
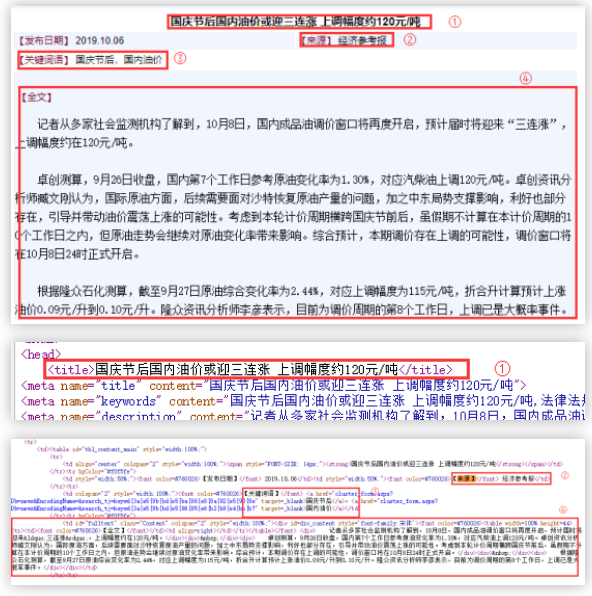
不用采集规则就可以采集
不想重复工作如何办?教你一键批量操作,群发、采集不用愁!
采集交流 • 优采云 发表了文章 • 0 个评论 • 356 次浏览 • 2020-08-24 22:25
网上营销常常须要注册多个帐号,大批量群发营销电邮或推广消息,是不是觉得重复劳动非常沉闷无趣?数据剖析时,是不是也时常为推行web采集和绕开访问验证的低效率而烦恼?
的确,这些企业业务发展中的基础工作,却常常占用职工大量时间,看起来很简单的任务,却总是历时无趣,浪费人工成本。
如何确保那些工作确切高效?
下面带你Get快速批量进行web操作的秘籍。介绍一个可视化脚本工具优采云浏览器,只须要把工作流程写在脚本中,就可以使脚本取代右手手动运行繁杂的任务了。
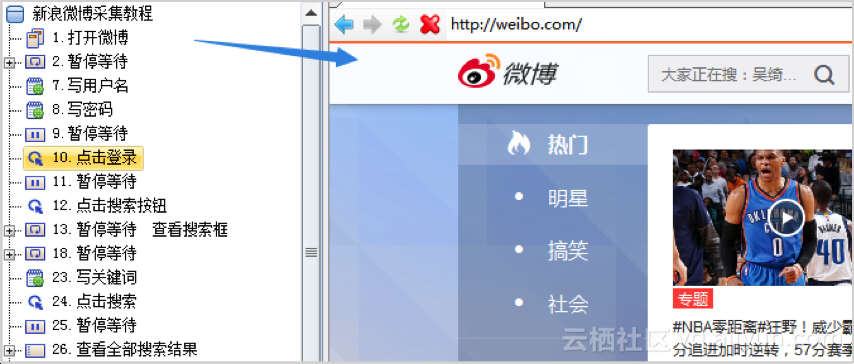
以微博采集发布为例,按照下边的步骤来设置流程:
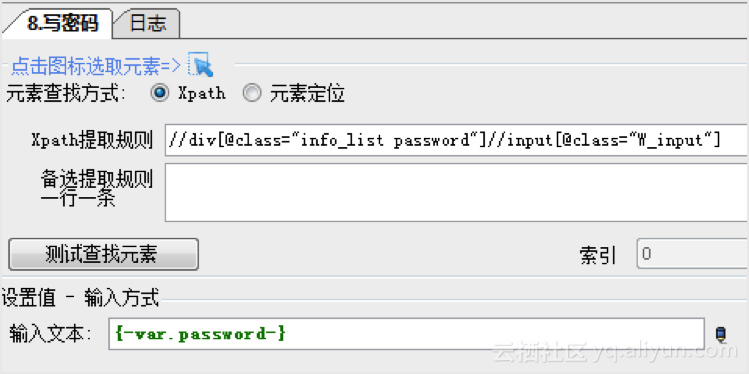
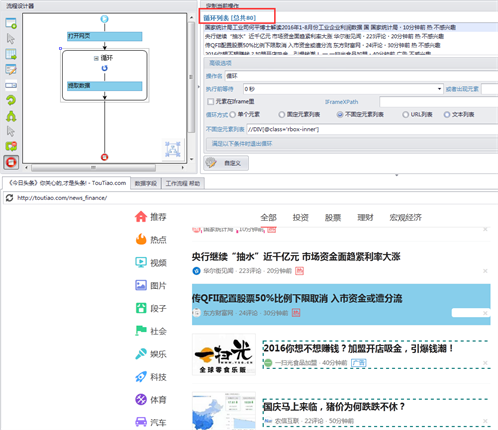
1、打开网页,登录帐号
配置一个打开网页的步骤,再配置写入用户名和密码。用户名和密码保存在变量中直接调用即可。配置时使用键盘放置在页面元素上,就可以手动显示Xpath提取规则,无需技术知识,上手十分简单。
写入后通过点击登陆按键来实现手动登入。
2、点击搜索,输入搜索内容
仍然是使用键盘点选元素找到输入框的Xpath,把输入内容,比如“热门话题”保存在变量中调用即可。
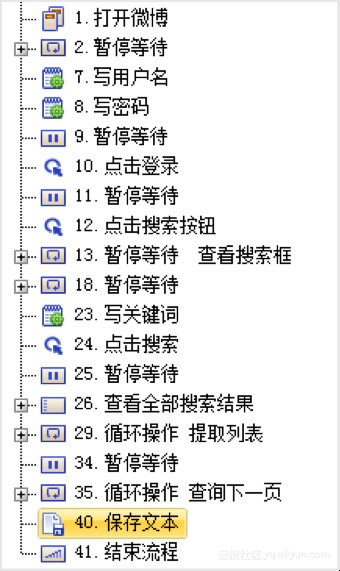
3、提取数据,保存内容
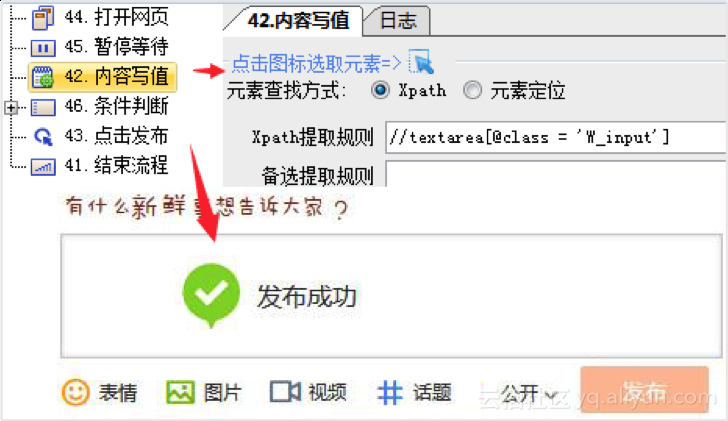
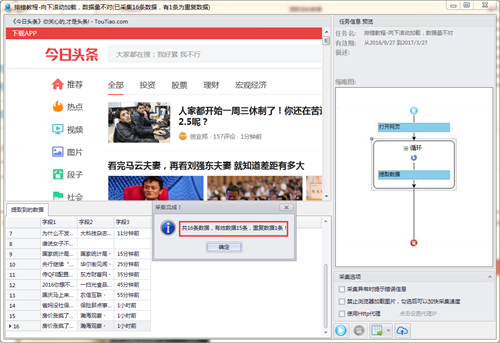
4、发布数据
如果须要发布,就配置几步发布流程即可。运行一下即可见到软件手动采集了数据并发布成功。
有了简单强悍的优采云浏览器,我们就可以把沉闷冗长的批量操作都交给软件,解放右手为我们的业务核心争取更多的工作时间。基于可视化提取技术的优采云浏览器可以确保操作准确性高,同时急剧提高工作效率,降低人力成本。
除营销、采集、群发之外,优采云浏览器还有更多应用可能,点击订购:
优采云浏览器万能数据采集发布脚本工具 查看全部
不想重复工作如何办?教你一键批量操作,群发、采集不用愁!
网上营销常常须要注册多个帐号,大批量群发营销电邮或推广消息,是不是觉得重复劳动非常沉闷无趣?数据剖析时,是不是也时常为推行web采集和绕开访问验证的低效率而烦恼?
的确,这些企业业务发展中的基础工作,却常常占用职工大量时间,看起来很简单的任务,却总是历时无趣,浪费人工成本。
如何确保那些工作确切高效?
下面带你Get快速批量进行web操作的秘籍。介绍一个可视化脚本工具优采云浏览器,只须要把工作流程写在脚本中,就可以使脚本取代右手手动运行繁杂的任务了。
以微博采集发布为例,按照下边的步骤来设置流程:
1、打开网页,登录帐号
配置一个打开网页的步骤,再配置写入用户名和密码。用户名和密码保存在变量中直接调用即可。配置时使用键盘放置在页面元素上,就可以手动显示Xpath提取规则,无需技术知识,上手十分简单。
写入后通过点击登陆按键来实现手动登入。
2、点击搜索,输入搜索内容
仍然是使用键盘点选元素找到输入框的Xpath,把输入内容,比如“热门话题”保存在变量中调用即可。
3、提取数据,保存内容
4、发布数据
如果须要发布,就配置几步发布流程即可。运行一下即可见到软件手动采集了数据并发布成功。
有了简单强悍的优采云浏览器,我们就可以把沉闷冗长的批量操作都交给软件,解放右手为我们的业务核心争取更多的工作时间。基于可视化提取技术的优采云浏览器可以确保操作准确性高,同时急剧提高工作效率,降低人力成本。
除营销、采集、群发之外,优采云浏览器还有更多应用可能,点击订购:
优采云浏览器万能数据采集发布脚本工具
新手怎么完善杰奇小说站?
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2020-08-24 20:48
本文针对想建书站的新人,老站长可以略过了。
本人建小说站只有不到一个月的时间,中间遇见了好多问题,走了好多弯路,如果不是有很多热心的站长帮忙,我想这个站()还要花更多的时间就能完善上去。为了使更多象我这样的新人能快速的构建起一个小说站,我把我的建站过程整理了一下,希望对新人有所帮助。费话不说了,我们开始吧。
一、建立本地测试环境
用杰奇做小说站,需要的环境:1.PHP (4.3.0 以上)、2.Zend Optimizer、3.MySQL (4.0 以上)、 4.Apache/Apache2。我在这里走了好多弯路,我把须要的软件一个一个的装,也不知道是那里操作不对,老是构建不好本地测试环境。后来有个热心的站长告诉我可以用phpnow一键安装,快的太,也不怕出错。
(下载地址:)
安装看它的说明就可以了,这里须要注意的是最好你的笔记本是干净的系统,没装过MYSQL,IIS。如果装过了,PHPNOW在安装的时侯会提示端口被占用,如果被占用,你只能先把占用端口的服务禁用掉。禁用服务的方式:开始——控制面板——管理工具——服务,把MYSQL和IIS禁用就OK了。
安装PHPNOW结束后打开IE在地址里输入:127.0.0.1出现下边的内容说明安装成功。
输入数据库密码点击联接,出现下边的结果,说明数据库联接成功。
MySQL 测试结果
服务器 localhost连接正常 (5.0.51b-community-nt-log)
数据库 test连接正常
到这里本地测试环境建立好了。
二、安装杰奇程序
1.下载:
我用的是杰奇1.5的破解版,现在这个版本在网路上随意搜索下就有一大堆。自己下载个吧,免得说我提权。下载解压后把杰奇文件夹内的内容全部复制到phpnow文件夹下的htdocs内。
2.导入数据库:
一般杰奇1.5破解版是不用全新安装的,意思说没有install文件夹的,安装的时侯只须要导出数据库文件即可,数据库文件是文本文件如(jq1.5.txt)。
导入数据库的方式:打开IE输入127.0.0.1/phpMyAdmin填入你数据库的帐号密码登入,一般帐号是root,我这儿密码是aswait。进入界面后找到导出并点击它。
导入数据库文件要注意选择文件的字符集为gbk,如上图。找到你的数据库文件点击执行后,数据库就导出成功了。
3.获取注册码,设置define.php文件:
打开你的杰奇文件夹,看下key.php是在那个文件夹内,我的是在根目录下就有。
打开IE输入127.0.0.1/key.php在出现的页面里填写你的域名。这里填写得到一串代码,把代码复制出来,打开杰奇文件夹下config文件夹内的define.php文件,按照下边输入内容填写:
@define('JIEQI_URL','http://127.0.0.1');(这个填写很重要,注意后面没有/)
@define('JIEQI_SITE_NAME','看书撒');
@define('JIEQI_CONTACT_EMAIL','xxx@163.com');
@define('JIEQI_MAIN_SERVER','http://127.0.0.1');
@define('JIEQI_USER_ENTRY','http://127.0.0.1');
@define('JIEQI_META_KEYWORDS','看书撒小说网;www.kanshu3.com;免费在线小说;玄幻小说;言情小说;网游小说;修真小说;都市小说;武侠小说;网络小说');
@define('JIEQI_META_DESCRIPTION','看书撒为国内最大的小说网站之一,免费提供,玄幻小说,言情小说,网游小说,修真小说,都市小说,武侠小说,网络小说等在线阅读,永做更新最快,小说最多的小说网.');
@define('JIEQI_META_COPYRIGHT','本小说站所有小说、发贴和小说评论均为网友更新!仅代表发布者个人行为,与本小说站(www.kanshu3.com)立场无关!
本站所有小说的版权为原作者所有!如无意中侵犯到您的权益,或是含有非法内容,请及时与我们联系,我们将在第一时间做出回应!谢谢!');
@define('JIEQI_BANNER','');
@define('这里填写刚才复制下的注册码');
@define('JIEQI_DB_TYPE','mysql');(这个是数据库类型,别改)
@define('JIEQI_DB_PREFIX','jieqi');
@define('JIEQI_DB_HOST','localhost');(这个别改)
@define('JIEQI_DB_USER','root');
@define('JIEQI_DB_PASS','123456');
@define('JIEQI_DB_NAME','mysql');(这个是数据库名称)
写好后保存即可。
4.测试网站并登陆后台:
打开IE输入127.0.0.1这个时侯才会出现杰奇程序的默认首页,输入127.0.0.1/admin步入后台,账号密码均为admin。至此,杰奇小说站程序安装完毕。
三、采集小说数据(可参见:”杰奇1.7--关关采集器使用教程“)
这时候可能有人会说,版面都没设置好,怎么就开始采集数据了呢?我得说明下,因为现今这个本地测试站是没有数据的,一本书都没有,怎么能看出版面疗效呢?所以我们可以先采集少量数据,排好版面后才会出疗效来。
1.采集规则:
找几个采集规则,网上搜索下大把的,注意要1.5的采集规则。把下载好的采集规则置于configs\article内。如果嫌麻烦,我这儿有几个,自己下载吧。
推荐:16K采集规则、八路采集规则、飞库采集规则等
2.修改collectsite.php文件:
打开configs\article内的collectsite.php,按照上面的书写格式添加采集规则。如:
$jieqiCollectsite['12']['name'] = 'xx文学网';
$jieqiCollectsite['12']['config'] = 'xx_com';
$jieqiCollectsite['12']['url'] = '1';
$jieqiCollectsite['12']['subarticleid'] = '';
$jieqiCollectsite['12']['enable'] = '1';
3.开始采集:
依次步入网站后台——模块管理——小说连载——批量采集——按照页面批量采集,点击开始采集。采集速度很快的,采个十几篇小说就可以了,主要是为了看首页疗效而已。 查看全部
新手怎么完善杰奇小说站?
本文针对想建书站的新人,老站长可以略过了。
本人建小说站只有不到一个月的时间,中间遇见了好多问题,走了好多弯路,如果不是有很多热心的站长帮忙,我想这个站()还要花更多的时间就能完善上去。为了使更多象我这样的新人能快速的构建起一个小说站,我把我的建站过程整理了一下,希望对新人有所帮助。费话不说了,我们开始吧。
一、建立本地测试环境
用杰奇做小说站,需要的环境:1.PHP (4.3.0 以上)、2.Zend Optimizer、3.MySQL (4.0 以上)、 4.Apache/Apache2。我在这里走了好多弯路,我把须要的软件一个一个的装,也不知道是那里操作不对,老是构建不好本地测试环境。后来有个热心的站长告诉我可以用phpnow一键安装,快的太,也不怕出错。
(下载地址:)
安装看它的说明就可以了,这里须要注意的是最好你的笔记本是干净的系统,没装过MYSQL,IIS。如果装过了,PHPNOW在安装的时侯会提示端口被占用,如果被占用,你只能先把占用端口的服务禁用掉。禁用服务的方式:开始——控制面板——管理工具——服务,把MYSQL和IIS禁用就OK了。
安装PHPNOW结束后打开IE在地址里输入:127.0.0.1出现下边的内容说明安装成功。
输入数据库密码点击联接,出现下边的结果,说明数据库联接成功。
MySQL 测试结果
服务器 localhost连接正常 (5.0.51b-community-nt-log)
数据库 test连接正常
到这里本地测试环境建立好了。
二、安装杰奇程序
1.下载:
我用的是杰奇1.5的破解版,现在这个版本在网路上随意搜索下就有一大堆。自己下载个吧,免得说我提权。下载解压后把杰奇文件夹内的内容全部复制到phpnow文件夹下的htdocs内。
2.导入数据库:
一般杰奇1.5破解版是不用全新安装的,意思说没有install文件夹的,安装的时侯只须要导出数据库文件即可,数据库文件是文本文件如(jq1.5.txt)。
导入数据库的方式:打开IE输入127.0.0.1/phpMyAdmin填入你数据库的帐号密码登入,一般帐号是root,我这儿密码是aswait。进入界面后找到导出并点击它。
导入数据库文件要注意选择文件的字符集为gbk,如上图。找到你的数据库文件点击执行后,数据库就导出成功了。
3.获取注册码,设置define.php文件:
打开你的杰奇文件夹,看下key.php是在那个文件夹内,我的是在根目录下就有。
打开IE输入127.0.0.1/key.php在出现的页面里填写你的域名。这里填写得到一串代码,把代码复制出来,打开杰奇文件夹下config文件夹内的define.php文件,按照下边输入内容填写:
@define('JIEQI_URL','http://127.0.0.1');(这个填写很重要,注意后面没有/)
@define('JIEQI_SITE_NAME','看书撒');
@define('JIEQI_CONTACT_EMAIL','xxx@163.com');
@define('JIEQI_MAIN_SERVER','http://127.0.0.1');
@define('JIEQI_USER_ENTRY','http://127.0.0.1');
@define('JIEQI_META_KEYWORDS','看书撒小说网;www.kanshu3.com;免费在线小说;玄幻小说;言情小说;网游小说;修真小说;都市小说;武侠小说;网络小说');
@define('JIEQI_META_DESCRIPTION','看书撒为国内最大的小说网站之一,免费提供,玄幻小说,言情小说,网游小说,修真小说,都市小说,武侠小说,网络小说等在线阅读,永做更新最快,小说最多的小说网.');
@define('JIEQI_META_COPYRIGHT','本小说站所有小说、发贴和小说评论均为网友更新!仅代表发布者个人行为,与本小说站(www.kanshu3.com)立场无关!
本站所有小说的版权为原作者所有!如无意中侵犯到您的权益,或是含有非法内容,请及时与我们联系,我们将在第一时间做出回应!谢谢!');
@define('JIEQI_BANNER','');
@define('这里填写刚才复制下的注册码');
@define('JIEQI_DB_TYPE','mysql');(这个是数据库类型,别改)
@define('JIEQI_DB_PREFIX','jieqi');
@define('JIEQI_DB_HOST','localhost');(这个别改)
@define('JIEQI_DB_USER','root');
@define('JIEQI_DB_PASS','123456');
@define('JIEQI_DB_NAME','mysql');(这个是数据库名称)
写好后保存即可。
4.测试网站并登陆后台:
打开IE输入127.0.0.1这个时侯才会出现杰奇程序的默认首页,输入127.0.0.1/admin步入后台,账号密码均为admin。至此,杰奇小说站程序安装完毕。
三、采集小说数据(可参见:”杰奇1.7--关关采集器使用教程“)
这时候可能有人会说,版面都没设置好,怎么就开始采集数据了呢?我得说明下,因为现今这个本地测试站是没有数据的,一本书都没有,怎么能看出版面疗效呢?所以我们可以先采集少量数据,排好版面后才会出疗效来。
1.采集规则:
找几个采集规则,网上搜索下大把的,注意要1.5的采集规则。把下载好的采集规则置于configs\article内。如果嫌麻烦,我这儿有几个,自己下载吧。
推荐:16K采集规则、八路采集规则、飞库采集规则等
2.修改collectsite.php文件:
打开configs\article内的collectsite.php,按照上面的书写格式添加采集规则。如:
$jieqiCollectsite['12']['name'] = 'xx文学网';
$jieqiCollectsite['12']['config'] = 'xx_com';
$jieqiCollectsite['12']['url'] = '1';
$jieqiCollectsite['12']['subarticleid'] = '';
$jieqiCollectsite['12']['enable'] = '1';
3.开始采集:
依次步入网站后台——模块管理——小说连载——批量采集——按照页面批量采集,点击开始采集。采集速度很快的,采个十几篇小说就可以了,主要是为了看首页疗效而已。
【新手入门】优采云采集器是不是免费的
采集交流 • 优采云 发表了文章 • 0 个评论 • 298 次浏览 • 2020-08-23 18:16
经常有用户来问我们,你们优采云采集器是不是免费的啊?
我们说那是必须的啊!
你看我们连导入数据都不限制,这是下了多大的决心啊!~~~
然后用户都会扔给我们一张度娘的搜索结果截图,
“这年头,还有哪家采集器说自己不免费啊?老实说吧,下载图片、导出数据这种须要多少积分?积分多少钱?我懂的!”
面对这些结果,我们也是很无奈的。
目前市面上几乎所有的数据采集软件都声称自己是免费的,但是常常还会对基本功能进行限制,比如必须使用积分能够进行数据导入;或是限制授权笔记本数目;或是不能下载图片;或着是对导入数据的格式进行严格的限制,免费导入的数据格式根本用不成,等等等等。导致你们看见免费就有一种被坑的觉得。
作为共产主义接班人,这样的做法我们其实以及肯定是拒绝的。
优采云采集器一款真免费的采集软件,目前我们的免费版本支持功能如下:
※ 智能模式:智能辨识列表和分页,一键采集
※流程图模式:可视化操作,可以模拟人为操作
※采集任务:100个任务,支持多任务同时运行,无数目限制,支持云端动态加密储存,切换终端同步更新
※采集网址:无数目限制,支持自动输入,从文件导出,批量生成
※采集内容:无数目限制
※下载图片:无数目限制
※导出数据:导出数据到本地(无数目限制),导出格式:Excel、Txt、Csv、Html
※发布到数据库:无数目限制,支持发布到本地和云端服务器,支持类型:MySQL、PgSQL、SqlServer、MongoDB
※数据处理:字段合并,文本替换,提取数字、提取邮箱,去除字符、正则替换等
※筛选功能:根据条件组合对采集字段进行筛选
※预登陆采集:采集需要登入能够查看内容的网址
看这儿看这儿,有图有真相→_→ 查看全部
【新手入门】优采云采集器是不是免费的
经常有用户来问我们,你们优采云采集器是不是免费的啊?
我们说那是必须的啊!

你看我们连导入数据都不限制,这是下了多大的决心啊!~~~

然后用户都会扔给我们一张度娘的搜索结果截图,
“这年头,还有哪家采集器说自己不免费啊?老实说吧,下载图片、导出数据这种须要多少积分?积分多少钱?我懂的!”

面对这些结果,我们也是很无奈的。

目前市面上几乎所有的数据采集软件都声称自己是免费的,但是常常还会对基本功能进行限制,比如必须使用积分能够进行数据导入;或是限制授权笔记本数目;或是不能下载图片;或着是对导入数据的格式进行严格的限制,免费导入的数据格式根本用不成,等等等等。导致你们看见免费就有一种被坑的觉得。

作为共产主义接班人,这样的做法我们其实以及肯定是拒绝的。

优采云采集器一款真免费的采集软件,目前我们的免费版本支持功能如下:
※ 智能模式:智能辨识列表和分页,一键采集
※流程图模式:可视化操作,可以模拟人为操作
※采集任务:100个任务,支持多任务同时运行,无数目限制,支持云端动态加密储存,切换终端同步更新
※采集网址:无数目限制,支持自动输入,从文件导出,批量生成
※采集内容:无数目限制
※下载图片:无数目限制
※导出数据:导出数据到本地(无数目限制),导出格式:Excel、Txt、Csv、Html
※发布到数据库:无数目限制,支持发布到本地和云端服务器,支持类型:MySQL、PgSQL、SqlServer、MongoDB
※数据处理:字段合并,文本替换,提取数字、提取邮箱,去除字符、正则替换等
※筛选功能:根据条件组合对采集字段进行筛选
※预登陆采集:采集需要登入能够查看内容的网址

看这儿看这儿,有图有真相→_→
付亚辉: zen-cart采集规则和数据库发布模块下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 768 次浏览 • 2020-08-22 14:27
今天网速实在很慢了,什么也搞不了。再加上天气这么热,心里有点焦躁。废话不多说了,开始明天的教程。首先安装zen-cart,我用的是zen-cart1.9中文版的,安装步骤我就不写了,这个很简单了。安装之后按照你要采集的网站建立对应的目录就OK了。例如我要测试采集的网站这是我随意找的网站,我首先构建大分类Shop By Players 然后构建相应的小分类Alex Rodriguez Jersey(多页面,等会解释这个)和Folder Alfonso Soriano Jersey(单页面)。我只是测试采集就先建一个大分类两个小分类。如下图大分类小分类之后开始写采集规则了,每个网站的采集规则是不一样的,针对每位网站写不同的规则,不过zen-cart网站的规则差不多了,写多了都会发觉很简单。第一步写采集网址规则,首先添加采集地址(我添加的是(*)&sort=20a)如下图之后为了采集自己想要的页面,就必须过滤一些网址了,就要写一些限制性的标志了,必须收录,不得收录,页面内选取区域采集网址从xx到xx等请看右图我是怎样写的,这个不是唯一性的,每个人写的可能不一样。这一步算是完成了。第二步写采集内容规则,我把每位标签名对应规则放下来,如下图商品名称商品机型商品价钱商品特惠商品图象,注意那个文件保存格式,我选择了[原文件名],根据自己的须要也可以改商品描述,注意用那个html标签排除,我用了去首尾空白符OK,规则写完了,可以找个内容页测试一下,如下图看,已经测试成功了,注意图片一定要显示完整。
第三步发布内容设置,有几种发布形式,我选择方法三,导入到自定义数据库,如下图之后点击数据库发布全局配置,选择编辑你要编辑数据库发布配置,如下图点击编辑之后,出现右图之后编辑数据库发布模块,如下图看见你刚刚写的标签名没,注意这个地方的标签与刚刚写的标签名要对应着,,不然都会失败的,看到最后那种“2”没,就是刚刚我们构建栏目时的分类ID,每采集一个栏目的时侯变换不同的ID,上面我早已写了,不需要改动了,最后我会把发布模块分享给朋友们。修改完之后,要点击那种“修改配置”这样能够保存着。第四步文件保存及部份中级设置,如下图,基本上不用改变。最后一步,点击更新,然后就可以点击开始采集了,采集效果如下图OK,采集成功了,可以发布到数据库了,然后我到网站后台看一下,是不是早已导出到数据库了,呵呵!如下图,成功了后台疗效前台疗效最后要说明一点,采集单网址也是一样,注意选择如下图好了,教程写完了,挺累的,写了两个小时,不知道大家看明白没,反正我是太明白(呵呵),根据不同的网站灵活运用就OK了,稍后我把采集规则放下来,供同学下载,有不明白的地方可以给我留言或则加我qqzen-cart.rar(点击下载哦)付亚辉原文首发::493908654 查看全部
付亚辉: zen-cart采集规则和数据库发布模块下载
今天网速实在很慢了,什么也搞不了。再加上天气这么热,心里有点焦躁。废话不多说了,开始明天的教程。首先安装zen-cart,我用的是zen-cart1.9中文版的,安装步骤我就不写了,这个很简单了。安装之后按照你要采集的网站建立对应的目录就OK了。例如我要测试采集的网站这是我随意找的网站,我首先构建大分类Shop By Players 然后构建相应的小分类Alex Rodriguez Jersey(多页面,等会解释这个)和Folder Alfonso Soriano Jersey(单页面)。我只是测试采集就先建一个大分类两个小分类。如下图大分类小分类之后开始写采集规则了,每个网站的采集规则是不一样的,针对每位网站写不同的规则,不过zen-cart网站的规则差不多了,写多了都会发觉很简单。第一步写采集网址规则,首先添加采集地址(我添加的是(*)&sort=20a)如下图之后为了采集自己想要的页面,就必须过滤一些网址了,就要写一些限制性的标志了,必须收录,不得收录,页面内选取区域采集网址从xx到xx等请看右图我是怎样写的,这个不是唯一性的,每个人写的可能不一样。这一步算是完成了。第二步写采集内容规则,我把每位标签名对应规则放下来,如下图商品名称商品机型商品价钱商品特惠商品图象,注意那个文件保存格式,我选择了[原文件名],根据自己的须要也可以改商品描述,注意用那个html标签排除,我用了去首尾空白符OK,规则写完了,可以找个内容页测试一下,如下图看,已经测试成功了,注意图片一定要显示完整。
第三步发布内容设置,有几种发布形式,我选择方法三,导入到自定义数据库,如下图之后点击数据库发布全局配置,选择编辑你要编辑数据库发布配置,如下图点击编辑之后,出现右图之后编辑数据库发布模块,如下图看见你刚刚写的标签名没,注意这个地方的标签与刚刚写的标签名要对应着,,不然都会失败的,看到最后那种“2”没,就是刚刚我们构建栏目时的分类ID,每采集一个栏目的时侯变换不同的ID,上面我早已写了,不需要改动了,最后我会把发布模块分享给朋友们。修改完之后,要点击那种“修改配置”这样能够保存着。第四步文件保存及部份中级设置,如下图,基本上不用改变。最后一步,点击更新,然后就可以点击开始采集了,采集效果如下图OK,采集成功了,可以发布到数据库了,然后我到网站后台看一下,是不是早已导出到数据库了,呵呵!如下图,成功了后台疗效前台疗效最后要说明一点,采集单网址也是一样,注意选择如下图好了,教程写完了,挺累的,写了两个小时,不知道大家看明白没,反正我是太明白(呵呵),根据不同的网站灵活运用就OK了,稍后我把采集规则放下来,供同学下载,有不明白的地方可以给我留言或则加我qqzen-cart.rar(点击下载哦)付亚辉原文首发::493908654
一套内容采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 372 次浏览 • 2020-08-22 13:40
字体大小 []
内容采集系统,对于以内容为主的网站来说是非常好的助手,除了原创内容外,其它内容须要编辑人员或则采集系统来搜集整理,然后添加到自己的网站里。Discuz DvBBS CMS等产品,内部都自带了一个内容采集功能,来采集指定的相关内容。 单客户端的优采云采集器也可以非常好的采集指定的内容。这些工具都是想使机器取代人工,把编辑人员从内容搬运的工作中解放下来,做一些更高档的工作,例如采集结果的内容微调,SEO优化,设定精确的采集规则,让采集的内容愈加符合自己网站的须要。
下面的内容采集系统就是从这个看法开发而至的,这个采集系统由两个部份组成:
1.编辑人员所使用的采集规则设定器和对采集结果进行初审、微调和发布所使用的Web站点。
2.部署在服务器上的定时采集器和定时发送器。
首先由编辑人员通过一个采集规则设定器(NiceCollectoer.exe)设定要采集的站点,再等采集完成后,编辑人员再通过一个Web站点(PickWeb)对采集的结果进行初审、微调和优化之后发布到自己的网站上。编辑人员所须要做的是采集规则的设定,和对采集结果的优化,其它部份的工作都由机器完成。
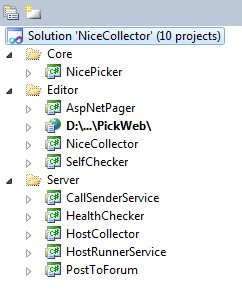
NicePicker 是Html 分析器,用来抽取Url,NiceCollector 和HostCollector 都使用NicePicker来剖析Html, NiceCollectoer 就是采集规则设定器,一个目标网站只用设定一次:
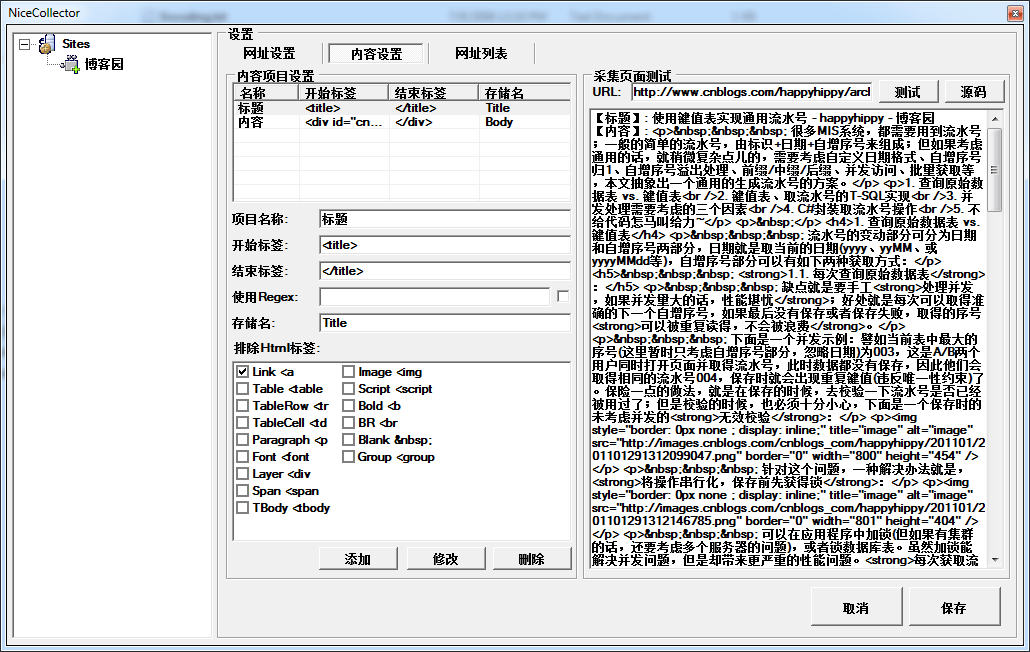
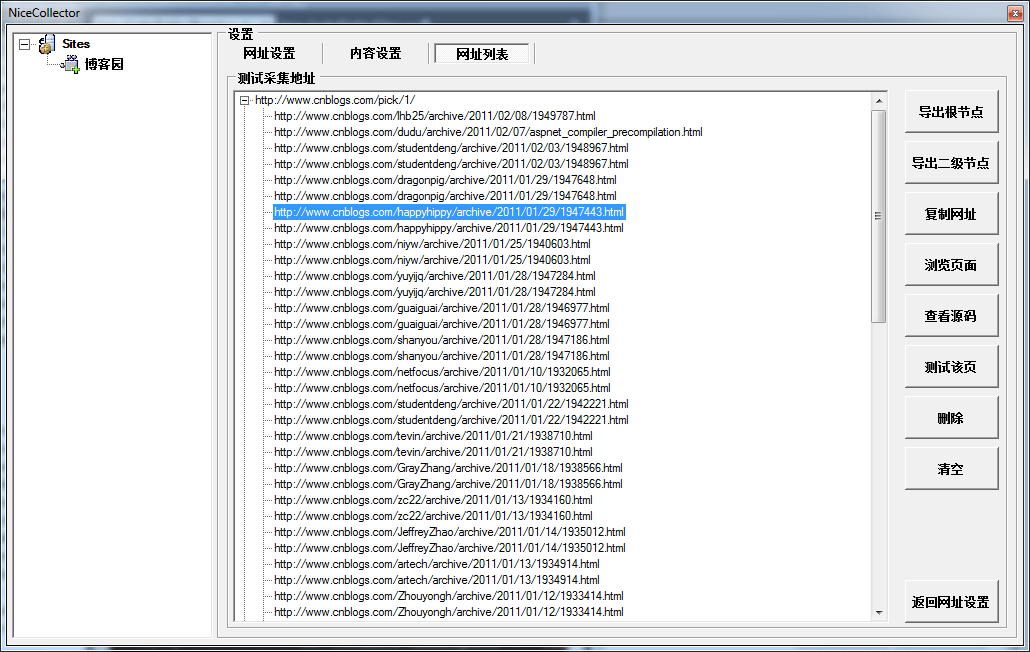
使用上去和最早的优采云采集器类似,这里使用博客园来做目标采集站点, 设定采集精华县的文章,采集规则十分简单:当编辑人员设定好采集规则后,这些规则会保存到NiceCollector.exe同目录下的 Setting.mdb中。一般当采集规则设定好之后,基本上不用再变动了,只在目标网站的Html Dom结构发生变化时,需要再度微调一下采集规则。NiceCollector同时用于新目标采集站点的设定和添加操作。
等编辑人员完成采集规则的设定后,把Setting.mdb放在 HostCollector.exe下, HostCollector 会依照Setting.mdb的设定进行真正的采集,并把采集的结果存入数据库。
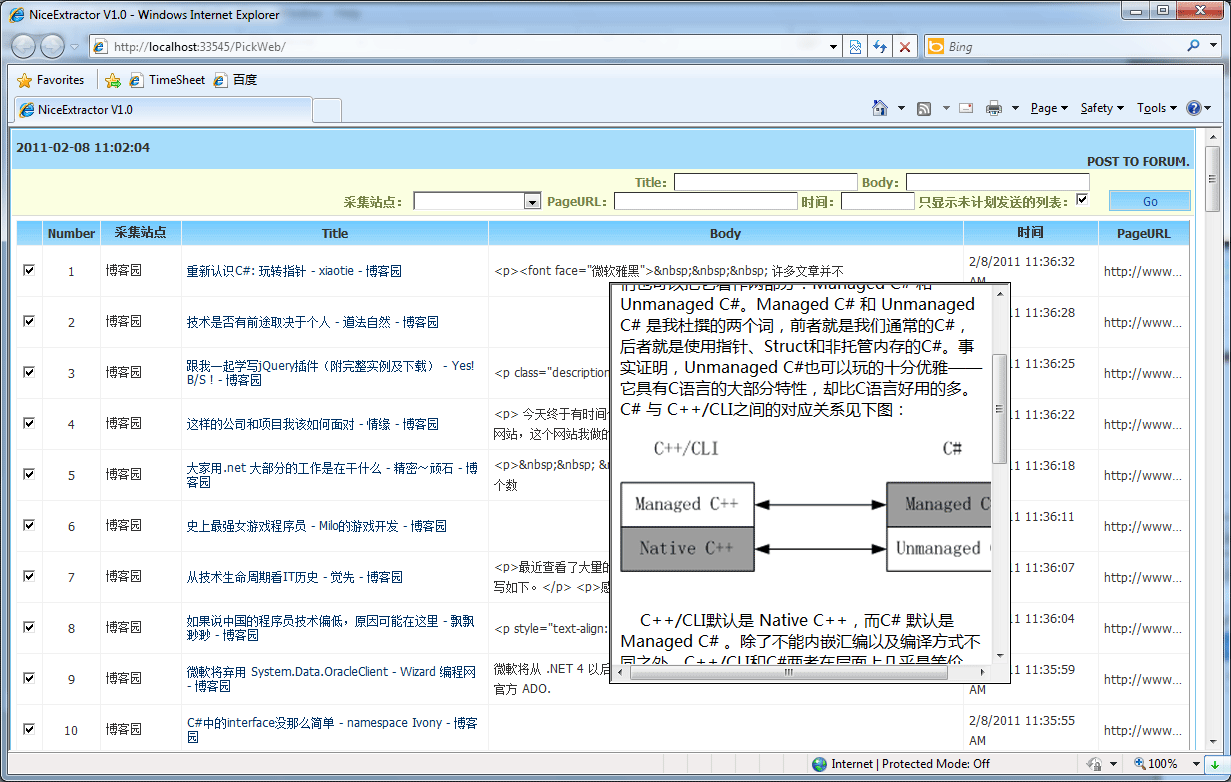
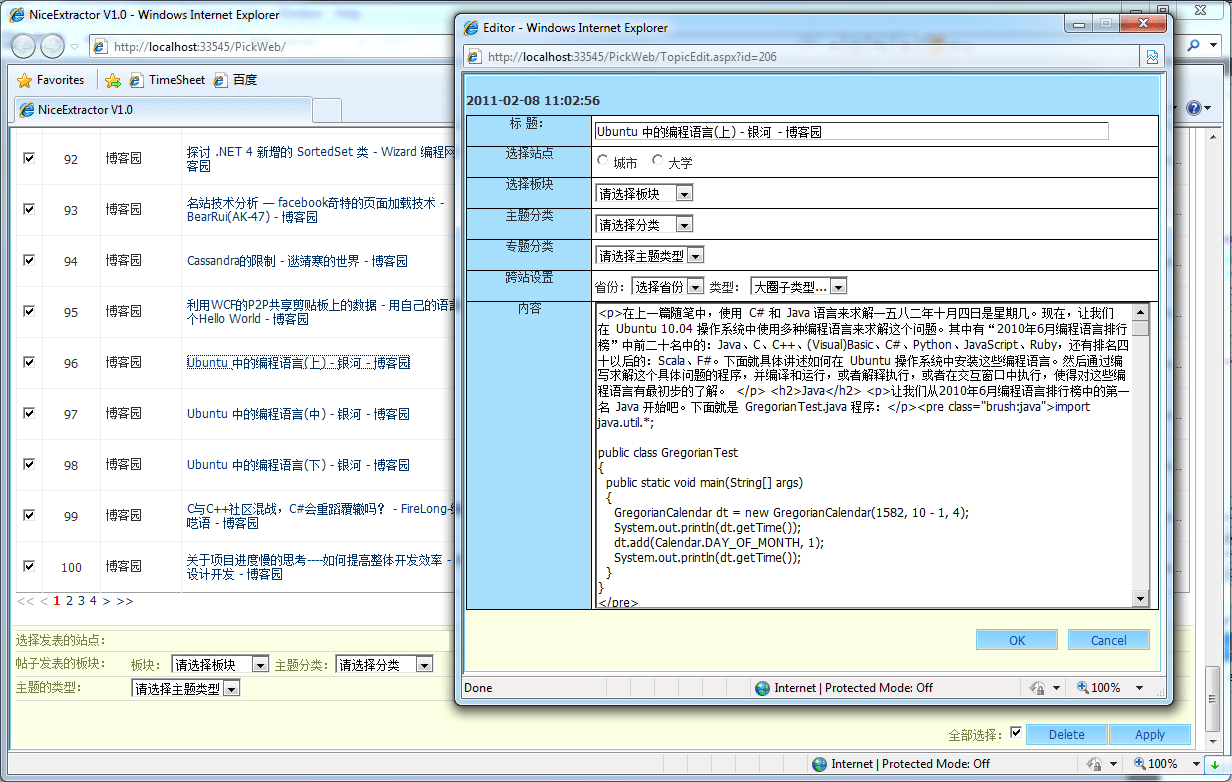
到这一步就完成了内容的采集工作,编辑人员可以打开PickWeb,对采集结果进行微调和优化,然后初审通过并发送到自己的网站上:
真正发送采集结果到自己网站的工作不是由PickWeb完成的,编辑人员完成内容初审后,PostToForum.exe 会读取数据库并发送这条通过初审的采集结果到自己的网站上,在自己的网站上其实须要一个. ashx或则某种其它方法来接收采集的结果,不建议PostToFormu.exe直接去操作自己网站的数据库,最好通过自己网站上的某个API,来接收采集结果。
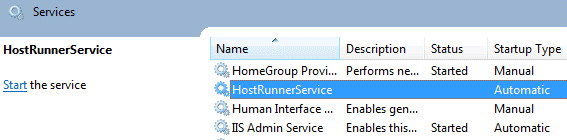
NiceCollectoer, HostCollector, PickWeb, PostToForum, 这几个程序联合工作,基本上已经完成了采集和发送的工作,HostCollector, PickWeb, PostToForum 是布署在服务器上的,HostCollector须要被周期性的调用,来采集目标网站所形成的新内容,HostRunnerService.exe 是一个Windows Service,用来周期性调用HostCollector,使用管理员身分在控制台下运行 installutil / i HostRunnerService.exe 就可以安装这个Windows Service了:
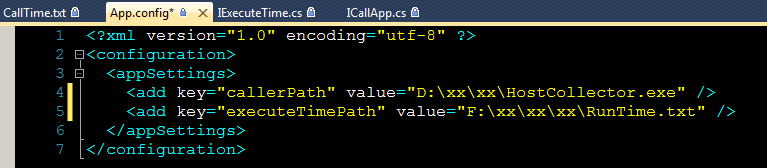
HostRunnerService 的配置也很简单:
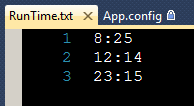
在RunTime.txt 中设定每晚定时采集几次:
当新内容被采集后,编辑人员须要定期的登陆PickWeb,来优化、微调、并初审新内容,也可以设定默认初审通过。同样PostToForum 也须要被周期性的调用,用来发送初审通过的新内容,CallSenderService.exe 与 HostRunnerService.exe类似,也是一个Windows Service,用来定期的调用PostToFormu.exe。
到这儿整个系统基本上完成了,除此之外还有两个小东东: SelfChecker.exe 和HealthChecker.exe。 SelfCheck.exe 是拿来检测Setting.mdb中设定的规则是否是一个有效的规则,例如检测采集规则是否设定了内容采集项。HealthChecker.exe拿来搜集HostCollector.exe 和 PostToForum.exe 所形成的log,然后将log发送给指定的系统维护人员。
这个内容采集系统还有好多地方须要改进和优化,现在的状态只能说是个Prototype吧,例如 NicePick 需要进一步具象和构建,给出更多的Interface,把剖析Html的各个环节插件化,在各个剖析步骤上,可以使用户加载自己的分析器。 在NiceCollector上,需要更多更全面的采集规则设定。在PickWeb上可以加入一些默认的SEO优化规则,如批量SEO优化Title的内容,等其它方面吧。
File: 执行文件
File: 源代码 查看全部
一套内容采集系统


