
vba抓取网页数据
vba抓取网页数据(《VBA信息获取与处理》教程共两册,八十四大智慧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-07 03:13
【分享成果,正能量庆幸】人的一生,肯定会遇到各种各样的挫折和挑战,巨大的压力会让你喘不过气来。然而,只有真正懂得适时弯腰的人,才能战胜危机,赢得胜利。这不是懦弱,也不是没有骨气,而是一种大智慧。武力和野蛮只会带来不必要的损失。《VBA信息获取与处理》教程是我的第六套教程,现在是第一次修订。本套教程定位于最高级,是初级和中级完成后的教程。本教程内容为:跨应用信息获取、随机信息利用、邮件发送、VBA上网数据抓取、VBA延时操作、剪贴板应用、Split函数扩展、工作表信息等应用交互、FSO对象的使用、工作表和文件夹信息的获取、图形信息的获取、工作表信息功能的定制等。文件由 32 位和 64 位 Office 系统测试。它非常抽象,更有研究价值。本教程共两卷,八十四讲。今天的内容是话题6“Using XMLHTTP in VBA to complete web data capture”的第三讲:VBA web数据捕捉结果链接 图形信息的获取,工作表信息功能的定制等。程序文件通过32位和64位Office系统测试。它非常抽象,更有研究价值。本教程共两卷,八十四讲。今天的内容是话题6“Using XMLHTTP in VBA to complete web data capture”的第三讲:VBA web数据捕捉结果链接 图形信息的获取,工作表信息功能的定制等。程序文件通过32位和64位Office系统测试。它非常抽象,更有研究价值。本教程共两卷,八十四讲。今天的内容是话题6“Using XMLHTTP in VBA to complete web data capture”的第三讲:VBA web数据捕捉结果链接
第三部分使用XMLHTTP抓取百度搜索数据的结果,并给出开放链接。在上一讲中,我们实现了使用XMLHTTP来捕获搜索关键词的数据,但是我们在网上搜索的时候,往往不仅需要一般的数据支持,还需要一些具体的数据,比如: 找到了哪些网址,标题是什么?如果我需要进一步检查,我经常需要打开链接。如何捕获这些数据?所以让我意识到这个问题。实现场景: 如下图,当我们点击右侧按钮“使用VBA提取数据进行搜索关键词,并给出下载链接”时,可以给出查询的结果在下面的数据区。
其实这种处理在工作中是经常遇到的,我们浏览的网页可以适当的保存一下,需要的时候再详细查询。特别是将这些数据以EXCEL形式存储,管理更加清晰。那么如何实现这个场景呢?我们仍然使用 XMLHTTP 来完成我们的工作。1 使用XMLHTTP实现数据查询和网页链接提取。我们先模拟直接在网页上查询数据。当我们输入数据并点击回车时,服务器会在我们的浏览器上反馈数据。我们需要检查网页的源代码进行分析,
上面的截图是我输入“VBA Language Expert”点击回车后在后台看到的源代码。你会发现我们要写入EXCEL表格的所有信息都出现在这里了。其中“title”可以通过innerText属性获取,链接可以通过href属性获取。这真的很容易。接下来我们将多页查询的结果填入excel表格中。这时候,我们在向服务器发送时使用下面的代码可以通过询问header检查查询时间得到: .setRequestHeader "If-Modified-Since", "0" 这样就可以达到我们的要求了。2 使用XMLHTTP实现数据查询,提取网页链接的代码实现过程。下面我们将上面的思路转换成代码,如下图:
<p>代码说明: 1) Set objXMLHTTP = CreateObject("MSXML2.XMLHTTP") Set objDOM = CreateObject("htmlfile") 上面的代码创建了两个引用,一个是XMLHTTP,一个是htmlfile,然后使用这两个参考来完成我们的工作。2)UU = Range("B1").Value 这是我们要查询的关键数据3)For i = 0 To 50 Step 10'五页这是使用i作为查询5次查询页码 4) strURL = "" strURL= strURL & "wd=" & UU strURL= strURL & "&pn=" & i 以上代码完成了我们要查询的请求URL。5) .Open "GET", strURL, False 使用 OPEN 方法。6) .setRequestHeader "If-Modified-Since", "0" 请求头将浏览器端缓存页面的最后修改时间一起发送到服务器,服务器会将此时间与服务器上实际文件的最后修改时间进行比较,以确保我们每次请求的数据不是重复。7) .send 注意在这个命令之前应该完成请求头的提交8)objDOM.body.innerHTML = .responseText'将.responseText的内容写入新的objDOM对象的body中< @9) 对于 objDOM 中的每个 objTitle。getElementsByTagName("h3") 遍历每个 H3 标签或标题。请注意,它是标签标题。定义最大的标题。定义最小的标题。服务器会将此时间与服务器上实际文件的最后修改时间进行比较,以确保我们每次请求的数据不会重复。7) .send 注意在这个命令之前应该完成请求头的提交8)objDOM.body.innerHTML = .responseText'将.responseText的内容写入新的objDOM对象的body中< @9) 对于 objDOM 中的每个 objTitle。getElementsByTagName("h3") 遍历每个 H3 标签或标题。请注意,它是标签标题。定义最大的标题。定义最小的标题。服务器会将此时间与服务器上实际文件的最后修改时间进行比较,以确保我们每次请求的数据不会重复。7) .send 注意在这个命令之前应该完成请求头的提交8)objDOM.body.innerHTML = .responseText'将.responseText的内容写入新的objDOM对象的body中< @9) 对于 objDOM 中的每个 objTitle。getElementsByTagName("h3") 遍历每个 H3 标签或标题。请注意,它是标签标题。定义最大的标题。定义最小的标题。将 .responseText 的内容写入新的 objDOM 对象 查看全部
vba抓取网页数据(《VBA信息获取与处理》教程共两册,八十四大智慧)
【分享成果,正能量庆幸】人的一生,肯定会遇到各种各样的挫折和挑战,巨大的压力会让你喘不过气来。然而,只有真正懂得适时弯腰的人,才能战胜危机,赢得胜利。这不是懦弱,也不是没有骨气,而是一种大智慧。武力和野蛮只会带来不必要的损失。《VBA信息获取与处理》教程是我的第六套教程,现在是第一次修订。本套教程定位于最高级,是初级和中级完成后的教程。本教程内容为:跨应用信息获取、随机信息利用、邮件发送、VBA上网数据抓取、VBA延时操作、剪贴板应用、Split函数扩展、工作表信息等应用交互、FSO对象的使用、工作表和文件夹信息的获取、图形信息的获取、工作表信息功能的定制等。文件由 32 位和 64 位 Office 系统测试。它非常抽象,更有研究价值。本教程共两卷,八十四讲。今天的内容是话题6“Using XMLHTTP in VBA to complete web data capture”的第三讲:VBA web数据捕捉结果链接 图形信息的获取,工作表信息功能的定制等。程序文件通过32位和64位Office系统测试。它非常抽象,更有研究价值。本教程共两卷,八十四讲。今天的内容是话题6“Using XMLHTTP in VBA to complete web data capture”的第三讲:VBA web数据捕捉结果链接 图形信息的获取,工作表信息功能的定制等。程序文件通过32位和64位Office系统测试。它非常抽象,更有研究价值。本教程共两卷,八十四讲。今天的内容是话题6“Using XMLHTTP in VBA to complete web data capture”的第三讲:VBA web数据捕捉结果链接

第三部分使用XMLHTTP抓取百度搜索数据的结果,并给出开放链接。在上一讲中,我们实现了使用XMLHTTP来捕获搜索关键词的数据,但是我们在网上搜索的时候,往往不仅需要一般的数据支持,还需要一些具体的数据,比如: 找到了哪些网址,标题是什么?如果我需要进一步检查,我经常需要打开链接。如何捕获这些数据?所以让我意识到这个问题。实现场景: 如下图,当我们点击右侧按钮“使用VBA提取数据进行搜索关键词,并给出下载链接”时,可以给出查询的结果在下面的数据区。

其实这种处理在工作中是经常遇到的,我们浏览的网页可以适当的保存一下,需要的时候再详细查询。特别是将这些数据以EXCEL形式存储,管理更加清晰。那么如何实现这个场景呢?我们仍然使用 XMLHTTP 来完成我们的工作。1 使用XMLHTTP实现数据查询和网页链接提取。我们先模拟直接在网页上查询数据。当我们输入数据并点击回车时,服务器会在我们的浏览器上反馈数据。我们需要检查网页的源代码进行分析,

上面的截图是我输入“VBA Language Expert”点击回车后在后台看到的源代码。你会发现我们要写入EXCEL表格的所有信息都出现在这里了。其中“title”可以通过innerText属性获取,链接可以通过href属性获取。这真的很容易。接下来我们将多页查询的结果填入excel表格中。这时候,我们在向服务器发送时使用下面的代码可以通过询问header检查查询时间得到: .setRequestHeader "If-Modified-Since", "0" 这样就可以达到我们的要求了。2 使用XMLHTTP实现数据查询,提取网页链接的代码实现过程。下面我们将上面的思路转换成代码,如下图:


<p>代码说明: 1) Set objXMLHTTP = CreateObject("MSXML2.XMLHTTP") Set objDOM = CreateObject("htmlfile") 上面的代码创建了两个引用,一个是XMLHTTP,一个是htmlfile,然后使用这两个参考来完成我们的工作。2)UU = Range("B1").Value 这是我们要查询的关键数据3)For i = 0 To 50 Step 10'五页这是使用i作为查询5次查询页码 4) strURL = "" strURL= strURL & "wd=" & UU strURL= strURL & "&pn=" & i 以上代码完成了我们要查询的请求URL。5) .Open "GET", strURL, False 使用 OPEN 方法。6) .setRequestHeader "If-Modified-Since", "0" 请求头将浏览器端缓存页面的最后修改时间一起发送到服务器,服务器会将此时间与服务器上实际文件的最后修改时间进行比较,以确保我们每次请求的数据不是重复。7) .send 注意在这个命令之前应该完成请求头的提交8)objDOM.body.innerHTML = .responseText'将.responseText的内容写入新的objDOM对象的body中< @9) 对于 objDOM 中的每个 objTitle。getElementsByTagName("h3") 遍历每个 H3 标签或标题。请注意,它是标签标题。定义最大的标题。定义最小的标题。服务器会将此时间与服务器上实际文件的最后修改时间进行比较,以确保我们每次请求的数据不会重复。7) .send 注意在这个命令之前应该完成请求头的提交8)objDOM.body.innerHTML = .responseText'将.responseText的内容写入新的objDOM对象的body中< @9) 对于 objDOM 中的每个 objTitle。getElementsByTagName("h3") 遍历每个 H3 标签或标题。请注意,它是标签标题。定义最大的标题。定义最小的标题。服务器会将此时间与服务器上实际文件的最后修改时间进行比较,以确保我们每次请求的数据不会重复。7) .send 注意在这个命令之前应该完成请求头的提交8)objDOM.body.innerHTML = .responseText'将.responseText的内容写入新的objDOM对象的body中< @9) 对于 objDOM 中的每个 objTitle。getElementsByTagName("h3") 遍历每个 H3 标签或标题。请注意,它是标签标题。定义最大的标题。定义最小的标题。将 .responseText 的内容写入新的 objDOM 对象
vba抓取网页数据(vba抓取网页数据怎么做?如何做好网页技术开发)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-12-26 18:11
vba抓取网页数据,或通过excel抓取简单的前后端分离或有数据交互(websocket),无线开发常用api;做单页面应用,如饿了么的有赞平台,都是js抓取,但接口和传递参数、页面跳转都要依赖前端模板引擎(js);前端做后端的渲染,对外表现页面内容;分页浏览数据库、bloomfilter、prequery技术已经不成问题了,当然这些都还只是起步。
前端支持js,不需要后端。用户刷新页面后,页面的数据也不会丢失。前端输出的数据,在系统中(包括app)都是一致的。
实际看到的前端有2种,即前端技术开发技术和产品技术开发技术。而还有第三种,即产品技术开发技术中的网页技术开发技术。浏览器端和手机客户端发起请求前端响应即可。这不代表没有后端来通过ajax进行数据交互的操作。
不需要后端你给人家打个请求,你就能获取人家的服务器上的内容?你应该考虑后端开发人员需要哪些人才?你应该考虑需要些什么工具配合你做这个事情?建议你不要用js了,该改的地方太多,你要有个好的平台做chatbot(参考ooxx),该有的功能都要有,就差不多了,你的js,需要多请求。多用js3上的传输来操作用户。
不然你搞一堆数据,到人家的服务器去交互,谁懂你的意思,还得会返回你的数据。传输的问题做这么一大堆,每一点都要去解决,那出来的东西跟后端没有任何联系,你用js都不可能知道整个网站的基本数据源自哪,又如何去爬取。而且,你有不同的网站,如果需要不同的传输方式和数据格式,你得考虑实际问题,设计的时候就没必要考虑像你说的那样多模型的操作了,要看看文档的怎么写。 查看全部
vba抓取网页数据(vba抓取网页数据怎么做?如何做好网页技术开发)
vba抓取网页数据,或通过excel抓取简单的前后端分离或有数据交互(websocket),无线开发常用api;做单页面应用,如饿了么的有赞平台,都是js抓取,但接口和传递参数、页面跳转都要依赖前端模板引擎(js);前端做后端的渲染,对外表现页面内容;分页浏览数据库、bloomfilter、prequery技术已经不成问题了,当然这些都还只是起步。
前端支持js,不需要后端。用户刷新页面后,页面的数据也不会丢失。前端输出的数据,在系统中(包括app)都是一致的。
实际看到的前端有2种,即前端技术开发技术和产品技术开发技术。而还有第三种,即产品技术开发技术中的网页技术开发技术。浏览器端和手机客户端发起请求前端响应即可。这不代表没有后端来通过ajax进行数据交互的操作。
不需要后端你给人家打个请求,你就能获取人家的服务器上的内容?你应该考虑后端开发人员需要哪些人才?你应该考虑需要些什么工具配合你做这个事情?建议你不要用js了,该改的地方太多,你要有个好的平台做chatbot(参考ooxx),该有的功能都要有,就差不多了,你的js,需要多请求。多用js3上的传输来操作用户。
不然你搞一堆数据,到人家的服务器去交互,谁懂你的意思,还得会返回你的数据。传输的问题做这么一大堆,每一点都要去解决,那出来的东西跟后端没有任何联系,你用js都不可能知道整个网站的基本数据源自哪,又如何去爬取。而且,你有不同的网站,如果需要不同的传输方式和数据格式,你得考虑实际问题,设计的时候就没必要考虑像你说的那样多模型的操作了,要看看文档的怎么写。
vba抓取网页数据(百度的文字识别可以让C#、Python等语言调用。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-12-23 18:02
通常需要将照片中的文字转换为可编辑的文字。
百度的文字识别可以用C#、Python等语言调用。我将其集成到 API 打包库中。
API包库的下载和部署请参考以下帖子:
下面我来演示一下如何在VBA中调用API包库中的Image2Character函数来提取照片中的数据。
在 Excel VBA 中添加外部引用 API 和正则表达式。
模块中的代码如下:
Private S As String
Sub GetData()
Dim B As New API.Baidu
Dim Result As String
S = B.Image2Character(imagepath:="E:\粉煤灰\2.jpg")
Debug.Print S
End Sub
Sub Split()
Dim Reg As RegExp, MC As MatchCollection, M As Match
Set Reg = New RegExp
With Reg
.Global = True
.Pattern = Chr(34) & "([0-9\.]+)mg/L" & Chr(34)
Set MC = .Execute(S)
For Each M In MC
Debug.Print M.SubMatches(0)
Next M
End With
End Sub
GetData 负责从计算机中的图片中提取文本并将其分配给变量 S。
Split 负责按照指定的模式对变量 S 进行分解。
本例涉及化学物质含量检测的科研图片。图片收录两个样本L22和L23的数据。我关注的是Conc栏,就是单位是mg/L。 查看全部
vba抓取网页数据(百度的文字识别可以让C#、Python等语言调用。)
通常需要将照片中的文字转换为可编辑的文字。
百度的文字识别可以用C#、Python等语言调用。我将其集成到 API 打包库中。
API包库的下载和部署请参考以下帖子:
下面我来演示一下如何在VBA中调用API包库中的Image2Character函数来提取照片中的数据。
在 Excel VBA 中添加外部引用 API 和正则表达式。
模块中的代码如下:
Private S As String
Sub GetData()
Dim B As New API.Baidu
Dim Result As String
S = B.Image2Character(imagepath:="E:\粉煤灰\2.jpg")
Debug.Print S
End Sub
Sub Split()
Dim Reg As RegExp, MC As MatchCollection, M As Match
Set Reg = New RegExp
With Reg
.Global = True
.Pattern = Chr(34) & "([0-9\.]+)mg/L" & Chr(34)
Set MC = .Execute(S)
For Each M In MC
Debug.Print M.SubMatches(0)
Next M
End With
End Sub
GetData 负责从计算机中的图片中提取文本并将其分配给变量 S。
Split 负责按照指定的模式对变量 S 进行分解。
本例涉及化学物质含量检测的科研图片。图片收录两个样本L22和L23的数据。我关注的是Conc栏,就是单位是mg/L。
vba抓取网页数据(我正在尝试从此网站上删除数据(-vbaweb))
网站优化 • 优采云 发表了文章 • 0 个评论 • 39 次浏览 • 2021-12-23 12:22
我正在尝试从此 网站 中删除数据。我已经编写了打开网站 然后搜索值的代码。单击搜索结果并打开最后一页,我必须从中选择详细信息。我需要选择红色提到的标签的详细信息
这是我打开所需页面的代码。我已经使用 Link.click 打开所需的页面。之后,我需要获取图像中提到的详细信息。温心提醒。
Sub hullByAshish() Dim html, html1 As HTMLDocument Dim ElementCol, ElementCol1 As Object Dim Link As Object Dim appIE As Object Dim a As String Dim i As Long Dim objElement As Object Dim objCollection As Object Set appIE = CreateObject("internetexplorer.application") a = "PONTOVREMON" With appIE .Navigate "https://www.marinetraffic.com/ ... ot%3B & a .Visible = True End With Do While appIE.Busy DoEvents Loop Application.Wait (Now() + TimeValue("00:00:01")) Set html = appIE.document Set ElementCol = html.getElementsByTagName("a") DoEvents For Each Link In ElementCol If Link.innerHTML = "PONTOVREMON" Then Link.Click End If Next Link End Sub
excelvbaexcel-vbaweb-scrapinginnerhtml 查看全部
vba抓取网页数据(我正在尝试从此网站上删除数据(-vbaweb))
我正在尝试从此 网站 中删除数据。我已经编写了打开网站 然后搜索值的代码。单击搜索结果并打开最后一页,我必须从中选择详细信息。我需要选择红色提到的标签的详细信息
这是我打开所需页面的代码。我已经使用 Link.click 打开所需的页面。之后,我需要获取图像中提到的详细信息。温心提醒。
Sub hullByAshish() Dim html, html1 As HTMLDocument Dim ElementCol, ElementCol1 As Object Dim Link As Object Dim appIE As Object Dim a As String Dim i As Long Dim objElement As Object Dim objCollection As Object Set appIE = CreateObject("internetexplorer.application") a = "PONTOVREMON" With appIE .Navigate "https://www.marinetraffic.com/ ... ot%3B & a .Visible = True End With Do While appIE.Busy DoEvents Loop Application.Wait (Now() + TimeValue("00:00:01")) Set html = appIE.document Set ElementCol = html.getElementsByTagName("a") DoEvents For Each Link In ElementCol If Link.innerHTML = "PONTOVREMON" Then Link.Click End If Next Link End Sub
excelvbaexcel-vbaweb-scrapinginnerhtml
vba抓取网页数据( 第3行字符串替换成网站的作用是创建一个IE应用程序对象)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-17 03:02
第3行字符串替换成网站的作用是创建一个IE应用程序对象)
VBA IE对象的操作方法
<p> (2013-10-27 11:39:29)
http://blog.sina.com.cn/s/blog_64173e0c0101bf9o.html
<a class="SG_aBtn SG_aBtn_ico SG_turn">转载▼</a>
标签: vba ie 标签 对象 图片 it 分类: 电子商务
IE和文档对象模型
我们在实际工作中遇到网站和网页相关往往要涉及到这类问题:如何下载网页数据?网页之间的通讯是怎么实现的、它们能不能被控制等等。分析网页根据不同协变色镜可以用不同的角度去看,如数据流、标记,不过,如果你是用VB/VBA/脚本或其它支持自动化对象(AUTOMATION)的语言编程,有一个值得了解方法是掌握对象模型,将网页视为对象来自行控制,这个方法需要了解的是IE的自动化对象(InternetExplorer.Application)或IE控件(Microsoft Internet Controls),以及标准的文档对象模型(Document)<br /> 以下代码在VBA环境下进行试验——我不在意你是用WORD还是EXCEL——可以先做一行过程模块,也可以在立即窗口下逐行输入:
</p>
Set ieA = CreateObject("InternetExplorer.Application") ‘创建对象
ieA.Visible = True ‘使IE页面可见,做完这一步,在VBA之外可以看到一个新的IE
ieA.navigate "about:blank" ‘空白页
这几行代码的作用就是创建一个IE应用程序对象(是的,它相当于一个IE应用程序)并打开一个空白的网页。此网页独立于 VBA 应用程序(WORD 或 EXCEL)。其实必须自己关闭,或者使用ieA.Quit命令退出——注意简单关闭VBA或者SET ieA=nothing都不会退出这个页面。当然,如果你在线并且愿意,你也可以将第3行的字符串替换为网站的名称,或者替换为你主机中的一个文档名——比如C:\XXX .HTM ,或者D:\PIC\XXX.GIF,就像你在IE地址栏中输入名称浏览这些文件一样。另一种替代方法是在宿主机上直接添加一个WEB BROWS浏览器控件比如VB/VBA的表单或者工作表,也相当于上面的IE应用
注意:WEB BROWSE 控件和单独的 IE 程序并不完全相同。比如WEB控件不能用QUIT方法退出。IE 的 NAVIGETE 方法没有复杂的 POST 参数,但同样可以引用文档对象。大多数事件和方法也是通用的
另外,如果你访问一个已有的网页,比如因为有异步延迟的可能,如果不是立即窗口,往往保证网页是按照READYSTATE状态加载的:
SUB LOADIE() ‘ 在代码的常见的处理情况
Set ieA = CreateObject("InternetExplorer.Application")
ieA.Visible = True
ieA.navigate "WWW.OOXX.COM" ‘←打开某个网页,要一定时间,但代码会往下执行
DO UNTIL ieA.Readystate=4 ‘ 检查网页是否加载完毕(4表示完全加载)
DOEVENTS ‘ 循环中交回工作权限给系统,以免“软死机”
LOOP
END SUB
如果你对这个IE应用对象的相关声明和事件感兴趣,必须参考IE控件才能找到对象中的常量和事件:SHDOCVW.DLL (MICROSOFT INTERNET CONTROL)
你可以看到,通过 ieA——创建的对象——我们可以操作它并访问它的属性。让我们继续。如果你在命令行输入并且打开的空白网页没有关闭,变量将继续有效:
设置 doc = ieA.Document' 获取网页的文档对象
doc.body.innerHTML = "Hello"'在文档的BODY标签中添加标记文本HELLO
网页上有一行小字,HELLO...一般约定俗成,当然可以写其他的,HI,我爱你,EXCEL,HOME等,但这不是最重要的,我们来知道这个对象下的结构。
由文档对象(Document)扩展而来的对象模型,它代表网页的内容,与之前的IE应用程序不是同一个系统——请注意这一点——如果我们需要使用对应的对象事件和常量编程时,VB/VBA要引用的类型库是MSHTML.TLB(MIRCOSOFT HTML OBJECT LIBRARY)
Documnet(文档)是文档对象模型的基础,相当于OFFICE对象中的APPLICATION。拿到Document后,无论是修改网页、读写网页、触发事件,一切都好说。每个URL对应一个Documnet(这是如果确定成功导航到那个URL完成Navigate,则需要确定IE对象的READSTATE,以确保该URL对应的Document被打开)
在Documnet下可以获得documentElement和body两个节点:
...... ‘前面已经取得了ieA对象,并打开空白网页,不再重复
set doc=ieA.Document
set xbody=doc.Body ‘取得body对象
set xDoc=doc. documentElement ‘取得根节点
body前面已经说过,相当于
标记对象,根节点相当于网页中被标记的元素对象。在MHTML类型库的定义中,它们都是HTMLHtmlElement类型的对象。下面我把这种类型的对象称为“节点”,但要注意文档对象不是节点对象,它是HTMLDocument类型的。根节点和正文节点的区别在于根节点包括整个网页。在 HTML 的文档对象模型中,这种类型的对象有几个属性来获取内容:
Object.innerHtml' 对象内的 HTML 文本
Object.OuterHtml' 对象中的 HTML 文本,包括对象本身的 HTML 标记
Object.innerText' 对象内的 TEXT,不包括 HTML 标记
Object.OuterText' 同上,包括对象本身的文本
所以,如果我们想抓取某个网站的所有HTML内容,代码可以这样写:
...... ‘前面已经取得了ieA对象,并打开某URL网页
set doc=ieA.Document
set xDoc=doc. documentElement ‘取得根节点
strX=xDoc.OuterHtml ‘取得所有的HTML内容
这种取值的方式不妨可以当成EXCEL的单元格取值:
set shDocX=APPLICATION.ACTIVEWORK.ACTIVESHEET ‘从应用程序、工作簿一直定位到当前工作表,这是EXCEL的工作簿对象模型
set rngX=shDocX.Rang(“a1”) ‘取得单元格(其实不一定是一个格子,只要是RANGE类型对象即可)
X=rngX.VALUE ‘取得VALUE值,也可以取只读的TEXT
网页上看到的mark是根节点或body下的mark节点对象(node)。每个被标记的节点对象下面,都有一个叫做ChildNodes的集合,里面收录了“节点正下方的标记”,听起来有点抽象——可以这么说,它就像一个文件目录,根目录下的一个子目录内容……
你好
001
在上面的网页示例中,HTML 标记是文档的根节点,并且是文档的 Childnodes 集合的成员。从属节点的集合,就像磁盘可以有从属目录,但它本身不是目录),BODY是根节点的ChildNodes集合的成员,两个节点DIV和P是ChildNodes的两个成员BODY的集合,同样也有自己的Childnoes集合——但是我们可以直观的看到,他们的下属集合是空的。
用程序代码提问的过程是怎样的?这种“目录式”的分层方法似乎非常有序。然后,将上面的内容保存为一个HTML文档,放到硬盘的某个目录下,写一段代码完成前面的工作。我不为你做:
…….假定你已经用ieA为名的对象浏览了上述网页文件
set doc=ieA.Document
set xbody=doc. body ‘取得body节点
set xI00= xbody.Childnodes.item(0) ‘取得body的第1个节点
set xI01=xbody.Childnodes.item(0) ‘取得bdoy的第2个节点
Msgbox xI00.innerText ‘显示第1个节点(DIV)的文本
Msgbox xI01.outerHtml ‘显示第2个节点(P)的完整内容
在VB/VBA/VBS系列的语言中,item是默认方法,可以省略,不过还是写在这里加深印象。
需要注意的是,在文档对象模型中,集合不同于OFFICE集合。首先,集合是从0开始计数的。习惯OFFICE VBA编程的朋友一定要注意,不同的对象架构有不同的方式。这是“0集合”。其次,它使用 Length 而不是 Count。不要习惯性地键入 Childnode.Count 来检查集合的数量。
除了ChildNodes集合,大家在web文档对象中常见的还有一个非常流行的集合:All集合,也就是“最迷惑”的集合。各级文档和节点都有这个集合,就像名字一样。如图,没有分层,但是使用起来也很方便:
…….
Set doc=ieA.Document
Set xCols=doc.All ;取得文档中的所有节点集合
Set xbCols=doc.body.All ;取得body节点下所有的节点集合
虽然任何标记节点都有ALL集合,但我们还是喜欢用DOCUMENT的ALL,原因无它,文档最大,一锅烩的ALL找起来也最合适。
ALL查找是有条件的:如果这个标记没有ID,你无法查到它的名字:
你好
擅长
set tag1=doc.All.item(“myTag”).item(0) ‘返回标记内部ID=myTag的集合并取第一个
一开始,在我个人看来,如果网页中的 HTML 标记已经有了 ID,那么直接返回一个带有文档对象的 getElementById 的对象会更直接。这个方法不需要遍历集合:
set tag1=doc. getElementById(“myTag”) ‘返回第一个内部标有ID=myTag的标记
不过,ALL集合有一个很方便的特性——至少在初学者看来是很好用的:ID可以挂到ALL集合之下:
strX=doc.All.mytag.innerhtml ‘呜呜呜,太好用了
另一种方法是以标记名为集合,要用到文档对象的getElementsByName方法:
set mydivs=doc. getElementsByName(“div”) ‘取得所有DIV标记,注意还是集合
今天先写到这里,下回......不定期休息
(补一小段,特别增加,关于FORMS,某位兄弟,下面真的真的没有了,不要期望我上传实例......)
关于文档对象的FORMS集合,因为大部分网页数据提交都是通过FORM标签提交的,所以当网页中没有FORM标签、没有ID标签或者重复ID时,可以使用FORMS集合来区分不同的FORM节点标签。:
引用:
设置 myForms=doc.Forms' 以获取所有 FORM 标签
Set frmX=myForms.item(0)'第一个FORM
FORM标签节点所代表的对象是很多朋友关心的内容——在网页对象中,它可以向服务器发送数据,让服务器刷新网页(实际上是服务器根据到一定的格式协议),我们就可以改变网页FORM作为远程函数调用接口。FORM标签中的ACTION指向的URL地址就是函数入口,FORM标签中的每一个INPUT标签节点都是该函数的参数。当 FORM.Submit 方法发出时,该函数被远程调用。是的,在服务器端,比如ASP,PHP就是老老实实的找FORM的参数,不管是用GET还是POST:
引用:
frmX.submit' 是的,只要Submit就相当于用户在页面上按下了FORM的send按钮
但是它的参数,即 INPUT 标签呢?当然,你可以自己修改,访问,嗯...如果你分析一个现有的网页,想用VBA从一个空白页面(ABOUT:BLANK)“凭空”生成FORM和INPUT节点,就靠对上面的方法还不够,我们还要“创建一个节点”(createElement_x)并连接到文档的对应位置(appendChild),但这已经是另一个问题了 查看全部
vba抓取网页数据(
第3行字符串替换成网站的作用是创建一个IE应用程序对象)
VBA IE对象的操作方法
<p> (2013-10-27 11:39:29)
http://blog.sina.com.cn/s/blog_64173e0c0101bf9o.html
<a class="SG_aBtn SG_aBtn_ico SG_turn">
标签: vba ie 标签 对象 图片 it 分类: 电子商务
IE和文档对象模型
我们在实际工作中遇到网站和网页相关往往要涉及到这类问题:如何下载网页数据?网页之间的通讯是怎么实现的、它们能不能被控制等等。分析网页根据不同协变色镜可以用不同的角度去看,如数据流、标记,不过,如果你是用VB/VBA/脚本或其它支持自动化对象(AUTOMATION)的语言编程,有一个值得了解方法是掌握对象模型,将网页视为对象来自行控制,这个方法需要了解的是IE的自动化对象(InternetExplorer.Application)或IE控件(Microsoft Internet Controls),以及标准的文档对象模型(Document)<br /> 以下代码在VBA环境下进行试验——我不在意你是用WORD还是EXCEL——可以先做一行过程模块,也可以在立即窗口下逐行输入:
</p>
Set ieA = CreateObject("InternetExplorer.Application") ‘创建对象
ieA.Visible = True ‘使IE页面可见,做完这一步,在VBA之外可以看到一个新的IE
ieA.navigate "about:blank" ‘空白页
这几行代码的作用就是创建一个IE应用程序对象(是的,它相当于一个IE应用程序)并打开一个空白的网页。此网页独立于 VBA 应用程序(WORD 或 EXCEL)。其实必须自己关闭,或者使用ieA.Quit命令退出——注意简单关闭VBA或者SET ieA=nothing都不会退出这个页面。当然,如果你在线并且愿意,你也可以将第3行的字符串替换为网站的名称,或者替换为你主机中的一个文档名——比如C:\XXX .HTM ,或者D:\PIC\XXX.GIF,就像你在IE地址栏中输入名称浏览这些文件一样。另一种替代方法是在宿主机上直接添加一个WEB BROWS浏览器控件比如VB/VBA的表单或者工作表,也相当于上面的IE应用
注意:WEB BROWSE 控件和单独的 IE 程序并不完全相同。比如WEB控件不能用QUIT方法退出。IE 的 NAVIGETE 方法没有复杂的 POST 参数,但同样可以引用文档对象。大多数事件和方法也是通用的
另外,如果你访问一个已有的网页,比如因为有异步延迟的可能,如果不是立即窗口,往往保证网页是按照READYSTATE状态加载的:
SUB LOADIE() ‘ 在代码的常见的处理情况
Set ieA = CreateObject("InternetExplorer.Application")
ieA.Visible = True
ieA.navigate "WWW.OOXX.COM" ‘←打开某个网页,要一定时间,但代码会往下执行
DO UNTIL ieA.Readystate=4 ‘ 检查网页是否加载完毕(4表示完全加载)
DOEVENTS ‘ 循环中交回工作权限给系统,以免“软死机”
LOOP
END SUB
如果你对这个IE应用对象的相关声明和事件感兴趣,必须参考IE控件才能找到对象中的常量和事件:SHDOCVW.DLL (MICROSOFT INTERNET CONTROL)
你可以看到,通过 ieA——创建的对象——我们可以操作它并访问它的属性。让我们继续。如果你在命令行输入并且打开的空白网页没有关闭,变量将继续有效:
设置 doc = ieA.Document' 获取网页的文档对象
doc.body.innerHTML = "Hello"'在文档的BODY标签中添加标记文本HELLO
网页上有一行小字,HELLO...一般约定俗成,当然可以写其他的,HI,我爱你,EXCEL,HOME等,但这不是最重要的,我们来知道这个对象下的结构。
由文档对象(Document)扩展而来的对象模型,它代表网页的内容,与之前的IE应用程序不是同一个系统——请注意这一点——如果我们需要使用对应的对象事件和常量编程时,VB/VBA要引用的类型库是MSHTML.TLB(MIRCOSOFT HTML OBJECT LIBRARY)
Documnet(文档)是文档对象模型的基础,相当于OFFICE对象中的APPLICATION。拿到Document后,无论是修改网页、读写网页、触发事件,一切都好说。每个URL对应一个Documnet(这是如果确定成功导航到那个URL完成Navigate,则需要确定IE对象的READSTATE,以确保该URL对应的Document被打开)
在Documnet下可以获得documentElement和body两个节点:
...... ‘前面已经取得了ieA对象,并打开空白网页,不再重复
set doc=ieA.Document
set xbody=doc.Body ‘取得body对象
set xDoc=doc. documentElement ‘取得根节点
body前面已经说过,相当于
标记对象,根节点相当于网页中被标记的元素对象。在MHTML类型库的定义中,它们都是HTMLHtmlElement类型的对象。下面我把这种类型的对象称为“节点”,但要注意文档对象不是节点对象,它是HTMLDocument类型的。根节点和正文节点的区别在于根节点包括整个网页。在 HTML 的文档对象模型中,这种类型的对象有几个属性来获取内容:
Object.innerHtml' 对象内的 HTML 文本
Object.OuterHtml' 对象中的 HTML 文本,包括对象本身的 HTML 标记
Object.innerText' 对象内的 TEXT,不包括 HTML 标记
Object.OuterText' 同上,包括对象本身的文本
所以,如果我们想抓取某个网站的所有HTML内容,代码可以这样写:
...... ‘前面已经取得了ieA对象,并打开某URL网页
set doc=ieA.Document
set xDoc=doc. documentElement ‘取得根节点
strX=xDoc.OuterHtml ‘取得所有的HTML内容
这种取值的方式不妨可以当成EXCEL的单元格取值:
set shDocX=APPLICATION.ACTIVEWORK.ACTIVESHEET ‘从应用程序、工作簿一直定位到当前工作表,这是EXCEL的工作簿对象模型
set rngX=shDocX.Rang(“a1”) ‘取得单元格(其实不一定是一个格子,只要是RANGE类型对象即可)
X=rngX.VALUE ‘取得VALUE值,也可以取只读的TEXT
网页上看到的mark是根节点或body下的mark节点对象(node)。每个被标记的节点对象下面,都有一个叫做ChildNodes的集合,里面收录了“节点正下方的标记”,听起来有点抽象——可以这么说,它就像一个文件目录,根目录下的一个子目录内容……
你好
001
在上面的网页示例中,HTML 标记是文档的根节点,并且是文档的 Childnodes 集合的成员。从属节点的集合,就像磁盘可以有从属目录,但它本身不是目录),BODY是根节点的ChildNodes集合的成员,两个节点DIV和P是ChildNodes的两个成员BODY的集合,同样也有自己的Childnoes集合——但是我们可以直观的看到,他们的下属集合是空的。
用程序代码提问的过程是怎样的?这种“目录式”的分层方法似乎非常有序。然后,将上面的内容保存为一个HTML文档,放到硬盘的某个目录下,写一段代码完成前面的工作。我不为你做:
…….假定你已经用ieA为名的对象浏览了上述网页文件
set doc=ieA.Document
set xbody=doc. body ‘取得body节点
set xI00= xbody.Childnodes.item(0) ‘取得body的第1个节点
set xI01=xbody.Childnodes.item(0) ‘取得bdoy的第2个节点
Msgbox xI00.innerText ‘显示第1个节点(DIV)的文本
Msgbox xI01.outerHtml ‘显示第2个节点(P)的完整内容
在VB/VBA/VBS系列的语言中,item是默认方法,可以省略,不过还是写在这里加深印象。
需要注意的是,在文档对象模型中,集合不同于OFFICE集合。首先,集合是从0开始计数的。习惯OFFICE VBA编程的朋友一定要注意,不同的对象架构有不同的方式。这是“0集合”。其次,它使用 Length 而不是 Count。不要习惯性地键入 Childnode.Count 来检查集合的数量。
除了ChildNodes集合,大家在web文档对象中常见的还有一个非常流行的集合:All集合,也就是“最迷惑”的集合。各级文档和节点都有这个集合,就像名字一样。如图,没有分层,但是使用起来也很方便:
…….
Set doc=ieA.Document
Set xCols=doc.All ;取得文档中的所有节点集合
Set xbCols=doc.body.All ;取得body节点下所有的节点集合
虽然任何标记节点都有ALL集合,但我们还是喜欢用DOCUMENT的ALL,原因无它,文档最大,一锅烩的ALL找起来也最合适。
ALL查找是有条件的:如果这个标记没有ID,你无法查到它的名字:
你好
擅长
set tag1=doc.All.item(“myTag”).item(0) ‘返回标记内部ID=myTag的集合并取第一个
一开始,在我个人看来,如果网页中的 HTML 标记已经有了 ID,那么直接返回一个带有文档对象的 getElementById 的对象会更直接。这个方法不需要遍历集合:
set tag1=doc. getElementById(“myTag”) ‘返回第一个内部标有ID=myTag的标记
不过,ALL集合有一个很方便的特性——至少在初学者看来是很好用的:ID可以挂到ALL集合之下:
strX=doc.All.mytag.innerhtml ‘呜呜呜,太好用了
另一种方法是以标记名为集合,要用到文档对象的getElementsByName方法:
set mydivs=doc. getElementsByName(“div”) ‘取得所有DIV标记,注意还是集合
今天先写到这里,下回......不定期休息
(补一小段,特别增加,关于FORMS,某位兄弟,下面真的真的没有了,不要期望我上传实例......)
关于文档对象的FORMS集合,因为大部分网页数据提交都是通过FORM标签提交的,所以当网页中没有FORM标签、没有ID标签或者重复ID时,可以使用FORMS集合来区分不同的FORM节点标签。:
引用:
设置 myForms=doc.Forms' 以获取所有 FORM 标签
Set frmX=myForms.item(0)'第一个FORM
FORM标签节点所代表的对象是很多朋友关心的内容——在网页对象中,它可以向服务器发送数据,让服务器刷新网页(实际上是服务器根据到一定的格式协议),我们就可以改变网页FORM作为远程函数调用接口。FORM标签中的ACTION指向的URL地址就是函数入口,FORM标签中的每一个INPUT标签节点都是该函数的参数。当 FORM.Submit 方法发出时,该函数被远程调用。是的,在服务器端,比如ASP,PHP就是老老实实的找FORM的参数,不管是用GET还是POST:
引用:
frmX.submit' 是的,只要Submit就相当于用户在页面上按下了FORM的send按钮
但是它的参数,即 INPUT 标签呢?当然,你可以自己修改,访问,嗯...如果你分析一个现有的网页,想用VBA从一个空白页面(ABOUT:BLANK)“凭空”生成FORM和INPUT节点,就靠对上面的方法还不够,我们还要“创建一个节点”(createElement_x)并连接到文档的对应位置(appendChild),但这已经是另一个问题了
vba抓取网页数据(“DOM资源管理器”中的信息是什么意思的? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-16 15:31
)
基本上,当我在浏览器中加载URL并手动单击F12时,我在抓取这个特定网页的数据时经历了一段糟糕的时光,但是当我尝试以编程方式执行以下操作时,我可以看到DOM Explorer中所需的相同信息(见下文)。htmldoc不收录我在DOM Explorer中看到的相同信息
公共子测试代码()
像SHDocVw一样暗淡。InternetExplorer
将HTMLDoc设置为MSHTML。HTMLDocument
设置IE=新SHDocVw。InternetExplorer
与IE
。导航“”
一会儿。忙=真或假。ReadyState ReadyState_uuu完成:Wend
设置HTMLDoc=。文件
以
端接头
有人能帮我访问DOM资源管理器中的信息吗?我知道HTML并不总是您在浏览器中看到的内容,而是您在浏览器中看到的内容的描述,但是必须有一种从HTML以编程方式创建DOM的方法
此外,我相信我想要获得的数据是通过脚本或iframe生成的,但我一直无法生成我正在寻找的数据
更新
请参见以下DOM Explorer图像:
查看全部
vba抓取网页数据(“DOM资源管理器”中的信息是什么意思的?
)
基本上,当我在浏览器中加载URL并手动单击F12时,我在抓取这个特定网页的数据时经历了一段糟糕的时光,但是当我尝试以编程方式执行以下操作时,我可以看到DOM Explorer中所需的相同信息(见下文)。htmldoc不收录我在DOM Explorer中看到的相同信息
公共子测试代码()
像SHDocVw一样暗淡。InternetExplorer
将HTMLDoc设置为MSHTML。HTMLDocument
设置IE=新SHDocVw。InternetExplorer
与IE
。导航“”
一会儿。忙=真或假。ReadyState ReadyState_uuu完成:Wend
设置HTMLDoc=。文件
以
端接头
有人能帮我访问DOM资源管理器中的信息吗?我知道HTML并不总是您在浏览器中看到的内容,而是您在浏览器中看到的内容的描述,但是必须有一种从HTML以编程方式创建DOM的方法
此外,我相信我想要获得的数据是通过脚本或iframe生成的,但我一直无法生成我正在寻找的数据
更新
请参见以下DOM Explorer图像:
vba抓取网页数据( 我正在尝试使用VBA脚本将收件箱中的信息拉入excel电子表格 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-12-14 01:11
我正在尝试使用VBA脚本将收件箱中的信息拉入excel电子表格
)
VBA Outlook 脚本错误:找不到对象
vbaexceloutlook
VBA Outlook 脚本错误:找不到对象、vba、excel、outlook、Vba、Excel、Outlook,我正在尝试使用 VBA 脚本将收件箱中电子邮件中的信息提取到 excel 电子表格中:'主题'到地址' From Address'CC Addresses 对于已离开组织且不再在 O365 中的发件人,此操作将失败。这是代码位:Function X400toSMTP(strAdr As String) As StringDim olkRcp As Outlook.Recipient, olkUsr As Outlook.ExchangeUserSet olkRcp = S
我正在尝试使用 VBA 脚本将收件箱中的电子邮件中的信息提取到 Excel 电子表格中:
'Subject
'To Address
'From Address
'CC Addresses
对于已离开组织且不再在 O365 中的发件人,此操作将失败
这是代码位:
Function X400toSMTP(strAdr As String) As String
Dim olkRcp As Outlook.Recipient, olkUsr As Outlook.ExchangeUser
Set olkRcp = Session.CreateRecipient(strAdr)
If olkRcp.AddressEntry = Empty Then
X400toSMTP = strAdr
ElseIf olkRcp.AddressEntry.AddressEntryUserType = olExchangeUserAddressEntry Then
olkRcp.Resolve
Set olkUsr = olkRcp.AddressEntry.GetExchangeUser
X400toSMTP = olkUsr.PrimarySmtpAddress
End If
Set olkRcp = Nothing
Set olkUsr = Nothing
End Function
我运行了调试,它在
AddressEntry
停在:
尝试的操作失败。找不到对象
我正在尝试找到一种方法,让脚本将地址字段留空,以便在 O365 上找不到的发件人,并进一步处理收件箱中的剩余项目
我尝试了以下方法:
If IsNull(olkRcp.AddressEntry) Then
X400toSMTP = strAdr
但我仍然收到相同的 AddressEntry 错误
我只是一个 VBA 菜鸟,所以非常感谢你的建议
太感谢了
在访问 AddressEntry 属性之前,请确保收件人已被解析——调用 olkRcp.Resolve。
如果 olkRcp.AddressEntry 为空,则可以这样写
,如果olkRcp.AddressEntry为空,则可以编写,如果olkRcp.AddressEntry=“”,则可以编写,非常感谢,Patrick!我已经试过了,但它仍然给我错误。也许值得一提的是,我正在一个共享邮箱上运行这个。我在收件箱中的一个子文件夹上尝试了这个脚本,但它并没有停在离开者地址,而是停在我知道它有效的某个通讯组列表上。我还尝试启用“下载共享文件夹”,但仍然无法用于共享邮箱。我确实尝试过,Dmitry。但是仍然会得到相同的错误哪种方法会引发错误?决定这意味着无法解析名称。如果在Outlook中键入“收件人”框并按Ctrl+K组合键,是否可以解决此问题?它会以某种方式超出解决范围。如果olkRcp.AddressEntry为空,则函数X400toSMTP(strAdr为字符串)作为字符串Dim olkRcp作为Outlook.Recipient,olkUsr作为Outlook.ExchangeUser Set olkRcp=Session.CreateRecipient(strAdr)停止olkRcp.Resolve如果olkRcp.AddressEntry为Nothing,则X400toSMTP=strAdr ElseIf olkRcp.AddressEntry.AddressEntryUserType=olExchangeUserAddressEntry,然后设置olkUsr=olkRcp.AddressEntry.GetExchangeUser X400toSMTP=olkUsr.PrimarySmtpAddress End如果设置olkRcp=NothingSet olkUsr=Nothing End Function我使用错误处理使其工作:函数X400toSMTP(strAdr作为字符串)作为字符串Dim olkRcp作为Outlook.Recipient,olkUsr作为Outlook.ExchangeUser Set olkRcp=Session.CreateRecipient(strAdr)错误时继续下一步如果olkRcp.AddressEntry.AddressEntryUserType=olExchangeUserAddressEntry,则olkRcp.Resolve Set-olkUsr=olkRcp.AddressEntry.GetExchangeUser X400toSMTP=olkUsr.PrimarySmtAddress End如果Set-olkRcp=Nothing设置olkUsr=Nothing,则返回0 End函数 查看全部
vba抓取网页数据(
我正在尝试使用VBA脚本将收件箱中的信息拉入excel电子表格
)
VBA Outlook 脚本错误:找不到对象
vbaexceloutlook
VBA Outlook 脚本错误:找不到对象、vba、excel、outlook、Vba、Excel、Outlook,我正在尝试使用 VBA 脚本将收件箱中电子邮件中的信息提取到 excel 电子表格中:'主题'到地址' From Address'CC Addresses 对于已离开组织且不再在 O365 中的发件人,此操作将失败。这是代码位:Function X400toSMTP(strAdr As String) As StringDim olkRcp As Outlook.Recipient, olkUsr As Outlook.ExchangeUserSet olkRcp = S
我正在尝试使用 VBA 脚本将收件箱中的电子邮件中的信息提取到 Excel 电子表格中:
'Subject
'To Address
'From Address
'CC Addresses
对于已离开组织且不再在 O365 中的发件人,此操作将失败
这是代码位:
Function X400toSMTP(strAdr As String) As String
Dim olkRcp As Outlook.Recipient, olkUsr As Outlook.ExchangeUser
Set olkRcp = Session.CreateRecipient(strAdr)
If olkRcp.AddressEntry = Empty Then
X400toSMTP = strAdr
ElseIf olkRcp.AddressEntry.AddressEntryUserType = olExchangeUserAddressEntry Then
olkRcp.Resolve
Set olkUsr = olkRcp.AddressEntry.GetExchangeUser
X400toSMTP = olkUsr.PrimarySmtpAddress
End If
Set olkRcp = Nothing
Set olkUsr = Nothing
End Function
我运行了调试,它在
AddressEntry
停在:
尝试的操作失败。找不到对象
我正在尝试找到一种方法,让脚本将地址字段留空,以便在 O365 上找不到的发件人,并进一步处理收件箱中的剩余项目
我尝试了以下方法:
If IsNull(olkRcp.AddressEntry) Then
X400toSMTP = strAdr
但我仍然收到相同的 AddressEntry 错误
我只是一个 VBA 菜鸟,所以非常感谢你的建议
太感谢了
在访问 AddressEntry 属性之前,请确保收件人已被解析——调用 olkRcp.Resolve。
如果 olkRcp.AddressEntry 为空,则可以这样写
,如果olkRcp.AddressEntry为空,则可以编写,如果olkRcp.AddressEntry=“”,则可以编写,非常感谢,Patrick!我已经试过了,但它仍然给我错误。也许值得一提的是,我正在一个共享邮箱上运行这个。我在收件箱中的一个子文件夹上尝试了这个脚本,但它并没有停在离开者地址,而是停在我知道它有效的某个通讯组列表上。我还尝试启用“下载共享文件夹”,但仍然无法用于共享邮箱。我确实尝试过,Dmitry。但是仍然会得到相同的错误哪种方法会引发错误?决定这意味着无法解析名称。如果在Outlook中键入“收件人”框并按Ctrl+K组合键,是否可以解决此问题?它会以某种方式超出解决范围。如果olkRcp.AddressEntry为空,则函数X400toSMTP(strAdr为字符串)作为字符串Dim olkRcp作为Outlook.Recipient,olkUsr作为Outlook.ExchangeUser Set olkRcp=Session.CreateRecipient(strAdr)停止olkRcp.Resolve如果olkRcp.AddressEntry为Nothing,则X400toSMTP=strAdr ElseIf olkRcp.AddressEntry.AddressEntryUserType=olExchangeUserAddressEntry,然后设置olkUsr=olkRcp.AddressEntry.GetExchangeUser X400toSMTP=olkUsr.PrimarySmtpAddress End如果设置olkRcp=NothingSet olkUsr=Nothing End Function我使用错误处理使其工作:函数X400toSMTP(strAdr作为字符串)作为字符串Dim olkRcp作为Outlook.Recipient,olkUsr作为Outlook.ExchangeUser Set olkRcp=Session.CreateRecipient(strAdr)错误时继续下一步如果olkRcp.AddressEntry.AddressEntryUserType=olExchangeUserAddressEntry,则olkRcp.Resolve Set-olkUsr=olkRcp.AddressEntry.GetExchangeUser X400toSMTP=olkUsr.PrimarySmtAddress End如果Set-olkRcp=Nothing设置olkUsr=Nothing,则返回0 End函数
vba抓取网页数据(UI学习大纲与UI的交互(UIInteraction)的GetText )
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-11-30 13:16
)
学习大纲
UI交互可以分为两种类型:输入和输出。
**输入**:让应用程序做一些事情。如鼠标单击、文本输入、键盘快捷键、鼠标右键单击、鼠标悬停等。
**输出**:从应用程序中提取信息。获取文本、查找元素和图片、操作剪贴板等。
1. 输入法
输入法**兼容性**运行速度支持后台工作支持热键自动清除内容
默认
100%
50%
X
√
X
窗口消息
80%
50%
√
√
X
模拟类型/点击
*70%
100%
√
X
√
*Simulate Type/Click 兼容 99% 的 Web 应用程序和 60% 的桌面应用程序
实例验证:
操作结果:
建议:尝试每种输入法。首先使用 Default 方法,因为它肯定会起作用。然后尝试使用 Simulate 或 WindowMessages 方法来提高运行速度或实现后台工作。
2. 输出方式:屏幕抓取
上一课使用的Get Text 活动仅适用于抓取简单和简短的文本。和屏幕
抓取可以抓取复杂元素中存在的较大文本片段。屏幕
刮取还可以获得文本的位置和颜色等信息。
使用 Screen Scraping 工具抓取信息时,您可以尝试以下三种方法:
**输出方式**运行速度**准确度**支持后台工作获取文本位置获取隐藏文本兼容Citrix
全文
很快
100%
√
X
√
X
本国的
快点
100%
X
√
X
X
文字识别
非常慢
98%
X
√
X
√
FullText 是默认的方法,大多数情况下也有一个有效的方法。
Native 的优点是可以获取文本的其他信息,例如单词或字母在屏幕上的坐标。
OCR 无法达到 100% 的准确率,但是当其他两种方法都不起作用时,OCR 是最后的手段。
*只有 OCR 可以在 Citrix 或虚拟环境中运行。OCR 还可以获取文本位置。
如何使用屏幕抓取:
1) 点击Design Ribbon中的Screen Scraping按钮,会出现选择界面。
2)点击选择要提取的信息。您可以选择收录多个元素的区域。
3) 选择后,会弹出 Screen Scraper Wizard 窗口。点击界面
元素或区域可以更改从中提取信息的区域。
这里UiPath自动选择了Native方法,可以在Options面板中改成其他两种方法。
从预览面板中可以看到,Native 方法只抓取可编辑区域中的文本。
4) 切换到全文方式后,预览面板中的信息发生了变化。
满的
Text方法不仅抓取可编辑区域的文字,还抓取不可编辑区域的文字和下拉列表中隐藏的文字。
*在选项面板中勾选忽略
Hidden 选项,然后单击 Re-scrape 按钮忽略隐藏的文本。
5) OCR 方法就更不一样了。它将所选区域视为图片来阅读文本。
由于错别字,OCR方法只适用于数据不需要完全正确的情况。
UiPath 提供两个 OCR 引擎。微软Office
OCR 适用于较大的图像,例如扫描的文档。
Google OCR 更适合读取较小、分辨率较低的图像,例如界面上的元素。
“选项”面板中的“反转”选项专门用于某些黑底白字的图片。缩放选项可以放大图片以获得更好的效果。
我们可以一一尝试这些选项,看看预览面板的结果有什么变化,找到最佳组合。
6) 设置好后,点击右下角的Continue按钮,会得到一个ScreenScraping Sequence。
Selector 代表要抓取文本的元素或区域。当多个活动的元素或区域相同时,可以将Selector中的内容直接复制到其他活动中,而无需重新选择元素或区域。Text 变量用于保存捕获的文本。
如果你想尝试另一个OCR,你可以删除谷歌OCR活动,然后更改MS Office
OCR活动拖进来,建议把Scale属性改成3,因为MS Office
OCR 更适合阅读较大的图片。
*如果您不使用屏幕抓取,您也可以手动添加活动。
手动添加的输出方式
基本录音
获取文本
全文
获取全文
本国的
获取可见文本
文字识别
获取 OCR 文本
*****在上面的例子中,Get Text 活动只能抓取“地址”这个词。
3. 数据抓取
Screen Scraping 用于捕获 Freeform Data(自由格式数据)。和数据
抓取用于捕获**结构化数据**。
什么是结构化数据?
当你在谷歌上搜索某个关键词时,你得到的搜索结果是由多条格式相同的数据组成,每条数据由三部分组成:标题、网址和描述。此类数据是结构化的
数据。
如何使用数据抓取:
以亚马逊的图书搜索页面为例。此页面上的数据也是结构化的
数据,但比 Google 的搜索结果页面更复杂。
1)单击设计功能区中的 Web
Scraping 按钮,会出现一个向导窗口,点击 Next 开始选择第一个元素。
2) 点击第一本书的书名,会再次弹出向导窗口。单击下一步继续。
3) 点击第二本书的书名,会再次弹出向导窗口。书名也是一个链接,因此向导窗口可以选择提取文本或 URL。
此处选中了这两个选项,它们被命名为 Title 和 URL。点击下一步按钮,弹出向导预览界面。
4)除了预览数据外,还标注了网页上的相应位置,方便查看。然后提取“作者”和“价格”并单击 ExtractCorrelated Data 按钮。
5)选择第一个元素时向导返回界面,重复上述步骤提取“作者”和“价格”信息。单击完成按钮。
6)UiPath 会询问我们数据是否跨页面分布。将页面下拉到您选择页码的位置,选择是,然后选择页面上的下一页元素。
7) 向导结束后,你会得到一个名为WebScraping的Sequence,并得到一个DataTable类型的Output变量。
添加写入 CSV 活动以将捕获的数据保存在 CSV 文件中。
8) 这个CSV文件有100条记录,但搜索结果远远超过100条。这是因为UiPath默认只抓取100条记录,你可以在属性面板中更改设置。
使用Web Scraping抓取网页上的表格(HTML表格),当您点击表格中的任何单元格时,会弹出Extract Table提示窗口。
如果选择是,则可以直接抓取整个表格的数据,而无需选择第二个元素。如果选择否,则需要重复前面的步骤来选择第二个元素。
4. 练习:
提取链接页面的 100 条记录,包括名称和价格,并将数据存储在新的 Excel 表中。
*第一次选择页面的名字,
第二次选择页面的姓氏。与第二次选择第二个名字相比,它更有可能生成一致的标识符
(一致的标识符)。
2) 不应用Recording功能完成如下操作:在记事本中打开字体对话框,将字体改为Arial,样式改为斜体,将字体大小增加5,并选择一个新的脚本
(脚本)。
在第二个Attach Window活动的Do中添加一个Click活动,点击格式菜单中的字体
(字体)按钮。
在弹出的字体对话框中添加一个新的附加窗口活动。
为第三个附加窗口活动的 Do 添加一个类型
进入activity,指定元素并点击字体输入框,输入Arial。
添加另一个 Type Into 活动,指定元素并单击字体样式输入框,输入斜体。
添加获取
在 Text 活动中,指定元素并单击字体大小的输入框。创建一个 Int32 类型的新变量 fontSize 并将其设置为 Get
文本活动的输出。
添加类型
进入activity,指定元素,点击字体大小的输入框,输入**(fontSize+5).ToString**.
添加选择
Item活动,指定Script下拉菜单为Target的Selector参数,输入Greek作为Input的Item参数。
注意:
*本课使用的新活动、方法、功能等:
加入万人职场社区,为你的事业保驾护航!
查看全部
vba抓取网页数据(UI学习大纲与UI的交互(UIInteraction)的GetText
)
学习大纲
UI交互可以分为两种类型:输入和输出。
**输入**:让应用程序做一些事情。如鼠标单击、文本输入、键盘快捷键、鼠标右键单击、鼠标悬停等。
**输出**:从应用程序中提取信息。获取文本、查找元素和图片、操作剪贴板等。
1. 输入法
输入法**兼容性**运行速度支持后台工作支持热键自动清除内容
默认
100%
50%
X
√
X
窗口消息
80%
50%
√
√
X
模拟类型/点击
*70%
100%
√
X
√
*Simulate Type/Click 兼容 99% 的 Web 应用程序和 60% 的桌面应用程序
实例验证:


