助的滚雪球模式,如下图所示。
在这里你可能会有一个疑问:如果你用几张图片训练一个小模型,然后用小模型过滤掉的数据训练它,如果不添加其他数据集,结果是不是不可能超越这个小模型?(数据集都是小模型检测出来的)。我们需要在这里做一些小技巧。我们知道,对于一个算法模型,通常有召回率和准确率两个指标来评估。在小模型筛选阶段,我们其实需要比较高的召回率,所以我们会把置信度阈值设置的比较低。这样,即使有很多误报(准确率低),也没有关系。当样本被标记时,将手动纠正错误以消除误报。然而,小模型的漏报确实会影响未来训练模型的召回率。这时候就需要其他来源的数据集来补充。
四、总结
本文针对碎片化场景下智能算法应用的数据样本采集问题,提出了一种通过运动检测和小模型过滤历史监控视频的方法。这里的机器辅助方法不仅适用于数据集的采集,也适用于数据的标注,利用一些小样本训练小模型进行预标注。智慧社区、智慧园区、智慧门店、智慧家庭等一系列智慧应用已逐渐渗透到我们的生活中。碎片化的智能场景将成为未来的主流,数据作为智能原材料将成为未来最有价值的东西。越早积累,越能赢得比赛。 查看全部
不用采集规则就可以采集(机器学习里的获取数据样本数据样本从哪里来?(上))
一、背景
当前,工业互联网蓬勃发展,企业也在进行数字化、智能化转型。在智能化方面,安防视频监控是最重要的智能化内容。要想实现智能化,需要计算机视觉能力的加持。现阶段,人脸、人体、车辆等相关算法在受限场景(如刺刀)下可以达到商用标准。但是,在智慧社区、智慧园区、工业生产等领域,存在很多碎片化的场景,比如垃圾识别、钓鱼等。检测、广场舞识别、垃圾识别等,这些碎片化场景智能化遇到的最大挑战就是训练数据集的获取。与人脸、人体、车辆首先是政府和公安部门需要的。早年的天网和雪亮项目也积累了大量的视频监控数据,也可以作为AI算法的原材料。但是,在前面提到的碎片化场景中,并没有很好的积累,也没有更好的方法来采集这些数据样本。
二、 数据样本从何而来
机器学习的前提还是需要大量的样本数据。样本数据的获取和标记或多或少需要人工参与。所以,在视觉算法圈里,有句话叫:“人多,智者多”,虽然是个玩笑,但也体现了人工在机器学习中的重要性。下面列出了一些获取数据样本的方法,仅供参考。
1. 手动站点采集
当完全没有数据样本时,可以利用人力资源在真实环境中拍照采集。比如我要识别电动车,那我可以拍遍大街小巷的电动车;想鉴定各种花,也可以去公园拍各种花。手工采集的优点是可以获得比较真实的样本,缺点是劳动强度大,有一定的适用范围。比如一些不正常的识别(火、持刀)不适合这种手动采集的方法。另外,手动字段采集的数据也有限,训练出来的模型泛化能力不强。
2.网上获取的公开数据
互联网上获取的公开数据分为两部分,一是机器学习的公开数据集,二是搜索引擎检索到的结果。更不用说公开的数据集了,大家拿到的都是一样的,没有区别。虽然从搜索引擎找到的图片与真实场景存在一定差距,但仍然可以作为重要的数据源,对模型的训练有积极的帮助。搜索引擎通常会搜索成百上千个样本数据。完成模型训练的初始冷启动并不难。
3.人造场景
对于一些不方便去网站采集的低频或者异常情况,我们可以人为的创建一些场景,然后拍照或者录像记录下来作为数据样本进行标注。比如,要识别不戴安全帽、不穿工作服、打架的行为,就可以人为地“行动”。虽然表现不是那么真实,但总比没有数据要好得多。对于一些成堆的材料和垃圾的识别,手动创建场景非常方便。和上面手工站点采集的缺点一样,人工制造的场景数据也非常有限,训练出来的模型泛化能力不足。
4.现场视频提取
对于一些有现场监控视频的情况,可以从视频中提取数据样本进行后续的标注和训练。这里可能存在一个问题,即当要检测的目标物体或事件只占整个视频的很小一部分时,从中提取有效部分仍然是一项繁重的任务。
5.甲方客户提供数据
在某些情况下,虽然发生异常事件的概率不高,但由于这些异常事件的影响比较大,甲方的客户端已经积累了过去的历史视频数据。这种情况在技术上当然是理想的,但客户通常希望保护他们的数据。通常的处理方式是通过私有化部署,在客户的私有网络中训练,训练出来的模型也是客户自己的产权。乙方通常无权将这些模型用于其他目的(除非有其他合作。条款)。
6.购买第三方数据集
如果其他方法无法获得足够的有效样本,或者获得的样本不能保证训练模型的准确性,那么你也可以找第三方购买特定场景的数据集。这种方法的缺点是要花钱,而且在碎片化方面没有太多的数据积累。
三、机器辅助采样和标记
在实际的ToB/ToG项目中,最常见的场景之一:用户现场部署摄像头,监控视频数据全部可用,需要新的AI模型检测一些异常行为和事件。但是,这种“异常”并不是普遍存在的,与客户自身的业务场景密切相关。例如,城管注重道路占用作业;业主注意抛物线高空和电动车进入电梯;在校园场景中,他们关注校园欺凌和早恋。互联网上没有这些场景的公开数据集,也没有公开的成熟模型。显然,您需要自己重新训练数据。然而,在现有的视频监控视频中,
在正常情况下,监控视频在画面静止时会是静态的,当它处于活动状态时也是如此。静止时只保留选中帧的一张截图,有活动时可以保留选中帧的所有截图。典型的做法是使用运动检测算法进行初步筛选,剔除无用信息。比如要提取垃圾桶是否满的样本数据,只能关注静止图片的瞬间(垃圾桶站不会一直活跃,长期静止图片只需要一张图片);如果要关注投掷垃圾的行为,那么只要有活动时关注屏幕,并通过运动检测的初步筛选,
除了运动检测,还有没有其他方法可以通过机器辅助的方法高效提取这些数据样本?一种思路是手动选择一个小样本集,比如几百个,生成一个小模型,然后通过这个小模型过滤海量的监控视频数据,然后利用选择的样本对模型进行优化,制作模型越来越精确。更精准的模型反过来更高效地提取数据样本,形成增强循环,可以形成手动冷启动加机器辅助的滚雪球模式,如下图所示。

在这里你可能会有一个疑问:如果你用几张图片训练一个小模型,然后用小模型过滤掉的数据训练它,如果不添加其他数据集,结果是不是不可能超越这个小模型?(数据集都是小模型检测出来的)。我们需要在这里做一些小技巧。我们知道,对于一个算法模型,通常有召回率和准确率两个指标来评估。在小模型筛选阶段,我们其实需要比较高的召回率,所以我们会把置信度阈值设置的比较低。这样,即使有很多误报(准确率低),也没有关系。当样本被标记时,将手动纠正错误以消除误报。然而,小模型的漏报确实会影响未来训练模型的召回率。这时候就需要其他来源的数据集来补充。
四、总结
本文针对碎片化场景下智能算法应用的数据样本采集问题,提出了一种通过运动检测和小模型过滤历史监控视频的方法。这里的机器辅助方法不仅适用于数据集的采集,也适用于数据的标注,利用一些小样本训练小模型进行预标注。智慧社区、智慧园区、智慧门店、智慧家庭等一系列智慧应用已逐渐渗透到我们的生活中。碎片化的智能场景将成为未来的主流,数据作为智能原材料将成为未来最有价值的东西。越早积累,越能赢得比赛。
不用采集规则就可以采集(【东哥福利】优采云采集器V9智联招聘信息采集规则分享)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-17 05:07
【以往福利】
【东哥福利】优采云采集器V9澎湃新闻网站资讯采集规则分享
【东哥福利】优采云采集器版本选择策略
【东哥福利】优采云采集器V9智联招聘信息采集规则分享
【东哥福利】优采云浏览器百度地图商家信息采集详解
【东哥福利】优采云采集器V9知乎采集规则分享
【东哥福利】优采云采集器V9微信公众号文章采集规则分享
【东哥福利】优采云采集器V9优酷视频电视剧采集规则分享
【东哥福利】优采云采集器V9版JSon功能讲解及示例规则分享
【东哥福利-新手必看】最新最全优采云采集器V9版学习资料
【东哥福利】优采云采集器V9财富网业绩预测信息采集规则分享
【东哥福利】优采云采集器V9信息采集规则分享
【东哥福利】优采云采集器V9安居客社区信息采集规则分享
【东哥福利】豆瓣电影采集规则并发布到本地CSV格式文件
【东哥福利】美图采集规则与DZ3.X门户发布规则分享
【东哥福利】优采云采集器58同城招聘信息采集规则分享
【东哥福利】优采云采集器软件-今日头条娱乐新闻采集规则
【东哥福利】优采云采集器V9携程景点采集规则分享
【东哥福利】优采云采集器V9京东商城商品信息采集规则分享
【东客福利】优采云采集器V9人气大众点评餐饮全国商家采集规则
-------------------------------------------------- ---------------------------
东哥微信tony_lsd,请注明:东哥福利
-------------------------------------------------- -----------------------------
[东哥福利]优采云采集器V9 unicode编码转换案例规则分享
今天和大家分享的规则主要是针对汉字编码转换的问题。这里提到的编码不是一批“GBk”或“UTF8”,而是一种unicode编码。先说说unicode编码是什么。
Unicode(Uniform Code、Universal Code、Single Code)是计算机科学领域的行业标准,包括字符集、编码方案等。Unicode 的诞生是为了解决传统字符编码方案的局限性。它为每种语言的每个字符设置了统一且唯一的二进制编码,以满足跨语言和跨平台文本转换和处理的要求。
什么?还是不明白?这么说吧,我们经常看到网站的源代码中的字符“\u5730\u4e0e\u9999\”是由字母数字字符和\组成的。这是 Unicode 代码。其实这些都是汉字。关于我的什么?采集 如何将这些字符转换成汉字?强大的优采云采集器,当然是有办法的。请看案例说明!
【案例说明】
采集案例网址:采集文章内容。
第 1 步:列出 URL采集
查看网页源码,源码中没有内容页的链接,需要使用抓包软件。推荐使用Fiddler(相关教程:)。我们先打开Fiddler软件,然后点击页面页面,可以多点击几个页面。通过抓包软件找到网址:""
像这样打开网站,如下图:
其实这就是Unicode编码,不过这里不需要转码。里面的汉字都是Unicode编码。如果你不明白,你可能已经错过了。其实这就是文章列表页,那么这就是起点。URL,“page=3”是分页参数。另外,这个 URL 可以简化为以下参数。你可以在采集器...&page_size=13&page=[地址参数]上这样设置,如图:
第二步:文章内容网址采集
当我们找到列表页面时,我们会找到文章页面的链接。根据页面内容,发现有标题、时间、ID等,好像没有文章链接。别着急,我们来看看文章页面URL的规则。让我们通过这个页面打开它,然后随意点击一篇文章文章,文章的链接是这样的,有一组数字“1305128”,我猜这是ID 文章的,你可以把这组数字在上面的页面搜索进去,如果有就确认是对的。然后就很容易了。我们只需要列表页面上采集的ID号,然后通过URL拼接,然后链接到采集文章页面,像这样[参数1]/我以为这就够了,但我没有 没想到后面会有坑。打开文章页面,查看源码,发现源码中没有文章的内容。不用着急,你也可以使用上面提到的抓包软件抓包,通过抓包找到内容URL。URL拼接规则应该改为【参数1】/?render=1&callback=news_【参数1】,如图:
原理很简单,我们只需要采集到ID,然后将ID拼接到内容URL中即可。
第三步:文章内容采集
如上所述,这个网站的文章的内容也需要被捕获。抓到的网址就是,我们打开这个网址,如图:
文章内容在哪里?显然,这是一堆你看不懂的字符。一开始我们讲了unicode汉字编码转换的案例。这是正确的。这些是unicode编码的汉字。我们需要 采集 下来并转换它们。变成真正的汉字。文章的标题和内容都是unicode编码,没关系,只要有规则就可以采集,规则设置如图:
开头的字符串是 pre_article"
*)title":"以"}结尾,测试内容采集如下:
是unicode编码,然后我们需要将数据转换为采集。在数据处理中,单击+号。高级功能里面有个“字符编码转换”,然后我们可以选择From Js String,参考下图:
采集 相同的内容,做相同的设置,如下图:
设置好后,我们测试一下采集,可以看到都是汉字,如下图:
你学会了吗?继续尝试!
-------------------------------------------------- ---------------
此规则为优采云采集器V9版本规则,其他低版本不可使用。
免费版用户可以使用。
本规则仅供用户学习交流参考,不得用于非法或商业用途。对于因使用本规则而引起的任何法律问题,我们概不负责。 查看全部
不用采集规则就可以采集(【东哥福利】优采云采集器V9智联招聘信息采集规则分享)
【以往福利】
【东哥福利】优采云采集器V9澎湃新闻网站资讯采集规则分享
【东哥福利】优采云采集器版本选择策略
【东哥福利】优采云采集器V9智联招聘信息采集规则分享
【东哥福利】优采云浏览器百度地图商家信息采集详解
【东哥福利】优采云采集器V9知乎采集规则分享
【东哥福利】优采云采集器V9微信公众号文章采集规则分享
【东哥福利】优采云采集器V9优酷视频电视剧采集规则分享
【东哥福利】优采云采集器V9版JSon功能讲解及示例规则分享
【东哥福利-新手必看】最新最全优采云采集器V9版学习资料
【东哥福利】优采云采集器V9财富网业绩预测信息采集规则分享
【东哥福利】优采云采集器V9信息采集规则分享
【东哥福利】优采云采集器V9安居客社区信息采集规则分享
【东哥福利】豆瓣电影采集规则并发布到本地CSV格式文件
【东哥福利】美图采集规则与DZ3.X门户发布规则分享
【东哥福利】优采云采集器58同城招聘信息采集规则分享
【东哥福利】优采云采集器软件-今日头条娱乐新闻采集规则
【东哥福利】优采云采集器V9携程景点采集规则分享
【东哥福利】优采云采集器V9京东商城商品信息采集规则分享
【东客福利】优采云采集器V9人气大众点评餐饮全国商家采集规则
-------------------------------------------------- ---------------------------
东哥微信tony_lsd,请注明:东哥福利
-------------------------------------------------- -----------------------------
[东哥福利]优采云采集器V9 unicode编码转换案例规则分享
今天和大家分享的规则主要是针对汉字编码转换的问题。这里提到的编码不是一批“GBk”或“UTF8”,而是一种unicode编码。先说说unicode编码是什么。
Unicode(Uniform Code、Universal Code、Single Code)是计算机科学领域的行业标准,包括字符集、编码方案等。Unicode 的诞生是为了解决传统字符编码方案的局限性。它为每种语言的每个字符设置了统一且唯一的二进制编码,以满足跨语言和跨平台文本转换和处理的要求。
什么?还是不明白?这么说吧,我们经常看到网站的源代码中的字符“\u5730\u4e0e\u9999\”是由字母数字字符和\组成的。这是 Unicode 代码。其实这些都是汉字。关于我的什么?采集 如何将这些字符转换成汉字?强大的优采云采集器,当然是有办法的。请看案例说明!
【案例说明】
采集案例网址:采集文章内容。
第 1 步:列出 URL采集
查看网页源码,源码中没有内容页的链接,需要使用抓包软件。推荐使用Fiddler(相关教程:)。我们先打开Fiddler软件,然后点击页面页面,可以多点击几个页面。通过抓包软件找到网址:""
像这样打开网站,如下图:
其实这就是Unicode编码,不过这里不需要转码。里面的汉字都是Unicode编码。如果你不明白,你可能已经错过了。其实这就是文章列表页,那么这就是起点。URL,“page=3”是分页参数。另外,这个 URL 可以简化为以下参数。你可以在采集器...&page_size=13&page=[地址参数]上这样设置,如图:
第二步:文章内容网址采集
当我们找到列表页面时,我们会找到文章页面的链接。根据页面内容,发现有标题、时间、ID等,好像没有文章链接。别着急,我们来看看文章页面URL的规则。让我们通过这个页面打开它,然后随意点击一篇文章文章,文章的链接是这样的,有一组数字“1305128”,我猜这是ID 文章的,你可以把这组数字在上面的页面搜索进去,如果有就确认是对的。然后就很容易了。我们只需要列表页面上采集的ID号,然后通过URL拼接,然后链接到采集文章页面,像这样[参数1]/我以为这就够了,但我没有 没想到后面会有坑。打开文章页面,查看源码,发现源码中没有文章的内容。不用着急,你也可以使用上面提到的抓包软件抓包,通过抓包找到内容URL。URL拼接规则应该改为【参数1】/?render=1&callback=news_【参数1】,如图:
原理很简单,我们只需要采集到ID,然后将ID拼接到内容URL中即可。
第三步:文章内容采集
如上所述,这个网站的文章的内容也需要被捕获。抓到的网址就是,我们打开这个网址,如图:
文章内容在哪里?显然,这是一堆你看不懂的字符。一开始我们讲了unicode汉字编码转换的案例。这是正确的。这些是unicode编码的汉字。我们需要 采集 下来并转换它们。变成真正的汉字。文章的标题和内容都是unicode编码,没关系,只要有规则就可以采集,规则设置如图:
开头的字符串是 pre_article"

*)title":"以"}结尾,测试内容采集如下:
是unicode编码,然后我们需要将数据转换为采集。在数据处理中,单击+号。高级功能里面有个“字符编码转换”,然后我们可以选择From Js String,参考下图:
采集 相同的内容,做相同的设置,如下图:
设置好后,我们测试一下采集,可以看到都是汉字,如下图:
你学会了吗?继续尝试!
-------------------------------------------------- ---------------
此规则为优采云采集器V9版本规则,其他低版本不可使用。
免费版用户可以使用。
本规则仅供用户学习交流参考,不得用于非法或商业用途。对于因使用本规则而引起的任何法律问题,我们概不负责。
不用采集规则就可以采集(优采云采集器致力于网站书库自动化采集发布,不需要人工干预!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-11 02:11
优采云采集器是一款高质量的大数据采集发布系统,你可以在电脑或手机上采集数据,几乎采集各类网页同时使用PHP+Mysql开发,允许用户部署在云服务器上,使数据库采集更加方便和智能。
优采云采集器致力于网站图书图书馆自动化采集的发布。软件与各种cms建站程序无缝对接,实现数据无需登录即可导入,也可定时定量自动发布,无需人工干预。
软件功能
关于软件
优采云采集器(天财记),致力于发布网站数据自动化采集,系统采用PHP+Mysql开发,可部署于云服务器赋能数据采集便捷、智能、云端,让您随时随地移动办公!
数据采集
支持多级、多页、分页采集,自定义采集规则(支持regular、XPATH、JSON等),精准匹配任何信息流,几乎采集所有类型的网页,大部分文章类型的页面内容都可以智能识别
内容发布
无缝对接各种cms建站程序,实现免登录导入数据,支持自定义数据发布插件,或直接导入数据库,存储为Excel文件,生成API接口等
自动化和云平台
软件实现定时定量自动发布采集,无需人工干预!内置云平台,用户可以分享和下载采集规则,发布供需信息,社区帮助,交流等
设置说明
设置包括:采集设置、站点设置、邮件发送设置、代理设置等
启用自动采集,设置采集参数,图片本地化
页面渲染设置
代理设置
防止被阻止的 IP
翻译设置
支持百度翻译和有道翻译
网站设置 查看全部
不用采集规则就可以采集(优采云采集器致力于网站书库自动化采集发布,不需要人工干预!)
优采云采集器是一款高质量的大数据采集发布系统,你可以在电脑或手机上采集数据,几乎采集各类网页同时使用PHP+Mysql开发,允许用户部署在云服务器上,使数据库采集更加方便和智能。

优采云采集器致力于网站图书图书馆自动化采集的发布。软件与各种cms建站程序无缝对接,实现数据无需登录即可导入,也可定时定量自动发布,无需人工干预。
软件功能
关于软件
优采云采集器(天财记),致力于发布网站数据自动化采集,系统采用PHP+Mysql开发,可部署于云服务器赋能数据采集便捷、智能、云端,让您随时随地移动办公!
数据采集
支持多级、多页、分页采集,自定义采集规则(支持regular、XPATH、JSON等),精准匹配任何信息流,几乎采集所有类型的网页,大部分文章类型的页面内容都可以智能识别
内容发布
无缝对接各种cms建站程序,实现免登录导入数据,支持自定义数据发布插件,或直接导入数据库,存储为Excel文件,生成API接口等
自动化和云平台
软件实现定时定量自动发布采集,无需人工干预!内置云平台,用户可以分享和下载采集规则,发布供需信息,社区帮助,交流等
设置说明
设置包括:采集设置、站点设置、邮件发送设置、代理设置等
启用自动采集,设置采集参数,图片本地化
页面渲染设置
代理设置
防止被阻止的 IP
翻译设置
支持百度翻译和有道翻译
网站设置
不用采集规则就可以采集(大数据时代的优采云规则定制(二)介绍及应用 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-10-10 13:08
)
1、优采云简介
2、什么是信息采集
3、什么是优采云
4、优采云 你是做什么的
5、优采云规则定制
6、规则编写过程
7、网站详解
8、详细解释
9、备注
什么是优采云?
我们打开了一个网站,看到一篇文章文章很不错,所以我们复制了文章的标题和内容,把这个文章传给了我们的网站上。我们这个过程可以叫做采集,把别人网站的有用信息传递给自己网站;网上的内容,大部分都是通过复制-修改-粘贴的过程产生的,所以信息采集很重要,也很常见。我们平台在网站上发送给文章,大部分也是这样的过程;为什么很多人觉得新闻更新很麻烦,因为这项工作重复、枯燥、耗时;
优采云是目前国内用户最多、功能最全、程序支持最全面、数据库支持最丰富的软件产品;现在大数据时代,可以快速、批量、大批量地获取。互联网上的数据以我们需要的格式存储;简单来说,它对我们有什么用?我们需要更新新闻和发送商机。如果要求你准备 1000 篇文章,你需要多长时间?5个小时?有了规则,优采云只需要5分钟!前提是有规则,所以首先要学会写规则。如果规则数量足够,一个规则几分钟就可以了,但是刚开始学习的时候会慢一些;
名称解释和规则编写过程
n以优采云8.6版本为准 第一步:打开—登录 第二步:新建组
第三步:右击组,新建任务,填写任务名称;
第四步:编写采集 URL规则(起始URL和多级URL获取)
第五步:写采集内容规则(如标题、内容)
第 6 步:发布内容设置
检查启用方法二
(1)保存格式:将一条记录保存为txt;
(2)保存位置自定义;
(3) 文件模板不需要移动;
(4)文件名格式:点击右侧倒笔字选择【标签:标题】;
(5)文件编码可以先utf-8,如果测试时数据正常,但保存的数据有乱码,选择gb2312;
第七步:采集设置,两者都选择100;
一种。单任务采集内容线程数:采集多个URL同时;
湾 采集 内容间隔时间,单位毫秒:两个任务之间的间隔时间;
C。单任务发布内容线程数:一次保存多少条数据;
d. 发布内容之间的毫秒数:两次保存数据之间的时间间隔;
注意:如果网站有反屏蔽采集机制(比如很多数据但是只有采集的一部分可以下载,或者打开页面需要多长时间) ,调整a的值,适当增加b的值;
第八步:保存,勾选并启动任务(如果在同一个组,可以在组上批量选择)
前一种方式:比如我要准备n篇文章,首先要找出这个文章在哪个网站上(比如采集peer A或者peer B), yes 在哪一栏(如产品信息或新闻信息)下,该栏下面有n条信息,我要选择哪一条,输入后复制标题,复制内容再输入另一个页面改标题复制内容,等等,然后同样的过程我要执行n次;
如何转换:如何将此流程转换为软件操作?我要准备n条新闻,也就是说我需要n个标题+对应的内容,还有n个新闻链接。这n个新闻链接是从网站的一个新闻栏目中找到的,而这个网站的新闻栏目可能是很多页,比如10页。这时候从peer A的网站—栏目—内页开始;也就是找到你要采集的网站,打开这个网站栏目页(确保是采集新闻或产品),在URL下写上所有新闻链接规则采集栏,然后写内容规则采集所有新闻链接文件中的标题和内容最后保存;
网站具体操作详解
找到你要采集 URL的版块页面,比如新闻版块
复制栏目首页链接网址,在起始网址右侧点击添加,将栏目首页链接粘贴到单个网址中点击添加,如
请改用右侧的 (*),因为已添加第一页,还剩 9 页。此时,在算术数列的那一行,将项数改为9,第一项为2(因为第2页的链接是,然后点击Add-Finish;
1、 点对应右边的加法,然后下图是一个例子,右边的大图是说明;
2、点击保存,点击右下角
看看能不能采集去新闻网站,
如果可以采集到达,则正确,双击新闻网址进入下一步;如果采集错误到达,返回修改直到成功;URL过滤可自行观察其对应规律;
1、进入采集内容规则后,选择作者、时间、来源并删除,如右一图所示,因为这些标签一般情况下是不会用到的;
2、选择title标签点击修改,或者直接双击标签进入编辑界面;
3、 输入后不要更改标签名称的“标题”,更改后需要更改相应的模板;
4、 以下数据提取方法:截取前后和开始结束字符串,尽量使用默认,不熟练的不要随意更改;
5、 点击下方数据处理中的Add——内容替换,如右图;
6、内容替换将标题后的所有内容替换为空。如果不替换,采集就是页面标题。这时候需要打开两个新闻页面,看看两个新闻页面的共同部分是什么,替换共同部分
示例:对于以下两个标题,“-”为共同部分,即替换为“空”;
【图片】你知道螺旋上料机的加工方法吗?你知道螺旋给料机的原理吗?