字体大小 []
内容采集系统,对于以内容为主的网站来说是非常好的助手,除了原创内容外,其它内容须要编辑人员或则采集系统来搜集整理,然后添加到自己的网站里。Discuz DvBBS CMS等产品,内部都自带了一个内容采集功能,来采集指定的相关内容。 单客户端的优采云采集器也可以非常好的采集指定的内容。这些工具都是想使机器取代人工,把编辑人员从内容搬运的工作中解放下来,做一些更高档的工作,例如采集结果的内容微调,SEO优化,设定精确的采集规则,让采集的内容愈加符合自己网站的须要。
下面的内容采集系统就是从这个看法开发而至的,这个采集系统由两个部份组成:
1.编辑人员所使用的采集规则设定器和对采集结果进行初审、微调和发布所使用的Web站点。
2.部署在服务器上的定时采集器和定时发送器。
首先由编辑人员通过一个采集规则设定器(NiceCollectoer.exe)设定要采集的站点,再等采集完成后,编辑人员再通过一个Web站点(PickWeb)对采集的结果进行初审、微调和优化之后发布到自己的网站上。编辑人员所须要做的是采集规则的设定,和对采集结果的优化,其它部份的工作都由机器完成。
NicePicker 是Html 分析器,用来抽取Url,NiceCollector 和HostCollector 都使用NicePicker来剖析Html, NiceCollectoer 就是采集规则设定器,一个目标网站只用设定一次:
使用上去和最早的优采云采集器类似,这里使用博客园来做目标采集站点, 设定采集精华县的文章,采集规则十分简单:当编辑人员设定好采集规则后,这些规则会保存到NiceCollector.exe同目录下的 Setting.mdb中。一般当采集规则设定好之后,基本上不用再变动了,只在目标网站的Html Dom结构发生变化时,需要再度微调一下采集规则。NiceCollector同时用于新目标采集站点的设定和添加操作。
等编辑人员完成采集规则的设定后,把Setting.mdb放在 HostCollector.exe下, HostCollector 会依照Setting.mdb的设定进行真正的采集,并把采集的结果存入数据库。
到这一步就完成了内容的采集工作,编辑人员可以打开PickWeb,对采集结果进行微调和优化,然后初审通过并发送到自己的网站上:
真正发送采集结果到自己网站的工作不是由PickWeb完成的,编辑人员完成内容初审后,PostToForum.exe 会读取数据库并发送这条通过初审的采集结果到自己的网站上,在自己的网站上其实须要一个. ashx或则某种其它方法来接收采集的结果,不建议PostToFormu.exe直接去操作自己网站的数据库,最好通过自己网站上的某个API,来接收采集结果。
NiceCollectoer, HostCollector, PickWeb, PostToForum, 这几个程序联合工作,基本上已经完成了采集和发送的工作,HostCollector, PickWeb, PostToForum 是布署在服务器上的,HostCollector须要被周期性的调用,来采集目标网站所形成的新内容,HostRunnerService.exe 是一个Windows Service,用来周期性调用HostCollector,使用管理员身分在控制台下运行 installutil / i HostRunnerService.exe 就可以安装这个Windows Service了:
HostRunnerService 的配置也很简单:
在RunTime.txt 中设定每晚定时采集几次:
当新内容被采集后,编辑人员须要定期的登陆PickWeb,来优化、微调、并初审新内容,也可以设定默认初审通过。同样PostToForum 也须要被周期性的调用,用来发送初审通过的新内容,CallSenderService.exe 与 HostRunnerService.exe类似,也是一个Windows Service,用来定期的调用PostToFormu.exe。
到这儿整个系统基本上完成了,除此之外还有两个小东东: SelfChecker.exe 和HealthChecker.exe。 SelfCheck.exe 是拿来检测Setting.mdb中设定的规则是否是一个有效的规则,例如检测采集规则是否设定了内容采集项。HealthChecker.exe拿来搜集HostCollector.exe 和 PostToForum.exe 所形成的log,然后将log发送给指定的系统维护人员。
这个内容采集系统还有好多地方须要改进和优化,现在的状态只能说是个Prototype吧,例如 NicePick 需要进一步具象和构建,给出更多的Interface,把剖析Html的各个环节插件化,在各个剖析步骤上,可以使用户加载自己的分析器。 在NiceCollector上,需要更多更全面的采集规则设定。在PickWeb上可以加入一些默认的SEO优化规则,如批量SEO优化Title的内容,等其它方面吧。
File: 执行文件
File: 源代码
Discuz!适合小白操作后台DXC批量采集插件使用详尽教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 553 次浏览 • 2020-08-22 11:51
想必用过Discuz!建站的站长都用过采集插件吧,那批量采集的插件呢?这个插件真的是为Discuz的站长撑起了站点内容的半边天啊,为什么这么说呢?如果你用这个插件在后台操作的话,就算你没有花钱去Discuz的应用中心订购商业版每晚用这个插件你可以在半个小时内就发布上百篇文章,当然如果你是商业版的话还可以设置定时手动采集发布功能,而且只要你采集的目标网站有足够的内容,你可以在设置好相关参数后便不用再天天去后台自动操作,这样是不是太省事呢?闲话不多说,我们来开始明天的经验分享。
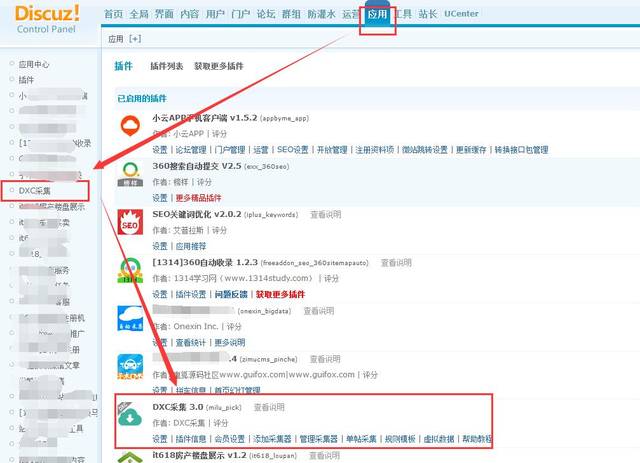
首先,我们进到后台选择“应用”→“DXC采集”→“设置”,如下图:
DXC插件
DXC采集插件
进入设置
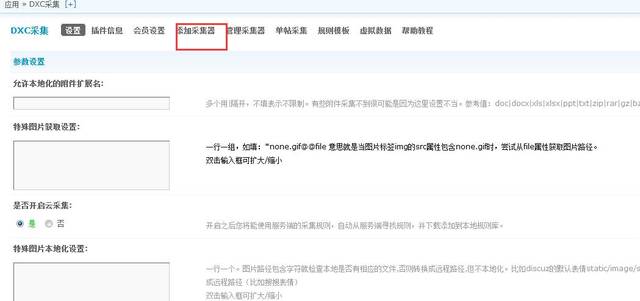
第二步,添加采集器,如图:
添加采集器
第三步,这是最重要的一步,要看仔细了哦!
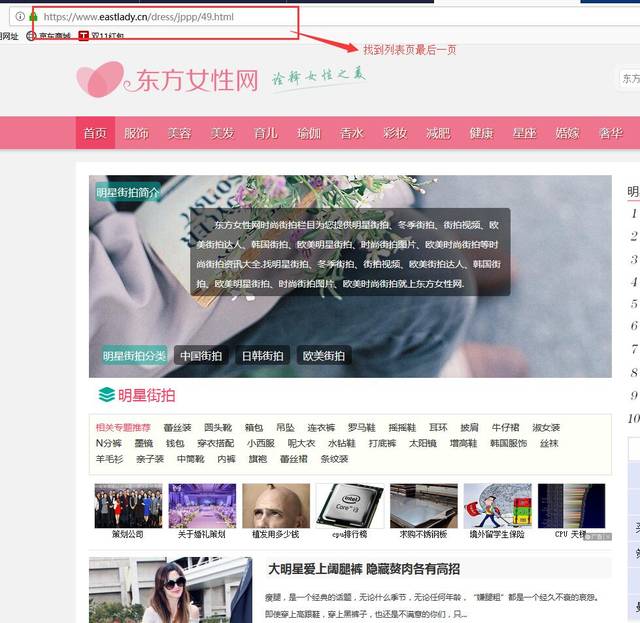
①找到目标网站的文章列表页面最后一页,注意:这里的列表页的页面地址必须是有规律的哦!如图:
目标列表页末页
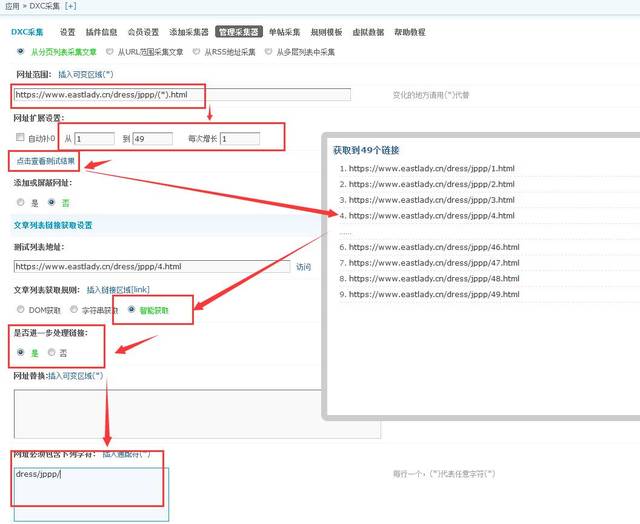
②在采集器填入列表页,设置好你要采集哪些列表页面的文章,采集页面的增长幅度,然后测试一下列表页采集是否设置成功;之后再将文章的获取规则设置为“智能获取”,如有必要限制采集内容的范围,就把须要限制的栏目名称相对地址写在下方的方框内,然后保存,如图:
设置列表页采集规则
③选择“内容规则”选项卡,进入页面内容采集设置步骤。先点击左侧的“点击手动获取”,这时会在右边的页面地址框内获取到一个你之前设置的列表页内的其中一篇文章的地址,点击访问步入该页,获取页面采集元素,如图:
获取文章页面
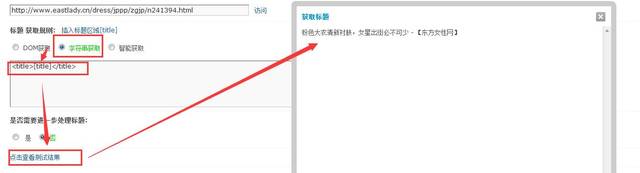
④进入内容页面后,直接键盘右键查看源代码,复制title代码,粘贴到标题采集规则框中,之后设置按图中所示即可,如图:
获取标题代码
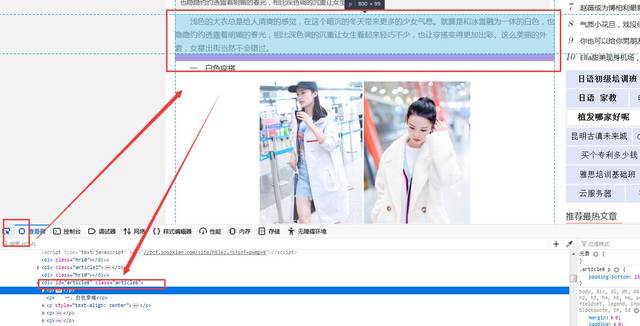
⑤设置页面内容获取规则,选择以“DOM获取”,然后步入文章页面找到文章内容区块所对应的区块辨识代码,如图5-1和5-2:
获取文章区块辨识代码
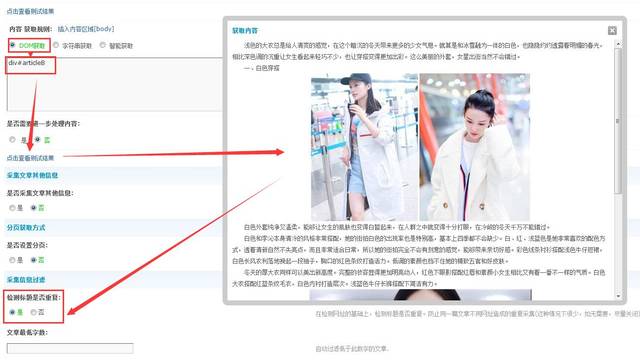
⑥将辨识代码填入规则框内,记住使用“div#(内容区块辨识代码)”,之后选择“检测标题是否重复:”如图
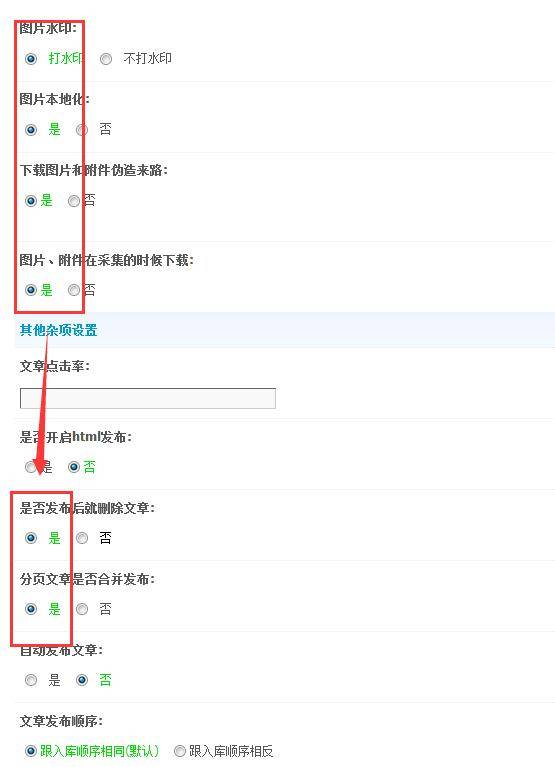
至此,页面列表采集及内容获取早已设置完成,之后一步很简单,发布规则设置,如图设置就行,至于你须要用哪些帐号发布的话只须要在发布设置下边的“自定义uid”框内输入ID号就可以(tips:uid1是网站的创始人)。如图:
发布规则设置
第三步,在其他设置选项上面设置采集停顿的时间就行,这里我推荐5,15的频度,这样不容易导致辨识超时,然后保存开始采集,如图:
其他设置
最后,激动人心的时刻到了,放开手去采集发布吧。至此,这个经验就结束了,如果你还有什么地方不懂得欢迎留言,我会及时给你们提供支持,谢谢 查看全部
Discuz!适合小白操作后台DXC批量采集插件使用详尽教程
想必用过Discuz!建站的站长都用过采集插件吧,那批量采集的插件呢?这个插件真的是为Discuz的站长撑起了站点内容的半边天啊,为什么这么说呢?如果你用这个插件在后台操作的话,就算你没有花钱去Discuz的应用中心订购商业版每晚用这个插件你可以在半个小时内就发布上百篇文章,当然如果你是商业版的话还可以设置定时手动采集发布功能,而且只要你采集的目标网站有足够的内容,你可以在设置好相关参数后便不用再天天去后台自动操作,这样是不是太省事呢?闲话不多说,我们来开始明天的经验分享。
首先,我们进到后台选择“应用”→“DXC采集”→“设置”,如下图:
DXC插件
DXC采集插件

进入设置
第二步,添加采集器,如图:
添加采集器
第三步,这是最重要的一步,要看仔细了哦!
①找到目标网站的文章列表页面最后一页,注意:这里的列表页的页面地址必须是有规律的哦!如图:
目标列表页末页
②在采集器填入列表页,设置好你要采集哪些列表页面的文章,采集页面的增长幅度,然后测试一下列表页采集是否设置成功;之后再将文章的获取规则设置为“智能获取”,如有必要限制采集内容的范围,就把须要限制的栏目名称相对地址写在下方的方框内,然后保存,如图:
设置列表页采集规则
③选择“内容规则”选项卡,进入页面内容采集设置步骤。先点击左侧的“点击手动获取”,这时会在右边的页面地址框内获取到一个你之前设置的列表页内的其中一篇文章的地址,点击访问步入该页,获取页面采集元素,如图:
获取文章页面
④进入内容页面后,直接键盘右键查看源代码,复制title代码,粘贴到标题采集规则框中,之后设置按图中所示即可,如图:

获取标题代码
⑤设置页面内容获取规则,选择以“DOM获取”,然后步入文章页面找到文章内容区块所对应的区块辨识代码,如图5-1和5-2:
获取文章区块辨识代码
⑥将辨识代码填入规则框内,记住使用“div#(内容区块辨识代码)”,之后选择“检测标题是否重复:”如图
至此,页面列表采集及内容获取早已设置完成,之后一步很简单,发布规则设置,如图设置就行,至于你须要用哪些帐号发布的话只须要在发布设置下边的“自定义uid”框内输入ID号就可以(tips:uid1是网站的创始人)。如图:
发布规则设置
第三步,在其他设置选项上面设置采集停顿的时间就行,这里我推荐5,15的频度,这样不容易导致辨识超时,然后保存开始采集,如图:
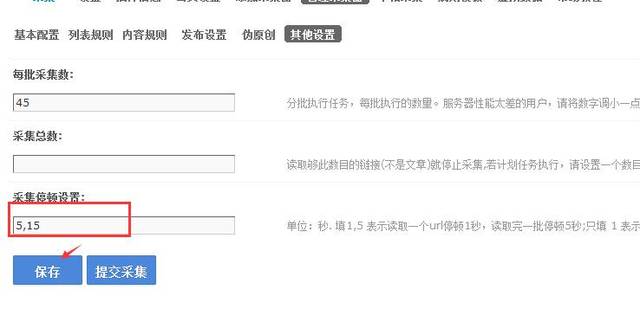
其他设置
最后,激动人心的时刻到了,放开手去采集发布吧。至此,这个经验就结束了,如果你还有什么地方不懂得欢迎留言,我会及时给你们提供支持,谢谢
如果我说数据采集圈子没有一个好产品你会打我么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 371 次浏览 • 2020-08-12 09:01
数据采集器圈子的竞品剖析
简单谈一下数据采集这个圈子里的公司
今天我谈一下我作为产品猫的看法。这里我们先剖析不同角色的需求。
作为数据需求提出者,也就是用户,我希望:
以最简单操作的方式获得我想要的数据数据获取可靠、完整、最新我需要个性化的服务,需要良好的售后服务和支持我希望我的数据容易读取、展示、清洗处理我希望我的数据采集过程可靠、稳定、可控、直观我希望很快就可以得到我想要的数据我希望以低廉的价钱获得数据
作为数据和规则提供者,我希望:
我需要可以以符合我开发习惯的方式开发爬虫我希望我开发的爬虫,只能让给我收钱订购的顾客使用而且不可传播和盗版我希望我开发的爬虫,可以使顾客运行在不同的平台上或则云端我希望研制过程中所需的外部支持,包括IP代理和验证码识别等可以简单易用的接入,并且可以使用户自己选择我希望我开发的爬虫可以更通用,一次开发可以使更多人使用我希望我的劳动可以得到合理的酬劳
作为平台,我希望:
买家和店家用户量、活跃度、评价持续提高平台可以挣钱,并且为股东、投资人、员工带来价值平台确实是平台,而不是打着平台幌子的小系统平台具备可持续发展性,不要深陷某个循环里
能满足所有人需求的产品?没有!是的,没有完美的平台,没有完美的系统,只有无限的可能性摆在我们的面前。(恩,光吐槽是没前途的,一边吐槽一边思索怎么构建才是产品猫应当做的事情)
造数科技目前是刚才起步,它主要解决的是操作复杂度问题,造数爬虫的上手曲线趋近于0。新手可以在接近于没有任何专业知识储备的情况下上手,但是可以采集的网站是大幅度遭到局限的。目前的造数作为普通用户只能达到2级页面深度和列表化采集,没有数据二次处理能力,比如替换、正则变换、日期规范化等。如果默认的点击未能把我想采集的列表都放进去,再点击只能再降低一列而已;如果页面的URL列表不是根据数字规范生成也不行。当然,这是必然情况,数据采集是专业性与复杂度并存的事情,简化操作的心没问题,但是问题是简化的可能性则是另一个问题,页面结构的复杂程度常常最终会超过我们的想像。现在,让我们以宽容的态度看这个年青团队的下一步发展以及她们的技术突破。
优采云正在往“供应链”方向发展,是的,你没看错,是采集供应链。以优采云采集器为面向顾客的基本端,延伸至微图进行数据基本清洗、语义剖析和BI可视化,最后以数多多为大平台融合数据和规则交易、需求发布等等。但是考虑到采集机制的问题,第一优采云在大多数页面上的采集速度是难以超过不需要渲染页面的爬虫的;第二规则的编撰并没有这么的简单,xpath和html的基础知识还是须要的,学习曲线还是比较险峻的;第三,单机采集和云采集之间的协调和融合机制还不够建立,有些单机采集没问题的到了云端采集不见得效果好,毕竟云是你们共用的;第四,单独win平台引起兼容性不够;第五,面对新的反采集措施,对抗能力不足(毕竟没有代码自由度高)。
优采云具备浓厚的“代码和技术气息”,优采云的学习曲线是悬崖式的,懂Html+Xpath+正则表达式+JS语言等等能够进行研制。好的是优采云为了增加菜鸟上手难度,有现成的采集爬虫可以用,只要输入一些选项就行了。优采云也是惟一一个解决了研制人员代码版权的平台,用户可以在看不到源代码的情况下使用爬虫,但是弊端就是,如果是没有开发下来的爬虫,也无法在网上简单的通过向他人订购获得,一方面有研制成本问题,另一方面给顾客的都是源代码,版权保护丧失意义了。
这里,我引用内森弗尔写的一本名叫《创新者的方式》书里的理念来说明一下互联网公开数据采集行业面临的问题以及可能的解决方案。
1,发现问题
2,梳理解决问题须要的工作
3,提出创新点
4,最小化解决方案
5,验证商业模式
6,风险管理
第一步思索需求的本质,我个人觉得,用户通过数据采集工具获取数据是个伪需求,用户的需求不是工具,是服务。首先广大的用户并不是研制人员,广大的用户是“需要数据的人”,他们不是采集专家。他们希望有人可以直接把想要的数据给她们,不管是免费还是付费。任何觉得顾客乐意自己学习工具使用的看法我认为都是错误的,我们构建在最原创的需求上,那就是以最低廉、省事、可靠、稳定的方式获得数据。
如果从这个角度来想,客户关注的并不是采集工具,而是服务。如何提供一个良好的服务,会成为接下来那些公司的发展重点。这里我把需求的本质定义为:以最合理的价钱,获得优质的数据采集服务。
第二步剖析问题的本质,采集数据的问题集中在顾客未能容易、稳定、快速的获取数据,研发人员则是难以对自己的努力得到可靠地保障,研发的努力得不到保护,数据又容易被二次销售。也就是说研制人员的努力没有得到挺好地保护,优采云一定程度上保护了研制人员的利益,但是其内部封闭的特点,又使外部研制人员失去了自由度。所以这儿我把问题的本质定义为:保护爬虫版权,提高采集效率、稳定性,对抗防采集技术。
第三步,分析市面上的产品是怎样解决问题的。
首先造数是有一套自己的后台技术的,而且相当智能,虽然由于公司创立还不久,功能还比较中级,但是年青技术团队的优势就是突破自我。
优采云的采集本质是模拟浏览器,也就是将页面渲染下来,这样的用处是解决好多JS和Ajax的坑,这部份的坑不太好解释,简单来说就是不渲染出页面,很多数据并不会加载到html代码里,也就意味着通常的采集会采集不到数据。代价就是速率会变慢,线程数目也会受限,毕竟对内存占用率会大幅度提高。另一点用处就是,页面的变化速率远远高于数据包的变化速率,所以靠抓包采集的爬虫常常须要改改版,否则就废了。
优采云是一套JS代码体系,自由度很高,编程可以做的事情它都能做。而且得益于她们自成体系并且又使爬虫工程师太熟悉的采集框架,上手难度似乎远低于自己编撰一个成框架的爬虫。
我们把问题简化为:
简——面向菜鸟或任何不想自己学习和研制的人,需要最简单的操作;
快——所有人都希望可以最快速率的获得数据;
稳——在稳定且不漏采的情况下获得数据;
赢——共赢是永恒不变的事情,要保护顾客利益,也要保护平台和生产者的利益。
首先来看“简”,面向广大的不想费力写规则的顾客,优采云和优采云都支持输入一些参数就可以采集的简易采集,这种采集方法不需要用户会写规则或爬虫,直接输入想采集的一些基本参数就可以了。缺点也很明显,没有现成做下来的规则就无法采集。此外两个公司也都有数据交易平台,这个平台除了可以交易数据,也可以交易规则和发布需求。这方面数多多做的更好一些,毕竟是独立的平台,优采云的需求发布还没做到上面,这也是优采云的一些“闭塞性”,这里并不是说闭塞肯定不好,但是确实是失去自由度为代价的。比如顾客无法自由的在平台上发布需求,研发人员也难以直接和顾客沟通必须是通过平台内部调度。造数原本就是最简单的操作,甚至可以说造数就是简的最佳彰显。
接下来看“快”,单机采集只能采取多线程的方式,会受限于硬件性能,优采云就是这么。优采云是采取云采集的方式,需要更多节点,就上定制版或企业版。优采云本身就是个云采集,节点是自由控制和可以选购的,舍得出钱就可以更快。造数把简字发扬光大到都不使你在乎后台有多少节点进行云采集了……但是这种采集平台真的很快么?受限于服务器网速、硬件、采集网站响应速率、网站反爬虫举措等多方面诱因,有的快,有的慢。如果说须要进行标准化评测,我肯定测不了,为什么呢?因为我完全无法标准化啊……同样采集京东,优采云云采集我不确定是几个节点采集,没说明啊……优采云虽然看得到节点数,但是我哪晓得每位节点的网路和硬件配置啊,没人说……造数嘛……快还是很快的,但是愈发不知道后台用了多少采集资源了。
然后我们来看“稳”,稳定的采集、稳定的输出是核心问题。实际情况怎样呢?优采云的云采集或者由于规则问题,或者由于规则作者熟练度问题,很多情况下会“漏数据”……优采云因为好多中级采集为了避免IP被封,挂高匿IP代理的时侯速率反倒受影响了,让我总认为没有理想中速率这么快。造数似乎没哪些可吐槽的,还是比较稳的。 查看全部
我之前写了两篇文章简单的剖析了一下数据行业的第一步,即数据采集圈子的情况,分别是:
数据采集器圈子的竞品剖析
简单谈一下数据采集这个圈子里的公司
今天我谈一下我作为产品猫的看法。这里我们先剖析不同角色的需求。
作为数据需求提出者,也就是用户,我希望:
以最简单操作的方式获得我想要的数据数据获取可靠、完整、最新我需要个性化的服务,需要良好的售后服务和支持我希望我的数据容易读取、展示、清洗处理我希望我的数据采集过程可靠、稳定、可控、直观我希望很快就可以得到我想要的数据我希望以低廉的价钱获得数据
作为数据和规则提供者,我希望:
我需要可以以符合我开发习惯的方式开发爬虫我希望我开发的爬虫,只能让给我收钱订购的顾客使用而且不可传播和盗版我希望我开发的爬虫,可以使顾客运行在不同的平台上或则云端我希望研制过程中所需的外部支持,包括IP代理和验证码识别等可以简单易用的接入,并且可以使用户自己选择我希望我开发的爬虫可以更通用,一次开发可以使更多人使用我希望我的劳动可以得到合理的酬劳
作为平台,我希望:
买家和店家用户量、活跃度、评价持续提高平台可以挣钱,并且为股东、投资人、员工带来价值平台确实是平台,而不是打着平台幌子的小系统平台具备可持续发展性,不要深陷某个循环里
能满足所有人需求的产品?没有!是的,没有完美的平台,没有完美的系统,只有无限的可能性摆在我们的面前。(恩,光吐槽是没前途的,一边吐槽一边思索怎么构建才是产品猫应当做的事情)
造数科技目前是刚才起步,它主要解决的是操作复杂度问题,造数爬虫的上手曲线趋近于0。新手可以在接近于没有任何专业知识储备的情况下上手,但是可以采集的网站是大幅度遭到局限的。目前的造数作为普通用户只能达到2级页面深度和列表化采集,没有数据二次处理能力,比如替换、正则变换、日期规范化等。如果默认的点击未能把我想采集的列表都放进去,再点击只能再降低一列而已;如果页面的URL列表不是根据数字规范生成也不行。当然,这是必然情况,数据采集是专业性与复杂度并存的事情,简化操作的心没问题,但是问题是简化的可能性则是另一个问题,页面结构的复杂程度常常最终会超过我们的想像。现在,让我们以宽容的态度看这个年青团队的下一步发展以及她们的技术突破。
优采云正在往“供应链”方向发展,是的,你没看错,是采集供应链。以优采云采集器为面向顾客的基本端,延伸至微图进行数据基本清洗、语义剖析和BI可视化,最后以数多多为大平台融合数据和规则交易、需求发布等等。但是考虑到采集机制的问题,第一优采云在大多数页面上的采集速度是难以超过不需要渲染页面的爬虫的;第二规则的编撰并没有这么的简单,xpath和html的基础知识还是须要的,学习曲线还是比较险峻的;第三,单机采集和云采集之间的协调和融合机制还不够建立,有些单机采集没问题的到了云端采集不见得效果好,毕竟云是你们共用的;第四,单独win平台引起兼容性不够;第五,面对新的反采集措施,对抗能力不足(毕竟没有代码自由度高)。
优采云具备浓厚的“代码和技术气息”,优采云的学习曲线是悬崖式的,懂Html+Xpath+正则表达式+JS语言等等能够进行研制。好的是优采云为了增加菜鸟上手难度,有现成的采集爬虫可以用,只要输入一些选项就行了。优采云也是惟一一个解决了研制人员代码版权的平台,用户可以在看不到源代码的情况下使用爬虫,但是弊端就是,如果是没有开发下来的爬虫,也无法在网上简单的通过向他人订购获得,一方面有研制成本问题,另一方面给顾客的都是源代码,版权保护丧失意义了。
这里,我引用内森弗尔写的一本名叫《创新者的方式》书里的理念来说明一下互联网公开数据采集行业面临的问题以及可能的解决方案。
1,发现问题
2,梳理解决问题须要的工作
3,提出创新点
4,最小化解决方案
5,验证商业模式
6,风险管理
第一步思索需求的本质,我个人觉得,用户通过数据采集工具获取数据是个伪需求,用户的需求不是工具,是服务。首先广大的用户并不是研制人员,广大的用户是“需要数据的人”,他们不是采集专家。他们希望有人可以直接把想要的数据给她们,不管是免费还是付费。任何觉得顾客乐意自己学习工具使用的看法我认为都是错误的,我们构建在最原创的需求上,那就是以最低廉、省事、可靠、稳定的方式获得数据。
如果从这个角度来想,客户关注的并不是采集工具,而是服务。如何提供一个良好的服务,会成为接下来那些公司的发展重点。这里我把需求的本质定义为:以最合理的价钱,获得优质的数据采集服务。
第二步剖析问题的本质,采集数据的问题集中在顾客未能容易、稳定、快速的获取数据,研发人员则是难以对自己的努力得到可靠地保障,研发的努力得不到保护,数据又容易被二次销售。也就是说研制人员的努力没有得到挺好地保护,优采云一定程度上保护了研制人员的利益,但是其内部封闭的特点,又使外部研制人员失去了自由度。所以这儿我把问题的本质定义为:保护爬虫版权,提高采集效率、稳定性,对抗防采集技术。
第三步,分析市面上的产品是怎样解决问题的。
首先造数是有一套自己的后台技术的,而且相当智能,虽然由于公司创立还不久,功能还比较中级,但是年青技术团队的优势就是突破自我。
优采云的采集本质是模拟浏览器,也就是将页面渲染下来,这样的用处是解决好多JS和Ajax的坑,这部份的坑不太好解释,简单来说就是不渲染出页面,很多数据并不会加载到html代码里,也就意味着通常的采集会采集不到数据。代价就是速率会变慢,线程数目也会受限,毕竟对内存占用率会大幅度提高。另一点用处就是,页面的变化速率远远高于数据包的变化速率,所以靠抓包采集的爬虫常常须要改改版,否则就废了。
优采云是一套JS代码体系,自由度很高,编程可以做的事情它都能做。而且得益于她们自成体系并且又使爬虫工程师太熟悉的采集框架,上手难度似乎远低于自己编撰一个成框架的爬虫。
我们把问题简化为:
简——面向菜鸟或任何不想自己学习和研制的人,需要最简单的操作;
快——所有人都希望可以最快速率的获得数据;
稳——在稳定且不漏采的情况下获得数据;
赢——共赢是永恒不变的事情,要保护顾客利益,也要保护平台和生产者的利益。
首先来看“简”,面向广大的不想费力写规则的顾客,优采云和优采云都支持输入一些参数就可以采集的简易采集,这种采集方法不需要用户会写规则或爬虫,直接输入想采集的一些基本参数就可以了。缺点也很明显,没有现成做下来的规则就无法采集。此外两个公司也都有数据交易平台,这个平台除了可以交易数据,也可以交易规则和发布需求。这方面数多多做的更好一些,毕竟是独立的平台,优采云的需求发布还没做到上面,这也是优采云的一些“闭塞性”,这里并不是说闭塞肯定不好,但是确实是失去自由度为代价的。比如顾客无法自由的在平台上发布需求,研发人员也难以直接和顾客沟通必须是通过平台内部调度。造数原本就是最简单的操作,甚至可以说造数就是简的最佳彰显。
接下来看“快”,单机采集只能采取多线程的方式,会受限于硬件性能,优采云就是这么。优采云是采取云采集的方式,需要更多节点,就上定制版或企业版。优采云本身就是个云采集,节点是自由控制和可以选购的,舍得出钱就可以更快。造数把简字发扬光大到都不使你在乎后台有多少节点进行云采集了……但是这种采集平台真的很快么?受限于服务器网速、硬件、采集网站响应速率、网站反爬虫举措等多方面诱因,有的快,有的慢。如果说须要进行标准化评测,我肯定测不了,为什么呢?因为我完全无法标准化啊……同样采集京东,优采云云采集我不确定是几个节点采集,没说明啊……优采云虽然看得到节点数,但是我哪晓得每位节点的网路和硬件配置啊,没人说……造数嘛……快还是很快的,但是愈发不知道后台用了多少采集资源了。
然后我们来看“稳”,稳定的采集、稳定的输出是核心问题。实际情况怎样呢?优采云的云采集或者由于规则问题,或者由于规则作者熟练度问题,很多情况下会“漏数据”……优采云因为好多中级采集为了避免IP被封,挂高匿IP代理的时侯速率反倒受影响了,让我总认为没有理想中速率这么快。造数似乎没哪些可吐槽的,还是比较稳的。
屏蔽广告功能说明(7.0版本)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2020-08-10 22:13
主要目的:
1、为了推动页面加载(广告会拖慢页面加载速率)
2、为了降低资源恳求(节省带宽资源)
界面位置:
基本操作:
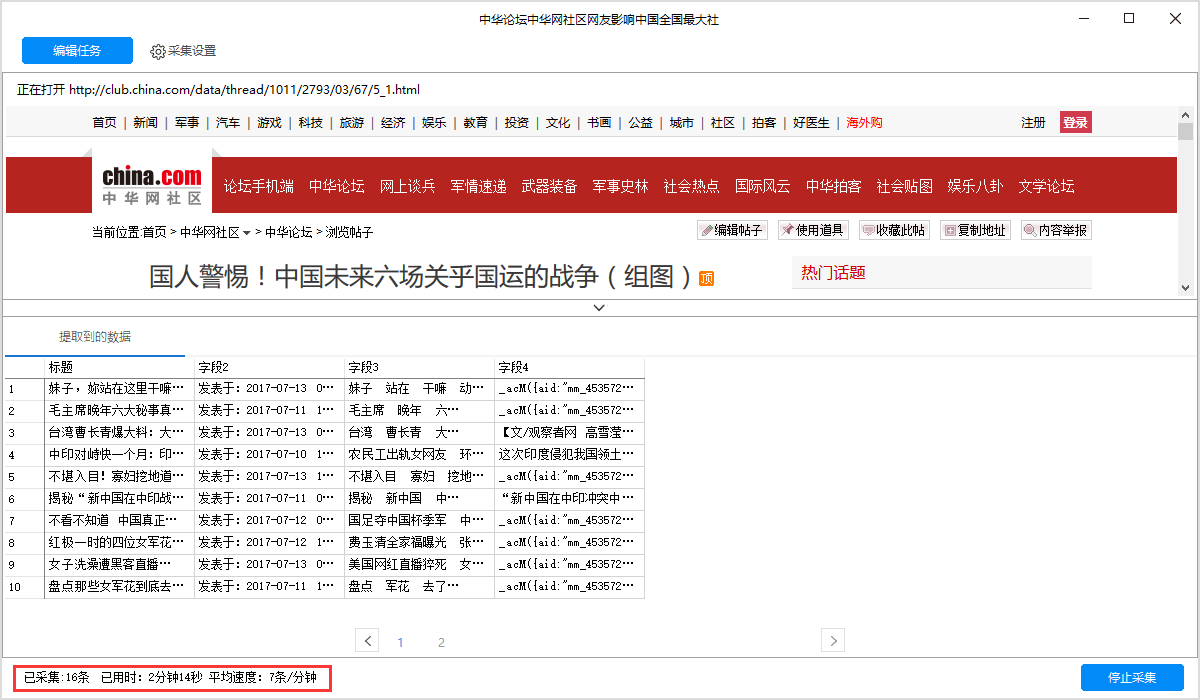
示例:
相同的任务开启不开启广告屏蔽和广告屏蔽,可以看见如下图采集速度有显著的不同。没有屏蔽广告的相同时间内只采集了12条,而屏蔽广告的相同时间内采集了100条
屏蔽广告示例:
不屏蔽广告示例:
开启广告屏蔽可能存在的不利影响:
部分页面可能会由于屏蔽广告,导致页面结构发生变化,优采云的任务中原本生成的xpath须要调整。这时候十分方便的做法就是在做规则之前就须要考虑清楚是否要勾屏蔽广告,然后再做规则。确保规则的准确性。
例如:现在采集这个网站
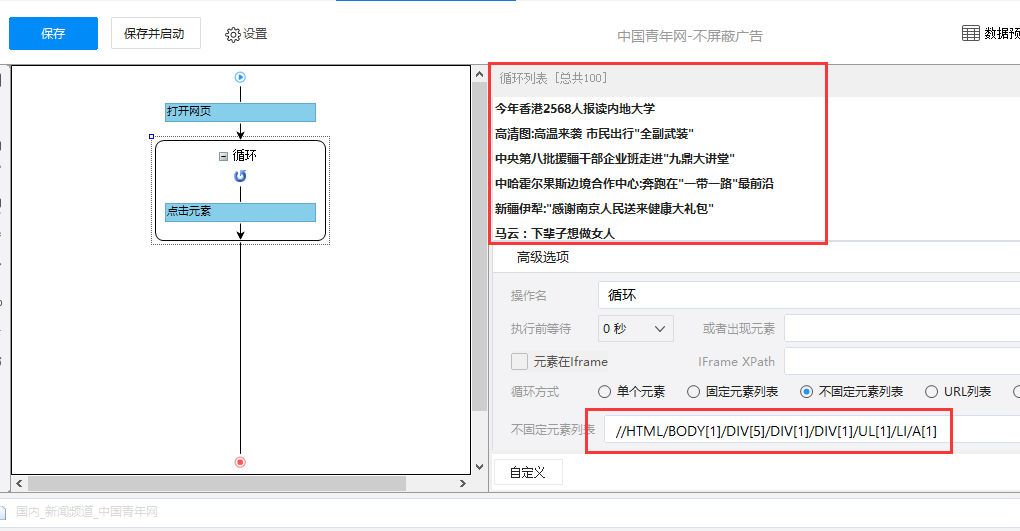
如果之前不勾选屏蔽广告,可以看见循环列表的xpath是这样的,而且循环列表也是正常的。如下图:
这时候返回勾选屏蔽广告,再看循环列表,可以看见勾上然后循环列表为空了。这样规则找不到循环列表就不会正常采集。
这就是部份页面由于屏蔽了广告,页面结构发生了变化。所以须要先确定是否勾屏蔽广告再做规则了。
同时,还存在部份网站,屏蔽广告后,网页仍然在加载的情况,采集无法进行。这时返回“编辑规则”,将“屏蔽广告功能”的勾选除去就可以了。请慎重使用该功能。 查看全部
在采集网页内容过程中,有些网页中会好多广告,甚至会弹出广告框。一是影响规则的制做,二是影响采集速度。为了改善这种情况,优采云中会有一个功能点:屏蔽网页广告。
主要目的:
1、为了推动页面加载(广告会拖慢页面加载速率)
2、为了降低资源恳求(节省带宽资源)
界面位置:
基本操作:

示例:
相同的任务开启不开启广告屏蔽和广告屏蔽,可以看见如下图采集速度有显著的不同。没有屏蔽广告的相同时间内只采集了12条,而屏蔽广告的相同时间内采集了100条
屏蔽广告示例:
不屏蔽广告示例:
开启广告屏蔽可能存在的不利影响:
部分页面可能会由于屏蔽广告,导致页面结构发生变化,优采云的任务中原本生成的xpath须要调整。这时候十分方便的做法就是在做规则之前就须要考虑清楚是否要勾屏蔽广告,然后再做规则。确保规则的准确性。
例如:现在采集这个网站
如果之前不勾选屏蔽广告,可以看见循环列表的xpath是这样的,而且循环列表也是正常的。如下图:
这时候返回勾选屏蔽广告,再看循环列表,可以看见勾上然后循环列表为空了。这样规则找不到循环列表就不会正常采集。
这就是部份页面由于屏蔽了广告,页面结构发生了变化。所以须要先确定是否勾屏蔽广告再做规则了。
同时,还存在部份网站,屏蔽广告后,网页仍然在加载的情况,采集无法进行。这时返回“编辑规则”,将“屏蔽广告功能”的勾选除去就可以了。请慎重使用该功能。
芭奇:不用编吃饭写采集规则也可轻松采集网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 287 次浏览 • 2020-08-09 21:31
然后我借助芭奇站群软件来采集这个搜索结果的所有文章。大家先可以剖析一下,这个页面,如果用各类类型采集器或网站自带程序来自定义采集所有文章,那是不可能采到的。因为互联网还没有这样的通用采集不同网站的功能,但如今,芭奇站群软件可以实现了。因为这个软件支持泛采集技术。
三、首页,我填上这个百度结果列表到软件的“起始采集的文章列表地址”上,如下图:
四、为了能正确采集我想要的列表,我们剖析结果列表上的文章,都有一个通用的后缀后,就是:html、shtml、ht,那么,这三个共同的地方就是:htm我定义到软件,这样的做法,是降低采集没用的页面,如下图:
五、现在可以采集了,不过,在这里提示一下你们,一般一个网站里面,带相同字符的会有很多,对于丰胸品这个百度列表的,也有百度自身的网页,但百度自身的网页内容,不是我要采的,那么还有一个地方可以排除不采带有百度网址的页面。如下图所示:
上面所说的都是芭奇站群软件的新采集功能,这个功能太强悍,但这个功能还要继续须要建立,以满足不同人的需求。有了这个工具,你就不用害怕自己不会写采集规则了,这个功能容易入门,容易操作,是新老站长最合适的一个功能。如有不懂的都可以加我QQ问我:509229860。
一两分钟后,采集过程结果如下图所示:
六、这里我就只采一部分文章,先停止不再采了,那现今瞧瞧采集后的内容:
七、上面就是采集的过程,按前面的步骤,你也可以采集其他地方列表的文章,特别是一些没有收录,或屏避收录的网站,这些都是原创的文章,大家可以自己去找一下。现在我给你们说一下,软件上的一些其他功能介绍:
1、如上图,这里就是除去网址和采集图片的功能,可以按你的需求,是否打勾。
2、如上图,这里就是设置采集的条数和采集的文章标题最少字数。
3、如上图,这里可以定义替换成语,支持代码替换,文字替换等,这里要灵活使用,对一些难采集的列表,这里就要用到了。可以将个别代码代换为空,才可以采集到列表链接。
这样定义后,就防止采到百度自己的页面了。那这样填好了,就可以直接采集文章了,点“保存后采集数据”:
感谢 stark 的投稿
我推测该不是中了大奖吧,心里那种兴奋呀,正在浮想连篇,老公回去了,进门就说:“我昨天把买彩票的20元钱市下了,特意给你买了只烤鸭 查看全部
这里我以百度的搜索页为采集源,比如这个地址:%B0%C5%C6%E6
然后我借助芭奇站群软件来采集这个搜索结果的所有文章。大家先可以剖析一下,这个页面,如果用各类类型采集器或网站自带程序来自定义采集所有文章,那是不可能采到的。因为互联网还没有这样的通用采集不同网站的功能,但如今,芭奇站群软件可以实现了。因为这个软件支持泛采集技术。
三、首页,我填上这个百度结果列表到软件的“起始采集的文章列表地址”上,如下图:
四、为了能正确采集我想要的列表,我们剖析结果列表上的文章,都有一个通用的后缀后,就是:html、shtml、ht,那么,这三个共同的地方就是:htm我定义到软件,这样的做法,是降低采集没用的页面,如下图:
五、现在可以采集了,不过,在这里提示一下你们,一般一个网站里面,带相同字符的会有很多,对于丰胸品这个百度列表的,也有百度自身的网页,但百度自身的网页内容,不是我要采的,那么还有一个地方可以排除不采带有百度网址的页面。如下图所示:
上面所说的都是芭奇站群软件的新采集功能,这个功能太强悍,但这个功能还要继续须要建立,以满足不同人的需求。有了这个工具,你就不用害怕自己不会写采集规则了,这个功能容易入门,容易操作,是新老站长最合适的一个功能。如有不懂的都可以加我QQ问我:509229860。
一两分钟后,采集过程结果如下图所示:
六、这里我就只采一部分文章,先停止不再采了,那现今瞧瞧采集后的内容:
七、上面就是采集的过程,按前面的步骤,你也可以采集其他地方列表的文章,特别是一些没有收录,或屏避收录的网站,这些都是原创的文章,大家可以自己去找一下。现在我给你们说一下,软件上的一些其他功能介绍:
1、如上图,这里就是除去网址和采集图片的功能,可以按你的需求,是否打勾。
2、如上图,这里就是设置采集的条数和采集的文章标题最少字数。
3、如上图,这里可以定义替换成语,支持代码替换,文字替换等,这里要灵活使用,对一些难采集的列表,这里就要用到了。可以将个别代码代换为空,才可以采集到列表链接。
这样定义后,就防止采到百度自己的页面了。那这样填好了,就可以直接采集文章了,点“保存后采集数据”:
感谢 stark 的投稿
我推测该不是中了大奖吧,心里那种兴奋呀,正在浮想连篇,老公回去了,进门就说:“我昨天把买彩票的20元钱市下了,特意给你买了只烤鸭
深维全能信息采集软件 V2.5.3
采集交流 • 优采云 发表了文章 • 0 个评论 • 277 次浏览 • 2020-08-09 12:04
【功能特性】
1.强大的信息采集功能。可采集几乎任何类型的网站信息,包括静态htm,html类型和动态ASP,ASPX,JSP等。可N级页面采集。深维全能信息采集软件官方版可手动下载二进制文件,比如图片,软件,mp3等。
2.网站登录。需要登入能够看见的信息,先在任务的'登录设置'处进行登陆,就可采集登录后就能看见的信息。
3.速度快,运行稳定。真正的多线程,多任务,运行时占用系统资源甚少,可稳定地长时间运行。(明显区别于其他软件)
4.数据保存格式丰富。可把采集的数据,保存为Txt,Excel和多种数据库格式(Access sqlserver Oracle Mysql等)。
5.强大的新闻采集,自动化处理功能。可手动保留新闻的格式,包括图片等。可通过设置,自动下载图片 ,自动把正文里图片的网路路径改为本地文件路径(也可保留原貌);可把采集的新闻手动处理成自己设计的模板格式;可采集具有分页方式的新闻。 通过这种功能,简单设置后即可在本地构建一个强悍的新闻系统,无需人工干预。
6.强大的信息手动再加工功能。对采集的信息,深维全能信息采集软件官方版可进行二次批量再加工,使之愈加符合您的实际要求。也可设置手动加工公式,在采集的过程中,按照公式手动加工处理,包括数据合并和数据替换等。
【软件特色】
1.通用:根据拟定采集规则,可以采集任何通过浏览器看得到的东西;
2.灵活:支持网站登录采集、网站跨层采集、POST采集、脚本采集、动态页面采集等中级功能;
3.扩展性强:支持存储过程、插件等,可由用户自由扩充功能,进行二次开发;
4.高效:为了使用户节约一分钟去做其它事情,软件做了悉心设计;
5.速度快:速度最快、效率最高的采集软件;
6.稳定:系统资源占用少、有详尽的运行报告、采集性能稳定; G、人性化:注重软件细节、强调人性化体验。
【更新日志】
1.争对Win10系统进行优化升级;
2.升级爬虫技术基类库,争对Https链接进行优化升级。 查看全部
深维全能信息采集软件是一款用于采集网站信息的站长工具,采用交互式策略和机器学习算法,极大简化了配置操作,普通用户几分钟内即可学习把握。通过简单的配置,还可以将所采集网页中的非结构化文本数据保存为结构化的数据。
【功能特性】
1.强大的信息采集功能。可采集几乎任何类型的网站信息,包括静态htm,html类型和动态ASP,ASPX,JSP等。可N级页面采集。深维全能信息采集软件官方版可手动下载二进制文件,比如图片,软件,mp3等。
2.网站登录。需要登入能够看见的信息,先在任务的'登录设置'处进行登陆,就可采集登录后就能看见的信息。
3.速度快,运行稳定。真正的多线程,多任务,运行时占用系统资源甚少,可稳定地长时间运行。(明显区别于其他软件)
4.数据保存格式丰富。可把采集的数据,保存为Txt,Excel和多种数据库格式(Access sqlserver Oracle Mysql等)。
5.强大的新闻采集,自动化处理功能。可手动保留新闻的格式,包括图片等。可通过设置,自动下载图片 ,自动把正文里图片的网路路径改为本地文件路径(也可保留原貌);可把采集的新闻手动处理成自己设计的模板格式;可采集具有分页方式的新闻。 通过这种功能,简单设置后即可在本地构建一个强悍的新闻系统,无需人工干预。
6.强大的信息手动再加工功能。对采集的信息,深维全能信息采集软件官方版可进行二次批量再加工,使之愈加符合您的实际要求。也可设置手动加工公式,在采集的过程中,按照公式手动加工处理,包括数据合并和数据替换等。
【软件特色】
1.通用:根据拟定采集规则,可以采集任何通过浏览器看得到的东西;
2.灵活:支持网站登录采集、网站跨层采集、POST采集、脚本采集、动态页面采集等中级功能;
3.扩展性强:支持存储过程、插件等,可由用户自由扩充功能,进行二次开发;
4.高效:为了使用户节约一分钟去做其它事情,软件做了悉心设计;
5.速度快:速度最快、效率最高的采集软件;
6.稳定:系统资源占用少、有详尽的运行报告、采集性能稳定; G、人性化:注重软件细节、强调人性化体验。
【更新日志】
1.争对Win10系统进行优化升级;
2.升级爬虫技术基类库,争对Https链接进行优化升级。
采集规则怎么排错?
采集交流 • 优采云 发表了文章 • 0 个评论 • 586 次浏览 • 2020-08-09 08:25
这里主要讲一下单机采集时碰到问题时,如何排错。单机采集出现问题,大都是因为规则中某个步骤没有执行,网页加载不完全或则步骤的中级选项设置不当。
官网中提供了很实用的排错教程,教程中详尽说明了在优采云中配置规则时,如何自动执行各步骤进行排查,这个是排错中很重要的一步,这里就不再重复。大家可以直接步入教程中心搜索“规则制做排错教程“
优采云采集数据原理:
优采云软件主要是模仿用户浏览网页的操作,比如打开网页、点击元素、输入文字、切换下拉选项、移动滑鼠到元素上。这些我们平常浏览网页也为进行相应的操作。
例子:
进入优采云官网界面(打开网页),鼠标置于产品介绍上(移动滑鼠到元素上),就会弹出一个红色的小框,鼠标移开,黑色方框都会隐藏。然后点击对面的教程中心(点击元素),进入教程中心页面,有个搜索框,输入“规则制做排错教程“(输入文字)。
优采云中还有个牛逼的步骤,循环。这也是我们才能大量采集数据的主要步骤。
循环翻页、循环点击元素、循环输入文本、循环打开网页
优采云主要是依据xpath去定位到元素,然后执行相应步骤。
规则排错主要思路
在自动执行基本没问题后(说明流程基本没有问题),进行单机采集。
然后观察单机采集界面中的网页变化,看网页是否根据每位步骤执行。如果有步骤没有执行,则该步骤出现问题。例如没有点击到详情页,没有循环翻页。重新编辑规则,在规则中的对应步骤重新调试。
下列是按照单机采集出现的问题进行讲解(5个):
1.单机运行,采集不到数据
(1)打开网页后,直接提示采集完成
主要诱因:有些网站的加载会太慢,网页还没有完全加载下来,优采云就执行下一个步骤,当优采云找不到相应的位置时,步骤难以执行,最终造成提取不到数据。
解决方式:可以将网页的超时时间加长,或者在下一个步骤设置执行前等待。让网页有足够长的时间加载。
(2)网页仍然在加载
主要诱因:主要是网站的问题,有些网站的加载会太慢。想要采集的数据没有出现。
解决方式:如果当前步骤是打开网页步骤,可以将网页的超时时间加长。如果是点击元素步骤,而且要采集的数据早已加载下来的时侯,可以在点击元素步骤设置ajax延时,
(3)网页没有步入采集页面
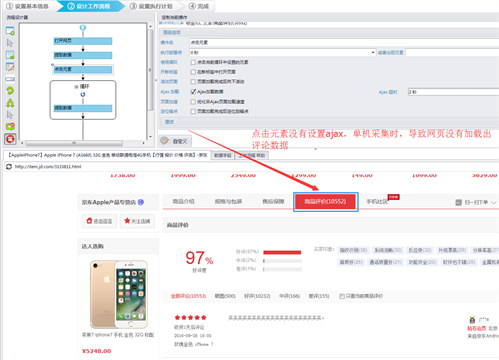
该问题往往是出现在点击元素步骤。有些网页中富含ajax链接时,根据点击位置判定是否须要设置。如果没有设置,在单机采集时会仍然卡在前一个步骤,采集不到数据。
主要诱因:当网页为异步加载时,没有设置ajax延时的话,操作通常不会正确执行,导致规则难以进行下一步,提取不到数据。
解决方式:在相应步骤设置ajax延时,一般是2-3S,如果网页加载时间较长,可以适当降低延时时长。点击元素,循环下一页、移动滑鼠到元素上,这三个步骤中都有ajax设置
例子:下图是采集京东网站下的一个手机商品的评论数据,需要点击商品评价,进入相应的评论页面。单机运行时,网页仍然卡在评论页面,没有评论数据出现。原因就在于点击元素没有设置ajax延时,导致网页没有步入相应的采集界面。
2.单机运行,漏采数据
(1)部分数组没有数据
主要诱因:单机采集时,发现有些数组信息为空,这时候就应当找到相应的采集页面,查看想要的采集的数据是否存在,有时并不是每位网页都富含所有数组信息。如果没有,字段为空是正常的。如果有的话,基本就是xpath定位问题,这时须要更改xpath,准确定位到相应数组。
解决方式:重新打开规则,手动执行验证。如需更改xpath,可以找xpath教程。
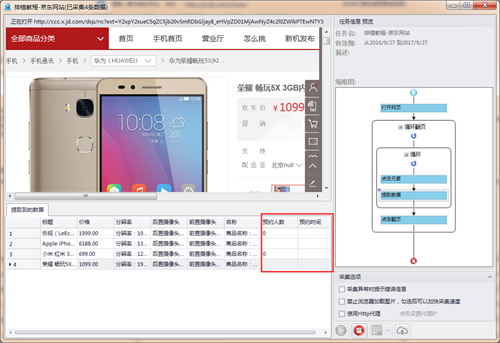
例子:下图中预约人数和预约时间出现空值,重新打开规则,手动执行,发现,页面是可以采集到数据(图二)。说明这个主要是网页加载问题,可以在下一个步骤前设置等待时长。第二条数据为空,是因为在第二个详情页本来就没有数据,属于正常。
(2)采集数据条数不对
采集数据条数不对,一般是循环翻页或则网页加载的问题。
有些网页数据须要向上滚动才能加载数据,如果在打开网页时,没有设置足够的向上滚动字数,网页加载下来的数据量也没有自动执行规则时的多。
如果翻页不正确,导致一部分页面的数据难以采集。比如出现不规则翻页,导致部份页面没有打开,数据难以采集。
主要解决方式:如果是翻页问题,修改翻页循环的xpath;如果是网页加载问题,则在打开网页的中级选项中设置滚动次数
例子:在制做规则时,循环选项是80条,而单机采集的时侯,只采集了16条。其中主要的缘由是网页没有设置向上滚动加载,导致加载的条数变少。
3.采集的数据错乱,不是对应信息
(1)多个提取数据步骤 查看全部
教程中已有详尽的排错图文教程
这里主要讲一下单机采集时碰到问题时,如何排错。单机采集出现问题,大都是因为规则中某个步骤没有执行,网页加载不完全或则步骤的中级选项设置不当。
官网中提供了很实用的排错教程,教程中详尽说明了在优采云中配置规则时,如何自动执行各步骤进行排查,这个是排错中很重要的一步,这里就不再重复。大家可以直接步入教程中心搜索“规则制做排错教程“
优采云采集数据原理:
优采云软件主要是模仿用户浏览网页的操作,比如打开网页、点击元素、输入文字、切换下拉选项、移动滑鼠到元素上。这些我们平常浏览网页也为进行相应的操作。
例子:
进入优采云官网界面(打开网页),鼠标置于产品介绍上(移动滑鼠到元素上),就会弹出一个红色的小框,鼠标移开,黑色方框都会隐藏。然后点击对面的教程中心(点击元素),进入教程中心页面,有个搜索框,输入“规则制做排错教程“(输入文字)。
优采云中还有个牛逼的步骤,循环。这也是我们才能大量采集数据的主要步骤。
循环翻页、循环点击元素、循环输入文本、循环打开网页
优采云主要是依据xpath去定位到元素,然后执行相应步骤。
规则排错主要思路
在自动执行基本没问题后(说明流程基本没有问题),进行单机采集。
然后观察单机采集界面中的网页变化,看网页是否根据每位步骤执行。如果有步骤没有执行,则该步骤出现问题。例如没有点击到详情页,没有循环翻页。重新编辑规则,在规则中的对应步骤重新调试。
下列是按照单机采集出现的问题进行讲解(5个):
1.单机运行,采集不到数据
(1)打开网页后,直接提示采集完成
主要诱因:有些网站的加载会太慢,网页还没有完全加载下来,优采云就执行下一个步骤,当优采云找不到相应的位置时,步骤难以执行,最终造成提取不到数据。
解决方式:可以将网页的超时时间加长,或者在下一个步骤设置执行前等待。让网页有足够长的时间加载。
(2)网页仍然在加载
主要诱因:主要是网站的问题,有些网站的加载会太慢。想要采集的数据没有出现。
解决方式:如果当前步骤是打开网页步骤,可以将网页的超时时间加长。如果是点击元素步骤,而且要采集的数据早已加载下来的时侯,可以在点击元素步骤设置ajax延时,
(3)网页没有步入采集页面
该问题往往是出现在点击元素步骤。有些网页中富含ajax链接时,根据点击位置判定是否须要设置。如果没有设置,在单机采集时会仍然卡在前一个步骤,采集不到数据。
主要诱因:当网页为异步加载时,没有设置ajax延时的话,操作通常不会正确执行,导致规则难以进行下一步,提取不到数据。
解决方式:在相应步骤设置ajax延时,一般是2-3S,如果网页加载时间较长,可以适当降低延时时长。点击元素,循环下一页、移动滑鼠到元素上,这三个步骤中都有ajax设置
例子:下图是采集京东网站下的一个手机商品的评论数据,需要点击商品评价,进入相应的评论页面。单机运行时,网页仍然卡在评论页面,没有评论数据出现。原因就在于点击元素没有设置ajax延时,导致网页没有步入相应的采集界面。
2.单机运行,漏采数据
(1)部分数组没有数据
主要诱因:单机采集时,发现有些数组信息为空,这时候就应当找到相应的采集页面,查看想要的采集的数据是否存在,有时并不是每位网页都富含所有数组信息。如果没有,字段为空是正常的。如果有的话,基本就是xpath定位问题,这时须要更改xpath,准确定位到相应数组。
解决方式:重新打开规则,手动执行验证。如需更改xpath,可以找xpath教程。
例子:下图中预约人数和预约时间出现空值,重新打开规则,手动执行,发现,页面是可以采集到数据(图二)。说明这个主要是网页加载问题,可以在下一个步骤前设置等待时长。第二条数据为空,是因为在第二个详情页本来就没有数据,属于正常。
(2)采集数据条数不对
采集数据条数不对,一般是循环翻页或则网页加载的问题。
有些网页数据须要向上滚动才能加载数据,如果在打开网页时,没有设置足够的向上滚动字数,网页加载下来的数据量也没有自动执行规则时的多。
如果翻页不正确,导致一部分页面的数据难以采集。比如出现不规则翻页,导致部份页面没有打开,数据难以采集。
主要解决方式:如果是翻页问题,修改翻页循环的xpath;如果是网页加载问题,则在打开网页的中级选项中设置滚动次数
例子:在制做规则时,循环选项是80条,而单机采集的时侯,只采集了16条。其中主要的缘由是网页没有设置向上滚动加载,导致加载的条数变少。
3.采集的数据错乱,不是对应信息
(1)多个提取数据步骤
节气1.7--使用离线采集器的指南
采集交流 • 优采云 发表了文章 • 0 个评论 • 271 次浏览 • 2020-08-09 07:26
规则文件夹,日志文件夹:
规则是我们发布采集规则的地方;
日志是一个日志内容,也就是说,当关闭采集器时,它将记录错误的信息. 当我们看到此消息时,我们将知道集合出了错;
现在,我们单击开关以关闭采集器,然后直接打开NovelSpider.exe以启动关闭采集器. (注意: 打开过程会有点慢,因此请单击一次并稍等片刻. 请勿再次单击“打开”,否则一段时间后将打开多个关闭采集器!)
在某些级别上会有一个提示框,因此无论如何都将其关闭.
了解有关采集器的一些常用信息
打开后,我们应立即修改“设置(S)”→“系统设置”. :
1. 修改本地网站目录,例如,我的位于D: \ xiaoshuo
2. 再次修改数据库连接字符串
DataSource = 127.0.0.1;
Database =数据库名称;
UserID =数据库管理用户名;
Password =数据库管理密码;
port = 3306;
charset = gbk
以上是设置采集器的方法. 这是您第一次使用它,您需要对其进行设置,并且在设置之后不需要再次进行设置.
关于“ Off Collector 1.7”分类设置
首先: 类别设置通常对应于类别,该类别对应于您网站的类别. 例如
1 | Fantasy Fantasy =,幻想,幻想,魔术,魔术,幻想魔术,幻想幻想,幻想小说,幻想·魔术,幻想世界,幻想幻想,
1是您网站上的第一个蓝米幻想幻想. 等号后的类别是采集目标网站可能遇到的类别. 越详细越好,某些模板网站会对应您的幻想幻想所没有的内容,因此您可以添加它.
第二个: 是设置中的一代
默认情况下无需修改. 第一个生成的目录页面html是您网站的新颖目录页面的html. 如果您的网站使用伪静态,则不需要生成它. 第二个生成的内容页面html用于新颖内容. 单击以查看小说的文本章节. 这与上面的第一个相同. 如果您的网站使用伪静态,则不需要生成它.
如果您要构建一个静态的新颖网站,则需要生成它,这非常消耗硬盘. 通常,一千本小说需要几GB的空间.
第三: 生成全文阅读. 不用担心.
第四: 生成OPF. 这必须生成,否则网站将无法打开,并且如果未生成您的新颖网站,则会错误打开. 只需在此处打勾. 不用担心其他设置,没有特殊要求您将无法使用它们.
(注意: [Settings-e-book settings]不需要控制,默认值就足够了,所以不要选择对勾,设置中的图片设置也是默认值,所以不要选择滴答声. )
第五: 文字广告. 如果要在新颖内容中添加广告,则可以在此处添加内容. 您需要选择第一个存储章节以添加文字广告. 真正的存储空间会将您的广告添加到您采集的小说中,这些路径的txt文件中的文件/文章/ txt / 0/1
这是您的小说,是一部移动版本,因此您需要选择第一本. 添加广告时,您会在章节阅读中看到它,但不要使用这些功能.
第六: 其他[过滤和替换],[文本到图片]. 无需控制
第七: 日志选择. 勾选所有人. 这是为了采集记录的遇到的错误的日志. 您可以基于此消除错误.
如何查看海关规则是否有效?
单击规则,进入规则管理器,我们选择我们不能做的三角形符号,下拉您要测试的规则,单击右侧的负载,然后单击“测试规则”,界面将弹出,如果这些是要获取ID和小说名称
这是为了获得包括小说名称分类介绍和封面在内的小说信息内容.
某些网站不会采集所有信息,如果我们将其采集回来,它将显得不完整. 这没有作用. 您可以阅读小说主要章节的内容. 然后这些是要采集的章节,这是小说的内容.
这是一个很好的采集规则. 我们可以使用此采集规则来采集新颖的更新.
如何采集
通常,我们使用标准的采集模式.
当我们单击“采集标准采集模式”时,有时会出现错误消息. 无论我们在采集框中单击一条规则,它都会显示在正确的位置. 有一些迹象表明我们也忽略了他,直接单击[继续].
输入标准采集品后输入正确的姿势后,通常使用第一个根据目标测站页面获取编号. 编写此规则时,将根据目标电台的最新更新小说进行设置,并将在采集过程中自动将其采集. 当我们更新对方的小说时,我们还将关注其他人的小说网站.
1. 设置ID范围,并根据目标站ID进行采集. 采集对方的某本书时很少使用.
2. 从对方采集某本书时,很少使用按目标站ID进行采集.
3. 该采集集基于您网站的小说ID,因此您需要先单击网站上的小说才能对其进行更新,但是模板网站可能没有这本书,因此采集速度很慢. 很少使用,基本上没有用.
4. 转到日志记录的底部,必须选择日志记录以记录无缘无故无法采集的新颖信息的采集. 还必须选择循环采集. 这是为了确保采集器在自动采集过程中自动采集另一方的网站. 循环时间设置取决于您自己的需求. 我通常将其设置为十分钟. 如果要继续采集,请将其设置为零.
如何设置采集动作?
[添加新书]: 添加书时添加;
[谨慎使用]: 以下两个单词是比较模板站的章节名称. 如果正确,请继续采集. 如果不对,请将其清空并再次采集. 不要使用它,这会引起很大的问题. 有时候,意外清空我收录在百度中的页面是一个悲剧. 对于其他一些功能,可以阅读文字;
[设置2]: 这是比较章节的选择,无论如何,它们几乎是相同的,为什么我没有什么不同?您可以默认设置;
[空章节的处理方法]: 这意味着模板站点中的某些小说是空的,具体取决于您的需求,但请注意,您不应选择第二本来跳过本章,因为跳过本章将使本章空白章节名称,下次您少采集一个章节名称并将该章节名称与模板站进行比较时,该书将无法更新;
[章节安排]: 这取决于目标站的图,这更加复杂. 我给您的采集规则按目标电台的顺序排列. 不要选择任何东西,通常使用[目标电台顺序]和[按照章节ID的顺序],不要使用其他内容. 这两个不会有问题,我将为您提供默认设置;
[过滤器设置]: 取决于您需要设置的内容,字面意思很明确;
[删除水印]: 这基本上是不必要的;
[Agent],[Progress]: 通常将上述三个数字设置为000;
这样,采集速度很快. 代理IP是阻止您进行采集的目标站点,然后您可以在Internet上找到一些代理,打开代理功能,然后进行采集.
我已经在这里讨论了其中一些功能,而其他功能则是一些辅助功能,您以后可以进一步了解.
在下面进行设置,然后单击以开始采集. 选择规则,然后选择要输入的采集操作,然后单击以开始;
如果出现提示“成功启动了采集模式”,则可以查看您的网站是否已更新. 查看全部
紧密采集器的主要焦点是两个文件夹
规则文件夹,日志文件夹:
规则是我们发布采集规则的地方;
日志是一个日志内容,也就是说,当关闭采集器时,它将记录错误的信息. 当我们看到此消息时,我们将知道集合出了错;
现在,我们单击开关以关闭采集器,然后直接打开NovelSpider.exe以启动关闭采集器. (注意: 打开过程会有点慢,因此请单击一次并稍等片刻. 请勿再次单击“打开”,否则一段时间后将打开多个关闭采集器!)
在某些级别上会有一个提示框,因此无论如何都将其关闭.
了解有关采集器的一些常用信息
打开后,我们应立即修改“设置(S)”→“系统设置”. :
1. 修改本地网站目录,例如,我的位于D: \ xiaoshuo
2. 再次修改数据库连接字符串
DataSource = 127.0.0.1;
Database =数据库名称;
UserID =数据库管理用户名;
Password =数据库管理密码;
port = 3306;
charset = gbk
以上是设置采集器的方法. 这是您第一次使用它,您需要对其进行设置,并且在设置之后不需要再次进行设置.
关于“ Off Collector 1.7”分类设置
首先: 类别设置通常对应于类别,该类别对应于您网站的类别. 例如
1 | Fantasy Fantasy =,幻想,幻想,魔术,魔术,幻想魔术,幻想幻想,幻想小说,幻想·魔术,幻想世界,幻想幻想,
1是您网站上的第一个蓝米幻想幻想. 等号后的类别是采集目标网站可能遇到的类别. 越详细越好,某些模板网站会对应您的幻想幻想所没有的内容,因此您可以添加它.
第二个: 是设置中的一代
默认情况下无需修改. 第一个生成的目录页面html是您网站的新颖目录页面的html. 如果您的网站使用伪静态,则不需要生成它. 第二个生成的内容页面html用于新颖内容. 单击以查看小说的文本章节. 这与上面的第一个相同. 如果您的网站使用伪静态,则不需要生成它.
如果您要构建一个静态的新颖网站,则需要生成它,这非常消耗硬盘. 通常,一千本小说需要几GB的空间.
第三: 生成全文阅读. 不用担心.
第四: 生成OPF. 这必须生成,否则网站将无法打开,并且如果未生成您的新颖网站,则会错误打开. 只需在此处打勾. 不用担心其他设置,没有特殊要求您将无法使用它们.
(注意: [Settings-e-book settings]不需要控制,默认值就足够了,所以不要选择对勾,设置中的图片设置也是默认值,所以不要选择滴答声. )
第五: 文字广告. 如果要在新颖内容中添加广告,则可以在此处添加内容. 您需要选择第一个存储章节以添加文字广告. 真正的存储空间会将您的广告添加到您采集的小说中,这些路径的txt文件中的文件/文章/ txt / 0/1
这是您的小说,是一部移动版本,因此您需要选择第一本. 添加广告时,您会在章节阅读中看到它,但不要使用这些功能.
第六: 其他[过滤和替换],[文本到图片]. 无需控制
第七: 日志选择. 勾选所有人. 这是为了采集记录的遇到的错误的日志. 您可以基于此消除错误.
如何查看海关规则是否有效?
单击规则,进入规则管理器,我们选择我们不能做的三角形符号,下拉您要测试的规则,单击右侧的负载,然后单击“测试规则”,界面将弹出,如果这些是要获取ID和小说名称
这是为了获得包括小说名称分类介绍和封面在内的小说信息内容.
某些网站不会采集所有信息,如果我们将其采集回来,它将显得不完整. 这没有作用. 您可以阅读小说主要章节的内容. 然后这些是要采集的章节,这是小说的内容.
这是一个很好的采集规则. 我们可以使用此采集规则来采集新颖的更新.
如何采集
通常,我们使用标准的采集模式.
当我们单击“采集标准采集模式”时,有时会出现错误消息. 无论我们在采集框中单击一条规则,它都会显示在正确的位置. 有一些迹象表明我们也忽略了他,直接单击[继续].
输入标准采集品后输入正确的姿势后,通常使用第一个根据目标测站页面获取编号. 编写此规则时,将根据目标电台的最新更新小说进行设置,并将在采集过程中自动将其采集. 当我们更新对方的小说时,我们还将关注其他人的小说网站.
1. 设置ID范围,并根据目标站ID进行采集. 采集对方的某本书时很少使用.
2. 从对方采集某本书时,很少使用按目标站ID进行采集.
3. 该采集集基于您网站的小说ID,因此您需要先单击网站上的小说才能对其进行更新,但是模板网站可能没有这本书,因此采集速度很慢. 很少使用,基本上没有用.
4. 转到日志记录的底部,必须选择日志记录以记录无缘无故无法采集的新颖信息的采集. 还必须选择循环采集. 这是为了确保采集器在自动采集过程中自动采集另一方的网站. 循环时间设置取决于您自己的需求. 我通常将其设置为十分钟. 如果要继续采集,请将其设置为零.
如何设置采集动作?
[添加新书]: 添加书时添加;
[谨慎使用]: 以下两个单词是比较模板站的章节名称. 如果正确,请继续采集. 如果不对,请将其清空并再次采集. 不要使用它,这会引起很大的问题. 有时候,意外清空我收录在百度中的页面是一个悲剧. 对于其他一些功能,可以阅读文字;
[设置2]: 这是比较章节的选择,无论如何,它们几乎是相同的,为什么我没有什么不同?您可以默认设置;
[空章节的处理方法]: 这意味着模板站点中的某些小说是空的,具体取决于您的需求,但请注意,您不应选择第二本来跳过本章,因为跳过本章将使本章空白章节名称,下次您少采集一个章节名称并将该章节名称与模板站进行比较时,该书将无法更新;
[章节安排]: 这取决于目标站的图,这更加复杂. 我给您的采集规则按目标电台的顺序排列. 不要选择任何东西,通常使用[目标电台顺序]和[按照章节ID的顺序],不要使用其他内容. 这两个不会有问题,我将为您提供默认设置;
[过滤器设置]: 取决于您需要设置的内容,字面意思很明确;
[删除水印]: 这基本上是不必要的;
[Agent],[Progress]: 通常将上述三个数字设置为000;
这样,采集速度很快. 代理IP是阻止您进行采集的目标站点,然后您可以在Internet上找到一些代理,打开代理功能,然后进行采集.
我已经在这里讨论了其中一些功能,而其他功能则是一些辅助功能,您以后可以进一步了解.
在下面进行设置,然后单击以开始采集. 选择规则,然后选择要输入的采集操作,然后单击以开始;
如果出现提示“成功启动了采集模式”,则可以查看您的网站是否已更新.
在10分钟内不会在58.com的微博,微信,搜狐上采集任何代码,数据和信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 351 次浏览 • 2020-08-08 03:51
Web scraper是Google强大的插件库中非常强大的数据采集插件. 它具有强大的防爬网功能. 您只需要简单地在插件上进行设置,就可以快速抓取知乎,jianshu,douban和public 58等大型,中小型网站,包括文本,图片,表格和其他内容,最后快速导出csv格式文件. 网络上的Google官方
scraper给出的描述是:
使用我们的扩展程序,您可以创建计划(站点地图),如何遍历网站以及应提取什么内容. 使用这些站点地图,网络抓取工具将相应地导航该站点并提取所有数据. 您可以稍后将剪辑数据导出到CSV.
Webscraperk课程将以知乎,Jianshu和其他网站为例,对该过程进行完整的介绍,以介绍如何采集文本,表格,多元素爬网,不规则页面爬网,辅助页面爬网和动态网站爬网. ,以及一些反爬行技术和所有内容.
安装网络抓取器
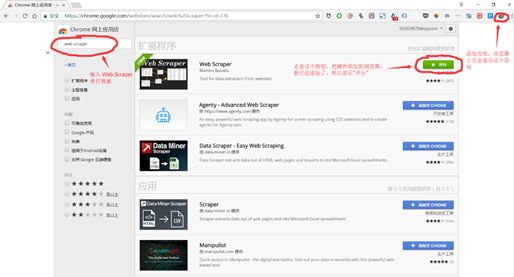
Web scraper是Google浏览器的扩展插件,其安装与其他插件相同.
以知乎为例,介绍完整的Webscraper爬网过程
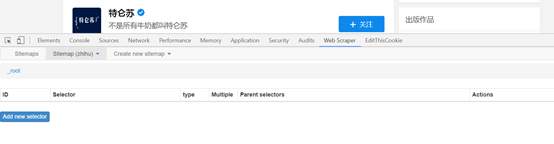
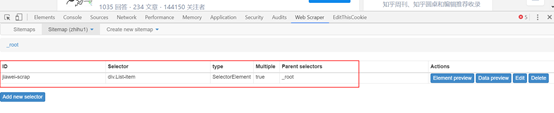
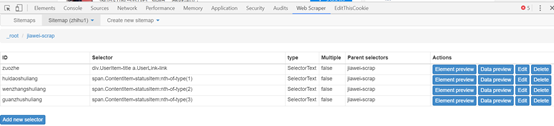
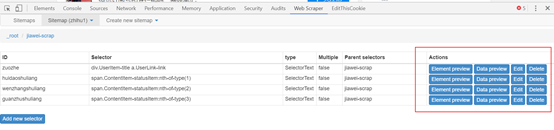
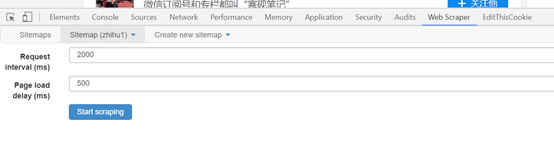
1. 打开目标网站. 这里以芝湖一号诉张家卫案的下列对象为例. 需要抓取的是关注者的姓名,答案数量,发表的文章数量以及关注者数量.
2. 右键单击网页上的鼠标,选择检查选项,或使用快捷键Ctrl + Shift + I / F12打开Web Scraper.
3. 打开后,单击创建站点地图,然后选择创建站点地图以创建站点地图.
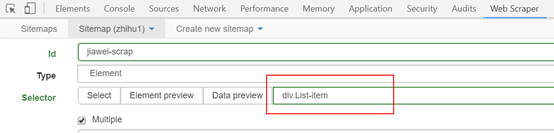
点击创建站点地图后,您将获得如图所示的页面. 您需要填写站点地图名称,即站点的名称. 只要您能理解它,就可以随便写. 您还需要填写starturl,即指向页面的链接. 填写后,单击创建站点地图以完成站点地图的创建.
4. 设置第一级选择器: 选择采集范围
下一个是最高优先级. 这是对Web爬虫的爬网逻辑的介绍: 您需要设置一个第一级选择器(选择器)来设置需要爬网的范围. 在第一级选择器下创建一个第二级选择器(选择器),并将其设置为获取元素和内容.
以张家卫的关注为例. 我们的范围是张家卫关注的目标. 然后,我们需要为此范围创建一个选择器. 次要选择者是张家卫关注的目标对象的粉丝数和文章数. 内容. 具体步骤如下:
(1)添加新的选择器以创建一级选择器选择器:
单击后,您将获得以下页面,并在此页面上设置了要抓取的内容.
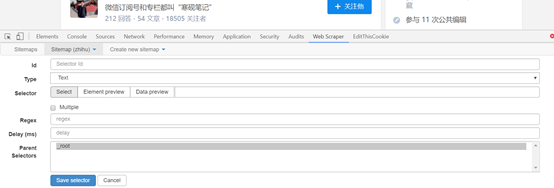
[if!supportLists] l [endif] id: 只需命名选择器,出于相同的原因,只要您能自己理解它,这里就叫jiawei-scrap.
[if!supportLists] l [endif] Type: 它是要捕获的内容的类型,例如元素元素/文本/链接链接/图片图像/元素在动态加载中向下滚动等,这里有多个元素选择元素.
[if!supportLists] l [endif] Selector: 是指要获取的内容的选择. 单击选择以选择页面上的内容. 这部分将在下面详细描述.
[if!supportLists] l [endif]选中多个: 选中“ Multiple”前面的小框,因为要选择多个元素而不是单个元素. 选中后,采集器插件将识别出存在相同属性的内容;
(2)在此步骤中,需要设置选定的内容,在选择选项下单击“选择”以获取以下图片:
将鼠标移到需要选择的内容上,此时需要选择的内容将变为绿色,表示已选择该内容. 在这里您需要提醒您,如果您需要的内容是多元素,则需要更改元素. 选择两者. 例如,如下图所示,绿色表示所选内容在绿色范围内.
选择内容范围后,单击鼠标,所选内容范围将变为红色,如下图所示:
当内容变成红色时,我们可以选择下一个内容. 单击后,Web采集器将自动识别您想要的内容,并且具有相同元素的内容将全部变为红色. 如下图所示:
在确认我们在此页面上需要的所有内容都变成红色后,可以单击“完成”选择选项,然后得到以下图片:
单击“保存选择器”以保存设置. 此后,将创建第一级选择器.
5. 设置辅助选择器: 选择要采集的元素内容.
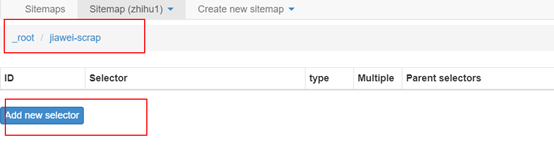
(1)单击下图红色框中的内容,进入第一级选择器jiawei-scrap:
(2)单击添加新选择器以创建用于选择特定内容的辅助选择器.
获取以下图片,该图片与第一级选择器的内容相同,但是设置不同.
[if!supportLists]Ø[endif] id: 表示捕获哪个字段. 您可以选择该领域的英语. 例如,如果要选择“作者”,请写“作者”;
[if!supportLists]Ø[endif]类型: 在此处选择“文本”选项,因为您要获取文本内容;
[if!supportLists]Ø[endif] Multiple: 请勿在Multiple前面的小方框中打勾,因为这是要捕获的单个元素;
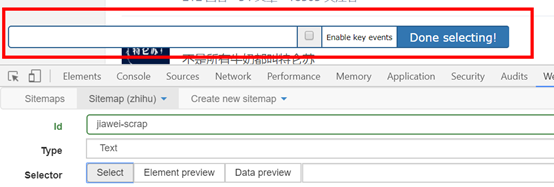
[如果!supportLists]Ø[endif]保留设置: 保留未提及的其他部分的默认设置.
(3)单击选择选项后,将鼠标移至特定元素,该元素将变为黄色,如下图所示:
在单击特定元素后,该元素将变为红色,这表示已选择内容.
(4)单击“完成选择”完成选择,然后单击“保存选择器”完成对关注者名称的选择.
重复上述操作,直到选择了要爬坡的田地为止.
(5)单击红色框以查看采集的内容.
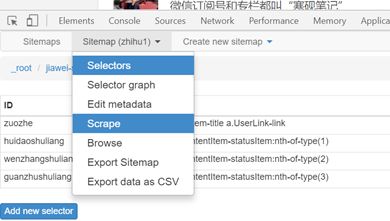
6. 抓取数据
(1)您只需要设置所有选择器,就可以开始爬网数据,单击“刮擦”图,选择刮擦;:
(2)单击后,将跳至时间设置页面,如下图所示. 由于集合的数量不大,因此您可以默认保存它. 点击开始抓取,然后会弹出一个窗口,然后开始正式采集.
(3)过一会儿,您可以获得采集效果,如下图所示:
(4)选择站点地图下的export data as csv选项,以表格形式导出采集的结果.
表格效果(部分数据):
此外,我们还使用网络抓取工具采集了58个城市的租赁信息,公众评论食物信息,微信公众号密蒙文章,京东小米手机评论等.
作者: 学者Wan Yau
博客:
·END· 查看全部
有必要学习信息并快速采集数据,因为它可以大大提高工作效率. 在学习python和优采云之前,web scraper是我最常用的采集工具. 设置简单,效率很高. 采集Mimeng文章的标题仅需2分钟,而采集58个相同城市中的5000个租借信息仅需5分钟.
Web scraper是Google强大的插件库中非常强大的数据采集插件. 它具有强大的防爬网功能. 您只需要简单地在插件上进行设置,就可以快速抓取知乎,jianshu,douban和public 58等大型,中小型网站,包括文本,图片,表格和其他内容,最后快速导出csv格式文件. 网络上的Google官方
scraper给出的描述是:
使用我们的扩展程序,您可以创建计划(站点地图),如何遍历网站以及应提取什么内容. 使用这些站点地图,网络抓取工具将相应地导航该站点并提取所有数据. 您可以稍后将剪辑数据导出到CSV.
Webscraperk课程将以知乎,Jianshu和其他网站为例,对该过程进行完整的介绍,以介绍如何采集文本,表格,多元素爬网,不规则页面爬网,辅助页面爬网和动态网站爬网. ,以及一些反爬行技术和所有内容.