操作结果:
建议:尝试每种输入法。首先使用 Default 方法,因为它肯定会起作用。然后尝试使用 Simulate 或 WindowMessages 方法来提高运行速度或实现后台工作。
2. 输出方式:屏幕抓取
上一课使用的Get Text 活动仅适用于抓取简单和简短的文本。和屏幕
抓取可以抓取复杂元素中存在的较大文本片段。屏幕
刮取还可以获得文本的位置和颜色等信息。
使用 Screen Scraping 工具抓取信息时,您可以尝试以下三种方法:
**输出方式**运行速度**准确度**支持后台工作获取文本位置获取隐藏文本兼容Citrix
全文
很快
100%
√
X
√
X
本国的
快点
100%
X
√
X
X
文字识别
非常慢
98%
X
√
X
√
FullText 是默认的方法,大多数情况下也有一个有效的方法。
Native 的优点是可以获取文本的其他信息,例如单词或字母在屏幕上的坐标。
OCR 无法达到 100% 的准确率,但是当其他两种方法都不起作用时,OCR 是最后的手段。
*只有 OCR 可以在 Citrix 或虚拟环境中运行。OCR 还可以获取文本位置。
如何使用屏幕抓取:
1) 点击Design Ribbon中的Screen Scraping按钮,会出现选择界面。

2)点击选择要提取的信息。您可以选择收录多个元素的区域。

3) 选择后,会弹出 Screen Scraper Wizard 窗口。点击界面
元素或区域可以更改从中提取信息的区域。
这里UiPath自动选择了Native方法,可以在Options面板中改成其他两种方法。

从预览面板中可以看到,Native 方法只抓取可编辑区域中的文本。
4) 切换到全文方式后,预览面板中的信息发生了变化。
满的
Text方法不仅抓取可编辑区域的文字,还抓取不可编辑区域的文字和下拉列表中隐藏的文字。

*在选项面板中勾选忽略
Hidden 选项,然后单击 Re-scrape 按钮忽略隐藏的文本。

5) OCR 方法就更不一样了。它将所选区域视为图片来阅读文本。
由于错别字,OCR方法只适用于数据不需要完全正确的情况。

UiPath 提供两个 OCR 引擎。微软Office
OCR 适用于较大的图像,例如扫描的文档。
Google OCR 更适合读取较小、分辨率较低的图像,例如界面上的元素。

“选项”面板中的“反转”选项专门用于某些黑底白字的图片。缩放选项可以放大图片以获得更好的效果。
我们可以一一尝试这些选项,看看预览面板的结果有什么变化,找到最佳组合。
6) 设置好后,点击右下角的Continue按钮,会得到一个ScreenScraping Sequence。


Selector 代表要抓取文本的元素或区域。当多个活动的元素或区域相同时,可以将Selector中的内容直接复制到其他活动中,而无需重新选择元素或区域。Text 变量用于保存捕获的文本。
如果你想尝试另一个OCR,你可以删除谷歌OCR活动,然后更改MS Office
OCR活动拖进来,建议把Scale属性改成3,因为MS Office
OCR 更适合阅读较大的图片。
*如果您不使用屏幕抓取,您也可以手动添加活动。
手动添加的输出方式
基本录音
获取文本
全文
获取全文
本国的
获取可见文本
文字识别
获取 OCR 文本
*****在上面的例子中,Get Text 活动只能抓取“地址”这个词。
3. 数据抓取
Screen Scraping 用于捕获 Freeform Data(自由格式数据)。和数据
抓取用于捕获**结构化数据**。
什么是结构化数据?
当你在谷歌上搜索某个关键词时,你得到的搜索结果是由多条格式相同的数据组成,每条数据由三部分组成:标题、网址和描述。此类数据是结构化的
数据。

如何使用数据抓取:
以亚马逊的图书搜索页面为例。此页面上的数据也是结构化的
数据,但比 Google 的搜索结果页面更复杂。

1)单击设计功能区中的 Web
Scraping 按钮,会出现一个向导窗口,点击 Next 开始选择第一个元素。


2) 点击第一本书的书名,会再次弹出向导窗口。单击下一步继续。


3) 点击第二本书的书名,会再次弹出向导窗口。书名也是一个链接,因此向导窗口可以选择提取文本或 URL。

此处选中了这两个选项,它们被命名为 Title 和 URL。点击下一步按钮,弹出向导预览界面。

4)除了预览数据外,还标注了网页上的相应位置,方便查看。然后提取“作者”和“价格”并单击 ExtractCorrelated Data 按钮。
5)选择第一个元素时向导返回界面,重复上述步骤提取“作者”和“价格”信息。单击完成按钮。
6)UiPath 会询问我们数据是否跨页面分布。将页面下拉到您选择页码的位置,选择是,然后选择页面上的下一页元素。


7) 向导结束后,你会得到一个名为WebScraping的Sequence,并得到一个DataTable类型的Output变量。
添加写入 CSV 活动以将捕获的数据保存在 CSV 文件中。
8) 这个CSV文件有100条记录,但搜索结果远远超过100条。这是因为UiPath默认只抓取100条记录,你可以在属性面板中更改设置。

使用Web Scraping抓取网页上的表格(HTML表格),当您点击表格中的任何单元格时,会弹出Extract Table提示窗口。
如果选择是,则可以直接抓取整个表格的数据,而无需选择第二个元素。如果选择否,则需要重复前面的步骤来选择第二个元素。

4. 练习:
提取链接页面的 100 条记录,包括名称和价格,并将数据存储在新的 Excel 表中。
*第一次选择页面的名字,
第二次选择页面的姓氏。与第二次选择第二个名字相比,它更有可能生成一致的标识符
(一致的标识符)。
2) 不应用Recording功能完成如下操作:在记事本中打开字体对话框,将字体改为Arial,样式改为斜体,将字体大小增加5,并选择一个新的脚本
(脚本)。
在第二个Attach Window活动的Do中添加一个Click活动,点击格式菜单中的字体
(字体)按钮。
在弹出的字体对话框中添加一个新的附加窗口活动。
为第三个附加窗口活动的 Do 添加一个类型
进入activity,指定元素并点击字体输入框,输入Arial。
添加另一个 Type Into 活动,指定元素并单击字体样式输入框,输入斜体。
添加获取
在 Text 活动中,指定元素并单击字体大小的输入框。创建一个 Int32 类型的新变量 fontSize 并将其设置为 Get
文本活动的输出。
添加类型
进入activity,指定元素,点击字体大小的输入框,输入**(fontSize+5).ToString**.
添加选择
Item活动,指定Script下拉菜单为Target的Selector参数,输入Greek作为Input的Item参数。
注意:
*本课使用的新活动、方法、功能等:
加入万人职场社区,为你的事业保驾护航!

vba抓取网页数据(UI学习大纲与UI的交互(UIInteraction)的GetText )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-25 05:18
)
学习大纲
UI交互可以分为两种类型:输入和输出。
**输入**:让应用程序做一些事情。如鼠标单击、文本输入、键盘快捷键、鼠标右键单击、鼠标悬停等。
**输出**:从应用程序中提取信息。获取文本、查找元素和图片、操作剪贴板等。
1. 输入法
输入法**兼容性**运行速度支持后台工作支持热键自动清除内容
默认
100%
50%
X
√
X
窗口消息
80%
50%
√
√
X
模拟类型/点击
*70%
100%
√
X
√
*Simulate Type/Click 兼容 99% 的 Web 应用程序和 60% 的桌面应用程序
实例验证:
操作结果:
建议:尝试每种输入法。首先使用 Default 方法,因为它肯定会起作用。然后尝试使用 Simulate 或 WindowMessages 方法来提高运行速度或实现后台工作。
2. 输出方式:屏幕抓取
上一课使用的Get Text 活动仅适用于抓取简单和简短的文本。和屏幕
抓取可以抓取复杂元素中存在的较大文本片段。屏幕
刮取还可以获得文本的位置和颜色等信息。
使用 Screen Scraping 工具抓取信息时,您可以尝试以下三种方法:
**输出方式**运行速度**准确度**支持后台工作获取文本位置获取隐藏文本兼容Citrix
全文
很快
100%
√
X
√
X
本国的
快点
100%
X
√
X
X
文字识别
非常慢
98%
X
√
X
√
FullText 是默认的方法,大多数情况下也有一个有效的方法。
Native 的优点是可以获取文本的其他信息,例如单词或字母在屏幕上的坐标。
OCR 无法达到 100% 的准确率,但是当其他两种方法都不起作用时,OCR 是最后的手段。
*只有 OCR 可以在 Citrix 或虚拟环境中运行。OCR 还可以获取文本位置。
如何使用屏幕抓取:
1) 点击Design Ribbon中的Screen Scraping按钮,会出现选择界面。
2)点击选择要提取的信息。您可以选择收录多个元素的区域。
3) 选择后,会弹出 Screen Scraper Wizard 窗口。点击界面
元素或区域可以更改从中提取信息的区域。
这里UiPath自动选择了Native方法,可以在Options面板中改成其他两种方法。
从预览面板中可以看到,Native 方法只抓取可编辑区域中的文本。
4) 切换到全文方式后,预览面板中的信息发生了变化。
满的
Text方法不仅抓取可编辑区域的文字,还抓取不可编辑区域的文字和下拉列表中隐藏的文字。
*在选项面板中勾选忽略
Hidden 选项,然后单击 Re-scrape 按钮忽略隐藏文本。
5) OCR 方法就更不一样了。它将所选区域视为图片来阅读文本。
由于错别字,OCR方法只适用于数据不需要完全正确的情况。
UiPath 提供两个 OCR 引擎。微软Office
OCR 适用于较大的图像,例如扫描的文档。
Google OCR 更适合读取较小、分辨率较低的图像,例如界面上的元素。
“选项”面板中的“反转”选项专门用于某些黑底白字的图片。缩放选项可以放大图片以获得更好的效果。
我们可以一一尝试这些选项,看看预览面板的结果有什么变化,找到最佳组合。
6) 设置好后,点击右下角的Continue按钮,会得到一个ScreenScraping Sequence。
Selector 代表要抓取文本的元素或区域。当多个活动的元素或区域相同时,可以将Selector中的内容直接复制到其他活动中,而无需重新选择元素或区域。Text 变量用于保存捕获的文本。
如果你想尝试另一个OCR,你可以删除谷歌OCR活动,然后MS Office
OCR活动拖进来,建议把Scale属性改成3,因为MS Office
OCR 更适合阅读较大的图片。
*如果您不使用屏幕抓取,您也可以手动添加活动。
手动添加的输出方式
基本录音
获取文本
全文
获取全文
本国的
获取可见文本
文字识别
获取 OCR 文本
*****在上面的例子中,Get Text 活动只能抓取“地址”这个词。
3. 数据抓取
Screen Scraping 用于捕获 Freeform Data(自由格式数据)。和数据
抓取用于捕获**结构化数据**。
什么是结构化数据?
当你在谷歌上搜索某个关键词时,你得到的搜索结果是由多条格式相同的数据组成,每条数据由三部分组成:标题、网址和描述。此类数据是结构化的
数据。
如何使用数据抓取:
以亚马逊的图书搜索页面为例。此页面上的数据也是结构化的
数据,但比 Google 的搜索结果页面更复杂。
1)单击设计功能区中的 Web
Scraping 按钮,会出现一个向导窗口,点击 Next 开始选择第一个元素。
2) 点击第一本书的书名,会再次弹出向导窗口。单击下一步继续。
3) 点击第二本书的书名,会再次弹出向导窗口。书名也是一个链接,因此向导窗口可以选择提取文本或 URL。
此处选中了这两个选项,它们被命名为 Title 和 URL。点击下一步按钮,弹出向导预览界面。
4)除了预览数据外,还标注了网页对应位置,方便查看。然后提取“作者”和“价格”并单击 ExtractCorrelated Data 按钮。
5)选择第一个元素时向导返回界面,重复上述步骤提取“作者”和“价格”信息。单击完成按钮。
6)UiPath 会询问我们数据是否跨页面分布。将页面下拉到您选择页码的位置,选择是,然后选择页面上的下一页元素。
7) 向导结束后,你会得到一个名为WebScraping的Sequence,并得到一个DataTable类型的Output变量。
添加写入 CSV 活动以将捕获的数据保存在 CSV 文件中。
8) 这个CSV文件有100条记录,但搜索结果远远超过100条。这是因为UiPath默认只抓取100条记录,你可以在属性面板中更改设置。
使用Web Scraping抓取网页上的表格(HTML表格),当您点击表格中的任何单元格时,会弹出Extract Table提示窗口。
如果选择是,则可以直接抓取整个表格的数据,而无需选择第二个元素。如果选择否,则需要重复前面的步骤来选择第二个元素。
4. 练习:
提取链接页面的 100 条记录,包括名称和价格,并将数据存储在新的 Excel 表中。
*第一次选择页面的名字,
第二次选择页面的姓氏。与第二次选择第二个名字相比,它更有可能生成一致的标识符
(一致的标识符)。
2) 不应用Recording功能完成如下操作:在记事本中打开字体对话框,将字体改为Arial,样式改为斜体,将字体大小增加5,并选择一个新的脚本
(脚本)。
在第二个Attach Window活动的Do中添加一个Click活动,点击格式菜单中的字体
(字体)按钮。
在弹出的字体对话框中添加一个新的附加窗口活动。
为第三个附加窗口活动的 Do 添加一个类型
进入activity,指定元素并点击字体输入框,输入Arial。
添加另一个 Type Into 活动,指定元素并单击字体样式输入框,输入斜体。
添加获取
在 Text 活动中,指定元素并单击字体大小的输入框。创建一个 Int32 类型的新变量 fontSize 并将其设置为 Get
文本活动的输出。
添加类型
进入activity,指定元素,点击字体大小的输入框,输入**(fontSize+5).ToString**.
添加选择
Item活动,指定Script下拉菜单为Target的Selector参数,输入Greek作为Input的Item参数。
注意:
*本课使用的新活动、方法、功能等:
加入万人职场社区,为你的事业保驾护航!
查看全部
vba抓取网页数据(UI学习大纲与UI的交互(UIInteraction)的GetText
)
学习大纲
UI交互可以分为两种类型:输入和输出。
**输入**:让应用程序做一些事情。如鼠标单击、文本输入、键盘快捷键、鼠标右键单击、鼠标悬停等。
**输出**:从应用程序中提取信息。获取文本、查找元素和图片、操作剪贴板等。
1. 输入法
输入法**兼容性**运行速度支持后台工作支持热键自动清除内容
默认
100%
50%
X
√
X
窗口消息
80%
50%
√
√
X
模拟类型/点击
*70%
100%
√
X
√
*Simulate Type/Click 兼容 99% 的 Web 应用程序和 60% 的桌面应用程序
实例验证:


操作结果:
建议:尝试每种输入法。首先使用 Default 方法,因为它肯定会起作用。然后尝试使用 Simulate 或 WindowMessages 方法来提高运行速度或实现后台工作。
2. 输出方式:屏幕抓取
上一课使用的Get Text 活动仅适用于抓取简单和简短的文本。和屏幕
抓取可以抓取复杂元素中存在的较大文本片段。屏幕
刮取还可以获得文本的位置和颜色等信息。
使用 Screen Scraping 工具抓取信息时,您可以尝试以下三种方法:
**输出方式**运行速度**准确度**支持后台工作获取文本位置获取隐藏文本兼容Citrix
全文
很快
100%
√
X
√
X
本国的
快点
100%
X
√
X
X
文字识别
非常慢
98%
X
√
X
√
FullText 是默认的方法,大多数情况下也有一个有效的方法。
Native 的优点是可以获取文本的其他信息,例如单词或字母在屏幕上的坐标。
OCR 无法达到 100% 的准确率,但是当其他两种方法都不起作用时,OCR 是最后的手段。
*只有 OCR 可以在 Citrix 或虚拟环境中运行。OCR 还可以获取文本位置。
如何使用屏幕抓取:
1) 点击Design Ribbon中的Screen Scraping按钮,会出现选择界面。

2)点击选择要提取的信息。您可以选择收录多个元素的区域。

3) 选择后,会弹出 Screen Scraper Wizard 窗口。点击界面
元素或区域可以更改从中提取信息的区域。
这里UiPath自动选择了Native方法,可以在Options面板中改成其他两种方法。

从预览面板中可以看到,Native 方法只抓取可编辑区域中的文本。
4) 切换到全文方式后,预览面板中的信息发生了变化。
满的
Text方法不仅抓取可编辑区域的文字,还抓取不可编辑区域的文字和下拉列表中隐藏的文字。

*在选项面板中勾选忽略
Hidden 选项,然后单击 Re-scrape 按钮忽略隐藏文本。

5) OCR 方法就更不一样了。它将所选区域视为图片来阅读文本。
由于错别字,OCR方法只适用于数据不需要完全正确的情况。

UiPath 提供两个 OCR 引擎。微软Office
OCR 适用于较大的图像,例如扫描的文档。
Google OCR 更适合读取较小、分辨率较低的图像,例如界面上的元素。

“选项”面板中的“反转”选项专门用于某些黑底白字的图片。缩放选项可以放大图片以获得更好的效果。
我们可以一一尝试这些选项,看看预览面板的结果有什么变化,找到最佳组合。
6) 设置好后,点击右下角的Continue按钮,会得到一个ScreenScraping Sequence。


Selector 代表要抓取文本的元素或区域。当多个活动的元素或区域相同时,可以将Selector中的内容直接复制到其他活动中,而无需重新选择元素或区域。Text 变量用于保存捕获的文本。
如果你想尝试另一个OCR,你可以删除谷歌OCR活动,然后MS Office
OCR活动拖进来,建议把Scale属性改成3,因为MS Office
OCR 更适合阅读较大的图片。
*如果您不使用屏幕抓取,您也可以手动添加活动。
手动添加的输出方式
基本录音
获取文本
全文
获取全文
本国的
获取可见文本
文字识别
获取 OCR 文本
*****在上面的例子中,Get Text 活动只能抓取“地址”这个词。
3. 数据抓取
Screen Scraping 用于捕获 Freeform Data(自由格式数据)。和数据
抓取用于捕获**结构化数据**。
什么是结构化数据?
当你在谷歌上搜索某个关键词时,你得到的搜索结果是由多条格式相同的数据组成,每条数据由三部分组成:标题、网址和描述。此类数据是结构化的
数据。

如何使用数据抓取:
以亚马逊的图书搜索页面为例。此页面上的数据也是结构化的
数据,但比 Google 的搜索结果页面更复杂。

1)单击设计功能区中的 Web
Scraping 按钮,会出现一个向导窗口,点击 Next 开始选择第一个元素。


2) 点击第一本书的书名,会再次弹出向导窗口。单击下一步继续。


3) 点击第二本书的书名,会再次弹出向导窗口。书名也是一个链接,因此向导窗口可以选择提取文本或 URL。

此处选中了这两个选项,它们被命名为 Title 和 URL。点击下一步按钮,弹出向导预览界面。

4)除了预览数据外,还标注了网页对应位置,方便查看。然后提取“作者”和“价格”并单击 ExtractCorrelated Data 按钮。
5)选择第一个元素时向导返回界面,重复上述步骤提取“作者”和“价格”信息。单击完成按钮。
6)UiPath 会询问我们数据是否跨页面分布。将页面下拉到您选择页码的位置,选择是,然后选择页面上的下一页元素。


7) 向导结束后,你会得到一个名为WebScraping的Sequence,并得到一个DataTable类型的Output变量。
添加写入 CSV 活动以将捕获的数据保存在 CSV 文件中。
8) 这个CSV文件有100条记录,但搜索结果远远超过100条。这是因为UiPath默认只抓取100条记录,你可以在属性面板中更改设置。

使用Web Scraping抓取网页上的表格(HTML表格),当您点击表格中的任何单元格时,会弹出Extract Table提示窗口。
如果选择是,则可以直接抓取整个表格的数据,而无需选择第二个元素。如果选择否,则需要重复前面的步骤来选择第二个元素。