【图文】气动送粉机的优点有哪些,您知道送粉机的工作原理吗?
1、选择要编辑的内容,或者双击进入内容标签编辑界面,不要更改标签名称;
2、 写开始和结束字符串就是找一个能把所有消息都包起来的字符串。它出现在所有新闻页面的所有新闻页面中,并且是唯一的字符串;即, this 页面模板中唯一的代码串;
例如:采集的内容时,需要选择内容区域,因为采集可能有n篇文章,比如100篇。这时候就需要考虑如何写一个 采集 to all ,方法是打开两个新闻链接。例如,查看第一篇新闻文章的源文件,找到新闻文本,然后查找与新闻第一句最接近的那个。这个页面是唯一的一段代码(如果不是唯一的,软件你能知道从哪一个开始吗?),但不是新闻的内容,比如
, 复制后,在第二个新闻页面的源文件中搜索,看看有没有,如果有,就可以使用了;类似地,找到新闻的最后一句话,并在最近的页面中找到唯一的一段代码。复制后,在第二个新闻页面的源文件中搜索,看看有没有,如果有,就可以使用了;数据处理:因为采集是其他网站信息,可能还有其他网站信息,如公司名称、联系方式、品牌等信息,也可能有其他网站 超链接和其他信息。这时候需要对信息进行过滤;数据处理——添加——标签过滤下面对应的参数HTML:将滚动轴水平拉到最后,在所有标签前打勾,点击确定;内容替换:把这个网站的信息换成你自己的,原理是整改后拆机,公司名称和电话(拆分),手机号码(拆分),邮箱地址,公司地址(拆分),品牌名称,网址(拆分);split 意味着分解和替换这些数据。这时候需要进行以下更换: 因为在新闻中,这是拆机更换的时候,才能更换干净。你可以多看看他的新闻,可能用的什么格式;您需要进行以下更换:因为在新闻中,这是拆卸和更换的时间,以便将其更换干净。你可以多看看他的新闻,可能用的什么格式;您需要进行以下更换:因为在新闻中,这是拆卸和更换的时间,以便将其更换干净。你可以多看看他的新闻,可能用的什么格式;
注意:数据处理还有很多技巧,需要在使用的过程中思考,是采集的核心。如果处理不好,可能是别人的嫁衣,所以一定要仔细观察,综合考虑,如果处理得当,从采集下来的文章甚至可以出版直接(不是您自己的企业站点)
预防措施()
1、 右击组:出现如下菜单,可以正常使用;
新建任务:在该组上新建一个任务;
运行该组中的所有任务:顾名思义;
新任务:在这个组下重新创建一个组;
编辑/删除组:编辑/删除当前组;
导入/导出分组规则:当前组下的所有任务都可以导出导入到同一版本优采云;
导入任务到该组:将导出的单个任务导入到该组;
粘贴组下任务:该项目只有在任务被复制后才会出现,您可以粘贴多个相同的任务,然后在粘贴的任务上进行编辑;
启动任务:同菜单栏启动;
编辑任务:编辑已写入的任务;
导出任务:可以将当前规则导出并在同版本的其他工具上导入,但导入数据时需要重复上述步骤6-发布内容设置,必须重新选择/填写;
复制任务到粘贴板:复制后,选择一个任务组,右击将不同数量的任务粘贴到该组中,避免多次写入同一个任务;
清除任务的所有采集数据:新建如果你采集之前有采集,想重新采集,需要先清除;
3、其他设置:点击顶部菜单栏中的Tools-Options,配置全局选项和默认选项;
全局选项:可以调整同时运行的最大任务数。一般为5,但不需要调整;
默认选项:是否忽略 case point is;
查看全部
不用采集规则就可以采集(大数据时代的优采云规则定制(二)介绍及应用
)
1、优采云简介
2、什么是信息采集
3、什么是优采云
4、优采云 你是做什么的
5、优采云规则定制
6、规则编写过程
7、网站详解
8、详细解释
9、备注
什么是优采云?
我们打开了一个网站,看到一篇文章文章很不错,所以我们复制了文章的标题和内容,把这个文章传给了我们的网站上。我们这个过程可以叫做采集,把别人网站的有用信息传递给自己网站;网上的内容,大部分都是通过复制-修改-粘贴的过程产生的,所以信息采集很重要,也很常见。我们平台在网站上发送给文章,大部分也是这样的过程;为什么很多人觉得新闻更新很麻烦,因为这项工作重复、枯燥、耗时;
优采云是目前国内用户最多、功能最全、程序支持最全面、数据库支持最丰富的软件产品;现在大数据时代,可以快速、批量、大批量地获取。互联网上的数据以我们需要的格式存储;简单来说,它对我们有什么用?我们需要更新新闻和发送商机。如果要求你准备 1000 篇文章,你需要多长时间?5个小时?有了规则,优采云只需要5分钟!前提是有规则,所以首先要学会写规则。如果规则数量足够,一个规则几分钟就可以了,但是刚开始学习的时候会慢一些;
名称解释和规则编写过程
n以优采云8.6版本为准 第一步:打开—登录 第二步:新建组
第三步:右击组,新建任务,填写任务名称;
第四步:编写采集 URL规则(起始URL和多级URL获取)
第五步:写采集内容规则(如标题、内容)
第 6 步:发布内容设置
检查启用方法二
(1)保存格式:将一条记录保存为txt;
(2)保存位置自定义;
(3) 文件模板不需要移动;
(4)文件名格式:点击右侧倒笔字选择【标签:标题】;
(5)文件编码可以先utf-8,如果测试时数据正常,但保存的数据有乱码,选择gb2312;
第七步:采集设置,两者都选择100;
一种。单任务采集内容线程数:采集多个URL同时;
湾 采集 内容间隔时间,单位毫秒:两个任务之间的间隔时间;
C。单任务发布内容线程数:一次保存多少条数据;
d. 发布内容之间的毫秒数:两次保存数据之间的时间间隔;
注意:如果网站有反屏蔽采集机制(比如很多数据但是只有采集的一部分可以下载,或者打开页面需要多长时间) ,调整a的值,适当增加b的值;
第八步:保存,勾选并启动任务(如果在同一个组,可以在组上批量选择)
前一种方式:比如我要准备n篇文章,首先要找出这个文章在哪个网站上(比如采集peer A或者peer B), yes 在哪一栏(如产品信息或新闻信息)下,该栏下面有n条信息,我要选择哪一条,输入后复制标题,复制内容再输入另一个页面改标题复制内容,等等,然后同样的过程我要执行n次;
如何转换:如何将此流程转换为软件操作?我要准备n条新闻,也就是说我需要n个标题+对应的内容,还有n个新闻链接。这n个新闻链接是从网站的一个新闻栏目中找到的,而这个网站的新闻栏目可能是很多页,比如10页。这时候从peer A的网站—栏目—内页开始;也就是找到你要采集的网站,打开这个网站栏目页(确保是采集新闻或产品),在URL下写上所有新闻链接规则采集栏,然后写内容规则采集所有新闻链接文件中的标题和内容最后保存;
网站具体操作详解
找到你要采集 URL的版块页面,比如新闻版块
复制栏目首页链接网址,在起始网址右侧点击添加,将栏目首页链接粘贴到单个网址中点击添加,如
请改用右侧的 (*),因为已添加第一页,还剩 9 页。此时,在算术数列的那一行,将项数改为9,第一项为2(因为第2页的链接是,然后点击Add-Finish;
1、 点对应右边的加法,然后下图是一个例子,右边的大图是说明;
2、点击保存,点击右下角
看看能不能采集去新闻网站,
如果可以采集到达,则正确,双击新闻网址进入下一步;如果采集错误到达,返回修改直到成功;URL过滤可自行观察其对应规律;
1、进入采集内容规则后,选择作者、时间、来源并删除,如右一图所示,因为这些标签一般情况下是不会用到的;
2、选择title标签点击修改,或者直接双击标签进入编辑界面;
3、 输入后不要更改标签名称的“标题”,更改后需要更改相应的模板;
4、 以下数据提取方法:截取前后和开始结束字符串,尽量使用默认,不熟练的不要随意更改;
5、 点击下方数据处理中的Add——内容替换,如右图;
6、内容替换将标题后的所有内容替换为空。如果不替换,采集就是页面标题。这时候需要打开两个新闻页面,看看两个新闻页面的共同部分是什么,替换共同部分
示例:对于以下两个标题,“-”为共同部分,即替换为“空”;
【图片】你知道螺旋上料机的加工方法吗?你知道螺旋给料机的原理吗?
【图文】气动送粉机的优点有哪些,您知道送粉机的工作原理吗?
1、选择要编辑的内容,或者双击进入内容标签编辑界面,不要更改标签名称;
2、 写开始和结束字符串就是找一个能把所有消息都包起来的字符串。它出现在所有新闻页面的所有新闻页面中,并且是唯一的字符串;即, this 页面模板中唯一的代码串;
例如:采集的内容时,需要选择内容区域,因为采集可能有n篇文章,比如100篇。这时候就需要考虑如何写一个 采集 to all ,方法是打开两个新闻链接。例如,查看第一篇新闻文章的源文件,找到新闻文本,然后查找与新闻第一句最接近的那个。这个页面是唯一的一段代码(如果不是唯一的,软件你能知道从哪一个开始吗?),但不是新闻的内容,比如
, 复制后,在第二个新闻页面的源文件中搜索,看看有没有,如果有,就可以使用了;类似地,找到新闻的最后一句话,并在最近的页面中找到唯一的一段代码。复制后,在第二个新闻页面的源文件中搜索,看看有没有,如果有,就可以使用了;数据处理:因为采集是其他网站信息,可能还有其他网站信息,如公司名称、联系方式、品牌等信息,也可能有其他网站 超链接和其他信息。这时候需要对信息进行过滤;数据处理——添加——标签过滤下面对应的参数HTML:将滚动轴水平拉到最后,在所有标签前打勾,点击确定;内容替换:把这个网站的信息换成你自己的,原理是整改后拆机,公司名称和电话(拆分),手机号码(拆分),邮箱地址,公司地址(拆分),品牌名称,网址(拆分);split 意味着分解和替换这些数据。这时候需要进行以下更换: 因为在新闻中,这是拆机更换的时候,才能更换干净。你可以多看看他的新闻,可能用的什么格式;您需要进行以下更换:因为在新闻中,这是拆卸和更换的时间,以便将其更换干净。你可以多看看他的新闻,可能用的什么格式;您需要进行以下更换:因为在新闻中,这是拆卸和更换的时间,以便将其更换干净。你可以多看看他的新闻,可能用的什么格式;
注意:数据处理还有很多技巧,需要在使用的过程中思考,是采集的核心。如果处理不好,可能是别人的嫁衣,所以一定要仔细观察,综合考虑,如果处理得当,从采集下来的文章甚至可以出版直接(不是您自己的企业站点)
预防措施()
1、 右击组:出现如下菜单,可以正常使用;
新建任务:在该组上新建一个任务;
运行该组中的所有任务:顾名思义;
新任务:在这个组下重新创建一个组;
编辑/删除组:编辑/删除当前组;
导入/导出分组规则:当前组下的所有任务都可以导出导入到同一版本优采云;
导入任务到该组:将导出的单个任务导入到该组;
粘贴组下任务:该项目只有在任务被复制后才会出现,您可以粘贴多个相同的任务,然后在粘贴的任务上进行编辑;
启动任务:同菜单栏启动;
编辑任务:编辑已写入的任务;
导出任务:可以将当前规则导出并在同版本的其他工具上导入,但导入数据时需要重复上述步骤6-发布内容设置,必须重新选择/填写;
复制任务到粘贴板:复制后,选择一个任务组,右击将不同数量的任务粘贴到该组中,避免多次写入同一个任务;
清除任务的所有采集数据:新建如果你采集之前有采集,想重新采集,需要先清除;
3、其他设置:点击顶部菜单栏中的Tools-Options,配置全局选项和默认选项;
全局选项:可以调整同时运行的最大任务数。一般为5,但不需要调整;
默认选项:是否忽略 case point is;
不用采集规则就可以采集(不用采集规则就可以采集高质量的网站太多了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-10-09 19:04
不用采集规则就可以采集的网站太多了,建议采集高质量的网站,一般情况下:有一个大的网站平台、有一个高质量的博客站、有一个普通的有一定量的普通用户群体,这三个就是普通的网站一般用户会采集的网站,这样是最好的。可以多关注一下一些源码源文件,你可以在网上搜到一些。
很多很多,我就不举例子了,找一些自己需要的就行。什么新闻源,seo黄金外链,论坛博客,爱问,知乎,百度知道,百度百科,高权重微博,百度文库,百度经验,网络报刊杂志等等,上网一搜一大把。一直一个观点,如果自己不动脑子提升,就算运气比别人好,也不一定能走的更远。
题主到底是要“搞定”还是“搞定好”?这两者之间是天壤之别。搞定好可以包括:也可以包括不包括等等。此外,还要具体到某一个网站。就如同社会学问题的边界问题,心理学问题的心理边界问题一样。做好一个网站本身,有时候在需要说明优势的时候就不是所有人都能弄懂其优势,总是要反复提炼很久。这种时候,能够读到优势只不过是其中表现的几个优势罢了。
或者说,全是优势,可能表现为seo方面,全是劣势。这种时候,只要弄懂了,就不是很难,提炼出特色就不是很难。比如,yahoo+就可以优势很好,不能说这个网站就比百度+差多少。这个包含的知识内容有点多,需要一点点读。 查看全部
不用采集规则就可以采集(不用采集规则就可以采集高质量的网站太多了)
不用采集规则就可以采集的网站太多了,建议采集高质量的网站,一般情况下:有一个大的网站平台、有一个高质量的博客站、有一个普通的有一定量的普通用户群体,这三个就是普通的网站一般用户会采集的网站,这样是最好的。可以多关注一下一些源码源文件,你可以在网上搜到一些。
很多很多,我就不举例子了,找一些自己需要的就行。什么新闻源,seo黄金外链,论坛博客,爱问,知乎,百度知道,百度百科,高权重微博,百度文库,百度经验,网络报刊杂志等等,上网一搜一大把。一直一个观点,如果自己不动脑子提升,就算运气比别人好,也不一定能走的更远。
题主到底是要“搞定”还是“搞定好”?这两者之间是天壤之别。搞定好可以包括:也可以包括不包括等等。此外,还要具体到某一个网站。就如同社会学问题的边界问题,心理学问题的心理边界问题一样。做好一个网站本身,有时候在需要说明优势的时候就不是所有人都能弄懂其优势,总是要反复提炼很久。这种时候,能够读到优势只不过是其中表现的几个优势罢了。
或者说,全是优势,可能表现为seo方面,全是劣势。这种时候,只要弄懂了,就不是很难,提炼出特色就不是很难。比如,yahoo+就可以优势很好,不能说这个网站就比百度+差多少。这个包含的知识内容有点多,需要一点点读。
不用采集规则就可以采集(掌握一种采集技巧对SEO站长而言还是很有帮助的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-06 01:28
好久没用优采云采集器了。想起以前做站群SEO的时候,经常登录优采云采集器去采集各大相关网站信息内容。而那个时候,采集之风盛行,到处都是各种采集站,特别是小说站,文章站等等,动不动就有采集几十万文章,网站很容易达到重量4.虽然大部分网站现在很少采集,但采集还是无处不在,因为一些所谓的原创网站,文章的内容很可能也会被采集后续处理。所以掌握一个采集技术对SEO站长还是很有帮助的。
优采云采集器URL 规则设置
第一步打开优采云采集器,点击【新建】新建任务,填写任务名称,设置采集 URL规则,设置列表页采集规则和列表页面所在的文章页面规则分为以下两步。
第一步:添加起始地址,点击【添加】,选择批量/多页,在地址格式设置中设置采集的网页链接,点击【添加】和【完成】。这一步的目的是建立有多少个栏目页面链接。
采集网页链接技巧说明:首先确定你要采集的网页栏目页,分别查看栏目页1、第2页和第3页链接规则,比较后,会发现page 2和page 3的链接很像,只有2和3变了(分页1也是一样,一般为SEO格式隐藏,所以分页1和栏目首页链接是一样的)即可按照等差数列分析,其实绝大多数网站专栏页面都是按等差数列排列的,包括尹华峰的博客。因此,填充规则是选择算术数列,在地址格式中填写第2页的链接,用(*)代替改变的数字,根据栏目页数设置项数。
第二步:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则。熟练后,建议使用结果网址过滤功能。写出需要收录和不需要收录的URL。可以测试一下规则是否填写正确,然后保存。这一步的目的是在每一栏下建立到文章页面的链接。
多级URL获取技巧说明:我们要获取的是本栏目下文章页面的链接,到原网页查看栏目页面源码,找到第一个链接到文章页面在源页面的位置,然后选择上面的一小段通用代码,一定是每列页面都会出现的代码,通常的表达形式会收录list或者文章。
优采云采集器内容规则设置
第二步是设置采集内容规则。可以在典型页面上填写一个文章页面链接进行测试,设置标题采集规则和内容采集规则,也分为两步。
步骤a:双击【标题】标签。一般网页的标题是一个标签,所以这一步可以默认。如有必要,您可以设置内容过滤和内容替换。
步骤 b:双击 [内容] 选项卡。内容抽取规则与第一步中的第2步多级URL获取方法相同。这里是获取内容,所以就是查看内容页的源码,找到这个页面的body内容,截取body第一段上面的一小段通用代码。此代码也出现在所有文章 页面上,通常的表达形式文章标签是开头和结尾。您还可以设置内容过滤、内容替换和标签过滤来过滤掉不需要的信息。如果不需要图片,可以勾选过滤掉img图片标签。
优采云采集器发布内容设置
第三步,发布内容设置,勾选需要启用的发布方式,保存,然后在任务列表中右键任务名称,点击【开始任务】,等待采集完成即可。
注意,优采云采集器分为两种发布内容的方式。第一种方式是通过web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个并保存为本地。至于文件模板,可以【查看默认模板】,然后选择TXT格式。
结论:优采云采集器很强大,除了采集文章还可以采集视频等,优采云采集器 使用规则并不难。您根本不需要了解任何编程语言。您只需要了解一些常见的简单代码即可。你基本上可以掌握它一次或两次。这是一个非常好的SEO工具。作为网站优化者,我们可以对采集文章之后的内容进行修改和调整,使内容更加完整,同时可以大大提高SEO人员的工作效率。优采云采集器 使用方法介绍到这里。如果不明白,可以在下方留言,尽我所知给予解答。 查看全部
不用采集规则就可以采集(掌握一种采集技巧对SEO站长而言还是很有帮助的)
好久没用优采云采集器了。想起以前做站群SEO的时候,经常登录优采云采集器去采集各大相关网站信息内容。而那个时候,采集之风盛行,到处都是各种采集站,特别是小说站,文章站等等,动不动就有采集几十万文章,网站很容易达到重量4.虽然大部分网站现在很少采集,但采集还是无处不在,因为一些所谓的原创网站,文章的内容很可能也会被采集后续处理。所以掌握一个采集技术对SEO站长还是很有帮助的。
优采云采集器URL 规则设置
第一步打开优采云采集器,点击【新建】新建任务,填写任务名称,设置采集 URL规则,设置列表页采集规则和列表页面所在的文章页面规则分为以下两步。
第一步:添加起始地址,点击【添加】,选择批量/多页,在地址格式设置中设置采集的网页链接,点击【添加】和【完成】。这一步的目的是建立有多少个栏目页面链接。
采集网页链接技巧说明:首先确定你要采集的网页栏目页,分别查看栏目页1、第2页和第3页链接规则,比较后,会发现page 2和page 3的链接很像,只有2和3变了(分页1也是一样,一般为SEO格式隐藏,所以分页1和栏目首页链接是一样的)即可按照等差数列分析,其实绝大多数网站专栏页面都是按等差数列排列的,包括尹华峰的博客。因此,填充规则是选择算术数列,在地址格式中填写第2页的链接,用(*)代替改变的数字,根据栏目页数设置项数。
第二步:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则。熟练后,建议使用结果网址过滤功能。写出需要收录和不需要收录的URL。可以测试一下规则是否填写正确,然后保存。这一步的目的是在每一栏下建立到文章页面的链接。
多级URL获取技巧说明:我们要获取的是本栏目下文章页面的链接,到原网页查看栏目页面源码,找到第一个链接到文章页面在源页面的位置,然后选择上面的一小段通用代码,一定是每列页面都会出现的代码,通常的表达形式会收录list或者文章。
优采云采集器内容规则设置
第二步是设置采集内容规则。可以在典型页面上填写一个文章页面链接进行测试,设置标题采集规则和内容采集规则,也分为两步。
步骤a:双击【标题】标签。一般网页的标题是一个标签,所以这一步可以默认。如有必要,您可以设置内容过滤和内容替换。
步骤 b:双击 [内容] 选项卡。内容抽取规则与第一步中的第2步多级URL获取方法相同。这里是获取内容,所以就是查看内容页的源码,找到这个页面的body内容,截取body第一段上面的一小段通用代码。此代码也出现在所有文章 页面上,通常的表达形式文章标签是开头和结尾。您还可以设置内容过滤、内容替换和标签过滤来过滤掉不需要的信息。如果不需要图片,可以勾选过滤掉img图片标签。
优采云采集器发布内容设置
第三步,发布内容设置,勾选需要启用的发布方式,保存,然后在任务列表中右键任务名称,点击【开始任务】,等待采集完成即可。
注意,优采云采集器分为两种发布内容的方式。第一种方式是通过web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个并保存为本地。至于文件模板,可以【查看默认模板】,然后选择TXT格式。
结论:优采云采集器很强大,除了采集文章还可以采集视频等,优采云采集器 使用规则并不难。您根本不需要了解任何编程语言。您只需要了解一些常见的简单代码即可。你基本上可以掌握它一次或两次。这是一个非常好的SEO工具。作为网站优化者,我们可以对采集文章之后的内容进行修改和调整,使内容更加完整,同时可以大大提高SEO人员的工作效率。优采云采集器 使用方法介绍到这里。如果不明白,可以在下方留言,尽我所知给予解答。
不用采集规则就可以采集(优采云采集器内置规则市场下载规则的好处,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-05 19:11
优采云采集器是一款技术领先的网页采集软件,为了避免配置采集规则的重复性工作,优采云采集器具有内置规则 在市场上,用户共享配置的采集规则,互相帮助。使用规则市场下载规则的好处是显而易见的,不需要花时间研究和配置采集流程。52z飞翔下载中心为您提供下载。
软件特点
操作简单,完全可视化的图形操作,不需要专业的IT人员,任何会用电脑上网的人都可以轻松掌握。
云采集
采集 任务自动分配到云端多台服务器同时执行,提高了采集的效率,短时间内可以获取上千条消息。
拖放采集流程
模拟人的操作思维模式,可以登录、输入数据、点击链接、按钮等,还可以针对不同的情况采用不同的采集流程。
图形识别
内置可扩展的OCR接口,支持对图片中的文字进行分析,可以提取图片上的文字。
定时自动采集
采集 任务自动运行,可以在指定周期内自动采集,还支持实时采集,速度快到一分钟一次。
2 分钟快速启动
内置从入门到精通的视频教程,2分钟即可上手,还有文档、论坛、qq群等。
免费使用
它是免费的,免费版没有功能限制。您可以立即试用,下载并立即安装。
特征
简单来说,使用优采云可以很容易的从任何网页中准确的采集你需要的数据,生成自定义的常规数据格式。优采云数据采集 系统可以做的包括但不限于以下内容:
1. 财务数据,如季报、年报、财报,自动包括最新的每日净值采集;
2.各大新闻门户网站实时监控,自动更新上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4. 监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6. 关注各大地产相关网站、采集新房、二手房的最新行情;
7. 采集主要车型网站 具体新车和二手车信息;
8. 发现和采集潜在客户信息;
9. 采集行业网站产品目录及产品信息;
10. 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
指示
首先我们新建一个任务-->进入流程设计页面-->给流程添加一个循环步骤-->选择循环步骤-->勾选软件右侧的URL列表复选框-- > 打开 URL 列表文本框--> 将准备好的 URL 列表填入文本框
接下来,将打开网页的步骤拖入循环中--> 选择打开网页的步骤--> 选中使用当前循环中的URL 作为导航地址的框--> 点击保存。系统会在界面底部的浏览器中打开循环选择的URL对应的网页
至此,打开网页循环的配置就完成了。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置采集 数据步骤,这里不再赘述。可以参考系列一:采集单个网页文章。下图是最终和过程
更新日志
1、增加联系客服功能,可以联系客服进行一对一人工服务
2、新增微图分析功能,一键分析数据采集
3、修复单机采集异常退出问题
4、修复云端部分问题采集
5、修复客户端启动时无响应的问题
6、修复导出相关问题
7、修复了循环提取数据,item无法勾选的问题
更多精彩APP,尽在52z飞翔下载网! 查看全部
不用采集规则就可以采集(优采云采集器内置规则市场下载规则的好处,)
优采云采集器是一款技术领先的网页采集软件,为了避免配置采集规则的重复性工作,优采云采集器具有内置规则 在市场上,用户共享配置的采集规则,互相帮助。使用规则市场下载规则的好处是显而易见的,不需要花时间研究和配置采集流程。52z飞翔下载中心为您提供下载。

软件特点
操作简单,完全可视化的图形操作,不需要专业的IT人员,任何会用电脑上网的人都可以轻松掌握。
云采集
采集 任务自动分配到云端多台服务器同时执行,提高了采集的效率,短时间内可以获取上千条消息。
拖放采集流程
模拟人的操作思维模式,可以登录、输入数据、点击链接、按钮等,还可以针对不同的情况采用不同的采集流程。
图形识别
内置可扩展的OCR接口,支持对图片中的文字进行分析,可以提取图片上的文字。
定时自动采集
采集 任务自动运行,可以在指定周期内自动采集,还支持实时采集,速度快到一分钟一次。
2 分钟快速启动
内置从入门到精通的视频教程,2分钟即可上手,还有文档、论坛、qq群等。
免费使用
它是免费的,免费版没有功能限制。您可以立即试用,下载并立即安装。
特征
简单来说,使用优采云可以很容易的从任何网页中准确的采集你需要的数据,生成自定义的常规数据格式。优采云数据采集 系统可以做的包括但不限于以下内容:
1. 财务数据,如季报、年报、财报,自动包括最新的每日净值采集;
2.各大新闻门户网站实时监控,自动更新上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4. 监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6. 关注各大地产相关网站、采集新房、二手房的最新行情;
7. 采集主要车型网站 具体新车和二手车信息;
8. 发现和采集潜在客户信息;
9. 采集行业网站产品目录及产品信息;
10. 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
指示
首先我们新建一个任务-->进入流程设计页面-->给流程添加一个循环步骤-->选择循环步骤-->勾选软件右侧的URL列表复选框-- > 打开 URL 列表文本框--> 将准备好的 URL 列表填入文本框
接下来,将打开网页的步骤拖入循环中--> 选择打开网页的步骤--> 选中使用当前循环中的URL 作为导航地址的框--> 点击保存。系统会在界面底部的浏览器中打开循环选择的URL对应的网页
至此,打开网页循环的配置就完成了。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置采集 数据步骤,这里不再赘述。可以参考系列一:采集单个网页文章。下图是最终和过程
更新日志
1、增加联系客服功能,可以联系客服进行一对一人工服务
2、新增微图分析功能,一键分析数据采集
3、修复单机采集异常退出问题
4、修复云端部分问题采集
5、修复客户端启动时无响应的问题
6、修复导出相关问题
7、修复了循环提取数据,item无法勾选的问题
更多精彩APP,尽在52z飞翔下载网!