安装网络抓取器
Web scraper是Google浏览器的扩展插件,其安装与其他插件相同.

以知乎为例,介绍完整的Webscraper爬网过程
1. 打开目标网站. 这里以芝湖一号诉张家卫案的下列对象为例. 需要抓取的是关注者的姓名,答案数量,发表的文章数量以及关注者数量.
2. 右键单击网页上的鼠标,选择检查选项,或使用快捷键Ctrl + Shift + I / F12打开Web Scraper.
3. 打开后,单击创建站点地图,然后选择创建站点地图以创建站点地图.

点击创建站点地图后,您将获得如图所示的页面. 您需要填写站点地图名称,即站点的名称. 只要您能理解它,就可以随便写. 您还需要填写starturl,即指向页面的链接. 填写后,单击创建站点地图以完成站点地图的创建.
4. 设置第一级选择器: 选择采集范围
下一个是最高优先级. 这是对Web爬虫的爬网逻辑的介绍: 您需要设置一个第一级选择器(选择器)来设置需要爬网的范围. 在第一级选择器下创建一个第二级选择器(选择器),并将其设置为获取元素和内容.
以张家卫的关注为例. 我们的范围是张家卫关注的目标. 然后,我们需要为此范围创建一个选择器. 次要选择者是张家卫关注的目标对象的粉丝数和文章数. 内容. 具体步骤如下:
(1)添加新的选择器以创建一级选择器选择器:
单击后,您将获得以下页面,并在此页面上设置了要抓取的内容.
[if!supportLists] l [endif] id: 只需命名选择器,出于相同的原因,只要您能自己理解它,这里就叫jiawei-scrap.
[if!supportLists] l [endif] Type: 它是要捕获的内容的类型,例如元素元素/文本/链接链接/图片图像/元素在动态加载中向下滚动等,这里有多个元素选择元素.
[if!supportLists] l [endif] Selector: 是指要获取的内容的选择. 单击选择以选择页面上的内容. 这部分将在下面详细描述.
[if!supportLists] l [endif]选中多个: 选中“ Multiple”前面的小框,因为要选择多个元素而不是单个元素. 选中后,采集器插件将识别出存在相同属性的内容;
(2)在此步骤中,需要设置选定的内容,在选择选项下单击“选择”以获取以下图片:
将鼠标移到需要选择的内容上,此时需要选择的内容将变为绿色,表示已选择该内容. 在这里您需要提醒您,如果您需要的内容是多元素,则需要更改元素. 选择两者. 例如,如下图所示,绿色表示所选内容在绿色范围内.
选择内容范围后,单击鼠标,所选内容范围将变为红色,如下图所示:
当内容变成红色时,我们可以选择下一个内容. 单击后,Web采集器将自动识别您想要的内容,并且具有相同元素的内容将全部变为红色. 如下图所示:
在确认我们在此页面上需要的所有内容都变成红色后,可以单击“完成”选择选项,然后得到以下图片:
单击“保存选择器”以保存设置. 此后,将创建第一级选择器.
5. 设置辅助选择器: 选择要采集的元素内容.
(1)单击下图红色框中的内容,进入第一级选择器jiawei-scrap:
(2)单击添加新选择器以创建用于选择特定内容的辅助选择器.
获取以下图片,该图片与第一级选择器的内容相同,但是设置不同.
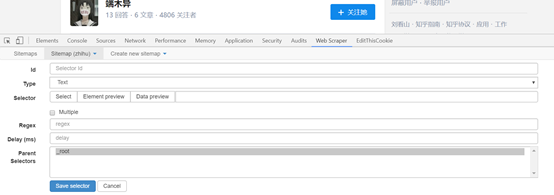
[if!supportLists]Ø[endif] id: 表示捕获哪个字段. 您可以选择该领域的英语. 例如,如果要选择“作者”,请写“作者”;
[if!supportLists]Ø[endif]类型: 在此处选择“文本”选项,因为您要获取文本内容;
[if!supportLists]Ø[endif] Multiple: 请勿在Multiple前面的小方框中打勾,因为这是要捕获的单个元素;
[如果!supportLists]Ø[endif]保留设置: 保留未提及的其他部分的默认设置.
(3)单击选择选项后,将鼠标移至特定元素,该元素将变为黄色,如下图所示:
在单击特定元素后,该元素将变为红色,这表示已选择内容.
(4)单击“完成选择”完成选择,然后单击“保存选择器”完成对关注者名称的选择.

重复上述操作,直到选择了要爬坡的田地为止.
(5)单击红色框以查看采集的内容.
6. 抓取数据
(1)您只需要设置所有选择器,就可以开始爬网数据,单击“刮擦”图,选择刮擦;:
(2)单击后,将跳至时间设置页面,如下图所示. 由于集合的数量不大,因此您可以默认保存它. 点击开始抓取,然后会弹出一个窗口,然后开始正式采集.
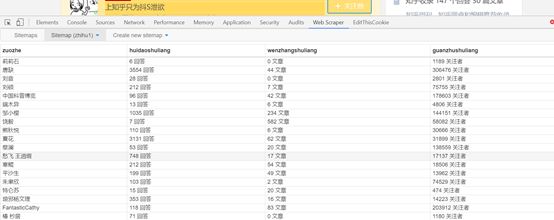
(3)过一会儿,您可以获得采集效果,如下图所示:
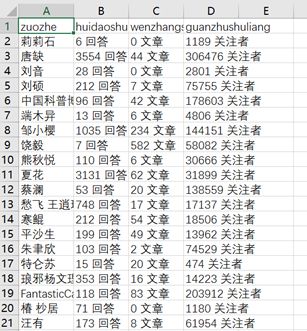
(4)选择站点地图下的export data as csv选项,以表格形式导出采集的结果.
表格效果(部分数据):
此外,我们还使用网络抓取工具采集了58个城市的租赁信息,公众评论食物信息,微信公众号密蒙文章,京东小米手机评论等.
作者: 学者Wan Yau
博客:
·END·
[03]基础: 将采集规则应用于相同的网页结构
采集交流 • 优采云 发表了文章 • 0 个评论 • 516 次浏览 • 2020-08-08 01:37
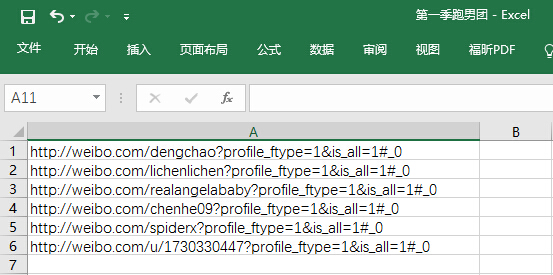
添加单个条目
点击“添加潜在客户”,输入潜在客户网址并保存.
批量添加
使用Excel存储潜在客户网址
单击“批量导入线索”添加附件,单击“批量导入”成功添加!
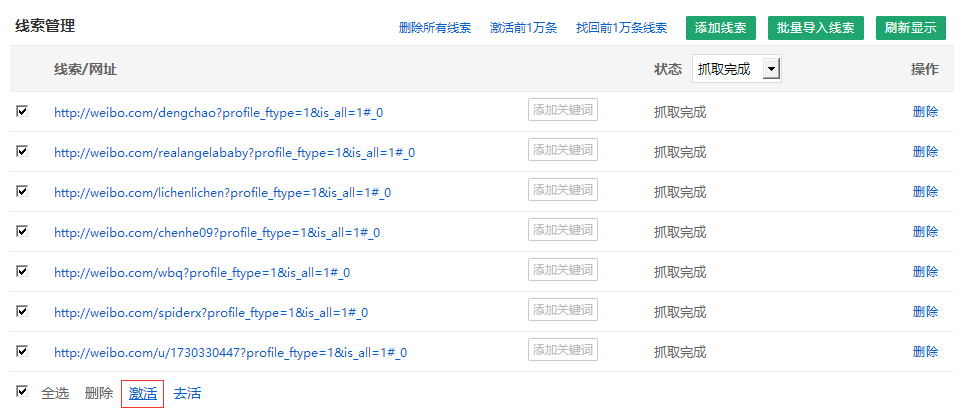
添加了六个,加上原创示例URL,总共有七个线索,现在它们都处于“待抓取”状态.
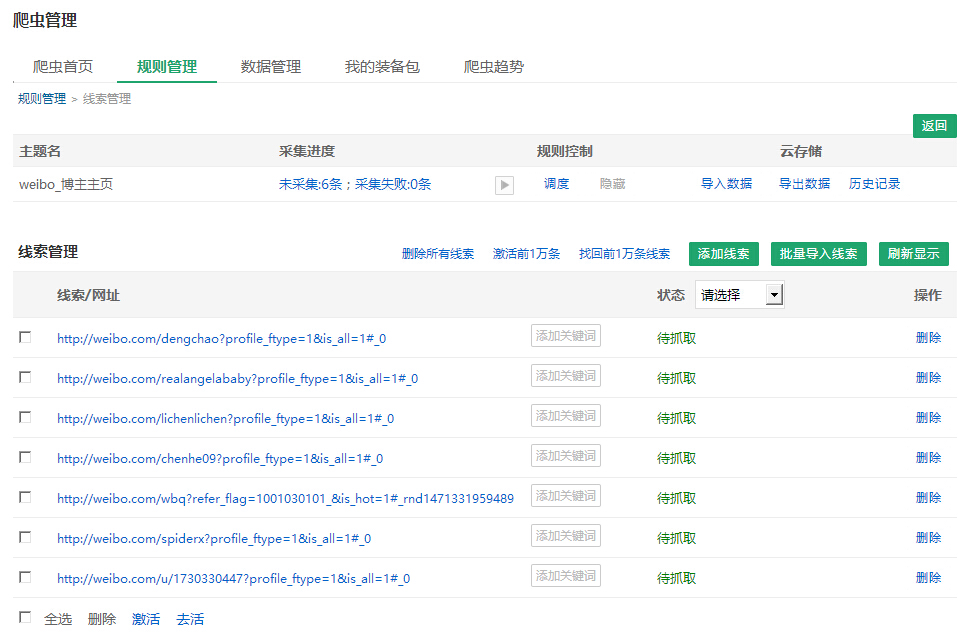
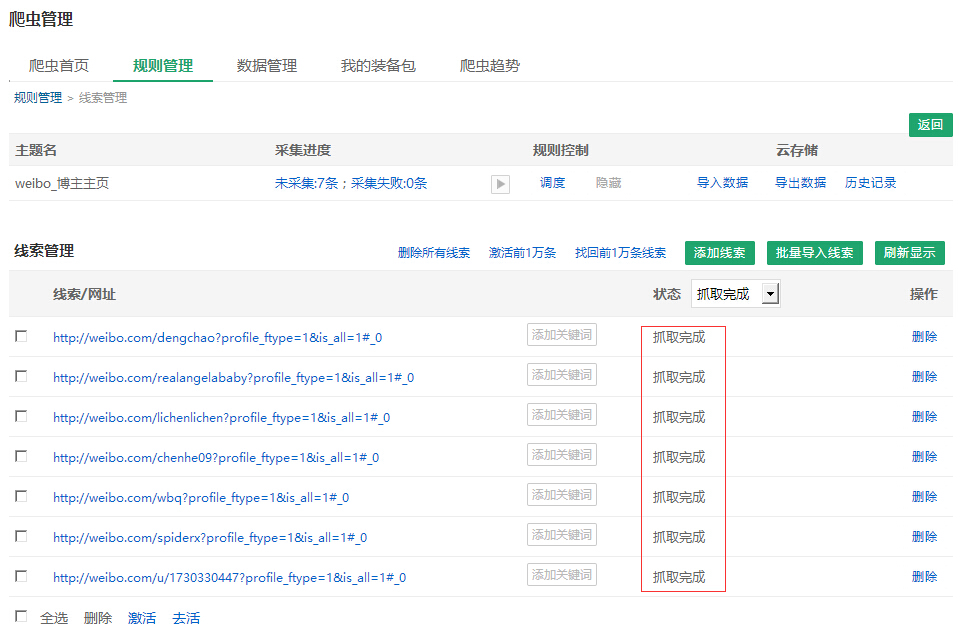
在此页面上,除了添加线索以外,您还可以激活,停用和删除线索.
如何运行线索?
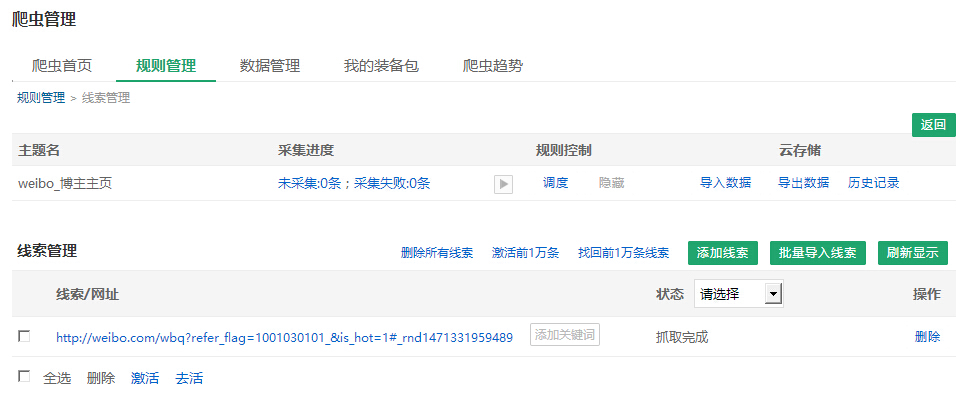
运行采集规则是运行规则中的线索.
从上图可以看出,“ weibo_blog主主页”规则中现在有7条线索,所有这些线索都处于“ Pending crawl”状态. 要运行这些线索,请从DS计数器开始.
打开DS计数机,搜索要运行的规则,然后单击“单一搜索”或“集合”以启动DS计数机以捕获数据.
单次搜索: 在当前DS窗口中采集;采集搜索: 弹出一个新窗口进行采集.
单击“采集”后,输入一些要爬网的线索,然后单击“确定”.
我们看到DS计数机正在运行并立即获取.
如果您不知道要抓取多少线索,请右键单击DS计数器上的计数线索.
如何激活销售线索?
我刚刚运行了“ weibo_bloglor主页”采集规则,并且在会员中心看到这7条线索全部处于“抓取完成”状态.
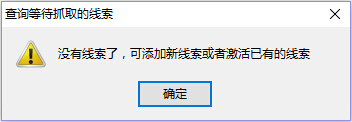
如果您按照上述步骤在DS计数器中再次运行该规则,则此时将提示您没有任何线索,因为这7条线索刚刚被运行.
要再次捕获这些线索,只需重新激活这些线索即可. 激活后,这些线索的状态将变为“待抓取”.
有两种激活方式-
规则管理激活
在规则管理中选择要激活的线索后,单击“激活”按钮.
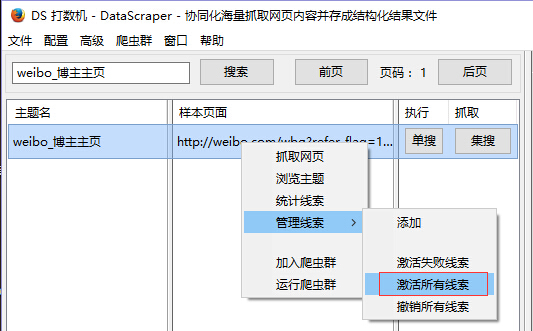
DS窗口激活
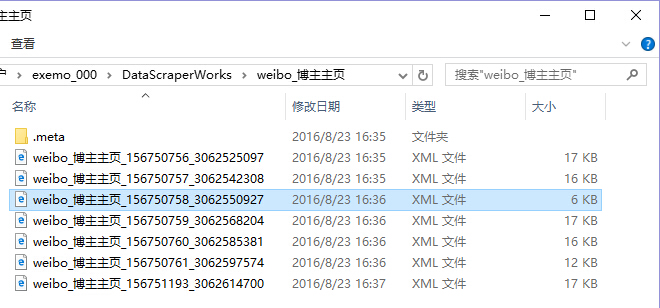
在这里,看看刚才运行的采集规则“ weibo_blog master homepage”的结果文件〜
在下一期中,结果文件将转换为Excel. 学习下一个问题之后,您将开始. 只要它不是复杂的网页,就可以采集它. 立于不败之地,令人兴奋吗?
转载于: 查看全部
添加单个条目
点击“添加潜在客户”,输入潜在客户网址并保存.

批量添加
使用Excel存储潜在客户网址
单击“批量导入线索”添加附件,单击“批量导入”成功添加!
添加了六个,加上原创示例URL,总共有七个线索,现在它们都处于“待抓取”状态.
在此页面上,除了添加线索以外,您还可以激活,停用和删除线索.
如何运行线索?
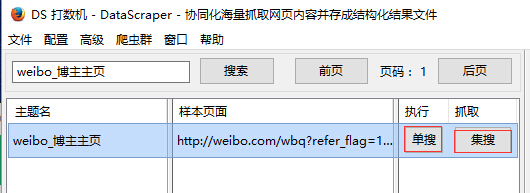
运行采集规则是运行规则中的线索.
从上图可以看出,“ weibo_blog主主页”规则中现在有7条线索,所有这些线索都处于“ Pending crawl”状态. 要运行这些线索,请从DS计数器开始.
打开DS计数机,搜索要运行的规则,然后单击“单一搜索”或“集合”以启动DS计数机以捕获数据.
单次搜索: 在当前DS窗口中采集;采集搜索: 弹出一个新窗口进行采集.
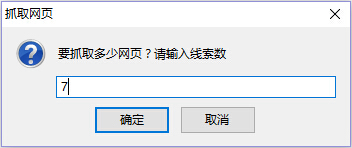
单击“采集”后,输入一些要爬网的线索,然后单击“确定”.
我们看到DS计数机正在运行并立即获取.
如果您不知道要抓取多少线索,请右键单击DS计数器上的计数线索.
如何激活销售线索?
我刚刚运行了“ weibo_bloglor主页”采集规则,并且在会员中心看到这7条线索全部处于“抓取完成”状态.
如果您按照上述步骤在DS计数器中再次运行该规则,则此时将提示您没有任何线索,因为这7条线索刚刚被运行.
要再次捕获这些线索,只需重新激活这些线索即可. 激活后,这些线索的状态将变为“待抓取”.
有两种激活方式-
规则管理激活
在规则管理中选择要激活的线索后,单击“激活”按钮.
DS窗口激活
在这里,看看刚才运行的采集规则“ weibo_blog master homepage”的结果文件〜
在下一期中,结果文件将转换为Excel. 学习下一个问题之后,您将开始. 只要它不是复杂的网页,就可以采集它. 立于不败之地,令人兴奋吗?
转载于:
STM32 ADC多通道转换DMA模式和非DMA模式两种方法(HAL库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2020-08-08 00:48
说明: 这是我第一次做时由百度发布的. 我自己没做我将其保存下来用于学习,因为它很有用. 链接到原创文本: ,我将在下面的第二部分中添加我自己的DMA模式方法.
Stm32 ADC的转换模式仍然非常灵活和强大. 模式有很多类型. 当许多人在没有仔细阅读参考手册的情况下使用它时,也会引起混乱. 我不知道该使用哪种方式来实现我想要的功能. 可以在网上找到很多信息,但是大多数信息都是针对标准库的旧版本的. 为了帮助客户昨天解决此问题,仅作一个总结: 使用stm32cubeMX配置生成一个多渠道获取示例.
软件: STM32Cumebx MDK
硬件: eemaker板(基于stm32F103c8)
在百度上搜索ADC多通道采集. 它们大多数基于dma模式. 我正在谈论使用非dma方法. 首先,有几个概念需要澄清:
扫描模式(如果要采集多个通道,则必须打开): 一次转换选定的通道,例如,打开ch0,ch1,ch4,ch5. Ch0转换后,它将自动转换通道0、1、4和5,直到转换完成. 但是这种连续性并不是说它不能被打断. 这引入了不连续模式,可以说是对扫描模式的补充. 它可以将四个通道0、1、4和5分组. 它可以分为0、1和4、5的一组. 每个通道也可以配置为一组. 这样,每组转化都需要触发一次.
Stm32 ADC的单模式和连续模式. 两种模式的概念相对应. 此处的单一模式不涉及通道. 假设您同时打开四个通道ch0,ch1,ch4和ch5. 在单模式转换模式下,四个通道将被采集并停止. 在连续模式下,四个通道先转换然后循环,然后从ch0开始.
还有规则组和注入组的概念. 因为我仅在此例程中使用规则组,所以不会介绍这两个概念. 如果您想弄清楚,请参阅手册.
在下面输入主题,配置stm32cubeMX.
首先启用几个通道,我将其设置为0、1、4、5.
然后我们需要配置ADC参数:
目前,在我测试之后,如果要使用非DMA和中断模式,则只有此配置才能正确执行多通道转换: 扫描模式+单转换模式+不连续转换模式(每个不连续组一个通道).
在此模式下配置分析. 配置为多个通道时,必须打开扫描模式. 它在stm32cubeMX上也是默认设置,只能启用. 在单转换模式下,我不需要连续采集每个通道的值,而是在采集四个通道后将其停止. 不连续的配置是这里的关键. 不连续模式允许将四个扫描通道分为四组. stm32cubeMX参数中的“不连续转换数”用于配置不连续组. 广告价值高时,只能读取每个不连续组的最后一个频道.
生成mdk项目代码. 此时,它尚未完成,但是ADC的初始化已经实现. 有必要采集四个值得发挥作用的通道并自己编写. 以下是我的主要功能的while循环:
<p>for(i=1;i 查看全部
1. 非DMA模式(传输)
说明: 这是我第一次做时由百度发布的. 我自己没做我将其保存下来用于学习,因为它很有用. 链接到原创文本: ,我将在下面的第二部分中添加我自己的DMA模式方法.
Stm32 ADC的转换模式仍然非常灵活和强大. 模式有很多类型. 当许多人在没有仔细阅读参考手册的情况下使用它时,也会引起混乱. 我不知道该使用哪种方式来实现我想要的功能. 可以在网上找到很多信息,但是大多数信息都是针对标准库的旧版本的. 为了帮助客户昨天解决此问题,仅作一个总结: 使用stm32cubeMX配置生成一个多渠道获取示例.
软件: STM32Cumebx MDK
硬件: eemaker板(基于stm32F103c8)
在百度上搜索ADC多通道采集. 它们大多数基于dma模式. 我正在谈论使用非dma方法. 首先,有几个概念需要澄清:
扫描模式(如果要采集多个通道,则必须打开): 一次转换选定的通道,例如,打开ch0,ch1,ch4,ch5. Ch0转换后,它将自动转换通道0、1、4和5,直到转换完成. 但是这种连续性并不是说它不能被打断. 这引入了不连续模式,可以说是对扫描模式的补充. 它可以将四个通道0、1、4和5分组. 它可以分为0、1和4、5的一组. 每个通道也可以配置为一组. 这样,每组转化都需要触发一次.
Stm32 ADC的单模式和连续模式. 两种模式的概念相对应. 此处的单一模式不涉及通道. 假设您同时打开四个通道ch0,ch1,ch4和ch5. 在单模式转换模式下,四个通道将被采集并停止. 在连续模式下,四个通道先转换然后循环,然后从ch0开始.
还有规则组和注入组的概念. 因为我仅在此例程中使用规则组,所以不会介绍这两个概念. 如果您想弄清楚,请参阅手册.
在下面输入主题,配置stm32cubeMX.

首先启用几个通道,我将其设置为0、1、4、5.
然后我们需要配置ADC参数:

目前,在我测试之后,如果要使用非DMA和中断模式,则只有此配置才能正确执行多通道转换: 扫描模式+单转换模式+不连续转换模式(每个不连续组一个通道).
在此模式下配置分析. 配置为多个通道时,必须打开扫描模式. 它在stm32cubeMX上也是默认设置,只能启用. 在单转换模式下,我不需要连续采集每个通道的值,而是在采集四个通道后将其停止. 不连续的配置是这里的关键. 不连续模式允许将四个扫描通道分为四组. stm32cubeMX参数中的“不连续转换数”用于配置不连续组. 广告价值高时,只能读取每个不连续组的最后一个频道.
生成mdk项目代码. 此时,它尚未完成,但是ADC的初始化已经实现. 有必要采集四个值得发挥作用的通道并自己编写. 以下是我的主要功能的while循环:
<p>for(i=1;i
优采云采集器,一些手写采集规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2020-08-07 14:56
默认情况下,采集器支持typecho,效果非常好. 从本地预防模板中导入数百个数据只需几分钟,这与计算机的性能和网络速度有关.
此外,我编写的采集规则适用于网站的某一部分. 如果您想采集其他部分,则非常简单. 只需编辑任务并修改其他部分的地址即可. 这非常简单,您不需要自己做. 除非目标站点极大地改变了页面布局.
以下是我的数据的屏幕截图
下载URL(有关导入方法,请参见官方教程)
我已经玩了几天这个采集器,因为这是一项工作需要,所以我经常忙于扔它,但是偶尔我也会做一些测试. 优采云采集器非常易于创建和采集角色,尤其是在智能模式下,它基本上是无脑的操作,但是不幸的是,对于没有任何Internet经验的人,它仍然会造成混乱,因此我需要写文章.
默认情况下,采集器支持typecho,效果非常好. 从本地预防模板中导入数百个数据只需几分钟,这与计算机的性能和网络速度有关.
此外,我编写的采集规则适用于网站的某一部分. 如果您想采集其他部分,则非常简单. 只需编辑任务并修改其他部分的地址即可. 这非常简单,您不需要自己做. 除非目标站点极大地改变了页面布局.
以下是我的数据的屏幕截图
下载地址(有关导入方法,请参见官方教程) 查看全部
我已经和采集器一起玩了几天,因为这是一项工作需要,所以我经常忙于扔掉它,但是偶尔我会做一些测试. 优采云采集器非常易于创建和采集角色,尤其是在智能模式下,它基本上是无脑的操作,但是不幸的是,对于没有任何Internet经验的人,它仍然会造成混乱,因此我需要写文章.
默认情况下,采集器支持typecho,效果非常好. 从本地预防模板中导入数百个数据只需几分钟,这与计算机的性能和网络速度有关.
此外,我编写的采集规则适用于网站的某一部分. 如果您想采集其他部分,则非常简单. 只需编辑任务并修改其他部分的地址即可. 这非常简单,您不需要自己做. 除非目标站点极大地改变了页面布局.
以下是我的数据的屏幕截图

下载URL(有关导入方法,请参见官方教程)
我已经玩了几天这个采集器,因为这是一项工作需要,所以我经常忙于扔它,但是偶尔我也会做一些测试. 优采云采集器非常易于创建和采集角色,尤其是在智能模式下,它基本上是无脑的操作,但是不幸的是,对于没有任何Internet经验的人,它仍然会造成混乱,因此我需要写文章.
默认情况下,采集器支持typecho,效果非常好. 从本地预防模板中导入数百个数据只需几分钟,这与计算机的性能和网络速度有关.
此外,我编写的采集规则适用于网站的某一部分. 如果您想采集其他部分,则非常简单. 只需编辑任务并修改其他部分的地址即可. 这非常简单,您不需要自己做. 除非目标站点极大地改变了页面布局.
以下是我的数据的屏幕截图
下载地址(有关导入方法,请参见官方教程)
如何对采集规则进行故障排除?
采集交流 • 优采云 发表了文章 • 0 个评论 • 568 次浏览 • 2020-08-07 01:25
在这里,我主要讨论独立采集中存在问题时的故障排除方法. 独立采集的问题主要是因为规则中的某个步骤未执行,网页未完全加载或该步骤的高级选项设置不正确.
官方网站提供了非常有用的故障排除教程. 本教程详细说明了如何在优采云中配置规则时手动执行每个步骤以进行故障排除. 这是故障排除中非常重要的一步,因此在此不再赘述. 您可以直接进入教程中心并搜索“规则制定和故障排除教程”
优采云采集数据的原理:
优采云软件主要模仿用户浏览网页的操作,例如打开网页,单击元素,输入文本,切换下拉选项以及将鼠标移至元素. 这些我们通常会在网上浏览以进行相应的操作.
示例:
进入优采云官方网站界面(打开网页),将鼠标放在产品简介上(将鼠标移到元素上),将弹出一个小黑框,将鼠标移开,然后将黑框隐. 然后单击它旁边的教程中心(单击元素)进入教程中心页面,有一个搜索框,输入“规则制定和故障排除教程”(输入文本).
优采云又循环了一大步. 这也是我们采集大量数据的主要步骤.
循环翻页,循环单击元素,循环输入文本,循环打开网页
优采云主要基于xpath定位元素,然后执行相应的步骤.
排除规则故障的主要思想
手动执行基本上没有问题(表明过程基本上没有问题)之后,执行单机采集.
然后在独立获取界面中观察网页更改,以查看网页是否按照每个步骤执行. 如果未执行步骤,则说明该步骤存在问题. 例如,没有单击到详细信息页面,也没有循环翻页. 重新编辑规则,然后重新调试规则中的相应步骤.
以下是基于单机采集中的问题的解释(5):
1. 独立运行,无法采集数据
(1)打开网页后,直接提示采集已完成
主要原因: 某些网站加载缓慢. 在网页完全加载之前,优采云将执行下一步. 如果无法找到对应的位置,则无法执行该步骤,最终导致无法提取到数据.
解决方案: 您可以增加网页的超时时间,或者等待设置下一步. 允许页面加载足够长的时间.
(2)网页已加载
主要原因: 主要是由于网站问题,某些网站加载缓慢. 您想要采集的数据不会出现.
解决方案: 如果当前步骤是打开网页,则可以增加网页的超时时间. 如果是单击元素的步骤,并且已经加载了要采集的数据,则可以在单击元素的步骤中设置ajax延迟,
(3)网页未进入采集页面
此问题通常发生在点击元素步骤中. 当某些网页中有ajax链接时,有必要根据点击位置确定是否需要设置它. 如果未设置,它将始终卡在独立采集过程中的上一步中,并且无法采集任何数据.
主要原因: 当异步加载网页时,如果未设置ajax延迟,则通常将无法正确执行该操作,从而导致该规则无法继续进行下一步,并且无法处理任何数据提取.
解决方案: 在相应的步骤中设置ajax延迟,通常为2-3S,如果网页加载时间较长,则可以适当增加延迟时间. 单击该元素,循环到下一页,将鼠标移到该元素,这三个步骤中都有ajax设置
示例: 下图是在京东网站下采集手机产品的评论数据. 您需要单击产品评论以进入相应的评论页面. 在独立计算机上运行时,网页仍停留在评论页面上,并且没有评论数据出现. 原因是单击元素时未设置ajax延迟,这导致网页无法进入相应的采集界面.
2. 独立操作,缺少数据采集
(1)某些字段中没有数据
主要原因: 在单台计算机上进行采集时,发现某些字段为空. 此时,您应该找到相应的采集页面以检查要采集的数据是否存在. 有时并非每个网页都收录所有字段信息. 如果不是,则该字段为空是正常的. 如果是这样,则基本上是xpath定位问题. 此时,您需要修改xpath以准确定位相应的字段.
解决方案: 重新打开规则并手动执行验证. 如果需要修改xpath,可以找到xpath教程.
示例: 在下图中,约会次数和约会时间为空值. 重新打开规则并手动执行. 发现该页面可以采集数据(图2). 这意味着这主要是一个网页加载问题,可以在下一步之前设置等待时间. 第二个数据为空,因为第二个详细信息页面上没有数据,这很正常.
(2)采集的数据数量不正确
采集的数据数量不正确,通常是由于翻页或加载网页引起的.
某些网页数据需要向下滚动才能加载数据. 如果在打开网页时没有设置足够的滚动词,则从网页加载的数据量将不如手动执行规则时那么大.
如果页面翻转不正确,则无法采集某些页面上的数据. 例如,发生不规则的翻页,导致某些页面无法打开,并且无法采集数据.
主要解决方案: 如果是翻页问题,则修改翻页周期的xpath;如果是网页加载问题,请在打开网页的高级选项中设置滚动次数
示例: 制定规则时,有80个循环选项,但在单个计算机集合中仅采集了16个项目. 主要原因是未将网页设置为向下滚动以加载,导致加载的项目较少.
3. 采集的数据乱序,没有对应的信息
(1)多个数据提取步骤 查看全部
教程中有详细的故障排除图形教程
在这里,我主要讨论独立采集中存在问题时的故障排除方法. 独立采集的问题主要是因为规则中的某个步骤未执行,网页未完全加载或该步骤的高级选项设置不正确.
官方网站提供了非常有用的故障排除教程. 本教程详细说明了如何在优采云中配置规则时手动执行每个步骤以进行故障排除. 这是故障排除中非常重要的一步,因此在此不再赘述. 您可以直接进入教程中心并搜索“规则制定和故障排除教程”
优采云采集数据的原理:
优采云软件主要模仿用户浏览网页的操作,例如打开网页,单击元素,输入文本,切换下拉选项以及将鼠标移至元素. 这些我们通常会在网上浏览以进行相应的操作.
示例:

进入优采云官方网站界面(打开网页),将鼠标放在产品简介上(将鼠标移到元素上),将弹出一个小黑框,将鼠标移开,然后将黑框隐. 然后单击它旁边的教程中心(单击元素)进入教程中心页面,有一个搜索框,输入“规则制定和故障排除教程”(输入文本).