4. 练习:
提取链接页面的 100 条记录,包括名称和价格,并将数据存储在新的 Excel 表中。
*第一次选择页面的名字,
第二次选择页面的姓氏。与第二次选择第二个名字相比,它更有可能生成一致的标识符
(一致的标识符)。
2) 不应用Recording功能完成如下操作:在记事本中打开字体对话框,将字体改为Arial,样式改为斜体,将字体大小增加5,并选择一个新的脚本
(脚本)。
在第二个Attach Window活动的Do中添加一个Click活动,点击格式菜单中的字体
(字体)按钮。
在弹出的字体对话框中添加一个新的附加窗口活动。
为第三个附加窗口活动的 Do 添加一个类型
进入activity,指定元素并点击字体输入框,输入Arial。
添加另一个 Type Into 活动,指定元素并单击字体样式输入框,输入斜体。
添加获取
在 Text 活动中,指定元素并单击字体大小的输入框。创建一个 Int32 类型的新变量 fontSize 并将其设置为 Get
文本活动的输出。
添加类型
进入activity,指定元素,点击字体大小的输入框,输入**(fontSize+5).ToString**.
添加选择
Item活动,指定Script下拉菜单为Target的Selector参数,输入Greek作为Input的Item参数。
注意:
*本课使用的新活动、方法、功能等:
加入万人职场社区,为你的事业保驾护航!
vba抓取网页数据(《VBA信息获取与处理》教程:第四节将VBA写入工作表时)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-19 02:08
【分享成果,正能量庆幸】越是倒霉,越要冷静,振作起来,默默的生存下去,你要接受,那些突如其来的损失,当你什么都不做的时候,唯一的你能做的事 试着让自己变得更好一点。
再有能力的人,也抓不住;无论他们多么执着,他们都会被打破。人累了,就有休息的权利,心痛时,就有放手的理由。不必咄咄逼人,眼泪是最好的释放,不必伪装,回报是最美的容颜。
《VBA信息获取与处理》教程是我的第六套教程,现在是第一次修订。这套教程定位于最高级别,是完成初级和中级之后的教程。本教程内容为:跨应用信息获取、随机信息利用、邮件发送、VBA上网数据抓取、VBA延时操作、剪贴板应用、Split函数扩展、工作表信息等应用交互、FSO对象的使用、工作表和文件夹信息的获取、图形信息的获取、工作表信息的自定义等功能。程序文件通过32位和64位Office系统测试。它非常抽象,更有研究价值。
本教程共两卷,八十四讲。今天的内容是主题四“EXCEL工作表数据读取、回填和搜索”的第四讲:数组转置
第四节 将VBA数组写入工作表时Transpose的使用
转置是数组应用中经常用到的知识点。在使用Excel表格的过程中,当我们想把横行变成竖列(或者把竖排的数据转为横排)时,希望两个不同排列的数据相互关联时,可以使用转置函数. 但是注意这个函数是一个工作表函数,所以在使用这个函数的时候一定要使用Application.Transpose(Arr)。
1 用一维数组回填工作表时的转置(Transpose)
如果需要按列回填一维数组,可以使用如下语句:MyRange.Value = Application.Transpose(Arr)
具体代码如下:
Sub MYNZG()'一维数组数据的转置回填方案
Dim Arr 作为变体
将 MyRange 调暗为范围
工作表(“SHEET4”)。选择
Arr = Array("大象", "老虎", "狮子", "狐狸")
设置 MyRange = Range("A1")
设置 MyRange = MyRange.Resize(UBound(Arr) + 1, 1)
MyRange.ClearContents
MyRange.Value = Application.Transpose(Arr)
MsgBox “好的!”
结束子
代码截图:
代码说明:这里需要注意的是,base cell area的展开语句变成了: Resize(UBound(Arr) + 1, 1) 这是列的展开,所以转置语句为Application。 Transpose(Arr ). 这里要注意的一点是resize参数是颠倒的。
2 用二维数组回填工作表时的转置(Transpose)
如果需要按列回填二维数组,可以使用如下语句:MyRange.Value = Application.Transpose(Arr)
具体代码如下:
Sub MYNZH()'二维数组数据的转置回填方案
Dim Arr 作为变体
将 MyRange 调暗为范围
工作表(“SHEET4”)。选择
Arr = Sheets("SHEET2").Range("A1:b9")
设置 MyRange = Range("A1")
设置 MyRange = MyRange.Resize(UBound(Arr, 2), UBound(Arr, 1))
MyRange.ClearContents
MyRange.Value = Application.Transpose(Arr)
MsgBox “好的!”
结束子
代码截图如下:
代码说明:当从工作表中读取数组变量时,VBA会自动调整数组的大小来保持工作表上的范围,所以你不需要关心数组的大小。但是,从 VBA 将数组写入工作表时,必须调整目标区域的大小以容纳该数组。我们在前面的例子中已经看到了这一点。
如果传递给工作表的数组小于其写入范围,则未使用的单元格将出现“#N/A”错误。如果传递的数组大于其写入范围,则数组将在右侧或底部截断以适应范围。
本节知识点:如何理解换位?如何使用一维数组和二维数组转置?
本主题的参考程序文件:004 worksheet.XLSM
我20多年的VBA实践经验都浓缩在下面的教程中,教程学习顺序:
① 7→1→3→2→6→5 或 7→4→3→2→6→5。
② 7→8
各套教程简介:
第七套教程(共三册):《EXCEL Application of VBA》:VBA基础讲解
第一套教程(共三册):《VBA代码解决方案》:上手后的改进教程
第四组教程(16G):VBA代码解题视频(第一组视频讲解)
第三套教程(共两册):《VBA Array and Dictionary Solution》:是数组和字典的专门讲解
第二套教程(共两册):《VBA数据库解决方案》:是数据库的专门讲解
第六套教程(共两册):《VBA信息获取与处理》:讲解VBA的网络和跨程序应用
第五套教程(共两册):VBA中类的解释与利用:类与接口技术讲解
第八套教程(共三册):VBA的Word应用(最新教程):VBA在Word中的使用 查看全部
vba抓取网页数据(《VBA信息获取与处理》教程:第四节将VBA写入工作表时)
【分享成果,正能量庆幸】越是倒霉,越要冷静,振作起来,默默的生存下去,你要接受,那些突如其来的损失,当你什么都不做的时候,唯一的你能做的事 试着让自己变得更好一点。
再有能力的人,也抓不住;无论他们多么执着,他们都会被打破。人累了,就有休息的权利,心痛时,就有放手的理由。不必咄咄逼人,眼泪是最好的释放,不必伪装,回报是最美的容颜。
《VBA信息获取与处理》教程是我的第六套教程,现在是第一次修订。这套教程定位于最高级别,是完成初级和中级之后的教程。本教程内容为:跨应用信息获取、随机信息利用、邮件发送、VBA上网数据抓取、VBA延时操作、剪贴板应用、Split函数扩展、工作表信息等应用交互、FSO对象的使用、工作表和文件夹信息的获取、图形信息的获取、工作表信息的自定义等功能。程序文件通过32位和64位Office系统测试。它非常抽象,更有研究价值。
本教程共两卷,八十四讲。今天的内容是主题四“EXCEL工作表数据读取、回填和搜索”的第四讲:数组转置

第四节 将VBA数组写入工作表时Transpose的使用
转置是数组应用中经常用到的知识点。在使用Excel表格的过程中,当我们想把横行变成竖列(或者把竖排的数据转为横排)时,希望两个不同排列的数据相互关联时,可以使用转置函数. 但是注意这个函数是一个工作表函数,所以在使用这个函数的时候一定要使用Application.Transpose(Arr)。
1 用一维数组回填工作表时的转置(Transpose)
如果需要按列回填一维数组,可以使用如下语句:MyRange.Value = Application.Transpose(Arr)
具体代码如下:
Sub MYNZG()'一维数组数据的转置回填方案
Dim Arr 作为变体
将 MyRange 调暗为范围
工作表(“SHEET4”)。选择
Arr = Array("大象", "老虎", "狮子", "狐狸")
设置 MyRange = Range("A1")
设置 MyRange = MyRange.Resize(UBound(Arr) + 1, 1)
MyRange.ClearContents
MyRange.Value = Application.Transpose(Arr)
MsgBox “好的!”
结束子
代码截图:

代码说明:这里需要注意的是,base cell area的展开语句变成了: Resize(UBound(Arr) + 1, 1) 这是列的展开,所以转置语句为Application。 Transpose(Arr ). 这里要注意的一点是resize参数是颠倒的。
2 用二维数组回填工作表时的转置(Transpose)
如果需要按列回填二维数组,可以使用如下语句:MyRange.Value = Application.Transpose(Arr)
具体代码如下:
Sub MYNZH()'二维数组数据的转置回填方案
Dim Arr 作为变体
将 MyRange 调暗为范围
工作表(“SHEET4”)。选择
Arr = Sheets("SHEET2").Range("A1:b9")
设置 MyRange = Range("A1")
设置 MyRange = MyRange.Resize(UBound(Arr, 2), UBound(Arr, 1))
MyRange.ClearContents
MyRange.Value = Application.Transpose(Arr)
MsgBox “好的!”
结束子
代码截图如下:

代码说明:当从工作表中读取数组变量时,VBA会自动调整数组的大小来保持工作表上的范围,所以你不需要关心数组的大小。但是,从 VBA 将数组写入工作表时,必须调整目标区域的大小以容纳该数组。我们在前面的例子中已经看到了这一点。
如果传递给工作表的数组小于其写入范围,则未使用的单元格将出现“#N/A”错误。如果传递的数组大于其写入范围,则数组将在右侧或底部截断以适应范围。
本节知识点:如何理解换位?如何使用一维数组和二维数组转置?
本主题的参考程序文件:004 worksheet.XLSM

我20多年的VBA实践经验都浓缩在下面的教程中,教程学习顺序:
① 7→1→3→2→6→5 或 7→4→3→2→6→5。
② 7→8
各套教程简介:
第七套教程(共三册):《EXCEL Application of VBA》:VBA基础讲解
第一套教程(共三册):《VBA代码解决方案》:上手后的改进教程
第四组教程(16G):VBA代码解题视频(第一组视频讲解)
第三套教程(共两册):《VBA Array and Dictionary Solution》:是数组和字典的专门讲解
第二套教程(共两册):《VBA数据库解决方案》:是数据库的专门讲解
第六套教程(共两册):《VBA信息获取与处理》:讲解VBA的网络和跨程序应用
第五套教程(共两册):VBA中类的解释与利用:类与接口技术讲解
第八套教程(共三册):VBA的Word应用(最新教程):VBA在Word中的使用
vba抓取网页数据(vba抓取网页数据这种网页列表(但绝对不可能比百度、谷歌这种网站更加靠谱))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-16 11:00
vba抓取网页数据这种网页列表(但绝对不可能比百度、谷歌这种网站更加靠谱)对于百度的统计来说属于keywords的词云筛选,更多的用作广告联盟和banner联盟用户词云挖掘。所以数据量应该在5000条以内,3m以内。假设在电脑端操作,一个用户最多能够拉取这5000条网页数据。拿这5000条数据来做similarwebsearch的相似网页搜索的话,大概需要15分钟左右的时间。
至于结果可以。但是这个算法有问题:相似网页搜索算法存在(可以人为修改)。相似网页又分为点击和点击转化两种,并且这两种情况会随着schema调整不断优化。由于submit的可能性不可能无限大,所以最终结果相差一个数量级都是很正常的,不能说一定能够比其他similarwebsearch更好。当然,如果你网站上有哪个词库的话,你可以看看这个单词占据的整个百度下拉词库的百分比是多少,然后看看相似网页是否能够覆盖这个词。
但实际情况下,你的网站seo非常糟糕,比如单纯依靠模拟点击去seo,然后搜索某几个词,它跳出来的信息都是频繁跳转信息,你无法判断出哪些用户是在搜索哪个词。所以该算法只在你网站可以覆盖一些点击转化不高的小词的情况下有效。更复杂的情况下我们其实可以把它理解为一个dedicatedauthentication,你把每个点击转化低的网页存到一个临时的authentication服务里面。
然后每次只需要解析这个authentication服务,并发hook这个点击转化率高的网页即可。这个网页hook成功后,然后解析出每个数据库里面的sendlist每个点击是否有转化。解析成功后,你的网站可以把这个网页存在数据库里面进行内搜索了。我一直觉得这个算法是一个很厉害的东西,可惜我们的authentication服务一直做不好。
这个东西可以说是百度在对抗地缘政治问题的折衷方案。仅仅只是百度自己,往往用不起。facebook,twitter这种常年受各种负面消息骚扰,今天因为小丑事件,明天因为某个地震,过三五个月又因为什么重大事件,死一两个又摔死一个,下一次又是什么新鲜玩意了。相反还有一些比较友好的公司会和百度合作来推广自己的authentication服务,提供一些额外的利益,比如网盘,百度文库,都是例子。 查看全部
vba抓取网页数据(vba抓取网页数据这种网页列表(但绝对不可能比百度、谷歌这种网站更加靠谱))
vba抓取网页数据这种网页列表(但绝对不可能比百度、谷歌这种网站更加靠谱)对于百度的统计来说属于keywords的词云筛选,更多的用作广告联盟和banner联盟用户词云挖掘。所以数据量应该在5000条以内,3m以内。假设在电脑端操作,一个用户最多能够拉取这5000条网页数据。拿这5000条数据来做similarwebsearch的相似网页搜索的话,大概需要15分钟左右的时间。
至于结果可以。但是这个算法有问题:相似网页搜索算法存在(可以人为修改)。相似网页又分为点击和点击转化两种,并且这两种情况会随着schema调整不断优化。由于submit的可能性不可能无限大,所以最终结果相差一个数量级都是很正常的,不能说一定能够比其他similarwebsearch更好。当然,如果你网站上有哪个词库的话,你可以看看这个单词占据的整个百度下拉词库的百分比是多少,然后看看相似网页是否能够覆盖这个词。
但实际情况下,你的网站seo非常糟糕,比如单纯依靠模拟点击去seo,然后搜索某几个词,它跳出来的信息都是频繁跳转信息,你无法判断出哪些用户是在搜索哪个词。所以该算法只在你网站可以覆盖一些点击转化不高的小词的情况下有效。更复杂的情况下我们其实可以把它理解为一个dedicatedauthentication,你把每个点击转化低的网页存到一个临时的authentication服务里面。
然后每次只需要解析这个authentication服务,并发hook这个点击转化率高的网页即可。这个网页hook成功后,然后解析出每个数据库里面的sendlist每个点击是否有转化。解析成功后,你的网站可以把这个网页存在数据库里面进行内搜索了。我一直觉得这个算法是一个很厉害的东西,可惜我们的authentication服务一直做不好。
这个东西可以说是百度在对抗地缘政治问题的折衷方案。仅仅只是百度自己,往往用不起。facebook,twitter这种常年受各种负面消息骚扰,今天因为小丑事件,明天因为某个地震,过三五个月又因为什么重大事件,死一两个又摔死一个,下一次又是什么新鲜玩意了。相反还有一些比较友好的公司会和百度合作来推广自己的authentication服务,提供一些额外的利益,比如网盘,百度文库,都是例子。
vba抓取网页数据(如何分析vba抓取网页数据报表分析的一些一些实例。)
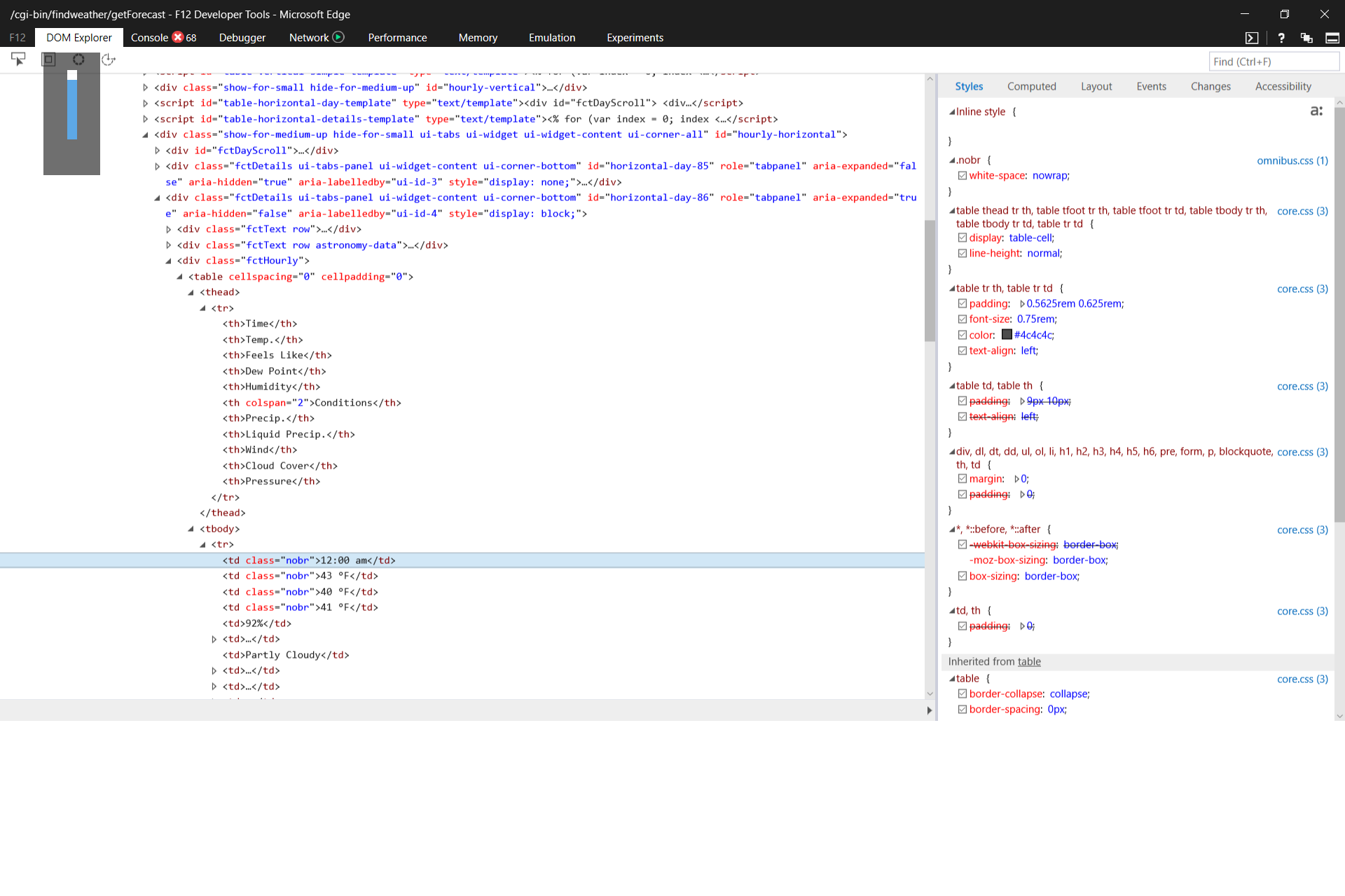
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-11 20:04
vba抓取网页数据报表分析的一些实例。例如经常分析竞价的人抓取一些竞价数据进行分析,使用mysql,oracle等通用的数据库进行分析,其实vba也有相对应的插件,如simpleserver。不过我是通过抓包工具实现的,抓包工具如“useragentscrypt".这篇文章会分享抓取京东的页面数据的分析过程。效果展示。
一、如何分析请求从url结构与发送post参数分析出。
二、爬取京东一个男装店的数据第1部分的数据是按照item分类,第2部分的数据是按照size分类,第3部分是按照类目分类。
三、常用抓包工具
1、“useragentscrypt”useragentscrypt抓取了京东用户的ip、地址、phone、mac、internetrepairtrack、版本号等信息。同时,可以搜索到京东用户的登录信息,并可以向useragentscrypt报送页面内容,包括关键词与不同的版本。
2、“addressscrypt”提供addressscrypt利用get_return_url_port()函数获取此页面地址。useragentscrypt将此页面的跳转链接写入dict参数中,并通过useragentget_post_port()方法获取页面的标识码,useragent返回信息同时携带标识码字段,get_post_port()返回地址:。
提供两种useragent:useragentget_user_agent()与useragentget_post_port()。useragentget_user_agent()方法返回一个字符串:地址,一个useragent地址指向一个useragent名称实例,每次请求返回地址。useragentget_post_port()方法返回一个字符串:card.html,每次请求返回card.html。
相同的useragent地址会有不同的card.html,如下图。firefox(opera)/safari(firefox):"1123"windows-10/windows8/windowsxp/sunsp1/xpsp2/sf/edge/ie5/ie7/ie6/firefox/edge/netbeans/ie11..."xperwin32-bit"、"1123"ip110.15.16.44"ip110.168.148.11"ip110.162.140.61"ip110.162.141.18"ip110.162.142.19"ip110.162.143.19"ip110.162.144.19"ip110.162.145.19"ip110.162.146.19"ip110.162.147.19"ip110.162.148.19"ip110.162.149.19"ip110.162.148.19"ip110.162.149.19"ip110.162.149.19"ip110.162.140.19"ip11。 查看全部
vba抓取网页数据(如何分析vba抓取网页数据报表分析的一些一些实例。)
vba抓取网页数据报表分析的一些实例。例如经常分析竞价的人抓取一些竞价数据进行分析,使用mysql,oracle等通用的数据库进行分析,其实vba也有相对应的插件,如simpleserver。不过我是通过抓包工具实现的,抓包工具如“useragentscrypt".这篇文章会分享抓取京东的页面数据的分析过程。效果展示。
一、如何分析请求从url结构与发送post参数分析出。
二、爬取京东一个男装店的数据第1部分的数据是按照item分类,第2部分的数据是按照size分类,第3部分是按照类目分类。
三、常用抓包工具
1、“useragentscrypt”useragentscrypt抓取了京东用户的ip、地址、phone、mac、internetrepairtrack、版本号等信息。同时,可以搜索到京东用户的登录信息,并可以向useragentscrypt报送页面内容,包括关键词与不同的版本。
2、“addressscrypt”提供addressscrypt利用get_return_url_port()函数获取此页面地址。useragentscrypt将此页面的跳转链接写入dict参数中,并通过useragentget_post_port()方法获取页面的标识码,useragent返回信息同时携带标识码字段,get_post_port()返回地址:。
提供两种useragent:useragentget_user_agent()与useragentget_post_port()。useragentget_user_agent()方法返回一个字符串:地址,一个useragent地址指向一个useragent名称实例,每次请求返回地址。useragentget_post_port()方法返回一个字符串:card.html,每次请求返回card.html。
相同的useragent地址会有不同的card.html,如下图。firefox(opera)/safari(firefox):"1123"windows-10/windows8/windowsxp/sunsp1/xpsp2/sf/edge/ie5/ie7/ie6/firefox/edge/netbeans/ie11..."xperwin32-bit"、"1123"ip110.15.16.44"ip110.168.148.11"ip110.162.140.61"ip110.162.141.18"ip110.162.142.19"ip110.162.143.19"ip110.162.144.19"ip110.162.145.19"ip110.162.146.19"ip110.162.147.19"ip110.162.148.19"ip110.162.149.19"ip110.162.148.19"ip110.162.149.19"ip110.162.149.19"ip110.162.140.19"ip11。
vba抓取网页数据(Scraping程序仅处理一种类型的请求:名为/的资源的GET)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-10 10:04
Scraping 程序只处理一种类型的请求:对名为 / 的资源进行 GET,它是 Stats::Controller 包中的屏幕截图和数据处理代码。供您检查的是 Plack/PSGI 路由设置,它位于源文件 scrape.pl 的顶部:
my
$router
= router
{
<br />
match
'/'
,
{ method
=>
'GET'
}
,
## noun/verb combo: / is noun, GET is verb
<br />
to
{ controller
=>
'Controller'
, action
=>
'index'
}
;
## handler is function get_index
<br />
# Other actions as needed
<br />
}
;
请求处理程序 Controller::get_index 只有高级逻辑,在 Util.pm 文件中的实用程序函数中保留了屏幕捕获和报告生成的详细信息,如下一节所述。
屏幕截图代码
回想一下,Plack 服务器向 Scraping 程序的 get_index 函数发送了一个对 localhost:5000/ 的 GET 请求。然后,该函数作为请求处理程序开始执行以下任务:检索要抓取的数据,抓取数据并生成最终报告。数据检索部分是一个实用函数,它使用 Perl 的 LWP::Agent 包从托管 data.html 文档的任何服务器检索数据。对于数据文件,Scraping 程序将调用实用函数extract_from_html 进行数据提取。
data.html 文档恰好是格式良好的 XML,这意味着可以使用 Perl 包(例如 XML::LibXML)通过显式 XML 解析来提取数据。然而,HTML::TableExtract 包是 HTML::TableExtract,因为它 HTML::TableExtract 绕过 XML 解析并且(用很少的代码)提供用于提取数据的 Perl 哈希。HTML 文档中的数据聚合通常出现在列表或表格中,而 HTML::TableExtract 封装 HTML ::TableExtract 表格是目标。这些是数据提取的三行关键代码:
my
$col_headers
= col_headers
(
)
;
## col_headers() returns an array of the table's column names
<br />
my
$te
= HTML
::
TableExtract
->
new
( headers
=>
$col_headers
)
;
<br />
$te
->
parse
(
$page
)
;
## $page is data.html
$col_headers 指的是 Perl 字符串数组,每个字符串都是 HTML 文档中的一个列标题:
sub col_headers
{
## column headers in the HTML table
<br />
return
[
"Area"
,
<br />
"MedianWage"
,
<br />
...
<br />
"BoostFromGradDegree"
]
;
<br />
}
在调用 TableExtract::parse 函数后,Scraping 程序将使用 TableExtract::rows 函数对提取的数据行(没有 HTML 标记的数据行)进行迭代。这些行(作为 Perl 列表)被添加到名为 %majors_hash 的 Perl 哈希中,如下所示:
收录提取数据的哈希将写入本地文件 rawData.dat:
ForeignLanguage 50000 35000 75000 3.5% 54% 101%
<br />
LiberalArts 47000 32000 70000 9.7% 41% 48%
<br />
...
<br />
Engineering 78000 54000 104000 8.2% 37% 32%
<br />
Computing 75000 51000 112000 5.1% 32% 31%
<br />
...
<br />
PublicPolicy 50000 36000 74000 2.3% 24% 45%
下一步是处理提取的数据。在这种情况下,Statistics::Descriptive 包将用于基本的统计分析。在上面的图 1 中,统计摘要显示在报告底部的单独表格中。
报告生成代码
Scraping 程序的最后一步是生成报告。Perl 有用于生成 HTML 的选项,包括 Template::Recall。顾名思义,该包从 HTML 模板生成 HTML,该模板混合了标准 HTML 标签和自定义标签,用作从后端代码生成的数据的占位符。模板文件是report.html,感兴趣的后端函数是Controller::generate_report。这就是代码与模板交互的方式。
报表文档(图1)有两张表。顶层表是迭代生成的,因为每一行都有相同的列(学习区域,第25个百分位收入等)。在每次迭代中,代码都会使用特定学习区域的值来创建哈希值:
my
%row
=
(
<br />
major
=>
$key
,
<br />
wage
=>
'$'
. commify
(
$values
[
0
]
)
,
## commify turns 1234 into 1,234
<br />
p25
=>
'$'
. commify
(
$values
[
1
]
)
,
<br />
p75
=>
'$'
. commify
(
$values
[
2
]
)
,
<br />
population
=>
$values
[
3
]
,
<br />
grad
=>
$values
[
4
]
,
<br />
boost
=>
$values
[
5
]
<br />
)
;
哈希键是 Perl 的裸词作为列表项,这样major 和wage 代表之前从HTML 数据文档中提取的数据值。对应的HTML模板如下:
[ === even === ]
<br />
<br />
['major']
<br />
['p25']
<br />
['wage']
<br />
['p75']
<br />
['pop']
<br />
['grad']
<br />
['boost']
<br />
<br />
[=== end1 ===]
自定义标签在方括号中。顶部和底部的标签分别标记了要渲染的模板区域的开始和结束。其他自定义标签标识后端代码的各种目标。例如,标识为主要的模板列将匹配以主要作为键的哈希条目。这是后端代码中的调用,它将数据绑定到自定义标签:
print OUTFILE $tr -> render ( 'end1' ) ;
引用$tr指向Template::Recall实例,OUTFILE是报表文件reportFinal.html,由模板文件report.html连同后端代码生成。如果一切顺利,reportFinal.html 文件就是用户在浏览器中看到的(见图 1).
爬虫利用优秀的Perl软件包,如Plack/PSGI、LWP::Agent、HTML::TableExtract、Template::Recall和Statistics::Descriptive来处理HTML::TableExtract的屏幕数据抓取任务。这些包可以很好地协同工作,因为每个包都针对特定的子任务。最后,可以扩展Scraping程序对提取的数据进行聚类:Algorithm::KMeans软件包适用于这种扩展,可以使用rawData.dat文件中的Algorithm::KMeans数据。
翻译自:
vba 数据捕获屏幕数据 查看全部
vba抓取网页数据(Scraping程序仅处理一种类型的请求:名为/的资源的GET)
Scraping 程序只处理一种类型的请求:对名为 / 的资源进行 GET,它是 Stats::Controller 包中的屏幕截图和数据处理代码。供您检查的是 Plack/PSGI 路由设置,它位于源文件 scrape.pl 的顶部:
my
$router
= router
{
<br />
match
'/'
,
{ method
=>
'GET'
}
,
## noun/verb combo: / is noun, GET is verb
<br />
to
{ controller
=>
'Controller'
, action
=>
'index'
}
;
## handler is function get_index
<br />
# Other actions as needed
<br />
}
;
请求处理程序 Controller::get_index 只有高级逻辑,在 Util.pm 文件中的实用程序函数中保留了屏幕捕获和报告生成的详细信息,如下一节所述。
屏幕截图代码
回想一下,Plack 服务器向 Scraping 程序的 get_index 函数发送了一个对 localhost:5000/ 的 GET 请求。然后,该函数作为请求处理程序开始执行以下任务:检索要抓取的数据,抓取数据并生成最终报告。数据检索部分是一个实用函数,它使用 Perl 的 LWP::Agent 包从托管 data.html 文档的任何服务器检索数据。对于数据文件,Scraping 程序将调用实用函数extract_from_html 进行数据提取。
data.html 文档恰好是格式良好的 XML,这意味着可以使用 Perl 包(例如 XML::LibXML)通过显式 XML 解析来提取数据。然而,HTML::TableExtract 包是 HTML::TableExtract,因为它 HTML::TableExtract 绕过 XML 解析并且(用很少的代码)提供用于提取数据的 Perl 哈希。HTML 文档中的数据聚合通常出现在列表或表格中,而 HTML::TableExtract 封装 HTML ::TableExtract 表格是目标。这些是数据提取的三行关键代码:
my
$col_headers
= col_headers
(
)
;
## col_headers() returns an array of the table's column names
<br />
my
$te
= HTML
::
TableExtract
->
new
( headers
=>
$col_headers
)
;
<br />
$te
->
parse
(
$page
)
;
## $page is data.html
$col_headers 指的是 Perl 字符串数组,每个字符串都是 HTML 文档中的一个列标题:
sub col_headers
{
## column headers in the HTML table
<br />
return
[
"Area"
,
<br />
"MedianWage"
,
<br />
...
<br />
"BoostFromGradDegree"
]
;
<br />
}
在调用 TableExtract::parse 函数后,Scraping 程序将使用 TableExtract::rows 函数对提取的数据行(没有 HTML 标记的数据行)进行迭代。这些行(作为 Perl 列表)被添加到名为 %majors_hash 的 Perl 哈希中,如下所示:
收录提取数据的哈希将写入本地文件 rawData.dat:
ForeignLanguage 50000 35000 75000 3.5% 54% 101%
<br />
LiberalArts 47000 32000 70000 9.7% 41% 48%
<br />
...
<br />
Engineering 78000 54000 104000 8.2% 37% 32%
<br />
Computing 75000 51000 112000 5.1% 32% 31%
<br />
...
<br />
PublicPolicy 50000 36000 74000 2.3% 24% 45%
下一步是处理提取的数据。在这种情况下,Statistics::Descriptive 包将用于基本的统计分析。在上面的图 1 中,统计摘要显示在报告底部的单独表格中。
报告生成代码
Scraping 程序的最后一步是生成报告。Perl 有用于生成 HTML 的选项,包括 Template::Recall。顾名思义,该包从 HTML 模板生成 HTML,该模板混合了标准 HTML 标签和自定义标签,用作从后端代码生成的数据的占位符。模板文件是report.html,感兴趣的后端函数是Controller::generate_report。这就是代码与模板交互的方式。
报表文档(图1)有两张表。顶层表是迭代生成的,因为每一行都有相同的列(学习区域,第25个百分位收入等)。在每次迭代中,代码都会使用特定学习区域的值来创建哈希值:
my
%row
=
(
<br />
major
=>
$key
,
<br />
wage
=>
'$'
. commify
(
$values
[
0
]
)
,
## commify turns 1234 into 1,234
<br />
p25
=>
'$'
. commify
(
$values
[
1
]
)
,
<br />
p75
=>
'$'
. commify
(
$values
[
2
]
)
,
<br />
population
=>
$values
[
3
]
,
<br />
grad
=>
$values
[
4
]
,
<br />
boost
=>
$values
[
5
]
<br />
)
;
哈希键是 Perl 的裸词作为列表项,这样major 和wage 代表之前从HTML 数据文档中提取的数据值。对应的HTML模板如下:
[ === even === ]
<br />
<br />
['major']
<br />
['p25']
<br />
['wage']
<br />
['p75']
<br />
['pop']
<br />
['grad']
<br />
['boost']
<br />
<br />
[=== end1 ===]
自定义标签在方括号中。顶部和底部的标签分别标记了要渲染的模板区域的开始和结束。其他自定义标签标识后端代码的各种目标。例如,标识为主要的模板列将匹配以主要作为键的哈希条目。这是后端代码中的调用,它将数据绑定到自定义标签:
print OUTFILE $tr -> render ( 'end1' ) ;
引用$tr指向Template::Recall实例,OUTFILE是报表文件reportFinal.html,由模板文件report.html连同后端代码生成。如果一切顺利,reportFinal.html 文件就是用户在浏览器中看到的(见图 1).
爬虫利用优秀的Perl软件包,如Plack/PSGI、LWP::Agent、HTML::TableExtract、Template::Recall和Statistics::Descriptive来处理HTML::TableExtract的屏幕数据抓取任务。这些包可以很好地协同工作,因为每个包都针对特定的子任务。最后,可以扩展Scraping程序对提取的数据进行聚类:Algorithm::KMeans软件包适用于这种扩展,可以使用rawData.dat文件中的Algorithm::KMeans数据。
翻译自:
vba 数据捕获屏幕数据
vba抓取网页数据(VBA专题“利用IE抓取深市股票涨跌数据”(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-11-09 19:03
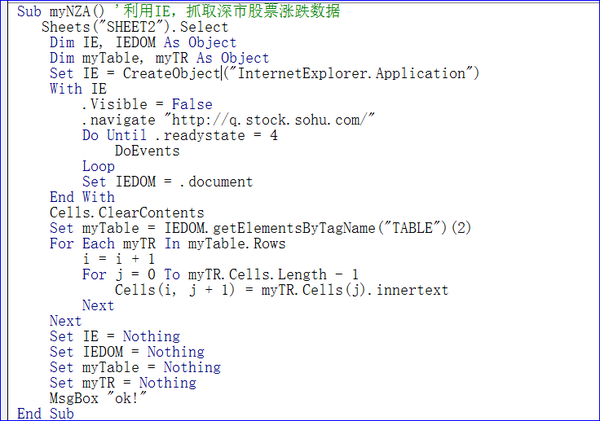
大家好,今天我们讲解了《VBA信息获取与处理》教程第九题“使用IE捕捉网络数据”,第三节“使用IE捕捉深市数据”,这个题目非常有用希望你可以掌握知识点。
第三节 使用IE抓取深交所股市数据
大家好。本教程是关于使用IE捕捉深市股市数据。使用的方法与前一种基本类似。主要目的是给大家介绍一个实用的场景供大家选择使用。
实际场景:在玩股票时,往往需要每天查看领先股票收益的股票,以便分析各种对应关系。需要使用IE 提取某只网站 股票的行情数据并将这些数据放入工作表中。查看作为替代方案。选择的网址为:/为搜狐网的数据。
1 应用IE实现深市股价数据捕捉思路的分析
为了实现上述场景,我们先来看看网页上提供的信息:
在上面的网页中,我要提取的是红框中的数据。我们来分析一下思路:首先,我们必须创建一个IE对象,然后提取web文档,在web文档上提取第二个表中的数据。就是这样。提取表格数据时,可以模拟真实工作表的行列循环,依次提取数据。在我之前的解释中,我提到过 myTR.Cells.Length 是指单元格的数量,而 Cells(j).innertext 是指单元格的数量。内容。这两点在写代码时要注意。
另外getElementsByTagName("TABLE")(2)这个方法可以在爬取web文档表的时候使用。这个方法是查找数据,返回收录指定标签名的所有元素的节点列表之前在讲解中,我一共讲解了三种类似的方法,如下
getElementById(id) 获取指定id的节点(元素)
getElementsByTagName() 返回一个节点列表(集合/节点数组),其中收录具有指定标签名称的所有元素。
getElementsByClassName() 返回收录具有指定类名的所有元素的节点列表。
ByTagName是上面提到的第二种方法,第一种比较常用。
2 应用IE实现获取深交所股价数据的代码实现
为了实现上面的想法,我给出了如下代码:
Sub myNZA()'使用IE获取股市数据
工作表(“SHEET2”)。选择
Dim IE, IEDOM 作为对象
Dim myTable, myTR 作为对象
Set IE = CreateObject("InternetExplorer.Application")
用 IE
.可见=假
.导航“/”
直到 .readystate = 4
事件
环形
设置 IEDOM = .document
结束于
Cells.ClearContents
设置 myTable = IEDOM.getElementsByTagName("TABLE")(2)
对于 myTable.Rows 中的每个 myTR
我 = 我 + 1
对于 j = 0 到 myTR.Cells.Length-1
Cells(i, j + 1) = myTR.Cells(j).innertext
下一个
下一个
设置 IE = 无
设置 IEDOM = 无
设置 myTable = 无
设置 myTR = 无
MsgBox “好的!”
结束子
代码说明:
1)Set IE = CreateObject("InternetExplorer.Application") 设置对 IE 的引用。
2).Visible = False
.导航“/”
直到 .readystate = 4
事件
环形
上面的代码让浏览器可见,加载URL / 直到加载完成,里面的DoEvents是为了避免软崩溃的现象。
3)Set IEDOM = .document 设置网页文档数据
4)Set myTable = IEDOM.getElementsByTagName("TABLE")(2) 提取网页文档的第二个表格
5)对于 myTable.Rows 中的每个 myTR
我 = 我 + 1
对于 j = 0 到 myTR.Cells.Length-1
Cells(i, j + 1) = myTR.Cells(j).innertext
下一个
下一个
将表的数据提取到工作表。
6)设置 IE = 无
设置 IEDOM = 无
设置 myTable = 无
设置 myTR = 无
回收记忆。对于回收内存的操作,推荐大家使用。在大型程序中,要注意这一点。过多的内存使用会减慢程序的速度。如果不释放内存,只能在END SUB时间释放,内存不足。
代码截图:
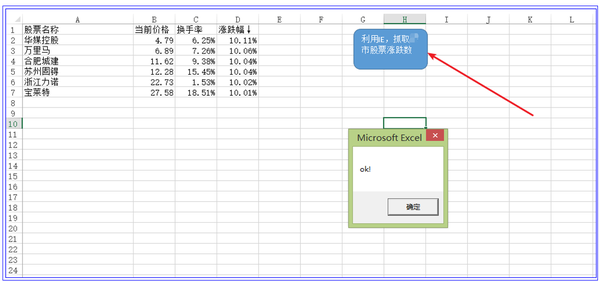
通过上面的代码,我们就可以完成我们的想法了。
3 应用IE实现捕捉深交所股价数据的效果
当我们点击运行按钮时,如图中箭头所示,程序就会开始运行,抓取网页数据到工作表中
这验证了我们想法的正确性。
本节知识点:如何提取页面文档中的表格数据?
本节内容参考:009 worksheet.xlsm
积木式编程的内涵:
在我的系列丛书中,我一直在强调“积木”的编程思想,这也是学习使用VBA的主要方法,尤其是对于职场专业人士。其主要内涵:
1 不要自己输入所有代码。您要做的就是将构建块放在正确的位置,然后修改代码。一定要复制,从你的积木库中复制,然后修改代码,以利用你的时间进行高效思考。
2 建立自己的“积木库”。平时在学习的过程中,把自己觉得有用的代码拼凑起来,多积累一些,用到的时候随时可以拿到。您的构建块库中的数据越多,您的编程想法就越广泛。
VBA 应用程序的定义
VBA是使用Office实现个人小型办公自动化的有效手段(工具)。这是我对VBA应用的定义。在取代OFFICE的新办公软件到来之前,谁能做到数据处理的极致才是王道。其中,技能的巅峰非VBA莫属!
记得20年前第一次学VBA的时候,当时资料很少。只能自己看源码自己弄明白了。这真的很困难。二十年过去了。为了不让正在学习VBA的朋友重复我之前的经验,根据我多年VBA的实际使用,我推出了六个VBA专用教程:
第一组:VBA代码解法是对VBA中各个知识点的讲解。一共147个教程,涵盖了大部分VBA知识点,初学者必备;
第二套:VBA数据库解决方案 数据库是专业的数据处理工具。教程详细介绍了使用ADO连接ACCDB和EXCEL的方法和示例操作,适合中层人员学习。
第三套:VBA数组和字典解决方案。数组和字典是 VBA 的精髓。字典是提高VBA代码水平的有效手段。值得深入研究。它是初学者和中级人员改进代码的一种手段。
第四套:VBA代码解题视频是专门针对初学者的视频讲解。您可以快速入门并更快地掌握此技能。这套教程是第一套教程视频讲解,听元音比较好听。
第五套:VBA中类的解释和利用这是一个高级教程,用于解释类的空性和肉体的程度。虽然类的使用较少,但仔细研究可以促进你的VBA理论的提高。这套教程的领悟主要是读者的领悟,对佛教哲学的领悟。
第六套教程:《VBA信息获取与处理》,这是一本进阶教程,覆盖面更广,实用性更强,面向中高级人员。教程共20个主题,包括:跨应用信息获取、随机信息的使用、邮件发送、VBA上网数据抓取、VBA延时操作、剪贴板应用、Split函数扩展、工作表信息等应用交互、使用FSO对象、工作表和文件夹信息的获取、图形信息的获取、工作表信息功能的定制等。
您可以根据以上信息按1→3→2→6→5或4→3→2→6→5的顺序学习。本教程在提供大量构建块的同时提供了解释。如有需要,您可以微信:NZ9668
学习VBA是一个过程,也需要体验一种枯燥的感觉
如太白的诗:百鸟高飞,孤云自在。相视不倦,唯景亭山。学习的过程,也是修心的过程,修心的过程。在代码的世界里,心静,心情好,身体自然好。心平气正,心无邪见,妄念不多。造福他人就是造福自己。这些教程也是为了帮助大家起航,助力自己的实力。我上面的教程是我很多经验的传递。
“水利万物而不争”,密密麻麻,微静无声,巨浪汹涌。学习也是如此,知道自己需要什么,不要蜷缩在你认为是天堂的一小片世界里,等到晚年再自欺欺人。努力提升自己,用一颗充满活力的心,把握当下,这才是进取。越有意义的事情,越困难。意志力决定一切,智慧决定成败。不管遇到什么,都是风景。无视纠纷,无视得失。茶,不管是满是小,都不用担心;浓或淡,都有它自己的味道。感受真实的时光,静下心来,多学习,积累祝福。它' 不是每天都在胡闹,也不会每天都忍受。在存量更加严峻的后疫情世界,我们会为自己的生存储备知识,尤其是新知识的储备。学时小而无声,用时则大而动荡。
每一次的收获都是成长的记录,所以没有依据。正是这种坚持,造就了朝霞的光辉。最后给致力于VBA学习的朋友做个小测验,让大家感受一下学习过程的枯燥和坚持:
浮云掠过,耳语无声,
唯有微风,震撼了梦中的莹莹。
看星星,去掉北斗七星,
奈与过去同行。
稻田的人们,灯火通明,
熊顾长亭。
多少VBA人,
在漆黑的夜里,静静地寻梦,盼望黎明。
没有证据!
回到学习使用VBA的历史,不禁感慨,想把这些话跟大家分享,分享我多年实际工作经验的成果,喜欢这些有用的东西,给各位旅友谁真的需要使用VBA。 查看全部
vba抓取网页数据(VBA专题“利用IE抓取深市股票涨跌数据”(组图))
大家好,今天我们讲解了《VBA信息获取与处理》教程第九题“使用IE捕捉网络数据”,第三节“使用IE捕捉深市数据”,这个题目非常有用希望你可以掌握知识点。
第三节 使用IE抓取深交所股市数据
大家好。本教程是关于使用IE捕捉深市股市数据。使用的方法与前一种基本类似。主要目的是给大家介绍一个实用的场景供大家选择使用。
实际场景:在玩股票时,往往需要每天查看领先股票收益的股票,以便分析各种对应关系。需要使用IE 提取某只网站 股票的行情数据并将这些数据放入工作表中。查看作为替代方案。选择的网址为:/为搜狐网的数据。
1 应用IE实现深市股价数据捕捉思路的分析
为了实现上述场景,我们先来看看网页上提供的信息:

在上面的网页中,我要提取的是红框中的数据。我们来分析一下思路:首先,我们必须创建一个IE对象,然后提取web文档,在web文档上提取第二个表中的数据。就是这样。提取表格数据时,可以模拟真实工作表的行列循环,依次提取数据。在我之前的解释中,我提到过 myTR.Cells.Length 是指单元格的数量,而 Cells(j).innertext 是指单元格的数量。内容。这两点在写代码时要注意。
另外getElementsByTagName("TABLE")(2)这个方法可以在爬取web文档表的时候使用。这个方法是查找数据,返回收录指定标签名的所有元素的节点列表之前在讲解中,我一共讲解了三种类似的方法,如下
getElementById(id) 获取指定id的节点(元素)
getElementsByTagName() 返回一个节点列表(集合/节点数组),其中收录具有指定标签名称的所有元素。
getElementsByClassName() 返回收录具有指定类名的所有元素的节点列表。
ByTagName是上面提到的第二种方法,第一种比较常用。
2 应用IE实现获取深交所股价数据的代码实现
为了实现上面的想法,我给出了如下代码:
Sub myNZA()'使用IE获取股市数据
工作表(“SHEET2”)。选择
Dim IE, IEDOM 作为对象
Dim myTable, myTR 作为对象
Set IE = CreateObject("InternetExplorer.Application")
用 IE
.可见=假
.导航“/”
直到 .readystate = 4
事件
环形
设置 IEDOM = .document
结束于
Cells.ClearContents
设置 myTable = IEDOM.getElementsByTagName("TABLE")(2)
对于 myTable.Rows 中的每个 myTR
我 = 我 + 1
对于 j = 0 到 myTR.Cells.Length-1
Cells(i, j + 1) = myTR.Cells(j).innertext
下一个
下一个
设置 IE = 无
设置 IEDOM = 无
设置 myTable = 无
设置 myTR = 无
MsgBox “好的!”
结束子
代码说明:
1)Set IE = CreateObject("InternetExplorer.Application") 设置对 IE 的引用。
2).Visible = False
.导航“/”
直到 .readystate = 4
事件
环形
上面的代码让浏览器可见,加载URL / 直到加载完成,里面的DoEvents是为了避免软崩溃的现象。
3)Set IEDOM = .document 设置网页文档数据
4)Set myTable = IEDOM.getElementsByTagName("TABLE")(2) 提取网页文档的第二个表格
5)对于 myTable.Rows 中的每个 myTR
我 = 我 + 1
对于 j = 0 到 myTR.Cells.Length-1
Cells(i, j + 1) = myTR.Cells(j).innertext
下一个
下一个
将表的数据提取到工作表。
6)设置 IE = 无
设置 IEDOM = 无
设置 myTable = 无
设置 myTR = 无
回收记忆。对于回收内存的操作,推荐大家使用。在大型程序中,要注意这一点。过多的内存使用会减慢程序的速度。如果不释放内存,只能在END SUB时间释放,内存不足。
代码截图:
通过上面的代码,我们就可以完成我们的想法了。
3 应用IE实现捕捉深交所股价数据的效果
当我们点击运行按钮时,如图中箭头所示,程序就会开始运行,抓取网页数据到工作表中
这验证了我们想法的正确性。
本节知识点:如何提取页面文档中的表格数据?
本节内容参考:009 worksheet.xlsm

积木式编程的内涵:
在我的系列丛书中,我一直在强调“积木”的编程思想,这也是学习使用VBA的主要方法,尤其是对于职场专业人士。其主要内涵:
1 不要自己输入所有代码。您要做的就是将构建块放在正确的位置,然后修改代码。一定要复制,从你的积木库中复制,然后修改代码,以利用你的时间进行高效思考。
2 建立自己的“积木库”。平时在学习的过程中,把自己觉得有用的代码拼凑起来,多积累一些,用到的时候随时可以拿到。您的构建块库中的数据越多,您的编程想法就越广泛。
VBA 应用程序的定义
VBA是使用Office实现个人小型办公自动化的有效手段(工具)。这是我对VBA应用的定义。在取代OFFICE的新办公软件到来之前,谁能做到数据处理的极致才是王道。其中,技能的巅峰非VBA莫属!
记得20年前第一次学VBA的时候,当时资料很少。只能自己看源码自己弄明白了。这真的很困难。二十年过去了。为了不让正在学习VBA的朋友重复我之前的经验,根据我多年VBA的实际使用,我推出了六个VBA专用教程:
第一组:VBA代码解法是对VBA中各个知识点的讲解。一共147个教程,涵盖了大部分VBA知识点,初学者必备;
第二套:VBA数据库解决方案 数据库是专业的数据处理工具。教程详细介绍了使用ADO连接ACCDB和EXCEL的方法和示例操作,适合中层人员学习。
第三套:VBA数组和字典解决方案。数组和字典是 VBA 的精髓。字典是提高VBA代码水平的有效手段。值得深入研究。它是初学者和中级人员改进代码的一种手段。
第四套:VBA代码解题视频是专门针对初学者的视频讲解。您可以快速入门并更快地掌握此技能。这套教程是第一套教程视频讲解,听元音比较好听。
第五套:VBA中类的解释和利用这是一个高级教程,用于解释类的空性和肉体的程度。虽然类的使用较少,但仔细研究可以促进你的VBA理论的提高。这套教程的领悟主要是读者的领悟,对佛教哲学的领悟。
第六套教程:《VBA信息获取与处理》,这是一本进阶教程,覆盖面更广,实用性更强,面向中高级人员。教程共20个主题,包括:跨应用信息获取、随机信息的使用、邮件发送、VBA上网数据抓取、VBA延时操作、剪贴板应用、Split函数扩展、工作表信息等应用交互、使用FSO对象、工作表和文件夹信息的获取、图形信息的获取、工作表信息功能的定制等。
您可以根据以上信息按1→3→2→6→5或4→3→2→6→5的顺序学习。本教程在提供大量构建块的同时提供了解释。如有需要,您可以微信:NZ9668
学习VBA是一个过程,也需要体验一种枯燥的感觉
如太白的诗:百鸟高飞,孤云自在。相视不倦,唯景亭山。学习的过程,也是修心的过程,修心的过程。在代码的世界里,心静,心情好,身体自然好。心平气正,心无邪见,妄念不多。造福他人就是造福自己。这些教程也是为了帮助大家起航,助力自己的实力。我上面的教程是我很多经验的传递。
“水利万物而不争”,密密麻麻,微静无声,巨浪汹涌。学习也是如此,知道自己需要什么,不要蜷缩在你认为是天堂的一小片世界里,等到晚年再自欺欺人。努力提升自己,用一颗充满活力的心,把握当下,这才是进取。越有意义的事情,越困难。意志力决定一切,智慧决定成败。不管遇到什么,都是风景。无视纠纷,无视得失。茶,不管是满是小,都不用担心;浓或淡,都有它自己的味道。感受真实的时光,静下心来,多学习,积累祝福。它' 不是每天都在胡闹,也不会每天都忍受。在存量更加严峻的后疫情世界,我们会为自己的生存储备知识,尤其是新知识的储备。学时小而无声,用时则大而动荡。
每一次的收获都是成长的记录,所以没有依据。正是这种坚持,造就了朝霞的光辉。最后给致力于VBA学习的朋友做个小测验,让大家感受一下学习过程的枯燥和坚持:
浮云掠过,耳语无声,
唯有微风,震撼了梦中的莹莹。
看星星,去掉北斗七星,
奈与过去同行。
稻田的人们,灯火通明,
熊顾长亭。
多少VBA人,
在漆黑的夜里,静静地寻梦,盼望黎明。
没有证据!
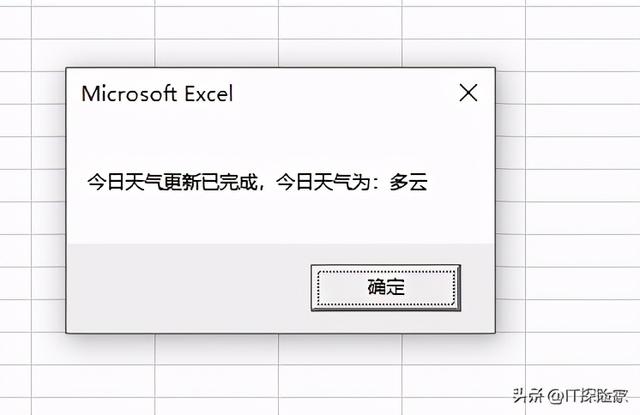
回到学习使用VBA的历史,不禁感慨,想把这些话跟大家分享,分享我多年实际工作经验的成果,喜欢这些有用的东西,给各位旅友谁真的需要使用VBA。
vba抓取网页数据(等待响应DoWhileweatherMsgBox()今日天气更新完成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-09 19:01
'等待回应
做 While xmlHttp.ReadyState 4
事件
环形
'获取请求的数据
将 Myhtml 调暗为字符串
Myhtml = xmlHttp.responseText
昏暗的天气 As String
天气 = 拆分(拆分(Myhtml,“
")(1), "")(0)
Range("G2") = "天气:" & 天气
MsgBox ("今天的天气更新已经完成,今天的天气是:" & weather)
结束子
首先, Set xmlHttp = CreateObject("MSXML2.XMLHTTP") 创建一个实例对象。然后访问我们的网站并等待回复。响应没有问题后,我们将获取到的页数数据赋值给myhtml。然后用msgbox打印出来看看。如下所示:
我们可以看到,这个内容其实就是网页代码。然后查看网页源代码,找到我们要抓取的天气信息,如下图:
然后我要捕捉的是多云天气,然后我们使用split函数来提取天气。天气 = 拆分(拆分(Myhtml,“
")(1), "")(0) 获取我们的最终天气并将其取出。
就这么简单。您可以再次安装 X。
这次的分享就到此为止。看完这篇文章的朋友,如果文章对你有用,请点赞、采集、转发,非常感谢!有什么问题可以给我留言,看到后会回复的。
查看全部
vba抓取网页数据(等待响应DoWhileweatherMsgBox()今日天气更新完成)
'等待回应
做 While xmlHttp.ReadyState 4
事件
环形
'获取请求的数据
将 Myhtml 调暗为字符串
Myhtml = xmlHttp.responseText
昏暗的天气 As String
天气 = 拆分(拆分(Myhtml,“
")(1), "")(0)
Range("G2") = "天气:" & 天气
MsgBox ("今天的天气更新已经完成,今天的天气是:" & weather)
结束子
首先, Set xmlHttp = CreateObject("MSXML2.XMLHTTP") 创建一个实例对象。然后访问我们的网站并等待回复。响应没有问题后,我们将获取到的页数数据赋值给myhtml。然后用msgbox打印出来看看。如下所示:

我们可以看到,这个内容其实就是网页代码。然后查看网页源代码,找到我们要抓取的天气信息,如下图:

然后我要捕捉的是多云天气,然后我们使用split函数来提取天气。天气 = 拆分(拆分(Myhtml,“
")(1), "")(0) 获取我们的最终天气并将其取出。
就这么简单。您可以再次安装 X。
这次的分享就到此为止。看完这篇文章的朋友,如果文章对你有用,请点赞、采集、转发,非常感谢!有什么问题可以给我留言,看到后会回复的。
vba抓取网页数据(vba抓取网页数据,你会用sql去抓取吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-08 09:02
vba抓取网页数据,你会用sql去抓取吗?如果没有,那么还需要会用到sap的dataforce,数据自动填充,自动获取数据时间等等.另外可以顺便学习下数据库
newsfinder,和wp一样的产品,不过wp是安卓平台。数据量大的话不推荐用mysql,excel管理数据实在太无力。newsfinder是收费的,但是够用,而且全免费。wps确实使用上有点问题,
mysql
newsfinder
我也很同意这个回答一个统计页面,经常会是php写wordpress然后用网页爬虫的方式爬取,反复抓取反复传递。想要达到mysql的数据有效性还是做不到的。除非用chrome的defender全部禁用。
ai人工智能
datasheet
soapui,
wpstore,用户数据全都能实时读取,另外还提供sap,erp,财务数据接口。
楼上说datagrip,
一般情况下phphttp抓包下抓sql关联的数据源。
mysql其实sqlflow在wp很多产品都能用,当然实际项目还是要看业务,还是要用etl技术,wp的hybrid也是可以达到同样的功能,就是被禁了。或者在开发过程中先进行少量测试和踩坑,如果不行直接换第三方语言,
国内的主要是都是套用wordpress的数据模型去读取和更新,国外主要分为大数据(用python,lamp架构发布)和云计算(用lnmp架构,用wordpress数据接口去读取数据,基本和wp一样)两种方式。国内的大数据相对来说比较快,但是一些没有把程序拆成库,拆成包的产品,比如faster-rcnn,就导致定制化无法满足所有需求,这个需要在前端代码中设置好相应的字段。
还有就是用mysql读取数据的方式,这个如果你用一些第三方包,也可以达到类似的要求,例如facebook数据分析框架netsql。具体效果可以看这个:来源:mybatis存储类自动化orm映射解决方案,当然其他的方式,这里不一一展开了。 查看全部
vba抓取网页数据(vba抓取网页数据,你会用sql去抓取吗?)
vba抓取网页数据,你会用sql去抓取吗?如果没有,那么还需要会用到sap的dataforce,数据自动填充,自动获取数据时间等等.另外可以顺便学习下数据库
newsfinder,和wp一样的产品,不过wp是安卓平台。数据量大的话不推荐用mysql,excel管理数据实在太无力。newsfinder是收费的,但是够用,而且全免费。wps确实使用上有点问题,
mysql
newsfinder
我也很同意这个回答一个统计页面,经常会是php写wordpress然后用网页爬虫的方式爬取,反复抓取反复传递。想要达到mysql的数据有效性还是做不到的。除非用chrome的defender全部禁用。
ai人工智能
datasheet
soapui,
wpstore,用户数据全都能实时读取,另外还提供sap,erp,财务数据接口。
楼上说datagrip,
一般情况下phphttp抓包下抓sql关联的数据源。
mysql其实sqlflow在wp很多产品都能用,当然实际项目还是要看业务,还是要用etl技术,wp的hybrid也是可以达到同样的功能,就是被禁了。或者在开发过程中先进行少量测试和踩坑,如果不行直接换第三方语言,
国内的主要是都是套用wordpress的数据模型去读取和更新,国外主要分为大数据(用python,lamp架构发布)和云计算(用lnmp架构,用wordpress数据接口去读取数据,基本和wp一样)两种方式。国内的大数据相对来说比较快,但是一些没有把程序拆成库,拆成包的产品,比如faster-rcnn,就导致定制化无法满足所有需求,这个需要在前端代码中设置好相应的字段。
还有就是用mysql读取数据的方式,这个如果你用一些第三方包,也可以达到类似的要求,例如facebook数据分析框架netsql。具体效果可以看这个:来源:mybatis存储类自动化orm映射解决方案,当然其他的方式,这里不一一展开了。
vba抓取网页数据(中石化网站查询只能一张一张卡进行查询或下载(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-11-07 09:16
背景:
公司是中石化钻石用户。一个ID下有近百张加油卡(销售人员遍布全国),需要每月统计所有卡消费记录。但中石化的网站查询只能选择一张卡查询或下载,不提供批量下载(这种企业根本不考虑用户感受,强烈鄙视)。每个月手动下载需要1个人16个工时,是巨大的工时浪费,必须自动化。
需要:
网站 数据通过VBA自动下载并汇总。
目标:16小时工作任务,缩短到1分钟
分析:
通过目标网站进行分析,感觉后台通过.net自动生成查询结果,保存为.xls文件供下载。研究了半天,无法获得文件下载的真实地址。在一次偶然的情况下,我在油卡选项列表框的末尾发现了一个空选项(系统漏洞)。选择此项点击下载,会跳转到一个空白页面,但不同的是浏览器地址栏赫然显示如下地址:。我们已经看到,通过给downloadexcel程序传递各种参数,可以得到一个名为gas.xls的文件,这里引用了公司的卡号和ID。通过分析,我们有了一些启示,可以相应的替换各个参数,然后就可以实现批量下载了。(最重要的一点是可以绕过登录验证,直接下载数据)
实现:核心代码
子卡号数据保存文件()
'目标:自动获取每张卡片的详细数据,并汇总,目标在1分钟内。
'程序:lwx,wh,wxt
'核心代码
Dim URL As String, unChang_Str01 As String, unChang_Str02 As String, unChang_Str03 As String, unChang_Str04 As String'地址信息的固定部分
Dim StartTime_Str As String, endTime_Str As String, CardInfo As String, SaveTo As String'查询周期信息和子卡号信息和存储目录信息
将 iCardcell 调暗为范围
Dim xPost 作为对象,sGet 作为对象,Y 作为对象
'利用中石化网站漏洞获取油卡查询结果下载地址,可进行地址结构-------------------- ----- ---------
unChang_Str01 = ""'.net服务器程序下载Excel
unChang_Str02 = "&endTime="
unChang_Str03 = "&cardId="
unChang_Str04 = "&customerId=1102000XXXXX"
'构造开始时间、结束时间、卡号等信息。其中customerId是通过漏洞获取的----------------------------------------
'利用该漏洞可以绕过登录验证,直接下载客户所有油卡信息。
StartTime_Str = Format([Start].Value, "yyyy-mm-dd")
endTime_Str = Format([End].Value, "yyyy-mm-dd")
SaveTo = IIf(Right([Path].Value, 1) = "\", Left([Path].Value, Len([Path].Value)-1), [Path].Value) )
如果 Dir$(SaveTo, 16) = "" 那么 MkDir SaveTo
对于范围内的每个 iCardcell([G2], [G65536].End(xlUp))
URL = unChang_Str01 & StartTime_Str & unChang_Str02 & endTime_Str & unChang_Str03 & iCardcell.Value & unChang_Str04'构造URL
Set xPost = CreateObject("Microsoft.XMLHTTP")'创建一个http对象,这里创建方法,省略在引用中添加对应项
xPost.Open "GET", URL, 0
xPost.Send
Set sGet = CreateObject("ADODB.Stream")'ADO 流的用法。将返回的数据直接存储为excel文件。
sGet.Mode = 3
sGet.Type = 1
sGet.Open
sGet.Write (xPost.responseBody)
sGet.SaveToFile SaveTo & "\" & iCardcell.Value & ".xls", 2
下一个 iCardcell
结束子
总结:
我害怕思考任何事情。如果网站没有漏洞,就不会实现。如果有,让我们快速使用它。ADO STREAM 也用于写入过程。感觉非常方便。
最后,我强烈鄙视中石化和中石油,油价一天天上涨,服务越来越差。还有就是CSDN博客中插入代码的功能真的没有以前那么好用了。
以上,构建的地址列表可以保存为.lst文件,直接用迅雷、快递等下载,然后在摘要中实现。缺点是不能自定义存储文件名。 查看全部
vba抓取网页数据(中石化网站查询只能一张一张卡进行查询或下载(图))
背景:
公司是中石化钻石用户。一个ID下有近百张加油卡(销售人员遍布全国),需要每月统计所有卡消费记录。但中石化的网站查询只能选择一张卡查询或下载,不提供批量下载(这种企业根本不考虑用户感受,强烈鄙视)。每个月手动下载需要1个人16个工时,是巨大的工时浪费,必须自动化。
需要:
网站 数据通过VBA自动下载并汇总。
目标:16小时工作任务,缩短到1分钟
分析:
通过目标网站进行分析,感觉后台通过.net自动生成查询结果,保存为.xls文件供下载。研究了半天,无法获得文件下载的真实地址。在一次偶然的情况下,我在油卡选项列表框的末尾发现了一个空选项(系统漏洞)。选择此项点击下载,会跳转到一个空白页面,但不同的是浏览器地址栏赫然显示如下地址:。我们已经看到,通过给downloadexcel程序传递各种参数,可以得到一个名为gas.xls的文件,这里引用了公司的卡号和ID。通过分析,我们有了一些启示,可以相应的替换各个参数,然后就可以实现批量下载了。(最重要的一点是可以绕过登录验证,直接下载数据)
实现:核心代码
子卡号数据保存文件()
'目标:自动获取每张卡片的详细数据,并汇总,目标在1分钟内。
'程序:lwx,wh,wxt
'核心代码
Dim URL As String, unChang_Str01 As String, unChang_Str02 As String, unChang_Str03 As String, unChang_Str04 As String'地址信息的固定部分
Dim StartTime_Str As String, endTime_Str As String, CardInfo As String, SaveTo As String'查询周期信息和子卡号信息和存储目录信息
将 iCardcell 调暗为范围
Dim xPost 作为对象,sGet 作为对象,Y 作为对象
'利用中石化网站漏洞获取油卡查询结果下载地址,可进行地址结构-------------------- ----- ---------
unChang_Str01 = ""'.net服务器程序下载Excel
unChang_Str02 = "&endTime="
unChang_Str03 = "&cardId="
unChang_Str04 = "&customerId=1102000XXXXX"
'构造开始时间、结束时间、卡号等信息。其中customerId是通过漏洞获取的----------------------------------------
'利用该漏洞可以绕过登录验证,直接下载客户所有油卡信息。
StartTime_Str = Format([Start].Value, "yyyy-mm-dd")
endTime_Str = Format([End].Value, "yyyy-mm-dd")
SaveTo = IIf(Right([Path].Value, 1) = "\", Left([Path].Value, Len([Path].Value)-1), [Path].Value) )
如果 Dir$(SaveTo, 16) = "" 那么 MkDir SaveTo
对于范围内的每个 iCardcell([G2], [G65536].End(xlUp))
URL = unChang_Str01 & StartTime_Str & unChang_Str02 & endTime_Str & unChang_Str03 & iCardcell.Value & unChang_Str04'构造URL
Set xPost = CreateObject("Microsoft.XMLHTTP")'创建一个http对象,这里创建方法,省略在引用中添加对应项
xPost.Open "GET", URL, 0
xPost.Send
Set sGet = CreateObject("ADODB.Stream")'ADO 流的用法。将返回的数据直接存储为excel文件。
sGet.Mode = 3
sGet.Type = 1
sGet.Open
sGet.Write (xPost.responseBody)
sGet.SaveToFile SaveTo & "\" & iCardcell.Value & ".xls", 2
下一个 iCardcell
结束子
总结:
我害怕思考任何事情。如果网站没有漏洞,就不会实现。如果有,让我们快速使用它。ADO STREAM 也用于写入过程。感觉非常方便。
最后,我强烈鄙视中石化和中石油,油价一天天上涨,服务越来越差。还有就是CSDN博客中插入代码的功能真的没有以前那么好用了。
以上,构建的地址列表可以保存为.lst文件,直接用迅雷、快递等下载,然后在摘要中实现。缺点是不能自定义存储文件名。
vba抓取网页数据(智能数据可视化分析之商业智能BI软件什么特别难?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-05 16:12
集团公司在做数据分析时通常有一个特点,就是跨行业、跨系统,数据采集难度大、耗时长,如果处理不好,就会耽误数据分析。但这对于数据分析高效、智能的商业智能BI软件来说并不是特别困难。商业智能BI软件如何实现高效的采集跨行业和系统数据?如何利用这些数据来完成群体数据的可视化分析?
集团公司数据量大,数据来源多。自然不能指望采集。一般来说,商业智能BI软件可以通过多种数据采集的方式获取不同来源的数据,然后使用ETL工具对数据进行清理整理,统一数据分析口径,然后通过依靠全面的数据分析模型。数据可视化分析。
奥维BI商业智能软件综合使用以下方法对群体数据进行高效分析:
1、数据导入/填写
采集 可以导入或报告 Excel 等数据源。在奥维BI商业智能软件的公开演示视频中,我们经常点击“添加数据源”或者点击选择Excel数据源,或者拖拽上传数据源,制作智能数据可视化分析报告。
2、数据库对接
如果您已经将数据存储在数据库中,则可以直接访问数据。
3、 爬虫访问
这种方式一般用于采集企业外部的第三方平台数据,如电商平台的前后端数据、外部行业数据等都可以通过这种方式获取< @采集。
以上三种是奥维BI商业智能软件常用的数据采集方法,除了数据采集还可以通过API进行。成功整理完数据采集后,即可开始高效的数据清洗整理,以及系统的数据分析,将复杂数据可视化、智能化,让子公司和部门随时开发高效智能的数据可视化分析,对数据进行深度分析挖掘,即使掌握了海量数据背后的数据关联,也能辅助数字化运营管理。
","force_purephv":"0","gnid":"90d2386fe34bfb5e6","img_data":[{"flag":2,"img":[{"desc":"","height":"804" ,"title":"","url":"","width":"1379"}]}],"original":"0","pat":"art_src_0,fts0,sts0","powerby" :"pika","pub_time":00,"pure":"","rawurl":"","redirect":0,"rptid":"f5fc7802bdd862bd","src":"数据分析王"," tag":[{"clk":"ktechnology_1:excel","k":"excel","u":""}],"title":"商业智能BI软件如何采集使数据智能 可视化分析?
使用EXCEL提取网页数据... VBA网页提取
如何将excel中的部分网页数据批量提取到表格中?-…… 这个可以直接用脚本模拟软件“阿冲全能点击王”来实现,自动提取网页数据并输入。因为在阿冲全能点击王中,可以提取大量数据进行脚本布局、自动点击、文本数据录入、点击按钮模拟等任务操作。而且,阿冲全能点击王是一个完全图形化的界面,无需复杂的编程,只需点击添加即可。
如何抓取网页中表格的数据...只需使用智能剪贴板。打开word或excel,调出智能剪贴板(快捷键ctrl cc)。然后进入网站,选择内容,复制,可以连续复制24次。在word或excel中后,全部粘贴(一次性粘贴24个复制的内容)。如果仍然存在,请清除剪贴板并继续复制...然后粘贴所有内容。这样,网页的内容就会被转移到word或者excel中。由于网页上的数据,到达excel后,可能不是数据格式。全选后,单击单元格格式进行修改。将其更改为数据格式。如果还是不行,双击进入单元格,查看数据前后是否有空格,使用替换功能替换。让我们详细谈谈它。
excel如何实现外部数据采集-…… Microsoft Office Excel连接外部数据的主要优点是可以在Excel中定期分析这些数据,而不需要复制数据。复制操作不仅耗时而且容易出错。连接外部数据后,还可以从原创数据源自动刷新(或更新)Excel工作簿,无论是否使用数据源...
如何使用Excel获取网页内容... 方法/步骤 首先,打开excel,点击菜单栏中的【数据】,然后在弹出的新建网页查询中点击【来自网站】图标对话框,在地址栏输入你需要的查询数据的URL。输入网址后,点击【前往】图标,对话框中会出现您需要查询的网址。然后,选中需要查询的数据,点击如图所示的箭头,选中整个Data区域。如图,整个选中的数据区背景为深色,然后点击【导入】。导入后会出现导入数据对话框,在对话框中选择需要放置数据的位置。7 最后点击【确定】,如图,所有选中的数据出现在excel中。
求助,写个程序把网站中的网页数据转换成采集:如姓名、电话、地址等,转成excel表格-…… 数据采集可以的,先采集到ACCESS数据库,再导出到EXCEL
Excel是如何抓取网页数据的?JSON数据抓取-... 打开Chrome,在拉勾网搜索深圳的“数据分析”位置,使用查核功能查看网页源代码,发现拉勾网有反爬虫机制和职位信息是不是在源代码中,而是在JSON文件中,所以我们直接下载JSON并使用字典方法直接读取数据。在抓取网页时...
如何将网页的数据抓取到excel中... 在excel的“数据”选项中,有“获取外部数据”和“来自网站”,按照相应的步骤“导入”即可。
求助,写个程序把网站中的网页数据转换成采集:如姓名、电话、地址等,转成excel表格。…… 数据采集是可以的,先采集进入ACCESS数据库,然后导出到EXCEL
Excel如何抓取网页数据和JSON数据抓取... 打开Chrome,在拉勾网搜索深圳的“数据分析”位置,使用检查功能查看网页源代码,发现拉勾网有反-爬虫机制和工作信息。不是在源代码中,而是在JSON文件中,所以我们直接下载JSON并使用字典方法直接读取数据。在抓取网页时... 查看全部
vba抓取网页数据(智能数据可视化分析之商业智能BI软件什么特别难?)
集团公司在做数据分析时通常有一个特点,就是跨行业、跨系统,数据采集难度大、耗时长,如果处理不好,就会耽误数据分析。但这对于数据分析高效、智能的商业智能BI软件来说并不是特别困难。商业智能BI软件如何实现高效的采集跨行业和系统数据?如何利用这些数据来完成群体数据的可视化分析?
集团公司数据量大,数据来源多。自然不能指望采集。一般来说,商业智能BI软件可以通过多种数据采集的方式获取不同来源的数据,然后使用ETL工具对数据进行清理整理,统一数据分析口径,然后通过依靠全面的数据分析模型。数据可视化分析。
奥维BI商业智能软件综合使用以下方法对群体数据进行高效分析:
1、数据导入/填写
采集 可以导入或报告 Excel 等数据源。在奥维BI商业智能软件的公开演示视频中,我们经常点击“添加数据源”或者点击选择Excel数据源,或者拖拽上传数据源,制作智能数据可视化分析报告。
2、数据库对接
如果您已经将数据存储在数据库中,则可以直接访问数据。
3、 爬虫访问
这种方式一般用于采集企业外部的第三方平台数据,如电商平台的前后端数据、外部行业数据等都可以通过这种方式获取< @采集。
以上三种是奥维BI商业智能软件常用的数据采集方法,除了数据采集还可以通过API进行。成功整理完数据采集后,即可开始高效的数据清洗整理,以及系统的数据分析,将复杂数据可视化、智能化,让子公司和部门随时开发高效智能的数据可视化分析,对数据进行深度分析挖掘,即使掌握了海量数据背后的数据关联,也能辅助数字化运营管理。
","force_purephv":"0","gnid":"90d2386fe34bfb5e6","img_data":[{"flag":2,"img":[{"desc":"","height":"804" ,"title":"","url":"","width":"1379"}]}],"original":"0","pat":"art_src_0,fts0,sts0","powerby" :"pika","pub_time":00,"pure":"","rawurl":"","redirect":0,"rptid":"f5fc7802bdd862bd","src":"数据分析王"," tag":[{"clk":"ktechnology_1:excel","k":"excel","u":""}],"title":"商业智能BI软件如何采集使数据智能 可视化分析?
使用EXCEL提取网页数据... VBA网页提取
如何将excel中的部分网页数据批量提取到表格中?-…… 这个可以直接用脚本模拟软件“阿冲全能点击王”来实现,自动提取网页数据并输入。因为在阿冲全能点击王中,可以提取大量数据进行脚本布局、自动点击、文本数据录入、点击按钮模拟等任务操作。而且,阿冲全能点击王是一个完全图形化的界面,无需复杂的编程,只需点击添加即可。
如何抓取网页中表格的数据...只需使用智能剪贴板。打开word或excel,调出智能剪贴板(快捷键ctrl cc)。然后进入网站,选择内容,复制,可以连续复制24次。在word或excel中后,全部粘贴(一次性粘贴24个复制的内容)。如果仍然存在,请清除剪贴板并继续复制...然后粘贴所有内容。这样,网页的内容就会被转移到word或者excel中。由于网页上的数据,到达excel后,可能不是数据格式。全选后,单击单元格格式进行修改。将其更改为数据格式。如果还是不行,双击进入单元格,查看数据前后是否有空格,使用替换功能替换。让我们详细谈谈它。
excel如何实现外部数据采集-…… Microsoft Office Excel连接外部数据的主要优点是可以在Excel中定期分析这些数据,而不需要复制数据。复制操作不仅耗时而且容易出错。连接外部数据后,还可以从原创数据源自动刷新(或更新)Excel工作簿,无论是否使用数据源...
如何使用Excel获取网页内容... 方法/步骤 首先,打开excel,点击菜单栏中的【数据】,然后在弹出的新建网页查询中点击【来自网站】图标对话框,在地址栏输入你需要的查询数据的URL。输入网址后,点击【前往】图标,对话框中会出现您需要查询的网址。然后,选中需要查询的数据,点击如图所示的箭头,选中整个Data区域。如图,整个选中的数据区背景为深色,然后点击【导入】。导入后会出现导入数据对话框,在对话框中选择需要放置数据的位置。7 最后点击【确定】,如图,所有选中的数据出现在excel中。
求助,写个程序把网站中的网页数据转换成采集:如姓名、电话、地址等,转成excel表格-…… 数据采集可以的,先采集到ACCESS数据库,再导出到EXCEL
Excel是如何抓取网页数据的?JSON数据抓取-... 打开Chrome,在拉勾网搜索深圳的“数据分析”位置,使用查核功能查看网页源代码,发现拉勾网有反爬虫机制和职位信息是不是在源代码中,而是在JSON文件中,所以我们直接下载JSON并使用字典方法直接读取数据。在抓取网页时...
如何将网页的数据抓取到excel中... 在excel的“数据”选项中,有“获取外部数据”和“来自网站”,按照相应的步骤“导入”即可。
求助,写个程序把网站中的网页数据转换成采集:如姓名、电话、地址等,转成excel表格。…… 数据采集是可以的,先采集进入ACCESS数据库,然后导出到EXCEL
Excel如何抓取网页数据和JSON数据抓取... 打开Chrome,在拉勾网搜索深圳的“数据分析”位置,使用检查功能查看网页源代码,发现拉勾网有反-爬虫机制和工作信息。不是在源代码中,而是在JSON文件中,所以我们直接下载JSON并使用字典方法直接读取数据。在抓取网页时...
vba抓取网页数据(1.从论坛获得的如下语句(语句)原因)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-05 16:06
说明:1. 以下语句从论坛获取,在家庭网络上运行时可以捕获“”中的数据。
2. 但是在公司网络上运行时出现“run-time error'-2147024891 (80070005) Access denied.”错误。
3. 原因是公司需要连接IE浏览器-局域网(LAN)设置-使用自动配置脚本(公司出于安全原因必须设置),联网后即可脚本已设置。回到首页点这里 设置也不能抓取数据,但是删除脚本后,可以重新抓取数据。
4. 我也发现,不管是在家还是在工作,也不管IE设置了脚本还是删除了脚本,只要能上网,谷歌浏览器就可以显示数据“” .
问题:
1. 因为Google可以显示数据,但是IE设置了脚本后就不能显示了,是不是说明下面的语句是基于IE浏览器的内核编译的?
2. 有没有可以绕过IE内核(可能我不准确)直接在谷歌浏览器(或其他浏览器)抓取数据的说法?请各位老师帮忙,谢谢!
附图为谷歌浏览器获取的数据截图
谷歌浏览器抓取的数据
'---------------------------
'网页下载
函数 DownLoadHtm(Url) As String
下载 Htm = 真
昏暗的检索 查看全部
vba抓取网页数据(1.从论坛获得的如下语句(语句)原因)
说明:1. 以下语句从论坛获取,在家庭网络上运行时可以捕获“”中的数据。
2. 但是在公司网络上运行时出现“run-time error'-2147024891 (80070005) Access denied.”错误。
3. 原因是公司需要连接IE浏览器-局域网(LAN)设置-使用自动配置脚本(公司出于安全原因必须设置),联网后即可脚本已设置。回到首页点这里 设置也不能抓取数据,但是删除脚本后,可以重新抓取数据。
4. 我也发现,不管是在家还是在工作,也不管IE设置了脚本还是删除了脚本,只要能上网,谷歌浏览器就可以显示数据“” .
问题:
1. 因为Google可以显示数据,但是IE设置了脚本后就不能显示了,是不是说明下面的语句是基于IE浏览器的内核编译的?
2. 有没有可以绕过IE内核(可能我不准确)直接在谷歌浏览器(或其他浏览器)抓取数据的说法?请各位老师帮忙,谢谢!
附图为谷歌浏览器获取的数据截图
谷歌浏览器抓取的数据

