
python多线程并发
使用Python编撰多线程爬虫抓取百度贴吧邮箱与手机号
采集交流 • 优采云 发表了文章 • 0 个评论 • 487 次浏览 • 2020-07-05 08:00
本爬虫主要是对百度贴吧中各类贴子的内容进行抓取,并且剖析贴子内容将其中的手机号和邮箱地址抓取下来。主要流程在代码注释中有详尽解释。
代码在Windows7 64bit,python 2.7 64bit(安装mysqldb扩充)以及centos 6.5,python 2.7(带mysqldb扩充)环境下测试通过
工欲善其事必先利其器,大家可以从截图看出我的环境是Windows 7 + PyCharm。我的Python环境是Python 2.7 64bit。这是比较适宜菜鸟使用的开发环境。然后我再建议你们安装一个easy_install,听名子就晓得这是一个安装器,它是拿来安装一些扩充包的,比如说在python中假如我们要操作mysql数据库的话,python原生是不支持的,我们必须安装mysqldb包来让python可以操作mysql数据库,如果有easy_install的话我们只须要一行命令就可以快速安装号mysqldb扩充包,他如同php中的composer,centos中的yum,Ubuntu中的apt-get一样便捷。
相关工具可在我的github中找到:cw1997/python-tools,其中easy_install的安装只须要在python命令行下运行哪个py脚本之后稍等片刻即可邮箱爬虫软件,他会手动加入Windows的环境变量,在Windows命令行下假如输入easy_install有回显说明安装成功。
至于电脑硬件其实是越快越好,内存至少8G起步,因为爬虫本身须要大量储存和解析中间数据,尤其是多线程爬虫,在遇到抓取带有分页的列表和详情页,并且抓取数据量很大的情况下使用queue队列分配抓取任务会特别占显存。包括有的时候我们抓取的数据是使用json,如果使用mongodb等nosql数据库储存,也会太占显存。
网络联接建议使用有线网,因为市面上一些劣质的无线路由器和普通的民用无线网卡在线程开的比较大的情况下会出现间歇性断网或则数据遗失,掉包等情况,这个我亲有感受。
至于操作系统和python其实肯定是选择64位。如果你使用的是32位的操作系统,那么难以使用大显存。如果你使用的是32位的python,可能在小规模抓取数据的时侯觉得不出有哪些问题,但是当数据量变大的时侯,比如说某个列表,队列,字典上面储存了大量数据,导致python的显存占用超过2g的时侯会报显存溢出错误。原因在我以前segmentfault上提过的问题中依云的回答有解释(java – python只要占用显存达到1.9G以后httplib模块就开始报内存溢出错误 – SegmentFault)
如果你打算使用mysql储存数据,建议使用mysql5.5之后的版本,因为mysql5.5版本支持json数据类型,这样的话可以抛弃mongodb了。(有人说mysql会比mongodb稳定一点,这个我不确定。)
至于现今python都早已出了3.x版本了,为什么我这儿还使用的是python2.7?我个人选择2.7版本的缘由是自己当年很早曾经买的python核心编程这本书是第二版的,仍然以2.7为示例版本。并且目前网上一直有大量的教程资料是以2.7为版本讲解,2.7在个别方面与3.x还是有很大差异,如果我们没有学过2.7,可能对于一些细微的句型差异不是太懂会导致我们理解上出现误差,或者看不懂demo代码。而且如今还是有部份依赖包只兼容2.7版本。我的建议是假如你是打算急着学python之后去公司工作,并且公司没有老代码须要维护,那么可以考虑直接上手3.x,如果你有比较充沛的时间,并且没有太系统的大牛带,只能借助网上零零散散的博客文章来学习,那么还是先学2.7在学3.x,毕竟学会了2.7以后3.x上手也很快。
其实对于任何软件项目而言,我们但凡想知道编撰这个项目须要哪些知识点,我们都可以观察一下这个项目的主要入口文件都导出了什么包。
现在来看一下我们这个项目,作为一个刚接触python的人,可能有一些包几乎都没有用过,那么我们在本小节就来简单的谈谈这种包起哪些作用,要把握她们分别会涉及到哪些知识点,这些知识点的关键词是哪些。这篇文章并不会耗费长篇大论来从基础讲起,因此我们要学会善用百度,搜索那些知识点的关键词来自学。下面就来一一剖析一下这种知识点。
我们的爬虫抓取数据本质上就是不停的发起http请求,获取http响应,将其存入我们的笔记本中。了解http协议有助于我们在抓取数据的时侯对一些才能加速抓取速率的参数才能精准的控制,比如说keep-alive等。
我们平常编撰的程序都是单线程程序,我们写的代码都在主线程上面运行,这个主线程又运行在python进程中。关于线程和进程的解释可以参考阮一峰的博客:进程与线程的一个简单解释 – 阮一峰的网路日志
在python中实现多线程是通过一个名子称作threading的模块来实现。之前还有thread模块,但是threading对于线程的控制更强,因此我们后来都改用threading来实现多线程编程了。
关于threading多线程的一些用法,我认为这篇文章不错:[python] 专题八.多线程编程之thread和threading 大家可以参考参考。
简单来说,使用threading模块编撰多线程程序,就是先自己定义一个类,然后这个类要承继threading.Thread,并且把每位线程要做的工作代码讲到一个类的run方式中,当然若果线程本身在创建的时侯假如要做一些初始化工作,那么就要在他的__init__方法中编撰好初始化工作所要执行的代码,这个方式如同php,java中的构造方式一样。
这里还要额外讲的一点就是线程安全这个概念。通常情况下我们单线程情况下每位时刻只有一个线程在对资源(文件,变量)操作,所以不可能会出现冲突。但是当多线程的情况下,可能会出现同一个时刻两个线程在操作同一个资源,导致资源受损,所以我们须要一种机制来解决这些冲突带来的破坏,通常有加锁等操作,比如说mysql数据库的innodb表引擎有行级锁等,文件操作有读取锁等等,这些都是她们的程序底层帮我们完成了。所以我们一般只要晓得这些操作,或者这些程序对于线程安全问题做了处理,然后就可以在多线程编程中去使用它们了。而这些考虑到线程安全问题的程序通常就叫做“线程安全版本”,比如说php就有TS版本,这个TS就是Thread Safety线程安全的意思。下面我们要提到的Queue模块就是一种线程安全的队列数据结构,所以我们可以放心的在多线程编程中使用它。
***我们就要来讲讲至关重要的线程阻塞这个概念了。当我们详尽学习完threading模块以后,大概就晓得怎样创建和启动线程了。但是假如我们把线程创建好了,然后调用了start方式,那么我们会发觉似乎整个程序立刻就结束了,这是如何回事呢?其实这是因为我们在主线程中只有负责启动子线程的代码,也就意味着主线程只有启动子线程的功能,至于子线程执行的这些代码,他们本质上只是写在类上面的一个方式,并没在主线程上面真正去执行他,所以主线程启动完子线程以后他的本职工作就早已全部完成了,已经光荣离场了。既然主线程都离场了,那么python进程就跟随结束了,那么其他线程也就没有显存空间继续执行了。所以我们应当是要使主线程大婶等到所有的子线程鄙人全部执行完毕再光荣离场,那么在线程对象中有哪些方式才能把主线程卡住呢?thread.sleep嘛?这确实是个办法,但是到底应当使主线程sleep多久呢?我们并不能确切晓得执行完一个任务要多久时间,肯定不能用这个办法。所以我们这个时侯应当上网查询一下有哪些办法才能使子线程“卡住”主线程呢?“卡住”这个词似乎很粗俗了,其实说专业一点,应该称作“阻塞”,所以我们可以查询“python 子线程阻塞主线程”,如果我们会正确使用搜索引擎的话,应该会查到一个方式称作join(),没错,这个join()方法就是子线程用于阻塞主线程的方式,当子线程还未执行完毕的时侯,主线程运行到富含join()方法的这一行都会卡在那里,直到所有线程都执行完毕才能执行join()方法前面的代码。
假设有一个这样的场景,我们须要抓取一个人的博客,我们晓得这个人的博客有两个页面,一个list.php页面显示的是此博客的所有文章链接,还有一个view.php页面显示的是一篇文章的具体内容。
如果我们要把这个人的博客上面所有文章内容抓取出来,编写单线程爬虫的思路是:先用正则表达式把这个list.php页面的所有链接a标签的href属性抓取出来,存入一个名子称作article_list的链表(在python中不叫链表,叫做list,中文名列表),然后再用一个for循环遍历这个article_list链表,用各类抓取网页内容的函数把内容抓取出来之后存入数据库。
如果我们要编撰一个多线程爬虫来完成这个任务的话,就假定我们的程序用10个线程把,那么我们就要想办法把之前抓取的article_list平均分成10份,分别把每一份分配给其中一个子线程。
但是问题来了,如果我们的article_list链表宽度不是10的倍数,也就是文章数量并不是10的整数倍,那么***一个线程都会比别的线程少分配到一些任务,那么它将会更快的结束。
如果仅仅是抓取这些只有几千字的博客文章这看似没哪些问题,但是假如我们一个任务(不一定是抓取网页的任务,有可能是物理估算,或者图形渲染等等历时任务)的运行时间太长,那么这将导致极大地资源和时间浪费。我们多线程的目的就是尽可能的借助一切估算资源而且估算时间,所以我们要想办法使任务才能愈发科学合理的分配。
并且我还要考虑一种情况,就是文章数量很大的情况下,我们要既能快速抓取到文章内容,又能尽早的看见我们早已抓取到的内容,这种需求在好多CMS采集站上常常会彰显下来。
比如说我们如今要抓取的目标博客,有几千万篇文章,通常这些情况下博客还会做分页处理,那么我们若果根据前面的传统思路先抓取完list.php的所有页面至少就要几个小时甚至几天,老板假如希望你还能早日显示出抓取内容,并且尽早将早已抓取到的内容诠释到我们的CMS采集站上,那么我们就要实现一边抓取list.php而且把早已抓取到的数据丢入一个article_list链表,一边用另一个线程从article_list链表中提取早已抓取到的文章URL地址,然后这个线程再去对应的URL地址中用正则表达式取到博客文章内容。如何实现这个功能呢?
我们就须要同时开启两类线程,一类线程专门负责抓取list.php中的url之后丢入article_list链表,另外一类线程专门负责从article_list中提取出url之后从对应的view.php页面中抓取出对应的博客内容。
但是我们是否还记得上面提及过线程安全这个概念?前一类线程一边往article_list字段中写入数据,另外那一类的线程从article_list中读取数据但是删掉早已读取完毕的数据。但是python中list并不是线程安全版本的数据结构,因此这样操作会导致不可预想的错误。所以我们可以尝试使用一个愈发便捷且线程安全的数据结构,这就是我们的子标题中所提及的Queue队列数据结构。
同样Queue也有一个join()方法,这个join()方法虽然和上一个小节所提到的threading中join()方法差不多,只不过在Queue中,join()的阻塞条件是当队列不为空空的时侯才阻塞,否则继续执行join()后面的代码。在这个爬虫中我便使用了这些技巧来阻塞主线程而不是直接通过线程的join方法来阻塞主线程,这样的用处是可以不用写一个死循环来判定当前任务队列中是否还有未执行完的任务,让程序运行愈发高效,也使代码愈发柔美。
还有一个细节就是在python2.7中队列模块的名子是Queue,而在python3.x中早已更名为queue,就是首字母大小写的区别,大家假如是复制网上的代码,要记得这个小区别。
如果你们学过c语言的话,对这个模块应当会太熟悉,他就是一个负责从命令行中的命令上面提取出附送参数的模块。比如说我们一般在命令行中操作mysql数据库,就是输入mysql -h127.0.0.1 -uroot -p,其中mysql前面的“-h127.0.0.1 -uroot -p”就是可以获取的参数部份。
我们平常在编撰爬虫的时侯,有一些参数是须要用户自己自动输入的,比如说mysql的主机IP,用户名密码等等。为了使我们的程序愈加友好通用,有一些配置项是不需要硬编码在代码上面,而是在执行他的时侯我们动态传入,结合getopt模块我们就可以实现这个功能。
哈希本质上就是一类物理算法的集合,这种物理算法有个特点就是你给定一个参数,他就能输出另外一个结果,虽然这个结果太短,但是他可以近似觉得是***的。比如说我们平常听过的md5,sha-1等等,他们都属于哈希算法。他们可以把一些文件,文字经过一系列的物理运算然后弄成短短不到一百位的一段数字中文混和的字符串。
python中的hashlib模块就为我们封装好了这种物理运算函数,我们只须要简单的调用它就可以完成哈希运算。
为什么在我这个爬虫中用到了这个包呢?因为在一些插口恳求中,服务器须要带上一些校验码,保证插口恳求的数据没有被篡改或则遗失,这些校验码通常都是hash算法,所以我们须要用到这个模块来完成这些运算。
很多时侯我们抓取到的数据不是html,而是一些json数据,json本质上只是一段富含通配符对的字符串,如果我们须要提取出其中特定的字符串,那么我们须要json这个模块来将这个json字符串转换为dict类型便捷我们操作。
有的时侯我们抓取到了一些网页内容,但是我们须要将网页中的一些特定格式的内容提取下来,比如说电子邮箱的格式通常都是上面几位英语数字字母加一个@符号加的域名,而要象计算机语言描述这些格式,我们可以使用一种称作正则表达式的表达式来抒发出这些格式,并且使计算机手动从一大段字符串上将符合这些特定格式的文字匹配下来。
这个模块主要用于处理一些系统方面的事情,在这个爬虫中我用他来解决输出编码问题。
稍微学过一点法语的人都还能猜下来这个模块用于处理时间,在这个爬虫中我用它来获取当前时间戳,然后通过在主线程末尾用当前时间戳除以程序开始运行时的时间戳,得到程序的运行时间。
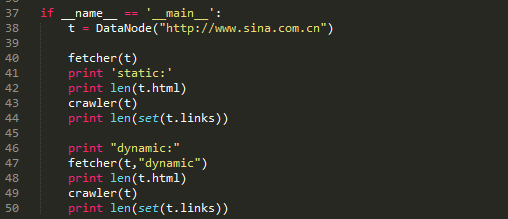
如图所示,开50个线程抓取100页(每页30个贴子,相当于抓取了3000个贴子)贴吧贴子内容而且从中提取出手机邮箱这个步骤共历时330秒。
这两个模块都是用于处理一些http请求,以及url低格方面的事情。我的爬虫http请求部份的核心代码就是使用这个模块完成的。
这是一个第三方模块,用于在python中操作mysql数据库。
这里我们要注意一个细节问题:mysqldb模块并不是线程安全版本,意味着我们不能在多线程中共享同一个mysql联接句柄。所以你们可以在我的代码中听到,我在每位线程的构造函数中都传入了一个新的mysql联接句柄。因此每位子线程只会用自己独立的mysql联接句柄。
这也是一个第三方模块,网上还能找到相关代码,这个模块主要用于向命令行中输出彩色字符串。比如说我们一般爬虫出现错误,要输出黄色的字体会比较醒目,就要使用到这个模块。
如果你们在网路质量不是挺好的环境下使用该爬虫,会发觉有的时侯会报如图所示的异常,这是我为了偷懒并没有写各类异常处理的逻辑。
通常情况下我们假如要编撰高度自动化的爬虫,那么就须要意料到我们的爬虫可能会遇见的所有异常情况邮箱爬虫软件,针对这种异常情况做处理。
比如说如图所示的错误,我们就应当把当时正在处理的任务重新伸入任务队列,否则我们还会出现遗漏信息的情况。这也是爬虫编撰的一个复杂点。
其实多线程爬虫的编撰也不复杂,多看示例代码,多自己动手尝试,多去社区,论坛交流,很多精典的书上对多线程编程也有特别详尽的解释。这篇文章本质上主要还是一篇科普文章,内容讲解的都不是太深入,大家还须要课外自己多结合网上各类资料自己学习。
【编辑推荐】
Python程序员都该用的一个库Python正则表达式re模块简明笔记这种方式推动Python开发者提升效率Python并发编程之线程池/进程池Python黑魔法之描述符 查看全部
不知道你们春节都是如何过的,反正栏主是在家睡了三天,醒来的时侯登QQ发觉有人找我要一份帖吧爬虫的源代码,想起之前练手的时侯写过一个抓取百度贴吧发贴记录中的邮箱与手机号的爬虫,于是开源分享给你们学习与参考。
本爬虫主要是对百度贴吧中各类贴子的内容进行抓取,并且剖析贴子内容将其中的手机号和邮箱地址抓取下来。主要流程在代码注释中有详尽解释。
代码在Windows7 64bit,python 2.7 64bit(安装mysqldb扩充)以及centos 6.5,python 2.7(带mysqldb扩充)环境下测试通过


工欲善其事必先利其器,大家可以从截图看出我的环境是Windows 7 + PyCharm。我的Python环境是Python 2.7 64bit。这是比较适宜菜鸟使用的开发环境。然后我再建议你们安装一个easy_install,听名子就晓得这是一个安装器,它是拿来安装一些扩充包的,比如说在python中假如我们要操作mysql数据库的话,python原生是不支持的,我们必须安装mysqldb包来让python可以操作mysql数据库,如果有easy_install的话我们只须要一行命令就可以快速安装号mysqldb扩充包,他如同php中的composer,centos中的yum,Ubuntu中的apt-get一样便捷。
相关工具可在我的github中找到:cw1997/python-tools,其中easy_install的安装只须要在python命令行下运行哪个py脚本之后稍等片刻即可邮箱爬虫软件,他会手动加入Windows的环境变量,在Windows命令行下假如输入easy_install有回显说明安装成功。
至于电脑硬件其实是越快越好,内存至少8G起步,因为爬虫本身须要大量储存和解析中间数据,尤其是多线程爬虫,在遇到抓取带有分页的列表和详情页,并且抓取数据量很大的情况下使用queue队列分配抓取任务会特别占显存。包括有的时候我们抓取的数据是使用json,如果使用mongodb等nosql数据库储存,也会太占显存。
网络联接建议使用有线网,因为市面上一些劣质的无线路由器和普通的民用无线网卡在线程开的比较大的情况下会出现间歇性断网或则数据遗失,掉包等情况,这个我亲有感受。
至于操作系统和python其实肯定是选择64位。如果你使用的是32位的操作系统,那么难以使用大显存。如果你使用的是32位的python,可能在小规模抓取数据的时侯觉得不出有哪些问题,但是当数据量变大的时侯,比如说某个列表,队列,字典上面储存了大量数据,导致python的显存占用超过2g的时侯会报显存溢出错误。原因在我以前segmentfault上提过的问题中依云的回答有解释(java – python只要占用显存达到1.9G以后httplib模块就开始报内存溢出错误 – SegmentFault)
如果你打算使用mysql储存数据,建议使用mysql5.5之后的版本,因为mysql5.5版本支持json数据类型,这样的话可以抛弃mongodb了。(有人说mysql会比mongodb稳定一点,这个我不确定。)
至于现今python都早已出了3.x版本了,为什么我这儿还使用的是python2.7?我个人选择2.7版本的缘由是自己当年很早曾经买的python核心编程这本书是第二版的,仍然以2.7为示例版本。并且目前网上一直有大量的教程资料是以2.7为版本讲解,2.7在个别方面与3.x还是有很大差异,如果我们没有学过2.7,可能对于一些细微的句型差异不是太懂会导致我们理解上出现误差,或者看不懂demo代码。而且如今还是有部份依赖包只兼容2.7版本。我的建议是假如你是打算急着学python之后去公司工作,并且公司没有老代码须要维护,那么可以考虑直接上手3.x,如果你有比较充沛的时间,并且没有太系统的大牛带,只能借助网上零零散散的博客文章来学习,那么还是先学2.7在学3.x,毕竟学会了2.7以后3.x上手也很快。
其实对于任何软件项目而言,我们但凡想知道编撰这个项目须要哪些知识点,我们都可以观察一下这个项目的主要入口文件都导出了什么包。

现在来看一下我们这个项目,作为一个刚接触python的人,可能有一些包几乎都没有用过,那么我们在本小节就来简单的谈谈这种包起哪些作用,要把握她们分别会涉及到哪些知识点,这些知识点的关键词是哪些。这篇文章并不会耗费长篇大论来从基础讲起,因此我们要学会善用百度,搜索那些知识点的关键词来自学。下面就来一一剖析一下这种知识点。
我们的爬虫抓取数据本质上就是不停的发起http请求,获取http响应,将其存入我们的笔记本中。了解http协议有助于我们在抓取数据的时侯对一些才能加速抓取速率的参数才能精准的控制,比如说keep-alive等。
我们平常编撰的程序都是单线程程序,我们写的代码都在主线程上面运行,这个主线程又运行在python进程中。关于线程和进程的解释可以参考阮一峰的博客:进程与线程的一个简单解释 – 阮一峰的网路日志
在python中实现多线程是通过一个名子称作threading的模块来实现。之前还有thread模块,但是threading对于线程的控制更强,因此我们后来都改用threading来实现多线程编程了。
关于threading多线程的一些用法,我认为这篇文章不错:[python] 专题八.多线程编程之thread和threading 大家可以参考参考。
简单来说,使用threading模块编撰多线程程序,就是先自己定义一个类,然后这个类要承继threading.Thread,并且把每位线程要做的工作代码讲到一个类的run方式中,当然若果线程本身在创建的时侯假如要做一些初始化工作,那么就要在他的__init__方法中编撰好初始化工作所要执行的代码,这个方式如同php,java中的构造方式一样。
这里还要额外讲的一点就是线程安全这个概念。通常情况下我们单线程情况下每位时刻只有一个线程在对资源(文件,变量)操作,所以不可能会出现冲突。但是当多线程的情况下,可能会出现同一个时刻两个线程在操作同一个资源,导致资源受损,所以我们须要一种机制来解决这些冲突带来的破坏,通常有加锁等操作,比如说mysql数据库的innodb表引擎有行级锁等,文件操作有读取锁等等,这些都是她们的程序底层帮我们完成了。所以我们一般只要晓得这些操作,或者这些程序对于线程安全问题做了处理,然后就可以在多线程编程中去使用它们了。而这些考虑到线程安全问题的程序通常就叫做“线程安全版本”,比如说php就有TS版本,这个TS就是Thread Safety线程安全的意思。下面我们要提到的Queue模块就是一种线程安全的队列数据结构,所以我们可以放心的在多线程编程中使用它。
***我们就要来讲讲至关重要的线程阻塞这个概念了。当我们详尽学习完threading模块以后,大概就晓得怎样创建和启动线程了。但是假如我们把线程创建好了,然后调用了start方式,那么我们会发觉似乎整个程序立刻就结束了,这是如何回事呢?其实这是因为我们在主线程中只有负责启动子线程的代码,也就意味着主线程只有启动子线程的功能,至于子线程执行的这些代码,他们本质上只是写在类上面的一个方式,并没在主线程上面真正去执行他,所以主线程启动完子线程以后他的本职工作就早已全部完成了,已经光荣离场了。既然主线程都离场了,那么python进程就跟随结束了,那么其他线程也就没有显存空间继续执行了。所以我们应当是要使主线程大婶等到所有的子线程鄙人全部执行完毕再光荣离场,那么在线程对象中有哪些方式才能把主线程卡住呢?thread.sleep嘛?这确实是个办法,但是到底应当使主线程sleep多久呢?我们并不能确切晓得执行完一个任务要多久时间,肯定不能用这个办法。所以我们这个时侯应当上网查询一下有哪些办法才能使子线程“卡住”主线程呢?“卡住”这个词似乎很粗俗了,其实说专业一点,应该称作“阻塞”,所以我们可以查询“python 子线程阻塞主线程”,如果我们会正确使用搜索引擎的话,应该会查到一个方式称作join(),没错,这个join()方法就是子线程用于阻塞主线程的方式,当子线程还未执行完毕的时侯,主线程运行到富含join()方法的这一行都会卡在那里,直到所有线程都执行完毕才能执行join()方法前面的代码。
假设有一个这样的场景,我们须要抓取一个人的博客,我们晓得这个人的博客有两个页面,一个list.php页面显示的是此博客的所有文章链接,还有一个view.php页面显示的是一篇文章的具体内容。
如果我们要把这个人的博客上面所有文章内容抓取出来,编写单线程爬虫的思路是:先用正则表达式把这个list.php页面的所有链接a标签的href属性抓取出来,存入一个名子称作article_list的链表(在python中不叫链表,叫做list,中文名列表),然后再用一个for循环遍历这个article_list链表,用各类抓取网页内容的函数把内容抓取出来之后存入数据库。
如果我们要编撰一个多线程爬虫来完成这个任务的话,就假定我们的程序用10个线程把,那么我们就要想办法把之前抓取的article_list平均分成10份,分别把每一份分配给其中一个子线程。
但是问题来了,如果我们的article_list链表宽度不是10的倍数,也就是文章数量并不是10的整数倍,那么***一个线程都会比别的线程少分配到一些任务,那么它将会更快的结束。
如果仅仅是抓取这些只有几千字的博客文章这看似没哪些问题,但是假如我们一个任务(不一定是抓取网页的任务,有可能是物理估算,或者图形渲染等等历时任务)的运行时间太长,那么这将导致极大地资源和时间浪费。我们多线程的目的就是尽可能的借助一切估算资源而且估算时间,所以我们要想办法使任务才能愈发科学合理的分配。
并且我还要考虑一种情况,就是文章数量很大的情况下,我们要既能快速抓取到文章内容,又能尽早的看见我们早已抓取到的内容,这种需求在好多CMS采集站上常常会彰显下来。
比如说我们如今要抓取的目标博客,有几千万篇文章,通常这些情况下博客还会做分页处理,那么我们若果根据前面的传统思路先抓取完list.php的所有页面至少就要几个小时甚至几天,老板假如希望你还能早日显示出抓取内容,并且尽早将早已抓取到的内容诠释到我们的CMS采集站上,那么我们就要实现一边抓取list.php而且把早已抓取到的数据丢入一个article_list链表,一边用另一个线程从article_list链表中提取早已抓取到的文章URL地址,然后这个线程再去对应的URL地址中用正则表达式取到博客文章内容。如何实现这个功能呢?
