
seq搜索引擎优化至少包括那几步?
seq搜索引擎优化至少包括那几步?(卷宗扫描仪网站长:SEO优化的各个方面是比较重要的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-01 07:14
Dossier Scanner网站认为:在SEO优化的各个方面,更重要的是优化网站的内容,只有内容更丰富的网站才能被搜索引擎搜索到收录,提高网站的排名,推动网站建设的发展。以下文件扫描器网络:简单步骤教你如何学习网站SEO优化?
一、关键词的选择,关键词的好选择是优化网站的第一步,通过关键词和page的关联建立索引库内容,是搜索引擎生存的基础,关键词的产生伴随着用户需求的产生。一个漂亮的TDK规划不是基于网站本身的主观臆断,而是用户真实需求的聚合。小编的SEO之路就是从TDK开始的。当时的导师一点一点的教,小编领悟后的实践,一点一点的体现出来最终的效果。从头到尾,小编亲自写TDK都觉得不舒服。有点懈怠,看似基本的东西,其实不一般,关键词 作为SEO五要素中最重要的一环,小编之所以再次提出来,是为了提醒那些痴迷于横着走、走灰走黑的人。路线的SEOer,千万不要忽视了最初出发的目的。
二、更新高质量原创文章。SEO优化的基础是坚持在网站上更新更多优质的文章,尽量让网站的页面丰富多样,赏心悦目,有一定的吸引力,但最重要的是不断更新优质的文章和信息,从而抢占更多的关键词,在行业竞争中获得优势。此外,一些权威的文章也会被站外一些媒体引用,扩大网站的影响力。
三、关键字应该布局合理。在优化文章的时候,重点关注关键词的密度,让关键词做到在文章中自然分布而不影响阅读,而不是关键词的很多无意义的堆叠@>,通常关键词出现在文章的开头和结尾,可以提高文章的相关性和权重。当然,对于文章的平滑性和自然性,关键词也可以进行形式的变换和拆分,这也是对文章的一种优化方式。根据 关键词 的接近程度,这些措施将优化 文章 的内容。
四、链接建立密钥。给网站一些链接如:友情链接、论坛链接、博客链接、微信链接等。友情链接,这个一定要做,至于它的重要性,我就不用过多赘述了。链接相关性,无论你如何扩展外链,你更喜欢与目标页面的主题内容相关的平台来获取外链资源;链接广度,如果你经常关注站长后台的链接分析,你会发现在同一个平台上发布的外部链接的数量是有限制的,可以被搜索引擎接受。高权重平台的外链数量适当增加,而权重较低的网站外链数量被搜索引擎认可。看点大布局很重要。
五、关注用户体验。其实网站的构造有很多需要注意的地方,比如如何设置网站的关键词,只要你意识到key 网站的网站是网络营销中不可或缺的一环,客户被分流到网站后,如果网站的打开速度太慢,布局体验差,或者没有内容客户感兴趣,销售和客服体验差,所有因素都会影响最终成交。糟糕的用户体验会导致前期推广失败。
Dossier 认为新手已经可以通过以上步骤为企业网站优化SEO。事实上,为了网站的长远发展和排名的快速提升,网站的管理者可以培养一个SEO意识的团队,能够提供高质量的文章对于网站,围绕已经给出的关键词,并且有很强的技术水平能够写出考虑网站的整体结构,调整关键词的布局,并在合适的时机为网站搭建新的内容平台,从而有长期稳定的输出,为关键词后续的快速发展提供了有力的支持。促进网站的整体发展, 查看全部
seq搜索引擎优化至少包括那几步?(卷宗扫描仪网站长:SEO优化的各个方面是比较重要的)
Dossier Scanner网站认为:在SEO优化的各个方面,更重要的是优化网站的内容,只有内容更丰富的网站才能被搜索引擎搜索到收录,提高网站的排名,推动网站建设的发展。以下文件扫描器网络:简单步骤教你如何学习网站SEO优化?
一、关键词的选择,关键词的好选择是优化网站的第一步,通过关键词和page的关联建立索引库内容,是搜索引擎生存的基础,关键词的产生伴随着用户需求的产生。一个漂亮的TDK规划不是基于网站本身的主观臆断,而是用户真实需求的聚合。小编的SEO之路就是从TDK开始的。当时的导师一点一点的教,小编领悟后的实践,一点一点的体现出来最终的效果。从头到尾,小编亲自写TDK都觉得不舒服。有点懈怠,看似基本的东西,其实不一般,关键词 作为SEO五要素中最重要的一环,小编之所以再次提出来,是为了提醒那些痴迷于横着走、走灰走黑的人。路线的SEOer,千万不要忽视了最初出发的目的。
二、更新高质量原创文章。SEO优化的基础是坚持在网站上更新更多优质的文章,尽量让网站的页面丰富多样,赏心悦目,有一定的吸引力,但最重要的是不断更新优质的文章和信息,从而抢占更多的关键词,在行业竞争中获得优势。此外,一些权威的文章也会被站外一些媒体引用,扩大网站的影响力。
三、关键字应该布局合理。在优化文章的时候,重点关注关键词的密度,让关键词做到在文章中自然分布而不影响阅读,而不是关键词的很多无意义的堆叠@>,通常关键词出现在文章的开头和结尾,可以提高文章的相关性和权重。当然,对于文章的平滑性和自然性,关键词也可以进行形式的变换和拆分,这也是对文章的一种优化方式。根据 关键词 的接近程度,这些措施将优化 文章 的内容。
四、链接建立密钥。给网站一些链接如:友情链接、论坛链接、博客链接、微信链接等。友情链接,这个一定要做,至于它的重要性,我就不用过多赘述了。链接相关性,无论你如何扩展外链,你更喜欢与目标页面的主题内容相关的平台来获取外链资源;链接广度,如果你经常关注站长后台的链接分析,你会发现在同一个平台上发布的外部链接的数量是有限制的,可以被搜索引擎接受。高权重平台的外链数量适当增加,而权重较低的网站外链数量被搜索引擎认可。看点大布局很重要。
五、关注用户体验。其实网站的构造有很多需要注意的地方,比如如何设置网站的关键词,只要你意识到key 网站的网站是网络营销中不可或缺的一环,客户被分流到网站后,如果网站的打开速度太慢,布局体验差,或者没有内容客户感兴趣,销售和客服体验差,所有因素都会影响最终成交。糟糕的用户体验会导致前期推广失败。
Dossier 认为新手已经可以通过以上步骤为企业网站优化SEO。事实上,为了网站的长远发展和排名的快速提升,网站的管理者可以培养一个SEO意识的团队,能够提供高质量的文章对于网站,围绕已经给出的关键词,并且有很强的技术水平能够写出考虑网站的整体结构,调整关键词的布局,并在合适的时机为网站搭建新的内容平台,从而有长期稳定的输出,为关键词后续的快速发展提供了有力的支持。促进网站的整体发展,
seq搜索引擎优化至少包括那几步?(网站优化也不只是传统的SEO吗?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-01 04:20
SEO是搜索引擎优化的首字母缩写。简单来说,SEO是指遵循搜索引擎的搜索原则,通过对网站的内外环境和内容的一系列优化,提高网站在搜索引擎中的相关搜索性能,从而提高网站访问流量的技术实现过程,最终提升网站的营销能力或宣传能力。
在国外,SEO发展较早,各行各业对SEO的理解和关注也比国内要好。不过,目前SEO市场需求和资金投入仍保持强劲增长势头。由于谷歌在搜索技术方面的强大优势和准确公正的搜索结果受到用户的青睐,谷歌也成为了全球搜索引擎优化的主要研究对象。
可能很多人都知道,SEO领域有黑帽和白帽之分。这是因为一些不公平的SEO人出于侥幸,为了获得暂时的高排名,做出了明确的搜索引擎指令。禁止的方法或作弊方法不仅会欺骗搜索引擎,还会对访问者不忠诚,最终可能会被搜索引擎惩罚或解雇,并永远从搜索结果中消失。这种不良的SEO行为被称为黑帽,或走在黑道中。相反,能被搜索引擎接受的正式的SEO方法被称为白帽,挺身而出,走白路。
国内很多公司和个人对SEO的理解有偏差。比如有人把SEO等同于网站优化,但其实SEO不仅仅是网站优化,网站优化也不仅仅是传统的SEO。搜索引擎优化是一个复杂的、长期的、动态的优化过程。网站优化只是根据搜索原理对网站进行的调整和修改工作。这只是为了让 网站 有更好的搜索引擎友好性、可见性、指示性等,而对于最终的搜索结果表现,影响因素远不止一点点,只是做一些优化工作远远不够。
传统的SEO经常误入歧途,即为SEO而SEO,为排名而拼命。因为 网站 的最终目的是向访问者推荐或展示您的产品或服务,而不是向搜索引擎展示它们,这可能只会帮助您吸引访问者。即使你的 网站 看起来对搜索引擎非常友好和重要,但对用户没有吸引力或烦人,你得到的只是暂时的高流量,实际上很可能不超过万分之三的访问者在你的网站上停留5秒以上,从长远来看,搜索引擎不可能总是有好的排名结果,那又如何?意义?正如 Google 官方 网站 中所说:网页应该面向用户,而不是面向搜索引擎。对用户诚实,并向搜索引擎提交与向用户显示的内容一致的内容。真正做SEO的人会在实施过程中“忘记”什么是SEO,始终坚持以用户为中心,以营销和服务为宗旨。真正的SEO不是靠手段得到只能得到60分的网站排名90或100,而是通过SEO改进只能得到60分的网站真正的90分或 100 分!
企业网站主要是树立良好的企业形象,让外界了解企业本身,网络营销外包,适当提供一定的服务网站。根据行业特点的差异,以及建立公司网站的目的和主要目标群体,公司大致可以分为网站:
基本信息类:主要面向客户、业内人士或普通观众,主要介绍公司基本信息,帮助树立企业形象;还可以酌情提供行业内的新闻或知识信息。这种类型的网站经常被比作企业的“WEBCatalog”。东莞网络优化
电子商务类型:主要针对企业产品(服务)的供应商、客户或消费群体,东莞建网站优化为直接在企业经营范围内提供某些服务或交易,或为商业服务提供服务或交易这样的网站可以说是处于电商的中间阶段。由于行业特点的差异以及企业投资的深度和广度,电子商务的发展程度可能处于从相对初级的服务支持、产品清单到在线支付的更高级阶段之一的阶段。通常这种类型可以形象地称为“在线XX企业”。例如,网上银行、网上酒店等。
多媒体广告类:主要针对企业产品(服务)的客户或消费群体,主要宣传公司核心品牌形象或主要产品(服务)。与普通的网站相比,这种类型在目的和实际表达上更像是平面广告或电视广告,所以用“多媒体广告”来称呼这种类型的网站更为贴切。小的。
在实际应用中,很多网站往往不能简单归类为某一类,无论是建站目的还是表达形式,都可能涵盖两种或两种以上;对于这类企业网站,可以根据以上类型的不同,分成不同的部分,每个部分基本可以看成是一个比较完整的网站类型。注:由于互联网公司的特殊性,网站互联网信息提供者或服务提供者不在此列。
6. 带有 i 的 JS
在互联网发展过程中,JS和I多以网络广告的形式存在,大部分广告管理都是通过JS和I来管理的。现在的WEB技术虽然可以用广告来补充网页的内容,但是太多的广告也可以干扰用户浏览网页内容。搜索引擎仍然没有“考虑” JS 和 I 中的内容。企业 网站SEO 将有用的信息放在 JS 中,它变成了无用的信息。大量的JS和我会被认为是页面太多。广告。
7.多个网站s用于交联(站群)
一个网站 比首页的权重最高,也是关键词 最容易排名的。大部分站长在网站首页上放了很多流行的关键词,因为首页位置有限,远远不能满足很多关键词的需求。许多站长创建了许多子站点来分隔一些流行的关键词。这是一种干扰搜索引擎排名的行为。搜索引擎也对此类行为采取了一定的措施,例如:延长新站点的排名时间,沙盒新的网站 采集分析,并对站群网站@进行一定的惩罚。 >。企业网站建设
站群(多个 网站 交叉链接),我们可以做到吗?当然,我们只需要掌握学位。用好对排名很有帮助,就像我们交换友链一样。
8. 网站 中有很多死链接
网站内部管理,一些栏目,文章等经常被删除,被删除的页面会产生大量死链接。死链接对搜索引擎和用户体验非常不友好,那么如何处理这些链接呢?网站一定要做好404错误页面的设置,并在robots中做特殊处理,我们建议尽量保留页面并在原页面上进行内容更改。
9. 缺少导入和导出链接
SEO人接手了很多网站的优化工作,网站大部分都有收录的问题。查了一下,发现很多网站都是闭门出站的(这个不用解释了)。吧)现象,没有合理的进出口环节。在互联网中,网页与网页之间的关系是通过链接建立的。如果网站与外界没有联系,如果没有联系,就会变成孤岛类型网站,搜索引擎无法知道网站的存在。
10. 复制网站
有的企业为了在网站的建设中省钱省力,直接抢了胡须和鼻子,直接使用现有的网站程序模板,却没有考虑网站的重要性@> 框架,这样就会有两个相似度非常高的网站。这样的新站点很难获得好的排名,老站点也会受到影响。推荐阅读:网站如何搭建
最后要记住的是学习SEO的重要理论点,以及SEO人学习和优化所必需的九种品质和精神。
东莞网站优化东莞网络公司
东莞整站优化
2012年企业营销九大趋势网站 查看全部
seq搜索引擎优化至少包括那几步?(网站优化也不只是传统的SEO吗?(图))
SEO是搜索引擎优化的首字母缩写。简单来说,SEO是指遵循搜索引擎的搜索原则,通过对网站的内外环境和内容的一系列优化,提高网站在搜索引擎中的相关搜索性能,从而提高网站访问流量的技术实现过程,最终提升网站的营销能力或宣传能力。
在国外,SEO发展较早,各行各业对SEO的理解和关注也比国内要好。不过,目前SEO市场需求和资金投入仍保持强劲增长势头。由于谷歌在搜索技术方面的强大优势和准确公正的搜索结果受到用户的青睐,谷歌也成为了全球搜索引擎优化的主要研究对象。
可能很多人都知道,SEO领域有黑帽和白帽之分。这是因为一些不公平的SEO人出于侥幸,为了获得暂时的高排名,做出了明确的搜索引擎指令。禁止的方法或作弊方法不仅会欺骗搜索引擎,还会对访问者不忠诚,最终可能会被搜索引擎惩罚或解雇,并永远从搜索结果中消失。这种不良的SEO行为被称为黑帽,或走在黑道中。相反,能被搜索引擎接受的正式的SEO方法被称为白帽,挺身而出,走白路。
国内很多公司和个人对SEO的理解有偏差。比如有人把SEO等同于网站优化,但其实SEO不仅仅是网站优化,网站优化也不仅仅是传统的SEO。搜索引擎优化是一个复杂的、长期的、动态的优化过程。网站优化只是根据搜索原理对网站进行的调整和修改工作。这只是为了让 网站 有更好的搜索引擎友好性、可见性、指示性等,而对于最终的搜索结果表现,影响因素远不止一点点,只是做一些优化工作远远不够。
传统的SEO经常误入歧途,即为SEO而SEO,为排名而拼命。因为 网站 的最终目的是向访问者推荐或展示您的产品或服务,而不是向搜索引擎展示它们,这可能只会帮助您吸引访问者。即使你的 网站 看起来对搜索引擎非常友好和重要,但对用户没有吸引力或烦人,你得到的只是暂时的高流量,实际上很可能不超过万分之三的访问者在你的网站上停留5秒以上,从长远来看,搜索引擎不可能总是有好的排名结果,那又如何?意义?正如 Google 官方 网站 中所说:网页应该面向用户,而不是面向搜索引擎。对用户诚实,并向搜索引擎提交与向用户显示的内容一致的内容。真正做SEO的人会在实施过程中“忘记”什么是SEO,始终坚持以用户为中心,以营销和服务为宗旨。真正的SEO不是靠手段得到只能得到60分的网站排名90或100,而是通过SEO改进只能得到60分的网站真正的90分或 100 分!
企业网站主要是树立良好的企业形象,让外界了解企业本身,网络营销外包,适当提供一定的服务网站。根据行业特点的差异,以及建立公司网站的目的和主要目标群体,公司大致可以分为网站:
基本信息类:主要面向客户、业内人士或普通观众,主要介绍公司基本信息,帮助树立企业形象;还可以酌情提供行业内的新闻或知识信息。这种类型的网站经常被比作企业的“WEBCatalog”。东莞网络优化
电子商务类型:主要针对企业产品(服务)的供应商、客户或消费群体,东莞建网站优化为直接在企业经营范围内提供某些服务或交易,或为商业服务提供服务或交易这样的网站可以说是处于电商的中间阶段。由于行业特点的差异以及企业投资的深度和广度,电子商务的发展程度可能处于从相对初级的服务支持、产品清单到在线支付的更高级阶段之一的阶段。通常这种类型可以形象地称为“在线XX企业”。例如,网上银行、网上酒店等。
多媒体广告类:主要针对企业产品(服务)的客户或消费群体,主要宣传公司核心品牌形象或主要产品(服务)。与普通的网站相比,这种类型在目的和实际表达上更像是平面广告或电视广告,所以用“多媒体广告”来称呼这种类型的网站更为贴切。小的。
在实际应用中,很多网站往往不能简单归类为某一类,无论是建站目的还是表达形式,都可能涵盖两种或两种以上;对于这类企业网站,可以根据以上类型的不同,分成不同的部分,每个部分基本可以看成是一个比较完整的网站类型。注:由于互联网公司的特殊性,网站互联网信息提供者或服务提供者不在此列。
6. 带有 i 的 JS
在互联网发展过程中,JS和I多以网络广告的形式存在,大部分广告管理都是通过JS和I来管理的。现在的WEB技术虽然可以用广告来补充网页的内容,但是太多的广告也可以干扰用户浏览网页内容。搜索引擎仍然没有“考虑” JS 和 I 中的内容。企业 网站SEO 将有用的信息放在 JS 中,它变成了无用的信息。大量的JS和我会被认为是页面太多。广告。
7.多个网站s用于交联(站群)
一个网站 比首页的权重最高,也是关键词 最容易排名的。大部分站长在网站首页上放了很多流行的关键词,因为首页位置有限,远远不能满足很多关键词的需求。许多站长创建了许多子站点来分隔一些流行的关键词。这是一种干扰搜索引擎排名的行为。搜索引擎也对此类行为采取了一定的措施,例如:延长新站点的排名时间,沙盒新的网站 采集分析,并对站群网站@进行一定的惩罚。 >。企业网站建设
站群(多个 网站 交叉链接),我们可以做到吗?当然,我们只需要掌握学位。用好对排名很有帮助,就像我们交换友链一样。
8. 网站 中有很多死链接
网站内部管理,一些栏目,文章等经常被删除,被删除的页面会产生大量死链接。死链接对搜索引擎和用户体验非常不友好,那么如何处理这些链接呢?网站一定要做好404错误页面的设置,并在robots中做特殊处理,我们建议尽量保留页面并在原页面上进行内容更改。
9. 缺少导入和导出链接
SEO人接手了很多网站的优化工作,网站大部分都有收录的问题。查了一下,发现很多网站都是闭门出站的(这个不用解释了)。吧)现象,没有合理的进出口环节。在互联网中,网页与网页之间的关系是通过链接建立的。如果网站与外界没有联系,如果没有联系,就会变成孤岛类型网站,搜索引擎无法知道网站的存在。
10. 复制网站
有的企业为了在网站的建设中省钱省力,直接抢了胡须和鼻子,直接使用现有的网站程序模板,却没有考虑网站的重要性@> 框架,这样就会有两个相似度非常高的网站。这样的新站点很难获得好的排名,老站点也会受到影响。推荐阅读:网站如何搭建
最后要记住的是学习SEO的重要理论点,以及SEO人学习和优化所必需的九种品质和精神。
东莞网站优化东莞网络公司
东莞整站优化
2012年企业营销九大趋势网站
seq搜索引擎优化至少包括那几步?(开源ElasticsearchType类型Document可以分组吗?(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-01 04:15
文章目录
前言一、基本概念全文搜索是最常见的需求,开源的Elasticsearch(以下简称Elastic)是目前全文搜索引擎的首选。它可以快速存储、搜索和分析海量数据。Wikipedia、Stack Overflow、Github 都使用它。底层 Elastic 是开源库 Lucene。但是,你不能直接使用Lucene,你必须自己编写代码来调用它的接口。Elastic 是 Lucene 的一个包,提供开箱即用的 REST API 操作接口。1. Node 节点和 Cluster 集群
Elastic 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器都可以运行多个 Elastic 实例。
单个 Elastic 实例称为节点。一组节点形成一个集群。
2. 索引索引
Elastic 索引所有字段并在处理后将它们写入倒排索引。查找数据时,直接查找索引。
因此,Elastic 数据管理的顶层单元称为 Index。它是单个数据库的同义词。每个索引(即数据库)的名称必须是小写的。
下面的命令可以查看当前节点的所有索引。
获取 /_mapping?pretty=true
3. 文档
索引中的单个记录称为文档。许多文档形成一个索引。
文档以 JSON 格式表示,以下是一个示例。
{
"user": "张三",
"title": "工程师",
"desc": "数据库管理"
}
同一个Index中的文档不要求结构(scheme)相同,但最好保持相同,有利于提高搜索效率。
4. 类型
可以对文档进行分组。例如,在天气指数中,它们可以按城市(北京和上海)或按气候(晴天和雨天)分组。这种分组称为Type,它是一个用于过滤Documents的虚拟逻辑分组。
不同的类型应该有相似的模式,例如,id 字段不能是一组中的字符串,而另一组中不能是数值。这是与关系数据库表的区别。具有完全不同属性的数据(例如产品和日志)应该存储为两个索引,而不是一个索引中的两种类型(尽管可以这样做)。
以下命令可以列出每个索引中收录的类型。(与上面的截图相同)
获取 /_mapping?pretty=true
按照计划,Elastic 6.x 版本只允许每个 Index 收录一个 Type,而 7.x 版本将彻底移除 Type。
5. 逻辑比较
上面提到的集群、节点、索引、类型、文档、分片(底层封装)和映射是什么?
如何区分和比较非关系型数据库elasticsearch和关系型数据库,elasticsearch是面向文档的
如下:关系型数据库和elasticsearch的客观对比!
关系型数据库 非关系型数据库
数据库数据库
指数
桌子
类型(版本 7 已完全弃用)
行
文档
字段列
场地
Elasticsearch(集群)可以收录多个索引(数据库),每个索引可以收录多个类型(表),每个类型收录多个文档(行),每个文档收录多个字段(列表)。
6. 物理设计
Elasticsearch在后台将每个索引分成多个shard,每个shard可以在集群中不同的服务器之间迁移。
集群的默认名称是 elasticsearch。
一个集群至少有一个节点,一个节点就是一个elasticsearch进程。一个节点可以有多个索引。默认情况下,如果创建索引,索引将由 5 个分片(primary shards,也称为主分片)组成。是的,每个主分片都会有一个副本(副本分片,也称为分配分片)
索引分为多个shard,每个shard就是一个Lucene索引,所以一个elasticsearch索引是由多个Lucene索引组成的。因为elasticsearch使用Lucene作为底层。
二、ES 命令风格
一种软件架构风格,而不是标准,它只是提供一组设计原则和约束,主要用于与客户端和服务器交互的软件。基于这种风格设计的软件可以更简洁、更有层次、更容易实现缓存等机制。
基本 RESTFUL 命令说明:
methodurl地址说明
放
本地主机:9200/index_name/type_name/document_id
创建文档(指定文档 ID)
邮政
本地主机:9200/index_name/type_name
创建文档(随机文档 ID)
邮政
本地主机:9200/index_name/type_name/document_id/_update
修改文档
删除
本地主机:9200/index_name/type_name/document_id
删除文件
得到
本地主机:9200/index_name/type_name/document_id
按文档id查询文档
邮政
本地主机:9200/index_name/type_name/document_id/_search
查询所有文件
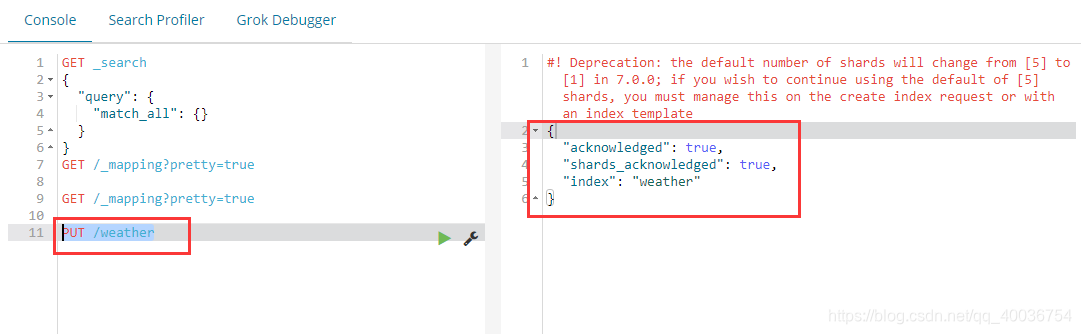
PUT:一般创建索引,类型,文档 POST:添加数据,创建索引,类型,查询 DELETE:删除索引,文档 GET:查询 三、 创建和删除索引 index 创建索引索引
放置/天气
相当于
curl -X PUT 'localhost:9200/天气'
服务器返回一个带有确认字段的 JSON 对象,表明操作成功。
然后,发出删除请求以删除索引。
删除/天气
相当于
curl -X DELETE 'localhost:9200/天气'
四、Tokenizer 使用与学习
elasticsearch的查询是先通过tokenizer对单词进行分词,然后使用倒排索引匹配查询。
1. 理论研究
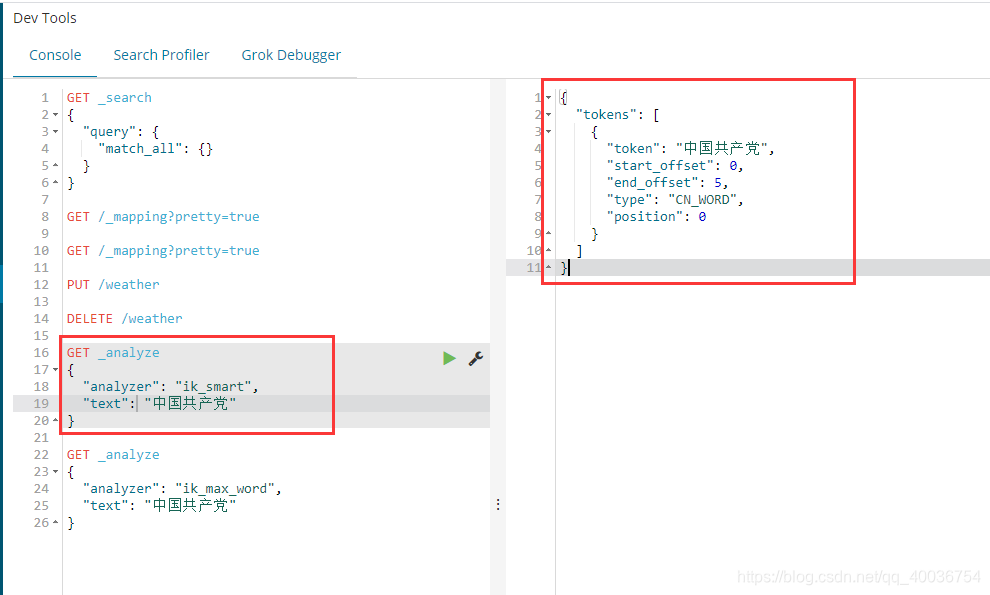
分词:就是将一段中文或者其他的一段分割成关键词,当我们搜索的时候,elasticsearch tokenizer会对自己的信息进行分词,对数据库或者索引库中的数据进行分词,然后执行一个匹配操作,默认的中文分词是将每个字符都当作一个词来对待,例如“我爱冯凡丽”会分为“我”、“爱”、“冯”、“凡”、“李”,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
ES默认分词是英文分词,对中文分词不太支持。如果要使用中文,推荐使用ik tokenizer!所以我们需要安装ik中文分词。
IK提供了两种分词算法:ik_smart和ik_max_word,其中ik_mart是最小分词,ik_max_word是最新粒度分词!我们将在一段时间内测试!
安装在第一篇博客中已经介绍过了,传送门:elasticsearch学习一:理解ES,版本之间的对应关系。安装 elasticsearch、kibana、head 插件、elasticsearch-ik 分词器。
2. 用 kibana 测试
ik_mart 是最少细分的
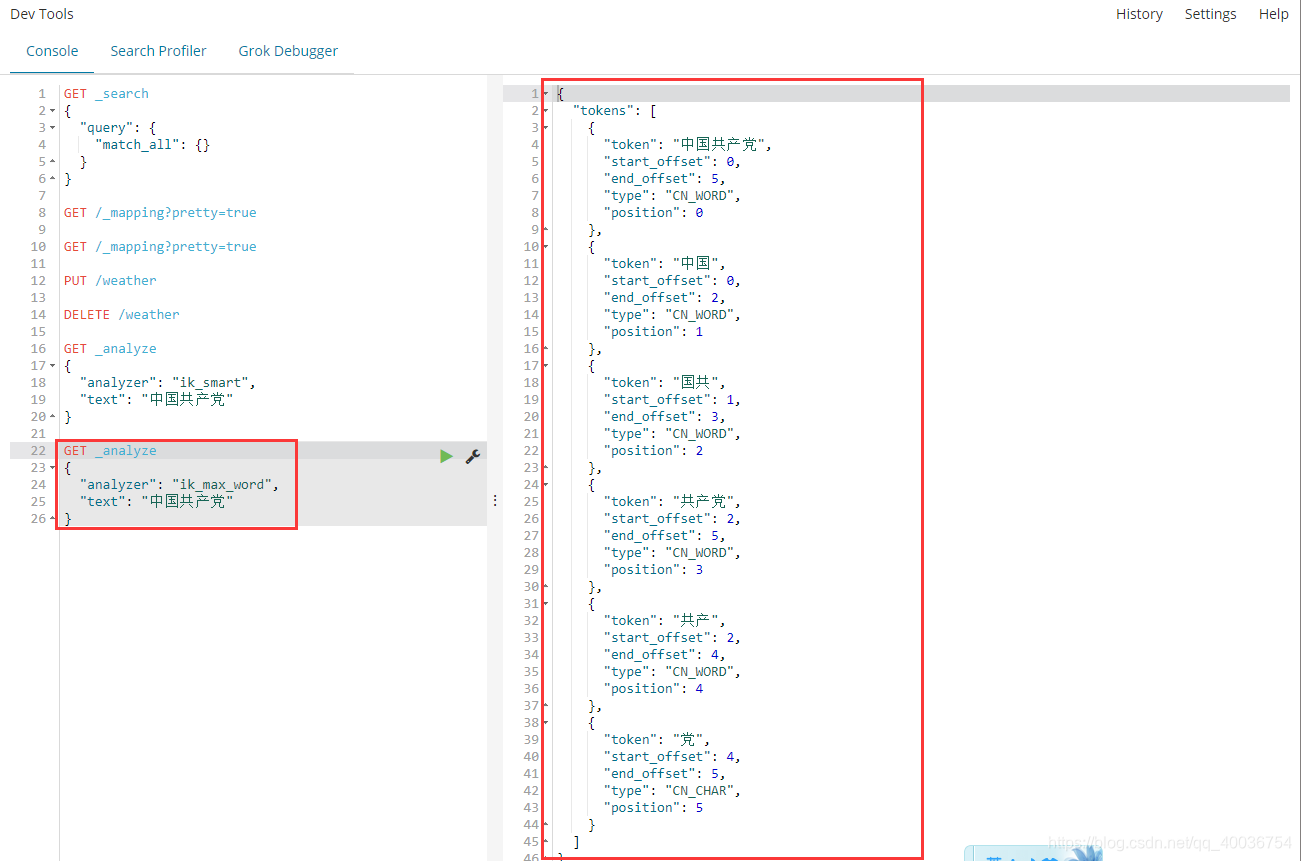
ik_max_word 是最新的粒度划分,它穷尽了词库的可能性。
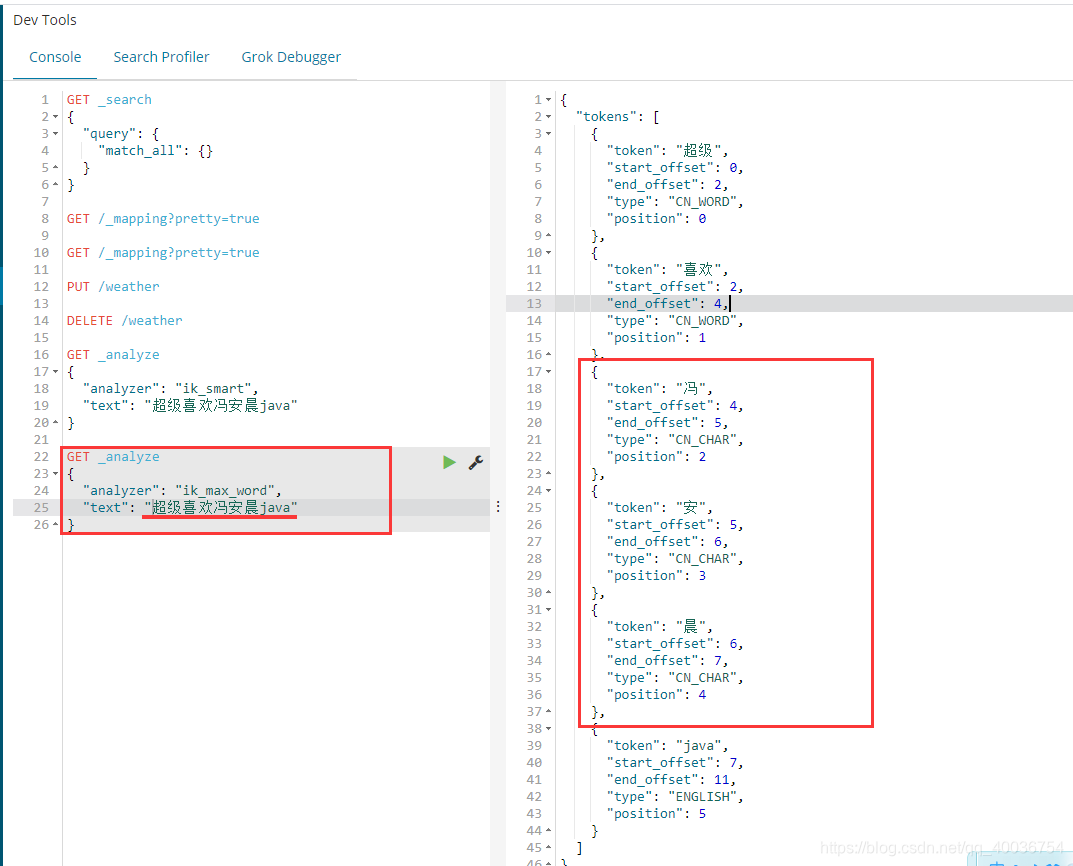
输入超喜欢冯安辰java
发现问题:风安辰被分开了,
你需要的这种词,你需要将它添加到我们的分词器的字典中!
ik tokenizer 添加了自己的配置!
ik分词器自定义配置,我写了一篇博客:elasticsearch学习之三:elasticsearch-ik分词器的自定义配置分词内容
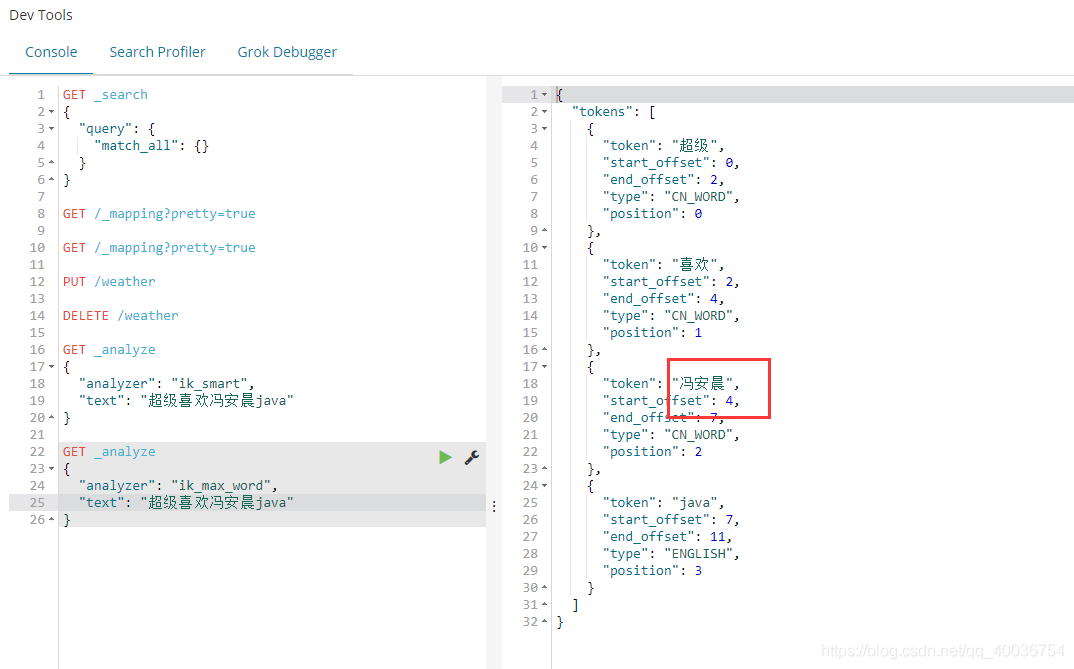
设置好后再次执行:
以后需要自己配置的分词可以在自己定义的dic文件中配置!五、数据操作1. 创建索引 创建索引方法1,简单创建索引
PUT/索引名称创建索引方式2、创建索引并添加数据,字段类型系统默认给出
该方法会直接创建索引名称、类型、id,并添加数据。
PUT /索引名/~类型名~/文档id
{请求体}
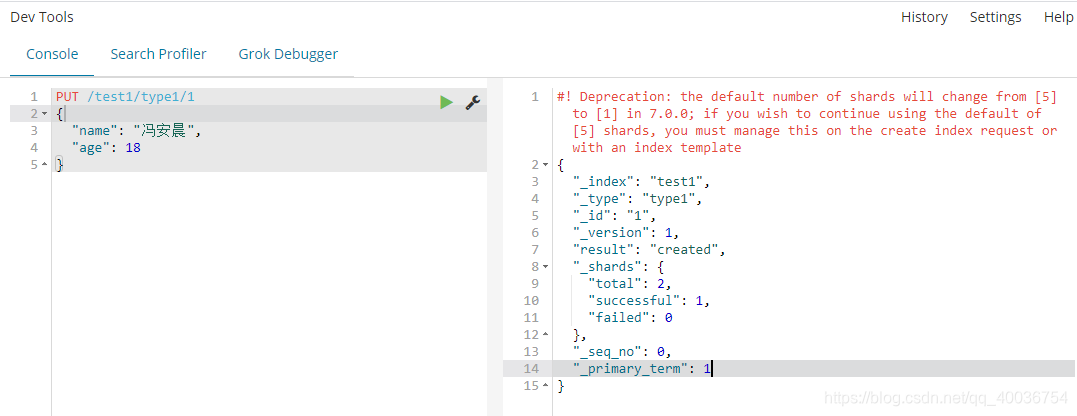
案件
PUT /test1/type1/1
{
"name": "冯安晨",
"age": 18
}
这样,index、type、id创建完成后,就添加了一条数据。
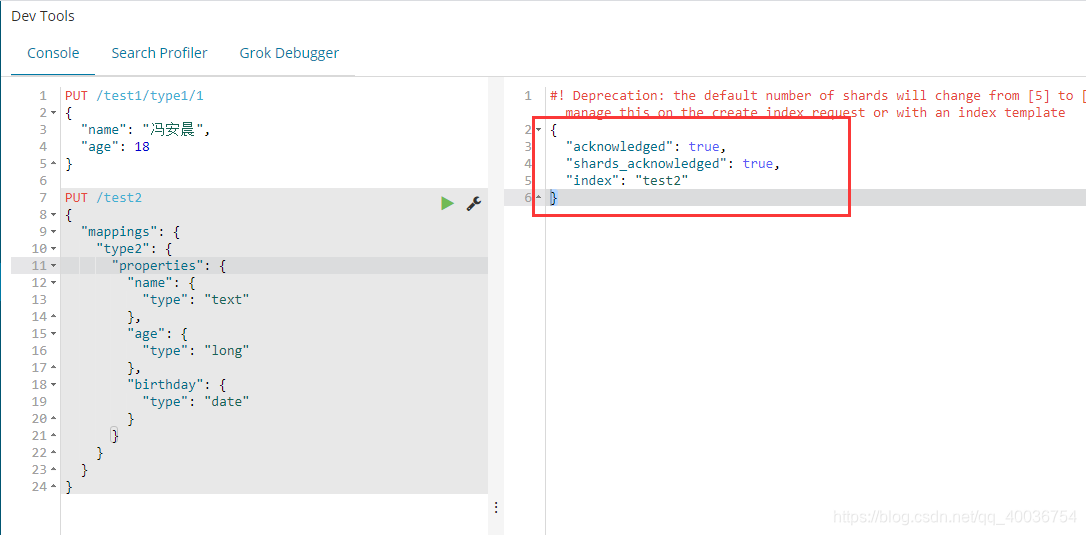
创建索引方法3、创建索引并指定字段类型
创建索引,指定类型名称,指定字段类型
PUT /test2
{
"mappings": {
"type2": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "long"
},
"birthday": {
"type": "date"
}
}
}
}
}
2. 字段类型摘要
那么上面的name字段就不需要指定类型了,毕竟我们的关系数据库需要指定类型!!
3. 查看规则信息
那就是看一下上面命令创建的细节
获取命令
GET /test1 : 查看索引信息
如果我们自己的文档字段没有指定,那么ES会给我们默认的配置字段类型!就是上面的test1索引,没有指定字段类型,所以ES默认指定类型。
4. 系统命令
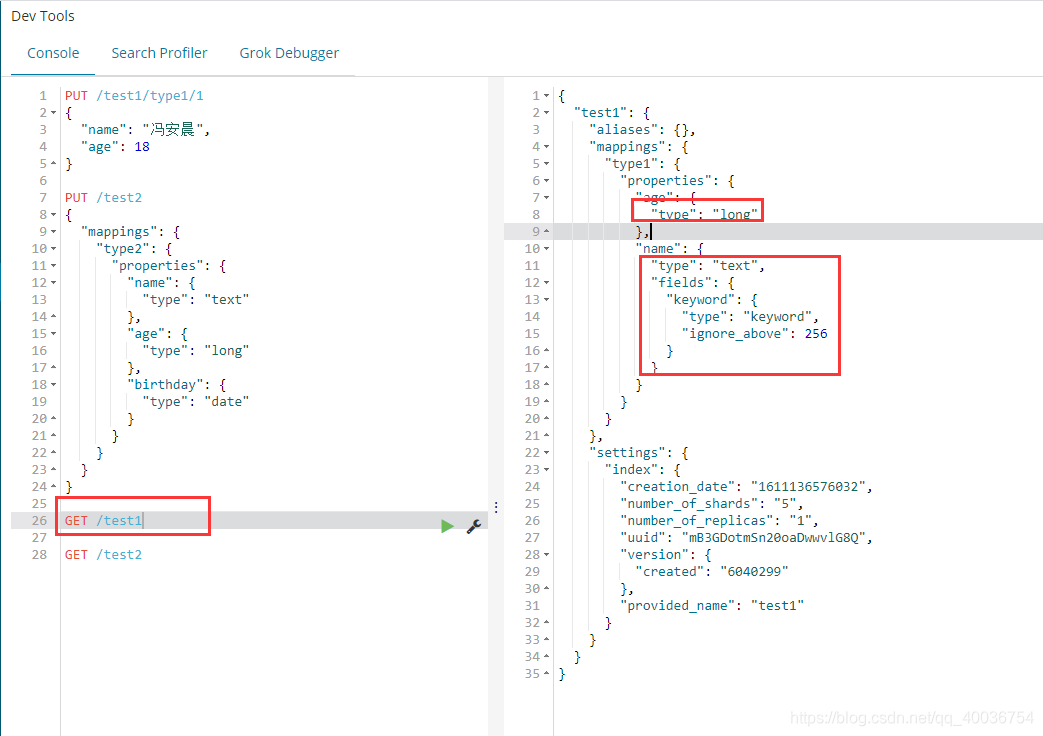
通过elasticsearch命令查看ES的各种信息!通过
获取_猫/
获取大量关于ES的最新信息!
GET _cat/indices/?v:查看索引情况
其他命令。
5 添加数据
默认指定数据类型
PUT /fenganchen/user/1
{
"name": "冯凡利",
"age": 18,
"desc": "一顿操作猛如虎,一看工资2500",
"tags": ["技术宅", "温暖", "直男"]
}
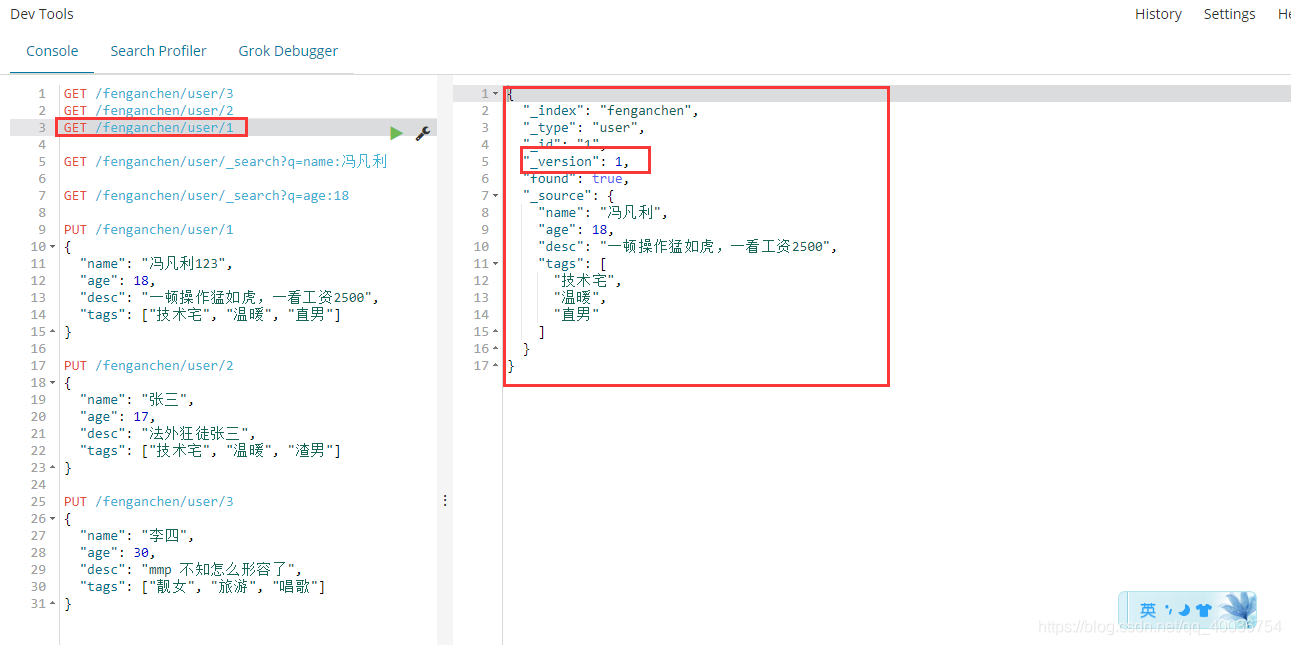
6. 修改数据 PUT 修改(不推荐)
修改类似于add,但是这个修改类似于overwrite,如果缺少某个字段,则某个字段消失
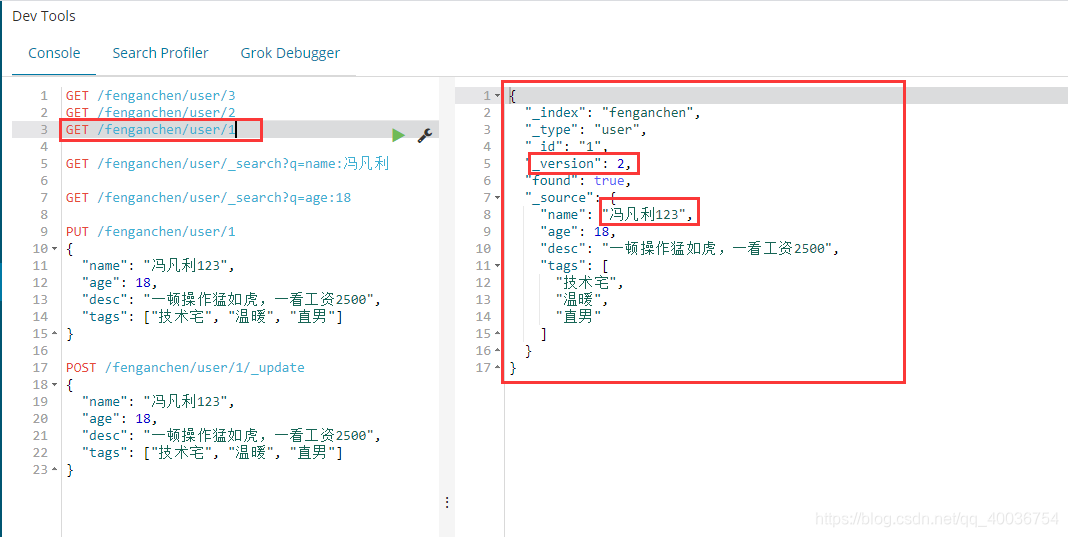
查看 GET /fenganchen/user/1(如下所述)
修订
PUT /fenganchen/user/1
{
"name": "冯凡利123",
"age": 18,
"desc": "一顿操作猛如虎,一看工资2500",
"tags": ["技术宅", "温暖", "直男"]
}
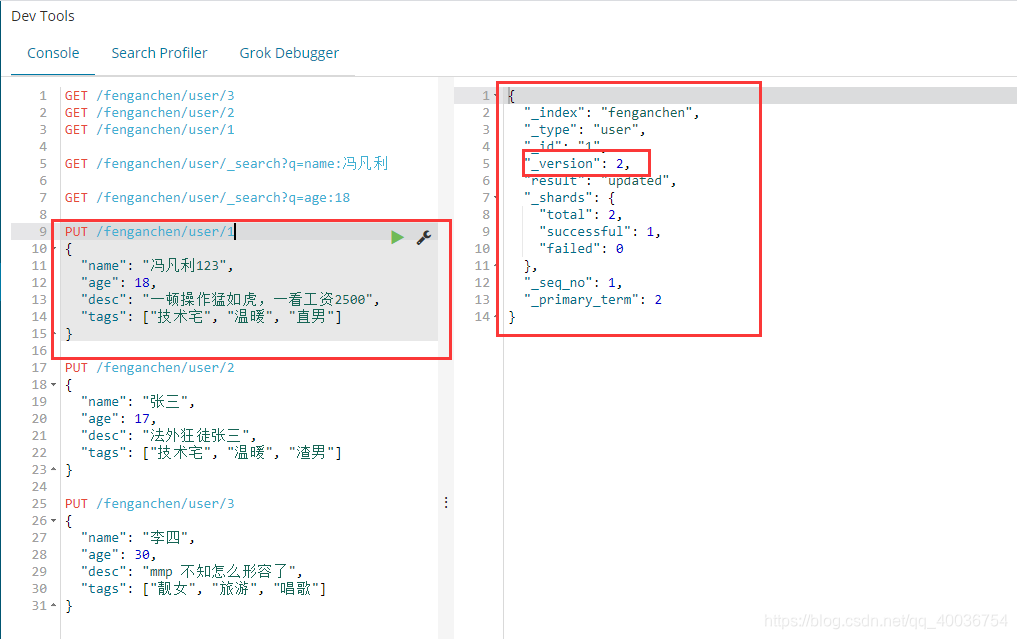
_version 表示被修改的次数
查看确认
获取 /fenganchen/user/1
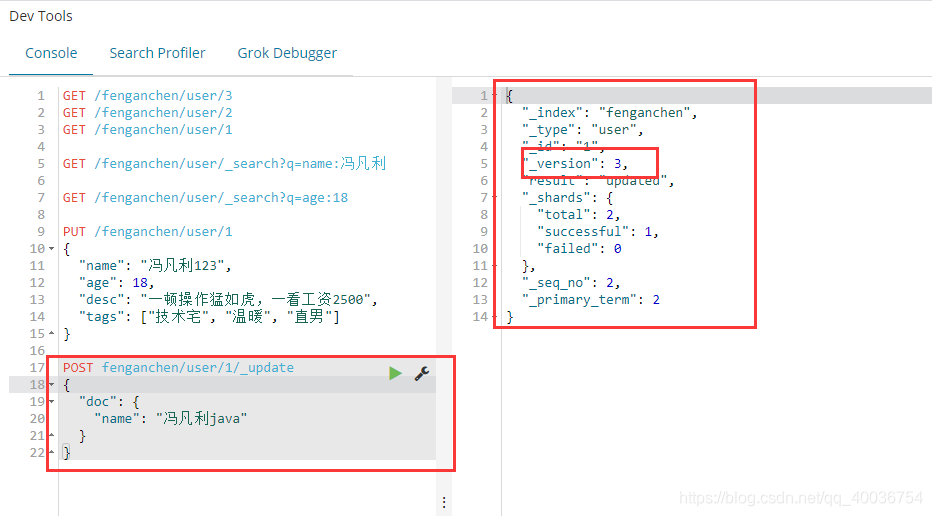
湾。_update 修改(推荐)修改
POST fenganchen/user/1/_update
{
"doc": {
"name": "冯凡利java"
}
}
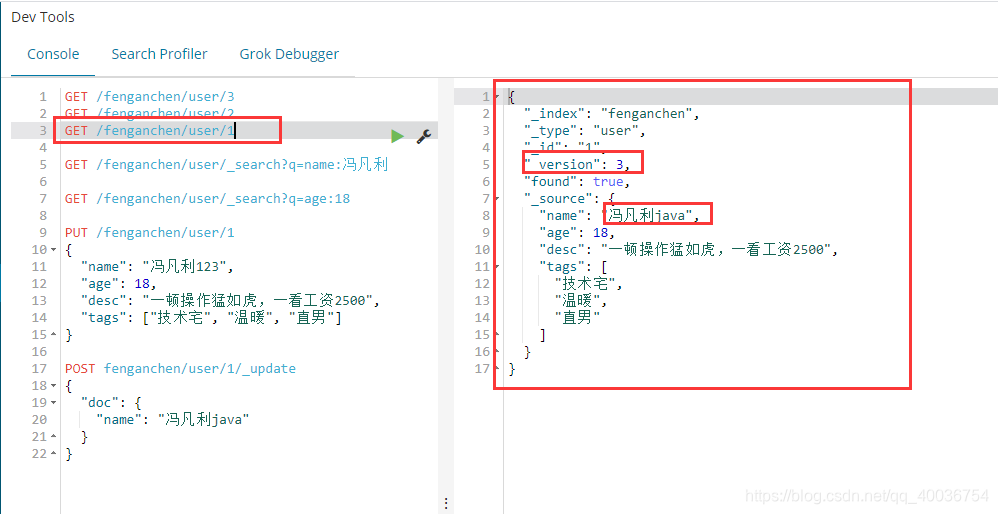
2. 查看
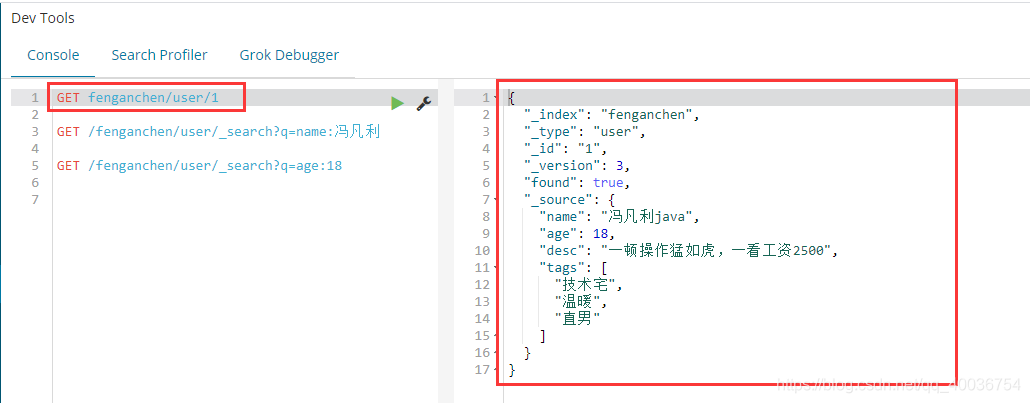
7. 删除7. 简单查询 GET fenganchen/user/1
简单的条件查询
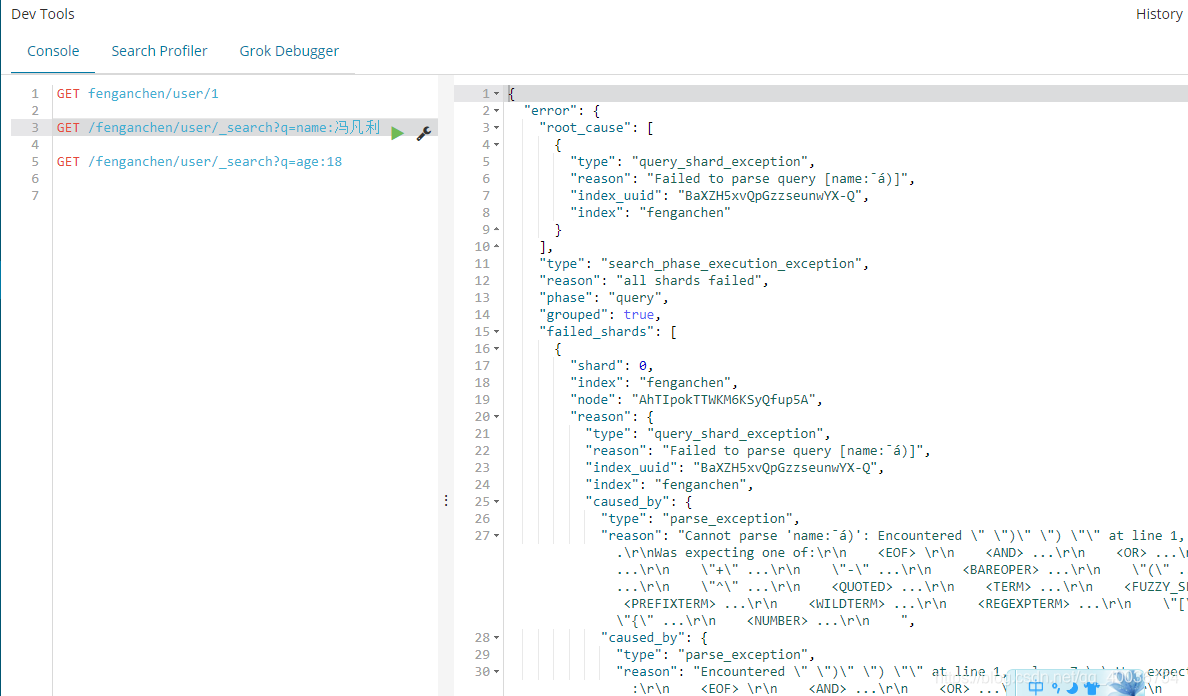
GET /fenganchen/user/_search?q=name:冯凡利 (报错,还未找到原因)
GET /fenganchen/user/_search?q=age:18
8.向复杂查询添加更多数据
PUT /fenganchen/user/2
{
"name": "张三",
"age": 17,
"desc": "法外狂徒张三",
"tags": ["技术宅", "温暖", "渣男"]
}
PUT /fenganchen/user/3
{
"name": "李四",
"age": 30,
"desc": "mmp 不知怎么形容了",
"tags": ["靓女", "旅游", "唱歌"]
}
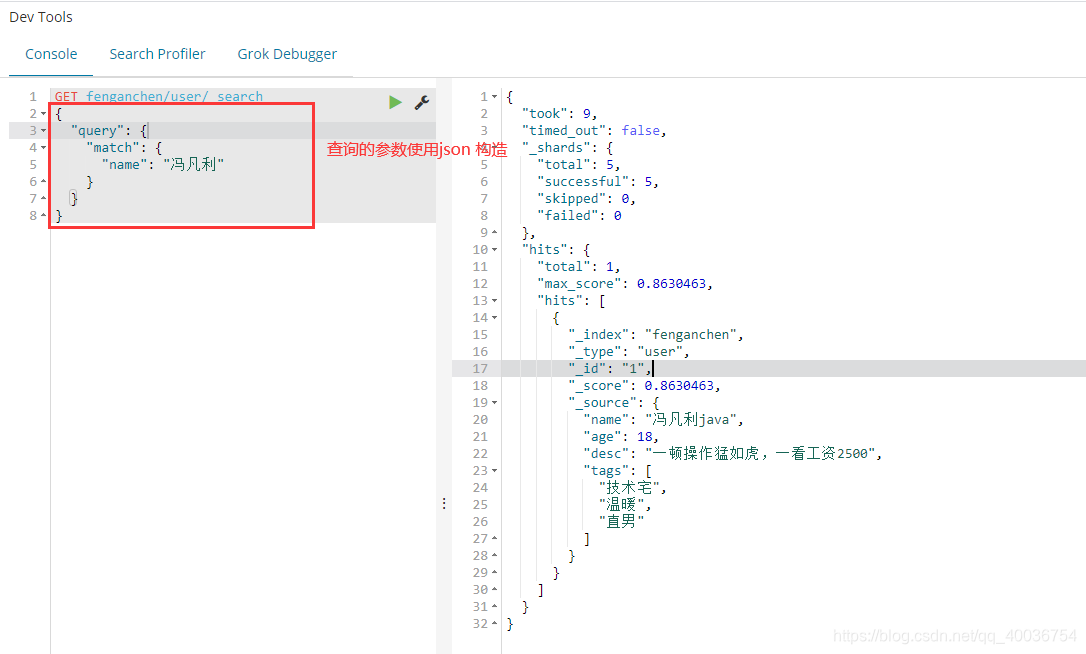
查询关键字:查询
match关键字:match,这里有很多选项,比如:match_all:匹配所有,bool:返回一个布尔值,exists:存在等等。
GET fenganchen/user/_search
{
"query": {
"match": {
"name": "冯凡利"
}
}
}
3. 再添加一条数据,方便查询和测试:
PUT /fenganchen/user/4
{
"name": "冯凡利前端",
"age": 3,
"desc": "一顿操作猛如虎,一看工资2500",
"tags": ["技术宅", "温暖", "直男"]
}
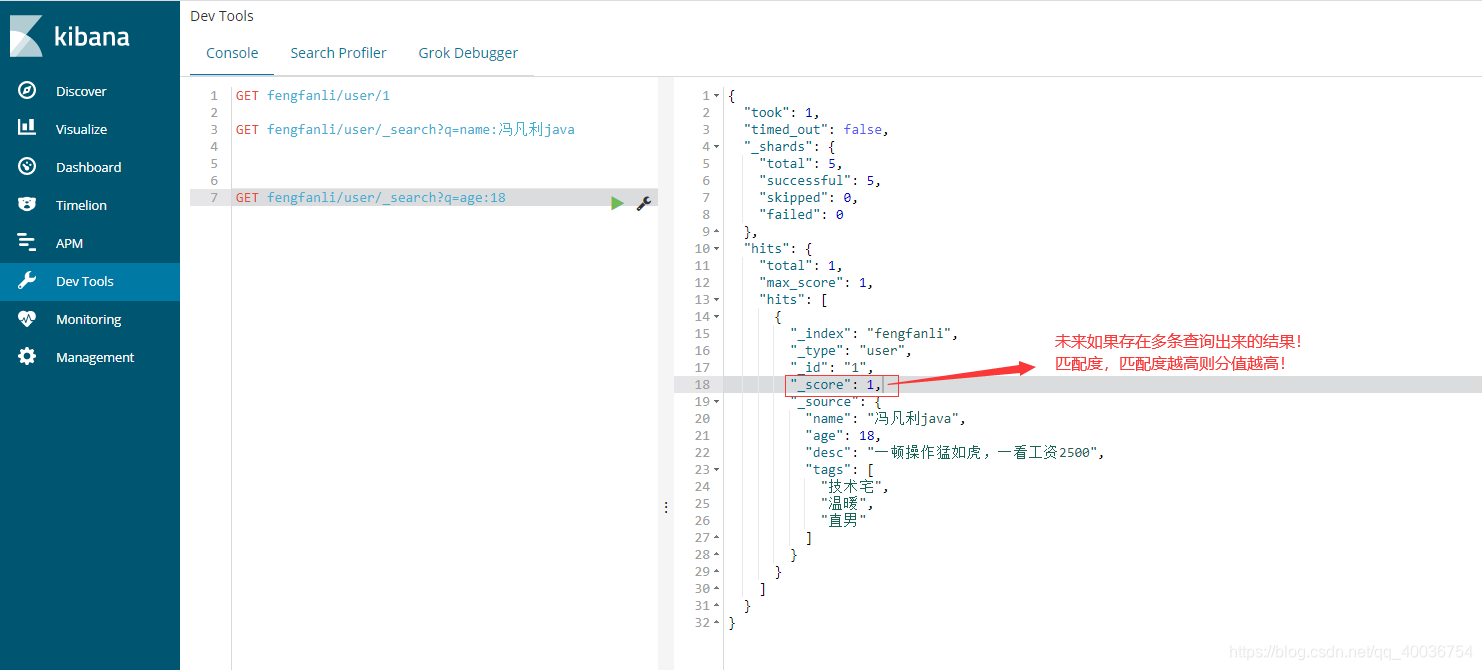
再次查询:如下图
Hits:包括索引和文档信息、查询结果总数、查询到的具体文档
max_score:最大分数,是下面数据中最大的匹配分数值,也是最合适的
_score:可以用来判断谁更符合结果,每个数据都有这个属性
_source:数据对象信息关键字。
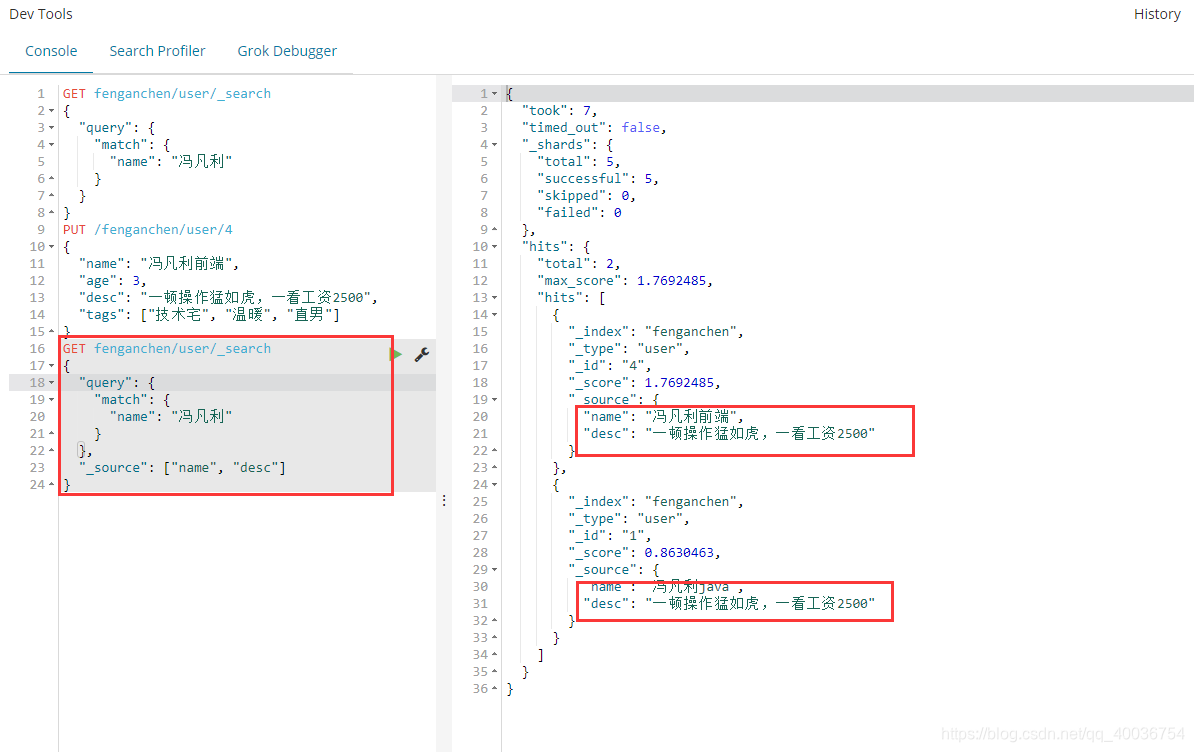
9 筛选结果
不想显示这么多字段,只想显示name和desc字段,可以使用数据对象信息关键字:_source来限制显示字段。
GET fenganchen/user/_search
{
"query": {
"match": {
"name": "冯凡利"
}
},
"_source": ["name", "desc"]
}
后面我们会用java来操作es,这里所有的方法和对象都是key:这个key也是hits、score等关键字。
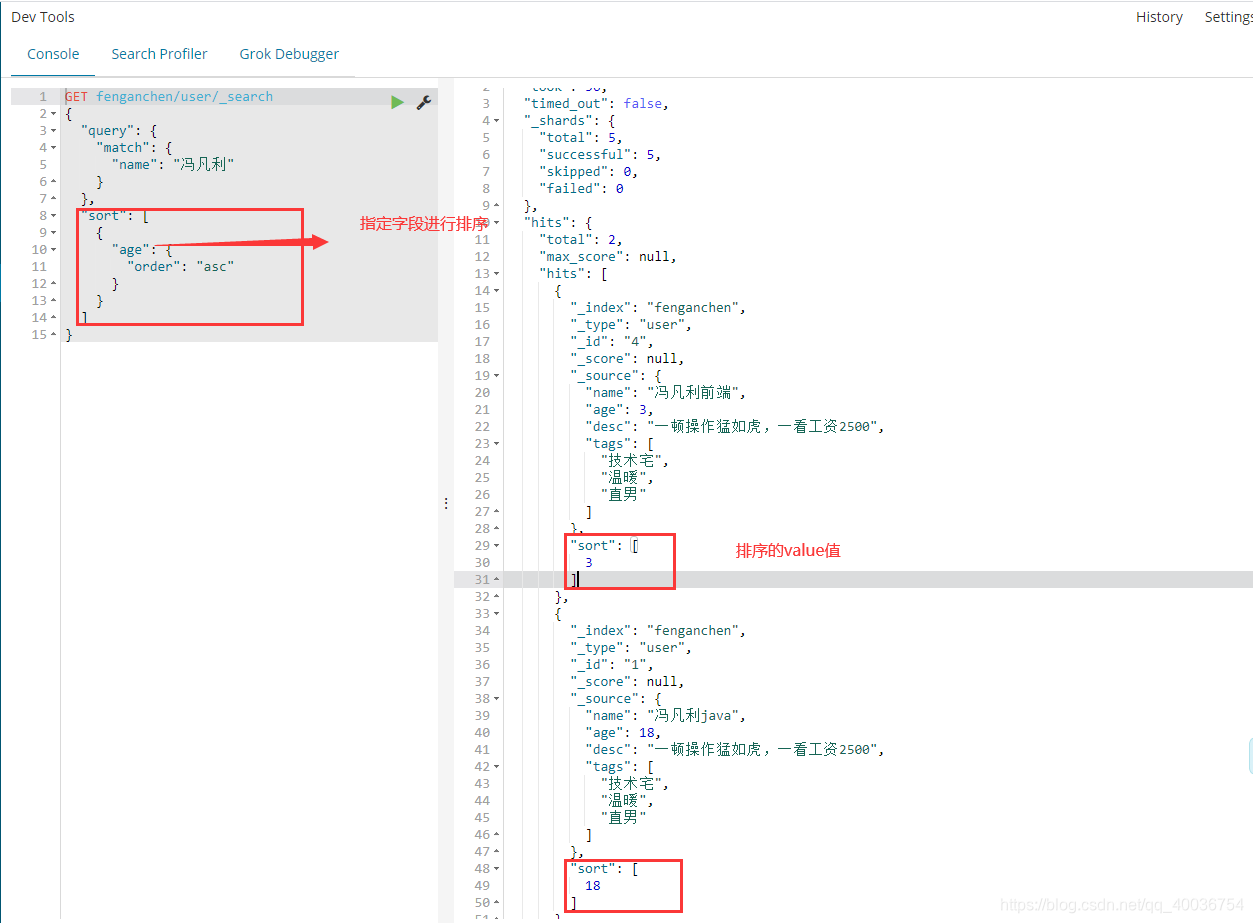
10. 排序
GET fenganchen/user/_search
{
"query": {
"match": {
"name": "冯凡利"
}
},
"sort": [
{
"age": {
"order": "asc"
}
}
]
}
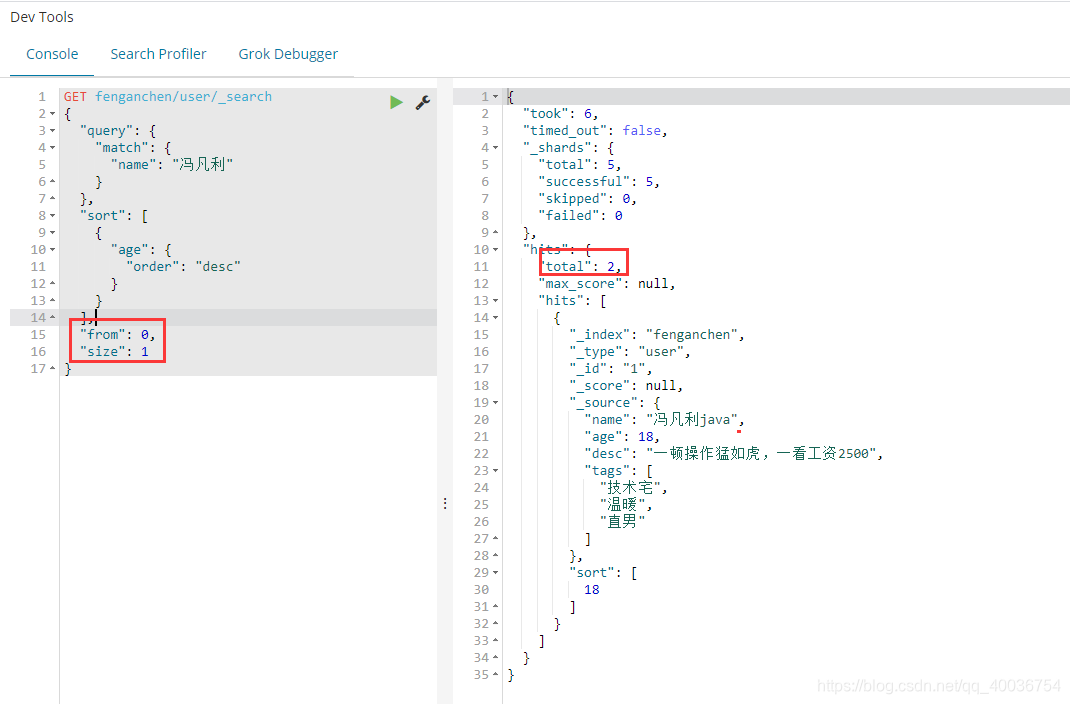
11.分页查询
GET fenganchen/user/_search
{
"query": {
"match": {
"name": "冯凡利"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 1
}
from:从第一条数据开始
size:返回多少条数据(单页数据)
数据下标还是从 0 开始,和所有学过的数据结构一样!
/搜索/{当前}/{页面大小}
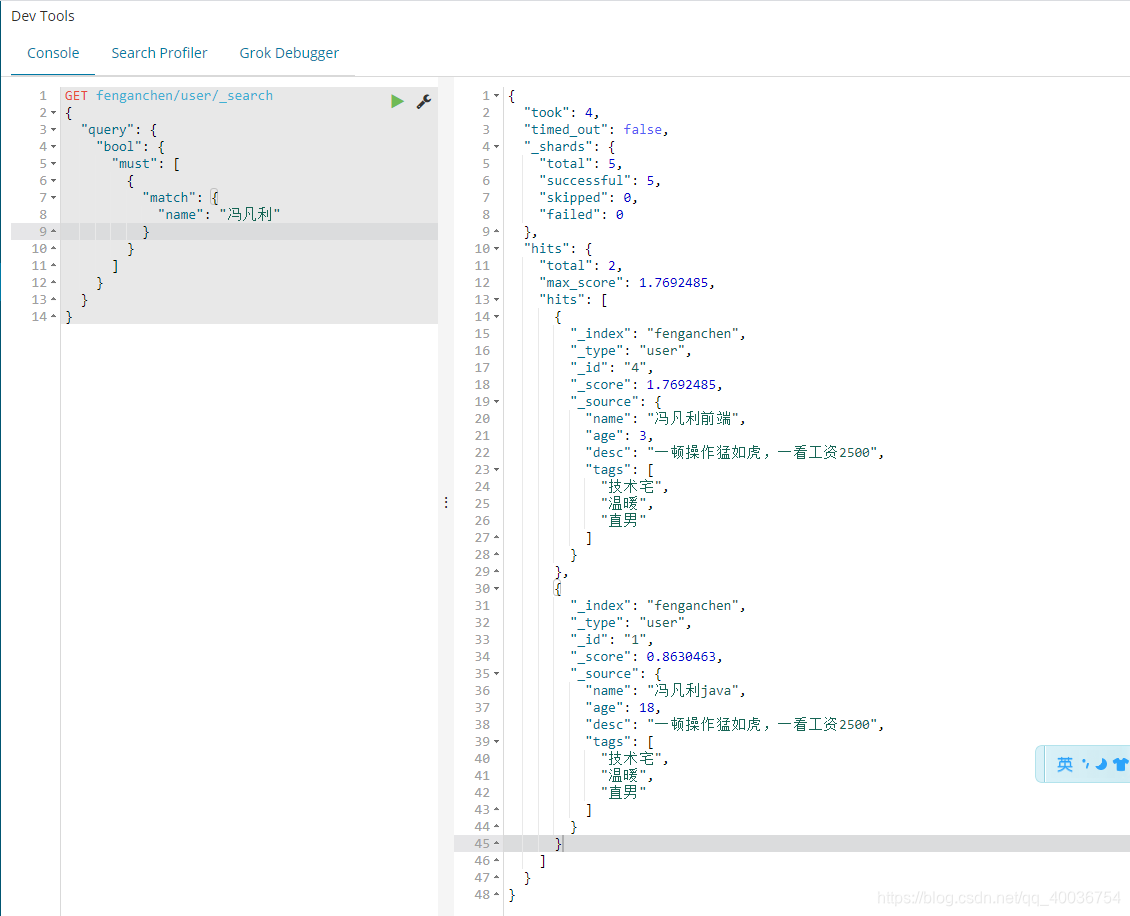
12. 布尔查询必须(and),必须满足所有条件,类似于:where id=1 and name=xxx
GET fengfanli/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "冯凡利"
}
},
{
"match": {
"age": "18"
}
}
]
}
}
}
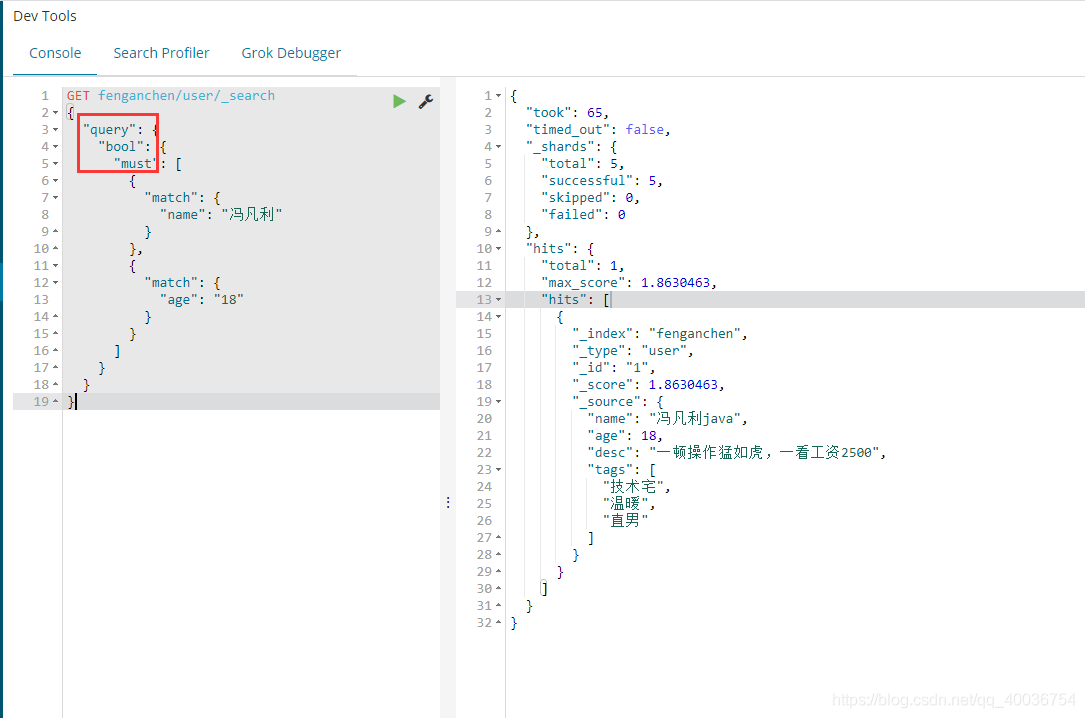
should(or),必须满足所有条件,类似于: where id=1 orname=xxx
GET fenganchen/user/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "冯凡利"
}
},
{
"match": {
"age": "18"
}
}
]
}
}
}
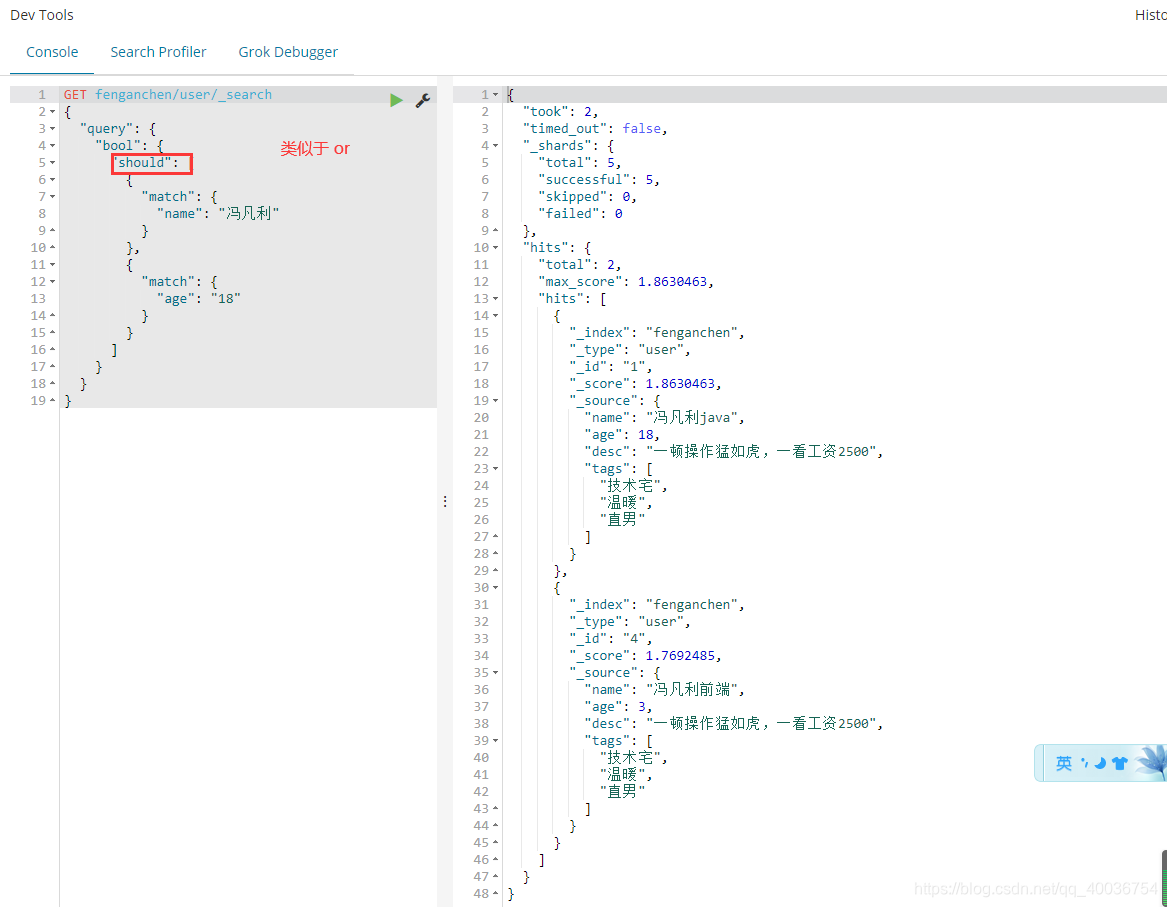
**must_not(not)**,必须满足所有条件,类似于: where id != 1
GET fenganchen/user/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"age": 3
}
}
]
}
}
}
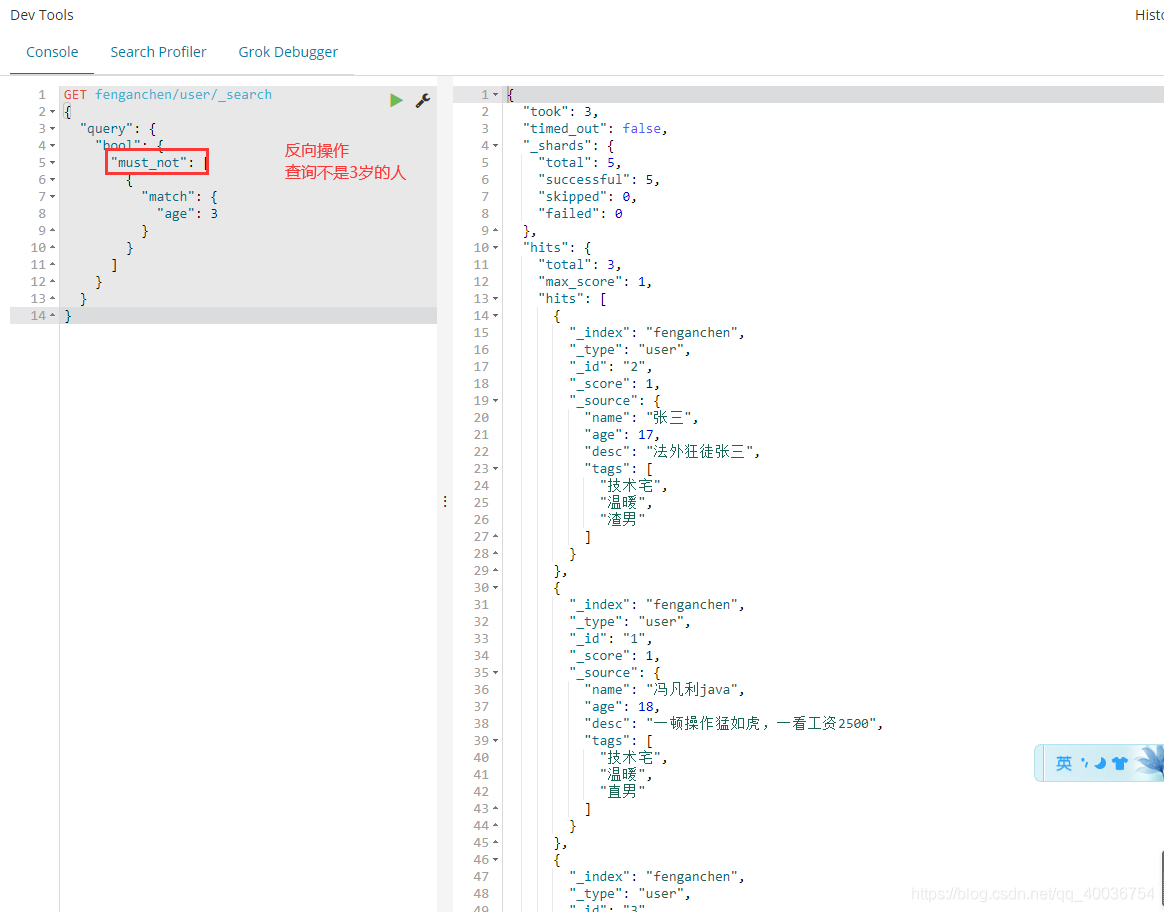
13.过滤常见匹配查询
任何收录风范里字符串的东西都会被找到
GET fenganchen/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "冯凡利"
}
}
]
}
}
}
添加过滤器,过滤器
filter关键字过滤查询的数据。
GET fenganchen/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "冯凡利"
}
}
],
"filter": {
"range": {
"age": {
"gt": 3
}
}
}
}
}
}
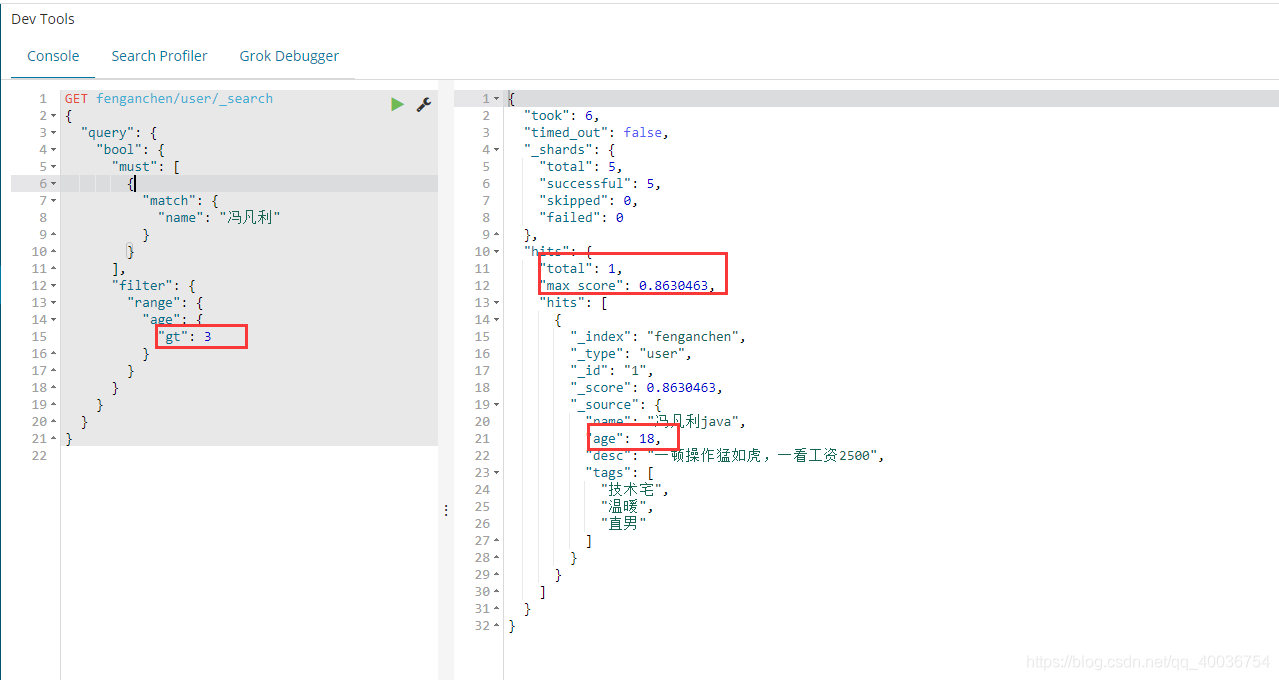
上面的语句是对查询语句进行过滤,过滤掉年龄大于3的数据
14. 个空格匹配多个条件
匹配关键字空间
多个条件,以空格分隔
只要隐藏其中一个结果,就能查出
这时候通过_score分数就可以做出一个基本的判断了。
以下查询语句的含义:在tags字段中找到male和technical的数据并进行查询
GET fenganchen/user/_search
{
"query": {
"match": {
"tags": "男 技术"
}
}
}
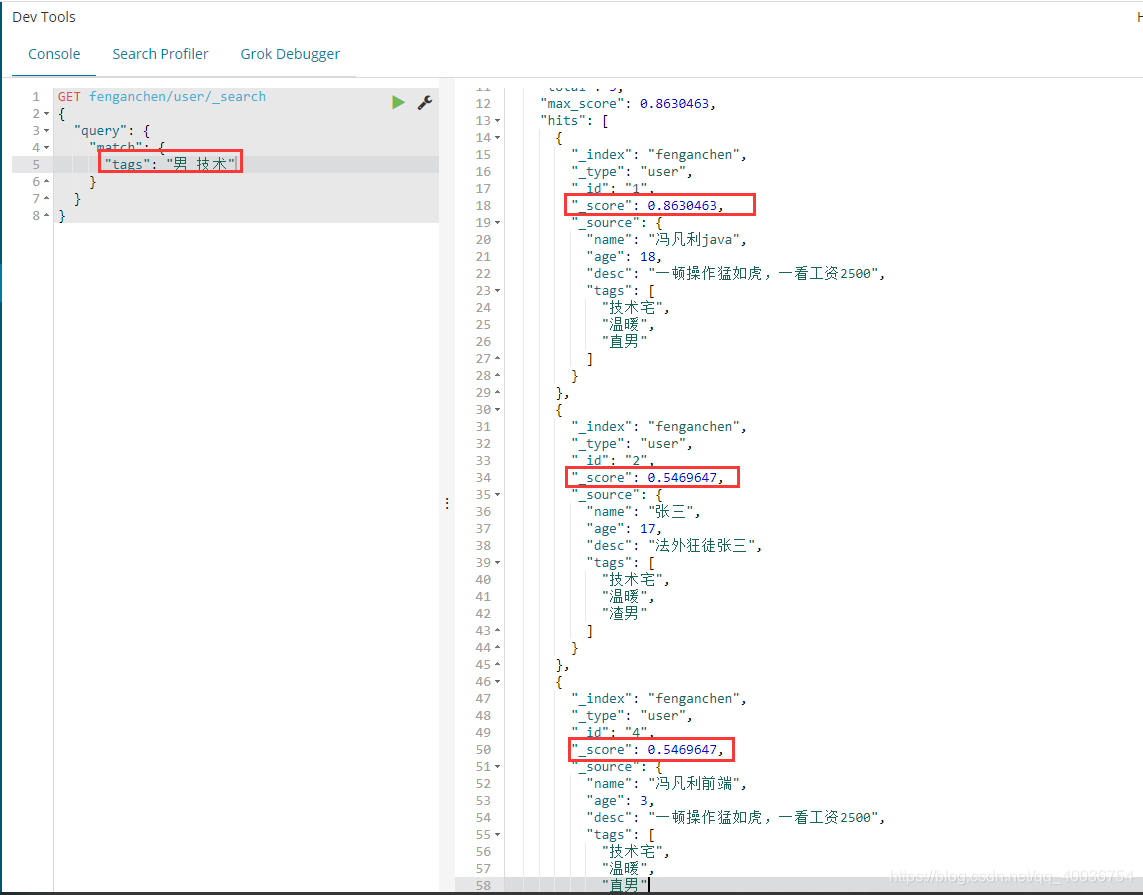
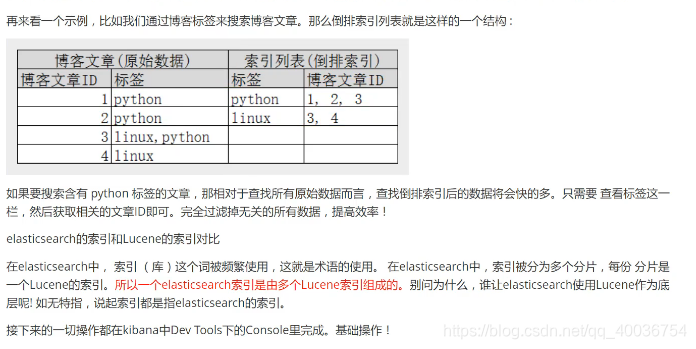
15. 词条精确查询 i。术语分析
词条查询是通过倒排索引指定词条的过程直接搜索的!
关于分词:
ii. 两类文字关键词详解
分词器不能使用两种类型的文本关键字
文本类型:可分段
关键字类型:不能分段
首先创建索引并指定属性规则,如下:
一个。版本 6 创建索引并指定规则
elasticsearch 6.X必须指定创建索引的类型,feng_type是索引的类型名
```json
PUT testdb
{
"mappings": {
"feng_type": {
"properties": {
"name": {
"type": "text"
},
"desc": {
"type": "keyword"
}
}
}
}
}
```
湾。版本 7 创建索引并指定规则
elasticsearch 7.x 不需要指定类型来创建索引,因为版本7弃用了类型关键词(这里我就不演示了,我用的是6.4. 2 版本在这里。)
```json
PUT testdb
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"desc": {
"type": "keyword"
}
}
}
}
```
C。添加数据
```json
PUT testdb/feng_type/1
{
"name": "冯凡利java name",
"desc": "冯凡利java desc"
}
PUT testdb/feng_type/2
{
"name": "冯凡利java name",
"desc": "冯凡利java desc2"
}
```
添加文档 1
添加文档 2
d。elasticsearch-head的google插件,查看testdb索引数据
e. elasticsearch-head 的 Google 插件,参见 testdb 映射规则
索引情况,可以查看索引的设置详情,以及映射映射规则包括类型和属性。
可以看到,name 属性是 text 类型,而 desc 是关键字类型。
F。默认标记器测试:关键字
KeywordAnalyzer 将整个输入视为单个词汇单元,以促进特定类型文本的索引和检索。使用 关键词 标记器为邮政编码和地址等文本信息创建索引项非常方便。
使用默认的关键字tokenizer进行分词,(比如说ik tokenizer是中文tokenizer),这里可以看出没有分析
G。默认标记器测试:标准
英文的处理能力和StopAnalyzer一样,支持中文的方法是分词。它将词汇单元转换为小写并删除停用词和标点符号。
使用默认的标准分词器进行分词,见这里分析
H。term 准确查找文本类型
一世。term 查找确切的关键字类型
j. 总结 h 和 i 的检验
在 testdb 索引中:
名称字段是文本类型,
desc 字段是关键字类型。
但是,当 term 精确搜索它们时,它会发现:
在查找文本类型的名称字段时,只需收录它,即文本类型可以被分词器解释。在查找关键字类型的 desc 字段时,必须完全收录,即关键字类型将整个输入匹配为单个词法单元,由分词器解释。16. 多词精确匹配 a. 添加多数
PUT testdb/feng_type/3
{
"t1": "22",
"t2": "2020-4-6"
}
PUT testdb/feng_type/4
{
"t1": "33",
"t2": "2020-4-7"
}
湾。查看 elasticsearch-head 的谷歌插件,查看 testdb 索引数据和映射规则。索引数据
映射规则
C。词条精确查询
@>
17. Highlight 高亮关键字:highlight
GET fenganchen/user/_search
{
"query": {
"match": {
"name": "冯凡利"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
自定义搜索突出显示
GET fenganchen/user/_search
{
"query": {
"match": {
"name": "冯凡利"
}
},
"highlight": {
"pre_tags": "<p class='key style='color:red'>",
"post_tags": "",
"fields": {
"name": {}
}
}
}
</p>
这些mysql也可以做,但是mysql的效率比较低 查看全部
seq搜索引擎优化至少包括那几步?(开源ElasticsearchType类型Document可以分组吗?(一)(组图))
文章目录
前言一、基本概念全文搜索是最常见的需求,开源的Elasticsearch(以下简称Elastic)是目前全文搜索引擎的首选。它可以快速存储、搜索和分析海量数据。Wikipedia、Stack Overflow、Github 都使用它。底层 Elastic 是开源库 Lucene。但是,你不能直接使用Lucene,你必须自己编写代码来调用它的接口。Elastic 是 Lucene 的一个包,提供开箱即用的 REST API 操作接口。1. Node 节点和 Cluster 集群
Elastic 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器都可以运行多个 Elastic 实例。
单个 Elastic 实例称为节点。一组节点形成一个集群。
2. 索引索引
Elastic 索引所有字段并在处理后将它们写入倒排索引。查找数据时,直接查找索引。
因此,Elastic 数据管理的顶层单元称为 Index。它是单个数据库的同义词。每个索引(即数据库)的名称必须是小写的。
下面的命令可以查看当前节点的所有索引。
获取 /_mapping?pretty=true