'---------------------------
'网页下载
函数 DownLoadHtm(Url) As String
下载 Htm = 真
昏暗的检索
vba抓取网页数据(【漫画】如何成为一个有意思的人?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-05 16:05
.打开“GET”,SURL,假
。发送
'tt = .responseBody
tt = .responseText
'tt = StrConv(.responsebody, vbUnicode)
结束于
如果 InStr(tt, "Sheet1.Cells(i, 13) = Split(Split(Split(tt, "")(0), ">")(1)@ >
别的
Sheet1.Cells(i, 13) = "-"
万一
If InStr(tt, "") Then'Grab the title
Sheet1.Cells(i, 14) = Trim(Replace(Split(Split(tt, "")(1)@>, "")(0), vbLf, " "))
别的
Sheet1.Cells(i, 14) = "-"
万一
If InStr(tt, "") Then'Fetch 评论
Sheet1.Cells(i, 15) = Split(Split(Split(tt, "")(1)@>, "")(0), "")(< @0)
别的
Sheet1.Cells(i, 15) = 0
万一
如果 InStr(tt, "Sheet1.Cells(i, 16) = Split(Split(Split(Split(tt, "")(0), "title="")) (1)@>, "")(0)
别的
Sheet1.Cells(i, 16) = 0
万一
如果 InStr(tt, "Sheet1.Cells(i, 17) = Split(Trim(Replace(Split(Split(Split(tt, "")(0), "") (1)@>, vbLf, "")), "")(0)
别的
Sheet1.Cells(i, 17) = 0
万一
如果 InStr(tt, "Sheet1.Cells(i, 18) = Split(Split(Split(tt, "")(0), ">")(1)@ >
别的
Sheet1.Cells(i, 18) = 0
万一
If InStr(tt, "") Then'Grab 类别
Sheet1.Cells(i, 19) = Replace(Split(Split(Split(Split(tt, "")(1)@>, "")(0), "在 ")(1)@>, "(")(0), "&", "&")
别的
Sheet1.Cells(i, 19) = "-"
万一
If InStr(tt, "") Then'Grab BSR1
Sheet1.Cells(i, 20) = Split(Split(Split(tt, "")(1)@>, "in ")(0), "#") (1)@>
别的
Sheet1.Cells(i, 20) = 0
万一
If InStr(tt, "") Then'抓住节点
Sheet1.Cells(i, 21)@> = Split(Split(Split(Split(Split(tt, "")(1)@>, "")(0), " ")(1)@>, "")(1)@>
别的
Sheet1.Cells(i, 21)@> = "-"
万一
If InStr(tt, "") Then'Grab BSR2
Sheet1.Cells(i, 22) = Split(Split(Split(Split(Split(tt, "")(1)@>, "")(0), " ")(1)@>, "")(0), "#")(1)@>
别的
Sheet1.Cells(i, 22) = 0
万一
接下来我
结束子
复制代码
本来可以正常抓取商品信息(标题、品牌、评论、星级...),但是最近抓取出错了。代码操作错误,(我们正常浏览商品页面也会出现这种现象,但只需要修改网站的语言设置,防止出现中文内容),请教:
能否在代码中指定一个浏览器,比如谷歌浏览器来获取数据(我在想代码是打开360还是IE网页,两者可能都有中文界面)
或者是其他问题引起的?
另外,我想在这段代码中加入setRequestHeader,避免网站的反爬系统,也希望得到老师的帮助
非常感谢老师的帮助
呸呸 查看全部
vba抓取网页数据(【漫画】如何成为一个有意思的人?(上))
.打开“GET”,SURL,假
。发送
'tt = .responseBody
tt = .responseText
'tt = StrConv(.responsebody, vbUnicode)
结束于
如果 InStr(tt, "Sheet1.Cells(i, 13) = Split(Split(Split(tt, "")(0), ">")(1)@ >
别的
Sheet1.Cells(i, 13) = "-"
万一
If InStr(tt, "") Then'Grab the title
Sheet1.Cells(i, 14) = Trim(Replace(Split(Split(tt, "")(1)@>, "")(0), vbLf, " "))
别的
Sheet1.Cells(i, 14) = "-"
万一
If InStr(tt, "") Then'Fetch 评论
Sheet1.Cells(i, 15) = Split(Split(Split(tt, "")(1)@>, "")(0), "")(< @0)
别的
Sheet1.Cells(i, 15) = 0
万一
如果 InStr(tt, "Sheet1.Cells(i, 16) = Split(Split(Split(Split(tt, "")(0), "title="")) (1)@>, "")(0)
别的
Sheet1.Cells(i, 16) = 0
万一
如果 InStr(tt, "Sheet1.Cells(i, 17) = Split(Trim(Replace(Split(Split(Split(tt, "")(0), "") (1)@>, vbLf, "")), "")(0)
别的
Sheet1.Cells(i, 17) = 0
万一
如果 InStr(tt, "Sheet1.Cells(i, 18) = Split(Split(Split(tt, "")(0), ">")(1)@ >
别的
Sheet1.Cells(i, 18) = 0
万一
If InStr(tt, "") Then'Grab 类别
Sheet1.Cells(i, 19) = Replace(Split(Split(Split(Split(tt, "")(1)@>, "")(0), "在 ")(1)@>, "(")(0), "&", "&")
别的
Sheet1.Cells(i, 19) = "-"
万一
If InStr(tt, "") Then'Grab BSR1
Sheet1.Cells(i, 20) = Split(Split(Split(tt, "")(1)@>, "in ")(0), "#") (1)@>
别的
Sheet1.Cells(i, 20) = 0
万一
If InStr(tt, "") Then'抓住节点
Sheet1.Cells(i, 21)@> = Split(Split(Split(Split(Split(tt, "")(1)@>, "")(0), " ")(1)@>, "")(1)@>
别的
Sheet1.Cells(i, 21)@> = "-"
万一
If InStr(tt, "") Then'Grab BSR2
Sheet1.Cells(i, 22) = Split(Split(Split(Split(Split(tt, "")(1)@>, "")(0), " ")(1)@>, "")(0), "#")(1)@>
别的
Sheet1.Cells(i, 22) = 0
万一
接下来我
结束子
复制代码
本来可以正常抓取商品信息(标题、品牌、评论、星级...),但是最近抓取出错了。代码操作错误,(我们正常浏览商品页面也会出现这种现象,但只需要修改网站的语言设置,防止出现中文内容),请教:
能否在代码中指定一个浏览器,比如谷歌浏览器来获取数据(我在想代码是打开360还是IE网页,两者可能都有中文界面)
或者是其他问题引起的?
另外,我想在这段代码中加入setRequestHeader,避免网站的反爬系统,也希望得到老师的帮助
非常感谢老师的帮助
呸呸
vba抓取网页数据(《VBA信息获取与处理》教程共两册,八十四大智慧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-07 03:13
【分享成果,正能量庆幸】人的一生,肯定会遇到各种各样的挫折和挑战,巨大的压力会让你喘不过气来。然而,只有真正懂得适时弯腰的人,才能战胜危机,赢得胜利。这不是懦弱,也不是没有骨气,而是一种大智慧。武力和野蛮只会带来不必要的损失。《VBA信息获取与处理》教程是我的第六套教程,现在是第一次修订。本套教程定位于最高级,是初级和中级完成后的教程。本教程内容为:跨应用信息获取、随机信息利用、邮件发送、VBA上网数据抓取、VBA延时操作、剪贴板应用、Split函数扩展、工作表信息等应用交互、FSO对象的使用、工作表和文件夹信息的获取、图形信息的获取、工作表信息功能的定制等。文件由 32 位和 64 位 Office 系统测试。它非常抽象,更有研究价值。本教程共两卷,八十四讲。今天的内容是话题6“Using XMLHTTP in VBA to complete web data capture”的第三讲:VBA web数据捕捉结果链接 图形信息的获取,工作表信息功能的定制等。程序文件通过32位和64位Office系统测试。它非常抽象,更有研究价值。本教程共两卷,八十四讲。今天的内容是话题6“Using XMLHTTP in VBA to complete web data capture”的第三讲:VBA web数据捕捉结果链接 图形信息的获取,工作表信息功能的定制等。程序文件通过32位和64位Office系统测试。它非常抽象,更有研究价值。本教程共两卷,八十四讲。今天的内容是话题6“Using XMLHTTP in VBA to complete web data capture”的第三讲:VBA web数据捕捉结果链接
第三部分使用XMLHTTP抓取百度搜索数据的结果,并给出开放链接。在上一讲中,我们实现了使用XMLHTTP来捕获搜索关键词的数据,但是我们在网上搜索的时候,往往不仅需要一般的数据支持,还需要一些具体的数据,比如: 找到了哪些网址,标题是什么?如果我需要进一步检查,我经常需要打开链接。如何捕获这些数据?所以让我意识到这个问题。实现场景: 如下图,当我们点击右侧按钮“使用VBA提取数据进行搜索关键词,并给出下载链接”时,可以给出查询的结果在下面的数据区。
其实这种处理在工作中是经常遇到的,我们浏览的网页可以适当的保存一下,需要的时候再详细查询。特别是将这些数据以EXCEL形式存储,管理更加清晰。那么如何实现这个场景呢?我们仍然使用 XMLHTTP 来完成我们的工作。1 使用XMLHTTP实现数据查询和网页链接提取。我们先模拟直接在网页上查询数据。当我们输入数据并点击回车时,服务器会在我们的浏览器上反馈数据。我们需要检查网页的源代码进行分析,
上面的截图是我输入“VBA Language Expert”点击回车后在后台看到的源代码。你会发现我们要写入EXCEL表格的所有信息都出现在这里了。其中“title”可以通过innerText属性获取,链接可以通过href属性获取。这真的很容易。接下来我们将多页查询的结果填入excel表格中。这时候,我们在向服务器发送时使用下面的代码可以通过询问header检查查询时间得到: .setRequestHeader "If-Modified-Since", "0" 这样就可以达到我们的要求了。2 使用XMLHTTP实现数据查询,提取网页链接的代码实现过程。下面我们将上面的思路转换成代码,如下图:
<p>代码说明: 1) Set objXMLHTTP = CreateObject("MSXML2.XMLHTTP") Set objDOM = CreateObject("htmlfile") 上面的代码创建了两个引用,一个是XMLHTTP,一个是htmlfile,然后使用这两个参考来完成我们的工作。2)UU = Range("B1").Value 这是我们要查询的关键数据3)For i = 0 To 50 Step 10'五页这是使用i作为查询5次查询页码 4) strURL = "" strURL= strURL & "wd=" & UU strURL= strURL & "&pn=" & i 以上代码完成了我们要查询的请求URL。5) .Open "GET", strURL, False 使用 OPEN 方法。6) .setRequestHeader "If-Modified-Since", "0" 请求头将浏览器端缓存页面的最后修改时间一起发送到服务器,服务器会将此时间与服务器上实际文件的最后修改时间进行比较,以确保我们每次请求的数据不是重复。7) .send 注意在这个命令之前应该完成请求头的提交8)objDOM.body.innerHTML = .responseText'将.responseText的内容写入新的objDOM对象的body中< @9) 对于 objDOM 中的每个 objTitle。getElementsByTagName("h3") 遍历每个 H3 标签或标题。请注意,它是标签标题。定义最大的标题。定义最小的标题。服务器会将此时间与服务器上实际文件的最后修改时间进行比较,以确保我们每次请求的数据不会重复。7) .send 注意在这个命令之前应该完成请求头的提交8)objDOM.body.innerHTML = .responseText'将.responseText的内容写入新的objDOM对象的body中< @9) 对于 objDOM 中的每个 objTitle。getElementsByTagName("h3") 遍历每个 H3 标签或标题。请注意,它是标签标题。定义最大的标题。定义最小的标题。服务器会将此时间与服务器上实际文件的最后修改时间进行比较,以确保我们每次请求的数据不会重复。7) .send 注意在这个命令之前应该完成请求头的提交8)objDOM.body.innerHTML = .responseText'将.responseText的内容写入新的objDOM对象的body中< @9) 对于 objDOM 中的每个 objTitle。getElementsByTagName("h3") 遍历每个 H3 标签或标题。请注意,它是标签标题。定义最大的标题。定义最小的标题。将 .responseText 的内容写入新的 objDOM 对象 查看全部
vba抓取网页数据(《VBA信息获取与处理》教程共两册,八十四大智慧)
【分享成果,正能量庆幸】人的一生,肯定会遇到各种各样的挫折和挑战,巨大的压力会让你喘不过气来。然而,只有真正懂得适时弯腰的人,才能战胜危机,赢得胜利。这不是懦弱,也不是没有骨气,而是一种大智慧。武力和野蛮只会带来不必要的损失。《VBA信息获取与处理》教程是我的第六套教程,现在是第一次修订。本套教程定位于最高级,是初级和中级完成后的教程。本教程内容为:跨应用信息获取、随机信息利用、邮件发送、VBA上网数据抓取、VBA延时操作、剪贴板应用、Split函数扩展、工作表信息等应用交互、FSO对象的使用、工作表和文件夹信息的获取、图形信息的获取、工作表信息功能的定制等。文件由 32 位和 64 位 Office 系统测试。它非常抽象,更有研究价值。本教程共两卷,八十四讲。今天的内容是话题6“Using XMLHTTP in VBA to complete web data capture”的第三讲:VBA web数据捕捉结果链接 图形信息的获取,工作表信息功能的定制等。程序文件通过32位和64位Office系统测试。它非常抽象,更有研究价值。本教程共两卷,八十四讲。今天的内容是话题6“Using XMLHTTP in VBA to complete web data capture”的第三讲:VBA web数据捕捉结果链接 图形信息的获取,工作表信息功能的定制等。程序文件通过32位和64位Office系统测试。它非常抽象,更有研究价值。本教程共两卷,八十四讲。今天的内容是话题6“Using XMLHTTP in VBA to complete web data capture”的第三讲:VBA web数据捕捉结果链接
第三部分使用XMLHTTP抓取百度搜索数据的结果,并给出开放链接。在上一讲中,我们实现了使用XMLHTTP来捕获搜索关键词的数据,但是我们在网上搜索的时候,往往不仅需要一般的数据支持,还需要一些具体的数据,比如: 找到了哪些网址,标题是什么?如果我需要进一步检查,我经常需要打开链接。如何捕获这些数据?所以让我意识到这个问题。实现场景: 如下图,当我们点击右侧按钮“使用VBA提取数据进行搜索关键词,并给出下载链接”时,可以给出查询的结果在下面的数据区。
其实这种处理在工作中是经常遇到的,我们浏览的网页可以适当的保存一下,需要的时候再详细查询。特别是将这些数据以EXCEL形式存储,管理更加清晰。那么如何实现这个场景呢?我们仍然使用 XMLHTTP 来完成我们的工作。1 使用XMLHTTP实现数据查询和网页链接提取。我们先模拟直接在网页上查询数据。当我们输入数据并点击回车时,服务器会在我们的浏览器上反馈数据。我们需要检查网页的源代码进行分析,
上面的截图是我输入“VBA Language Expert”点击回车后在后台看到的源代码。你会发现我们要写入EXCEL表格的所有信息都出现在这里了。其中“title”可以通过innerText属性获取,链接可以通过href属性获取。这真的很容易。接下来我们将多页查询的结果填入excel表格中。这时候,我们在向服务器发送时使用下面的代码可以通过询问header检查查询时间得到: .setRequestHeader "If-Modified-Since", "0" 这样就可以达到我们的要求了。2 使用XMLHTTP实现数据查询,提取网页链接的代码实现过程。下面我们将上面的思路转换成代码,如下图:
<p>代码说明: 1) Set objXMLHTTP = CreateObject("MSXML2.XMLHTTP") Set objDOM = CreateObject("htmlfile") 上面的代码创建了两个引用,一个是XMLHTTP,一个是htmlfile,然后使用这两个参考来完成我们的工作。2)UU = Range("B1").Value 这是我们要查询的关键数据3)For i = 0 To 50 Step 10'五页这是使用i作为查询5次查询页码 4) strURL = "" strURL= strURL & "wd=" & UU strURL= strURL & "&pn=" & i 以上代码完成了我们要查询的请求URL。5) .Open "GET", strURL, False 使用 OPEN 方法。6) .setRequestHeader "If-Modified-Since", "0" 请求头将浏览器端缓存页面的最后修改时间一起发送到服务器,服务器会将此时间与服务器上实际文件的最后修改时间进行比较,以确保我们每次请求的数据不是重复。7) .send 注意在这个命令之前应该完成请求头的提交8)objDOM.body.innerHTML = .responseText'将.responseText的内容写入新的objDOM对象的body中< @9) 对于 objDOM 中的每个 objTitle。getElementsByTagName("h3") 遍历每个 H3 标签或标题。请注意,它是标签标题。定义最大的标题。定义最小的标题。服务器会将此时间与服务器上实际文件的最后修改时间进行比较,以确保我们每次请求的数据不会重复。7) .send 注意在这个命令之前应该完成请求头的提交8)objDOM.body.innerHTML = .responseText'将.responseText的内容写入新的objDOM对象的body中< @9) 对于 objDOM 中的每个 objTitle。getElementsByTagName("h3") 遍历每个 H3 标签或标题。请注意,它是标签标题。定义最大的标题。定义最小的标题。服务器会将此时间与服务器上实际文件的最后修改时间进行比较,以确保我们每次请求的数据不会重复。7) .send 注意在这个命令之前应该完成请求头的提交8)objDOM.body.innerHTML = .responseText'将.responseText的内容写入新的objDOM对象的body中< @9) 对于 objDOM 中的每个 objTitle。getElementsByTagName("h3") 遍历每个 H3 标签或标题。请注意,它是标签标题。定义最大的标题。定义最小的标题。将 .responseText 的内容写入新的 objDOM 对象
vba抓取网页数据(vba抓取网页数据怎么做?如何做好网页技术开发)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-12-26 18:11
vba抓取网页数据,或通过excel抓取简单的前后端分离或有数据交互(websocket),无线开发常用api;做单页面应用,如饿了么的有赞平台,都是js抓取,但接口和传递参数、页面跳转都要依赖前端模板引擎(js);前端做后端的渲染,对外表现页面内容;分页浏览数据库、bloomfilter、prequery技术已经不成问题了,当然这些都还只是起步。
前端支持js,不需要后端。用户刷新页面后,页面的数据也不会丢失。前端输出的数据,在系统中(包括app)都是一致的。
实际看到的前端有2种,即前端技术开发技术和产品技术开发技术。而还有第三种,即产品技术开发技术中的网页技术开发技术。浏览器端和手机客户端发起请求前端响应即可。这不代表没有后端来通过ajax进行数据交互的操作。
不需要后端你给人家打个请求,你就能获取人家的服务器上的内容?你应该考虑后端开发人员需要哪些人才?你应该考虑需要些什么工具配合你做这个事情?建议你不要用js了,该改的地方太多,你要有个好的平台做chatbot(参考ooxx),该有的功能都要有,就差不多了,你的js,需要多请求。多用js3上的传输来操作用户。
不然你搞一堆数据,到人家的服务器去交互,谁懂你的意思,还得会返回你的数据。传输的问题做这么一大堆,每一点都要去解决,那出来的东西跟后端没有任何联系,你用js都不可能知道整个网站的基本数据源自哪,又如何去爬取。而且,你有不同的网站,如果需要不同的传输方式和数据格式,你得考虑实际问题,设计的时候就没必要考虑像你说的那样多模型的操作了,要看看文档的怎么写。 查看全部
vba抓取网页数据(vba抓取网页数据怎么做?如何做好网页技术开发)
vba抓取网页数据,或通过excel抓取简单的前后端分离或有数据交互(websocket),无线开发常用api;做单页面应用,如饿了么的有赞平台,都是js抓取,但接口和传递参数、页面跳转都要依赖前端模板引擎(js);前端做后端的渲染,对外表现页面内容;分页浏览数据库、bloomfilter、prequery技术已经不成问题了,当然这些都还只是起步。
前端支持js,不需要后端。用户刷新页面后,页面的数据也不会丢失。前端输出的数据,在系统中(包括app)都是一致的。
实际看到的前端有2种,即前端技术开发技术和产品技术开发技术。而还有第三种,即产品技术开发技术中的网页技术开发技术。浏览器端和手机客户端发起请求前端响应即可。这不代表没有后端来通过ajax进行数据交互的操作。
不需要后端你给人家打个请求,你就能获取人家的服务器上的内容?你应该考虑后端开发人员需要哪些人才?你应该考虑需要些什么工具配合你做这个事情?建议你不要用js了,该改的地方太多,你要有个好的平台做chatbot(参考ooxx),该有的功能都要有,就差不多了,你的js,需要多请求。多用js3上的传输来操作用户。
不然你搞一堆数据,到人家的服务器去交互,谁懂你的意思,还得会返回你的数据。传输的问题做这么一大堆,每一点都要去解决,那出来的东西跟后端没有任何联系,你用js都不可能知道整个网站的基本数据源自哪,又如何去爬取。而且,你有不同的网站,如果需要不同的传输方式和数据格式,你得考虑实际问题,设计的时候就没必要考虑像你说的那样多模型的操作了,要看看文档的怎么写。
vba抓取网页数据(百度的文字识别可以让C#、Python等语言调用。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-12-23 18:02
通常需要将照片中的文字转换为可编辑的文字。
百度的文字识别可以用C#、Python等语言调用。我将其集成到 API 打包库中。
API包库的下载和部署请参考以下帖子:
下面我来演示一下如何在VBA中调用API包库中的Image2Character函数来提取照片中的数据。
在 Excel VBA 中添加外部引用 API 和正则表达式。
模块中的代码如下:
Private S As String
Sub GetData()
Dim B As New API.Baidu
Dim Result As String
S = B.Image2Character(imagepath:="E:\粉煤灰\2.jpg")
Debug.Print S
End Sub
Sub Split()
Dim Reg As RegExp, MC As MatchCollection, M As Match
Set Reg = New RegExp
With Reg
.Global = True
.Pattern = Chr(34) & "([0-9\.]+)mg/L" & Chr(34)
Set MC = .Execute(S)
For Each M In MC
Debug.Print M.SubMatches(0)
Next M
End With
End Sub
GetData 负责从计算机中的图片中提取文本并将其分配给变量 S。
Split 负责按照指定的模式对变量 S 进行分解。
本例涉及化学物质含量检测的科研图片。图片收录两个样本L22和L23的数据。我关注的是Conc栏,就是单位是mg/L。 查看全部
vba抓取网页数据(百度的文字识别可以让C#、Python等语言调用。)
通常需要将照片中的文字转换为可编辑的文字。
百度的文字识别可以用C#、Python等语言调用。我将其集成到 API 打包库中。
API包库的下载和部署请参考以下帖子:
下面我来演示一下如何在VBA中调用API包库中的Image2Character函数来提取照片中的数据。
在 Excel VBA 中添加外部引用 API 和正则表达式。
模块中的代码如下:
Private S As String
Sub GetData()
Dim B As New API.Baidu
Dim Result As String
S = B.Image2Character(imagepath:="E:\粉煤灰\2.jpg")
Debug.Print S
End Sub
Sub Split()
Dim Reg As RegExp, MC As MatchCollection, M As Match
Set Reg = New RegExp
With Reg
.Global = True
.Pattern = Chr(34) & "([0-9\.]+)mg/L" & Chr(34)
Set MC = .Execute(S)
For Each M In MC
Debug.Print M.SubMatches(0)
Next M
End With
End Sub
GetData 负责从计算机中的图片中提取文本并将其分配给变量 S。
Split 负责按照指定的模式对变量 S 进行分解。
本例涉及化学物质含量检测的科研图片。图片收录两个样本L22和L23的数据。我关注的是Conc栏,就是单位是mg/L。
vba抓取网页数据(我正在尝试从此网站上删除数据(-vbaweb))
网站优化 • 优采云 发表了文章 • 0 个评论 • 39 次浏览 • 2021-12-23 12:22
我正在尝试从此 网站 中删除数据。我已经编写了打开网站 然后搜索值的代码。单击搜索结果并打开最后一页,我必须从中选择详细信息。我需要选择红色提到的标签的详细信息
这是我打开所需页面的代码。我已经使用 Link.click 打开所需的页面。之后,我需要获取图像中提到的详细信息。温心提醒。
Sub hullByAshish() Dim html, html1 As HTMLDocument Dim ElementCol, ElementCol1 As Object Dim Link As Object Dim appIE As Object Dim a As String Dim i As Long Dim objElement As Object Dim objCollection As Object Set appIE = CreateObject("internetexplorer.application") a = "PONTOVREMON" With appIE .Navigate "https://www.marinetraffic.com/ ... ot%3B & a .Visible = True End With Do While appIE.Busy DoEvents Loop Application.Wait (Now() + TimeValue("00:00:01")) Set html = appIE.document Set ElementCol = html.getElementsByTagName("a") DoEvents For Each Link In ElementCol If Link.innerHTML = "PONTOVREMON" Then Link.Click End If Next Link End Sub
excelvbaexcel-vbaweb-scrapinginnerhtml 查看全部
vba抓取网页数据(我正在尝试从此网站上删除数据(-vbaweb))
我正在尝试从此 网站 中删除数据。我已经编写了打开网站 然后搜索值的代码。单击搜索结果并打开最后一页,我必须从中选择详细信息。我需要选择红色提到的标签的详细信息
这是我打开所需页面的代码。我已经使用 Link.click 打开所需的页面。之后,我需要获取图像中提到的详细信息。温心提醒。
Sub hullByAshish() Dim html, html1 As HTMLDocument Dim ElementCol, ElementCol1 As Object Dim Link As Object Dim appIE As Object Dim a As String Dim i As Long Dim objElement As Object Dim objCollection As Object Set appIE = CreateObject("internetexplorer.application") a = "PONTOVREMON" With appIE .Navigate "https://www.marinetraffic.com/ ... ot%3B & a .Visible = True End With Do While appIE.Busy DoEvents Loop Application.Wait (Now() + TimeValue("00:00:01")) Set html = appIE.document Set ElementCol = html.getElementsByTagName("a") DoEvents For Each Link In ElementCol If Link.innerHTML = "PONTOVREMON" Then Link.Click End If Next Link End Sub
excelvbaexcel-vbaweb-scrapinginnerhtml
vba抓取网页数据( 第3行字符串替换成网站的作用是创建一个IE应用程序对象)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-17 03:02
第3行字符串替换成网站的作用是创建一个IE应用程序对象)
VBA IE对象的操作方法
<p> (2013-10-27 11:39:29)
http://blog.sina.com.cn/s/blog_64173e0c0101bf9o.html
<a class="SG_aBtn SG_aBtn_ico SG_turn">转载▼</a>
标签: vba ie 标签 对象 图片 it 分类: 电子商务
IE和文档对象模型
我们在实际工作中遇到网站和网页相关往往要涉及到这类问题:如何下载网页数据?网页之间的通讯是怎么实现的、它们能不能被控制等等。分析网页根据不同协变色镜可以用不同的角度去看,如数据流、标记,不过,如果你是用VB/VBA/脚本或其它支持自动化对象(AUTOMATION)的语言编程,有一个值得了解方法是掌握对象模型,将网页视为对象来自行控制,这个方法需要了解的是IE的自动化对象(InternetExplorer.Application)或IE控件(Microsoft Internet Controls),以及标准的文档对象模型(Document)<br /> 以下代码在VBA环境下进行试验——我不在意你是用WORD还是EXCEL——可以先做一行过程模块,也可以在立即窗口下逐行输入:
</p>
Set ieA = CreateObject("InternetExplorer.Application") ‘创建对象
ieA.Visible = True ‘使IE页面可见,做完这一步,在VBA之外可以看到一个新的IE
ieA.navigate "about:blank" ‘空白页
这几行代码的作用就是创建一个IE应用程序对象(是的,它相当于一个IE应用程序)并打开一个空白的网页。此网页独立于 VBA 应用程序(WORD 或 EXCEL)。其实必须自己关闭,或者使用ieA.Quit命令退出——注意简单关闭VBA或者SET ieA=nothing都不会退出这个页面。当然,如果你在线并且愿意,你也可以将第3行的字符串替换为网站的名称,或者替换为你主机中的一个文档名——比如C:\XXX .HTM ,或者D:\PIC\XXX.GIF,就像你在IE地址栏中输入名称浏览这些文件一样。另一种替代方法是在宿主机上直接添加一个WEB BROWS浏览器控件比如VB/VBA的表单或者工作表,也相当于上面的IE应用
注意:WEB BROWSE 控件和单独的 IE 程序并不完全相同。比如WEB控件不能用QUIT方法退出。IE 的 NAVIGETE 方法没有复杂的 POST 参数,但同样可以引用文档对象。大多数事件和方法也是通用的
另外,如果你访问一个已有的网页,比如因为有异步延迟的可能,如果不是立即窗口,往往保证网页是按照READYSTATE状态加载的:
SUB LOADIE() ‘ 在代码的常见的处理情况
Set ieA = CreateObject("InternetExplorer.Application")
ieA.Visible = True
ieA.navigate "WWW.OOXX.COM" ‘←打开某个网页,要一定时间,但代码会往下执行
DO UNTIL ieA.Readystate=4 ‘ 检查网页是否加载完毕(4表示完全加载)
DOEVENTS ‘ 循环中交回工作权限给系统,以免“软死机”
LOOP
END SUB
如果你对这个IE应用对象的相关声明和事件感兴趣,必须参考IE控件才能找到对象中的常量和事件:SHDOCVW.DLL (MICROSOFT INTERNET CONTROL)
你可以看到,通过 ieA——创建的对象——我们可以操作它并访问它的属性。让我们继续。如果你在命令行输入并且打开的空白网页没有关闭,变量将继续有效:
设置 doc = ieA.Document' 获取网页的文档对象
doc.body.innerHTML = "Hello"'在文档的BODY标签中添加标记文本HELLO
网页上有一行小字,HELLO...一般约定俗成,当然可以写其他的,HI,我爱你,EXCEL,HOME等,但这不是最重要的,我们来知道这个对象下的结构。
由文档对象(Document)扩展而来的对象模型,它代表网页的内容,与之前的IE应用程序不是同一个系统——请注意这一点——如果我们需要使用对应的对象事件和常量编程时,VB/VBA要引用的类型库是MSHTML.TLB(MIRCOSOFT HTML OBJECT LIBRARY)
Documnet(文档)是文档对象模型的基础,相当于OFFICE对象中的APPLICATION。拿到Document后,无论是修改网页、读写网页、触发事件,一切都好说。每个URL对应一个Documnet(这是如果确定成功导航到那个URL完成Navigate,则需要确定IE对象的READSTATE,以确保该URL对应的Document被打开)
在Documnet下可以获得documentElement和body两个节点:
...... ‘前面已经取得了ieA对象,并打开空白网页,不再重复
set doc=ieA.Document
set xbody=doc.Body ‘取得body对象
set xDoc=doc. documentElement ‘取得根节点
body前面已经说过,相当于
标记对象,根节点相当于网页中被标记的元素对象。在MHTML类型库的定义中,它们都是HTMLHtmlElement类型的对象。下面我把这种类型的对象称为“节点”,但要注意文档对象不是节点对象,它是HTMLDocument类型的。根节点和正文节点的区别在于根节点包括整个网页。在 HTML 的文档对象模型中,这种类型的对象有几个属性来获取内容:
Object.innerHtml' 对象内的 HTML 文本
Object.OuterHtml' 对象中的 HTML 文本,包括对象本身的 HTML 标记
Object.innerText' 对象内的 TEXT,不包括 HTML 标记
Object.OuterText' 同上,包括对象本身的文本
所以,如果我们想抓取某个网站的所有HTML内容,代码可以这样写:
...... ‘前面已经取得了ieA对象,并打开某URL网页
set doc=ieA.Document
set xDoc=doc. documentElement ‘取得根节点
strX=xDoc.OuterHtml ‘取得所有的HTML内容
这种取值的方式不妨可以当成EXCEL的单元格取值:
set shDocX=APPLICATION.ACTIVEWORK.ACTIVESHEET ‘从应用程序、工作簿一直定位到当前工作表,这是EXCEL的工作簿对象模型
set rngX=shDocX.Rang(“a1”) ‘取得单元格(其实不一定是一个格子,只要是RANGE类型对象即可)
X=rngX.VALUE ‘取得VALUE值,也可以取只读的TEXT
网页上看到的mark是根节点或body下的mark节点对象(node)。每个被标记的节点对象下面,都有一个叫做ChildNodes的集合,里面收录了“节点正下方的标记”,听起来有点抽象——可以这么说,它就像一个文件目录,根目录下的一个子目录内容……
你好
001
在上面的网页示例中,HTML 标记是文档的根节点,并且是文档的 Childnodes 集合的成员。从属节点的集合,就像磁盘可以有从属目录,但它本身不是目录),BODY是根节点的ChildNodes集合的成员,两个节点DIV和P是ChildNodes的两个成员BODY的集合,同样也有自己的Childnoes集合——但是我们可以直观的看到,他们的下属集合是空的。
用程序代码提问的过程是怎样的?这种“目录式”的分层方法似乎非常有序。然后,将上面的内容保存为一个HTML文档,放到硬盘的某个目录下,写一段代码完成前面的工作。我不为你做:
…….假定你已经用ieA为名的对象浏览了上述网页文件
set doc=ieA.Document
set xbody=doc. body ‘取得body节点
set xI00= xbody.Childnodes.item(0) ‘取得body的第1个节点
set xI01=xbody.Childnodes.item(0) ‘取得bdoy的第2个节点
Msgbox xI00.innerText ‘显示第1个节点(DIV)的文本
Msgbox xI01.outerHtml ‘显示第2个节点(P)的完整内容
在VB/VBA/VBS系列的语言中,item是默认方法,可以省略,不过还是写在这里加深印象。
需要注意的是,在文档对象模型中,集合不同于OFFICE集合。首先,集合是从0开始计数的。习惯OFFICE VBA编程的朋友一定要注意,不同的对象架构有不同的方式。这是“0集合”。其次,它使用 Length 而不是 Count。不要习惯性地键入 Childnode.Count 来检查集合的数量。
除了ChildNodes集合,大家在web文档对象中常见的还有一个非常流行的集合:All集合,也就是“最迷惑”的集合。各级文档和节点都有这个集合,就像名字一样。如图,没有分层,但是使用起来也很方便:
…….
Set doc=ieA.Document
Set xCols=doc.All ;取得文档中的所有节点集合
Set xbCols=doc.body.All ;取得body节点下所有的节点集合
虽然任何标记节点都有ALL集合,但我们还是喜欢用DOCUMENT的ALL,原因无它,文档最大,一锅烩的ALL找起来也最合适。
ALL查找是有条件的:如果这个标记没有ID,你无法查到它的名字:
你好
擅长
set tag1=doc.All.item(“myTag”).item(0) ‘返回标记内部ID=myTag的集合并取第一个
一开始,在我个人看来,如果网页中的 HTML 标记已经有了 ID,那么直接返回一个带有文档对象的 getElementById 的对象会更直接。这个方法不需要遍历集合:
set tag1=doc. getElementById(“myTag”) ‘返回第一个内部标有ID=myTag的标记
不过,ALL集合有一个很方便的特性——至少在初学者看来是很好用的:ID可以挂到ALL集合之下:
strX=doc.All.mytag.innerhtml ‘呜呜呜,太好用了
另一种方法是以标记名为集合,要用到文档对象的getElementsByName方法:
set mydivs=doc. getElementsByName(“div”) ‘取得所有DIV标记,注意还是集合
今天先写到这里,下回......不定期休息
(补一小段,特别增加,关于FORMS,某位兄弟,下面真的真的没有了,不要期望我上传实例......)
关于文档对象的FORMS集合,因为大部分网页数据提交都是通过FORM标签提交的,所以当网页中没有FORM标签、没有ID标签或者重复ID时,可以使用FORMS集合来区分不同的FORM节点标签。:
引用:
设置 myForms=doc.Forms' 以获取所有 FORM 标签
Set frmX=myForms.item(0)'第一个FORM
FORM标签节点所代表的对象是很多朋友关心的内容——在网页对象中,它可以向服务器发送数据,让服务器刷新网页(实际上是服务器根据到一定的格式协议),我们就可以改变网页FORM作为远程函数调用接口。FORM标签中的ACTION指向的URL地址就是函数入口,FORM标签中的每一个INPUT标签节点都是该函数的参数。当 FORM.Submit 方法发出时,该函数被远程调用。是的,在服务器端,比如ASP,PHP就是老老实实的找FORM的参数,不管是用GET还是POST:
引用:
frmX.submit' 是的,只要Submit就相当于用户在页面上按下了FORM的send按钮
但是它的参数,即 INPUT 标签呢?当然,你可以自己修改,访问,嗯...如果你分析一个现有的网页,想用VBA从一个空白页面(ABOUT:BLANK)“凭空”生成FORM和INPUT节点,就靠对上面的方法还不够,我们还要“创建一个节点”(createElement_x)并连接到文档的对应位置(appendChild),但这已经是另一个问题了 查看全部
vba抓取网页数据(
第3行字符串替换成网站的作用是创建一个IE应用程序对象)
VBA IE对象的操作方法
<p> (2013-10-27 11:39:29)
http://blog.sina.com.cn/s/blog_64173e0c0101bf9o.html
<a class="SG_aBtn SG_aBtn_ico SG_turn">
标签: vba ie 标签 对象 图片 it 分类: 电子商务
IE和文档对象模型
我们在实际工作中遇到网站和网页相关往往要涉及到这类问题:如何下载网页数据?网页之间的通讯是怎么实现的、它们能不能被控制等等。分析网页根据不同协变色镜可以用不同的角度去看,如数据流、标记,不过,如果你是用VB/VBA/脚本或其它支持自动化对象(AUTOMATION)的语言编程,有一个值得了解方法是掌握对象模型,将网页视为对象来自行控制,这个方法需要了解的是IE的自动化对象(InternetExplorer.Application)或IE控件(Microsoft Internet Controls),以及标准的文档对象模型(Document)<br /> 以下代码在VBA环境下进行试验——我不在意你是用WORD还是EXCEL——可以先做一行过程模块,也可以在立即窗口下逐行输入:
</p>
Set ieA = CreateObject("InternetExplorer.Application") ‘创建对象
ieA.Visible = True ‘使IE页面可见,做完这一步,在VBA之外可以看到一个新的IE
ieA.navigate "about:blank" ‘空白页
这几行代码的作用就是创建一个IE应用程序对象(是的,它相当于一个IE应用程序)并打开一个空白的网页。此网页独立于 VBA 应用程序(WORD 或 EXCEL)。其实必须自己关闭,或者使用ieA.Quit命令退出——注意简单关闭VBA或者SET ieA=nothing都不会退出这个页面。当然,如果你在线并且愿意,你也可以将第3行的字符串替换为网站的名称,或者替换为你主机中的一个文档名——比如C:\XXX .HTM ,或者D:\PIC\XXX.GIF,就像你在IE地址栏中输入名称浏览这些文件一样。另一种替代方法是在宿主机上直接添加一个WEB BROWS浏览器控件比如VB/VBA的表单或者工作表,也相当于上面的IE应用
注意:WEB BROWSE 控件和单独的 IE 程序并不完全相同。比如WEB控件不能用QUIT方法退出。IE 的 NAVIGETE 方法没有复杂的 POST 参数,但同样可以引用文档对象。大多数事件和方法也是通用的
另外,如果你访问一个已有的网页,比如因为有异步延迟的可能,如果不是立即窗口,往往保证网页是按照READYSTATE状态加载的:
SUB LOADIE() ‘ 在代码的常见的处理情况
Set ieA = CreateObject("InternetExplorer.Application")
ieA.Visible = True
ieA.navigate "WWW.OOXX.COM" ‘←打开某个网页,要一定时间,但代码会往下执行
DO UNTIL ieA.Readystate=4 ‘ 检查网页是否加载完毕(4表示完全加载)
DOEVENTS ‘ 循环中交回工作权限给系统,以免“软死机”
LOOP
END SUB
如果你对这个IE应用对象的相关声明和事件感兴趣,必须参考IE控件才能找到对象中的常量和事件:SHDOCVW.DLL (MICROSOFT INTERNET CONTROL)
你可以看到,通过 ieA——创建的对象——我们可以操作它并访问它的属性。让我们继续。如果你在命令行输入并且打开的空白网页没有关闭,变量将继续有效:
设置 doc = ieA.Document' 获取网页的文档对象
doc.body.innerHTML = "Hello"'在文档的BODY标签中添加标记文本HELLO