我们就须要同时开启两类线程,一类线程专门负责抓取list.php中的url之后丢入article_list链表,另外一类线程专门负责从article_list中提取出url之后从对应的view.php页面中抓取出对应的博客内容。
但是我们是否还记得上面提及过线程安全这个概念?前一类线程一边往article_list字段中写入数据,另外那一类的线程从article_list中读取数据但是删掉早已读取完毕的数据。但是python中list并不是线程安全版本的数据结构,因此这样操作会导致不可预想的错误。所以我们可以尝试使用一个愈发便捷且线程安全的数据结构,这就是我们的子标题中所提及的Queue队列数据结构。
同样Queue也有一个join()方法,这个join()方法虽然和上一个小节所提到的threading中join()方法差不多,只不过在Queue中,join()的阻塞条件是当队列不为空空的时侯才阻塞,否则继续执行join()后面的代码。在这个爬虫中我便使用了这些技巧来阻塞主线程而不是直接通过线程的join方法来阻塞主线程,这样的用处是可以不用写一个死循环来判定当前任务队列中是否还有未执行完的任务,让程序运行愈发高效,也使代码愈发柔美。
还有一个细节就是在python2.7中队列模块的名子是Queue,而在python3.x中早已更名为queue,就是首字母大小写的区别,大家假如是复制网上的代码,要记得这个小区别。
如果你们学过c语言的话,对这个模块应当会太熟悉,他就是一个负责从命令行中的命令上面提取出附送参数的模块。比如说我们一般在命令行中操作mysql数据库,就是输入mysql -h127.0.0.1 -uroot -p,其中mysql前面的“-h127.0.0.1 -uroot -p”就是可以获取的参数部份。
我们平常在编撰爬虫的时侯,有一些参数是须要用户自己自动输入的,比如说mysql的主机IP,用户名密码等等。为了使我们的程序愈加友好通用,有一些配置项是不需要硬编码在代码上面,而是在执行他的时侯我们动态传入,结合getopt模块我们就可以实现这个功能。
哈希本质上就是一类物理算法的集合,这种物理算法有个特点就是你给定一个参数,他就能输出另外一个结果,虽然这个结果太短,但是他可以近似觉得是***的。比如说我们平常听过的md5,sha-1等等,他们都属于哈希算法。他们可以把一些文件,文字经过一系列的物理运算然后弄成短短不到一百位的一段数字中文混和的字符串。
python中的hashlib模块就为我们封装好了这种物理运算函数,我们只须要简单的调用它就可以完成哈希运算。
为什么在我这个爬虫中用到了这个包呢?因为在一些插口恳求中,服务器须要带上一些校验码,保证插口恳求的数据没有被篡改或则遗失,这些校验码通常都是hash算法,所以我们须要用到这个模块来完成这些运算。
很多时侯我们抓取到的数据不是html,而是一些json数据,json本质上只是一段富含通配符对的字符串,如果我们须要提取出其中特定的字符串,那么我们须要json这个模块来将这个json字符串转换为dict类型便捷我们操作。
有的时侯我们抓取到了一些网页内容,但是我们须要将网页中的一些特定格式的内容提取下来,比如说电子邮箱的格式通常都是上面几位英语数字字母加一个@符号加的域名,而要象计算机语言描述这些格式,我们可以使用一种称作正则表达式的表达式来抒发出这些格式,并且使计算机手动从一大段字符串上将符合这些特定格式的文字匹配下来。
这个模块主要用于处理一些系统方面的事情,在这个爬虫中我用他来解决输出编码问题。
稍微学过一点法语的人都还能猜下来这个模块用于处理时间,在这个爬虫中我用它来获取当前时间戳,然后通过在主线程末尾用当前时间戳除以程序开始运行时的时间戳,得到程序的运行时间。

如图所示,开50个线程抓取100页(每页30个贴子,相当于抓取了3000个贴子)贴吧贴子内容而且从中提取出手机邮箱这个步骤共历时330秒。
这两个模块都是用于处理一些http请求,以及url低格方面的事情。我的爬虫http请求部份的核心代码就是使用这个模块完成的。
这是一个第三方模块,用于在python中操作mysql数据库。
这里我们要注意一个细节问题:mysqldb模块并不是线程安全版本,意味着我们不能在多线程中共享同一个mysql联接句柄。所以你们可以在我的代码中听到,我在每位线程的构造函数中都传入了一个新的mysql联接句柄。因此每位子线程只会用自己独立的mysql联接句柄。
这也是一个第三方模块,网上还能找到相关代码,这个模块主要用于向命令行中输出彩色字符串。比如说我们一般爬虫出现错误,要输出黄色的字体会比较醒目,就要使用到这个模块。

如果你们在网路质量不是挺好的环境下使用该爬虫,会发觉有的时侯会报如图所示的异常,这是我为了偷懒并没有写各类异常处理的逻辑。
通常情况下我们假如要编撰高度自动化的爬虫,那么就须要意料到我们的爬虫可能会遇见的所有异常情况邮箱爬虫软件,针对这种异常情况做处理。
比如说如图所示的错误,我们就应当把当时正在处理的任务重新伸入任务队列,否则我们还会出现遗漏信息的情况。这也是爬虫编撰的一个复杂点。
其实多线程爬虫的编撰也不复杂,多看示例代码,多自己动手尝试,多去社区,论坛交流,很多精典的书上对多线程编程也有特别详尽的解释。这篇文章本质上主要还是一篇科普文章,内容讲解的都不是太深入,大家还须要课外自己多结合网上各类资料自己学习。
【编辑推荐】
Python程序员都该用的一个库Python正则表达式re模块简明笔记这种方式推动Python开发者提升效率Python并发编程之线程池/进程池Python黑魔法之描述符
Python做爬虫到底比其他语言好在哪儿呢?
采集交流 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2020-05-25 08:02
2038
哪种语言合适写爬虫程序
1、如果是定向爬取几个页面,做一些简单的页面解析,爬取效率不是核心要求,这么用哪些语言差别不大。其实要是页面结构复杂,正则表达式写得巨复杂,尤其是用过这些支持xpath的解释器/爬虫库后,才会发觉此种方法尽管入门门槛低,但扩充性、可维护性等都奇差。因而此种情况下还是推荐采用一些现成的爬虫库,例如xpath、多线程支持还是必须考虑的诱因。2、如果是定向爬取,且主要目标是解析...
延瓒
01-01
1万+
Python/打响2019年第一炮-Python爬虫入门(一)
打响2019第一炮-Python爬虫入门 2018年早已成为过去,还记得在2018年元旦写过一篇【Shell编程】打响2018第一炮-shell编程之for循环句子,那在此时此刻,也是写一篇关于编程方面,不过要比18年的稍稍中级点。So,mark一下,也希望对您有所帮助。 步入题外话,在双十二想必你们都逛过网店and易迅,例如我们须要买一部手机或笔记本,而且我们须要点开手机或则笔记本页面看......
ROSE_ty的博客
03-04
2897
Python爬虫出现�乱码的解决办法
明天学习Python爬虫,再读取页面内容时出现以下情况,虽然使用了‘utf-8’后来通过阅读文章,将编码改为GBK后可正常显示...
ahkeyan的博客
03-15
1933
网路爬虫尝试(VB编撰)
PrivateSubForm_Load()a=getHTTPPage(“”)b=Split(a,“[”)(1)c=Split(b,“]”)(0)MsgBoxcEndSubFunctiongetHTTPPage(url)OnErrorResumeNextDimhttpSethttp=CreateObj...
qq_41514083的博客
07-17
1307
IDEA中JDBC的使用--完成对于数据库中数据的增删改查
IDEA中JDBC的使用--完成对于数据库中数据的增删改查1.在IDEA中新建一个项目2.进行各个类的编撰3.项目结果展示1.在IDEA中新建一个项目1.1点击右上角file,在new中选择project,在两侧选择Java项目,选择自己所安装的SDK包,点击next1.2继续点击next1.3决定项目的名子以及项目储存的文件夹,然后点击finish,完成项目的创建2.进行各个类的......
weixin_33863087的博客
04-25
2255
爬虫可以使用哪些语言
有好多刚才做爬虫工作者得菜鸟常常会问道这样一个问题,做爬虫须要哪些语言,个人认为任何语言,只要具备访问网路的标准库,都可以做到这一点。其实了解必要的爬虫工具也是必然的,比如代理IP刚才接触爬虫,好多菜鸟会苦恼于用Python来做爬虫,而且无论是JAVA,PHP还是其他更低级语言,都可以很便捷的实现,静态语言出现错误的可能性很低,低级语言运行速率会更快一些。并且Python的优势在于库更......
大数据
04-24
2341
网路爬虫有哪些用?如何爬?手把手教你爬网页(Python代码)
导读:本文主要分为两个部份:一部份是网路爬虫的概述,帮助你们详尽了解网路爬虫;另一部份是HTTP恳求的Python实现,帮助你们了解Python中实现HTTP恳求的各类方...
小蓝枣的博客
03-06
4846
Python爬虫篇-爬取页面所有可用的链接
原理也很简单,html链接都是在a元素里的,我们就是匹配出所有的a元素,其实a可以是空的链接,空的链接是None,也可能是无效的链接。我们通过urllib库的request来测试链接的有效性。当链接无效的话会抛出异常,我们把异常捕获下来,并提示下来,没有异常就是有效的,我们直接显示下来就好了。...
点点寒彬的博客
05-16
5万+
简单谈谈Python与Go的区别
背景工作中的主力语言是Python,明年要搞性能测试的工具,因为GIL锁的缘由,Python的性能实在是低迷,须要学一门性能高的语言来世成性能测试的压力端。为此我把眼神置于了如今的新秀Go。经过一段时间的学习,也写了一个小工具,记一下这两个语言的区别。需求工具是一个小爬虫,拿来爬某网站的某个产品的迭代记录,实现逻辑就是运行脚本后,使用者从命令行输入个别元素(产品ID等)后网络爬虫语言,脚本导入......
捉虫李高人
03-05
3万+
闲话网路爬虫-CSharp对比Python
这一期给男子伴们普及下网路爬虫这块的东西,吹下牛,宣传一波C#爬虫的优势,希望Python的老铁们轻喷,哈哈!大致对比了下Python爬虫和C#爬虫的优劣势,可以汲取Python爬虫的框架,进一步封装好C#爬虫须要用到的方方面面,然后用上去还是会蛮爽的,起码单看在数据抓取方面不输Python,Python应该是借助上去做它更擅长的其他方面的事情,而不是大势宣传它在爬虫方面的......
Yeoman92的博客
10-17
6358
python爬虫:使用selenium+ChromeDriver爬取途家网
本站(途家网)通过常规抓页面的方式不能获取数据,可以使用selenium+ChromeDriver来获取页面数据。
dengguawei0519的博客
02-08
129
(转)各类语言写网路爬虫有哪些优点缺点
我用PHP和Python都写过爬虫和正文提取程序。最开始使用PHP所以先谈谈PHP的优点:1.语言比较简单,PHP是极其随便的一种语言。写上去容易让你把精力放到你要做的事情上,而不是各类句型规则等等。2.各类功能模块齐全,这儿分两部份:1.网页下载:curl等扩充库;2.文档解析:dom、xpath、tidy、各种转码工具,可能跟题主的问题不太一样,我的爬虫须要提取正......
hs947463167的博客
03-06
3300
基于python的-提高爬虫效率的方法
#-*-coding:utf-8-*-"""明显提高爬虫效率的方法:1.换个性能更好的机器2.网路使用光纤3.多线程4.多进程5.分布式6.提高数据的写入速率""""""反爬虫的应对举措:1.随机更改User-Agent2.禁用Cookie追踪3.放慢爬虫速率4......
shenjian58的博客
03-22
3万+
男人更看重女孩的体型脸部,还是思想?
常常,我们看不进去大段大段的逻辑。深刻的哲理,常常短而精悍,一阵见血。问:产品总监挺漂亮的,有茶点动,但不晓得合不般配。女孩更看重女孩的体型脸部,还是...
静水流深的博客
03-29
4069
python爬虫(1)-使用requests和beautifulsoup库爬取中国天气网
python爬虫(1)-使用requests和beautifulsoup库爬取中国天气网使用工具及打算python3.7(python3以上都可以)pycharmIDE(本人习惯使用pycharm,也可以使用其他的)URL:、requests、lxml库(p...
天镇少年
10-16
2万+
Python爬虫的N种坐姿
问题的来历 前几天,在陌陌公众号(Python爬虫及算法)上有个人问了笔者一个问题,怎样借助爬虫来实现如下的需求,须要爬取的网页如下(网址为::WhatLinksHere/Q5&limit=500&from=0): 我们的需求为爬取白色框框内的名人(有500条记录,图片只展......
weixin_42530834的博客
06-23
3万+
一、最简单的爬虫(python3爬虫小白系列文章)
运行平台:WindowsPython版本:Python3.xIDE:Pycharm2017.2.4看了崔老师的python3网路爬虫实战,获益颇丰,为了帮助自己更好的理解这种知识点,于是准备趁着这股热乎劲,针对爬虫实战进行一系列的教程。阅读文章前,我会默认你早已具备一下几个要素1.python3安装完毕Windows:
Zhangguohao666的博客
03-30
4万+
Python爬虫,高清美图我全都要(彼岸桌面墙纸)
爬取彼岸桌面网站较为简单,用到了requests、lxml、BeautifulSoup4
启舰
03-23
3万+
程序员结业去大公司好还是小公司好?
其实大公司并不是人人都能进,但我仍建议还未结业的朋友,竭力地通过校招向大公司挤,即便挤进去,你这一生会容易好多。大公司那里好?没能进大公司如何办?答案都在这儿了,记得帮我点赞哦。目录:技术气氛内部晋升与跳槽啥也没学会,公司倒闭了?不同的人脉圈,注定会有不同的结果没能去大厂如何办?一、技术气氛综观整个程序员技术领域,那个在行业有所名气的大牛,不是在大厂?并且众所......
weixin_34132768的博客
12-12
599
为何python爬虫工程师岗位如此火爆?
哪些是网路爬虫?网路爬虫是一个手动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直至满足系统的一定停止条件。爬虫有哪些用?做为通用搜索引擎网页搜集器。(google,baidu)做垂直搜索引擎.科学研究:在线人类行为,在线社群演变,人类动力学研究,计......
学习python的正确坐姿
05-06
1209
python爬虫13|秒爬,python这多线程爬取速率也太猛了,此次就是要让你的爬虫效率杠杠的
快快了啊嘿小侄儿想啥呢明天这篇爬虫教程的主题就是一个字快想要做到秒爬就须要晓得哪些是多进程哪些是多线程哪些是轮询(微线程)你先去沏杯茶坐出来小帅b这就好好给你说道说道关于线程这玩意儿沏好茶了吗这么...
weixin_34273481的博客
05-31
1728
8个最高效的Python爬虫框架,你用过几个?
小编搜集了一些较为高效的Python爬虫框架。分享给你们。1.ScrapyScrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。项目地址:是一个用python实现的功能......
空悲切
12-23
1万+
怎么高贵地使用c语言编撰爬虫
序言你们在平常或多或少地就会有编撰网路爬虫的需求。通常来说,编撰爬虫的首选自然非python莫属,除此之外,java等语言也是不错的选择。选择上述语言的诱因不仅仅在于它们均有十分不错的网路恳求库和字符串处理库,还在于基于上述语言的爬虫框架十分之多和健全。良好的爬虫框架可以确保爬虫程序的稳定性,以及编撰程序的方便性。所以,这个cspider爬虫库的使命在于,我们才能使用c语言,仍然还能高贵地编撰爬...
CSDN资讯
09-03
4万+
学Python后究竟能干哪些?网友:我太难了
觉得全世界营销文都在推Python,并且找不到工作的话,又有那个机构会站下来给我推荐工作?笔者冷静剖析多方数据,想跟你们说:关于赶超老牌霸主Java,过去几年间Pytho...
Rainbow
04-28
2万+
python爬虫之一:爬取网页小说(魂破九天)
近日做一个项目须要用到python,只懂皮毛的我花了三天时间将python重新捡起啃一啃,终于对python有了一定的认识。之后有按照爬虫基本原理爬取了一本小说,其他爬取小说的方式类似,结果见个人资源下载(本想下载分设置为0,结果CSDN设置最低为2分,没有积分的可以加我qq要该小说)。**爬虫原理:1、模拟人打开一页小说网页2、将网页保存出来......
毕易方达的博客
08-09
7795
全面了解Java中Native关键字的作用
初次遇到native是在java.lang.Object源码中的一个hashCode方式:1publicnativeinthashCode();为何有个native呢?这是我所要学习的地方。所以下边想要总结下native。一、认识native即JNI,JavaNativeInterface但凡一种语言,都希望是纯。例如解决某一个方案都喜欢就单单这个语言......
做人还是高调点
05-08
4万+
笔试:第十六章:Java高级开发(16k)
HashMap底层实现原理,黑红树,B+树,B树的结构原理Spring的AOP和IOC是哪些?它们常见的使用场景有什么?Spring事务,事务的属性,传播行为,数据库隔离级别Spring和SpringMVC,MyBatis以及SpringBoot的注解分别有什么?SpringMVC的工作原理,SpringBoot框架的优点,MyBatis框架的优点SpringCould组件有什么,她们......
Bo_wen_的博客
03-13
16万+
python网路爬虫入门(一)———第一个python爬虫实例
近来七天学习了一下python,并自己写了一个网路爬虫的反例。python版本:3.5IDE:pycharm5.0.4要用到的包可以用pycharm下载:File->DefaultSettings->DefaultProject->ProjectInterpreter选择python版本并点一侧的减号安装想要的包我选择的网站是中国天气网中的上海天气,打算抓取近来...
jsmok_xingkong的博客
11-05
3143
Python-爬虫初体验
在网易云课堂上看的教学视频,如今来巩固一下知识:1.先确定自己要爬的网站,以新浪新闻网站为例确importrequests#跟java的导包差不多,python叫导出库res=requests.get('#039;)#爬取网页内容res.encoding='utf-8'#将得到的网页内容转码,防止乱...
CSDN资讯
03-27
4万+
无代码时代将至,程序员怎样保住饭碗?
编程语言层出不穷,从最初的机器语言到现在2500种以上的中级语言,程序员们大呼“学到头秃”。程序员一边面临编程语言不断推陈出新,一边面临因为许多代码已存在,程序员编撰新应用程序时存在重复“搬砖”的现象。无代码/低代码编程应运而生。无代码/低代码是一种创建应用的方式,它可以让开发者使用最少的编码知识来快速开发应用程序。开发者通过图形界面中,可视化建模来组装和配置应用程序。这样一来,开发者直......
明明如月的专栏
03-01
1万+
将一个插口响应时间从2s优化到200ms以内的一个案例
一、背景在开发联调阶段发觉一个插口的响应时间非常长,常常超时,囧…本文讲讲是怎样定位到性能困局以及更改的思路,将该插口从2s左右优化到200ms以内。二、步骤2.1定位定位性能困局有两个思路,一个是通过工具去监控,一个是通过经验去猜测。2.1.1工具监控就工具而言,推荐使用arthas,用到的是trace命令具体安装步骤很简单,你们自行研究。我的使用步骤是......
tboyer
03-24
95
python3爬坑日记(二)——大文本读取
python3爬坑日记(二)——大文本读取一般我们使用python读取文件直接使用:fopen=open("test.txt")str=fopen.read()fopen.close()假如文件内容较小,使用以上方式其实没问题。并且,有时我们须要读取类似字典,日志等富含大量内容的文件时使用上述方式因为显存缘由常常会抛出异常。这时请使用:withopen("test.tx......
aa804738534的博客
01-19
646
STL(四)容器手动排序set
#include<set>#include<iostream>#include<set>#include<string>usingnamespacestd;template<typenameT>voidshowset(set<T>v){for(typenamestd::set...
薛定谔的雄猫的博客
04-30
2万+
怎样柔美的替换掉代码中的ifelse
平常我们在写代码时,处理不同的业务逻辑,用得最多的就是if和else,简单粗鲁省事,并且ifelse不是最好的方法,本文将通过设计模式来替换ifelse,使代码更高贵简约。
非知名程序员
01-30
7万+
非典逼出了天猫和易迅,新冠病毒才能逼出哪些?
loonggg读完须要5分钟速读仅需2分钟你们好,我是大家的市长。我晓得你们在家里都憋坏了,你们可能相对于封闭在家里“坐月子”,更希望才能尽快下班。明天我带着你们换个思路来聊一个问题...
九章算法的博客
02-06
19万+
B站上有什么挺好的学习资源?
哇说起B站,在小九眼中就是宝藏般的存在,放休假宅在家时三天刷6、7个小时不在话下,更别提去年的跨年晚宴,我简直是跪着看完的!!最早你们聚在在B站是为了追番,再后来我在里面刷欧美新曲和漂亮小妹妹的街舞视频,近来三年我和周围的同学们早已把B站当成学习课室了,但是学习成本还免费,真是个励志的好平台ヽ(.◕ฺˇдˇ◕ฺ;)ノ下边我们就来盘点一下B站上优质的学习资源:综合类Oeasy:综合......
王泽岭的博客
08-19
479
几种语言在爬虫场景下的力量对比
PHP爬虫:代码简单,并发处理能力较弱:因为当时PHP没有线程、进程功能要想实现并发须要借用多路复用模型R语言爬虫:操作简单,功能太弱,只适用于小规模的爬取,不适宜大规模的爬取Python爬虫:有着各类成熟的爬虫框架(eg:scrapy家族),可以便捷高效的下载网页而且支持多线程,进程模型成熟稳定,爬虫是是一个典型的多任务处理场景,恳求页面时会有较长的延后,总体来说更多的是等待,多线......
九章算法的博客
03-17
4580
作为程序员,有没有让你倍感既无语又崩溃的代码注释?
作为一个程序员,堪称是天天通宵来加班,也难以阅遍无数的程序代码,不晓得有多少次看到这些让人既倍感无语又奔溃的代码注释了。你以为自己能看懂这种代码,但是有信心可以优化这种代码,一旦你开始尝试这种代码,你将会被困在无尽的熬夜中,在痛斥中结束这段痛楚的历程。更有有网友坦承,自己写代码都是拼音变量名和英文注释,担心被踢出程序员队伍。下边这个代码注释大约说出了好多写代码人的心里话了。//我写这一行的时侯......
CSDN大学
03-10
2万+
刚回应!删库报复!一行代码蒸发数10亿!
年后开工大戏,又降低一出:删库跑路!此举直接给公司带来数10亿的估值蒸发损失,并引起一段“狗血宿怨剧情”,说实话电视剧都不敢如此拍!此次不是他人,正是陌陌生态的第三方服务商微盟,在这个"远程办公”的节骨眼出事了。2月25日,微盟集团(SEHK:02013)发布公告称,Saas生产环境及数据受到职工“人为破坏”导致公司当前暂时未能向顾客提供SaaS产品。犯罪嫌疑人是微盟研制......
爪白白的个人博客
04-25
5万+
总结了150余个神奇网站,你不来看看吗?
原博客再更新,可能就没了,然后将持续更新本篇博客。
11-03
8645
二次型(求梯度)——公式的简化
1.基本方程
程序人生的博客
02-11
5636
大地震!某大厂“硬核”抢人,放话:只要AI人才,中学结业都行!
特斯拉创始人马斯克,在2019年曾许下好多承诺网络爬虫语言,其中一个就是:2019年末实现完全的手动驾驶。其实这个承诺又成了flag,并且不阻碍他去年继续为这个承诺努力。这不,就在上周四,马斯克之间...
3y
03-16
9万+
我说我不会算法,阿里把我挂了。
不说了,字节跳动也反手把我挂了。
qq_40618664的博客
05-07
3万+
Auto.JS实现抖音,刷宝等刷视频app,自动点赞,手动滑屏,手动切换视频
Auto.JS实现抖音,刷宝等刷视频app,自动点赞,手动滑屏,手动切换视频代码如下auto();varappName=rawInput("","刷宝短视频");launchApp(appName);sleep("5000");setScreenMetrics(1080,1920);toast("1023732997");sleep("3000");varnum=200...
lmseo5hy的博客
05-14
1万+
Python与其他语言相比异同点python零基础入门
python作为一门中级编程语言,它的诞生其实很碰巧,并且它得到程序员的喜爱却是必然之路,以下是Python与其他编程语言的异同点对比:1.Python优势:简单易学,才能把用其他语言制做的各类模块很轻松地连结在一起。劣势:速率较慢,且有一些特定情况下才能出现(未能再现)的bug2.C/C++C/C++优势:可以被嵌入任何现代处理器中,几乎所有操作系统都支持C/C++,跨平台性十分好劣势:学习......
WUTab的博客
07-30
2549
找出链表X和Y中所有2n个元素的中位数
算法总论第三版,9.3-8算法:假如两个字段宽度为1,选出较小的那种一个否则,取出两个字段的中位数。取有较大中位数的链表的低区和较低中位数链表的高区,组合成新的宽度为n的链表。找出新链表的中位数思路:既然用递归分治,一定有基本情况,基本情况就是链表宽度为1.观察会发觉总的中位数介于两个字段的中位数之间。详尽证明如下:设总的中位数是MM,XX的中位数是MXM_X,YY的中位数是...
程松
03-30
10万+
5分钟,6行代码教你写爬虫!(python)
5分钟,6行代码教你写会爬虫!适用人士:对数据量需求不大,简单的从网站上爬些数据。好,不浪费时间了,开始!先来个反例:输入以下代码(共6行)importrequestsfromlxmlimporthtmlurl='#039;#须要爬数据的网址page=requests.Session().get(url)tree=html.f... 查看全部
07-22

2038
哪种语言合适写爬虫程序
1、如果是定向爬取几个页面,做一些简单的页面解析,爬取效率不是核心要求,这么用哪些语言差别不大。其实要是页面结构复杂,正则表达式写得巨复杂,尤其是用过这些支持xpath的解释器/爬虫库后,才会发觉此种方法尽管入门门槛低,但扩充性、可维护性等都奇差。因而此种情况下还是推荐采用一些现成的爬虫库,例如xpath、多线程支持还是必须考虑的诱因。2、如果是定向爬取,且主要目标是解析...
延瓒
01-01
1万+
Python/打响2019年第一炮-Python爬虫入门(一)
打响2019第一炮-Python爬虫入门 2018年早已成为过去,还记得在2018年元旦写过一篇【Shell编程】打响2018第一炮-shell编程之for循环句子,那在此时此刻,也是写一篇关于编程方面,不过要比18年的稍稍中级点。So,mark一下,也希望对您有所帮助。 步入题外话,在双十二想必你们都逛过网店and易迅,例如我们须要买一部手机或笔记本,而且我们须要点开手机或则笔记本页面看......
ROSE_ty的博客
03-04
2897
Python爬虫出现�乱码的解决办法
明天学习Python爬虫,再读取页面内容时出现以下情况,虽然使用了‘utf-8’后来通过阅读文章,将编码改为GBK后可正常显示...
ahkeyan的博客
03-15
1933
网路爬虫尝试(VB编撰)
PrivateSubForm_Load()a=getHTTPPage(“”)b=Split(a,“[”)(1)c=Split(b,“]”)(0)MsgBoxcEndSubFunctiongetHTTPPage(url)OnErrorResumeNextDimhttpSethttp=CreateObj...
qq_41514083的博客
07-17
1307
IDEA中JDBC的使用--完成对于数据库中数据的增删改查
IDEA中JDBC的使用--完成对于数据库中数据的增删改查1.在IDEA中新建一个项目2.进行各个类的编撰3.项目结果展示1.在IDEA中新建一个项目1.1点击右上角file,在new中选择project,在两侧选择Java项目,选择自己所安装的SDK包,点击next1.2继续点击next1.3决定项目的名子以及项目储存的文件夹,然后点击finish,完成项目的创建2.进行各个类的......
weixin_33863087的博客
04-25
2255
爬虫可以使用哪些语言
有好多刚才做爬虫工作者得菜鸟常常会问道这样一个问题,做爬虫须要哪些语言,个人认为任何语言,只要具备访问网路的标准库,都可以做到这一点。其实了解必要的爬虫工具也是必然的,比如代理IP刚才接触爬虫,好多菜鸟会苦恼于用Python来做爬虫,而且无论是JAVA,PHP还是其他更低级语言,都可以很便捷的实现,静态语言出现错误的可能性很低,低级语言运行速率会更快一些。并且Python的优势在于库更......
大数据
04-24
2341
网路爬虫有哪些用?如何爬?手把手教你爬网页(Python代码)
导读:本文主要分为两个部份:一部份是网路爬虫的概述,帮助你们详尽了解网路爬虫;另一部份是HTTP恳求的Python实现,帮助你们了解Python中实现HTTP恳求的各类方...
小蓝枣的博客
03-06
4846
Python爬虫篇-爬取页面所有可用的链接
原理也很简单,html链接都是在a元素里的,我们就是匹配出所有的a元素,其实a可以是空的链接,空的链接是None,也可能是无效的链接。我们通过urllib库的request来测试链接的有效性。当链接无效的话会抛出异常,我们把异常捕获下来,并提示下来,没有异常就是有效的,我们直接显示下来就好了。...
点点寒彬的博客
05-16
5万+
简单谈谈Python与Go的区别
背景工作中的主力语言是Python,明年要搞性能测试的工具,因为GIL锁的缘由,Python的性能实在是低迷,须要学一门性能高的语言来世成性能测试的压力端。为此我把眼神置于了如今的新秀Go。经过一段时间的学习,也写了一个小工具,记一下这两个语言的区别。需求工具是一个小爬虫,拿来爬某网站的某个产品的迭代记录,实现逻辑就是运行脚本后,使用者从命令行输入个别元素(产品ID等)后网络爬虫语言,脚本导入......
捉虫李高人
03-05
3万+
闲话网路爬虫-CSharp对比Python
这一期给男子伴们普及下网路爬虫这块的东西,吹下牛,宣传一波C#爬虫的优势,希望Python的老铁们轻喷,哈哈!大致对比了下Python爬虫和C#爬虫的优劣势,可以汲取Python爬虫的框架,进一步封装好C#爬虫须要用到的方方面面,然后用上去还是会蛮爽的,起码单看在数据抓取方面不输Python,Python应该是借助上去做它更擅长的其他方面的事情,而不是大势宣传它在爬虫方面的......
