vba抓取网页数据(UI学习大纲与UI的交互(UIInteraction)的GetText )
优采云 发布时间: 2021-11-30 13:16vba抓取网页数据(UI学习大纲与UI的交互(UIInteraction)的GetText
)
学习大纲
UI交互可以分为两种类型:输入和输出。
**输入**:让应用程序做一些事情。如鼠标单击、文本输入、键盘快捷键、鼠标右键单击、鼠标悬停等。
**输出**:从应用程序中提取信息。获取文本、查找元素和图片、操作剪贴板等。
1. 输入法
输入法**兼容性**运行速度支持后台工作支持热键自动清除内容
默认
100%
50%
X
√
X
窗口消息
80%
50%
√
√
X
模拟类型/点击
*70%
100%
√
X
√
*Simulate Type/Click 兼容 99% 的 Web 应用程序和 60% 的桌面应用程序
实例验证:
操作结果:
建议:尝试每种输入法。首先使用 Default 方法,因为它肯定会起作用。然后尝试使用 Simulate 或 WindowMessages 方法来提高运行速度或实现后台工作。
2. 输出方式:屏幕抓取
上一课使用的Get Text 活动仅适用于抓取简单和简短的文本。和屏幕
抓取可以抓取复杂元素中存在的较大文本片段。屏幕
刮取还可以获得文本的位置和颜色等信息。
使用 Screen Scraping 工具抓取信息时,您可以尝试以下三种方法:
**输出方式**运行速度**准确度**支持后台工作获取文本位置获取隐藏文本兼容Citrix
全文
很快
100%
√
X
√
X
本国的
快点
100%
X
√
X
X
文字识别
非常慢
98%
X
√
X
√
FullText 是默认的方法,大多数情况下也有一个有效的方法。
Native 的优点是可以获取文本的其他信息,例如单词或字母在屏幕上的坐标。
OCR 无法达到 100% 的准确率,但是当其他两种方法都不起作用时,OCR 是最后的手段。
*只有 OCR 可以在 Citrix 或虚拟环境中运行。OCR 还可以获取文本位置。
如何使用屏幕抓取:
1) 点击Design Ribbon中的Screen Scraping按钮,会出现选择界面。
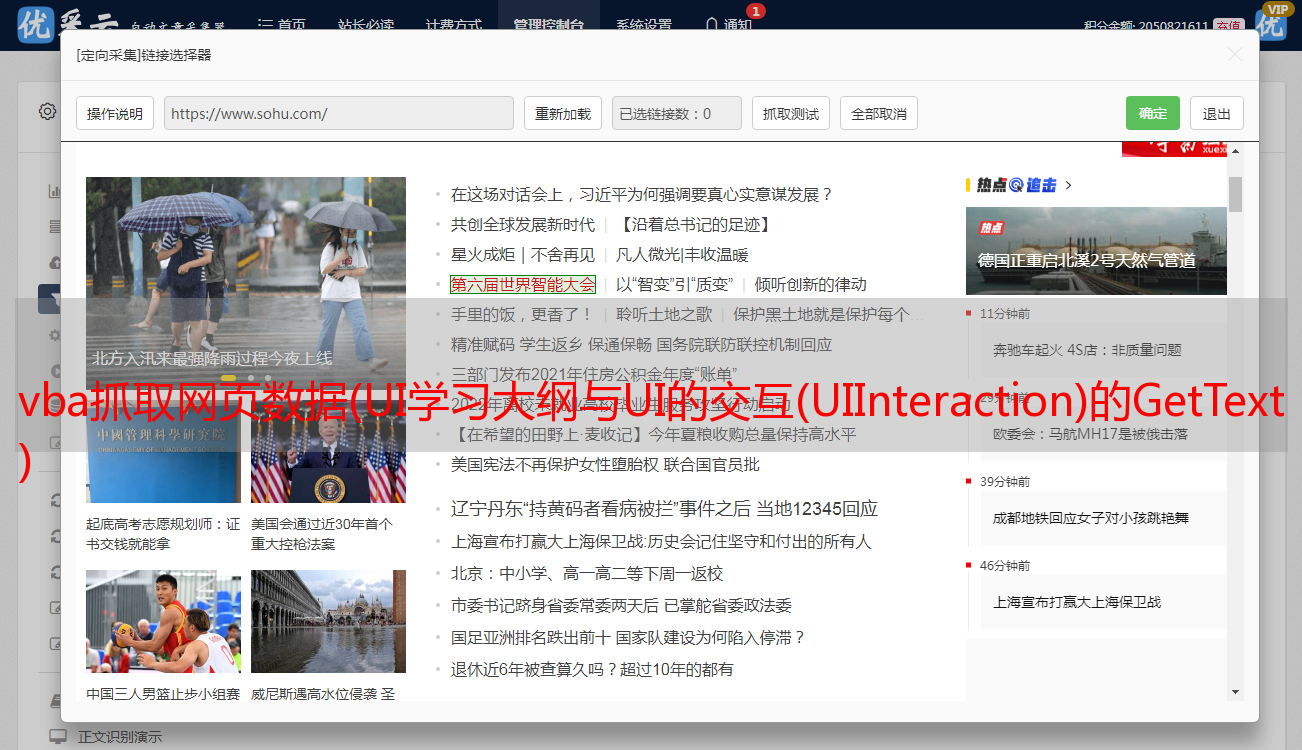
2)点击选择要提取的信息。您可以选择收录多个元素的区域。
3) 选择后,会弹出 Screen Scraper Wizard 窗口。点击界面
元素或区域可以更改从中提取信息的区域。
这里UiPath自动选择了Native方法,可以在Options面板中改成其他两种方法。
从预览面板中可以看到,Native 方法只抓取可编辑区域中的文本。
4) 切换到全文方式后,预览面板中的信息发生了变化。
满的
Text方法不仅抓取可编辑区域的文字,还抓取不可编辑区域的文字和下拉列表中隐藏的文字。
*在选项面板中勾选忽略
Hidden 选项,然后单击 Re-scrape 按钮忽略隐藏的文本。
5) OCR 方法就更不一样了。它将所选区域视为图片来阅读文本。
由于错别字,OCR方法只适用于数据不需要完全正确的情况。
UiPath 提供两个 OCR 引擎。微软Office
OCR 适用于较大的图像,例如扫描的文档。
Google OCR 更适合读取较小、分辨率较低的图像,例如界面上的元素。
“选项”面板中的“反转”选项专门用于某些黑底白字的图片。缩放选项可以放大图片以获得更好的效果。
我们可以一一尝试这些选项,看看预览面板的结果有什么变化,找到最佳组合。
6) 设置好后,点击右下角的Continue按钮,会得到一个ScreenScraping Sequence。
Selector 代表要抓取文本的元素或区域。当多个活动的元素或区域相同时,可以将Selector中的内容直接复制到其他活动中,而无需重新选择元素或区域。Text 变量用于保存捕获的文本。