网页上有一行小字,HELLO...一般约定俗成,当然可以写其他的,HI,我爱你,EXCEL,HOME等,但这不是最重要的,我们来知道这个对象下的结构。
由文档对象(Document)扩展而来的对象模型,它代表网页的内容,与之前的IE应用程序不是同一个系统——请注意这一点——如果我们需要使用对应的对象事件和常量编程时,VB/VBA要引用的类型库是MSHTML.TLB(MIRCOSOFT HTML OBJECT LIBRARY)
Documnet(文档)是文档对象模型的基础,相当于OFFICE对象中的APPLICATION。拿到Document后,无论是修改网页、读写网页、触发事件,一切都好说。每个URL对应一个Documnet(这是如果确定成功导航到那个URL完成Navigate,则需要确定IE对象的READSTATE,以确保该URL对应的Document被打开)
在Documnet下可以获得documentElement和body两个节点:
...... ‘前面已经取得了ieA对象,并打开空白网页,不再重复
set doc=ieA.Document
set xbody=doc.Body ‘取得body对象
set xDoc=doc. documentElement ‘取得根节点
body前面已经说过,相当于
标记对象,根节点相当于网页中被标记的元素对象。在MHTML类型库的定义中,它们都是HTMLHtmlElement类型的对象。下面我把这种类型的对象称为“节点”,但要注意文档对象不是节点对象,它是HTMLDocument类型的。根节点和正文节点的区别在于根节点包括整个网页。在 HTML 的文档对象模型中,这种类型的对象有几个属性来获取内容:
Object.innerHtml' 对象内的 HTML 文本
Object.OuterHtml' 对象中的 HTML 文本,包括对象本身的 HTML 标记
Object.innerText' 对象内的 TEXT,不包括 HTML 标记
Object.OuterText' 同上,包括对象本身的文本
所以,如果我们想抓取某个网站的所有HTML内容,代码可以这样写:
...... ‘前面已经取得了ieA对象,并打开某URL网页
set doc=ieA.Document
set xDoc=doc. documentElement ‘取得根节点
strX=xDoc.OuterHtml ‘取得所有的HTML内容
这种取值的方式不妨可以当成EXCEL的单元格取值:
set shDocX=APPLICATION.ACTIVEWORK.ACTIVESHEET ‘从应用程序、工作簿一直定位到当前工作表,这是EXCEL的工作簿对象模型
set rngX=shDocX.Rang(“a1”) ‘取得单元格(其实不一定是一个格子,只要是RANGE类型对象即可)
X=rngX.VALUE ‘取得VALUE值,也可以取只读的TEXT
网页上看到的mark是根节点或body下的mark节点对象(node)。每个被标记的节点对象下面,都有一个叫做ChildNodes的集合,里面收录了“节点正下方的标记”,听起来有点抽象——可以这么说,它就像一个文件目录,根目录下的一个子目录内容……
你好
001
在上面的网页示例中,HTML 标记是文档的根节点,并且是文档的 Childnodes 集合的成员。从属节点的集合,就像磁盘可以有从属目录,但它本身不是目录),BODY是根节点的ChildNodes集合的成员,两个节点DIV和P是ChildNodes的两个成员BODY的集合,同样也有自己的Childnoes集合——但是我们可以直观的看到,他们的下属集合是空的。
用程序代码提问的过程是怎样的?这种“目录式”的分层方法似乎非常有序。然后,将上面的内容保存为一个HTML文档,放到硬盘的某个目录下,写一段代码完成前面的工作。我不为你做:
…….假定你已经用ieA为名的对象浏览了上述网页文件
set doc=ieA.Document
set xbody=doc. body ‘取得body节点
set xI00= xbody.Childnodes.item(0) ‘取得body的第1个节点
set xI01=xbody.Childnodes.item(0) ‘取得bdoy的第2个节点
Msgbox xI00.innerText ‘显示第1个节点(DIV)的文本
Msgbox xI01.outerHtml ‘显示第2个节点(P)的完整内容
在VB/VBA/VBS系列的语言中,item是默认方法,可以省略,不过还是写在这里加深印象。
需要注意的是,在文档对象模型中,集合不同于OFFICE集合。首先,集合是从0开始计数的。习惯OFFICE VBA编程的朋友一定要注意,不同的对象架构有不同的方式。这是“0集合”。其次,它使用 Length 而不是 Count。不要习惯性地键入 Childnode.Count 来检查集合的数量。
除了ChildNodes集合,大家在web文档对象中常见的还有一个非常流行的集合:All集合,也就是“最迷惑”的集合。各级文档和节点都有这个集合,就像名字一样。如图,没有分层,但是使用起来也很方便:
…….
Set doc=ieA.Document
Set xCols=doc.All ;取得文档中的所有节点集合
Set xbCols=doc.body.All ;取得body节点下所有的节点集合
虽然任何标记节点都有ALL集合,但我们还是喜欢用DOCUMENT的ALL,原因无它,文档最大,一锅烩的ALL找起来也最合适。
ALL查找是有条件的:如果这个标记没有ID,你无法查到它的名字:
你好
擅长
set tag1=doc.All.item(“myTag”).item(0) ‘返回标记内部ID=myTag的集合并取第一个
一开始,在我个人看来,如果网页中的 HTML 标记已经有了 ID,那么直接返回一个带有文档对象的 getElementById 的对象会更直接。这个方法不需要遍历集合:
set tag1=doc. getElementById(“myTag”) ‘返回第一个内部标有ID=myTag的标记
不过,ALL集合有一个很方便的特性——至少在初学者看来是很好用的:ID可以挂到ALL集合之下:
strX=doc.All.mytag.innerhtml ‘呜呜呜,太好用了
另一种方法是以标记名为集合,要用到文档对象的getElementsByName方法:
set mydivs=doc. getElementsByName(“div”) ‘取得所有DIV标记,注意还是集合
今天先写到这里,下回......不定期休息
(补一小段,特别增加,关于FORMS,某位兄弟,下面真的真的没有了,不要期望我上传实例......)
关于文档对象的FORMS集合,因为大部分网页数据提交都是通过FORM标签提交的,所以当网页中没有FORM标签、没有ID标签或者重复ID时,可以使用FORMS集合来区分不同的FORM节点标签。:
引用:
设置 myForms=doc.Forms' 以获取所有 FORM 标签
Set frmX=myForms.item(0)'第一个FORM
FORM标签节点所代表的对象是很多朋友关心的内容——在网页对象中,它可以向服务器发送数据,让服务器刷新网页(实际上是服务器根据到一定的格式协议),我们就可以改变网页FORM作为远程函数调用接口。FORM标签中的ACTION指向的URL地址就是函数入口,FORM标签中的每一个INPUT标签节点都是该函数的参数。当 FORM.Submit 方法发出时,该函数被远程调用。是的,在服务器端,比如ASP,PHP就是老老实实的找FORM的参数,不管是用GET还是POST:
引用:
frmX.submit' 是的,只要Submit就相当于用户在页面上按下了FORM的send按钮
但是它的参数,即 INPUT 标签呢?当然,你可以自己修改,访问,嗯...如果你分析一个现有的网页,想用VBA从一个空白页面(ABOUT:BLANK)“凭空”生成FORM和INPUT节点,就靠对上面的方法还不够,我们还要“创建一个节点”(createElement_x)并连接到文档的对应位置(appendChild),但这已经是另一个问题了
vba抓取网页数据(“DOM资源管理器”中的信息是什么意思的? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-16 15:31
)
基本上,当我在浏览器中加载URL并手动单击F12时,我在抓取这个特定网页的数据时经历了一段糟糕的时光,但是当我尝试以编程方式执行以下操作时,我可以看到DOM Explorer中所需的相同信息(见下文)。htmldoc不收录我在DOM Explorer中看到的相同信息
公共子测试代码()
像SHDocVw一样暗淡。InternetExplorer
将HTMLDoc设置为MSHTML。HTMLDocument
设置IE=新SHDocVw。InternetExplorer
与IE
。导航“”
一会儿。忙=真或假。ReadyState ReadyState_uuu完成:Wend
设置HTMLDoc=。文件
以
端接头
有人能帮我访问DOM资源管理器中的信息吗?我知道HTML并不总是您在浏览器中看到的内容,而是您在浏览器中看到的内容的描述,但是必须有一种从HTML以编程方式创建DOM的方法
此外,我相信我想要获得的数据是通过脚本或iframe生成的,但我一直无法生成我正在寻找的数据
更新
请参见以下DOM Explorer图像:
查看全部
vba抓取网页数据(“DOM资源管理器”中的信息是什么意思的?
)
基本上,当我在浏览器中加载URL并手动单击F12时,我在抓取这个特定网页的数据时经历了一段糟糕的时光,但是当我尝试以编程方式执行以下操作时,我可以看到DOM Explorer中所需的相同信息(见下文)。htmldoc不收录我在DOM Explorer中看到的相同信息
公共子测试代码()
像SHDocVw一样暗淡。InternetExplorer
将HTMLDoc设置为MSHTML。HTMLDocument
设置IE=新SHDocVw。InternetExplorer
与IE
。导航“”
一会儿。忙=真或假。ReadyState ReadyState_uuu完成:Wend
设置HTMLDoc=。文件
以
端接头
有人能帮我访问DOM资源管理器中的信息吗?我知道HTML并不总是您在浏览器中看到的内容,而是您在浏览器中看到的内容的描述,但是必须有一种从HTML以编程方式创建DOM的方法
此外,我相信我想要获得的数据是通过脚本或iframe生成的,但我一直无法生成我正在寻找的数据
更新
请参见以下DOM Explorer图像:
vba抓取网页数据( 我正在尝试使用VBA脚本将收件箱中的信息拉入excel电子表格 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-12-14 01:11
我正在尝试使用VBA脚本将收件箱中的信息拉入excel电子表格
)
VBA Outlook 脚本错误:找不到对象
vbaexceloutlook
VBA Outlook 脚本错误:找不到对象、vba、excel、outlook、Vba、Excel、Outlook,我正在尝试使用 VBA 脚本将收件箱中电子邮件中的信息提取到 excel 电子表格中:'主题'到地址' From Address'CC Addresses 对于已离开组织且不再在 O365 中的发件人,此操作将失败。这是代码位:Function X400toSMTP(strAdr As String) As StringDim olkRcp As Outlook.Recipient, olkUsr As Outlook.ExchangeUserSet olkRcp = S
我正在尝试使用 VBA 脚本将收件箱中的电子邮件中的信息提取到 Excel 电子表格中:
'Subject
'To Address
'From Address
'CC Addresses
对于已离开组织且不再在 O365 中的发件人,此操作将失败
这是代码位:
Function X400toSMTP(strAdr As String) As String
Dim olkRcp As Outlook.Recipient, olkUsr As Outlook.ExchangeUser
Set olkRcp = Session.CreateRecipient(strAdr)
If olkRcp.AddressEntry = Empty Then
X400toSMTP = strAdr
ElseIf olkRcp.AddressEntry.AddressEntryUserType = olExchangeUserAddressEntry Then
olkRcp.Resolve
Set olkUsr = olkRcp.AddressEntry.GetExchangeUser
X400toSMTP = olkUsr.PrimarySmtpAddress
End If
Set olkRcp = Nothing
Set olkUsr = Nothing
End Function
我运行了调试,它在
AddressEntry
停在:
尝试的操作失败。找不到对象
我正在尝试找到一种方法,让脚本将地址字段留空,以便在 O365 上找不到的发件人,并进一步处理收件箱中的剩余项目
我尝试了以下方法:
If IsNull(olkRcp.AddressEntry) Then
X400toSMTP = strAdr
但我仍然收到相同的 AddressEntry 错误
我只是一个 VBA 菜鸟,所以非常感谢你的建议
太感谢了
在访问 AddressEntry 属性之前,请确保收件人已被解析——调用 olkRcp.Resolve。
如果 olkRcp.AddressEntry 为空,则可以这样写
,如果olkRcp.AddressEntry为空,则可以编写,如果olkRcp.AddressEntry=“”,则可以编写,非常感谢,Patrick!我已经试过了,但它仍然给我错误。也许值得一提的是,我正在一个共享邮箱上运行这个。我在收件箱中的一个子文件夹上尝试了这个脚本,但它并没有停在离开者地址,而是停在我知道它有效的某个通讯组列表上。我还尝试启用“下载共享文件夹”,但仍然无法用于共享邮箱。我确实尝试过,Dmitry。但是仍然会得到相同的错误哪种方法会引发错误?决定这意味着无法解析名称。如果在Outlook中键入“收件人”框并按Ctrl+K组合键,是否可以解决此问题?它会以某种方式超出解决范围。如果olkRcp.AddressEntry为空,则函数X400toSMTP(strAdr为字符串)作为字符串Dim olkRcp作为Outlook.Recipient,olkUsr作为Outlook.ExchangeUser Set olkRcp=Session.CreateRecipient(strAdr)停止olkRcp.Resolve如果olkRcp.AddressEntry为Nothing,则X400toSMTP=strAdr ElseIf olkRcp.AddressEntry.AddressEntryUserType=olExchangeUserAddressEntry,然后设置olkUsr=olkRcp.AddressEntry.GetExchangeUser X400toSMTP=olkUsr.PrimarySmtpAddress End如果设置olkRcp=NothingSet olkUsr=Nothing End Function我使用错误处理使其工作:函数X400toSMTP(strAdr作为字符串)作为字符串Dim olkRcp作为Outlook.Recipient,olkUsr作为Outlook.ExchangeUser Set olkRcp=Session.CreateRecipient(strAdr)错误时继续下一步如果olkRcp.AddressEntry.AddressEntryUserType=olExchangeUserAddressEntry,则olkRcp.Resolve Set-olkUsr=olkRcp.AddressEntry.GetExchangeUser X400toSMTP=olkUsr.PrimarySmtAddress End如果Set-olkRcp=Nothing设置olkUsr=Nothing,则返回0 End函数 查看全部
vba抓取网页数据(
我正在尝试使用VBA脚本将收件箱中的信息拉入excel电子表格
)
VBA Outlook 脚本错误:找不到对象
vbaexceloutlook
VBA Outlook 脚本错误:找不到对象、vba、excel、outlook、Vba、Excel、Outlook,我正在尝试使用 VBA 脚本将收件箱中电子邮件中的信息提取到 excel 电子表格中:'主题'到地址' From Address'CC Addresses 对于已离开组织且不再在 O365 中的发件人,此操作将失败。这是代码位:Function X400toSMTP(strAdr As String) As StringDim olkRcp As Outlook.Recipient, olkUsr As Outlook.ExchangeUserSet olkRcp = S
我正在尝试使用 VBA 脚本将收件箱中的电子邮件中的信息提取到 Excel 电子表格中:
'Subject
'To Address
'From Address
'CC Addresses
对于已离开组织且不再在 O365 中的发件人,此操作将失败
这是代码位:
Function X400toSMTP(strAdr As String) As String
Dim olkRcp As Outlook.Recipient, olkUsr As Outlook.ExchangeUser
Set olkRcp = Session.CreateRecipient(strAdr)
If olkRcp.AddressEntry = Empty Then
X400toSMTP = strAdr
ElseIf olkRcp.AddressEntry.AddressEntryUserType = olExchangeUserAddressEntry Then
olkRcp.Resolve
Set olkUsr = olkRcp.AddressEntry.GetExchangeUser
X400toSMTP = olkUsr.PrimarySmtpAddress
End If
Set olkRcp = Nothing
Set olkUsr = Nothing
End Function
我运行了调试,它在
AddressEntry
停在:
尝试的操作失败。找不到对象
我正在尝试找到一种方法,让脚本将地址字段留空,以便在 O365 上找不到的发件人,并进一步处理收件箱中的剩余项目
我尝试了以下方法:
If IsNull(olkRcp.AddressEntry) Then
X400toSMTP = strAdr
但我仍然收到相同的 AddressEntry 错误
我只是一个 VBA 菜鸟,所以非常感谢你的建议
太感谢了
在访问 AddressEntry 属性之前,请确保收件人已被解析——调用 olkRcp.Resolve。
如果 olkRcp.AddressEntry 为空,则可以这样写
,如果olkRcp.AddressEntry为空,则可以编写,如果olkRcp.AddressEntry=“”,则可以编写,非常感谢,Patrick!我已经试过了,但它仍然给我错误。也许值得一提的是,我正在一个共享邮箱上运行这个。我在收件箱中的一个子文件夹上尝试了这个脚本,但它并没有停在离开者地址,而是停在我知道它有效的某个通讯组列表上。我还尝试启用“下载共享文件夹”,但仍然无法用于共享邮箱。我确实尝试过,Dmitry。但是仍然会得到相同的错误哪种方法会引发错误?决定这意味着无法解析名称。如果在Outlook中键入“收件人”框并按Ctrl+K组合键,是否可以解决此问题?它会以某种方式超出解决范围。如果olkRcp.AddressEntry为空,则函数X400toSMTP(strAdr为字符串)作为字符串Dim olkRcp作为Outlook.Recipient,olkUsr作为Outlook.ExchangeUser Set olkRcp=Session.CreateRecipient(strAdr)停止olkRcp.Resolve如果olkRcp.AddressEntry为Nothing,则X400toSMTP=strAdr ElseIf olkRcp.AddressEntry.AddressEntryUserType=olExchangeUserAddressEntry,然后设置olkUsr=olkRcp.AddressEntry.GetExchangeUser X400toSMTP=olkUsr.PrimarySmtpAddress End如果设置olkRcp=NothingSet olkUsr=Nothing End Function我使用错误处理使其工作:函数X400toSMTP(strAdr作为字符串)作为字符串Dim olkRcp作为Outlook.Recipient,olkUsr作为Outlook.ExchangeUser Set olkRcp=Session.CreateRecipient(strAdr)错误时继续下一步如果olkRcp.AddressEntry.AddressEntryUserType=olExchangeUserAddressEntry,则olkRcp.Resolve Set-olkUsr=olkRcp.AddressEntry.GetExchangeUser X400toSMTP=olkUsr.PrimarySmtAddress End如果Set-olkRcp=Nothing设置olkUsr=Nothing,则返回0 End函数
vba抓取网页数据(UI学习大纲与UI的交互(UIInteraction)的GetText )
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-11-30 13:16
)
学习大纲
UI交互可以分为两种类型:输入和输出。
**输入**:让应用程序做一些事情。如鼠标单击、文本输入、键盘快捷键、鼠标右键单击、鼠标悬停等。
**输出**:从应用程序中提取信息。获取文本、查找元素和图片、操作剪贴板等。
1. 输入法
输入法**兼容性**运行速度支持后台工作支持热键自动清除内容
默认
100%
50%
X
√
X
窗口消息
80%
50%
√
√
X
模拟类型/点击
*70%
100%
√
X
√
*Simulate Type/Click 兼容 99% 的 Web 应用程序和 60% 的桌面应用程序
实例验证:
操作结果:
建议:尝试每种输入法。首先使用 Default 方法,因为它肯定会起作用。然后尝试使用 Simulate 或 WindowMessages 方法来提高运行速度或实现后台工作。
2. 输出方式:屏幕抓取
上一课使用的Get Text 活动仅适用于抓取简单和简短的文本。和屏幕
抓取可以抓取复杂元素中存在的较大文本片段。屏幕
刮取还可以获得文本的位置和颜色等信息。
使用 Screen Scraping 工具抓取信息时,您可以尝试以下三种方法:
**输出方式**运行速度**准确度**支持后台工作获取文本位置获取隐藏文本兼容Citrix
全文
很快
100%
√
X
√
X
本国的
快点
100%
X
√
X
X
文字识别
非常慢
98%
X
√
X
√
FullText 是默认的方法,大多数情况下也有一个有效的方法。
Native 的优点是可以获取文本的其他信息,例如单词或字母在屏幕上的坐标。
OCR 无法达到 100% 的准确率,但是当其他两种方法都不起作用时,OCR 是最后的手段。
*只有 OCR 可以在 Citrix 或虚拟环境中运行。OCR 还可以获取文本位置。
如何使用屏幕抓取:
1) 点击Design Ribbon中的Screen Scraping按钮,会出现选择界面。
2)点击选择要提取的信息。您可以选择收录多个元素的区域。
3) 选择后,会弹出 Screen Scraper Wizard 窗口。点击界面
元素或区域可以更改从中提取信息的区域。
这里UiPath自动选择了Native方法,可以在Options面板中改成其他两种方法。
从预览面板中可以看到,Native 方法只抓取可编辑区域中的文本。
4) 切换到全文方式后,预览面板中的信息发生了变化。
满的
Text方法不仅抓取可编辑区域的文字,还抓取不可编辑区域的文字和下拉列表中隐藏的文字。
*在选项面板中勾选忽略
Hidden 选项,然后单击 Re-scrape 按钮忽略隐藏的文本。
5) OCR 方法就更不一样了。它将所选区域视为图片来阅读文本。
由于错别字,OCR方法只适用于数据不需要完全正确的情况。
UiPath 提供两个 OCR 引擎。微软Office
OCR 适用于较大的图像,例如扫描的文档。
Google OCR 更适合读取较小、分辨率较低的图像,例如界面上的元素。
“选项”面板中的“反转”选项专门用于某些黑底白字的图片。缩放选项可以放大图片以获得更好的效果。
我们可以一一尝试这些选项,看看预览面板的结果有什么变化,找到最佳组合。
6) 设置好后,点击右下角的Continue按钮,会得到一个ScreenScraping Sequence。
Selector 代表要抓取文本的元素或区域。当多个活动的元素或区域相同时,可以将Selector中的内容直接复制到其他活动中,而无需重新选择元素或区域。Text 变量用于保存捕获的文本。
如果你想尝试另一个OCR,你可以删除谷歌OCR活动,然后更改MS Office
OCR活动拖进来,建议把Scale属性改成3,因为MS Office
OCR 更适合阅读较大的图片。
*如果您不使用屏幕抓取,您也可以手动添加活动。
手动添加的输出方式
基本录音
获取文本
全文
获取全文
本国的
获取可见文本
文字识别
获取 OCR 文本
*****在上面的例子中,Get Text 活动只能抓取“地址”这个词。
3. 数据抓取
Screen Scraping 用于捕获 Freeform Data(自由格式数据)。和数据
抓取用于捕获**结构化数据**。
什么是结构化数据?
当你在谷歌上搜索某个关键词时,你得到的搜索结果是由多条格式相同的数据组成,每条数据由三部分组成:标题、网址和描述。此类数据是结构化的
数据。
如何使用数据抓取:
以亚马逊的图书搜索页面为例。此页面上的数据也是结构化的
数据,但比 Google 的搜索结果页面更复杂。
1)单击设计功能区中的 Web
Scraping 按钮,会出现一个向导窗口,点击 Next 开始选择第一个元素。
2) 点击第一本书的书名,会再次弹出向导窗口。单击下一步继续。
3) 点击第二本书的书名,会再次弹出向导窗口。书名也是一个链接,因此向导窗口可以选择提取文本或 URL。
此处选中了这两个选项,它们被命名为 Title 和 URL。点击下一步按钮,弹出向导预览界面。
4)除了预览数据外,还标注了网页上的相应位置,方便查看。然后提取“作者”和“价格”并单击 ExtractCorrelated Data 按钮。
5)选择第一个元素时向导返回界面,重复上述步骤提取“作者”和“价格”信息。单击完成按钮。
6)UiPath 会询问我们数据是否跨页面分布。将页面下拉到您选择页码的位置,选择是,然后选择页面上的下一页元素。
7) 向导结束后,你会得到一个名为WebScraping的Sequence,并得到一个DataTable类型的Output变量。
添加写入 CSV 活动以将捕获的数据保存在 CSV 文件中。
8) 这个CSV文件有100条记录,但搜索结果远远超过100条。这是因为UiPath默认只抓取100条记录,你可以在属性面板中更改设置。
使用Web Scraping抓取网页上的表格(HTML表格),当您点击表格中的任何单元格时,会弹出Extract Table提示窗口。
如果选择是,则可以直接抓取整个表格的数据,而无需选择第二个元素。如果选择否,则需要重复前面的步骤来选择第二个元素。
4. 练习:
提取链接页面的 100 条记录,包括名称和价格,并将数据存储在新的 Excel 表中。
*第一次选择页面的名字,
第二次选择页面的姓氏。与第二次选择第二个名字相比,它更有可能生成一致的标识符
(一致的标识符)。
2) 不应用Recording功能完成如下操作:在记事本中打开字体对话框,将字体改为Arial,样式改为斜体,将字体大小增加5,并选择一个新的脚本
(脚本)。
在第二个Attach Window活动的Do中添加一个Click活动,点击格式菜单中的字体
(字体)按钮。
在弹出的字体对话框中添加一个新的附加窗口活动。
为第三个附加窗口活动的 Do 添加一个类型
进入activity,指定元素并点击字体输入框,输入Arial。
添加另一个 Type Into 活动,指定元素并单击字体样式输入框,输入斜体。
添加获取
在 Text 活动中,指定元素并单击字体大小的输入框。创建一个 Int32 类型的新变量 fontSize 并将其设置为 Get
文本活动的输出。
添加类型
进入activity,指定元素,点击字体大小的输入框,输入**(fontSize+5).ToString**.
添加选择
Item活动,指定Script下拉菜单为Target的Selector参数,输入Greek作为Input的Item参数。
注意:
*本课使用的新活动、方法、功能等:
加入万人职场社区,为你的事业保驾护航!
查看全部
vba抓取网页数据(UI学习大纲与UI的交互(UIInteraction)的GetText
)
学习大纲
UI交互可以分为两种类型:输入和输出。
**输入**:让应用程序做一些事情。如鼠标单击、文本输入、键盘快捷键、鼠标右键单击、鼠标悬停等。
**输出**:从应用程序中提取信息。获取文本、查找元素和图片、操作剪贴板等。
1. 输入法
输入法**兼容性**运行速度支持后台工作支持热键自动清除内容
默认
100%
50%
X
√
X
窗口消息
80%
50%
√
√
X
模拟类型/点击
*70%
100%
√
X
√
*Simulate Type/Click 兼容 99% 的 Web 应用程序和 60% 的桌面应用程序
实例验证:
操作结果:
建议:尝试每种输入法。首先使用 Default 方法,因为它肯定会起作用。然后尝试使用 Simulate 或 WindowMessages 方法来提高运行速度或实现后台工作。
2. 输出方式:屏幕抓取
上一课使用的Get Text 活动仅适用于抓取简单和简短的文本。和屏幕
抓取可以抓取复杂元素中存在的较大文本片段。屏幕
刮取还可以获得文本的位置和颜色等信息。
使用 Screen Scraping 工具抓取信息时,您可以尝试以下三种方法:
**输出方式**运行速度**准确度**支持后台工作获取文本位置获取隐藏文本兼容Citrix
全文
很快
100%
√
X
√
X
本国的
快点
100%
X
√
X
X
文字识别
非常慢
98%
X
√
X
√
FullText 是默认的方法,大多数情况下也有一个有效的方法。
Native 的优点是可以获取文本的其他信息,例如单词或字母在屏幕上的坐标。
OCR 无法达到 100% 的准确率,但是当其他两种方法都不起作用时,OCR 是最后的手段。
*只有 OCR 可以在 Citrix 或虚拟环境中运行。OCR 还可以获取文本位置。
如何使用屏幕抓取:
1) 点击Design Ribbon中的Screen Scraping按钮,会出现选择界面。
2)点击选择要提取的信息。您可以选择收录多个元素的区域。
3) 选择后,会弹出 Screen Scraper Wizard 窗口。点击界面
元素或区域可以更改从中提取信息的区域。
这里UiPath自动选择了Native方法,可以在Options面板中改成其他两种方法。
从预览面板中可以看到,Native 方法只抓取可编辑区域中的文本。
4) 切换到全文方式后,预览面板中的信息发生了变化。
满的
Text方法不仅抓取可编辑区域的文字,还抓取不可编辑区域的文字和下拉列表中隐藏的文字。
*在选项面板中勾选忽略
Hidden 选项,然后单击 Re-scrape 按钮忽略隐藏的文本。
5) OCR 方法就更不一样了。它将所选区域视为图片来阅读文本。
由于错别字,OCR方法只适用于数据不需要完全正确的情况。
UiPath 提供两个 OCR 引擎。微软Office
OCR 适用于较大的图像,例如扫描的文档。
Google OCR 更适合读取较小、分辨率较低的图像,例如界面上的元素。
“选项”面板中的“反转”选项专门用于某些黑底白字的图片。缩放选项可以放大图片以获得更好的效果。
我们可以一一尝试这些选项,看看预览面板的结果有什么变化,找到最佳组合。
6) 设置好后,点击右下角的Continue按钮,会得到一个ScreenScraping Sequence。
Selector 代表要抓取文本的元素或区域。当多个活动的元素或区域相同时,可以将Selector中的内容直接复制到其他活动中,而无需重新选择元素或区域。Text 变量用于保存捕获的文本。
如果你想尝试另一个OCR,你可以删除谷歌OCR活动,然后更改MS Office
OCR活动拖进来,建议把Scale属性改成3,因为MS Office
OCR 更适合阅读较大的图片。
*如果您不使用屏幕抓取,您也可以手动添加活动。
手动添加的输出方式
基本录音
获取文本
全文
获取全文
本国的
获取可见文本
文字识别
获取 OCR 文本
*****在上面的例子中,Get Text 活动只能抓取“地址”这个词。
3. 数据抓取
Screen Scraping 用于捕获 Freeform Data(自由格式数据)。和数据
抓取用于捕获**结构化数据**。
什么是结构化数据?
当你在谷歌上搜索某个关键词时,你得到的搜索结果是由多条格式相同的数据组成,每条数据由三部分组成:标题、网址和描述。此类数据是结构化的
数据。
如何使用数据抓取:
以亚马逊的图书搜索页面为例。此页面上的数据也是结构化的
数据,但比 Google 的搜索结果页面更复杂。
1)单击设计功能区中的 Web
Scraping 按钮,会出现一个向导窗口,点击 Next 开始选择第一个元素。
2) 点击第一本书的书名,会再次弹出向导窗口。单击下一步继续。
3) 点击第二本书的书名,会再次弹出向导窗口。书名也是一个链接,因此向导窗口可以选择提取文本或 URL。
此处选中了这两个选项,它们被命名为 Title 和 URL。点击下一步按钮,弹出向导预览界面。
4)除了预览数据外,还标注了网页上的相应位置,方便查看。然后提取“作者”和“价格”并单击 ExtractCorrelated Data 按钮。
5)选择第一个元素时向导返回界面,重复上述步骤提取“作者”和“价格”信息。单击完成按钮。
6)UiPath 会询问我们数据是否跨页面分布。将页面下拉到您选择页码的位置,选择是,然后选择页面上的下一页元素。
7) 向导结束后,你会得到一个名为WebScraping的Sequence,并得到一个DataTable类型的Output变量。
添加写入 CSV 活动以将捕获的数据保存在 CSV 文件中。
8) 这个CSV文件有100条记录,但搜索结果远远超过100条。这是因为UiPath默认只抓取100条记录,你可以在属性面板中更改设置。
使用Web Scraping抓取网页上的表格(HTML表格),当您点击表格中的任何单元格时,会弹出Extract Table提示窗口。
如果选择是,则可以直接抓取整个表格的数据,而无需选择第二个元素。如果选择否,则需要重复前面的步骤来选择第二个元素。
4. 练习:
提取链接页面的 100 条记录,包括名称和价格,并将数据存储在新的 Excel 表中。
*第一次选择页面的名字,
第二次选择页面的姓氏。与第二次选择第二个名字相比,它更有可能生成一致的标识符
(一致的标识符)。
2) 不应用Recording功能完成如下操作:在记事本中打开字体对话框,将字体改为Arial,样式改为斜体,将字体大小增加5,并选择一个新的脚本
(脚本)。
在第二个Attach Window活动的Do中添加一个Click活动,点击格式菜单中的字体
(字体)按钮。
在弹出的字体对话框中添加一个新的附加窗口活动。
为第三个附加窗口活动的 Do 添加一个类型
进入activity,指定元素并点击字体输入框,输入Arial。
添加另一个 Type Into 活动,指定元素并单击字体样式输入框,输入斜体。
添加获取
在 Text 活动中,指定元素并单击字体大小的输入框。创建一个 Int32 类型的新变量 fontSize 并将其设置为 Get
文本活动的输出。
添加类型
进入activity,指定元素,点击字体大小的输入框,输入**(fontSize+5).ToString**.
添加选择
Item活动,指定Script下拉菜单为Target的Selector参数,输入Greek作为Input的Item参数。
注意:
*本课使用的新活动、方法、功能等:
加入万人职场社区,为你的事业保驾护航!
vba抓取网页数据(UI学习大纲与UI的交互(UIInteraction)的GetText )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-25 05:18
)
学习大纲
UI交互可以分为两种类型:输入和输出。
**输入**:让应用程序做一些事情。如鼠标单击、文本输入、键盘快捷键、鼠标右键单击、鼠标悬停等。
**输出**:从应用程序中提取信息。获取文本、查找元素和图片、操作剪贴板等。
1. 输入法
输入法**兼容性**运行速度支持后台工作支持热键自动清除内容
默认
100%
50%
X
√
X
窗口消息
80%
50%
√
√
X
模拟类型/点击
*70%
100%
√
X
√
*Simulate Type/Click 兼容 99% 的 Web 应用程序和 60% 的桌面应用程序
实例验证:
操作结果:
建议:尝试每种输入法。首先使用 Default 方法,因为它肯定会起作用。然后尝试使用 Simulate 或 WindowMessages 方法来提高运行速度或实现后台工作。
2. 输出方式:屏幕抓取
上一课使用的Get Text 活动仅适用于抓取简单和简短的文本。和屏幕
抓取可以抓取复杂元素中存在的较大文本片段。屏幕
刮取还可以获得文本的位置和颜色等信息。
使用 Screen Scraping 工具抓取信息时,您可以尝试以下三种方法:
**输出方式**运行速度**准确度**支持后台工作获取文本位置获取隐藏文本兼容Citrix
全文
很快
100%
√
X
√
X
本国的
快点
100%
X
√
X
X
文字识别
非常慢
98%
X
√
X
√
FullText 是默认的方法,大多数情况下也有一个有效的方法。
Native 的优点是可以获取文本的其他信息,例如单词或字母在屏幕上的坐标。
OCR 无法达到 100% 的准确率,但是当其他两种方法都不起作用时,OCR 是最后的手段。
*只有 OCR 可以在 Citrix 或虚拟环境中运行。OCR 还可以获取文本位置。
如何使用屏幕抓取:
1) 点击Design Ribbon中的Screen Scraping按钮,会出现选择界面。
2)点击选择要提取的信息。您可以选择收录多个元素的区域。
3) 选择后,会弹出 Screen Scraper Wizard 窗口。点击界面
元素或区域可以更改从中提取信息的区域。
这里UiPath自动选择了Native方法,可以在Options面板中改成其他两种方法。
从预览面板中可以看到,Native 方法只抓取可编辑区域中的文本。
4) 切换到全文方式后,预览面板中的信息发生了变化。
满的
Text方法不仅抓取可编辑区域的文字,还抓取不可编辑区域的文字和下拉列表中隐藏的文字。
*在选项面板中勾选忽略
Hidden 选项,然后单击 Re-scrape 按钮忽略隐藏文本。
5) OCR 方法就更不一样了。它将所选区域视为图片来阅读文本。
由于错别字,OCR方法只适用于数据不需要完全正确的情况。
UiPath 提供两个 OCR 引擎。微软Office
OCR 适用于较大的图像,例如扫描的文档。
Google OCR 更适合读取较小、分辨率较低的图像,例如界面上的元素。
“选项”面板中的“反转”选项专门用于某些黑底白字的图片。缩放选项可以放大图片以获得更好的效果。
我们可以一一尝试这些选项,看看预览面板的结果有什么变化,找到最佳组合。
6) 设置好后,点击右下角的Continue按钮,会得到一个ScreenScraping Sequence。
Selector 代表要抓取文本的元素或区域。当多个活动的元素或区域相同时,可以将Selector中的内容直接复制到其他活动中,而无需重新选择元素或区域。Text 变量用于保存捕获的文本。
如果你想尝试另一个OCR,你可以删除谷歌OCR活动,然后MS Office
OCR活动拖进来,建议把Scale属性改成3,因为MS Office
OCR 更适合阅读较大的图片。
*如果您不使用屏幕抓取,您也可以手动添加活动。
手动添加的输出方式
基本录音
获取文本
全文
获取全文
本国的
获取可见文本
文字识别
获取 OCR 文本
*****在上面的例子中,Get Text 活动只能抓取“地址”这个词。
3. 数据抓取
Screen Scraping 用于捕获 Freeform Data(自由格式数据)。和数据
抓取用于捕获**结构化数据**。
什么是结构化数据?
当你在谷歌上搜索某个关键词时,你得到的搜索结果是由多条格式相同的数据组成,每条数据由三部分组成:标题、网址和描述。此类数据是结构化的
数据。
如何使用数据抓取:
以亚马逊的图书搜索页面为例。此页面上的数据也是结构化的
数据,但比 Google 的搜索结果页面更复杂。
1)单击设计功能区中的 Web
Scraping 按钮,会出现一个向导窗口,点击 Next 开始选择第一个元素。
2) 点击第一本书的书名,会再次弹出向导窗口。单击下一步继续。
3) 点击第二本书的书名,会再次弹出向导窗口。书名也是一个链接,因此向导窗口可以选择提取文本或 URL。
此处选中了这两个选项,它们被命名为 Title 和 URL。点击下一步按钮,弹出向导预览界面。
4)除了预览数据外,还标注了网页对应位置,方便查看。然后提取“作者”和“价格”并单击 ExtractCorrelated Data 按钮。
5)选择第一个元素时向导返回界面,重复上述步骤提取“作者”和“价格”信息。单击完成按钮。
6)UiPath 会询问我们数据是否跨页面分布。将页面下拉到您选择页码的位置,选择是,然后选择页面上的下一页元素。
7) 向导结束后,你会得到一个名为WebScraping的Sequence,并得到一个DataTable类型的Output变量。
添加写入 CSV 活动以将捕获的数据保存在 CSV 文件中。
8) 这个CSV文件有100条记录,但搜索结果远远超过100条。这是因为UiPath默认只抓取100条记录,你可以在属性面板中更改设置。
使用Web Scraping抓取网页上的表格(HTML表格),当您点击表格中的任何单元格时,会弹出Extract Table提示窗口。
如果选择是,则可以直接抓取整个表格的数据,而无需选择第二个元素。如果选择否,则需要重复前面的步骤来选择第二个元素。
4. 练习:
提取链接页面的 100 条记录,包括名称和价格,并将数据存储在新的 Excel 表中。
*第一次选择页面的名字,
第二次选择页面的姓氏。与第二次选择第二个名字相比,它更有可能生成一致的标识符
(一致的标识符)。
2) 不应用Recording功能完成如下操作:在记事本中打开字体对话框,将字体改为Arial,样式改为斜体,将字体大小增加5,并选择一个新的脚本
(脚本)。
在第二个Attach Window活动的Do中添加一个Click活动,点击格式菜单中的字体
(字体)按钮。
在弹出的字体对话框中添加一个新的附加窗口活动。
为第三个附加窗口活动的 Do 添加一个类型
进入activity,指定元素并点击字体输入框,输入Arial。
添加另一个 Type Into 活动,指定元素并单击字体样式输入框,输入斜体。
添加获取
在 Text 活动中,指定元素并单击字体大小的输入框。创建一个 Int32 类型的新变量 fontSize 并将其设置为 Get
文本活动的输出。
添加类型
进入activity,指定元素,点击字体大小的输入框,输入**(fontSize+5).ToString**.
添加选择
Item活动,指定Script下拉菜单为Target的Selector参数,输入Greek作为Input的Item参数。
注意:
*本课使用的新活动、方法、功能等:
加入万人职场社区,为你的事业保驾护航!
查看全部
vba抓取网页数据(UI学习大纲与UI的交互(UIInteraction)的GetText
)
学习大纲
UI交互可以分为两种类型:输入和输出。
**输入**:让应用程序做一些事情。如鼠标单击、文本输入、键盘快捷键、鼠标右键单击、鼠标悬停等。
**输出**:从应用程序中提取信息。获取文本、查找元素和图片、操作剪贴板等。
1. 输入法
输入法**兼容性**运行速度支持后台工作支持热键自动清除内容
默认
100%
50%
X
√
X
窗口消息
80%
50%
√
√
X
模拟类型/点击
*70%
100%
√
X
√
*Simulate Type/Click 兼容 99% 的 Web 应用程序和 60% 的桌面应用程序
实例验证:
操作结果:
建议:尝试每种输入法。首先使用 Default 方法,因为它肯定会起作用。然后尝试使用 Simulate 或 WindowMessages 方法来提高运行速度或实现后台工作。
2. 输出方式:屏幕抓取
上一课使用的Get Text 活动仅适用于抓取简单和简短的文本。和屏幕
抓取可以抓取复杂元素中存在的较大文本片段。屏幕
刮取还可以获得文本的位置和颜色等信息。
使用 Screen Scraping 工具抓取信息时,您可以尝试以下三种方法:
**输出方式**运行速度**准确度**支持后台工作获取文本位置获取隐藏文本兼容Citrix
全文
很快
100%
√
X
√
X
本国的
快点
100%
X
√
X
X
文字识别
非常慢
98%
X
√
X
√
FullText 是默认的方法,大多数情况下也有一个有效的方法。
Native 的优点是可以获取文本的其他信息,例如单词或字母在屏幕上的坐标。
OCR 无法达到 100% 的准确率,但是当其他两种方法都不起作用时,OCR 是最后的手段。
*只有 OCR 可以在 Citrix 或虚拟环境中运行。OCR 还可以获取文本位置。
如何使用屏幕抓取:
1) 点击Design Ribbon中的Screen Scraping按钮,会出现选择界面。
2)点击选择要提取的信息。您可以选择收录多个元素的区域。
3) 选择后,会弹出 Screen Scraper Wizard 窗口。点击界面
元素或区域可以更改从中提取信息的区域。
这里UiPath自动选择了Native方法,可以在Options面板中改成其他两种方法。
从预览面板中可以看到,Native 方法只抓取可编辑区域中的文本。
4) 切换到全文方式后,预览面板中的信息发生了变化。
满的
Text方法不仅抓取可编辑区域的文字,还抓取不可编辑区域的文字和下拉列表中隐藏的文字。
*在选项面板中勾选忽略
Hidden 选项,然后单击 Re-scrape 按钮忽略隐藏文本。
5) OCR 方法就更不一样了。它将所选区域视为图片来阅读文本。
由于错别字,OCR方法只适用于数据不需要完全正确的情况。
UiPath 提供两个 OCR 引擎。微软Office
OCR 适用于较大的图像,例如扫描的文档。
Google OCR 更适合读取较小、分辨率较低的图像,例如界面上的元素。
“选项”面板中的“反转”选项专门用于某些黑底白字的图片。缩放选项可以放大图片以获得更好的效果。
我们可以一一尝试这些选项,看看预览面板的结果有什么变化,找到最佳组合。
6) 设置好后,点击右下角的Continue按钮,会得到一个ScreenScraping Sequence。
Selector 代表要抓取文本的元素或区域。当多个活动的元素或区域相同时,可以将Selector中的内容直接复制到其他活动中,而无需重新选择元素或区域。Text 变量用于保存捕获的文本。
如果你想尝试另一个OCR,你可以删除谷歌OCR活动,然后MS Office
OCR活动拖进来,建议把Scale属性改成3,因为MS Office
OCR 更适合阅读较大的图片。
*如果您不使用屏幕抓取,您也可以手动添加活动。
手动添加的输出方式
基本录音
获取文本
全文
获取全文
本国的
获取可见文本