Yeoman92的博客
10-17
6358
python爬虫:使用selenium+ChromeDriver爬取途家网
本站(途家网)通过常规抓页面的方式不能获取数据,可以使用selenium+ChromeDriver来获取页面数据。
dengguawei0519的博客
02-08
129
(转)各类语言写网路爬虫有哪些优点缺点
我用PHP和Python都写过爬虫和正文提取程序。最开始使用PHP所以先谈谈PHP的优点:1.语言比较简单,PHP是极其随便的一种语言。写上去容易让你把精力放到你要做的事情上,而不是各类句型规则等等。2.各类功能模块齐全,这儿分两部份:1.网页下载:curl等扩充库;2.文档解析:dom、xpath、tidy、各种转码工具,可能跟题主的问题不太一样,我的爬虫须要提取正......
hs947463167的博客
03-06
3300
基于python的-提高爬虫效率的方法
#-*-coding:utf-8-*-"""明显提高爬虫效率的方法:1.换个性能更好的机器2.网路使用光纤3.多线程4.多进程5.分布式6.提高数据的写入速率""""""反爬虫的应对举措:1.随机更改User-Agent2.禁用Cookie追踪3.放慢爬虫速率4......
shenjian58的博客
03-22
3万+
男人更看重女孩的体型脸部,还是思想?
常常,我们看不进去大段大段的逻辑。深刻的哲理,常常短而精悍,一阵见血。问:产品总监挺漂亮的,有茶点动,但不晓得合不般配。女孩更看重女孩的体型脸部,还是...
静水流深的博客
03-29
4069
python爬虫(1)-使用requests和beautifulsoup库爬取中国天气网
python爬虫(1)-使用requests和beautifulsoup库爬取中国天气网使用工具及打算python3.7(python3以上都可以)pycharmIDE(本人习惯使用pycharm,也可以使用其他的)URL:、requests、lxml库(p...
天镇少年
10-16
2万+
Python爬虫的N种坐姿
问题的来历 前几天,在陌陌公众号(Python爬虫及算法)上有个人问了笔者一个问题,怎样借助爬虫来实现如下的需求,须要爬取的网页如下(网址为::WhatLinksHere/Q5&amp;limit=500&amp;from=0): 我们的需求为爬取白色框框内的名人(有500条记录,图片只展......
weixin_42530834的博客
06-23
3万+
一、最简单的爬虫(python3爬虫小白系列文章)
运行平台:WindowsPython版本:Python3.xIDE:Pycharm2017.2.4看了崔老师的python3网路爬虫实战,获益颇丰,为了帮助自己更好的理解这种知识点,于是准备趁着这股热乎劲,针对爬虫实战进行一系列的教程。阅读文章前,我会默认你早已具备一下几个要素1.python3安装完毕Windows:
Zhangguohao666的博客
03-30
4万+
Python爬虫,高清美图我全都要(彼岸桌面墙纸)
爬取彼岸桌面网站较为简单,用到了requests、lxml、BeautifulSoup4
启舰
03-23
3万+
程序员结业去大公司好还是小公司好?
其实大公司并不是人人都能进,但我仍建议还未结业的朋友,竭力地通过校招向大公司挤,即便挤进去,你这一生会容易好多。大公司那里好?没能进大公司如何办?答案都在这儿了,记得帮我点赞哦。目录:技术气氛内部晋升与跳槽啥也没学会,公司倒闭了?不同的人脉圈,注定会有不同的结果没能去大厂如何办?一、技术气氛综观整个程序员技术领域,那个在行业有所名气的大牛,不是在大厂?并且众所......
weixin_34132768的博客
12-12
599
为何python爬虫工程师岗位如此火爆?
哪些是网路爬虫?网路爬虫是一个手动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直至满足系统的一定停止条件。爬虫有哪些用?做为通用搜索引擎网页搜集器。(google,baidu)做垂直搜索引擎.科学研究:在线人类行为,在线社群演变,人类动力学研究,计......
学习python的正确坐姿
05-06
1209
python爬虫13|秒爬,python这多线程爬取速率也太猛了,此次就是要让你的爬虫效率杠杠的
快快了啊嘿小侄儿想啥呢明天这篇爬虫教程的主题就是一个字快想要做到秒爬就须要晓得哪些是多进程哪些是多线程哪些是轮询(微线程)你先去沏杯茶坐出来小帅b这就好好给你说道说道关于线程这玩意儿沏好茶了吗这么...
weixin_34273481的博客
05-31
1728
8个最高效的Python爬虫框架,你用过几个?
小编搜集了一些较为高效的Python爬虫框架。分享给你们。1.ScrapyScrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。项目地址:是一个用python实现的功能......
空悲切
12-23
1万+
怎么高贵地使用c语言编撰爬虫
序言你们在平常或多或少地就会有编撰网路爬虫的需求。通常来说,编撰爬虫的首选自然非python莫属,除此之外,java等语言也是不错的选择。选择上述语言的诱因不仅仅在于它们均有十分不错的网路恳求库和字符串处理库,还在于基于上述语言的爬虫框架十分之多和健全。良好的爬虫框架可以确保爬虫程序的稳定性,以及编撰程序的方便性。所以,这个cspider爬虫库的使命在于,我们才能使用c语言,仍然还能高贵地编撰爬...
CSDN资讯
09-03
4万+
学Python后究竟能干哪些?网友:我太难了
觉得全世界营销文都在推Python,并且找不到工作的话,又有那个机构会站下来给我推荐工作?笔者冷静剖析多方数据,想跟你们说:关于赶超老牌霸主Java,过去几年间Pytho...
Rainbow
04-28
2万+
python爬虫之一:爬取网页小说(魂破九天)
近日做一个项目须要用到python,只懂皮毛的我花了三天时间将python重新捡起啃一啃,终于对python有了一定的认识。之后有按照爬虫基本原理爬取了一本小说,其他爬取小说的方式类似,结果见个人资源下载(本想下载分设置为0,结果CSDN设置最低为2分,没有积分的可以加我qq要该小说)。**爬虫原理:1、模拟人打开一页小说网页2、将网页保存出来......
毕易方达的博客
08-09
7795
全面了解Java中Native关键字的作用
初次遇到native是在java.lang.Object源码中的一个hashCode方式:1publicnativeinthashCode();为何有个native呢?这是我所要学习的地方。所以下边想要总结下native。一、认识native即JNI,JavaNativeInterface但凡一种语言,都希望是纯。例如解决某一个方案都喜欢就单单这个语言......
做人还是高调点
05-08
4万+
笔试:第十六章:Java高级开发(16k)
HashMap底层实现原理,黑红树,B+树,B树的结构原理Spring的AOP和IOC是哪些?它们常见的使用场景有什么?Spring事务,事务的属性,传播行为,数据库隔离级别Spring和SpringMVC,MyBatis以及SpringBoot的注解分别有什么?SpringMVC的工作原理,SpringBoot框架的优点,MyBatis框架的优点SpringCould组件有什么,她们......
Bo_wen_的博客
03-13
16万+
python网路爬虫入门(一)———第一个python爬虫实例
近来七天学习了一下python,并自己写了一个网路爬虫的反例。python版本:3.5IDE:pycharm5.0.4要用到的包可以用pycharm下载:File->DefaultSettings->DefaultProject->ProjectInterpreter选择python版本并点一侧的减号安装想要的包我选择的网站是中国天气网中的上海天气,打算抓取近来...
jsmok_xingkong的博客
11-05
3143
Python-爬虫初体验
在网易云课堂上看的教学视频,如今来巩固一下知识:1.先确定自己要爬的网站,以新浪新闻网站为例确importrequests#跟java的导包差不多,python叫导出库res=requests.get('#039;)#爬取网页内容res.encoding='utf-8'#将得到的网页内容转码,防止乱...
CSDN资讯
03-27
4万+
无代码时代将至,程序员怎样保住饭碗?
编程语言层出不穷,从最初的机器语言到现在2500种以上的中级语言,程序员们大呼“学到头秃”。程序员一边面临编程语言不断推陈出新,一边面临因为许多代码已存在,程序员编撰新应用程序时存在重复“搬砖”的现象。无代码/低代码编程应运而生。无代码/低代码是一种创建应用的方式,它可以让开发者使用最少的编码知识来快速开发应用程序。开发者通过图形界面中,可视化建模来组装和配置应用程序。这样一来,开发者直......
明明如月的专栏
03-01
1万+
将一个插口响应时间从2s优化到200ms以内的一个案例
一、背景在开发联调阶段发觉一个插口的响应时间非常长,常常超时,囧…本文讲讲是怎样定位到性能困局以及更改的思路,将该插口从2s左右优化到200ms以内。二、步骤2.1定位定位性能困局有两个思路,一个是通过工具去监控,一个是通过经验去猜测。2.1.1工具监控就工具而言,推荐使用arthas,用到的是trace命令具体安装步骤很简单,你们自行研究。我的使用步骤是......
tboyer
03-24
95
python3爬坑日记(二)——大文本读取
python3爬坑日记(二)——大文本读取一般我们使用python读取文件直接使用:fopen=open("test.txt")str=fopen.read()fopen.close()假如文件内容较小,使用以上方式其实没问题。并且,有时我们须要读取类似字典,日志等富含大量内容的文件时使用上述方式因为显存缘由常常会抛出异常。这时请使用:withopen("test.tx......
aa804738534的博客
01-19
646
STL(四)容器手动排序set
#include<set>#include<iostream>#include<set>#include<string>usingnamespacestd;template<typenameT>voidshowset(set<T>v){for(typenamestd::set...
薛定谔的雄猫的博客
04-30
2万+
怎样柔美的替换掉代码中的ifelse
平常我们在写代码时,处理不同的业务逻辑,用得最多的就是if和else,简单粗鲁省事,并且ifelse不是最好的方法,本文将通过设计模式来替换ifelse,使代码更高贵简约。
非知名程序员
01-30
7万+
非典逼出了天猫和易迅,新冠病毒才能逼出哪些?
loonggg读完须要5分钟速读仅需2分钟你们好,我是大家的市长。我晓得你们在家里都憋坏了,你们可能相对于封闭在家里“坐月子”,更希望才能尽快下班。明天我带着你们换个思路来聊一个问题...
九章算法的博客
02-06
19万+
B站上有什么挺好的学习资源?
哇说起B站,在小九眼中就是宝藏般的存在,放休假宅在家时三天刷6、7个小时不在话下,更别提去年的跨年晚宴,我简直是跪着看完的!!最早你们聚在在B站是为了追番,再后来我在里面刷欧美新曲和漂亮小妹妹的街舞视频,近来三年我和周围的同学们早已把B站当成学习课室了,但是学习成本还免费,真是个励志的好平台ヽ(.◕ฺˇдˇ◕ฺ;)ノ下边我们就来盘点一下B站上优质的学习资源:综合类Oeasy:综合......
王泽岭的博客
08-19
479
几种语言在爬虫场景下的力量对比
PHP爬虫:代码简单,并发处理能力较弱:因为当时PHP没有线程、进程功能要想实现并发须要借用多路复用模型R语言爬虫:操作简单,功能太弱,只适用于小规模的爬取,不适宜大规模的爬取Python爬虫:有着各类成熟的爬虫框架(eg:scrapy家族),可以便捷高效的下载网页而且支持多线程,进程模型成熟稳定,爬虫是是一个典型的多任务处理场景,恳求页面时会有较长的延后,总体来说更多的是等待,多线......
九章算法的博客
03-17
4580
作为程序员,有没有让你倍感既无语又崩溃的代码注释?
作为一个程序员,堪称是天天通宵来加班,也难以阅遍无数的程序代码,不晓得有多少次看到这些让人既倍感无语又奔溃的代码注释了。你以为自己能看懂这种代码,但是有信心可以优化这种代码,一旦你开始尝试这种代码,你将会被困在无尽的熬夜中,在痛斥中结束这段痛楚的历程。更有有网友坦承,自己写代码都是拼音变量名和英文注释,担心被踢出程序员队伍。下边这个代码注释大约说出了好多写代码人的心里话了。//我写这一行的时侯......
CSDN大学
03-10
2万+
刚回应!删库报复!一行代码蒸发数10亿!
年后开工大戏,又降低一出:删库跑路!此举直接给公司带来数10亿的估值蒸发损失,并引起一段“狗血宿怨剧情”,说实话电视剧都不敢如此拍!此次不是他人,正是陌陌生态的第三方服务商微盟,在这个"远程办公”的节骨眼出事了。2月25日,微盟集团(SEHK:02013)发布公告称,Saas生产环境及数据受到职工“人为破坏”导致公司当前暂时未能向顾客提供SaaS产品。犯罪嫌疑人是微盟研制......
爪白白的个人博客
04-25
5万+
总结了150余个神奇网站,你不来看看吗?
原博客再更新,可能就没了,然后将持续更新本篇博客。
11-03
8645
二次型(求梯度)——公式的简化
1.基本方程
程序人生的博客
02-11
5636
大地震!某大厂“硬核”抢人,放话:只要AI人才,中学结业都行!
特斯拉创始人马斯克,在2019年曾许下好多承诺网络爬虫语言,其中一个就是:2019年末实现完全的手动驾驶。其实这个承诺又成了flag,并且不阻碍他去年继续为这个承诺努力。这不,就在上周四,马斯克之间...
3y
03-16
9万+
我说我不会算法,阿里把我挂了。
不说了,字节跳动也反手把我挂了。
qq_40618664的博客
05-07
3万+
Auto.JS实现抖音,刷宝等刷视频app,自动点赞,手动滑屏,手动切换视频
Auto.JS实现抖音,刷宝等刷视频app,自动点赞,手动滑屏,手动切换视频代码如下auto();varappName=rawInput("","刷宝短视频");launchApp(appName);sleep("5000");setScreenMetrics(1080,1920);toast("1023732997");sleep("3000");varnum=200...
lmseo5hy的博客
05-14
1万+
Python与其他语言相比异同点python零基础入门
python作为一门中级编程语言,它的诞生其实很碰巧,并且它得到程序员的喜爱却是必然之路,以下是Python与其他编程语言的异同点对比:1.Python优势:简单易学,才能把用其他语言制做的各类模块很轻松地连结在一起。劣势:速率较慢,且有一些特定情况下才能出现(未能再现)的bug2.C/C++C/C++优势:可以被嵌入任何现代处理器中,几乎所有操作系统都支持C/C++,跨平台性十分好劣势:学习......
WUTab的博客
07-30
2549
找出链表X和Y中所有2n个元素的中位数
算法总论第三版,9.3-8算法:假如两个字段宽度为1,选出较小的那种一个否则,取出两个字段的中位数。取有较大中位数的链表的低区和较低中位数链表的高区,组合成新的宽度为n的链表。找出新链表的中位数思路:既然用递归分治,一定有基本情况,基本情况就是链表宽度为1.观察会发觉总的中位数介于两个字段的中位数之间。详尽证明如下:设总的中位数是MM,XX的中位数是MXM_X,YY的中位数是...
程松
03-30
10万+
5分钟,6行代码教你写爬虫!(python)
5分钟,6行代码教你写会爬虫!适用人士:对数据量需求不大,简单的从网站上爬些数据。好,不浪费时间了,开始!先来个反例:输入以下代码(共6行)importrequestsfromlxmlimporthtmlurl='#039;#须要爬数据的网址page=requests.Session().get(url)tree=html.f...
【黑马程序员】Python爬虫是哪些?爬虫教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 482 次浏览 • 2020-05-19 08:01
【黑马程序员】Python 爬虫是哪些?爬虫教程假如你仔细观察,就不难发觉,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取 的数据越来越多,另一方面,像 Python 这样的编程语言提供越来越多的优秀工具,让爬虫 变得简单、容易上手。 利用爬虫我们可以获取大量的价值数据,从而获得感性认识中不能得到的信息,比如: 知乎:爬取优质答案,为你筛选出各话题下最优质的内容。淘宝、京东:抓取商品、评论及 销量数据,对各类商品及用户的消费场景进行剖析。安居客、链家:抓取房产买卖及租售信 息,分析楼市变化趋势、做不同区域的楼价剖析。拉勾网、智联:爬取各种职位信息,分析 各行业人才需求情况及薪酬水平。雪球网:抓取雪球高回报用户的行为,对股票市场进行分 析和预测。 爬虫是入门 Python 最好的形式,没有之一。Python 有很多应用的方向,比如后台开发、 web 开发、科学估算等等,但爬虫对于初学者而言更友好,原理简单,几行代码能够实现 基本的爬虫,学习的过程愈发平滑,你能感受更大的成就感。 掌握基本的爬虫后,你再去学习 Python 数据剖析、web 开发甚至机器学习,都会更得心 应手。因为这个过程中,Python 基本句型、库的使用,以及怎样查找文档你都十分熟悉了。
对于小白来说,爬虫可能是一件十分复杂、技术门槛很高的事情。比如有人觉得学爬虫必须 精通 Python,然后哼哧哼哧系统学习 Python 的每位知识点,很久以后发觉一直爬不了数 据;有的人则觉得先要把握网页的知识,遂开始 HTML\CSS,结果入了后端的坑,瘁…… 但把握正确的方式,在短时间内做到才能爬取主流网站的数据,其实十分容易实现,但建议 你从一开始就要有一个具体的目标。视频库网址:资料发放:3285264708在目标的驱动下,你的学习才能愈发精准和高效。那些所有你觉得必须的后置知识,都是可 以在完成目标的过程小学到的。这里给你一条平滑的、零基础快速入门的学习路径。 文章目录: 1. 学习 Python 包并实现基本的爬虫过程 2. 了解非结构化数据的储存 3. 学习 scrapy,搭建工程化爬虫 4. 学习数据库知识,应对大规模数据储存与提取 5. 掌握各类方法,应对特殊网站的反爬举措 6. 分布式爬虫,实现大规模并发采集,提升效率-? 学习 Python 包并实现基本的爬虫过程大部分爬虫都是按“发送恳求——获得页面——解析页面——抽取并存储内容”这样的流 程来进行,这或许也是模拟了我们使用浏览器获取网页信息的过程。
Python 中爬虫相关的包好多:urllib、requests、bs4、scrapy、pyspider 等,建议从 requests+Xpath 开始,requests 负责联接网站,返回网页,Xpath 用于解析网页,便于 抽取数据。 如果你用过 BeautifulSoup,会发觉 Xpath 要省事不少,一层一层检测元素代码的工作, 全都省略了。这样出来基本套路都差不多,一般的静态网站根本不在话下,豆瓣、糗事百科、 腾讯新闻等基本上都可以上手了。 当然假如你须要爬取异步加载的网站,可以学习浏览器抓包剖析真实恳求或则学习 Selenium 来实现自动化,这样,知乎、时光网、猫途鹰这种动态的网站也可以迎刃而解。视频库网址:资料发放:3285264708-? 了解非结构化数据的储存爬回去的数据可以直接用文档方式存在本地,也可以存入数据库中。 开始数据量不大的时侯,你可以直接通过 Python 的句型或 pandas 的方式将数据存为 csv 这样的文件。 当然你可能发觉爬回去的数据并不是干净的python爬虫是什么意思,可能会有缺位、错误等等,你还须要对数据进 行清洗,可以学习 pandas 包的基本用法来做数据的预处理,得到更干净的数据。
-? 学习 scrapy,搭建工程化的爬虫把握后面的技术通常量级的数据和代码基本没有问题了,但是在碰到十分复杂的情况,可能 仍然会力不从心,这个时侯,强大的 scrapy 框架就十分有用了。 scrapy 是一个功能十分强悍的爬虫框架,它除了能方便地建立 request,还有强悍的 selector 能够便捷地解析 response,然而它最使人惊喜的还是它超高的性能,让你可以 将爬虫工程化、模块化。 学会 scrapy,你可以自己去搭建一些爬虫框架,你就基本具备爬虫工程师的思维了。-? 学习数据库基础,应对大规模数据储存爬回去的数据量小的时侯,你可以用文档的方式来储存,一旦数据量大了,这就有点行不通 了。所以把握一种数据库是必须的,学习目前比较主流的 MongoDB 就 OK。视频库网址:资料发放:3285264708MongoDB 可以便捷你去储存一些非结构化的数据,比如各类评论的文本,图片的链接等 等。你也可以借助 PyMongo,更方便地在 Python 中操作 MongoDB。 因为这儿要用到的数据库知识似乎十分简单,主要是数据怎么入库、如何进行提取,在须要 的时侯再学习就行。
-? 掌握各类方法,应对特殊网站的反爬举措其实,爬虫过程中也会经历一些绝望啊,比如被网站封 IP、比如各类奇怪的验证码、 userAgent 访问限制、各种动态加载等等。 遇到这种反爬虫的手段,当然还须要一些中级的方法来应对,常规的例如访问频度控制、使 用代理 IP 池、抓包、验证码的 OCR 处理等等。 往往网站在高效开发和反爬虫之间会偏向后者,这也为爬虫提供了空间,掌握这种应对反爬 虫的方法,绝大部分的网站已经难不到你了。-? 分布式爬虫,实现大规模并发采集爬取基本数据早已不是问题了,你的困局会集中到爬取海量数据的效率。这个时侯,相信你 会很自然地接触到一个很厉害的名子:分布式爬虫。 分布式这个东西,听上去太惊悚,但毕竟就是借助多线程的原理使多个爬虫同时工作,需要 你把握 Scrapy + MongoDB + Redis 这三种工具。 Scrapy 前面我们说过了,用于做基本的页面爬取,MongoDB 用于储存爬取的数据,Redis 则拿来储存要爬取的网页队列,也就是任务队列。视频库网址:资料发放:3285264708所以有些东西看起来太吓人,但毕竟分解开来,也不过如此。当你才能写分布式的爬虫的时 候,那么你可以去尝试构建一些基本的爬虫构架了python爬虫是什么意思,实现一些愈发自动化的数据获取。
你看,这一条学习路径出来,你已经可以成为老司机了,非常的顺畅。所以在一开始的时侯, 尽量不要系统地去啃一些东西,找一个实际的项目(开始可以从豆瓣、小猪这些简单的入手), 直接开始就好。 因为爬虫这些技术,既不需要你系统地精通一门语言,也不需要多么深奥的数据库技术,高 效的坐姿就是从实际的项目中去学习这种零散的知识点,你能保证每次学到的都是最须要的 那部份。 当然惟一麻烦的是,在具体的问题中,如何找到具体须要的那部份学习资源、如何筛选和甄 别,是好多初学者面临的一个大问题。黑马程序员视频库网址:(海量热门编程视频、资料免费学习) 学习路线图、学习大纲、各阶段知识点、资料云盘免费发放+QQ 3285264708 / 3549664195视频库网址:资料发放:3285264708 查看全部

【黑马程序员】Python 爬虫是哪些?爬虫教程假如你仔细观察,就不难发觉,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取 的数据越来越多,另一方面,像 Python 这样的编程语言提供越来越多的优秀工具,让爬虫 变得简单、容易上手。 利用爬虫我们可以获取大量的价值数据,从而获得感性认识中不能得到的信息,比如: 知乎:爬取优质答案,为你筛选出各话题下最优质的内容。淘宝、京东:抓取商品、评论及 销量数据,对各类商品及用户的消费场景进行剖析。安居客、链家:抓取房产买卖及租售信 息,分析楼市变化趋势、做不同区域的楼价剖析。拉勾网、智联:爬取各种职位信息,分析 各行业人才需求情况及薪酬水平。雪球网:抓取雪球高回报用户的行为,对股票市场进行分 析和预测。 爬虫是入门 Python 最好的形式,没有之一。Python 有很多应用的方向,比如后台开发、 web 开发、科学估算等等,但爬虫对于初学者而言更友好,原理简单,几行代码能够实现 基本的爬虫,学习的过程愈发平滑,你能感受更大的成就感。 掌握基本的爬虫后,你再去学习 Python 数据剖析、web 开发甚至机器学习,都会更得心 应手。因为这个过程中,Python 基本句型、库的使用,以及怎样查找文档你都十分熟悉了。
对于小白来说,爬虫可能是一件十分复杂、技术门槛很高的事情。比如有人觉得学爬虫必须 精通 Python,然后哼哧哼哧系统学习 Python 的每位知识点,很久以后发觉一直爬不了数 据;有的人则觉得先要把握网页的知识,遂开始 HTML\CSS,结果入了后端的坑,瘁…… 但把握正确的方式,在短时间内做到才能爬取主流网站的数据,其实十分容易实现,但建议 你从一开始就要有一个具体的目标。视频库网址:资料发放:3285264708在目标的驱动下,你的学习才能愈发精准和高效。那些所有你觉得必须的后置知识,都是可 以在完成目标的过程小学到的。这里给你一条平滑的、零基础快速入门的学习路径。 文章目录: 1. 学习 Python 包并实现基本的爬虫过程 2. 了解非结构化数据的储存 3. 学习 scrapy,搭建工程化爬虫 4. 学习数据库知识,应对大规模数据储存与提取 5. 掌握各类方法,应对特殊网站的反爬举措 6. 分布式爬虫,实现大规模并发采集,提升效率-? 学习 Python 包并实现基本的爬虫过程大部分爬虫都是按“发送恳求——获得页面——解析页面——抽取并存储内容”这样的流 程来进行,这或许也是模拟了我们使用浏览器获取网页信息的过程。
Python 中爬虫相关的包好多:urllib、requests、bs4、scrapy、pyspider 等,建议从 requests+Xpath 开始,requests 负责联接网站,返回网页,Xpath 用于解析网页,便于 抽取数据。 如果你用过 BeautifulSoup,会发觉 Xpath 要省事不少,一层一层检测元素代码的工作, 全都省略了。这样出来基本套路都差不多,一般的静态网站根本不在话下,豆瓣、糗事百科、 腾讯新闻等基本上都可以上手了。 当然假如你须要爬取异步加载的网站,可以学习浏览器抓包剖析真实恳求或则学习 Selenium 来实现自动化,这样,知乎、时光网、猫途鹰这种动态的网站也可以迎刃而解。视频库网址:资料发放:3285264708-? 了解非结构化数据的储存爬回去的数据可以直接用文档方式存在本地,也可以存入数据库中。 开始数据量不大的时侯,你可以直接通过 Python 的句型或 pandas 的方式将数据存为 csv 这样的文件。 当然你可能发觉爬回去的数据并不是干净的python爬虫是什么意思,可能会有缺位、错误等等,你还须要对数据进 行清洗,可以学习 pandas 包的基本用法来做数据的预处理,得到更干净的数据。
-? 学习 scrapy,搭建工程化的爬虫把握后面的技术通常量级的数据和代码基本没有问题了,但是在碰到十分复杂的情况,可能 仍然会力不从心,这个时侯,强大的 scrapy 框架就十分有用了。 scrapy 是一个功能十分强悍的爬虫框架,它除了能方便地建立 request,还有强悍的 selector 能够便捷地解析 response,然而它最使人惊喜的还是它超高的性能,让你可以 将爬虫工程化、模块化。 学会 scrapy,你可以自己去搭建一些爬虫框架,你就基本具备爬虫工程师的思维了。-? 学习数据库基础,应对大规模数据储存爬回去的数据量小的时侯,你可以用文档的方式来储存,一旦数据量大了,这就有点行不通 了。所以把握一种数据库是必须的,学习目前比较主流的 MongoDB 就 OK。视频库网址:资料发放:3285264708MongoDB 可以便捷你去储存一些非结构化的数据,比如各类评论的文本,图片的链接等 等。你也可以借助 PyMongo,更方便地在 Python 中操作 MongoDB。 因为这儿要用到的数据库知识似乎十分简单,主要是数据怎么入库、如何进行提取,在须要 的时侯再学习就行。