3. 文档
索引中的单个记录称为文档。许多文档形成一个索引。
文档以 JSON 格式表示,以下是一个示例。
{
"user": "张三",
"title": "工程师",
"desc": "数据库管理"
}
同一个Index中的文档不要求结构(scheme)相同,但最好保持相同,有利于提高搜索效率。
4. 类型
可以对文档进行分组。例如,在天气指数中,它们可以按城市(北京和上海)或按气候(晴天和雨天)分组。这种分组称为Type,它是一个用于过滤Documents的虚拟逻辑分组。
不同的类型应该有相似的模式,例如,id 字段不能是一组中的字符串,而另一组中不能是数值。这是与关系数据库表的区别。具有完全不同属性的数据(例如产品和日志)应该存储为两个索引,而不是一个索引中的两种类型(尽管可以这样做)。
以下命令可以列出每个索引中收录的类型。(与上面的截图相同)
获取 /_mapping?pretty=true
按照计划,Elastic 6.x 版本只允许每个 Index 收录一个 Type,而 7.x 版本将彻底移除 Type。
5. 逻辑比较
上面提到的集群、节点、索引、类型、文档、分片(底层封装)和映射是什么?
如何区分和比较非关系型数据库elasticsearch和关系型数据库,elasticsearch是面向文档的
如下:关系型数据库和elasticsearch的客观对比!
关系型数据库 非关系型数据库
数据库数据库
指数
桌子
类型(版本 7 已完全弃用)
行
文档
字段列
场地
Elasticsearch(集群)可以收录多个索引(数据库),每个索引可以收录多个类型(表),每个类型收录多个文档(行),每个文档收录多个字段(列表)。
6. 物理设计
Elasticsearch在后台将每个索引分成多个shard,每个shard可以在集群中不同的服务器之间迁移。
集群的默认名称是 elasticsearch。
一个集群至少有一个节点,一个节点就是一个elasticsearch进程。一个节点可以有多个索引。默认情况下,如果创建索引,索引将由 5 个分片(primary shards,也称为主分片)组成。是的,每个主分片都会有一个副本(副本分片,也称为分配分片)

索引分为多个shard,每个shard就是一个Lucene索引,所以一个elasticsearch索引是由多个Lucene索引组成的。因为elasticsearch使用Lucene作为底层。
二、ES 命令风格
一种软件架构风格,而不是标准,它只是提供一组设计原则和约束,主要用于与客户端和服务器交互的软件。基于这种风格设计的软件可以更简洁、更有层次、更容易实现缓存等机制。
基本 RESTFUL 命令说明:
methodurl地址说明
放
本地主机:9200/index_name/type_name/document_id
创建文档(指定文档 ID)
邮政
本地主机:9200/index_name/type_name
创建文档(随机文档 ID)
邮政
本地主机:9200/index_name/type_name/document_id/_update
修改文档
删除
本地主机:9200/index_name/type_name/document_id
删除文件
得到
本地主机:9200/index_name/type_name/document_id
按文档id查询文档
邮政
本地主机:9200/index_name/type_name/document_id/_search
查询所有文件
PUT:一般创建索引,类型,文档 POST:添加数据,创建索引,类型,查询 DELETE:删除索引,文档 GET:查询 三、 创建和删除索引 index 创建索引索引
放置/天气
相当于
curl -X PUT 'localhost:9200/天气'
服务器返回一个带有确认字段的 JSON 对象,表明操作成功。
然后,发出删除请求以删除索引。
删除/天气
相当于
curl -X DELETE 'localhost:9200/天气'

四、Tokenizer 使用与学习
elasticsearch的查询是先通过tokenizer对单词进行分词,然后使用倒排索引匹配查询。
1. 理论研究
分词:就是将一段中文或者其他的一段分割成关键词,当我们搜索的时候,elasticsearch tokenizer会对自己的信息进行分词,对数据库或者索引库中的数据进行分词,然后执行一个匹配操作,默认的中文分词是将每个字符都当作一个词来对待,例如“我爱冯凡丽”会分为“我”、“爱”、“冯”、“凡”、“李”,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
ES默认分词是英文分词,对中文分词不太支持。如果要使用中文,推荐使用ik tokenizer!所以我们需要安装ik中文分词。
IK提供了两种分词算法:ik_smart和ik_max_word,其中ik_mart是最小分词,ik_max_word是最新粒度分词!我们将在一段时间内测试!
安装在第一篇博客中已经介绍过了,传送门:elasticsearch学习一:理解ES,版本之间的对应关系。安装 elasticsearch、kibana、head 插件、elasticsearch-ik 分词器。
2. 用 kibana 测试
ik_mart 是最少细分的
ik_max_word 是最新的粒度划分,它穷尽了词库的可能性。
输入超喜欢冯安辰java
发现问题:风安辰被分开了,
你需要的这种词,你需要将它添加到我们的分词器的字典中!
ik tokenizer 添加了自己的配置!
ik分词器自定义配置,我写了一篇博客:elasticsearch学习之三:elasticsearch-ik分词器的自定义配置分词内容
设置好后再次执行:
以后需要自己配置的分词可以在自己定义的dic文件中配置!五、数据操作1. 创建索引 创建索引方法1,简单创建索引
PUT/索引名称创建索引方式2、创建索引并添加数据,字段类型系统默认给出
该方法会直接创建索引名称、类型、id,并添加数据。
PUT /索引名/~类型名~/文档id
{请求体}
案件
PUT /test1/type1/1
{
"name": "冯安晨",
"age": 18
}
这样,index、type、id创建完成后,就添加了一条数据。
创建索引方法3、创建索引并指定字段类型
创建索引,指定类型名称,指定字段类型
PUT /test2
{
"mappings": {
"type2": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "long"
},
"birthday": {
"type": "date"
}
}
}
}
}
2. 字段类型摘要
那么上面的name字段就不需要指定类型了,毕竟我们的关系数据库需要指定类型!!
3. 查看规则信息
那就是看一下上面命令创建的细节
获取命令
GET /test1 : 查看索引信息
如果我们自己的文档字段没有指定,那么ES会给我们默认的配置字段类型!就是上面的test1索引,没有指定字段类型,所以ES默认指定类型。
4. 系统命令
通过elasticsearch命令查看ES的各种信息!通过
获取_猫/
获取大量关于ES的最新信息!
GET _cat/indices/?v:查看索引情况
其他命令。
5 添加数据
默认指定数据类型
PUT /fenganchen/user/1
{
"name": "冯凡利",
"age": 18,
"desc": "一顿操作猛如虎,一看工资2500",
"tags": ["技术宅", "温暖", "直男"]
}
6. 修改数据 PUT 修改(不推荐)
修改类似于add,但是这个修改类似于overwrite,如果缺少某个字段,则某个字段消失
查看 GET /fenganchen/user/1(如下所述)
修订
PUT /fenganchen/user/1
{
"name": "冯凡利123",
"age": 18,
"desc": "一顿操作猛如虎,一看工资2500",
"tags": ["技术宅", "温暖", "直男"]
}
_version 表示被修改的次数
查看确认
获取 /fenganchen/user/1
湾。_update 修改(推荐)修改
POST fenganchen/user/1/_update
{
"doc": {
"name": "冯凡利java"
}
}
2. 查看
7. 删除7. 简单查询 GET fenganchen/user/1
简单的条件查询
GET /fenganchen/user/_search?q=name:冯凡利 (报错,还未找到原因)
GET /fenganchen/user/_search?q=age:18
8.向复杂查询添加更多数据
PUT /fenganchen/user/2
{
"name": "张三",
"age": 17,
"desc": "法外狂徒张三",
"tags": ["技术宅", "温暖", "渣男"]
}
PUT /fenganchen/user/3
{
"name": "李四",
"age": 30,
"desc": "mmp 不知怎么形容了",
"tags": ["靓女", "旅游", "唱歌"]
}
查询关键字:查询
match关键字:match,这里有很多选项,比如:match_all:匹配所有,bool:返回一个布尔值,exists:存在等等。
GET fenganchen/user/_search
{
"query": {
"match": {
"name": "冯凡利"
}
}
}
3. 再添加一条数据,方便查询和测试:
PUT /fenganchen/user/4
{
"name": "冯凡利前端",
"age": 3,
"desc": "一顿操作猛如虎,一看工资2500",
"tags": ["技术宅", "温暖", "直男"]
}
再次查询:如下图
Hits:包括索引和文档信息、查询结果总数、查询到的具体文档
max_score:最大分数,是下面数据中最大的匹配分数值,也是最合适的
_score:可以用来判断谁更符合结果,每个数据都有这个属性
_source:数据对象信息关键字。
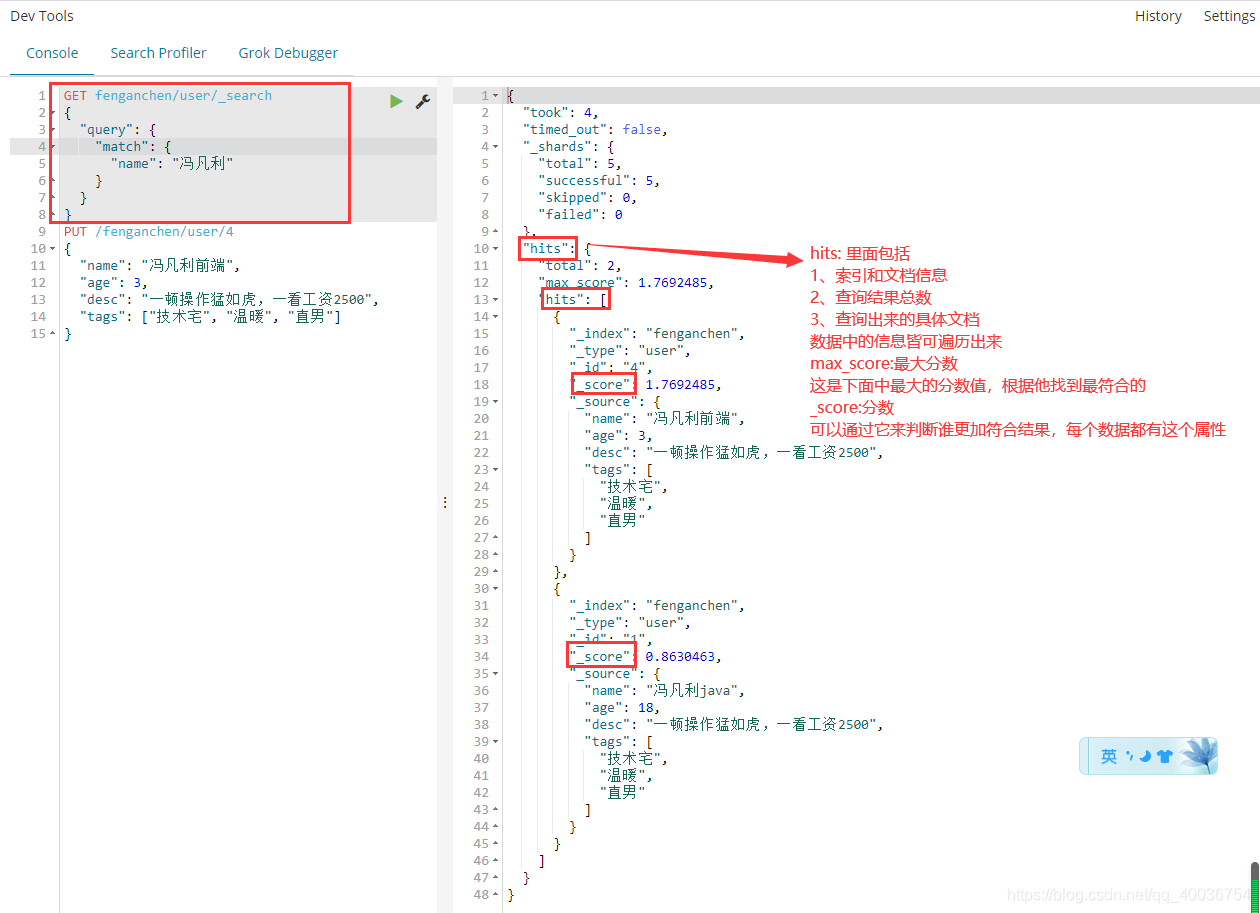
9 筛选结果
不想显示这么多字段,只想显示name和desc字段,可以使用数据对象信息关键字:_source来限制显示字段。
GET fenganchen/user/_search
{
"query": {
"match": {
"name": "冯凡利"
}
},
"_source": ["name", "desc"]
}
后面我们会用java来操作es,这里所有的方法和对象都是key:这个key也是hits、score等关键字。
10. 排序
GET fenganchen/user/_search
{
"query": {
"match": {
"name": "冯凡利"
}
},
"sort": [
{
"age": {
"order": "asc"
}
}
]
}
11.分页查询
GET fenganchen/user/_search
{
"query": {
"match": {
"name": "冯凡利"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 1
}
from:从第一条数据开始
size:返回多少条数据(单页数据)
数据下标还是从 0 开始,和所有学过的数据结构一样!
/搜索/{当前}/{页面大小}
12. 布尔查询必须(and),必须满足所有条件,类似于:where id=1 and name=xxx
GET fengfanli/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "冯凡利"
}
},
{
"match": {
"age": "18"
}
}
]
}
}
}
should(or),必须满足所有条件,类似于: where id=1 orname=xxx
GET fenganchen/user/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "冯凡利"
}
},
{
"match": {
"age": "18"
}
}
]
}
}
}
**must_not(not)**,必须满足所有条件,类似于: where id != 1
GET fenganchen/user/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"age": 3
}
}
]
}
}
}
13.过滤常见匹配查询
任何收录风范里字符串的东西都会被找到
GET fenganchen/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "冯凡利"
}
}
]
}
}
}
添加过滤器,过滤器
filter关键字过滤查询的数据。
GET fenganchen/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "冯凡利"
}
}
],
"filter": {
"range": {
"age": {
"gt": 3
}
}
}
}
}
}
上面的语句是对查询语句进行过滤,过滤掉年龄大于3的数据
14. 个空格匹配多个条件
匹配关键字空间
多个条件,以空格分隔
只要隐藏其中一个结果,就能查出
这时候通过_score分数就可以做出一个基本的判断了。
以下查询语句的含义:在tags字段中找到male和technical的数据并进行查询
GET fenganchen/user/_search
{
"query": {
"match": {
"tags": "男 技术"
}
}
}
15. 词条精确查询 i。术语分析
词条查询是通过倒排索引指定词条的过程直接搜索的!
关于分词:
ii. 两类文字关键词详解
分词器不能使用两种类型的文本关键字
文本类型:可分段
关键字类型:不能分段
首先创建索引并指定属性规则,如下:
一个。版本 6 创建索引并指定规则
elasticsearch 6.X必须指定创建索引的类型,feng_type是索引的类型名
```json
PUT testdb
{
"mappings": {
"feng_type": {
"properties": {
"name": {
"type": "text"
},
"desc": {
"type": "keyword"
}
}
}
}
}
```

湾。版本 7 创建索引并指定规则
elasticsearch 7.x 不需要指定类型来创建索引,因为版本7弃用了类型关键词(这里我就不演示了,我用的是6.4. 2 版本在这里。)
```json
PUT testdb
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"desc": {
"type": "keyword"
}
}
}
}
```
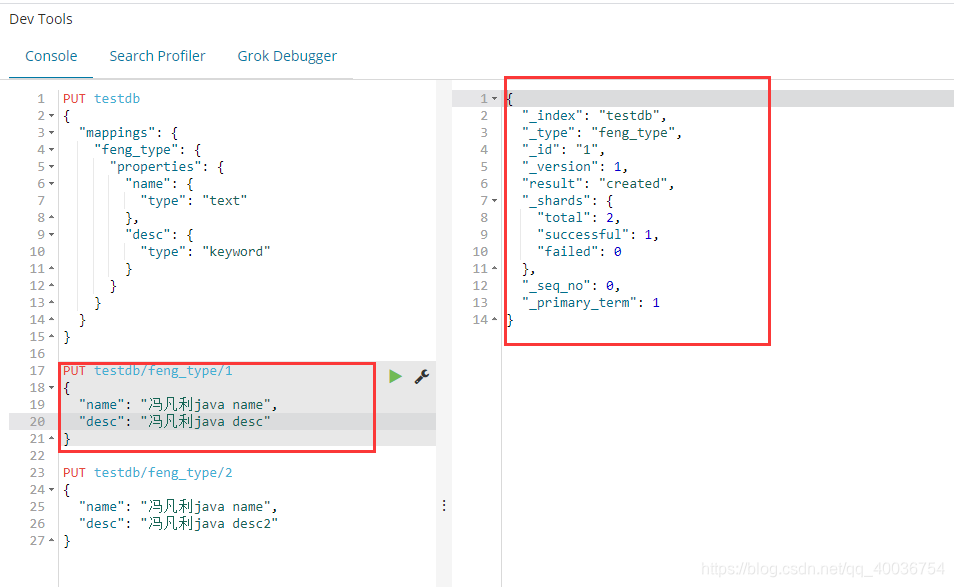
C。添加数据
```json
PUT testdb/feng_type/1
{
"name": "冯凡利java name",
"desc": "冯凡利java desc"
}
PUT testdb/feng_type/2
{
"name": "冯凡利java name",
"desc": "冯凡利java desc2"
}
```
添加文档 1
添加文档 2
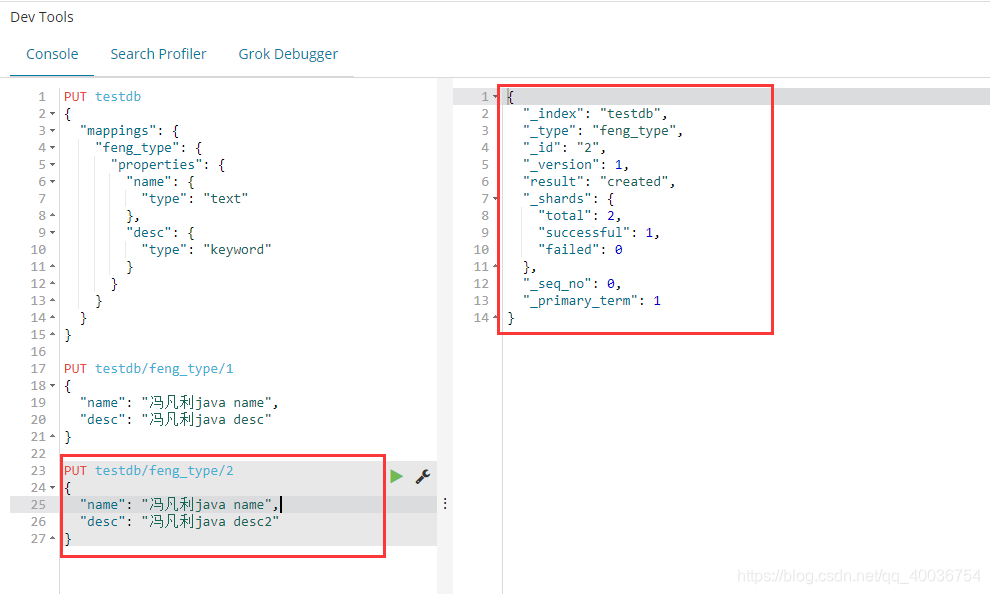
d。elasticsearch-head的google插件,查看testdb索引数据
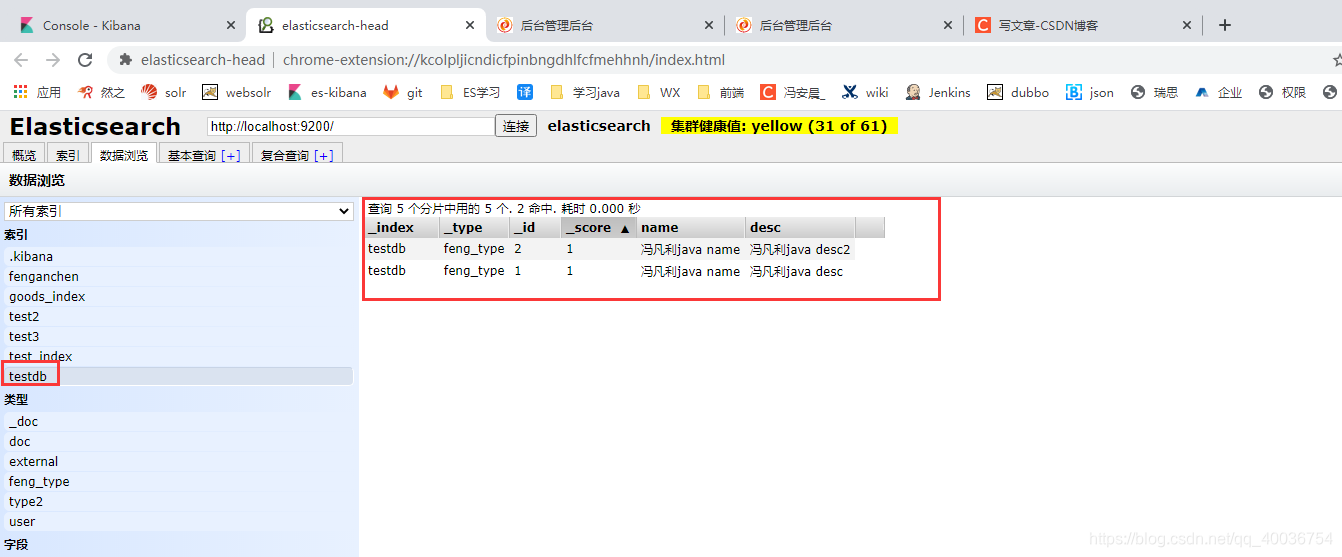
e. elasticsearch-head 的 Google 插件,参见 testdb 映射规则
索引情况,可以查看索引的设置详情,以及映射映射规则包括类型和属性。
可以看到,name 属性是 text 类型,而 desc 是关键字类型。
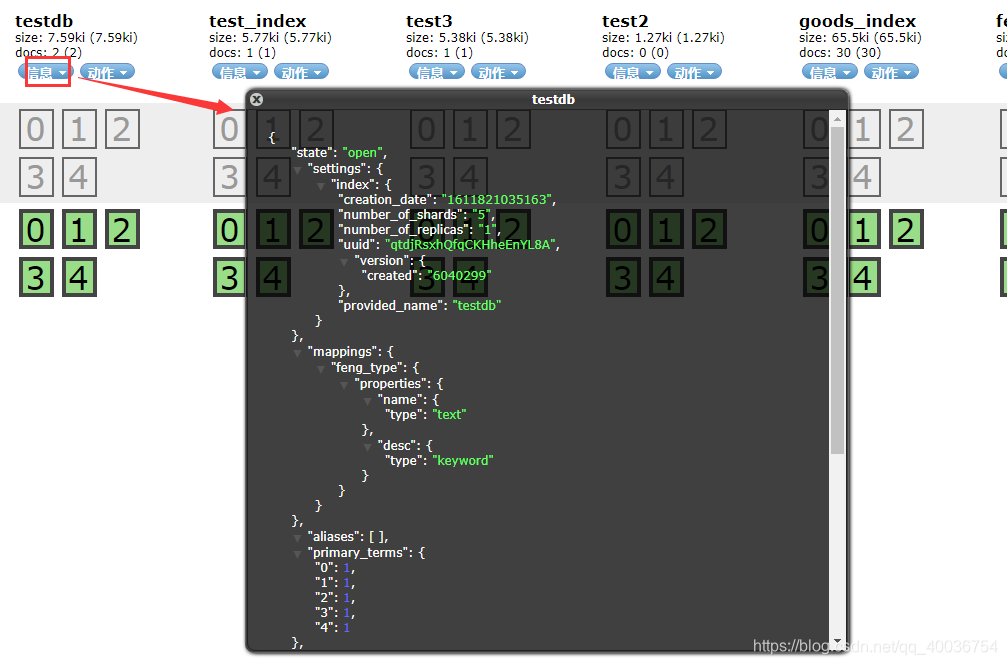
F。默认标记器测试:关键字
KeywordAnalyzer 将整个输入视为单个词汇单元,以促进特定类型文本的索引和检索。使用 关键词 标记器为邮政编码和地址等文本信息创建索引项非常方便。
使用默认的关键字tokenizer进行分词,(比如说ik tokenizer是中文tokenizer),这里可以看出没有分析
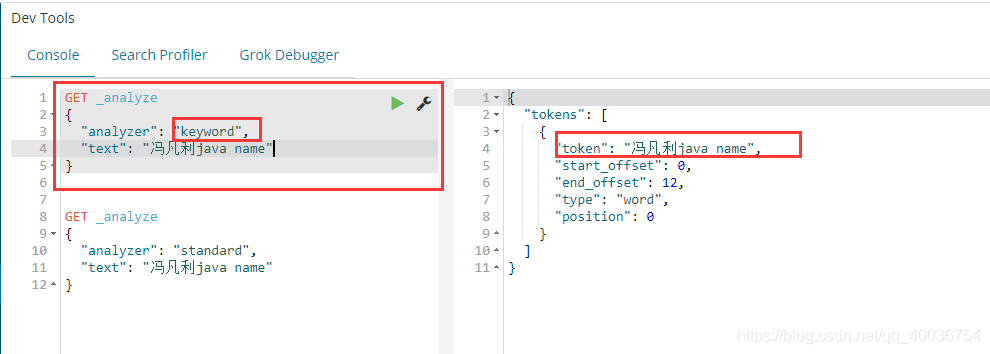
G。默认标记器测试:标准
英文的处理能力和StopAnalyzer一样,支持中文的方法是分词。它将词汇单元转换为小写并删除停用词和标点符号。
使用默认的标准分词器进行分词,见这里分析
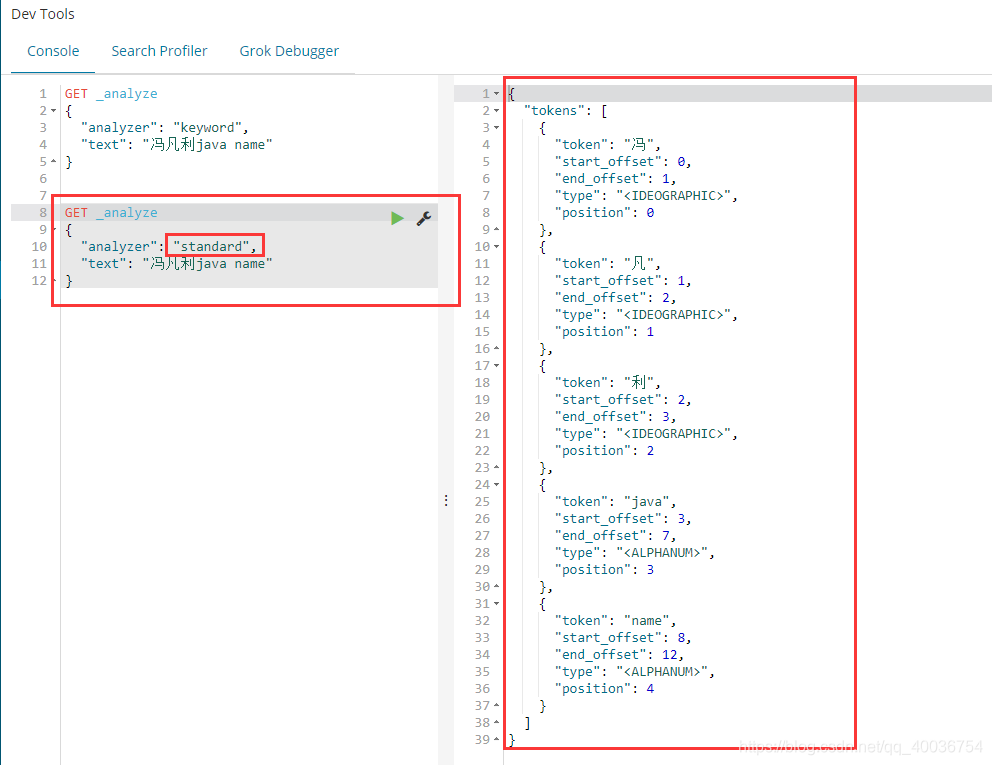
H。term 准确查找文本类型
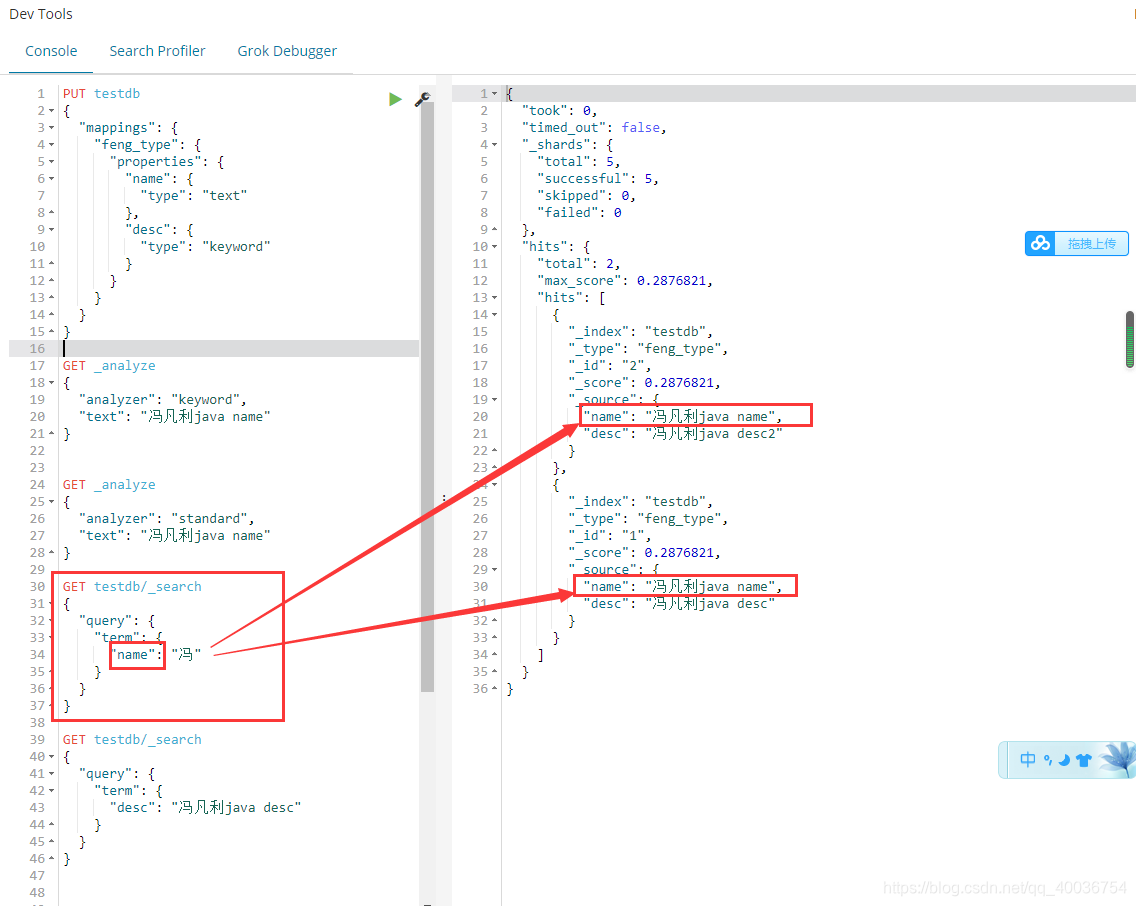
一世。term 查找确切的关键字类型

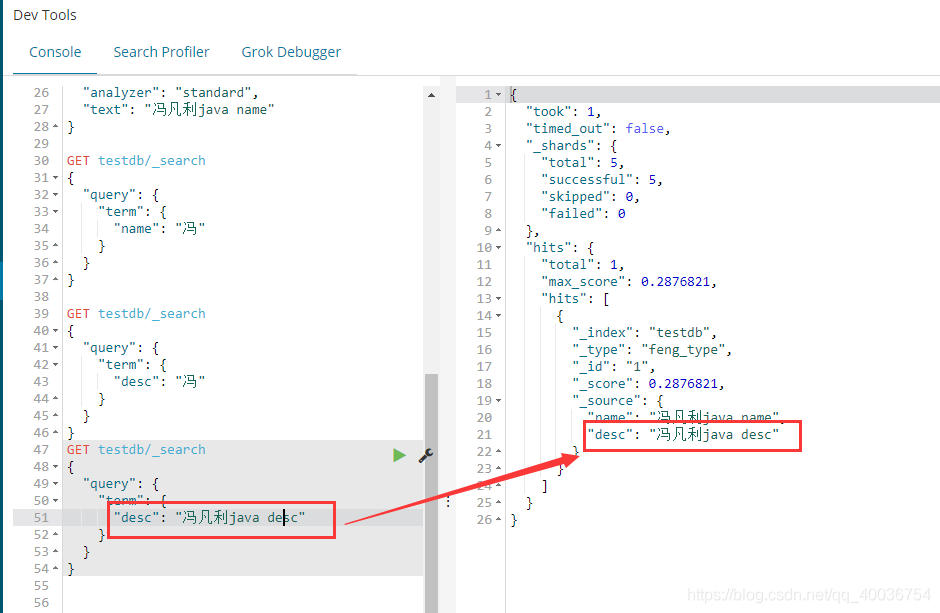
j. 总结 h 和 i 的检验
在 testdb 索引中:
名称字段是文本类型,
desc 字段是关键字类型。
但是,当 term 精确搜索它们时,它会发现:
在查找文本类型的名称字段时,只需收录它,即文本类型可以被分词器解释。在查找关键字类型的 desc 字段时,必须完全收录,即关键字类型将整个输入匹配为单个词法单元,由分词器解释。16. 多词精确匹配 a. 添加多数
PUT testdb/feng_type/3
{
"t1": "22",
"t2": "2020-4-6"
}
PUT testdb/feng_type/4
{
"t1": "33",
"t2": "2020-4-7"
}
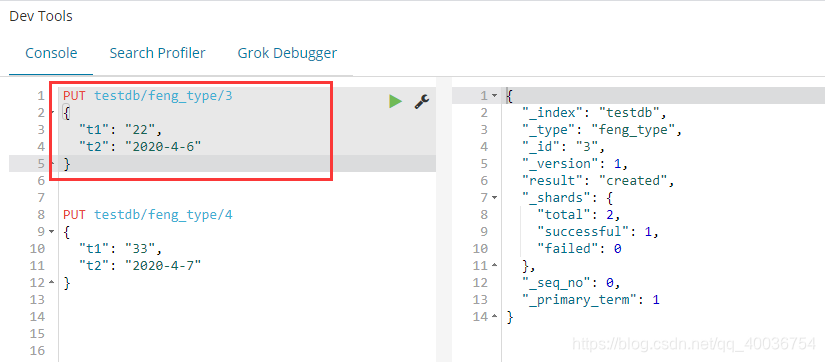
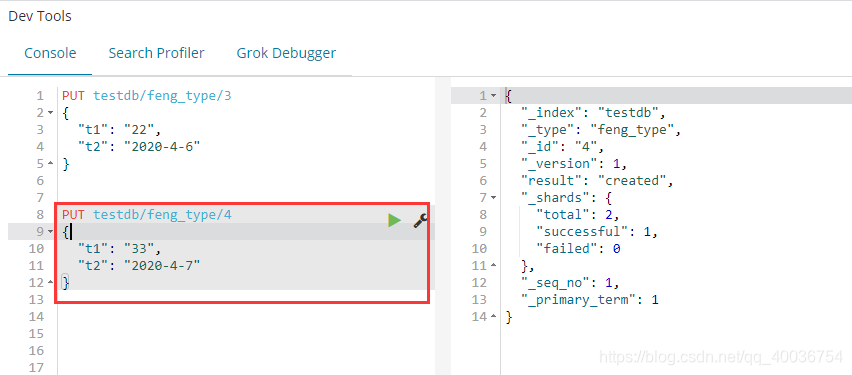
湾。查看 elasticsearch-head 的谷歌插件,查看 testdb 索引数据和映射规则。索引数据