如果你想尝试另一个OCR,你可以删除谷歌OCR活动,然后更改MS Office
OCR活动拖进来,建议把Scale属性改成3,因为MS Office
OCR 更适合阅读较大的图片。
*如果您不使用屏幕抓取,您也可以手动添加活动。
手动添加的输出方式
基本录音
获取文本
全文
获取全文
本国的
获取可见文本
文字识别
获取 OCR 文本
*****在上面的例子中,Get Text 活动只能抓取“地址”这个词。
3. 数据抓取
Screen Scraping 用于捕获 Freeform Data(自由格式数据)。和数据
抓取用于捕获**结构化数据**。
什么是结构化数据?
当你在谷歌上搜索某个关键词时,你得到的搜索结果是由多条格式相同的数据组成,每条数据由三部分组成:标题、网址和描述。此类数据是结构化的
数据。
如何使用数据抓取:
以亚马逊的图书搜索页面为例。此页面上的数据也是结构化的
数据,但比 Google 的搜索结果页面更复杂。
1)单击设计功能区中的 Web
Scraping 按钮,会出现一个向导窗口,点击 Next 开始选择第一个元素。
2) 点击第一本书的书名,会再次弹出向导窗口。单击下一步继续。
3) 点击第二本书的书名,会再次弹出向导窗口。书名也是一个链接,因此向导窗口可以选择提取文本或 URL。
此处选中了这两个选项,它们被命名为 Title 和 URL。点击下一步按钮,弹出向导预览界面。
4)除了预览数据外,还标注了网页上的相应位置,方便查看。然后提取“作者”和“价格”并单击 ExtractCorrelated Data 按钮。
5)选择第一个元素时向导返回界面,重复上述步骤提取“作者”和“价格”信息。单击完成按钮。
6)UiPath 会询问我们数据是否跨页面分布。将页面下拉到您选择页码的位置,选择是,然后选择页面上的下一页元素。
7) 向导结束后,你会得到一个名为WebScraping的Sequence,并得到一个DataTable类型的Output变量。
添加写入 CSV 活动以将捕获的数据保存在 CSV 文件中。
8) 这个CSV文件有100条记录,但搜索结果远远超过100条。这是因为UiPath默认只抓取100条记录,你可以在属性面板中更改设置。
使用Web Scraping抓取网页上的表格(HTML表格),当您点击表格中的任何单元格时,会弹出Extract Table提示窗口。
如果选择是,则可以直接抓取整个表格的数据,而无需选择第二个元素。如果选择否,则需要重复前面的步骤来选择第二个元素。
4. 练习:
提取链接页面的 100 条记录,包括名称和价格,并将数据存储在新的 Excel 表中。
*第一次选择页面的名字,
第二次选择页面的姓氏。与第二次选择第二个名字相比,它更有可能生成一致的标识符
(一致的标识符)。
2) 不应用Recording功能完成如下操作:在记事本中打开字体对话框,将字体改为Arial,样式改为斜体,将字体大小增加5,并选择一个新的脚本
(脚本)。
在第二个Attach Window活动的Do中添加一个Click活动,点击格式菜单中的字体
(字体)按钮。
在弹出的字体对话框中添加一个新的附加窗口活动。
为第三个附加窗口活动的 Do 添加一个类型
进入activity,指定元素并点击字体输入框,输入Arial。
添加另一个 Type Into 活动,指定元素并单击字体样式输入框,输入斜体。
添加获取
在 Text 活动中,指定元素并单击字体大小的输入框。创建一个 Int32 类型的新变量 fontSize 并将其设置为 Get
文本活动的输出。
添加类型
进入activity,指定元素,点击字体大小的输入框,输入**(fontSize+5).ToString**.
添加选择
Item活动,指定Script下拉菜单为Target的Selector参数,输入Greek作为Input的Item参数。
注意:
*本课使用的新活动、方法、功能等:
加入万人职场社区,为你的事业保驾护航!