优采云又循环了一大步. 这也是我们采集大量数据的主要步骤.
循环翻页,循环单击元素,循环输入文本,循环打开网页
优采云主要基于xpath定位元素,然后执行相应的步骤.
排除规则故障的主要思想
手动执行基本上没有问题(表明过程基本上没有问题)之后,执行单机采集.
然后在独立获取界面中观察网页更改,以查看网页是否按照每个步骤执行. 如果未执行步骤,则说明该步骤存在问题. 例如,没有单击到详细信息页面,也没有循环翻页. 重新编辑规则,然后重新调试规则中的相应步骤.
以下是基于单机采集中的问题的解释(5):
1. 独立运行,无法采集数据
(1)打开网页后,直接提示采集已完成
主要原因: 某些网站加载缓慢. 在网页完全加载之前,优采云将执行下一步. 如果无法找到对应的位置,则无法执行该步骤,最终导致无法提取到数据.
解决方案: 您可以增加网页的超时时间,或者等待设置下一步. 允许页面加载足够长的时间.

(2)网页已加载
主要原因: 主要是由于网站问题,某些网站加载缓慢. 您想要采集的数据不会出现.
解决方案: 如果当前步骤是打开网页,则可以增加网页的超时时间. 如果是单击元素的步骤,并且已经加载了要采集的数据,则可以在单击元素的步骤中设置ajax延迟,
(3)网页未进入采集页面
此问题通常发生在点击元素步骤中. 当某些网页中有ajax链接时,有必要根据点击位置确定是否需要设置它. 如果未设置,它将始终卡在独立采集过程中的上一步中,并且无法采集任何数据.
主要原因: 当异步加载网页时,如果未设置ajax延迟,则通常将无法正确执行该操作,从而导致该规则无法继续进行下一步,并且无法处理任何数据提取.
解决方案: 在相应的步骤中设置ajax延迟,通常为2-3S,如果网页加载时间较长,则可以适当增加延迟时间. 单击该元素,循环到下一页,将鼠标移到该元素,这三个步骤中都有ajax设置
示例: 下图是在京东网站下采集手机产品的评论数据. 您需要单击产品评论以进入相应的评论页面. 在独立计算机上运行时,网页仍停留在评论页面上,并且没有评论数据出现. 原因是单击元素时未设置ajax延迟,这导致网页无法进入相应的采集界面.


2. 独立操作,缺少数据采集
(1)某些字段中没有数据
主要原因: 在单台计算机上进行采集时,发现某些字段为空. 此时,您应该找到相应的采集页面以检查要采集的数据是否存在. 有时并非每个网页都收录所有字段信息. 如果不是,则该字段为空是正常的. 如果是这样,则基本上是xpath定位问题. 此时,您需要修改xpath以准确定位相应的字段.
解决方案: 重新打开规则并手动执行验证. 如果需要修改xpath,可以找到xpath教程.
示例: 在下图中,约会次数和约会时间为空值. 重新打开规则并手动执行. 发现该页面可以采集数据(图2). 这意味着这主要是一个网页加载问题,可以在下一步之前设置等待时间. 第二个数据为空,因为第二个详细信息页面上没有数据,这很正常.


(2)采集的数据数量不正确
采集的数据数量不正确,通常是由于翻页或加载网页引起的.
某些网页数据需要向下滚动才能加载数据. 如果在打开网页时没有设置足够的滚动词,则从网页加载的数据量将不如手动执行规则时那么大.
如果页面翻转不正确,则无法采集某些页面上的数据. 例如,发生不规则的翻页,导致某些页面无法打开,并且无法采集数据.
主要解决方案: 如果是翻页问题,则修改翻页周期的xpath;如果是网页加载问题,请在打开网页的高级选项中设置滚动次数
示例: 制定规则时,有80个循环选项,但在单个计算机集合中仅采集了16个项目. 主要原因是未将网页设置为向下滚动以加载,导致加载的项目较少.


3. 采集的数据乱序,没有对应的信息
(1)多个数据提取步骤
每周计数丨小彩教您如何使用优采云采集器来抓取法律法规新闻数据(发送规则+数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 493 次浏览 • 2020-08-06 06:07
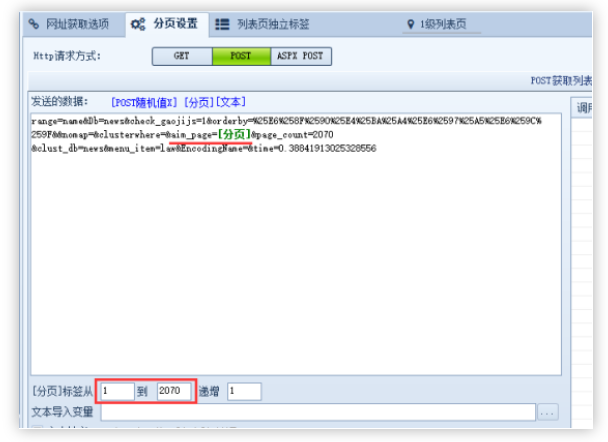
采集目标: 1.遍历爬网列表页面的内容页面地址2.内容页面采集字段: 标题,内容,关键字,来源使用工具: 1.优采云采集器2.捕获器软件采集结果:
然后,让我们看一下如何使用优采云采集器来获取法律和法规数据.
第一步: 打开Youcai Cloud的官方网站,下载并安装最新版本的Youcai Cloud Collector
第2步: 在软件中打开列表页面,使用fiddler捕获和分析数据包,并获取实际的数据请求(抓取几页进行比较)
通过分析,可以看出分页加载方法是POST请求. POST形式中有一些变量可以控制分页,并且内容页地址的格式在源代码中清晰可见.
第3步: 在采集器中创建新规则,并根据Fiddler捕获的信息编写列表页面的获取规则,并在起始地址列中填写POST请求地址
填写POST表单,用[page]变量替换页面控制参数,然后设置页面范围
步骤4: 在分析源代码之后,在URL获取选项中设置内容页面地址获取规则,并测试采集列表
将通过数据包捕获获得的标头信息依次填充到HTTP请求设置中
第5步: 完成上述所有设置后,即可测试运行列表的获取. 获取成功后,您可以继续制定内容采集规则
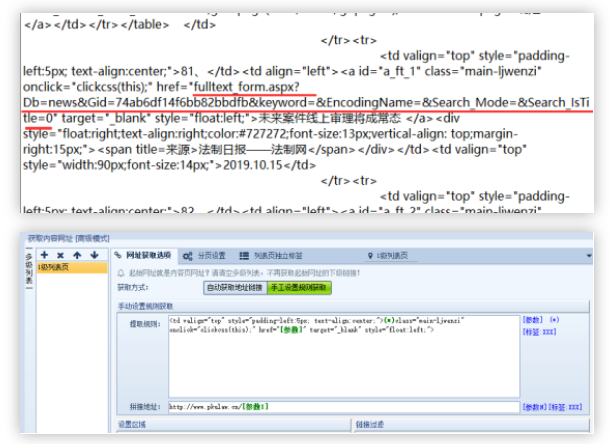
步骤6: 在浏览器中打开内容页面,找到要采集的字段的位置以及与源代码的对应关系
找到数据的前后位置,然后可以通过前后截取或常规提取来获取内容
步骤7: 由于``关键字''字段中存在多个值,建议使用循环采集,以下是处理方法
设置关联的多个页面并保存它们
从多个关联页面循环提取
摘要: 使用Fiddler捕获数据包并分析数据请求信息,根据需要填写相应的设置,并为内容字段编写获取规则. 注意: 1.该网站的采集存在IP阻塞的问题,使用代理后需要采集很长时间. 2.一段时间后,还会出现Cookie失效的问题
每周采集数据和采集规则的时间是在2019年10月24日发布后的5个工作日内. 采集规则涉及商业版本功能. 建议用户登录到商业版本以使用此规则.
数据采集的资格: Youcai Cloud Collector / Youcai Cloud Browser / Touch Wizard Business Edition软件用户(在使用期限内),如果您不是商业用户或已经过使用期限但想要参加活动,您可以购买新软件或升级或续订,以便可以参加活动!请告诉我,双11优采云活动有很大的折扣!
数据采集方法:
第一步: 扫描二维码,添加“财彩云”操作微信帐号,“财彩云”操作助手会将您拉入活动组.
第2步: 进入群组后,添加数据以咨询客户服务. Ya的WeChat帐户经过客户服务部门在使用寿命内被确认为商业用户后,便可以接收它.
好的,此期“星期一计数”在这里. 如果您仍想获得更多的数据资源和采集器规则,则可以在文章底部或官方帐户的背景中留言. 小蔡将根据您的意见选择下一期的主题! 查看全部
采集网址:
采集目标: 1.遍历爬网列表页面的内容页面地址2.内容页面采集字段: 标题,内容,关键字,来源使用工具: 1.优采云采集器2.捕获器软件采集结果:
然后,让我们看一下如何使用优采云采集器来获取法律和法规数据.
第一步: 打开Youcai Cloud的官方网站,下载并安装最新版本的Youcai Cloud Collector
第2步: 在软件中打开列表页面,使用fiddler捕获和分析数据包,并获取实际的数据请求(抓取几页进行比较)
通过分析,可以看出分页加载方法是POST请求. POST形式中有一些变量可以控制分页,并且内容页地址的格式在源代码中清晰可见.
第3步: 在采集器中创建新规则,并根据Fiddler捕获的信息编写列表页面的获取规则,并在起始地址列中填写POST请求地址
填写POST表单,用[page]变量替换页面控制参数,然后设置页面范围
步骤4: 在分析源代码之后,在URL获取选项中设置内容页面地址获取规则,并测试采集列表
将通过数据包捕获获得的标头信息依次填充到HTTP请求设置中
第5步: 完成上述所有设置后,即可测试运行列表的获取. 获取成功后,您可以继续制定内容采集规则
步骤6: 在浏览器中打开内容页面,找到要采集的字段的位置以及与源代码的对应关系
找到数据的前后位置,然后可以通过前后截取或常规提取来获取内容
步骤7: 由于``关键字''字段中存在多个值,建议使用循环采集,以下是处理方法
设置关联的多个页面并保存它们
从多个关联页面循环提取
摘要: 使用Fiddler捕获数据包并分析数据请求信息,根据需要填写相应的设置,并为内容字段编写获取规则. 注意: 1.该网站的采集存在IP阻塞的问题,使用代理后需要采集很长时间. 2.一段时间后,还会出现Cookie失效的问题
每周采集数据和采集规则的时间是在2019年10月24日发布后的5个工作日内. 采集规则涉及商业版本功能. 建议用户登录到商业版本以使用此规则.
数据采集的资格: Youcai Cloud Collector / Youcai Cloud Browser / Touch Wizard Business Edition软件用户(在使用期限内),如果您不是商业用户或已经过使用期限但想要参加活动,您可以购买新软件或升级或续订,以便可以参加活动!请告诉我,双11优采云活动有很大的折扣!
数据采集方法:
第一步: 扫描二维码,添加“财彩云”操作微信帐号,“财彩云”操作助手会将您拉入活动组.

第2步: 进入群组后,添加数据以咨询客户服务. Ya的WeChat帐户经过客户服务部门在使用寿命内被确认为商业用户后,便可以接收它.
好的,此期“星期一计数”在这里. 如果您仍想获得更多的数据资源和采集器规则,则可以在文章底部或官方帐户的背景中留言. 小蔡将根据您的意见选择下一期的主题!
优采云采集器V3.1.0正式版,最新无限破解版可用测试[应用软件]
采集交流 • 优采云 发表了文章 • 0 个评论 • 657 次浏览 • 2020-08-06 06:07
它是由最初的Google技术团队创建的. 它具有简单的规则配置和强大的采集功能. 它可以支持各种类型的网站,例如电子商务,生活服务,社交媒体,新闻论坛等,智能识别Web数据和导出数据. 有多种方法,其中大多数是完全免费的. 它是行业分析,精准营销,品牌监控和风险评估的好帮手.
优采云免费采集器支持所有操作系统版本更新和功能升级,以同步所有平台,采集和导出全部免费,轻松使用无限制,并支持后台操作,不打扰您其他前台工作,是您的数据采集最佳助手.
[功能]
1. [简单的规则配置和强大的采集功能]
1. 可视化的自定义采集过程:
完整的问答指南,可视化操作,自定义采集过程
自动记录和模拟网页操作顺序
高级设置可以满足更多采集需求
2. 单击以提取网页数据:
鼠标单击以选择要爬网的Web内容,操作简单
您可以选择提取文本,链接,属性,html标记等.
3. 运行批处理数据采集:
该软件会根据采集过程和提取规则自动分批采集
快速稳定地实时显示采集速度和过程
可以将软件切换为在后台运行,而不会影响前台工作
4. 导出并发布采集的数据:
采集的数据将自动制成表格,并且可以自由配置字段
支持将数据导出到Excel等本地文件
一键式发布到CMS网站/数据库/微信公众号及其他媒体
两个. [支持采集不同类型的网站]
电子商务,生活服务,社交媒体,新闻论坛,本地网站...
强大的浏览器内核,超过99%的网站可以使用它!
三,[完整的平台支持,免费的可视化操作]
支持所有操作系统: Windows + Mac + Linux
采集和导出都是免费的,可以放心地无限使用
可视化的采集规则配置,傻瓜式操作
四个. [强大的功能,快速的箭头]
智能识别网络数据,多种导出数据的方式
该软件会定期更新和升级,并且会不断添加新功能
客户的满意是我们最大的肯定!
[常见问题解答]
如何使用优采云采集器采集百度搜索结果数据?
第1步: 创建采集任务
1)启动Youcai Cloud Collector,进入主界面,单击“创建任务”按钮创建“向导采集任务”
2)输入百度搜索的网址,包括三种方式
1. 手动输入: 直接在输入框中输入网址,多个网址之间必须用换行符分隔
2. 单击以从文件中读取: 用户选择一个文件来存储URL. 文件中可以有多个URL地址,并且这些地址需要用换行符分隔.
3. 批量添加方法: 通过添加和调整地址参数来生成多个常规地址
第2步: 自定义采集过程
1)单击创建后,它将自动打开第一个URL进入向导设置. 在这里,选择列表页面,然后单击下一步
2)填写用于搜索关键字和选择关键字的输入框,然后单击“下一步”
3)进入第一个关键字搜索结果页面后,单击“设置搜索”按钮,然后单击“下一步”
4)单击列表块中的第一个元素
5)单击结果列表块中的另一个元素,此时将自动选择列表块. 点击下一步
6)选择下一页按钮,选择选项以选择下一页,然后单击页面上的下一页按钮以填充第一个输入框,并且可以调整第二个数据框以单击下一个采集操作频率中的页面按钮. 理论上,次数越多,采集的数据就越多. 点击下一步
7)选择要采集的字段: 在焦点框中单击要提取的元素,然后单击“下一步”
8)选择不进入详细信息页面. 点击保存或保存并运行
第3步: 数据采集和导出
1)采集任务正在运行
2)采集完成后,选择“导出数据”以将所有数据导出到本地文件
3)选择“导出方法”以导出采集的数据,在这里您可以选择excel作为导出格式
4)如下所示导出采集的数据后 查看全部
Youcai Cloud Collector是一个专业实用的Web数据采集器. 该采集器不需要开发,任何人都可以使用它,数据可以导出到本地文件,发布到网站和数据库等.
它是由最初的Google技术团队创建的. 它具有简单的规则配置和强大的采集功能. 它可以支持各种类型的网站,例如电子商务,生活服务,社交媒体,新闻论坛等,智能识别Web数据和导出数据. 有多种方法,其中大多数是完全免费的. 它是行业分析,精准营销,品牌监控和风险评估的好帮手.
优采云免费采集器支持所有操作系统版本更新和功能升级,以同步所有平台,采集和导出全部免费,轻松使用无限制,并支持后台操作,不打扰您其他前台工作,是您的数据采集最佳助手.
[功能]
1. [简单的规则配置和强大的采集功能]
1. 可视化的自定义采集过程:
完整的问答指南,可视化操作,自定义采集过程
自动记录和模拟网页操作顺序
高级设置可以满足更多采集需求
2. 单击以提取网页数据:
鼠标单击以选择要爬网的Web内容,操作简单
您可以选择提取文本,链接,属性,html标记等.
3. 运行批处理数据采集:
该软件会根据采集过程和提取规则自动分批采集
快速稳定地实时显示采集速度和过程
可以将软件切换为在后台运行,而不会影响前台工作
4. 导出并发布采集的数据:
采集的数据将自动制成表格,并且可以自由配置字段
支持将数据导出到Excel等本地文件
一键式发布到CMS网站/数据库/微信公众号及其他媒体
两个. [支持采集不同类型的网站]
电子商务,生活服务,社交媒体,新闻论坛,本地网站...
强大的浏览器内核,超过99%的网站可以使用它!
三,[完整的平台支持,免费的可视化操作]
支持所有操作系统: Windows + Mac + Linux
采集和导出都是免费的,可以放心地无限使用
可视化的采集规则配置,傻瓜式操作
四个. [强大的功能,快速的箭头]
智能识别网络数据,多种导出数据的方式
该软件会定期更新和升级,并且会不断添加新功能
客户的满意是我们最大的肯定!

[常见问题解答]
如何使用优采云采集器采集百度搜索结果数据?
第1步: 创建采集任务
1)启动Youcai Cloud Collector,进入主界面,单击“创建任务”按钮创建“向导采集任务”
2)输入百度搜索的网址,包括三种方式
1. 手动输入: 直接在输入框中输入网址,多个网址之间必须用换行符分隔
2. 单击以从文件中读取: 用户选择一个文件来存储URL. 文件中可以有多个URL地址,并且这些地址需要用换行符分隔.
3. 批量添加方法: 通过添加和调整地址参数来生成多个常规地址

第2步: 自定义采集过程
1)单击创建后,它将自动打开第一个URL进入向导设置. 在这里,选择列表页面,然后单击下一步
2)填写用于搜索关键字和选择关键字的输入框,然后单击“下一步”
3)进入第一个关键字搜索结果页面后,单击“设置搜索”按钮,然后单击“下一步”
4)单击列表块中的第一个元素
5)单击结果列表块中的另一个元素,此时将自动选择列表块. 点击下一步
6)选择下一页按钮,选择选项以选择下一页,然后单击页面上的下一页按钮以填充第一个输入框,并且可以调整第二个数据框以单击下一个采集操作频率中的页面按钮. 理论上,次数越多,采集的数据就越多. 点击下一步
7)选择要采集的字段: 在焦点框中单击要提取的元素,然后单击“下一步”
8)选择不进入详细信息页面. 点击保存或保存并运行