映射规则
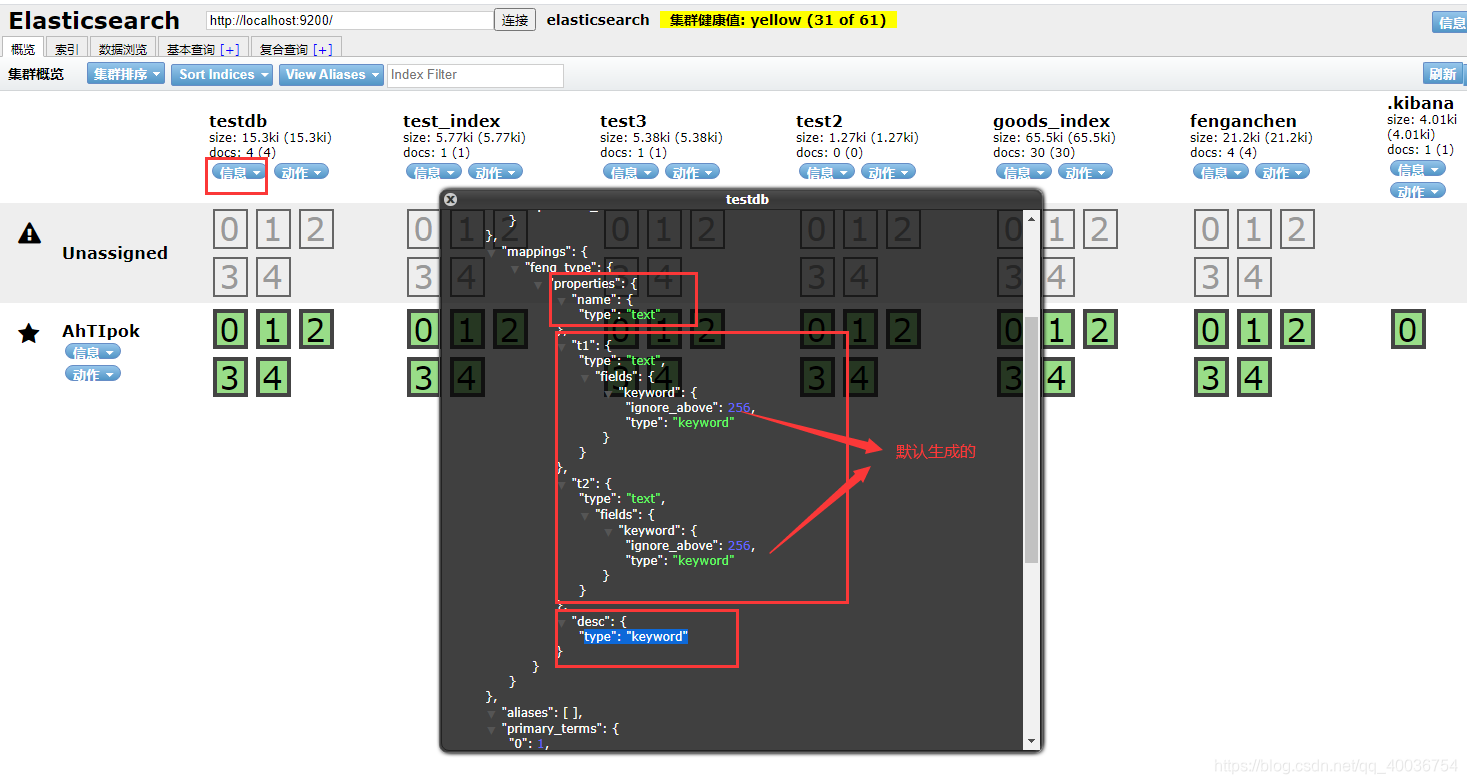
C。词条精确查询
 @>
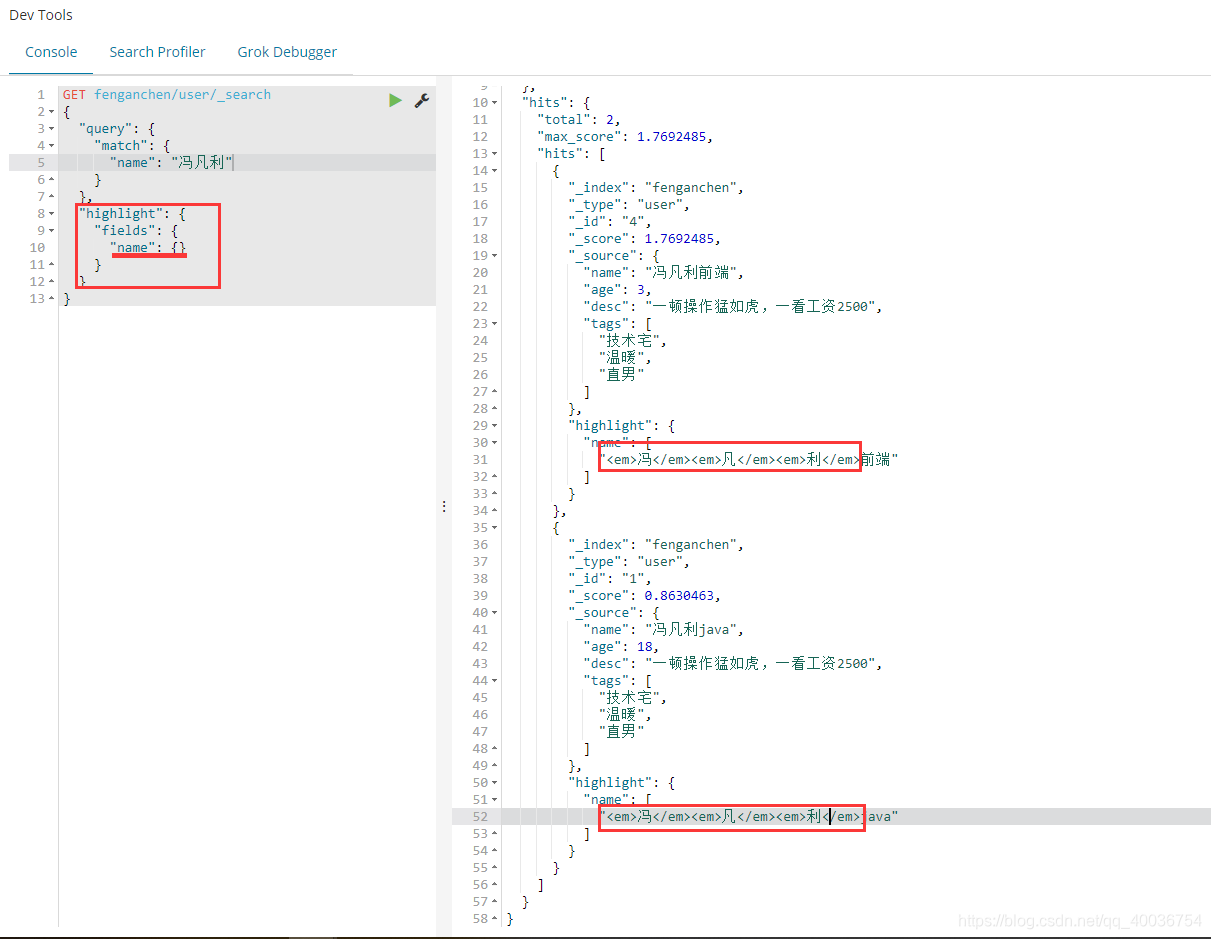
@>17. Highlight 高亮关键字:highlight
GET fenganchen/user/_search
{
"query": {
"match": {
"name": "冯凡利"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
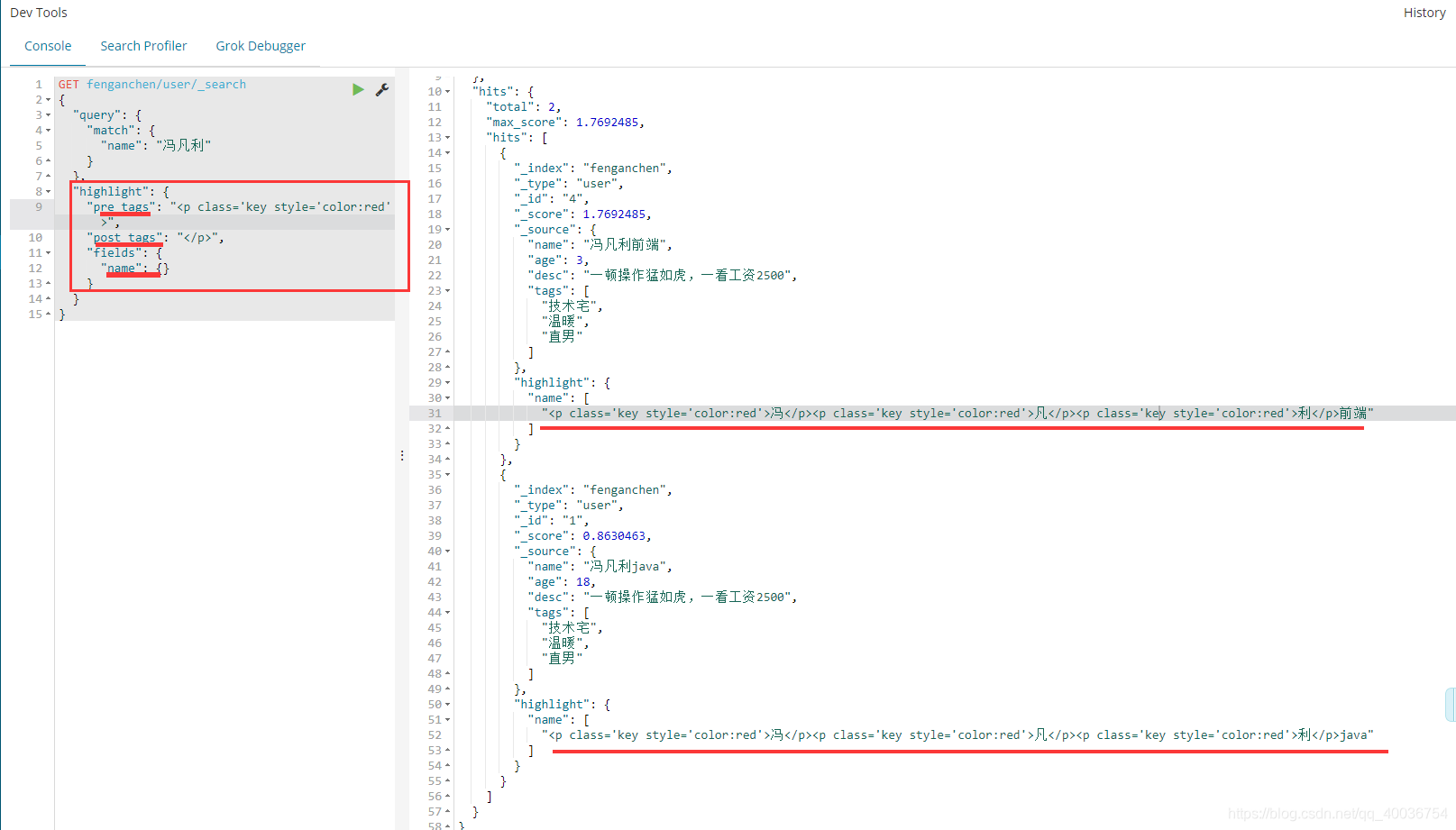
自定义搜索突出显示
GET fenganchen/user/_search
{
"query": {
"match": {
"name": "冯凡利"
}
},
"highlight": {
"pre_tags": "<p class='key style='color:red'>",
"post_tags": "",
"fields": {
"name": {}
}
}
}
</p>
这些mysql也可以做,但是mysql的效率比较低
seq搜索引擎优化至少包括那几步?(本文主要分享&;全能选手&;召回表征算法实践)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-01-30 09:17
本文主要分享“全能型”召回表示算法的实践。首先简单介绍一下业务背景:
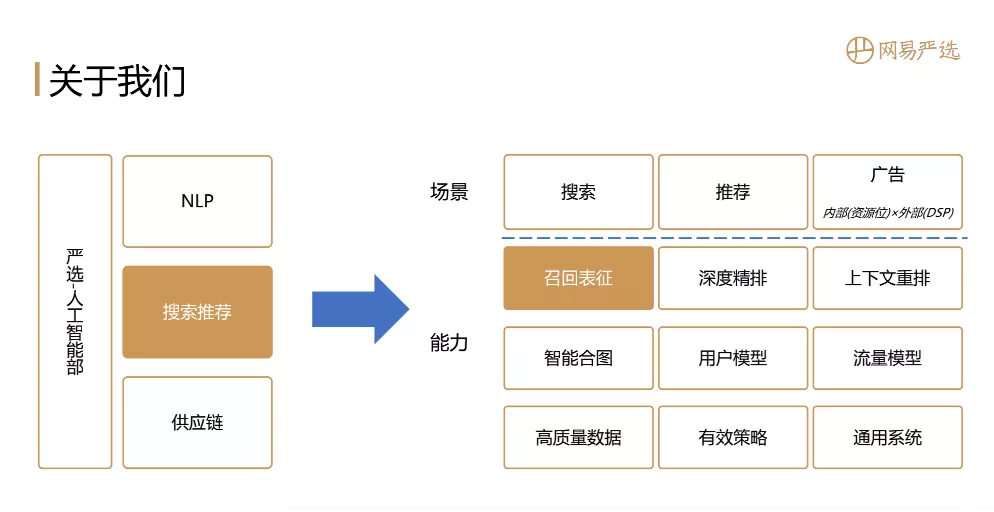
网易主要有NLP、搜索推荐、供应链三大方向。我们主要负责搜索推荐。搜索推荐与营销侧的业务场景密切相关,管理最大的流量入口进行严格的选择。我们团队的主要目标是优化转化率和GMV相关指标,具体业务是搜索、推荐、广告(包括内部库存广告和外部DPS广告)。
如图所示,在这些个性化场景中,就是我们拥有的能力矩阵。刚收到邀请的时候,想谈一下燕轩商业场景中个性化相关的事情,但是我们基本上已经做了2到3年的生意了。如果我们想在短时间内完成聊天,我们只能介绍我们做了什么。工作以及实现了什么商业价值。但是,每个人的业务场景都大相径庭。我们这边的最优实施方案未必是其他场景下的最优方案。听了大家的话,可能收获不大。与其这样,不如集中在一个小模块上详细讲,所以今天我就选择recall表示的部分,由此引出本次分享的主题:“全能玩家”
01
问题定义
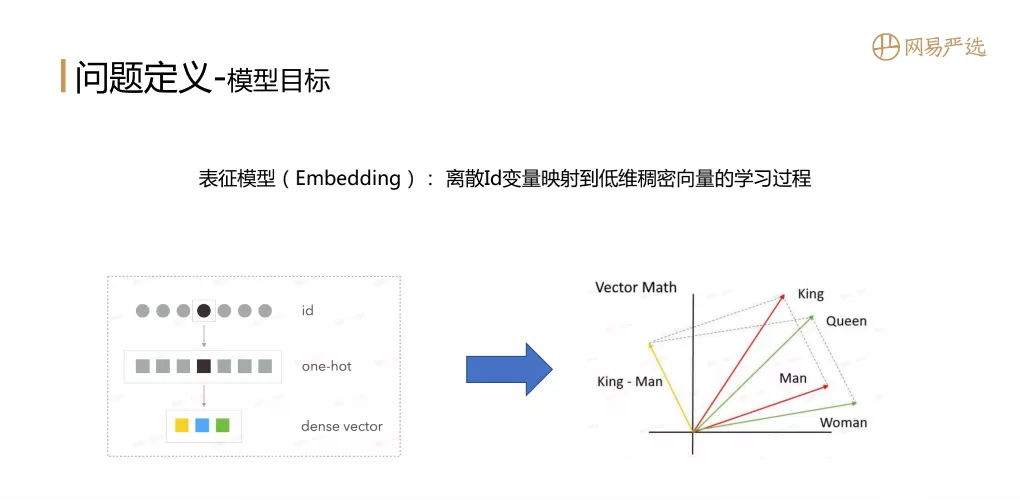
1. 模型目标
首先说一下问题的定义,也就是模型要做的目标是什么?Embedding:这是一个将离散的 id 变量映射到低维密集向量的学习过程。使用离散id作为特征时,一般先进行one-hot编码,然后再映射成稠密向量。Embedding 的目标是在大数据中反映相关主题。通过Embedding向量表示学习到主体的向量信息,也可以通过向量度量公式来反映主体之间的相关性。比如右边的例子,红线代表 King 和 Man ,如果 King 和 Man 都训练了一个向量表示结果,我们希望 King 和 Man 的内积大于 Queen 和 Man 的内积,
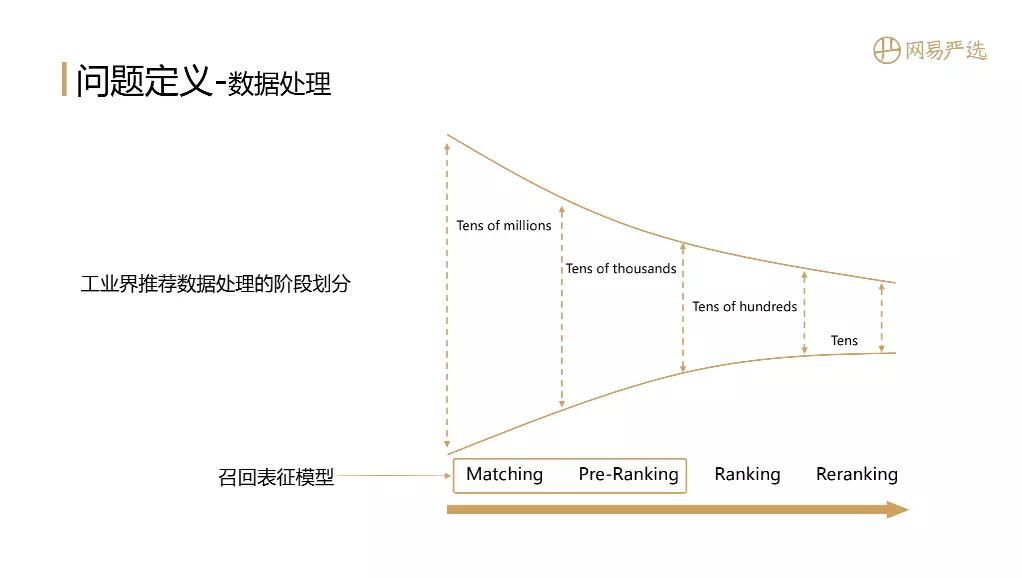
2. 数据处理
实际上,Embedding 是一个非常通用的主题学习和表达模型。它广泛用于自然语言处理、搜索、推荐和图像。那么Embedding是如何在具体业务场景下对搜索推荐起到作用的呢?下图是业内非常经典的推荐数据处理阶段划分。从左到右是数据逐层递减的过程,依次是召回(Matching)、粗排名(Pre-Ranking)、细排名(Ranking)、Reranking。我们的召回表示模型的范围主要是召回和粗略排名两个阶段,在搜索推荐中起着基石的作用。
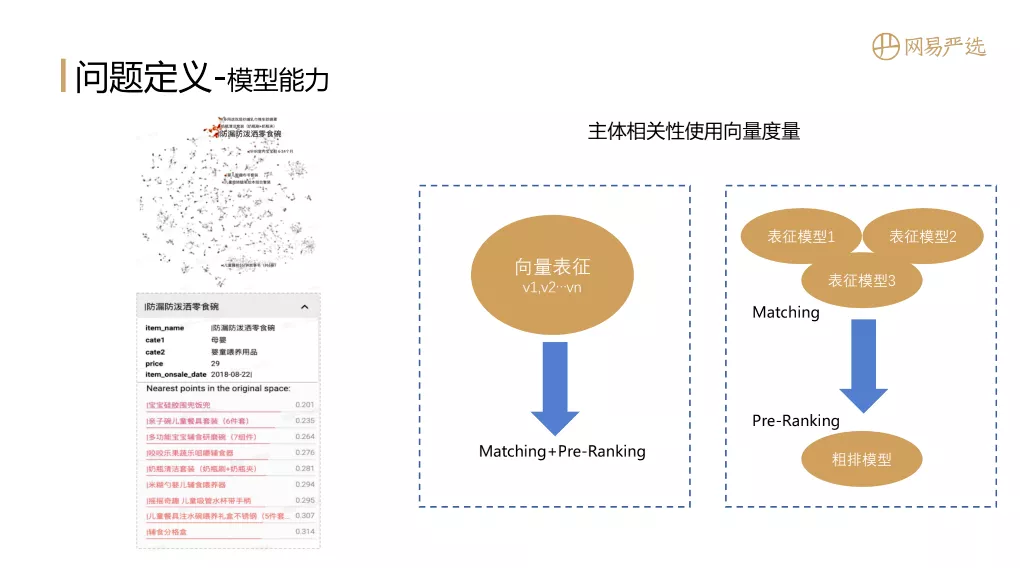
3. 模型能力
训练模型时,可以通过向量相似度来衡量受试者的相关性。下图显示了一些项目的表示。如果几件物品相似,它们的距离比较小,内积比较大,比如和相似的零食碗都是同一个品类的产品。如果我们只有一个向量表示模型,那么可以使用模型的Embedding进行recall,或者可以将两个item的embedding向量的内积作为粗排序的基础,这样recall和recall两种场景粗略的排序可以一次完成。但是,在大多数情况下,会有多个表示模型,每个表示模型都会被调用。在这种情况下,需要引入一个粗略的排序模型来对多个表示模型的召回结果进行合并和排序。用于合并的粗选能力可以与蒸馏模型进行策略性的结合,这里不做介绍。
02
模型值
为什么表示模型值得深入研究?
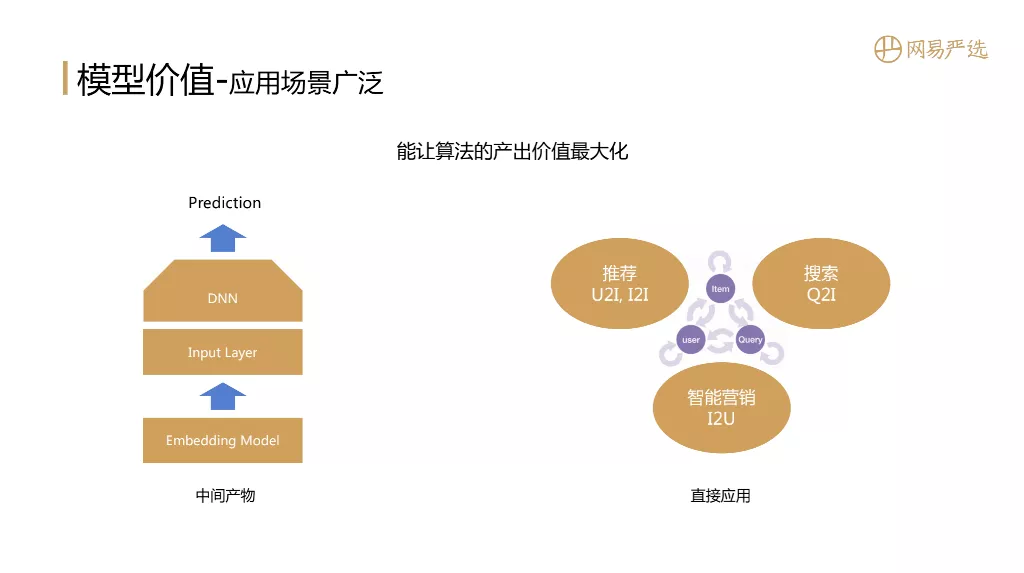
1. 应用场景广泛
接下来,我将介绍为什么表示模型值得深入做?它可以产生什么价值?问题的答案与文章的标题息息相关:Embedding是一个应用范围很广的全能者,可以最大化算法输出的价值。应用场景包括:
2. 工程解决方案成熟
Embedding矢量已经可用,需要矢量搜索引擎来推动矢量在线使用,具有在线响应能力。根据向量搜索引擎提供的接口,可以找到内积最大或与给定向量距离最近的TopN向量。第一个是Facebook早前提出的Faiss方案,第二个是Google提出的SCANN方案;这两种方案都非常好,可以大大降低工程门槛。
3. 技术飞速发展
向量表示是学术界的热点,并且不断创新,尤其是GCN(图卷积神经网络)和GNN(图神经网络)非常流行,学术界每年都会发表很多论文。与学术研究的快速发展相关的技术红利可以为业务带来增量价值。接下来从两个方向讲向量表示的模型,一个是序列模型SeqModel,一个是图网络模型,两者都可以解决向量表示的问题。在选择模型时,应该选择两种模型中的哪一种?这与产品数据密切相关。如果产品数据具有很强的时间相关性,那么使用序列模型的效果肯定不会差;如果产品数据的节点比较稀疏,则需要使用邻居节点进行信息协同建模。这时候,推荐尝试 GNN。图数据几乎可以收录在任何场景生成的数据关系中,所以GNN是通用的模型解决方案,具有很高的通用性,但并不意味着GNN在所有场景下都优于序列模型。方案比较。接下来,基于我们搜索推荐业务场景的总结,给大家分享一下序列模型和GNN模型的迭代。所以GNN是一种通用的模型解决方案,具有很高的通用性,但这并不意味着GNN在所有场景下都优于序列模型。方案比较。接下来,基于我们搜索推荐业务场景的总结,给大家分享一下序列模型和GNN模型的迭代。所以GNN是一种通用的模型解决方案,具有很高的通用性,但这并不意味着GNN在所有场景下都优于序列模型。方案比较。接下来,基于我们搜索推荐业务场景的总结,给大家分享一下序列模型和GNN模型的迭代。
03
迭代实现
1. 关注项目嵌入
艳选业务的用户数量远大于商品数量。由于用户数量众多,实验稀疏,User Embedding 并不是很有效。因此,我们在初始阶段专注于Item Embedding。商品数量少,落地成本低。,关联数据密集,表示效果较好。
① SeqModel优化
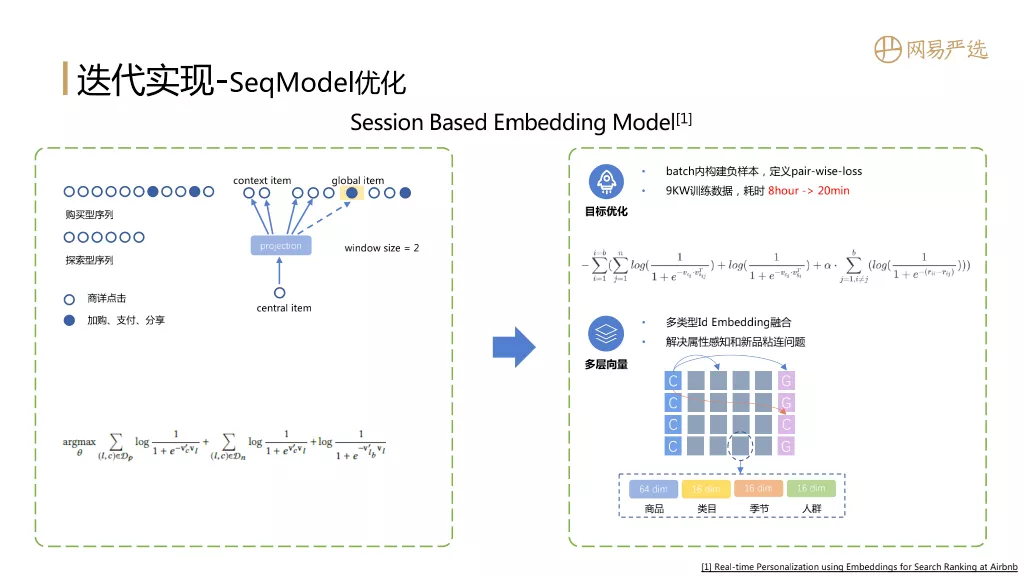
第一个模型是我们定制和优化的基于会话的嵌入模型。它的主要思想来自 Aribnb 的一篇 Embedding 论文(这篇论文写得非常好,建议大家学习一下)。该模型的主要思想是构造一个类似于word2vec的序列,重点关注向量在序列数据的上下文时间窗口中的相关性。图中每个圆圈代表一个项目,多个圆圈构成一个行为序列。行为序列来自用户在连续一段时间内的行为数据。传统的 word2vec 只关注上下文信息。这篇论文的核心思想是提出全局item,跳出了序列模型窗口的限制。全局item是指序列数据中的一些重要节点(图中实心节点),如用户的插件购买、支付、分享等行为。全局item打破了模型窗口的限制,使得item向量可以学习到一些高阶连接信息,大大提高了序列模型的表示效果。
在此之上,我们对损失函数做了一些优化,包括在batch中去除负采样和建立pair-wise loss的过程,可以大大提高训练速度;同时我们还引入了多层向量,也就是side-info嵌入的思想,不仅是在对item做向量表示的时候使用它的id类型的特征,还引入了产品属性等特征,类别、适用季节和适用组,进一步提高向量表示的效果,同时缓解新项目冷启动表征问题。
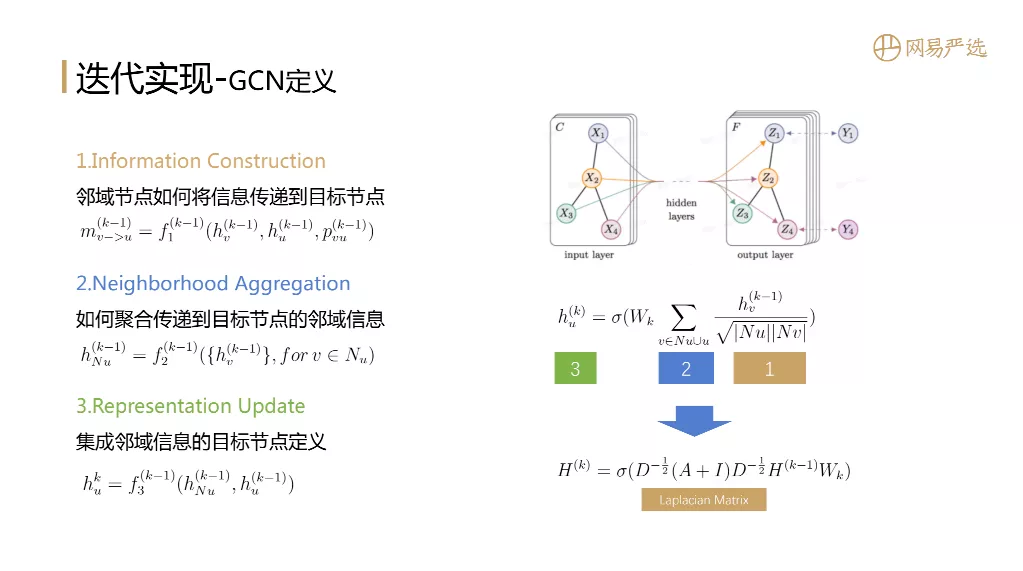
② GCN 定义
接下来说说学术界比较火的GCN/GNN模型。图神经网络一般有三个阶段的定义:
目前,很多关于 GNN 的论文都有关于这三个阶段的定义。图右侧是GCN的示意图。图中的公式对应了三个阶段,很巧妙的是,这个公式可以转化为矩阵运算形式,可以充分利用GPU的计算能力。但是这个矩阵的节点数是(#users+#items)×(#users+#items),而且规模大到行业很难落地。
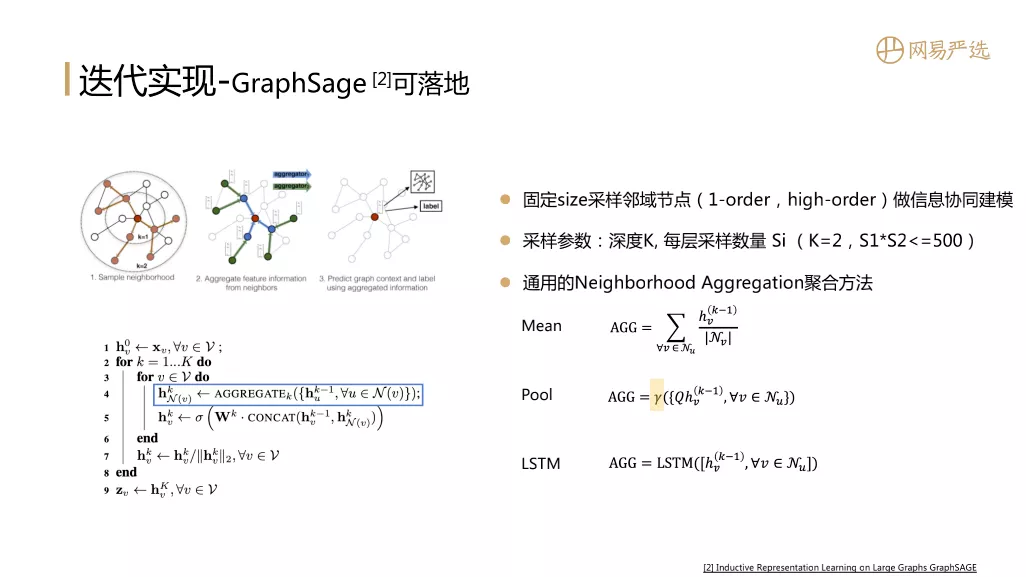
③ GraphSage 可以登陆
GraphSage是一个基于采样的思想降低落地难度,用采样代替矩阵计算的过程。采样深度(一般深度不会超过2)对应迭代次数。多次迭代可以获得高层域信息进行信息协同建模,同时每次迭代的样本数可以调整。该模型最大的贡献在于提供了一种通用的Neighborhood Aggregation聚合方法,可以通过均值的方式进行聚合,也可以引入池化层,也可以引入LSTM进行序列聚合。
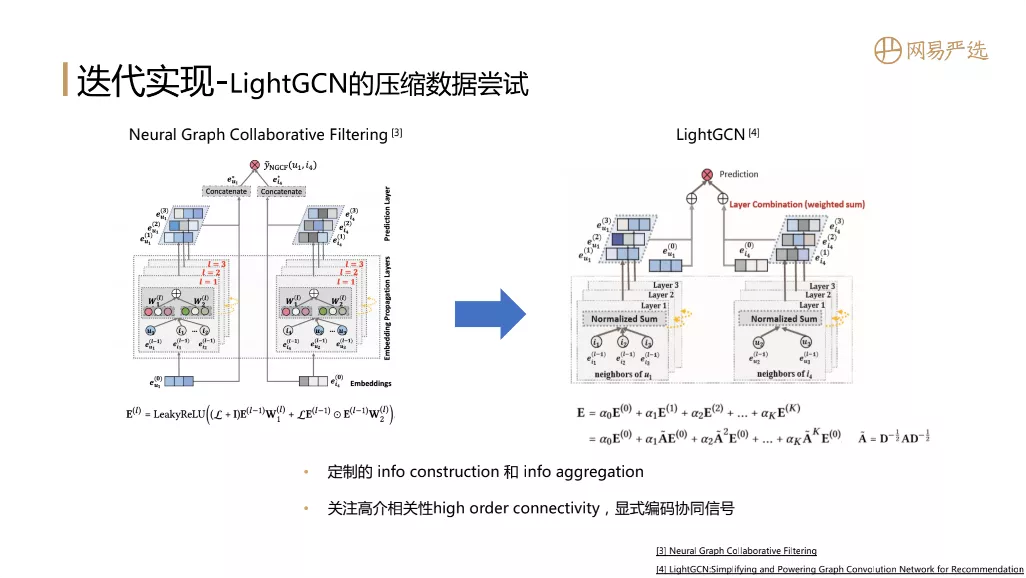
④ LightGCN的压缩数据尝试
GCN 需要很大的矩阵计算过程。与工程理念相比,两者的效果有何不同?是否可以通过减少现有数据来实现 GCN 与其他模型的对比?所以我们实现了一个LightGCN,主要参考了图中的两篇论文。两篇论文来自同一个团队。论文定制了信息的构建和聚合过程,可以捕获节点的高阶相关性,并对协作信号进行显式编码。一般GCN的网络深度不会超过2,而这里的LightGCN可以做到三层,其中的节点已经覆盖了用户和物品。在本文的最后,我们将比较所有的效果。在知识表达方面,这两篇论文写得都不错。您可以研究它们并更好地了解GCN。
2. 获取用户嵌入
我们在第一阶段获得了Item Embedding,如何从Item Embedding中获得User Embedding?主要有两种思路:策略法和模型法。
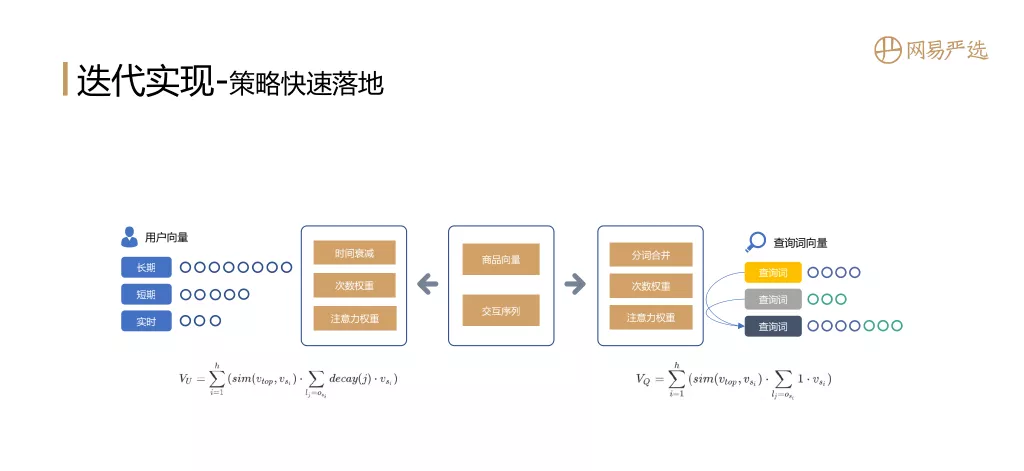
① 战略快速落地
该策略是一个可以快速实施的解决方案,是一个非常好的和稳定的基线。我们可以利用已知的物品隐向量和用户在会话中的交互行为序列,基于时间衰减、时间加权和注意力机制得到用户的向量表示。在相同的搜索场景下,也可以通过分词组合、次数权重、查询词的注意力权重得到查询词的向量表示。
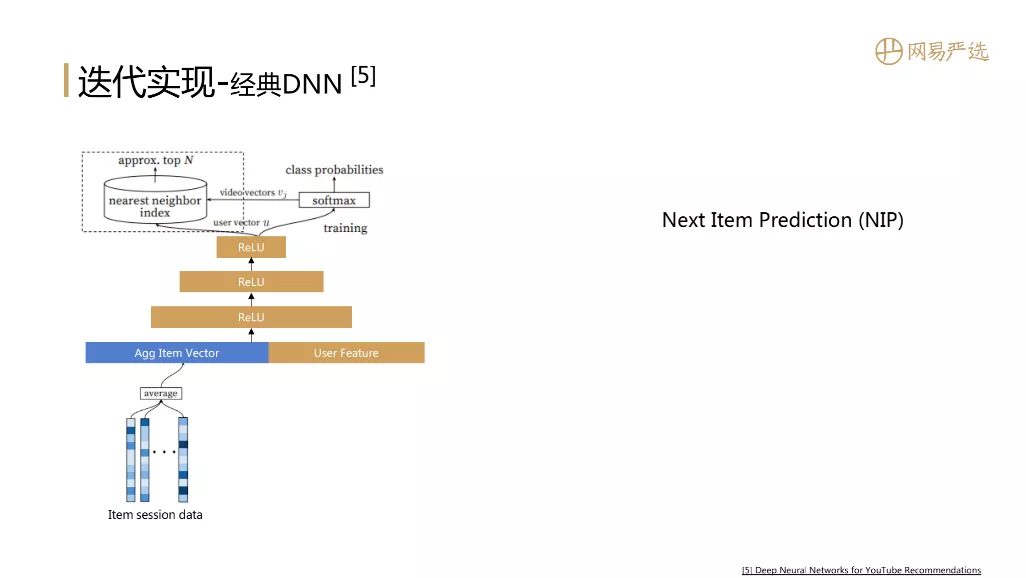
② 经典 DNN
接下来是经典的模型DNN,直接通过模型得到用户的向量。参考图中YouTube上的这篇经典论文,模型本质上是一个有监督的NextItemPrediction训练过程,用户的Item会话数据,简单的平均聚合,用户特征作为深度模型的输入特征数据。输入特征数据逐层传播,最后一层得到用户向量。用户向量和项目向量做softmax完成一个概率分布预测,模型的loss也得到了。模型训练完成后,同时得到User和Item的向量表示。
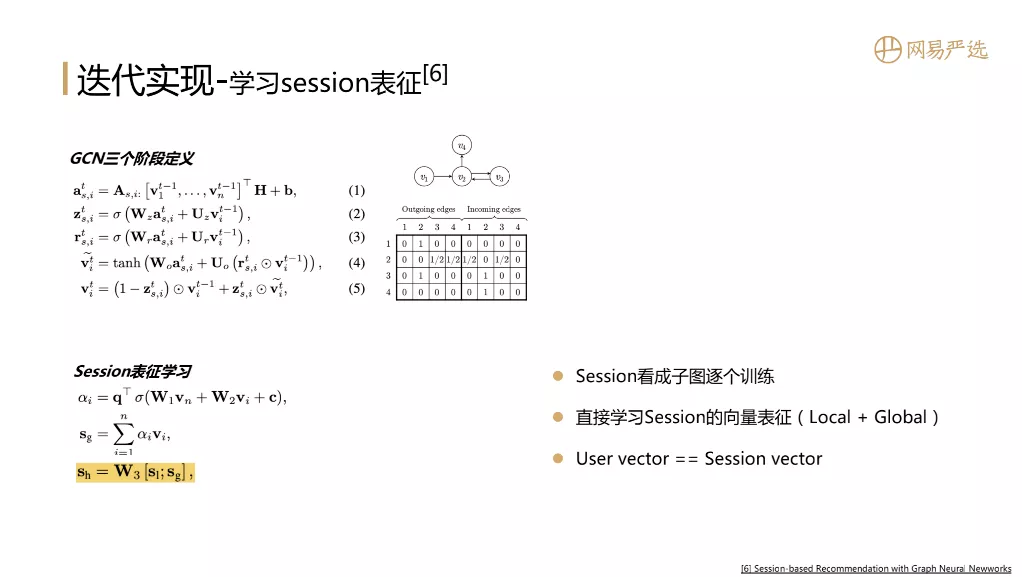
③ 学习会话表示
当然我们要通过图模型得到用户的向量。用户的行为基于会话来表示。如果有方法可以直接将会话表示为向量,那么可以直接得到行为序列下的用户向量。下图中的论文通过学习会话向量的表示来解决这个问题。它也有GCN的三个阶段的定义。在定义过程中,还引入了门的参数来设置最终向量的表示过程。最有价值的一点是它进行会话表示学习。在训练过程中,每一个session都被视为一个子图,一个一个地训练,然后将局部向量(会话中的最后一个项目向量)添加到全局向量(会话中的其他项目向量)。注意力聚合后得到一个全局向量作为会话向量,最后用会话向量表示用户向量。该模型的效果在离线评估中更为突出。
④ 多用户向量
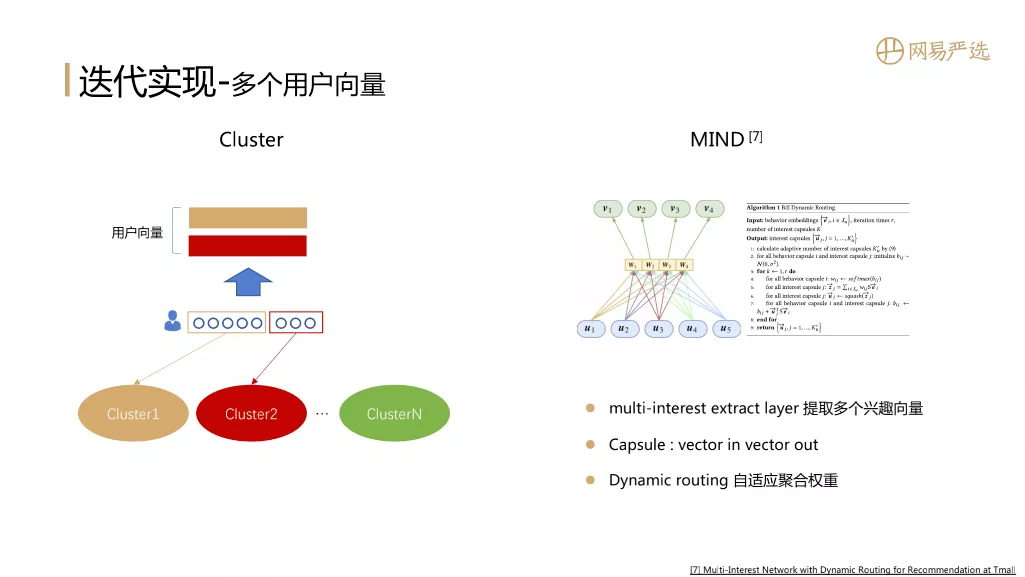
我们之前一直在用单个向量来表征用户,那么我们可以用多个用户向量来表征用户的兴趣吗?答案是肯定的,因为如果用户的兴趣比较广泛,使用一个向量来表示用户时会损失信息丰富度,使用多个向量来表示用户可能会更好。
第一个思路是聚类方法:首先对item K-means进行聚类,得到多个聚类,每个聚类都有一个向量表示。如果用户行为序列中的项目涉及多个聚类,则将属于同一聚类的向量聚合起来代表用户。聚合方法可以用簇向量计算权重并逐位相加。用户向量的数量等于序列中簇的数量。
第二个想法是 MIND:它使用胶囊网络来形成多个兴趣向量。结构中有一个多兴趣提取层,负责提取多个兴趣向量。图中,u1、u2是用户行为序列中的item,它们作为胶囊网络的输入,v1、v2是用户的多个兴趣向量,胶囊网络的输出. 同时,胶囊网络还支持动态路由,多次迭代自适应地迭代获得聚合权重。
3. 效果对比
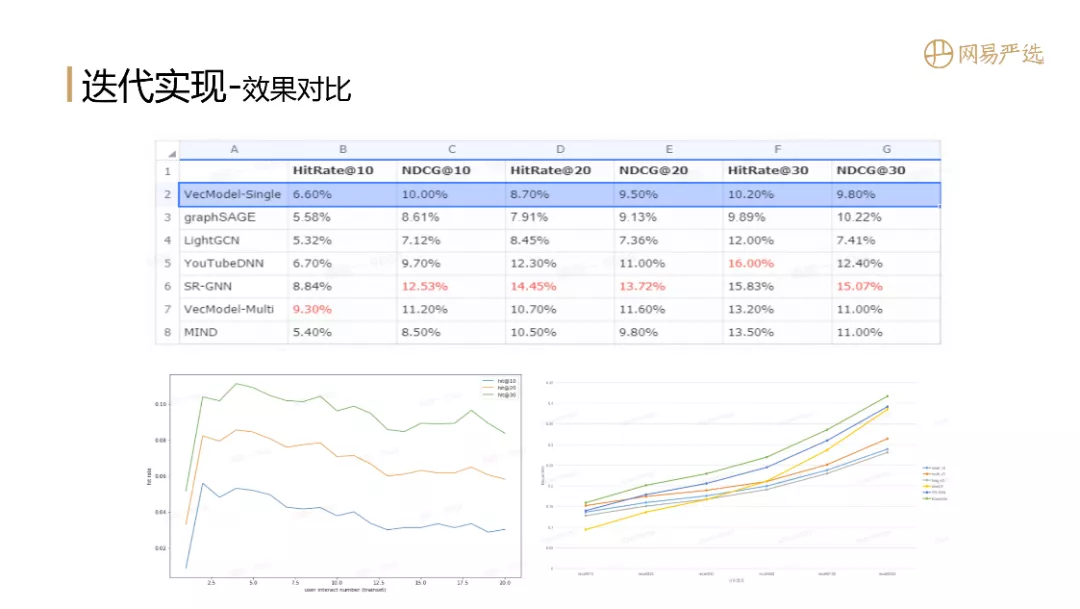
接下来,我们对这些网络模型进行比较。比较指标是 HitRate 和 NDCG。我们采用 VecModel-Single(基于序列模型会话的嵌入模型)作为基线模型。
在我们的场景数据中,graphSAGE 作为 GCN 的工业实现指标并不突出,在 NDCG@30 上略超过基线模型。LightGCN通过减少数据来适应当前最大的锅,然后产生最大的蛋糕;LightGCN 使用矩阵来学习向量表示,效果相比基线模型并不是特别突出,只是在个别指标 HitRate@30 上有一些提升。YouTubeDNN 在 4 个指标上有明显提升。SR-GNN 直接表示会话的用户向量,通过模型参数学习得到用户向量。也是离线效果最好的机型。VecModel-Multi是基于序列模型,加入聚类用户多兴趣向量表示,MIND是基于胶囊网络的多兴趣向量模型;
左下图是不同用户行为分组的模型效果,X轴是用户行为数,Y轴是HitRate。一开始,用户在没有行为的情况下无法感知用户偏好,模型效果比较差(User Type Embedding实现了NIP)。当用户有1、2个行为时,性能指标大大提高。这也很容易理解,因为新用户在来到一个场景产生初始行为的时候兴趣更加集中,但是随着用户行为数量的增加,只使用向量模型进行召回和排序会减少指标,进而需要连接细化和重新排列模型,以进一步提高业务成果。右下图是HitRate@N中多个模型的效果,其中绿色曲线是使用该策略融合多个模型的结果后的表现。可以看出,只是简单的合并,相比其他单一模型有明显提升。. 以后也可以用粗排模型来合并各个表示模型的结果,效果应该会有所提高(用于合并的粗排模型还在进行中)。
04
业务落地
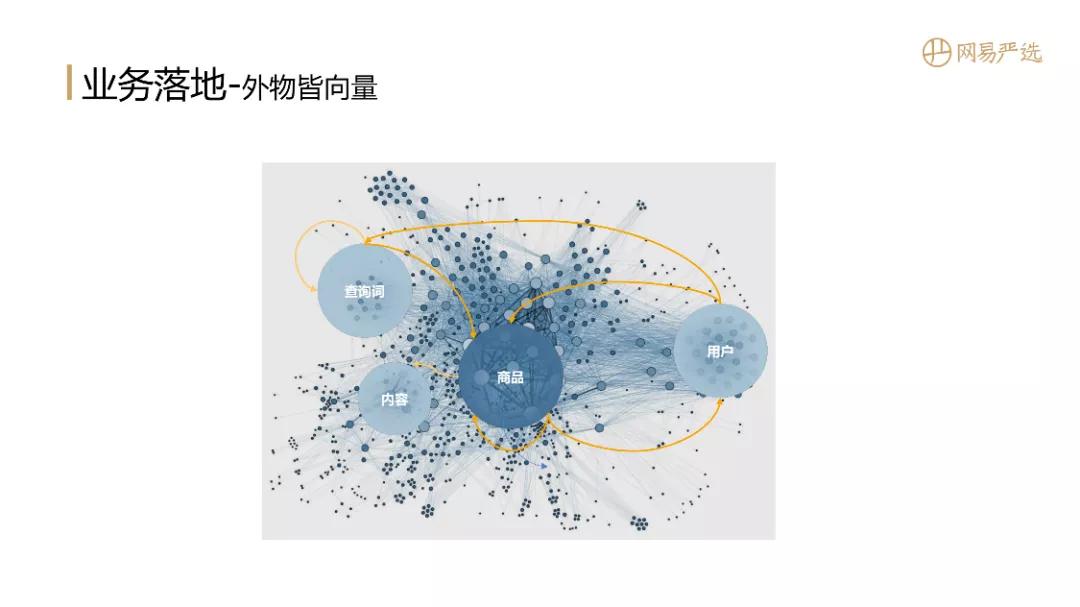
1. 异物是向量
接下来说说业务是如何实现的。异物是向量是 Facebook 提出的口号。如果我们有一套完整的向量系统,那么业务场景中的所有科目都可以向量化,然后就可以做U2I,I2I和Q2I的召回就很方便了。
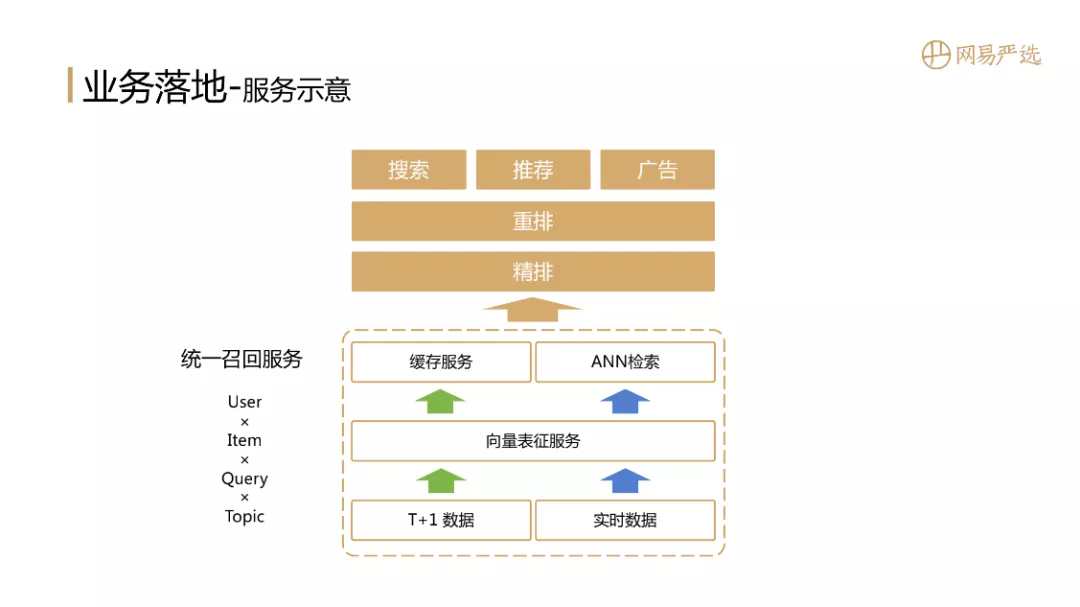
2. 服务说明
该图是一个简单的服务图。整体是一个一体化的统一召回服务。核心向量表示服务具有表示用户和项目向量的能力。它可以使用 T+1 数据进行表示,也可以使用实时数据进行用户实时表示。利益代表。统一召回服务的输出经过提炼和重排后,可以应用于搜索、推荐、广告等业务场景。因此,召回服务是每一项业务的基石。召回效果的提升可以提升多场景的效果。投入产出比非常高的技术方向。
3. 应用效果
有了一切矢量化的基础后,下面是一些具体应用的落地效果。比如搜索中搜索词的推荐(U2Q)和搜索结果的语义匹配(Q2I),推荐中很多简单的场景可以直接使用基于向量的排序模型,效果也不错。内部第一焦点广告中还有图片的智能组合。通过 User2Topic,User2Item 选择用户最感兴趣的活跃产品呈现个性化的 Banner。
作者:潘胜义 网易严选算法专家,搜索推荐负责人。团队负责的业务包括搜索、推荐、内外广告、用户模型等。 查看全部
seq搜索引擎优化至少包括那几步?(本文主要分享&;全能选手&;召回表征算法实践)
本文主要分享“全能型”召回表示算法的实践。首先简单介绍一下业务背景:
网易主要有NLP、搜索推荐、供应链三大方向。我们主要负责搜索推荐。搜索推荐与营销侧的业务场景密切相关,管理最大的流量入口进行严格的选择。我们团队的主要目标是优化转化率和GMV相关指标,具体业务是搜索、推荐、广告(包括内部库存广告和外部DPS广告)。
如图所示,在这些个性化场景中,就是我们拥有的能力矩阵。刚收到邀请的时候,想谈一下燕轩商业场景中个性化相关的事情,但是我们基本上已经做了2到3年的生意了。如果我们想在短时间内完成聊天,我们只能介绍我们做了什么。工作以及实现了什么商业价值。但是,每个人的业务场景都大相径庭。我们这边的最优实施方案未必是其他场景下的最优方案。听了大家的话,可能收获不大。与其这样,不如集中在一个小模块上详细讲,所以今天我就选择recall表示的部分,由此引出本次分享的主题:“全能玩家”
01
问题定义
1. 模型目标
首先说一下问题的定义,也就是模型要做的目标是什么?Embedding:这是一个将离散的 id 变量映射到低维密集向量的学习过程。使用离散id作为特征时,一般先进行one-hot编码,然后再映射成稠密向量。Embedding 的目标是在大数据中反映相关主题。通过Embedding向量表示学习到主体的向量信息,也可以通过向量度量公式来反映主体之间的相关性。比如右边的例子,红线代表 King 和 Man ,如果 King 和 Man 都训练了一个向量表示结果,我们希望 King 和 Man 的内积大于 Queen 和 Man 的内积,
2. 数据处理
实际上,Embedding 是一个非常通用的主题学习和表达模型。它广泛用于自然语言处理、搜索、推荐和图像。那么Embedding是如何在具体业务场景下对搜索推荐起到作用的呢?下图是业内非常经典的推荐数据处理阶段划分。从左到右是数据逐层递减的过程,依次是召回(Matching)、粗排名(Pre-Ranking)、细排名(Ranking)、Reranking。我们的召回表示模型的范围主要是召回和粗略排名两个阶段,在搜索推荐中起着基石的作用。
3. 模型能力
训练模型时,可以通过向量相似度来衡量受试者的相关性。下图显示了一些项目的表示。如果几件物品相似,它们的距离比较小,内积比较大,比如和相似的零食碗都是同一个品类的产品。如果我们只有一个向量表示模型,那么可以使用模型的Embedding进行recall,或者可以将两个item的embedding向量的内积作为粗排序的基础,这样recall和recall两种场景粗略的排序可以一次完成。但是,在大多数情况下,会有多个表示模型,每个表示模型都会被调用。在这种情况下,需要引入一个粗略的排序模型来对多个表示模型的召回结果进行合并和排序。用于合并的粗选能力可以与蒸馏模型进行策略性的结合,这里不做介绍。
02
模型值
为什么表示模型值得深入研究?
1. 应用场景广泛
接下来,我将介绍为什么表示模型值得深入做?它可以产生什么价值?问题的答案与文章的标题息息相关:Embedding是一个应用范围很广的全能者,可以最大化算法输出的价值。应用场景包括:
2. 工程解决方案成熟

Embedding矢量已经可用,需要矢量搜索引擎来推动矢量在线使用,具有在线响应能力。根据向量搜索引擎提供的接口,可以找到内积最大或与给定向量距离最近的TopN向量。第一个是Facebook早前提出的Faiss方案,第二个是Google提出的SCANN方案;这两种方案都非常好,可以大大降低工程门槛。
3. 技术飞速发展

向量表示是学术界的热点,并且不断创新,尤其是GCN(图卷积神经网络)和GNN(图神经网络)非常流行,学术界每年都会发表很多论文。与学术研究的快速发展相关的技术红利可以为业务带来增量价值。接下来从两个方向讲向量表示的模型,一个是序列模型SeqModel,一个是图网络模型,两者都可以解决向量表示的问题。在选择模型时,应该选择两种模型中的哪一种?这与产品数据密切相关。如果产品数据具有很强的时间相关性,那么使用序列模型的效果肯定不会差;如果产品数据的节点比较稀疏,则需要使用邻居节点进行信息协同建模。这时候,推荐尝试 GNN。图数据几乎可以收录在任何场景生成的数据关系中,所以GNN是通用的模型解决方案,具有很高的通用性,但并不意味着GNN在所有场景下都优于序列模型。方案比较。接下来,基于我们搜索推荐业务场景的总结,给大家分享一下序列模型和GNN模型的迭代。所以GNN是一种通用的模型解决方案,具有很高的通用性,但这并不意味着GNN在所有场景下都优于序列模型。方案比较。接下来,基于我们搜索推荐业务场景的总结,给大家分享一下序列模型和GNN模型的迭代。所以GNN是一种通用的模型解决方案,具有很高的通用性,但这并不意味着GNN在所有场景下都优于序列模型。方案比较。接下来,基于我们搜索推荐业务场景的总结,给大家分享一下序列模型和GNN模型的迭代。
03
迭代实现
1. 关注项目嵌入
艳选业务的用户数量远大于商品数量。由于用户数量众多,实验稀疏,User Embedding 并不是很有效。因此,我们在初始阶段专注于Item Embedding。商品数量少,落地成本低。,关联数据密集,表示效果较好。
① SeqModel优化
第一个模型是我们定制和优化的基于会话的嵌入模型。它的主要思想来自 Aribnb 的一篇 Embedding 论文(这篇论文写得非常好,建议大家学习一下)。该模型的主要思想是构造一个类似于word2vec的序列,重点关注向量在序列数据的上下文时间窗口中的相关性。图中每个圆圈代表一个项目,多个圆圈构成一个行为序列。行为序列来自用户在连续一段时间内的行为数据。传统的 word2vec 只关注上下文信息。这篇论文的核心思想是提出全局item,跳出了序列模型窗口的限制。全局item是指序列数据中的一些重要节点(图中实心节点),如用户的插件购买、支付、分享等行为。全局item打破了模型窗口的限制,使得item向量可以学习到一些高阶连接信息,大大提高了序列模型的表示效果。
在此之上,我们对损失函数做了一些优化,包括在batch中去除负采样和建立pair-wise loss的过程,可以大大提高训练速度;同时我们还引入了多层向量,也就是side-info嵌入的思想,不仅是在对item做向量表示的时候使用它的id类型的特征,还引入了产品属性等特征,类别、适用季节和适用组,进一步提高向量表示的效果,同时缓解新项目冷启动表征问题。
② GCN 定义
接下来说说学术界比较火的GCN/GNN模型。图神经网络一般有三个阶段的定义:
目前,很多关于 GNN 的论文都有关于这三个阶段的定义。图右侧是GCN的示意图。图中的公式对应了三个阶段,很巧妙的是,这个公式可以转化为矩阵运算形式,可以充分利用GPU的计算能力。但是这个矩阵的节点数是(#users+#items)×(#users+#items),而且规模大到行业很难落地。
③ GraphSage 可以登陆
GraphSage是一个基于采样的思想降低落地难度,用采样代替矩阵计算的过程。采样深度(一般深度不会超过2)对应迭代次数。多次迭代可以获得高层域信息进行信息协同建模,同时每次迭代的样本数可以调整。该模型最大的贡献在于提供了一种通用的Neighborhood Aggregation聚合方法,可以通过均值的方式进行聚合,也可以引入池化层,也可以引入LSTM进行序列聚合。
④ LightGCN的压缩数据尝试
GCN 需要很大的矩阵计算过程。与工程理念相比,两者的效果有何不同?是否可以通过减少现有数据来实现 GCN 与其他模型的对比?所以我们实现了一个LightGCN,主要参考了图中的两篇论文。两篇论文来自同一个团队。论文定制了信息的构建和聚合过程,可以捕获节点的高阶相关性,并对协作信号进行显式编码。一般GCN的网络深度不会超过2,而这里的LightGCN可以做到三层,其中的节点已经覆盖了用户和物品。在本文的最后,我们将比较所有的效果。在知识表达方面,这两篇论文写得都不错。您可以研究它们并更好地了解GCN。
2. 获取用户嵌入
我们在第一阶段获得了Item Embedding,如何从Item Embedding中获得User Embedding?主要有两种思路:策略法和模型法。
① 战略快速落地
该策略是一个可以快速实施的解决方案,是一个非常好的和稳定的基线。我们可以利用已知的物品隐向量和用户在会话中的交互行为序列,基于时间衰减、时间加权和注意力机制得到用户的向量表示。在相同的搜索场景下,也可以通过分词组合、次数权重、查询词的注意力权重得到查询词的向量表示。
② 经典 DNN
接下来是经典的模型DNN,直接通过模型得到用户的向量。参考图中YouTube上的这篇经典论文,模型本质上是一个有监督的NextItemPrediction训练过程,用户的Item会话数据,简单的平均聚合,用户特征作为深度模型的输入特征数据。输入特征数据逐层传播,最后一层得到用户向量。用户向量和项目向量做softmax完成一个概率分布预测,模型的loss也得到了。模型训练完成后,同时得到User和Item的向量表示。
③ 学习会话表示
当然我们要通过图模型得到用户的向量。用户的行为基于会话来表示。如果有方法可以直接将会话表示为向量,那么可以直接得到行为序列下的用户向量。下图中的论文通过学习会话向量的表示来解决这个问题。它也有GCN的三个阶段的定义。在定义过程中,还引入了门的参数来设置最终向量的表示过程。最有价值的一点是它进行会话表示学习。在训练过程中,每一个session都被视为一个子图,一个一个地训练,然后将局部向量(会话中的最后一个项目向量)添加到全局向量(会话中的其他项目向量)。注意力聚合后得到一个全局向量作为会话向量,最后用会话向量表示用户向量。该模型的效果在离线评估中更为突出。
④ 多用户向量
我们之前一直在用单个向量来表征用户,那么我们可以用多个用户向量来表征用户的兴趣吗?答案是肯定的,因为如果用户的兴趣比较广泛,使用一个向量来表示用户时会损失信息丰富度,使用多个向量来表示用户可能会更好。
第一个思路是聚类方法:首先对item K-means进行聚类,得到多个聚类,每个聚类都有一个向量表示。如果用户行为序列中的项目涉及多个聚类,则将属于同一聚类的向量聚合起来代表用户。聚合方法可以用簇向量计算权重并逐位相加。用户向量的数量等于序列中簇的数量。
第二个想法是 MIND:它使用胶囊网络来形成多个兴趣向量。结构中有一个多兴趣提取层,负责提取多个兴趣向量。图中,u1、u2是用户行为序列中的item,它们作为胶囊网络的输入,v1、v2是用户的多个兴趣向量,胶囊网络的输出. 同时,胶囊网络还支持动态路由,多次迭代自适应地迭代获得聚合权重。
3. 效果对比
接下来,我们对这些网络模型进行比较。比较指标是 HitRate 和 NDCG。我们采用 VecModel-Single(基于序列模型会话的嵌入模型)作为基线模型。
在我们的场景数据中,graphSAGE 作为 GCN 的工业实现指标并不突出,在 NDCG@30 上略超过基线模型。LightGCN通过减少数据来适应当前最大的锅,然后产生最大的蛋糕;LightGCN 使用矩阵来学习向量表示,效果相比基线模型并不是特别突出,只是在个别指标 HitRate@30 上有一些提升。YouTubeDNN 在 4 个指标上有明显提升。SR-GNN 直接表示会话的用户向量,通过模型参数学习得到用户向量。也是离线效果最好的机型。VecModel-Multi是基于序列模型,加入聚类用户多兴趣向量表示,MIND是基于胶囊网络的多兴趣向量模型;
左下图是不同用户行为分组的模型效果,X轴是用户行为数,Y轴是HitRate。一开始,用户在没有行为的情况下无法感知用户偏好,模型效果比较差(User Type Embedding实现了NIP)。当用户有1、2个行为时,性能指标大大提高。这也很容易理解,因为新用户在来到一个场景产生初始行为的时候兴趣更加集中,但是随着用户行为数量的增加,只使用向量模型进行召回和排序会减少指标,进而需要连接细化和重新排列模型,以进一步提高业务成果。右下图是HitRate@N中多个模型的效果,其中绿色曲线是使用该策略融合多个模型的结果后的表现。可以看出,只是简单的合并,相比其他单一模型有明显提升。. 以后也可以用粗排模型来合并各个表示模型的结果,效果应该会有所提高(用于合并的粗排模型还在进行中)。
04
业务落地
1. 异物是向量
接下来说说业务是如何实现的。异物是向量是 Facebook 提出的口号。如果我们有一套完整的向量系统,那么业务场景中的所有科目都可以向量化,然后就可以做U2I,I2I和Q2I的召回就很方便了。
2. 服务说明
该图是一个简单的服务图。整体是一个一体化的统一召回服务。核心向量表示服务具有表示用户和项目向量的能力。它可以使用 T+1 数据进行表示,也可以使用实时数据进行用户实时表示。利益代表。统一召回服务的输出经过提炼和重排后,可以应用于搜索、推荐、广告等业务场景。因此,召回服务是每一项业务的基石。召回效果的提升可以提升多场景的效果。投入产出比非常高的技术方向。
3. 应用效果
有了一切矢量化的基础后,下面是一些具体应用的落地效果。比如搜索中搜索词的推荐(U2Q)和搜索结果的语义匹配(Q2I),推荐中很多简单的场景可以直接使用基于向量的排序模型,效果也不错。内部第一焦点广告中还有图片的智能组合。通过 User2Topic,User2Item 选择用户最感兴趣的活跃产品呈现个性化的 Banner。
作者:潘胜义 网易严选算法专家,搜索推荐负责人。团队负责的业务包括搜索、推荐、内外广告、用户模型等。
seq搜索引擎优化至少包括那几步?(逻辑计划优化(LogicalLogical)阶段把标准的基于规则(Rule-based)的优化策略应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-01-30 09:16
逻辑优化阶段将标准的基于规则的优化策略应用于已分析的已解决逻辑计划。
优化规则的分类
逻辑计划的默认优化规则集在 Optimizer#defaultBatches 变量中定义。与逻辑计划的分析规则一样,逻辑计划的优化规则也是以规则集(Batch对象)的形式组织起来的,每个规则集中收录多个优化规则。
规则集定义及实现代码如下(有删减):
def defaultBatches: Seq[Batch] = {
...
Batch("Union", Once, CombineUnions) ::
Batch("LocalRelation early", fixedPoint, ...) ::
Batch("Pullup Correlated Expressions", Once, ...) ::
Batch("Subquery", Once, OptimizeSubqueries) ::
Batch("Replace Operators", fixedPoint,...) ::
Batch("Aggregate", fixedPoint, ...) :: Nil ++) :+
Batch("Join Reorder", Once, ...) :+
Batch("Remove Redundant Sorts", Once, ...) :+
Batch("Decimal Optimizations", fixedPoint, ...) :+
...
由于优化规则集数量众多,在某些情况下并非所有规则集都需要使用。为了让用户排除一些不必要的规则集,Spark SQL 增加了一个配置项:spark.sql.optimizer.excludedRules,默认为null。该配置项可用于配置要排除的优化规则名称列表,以逗号分隔。这些规则存储在 excludeRules 变量中。
排除优化规则的选项为用户提供了一些控制权,但对于 Spark SQL,一些优化规则是必需的,不能删除。因此,Spark SQL 在优化器中定义了另一个变量:nonExcludableRules,用于保存必须保留的优化规则。其代码实现(有删减)如下:
def nonExcludableRules: Seq[String] =
EliminateDistinct.ruleName ::
EliminateSubqueryAliases.ruleName ::
EliminateView.ruleName ::
ReplaceExpressions.ruleName ::
ComputeCurrentTime.ruleName ::
...
因此,最终使用的规则集是:
(defaultBatches - (excludedRules - nonExcludableRules))
// 也就是
默认规则集 -(排除规则集 - 保留规则集)
可以理解,原则上是默认规则集减去用户配置的排除规则集,但系统保留的规则集不能排除,所以必须从用户配置的列表中减去。换句话说,即使用户配置了要排除的规则集列表,如果它们在 nonExcludableRules(系统保留规则集)中,它们也不会被排除。
运营优化规则集
在优化规则集中,有一大类:操作优化规则集。操作优化规则集定义了操作的各种优化,是我们在查看逻辑计划时经常可以看到的非常重要的优化规则。操作优化规则集包括:
优化器:优化器
Optimizer 类对象实现逻辑计划规则的优化。Optimizer 是一个抽象父类,只有一个实现类:SparkOptimizer。Optimizer类继承了RuleExecutor,它们之间的关系如下:
RuleExecutor
|
Optimizer
|
SparkOptimizer
各种逻辑计划的优化规则集定义在抽象父类Optimizer中,实现类可以直接使用这些规则。
执行逻辑计划优化
在前面对文章的分析中,执行逻辑计划优化的函数调用如下:
// 2.对分析后的逻辑计划进行优化,得到优化后的逻辑计划
lazy val optimizedPlan: LogicalPlan = sparkSession.sessionState.optimizer.execute(withCachedData)
这个函数最终调用了父类的execute函数,也就是RuleExecutor中定义的execute函数。该功能的实现逻辑在《Spark SQL实现原理——逻辑计划分析的实现》一文中已有介绍。大致思路是依次遍历逻辑计划树的各个节点,根据优化规则集和执行策略对逻辑计划树的各个节点进行处理,直到逻辑计划树没有变化或者执行阈值达到到达。具体实现逻辑如下:
1. 依次遍历规则集列表:Optimizer#batches中的每个规则集(Batch);
2. 依次遍历规则集中的每条规则(Rule),并使用每条规则处理逻辑计划,将每条处理结果传递给下一条处理规则。
3.当一个规则集中的所有规则都被遍历(使用)后,会做出如下判断:
1)检查是否达到执行策略的阈值(迭代次数)。如果大于等于阈值,则不会遍历执行当前规则集。
2)检查使用该规则集前后的逻辑计划是否相等。如果相等,则表示不需要执行当前规则集。
如果满足1)和2)中的任何一个,则跳到4执行,否则继续使用当前规则集。
4.下一个规则集的每一个规则都被遍历使用,并按照步骤3的逻辑进行处理。
如何编写优化规则
除了 Spark SQL 自带的各种逻辑计划优化规则集外,您还可以编写自己的优化规则。《Spark SQL:Spark 中的关系数据处理》一文中介绍了自定义优化规则。
这条规则的目的是:在Spark SQL中添加一个固定精度的DECIMAL类型时,想在一个小精度的DECIMAL上优化求和或平均等聚合操作;用 12 行代码编写一个规则,用 SUM 和 AVG 表示 在公式中找到这样的小数,将它们转换为未缩放的 64 位 LONG,将它们聚合,然后将结果转换回 DECIMAL 类型。
object DecimalAggregates extends Rule[LogicalPlan] {
/** Maximum number of decimal digits in a Long */
val MAX_LONG_DIGITS = 18
def apply(plan: LogicalPlan): LogicalPlan = {
plan transformAllExpressions {
case Sum(e @ DecimalType.Expression(prec , scale))
if prec + 10
MakeDecimal(Sum(LongValue(e)), prec + 10, scale)
}
}
能够在规则中使用任意 Scala 代码使得表达这些超越子树结构模式匹配的优化变得容易。可见,编写逻辑计划优化规则并不难,只要遵循以下接口的编写规范即可。
object YourName extends Rule[LogicalPlan] {
// ...
def apply(plan: LogicalPlan): LogicalPlan = {
plan transformAllExpressions {
case xx1(...) if ... => // xx1是你想优化的逻辑计划节点对象
// ...
xxx2(...) // 优化后的目标逻辑计划节点对象
}
}
但是,要编写逻辑计划优化规则,首先需要熟悉现有的优化规则和每个逻辑计划节点,然后根据需求抽象出需要优化的逻辑。
逻辑计划优化视图
查看优化后的逻辑计划有多种方式,以scala终端为例。
(1)通过解释查看(true)
通过explain(true)可以看到从整个逻辑计划到物理计划的全过程:
scala> var ds1 = spark.range(100)
ds1: org.apache.spark.sql.Dataset[Long] = [id: bigint]
scala> var ds2 = spark.range(200)
ds2: org.apache.spark.sql.Dataset[Long] = [id: bigint]
scala> ds1.filter("id>10").union(ds2).filter("id>20").select("id").explain(true)
== Parsed Logical Plan ==
'Project [unresolvedalias('id, None)]
+- Filter (id#0L > cast(20 as bigint))
+- Union
:- Filter (id#0L > cast(10 as bigint))
: +- Range (0, 100, step=1, splits=Some(1))
+- Range (0, 200, step=1, splits=Some(1))
== Analyzed Logical Plan ==
id: bigint
Project [id#0L]
+- Filter (id#0L > cast(20 as bigint))
+- Union
:- Filter (id#0L > cast(10 as bigint))
: +- Range (0, 100, step=1, splits=Some(1))
+- Range (0, 200, step=1, splits=Some(1))
== Optimized Logical Plan ==
Union
:- Filter ((id#0L > 10) && (id#0L > 20))
: +- Range (0, 100, step=1, splits=Some(1))
+- Filter (id#2L > 20)
+- Range (0, 200, step=1, splits=Some(1))
//...
另外,可以通过以下命令查看逻辑计划节点和参数:
scala> ds1.filter("id>10").union(ds2).filter("id>20").select("id").queryExecution.optimizedPlan.prettyJson
(2)通过queryExecution对象查看
通过queryExecution,可以单独查看优化后的逻辑计划。
scala> ds1.filter("id>10").union(ds2).filter("id>20").select("id").queryExecution.optimizedPlan
res9: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
Union
:- Filter ((id#0L > 10) && (id#0L > 20))
: +- Range (0, 100, step=1, splits=Some(1))
+- Filter (id#2L > 20)
+- Range (0, 200, step=1, splits=Some(1))
概括
本文分析了逻辑计划优化的总体实现过程,并简要介绍了实现自己的优化规则的优化规则。最后介绍了如何查看逻辑计划优化的结果。逻辑计划的优化可以说是 Catalyst 项目的核心。接下来,我们将通过一系列文章来介绍各种逻辑计划优化规则的使用和实现原理。 查看全部
seq搜索引擎优化至少包括那几步?(逻辑计划优化(LogicalLogical)阶段把标准的基于规则(Rule-based)的优化策略应用)
逻辑优化阶段将标准的基于规则的优化策略应用于已分析的已解决逻辑计划。
优化规则的分类
逻辑计划的默认优化规则集在 Optimizer#defaultBatches 变量中定义。与逻辑计划的分析规则一样,逻辑计划的优化规则也是以规则集(Batch对象)的形式组织起来的,每个规则集中收录多个优化规则。
规则集定义及实现代码如下(有删减):
def defaultBatches: Seq[Batch] = {
...
Batch("Union", Once, CombineUnions) ::
Batch("LocalRelation early", fixedPoint, ...) ::
Batch("Pullup Correlated Expressions", Once, ...) ::
Batch("Subquery", Once, OptimizeSubqueries) ::
Batch("Replace Operators", fixedPoint,...) ::
Batch("Aggregate", fixedPoint, ...) :: Nil ++) :+
Batch("Join Reorder", Once, ...) :+
Batch("Remove Redundant Sorts", Once, ...) :+
Batch("Decimal Optimizations", fixedPoint, ...) :+
...
由于优化规则集数量众多,在某些情况下并非所有规则集都需要使用。为了让用户排除一些不必要的规则集,Spark SQL 增加了一个配置项:spark.sql.optimizer.excludedRules,默认为null。该配置项可用于配置要排除的优化规则名称列表,以逗号分隔。这些规则存储在 excludeRules 变量中。
排除优化规则的选项为用户提供了一些控制权,但对于 Spark SQL,一些优化规则是必需的,不能删除。因此,Spark SQL 在优化器中定义了另一个变量:nonExcludableRules,用于保存必须保留的优化规则。其代码实现(有删减)如下:
def nonExcludableRules: Seq[String] =
EliminateDistinct.ruleName ::
EliminateSubqueryAliases.ruleName ::
EliminateView.ruleName ::
ReplaceExpressions.ruleName ::
ComputeCurrentTime.ruleName ::
...
因此,最终使用的规则集是:
(defaultBatches - (excludedRules - nonExcludableRules))
// 也就是
默认规则集 -(排除规则集 - 保留规则集)
可以理解,原则上是默认规则集减去用户配置的排除规则集,但系统保留的规则集不能排除,所以必须从用户配置的列表中减去。换句话说,即使用户配置了要排除的规则集列表,如果它们在 nonExcludableRules(系统保留规则集)中,它们也不会被排除。
运营优化规则集
在优化规则集中,有一大类:操作优化规则集。操作优化规则集定义了操作的各种优化,是我们在查看逻辑计划时经常可以看到的非常重要的优化规则。操作优化规则集包括:
优化器:优化器
Optimizer 类对象实现逻辑计划规则的优化。Optimizer 是一个抽象父类,只有一个实现类:SparkOptimizer。Optimizer类继承了RuleExecutor,它们之间的关系如下:
RuleExecutor
|
Optimizer
|
SparkOptimizer
各种逻辑计划的优化规则集定义在抽象父类Optimizer中,实现类可以直接使用这些规则。
执行逻辑计划优化
在前面对文章的分析中,执行逻辑计划优化的函数调用如下:
// 2.对分析后的逻辑计划进行优化,得到优化后的逻辑计划
lazy val optimizedPlan: LogicalPlan = sparkSession.sessionState.optimizer.execute(withCachedData)
这个函数最终调用了父类的execute函数,也就是RuleExecutor中定义的execute函数。该功能的实现逻辑在《Spark SQL实现原理——逻辑计划分析的实现》一文中已有介绍。大致思路是依次遍历逻辑计划树的各个节点,根据优化规则集和执行策略对逻辑计划树的各个节点进行处理,直到逻辑计划树没有变化或者执行阈值达到到达。具体实现逻辑如下:
1. 依次遍历规则集列表:Optimizer#batches中的每个规则集(Batch);
2. 依次遍历规则集中的每条规则(Rule),并使用每条规则处理逻辑计划,将每条处理结果传递给下一条处理规则。
3.当一个规则集中的所有规则都被遍历(使用)后,会做出如下判断:
1)检查是否达到执行策略的阈值(迭代次数)。如果大于等于阈值,则不会遍历执行当前规则集。
2)检查使用该规则集前后的逻辑计划是否相等。如果相等,则表示不需要执行当前规则集。
如果满足1)和2)中的任何一个,则跳到4执行,否则继续使用当前规则集。
4.下一个规则集的每一个规则都被遍历使用,并按照步骤3的逻辑进行处理。
如何编写优化规则
除了 Spark SQL 自带的各种逻辑计划优化规则集外,您还可以编写自己的优化规则。《Spark SQL:Spark 中的关系数据处理》一文中介绍了自定义优化规则。
这条规则的目的是:在Spark SQL中添加一个固定精度的DECIMAL类型时,想在一个小精度的DECIMAL上优化求和或平均等聚合操作;用 12 行代码编写一个规则,用 SUM 和 AVG 表示 在公式中找到这样的小数,将它们转换为未缩放的 64 位 LONG,将它们聚合,然后将结果转换回 DECIMAL 类型。
object DecimalAggregates extends Rule[LogicalPlan] {
/** Maximum number of decimal digits in a Long */
val MAX_LONG_DIGITS = 18
def apply(plan: LogicalPlan): LogicalPlan = {
plan transformAllExpressions {
case Sum(e @ DecimalType.Expression(prec , scale))
if prec + 10
MakeDecimal(Sum(LongValue(e)), prec + 10, scale)
}
}
能够在规则中使用任意 Scala 代码使得表达这些超越子树结构模式匹配的优化变得容易。可见,编写逻辑计划优化规则并不难,只要遵循以下接口的编写规范即可。
object YourName extends Rule[LogicalPlan] {
// ...
def apply(plan: LogicalPlan): LogicalPlan = {
plan transformAllExpressions {
case xx1(...) if ... => // xx1是你想优化的逻辑计划节点对象
// ...
xxx2(...) // 优化后的目标逻辑计划节点对象
}
}
但是,要编写逻辑计划优化规则,首先需要熟悉现有的优化规则和每个逻辑计划节点,然后根据需求抽象出需要优化的逻辑。
逻辑计划优化视图
查看优化后的逻辑计划有多种方式,以scala终端为例。
(1)通过解释查看(true)
通过explain(true)可以看到从整个逻辑计划到物理计划的全过程:
scala> var ds1 = spark.range(100)
ds1: org.apache.spark.sql.Dataset[Long] = [id: bigint]
scala> var ds2 = spark.range(200)
ds2: org.apache.spark.sql.Dataset[Long] = [id: bigint]
scala> ds1.filter("id>10").union(ds2).filter("id>20").select("id").explain(true)
== Parsed Logical Plan ==
'Project [unresolvedalias('id, None)]
+- Filter (id#0L > cast(20 as bigint))
+- Union
:- Filter (id#0L > cast(10 as bigint))
: +- Range (0, 100, step=1, splits=Some(1))
+- Range (0, 200, step=1, splits=Some(1))
== Analyzed Logical Plan ==
id: bigint
Project [id#0L]
+- Filter (id#0L > cast(20 as bigint))
+- Union
:- Filter (id#0L > cast(10 as bigint))
: +- Range (0, 100, step=1, splits=Some(1))
+- Range (0, 200, step=1, splits=Some(1))
== Optimized Logical Plan ==
Union
:- Filter ((id#0L > 10) && (id#0L > 20))
: +- Range (0, 100, step=1, splits=Some(1))
+- Filter (id#2L > 20)
+- Range (0, 200, step=1, splits=Some(1))
//...
另外,可以通过以下命令查看逻辑计划节点和参数:
scala> ds1.filter("id>10").union(ds2).filter("id>20").select("id").queryExecution.optimizedPlan.prettyJson
(2)通过queryExecution对象查看
通过queryExecution,可以单独查看优化后的逻辑计划。
scala> ds1.filter("id>10").union(ds2).filter("id>20").select("id").queryExecution.optimizedPlan
res9: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
Union
:- Filter ((id#0L > 10) && (id#0L > 20))
: +- Range (0, 100, step=1, splits=Some(1))
+- Filter (id#2L > 20)
+- Range (0, 200, step=1, splits=Some(1))
概括
本文分析了逻辑计划优化的总体实现过程,并简要介绍了实现自己的优化规则的优化规则。最后介绍了如何查看逻辑计划优化的结果。逻辑计划的优化可以说是 Catalyst 项目的核心。接下来,我们将通过一系列文章来介绍各种逻辑计划优化规则的使用和实现原理。
seq搜索引擎优化至少包括那几步?(spark集群部署大数据JUC面试题集群集群的数据生态体系)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-30 09:15
问题
当使用这个partition BETWEEN 'start' AND 'end' OR (partition = 'other' AND column 'value') 条件查询spark-sql中的数据时,程序会拉取整个分区中的数据。
解决方案
前面我们提到在使用spark-sql读取hive分区表的时候,使用了PredicateHelper中的方法,但是增加了一个新的splitPredicates方法,因为PredicateHelper只有splitConjunctivePredicates和splitDisjunctivePredicates方法。
protected def splitConjunctivePredicates(condition: Expression): Seq[Expression] = {
condition match {
case And(cond1, cond2) =>
splitConjunctivePredicates(cond1) ++ splitConjunctivePredicates(cond2)
case other => other :: Nil
}
}
protected def splitDisjunctivePredicates(condition: Expression): Seq[Expression] = {
condition match {
case Or(cond1, cond2) =>
splitDisjunctivePredicates(cond1) ++ splitDisjunctivePredicates(cond2)
case other => other :: Nil
}
}
在 PhysicalOperation 类中,仅对 Filter 进行如下处理:
可以看出,解析Filter语法树时只调用了splitConjunctivePredicates方法,即只处理AND表达式;
PruneFileSourcePartitions类匹配PhysicalOperation,生成的过滤器就是上面collectProjectsAndFilters中Filter处理的结果;
private[sql] object PruneFileSourcePartitions extends Rule[LogicalPlan] {
override def apply(plan: LogicalPlan): LogicalPlan = plan transformDown {
case op @ PhysicalOperation(projects, filters,
logicalRelation @
LogicalRelation(fsRelation @
HadoopFsRelation(catalogFileIndex: CatalogFileIndex, partitionSchema, _, _, _, _), _, _))
if filters.nonEmpty && fsRelation.partitionSchemaOption.isDefined =>
以下是 PruneFileSourcePartitions 中的原创代码。将这部分代码替换为指定分区数的过滤方法中获取分区表达式的代码即可轻松解决上述问题。
val sparkSession = fsRelation.sparkSession
val partitionColumns =
logicalRelation.resolve(
partitionSchema, sparkSession.sessionState.analyzer.resolver)
val partitionSet = AttributeSet(partitionColumns)
val partitionKeyFilters =
ExpressionSet(normalizedFilters.filter(_.references.subsetOf(partitionSet)))
修改后的代码如下:
val partitionColumns =
logicalRelation.resolve(
partitionSchema,
sparkSession.sessionState.analyzer.resolver)
val partitionSet = AttributeSet(partitionColumns)
val partitionKeyFilters = splitPredicates(normalizedFilters.reduceLeft(And),parti
大数据与云计算的关系
大数据技术生态系统
大数据的切片机制有哪些?
大数据的Kafka集群部署
大数据JUC面试题 查看全部
seq搜索引擎优化至少包括那几步?(spark集群部署大数据JUC面试题集群集群的数据生态体系)
问题
当使用这个partition BETWEEN 'start' AND 'end' OR (partition = 'other' AND column 'value') 条件查询spark-sql中的数据时,程序会拉取整个分区中的数据。
解决方案
前面我们提到在使用spark-sql读取hive分区表的时候,使用了PredicateHelper中的方法,但是增加了一个新的splitPredicates方法,因为PredicateHelper只有splitConjunctivePredicates和splitDisjunctivePredicates方法。
protected def splitConjunctivePredicates(condition: Expression): Seq[Expression] = {
condition match {
case And(cond1, cond2) =>
splitConjunctivePredicates(cond1) ++ splitConjunctivePredicates(cond2)
case other => other :: Nil
}
}
protected def splitDisjunctivePredicates(condition: Expression): Seq[Expression] = {
condition match {
case Or(cond1, cond2) =>
splitDisjunctivePredicates(cond1) ++ splitDisjunctivePredicates(cond2)
case other => other :: Nil
}
}
在 PhysicalOperation 类中,仅对 Filter 进行如下处理:
可以看出,解析Filter语法树时只调用了splitConjunctivePredicates方法,即只处理AND表达式;
PruneFileSourcePartitions类匹配PhysicalOperation,生成的过滤器就是上面collectProjectsAndFilters中Filter处理的结果;
private[sql] object PruneFileSourcePartitions extends Rule[LogicalPlan] {
override def apply(plan: LogicalPlan): LogicalPlan = plan transformDown {
case op @ PhysicalOperation(projects, filters,
logicalRelation @
LogicalRelation(fsRelation @
HadoopFsRelation(catalogFileIndex: CatalogFileIndex, partitionSchema, _, _, _, _), _, _))
if filters.nonEmpty && fsRelation.partitionSchemaOption.isDefined =>
以下是 PruneFileSourcePartitions 中的原创代码。将这部分代码替换为指定分区数的过滤方法中获取分区表达式的代码即可轻松解决上述问题。
val sparkSession = fsRelation.sparkSession
val partitionColumns =
logicalRelation.resolve(
partitionSchema, sparkSession.sessionState.analyzer.resolver)
val partitionSet = AttributeSet(partitionColumns)
val partitionKeyFilters =
ExpressionSet(normalizedFilters.filter(_.references.subsetOf(partitionSet)))
修改后的代码如下:
val partitionColumns =
logicalRelation.resolve(
partitionSchema,
sparkSession.sessionState.analyzer.resolver)
val partitionSet = AttributeSet(partitionColumns)
val partitionKeyFilters = splitPredicates(normalizedFilters.reduceLeft(And),parti
大数据与云计算的关系
大数据技术生态系统
大数据的切片机制有哪些?
大数据的Kafka集群部署
大数据JUC面试题
seq搜索引擎优化至少包括那几步?(google《想做好谷歌排名优化只需要这4个步骤》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-27 13:10
很多朋友在谈到Google左侧排名时,总是认为是单页标签优化的过程。事实上,这种看法是错误的。谷歌左排名服务需要做以下步骤:【谷歌优化】
第一步:网站诊断
网站结构诊断:看是否符合搜索引擎习惯;
网站页面诊断:看看它的布局是否合理,处理得当;
网站文件名诊断:查看是否使用了不合理的文件名;
网站营销基本诊断:看目前使用的网络推广方面是否合理。
第二步:网站基础流量分析
交通统计系统安装
流量来源分析
区域分布分析
第三步:谷歌优化处理
网站结构优化:合理化网站结构以适应搜索引擎习惯
网站页面优化:关键词布局、图形处理等。
网站连接优化:将网站的整体连接系统化,一方面有利于搜索引擎搜索,另一方面结合用户习惯引导用户阅读内容网站,以便于最终的业务交易
网站标签优化:网站标签设计
第四步:GOOGLE排名优化其他策略
产生流量:GOOGLE排名优化的关键是流量。在这个过程中我们会用到很多网络营销的方法。
建立外部联系:通过友谊联系、文章 促销、帖子促销等来改善网站 外部联系。
网站要想在谷歌左侧排名好,首先要做好自己,做好推广,才能获得更好的排名。所以对于网站的GOOGLE排名优化应该从综合营销的角度来考虑,然后去做。这是如何达到效果的。
如果想靠单标签优化和作弊来达到考前GOOGLE排名的效果,那是非常幼稚和可笑的。毕竟GOOGLE排名优化还是为了推广网站。那么,网站的综合推广就完成了,在谷歌优化中获得更好的排名也就理所当然了。
以上就是《优化谷歌排名只需要这4步》的全部内容。仅供站长朋友交流学习。SEO优化是一个需要坚持的过程。希望大家一起进步。 查看全部
seq搜索引擎优化至少包括那几步?(google《想做好谷歌排名优化只需要这4个步骤》)
很多朋友在谈到Google左侧排名时,总是认为是单页标签优化的过程。事实上,这种看法是错误的。谷歌左排名服务需要做以下步骤:【谷歌优化】
第一步:网站诊断
网站结构诊断:看是否符合搜索引擎习惯;
网站页面诊断:看看它的布局是否合理,处理得当;
网站文件名诊断:查看是否使用了不合理的文件名;
网站营销基本诊断:看目前使用的网络推广方面是否合理。
第二步:网站基础流量分析
交通统计系统安装
流量来源分析
区域分布分析
第三步:谷歌优化处理
网站结构优化:合理化网站结构以适应搜索引擎习惯
网站页面优化:关键词布局、图形处理等。
网站连接优化:将网站的整体连接系统化,一方面有利于搜索引擎搜索,另一方面结合用户习惯引导用户阅读内容网站,以便于最终的业务交易
网站标签优化:网站标签设计
第四步:GOOGLE排名优化其他策略
产生流量:GOOGLE排名优化的关键是流量。在这个过程中我们会用到很多网络营销的方法。
建立外部联系:通过友谊联系、文章 促销、帖子促销等来改善网站 外部联系。
网站要想在谷歌左侧排名好,首先要做好自己,做好推广,才能获得更好的排名。所以对于网站的GOOGLE排名优化应该从综合营销的角度来考虑,然后去做。这是如何达到效果的。
如果想靠单标签优化和作弊来达到考前GOOGLE排名的效果,那是非常幼稚和可笑的。毕竟GOOGLE排名优化还是为了推广网站。那么,网站的综合推广就完成了,在谷歌优化中获得更好的排名也就理所当然了。
以上就是《优化谷歌排名只需要这4步》的全部内容。仅供站长朋友交流学习。SEO优化是一个需要坚持的过程。希望大家一起进步。
seq搜索引擎优化至少包括那几步?(卷宗扫描仪网站长:SEO优化的各个方面是比较重要的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-27 13:07
Dossier Scanner网站认为:在SEO优化的各个方面,更重要的是优化网站的内容,只有内容更丰富的网站才能被搜索引擎搜索到收录,提高网站的排名,推动网站建设的发展。以下文件扫描器网络:简单步骤教你如何学习网站SEO优化?
一、关键词的选择,关键词的好选择是优化网站的第一步,基于关键词与页面内容,是搜索引擎生存的基础,关键词的产生伴随着用户需求的产生。一个漂亮的TDK规划不是基于网站本身的主观臆断,而是用户真实需求的聚合。小编的SEO之路就是从TDK开始的。当时的导师一点一点的教,小编领悟后的实践,一点一点的体现出来最终的效果。从头到尾,小编亲自写TDK都觉得不舒服。有点懈怠,看似基本的东西,其实不一般,关键词 作为SEO五要素中最重要的一环,小编之所以再次提出来,是为了提醒那些痴迷于横着走、走灰走黑的人。路线的SEOer,千万不要忽视了最初出发的目的。
二、更新高质量原创文章。SEO优化的基础是坚持在网站上更新更多优质的文章,尽量让网站的页面丰富多样,赏心悦目,有一定的吸引力,但最重要的是不断更新优质的文章和信息,从而抢占更多的关键词,在行业竞争中获得优势,此外,一些权威的文章也会被站外一些媒体引用,扩大网站的影响力。
三、关键字应该正确放置。在优化文章的时候,重点关注关键词的密度,让关键词做到在文章中自然分布而不影响阅读,而不是关键词的很多无意义的堆积@>,通常关键词出现在文章的开头和结尾可以增加文章的相关性和权重。当然,对于文章的平滑性和自然性,关键词也可以进行形式的变换和拆分,这也是对文章的一种优化方式。根据 关键词 的接近程度,这些措施将优化 文章 的内容。
四、链接建立密钥。给网站一些链接如:友情链接、论坛链接、博客链接、微信链接等。友情链接,这个一定要做,至于它的重要性,我就不用过多赘述了。链接相关性,无论你如何扩展外链,你更喜欢与目标页面主题内容相关的平台获取外链资源;链接广度,如果你经常关注站长后台的链接分析,你会发现在同一个平台上发布的外部链接的数量是有限制的,可以被搜索引擎接受。高权重平台的外链数量适当增加,而权重较低的网站外链数量较少被搜索引擎识别,因此外链数量较少。
<p>五、关注用户体验。其实网站的构造有很多需要注意的地方,比如如何设置网站的关键词,只要你意识到 查看全部
seq搜索引擎优化至少包括那几步?(卷宗扫描仪网站长:SEO优化的各个方面是比较重要的)
Dossier Scanner网站认为:在SEO优化的各个方面,更重要的是优化网站的内容,只有内容更丰富的网站才能被搜索引擎搜索到收录,提高网站的排名,推动网站建设的发展。以下文件扫描器网络:简单步骤教你如何学习网站SEO优化?
一、关键词的选择,关键词的好选择是优化网站的第一步,基于关键词与页面内容,是搜索引擎生存的基础,关键词的产生伴随着用户需求的产生。一个漂亮的TDK规划不是基于网站本身的主观臆断,而是用户真实需求的聚合。小编的SEO之路就是从TDK开始的。当时的导师一点一点的教,小编领悟后的实践,一点一点的体现出来最终的效果。从头到尾,小编亲自写TDK都觉得不舒服。有点懈怠,看似基本的东西,其实不一般,关键词 作为SEO五要素中最重要的一环,小编之所以再次提出来,是为了提醒那些痴迷于横着走、走灰走黑的人。路线的SEOer,千万不要忽视了最初出发的目的。