-? 掌握各类方法,应对特殊网站的反爬举措其实,爬虫过程中也会经历一些绝望啊,比如被网站封 IP、比如各类奇怪的验证码、 userAgent 访问限制、各种动态加载等等。 遇到这种反爬虫的手段,当然还须要一些中级的方法来应对,常规的例如访问频度控制、使 用代理 IP 池、抓包、验证码的 OCR 处理等等。 往往网站在高效开发和反爬虫之间会偏向后者,这也为爬虫提供了空间,掌握这种应对反爬 虫的方法,绝大部分的网站已经难不到你了。-? 分布式爬虫,实现大规模并发采集爬取基本数据早已不是问题了,你的困局会集中到爬取海量数据的效率。这个时侯,相信你 会很自然地接触到一个很厉害的名子:分布式爬虫。 分布式这个东西,听上去太惊悚,但毕竟就是借助多线程的原理使多个爬虫同时工作,需要 你把握 Scrapy + MongoDB + Redis 这三种工具。 Scrapy 前面我们说过了,用于做基本的页面爬取,MongoDB 用于储存爬取的数据,Redis 则拿来储存要爬取的网页队列,也就是任务队列。视频库网址:资料发放:3285264708所以有些东西看起来太吓人,但毕竟分解开来,也不过如此。当你才能写分布式的爬虫的时 候,那么你可以去尝试构建一些基本的爬虫构架了python爬虫是什么意思,实现一些愈发自动化的数据获取。
你看,这一条学习路径出来,你已经可以成为老司机了,非常的顺畅。所以在一开始的时侯, 尽量不要系统地去啃一些东西,找一个实际的项目(开始可以从豆瓣、小猪这些简单的入手), 直接开始就好。 因为爬虫这些技术,既不需要你系统地精通一门语言,也不需要多么深奥的数据库技术,高 效的坐姿就是从实际的项目中去学习这种零散的知识点,你能保证每次学到的都是最须要的 那部份。 当然惟一麻烦的是,在具体的问题中,如何找到具体须要的那部份学习资源、如何筛选和甄 别,是好多初学者面临的一个大问题。黑马程序员视频库网址:(海量热门编程视频、资料免费学习) 学习路线图、学习大纲、各阶段知识点、资料云盘免费发放+QQ 3285264708 / 3549664195视频库网址:资料发放:3285264708
爬虫技术浅析
采集交流 • 优采云 发表了文章 • 0 个评论 • 361 次浏览 • 2020-05-02 08:09
上图是Scrapy的构架图,绿线是数据流向,首先从初始URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载以后会交给 Spider 进行剖析,需要保存的数据则会被送到Item Pipeline,那是对数据进行后期处理。另外,在数据流动的通道里还可以安装各类中间件,进行必要的处理。 因此在开发爬虫的时侯,最好也先规划好各类模块。我的做法是单独规划下载模块,爬行模块,调度模块,数据储存模块。
页面下载分为静态和动态两种下载形式。
传统爬虫借助的是静态下载形式,静态下载的优势是下载过程快,但是页面只是一个无趣的html,因此页面链接剖析中获取的只是< a >标签的href属性或则大神可以自己剖析js,form之类的标签捕获一些链接。在python中可以借助urllib2模块或requests模块实现功能。 动态爬虫在web2.0时代则有特殊的优势,由于网页会使用javascript处理,网页内容通过Ajax异步获取。所以,动态爬虫须要剖析经过javascript处理和ajax获取内容后的页面。目前简单的解决方式是通过基于webkit的模块直接处理。PYQT4、Splinter和Selenium这三个模块都可以达到目的。对于爬虫而言,浏览器界面是不需要的,因此使用一个headless browser是十分实惠的,HtmlUnit和phantomjs都是可以使用的headless browser。
以上这段代码是访问新浪网主站。通过对比静态抓取页面和动态抓取页面的厚度和对比静态抓取页面和动态抓取页面内抓取的链接个数。
在静态抓取中,页面的宽度是563838,页面内抓取的链接数目只有166个。而在动态抓取中,页面的宽度下降到了695991,而链接数达到了1422,有了逾10倍的提高。
抓链接表达式
正则:re.compile("href=\"([^\"]*)\"")
Xpath:xpath('//*[@href]')
页面解析是实现抓取页面内链接和抓取特定数据的模块,页面解析主要是对字符串的处理,而html是一种特殊的字符串,在Python中re、beautifulsoup、HTMLParser、lxml等模块都可以解决问题。对于链接,主要抓取a标签下的href属性,还有其他一些标签的src属性。
URL去重是爬虫运行中一项关键的步骤,由于运行中的爬虫主要阻塞在网路交互中,因此防止重复的网路交互至关重要。爬虫通常会将待抓取的URL置于一个队列中,从抓取后的网页中提取到新的URL,在她们被装入队列之前,首先要确定这种新的URL没有被抓取过,如果之前早已抓取过了,就不再装入队列了。
Hash表
利用hash表做去重操作通常是最容易想到的方式,因为hash表查询的时间复杂度是O(1),而且在hash表足够大的情况下,hash冲突的机率就显得太小,因此URL是否重复的判定准确性就十分高。利用hash表去重的这个做法是一个比较简单的解决方式。但是普通hash表也有显著的缺陷爬虫技术,在考虑显存的情况下,使用一张大的hash表是不妥的。Python中可以使用字典这一数据结构。
URL压缩
如果hash表中,当每位节点存储的是一个str方式的具体URL,是十分占用显存的,如果把这个URL进行压缩成一个int型变量,内存占用程度上便有了3倍以上的缩小。因此可以借助Python的hashlib模块来进行URL压缩。 思路:把hash表的节点的数据结构设置为集合,集合内贮存压缩后的URL。
Bloom Filter
Bloom Filter是通过很少的错误换取了储存空间的极大节约。Bloom Filter 是通过一组k 个定义在n 个输入key 上的Hash Function,将上述n 个key 映射到m 位上的数据容器。
上图太清楚的说明了Bloom Filter的优势,在可控的容器宽度内,所有hash函数对同一个元素估算的hash值都为1时,就判定这个元素存在。 Python中hashlib,自带多种hash函数,有MD5,sha1,sha224,sha256,sha384,sha512。代码中还可以进行加水处理,还是很方便的。 Bloom Filter也会形成冲突的情况,具体内容查看文章结尾的参考文章。
在Python编程过程中,可以使用jaybaird提供的BloomFilter插口,或者自己造轮子。
小细节
有个小细节,在构建hash表的时侯选择容器很重要。hash表占用空间很大是个太不爽的问题,因此针对爬虫去重,下列方式可以解决一些问题。
上面这段代码简单验证了生成容器的运行时间。
由上图可以看出,建立一个宽度为1亿的容器时,选择list容器程序的运行时间耗费了7.2s,而选择字符串作为容器时,才耗费了0.2s的运行时间。
接下来瞧瞧显存的占用情况。
如果构建1亿的列表占用了794660k显存。
而构建1亿宽度的字符串却占用了109720k显存,空间占用大概降低了700000k。
初级算法
对于URL相似性,我只是实践一个十分简单的技巧。
在保证不进行重复爬去的情况下,还须要对类似的URL进行判定。我采用的是sponge和ly5066113提供的思路。具体资料在参考文章里。
下列是一组可以判定为相像的URL组
按照预期,以上URL归并后应当为
思路如下,需要提取如下特点
1,host字符串
2,目录深度(以’/’分割)
3,尾页特点
具体算法
算法本身太菜,各位一看才能懂。
实际疗效:
上图显示了把8个不一样的url,算出了2个值。通过实践,在一张千万级的hash表中,冲突的情况是可以接受的。
Python中的并发操作主要涉及的模型有:多线程模型、多进程模型、协程模型。Elias专门写了一篇文章爬虫技术,来比较常用的几种模型并发方案的性能。对于爬虫本身来说,限制爬虫速率主要来自目标服务器的响应速率,因此选择一个控制上去顺手的模块才是对的。
多线程模型,是最容易上手的,Python中自带的threading模块能挺好的实现并发需求,配合Queue模块来实现共享数据。
多进程模型和多线程模型类似,multiprocessing模块中也有类似的Queue模块来实现数据共享。在linux中,用户态的进程可以借助多核心的优势,因此在多核背景下,能解决爬虫的并发问题。
协程模型,在Elias的文章中,基于greenlet实现的解释器程序的性能仅次于Stackless Python,大致比Stackless Python慢一倍,比其他方案快接近一个数量级。因此基于gevent(封装了greenlet)的并发程序会有挺好的性能优势。
具体说明下gevent(非阻塞异步IO)。,“Gevent是一种基于解释器的Python网络库,它用到Greenlet提供的,封装了libevent风波循环的高层同步API。”
从实际的编程疗效来看,协程模型确实表现非常好,运行结果的可控性显著强了不少, gevent库的封装易用性极强。
数据储存本身设计的技术就十分多,作为小菜不敢乱说,但是工作还是有一些小经验是可以分享的。
前提:使用关系数据库,测试中选择的是mysql,其他类似sqlite,SqlServer思路上没有区别。
当我们进行数据储存时,目的就是降低与数据库的交互操作,这样可以增强性能。通常情况下,每当一个URL节点被读取,就进行一次数据储存,对于这样的逻辑进行无限循环。其实这样的性能体验是十分差的,存储速率特别慢。
进阶做法,为了减轻与数据库的交互次数,每次与数据库交互从之前传送1个节点弄成传送10个节点,到传送100个节点内容,这样效率变有了10倍至100倍的提高,在实际应用中,效果是非常好的。:D
爬虫模型
目前这个爬虫模型如上图,调度模块是核心模块。调度模块分别与下载模块,析取模块,存储模块共享三个队列,下载模块与析取模块共享一个队列。数据传递方向如图示。 查看全部
 谈到爬虫构架,不得不提的是Scrapy的爬虫构架。Scrapy,是Python开发的一个快速,高层次的爬虫框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。Scrapy吸引人的地方在于它是一个框架,任何人都可以依照需求便捷的更改。它也提供了多种类型爬虫的子类,如BaseSpider、sitemap爬虫等。
谈到爬虫构架,不得不提的是Scrapy的爬虫构架。Scrapy,是Python开发的一个快速,高层次的爬虫框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。Scrapy吸引人的地方在于它是一个框架,任何人都可以依照需求便捷的更改。它也提供了多种类型爬虫的子类,如BaseSpider、sitemap爬虫等。上图是Scrapy的构架图,绿线是数据流向,首先从初始URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载以后会交给 Spider 进行剖析,需要保存的数据则会被送到Item Pipeline,那是对数据进行后期处理。另外,在数据流动的通道里还可以安装各类中间件,进行必要的处理。 因此在开发爬虫的时侯,最好也先规划好各类模块。我的做法是单独规划下载模块,爬行模块,调度模块,数据储存模块。
页面下载分为静态和动态两种下载形式。
传统爬虫借助的是静态下载形式,静态下载的优势是下载过程快,但是页面只是一个无趣的html,因此页面链接剖析中获取的只是< a >标签的href属性或则大神可以自己剖析js,form之类的标签捕获一些链接。在python中可以借助urllib2模块或requests模块实现功能。 动态爬虫在web2.0时代则有特殊的优势,由于网页会使用javascript处理,网页内容通过Ajax异步获取。所以,动态爬虫须要剖析经过javascript处理和ajax获取内容后的页面。目前简单的解决方式是通过基于webkit的模块直接处理。PYQT4、Splinter和Selenium这三个模块都可以达到目的。对于爬虫而言,浏览器界面是不需要的,因此使用一个headless browser是十分实惠的,HtmlUnit和phantomjs都是可以使用的headless browser。
以上这段代码是访问新浪网主站。通过对比静态抓取页面和动态抓取页面的厚度和对比静态抓取页面和动态抓取页面内抓取的链接个数。

在静态抓取中,页面的宽度是563838,页面内抓取的链接数目只有166个。而在动态抓取中,页面的宽度下降到了695991,而链接数达到了1422,有了逾10倍的提高。
抓链接表达式
正则:re.compile("href=\"([^\"]*)\"")
Xpath:xpath('//*[@href]')
页面解析是实现抓取页面内链接和抓取特定数据的模块,页面解析主要是对字符串的处理,而html是一种特殊的字符串,在Python中re、beautifulsoup、HTMLParser、lxml等模块都可以解决问题。对于链接,主要抓取a标签下的href属性,还有其他一些标签的src属性。
URL去重是爬虫运行中一项关键的步骤,由于运行中的爬虫主要阻塞在网路交互中,因此防止重复的网路交互至关重要。爬虫通常会将待抓取的URL置于一个队列中,从抓取后的网页中提取到新的URL,在她们被装入队列之前,首先要确定这种新的URL没有被抓取过,如果之前早已抓取过了,就不再装入队列了。
Hash表
利用hash表做去重操作通常是最容易想到的方式,因为hash表查询的时间复杂度是O(1),而且在hash表足够大的情况下,hash冲突的机率就显得太小,因此URL是否重复的判定准确性就十分高。利用hash表去重的这个做法是一个比较简单的解决方式。但是普通hash表也有显著的缺陷爬虫技术,在考虑显存的情况下,使用一张大的hash表是不妥的。Python中可以使用字典这一数据结构。
URL压缩
如果hash表中,当每位节点存储的是一个str方式的具体URL,是十分占用显存的,如果把这个URL进行压缩成一个int型变量,内存占用程度上便有了3倍以上的缩小。因此可以借助Python的hashlib模块来进行URL压缩。 思路:把hash表的节点的数据结构设置为集合,集合内贮存压缩后的URL。
Bloom Filter
Bloom Filter是通过很少的错误换取了储存空间的极大节约。Bloom Filter 是通过一组k 个定义在n 个输入key 上的Hash Function,将上述n 个key 映射到m 位上的数据容器。
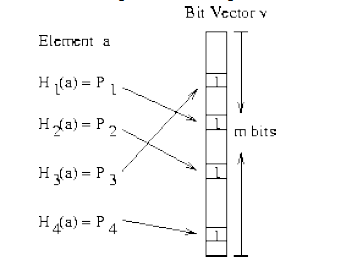
上图太清楚的说明了Bloom Filter的优势,在可控的容器宽度内,所有hash函数对同一个元素估算的hash值都为1时,就判定这个元素存在。 Python中hashlib,自带多种hash函数,有MD5,sha1,sha224,sha256,sha384,sha512。代码中还可以进行加水处理,还是很方便的。 Bloom Filter也会形成冲突的情况,具体内容查看文章结尾的参考文章。
在Python编程过程中,可以使用jaybaird提供的BloomFilter插口,或者自己造轮子。
小细节
有个小细节,在构建hash表的时侯选择容器很重要。hash表占用空间很大是个太不爽的问题,因此针对爬虫去重,下列方式可以解决一些问题。
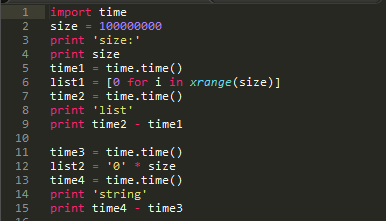
上面这段代码简单验证了生成容器的运行时间。
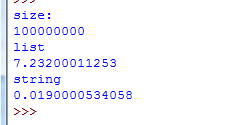
由上图可以看出,建立一个宽度为1亿的容器时,选择list容器程序的运行时间耗费了7.2s,而选择字符串作为容器时,才耗费了0.2s的运行时间。
接下来瞧瞧显存的占用情况。
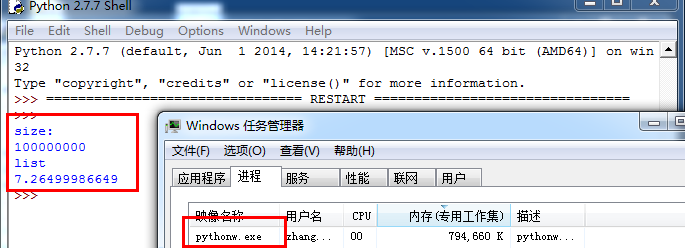
如果构建1亿的列表占用了794660k显存。
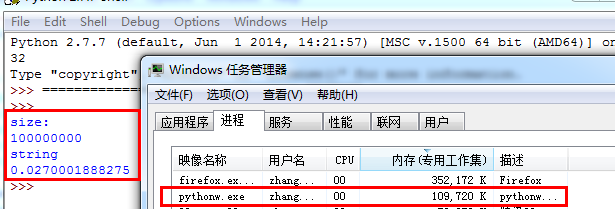
而构建1亿宽度的字符串却占用了109720k显存,空间占用大概降低了700000k。
初级算法
对于URL相似性,我只是实践一个十分简单的技巧。
在保证不进行重复爬去的情况下,还须要对类似的URL进行判定。我采用的是sponge和ly5066113提供的思路。具体资料在参考文章里。
下列是一组可以判定为相像的URL组
按照预期,以上URL归并后应当为
思路如下,需要提取如下特点
1,host字符串
2,目录深度(以’/’分割)
3,尾页特点
具体算法
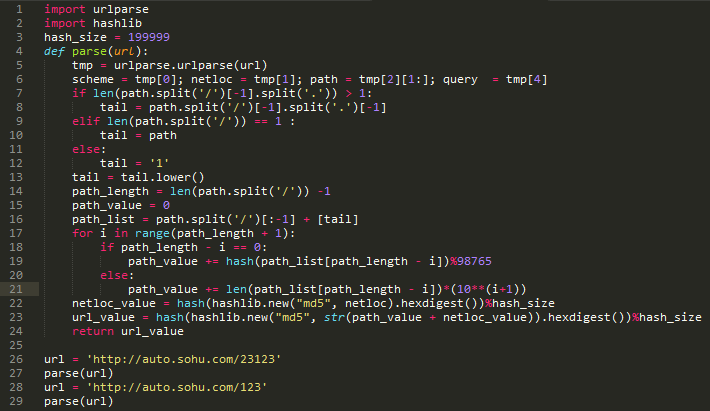
算法本身太菜,各位一看才能懂。
实际疗效:
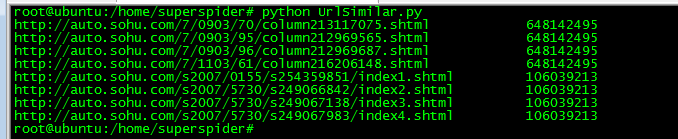
上图显示了把8个不一样的url,算出了2个值。通过实践,在一张千万级的hash表中,冲突的情况是可以接受的。
Python中的并发操作主要涉及的模型有:多线程模型、多进程模型、协程模型。Elias专门写了一篇文章爬虫技术,来比较常用的几种模型并发方案的性能。对于爬虫本身来说,限制爬虫速率主要来自目标服务器的响应速率,因此选择一个控制上去顺手的模块才是对的。
多线程模型,是最容易上手的,Python中自带的threading模块能挺好的实现并发需求,配合Queue模块来实现共享数据。
多进程模型和多线程模型类似,multiprocessing模块中也有类似的Queue模块来实现数据共享。在linux中,用户态的进程可以借助多核心的优势,因此在多核背景下,能解决爬虫的并发问题。
协程模型,在Elias的文章中,基于greenlet实现的解释器程序的性能仅次于Stackless Python,大致比Stackless Python慢一倍,比其他方案快接近一个数量级。因此基于gevent(封装了greenlet)的并发程序会有挺好的性能优势。
具体说明下gevent(非阻塞异步IO)。,“Gevent是一种基于解释器的Python网络库,它用到Greenlet提供的,封装了libevent风波循环的高层同步API。”
从实际的编程疗效来看,协程模型确实表现非常好,运行结果的可控性显著强了不少, gevent库的封装易用性极强。
数据储存本身设计的技术就十分多,作为小菜不敢乱说,但是工作还是有一些小经验是可以分享的。
前提:使用关系数据库,测试中选择的是mysql,其他类似sqlite,SqlServer思路上没有区别。
当我们进行数据储存时,目的就是降低与数据库的交互操作,这样可以增强性能。通常情况下,每当一个URL节点被读取,就进行一次数据储存,对于这样的逻辑进行无限循环。其实这样的性能体验是十分差的,存储速率特别慢。
进阶做法,为了减轻与数据库的交互次数,每次与数据库交互从之前传送1个节点弄成传送10个节点,到传送100个节点内容,这样效率变有了10倍至100倍的提高,在实际应用中,效果是非常好的。:D
爬虫模型

目前这个爬虫模型如上图,调度模块是核心模块。调度模块分别与下载模块,析取模块,存储模块共享三个队列,下载模块与析取模块共享一个队列。数据传递方向如图示。
Python库大全
采集交流 • 优采云 发表了文章 • 0 个评论 • 329 次浏览 • 2020-04-05 11:09
urlib -网络库(stdlib)。requests -网络库。
grab -网络库(基于pycurl)。pycurl -网络库(绑定libcurl)
ullib3 - Python HTTP库,安全连接池、支持文件post、可用性高。httplib2一网络库。
RoboBrowser -一个简单的、极具Python风格的Python库,无需独立的浏览器即可浏览网页。
MechanicalSoup一个与网站自动交互Python库。
mechanize -有状态、可编程的Web浏览库。socket -底层网路插口(stdlib)。
Unirest for Python - Unirest是一套可用于 多种语言的轻量级的HTTP库。
hyper - Python的HTTP/2客户端。
PySocks - SocksiPy更新并积极维护的版本,包括错误修补和一些其他的特点。作为socket模块的直接替换。
网络爬虫框架
grab -网络爬虫框架(基 于pycur/multicur)。
scrapy -网络爬虫框架(基 于twisted), 不支持Python3。
pyspider -一个强悍的爬虫系统。cola-一个分布式爬虫框架。其他
portia -基于Scrapy的可视化爬虫。
restkit - Python的HTTP资源工具包。它可以使你轻松地访问HTTP资源,并围绕它完善的对象。
demiurge -基于PyQuery的爬虫微框架。HTML/XML解析器
lxml - C语言编撰高效HTML/ XML处理库。支持XPath。
cssselect -解析DOM树和CSS选择器。pyquery -解析DOM树和jQuery选择器。
BeautIFulSoup -低效HTML/ XML处理库,纯Python实现。
html5lib -根据WHATWG规范生成HTML/ XML文档的DOM。该规范被用在现今所有的浏览器上。
feedparser一解析RSS/ATOM feeds。
MarkupSafe -为XML/HTML/XHTML提供了安全通配符的字符串。
xmltodict-一个可以使你在处理XML时觉得象在处理JSON一样的Python模块。
xhtml2pdf -将HTML/CSS转换为PDF。
untangle -轻松实现将XML文件转换为Python对象。清理
Bleach -清理HTML (需要html5lib)。sanitize -为混乱的数据世界带来端午。文本处理
用于解析和操作简单文本的库。
difflib - (Python标准库) 帮助进行差异化比较。
Levenshtein一快速估算L evenshtein距离和字符串相似度。
fuzzywuzzy -模糊字符串匹配。esmre -正则表达式加速器。
ftfy-自动整理Unicode文本,减少碎片化。.自然语言处理
处理人类语言问题的库。
NLTK -编写Python程序来处理人类语言数据的最好平台。
Pattern一Python的网路挖掘模块。他有自然语言处理工具,机器学习以及其它。
TextBlob -为深入自然语言处理任务提供了一致的API。是基于NLTK以及Pattern的巨人之肩上发展的。
jieba-中文动词工具。
SnowNLP -中文文本处理库。
loso-另一个英文分词库。浏览器自动化与仿真
selenium一自动化真正的浏览器(Chrome浏览器,火狐浏览器,Opera浏览器, IE浏览器)。
Ghost.py -对PyQt的webkit的封装(需 要PyQT)。
Spynner -对PyQt的webkit的封装(需要PyQT),
Splinter -通用API浏览器模拟器(seleniumweb驱动,Django顾客 端,Zope) 。多重处理
threading - Python标准库的线程运行。对于I/0密集型任务太有效。对于CPU绑定的任务没用,因为python GIL。
multiprocessing -标准的Python库运行多进程。
celery -基于分布式消息传递的异步任务队列/作业队列。;
concurrent-futures一concurrent-futures模块为调用异步执行提供了一个高层次的插口。
异步网路编程库
asyncio- (在Python 3.4 +版本以上的Python标准库)异步I/O, 时间循环,协同程序和任务。
Twisted一基于风波驱动的网路引|擎框架。Tornado -一个网路框架和异步网路库。pulsar - Python风波驱动的并发框架。
diesel - Python的基于红色风波的I/O框架。gevent -一个使用greenlet的基于解释器的Python网路库。
eventlet -有WSGI支持的异步框架。
Tomorrow -异步代码的奇妙的修饰句型。队列
celery -基于分布式消息传递的异步任务队列/作业队列。
huey -小型多线程任务队列。
mrq - Mr. Queue -使用redis & Gevent的Python分布式工作任务队列。
RQ -基于Redis的轻量级任务队列管理器。simpleq--个简单的,可无限扩充,基于Amazon SQS的队列。
python-geARMan一Gearman的Python API。
云计算
picloud -云端执行Python代码。
dominoup.com -云端执行R,Python和matlab代码网页内容提取
提取网页内容的库。
HTML页面的文本和元数据
newspaper -用Python进行新闻提取、文章提I取和内容策展。
html2text -将HTML转为Markdown格式文本。
python-goose一HTML内容/文章提取器。lassie -人性化的网页内容检索工具WebSocket
用于WebSocket的库。
Crossbar -开源的应用消息传递路由器
(Python实现的用于Autobahn的WebSocket和WAMP)。
AutobahnPython -提供了WebSocket合同和WAMP合同的Python实现而且开源。
WebSocket-for-Python - Python 2和3以及PyPy的WebSocket客户端和服务器库。DNS解析
dnsyo -在全球超过1 500个的DNS服务器.上检测你的DNS。
pycares - c-ares的插口。c-ares是 进行DNS恳求和异步名称决议的C语言库。
计算机视觉
SimpleCV -用于照相机、图像处理、特征提取、格式转换的简介,可读性强的插口(基于OpenCV)。
Flask是一个轻量级的Web应用框架,使用Python编撰。基于WerkzeugWSGI工具箱和Jinja2模板引擎。使用BSD授权。
Flask也被称为"microframework" ,因为它使用简单的核心,用extension降低其他功能。Flask没有默认使用的数据库、窗体验证工具。然而,Flask保留了扩增的弹性,可以用Flask-extension加入这种功能: ORM、窗体验证工具、文件上传、各种开放式身分验证技术。
Web2py是一个用Python语言 编写的免费的开源Web框架,旨在敏捷快速的开发Web应用,具有快速、可扩充、安全以及可移植的数据库驱动的应用,遵循LGPLv3开 源合同。
Web2py提供一站式的解决方案,整个开发过程都可以在浏览器上进行,提供了Web版的在线开发,HTML模版编撰,静态文件的上传,数据库的编撰的功能。其它的还有日志功能,以及一个自动化的admin插口。
4.Tornado
Tornado即是一.个Web server(对此本文不作阐述)python分布式爬虫框架,同时又是一个类web.py的micro-framework,作为框架Tornado的思想主要来源于Web.py,大家在Web.py的网站首页也可以见到Tornado的大鳄Bret Taylor的那么一段话(他这儿说的FriendFeed用的框架跟Tornado可以看作是一个东西) :
"[web.pyinspired the] Web framework we useat FriendFeed [and] the webapp frameworkthat ships with App Engin...”