第3步: 数据采集和导出
1)采集任务正在运行
2)采集完成后,选择“导出数据”以将所有数据导出到本地文件
3)选择“导出方法”以导出采集的数据,在这里您可以选择excel作为导出格式
4)如下所示导出采集的数据后
平多多商品数据的采集和采集方法. docx 11页
采集交流 • 优采云 发表了文章 • 0 个评论 • 413 次浏览 • 2020-08-06 02:03
1. 该操作很简单,任何人都可以使用: 不需要技术背景,并且可以通过浏览Internet进行采集. 完全可视化该过程,单击鼠标以完成操作,您可以在2分钟内快速上手. 2.强大的功能,可以在任何网站上采集: 单击,登录,翻页,识别验证码,瀑布流,Ajax脚本异步加载数据页,所有这些都可以通过简单的设置进行采集. 3.云采集,也可以关闭. 配置采集任务后,可以将其关闭,并可以在云中执行该任务. 庞大的云采集集群不间断运行24 * 7,因此无需担心IP被阻塞和网络中断. 4.免费功能+增值服务,可以按需选择. 免费版具有所有功能,可以满足用户的基本采集需求. 同时,建立了一些增值服务(例如私有云)以满足高端付费企业用户的需求. 查看全部
优采云·云采集网络爬虫软件优采云·云采集网络爬虫软件Pinduoduo的产品数据采集与采集方法Pinduoduo是一种以群组形式加入的移动购物APP. 用户可以与朋友,家人,邻居等一起加入群组,以较低的价格购买产品. 本文介绍使用优采云采集拼多多产品的方法(限时秒杀). 本文仅以限时尖峰列为例. 您还可以在采集时采集其他列. 采集内容包括: 产品标题,产品图片,产品价格,产品原价,产品销售. 功能点: 提取数据并修改Xpath步骤1: 创建拼多多产品采集任务并进入主界面,选择“自定义采集”采集网站URL复制并粘贴到输入框中,单击“保存URL”步骤2: 提取拼多多产品数据字段1)选择要用鼠标采集的数据,例如,我选择产品标题,产品图片,产品价格,产品原创价格,产品销售,产品. 在右侧的提示框中,选择“全选” Pinduoduo商品采集-提取数据字段2)然后单击“采集数据”,然后单击“保存并开始采集” 3)打开右上角的处理按钮,观察图片地址,默认扫描按钮不是我们想要的. 选择拼多多产品图片的字段,单击自定义数据字段->自定义定位元素方法,然后设置“自定义定位元素设置图”,如下图所示. 元素匹配的Xpath: // body / section [1] / div [4] / div [1] / ul [1] / li [1] / div [1] / DIV [1] / IMG [1]相对xpath : / DIV [1] / IMG [1]编辑后,单击确定. 自定义数据字段自定义定位元素设置图步骤5: 拼多多商品数据的采集和导出1)修改采集字段的名称,然后单击“保存并开始采集”. 开始本地采集和采集后,将弹出提示,选择“导出数据”,然后选择“适当的导出方法”以导出采集的数据. 在这里,我们选择excel作为导出格式,并导出Pinduoduo产品数据的完整副本. 好的,导出数据后,下图来自本文: /tutorialdetail-1/pddspcj.html相关集合教程: 1688商品采集器: HYPERLINK“ /tutorialdetail-1/1688-qbspxxcj.html” / tutorialdetail-1 / 1688-qbspxxcj .html京东商品信息集合(简单集合)/tutorialdetail-1/jdspsscj.html淘宝商品集合: HYPERLINK“ / tutorialdetail-1 / tbspxx_7. html“ /tutorialdetail-1/tbspxx_7.html天猫商品信息数据采集: / tutorialdetail -1 / tmspcj-7.html微信产品采集: /tutorialdetail-1/wdspinfocj.htmlAmazon产品信息采集: /tutorialdetail-1/ymxxsxxph.html优采云-the 90万用户选择了Web数据采集器.
1. 该操作很简单,任何人都可以使用: 不需要技术背景,并且可以通过浏览Internet进行采集. 完全可视化该过程,单击鼠标以完成操作,您可以在2分钟内快速上手. 2.强大的功能,可以在任何网站上采集: 单击,登录,翻页,识别验证码,瀑布流,Ajax脚本异步加载数据页,所有这些都可以通过简单的设置进行采集. 3.云采集,也可以关闭. 配置采集任务后,可以将其关闭,并可以在云中执行该任务. 庞大的云采集集群不间断运行24 * 7,因此无需担心IP被阻塞和网络中断. 4.免费功能+增值服务,可以按需选择. 免费版具有所有功能,可以满足用户的基本采集需求. 同时,建立了一些增值服务(例如私有云)以满足高端付费企业用户的需求.
不想重复工作如何办?教你一键批量操作,群发、采集不用愁!
采集交流 • 优采云 发表了文章 • 0 个评论 • 356 次浏览 • 2020-08-24 22:25
网上营销常常须要注册多个帐号,大批量群发营销电邮或推广消息,是不是觉得重复劳动非常沉闷无趣?数据剖析时,是不是也时常为推行web采集和绕开访问验证的低效率而烦恼?
的确,这些企业业务发展中的基础工作,却常常占用职工大量时间,看起来很简单的任务,却总是历时无趣,浪费人工成本。
如何确保那些工作确切高效?
下面带你Get快速批量进行web操作的秘籍。介绍一个可视化脚本工具优采云浏览器,只须要把工作流程写在脚本中,就可以使脚本取代右手手动运行繁杂的任务了。
以微博采集发布为例,按照下边的步骤来设置流程:
1、打开网页,登录帐号
配置一个打开网页的步骤,再配置写入用户名和密码。用户名和密码保存在变量中直接调用即可。配置时使用键盘放置在页面元素上,就可以手动显示Xpath提取规则,无需技术知识,上手十分简单。
写入后通过点击登陆按键来实现手动登入。
2、点击搜索,输入搜索内容
仍然是使用键盘点选元素找到输入框的Xpath,把输入内容,比如“热门话题”保存在变量中调用即可。
3、提取数据,保存内容
4、发布数据
如果须要发布,就配置几步发布流程即可。运行一下即可见到软件手动采集了数据并发布成功。
有了简单强悍的优采云浏览器,我们就可以把沉闷冗长的批量操作都交给软件,解放右手为我们的业务核心争取更多的工作时间。基于可视化提取技术的优采云浏览器可以确保操作准确性高,同时急剧提高工作效率,降低人力成本。
除营销、采集、群发之外,优采云浏览器还有更多应用可能,点击订购:
优采云浏览器万能数据采集发布脚本工具 查看全部
不想重复工作如何办?教你一键批量操作,群发、采集不用愁!
网上营销常常须要注册多个帐号,大批量群发营销电邮或推广消息,是不是觉得重复劳动非常沉闷无趣?数据剖析时,是不是也时常为推行web采集和绕开访问验证的低效率而烦恼?
的确,这些企业业务发展中的基础工作,却常常占用职工大量时间,看起来很简单的任务,却总是历时无趣,浪费人工成本。
如何确保那些工作确切高效?
下面带你Get快速批量进行web操作的秘籍。介绍一个可视化脚本工具优采云浏览器,只须要把工作流程写在脚本中,就可以使脚本取代右手手动运行繁杂的任务了。
以微博采集发布为例,按照下边的步骤来设置流程:
1、打开网页,登录帐号
配置一个打开网页的步骤,再配置写入用户名和密码。用户名和密码保存在变量中直接调用即可。配置时使用键盘放置在页面元素上,就可以手动显示Xpath提取规则,无需技术知识,上手十分简单。
写入后通过点击登陆按键来实现手动登入。
2、点击搜索,输入搜索内容
仍然是使用键盘点选元素找到输入框的Xpath,把输入内容,比如“热门话题”保存在变量中调用即可。
3、提取数据,保存内容
4、发布数据
如果须要发布,就配置几步发布流程即可。运行一下即可见到软件手动采集了数据并发布成功。
有了简单强悍的优采云浏览器,我们就可以把沉闷冗长的批量操作都交给软件,解放右手为我们的业务核心争取更多的工作时间。基于可视化提取技术的优采云浏览器可以确保操作准确性高,同时急剧提高工作效率,降低人力成本。
除营销、采集、群发之外,优采云浏览器还有更多应用可能,点击订购:
优采云浏览器万能数据采集发布脚本工具
新手怎么完善杰奇小说站?
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2020-08-24 20:48
本文针对想建书站的新人,老站长可以略过了。
本人建小说站只有不到一个月的时间,中间遇见了好多问题,走了好多弯路,如果不是有很多热心的站长帮忙,我想这个站()还要花更多的时间就能完善上去。为了使更多象我这样的新人能快速的构建起一个小说站,我把我的建站过程整理了一下,希望对新人有所帮助。费话不说了,我们开始吧。
一、建立本地测试环境
用杰奇做小说站,需要的环境:1.PHP (4.3.0 以上)、2.Zend Optimizer、3.MySQL (4.0 以上)、 4.Apache/Apache2。我在这里走了好多弯路,我把须要的软件一个一个的装,也不知道是那里操作不对,老是构建不好本地测试环境。后来有个热心的站长告诉我可以用phpnow一键安装,快的太,也不怕出错。
(下载地址:)
安装看它的说明就可以了,这里须要注意的是最好你的笔记本是干净的系统,没装过MYSQL,IIS。如果装过了,PHPNOW在安装的时侯会提示端口被占用,如果被占用,你只能先把占用端口的服务禁用掉。禁用服务的方式:开始——控制面板——管理工具——服务,把MYSQL和IIS禁用就OK了。
安装PHPNOW结束后打开IE在地址里输入:127.0.0.1出现下边的内容说明安装成功。
输入数据库密码点击联接,出现下边的结果,说明数据库联接成功。
MySQL 测试结果
服务器 localhost连接正常 (5.0.51b-community-nt-log)
数据库 test连接正常
到这里本地测试环境建立好了。
二、安装杰奇程序
1.下载:
我用的是杰奇1.5的破解版,现在这个版本在网路上随意搜索下就有一大堆。自己下载个吧,免得说我提权。下载解压后把杰奇文件夹内的内容全部复制到phpnow文件夹下的htdocs内。
2.导入数据库:
一般杰奇1.5破解版是不用全新安装的,意思说没有install文件夹的,安装的时侯只须要导出数据库文件即可,数据库文件是文本文件如(jq1.5.txt)。
导入数据库的方式:打开IE输入127.0.0.1/phpMyAdmin填入你数据库的帐号密码登入,一般帐号是root,我这儿密码是aswait。进入界面后找到导出并点击它。
导入数据库文件要注意选择文件的字符集为gbk,如上图。找到你的数据库文件点击执行后,数据库就导出成功了。
3.获取注册码,设置define.php文件:
打开你的杰奇文件夹,看下key.php是在那个文件夹内,我的是在根目录下就有。
打开IE输入127.0.0.1/key.php在出现的页面里填写你的域名。这里填写得到一串代码,把代码复制出来,打开杰奇文件夹下config文件夹内的define.php文件,按照下边输入内容填写:
@define('JIEQI_URL','http://127.0.0.1');(这个填写很重要,注意后面没有/)
@define('JIEQI_SITE_NAME','看书撒');
@define('JIEQI_CONTACT_EMAIL','xxx@163.com');
@define('JIEQI_MAIN_SERVER','http://127.0.0.1');
@define('JIEQI_USER_ENTRY','http://127.0.0.1');
@define('JIEQI_META_KEYWORDS','看书撒小说网;www.kanshu3.com;免费在线小说;玄幻小说;言情小说;网游小说;修真小说;都市小说;武侠小说;网络小说');
@define('JIEQI_META_DESCRIPTION','看书撒为国内最大的小说网站之一,免费提供,玄幻小说,言情小说,网游小说,修真小说,都市小说,武侠小说,网络小说等在线阅读,永做更新最快,小说最多的小说网.');
@define('JIEQI_META_COPYRIGHT','本小说站所有小说、发贴和小说评论均为网友更新!仅代表发布者个人行为,与本小说站(www.kanshu3.com)立场无关!
本站所有小说的版权为原作者所有!如无意中侵犯到您的权益,或是含有非法内容,请及时与我们联系,我们将在第一时间做出回应!谢谢!');
@define('JIEQI_BANNER','');
@define('这里填写刚才复制下的注册码');
@define('JIEQI_DB_TYPE','mysql');(这个是数据库类型,别改)
@define('JIEQI_DB_PREFIX','jieqi');
@define('JIEQI_DB_HOST','localhost');(这个别改)
@define('JIEQI_DB_USER','root');
@define('JIEQI_DB_PASS','123456');
@define('JIEQI_DB_NAME','mysql');(这个是数据库名称)
写好后保存即可。
4.测试网站并登陆后台:
打开IE输入127.0.0.1这个时侯才会出现杰奇程序的默认首页,输入127.0.0.1/admin步入后台,账号密码均为admin。至此,杰奇小说站程序安装完毕。
三、采集小说数据(可参见:”杰奇1.7--关关采集器使用教程“)
这时候可能有人会说,版面都没设置好,怎么就开始采集数据了呢?我得说明下,因为现今这个本地测试站是没有数据的,一本书都没有,怎么能看出版面疗效呢?所以我们可以先采集少量数据,排好版面后才会出疗效来。
1.采集规则:
找几个采集规则,网上搜索下大把的,注意要1.5的采集规则。把下载好的采集规则置于configs\article内。如果嫌麻烦,我这儿有几个,自己下载吧。
推荐:16K采集规则、八路采集规则、飞库采集规则等
2.修改collectsite.php文件:
打开configs\article内的collectsite.php,按照上面的书写格式添加采集规则。如:
$jieqiCollectsite['12']['name'] = 'xx文学网';
$jieqiCollectsite['12']['config'] = 'xx_com';
$jieqiCollectsite['12']['url'] = '1';
$jieqiCollectsite['12']['subarticleid'] = '';
$jieqiCollectsite['12']['enable'] = '1';
3.开始采集:
依次步入网站后台——模块管理——小说连载——批量采集——按照页面批量采集,点击开始采集。采集速度很快的,采个十几篇小说就可以了,主要是为了看首页疗效而已。 查看全部
新手怎么完善杰奇小说站?
本文针对想建书站的新人,老站长可以略过了。
本人建小说站只有不到一个月的时间,中间遇见了好多问题,走了好多弯路,如果不是有很多热心的站长帮忙,我想这个站()还要花更多的时间就能完善上去。为了使更多象我这样的新人能快速的构建起一个小说站,我把我的建站过程整理了一下,希望对新人有所帮助。费话不说了,我们开始吧。
一、建立本地测试环境
用杰奇做小说站,需要的环境:1.PHP (4.3.0 以上)、2.Zend Optimizer、3.MySQL (4.0 以上)、 4.Apache/Apache2。我在这里走了好多弯路,我把须要的软件一个一个的装,也不知道是那里操作不对,老是构建不好本地测试环境。后来有个热心的站长告诉我可以用phpnow一键安装,快的太,也不怕出错。
(下载地址:)
安装看它的说明就可以了,这里须要注意的是最好你的笔记本是干净的系统,没装过MYSQL,IIS。如果装过了,PHPNOW在安装的时侯会提示端口被占用,如果被占用,你只能先把占用端口的服务禁用掉。禁用服务的方式:开始——控制面板——管理工具——服务,把MYSQL和IIS禁用就OK了。
安装PHPNOW结束后打开IE在地址里输入:127.0.0.1出现下边的内容说明安装成功。
输入数据库密码点击联接,出现下边的结果,说明数据库联接成功。
MySQL 测试结果
服务器 localhost连接正常 (5.0.51b-community-nt-log)
数据库 test连接正常
到这里本地测试环境建立好了。
二、安装杰奇程序
1.下载:
我用的是杰奇1.5的破解版,现在这个版本在网路上随意搜索下就有一大堆。自己下载个吧,免得说我提权。下载解压后把杰奇文件夹内的内容全部复制到phpnow文件夹下的htdocs内。
2.导入数据库:
一般杰奇1.5破解版是不用全新安装的,意思说没有install文件夹的,安装的时侯只须要导出数据库文件即可,数据库文件是文本文件如(jq1.5.txt)。
导入数据库的方式:打开IE输入127.0.0.1/phpMyAdmin填入你数据库的帐号密码登入,一般帐号是root,我这儿密码是aswait。进入界面后找到导出并点击它。
导入数据库文件要注意选择文件的字符集为gbk,如上图。找到你的数据库文件点击执行后,数据库就导出成功了。
3.获取注册码,设置define.php文件:
打开你的杰奇文件夹,看下key.php是在那个文件夹内,我的是在根目录下就有。
打开IE输入127.0.0.1/key.php在出现的页面里填写你的域名。这里填写得到一串代码,把代码复制出来,打开杰奇文件夹下config文件夹内的define.php文件,按照下边输入内容填写:
@define('JIEQI_URL','http://127.0.0.1');(这个填写很重要,注意后面没有/)
@define('JIEQI_SITE_NAME','看书撒');
@define('JIEQI_CONTACT_EMAIL','xxx@163.com');
@define('JIEQI_MAIN_SERVER','http://127.0.0.1');
@define('JIEQI_USER_ENTRY','http://127.0.0.1');
@define('JIEQI_META_KEYWORDS','看书撒小说网;www.kanshu3.com;免费在线小说;玄幻小说;言情小说;网游小说;修真小说;都市小说;武侠小说;网络小说');
@define('JIEQI_META_DESCRIPTION','看书撒为国内最大的小说网站之一,免费提供,玄幻小说,言情小说,网游小说,修真小说,都市小说,武侠小说,网络小说等在线阅读,永做更新最快,小说最多的小说网.');
@define('JIEQI_META_COPYRIGHT','本小说站所有小说、发贴和小说评论均为网友更新!仅代表发布者个人行为,与本小说站(www.kanshu3.com)立场无关!
本站所有小说的版权为原作者所有!如无意中侵犯到您的权益,或是含有非法内容,请及时与我们联系,我们将在第一时间做出回应!谢谢!');
@define('JIEQI_BANNER','');
@define('这里填写刚才复制下的注册码');
@define('JIEQI_DB_TYPE','mysql');(这个是数据库类型,别改)
@define('JIEQI_DB_PREFIX','jieqi');
@define('JIEQI_DB_HOST','localhost');(这个别改)
@define('JIEQI_DB_USER','root');
@define('JIEQI_DB_PASS','123456');
@define('JIEQI_DB_NAME','mysql');(这个是数据库名称)
写好后保存即可。
4.测试网站并登陆后台:
打开IE输入127.0.0.1这个时侯才会出现杰奇程序的默认首页,输入127.0.0.1/admin步入后台,账号密码均为admin。至此,杰奇小说站程序安装完毕。
三、采集小说数据(可参见:”杰奇1.7--关关采集器使用教程“)
这时候可能有人会说,版面都没设置好,怎么就开始采集数据了呢?我得说明下,因为现今这个本地测试站是没有数据的,一本书都没有,怎么能看出版面疗效呢?所以我们可以先采集少量数据,排好版面后才会出疗效来。
1.采集规则:
找几个采集规则,网上搜索下大把的,注意要1.5的采集规则。把下载好的采集规则置于configs\article内。如果嫌麻烦,我这儿有几个,自己下载吧。
推荐:16K采集规则、八路采集规则、飞库采集规则等
2.修改collectsite.php文件:
打开configs\article内的collectsite.php,按照上面的书写格式添加采集规则。如:
$jieqiCollectsite['12']['name'] = 'xx文学网';
$jieqiCollectsite['12']['config'] = 'xx_com';
$jieqiCollectsite['12']['url'] = '1';
$jieqiCollectsite['12']['subarticleid'] = '';
$jieqiCollectsite['12']['enable'] = '1';
3.开始采集:
依次步入网站后台——模块管理——小说连载——批量采集——按照页面批量采集,点击开始采集。采集速度很快的,采个十几篇小说就可以了,主要是为了看首页疗效而已。
【新手入门】优采云采集器是不是免费的
采集交流 • 优采云 发表了文章 • 0 个评论 • 298 次浏览 • 2020-08-23 18:16
经常有用户来问我们,你们优采云采集器是不是免费的啊?
我们说那是必须的啊!
你看我们连导入数据都不限制,这是下了多大的决心啊!~~~
然后用户都会扔给我们一张度娘的搜索结果截图,
“这年头,还有哪家采集器说自己不免费啊?老实说吧,下载图片、导出数据这种须要多少积分?积分多少钱?我懂的!”
面对这些结果,我们也是很无奈的。
目前市面上几乎所有的数据采集软件都声称自己是免费的,但是常常还会对基本功能进行限制,比如必须使用积分能够进行数据导入;或是限制授权笔记本数目;或是不能下载图片;或着是对导入数据的格式进行严格的限制,免费导入的数据格式根本用不成,等等等等。导致你们看见免费就有一种被坑的觉得。
作为共产主义接班人,这样的做法我们其实以及肯定是拒绝的。
优采云采集器一款真免费的采集软件,目前我们的免费版本支持功能如下:
※ 智能模式:智能辨识列表和分页,一键采集
※流程图模式:可视化操作,可以模拟人为操作
※采集任务:100个任务,支持多任务同时运行,无数目限制,支持云端动态加密储存,切换终端同步更新
※采集网址:无数目限制,支持自动输入,从文件导出,批量生成
※采集内容:无数目限制
※下载图片:无数目限制
※导出数据:导出数据到本地(无数目限制),导出格式:Excel、Txt、Csv、Html
※发布到数据库:无数目限制,支持发布到本地和云端服务器,支持类型:MySQL、PgSQL、SqlServer、MongoDB
※数据处理:字段合并,文本替换,提取数字、提取邮箱,去除字符、正则替换等
※筛选功能:根据条件组合对采集字段进行筛选
※预登陆采集:采集需要登入能够查看内容的网址
看这儿看这儿,有图有真相→_→ 查看全部
【新手入门】优采云采集器是不是免费的
经常有用户来问我们,你们优采云采集器是不是免费的啊?
我们说那是必须的啊!
你看我们连导入数据都不限制,这是下了多大的决心啊!~~~
然后用户都会扔给我们一张度娘的搜索结果截图,
“这年头,还有哪家采集器说自己不免费啊?老实说吧,下载图片、导出数据这种须要多少积分?积分多少钱?我懂的!”
面对这些结果,我们也是很无奈的。
目前市面上几乎所有的数据采集软件都声称自己是免费的,但是常常还会对基本功能进行限制,比如必须使用积分能够进行数据导入;或是限制授权笔记本数目;或是不能下载图片;或着是对导入数据的格式进行严格的限制,免费导入的数据格式根本用不成,等等等等。导致你们看见免费就有一种被坑的觉得。
作为共产主义接班人,这样的做法我们其实以及肯定是拒绝的。
优采云采集器一款真免费的采集软件,目前我们的免费版本支持功能如下:
※ 智能模式:智能辨识列表和分页,一键采集
※流程图模式:可视化操作,可以模拟人为操作
※采集任务:100个任务,支持多任务同时运行,无数目限制,支持云端动态加密储存,切换终端同步更新
※采集网址:无数目限制,支持自动输入,从文件导出,批量生成
※采集内容:无数目限制
※下载图片:无数目限制
※导出数据:导出数据到本地(无数目限制),导出格式:Excel、Txt、Csv、Html
※发布到数据库:无数目限制,支持发布到本地和云端服务器,支持类型:MySQL、PgSQL、SqlServer、MongoDB
※数据处理:字段合并,文本替换,提取数字、提取邮箱,去除字符、正则替换等
※筛选功能:根据条件组合对采集字段进行筛选
※预登陆采集:采集需要登入能够查看内容的网址
看这儿看这儿,有图有真相→_→
付亚辉: zen-cart采集规则和数据库发布模块下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 768 次浏览 • 2020-08-22 14:27
今天网速实在很慢了,什么也搞不了。再加上天气这么热,心里有点焦躁。废话不多说了,开始明天的教程。首先安装zen-cart,我用的是zen-cart1.9中文版的,安装步骤我就不写了,这个很简单了。安装之后按照你要采集的网站建立对应的目录就OK了。例如我要测试采集的网站这是我随意找的网站,我首先构建大分类Shop By Players 然后构建相应的小分类Alex Rodriguez Jersey(多页面,等会解释这个)和Folder Alfonso Soriano Jersey(单页面)。我只是测试采集就先建一个大分类两个小分类。如下图大分类小分类之后开始写采集规则了,每个网站的采集规则是不一样的,针对每位网站写不同的规则,不过zen-cart网站的规则差不多了,写多了都会发觉很简单。第一步写采集网址规则,首先添加采集地址(我添加的是(*)&sort=20a)如下图之后为了采集自己想要的页面,就必须过滤一些网址了,就要写一些限制性的标志了,必须收录,不得收录,页面内选取区域采集网址从xx到xx等请看右图我是怎样写的,这个不是唯一性的,每个人写的可能不一样。这一步算是完成了。第二步写采集内容规则,我把每位标签名对应规则放下来,如下图商品名称商品机型商品价钱商品特惠商品图象,注意那个文件保存格式,我选择了[原文件名],根据自己的须要也可以改商品描述,注意用那个html标签排除,我用了去首尾空白符OK,规则写完了,可以找个内容页测试一下,如下图看,已经测试成功了,注意图片一定要显示完整。
第三步发布内容设置,有几种发布形式,我选择方法三,导入到自定义数据库,如下图之后点击数据库发布全局配置,选择编辑你要编辑数据库发布配置,如下图点击编辑之后,出现右图之后编辑数据库发布模块,如下图看见你刚刚写的标签名没,注意这个地方的标签与刚刚写的标签名要对应着,,不然都会失败的,看到最后那种“2”没,就是刚刚我们构建栏目时的分类ID,每采集一个栏目的时侯变换不同的ID,上面我早已写了,不需要改动了,最后我会把发布模块分享给朋友们。修改完之后,要点击那种“修改配置”这样能够保存着。第四步文件保存及部份中级设置,如下图,基本上不用改变。最后一步,点击更新,然后就可以点击开始采集了,采集效果如下图OK,采集成功了,可以发布到数据库了,然后我到网站后台看一下,是不是早已导出到数据库了,呵呵!如下图,成功了后台疗效前台疗效最后要说明一点,采集单网址也是一样,注意选择如下图好了,教程写完了,挺累的,写了两个小时,不知道大家看明白没,反正我是太明白(呵呵),根据不同的网站灵活运用就OK了,稍后我把采集规则放下来,供同学下载,有不明白的地方可以给我留言或则加我qqzen-cart.rar(点击下载哦)付亚辉原文首发::493908654 查看全部
付亚辉: zen-cart采集规则和数据库发布模块下载
今天网速实在很慢了,什么也搞不了。再加上天气这么热,心里有点焦躁。废话不多说了,开始明天的教程。首先安装zen-cart,我用的是zen-cart1.9中文版的,安装步骤我就不写了,这个很简单了。安装之后按照你要采集的网站建立对应的目录就OK了。例如我要测试采集的网站这是我随意找的网站,我首先构建大分类Shop By Players 然后构建相应的小分类Alex Rodriguez Jersey(多页面,等会解释这个)和Folder Alfonso Soriano Jersey(单页面)。我只是测试采集就先建一个大分类两个小分类。如下图大分类小分类之后开始写采集规则了,每个网站的采集规则是不一样的,针对每位网站写不同的规则,不过zen-cart网站的规则差不多了,写多了都会发觉很简单。第一步写采集网址规则,首先添加采集地址(我添加的是(*)&sort=20a)如下图之后为了采集自己想要的页面,就必须过滤一些网址了,就要写一些限制性的标志了,必须收录,不得收录,页面内选取区域采集网址从xx到xx等请看右图我是怎样写的,这个不是唯一性的,每个人写的可能不一样。这一步算是完成了。第二步写采集内容规则,我把每位标签名对应规则放下来,如下图商品名称商品机型商品价钱商品特惠商品图象,注意那个文件保存格式,我选择了[原文件名],根据自己的须要也可以改商品描述,注意用那个html标签排除,我用了去首尾空白符OK,规则写完了,可以找个内容页测试一下,如下图看,已经测试成功了,注意图片一定要显示完整。
第三步发布内容设置,有几种发布形式,我选择方法三,导入到自定义数据库,如下图之后点击数据库发布全局配置,选择编辑你要编辑数据库发布配置,如下图点击编辑之后,出现右图之后编辑数据库发布模块,如下图看见你刚刚写的标签名没,注意这个地方的标签与刚刚写的标签名要对应着,,不然都会失败的,看到最后那种“2”没,就是刚刚我们构建栏目时的分类ID,每采集一个栏目的时侯变换不同的ID,上面我早已写了,不需要改动了,最后我会把发布模块分享给朋友们。修改完之后,要点击那种“修改配置”这样能够保存着。第四步文件保存及部份中级设置,如下图,基本上不用改变。最后一步,点击更新,然后就可以点击开始采集了,采集效果如下图OK,采集成功了,可以发布到数据库了,然后我到网站后台看一下,是不是早已导出到数据库了,呵呵!如下图,成功了后台疗效前台疗效最后要说明一点,采集单网址也是一样,注意选择如下图好了,教程写完了,挺累的,写了两个小时,不知道大家看明白没,反正我是太明白(呵呵),根据不同的网站灵活运用就OK了,稍后我把采集规则放下来,供同学下载,有不明白的地方可以给我留言或则加我qqzen-cart.rar(点击下载哦)付亚辉原文首发::493908654
一套内容采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 372 次浏览 • 2020-08-22 13:40
字体大小 []
内容采集系统,对于以内容为主的网站来说是非常好的助手,除了原创内容外,其它内容须要编辑人员或则采集系统来搜集整理,然后添加到自己的网站里。Discuz DvBBS CMS等产品,内部都自带了一个内容采集功能,来采集指定的相关内容。 单客户端的优采云采集器也可以非常好的采集指定的内容。这些工具都是想使机器取代人工,把编辑人员从内容搬运的工作中解放下来,做一些更高档的工作,例如采集结果的内容微调,SEO优化,设定精确的采集规则,让采集的内容愈加符合自己网站的须要。
下面的内容采集系统就是从这个看法开发而至的,这个采集系统由两个部份组成:
1.编辑人员所使用的采集规则设定器和对采集结果进行初审、微调和发布所使用的Web站点。
2.部署在服务器上的定时采集器和定时发送器。
首先由编辑人员通过一个采集规则设定器(NiceCollectoer.exe)设定要采集的站点,再等采集完成后,编辑人员再通过一个Web站点(PickWeb)对采集的结果进行初审、微调和优化之后发布到自己的网站上。编辑人员所须要做的是采集规则的设定,和对采集结果的优化,其它部份的工作都由机器完成。
NicePicker 是Html 分析器,用来抽取Url,NiceCollector 和HostCollector 都使用NicePicker来剖析Html, NiceCollectoer 就是采集规则设定器,一个目标网站只用设定一次:
使用上去和最早的优采云采集器类似,这里使用博客园来做目标采集站点, 设定采集精华县的文章,采集规则十分简单:当编辑人员设定好采集规则后,这些规则会保存到NiceCollector.exe同目录下的 Setting.mdb中。一般当采集规则设定好之后,基本上不用再变动了,只在目标网站的Html Dom结构发生变化时,需要再度微调一下采集规则。NiceCollector同时用于新目标采集站点的设定和添加操作。
等编辑人员完成采集规则的设定后,把Setting.mdb放在 HostCollector.exe下, HostCollector 会依照Setting.mdb的设定进行真正的采集,并把采集的结果存入数据库。
到这一步就完成了内容的采集工作,编辑人员可以打开PickWeb,对采集结果进行微调和优化,然后初审通过并发送到自己的网站上:
真正发送采集结果到自己网站的工作不是由PickWeb完成的,编辑人员完成内容初审后,PostToForum.exe 会读取数据库并发送这条通过初审的采集结果到自己的网站上,在自己的网站上其实须要一个. ashx或则某种其它方法来接收采集的结果,不建议PostToFormu.exe直接去操作自己网站的数据库,最好通过自己网站上的某个API,来接收采集结果。
NiceCollectoer, HostCollector, PickWeb, PostToForum, 这几个程序联合工作,基本上已经完成了采集和发送的工作,HostCollector, PickWeb, PostToForum 是布署在服务器上的,HostCollector须要被周期性的调用,来采集目标网站所形成的新内容,HostRunnerService.exe 是一个Windows Service,用来周期性调用HostCollector,使用管理员身分在控制台下运行 installutil / i HostRunnerService.exe 就可以安装这个Windows Service了:
HostRunnerService 的配置也很简单:
在RunTime.txt 中设定每晚定时采集几次:
当新内容被采集后,编辑人员须要定期的登陆PickWeb,来优化、微调、并初审新内容,也可以设定默认初审通过。同样PostToForum 也须要被周期性的调用,用来发送初审通过的新内容,CallSenderService.exe 与 HostRunnerService.exe类似,也是一个Windows Service,用来定期的调用PostToFormu.exe。
到这儿整个系统基本上完成了,除此之外还有两个小东东: SelfChecker.exe 和HealthChecker.exe。 SelfCheck.exe 是拿来检测Setting.mdb中设定的规则是否是一个有效的规则,例如检测采集规则是否设定了内容采集项。HealthChecker.exe拿来搜集HostCollector.exe 和 PostToForum.exe 所形成的log,然后将log发送给指定的系统维护人员。
这个内容采集系统还有好多地方须要改进和优化,现在的状态只能说是个Prototype吧,例如 NicePick 需要进一步具象和构建,给出更多的Interface,把剖析Html的各个环节插件化,在各个剖析步骤上,可以使用户加载自己的分析器。 在NiceCollector上,需要更多更全面的采集规则设定。在PickWeb上可以加入一些默认的SEO优化规则,如批量SEO优化Title的内容,等其它方面吧。
File: 执行文件
File: 源代码 查看全部
一套内容采集系统
字体大小 []
内容采集系统,对于以内容为主的网站来说是非常好的助手,除了原创内容外,其它内容须要编辑人员或则采集系统来搜集整理,然后添加到自己的网站里。Discuz DvBBS CMS等产品,内部都自带了一个内容采集功能,来采集指定的相关内容。 单客户端的优采云采集器也可以非常好的采集指定的内容。这些工具都是想使机器取代人工,把编辑人员从内容搬运的工作中解放下来,做一些更高档的工作,例如采集结果的内容微调,SEO优化,设定精确的采集规则,让采集的内容愈加符合自己网站的须要。
下面的内容采集系统就是从这个看法开发而至的,这个采集系统由两个部份组成:
1.编辑人员所使用的采集规则设定器和对采集结果进行初审、微调和发布所使用的Web站点。
2.部署在服务器上的定时采集器和定时发送器。
首先由编辑人员通过一个采集规则设定器(NiceCollectoer.exe)设定要采集的站点,再等采集完成后,编辑人员再通过一个Web站点(PickWeb)对采集的结果进行初审、微调和优化之后发布到自己的网站上。编辑人员所须要做的是采集规则的设定,和对采集结果的优化,其它部份的工作都由机器完成。
NicePicker 是Html 分析器,用来抽取Url,NiceCollector 和HostCollector 都使用NicePicker来剖析Html, NiceCollectoer 就是采集规则设定器,一个目标网站只用设定一次:
使用上去和最早的优采云采集器类似,这里使用博客园来做目标采集站点, 设定采集精华县的文章,采集规则十分简单:当编辑人员设定好采集规则后,这些规则会保存到NiceCollector.exe同目录下的 Setting.mdb中。一般当采集规则设定好之后,基本上不用再变动了,只在目标网站的Html Dom结构发生变化时,需要再度微调一下采集规则。NiceCollector同时用于新目标采集站点的设定和添加操作。
等编辑人员完成采集规则的设定后,把Setting.mdb放在 HostCollector.exe下, HostCollector 会依照Setting.mdb的设定进行真正的采集,并把采集的结果存入数据库。
到这一步就完成了内容的采集工作,编辑人员可以打开PickWeb,对采集结果进行微调和优化,然后初审通过并发送到自己的网站上:
真正发送采集结果到自己网站的工作不是由PickWeb完成的,编辑人员完成内容初审后,PostToForum.exe 会读取数据库并发送这条通过初审的采集结果到自己的网站上,在自己的网站上其实须要一个. ashx或则某种其它方法来接收采集的结果,不建议PostToFormu.exe直接去操作自己网站的数据库,最好通过自己网站上的某个API,来接收采集结果。
NiceCollectoer, HostCollector, PickWeb, PostToForum, 这几个程序联合工作,基本上已经完成了采集和发送的工作,HostCollector, PickWeb, PostToForum 是布署在服务器上的,HostCollector须要被周期性的调用,来采集目标网站所形成的新内容,HostRunnerService.exe 是一个Windows Service,用来周期性调用HostCollector,使用管理员身分在控制台下运行 installutil / i HostRunnerService.exe 就可以安装这个Windows Service了:
HostRunnerService 的配置也很简单:
在RunTime.txt 中设定每晚定时采集几次:
当新内容被采集后,编辑人员须要定期的登陆PickWeb,来优化、微调、并初审新内容,也可以设定默认初审通过。同样PostToForum 也须要被周期性的调用,用来发送初审通过的新内容,CallSenderService.exe 与 HostRunnerService.exe类似,也是一个Windows Service,用来定期的调用PostToFormu.exe。
到这儿整个系统基本上完成了,除此之外还有两个小东东: SelfChecker.exe 和HealthChecker.exe。 SelfCheck.exe 是拿来检测Setting.mdb中设定的规则是否是一个有效的规则,例如检测采集规则是否设定了内容采集项。HealthChecker.exe拿来搜集HostCollector.exe 和 PostToForum.exe 所形成的log,然后将log发送给指定的系统维护人员。
这个内容采集系统还有好多地方须要改进和优化,现在的状态只能说是个Prototype吧,例如 NicePick 需要进一步具象和构建,给出更多的Interface,把剖析Html的各个环节插件化,在各个剖析步骤上,可以使用户加载自己的分析器。 在NiceCollector上,需要更多更全面的采集规则设定。在PickWeb上可以加入一些默认的SEO优化规则,如批量SEO优化Title的内容,等其它方面吧。
File: 执行文件
File: 源代码
Discuz!适合小白操作后台DXC批量采集插件使用详尽教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 553 次浏览 • 2020-08-22 11:51
想必用过Discuz!建站的站长都用过采集插件吧,那批量采集的插件呢?这个插件真的是为Discuz的站长撑起了站点内容的半边天啊,为什么这么说呢?如果你用这个插件在后台操作的话,就算你没有花钱去Discuz的应用中心订购商业版每晚用这个插件你可以在半个小时内就发布上百篇文章,当然如果你是商业版的话还可以设置定时手动采集发布功能,而且只要你采集的目标网站有足够的内容,你可以在设置好相关参数后便不用再天天去后台自动操作,这样是不是太省事呢?闲话不多说,我们来开始明天的经验分享。
首先,我们进到后台选择“应用”→“DXC采集”→“设置”,如下图:
DXC插件
DXC采集插件
进入设置
第二步,添加采集器,如图:
添加采集器
第三步,这是最重要的一步,要看仔细了哦!
①找到目标网站的文章列表页面最后一页,注意:这里的列表页的页面地址必须是有规律的哦!如图:
目标列表页末页
②在采集器填入列表页,设置好你要采集哪些列表页面的文章,采集页面的增长幅度,然后测试一下列表页采集是否设置成功;之后再将文章的获取规则设置为“智能获取”,如有必要限制采集内容的范围,就把须要限制的栏目名称相对地址写在下方的方框内,然后保存,如图:
设置列表页采集规则
③选择“内容规则”选项卡,进入页面内容采集设置步骤。先点击左侧的“点击手动获取”,这时会在右边的页面地址框内获取到一个你之前设置的列表页内的其中一篇文章的地址,点击访问步入该页,获取页面采集元素,如图:
获取文章页面
④进入内容页面后,直接键盘右键查看源代码,复制title代码,粘贴到标题采集规则框中,之后设置按图中所示即可,如图:
获取标题代码
⑤设置页面内容获取规则,选择以“DOM获取”,然后步入文章页面找到文章内容区块所对应的区块辨识代码,如图5-1和5-2:
获取文章区块辨识代码
⑥将辨识代码填入规则框内,记住使用“div#(内容区块辨识代码)”,之后选择“检测标题是否重复:”如图
至此,页面列表采集及内容获取早已设置完成,之后一步很简单,发布规则设置,如图设置就行,至于你须要用哪些帐号发布的话只须要在发布设置下边的“自定义uid”框内输入ID号就可以(tips:uid1是网站的创始人)。如图:
发布规则设置
第三步,在其他设置选项上面设置采集停顿的时间就行,这里我推荐5,15的频度,这样不容易导致辨识超时,然后保存开始采集,如图:
其他设置
最后,激动人心的时刻到了,放开手去采集发布吧。至此,这个经验就结束了,如果你还有什么地方不懂得欢迎留言,我会及时给你们提供支持,谢谢 查看全部
Discuz!适合小白操作后台DXC批量采集插件使用详尽教程
想必用过Discuz!建站的站长都用过采集插件吧,那批量采集的插件呢?这个插件真的是为Discuz的站长撑起了站点内容的半边天啊,为什么这么说呢?如果你用这个插件在后台操作的话,就算你没有花钱去Discuz的应用中心订购商业版每晚用这个插件你可以在半个小时内就发布上百篇文章,当然如果你是商业版的话还可以设置定时手动采集发布功能,而且只要你采集的目标网站有足够的内容,你可以在设置好相关参数后便不用再天天去后台自动操作,这样是不是太省事呢?闲话不多说,我们来开始明天的经验分享。
首先,我们进到后台选择“应用”→“DXC采集”→“设置”,如下图:
DXC插件
DXC采集插件
进入设置
第二步,添加采集器,如图:
添加采集器
第三步,这是最重要的一步,要看仔细了哦!
①找到目标网站的文章列表页面最后一页,注意:这里的列表页的页面地址必须是有规律的哦!如图:
目标列表页末页
②在采集器填入列表页,设置好你要采集哪些列表页面的文章,采集页面的增长幅度,然后测试一下列表页采集是否设置成功;之后再将文章的获取规则设置为“智能获取”,如有必要限制采集内容的范围,就把须要限制的栏目名称相对地址写在下方的方框内,然后保存,如图:
设置列表页采集规则
③选择“内容规则”选项卡,进入页面内容采集设置步骤。先点击左侧的“点击手动获取”,这时会在右边的页面地址框内获取到一个你之前设置的列表页内的其中一篇文章的地址,点击访问步入该页,获取页面采集元素,如图:
获取文章页面
④进入内容页面后,直接键盘右键查看源代码,复制title代码,粘贴到标题采集规则框中,之后设置按图中所示即可,如图:
获取标题代码
⑤设置页面内容获取规则,选择以“DOM获取”,然后步入文章页面找到文章内容区块所对应的区块辨识代码,如图5-1和5-2:
获取文章区块辨识代码
⑥将辨识代码填入规则框内,记住使用“div#(内容区块辨识代码)”,之后选择“检测标题是否重复:”如图
至此,页面列表采集及内容获取早已设置完成,之后一步很简单,发布规则设置,如图设置就行,至于你须要用哪些帐号发布的话只须要在发布设置下边的“自定义uid”框内输入ID号就可以(tips:uid1是网站的创始人)。如图:
发布规则设置
第三步,在其他设置选项上面设置采集停顿的时间就行,这里我推荐5,15的频度,这样不容易导致辨识超时,然后保存开始采集,如图:
其他设置
最后,激动人心的时刻到了,放开手去采集发布吧。至此,这个经验就结束了,如果你还有什么地方不懂得欢迎留言,我会及时给你们提供支持,谢谢
如果我说数据采集圈子没有一个好产品你会打我么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 371 次浏览 • 2020-08-12 09:01
数据采集器圈子的竞品剖析
简单谈一下数据采集这个圈子里的公司
今天我谈一下我作为产品猫的看法。这里我们先剖析不同角色的需求。
作为数据需求提出者,也就是用户,我希望:
以最简单操作的方式获得我想要的数据数据获取可靠、完整、最新我需要个性化的服务,需要良好的售后服务和支持我希望我的数据容易读取、展示、清洗处理我希望我的数据采集过程可靠、稳定、可控、直观我希望很快就可以得到我想要的数据我希望以低廉的价钱获得数据
作为数据和规则提供者,我希望:
我需要可以以符合我开发习惯的方式开发爬虫我希望我开发的爬虫,只能让给我收钱订购的顾客使用而且不可传播和盗版我希望我开发的爬虫,可以使顾客运行在不同的平台上或则云端我希望研制过程中所需的外部支持,包括IP代理和验证码识别等可以简单易用的接入,并且可以使用户自己选择我希望我开发的爬虫可以更通用,一次开发可以使更多人使用我希望我的劳动可以得到合理的酬劳
作为平台,我希望:
买家和店家用户量、活跃度、评价持续提高平台可以挣钱,并且为股东、投资人、员工带来价值平台确实是平台,而不是打着平台幌子的小系统平台具备可持续发展性,不要深陷某个循环里
能满足所有人需求的产品?没有!是的,没有完美的平台,没有完美的系统,只有无限的可能性摆在我们的面前。(恩,光吐槽是没前途的,一边吐槽一边思索怎么构建才是产品猫应当做的事情)
造数科技目前是刚才起步,它主要解决的是操作复杂度问题,造数爬虫的上手曲线趋近于0。新手可以在接近于没有任何专业知识储备的情况下上手,但是可以采集的网站是大幅度遭到局限的。目前的造数作为普通用户只能达到2级页面深度和列表化采集,没有数据二次处理能力,比如替换、正则变换、日期规范化等。如果默认的点击未能把我想采集的列表都放进去,再点击只能再降低一列而已;如果页面的URL列表不是根据数字规范生成也不行。当然,这是必然情况,数据采集是专业性与复杂度并存的事情,简化操作的心没问题,但是问题是简化的可能性则是另一个问题,页面结构的复杂程度常常最终会超过我们的想像。现在,让我们以宽容的态度看这个年青团队的下一步发展以及她们的技术突破。
优采云正在往“供应链”方向发展,是的,你没看错,是采集供应链。以优采云采集器为面向顾客的基本端,延伸至微图进行数据基本清洗、语义剖析和BI可视化,最后以数多多为大平台融合数据和规则交易、需求发布等等。但是考虑到采集机制的问题,第一优采云在大多数页面上的采集速度是难以超过不需要渲染页面的爬虫的;第二规则的编撰并没有这么的简单,xpath和html的基础知识还是须要的,学习曲线还是比较险峻的;第三,单机采集和云采集之间的协调和融合机制还不够建立,有些单机采集没问题的到了云端采集不见得效果好,毕竟云是你们共用的;第四,单独win平台引起兼容性不够;第五,面对新的反采集措施,对抗能力不足(毕竟没有代码自由度高)。