二、更新高质量原创文章。SEO优化的基础是坚持在网站上更新更多优质的文章,尽量让网站的页面丰富多样,赏心悦目,有一定的吸引力,但最重要的是不断更新优质的文章和信息,从而抢占更多的关键词,在行业竞争中获得优势,此外,一些权威的文章也会被站外一些媒体引用,扩大网站的影响力。
三、关键字应该正确放置。在优化文章的时候,重点关注关键词的密度,让关键词做到在文章中自然分布而不影响阅读,而不是关键词的很多无意义的堆积@>,通常关键词出现在文章的开头和结尾可以增加文章的相关性和权重。当然,对于文章的平滑性和自然性,关键词也可以进行形式的变换和拆分,这也是对文章的一种优化方式。根据 关键词 的接近程度,这些措施将优化 文章 的内容。
四、链接建立密钥。给网站一些链接如:友情链接、论坛链接、博客链接、微信链接等。友情链接,这个一定要做,至于它的重要性,我就不用过多赘述了。链接相关性,无论你如何扩展外链,你更喜欢与目标页面主题内容相关的平台获取外链资源;链接广度,如果你经常关注站长后台的链接分析,你会发现在同一个平台上发布的外部链接的数量是有限制的,可以被搜索引擎接受。高权重平台的外链数量适当增加,而权重较低的网站外链数量较少被搜索引擎识别,因此外链数量较少。
<p>五、关注用户体验。其实网站的构造有很多需要注意的地方,比如如何设置网站的关键词,只要你意识到
seq搜索引擎优化至少包括那几步?( 如要提升您的网站在Google上的排名要怎么做呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-27 13:06
如要提升您的网站在Google上的排名要怎么做呢?)
您的独立站点已启动并正在运行,它看起来很棒,并且第一批客户订单即将到来。
完美的!
如果您还没有准备好在 Facebook 或 Google 上做广告
下一步是通过谷歌产生一些免费流量
让我们想象一下。如果您的独立商店位于 Google 搜索结果的首页,那么您无需在广告上花费一分钱即可进行销售。
当然,在谷歌首页上排名并不是一件容易的事。但是通过一些聪明的 SEO 可以将 网站 排名靠前。
您可以做些什么来提高您在 Google 上的 网站 排名?
这里有 9 个 SEO 技巧,可帮助您提高排名
1.选择完美的关键字,以便 Google 找到您
关键词 是 SEO 的核心。关键字告诉谷歌你的真实身份和你做了什么。
要提出最好的 关键词,请将自己定位为客户。你会搜索什么来找到你的产品?也许是“耐克 T 恤”或“舞会礼服”。
选择 关键词 时有一个最佳选择。很难对 关键词 进行广泛的排名,例如“鞋子”,因为最大的零售商占据主导地位。另一方面,像“purple Velcro (brand name) shoes”这样的小众关键词不会获得足够的搜索量。在中间尝试一些东西,例如输入鞋子的品牌名称“name+shoes”。
选择正确的单词和短语是一门科学。后面我会写一篇详细的文章关于关键词的选择。
2.选择实际销售的关键字或词组
你想要真正买东西的搜索者。
假设您在 shopyy 独立网站上销售手工珠宝。搜索“手工珠宝”的人可能正在寻找制作珠宝的信息。你对那些人不感兴趣。
您需要一位想购买手工珠宝的客户。尝试修改您的关键字或词组以收录“购买”、“最佳”、“便宜”等有效字词。
寻找暗示购买意图的关键词或短语。
3.把这些关键词放在所有合适的地方
现在您有了 关键词,是时候将它们放在 Google 可以找到它们的地方了。
Shopyy 有五个放置关键字的关键位置:
1.你的页面标题
这是将出现在 Google 结果页面上的标题。
请注意这家商店是如何在商店名称之前放置关键词“wood 太阳镜”的?那是因为越来越多的人在寻找“木制太阳镜”。考虑在标题中描述您的商店。
转到界面 > SEO 设置。
专业提示:尝试让您的标题成为号召性用语。把它想象成一个吸引人的标题。了解 House of Fraser 如何使用有效的 CTA:“在线购买手表”
2.元描述
元描述是标题下方显示的简短介绍。再次,将您的关键字放在这里,但尽量使它们具有描述性和吸引力。这是您说服客户点击的机会。
确保每个页面都有不同的元描述。再次,前往界面 > SEO 设置。
3.图片描述和Alt标签
谷歌很聪明,但还是看不到红袜子的照片。你必须告诉谷歌这是一只红袜子。为此,请在上传前自动将“red sock”添加到产品标题名称中。
SHOPYY 会自动为所有产品相关图片添加 ALT 标签
使图像具有描述性并收录您的关键字。现在,谷歌可以找到它、阅读它并对其进行排名。
4.标题和标题(H1 标签)
您的标题是 Google 最先查看您的 网站 内容的地方之一。确保您的产品页面都收录描述性标题,并且不要忘记收录您的关键字。
主流搜索引擎关注H1标签中的文字信息。一个好的H1有助于提高关键词的排名,提高页面权重
H1 标签是可见的,而不是对用户隐藏。H1标题过多会被搜索引擎认为作弊,会被降级
SHOPYY网站的H1主要用于文章的、商品、话题等核心内容。
5.产品描述和复制
始终在产品说明中收录关键字,以帮助 Google 找到您的页面。您必须编写独特而令人兴奋的产品描述。
不要只是复制制造商的描述,因为 - 很可能 - 复制粘贴已经在互联网上,而 Google 讨厌复制粘贴。此外,您的描述很有可能表现出您自己的语气并说服客户购买。
4.使用内部链接连接您的页面和内容
除了关键字,链接是 SEO 的基本排名因素。首先在整个 网站 中使用内部链接。从主页链接到您的产品页面。在您的博客中设置类别链接和产品链接。
您网站连接得越多,Google 就越能更好地了解您的商店及其产品。将其视为您的 网站 构建基础或支柱。
5.创建指向您 Shopyy 商店的反向链接
为了对您的商店进行排名,Google 会查看哪些其他 网站 链接链接到您。Google 使用基于链接数量和链接到您的 网站 权限的算法来确定您的分数。
例如,如果华尔街和纽约时报 网站 链接到您的产品,Google 知道您必须拥有一些真正的权威,因此您的排名会更高。
有无数种方法可以生成返回 Shopyy 商店的链接。发送新闻稿有助于接触博主并提供返回您的 网站 的链接。在您的利基中提供博客的客座帖子也将获得链接,并且产品链接也可以在博客中提及以获得产品页面流量。您也可以直接通过电子邮件发送 网站 并要求他们查看或链接到您的产品。
专业提示:永远不要购买链接,使用链接交换。Google 使用这些技术来搜索 网站。您正在寻找自然链接行为。 查看全部
seq搜索引擎优化至少包括那几步?(
如要提升您的网站在Google上的排名要怎么做呢?)

您的独立站点已启动并正在运行,它看起来很棒,并且第一批客户订单即将到来。
完美的!
如果您还没有准备好在 Facebook 或 Google 上做广告
下一步是通过谷歌产生一些免费流量
让我们想象一下。如果您的独立商店位于 Google 搜索结果的首页,那么您无需在广告上花费一分钱即可进行销售。
当然,在谷歌首页上排名并不是一件容易的事。但是通过一些聪明的 SEO 可以将 网站 排名靠前。
您可以做些什么来提高您在 Google 上的 网站 排名?
这里有 9 个 SEO 技巧,可帮助您提高排名
1.选择完美的关键字,以便 Google 找到您
关键词 是 SEO 的核心。关键字告诉谷歌你的真实身份和你做了什么。
要提出最好的 关键词,请将自己定位为客户。你会搜索什么来找到你的产品?也许是“耐克 T 恤”或“舞会礼服”。
选择 关键词 时有一个最佳选择。很难对 关键词 进行广泛的排名,例如“鞋子”,因为最大的零售商占据主导地位。另一方面,像“purple Velcro (brand name) shoes”这样的小众关键词不会获得足够的搜索量。在中间尝试一些东西,例如输入鞋子的品牌名称“name+shoes”。
选择正确的单词和短语是一门科学。后面我会写一篇详细的文章关于关键词的选择。
2.选择实际销售的关键字或词组
你想要真正买东西的搜索者。
假设您在 shopyy 独立网站上销售手工珠宝。搜索“手工珠宝”的人可能正在寻找制作珠宝的信息。你对那些人不感兴趣。
您需要一位想购买手工珠宝的客户。尝试修改您的关键字或词组以收录“购买”、“最佳”、“便宜”等有效字词。
寻找暗示购买意图的关键词或短语。
3.把这些关键词放在所有合适的地方
现在您有了 关键词,是时候将它们放在 Google 可以找到它们的地方了。
Shopyy 有五个放置关键字的关键位置:
1.你的页面标题
这是将出现在 Google 结果页面上的标题。
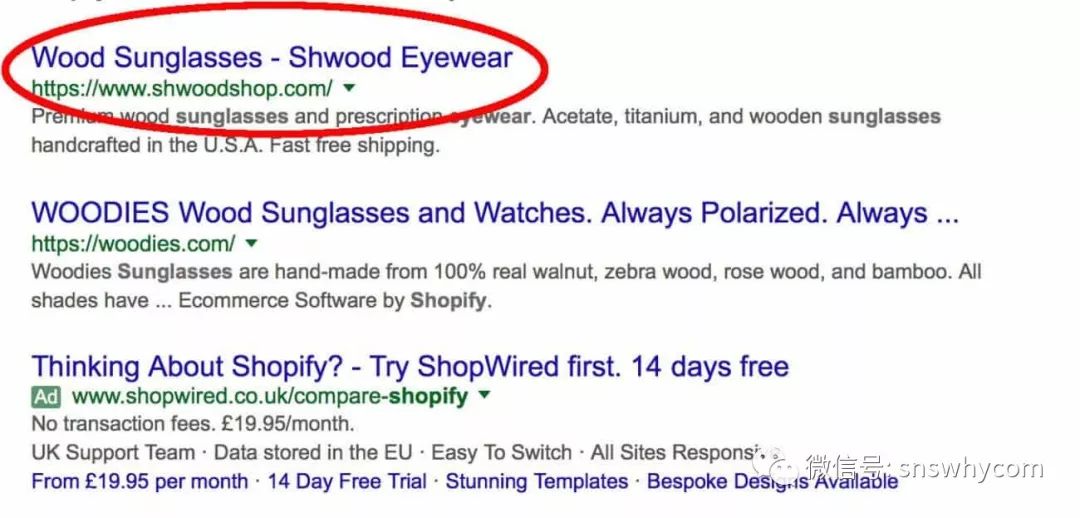
请注意这家商店是如何在商店名称之前放置关键词“wood 太阳镜”的?那是因为越来越多的人在寻找“木制太阳镜”。考虑在标题中描述您的商店。
转到界面 > SEO 设置。
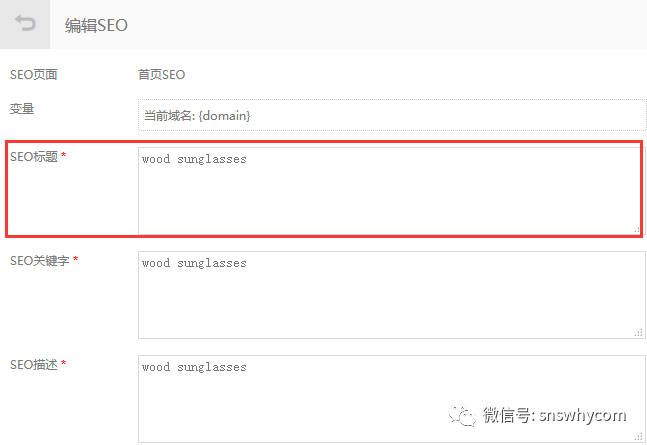
专业提示:尝试让您的标题成为号召性用语。把它想象成一个吸引人的标题。了解 House of Fraser 如何使用有效的 CTA:“在线购买手表”

2.元描述
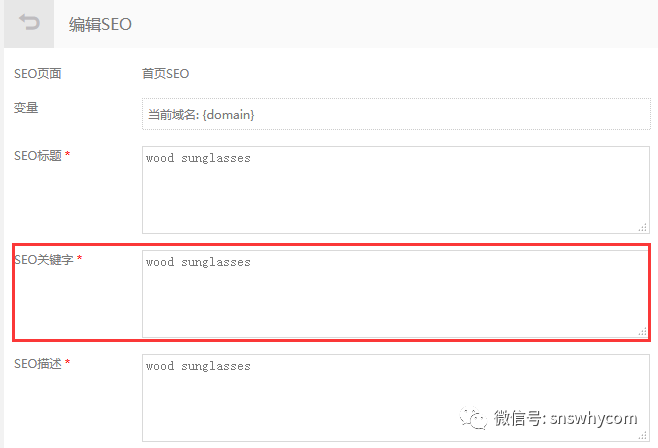
元描述是标题下方显示的简短介绍。再次,将您的关键字放在这里,但尽量使它们具有描述性和吸引力。这是您说服客户点击的机会。
确保每个页面都有不同的元描述。再次,前往界面 > SEO 设置。
3.图片描述和Alt标签
谷歌很聪明,但还是看不到红袜子的照片。你必须告诉谷歌这是一只红袜子。为此,请在上传前自动将“red sock”添加到产品标题名称中。
SHOPYY 会自动为所有产品相关图片添加 ALT 标签
使图像具有描述性并收录您的关键字。现在,谷歌可以找到它、阅读它并对其进行排名。

4.标题和标题(H1 标签)
您的标题是 Google 最先查看您的 网站 内容的地方之一。确保您的产品页面都收录描述性标题,并且不要忘记收录您的关键字。
主流搜索引擎关注H1标签中的文字信息。一个好的H1有助于提高关键词的排名,提高页面权重
H1 标签是可见的,而不是对用户隐藏。H1标题过多会被搜索引擎认为作弊,会被降级
SHOPYY网站的H1主要用于文章的、商品、话题等核心内容。

5.产品描述和复制
始终在产品说明中收录关键字,以帮助 Google 找到您的页面。您必须编写独特而令人兴奋的产品描述。
不要只是复制制造商的描述,因为 - 很可能 - 复制粘贴已经在互联网上,而 Google 讨厌复制粘贴。此外,您的描述很有可能表现出您自己的语气并说服客户购买。
4.使用内部链接连接您的页面和内容
除了关键字,链接是 SEO 的基本排名因素。首先在整个 网站 中使用内部链接。从主页链接到您的产品页面。在您的博客中设置类别链接和产品链接。
您网站连接得越多,Google 就越能更好地了解您的商店及其产品。将其视为您的 网站 构建基础或支柱。
5.创建指向您 Shopyy 商店的反向链接
为了对您的商店进行排名,Google 会查看哪些其他 网站 链接链接到您。Google 使用基于链接数量和链接到您的 网站 权限的算法来确定您的分数。
例如,如果华尔街和纽约时报 网站 链接到您的产品,Google 知道您必须拥有一些真正的权威,因此您的排名会更高。
有无数种方法可以生成返回 Shopyy 商店的链接。发送新闻稿有助于接触博主并提供返回您的 网站 的链接。在您的利基中提供博客的客座帖子也将获得链接,并且产品链接也可以在博客中提及以获得产品页面流量。您也可以直接通过电子邮件发送 网站 并要求他们查看或链接到您的产品。
专业提示:永远不要购买链接,使用链接交换。Google 使用这些技术来搜索 网站。您正在寻找自然链接行为。
seq搜索引擎优化至少包括那几步?(深圳网站优化必须完成的20网页H1标签是仅次于title)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-27 13:05
深圳网站优化就是优化所有的搜索引擎。一般某个搜索引擎的排名比较好,其他搜索引擎的排名也差不多。
因此,今天的业星信息科技整理了网站优化必须要做的事情。做完这些事情,网站优化已经完成了90%左右。只有细节比拼的能力,这部分知识会在下面的文章中继续和大家讨论。
优化 网站 必须做到以下几点
站点机器人文件是指导搜索引擎工作的基本文件。它可以指定搜索引擎读取哪些文件,以免无目的搜索网页
301重定向和URL规范化有很多重要的功能,主要是为了统一顶级域和二级域的权重
站点地图 站点地图是搜索引擎到达您的站点后提供给搜索引擎的地图,使搜索引擎更容易工作。毕竟优化网站是满足搜索引擎的过程
404错误页面,收录页面由于人为原因被删除后,必须显示给搜索引擎。如果你不做 404 页面,搜索引擎不会喜欢你的 网站
写网页的标题,即网页的标题很重要,网页标题的重要性占网站优化的20%
网页的 H1 标签是仅次于标题的第二重要标签
关键字标签变得越来越不重要,但它对搜索引擎非常重要。例如,如果一个人的耳朵被切断,它可以被听到。可以剪掉吗?哈恩,哈恩,哈恩,哈恩,哈恩
description标签是一个页面描述标签,它有两个功能。一是向搜索引擎展示页面内容,二是展示搜索引擎的结果页面,这对用户体验也很重要。
以上就是网站优化必须完成的八个步骤,网站优化必须完成。 查看全部
seq搜索引擎优化至少包括那几步?(深圳网站优化必须完成的20网页H1标签是仅次于title)
深圳网站优化就是优化所有的搜索引擎。一般某个搜索引擎的排名比较好,其他搜索引擎的排名也差不多。
因此,今天的业星信息科技整理了网站优化必须要做的事情。做完这些事情,网站优化已经完成了90%左右。只有细节比拼的能力,这部分知识会在下面的文章中继续和大家讨论。
优化 网站 必须做到以下几点

站点机器人文件是指导搜索引擎工作的基本文件。它可以指定搜索引擎读取哪些文件,以免无目的搜索网页
301重定向和URL规范化有很多重要的功能,主要是为了统一顶级域和二级域的权重
站点地图 站点地图是搜索引擎到达您的站点后提供给搜索引擎的地图,使搜索引擎更容易工作。毕竟优化网站是满足搜索引擎的过程
404错误页面,收录页面由于人为原因被删除后,必须显示给搜索引擎。如果你不做 404 页面,搜索引擎不会喜欢你的 网站
写网页的标题,即网页的标题很重要,网页标题的重要性占网站优化的20%
网页的 H1 标签是仅次于标题的第二重要标签
关键字标签变得越来越不重要,但它对搜索引擎非常重要。例如,如果一个人的耳朵被切断,它可以被听到。可以剪掉吗?哈恩,哈恩,哈恩,哈恩,哈恩
description标签是一个页面描述标签,它有两个功能。一是向搜索引擎展示页面内容,二是展示搜索引擎的结果页面,这对用户体验也很重要。
以上就是网站优化必须完成的八个步骤,网站优化必须完成。
seq搜索引擎优化至少包括那几步?(如何找到最适合你的SEO涉及面比较广的技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-01-26 17:08
因为SEO涉及的范围很广,我给大家发一些小窍门。以下信息来自我自己的网站。有什么问题可以咨询HI,希望对你有帮助:
我们知道在搜索引擎中检索信息是通过键入 关键词 来完成的。因此,顾名思义,关键词 非常关键。是整个网站登录过程中最基本也是最重要的一步,也是我们网页优化的基础。因此,它的重要性怎么强调都不为过。但是关键词的确定并不是一件容易的事,要考虑很多因素,比如关键词必须和你的网站内容有关,单词如何组合排列,是否符合搜索工具的要求,尽量避免流行的关键词等。所以选择合适的关键词肯定需要做很多工作。
那么如何找到适合您的 关键词 呢?首先,仔细考虑潜在客户的心理,绞尽脑汁想象他们在寻找有关您的信息时最有可能使用的关键词,并将这些单词一一记录下来。不要担心列出太多 关键词,相反,您找到的 关键词 越多,您的覆盖面就越大,您挑选最佳 关键词 的机会就越大。
我们经常听到一个公司网站在搜索引擎上排名前20,业务量跃升10倍的故事。另一家公司也在前 20 名,但其业务量完全没有变化。是什么造成了如此大的不同?原因很简单,前者选择了正确的关键词,而后者在这方面犯了一个致命的错误。这个例子说明了正确的选择关键词对于企业网站营销的成败有多么重要。
选择相关的 关键词
对于一个企业来说,选择关键词当然必须和它自己的产品或服务相关。不要听信靠不相关的点击关键词来拉动更多流量的宣传,这不仅不道德,而且毫无意义。想象一下有人查找“Monica Lewinsky”,您会对您生产的酱油感兴趣吗?当然不是。诚然,有时这确实会增加 网站 的流量,但既然您是在销售产品,而不是提供免费的小道消息,那么通过作弊来增加流量有什么意义呢?
选择一个特定的 关键词
还有一点我们在选择关键词时要注意的一点是避免使用泛泛的词作为主要的关键词,而要根据你的业务或产品的类型尽可能选择具体的词. 例如,一家销售木工工具的制造商,“木匠工具”不是正确的选择关键词,“链锯”可能是明智的选择。
有人会问,既然“木匠工具”是一个集合名词,涵盖了厂家的所有产品,为什么不用呢?我们不妨把 Carpenter Tools 带到 Google,你会发现搜索结果超过 6 位(实际数字是 189,000),这意味着你的竞争对手有近 200,000!在其中脱颖而出!许多竞争对手几乎是“不可能完成的任务”。相反,“链锯”(69,800)下的搜索结果要少得多,您有更多机会排名领先于竞争对手。
选择更长的 关键词
与查询信息时尽可能使用单词的原创形式相反,提交网站时最好使用单词的较长形式。例如,可以使用“游戏”时,尽量不要选择“游戏”。因为在搜索引擎支持词多态或者分词查询的情况下,选择“游戏”可以保证你在搜索“游戏”和“游戏”时可以检索到你的网页。
不要忘记拼错的单词?
许多文章关于如何选择关键词特别提到了单词的拼写错误,例如“当代现代咖啡桌”,提醒我们不要忘记将它们收录在关键词选项中。理论是一些词经常被用户拼错,并且考虑到一般人不会针对错别字关键词,所以如果你足够聪明,可以找到优化页面以防止拼写错误的技巧,那么一旦你遇到用户并使用此错字进行搜索,您将站在搜索结果的最前沿!
真的是这样吗?首先,我们来看看上面的例子有什么问题。“contemorary”其实就是“contemporary”,虽然是一个字母的区别,但是从关键词的角度来看,两者相差甚远。奇怪的是,根据关键词监测统计报告,“contemorary”在两个月内出现了多达66次!所以我们要不要快点把它放到关键词列表中?等一下。我们先来分析一下谁会经常写错别字。它是受过教育的正规商人吗?毕竟,“当代”不是一个硬性的拉丁语借词,这不太可能。似乎有些粗心的丈夫或节俭的家庭主妇更值得怀疑。平心而论,他们将是您宝贵的客户,但不太可能成为您理想的商业伙伴。
相反,如果潜在客户不小心拼错了一个单词,却看到你的 网站 出现在他面前,并且那个拼写错误多次显眼地加粗,他会如何反应?他会像发现金矿一样欣喜若狂吗?还是你对这家公司的质量还有一点怀疑?他会认为一个连基本语法都没有掌握的厂商,真的是有问题的。所以,拼写错误的 关键词 是一个陷阱,我们必须三思而后行。
此外,目前一些搜索引擎(如谷歌)已经增加了自动拼写检查功能。当用户输入错字时,系统会自动提供正确的单词选择。当用户意识到他们错了,大多数人倾向于通过正确的 关键词 提示进行搜索。所以到了这个阶段,优化拼写错误的网页已经基本失去了意义。
寻找 关键词 提示
作为网站的所有者,当然你是最了解你的业务的人,所以你总能找到最能反映你业务的关键词。但仅仅依靠自己的努力,难免会出现一些疏漏。这个时候,你不妨去搜索引擎,找到竞争对手的网站,看看他们用的是哪个关键词,或许可以从中得到一些信息。有些启发。
另外,借助一些关键词自动分析软件,可以快速从你或你竞争对手的网页中提取出合适的关键词,你的工作效率可以成倍提升,我们可以通过这些软件找到很多< @关键词 之前没有考虑过,大大扩展了我们的 关键词 列表。
停用词/过滤词
两者含义相同,都是指太常用而没有任何检索价值的词,如“a”、“the”、“and”、“of”、“web”、“home page”和很快。搜索引擎通常会在遇到这些术语时过滤掉它们。因此,为了节省篇幅,应尽量避免使用此类词,尤其是在字数有严格限制的地方。(为了验证上述规则,您可以尝试在搜索引擎中搜索“stay the night”。您会发现“the”这个词与搜索条件匹配,但不是粗体,表示它被忽略了。)
重复 关键词 1000 次
既然关键词出现的频率是决定网站排名的重要因素,为什么不重复1000次,简单又有效呢?停止。众所周知,这就是搜索引擎的“石器时代”做法,在当时确实奏效,但现在早已被搜索引擎抛弃。
当时的典型做法是:“关键词, 关键词, 关键词...”。重复次数越多,网站 排名越高。所以登录搜索引擎变成了无休止的关键词重复竞赛。你重复500次不算太多,我会重复600次,而且重复关键词数千次的人很多。搜索引擎很快意识到了这种做法的危险性,终于在忍无可忍的时候站了起来,警告那些走得太远的人网站,如果他们继续执迷不悟,不仅达不到他们的目标,但他们也可能被判处死刑。- 永远不要让你的 网站 出来!
所以不要刻意重复某个关键词太多,尤其是不要连续使用某个关键词超过2次。使用关键词时,尽量做到自然流畅,符合基本语法规则。
错误的代码会损害您的搜索引擎排名
糟糕的代码会损害您的搜索引擎排名 简单的网页错误可能会导致搜索引擎蜘蛛错误地索引页面或完全丢弃页面。在穿上之前检查您的代码和连接。TML 代码错误会对您的搜索引擎排名产生负面影响吗?大多数网站管理员没有意识到搜索引擎要求占据中心位置。糟糕的代码会以多种方式损害搜索引擎网站。当搜索引擎在主 HTML 中查找关键字和相关条件时,如果遇到无法理解的 HTML,蜘蛛就会降级或离开您的页面。诸如标签放置不当的错误(例如 优采云tower,标签放置在主体内部而不是头部内部)可能会导致蜘蛛忽略该标签,从而降低您的相关性得分和随后的排名。其他页面上的错误也会限制搜索引擎将您的网站编入索引。损坏的链接将成为蜘蛛的障碍,破坏搜索引擎蜘蛛索引正文和后面的链接。如果他们来到您的 网站 并遇到连接中断,他们将无法完全索引该站点,甚至他们会丢弃此 网站(他们更多的是 网站 等待索引,为什么要把时间浪费在损坏的 网站 上?!)亚利桑那州的职业计算机顾问和 SEO 所有者 John Bryant 向我们讲述了她的经历。有一次我忘记修改我的 HTML,它让我失去了前 10 名的排名!我的一小段 HTML 犯了一个现代的 网站 错误,它破坏了 网站 在搜索引擎中的排名。打破搜索引擎蜘蛛索引正文和随后的链接。如果他们来到您的 网站 并遇到连接中断,他们将无法完全索引该站点,甚至他们会丢弃此 网站(他们更多的是 网站 等待索引,为什么要把时间浪费在损坏的 网站 上?!)亚利桑那州的职业计算机顾问和 SEO 所有者 John Bryant 向我们讲述了她的经历。有一次我忘记修改我的 HTML,它让我失去了前 10 名的排名!我的一小段 HTML 犯了一个现代的 网站 错误,它破坏了 网站 在搜索引擎中的排名。打破搜索引擎蜘蛛索引正文和随后的链接。如果他们来到您的 网站 并遇到连接中断,他们将无法完全索引该站点,甚至他们会丢弃此 网站(他们更多的是 网站 等待索引,为什么要把时间浪费在损坏的 网站 上?!)亚利桑那州的职业计算机顾问和 SEO 所有者 John Bryant 向我们讲述了她的经历。有一次我忘记修改我的 HTML,它让我失去了前 10 名的排名!我的一小段 HTML 犯了一个现代的 网站 错误,它破坏了 网站 在搜索引擎中的排名。为什么要把时间浪费在损坏的 网站 上?!) 亚利桑那州的职业计算机顾问和 SEO 所有者 John Bryant 向我们讲述了她的经历。有一次我忘记修改我的 HTML,它让我失去了前 10 名的排名!我的一小段 HTML 犯了一个现代的 网站 错误,它破坏了 网站 在搜索引擎中的排名。为什么要把时间浪费在损坏的 网站 上?!) 亚利桑那州的职业计算机顾问和 SEO 所有者 John Bryant 向我们讲述了她的经历。有一次我忘记修改我的 HTML,它让我失去了前 10 名的排名!我的一小段 HTML 犯了一个现代的 网站 错误,它破坏了 网站 在搜索引擎中的排名。
从第一页的前十位下降到第三页。幸运的是,这个故事有个美好的结局。一位广为人知的专业工程师立即注意到搜索引擎排名下降,并确认原因是 HTML 错误。他修复了错误并再次提交页面。几周后,他重新获得了搜索引擎排名。错误也伤害了目录!代码中的错误和问题会阻止搜索引擎工作——它也会影响目录。在搜索引擎策略中,致力于搜索引擎服务的 Yahoo 和 LookSmart 站点都拒绝此类连接和错误。我们的 网站 修复工具将确保您避免此 HTML 问题。错误如何输入代码?我的网站管理员知道代码 - 他不会犯错误。“不是故意的,而是让” s 考虑您的网站管理员所处的工作环境。有限的时间,多人一起工作,不断改进的压力网站 - 事实是,网站管理员的世界很忙,压力很大。疲惫的站长努力跟上,有时,一个小错误会改变网站,让改变高速旋转。考虑一下这个脚本 - 您的销售部门将一些很棒的新主页交给您的网站管理员。他们已与贵公司的 SEO 专家协调,并在新文本中战略性地放置关键字。为了小心,您的网站管理员提交了添加新文本的任务,但不小心剪掉了段落涂鸦的右方括号,因此您的文本如下所示:这是您的关键字富文本,当搜索引擎在不关闭括号的情况下读取您的页面时,销售和 SEO 添加在一起,它假定所有关键字丰富的正文都是段落标签的属性 - 并忽略它。搜索引擎在您的页面上强调可见的正文文本,这会尽可能地完善正文,明确添加关键字来推动您的网站与您的相关性只是失去了证明您与搜索引擎相关性的巨大机会。提高搜索引擎中的其他无错误排名和网站流量需要多少费用。明确地添加关键字来推动您的网站与您的相关性只是失去了一个巨大的机会来证明您与搜索引擎的相关性。提高搜索引擎中的其他无错误排名和网站流量需要多少费用。明确地添加关键字来推动您的网站与您的相关性只是失去了一个巨大的机会来证明您与搜索引擎的相关性。提高搜索引擎中的其他无错误排名和网站流量需要多少费用。
搜索引擎提交提示
网页优化只是登录搜索引擎的准备工作。最后,我们要把优化后的网站提交给搜索引擎,这也是网站注册的一个很重要的环节。
1. 出现在带有 关键词 的 URL 中(英文)
2. 关键词 (1-3) 出现在页面标题中
3. 关键词 标签出现在 关键词 (1-3)
4. 与 关键词 一起出现在描述标签中(主要的 关键词 重复 2 次)
5. 自然出现在内容中关键词
6. 出现第一段和最后一段内容关键词
7. H1、H2标签出现关键词
8. 导出链接锚文本收录 关键词
9. 图像的文件名收录 关键词
10. 出现在 关键词 的 ALT 属性中
11.关键词密度6-8%
12. 变为粗体或斜体 关键词
提高 关键词 排名的 28 个 SEO 技巧
28 个使 关键词 排名显着提高的 SEO 技巧:
关键词位置、密度、治疗
关键词 出现在 URL 中(英文)
关键词 (1-3) 出现在页面标题中
关键词 出现在 关键词 标记中 (1-3)
关键词 出现在描述标签中(主要的 关键词 重复了 2 次)
关键词 自然出现在内容中
内容的第一段和最后一段出现关键词
关键词 出现在 H1、H2 标签中
导出链接锚文本收录 关键词
图像的文件名收录 关键词
关键词 出现在 ALT 属性中
关键词密度6-8%
粗体或斜体 关键词
内容质量、更新频率、相关性
原创的内容最好了,不宜多次转载
内容独立,与其他页面至少有 30% 的差异
1000-2000字,合理切分
定期更新,最好每天更新
内容围绕页面关键词,与整个网站的主题相关 查看全部
seq搜索引擎优化至少包括那几步?(如何找到最适合你的SEO涉及面比较广的技巧)
因为SEO涉及的范围很广,我给大家发一些小窍门。以下信息来自我自己的网站。有什么问题可以咨询HI,希望对你有帮助:
我们知道在搜索引擎中检索信息是通过键入 关键词 来完成的。因此,顾名思义,关键词 非常关键。是整个网站登录过程中最基本也是最重要的一步,也是我们网页优化的基础。因此,它的重要性怎么强调都不为过。但是关键词的确定并不是一件容易的事,要考虑很多因素,比如关键词必须和你的网站内容有关,单词如何组合排列,是否符合搜索工具的要求,尽量避免流行的关键词等。所以选择合适的关键词肯定需要做很多工作。
那么如何找到适合您的 关键词 呢?首先,仔细考虑潜在客户的心理,绞尽脑汁想象他们在寻找有关您的信息时最有可能使用的关键词,并将这些单词一一记录下来。不要担心列出太多 关键词,相反,您找到的 关键词 越多,您的覆盖面就越大,您挑选最佳 关键词 的机会就越大。
我们经常听到一个公司网站在搜索引擎上排名前20,业务量跃升10倍的故事。另一家公司也在前 20 名,但其业务量完全没有变化。是什么造成了如此大的不同?原因很简单,前者选择了正确的关键词,而后者在这方面犯了一个致命的错误。这个例子说明了正确的选择关键词对于企业网站营销的成败有多么重要。
选择相关的 关键词
对于一个企业来说,选择关键词当然必须和它自己的产品或服务相关。不要听信靠不相关的点击关键词来拉动更多流量的宣传,这不仅不道德,而且毫无意义。想象一下有人查找“Monica Lewinsky”,您会对您生产的酱油感兴趣吗?当然不是。诚然,有时这确实会增加 网站 的流量,但既然您是在销售产品,而不是提供免费的小道消息,那么通过作弊来增加流量有什么意义呢?
选择一个特定的 关键词
还有一点我们在选择关键词时要注意的一点是避免使用泛泛的词作为主要的关键词,而要根据你的业务或产品的类型尽可能选择具体的词. 例如,一家销售木工工具的制造商,“木匠工具”不是正确的选择关键词,“链锯”可能是明智的选择。
有人会问,既然“木匠工具”是一个集合名词,涵盖了厂家的所有产品,为什么不用呢?我们不妨把 Carpenter Tools 带到 Google,你会发现搜索结果超过 6 位(实际数字是 189,000),这意味着你的竞争对手有近 200,000!在其中脱颖而出!许多竞争对手几乎是“不可能完成的任务”。相反,“链锯”(69,800)下的搜索结果要少得多,您有更多机会排名领先于竞争对手。
选择更长的 关键词
与查询信息时尽可能使用单词的原创形式相反,提交网站时最好使用单词的较长形式。例如,可以使用“游戏”时,尽量不要选择“游戏”。因为在搜索引擎支持词多态或者分词查询的情况下,选择“游戏”可以保证你在搜索“游戏”和“游戏”时可以检索到你的网页。
不要忘记拼错的单词?
许多文章关于如何选择关键词特别提到了单词的拼写错误,例如“当代现代咖啡桌”,提醒我们不要忘记将它们收录在关键词选项中。理论是一些词经常被用户拼错,并且考虑到一般人不会针对错别字关键词,所以如果你足够聪明,可以找到优化页面以防止拼写错误的技巧,那么一旦你遇到用户并使用此错字进行搜索,您将站在搜索结果的最前沿!
真的是这样吗?首先,我们来看看上面的例子有什么问题。“contemorary”其实就是“contemporary”,虽然是一个字母的区别,但是从关键词的角度来看,两者相差甚远。奇怪的是,根据关键词监测统计报告,“contemorary”在两个月内出现了多达66次!所以我们要不要快点把它放到关键词列表中?等一下。我们先来分析一下谁会经常写错别字。它是受过教育的正规商人吗?毕竟,“当代”不是一个硬性的拉丁语借词,这不太可能。似乎有些粗心的丈夫或节俭的家庭主妇更值得怀疑。平心而论,他们将是您宝贵的客户,但不太可能成为您理想的商业伙伴。
相反,如果潜在客户不小心拼错了一个单词,却看到你的 网站 出现在他面前,并且那个拼写错误多次显眼地加粗,他会如何反应?他会像发现金矿一样欣喜若狂吗?还是你对这家公司的质量还有一点怀疑?他会认为一个连基本语法都没有掌握的厂商,真的是有问题的。所以,拼写错误的 关键词 是一个陷阱,我们必须三思而后行。
此外,目前一些搜索引擎(如谷歌)已经增加了自动拼写检查功能。当用户输入错字时,系统会自动提供正确的单词选择。当用户意识到他们错了,大多数人倾向于通过正确的 关键词 提示进行搜索。所以到了这个阶段,优化拼写错误的网页已经基本失去了意义。
寻找 关键词 提示
作为网站的所有者,当然你是最了解你的业务的人,所以你总能找到最能反映你业务的关键词。但仅仅依靠自己的努力,难免会出现一些疏漏。这个时候,你不妨去搜索引擎,找到竞争对手的网站,看看他们用的是哪个关键词,或许可以从中得到一些信息。有些启发。
另外,借助一些关键词自动分析软件,可以快速从你或你竞争对手的网页中提取出合适的关键词,你的工作效率可以成倍提升,我们可以通过这些软件找到很多< @关键词 之前没有考虑过,大大扩展了我们的 关键词 列表。
停用词/过滤词
两者含义相同,都是指太常用而没有任何检索价值的词,如“a”、“the”、“and”、“of”、“web”、“home page”和很快。搜索引擎通常会在遇到这些术语时过滤掉它们。因此,为了节省篇幅,应尽量避免使用此类词,尤其是在字数有严格限制的地方。(为了验证上述规则,您可以尝试在搜索引擎中搜索“stay the night”。您会发现“the”这个词与搜索条件匹配,但不是粗体,表示它被忽略了。)
重复 关键词 1000 次
既然关键词出现的频率是决定网站排名的重要因素,为什么不重复1000次,简单又有效呢?停止。众所周知,这就是搜索引擎的“石器时代”做法,在当时确实奏效,但现在早已被搜索引擎抛弃。
当时的典型做法是:“关键词, 关键词, 关键词...”。重复次数越多,网站 排名越高。所以登录搜索引擎变成了无休止的关键词重复竞赛。你重复500次不算太多,我会重复600次,而且重复关键词数千次的人很多。搜索引擎很快意识到了这种做法的危险性,终于在忍无可忍的时候站了起来,警告那些走得太远的人网站,如果他们继续执迷不悟,不仅达不到他们的目标,但他们也可能被判处死刑。- 永远不要让你的 网站 出来!
所以不要刻意重复某个关键词太多,尤其是不要连续使用某个关键词超过2次。使用关键词时,尽量做到自然流畅,符合基本语法规则。
错误的代码会损害您的搜索引擎排名
糟糕的代码会损害您的搜索引擎排名 简单的网页错误可能会导致搜索引擎蜘蛛错误地索引页面或完全丢弃页面。在穿上之前检查您的代码和连接。TML 代码错误会对您的搜索引擎排名产生负面影响吗?大多数网站管理员没有意识到搜索引擎要求占据中心位置。糟糕的代码会以多种方式损害搜索引擎网站。当搜索引擎在主 HTML 中查找关键字和相关条件时,如果遇到无法理解的 HTML,蜘蛛就会降级或离开您的页面。诸如标签放置不当的错误(例如 优采云tower,标签放置在主体内部而不是头部内部)可能会导致蜘蛛忽略该标签,从而降低您的相关性得分和随后的排名。其他页面上的错误也会限制搜索引擎将您的网站编入索引。损坏的链接将成为蜘蛛的障碍,破坏搜索引擎蜘蛛索引正文和后面的链接。如果他们来到您的 网站 并遇到连接中断,他们将无法完全索引该站点,甚至他们会丢弃此 网站(他们更多的是 网站 等待索引,为什么要把时间浪费在损坏的 网站 上?!)亚利桑那州的职业计算机顾问和 SEO 所有者 John Bryant 向我们讲述了她的经历。有一次我忘记修改我的 HTML,它让我失去了前 10 名的排名!我的一小段 HTML 犯了一个现代的 网站 错误,它破坏了 网站 在搜索引擎中的排名。打破搜索引擎蜘蛛索引正文和随后的链接。如果他们来到您的 网站 并遇到连接中断,他们将无法完全索引该站点,甚至他们会丢弃此 网站(他们更多的是 网站 等待索引,为什么要把时间浪费在损坏的 网站 上?!)亚利桑那州的职业计算机顾问和 SEO 所有者 John Bryant 向我们讲述了她的经历。有一次我忘记修改我的 HTML,它让我失去了前 10 名的排名!我的一小段 HTML 犯了一个现代的 网站 错误,它破坏了 网站 在搜索引擎中的排名。打破搜索引擎蜘蛛索引正文和随后的链接。如果他们来到您的 网站 并遇到连接中断,他们将无法完全索引该站点,甚至他们会丢弃此 网站(他们更多的是 网站 等待索引,为什么要把时间浪费在损坏的 网站 上?!)亚利桑那州的职业计算机顾问和 SEO 所有者 John Bryant 向我们讲述了她的经历。有一次我忘记修改我的 HTML,它让我失去了前 10 名的排名!我的一小段 HTML 犯了一个现代的 网站 错误,它破坏了 网站 在搜索引擎中的排名。为什么要把时间浪费在损坏的 网站 上?!) 亚利桑那州的职业计算机顾问和 SEO 所有者 John Bryant 向我们讲述了她的经历。有一次我忘记修改我的 HTML,它让我失去了前 10 名的排名!我的一小段 HTML 犯了一个现代的 网站 错误,它破坏了 网站 在搜索引擎中的排名。为什么要把时间浪费在损坏的 网站 上?!) 亚利桑那州的职业计算机顾问和 SEO 所有者 John Bryant 向我们讲述了她的经历。有一次我忘记修改我的 HTML,它让我失去了前 10 名的排名!我的一小段 HTML 犯了一个现代的 网站 错误,它破坏了 网站 在搜索引擎中的排名。
从第一页的前十位下降到第三页。幸运的是,这个故事有个美好的结局。一位广为人知的专业工程师立即注意到搜索引擎排名下降,并确认原因是 HTML 错误。他修复了错误并再次提交页面。几周后,他重新获得了搜索引擎排名。错误也伤害了目录!代码中的错误和问题会阻止搜索引擎工作——它也会影响目录。在搜索引擎策略中,致力于搜索引擎服务的 Yahoo 和 LookSmart 站点都拒绝此类连接和错误。我们的 网站 修复工具将确保您避免此 HTML 问题。错误如何输入代码?我的网站管理员知道代码 - 他不会犯错误。“不是故意的,而是让” s 考虑您的网站管理员所处的工作环境。有限的时间,多人一起工作,不断改进的压力网站 - 事实是,网站管理员的世界很忙,压力很大。疲惫的站长努力跟上,有时,一个小错误会改变网站,让改变高速旋转。考虑一下这个脚本 - 您的销售部门将一些很棒的新主页交给您的网站管理员。他们已与贵公司的 SEO 专家协调,并在新文本中战略性地放置关键字。为了小心,您的网站管理员提交了添加新文本的任务,但不小心剪掉了段落涂鸦的右方括号,因此您的文本如下所示:这是您的关键字富文本,当搜索引擎在不关闭括号的情况下读取您的页面时,销售和 SEO 添加在一起,它假定所有关键字丰富的正文都是段落标签的属性 - 并忽略它。搜索引擎在您的页面上强调可见的正文文本,这会尽可能地完善正文,明确添加关键字来推动您的网站与您的相关性只是失去了证明您与搜索引擎相关性的巨大机会。提高搜索引擎中的其他无错误排名和网站流量需要多少费用。明确地添加关键字来推动您的网站与您的相关性只是失去了一个巨大的机会来证明您与搜索引擎的相关性。提高搜索引擎中的其他无错误排名和网站流量需要多少费用。明确地添加关键字来推动您的网站与您的相关性只是失去了一个巨大的机会来证明您与搜索引擎的相关性。提高搜索引擎中的其他无错误排名和网站流量需要多少费用。
搜索引擎提交提示
网页优化只是登录搜索引擎的准备工作。最后,我们要把优化后的网站提交给搜索引擎,这也是网站注册的一个很重要的环节。
1. 出现在带有 关键词 的 URL 中(英文)
2. 关键词 (1-3) 出现在页面标题中
3. 关键词 标签出现在 关键词 (1-3)
4. 与 关键词 一起出现在描述标签中(主要的 关键词 重复 2 次)
5. 自然出现在内容中关键词
6. 出现第一段和最后一段内容关键词
7. H1、H2标签出现关键词
8. 导出链接锚文本收录 关键词
9. 图像的文件名收录 关键词
10. 出现在 关键词 的 ALT 属性中
11.关键词密度6-8%
12. 变为粗体或斜体 关键词
提高 关键词 排名的 28 个 SEO 技巧
28 个使 关键词 排名显着提高的 SEO 技巧:
关键词位置、密度、治疗
关键词 出现在 URL 中(英文)
关键词 (1-3) 出现在页面标题中
关键词 出现在 关键词 标记中 (1-3)
关键词 出现在描述标签中(主要的 关键词 重复了 2 次)
关键词 自然出现在内容中
内容的第一段和最后一段出现关键词
关键词 出现在 H1、H2 标签中
导出链接锚文本收录 关键词
图像的文件名收录 关键词
关键词 出现在 ALT 属性中
关键词密度6-8%
粗体或斜体 关键词
内容质量、更新频率、相关性
原创的内容最好了,不宜多次转载
内容独立,与其他页面至少有 30% 的差异
1000-2000字,合理切分
定期更新,最好每天更新
内容围绕页面关键词,与整个网站的主题相关
seq搜索引擎优化至少包括那几步?(告诉你做好网站优化需要走好哪几步)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-01-24 11:03
要想做好网站优化,首先要知道网站优化依赖哪些方面,找到关键,然后才能解决,做好. 今天,我会告诉你在网站优化中你需要做好什么。要走多少步。
一、首先,你需要链接到搜索引擎的偏好。不要在您的网页上显示图片或动画。搜索引擎无法识别这些东西,所以不要这样做。
二、标签的使用,标签的正确使用会增加或减少网站的权重,首先我们要让客户知道网站的重点是什么看到标签,搜索引擎看到网站标签和网站相关,那么自然权重会增加,那么我们标签中的关键词的权重也会增加。
三、注意链接的相关性,如果行业不相关,尽量不要做友情链接。这是网站权重的损失,网络之间的链接一定是相关的。
四、网站文章的布局要合理。首先要提高网站长尾关键词的排名。搜索引擎的第一步一般是抓取关键内容,索引要把重要内容放在最前面,所以需要改进网站长尾关键词,只要长tail关键词就是收录,它可以给网站带来很大的流量。
做好这些步骤,相信你的网站优化会更好。只有找到正确的方法,才能更好地解决问题。这是 网站 优化。虽然内部因素很多,但共同因素还是可以解决的。
网站 优化
Shiso Network为您提供网络推广、网络营销、网站建设、SEO优化、微信开发、网站托管等服务,服务热线:0311-66697360 查看全部
seq搜索引擎优化至少包括那几步?(告诉你做好网站优化需要走好哪几步)
要想做好网站优化,首先要知道网站优化依赖哪些方面,找到关键,然后才能解决,做好. 今天,我会告诉你在网站优化中你需要做好什么。要走多少步。
一、首先,你需要链接到搜索引擎的偏好。不要在您的网页上显示图片或动画。搜索引擎无法识别这些东西,所以不要这样做。
二、标签的使用,标签的正确使用会增加或减少网站的权重,首先我们要让客户知道网站的重点是什么看到标签,搜索引擎看到网站标签和网站相关,那么自然权重会增加,那么我们标签中的关键词的权重也会增加。
三、注意链接的相关性,如果行业不相关,尽量不要做友情链接。这是网站权重的损失,网络之间的链接一定是相关的。
四、网站文章的布局要合理。首先要提高网站长尾关键词的排名。搜索引擎的第一步一般是抓取关键内容,索引要把重要内容放在最前面,所以需要改进网站长尾关键词,只要长tail关键词就是收录,它可以给网站带来很大的流量。
做好这些步骤,相信你的网站优化会更好。只有找到正确的方法,才能更好地解决问题。这是 网站 优化。虽然内部因素很多,但共同因素还是可以解决的。
网站 优化
Shiso Network为您提供网络推广、网络营销、网站建设、SEO优化、微信开发、网站托管等服务,服务热线:0311-66697360
seq搜索引擎优化至少包括那几步?(SEO工作具体都有哪些前段seo优化一般包括哪些内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-01-24 10:18
所谓前端SEO优化一般包括什么内容,也就是搜索引擎优化的前端SEO优化一般包括什么内容。通过SEO,让网站在相关的关键词搜索页面中排名靠前,从而获得更多流量,最终实现转化。可以说,无论互联网发展到什么程度,只要有搜索引擎,只要搜索是人们解决问题最直接的方式,SEO就永远不会过时。
很多公司想做SEO,往往以为有一个网站,然后让人天天更新文章。事实上,SEO的工作远没有看起来那么简单。今天小编就和大家分享一下前端SEO优化中SEO工作的具体内容有哪些?
一、网站建筑
SEO 和 网站 建设密不可分。如果想让网站排名高,第一步是让搜索引擎爬虫爬取网站,为了按照算法排名,如果爬虫爬不上网站的页面@> 完全没有,所以没有排名。因此,在建站之初,就要考虑到SEO。主要体现在以下两个方面:
网站合理规划
主要有网站平面布局、辅助导航、内链设计、页面结构等。网站前期规划相当于为爬虫的到来做准备,让爬虫觉得这是一个友好、整洁的网站。
网站代码优化
这些主要包括站点地图、robots文件、404模板、301重定向、图片ALT、标题标签、网站TDK、关键词优化、nofollow、页面元等,通过代码优化让爬虫进入网站为了在网站中爬得更顺畅,将网站的关键词传递给爬虫以便更好地爬取,使其在网站中爬得更顺畅,传递关键词 网站 > 明确传给爬虫,这样不被抓就不会迷路,不会被抓到。
二、内容填充
网站的内容是网站的核心元素,是围绕企业品牌和经营产品进行的填充工作。向网页添加内容时,请注意以下几点:
关键词Layout:标题,文章段落中的关键词,排版第一段的SEO优化中一般收录什么内容;文章关键词 第一段和最后一段的布局;关键词布局等等。内链建设:主要体现在文章中设置锚文本。文章内容:虽然爬虫更喜欢原创的内容,但要以网站相关的主题为基础,保证网站内容的垂直性。追求原创,让网站内容缺乏话题性。更新频率:需要稳定更新,频率取决于企业网站的内容。热门的可以更频繁地更新,比如每天更新或者每周更新3-5次;对于小众方向网站,内容欠缺。如果不能每天或每周更新,可以选择每两周更新一次,或者每月更新一次。不要重复无内容的 网站 以使内容看起来丰富而频繁。@文章。三、站外优化
所谓站外优化,其实就是外链,可以通过友情链接、论坛、博客、文摘、自媒体平台等方式进行,注意一定要制作高质量的外链,千万不要做垃圾外链,很容易被搜索引擎down掉。
四、数据分析
通过百度站长工具或者其他平台的查询工具,可以看到网站的相关访问数据,比如来源关键词、用户访问路径等,通过相关数据可以监控SEO工作实时,未雨绸缪,如果有一些关键词流量下降,可以指定解决方案。
五、竞争分析
<p>除了自己做网站内外优化外,还要分析竞争对手的排名,他们的关键词设置,外链分布,内链布局,网站结构, 查看全部
seq搜索引擎优化至少包括那几步?(SEO工作具体都有哪些前段seo优化一般包括哪些内容)
所谓前端SEO优化一般包括什么内容,也就是搜索引擎优化的前端SEO优化一般包括什么内容。通过SEO,让网站在相关的关键词搜索页面中排名靠前,从而获得更多流量,最终实现转化。可以说,无论互联网发展到什么程度,只要有搜索引擎,只要搜索是人们解决问题最直接的方式,SEO就永远不会过时。

很多公司想做SEO,往往以为有一个网站,然后让人天天更新文章。事实上,SEO的工作远没有看起来那么简单。今天小编就和大家分享一下前端SEO优化中SEO工作的具体内容有哪些?
一、网站建筑
SEO 和 网站 建设密不可分。如果想让网站排名高,第一步是让搜索引擎爬虫爬取网站,为了按照算法排名,如果爬虫爬不上网站的页面@> 完全没有,所以没有排名。因此,在建站之初,就要考虑到SEO。主要体现在以下两个方面:
网站合理规划
主要有网站平面布局、辅助导航、内链设计、页面结构等。网站前期规划相当于为爬虫的到来做准备,让爬虫觉得这是一个友好、整洁的网站。
网站代码优化
这些主要包括站点地图、robots文件、404模板、301重定向、图片ALT、标题标签、网站TDK、关键词优化、nofollow、页面元等,通过代码优化让爬虫进入网站为了在网站中爬得更顺畅,将网站的关键词传递给爬虫以便更好地爬取,使其在网站中爬得更顺畅,传递关键词 网站 > 明确传给爬虫,这样不被抓就不会迷路,不会被抓到。
二、内容填充
网站的内容是网站的核心元素,是围绕企业品牌和经营产品进行的填充工作。向网页添加内容时,请注意以下几点:
关键词Layout:标题,文章段落中的关键词,排版第一段的SEO优化中一般收录什么内容;文章关键词 第一段和最后一段的布局;关键词布局等等。内链建设:主要体现在文章中设置锚文本。文章内容:虽然爬虫更喜欢原创的内容,但要以网站相关的主题为基础,保证网站内容的垂直性。追求原创,让网站内容缺乏话题性。更新频率:需要稳定更新,频率取决于企业网站的内容。热门的可以更频繁地更新,比如每天更新或者每周更新3-5次;对于小众方向网站,内容欠缺。如果不能每天或每周更新,可以选择每两周更新一次,或者每月更新一次。不要重复无内容的 网站 以使内容看起来丰富而频繁。@文章。三、站外优化
所谓站外优化,其实就是外链,可以通过友情链接、论坛、博客、文摘、自媒体平台等方式进行,注意一定要制作高质量的外链,千万不要做垃圾外链,很容易被搜索引擎down掉。
四、数据分析
通过百度站长工具或者其他平台的查询工具,可以看到网站的相关访问数据,比如来源关键词、用户访问路径等,通过相关数据可以监控SEO工作实时,未雨绸缪,如果有一些关键词流量下降,可以指定解决方案。
五、竞争分析
<p>除了自己做网站内外优化外,还要分析竞争对手的排名,他们的关键词设置,外链分布,内链布局,网站结构,
seq搜索引擎优化至少包括那几步?(加强SEO和内容营销关系的战略策略#1#2)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-22 20:16
下面,我列出了一些策略,以确保两个团队开始共同实现这一目标。
加强搜索引擎优化和内容营销之间关系的战略策略#1。将这两种策略组合成一个共同的内容路线图
在大多数组织中,内容和 SEO 团队都有策略文档。他们定义了每个团队的目标,并提供了实现这些目标的路线图。
为了开始加强这种关系,团队会比较他们的战略文件以确定:
为什么?内容团队可能已经意识到特定的受众问题。然后,他们的 SEO 同事通过关键字研究和其他分析对其进行验证。
例如,使用我们的 AI 驱动的内容编写者 Content Fusion,作者从关键词研究数据开始 SEO 以塑造内容。
在开始内容编写过程之前,首先确定要定位的搜索意图。
(内容融合关键字报告显示搜索意图。)
接下来,重要的是要找出哪些特定信息也会吸引您的受众。为此,请分析副本中收录的语义关键词,以确保您已掌握该主题。
我们在上图中看到了语义 关键词 的一些潜行高峰,但让我们看看完整列表:
(内容融合中的语义关键字报告。)
策略#2。审核 SEO 和引人入胜的内容
然后,内容作者或策略师会找到新的方法来丰富文案。您可以手动执行此操作并查看目标关键字的排名靠前的页面。此过程允许您确定要收录哪些新主题。上面提到的内容融合让您无需做足够的研究来理解语义相关领域、提高相关性并评估它们的权威与其他热门内容的关系就可以做到这一点。
反过来,搜索引擎优化团队确定新的关键字、目标并满足受众的需求。
例如,使用 seoClarity 的内容创意,内容作者可以研究观众在线提出的问题。
(内容创意报告查询“承诺戒指”。)
通过内容差距,作者可以将他们在搜索中的排名与竞争对手的关键词进行比较。在此过程中,他们确定了要定位和优化的新短语。
(内容差距报告显示了关键字和流量的机会。)
最后一步是对排名靠前的内容进行反向链接分析。首先,它决定了表现最好的页面有多少链接。它还确定他们是否能够重新创建任何反向链接机会。
(反向链接报告显示指向特定 URL 的链接。)
策略#3。通过 SEO 和内容数据识别用户需求
我相信 seo 和内容团队都知道这一点:
要与当今的观众互动,您需要了解他们的问题并提供信息来帮助他们解决问题。
当然,每个团队都在应对这一挑战。SEOS 着眼于关键词数据,以揭示其目标受众研究的趋势和主题。内容营销人员专注于社交媒体参与度、粘性和高流量博客,然后“重复”。
想象一下如果你结合这些方法会发生什么!
以下是它的工作原理:
作者确定了新的受众挑战。然后,她将她的发现传达给 SEO 团队,以研究与这些问题相匹配的相关关键字。
然后,他们都对主题进行微调以确保内容的全面覆盖,将他们的想法与搜索意图保持一致,并评估如何超越当前排名页面。
Seoclarity 的完整内容营销套件允许此流程在团队之间无缝工作,提供:
策略#4。一起评估比赛
为了满足排名,它必须针对竞争对手的表现。
事实上,分析排名级别的内容是发现新机会的最短途径。两个团队都应该提供揭示这些的见解。
搜索引擎优化团队利用他们的优势来确定使这些页面如此之高的因素。例如,长度、通用结构、收录的信息类型等。
您可以使用内容融合来简化您的流程,例如,显示排名内容的元数据。
(内容融合中的元描述报告。)
另一方面,内容团队可以利用社交媒体数据来确定这些页面如何与受众互动。反过来,发现如何创建更好的内容。
综上所述
搜索引擎优化和内容对于当今的任何营销策略都至关重要。不幸的是,我们经常听到他们选择独立工作的团队负责团队,尽管这两个团队本质上都在推动增长。
希望通过这个简短的指南,您已经发现了如何改变这种状况并结合每个团队的专业知识来推动更高的营销投资回报率。
内容团队和 SEO 团队如何协同工作?在下面的评论部分给我们留言! 查看全部
seq搜索引擎优化至少包括那几步?(加强SEO和内容营销关系的战略策略#1#2)
下面,我列出了一些策略,以确保两个团队开始共同实现这一目标。
加强搜索引擎优化和内容营销之间关系的战略策略#1。将这两种策略组合成一个共同的内容路线图
在大多数组织中,内容和 SEO 团队都有策略文档。他们定义了每个团队的目标,并提供了实现这些目标的路线图。
为了开始加强这种关系,团队会比较他们的战略文件以确定:
为什么?内容团队可能已经意识到特定的受众问题。然后,他们的 SEO 同事通过关键字研究和其他分析对其进行验证。
例如,使用我们的 AI 驱动的内容编写者 Content Fusion,作者从关键词研究数据开始 SEO 以塑造内容。
在开始内容编写过程之前,首先确定要定位的搜索意图。

(内容融合关键字报告显示搜索意图。)
接下来,重要的是要找出哪些特定信息也会吸引您的受众。为此,请分析副本中收录的语义关键词,以确保您已掌握该主题。

我们在上图中看到了语义 关键词 的一些潜行高峰,但让我们看看完整列表:

(内容融合中的语义关键字报告。)
策略#2。审核 SEO 和引人入胜的内容
然后,内容作者或策略师会找到新的方法来丰富文案。您可以手动执行此操作并查看目标关键字的排名靠前的页面。此过程允许您确定要收录哪些新主题。上面提到的内容融合让您无需做足够的研究来理解语义相关领域、提高相关性并评估它们的权威与其他热门内容的关系就可以做到这一点。
反过来,搜索引擎优化团队确定新的关键字、目标并满足受众的需求。
例如,使用 seoClarity 的内容创意,内容作者可以研究观众在线提出的问题。

(内容创意报告查询“承诺戒指”。)
通过内容差距,作者可以将他们在搜索中的排名与竞争对手的关键词进行比较。在此过程中,他们确定了要定位和优化的新短语。
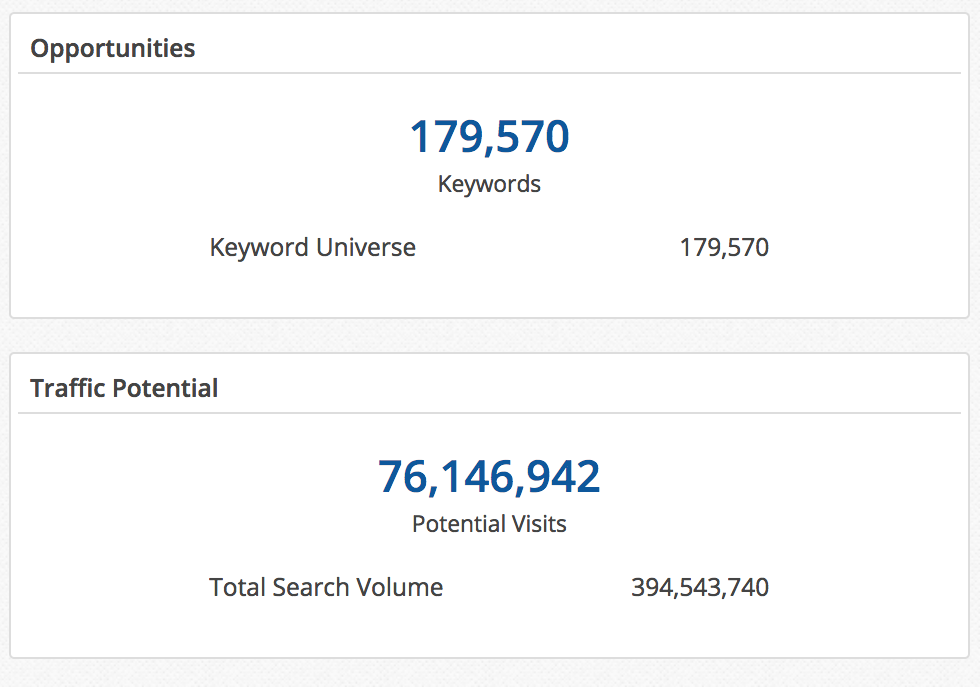
(内容差距报告显示了关键字和流量的机会。)
最后一步是对排名靠前的内容进行反向链接分析。首先,它决定了表现最好的页面有多少链接。它还确定他们是否能够重新创建任何反向链接机会。
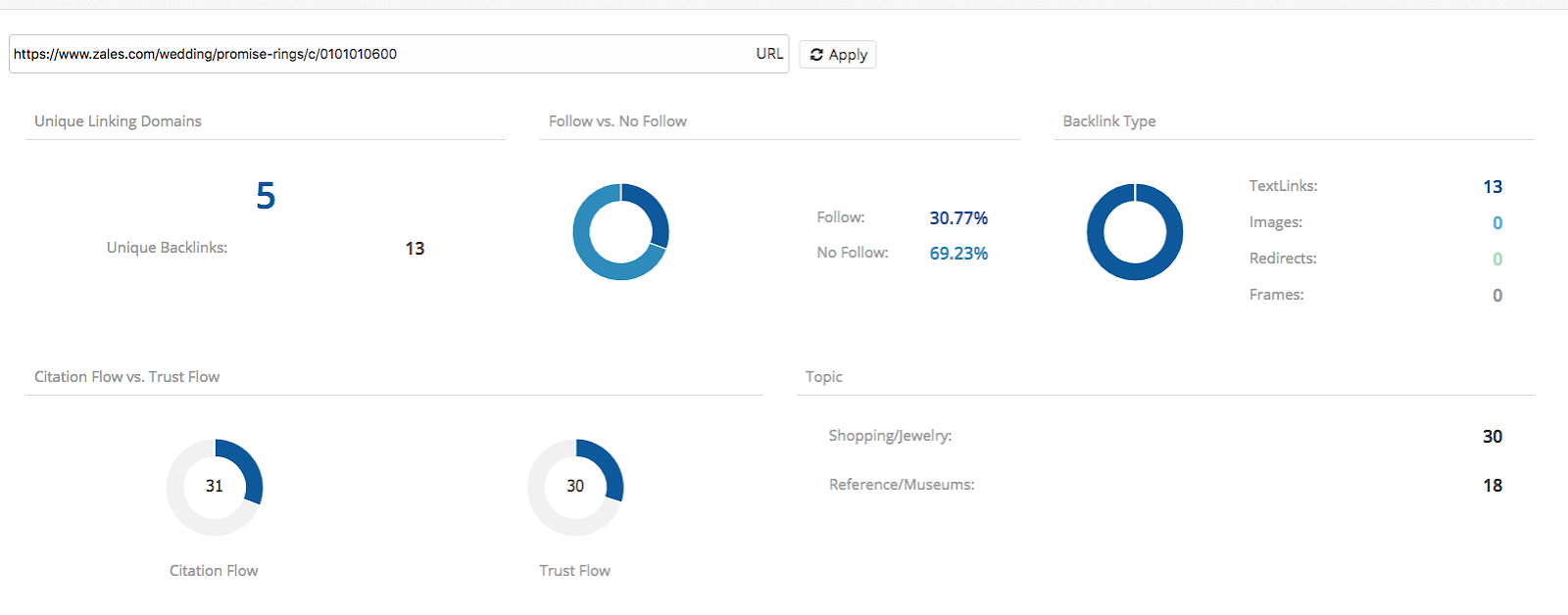
(反向链接报告显示指向特定 URL 的链接。)
策略#3。通过 SEO 和内容数据识别用户需求
我相信 seo 和内容团队都知道这一点:
要与当今的观众互动,您需要了解他们的问题并提供信息来帮助他们解决问题。
当然,每个团队都在应对这一挑战。SEOS 着眼于关键词数据,以揭示其目标受众研究的趋势和主题。内容营销人员专注于社交媒体参与度、粘性和高流量博客,然后“重复”。
想象一下如果你结合这些方法会发生什么!
以下是它的工作原理:
作者确定了新的受众挑战。然后,她将她的发现传达给 SEO 团队,以研究与这些问题相匹配的相关关键字。
然后,他们都对主题进行微调以确保内容的全面覆盖,将他们的想法与搜索意图保持一致,并评估如何超越当前排名页面。
Seoclarity 的完整内容营销套件允许此流程在团队之间无缝工作,提供:
策略#4。一起评估比赛
为了满足排名,它必须针对竞争对手的表现。
事实上,分析排名级别的内容是发现新机会的最短途径。两个团队都应该提供揭示这些的见解。
搜索引擎优化团队利用他们的优势来确定使这些页面如此之高的因素。例如,长度、通用结构、收录的信息类型等。
您可以使用内容融合来简化您的流程,例如,显示排名内容的元数据。