不用采集规则就可以采集(怎么写织梦5.3的采集规则教程!其他版本也类似)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-10-05 16:10
本文首发于小凡新浪博客,今天转给新手学习~
今天给大家讲讲织梦5.3的采集规则教程怎么写!其他版本类似!
首先我们打开织梦后台,点击采集-采集节点管理-添加新节点
这里我们以采集normal文章为例,我们选择normal文章,然后确认
我们进入采集的设置页面,填写节点名称,也就是给这个新节点起个名字,这里可以随意填写。
然后打开你要采集的文章列表页面,这里我们以织梦的官网为例打开这个页面,右键-查看源文件
找到目标页面编码,就在charset之后
页面基本信息一般忽略,填写后如图
现在让我们填写列表URL获取规则
查看文章列表第一页的地址
比较第二页的地址
我们发现除了49_后面的数字都一样,所以我们可以这样写
(*).html
就用(*)代替1,因为只有2页,所以我们从1填到2,每页加1,当然2-1...等于1。
到此我们完成了
可能你的一些采集列表没有规则,所以你只需要手动指定列表URL,如图
每行写一个页面地址
列表规则写好后,开始编写文章 URL匹配规则,返回文章列表页面
右键查看源文件找到区域开头的HTML,也就是找到文章列表开头的标记。
我们可以很容易地找到如图所示的“新闻列表”。从这里开始,以下是文章的列表
让我们找到 文章 列表末尾的 HTML
就是这样,一个很容易找到的标志
如果链接收录图片:
不要将采集处理成缩略图,这里根据自己的需要选择
再次过滤区域 URL:
(使用正则表达式)
必须收录:(优先级高于后者)
不能收录:
打开源文件,我们可以清楚地看到文章链接都是以.html结尾的
所以,一定要在.html的后面填写,如果遇到一些比较麻烦的列表,也可以填写后面的不能收录
我们点击保存设置进入下一步,可以看到我们获取到的文章 URL
看到这个是对的,我们保存信息,进入下一步设置内容字段获取规则
看看文章有没有分页,随便输入一篇文章看看吧。. 我们看到文章中没有分页
所以这里我们默认了
现在我们找到文章标题等,输入一篇文章文章,右键查看源文件
看看这些
根据源码填写
让我们填写文章内容的开头和结尾
同上,找到开始和结束标志
开始:
结束:
要过滤什么内容文章写在过滤规则里,比如要过滤文章中的图片
选择通用规则
然后检查IMG并确认
这样我们过滤文本中的图片
设置完成后,点击保存设置并预览
这样的采集规则就写好了。这很简单。有些网站写起来难,但你需要更努力。
让我们点击保存并启动 采集-start 采集 网页并工作一段时间,采集 就结束了
让我们看看我们采集到达了什么文章
456
好像成功了,导出数据
完成,更新文档,可以看到采集来了文章
因为我们过滤了图片,里面的一张图片不见了!
写采集规则其实很简单~
第一次写东西,写的不好请补充,有错误请留言,我会及时改正! 查看全部
不用采集规则就可以采集(怎么写织梦5.3的采集规则教程!其他版本也类似)
本文首发于小凡新浪博客,今天转给新手学习~
今天给大家讲讲织梦5.3的采集规则教程怎么写!其他版本类似!
首先我们打开织梦后台,点击采集-采集节点管理-添加新节点
这里我们以采集normal文章为例,我们选择normal文章,然后确认
我们进入采集的设置页面,填写节点名称,也就是给这个新节点起个名字,这里可以随意填写。
然后打开你要采集的文章列表页面,这里我们以织梦的官网为例打开这个页面,右键-查看源文件
找到目标页面编码,就在charset之后
页面基本信息一般忽略,填写后如图
现在让我们填写列表URL获取规则
查看文章列表第一页的地址
比较第二页的地址
我们发现除了49_后面的数字都一样,所以我们可以这样写
(*).html
就用(*)代替1,因为只有2页,所以我们从1填到2,每页加1,当然2-1...等于1。
到此我们完成了
可能你的一些采集列表没有规则,所以你只需要手动指定列表URL,如图
每行写一个页面地址
列表规则写好后,开始编写文章 URL匹配规则,返回文章列表页面
右键查看源文件找到区域开头的HTML,也就是找到文章列表开头的标记。
我们可以很容易地找到如图所示的“新闻列表”。从这里开始,以下是文章的列表
让我们找到 文章 列表末尾的 HTML
就是这样,一个很容易找到的标志
如果链接收录图片:
不要将采集处理成缩略图,这里根据自己的需要选择
再次过滤区域 URL:
(使用正则表达式)
必须收录:(优先级高于后者)
不能收录:
打开源文件,我们可以清楚地看到文章链接都是以.html结尾的
所以,一定要在.html的后面填写,如果遇到一些比较麻烦的列表,也可以填写后面的不能收录
我们点击保存设置进入下一步,可以看到我们获取到的文章 URL
看到这个是对的,我们保存信息,进入下一步设置内容字段获取规则
看看文章有没有分页,随便输入一篇文章看看吧。. 我们看到文章中没有分页
所以这里我们默认了
现在我们找到文章标题等,输入一篇文章文章,右键查看源文件
看看这些
根据源码填写
让我们填写文章内容的开头和结尾
同上,找到开始和结束标志
开始:
结束:
要过滤什么内容文章写在过滤规则里,比如要过滤文章中的图片
选择通用规则
然后检查IMG并确认
这样我们过滤文本中的图片
设置完成后,点击保存设置并预览
这样的采集规则就写好了。这很简单。有些网站写起来难,但你需要更努力。
让我们点击保存并启动 采集-start 采集 网页并工作一段时间,采集 就结束了
让我们看看我们采集到达了什么文章
456
好像成功了,导出数据
完成,更新文档,可以看到采集来了文章
因为我们过滤了图片,里面的一张图片不见了!
写采集规则其实很简单~
第一次写东西,写的不好请补充,有错误请留言,我会及时改正!
不用采集规则就可以采集(不用采集规则就可以采集,只需要有起始访问url)
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-09-27 22:02
不用采集规则就可以采集,只需要有起始访问url就可以了起始访问url:a001就可以,然后这个url采集器就可以识别一个整站,就不用自己手动采集了,包括结果都可以生成pdf
根据url规则自动生成
百度从去年开始就已经开放采集功能。百度百科可以直接生成pdf版本的。直接把百科网址拿来做站群,有人搜的时候生成网址,然后把百科文章链接塞到里面。下载站点详细的教程可以看我写的文章。
给大家推荐个工具:/:注册登录后用实名的qq号,或者邮箱,用微信绑定就行,电脑手机都可以操作。安全方便快捷,下载的文件有原文链接和密码。会员之间有通过关键词的百科问答分享优惠券等等功能。付费99元或更高可以获得一键操作功能。awsling的社群里学员可以免费体验。
各位,不是我打击你你可以去试一试我的sofish网站,sofish博客|wordpress优质内容创作平台这个网站上没有你要的资源(api),
百度经验:最全面最权威的php5从入门到精通学习网站_百度经验php微学院::,且可以和现在的资源一起读。因为现在的资源已经全面升级了,不再针对php5。
php5.6的只要人人学php就可以让您自己成为php大牛
以下全部是经验所得的教程中文站, 查看全部
不用采集规则就可以采集(不用采集规则就可以采集,只需要有起始访问url)
不用采集规则就可以采集,只需要有起始访问url就可以了起始访问url:a001就可以,然后这个url采集器就可以识别一个整站,就不用自己手动采集了,包括结果都可以生成pdf
根据url规则自动生成
百度从去年开始就已经开放采集功能。百度百科可以直接生成pdf版本的。直接把百科网址拿来做站群,有人搜的时候生成网址,然后把百科文章链接塞到里面。下载站点详细的教程可以看我写的文章。
给大家推荐个工具:/:注册登录后用实名的qq号,或者邮箱,用微信绑定就行,电脑手机都可以操作。安全方便快捷,下载的文件有原文链接和密码。会员之间有通过关键词的百科问答分享优惠券等等功能。付费99元或更高可以获得一键操作功能。awsling的社群里学员可以免费体验。
各位,不是我打击你你可以去试一试我的sofish网站,sofish博客|wordpress优质内容创作平台这个网站上没有你要的资源(api),
百度经验:最全面最权威的php5从入门到精通学习网站_百度经验php微学院::,且可以和现在的资源一起读。因为现在的资源已经全面升级了,不再针对php5。
php5.6的只要人人学php就可以让您自己成为php大牛
以下全部是经验所得的教程中文站,
不用采集规则就可以采集(不用采集规则就可以采集上的所有东西,我会给你分享)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-11-14 04:07
不用采集规则就可以采集上的所有东西,软件有我会在附件列举出软件的收费情况,方便大家根据自己的情况去选择一款适合自己的。想用我软件的可以+我,我会给你分享,感谢信任可以关注我随时给我分享资料哦。
您这个需求可以采集网的。也可以采集京东商品,但是我建议您采集店铺的商品。有很多人可能会担心用这个软件采集到了数据是不是上架的,的商品是不是全部都是您采集到的数据,这个是不可能的,商品都会以邮件形式发送,如果您有上架卖卖商品的需求,可以关注我的知乎号获取获取,或者私信我也行。
自从某乎开始对于类似问题区别对待后,这种问题也是开始出现,之前一直请不要来说软件不好,我只是对软件有意见。现在出现的是,又想要软件的功能,又嫌嫌自己买软件贵的,这就是问题出现的根源。软件当然有好处,就像主机游戏一样,可以通过软件自行编辑游戏内容,写代码设置战斗机制,只要你会编程的基本编程。软件坏处也是有的,就是很大,商品很多,请问软件从何下手呢?不过现在主流软件都支持多店铺自动化的销售,价格也是比较贵,不好买。
您上某宝的话,不会这些会很麻烦的。另外会因为卖家嫌麻烦不提供营业执照这种,搞不好就被关店,或者财务、商品、物流都会有问题。我个人建议,使用从某宝抓取的商品信息进行某宝店铺采集以后上架操作。可以大量节省你自己采集等待时间,而且是商品数量少,不存在商品数量多货源不够货源是不可能的,通过采集全部数据完成铺货,店铺运营简单快捷,每天签到获取销量和某宝新品销量。
小店商品不算多,容易采集,也容易上架上新。某宝小店和商品相似度,店铺违规率,销量统计分析困难,人工一套简单的shuadao方案就足够运营。最重要的是销量和销量简单化。商品发布一次即可上架展示全部内容同款商品低价包邮商品可以有效增加销量,也能大量商品上架增加店铺曝光,也可以在商品上架后就展示产品进行直通车方案的压缩。
可以很多办法找到那些价格低质量好的产品以上方案供您参考一下。最后提醒,某宝不允许第三方软件采集上传商品,一旦违规轻则罚款销量,重则封店。 查看全部
不用采集规则就可以采集(不用采集规则就可以采集上的所有东西,我会给你分享)
不用采集规则就可以采集上的所有东西,软件有我会在附件列举出软件的收费情况,方便大家根据自己的情况去选择一款适合自己的。想用我软件的可以+我,我会给你分享,感谢信任可以关注我随时给我分享资料哦。
您这个需求可以采集网的。也可以采集京东商品,但是我建议您采集店铺的商品。有很多人可能会担心用这个软件采集到了数据是不是上架的,的商品是不是全部都是您采集到的数据,这个是不可能的,商品都会以邮件形式发送,如果您有上架卖卖商品的需求,可以关注我的知乎号获取获取,或者私信我也行。
自从某乎开始对于类似问题区别对待后,这种问题也是开始出现,之前一直请不要来说软件不好,我只是对软件有意见。现在出现的是,又想要软件的功能,又嫌嫌自己买软件贵的,这就是问题出现的根源。软件当然有好处,就像主机游戏一样,可以通过软件自行编辑游戏内容,写代码设置战斗机制,只要你会编程的基本编程。软件坏处也是有的,就是很大,商品很多,请问软件从何下手呢?不过现在主流软件都支持多店铺自动化的销售,价格也是比较贵,不好买。
您上某宝的话,不会这些会很麻烦的。另外会因为卖家嫌麻烦不提供营业执照这种,搞不好就被关店,或者财务、商品、物流都会有问题。我个人建议,使用从某宝抓取的商品信息进行某宝店铺采集以后上架操作。可以大量节省你自己采集等待时间,而且是商品数量少,不存在商品数量多货源不够货源是不可能的,通过采集全部数据完成铺货,店铺运营简单快捷,每天签到获取销量和某宝新品销量。
小店商品不算多,容易采集,也容易上架上新。某宝小店和商品相似度,店铺违规率,销量统计分析困难,人工一套简单的shuadao方案就足够运营。最重要的是销量和销量简单化。商品发布一次即可上架展示全部内容同款商品低价包邮商品可以有效增加销量,也能大量商品上架增加店铺曝光,也可以在商品上架后就展示产品进行直通车方案的压缩。
可以很多办法找到那些价格低质量好的产品以上方案供您参考一下。最后提醒,某宝不允许第三方软件采集上传商品,一旦违规轻则罚款销量,重则封店。
不用采集规则就可以采集(优采云站群软件新出一个新的新型采集功能--指定网址采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-11-13 20:10
长期以来,大家都在使用各种类型的采集器或者网站程序内置的采集函数,它们有一个共同的特点,就是需要写采集 规则。从采集到文章,这个技术问题对于新人推广来说并不是一件容易的事,对于老站长来说也是一件费力的事情。所以,如果你做站群,每个站都要定义一个采集规则,那真的很惨。有人说站长是网络搬运工。这个说法也有道理。网上很多文章都是你感动了我,我也感动了你。为了生活,我必须做我必须做的事。现在优采云站群软件新增了采集功能,可以大大减少站长“搬运工”的时间 并且无需编写烦人的 采集 规则。是的,这个功能是互联网的第一个功能---指定网址采集。让我教你如何使用这个功能:
一、 先开启这个功能。在网站游鉴中可以看到这个功能:如下
三、首页,我把这个百度结果列表填到软件的“起始采集文章列表地址”,如下图:
以上都是优采云站群软件新增的采集功能。这个功能很强大,但是这个功能还需要继续完善,以满足不同人的需求。有了这个工具,你就不用担心不知道如何编写采集 规则了。该功能上手容易,操作简单。是新老站长最适合的功能。关于优采云站群软件的其他强大功能,我们稍后会一起讨论。如果不明白,请联系我:509229860。欢迎各位站长向我们推荐更好的功能。
做站群永远是一个永不过时的话题。重要的是要了解您的想法。关注优采云,每天都有新发现!因为优采云是一个注重站长体验的品牌,无论是售后还是售后,都会为站长提供优质的服务!欢迎关注优采云官方网站:原文地址:转载请注明出处!
与优采云相关:你可以轻松采集网站,不用写采集规则文章:
优采云:站长如何使用软件生成原创文章
奇数指定网址采集示例图片教程
优采云站群软件是真实的
以优采云软件为站点组的SEO优化策略要点
优采云:内容同义词的递归替换功能是什么? 查看全部
不用采集规则就可以采集(优采云站群软件新出一个新的新型采集功能--指定网址采集)
长期以来,大家都在使用各种类型的采集器或者网站程序内置的采集函数,它们有一个共同的特点,就是需要写采集 规则。从采集到文章,这个技术问题对于新人推广来说并不是一件容易的事,对于老站长来说也是一件费力的事情。所以,如果你做站群,每个站都要定义一个采集规则,那真的很惨。有人说站长是网络搬运工。这个说法也有道理。网上很多文章都是你感动了我,我也感动了你。为了生活,我必须做我必须做的事。现在优采云站群软件新增了采集功能,可以大大减少站长“搬运工”的时间 并且无需编写烦人的 采集 规则。是的,这个功能是互联网的第一个功能---指定网址采集。让我教你如何使用这个功能:
一、 先开启这个功能。在网站游鉴中可以看到这个功能:如下
三、首页,我把这个百度结果列表填到软件的“起始采集文章列表地址”,如下图:
以上都是优采云站群软件新增的采集功能。这个功能很强大,但是这个功能还需要继续完善,以满足不同人的需求。有了这个工具,你就不用担心不知道如何编写采集 规则了。该功能上手容易,操作简单。是新老站长最适合的功能。关于优采云站群软件的其他强大功能,我们稍后会一起讨论。如果不明白,请联系我:509229860。欢迎各位站长向我们推荐更好的功能。
做站群永远是一个永不过时的话题。重要的是要了解您的想法。关注优采云,每天都有新发现!因为优采云是一个注重站长体验的品牌,无论是售后还是售后,都会为站长提供优质的服务!欢迎关注优采云官方网站:原文地址:转载请注明出处!
与优采云相关:你可以轻松采集网站,不用写采集规则文章:
优采云:站长如何使用软件生成原创文章
奇数指定网址采集示例图片教程
优采云站群软件是真实的
以优采云软件为站点组的SEO优化策略要点
优采云:内容同义词的递归替换功能是什么?