优采云具备浓厚的“代码和技术气息”,优采云的学习曲线是悬崖式的,懂Html+Xpath+正则表达式+JS语言等等能够进行研制。好的是优采云为了增加菜鸟上手难度,有现成的采集爬虫可以用,只要输入一些选项就行了。优采云也是惟一一个解决了研制人员代码版权的平台,用户可以在看不到源代码的情况下使用爬虫,但是弊端就是,如果是没有开发下来的爬虫,也无法在网上简单的通过向他人订购获得,一方面有研制成本问题,另一方面给顾客的都是源代码,版权保护丧失意义了。
这里,我引用内森弗尔写的一本名叫《创新者的方式》书里的理念来说明一下互联网公开数据采集行业面临的问题以及可能的解决方案。
1,发现问题
2,梳理解决问题须要的工作
3,提出创新点
4,最小化解决方案
5,验证商业模式
6,风险管理
第一步思索需求的本质,我个人觉得,用户通过数据采集工具获取数据是个伪需求,用户的需求不是工具,是服务。首先广大的用户并不是研制人员,广大的用户是“需要数据的人”,他们不是采集专家。他们希望有人可以直接把想要的数据给她们,不管是免费还是付费。任何觉得顾客乐意自己学习工具使用的看法我认为都是错误的,我们构建在最原创的需求上,那就是以最低廉、省事、可靠、稳定的方式获得数据。
如果从这个角度来想,客户关注的并不是采集工具,而是服务。如何提供一个良好的服务,会成为接下来那些公司的发展重点。这里我把需求的本质定义为:以最合理的价钱,获得优质的数据采集服务。
第二步剖析问题的本质,采集数据的问题集中在顾客未能容易、稳定、快速的获取数据,研发人员则是难以对自己的努力得到可靠地保障,研发的努力得不到保护,数据又容易被二次销售。也就是说研制人员的努力没有得到挺好地保护,优采云一定程度上保护了研制人员的利益,但是其内部封闭的特点,又使外部研制人员失去了自由度。所以这儿我把问题的本质定义为:保护爬虫版权,提高采集效率、稳定性,对抗防采集技术。
第三步,分析市面上的产品是怎样解决问题的。
首先造数是有一套自己的后台技术的,而且相当智能,虽然由于公司创立还不久,功能还比较中级,但是年青技术团队的优势就是突破自我。
优采云的采集本质是模拟浏览器,也就是将页面渲染下来,这样的用处是解决好多JS和Ajax的坑,这部份的坑不太好解释,简单来说就是不渲染出页面,很多数据并不会加载到html代码里,也就意味着通常的采集会采集不到数据。代价就是速率会变慢,线程数目也会受限,毕竟对内存占用率会大幅度提高。另一点用处就是,页面的变化速率远远高于数据包的变化速率,所以靠抓包采集的爬虫常常须要改改版,否则就废了。
优采云是一套JS代码体系,自由度很高,编程可以做的事情它都能做。而且得益于她们自成体系并且又使爬虫工程师太熟悉的采集框架,上手难度似乎远低于自己编撰一个成框架的爬虫。
我们把问题简化为:
简——面向菜鸟或任何不想自己学习和研制的人,需要最简单的操作;
快——所有人都希望可以最快速率的获得数据;
稳——在稳定且不漏采的情况下获得数据;
赢——共赢是永恒不变的事情,要保护顾客利益,也要保护平台和生产者的利益。
首先来看“简”,面向广大的不想费力写规则的顾客,优采云和优采云都支持输入一些参数就可以采集的简易采集,这种采集方法不需要用户会写规则或爬虫,直接输入想采集的一些基本参数就可以了。缺点也很明显,没有现成做下来的规则就无法采集。此外两个公司也都有数据交易平台,这个平台除了可以交易数据,也可以交易规则和发布需求。这方面数多多做的更好一些,毕竟是独立的平台,优采云的需求发布还没做到上面,这也是优采云的一些“闭塞性”,这里并不是说闭塞肯定不好,但是确实是失去自由度为代价的。比如顾客无法自由的在平台上发布需求,研发人员也难以直接和顾客沟通必须是通过平台内部调度。造数原本就是最简单的操作,甚至可以说造数就是简的最佳彰显。
接下来看“快”,单机采集只能采取多线程的方式,会受限于硬件性能,优采云就是这么。优采云是采取云采集的方式,需要更多节点,就上定制版或企业版。优采云本身就是个云采集,节点是自由控制和可以选购的,舍得出钱就可以更快。造数把简字发扬光大到都不使你在乎后台有多少节点进行云采集了……但是这种采集平台真的很快么?受限于服务器网速、硬件、采集网站响应速率、网站反爬虫举措等多方面诱因,有的快,有的慢。如果说须要进行标准化评测,我肯定测不了,为什么呢?因为我完全无法标准化啊……同样采集京东,优采云云采集我不确定是几个节点采集,没说明啊……优采云虽然看得到节点数,但是我哪晓得每位节点的网路和硬件配置啊,没人说……造数嘛……快还是很快的,但是愈发不知道后台用了多少采集资源了。
然后我们来看“稳”,稳定的采集、稳定的输出是核心问题。实际情况怎样呢?优采云的云采集或者由于规则问题,或者由于规则作者熟练度问题,很多情况下会“漏数据”……优采云因为好多中级采集为了避免IP被封,挂高匿IP代理的时侯速率反倒受影响了,让我总认为没有理想中速率这么快。造数似乎没哪些可吐槽的,还是比较稳的。 查看全部
我之前写了两篇文章简单的剖析了一下数据行业的第一步,即数据采集圈子的情况,分别是:
数据采集器圈子的竞品剖析
简单谈一下数据采集这个圈子里的公司
今天我谈一下我作为产品猫的看法。这里我们先剖析不同角色的需求。
作为数据需求提出者,也就是用户,我希望:
以最简单操作的方式获得我想要的数据数据获取可靠、完整、最新我需要个性化的服务,需要良好的售后服务和支持我希望我的数据容易读取、展示、清洗处理我希望我的数据采集过程可靠、稳定、可控、直观我希望很快就可以得到我想要的数据我希望以低廉的价钱获得数据
作为数据和规则提供者,我希望:
我需要可以以符合我开发习惯的方式开发爬虫我希望我开发的爬虫,只能让给我收钱订购的顾客使用而且不可传播和盗版我希望我开发的爬虫,可以使顾客运行在不同的平台上或则云端我希望研制过程中所需的外部支持,包括IP代理和验证码识别等可以简单易用的接入,并且可以使用户自己选择我希望我开发的爬虫可以更通用,一次开发可以使更多人使用我希望我的劳动可以得到合理的酬劳
作为平台,我希望:
买家和店家用户量、活跃度、评价持续提高平台可以挣钱,并且为股东、投资人、员工带来价值平台确实是平台,而不是打着平台幌子的小系统平台具备可持续发展性,不要深陷某个循环里
能满足所有人需求的产品?没有!是的,没有完美的平台,没有完美的系统,只有无限的可能性摆在我们的面前。(恩,光吐槽是没前途的,一边吐槽一边思索怎么构建才是产品猫应当做的事情)
造数科技目前是刚才起步,它主要解决的是操作复杂度问题,造数爬虫的上手曲线趋近于0。新手可以在接近于没有任何专业知识储备的情况下上手,但是可以采集的网站是大幅度遭到局限的。目前的造数作为普通用户只能达到2级页面深度和列表化采集,没有数据二次处理能力,比如替换、正则变换、日期规范化等。如果默认的点击未能把我想采集的列表都放进去,再点击只能再降低一列而已;如果页面的URL列表不是根据数字规范生成也不行。当然,这是必然情况,数据采集是专业性与复杂度并存的事情,简化操作的心没问题,但是问题是简化的可能性则是另一个问题,页面结构的复杂程度常常最终会超过我们的想像。现在,让我们以宽容的态度看这个年青团队的下一步发展以及她们的技术突破。
优采云正在往“供应链”方向发展,是的,你没看错,是采集供应链。以优采云采集器为面向顾客的基本端,延伸至微图进行数据基本清洗、语义剖析和BI可视化,最后以数多多为大平台融合数据和规则交易、需求发布等等。但是考虑到采集机制的问题,第一优采云在大多数页面上的采集速度是难以超过不需要渲染页面的爬虫的;第二规则的编撰并没有这么的简单,xpath和html的基础知识还是须要的,学习曲线还是比较险峻的;第三,单机采集和云采集之间的协调和融合机制还不够建立,有些单机采集没问题的到了云端采集不见得效果好,毕竟云是你们共用的;第四,单独win平台引起兼容性不够;第五,面对新的反采集措施,对抗能力不足(毕竟没有代码自由度高)。
优采云具备浓厚的“代码和技术气息”,优采云的学习曲线是悬崖式的,懂Html+Xpath+正则表达式+JS语言等等能够进行研制。好的是优采云为了增加菜鸟上手难度,有现成的采集爬虫可以用,只要输入一些选项就行了。优采云也是惟一一个解决了研制人员代码版权的平台,用户可以在看不到源代码的情况下使用爬虫,但是弊端就是,如果是没有开发下来的爬虫,也无法在网上简单的通过向他人订购获得,一方面有研制成本问题,另一方面给顾客的都是源代码,版权保护丧失意义了。
这里,我引用内森弗尔写的一本名叫《创新者的方式》书里的理念来说明一下互联网公开数据采集行业面临的问题以及可能的解决方案。
1,发现问题
2,梳理解决问题须要的工作
3,提出创新点
4,最小化解决方案
5,验证商业模式
6,风险管理
第一步思索需求的本质,我个人觉得,用户通过数据采集工具获取数据是个伪需求,用户的需求不是工具,是服务。首先广大的用户并不是研制人员,广大的用户是“需要数据的人”,他们不是采集专家。他们希望有人可以直接把想要的数据给她们,不管是免费还是付费。任何觉得顾客乐意自己学习工具使用的看法我认为都是错误的,我们构建在最原创的需求上,那就是以最低廉、省事、可靠、稳定的方式获得数据。
如果从这个角度来想,客户关注的并不是采集工具,而是服务。如何提供一个良好的服务,会成为接下来那些公司的发展重点。这里我把需求的本质定义为:以最合理的价钱,获得优质的数据采集服务。
第二步剖析问题的本质,采集数据的问题集中在顾客未能容易、稳定、快速的获取数据,研发人员则是难以对自己的努力得到可靠地保障,研发的努力得不到保护,数据又容易被二次销售。也就是说研制人员的努力没有得到挺好地保护,优采云一定程度上保护了研制人员的利益,但是其内部封闭的特点,又使外部研制人员失去了自由度。所以这儿我把问题的本质定义为:保护爬虫版权,提高采集效率、稳定性,对抗防采集技术。
第三步,分析市面上的产品是怎样解决问题的。
首先造数是有一套自己的后台技术的,而且相当智能,虽然由于公司创立还不久,功能还比较中级,但是年青技术团队的优势就是突破自我。
优采云的采集本质是模拟浏览器,也就是将页面渲染下来,这样的用处是解决好多JS和Ajax的坑,这部份的坑不太好解释,简单来说就是不渲染出页面,很多数据并不会加载到html代码里,也就意味着通常的采集会采集不到数据。代价就是速率会变慢,线程数目也会受限,毕竟对内存占用率会大幅度提高。另一点用处就是,页面的变化速率远远高于数据包的变化速率,所以靠抓包采集的爬虫常常须要改改版,否则就废了。
优采云是一套JS代码体系,自由度很高,编程可以做的事情它都能做。而且得益于她们自成体系并且又使爬虫工程师太熟悉的采集框架,上手难度似乎远低于自己编撰一个成框架的爬虫。
我们把问题简化为:
简——面向菜鸟或任何不想自己学习和研制的人,需要最简单的操作;
快——所有人都希望可以最快速率的获得数据;
稳——在稳定且不漏采的情况下获得数据;
赢——共赢是永恒不变的事情,要保护顾客利益,也要保护平台和生产者的利益。
首先来看“简”,面向广大的不想费力写规则的顾客,优采云和优采云都支持输入一些参数就可以采集的简易采集,这种采集方法不需要用户会写规则或爬虫,直接输入想采集的一些基本参数就可以了。缺点也很明显,没有现成做下来的规则就无法采集。此外两个公司也都有数据交易平台,这个平台除了可以交易数据,也可以交易规则和发布需求。这方面数多多做的更好一些,毕竟是独立的平台,优采云的需求发布还没做到上面,这也是优采云的一些“闭塞性”,这里并不是说闭塞肯定不好,但是确实是失去自由度为代价的。比如顾客无法自由的在平台上发布需求,研发人员也难以直接和顾客沟通必须是通过平台内部调度。造数原本就是最简单的操作,甚至可以说造数就是简的最佳彰显。
接下来看“快”,单机采集只能采取多线程的方式,会受限于硬件性能,优采云就是这么。优采云是采取云采集的方式,需要更多节点,就上定制版或企业版。优采云本身就是个云采集,节点是自由控制和可以选购的,舍得出钱就可以更快。造数把简字发扬光大到都不使你在乎后台有多少节点进行云采集了……但是这种采集平台真的很快么?受限于服务器网速、硬件、采集网站响应速率、网站反爬虫举措等多方面诱因,有的快,有的慢。如果说须要进行标准化评测,我肯定测不了,为什么呢?因为我完全无法标准化啊……同样采集京东,优采云云采集我不确定是几个节点采集,没说明啊……优采云虽然看得到节点数,但是我哪晓得每位节点的网路和硬件配置啊,没人说……造数嘛……快还是很快的,但是愈发不知道后台用了多少采集资源了。
然后我们来看“稳”,稳定的采集、稳定的输出是核心问题。实际情况怎样呢?优采云的云采集或者由于规则问题,或者由于规则作者熟练度问题,很多情况下会“漏数据”……优采云因为好多中级采集为了避免IP被封,挂高匿IP代理的时侯速率反倒受影响了,让我总认为没有理想中速率这么快。造数似乎没哪些可吐槽的,还是比较稳的。
屏蔽广告功能说明(7.0版本)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2020-08-10 22:13
主要目的:
1、为了推动页面加载(广告会拖慢页面加载速率)
2、为了降低资源恳求(节省带宽资源)
界面位置:
基本操作:
示例:
相同的任务开启不开启广告屏蔽和广告屏蔽,可以看见如下图采集速度有显著的不同。没有屏蔽广告的相同时间内只采集了12条,而屏蔽广告的相同时间内采集了100条
屏蔽广告示例:
不屏蔽广告示例:
开启广告屏蔽可能存在的不利影响:
部分页面可能会由于屏蔽广告,导致页面结构发生变化,优采云的任务中原本生成的xpath须要调整。这时候十分方便的做法就是在做规则之前就须要考虑清楚是否要勾屏蔽广告,然后再做规则。确保规则的准确性。
例如:现在采集这个网站
如果之前不勾选屏蔽广告,可以看见循环列表的xpath是这样的,而且循环列表也是正常的。如下图:
这时候返回勾选屏蔽广告,再看循环列表,可以看见勾上然后循环列表为空了。这样规则找不到循环列表就不会正常采集。
这就是部份页面由于屏蔽了广告,页面结构发生了变化。所以须要先确定是否勾屏蔽广告再做规则了。
同时,还存在部份网站,屏蔽广告后,网页仍然在加载的情况,采集无法进行。这时返回“编辑规则”,将“屏蔽广告功能”的勾选除去就可以了。请慎重使用该功能。 查看全部
在采集网页内容过程中,有些网页中会好多广告,甚至会弹出广告框。一是影响规则的制做,二是影响采集速度。为了改善这种情况,优采云中会有一个功能点:屏蔽网页广告。
主要目的:
1、为了推动页面加载(广告会拖慢页面加载速率)
2、为了降低资源恳求(节省带宽资源)
界面位置:
基本操作:
示例:
相同的任务开启不开启广告屏蔽和广告屏蔽,可以看见如下图采集速度有显著的不同。没有屏蔽广告的相同时间内只采集了12条,而屏蔽广告的相同时间内采集了100条
屏蔽广告示例:
不屏蔽广告示例:
开启广告屏蔽可能存在的不利影响:
部分页面可能会由于屏蔽广告,导致页面结构发生变化,优采云的任务中原本生成的xpath须要调整。这时候十分方便的做法就是在做规则之前就须要考虑清楚是否要勾屏蔽广告,然后再做规则。确保规则的准确性。
例如:现在采集这个网站
如果之前不勾选屏蔽广告,可以看见循环列表的xpath是这样的,而且循环列表也是正常的。如下图:
这时候返回勾选屏蔽广告,再看循环列表,可以看见勾上然后循环列表为空了。这样规则找不到循环列表就不会正常采集。
这就是部份页面由于屏蔽了广告,页面结构发生了变化。所以须要先确定是否勾屏蔽广告再做规则了。
同时,还存在部份网站,屏蔽广告后,网页仍然在加载的情况,采集无法进行。这时返回“编辑规则”,将“屏蔽广告功能”的勾选除去就可以了。请慎重使用该功能。
芭奇:不用编吃饭写采集规则也可轻松采集网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 287 次浏览 • 2020-08-09 21:31
然后我借助芭奇站群软件来采集这个搜索结果的所有文章。大家先可以剖析一下,这个页面,如果用各类类型采集器或网站自带程序来自定义采集所有文章,那是不可能采到的。因为互联网还没有这样的通用采集不同网站的功能,但如今,芭奇站群软件可以实现了。因为这个软件支持泛采集技术。
三、首页,我填上这个百度结果列表到软件的“起始采集的文章列表地址”上,如下图:
四、为了能正确采集我想要的列表,我们剖析结果列表上的文章,都有一个通用的后缀后,就是:html、shtml、ht,那么,这三个共同的地方就是:htm我定义到软件,这样的做法,是降低采集没用的页面,如下图:
五、现在可以采集了,不过,在这里提示一下你们,一般一个网站里面,带相同字符的会有很多,对于丰胸品这个百度列表的,也有百度自身的网页,但百度自身的网页内容,不是我要采的,那么还有一个地方可以排除不采带有百度网址的页面。如下图所示:
上面所说的都是芭奇站群软件的新采集功能,这个功能太强悍,但这个功能还要继续须要建立,以满足不同人的需求。有了这个工具,你就不用害怕自己不会写采集规则了,这个功能容易入门,容易操作,是新老站长最合适的一个功能。如有不懂的都可以加我QQ问我:509229860。
一两分钟后,采集过程结果如下图所示:
六、这里我就只采一部分文章,先停止不再采了,那现今瞧瞧采集后的内容:
七、上面就是采集的过程,按前面的步骤,你也可以采集其他地方列表的文章,特别是一些没有收录,或屏避收录的网站,这些都是原创的文章,大家可以自己去找一下。现在我给你们说一下,软件上的一些其他功能介绍:
1、如上图,这里就是除去网址和采集图片的功能,可以按你的需求,是否打勾。
2、如上图,这里就是设置采集的条数和采集的文章标题最少字数。
3、如上图,这里可以定义替换成语,支持代码替换,文字替换等,这里要灵活使用,对一些难采集的列表,这里就要用到了。可以将个别代码代换为空,才可以采集到列表链接。
这样定义后,就防止采到百度自己的页面了。那这样填好了,就可以直接采集文章了,点“保存后采集数据”:
感谢 stark 的投稿
我推测该不是中了大奖吧,心里那种兴奋呀,正在浮想连篇,老公回去了,进门就说:“我昨天把买彩票的20元钱市下了,特意给你买了只烤鸭 查看全部
这里我以百度的搜索页为采集源,比如这个地址:%B0%C5%C6%E6
然后我借助芭奇站群软件来采集这个搜索结果的所有文章。大家先可以剖析一下,这个页面,如果用各类类型采集器或网站自带程序来自定义采集所有文章,那是不可能采到的。因为互联网还没有这样的通用采集不同网站的功能,但如今,芭奇站群软件可以实现了。因为这个软件支持泛采集技术。
三、首页,我填上这个百度结果列表到软件的“起始采集的文章列表地址”上,如下图:
四、为了能正确采集我想要的列表,我们剖析结果列表上的文章,都有一个通用的后缀后,就是:html、shtml、ht,那么,这三个共同的地方就是:htm我定义到软件,这样的做法,是降低采集没用的页面,如下图:
五、现在可以采集了,不过,在这里提示一下你们,一般一个网站里面,带相同字符的会有很多,对于丰胸品这个百度列表的,也有百度自身的网页,但百度自身的网页内容,不是我要采的,那么还有一个地方可以排除不采带有百度网址的页面。如下图所示:
上面所说的都是芭奇站群软件的新采集功能,这个功能太强悍,但这个功能还要继续须要建立,以满足不同人的需求。有了这个工具,你就不用害怕自己不会写采集规则了,这个功能容易入门,容易操作,是新老站长最合适的一个功能。如有不懂的都可以加我QQ问我:509229860。
一两分钟后,采集过程结果如下图所示:
六、这里我就只采一部分文章,先停止不再采了,那现今瞧瞧采集后的内容:
七、上面就是采集的过程,按前面的步骤,你也可以采集其他地方列表的文章,特别是一些没有收录,或屏避收录的网站,这些都是原创的文章,大家可以自己去找一下。现在我给你们说一下,软件上的一些其他功能介绍:
1、如上图,这里就是除去网址和采集图片的功能,可以按你的需求,是否打勾。
2、如上图,这里就是设置采集的条数和采集的文章标题最少字数。
3、如上图,这里可以定义替换成语,支持代码替换,文字替换等,这里要灵活使用,对一些难采集的列表,这里就要用到了。可以将个别代码代换为空,才可以采集到列表链接。
这样定义后,就防止采到百度自己的页面了。那这样填好了,就可以直接采集文章了,点“保存后采集数据”:
感谢 stark 的投稿
我推测该不是中了大奖吧,心里那种兴奋呀,正在浮想连篇,老公回去了,进门就说:“我昨天把买彩票的20元钱市下了,特意给你买了只烤鸭
深维全能信息采集软件 V2.5.3
采集交流 • 优采云 发表了文章 • 0 个评论 • 277 次浏览 • 2020-08-09 12:04
【功能特性】
1.强大的信息采集功能。可采集几乎任何类型的网站信息,包括静态htm,html类型和动态ASP,ASPX,JSP等。可N级页面采集。深维全能信息采集软件官方版可手动下载二进制文件,比如图片,软件,mp3等。
2.网站登录。需要登入能够看见的信息,先在任务的'登录设置'处进行登陆,就可采集登录后就能看见的信息。
3.速度快,运行稳定。真正的多线程,多任务,运行时占用系统资源甚少,可稳定地长时间运行。(明显区别于其他软件)
4.数据保存格式丰富。可把采集的数据,保存为Txt,Excel和多种数据库格式(Access sqlserver Oracle Mysql等)。
5.强大的新闻采集,自动化处理功能。可手动保留新闻的格式,包括图片等。可通过设置,自动下载图片 ,自动把正文里图片的网路路径改为本地文件路径(也可保留原貌);可把采集的新闻手动处理成自己设计的模板格式;可采集具有分页方式的新闻。 通过这种功能,简单设置后即可在本地构建一个强悍的新闻系统,无需人工干预。
6.强大的信息手动再加工功能。对采集的信息,深维全能信息采集软件官方版可进行二次批量再加工,使之愈加符合您的实际要求。也可设置手动加工公式,在采集的过程中,按照公式手动加工处理,包括数据合并和数据替换等。
【软件特色】
1.通用:根据拟定采集规则,可以采集任何通过浏览器看得到的东西;
2.灵活:支持网站登录采集、网站跨层采集、POST采集、脚本采集、动态页面采集等中级功能;
3.扩展性强:支持存储过程、插件等,可由用户自由扩充功能,进行二次开发;
4.高效:为了使用户节约一分钟去做其它事情,软件做了悉心设计;
5.速度快:速度最快、效率最高的采集软件;
6.稳定:系统资源占用少、有详尽的运行报告、采集性能稳定; G、人性化:注重软件细节、强调人性化体验。
【更新日志】
1.争对Win10系统进行优化升级;
2.升级爬虫技术基类库,争对Https链接进行优化升级。 查看全部
深维全能信息采集软件是一款用于采集网站信息的站长工具,采用交互式策略和机器学习算法,极大简化了配置操作,普通用户几分钟内即可学习把握。通过简单的配置,还可以将所采集网页中的非结构化文本数据保存为结构化的数据。
【功能特性】
1.强大的信息采集功能。可采集几乎任何类型的网站信息,包括静态htm,html类型和动态ASP,ASPX,JSP等。可N级页面采集。深维全能信息采集软件官方版可手动下载二进制文件,比如图片,软件,mp3等。
2.网站登录。需要登入能够看见的信息,先在任务的'登录设置'处进行登陆,就可采集登录后就能看见的信息。
3.速度快,运行稳定。真正的多线程,多任务,运行时占用系统资源甚少,可稳定地长时间运行。(明显区别于其他软件)
4.数据保存格式丰富。可把采集的数据,保存为Txt,Excel和多种数据库格式(Access sqlserver Oracle Mysql等)。
5.强大的新闻采集,自动化处理功能。可手动保留新闻的格式,包括图片等。可通过设置,自动下载图片 ,自动把正文里图片的网路路径改为本地文件路径(也可保留原貌);可把采集的新闻手动处理成自己设计的模板格式;可采集具有分页方式的新闻。 通过这种功能,简单设置后即可在本地构建一个强悍的新闻系统,无需人工干预。
6.强大的信息手动再加工功能。对采集的信息,深维全能信息采集软件官方版可进行二次批量再加工,使之愈加符合您的实际要求。也可设置手动加工公式,在采集的过程中,按照公式手动加工处理,包括数据合并和数据替换等。
【软件特色】
1.通用:根据拟定采集规则,可以采集任何通过浏览器看得到的东西;
2.灵活:支持网站登录采集、网站跨层采集、POST采集、脚本采集、动态页面采集等中级功能;
3.扩展性强:支持存储过程、插件等,可由用户自由扩充功能,进行二次开发;
4.高效:为了使用户节约一分钟去做其它事情,软件做了悉心设计;
5.速度快:速度最快、效率最高的采集软件;
6.稳定:系统资源占用少、有详尽的运行报告、采集性能稳定; G、人性化:注重软件细节、强调人性化体验。
【更新日志】
1.争对Win10系统进行优化升级;
2.升级爬虫技术基类库,争对Https链接进行优化升级。
采集规则怎么排错?
采集交流 • 优采云 发表了文章 • 0 个评论 • 586 次浏览 • 2020-08-09 08:25
这里主要讲一下单机采集时碰到问题时,如何排错。单机采集出现问题,大都是因为规则中某个步骤没有执行,网页加载不完全或则步骤的中级选项设置不当。
官网中提供了很实用的排错教程,教程中详尽说明了在优采云中配置规则时,如何自动执行各步骤进行排查,这个是排错中很重要的一步,这里就不再重复。大家可以直接步入教程中心搜索“规则制做排错教程“
优采云采集数据原理:
优采云软件主要是模仿用户浏览网页的操作,比如打开网页、点击元素、输入文字、切换下拉选项、移动滑鼠到元素上。这些我们平常浏览网页也为进行相应的操作。
例子:
进入优采云官网界面(打开网页),鼠标置于产品介绍上(移动滑鼠到元素上),就会弹出一个红色的小框,鼠标移开,黑色方框都会隐藏。然后点击对面的教程中心(点击元素),进入教程中心页面,有个搜索框,输入“规则制做排错教程“(输入文字)。
优采云中还有个牛逼的步骤,循环。这也是我们才能大量采集数据的主要步骤。
循环翻页、循环点击元素、循环输入文本、循环打开网页
优采云主要是依据xpath去定位到元素,然后执行相应步骤。
规则排错主要思路
在自动执行基本没问题后(说明流程基本没有问题),进行单机采集。
然后观察单机采集界面中的网页变化,看网页是否根据每位步骤执行。如果有步骤没有执行,则该步骤出现问题。例如没有点击到详情页,没有循环翻页。重新编辑规则,在规则中的对应步骤重新调试。
下列是按照单机采集出现的问题进行讲解(5个):
1.单机运行,采集不到数据
(1)打开网页后,直接提示采集完成
主要诱因:有些网站的加载会太慢,网页还没有完全加载下来,优采云就执行下一个步骤,当优采云找不到相应的位置时,步骤难以执行,最终造成提取不到数据。
解决方式:可以将网页的超时时间加长,或者在下一个步骤设置执行前等待。让网页有足够长的时间加载。
(2)网页仍然在加载
主要诱因:主要是网站的问题,有些网站的加载会太慢。想要采集的数据没有出现。
解决方式:如果当前步骤是打开网页步骤,可以将网页的超时时间加长。如果是点击元素步骤,而且要采集的数据早已加载下来的时侯,可以在点击元素步骤设置ajax延时,
(3)网页没有步入采集页面
该问题往往是出现在点击元素步骤。有些网页中富含ajax链接时,根据点击位置判定是否须要设置。如果没有设置,在单机采集时会仍然卡在前一个步骤,采集不到数据。
主要诱因:当网页为异步加载时,没有设置ajax延时的话,操作通常不会正确执行,导致规则难以进行下一步,提取不到数据。
解决方式:在相应步骤设置ajax延时,一般是2-3S,如果网页加载时间较长,可以适当降低延时时长。点击元素,循环下一页、移动滑鼠到元素上,这三个步骤中都有ajax设置
例子:下图是采集京东网站下的一个手机商品的评论数据,需要点击商品评价,进入相应的评论页面。单机运行时,网页仍然卡在评论页面,没有评论数据出现。原因就在于点击元素没有设置ajax延时,导致网页没有步入相应的采集界面。
2.单机运行,漏采数据
(1)部分数组没有数据
主要诱因:单机采集时,发现有些数组信息为空,这时候就应当找到相应的采集页面,查看想要的采集的数据是否存在,有时并不是每位网页都富含所有数组信息。如果没有,字段为空是正常的。如果有的话,基本就是xpath定位问题,这时须要更改xpath,准确定位到相应数组。
解决方式:重新打开规则,手动执行验证。如需更改xpath,可以找xpath教程。
例子:下图中预约人数和预约时间出现空值,重新打开规则,手动执行,发现,页面是可以采集到数据(图二)。说明这个主要是网页加载问题,可以在下一个步骤前设置等待时长。第二条数据为空,是因为在第二个详情页本来就没有数据,属于正常。
(2)采集数据条数不对
采集数据条数不对,一般是循环翻页或则网页加载的问题。
有些网页数据须要向上滚动才能加载数据,如果在打开网页时,没有设置足够的向上滚动字数,网页加载下来的数据量也没有自动执行规则时的多。
如果翻页不正确,导致一部分页面的数据难以采集。比如出现不规则翻页,导致部份页面没有打开,数据难以采集。
主要解决方式:如果是翻页问题,修改翻页循环的xpath;如果是网页加载问题,则在打开网页的中级选项中设置滚动次数
例子:在制做规则时,循环选项是80条,而单机采集的时侯,只采集了16条。其中主要的缘由是网页没有设置向上滚动加载,导致加载的条数变少。
3.采集的数据错乱,不是对应信息
(1)多个提取数据步骤 查看全部
教程中已有详尽的排错图文教程
这里主要讲一下单机采集时碰到问题时,如何排错。单机采集出现问题,大都是因为规则中某个步骤没有执行,网页加载不完全或则步骤的中级选项设置不当。
官网中提供了很实用的排错教程,教程中详尽说明了在优采云中配置规则时,如何自动执行各步骤进行排查,这个是排错中很重要的一步,这里就不再重复。大家可以直接步入教程中心搜索“规则制做排错教程“
优采云采集数据原理:
优采云软件主要是模仿用户浏览网页的操作,比如打开网页、点击元素、输入文字、切换下拉选项、移动滑鼠到元素上。这些我们平常浏览网页也为进行相应的操作。
例子:
进入优采云官网界面(打开网页),鼠标置于产品介绍上(移动滑鼠到元素上),就会弹出一个红色的小框,鼠标移开,黑色方框都会隐藏。然后点击对面的教程中心(点击元素),进入教程中心页面,有个搜索框,输入“规则制做排错教程“(输入文字)。
优采云中还有个牛逼的步骤,循环。这也是我们才能大量采集数据的主要步骤。
循环翻页、循环点击元素、循环输入文本、循环打开网页
优采云主要是依据xpath去定位到元素,然后执行相应步骤。
规则排错主要思路
在自动执行基本没问题后(说明流程基本没有问题),进行单机采集。
然后观察单机采集界面中的网页变化,看网页是否根据每位步骤执行。如果有步骤没有执行,则该步骤出现问题。例如没有点击到详情页,没有循环翻页。重新编辑规则,在规则中的对应步骤重新调试。
下列是按照单机采集出现的问题进行讲解(5个):
1.单机运行,采集不到数据
(1)打开网页后,直接提示采集完成
主要诱因:有些网站的加载会太慢,网页还没有完全加载下来,优采云就执行下一个步骤,当优采云找不到相应的位置时,步骤难以执行,最终造成提取不到数据。
解决方式:可以将网页的超时时间加长,或者在下一个步骤设置执行前等待。让网页有足够长的时间加载。
(2)网页仍然在加载
主要诱因:主要是网站的问题,有些网站的加载会太慢。想要采集的数据没有出现。
解决方式:如果当前步骤是打开网页步骤,可以将网页的超时时间加长。如果是点击元素步骤,而且要采集的数据早已加载下来的时侯,可以在点击元素步骤设置ajax延时,
(3)网页没有步入采集页面
该问题往往是出现在点击元素步骤。有些网页中富含ajax链接时,根据点击位置判定是否须要设置。如果没有设置,在单机采集时会仍然卡在前一个步骤,采集不到数据。
主要诱因:当网页为异步加载时,没有设置ajax延时的话,操作通常不会正确执行,导致规则难以进行下一步,提取不到数据。
解决方式:在相应步骤设置ajax延时,一般是2-3S,如果网页加载时间较长,可以适当降低延时时长。点击元素,循环下一页、移动滑鼠到元素上,这三个步骤中都有ajax设置
例子:下图是采集京东网站下的一个手机商品的评论数据,需要点击商品评价,进入相应的评论页面。单机运行时,网页仍然卡在评论页面,没有评论数据出现。原因就在于点击元素没有设置ajax延时,导致网页没有步入相应的采集界面。
2.单机运行,漏采数据
(1)部分数组没有数据
主要诱因:单机采集时,发现有些数组信息为空,这时候就应当找到相应的采集页面,查看想要的采集的数据是否存在,有时并不是每位网页都富含所有数组信息。如果没有,字段为空是正常的。如果有的话,基本就是xpath定位问题,这时须要更改xpath,准确定位到相应数组。
解决方式:重新打开规则,手动执行验证。如需更改xpath,可以找xpath教程。
例子:下图中预约人数和预约时间出现空值,重新打开规则,手动执行,发现,页面是可以采集到数据(图二)。说明这个主要是网页加载问题,可以在下一个步骤前设置等待时长。第二条数据为空,是因为在第二个详情页本来就没有数据,属于正常。
(2)采集数据条数不对
采集数据条数不对,一般是循环翻页或则网页加载的问题。
有些网页数据须要向上滚动才能加载数据,如果在打开网页时,没有设置足够的向上滚动字数,网页加载下来的数据量也没有自动执行规则时的多。
如果翻页不正确,导致一部分页面的数据难以采集。比如出现不规则翻页,导致部份页面没有打开,数据难以采集。
主要解决方式:如果是翻页问题,修改翻页循环的xpath;如果是网页加载问题,则在打开网页的中级选项中设置滚动次数
例子:在制做规则时,循环选项是80条,而单机采集的时侯,只采集了16条。其中主要的缘由是网页没有设置向上滚动加载,导致加载的条数变少。
3.采集的数据错乱,不是对应信息
(1)多个提取数据步骤
节气1.7--使用离线采集器的指南
采集交流 • 优采云 发表了文章 • 0 个评论 • 271 次浏览 • 2020-08-09 07:26
规则文件夹,日志文件夹:
规则是我们发布采集规则的地方;
日志是一个日志内容,也就是说,当关闭采集器时,它将记录错误的信息. 当我们看到此消息时,我们将知道集合出了错;
现在,我们单击开关以关闭采集器,然后直接打开NovelSpider.exe以启动关闭采集器. (注意: 打开过程会有点慢,因此请单击一次并稍等片刻. 请勿再次单击“打开”,否则一段时间后将打开多个关闭采集器!)
在某些级别上会有一个提示框,因此无论如何都将其关闭.
了解有关采集器的一些常用信息
打开后,我们应立即修改“设置(S)”→“系统设置”. :
1. 修改本地网站目录,例如,我的位于D: \ xiaoshuo
2. 再次修改数据库连接字符串
DataSource = 127.0.0.1;
Database =数据库名称;
UserID =数据库管理用户名;
Password =数据库管理密码;
port = 3306;
charset = gbk
以上是设置采集器的方法. 这是您第一次使用它,您需要对其进行设置,并且在设置之后不需要再次进行设置.
关于“ Off Collector 1.7”分类设置
首先: 类别设置通常对应于类别,该类别对应于您网站的类别. 例如
1 | Fantasy Fantasy =,幻想,幻想,魔术,魔术,幻想魔术,幻想幻想,幻想小说,幻想·魔术,幻想世界,幻想幻想,
1是您网站上的第一个蓝米幻想幻想. 等号后的类别是采集目标网站可能遇到的类别. 越详细越好,某些模板网站会对应您的幻想幻想所没有的内容,因此您可以添加它.
第二个: 是设置中的一代
默认情况下无需修改. 第一个生成的目录页面html是您网站的新颖目录页面的html. 如果您的网站使用伪静态,则不需要生成它. 第二个生成的内容页面html用于新颖内容. 单击以查看小说的文本章节. 这与上面的第一个相同. 如果您的网站使用伪静态,则不需要生成它.
如果您要构建一个静态的新颖网站,则需要生成它,这非常消耗硬盘. 通常,一千本小说需要几GB的空间.
第三: 生成全文阅读. 不用担心.
第四: 生成OPF. 这必须生成,否则网站将无法打开,并且如果未生成您的新颖网站,则会错误打开. 只需在此处打勾. 不用担心其他设置,没有特殊要求您将无法使用它们.
(注意: [Settings-e-book settings]不需要控制,默认值就足够了,所以不要选择对勾,设置中的图片设置也是默认值,所以不要选择滴答声. )
第五: 文字广告. 如果要在新颖内容中添加广告,则可以在此处添加内容. 您需要选择第一个存储章节以添加文字广告. 真正的存储空间会将您的广告添加到您采集的小说中,这些路径的txt文件中的文件/文章/ txt / 0/1
这是您的小说,是一部移动版本,因此您需要选择第一本. 添加广告时,您会在章节阅读中看到它,但不要使用这些功能.
第六: 其他[过滤和替换],[文本到图片]. 无需控制
第七: 日志选择. 勾选所有人. 这是为了采集记录的遇到的错误的日志. 您可以基于此消除错误.
如何查看海关规则是否有效?
单击规则,进入规则管理器,我们选择我们不能做的三角形符号,下拉您要测试的规则,单击右侧的负载,然后单击“测试规则”,界面将弹出,如果这些是要获取ID和小说名称
这是为了获得包括小说名称分类介绍和封面在内的小说信息内容.
某些网站不会采集所有信息,如果我们将其采集回来,它将显得不完整. 这没有作用. 您可以阅读小说主要章节的内容. 然后这些是要采集的章节,这是小说的内容.
这是一个很好的采集规则. 我们可以使用此采集规则来采集新颖的更新.
如何采集
通常,我们使用标准的采集模式.
当我们单击“采集标准采集模式”时,有时会出现错误消息. 无论我们在采集框中单击一条规则,它都会显示在正确的位置. 有一些迹象表明我们也忽略了他,直接单击[继续].
输入标准采集品后输入正确的姿势后,通常使用第一个根据目标测站页面获取编号. 编写此规则时,将根据目标电台的最新更新小说进行设置,并将在采集过程中自动将其采集. 当我们更新对方的小说时,我们还将关注其他人的小说网站.
1. 设置ID范围,并根据目标站ID进行采集. 采集对方的某本书时很少使用.
2. 从对方采集某本书时,很少使用按目标站ID进行采集.
3. 该采集集基于您网站的小说ID,因此您需要先单击网站上的小说才能对其进行更新,但是模板网站可能没有这本书,因此采集速度很慢. 很少使用,基本上没有用.
4. 转到日志记录的底部,必须选择日志记录以记录无缘无故无法采集的新颖信息的采集. 还必须选择循环采集. 这是为了确保采集器在自动采集过程中自动采集另一方的网站. 循环时间设置取决于您自己的需求. 我通常将其设置为十分钟. 如果要继续采集,请将其设置为零.
如何设置采集动作?
[添加新书]: 添加书时添加;
[谨慎使用]: 以下两个单词是比较模板站的章节名称. 如果正确,请继续采集. 如果不对,请将其清空并再次采集. 不要使用它,这会引起很大的问题. 有时候,意外清空我收录在百度中的页面是一个悲剧. 对于其他一些功能,可以阅读文字;
[设置2]: 这是比较章节的选择,无论如何,它们几乎是相同的,为什么我没有什么不同?您可以默认设置;
[空章节的处理方法]: 这意味着模板站点中的某些小说是空的,具体取决于您的需求,但请注意,您不应选择第二本来跳过本章,因为跳过本章将使本章空白章节名称,下次您少采集一个章节名称并将该章节名称与模板站进行比较时,该书将无法更新;
[章节安排]: 这取决于目标站的图,这更加复杂. 我给您的采集规则按目标电台的顺序排列. 不要选择任何东西,通常使用[目标电台顺序]和[按照章节ID的顺序],不要使用其他内容. 这两个不会有问题,我将为您提供默认设置;
[过滤器设置]: 取决于您需要设置的内容,字面意思很明确;
[删除水印]: 这基本上是不必要的;
[Agent],[Progress]: 通常将上述三个数字设置为000;
这样,采集速度很快. 代理IP是阻止您进行采集的目标站点,然后您可以在Internet上找到一些代理,打开代理功能,然后进行采集.
我已经在这里讨论了其中一些功能,而其他功能则是一些辅助功能,您以后可以进一步了解.
在下面进行设置,然后单击以开始采集. 选择规则,然后选择要输入的采集操作,然后单击以开始;
如果出现提示“成功启动了采集模式”,则可以查看您的网站是否已更新. 查看全部
紧密采集器的主要焦点是两个文件夹
规则文件夹,日志文件夹:
规则是我们发布采集规则的地方;
日志是一个日志内容,也就是说,当关闭采集器时,它将记录错误的信息. 当我们看到此消息时,我们将知道集合出了错;
现在,我们单击开关以关闭采集器,然后直接打开NovelSpider.exe以启动关闭采集器. (注意: 打开过程会有点慢,因此请单击一次并稍等片刻. 请勿再次单击“打开”,否则一段时间后将打开多个关闭采集器!)
在某些级别上会有一个提示框,因此无论如何都将其关闭.
了解有关采集器的一些常用信息
打开后,我们应立即修改“设置(S)”→“系统设置”. :
1. 修改本地网站目录,例如,我的位于D: \ xiaoshuo
2. 再次修改数据库连接字符串
DataSource = 127.0.0.1;
Database =数据库名称;
UserID =数据库管理用户名;
Password =数据库管理密码;
port = 3306;
charset = gbk
以上是设置采集器的方法. 这是您第一次使用它,您需要对其进行设置,并且在设置之后不需要再次进行设置.
关于“ Off Collector 1.7”分类设置
首先: 类别设置通常对应于类别,该类别对应于您网站的类别. 例如
1 | Fantasy Fantasy =,幻想,幻想,魔术,魔术,幻想魔术,幻想幻想,幻想小说,幻想·魔术,幻想世界,幻想幻想,
1是您网站上的第一个蓝米幻想幻想. 等号后的类别是采集目标网站可能遇到的类别. 越详细越好,某些模板网站会对应您的幻想幻想所没有的内容,因此您可以添加它.
第二个: 是设置中的一代
默认情况下无需修改. 第一个生成的目录页面html是您网站的新颖目录页面的html. 如果您的网站使用伪静态,则不需要生成它. 第二个生成的内容页面html用于新颖内容. 单击以查看小说的文本章节. 这与上面的第一个相同. 如果您的网站使用伪静态,则不需要生成它.
如果您要构建一个静态的新颖网站,则需要生成它,这非常消耗硬盘. 通常,一千本小说需要几GB的空间.
第三: 生成全文阅读. 不用担心.
第四: 生成OPF. 这必须生成,否则网站将无法打开,并且如果未生成您的新颖网站,则会错误打开. 只需在此处打勾. 不用担心其他设置,没有特殊要求您将无法使用它们.
(注意: [Settings-e-book settings]不需要控制,默认值就足够了,所以不要选择对勾,设置中的图片设置也是默认值,所以不要选择滴答声. )
第五: 文字广告. 如果要在新颖内容中添加广告,则可以在此处添加内容. 您需要选择第一个存储章节以添加文字广告. 真正的存储空间会将您的广告添加到您采集的小说中,这些路径的txt文件中的文件/文章/ txt / 0/1
这是您的小说,是一部移动版本,因此您需要选择第一本. 添加广告时,您会在章节阅读中看到它,但不要使用这些功能.
第六: 其他[过滤和替换],[文本到图片]. 无需控制
第七: 日志选择. 勾选所有人. 这是为了采集记录的遇到的错误的日志. 您可以基于此消除错误.
如何查看海关规则是否有效?
单击规则,进入规则管理器,我们选择我们不能做的三角形符号,下拉您要测试的规则,单击右侧的负载,然后单击“测试规则”,界面将弹出,如果这些是要获取ID和小说名称
这是为了获得包括小说名称分类介绍和封面在内的小说信息内容.
某些网站不会采集所有信息,如果我们将其采集回来,它将显得不完整. 这没有作用. 您可以阅读小说主要章节的内容. 然后这些是要采集的章节,这是小说的内容.
这是一个很好的采集规则. 我们可以使用此采集规则来采集新颖的更新.
如何采集
通常,我们使用标准的采集模式.
当我们单击“采集标准采集模式”时,有时会出现错误消息. 无论我们在采集框中单击一条规则,它都会显示在正确的位置. 有一些迹象表明我们也忽略了他,直接单击[继续].
输入标准采集品后输入正确的姿势后,通常使用第一个根据目标测站页面获取编号. 编写此规则时,将根据目标电台的最新更新小说进行设置,并将在采集过程中自动将其采集. 当我们更新对方的小说时,我们还将关注其他人的小说网站.
1. 设置ID范围,并根据目标站ID进行采集. 采集对方的某本书时很少使用.
2. 从对方采集某本书时,很少使用按目标站ID进行采集.
3. 该采集集基于您网站的小说ID,因此您需要先单击网站上的小说才能对其进行更新,但是模板网站可能没有这本书,因此采集速度很慢. 很少使用,基本上没有用.
4. 转到日志记录的底部,必须选择日志记录以记录无缘无故无法采集的新颖信息的采集. 还必须选择循环采集. 这是为了确保采集器在自动采集过程中自动采集另一方的网站. 循环时间设置取决于您自己的需求. 我通常将其设置为十分钟. 如果要继续采集,请将其设置为零.
如何设置采集动作?
[添加新书]: 添加书时添加;
[谨慎使用]: 以下两个单词是比较模板站的章节名称. 如果正确,请继续采集. 如果不对,请将其清空并再次采集. 不要使用它,这会引起很大的问题. 有时候,意外清空我收录在百度中的页面是一个悲剧. 对于其他一些功能,可以阅读文字;
[设置2]: 这是比较章节的选择,无论如何,它们几乎是相同的,为什么我没有什么不同?您可以默认设置;
[空章节的处理方法]: 这意味着模板站点中的某些小说是空的,具体取决于您的需求,但请注意,您不应选择第二本来跳过本章,因为跳过本章将使本章空白章节名称,下次您少采集一个章节名称并将该章节名称与模板站进行比较时,该书将无法更新;
[章节安排]: 这取决于目标站的图,这更加复杂. 我给您的采集规则按目标电台的顺序排列. 不要选择任何东西,通常使用[目标电台顺序]和[按照章节ID的顺序],不要使用其他内容. 这两个不会有问题,我将为您提供默认设置;
[过滤器设置]: 取决于您需要设置的内容,字面意思很明确;
[删除水印]: 这基本上是不必要的;
[Agent],[Progress]: 通常将上述三个数字设置为000;
这样,采集速度很快. 代理IP是阻止您进行采集的目标站点,然后您可以在Internet上找到一些代理,打开代理功能,然后进行采集.
我已经在这里讨论了其中一些功能,而其他功能则是一些辅助功能,您以后可以进一步了解.
在下面进行设置,然后单击以开始采集. 选择规则,然后选择要输入的采集操作,然后单击以开始;
如果出现提示“成功启动了采集模式”,则可以查看您的网站是否已更新.
在10分钟内不会在58.com的微博,微信,搜狐上采集任何代码,数据和信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 351 次浏览 • 2020-08-08 03:51
Web scraper是Google强大的插件库中非常强大的数据采集插件. 它具有强大的防爬网功能. 您只需要简单地在插件上进行设置,就可以快速抓取知乎,jianshu,douban和public 58等大型,中小型网站,包括文本,图片,表格和其他内容,最后快速导出csv格式文件. 网络上的Google官方
scraper给出的描述是:
使用我们的扩展程序,您可以创建计划(站点地图),如何遍历网站以及应提取什么内容. 使用这些站点地图,网络抓取工具将相应地导航该站点并提取所有数据. 您可以稍后将剪辑数据导出到CSV.
Webscraperk课程将以知乎,Jianshu和其他网站为例,对该过程进行完整的介绍,以介绍如何采集文本,表格,多元素爬网,不规则页面爬网,辅助页面爬网和动态网站爬网. ,以及一些反爬行技术和所有内容.
安装网络抓取器
Web scraper是Google浏览器的扩展插件,其安装与其他插件相同.
以知乎为例,介绍完整的Webscraper爬网过程
1. 打开目标网站. 这里以芝湖一号诉张家卫案的下列对象为例. 需要抓取的是关注者的姓名,答案数量,发表的文章数量以及关注者数量.
2. 右键单击网页上的鼠标,选择检查选项,或使用快捷键Ctrl + Shift + I / F12打开Web Scraper.
3. 打开后,单击创建站点地图,然后选择创建站点地图以创建站点地图.
点击创建站点地图后,您将获得如图所示的页面. 您需要填写站点地图名称,即站点的名称. 只要您能理解它,就可以随便写. 您还需要填写starturl,即指向页面的链接. 填写后,单击创建站点地图以完成站点地图的创建.
4. 设置第一级选择器: 选择采集范围
下一个是最高优先级. 这是对Web爬虫的爬网逻辑的介绍: 您需要设置一个第一级选择器(选择器)来设置需要爬网的范围. 在第一级选择器下创建一个第二级选择器(选择器),并将其设置为获取元素和内容.
以张家卫的关注为例. 我们的范围是张家卫关注的目标. 然后,我们需要为此范围创建一个选择器. 次要选择者是张家卫关注的目标对象的粉丝数和文章数. 内容. 具体步骤如下:
(1)添加新的选择器以创建一级选择器选择器:
单击后,您将获得以下页面,并在此页面上设置了要抓取的内容.
[if!supportLists] l [endif] id: 只需命名选择器,出于相同的原因,只要您能自己理解它,这里就叫jiawei-scrap.
[if!supportLists] l [endif] Type: 它是要捕获的内容的类型,例如元素元素/文本/链接链接/图片图像/元素在动态加载中向下滚动等,这里有多个元素选择元素.
[if!supportLists] l [endif] Selector: 是指要获取的内容的选择. 单击选择以选择页面上的内容. 这部分将在下面详细描述.
[if!supportLists] l [endif]选中多个: 选中“ Multiple”前面的小框,因为要选择多个元素而不是单个元素. 选中后,采集器插件将识别出存在相同属性的内容;
(2)在此步骤中,需要设置选定的内容,在选择选项下单击“选择”以获取以下图片:
将鼠标移到需要选择的内容上,此时需要选择的内容将变为绿色,表示已选择该内容. 在这里您需要提醒您,如果您需要的内容是多元素,则需要更改元素. 选择两者. 例如,如下图所示,绿色表示所选内容在绿色范围内.
选择内容范围后,单击鼠标,所选内容范围将变为红色,如下图所示:
当内容变成红色时,我们可以选择下一个内容. 单击后,Web采集器将自动识别您想要的内容,并且具有相同元素的内容将全部变为红色. 如下图所示:
在确认我们在此页面上需要的所有内容都变成红色后,可以单击“完成”选择选项,然后得到以下图片:
单击“保存选择器”以保存设置. 此后,将创建第一级选择器.
5. 设置辅助选择器: 选择要采集的元素内容.
(1)单击下图红色框中的内容,进入第一级选择器jiawei-scrap:
(2)单击添加新选择器以创建用于选择特定内容的辅助选择器.
获取以下图片,该图片与第一级选择器的内容相同,但是设置不同.
[if!supportLists]Ø[endif] id: 表示捕获哪个字段. 您可以选择该领域的英语. 例如,如果要选择“作者”,请写“作者”;
[if!supportLists]Ø[endif]类型: 在此处选择“文本”选项,因为您要获取文本内容;
[if!supportLists]Ø[endif] Multiple: 请勿在Multiple前面的小方框中打勾,因为这是要捕获的单个元素;
[如果!supportLists]Ø[endif]保留设置: 保留未提及的其他部分的默认设置.
(3)单击选择选项后,将鼠标移至特定元素,该元素将变为黄色,如下图所示:
在单击特定元素后,该元素将变为红色,这表示已选择内容.
(4)单击“完成选择”完成选择,然后单击“保存选择器”完成对关注者名称的选择.
重复上述操作,直到选择了要爬坡的田地为止.
(5)单击红色框以查看采集的内容.
6. 抓取数据
(1)您只需要设置所有选择器,就可以开始爬网数据,单击“刮擦”图,选择刮擦;:
(2)单击后,将跳至时间设置页面,如下图所示. 由于集合的数量不大,因此您可以默认保存它. 点击开始抓取,然后会弹出一个窗口,然后开始正式采集.
(3)过一会儿,您可以获得采集效果,如下图所示:
(4)选择站点地图下的export data as csv选项,以表格形式导出采集的结果.
表格效果(部分数据):
此外,我们还使用网络抓取工具采集了58个城市的租赁信息,公众评论食物信息,微信公众号密蒙文章,京东小米手机评论等.
作者: 学者Wan Yau
博客:
·END· 查看全部
有必要学习信息并快速采集数据,因为它可以大大提高工作效率. 在学习python和优采云之前,web scraper是我最常用的采集工具. 设置简单,效率很高. 采集Mimeng文章的标题仅需2分钟,而采集58个相同城市中的5000个租借信息仅需5分钟.
Web scraper是Google强大的插件库中非常强大的数据采集插件. 它具有强大的防爬网功能. 您只需要简单地在插件上进行设置,就可以快速抓取知乎,jianshu,douban和public 58等大型,中小型网站,包括文本,图片,表格和其他内容,最后快速导出csv格式文件. 网络上的Google官方
scraper给出的描述是:
使用我们的扩展程序,您可以创建计划(站点地图),如何遍历网站以及应提取什么内容. 使用这些站点地图,网络抓取工具将相应地导航该站点并提取所有数据. 您可以稍后将剪辑数据导出到CSV.
Webscraperk课程将以知乎,Jianshu和其他网站为例,对该过程进行完整的介绍,以介绍如何采集文本,表格,多元素爬网,不规则页面爬网,辅助页面爬网和动态网站爬网. ,以及一些反爬行技术和所有内容.
安装网络抓取器
Web scraper是Google浏览器的扩展插件,其安装与其他插件相同.
以知乎为例,介绍完整的Webscraper爬网过程
1. 打开目标网站. 这里以芝湖一号诉张家卫案的下列对象为例. 需要抓取的是关注者的姓名,答案数量,发表的文章数量以及关注者数量.
2. 右键单击网页上的鼠标,选择检查选项,或使用快捷键Ctrl + Shift + I / F12打开Web Scraper.
3. 打开后,单击创建站点地图,然后选择创建站点地图以创建站点地图.
点击创建站点地图后,您将获得如图所示的页面. 您需要填写站点地图名称,即站点的名称. 只要您能理解它,就可以随便写. 您还需要填写starturl,即指向页面的链接. 填写后,单击创建站点地图以完成站点地图的创建.
4. 设置第一级选择器: 选择采集范围
下一个是最高优先级. 这是对Web爬虫的爬网逻辑的介绍: 您需要设置一个第一级选择器(选择器)来设置需要爬网的范围. 在第一级选择器下创建一个第二级选择器(选择器),并将其设置为获取元素和内容.
以张家卫的关注为例. 我们的范围是张家卫关注的目标. 然后,我们需要为此范围创建一个选择器. 次要选择者是张家卫关注的目标对象的粉丝数和文章数. 内容. 具体步骤如下:
(1)添加新的选择器以创建一级选择器选择器:
单击后,您将获得以下页面,并在此页面上设置了要抓取的内容.
[if!supportLists] l [endif] id: 只需命名选择器,出于相同的原因,只要您能自己理解它,这里就叫jiawei-scrap.
[if!supportLists] l [endif] Type: 它是要捕获的内容的类型,例如元素元素/文本/链接链接/图片图像/元素在动态加载中向下滚动等,这里有多个元素选择元素.
[if!supportLists] l [endif] Selector: 是指要获取的内容的选择. 单击选择以选择页面上的内容. 这部分将在下面详细描述.
[if!supportLists] l [endif]选中多个: 选中“ Multiple”前面的小框,因为要选择多个元素而不是单个元素. 选中后,采集器插件将识别出存在相同属性的内容;
(2)在此步骤中,需要设置选定的内容,在选择选项下单击“选择”以获取以下图片:
将鼠标移到需要选择的内容上,此时需要选择的内容将变为绿色,表示已选择该内容. 在这里您需要提醒您,如果您需要的内容是多元素,则需要更改元素. 选择两者. 例如,如下图所示,绿色表示所选内容在绿色范围内.
选择内容范围后,单击鼠标,所选内容范围将变为红色,如下图所示:
当内容变成红色时,我们可以选择下一个内容. 单击后,Web采集器将自动识别您想要的内容,并且具有相同元素的内容将全部变为红色. 如下图所示:
在确认我们在此页面上需要的所有内容都变成红色后,可以单击“完成”选择选项,然后得到以下图片:
单击“保存选择器”以保存设置. 此后,将创建第一级选择器.
5. 设置辅助选择器: 选择要采集的元素内容.
(1)单击下图红色框中的内容,进入第一级选择器jiawei-scrap:
(2)单击添加新选择器以创建用于选择特定内容的辅助选择器.
获取以下图片,该图片与第一级选择器的内容相同,但是设置不同.
[if!supportLists]Ø[endif] id: 表示捕获哪个字段. 您可以选择该领域的英语. 例如,如果要选择“作者”,请写“作者”;
[if!supportLists]Ø[endif]类型: 在此处选择“文本”选项,因为您要获取文本内容;
[if!supportLists]Ø[endif] Multiple: 请勿在Multiple前面的小方框中打勾,因为这是要捕获的单个元素;
[如果!supportLists]Ø[endif]保留设置: 保留未提及的其他部分的默认设置.
(3)单击选择选项后,将鼠标移至特定元素,该元素将变为黄色,如下图所示:
在单击特定元素后,该元素将变为红色,这表示已选择内容.
(4)单击“完成选择”完成选择,然后单击“保存选择器”完成对关注者名称的选择.
重复上述操作,直到选择了要爬坡的田地为止.
(5)单击红色框以查看采集的内容.
6. 抓取数据
(1)您只需要设置所有选择器,就可以开始爬网数据,单击“刮擦”图,选择刮擦;:
(2)单击后,将跳至时间设置页面,如下图所示. 由于集合的数量不大,因此您可以默认保存它. 点击开始抓取,然后会弹出一个窗口,然后开始正式采集.
(3)过一会儿,您可以获得采集效果,如下图所示:
(4)选择站点地图下的export data as csv选项,以表格形式导出采集的结果.
表格效果(部分数据):
此外,我们还使用网络抓取工具采集了58个城市的租赁信息,公众评论食物信息,微信公众号密蒙文章,京东小米手机评论等.
作者: 学者Wan Yau
博客:
·END·
[03]基础: 将采集规则应用于相同的网页结构
采集交流 • 优采云 发表了文章 • 0 个评论 • 516 次浏览 • 2020-08-08 01:37
添加单个条目
点击“添加潜在客户”,输入潜在客户网址并保存.
批量添加
使用Excel存储潜在客户网址
单击“批量导入线索”添加附件,单击“批量导入”成功添加!
添加了六个,加上原创示例URL,总共有七个线索,现在它们都处于“待抓取”状态.
在此页面上,除了添加线索以外,您还可以激活,停用和删除线索.
如何运行线索?
运行采集规则是运行规则中的线索.
从上图可以看出,“ weibo_blog主主页”规则中现在有7条线索,所有这些线索都处于“ Pending crawl”状态. 要运行这些线索,请从DS计数器开始.
打开DS计数机,搜索要运行的规则,然后单击“单一搜索”或“集合”以启动DS计数机以捕获数据.
单次搜索: 在当前DS窗口中采集;采集搜索: 弹出一个新窗口进行采集.
单击“采集”后,输入一些要爬网的线索,然后单击“确定”.
我们看到DS计数机正在运行并立即获取.
如果您不知道要抓取多少线索,请右键单击DS计数器上的计数线索.
如何激活销售线索?
我刚刚运行了“ weibo_bloglor主页”采集规则,并且在会员中心看到这7条线索全部处于“抓取完成”状态.
如果您按照上述步骤在DS计数器中再次运行该规则,则此时将提示您没有任何线索,因为这7条线索刚刚被运行.
要再次捕获这些线索,只需重新激活这些线索即可. 激活后,这些线索的状态将变为“待抓取”.
有两种激活方式-
规则管理激活
在规则管理中选择要激活的线索后,单击“激活”按钮.
DS窗口激活
在这里,看看刚才运行的采集规则“ weibo_blog master homepage”的结果文件〜
在下一期中,结果文件将转换为Excel. 学习下一个问题之后,您将开始. 只要它不是复杂的网页,就可以采集它. 立于不败之地,令人兴奋吗?
转载于: 查看全部
添加单个条目
点击“添加潜在客户”,输入潜在客户网址并保存.
批量添加
使用Excel存储潜在客户网址
单击“批量导入线索”添加附件,单击“批量导入”成功添加!
添加了六个,加上原创示例URL,总共有七个线索,现在它们都处于“待抓取”状态.
在此页面上,除了添加线索以外,您还可以激活,停用和删除线索.
如何运行线索?
运行采集规则是运行规则中的线索.
从上图可以看出,“ weibo_blog主主页”规则中现在有7条线索,所有这些线索都处于“ Pending crawl”状态. 要运行这些线索,请从DS计数器开始.
打开DS计数机,搜索要运行的规则,然后单击“单一搜索”或“集合”以启动DS计数机以捕获数据.
单次搜索: 在当前DS窗口中采集;采集搜索: 弹出一个新窗口进行采集.
单击“采集”后,输入一些要爬网的线索,然后单击“确定”.
我们看到DS计数机正在运行并立即获取.
如果您不知道要抓取多少线索,请右键单击DS计数器上的计数线索.
如何激活销售线索?
我刚刚运行了“ weibo_bloglor主页”采集规则,并且在会员中心看到这7条线索全部处于“抓取完成”状态.
如果您按照上述步骤在DS计数器中再次运行该规则,则此时将提示您没有任何线索,因为这7条线索刚刚被运行.
要再次捕获这些线索,只需重新激活这些线索即可. 激活后,这些线索的状态将变为“待抓取”.
有两种激活方式-
规则管理激活
在规则管理中选择要激活的线索后,单击“激活”按钮.
DS窗口激活
在这里,看看刚才运行的采集规则“ weibo_blog master homepage”的结果文件〜
在下一期中,结果文件将转换为Excel. 学习下一个问题之后,您将开始. 只要它不是复杂的网页,就可以采集它. 立于不败之地,令人兴奋吗?
转载于:
STM32 ADC多通道转换DMA模式和非DMA模式两种方法(HAL库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2020-08-08 00:48
说明: 这是我第一次做时由百度发布的. 我自己没做我将其保存下来用于学习,因为它很有用. 链接到原创文本: ,我将在下面的第二部分中添加我自己的DMA模式方法.
Stm32 ADC的转换模式仍然非常灵活和强大. 模式有很多类型. 当许多人在没有仔细阅读参考手册的情况下使用它时,也会引起混乱. 我不知道该使用哪种方式来实现我想要的功能. 可以在网上找到很多信息,但是大多数信息都是针对标准库的旧版本的. 为了帮助客户昨天解决此问题,仅作一个总结: 使用stm32cubeMX配置生成一个多渠道获取示例.
软件: STM32Cumebx MDK
硬件: eemaker板(基于stm32F103c8)
在百度上搜索ADC多通道采集. 它们大多数基于dma模式. 我正在谈论使用非dma方法. 首先,有几个概念需要澄清:
扫描模式(如果要采集多个通道,则必须打开): 一次转换选定的通道,例如,打开ch0,ch1,ch4,ch5. Ch0转换后,它将自动转换通道0、1、4和5,直到转换完成. 但是这种连续性并不是说它不能被打断. 这引入了不连续模式,可以说是对扫描模式的补充. 它可以将四个通道0、1、4和5分组. 它可以分为0、1和4、5的一组. 每个通道也可以配置为一组. 这样,每组转化都需要触发一次.
Stm32 ADC的单模式和连续模式. 两种模式的概念相对应. 此处的单一模式不涉及通道. 假设您同时打开四个通道ch0,ch1,ch4和ch5. 在单模式转换模式下,四个通道将被采集并停止. 在连续模式下,四个通道先转换然后循环,然后从ch0开始.
还有规则组和注入组的概念. 因为我仅在此例程中使用规则组,所以不会介绍这两个概念. 如果您想弄清楚,请参阅手册.
在下面输入主题,配置stm32cubeMX.
首先启用几个通道,我将其设置为0、1、4、5.
然后我们需要配置ADC参数:
目前,在我测试之后,如果要使用非DMA和中断模式,则只有此配置才能正确执行多通道转换: 扫描模式+单转换模式+不连续转换模式(每个不连续组一个通道).
在此模式下配置分析. 配置为多个通道时,必须打开扫描模式. 它在stm32cubeMX上也是默认设置,只能启用. 在单转换模式下,我不需要连续采集每个通道的值,而是在采集四个通道后将其停止. 不连续的配置是这里的关键. 不连续模式允许将四个扫描通道分为四组. stm32cubeMX参数中的“不连续转换数”用于配置不连续组. 广告价值高时,只能读取每个不连续组的最后一个频道.
生成mdk项目代码. 此时,它尚未完成,但是ADC的初始化已经实现. 有必要采集四个值得发挥作用的通道并自己编写. 以下是我的主要功能的while循环:
<p>for(i=1;i 查看全部
1. 非DMA模式(传输)
说明: 这是我第一次做时由百度发布的. 我自己没做我将其保存下来用于学习,因为它很有用. 链接到原创文本: ,我将在下面的第二部分中添加我自己的DMA模式方法.
Stm32 ADC的转换模式仍然非常灵活和强大. 模式有很多类型. 当许多人在没有仔细阅读参考手册的情况下使用它时,也会引起混乱. 我不知道该使用哪种方式来实现我想要的功能. 可以在网上找到很多信息,但是大多数信息都是针对标准库的旧版本的. 为了帮助客户昨天解决此问题,仅作一个总结: 使用stm32cubeMX配置生成一个多渠道获取示例.
软件: STM32Cumebx MDK
硬件: eemaker板(基于stm32F103c8)
在百度上搜索ADC多通道采集. 它们大多数基于dma模式. 我正在谈论使用非dma方法. 首先,有几个概念需要澄清:
扫描模式(如果要采集多个通道,则必须打开): 一次转换选定的通道,例如,打开ch0,ch1,ch4,ch5. Ch0转换后,它将自动转换通道0、1、4和5,直到转换完成. 但是这种连续性并不是说它不能被打断. 这引入了不连续模式,可以说是对扫描模式的补充. 它可以将四个通道0、1、4和5分组. 它可以分为0、1和4、5的一组. 每个通道也可以配置为一组. 这样,每组转化都需要触发一次.
Stm32 ADC的单模式和连续模式. 两种模式的概念相对应. 此处的单一模式不涉及通道. 假设您同时打开四个通道ch0,ch1,ch4和ch5. 在单模式转换模式下,四个通道将被采集并停止. 在连续模式下,四个通道先转换然后循环,然后从ch0开始.
还有规则组和注入组的概念. 因为我仅在此例程中使用规则组,所以不会介绍这两个概念. 如果您想弄清楚,请参阅手册.
在下面输入主题,配置stm32cubeMX.
首先启用几个通道,我将其设置为0、1、4、5.
然后我们需要配置ADC参数:
目前,在我测试之后,如果要使用非DMA和中断模式,则只有此配置才能正确执行多通道转换: 扫描模式+单转换模式+不连续转换模式(每个不连续组一个通道).
在此模式下配置分析. 配置为多个通道时,必须打开扫描模式. 它在stm32cubeMX上也是默认设置,只能启用. 在单转换模式下,我不需要连续采集每个通道的值,而是在采集四个通道后将其停止. 不连续的配置是这里的关键. 不连续模式允许将四个扫描通道分为四组. stm32cubeMX参数中的“不连续转换数”用于配置不连续组. 广告价值高时,只能读取每个不连续组的最后一个频道.
生成mdk项目代码. 此时,它尚未完成,但是ADC的初始化已经实现. 有必要采集四个值得发挥作用的通道并自己编写. 以下是我的主要功能的while循环:
<p>for(i=1;i
优采云采集器,一些手写采集规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2020-08-07 14:56
默认情况下,采集器支持typecho,效果非常好. 从本地预防模板中导入数百个数据只需几分钟,这与计算机的性能和网络速度有关.
此外,我编写的采集规则适用于网站的某一部分. 如果您想采集其他部分,则非常简单. 只需编辑任务并修改其他部分的地址即可. 这非常简单,您不需要自己做. 除非目标站点极大地改变了页面布局.
以下是我的数据的屏幕截图
下载URL(有关导入方法,请参见官方教程)
我已经玩了几天这个采集器,因为这是一项工作需要,所以我经常忙于扔它,但是偶尔我也会做一些测试. 优采云采集器非常易于创建和采集角色,尤其是在智能模式下,它基本上是无脑的操作,但是不幸的是,对于没有任何Internet经验的人,它仍然会造成混乱,因此我需要写文章.
默认情况下,采集器支持typecho,效果非常好. 从本地预防模板中导入数百个数据只需几分钟,这与计算机的性能和网络速度有关.
此外,我编写的采集规则适用于网站的某一部分. 如果您想采集其他部分,则非常简单. 只需编辑任务并修改其他部分的地址即可. 这非常简单,您不需要自己做. 除非目标站点极大地改变了页面布局.
以下是我的数据的屏幕截图
下载地址(有关导入方法,请参见官方教程) 查看全部
我已经和采集器一起玩了几天,因为这是一项工作需要,所以我经常忙于扔掉它,但是偶尔我会做一些测试. 优采云采集器非常易于创建和采集角色,尤其是在智能模式下,它基本上是无脑的操作,但是不幸的是,对于没有任何Internet经验的人,它仍然会造成混乱,因此我需要写文章.
默认情况下,采集器支持typecho,效果非常好. 从本地预防模板中导入数百个数据只需几分钟,这与计算机的性能和网络速度有关.
此外,我编写的采集规则适用于网站的某一部分. 如果您想采集其他部分,则非常简单. 只需编辑任务并修改其他部分的地址即可. 这非常简单,您不需要自己做. 除非目标站点极大地改变了页面布局.
以下是我的数据的屏幕截图
下载URL(有关导入方法,请参见官方教程)
我已经玩了几天这个采集器,因为这是一项工作需要,所以我经常忙于扔它,但是偶尔我也会做一些测试. 优采云采集器非常易于创建和采集角色,尤其是在智能模式下,它基本上是无脑的操作,但是不幸的是,对于没有任何Internet经验的人,它仍然会造成混乱,因此我需要写文章.
默认情况下,采集器支持typecho,效果非常好. 从本地预防模板中导入数百个数据只需几分钟,这与计算机的性能和网络速度有关.
此外,我编写的采集规则适用于网站的某一部分. 如果您想采集其他部分,则非常简单. 只需编辑任务并修改其他部分的地址即可. 这非常简单,您不需要自己做. 除非目标站点极大地改变了页面布局.
以下是我的数据的屏幕截图
下载地址(有关导入方法,请参见官方教程)
如何对采集规则进行故障排除?
采集交流 • 优采云 发表了文章 • 0 个评论 • 568 次浏览 • 2020-08-07 01:25
在这里,我主要讨论独立采集中存在问题时的故障排除方法. 独立采集的问题主要是因为规则中的某个步骤未执行,网页未完全加载或该步骤的高级选项设置不正确.
官方网站提供了非常有用的故障排除教程. 本教程详细说明了如何在优采云中配置规则时手动执行每个步骤以进行故障排除. 这是故障排除中非常重要的一步,因此在此不再赘述. 您可以直接进入教程中心并搜索“规则制定和故障排除教程”
优采云采集数据的原理:
优采云软件主要模仿用户浏览网页的操作,例如打开网页,单击元素,输入文本,切换下拉选项以及将鼠标移至元素. 这些我们通常会在网上浏览以进行相应的操作.
示例:
进入优采云官方网站界面(打开网页),将鼠标放在产品简介上(将鼠标移到元素上),将弹出一个小黑框,将鼠标移开,然后将黑框隐. 然后单击它旁边的教程中心(单击元素)进入教程中心页面,有一个搜索框,输入“规则制定和故障排除教程”(输入文本).
优采云又循环了一大步. 这也是我们采集大量数据的主要步骤.
循环翻页,循环单击元素,循环输入文本,循环打开网页
优采云主要基于xpath定位元素,然后执行相应的步骤.
排除规则故障的主要思想
手动执行基本上没有问题(表明过程基本上没有问题)之后,执行单机采集.
然后在独立获取界面中观察网页更改,以查看网页是否按照每个步骤执行. 如果未执行步骤,则说明该步骤存在问题. 例如,没有单击到详细信息页面,也没有循环翻页. 重新编辑规则,然后重新调试规则中的相应步骤.
以下是基于单机采集中的问题的解释(5):
1. 独立运行,无法采集数据
(1)打开网页后,直接提示采集已完成
主要原因: 某些网站加载缓慢. 在网页完全加载之前,优采云将执行下一步. 如果无法找到对应的位置,则无法执行该步骤,最终导致无法提取到数据.
解决方案: 您可以增加网页的超时时间,或者等待设置下一步. 允许页面加载足够长的时间.
(2)网页已加载
主要原因: 主要是由于网站问题,某些网站加载缓慢. 您想要采集的数据不会出现.
解决方案: 如果当前步骤是打开网页,则可以增加网页的超时时间. 如果是单击元素的步骤,并且已经加载了要采集的数据,则可以在单击元素的步骤中设置ajax延迟,
(3)网页未进入采集页面
此问题通常发生在点击元素步骤中. 当某些网页中有ajax链接时,有必要根据点击位置确定是否需要设置它. 如果未设置,它将始终卡在独立采集过程中的上一步中,并且无法采集任何数据.
主要原因: 当异步加载网页时,如果未设置ajax延迟,则通常将无法正确执行该操作,从而导致该规则无法继续进行下一步,并且无法处理任何数据提取.
解决方案: 在相应的步骤中设置ajax延迟,通常为2-3S,如果网页加载时间较长,则可以适当增加延迟时间. 单击该元素,循环到下一页,将鼠标移到该元素,这三个步骤中都有ajax设置
示例: 下图是在京东网站下采集手机产品的评论数据. 您需要单击产品评论以进入相应的评论页面. 在独立计算机上运行时,网页仍停留在评论页面上,并且没有评论数据出现. 原因是单击元素时未设置ajax延迟,这导致网页无法进入相应的采集界面.
2. 独立操作,缺少数据采集
(1)某些字段中没有数据
主要原因: 在单台计算机上进行采集时,发现某些字段为空. 此时,您应该找到相应的采集页面以检查要采集的数据是否存在. 有时并非每个网页都收录所有字段信息. 如果不是,则该字段为空是正常的. 如果是这样,则基本上是xpath定位问题. 此时,您需要修改xpath以准确定位相应的字段.
解决方案: 重新打开规则并手动执行验证. 如果需要修改xpath,可以找到xpath教程.
示例: 在下图中,约会次数和约会时间为空值. 重新打开规则并手动执行. 发现该页面可以采集数据(图2). 这意味着这主要是一个网页加载问题,可以在下一步之前设置等待时间. 第二个数据为空,因为第二个详细信息页面上没有数据,这很正常.
(2)采集的数据数量不正确
采集的数据数量不正确,通常是由于翻页或加载网页引起的.
某些网页数据需要向下滚动才能加载数据. 如果在打开网页时没有设置足够的滚动词,则从网页加载的数据量将不如手动执行规则时那么大.
如果页面翻转不正确,则无法采集某些页面上的数据. 例如,发生不规则的翻页,导致某些页面无法打开,并且无法采集数据.
主要解决方案: 如果是翻页问题,则修改翻页周期的xpath;如果是网页加载问题,请在打开网页的高级选项中设置滚动次数
示例: 制定规则时,有80个循环选项,但在单个计算机集合中仅采集了16个项目. 主要原因是未将网页设置为向下滚动以加载,导致加载的项目较少.
3. 采集的数据乱序,没有对应的信息
(1)多个数据提取步骤 查看全部
教程中有详细的故障排除图形教程
在这里,我主要讨论独立采集中存在问题时的故障排除方法. 独立采集的问题主要是因为规则中的某个步骤未执行,网页未完全加载或该步骤的高级选项设置不正确.
官方网站提供了非常有用的故障排除教程. 本教程详细说明了如何在优采云中配置规则时手动执行每个步骤以进行故障排除. 这是故障排除中非常重要的一步,因此在此不再赘述. 您可以直接进入教程中心并搜索“规则制定和故障排除教程”
优采云采集数据的原理:
优采云软件主要模仿用户浏览网页的操作,例如打开网页,单击元素,输入文本,切换下拉选项以及将鼠标移至元素. 这些我们通常会在网上浏览以进行相应的操作.
示例:
进入优采云官方网站界面(打开网页),将鼠标放在产品简介上(将鼠标移到元素上),将弹出一个小黑框,将鼠标移开,然后将黑框隐. 然后单击它旁边的教程中心(单击元素)进入教程中心页面,有一个搜索框,输入“规则制定和故障排除教程”(输入文本).
优采云又循环了一大步. 这也是我们采集大量数据的主要步骤.
循环翻页,循环单击元素,循环输入文本,循环打开网页
优采云主要基于xpath定位元素,然后执行相应的步骤.
排除规则故障的主要思想
手动执行基本上没有问题(表明过程基本上没有问题)之后,执行单机采集.
然后在独立获取界面中观察网页更改,以查看网页是否按照每个步骤执行. 如果未执行步骤,则说明该步骤存在问题. 例如,没有单击到详细信息页面,也没有循环翻页. 重新编辑规则,然后重新调试规则中的相应步骤.
以下是基于单机采集中的问题的解释(5):
1. 独立运行,无法采集数据
(1)打开网页后,直接提示采集已完成
主要原因: 某些网站加载缓慢. 在网页完全加载之前,优采云将执行下一步. 如果无法找到对应的位置,则无法执行该步骤,最终导致无法提取到数据.
解决方案: 您可以增加网页的超时时间,或者等待设置下一步. 允许页面加载足够长的时间.
(2)网页已加载
主要原因: 主要是由于网站问题,某些网站加载缓慢. 您想要采集的数据不会出现.
解决方案: 如果当前步骤是打开网页,则可以增加网页的超时时间. 如果是单击元素的步骤,并且已经加载了要采集的数据,则可以在单击元素的步骤中设置ajax延迟,
(3)网页未进入采集页面
此问题通常发生在点击元素步骤中. 当某些网页中有ajax链接时,有必要根据点击位置确定是否需要设置它. 如果未设置,它将始终卡在独立采集过程中的上一步中,并且无法采集任何数据.
主要原因: 当异步加载网页时,如果未设置ajax延迟,则通常将无法正确执行该操作,从而导致该规则无法继续进行下一步,并且无法处理任何数据提取.
解决方案: 在相应的步骤中设置ajax延迟,通常为2-3S,如果网页加载时间较长,则可以适当增加延迟时间. 单击该元素,循环到下一页,将鼠标移到该元素,这三个步骤中都有ajax设置
示例: 下图是在京东网站下采集手机产品的评论数据. 您需要单击产品评论以进入相应的评论页面. 在独立计算机上运行时,网页仍停留在评论页面上,并且没有评论数据出现. 原因是单击元素时未设置ajax延迟,这导致网页无法进入相应的采集界面.
2. 独立操作,缺少数据采集
(1)某些字段中没有数据
主要原因: 在单台计算机上进行采集时,发现某些字段为空. 此时,您应该找到相应的采集页面以检查要采集的数据是否存在. 有时并非每个网页都收录所有字段信息. 如果不是,则该字段为空是正常的. 如果是这样,则基本上是xpath定位问题. 此时,您需要修改xpath以准确定位相应的字段.
解决方案: 重新打开规则并手动执行验证. 如果需要修改xpath,可以找到xpath教程.
示例: 在下图中,约会次数和约会时间为空值. 重新打开规则并手动执行. 发现该页面可以采集数据(图2). 这意味着这主要是一个网页加载问题,可以在下一步之前设置等待时间. 第二个数据为空,因为第二个详细信息页面上没有数据,这很正常.
(2)采集的数据数量不正确
采集的数据数量不正确,通常是由于翻页或加载网页引起的.
某些网页数据需要向下滚动才能加载数据. 如果在打开网页时没有设置足够的滚动词,则从网页加载的数据量将不如手动执行规则时那么大.
如果页面翻转不正确,则无法采集某些页面上的数据. 例如,发生不规则的翻页,导致某些页面无法打开,并且无法采集数据.
主要解决方案: 如果是翻页问题,则修改翻页周期的xpath;如果是网页加载问题,请在打开网页的高级选项中设置滚动次数
示例: 制定规则时,有80个循环选项,但在单个计算机集合中仅采集了16个项目. 主要原因是未将网页设置为向下滚动以加载,导致加载的项目较少.
3. 采集的数据乱序,没有对应的信息
(1)多个数据提取步骤
每周计数丨小彩教您如何使用优采云采集器来抓取法律法规新闻数据(发送规则+数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 493 次浏览 • 2020-08-06 06:07
采集目标: 1.遍历爬网列表页面的内容页面地址2.内容页面采集字段: 标题,内容,关键字,来源使用工具: 1.优采云采集器2.捕获器软件采集结果:
然后,让我们看一下如何使用优采云采集器来获取法律和法规数据.
第一步: 打开Youcai Cloud的官方网站,下载并安装最新版本的Youcai Cloud Collector
第2步: 在软件中打开列表页面,使用fiddler捕获和分析数据包,并获取实际的数据请求(抓取几页进行比较)
通过分析,可以看出分页加载方法是POST请求. POST形式中有一些变量可以控制分页,并且内容页地址的格式在源代码中清晰可见.
第3步: 在采集器中创建新规则,并根据Fiddler捕获的信息编写列表页面的获取规则,并在起始地址列中填写POST请求地址
填写POST表单,用[page]变量替换页面控制参数,然后设置页面范围
步骤4: 在分析源代码之后,在URL获取选项中设置内容页面地址获取规则,并测试采集列表
将通过数据包捕获获得的标头信息依次填充到HTTP请求设置中
第5步: 完成上述所有设置后,即可测试运行列表的获取. 获取成功后,您可以继续制定内容采集规则
步骤6: 在浏览器中打开内容页面,找到要采集的字段的位置以及与源代码的对应关系
找到数据的前后位置,然后可以通过前后截取或常规提取来获取内容
步骤7: 由于``关键字''字段中存在多个值,建议使用循环采集,以下是处理方法
设置关联的多个页面并保存它们
从多个关联页面循环提取
摘要: 使用Fiddler捕获数据包并分析数据请求信息,根据需要填写相应的设置,并为内容字段编写获取规则. 注意: 1.该网站的采集存在IP阻塞的问题,使用代理后需要采集很长时间. 2.一段时间后,还会出现Cookie失效的问题
每周采集数据和采集规则的时间是在2019年10月24日发布后的5个工作日内. 采集规则涉及商业版本功能. 建议用户登录到商业版本以使用此规则.
数据采集的资格: Youcai Cloud Collector / Youcai Cloud Browser / Touch Wizard Business Edition软件用户(在使用期限内),如果您不是商业用户或已经过使用期限但想要参加活动,您可以购买新软件或升级或续订,以便可以参加活动!请告诉我,双11优采云活动有很大的折扣!
数据采集方法:
第一步: 扫描二维码,添加“财彩云”操作微信帐号,“财彩云”操作助手会将您拉入活动组.
第2步: 进入群组后,添加数据以咨询客户服务. Ya的WeChat帐户经过客户服务部门在使用寿命内被确认为商业用户后,便可以接收它.
好的,此期“星期一计数”在这里. 如果您仍想获得更多的数据资源和采集器规则,则可以在文章底部或官方帐户的背景中留言. 小蔡将根据您的意见选择下一期的主题! 查看全部
采集网址:
采集目标: 1.遍历爬网列表页面的内容页面地址2.内容页面采集字段: 标题,内容,关键字,来源使用工具: 1.优采云采集器2.捕获器软件采集结果:
然后,让我们看一下如何使用优采云采集器来获取法律和法规数据.
第一步: 打开Youcai Cloud的官方网站,下载并安装最新版本的Youcai Cloud Collector
第2步: 在软件中打开列表页面,使用fiddler捕获和分析数据包,并获取实际的数据请求(抓取几页进行比较)
通过分析,可以看出分页加载方法是POST请求. POST形式中有一些变量可以控制分页,并且内容页地址的格式在源代码中清晰可见.
第3步: 在采集器中创建新规则,并根据Fiddler捕获的信息编写列表页面的获取规则,并在起始地址列中填写POST请求地址
填写POST表单,用[page]变量替换页面控制参数,然后设置页面范围
步骤4: 在分析源代码之后,在URL获取选项中设置内容页面地址获取规则,并测试采集列表
将通过数据包捕获获得的标头信息依次填充到HTTP请求设置中
第5步: 完成上述所有设置后,即可测试运行列表的获取. 获取成功后,您可以继续制定内容采集规则
步骤6: 在浏览器中打开内容页面,找到要采集的字段的位置以及与源代码的对应关系
找到数据的前后位置,然后可以通过前后截取或常规提取来获取内容
步骤7: 由于``关键字''字段中存在多个值,建议使用循环采集,以下是处理方法
设置关联的多个页面并保存它们
从多个关联页面循环提取
摘要: 使用Fiddler捕获数据包并分析数据请求信息,根据需要填写相应的设置,并为内容字段编写获取规则. 注意: 1.该网站的采集存在IP阻塞的问题,使用代理后需要采集很长时间. 2.一段时间后,还会出现Cookie失效的问题
每周采集数据和采集规则的时间是在2019年10月24日发布后的5个工作日内. 采集规则涉及商业版本功能. 建议用户登录到商业版本以使用此规则.
数据采集的资格: Youcai Cloud Collector / Youcai Cloud Browser / Touch Wizard Business Edition软件用户(在使用期限内),如果您不是商业用户或已经过使用期限但想要参加活动,您可以购买新软件或升级或续订,以便可以参加活动!请告诉我,双11优采云活动有很大的折扣!
数据采集方法:
第一步: 扫描二维码,添加“财彩云”操作微信帐号,“财彩云”操作助手会将您拉入活动组.
第2步: 进入群组后,添加数据以咨询客户服务. Ya的WeChat帐户经过客户服务部门在使用寿命内被确认为商业用户后,便可以接收它.
好的,此期“星期一计数”在这里. 如果您仍想获得更多的数据资源和采集器规则,则可以在文章底部或官方帐户的背景中留言. 小蔡将根据您的意见选择下一期的主题!
优采云采集器V3.1.0正式版,最新无限破解版可用测试[应用软件]
采集交流 • 优采云 发表了文章 • 0 个评论 • 657 次浏览 • 2020-08-06 06:07
它是由最初的Google技术团队创建的. 它具有简单的规则配置和强大的采集功能. 它可以支持各种类型的网站,例如电子商务,生活服务,社交媒体,新闻论坛等,智能识别Web数据和导出数据. 有多种方法,其中大多数是完全免费的. 它是行业分析,精准营销,品牌监控和风险评估的好帮手.
优采云免费采集器支持所有操作系统版本更新和功能升级,以同步所有平台,采集和导出全部免费,轻松使用无限制,并支持后台操作,不打扰您其他前台工作,是您的数据采集最佳助手.
[功能]
1. [简单的规则配置和强大的采集功能]
1. 可视化的自定义采集过程:
完整的问答指南,可视化操作,自定义采集过程
自动记录和模拟网页操作顺序
高级设置可以满足更多采集需求
2. 单击以提取网页数据:
鼠标单击以选择要爬网的Web内容,操作简单
您可以选择提取文本,链接,属性,html标记等.
3. 运行批处理数据采集:
该软件会根据采集过程和提取规则自动分批采集
快速稳定地实时显示采集速度和过程
可以将软件切换为在后台运行,而不会影响前台工作
4. 导出并发布采集的数据:
采集的数据将自动制成表格,并且可以自由配置字段
支持将数据导出到Excel等本地文件
一键式发布到CMS网站/数据库/微信公众号及其他媒体
两个. [支持采集不同类型的网站]
电子商务,生活服务,社交媒体,新闻论坛,本地网站...
强大的浏览器内核,超过99%的网站可以使用它!
三,[完整的平台支持,免费的可视化操作]
支持所有操作系统: Windows + Mac + Linux
采集和导出都是免费的,可以放心地无限使用
可视化的采集规则配置,傻瓜式操作
四个. [强大的功能,快速的箭头]
智能识别网络数据,多种导出数据的方式
该软件会定期更新和升级,并且会不断添加新功能
客户的满意是我们最大的肯定!
[常见问题解答]
如何使用优采云采集器采集百度搜索结果数据?
第1步: 创建采集任务
1)启动Youcai Cloud Collector,进入主界面,单击“创建任务”按钮创建“向导采集任务”
2)输入百度搜索的网址,包括三种方式
1. 手动输入: 直接在输入框中输入网址,多个网址之间必须用换行符分隔
2. 单击以从文件中读取: 用户选择一个文件来存储URL. 文件中可以有多个URL地址,并且这些地址需要用换行符分隔.
3. 批量添加方法: 通过添加和调整地址参数来生成多个常规地址
第2步: 自定义采集过程
1)单击创建后,它将自动打开第一个URL进入向导设置. 在这里,选择列表页面,然后单击下一步
2)填写用于搜索关键字和选择关键字的输入框,然后单击“下一步”
3)进入第一个关键字搜索结果页面后,单击“设置搜索”按钮,然后单击“下一步”
4)单击列表块中的第一个元素
5)单击结果列表块中的另一个元素,此时将自动选择列表块. 点击下一步
6)选择下一页按钮,选择选项以选择下一页,然后单击页面上的下一页按钮以填充第一个输入框,并且可以调整第二个数据框以单击下一个采集操作频率中的页面按钮. 理论上,次数越多,采集的数据就越多. 点击下一步
7)选择要采集的字段: 在焦点框中单击要提取的元素,然后单击“下一步”
8)选择不进入详细信息页面. 点击保存或保存并运行
第3步: 数据采集和导出
1)采集任务正在运行
2)采集完成后,选择“导出数据”以将所有数据导出到本地文件
3)选择“导出方法”以导出采集的数据,在这里您可以选择excel作为导出格式
4)如下所示导出采集的数据后 查看全部
Youcai Cloud Collector是一个专业实用的Web数据采集器. 该采集器不需要开发,任何人都可以使用它,数据可以导出到本地文件,发布到网站和数据库等.
它是由最初的Google技术团队创建的. 它具有简单的规则配置和强大的采集功能. 它可以支持各种类型的网站,例如电子商务,生活服务,社交媒体,新闻论坛等,智能识别Web数据和导出数据. 有多种方法,其中大多数是完全免费的. 它是行业分析,精准营销,品牌监控和风险评估的好帮手.
优采云免费采集器支持所有操作系统版本更新和功能升级,以同步所有平台,采集和导出全部免费,轻松使用无限制,并支持后台操作,不打扰您其他前台工作,是您的数据采集最佳助手.
[功能]
1. [简单的规则配置和强大的采集功能]
1. 可视化的自定义采集过程:
完整的问答指南,可视化操作,自定义采集过程
自动记录和模拟网页操作顺序
高级设置可以满足更多采集需求
2. 单击以提取网页数据:
鼠标单击以选择要爬网的Web内容,操作简单
您可以选择提取文本,链接,属性,html标记等.
3. 运行批处理数据采集:
该软件会根据采集过程和提取规则自动分批采集
快速稳定地实时显示采集速度和过程
可以将软件切换为在后台运行,而不会影响前台工作
4. 导出并发布采集的数据:
采集的数据将自动制成表格,并且可以自由配置字段
支持将数据导出到Excel等本地文件
一键式发布到CMS网站/数据库/微信公众号及其他媒体
两个. [支持采集不同类型的网站]
电子商务,生活服务,社交媒体,新闻论坛,本地网站...
强大的浏览器内核,超过99%的网站可以使用它!
三,[完整的平台支持,免费的可视化操作]
支持所有操作系统: Windows + Mac + Linux
采集和导出都是免费的,可以放心地无限使用
可视化的采集规则配置,傻瓜式操作
四个. [强大的功能,快速的箭头]
智能识别网络数据,多种导出数据的方式
该软件会定期更新和升级,并且会不断添加新功能
客户的满意是我们最大的肯定!
[常见问题解答]
如何使用优采云采集器采集百度搜索结果数据?
第1步: 创建采集任务
1)启动Youcai Cloud Collector,进入主界面,单击“创建任务”按钮创建“向导采集任务”
2)输入百度搜索的网址,包括三种方式
1. 手动输入: 直接在输入框中输入网址,多个网址之间必须用换行符分隔
2. 单击以从文件中读取: 用户选择一个文件来存储URL. 文件中可以有多个URL地址,并且这些地址需要用换行符分隔.
3. 批量添加方法: 通过添加和调整地址参数来生成多个常规地址
第2步: 自定义采集过程
1)单击创建后,它将自动打开第一个URL进入向导设置. 在这里,选择列表页面,然后单击下一步
2)填写用于搜索关键字和选择关键字的输入框,然后单击“下一步”
3)进入第一个关键字搜索结果页面后,单击“设置搜索”按钮,然后单击“下一步”
4)单击列表块中的第一个元素
5)单击结果列表块中的另一个元素,此时将自动选择列表块. 点击下一步
6)选择下一页按钮,选择选项以选择下一页,然后单击页面上的下一页按钮以填充第一个输入框,并且可以调整第二个数据框以单击下一个采集操作频率中的页面按钮. 理论上,次数越多,采集的数据就越多. 点击下一步
7)选择要采集的字段: 在焦点框中单击要提取的元素,然后单击“下一步”
8)选择不进入详细信息页面. 点击保存或保存并运行
第3步: 数据采集和导出
1)采集任务正在运行
2)采集完成后,选择“导出数据”以将所有数据导出到本地文件
3)选择“导出方法”以导出采集的数据,在这里您可以选择excel作为导出格式
4)如下所示导出采集的数据后
平多多商品数据的采集和采集方法. docx 11页
采集交流 • 优采云 发表了文章 • 0 个评论 • 413 次浏览 • 2020-08-06 02:03
1. 该操作很简单,任何人都可以使用: 不需要技术背景,并且可以通过浏览Internet进行采集. 完全可视化该过程,单击鼠标以完成操作,您可以在2分钟内快速上手. 2.强大的功能,可以在任何网站上采集: 单击,登录,翻页,识别验证码,瀑布流,Ajax脚本异步加载数据页,所有这些都可以通过简单的设置进行采集. 3.云采集,也可以关闭. 配置采集任务后,可以将其关闭,并可以在云中执行该任务. 庞大的云采集集群不间断运行24 * 7,因此无需担心IP被阻塞和网络中断. 4.免费功能+增值服务,可以按需选择. 免费版具有所有功能,可以满足用户的基本采集需求. 同时,建立了一些增值服务(例如私有云)以满足高端付费企业用户的需求. 查看全部
优采云·云采集网络爬虫软件优采云·云采集网络爬虫软件Pinduoduo的产品数据采集与采集方法Pinduoduo是一种以群组形式加入的移动购物APP. 用户可以与朋友,家人,邻居等一起加入群组,以较低的价格购买产品. 本文介绍使用优采云采集拼多多产品的方法(限时秒杀). 本文仅以限时尖峰列为例. 您还可以在采集时采集其他列. 采集内容包括: 产品标题,产品图片,产品价格,产品原价,产品销售. 功能点: 提取数据并修改Xpath步骤1: 创建拼多多产品采集任务并进入主界面,选择“自定义采集”采集网站URL复制并粘贴到输入框中,单击“保存URL”步骤2: 提取拼多多产品数据字段1)选择要用鼠标采集的数据,例如,我选择产品标题,产品图片,产品价格,产品原创价格,产品销售,产品. 在右侧的提示框中,选择“全选” Pinduoduo商品采集-提取数据字段2)然后单击“采集数据”,然后单击“保存并开始采集” 3)打开右上角的处理按钮,观察图片地址,默认扫描按钮不是我们想要的. 选择拼多多产品图片的字段,单击自定义数据字段->自定义定位元素方法,然后设置“自定义定位元素设置图”,如下图所示. 元素匹配的Xpath: // body / section [1] / div [4] / div [1] / ul [1] / li [1] / div [1] / DIV [1] / IMG [1]相对xpath : / DIV [1] / IMG [1]编辑后,单击确定. 自定义数据字段自定义定位元素设置图步骤5: 拼多多商品数据的采集和导出1)修改采集字段的名称,然后单击“保存并开始采集”. 开始本地采集和采集后,将弹出提示,选择“导出数据”,然后选择“适当的导出方法”以导出采集的数据. 在这里,我们选择excel作为导出格式,并导出Pinduoduo产品数据的完整副本. 好的,导出数据后,下图来自本文: /tutorialdetail-1/pddspcj.html相关集合教程: 1688商品采集器: HYPERLINK“ /tutorialdetail-1/1688-qbspxxcj.html” / tutorialdetail-1 / 1688-qbspxxcj .html京东商品信息集合(简单集合)/tutorialdetail-1/jdspsscj.html淘宝商品集合: HYPERLINK“ / tutorialdetail-1 / tbspxx_7. html“ /tutorialdetail-1/tbspxx_7.html天猫商品信息数据采集: / tutorialdetail -1 / tmspcj-7.html微信产品采集: /tutorialdetail-1/wdspinfocj.htmlAmazon产品信息采集: /tutorialdetail-1/ymxxsxxph.html优采云-the 90万用户选择了Web数据采集器.
1. 该操作很简单,任何人都可以使用: 不需要技术背景,并且可以通过浏览Internet进行采集. 完全可视化该过程,单击鼠标以完成操作,您可以在2分钟内快速上手. 2.强大的功能,可以在任何网站上采集: 单击,登录,翻页,识别验证码,瀑布流,Ajax脚本异步加载数据页,所有这些都可以通过简单的设置进行采集. 3.云采集,也可以关闭. 配置采集任务后,可以将其关闭,并可以在云中执行该任务. 庞大的云采集集群不间断运行24 * 7,因此无需担心IP被阻塞和网络中断. 4.免费功能+增值服务,可以按需选择. 免费版具有所有功能,可以满足用户的基本采集需求. 同时,建立了一些增值服务(例如私有云)以满足高端付费企业用户的需求.