(内容融合中的元描述报告。)
另一方面,内容团队可以利用社交媒体数据来确定这些页面如何与受众互动。反过来,发现如何创建更好的内容。
综上所述
搜索引擎优化和内容对于当今的任何营销策略都至关重要。不幸的是,我们经常听到他们选择独立工作的团队负责团队,尽管这两个团队本质上都在推动增长。
希望通过这个简短的指南,您已经发现了如何改变这种状况并结合每个团队的专业知识来推动更高的营销投资回报率。
内容团队和 SEO 团队如何协同工作?在下面的评论部分给我们留言!
seq搜索引擎优化至少包括那几步?(网站优化SEO一般有哪些步骤呢[邵阳SEO]?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-21 22:06
我们搜索 SEO。百科对SEO的定义是:利用搜索引擎的搜索规则,提高网站目前在相关搜索引擎中的自然排名的一种方式。SEO包括两个方面:站内SEO和站外SEO;网站内外优化,提高网站在搜索引擎中的自然排名,吸引更多人点击,从而获得更多流量,达到网络营销和品牌建设的效果。
网站优化SEO[邵阳SEO]的一般步骤是什么?
在济南做了几年SEO优化并有一定经验的老魏认为,SEO大致分为五个主要环节。首先,挖掘网站的关键词,做长远发展。这是最重要的一步。分析关键词的长尾词、竞争对手的网站、关键词的预期排名等;二、网站的结构分析,整个网站要符合搜索引擎爬虫的喜好,去掉网站的不良内容,比如一些没用的js 、flash等,做合理的导航和链接;三、网站目录和页面,实现树状目录结构,金字塔模式,做好每个页面的布局优化;四、定期发布内容,蜘蛛我喜欢定期更新【邵阳SEO】网站,所以要合理安排时间更新网站,让搜索引擎明白网站的核心关键词是什么@> 是,link 合理扩展;五、网站流量分析,登录各大站长平台,查看页面的收录级别,分析网站的流量数据。如果这五点能做好,网站提升排名指日可待。并分析网站的流量数据。如果这五点能做好,网站提升排名指日可待。并分析网站的流量数据。如果这五点能做好,网站提升排名指日可待。
据调查,87%的网民会使用搜索引擎服务来查找他们需要的信息,以优化网页内容,使其符合用户的浏览习惯,同时不影响用户体验。为了提高搜索引擎排名,增加网站的知名度,达到营销效果,切记不要为了SEO而使用SEO。 查看全部
seq搜索引擎优化至少包括那几步?(网站优化SEO一般有哪些步骤呢[邵阳SEO]?)
我们搜索 SEO。百科对SEO的定义是:利用搜索引擎的搜索规则,提高网站目前在相关搜索引擎中的自然排名的一种方式。SEO包括两个方面:站内SEO和站外SEO;网站内外优化,提高网站在搜索引擎中的自然排名,吸引更多人点击,从而获得更多流量,达到网络营销和品牌建设的效果。
网站优化SEO[邵阳SEO]的一般步骤是什么?
在济南做了几年SEO优化并有一定经验的老魏认为,SEO大致分为五个主要环节。首先,挖掘网站的关键词,做长远发展。这是最重要的一步。分析关键词的长尾词、竞争对手的网站、关键词的预期排名等;二、网站的结构分析,整个网站要符合搜索引擎爬虫的喜好,去掉网站的不良内容,比如一些没用的js 、flash等,做合理的导航和链接;三、网站目录和页面,实现树状目录结构,金字塔模式,做好每个页面的布局优化;四、定期发布内容,蜘蛛我喜欢定期更新【邵阳SEO】网站,所以要合理安排时间更新网站,让搜索引擎明白网站的核心关键词是什么@> 是,link 合理扩展;五、网站流量分析,登录各大站长平台,查看页面的收录级别,分析网站的流量数据。如果这五点能做好,网站提升排名指日可待。并分析网站的流量数据。如果这五点能做好,网站提升排名指日可待。并分析网站的流量数据。如果这五点能做好,网站提升排名指日可待。
据调查,87%的网民会使用搜索引擎服务来查找他们需要的信息,以优化网页内容,使其符合用户的浏览习惯,同时不影响用户体验。为了提高搜索引擎排名,增加网站的知名度,达到营销效果,切记不要为了SEO而使用SEO。
seq搜索引擎优化至少包括那几步?(网站关键词优化哪一个前端网站的优化影响是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-20 02:07
我们这里所说的网站优化并不是针对某些特定关键词的排名进行优化,而是对网站整体页面进行优化,优化页面内容的布局,使网站在搜索引擎上的整体表现不错,可以让客户的转化率更高。例如,电子商务网站 或信息型企业网站 可能期望整个页面都在搜索引擎中。而不是在关键词搜索引擎排名上的一个或几个排名可能期望每个产品页面都有很好的转化率所以这里网站优化服务将发挥作用网站@k17的整体营销价值>而不是纯粹的搜索引擎排名值。
3、好网站优化可以适当降低企业宣传成本
我们都知道死链接不利于网站优化,但是死链接在网站上很常见。很多人想知道为什么网站总是有死链接,不知道有什么影响。让易帆的编辑为您解释一下。
最后,SEO优化排名需要实战才有发言权。在整个不断学习的过程中,善于总结和创新,相信你的网站优化可以取得不错的效果。如果你看了一些网站优化课程或者参加了相关培训学校之后不去实战,就说做就做,那么SEO优化排名就会起到反作用。
网站关键词要优化哪个前端网站2010 年优化:对 Web 的 30 条预测
标签收费模具搜索社交媒体 2010
阿里云服务器“爆品优惠”独家精选产品,历史时间最低优惠!
社交媒体
与 Twitter 相关的集成和应用程序在 2009 年很流行,而在 2010 年这种时尚趋势将重演。
Tumblr 在 Twitter 的阴影下再次成长,而当 Twitter 陷入黑暗时,Tumblr 最终可能会成为气候。
最终,社交媒体将只剩下几个大玩家,Twitter、Facebook,还有谁?
社交新闻报道互联网(Digg、Reddit)、便签互联网(Delicious)将会过时,事实上,它们已经输给了Twitter。
互联网的社交访问(StumbleUpon)早已不复存在,2008 年有十几个这样的网络,现在基础已经衰落,这种趋势将继续下去。
商务接待
很多客户没有达到一定规模的创业公司在烧完钱后就死了。
随着风险投资变得越来越稀少,越来越多的公司必须通过完全免费的整合收费来生存。
为了生存,企业和知名品牌必须在2010年制定社交媒体发展战略。
2010 年,Twitter 将刚刚开始盈利,商业服务帐户和查看数据和信息的费用。
移动
部分智能手机系统软件因销售市场不足而死掉。
iPhone 将失去市场份额,虽然 iPhone 仍然会发光,但他们不能仅仅依靠一件产品来保持发光。
谢谢谷歌,大家很可能会在手机上看到免费和免费通话,谷歌正在提前准备在真机上完成谷歌语音及其VOIP,完成真正的400通话。
营销
网络广告行业会更加专一,随着Web的完善,大家被骗的难度会越来越大。
网络上的广告将被内容运营所取代。
搜索
即时搜索将变得更加普遍。
为了保持在搜索广告销售市场的领先地位,谷歌和必应将相互效仿。
搜索定制将完成完整的个性化搜索。
搜索引擎优化
搜索引擎优化将无处不在,而不是 BBC。
许多搜索引擎优化机构将转入地下。
不管你喜不喜欢,你会看到越来越多的 jQuery 弹出窗口。
网页设计开发
移动智能终端再次蓬勃发展,针对移动终端的网页优化将越来越普遍。
HTML5 和 CSS3 将为网页室内设计师提供更多智能,但仍会向前适应。
YouTube 的审查将导致一些开源系统视频被放置在技术和健身运动中。
博客
移动应用
云计算技术和基于网络的手机软件将成为气候。
对端网站的内链建设怎么样,内链有哪些优势可供参考,除了考察网站的内链循环,还可以通过分析网站的外链,比如网站外链的数量和质量,网站友好链接的数量和质量等等,这样我们就可以看出两者的区别了我们的网站促销和同行。然后才知道我后期网站优化的方式和工作重点。
除了核心行业用户关键词的高搜索量,像长尾关键词也是关键词优化的重点。这是一个简单的长尾 关键词 挖掘技术。你在百度搜索框输入核心关键词,然后可以找到一些长尾关键词,比如你在搜索框中输入网站优化,那么你会得到上海网站优化,网站哪个更好等等。这些长尾关键词都是人搜的,不信你可以用百度索引搜这个关键词,你就会知道这次是长尾关键词百度索引。
SEO优化:影响网站优化排名4、附属链接失败的6个因素作为网站管理员,您应该经常检查友谊链接。一旦发现友情链接失效,会影响自己网站的关键词排名、权重、收录、快照掉落。毕竟,友情链接就像一个圆圈。把几个网站围成一圈,互相扶持。一旦出现故障,可能会认为圈子坏了,会被拉下来。SEO优化:影响网站优化排名的6个因素
说到遵义关键词,了解遵义关键词的相关知识点,有助于我们更好地选择遵义关键词。接下来,我们来看看还有哪些需要注意的信息。当人们搜索某个词时,网站在搜索结果中的排名很好,普通用户认为这些排名靠前的网站是比较靠谱的品牌。从SEO的角度来看,搜索商业价值高的关键词,自然排名网站,也是业内非常权威的网站。由于良好的排名带来的人气和流量,用户进入网站后,用户开始使用网站显示的联系方式与企业客服沟通,最终完成订单的转化。,
网站关键词优化哪个前端网站优化济南
标签网站外链排名长尾关键词网站优化关键词
济南SEO服务项目有哪些内容?
1、大师关键词:
11 总体目标 关键词 是什么意思?
12 如何找到关键词
13 如何找到人气关键词
14关键词市场竞争分析
15关键词选择过程
16关键词分类部署
17 如何正确选择创建关键词字典
18关键词位置、相对密度、解
19关键词相对密度深科学研究
2、长尾关键词:
21 什么是长尾关键词?
选择长尾的22个理由关键词
23网站优化长尾有什么作用关键词
24 详细讲解站内长尾关键词三部曲的合理布局
3、网站构造:
31 网站的一般结构
32网站施工对seo的危害
33 搜索引擎友好网站构造的三个规则
34 个 网站 最好的 网站 内部结构
35 不友好 网站 构建搜索引擎蜘蛛陷阱
36 网站的多孔结构是什么
37网站树结构和扁平树结构哪个更好
4、网址:
标准
42 静态数据 url 与动态 url
43301 跳转如何进行URL规范化设置
5、SEO 外部链接:
51 外链有哪些表现形式?
52 推广外链的一些常见问题
53 如何创建高质量的外部链接
54 哪些外部链接是欺诈性外部链接?
55 如何查看竞争对手的新外部链接
56 外部链接是否是SEO的唯一途径
57 不相关的外部链接有什么用?
58 思维拓展:现在外链怎么办?
6、seo专用工具应用:
61 强烈推荐很多seo好用的专用工具
综合查询工具的应用
63网站收录批量查询专用工具
64个网页相似度检测专用工具强烈推荐
65友链检测专用工具的应用
66网站历史时间搜索工具全集
死链接检测的专用工具
68网站地形图在线制作专用工具的应用
济南SEO数据如何进行统计分析?
1 做SEO前分析关键词排名数据信息
2网站系统日志检测与分析
3 哪些数据信息必须作为seo进行分析
4 SEO必须测试的其他四点数据信息
5 负面信息的个人行为正在损害您的网站排名
6 分析竞争对手的三种方法
济南SEO网站经典案例
1、济南搬家公司网站SEO实例
2、济南房地产企业网站SEO实例
3、济南培训机构网站SEO实例
4、济南家教补课网站SEO实例
5、济南男子医院门诊网站SEO实例
6、济南女子医院门诊网站SEO实例
7、济南家政医院门诊网站SEO实例
为什么济南公司网站做SEO?
每家公司都有自己的网站,不管别人怎么说,还是为了展示知名品牌,才刚刚开始从线下推广到线上,一批SEOer正在兴起。今天和大家讨论一下,济南的企业网站为什么要做SEO?
第一,可以快速在各大搜索引擎上获得不错的排名,就像在人流量很大的地区开店,每天都有很多人光顾,做生意会更好。网站 可以帮助公司赚钱。做好SEO和搜索引擎优化,需要进行网站优化。根据基于网页的优化策略和针对非网页的优化策略不同。达到优化网站的总体目标,最终提升网站网页在搜索引擎中排名的实际效果。根据网页的优化策略,可以理解为是针对网站进行优化,而不是根据网页的优化策略,俗称网站
二是互联网广告成本太高,部分中小企业负担不起,网站优化超额支付成本一键支付。网络上的免费餐太多了,想要节省网络营销成本,就需要进行网站优化。
对于公司来说,为了让自己的网站真正成为扩大公司知名度、拓宽公司产品营销渠道的服务平台,我认为有必要请技术专业的SEOer搜索引擎优化师到公司的< @网站进行整体优化,配合其他合理的搜索引擎营销推广等网站推广方式,提升网站的排名,真正为公司生成客户和订单信息,并帮公司赚到钱。
很多人可能会问,那我们就不用整天干别的了。我们每天都制作视频。我想说的是,兄弟姐妹们,你们可以上传不同名字的视频。您的一个视频可以多次使用。,天津网站优化公司排名,请不要硬着头皮,上传视频一点都不专业。不需要专业的技术人员或者优化师,公司任何人都可以做,而且视频引流的作用非常大,尤其是那些比较有帮助的视频,比如一些技术交流视频和一些文化课教程等。 ,会有很好的效果。
遵义seo内部优化 遵义网站对seo公司进行优化,访问者主要来源是网站的吸引力,一般是通过文章上网站,所以在网站的过程中@k7 在构造@>的时候,需要注意要权威,同时用更严格的数据来证明自己的可信度。同时文章要注意尽可能保证企业的专业性,帮助促进良好品牌的树立。描述的时候尽量说清楚,否则会被搜索引擎认为是混淆视听,显得毫无意义,访问量也会减少很多。
以上就是网站优化中如何避免蜘蛛陷阱的知识介绍。相信现在大家都明白了。也希望对大家有所帮助。如果您有任何问题,欢迎您随时与我们联系。
广西seo〖seo关键词优化〗要多练,敢练网站优化教程思维会帮助我们提高蜘蛛排名网站排名优化一定要有效百度优化需要分析网站 @>要看现在的情况,分析情况处理。您可以实现百度优化和网站布局更改和设计。毕竟百度优化网站排名优化的优势对个人和工厂都会有效。持之以恒是百度优化应该遵循的成功之路,适时网站布局变化也是必要的。其他操作方式:
如有任何问题,请联系站长61910465 查看全部
seq搜索引擎优化至少包括那几步?(网站关键词优化哪一个前端网站的优化影响是什么?)
我们这里所说的网站优化并不是针对某些特定关键词的排名进行优化,而是对网站整体页面进行优化,优化页面内容的布局,使网站在搜索引擎上的整体表现不错,可以让客户的转化率更高。例如,电子商务网站 或信息型企业网站 可能期望整个页面都在搜索引擎中。而不是在关键词搜索引擎排名上的一个或几个排名可能期望每个产品页面都有很好的转化率所以这里网站优化服务将发挥作用网站@k17的整体营销价值>而不是纯粹的搜索引擎排名值。
3、好网站优化可以适当降低企业宣传成本
我们都知道死链接不利于网站优化,但是死链接在网站上很常见。很多人想知道为什么网站总是有死链接,不知道有什么影响。让易帆的编辑为您解释一下。
最后,SEO优化排名需要实战才有发言权。在整个不断学习的过程中,善于总结和创新,相信你的网站优化可以取得不错的效果。如果你看了一些网站优化课程或者参加了相关培训学校之后不去实战,就说做就做,那么SEO优化排名就会起到反作用。
网站关键词要优化哪个前端网站2010 年优化:对 Web 的 30 条预测
标签收费模具搜索社交媒体 2010
阿里云服务器“爆品优惠”独家精选产品,历史时间最低优惠!
社交媒体
与 Twitter 相关的集成和应用程序在 2009 年很流行,而在 2010 年这种时尚趋势将重演。
Tumblr 在 Twitter 的阴影下再次成长,而当 Twitter 陷入黑暗时,Tumblr 最终可能会成为气候。
最终,社交媒体将只剩下几个大玩家,Twitter、Facebook,还有谁?
社交新闻报道互联网(Digg、Reddit)、便签互联网(Delicious)将会过时,事实上,它们已经输给了Twitter。
互联网的社交访问(StumbleUpon)早已不复存在,2008 年有十几个这样的网络,现在基础已经衰落,这种趋势将继续下去。
商务接待
很多客户没有达到一定规模的创业公司在烧完钱后就死了。
随着风险投资变得越来越稀少,越来越多的公司必须通过完全免费的整合收费来生存。
为了生存,企业和知名品牌必须在2010年制定社交媒体发展战略。
2010 年,Twitter 将刚刚开始盈利,商业服务帐户和查看数据和信息的费用。
移动
部分智能手机系统软件因销售市场不足而死掉。
iPhone 将失去市场份额,虽然 iPhone 仍然会发光,但他们不能仅仅依靠一件产品来保持发光。
谢谢谷歌,大家很可能会在手机上看到免费和免费通话,谷歌正在提前准备在真机上完成谷歌语音及其VOIP,完成真正的400通话。
营销
网络广告行业会更加专一,随着Web的完善,大家被骗的难度会越来越大。
网络上的广告将被内容运营所取代。
搜索
即时搜索将变得更加普遍。
为了保持在搜索广告销售市场的领先地位,谷歌和必应将相互效仿。
搜索定制将完成完整的个性化搜索。
搜索引擎优化
搜索引擎优化将无处不在,而不是 BBC。
许多搜索引擎优化机构将转入地下。
不管你喜不喜欢,你会看到越来越多的 jQuery 弹出窗口。
网页设计开发
移动智能终端再次蓬勃发展,针对移动终端的网页优化将越来越普遍。
HTML5 和 CSS3 将为网页室内设计师提供更多智能,但仍会向前适应。
YouTube 的审查将导致一些开源系统视频被放置在技术和健身运动中。
博客
移动应用
云计算技术和基于网络的手机软件将成为气候。
对端网站的内链建设怎么样,内链有哪些优势可供参考,除了考察网站的内链循环,还可以通过分析网站的外链,比如网站外链的数量和质量,网站友好链接的数量和质量等等,这样我们就可以看出两者的区别了我们的网站促销和同行。然后才知道我后期网站优化的方式和工作重点。
除了核心行业用户关键词的高搜索量,像长尾关键词也是关键词优化的重点。这是一个简单的长尾 关键词 挖掘技术。你在百度搜索框输入核心关键词,然后可以找到一些长尾关键词,比如你在搜索框中输入网站优化,那么你会得到上海网站优化,网站哪个更好等等。这些长尾关键词都是人搜的,不信你可以用百度索引搜这个关键词,你就会知道这次是长尾关键词百度索引。
SEO优化:影响网站优化排名4、附属链接失败的6个因素作为网站管理员,您应该经常检查友谊链接。一旦发现友情链接失效,会影响自己网站的关键词排名、权重、收录、快照掉落。毕竟,友情链接就像一个圆圈。把几个网站围成一圈,互相扶持。一旦出现故障,可能会认为圈子坏了,会被拉下来。SEO优化:影响网站优化排名的6个因素
说到遵义关键词,了解遵义关键词的相关知识点,有助于我们更好地选择遵义关键词。接下来,我们来看看还有哪些需要注意的信息。当人们搜索某个词时,网站在搜索结果中的排名很好,普通用户认为这些排名靠前的网站是比较靠谱的品牌。从SEO的角度来看,搜索商业价值高的关键词,自然排名网站,也是业内非常权威的网站。由于良好的排名带来的人气和流量,用户进入网站后,用户开始使用网站显示的联系方式与企业客服沟通,最终完成订单的转化。,
网站关键词优化哪个前端网站优化济南
标签网站外链排名长尾关键词网站优化关键词
济南SEO服务项目有哪些内容?
1、大师关键词:
11 总体目标 关键词 是什么意思?
12 如何找到关键词
13 如何找到人气关键词
14关键词市场竞争分析
15关键词选择过程
16关键词分类部署
17 如何正确选择创建关键词字典
18关键词位置、相对密度、解
19关键词相对密度深科学研究
2、长尾关键词:
21 什么是长尾关键词?
选择长尾的22个理由关键词
23网站优化长尾有什么作用关键词
24 详细讲解站内长尾关键词三部曲的合理布局
3、网站构造:
31 网站的一般结构
32网站施工对seo的危害
33 搜索引擎友好网站构造的三个规则
34 个 网站 最好的 网站 内部结构
35 不友好 网站 构建搜索引擎蜘蛛陷阱
36 网站的多孔结构是什么
37网站树结构和扁平树结构哪个更好
4、网址:
标准
42 静态数据 url 与动态 url
43301 跳转如何进行URL规范化设置
5、SEO 外部链接:
51 外链有哪些表现形式?
52 推广外链的一些常见问题
53 如何创建高质量的外部链接
54 哪些外部链接是欺诈性外部链接?
55 如何查看竞争对手的新外部链接
56 外部链接是否是SEO的唯一途径
57 不相关的外部链接有什么用?
58 思维拓展:现在外链怎么办?
6、seo专用工具应用:
61 强烈推荐很多seo好用的专用工具
综合查询工具的应用
63网站收录批量查询专用工具
64个网页相似度检测专用工具强烈推荐
65友链检测专用工具的应用
66网站历史时间搜索工具全集
死链接检测的专用工具
68网站地形图在线制作专用工具的应用
济南SEO数据如何进行统计分析?
1 做SEO前分析关键词排名数据信息
2网站系统日志检测与分析
3 哪些数据信息必须作为seo进行分析
4 SEO必须测试的其他四点数据信息
5 负面信息的个人行为正在损害您的网站排名
6 分析竞争对手的三种方法
济南SEO网站经典案例
1、济南搬家公司网站SEO实例
2、济南房地产企业网站SEO实例
3、济南培训机构网站SEO实例
4、济南家教补课网站SEO实例
5、济南男子医院门诊网站SEO实例
6、济南女子医院门诊网站SEO实例
7、济南家政医院门诊网站SEO实例
为什么济南公司网站做SEO?
每家公司都有自己的网站,不管别人怎么说,还是为了展示知名品牌,才刚刚开始从线下推广到线上,一批SEOer正在兴起。今天和大家讨论一下,济南的企业网站为什么要做SEO?
第一,可以快速在各大搜索引擎上获得不错的排名,就像在人流量很大的地区开店,每天都有很多人光顾,做生意会更好。网站 可以帮助公司赚钱。做好SEO和搜索引擎优化,需要进行网站优化。根据基于网页的优化策略和针对非网页的优化策略不同。达到优化网站的总体目标,最终提升网站网页在搜索引擎中排名的实际效果。根据网页的优化策略,可以理解为是针对网站进行优化,而不是根据网页的优化策略,俗称网站
二是互联网广告成本太高,部分中小企业负担不起,网站优化超额支付成本一键支付。网络上的免费餐太多了,想要节省网络营销成本,就需要进行网站优化。
对于公司来说,为了让自己的网站真正成为扩大公司知名度、拓宽公司产品营销渠道的服务平台,我认为有必要请技术专业的SEOer搜索引擎优化师到公司的< @网站进行整体优化,配合其他合理的搜索引擎营销推广等网站推广方式,提升网站的排名,真正为公司生成客户和订单信息,并帮公司赚到钱。
很多人可能会问,那我们就不用整天干别的了。我们每天都制作视频。我想说的是,兄弟姐妹们,你们可以上传不同名字的视频。您的一个视频可以多次使用。,天津网站优化公司排名,请不要硬着头皮,上传视频一点都不专业。不需要专业的技术人员或者优化师,公司任何人都可以做,而且视频引流的作用非常大,尤其是那些比较有帮助的视频,比如一些技术交流视频和一些文化课教程等。 ,会有很好的效果。
遵义seo内部优化 遵义网站对seo公司进行优化,访问者主要来源是网站的吸引力,一般是通过文章上网站,所以在网站的过程中@k7 在构造@>的时候,需要注意要权威,同时用更严格的数据来证明自己的可信度。同时文章要注意尽可能保证企业的专业性,帮助促进良好品牌的树立。描述的时候尽量说清楚,否则会被搜索引擎认为是混淆视听,显得毫无意义,访问量也会减少很多。
以上就是网站优化中如何避免蜘蛛陷阱的知识介绍。相信现在大家都明白了。也希望对大家有所帮助。如果您有任何问题,欢迎您随时与我们联系。
广西seo〖seo关键词优化〗要多练,敢练网站优化教程思维会帮助我们提高蜘蛛排名网站排名优化一定要有效百度优化需要分析网站 @>要看现在的情况,分析情况处理。您可以实现百度优化和网站布局更改和设计。毕竟百度优化网站排名优化的优势对个人和工厂都会有效。持之以恒是百度优化应该遵循的成功之路,适时网站布局变化也是必要的。其他操作方式:
如有任何问题,请联系站长61910465
seq搜索引擎优化至少包括那几步?(1前端需要注意哪些SEO2的的请求方法用途)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-19 15:21
1 SEO在前端需要注意什么2
title 和 alt 3 有什么区别 使用了几种 HTTP 请求方式
基础版
详细版
在浏览器地址栏中输入 URL 以查看缓存。如果请求的资源在缓存中并且是新鲜的,则跳转到转码步骤。如果资源没有被缓存,则发起一个新的请求。如果有缓存,检查是否足够新鲜,直接提供给客户。侧,否则向服务器进行身份验证。检查新鲜度通常有两个HTTP头来控制Expires和Cache-Control:HTTP1.0提供Expires,该值是一个绝对时间表示缓存新鲜日期HTTP1.1增加Cache-Control:max-年龄=,
2)被css隐藏的节点,比如display: none 对于每个可见节点,找到合适的CSSOM规则,应用可见节点的内容,计算样式。js解析如下:浏览器创建一个Document对象并解析HTML,将解析后的元素和文本节点添加到文档中。此时,document.readystate 正在加载。当 HTML 解析器遇到没有 async 和 defer 的脚本时,将它们添加到文档中,然后执行内联或外部脚本。脚本是同步执行的,并且在脚本下载和执行时会暂停解析器。这允许使用 document.write() 将文本插入到输入流中。同步脚本通常只是简单地定义函数并注册可以遍历和操作脚本及其先前文档内容的事件处理程序。当解析器遇到设置了 async 属性的脚本时,它会开始下载脚本并继续解析文档。该脚本将在下载后立即执行,但解析器不会停止并等待它下载。禁止异步脚本使用 document.write(),它们可以访问自己的脚本和之前的文档元素。解析文档时,document.readState 变为交互式。所有延迟脚本都按照它们在文档中出现的顺序执行,延迟脚本可以访问完整的文档树。, 禁止使用 document.write() 浏览器触发 Document 对象上的 DOMContentLoaded 事件。此时,文档已经完全解析完毕,浏览器可能还在等待图片等内容的加载。
详细的短版
<p>从浏览器接收url到开启网络请求线程(这部分可以扩展浏览器的机制以及进程与线程的关系),启动网络线程发出完整的HTTP请求(这部分涉及到dns查询, TCP/IP请求、互联网五层协议栈知识等)从服务器接收请求到相应后台接收请求(这部分可能涉及负载均衡、安全拦截、后台内部处理等) ) 后台与前台的HTTP交互(这部分包括HTTP的headers、响应码、消息结构、cookies等知识,可以提到静态资源的cookie优化,以及编解码,比如gzip压缩。 , ETag, 捕捉控制等)浏览器接收到HTTP包后的解析过程(解析html-词法分析然后解析成dom树,解析css生成css规则树,合并成render树,然后布局,paint渲染,复合层组成、GPU绘制、外链资源处理、加载和DOMContentLoaded等) CSS可视化格式模型(元素渲染规则,如收录块、控制框、BFC、IFC等概念) JS引擎解析过程(JS解释阶段、预处理stage、执行阶段生成执行上下文、VO、作用域链、回收机制等)其他(可以扩展不同的知识模块,如跨域、web安全、混合模式等) #5 怎么做 < @网站性能优化性能优化性能优化解析css生成css规则树,合并成render树,然后布局,paint渲染,复合层合成,GPU绘制,外链资源处理,loaded和DOMContentLoaded等) CSS可视化格式模型(元素渲染规则,如如收录块、控制框、BFC、IFC等概念)JS引擎解析过程(JS解释阶段、预处理阶段、执行阶段生成执行上下文、VO、作用域链、回收机制等)其他(可以扩展不同的知识模块,比如跨域、web安全、混合模式等)#5怎么做 查看全部
seq搜索引擎优化至少包括那几步?(1前端需要注意哪些SEO2的的请求方法用途)
1 SEO在前端需要注意什么2
title 和 alt 3 有什么区别 使用了几种 HTTP 请求方式
基础版
详细版
在浏览器地址栏中输入 URL 以查看缓存。如果请求的资源在缓存中并且是新鲜的,则跳转到转码步骤。如果资源没有被缓存,则发起一个新的请求。如果有缓存,检查是否足够新鲜,直接提供给客户。侧,否则向服务器进行身份验证。检查新鲜度通常有两个HTTP头来控制Expires和Cache-Control:HTTP1.0提供Expires,该值是一个绝对时间表示缓存新鲜日期HTTP1.1增加Cache-Control:max-年龄=,
2)被css隐藏的节点,比如display: none 对于每个可见节点,找到合适的CSSOM规则,应用可见节点的内容,计算样式。js解析如下:浏览器创建一个Document对象并解析HTML,将解析后的元素和文本节点添加到文档中。此时,document.readystate 正在加载。当 HTML 解析器遇到没有 async 和 defer 的脚本时,将它们添加到文档中,然后执行内联或外部脚本。脚本是同步执行的,并且在脚本下载和执行时会暂停解析器。这允许使用 document.write() 将文本插入到输入流中。同步脚本通常只是简单地定义函数并注册可以遍历和操作脚本及其先前文档内容的事件处理程序。当解析器遇到设置了 async 属性的脚本时,它会开始下载脚本并继续解析文档。该脚本将在下载后立即执行,但解析器不会停止并等待它下载。禁止异步脚本使用 document.write(),它们可以访问自己的脚本和之前的文档元素。解析文档时,document.readState 变为交互式。所有延迟脚本都按照它们在文档中出现的顺序执行,延迟脚本可以访问完整的文档树。, 禁止使用 document.write() 浏览器触发 Document 对象上的 DOMContentLoaded 事件。此时,文档已经完全解析完毕,浏览器可能还在等待图片等内容的加载。
详细的短版
<p>从浏览器接收url到开启网络请求线程(这部分可以扩展浏览器的机制以及进程与线程的关系),启动网络线程发出完整的HTTP请求(这部分涉及到dns查询, TCP/IP请求、互联网五层协议栈知识等)从服务器接收请求到相应后台接收请求(这部分可能涉及负载均衡、安全拦截、后台内部处理等) ) 后台与前台的HTTP交互(这部分包括HTTP的headers、响应码、消息结构、cookies等知识,可以提到静态资源的cookie优化,以及编解码,比如gzip压缩。 , ETag, 捕捉控制等)浏览器接收到HTTP包后的解析过程(解析html-词法分析然后解析成dom树,解析css生成css规则树,合并成render树,然后布局,paint渲染,复合层组成、GPU绘制、外链资源处理、加载和DOMContentLoaded等) CSS可视化格式模型(元素渲染规则,如收录块、控制框、BFC、IFC等概念) JS引擎解析过程(JS解释阶段、预处理stage、执行阶段生成执行上下文、VO、作用域链、回收机制等)其他(可以扩展不同的知识模块,如跨域、web安全、混合模式等) #5 怎么做 < @网站性能优化性能优化性能优化解析css生成css规则树,合并成render树,然后布局,paint渲染,复合层合成,GPU绘制,外链资源处理,loaded和DOMContentLoaded等) CSS可视化格式模型(元素渲染规则,如如收录块、控制框、BFC、IFC等概念)JS引擎解析过程(JS解释阶段、预处理阶段、执行阶段生成执行上下文、VO、作用域链、回收机制等)其他(可以扩展不同的知识模块,比如跨域、web安全、混合模式等)#5怎么做
seq搜索引擎优化至少包括那几步?(企达搜索引擎优化工具(疯狂相关),帮你快速提高网站流量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-01-17 05:25
各位站长,今天给大家介绍一款奇达搜索引擎优化工具(疯狂相关),可以帮助您快速推广相关搜索关键词,帮助您快速提升网站的流量,快速提升人气,用于跟踪国内各大搜索引擎的算法更专业、更有效、更易于使用。
软件说明:
当我们进入搜索引擎首页时,当你在搜索框中输入关键词时,网站会根据你的输入显示一个下拉提示,称为“关联提示区” . 按钮后的页面底部会有一些相关的搜索提示词,称为“相关搜索区”。
“疯狂关联”是针对“关联提示区”和“关联搜索区”优化的SEO工具。这些领域的排名有复杂的算法,可能会有搜索引擎的人为干预,但更多的还是机器自动处理的。所以我们得出结论:优化软件不是万能的,但绝对不可能不优化软件。
本软件采用“租借制”,按天收费。与同类软件上千元相比,成本更低,注册更灵活。为什么不花几块钱试试优化效果呢?
主要特征:
1)。支持国内主要搜索引擎:包括:百度、谷歌、雅虎、搜搜、搜狗、有道、必应;
2).多任务支持:多个任务可以同时刷新,互不干扰。程序在后台运行,不影响前台运行;
3).灵活代理:程序自动搜索代理服务器,未来还将支持ADSL断线换IP,还支持混合模式,即先使用代理服务器刷新几次,然后断开并更改IP并刷新几次,依此类推;
4).人性化设计:继承了“疯狂刷新”的一些特性,比如定时启动和停止任务,比如自动查询相关搜索排名,比如批量设置任务参数等;
5).灵活的注册方式:节目采用“租借制”,按天收费。您可以根据需要选择注册1天或365天或更长时间。如果软件有效,请购买长期许可证。如果效果不好,就不会再更新了。用户有主动权;
6)。更宽松的授权方式:软件不限机器,一个关键词对应一个激活码,可以在任何机器上使用。就算是出差也不用着急,去网吧打包一台机器,输入激活码,刷卡就可以了。
重要的提示:
搜索引擎中的相关搜索和下拉提示是另一种 SEO 优化方法。您需要一定的专业知识才能灵活使用它们以达到最佳效果。如果您不知道什么是SEO,请填写相关知识。. 疯狂相关软件是精通SEO优化技术的专业人士的SEO助手工具。如果你是 SEO 的门外汉,那么这个软件可能不适合你。
SEO是一项高风险、高收益的工作。如果用得好,可以节省大量的广告费用,对网络推广有很好的效果。否则可能导致网站为K,得不偿失。因此,在下载疯狂的相关软件之前,您需要对这款软件的功能和风险有一个清晰的认识。
参数介绍
启动疯狂相关,点击添加按钮进入任务窗口,设置通用参数,然后选择“搜索点击”选项卡,看到如下界面:
1.启用搜索点击
选中以启用点击功能,取消选择以关闭搜索点击功能。
2.网址链接
请输入要点击的网站链接,该链接必须在搜索目标词时出现在搜索结果中,如果您的网站没有被搜索引擎收录搜索到,那么程序无法完成单击功能。
程序点击时使用模糊匹配,只要搜索结果中的链接收录用户输入的内容,匹配成功。因此,您可以只输入链接的一部分进行模糊匹配;您还可以输入完整的链接以完全匹配页面。
如上图所示的用户设置的URL链接,在搜索目标词“疯狂相关”的过程中,只要在搜索结果中找到收录的链接,就认为匹配成功并点击,即使搜索结果中的链接指向该页面,程序也认为匹配成功,这称为模糊匹配,即输入的链接越短,越容易匹配成功,输入链接越精确,匹配范围越小。
3.搜索范围
搜索范围也可以称为点击范围,意思是软件在转到用户设置的页面时,只会搜索搜索结果中的链接,匹配成功则点击。在第一个框中输入起始页码,在第二个框中输入结束页码。
如上图所示,搜索范围为2-5页。程序运行时,只会匹配第二到第五页的搜索结果,点击收录的链接。自动跳过第一页和第五页之后的结果,也就是说,即使搜索“疯狂相关”,第一页也有启达软件的链接,程序不会点击,因为点击由用户设置 范围从第二页开始。
4.点击机会
如果每次刷新操作都点击了指定页面,那么机器刷新的痕迹在搜索引擎眼里就太重了,所以有一定概率给用户设置。概率越高,被点击的可能性就越大,反之亦然。
5.点击图层
点击层数是指点击用户设置的链接后,软件继续模拟点击的层数。如上图,中间层数为5,表示从搜索引擎点击后,页面中的链接会继续被点击。随机点击循环5次,模拟用户从搜索引擎进入网站后继续浏览其他页面的过程。
分层点击的过程:首先在搜索结果中的某个页面,我们称之为A站,输入用户设置的网站,然后根据A站随机选择一个链接点击进入B站. 基于B站,随机点击进入C站,以此类推,直到点击用户设置的层数。
在随机点击的过程中,软件不区分站内链接和站外链接,也就是说,无论是站内链接还是站外链接,都可能被点击。由于 Flash 中的链接无法提取,所以本软件不会点击 Flash 中的链接。
发行说明:
1.刷新过程增加隐私浏览模式,隔离系统cookie;
2.增强了清除缓存和cookies的能力;
3.更新搜狗刷新算法;
4.更新谷歌的点击算法;
5.更新雅虎点击算法;
金华seo优化工具(jinhua关键词查询工具)6.8.7绿色免费版
类型:搜索查询大小:1.6M 语言:中文时间:8-6 评分:5.0
亲,因为这个软件有注册机或者是易语言写的,涉及到内存的读写,所以被360、QQ管家等杀毒安全防护软件举报。它不会收录任何损坏用户计算机的恶意绑定软件。本软件经本站编辑在虚拟机上测试,未发现本软件对电脑有任何影响。这纯粹是一个误报。请自行决定是否下载。如需使用软件,请将软件加入信任列表,请参考本站360病毒举报处理文档或阅读下载帮助
电脑正式版
安卓官方手机版
IOS官方手机版 查看全部
seq搜索引擎优化至少包括那几步?(企达搜索引擎优化工具(疯狂相关),帮你快速提高网站流量)
各位站长,今天给大家介绍一款奇达搜索引擎优化工具(疯狂相关),可以帮助您快速推广相关搜索关键词,帮助您快速提升网站的流量,快速提升人气,用于跟踪国内各大搜索引擎的算法更专业、更有效、更易于使用。
软件说明:
当我们进入搜索引擎首页时,当你在搜索框中输入关键词时,网站会根据你的输入显示一个下拉提示,称为“关联提示区” . 按钮后的页面底部会有一些相关的搜索提示词,称为“相关搜索区”。
“疯狂关联”是针对“关联提示区”和“关联搜索区”优化的SEO工具。这些领域的排名有复杂的算法,可能会有搜索引擎的人为干预,但更多的还是机器自动处理的。所以我们得出结论:优化软件不是万能的,但绝对不可能不优化软件。
本软件采用“租借制”,按天收费。与同类软件上千元相比,成本更低,注册更灵活。为什么不花几块钱试试优化效果呢?
主要特征:
1)。支持国内主要搜索引擎:包括:百度、谷歌、雅虎、搜搜、搜狗、有道、必应;
2).多任务支持:多个任务可以同时刷新,互不干扰。程序在后台运行,不影响前台运行;
3).灵活代理:程序自动搜索代理服务器,未来还将支持ADSL断线换IP,还支持混合模式,即先使用代理服务器刷新几次,然后断开并更改IP并刷新几次,依此类推;
4).人性化设计:继承了“疯狂刷新”的一些特性,比如定时启动和停止任务,比如自动查询相关搜索排名,比如批量设置任务参数等;
5).灵活的注册方式:节目采用“租借制”,按天收费。您可以根据需要选择注册1天或365天或更长时间。如果软件有效,请购买长期许可证。如果效果不好,就不会再更新了。用户有主动权;
6)。更宽松的授权方式:软件不限机器,一个关键词对应一个激活码,可以在任何机器上使用。就算是出差也不用着急,去网吧打包一台机器,输入激活码,刷卡就可以了。
重要的提示:
搜索引擎中的相关搜索和下拉提示是另一种 SEO 优化方法。您需要一定的专业知识才能灵活使用它们以达到最佳效果。如果您不知道什么是SEO,请填写相关知识。. 疯狂相关软件是精通SEO优化技术的专业人士的SEO助手工具。如果你是 SEO 的门外汉,那么这个软件可能不适合你。
SEO是一项高风险、高收益的工作。如果用得好,可以节省大量的广告费用,对网络推广有很好的效果。否则可能导致网站为K,得不偿失。因此,在下载疯狂的相关软件之前,您需要对这款软件的功能和风险有一个清晰的认识。
参数介绍
启动疯狂相关,点击添加按钮进入任务窗口,设置通用参数,然后选择“搜索点击”选项卡,看到如下界面:
1.启用搜索点击
选中以启用点击功能,取消选择以关闭搜索点击功能。
2.网址链接
请输入要点击的网站链接,该链接必须在搜索目标词时出现在搜索结果中,如果您的网站没有被搜索引擎收录搜索到,那么程序无法完成单击功能。
程序点击时使用模糊匹配,只要搜索结果中的链接收录用户输入的内容,匹配成功。因此,您可以只输入链接的一部分进行模糊匹配;您还可以输入完整的链接以完全匹配页面。
如上图所示的用户设置的URL链接,在搜索目标词“疯狂相关”的过程中,只要在搜索结果中找到收录的链接,就认为匹配成功并点击,即使搜索结果中的链接指向该页面,程序也认为匹配成功,这称为模糊匹配,即输入的链接越短,越容易匹配成功,输入链接越精确,匹配范围越小。
3.搜索范围
搜索范围也可以称为点击范围,意思是软件在转到用户设置的页面时,只会搜索搜索结果中的链接,匹配成功则点击。在第一个框中输入起始页码,在第二个框中输入结束页码。
如上图所示,搜索范围为2-5页。程序运行时,只会匹配第二到第五页的搜索结果,点击收录的链接。自动跳过第一页和第五页之后的结果,也就是说,即使搜索“疯狂相关”,第一页也有启达软件的链接,程序不会点击,因为点击由用户设置 范围从第二页开始。
4.点击机会
如果每次刷新操作都点击了指定页面,那么机器刷新的痕迹在搜索引擎眼里就太重了,所以有一定概率给用户设置。概率越高,被点击的可能性就越大,反之亦然。
5.点击图层
点击层数是指点击用户设置的链接后,软件继续模拟点击的层数。如上图,中间层数为5,表示从搜索引擎点击后,页面中的链接会继续被点击。随机点击循环5次,模拟用户从搜索引擎进入网站后继续浏览其他页面的过程。
分层点击的过程:首先在搜索结果中的某个页面,我们称之为A站,输入用户设置的网站,然后根据A站随机选择一个链接点击进入B站. 基于B站,随机点击进入C站,以此类推,直到点击用户设置的层数。
在随机点击的过程中,软件不区分站内链接和站外链接,也就是说,无论是站内链接还是站外链接,都可能被点击。由于 Flash 中的链接无法提取,所以本软件不会点击 Flash 中的链接。
发行说明:
1.刷新过程增加隐私浏览模式,隔离系统cookie;
2.增强了清除缓存和cookies的能力;
3.更新搜狗刷新算法;
4.更新谷歌的点击算法;
5.更新雅虎点击算法;