不用采集规则就可以采集( 优采云采集器系统会自动播放使用指南怎么安装?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-11-10 06:10
优采云采集器系统会自动播放使用指南怎么安装?(组图))
【最新】优采云采集器-新手攻略下载合同下载合同模板下载红头文件模板免费下载简历免费下载模板工作简历模板免费下载安装优采云采集器 目前仅支持安装在windows操作系统上,为了保证运行稳定,达到最佳性能,建议您开启windows自动更新,将windows系统升级到最新版本。该系统需要网络框架支持。请确保您的系统已安装 NetFramework。详情请参考以下提示。需要NET35SP1支持Win7内置对XP系统的支持。需要安装软件。安装时会自动检测是否安装了NET35SP1。如果没有安装,它会从微软官方在线自动安装。国内在线安装很慢。建议从下载页面上的下载链接安装。NET35SP1,然后安装优采云采集器 如果下载的是压缩文件,请先解压。您将看到如下图所示的安装文件。安装前请仔细阅读安装前的txt,然后双击setupexe 一般情况下选择默认设置,多次点击下一步即可完成安装。如果您的操作系统缺少 NETFramework,系统会提示您安装它。这将需要一段时间。如果想快速安装,请按照以上提示自行安装NETFramework,然后安装优采云采集器 如何启动 安装完成后,您可以在桌面或开始菜单中找到下图所示的快捷方式。双击启动优采云采集器第一次开通注册账号优采云采集器会打开登录界面。如果您还没有注册Vision Pass,则需要在登录界面点击免费注册链接,完成账户注册流程。请注意,您必须提供真实正确的电子邮件地址。此邮箱将用于接收帐户。激活电子邮件也是您忘记密码时找回密码的唯一途径。注册后,您可以登录您的邮箱,您将收到一封激活邮件。如果您没有看到它,请检查您的垃圾邮件邮箱。您的邮箱可能会阻止激活电子邮件。如果您确定没有收到激活邮件,请打开视觉科技网站登录您刚刚在wwwskieercom注册的账号。登录后,点击你的名字,进入用户中心。您可以重新发送激活电子邮件。单击激活电子邮件中的链接以自动激活您的帐户。这时候可以用账号登录优采云采集器优采云采集器界面介绍如果使用优采云采集器第一次,系统会自动播放。使用指南主要介绍界面构成和主要使用过程 使用指南在您第一次使用时只播放一次,所以如果您是第一次使用,请务必仔细阅读。
导航菜单区介绍 菜单导航分为三个部分: 快速启动用于新建采集任务点击快速启动然后点击里面的创建任务新建采集任务我的您创建的任务 所有任务都可以在我的任务下找到。在我的任务列表中,您可以通过鼠标左键单击并双击打开任务来选择任务。任务状态可以查看正在执行的任务、等待执行的任务、执行完成和终止。任务也可以启动和停止任务。对于采集完成的任务,还可以将采集的数据导出到视频教程区。这里是最简单的介绍视频和来自采集一个简单的网页循环采集 再到高级设置和很多其他从入门到精通需要了解的视频知识。对于新手来说,看视频然后用视频练习是最快最好的学习方式优采云采集器特别是对于一些使用过其他采集器的用户优采云采集器是一种全新的运作方式,内在原理与一般的采集器有很大不同,采集器形成的其他思维模式和经验不仅不能直接用于优采云 采集器,但可能会影响优采云使用的快速掌握,建议大家仔细看视频。练习并开始配置自己的任务采集 对于一些客户,尤其是企业客户来说,时间就是金钱,效率就是生命。此外,企业对于数据的速度和稳定性总是有各种非常特殊的需求采集 采集 规模采集 也有比一般客户更高的要求。我们为此提供各种服务。1自定义数据要求客户只需告诉我们您需要的数据和具体情况。根据要求,我们会在一两天内提供您想要的数据。2 获取数据包。有些数据属于很多客户需要的数据,比如商家名录行业数据等,对于那些已经采集好的数据,特别是不会随时间变化的数据,我们有完整的数据包供客户下载直接地。3DataAPI 很多企业客户也有自己的内部系统,希望能自动连接数据采集 系统实现数据自动化采集同步企业数据服务DataAPI是为企业量身打造的数据接口。使用DataAPI数据可以自动进入企业内部系统,提供更稳定的数据支持。例如采集网站Revision网站Instability等因素不会影响数据接口的稳定性。4 获取采集的规则我们采集整理了很多网友写的采集的规则,这样如果有人和你有相同或相似的需求并且你已经写了规则,你可以直接导入要使用的规则,而不是花时间自己配置规则。这将节省大量时间。同步企业数据服务DataAPI是为企业量身打造的数据接口。使用DataAPI数据可以自动进入企业内部系统,提供更稳定的数据支持。比如采集网站Revision网站Instability等因素不会影响数据接口的稳定性。4 获取采集的规则我们采集整理了很多网友写的采集的规则,这样如果有人和你有相同或相似的需求并且你写了规则,你可以直接导入要使用的规则,而不是花时间自己配置规则。这将节省大量时间。同步企业数据服务DataAPI是为企业量身打造的数据接口。使用DataAPI数据可以自动进入企业内部系统,提供更稳定的数据支持。比如采集网站Revision网站Instability等因素不会影响数据接口的稳定性。4 获取采集的规则我们采集整理了很多网友写的采集的规则,这样如果有人和你有相同或相似的需求并且你已经写了规则,你可以直接导入要使用的规则,而不是花时间自己配置规则。这将节省大量时间。改版网站不稳定等因素不会影响数据接口的稳定性。4 获取采集的规则我们采集整理了很多网友写的采集的规则,这样如果有人和你有相同或相似的需求并且你已经写了规则,你可以直接导入要使用的规则,而不是花时间自己配置规则。这将节省大量时间。改版网站不稳定等因素不会影响数据接口的稳定性。4 获取采集的规则我们采集整理了很多网友写的采集的规则,这样如果有人和你有相同或相似的需求并且你已经写了规则,你可以直接导入要使用的规则,而不是花时间自己配置规则。这将节省大量时间。
如果规则略有不同,您也可以通过适当修改导入的规则来实现自己的需求。5、在使用过程中遇到任何问题,可以随时到论坛求助活动区。团队将持续推出各类活动,帮助用户参与活动。您可以轻松获得积分和其他奖励。比如每天点击签到或者推荐好友注册使用优采云采集器不仅可以获得积分奖励,被推荐的好友也可以获得积分奖励优采云采集器如何使用优采云采集器 最常用的是配置采集任务,配置一个采集任务只需要4个简单的步骤。按照上面的说明,首先单击快速启动,然后单击新任务系统将打开新任务向导。第一步是设置基本信息。这一步主要是输入任务名称创建新任务或选择任务组并输入一些备注。备注可以是 采集 的 URL 或任何段落。为帮助您了解此任务的目的,组名备注用于帮助用户管理任务。你可以把有采集信息的任务放在一个组里,在备注里写采集的网站地址加上一些文字说明采集有什么样的数据,让你以后可以随时打开这个任务,你就会知道它在做什么。当有更多任务时,此信息非常有用。第二步设计工作流优采云 工作原理和人的思维方式很相似,所以设计优采云采集器的工作流其实就相当于把人的采集一个网站数据的过程分割成一些动作和步骤 组织这些步骤来完成工作采集比如一个人去一个网页采集一些数据,通常的方法是打开网页,等待网页加载然后选择采集数据然后右击复制或者按CtrlC复制如果你用优采云采集器这样做也是一样的。第一步是从左侧的工具栏中拖动以打开网页。将此步骤拖到流程设计器的中间。当出现可以释放的标志并释放鼠标左键时,该步骤将成为一个过程。第一步如上图所示,然后选择这一步。每当在流程设计器的右侧选择一个步骤时,都会在此处显示所选步骤的一些特定配置信息。URL输入框,输入此处要打开的URL并在保存任何步骤优采云 采集器将在下面的浏览器中仿真执行步骤,并在选择另一个进程步骤时打开它。下面的工作流帮助会看到这一步的描述以及如何配置各个配置项的帮助信息。打开网页后,当鼠标在下面的浏览器上移动时,可以看到有一种颜色会被选中。此处将显示所选步骤的一些具体配置信息。URL输入框,输入此处要打开的URL并在保存任何步骤优采云 采集器将在下面的浏览器中仿真执行步骤,并在选择另一个进程步骤时打开它。下面的工作流帮助会看到这一步的描述以及如何配置各个配置项的帮助信息。打开网页后,当鼠标在下面的浏览器上移动时,可以看到有一种颜色会被选中。此处将显示所选步骤的一些具体配置信息。URL输入框,输入此处要打开的URL并在保存任何步骤优采云 采集器将在下面的浏览器中仿真执行步骤,并在选择另一个进程步骤时打开它。下面的工作流帮助会看到这一步的描述以及如何配置各个配置项的帮助信息。打开网页后,当鼠标在下面的浏览器上移动时,可以看到有一种颜色会被选中。下面的工作流帮助会看到这一步的描述以及如何配置各个配置项的帮助信息。打开网页后,当鼠标在下面的浏览器上移动时,可以看到有一种颜色会被选中。下面的工作流帮助会看到这一步的描述以及如何配置各个配置项的帮助信息。打开网页后,当鼠标在下面的浏览器上移动时,可以看到有一种颜色会被选中。
页面元素,鼠标移动时点击需要采集的数据,弹出选项对话框。选择提取的文本,所选元素的文本将是 采集。其他选项在原理和操作方式上类似。提取字段后,系统会自动添加提取数据的步骤。如果多个字段为采集,这些字段会出现在采集步骤的配置项中。参考上面第三步设置执行计划。OK 采集 规则后,可以选择执行计划。如果只是一次性采集数据,那么可以选择手动或者一次性手动,那么就可以做单机采集或者云采集单机采集 是使用本地计算机进行采集cloud采集 就是不用本地电脑用优采云的云采集服务器采集这样不仅可以实现定时采集还有很多优点,比如采集@ > 最快速度可加速100倍。不用担心IP被封,网络不稳定等,你也可以关掉电脑。优采云云采集服务器集群为你完成采集的所有工作。关于云采集和单机采集的区别,以及各个计时选项的用法,可以向上移动鼠标,会有详细的提示。这里不再重复描述。步骤完成配置。其实经过上面三步采集任务的配置之后,第四步主要是用来测试配置是否正确。第一个选项检查任务会打开任务测试界面,点击开始测试按钮开始测试,同时测试采集其实和单机是同一个界面。如果测试过程发现没有按预期运行或者网站出现意外问题,例如采集的字段不存在,网页样式变化很大等,可以随时停止测试,继续修改任务配置再重新测试。经过多次测试修改,如果确定任务没有问题,可以点击完成进入任务列表,选择配置的任务继续采集如果是单机采集,然后 采集 将立即开始在本地计算机上执行。采集 完成后,会有提示完成。单击导出数据按钮将所有数据导出到采集。如果在执行计划界面选择手动启动并点击云采集,任务会立即在云采集服务器上启动。如果执行计划选择定期自动启动,则不需要手动启动,直到指定时间任务会自动启动。更多说明。本文档是对优采云采集器的简单介绍,主要面向刚开始学习使用优采云采集器的用户,当然优采云采集器有还有很多更强大的功能,在本文档中没有解释。有关更多说明,请查看视频教程和其他文档。如果您还没有看完视频教程,我们强烈建议您仔细阅读。半小时即可学会所有官方视频教程 查看全部
不用采集规则就可以采集(
优采云采集器系统会自动播放使用指南怎么安装?(组图))
【最新】优采云采集器-新手攻略下载合同下载合同模板下载红头文件模板免费下载简历免费下载模板工作简历模板免费下载安装优采云采集器 目前仅支持安装在windows操作系统上,为了保证运行稳定,达到最佳性能,建议您开启windows自动更新,将windows系统升级到最新版本。该系统需要网络框架支持。请确保您的系统已安装 NetFramework。详情请参考以下提示。需要NET35SP1支持Win7内置对XP系统的支持。需要安装软件。安装时会自动检测是否安装了NET35SP1。如果没有安装,它会从微软官方在线自动安装。国内在线安装很慢。建议从下载页面上的下载链接安装。NET35SP1,然后安装优采云采集器 如果下载的是压缩文件,请先解压。您将看到如下图所示的安装文件。安装前请仔细阅读安装前的txt,然后双击setupexe 一般情况下选择默认设置,多次点击下一步即可完成安装。如果您的操作系统缺少 NETFramework,系统会提示您安装它。这将需要一段时间。如果想快速安装,请按照以上提示自行安装NETFramework,然后安装优采云采集器 如何启动 安装完成后,您可以在桌面或开始菜单中找到下图所示的快捷方式。双击启动优采云采集器第一次开通注册账号优采云采集器会打开登录界面。如果您还没有注册Vision Pass,则需要在登录界面点击免费注册链接,完成账户注册流程。请注意,您必须提供真实正确的电子邮件地址。此邮箱将用于接收帐户。激活电子邮件也是您忘记密码时找回密码的唯一途径。注册后,您可以登录您的邮箱,您将收到一封激活邮件。如果您没有看到它,请检查您的垃圾邮件邮箱。您的邮箱可能会阻止激活电子邮件。如果您确定没有收到激活邮件,请打开视觉科技网站登录您刚刚在wwwskieercom注册的账号。登录后,点击你的名字,进入用户中心。您可以重新发送激活电子邮件。单击激活电子邮件中的链接以自动激活您的帐户。这时候可以用账号登录优采云采集器优采云采集器界面介绍如果使用优采云采集器第一次,系统会自动播放。使用指南主要介绍界面构成和主要使用过程 使用指南在您第一次使用时只播放一次,所以如果您是第一次使用,请务必仔细阅读。
导航菜单区介绍 菜单导航分为三个部分: 快速启动用于新建采集任务点击快速启动然后点击里面的创建任务新建采集任务我的您创建的任务 所有任务都可以在我的任务下找到。在我的任务列表中,您可以通过鼠标左键单击并双击打开任务来选择任务。任务状态可以查看正在执行的任务、等待执行的任务、执行完成和终止。任务也可以启动和停止任务。对于采集完成的任务,还可以将采集的数据导出到视频教程区。这里是最简单的介绍视频和来自采集一个简单的网页循环采集 再到高级设置和很多其他从入门到精通需要了解的视频知识。对于新手来说,看视频然后用视频练习是最快最好的学习方式优采云采集器特别是对于一些使用过其他采集器的用户优采云采集器是一种全新的运作方式,内在原理与一般的采集器有很大不同,采集器形成的其他思维模式和经验不仅不能直接用于优采云 采集器,但可能会影响优采云使用的快速掌握,建议大家仔细看视频。练习并开始配置自己的任务采集 对于一些客户,尤其是企业客户来说,时间就是金钱,效率就是生命。此外,企业对于数据的速度和稳定性总是有各种非常特殊的需求采集 采集 规模采集 也有比一般客户更高的要求。我们为此提供各种服务。1自定义数据要求客户只需告诉我们您需要的数据和具体情况。根据要求,我们会在一两天内提供您想要的数据。2 获取数据包。有些数据属于很多客户需要的数据,比如商家名录行业数据等,对于那些已经采集好的数据,特别是不会随时间变化的数据,我们有完整的数据包供客户下载直接地。3DataAPI 很多企业客户也有自己的内部系统,希望能自动连接数据采集 系统实现数据自动化采集同步企业数据服务DataAPI是为企业量身打造的数据接口。使用DataAPI数据可以自动进入企业内部系统,提供更稳定的数据支持。例如采集网站Revision网站Instability等因素不会影响数据接口的稳定性。4 获取采集的规则我们采集整理了很多网友写的采集的规则,这样如果有人和你有相同或相似的需求并且你已经写了规则,你可以直接导入要使用的规则,而不是花时间自己配置规则。这将节省大量时间。同步企业数据服务DataAPI是为企业量身打造的数据接口。使用DataAPI数据可以自动进入企业内部系统,提供更稳定的数据支持。比如采集网站Revision网站Instability等因素不会影响数据接口的稳定性。4 获取采集的规则我们采集整理了很多网友写的采集的规则,这样如果有人和你有相同或相似的需求并且你写了规则,你可以直接导入要使用的规则,而不是花时间自己配置规则。这将节省大量时间。同步企业数据服务DataAPI是为企业量身打造的数据接口。使用DataAPI数据可以自动进入企业内部系统,提供更稳定的数据支持。比如采集网站Revision网站Instability等因素不会影响数据接口的稳定性。4 获取采集的规则我们采集整理了很多网友写的采集的规则,这样如果有人和你有相同或相似的需求并且你已经写了规则,你可以直接导入要使用的规则,而不是花时间自己配置规则。这将节省大量时间。改版网站不稳定等因素不会影响数据接口的稳定性。4 获取采集的规则我们采集整理了很多网友写的采集的规则,这样如果有人和你有相同或相似的需求并且你已经写了规则,你可以直接导入要使用的规则,而不是花时间自己配置规则。这将节省大量时间。改版网站不稳定等因素不会影响数据接口的稳定性。4 获取采集的规则我们采集整理了很多网友写的采集的规则,这样如果有人和你有相同或相似的需求并且你已经写了规则,你可以直接导入要使用的规则,而不是花时间自己配置规则。这将节省大量时间。
如果规则略有不同,您也可以通过适当修改导入的规则来实现自己的需求。5、在使用过程中遇到任何问题,可以随时到论坛求助活动区。团队将持续推出各类活动,帮助用户参与活动。您可以轻松获得积分和其他奖励。比如每天点击签到或者推荐好友注册使用优采云采集器不仅可以获得积分奖励,被推荐的好友也可以获得积分奖励优采云采集器如何使用优采云采集器 最常用的是配置采集任务,配置一个采集任务只需要4个简单的步骤。按照上面的说明,首先单击快速启动,然后单击新任务系统将打开新任务向导。第一步是设置基本信息。这一步主要是输入任务名称创建新任务或选择任务组并输入一些备注。备注可以是 采集 的 URL 或任何段落。为帮助您了解此任务的目的,组名备注用于帮助用户管理任务。你可以把有采集信息的任务放在一个组里,在备注里写采集的网站地址加上一些文字说明采集有什么样的数据,让你以后可以随时打开这个任务,你就会知道它在做什么。当有更多任务时,此信息非常有用。第二步设计工作流优采云 工作原理和人的思维方式很相似,所以设计优采云采集器的工作流其实就相当于把人的采集一个网站数据的过程分割成一些动作和步骤 组织这些步骤来完成工作采集比如一个人去一个网页采集一些数据,通常的方法是打开网页,等待网页加载然后选择采集数据然后右击复制或者按CtrlC复制如果你用优采云采集器这样做也是一样的。第一步是从左侧的工具栏中拖动以打开网页。将此步骤拖到流程设计器的中间。当出现可以释放的标志并释放鼠标左键时,该步骤将成为一个过程。第一步如上图所示,然后选择这一步。每当在流程设计器的右侧选择一个步骤时,都会在此处显示所选步骤的一些特定配置信息。URL输入框,输入此处要打开的URL并在保存任何步骤优采云 采集器将在下面的浏览器中仿真执行步骤,并在选择另一个进程步骤时打开它。下面的工作流帮助会看到这一步的描述以及如何配置各个配置项的帮助信息。打开网页后,当鼠标在下面的浏览器上移动时,可以看到有一种颜色会被选中。此处将显示所选步骤的一些具体配置信息。URL输入框,输入此处要打开的URL并在保存任何步骤优采云 采集器将在下面的浏览器中仿真执行步骤,并在选择另一个进程步骤时打开它。下面的工作流帮助会看到这一步的描述以及如何配置各个配置项的帮助信息。打开网页后,当鼠标在下面的浏览器上移动时,可以看到有一种颜色会被选中。此处将显示所选步骤的一些具体配置信息。URL输入框,输入此处要打开的URL并在保存任何步骤优采云 采集器将在下面的浏览器中仿真执行步骤,并在选择另一个进程步骤时打开它。下面的工作流帮助会看到这一步的描述以及如何配置各个配置项的帮助信息。打开网页后,当鼠标在下面的浏览器上移动时,可以看到有一种颜色会被选中。下面的工作流帮助会看到这一步的描述以及如何配置各个配置项的帮助信息。打开网页后,当鼠标在下面的浏览器上移动时,可以看到有一种颜色会被选中。下面的工作流帮助会看到这一步的描述以及如何配置各个配置项的帮助信息。打开网页后,当鼠标在下面的浏览器上移动时,可以看到有一种颜色会被选中。
页面元素,鼠标移动时点击需要采集的数据,弹出选项对话框。选择提取的文本,所选元素的文本将是 采集。其他选项在原理和操作方式上类似。提取字段后,系统会自动添加提取数据的步骤。如果多个字段为采集,这些字段会出现在采集步骤的配置项中。参考上面第三步设置执行计划。OK 采集 规则后,可以选择执行计划。如果只是一次性采集数据,那么可以选择手动或者一次性手动,那么就可以做单机采集或者云采集单机采集 是使用本地计算机进行采集cloud采集 就是不用本地电脑用优采云的云采集服务器采集这样不仅可以实现定时采集还有很多优点,比如采集@ > 最快速度可加速100倍。不用担心IP被封,网络不稳定等,你也可以关掉电脑。优采云云采集服务器集群为你完成采集的所有工作。关于云采集和单机采集的区别,以及各个计时选项的用法,可以向上移动鼠标,会有详细的提示。这里不再重复描述。步骤完成配置。其实经过上面三步采集任务的配置之后,第四步主要是用来测试配置是否正确。第一个选项检查任务会打开任务测试界面,点击开始测试按钮开始测试,同时测试采集其实和单机是同一个界面。如果测试过程发现没有按预期运行或者网站出现意外问题,例如采集的字段不存在,网页样式变化很大等,可以随时停止测试,继续修改任务配置再重新测试。经过多次测试修改,如果确定任务没有问题,可以点击完成进入任务列表,选择配置的任务继续采集如果是单机采集,然后 采集 将立即开始在本地计算机上执行。采集 完成后,会有提示完成。单击导出数据按钮将所有数据导出到采集。如果在执行计划界面选择手动启动并点击云采集,任务会立即在云采集服务器上启动。如果执行计划选择定期自动启动,则不需要手动启动,直到指定时间任务会自动启动。更多说明。本文档是对优采云采集器的简单介绍,主要面向刚开始学习使用优采云采集器的用户,当然优采云采集器有还有很多更强大的功能,在本文档中没有解释。有关更多说明,请查看视频教程和其他文档。如果您还没有看完视频教程,我们强烈建议您仔细阅读。半小时即可学会所有官方视频教程
不用采集规则就可以采集(辣鸡采集世界上所有辣鸡数据欢迎大家来采集基于fesiong优采云采集器底层开发)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-11-10 06:07
麻辣鸡采集 laji-collect 介绍
麻辣鸡采集,采集全世界麻辣鸡资料欢迎大家来采集
基于fesiong优采云采集器的底层开发
优采云采集器
开发语言
高朗
官网案例
香辣鸡采集
为什么会有这个辣鸡文章采集器辣鸡文章采集器can采集
这个采集器可以是采集的内容有:文章标题、文章关键词、文章描述、文章详情、文章 作者、文章 发布时间、文章 浏览量。
什么时候需要用辣鸡文章采集器
当我们需要给网站采集文章时,这个采集器可以派上用场,这个采集器不需要有人值班,24小时不间断day Run,它会每10分钟自动遍历一次采集列表,抓取收录文章的链接,随时抓取回文,也可以设置自动发布自动发布到指定的文章在表中。
麻辣鸡文章采集器哪里可以跑
这个采集器可以在Windows、Mac、Linux(Centos、Ubuntu等)上运行,可以下载编译好的程序直接执行,也可以下载源码自己编译。
香辣鸡文章采集器有售伪原创
这个采集器暂时不支持伪原创功能,后续会添加合适的伪原创选项。
如何安装和使用
go env -w GOPROXY=https://goproxy.cn,direct
最后执行以下命令
编译结束后,运行编译好的文件,然后双击运行可执行文件。在打开的浏览器的可视化界面中,填写数据库信息,完成初始配置,添加采集源码开始采集之旅。
发展计划官网微信交流群
帮助改进
欢迎有能力和有奉献精神的个人或团体参与本采集器的开发和完善,共同完善采集的功能。请fork一个分支,然后修改,修改后提交pull request合并请求。 查看全部
不用采集规则就可以采集(辣鸡采集世界上所有辣鸡数据欢迎大家来采集基于fesiong优采云采集器底层开发)
麻辣鸡采集 laji-collect 介绍
麻辣鸡采集,采集全世界麻辣鸡资料欢迎大家来采集
基于fesiong优采云采集器的底层开发
优采云采集器
开发语言
高朗
官网案例
香辣鸡采集
为什么会有这个辣鸡文章采集器辣鸡文章采集器can采集
这个采集器可以是采集的内容有:文章标题、文章关键词、文章描述、文章详情、文章 作者、文章 发布时间、文章 浏览量。
什么时候需要用辣鸡文章采集器
当我们需要给网站采集文章时,这个采集器可以派上用场,这个采集器不需要有人值班,24小时不间断day Run,它会每10分钟自动遍历一次采集列表,抓取收录文章的链接,随时抓取回文,也可以设置自动发布自动发布到指定的文章在表中。
麻辣鸡文章采集器哪里可以跑
这个采集器可以在Windows、Mac、Linux(Centos、Ubuntu等)上运行,可以下载编译好的程序直接执行,也可以下载源码自己编译。
香辣鸡文章采集器有售伪原创
这个采集器暂时不支持伪原创功能,后续会添加合适的伪原创选项。
如何安装和使用
go env -w GOPROXY=https://goproxy.cn,direct
最后执行以下命令
编译结束后,运行编译好的文件,然后双击运行可执行文件。在打开的浏览器的可视化界面中,填写数据库信息,完成初始配置,添加采集源码开始采集之旅。
发展计划官网微信交流群
帮助改进
欢迎有能力和有奉献精神的个人或团体参与本采集器的开发和完善,共同完善采集的功能。请fork一个分支,然后修改,修改后提交pull request合并请求。
不用采集规则就可以采集(大佬这个怎么解决(16:15:26)(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-11-05 20:13
如何解决这个大家伙
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍等","host-name":"bjfk-rs7180.@ >yz02"}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍等","host-name":"st-dz-rs46< @3.yz"}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"bjzyx-c3891.zqy"}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"bjpg-rs1715.@ >yz02"}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"bjpg-rs1715.@ >yz02"}
[16:15:26] 当前 Cookie:kuaishou.live.bfb1s=7206d814e5c089a58c910ed8bf52ace5;客户 ID=3; did=web_17f781c999e79d2bd8d5b8a11cc11291; client_key=65890b29;
[16:15:26] | 采集完成:0
[16:15:33] 获取方式:用户链接
[16:15:33] 开始查询
[16:15:33] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:33] 错误日志:{"result":2,"error_msg":"操作太快,请稍等","host-name":"st-dz-rs46< @3.yz"}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快了,请稍候","host-name":"bjzyx-c3907.zqy"}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"st-dz-rs46< @3.yz"}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"bjfk-rs7174.@ >yz02"}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"st-dz-rs46< @3.yz"}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"st-dz-rs46< @3.yz"}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"st-dz-rs46< @3.yz"}
[16:15:34] 当前 Cookie:kuaishou.live.bfb1s=7206d814e5c089a58c910ed8bf52ace5;客户 ID=3; did=web_17f781c999e79d2bd8d5b8a11cc11291; client_key=65890b29;
[16:15:34] | 采集完成:0 查看全部
不用采集规则就可以采集(大佬这个怎么解决(16:15:26)(组图))
如何解决这个大家伙
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍等","host-name":"bjfk-rs7180.@ >yz02"}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍等","host-name":"st-dz-rs46< @3.yz"}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"bjzyx-c3891.zqy"}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"bjpg-rs1715.@ >yz02"}
[16:15:26] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"bjpg-rs1715.@ >yz02"}
[16:15:26] 当前 Cookie:kuaishou.live.bfb1s=7206d814e5c089a58c910ed8bf52ace5;客户 ID=3; did=web_17f781c999e79d2bd8d5b8a11cc11291; client_key=65890b29;
[16:15:26] | 采集完成:0
[16:15:33] 获取方式:用户链接
[16:15:33] 开始查询
[16:15:33] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:33] 错误日志:{"result":2,"error_msg":"操作太快,请稍等","host-name":"st-dz-rs46< @3.yz"}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快了,请稍候","host-name":"bjzyx-c3907.zqy"}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"st-dz-rs46< @3.yz"}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"bjfk-rs7174.@ >yz02"}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"st-dz-rs46< @3.yz"}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":""}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"st-dz-rs46< @3.yz"}
[16:15:34] 错误日志:{"result":2,"error_msg":"操作太快,请稍候","host-name":"st-dz-rs46< @3.yz"}
[16:15:34] 当前 Cookie:kuaishou.live.bfb1s=7206d814e5c089a58c910ed8bf52ace5;客户 ID=3; did=web_17f781c999e79d2bd8d5b8a11cc11291; client_key=65890b29;
[16:15:34] | 采集完成:0
不用采集规则就可以采集(不是规则多少不会出现分类错误(附解决方法汇总))
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-11-03 00:19
7、如果采集不是资源站,每个播放地址应该有单独的页面采集根据数量而定采集速度可能会慢
提示:本工具会在根目录下生成配置文件记录以备下次使用,如果是公用电脑,请在使用后删除。
———————————————————————————————————————
自动分类说明
示例:[@]动作|8[/@]
表达能力有限,请自行理解
1、 自动分类规则如上例写法,括号字符必须相同,不能为[]。
2、 "|" 前面是采集网站 得到的category后面是网站对应的category的ID。
3、点击阅读网站分类按钮查看ID(前提:连接数据库)。
4、自动分类规则可以通用到一个网站,不管有多少规则,都不会出现分类错误(前提:你没有写错规则),因为理论上采集 到 网站@ >分类无法匹配自动分类规则中的 2 条规则。
5、自动分类可与采集采集中的分类灵活使用。比如资源站有日韩分类,你网站日韩是分开的,你可以采集资源站的区域作为分类规则[@]韩国|(我自己网站韩剧ID)[/@],[/@]欧美|10[/@]
重要提示:
1、 错误的规则可能会导致仓储分类错误。了解使用方法后再使用。
2!!!!!!!养成备份数据库的习惯!!!!!!