因为有这层关系,后面不再单独讨论Tornado。
5.CherryPy
CherryPy是一种用于Python的、简单而特别有用的Web框架,其主要作用是以尽可能少的操作将Web服务器与Python代码联接,其功能包括外置的剖析功能、灵活的插件系统以及一次运行多个HTTP服务器的功能python分布式爬虫框架,可与运行在最新版本的Python、Jython、 Android上。 查看全部

urlib -网络库(stdlib)。requests -网络库。
grab -网络库(基于pycurl)。pycurl -网络库(绑定libcurl)
ullib3 - Python HTTP库,安全连接池、支持文件post、可用性高。httplib2一网络库。
RoboBrowser -一个简单的、极具Python风格的Python库,无需独立的浏览器即可浏览网页。
MechanicalSoup一个与网站自动交互Python库。
mechanize -有状态、可编程的Web浏览库。socket -底层网路插口(stdlib)。
Unirest for Python - Unirest是一套可用于 多种语言的轻量级的HTTP库。
hyper - Python的HTTP/2客户端。
PySocks - SocksiPy更新并积极维护的版本,包括错误修补和一些其他的特点。作为socket模块的直接替换。
网络爬虫框架
grab -网络爬虫框架(基 于pycur/multicur)。
scrapy -网络爬虫框架(基 于twisted), 不支持Python3。
pyspider -一个强悍的爬虫系统。cola-一个分布式爬虫框架。其他
portia -基于Scrapy的可视化爬虫。
restkit - Python的HTTP资源工具包。它可以使你轻松地访问HTTP资源,并围绕它完善的对象。
demiurge -基于PyQuery的爬虫微框架。HTML/XML解析器
lxml - C语言编撰高效HTML/ XML处理库。支持XPath。
cssselect -解析DOM树和CSS选择器。pyquery -解析DOM树和jQuery选择器。
BeautIFulSoup -低效HTML/ XML处理库,纯Python实现。
html5lib -根据WHATWG规范生成HTML/ XML文档的DOM。该规范被用在现今所有的浏览器上。
feedparser一解析RSS/ATOM feeds。
MarkupSafe -为XML/HTML/XHTML提供了安全通配符的字符串。
xmltodict-一个可以使你在处理XML时觉得象在处理JSON一样的Python模块。
xhtml2pdf -将HTML/CSS转换为PDF。
untangle -轻松实现将XML文件转换为Python对象。清理
Bleach -清理HTML (需要html5lib)。sanitize -为混乱的数据世界带来端午。文本处理
用于解析和操作简单文本的库。
difflib - (Python标准库) 帮助进行差异化比较。
Levenshtein一快速估算L evenshtein距离和字符串相似度。
fuzzywuzzy -模糊字符串匹配。esmre -正则表达式加速器。
ftfy-自动整理Unicode文本,减少碎片化。.自然语言处理
处理人类语言问题的库。
NLTK -编写Python程序来处理人类语言数据的最好平台。
Pattern一Python的网路挖掘模块。他有自然语言处理工具,机器学习以及其它。
TextBlob -为深入自然语言处理任务提供了一致的API。是基于NLTK以及Pattern的巨人之肩上发展的。
jieba-中文动词工具。
SnowNLP -中文文本处理库。
loso-另一个英文分词库。浏览器自动化与仿真
selenium一自动化真正的浏览器(Chrome浏览器,火狐浏览器,Opera浏览器, IE浏览器)。
Ghost.py -对PyQt的webkit的封装(需 要PyQT)。
Spynner -对PyQt的webkit的封装(需要PyQT),
Splinter -通用API浏览器模拟器(seleniumweb驱动,Django顾客 端,Zope) 。多重处理
threading - Python标准库的线程运行。对于I/0密集型任务太有效。对于CPU绑定的任务没用,因为python GIL。
multiprocessing -标准的Python库运行多进程。
celery -基于分布式消息传递的异步任务队列/作业队列。;
concurrent-futures一concurrent-futures模块为调用异步执行提供了一个高层次的插口。
异步网路编程库
asyncio- (在Python 3.4 +版本以上的Python标准库)异步I/O, 时间循环,协同程序和任务。
Twisted一基于风波驱动的网路引|擎框架。Tornado -一个网路框架和异步网路库。pulsar - Python风波驱动的并发框架。
diesel - Python的基于红色风波的I/O框架。gevent -一个使用greenlet的基于解释器的Python网路库。
eventlet -有WSGI支持的异步框架。
Tomorrow -异步代码的奇妙的修饰句型。队列
celery -基于分布式消息传递的异步任务队列/作业队列。
huey -小型多线程任务队列。
mrq - Mr. Queue -使用redis & Gevent的Python分布式工作任务队列。
RQ -基于Redis的轻量级任务队列管理器。simpleq--个简单的,可无限扩充,基于Amazon SQS的队列。
python-geARMan一Gearman的Python API。
云计算
picloud -云端执行Python代码。
dominoup.com -云端执行R,Python和matlab代码网页内容提取
提取网页内容的库。
HTML页面的文本和元数据
newspaper -用Python进行新闻提取、文章提I取和内容策展。
html2text -将HTML转为Markdown格式文本。
python-goose一HTML内容/文章提取器。lassie -人性化的网页内容检索工具WebSocket
用于WebSocket的库。
Crossbar -开源的应用消息传递路由器
(Python实现的用于Autobahn的WebSocket和WAMP)。
AutobahnPython -提供了WebSocket合同和WAMP合同的Python实现而且开源。
WebSocket-for-Python - Python 2和3以及PyPy的WebSocket客户端和服务器库。DNS解析
dnsyo -在全球超过1 500个的DNS服务器.上检测你的DNS。
pycares - c-ares的插口。c-ares是 进行DNS恳求和异步名称决议的C语言库。
计算机视觉
SimpleCV -用于照相机、图像处理、特征提取、格式转换的简介,可读性强的插口(基于OpenCV)。
Flask是一个轻量级的Web应用框架,使用Python编撰。基于WerkzeugWSGI工具箱和Jinja2模板引擎。使用BSD授权。
Flask也被称为"microframework" ,因为它使用简单的核心,用extension降低其他功能。Flask没有默认使用的数据库、窗体验证工具。然而,Flask保留了扩增的弹性,可以用Flask-extension加入这种功能: ORM、窗体验证工具、文件上传、各种开放式身分验证技术。
Web2py是一个用Python语言 编写的免费的开源Web框架,旨在敏捷快速的开发Web应用,具有快速、可扩充、安全以及可移植的数据库驱动的应用,遵循LGPLv3开 源合同。
Web2py提供一站式的解决方案,整个开发过程都可以在浏览器上进行,提供了Web版的在线开发,HTML模版编撰,静态文件的上传,数据库的编撰的功能。其它的还有日志功能,以及一个自动化的admin插口。
4.Tornado
Tornado即是一.个Web server(对此本文不作阐述)python分布式爬虫框架,同时又是一个类web.py的micro-framework,作为框架Tornado的思想主要来源于Web.py,大家在Web.py的网站首页也可以见到Tornado的大鳄Bret Taylor的那么一段话(他这儿说的FriendFeed用的框架跟Tornado可以看作是一个东西) :
"[web.pyinspired the] Web framework we useat FriendFeed [and] the webapp frameworkthat ships with App Engin...”
因为有这层关系,后面不再单独讨论Tornado。
5.CherryPy
CherryPy是一种用于Python的、简单而特别有用的Web框架,其主要作用是以尽可能少的操作将Web服务器与Python代码联接,其功能包括外置的剖析功能、灵活的插件系统以及一次运行多个HTTP服务器的功能python分布式爬虫框架,可与运行在最新版本的Python、Jython、 Android上。
使用Python编撰多线程爬虫抓取百度贴吧邮箱与手机号
采集交流 • 优采云 发表了文章 • 0 个评论 • 487 次浏览 • 2020-07-05 08:00
本爬虫主要是对百度贴吧中各类贴子的内容进行抓取,并且剖析贴子内容将其中的手机号和邮箱地址抓取下来。主要流程在代码注释中有详尽解释。
代码在Windows7 64bit,python 2.7 64bit(安装mysqldb扩充)以及centos 6.5,python 2.7(带mysqldb扩充)环境下测试通过
工欲善其事必先利其器,大家可以从截图看出我的环境是Windows 7 + PyCharm。我的Python环境是Python 2.7 64bit。这是比较适宜菜鸟使用的开发环境。然后我再建议你们安装一个easy_install,听名子就晓得这是一个安装器,它是拿来安装一些扩充包的,比如说在python中假如我们要操作mysql数据库的话,python原生是不支持的,我们必须安装mysqldb包来让python可以操作mysql数据库,如果有easy_install的话我们只须要一行命令就可以快速安装号mysqldb扩充包,他如同php中的composer,centos中的yum,Ubuntu中的apt-get一样便捷。
相关工具可在我的github中找到:cw1997/python-tools,其中easy_install的安装只须要在python命令行下运行哪个py脚本之后稍等片刻即可邮箱爬虫软件,他会手动加入Windows的环境变量,在Windows命令行下假如输入easy_install有回显说明安装成功。
至于电脑硬件其实是越快越好,内存至少8G起步,因为爬虫本身须要大量储存和解析中间数据,尤其是多线程爬虫,在遇到抓取带有分页的列表和详情页,并且抓取数据量很大的情况下使用queue队列分配抓取任务会特别占显存。包括有的时候我们抓取的数据是使用json,如果使用mongodb等nosql数据库储存,也会太占显存。
网络联接建议使用有线网,因为市面上一些劣质的无线路由器和普通的民用无线网卡在线程开的比较大的情况下会出现间歇性断网或则数据遗失,掉包等情况,这个我亲有感受。
至于操作系统和python其实肯定是选择64位。如果你使用的是32位的操作系统,那么难以使用大显存。如果你使用的是32位的python,可能在小规模抓取数据的时侯觉得不出有哪些问题,但是当数据量变大的时侯,比如说某个列表,队列,字典上面储存了大量数据,导致python的显存占用超过2g的时侯会报显存溢出错误。原因在我以前segmentfault上提过的问题中依云的回答有解释(java – python只要占用显存达到1.9G以后httplib模块就开始报内存溢出错误 – SegmentFault)
如果你打算使用mysql储存数据,建议使用mysql5.5之后的版本,因为mysql5.5版本支持json数据类型,这样的话可以抛弃mongodb了。(有人说mysql会比mongodb稳定一点,这个我不确定。)
至于现今python都早已出了3.x版本了,为什么我这儿还使用的是python2.7?我个人选择2.7版本的缘由是自己当年很早曾经买的python核心编程这本书是第二版的,仍然以2.7为示例版本。并且目前网上一直有大量的教程资料是以2.7为版本讲解,2.7在个别方面与3.x还是有很大差异,如果我们没有学过2.7,可能对于一些细微的句型差异不是太懂会导致我们理解上出现误差,或者看不懂demo代码。而且如今还是有部份依赖包只兼容2.7版本。我的建议是假如你是打算急着学python之后去公司工作,并且公司没有老代码须要维护,那么可以考虑直接上手3.x,如果你有比较充沛的时间,并且没有太系统的大牛带,只能借助网上零零散散的博客文章来学习,那么还是先学2.7在学3.x,毕竟学会了2.7以后3.x上手也很快。
其实对于任何软件项目而言,我们但凡想知道编撰这个项目须要哪些知识点,我们都可以观察一下这个项目的主要入口文件都导出了什么包。
现在来看一下我们这个项目,作为一个刚接触python的人,可能有一些包几乎都没有用过,那么我们在本小节就来简单的谈谈这种包起哪些作用,要把握她们分别会涉及到哪些知识点,这些知识点的关键词是哪些。这篇文章并不会耗费长篇大论来从基础讲起,因此我们要学会善用百度,搜索那些知识点的关键词来自学。下面就来一一剖析一下这种知识点。
我们的爬虫抓取数据本质上就是不停的发起http请求,获取http响应,将其存入我们的笔记本中。了解http协议有助于我们在抓取数据的时侯对一些才能加速抓取速率的参数才能精准的控制,比如说keep-alive等。
我们平常编撰的程序都是单线程程序,我们写的代码都在主线程上面运行,这个主线程又运行在python进程中。关于线程和进程的解释可以参考阮一峰的博客:进程与线程的一个简单解释 – 阮一峰的网路日志
在python中实现多线程是通过一个名子称作threading的模块来实现。之前还有thread模块,但是threading对于线程的控制更强,因此我们后来都改用threading来实现多线程编程了。
关于threading多线程的一些用法,我认为这篇文章不错:[python] 专题八.多线程编程之thread和threading 大家可以参考参考。
简单来说,使用threading模块编撰多线程程序,就是先自己定义一个类,然后这个类要承继threading.Thread,并且把每位线程要做的工作代码讲到一个类的run方式中,当然若果线程本身在创建的时侯假如要做一些初始化工作,那么就要在他的__init__方法中编撰好初始化工作所要执行的代码,这个方式如同php,java中的构造方式一样。
这里还要额外讲的一点就是线程安全这个概念。通常情况下我们单线程情况下每位时刻只有一个线程在对资源(文件,变量)操作,所以不可能会出现冲突。但是当多线程的情况下,可能会出现同一个时刻两个线程在操作同一个资源,导致资源受损,所以我们须要一种机制来解决这些冲突带来的破坏,通常有加锁等操作,比如说mysql数据库的innodb表引擎有行级锁等,文件操作有读取锁等等,这些都是她们的程序底层帮我们完成了。所以我们一般只要晓得这些操作,或者这些程序对于线程安全问题做了处理,然后就可以在多线程编程中去使用它们了。而这些考虑到线程安全问题的程序通常就叫做“线程安全版本”,比如说php就有TS版本,这个TS就是Thread Safety线程安全的意思。下面我们要提到的Queue模块就是一种线程安全的队列数据结构,所以我们可以放心的在多线程编程中使用它。
***我们就要来讲讲至关重要的线程阻塞这个概念了。当我们详尽学习完threading模块以后,大概就晓得怎样创建和启动线程了。但是假如我们把线程创建好了,然后调用了start方式,那么我们会发觉似乎整个程序立刻就结束了,这是如何回事呢?其实这是因为我们在主线程中只有负责启动子线程的代码,也就意味着主线程只有启动子线程的功能,至于子线程执行的这些代码,他们本质上只是写在类上面的一个方式,并没在主线程上面真正去执行他,所以主线程启动完子线程以后他的本职工作就早已全部完成了,已经光荣离场了。既然主线程都离场了,那么python进程就跟随结束了,那么其他线程也就没有显存空间继续执行了。所以我们应当是要使主线程大婶等到所有的子线程鄙人全部执行完毕再光荣离场,那么在线程对象中有哪些方式才能把主线程卡住呢?thread.sleep嘛?这确实是个办法,但是到底应当使主线程sleep多久呢?我们并不能确切晓得执行完一个任务要多久时间,肯定不能用这个办法。所以我们这个时侯应当上网查询一下有哪些办法才能使子线程“卡住”主线程呢?“卡住”这个词似乎很粗俗了,其实说专业一点,应该称作“阻塞”,所以我们可以查询“python 子线程阻塞主线程”,如果我们会正确使用搜索引擎的话,应该会查到一个方式称作join(),没错,这个join()方法就是子线程用于阻塞主线程的方式,当子线程还未执行完毕的时侯,主线程运行到富含join()方法的这一行都会卡在那里,直到所有线程都执行完毕才能执行join()方法前面的代码。
假设有一个这样的场景,我们须要抓取一个人的博客,我们晓得这个人的博客有两个页面,一个list.php页面显示的是此博客的所有文章链接,还有一个view.php页面显示的是一篇文章的具体内容。
如果我们要把这个人的博客上面所有文章内容抓取出来,编写单线程爬虫的思路是:先用正则表达式把这个list.php页面的所有链接a标签的href属性抓取出来,存入一个名子称作article_list的链表(在python中不叫链表,叫做list,中文名列表),然后再用一个for循环遍历这个article_list链表,用各类抓取网页内容的函数把内容抓取出来之后存入数据库。
如果我们要编撰一个多线程爬虫来完成这个任务的话,就假定我们的程序用10个线程把,那么我们就要想办法把之前抓取的article_list平均分成10份,分别把每一份分配给其中一个子线程。
但是问题来了,如果我们的article_list链表宽度不是10的倍数,也就是文章数量并不是10的整数倍,那么***一个线程都会比别的线程少分配到一些任务,那么它将会更快的结束。
如果仅仅是抓取这些只有几千字的博客文章这看似没哪些问题,但是假如我们一个任务(不一定是抓取网页的任务,有可能是物理估算,或者图形渲染等等历时任务)的运行时间太长,那么这将导致极大地资源和时间浪费。我们多线程的目的就是尽可能的借助一切估算资源而且估算时间,所以我们要想办法使任务才能愈发科学合理的分配。
并且我还要考虑一种情况,就是文章数量很大的情况下,我们要既能快速抓取到文章内容,又能尽早的看见我们早已抓取到的内容,这种需求在好多CMS采集站上常常会彰显下来。
比如说我们如今要抓取的目标博客,有几千万篇文章,通常这些情况下博客还会做分页处理,那么我们若果根据前面的传统思路先抓取完list.php的所有页面至少就要几个小时甚至几天,老板假如希望你还能早日显示出抓取内容,并且尽早将早已抓取到的内容诠释到我们的CMS采集站上,那么我们就要实现一边抓取list.php而且把早已抓取到的数据丢入一个article_list链表,一边用另一个线程从article_list链表中提取早已抓取到的文章URL地址,然后这个线程再去对应的URL地址中用正则表达式取到博客文章内容。如何实现这个功能呢?
我们就须要同时开启两类线程,一类线程专门负责抓取list.php中的url之后丢入article_list链表,另外一类线程专门负责从article_list中提取出url之后从对应的view.php页面中抓取出对应的博客内容。
但是我们是否还记得上面提及过线程安全这个概念?前一类线程一边往article_list字段中写入数据,另外那一类的线程从article_list中读取数据但是删掉早已读取完毕的数据。但是python中list并不是线程安全版本的数据结构,因此这样操作会导致不可预想的错误。所以我们可以尝试使用一个愈发便捷且线程安全的数据结构,这就是我们的子标题中所提及的Queue队列数据结构。
同样Queue也有一个join()方法,这个join()方法虽然和上一个小节所提到的threading中join()方法差不多,只不过在Queue中,join()的阻塞条件是当队列不为空空的时侯才阻塞,否则继续执行join()后面的代码。在这个爬虫中我便使用了这些技巧来阻塞主线程而不是直接通过线程的join方法来阻塞主线程,这样的用处是可以不用写一个死循环来判定当前任务队列中是否还有未执行完的任务,让程序运行愈发高效,也使代码愈发柔美。
还有一个细节就是在python2.7中队列模块的名子是Queue,而在python3.x中早已更名为queue,就是首字母大小写的区别,大家假如是复制网上的代码,要记得这个小区别。
如果你们学过c语言的话,对这个模块应当会太熟悉,他就是一个负责从命令行中的命令上面提取出附送参数的模块。比如说我们一般在命令行中操作mysql数据库,就是输入mysql -h127.0.0.1 -uroot -p,其中mysql前面的“-h127.0.0.1 -uroot -p”就是可以获取的参数部份。
我们平常在编撰爬虫的时侯,有一些参数是须要用户自己自动输入的,比如说mysql的主机IP,用户名密码等等。为了使我们的程序愈加友好通用,有一些配置项是不需要硬编码在代码上面,而是在执行他的时侯我们动态传入,结合getopt模块我们就可以实现这个功能。
哈希本质上就是一类物理算法的集合,这种物理算法有个特点就是你给定一个参数,他就能输出另外一个结果,虽然这个结果太短,但是他可以近似觉得是***的。比如说我们平常听过的md5,sha-1等等,他们都属于哈希算法。他们可以把一些文件,文字经过一系列的物理运算然后弄成短短不到一百位的一段数字中文混和的字符串。
python中的hashlib模块就为我们封装好了这种物理运算函数,我们只须要简单的调用它就可以完成哈希运算。
为什么在我这个爬虫中用到了这个包呢?因为在一些插口恳求中,服务器须要带上一些校验码,保证插口恳求的数据没有被篡改或则遗失,这些校验码通常都是hash算法,所以我们须要用到这个模块来完成这些运算。
很多时侯我们抓取到的数据不是html,而是一些json数据,json本质上只是一段富含通配符对的字符串,如果我们须要提取出其中特定的字符串,那么我们须要json这个模块来将这个json字符串转换为dict类型便捷我们操作。
有的时侯我们抓取到了一些网页内容,但是我们须要将网页中的一些特定格式的内容提取下来,比如说电子邮箱的格式通常都是上面几位英语数字字母加一个@符号加的域名,而要象计算机语言描述这些格式,我们可以使用一种称作正则表达式的表达式来抒发出这些格式,并且使计算机手动从一大段字符串上将符合这些特定格式的文字匹配下来。
这个模块主要用于处理一些系统方面的事情,在这个爬虫中我用他来解决输出编码问题。
稍微学过一点法语的人都还能猜下来这个模块用于处理时间,在这个爬虫中我用它来获取当前时间戳,然后通过在主线程末尾用当前时间戳除以程序开始运行时的时间戳,得到程序的运行时间。
如图所示,开50个线程抓取100页(每页30个贴子,相当于抓取了3000个贴子)贴吧贴子内容而且从中提取出手机邮箱这个步骤共历时330秒。
这两个模块都是用于处理一些http请求,以及url低格方面的事情。我的爬虫http请求部份的核心代码就是使用这个模块完成的。
这是一个第三方模块,用于在python中操作mysql数据库。
这里我们要注意一个细节问题:mysqldb模块并不是线程安全版本,意味着我们不能在多线程中共享同一个mysql联接句柄。所以你们可以在我的代码中听到,我在每位线程的构造函数中都传入了一个新的mysql联接句柄。因此每位子线程只会用自己独立的mysql联接句柄。
这也是一个第三方模块,网上还能找到相关代码,这个模块主要用于向命令行中输出彩色字符串。比如说我们一般爬虫出现错误,要输出黄色的字体会比较醒目,就要使用到这个模块。
如果你们在网路质量不是挺好的环境下使用该爬虫,会发觉有的时侯会报如图所示的异常,这是我为了偷懒并没有写各类异常处理的逻辑。
通常情况下我们假如要编撰高度自动化的爬虫,那么就须要意料到我们的爬虫可能会遇见的所有异常情况邮箱爬虫软件,针对这种异常情况做处理。
比如说如图所示的错误,我们就应当把当时正在处理的任务重新伸入任务队列,否则我们还会出现遗漏信息的情况。这也是爬虫编撰的一个复杂点。
其实多线程爬虫的编撰也不复杂,多看示例代码,多自己动手尝试,多去社区,论坛交流,很多精典的书上对多线程编程也有特别详尽的解释。这篇文章本质上主要还是一篇科普文章,内容讲解的都不是太深入,大家还须要课外自己多结合网上各类资料自己学习。
【编辑推荐】
Python程序员都该用的一个库Python正则表达式re模块简明笔记这种方式推动Python开发者提升效率Python并发编程之线程池/进程池Python黑魔法之描述符 查看全部
不知道你们春节都是如何过的,反正栏主是在家睡了三天,醒来的时侯登QQ发觉有人找我要一份帖吧爬虫的源代码,想起之前练手的时侯写过一个抓取百度贴吧发贴记录中的邮箱与手机号的爬虫,于是开源分享给你们学习与参考。
本爬虫主要是对百度贴吧中各类贴子的内容进行抓取,并且剖析贴子内容将其中的手机号和邮箱地址抓取下来。主要流程在代码注释中有详尽解释。
代码在Windows7 64bit,python 2.7 64bit(安装mysqldb扩充)以及centos 6.5,python 2.7(带mysqldb扩充)环境下测试通过
工欲善其事必先利其器,大家可以从截图看出我的环境是Windows 7 + PyCharm。我的Python环境是Python 2.7 64bit。这是比较适宜菜鸟使用的开发环境。然后我再建议你们安装一个easy_install,听名子就晓得这是一个安装器,它是拿来安装一些扩充包的,比如说在python中假如我们要操作mysql数据库的话,python原生是不支持的,我们必须安装mysqldb包来让python可以操作mysql数据库,如果有easy_install的话我们只须要一行命令就可以快速安装号mysqldb扩充包,他如同php中的composer,centos中的yum,Ubuntu中的apt-get一样便捷。
相关工具可在我的github中找到:cw1997/python-tools,其中easy_install的安装只须要在python命令行下运行哪个py脚本之后稍等片刻即可邮箱爬虫软件,他会手动加入Windows的环境变量,在Windows命令行下假如输入easy_install有回显说明安装成功。
至于电脑硬件其实是越快越好,内存至少8G起步,因为爬虫本身须要大量储存和解析中间数据,尤其是多线程爬虫,在遇到抓取带有分页的列表和详情页,并且抓取数据量很大的情况下使用queue队列分配抓取任务会特别占显存。包括有的时候我们抓取的数据是使用json,如果使用mongodb等nosql数据库储存,也会太占显存。
网络联接建议使用有线网,因为市面上一些劣质的无线路由器和普通的民用无线网卡在线程开的比较大的情况下会出现间歇性断网或则数据遗失,掉包等情况,这个我亲有感受。
至于操作系统和python其实肯定是选择64位。如果你使用的是32位的操作系统,那么难以使用大显存。如果你使用的是32位的python,可能在小规模抓取数据的时侯觉得不出有哪些问题,但是当数据量变大的时侯,比如说某个列表,队列,字典上面储存了大量数据,导致python的显存占用超过2g的时侯会报显存溢出错误。原因在我以前segmentfault上提过的问题中依云的回答有解释(java – python只要占用显存达到1.9G以后httplib模块就开始报内存溢出错误 – SegmentFault)
如果你打算使用mysql储存数据,建议使用mysql5.5之后的版本,因为mysql5.5版本支持json数据类型,这样的话可以抛弃mongodb了。(有人说mysql会比mongodb稳定一点,这个我不确定。)
至于现今python都早已出了3.x版本了,为什么我这儿还使用的是python2.7?我个人选择2.7版本的缘由是自己当年很早曾经买的python核心编程这本书是第二版的,仍然以2.7为示例版本。并且目前网上一直有大量的教程资料是以2.7为版本讲解,2.7在个别方面与3.x还是有很大差异,如果我们没有学过2.7,可能对于一些细微的句型差异不是太懂会导致我们理解上出现误差,或者看不懂demo代码。而且如今还是有部份依赖包只兼容2.7版本。我的建议是假如你是打算急着学python之后去公司工作,并且公司没有老代码须要维护,那么可以考虑直接上手3.x,如果你有比较充沛的时间,并且没有太系统的大牛带,只能借助网上零零散散的博客文章来学习,那么还是先学2.7在学3.x,毕竟学会了2.7以后3.x上手也很快。
其实对于任何软件项目而言,我们但凡想知道编撰这个项目须要哪些知识点,我们都可以观察一下这个项目的主要入口文件都导出了什么包。
现在来看一下我们这个项目,作为一个刚接触python的人,可能有一些包几乎都没有用过,那么我们在本小节就来简单的谈谈这种包起哪些作用,要把握她们分别会涉及到哪些知识点,这些知识点的关键词是哪些。这篇文章并不会耗费长篇大论来从基础讲起,因此我们要学会善用百度,搜索那些知识点的关键词来自学。下面就来一一剖析一下这种知识点。
我们的爬虫抓取数据本质上就是不停的发起http请求,获取http响应,将其存入我们的笔记本中。了解http协议有助于我们在抓取数据的时侯对一些才能加速抓取速率的参数才能精准的控制,比如说keep-alive等。
我们平常编撰的程序都是单线程程序,我们写的代码都在主线程上面运行,这个主线程又运行在python进程中。关于线程和进程的解释可以参考阮一峰的博客:进程与线程的一个简单解释 – 阮一峰的网路日志
在python中实现多线程是通过一个名子称作threading的模块来实现。之前还有thread模块,但是threading对于线程的控制更强,因此我们后来都改用threading来实现多线程编程了。
关于threading多线程的一些用法,我认为这篇文章不错:[python] 专题八.多线程编程之thread和threading 大家可以参考参考。
简单来说,使用threading模块编撰多线程程序,就是先自己定义一个类,然后这个类要承继threading.Thread,并且把每位线程要做的工作代码讲到一个类的run方式中,当然若果线程本身在创建的时侯假如要做一些初始化工作,那么就要在他的__init__方法中编撰好初始化工作所要执行的代码,这个方式如同php,java中的构造方式一样。
这里还要额外讲的一点就是线程安全这个概念。通常情况下我们单线程情况下每位时刻只有一个线程在对资源(文件,变量)操作,所以不可能会出现冲突。但是当多线程的情况下,可能会出现同一个时刻两个线程在操作同一个资源,导致资源受损,所以我们须要一种机制来解决这些冲突带来的破坏,通常有加锁等操作,比如说mysql数据库的innodb表引擎有行级锁等,文件操作有读取锁等等,这些都是她们的程序底层帮我们完成了。所以我们一般只要晓得这些操作,或者这些程序对于线程安全问题做了处理,然后就可以在多线程编程中去使用它们了。而这些考虑到线程安全问题的程序通常就叫做“线程安全版本”,比如说php就有TS版本,这个TS就是Thread Safety线程安全的意思。下面我们要提到的Queue模块就是一种线程安全的队列数据结构,所以我们可以放心的在多线程编程中使用它。
***我们就要来讲讲至关重要的线程阻塞这个概念了。当我们详尽学习完threading模块以后,大概就晓得怎样创建和启动线程了。但是假如我们把线程创建好了,然后调用了start方式,那么我们会发觉似乎整个程序立刻就结束了,这是如何回事呢?其实这是因为我们在主线程中只有负责启动子线程的代码,也就意味着主线程只有启动子线程的功能,至于子线程执行的这些代码,他们本质上只是写在类上面的一个方式,并没在主线程上面真正去执行他,所以主线程启动完子线程以后他的本职工作就早已全部完成了,已经光荣离场了。既然主线程都离场了,那么python进程就跟随结束了,那么其他线程也就没有显存空间继续执行了。所以我们应当是要使主线程大婶等到所有的子线程鄙人全部执行完毕再光荣离场,那么在线程对象中有哪些方式才能把主线程卡住呢?thread.sleep嘛?这确实是个办法,但是到底应当使主线程sleep多久呢?我们并不能确切晓得执行完一个任务要多久时间,肯定不能用这个办法。所以我们这个时侯应当上网查询一下有哪些办法才能使子线程“卡住”主线程呢?“卡住”这个词似乎很粗俗了,其实说专业一点,应该称作“阻塞”,所以我们可以查询“python 子线程阻塞主线程”,如果我们会正确使用搜索引擎的话,应该会查到一个方式称作join(),没错,这个join()方法就是子线程用于阻塞主线程的方式,当子线程还未执行完毕的时侯,主线程运行到富含join()方法的这一行都会卡在那里,直到所有线程都执行完毕才能执行join()方法前面的代码。
假设有一个这样的场景,我们须要抓取一个人的博客,我们晓得这个人的博客有两个页面,一个list.php页面显示的是此博客的所有文章链接,还有一个view.php页面显示的是一篇文章的具体内容。
如果我们要把这个人的博客上面所有文章内容抓取出来,编写单线程爬虫的思路是:先用正则表达式把这个list.php页面的所有链接a标签的href属性抓取出来,存入一个名子称作article_list的链表(在python中不叫链表,叫做list,中文名列表),然后再用一个for循环遍历这个article_list链表,用各类抓取网页内容的函数把内容抓取出来之后存入数据库。
如果我们要编撰一个多线程爬虫来完成这个任务的话,就假定我们的程序用10个线程把,那么我们就要想办法把之前抓取的article_list平均分成10份,分别把每一份分配给其中一个子线程。
但是问题来了,如果我们的article_list链表宽度不是10的倍数,也就是文章数量并不是10的整数倍,那么***一个线程都会比别的线程少分配到一些任务,那么它将会更快的结束。
如果仅仅是抓取这些只有几千字的博客文章这看似没哪些问题,但是假如我们一个任务(不一定是抓取网页的任务,有可能是物理估算,或者图形渲染等等历时任务)的运行时间太长,那么这将导致极大地资源和时间浪费。我们多线程的目的就是尽可能的借助一切估算资源而且估算时间,所以我们要想办法使任务才能愈发科学合理的分配。
并且我还要考虑一种情况,就是文章数量很大的情况下,我们要既能快速抓取到文章内容,又能尽早的看见我们早已抓取到的内容,这种需求在好多CMS采集站上常常会彰显下来。
比如说我们如今要抓取的目标博客,有几千万篇文章,通常这些情况下博客还会做分页处理,那么我们若果根据前面的传统思路先抓取完list.php的所有页面至少就要几个小时甚至几天,老板假如希望你还能早日显示出抓取内容,并且尽早将早已抓取到的内容诠释到我们的CMS采集站上,那么我们就要实现一边抓取list.php而且把早已抓取到的数据丢入一个article_list链表,一边用另一个线程从article_list链表中提取早已抓取到的文章URL地址,然后这个线程再去对应的URL地址中用正则表达式取到博客文章内容。如何实现这个功能呢?