金华seo优化工具(jinhua关键词查询工具)6.8.7绿色免费版
类型:搜索查询大小:1.6M 语言:中文时间:8-6 评分:5.0
亲,因为这个软件有注册机或者是易语言写的,涉及到内存的读写,所以被360、QQ管家等杀毒安全防护软件举报。它不会收录任何损坏用户计算机的恶意绑定软件。本软件经本站编辑在虚拟机上测试,未发现本软件对电脑有任何影响。这纯粹是一个误报。请自行决定是否下载。如需使用软件,请将软件加入信任列表,请参考本站360病毒举报处理文档或阅读下载帮助
电脑正式版
安卓官方手机版
IOS官方手机版
seq搜索引擎优化至少包括那几步?(湖南网站优化:电子邮件营销是可以帮助你的SEO工作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-17 05:23
电子邮件营销现在被越来越广泛地使用。说到推广方式,湖南网站优化相信大家可以说很多,这里就不重复了,直接进入正题。搜索引擎优化的这方面之前很少有人讨论过,所以今天我要谈谈电子邮件营销,它可以帮助您的 SEO 工作。数字营销是一件复杂的事情,必须将工作的各个方面有效地结合起来,才能获得有针对性的流量和转化。电子邮件营销是一个很大的话题,我们在这里谈论的是电子邮件营销在seo工作中的作用。众所周知,成功的 SEO 的两大支柱是杀手级内容和高质量的反向链接。SEO的最终目标是目标转换。
那么,我们如何才能充分利用电子邮件营销,以及如何在 seo 中获得电子邮件营销帮助?我们从几个方面来谈:
一、内容
创建内容是一项艰苦的工作。当它被创建时,我们得到了它的大部分里程。网络营销的新手经常犯在网络上重复使用相同内容的错误,例如,将相同的帖子放在他们的主要 网站文章 上,然后放在博客和 文章 目录上,反向链接的好处。但是,搜索引擎眼中的“转载”只会创建重复的内容,这往往会伤害您的 网站 SEO,也会降低这些反向链接的价值。然而,尽管这在未来可能会改变,但当前的搜索引擎无法读取或索引电子邮件。如果您有一个邮件列表,您可以创建一个时事通讯并将其通过电子邮件发送给您的用户,也可以将其发布到您的 网站 上,而无需担心重复。这和双倍里程是一样的。
二、反向链接
这就是 SEO 的重点。链接建设的挑战之一是让潜在读者知道您拥有新鲜和令人惊叹的内容。营销人员越来越意识到社交网络推广可以帮助这个部门,但他们有时会忘记好的旧电子邮件也一样好!使用您的电子邮件通讯让您的用户知道您更新了 <网站,包括指向新页面简要说明的链接。这将为这些页面带来流量,并且用户会想要您的反向链接。如果您的电子邮件通讯通过转发“传播开来”,链接奇迹就会发生。
三、目标转换
如果你的产品或服务的销售周期长、复杂,湖南SEO想说的是,单靠SEO是做不到的。有时,潜在客户在承诺购买一种或另一种解决方案之前需要整整两个月的时间进行尽职调查。他们倾向于从信息而不是面向贸易的搜索查询开始。客户可能首先找到您的网站,并通过某种查询了解您的网站,但他们也很容易忘记您。但是,如果您让他们订阅时事通讯,您可以在整个销售周期中建立信任并保持品牌。在这种情况下,电子邮件营销不一定会改善您的 SEO 等,但它可以帮助它实现目标,好吧,写到这里,希望 文章 能启发大家。
您可能喜欢下面的 文章? 查看全部
seq搜索引擎优化至少包括那几步?(湖南网站优化:电子邮件营销是可以帮助你的SEO工作)
电子邮件营销现在被越来越广泛地使用。说到推广方式,湖南网站优化相信大家可以说很多,这里就不重复了,直接进入正题。搜索引擎优化的这方面之前很少有人讨论过,所以今天我要谈谈电子邮件营销,它可以帮助您的 SEO 工作。数字营销是一件复杂的事情,必须将工作的各个方面有效地结合起来,才能获得有针对性的流量和转化。电子邮件营销是一个很大的话题,我们在这里谈论的是电子邮件营销在seo工作中的作用。众所周知,成功的 SEO 的两大支柱是杀手级内容和高质量的反向链接。SEO的最终目标是目标转换。
那么,我们如何才能充分利用电子邮件营销,以及如何在 seo 中获得电子邮件营销帮助?我们从几个方面来谈:
一、内容
创建内容是一项艰苦的工作。当它被创建时,我们得到了它的大部分里程。网络营销的新手经常犯在网络上重复使用相同内容的错误,例如,将相同的帖子放在他们的主要 网站文章 上,然后放在博客和 文章 目录上,反向链接的好处。但是,搜索引擎眼中的“转载”只会创建重复的内容,这往往会伤害您的 网站 SEO,也会降低这些反向链接的价值。然而,尽管这在未来可能会改变,但当前的搜索引擎无法读取或索引电子邮件。如果您有一个邮件列表,您可以创建一个时事通讯并将其通过电子邮件发送给您的用户,也可以将其发布到您的 网站 上,而无需担心重复。这和双倍里程是一样的。
二、反向链接
这就是 SEO 的重点。链接建设的挑战之一是让潜在读者知道您拥有新鲜和令人惊叹的内容。营销人员越来越意识到社交网络推广可以帮助这个部门,但他们有时会忘记好的旧电子邮件也一样好!使用您的电子邮件通讯让您的用户知道您更新了 <网站,包括指向新页面简要说明的链接。这将为这些页面带来流量,并且用户会想要您的反向链接。如果您的电子邮件通讯通过转发“传播开来”,链接奇迹就会发生。
三、目标转换
如果你的产品或服务的销售周期长、复杂,湖南SEO想说的是,单靠SEO是做不到的。有时,潜在客户在承诺购买一种或另一种解决方案之前需要整整两个月的时间进行尽职调查。他们倾向于从信息而不是面向贸易的搜索查询开始。客户可能首先找到您的网站,并通过某种查询了解您的网站,但他们也很容易忘记您。但是,如果您让他们订阅时事通讯,您可以在整个销售周期中建立信任并保持品牌。在这种情况下,电子邮件营销不一定会改善您的 SEO 等,但它可以帮助它实现目标,好吧,写到这里,希望 文章 能启发大家。
您可能喜欢下面的 文章?
seq搜索引擎优化至少包括那几步?(基于Vue和Quasar的前端SPA项目实战之数据库逆向(十二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-16 09:03
基于Vue和Quasar的前端SPA项目数据库逆向(十二)回顾
通过引入之前的文章“开源免费”动态表单设计器(五)基于Vue和Quasar),实现动态表单功能。如果是一个全新的项目,通过配置元数据,创建物理表,这样就可以自动实现业务数据的CRUD增删改查。但是如果数据库表已经存在,如何通过配置表单元数据来管理呢?这时候就需要数据库逆向功能了。
介绍
数据库逆向是读取数据库物理表schema信息,然后生成表单元数据,可以认为是“dbfirst”模式,即先有数据库表,然后根据表生成元数据。逆向形式的后续操作与普通动态形式类似。
用户界面界面
数据库反向
输入物理表名,启用“数据库反向”功能,然后点击“加载元数据”,表单字段相关的元数据信息就会自动填充。
数据表准备
以ca_product产品为例,通过phpmyadmin创建表
#创建产品表
CREATE TABLE `ca_product` (
`id` bigint UNSIGNED NOT NULL COMMENT '编号',
`name` varchar(200) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '名称',
`fullTextBody` text COLLATE utf8mb4_unicode_ci COMMENT '全文索引',
`createdDate` datetime NOT NULL COMMENT '创建时间',
`lastModifiedDate` datetime DEFAULT NULL COMMENT '修改时间',
`code` varchar(200) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '编码',
`brand` varchar(200) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '品牌',
`price` decimal(10,0) DEFAULT NULL COMMENT '单价',
`weight` decimal(10,0) DEFAULT NULL COMMENT '重量',
`length` decimal(10,0) DEFAULT NULL COMMENT '长',
`width` decimal(10,0) DEFAULT NULL COMMENT '宽',
`high` decimal(10,0) DEFAULT NULL COMMENT '高',
`ats` bigint DEFAULT NULL COMMENT '库存个数'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='产品';
ALTER TABLE `ca_product`
ADD PRIMARY KEY (`id`),
ADD UNIQUE KEY `UQ_CODE` (`code`) USING BTREE;
ALTER TABLE `ca_product` ADD FULLTEXT KEY `ft_fulltext_body` (`fullTextBody`);
ALTER TABLE `ca_product`
MODIFY `id` bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '编号', AUTO_INCREMENT=1;
COMMIT;
phpmyadmin
查询模式
MySQL数据库可以通过以下SQL语句查询表单、字段、索引等信息
SHOW TABLE STATUS LIKE TABLE_NAME
SHOW FULL COLUMNS FROM TABLE_NAME
SHOW INDEX FROM TABLE_NAME
表基本信息
表基本信息
字段信息
字段信息
索引信息
API JSON
通过API查询ca_product的schema信息:/api/metadata/tables/metadata/ca_product,格式如下:
{
"Name": "ca_product",
"Engine": "InnoDB",
"Version": 10,
"Row_format": "Dynamic",
"Rows": 0,
"Avg_row_length": 0,
"Data_length": 16384,
"Max_data_length": 0,
"Index_length": 32768,
"Data_free": 0,
"Auto_increment": 2,
"Create_time": 1628141282000,
"Update_time": 1628141304000,
"Collation": "utf8mb4_unicode_ci",
"Create_options": "",
"Comment": "产品",
"columns": [{
"Field": "id",
"Type": "bigint unsigned",
"Null": "NO",
"Key": "PRI",
"Extra": "auto_increment",
"Privileges": "select,insert,update,references",
"Comment": "编号"
}, {
"Field": "name",
"Type": "varchar(200)",
"Collation": "utf8mb4_unicode_ci",
"Null": "NO",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "名称"
}, {
"Field": "fullTextBody",
"Type": "text",
"Collation": "utf8mb4_unicode_ci",
"Null": "YES",
"Key": "MUL",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "全文索引"
}, {
"Field": "createdDate",
"Type": "datetime",
"Null": "NO",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "创建时间"
}, {
"Field": "lastModifiedDate",
"Type": "datetime",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "修改时间"
}, {
"Field": "code",
"Type": "varchar(200)",
"Collation": "utf8mb4_unicode_ci",
"Null": "YES",
"Key": "UNI",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "编码"
}, {
"Field": "brand",
"Type": "varchar(200)",
"Collation": "utf8mb4_unicode_ci",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "品牌"
}, {
"Field": "price",
"Type": "decimal(10,0)",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "单价"
}, {
"Field": "weight",
"Type": "decimal(10,0)",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "重量"
}, {
"Field": "length",
"Type": "decimal(10,0)",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "长"
}, {
"Field": "width",
"Type": "decimal(10,0)",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "宽"
}, {
"Field": "high",
"Type": "decimal(10,0)",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "高"
}, {
"Field": "ats",
"Type": "bigint",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "库存个数"
}],
"indexs": [{
"Table": "ca_product",
"Non_unique": 0,
"Key_name": "PRIMARY",
"Seq_in_index": 1,
"Column_name": "id",
"Collation": "A",
"Cardinality": 0,
"Null": "",
"Index_type": "BTREE",
"Comment": "",
"Index_comment": "",
"Visible": "YES"
}, {
"Table": "ca_product",
"Non_unique": 0,
"Key_name": "UQ_CODE",
"Seq_in_index": 1,
"Column_name": "code",
"Collation": "A",
"Cardinality": 0,
"Null": "YES",
"Index_type": "BTREE",
"Comment": "",
"Index_comment": "",
"Visible": "YES"
}, {
"Table": "ca_product",
"Non_unique": 1,
"Key_name": "ft_fulltext_body",
"Seq_in_index": 1,
"Column_name": "fullTextBody",
"Cardinality": 0,
"Null": "YES",
"Index_type": "FULLTEXT",
"Comment": "",
"Index_comment": "",
"Visible": "YES"
}]
}
核心代码
前端将 API 返回的 schema 信息转换为 crudapi 的元数据格式,并显示在 UI 上。主要代码在文件 metadata/table/new.vue 中,通过 addRowFromMetadata 方法添加字段,addIndexFromMetadata 添加联合索引。
addRowFromMetadata(id, t, singleIndexColumns) {
const columns = this.table.columns;
const index = columns.length + 1;
const type = t.Type.toUpperCase();
const name = t.Field;
let length = null;
let precision = null;
let scale = null;
let typeArr = type.split("(");
if (typeArr.length > 1) {
const lengthOrprecisionScale = typeArr[1].split(")")[0];
if (lengthOrprecisionScale.indexOf(",") > 0) {
precision = lengthOrprecisionScale.split(",")[0];
scale = lengthOrprecisionScale.split(",")[1];
} else {
length = lengthOrprecisionScale;
}
}
let indexType = null;
let indexStorage = null;
let indexName = null;
let indexColumn = singleIndexColumns[name];
if (indexColumn) {
if (indexColumn.Key_name === "PRIMARY") {
indexType = "PRIMARY";
} else if (indexColumn.Index_type === "FULLTEXT") {
indexType = "FULLTEXT";
indexName = indexColumn.Key_name;
} else if (indexColumn.Non_unique === 0) {
indexType = "UNIQUE";
indexName = indexColumn.Key_name;
indexStorage = indexColumn.Index_type;
} else {
indexType = "INDEX";
indexName = indexColumn.Key_name;
indexStorage = indexColumn.Index_type;
}
}
const comment = t.Comment ? t.Comment : name;
const newRow = {
id: id,
autoIncrement: (t.Extra === "auto_increment"),
displayOrder: columns.length,
insertable: true,
nullable: (t.Null === "YES"),
queryable: true,
displayable: false,
unsigned: type.indexOf("UNSIGNED") >= 0,
updatable: true,
dataType : typeArr[0].replace("UNSIGNED", "").trim(),
indexType: indexType,
indexStorage: indexStorage,
indexName: indexName,
name: name,
caption: comment,
description: comment,
length: length,
precision: precision,
scale: scale,
systemable: false
};
this.table.columns = [ ...columns.slice(0, index), newRow, ...columns.slice(index) ];
},
addIndexFromMetadata(union) {
let baseId = (new Date()).valueOf();
let newIndexs = [];
const tableColumns = this.table.columns;
console.dir(tableColumns);
for (let key in union) {
const unionLines = union[key];
const newIndexLines = [];
unionLines.forEach((item) => {
const columnName = item.Column_name;
const columnId = tableColumns.find(t => t.name === columnName).id;
newIndexLines.push({
column: {
id: columnId,
name: columnName
}
});
});
const unionLineFirst = unionLines[0];
let indexType = null;
let indexStorage = null;
if (unionLineFirst.Key_name === "PRIMARY") {
indexType = "PRIMARY";
} else if (unionLineFirst.Non_unique === 0) {
indexType = "UNIQUE";
indexStorage = unionLineFirst.Index_type;
} else {
indexType = "INDEX";
indexStorage = unionLineFirst.Index_type;
}
const indexComment = unionLineFirst.Index_comment ? unionLineFirst.Index_comment: unionLineFirst.Key_name;
const newIndex = {
id: baseId++,
isNewRow: true,
caption: indexComment,
description: indexComment,
indexStorage: indexStorage,
indexType: indexType,
name: unionLineFirst.Key_name,
indexLines: newIndexLines
}
newIndexs.push(newIndex);
}
this.table.indexs = newIndexs;
if (this.table.indexs) {
this.indexCount = this.table.indexs.length;
} else {
this.indexCount = 0;
}
}
例子
ca_product
以ca_product为例,点击“加载元数据”后,表格字段和索引显示正确。保存成功后,现有物理表 ca_product 将由元数据自动管理,您可以通过 crudapi 后台继续对其进行编辑。通过数据库逆向功能,零码实现物理表ca_product的CRUD增删改查功能。
概括
本文主要介绍数据库反向功能。在现有数据库形式的基础上,通过数据库反向功能,可以快速生成元数据。无需一行代码,我们就可以获取现有数据库的基本 crud 功能,包括 API 和 UI。类似于phpmyadmin等数据库UI管理系统,但比数据库UI管理系统更加灵活友好。目前,数据库一次只反转一个表。如果同时有很多物理表,需要进行批量操作。后续优化将继续实现批量数据库的逆向功能。
温馨提示:点击原文链接逆向基于Vue和Quasar的前端SPA项目的数据库(十二)|crudapi可以去官网查看源码! 查看全部
seq搜索引擎优化至少包括那几步?(基于Vue和Quasar的前端SPA项目实战之数据库逆向(十二))
基于Vue和Quasar的前端SPA项目数据库逆向(十二)回顾
通过引入之前的文章“开源免费”动态表单设计器(五)基于Vue和Quasar),实现动态表单功能。如果是一个全新的项目,通过配置元数据,创建物理表,这样就可以自动实现业务数据的CRUD增删改查。但是如果数据库表已经存在,如何通过配置表单元数据来管理呢?这时候就需要数据库逆向功能了。
介绍
数据库逆向是读取数据库物理表schema信息,然后生成表单元数据,可以认为是“dbfirst”模式,即先有数据库表,然后根据表生成元数据。逆向形式的后续操作与普通动态形式类似。
用户界面界面
数据库反向
输入物理表名,启用“数据库反向”功能,然后点击“加载元数据”,表单字段相关的元数据信息就会自动填充。
数据表准备
以ca_product产品为例,通过phpmyadmin创建表
#创建产品表
CREATE TABLE `ca_product` (
`id` bigint UNSIGNED NOT NULL COMMENT '编号',
`name` varchar(200) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '名称',
`fullTextBody` text COLLATE utf8mb4_unicode_ci COMMENT '全文索引',
`createdDate` datetime NOT NULL COMMENT '创建时间',
`lastModifiedDate` datetime DEFAULT NULL COMMENT '修改时间',
`code` varchar(200) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '编码',
`brand` varchar(200) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '品牌',
`price` decimal(10,0) DEFAULT NULL COMMENT '单价',
`weight` decimal(10,0) DEFAULT NULL COMMENT '重量',
`length` decimal(10,0) DEFAULT NULL COMMENT '长',
`width` decimal(10,0) DEFAULT NULL COMMENT '宽',
`high` decimal(10,0) DEFAULT NULL COMMENT '高',
`ats` bigint DEFAULT NULL COMMENT '库存个数'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='产品';
ALTER TABLE `ca_product`
ADD PRIMARY KEY (`id`),
ADD UNIQUE KEY `UQ_CODE` (`code`) USING BTREE;
ALTER TABLE `ca_product` ADD FULLTEXT KEY `ft_fulltext_body` (`fullTextBody`);
ALTER TABLE `ca_product`
MODIFY `id` bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '编号', AUTO_INCREMENT=1;
COMMIT;
phpmyadmin
查询模式
MySQL数据库可以通过以下SQL语句查询表单、字段、索引等信息
SHOW TABLE STATUS LIKE TABLE_NAME
SHOW FULL COLUMNS FROM TABLE_NAME
SHOW INDEX FROM TABLE_NAME
表基本信息
表基本信息
字段信息
字段信息
索引信息
API JSON
通过API查询ca_product的schema信息:/api/metadata/tables/metadata/ca_product,格式如下:
{
"Name": "ca_product",
"Engine": "InnoDB",
"Version": 10,
"Row_format": "Dynamic",
"Rows": 0,
"Avg_row_length": 0,
"Data_length": 16384,
"Max_data_length": 0,
"Index_length": 32768,
"Data_free": 0,
"Auto_increment": 2,
"Create_time": 1628141282000,
"Update_time": 1628141304000,
"Collation": "utf8mb4_unicode_ci",
"Create_options": "",
"Comment": "产品",
"columns": [{
"Field": "id",
"Type": "bigint unsigned",
"Null": "NO",
"Key": "PRI",
"Extra": "auto_increment",
"Privileges": "select,insert,update,references",
"Comment": "编号"
}, {
"Field": "name",
"Type": "varchar(200)",
"Collation": "utf8mb4_unicode_ci",
"Null": "NO",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "名称"
}, {
"Field": "fullTextBody",
"Type": "text",
"Collation": "utf8mb4_unicode_ci",
"Null": "YES",
"Key": "MUL",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "全文索引"
}, {
"Field": "createdDate",
"Type": "datetime",
"Null": "NO",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "创建时间"
}, {
"Field": "lastModifiedDate",
"Type": "datetime",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "修改时间"
}, {
"Field": "code",
"Type": "varchar(200)",
"Collation": "utf8mb4_unicode_ci",
"Null": "YES",
"Key": "UNI",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "编码"
}, {
"Field": "brand",
"Type": "varchar(200)",
"Collation": "utf8mb4_unicode_ci",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "品牌"
}, {
"Field": "price",
"Type": "decimal(10,0)",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "单价"
}, {
"Field": "weight",
"Type": "decimal(10,0)",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "重量"
}, {
"Field": "length",
"Type": "decimal(10,0)",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "长"
}, {
"Field": "width",
"Type": "decimal(10,0)",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "宽"
}, {
"Field": "high",
"Type": "decimal(10,0)",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "高"
}, {
"Field": "ats",
"Type": "bigint",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "库存个数"
}],
"indexs": [{
"Table": "ca_product",
"Non_unique": 0,
"Key_name": "PRIMARY",
"Seq_in_index": 1,
"Column_name": "id",
"Collation": "A",
"Cardinality": 0,
"Null": "",
"Index_type": "BTREE",
"Comment": "",
"Index_comment": "",
"Visible": "YES"
}, {
"Table": "ca_product",
"Non_unique": 0,
"Key_name": "UQ_CODE",
"Seq_in_index": 1,
"Column_name": "code",
"Collation": "A",
"Cardinality": 0,
"Null": "YES",
"Index_type": "BTREE",
"Comment": "",
"Index_comment": "",
"Visible": "YES"
}, {
"Table": "ca_product",
"Non_unique": 1,
"Key_name": "ft_fulltext_body",
"Seq_in_index": 1,
"Column_name": "fullTextBody",
"Cardinality": 0,
"Null": "YES",
"Index_type": "FULLTEXT",
"Comment": "",
"Index_comment": "",
"Visible": "YES"
}]
}
核心代码
前端将 API 返回的 schema 信息转换为 crudapi 的元数据格式,并显示在 UI 上。主要代码在文件 metadata/table/new.vue 中,通过 addRowFromMetadata 方法添加字段,addIndexFromMetadata 添加联合索引。
addRowFromMetadata(id, t, singleIndexColumns) {
const columns = this.table.columns;
const index = columns.length + 1;
const type = t.Type.toUpperCase();
const name = t.Field;
let length = null;
let precision = null;
let scale = null;
let typeArr = type.split("(");
if (typeArr.length > 1) {
const lengthOrprecisionScale = typeArr[1].split(")")[0];
if (lengthOrprecisionScale.indexOf(",") > 0) {
precision = lengthOrprecisionScale.split(",")[0];
scale = lengthOrprecisionScale.split(",")[1];
} else {
length = lengthOrprecisionScale;
}
}
let indexType = null;
let indexStorage = null;
let indexName = null;
let indexColumn = singleIndexColumns[name];
if (indexColumn) {
if (indexColumn.Key_name === "PRIMARY") {
indexType = "PRIMARY";
} else if (indexColumn.Index_type === "FULLTEXT") {
indexType = "FULLTEXT";
indexName = indexColumn.Key_name;
} else if (indexColumn.Non_unique === 0) {
indexType = "UNIQUE";
indexName = indexColumn.Key_name;
indexStorage = indexColumn.Index_type;
} else {
indexType = "INDEX";
indexName = indexColumn.Key_name;
indexStorage = indexColumn.Index_type;
}
}
const comment = t.Comment ? t.Comment : name;
const newRow = {
id: id,
autoIncrement: (t.Extra === "auto_increment"),
displayOrder: columns.length,
insertable: true,
nullable: (t.Null === "YES"),
queryable: true,
displayable: false,
unsigned: type.indexOf("UNSIGNED") >= 0,
updatable: true,
dataType : typeArr[0].replace("UNSIGNED", "").trim(),
indexType: indexType,
indexStorage: indexStorage,
indexName: indexName,
name: name,
caption: comment,
description: comment,
length: length,
precision: precision,
scale: scale,
systemable: false
};
this.table.columns = [ ...columns.slice(0, index), newRow, ...columns.slice(index) ];
},
addIndexFromMetadata(union) {
let baseId = (new Date()).valueOf();
let newIndexs = [];
const tableColumns = this.table.columns;
console.dir(tableColumns);
for (let key in union) {
const unionLines = union[key];
const newIndexLines = [];
unionLines.forEach((item) => {
const columnName = item.Column_name;
const columnId = tableColumns.find(t => t.name === columnName).id;
newIndexLines.push({
column: {
id: columnId,
name: columnName
}
});
});
const unionLineFirst = unionLines[0];
let indexType = null;
let indexStorage = null;
if (unionLineFirst.Key_name === "PRIMARY") {
indexType = "PRIMARY";
} else if (unionLineFirst.Non_unique === 0) {
indexType = "UNIQUE";
indexStorage = unionLineFirst.Index_type;
} else {
indexType = "INDEX";
indexStorage = unionLineFirst.Index_type;
}
const indexComment = unionLineFirst.Index_comment ? unionLineFirst.Index_comment: unionLineFirst.Key_name;
const newIndex = {
id: baseId++,
isNewRow: true,
caption: indexComment,
description: indexComment,
indexStorage: indexStorage,
indexType: indexType,
name: unionLineFirst.Key_name,
indexLines: newIndexLines
}
newIndexs.push(newIndex);
}
this.table.indexs = newIndexs;
if (this.table.indexs) {
this.indexCount = this.table.indexs.length;
} else {
this.indexCount = 0;
}
}
例子
ca_product
以ca_product为例,点击“加载元数据”后,表格字段和索引显示正确。保存成功后,现有物理表 ca_product 将由元数据自动管理,您可以通过 crudapi 后台继续对其进行编辑。通过数据库逆向功能,零码实现物理表ca_product的CRUD增删改查功能。
概括
本文主要介绍数据库反向功能。在现有数据库形式的基础上,通过数据库反向功能,可以快速生成元数据。无需一行代码,我们就可以获取现有数据库的基本 crud 功能,包括 API 和 UI。类似于phpmyadmin等数据库UI管理系统,但比数据库UI管理系统更加灵活友好。目前,数据库一次只反转一个表。如果同时有很多物理表,需要进行批量操作。后续优化将继续实现批量数据库的逆向功能。
温馨提示:点击原文链接逆向基于Vue和Quasar的前端SPA项目的数据库(十二)|crudapi可以去官网查看源码!
seq搜索引擎优化至少包括那几步?(卷宗扫描仪网站长:SEO优化的各个方面是比较重要的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-01 07:14
Dossier Scanner网站认为:在SEO优化的各个方面,更重要的是优化网站的内容,只有内容更丰富的网站才能被搜索引擎搜索到收录,提高网站的排名,推动网站建设的发展。以下文件扫描器网络:简单步骤教你如何学习网站SEO优化?
一、关键词的选择,关键词的好选择是优化网站的第一步,通过关键词和page的关联建立索引库内容,是搜索引擎生存的基础,关键词的产生伴随着用户需求的产生。一个漂亮的TDK规划不是基于网站本身的主观臆断,而是用户真实需求的聚合。小编的SEO之路就是从TDK开始的。当时的导师一点一点的教,小编领悟后的实践,一点一点的体现出来最终的效果。从头到尾,小编亲自写TDK都觉得不舒服。有点懈怠,看似基本的东西,其实不一般,关键词 作为SEO五要素中最重要的一环,小编之所以再次提出来,是为了提醒那些痴迷于横着走、走灰走黑的人。路线的SEOer,千万不要忽视了最初出发的目的。
二、更新高质量原创文章。SEO优化的基础是坚持在网站上更新更多优质的文章,尽量让网站的页面丰富多样,赏心悦目,有一定的吸引力,但最重要的是不断更新优质的文章和信息,从而抢占更多的关键词,在行业竞争中获得优势。此外,一些权威的文章也会被站外一些媒体引用,扩大网站的影响力。
三、关键字应该布局合理。在优化文章的时候,重点关注关键词的密度,让关键词做到在文章中自然分布而不影响阅读,而不是关键词的很多无意义的堆叠@>,通常关键词出现在文章的开头和结尾,可以提高文章的相关性和权重。当然,对于文章的平滑性和自然性,关键词也可以进行形式的变换和拆分,这也是对文章的一种优化方式。根据 关键词 的接近程度,这些措施将优化 文章 的内容。
四、链接建立密钥。给网站一些链接如:友情链接、论坛链接、博客链接、微信链接等。友情链接,这个一定要做,至于它的重要性,我就不用过多赘述了。链接相关性,无论你如何扩展外链,你更喜欢与目标页面的主题内容相关的平台来获取外链资源;链接广度,如果你经常关注站长后台的链接分析,你会发现在同一个平台上发布的外部链接的数量是有限制的,可以被搜索引擎接受。高权重平台的外链数量适当增加,而权重较低的网站外链数量被搜索引擎认可。看点大布局很重要。
五、关注用户体验。其实网站的构造有很多需要注意的地方,比如如何设置网站的关键词,只要你意识到key 网站的网站是网络营销中不可或缺的一环,客户被分流到网站后,如果网站的打开速度太慢,布局体验差,或者没有内容客户感兴趣,销售和客服体验差,所有因素都会影响最终成交。糟糕的用户体验会导致前期推广失败。
Dossier 认为新手已经可以通过以上步骤为企业网站优化SEO。事实上,为了网站的长远发展和排名的快速提升,网站的管理者可以培养一个SEO意识的团队,能够提供高质量的文章对于网站,围绕已经给出的关键词,并且有很强的技术水平能够写出考虑网站的整体结构,调整关键词的布局,并在合适的时机为网站搭建新的内容平台,从而有长期稳定的输出,为关键词后续的快速发展提供了有力的支持。促进网站的整体发展, 查看全部
seq搜索引擎优化至少包括那几步?(卷宗扫描仪网站长:SEO优化的各个方面是比较重要的)
Dossier Scanner网站认为:在SEO优化的各个方面,更重要的是优化网站的内容,只有内容更丰富的网站才能被搜索引擎搜索到收录,提高网站的排名,推动网站建设的发展。以下文件扫描器网络:简单步骤教你如何学习网站SEO优化?
一、关键词的选择,关键词的好选择是优化网站的第一步,通过关键词和page的关联建立索引库内容,是搜索引擎生存的基础,关键词的产生伴随着用户需求的产生。一个漂亮的TDK规划不是基于网站本身的主观臆断,而是用户真实需求的聚合。小编的SEO之路就是从TDK开始的。当时的导师一点一点的教,小编领悟后的实践,一点一点的体现出来最终的效果。从头到尾,小编亲自写TDK都觉得不舒服。有点懈怠,看似基本的东西,其实不一般,关键词 作为SEO五要素中最重要的一环,小编之所以再次提出来,是为了提醒那些痴迷于横着走、走灰走黑的人。路线的SEOer,千万不要忽视了最初出发的目的。
二、更新高质量原创文章。SEO优化的基础是坚持在网站上更新更多优质的文章,尽量让网站的页面丰富多样,赏心悦目,有一定的吸引力,但最重要的是不断更新优质的文章和信息,从而抢占更多的关键词,在行业竞争中获得优势。此外,一些权威的文章也会被站外一些媒体引用,扩大网站的影响力。
三、关键字应该布局合理。在优化文章的时候,重点关注关键词的密度,让关键词做到在文章中自然分布而不影响阅读,而不是关键词的很多无意义的堆叠@>,通常关键词出现在文章的开头和结尾,可以提高文章的相关性和权重。当然,对于文章的平滑性和自然性,关键词也可以进行形式的变换和拆分,这也是对文章的一种优化方式。根据 关键词 的接近程度,这些措施将优化 文章 的内容。
四、链接建立密钥。给网站一些链接如:友情链接、论坛链接、博客链接、微信链接等。友情链接,这个一定要做,至于它的重要性,我就不用过多赘述了。链接相关性,无论你如何扩展外链,你更喜欢与目标页面的主题内容相关的平台来获取外链资源;链接广度,如果你经常关注站长后台的链接分析,你会发现在同一个平台上发布的外部链接的数量是有限制的,可以被搜索引擎接受。高权重平台的外链数量适当增加,而权重较低的网站外链数量被搜索引擎认可。看点大布局很重要。
五、关注用户体验。其实网站的构造有很多需要注意的地方,比如如何设置网站的关键词,只要你意识到key 网站的网站是网络营销中不可或缺的一环,客户被分流到网站后,如果网站的打开速度太慢,布局体验差,或者没有内容客户感兴趣,销售和客服体验差,所有因素都会影响最终成交。糟糕的用户体验会导致前期推广失败。
Dossier 认为新手已经可以通过以上步骤为企业网站优化SEO。事实上,为了网站的长远发展和排名的快速提升,网站的管理者可以培养一个SEO意识的团队,能够提供高质量的文章对于网站,围绕已经给出的关键词,并且有很强的技术水平能够写出考虑网站的整体结构,调整关键词的布局,并在合适的时机为网站搭建新的内容平台,从而有长期稳定的输出,为关键词后续的快速发展提供了有力的支持。促进网站的整体发展,
seq搜索引擎优化至少包括那几步?(网站优化也不只是传统的SEO吗?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-01 04:20
SEO是搜索引擎优化的首字母缩写。简单来说,SEO是指遵循搜索引擎的搜索原则,通过对网站的内外环境和内容的一系列优化,提高网站在搜索引擎中的相关搜索性能,从而提高网站访问流量的技术实现过程,最终提升网站的营销能力或宣传能力。
在国外,SEO发展较早,各行各业对SEO的理解和关注也比国内要好。不过,目前SEO市场需求和资金投入仍保持强劲增长势头。由于谷歌在搜索技术方面的强大优势和准确公正的搜索结果受到用户的青睐,谷歌也成为了全球搜索引擎优化的主要研究对象。
可能很多人都知道,SEO领域有黑帽和白帽之分。这是因为一些不公平的SEO人出于侥幸,为了获得暂时的高排名,做出了明确的搜索引擎指令。禁止的方法或作弊方法不仅会欺骗搜索引擎,还会对访问者不忠诚,最终可能会被搜索引擎惩罚或解雇,并永远从搜索结果中消失。这种不良的SEO行为被称为黑帽,或走在黑道中。相反,能被搜索引擎接受的正式的SEO方法被称为白帽,挺身而出,走白路。
国内很多公司和个人对SEO的理解有偏差。比如有人把SEO等同于网站优化,但其实SEO不仅仅是网站优化,网站优化也不仅仅是传统的SEO。搜索引擎优化是一个复杂的、长期的、动态的优化过程。网站优化只是根据搜索原理对网站进行的调整和修改工作。这只是为了让 网站 有更好的搜索引擎友好性、可见性、指示性等,而对于最终的搜索结果表现,影响因素远不止一点点,只是做一些优化工作远远不够。
传统的SEO经常误入歧途,即为SEO而SEO,为排名而拼命。因为 网站 的最终目的是向访问者推荐或展示您的产品或服务,而不是向搜索引擎展示它们,这可能只会帮助您吸引访问者。即使你的 网站 看起来对搜索引擎非常友好和重要,但对用户没有吸引力或烦人,你得到的只是暂时的高流量,实际上很可能不超过万分之三的访问者在你的网站上停留5秒以上,从长远来看,搜索引擎不可能总是有好的排名结果,那又如何?意义?正如 Google 官方 网站 中所说:网页应该面向用户,而不是面向搜索引擎。对用户诚实,并向搜索引擎提交与向用户显示的内容一致的内容。真正做SEO的人会在实施过程中“忘记”什么是SEO,始终坚持以用户为中心,以营销和服务为宗旨。真正的SEO不是靠手段得到只能得到60分的网站排名90或100,而是通过SEO改进只能得到60分的网站真正的90分或 100 分!
企业网站主要是树立良好的企业形象,让外界了解企业本身,网络营销外包,适当提供一定的服务网站。根据行业特点的差异,以及建立公司网站的目的和主要目标群体,公司大致可以分为网站:
基本信息类:主要面向客户、业内人士或普通观众,主要介绍公司基本信息,帮助树立企业形象;还可以酌情提供行业内的新闻或知识信息。这种类型的网站经常被比作企业的“WEBCatalog”。东莞网络优化
电子商务类型:主要针对企业产品(服务)的供应商、客户或消费群体,东莞建网站优化为直接在企业经营范围内提供某些服务或交易,或为商业服务提供服务或交易这样的网站可以说是处于电商的中间阶段。由于行业特点的差异以及企业投资的深度和广度,电子商务的发展程度可能处于从相对初级的服务支持、产品清单到在线支付的更高级阶段之一的阶段。通常这种类型可以形象地称为“在线XX企业”。例如,网上银行、网上酒店等。
多媒体广告类:主要针对企业产品(服务)的客户或消费群体,主要宣传公司核心品牌形象或主要产品(服务)。与普通的网站相比,这种类型在目的和实际表达上更像是平面广告或电视广告,所以用“多媒体广告”来称呼这种类型的网站更为贴切。小的。
在实际应用中,很多网站往往不能简单归类为某一类,无论是建站目的还是表达形式,都可能涵盖两种或两种以上;对于这类企业网站,可以根据以上类型的不同,分成不同的部分,每个部分基本可以看成是一个比较完整的网站类型。注:由于互联网公司的特殊性,网站互联网信息提供者或服务提供者不在此列。
6. 带有 i 的 JS
在互联网发展过程中,JS和I多以网络广告的形式存在,大部分广告管理都是通过JS和I来管理的。现在的WEB技术虽然可以用广告来补充网页的内容,但是太多的广告也可以干扰用户浏览网页内容。搜索引擎仍然没有“考虑” JS 和 I 中的内容。企业 网站SEO 将有用的信息放在 JS 中,它变成了无用的信息。大量的JS和我会被认为是页面太多。广告。
7.多个网站s用于交联(站群)
一个网站 比首页的权重最高,也是关键词 最容易排名的。大部分站长在网站首页上放了很多流行的关键词,因为首页位置有限,远远不能满足很多关键词的需求。许多站长创建了许多子站点来分隔一些流行的关键词。这是一种干扰搜索引擎排名的行为。搜索引擎也对此类行为采取了一定的措施,例如:延长新站点的排名时间,沙盒新的网站 采集分析,并对站群网站@进行一定的惩罚。 >。企业网站建设
站群(多个 网站 交叉链接),我们可以做到吗?当然,我们只需要掌握学位。用好对排名很有帮助,就像我们交换友链一样。
8. 网站 中有很多死链接
网站内部管理,一些栏目,文章等经常被删除,被删除的页面会产生大量死链接。死链接对搜索引擎和用户体验非常不友好,那么如何处理这些链接呢?网站一定要做好404错误页面的设置,并在robots中做特殊处理,我们建议尽量保留页面并在原页面上进行内容更改。
9. 缺少导入和导出链接
SEO人接手了很多网站的优化工作,网站大部分都有收录的问题。查了一下,发现很多网站都是闭门出站的(这个不用解释了)。吧)现象,没有合理的进出口环节。在互联网中,网页与网页之间的关系是通过链接建立的。如果网站与外界没有联系,如果没有联系,就会变成孤岛类型网站,搜索引擎无法知道网站的存在。
10. 复制网站
有的企业为了在网站的建设中省钱省力,直接抢了胡须和鼻子,直接使用现有的网站程序模板,却没有考虑网站的重要性@> 框架,这样就会有两个相似度非常高的网站。这样的新站点很难获得好的排名,老站点也会受到影响。推荐阅读:网站如何搭建
最后要记住的是学习SEO的重要理论点,以及SEO人学习和优化所必需的九种品质和精神。
东莞网站优化东莞网络公司
东莞整站优化
2012年企业营销九大趋势网站 查看全部
seq搜索引擎优化至少包括那几步?(网站优化也不只是传统的SEO吗?(图))
SEO是搜索引擎优化的首字母缩写。简单来说,SEO是指遵循搜索引擎的搜索原则,通过对网站的内外环境和内容的一系列优化,提高网站在搜索引擎中的相关搜索性能,从而提高网站访问流量的技术实现过程,最终提升网站的营销能力或宣传能力。
在国外,SEO发展较早,各行各业对SEO的理解和关注也比国内要好。不过,目前SEO市场需求和资金投入仍保持强劲增长势头。由于谷歌在搜索技术方面的强大优势和准确公正的搜索结果受到用户的青睐,谷歌也成为了全球搜索引擎优化的主要研究对象。
可能很多人都知道,SEO领域有黑帽和白帽之分。这是因为一些不公平的SEO人出于侥幸,为了获得暂时的高排名,做出了明确的搜索引擎指令。禁止的方法或作弊方法不仅会欺骗搜索引擎,还会对访问者不忠诚,最终可能会被搜索引擎惩罚或解雇,并永远从搜索结果中消失。这种不良的SEO行为被称为黑帽,或走在黑道中。相反,能被搜索引擎接受的正式的SEO方法被称为白帽,挺身而出,走白路。
国内很多公司和个人对SEO的理解有偏差。比如有人把SEO等同于网站优化,但其实SEO不仅仅是网站优化,网站优化也不仅仅是传统的SEO。搜索引擎优化是一个复杂的、长期的、动态的优化过程。网站优化只是根据搜索原理对网站进行的调整和修改工作。这只是为了让 网站 有更好的搜索引擎友好性、可见性、指示性等,而对于最终的搜索结果表现,影响因素远不止一点点,只是做一些优化工作远远不够。
传统的SEO经常误入歧途,即为SEO而SEO,为排名而拼命。因为 网站 的最终目的是向访问者推荐或展示您的产品或服务,而不是向搜索引擎展示它们,这可能只会帮助您吸引访问者。即使你的 网站 看起来对搜索引擎非常友好和重要,但对用户没有吸引力或烦人,你得到的只是暂时的高流量,实际上很可能不超过万分之三的访问者在你的网站上停留5秒以上,从长远来看,搜索引擎不可能总是有好的排名结果,那又如何?意义?正如 Google 官方 网站 中所说:网页应该面向用户,而不是面向搜索引擎。对用户诚实,并向搜索引擎提交与向用户显示的内容一致的内容。真正做SEO的人会在实施过程中“忘记”什么是SEO,始终坚持以用户为中心,以营销和服务为宗旨。真正的SEO不是靠手段得到只能得到60分的网站排名90或100,而是通过SEO改进只能得到60分的网站真正的90分或 100 分!
企业网站主要是树立良好的企业形象,让外界了解企业本身,网络营销外包,适当提供一定的服务网站。根据行业特点的差异,以及建立公司网站的目的和主要目标群体,公司大致可以分为网站:
基本信息类:主要面向客户、业内人士或普通观众,主要介绍公司基本信息,帮助树立企业形象;还可以酌情提供行业内的新闻或知识信息。这种类型的网站经常被比作企业的“WEBCatalog”。东莞网络优化
电子商务类型:主要针对企业产品(服务)的供应商、客户或消费群体,东莞建网站优化为直接在企业经营范围内提供某些服务或交易,或为商业服务提供服务或交易这样的网站可以说是处于电商的中间阶段。由于行业特点的差异以及企业投资的深度和广度,电子商务的发展程度可能处于从相对初级的服务支持、产品清单到在线支付的更高级阶段之一的阶段。通常这种类型可以形象地称为“在线XX企业”。例如,网上银行、网上酒店等。
多媒体广告类:主要针对企业产品(服务)的客户或消费群体,主要宣传公司核心品牌形象或主要产品(服务)。与普通的网站相比,这种类型在目的和实际表达上更像是平面广告或电视广告,所以用“多媒体广告”来称呼这种类型的网站更为贴切。小的。
在实际应用中,很多网站往往不能简单归类为某一类,无论是建站目的还是表达形式,都可能涵盖两种或两种以上;对于这类企业网站,可以根据以上类型的不同,分成不同的部分,每个部分基本可以看成是一个比较完整的网站类型。注:由于互联网公司的特殊性,网站互联网信息提供者或服务提供者不在此列。
6. 带有 i 的 JS
在互联网发展过程中,JS和I多以网络广告的形式存在,大部分广告管理都是通过JS和I来管理的。现在的WEB技术虽然可以用广告来补充网页的内容,但是太多的广告也可以干扰用户浏览网页内容。搜索引擎仍然没有“考虑” JS 和 I 中的内容。企业 网站SEO 将有用的信息放在 JS 中,它变成了无用的信息。大量的JS和我会被认为是页面太多。广告。
7.多个网站s用于交联(站群)
一个网站 比首页的权重最高,也是关键词 最容易排名的。大部分站长在网站首页上放了很多流行的关键词,因为首页位置有限,远远不能满足很多关键词的需求。许多站长创建了许多子站点来分隔一些流行的关键词。这是一种干扰搜索引擎排名的行为。搜索引擎也对此类行为采取了一定的措施,例如:延长新站点的排名时间,沙盒新的网站 采集分析,并对站群网站@进行一定的惩罚。 >。企业网站建设
站群(多个 网站 交叉链接),我们可以做到吗?当然,我们只需要掌握学位。用好对排名很有帮助,就像我们交换友链一样。
8. 网站 中有很多死链接
网站内部管理,一些栏目,文章等经常被删除,被删除的页面会产生大量死链接。死链接对搜索引擎和用户体验非常不友好,那么如何处理这些链接呢?网站一定要做好404错误页面的设置,并在robots中做特殊处理,我们建议尽量保留页面并在原页面上进行内容更改。
9. 缺少导入和导出链接
SEO人接手了很多网站的优化工作,网站大部分都有收录的问题。查了一下,发现很多网站都是闭门出站的(这个不用解释了)。吧)现象,没有合理的进出口环节。在互联网中,网页与网页之间的关系是通过链接建立的。如果网站与外界没有联系,如果没有联系,就会变成孤岛类型网站,搜索引擎无法知道网站的存在。
10. 复制网站
有的企业为了在网站的建设中省钱省力,直接抢了胡须和鼻子,直接使用现有的网站程序模板,却没有考虑网站的重要性@> 框架,这样就会有两个相似度非常高的网站。这样的新站点很难获得好的排名,老站点也会受到影响。推荐阅读:网站如何搭建
最后要记住的是学习SEO的重要理论点,以及SEO人学习和优化所必需的九种品质和精神。
东莞网站优化东莞网络公司
东莞整站优化
2012年企业营销九大趋势网站
seq搜索引擎优化至少包括那几步?(开源ElasticsearchType类型Document可以分组吗?(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-01 04:15
文章目录
前言一、基本概念全文搜索是最常见的需求,开源的Elasticsearch(以下简称Elastic)是目前全文搜索引擎的首选。它可以快速存储、搜索和分析海量数据。Wikipedia、Stack Overflow、Github 都使用它。底层 Elastic 是开源库 Lucene。但是,你不能直接使用Lucene,你必须自己编写代码来调用它的接口。Elastic 是 Lucene 的一个包,提供开箱即用的 REST API 操作接口。1. Node 节点和 Cluster 集群
Elastic 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器都可以运行多个 Elastic 实例。
单个 Elastic 实例称为节点。一组节点形成一个集群。
2. 索引索引
Elastic 索引所有字段并在处理后将它们写入倒排索引。查找数据时,直接查找索引。
因此,Elastic 数据管理的顶层单元称为 Index。它是单个数据库的同义词。每个索引(即数据库)的名称必须是小写的。
下面的命令可以查看当前节点的所有索引。
获取 /_mapping?pretty=true
3. 文档
索引中的单个记录称为文档。许多文档形成一个索引。
文档以 JSON 格式表示,以下是一个示例。
{
"user": "张三",
"title": "工程师",
"desc": "数据库管理"
}
同一个Index中的文档不要求结构(scheme)相同,但最好保持相同,有利于提高搜索效率。
4. 类型
可以对文档进行分组。例如,在天气指数中,它们可以按城市(北京和上海)或按气候(晴天和雨天)分组。这种分组称为Type,它是一个用于过滤Documents的虚拟逻辑分组。
不同的类型应该有相似的模式,例如,id 字段不能是一组中的字符串,而另一组中不能是数值。这是与关系数据库表的区别。具有完全不同属性的数据(例如产品和日志)应该存储为两个索引,而不是一个索引中的两种类型(尽管可以这样做)。
以下命令可以列出每个索引中收录的类型。(与上面的截图相同)
获取 /_mapping?pretty=true
按照计划,Elastic 6.x 版本只允许每个 Index 收录一个 Type,而 7.x 版本将彻底移除 Type。
5. 逻辑比较
上面提到的集群、节点、索引、类型、文档、分片(底层封装)和映射是什么?
如何区分和比较非关系型数据库elasticsearch和关系型数据库,elasticsearch是面向文档的
如下:关系型数据库和elasticsearch的客观对比!
关系型数据库 非关系型数据库
数据库数据库
指数
桌子
类型(版本 7 已完全弃用)
行
文档
字段列
场地
Elasticsearch(集群)可以收录多个索引(数据库),每个索引可以收录多个类型(表),每个类型收录多个文档(行),每个文档收录多个字段(列表)。
6. 物理设计
Elasticsearch在后台将每个索引分成多个shard,每个shard可以在集群中不同的服务器之间迁移。
集群的默认名称是 elasticsearch。
一个集群至少有一个节点,一个节点就是一个elasticsearch进程。一个节点可以有多个索引。默认情况下,如果创建索引,索引将由 5 个分片(primary shards,也称为主分片)组成。是的,每个主分片都会有一个副本(副本分片,也称为分配分片)
索引分为多个shard,每个shard就是一个Lucene索引,所以一个elasticsearch索引是由多个Lucene索引组成的。因为elasticsearch使用Lucene作为底层。
二、ES 命令风格
一种软件架构风格,而不是标准,它只是提供一组设计原则和约束,主要用于与客户端和服务器交互的软件。基于这种风格设计的软件可以更简洁、更有层次、更容易实现缓存等机制。
基本 RESTFUL 命令说明:
methodurl地址说明
放
本地主机:9200/index_name/type_name/document_id
创建文档(指定文档 ID)
邮政
本地主机:9200/index_name/type_name
创建文档(随机文档 ID)
邮政
本地主机:9200/index_name/type_name/document_id/_update
修改文档
删除
本地主机:9200/index_name/type_name/document_id
删除文件
得到
本地主机:9200/index_name/type_name/document_id
按文档id查询文档
邮政
本地主机:9200/index_name/type_name/document_id/_search
查询所有文件
PUT:一般创建索引,类型,文档 POST:添加数据,创建索引,类型,查询 DELETE:删除索引,文档 GET:查询 三、 创建和删除索引 index 创建索引索引
放置/天气
相当于
curl -X PUT 'localhost:9200/天气'
服务器返回一个带有确认字段的 JSON 对象,表明操作成功。
然后,发出删除请求以删除索引。
删除/天气
相当于
curl -X DELETE 'localhost:9200/天气'
四、Tokenizer 使用与学习
elasticsearch的查询是先通过tokenizer对单词进行分词,然后使用倒排索引匹配查询。
1. 理论研究
分词:就是将一段中文或者其他的一段分割成关键词,当我们搜索的时候,elasticsearch tokenizer会对自己的信息进行分词,对数据库或者索引库中的数据进行分词,然后执行一个匹配操作,默认的中文分词是将每个字符都当作一个词来对待,例如“我爱冯凡丽”会分为“我”、“爱”、“冯”、“凡”、“李”,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
ES默认分词是英文分词,对中文分词不太支持。如果要使用中文,推荐使用ik tokenizer!所以我们需要安装ik中文分词。
IK提供了两种分词算法:ik_smart和ik_max_word,其中ik_mart是最小分词,ik_max_word是最新粒度分词!我们将在一段时间内测试!
安装在第一篇博客中已经介绍过了,传送门:elasticsearch学习一:理解ES,版本之间的对应关系。安装 elasticsearch、kibana、head 插件、elasticsearch-ik 分词器。
2. 用 kibana 测试
ik_mart 是最少细分的
ik_max_word 是最新的粒度划分,它穷尽了词库的可能性。
输入超喜欢冯安辰java
发现问题:风安辰被分开了,
你需要的这种词,你需要将它添加到我们的分词器的字典中!
ik tokenizer 添加了自己的配置!
ik分词器自定义配置,我写了一篇博客:elasticsearch学习之三:elasticsearch-ik分词器的自定义配置分词内容
设置好后再次执行:
以后需要自己配置的分词可以在自己定义的dic文件中配置!五、数据操作1. 创建索引 创建索引方法1,简单创建索引
PUT/索引名称创建索引方式2、创建索引并添加数据,字段类型系统默认给出
该方法会直接创建索引名称、类型、id,并添加数据。
PUT /索引名/~类型名~/文档id
{请求体}
案件
PUT /test1/type1/1
{
"name": "冯安晨",
"age": 18
}
这样,index、type、id创建完成后,就添加了一条数据。
创建索引方法3、创建索引并指定字段类型
创建索引,指定类型名称,指定字段类型
PUT /test2
{
"mappings": {
"type2": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "long"
},
"birthday": {
"type": "date"
}
}
}
}
}
2. 字段类型摘要
那么上面的name字段就不需要指定类型了,毕竟我们的关系数据库需要指定类型!!
3. 查看规则信息
那就是看一下上面命令创建的细节
获取命令
GET /test1 : 查看索引信息
如果我们自己的文档字段没有指定,那么ES会给我们默认的配置字段类型!就是上面的test1索引,没有指定字段类型,所以ES默认指定类型。
4. 系统命令
通过elasticsearch命令查看ES的各种信息!通过
获取_猫/
获取大量关于ES的最新信息!
GET _cat/indices/?v:查看索引情况
其他命令。
5 添加数据
默认指定数据类型
PUT /fenganchen/user/1
{
"name": "冯凡利",
"age": 18,
"desc": "一顿操作猛如虎,一看工资2500",
"tags": ["技术宅", "温暖", "直男"]
}
6. 修改数据 PUT 修改(不推荐)
修改类似于add,但是这个修改类似于overwrite,如果缺少某个字段,则某个字段消失
查看 GET /fenganchen/user/1(如下所述)
修订
PUT /fenganchen/user/1
{
"name": "冯凡利123",
"age": 18,
"desc": "一顿操作猛如虎,一看工资2500",
"tags": ["技术宅", "温暖", "直男"]
}
_version 表示被修改的次数
查看确认
获取 /fenganchen/user/1
湾。_update 修改(推荐)修改
POST fenganchen/user/1/_update
{
"doc": {
"name": "冯凡利java"
}
}
2. 查看
7. 删除7. 简单查询 GET fenganchen/user/1
简单的条件查询
GET /fenganchen/user/_search?q=name:冯凡利 (报错,还未找到原因)
GET /fenganchen/user/_search?q=age:18
8.向复杂查询添加更多数据
PUT /fenganchen/user/2
{
"name": "张三",
"age": 17,
"desc": "法外狂徒张三",
"tags": ["技术宅", "温暖", "渣男"]
}
PUT /fenganchen/user/3
{
"name": "李四",
"age": 30,
"desc": "mmp 不知怎么形容了",
"tags": ["靓女", "旅游", "唱歌"]
}
查询关键字:查询
match关键字:match,这里有很多选项,比如:match_all:匹配所有,bool:返回一个布尔值,exists:存在等等。
GET fenganchen/user/_search
{
"query": {
"match": {
"name": "冯凡利"
}
}
}
3. 再添加一条数据,方便查询和测试:
PUT /fenganchen/user/4
{
"name": "冯凡利前端",
"age": 3,
"desc": "一顿操作猛如虎,一看工资2500",
"tags": ["技术宅", "温暖", "直男"]
}
再次查询:如下图
Hits:包括索引和文档信息、查询结果总数、查询到的具体文档
max_score:最大分数,是下面数据中最大的匹配分数值,也是最合适的
_score:可以用来判断谁更符合结果,每个数据都有这个属性
_source:数据对象信息关键字。
9 筛选结果
不想显示这么多字段,只想显示name和desc字段,可以使用数据对象信息关键字:_source来限制显示字段。
GET fenganchen/user/_search
{
"query": {
"match": {
"name": "冯凡利"
}
},
"_source": ["name", "desc"]
}
后面我们会用java来操作es,这里所有的方法和对象都是key:这个key也是hits、score等关键字。
10. 排序
GET fenganchen/user/_search
{
"query": {
"match": {
"name": "冯凡利"
}
},
"sort": [
{
"age": {
"order": "asc"
}
}
]
}
11.分页查询
GET fenganchen/user/_search
{
"query": {
"match": {
"name": "冯凡利"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 1
}
from:从第一条数据开始
size:返回多少条数据(单页数据)
数据下标还是从 0 开始,和所有学过的数据结构一样!
/搜索/{当前}/{页面大小}
12. 布尔查询必须(and),必须满足所有条件,类似于:where id=1 and name=xxx
GET fengfanli/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "冯凡利"
}
},
{
"match": {
"age": "18"
}
}
]
}
}
}
should(or),必须满足所有条件,类似于: where id=1 orname=xxx
GET fenganchen/user/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "冯凡利"
}
},
{
"match": {
"age": "18"
}
}
]
}
}
}
**must_not(not)**,必须满足所有条件,类似于: where id != 1
GET fenganchen/user/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"age": 3
}
}
]
}
}
}
13.过滤常见匹配查询
任何收录风范里字符串的东西都会被找到
GET fenganchen/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "冯凡利"
}
}
]
}
}
}
添加过滤器,过滤器
filter关键字过滤查询的数据。
GET fenganchen/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "冯凡利"
}
}
],
"filter": {
"range": {
"age": {
"gt": 3
}
}
}
}
}
}
上面的语句是对查询语句进行过滤,过滤掉年龄大于3的数据
14. 个空格匹配多个条件
匹配关键字空间
多个条件,以空格分隔
只要隐藏其中一个结果,就能查出
这时候通过_score分数就可以做出一个基本的判断了。
以下查询语句的含义:在tags字段中找到male和technical的数据并进行查询
GET fenganchen/user/_search
{
"query": {
"match": {
"tags": "男 技术"
}
}
}
15. 词条精确查询 i。术语分析
词条查询是通过倒排索引指定词条的过程直接搜索的!
关于分词:
ii. 两类文字关键词详解
分词器不能使用两种类型的文本关键字
文本类型:可分段
关键字类型:不能分段
首先创建索引并指定属性规则,如下:
一个。版本 6 创建索引并指定规则
elasticsearch 6.X必须指定创建索引的类型,feng_type是索引的类型名
```json
PUT testdb
{
"mappings": {
"feng_type": {
"properties": {
"name": {
"type": "text"
},
"desc": {
"type": "keyword"
}
}
}
}
}
```
湾。版本 7 创建索引并指定规则
elasticsearch 7.x 不需要指定类型来创建索引,因为版本7弃用了类型关键词(这里我就不演示了,我用的是6.4. 2 版本在这里。)
```json
PUT testdb
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"desc": {
"type": "keyword"
}
}
}
}
```
C。添加数据
```json
PUT testdb/feng_type/1
{
"name": "冯凡利java name",
"desc": "冯凡利java desc"
}
PUT testdb/feng_type/2
{
"name": "冯凡利java name",
"desc": "冯凡利java desc2"
}
```
添加文档 1
添加文档 2
d。elasticsearch-head的google插件,查看testdb索引数据
e. elasticsearch-head 的 Google 插件,参见 testdb 映射规则
索引情况,可以查看索引的设置详情,以及映射映射规则包括类型和属性。
可以看到,name 属性是 text 类型,而 desc 是关键字类型。
F。默认标记器测试:关键字
KeywordAnalyzer 将整个输入视为单个词汇单元,以促进特定类型文本的索引和检索。使用 关键词 标记器为邮政编码和地址等文本信息创建索引项非常方便。
使用默认的关键字tokenizer进行分词,(比如说ik tokenizer是中文tokenizer),这里可以看出没有分析
G。默认标记器测试:标准
英文的处理能力和StopAnalyzer一样,支持中文的方法是分词。它将词汇单元转换为小写并删除停用词和标点符号。
使用默认的标准分词器进行分词,见这里分析
H。term 准确查找文本类型
一世。term 查找确切的关键字类型
j. 总结 h 和 i 的检验
在 testdb 索引中:
名称字段是文本类型,
desc 字段是关键字类型。
但是,当 term 精确搜索它们时,它会发现:
在查找文本类型的名称字段时,只需收录它,即文本类型可以被分词器解释。在查找关键字类型的 desc 字段时,必须完全收录,即关键字类型将整个输入匹配为单个词法单元,由分词器解释。16. 多词精确匹配 a. 添加多数
PUT testdb/feng_type/3
{
"t1": "22",
"t2": "2020-4-6"
}
PUT testdb/feng_type/4
{
"t1": "33",
"t2": "2020-4-7"
}
湾。查看 elasticsearch-head 的谷歌插件,查看 testdb 索引数据和映射规则。索引数据
映射规则
C。词条精确查询
@>
17. Highlight 高亮关键字:highlight
GET fenganchen/user/_search
{
"query": {
"match": {
"name": "冯凡利"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
自定义搜索突出显示
GET fenganchen/user/_search
{
"query": {
"match": {
"name": "冯凡利"
}
},
"highlight": {
"pre_tags": "<p class='key style='color:red'>",
"post_tags": "",
"fields": {
"name": {}
}
}
}
</p>
这些mysql也可以做,但是mysql的效率比较低 查看全部
seq搜索引擎优化至少包括那几步?(开源ElasticsearchType类型Document可以分组吗?(一)(组图))
文章目录
前言一、基本概念全文搜索是最常见的需求,开源的Elasticsearch(以下简称Elastic)是目前全文搜索引擎的首选。它可以快速存储、搜索和分析海量数据。Wikipedia、Stack Overflow、Github 都使用它。底层 Elastic 是开源库 Lucene。但是,你不能直接使用Lucene,你必须自己编写代码来调用它的接口。Elastic 是 Lucene 的一个包,提供开箱即用的 REST API 操作接口。1. Node 节点和 Cluster 集群
Elastic 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器都可以运行多个 Elastic 实例。
单个 Elastic 实例称为节点。一组节点形成一个集群。
2. 索引索引
Elastic 索引所有字段并在处理后将它们写入倒排索引。查找数据时,直接查找索引。
因此,Elastic 数据管理的顶层单元称为 Index。它是单个数据库的同义词。每个索引(即数据库)的名称必须是小写的。
下面的命令可以查看当前节点的所有索引。
获取 /_mapping?pretty=true
3. 文档
索引中的单个记录称为文档。许多文档形成一个索引。
文档以 JSON 格式表示,以下是一个示例。
{
"user": "张三",
"title": "工程师",
"desc": "数据库管理"
}
同一个Index中的文档不要求结构(scheme)相同,但最好保持相同,有利于提高搜索效率。
4. 类型
可以对文档进行分组。例如,在天气指数中,它们可以按城市(北京和上海)或按气候(晴天和雨天)分组。这种分组称为Type,它是一个用于过滤Documents的虚拟逻辑分组。
不同的类型应该有相似的模式,例如,id 字段不能是一组中的字符串,而另一组中不能是数值。这是与关系数据库表的区别。具有完全不同属性的数据(例如产品和日志)应该存储为两个索引,而不是一个索引中的两种类型(尽管可以这样做)。
以下命令可以列出每个索引中收录的类型。(与上面的截图相同)
获取 /_mapping?pretty=true
按照计划,Elastic 6.x 版本只允许每个 Index 收录一个 Type,而 7.x 版本将彻底移除 Type。
5. 逻辑比较
上面提到的集群、节点、索引、类型、文档、分片(底层封装)和映射是什么?
如何区分和比较非关系型数据库elasticsearch和关系型数据库,elasticsearch是面向文档的
如下:关系型数据库和elasticsearch的客观对比!
关系型数据库 非关系型数据库
数据库数据库
指数
桌子
类型(版本 7 已完全弃用)
行
文档
字段列
场地
Elasticsearch(集群)可以收录多个索引(数据库),每个索引可以收录多个类型(表),每个类型收录多个文档(行),每个文档收录多个字段(列表)。
6. 物理设计
Elasticsearch在后台将每个索引分成多个shard,每个shard可以在集群中不同的服务器之间迁移。
集群的默认名称是 elasticsearch。
一个集群至少有一个节点,一个节点就是一个elasticsearch进程。一个节点可以有多个索引。默认情况下,如果创建索引,索引将由 5 个分片(primary shards,也称为主分片)组成。是的,每个主分片都会有一个副本(副本分片,也称为分配分片)
索引分为多个shard,每个shard就是一个Lucene索引,所以一个elasticsearch索引是由多个Lucene索引组成的。因为elasticsearch使用Lucene作为底层。
二、ES 命令风格
一种软件架构风格,而不是标准,它只是提供一组设计原则和约束,主要用于与客户端和服务器交互的软件。基于这种风格设计的软件可以更简洁、更有层次、更容易实现缓存等机制。
基本 RESTFUL 命令说明:
methodurl地址说明
放
本地主机:9200/index_name/type_name/document_id
创建文档(指定文档 ID)
邮政
本地主机:9200/index_name/type_name
创建文档(随机文档 ID)
邮政
本地主机:9200/index_name/type_name/document_id/_update
修改文档
删除
本地主机:9200/index_name/type_name/document_id
删除文件
得到
本地主机:9200/index_name/type_name/document_id
按文档id查询文档
邮政
本地主机:9200/index_name/type_name/document_id/_search
查询所有文件
PUT:一般创建索引,类型,文档 POST:添加数据,创建索引,类型,查询 DELETE:删除索引,文档 GET:查询 三、 创建和删除索引 index 创建索引索引
放置/天气
相当于
curl -X PUT 'localhost:9200/天气'
服务器返回一个带有确认字段的 JSON 对象,表明操作成功。
然后,发出删除请求以删除索引。
删除/天气
相当于
curl -X DELETE 'localhost:9200/天气'
四、Tokenizer 使用与学习
elasticsearch的查询是先通过tokenizer对单词进行分词,然后使用倒排索引匹配查询。
1. 理论研究
分词:就是将一段中文或者其他的一段分割成关键词,当我们搜索的时候,elasticsearch tokenizer会对自己的信息进行分词,对数据库或者索引库中的数据进行分词,然后执行一个匹配操作,默认的中文分词是将每个字符都当作一个词来对待,例如“我爱冯凡丽”会分为“我”、“爱”、“冯”、“凡”、“李”,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
ES默认分词是英文分词,对中文分词不太支持。如果要使用中文,推荐使用ik tokenizer!所以我们需要安装ik中文分词。
IK提供了两种分词算法:ik_smart和ik_max_word,其中ik_mart是最小分词,ik_max_word是最新粒度分词!我们将在一段时间内测试!
安装在第一篇博客中已经介绍过了,传送门:elasticsearch学习一:理解ES,版本之间的对应关系。安装 elasticsearch、kibana、head 插件、elasticsearch-ik 分词器。
2. 用 kibana 测试
ik_mart 是最少细分的
ik_max_word 是最新的粒度划分,它穷尽了词库的可能性。
输入超喜欢冯安辰java
发现问题:风安辰被分开了,
你需要的这种词,你需要将它添加到我们的分词器的字典中!
ik tokenizer 添加了自己的配置!
ik分词器自定义配置,我写了一篇博客:elasticsearch学习之三:elasticsearch-ik分词器的自定义配置分词内容
设置好后再次执行:
以后需要自己配置的分词可以在自己定义的dic文件中配置!五、数据操作1. 创建索引 创建索引方法1,简单创建索引
PUT/索引名称创建索引方式2、创建索引并添加数据,字段类型系统默认给出
该方法会直接创建索引名称、类型、id,并添加数据。
PUT /索引名/~类型名~/文档id
{请求体}
案件
PUT /test1/type1/1
{
"name": "冯安晨",
"age": 18
}
这样,index、type、id创建完成后,就添加了一条数据。
创建索引方法3、创建索引并指定字段类型
创建索引,指定类型名称,指定字段类型
PUT /test2
{
"mappings": {
"type2": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "long"
},
"birthday": {
"type": "date"
}
}
}
}
}
2. 字段类型摘要
那么上面的name字段就不需要指定类型了,毕竟我们的关系数据库需要指定类型!!
3. 查看规则信息
那就是看一下上面命令创建的细节
获取命令
GET /test1 : 查看索引信息
如果我们自己的文档字段没有指定,那么ES会给我们默认的配置字段类型!就是上面的test1索引,没有指定字段类型,所以ES默认指定类型。
4. 系统命令
通过elasticsearch命令查看ES的各种信息!通过
获取_猫/
获取大量关于ES的最新信息!
GET _cat/indices/?v:查看索引情况
其他命令。
5 添加数据
默认指定数据类型
PUT /fenganchen/user/1
{
"name": "冯凡利",
"age": 18,
"desc": "一顿操作猛如虎,一看工资2500",
"tags": ["技术宅", "温暖", "直男"]
}
6. 修改数据 PUT 修改(不推荐)
修改类似于add,但是这个修改类似于overwrite,如果缺少某个字段,则某个字段消失
查看 GET /fenganchen/user/1(如下所述)
修订
PUT /fenganchen/user/1
{
"name": "冯凡利123",
"age": 18,
"desc": "一顿操作猛如虎,一看工资2500",
"tags": ["技术宅", "温暖", "直男"]
}
_version 表示被修改的次数
查看确认
获取 /fenganchen/user/1
湾。_update 修改(推荐)修改
POST fenganchen/user/1/_update
{
"doc": {
"name": "冯凡利java"
}
}
2. 查看
7. 删除7. 简单查询 GET fenganchen/user/1
简单的条件查询
GET /fenganchen/user/_search?q=name:冯凡利 (报错,还未找到原因)
GET /fenganchen/user/_search?q=age:18
8.向复杂查询添加更多数据
PUT /fenganchen/user/2
{
"name": "张三",
"age": 17,
"desc": "法外狂徒张三",
"tags": ["技术宅", "温暖", "渣男"]
}
PUT /fenganchen/user/3
{
"name": "李四",
"age": 30,
"desc": "mmp 不知怎么形容了",
"tags": ["靓女", "旅游", "唱歌"]
}
查询关键字:查询
match关键字:match,这里有很多选项,比如:match_all:匹配所有,bool:返回一个布尔值,exists:存在等等。
GET fenganchen/user/_search
{
"query": {
"match": {
"name": "冯凡利"
}
}
}
3. 再添加一条数据,方便查询和测试:
PUT /fenganchen/user/4
{
"name": "冯凡利前端",
"age": 3,
"desc": "一顿操作猛如虎,一看工资2500",
"tags": ["技术宅", "温暖", "直男"]
}
再次查询:如下图
Hits:包括索引和文档信息、查询结果总数、查询到的具体文档
max_score:最大分数,是下面数据中最大的匹配分数值,也是最合适的
_score:可以用来判断谁更符合结果,每个数据都有这个属性
_source:数据对象信息关键字。
9 筛选结果
不想显示这么多字段,只想显示name和desc字段,可以使用数据对象信息关键字:_source来限制显示字段。
GET fenganchen/user/_search
{
"query": {
"match": {
"name": "冯凡利"
}
},
"_source": ["name", "desc"]
}
后面我们会用java来操作es,这里所有的方法和对象都是key:这个key也是hits、score等关键字。
10. 排序
GET fenganchen/user/_search
{
"query": {
"match": {
"name": "冯凡利"
}
},
"sort": [
{
"age": {
"order": "asc"
}
}
]
}
11.分页查询
GET fenganchen/user/_search
{
"query": {
"match": {
"name": "冯凡利"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 1
}
from:从第一条数据开始
size:返回多少条数据(单页数据)
数据下标还是从 0 开始,和所有学过的数据结构一样!
/搜索/{当前}/{页面大小}
12. 布尔查询必须(and),必须满足所有条件,类似于:where id=1 and name=xxx
GET fengfanli/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "冯凡利"
}
},
{
"match": {
"age": "18"
}
}
]
}
}
}
should(or),必须满足所有条件,类似于: where id=1 orname=xxx
GET fenganchen/user/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "冯凡利"
}
},
{
"match": {
"age": "18"
}
}
]
}
}
}
**must_not(not)**,必须满足所有条件,类似于: where id != 1
GET fenganchen/user/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"age": 3
}
}
]
}
}
}
13.过滤常见匹配查询
任何收录风范里字符串的东西都会被找到
GET fenganchen/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "冯凡利"
}
}
]
}
}
}
添加过滤器,过滤器
filter关键字过滤查询的数据。
GET fenganchen/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "冯凡利"
}
}
],
"filter": {
"range": {
"age": {
"gt": 3
}
}
}
}
}
}
上面的语句是对查询语句进行过滤,过滤掉年龄大于3的数据
14. 个空格匹配多个条件
匹配关键字空间
多个条件,以空格分隔
只要隐藏其中一个结果,就能查出
这时候通过_score分数就可以做出一个基本的判断了。
以下查询语句的含义:在tags字段中找到male和technical的数据并进行查询
GET fenganchen/user/_search
{
"query": {
"match": {
"tags": "男 技术"
}
}
}
15. 词条精确查询 i。术语分析
词条查询是通过倒排索引指定词条的过程直接搜索的!
关于分词:
ii. 两类文字关键词详解
分词器不能使用两种类型的文本关键字
文本类型:可分段
关键字类型:不能分段
首先创建索引并指定属性规则,如下:
一个。版本 6 创建索引并指定规则
elasticsearch 6.X必须指定创建索引的类型,feng_type是索引的类型名
```json
PUT testdb
{
"mappings": {
"feng_type": {
"properties": {
"name": {
"type": "text"
},
"desc": {
"type": "keyword"
}
}
}
}
}
```
湾。版本 7 创建索引并指定规则
elasticsearch 7.x 不需要指定类型来创建索引,因为版本7弃用了类型关键词(这里我就不演示了,我用的是6.4. 2 版本在这里。)
```json
PUT testdb
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"desc": {
"type": "keyword"
}
}
}
}
```
C。添加数据
```json
PUT testdb/feng_type/1
{
"name": "冯凡利java name",
"desc": "冯凡利java desc"
}
PUT testdb/feng_type/2
{
"name": "冯凡利java name",
"desc": "冯凡利java desc2"
}
```
添加文档 1
添加文档 2
d。elasticsearch-head的google插件,查看testdb索引数据
e. elasticsearch-head 的 Google 插件,参见 testdb 映射规则
索引情况,可以查看索引的设置详情,以及映射映射规则包括类型和属性。
可以看到,name 属性是 text 类型,而 desc 是关键字类型。
F。默认标记器测试:关键字
KeywordAnalyzer 将整个输入视为单个词汇单元,以促进特定类型文本的索引和检索。使用 关键词 标记器为邮政编码和地址等文本信息创建索引项非常方便。
使用默认的关键字tokenizer进行分词,(比如说ik tokenizer是中文tokenizer),这里可以看出没有分析
G。默认标记器测试:标准
英文的处理能力和StopAnalyzer一样,支持中文的方法是分词。它将词汇单元转换为小写并删除停用词和标点符号。
使用默认的标准分词器进行分词,见这里分析
H。term 准确查找文本类型
一世。term 查找确切的关键字类型
j. 总结 h 和 i 的检验
在 testdb 索引中:
名称字段是文本类型,
desc 字段是关键字类型。
但是,当 term 精确搜索它们时,它会发现:
在查找文本类型的名称字段时,只需收录它,即文本类型可以被分词器解释。在查找关键字类型的 desc 字段时,必须完全收录,即关键字类型将整个输入匹配为单个词法单元,由分词器解释。16. 多词精确匹配 a. 添加多数
PUT testdb/feng_type/3
{
"t1": "22",
"t2": "2020-4-6"
}
PUT testdb/feng_type/4
{
"t1": "33",
"t2": "2020-4-7"
}
湾。查看 elasticsearch-head 的谷歌插件,查看 testdb 索引数据和映射规则。索引数据
映射规则
C。词条精确查询
@>17. Highlight 高亮关键字:highlight
GET fenganchen/user/_search
{
"query": {
"match": {
"name": "冯凡利"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
自定义搜索突出显示
GET fenganchen/user/_search
{
"query": {
"match": {
"name": "冯凡利"
}
},
"highlight": {
"pre_tags": "<p class='key style='color:red'>",
"post_tags": "",
"fields": {
"name": {}
}
}
}
</p>
这些mysql也可以做,但是mysql的效率比较低
seq搜索引擎优化至少包括那几步?(本文主要分享&;全能选手&;召回表征算法实践)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-01-30 09:17
本文主要分享“全能型”召回表示算法的实践。首先简单介绍一下业务背景:
网易主要有NLP、搜索推荐、供应链三大方向。我们主要负责搜索推荐。搜索推荐与营销侧的业务场景密切相关,管理最大的流量入口进行严格的选择。我们团队的主要目标是优化转化率和GMV相关指标,具体业务是搜索、推荐、广告(包括内部库存广告和外部DPS广告)。
如图所示,在这些个性化场景中,就是我们拥有的能力矩阵。刚收到邀请的时候,想谈一下燕轩商业场景中个性化相关的事情,但是我们基本上已经做了2到3年的生意了。如果我们想在短时间内完成聊天,我们只能介绍我们做了什么。工作以及实现了什么商业价值。但是,每个人的业务场景都大相径庭。我们这边的最优实施方案未必是其他场景下的最优方案。听了大家的话,可能收获不大。与其这样,不如集中在一个小模块上详细讲,所以今天我就选择recall表示的部分,由此引出本次分享的主题:“全能玩家”
01
问题定义
1. 模型目标
首先说一下问题的定义,也就是模型要做的目标是什么?Embedding:这是一个将离散的 id 变量映射到低维密集向量的学习过程。使用离散id作为特征时,一般先进行one-hot编码,然后再映射成稠密向量。Embedding 的目标是在大数据中反映相关主题。通过Embedding向量表示学习到主体的向量信息,也可以通过向量度量公式来反映主体之间的相关性。比如右边的例子,红线代表 King 和 Man ,如果 King 和 Man 都训练了一个向量表示结果,我们希望 King 和 Man 的内积大于 Queen 和 Man 的内积,
2. 数据处理