重要声明:本工具仅供辅助使用,使用中出现任何问题本人概不负责!!!!!!!!
发行说明:
1.0.3 解决导入时间错误到1970
1.0.2 及时解决个别错误读取类别ID
1.0.1 更新内容
1.解决年份为空时存储失败
2.添加手动添加视频功能
3.增加公告,及时了解最新动态
4.优化部分代码
1.0版本所以会有不足,希望提供宝贵意见
支持最新的飞飞cms php版本,
支持自定义写入采集规则,
支持规则绑定网站分类,
支持自动入库,
支持编辑,
采集 规则会不定期添加到群里 查看全部
不用采集规则就可以采集(不是规则多少不会出现分类错误(附解决方法汇总))
7、如果采集不是资源站,每个播放地址应该有单独的页面采集根据数量而定采集速度可能会慢
提示:本工具会在根目录下生成配置文件记录以备下次使用,如果是公用电脑,请在使用后删除。
———————————————————————————————————————
自动分类说明
示例:[@]动作|8[/@]
表达能力有限,请自行理解
1、 自动分类规则如上例写法,括号字符必须相同,不能为[]。
2、 "|" 前面是采集网站 得到的category后面是网站对应的category的ID。
3、点击阅读网站分类按钮查看ID(前提:连接数据库)。
4、自动分类规则可以通用到一个网站,不管有多少规则,都不会出现分类错误(前提:你没有写错规则),因为理论上采集 到 网站@ >分类无法匹配自动分类规则中的 2 条规则。
5、自动分类可与采集采集中的分类灵活使用。比如资源站有日韩分类,你网站日韩是分开的,你可以采集资源站的区域作为分类规则[@]韩国|(我自己网站韩剧ID)[/@],[/@]欧美|10[/@]
重要提示:
1、 错误的规则可能会导致仓储分类错误。了解使用方法后再使用。
2!!!!!!!养成备份数据库的习惯!!!!!!
重要声明:本工具仅供辅助使用,使用中出现任何问题本人概不负责!!!!!!!!
发行说明:
1.0.3 解决导入时间错误到1970
1.0.2 及时解决个别错误读取类别ID
1.0.1 更新内容
1.解决年份为空时存储失败
2.添加手动添加视频功能
3.增加公告,及时了解最新动态
4.优化部分代码
1.0版本所以会有不足,希望提供宝贵意见
支持最新的飞飞cms php版本,
支持自定义写入采集规则,
支持规则绑定网站分类,
支持自动入库,
支持编辑,
采集 规则会不定期添加到群里
不用采集规则就可以采集( 代理IP为何成了爬虫的标配?不需要代理ip就能爬虫吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-10-30 13:01
代理IP为何成了爬虫的标配?不需要代理ip就能爬虫吗?)
互联网时代,现在大家对大数据、爬虫、编码、代理服务器、代理这些词汇已经不再陌生。如今,为什么代理IP成为爬虫的标准配置?没有代理IP可以爬行吗?
1、当爬虫抓取到某个站点的数据时,就相当于不断的向别人打招呼,很可能会变黑。
用代理IP替换不同的IP,对方网站每次都认为是新用户,自然没有被黑的危险。
2、爬行时,被爬行网站有反爬行机制。
如果使用一个IP重复访问一个网页,很容易被IP限制,无法再访问网站。在这种情况下,您需要使用代理 IP。
3、如果业务量不大,对工作效率要求不高,可以不用代理IP。
如果工作量大,爬取速度快,目标服务器很容易找到。因此,需要使用代理IP来交换IP并对其进行爬取。
经过上面的介绍,说明网络爬虫不一定要使用代理IP,但确实是一个有效工作的好工具。
特别是当前数据采集越来越大,需要获取的数据量和样本量也越来越大,所以大规模爬取还是需要使用质量稳定的代理IP .
大数据时代,数据采集已经成为不可或缺的一部分。在数据采集的过程中,很多人会使用代理IP,那么网络爬虫一定要使用代理IP吗?虽然答案是否定的,但在以下情况下必须使用代理IP。
如果想尝试使用代理ip,可以到拼音http代理ip官网了解更多。提供高度隐蔽且稳定的代理ip,支持HTTP/HTTPS/SOCKS5代理协议,提供动态IP、静态IP等服务。百兆带宽,千万IP资源,保障爬虫数据传输安全。快速获取网站数据,现在还有免费测试和免费ip活动! 查看全部
不用采集规则就可以采集(
代理IP为何成了爬虫的标配?不需要代理ip就能爬虫吗?)
互联网时代,现在大家对大数据、爬虫、编码、代理服务器、代理这些词汇已经不再陌生。如今,为什么代理IP成为爬虫的标准配置?没有代理IP可以爬行吗?
1、当爬虫抓取到某个站点的数据时,就相当于不断的向别人打招呼,很可能会变黑。
用代理IP替换不同的IP,对方网站每次都认为是新用户,自然没有被黑的危险。
2、爬行时,被爬行网站有反爬行机制。
如果使用一个IP重复访问一个网页,很容易被IP限制,无法再访问网站。在这种情况下,您需要使用代理 IP。
3、如果业务量不大,对工作效率要求不高,可以不用代理IP。
如果工作量大,爬取速度快,目标服务器很容易找到。因此,需要使用代理IP来交换IP并对其进行爬取。
经过上面的介绍,说明网络爬虫不一定要使用代理IP,但确实是一个有效工作的好工具。
特别是当前数据采集越来越大,需要获取的数据量和样本量也越来越大,所以大规模爬取还是需要使用质量稳定的代理IP .
大数据时代,数据采集已经成为不可或缺的一部分。在数据采集的过程中,很多人会使用代理IP,那么网络爬虫一定要使用代理IP吗?虽然答案是否定的,但在以下情况下必须使用代理IP。
如果想尝试使用代理ip,可以到拼音http代理ip官网了解更多。提供高度隐蔽且稳定的代理ip,支持HTTP/HTTPS/SOCKS5代理协议,提供动态IP、静态IP等服务。百兆带宽,千万IP资源,保障爬虫数据传输安全。快速获取网站数据,现在还有免费测试和免费ip活动!
不用采集规则就可以采集(明泽文章采集器有什么优势万能文章能采集哪些内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-10-29 05:14
一直以来,大家都在使用各种采集器或者网站内置的采集功能,比如织梦采集侠、优采云< @采集器、优采云采集器等,这些采集软件有一个共同的特点,就是必须把采集规则写到采集 文章,这个技术问题,对于新手来说,经常被张二和尚搞糊涂,但真的不是一件容易的事。即使是老站长,当需要采集多个网站数据时,需要为不同的网站编写不同的采集规则,既费力又费时。工作。很多做站群的朋友,对于每个站都需要写采集的规则有很深的体会,简直惨不忍睹。有人说站长是网络搬运工,这是有道理的。网上的文章都是你动我,我动你,彼此动。那么有没有既免费又开源的采集软件?明泽文章采集器就像定制的采集软件,这个采集器内置了常用的采集规则,只需添加文章列表连接,可以返回内容采集。
明泽文章采集器全能有什么优点文章采集器可以采集什么内容
这个采集器可以是采集的内容有:文章标题、文章关键词、文章描述、文章详情、文章 作者、文章 发布时间、文章 浏览量。
Universal文章采集器 在哪里可以运行
采集器可以在Windows、Mac、Linux(Centos、Ubuntu等)上运行,可以下载编译好的程序直接执行,也可以下载源码自己编译。
明泽文章采集软件教程结束语
以上就是明泽文章采集器的用法和工作原理。按照上面的步骤,你就可以轻松采集到你想要的文章,24小时不间断,如果有效,你打开采集器,它会给你源源不断的能量采集文章并自动发布。 查看全部
不用采集规则就可以采集(明泽文章采集器有什么优势万能文章能采集哪些内容)
一直以来,大家都在使用各种采集器或者网站内置的采集功能,比如织梦采集侠、优采云< @采集器、优采云采集器等,这些采集软件有一个共同的特点,就是必须把采集规则写到采集 文章,这个技术问题,对于新手来说,经常被张二和尚搞糊涂,但真的不是一件容易的事。即使是老站长,当需要采集多个网站数据时,需要为不同的网站编写不同的采集规则,既费力又费时。工作。很多做站群的朋友,对于每个站都需要写采集的规则有很深的体会,简直惨不忍睹。有人说站长是网络搬运工,这是有道理的。网上的文章都是你动我,我动你,彼此动。那么有没有既免费又开源的采集软件?明泽文章采集器就像定制的采集软件,这个采集器内置了常用的采集规则,只需添加文章列表连接,可以返回内容采集。
明泽文章采集器全能有什么优点文章采集器可以采集什么内容
这个采集器可以是采集的内容有:文章标题、文章关键词、文章描述、文章详情、文章 作者、文章 发布时间、文章 浏览量。
Universal文章采集器 在哪里可以运行
采集器可以在Windows、Mac、Linux(Centos、Ubuntu等)上运行,可以下载编译好的程序直接执行,也可以下载源码自己编译。
明泽文章采集软件教程结束语
以上就是明泽文章采集器的用法和工作原理。按照上面的步骤,你就可以轻松采集到你想要的文章,24小时不间断,如果有效,你打开采集器,它会给你源源不断的能量采集文章并自动发布。
不用采集规则就可以采集(绝大多数规则防采集而又不防搜索引擎从前面的我讲)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-28 02:07
六、只允许通过本站页面查看,如:Request.ServerVariables("HTTP_REFERER")
缺点:影响搜索引擎收录
采集 对策:不知道能不能模拟一下网页的来源。. . . 目前我没有针对这种方法的对策采集
建议:目前没有很好的改进建议
点评:建议靠搜索引擎拉流量的站长不要用这种方法。不过,这种方法对于防止一般的采集程序还是有些效果的。
从上面可以看出,目前常用的防止采集的方法要么对搜索引擎收录影响较大,要么采集效果不好,而且它将无法阻止采集的效果。那么,有没有有效的方法可以在不影响搜索引擎收录的情况下防止采集?那么请继续往下看,精彩的地方马上呈现给大家。
以下是我的反采集策略,反采集而不是反搜索引擎
从前面讲的采集的原理可以看出,大多数采集程序都是依赖于对采集的分析规则,比如分析分页文件名规则,分析页面代码。规则。
一、分页文件名规则防止采集对策
大部分采集器都是依靠分析分页文件名规则来进行批量多页采集。如果别人找不到你的分页文件的文件名规则,那么别人就不能对你的网站做批量多页采集。
执行:
我认为用MD5加密分页文件名是更好的方法。说到这个,有人会说你用MD5加密分页文件名。其他人也可以模仿你的加密规则,根据这个规则得到你的分页文件名。
我要指出的是,我们在对分页文件名进行加密时,不要只对文件名的变化部分进行加密
如果我代表页面的页码,那我们就不要这样加密了
page_name=Md5(I,16)&".htm"
最好在要加密的页码上跟上一个或多个字符,如:page_name=Md5(I&"any one or几个字母",16)&".htm"
因为MD5无法解密,别人看到的页面上的字母都是MD5加密的结果,所以加法器无法知道你跟在我后面的字母是什么,除非他对****MD5使用蛮力,但不是很实际的。
二、页面代码规则防止采集对策
如果我们说我们的内容页面没有代码规则,那么其他人将无法从您的代码中提取他们需要的内容片段。
所以我们要防止采集的一步就是让代码变得不规则。
执行:
随机化对方需要提取的token
1、自定义多个网页模板。每个网页模板中重要的 HTML 标签都不同。页面内容呈现时,随机选择网页模板。有些页面使用CSS+DIV布局,有些页面使用表格布局。这个方法有点麻烦。对于一个内容页面,需要多做几个模板页面,但是反采集本身就是一件很麻烦的事情。多做一个模板可以起到防采集的作用。对很多人来说,这是值得的。
2、 如果觉得上面的方法太繁琐,可以将网页中重要的HTML标签随机化。
做的网页模板越多,html代码越随意,对方解析内容代码时就越麻烦。当对方专门为你写一个采集策略时,难度就越大。这时候,绝大多数人会因为懒惰而退却,所以可以采集其他网站数据~~~说说吧,目前大部分人都拿,毕竟是开发的人< @采集 程序对采集 数据的采集 由别人开发,自己开发采集 程序对采集 数据的很少。
还有一些简单的想法给大家:
1、使用客户端脚本显示对数据重要但对搜索引擎不重要的内容
2、 将一页数据分成N页展示,这也是增加采集难度的一种方式
3、 使用更深层次的连接,因为大多数采集 程序只能采集 去网站 内容的前3 层。如果内容处于更深层次的联系,也可以避免被采集。但是,这可能会给客户带来浏览不便。
喜欢:
网站大部分是首页----内容索引分页----内容页
如果将其更改为:
首页----内容索引分页----内容页入口----内容页
注:内容页的入口最好添加代码自动跳转到内容页
其实只要第一步防范采集(加密分页文件名规则),防范采集的效果就已经不错了。建议同时使用两种反采集方法。给采集的人增加采集的难度,让他们知道翻页难。 查看全部
不用采集规则就可以采集(绝大多数规则防采集而又不防搜索引擎从前面的我讲)
六、只允许通过本站页面查看,如:Request.ServerVariables("HTTP_REFERER")
缺点:影响搜索引擎收录
采集 对策:不知道能不能模拟一下网页的来源。. . . 目前我没有针对这种方法的对策采集
建议:目前没有很好的改进建议
点评:建议靠搜索引擎拉流量的站长不要用这种方法。不过,这种方法对于防止一般的采集程序还是有些效果的。
从上面可以看出,目前常用的防止采集的方法要么对搜索引擎收录影响较大,要么采集效果不好,而且它将无法阻止采集的效果。那么,有没有有效的方法可以在不影响搜索引擎收录的情况下防止采集?那么请继续往下看,精彩的地方马上呈现给大家。
以下是我的反采集策略,反采集而不是反搜索引擎
从前面讲的采集的原理可以看出,大多数采集程序都是依赖于对采集的分析规则,比如分析分页文件名规则,分析页面代码。规则。
一、分页文件名规则防止采集对策
大部分采集器都是依靠分析分页文件名规则来进行批量多页采集。如果别人找不到你的分页文件的文件名规则,那么别人就不能对你的网站做批量多页采集。
执行:
我认为用MD5加密分页文件名是更好的方法。说到这个,有人会说你用MD5加密分页文件名。其他人也可以模仿你的加密规则,根据这个规则得到你的分页文件名。
我要指出的是,我们在对分页文件名进行加密时,不要只对文件名的变化部分进行加密
如果我代表页面的页码,那我们就不要这样加密了
page_name=Md5(I,16)&".htm"
最好在要加密的页码上跟上一个或多个字符,如:page_name=Md5(I&"any one or几个字母",16)&".htm"
因为MD5无法解密,别人看到的页面上的字母都是MD5加密的结果,所以加法器无法知道你跟在我后面的字母是什么,除非他对****MD5使用蛮力,但不是很实际的。
二、页面代码规则防止采集对策
如果我们说我们的内容页面没有代码规则,那么其他人将无法从您的代码中提取他们需要的内容片段。
所以我们要防止采集的一步就是让代码变得不规则。
执行:
随机化对方需要提取的token
1、自定义多个网页模板。每个网页模板中重要的 HTML 标签都不同。页面内容呈现时,随机选择网页模板。有些页面使用CSS+DIV布局,有些页面使用表格布局。这个方法有点麻烦。对于一个内容页面,需要多做几个模板页面,但是反采集本身就是一件很麻烦的事情。多做一个模板可以起到防采集的作用。对很多人来说,这是值得的。
2、 如果觉得上面的方法太繁琐,可以将网页中重要的HTML标签随机化。
做的网页模板越多,html代码越随意,对方解析内容代码时就越麻烦。当对方专门为你写一个采集策略时,难度就越大。这时候,绝大多数人会因为懒惰而退却,所以可以采集其他网站数据~~~说说吧,目前大部分人都拿,毕竟是开发的人< @采集 程序对采集 数据的采集 由别人开发,自己开发采集 程序对采集 数据的很少。
还有一些简单的想法给大家:
1、使用客户端脚本显示对数据重要但对搜索引擎不重要的内容
2、 将一页数据分成N页展示,这也是增加采集难度的一种方式
3、 使用更深层次的连接,因为大多数采集 程序只能采集 去网站 内容的前3 层。如果内容处于更深层次的联系,也可以避免被采集。但是,这可能会给客户带来浏览不便。
喜欢:
网站大部分是首页----内容索引分页----内容页
如果将其更改为:
首页----内容索引分页----内容页入口----内容页
注:内容页的入口最好添加代码自动跳转到内容页
其实只要第一步防范采集(加密分页文件名规则),防范采集的效果就已经不错了。建议同时使用两种反采集方法。给采集的人增加采集的难度,让他们知道翻页难。
不用采集规则就可以采集(Get快速批量进行web操作的秘笈-一个可视化脚本工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-10-23 22:01
在线营销通常需要注册多个帐户并发送大量营销电子邮件或促销信息。重复工作会不会觉得枯燥乏味?在分析数据的时候,你是否经常担心实现web采集和绕过访问验证的效率低下?
的确,这些企业在业务发展中的这些基本任务,往往会占用员工大量的时间,而看似简单的任务却总是耗时枯燥,浪费人力成本。
如何确保这些任务准确高效?
这里有一些提示,可帮助您快速和批量地进行 Web 操作。引入可视化脚本工具优采云 浏览器。您只需要在脚本中编写工作流,脚本就可以代替您的双手自动运行繁琐的任务。
以微博采集发布为例,设置流程如下:
1、打开网页并登录您的帐户
配置一个步骤打开网页,然后配置要写入的用户名和密码。用户名和密码保存在变量中,可以直接调用。配置时使用鼠标放置在页面元素上,即可自动显示Xpath提取规则,无需技术知识,非常容易上手。
写入后,点击登录按钮,实现自动登录。
2、点击搜索,输入搜索内容
还是用鼠标点击元素,找到输入框的Xpath,把输入的内容,比如“热门话题”保存在一个变量中,调用即可。
3、提取数据并保存内容
4、发布数据
如果您需要发布,只需配置发布流程的几个步骤。运行一次可以看到软件自动采集数据并发布成功。
借助简单而强大的优采云浏览器,我们可以将繁琐繁琐的批量操作交给软件,解放双手,为我们的业务核心争取更多的工作时间。基于视觉提取技术的优采云浏览器,可以保证操作的高精度,同时大大提高工作效率,降低人工成本。
除了营销、采集、群发,优采云的浏览器中还有更多应用成为可能,点击购买:
优采云浏览器通用数据采集 发布脚本工具 查看全部
不用采集规则就可以采集(Get快速批量进行web操作的秘笈-一个可视化脚本工具)
在线营销通常需要注册多个帐户并发送大量营销电子邮件或促销信息。重复工作会不会觉得枯燥乏味?在分析数据的时候,你是否经常担心实现web采集和绕过访问验证的效率低下?
的确,这些企业在业务发展中的这些基本任务,往往会占用员工大量的时间,而看似简单的任务却总是耗时枯燥,浪费人力成本。
如何确保这些任务准确高效?
这里有一些提示,可帮助您快速和批量地进行 Web 操作。引入可视化脚本工具优采云 浏览器。您只需要在脚本中编写工作流,脚本就可以代替您的双手自动运行繁琐的任务。
以微博采集发布为例,设置流程如下:
1、打开网页并登录您的帐户
配置一个步骤打开网页,然后配置要写入的用户名和密码。用户名和密码保存在变量中,可以直接调用。配置时使用鼠标放置在页面元素上,即可自动显示Xpath提取规则,无需技术知识,非常容易上手。
写入后,点击登录按钮,实现自动登录。
2、点击搜索,输入搜索内容
还是用鼠标点击元素,找到输入框的Xpath,把输入的内容,比如“热门话题”保存在一个变量中,调用即可。
3、提取数据并保存内容
4、发布数据
如果您需要发布,只需配置发布流程的几个步骤。运行一次可以看到软件自动采集数据并发布成功。
借助简单而强大的优采云浏览器,我们可以将繁琐繁琐的批量操作交给软件,解放双手,为我们的业务核心争取更多的工作时间。基于视觉提取技术的优采云浏览器,可以保证操作的高精度,同时大大提高工作效率,降低人工成本。
除了营销、采集、群发,优采云的浏览器中还有更多应用成为可能,点击购买:
优采云浏览器通用数据采集 发布脚本工具
不用采集规则就可以采集(Prometheusmetrics的入门介绍(二)-k/v的数据形式)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-20 18:19
1、Prometheus 度量的概念
2、k/v 数据格式
3、Prometheus 导出器的使用(拉取表单 采集 数据)
4、Prometheus pushgateway介绍(推送表单采集数据)
在Prometheus监控中,来自采集的数据统称为metrics数据
度量,熟悉大数据系统的人,从来没有听说过度量。当我们需要对某个系统中的某个服务进行监控和统计时,就需要用到Metrics。
Metrics是采样数据的总称(metrics不代表特定的数据格式,而是度量单位的抽象)
几种主要类型的指标
最简单的指标是简单的返回值或瞬时状态。例如,我们想以更简单的方式衡量一个处理队列中的任务数量。
例如:如果我想监控硬盘容量或内存使用情况,我应该使用 Gauges 的度量格式来衡量
因为硬盘的容量或使用的内存量会随着时间的推移而不断地、瞬间地发生变化。
这种变化是不规律的,目前是多少,采集又是多少
不确定会不会继续增长,也不确定会不会继续减少。
就这样了。这是所用仪表类型的代表。
如图,CPU的波动是采集 Gauge形式的metrics数据不规则
计数器类型指标
计数器是一个计数器。它从数据量 0 开始,累加计算。理想状态下,只能永远增持,不会减持(某些特殊情况另说)
例如
例如,用户访问的抽样数据
我们的产品被用户访问一次,10分钟后为1,累计到100
一天后累积到20000
一周后累积到100000-150000
如下图所示。计数器数据从0开始,不断累加,不断累加,所以在理想状态下,没有任何减少的可能。
最多只能保持一个不变(例如:用户不再访问,那么当前累计总访问量将保持为一条水平线,直到再次访问)
下图显示了一个计数器类型的指标数据采集。采集 为用户累计访问量
直方图
直方图统计的分布。例如,最小值、最大值、中位数、中位数、第 75 个百分位数、第 90 个百分位数、第 95 个百分位数、第 98 个百分位数、第 99 个百分位数和第 99.9 个百分位数。
这是一种特殊的度量数据类型,它代表一个
近似百分比估计
这是最难理解的指标类型(但它非常实用)。估计大部分数学家都会看上面几行的定义,header会很大。
介绍什么是直方图数据
直方图类型(prometheus其实提供了一个基于直方图算法的函数,可以直接使用),可以分别统计所有用户的响应时间~=0.05秒,多少个0~0. 05 多少秒,> 2 秒,> 10 秒 => 1%
可以清楚地看到在当前系统中,有多少用户(或请求)处于基本正常状态,有多少是极速用户,有多少是慢速或有问题的请求
k/v 数据格式
Prometheus的数据类型是根据metric的类型计算的
对于采集返回的数据类型,必须以特定的数据格式查看和使用
看一个exporter采集服务器上的k/v格式metrics数据
当导出器 (node_exporter) 安装并在受监控服务器上运行时
使用简单的curl命令查看exporter采集的metrics数据,以k/v的形式显示并保存curl localhost:9100/metrics
curl后输出的结果如上图
Prometheus_server
带#的那一行是注释行,解释下面的k/v值是什么采样数据
而真正关心的是数据
用空格分隔 KEY/Value 数据
第一个代表采集的当前最大文件句柄数为65535
第二个代表采集当前打开的文件句柄数为10。
也看看这里
第二行#告诉我们这个数据的metrics类型属于gaugeexporter的使用
官网提供了丰富的成型导出器插件,可以使用
举几个例子
pushgateway的概念介绍
导出器首先安装在被监控的服务器上并在后台运行
然后自动采集系统数据,它本身是一个HTTP_server,可以由Prometheus服务器定期发送到HTTP GET以pull的形式获取数据
如果你逆转这个过程
push 18 pushgatewat 的形式是安装在客户端还是服务器上(其实安装在哪里都无所谓)
pushgateway 本身也是一个 http 服务器
运维用自己的脚本抓取自己想要的监控数据,然后push到pushgateway再pushgateway到prometheus服务器是反向的被动模式
已经有了node_exporter采集这么强大的pull形式,为什么还需要pushgateway形式呢?