文字识别
获取 OCR 文本
*****在上面的例子中,Get Text 活动只能抓取“地址”这个词。
3. 数据抓取
Screen Scraping 用于捕获 Freeform Data(自由格式数据)。和数据
抓取用于捕获**结构化数据**。
什么是结构化数据?
当你在谷歌上搜索某个关键词时,你得到的搜索结果是由多条格式相同的数据组成,每条数据由三部分组成:标题、网址和描述。此类数据是结构化的
数据。
如何使用数据抓取:
以亚马逊的图书搜索页面为例。此页面上的数据也是结构化的
数据,但比 Google 的搜索结果页面更复杂。
1)单击设计功能区中的 Web
Scraping 按钮,会出现一个向导窗口,点击 Next 开始选择第一个元素。
2) 点击第一本书的书名,会再次弹出向导窗口。单击下一步继续。
3) 点击第二本书的书名,会再次弹出向导窗口。书名也是一个链接,因此向导窗口可以选择提取文本或 URL。
此处选中了这两个选项,它们被命名为 Title 和 URL。点击下一步按钮,弹出向导预览界面。
4)除了预览数据外,还标注了网页对应位置,方便查看。然后提取“作者”和“价格”并单击 ExtractCorrelated Data 按钮。
5)选择第一个元素时向导返回界面,重复上述步骤提取“作者”和“价格”信息。单击完成按钮。
6)UiPath 会询问我们数据是否跨页面分布。将页面下拉到您选择页码的位置,选择是,然后选择页面上的下一页元素。
7) 向导结束后,你会得到一个名为WebScraping的Sequence,并得到一个DataTable类型的Output变量。
添加写入 CSV 活动以将捕获的数据保存在 CSV 文件中。
8) 这个CSV文件有100条记录,但搜索结果远远超过100条。这是因为UiPath默认只抓取100条记录,你可以在属性面板中更改设置。
使用Web Scraping抓取网页上的表格(HTML表格),当您点击表格中的任何单元格时,会弹出Extract Table提示窗口。
如果选择是,则可以直接抓取整个表格的数据,而无需选择第二个元素。如果选择否,则需要重复前面的步骤来选择第二个元素。
4. 练习:
提取链接页面的 100 条记录,包括名称和价格,并将数据存储在新的 Excel 表中。
*第一次选择页面的名字,
第二次选择页面的姓氏。与第二次选择第二个名字相比,它更有可能生成一致的标识符
(一致的标识符)。
2) 不应用Recording功能完成如下操作:在记事本中打开字体对话框,将字体改为Arial,样式改为斜体,将字体大小增加5,并选择一个新的脚本
(脚本)。
在第二个Attach Window活动的Do中添加一个Click活动,点击格式菜单中的字体
(字体)按钮。
在弹出的字体对话框中添加一个新的附加窗口活动。
为第三个附加窗口活动的 Do 添加一个类型
进入activity,指定元素并点击字体输入框,输入Arial。
添加另一个 Type Into 活动,指定元素并单击字体样式输入框,输入斜体。
添加获取
在 Text 活动中,指定元素并单击字体大小的输入框。创建一个 Int32 类型的新变量 fontSize 并将其设置为 Get
文本活动的输出。
添加类型
进入activity,指定元素,点击字体大小的输入框,输入**(fontSize+5).ToString**.
添加选择
Item活动,指定Script下拉菜单为Target的Selector参数,输入Greek作为Input的Item参数。
注意:
*本课使用的新活动、方法、功能等:
加入万人职场社区,为你的事业保驾护航!
vba抓取网页数据(《VBA信息获取与处理》教程:第四节将VBA写入工作表时)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-19 02:08
【分享成果,正能量庆幸】越是倒霉,越要冷静,振作起来,默默的生存下去,你要接受,那些突如其来的损失,当你什么都不做的时候,唯一的你能做的事 试着让自己变得更好一点。
再有能力的人,也抓不住;无论他们多么执着,他们都会被打破。人累了,就有休息的权利,心痛时,就有放手的理由。不必咄咄逼人,眼泪是最好的释放,不必伪装,回报是最美的容颜。
《VBA信息获取与处理》教程是我的第六套教程,现在是第一次修订。这套教程定位于最高级别,是完成初级和中级之后的教程。本教程内容为:跨应用信息获取、随机信息利用、邮件发送、VBA上网数据抓取、VBA延时操作、剪贴板应用、Split函数扩展、工作表信息等应用交互、FSO对象的使用、工作表和文件夹信息的获取、图形信息的获取、工作表信息的自定义等功能。程序文件通过32位和64位Office系统测试。它非常抽象,更有研究价值。
本教程共两卷,八十四讲。今天的内容是主题四“EXCEL工作表数据读取、回填和搜索”的第四讲:数组转置
第四节 将VBA数组写入工作表时Transpose的使用
转置是数组应用中经常用到的知识点。在使用Excel表格的过程中,当我们想把横行变成竖列(或者把竖排的数据转为横排)时,希望两个不同排列的数据相互关联时,可以使用转置函数. 但是注意这个函数是一个工作表函数,所以在使用这个函数的时候一定要使用Application.Transpose(Arr)。
1 用一维数组回填工作表时的转置(Transpose)
如果需要按列回填一维数组,可以使用如下语句:MyRange.Value = Application.Transpose(Arr)
具体代码如下:
Sub MYNZG()'一维数组数据的转置回填方案
Dim Arr 作为变体
将 MyRange 调暗为范围
工作表(“SHEET4”)。选择
Arr = Array("大象", "老虎", "狮子", "狐狸")
设置 MyRange = Range("A1")
设置 MyRange = MyRange.Resize(UBound(Arr) + 1, 1)
MyRange.ClearContents
MyRange.Value = Application.Transpose(Arr)
MsgBox “好的!”
结束子
代码截图:
代码说明:这里需要注意的是,base cell area的展开语句变成了: Resize(UBound(Arr) + 1, 1) 这是列的展开,所以转置语句为Application。 Transpose(Arr ). 这里要注意的一点是resize参数是颠倒的。
2 用二维数组回填工作表时的转置(Transpose)
如果需要按列回填二维数组,可以使用如下语句:MyRange.Value = Application.Transpose(Arr)
具体代码如下:
Sub MYNZH()'二维数组数据的转置回填方案
Dim Arr 作为变体
将 MyRange 调暗为范围
工作表(“SHEET4”)。选择
Arr = Sheets("SHEET2").Range("A1:b9")
设置 MyRange = Range("A1")
设置 MyRange = MyRange.Resize(UBound(Arr, 2), UBound(Arr, 1))
MyRange.ClearContents
MyRange.Value = Application.Transpose(Arr)
MsgBox “好的!”
结束子
代码截图如下:
代码说明:当从工作表中读取数组变量时,VBA会自动调整数组的大小来保持工作表上的范围,所以你不需要关心数组的大小。但是,从 VBA 将数组写入工作表时,必须调整目标区域的大小以容纳该数组。我们在前面的例子中已经看到了这一点。
如果传递给工作表的数组小于其写入范围,则未使用的单元格将出现“#N/A”错误。如果传递的数组大于其写入范围,则数组将在右侧或底部截断以适应范围。
本节知识点:如何理解换位?如何使用一维数组和二维数组转置?
本主题的参考程序文件:004 worksheet.XLSM
我20多年的VBA实践经验都浓缩在下面的教程中,教程学习顺序:
① 7→1→3→2→6→5 或 7→4→3→2→6→5。
② 7→8
各套教程简介:
第七套教程(共三册):《EXCEL Application of VBA》:VBA基础讲解
第一套教程(共三册):《VBA代码解决方案》:上手后的改进教程
第四组教程(16G):VBA代码解题视频(第一组视频讲解)
第三套教程(共两册):《VBA Array and Dictionary Solution》:是数组和字典的专门讲解
第二套教程(共两册):《VBA数据库解决方案》:是数据库的专门讲解
第六套教程(共两册):《VBA信息获取与处理》:讲解VBA的网络和跨程序应用
第五套教程(共两册):VBA中类的解释与利用:类与接口技术讲解
第八套教程(共三册):VBA的Word应用(最新教程):VBA在Word中的使用 查看全部
vba抓取网页数据(《VBA信息获取与处理》教程:第四节将VBA写入工作表时)
【分享成果,正能量庆幸】越是倒霉,越要冷静,振作起来,默默的生存下去,你要接受,那些突如其来的损失,当你什么都不做的时候,唯一的你能做的事 试着让自己变得更好一点。
再有能力的人,也抓不住;无论他们多么执着,他们都会被打破。人累了,就有休息的权利,心痛时,就有放手的理由。不必咄咄逼人,眼泪是最好的释放,不必伪装,回报是最美的容颜。
《VBA信息获取与处理》教程是我的第六套教程,现在是第一次修订。这套教程定位于最高级别,是完成初级和中级之后的教程。本教程内容为:跨应用信息获取、随机信息利用、邮件发送、VBA上网数据抓取、VBA延时操作、剪贴板应用、Split函数扩展、工作表信息等应用交互、FSO对象的使用、工作表和文件夹信息的获取、图形信息的获取、工作表信息的自定义等功能。程序文件通过32位和64位Office系统测试。它非常抽象,更有研究价值。
本教程共两卷,八十四讲。今天的内容是主题四“EXCEL工作表数据读取、回填和搜索”的第四讲:数组转置
第四节 将VBA数组写入工作表时Transpose的使用
转置是数组应用中经常用到的知识点。在使用Excel表格的过程中,当我们想把横行变成竖列(或者把竖排的数据转为横排)时,希望两个不同排列的数据相互关联时,可以使用转置函数. 但是注意这个函数是一个工作表函数,所以在使用这个函数的时候一定要使用Application.Transpose(Arr)。
1 用一维数组回填工作表时的转置(Transpose)
如果需要按列回填一维数组,可以使用如下语句:MyRange.Value = Application.Transpose(Arr)
具体代码如下:
Sub MYNZG()'一维数组数据的转置回填方案
Dim Arr 作为变体
将 MyRange 调暗为范围
工作表(“SHEET4”)。选择
Arr = Array("大象", "老虎", "狮子", "狐狸")
设置 MyRange = Range("A1")
设置 MyRange = MyRange.Resize(UBound(Arr) + 1, 1)
MyRange.ClearContents
MyRange.Value = Application.Transpose(Arr)
MsgBox “好的!”
结束子
代码截图:
代码说明:这里需要注意的是,base cell area的展开语句变成了: Resize(UBound(Arr) + 1, 1) 这是列的展开,所以转置语句为Application。 Transpose(Arr ). 这里要注意的一点是resize参数是颠倒的。
2 用二维数组回填工作表时的转置(Transpose)
如果需要按列回填二维数组,可以使用如下语句:MyRange.Value = Application.Transpose(Arr)
具体代码如下:
Sub MYNZH()'二维数组数据的转置回填方案
Dim Arr 作为变体
将 MyRange 调暗为范围
工作表(“SHEET4”)。选择
Arr = Sheets("SHEET2").Range("A1:b9")
设置 MyRange = Range("A1")
设置 MyRange = MyRange.Resize(UBound(Arr, 2), UBound(Arr, 1))
MyRange.ClearContents
MyRange.Value = Application.Transpose(Arr)
MsgBox “好的!”
结束子
代码截图如下:
代码说明:当从工作表中读取数组变量时,VBA会自动调整数组的大小来保持工作表上的范围,所以你不需要关心数组的大小。但是,从 VBA 将数组写入工作表时,必须调整目标区域的大小以容纳该数组。我们在前面的例子中已经看到了这一点。
如果传递给工作表的数组小于其写入范围,则未使用的单元格将出现“#N/A”错误。如果传递的数组大于其写入范围,则数组将在右侧或底部截断以适应范围。
本节知识点:如何理解换位?如何使用一维数组和二维数组转置?
本主题的参考程序文件:004 worksheet.XLSM
我20多年的VBA实践经验都浓缩在下面的教程中,教程学习顺序:
① 7→1→3→2→6→5 或 7→4→3→2→6→5。
② 7→8
各套教程简介:
第七套教程(共三册):《EXCEL Application of VBA》:VBA基础讲解
第一套教程(共三册):《VBA代码解决方案》:上手后的改进教程
第四组教程(16G):VBA代码解题视频(第一组视频讲解)
第三套教程(共两册):《VBA Array and Dictionary Solution》:是数组和字典的专门讲解
第二套教程(共两册):《VBA数据库解决方案》:是数据库的专门讲解
第六套教程(共两册):《VBA信息获取与处理》:讲解VBA的网络和跨程序应用
第五套教程(共两册):VBA中类的解释与利用:类与接口技术讲解
第八套教程(共三册):VBA的Word应用(最新教程):VBA在Word中的使用
vba抓取网页数据(vba抓取网页数据这种网页列表(但绝对不可能比百度、谷歌这种网站更加靠谱))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-16 11:00
vba抓取网页数据这种网页列表(但绝对不可能比百度、谷歌这种网站更加靠谱)对于百度的统计来说属于keywords的词云筛选,更多的用作广告联盟和banner联盟用户词云挖掘。所以数据量应该在5000条以内,3m以内。假设在电脑端操作,一个用户最多能够拉取这5000条网页数据。拿这5000条数据来做similarwebsearch的相似网页搜索的话,大概需要15分钟左右的时间。
至于结果可以。但是这个算法有问题:相似网页搜索算法存在(可以人为修改)。相似网页又分为点击和点击转化两种,并且这两种情况会随着schema调整不断优化。由于submit的可能性不可能无限大,所以最终结果相差一个数量级都是很正常的,不能说一定能够比其他similarwebsearch更好。当然,如果你网站上有哪个词库的话,你可以看看这个单词占据的整个百度下拉词库的百分比是多少,然后看看相似网页是否能够覆盖这个词。
但实际情况下,你的网站seo非常糟糕,比如单纯依靠模拟点击去seo,然后搜索某几个词,它跳出来的信息都是频繁跳转信息,你无法判断出哪些用户是在搜索哪个词。所以该算法只在你网站可以覆盖一些点击转化不高的小词的情况下有效。更复杂的情况下我们其实可以把它理解为一个dedicatedauthentication,你把每个点击转化低的网页存到一个临时的authentication服务里面。
然后每次只需要解析这个authentication服务,并发hook这个点击转化率高的网页即可。这个网页hook成功后,然后解析出每个数据库里面的sendlist每个点击是否有转化。解析成功后,你的网站可以把这个网页存在数据库里面进行内搜索了。我一直觉得这个算法是一个很厉害的东西,可惜我们的authentication服务一直做不好。
这个东西可以说是百度在对抗地缘政治问题的折衷方案。仅仅只是百度自己,往往用不起。facebook,twitter这种常年受各种负面消息骚扰,今天因为小丑事件,明天因为某个地震,过三五个月又因为什么重大事件,死一两个又摔死一个,下一次又是什么新鲜玩意了。相反还有一些比较友好的公司会和百度合作来推广自己的authentication服务,提供一些额外的利益,比如网盘,百度文库,都是例子。 查看全部
vba抓取网页数据(vba抓取网页数据这种网页列表(但绝对不可能比百度、谷歌这种网站更加靠谱))
vba抓取网页数据这种网页列表(但绝对不可能比百度、谷歌这种网站更加靠谱)对于百度的统计来说属于keywords的词云筛选,更多的用作广告联盟和banner联盟用户词云挖掘。所以数据量应该在5000条以内,3m以内。假设在电脑端操作,一个用户最多能够拉取这5000条网页数据。拿这5000条数据来做similarwebsearch的相似网页搜索的话,大概需要15分钟左右的时间。
至于结果可以。但是这个算法有问题:相似网页搜索算法存在(可以人为修改)。相似网页又分为点击和点击转化两种,并且这两种情况会随着schema调整不断优化。由于submit的可能性不可能无限大,所以最终结果相差一个数量级都是很正常的,不能说一定能够比其他similarwebsearch更好。当然,如果你网站上有哪个词库的话,你可以看看这个单词占据的整个百度下拉词库的百分比是多少,然后看看相似网页是否能够覆盖这个词。
但实际情况下,你的网站seo非常糟糕,比如单纯依靠模拟点击去seo,然后搜索某几个词,它跳出来的信息都是频繁跳转信息,你无法判断出哪些用户是在搜索哪个词。所以该算法只在你网站可以覆盖一些点击转化不高的小词的情况下有效。更复杂的情况下我们其实可以把它理解为一个dedicatedauthentication,你把每个点击转化低的网页存到一个临时的authentication服务里面。
然后每次只需要解析这个authentication服务,并发hook这个点击转化率高的网页即可。这个网页hook成功后,然后解析出每个数据库里面的sendlist每个点击是否有转化。解析成功后,你的网站可以把这个网页存在数据库里面进行内搜索了。我一直觉得这个算法是一个很厉害的东西,可惜我们的authentication服务一直做不好。
这个东西可以说是百度在对抗地缘政治问题的折衷方案。仅仅只是百度自己,往往用不起。facebook,twitter这种常年受各种负面消息骚扰,今天因为小丑事件,明天因为某个地震,过三五个月又因为什么重大事件,死一两个又摔死一个,下一次又是什么新鲜玩意了。相反还有一些比较友好的公司会和百度合作来推广自己的authentication服务,提供一些额外的利益,比如网盘,百度文库,都是例子。
vba抓取网页数据(如何分析vba抓取网页数据报表分析的一些一些实例。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-11 20:04
vba抓取网页数据报表分析的一些实例。例如经常分析竞价的人抓取一些竞价数据进行分析,使用mysql,oracle等通用的数据库进行分析,其实vba也有相对应的插件,如simpleserver。不过我是通过抓包工具实现的,抓包工具如“useragentscrypt".这篇文章会分享抓取京东的页面数据的分析过程。效果展示。
一、如何分析请求从url结构与发送post参数分析出。
二、爬取京东一个男装店的数据第1部分的数据是按照item分类,第2部分的数据是按照size分类,第3部分是按照类目分类。
三、常用抓包工具
1、“useragentscrypt”useragentscrypt抓取了京东用户的ip、地址、phone、mac、internetrepairtrack、版本号等信息。同时,可以搜索到京东用户的登录信息,并可以向useragentscrypt报送页面内容,包括关键词与不同的版本。
2、“addressscrypt”提供addressscrypt利用get_return_url_port()函数获取此页面地址。useragentscrypt将此页面的跳转链接写入dict参数中,并通过useragentget_post_port()方法获取页面的标识码,useragent返回信息同时携带标识码字段,get_post_port()返回地址:。
提供两种useragent:useragentget_user_agent()与useragentget_post_port()。useragentget_user_agent()方法返回一个字符串:地址,一个useragent地址指向一个useragent名称实例,每次请求返回地址。useragentget_post_port()方法返回一个字符串:card.html,每次请求返回card.html。
相同的useragent地址会有不同的card.html,如下图。firefox(opera)/safari(firefox):"1123"windows-10/windows8/windowsxp/sunsp1/xpsp2/sf/edge/ie5/ie7/ie6/firefox/edge/netbeans/ie11..."xperwin32-bit"、"1123"ip110.15.16.44"ip110.168.148.11"ip110.162.140.61"ip110.162.141.18"ip110.162.142.19"ip110.162.143.19"ip110.162.144.19"ip110.162.145.19"ip110.162.146.19"ip110.162.147.19"ip110.162.148.19"ip110.162.149.19"ip110.162.148.19"ip110.162.149.19"ip110.162.149.19"ip110.162.140.19"ip11。 查看全部
vba抓取网页数据(如何分析vba抓取网页数据报表分析的一些一些实例。)
vba抓取网页数据报表分析的一些实例。例如经常分析竞价的人抓取一些竞价数据进行分析,使用mysql,oracle等通用的数据库进行分析,其实vba也有相对应的插件,如simpleserver。不过我是通过抓包工具实现的,抓包工具如“useragentscrypt".这篇文章会分享抓取京东的页面数据的分析过程。效果展示。
一、如何分析请求从url结构与发送post参数分析出。
二、爬取京东一个男装店的数据第1部分的数据是按照item分类,第2部分的数据是按照size分类,第3部分是按照类目分类。
三、常用抓包工具
1、“useragentscrypt”useragentscrypt抓取了京东用户的ip、地址、phone、mac、internetrepairtrack、版本号等信息。同时,可以搜索到京东用户的登录信息,并可以向useragentscrypt报送页面内容,包括关键词与不同的版本。
2、“addressscrypt”提供addressscrypt利用get_return_url_port()函数获取此页面地址。useragentscrypt将此页面的跳转链接写入dict参数中,并通过useragentget_post_port()方法获取页面的标识码,useragent返回信息同时携带标识码字段,get_post_port()返回地址:。
提供两种useragent:useragentget_user_agent()与useragentget_post_port()。useragentget_user_agent()方法返回一个字符串:地址,一个useragent地址指向一个useragent名称实例,每次请求返回地址。useragentget_post_port()方法返回一个字符串:card.html,每次请求返回card.html。
相同的useragent地址会有不同的card.html,如下图。firefox(opera)/safari(firefox):"1123"windows-10/windows8/windowsxp/sunsp1/xpsp2/sf/edge/ie5/ie7/ie6/firefox/edge/netbeans/ie11..."xperwin32-bit"、"1123"ip110.15.16.44"ip110.168.148.11"ip110.162.140.61"ip110.162.141.18"ip110.162.142.19"ip110.162.143.19"ip110.162.144.19"ip110.162.145.19"ip110.162.146.19"ip110.162.147.19"ip110.162.148.19"ip110.162.149.19"ip110.162.148.19"ip110.162.149.19"ip110.162.149.19"ip110.162.140.19"ip11。
vba抓取网页数据(Scraping程序仅处理一种类型的请求:名为/的资源的GET)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-10 10:04
Scraping 程序只处理一种类型的请求:对名为 / 的资源进行 GET,它是 Stats::Controller 包中的屏幕截图和数据处理代码。供您检查的是 Plack/PSGI 路由设置,它位于源文件 scrape.pl 的顶部:
my
$router
= router
{
<br />
match
'/'
,
{ method
=>
'GET'
}
,
## noun/verb combo: / is noun, GET is verb
<br />
to
{ controller
=>
'Controller'
, action
=>
'index'
}
;
## handler is function get_index
<br />
# Other actions as needed
<br />
}
;
请求处理程序 Controller::get_index 只有高级逻辑,在 Util.pm 文件中的实用程序函数中保留了屏幕捕获和报告生成的详细信息,如下一节所述。
屏幕截图代码
回想一下,Plack 服务器向 Scraping 程序的 get_index 函数发送了一个对 localhost:5000/ 的 GET 请求。然后,该函数作为请求处理程序开始执行以下任务:检索要抓取的数据,抓取数据并生成最终报告。数据检索部分是一个实用函数,它使用 Perl 的 LWP::Agent 包从托管 data.html 文档的任何服务器检索数据。对于数据文件,Scraping 程序将调用实用函数extract_from_html 进行数据提取。
data.html 文档恰好是格式良好的 XML,这意味着可以使用 Perl 包(例如 XML::LibXML)通过显式 XML 解析来提取数据。然而,HTML::TableExtract 包是 HTML::TableExtract,因为它 HTML::TableExtract 绕过 XML 解析并且(用很少的代码)提供用于提取数据的 Perl 哈希。HTML 文档中的数据聚合通常出现在列表或表格中,而 HTML::TableExtract 封装 HTML ::TableExtract 表格是目标。这些是数据提取的三行关键代码:
my
$col_headers
= col_headers
(
)
;
## col_headers() returns an array of the table's column names
<br />
my
$te
= HTML
::
TableExtract
->
new
( headers
=>
$col_headers
)
;
<br />
$te
->
parse
(
$page
)
;
## $page is data.html
$col_headers 指的是 Perl 字符串数组,每个字符串都是 HTML 文档中的一个列标题:
sub col_headers
{
## column headers in the HTML table
<br />
return
[
"Area"
,
<br />
"MedianWage"
,
<br />
...
<br />
"BoostFromGradDegree"
]
;
<br />
}
在调用 TableExtract::parse 函数后,Scraping 程序将使用 TableExtract::rows 函数对提取的数据行(没有 HTML 标记的数据行)进行迭代。这些行(作为 Perl 列表)被添加到名为 %majors_hash 的 Perl 哈希中,如下所示:
收录提取数据的哈希将写入本地文件 rawData.dat:
ForeignLanguage 50000 35000 75000 3.5% 54% 101%
<br />
LiberalArts 47000 32000 70000 9.7% 41% 48%
<br />
...
<br />
Engineering 78000 54000 104000 8.2% 37% 32%
<br />
Computing 75000 51000 112000 5.1% 32% 31%
<br />
...
<br />
PublicPolicy 50000 36000 74000 2.3% 24% 45%
下一步是处理提取的数据。在这种情况下,Statistics::Descriptive 包将用于基本的统计分析。在上面的图 1 中,统计摘要显示在报告底部的单独表格中。
报告生成代码
Scraping 程序的最后一步是生成报告。Perl 有用于生成 HTML 的选项,包括 Template::Recall。顾名思义,该包从 HTML 模板生成 HTML,该模板混合了标准 HTML 标签和自定义标签,用作从后端代码生成的数据的占位符。模板文件是report.html,感兴趣的后端函数是Controller::generate_report。这就是代码与模板交互的方式。
报表文档(图1)有两张表。顶层表是迭代生成的,因为每一行都有相同的列(学习区域,第25个百分位收入等)。在每次迭代中,代码都会使用特定学习区域的值来创建哈希值:
my
%row
=
(
<br />
major
=>
$key
,
<br />
wage
=>
'$'
. commify
(
$values
[
0
]
)
,
## commify turns 1234 into 1,234
<br />
p25
=>
'$'
. commify
(
$values
[
1
]
)
,
<br />
p75
=>
'$'
. commify
(
$values
[
2
]
)
,
<br />
population
=>
$values
[
3
]
,
<br />
grad
=>
$values
[
4
]
,
<br />
boost
=>
$values
[
5
]
<br />
)
;
哈希键是 Perl 的裸词作为列表项,这样major 和wage 代表之前从HTML 数据文档中提取的数据值。对应的HTML模板如下:
[ === even === ]
<br />
<br />
['major']
<br />
['p25']
<br />
['wage']
<br />
['p75']
<br />
['pop']
<br />
['grad']
<br />
['boost']
<br />
<br />
[=== end1 ===]
自定义标签在方括号中。顶部和底部的标签分别标记了要渲染的模板区域的开始和结束。其他自定义标签标识后端代码的各种目标。例如,标识为主要的模板列将匹配以主要作为键的哈希条目。这是后端代码中的调用,它将数据绑定到自定义标签:
print OUTFILE $tr -> render ( 'end1' ) ;
引用$tr指向Template::Recall实例,OUTFILE是报表文件reportFinal.html,由模板文件report.html连同后端代码生成。如果一切顺利,reportFinal.html 文件就是用户在浏览器中看到的(见图 1).
爬虫利用优秀的Perl软件包,如Plack/PSGI、LWP::Agent、HTML::TableExtract、Template::Recall和Statistics::Descriptive来处理HTML::TableExtract的屏幕数据抓取任务。这些包可以很好地协同工作,因为每个包都针对特定的子任务。最后,可以扩展Scraping程序对提取的数据进行聚类:Algorithm::KMeans软件包适用于这种扩展,可以使用rawData.dat文件中的Algorithm::KMeans数据。
翻译自:
vba 数据捕获屏幕数据 查看全部
vba抓取网页数据(Scraping程序仅处理一种类型的请求:名为/的资源的GET)
Scraping 程序只处理一种类型的请求:对名为 / 的资源进行 GET,它是 Stats::Controller 包中的屏幕截图和数据处理代码。供您检查的是 Plack/PSGI 路由设置,它位于源文件 scrape.pl 的顶部:
my
$router
= router
{
<br />
match
'/'
,
{ method
=>
'GET'
}
,
## noun/verb combo: / is noun, GET is verb
<br />
to
{ controller
=>
'Controller'
, action
=>
'index'
}
;
## handler is function get_index
<br />
# Other actions as needed
<br />
}
;
请求处理程序 Controller::get_index 只有高级逻辑,在 Util.pm 文件中的实用程序函数中保留了屏幕捕获和报告生成的详细信息,如下一节所述。
屏幕截图代码
回想一下,Plack 服务器向 Scraping 程序的 get_index 函数发送了一个对 localhost:5000/ 的 GET 请求。然后,该函数作为请求处理程序开始执行以下任务:检索要抓取的数据,抓取数据并生成最终报告。数据检索部分是一个实用函数,它使用 Perl 的 LWP::Agent 包从托管 data.html 文档的任何服务器检索数据。对于数据文件,Scraping 程序将调用实用函数extract_from_html 进行数据提取。
data.html 文档恰好是格式良好的 XML,这意味着可以使用 Perl 包(例如 XML::LibXML)通过显式 XML 解析来提取数据。然而,HTML::TableExtract 包是 HTML::TableExtract,因为它 HTML::TableExtract 绕过 XML 解析并且(用很少的代码)提供用于提取数据的 Perl 哈希。HTML 文档中的数据聚合通常出现在列表或表格中,而 HTML::TableExtract 封装 HTML ::TableExtract 表格是目标。这些是数据提取的三行关键代码:
my
$col_headers
= col_headers
(
)
;
## col_headers() returns an array of the table's column names
<br />
my
$te
= HTML
::
TableExtract
->
new
( headers
=>
$col_headers
)
;
<br />
$te
->
parse
(
$page
)
;
## $page is data.html
$col_headers 指的是 Perl 字符串数组,每个字符串都是 HTML 文档中的一个列标题:
sub col_headers
{
## column headers in the HTML table
<br />
return
[
"Area"
,
<br />
"MedianWage"
,
<br />
...
<br />
"BoostFromGradDegree"
]
;
<br />
}
在调用 TableExtract::parse 函数后,Scraping 程序将使用 TableExtract::rows 函数对提取的数据行(没有 HTML 标记的数据行)进行迭代。这些行(作为 Perl 列表)被添加到名为 %majors_hash 的 Perl 哈希中,如下所示:
收录提取数据的哈希将写入本地文件 rawData.dat:
ForeignLanguage 50000 35000 75000 3.5% 54% 101%
<br />
LiberalArts 47000 32000 70000 9.7% 41% 48%
<br />
...
<br />
Engineering 78000 54000 104000 8.2% 37% 32%
<br />
Computing 75000 51000 112000 5.1% 32% 31%
<br />
...
<br />
PublicPolicy 50000 36000 74000 2.3% 24% 45%
下一步是处理提取的数据。在这种情况下,Statistics::Descriptive 包将用于基本的统计分析。在上面的图 1 中,统计摘要显示在报告底部的单独表格中。
报告生成代码
Scraping 程序的最后一步是生成报告。Perl 有用于生成 HTML 的选项,包括 Template::Recall。顾名思义,该包从 HTML 模板生成 HTML,该模板混合了标准 HTML 标签和自定义标签,用作从后端代码生成的数据的占位符。模板文件是report.html,感兴趣的后端函数是Controller::generate_report。这就是代码与模板交互的方式。
报表文档(图1)有两张表。顶层表是迭代生成的,因为每一行都有相同的列(学习区域,第25个百分位收入等)。在每次迭代中,代码都会使用特定学习区域的值来创建哈希值:
my
%row
=
(
<br />
major
=>
$key
,
<br />
wage
=>
'$'
. commify
(
$values
[
0
]
)
,
## commify turns 1234 into 1,234
<br />
p25
=>
'$'
. commify
(
$values
[
1
]
)
,
<br />
p75
=>
'$'
. commify
(
$values
[
2
]
)
,
<br />
population
=>
$values
[
3
]
,
<br />
grad
=>
$values
[
4
]
,
<br />
boost
=>
$values
[
5
]
<br />
)
;
哈希键是 Perl 的裸词作为列表项,这样major 和wage 代表之前从HTML 数据文档中提取的数据值。对应的HTML模板如下:
[ === even === ]
<br />
<br />
['major']
<br />
['p25']
<br />
['wage']
<br />
['p75']
<br />
['pop']
<br />
['grad']
<br />
['boost']
<br />
<br />
[=== end1 ===]
自定义标签在方括号中。顶部和底部的标签分别标记了要渲染的模板区域的开始和结束。其他自定义标签标识后端代码的各种目标。例如,标识为主要的模板列将匹配以主要作为键的哈希条目。这是后端代码中的调用,它将数据绑定到自定义标签:
print OUTFILE $tr -> render ( 'end1' ) ;
引用$tr指向Template::Recall实例,OUTFILE是报表文件reportFinal.html,由模板文件report.html连同后端代码生成。如果一切顺利,reportFinal.html 文件就是用户在浏览器中看到的(见图 1).
爬虫利用优秀的Perl软件包,如Plack/PSGI、LWP::Agent、HTML::TableExtract、Template::Recall和Statistics::Descriptive来处理HTML::TableExtract的屏幕数据抓取任务。这些包可以很好地协同工作,因为每个包都针对特定的子任务。最后,可以扩展Scraping程序对提取的数据进行聚类:Algorithm::KMeans软件包适用于这种扩展,可以使用rawData.dat文件中的Algorithm::KMeans数据。
翻译自:
vba 数据捕获屏幕数据
vba抓取网页数据(VBA专题“利用IE抓取深市股票涨跌数据”(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-11-09 19:03
大家好,今天我们讲解了《VBA信息获取与处理》教程第九题“使用IE捕捉网络数据”,第三节“使用IE捕捉深市数据”,这个题目非常有用希望你可以掌握知识点。
第三节 使用IE抓取深交所股市数据
大家好。本教程是关于使用IE捕捉深市股市数据。使用的方法与前一种基本类似。主要目的是给大家介绍一个实用的场景供大家选择使用。
实际场景:在玩股票时,往往需要每天查看领先股票收益的股票,以便分析各种对应关系。需要使用IE 提取某只网站 股票的行情数据并将这些数据放入工作表中。查看作为替代方案。选择的网址为:/为搜狐网的数据。
1 应用IE实现深市股价数据捕捉思路的分析
为了实现上述场景,我们先来看看网页上提供的信息:
在上面的网页中,我要提取的是红框中的数据。我们来分析一下思路:首先,我们必须创建一个IE对象,然后提取web文档,在web文档上提取第二个表中的数据。就是这样。提取表格数据时,可以模拟真实工作表的行列循环,依次提取数据。在我之前的解释中,我提到过 myTR.Cells.Length 是指单元格的数量,而 Cells(j).innertext 是指单元格的数量。内容。这两点在写代码时要注意。
另外getElementsByTagName("TABLE")(2)这个方法可以在爬取web文档表的时候使用。这个方法是查找数据,返回收录指定标签名的所有元素的节点列表之前在讲解中,我一共讲解了三种类似的方法,如下
getElementById(id) 获取指定id的节点(元素)
getElementsByTagName() 返回一个节点列表(集合/节点数组),其中收录具有指定标签名称的所有元素。
getElementsByClassName() 返回收录具有指定类名的所有元素的节点列表。
ByTagName是上面提到的第二种方法,第一种比较常用。
2 应用IE实现获取深交所股价数据的代码实现
为了实现上面的想法,我给出了如下代码:
Sub myNZA()'使用IE获取股市数据
工作表(“SHEET2”)。选择
Dim IE, IEDOM 作为对象
Dim myTable, myTR 作为对象
Set IE = CreateObject("InternetExplorer.Application")
用 IE
.可见=假
.导航“/”
直到 .readystate = 4
事件
环形
设置 IEDOM = .document
结束于
Cells.ClearContents
设置 myTable = IEDOM.getElementsByTagName("TABLE")(2)
对于 myTable.Rows 中的每个 myTR
我 = 我 + 1
对于 j = 0 到 myTR.Cells.Length-1
Cells(i, j + 1) = myTR.Cells(j).innertext
下一个
下一个
设置 IE = 无
设置 IEDOM = 无
设置 myTable = 无
设置 myTR = 无
MsgBox “好的!”
结束子
代码说明:
1)Set IE = CreateObject("InternetExplorer.Application") 设置对 IE 的引用。
2).Visible = False
.导航“/”
直到 .readystate = 4
事件
环形
上面的代码让浏览器可见,加载URL / 直到加载完成,里面的DoEvents是为了避免软崩溃的现象。
3)Set IEDOM = .document 设置网页文档数据
4)Set myTable = IEDOM.getElementsByTagName("TABLE")(2) 提取网页文档的第二个表格
5)对于 myTable.Rows 中的每个 myTR
我 = 我 + 1
对于 j = 0 到 myTR.Cells.Length-1
Cells(i, j + 1) = myTR.Cells(j).innertext
下一个
下一个
将表的数据提取到工作表。
6)设置 IE = 无
设置 IEDOM = 无
设置 myTable = 无
设置 myTR = 无
回收记忆。对于回收内存的操作,推荐大家使用。在大型程序中,要注意这一点。过多的内存使用会减慢程序的速度。如果不释放内存,只能在END SUB时间释放,内存不足。
代码截图:
通过上面的代码,我们就可以完成我们的想法了。
3 应用IE实现捕捉深交所股价数据的效果
当我们点击运行按钮时,如图中箭头所示,程序就会开始运行,抓取网页数据到工作表中
这验证了我们想法的正确性。
本节知识点:如何提取页面文档中的表格数据?
本节内容参考:009 worksheet.xlsm
积木式编程的内涵:
在我的系列丛书中,我一直在强调“积木”的编程思想,这也是学习使用VBA的主要方法,尤其是对于职场专业人士。其主要内涵:
1 不要自己输入所有代码。您要做的就是将构建块放在正确的位置,然后修改代码。一定要复制,从你的积木库中复制,然后修改代码,以利用你的时间进行高效思考。
2 建立自己的“积木库”。平时在学习的过程中,把自己觉得有用的代码拼凑起来,多积累一些,用到的时候随时可以拿到。您的构建块库中的数据越多,您的编程想法就越广泛。
VBA 应用程序的定义
VBA是使用Office实现个人小型办公自动化的有效手段(工具)。这是我对VBA应用的定义。在取代OFFICE的新办公软件到来之前,谁能做到数据处理的极致才是王道。其中,技能的巅峰非VBA莫属!
记得20年前第一次学VBA的时候,当时资料很少。只能自己看源码自己弄明白了。这真的很困难。二十年过去了。为了不让正在学习VBA的朋友重复我之前的经验,根据我多年VBA的实际使用,我推出了六个VBA专用教程:
第一组:VBA代码解法是对VBA中各个知识点的讲解。一共147个教程,涵盖了大部分VBA知识点,初学者必备;
第二套:VBA数据库解决方案 数据库是专业的数据处理工具。教程详细介绍了使用ADO连接ACCDB和EXCEL的方法和示例操作,适合中层人员学习。
第三套:VBA数组和字典解决方案。数组和字典是 VBA 的精髓。字典是提高VBA代码水平的有效手段。值得深入研究。它是初学者和中级人员改进代码的一种手段。
第四套:VBA代码解题视频是专门针对初学者的视频讲解。您可以快速入门并更快地掌握此技能。这套教程是第一套教程视频讲解,听元音比较好听。
第五套:VBA中类的解释和利用这是一个高级教程,用于解释类的空性和肉体的程度。虽然类的使用较少,但仔细研究可以促进你的VBA理论的提高。这套教程的领悟主要是读者的领悟,对佛教哲学的领悟。
第六套教程:《VBA信息获取与处理》,这是一本进阶教程,覆盖面更广,实用性更强,面向中高级人员。教程共20个主题,包括:跨应用信息获取、随机信息的使用、邮件发送、VBA上网数据抓取、VBA延时操作、剪贴板应用、Split函数扩展、工作表信息等应用交互、使用FSO对象、工作表和文件夹信息的获取、图形信息的获取、工作表信息功能的定制等。
您可以根据以上信息按1→3→2→6→5或4→3→2→6→5的顺序学习。本教程在提供大量构建块的同时提供了解释。如有需要,您可以微信:NZ9668
学习VBA是一个过程,也需要体验一种枯燥的感觉
如太白的诗:百鸟高飞,孤云自在。相视不倦,唯景亭山。学习的过程,也是修心的过程,修心的过程。在代码的世界里,心静,心情好,身体自然好。心平气正,心无邪见,妄念不多。造福他人就是造福自己。这些教程也是为了帮助大家起航,助力自己的实力。我上面的教程是我很多经验的传递。
“水利万物而不争”,密密麻麻,微静无声,巨浪汹涌。学习也是如此,知道自己需要什么,不要蜷缩在你认为是天堂的一小片世界里,等到晚年再自欺欺人。努力提升自己,用一颗充满活力的心,把握当下,这才是进取。越有意义的事情,越困难。意志力决定一切,智慧决定成败。不管遇到什么,都是风景。无视纠纷,无视得失。茶,不管是满是小,都不用担心;浓或淡,都有它自己的味道。感受真实的时光,静下心来,多学习,积累祝福。它' 不是每天都在胡闹,也不会每天都忍受。在存量更加严峻的后疫情世界,我们会为自己的生存储备知识,尤其是新知识的储备。学时小而无声,用时则大而动荡。