实际上,Embedding 是一个非常通用的主题学习和表达模型。它广泛用于自然语言处理、搜索、推荐和图像。那么Embedding是如何在具体业务场景下对搜索推荐起到作用的呢?下图是业内非常经典的推荐数据处理阶段划分。从左到右是数据逐层递减的过程,依次是召回(Matching)、粗排名(Pre-Ranking)、细排名(Ranking)、Reranking。我们的召回表示模型的范围主要是召回和粗略排名两个阶段,在搜索推荐中起着基石的作用。
3. 模型能力
训练模型时,可以通过向量相似度来衡量受试者的相关性。下图显示了一些项目的表示。如果几件物品相似,它们的距离比较小,内积比较大,比如和相似的零食碗都是同一个品类的产品。如果我们只有一个向量表示模型,那么可以使用模型的Embedding进行recall,或者可以将两个item的embedding向量的内积作为粗排序的基础,这样recall和recall两种场景粗略的排序可以一次完成。但是,在大多数情况下,会有多个表示模型,每个表示模型都会被调用。在这种情况下,需要引入一个粗略的排序模型来对多个表示模型的召回结果进行合并和排序。用于合并的粗选能力可以与蒸馏模型进行策略性的结合,这里不做介绍。
02
模型值
为什么表示模型值得深入研究?
1. 应用场景广泛
接下来,我将介绍为什么表示模型值得深入做?它可以产生什么价值?问题的答案与文章的标题息息相关:Embedding是一个应用范围很广的全能者,可以最大化算法输出的价值。应用场景包括:
2. 工程解决方案成熟
Embedding矢量已经可用,需要矢量搜索引擎来推动矢量在线使用,具有在线响应能力。根据向量搜索引擎提供的接口,可以找到内积最大或与给定向量距离最近的TopN向量。第一个是Facebook早前提出的Faiss方案,第二个是Google提出的SCANN方案;这两种方案都非常好,可以大大降低工程门槛。
3. 技术飞速发展
向量表示是学术界的热点,并且不断创新,尤其是GCN(图卷积神经网络)和GNN(图神经网络)非常流行,学术界每年都会发表很多论文。与学术研究的快速发展相关的技术红利可以为业务带来增量价值。接下来从两个方向讲向量表示的模型,一个是序列模型SeqModel,一个是图网络模型,两者都可以解决向量表示的问题。在选择模型时,应该选择两种模型中的哪一种?这与产品数据密切相关。如果产品数据具有很强的时间相关性,那么使用序列模型的效果肯定不会差;如果产品数据的节点比较稀疏,则需要使用邻居节点进行信息协同建模。这时候,推荐尝试 GNN。图数据几乎可以收录在任何场景生成的数据关系中,所以GNN是通用的模型解决方案,具有很高的通用性,但并不意味着GNN在所有场景下都优于序列模型。方案比较。接下来,基于我们搜索推荐业务场景的总结,给大家分享一下序列模型和GNN模型的迭代。所以GNN是一种通用的模型解决方案,具有很高的通用性,但这并不意味着GNN在所有场景下都优于序列模型。方案比较。接下来,基于我们搜索推荐业务场景的总结,给大家分享一下序列模型和GNN模型的迭代。所以GNN是一种通用的模型解决方案,具有很高的通用性,但这并不意味着GNN在所有场景下都优于序列模型。方案比较。接下来,基于我们搜索推荐业务场景的总结,给大家分享一下序列模型和GNN模型的迭代。
03
迭代实现
1. 关注项目嵌入
艳选业务的用户数量远大于商品数量。由于用户数量众多,实验稀疏,User Embedding 并不是很有效。因此,我们在初始阶段专注于Item Embedding。商品数量少,落地成本低。,关联数据密集,表示效果较好。
① SeqModel优化
第一个模型是我们定制和优化的基于会话的嵌入模型。它的主要思想来自 Aribnb 的一篇 Embedding 论文(这篇论文写得非常好,建议大家学习一下)。该模型的主要思想是构造一个类似于word2vec的序列,重点关注向量在序列数据的上下文时间窗口中的相关性。图中每个圆圈代表一个项目,多个圆圈构成一个行为序列。行为序列来自用户在连续一段时间内的行为数据。传统的 word2vec 只关注上下文信息。这篇论文的核心思想是提出全局item,跳出了序列模型窗口的限制。全局item是指序列数据中的一些重要节点(图中实心节点),如用户的插件购买、支付、分享等行为。全局item打破了模型窗口的限制,使得item向量可以学习到一些高阶连接信息,大大提高了序列模型的表示效果。
在此之上,我们对损失函数做了一些优化,包括在batch中去除负采样和建立pair-wise loss的过程,可以大大提高训练速度;同时我们还引入了多层向量,也就是side-info嵌入的思想,不仅是在对item做向量表示的时候使用它的id类型的特征,还引入了产品属性等特征,类别、适用季节和适用组,进一步提高向量表示的效果,同时缓解新项目冷启动表征问题。
② GCN 定义
接下来说说学术界比较火的GCN/GNN模型。图神经网络一般有三个阶段的定义:
目前,很多关于 GNN 的论文都有关于这三个阶段的定义。图右侧是GCN的示意图。图中的公式对应了三个阶段,很巧妙的是,这个公式可以转化为矩阵运算形式,可以充分利用GPU的计算能力。但是这个矩阵的节点数是(#users+#items)×(#users+#items),而且规模大到行业很难落地。
③ GraphSage 可以登陆
GraphSage是一个基于采样的思想降低落地难度,用采样代替矩阵计算的过程。采样深度(一般深度不会超过2)对应迭代次数。多次迭代可以获得高层域信息进行信息协同建模,同时每次迭代的样本数可以调整。该模型最大的贡献在于提供了一种通用的Neighborhood Aggregation聚合方法,可以通过均值的方式进行聚合,也可以引入池化层,也可以引入LSTM进行序列聚合。
④ LightGCN的压缩数据尝试
GCN 需要很大的矩阵计算过程。与工程理念相比,两者的效果有何不同?是否可以通过减少现有数据来实现 GCN 与其他模型的对比?所以我们实现了一个LightGCN,主要参考了图中的两篇论文。两篇论文来自同一个团队。论文定制了信息的构建和聚合过程,可以捕获节点的高阶相关性,并对协作信号进行显式编码。一般GCN的网络深度不会超过2,而这里的LightGCN可以做到三层,其中的节点已经覆盖了用户和物品。在本文的最后,我们将比较所有的效果。在知识表达方面,这两篇论文写得都不错。您可以研究它们并更好地了解GCN。
2. 获取用户嵌入
我们在第一阶段获得了Item Embedding,如何从Item Embedding中获得User Embedding?主要有两种思路:策略法和模型法。
① 战略快速落地
该策略是一个可以快速实施的解决方案,是一个非常好的和稳定的基线。我们可以利用已知的物品隐向量和用户在会话中的交互行为序列,基于时间衰减、时间加权和注意力机制得到用户的向量表示。在相同的搜索场景下,也可以通过分词组合、次数权重、查询词的注意力权重得到查询词的向量表示。
② 经典 DNN
接下来是经典的模型DNN,直接通过模型得到用户的向量。参考图中YouTube上的这篇经典论文,模型本质上是一个有监督的NextItemPrediction训练过程,用户的Item会话数据,简单的平均聚合,用户特征作为深度模型的输入特征数据。输入特征数据逐层传播,最后一层得到用户向量。用户向量和项目向量做softmax完成一个概率分布预测,模型的loss也得到了。模型训练完成后,同时得到User和Item的向量表示。
③ 学习会话表示
当然我们要通过图模型得到用户的向量。用户的行为基于会话来表示。如果有方法可以直接将会话表示为向量,那么可以直接得到行为序列下的用户向量。下图中的论文通过学习会话向量的表示来解决这个问题。它也有GCN的三个阶段的定义。在定义过程中,还引入了门的参数来设置最终向量的表示过程。最有价值的一点是它进行会话表示学习。在训练过程中,每一个session都被视为一个子图,一个一个地训练,然后将局部向量(会话中的最后一个项目向量)添加到全局向量(会话中的其他项目向量)。注意力聚合后得到一个全局向量作为会话向量,最后用会话向量表示用户向量。该模型的效果在离线评估中更为突出。
④ 多用户向量
我们之前一直在用单个向量来表征用户,那么我们可以用多个用户向量来表征用户的兴趣吗?答案是肯定的,因为如果用户的兴趣比较广泛,使用一个向量来表示用户时会损失信息丰富度,使用多个向量来表示用户可能会更好。
第一个思路是聚类方法:首先对item K-means进行聚类,得到多个聚类,每个聚类都有一个向量表示。如果用户行为序列中的项目涉及多个聚类,则将属于同一聚类的向量聚合起来代表用户。聚合方法可以用簇向量计算权重并逐位相加。用户向量的数量等于序列中簇的数量。
第二个想法是 MIND:它使用胶囊网络来形成多个兴趣向量。结构中有一个多兴趣提取层,负责提取多个兴趣向量。图中,u1、u2是用户行为序列中的item,它们作为胶囊网络的输入,v1、v2是用户的多个兴趣向量,胶囊网络的输出. 同时,胶囊网络还支持动态路由,多次迭代自适应地迭代获得聚合权重。
3. 效果对比
接下来,我们对这些网络模型进行比较。比较指标是 HitRate 和 NDCG。我们采用 VecModel-Single(基于序列模型会话的嵌入模型)作为基线模型。
在我们的场景数据中,graphSAGE 作为 GCN 的工业实现指标并不突出,在 NDCG@30 上略超过基线模型。LightGCN通过减少数据来适应当前最大的锅,然后产生最大的蛋糕;LightGCN 使用矩阵来学习向量表示,效果相比基线模型并不是特别突出,只是在个别指标 HitRate@30 上有一些提升。YouTubeDNN 在 4 个指标上有明显提升。SR-GNN 直接表示会话的用户向量,通过模型参数学习得到用户向量。也是离线效果最好的机型。VecModel-Multi是基于序列模型,加入聚类用户多兴趣向量表示,MIND是基于胶囊网络的多兴趣向量模型;
左下图是不同用户行为分组的模型效果,X轴是用户行为数,Y轴是HitRate。一开始,用户在没有行为的情况下无法感知用户偏好,模型效果比较差(User Type Embedding实现了NIP)。当用户有1、2个行为时,性能指标大大提高。这也很容易理解,因为新用户在来到一个场景产生初始行为的时候兴趣更加集中,但是随着用户行为数量的增加,只使用向量模型进行召回和排序会减少指标,进而需要连接细化和重新排列模型,以进一步提高业务成果。右下图是HitRate@N中多个模型的效果,其中绿色曲线是使用该策略融合多个模型的结果后的表现。可以看出,只是简单的合并,相比其他单一模型有明显提升。. 以后也可以用粗排模型来合并各个表示模型的结果,效果应该会有所提高(用于合并的粗排模型还在进行中)。
04
业务落地
1. 异物是向量
接下来说说业务是如何实现的。异物是向量是 Facebook 提出的口号。如果我们有一套完整的向量系统,那么业务场景中的所有科目都可以向量化,然后就可以做U2I,I2I和Q2I的召回就很方便了。
2. 服务说明
该图是一个简单的服务图。整体是一个一体化的统一召回服务。核心向量表示服务具有表示用户和项目向量的能力。它可以使用 T+1 数据进行表示,也可以使用实时数据进行用户实时表示。利益代表。统一召回服务的输出经过提炼和重排后,可以应用于搜索、推荐、广告等业务场景。因此,召回服务是每一项业务的基石。召回效果的提升可以提升多场景的效果。投入产出比非常高的技术方向。
3. 应用效果
有了一切矢量化的基础后,下面是一些具体应用的落地效果。比如搜索中搜索词的推荐(U2Q)和搜索结果的语义匹配(Q2I),推荐中很多简单的场景可以直接使用基于向量的排序模型,效果也不错。内部第一焦点广告中还有图片的智能组合。通过 User2Topic,User2Item 选择用户最感兴趣的活跃产品呈现个性化的 Banner。
作者:潘胜义 网易严选算法专家,搜索推荐负责人。团队负责的业务包括搜索、推荐、内外广告、用户模型等。 查看全部
seq搜索引擎优化至少包括那几步?(本文主要分享&;全能选手&;召回表征算法实践)
本文主要分享“全能型”召回表示算法的实践。首先简单介绍一下业务背景:
网易主要有NLP、搜索推荐、供应链三大方向。我们主要负责搜索推荐。搜索推荐与营销侧的业务场景密切相关,管理最大的流量入口进行严格的选择。我们团队的主要目标是优化转化率和GMV相关指标,具体业务是搜索、推荐、广告(包括内部库存广告和外部DPS广告)。
如图所示,在这些个性化场景中,就是我们拥有的能力矩阵。刚收到邀请的时候,想谈一下燕轩商业场景中个性化相关的事情,但是我们基本上已经做了2到3年的生意了。如果我们想在短时间内完成聊天,我们只能介绍我们做了什么。工作以及实现了什么商业价值。但是,每个人的业务场景都大相径庭。我们这边的最优实施方案未必是其他场景下的最优方案。听了大家的话,可能收获不大。与其这样,不如集中在一个小模块上详细讲,所以今天我就选择recall表示的部分,由此引出本次分享的主题:“全能玩家”
01
问题定义
1. 模型目标
首先说一下问题的定义,也就是模型要做的目标是什么?Embedding:这是一个将离散的 id 变量映射到低维密集向量的学习过程。使用离散id作为特征时,一般先进行one-hot编码,然后再映射成稠密向量。Embedding 的目标是在大数据中反映相关主题。通过Embedding向量表示学习到主体的向量信息,也可以通过向量度量公式来反映主体之间的相关性。比如右边的例子,红线代表 King 和 Man ,如果 King 和 Man 都训练了一个向量表示结果,我们希望 King 和 Man 的内积大于 Queen 和 Man 的内积,
2. 数据处理
实际上,Embedding 是一个非常通用的主题学习和表达模型。它广泛用于自然语言处理、搜索、推荐和图像。那么Embedding是如何在具体业务场景下对搜索推荐起到作用的呢?下图是业内非常经典的推荐数据处理阶段划分。从左到右是数据逐层递减的过程,依次是召回(Matching)、粗排名(Pre-Ranking)、细排名(Ranking)、Reranking。我们的召回表示模型的范围主要是召回和粗略排名两个阶段,在搜索推荐中起着基石的作用。
3. 模型能力
训练模型时,可以通过向量相似度来衡量受试者的相关性。下图显示了一些项目的表示。如果几件物品相似,它们的距离比较小,内积比较大,比如和相似的零食碗都是同一个品类的产品。如果我们只有一个向量表示模型,那么可以使用模型的Embedding进行recall,或者可以将两个item的embedding向量的内积作为粗排序的基础,这样recall和recall两种场景粗略的排序可以一次完成。但是,在大多数情况下,会有多个表示模型,每个表示模型都会被调用。在这种情况下,需要引入一个粗略的排序模型来对多个表示模型的召回结果进行合并和排序。用于合并的粗选能力可以与蒸馏模型进行策略性的结合,这里不做介绍。
02
模型值
为什么表示模型值得深入研究?
1. 应用场景广泛
接下来,我将介绍为什么表示模型值得深入做?它可以产生什么价值?问题的答案与文章的标题息息相关:Embedding是一个应用范围很广的全能者,可以最大化算法输出的价值。应用场景包括:
2. 工程解决方案成熟
Embedding矢量已经可用,需要矢量搜索引擎来推动矢量在线使用,具有在线响应能力。根据向量搜索引擎提供的接口,可以找到内积最大或与给定向量距离最近的TopN向量。第一个是Facebook早前提出的Faiss方案,第二个是Google提出的SCANN方案;这两种方案都非常好,可以大大降低工程门槛。
3. 技术飞速发展
向量表示是学术界的热点,并且不断创新,尤其是GCN(图卷积神经网络)和GNN(图神经网络)非常流行,学术界每年都会发表很多论文。与学术研究的快速发展相关的技术红利可以为业务带来增量价值。接下来从两个方向讲向量表示的模型,一个是序列模型SeqModel,一个是图网络模型,两者都可以解决向量表示的问题。在选择模型时,应该选择两种模型中的哪一种?这与产品数据密切相关。如果产品数据具有很强的时间相关性,那么使用序列模型的效果肯定不会差;如果产品数据的节点比较稀疏,则需要使用邻居节点进行信息协同建模。这时候,推荐尝试 GNN。图数据几乎可以收录在任何场景生成的数据关系中,所以GNN是通用的模型解决方案,具有很高的通用性,但并不意味着GNN在所有场景下都优于序列模型。方案比较。接下来,基于我们搜索推荐业务场景的总结,给大家分享一下序列模型和GNN模型的迭代。所以GNN是一种通用的模型解决方案,具有很高的通用性,但这并不意味着GNN在所有场景下都优于序列模型。方案比较。接下来,基于我们搜索推荐业务场景的总结,给大家分享一下序列模型和GNN模型的迭代。所以GNN是一种通用的模型解决方案,具有很高的通用性,但这并不意味着GNN在所有场景下都优于序列模型。方案比较。接下来,基于我们搜索推荐业务场景的总结,给大家分享一下序列模型和GNN模型的迭代。
03
迭代实现
1. 关注项目嵌入
艳选业务的用户数量远大于商品数量。由于用户数量众多,实验稀疏,User Embedding 并不是很有效。因此,我们在初始阶段专注于Item Embedding。商品数量少,落地成本低。,关联数据密集,表示效果较好。
① SeqModel优化
第一个模型是我们定制和优化的基于会话的嵌入模型。它的主要思想来自 Aribnb 的一篇 Embedding 论文(这篇论文写得非常好,建议大家学习一下)。该模型的主要思想是构造一个类似于word2vec的序列,重点关注向量在序列数据的上下文时间窗口中的相关性。图中每个圆圈代表一个项目,多个圆圈构成一个行为序列。行为序列来自用户在连续一段时间内的行为数据。传统的 word2vec 只关注上下文信息。这篇论文的核心思想是提出全局item,跳出了序列模型窗口的限制。全局item是指序列数据中的一些重要节点(图中实心节点),如用户的插件购买、支付、分享等行为。全局item打破了模型窗口的限制,使得item向量可以学习到一些高阶连接信息,大大提高了序列模型的表示效果。
在此之上,我们对损失函数做了一些优化,包括在batch中去除负采样和建立pair-wise loss的过程,可以大大提高训练速度;同时我们还引入了多层向量,也就是side-info嵌入的思想,不仅是在对item做向量表示的时候使用它的id类型的特征,还引入了产品属性等特征,类别、适用季节和适用组,进一步提高向量表示的效果,同时缓解新项目冷启动表征问题。
② GCN 定义
接下来说说学术界比较火的GCN/GNN模型。图神经网络一般有三个阶段的定义:
目前,很多关于 GNN 的论文都有关于这三个阶段的定义。图右侧是GCN的示意图。图中的公式对应了三个阶段,很巧妙的是,这个公式可以转化为矩阵运算形式,可以充分利用GPU的计算能力。但是这个矩阵的节点数是(#users+#items)×(#users+#items),而且规模大到行业很难落地。
③ GraphSage 可以登陆
GraphSage是一个基于采样的思想降低落地难度,用采样代替矩阵计算的过程。采样深度(一般深度不会超过2)对应迭代次数。多次迭代可以获得高层域信息进行信息协同建模,同时每次迭代的样本数可以调整。该模型最大的贡献在于提供了一种通用的Neighborhood Aggregation聚合方法,可以通过均值的方式进行聚合,也可以引入池化层,也可以引入LSTM进行序列聚合。
④ LightGCN的压缩数据尝试
GCN 需要很大的矩阵计算过程。与工程理念相比,两者的效果有何不同?是否可以通过减少现有数据来实现 GCN 与其他模型的对比?所以我们实现了一个LightGCN,主要参考了图中的两篇论文。两篇论文来自同一个团队。论文定制了信息的构建和聚合过程,可以捕获节点的高阶相关性,并对协作信号进行显式编码。一般GCN的网络深度不会超过2,而这里的LightGCN可以做到三层,其中的节点已经覆盖了用户和物品。在本文的最后,我们将比较所有的效果。在知识表达方面,这两篇论文写得都不错。您可以研究它们并更好地了解GCN。
2. 获取用户嵌入
我们在第一阶段获得了Item Embedding,如何从Item Embedding中获得User Embedding?主要有两种思路:策略法和模型法。
① 战略快速落地
该策略是一个可以快速实施的解决方案,是一个非常好的和稳定的基线。我们可以利用已知的物品隐向量和用户在会话中的交互行为序列,基于时间衰减、时间加权和注意力机制得到用户的向量表示。在相同的搜索场景下,也可以通过分词组合、次数权重、查询词的注意力权重得到查询词的向量表示。
② 经典 DNN
接下来是经典的模型DNN,直接通过模型得到用户的向量。参考图中YouTube上的这篇经典论文,模型本质上是一个有监督的NextItemPrediction训练过程,用户的Item会话数据,简单的平均聚合,用户特征作为深度模型的输入特征数据。输入特征数据逐层传播,最后一层得到用户向量。用户向量和项目向量做softmax完成一个概率分布预测,模型的loss也得到了。模型训练完成后,同时得到User和Item的向量表示。
③ 学习会话表示
当然我们要通过图模型得到用户的向量。用户的行为基于会话来表示。如果有方法可以直接将会话表示为向量,那么可以直接得到行为序列下的用户向量。下图中的论文通过学习会话向量的表示来解决这个问题。它也有GCN的三个阶段的定义。在定义过程中,还引入了门的参数来设置最终向量的表示过程。最有价值的一点是它进行会话表示学习。在训练过程中,每一个session都被视为一个子图,一个一个地训练,然后将局部向量(会话中的最后一个项目向量)添加到全局向量(会话中的其他项目向量)。注意力聚合后得到一个全局向量作为会话向量,最后用会话向量表示用户向量。该模型的效果在离线评估中更为突出。
④ 多用户向量
我们之前一直在用单个向量来表征用户,那么我们可以用多个用户向量来表征用户的兴趣吗?答案是肯定的,因为如果用户的兴趣比较广泛,使用一个向量来表示用户时会损失信息丰富度,使用多个向量来表示用户可能会更好。
第一个思路是聚类方法:首先对item K-means进行聚类,得到多个聚类,每个聚类都有一个向量表示。如果用户行为序列中的项目涉及多个聚类,则将属于同一聚类的向量聚合起来代表用户。聚合方法可以用簇向量计算权重并逐位相加。用户向量的数量等于序列中簇的数量。
第二个想法是 MIND:它使用胶囊网络来形成多个兴趣向量。结构中有一个多兴趣提取层,负责提取多个兴趣向量。图中,u1、u2是用户行为序列中的item,它们作为胶囊网络的输入,v1、v2是用户的多个兴趣向量,胶囊网络的输出. 同时,胶囊网络还支持动态路由,多次迭代自适应地迭代获得聚合权重。
3. 效果对比
接下来,我们对这些网络模型进行比较。比较指标是 HitRate 和 NDCG。我们采用 VecModel-Single(基于序列模型会话的嵌入模型)作为基线模型。
在我们的场景数据中,graphSAGE 作为 GCN 的工业实现指标并不突出,在 NDCG@30 上略超过基线模型。LightGCN通过减少数据来适应当前最大的锅,然后产生最大的蛋糕;LightGCN 使用矩阵来学习向量表示,效果相比基线模型并不是特别突出,只是在个别指标 HitRate@30 上有一些提升。YouTubeDNN 在 4 个指标上有明显提升。SR-GNN 直接表示会话的用户向量,通过模型参数学习得到用户向量。也是离线效果最好的机型。VecModel-Multi是基于序列模型,加入聚类用户多兴趣向量表示,MIND是基于胶囊网络的多兴趣向量模型;
左下图是不同用户行为分组的模型效果,X轴是用户行为数,Y轴是HitRate。一开始,用户在没有行为的情况下无法感知用户偏好,模型效果比较差(User Type Embedding实现了NIP)。当用户有1、2个行为时,性能指标大大提高。这也很容易理解,因为新用户在来到一个场景产生初始行为的时候兴趣更加集中,但是随着用户行为数量的增加,只使用向量模型进行召回和排序会减少指标,进而需要连接细化和重新排列模型,以进一步提高业务成果。右下图是HitRate@N中多个模型的效果,其中绿色曲线是使用该策略融合多个模型的结果后的表现。可以看出,只是简单的合并,相比其他单一模型有明显提升。. 以后也可以用粗排模型来合并各个表示模型的结果,效果应该会有所提高(用于合并的粗排模型还在进行中)。
04
业务落地
1. 异物是向量
接下来说说业务是如何实现的。异物是向量是 Facebook 提出的口号。如果我们有一套完整的向量系统,那么业务场景中的所有科目都可以向量化,然后就可以做U2I,I2I和Q2I的召回就很方便了。
2. 服务说明
该图是一个简单的服务图。整体是一个一体化的统一召回服务。核心向量表示服务具有表示用户和项目向量的能力。它可以使用 T+1 数据进行表示,也可以使用实时数据进行用户实时表示。利益代表。统一召回服务的输出经过提炼和重排后,可以应用于搜索、推荐、广告等业务场景。因此,召回服务是每一项业务的基石。召回效果的提升可以提升多场景的效果。投入产出比非常高的技术方向。
3. 应用效果
有了一切矢量化的基础后,下面是一些具体应用的落地效果。比如搜索中搜索词的推荐(U2Q)和搜索结果的语义匹配(Q2I),推荐中很多简单的场景可以直接使用基于向量的排序模型,效果也不错。内部第一焦点广告中还有图片的智能组合。通过 User2Topic,User2Item 选择用户最感兴趣的活跃产品呈现个性化的 Banner。
作者:潘胜义 网易严选算法专家,搜索推荐负责人。团队负责的业务包括搜索、推荐、内外广告、用户模型等。
seq搜索引擎优化至少包括那几步?(逻辑计划优化(LogicalLogical)阶段把标准的基于规则(Rule-based)的优化策略应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-01-30 09:16
逻辑优化阶段将标准的基于规则的优化策略应用于已分析的已解决逻辑计划。
优化规则的分类
逻辑计划的默认优化规则集在 Optimizer#defaultBatches 变量中定义。与逻辑计划的分析规则一样,逻辑计划的优化规则也是以规则集(Batch对象)的形式组织起来的,每个规则集中收录多个优化规则。
规则集定义及实现代码如下(有删减):
def defaultBatches: Seq[Batch] = {
...
Batch("Union", Once, CombineUnions) ::
Batch("LocalRelation early", fixedPoint, ...) ::
Batch("Pullup Correlated Expressions", Once, ...) ::
Batch("Subquery", Once, OptimizeSubqueries) ::
Batch("Replace Operators", fixedPoint,...) ::
Batch("Aggregate", fixedPoint, ...) :: Nil ++) :+
Batch("Join Reorder", Once, ...) :+
Batch("Remove Redundant Sorts", Once, ...) :+
Batch("Decimal Optimizations", fixedPoint, ...) :+
...
由于优化规则集数量众多,在某些情况下并非所有规则集都需要使用。为了让用户排除一些不必要的规则集,Spark SQL 增加了一个配置项:spark.sql.optimizer.excludedRules,默认为null。该配置项可用于配置要排除的优化规则名称列表,以逗号分隔。这些规则存储在 excludeRules 变量中。
排除优化规则的选项为用户提供了一些控制权,但对于 Spark SQL,一些优化规则是必需的,不能删除。因此,Spark SQL 在优化器中定义了另一个变量:nonExcludableRules,用于保存必须保留的优化规则。其代码实现(有删减)如下:
def nonExcludableRules: Seq[String] =
EliminateDistinct.ruleName ::
EliminateSubqueryAliases.ruleName ::
EliminateView.ruleName ::
ReplaceExpressions.ruleName ::
ComputeCurrentTime.ruleName ::
...
因此,最终使用的规则集是:
(defaultBatches - (excludedRules - nonExcludableRules))
// 也就是
默认规则集 -(排除规则集 - 保留规则集)
可以理解,原则上是默认规则集减去用户配置的排除规则集,但系统保留的规则集不能排除,所以必须从用户配置的列表中减去。换句话说,即使用户配置了要排除的规则集列表,如果它们在 nonExcludableRules(系统保留规则集)中,它们也不会被排除。
运营优化规则集
在优化规则集中,有一大类:操作优化规则集。操作优化规则集定义了操作的各种优化,是我们在查看逻辑计划时经常可以看到的非常重要的优化规则。操作优化规则集包括:
优化器:优化器
Optimizer 类对象实现逻辑计划规则的优化。Optimizer 是一个抽象父类,只有一个实现类:SparkOptimizer。Optimizer类继承了RuleExecutor,它们之间的关系如下:
RuleExecutor
|
Optimizer
|
SparkOptimizer
各种逻辑计划的优化规则集定义在抽象父类Optimizer中,实现类可以直接使用这些规则。
执行逻辑计划优化
在前面对文章的分析中,执行逻辑计划优化的函数调用如下:
// 2.对分析后的逻辑计划进行优化,得到优化后的逻辑计划
lazy val optimizedPlan: LogicalPlan = sparkSession.sessionState.optimizer.execute(withCachedData)
这个函数最终调用了父类的execute函数,也就是RuleExecutor中定义的execute函数。该功能的实现逻辑在《Spark SQL实现原理——逻辑计划分析的实现》一文中已有介绍。大致思路是依次遍历逻辑计划树的各个节点,根据优化规则集和执行策略对逻辑计划树的各个节点进行处理,直到逻辑计划树没有变化或者执行阈值达到到达。具体实现逻辑如下:
1. 依次遍历规则集列表:Optimizer#batches中的每个规则集(Batch);
2. 依次遍历规则集中的每条规则(Rule),并使用每条规则处理逻辑计划,将每条处理结果传递给下一条处理规则。
3.当一个规则集中的所有规则都被遍历(使用)后,会做出如下判断:
1)检查是否达到执行策略的阈值(迭代次数)。如果大于等于阈值,则不会遍历执行当前规则集。
2)检查使用该规则集前后的逻辑计划是否相等。如果相等,则表示不需要执行当前规则集。
如果满足1)和2)中的任何一个,则跳到4执行,否则继续使用当前规则集。
4.下一个规则集的每一个规则都被遍历使用,并按照步骤3的逻辑进行处理。
如何编写优化规则
除了 Spark SQL 自带的各种逻辑计划优化规则集外,您还可以编写自己的优化规则。《Spark SQL:Spark 中的关系数据处理》一文中介绍了自定义优化规则。
这条规则的目的是:在Spark SQL中添加一个固定精度的DECIMAL类型时,想在一个小精度的DECIMAL上优化求和或平均等聚合操作;用 12 行代码编写一个规则,用 SUM 和 AVG 表示 在公式中找到这样的小数,将它们转换为未缩放的 64 位 LONG,将它们聚合,然后将结果转换回 DECIMAL 类型。
object DecimalAggregates extends Rule[LogicalPlan] {
/** Maximum number of decimal digits in a Long */
val MAX_LONG_DIGITS = 18
def apply(plan: LogicalPlan): LogicalPlan = {
plan transformAllExpressions {
case Sum(e @ DecimalType.Expression(prec , scale))
if prec + 10
MakeDecimal(Sum(LongValue(e)), prec + 10, scale)
}
}
能够在规则中使用任意 Scala 代码使得表达这些超越子树结构模式匹配的优化变得容易。可见,编写逻辑计划优化规则并不难,只要遵循以下接口的编写规范即可。
object YourName extends Rule[LogicalPlan] {
// ...
def apply(plan: LogicalPlan): LogicalPlan = {
plan transformAllExpressions {
case xx1(...) if ... => // xx1是你想优化的逻辑计划节点对象
// ...
xxx2(...) // 优化后的目标逻辑计划节点对象
}
}
但是,要编写逻辑计划优化规则,首先需要熟悉现有的优化规则和每个逻辑计划节点,然后根据需求抽象出需要优化的逻辑。
逻辑计划优化视图
查看优化后的逻辑计划有多种方式,以scala终端为例。
(1)通过解释查看(true)
通过explain(true)可以看到从整个逻辑计划到物理计划的全过程:
scala> var ds1 = spark.range(100)
ds1: org.apache.spark.sql.Dataset[Long] = [id: bigint]
scala> var ds2 = spark.range(200)
ds2: org.apache.spark.sql.Dataset[Long] = [id: bigint]
scala> ds1.filter("id>10").union(ds2).filter("id>20").select("id").explain(true)
== Parsed Logical Plan ==
'Project [unresolvedalias('id, None)]
+- Filter (id#0L > cast(20 as bigint))
+- Union
:- Filter (id#0L > cast(10 as bigint))
: +- Range (0, 100, step=1, splits=Some(1))
+- Range (0, 200, step=1, splits=Some(1))
== Analyzed Logical Plan ==
id: bigint
Project [id#0L]
+- Filter (id#0L > cast(20 as bigint))
+- Union
:- Filter (id#0L > cast(10 as bigint))
: +- Range (0, 100, step=1, splits=Some(1))
+- Range (0, 200, step=1, splits=Some(1))
== Optimized Logical Plan ==
Union
:- Filter ((id#0L > 10) && (id#0L > 20))
: +- Range (0, 100, step=1, splits=Some(1))
+- Filter (id#2L > 20)
+- Range (0, 200, step=1, splits=Some(1))
//...
另外,可以通过以下命令查看逻辑计划节点和参数:
scala> ds1.filter("id>10").union(ds2).filter("id>20").select("id").queryExecution.optimizedPlan.prettyJson
(2)通过queryExecution对象查看
通过queryExecution,可以单独查看优化后的逻辑计划。
scala> ds1.filter("id>10").union(ds2).filter("id>20").select("id").queryExecution.optimizedPlan
res9: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
Union
:- Filter ((id#0L > 10) && (id#0L > 20))
: +- Range (0, 100, step=1, splits=Some(1))
+- Filter (id#2L > 20)
+- Range (0, 200, step=1, splits=Some(1))
概括
本文分析了逻辑计划优化的总体实现过程,并简要介绍了实现自己的优化规则的优化规则。最后介绍了如何查看逻辑计划优化的结果。逻辑计划的优化可以说是 Catalyst 项目的核心。接下来,我们将通过一系列文章来介绍各种逻辑计划优化规则的使用和实现原理。 查看全部
seq搜索引擎优化至少包括那几步?(逻辑计划优化(LogicalLogical)阶段把标准的基于规则(Rule-based)的优化策略应用)
逻辑优化阶段将标准的基于规则的优化策略应用于已分析的已解决逻辑计划。
优化规则的分类
逻辑计划的默认优化规则集在 Optimizer#defaultBatches 变量中定义。与逻辑计划的分析规则一样,逻辑计划的优化规则也是以规则集(Batch对象)的形式组织起来的,每个规则集中收录多个优化规则。
规则集定义及实现代码如下(有删减):
def defaultBatches: Seq[Batch] = {
...
Batch("Union", Once, CombineUnions) ::
Batch("LocalRelation early", fixedPoint, ...) ::
Batch("Pullup Correlated Expressions", Once, ...) ::
Batch("Subquery", Once, OptimizeSubqueries) ::
Batch("Replace Operators", fixedPoint,...) ::
Batch("Aggregate", fixedPoint, ...) :: Nil ++) :+
Batch("Join Reorder", Once, ...) :+
Batch("Remove Redundant Sorts", Once, ...) :+
Batch("Decimal Optimizations", fixedPoint, ...) :+
...
由于优化规则集数量众多,在某些情况下并非所有规则集都需要使用。为了让用户排除一些不必要的规则集,Spark SQL 增加了一个配置项:spark.sql.optimizer.excludedRules,默认为null。该配置项可用于配置要排除的优化规则名称列表,以逗号分隔。这些规则存储在 excludeRules 变量中。
排除优化规则的选项为用户提供了一些控制权,但对于 Spark SQL,一些优化规则是必需的,不能删除。因此,Spark SQL 在优化器中定义了另一个变量:nonExcludableRules,用于保存必须保留的优化规则。其代码实现(有删减)如下:
def nonExcludableRules: Seq[String] =
EliminateDistinct.ruleName ::
EliminateSubqueryAliases.ruleName ::
EliminateView.ruleName ::
ReplaceExpressions.ruleName ::
ComputeCurrentTime.ruleName ::
...
因此,最终使用的规则集是:
(defaultBatches - (excludedRules - nonExcludableRules))
// 也就是
默认规则集 -(排除规则集 - 保留规则集)
可以理解,原则上是默认规则集减去用户配置的排除规则集,但系统保留的规则集不能排除,所以必须从用户配置的列表中减去。换句话说,即使用户配置了要排除的规则集列表,如果它们在 nonExcludableRules(系统保留规则集)中,它们也不会被排除。
运营优化规则集
在优化规则集中,有一大类:操作优化规则集。操作优化规则集定义了操作的各种优化,是我们在查看逻辑计划时经常可以看到的非常重要的优化规则。操作优化规则集包括:
优化器:优化器
Optimizer 类对象实现逻辑计划规则的优化。Optimizer 是一个抽象父类,只有一个实现类:SparkOptimizer。Optimizer类继承了RuleExecutor,它们之间的关系如下:
RuleExecutor
|
Optimizer
|
SparkOptimizer
各种逻辑计划的优化规则集定义在抽象父类Optimizer中,实现类可以直接使用这些规则。
执行逻辑计划优化
在前面对文章的分析中,执行逻辑计划优化的函数调用如下:
// 2.对分析后的逻辑计划进行优化,得到优化后的逻辑计划
lazy val optimizedPlan: LogicalPlan = sparkSession.sessionState.optimizer.execute(withCachedData)
这个函数最终调用了父类的execute函数,也就是RuleExecutor中定义的execute函数。该功能的实现逻辑在《Spark SQL实现原理——逻辑计划分析的实现》一文中已有介绍。大致思路是依次遍历逻辑计划树的各个节点,根据优化规则集和执行策略对逻辑计划树的各个节点进行处理,直到逻辑计划树没有变化或者执行阈值达到到达。具体实现逻辑如下:
1. 依次遍历规则集列表:Optimizer#batches中的每个规则集(Batch);
2. 依次遍历规则集中的每条规则(Rule),并使用每条规则处理逻辑计划,将每条处理结果传递给下一条处理规则。
3.当一个规则集中的所有规则都被遍历(使用)后,会做出如下判断:
1)检查是否达到执行策略的阈值(迭代次数)。如果大于等于阈值,则不会遍历执行当前规则集。
2)检查使用该规则集前后的逻辑计划是否相等。如果相等,则表示不需要执行当前规则集。
如果满足1)和2)中的任何一个,则跳到4执行,否则继续使用当前规则集。
4.下一个规则集的每一个规则都被遍历使用,并按照步骤3的逻辑进行处理。
如何编写优化规则
除了 Spark SQL 自带的各种逻辑计划优化规则集外,您还可以编写自己的优化规则。《Spark SQL:Spark 中的关系数据处理》一文中介绍了自定义优化规则。
这条规则的目的是:在Spark SQL中添加一个固定精度的DECIMAL类型时,想在一个小精度的DECIMAL上优化求和或平均等聚合操作;用 12 行代码编写一个规则,用 SUM 和 AVG 表示 在公式中找到这样的小数,将它们转换为未缩放的 64 位 LONG,将它们聚合,然后将结果转换回 DECIMAL 类型。
object DecimalAggregates extends Rule[LogicalPlan] {
/** Maximum number of decimal digits in a Long */
val MAX_LONG_DIGITS = 18
def apply(plan: LogicalPlan): LogicalPlan = {
plan transformAllExpressions {
case Sum(e @ DecimalType.Expression(prec , scale))
if prec + 10
MakeDecimal(Sum(LongValue(e)), prec + 10, scale)
}
}
能够在规则中使用任意 Scala 代码使得表达这些超越子树结构模式匹配的优化变得容易。可见,编写逻辑计划优化规则并不难,只要遵循以下接口的编写规范即可。
object YourName extends Rule[LogicalPlan] {
// ...
def apply(plan: LogicalPlan): LogicalPlan = {
plan transformAllExpressions {
case xx1(...) if ... => // xx1是你想优化的逻辑计划节点对象
// ...
xxx2(...) // 优化后的目标逻辑计划节点对象
}
}
但是,要编写逻辑计划优化规则,首先需要熟悉现有的优化规则和每个逻辑计划节点,然后根据需求抽象出需要优化的逻辑。
逻辑计划优化视图
查看优化后的逻辑计划有多种方式,以scala终端为例。
(1)通过解释查看(true)
通过explain(true)可以看到从整个逻辑计划到物理计划的全过程:
scala> var ds1 = spark.range(100)
ds1: org.apache.spark.sql.Dataset[Long] = [id: bigint]
scala> var ds2 = spark.range(200)
ds2: org.apache.spark.sql.Dataset[Long] = [id: bigint]
scala> ds1.filter("id>10").union(ds2).filter("id>20").select("id").explain(true)
== Parsed Logical Plan ==
'Project [unresolvedalias('id, None)]
+- Filter (id#0L > cast(20 as bigint))
+- Union
:- Filter (id#0L > cast(10 as bigint))
: +- Range (0, 100, step=1, splits=Some(1))
+- Range (0, 200, step=1, splits=Some(1))
== Analyzed Logical Plan ==
id: bigint
Project [id#0L]
+- Filter (id#0L > cast(20 as bigint))
+- Union
:- Filter (id#0L > cast(10 as bigint))
: +- Range (0, 100, step=1, splits=Some(1))
+- Range (0, 200, step=1, splits=Some(1))
== Optimized Logical Plan ==
Union
:- Filter ((id#0L > 10) && (id#0L > 20))
: +- Range (0, 100, step=1, splits=Some(1))
+- Filter (id#2L > 20)
+- Range (0, 200, step=1, splits=Some(1))
//...
另外,可以通过以下命令查看逻辑计划节点和参数:
scala> ds1.filter("id>10").union(ds2).filter("id>20").select("id").queryExecution.optimizedPlan.prettyJson
(2)通过queryExecution对象查看
通过queryExecution,可以单独查看优化后的逻辑计划。
scala> ds1.filter("id>10").union(ds2).filter("id>20").select("id").queryExecution.optimizedPlan
res9: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
Union
:- Filter ((id#0L > 10) && (id#0L > 20))
: +- Range (0, 100, step=1, splits=Some(1))
+- Filter (id#2L > 20)
+- Range (0, 200, step=1, splits=Some(1))
概括
本文分析了逻辑计划优化的总体实现过程,并简要介绍了实现自己的优化规则的优化规则。最后介绍了如何查看逻辑计划优化的结果。逻辑计划的优化可以说是 Catalyst 项目的核心。接下来,我们将通过一系列文章来介绍各种逻辑计划优化规则的使用和实现原理。
seq搜索引擎优化至少包括那几步?(spark集群部署大数据JUC面试题集群集群的数据生态体系)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-30 09:15
问题
当使用这个partition BETWEEN 'start' AND 'end' OR (partition = 'other' AND column 'value') 条件查询spark-sql中的数据时,程序会拉取整个分区中的数据。
解决方案
前面我们提到在使用spark-sql读取hive分区表的时候,使用了PredicateHelper中的方法,但是增加了一个新的splitPredicates方法,因为PredicateHelper只有splitConjunctivePredicates和splitDisjunctivePredicates方法。
protected def splitConjunctivePredicates(condition: Expression): Seq[Expression] = {
condition match {
case And(cond1, cond2) =>
splitConjunctivePredicates(cond1) ++ splitConjunctivePredicates(cond2)
case other => other :: Nil
}
}
protected def splitDisjunctivePredicates(condition: Expression): Seq[Expression] = {
condition match {
case Or(cond1, cond2) =>
splitDisjunctivePredicates(cond1) ++ splitDisjunctivePredicates(cond2)
case other => other :: Nil
}
}
在 PhysicalOperation 类中,仅对 Filter 进行如下处理:
可以看出,解析Filter语法树时只调用了splitConjunctivePredicates方法,即只处理AND表达式;
PruneFileSourcePartitions类匹配PhysicalOperation,生成的过滤器就是上面collectProjectsAndFilters中Filter处理的结果;
private[sql] object PruneFileSourcePartitions extends Rule[LogicalPlan] {
override def apply(plan: LogicalPlan): LogicalPlan = plan transformDown {
case op @ PhysicalOperation(projects, filters,
logicalRelation @
LogicalRelation(fsRelation @
HadoopFsRelation(catalogFileIndex: CatalogFileIndex, partitionSchema, _, _, _, _), _, _))
if filters.nonEmpty && fsRelation.partitionSchemaOption.isDefined =>
以下是 PruneFileSourcePartitions 中的原创代码。将这部分代码替换为指定分区数的过滤方法中获取分区表达式的代码即可轻松解决上述问题。
val sparkSession = fsRelation.sparkSession
val partitionColumns =
logicalRelation.resolve(
partitionSchema, sparkSession.sessionState.analyzer.resolver)
val partitionSet = AttributeSet(partitionColumns)
val partitionKeyFilters =
ExpressionSet(normalizedFilters.filter(_.references.subsetOf(partitionSet)))
修改后的代码如下:
val partitionColumns =
logicalRelation.resolve(
partitionSchema,
sparkSession.sessionState.analyzer.resolver)
val partitionSet = AttributeSet(partitionColumns)
val partitionKeyFilters = splitPredicates(normalizedFilters.reduceLeft(And),parti
大数据与云计算的关系
大数据技术生态系统
大数据的切片机制有哪些?
大数据的Kafka集群部署
大数据JUC面试题 查看全部
seq搜索引擎优化至少包括那几步?(spark集群部署大数据JUC面试题集群集群的数据生态体系)
问题
当使用这个partition BETWEEN 'start' AND 'end' OR (partition = 'other' AND column 'value') 条件查询spark-sql中的数据时,程序会拉取整个分区中的数据。
解决方案
前面我们提到在使用spark-sql读取hive分区表的时候,使用了PredicateHelper中的方法,但是增加了一个新的splitPredicates方法,因为PredicateHelper只有splitConjunctivePredicates和splitDisjunctivePredicates方法。
protected def splitConjunctivePredicates(condition: Expression): Seq[Expression] = {
condition match {
case And(cond1, cond2) =>
splitConjunctivePredicates(cond1) ++ splitConjunctivePredicates(cond2)
case other => other :: Nil
}
}
protected def splitDisjunctivePredicates(condition: Expression): Seq[Expression] = {
condition match {
case Or(cond1, cond2) =>
splitDisjunctivePredicates(cond1) ++ splitDisjunctivePredicates(cond2)
case other => other :: Nil
}
}
在 PhysicalOperation 类中,仅对 Filter 进行如下处理:
可以看出,解析Filter语法树时只调用了splitConjunctivePredicates方法,即只处理AND表达式;
PruneFileSourcePartitions类匹配PhysicalOperation,生成的过滤器就是上面collectProjectsAndFilters中Filter处理的结果;
private[sql] object PruneFileSourcePartitions extends Rule[LogicalPlan] {
override def apply(plan: LogicalPlan): LogicalPlan = plan transformDown {
case op @ PhysicalOperation(projects, filters,
logicalRelation @
LogicalRelation(fsRelation @
HadoopFsRelation(catalogFileIndex: CatalogFileIndex, partitionSchema, _, _, _, _), _, _))
if filters.nonEmpty && fsRelation.partitionSchemaOption.isDefined =>
以下是 PruneFileSourcePartitions 中的原创代码。将这部分代码替换为指定分区数的过滤方法中获取分区表达式的代码即可轻松解决上述问题。
val sparkSession = fsRelation.sparkSession
val partitionColumns =
logicalRelation.resolve(
partitionSchema, sparkSession.sessionState.analyzer.resolver)
val partitionSet = AttributeSet(partitionColumns)
val partitionKeyFilters =
ExpressionSet(normalizedFilters.filter(_.references.subsetOf(partitionSet)))
修改后的代码如下:
val partitionColumns =
logicalRelation.resolve(
partitionSchema,
sparkSession.sessionState.analyzer.resolver)
val partitionSet = AttributeSet(partitionColumns)
val partitionKeyFilters = splitPredicates(normalizedFilters.reduceLeft(And),parti
大数据与云计算的关系
大数据技术生态系统
大数据的切片机制有哪些?
大数据的Kafka集群部署
大数据JUC面试题
seq搜索引擎优化至少包括那几步?(google《想做好谷歌排名优化只需要这4个步骤》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-27 13:10
很多朋友在谈到Google左侧排名时,总是认为是单页标签优化的过程。事实上,这种看法是错误的。谷歌左排名服务需要做以下步骤:【谷歌优化】
第一步:网站诊断
网站结构诊断:看是否符合搜索引擎习惯;
网站页面诊断:看看它的布局是否合理,处理得当;
网站文件名诊断:查看是否使用了不合理的文件名;
网站营销基本诊断:看目前使用的网络推广方面是否合理。
第二步:网站基础流量分析
交通统计系统安装
流量来源分析
区域分布分析
第三步:谷歌优化处理
网站结构优化:合理化网站结构以适应搜索引擎习惯
网站页面优化:关键词布局、图形处理等。
网站连接优化:将网站的整体连接系统化,一方面有利于搜索引擎搜索,另一方面结合用户习惯引导用户阅读内容网站,以便于最终的业务交易
网站标签优化:网站标签设计
第四步:GOOGLE排名优化其他策略
产生流量:GOOGLE排名优化的关键是流量。在这个过程中我们会用到很多网络营销的方法。
建立外部联系:通过友谊联系、文章 促销、帖子促销等来改善网站 外部联系。
网站要想在谷歌左侧排名好,首先要做好自己,做好推广,才能获得更好的排名。所以对于网站的GOOGLE排名优化应该从综合营销的角度来考虑,然后去做。这是如何达到效果的。
如果想靠单标签优化和作弊来达到考前GOOGLE排名的效果,那是非常幼稚和可笑的。毕竟GOOGLE排名优化还是为了推广网站。那么,网站的综合推广就完成了,在谷歌优化中获得更好的排名也就理所当然了。
以上就是《优化谷歌排名只需要这4步》的全部内容。仅供站长朋友交流学习。SEO优化是一个需要坚持的过程。希望大家一起进步。 查看全部
seq搜索引擎优化至少包括那几步?(google《想做好谷歌排名优化只需要这4个步骤》)
很多朋友在谈到Google左侧排名时,总是认为是单页标签优化的过程。事实上,这种看法是错误的。谷歌左排名服务需要做以下步骤:【谷歌优化】
第一步:网站诊断
网站结构诊断:看是否符合搜索引擎习惯;
网站页面诊断:看看它的布局是否合理,处理得当;
网站文件名诊断:查看是否使用了不合理的文件名;
网站营销基本诊断:看目前使用的网络推广方面是否合理。
第二步:网站基础流量分析
交通统计系统安装
流量来源分析
区域分布分析
第三步:谷歌优化处理
网站结构优化:合理化网站结构以适应搜索引擎习惯
网站页面优化:关键词布局、图形处理等。
网站连接优化:将网站的整体连接系统化,一方面有利于搜索引擎搜索,另一方面结合用户习惯引导用户阅读内容网站,以便于最终的业务交易
网站标签优化:网站标签设计
第四步:GOOGLE排名优化其他策略
产生流量:GOOGLE排名优化的关键是流量。在这个过程中我们会用到很多网络营销的方法。
建立外部联系:通过友谊联系、文章 促销、帖子促销等来改善网站 外部联系。
网站要想在谷歌左侧排名好,首先要做好自己,做好推广,才能获得更好的排名。所以对于网站的GOOGLE排名优化应该从综合营销的角度来考虑,然后去做。这是如何达到效果的。
如果想靠单标签优化和作弊来达到考前GOOGLE排名的效果,那是非常幼稚和可笑的。毕竟GOOGLE排名优化还是为了推广网站。那么,网站的综合推广就完成了,在谷歌优化中获得更好的排名也就理所当然了。
以上就是《优化谷歌排名只需要这4步》的全部内容。仅供站长朋友交流学习。SEO优化是一个需要坚持的过程。希望大家一起进步。
seq搜索引擎优化至少包括那几步?(卷宗扫描仪网站长:SEO优化的各个方面是比较重要的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-27 13:07
Dossier Scanner网站认为:在SEO优化的各个方面,更重要的是优化网站的内容,只有内容更丰富的网站才能被搜索引擎搜索到收录,提高网站的排名,推动网站建设的发展。以下文件扫描器网络:简单步骤教你如何学习网站SEO优化?
一、关键词的选择,关键词的好选择是优化网站的第一步,基于关键词与页面内容,是搜索引擎生存的基础,关键词的产生伴随着用户需求的产生。一个漂亮的TDK规划不是基于网站本身的主观臆断,而是用户真实需求的聚合。小编的SEO之路就是从TDK开始的。当时的导师一点一点的教,小编领悟后的实践,一点一点的体现出来最终的效果。从头到尾,小编亲自写TDK都觉得不舒服。有点懈怠,看似基本的东西,其实不一般,关键词 作为SEO五要素中最重要的一环,小编之所以再次提出来,是为了提醒那些痴迷于横着走、走灰走黑的人。路线的SEOer,千万不要忽视了最初出发的目的。
二、更新高质量原创文章。SEO优化的基础是坚持在网站上更新更多优质的文章,尽量让网站的页面丰富多样,赏心悦目,有一定的吸引力,但最重要的是不断更新优质的文章和信息,从而抢占更多的关键词,在行业竞争中获得优势,此外,一些权威的文章也会被站外一些媒体引用,扩大网站的影响力。
三、关键字应该正确放置。在优化文章的时候,重点关注关键词的密度,让关键词做到在文章中自然分布而不影响阅读,而不是关键词的很多无意义的堆积@>,通常关键词出现在文章的开头和结尾可以增加文章的相关性和权重。当然,对于文章的平滑性和自然性,关键词也可以进行形式的变换和拆分,这也是对文章的一种优化方式。根据 关键词 的接近程度,这些措施将优化 文章 的内容。
四、链接建立密钥。给网站一些链接如:友情链接、论坛链接、博客链接、微信链接等。友情链接,这个一定要做,至于它的重要性,我就不用过多赘述了。链接相关性,无论你如何扩展外链,你更喜欢与目标页面主题内容相关的平台获取外链资源;链接广度,如果你经常关注站长后台的链接分析,你会发现在同一个平台上发布的外部链接的数量是有限制的,可以被搜索引擎接受。高权重平台的外链数量适当增加,而权重较低的网站外链数量较少被搜索引擎识别,因此外链数量较少。
<p>五、关注用户体验。其实网站的构造有很多需要注意的地方,比如如何设置网站的关键词,只要你意识到 查看全部
seq搜索引擎优化至少包括那几步?(卷宗扫描仪网站长:SEO优化的各个方面是比较重要的)
Dossier Scanner网站认为:在SEO优化的各个方面,更重要的是优化网站的内容,只有内容更丰富的网站才能被搜索引擎搜索到收录,提高网站的排名,推动网站建设的发展。以下文件扫描器网络:简单步骤教你如何学习网站SEO优化?
一、关键词的选择,关键词的好选择是优化网站的第一步,基于关键词与页面内容,是搜索引擎生存的基础,关键词的产生伴随着用户需求的产生。一个漂亮的TDK规划不是基于网站本身的主观臆断,而是用户真实需求的聚合。小编的SEO之路就是从TDK开始的。当时的导师一点一点的教,小编领悟后的实践,一点一点的体现出来最终的效果。从头到尾,小编亲自写TDK都觉得不舒服。有点懈怠,看似基本的东西,其实不一般,关键词 作为SEO五要素中最重要的一环,小编之所以再次提出来,是为了提醒那些痴迷于横着走、走灰走黑的人。路线的SEOer,千万不要忽视了最初出发的目的。
二、更新高质量原创文章。SEO优化的基础是坚持在网站上更新更多优质的文章,尽量让网站的页面丰富多样,赏心悦目,有一定的吸引力,但最重要的是不断更新优质的文章和信息,从而抢占更多的关键词,在行业竞争中获得优势,此外,一些权威的文章也会被站外一些媒体引用,扩大网站的影响力。
三、关键字应该正确放置。在优化文章的时候,重点关注关键词的密度,让关键词做到在文章中自然分布而不影响阅读,而不是关键词的很多无意义的堆积@>,通常关键词出现在文章的开头和结尾可以增加文章的相关性和权重。当然,对于文章的平滑性和自然性,关键词也可以进行形式的变换和拆分,这也是对文章的一种优化方式。根据 关键词 的接近程度,这些措施将优化 文章 的内容。
四、链接建立密钥。给网站一些链接如:友情链接、论坛链接、博客链接、微信链接等。友情链接,这个一定要做,至于它的重要性,我就不用过多赘述了。链接相关性,无论你如何扩展外链,你更喜欢与目标页面主题内容相关的平台获取外链资源;链接广度,如果你经常关注站长后台的链接分析,你会发现在同一个平台上发布的外部链接的数量是有限制的,可以被搜索引擎接受。高权重平台的外链数量适当增加,而权重较低的网站外链数量较少被搜索引擎识别,因此外链数量较少。
<p>五、关注用户体验。其实网站的构造有很多需要注意的地方,比如如何设置网站的关键词,只要你意识到
seq搜索引擎优化至少包括那几步?( 如要提升您的网站在Google上的排名要怎么做呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-27 13:06
如要提升您的网站在Google上的排名要怎么做呢?)
您的独立站点已启动并正在运行,它看起来很棒,并且第一批客户订单即将到来。
完美的!
如果您还没有准备好在 Facebook 或 Google 上做广告
下一步是通过谷歌产生一些免费流量
让我们想象一下。如果您的独立商店位于 Google 搜索结果的首页,那么您无需在广告上花费一分钱即可进行销售。
当然,在谷歌首页上排名并不是一件容易的事。但是通过一些聪明的 SEO 可以将 网站 排名靠前。
您可以做些什么来提高您在 Google 上的 网站 排名?
这里有 9 个 SEO 技巧,可帮助您提高排名
1.选择完美的关键字,以便 Google 找到您
关键词 是 SEO 的核心。关键字告诉谷歌你的真实身份和你做了什么。
要提出最好的 关键词,请将自己定位为客户。你会搜索什么来找到你的产品?也许是“耐克 T 恤”或“舞会礼服”。
选择 关键词 时有一个最佳选择。很难对 关键词 进行广泛的排名,例如“鞋子”,因为最大的零售商占据主导地位。另一方面,像“purple Velcro (brand name) shoes”这样的小众关键词不会获得足够的搜索量。在中间尝试一些东西,例如输入鞋子的品牌名称“name+shoes”。
选择正确的单词和短语是一门科学。后面我会写一篇详细的文章关于关键词的选择。
2.选择实际销售的关键字或词组
你想要真正买东西的搜索者。
假设您在 shopyy 独立网站上销售手工珠宝。搜索“手工珠宝”的人可能正在寻找制作珠宝的信息。你对那些人不感兴趣。
您需要一位想购买手工珠宝的客户。尝试修改您的关键字或词组以收录“购买”、“最佳”、“便宜”等有效字词。
寻找暗示购买意图的关键词或短语。
3.把这些关键词放在所有合适的地方
现在您有了 关键词,是时候将它们放在 Google 可以找到它们的地方了。
Shopyy 有五个放置关键字的关键位置:
1.你的页面标题
这是将出现在 Google 结果页面上的标题。
请注意这家商店是如何在商店名称之前放置关键词“wood 太阳镜”的?那是因为越来越多的人在寻找“木制太阳镜”。考虑在标题中描述您的商店。
转到界面 > SEO 设置。
专业提示:尝试让您的标题成为号召性用语。把它想象成一个吸引人的标题。了解 House of Fraser 如何使用有效的 CTA:“在线购买手表”
2.元描述
元描述是标题下方显示的简短介绍。再次,将您的关键字放在这里,但尽量使它们具有描述性和吸引力。这是您说服客户点击的机会。
确保每个页面都有不同的元描述。再次,前往界面 > SEO 设置。
3.图片描述和Alt标签
谷歌很聪明,但还是看不到红袜子的照片。你必须告诉谷歌这是一只红袜子。为此,请在上传前自动将“red sock”添加到产品标题名称中。
SHOPYY 会自动为所有产品相关图片添加 ALT 标签
使图像具有描述性并收录您的关键字。现在,谷歌可以找到它、阅读它并对其进行排名。
4.标题和标题(H1 标签)
您的标题是 Google 最先查看您的 网站 内容的地方之一。确保您的产品页面都收录描述性标题,并且不要忘记收录您的关键字。
主流搜索引擎关注H1标签中的文字信息。一个好的H1有助于提高关键词的排名,提高页面权重
H1 标签是可见的,而不是对用户隐藏。H1标题过多会被搜索引擎认为作弊,会被降级
SHOPYY网站的H1主要用于文章的、商品、话题等核心内容。
5.产品描述和复制
始终在产品说明中收录关键字,以帮助 Google 找到您的页面。您必须编写独特而令人兴奋的产品描述。
不要只是复制制造商的描述,因为 - 很可能 - 复制粘贴已经在互联网上,而 Google 讨厌复制粘贴。此外,您的描述很有可能表现出您自己的语气并说服客户购买。
4.使用内部链接连接您的页面和内容
除了关键字,链接是 SEO 的基本排名因素。首先在整个 网站 中使用内部链接。从主页链接到您的产品页面。在您的博客中设置类别链接和产品链接。
您网站连接得越多,Google 就越能更好地了解您的商店及其产品。将其视为您的 网站 构建基础或支柱。
5.创建指向您 Shopyy 商店的反向链接
为了对您的商店进行排名,Google 会查看哪些其他 网站 链接链接到您。Google 使用基于链接数量和链接到您的 网站 权限的算法来确定您的分数。
例如,如果华尔街和纽约时报 网站 链接到您的产品,Google 知道您必须拥有一些真正的权威,因此您的排名会更高。
有无数种方法可以生成返回 Shopyy 商店的链接。发送新闻稿有助于接触博主并提供返回您的 网站 的链接。在您的利基中提供博客的客座帖子也将获得链接,并且产品链接也可以在博客中提及以获得产品页面流量。您也可以直接通过电子邮件发送 网站 并要求他们查看或链接到您的产品。
专业提示:永远不要购买链接,使用链接交换。Google 使用这些技术来搜索 网站。您正在寻找自然链接行为。 查看全部
seq搜索引擎优化至少包括那几步?(
如要提升您的网站在Google上的排名要怎么做呢?)
您的独立站点已启动并正在运行,它看起来很棒,并且第一批客户订单即将到来。
完美的!
如果您还没有准备好在 Facebook 或 Google 上做广告
下一步是通过谷歌产生一些免费流量
让我们想象一下。如果您的独立商店位于 Google 搜索结果的首页,那么您无需在广告上花费一分钱即可进行销售。
当然,在谷歌首页上排名并不是一件容易的事。但是通过一些聪明的 SEO 可以将 网站 排名靠前。
您可以做些什么来提高您在 Google 上的 网站 排名?
这里有 9 个 SEO 技巧,可帮助您提高排名
1.选择完美的关键字,以便 Google 找到您
关键词 是 SEO 的核心。关键字告诉谷歌你的真实身份和你做了什么。
要提出最好的 关键词,请将自己定位为客户。你会搜索什么来找到你的产品?也许是“耐克 T 恤”或“舞会礼服”。
选择 关键词 时有一个最佳选择。很难对 关键词 进行广泛的排名,例如“鞋子”,因为最大的零售商占据主导地位。另一方面,像“purple Velcro (brand name) shoes”这样的小众关键词不会获得足够的搜索量。在中间尝试一些东西,例如输入鞋子的品牌名称“name+shoes”。
选择正确的单词和短语是一门科学。后面我会写一篇详细的文章关于关键词的选择。
2.选择实际销售的关键字或词组
你想要真正买东西的搜索者。
假设您在 shopyy 独立网站上销售手工珠宝。搜索“手工珠宝”的人可能正在寻找制作珠宝的信息。你对那些人不感兴趣。
您需要一位想购买手工珠宝的客户。尝试修改您的关键字或词组以收录“购买”、“最佳”、“便宜”等有效字词。
寻找暗示购买意图的关键词或短语。
3.把这些关键词放在所有合适的地方
现在您有了 关键词,是时候将它们放在 Google 可以找到它们的地方了。
Shopyy 有五个放置关键字的关键位置:
1.你的页面标题
这是将出现在 Google 结果页面上的标题。
请注意这家商店是如何在商店名称之前放置关键词“wood 太阳镜”的?那是因为越来越多的人在寻找“木制太阳镜”。考虑在标题中描述您的商店。
转到界面 > SEO 设置。
专业提示:尝试让您的标题成为号召性用语。把它想象成一个吸引人的标题。了解 House of Fraser 如何使用有效的 CTA:“在线购买手表”
2.元描述
元描述是标题下方显示的简短介绍。再次,将您的关键字放在这里,但尽量使它们具有描述性和吸引力。这是您说服客户点击的机会。
确保每个页面都有不同的元描述。再次,前往界面 > SEO 设置。
3.图片描述和Alt标签
谷歌很聪明,但还是看不到红袜子的照片。你必须告诉谷歌这是一只红袜子。为此,请在上传前自动将“red sock”添加到产品标题名称中。
SHOPYY 会自动为所有产品相关图片添加 ALT 标签
使图像具有描述性并收录您的关键字。现在,谷歌可以找到它、阅读它并对其进行排名。
4.标题和标题(H1 标签)
您的标题是 Google 最先查看您的 网站 内容的地方之一。确保您的产品页面都收录描述性标题,并且不要忘记收录您的关键字。
主流搜索引擎关注H1标签中的文字信息。一个好的H1有助于提高关键词的排名,提高页面权重
H1 标签是可见的,而不是对用户隐藏。H1标题过多会被搜索引擎认为作弊,会被降级
SHOPYY网站的H1主要用于文章的、商品、话题等核心内容。
5.产品描述和复制
始终在产品说明中收录关键字,以帮助 Google 找到您的页面。您必须编写独特而令人兴奋的产品描述。
不要只是复制制造商的描述,因为 - 很可能 - 复制粘贴已经在互联网上,而 Google 讨厌复制粘贴。此外,您的描述很有可能表现出您自己的语气并说服客户购买。
4.使用内部链接连接您的页面和内容
除了关键字,链接是 SEO 的基本排名因素。首先在整个 网站 中使用内部链接。从主页链接到您的产品页面。在您的博客中设置类别链接和产品链接。
您网站连接得越多,Google 就越能更好地了解您的商店及其产品。将其视为您的 网站 构建基础或支柱。
5.创建指向您 Shopyy 商店的反向链接
为了对您的商店进行排名,Google 会查看哪些其他 网站 链接链接到您。Google 使用基于链接数量和链接到您的 网站 权限的算法来确定您的分数。
例如,如果华尔街和纽约时报 网站 链接到您的产品,Google 知道您必须拥有一些真正的权威,因此您的排名会更高。
有无数种方法可以生成返回 Shopyy 商店的链接。发送新闻稿有助于接触博主并提供返回您的 网站 的链接。在您的利基中提供博客的客座帖子也将获得链接,并且产品链接也可以在博客中提及以获得产品页面流量。您也可以直接通过电子邮件发送 网站 并要求他们查看或链接到您的产品。
专业提示:永远不要购买链接,使用链接交换。Google 使用这些技术来搜索 网站。您正在寻找自然链接行为。
seq搜索引擎优化至少包括那几步?(深圳网站优化必须完成的20网页H1标签是仅次于title)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-27 13:05
深圳网站优化就是优化所有的搜索引擎。一般某个搜索引擎的排名比较好,其他搜索引擎的排名也差不多。
因此,今天的业星信息科技整理了网站优化必须要做的事情。做完这些事情,网站优化已经完成了90%左右。只有细节比拼的能力,这部分知识会在下面的文章中继续和大家讨论。
优化 网站 必须做到以下几点
站点机器人文件是指导搜索引擎工作的基本文件。它可以指定搜索引擎读取哪些文件,以免无目的搜索网页
301重定向和URL规范化有很多重要的功能,主要是为了统一顶级域和二级域的权重
站点地图 站点地图是搜索引擎到达您的站点后提供给搜索引擎的地图,使搜索引擎更容易工作。毕竟优化网站是满足搜索引擎的过程
404错误页面,收录页面由于人为原因被删除后,必须显示给搜索引擎。如果你不做 404 页面,搜索引擎不会喜欢你的 网站
写网页的标题,即网页的标题很重要,网页标题的重要性占网站优化的20%
网页的 H1 标签是仅次于标题的第二重要标签
关键字标签变得越来越不重要,但它对搜索引擎非常重要。例如,如果一个人的耳朵被切断,它可以被听到。可以剪掉吗?哈恩,哈恩,哈恩,哈恩,哈恩
description标签是一个页面描述标签,它有两个功能。一是向搜索引擎展示页面内容,二是展示搜索引擎的结果页面,这对用户体验也很重要。
以上就是网站优化必须完成的八个步骤,网站优化必须完成。 查看全部
seq搜索引擎优化至少包括那几步?(深圳网站优化必须完成的20网页H1标签是仅次于title)
深圳网站优化就是优化所有的搜索引擎。一般某个搜索引擎的排名比较好,其他搜索引擎的排名也差不多。
因此,今天的业星信息科技整理了网站优化必须要做的事情。做完这些事情,网站优化已经完成了90%左右。只有细节比拼的能力,这部分知识会在下面的文章中继续和大家讨论。
优化 网站 必须做到以下几点
站点机器人文件是指导搜索引擎工作的基本文件。它可以指定搜索引擎读取哪些文件,以免无目的搜索网页
301重定向和URL规范化有很多重要的功能,主要是为了统一顶级域和二级域的权重
站点地图 站点地图是搜索引擎到达您的站点后提供给搜索引擎的地图,使搜索引擎更容易工作。毕竟优化网站是满足搜索引擎的过程
404错误页面,收录页面由于人为原因被删除后,必须显示给搜索引擎。如果你不做 404 页面,搜索引擎不会喜欢你的 网站
写网页的标题,即网页的标题很重要,网页标题的重要性占网站优化的20%
网页的 H1 标签是仅次于标题的第二重要标签
关键字标签变得越来越不重要,但它对搜索引擎非常重要。例如,如果一个人的耳朵被切断,它可以被听到。可以剪掉吗?哈恩,哈恩,哈恩,哈恩,哈恩
description标签是一个页面描述标签,它有两个功能。一是向搜索引擎展示页面内容,二是展示搜索引擎的结果页面,这对用户体验也很重要。
以上就是网站优化必须完成的八个步骤,网站优化必须完成。
seq搜索引擎优化至少包括那几步?(如何找到最适合你的SEO涉及面比较广的技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-01-26 17:08
因为SEO涉及的范围很广,我给大家发一些小窍门。以下信息来自我自己的网站。有什么问题可以咨询HI,希望对你有帮助:
我们知道在搜索引擎中检索信息是通过键入 关键词 来完成的。因此,顾名思义,关键词 非常关键。是整个网站登录过程中最基本也是最重要的一步,也是我们网页优化的基础。因此,它的重要性怎么强调都不为过。但是关键词的确定并不是一件容易的事,要考虑很多因素,比如关键词必须和你的网站内容有关,单词如何组合排列,是否符合搜索工具的要求,尽量避免流行的关键词等。所以选择合适的关键词肯定需要做很多工作。
那么如何找到适合您的 关键词 呢?首先,仔细考虑潜在客户的心理,绞尽脑汁想象他们在寻找有关您的信息时最有可能使用的关键词,并将这些单词一一记录下来。不要担心列出太多 关键词,相反,您找到的 关键词 越多,您的覆盖面就越大,您挑选最佳 关键词 的机会就越大。
我们经常听到一个公司网站在搜索引擎上排名前20,业务量跃升10倍的故事。另一家公司也在前 20 名,但其业务量完全没有变化。是什么造成了如此大的不同?原因很简单,前者选择了正确的关键词,而后者在这方面犯了一个致命的错误。这个例子说明了正确的选择关键词对于企业网站营销的成败有多么重要。
选择相关的 关键词
对于一个企业来说,选择关键词当然必须和它自己的产品或服务相关。不要听信靠不相关的点击关键词来拉动更多流量的宣传,这不仅不道德,而且毫无意义。想象一下有人查找“Monica Lewinsky”,您会对您生产的酱油感兴趣吗?当然不是。诚然,有时这确实会增加 网站 的流量,但既然您是在销售产品,而不是提供免费的小道消息,那么通过作弊来增加流量有什么意义呢?
选择一个特定的 关键词
还有一点我们在选择关键词时要注意的一点是避免使用泛泛的词作为主要的关键词,而要根据你的业务或产品的类型尽可能选择具体的词. 例如,一家销售木工工具的制造商,“木匠工具”不是正确的选择关键词,“链锯”可能是明智的选择。
有人会问,既然“木匠工具”是一个集合名词,涵盖了厂家的所有产品,为什么不用呢?我们不妨把 Carpenter Tools 带到 Google,你会发现搜索结果超过 6 位(实际数字是 189,000),这意味着你的竞争对手有近 200,000!在其中脱颖而出!许多竞争对手几乎是“不可能完成的任务”。相反,“链锯”(69,800)下的搜索结果要少得多,您有更多机会排名领先于竞争对手。
选择更长的 关键词
与查询信息时尽可能使用单词的原创形式相反,提交网站时最好使用单词的较长形式。例如,可以使用“游戏”时,尽量不要选择“游戏”。因为在搜索引擎支持词多态或者分词查询的情况下,选择“游戏”可以保证你在搜索“游戏”和“游戏”时可以检索到你的网页。
不要忘记拼错的单词?
许多文章关于如何选择关键词特别提到了单词的拼写错误,例如“当代现代咖啡桌”,提醒我们不要忘记将它们收录在关键词选项中。理论是一些词经常被用户拼错,并且考虑到一般人不会针对错别字关键词,所以如果你足够聪明,可以找到优化页面以防止拼写错误的技巧,那么一旦你遇到用户并使用此错字进行搜索,您将站在搜索结果的最前沿!
真的是这样吗?首先,我们来看看上面的例子有什么问题。“contemorary”其实就是“contemporary”,虽然是一个字母的区别,但是从关键词的角度来看,两者相差甚远。奇怪的是,根据关键词监测统计报告,“contemorary”在两个月内出现了多达66次!所以我们要不要快点把它放到关键词列表中?等一下。我们先来分析一下谁会经常写错别字。它是受过教育的正规商人吗?毕竟,“当代”不是一个硬性的拉丁语借词,这不太可能。似乎有些粗心的丈夫或节俭的家庭主妇更值得怀疑。平心而论,他们将是您宝贵的客户,但不太可能成为您理想的商业伙伴。
相反,如果潜在客户不小心拼错了一个单词,却看到你的 网站 出现在他面前,并且那个拼写错误多次显眼地加粗,他会如何反应?他会像发现金矿一样欣喜若狂吗?还是你对这家公司的质量还有一点怀疑?他会认为一个连基本语法都没有掌握的厂商,真的是有问题的。所以,拼写错误的 关键词 是一个陷阱,我们必须三思而后行。
此外,目前一些搜索引擎(如谷歌)已经增加了自动拼写检查功能。当用户输入错字时,系统会自动提供正确的单词选择。当用户意识到他们错了,大多数人倾向于通过正确的 关键词 提示进行搜索。所以到了这个阶段,优化拼写错误的网页已经基本失去了意义。
寻找 关键词 提示
作为网站的所有者,当然你是最了解你的业务的人,所以你总能找到最能反映你业务的关键词。但仅仅依靠自己的努力,难免会出现一些疏漏。这个时候,你不妨去搜索引擎,找到竞争对手的网站,看看他们用的是哪个关键词,或许可以从中得到一些信息。有些启发。
另外,借助一些关键词自动分析软件,可以快速从你或你竞争对手的网页中提取出合适的关键词,你的工作效率可以成倍提升,我们可以通过这些软件找到很多< @关键词 之前没有考虑过,大大扩展了我们的 关键词 列表。
停用词/过滤词
两者含义相同,都是指太常用而没有任何检索价值的词,如“a”、“the”、“and”、“of”、“web”、“home page”和很快。搜索引擎通常会在遇到这些术语时过滤掉它们。因此,为了节省篇幅,应尽量避免使用此类词,尤其是在字数有严格限制的地方。(为了验证上述规则,您可以尝试在搜索引擎中搜索“stay the night”。您会发现“the”这个词与搜索条件匹配,但不是粗体,表示它被忽略了。)
重复 关键词 1000 次
既然关键词出现的频率是决定网站排名的重要因素,为什么不重复1000次,简单又有效呢?停止。众所周知,这就是搜索引擎的“石器时代”做法,在当时确实奏效,但现在早已被搜索引擎抛弃。
当时的典型做法是:“关键词, 关键词, 关键词...”。重复次数越多,网站 排名越高。所以登录搜索引擎变成了无休止的关键词重复竞赛。你重复500次不算太多,我会重复600次,而且重复关键词数千次的人很多。搜索引擎很快意识到了这种做法的危险性,终于在忍无可忍的时候站了起来,警告那些走得太远的人网站,如果他们继续执迷不悟,不仅达不到他们的目标,但他们也可能被判处死刑。- 永远不要让你的 网站 出来!
所以不要刻意重复某个关键词太多,尤其是不要连续使用某个关键词超过2次。使用关键词时,尽量做到自然流畅,符合基本语法规则。
错误的代码会损害您的搜索引擎排名
糟糕的代码会损害您的搜索引擎排名 简单的网页错误可能会导致搜索引擎蜘蛛错误地索引页面或完全丢弃页面。在穿上之前检查您的代码和连接。TML 代码错误会对您的搜索引擎排名产生负面影响吗?大多数网站管理员没有意识到搜索引擎要求占据中心位置。糟糕的代码会以多种方式损害搜索引擎网站。当搜索引擎在主 HTML 中查找关键字和相关条件时,如果遇到无法理解的 HTML,蜘蛛就会降级或离开您的页面。诸如标签放置不当的错误(例如 优采云tower,标签放置在主体内部而不是头部内部)可能会导致蜘蛛忽略该标签,从而降低您的相关性得分和随后的排名。其他页面上的错误也会限制搜索引擎将您的网站编入索引。损坏的链接将成为蜘蛛的障碍,破坏搜索引擎蜘蛛索引正文和后面的链接。如果他们来到您的 网站 并遇到连接中断,他们将无法完全索引该站点,甚至他们会丢弃此 网站(他们更多的是 网站 等待索引,为什么要把时间浪费在损坏的 网站 上?!)亚利桑那州的职业计算机顾问和 SEO 所有者 John Bryant 向我们讲述了她的经历。有一次我忘记修改我的 HTML,它让我失去了前 10 名的排名!我的一小段 HTML 犯了一个现代的 网站 错误,它破坏了 网站 在搜索引擎中的排名。打破搜索引擎蜘蛛索引正文和随后的链接。如果他们来到您的 网站 并遇到连接中断,他们将无法完全索引该站点,甚至他们会丢弃此 网站(他们更多的是 网站 等待索引,为什么要把时间浪费在损坏的 网站 上?!)亚利桑那州的职业计算机顾问和 SEO 所有者 John Bryant 向我们讲述了她的经历。有一次我忘记修改我的 HTML,它让我失去了前 10 名的排名!我的一小段 HTML 犯了一个现代的 网站 错误,它破坏了 网站 在搜索引擎中的排名。打破搜索引擎蜘蛛索引正文和随后的链接。如果他们来到您的 网站 并遇到连接中断,他们将无法完全索引该站点,甚至他们会丢弃此 网站(他们更多的是 网站 等待索引,为什么要把时间浪费在损坏的 网站 上?!)亚利桑那州的职业计算机顾问和 SEO 所有者 John Bryant 向我们讲述了她的经历。有一次我忘记修改我的 HTML,它让我失去了前 10 名的排名!我的一小段 HTML 犯了一个现代的 网站 错误,它破坏了 网站 在搜索引擎中的排名。为什么要把时间浪费在损坏的 网站 上?!) 亚利桑那州的职业计算机顾问和 SEO 所有者 John Bryant 向我们讲述了她的经历。有一次我忘记修改我的 HTML,它让我失去了前 10 名的排名!我的一小段 HTML 犯了一个现代的 网站 错误,它破坏了 网站 在搜索引擎中的排名。为什么要把时间浪费在损坏的 网站 上?!) 亚利桑那州的职业计算机顾问和 SEO 所有者 John Bryant 向我们讲述了她的经历。有一次我忘记修改我的 HTML,它让我失去了前 10 名的排名!我的一小段 HTML 犯了一个现代的 网站 错误,它破坏了 网站 在搜索引擎中的排名。
从第一页的前十位下降到第三页。幸运的是,这个故事有个美好的结局。一位广为人知的专业工程师立即注意到搜索引擎排名下降,并确认原因是 HTML 错误。他修复了错误并再次提交页面。几周后,他重新获得了搜索引擎排名。错误也伤害了目录!代码中的错误和问题会阻止搜索引擎工作——它也会影响目录。在搜索引擎策略中,致力于搜索引擎服务的 Yahoo 和 LookSmart 站点都拒绝此类连接和错误。我们的 网站 修复工具将确保您避免此 HTML 问题。错误如何输入代码?我的网站管理员知道代码 - 他不会犯错误。“不是故意的,而是让” s 考虑您的网站管理员所处的工作环境。有限的时间,多人一起工作,不断改进的压力网站 - 事实是,网站管理员的世界很忙,压力很大。疲惫的站长努力跟上,有时,一个小错误会改变网站,让改变高速旋转。考虑一下这个脚本 - 您的销售部门将一些很棒的新主页交给您的网站管理员。他们已与贵公司的 SEO 专家协调,并在新文本中战略性地放置关键字。为了小心,您的网站管理员提交了添加新文本的任务,但不小心剪掉了段落涂鸦的右方括号,因此您的文本如下所示:这是您的关键字富文本,当搜索引擎在不关闭括号的情况下读取您的页面时,销售和 SEO 添加在一起,它假定所有关键字丰富的正文都是段落标签的属性 - 并忽略它。搜索引擎在您的页面上强调可见的正文文本,这会尽可能地完善正文,明确添加关键字来推动您的网站与您的相关性只是失去了证明您与搜索引擎相关性的巨大机会。提高搜索引擎中的其他无错误排名和网站流量需要多少费用。明确地添加关键字来推动您的网站与您的相关性只是失去了一个巨大的机会来证明您与搜索引擎的相关性。提高搜索引擎中的其他无错误排名和网站流量需要多少费用。明确地添加关键字来推动您的网站与您的相关性只是失去了一个巨大的机会来证明您与搜索引擎的相关性。提高搜索引擎中的其他无错误排名和网站流量需要多少费用。
搜索引擎提交提示
网页优化只是登录搜索引擎的准备工作。最后,我们要把优化后的网站提交给搜索引擎,这也是网站注册的一个很重要的环节。
1. 出现在带有 关键词 的 URL 中(英文)
2. 关键词 (1-3) 出现在页面标题中
3. 关键词 标签出现在 关键词 (1-3)
4. 与 关键词 一起出现在描述标签中(主要的 关键词 重复 2 次)
5. 自然出现在内容中关键词
6. 出现第一段和最后一段内容关键词
7. H1、H2标签出现关键词
8. 导出链接锚文本收录 关键词
9. 图像的文件名收录 关键词
10. 出现在 关键词 的 ALT 属性中
11.关键词密度6-8%
12. 变为粗体或斜体 关键词
提高 关键词 排名的 28 个 SEO 技巧
28 个使 关键词 排名显着提高的 SEO 技巧:
关键词位置、密度、治疗
关键词 出现在 URL 中(英文)
关键词 (1-3) 出现在页面标题中
关键词 出现在 关键词 标记中 (1-3)
关键词 出现在描述标签中(主要的 关键词 重复了 2 次)
关键词 自然出现在内容中
内容的第一段和最后一段出现关键词
关键词 出现在 H1、H2 标签中
导出链接锚文本收录 关键词
图像的文件名收录 关键词
关键词 出现在 ALT 属性中
关键词密度6-8%
粗体或斜体 关键词
内容质量、更新频率、相关性
原创的内容最好了,不宜多次转载
内容独立,与其他页面至少有 30% 的差异
1000-2000字,合理切分
定期更新,最好每天更新
内容围绕页面关键词,与整个网站的主题相关 查看全部
seq搜索引擎优化至少包括那几步?(如何找到最适合你的SEO涉及面比较广的技巧)
因为SEO涉及的范围很广,我给大家发一些小窍门。以下信息来自我自己的网站。有什么问题可以咨询HI,希望对你有帮助:
我们知道在搜索引擎中检索信息是通过键入 关键词 来完成的。因此,顾名思义,关键词 非常关键。是整个网站登录过程中最基本也是最重要的一步,也是我们网页优化的基础。因此,它的重要性怎么强调都不为过。但是关键词的确定并不是一件容易的事,要考虑很多因素,比如关键词必须和你的网站内容有关,单词如何组合排列,是否符合搜索工具的要求,尽量避免流行的关键词等。所以选择合适的关键词肯定需要做很多工作。
那么如何找到适合您的 关键词 呢?首先,仔细考虑潜在客户的心理,绞尽脑汁想象他们在寻找有关您的信息时最有可能使用的关键词,并将这些单词一一记录下来。不要担心列出太多 关键词,相反,您找到的 关键词 越多,您的覆盖面就越大,您挑选最佳 关键词 的机会就越大。
我们经常听到一个公司网站在搜索引擎上排名前20,业务量跃升10倍的故事。另一家公司也在前 20 名,但其业务量完全没有变化。是什么造成了如此大的不同?原因很简单,前者选择了正确的关键词,而后者在这方面犯了一个致命的错误。这个例子说明了正确的选择关键词对于企业网站营销的成败有多么重要。
选择相关的 关键词
对于一个企业来说,选择关键词当然必须和它自己的产品或服务相关。不要听信靠不相关的点击关键词来拉动更多流量的宣传,这不仅不道德,而且毫无意义。想象一下有人查找“Monica Lewinsky”,您会对您生产的酱油感兴趣吗?当然不是。诚然,有时这确实会增加 网站 的流量,但既然您是在销售产品,而不是提供免费的小道消息,那么通过作弊来增加流量有什么意义呢?
选择一个特定的 关键词
还有一点我们在选择关键词时要注意的一点是避免使用泛泛的词作为主要的关键词,而要根据你的业务或产品的类型尽可能选择具体的词. 例如,一家销售木工工具的制造商,“木匠工具”不是正确的选择关键词,“链锯”可能是明智的选择。
有人会问,既然“木匠工具”是一个集合名词,涵盖了厂家的所有产品,为什么不用呢?我们不妨把 Carpenter Tools 带到 Google,你会发现搜索结果超过 6 位(实际数字是 189,000),这意味着你的竞争对手有近 200,000!在其中脱颖而出!许多竞争对手几乎是“不可能完成的任务”。相反,“链锯”(69,800)下的搜索结果要少得多,您有更多机会排名领先于竞争对手。
选择更长的 关键词
与查询信息时尽可能使用单词的原创形式相反,提交网站时最好使用单词的较长形式。例如,可以使用“游戏”时,尽量不要选择“游戏”。因为在搜索引擎支持词多态或者分词查询的情况下,选择“游戏”可以保证你在搜索“游戏”和“游戏”时可以检索到你的网页。
不要忘记拼错的单词?
许多文章关于如何选择关键词特别提到了单词的拼写错误,例如“当代现代咖啡桌”,提醒我们不要忘记将它们收录在关键词选项中。理论是一些词经常被用户拼错,并且考虑到一般人不会针对错别字关键词,所以如果你足够聪明,可以找到优化页面以防止拼写错误的技巧,那么一旦你遇到用户并使用此错字进行搜索,您将站在搜索结果的最前沿!
真的是这样吗?首先,我们来看看上面的例子有什么问题。“contemorary”其实就是“contemporary”,虽然是一个字母的区别,但是从关键词的角度来看,两者相差甚远。奇怪的是,根据关键词监测统计报告,“contemorary”在两个月内出现了多达66次!所以我们要不要快点把它放到关键词列表中?等一下。我们先来分析一下谁会经常写错别字。它是受过教育的正规商人吗?毕竟,“当代”不是一个硬性的拉丁语借词,这不太可能。似乎有些粗心的丈夫或节俭的家庭主妇更值得怀疑。平心而论,他们将是您宝贵的客户,但不太可能成为您理想的商业伙伴。
相反,如果潜在客户不小心拼错了一个单词,却看到你的 网站 出现在他面前,并且那个拼写错误多次显眼地加粗,他会如何反应?他会像发现金矿一样欣喜若狂吗?还是你对这家公司的质量还有一点怀疑?他会认为一个连基本语法都没有掌握的厂商,真的是有问题的。所以,拼写错误的 关键词 是一个陷阱,我们必须三思而后行。
此外,目前一些搜索引擎(如谷歌)已经增加了自动拼写检查功能。当用户输入错字时,系统会自动提供正确的单词选择。当用户意识到他们错了,大多数人倾向于通过正确的 关键词 提示进行搜索。所以到了这个阶段,优化拼写错误的网页已经基本失去了意义。
寻找 关键词 提示
作为网站的所有者,当然你是最了解你的业务的人,所以你总能找到最能反映你业务的关键词。但仅仅依靠自己的努力,难免会出现一些疏漏。这个时候,你不妨去搜索引擎,找到竞争对手的网站,看看他们用的是哪个关键词,或许可以从中得到一些信息。有些启发。
另外,借助一些关键词自动分析软件,可以快速从你或你竞争对手的网页中提取出合适的关键词,你的工作效率可以成倍提升,我们可以通过这些软件找到很多< @关键词 之前没有考虑过,大大扩展了我们的 关键词 列表。
停用词/过滤词
两者含义相同,都是指太常用而没有任何检索价值的词,如“a”、“the”、“and”、“of”、“web”、“home page”和很快。搜索引擎通常会在遇到这些术语时过滤掉它们。因此,为了节省篇幅,应尽量避免使用此类词,尤其是在字数有严格限制的地方。(为了验证上述规则,您可以尝试在搜索引擎中搜索“stay the night”。您会发现“the”这个词与搜索条件匹配,但不是粗体,表示它被忽略了。)
重复 关键词 1000 次
既然关键词出现的频率是决定网站排名的重要因素,为什么不重复1000次,简单又有效呢?停止。众所周知,这就是搜索引擎的“石器时代”做法,在当时确实奏效,但现在早已被搜索引擎抛弃。
当时的典型做法是:“关键词, 关键词, 关键词...”。重复次数越多,网站 排名越高。所以登录搜索引擎变成了无休止的关键词重复竞赛。你重复500次不算太多,我会重复600次,而且重复关键词数千次的人很多。搜索引擎很快意识到了这种做法的危险性,终于在忍无可忍的时候站了起来,警告那些走得太远的人网站,如果他们继续执迷不悟,不仅达不到他们的目标,但他们也可能被判处死刑。- 永远不要让你的 网站 出来!
所以不要刻意重复某个关键词太多,尤其是不要连续使用某个关键词超过2次。使用关键词时,尽量做到自然流畅,符合基本语法规则。
错误的代码会损害您的搜索引擎排名
糟糕的代码会损害您的搜索引擎排名 简单的网页错误可能会导致搜索引擎蜘蛛错误地索引页面或完全丢弃页面。在穿上之前检查您的代码和连接。TML 代码错误会对您的搜索引擎排名产生负面影响吗?大多数网站管理员没有意识到搜索引擎要求占据中心位置。糟糕的代码会以多种方式损害搜索引擎网站。当搜索引擎在主 HTML 中查找关键字和相关条件时,如果遇到无法理解的 HTML,蜘蛛就会降级或离开您的页面。诸如标签放置不当的错误(例如 优采云tower,标签放置在主体内部而不是头部内部)可能会导致蜘蛛忽略该标签,从而降低您的相关性得分和随后的排名。其他页面上的错误也会限制搜索引擎将您的网站编入索引。损坏的链接将成为蜘蛛的障碍,破坏搜索引擎蜘蛛索引正文和后面的链接。如果他们来到您的 网站 并遇到连接中断,他们将无法完全索引该站点,甚至他们会丢弃此 网站(他们更多的是 网站 等待索引,为什么要把时间浪费在损坏的 网站 上?!)亚利桑那州的职业计算机顾问和 SEO 所有者 John Bryant 向我们讲述了她的经历。有一次我忘记修改我的 HTML,它让我失去了前 10 名的排名!我的一小段 HTML 犯了一个现代的 网站 错误,它破坏了 网站 在搜索引擎中的排名。打破搜索引擎蜘蛛索引正文和随后的链接。如果他们来到您的 网站 并遇到连接中断,他们将无法完全索引该站点,甚至他们会丢弃此 网站(他们更多的是 网站 等待索引,为什么要把时间浪费在损坏的 网站 上?!)亚利桑那州的职业计算机顾问和 SEO 所有者 John Bryant 向我们讲述了她的经历。有一次我忘记修改我的 HTML,它让我失去了前 10 名的排名!我的一小段 HTML 犯了一个现代的 网站 错误,它破坏了 网站 在搜索引擎中的排名。打破搜索引擎蜘蛛索引正文和随后的链接。如果他们来到您的 网站 并遇到连接中断,他们将无法完全索引该站点,甚至他们会丢弃此 网站(他们更多的是 网站 等待索引,为什么要把时间浪费在损坏的 网站 上?!)亚利桑那州的职业计算机顾问和 SEO 所有者 John Bryant 向我们讲述了她的经历。有一次我忘记修改我的 HTML,它让我失去了前 10 名的排名!我的一小段 HTML 犯了一个现代的 网站 错误,它破坏了 网站 在搜索引擎中的排名。为什么要把时间浪费在损坏的 网站 上?!) 亚利桑那州的职业计算机顾问和 SEO 所有者 John Bryant 向我们讲述了她的经历。有一次我忘记修改我的 HTML,它让我失去了前 10 名的排名!我的一小段 HTML 犯了一个现代的 网站 错误,它破坏了 网站 在搜索引擎中的排名。为什么要把时间浪费在损坏的 网站 上?!) 亚利桑那州的职业计算机顾问和 SEO 所有者 John Bryant 向我们讲述了她的经历。有一次我忘记修改我的 HTML,它让我失去了前 10 名的排名!我的一小段 HTML 犯了一个现代的 网站 错误,它破坏了 网站 在搜索引擎中的排名。
从第一页的前十位下降到第三页。幸运的是,这个故事有个美好的结局。一位广为人知的专业工程师立即注意到搜索引擎排名下降,并确认原因是 HTML 错误。他修复了错误并再次提交页面。几周后,他重新获得了搜索引擎排名。错误也伤害了目录!代码中的错误和问题会阻止搜索引擎工作——它也会影响目录。在搜索引擎策略中,致力于搜索引擎服务的 Yahoo 和 LookSmart 站点都拒绝此类连接和错误。我们的 网站 修复工具将确保您避免此 HTML 问题。错误如何输入代码?我的网站管理员知道代码 - 他不会犯错误。“不是故意的,而是让” s 考虑您的网站管理员所处的工作环境。有限的时间,多人一起工作,不断改进的压力网站 - 事实是,网站管理员的世界很忙,压力很大。疲惫的站长努力跟上,有时,一个小错误会改变网站,让改变高速旋转。考虑一下这个脚本 - 您的销售部门将一些很棒的新主页交给您的网站管理员。他们已与贵公司的 SEO 专家协调,并在新文本中战略性地放置关键字。为了小心,您的网站管理员提交了添加新文本的任务,但不小心剪掉了段落涂鸦的右方括号,因此您的文本如下所示:这是您的关键字富文本,当搜索引擎在不关闭括号的情况下读取您的页面时,销售和 SEO 添加在一起,它假定所有关键字丰富的正文都是段落标签的属性 - 并忽略它。搜索引擎在您的页面上强调可见的正文文本,这会尽可能地完善正文,明确添加关键字来推动您的网站与您的相关性只是失去了证明您与搜索引擎相关性的巨大机会。提高搜索引擎中的其他无错误排名和网站流量需要多少费用。明确地添加关键字来推动您的网站与您的相关性只是失去了一个巨大的机会来证明您与搜索引擎的相关性。提高搜索引擎中的其他无错误排名和网站流量需要多少费用。明确地添加关键字来推动您的网站与您的相关性只是失去了一个巨大的机会来证明您与搜索引擎的相关性。提高搜索引擎中的其他无错误排名和网站流量需要多少费用。