我们就须要同时开启两类线程,一类线程专门负责抓取list.php中的url之后丢入article_list链表,另外一类线程专门负责从article_list中提取出url之后从对应的view.php页面中抓取出对应的博客内容。
但是我们是否还记得上面提及过线程安全这个概念?前一类线程一边往article_list字段中写入数据,另外那一类的线程从article_list中读取数据但是删掉早已读取完毕的数据。但是python中list并不是线程安全版本的数据结构,因此这样操作会导致不可预想的错误。所以我们可以尝试使用一个愈发便捷且线程安全的数据结构,这就是我们的子标题中所提及的Queue队列数据结构。
同样Queue也有一个join()方法,这个join()方法虽然和上一个小节所提到的threading中join()方法差不多,只不过在Queue中,join()的阻塞条件是当队列不为空空的时侯才阻塞,否则继续执行join()后面的代码。在这个爬虫中我便使用了这些技巧来阻塞主线程而不是直接通过线程的join方法来阻塞主线程,这样的用处是可以不用写一个死循环来判定当前任务队列中是否还有未执行完的任务,让程序运行愈发高效,也使代码愈发柔美。
还有一个细节就是在python2.7中队列模块的名子是Queue,而在python3.x中早已更名为queue,就是首字母大小写的区别,大家假如是复制网上的代码,要记得这个小区别。
如果你们学过c语言的话,对这个模块应当会太熟悉,他就是一个负责从命令行中的命令上面提取出附送参数的模块。比如说我们一般在命令行中操作mysql数据库,就是输入mysql -h127.0.0.1 -uroot -p,其中mysql前面的“-h127.0.0.1 -uroot -p”就是可以获取的参数部份。
我们平常在编撰爬虫的时侯,有一些参数是须要用户自己自动输入的,比如说mysql的主机IP,用户名密码等等。为了使我们的程序愈加友好通用,有一些配置项是不需要硬编码在代码上面,而是在执行他的时侯我们动态传入,结合getopt模块我们就可以实现这个功能。
哈希本质上就是一类物理算法的集合,这种物理算法有个特点就是你给定一个参数,他就能输出另外一个结果,虽然这个结果太短,但是他可以近似觉得是***的。比如说我们平常听过的md5,sha-1等等,他们都属于哈希算法。他们可以把一些文件,文字经过一系列的物理运算然后弄成短短不到一百位的一段数字中文混和的字符串。
python中的hashlib模块就为我们封装好了这种物理运算函数,我们只须要简单的调用它就可以完成哈希运算。
为什么在我这个爬虫中用到了这个包呢?因为在一些插口恳求中,服务器须要带上一些校验码,保证插口恳求的数据没有被篡改或则遗失,这些校验码通常都是hash算法,所以我们须要用到这个模块来完成这些运算。
很多时侯我们抓取到的数据不是html,而是一些json数据,json本质上只是一段富含通配符对的字符串,如果我们须要提取出其中特定的字符串,那么我们须要json这个模块来将这个json字符串转换为dict类型便捷我们操作。
有的时侯我们抓取到了一些网页内容,但是我们须要将网页中的一些特定格式的内容提取下来,比如说电子邮箱的格式通常都是上面几位英语数字字母加一个@符号加的域名,而要象计算机语言描述这些格式,我们可以使用一种称作正则表达式的表达式来抒发出这些格式,并且使计算机手动从一大段字符串上将符合这些特定格式的文字匹配下来。
这个模块主要用于处理一些系统方面的事情,在这个爬虫中我用他来解决输出编码问题。
稍微学过一点法语的人都还能猜下来这个模块用于处理时间,在这个爬虫中我用它来获取当前时间戳,然后通过在主线程末尾用当前时间戳除以程序开始运行时的时间戳,得到程序的运行时间。
如图所示,开50个线程抓取100页(每页30个贴子,相当于抓取了3000个贴子)贴吧贴子内容而且从中提取出手机邮箱这个步骤共历时330秒。
这两个模块都是用于处理一些http请求,以及url低格方面的事情。我的爬虫http请求部份的核心代码就是使用这个模块完成的。
这是一个第三方模块,用于在python中操作mysql数据库。
这里我们要注意一个细节问题:mysqldb模块并不是线程安全版本,意味着我们不能在多线程中共享同一个mysql联接句柄。所以你们可以在我的代码中听到,我在每位线程的构造函数中都传入了一个新的mysql联接句柄。因此每位子线程只会用自己独立的mysql联接句柄。
这也是一个第三方模块,网上还能找到相关代码,这个模块主要用于向命令行中输出彩色字符串。比如说我们一般爬虫出现错误,要输出黄色的字体会比较醒目,就要使用到这个模块。
如果你们在网路质量不是挺好的环境下使用该爬虫,会发觉有的时侯会报如图所示的异常,这是我为了偷懒并没有写各类异常处理的逻辑。
通常情况下我们假如要编撰高度自动化的爬虫,那么就须要意料到我们的爬虫可能会遇见的所有异常情况邮箱爬虫软件,针对这种异常情况做处理。
比如说如图所示的错误,我们就应当把当时正在处理的任务重新伸入任务队列,否则我们还会出现遗漏信息的情况。这也是爬虫编撰的一个复杂点。
其实多线程爬虫的编撰也不复杂,多看示例代码,多自己动手尝试,多去社区,论坛交流,很多精典的书上对多线程编程也有特别详尽的解释。这篇文章本质上主要还是一篇科普文章,内容讲解的都不是太深入,大家还须要课外自己多结合网上各类资料自己学习。
【编辑推荐】
Python程序员都该用的一个库Python正则表达式re模块简明笔记这种方式推动Python开发者提升效率Python并发编程之线程池/进程池Python黑魔法之描述符
Python做爬虫到底比其他语言好在哪儿呢?
采集交流 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2020-05-25 08:02
2038
哪种语言合适写爬虫程序
1、如果是定向爬取几个页面,做一些简单的页面解析,爬取效率不是核心要求,这么用哪些语言差别不大。其实要是页面结构复杂,正则表达式写得巨复杂,尤其是用过这些支持xpath的解释器/爬虫库后,才会发觉此种方法尽管入门门槛低,但扩充性、可维护性等都奇差。因而此种情况下还是推荐采用一些现成的爬虫库,例如xpath、多线程支持还是必须考虑的诱因。2、如果是定向爬取,且主要目标是解析...
延瓒
01-01
1万+
Python/打响2019年第一炮-Python爬虫入门(一)
打响2019第一炮-Python爬虫入门 2018年早已成为过去,还记得在2018年元旦写过一篇【Shell编程】打响2018第一炮-shell编程之for循环句子,那在此时此刻,也是写一篇关于编程方面,不过要比18年的稍稍中级点。So,mark一下,也希望对您有所帮助。 步入题外话,在双十二想必你们都逛过网店and易迅,例如我们须要买一部手机或笔记本,而且我们须要点开手机或则笔记本页面看......
ROSE_ty的博客
03-04
2897
Python爬虫出现�乱码的解决办法
明天学习Python爬虫,再读取页面内容时出现以下情况,虽然使用了‘utf-8’后来通过阅读文章,将编码改为GBK后可正常显示...
ahkeyan的博客
03-15
1933
网路爬虫尝试(VB编撰)
PrivateSubForm_Load()a=getHTTPPage(“”)b=Split(a,“[”)(1)c=Split(b,“]”)(0)MsgBoxcEndSubFunctiongetHTTPPage(url)OnErrorResumeNextDimhttpSethttp=CreateObj...
qq_41514083的博客
07-17
1307
IDEA中JDBC的使用--完成对于数据库中数据的增删改查
IDEA中JDBC的使用--完成对于数据库中数据的增删改查1.在IDEA中新建一个项目2.进行各个类的编撰3.项目结果展示1.在IDEA中新建一个项目1.1点击右上角file,在new中选择project,在两侧选择Java项目,选择自己所安装的SDK包,点击next1.2继续点击next1.3决定项目的名子以及项目储存的文件夹,然后点击finish,完成项目的创建2.进行各个类的......
weixin_33863087的博客
04-25
2255
爬虫可以使用哪些语言
有好多刚才做爬虫工作者得菜鸟常常会问道这样一个问题,做爬虫须要哪些语言,个人认为任何语言,只要具备访问网路的标准库,都可以做到这一点。其实了解必要的爬虫工具也是必然的,比如代理IP刚才接触爬虫,好多菜鸟会苦恼于用Python来做爬虫,而且无论是JAVA,PHP还是其他更低级语言,都可以很便捷的实现,静态语言出现错误的可能性很低,低级语言运行速率会更快一些。并且Python的优势在于库更......
大数据
04-24
2341
网路爬虫有哪些用?如何爬?手把手教你爬网页(Python代码)
导读:本文主要分为两个部份:一部份是网路爬虫的概述,帮助你们详尽了解网路爬虫;另一部份是HTTP恳求的Python实现,帮助你们了解Python中实现HTTP恳求的各类方...
小蓝枣的博客
03-06
4846
Python爬虫篇-爬取页面所有可用的链接
原理也很简单,html链接都是在a元素里的,我们就是匹配出所有的a元素,其实a可以是空的链接,空的链接是None,也可能是无效的链接。我们通过urllib库的request来测试链接的有效性。当链接无效的话会抛出异常,我们把异常捕获下来,并提示下来,没有异常就是有效的,我们直接显示下来就好了。...
点点寒彬的博客
05-16
5万+
简单谈谈Python与Go的区别
背景工作中的主力语言是Python,明年要搞性能测试的工具,因为GIL锁的缘由,Python的性能实在是低迷,须要学一门性能高的语言来世成性能测试的压力端。为此我把眼神置于了如今的新秀Go。经过一段时间的学习,也写了一个小工具,记一下这两个语言的区别。需求工具是一个小爬虫,拿来爬某网站的某个产品的迭代记录,实现逻辑就是运行脚本后,使用者从命令行输入个别元素(产品ID等)后网络爬虫语言,脚本导入......
捉虫李高人
03-05
3万+
闲话网路爬虫-CSharp对比Python
这一期给男子伴们普及下网路爬虫这块的东西,吹下牛,宣传一波C#爬虫的优势,希望Python的老铁们轻喷,哈哈!大致对比了下Python爬虫和C#爬虫的优劣势,可以汲取Python爬虫的框架,进一步封装好C#爬虫须要用到的方方面面,然后用上去还是会蛮爽的,起码单看在数据抓取方面不输Python,Python应该是借助上去做它更擅长的其他方面的事情,而不是大势宣传它在爬虫方面的......
Yeoman92的博客
10-17
6358
python爬虫:使用selenium+ChromeDriver爬取途家网
本站(途家网)通过常规抓页面的方式不能获取数据,可以使用selenium+ChromeDriver来获取页面数据。
dengguawei0519的博客
02-08
129
(转)各类语言写网路爬虫有哪些优点缺点
我用PHP和Python都写过爬虫和正文提取程序。最开始使用PHP所以先谈谈PHP的优点:1.语言比较简单,PHP是极其随便的一种语言。写上去容易让你把精力放到你要做的事情上,而不是各类句型规则等等。2.各类功能模块齐全,这儿分两部份:1.网页下载:curl等扩充库;2.文档解析:dom、xpath、tidy、各种转码工具,可能跟题主的问题不太一样,我的爬虫须要提取正......
hs947463167的博客
03-06
3300
基于python的-提高爬虫效率的方法
#-*-coding:utf-8-*-"""明显提高爬虫效率的方法:1.换个性能更好的机器2.网路使用光纤3.多线程4.多进程5.分布式6.提高数据的写入速率""""""反爬虫的应对举措:1.随机更改User-Agent2.禁用Cookie追踪3.放慢爬虫速率4......
shenjian58的博客
03-22
3万+
男人更看重女孩的体型脸部,还是思想?
常常,我们看不进去大段大段的逻辑。深刻的哲理,常常短而精悍,一阵见血。问:产品总监挺漂亮的,有茶点动,但不晓得合不般配。女孩更看重女孩的体型脸部,还是...
静水流深的博客
03-29
4069
python爬虫(1)-使用requests和beautifulsoup库爬取中国天气网
python爬虫(1)-使用requests和beautifulsoup库爬取中国天气网使用工具及打算python3.7(python3以上都可以)pycharmIDE(本人习惯使用pycharm,也可以使用其他的)URL:、requests、lxml库(p...
天镇少年
10-16
2万+
Python爬虫的N种坐姿
问题的来历 前几天,在陌陌公众号(Python爬虫及算法)上有个人问了笔者一个问题,怎样借助爬虫来实现如下的需求,须要爬取的网页如下(网址为::WhatLinksHere/Q5&amp;limit=500&amp;from=0): 我们的需求为爬取白色框框内的名人(有500条记录,图片只展......
weixin_42530834的博客
06-23
3万+
一、最简单的爬虫(python3爬虫小白系列文章)
运行平台:WindowsPython版本:Python3.xIDE:Pycharm2017.2.4看了崔老师的python3网路爬虫实战,获益颇丰,为了帮助自己更好的理解这种知识点,于是准备趁着这股热乎劲,针对爬虫实战进行一系列的教程。阅读文章前,我会默认你早已具备一下几个要素1.python3安装完毕Windows:
Zhangguohao666的博客
03-30
4万+
Python爬虫,高清美图我全都要(彼岸桌面墙纸)
爬取彼岸桌面网站较为简单,用到了requests、lxml、BeautifulSoup4
启舰
03-23
3万+
程序员结业去大公司好还是小公司好?
其实大公司并不是人人都能进,但我仍建议还未结业的朋友,竭力地通过校招向大公司挤,即便挤进去,你这一生会容易好多。大公司那里好?没能进大公司如何办?答案都在这儿了,记得帮我点赞哦。目录:技术气氛内部晋升与跳槽啥也没学会,公司倒闭了?不同的人脉圈,注定会有不同的结果没能去大厂如何办?一、技术气氛综观整个程序员技术领域,那个在行业有所名气的大牛,不是在大厂?并且众所......
weixin_34132768的博客
12-12
599
为何python爬虫工程师岗位如此火爆?
哪些是网路爬虫?网路爬虫是一个手动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直至满足系统的一定停止条件。爬虫有哪些用?做为通用搜索引擎网页搜集器。(google,baidu)做垂直搜索引擎.科学研究:在线人类行为,在线社群演变,人类动力学研究,计......
学习python的正确坐姿
05-06
1209
python爬虫13|秒爬,python这多线程爬取速率也太猛了,此次就是要让你的爬虫效率杠杠的
快快了啊嘿小侄儿想啥呢明天这篇爬虫教程的主题就是一个字快想要做到秒爬就须要晓得哪些是多进程哪些是多线程哪些是轮询(微线程)你先去沏杯茶坐出来小帅b这就好好给你说道说道关于线程这玩意儿沏好茶了吗这么...
weixin_34273481的博客
05-31
1728
8个最高效的Python爬虫框架,你用过几个?
小编搜集了一些较为高效的Python爬虫框架。分享给你们。1.ScrapyScrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。项目地址:是一个用python实现的功能......
空悲切
12-23
1万+
怎么高贵地使用c语言编撰爬虫
序言你们在平常或多或少地就会有编撰网路爬虫的需求。通常来说,编撰爬虫的首选自然非python莫属,除此之外,java等语言也是不错的选择。选择上述语言的诱因不仅仅在于它们均有十分不错的网路恳求库和字符串处理库,还在于基于上述语言的爬虫框架十分之多和健全。良好的爬虫框架可以确保爬虫程序的稳定性,以及编撰程序的方便性。所以,这个cspider爬虫库的使命在于,我们才能使用c语言,仍然还能高贵地编撰爬...
CSDN资讯
09-03
4万+
学Python后究竟能干哪些?网友:我太难了
觉得全世界营销文都在推Python,并且找不到工作的话,又有那个机构会站下来给我推荐工作?笔者冷静剖析多方数据,想跟你们说:关于赶超老牌霸主Java,过去几年间Pytho...
Rainbow
04-28
2万+
python爬虫之一:爬取网页小说(魂破九天)
近日做一个项目须要用到python,只懂皮毛的我花了三天时间将python重新捡起啃一啃,终于对python有了一定的认识。之后有按照爬虫基本原理爬取了一本小说,其他爬取小说的方式类似,结果见个人资源下载(本想下载分设置为0,结果CSDN设置最低为2分,没有积分的可以加我qq要该小说)。**爬虫原理:1、模拟人打开一页小说网页2、将网页保存出来......
毕易方达的博客
08-09
7795
全面了解Java中Native关键字的作用
初次遇到native是在java.lang.Object源码中的一个hashCode方式:1publicnativeinthashCode();为何有个native呢?这是我所要学习的地方。所以下边想要总结下native。一、认识native即JNI,JavaNativeInterface但凡一种语言,都希望是纯。例如解决某一个方案都喜欢就单单这个语言......
做人还是高调点
05-08
4万+
笔试:第十六章:Java高级开发(16k)
HashMap底层实现原理,黑红树,B+树,B树的结构原理Spring的AOP和IOC是哪些?它们常见的使用场景有什么?Spring事务,事务的属性,传播行为,数据库隔离级别Spring和SpringMVC,MyBatis以及SpringBoot的注解分别有什么?SpringMVC的工作原理,SpringBoot框架的优点,MyBatis框架的优点SpringCould组件有什么,她们......
Bo_wen_的博客
03-13
16万+
python网路爬虫入门(一)———第一个python爬虫实例
近来七天学习了一下python,并自己写了一个网路爬虫的反例。python版本:3.5IDE:pycharm5.0.4要用到的包可以用pycharm下载:File->DefaultSettings->DefaultProject->ProjectInterpreter选择python版本并点一侧的减号安装想要的包我选择的网站是中国天气网中的上海天气,打算抓取近来...
jsmok_xingkong的博客
11-05
3143
Python-爬虫初体验
在网易云课堂上看的教学视频,如今来巩固一下知识:1.先确定自己要爬的网站,以新浪新闻网站为例确importrequests#跟java的导包差不多,python叫导出库res=requests.get('#039;)#爬取网页内容res.encoding='utf-8'#将得到的网页内容转码,防止乱...
CSDN资讯
03-27
4万+
无代码时代将至,程序员怎样保住饭碗?
编程语言层出不穷,从最初的机器语言到现在2500种以上的中级语言,程序员们大呼“学到头秃”。程序员一边面临编程语言不断推陈出新,一边面临因为许多代码已存在,程序员编撰新应用程序时存在重复“搬砖”的现象。无代码/低代码编程应运而生。无代码/低代码是一种创建应用的方式,它可以让开发者使用最少的编码知识来快速开发应用程序。开发者通过图形界面中,可视化建模来组装和配置应用程序。这样一来,开发者直......
明明如月的专栏
03-01
1万+
将一个插口响应时间从2s优化到200ms以内的一个案例
一、背景在开发联调阶段发觉一个插口的响应时间非常长,常常超时,囧…本文讲讲是怎样定位到性能困局以及更改的思路,将该插口从2s左右优化到200ms以内。二、步骤2.1定位定位性能困局有两个思路,一个是通过工具去监控,一个是通过经验去猜测。2.1.1工具监控就工具而言,推荐使用arthas,用到的是trace命令具体安装步骤很简单,你们自行研究。我的使用步骤是......
tboyer
03-24
95
python3爬坑日记(二)——大文本读取
python3爬坑日记(二)——大文本读取一般我们使用python读取文件直接使用:fopen=open("test.txt")str=fopen.read()fopen.close()假如文件内容较小,使用以上方式其实没问题。并且,有时我们须要读取类似字典,日志等富含大量内容的文件时使用上述方式因为显存缘由常常会抛出异常。这时请使用:withopen("test.tx......
aa804738534的博客
01-19
646
STL(四)容器手动排序set
#include<set>#include<iostream>#include<set>#include<string>usingnamespacestd;template<typenameT>voidshowset(set<T>v){for(typenamestd::set...
薛定谔的雄猫的博客
04-30
2万+
怎样柔美的替换掉代码中的ifelse
平常我们在写代码时,处理不同的业务逻辑,用得最多的就是if和else,简单粗鲁省事,并且ifelse不是最好的方法,本文将通过设计模式来替换ifelse,使代码更高贵简约。
非知名程序员
01-30
7万+
非典逼出了天猫和易迅,新冠病毒才能逼出哪些?
loonggg读完须要5分钟速读仅需2分钟你们好,我是大家的市长。我晓得你们在家里都憋坏了,你们可能相对于封闭在家里“坐月子”,更希望才能尽快下班。明天我带着你们换个思路来聊一个问题...
九章算法的博客
02-06
19万+
B站上有什么挺好的学习资源?
哇说起B站,在小九眼中就是宝藏般的存在,放休假宅在家时三天刷6、7个小时不在话下,更别提去年的跨年晚宴,我简直是跪着看完的!!最早你们聚在在B站是为了追番,再后来我在里面刷欧美新曲和漂亮小妹妹的街舞视频,近来三年我和周围的同学们早已把B站当成学习课室了,但是学习成本还免费,真是个励志的好平台ヽ(.◕ฺˇдˇ◕ฺ;)ノ下边我们就来盘点一下B站上优质的学习资源:综合类Oeasy:综合......
王泽岭的博客
08-19
479
几种语言在爬虫场景下的力量对比
PHP爬虫:代码简单,并发处理能力较弱:因为当时PHP没有线程、进程功能要想实现并发须要借用多路复用模型R语言爬虫:操作简单,功能太弱,只适用于小规模的爬取,不适宜大规模的爬取Python爬虫:有着各类成熟的爬虫框架(eg:scrapy家族),可以便捷高效的下载网页而且支持多线程,进程模型成熟稳定,爬虫是是一个典型的多任务处理场景,恳求页面时会有较长的延后,总体来说更多的是等待,多线......
九章算法的博客
03-17
4580
作为程序员,有没有让你倍感既无语又崩溃的代码注释?
作为一个程序员,堪称是天天通宵来加班,也难以阅遍无数的程序代码,不晓得有多少次看到这些让人既倍感无语又奔溃的代码注释了。你以为自己能看懂这种代码,但是有信心可以优化这种代码,一旦你开始尝试这种代码,你将会被困在无尽的熬夜中,在痛斥中结束这段痛楚的历程。更有有网友坦承,自己写代码都是拼音变量名和英文注释,担心被踢出程序员队伍。下边这个代码注释大约说出了好多写代码人的心里话了。//我写这一行的时侯......
CSDN大学
03-10
2万+
刚回应!删库报复!一行代码蒸发数10亿!
年后开工大戏,又降低一出:删库跑路!此举直接给公司带来数10亿的估值蒸发损失,并引起一段“狗血宿怨剧情”,说实话电视剧都不敢如此拍!此次不是他人,正是陌陌生态的第三方服务商微盟,在这个"远程办公”的节骨眼出事了。2月25日,微盟集团(SEHK:02013)发布公告称,Saas生产环境及数据受到职工“人为破坏”导致公司当前暂时未能向顾客提供SaaS产品。犯罪嫌疑人是微盟研制......
爪白白的个人博客
04-25
5万+
总结了150余个神奇网站,你不来看看吗?
原博客再更新,可能就没了,然后将持续更新本篇博客。
11-03
8645
二次型(求梯度)——公式的简化
1.基本方程
程序人生的博客
02-11
5636
大地震!某大厂“硬核”抢人,放话:只要AI人才,中学结业都行!
特斯拉创始人马斯克,在2019年曾许下好多承诺网络爬虫语言,其中一个就是:2019年末实现完全的手动驾驶。其实这个承诺又成了flag,并且不阻碍他去年继续为这个承诺努力。这不,就在上周四,马斯克之间...