每一次的收获都是成长的记录,所以没有依据。正是这种坚持,造就了朝霞的光辉。最后给致力于VBA学习的朋友做个小测验,让大家感受一下学习过程的枯燥和坚持:
浮云掠过,耳语无声,
唯有微风,震撼了梦中的莹莹。
看星星,去掉北斗七星,
奈与过去同行。
稻田的人们,灯火通明,
熊顾长亭。
多少VBA人,
在漆黑的夜里,静静地寻梦,盼望黎明。
没有证据!
回到学习使用VBA的历史,不禁感慨,想把这些话跟大家分享,分享我多年实际工作经验的成果,喜欢这些有用的东西,给各位旅友谁真的需要使用VBA。 查看全部
vba抓取网页数据(VBA专题“利用IE抓取深市股票涨跌数据”(组图))
大家好,今天我们讲解了《VBA信息获取与处理》教程第九题“使用IE捕捉网络数据”,第三节“使用IE捕捉深市数据”,这个题目非常有用希望你可以掌握知识点。
第三节 使用IE抓取深交所股市数据
大家好。本教程是关于使用IE捕捉深市股市数据。使用的方法与前一种基本类似。主要目的是给大家介绍一个实用的场景供大家选择使用。
实际场景:在玩股票时,往往需要每天查看领先股票收益的股票,以便分析各种对应关系。需要使用IE 提取某只网站 股票的行情数据并将这些数据放入工作表中。查看作为替代方案。选择的网址为:/为搜狐网的数据。
1 应用IE实现深市股价数据捕捉思路的分析
为了实现上述场景,我们先来看看网页上提供的信息:
在上面的网页中,我要提取的是红框中的数据。我们来分析一下思路:首先,我们必须创建一个IE对象,然后提取web文档,在web文档上提取第二个表中的数据。就是这样。提取表格数据时,可以模拟真实工作表的行列循环,依次提取数据。在我之前的解释中,我提到过 myTR.Cells.Length 是指单元格的数量,而 Cells(j).innertext 是指单元格的数量。内容。这两点在写代码时要注意。
另外getElementsByTagName("TABLE")(2)这个方法可以在爬取web文档表的时候使用。这个方法是查找数据,返回收录指定标签名的所有元素的节点列表之前在讲解中,我一共讲解了三种类似的方法,如下
getElementById(id) 获取指定id的节点(元素)
getElementsByTagName() 返回一个节点列表(集合/节点数组),其中收录具有指定标签名称的所有元素。
getElementsByClassName() 返回收录具有指定类名的所有元素的节点列表。
ByTagName是上面提到的第二种方法,第一种比较常用。
2 应用IE实现获取深交所股价数据的代码实现
为了实现上面的想法,我给出了如下代码:
Sub myNZA()'使用IE获取股市数据
工作表(“SHEET2”)。选择
Dim IE, IEDOM 作为对象
Dim myTable, myTR 作为对象
Set IE = CreateObject("InternetExplorer.Application")
用 IE
.可见=假
.导航“/”
直到 .readystate = 4
事件
环形
设置 IEDOM = .document
结束于
Cells.ClearContents
设置 myTable = IEDOM.getElementsByTagName("TABLE")(2)
对于 myTable.Rows 中的每个 myTR
我 = 我 + 1
对于 j = 0 到 myTR.Cells.Length-1
Cells(i, j + 1) = myTR.Cells(j).innertext
下一个
下一个
设置 IE = 无
设置 IEDOM = 无
设置 myTable = 无
设置 myTR = 无
MsgBox “好的!”
结束子
代码说明:
1)Set IE = CreateObject("InternetExplorer.Application") 设置对 IE 的引用。
2).Visible = False
.导航“/”
直到 .readystate = 4
事件
环形
上面的代码让浏览器可见,加载URL / 直到加载完成,里面的DoEvents是为了避免软崩溃的现象。
3)Set IEDOM = .document 设置网页文档数据
4)Set myTable = IEDOM.getElementsByTagName("TABLE")(2) 提取网页文档的第二个表格
5)对于 myTable.Rows 中的每个 myTR
我 = 我 + 1
对于 j = 0 到 myTR.Cells.Length-1
Cells(i, j + 1) = myTR.Cells(j).innertext
下一个
下一个
将表的数据提取到工作表。
6)设置 IE = 无
设置 IEDOM = 无
设置 myTable = 无
设置 myTR = 无
回收记忆。对于回收内存的操作,推荐大家使用。在大型程序中,要注意这一点。过多的内存使用会减慢程序的速度。如果不释放内存,只能在END SUB时间释放,内存不足。
代码截图:
通过上面的代码,我们就可以完成我们的想法了。
3 应用IE实现捕捉深交所股价数据的效果
当我们点击运行按钮时,如图中箭头所示,程序就会开始运行,抓取网页数据到工作表中
这验证了我们想法的正确性。
本节知识点:如何提取页面文档中的表格数据?
本节内容参考:009 worksheet.xlsm
积木式编程的内涵:
在我的系列丛书中,我一直在强调“积木”的编程思想,这也是学习使用VBA的主要方法,尤其是对于职场专业人士。其主要内涵:
1 不要自己输入所有代码。您要做的就是将构建块放在正确的位置,然后修改代码。一定要复制,从你的积木库中复制,然后修改代码,以利用你的时间进行高效思考。
2 建立自己的“积木库”。平时在学习的过程中,把自己觉得有用的代码拼凑起来,多积累一些,用到的时候随时可以拿到。您的构建块库中的数据越多,您的编程想法就越广泛。
VBA 应用程序的定义
VBA是使用Office实现个人小型办公自动化的有效手段(工具)。这是我对VBA应用的定义。在取代OFFICE的新办公软件到来之前,谁能做到数据处理的极致才是王道。其中,技能的巅峰非VBA莫属!
记得20年前第一次学VBA的时候,当时资料很少。只能自己看源码自己弄明白了。这真的很困难。二十年过去了。为了不让正在学习VBA的朋友重复我之前的经验,根据我多年VBA的实际使用,我推出了六个VBA专用教程:
第一组:VBA代码解法是对VBA中各个知识点的讲解。一共147个教程,涵盖了大部分VBA知识点,初学者必备;
第二套:VBA数据库解决方案 数据库是专业的数据处理工具。教程详细介绍了使用ADO连接ACCDB和EXCEL的方法和示例操作,适合中层人员学习。
第三套:VBA数组和字典解决方案。数组和字典是 VBA 的精髓。字典是提高VBA代码水平的有效手段。值得深入研究。它是初学者和中级人员改进代码的一种手段。
第四套:VBA代码解题视频是专门针对初学者的视频讲解。您可以快速入门并更快地掌握此技能。这套教程是第一套教程视频讲解,听元音比较好听。
第五套:VBA中类的解释和利用这是一个高级教程,用于解释类的空性和肉体的程度。虽然类的使用较少,但仔细研究可以促进你的VBA理论的提高。这套教程的领悟主要是读者的领悟,对佛教哲学的领悟。
第六套教程:《VBA信息获取与处理》,这是一本进阶教程,覆盖面更广,实用性更强,面向中高级人员。教程共20个主题,包括:跨应用信息获取、随机信息的使用、邮件发送、VBA上网数据抓取、VBA延时操作、剪贴板应用、Split函数扩展、工作表信息等应用交互、使用FSO对象、工作表和文件夹信息的获取、图形信息的获取、工作表信息功能的定制等。
您可以根据以上信息按1→3→2→6→5或4→3→2→6→5的顺序学习。本教程在提供大量构建块的同时提供了解释。如有需要,您可以微信:NZ9668
学习VBA是一个过程,也需要体验一种枯燥的感觉
如太白的诗:百鸟高飞,孤云自在。相视不倦,唯景亭山。学习的过程,也是修心的过程,修心的过程。在代码的世界里,心静,心情好,身体自然好。心平气正,心无邪见,妄念不多。造福他人就是造福自己。这些教程也是为了帮助大家起航,助力自己的实力。我上面的教程是我很多经验的传递。
“水利万物而不争”,密密麻麻,微静无声,巨浪汹涌。学习也是如此,知道自己需要什么,不要蜷缩在你认为是天堂的一小片世界里,等到晚年再自欺欺人。努力提升自己,用一颗充满活力的心,把握当下,这才是进取。越有意义的事情,越困难。意志力决定一切,智慧决定成败。不管遇到什么,都是风景。无视纠纷,无视得失。茶,不管是满是小,都不用担心;浓或淡,都有它自己的味道。感受真实的时光,静下心来,多学习,积累祝福。它' 不是每天都在胡闹,也不会每天都忍受。在存量更加严峻的后疫情世界,我们会为自己的生存储备知识,尤其是新知识的储备。学时小而无声,用时则大而动荡。
每一次的收获都是成长的记录,所以没有依据。正是这种坚持,造就了朝霞的光辉。最后给致力于VBA学习的朋友做个小测验,让大家感受一下学习过程的枯燥和坚持:
浮云掠过,耳语无声,
唯有微风,震撼了梦中的莹莹。
看星星,去掉北斗七星,
奈与过去同行。
稻田的人们,灯火通明,
熊顾长亭。
多少VBA人,
在漆黑的夜里,静静地寻梦,盼望黎明。
没有证据!
回到学习使用VBA的历史,不禁感慨,想把这些话跟大家分享,分享我多年实际工作经验的成果,喜欢这些有用的东西,给各位旅友谁真的需要使用VBA。
vba抓取网页数据(等待响应DoWhileweatherMsgBox()今日天气更新完成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-09 19:01
'等待回应
做 While xmlHttp.ReadyState 4
事件
环形
'获取请求的数据
将 Myhtml 调暗为字符串
Myhtml = xmlHttp.responseText
昏暗的天气 As String
天气 = 拆分(拆分(Myhtml,“
")(1), "")(0)
Range("G2") = "天气:" & 天气
MsgBox ("今天的天气更新已经完成,今天的天气是:" & weather)
结束子
首先, Set xmlHttp = CreateObject("MSXML2.XMLHTTP") 创建一个实例对象。然后访问我们的网站并等待回复。响应没有问题后,我们将获取到的页数数据赋值给myhtml。然后用msgbox打印出来看看。如下所示:
我们可以看到,这个内容其实就是网页代码。然后查看网页源代码,找到我们要抓取的天气信息,如下图:
然后我要捕捉的是多云天气,然后我们使用split函数来提取天气。天气 = 拆分(拆分(Myhtml,“
")(1), "")(0) 获取我们的最终天气并将其取出。
就这么简单。您可以再次安装 X。
这次的分享就到此为止。看完这篇文章的朋友,如果文章对你有用,请点赞、采集、转发,非常感谢!有什么问题可以给我留言,看到后会回复的。
查看全部
vba抓取网页数据(等待响应DoWhileweatherMsgBox()今日天气更新完成)
'等待回应
做 While xmlHttp.ReadyState 4
事件
环形
'获取请求的数据
将 Myhtml 调暗为字符串
Myhtml = xmlHttp.responseText
昏暗的天气 As String
天气 = 拆分(拆分(Myhtml,“
")(1), "")(0)
Range("G2") = "天气:" & 天气
MsgBox ("今天的天气更新已经完成,今天的天气是:" & weather)
结束子
首先, Set xmlHttp = CreateObject("MSXML2.XMLHTTP") 创建一个实例对象。然后访问我们的网站并等待回复。响应没有问题后,我们将获取到的页数数据赋值给myhtml。然后用msgbox打印出来看看。如下所示:
我们可以看到,这个内容其实就是网页代码。然后查看网页源代码,找到我们要抓取的天气信息,如下图:
然后我要捕捉的是多云天气,然后我们使用split函数来提取天气。天气 = 拆分(拆分(Myhtml,“
")(1), "")(0) 获取我们的最终天气并将其取出。
就这么简单。您可以再次安装 X。
这次的分享就到此为止。看完这篇文章的朋友,如果文章对你有用,请点赞、采集、转发,非常感谢!有什么问题可以给我留言,看到后会回复的。
vba抓取网页数据(vba抓取网页数据,你会用sql去抓取吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-08 09:02
vba抓取网页数据,你会用sql去抓取吗?如果没有,那么还需要会用到sap的dataforce,数据自动填充,自动获取数据时间等等.另外可以顺便学习下数据库
newsfinder,和wp一样的产品,不过wp是安卓平台。数据量大的话不推荐用mysql,excel管理数据实在太无力。newsfinder是收费的,但是够用,而且全免费。wps确实使用上有点问题,
mysql
newsfinder
我也很同意这个回答一个统计页面,经常会是php写wordpress然后用网页爬虫的方式爬取,反复抓取反复传递。想要达到mysql的数据有效性还是做不到的。除非用chrome的defender全部禁用。
ai人工智能
datasheet
soapui,
wpstore,用户数据全都能实时读取,另外还提供sap,erp,财务数据接口。
楼上说datagrip,
一般情况下phphttp抓包下抓sql关联的数据源。
mysql其实sqlflow在wp很多产品都能用,当然实际项目还是要看业务,还是要用etl技术,wp的hybrid也是可以达到同样的功能,就是被禁了。或者在开发过程中先进行少量测试和踩坑,如果不行直接换第三方语言,
国内的主要是都是套用wordpress的数据模型去读取和更新,国外主要分为大数据(用python,lamp架构发布)和云计算(用lnmp架构,用wordpress数据接口去读取数据,基本和wp一样)两种方式。国内的大数据相对来说比较快,但是一些没有把程序拆成库,拆成包的产品,比如faster-rcnn,就导致定制化无法满足所有需求,这个需要在前端代码中设置好相应的字段。
还有就是用mysql读取数据的方式,这个如果你用一些第三方包,也可以达到类似的要求,例如facebook数据分析框架netsql。具体效果可以看这个:来源:mybatis存储类自动化orm映射解决方案,当然其他的方式,这里不一一展开了。 查看全部
vba抓取网页数据(vba抓取网页数据,你会用sql去抓取吗?)
vba抓取网页数据,你会用sql去抓取吗?如果没有,那么还需要会用到sap的dataforce,数据自动填充,自动获取数据时间等等.另外可以顺便学习下数据库
newsfinder,和wp一样的产品,不过wp是安卓平台。数据量大的话不推荐用mysql,excel管理数据实在太无力。newsfinder是收费的,但是够用,而且全免费。wps确实使用上有点问题,
mysql
newsfinder
我也很同意这个回答一个统计页面,经常会是php写wordpress然后用网页爬虫的方式爬取,反复抓取反复传递。想要达到mysql的数据有效性还是做不到的。除非用chrome的defender全部禁用。
ai人工智能
datasheet
soapui,
wpstore,用户数据全都能实时读取,另外还提供sap,erp,财务数据接口。
楼上说datagrip,
一般情况下phphttp抓包下抓sql关联的数据源。
mysql其实sqlflow在wp很多产品都能用,当然实际项目还是要看业务,还是要用etl技术,wp的hybrid也是可以达到同样的功能,就是被禁了。或者在开发过程中先进行少量测试和踩坑,如果不行直接换第三方语言,
国内的主要是都是套用wordpress的数据模型去读取和更新,国外主要分为大数据(用python,lamp架构发布)和云计算(用lnmp架构,用wordpress数据接口去读取数据,基本和wp一样)两种方式。国内的大数据相对来说比较快,但是一些没有把程序拆成库,拆成包的产品,比如faster-rcnn,就导致定制化无法满足所有需求,这个需要在前端代码中设置好相应的字段。
还有就是用mysql读取数据的方式,这个如果你用一些第三方包,也可以达到类似的要求,例如facebook数据分析框架netsql。具体效果可以看这个:来源:mybatis存储类自动化orm映射解决方案,当然其他的方式,这里不一一展开了。
vba抓取网页数据(中石化网站查询只能一张一张卡进行查询或下载(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-11-07 09:16
背景:
公司是中石化钻石用户。一个ID下有近百张加油卡(销售人员遍布全国),需要每月统计所有卡消费记录。但中石化的网站查询只能选择一张卡查询或下载,不提供批量下载(这种企业根本不考虑用户感受,强烈鄙视)。每个月手动下载需要1个人16个工时,是巨大的工时浪费,必须自动化。
需要:
网站 数据通过VBA自动下载并汇总。
目标:16小时工作任务,缩短到1分钟
分析:
通过目标网站进行分析,感觉后台通过.net自动生成查询结果,保存为.xls文件供下载。研究了半天,无法获得文件下载的真实地址。在一次偶然的情况下,我在油卡选项列表框的末尾发现了一个空选项(系统漏洞)。选择此项点击下载,会跳转到一个空白页面,但不同的是浏览器地址栏赫然显示如下地址:。我们已经看到,通过给downloadexcel程序传递各种参数,可以得到一个名为gas.xls的文件,这里引用了公司的卡号和ID。通过分析,我们有了一些启示,可以相应的替换各个参数,然后就可以实现批量下载了。(最重要的一点是可以绕过登录验证,直接下载数据)
实现:核心代码
子卡号数据保存文件()
'目标:自动获取每张卡片的详细数据,并汇总,目标在1分钟内。
'程序:lwx,wh,wxt
'核心代码
Dim URL As String, unChang_Str01 As String, unChang_Str02 As String, unChang_Str03 As String, unChang_Str04 As String'地址信息的固定部分
Dim StartTime_Str As String, endTime_Str As String, CardInfo As String, SaveTo As String'查询周期信息和子卡号信息和存储目录信息
将 iCardcell 调暗为范围
Dim xPost 作为对象,sGet 作为对象,Y 作为对象
'利用中石化网站漏洞获取油卡查询结果下载地址,可进行地址结构-------------------- ----- ---------
unChang_Str01 = ""'.net服务器程序下载Excel
unChang_Str02 = "&endTime="
unChang_Str03 = "&cardId="
unChang_Str04 = "&customerId=1102000XXXXX"
'构造开始时间、结束时间、卡号等信息。其中customerId是通过漏洞获取的----------------------------------------
'利用该漏洞可以绕过登录验证,直接下载客户所有油卡信息。
StartTime_Str = Format([Start].Value, "yyyy-mm-dd")
endTime_Str = Format([End].Value, "yyyy-mm-dd")
SaveTo = IIf(Right([Path].Value, 1) = "\", Left([Path].Value, Len([Path].Value)-1), [Path].Value) )
如果 Dir$(SaveTo, 16) = "" 那么 MkDir SaveTo
对于范围内的每个 iCardcell([G2], [G65536].End(xlUp))
URL = unChang_Str01 & StartTime_Str & unChang_Str02 & endTime_Str & unChang_Str03 & iCardcell.Value & unChang_Str04'构造URL
Set xPost = CreateObject("Microsoft.XMLHTTP")'创建一个http对象,这里创建方法,省略在引用中添加对应项
xPost.Open "GET", URL, 0
xPost.Send
Set sGet = CreateObject("ADODB.Stream")'ADO 流的用法。将返回的数据直接存储为excel文件。
sGet.Mode = 3
sGet.Type = 1
sGet.Open
sGet.Write (xPost.responseBody)
sGet.SaveToFile SaveTo & "\" & iCardcell.Value & ".xls", 2
下一个 iCardcell
结束子
总结:
我害怕思考任何事情。如果网站没有漏洞,就不会实现。如果有,让我们快速使用它。ADO STREAM 也用于写入过程。感觉非常方便。
最后,我强烈鄙视中石化和中石油,油价一天天上涨,服务越来越差。还有就是CSDN博客中插入代码的功能真的没有以前那么好用了。
以上,构建的地址列表可以保存为.lst文件,直接用迅雷、快递等下载,然后在摘要中实现。缺点是不能自定义存储文件名。 查看全部
vba抓取网页数据(中石化网站查询只能一张一张卡进行查询或下载(图))
背景:
公司是中石化钻石用户。一个ID下有近百张加油卡(销售人员遍布全国),需要每月统计所有卡消费记录。但中石化的网站查询只能选择一张卡查询或下载,不提供批量下载(这种企业根本不考虑用户感受,强烈鄙视)。每个月手动下载需要1个人16个工时,是巨大的工时浪费,必须自动化。
需要:
网站 数据通过VBA自动下载并汇总。
目标:16小时工作任务,缩短到1分钟
分析:
通过目标网站进行分析,感觉后台通过.net自动生成查询结果,保存为.xls文件供下载。研究了半天,无法获得文件下载的真实地址。在一次偶然的情况下,我在油卡选项列表框的末尾发现了一个空选项(系统漏洞)。选择此项点击下载,会跳转到一个空白页面,但不同的是浏览器地址栏赫然显示如下地址:。我们已经看到,通过给downloadexcel程序传递各种参数,可以得到一个名为gas.xls的文件,这里引用了公司的卡号和ID。通过分析,我们有了一些启示,可以相应的替换各个参数,然后就可以实现批量下载了。(最重要的一点是可以绕过登录验证,直接下载数据)
实现:核心代码
子卡号数据保存文件()
'目标:自动获取每张卡片的详细数据,并汇总,目标在1分钟内。
'程序:lwx,wh,wxt
'核心代码
Dim URL As String, unChang_Str01 As String, unChang_Str02 As String, unChang_Str03 As String, unChang_Str04 As String'地址信息的固定部分
Dim StartTime_Str As String, endTime_Str As String, CardInfo As String, SaveTo As String'查询周期信息和子卡号信息和存储目录信息
将 iCardcell 调暗为范围
Dim xPost 作为对象,sGet 作为对象,Y 作为对象
'利用中石化网站漏洞获取油卡查询结果下载地址,可进行地址结构-------------------- ----- ---------
unChang_Str01 = ""'.net服务器程序下载Excel
unChang_Str02 = "&endTime="
unChang_Str03 = "&cardId="
unChang_Str04 = "&customerId=1102000XXXXX"
'构造开始时间、结束时间、卡号等信息。其中customerId是通过漏洞获取的----------------------------------------
'利用该漏洞可以绕过登录验证,直接下载客户所有油卡信息。
StartTime_Str = Format([Start].Value, "yyyy-mm-dd")
endTime_Str = Format([End].Value, "yyyy-mm-dd")
SaveTo = IIf(Right([Path].Value, 1) = "\", Left([Path].Value, Len([Path].Value)-1), [Path].Value) )
如果 Dir$(SaveTo, 16) = "" 那么 MkDir SaveTo
对于范围内的每个 iCardcell([G2], [G65536].End(xlUp))
URL = unChang_Str01 & StartTime_Str & unChang_Str02 & endTime_Str & unChang_Str03 & iCardcell.Value & unChang_Str04'构造URL
Set xPost = CreateObject("Microsoft.XMLHTTP")'创建一个http对象,这里创建方法,省略在引用中添加对应项
xPost.Open "GET", URL, 0
xPost.Send
Set sGet = CreateObject("ADODB.Stream")'ADO 流的用法。将返回的数据直接存储为excel文件。
sGet.Mode = 3
sGet.Type = 1
sGet.Open
sGet.Write (xPost.responseBody)
sGet.SaveToFile SaveTo & "\" & iCardcell.Value & ".xls", 2
下一个 iCardcell
结束子
总结:
我害怕思考任何事情。如果网站没有漏洞,就不会实现。如果有,让我们快速使用它。ADO STREAM 也用于写入过程。感觉非常方便。
最后,我强烈鄙视中石化和中石油,油价一天天上涨,服务越来越差。还有就是CSDN博客中插入代码的功能真的没有以前那么好用了。
以上,构建的地址列表可以保存为.lst文件,直接用迅雷、快递等下载,然后在摘要中实现。缺点是不能自定义存储文件名。
vba抓取网页数据(智能数据可视化分析之商业智能BI软件什么特别难?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-05 16:12
集团公司在做数据分析时通常有一个特点,就是跨行业、跨系统,数据采集难度大、耗时长,如果处理不好,就会耽误数据分析。但这对于数据分析高效、智能的商业智能BI软件来说并不是特别困难。商业智能BI软件如何实现高效的采集跨行业和系统数据?如何利用这些数据来完成群体数据的可视化分析?
集团公司数据量大,数据来源多。自然不能指望采集。一般来说,商业智能BI软件可以通过多种数据采集的方式获取不同来源的数据,然后使用ETL工具对数据进行清理整理,统一数据分析口径,然后通过依靠全面的数据分析模型。数据可视化分析。
奥维BI商业智能软件综合使用以下方法对群体数据进行高效分析:
1、数据导入/填写
采集 可以导入或报告 Excel 等数据源。在奥维BI商业智能软件的公开演示视频中,我们经常点击“添加数据源”或者点击选择Excel数据源,或者拖拽上传数据源,制作智能数据可视化分析报告。
2、数据库对接
如果您已经将数据存储在数据库中,则可以直接访问数据。
3、 爬虫访问
这种方式一般用于采集企业外部的第三方平台数据,如电商平台的前后端数据、外部行业数据等都可以通过这种方式获取< @采集。
以上三种是奥维BI商业智能软件常用的数据采集方法,除了数据采集还可以通过API进行。成功整理完数据采集后,即可开始高效的数据清洗整理,以及系统的数据分析,将复杂数据可视化、智能化,让子公司和部门随时开发高效智能的数据可视化分析,对数据进行深度分析挖掘,即使掌握了海量数据背后的数据关联,也能辅助数字化运营管理。
","force_purephv":"0","gnid":"90d2386fe34bfb5e6","img_data":[{"flag":2,"img":[{"desc":"","height":"804" ,"title":"","url":"","width":"1379"}]}],"original":"0","pat":"art_src_0,fts0,sts0","powerby" :"pika","pub_time":00,"pure":"","rawurl":"","redirect":0,"rptid":"f5fc7802bdd862bd","src":"数据分析王"," tag":[{"clk":"ktechnology_1:excel","k":"excel","u":""}],"title":"商业智能BI软件如何采集使数据智能 可视化分析?
使用EXCEL提取网页数据... VBA网页提取
如何将excel中的部分网页数据批量提取到表格中?-…… 这个可以直接用脚本模拟软件“阿冲全能点击王”来实现,自动提取网页数据并输入。因为在阿冲全能点击王中,可以提取大量数据进行脚本布局、自动点击、文本数据录入、点击按钮模拟等任务操作。而且,阿冲全能点击王是一个完全图形化的界面,无需复杂的编程,只需点击添加即可。
如何抓取网页中表格的数据...只需使用智能剪贴板。打开word或excel,调出智能剪贴板(快捷键ctrl cc)。然后进入网站,选择内容,复制,可以连续复制24次。在word或excel中后,全部粘贴(一次性粘贴24个复制的内容)。如果仍然存在,请清除剪贴板并继续复制...然后粘贴所有内容。这样,网页的内容就会被转移到word或者excel中。由于网页上的数据,到达excel后,可能不是数据格式。全选后,单击单元格格式进行修改。将其更改为数据格式。如果还是不行,双击进入单元格,查看数据前后是否有空格,使用替换功能替换。让我们详细谈谈它。
excel如何实现外部数据采集-…… Microsoft Office Excel连接外部数据的主要优点是可以在Excel中定期分析这些数据,而不需要复制数据。复制操作不仅耗时而且容易出错。连接外部数据后,还可以从原创数据源自动刷新(或更新)Excel工作簿,无论是否使用数据源...
如何使用Excel获取网页内容... 方法/步骤 首先,打开excel,点击菜单栏中的【数据】,然后在弹出的新建网页查询中点击【来自网站】图标对话框,在地址栏输入你需要的查询数据的URL。输入网址后,点击【前往】图标,对话框中会出现您需要查询的网址。然后,选中需要查询的数据,点击如图所示的箭头,选中整个Data区域。如图,整个选中的数据区背景为深色,然后点击【导入】。导入后会出现导入数据对话框,在对话框中选择需要放置数据的位置。7 最后点击【确定】,如图,所有选中的数据出现在excel中。
求助,写个程序把网站中的网页数据转换成采集:如姓名、电话、地址等,转成excel表格-…… 数据采集可以的,先采集到ACCESS数据库,再导出到EXCEL
Excel是如何抓取网页数据的?JSON数据抓取-... 打开Chrome,在拉勾网搜索深圳的“数据分析”位置,使用查核功能查看网页源代码,发现拉勾网有反爬虫机制和职位信息是不是在源代码中,而是在JSON文件中,所以我们直接下载JSON并使用字典方法直接读取数据。在抓取网页时...
如何将网页的数据抓取到excel中... 在excel的“数据”选项中,有“获取外部数据”和“来自网站”,按照相应的步骤“导入”即可。
求助,写个程序把网站中的网页数据转换成采集:如姓名、电话、地址等,转成excel表格。…… 数据采集是可以的,先采集进入ACCESS数据库,然后导出到EXCEL
Excel如何抓取网页数据和JSON数据抓取... 打开Chrome,在拉勾网搜索深圳的“数据分析”位置,使用检查功能查看网页源代码,发现拉勾网有反-爬虫机制和工作信息。不是在源代码中,而是在JSON文件中,所以我们直接下载JSON并使用字典方法直接读取数据。在抓取网页时... 查看全部
vba抓取网页数据(智能数据可视化分析之商业智能BI软件什么特别难?)
集团公司在做数据分析时通常有一个特点,就是跨行业、跨系统,数据采集难度大、耗时长,如果处理不好,就会耽误数据分析。但这对于数据分析高效、智能的商业智能BI软件来说并不是特别困难。商业智能BI软件如何实现高效的采集跨行业和系统数据?如何利用这些数据来完成群体数据的可视化分析?
集团公司数据量大,数据来源多。自然不能指望采集。一般来说,商业智能BI软件可以通过多种数据采集的方式获取不同来源的数据,然后使用ETL工具对数据进行清理整理,统一数据分析口径,然后通过依靠全面的数据分析模型。数据可视化分析。
奥维BI商业智能软件综合使用以下方法对群体数据进行高效分析:
1、数据导入/填写
采集 可以导入或报告 Excel 等数据源。在奥维BI商业智能软件的公开演示视频中,我们经常点击“添加数据源”或者点击选择Excel数据源,或者拖拽上传数据源,制作智能数据可视化分析报告。
2、数据库对接
如果您已经将数据存储在数据库中,则可以直接访问数据。
3、 爬虫访问
这种方式一般用于采集企业外部的第三方平台数据,如电商平台的前后端数据、外部行业数据等都可以通过这种方式获取< @采集。
以上三种是奥维BI商业智能软件常用的数据采集方法,除了数据采集还可以通过API进行。成功整理完数据采集后,即可开始高效的数据清洗整理,以及系统的数据分析,将复杂数据可视化、智能化,让子公司和部门随时开发高效智能的数据可视化分析,对数据进行深度分析挖掘,即使掌握了海量数据背后的数据关联,也能辅助数字化运营管理。
","force_purephv":"0","gnid":"90d2386fe34bfb5e6","img_data":[{"flag":2,"img":[{"desc":"","height":"804" ,"title":"","url":"","width":"1379"}]}],"original":"0","pat":"art_src_0,fts0,sts0","powerby" :"pika","pub_time":00,"pure":"","rawurl":"","redirect":0,"rptid":"f5fc7802bdd862bd","src":"数据分析王"," tag":[{"clk":"ktechnology_1:excel","k":"excel","u":""}],"title":"商业智能BI软件如何采集使数据智能 可视化分析?
使用EXCEL提取网页数据... VBA网页提取
如何将excel中的部分网页数据批量提取到表格中?-…… 这个可以直接用脚本模拟软件“阿冲全能点击王”来实现,自动提取网页数据并输入。因为在阿冲全能点击王中,可以提取大量数据进行脚本布局、自动点击、文本数据录入、点击按钮模拟等任务操作。而且,阿冲全能点击王是一个完全图形化的界面,无需复杂的编程,只需点击添加即可。
如何抓取网页中表格的数据...只需使用智能剪贴板。打开word或excel,调出智能剪贴板(快捷键ctrl cc)。然后进入网站,选择内容,复制,可以连续复制24次。在word或excel中后,全部粘贴(一次性粘贴24个复制的内容)。如果仍然存在,请清除剪贴板并继续复制...然后粘贴所有内容。这样,网页的内容就会被转移到word或者excel中。由于网页上的数据,到达excel后,可能不是数据格式。全选后,单击单元格格式进行修改。将其更改为数据格式。如果还是不行,双击进入单元格,查看数据前后是否有空格,使用替换功能替换。让我们详细谈谈它。
excel如何实现外部数据采集-…… Microsoft Office Excel连接外部数据的主要优点是可以在Excel中定期分析这些数据,而不需要复制数据。复制操作不仅耗时而且容易出错。连接外部数据后,还可以从原创数据源自动刷新(或更新)Excel工作簿,无论是否使用数据源...
如何使用Excel获取网页内容... 方法/步骤 首先,打开excel,点击菜单栏中的【数据】,然后在弹出的新建网页查询中点击【来自网站】图标对话框,在地址栏输入你需要的查询数据的URL。输入网址后,点击【前往】图标,对话框中会出现您需要查询的网址。然后,选中需要查询的数据,点击如图所示的箭头,选中整个Data区域。如图,整个选中的数据区背景为深色,然后点击【导入】。导入后会出现导入数据对话框,在对话框中选择需要放置数据的位置。7 最后点击【确定】,如图,所有选中的数据出现在excel中。
求助,写个程序把网站中的网页数据转换成采集:如姓名、电话、地址等,转成excel表格-…… 数据采集可以的,先采集到ACCESS数据库,再导出到EXCEL
Excel是如何抓取网页数据的?JSON数据抓取-... 打开Chrome,在拉勾网搜索深圳的“数据分析”位置,使用查核功能查看网页源代码,发现拉勾网有反爬虫机制和职位信息是不是在源代码中,而是在JSON文件中,所以我们直接下载JSON并使用字典方法直接读取数据。在抓取网页时...
如何将网页的数据抓取到excel中... 在excel的“数据”选项中,有“获取外部数据”和“来自网站”,按照相应的步骤“导入”即可。
求助,写个程序把网站中的网页数据转换成采集:如姓名、电话、地址等,转成excel表格。…… 数据采集是可以的,先采集进入ACCESS数据库,然后导出到EXCEL
Excel如何抓取网页数据和JSON数据抓取... 打开Chrome,在拉勾网搜索深圳的“数据分析”位置,使用检查功能查看网页源代码,发现拉勾网有反-爬虫机制和工作信息。不是在源代码中,而是在JSON文件中,所以我们直接下载JSON并使用字典方法直接读取数据。在抓取网页时...
vba抓取网页数据(1.从论坛获得的如下语句(语句)原因)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-05 16:06
说明:1. 以下语句从论坛获取,在家庭网络上运行时可以捕获“”中的数据。
2. 但是在公司网络上运行时出现“run-time error'-2147024891 (80070005) Access denied.”错误。
3. 原因是公司需要连接IE浏览器-局域网(LAN)设置-使用自动配置脚本(公司出于安全原因必须设置),联网后即可脚本已设置。回到首页点这里 设置也不能抓取数据,但是删除脚本后,可以重新抓取数据。
4. 我也发现,不管是在家还是在工作,也不管IE设置了脚本还是删除了脚本,只要能上网,谷歌浏览器就可以显示数据“” .
问题:
1. 因为Google可以显示数据,但是IE设置了脚本后就不能显示了,是不是说明下面的语句是基于IE浏览器的内核编译的?
2. 有没有可以绕过IE内核(可能我不准确)直接在谷歌浏览器(或其他浏览器)抓取数据的说法?请各位老师帮忙,谢谢!
附图为谷歌浏览器获取的数据截图
谷歌浏览器抓取的数据
'---------------------------
'网页下载
函数 DownLoadHtm(Url) As String
下载 Htm = 真
昏暗的检索 查看全部
vba抓取网页数据(1.从论坛获得的如下语句(语句)原因)
说明:1. 以下语句从论坛获取,在家庭网络上运行时可以捕获“”中的数据。
2. 但是在公司网络上运行时出现“run-time error'-2147024891 (80070005) Access denied.”错误。
3. 原因是公司需要连接IE浏览器-局域网(LAN)设置-使用自动配置脚本(公司出于安全原因必须设置),联网后即可脚本已设置。回到首页点这里 设置也不能抓取数据,但是删除脚本后,可以重新抓取数据。
4. 我也发现,不管是在家还是在工作,也不管IE设置了脚本还是删除了脚本,只要能上网,谷歌浏览器就可以显示数据“” .
问题:
1. 因为Google可以显示数据,但是IE设置了脚本后就不能显示了,是不是说明下面的语句是基于IE浏览器的内核编译的?
2. 有没有可以绕过IE内核(可能我不准确)直接在谷歌浏览器(或其他浏览器)抓取数据的说法?请各位老师帮忙,谢谢!
附图为谷歌浏览器获取的数据截图
谷歌浏览器抓取的数据
'---------------------------
'网页下载
函数 DownLoadHtm(Url) As String
下载 Htm = 真
昏暗的检索
vba抓取网页数据(【漫画】如何成为一个有意思的人?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-05 16:05
.打开“GET”,SURL,假
。发送
'tt = .responseBody
tt = .responseText
'tt = StrConv(.responsebody, vbUnicode)
结束于
如果 InStr(tt, "Sheet1.Cells(i, 13) = Split(Split(Split(tt, "")(0), ">")(1)@ >
别的
Sheet1.Cells(i, 13) = "-"
万一
If InStr(tt, "") Then'Grab the title
Sheet1.Cells(i, 14) = Trim(Replace(Split(Split(tt, "")(1)@>, "")(0), vbLf, " "))
别的
Sheet1.Cells(i, 14) = "-"
万一
If InStr(tt, "") Then'Fetch 评论
Sheet1.Cells(i, 15) = Split(Split(Split(tt, "")(1)@>, "")(0), "")(< @0)
别的
Sheet1.Cells(i, 15) = 0
万一
如果 InStr(tt, "Sheet1.Cells(i, 16) = Split(Split(Split(Split(tt, "")(0), "title="")) (1)@>, "")(0)
别的
Sheet1.Cells(i, 16) = 0
万一
如果 InStr(tt, "Sheet1.Cells(i, 17) = Split(Trim(Replace(Split(Split(Split(tt, "")(0), "") (1)@>, vbLf, "")), "")(0)
别的
Sheet1.Cells(i, 17) = 0
万一
如果 InStr(tt, "Sheet1.Cells(i, 18) = Split(Split(Split(tt, "")(0), ">")(1)@ >
别的
Sheet1.Cells(i, 18) = 0
万一
If InStr(tt, "") Then'Grab 类别
Sheet1.Cells(i, 19) = Replace(Split(Split(Split(Split(tt, "")(1)@>, "")(0), "在 ")(1)@>, "(")(0), "&", "&")
别的
Sheet1.Cells(i, 19) = "-"
万一
If InStr(tt, "") Then'Grab BSR1
Sheet1.Cells(i, 20) = Split(Split(Split(tt, "")(1)@>, "in ")(0), "#") (1)@>
别的
Sheet1.Cells(i, 20) = 0
万一
If InStr(tt, "") Then'抓住节点
Sheet1.Cells(i, 21)@> = Split(Split(Split(Split(Split(tt, "")(1)@>, "")(0), " ")(1)@>, "")(1)@>
别的
Sheet1.Cells(i, 21)@> = "-"
万一
If InStr(tt, "") Then'Grab BSR2
Sheet1.Cells(i, 22) = Split(Split(Split(Split(Split(tt, "")(1)@>, "")(0), " ")(1)@>, "")(0), "#")(1)@>
别的
Sheet1.Cells(i, 22) = 0
万一
接下来我
结束子
复制代码
本来可以正常抓取商品信息(标题、品牌、评论、星级...),但是最近抓取出错了。代码操作错误,(我们正常浏览商品页面也会出现这种现象,但只需要修改网站的语言设置,防止出现中文内容),请教:
能否在代码中指定一个浏览器,比如谷歌浏览器来获取数据(我在想代码是打开360还是IE网页,两者可能都有中文界面)
或者是其他问题引起的?
另外,我想在这段代码中加入setRequestHeader,避免网站的反爬系统,也希望得到老师的帮助
非常感谢老师的帮助
呸呸 查看全部
vba抓取网页数据(【漫画】如何成为一个有意思的人?(上))
.打开“GET”,SURL,假
。发送
'tt = .responseBody
tt = .responseText
'tt = StrConv(.responsebody, vbUnicode)
结束于
如果 InStr(tt, "Sheet1.Cells(i, 13) = Split(Split(Split(tt, "")(0), ">")(1)@ >
别的
Sheet1.Cells(i, 13) = "-"
万一
If InStr(tt, "") Then'Grab the title
Sheet1.Cells(i, 14) = Trim(Replace(Split(Split(tt, "")(1)@>, "")(0), vbLf, " "))
别的
Sheet1.Cells(i, 14) = "-"
万一
If InStr(tt, "") Then'Fetch 评论
Sheet1.Cells(i, 15) = Split(Split(Split(tt, "")(1)@>, "")(0), "")(< @0)
别的
Sheet1.Cells(i, 15) = 0
万一
如果 InStr(tt, "Sheet1.Cells(i, 16) = Split(Split(Split(Split(tt, "")(0), "title="")) (1)@>, "")(0)
别的
Sheet1.Cells(i, 16) = 0
万一
如果 InStr(tt, "Sheet1.Cells(i, 17) = Split(Trim(Replace(Split(Split(Split(tt, "")(0), "") (1)@>, vbLf, "")), "")(0)
别的
Sheet1.Cells(i, 17) = 0
万一
如果 InStr(tt, "Sheet1.Cells(i, 18) = Split(Split(Split(tt, "")(0), ">")(1)@ >
别的
Sheet1.Cells(i, 18) = 0
万一
If InStr(tt, "") Then'Grab 类别
Sheet1.Cells(i, 19) = Replace(Split(Split(Split(Split(tt, "")(1)@>, "")(0), "在 ")(1)@>, "(")(0), "&", "&")
别的
Sheet1.Cells(i, 19) = "-"
万一
If InStr(tt, "") Then'Grab BSR1
Sheet1.Cells(i, 20) = Split(Split(Split(tt, "")(1)@>, "in ")(0), "#") (1)@>
别的
Sheet1.Cells(i, 20) = 0
万一
If InStr(tt, "") Then'抓住节点
Sheet1.Cells(i, 21)@> = Split(Split(Split(Split(Split(tt, "")(1)@>, "")(0), " ")(1)@>, "")(1)@>
别的
Sheet1.Cells(i, 21)@> = "-"
万一
If InStr(tt, "") Then'Grab BSR2
Sheet1.Cells(i, 22) = Split(Split(Split(Split(Split(tt, "")(1)@>, "")(0), " ")(1)@>, "")(0), "#")(1)@>
别的
Sheet1.Cells(i, 22) = 0
万一
接下来我
结束子
复制代码
本来可以正常抓取商品信息(标题、品牌、评论、星级...),但是最近抓取出错了。代码操作错误,(我们正常浏览商品页面也会出现这种现象,但只需要修改网站的语言设置,防止出现中文内容),请教:
能否在代码中指定一个浏览器,比如谷歌浏览器来获取数据(我在想代码是打开360还是IE网页,两者可能都有中文界面)
或者是其他问题引起的?
另外,我想在这段代码中加入setRequestHeader,避免网站的反爬系统,也希望得到老师的帮助
非常感谢老师的帮助
呸呸