1、 虽然出口商采集的类型已经很丰富了,但是我们还是需要大量的自制监测数据,不定期的自行定制
2、exporter 由于采集的数据类型比较多,其实很多数据或者大部分数据其实并没有用到我们的监控中。使用pushgateway就是定义一段数据。采集着一节约资源
3、 开发一个新的自定义pushgateway脚本比开发一个全新的exporter更简单、更快捷!!!(exporter的开发需要使用真正的编程语言,shell等快速脚本不行,需要了解很多Prometheus自定义编程格式才能开始做大量工作)
4、虽然exporter已经很丰富了,但是我们需要的采集的形式还有很多,exporter不能提供,或者现有expoter不支持,但是如果用pushgateway的话可以随心所欲 灵活,可以随心所欲,而且非常快 查看全部
不用采集规则就可以采集(Prometheusmetrics的入门介绍(二)-k/v的数据形式)
1、Prometheus 度量的概念
2、k/v 数据格式
3、Prometheus 导出器的使用(拉取表单 采集 数据)
4、Prometheus pushgateway介绍(推送表单采集数据)
在Prometheus监控中,来自采集的数据统称为metrics数据
度量,熟悉大数据系统的人,从来没有听说过度量。当我们需要对某个系统中的某个服务进行监控和统计时,就需要用到Metrics。
Metrics是采样数据的总称(metrics不代表特定的数据格式,而是度量单位的抽象)
几种主要类型的指标
最简单的指标是简单的返回值或瞬时状态。例如,我们想以更简单的方式衡量一个处理队列中的任务数量。
例如:如果我想监控硬盘容量或内存使用情况,我应该使用 Gauges 的度量格式来衡量
因为硬盘的容量或使用的内存量会随着时间的推移而不断地、瞬间地发生变化。
这种变化是不规律的,目前是多少,采集又是多少
不确定会不会继续增长,也不确定会不会继续减少。
就这样了。这是所用仪表类型的代表。
如图,CPU的波动是采集 Gauge形式的metrics数据不规则
计数器类型指标
计数器是一个计数器。它从数据量 0 开始,累加计算。理想状态下,只能永远增持,不会减持(某些特殊情况另说)
例如
例如,用户访问的抽样数据
我们的产品被用户访问一次,10分钟后为1,累计到100
一天后累积到20000
一周后累积到100000-150000
如下图所示。计数器数据从0开始,不断累加,不断累加,所以在理想状态下,没有任何减少的可能。
最多只能保持一个不变(例如:用户不再访问,那么当前累计总访问量将保持为一条水平线,直到再次访问)
下图显示了一个计数器类型的指标数据采集。采集 为用户累计访问量
直方图
直方图统计的分布。例如,最小值、最大值、中位数、中位数、第 75 个百分位数、第 90 个百分位数、第 95 个百分位数、第 98 个百分位数、第 99 个百分位数和第 99.9 个百分位数。
这是一种特殊的度量数据类型,它代表一个
近似百分比估计
这是最难理解的指标类型(但它非常实用)。估计大部分数学家都会看上面几行的定义,header会很大。
介绍什么是直方图数据
直方图类型(prometheus其实提供了一个基于直方图算法的函数,可以直接使用),可以分别统计所有用户的响应时间~=0.05秒,多少个0~0. 05 多少秒,> 2 秒,> 10 秒 => 1%
可以清楚地看到在当前系统中,有多少用户(或请求)处于基本正常状态,有多少是极速用户,有多少是慢速或有问题的请求
k/v 数据格式
Prometheus的数据类型是根据metric的类型计算的
对于采集返回的数据类型,必须以特定的数据格式查看和使用
看一个exporter采集服务器上的k/v格式metrics数据
当导出器 (node_exporter) 安装并在受监控服务器上运行时
使用简单的curl命令查看exporter采集的metrics数据,以k/v的形式显示并保存curl localhost:9100/metrics
curl后输出的结果如上图
Prometheus_server
带#的那一行是注释行,解释下面的k/v值是什么采样数据
而真正关心的是数据
用空格分隔 KEY/Value 数据
第一个代表采集的当前最大文件句柄数为65535
第二个代表采集当前打开的文件句柄数为10。
也看看这里
第二行#告诉我们这个数据的metrics类型属于gaugeexporter的使用
官网提供了丰富的成型导出器插件,可以使用
举几个例子
pushgateway的概念介绍
导出器首先安装在被监控的服务器上并在后台运行
然后自动采集系统数据,它本身是一个HTTP_server,可以由Prometheus服务器定期发送到HTTP GET以pull的形式获取数据
如果你逆转这个过程
push 18 pushgatewat 的形式是安装在客户端还是服务器上(其实安装在哪里都无所谓)
pushgateway 本身也是一个 http 服务器
运维用自己的脚本抓取自己想要的监控数据,然后push到pushgateway再pushgateway到prometheus服务器是反向的被动模式
已经有了node_exporter采集这么强大的pull形式,为什么还需要pushgateway形式呢?
1、 虽然出口商采集的类型已经很丰富了,但是我们还是需要大量的自制监测数据,不定期的自行定制
2、exporter 由于采集的数据类型比较多,其实很多数据或者大部分数据其实并没有用到我们的监控中。使用pushgateway就是定义一段数据。采集着一节约资源
3、 开发一个新的自定义pushgateway脚本比开发一个全新的exporter更简单、更快捷!!!(exporter的开发需要使用真正的编程语言,shell等快速脚本不行,需要了解很多Prometheus自定义编程格式才能开始做大量工作)
4、虽然exporter已经很丰富了,但是我们需要的采集的形式还有很多,exporter不能提供,或者现有expoter不支持,但是如果用pushgateway的话可以随心所欲 灵活,可以随心所欲,而且非常快
不用采集规则就可以采集(机器学习里的获取数据样本数据样本从哪里来?(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-10-19 20:05
一、背景
当前,工业互联网蓬勃发展,企业也在进行数字化、智能化转型。在智能化方面,安防视频监控是最重要的智能化内容。要想实现智能化,需要计算机视觉能力的加持。现阶段,人脸、人体、车辆等相关算法在受限场景(如刺刀)下可以达到商用标准。但是,在智慧社区、智慧园区、工业生产等领域,存在很多碎片化的场景,比如垃圾识别、钓鱼等。检测、广场舞识别、垃圾识别等,这些碎片化场景智能化遇到的最大挑战就是训练数据集的获取。与人脸、人体、车辆首先是政府和公安部门需要的。早年的天网和雪亮项目也积累了大量的视频监控数据,也可以作为AI算法的原材料。但是,在前面提到的碎片化场景中,并没有很好的积累,也没有更好的方法来采集这些数据样本。
二、 数据样本从何而来
机器学习的前提还是需要大量的样本数据。样本数据的获取和标记或多或少需要人工参与。所以,在视觉算法圈里,有句话叫:“人多,智者多”,虽然是个玩笑,但也体现了人工在机器学习中的重要性。下面列出了一些获取数据样本的方法,仅供参考。
1. 手动站点采集
当完全没有数据样本时,可以利用人力资源在真实环境中拍照采集。比如我要识别电动车,那我可以拍遍大街小巷的电动车;想鉴定各种花,也可以去公园拍各种花。手工采集的优点是可以获得比较真实的样本,缺点是劳动强度大,有一定的适用范围。比如一些不正常的识别(火、持刀)不适合这种手动采集的方法。另外,手动字段采集的数据也有限,训练出来的模型泛化能力不强。
2.网上获取的公开数据
互联网上获取的公开数据分为两部分,一是机器学习的公开数据集,二是搜索引擎检索到的结果。更不用说公开的数据集了,大家拿到的都是一样的,没有区别。虽然从搜索引擎找到的图片与真实场景存在一定差距,但仍然可以作为重要的数据源,对模型的训练有积极的帮助。搜索引擎通常会搜索成百上千个样本数据。完成模型训练的初始冷启动并不难。
3.人造场景
对于一些不方便去网站采集的低频或者异常情况,我们可以人为的创建一些场景,然后拍照或者录像记录下来作为数据样本进行标注。比如,要识别不戴安全帽、不穿工作服、打架的行为,就可以人为地“行动”。虽然表现不是那么真实,但总比没有数据要好得多。对于一些成堆的材料和垃圾的识别,手动创建场景非常方便。和上面手工站点采集的缺点一样,人工制造的场景数据也非常有限,训练出来的模型泛化能力不足。
4.现场视频提取
对于一些有现场监控视频的情况,可以从视频中提取数据样本进行后续的标注和训练。这里可能存在一个问题,即当要检测的目标物体或事件只占整个视频的很小一部分时,从中提取有效部分仍然是一项繁重的任务。
5.甲方客户提供数据
在某些情况下,虽然发生异常事件的概率不高,但由于这些异常事件的影响比较大,甲方的客户端已经积累了过去的历史视频数据。这种情况在技术上当然是理想的,但客户通常希望保护他们的数据。通常的处理方式是通过私有化部署,在客户的私有网络中训练,训练出来的模型也是客户自己的产权。乙方通常无权将这些模型用于其他目的(除非有其他合作。条款)。
6.购买第三方数据集
如果其他方法无法获得足够的有效样本,或者获得的样本不能保证训练模型的准确性,那么你也可以找第三方购买特定场景的数据集。这种方法的缺点是要花钱,而且在碎片化方面没有太多的数据积累。
三、机器辅助采样和标记
在实际的ToB/ToG项目中,最常见的场景之一:用户现场部署摄像头,监控视频数据全部可用,需要新的AI模型检测一些异常行为和事件。但是,这种“异常”并不是普遍存在的,与客户自身的业务场景密切相关。例如,城管注重道路占用作业;业主注意抛物线高空和电动车进入电梯;在校园场景中,他们关注校园欺凌和早恋。互联网上没有这些场景的公开数据集,也没有公开的成熟模型。显然,您需要自己重新训练数据。然而,在现有的视频监控视频中,
在正常情况下,监控视频在画面静止时会是静态的,当它处于活动状态时也是如此。静止时只保留选中帧的一张截图,有活动时可以保留选中帧的所有截图。典型的做法是使用运动检测算法进行初步筛选,剔除无用信息。比如要提取垃圾桶是否满的样本数据,只能关注静止图片的瞬间(垃圾桶站不会一直活跃,长期静止图片只需要一张图片);如果要关注投掷垃圾的行为,那么只要有活动时关注屏幕,并通过运动检测的初步筛选,
除了运动检测,还有没有其他方法可以通过机器辅助的方法高效提取这些数据样本?一种思路是手动选择一个小样本集,比如几百个,生成一个小模型,然后通过这个小模型过滤海量的监控视频数据,然后利用选择的样本对模型进行优化,制作模型越来越精确。更精准的模型反过来更高效地提取数据样本,形成增强循环,可以形成手动冷启动加机器辅助的滚雪球模式,如下图所示。
在这里你可能会有一个疑问:如果你用几张图片训练一个小模型,然后用小模型过滤掉的数据训练它,如果不添加其他数据集,结果是不是不可能超越这个小模型?(数据集都是小模型检测出来的)。我们需要在这里做一些小技巧。我们知道,对于一个算法模型,通常有召回率和准确率两个指标来评估。在小模型筛选阶段,我们其实需要比较高的召回率,所以我们会把置信度阈值设置的比较低。这样,即使有很多误报(准确率低),也没有关系。当样本被标记时,将手动纠正错误以消除误报。然而,小模型的漏报确实会影响未来训练模型的召回率。这时候就需要其他来源的数据集来补充。
四、总结
本文针对碎片化场景下智能算法应用的数据样本采集问题,提出了一种通过运动检测和小模型过滤历史监控视频的方法。这里的机器辅助方法不仅适用于数据集的采集,也适用于数据的标注,利用一些小样本训练小模型进行预标注。智慧社区、智慧园区、智慧门店、智慧家庭等一系列智慧应用已逐渐渗透到我们的生活中。碎片化的智能场景将成为未来的主流,数据作为智能原材料将成为未来最有价值的东西。越早积累,越能赢得比赛。 查看全部
不用采集规则就可以采集(机器学习里的获取数据样本数据样本从哪里来?(上))
一、背景
当前,工业互联网蓬勃发展,企业也在进行数字化、智能化转型。在智能化方面,安防视频监控是最重要的智能化内容。要想实现智能化,需要计算机视觉能力的加持。现阶段,人脸、人体、车辆等相关算法在受限场景(如刺刀)下可以达到商用标准。但是,在智慧社区、智慧园区、工业生产等领域,存在很多碎片化的场景,比如垃圾识别、钓鱼等。检测、广场舞识别、垃圾识别等,这些碎片化场景智能化遇到的最大挑战就是训练数据集的获取。与人脸、人体、车辆首先是政府和公安部门需要的。早年的天网和雪亮项目也积累了大量的视频监控数据,也可以作为AI算法的原材料。但是,在前面提到的碎片化场景中,并没有很好的积累,也没有更好的方法来采集这些数据样本。
二、 数据样本从何而来
机器学习的前提还是需要大量的样本数据。样本数据的获取和标记或多或少需要人工参与。所以,在视觉算法圈里,有句话叫:“人多,智者多”,虽然是个玩笑,但也体现了人工在机器学习中的重要性。下面列出了一些获取数据样本的方法,仅供参考。
1. 手动站点采集
当完全没有数据样本时,可以利用人力资源在真实环境中拍照采集。比如我要识别电动车,那我可以拍遍大街小巷的电动车;想鉴定各种花,也可以去公园拍各种花。手工采集的优点是可以获得比较真实的样本,缺点是劳动强度大,有一定的适用范围。比如一些不正常的识别(火、持刀)不适合这种手动采集的方法。另外,手动字段采集的数据也有限,训练出来的模型泛化能力不强。
2.网上获取的公开数据
互联网上获取的公开数据分为两部分,一是机器学习的公开数据集,二是搜索引擎检索到的结果。更不用说公开的数据集了,大家拿到的都是一样的,没有区别。虽然从搜索引擎找到的图片与真实场景存在一定差距,但仍然可以作为重要的数据源,对模型的训练有积极的帮助。搜索引擎通常会搜索成百上千个样本数据。完成模型训练的初始冷启动并不难。
3.人造场景
对于一些不方便去网站采集的低频或者异常情况,我们可以人为的创建一些场景,然后拍照或者录像记录下来作为数据样本进行标注。比如,要识别不戴安全帽、不穿工作服、打架的行为,就可以人为地“行动”。虽然表现不是那么真实,但总比没有数据要好得多。对于一些成堆的材料和垃圾的识别,手动创建场景非常方便。和上面手工站点采集的缺点一样,人工制造的场景数据也非常有限,训练出来的模型泛化能力不足。
4.现场视频提取
对于一些有现场监控视频的情况,可以从视频中提取数据样本进行后续的标注和训练。这里可能存在一个问题,即当要检测的目标物体或事件只占整个视频的很小一部分时,从中提取有效部分仍然是一项繁重的任务。
5.甲方客户提供数据
在某些情况下,虽然发生异常事件的概率不高,但由于这些异常事件的影响比较大,甲方的客户端已经积累了过去的历史视频数据。这种情况在技术上当然是理想的,但客户通常希望保护他们的数据。通常的处理方式是通过私有化部署,在客户的私有网络中训练,训练出来的模型也是客户自己的产权。乙方通常无权将这些模型用于其他目的(除非有其他合作。条款)。
6.购买第三方数据集
如果其他方法无法获得足够的有效样本,或者获得的样本不能保证训练模型的准确性,那么你也可以找第三方购买特定场景的数据集。这种方法的缺点是要花钱,而且在碎片化方面没有太多的数据积累。
三、机器辅助采样和标记
在实际的ToB/ToG项目中,最常见的场景之一:用户现场部署摄像头,监控视频数据全部可用,需要新的AI模型检测一些异常行为和事件。但是,这种“异常”并不是普遍存在的,与客户自身的业务场景密切相关。例如,城管注重道路占用作业;业主注意抛物线高空和电动车进入电梯;在校园场景中,他们关注校园欺凌和早恋。互联网上没有这些场景的公开数据集,也没有公开的成熟模型。显然,您需要自己重新训练数据。然而,在现有的视频监控视频中,
在正常情况下,监控视频在画面静止时会是静态的,当它处于活动状态时也是如此。静止时只保留选中帧的一张截图,有活动时可以保留选中帧的所有截图。典型的做法是使用运动检测算法进行初步筛选,剔除无用信息。比如要提取垃圾桶是否满的样本数据,只能关注静止图片的瞬间(垃圾桶站不会一直活跃,长期静止图片只需要一张图片);如果要关注投掷垃圾的行为,那么只要有活动时关注屏幕,并通过运动检测的初步筛选,
除了运动检测,还有没有其他方法可以通过机器辅助的方法高效提取这些数据样本?一种思路是手动选择一个小样本集,比如几百个,生成一个小模型,然后通过这个小模型过滤海量的监控视频数据,然后利用选择的样本对模型进行优化,制作模型越来越精确。更精准的模型反过来更高效地提取数据样本,形成增强循环,可以形成手动冷启动加机器辅助的滚雪球模式,如下图所示。
在这里你可能会有一个疑问:如果你用几张图片训练一个小模型,然后用小模型过滤掉的数据训练它,如果不添加其他数据集,结果是不是不可能超越这个小模型?(数据集都是小模型检测出来的)。我们需要在这里做一些小技巧。我们知道,对于一个算法模型,通常有召回率和准确率两个指标来评估。在小模型筛选阶段,我们其实需要比较高的召回率,所以我们会把置信度阈值设置的比较低。这样,即使有很多误报(准确率低),也没有关系。当样本被标记时,将手动纠正错误以消除误报。然而,小模型的漏报确实会影响未来训练模型的召回率。这时候就需要其他来源的数据集来补充。
四、总结
本文针对碎片化场景下智能算法应用的数据样本采集问题,提出了一种通过运动检测和小模型过滤历史监控视频的方法。这里的机器辅助方法不仅适用于数据集的采集,也适用于数据的标注,利用一些小样本训练小模型进行预标注。智慧社区、智慧园区、智慧门店、智慧家庭等一系列智慧应用已逐渐渗透到我们的生活中。碎片化的智能场景将成为未来的主流,数据作为智能原材料将成为未来最有价值的东西。越早积累,越能赢得比赛。
不用采集规则就可以采集(【东哥福利】优采云采集器V9智联招聘信息采集规则分享)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-17 05:07
【以往福利】
【东哥福利】优采云采集器V9澎湃新闻网站资讯采集规则分享
【东哥福利】优采云采集器版本选择策略
【东哥福利】优采云采集器V9智联招聘信息采集规则分享
【东哥福利】优采云浏览器百度地图商家信息采集详解
【东哥福利】优采云采集器V9知乎采集规则分享
【东哥福利】优采云采集器V9微信公众号文章采集规则分享
【东哥福利】优采云采集器V9优酷视频电视剧采集规则分享
【东哥福利】优采云采集器V9版JSon功能讲解及示例规则分享
【东哥福利-新手必看】最新最全优采云采集器V9版学习资料
【东哥福利】优采云采集器V9财富网业绩预测信息采集规则分享
【东哥福利】优采云采集器V9信息采集规则分享
【东哥福利】优采云采集器V9安居客社区信息采集规则分享
【东哥福利】豆瓣电影采集规则并发布到本地CSV格式文件
【东哥福利】美图采集规则与DZ3.X门户发布规则分享
【东哥福利】优采云采集器58同城招聘信息采集规则分享
【东哥福利】优采云采集器软件-今日头条娱乐新闻采集规则
【东哥福利】优采云采集器V9携程景点采集规则分享
【东哥福利】优采云采集器V9京东商城商品信息采集规则分享
【东客福利】优采云采集器V9人气大众点评餐饮全国商家采集规则
-------------------------------------------------- ---------------------------
东哥微信tony_lsd,请注明:东哥福利
-------------------------------------------------- -----------------------------
[东哥福利]优采云采集器V9 unicode编码转换案例规则分享
今天和大家分享的规则主要是针对汉字编码转换的问题。这里提到的编码不是一批“GBk”或“UTF8”,而是一种unicode编码。先说说unicode编码是什么。
Unicode(Uniform Code、Universal Code、Single Code)是计算机科学领域的行业标准,包括字符集、编码方案等。Unicode 的诞生是为了解决传统字符编码方案的局限性。它为每种语言的每个字符设置了统一且唯一的二进制编码,以满足跨语言和跨平台文本转换和处理的要求。
什么?还是不明白?这么说吧,我们经常看到网站的源代码中的字符“\u5730\u4e0e\u9999\”是由字母数字字符和\组成的。这是 Unicode 代码。其实这些都是汉字。关于我的什么?采集 如何将这些字符转换成汉字?强大的优采云采集器,当然是有办法的。请看案例说明!
【案例说明】
采集案例网址:采集文章内容。
第 1 步:列出 URL采集
查看网页源码,源码中没有内容页的链接,需要使用抓包软件。推荐使用Fiddler(相关教程:)。我们先打开Fiddler软件,然后点击页面页面,可以多点击几个页面。通过抓包软件找到网址:""
像这样打开网站,如下图:
其实这就是Unicode编码,不过这里不需要转码。里面的汉字都是Unicode编码。如果你不明白,你可能已经错过了。其实这就是文章列表页,那么这就是起点。URL,“page=3”是分页参数。另外,这个 URL 可以简化为以下参数。你可以在采集器...&page_size=13&page=[地址参数]上这样设置,如图:
第二步:文章内容网址采集
当我们找到列表页面时,我们会找到文章页面的链接。根据页面内容,发现有标题、时间、ID等,好像没有文章链接。别着急,我们来看看文章页面URL的规则。让我们通过这个页面打开它,然后随意点击一篇文章文章,文章的链接是这样的,有一组数字“1305128”,我猜这是ID 文章的,你可以把这组数字在上面的页面搜索进去,如果有就确认是对的。然后就很容易了。我们只需要列表页面上采集的ID号,然后通过URL拼接,然后链接到采集文章页面,像这样[参数1]/我以为这就够了,但我没有 没想到后面会有坑。打开文章页面,查看源码,发现源码中没有文章的内容。不用着急,你也可以使用上面提到的抓包软件抓包,通过抓包找到内容URL。URL拼接规则应该改为【参数1】/?render=1&callback=news_【参数1】,如图:
原理很简单,我们只需要采集到ID,然后将ID拼接到内容URL中即可。
第三步:文章内容采集
如上所述,这个网站的文章的内容也需要被捕获。抓到的网址就是,我们打开这个网址,如图:
文章内容在哪里?显然,这是一堆你看不懂的字符。一开始我们讲了unicode汉字编码转换的案例。这是正确的。这些是unicode编码的汉字。我们需要 采集 下来并转换它们。变成真正的汉字。文章的标题和内容都是unicode编码,没关系,只要有规则就可以采集,规则设置如图:
开头的字符串是 pre_article"
*)title":"以"}结尾,测试内容采集如下:
是unicode编码,然后我们需要将数据转换为采集。在数据处理中,单击+号。高级功能里面有个“字符编码转换”,然后我们可以选择From Js String,参考下图:
采集 相同的内容,做相同的设置,如下图:
设置好后,我们测试一下采集,可以看到都是汉字,如下图:
你学会了吗?继续尝试!