3y
03-16
9万+
我说我不会算法,阿里把我挂了。
不说了,字节跳动也反手把我挂了。
qq_40618664的博客
05-07
3万+
Auto.JS实现抖音,刷宝等刷视频app,自动点赞,手动滑屏,手动切换视频
Auto.JS实现抖音,刷宝等刷视频app,自动点赞,手动滑屏,手动切换视频代码如下auto();varappName=rawInput("","刷宝短视频");launchApp(appName);sleep("5000");setScreenMetrics(1080,1920);toast("1023732997");sleep("3000");varnum=200...
lmseo5hy的博客
05-14
1万+
Python与其他语言相比异同点python零基础入门
python作为一门中级编程语言,它的诞生其实很碰巧,并且它得到程序员的喜爱却是必然之路,以下是Python与其他编程语言的异同点对比:1.Python优势:简单易学,才能把用其他语言制做的各类模块很轻松地连结在一起。劣势:速率较慢,且有一些特定情况下才能出现(未能再现)的bug2.C/C++C/C++优势:可以被嵌入任何现代处理器中,几乎所有操作系统都支持C/C++,跨平台性十分好劣势:学习......
WUTab的博客
07-30
2549
找出链表X和Y中所有2n个元素的中位数
算法总论第三版,9.3-8算法:假如两个字段宽度为1,选出较小的那种一个否则,取出两个字段的中位数。取有较大中位数的链表的低区和较低中位数链表的高区,组合成新的宽度为n的链表。找出新链表的中位数思路:既然用递归分治,一定有基本情况,基本情况就是链表宽度为1.观察会发觉总的中位数介于两个字段的中位数之间。详尽证明如下:设总的中位数是MM,XX的中位数是MXM_X,YY的中位数是...
程松
03-30
10万+
5分钟,6行代码教你写爬虫!(python)
5分钟,6行代码教你写会爬虫!适用人士:对数据量需求不大,简单的从网站上爬些数据。好,不浪费时间了,开始!先来个反例:输入以下代码(共6行)importrequestsfromlxmlimporthtmlurl='#039;#须要爬数据的网址page=requests.Session().get(url)tree=html.f... 查看全部
07-22
2038
哪种语言合适写爬虫程序
1、如果是定向爬取几个页面,做一些简单的页面解析,爬取效率不是核心要求,这么用哪些语言差别不大。其实要是页面结构复杂,正则表达式写得巨复杂,尤其是用过这些支持xpath的解释器/爬虫库后,才会发觉此种方法尽管入门门槛低,但扩充性、可维护性等都奇差。因而此种情况下还是推荐采用一些现成的爬虫库,例如xpath、多线程支持还是必须考虑的诱因。2、如果是定向爬取,且主要目标是解析...
延瓒
01-01
1万+
Python/打响2019年第一炮-Python爬虫入门(一)
打响2019第一炮-Python爬虫入门 2018年早已成为过去,还记得在2018年元旦写过一篇【Shell编程】打响2018第一炮-shell编程之for循环句子,那在此时此刻,也是写一篇关于编程方面,不过要比18年的稍稍中级点。So,mark一下,也希望对您有所帮助。 步入题外话,在双十二想必你们都逛过网店and易迅,例如我们须要买一部手机或笔记本,而且我们须要点开手机或则笔记本页面看......
ROSE_ty的博客
03-04
2897
Python爬虫出现�乱码的解决办法
明天学习Python爬虫,再读取页面内容时出现以下情况,虽然使用了‘utf-8’后来通过阅读文章,将编码改为GBK后可正常显示...
ahkeyan的博客
03-15
1933
网路爬虫尝试(VB编撰)
PrivateSubForm_Load()a=getHTTPPage(“”)b=Split(a,“[”)(1)c=Split(b,“]”)(0)MsgBoxcEndSubFunctiongetHTTPPage(url)OnErrorResumeNextDimhttpSethttp=CreateObj...
qq_41514083的博客
07-17
1307
IDEA中JDBC的使用--完成对于数据库中数据的增删改查
IDEA中JDBC的使用--完成对于数据库中数据的增删改查1.在IDEA中新建一个项目2.进行各个类的编撰3.项目结果展示1.在IDEA中新建一个项目1.1点击右上角file,在new中选择project,在两侧选择Java项目,选择自己所安装的SDK包,点击next1.2继续点击next1.3决定项目的名子以及项目储存的文件夹,然后点击finish,完成项目的创建2.进行各个类的......
weixin_33863087的博客
04-25
2255
爬虫可以使用哪些语言
有好多刚才做爬虫工作者得菜鸟常常会问道这样一个问题,做爬虫须要哪些语言,个人认为任何语言,只要具备访问网路的标准库,都可以做到这一点。其实了解必要的爬虫工具也是必然的,比如代理IP刚才接触爬虫,好多菜鸟会苦恼于用Python来做爬虫,而且无论是JAVA,PHP还是其他更低级语言,都可以很便捷的实现,静态语言出现错误的可能性很低,低级语言运行速率会更快一些。并且Python的优势在于库更......
大数据
04-24
2341
网路爬虫有哪些用?如何爬?手把手教你爬网页(Python代码)
导读:本文主要分为两个部份:一部份是网路爬虫的概述,帮助你们详尽了解网路爬虫;另一部份是HTTP恳求的Python实现,帮助你们了解Python中实现HTTP恳求的各类方...
小蓝枣的博客
03-06
4846
Python爬虫篇-爬取页面所有可用的链接
原理也很简单,html链接都是在a元素里的,我们就是匹配出所有的a元素,其实a可以是空的链接,空的链接是None,也可能是无效的链接。我们通过urllib库的request来测试链接的有效性。当链接无效的话会抛出异常,我们把异常捕获下来,并提示下来,没有异常就是有效的,我们直接显示下来就好了。...
点点寒彬的博客
05-16
5万+
简单谈谈Python与Go的区别
背景工作中的主力语言是Python,明年要搞性能测试的工具,因为GIL锁的缘由,Python的性能实在是低迷,须要学一门性能高的语言来世成性能测试的压力端。为此我把眼神置于了如今的新秀Go。经过一段时间的学习,也写了一个小工具,记一下这两个语言的区别。需求工具是一个小爬虫,拿来爬某网站的某个产品的迭代记录,实现逻辑就是运行脚本后,使用者从命令行输入个别元素(产品ID等)后网络爬虫语言,脚本导入......
捉虫李高人
03-05
3万+
闲话网路爬虫-CSharp对比Python
这一期给男子伴们普及下网路爬虫这块的东西,吹下牛,宣传一波C#爬虫的优势,希望Python的老铁们轻喷,哈哈!大致对比了下Python爬虫和C#爬虫的优劣势,可以汲取Python爬虫的框架,进一步封装好C#爬虫须要用到的方方面面,然后用上去还是会蛮爽的,起码单看在数据抓取方面不输Python,Python应该是借助上去做它更擅长的其他方面的事情,而不是大势宣传它在爬虫方面的......
Yeoman92的博客
10-17
6358
python爬虫:使用selenium+ChromeDriver爬取途家网
本站(途家网)通过常规抓页面的方式不能获取数据,可以使用selenium+ChromeDriver来获取页面数据。
dengguawei0519的博客
02-08
129
(转)各类语言写网路爬虫有哪些优点缺点
我用PHP和Python都写过爬虫和正文提取程序。最开始使用PHP所以先谈谈PHP的优点:1.语言比较简单,PHP是极其随便的一种语言。写上去容易让你把精力放到你要做的事情上,而不是各类句型规则等等。2.各类功能模块齐全,这儿分两部份:1.网页下载:curl等扩充库;2.文档解析:dom、xpath、tidy、各种转码工具,可能跟题主的问题不太一样,我的爬虫须要提取正......
hs947463167的博客
03-06
3300
基于python的-提高爬虫效率的方法
#-*-coding:utf-8-*-"""明显提高爬虫效率的方法:1.换个性能更好的机器2.网路使用光纤3.多线程4.多进程5.分布式6.提高数据的写入速率""""""反爬虫的应对举措:1.随机更改User-Agent2.禁用Cookie追踪3.放慢爬虫速率4......
shenjian58的博客
03-22
3万+
男人更看重女孩的体型脸部,还是思想?
常常,我们看不进去大段大段的逻辑。深刻的哲理,常常短而精悍,一阵见血。问:产品总监挺漂亮的,有茶点动,但不晓得合不般配。女孩更看重女孩的体型脸部,还是...
静水流深的博客
03-29
4069
python爬虫(1)-使用requests和beautifulsoup库爬取中国天气网
python爬虫(1)-使用requests和beautifulsoup库爬取中国天气网使用工具及打算python3.7(python3以上都可以)pycharmIDE(本人习惯使用pycharm,也可以使用其他的)URL:、requests、lxml库(p...
天镇少年
10-16
2万+
Python爬虫的N种坐姿
问题的来历 前几天,在陌陌公众号(Python爬虫及算法)上有个人问了笔者一个问题,怎样借助爬虫来实现如下的需求,须要爬取的网页如下(网址为::WhatLinksHere/Q5&amp;limit=500&amp;from=0): 我们的需求为爬取白色框框内的名人(有500条记录,图片只展......
weixin_42530834的博客
06-23
3万+
一、最简单的爬虫(python3爬虫小白系列文章)
运行平台:WindowsPython版本:Python3.xIDE:Pycharm2017.2.4看了崔老师的python3网路爬虫实战,获益颇丰,为了帮助自己更好的理解这种知识点,于是准备趁着这股热乎劲,针对爬虫实战进行一系列的教程。阅读文章前,我会默认你早已具备一下几个要素1.python3安装完毕Windows:
Zhangguohao666的博客
03-30
4万+
Python爬虫,高清美图我全都要(彼岸桌面墙纸)
爬取彼岸桌面网站较为简单,用到了requests、lxml、BeautifulSoup4
启舰
03-23
3万+
程序员结业去大公司好还是小公司好?
其实大公司并不是人人都能进,但我仍建议还未结业的朋友,竭力地通过校招向大公司挤,即便挤进去,你这一生会容易好多。大公司那里好?没能进大公司如何办?答案都在这儿了,记得帮我点赞哦。目录:技术气氛内部晋升与跳槽啥也没学会,公司倒闭了?不同的人脉圈,注定会有不同的结果没能去大厂如何办?一、技术气氛综观整个程序员技术领域,那个在行业有所名气的大牛,不是在大厂?并且众所......
weixin_34132768的博客
12-12
599
为何python爬虫工程师岗位如此火爆?
哪些是网路爬虫?网路爬虫是一个手动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直至满足系统的一定停止条件。爬虫有哪些用?做为通用搜索引擎网页搜集器。(google,baidu)做垂直搜索引擎.科学研究:在线人类行为,在线社群演变,人类动力学研究,计......
学习python的正确坐姿
05-06
1209
python爬虫13|秒爬,python这多线程爬取速率也太猛了,此次就是要让你的爬虫效率杠杠的
快快了啊嘿小侄儿想啥呢明天这篇爬虫教程的主题就是一个字快想要做到秒爬就须要晓得哪些是多进程哪些是多线程哪些是轮询(微线程)你先去沏杯茶坐出来小帅b这就好好给你说道说道关于线程这玩意儿沏好茶了吗这么...
weixin_34273481的博客
05-31
1728
8个最高效的Python爬虫框架,你用过几个?
小编搜集了一些较为高效的Python爬虫框架。分享给你们。1.ScrapyScrapy是一个为了爬取网站数据,提取结构性数据而编撰的应用框架。可以应用在包括数据挖掘,信息处理或储存历史数据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。项目地址:是一个用python实现的功能......
空悲切
12-23
1万+
怎么高贵地使用c语言编撰爬虫
序言你们在平常或多或少地就会有编撰网路爬虫的需求。通常来说,编撰爬虫的首选自然非python莫属,除此之外,java等语言也是不错的选择。选择上述语言的诱因不仅仅在于它们均有十分不错的网路恳求库和字符串处理库,还在于基于上述语言的爬虫框架十分之多和健全。良好的爬虫框架可以确保爬虫程序的稳定性,以及编撰程序的方便性。所以,这个cspider爬虫库的使命在于,我们才能使用c语言,仍然还能高贵地编撰爬...
CSDN资讯
09-03
4万+
学Python后究竟能干哪些?网友:我太难了
觉得全世界营销文都在推Python,并且找不到工作的话,又有那个机构会站下来给我推荐工作?笔者冷静剖析多方数据,想跟你们说:关于赶超老牌霸主Java,过去几年间Pytho...
Rainbow
04-28
2万+
python爬虫之一:爬取网页小说(魂破九天)
近日做一个项目须要用到python,只懂皮毛的我花了三天时间将python重新捡起啃一啃,终于对python有了一定的认识。之后有按照爬虫基本原理爬取了一本小说,其他爬取小说的方式类似,结果见个人资源下载(本想下载分设置为0,结果CSDN设置最低为2分,没有积分的可以加我qq要该小说)。**爬虫原理:1、模拟人打开一页小说网页2、将网页保存出来......
毕易方达的博客
08-09
7795
全面了解Java中Native关键字的作用
初次遇到native是在java.lang.Object源码中的一个hashCode方式:1publicnativeinthashCode();为何有个native呢?这是我所要学习的地方。所以下边想要总结下native。一、认识native即JNI,JavaNativeInterface但凡一种语言,都希望是纯。例如解决某一个方案都喜欢就单单这个语言......
做人还是高调点
05-08
4万+
笔试:第十六章:Java高级开发(16k)
HashMap底层实现原理,黑红树,B+树,B树的结构原理Spring的AOP和IOC是哪些?它们常见的使用场景有什么?Spring事务,事务的属性,传播行为,数据库隔离级别Spring和SpringMVC,MyBatis以及SpringBoot的注解分别有什么?SpringMVC的工作原理,SpringBoot框架的优点,MyBatis框架的优点SpringCould组件有什么,她们......
Bo_wen_的博客
03-13
16万+
python网路爬虫入门(一)———第一个python爬虫实例
近来七天学习了一下python,并自己写了一个网路爬虫的反例。python版本:3.5IDE:pycharm5.0.4要用到的包可以用pycharm下载:File->DefaultSettings->DefaultProject->ProjectInterpreter选择python版本并点一侧的减号安装想要的包我选择的网站是中国天气网中的上海天气,打算抓取近来...
jsmok_xingkong的博客
11-05
3143
Python-爬虫初体验
在网易云课堂上看的教学视频,如今来巩固一下知识:1.先确定自己要爬的网站,以新浪新闻网站为例确importrequests#跟java的导包差不多,python叫导出库res=requests.get('#039;)#爬取网页内容res.encoding='utf-8'#将得到的网页内容转码,防止乱...
CSDN资讯
03-27
4万+
无代码时代将至,程序员怎样保住饭碗?
编程语言层出不穷,从最初的机器语言到现在2500种以上的中级语言,程序员们大呼“学到头秃”。程序员一边面临编程语言不断推陈出新,一边面临因为许多代码已存在,程序员编撰新应用程序时存在重复“搬砖”的现象。无代码/低代码编程应运而生。无代码/低代码是一种创建应用的方式,它可以让开发者使用最少的编码知识来快速开发应用程序。开发者通过图形界面中,可视化建模来组装和配置应用程序。这样一来,开发者直......
明明如月的专栏
03-01
1万+
将一个插口响应时间从2s优化到200ms以内的一个案例
一、背景在开发联调阶段发觉一个插口的响应时间非常长,常常超时,囧…本文讲讲是怎样定位到性能困局以及更改的思路,将该插口从2s左右优化到200ms以内。二、步骤2.1定位定位性能困局有两个思路,一个是通过工具去监控,一个是通过经验去猜测。2.1.1工具监控就工具而言,推荐使用arthas,用到的是trace命令具体安装步骤很简单,你们自行研究。我的使用步骤是......
tboyer
03-24
95
python3爬坑日记(二)——大文本读取
python3爬坑日记(二)——大文本读取一般我们使用python读取文件直接使用:fopen=open("test.txt")str=fopen.read()fopen.close()假如文件内容较小,使用以上方式其实没问题。并且,有时我们须要读取类似字典,日志等富含大量内容的文件时使用上述方式因为显存缘由常常会抛出异常。这时请使用:withopen("test.tx......
aa804738534的博客
01-19
646
STL(四)容器手动排序set
#include<set>#include<iostream>#include<set>#include<string>usingnamespacestd;template<typenameT>voidshowset(set<T>v){for(typenamestd::set...
薛定谔的雄猫的博客
04-30
2万+
怎样柔美的替换掉代码中的ifelse
平常我们在写代码时,处理不同的业务逻辑,用得最多的就是if和else,简单粗鲁省事,并且ifelse不是最好的方法,本文将通过设计模式来替换ifelse,使代码更高贵简约。
非知名程序员
01-30
7万+
非典逼出了天猫和易迅,新冠病毒才能逼出哪些?
loonggg读完须要5分钟速读仅需2分钟你们好,我是大家的市长。我晓得你们在家里都憋坏了,你们可能相对于封闭在家里“坐月子”,更希望才能尽快下班。明天我带着你们换个思路来聊一个问题...
九章算法的博客
02-06
19万+
B站上有什么挺好的学习资源?
哇说起B站,在小九眼中就是宝藏般的存在,放休假宅在家时三天刷6、7个小时不在话下,更别提去年的跨年晚宴,我简直是跪着看完的!!最早你们聚在在B站是为了追番,再后来我在里面刷欧美新曲和漂亮小妹妹的街舞视频,近来三年我和周围的同学们早已把B站当成学习课室了,但是学习成本还免费,真是个励志的好平台ヽ(.◕ฺˇдˇ◕ฺ;)ノ下边我们就来盘点一下B站上优质的学习资源:综合类Oeasy:综合......
王泽岭的博客
08-19
479
几种语言在爬虫场景下的力量对比
PHP爬虫:代码简单,并发处理能力较弱:因为当时PHP没有线程、进程功能要想实现并发须要借用多路复用模型R语言爬虫:操作简单,功能太弱,只适用于小规模的爬取,不适宜大规模的爬取Python爬虫:有着各类成熟的爬虫框架(eg:scrapy家族),可以便捷高效的下载网页而且支持多线程,进程模型成熟稳定,爬虫是是一个典型的多任务处理场景,恳求页面时会有较长的延后,总体来说更多的是等待,多线......
九章算法的博客
03-17
4580
作为程序员,有没有让你倍感既无语又崩溃的代码注释?
作为一个程序员,堪称是天天通宵来加班,也难以阅遍无数的程序代码,不晓得有多少次看到这些让人既倍感无语又奔溃的代码注释了。你以为自己能看懂这种代码,但是有信心可以优化这种代码,一旦你开始尝试这种代码,你将会被困在无尽的熬夜中,在痛斥中结束这段痛楚的历程。更有有网友坦承,自己写代码都是拼音变量名和英文注释,担心被踢出程序员队伍。下边这个代码注释大约说出了好多写代码人的心里话了。//我写这一行的时侯......
CSDN大学
03-10
2万+
刚回应!删库报复!一行代码蒸发数10亿!
年后开工大戏,又降低一出:删库跑路!此举直接给公司带来数10亿的估值蒸发损失,并引起一段“狗血宿怨剧情”,说实话电视剧都不敢如此拍!此次不是他人,正是陌陌生态的第三方服务商微盟,在这个"远程办公”的节骨眼出事了。2月25日,微盟集团(SEHK:02013)发布公告称,Saas生产环境及数据受到职工“人为破坏”导致公司当前暂时未能向顾客提供SaaS产品。犯罪嫌疑人是微盟研制......
爪白白的个人博客
04-25
5万+
总结了150余个神奇网站,你不来看看吗?
原博客再更新,可能就没了,然后将持续更新本篇博客。
11-03
8645
二次型(求梯度)——公式的简化
1.基本方程
程序人生的博客
02-11
5636
大地震!某大厂“硬核”抢人,放话:只要AI人才,中学结业都行!
特斯拉创始人马斯克,在2019年曾许下好多承诺网络爬虫语言,其中一个就是:2019年末实现完全的手动驾驶。其实这个承诺又成了flag,并且不阻碍他去年继续为这个承诺努力。这不,就在上周四,马斯克之间...
3y
03-16
9万+
我说我不会算法,阿里把我挂了。
不说了,字节跳动也反手把我挂了。
qq_40618664的博客
05-07
3万+
Auto.JS实现抖音,刷宝等刷视频app,自动点赞,手动滑屏,手动切换视频
Auto.JS实现抖音,刷宝等刷视频app,自动点赞,手动滑屏,手动切换视频代码如下auto();varappName=rawInput("","刷宝短视频");launchApp(appName);sleep("5000");setScreenMetrics(1080,1920);toast("1023732997");sleep("3000");varnum=200...
lmseo5hy的博客
05-14
1万+
Python与其他语言相比异同点python零基础入门
python作为一门中级编程语言,它的诞生其实很碰巧,并且它得到程序员的喜爱却是必然之路,以下是Python与其他编程语言的异同点对比:1.Python优势:简单易学,才能把用其他语言制做的各类模块很轻松地连结在一起。劣势:速率较慢,且有一些特定情况下才能出现(未能再现)的bug2.C/C++C/C++优势:可以被嵌入任何现代处理器中,几乎所有操作系统都支持C/C++,跨平台性十分好劣势:学习......
WUTab的博客
07-30
2549
找出链表X和Y中所有2n个元素的中位数
算法总论第三版,9.3-8算法:假如两个字段宽度为1,选出较小的那种一个否则,取出两个字段的中位数。取有较大中位数的链表的低区和较低中位数链表的高区,组合成新的宽度为n的链表。找出新链表的中位数思路:既然用递归分治,一定有基本情况,基本情况就是链表宽度为1.观察会发觉总的中位数介于两个字段的中位数之间。详尽证明如下:设总的中位数是MM,XX的中位数是MXM_X,YY的中位数是...
程松
03-30
10万+
5分钟,6行代码教你写爬虫!(python)
5分钟,6行代码教你写会爬虫!适用人士:对数据量需求不大,简单的从网站上爬些数据。好,不浪费时间了,开始!先来个反例:输入以下代码(共6行)importrequestsfromlxmlimporthtmlurl='#039;#须要爬数据的网址page=requests.Session().get(url)tree=html.f...