搜索引擎提交提示
网页优化只是登录搜索引擎的准备工作。最后,我们要把优化后的网站提交给搜索引擎,这也是网站注册的一个很重要的环节。
1. 出现在带有 关键词 的 URL 中(英文)
2. 关键词 (1-3) 出现在页面标题中
3. 关键词 标签出现在 关键词 (1-3)
4. 与 关键词 一起出现在描述标签中(主要的 关键词 重复 2 次)
5. 自然出现在内容中关键词
6. 出现第一段和最后一段内容关键词
7. H1、H2标签出现关键词
8. 导出链接锚文本收录 关键词
9. 图像的文件名收录 关键词
10. 出现在 关键词 的 ALT 属性中
11.关键词密度6-8%
12. 变为粗体或斜体 关键词
提高 关键词 排名的 28 个 SEO 技巧
28 个使 关键词 排名显着提高的 SEO 技巧:
关键词位置、密度、治疗
关键词 出现在 URL 中(英文)
关键词 (1-3) 出现在页面标题中
关键词 出现在 关键词 标记中 (1-3)
关键词 出现在描述标签中(主要的 关键词 重复了 2 次)
关键词 自然出现在内容中
内容的第一段和最后一段出现关键词
关键词 出现在 H1、H2 标签中
导出链接锚文本收录 关键词
图像的文件名收录 关键词
关键词 出现在 ALT 属性中
关键词密度6-8%
粗体或斜体 关键词
内容质量、更新频率、相关性
原创的内容最好了,不宜多次转载
内容独立,与其他页面至少有 30% 的差异
1000-2000字,合理切分
定期更新,最好每天更新
内容围绕页面关键词,与整个网站的主题相关
seq搜索引擎优化至少包括那几步?(告诉你做好网站优化需要走好哪几步)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-01-24 11:03
要想做好网站优化,首先要知道网站优化依赖哪些方面,找到关键,然后才能解决,做好. 今天,我会告诉你在网站优化中你需要做好什么。要走多少步。
一、首先,你需要链接到搜索引擎的偏好。不要在您的网页上显示图片或动画。搜索引擎无法识别这些东西,所以不要这样做。
二、标签的使用,标签的正确使用会增加或减少网站的权重,首先我们要让客户知道网站的重点是什么看到标签,搜索引擎看到网站标签和网站相关,那么自然权重会增加,那么我们标签中的关键词的权重也会增加。
三、注意链接的相关性,如果行业不相关,尽量不要做友情链接。这是网站权重的损失,网络之间的链接一定是相关的。
四、网站文章的布局要合理。首先要提高网站长尾关键词的排名。搜索引擎的第一步一般是抓取关键内容,索引要把重要内容放在最前面,所以需要改进网站长尾关键词,只要长tail关键词就是收录,它可以给网站带来很大的流量。
做好这些步骤,相信你的网站优化会更好。只有找到正确的方法,才能更好地解决问题。这是 网站 优化。虽然内部因素很多,但共同因素还是可以解决的。
网站 优化
Shiso Network为您提供网络推广、网络营销、网站建设、SEO优化、微信开发、网站托管等服务,服务热线:0311-66697360 查看全部
seq搜索引擎优化至少包括那几步?(告诉你做好网站优化需要走好哪几步)
要想做好网站优化,首先要知道网站优化依赖哪些方面,找到关键,然后才能解决,做好. 今天,我会告诉你在网站优化中你需要做好什么。要走多少步。
一、首先,你需要链接到搜索引擎的偏好。不要在您的网页上显示图片或动画。搜索引擎无法识别这些东西,所以不要这样做。
二、标签的使用,标签的正确使用会增加或减少网站的权重,首先我们要让客户知道网站的重点是什么看到标签,搜索引擎看到网站标签和网站相关,那么自然权重会增加,那么我们标签中的关键词的权重也会增加。
三、注意链接的相关性,如果行业不相关,尽量不要做友情链接。这是网站权重的损失,网络之间的链接一定是相关的。
四、网站文章的布局要合理。首先要提高网站长尾关键词的排名。搜索引擎的第一步一般是抓取关键内容,索引要把重要内容放在最前面,所以需要改进网站长尾关键词,只要长tail关键词就是收录,它可以给网站带来很大的流量。
做好这些步骤,相信你的网站优化会更好。只有找到正确的方法,才能更好地解决问题。这是 网站 优化。虽然内部因素很多,但共同因素还是可以解决的。
网站 优化
Shiso Network为您提供网络推广、网络营销、网站建设、SEO优化、微信开发、网站托管等服务,服务热线:0311-66697360
seq搜索引擎优化至少包括那几步?(SEO工作具体都有哪些前段seo优化一般包括哪些内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-01-24 10:18
所谓前端SEO优化一般包括什么内容,也就是搜索引擎优化的前端SEO优化一般包括什么内容。通过SEO,让网站在相关的关键词搜索页面中排名靠前,从而获得更多流量,最终实现转化。可以说,无论互联网发展到什么程度,只要有搜索引擎,只要搜索是人们解决问题最直接的方式,SEO就永远不会过时。
很多公司想做SEO,往往以为有一个网站,然后让人天天更新文章。事实上,SEO的工作远没有看起来那么简单。今天小编就和大家分享一下前端SEO优化中SEO工作的具体内容有哪些?
一、网站建筑
SEO 和 网站 建设密不可分。如果想让网站排名高,第一步是让搜索引擎爬虫爬取网站,为了按照算法排名,如果爬虫爬不上网站的页面@> 完全没有,所以没有排名。因此,在建站之初,就要考虑到SEO。主要体现在以下两个方面:
网站合理规划
主要有网站平面布局、辅助导航、内链设计、页面结构等。网站前期规划相当于为爬虫的到来做准备,让爬虫觉得这是一个友好、整洁的网站。
网站代码优化
这些主要包括站点地图、robots文件、404模板、301重定向、图片ALT、标题标签、网站TDK、关键词优化、nofollow、页面元等,通过代码优化让爬虫进入网站为了在网站中爬得更顺畅,将网站的关键词传递给爬虫以便更好地爬取,使其在网站中爬得更顺畅,传递关键词 网站 > 明确传给爬虫,这样不被抓就不会迷路,不会被抓到。
二、内容填充
网站的内容是网站的核心元素,是围绕企业品牌和经营产品进行的填充工作。向网页添加内容时,请注意以下几点:
关键词Layout:标题,文章段落中的关键词,排版第一段的SEO优化中一般收录什么内容;文章关键词 第一段和最后一段的布局;关键词布局等等。内链建设:主要体现在文章中设置锚文本。文章内容:虽然爬虫更喜欢原创的内容,但要以网站相关的主题为基础,保证网站内容的垂直性。追求原创,让网站内容缺乏话题性。更新频率:需要稳定更新,频率取决于企业网站的内容。热门的可以更频繁地更新,比如每天更新或者每周更新3-5次;对于小众方向网站,内容欠缺。如果不能每天或每周更新,可以选择每两周更新一次,或者每月更新一次。不要重复无内容的 网站 以使内容看起来丰富而频繁。@文章。三、站外优化
所谓站外优化,其实就是外链,可以通过友情链接、论坛、博客、文摘、自媒体平台等方式进行,注意一定要制作高质量的外链,千万不要做垃圾外链,很容易被搜索引擎down掉。
四、数据分析
通过百度站长工具或者其他平台的查询工具,可以看到网站的相关访问数据,比如来源关键词、用户访问路径等,通过相关数据可以监控SEO工作实时,未雨绸缪,如果有一些关键词流量下降,可以指定解决方案。
五、竞争分析
<p>除了自己做网站内外优化外,还要分析竞争对手的排名,他们的关键词设置,外链分布,内链布局,网站结构, 查看全部
seq搜索引擎优化至少包括那几步?(SEO工作具体都有哪些前段seo优化一般包括哪些内容)
所谓前端SEO优化一般包括什么内容,也就是搜索引擎优化的前端SEO优化一般包括什么内容。通过SEO,让网站在相关的关键词搜索页面中排名靠前,从而获得更多流量,最终实现转化。可以说,无论互联网发展到什么程度,只要有搜索引擎,只要搜索是人们解决问题最直接的方式,SEO就永远不会过时。
很多公司想做SEO,往往以为有一个网站,然后让人天天更新文章。事实上,SEO的工作远没有看起来那么简单。今天小编就和大家分享一下前端SEO优化中SEO工作的具体内容有哪些?
一、网站建筑
SEO 和 网站 建设密不可分。如果想让网站排名高,第一步是让搜索引擎爬虫爬取网站,为了按照算法排名,如果爬虫爬不上网站的页面@> 完全没有,所以没有排名。因此,在建站之初,就要考虑到SEO。主要体现在以下两个方面:
网站合理规划
主要有网站平面布局、辅助导航、内链设计、页面结构等。网站前期规划相当于为爬虫的到来做准备,让爬虫觉得这是一个友好、整洁的网站。
网站代码优化
这些主要包括站点地图、robots文件、404模板、301重定向、图片ALT、标题标签、网站TDK、关键词优化、nofollow、页面元等,通过代码优化让爬虫进入网站为了在网站中爬得更顺畅,将网站的关键词传递给爬虫以便更好地爬取,使其在网站中爬得更顺畅,传递关键词 网站 > 明确传给爬虫,这样不被抓就不会迷路,不会被抓到。
二、内容填充
网站的内容是网站的核心元素,是围绕企业品牌和经营产品进行的填充工作。向网页添加内容时,请注意以下几点:
关键词Layout:标题,文章段落中的关键词,排版第一段的SEO优化中一般收录什么内容;文章关键词 第一段和最后一段的布局;关键词布局等等。内链建设:主要体现在文章中设置锚文本。文章内容:虽然爬虫更喜欢原创的内容,但要以网站相关的主题为基础,保证网站内容的垂直性。追求原创,让网站内容缺乏话题性。更新频率:需要稳定更新,频率取决于企业网站的内容。热门的可以更频繁地更新,比如每天更新或者每周更新3-5次;对于小众方向网站,内容欠缺。如果不能每天或每周更新,可以选择每两周更新一次,或者每月更新一次。不要重复无内容的 网站 以使内容看起来丰富而频繁。@文章。三、站外优化
所谓站外优化,其实就是外链,可以通过友情链接、论坛、博客、文摘、自媒体平台等方式进行,注意一定要制作高质量的外链,千万不要做垃圾外链,很容易被搜索引擎down掉。
四、数据分析
通过百度站长工具或者其他平台的查询工具,可以看到网站的相关访问数据,比如来源关键词、用户访问路径等,通过相关数据可以监控SEO工作实时,未雨绸缪,如果有一些关键词流量下降,可以指定解决方案。
五、竞争分析
<p>除了自己做网站内外优化外,还要分析竞争对手的排名,他们的关键词设置,外链分布,内链布局,网站结构,
seq搜索引擎优化至少包括那几步?(加强SEO和内容营销关系的战略策略#1#2)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-22 20:16
下面,我列出了一些策略,以确保两个团队开始共同实现这一目标。
加强搜索引擎优化和内容营销之间关系的战略策略#1。将这两种策略组合成一个共同的内容路线图
在大多数组织中,内容和 SEO 团队都有策略文档。他们定义了每个团队的目标,并提供了实现这些目标的路线图。
为了开始加强这种关系,团队会比较他们的战略文件以确定:
为什么?内容团队可能已经意识到特定的受众问题。然后,他们的 SEO 同事通过关键字研究和其他分析对其进行验证。
例如,使用我们的 AI 驱动的内容编写者 Content Fusion,作者从关键词研究数据开始 SEO 以塑造内容。
在开始内容编写过程之前,首先确定要定位的搜索意图。
(内容融合关键字报告显示搜索意图。)
接下来,重要的是要找出哪些特定信息也会吸引您的受众。为此,请分析副本中收录的语义关键词,以确保您已掌握该主题。
我们在上图中看到了语义 关键词 的一些潜行高峰,但让我们看看完整列表:
(内容融合中的语义关键字报告。)
策略#2。审核 SEO 和引人入胜的内容
然后,内容作者或策略师会找到新的方法来丰富文案。您可以手动执行此操作并查看目标关键字的排名靠前的页面。此过程允许您确定要收录哪些新主题。上面提到的内容融合让您无需做足够的研究来理解语义相关领域、提高相关性并评估它们的权威与其他热门内容的关系就可以做到这一点。
反过来,搜索引擎优化团队确定新的关键字、目标并满足受众的需求。
例如,使用 seoClarity 的内容创意,内容作者可以研究观众在线提出的问题。
(内容创意报告查询“承诺戒指”。)
通过内容差距,作者可以将他们在搜索中的排名与竞争对手的关键词进行比较。在此过程中,他们确定了要定位和优化的新短语。
(内容差距报告显示了关键字和流量的机会。)
最后一步是对排名靠前的内容进行反向链接分析。首先,它决定了表现最好的页面有多少链接。它还确定他们是否能够重新创建任何反向链接机会。
(反向链接报告显示指向特定 URL 的链接。)
策略#3。通过 SEO 和内容数据识别用户需求
我相信 seo 和内容团队都知道这一点:
要与当今的观众互动,您需要了解他们的问题并提供信息来帮助他们解决问题。
当然,每个团队都在应对这一挑战。SEOS 着眼于关键词数据,以揭示其目标受众研究的趋势和主题。内容营销人员专注于社交媒体参与度、粘性和高流量博客,然后“重复”。
想象一下如果你结合这些方法会发生什么!
以下是它的工作原理:
作者确定了新的受众挑战。然后,她将她的发现传达给 SEO 团队,以研究与这些问题相匹配的相关关键字。
然后,他们都对主题进行微调以确保内容的全面覆盖,将他们的想法与搜索意图保持一致,并评估如何超越当前排名页面。
Seoclarity 的完整内容营销套件允许此流程在团队之间无缝工作,提供:
策略#4。一起评估比赛
为了满足排名,它必须针对竞争对手的表现。
事实上,分析排名级别的内容是发现新机会的最短途径。两个团队都应该提供揭示这些的见解。
搜索引擎优化团队利用他们的优势来确定使这些页面如此之高的因素。例如,长度、通用结构、收录的信息类型等。
您可以使用内容融合来简化您的流程,例如,显示排名内容的元数据。
(内容融合中的元描述报告。)
另一方面,内容团队可以利用社交媒体数据来确定这些页面如何与受众互动。反过来,发现如何创建更好的内容。
综上所述
搜索引擎优化和内容对于当今的任何营销策略都至关重要。不幸的是,我们经常听到他们选择独立工作的团队负责团队,尽管这两个团队本质上都在推动增长。
希望通过这个简短的指南,您已经发现了如何改变这种状况并结合每个团队的专业知识来推动更高的营销投资回报率。
内容团队和 SEO 团队如何协同工作?在下面的评论部分给我们留言! 查看全部
seq搜索引擎优化至少包括那几步?(加强SEO和内容营销关系的战略策略#1#2)
下面,我列出了一些策略,以确保两个团队开始共同实现这一目标。
加强搜索引擎优化和内容营销之间关系的战略策略#1。将这两种策略组合成一个共同的内容路线图
在大多数组织中,内容和 SEO 团队都有策略文档。他们定义了每个团队的目标,并提供了实现这些目标的路线图。
为了开始加强这种关系,团队会比较他们的战略文件以确定:
为什么?内容团队可能已经意识到特定的受众问题。然后,他们的 SEO 同事通过关键字研究和其他分析对其进行验证。
例如,使用我们的 AI 驱动的内容编写者 Content Fusion,作者从关键词研究数据开始 SEO 以塑造内容。
在开始内容编写过程之前,首先确定要定位的搜索意图。
(内容融合关键字报告显示搜索意图。)
接下来,重要的是要找出哪些特定信息也会吸引您的受众。为此,请分析副本中收录的语义关键词,以确保您已掌握该主题。
我们在上图中看到了语义 关键词 的一些潜行高峰,但让我们看看完整列表:
(内容融合中的语义关键字报告。)
策略#2。审核 SEO 和引人入胜的内容
然后,内容作者或策略师会找到新的方法来丰富文案。您可以手动执行此操作并查看目标关键字的排名靠前的页面。此过程允许您确定要收录哪些新主题。上面提到的内容融合让您无需做足够的研究来理解语义相关领域、提高相关性并评估它们的权威与其他热门内容的关系就可以做到这一点。
反过来,搜索引擎优化团队确定新的关键字、目标并满足受众的需求。
例如,使用 seoClarity 的内容创意,内容作者可以研究观众在线提出的问题。
(内容创意报告查询“承诺戒指”。)
通过内容差距,作者可以将他们在搜索中的排名与竞争对手的关键词进行比较。在此过程中,他们确定了要定位和优化的新短语。
(内容差距报告显示了关键字和流量的机会。)
最后一步是对排名靠前的内容进行反向链接分析。首先,它决定了表现最好的页面有多少链接。它还确定他们是否能够重新创建任何反向链接机会。
(反向链接报告显示指向特定 URL 的链接。)
策略#3。通过 SEO 和内容数据识别用户需求
我相信 seo 和内容团队都知道这一点:
要与当今的观众互动,您需要了解他们的问题并提供信息来帮助他们解决问题。
当然,每个团队都在应对这一挑战。SEOS 着眼于关键词数据,以揭示其目标受众研究的趋势和主题。内容营销人员专注于社交媒体参与度、粘性和高流量博客,然后“重复”。
想象一下如果你结合这些方法会发生什么!
以下是它的工作原理:
作者确定了新的受众挑战。然后,她将她的发现传达给 SEO 团队,以研究与这些问题相匹配的相关关键字。
然后,他们都对主题进行微调以确保内容的全面覆盖,将他们的想法与搜索意图保持一致,并评估如何超越当前排名页面。
Seoclarity 的完整内容营销套件允许此流程在团队之间无缝工作,提供:
策略#4。一起评估比赛
为了满足排名,它必须针对竞争对手的表现。
事实上,分析排名级别的内容是发现新机会的最短途径。两个团队都应该提供揭示这些的见解。
搜索引擎优化团队利用他们的优势来确定使这些页面如此之高的因素。例如,长度、通用结构、收录的信息类型等。
您可以使用内容融合来简化您的流程,例如,显示排名内容的元数据。
(内容融合中的元描述报告。)
另一方面,内容团队可以利用社交媒体数据来确定这些页面如何与受众互动。反过来,发现如何创建更好的内容。
综上所述
搜索引擎优化和内容对于当今的任何营销策略都至关重要。不幸的是,我们经常听到他们选择独立工作的团队负责团队,尽管这两个团队本质上都在推动增长。
希望通过这个简短的指南,您已经发现了如何改变这种状况并结合每个团队的专业知识来推动更高的营销投资回报率。
内容团队和 SEO 团队如何协同工作?在下面的评论部分给我们留言!
seq搜索引擎优化至少包括那几步?(网站优化SEO一般有哪些步骤呢[邵阳SEO]?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-21 22:06
我们搜索 SEO。百科对SEO的定义是:利用搜索引擎的搜索规则,提高网站目前在相关搜索引擎中的自然排名的一种方式。SEO包括两个方面:站内SEO和站外SEO;网站内外优化,提高网站在搜索引擎中的自然排名,吸引更多人点击,从而获得更多流量,达到网络营销和品牌建设的效果。
网站优化SEO[邵阳SEO]的一般步骤是什么?
在济南做了几年SEO优化并有一定经验的老魏认为,SEO大致分为五个主要环节。首先,挖掘网站的关键词,做长远发展。这是最重要的一步。分析关键词的长尾词、竞争对手的网站、关键词的预期排名等;二、网站的结构分析,整个网站要符合搜索引擎爬虫的喜好,去掉网站的不良内容,比如一些没用的js 、flash等,做合理的导航和链接;三、网站目录和页面,实现树状目录结构,金字塔模式,做好每个页面的布局优化;四、定期发布内容,蜘蛛我喜欢定期更新【邵阳SEO】网站,所以要合理安排时间更新网站,让搜索引擎明白网站的核心关键词是什么@> 是,link 合理扩展;五、网站流量分析,登录各大站长平台,查看页面的收录级别,分析网站的流量数据。如果这五点能做好,网站提升排名指日可待。并分析网站的流量数据。如果这五点能做好,网站提升排名指日可待。并分析网站的流量数据。如果这五点能做好,网站提升排名指日可待。
据调查,87%的网民会使用搜索引擎服务来查找他们需要的信息,以优化网页内容,使其符合用户的浏览习惯,同时不影响用户体验。为了提高搜索引擎排名,增加网站的知名度,达到营销效果,切记不要为了SEO而使用SEO。 查看全部
seq搜索引擎优化至少包括那几步?(网站优化SEO一般有哪些步骤呢[邵阳SEO]?)
我们搜索 SEO。百科对SEO的定义是:利用搜索引擎的搜索规则,提高网站目前在相关搜索引擎中的自然排名的一种方式。SEO包括两个方面:站内SEO和站外SEO;网站内外优化,提高网站在搜索引擎中的自然排名,吸引更多人点击,从而获得更多流量,达到网络营销和品牌建设的效果。
网站优化SEO[邵阳SEO]的一般步骤是什么?
在济南做了几年SEO优化并有一定经验的老魏认为,SEO大致分为五个主要环节。首先,挖掘网站的关键词,做长远发展。这是最重要的一步。分析关键词的长尾词、竞争对手的网站、关键词的预期排名等;二、网站的结构分析,整个网站要符合搜索引擎爬虫的喜好,去掉网站的不良内容,比如一些没用的js 、flash等,做合理的导航和链接;三、网站目录和页面,实现树状目录结构,金字塔模式,做好每个页面的布局优化;四、定期发布内容,蜘蛛我喜欢定期更新【邵阳SEO】网站,所以要合理安排时间更新网站,让搜索引擎明白网站的核心关键词是什么@> 是,link 合理扩展;五、网站流量分析,登录各大站长平台,查看页面的收录级别,分析网站的流量数据。如果这五点能做好,网站提升排名指日可待。并分析网站的流量数据。如果这五点能做好,网站提升排名指日可待。并分析网站的流量数据。如果这五点能做好,网站提升排名指日可待。
据调查,87%的网民会使用搜索引擎服务来查找他们需要的信息,以优化网页内容,使其符合用户的浏览习惯,同时不影响用户体验。为了提高搜索引擎排名,增加网站的知名度,达到营销效果,切记不要为了SEO而使用SEO。
seq搜索引擎优化至少包括那几步?(网站关键词优化哪一个前端网站的优化影响是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-20 02:07
我们这里所说的网站优化并不是针对某些特定关键词的排名进行优化,而是对网站整体页面进行优化,优化页面内容的布局,使网站在搜索引擎上的整体表现不错,可以让客户的转化率更高。例如,电子商务网站 或信息型企业网站 可能期望整个页面都在搜索引擎中。而不是在关键词搜索引擎排名上的一个或几个排名可能期望每个产品页面都有很好的转化率所以这里网站优化服务将发挥作用网站@k17的整体营销价值>而不是纯粹的搜索引擎排名值。
3、好网站优化可以适当降低企业宣传成本
我们都知道死链接不利于网站优化,但是死链接在网站上很常见。很多人想知道为什么网站总是有死链接,不知道有什么影响。让易帆的编辑为您解释一下。
最后,SEO优化排名需要实战才有发言权。在整个不断学习的过程中,善于总结和创新,相信你的网站优化可以取得不错的效果。如果你看了一些网站优化课程或者参加了相关培训学校之后不去实战,就说做就做,那么SEO优化排名就会起到反作用。
网站关键词要优化哪个前端网站2010 年优化:对 Web 的 30 条预测
标签收费模具搜索社交媒体 2010
阿里云服务器“爆品优惠”独家精选产品,历史时间最低优惠!
社交媒体
与 Twitter 相关的集成和应用程序在 2009 年很流行,而在 2010 年这种时尚趋势将重演。
Tumblr 在 Twitter 的阴影下再次成长,而当 Twitter 陷入黑暗时,Tumblr 最终可能会成为气候。
最终,社交媒体将只剩下几个大玩家,Twitter、Facebook,还有谁?
社交新闻报道互联网(Digg、Reddit)、便签互联网(Delicious)将会过时,事实上,它们已经输给了Twitter。
互联网的社交访问(StumbleUpon)早已不复存在,2008 年有十几个这样的网络,现在基础已经衰落,这种趋势将继续下去。
商务接待
很多客户没有达到一定规模的创业公司在烧完钱后就死了。
随着风险投资变得越来越稀少,越来越多的公司必须通过完全免费的整合收费来生存。
为了生存,企业和知名品牌必须在2010年制定社交媒体发展战略。
2010 年,Twitter 将刚刚开始盈利,商业服务帐户和查看数据和信息的费用。
移动
部分智能手机系统软件因销售市场不足而死掉。
iPhone 将失去市场份额,虽然 iPhone 仍然会发光,但他们不能仅仅依靠一件产品来保持发光。
谢谢谷歌,大家很可能会在手机上看到免费和免费通话,谷歌正在提前准备在真机上完成谷歌语音及其VOIP,完成真正的400通话。
营销
网络广告行业会更加专一,随着Web的完善,大家被骗的难度会越来越大。
网络上的广告将被内容运营所取代。
搜索
即时搜索将变得更加普遍。
为了保持在搜索广告销售市场的领先地位,谷歌和必应将相互效仿。
搜索定制将完成完整的个性化搜索。
搜索引擎优化
搜索引擎优化将无处不在,而不是 BBC。
许多搜索引擎优化机构将转入地下。
不管你喜不喜欢,你会看到越来越多的 jQuery 弹出窗口。
网页设计开发
移动智能终端再次蓬勃发展,针对移动终端的网页优化将越来越普遍。
HTML5 和 CSS3 将为网页室内设计师提供更多智能,但仍会向前适应。
YouTube 的审查将导致一些开源系统视频被放置在技术和健身运动中。
博客
移动应用
云计算技术和基于网络的手机软件将成为气候。
对端网站的内链建设怎么样,内链有哪些优势可供参考,除了考察网站的内链循环,还可以通过分析网站的外链,比如网站外链的数量和质量,网站友好链接的数量和质量等等,这样我们就可以看出两者的区别了我们的网站促销和同行。然后才知道我后期网站优化的方式和工作重点。
除了核心行业用户关键词的高搜索量,像长尾关键词也是关键词优化的重点。这是一个简单的长尾 关键词 挖掘技术。你在百度搜索框输入核心关键词,然后可以找到一些长尾关键词,比如你在搜索框中输入网站优化,那么你会得到上海网站优化,网站哪个更好等等。这些长尾关键词都是人搜的,不信你可以用百度索引搜这个关键词,你就会知道这次是长尾关键词百度索引。
SEO优化:影响网站优化排名4、附属链接失败的6个因素作为网站管理员,您应该经常检查友谊链接。一旦发现友情链接失效,会影响自己网站的关键词排名、权重、收录、快照掉落。毕竟,友情链接就像一个圆圈。把几个网站围成一圈,互相扶持。一旦出现故障,可能会认为圈子坏了,会被拉下来。SEO优化:影响网站优化排名的6个因素
说到遵义关键词,了解遵义关键词的相关知识点,有助于我们更好地选择遵义关键词。接下来,我们来看看还有哪些需要注意的信息。当人们搜索某个词时,网站在搜索结果中的排名很好,普通用户认为这些排名靠前的网站是比较靠谱的品牌。从SEO的角度来看,搜索商业价值高的关键词,自然排名网站,也是业内非常权威的网站。由于良好的排名带来的人气和流量,用户进入网站后,用户开始使用网站显示的联系方式与企业客服沟通,最终完成订单的转化。,
网站关键词优化哪个前端网站优化济南
标签网站外链排名长尾关键词网站优化关键词
济南SEO服务项目有哪些内容?
1、大师关键词:
11 总体目标 关键词 是什么意思?
12 如何找到关键词
13 如何找到人气关键词
14关键词市场竞争分析
15关键词选择过程
16关键词分类部署
17 如何正确选择创建关键词字典
18关键词位置、相对密度、解
19关键词相对密度深科学研究
2、长尾关键词:
21 什么是长尾关键词?
选择长尾的22个理由关键词
23网站优化长尾有什么作用关键词
24 详细讲解站内长尾关键词三部曲的合理布局
3、网站构造:
31 网站的一般结构
32网站施工对seo的危害
33 搜索引擎友好网站构造的三个规则
34 个 网站 最好的 网站 内部结构
35 不友好 网站 构建搜索引擎蜘蛛陷阱
36 网站的多孔结构是什么
37网站树结构和扁平树结构哪个更好
4、网址:
标准
42 静态数据 url 与动态 url
43301 跳转如何进行URL规范化设置
5、SEO 外部链接:
51 外链有哪些表现形式?
52 推广外链的一些常见问题
53 如何创建高质量的外部链接
54 哪些外部链接是欺诈性外部链接?
55 如何查看竞争对手的新外部链接
56 外部链接是否是SEO的唯一途径
57 不相关的外部链接有什么用?
58 思维拓展:现在外链怎么办?
6、seo专用工具应用:
61 强烈推荐很多seo好用的专用工具
综合查询工具的应用
63网站收录批量查询专用工具
64个网页相似度检测专用工具强烈推荐
65友链检测专用工具的应用
66网站历史时间搜索工具全集
死链接检测的专用工具
68网站地形图在线制作专用工具的应用
济南SEO数据如何进行统计分析?
1 做SEO前分析关键词排名数据信息
2网站系统日志检测与分析
3 哪些数据信息必须作为seo进行分析
4 SEO必须测试的其他四点数据信息
5 负面信息的个人行为正在损害您的网站排名
6 分析竞争对手的三种方法
济南SEO网站经典案例
1、济南搬家公司网站SEO实例
2、济南房地产企业网站SEO实例
3、济南培训机构网站SEO实例
4、济南家教补课网站SEO实例
5、济南男子医院门诊网站SEO实例
6、济南女子医院门诊网站SEO实例
7、济南家政医院门诊网站SEO实例
为什么济南公司网站做SEO?
每家公司都有自己的网站,不管别人怎么说,还是为了展示知名品牌,才刚刚开始从线下推广到线上,一批SEOer正在兴起。今天和大家讨论一下,济南的企业网站为什么要做SEO?
第一,可以快速在各大搜索引擎上获得不错的排名,就像在人流量很大的地区开店,每天都有很多人光顾,做生意会更好。网站 可以帮助公司赚钱。做好SEO和搜索引擎优化,需要进行网站优化。根据基于网页的优化策略和针对非网页的优化策略不同。达到优化网站的总体目标,最终提升网站网页在搜索引擎中排名的实际效果。根据网页的优化策略,可以理解为是针对网站进行优化,而不是根据网页的优化策略,俗称网站
二是互联网广告成本太高,部分中小企业负担不起,网站优化超额支付成本一键支付。网络上的免费餐太多了,想要节省网络营销成本,就需要进行网站优化。
对于公司来说,为了让自己的网站真正成为扩大公司知名度、拓宽公司产品营销渠道的服务平台,我认为有必要请技术专业的SEOer搜索引擎优化师到公司的< @网站进行整体优化,配合其他合理的搜索引擎营销推广等网站推广方式,提升网站的排名,真正为公司生成客户和订单信息,并帮公司赚到钱。
很多人可能会问,那我们就不用整天干别的了。我们每天都制作视频。我想说的是,兄弟姐妹们,你们可以上传不同名字的视频。您的一个视频可以多次使用。,天津网站优化公司排名,请不要硬着头皮,上传视频一点都不专业。不需要专业的技术人员或者优化师,公司任何人都可以做,而且视频引流的作用非常大,尤其是那些比较有帮助的视频,比如一些技术交流视频和一些文化课教程等。 ,会有很好的效果。
遵义seo内部优化 遵义网站对seo公司进行优化,访问者主要来源是网站的吸引力,一般是通过文章上网站,所以在网站的过程中@k7 在构造@>的时候,需要注意要权威,同时用更严格的数据来证明自己的可信度。同时文章要注意尽可能保证企业的专业性,帮助促进良好品牌的树立。描述的时候尽量说清楚,否则会被搜索引擎认为是混淆视听,显得毫无意义,访问量也会减少很多。
以上就是网站优化中如何避免蜘蛛陷阱的知识介绍。相信现在大家都明白了。也希望对大家有所帮助。如果您有任何问题,欢迎您随时与我们联系。
广西seo〖seo关键词优化〗要多练,敢练网站优化教程思维会帮助我们提高蜘蛛排名网站排名优化一定要有效百度优化需要分析网站 @>要看现在的情况,分析情况处理。您可以实现百度优化和网站布局更改和设计。毕竟百度优化网站排名优化的优势对个人和工厂都会有效。持之以恒是百度优化应该遵循的成功之路,适时网站布局变化也是必要的。其他操作方式:
如有任何问题,请联系站长61910465 查看全部
seq搜索引擎优化至少包括那几步?(网站关键词优化哪一个前端网站的优化影响是什么?)
我们这里所说的网站优化并不是针对某些特定关键词的排名进行优化,而是对网站整体页面进行优化,优化页面内容的布局,使网站在搜索引擎上的整体表现不错,可以让客户的转化率更高。例如,电子商务网站 或信息型企业网站 可能期望整个页面都在搜索引擎中。而不是在关键词搜索引擎排名上的一个或几个排名可能期望每个产品页面都有很好的转化率所以这里网站优化服务将发挥作用网站@k17的整体营销价值>而不是纯粹的搜索引擎排名值。
3、好网站优化可以适当降低企业宣传成本
我们都知道死链接不利于网站优化,但是死链接在网站上很常见。很多人想知道为什么网站总是有死链接,不知道有什么影响。让易帆的编辑为您解释一下。
最后,SEO优化排名需要实战才有发言权。在整个不断学习的过程中,善于总结和创新,相信你的网站优化可以取得不错的效果。如果你看了一些网站优化课程或者参加了相关培训学校之后不去实战,就说做就做,那么SEO优化排名就会起到反作用。
网站关键词要优化哪个前端网站2010 年优化:对 Web 的 30 条预测
标签收费模具搜索社交媒体 2010
阿里云服务器“爆品优惠”独家精选产品,历史时间最低优惠!
社交媒体
与 Twitter 相关的集成和应用程序在 2009 年很流行,而在 2010 年这种时尚趋势将重演。
Tumblr 在 Twitter 的阴影下再次成长,而当 Twitter 陷入黑暗时,Tumblr 最终可能会成为气候。
最终,社交媒体将只剩下几个大玩家,Twitter、Facebook,还有谁?
社交新闻报道互联网(Digg、Reddit)、便签互联网(Delicious)将会过时,事实上,它们已经输给了Twitter。
互联网的社交访问(StumbleUpon)早已不复存在,2008 年有十几个这样的网络,现在基础已经衰落,这种趋势将继续下去。
商务接待
很多客户没有达到一定规模的创业公司在烧完钱后就死了。
随着风险投资变得越来越稀少,越来越多的公司必须通过完全免费的整合收费来生存。
为了生存,企业和知名品牌必须在2010年制定社交媒体发展战略。
2010 年,Twitter 将刚刚开始盈利,商业服务帐户和查看数据和信息的费用。
移动
部分智能手机系统软件因销售市场不足而死掉。
iPhone 将失去市场份额,虽然 iPhone 仍然会发光,但他们不能仅仅依靠一件产品来保持发光。
谢谢谷歌,大家很可能会在手机上看到免费和免费通话,谷歌正在提前准备在真机上完成谷歌语音及其VOIP,完成真正的400通话。
营销
网络广告行业会更加专一,随着Web的完善,大家被骗的难度会越来越大。
网络上的广告将被内容运营所取代。
搜索
即时搜索将变得更加普遍。
为了保持在搜索广告销售市场的领先地位,谷歌和必应将相互效仿。
搜索定制将完成完整的个性化搜索。
搜索引擎优化
搜索引擎优化将无处不在,而不是 BBC。
许多搜索引擎优化机构将转入地下。
不管你喜不喜欢,你会看到越来越多的 jQuery 弹出窗口。
网页设计开发
移动智能终端再次蓬勃发展,针对移动终端的网页优化将越来越普遍。
HTML5 和 CSS3 将为网页室内设计师提供更多智能,但仍会向前适应。
YouTube 的审查将导致一些开源系统视频被放置在技术和健身运动中。
博客
移动应用
云计算技术和基于网络的手机软件将成为气候。
对端网站的内链建设怎么样,内链有哪些优势可供参考,除了考察网站的内链循环,还可以通过分析网站的外链,比如网站外链的数量和质量,网站友好链接的数量和质量等等,这样我们就可以看出两者的区别了我们的网站促销和同行。然后才知道我后期网站优化的方式和工作重点。
除了核心行业用户关键词的高搜索量,像长尾关键词也是关键词优化的重点。这是一个简单的长尾 关键词 挖掘技术。你在百度搜索框输入核心关键词,然后可以找到一些长尾关键词,比如你在搜索框中输入网站优化,那么你会得到上海网站优化,网站哪个更好等等。这些长尾关键词都是人搜的,不信你可以用百度索引搜这个关键词,你就会知道这次是长尾关键词百度索引。
SEO优化:影响网站优化排名4、附属链接失败的6个因素作为网站管理员,您应该经常检查友谊链接。一旦发现友情链接失效,会影响自己网站的关键词排名、权重、收录、快照掉落。毕竟,友情链接就像一个圆圈。把几个网站围成一圈,互相扶持。一旦出现故障,可能会认为圈子坏了,会被拉下来。SEO优化:影响网站优化排名的6个因素
说到遵义关键词,了解遵义关键词的相关知识点,有助于我们更好地选择遵义关键词。接下来,我们来看看还有哪些需要注意的信息。当人们搜索某个词时,网站在搜索结果中的排名很好,普通用户认为这些排名靠前的网站是比较靠谱的品牌。从SEO的角度来看,搜索商业价值高的关键词,自然排名网站,也是业内非常权威的网站。由于良好的排名带来的人气和流量,用户进入网站后,用户开始使用网站显示的联系方式与企业客服沟通,最终完成订单的转化。,
网站关键词优化哪个前端网站优化济南
标签网站外链排名长尾关键词网站优化关键词
济南SEO服务项目有哪些内容?
1、大师关键词:
11 总体目标 关键词 是什么意思?
12 如何找到关键词
13 如何找到人气关键词
14关键词市场竞争分析
15关键词选择过程
16关键词分类部署
17 如何正确选择创建关键词字典
18关键词位置、相对密度、解
19关键词相对密度深科学研究
2、长尾关键词:
21 什么是长尾关键词?
选择长尾的22个理由关键词
23网站优化长尾有什么作用关键词
24 详细讲解站内长尾关键词三部曲的合理布局
3、网站构造:
31 网站的一般结构
32网站施工对seo的危害
33 搜索引擎友好网站构造的三个规则
34 个 网站 最好的 网站 内部结构
35 不友好 网站 构建搜索引擎蜘蛛陷阱
36 网站的多孔结构是什么
37网站树结构和扁平树结构哪个更好
4、网址:
标准
42 静态数据 url 与动态 url
43301 跳转如何进行URL规范化设置
5、SEO 外部链接:
51 外链有哪些表现形式?
52 推广外链的一些常见问题
53 如何创建高质量的外部链接
54 哪些外部链接是欺诈性外部链接?
55 如何查看竞争对手的新外部链接
56 外部链接是否是SEO的唯一途径
57 不相关的外部链接有什么用?
58 思维拓展:现在外链怎么办?
6、seo专用工具应用:
61 强烈推荐很多seo好用的专用工具
综合查询工具的应用
63网站收录批量查询专用工具
64个网页相似度检测专用工具强烈推荐
65友链检测专用工具的应用
66网站历史时间搜索工具全集
死链接检测的专用工具
68网站地形图在线制作专用工具的应用
济南SEO数据如何进行统计分析?
1 做SEO前分析关键词排名数据信息
2网站系统日志检测与分析
3 哪些数据信息必须作为seo进行分析
4 SEO必须测试的其他四点数据信息
5 负面信息的个人行为正在损害您的网站排名
6 分析竞争对手的三种方法
济南SEO网站经典案例
1、济南搬家公司网站SEO实例
2、济南房地产企业网站SEO实例
3、济南培训机构网站SEO实例
4、济南家教补课网站SEO实例
5、济南男子医院门诊网站SEO实例
6、济南女子医院门诊网站SEO实例
7、济南家政医院门诊网站SEO实例
为什么济南公司网站做SEO?
每家公司都有自己的网站,不管别人怎么说,还是为了展示知名品牌,才刚刚开始从线下推广到线上,一批SEOer正在兴起。今天和大家讨论一下,济南的企业网站为什么要做SEO?
第一,可以快速在各大搜索引擎上获得不错的排名,就像在人流量很大的地区开店,每天都有很多人光顾,做生意会更好。网站 可以帮助公司赚钱。做好SEO和搜索引擎优化,需要进行网站优化。根据基于网页的优化策略和针对非网页的优化策略不同。达到优化网站的总体目标,最终提升网站网页在搜索引擎中排名的实际效果。根据网页的优化策略,可以理解为是针对网站进行优化,而不是根据网页的优化策略,俗称网站
二是互联网广告成本太高,部分中小企业负担不起,网站优化超额支付成本一键支付。网络上的免费餐太多了,想要节省网络营销成本,就需要进行网站优化。
对于公司来说,为了让自己的网站真正成为扩大公司知名度、拓宽公司产品营销渠道的服务平台,我认为有必要请技术专业的SEOer搜索引擎优化师到公司的< @网站进行整体优化,配合其他合理的搜索引擎营销推广等网站推广方式,提升网站的排名,真正为公司生成客户和订单信息,并帮公司赚到钱。
很多人可能会问,那我们就不用整天干别的了。我们每天都制作视频。我想说的是,兄弟姐妹们,你们可以上传不同名字的视频。您的一个视频可以多次使用。,天津网站优化公司排名,请不要硬着头皮,上传视频一点都不专业。不需要专业的技术人员或者优化师,公司任何人都可以做,而且视频引流的作用非常大,尤其是那些比较有帮助的视频,比如一些技术交流视频和一些文化课教程等。 ,会有很好的效果。
遵义seo内部优化 遵义网站对seo公司进行优化,访问者主要来源是网站的吸引力,一般是通过文章上网站,所以在网站的过程中@k7 在构造@>的时候,需要注意要权威,同时用更严格的数据来证明自己的可信度。同时文章要注意尽可能保证企业的专业性,帮助促进良好品牌的树立。描述的时候尽量说清楚,否则会被搜索引擎认为是混淆视听,显得毫无意义,访问量也会减少很多。
以上就是网站优化中如何避免蜘蛛陷阱的知识介绍。相信现在大家都明白了。也希望对大家有所帮助。如果您有任何问题,欢迎您随时与我们联系。
广西seo〖seo关键词优化〗要多练,敢练网站优化教程思维会帮助我们提高蜘蛛排名网站排名优化一定要有效百度优化需要分析网站 @>要看现在的情况,分析情况处理。您可以实现百度优化和网站布局更改和设计。毕竟百度优化网站排名优化的优势对个人和工厂都会有效。持之以恒是百度优化应该遵循的成功之路,适时网站布局变化也是必要的。其他操作方式:
如有任何问题,请联系站长61910465
seq搜索引擎优化至少包括那几步?(1前端需要注意哪些SEO2的的请求方法用途)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-19 15:21
1 SEO在前端需要注意什么2
title 和 alt 3 有什么区别 使用了几种 HTTP 请求方式
基础版
详细版
在浏览器地址栏中输入 URL 以查看缓存。如果请求的资源在缓存中并且是新鲜的,则跳转到转码步骤。如果资源没有被缓存,则发起一个新的请求。如果有缓存,检查是否足够新鲜,直接提供给客户。侧,否则向服务器进行身份验证。检查新鲜度通常有两个HTTP头来控制Expires和Cache-Control:HTTP1.0提供Expires,该值是一个绝对时间表示缓存新鲜日期HTTP1.1增加Cache-Control:max-年龄=,
2)被css隐藏的节点,比如display: none 对于每个可见节点,找到合适的CSSOM规则,应用可见节点的内容,计算样式。js解析如下:浏览器创建一个Document对象并解析HTML,将解析后的元素和文本节点添加到文档中。此时,document.readystate 正在加载。当 HTML 解析器遇到没有 async 和 defer 的脚本时,将它们添加到文档中,然后执行内联或外部脚本。脚本是同步执行的,并且在脚本下载和执行时会暂停解析器。这允许使用 document.write() 将文本插入到输入流中。同步脚本通常只是简单地定义函数并注册可以遍历和操作脚本及其先前文档内容的事件处理程序。当解析器遇到设置了 async 属性的脚本时,它会开始下载脚本并继续解析文档。该脚本将在下载后立即执行,但解析器不会停止并等待它下载。禁止异步脚本使用 document.write(),它们可以访问自己的脚本和之前的文档元素。解析文档时,document.readState 变为交互式。所有延迟脚本都按照它们在文档中出现的顺序执行,延迟脚本可以访问完整的文档树。, 禁止使用 document.write() 浏览器触发 Document 对象上的 DOMContentLoaded 事件。此时,文档已经完全解析完毕,浏览器可能还在等待图片等内容的加载。
详细的短版
<p>从浏览器接收url到开启网络请求线程(这部分可以扩展浏览器的机制以及进程与线程的关系),启动网络线程发出完整的HTTP请求(这部分涉及到dns查询, TCP/IP请求、互联网五层协议栈知识等)从服务器接收请求到相应后台接收请求(这部分可能涉及负载均衡、安全拦截、后台内部处理等) ) 后台与前台的HTTP交互(这部分包括HTTP的headers、响应码、消息结构、cookies等知识,可以提到静态资源的cookie优化,以及编解码,比如gzip压缩。 , ETag, 捕捉控制等)浏览器接收到HTTP包后的解析过程(解析html-词法分析然后解析成dom树,解析css生成css规则树,合并成render树,然后布局,paint渲染,复合层组成、GPU绘制、外链资源处理、加载和DOMContentLoaded等) CSS可视化格式模型(元素渲染规则,如收录块、控制框、BFC、IFC等概念) JS引擎解析过程(JS解释阶段、预处理stage、执行阶段生成执行上下文、VO、作用域链、回收机制等)其他(可以扩展不同的知识模块,如跨域、web安全、混合模式等) #5 怎么做 < @网站性能优化性能优化性能优化解析css生成css规则树,合并成render树,然后布局,paint渲染,复合层合成,GPU绘制,外链资源处理,loaded和DOMContentLoaded等) CSS可视化格式模型(元素渲染规则,如如收录块、控制框、BFC、IFC等概念)JS引擎解析过程(JS解释阶段、预处理阶段、执行阶段生成执行上下文、VO、作用域链、回收机制等)其他(可以扩展不同的知识模块,比如跨域、web安全、混合模式等)#5怎么做 查看全部
seq搜索引擎优化至少包括那几步?(1前端需要注意哪些SEO2的的请求方法用途)
1 SEO在前端需要注意什么2
title 和 alt 3 有什么区别 使用了几种 HTTP 请求方式
基础版
详细版
在浏览器地址栏中输入 URL 以查看缓存。如果请求的资源在缓存中并且是新鲜的,则跳转到转码步骤。如果资源没有被缓存,则发起一个新的请求。如果有缓存,检查是否足够新鲜,直接提供给客户。侧,否则向服务器进行身份验证。检查新鲜度通常有两个HTTP头来控制Expires和Cache-Control:HTTP1.0提供Expires,该值是一个绝对时间表示缓存新鲜日期HTTP1.1增加Cache-Control:max-年龄=,
2)被css隐藏的节点,比如display: none 对于每个可见节点,找到合适的CSSOM规则,应用可见节点的内容,计算样式。js解析如下:浏览器创建一个Document对象并解析HTML,将解析后的元素和文本节点添加到文档中。此时,document.readystate 正在加载。当 HTML 解析器遇到没有 async 和 defer 的脚本时,将它们添加到文档中,然后执行内联或外部脚本。脚本是同步执行的,并且在脚本下载和执行时会暂停解析器。这允许使用 document.write() 将文本插入到输入流中。同步脚本通常只是简单地定义函数并注册可以遍历和操作脚本及其先前文档内容的事件处理程序。当解析器遇到设置了 async 属性的脚本时,它会开始下载脚本并继续解析文档。该脚本将在下载后立即执行,但解析器不会停止并等待它下载。禁止异步脚本使用 document.write(),它们可以访问自己的脚本和之前的文档元素。解析文档时,document.readState 变为交互式。所有延迟脚本都按照它们在文档中出现的顺序执行,延迟脚本可以访问完整的文档树。, 禁止使用 document.write() 浏览器触发 Document 对象上的 DOMContentLoaded 事件。此时,文档已经完全解析完毕,浏览器可能还在等待图片等内容的加载。
详细的短版
<p>从浏览器接收url到开启网络请求线程(这部分可以扩展浏览器的机制以及进程与线程的关系),启动网络线程发出完整的HTTP请求(这部分涉及到dns查询, TCP/IP请求、互联网五层协议栈知识等)从服务器接收请求到相应后台接收请求(这部分可能涉及负载均衡、安全拦截、后台内部处理等) ) 后台与前台的HTTP交互(这部分包括HTTP的headers、响应码、消息结构、cookies等知识,可以提到静态资源的cookie优化,以及编解码,比如gzip压缩。 , ETag, 捕捉控制等)浏览器接收到HTTP包后的解析过程(解析html-词法分析然后解析成dom树,解析css生成css规则树,合并成render树,然后布局,paint渲染,复合层组成、GPU绘制、外链资源处理、加载和DOMContentLoaded等) CSS可视化格式模型(元素渲染规则,如收录块、控制框、BFC、IFC等概念) JS引擎解析过程(JS解释阶段、预处理stage、执行阶段生成执行上下文、VO、作用域链、回收机制等)其他(可以扩展不同的知识模块,如跨域、web安全、混合模式等) #5 怎么做 < @网站性能优化性能优化性能优化解析css生成css规则树,合并成render树,然后布局,paint渲染,复合层合成,GPU绘制,外链资源处理,loaded和DOMContentLoaded等) CSS可视化格式模型(元素渲染规则,如如收录块、控制框、BFC、IFC等概念)JS引擎解析过程(JS解释阶段、预处理阶段、执行阶段生成执行上下文、VO、作用域链、回收机制等)其他(可以扩展不同的知识模块,比如跨域、web安全、混合模式等)#5怎么做
seq搜索引擎优化至少包括那几步?(企达搜索引擎优化工具(疯狂相关),帮你快速提高网站流量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-01-17 05:25
各位站长,今天给大家介绍一款奇达搜索引擎优化工具(疯狂相关),可以帮助您快速推广相关搜索关键词,帮助您快速提升网站的流量,快速提升人气,用于跟踪国内各大搜索引擎的算法更专业、更有效、更易于使用。
软件说明:
当我们进入搜索引擎首页时,当你在搜索框中输入关键词时,网站会根据你的输入显示一个下拉提示,称为“关联提示区” . 按钮后的页面底部会有一些相关的搜索提示词,称为“相关搜索区”。
“疯狂关联”是针对“关联提示区”和“关联搜索区”优化的SEO工具。这些领域的排名有复杂的算法,可能会有搜索引擎的人为干预,但更多的还是机器自动处理的。所以我们得出结论:优化软件不是万能的,但绝对不可能不优化软件。
本软件采用“租借制”,按天收费。与同类软件上千元相比,成本更低,注册更灵活。为什么不花几块钱试试优化效果呢?
主要特征:
1)。支持国内主要搜索引擎:包括:百度、谷歌、雅虎、搜搜、搜狗、有道、必应;
2).多任务支持:多个任务可以同时刷新,互不干扰。程序在后台运行,不影响前台运行;
3).灵活代理:程序自动搜索代理服务器,未来还将支持ADSL断线换IP,还支持混合模式,即先使用代理服务器刷新几次,然后断开并更改IP并刷新几次,依此类推;
4).人性化设计:继承了“疯狂刷新”的一些特性,比如定时启动和停止任务,比如自动查询相关搜索排名,比如批量设置任务参数等;
5).灵活的注册方式:节目采用“租借制”,按天收费。您可以根据需要选择注册1天或365天或更长时间。如果软件有效,请购买长期许可证。如果效果不好,就不会再更新了。用户有主动权;
6)。更宽松的授权方式:软件不限机器,一个关键词对应一个激活码,可以在任何机器上使用。就算是出差也不用着急,去网吧打包一台机器,输入激活码,刷卡就可以了。
重要的提示:
搜索引擎中的相关搜索和下拉提示是另一种 SEO 优化方法。您需要一定的专业知识才能灵活使用它们以达到最佳效果。如果您不知道什么是SEO,请填写相关知识。. 疯狂相关软件是精通SEO优化技术的专业人士的SEO助手工具。如果你是 SEO 的门外汉,那么这个软件可能不适合你。
SEO是一项高风险、高收益的工作。如果用得好,可以节省大量的广告费用,对网络推广有很好的效果。否则可能导致网站为K,得不偿失。因此,在下载疯狂的相关软件之前,您需要对这款软件的功能和风险有一个清晰的认识。
参数介绍
启动疯狂相关,点击添加按钮进入任务窗口,设置通用参数,然后选择“搜索点击”选项卡,看到如下界面:
1.启用搜索点击
选中以启用点击功能,取消选择以关闭搜索点击功能。
2.网址链接
请输入要点击的网站链接,该链接必须在搜索目标词时出现在搜索结果中,如果您的网站没有被搜索引擎收录搜索到,那么程序无法完成单击功能。
程序点击时使用模糊匹配,只要搜索结果中的链接收录用户输入的内容,匹配成功。因此,您可以只输入链接的一部分进行模糊匹配;您还可以输入完整的链接以完全匹配页面。
如上图所示的用户设置的URL链接,在搜索目标词“疯狂相关”的过程中,只要在搜索结果中找到收录的链接,就认为匹配成功并点击,即使搜索结果中的链接指向该页面,程序也认为匹配成功,这称为模糊匹配,即输入的链接越短,越容易匹配成功,输入链接越精确,匹配范围越小。
3.搜索范围
搜索范围也可以称为点击范围,意思是软件在转到用户设置的页面时,只会搜索搜索结果中的链接,匹配成功则点击。在第一个框中输入起始页码,在第二个框中输入结束页码。
如上图所示,搜索范围为2-5页。程序运行时,只会匹配第二到第五页的搜索结果,点击收录的链接。自动跳过第一页和第五页之后的结果,也就是说,即使搜索“疯狂相关”,第一页也有启达软件的链接,程序不会点击,因为点击由用户设置 范围从第二页开始。
4.点击机会
如果每次刷新操作都点击了指定页面,那么机器刷新的痕迹在搜索引擎眼里就太重了,所以有一定概率给用户设置。概率越高,被点击的可能性就越大,反之亦然。
5.点击图层
点击层数是指点击用户设置的链接后,软件继续模拟点击的层数。如上图,中间层数为5,表示从搜索引擎点击后,页面中的链接会继续被点击。随机点击循环5次,模拟用户从搜索引擎进入网站后继续浏览其他页面的过程。
分层点击的过程:首先在搜索结果中的某个页面,我们称之为A站,输入用户设置的网站,然后根据A站随机选择一个链接点击进入B站. 基于B站,随机点击进入C站,以此类推,直到点击用户设置的层数。
在随机点击的过程中,软件不区分站内链接和站外链接,也就是说,无论是站内链接还是站外链接,都可能被点击。由于 Flash 中的链接无法提取,所以本软件不会点击 Flash 中的链接。
发行说明:
1.刷新过程增加隐私浏览模式,隔离系统cookie;
2.增强了清除缓存和cookies的能力;
3.更新搜狗刷新算法;
4.更新谷歌的点击算法;
5.更新雅虎点击算法;
金华seo优化工具(jinhua关键词查询工具)6.8.7绿色免费版
类型:搜索查询大小:1.6M 语言:中文时间:8-6 评分:5.0
亲,因为这个软件有注册机或者是易语言写的,涉及到内存的读写,所以被360、QQ管家等杀毒安全防护软件举报。它不会收录任何损坏用户计算机的恶意绑定软件。本软件经本站编辑在虚拟机上测试,未发现本软件对电脑有任何影响。这纯粹是一个误报。请自行决定是否下载。如需使用软件,请将软件加入信任列表,请参考本站360病毒举报处理文档或阅读下载帮助
电脑正式版
安卓官方手机版
IOS官方手机版 查看全部
seq搜索引擎优化至少包括那几步?(企达搜索引擎优化工具(疯狂相关),帮你快速提高网站流量)
各位站长,今天给大家介绍一款奇达搜索引擎优化工具(疯狂相关),可以帮助您快速推广相关搜索关键词,帮助您快速提升网站的流量,快速提升人气,用于跟踪国内各大搜索引擎的算法更专业、更有效、更易于使用。
软件说明:
当我们进入搜索引擎首页时,当你在搜索框中输入关键词时,网站会根据你的输入显示一个下拉提示,称为“关联提示区” . 按钮后的页面底部会有一些相关的搜索提示词,称为“相关搜索区”。
“疯狂关联”是针对“关联提示区”和“关联搜索区”优化的SEO工具。这些领域的排名有复杂的算法,可能会有搜索引擎的人为干预,但更多的还是机器自动处理的。所以我们得出结论:优化软件不是万能的,但绝对不可能不优化软件。
本软件采用“租借制”,按天收费。与同类软件上千元相比,成本更低,注册更灵活。为什么不花几块钱试试优化效果呢?
主要特征:
1)。支持国内主要搜索引擎:包括:百度、谷歌、雅虎、搜搜、搜狗、有道、必应;
2).多任务支持:多个任务可以同时刷新,互不干扰。程序在后台运行,不影响前台运行;
3).灵活代理:程序自动搜索代理服务器,未来还将支持ADSL断线换IP,还支持混合模式,即先使用代理服务器刷新几次,然后断开并更改IP并刷新几次,依此类推;
4).人性化设计:继承了“疯狂刷新”的一些特性,比如定时启动和停止任务,比如自动查询相关搜索排名,比如批量设置任务参数等;
5).灵活的注册方式:节目采用“租借制”,按天收费。您可以根据需要选择注册1天或365天或更长时间。如果软件有效,请购买长期许可证。如果效果不好,就不会再更新了。用户有主动权;
6)。更宽松的授权方式:软件不限机器,一个关键词对应一个激活码,可以在任何机器上使用。就算是出差也不用着急,去网吧打包一台机器,输入激活码,刷卡就可以了。
重要的提示:
搜索引擎中的相关搜索和下拉提示是另一种 SEO 优化方法。您需要一定的专业知识才能灵活使用它们以达到最佳效果。如果您不知道什么是SEO,请填写相关知识。. 疯狂相关软件是精通SEO优化技术的专业人士的SEO助手工具。如果你是 SEO 的门外汉,那么这个软件可能不适合你。
SEO是一项高风险、高收益的工作。如果用得好,可以节省大量的广告费用,对网络推广有很好的效果。否则可能导致网站为K,得不偿失。因此,在下载疯狂的相关软件之前,您需要对这款软件的功能和风险有一个清晰的认识。
参数介绍
启动疯狂相关,点击添加按钮进入任务窗口,设置通用参数,然后选择“搜索点击”选项卡,看到如下界面:
1.启用搜索点击
选中以启用点击功能,取消选择以关闭搜索点击功能。
2.网址链接
请输入要点击的网站链接,该链接必须在搜索目标词时出现在搜索结果中,如果您的网站没有被搜索引擎收录搜索到,那么程序无法完成单击功能。
程序点击时使用模糊匹配,只要搜索结果中的链接收录用户输入的内容,匹配成功。因此,您可以只输入链接的一部分进行模糊匹配;您还可以输入完整的链接以完全匹配页面。
如上图所示的用户设置的URL链接,在搜索目标词“疯狂相关”的过程中,只要在搜索结果中找到收录的链接,就认为匹配成功并点击,即使搜索结果中的链接指向该页面,程序也认为匹配成功,这称为模糊匹配,即输入的链接越短,越容易匹配成功,输入链接越精确,匹配范围越小。
3.搜索范围
搜索范围也可以称为点击范围,意思是软件在转到用户设置的页面时,只会搜索搜索结果中的链接,匹配成功则点击。在第一个框中输入起始页码,在第二个框中输入结束页码。
如上图所示,搜索范围为2-5页。程序运行时,只会匹配第二到第五页的搜索结果,点击收录的链接。自动跳过第一页和第五页之后的结果,也就是说,即使搜索“疯狂相关”,第一页也有启达软件的链接,程序不会点击,因为点击由用户设置 范围从第二页开始。
4.点击机会
如果每次刷新操作都点击了指定页面,那么机器刷新的痕迹在搜索引擎眼里就太重了,所以有一定概率给用户设置。概率越高,被点击的可能性就越大,反之亦然。
5.点击图层
点击层数是指点击用户设置的链接后,软件继续模拟点击的层数。如上图,中间层数为5,表示从搜索引擎点击后,页面中的链接会继续被点击。随机点击循环5次,模拟用户从搜索引擎进入网站后继续浏览其他页面的过程。
分层点击的过程:首先在搜索结果中的某个页面,我们称之为A站,输入用户设置的网站,然后根据A站随机选择一个链接点击进入B站. 基于B站,随机点击进入C站,以此类推,直到点击用户设置的层数。
在随机点击的过程中,软件不区分站内链接和站外链接,也就是说,无论是站内链接还是站外链接,都可能被点击。由于 Flash 中的链接无法提取,所以本软件不会点击 Flash 中的链接。
发行说明:
1.刷新过程增加隐私浏览模式,隔离系统cookie;
2.增强了清除缓存和cookies的能力;
3.更新搜狗刷新算法;
4.更新谷歌的点击算法;
5.更新雅虎点击算法;
金华seo优化工具(jinhua关键词查询工具)6.8.7绿色免费版
类型:搜索查询大小:1.6M 语言:中文时间:8-6 评分:5.0
亲,因为这个软件有注册机或者是易语言写的,涉及到内存的读写,所以被360、QQ管家等杀毒安全防护软件举报。它不会收录任何损坏用户计算机的恶意绑定软件。本软件经本站编辑在虚拟机上测试,未发现本软件对电脑有任何影响。这纯粹是一个误报。请自行决定是否下载。如需使用软件,请将软件加入信任列表,请参考本站360病毒举报处理文档或阅读下载帮助
电脑正式版
安卓官方手机版
IOS官方手机版
seq搜索引擎优化至少包括那几步?(湖南网站优化:电子邮件营销是可以帮助你的SEO工作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-17 05:23
电子邮件营销现在被越来越广泛地使用。说到推广方式,湖南网站优化相信大家可以说很多,这里就不重复了,直接进入正题。搜索引擎优化的这方面之前很少有人讨论过,所以今天我要谈谈电子邮件营销,它可以帮助您的 SEO 工作。数字营销是一件复杂的事情,必须将工作的各个方面有效地结合起来,才能获得有针对性的流量和转化。电子邮件营销是一个很大的话题,我们在这里谈论的是电子邮件营销在seo工作中的作用。众所周知,成功的 SEO 的两大支柱是杀手级内容和高质量的反向链接。SEO的最终目标是目标转换。
那么,我们如何才能充分利用电子邮件营销,以及如何在 seo 中获得电子邮件营销帮助?我们从几个方面来谈:
一、内容
创建内容是一项艰苦的工作。当它被创建时,我们得到了它的大部分里程。网络营销的新手经常犯在网络上重复使用相同内容的错误,例如,将相同的帖子放在他们的主要 网站文章 上,然后放在博客和 文章 目录上,反向链接的好处。但是,搜索引擎眼中的“转载”只会创建重复的内容,这往往会伤害您的 网站 SEO,也会降低这些反向链接的价值。然而,尽管这在未来可能会改变,但当前的搜索引擎无法读取或索引电子邮件。如果您有一个邮件列表,您可以创建一个时事通讯并将其通过电子邮件发送给您的用户,也可以将其发布到您的 网站 上,而无需担心重复。这和双倍里程是一样的。
二、反向链接
这就是 SEO 的重点。链接建设的挑战之一是让潜在读者知道您拥有新鲜和令人惊叹的内容。营销人员越来越意识到社交网络推广可以帮助这个部门,但他们有时会忘记好的旧电子邮件也一样好!使用您的电子邮件通讯让您的用户知道您更新了 <网站,包括指向新页面简要说明的链接。这将为这些页面带来流量,并且用户会想要您的反向链接。如果您的电子邮件通讯通过转发“传播开来”,链接奇迹就会发生。
三、目标转换
如果你的产品或服务的销售周期长、复杂,湖南SEO想说的是,单靠SEO是做不到的。有时,潜在客户在承诺购买一种或另一种解决方案之前需要整整两个月的时间进行尽职调查。他们倾向于从信息而不是面向贸易的搜索查询开始。客户可能首先找到您的网站,并通过某种查询了解您的网站,但他们也很容易忘记您。但是,如果您让他们订阅时事通讯,您可以在整个销售周期中建立信任并保持品牌。在这种情况下,电子邮件营销不一定会改善您的 SEO 等,但它可以帮助它实现目标,好吧,写到这里,希望 文章 能启发大家。
您可能喜欢下面的 文章? 查看全部
seq搜索引擎优化至少包括那几步?(湖南网站优化:电子邮件营销是可以帮助你的SEO工作)
电子邮件营销现在被越来越广泛地使用。说到推广方式,湖南网站优化相信大家可以说很多,这里就不重复了,直接进入正题。搜索引擎优化的这方面之前很少有人讨论过,所以今天我要谈谈电子邮件营销,它可以帮助您的 SEO 工作。数字营销是一件复杂的事情,必须将工作的各个方面有效地结合起来,才能获得有针对性的流量和转化。电子邮件营销是一个很大的话题,我们在这里谈论的是电子邮件营销在seo工作中的作用。众所周知,成功的 SEO 的两大支柱是杀手级内容和高质量的反向链接。SEO的最终目标是目标转换。
那么,我们如何才能充分利用电子邮件营销,以及如何在 seo 中获得电子邮件营销帮助?我们从几个方面来谈:
一、内容
创建内容是一项艰苦的工作。当它被创建时,我们得到了它的大部分里程。网络营销的新手经常犯在网络上重复使用相同内容的错误,例如,将相同的帖子放在他们的主要 网站文章 上,然后放在博客和 文章 目录上,反向链接的好处。但是,搜索引擎眼中的“转载”只会创建重复的内容,这往往会伤害您的 网站 SEO,也会降低这些反向链接的价值。然而,尽管这在未来可能会改变,但当前的搜索引擎无法读取或索引电子邮件。如果您有一个邮件列表,您可以创建一个时事通讯并将其通过电子邮件发送给您的用户,也可以将其发布到您的 网站 上,而无需担心重复。这和双倍里程是一样的。
二、反向链接
这就是 SEO 的重点。链接建设的挑战之一是让潜在读者知道您拥有新鲜和令人惊叹的内容。营销人员越来越意识到社交网络推广可以帮助这个部门,但他们有时会忘记好的旧电子邮件也一样好!使用您的电子邮件通讯让您的用户知道您更新了 <网站,包括指向新页面简要说明的链接。这将为这些页面带来流量,并且用户会想要您的反向链接。如果您的电子邮件通讯通过转发“传播开来”,链接奇迹就会发生。
三、目标转换
如果你的产品或服务的销售周期长、复杂,湖南SEO想说的是,单靠SEO是做不到的。有时,潜在客户在承诺购买一种或另一种解决方案之前需要整整两个月的时间进行尽职调查。他们倾向于从信息而不是面向贸易的搜索查询开始。客户可能首先找到您的网站,并通过某种查询了解您的网站,但他们也很容易忘记您。但是,如果您让他们订阅时事通讯,您可以在整个销售周期中建立信任并保持品牌。在这种情况下,电子邮件营销不一定会改善您的 SEO 等,但它可以帮助它实现目标,好吧,写到这里,希望 文章 能启发大家。
您可能喜欢下面的 文章?
seq搜索引擎优化至少包括那几步?(基于Vue和Quasar的前端SPA项目实战之数据库逆向(十二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-16 09:03
基于Vue和Quasar的前端SPA项目数据库逆向(十二)回顾
通过引入之前的文章“开源免费”动态表单设计器(五)基于Vue和Quasar),实现动态表单功能。如果是一个全新的项目,通过配置元数据,创建物理表,这样就可以自动实现业务数据的CRUD增删改查。但是如果数据库表已经存在,如何通过配置表单元数据来管理呢?这时候就需要数据库逆向功能了。
介绍
数据库逆向是读取数据库物理表schema信息,然后生成表单元数据,可以认为是“dbfirst”模式,即先有数据库表,然后根据表生成元数据。逆向形式的后续操作与普通动态形式类似。
用户界面界面
数据库反向
输入物理表名,启用“数据库反向”功能,然后点击“加载元数据”,表单字段相关的元数据信息就会自动填充。
数据表准备
以ca_product产品为例,通过phpmyadmin创建表
#创建产品表
CREATE TABLE `ca_product` (
`id` bigint UNSIGNED NOT NULL COMMENT '编号',
`name` varchar(200) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '名称',
`fullTextBody` text COLLATE utf8mb4_unicode_ci COMMENT '全文索引',
`createdDate` datetime NOT NULL COMMENT '创建时间',
`lastModifiedDate` datetime DEFAULT NULL COMMENT '修改时间',
`code` varchar(200) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '编码',
`brand` varchar(200) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '品牌',
`price` decimal(10,0) DEFAULT NULL COMMENT '单价',
`weight` decimal(10,0) DEFAULT NULL COMMENT '重量',
`length` decimal(10,0) DEFAULT NULL COMMENT '长',
`width` decimal(10,0) DEFAULT NULL COMMENT '宽',
`high` decimal(10,0) DEFAULT NULL COMMENT '高',
`ats` bigint DEFAULT NULL COMMENT '库存个数'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='产品';
ALTER TABLE `ca_product`
ADD PRIMARY KEY (`id`),
ADD UNIQUE KEY `UQ_CODE` (`code`) USING BTREE;
ALTER TABLE `ca_product` ADD FULLTEXT KEY `ft_fulltext_body` (`fullTextBody`);
ALTER TABLE `ca_product`
MODIFY `id` bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '编号', AUTO_INCREMENT=1;
COMMIT;
phpmyadmin
查询模式
MySQL数据库可以通过以下SQL语句查询表单、字段、索引等信息
SHOW TABLE STATUS LIKE TABLE_NAME
SHOW FULL COLUMNS FROM TABLE_NAME
SHOW INDEX FROM TABLE_NAME
表基本信息
表基本信息
字段信息
字段信息
索引信息
API JSON
通过API查询ca_product的schema信息:/api/metadata/tables/metadata/ca_product,格式如下:
{
"Name": "ca_product",
"Engine": "InnoDB",
"Version": 10,
"Row_format": "Dynamic",
"Rows": 0,
"Avg_row_length": 0,
"Data_length": 16384,
"Max_data_length": 0,
"Index_length": 32768,
"Data_free": 0,
"Auto_increment": 2,
"Create_time": 1628141282000,
"Update_time": 1628141304000,
"Collation": "utf8mb4_unicode_ci",
"Create_options": "",
"Comment": "产品",
"columns": [{
"Field": "id",
"Type": "bigint unsigned",
"Null": "NO",
"Key": "PRI",
"Extra": "auto_increment",
"Privileges": "select,insert,update,references",
"Comment": "编号"
}, {
"Field": "name",
"Type": "varchar(200)",
"Collation": "utf8mb4_unicode_ci",
"Null": "NO",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "名称"
}, {
"Field": "fullTextBody",
"Type": "text",
"Collation": "utf8mb4_unicode_ci",
"Null": "YES",
"Key": "MUL",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "全文索引"
}, {
"Field": "createdDate",
"Type": "datetime",
"Null": "NO",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "创建时间"
}, {
"Field": "lastModifiedDate",
"Type": "datetime",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "修改时间"
}, {
"Field": "code",
"Type": "varchar(200)",
"Collation": "utf8mb4_unicode_ci",
"Null": "YES",
"Key": "UNI",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "编码"
}, {
"Field": "brand",
"Type": "varchar(200)",
"Collation": "utf8mb4_unicode_ci",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "品牌"
}, {
"Field": "price",
"Type": "decimal(10,0)",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "单价"
}, {
"Field": "weight",
"Type": "decimal(10,0)",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "重量"
}, {
"Field": "length",
"Type": "decimal(10,0)",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "长"
}, {
"Field": "width",
"Type": "decimal(10,0)",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "宽"
}, {
"Field": "high",
"Type": "decimal(10,0)",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "高"
}, {
"Field": "ats",
"Type": "bigint",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "库存个数"
}],
"indexs": [{
"Table": "ca_product",
"Non_unique": 0,
"Key_name": "PRIMARY",
"Seq_in_index": 1,
"Column_name": "id",
"Collation": "A",
"Cardinality": 0,
"Null": "",
"Index_type": "BTREE",
"Comment": "",
"Index_comment": "",
"Visible": "YES"
}, {
"Table": "ca_product",
"Non_unique": 0,
"Key_name": "UQ_CODE",
"Seq_in_index": 1,
"Column_name": "code",
"Collation": "A",
"Cardinality": 0,
"Null": "YES",
"Index_type": "BTREE",
"Comment": "",
"Index_comment": "",
"Visible": "YES"
}, {
"Table": "ca_product",
"Non_unique": 1,
"Key_name": "ft_fulltext_body",
"Seq_in_index": 1,
"Column_name": "fullTextBody",
"Cardinality": 0,
"Null": "YES",
"Index_type": "FULLTEXT",
"Comment": "",
"Index_comment": "",
"Visible": "YES"
}]
}
核心代码
前端将 API 返回的 schema 信息转换为 crudapi 的元数据格式,并显示在 UI 上。主要代码在文件 metadata/table/new.vue 中,通过 addRowFromMetadata 方法添加字段,addIndexFromMetadata 添加联合索引。
addRowFromMetadata(id, t, singleIndexColumns) {
const columns = this.table.columns;
const index = columns.length + 1;
const type = t.Type.toUpperCase();
const name = t.Field;
let length = null;
let precision = null;
let scale = null;
let typeArr = type.split("(");
if (typeArr.length > 1) {
const lengthOrprecisionScale = typeArr[1].split(")")[0];
if (lengthOrprecisionScale.indexOf(",") > 0) {
precision = lengthOrprecisionScale.split(",")[0];
scale = lengthOrprecisionScale.split(",")[1];
} else {
length = lengthOrprecisionScale;
}
}
let indexType = null;
let indexStorage = null;
let indexName = null;
let indexColumn = singleIndexColumns[name];
if (indexColumn) {
if (indexColumn.Key_name === "PRIMARY") {
indexType = "PRIMARY";
} else if (indexColumn.Index_type === "FULLTEXT") {
indexType = "FULLTEXT";
indexName = indexColumn.Key_name;
} else if (indexColumn.Non_unique === 0) {
indexType = "UNIQUE";
indexName = indexColumn.Key_name;
indexStorage = indexColumn.Index_type;
} else {
indexType = "INDEX";
indexName = indexColumn.Key_name;
indexStorage = indexColumn.Index_type;
}
}
const comment = t.Comment ? t.Comment : name;
const newRow = {
id: id,
autoIncrement: (t.Extra === "auto_increment"),
displayOrder: columns.length,
insertable: true,
nullable: (t.Null === "YES"),
queryable: true,
displayable: false,
unsigned: type.indexOf("UNSIGNED") >= 0,
updatable: true,
dataType : typeArr[0].replace("UNSIGNED", "").trim(),
indexType: indexType,
indexStorage: indexStorage,
indexName: indexName,
name: name,
caption: comment,
description: comment,
length: length,
precision: precision,
scale: scale,
systemable: false
};
this.table.columns = [ ...columns.slice(0, index), newRow, ...columns.slice(index) ];
},
addIndexFromMetadata(union) {
let baseId = (new Date()).valueOf();
let newIndexs = [];
const tableColumns = this.table.columns;
console.dir(tableColumns);
for (let key in union) {
const unionLines = union[key];
const newIndexLines = [];
unionLines.forEach((item) => {
const columnName = item.Column_name;
const columnId = tableColumns.find(t => t.name === columnName).id;
newIndexLines.push({
column: {
id: columnId,
name: columnName
}
});
});
const unionLineFirst = unionLines[0];
let indexType = null;
let indexStorage = null;
if (unionLineFirst.Key_name === "PRIMARY") {
indexType = "PRIMARY";
} else if (unionLineFirst.Non_unique === 0) {
indexType = "UNIQUE";
indexStorage = unionLineFirst.Index_type;
} else {
indexType = "INDEX";
indexStorage = unionLineFirst.Index_type;
}
const indexComment = unionLineFirst.Index_comment ? unionLineFirst.Index_comment: unionLineFirst.Key_name;
const newIndex = {
id: baseId++,
isNewRow: true,
caption: indexComment,
description: indexComment,
indexStorage: indexStorage,
indexType: indexType,
name: unionLineFirst.Key_name,
indexLines: newIndexLines
}
newIndexs.push(newIndex);
}
this.table.indexs = newIndexs;
if (this.table.indexs) {
this.indexCount = this.table.indexs.length;
} else {
this.indexCount = 0;
}
}
例子
ca_product
以ca_product为例,点击“加载元数据”后,表格字段和索引显示正确。保存成功后,现有物理表 ca_product 将由元数据自动管理,您可以通过 crudapi 后台继续对其进行编辑。通过数据库逆向功能,零码实现物理表ca_product的CRUD增删改查功能。
概括
本文主要介绍数据库反向功能。在现有数据库形式的基础上,通过数据库反向功能,可以快速生成元数据。无需一行代码,我们就可以获取现有数据库的基本 crud 功能,包括 API 和 UI。类似于phpmyadmin等数据库UI管理系统,但比数据库UI管理系统更加灵活友好。目前,数据库一次只反转一个表。如果同时有很多物理表,需要进行批量操作。后续优化将继续实现批量数据库的逆向功能。
温馨提示:点击原文链接逆向基于Vue和Quasar的前端SPA项目的数据库(十二)|crudapi可以去官网查看源码! 查看全部
seq搜索引擎优化至少包括那几步?(基于Vue和Quasar的前端SPA项目实战之数据库逆向(十二))
基于Vue和Quasar的前端SPA项目数据库逆向(十二)回顾
通过引入之前的文章“开源免费”动态表单设计器(五)基于Vue和Quasar),实现动态表单功能。如果是一个全新的项目,通过配置元数据,创建物理表,这样就可以自动实现业务数据的CRUD增删改查。但是如果数据库表已经存在,如何通过配置表单元数据来管理呢?这时候就需要数据库逆向功能了。
介绍
数据库逆向是读取数据库物理表schema信息,然后生成表单元数据,可以认为是“dbfirst”模式,即先有数据库表,然后根据表生成元数据。逆向形式的后续操作与普通动态形式类似。
用户界面界面
数据库反向
输入物理表名,启用“数据库反向”功能,然后点击“加载元数据”,表单字段相关的元数据信息就会自动填充。
数据表准备
以ca_product产品为例,通过phpmyadmin创建表
#创建产品表
CREATE TABLE `ca_product` (
`id` bigint UNSIGNED NOT NULL COMMENT '编号',
`name` varchar(200) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '名称',
`fullTextBody` text COLLATE utf8mb4_unicode_ci COMMENT '全文索引',
`createdDate` datetime NOT NULL COMMENT '创建时间',
`lastModifiedDate` datetime DEFAULT NULL COMMENT '修改时间',
`code` varchar(200) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '编码',
`brand` varchar(200) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '品牌',
`price` decimal(10,0) DEFAULT NULL COMMENT '单价',
`weight` decimal(10,0) DEFAULT NULL COMMENT '重量',
`length` decimal(10,0) DEFAULT NULL COMMENT '长',
`width` decimal(10,0) DEFAULT NULL COMMENT '宽',
`high` decimal(10,0) DEFAULT NULL COMMENT '高',
`ats` bigint DEFAULT NULL COMMENT '库存个数'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='产品';
ALTER TABLE `ca_product`
ADD PRIMARY KEY (`id`),
ADD UNIQUE KEY `UQ_CODE` (`code`) USING BTREE;
ALTER TABLE `ca_product` ADD FULLTEXT KEY `ft_fulltext_body` (`fullTextBody`);
ALTER TABLE `ca_product`
MODIFY `id` bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '编号', AUTO_INCREMENT=1;
COMMIT;
phpmyadmin
查询模式
MySQL数据库可以通过以下SQL语句查询表单、字段、索引等信息
SHOW TABLE STATUS LIKE TABLE_NAME
SHOW FULL COLUMNS FROM TABLE_NAME
SHOW INDEX FROM TABLE_NAME
表基本信息
表基本信息
字段信息
字段信息
索引信息
API JSON
通过API查询ca_product的schema信息:/api/metadata/tables/metadata/ca_product,格式如下:
{
"Name": "ca_product",
"Engine": "InnoDB",
"Version": 10,
"Row_format": "Dynamic",
"Rows": 0,
"Avg_row_length": 0,
"Data_length": 16384,
"Max_data_length": 0,
"Index_length": 32768,
"Data_free": 0,
"Auto_increment": 2,
"Create_time": 1628141282000,
"Update_time": 1628141304000,
"Collation": "utf8mb4_unicode_ci",
"Create_options": "",
"Comment": "产品",
"columns": [{
"Field": "id",
"Type": "bigint unsigned",
"Null": "NO",
"Key": "PRI",
"Extra": "auto_increment",
"Privileges": "select,insert,update,references",
"Comment": "编号"
}, {
"Field": "name",
"Type": "varchar(200)",
"Collation": "utf8mb4_unicode_ci",
"Null": "NO",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "名称"
}, {
"Field": "fullTextBody",
"Type": "text",
"Collation": "utf8mb4_unicode_ci",
"Null": "YES",
"Key": "MUL",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "全文索引"
}, {
"Field": "createdDate",
"Type": "datetime",
"Null": "NO",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "创建时间"
}, {
"Field": "lastModifiedDate",
"Type": "datetime",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "修改时间"
}, {
"Field": "code",
"Type": "varchar(200)",
"Collation": "utf8mb4_unicode_ci",
"Null": "YES",
"Key": "UNI",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "编码"
}, {
"Field": "brand",
"Type": "varchar(200)",
"Collation": "utf8mb4_unicode_ci",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "品牌"
}, {
"Field": "price",
"Type": "decimal(10,0)",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "单价"
}, {
"Field": "weight",
"Type": "decimal(10,0)",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "重量"
}, {
"Field": "length",
"Type": "decimal(10,0)",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "长"
}, {
"Field": "width",
"Type": "decimal(10,0)",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "宽"
}, {
"Field": "high",
"Type": "decimal(10,0)",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "高"
}, {
"Field": "ats",
"Type": "bigint",
"Null": "YES",
"Key": "",
"Extra": "",
"Privileges": "select,insert,update,references",
"Comment": "库存个数"
}],
"indexs": [{
"Table": "ca_product",
"Non_unique": 0,
"Key_name": "PRIMARY",
"Seq_in_index": 1,
"Column_name": "id",
"Collation": "A",
"Cardinality": 0,
"Null": "",
"Index_type": "BTREE",
"Comment": "",
"Index_comment": "",
"Visible": "YES"
}, {
"Table": "ca_product",
"Non_unique": 0,
"Key_name": "UQ_CODE",
"Seq_in_index": 1,
"Column_name": "code",
"Collation": "A",
"Cardinality": 0,
"Null": "YES",
"Index_type": "BTREE",
"Comment": "",
"Index_comment": "",
"Visible": "YES"
}, {
"Table": "ca_product",
"Non_unique": 1,
"Key_name": "ft_fulltext_body",
"Seq_in_index": 1,
"Column_name": "fullTextBody",
"Cardinality": 0,
"Null": "YES",
"Index_type": "FULLTEXT",
"Comment": "",
"Index_comment": "",
"Visible": "YES"
}]
}
核心代码
前端将 API 返回的 schema 信息转换为 crudapi 的元数据格式,并显示在 UI 上。主要代码在文件 metadata/table/new.vue 中,通过 addRowFromMetadata 方法添加字段,addIndexFromMetadata 添加联合索引。
addRowFromMetadata(id, t, singleIndexColumns) {
const columns = this.table.columns;
const index = columns.length + 1;
const type = t.Type.toUpperCase();
const name = t.Field;
let length = null;
let precision = null;
let scale = null;
let typeArr = type.split("(");
if (typeArr.length > 1) {
const lengthOrprecisionScale = typeArr[1].split(")")[0];
if (lengthOrprecisionScale.indexOf(",") > 0) {
precision = lengthOrprecisionScale.split(",")[0];
scale = lengthOrprecisionScale.split(",")[1];
} else {
length = lengthOrprecisionScale;
}
}
let indexType = null;
let indexStorage = null;
let indexName = null;
let indexColumn = singleIndexColumns[name];
if (indexColumn) {
if (indexColumn.Key_name === "PRIMARY") {
indexType = "PRIMARY";
} else if (indexColumn.Index_type === "FULLTEXT") {
indexType = "FULLTEXT";
indexName = indexColumn.Key_name;
} else if (indexColumn.Non_unique === 0) {
indexType = "UNIQUE";
indexName = indexColumn.Key_name;
indexStorage = indexColumn.Index_type;
} else {
indexType = "INDEX";
indexName = indexColumn.Key_name;
indexStorage = indexColumn.Index_type;
}
}
const comment = t.Comment ? t.Comment : name;
const newRow = {
id: id,
autoIncrement: (t.Extra === "auto_increment"),
displayOrder: columns.length,
insertable: true,
nullable: (t.Null === "YES"),
queryable: true,
displayable: false,
unsigned: type.indexOf("UNSIGNED") >= 0,
updatable: true,
dataType : typeArr[0].replace("UNSIGNED", "").trim(),
indexType: indexType,
indexStorage: indexStorage,
indexName: indexName,
name: name,
caption: comment,
description: comment,
length: length,
precision: precision,
scale: scale,
systemable: false
};
this.table.columns = [ ...columns.slice(0, index), newRow, ...columns.slice(index) ];
},
addIndexFromMetadata(union) {
let baseId = (new Date()).valueOf();
let newIndexs = [];
const tableColumns = this.table.columns;
console.dir(tableColumns);
for (let key in union) {
const unionLines = union[key];
const newIndexLines = [];
unionLines.forEach((item) => {
const columnName = item.Column_name;
const columnId = tableColumns.find(t => t.name === columnName).id;
newIndexLines.push({
column: {
id: columnId,
name: columnName
}
});
});
const unionLineFirst = unionLines[0];
let indexType = null;
let indexStorage = null;
if (unionLineFirst.Key_name === "PRIMARY") {
indexType = "PRIMARY";
} else if (unionLineFirst.Non_unique === 0) {
indexType = "UNIQUE";
indexStorage = unionLineFirst.Index_type;
} else {
indexType = "INDEX";
indexStorage = unionLineFirst.Index_type;
}
const indexComment = unionLineFirst.Index_comment ? unionLineFirst.Index_comment: unionLineFirst.Key_name;
const newIndex = {
id: baseId++,
isNewRow: true,
caption: indexComment,
description: indexComment,
indexStorage: indexStorage,
indexType: indexType,
name: unionLineFirst.Key_name,
indexLines: newIndexLines
}
newIndexs.push(newIndex);
}
this.table.indexs = newIndexs;
if (this.table.indexs) {
this.indexCount = this.table.indexs.length;
} else {
this.indexCount = 0;
}
}
例子
ca_product
以ca_product为例,点击“加载元数据”后,表格字段和索引显示正确。保存成功后,现有物理表 ca_product 将由元数据自动管理,您可以通过 crudapi 后台继续对其进行编辑。通过数据库逆向功能,零码实现物理表ca_product的CRUD增删改查功能。
概括
本文主要介绍数据库反向功能。在现有数据库形式的基础上,通过数据库反向功能,可以快速生成元数据。无需一行代码,我们就可以获取现有数据库的基本 crud 功能,包括 API 和 UI。类似于phpmyadmin等数据库UI管理系统,但比数据库UI管理系统更加灵活友好。目前,数据库一次只反转一个表。如果同时有很多物理表,需要进行批量操作。后续优化将继续实现批量数据库的逆向功能。
温馨提示:点击原文链接逆向基于Vue和Quasar的前端SPA项目的数据库(十二)|crudapi可以去官网查看源码!