-------------------------------------------------- ---------------
此规则为优采云采集器V9版本规则,其他低版本不可使用。
免费版用户可以使用。
本规则仅供用户学习交流参考,不得用于非法或商业用途。对于因使用本规则而引起的任何法律问题,我们概不负责。 查看全部
不用采集规则就可以采集(【东哥福利】优采云采集器V9智联招聘信息采集规则分享)
【以往福利】
【东哥福利】优采云采集器V9澎湃新闻网站资讯采集规则分享
【东哥福利】优采云采集器版本选择策略
【东哥福利】优采云采集器V9智联招聘信息采集规则分享
【东哥福利】优采云浏览器百度地图商家信息采集详解
【东哥福利】优采云采集器V9知乎采集规则分享
【东哥福利】优采云采集器V9微信公众号文章采集规则分享
【东哥福利】优采云采集器V9优酷视频电视剧采集规则分享
【东哥福利】优采云采集器V9版JSon功能讲解及示例规则分享
【东哥福利-新手必看】最新最全优采云采集器V9版学习资料
【东哥福利】优采云采集器V9财富网业绩预测信息采集规则分享
【东哥福利】优采云采集器V9信息采集规则分享
【东哥福利】优采云采集器V9安居客社区信息采集规则分享
【东哥福利】豆瓣电影采集规则并发布到本地CSV格式文件
【东哥福利】美图采集规则与DZ3.X门户发布规则分享
【东哥福利】优采云采集器58同城招聘信息采集规则分享
【东哥福利】优采云采集器软件-今日头条娱乐新闻采集规则
【东哥福利】优采云采集器V9携程景点采集规则分享
【东哥福利】优采云采集器V9京东商城商品信息采集规则分享
【东客福利】优采云采集器V9人气大众点评餐饮全国商家采集规则
-------------------------------------------------- ---------------------------
东哥微信tony_lsd,请注明:东哥福利
-------------------------------------------------- -----------------------------
[东哥福利]优采云采集器V9 unicode编码转换案例规则分享
今天和大家分享的规则主要是针对汉字编码转换的问题。这里提到的编码不是一批“GBk”或“UTF8”,而是一种unicode编码。先说说unicode编码是什么。
Unicode(Uniform Code、Universal Code、Single Code)是计算机科学领域的行业标准,包括字符集、编码方案等。Unicode 的诞生是为了解决传统字符编码方案的局限性。它为每种语言的每个字符设置了统一且唯一的二进制编码,以满足跨语言和跨平台文本转换和处理的要求。
什么?还是不明白?这么说吧,我们经常看到网站的源代码中的字符“\u5730\u4e0e\u9999\”是由字母数字字符和\组成的。这是 Unicode 代码。其实这些都是汉字。关于我的什么?采集 如何将这些字符转换成汉字?强大的优采云采集器,当然是有办法的。请看案例说明!
【案例说明】
采集案例网址:采集文章内容。
第 1 步:列出 URL采集
查看网页源码,源码中没有内容页的链接,需要使用抓包软件。推荐使用Fiddler(相关教程:)。我们先打开Fiddler软件,然后点击页面页面,可以多点击几个页面。通过抓包软件找到网址:""
像这样打开网站,如下图:
其实这就是Unicode编码,不过这里不需要转码。里面的汉字都是Unicode编码。如果你不明白,你可能已经错过了。其实这就是文章列表页,那么这就是起点。URL,“page=3”是分页参数。另外,这个 URL 可以简化为以下参数。你可以在采集器...&page_size=13&page=[地址参数]上这样设置,如图:
第二步:文章内容网址采集
当我们找到列表页面时,我们会找到文章页面的链接。根据页面内容,发现有标题、时间、ID等,好像没有文章链接。别着急,我们来看看文章页面URL的规则。让我们通过这个页面打开它,然后随意点击一篇文章文章,文章的链接是这样的,有一组数字“1305128”,我猜这是ID 文章的,你可以把这组数字在上面的页面搜索进去,如果有就确认是对的。然后就很容易了。我们只需要列表页面上采集的ID号,然后通过URL拼接,然后链接到采集文章页面,像这样[参数1]/我以为这就够了,但我没有 没想到后面会有坑。打开文章页面,查看源码,发现源码中没有文章的内容。不用着急,你也可以使用上面提到的抓包软件抓包,通过抓包找到内容URL。URL拼接规则应该改为【参数1】/?render=1&callback=news_【参数1】,如图:
原理很简单,我们只需要采集到ID,然后将ID拼接到内容URL中即可。
第三步:文章内容采集
如上所述,这个网站的文章的内容也需要被捕获。抓到的网址就是,我们打开这个网址,如图:
文章内容在哪里?显然,这是一堆你看不懂的字符。一开始我们讲了unicode汉字编码转换的案例。这是正确的。这些是unicode编码的汉字。我们需要 采集 下来并转换它们。变成真正的汉字。文章的标题和内容都是unicode编码,没关系,只要有规则就可以采集,规则设置如图:
开头的字符串是 pre_article"
*)title":"以"}结尾,测试内容采集如下:
是unicode编码,然后我们需要将数据转换为采集。在数据处理中,单击+号。高级功能里面有个“字符编码转换”,然后我们可以选择From Js String,参考下图:
采集 相同的内容,做相同的设置,如下图:
设置好后,我们测试一下采集,可以看到都是汉字,如下图:
你学会了吗?继续尝试!
-------------------------------------------------- ---------------
此规则为优采云采集器V9版本规则,其他低版本不可使用。
免费版用户可以使用。
本规则仅供用户学习交流参考,不得用于非法或商业用途。对于因使用本规则而引起的任何法律问题,我们概不负责。
不用采集规则就可以采集(优采云采集器致力于网站书库自动化采集发布,不需要人工干预!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-11 02:11
优采云采集器是一款高质量的大数据采集发布系统,你可以在电脑或手机上采集数据,几乎采集各类网页同时使用PHP+Mysql开发,允许用户部署在云服务器上,使数据库采集更加方便和智能。
优采云采集器致力于网站图书图书馆自动化采集的发布。软件与各种cms建站程序无缝对接,实现数据无需登录即可导入,也可定时定量自动发布,无需人工干预。
软件功能
关于软件
优采云采集器(天财记),致力于发布网站数据自动化采集,系统采用PHP+Mysql开发,可部署于云服务器赋能数据采集便捷、智能、云端,让您随时随地移动办公!
数据采集
支持多级、多页、分页采集,自定义采集规则(支持regular、XPATH、JSON等),精准匹配任何信息流,几乎采集所有类型的网页,大部分文章类型的页面内容都可以智能识别
内容发布
无缝对接各种cms建站程序,实现免登录导入数据,支持自定义数据发布插件,或直接导入数据库,存储为Excel文件,生成API接口等
自动化和云平台
软件实现定时定量自动发布采集,无需人工干预!内置云平台,用户可以分享和下载采集规则,发布供需信息,社区帮助,交流等
设置说明
设置包括:采集设置、站点设置、邮件发送设置、代理设置等
启用自动采集,设置采集参数,图片本地化
页面渲染设置
代理设置
防止被阻止的 IP
翻译设置
支持百度翻译和有道翻译
网站设置 查看全部
不用采集规则就可以采集(优采云采集器致力于网站书库自动化采集发布,不需要人工干预!)
优采云采集器是一款高质量的大数据采集发布系统,你可以在电脑或手机上采集数据,几乎采集各类网页同时使用PHP+Mysql开发,允许用户部署在云服务器上,使数据库采集更加方便和智能。
优采云采集器致力于网站图书图书馆自动化采集的发布。软件与各种cms建站程序无缝对接,实现数据无需登录即可导入,也可定时定量自动发布,无需人工干预。
软件功能
关于软件
优采云采集器(天财记),致力于发布网站数据自动化采集,系统采用PHP+Mysql开发,可部署于云服务器赋能数据采集便捷、智能、云端,让您随时随地移动办公!
数据采集
支持多级、多页、分页采集,自定义采集规则(支持regular、XPATH、JSON等),精准匹配任何信息流,几乎采集所有类型的网页,大部分文章类型的页面内容都可以智能识别
内容发布
无缝对接各种cms建站程序,实现免登录导入数据,支持自定义数据发布插件,或直接导入数据库,存储为Excel文件,生成API接口等
自动化和云平台
软件实现定时定量自动发布采集,无需人工干预!内置云平台,用户可以分享和下载采集规则,发布供需信息,社区帮助,交流等
设置说明
设置包括:采集设置、站点设置、邮件发送设置、代理设置等
启用自动采集,设置采集参数,图片本地化
页面渲染设置
代理设置
防止被阻止的 IP
翻译设置
支持百度翻译和有道翻译
网站设置
不用采集规则就可以采集(大数据时代的优采云规则定制(二)介绍及应用 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-10-10 13:08
)
1、优采云简介
2、什么是信息采集
3、什么是优采云
4、优采云 你是做什么的
5、优采云规则定制
6、规则编写过程
7、网站详解
8、详细解释
9、备注
什么是优采云?
我们打开了一个网站,看到一篇文章文章很不错,所以我们复制了文章的标题和内容,把这个文章传给了我们的网站上。我们这个过程可以叫做采集,把别人网站的有用信息传递给自己网站;网上的内容,大部分都是通过复制-修改-粘贴的过程产生的,所以信息采集很重要,也很常见。我们平台在网站上发送给文章,大部分也是这样的过程;为什么很多人觉得新闻更新很麻烦,因为这项工作重复、枯燥、耗时;
优采云是目前国内用户最多、功能最全、程序支持最全面、数据库支持最丰富的软件产品;现在大数据时代,可以快速、批量、大批量地获取。互联网上的数据以我们需要的格式存储;简单来说,它对我们有什么用?我们需要更新新闻和发送商机。如果要求你准备 1000 篇文章,你需要多长时间?5个小时?有了规则,优采云只需要5分钟!前提是有规则,所以首先要学会写规则。如果规则数量足够,一个规则几分钟就可以了,但是刚开始学习的时候会慢一些;
名称解释和规则编写过程
n以优采云8.6版本为准 第一步:打开—登录 第二步:新建组
第三步:右击组,新建任务,填写任务名称;
第四步:编写采集 URL规则(起始URL和多级URL获取)
第五步:写采集内容规则(如标题、内容)
第 6 步:发布内容设置
检查启用方法二
(1)保存格式:将一条记录保存为txt;
(2)保存位置自定义;
(3) 文件模板不需要移动;
(4)文件名格式:点击右侧倒笔字选择【标签:标题】;
(5)文件编码可以先utf-8,如果测试时数据正常,但保存的数据有乱码,选择gb2312;
第七步:采集设置,两者都选择100;
一种。单任务采集内容线程数:采集多个URL同时;
湾 采集 内容间隔时间,单位毫秒:两个任务之间的间隔时间;
C。单任务发布内容线程数:一次保存多少条数据;
d. 发布内容之间的毫秒数:两次保存数据之间的时间间隔;
注意:如果网站有反屏蔽采集机制(比如很多数据但是只有采集的一部分可以下载,或者打开页面需要多长时间) ,调整a的值,适当增加b的值;
第八步:保存,勾选并启动任务(如果在同一个组,可以在组上批量选择)
前一种方式:比如我要准备n篇文章,首先要找出这个文章在哪个网站上(比如采集peer A或者peer B), yes 在哪一栏(如产品信息或新闻信息)下,该栏下面有n条信息,我要选择哪一条,输入后复制标题,复制内容再输入另一个页面改标题复制内容,等等,然后同样的过程我要执行n次;
如何转换:如何将此流程转换为软件操作?我要准备n条新闻,也就是说我需要n个标题+对应的内容,还有n个新闻链接。这n个新闻链接是从网站的一个新闻栏目中找到的,而这个网站的新闻栏目可能是很多页,比如10页。这时候从peer A的网站—栏目—内页开始;也就是找到你要采集的网站,打开这个网站栏目页(确保是采集新闻或产品),在URL下写上所有新闻链接规则采集栏,然后写内容规则采集所有新闻链接文件中的标题和内容最后保存;
网站具体操作详解
找到你要采集 URL的版块页面,比如新闻版块
复制栏目首页链接网址,在起始网址右侧点击添加,将栏目首页链接粘贴到单个网址中点击添加,如
请改用右侧的 (*),因为已添加第一页,还剩 9 页。此时,在算术数列的那一行,将项数改为9,第一项为2(因为第2页的链接是,然后点击Add-Finish;
1、 点对应右边的加法,然后下图是一个例子,右边的大图是说明;
2、点击保存,点击右下角
看看能不能采集去新闻网站,
如果可以采集到达,则正确,双击新闻网址进入下一步;如果采集错误到达,返回修改直到成功;URL过滤可自行观察其对应规律;
1、进入采集内容规则后,选择作者、时间、来源并删除,如右一图所示,因为这些标签一般情况下是不会用到的;
2、选择title标签点击修改,或者直接双击标签进入编辑界面;
3、 输入后不要更改标签名称的“标题”,更改后需要更改相应的模板;
4、 以下数据提取方法:截取前后和开始结束字符串,尽量使用默认,不熟练的不要随意更改;
5、 点击下方数据处理中的Add——内容替换,如右图;
6、内容替换将标题后的所有内容替换为空。如果不替换,采集就是页面标题。这时候需要打开两个新闻页面,看看两个新闻页面的共同部分是什么,替换共同部分
示例:对于以下两个标题,“-”为共同部分,即替换为“空”;
【图片】你知道螺旋上料机的加工方法吗?你知道螺旋给料机的原理吗?
【图文】气动送粉机的优点有哪些,您知道送粉机的工作原理吗?
1、选择要编辑的内容,或者双击进入内容标签编辑界面,不要更改标签名称;
2、 写开始和结束字符串就是找一个能把所有消息都包起来的字符串。它出现在所有新闻页面的所有新闻页面中,并且是唯一的字符串;即, this 页面模板中唯一的代码串;
例如:采集的内容时,需要选择内容区域,因为采集可能有n篇文章,比如100篇。这时候就需要考虑如何写一个 采集 to all ,方法是打开两个新闻链接。例如,查看第一篇新闻文章的源文件,找到新闻文本,然后查找与新闻第一句最接近的那个。这个页面是唯一的一段代码(如果不是唯一的,软件你能知道从哪一个开始吗?),但不是新闻的内容,比如
, 复制后,在第二个新闻页面的源文件中搜索,看看有没有,如果有,就可以使用了;类似地,找到新闻的最后一句话,并在最近的页面中找到唯一的一段代码。复制后,在第二个新闻页面的源文件中搜索,看看有没有,如果有,就可以使用了;数据处理:因为采集是其他网站信息,可能还有其他网站信息,如公司名称、联系方式、品牌等信息,也可能有其他网站 超链接和其他信息。这时候需要对信息进行过滤;数据处理——添加——标签过滤下面对应的参数HTML:将滚动轴水平拉到最后,在所有标签前打勾,点击确定;内容替换:把这个网站的信息换成你自己的,原理是整改后拆机,公司名称和电话(拆分),手机号码(拆分),邮箱地址,公司地址(拆分),品牌名称,网址(拆分);split 意味着分解和替换这些数据。这时候需要进行以下更换: 因为在新闻中,这是拆机更换的时候,才能更换干净。你可以多看看他的新闻,可能用的什么格式;您需要进行以下更换:因为在新闻中,这是拆卸和更换的时间,以便将其更换干净。你可以多看看他的新闻,可能用的什么格式;您需要进行以下更换:因为在新闻中,这是拆卸和更换的时间,以便将其更换干净。你可以多看看他的新闻,可能用的什么格式;
注意:数据处理还有很多技巧,需要在使用的过程中思考,是采集的核心。如果处理不好,可能是别人的嫁衣,所以一定要仔细观察,综合考虑,如果处理得当,从采集下来的文章甚至可以出版直接(不是您自己的企业站点)
预防措施()
1、 右击组:出现如下菜单,可以正常使用;
新建任务:在该组上新建一个任务;
运行该组中的所有任务:顾名思义;
新任务:在这个组下重新创建一个组;
编辑/删除组:编辑/删除当前组;
导入/导出分组规则:当前组下的所有任务都可以导出导入到同一版本优采云;
导入任务到该组:将导出的单个任务导入到该组;
粘贴组下任务:该项目只有在任务被复制后才会出现,您可以粘贴多个相同的任务,然后在粘贴的任务上进行编辑;
启动任务:同菜单栏启动;
编辑任务:编辑已写入的任务;
导出任务:可以将当前规则导出并在同版本的其他工具上导入,但导入数据时需要重复上述步骤6-发布内容设置,必须重新选择/填写;
复制任务到粘贴板:复制后,选择一个任务组,右击将不同数量的任务粘贴到该组中,避免多次写入同一个任务;
清除任务的所有采集数据:新建如果你采集之前有采集,想重新采集,需要先清除;
3、其他设置:点击顶部菜单栏中的Tools-Options,配置全局选项和默认选项;
全局选项:可以调整同时运行的最大任务数。一般为5,但不需要调整;
默认选项:是否忽略 case point is;
查看全部
不用采集规则就可以采集(大数据时代的优采云规则定制(二)介绍及应用
)
1、优采云简介
2、什么是信息采集
3、什么是优采云
4、优采云 你是做什么的
5、优采云规则定制
6、规则编写过程
7、网站详解
8、详细解释
9、备注
什么是优采云?
我们打开了一个网站,看到一篇文章文章很不错,所以我们复制了文章的标题和内容,把这个文章传给了我们的网站上。我们这个过程可以叫做采集,把别人网站的有用信息传递给自己网站;网上的内容,大部分都是通过复制-修改-粘贴的过程产生的,所以信息采集很重要,也很常见。我们平台在网站上发送给文章,大部分也是这样的过程;为什么很多人觉得新闻更新很麻烦,因为这项工作重复、枯燥、耗时;
优采云是目前国内用户最多、功能最全、程序支持最全面、数据库支持最丰富的软件产品;现在大数据时代,可以快速、批量、大批量地获取。互联网上的数据以我们需要的格式存储;简单来说,它对我们有什么用?我们需要更新新闻和发送商机。如果要求你准备 1000 篇文章,你需要多长时间?5个小时?有了规则,优采云只需要5分钟!前提是有规则,所以首先要学会写规则。如果规则数量足够,一个规则几分钟就可以了,但是刚开始学习的时候会慢一些;
名称解释和规则编写过程
n以优采云8.6版本为准 第一步:打开—登录 第二步:新建组
第三步:右击组,新建任务,填写任务名称;
第四步:编写采集 URL规则(起始URL和多级URL获取)
第五步:写采集内容规则(如标题、内容)
第 6 步:发布内容设置
检查启用方法二
(1)保存格式:将一条记录保存为txt;
(2)保存位置自定义;
(3) 文件模板不需要移动;
(4)文件名格式:点击右侧倒笔字选择【标签:标题】;
(5)文件编码可以先utf-8,如果测试时数据正常,但保存的数据有乱码,选择gb2312;
第七步:采集设置,两者都选择100;
一种。单任务采集内容线程数:采集多个URL同时;
湾 采集 内容间隔时间,单位毫秒:两个任务之间的间隔时间;
C。单任务发布内容线程数:一次保存多少条数据;
d. 发布内容之间的毫秒数:两次保存数据之间的时间间隔;
注意:如果网站有反屏蔽采集机制(比如很多数据但是只有采集的一部分可以下载,或者打开页面需要多长时间) ,调整a的值,适当增加b的值;
第八步:保存,勾选并启动任务(如果在同一个组,可以在组上批量选择)
前一种方式:比如我要准备n篇文章,首先要找出这个文章在哪个网站上(比如采集peer A或者peer B), yes 在哪一栏(如产品信息或新闻信息)下,该栏下面有n条信息,我要选择哪一条,输入后复制标题,复制内容再输入另一个页面改标题复制内容,等等,然后同样的过程我要执行n次;
如何转换:如何将此流程转换为软件操作?我要准备n条新闻,也就是说我需要n个标题+对应的内容,还有n个新闻链接。这n个新闻链接是从网站的一个新闻栏目中找到的,而这个网站的新闻栏目可能是很多页,比如10页。这时候从peer A的网站—栏目—内页开始;也就是找到你要采集的网站,打开这个网站栏目页(确保是采集新闻或产品),在URL下写上所有新闻链接规则采集栏,然后写内容规则采集所有新闻链接文件中的标题和内容最后保存;
网站具体操作详解
找到你要采集 URL的版块页面,比如新闻版块
复制栏目首页链接网址,在起始网址右侧点击添加,将栏目首页链接粘贴到单个网址中点击添加,如
请改用右侧的 (*),因为已添加第一页,还剩 9 页。此时,在算术数列的那一行,将项数改为9,第一项为2(因为第2页的链接是,然后点击Add-Finish;
1、 点对应右边的加法,然后下图是一个例子,右边的大图是说明;
2、点击保存,点击右下角
看看能不能采集去新闻网站,
如果可以采集到达,则正确,双击新闻网址进入下一步;如果采集错误到达,返回修改直到成功;URL过滤可自行观察其对应规律;
1、进入采集内容规则后,选择作者、时间、来源并删除,如右一图所示,因为这些标签一般情况下是不会用到的;
2、选择title标签点击修改,或者直接双击标签进入编辑界面;
3、 输入后不要更改标签名称的“标题”,更改后需要更改相应的模板;
4、 以下数据提取方法:截取前后和开始结束字符串,尽量使用默认,不熟练的不要随意更改;
5、 点击下方数据处理中的Add——内容替换,如右图;
6、内容替换将标题后的所有内容替换为空。如果不替换,采集就是页面标题。这时候需要打开两个新闻页面,看看两个新闻页面的共同部分是什么,替换共同部分
示例:对于以下两个标题,“-”为共同部分,即替换为“空”;
【图片】你知道螺旋上料机的加工方法吗?你知道螺旋给料机的原理吗?
【图文】气动送粉机的优点有哪些,您知道送粉机的工作原理吗?
1、选择要编辑的内容,或者双击进入内容标签编辑界面,不要更改标签名称;
2、 写开始和结束字符串就是找一个能把所有消息都包起来的字符串。它出现在所有新闻页面的所有新闻页面中,并且是唯一的字符串;即, this 页面模板中唯一的代码串;
例如:采集的内容时,需要选择内容区域,因为采集可能有n篇文章,比如100篇。这时候就需要考虑如何写一个 采集 to all ,方法是打开两个新闻链接。例如,查看第一篇新闻文章的源文件,找到新闻文本,然后查找与新闻第一句最接近的那个。这个页面是唯一的一段代码(如果不是唯一的,软件你能知道从哪一个开始吗?),但不是新闻的内容,比如
, 复制后,在第二个新闻页面的源文件中搜索,看看有没有,如果有,就可以使用了;类似地,找到新闻的最后一句话,并在最近的页面中找到唯一的一段代码。复制后,在第二个新闻页面的源文件中搜索,看看有没有,如果有,就可以使用了;数据处理:因为采集是其他网站信息,可能还有其他网站信息,如公司名称、联系方式、品牌等信息,也可能有其他网站 超链接和其他信息。这时候需要对信息进行过滤;数据处理——添加——标签过滤下面对应的参数HTML:将滚动轴水平拉到最后,在所有标签前打勾,点击确定;内容替换:把这个网站的信息换成你自己的,原理是整改后拆机,公司名称和电话(拆分),手机号码(拆分),邮箱地址,公司地址(拆分),品牌名称,网址(拆分);split 意味着分解和替换这些数据。这时候需要进行以下更换: 因为在新闻中,这是拆机更换的时候,才能更换干净。你可以多看看他的新闻,可能用的什么格式;您需要进行以下更换:因为在新闻中,这是拆卸和更换的时间,以便将其更换干净。你可以多看看他的新闻,可能用的什么格式;您需要进行以下更换:因为在新闻中,这是拆卸和更换的时间,以便将其更换干净。你可以多看看他的新闻,可能用的什么格式;
注意:数据处理还有很多技巧,需要在使用的过程中思考,是采集的核心。如果处理不好,可能是别人的嫁衣,所以一定要仔细观察,综合考虑,如果处理得当,从采集下来的文章甚至可以出版直接(不是您自己的企业站点)
预防措施()
1、 右击组:出现如下菜单,可以正常使用;
新建任务:在该组上新建一个任务;
运行该组中的所有任务:顾名思义;
新任务:在这个组下重新创建一个组;
编辑/删除组:编辑/删除当前组;
导入/导出分组规则:当前组下的所有任务都可以导出导入到同一版本优采云;
导入任务到该组:将导出的单个任务导入到该组;
粘贴组下任务:该项目只有在任务被复制后才会出现,您可以粘贴多个相同的任务,然后在粘贴的任务上进行编辑;
启动任务:同菜单栏启动;
编辑任务:编辑已写入的任务;
导出任务:可以将当前规则导出并在同版本的其他工具上导入,但导入数据时需要重复上述步骤6-发布内容设置,必须重新选择/填写;
复制任务到粘贴板:复制后,选择一个任务组,右击将不同数量的任务粘贴到该组中,避免多次写入同一个任务;
清除任务的所有采集数据:新建如果你采集之前有采集,想重新采集,需要先清除;
3、其他设置:点击顶部菜单栏中的Tools-Options,配置全局选项和默认选项;
全局选项:可以调整同时运行的最大任务数。一般为5,但不需要调整;
默认选项:是否忽略 case point is;
不用采集规则就可以采集(不用采集规则就可以采集高质量的网站太多了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-10-09 19:04
不用采集规则就可以采集的网站太多了,建议采集高质量的网站,一般情况下:有一个大的网站平台、有一个高质量的博客站、有一个普通的有一定量的普通用户群体,这三个就是普通的网站一般用户会采集的网站,这样是最好的。可以多关注一下一些源码源文件,你可以在网上搜到一些。
很多很多,我就不举例子了,找一些自己需要的就行。什么新闻源,seo黄金外链,论坛博客,爱问,知乎,百度知道,百度百科,高权重微博,百度文库,百度经验,网络报刊杂志等等,上网一搜一大把。一直一个观点,如果自己不动脑子提升,就算运气比别人好,也不一定能走的更远。
题主到底是要“搞定”还是“搞定好”?这两者之间是天壤之别。搞定好可以包括:也可以包括不包括等等。此外,还要具体到某一个网站。就如同社会学问题的边界问题,心理学问题的心理边界问题一样。做好一个网站本身,有时候在需要说明优势的时候就不是所有人都能弄懂其优势,总是要反复提炼很久。这种时候,能够读到优势只不过是其中表现的几个优势罢了。
或者说,全是优势,可能表现为seo方面,全是劣势。这种时候,只要弄懂了,就不是很难,提炼出特色就不是很难。比如,yahoo+就可以优势很好,不能说这个网站就比百度+差多少。这个包含的知识内容有点多,需要一点点读。 查看全部
不用采集规则就可以采集(不用采集规则就可以采集高质量的网站太多了)
不用采集规则就可以采集的网站太多了,建议采集高质量的网站,一般情况下:有一个大的网站平台、有一个高质量的博客站、有一个普通的有一定量的普通用户群体,这三个就是普通的网站一般用户会采集的网站,这样是最好的。可以多关注一下一些源码源文件,你可以在网上搜到一些。
很多很多,我就不举例子了,找一些自己需要的就行。什么新闻源,seo黄金外链,论坛博客,爱问,知乎,百度知道,百度百科,高权重微博,百度文库,百度经验,网络报刊杂志等等,上网一搜一大把。一直一个观点,如果自己不动脑子提升,就算运气比别人好,也不一定能走的更远。
题主到底是要“搞定”还是“搞定好”?这两者之间是天壤之别。搞定好可以包括:也可以包括不包括等等。此外,还要具体到某一个网站。就如同社会学问题的边界问题,心理学问题的心理边界问题一样。做好一个网站本身,有时候在需要说明优势的时候就不是所有人都能弄懂其优势,总是要反复提炼很久。这种时候,能够读到优势只不过是其中表现的几个优势罢了。
或者说,全是优势,可能表现为seo方面,全是劣势。这种时候,只要弄懂了,就不是很难,提炼出特色就不是很难。比如,yahoo+就可以优势很好,不能说这个网站就比百度+差多少。这个包含的知识内容有点多,需要一点点读。
不用采集规则就可以采集(掌握一种采集技巧对SEO站长而言还是很有帮助的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-06 01:28
好久没用优采云采集器了。想起以前做站群SEO的时候,经常登录优采云采集器去采集各大相关网站信息内容。而那个时候,采集之风盛行,到处都是各种采集站,特别是小说站,文章站等等,动不动就有采集几十万文章,网站很容易达到重量4.虽然大部分网站现在很少采集,但采集还是无处不在,因为一些所谓的原创网站,文章的内容很可能也会被采集后续处理。所以掌握一个采集技术对SEO站长还是很有帮助的。
优采云采集器URL 规则设置
第一步打开优采云采集器,点击【新建】新建任务,填写任务名称,设置采集 URL规则,设置列表页采集规则和列表页面所在的文章页面规则分为以下两步。
第一步:添加起始地址,点击【添加】,选择批量/多页,在地址格式设置中设置采集的网页链接,点击【添加】和【完成】。这一步的目的是建立有多少个栏目页面链接。
采集网页链接技巧说明:首先确定你要采集的网页栏目页,分别查看栏目页1、第2页和第3页链接规则,比较后,会发现page 2和page 3的链接很像,只有2和3变了(分页1也是一样,一般为SEO格式隐藏,所以分页1和栏目首页链接是一样的)即可按照等差数列分析,其实绝大多数网站专栏页面都是按等差数列排列的,包括尹华峰的博客。因此,填充规则是选择算术数列,在地址格式中填写第2页的链接,用(*)代替改变的数字,根据栏目页数设置项数。
第二步:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则。熟练后,建议使用结果网址过滤功能。写出需要收录和不需要收录的URL。可以测试一下规则是否填写正确,然后保存。这一步的目的是在每一栏下建立到文章页面的链接。
多级URL获取技巧说明:我们要获取的是本栏目下文章页面的链接,到原网页查看栏目页面源码,找到第一个链接到文章页面在源页面的位置,然后选择上面的一小段通用代码,一定是每列页面都会出现的代码,通常的表达形式会收录list或者文章。
优采云采集器内容规则设置
第二步是设置采集内容规则。可以在典型页面上填写一个文章页面链接进行测试,设置标题采集规则和内容采集规则,也分为两步。
步骤a:双击【标题】标签。一般网页的标题是一个标签,所以这一步可以默认。如有必要,您可以设置内容过滤和内容替换。
步骤 b:双击 [内容] 选项卡。内容抽取规则与第一步中的第2步多级URL获取方法相同。这里是获取内容,所以就是查看内容页的源码,找到这个页面的body内容,截取body第一段上面的一小段通用代码。此代码也出现在所有文章 页面上,通常的表达形式文章标签是开头和结尾。您还可以设置内容过滤、内容替换和标签过滤来过滤掉不需要的信息。如果不需要图片,可以勾选过滤掉img图片标签。
优采云采集器发布内容设置
第三步,发布内容设置,勾选需要启用的发布方式,保存,然后在任务列表中右键任务名称,点击【开始任务】,等待采集完成即可。
注意,优采云采集器分为两种发布内容的方式。第一种方式是通过web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个并保存为本地。至于文件模板,可以【查看默认模板】,然后选择TXT格式。
结论:优采云采集器很强大,除了采集文章还可以采集视频等,优采云采集器 使用规则并不难。您根本不需要了解任何编程语言。您只需要了解一些常见的简单代码即可。你基本上可以掌握它一次或两次。这是一个非常好的SEO工具。作为网站优化者,我们可以对采集文章之后的内容进行修改和调整,使内容更加完整,同时可以大大提高SEO人员的工作效率。优采云采集器 使用方法介绍到这里。如果不明白,可以在下方留言,尽我所知给予解答。 查看全部
不用采集规则就可以采集(掌握一种采集技巧对SEO站长而言还是很有帮助的)
好久没用优采云采集器了。想起以前做站群SEO的时候,经常登录优采云采集器去采集各大相关网站信息内容。而那个时候,采集之风盛行,到处都是各种采集站,特别是小说站,文章站等等,动不动就有采集几十万文章,网站很容易达到重量4.虽然大部分网站现在很少采集,但采集还是无处不在,因为一些所谓的原创网站,文章的内容很可能也会被采集后续处理。所以掌握一个采集技术对SEO站长还是很有帮助的。
优采云采集器URL 规则设置
第一步打开优采云采集器,点击【新建】新建任务,填写任务名称,设置采集 URL规则,设置列表页采集规则和列表页面所在的文章页面规则分为以下两步。
第一步:添加起始地址,点击【添加】,选择批量/多页,在地址格式设置中设置采集的网页链接,点击【添加】和【完成】。这一步的目的是建立有多少个栏目页面链接。
采集网页链接技巧说明:首先确定你要采集的网页栏目页,分别查看栏目页1、第2页和第3页链接规则,比较后,会发现page 2和page 3的链接很像,只有2和3变了(分页1也是一样,一般为SEO格式隐藏,所以分页1和栏目首页链接是一样的)即可按照等差数列分析,其实绝大多数网站专栏页面都是按等差数列排列的,包括尹华峰的博客。因此,填充规则是选择算术数列,在地址格式中填写第2页的链接,用(*)代替改变的数字,根据栏目页数设置项数。
第二步:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则。熟练后,建议使用结果网址过滤功能。写出需要收录和不需要收录的URL。可以测试一下规则是否填写正确,然后保存。这一步的目的是在每一栏下建立到文章页面的链接。
多级URL获取技巧说明:我们要获取的是本栏目下文章页面的链接,到原网页查看栏目页面源码,找到第一个链接到文章页面在源页面的位置,然后选择上面的一小段通用代码,一定是每列页面都会出现的代码,通常的表达形式会收录list或者文章。
优采云采集器内容规则设置
第二步是设置采集内容规则。可以在典型页面上填写一个文章页面链接进行测试,设置标题采集规则和内容采集规则,也分为两步。
步骤a:双击【标题】标签。一般网页的标题是一个标签,所以这一步可以默认。如有必要,您可以设置内容过滤和内容替换。
步骤 b:双击 [内容] 选项卡。内容抽取规则与第一步中的第2步多级URL获取方法相同。这里是获取内容,所以就是查看内容页的源码,找到这个页面的body内容,截取body第一段上面的一小段通用代码。此代码也出现在所有文章 页面上,通常的表达形式文章标签是开头和结尾。您还可以设置内容过滤、内容替换和标签过滤来过滤掉不需要的信息。如果不需要图片,可以勾选过滤掉img图片标签。
优采云采集器发布内容设置
第三步,发布内容设置,勾选需要启用的发布方式,保存,然后在任务列表中右键任务名称,点击【开始任务】,等待采集完成即可。
注意,优采云采集器分为两种发布内容的方式。第一种方式是通过web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个并保存为本地。至于文件模板,可以【查看默认模板】,然后选择TXT格式。
结论:优采云采集器很强大,除了采集文章还可以采集视频等,优采云采集器 使用规则并不难。您根本不需要了解任何编程语言。您只需要了解一些常见的简单代码即可。你基本上可以掌握它一次或两次。这是一个非常好的SEO工具。作为网站优化者,我们可以对采集文章之后的内容进行修改和调整,使内容更加完整,同时可以大大提高SEO人员的工作效率。优采云采集器 使用方法介绍到这里。如果不明白,可以在下方留言,尽我所知给予解答。
不用采集规则就可以采集(优采云采集器内置规则市场下载规则的好处,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-05 19:11
优采云采集器是一款技术领先的网页采集软件,为了避免配置采集规则的重复性工作,优采云采集器具有内置规则 在市场上,用户共享配置的采集规则,互相帮助。使用规则市场下载规则的好处是显而易见的,不需要花时间研究和配置采集流程。52z飞翔下载中心为您提供下载。
软件特点
操作简单,完全可视化的图形操作,不需要专业的IT人员,任何会用电脑上网的人都可以轻松掌握。
云采集
采集 任务自动分配到云端多台服务器同时执行,提高了采集的效率,短时间内可以获取上千条消息。
拖放采集流程
模拟人的操作思维模式,可以登录、输入数据、点击链接、按钮等,还可以针对不同的情况采用不同的采集流程。
图形识别
内置可扩展的OCR接口,支持对图片中的文字进行分析,可以提取图片上的文字。
定时自动采集
采集 任务自动运行,可以在指定周期内自动采集,还支持实时采集,速度快到一分钟一次。
2 分钟快速启动
内置从入门到精通的视频教程,2分钟即可上手,还有文档、论坛、qq群等。
免费使用
它是免费的,免费版没有功能限制。您可以立即试用,下载并立即安装。
特征
简单来说,使用优采云可以很容易的从任何网页中准确的采集你需要的数据,生成自定义的常规数据格式。优采云数据采集 系统可以做的包括但不限于以下内容:
1. 财务数据,如季报、年报、财报,自动包括最新的每日净值采集;
2.各大新闻门户网站实时监控,自动更新上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4. 监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6. 关注各大地产相关网站、采集新房、二手房的最新行情;
7. 采集主要车型网站 具体新车和二手车信息;
8. 发现和采集潜在客户信息;
9. 采集行业网站产品目录及产品信息;
10. 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
指示
首先我们新建一个任务-->进入流程设计页面-->给流程添加一个循环步骤-->选择循环步骤-->勾选软件右侧的URL列表复选框-- > 打开 URL 列表文本框--> 将准备好的 URL 列表填入文本框
接下来,将打开网页的步骤拖入循环中--> 选择打开网页的步骤--> 选中使用当前循环中的URL 作为导航地址的框--> 点击保存。系统会在界面底部的浏览器中打开循环选择的URL对应的网页
至此,打开网页循环的配置就完成了。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置采集 数据步骤,这里不再赘述。可以参考系列一:采集单个网页文章。下图是最终和过程
更新日志
1、增加联系客服功能,可以联系客服进行一对一人工服务
2、新增微图分析功能,一键分析数据采集
3、修复单机采集异常退出问题
4、修复云端部分问题采集
5、修复客户端启动时无响应的问题
6、修复导出相关问题
7、修复了循环提取数据,item无法勾选的问题
更多精彩APP,尽在52z飞翔下载网! 查看全部
不用采集规则就可以采集(优采云采集器内置规则市场下载规则的好处,)
优采云采集器是一款技术领先的网页采集软件,为了避免配置采集规则的重复性工作,优采云采集器具有内置规则 在市场上,用户共享配置的采集规则,互相帮助。使用规则市场下载规则的好处是显而易见的,不需要花时间研究和配置采集流程。52z飞翔下载中心为您提供下载。
软件特点
操作简单,完全可视化的图形操作,不需要专业的IT人员,任何会用电脑上网的人都可以轻松掌握。
云采集
采集 任务自动分配到云端多台服务器同时执行,提高了采集的效率,短时间内可以获取上千条消息。
拖放采集流程
模拟人的操作思维模式,可以登录、输入数据、点击链接、按钮等,还可以针对不同的情况采用不同的采集流程。
图形识别
内置可扩展的OCR接口,支持对图片中的文字进行分析,可以提取图片上的文字。
定时自动采集
采集 任务自动运行,可以在指定周期内自动采集,还支持实时采集,速度快到一分钟一次。
2 分钟快速启动
内置从入门到精通的视频教程,2分钟即可上手,还有文档、论坛、qq群等。
免费使用
它是免费的,免费版没有功能限制。您可以立即试用,下载并立即安装。
特征
简单来说,使用优采云可以很容易的从任何网页中准确的采集你需要的数据,生成自定义的常规数据格式。优采云数据采集 系统可以做的包括但不限于以下内容:
1. 财务数据,如季报、年报、财报,自动包括最新的每日净值采集;
2.各大新闻门户网站实时监控,自动更新上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4. 监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6. 关注各大地产相关网站、采集新房、二手房的最新行情;
7. 采集主要车型网站 具体新车和二手车信息;
8. 发现和采集潜在客户信息;
9. 采集行业网站产品目录及产品信息;
10. 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
指示
首先我们新建一个任务-->进入流程设计页面-->给流程添加一个循环步骤-->选择循环步骤-->勾选软件右侧的URL列表复选框-- > 打开 URL 列表文本框--> 将准备好的 URL 列表填入文本框
接下来,将打开网页的步骤拖入循环中--> 选择打开网页的步骤--> 选中使用当前循环中的URL 作为导航地址的框--> 点击保存。系统会在界面底部的浏览器中打开循环选择的URL对应的网页
至此,打开网页循环的配置就完成了。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置采集 数据步骤,这里不再赘述。可以参考系列一:采集单个网页文章。下图是最终和过程
更新日志
1、增加联系客服功能,可以联系客服进行一对一人工服务
2、新增微图分析功能,一键分析数据采集
3、修复单机采集异常退出问题
4、修复云端部分问题采集
5、修复客户端启动时无响应的问题
6、修复导出相关问题
7、修复了循环提取数据,item无法勾选的问题
更多精彩APP,尽在52z飞翔下载网!
不用采集规则就可以采集(怎么写织梦5.3的采集规则教程!其他版本也类似)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-10-05 16:10
本文首发于小凡新浪博客,今天转给新手学习~
今天给大家讲讲织梦5.3的采集规则教程怎么写!其他版本类似!
首先我们打开织梦后台,点击采集-采集节点管理-添加新节点
这里我们以采集normal文章为例,我们选择normal文章,然后确认
我们进入采集的设置页面,填写节点名称,也就是给这个新节点起个名字,这里可以随意填写。
然后打开你要采集的文章列表页面,这里我们以织梦的官网为例打开这个页面,右键-查看源文件
找到目标页面编码,就在charset之后
页面基本信息一般忽略,填写后如图
现在让我们填写列表URL获取规则
查看文章列表第一页的地址
比较第二页的地址
我们发现除了49_后面的数字都一样,所以我们可以这样写
(*).html
就用(*)代替1,因为只有2页,所以我们从1填到2,每页加1,当然2-1...等于1。
到此我们完成了
可能你的一些采集列表没有规则,所以你只需要手动指定列表URL,如图
每行写一个页面地址
列表规则写好后,开始编写文章 URL匹配规则,返回文章列表页面
右键查看源文件找到区域开头的HTML,也就是找到文章列表开头的标记。
我们可以很容易地找到如图所示的“新闻列表”。从这里开始,以下是文章的列表
让我们找到 文章 列表末尾的 HTML
就是这样,一个很容易找到的标志
如果链接收录图片:
不要将采集处理成缩略图,这里根据自己的需要选择
再次过滤区域 URL:
(使用正则表达式)
必须收录:(优先级高于后者)
不能收录:
打开源文件,我们可以清楚地看到文章链接都是以.html结尾的
所以,一定要在.html的后面填写,如果遇到一些比较麻烦的列表,也可以填写后面的不能收录
我们点击保存设置进入下一步,可以看到我们获取到的文章 URL
看到这个是对的,我们保存信息,进入下一步设置内容字段获取规则
看看文章有没有分页,随便输入一篇文章看看吧。. 我们看到文章中没有分页
所以这里我们默认了
现在我们找到文章标题等,输入一篇文章文章,右键查看源文件
看看这些
根据源码填写
让我们填写文章内容的开头和结尾
同上,找到开始和结束标志
开始:
结束:
要过滤什么内容文章写在过滤规则里,比如要过滤文章中的图片
选择通用规则
然后检查IMG并确认
这样我们过滤文本中的图片
设置完成后,点击保存设置并预览
这样的采集规则就写好了。这很简单。有些网站写起来难,但你需要更努力。
让我们点击保存并启动 采集-start 采集 网页并工作一段时间,采集 就结束了
让我们看看我们采集到达了什么文章
456
好像成功了,导出数据
完成,更新文档,可以看到采集来了文章
因为我们过滤了图片,里面的一张图片不见了!
写采集规则其实很简单~
第一次写东西,写的不好请补充,有错误请留言,我会及时改正! 查看全部
不用采集规则就可以采集(怎么写织梦5.3的采集规则教程!其他版本也类似)
本文首发于小凡新浪博客,今天转给新手学习~
今天给大家讲讲织梦5.3的采集规则教程怎么写!其他版本类似!
首先我们打开织梦后台,点击采集-采集节点管理-添加新节点
这里我们以采集normal文章为例,我们选择normal文章,然后确认
我们进入采集的设置页面,填写节点名称,也就是给这个新节点起个名字,这里可以随意填写。
然后打开你要采集的文章列表页面,这里我们以织梦的官网为例打开这个页面,右键-查看源文件
找到目标页面编码,就在charset之后
页面基本信息一般忽略,填写后如图
现在让我们填写列表URL获取规则
查看文章列表第一页的地址
比较第二页的地址
我们发现除了49_后面的数字都一样,所以我们可以这样写
(*).html
就用(*)代替1,因为只有2页,所以我们从1填到2,每页加1,当然2-1...等于1。
到此我们完成了
可能你的一些采集列表没有规则,所以你只需要手动指定列表URL,如图
每行写一个页面地址
列表规则写好后,开始编写文章 URL匹配规则,返回文章列表页面
右键查看源文件找到区域开头的HTML,也就是找到文章列表开头的标记。
我们可以很容易地找到如图所示的“新闻列表”。从这里开始,以下是文章的列表
让我们找到 文章 列表末尾的 HTML
就是这样,一个很容易找到的标志
如果链接收录图片:
不要将采集处理成缩略图,这里根据自己的需要选择
再次过滤区域 URL:
(使用正则表达式)
必须收录:(优先级高于后者)
不能收录:
打开源文件,我们可以清楚地看到文章链接都是以.html结尾的
所以,一定要在.html的后面填写,如果遇到一些比较麻烦的列表,也可以填写后面的不能收录
我们点击保存设置进入下一步,可以看到我们获取到的文章 URL
看到这个是对的,我们保存信息,进入下一步设置内容字段获取规则
看看文章有没有分页,随便输入一篇文章看看吧。. 我们看到文章中没有分页
所以这里我们默认了
现在我们找到文章标题等,输入一篇文章文章,右键查看源文件
看看这些
根据源码填写
让我们填写文章内容的开头和结尾
同上,找到开始和结束标志
开始:
结束:
要过滤什么内容文章写在过滤规则里,比如要过滤文章中的图片
选择通用规则
然后检查IMG并确认
这样我们过滤文本中的图片
设置完成后,点击保存设置并预览
这样的采集规则就写好了。这很简单。有些网站写起来难,但你需要更努力。
让我们点击保存并启动 采集-start 采集 网页并工作一段时间,采集 就结束了
让我们看看我们采集到达了什么文章
456
好像成功了,导出数据
完成,更新文档,可以看到采集来了文章
因为我们过滤了图片,里面的一张图片不见了!
写采集规则其实很简单~
第一次写东西,写的不好请补充,有错误请留言,我会及时改正!
不用采集规则就可以采集(不用采集规则就可以采集,只需要有起始访问url)
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-09-27 22:02
不用采集规则就可以采集,只需要有起始访问url就可以了起始访问url:a001就可以,然后这个url采集器就可以识别一个整站,就不用自己手动采集了,包括结果都可以生成pdf
根据url规则自动生成
百度从去年开始就已经开放采集功能。百度百科可以直接生成pdf版本的。直接把百科网址拿来做站群,有人搜的时候生成网址,然后把百科文章链接塞到里面。下载站点详细的教程可以看我写的文章。
给大家推荐个工具:/:注册登录后用实名的qq号,或者邮箱,用微信绑定就行,电脑手机都可以操作。安全方便快捷,下载的文件有原文链接和密码。会员之间有通过关键词的百科问答分享优惠券等等功能。付费99元或更高可以获得一键操作功能。awsling的社群里学员可以免费体验。
各位,不是我打击你你可以去试一试我的sofish网站,sofish博客|wordpress优质内容创作平台这个网站上没有你要的资源(api),
百度经验:最全面最权威的php5从入门到精通学习网站_百度经验php微学院::,且可以和现在的资源一起读。因为现在的资源已经全面升级了,不再针对php5。
php5.6的只要人人学php就可以让您自己成为php大牛
以下全部是经验所得的教程中文站, 查看全部
不用采集规则就可以采集(不用采集规则就可以采集,只需要有起始访问url)
不用采集规则就可以采集,只需要有起始访问url就可以了起始访问url:a001就可以,然后这个url采集器就可以识别一个整站,就不用自己手动采集了,包括结果都可以生成pdf
根据url规则自动生成
百度从去年开始就已经开放采集功能。百度百科可以直接生成pdf版本的。直接把百科网址拿来做站群,有人搜的时候生成网址,然后把百科文章链接塞到里面。下载站点详细的教程可以看我写的文章。
给大家推荐个工具:/:注册登录后用实名的qq号,或者邮箱,用微信绑定就行,电脑手机都可以操作。安全方便快捷,下载的文件有原文链接和密码。会员之间有通过关键词的百科问答分享优惠券等等功能。付费99元或更高可以获得一键操作功能。awsling的社群里学员可以免费体验。
各位,不是我打击你你可以去试一试我的sofish网站,sofish博客|wordpress优质内容创作平台这个网站上没有你要的资源(api),
百度经验:最全面最权威的php5从入门到精通学习网站_百度经验php微学院::,且可以和现在的资源一起读。因为现在的资源已经全面升级了,不再针对php5。
php5.6的只要人人学php就可以让您自己成为php大牛
以下全部是经验所得的教程中文站,