【黑马程序员】Python爬虫是哪些?爬虫教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 482 次浏览 • 2020-05-19 08:01
【黑马程序员】Python 爬虫是哪些?爬虫教程假如你仔细观察,就不难发觉,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取 的数据越来越多,另一方面,像 Python 这样的编程语言提供越来越多的优秀工具,让爬虫 变得简单、容易上手。 利用爬虫我们可以获取大量的价值数据,从而获得感性认识中不能得到的信息,比如: 知乎:爬取优质答案,为你筛选出各话题下最优质的内容。淘宝、京东:抓取商品、评论及 销量数据,对各类商品及用户的消费场景进行剖析。安居客、链家:抓取房产买卖及租售信 息,分析楼市变化趋势、做不同区域的楼价剖析。拉勾网、智联:爬取各种职位信息,分析 各行业人才需求情况及薪酬水平。雪球网:抓取雪球高回报用户的行为,对股票市场进行分 析和预测。 爬虫是入门 Python 最好的形式,没有之一。Python 有很多应用的方向,比如后台开发、 web 开发、科学估算等等,但爬虫对于初学者而言更友好,原理简单,几行代码能够实现 基本的爬虫,学习的过程愈发平滑,你能感受更大的成就感。 掌握基本的爬虫后,你再去学习 Python 数据剖析、web 开发甚至机器学习,都会更得心 应手。因为这个过程中,Python 基本句型、库的使用,以及怎样查找文档你都十分熟悉了。
对于小白来说,爬虫可能是一件十分复杂、技术门槛很高的事情。比如有人觉得学爬虫必须 精通 Python,然后哼哧哼哧系统学习 Python 的每位知识点,很久以后发觉一直爬不了数 据;有的人则觉得先要把握网页的知识,遂开始 HTML\CSS,结果入了后端的坑,瘁…… 但把握正确的方式,在短时间内做到才能爬取主流网站的数据,其实十分容易实现,但建议 你从一开始就要有一个具体的目标。视频库网址:资料发放:3285264708在目标的驱动下,你的学习才能愈发精准和高效。那些所有你觉得必须的后置知识,都是可 以在完成目标的过程小学到的。这里给你一条平滑的、零基础快速入门的学习路径。 文章目录: 1. 学习 Python 包并实现基本的爬虫过程 2. 了解非结构化数据的储存 3. 学习 scrapy,搭建工程化爬虫 4. 学习数据库知识,应对大规模数据储存与提取 5. 掌握各类方法,应对特殊网站的反爬举措 6. 分布式爬虫,实现大规模并发采集,提升效率-? 学习 Python 包并实现基本的爬虫过程大部分爬虫都是按“发送恳求——获得页面——解析页面——抽取并存储内容”这样的流 程来进行,这或许也是模拟了我们使用浏览器获取网页信息的过程。
Python 中爬虫相关的包好多:urllib、requests、bs4、scrapy、pyspider 等,建议从 requests+Xpath 开始,requests 负责联接网站,返回网页,Xpath 用于解析网页,便于 抽取数据。 如果你用过 BeautifulSoup,会发觉 Xpath 要省事不少,一层一层检测元素代码的工作, 全都省略了。这样出来基本套路都差不多,一般的静态网站根本不在话下,豆瓣、糗事百科、 腾讯新闻等基本上都可以上手了。 当然假如你须要爬取异步加载的网站,可以学习浏览器抓包剖析真实恳求或则学习 Selenium 来实现自动化,这样,知乎、时光网、猫途鹰这种动态的网站也可以迎刃而解。视频库网址:资料发放:3285264708-? 了解非结构化数据的储存爬回去的数据可以直接用文档方式存在本地,也可以存入数据库中。 开始数据量不大的时侯,你可以直接通过 Python 的句型或 pandas 的方式将数据存为 csv 这样的文件。 当然你可能发觉爬回去的数据并不是干净的python爬虫是什么意思,可能会有缺位、错误等等,你还须要对数据进 行清洗,可以学习 pandas 包的基本用法来做数据的预处理,得到更干净的数据。
-? 学习 scrapy,搭建工程化的爬虫把握后面的技术通常量级的数据和代码基本没有问题了,但是在碰到十分复杂的情况,可能 仍然会力不从心,这个时侯,强大的 scrapy 框架就十分有用了。 scrapy 是一个功能十分强悍的爬虫框架,它除了能方便地建立 request,还有强悍的 selector 能够便捷地解析 response,然而它最使人惊喜的还是它超高的性能,让你可以 将爬虫工程化、模块化。 学会 scrapy,你可以自己去搭建一些爬虫框架,你就基本具备爬虫工程师的思维了。-? 学习数据库基础,应对大规模数据储存爬回去的数据量小的时侯,你可以用文档的方式来储存,一旦数据量大了,这就有点行不通 了。所以把握一种数据库是必须的,学习目前比较主流的 MongoDB 就 OK。视频库网址:资料发放:3285264708MongoDB 可以便捷你去储存一些非结构化的数据,比如各类评论的文本,图片的链接等 等。你也可以借助 PyMongo,更方便地在 Python 中操作 MongoDB。 因为这儿要用到的数据库知识似乎十分简单,主要是数据怎么入库、如何进行提取,在须要 的时侯再学习就行。
-? 掌握各类方法,应对特殊网站的反爬举措其实,爬虫过程中也会经历一些绝望啊,比如被网站封 IP、比如各类奇怪的验证码、 userAgent 访问限制、各种动态加载等等。 遇到这种反爬虫的手段,当然还须要一些中级的方法来应对,常规的例如访问频度控制、使 用代理 IP 池、抓包、验证码的 OCR 处理等等。 往往网站在高效开发和反爬虫之间会偏向后者,这也为爬虫提供了空间,掌握这种应对反爬 虫的方法,绝大部分的网站已经难不到你了。-? 分布式爬虫,实现大规模并发采集爬取基本数据早已不是问题了,你的困局会集中到爬取海量数据的效率。这个时侯,相信你 会很自然地接触到一个很厉害的名子:分布式爬虫。 分布式这个东西,听上去太惊悚,但毕竟就是借助多线程的原理使多个爬虫同时工作,需要 你把握 Scrapy + MongoDB + Redis 这三种工具。 Scrapy 前面我们说过了,用于做基本的页面爬取,MongoDB 用于储存爬取的数据,Redis 则拿来储存要爬取的网页队列,也就是任务队列。视频库网址:资料发放:3285264708所以有些东西看起来太吓人,但毕竟分解开来,也不过如此。当你才能写分布式的爬虫的时 候,那么你可以去尝试构建一些基本的爬虫构架了python爬虫是什么意思,实现一些愈发自动化的数据获取。
你看,这一条学习路径出来,你已经可以成为老司机了,非常的顺畅。所以在一开始的时侯, 尽量不要系统地去啃一些东西,找一个实际的项目(开始可以从豆瓣、小猪这些简单的入手), 直接开始就好。 因为爬虫这些技术,既不需要你系统地精通一门语言,也不需要多么深奥的数据库技术,高 效的坐姿就是从实际的项目中去学习这种零散的知识点,你能保证每次学到的都是最须要的 那部份。 当然惟一麻烦的是,在具体的问题中,如何找到具体须要的那部份学习资源、如何筛选和甄 别,是好多初学者面临的一个大问题。黑马程序员视频库网址:(海量热门编程视频、资料免费学习) 学习路线图、学习大纲、各阶段知识点、资料云盘免费发放+QQ 3285264708 / 3549664195视频库网址:资料发放:3285264708 查看全部
【黑马程序员】Python 爬虫是哪些?爬虫教程假如你仔细观察,就不难发觉,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取 的数据越来越多,另一方面,像 Python 这样的编程语言提供越来越多的优秀工具,让爬虫 变得简单、容易上手。 利用爬虫我们可以获取大量的价值数据,从而获得感性认识中不能得到的信息,比如: 知乎:爬取优质答案,为你筛选出各话题下最优质的内容。淘宝、京东:抓取商品、评论及 销量数据,对各类商品及用户的消费场景进行剖析。安居客、链家:抓取房产买卖及租售信 息,分析楼市变化趋势、做不同区域的楼价剖析。拉勾网、智联:爬取各种职位信息,分析 各行业人才需求情况及薪酬水平。雪球网:抓取雪球高回报用户的行为,对股票市场进行分 析和预测。 爬虫是入门 Python 最好的形式,没有之一。Python 有很多应用的方向,比如后台开发、 web 开发、科学估算等等,但爬虫对于初学者而言更友好,原理简单,几行代码能够实现 基本的爬虫,学习的过程愈发平滑,你能感受更大的成就感。 掌握基本的爬虫后,你再去学习 Python 数据剖析、web 开发甚至机器学习,都会更得心 应手。因为这个过程中,Python 基本句型、库的使用,以及怎样查找文档你都十分熟悉了。
对于小白来说,爬虫可能是一件十分复杂、技术门槛很高的事情。比如有人觉得学爬虫必须 精通 Python,然后哼哧哼哧系统学习 Python 的每位知识点,很久以后发觉一直爬不了数 据;有的人则觉得先要把握网页的知识,遂开始 HTML\CSS,结果入了后端的坑,瘁…… 但把握正确的方式,在短时间内做到才能爬取主流网站的数据,其实十分容易实现,但建议 你从一开始就要有一个具体的目标。视频库网址:资料发放:3285264708在目标的驱动下,你的学习才能愈发精准和高效。那些所有你觉得必须的后置知识,都是可 以在完成目标的过程小学到的。这里给你一条平滑的、零基础快速入门的学习路径。 文章目录: 1. 学习 Python 包并实现基本的爬虫过程 2. 了解非结构化数据的储存 3. 学习 scrapy,搭建工程化爬虫 4. 学习数据库知识,应对大规模数据储存与提取 5. 掌握各类方法,应对特殊网站的反爬举措 6. 分布式爬虫,实现大规模并发采集,提升效率-? 学习 Python 包并实现基本的爬虫过程大部分爬虫都是按“发送恳求——获得页面——解析页面——抽取并存储内容”这样的流 程来进行,这或许也是模拟了我们使用浏览器获取网页信息的过程。
Python 中爬虫相关的包好多:urllib、requests、bs4、scrapy、pyspider 等,建议从 requests+Xpath 开始,requests 负责联接网站,返回网页,Xpath 用于解析网页,便于 抽取数据。 如果你用过 BeautifulSoup,会发觉 Xpath 要省事不少,一层一层检测元素代码的工作, 全都省略了。这样出来基本套路都差不多,一般的静态网站根本不在话下,豆瓣、糗事百科、 腾讯新闻等基本上都可以上手了。 当然假如你须要爬取异步加载的网站,可以学习浏览器抓包剖析真实恳求或则学习 Selenium 来实现自动化,这样,知乎、时光网、猫途鹰这种动态的网站也可以迎刃而解。视频库网址:资料发放:3285264708-? 了解非结构化数据的储存爬回去的数据可以直接用文档方式存在本地,也可以存入数据库中。 开始数据量不大的时侯,你可以直接通过 Python 的句型或 pandas 的方式将数据存为 csv 这样的文件。 当然你可能发觉爬回去的数据并不是干净的python爬虫是什么意思,可能会有缺位、错误等等,你还须要对数据进 行清洗,可以学习 pandas 包的基本用法来做数据的预处理,得到更干净的数据。
-? 学习 scrapy,搭建工程化的爬虫把握后面的技术通常量级的数据和代码基本没有问题了,但是在碰到十分复杂的情况,可能 仍然会力不从心,这个时侯,强大的 scrapy 框架就十分有用了。 scrapy 是一个功能十分强悍的爬虫框架,它除了能方便地建立 request,还有强悍的 selector 能够便捷地解析 response,然而它最使人惊喜的还是它超高的性能,让你可以 将爬虫工程化、模块化。 学会 scrapy,你可以自己去搭建一些爬虫框架,你就基本具备爬虫工程师的思维了。-? 学习数据库基础,应对大规模数据储存爬回去的数据量小的时侯,你可以用文档的方式来储存,一旦数据量大了,这就有点行不通 了。所以把握一种数据库是必须的,学习目前比较主流的 MongoDB 就 OK。视频库网址:资料发放:3285264708MongoDB 可以便捷你去储存一些非结构化的数据,比如各类评论的文本,图片的链接等 等。你也可以借助 PyMongo,更方便地在 Python 中操作 MongoDB。 因为这儿要用到的数据库知识似乎十分简单,主要是数据怎么入库、如何进行提取,在须要 的时侯再学习就行。
-? 掌握各类方法,应对特殊网站的反爬举措其实,爬虫过程中也会经历一些绝望啊,比如被网站封 IP、比如各类奇怪的验证码、 userAgent 访问限制、各种动态加载等等。 遇到这种反爬虫的手段,当然还须要一些中级的方法来应对,常规的例如访问频度控制、使 用代理 IP 池、抓包、验证码的 OCR 处理等等。 往往网站在高效开发和反爬虫之间会偏向后者,这也为爬虫提供了空间,掌握这种应对反爬 虫的方法,绝大部分的网站已经难不到你了。-? 分布式爬虫,实现大规模并发采集爬取基本数据早已不是问题了,你的困局会集中到爬取海量数据的效率。这个时侯,相信你 会很自然地接触到一个很厉害的名子:分布式爬虫。 分布式这个东西,听上去太惊悚,但毕竟就是借助多线程的原理使多个爬虫同时工作,需要 你把握 Scrapy + MongoDB + Redis 这三种工具。 Scrapy 前面我们说过了,用于做基本的页面爬取,MongoDB 用于储存爬取的数据,Redis 则拿来储存要爬取的网页队列,也就是任务队列。视频库网址:资料发放:3285264708所以有些东西看起来太吓人,但毕竟分解开来,也不过如此。当你才能写分布式的爬虫的时 候,那么你可以去尝试构建一些基本的爬虫构架了python爬虫是什么意思,实现一些愈发自动化的数据获取。
你看,这一条学习路径出来,你已经可以成为老司机了,非常的顺畅。所以在一开始的时侯, 尽量不要系统地去啃一些东西,找一个实际的项目(开始可以从豆瓣、小猪这些简单的入手), 直接开始就好。 因为爬虫这些技术,既不需要你系统地精通一门语言,也不需要多么深奥的数据库技术,高 效的坐姿就是从实际的项目中去学习这种零散的知识点,你能保证每次学到的都是最须要的 那部份。 当然惟一麻烦的是,在具体的问题中,如何找到具体须要的那部份学习资源、如何筛选和甄 别,是好多初学者面临的一个大问题。黑马程序员视频库网址:(海量热门编程视频、资料免费学习) 学习路线图、学习大纲、各阶段知识点、资料云盘免费发放+QQ 3285264708 / 3549664195视频库网址:资料发放:3285264708
爬虫技术浅析
采集交流 • 优采云 发表了文章 • 0 个评论 • 361 次浏览 • 2020-05-02 08:09
上图是Scrapy的构架图,绿线是数据流向,首先从初始URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载以后会交给 Spider 进行剖析,需要保存的数据则会被送到Item Pipeline,那是对数据进行后期处理。另外,在数据流动的通道里还可以安装各类中间件,进行必要的处理。 因此在开发爬虫的时侯,最好也先规划好各类模块。我的做法是单独规划下载模块,爬行模块,调度模块,数据储存模块。
页面下载分为静态和动态两种下载形式。
传统爬虫借助的是静态下载形式,静态下载的优势是下载过程快,但是页面只是一个无趣的html,因此页面链接剖析中获取的只是< a >标签的href属性或则大神可以自己剖析js,form之类的标签捕获一些链接。在python中可以借助urllib2模块或requests模块实现功能。 动态爬虫在web2.0时代则有特殊的优势,由于网页会使用javascript处理,网页内容通过Ajax异步获取。所以,动态爬虫须要剖析经过javascript处理和ajax获取内容后的页面。目前简单的解决方式是通过基于webkit的模块直接处理。PYQT4、Splinter和Selenium这三个模块都可以达到目的。对于爬虫而言,浏览器界面是不需要的,因此使用一个headless browser是十分实惠的,HtmlUnit和phantomjs都是可以使用的headless browser。
以上这段代码是访问新浪网主站。通过对比静态抓取页面和动态抓取页面的厚度和对比静态抓取页面和动态抓取页面内抓取的链接个数。
在静态抓取中,页面的宽度是563838,页面内抓取的链接数目只有166个。而在动态抓取中,页面的宽度下降到了695991,而链接数达到了1422,有了逾10倍的提高。
抓链接表达式
正则:re.compile("href=\"([^\"]*)\"")
Xpath:xpath('//*[@href]')
页面解析是实现抓取页面内链接和抓取特定数据的模块,页面解析主要是对字符串的处理,而html是一种特殊的字符串,在Python中re、beautifulsoup、HTMLParser、lxml等模块都可以解决问题。对于链接,主要抓取a标签下的href属性,还有其他一些标签的src属性。
URL去重是爬虫运行中一项关键的步骤,由于运行中的爬虫主要阻塞在网路交互中,因此防止重复的网路交互至关重要。爬虫通常会将待抓取的URL置于一个队列中,从抓取后的网页中提取到新的URL,在她们被装入队列之前,首先要确定这种新的URL没有被抓取过,如果之前早已抓取过了,就不再装入队列了。
Hash表
利用hash表做去重操作通常是最容易想到的方式,因为hash表查询的时间复杂度是O(1),而且在hash表足够大的情况下,hash冲突的机率就显得太小,因此URL是否重复的判定准确性就十分高。利用hash表去重的这个做法是一个比较简单的解决方式。但是普通hash表也有显著的缺陷爬虫技术,在考虑显存的情况下,使用一张大的hash表是不妥的。Python中可以使用字典这一数据结构。
URL压缩
如果hash表中,当每位节点存储的是一个str方式的具体URL,是十分占用显存的,如果把这个URL进行压缩成一个int型变量,内存占用程度上便有了3倍以上的缩小。因此可以借助Python的hashlib模块来进行URL压缩。 思路:把hash表的节点的数据结构设置为集合,集合内贮存压缩后的URL。
Bloom Filter
Bloom Filter是通过很少的错误换取了储存空间的极大节约。Bloom Filter 是通过一组k 个定义在n 个输入key 上的Hash Function,将上述n 个key 映射到m 位上的数据容器。
上图太清楚的说明了Bloom Filter的优势,在可控的容器宽度内,所有hash函数对同一个元素估算的hash值都为1时,就判定这个元素存在。 Python中hashlib,自带多种hash函数,有MD5,sha1,sha224,sha256,sha384,sha512。代码中还可以进行加水处理,还是很方便的。 Bloom Filter也会形成冲突的情况,具体内容查看文章结尾的参考文章。
在Python编程过程中,可以使用jaybaird提供的BloomFilter插口,或者自己造轮子。
小细节
有个小细节,在构建hash表的时侯选择容器很重要。hash表占用空间很大是个太不爽的问题,因此针对爬虫去重,下列方式可以解决一些问题。
上面这段代码简单验证了生成容器的运行时间。
由上图可以看出,建立一个宽度为1亿的容器时,选择list容器程序的运行时间耗费了7.2s,而选择字符串作为容器时,才耗费了0.2s的运行时间。
接下来瞧瞧显存的占用情况。
如果构建1亿的列表占用了794660k显存。
而构建1亿宽度的字符串却占用了109720k显存,空间占用大概降低了700000k。
初级算法
对于URL相似性,我只是实践一个十分简单的技巧。
在保证不进行重复爬去的情况下,还须要对类似的URL进行判定。我采用的是sponge和ly5066113提供的思路。具体资料在参考文章里。
下列是一组可以判定为相像的URL组
按照预期,以上URL归并后应当为
思路如下,需要提取如下特点
1,host字符串
2,目录深度(以’/’分割)
3,尾页特点
具体算法
算法本身太菜,各位一看才能懂。
实际疗效:
上图显示了把8个不一样的url,算出了2个值。通过实践,在一张千万级的hash表中,冲突的情况是可以接受的。
Python中的并发操作主要涉及的模型有:多线程模型、多进程模型、协程模型。Elias专门写了一篇文章爬虫技术,来比较常用的几种模型并发方案的性能。对于爬虫本身来说,限制爬虫速率主要来自目标服务器的响应速率,因此选择一个控制上去顺手的模块才是对的。
多线程模型,是最容易上手的,Python中自带的threading模块能挺好的实现并发需求,配合Queue模块来实现共享数据。
多进程模型和多线程模型类似,multiprocessing模块中也有类似的Queue模块来实现数据共享。在linux中,用户态的进程可以借助多核心的优势,因此在多核背景下,能解决爬虫的并发问题。
协程模型,在Elias的文章中,基于greenlet实现的解释器程序的性能仅次于Stackless Python,大致比Stackless Python慢一倍,比其他方案快接近一个数量级。因此基于gevent(封装了greenlet)的并发程序会有挺好的性能优势。
具体说明下gevent(非阻塞异步IO)。,“Gevent是一种基于解释器的Python网络库,它用到Greenlet提供的,封装了libevent风波循环的高层同步API。”
从实际的编程疗效来看,协程模型确实表现非常好,运行结果的可控性显著强了不少, gevent库的封装易用性极强。
数据储存本身设计的技术就十分多,作为小菜不敢乱说,但是工作还是有一些小经验是可以分享的。
前提:使用关系数据库,测试中选择的是mysql,其他类似sqlite,SqlServer思路上没有区别。
当我们进行数据储存时,目的就是降低与数据库的交互操作,这样可以增强性能。通常情况下,每当一个URL节点被读取,就进行一次数据储存,对于这样的逻辑进行无限循环。其实这样的性能体验是十分差的,存储速率特别慢。
进阶做法,为了减轻与数据库的交互次数,每次与数据库交互从之前传送1个节点弄成传送10个节点,到传送100个节点内容,这样效率变有了10倍至100倍的提高,在实际应用中,效果是非常好的。:D
爬虫模型
目前这个爬虫模型如上图,调度模块是核心模块。调度模块分别与下载模块,析取模块,存储模块共享三个队列,下载模块与析取模块共享一个队列。数据传递方向如图示。 查看全部
谈到爬虫构架,不得不提的是Scrapy的爬虫构架。Scrapy,是Python开发的一个快速,高层次的爬虫框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。Scrapy吸引人的地方在于它是一个框架,任何人都可以依照需求便捷的更改。它也提供了多种类型爬虫的子类,如BaseSpider、sitemap爬虫等。上图是Scrapy的构架图,绿线是数据流向,首先从初始URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载以后会交给 Spider 进行剖析,需要保存的数据则会被送到Item Pipeline,那是对数据进行后期处理。另外,在数据流动的通道里还可以安装各类中间件,进行必要的处理。 因此在开发爬虫的时侯,最好也先规划好各类模块。我的做法是单独规划下载模块,爬行模块,调度模块,数据储存模块。
页面下载分为静态和动态两种下载形式。
传统爬虫借助的是静态下载形式,静态下载的优势是下载过程快,但是页面只是一个无趣的html,因此页面链接剖析中获取的只是< a >标签的href属性或则大神可以自己剖析js,form之类的标签捕获一些链接。在python中可以借助urllib2模块或requests模块实现功能。 动态爬虫在web2.0时代则有特殊的优势,由于网页会使用javascript处理,网页内容通过Ajax异步获取。所以,动态爬虫须要剖析经过javascript处理和ajax获取内容后的页面。目前简单的解决方式是通过基于webkit的模块直接处理。PYQT4、Splinter和Selenium这三个模块都可以达到目的。对于爬虫而言,浏览器界面是不需要的,因此使用一个headless browser是十分实惠的,HtmlUnit和phantomjs都是可以使用的headless browser。
以上这段代码是访问新浪网主站。通过对比静态抓取页面和动态抓取页面的厚度和对比静态抓取页面和动态抓取页面内抓取的链接个数。
在静态抓取中,页面的宽度是563838,页面内抓取的链接数目只有166个。而在动态抓取中,页面的宽度下降到了695991,而链接数达到了1422,有了逾10倍的提高。
抓链接表达式
正则:re.compile("href=\"([^\"]*)\"")
Xpath:xpath('//*[@href]')
页面解析是实现抓取页面内链接和抓取特定数据的模块,页面解析主要是对字符串的处理,而html是一种特殊的字符串,在Python中re、beautifulsoup、HTMLParser、lxml等模块都可以解决问题。对于链接,主要抓取a标签下的href属性,还有其他一些标签的src属性。
URL去重是爬虫运行中一项关键的步骤,由于运行中的爬虫主要阻塞在网路交互中,因此防止重复的网路交互至关重要。爬虫通常会将待抓取的URL置于一个队列中,从抓取后的网页中提取到新的URL,在她们被装入队列之前,首先要确定这种新的URL没有被抓取过,如果之前早已抓取过了,就不再装入队列了。
Hash表
利用hash表做去重操作通常是最容易想到的方式,因为hash表查询的时间复杂度是O(1),而且在hash表足够大的情况下,hash冲突的机率就显得太小,因此URL是否重复的判定准确性就十分高。利用hash表去重的这个做法是一个比较简单的解决方式。但是普通hash表也有显著的缺陷爬虫技术,在考虑显存的情况下,使用一张大的hash表是不妥的。Python中可以使用字典这一数据结构。
URL压缩
如果hash表中,当每位节点存储的是一个str方式的具体URL,是十分占用显存的,如果把这个URL进行压缩成一个int型变量,内存占用程度上便有了3倍以上的缩小。因此可以借助Python的hashlib模块来进行URL压缩。 思路:把hash表的节点的数据结构设置为集合,集合内贮存压缩后的URL。
Bloom Filter
Bloom Filter是通过很少的错误换取了储存空间的极大节约。Bloom Filter 是通过一组k 个定义在n 个输入key 上的Hash Function,将上述n 个key 映射到m 位上的数据容器。
上图太清楚的说明了Bloom Filter的优势,在可控的容器宽度内,所有hash函数对同一个元素估算的hash值都为1时,就判定这个元素存在。 Python中hashlib,自带多种hash函数,有MD5,sha1,sha224,sha256,sha384,sha512。代码中还可以进行加水处理,还是很方便的。 Bloom Filter也会形成冲突的情况,具体内容查看文章结尾的参考文章。
在Python编程过程中,可以使用jaybaird提供的BloomFilter插口,或者自己造轮子。
小细节
有个小细节,在构建hash表的时侯选择容器很重要。hash表占用空间很大是个太不爽的问题,因此针对爬虫去重,下列方式可以解决一些问题。
上面这段代码简单验证了生成容器的运行时间。
由上图可以看出,建立一个宽度为1亿的容器时,选择list容器程序的运行时间耗费了7.2s,而选择字符串作为容器时,才耗费了0.2s的运行时间。
接下来瞧瞧显存的占用情况。
如果构建1亿的列表占用了794660k显存。
而构建1亿宽度的字符串却占用了109720k显存,空间占用大概降低了700000k。
初级算法
对于URL相似性,我只是实践一个十分简单的技巧。
在保证不进行重复爬去的情况下,还须要对类似的URL进行判定。我采用的是sponge和ly5066113提供的思路。具体资料在参考文章里。
下列是一组可以判定为相像的URL组
按照预期,以上URL归并后应当为
思路如下,需要提取如下特点
1,host字符串
2,目录深度(以’/’分割)
3,尾页特点
具体算法
算法本身太菜,各位一看才能懂。
实际疗效:
上图显示了把8个不一样的url,算出了2个值。通过实践,在一张千万级的hash表中,冲突的情况是可以接受的。
Python中的并发操作主要涉及的模型有:多线程模型、多进程模型、协程模型。Elias专门写了一篇文章爬虫技术,来比较常用的几种模型并发方案的性能。对于爬虫本身来说,限制爬虫速率主要来自目标服务器的响应速率,因此选择一个控制上去顺手的模块才是对的。
多线程模型,是最容易上手的,Python中自带的threading模块能挺好的实现并发需求,配合Queue模块来实现共享数据。
多进程模型和多线程模型类似,multiprocessing模块中也有类似的Queue模块来实现数据共享。在linux中,用户态的进程可以借助多核心的优势,因此在多核背景下,能解决爬虫的并发问题。
协程模型,在Elias的文章中,基于greenlet实现的解释器程序的性能仅次于Stackless Python,大致比Stackless Python慢一倍,比其他方案快接近一个数量级。因此基于gevent(封装了greenlet)的并发程序会有挺好的性能优势。
具体说明下gevent(非阻塞异步IO)。,“Gevent是一种基于解释器的Python网络库,它用到Greenlet提供的,封装了libevent风波循环的高层同步API。”
从实际的编程疗效来看,协程模型确实表现非常好,运行结果的可控性显著强了不少, gevent库的封装易用性极强。
数据储存本身设计的技术就十分多,作为小菜不敢乱说,但是工作还是有一些小经验是可以分享的。
前提:使用关系数据库,测试中选择的是mysql,其他类似sqlite,SqlServer思路上没有区别。
当我们进行数据储存时,目的就是降低与数据库的交互操作,这样可以增强性能。通常情况下,每当一个URL节点被读取,就进行一次数据储存,对于这样的逻辑进行无限循环。其实这样的性能体验是十分差的,存储速率特别慢。
进阶做法,为了减轻与数据库的交互次数,每次与数据库交互从之前传送1个节点弄成传送10个节点,到传送100个节点内容,这样效率变有了10倍至100倍的提高,在实际应用中,效果是非常好的。:D
爬虫模型
目前这个爬虫模型如上图,调度模块是核心模块。调度模块分别与下载模块,析取模块,存储模块共享三个队列,下载模块与析取模块共享一个队列。数据传递方向如图示。
Python库大全
采集交流 • 优采云 发表了文章 • 0 个评论 • 329 次浏览 • 2020-04-05 11:09
urlib -网络库(stdlib)。requests -网络库。
grab -网络库(基于pycurl)。pycurl -网络库(绑定libcurl)
ullib3 - Python HTTP库,安全连接池、支持文件post、可用性高。httplib2一网络库。
RoboBrowser -一个简单的、极具Python风格的Python库,无需独立的浏览器即可浏览网页。
MechanicalSoup一个与网站自动交互Python库。
mechanize -有状态、可编程的Web浏览库。socket -底层网路插口(stdlib)。
Unirest for Python - Unirest是一套可用于 多种语言的轻量级的HTTP库。
hyper - Python的HTTP/2客户端。
PySocks - SocksiPy更新并积极维护的版本,包括错误修补和一些其他的特点。作为socket模块的直接替换。
网络爬虫框架
grab -网络爬虫框架(基 于pycur/multicur)。
scrapy -网络爬虫框架(基 于twisted), 不支持Python3。
pyspider -一个强悍的爬虫系统。cola-一个分布式爬虫框架。其他
portia -基于Scrapy的可视化爬虫。
restkit - Python的HTTP资源工具包。它可以使你轻松地访问HTTP资源,并围绕它完善的对象。
demiurge -基于PyQuery的爬虫微框架。HTML/XML解析器
lxml - C语言编撰高效HTML/ XML处理库。支持XPath。
cssselect -解析DOM树和CSS选择器。pyquery -解析DOM树和jQuery选择器。
BeautIFulSoup -低效HTML/ XML处理库,纯Python实现。
html5lib -根据WHATWG规范生成HTML/ XML文档的DOM。该规范被用在现今所有的浏览器上。
feedparser一解析RSS/ATOM feeds。
MarkupSafe -为XML/HTML/XHTML提供了安全通配符的字符串。
xmltodict-一个可以使你在处理XML时觉得象在处理JSON一样的Python模块。
xhtml2pdf -将HTML/CSS转换为PDF。
untangle -轻松实现将XML文件转换为Python对象。清理
Bleach -清理HTML (需要html5lib)。sanitize -为混乱的数据世界带来端午。文本处理
用于解析和操作简单文本的库。
difflib - (Python标准库) 帮助进行差异化比较。
Levenshtein一快速估算L evenshtein距离和字符串相似度。
fuzzywuzzy -模糊字符串匹配。esmre -正则表达式加速器。
ftfy-自动整理Unicode文本,减少碎片化。.自然语言处理
处理人类语言问题的库。
NLTK -编写Python程序来处理人类语言数据的最好平台。
Pattern一Python的网路挖掘模块。他有自然语言处理工具,机器学习以及其它。
TextBlob -为深入自然语言处理任务提供了一致的API。是基于NLTK以及Pattern的巨人之肩上发展的。
jieba-中文动词工具。
SnowNLP -中文文本处理库。
loso-另一个英文分词库。浏览器自动化与仿真
selenium一自动化真正的浏览器(Chrome浏览器,火狐浏览器,Opera浏览器, IE浏览器)。
Ghost.py -对PyQt的webkit的封装(需 要PyQT)。
Spynner -对PyQt的webkit的封装(需要PyQT),
Splinter -通用API浏览器模拟器(seleniumweb驱动,Django顾客 端,Zope) 。多重处理
threading - Python标准库的线程运行。对于I/0密集型任务太有效。对于CPU绑定的任务没用,因为python GIL。
multiprocessing -标准的Python库运行多进程。
celery -基于分布式消息传递的异步任务队列/作业队列。;
concurrent-futures一concurrent-futures模块为调用异步执行提供了一个高层次的插口。
异步网路编程库
asyncio- (在Python 3.4 +版本以上的Python标准库)异步I/O, 时间循环,协同程序和任务。
Twisted一基于风波驱动的网路引|擎框架。Tornado -一个网路框架和异步网路库。pulsar - Python风波驱动的并发框架。
diesel - Python的基于红色风波的I/O框架。gevent -一个使用greenlet的基于解释器的Python网路库。
eventlet -有WSGI支持的异步框架。
Tomorrow -异步代码的奇妙的修饰句型。队列
celery -基于分布式消息传递的异步任务队列/作业队列。
huey -小型多线程任务队列。
mrq - Mr. Queue -使用redis & Gevent的Python分布式工作任务队列。
RQ -基于Redis的轻量级任务队列管理器。simpleq--个简单的,可无限扩充,基于Amazon SQS的队列。
python-geARMan一Gearman的Python API。
云计算
picloud -云端执行Python代码。
dominoup.com -云端执行R,Python和matlab代码网页内容提取
提取网页内容的库。
HTML页面的文本和元数据
newspaper -用Python进行新闻提取、文章提I取和内容策展。
html2text -将HTML转为Markdown格式文本。
python-goose一HTML内容/文章提取器。lassie -人性化的网页内容检索工具WebSocket
用于WebSocket的库。
Crossbar -开源的应用消息传递路由器
(Python实现的用于Autobahn的WebSocket和WAMP)。
AutobahnPython -提供了WebSocket合同和WAMP合同的Python实现而且开源。
WebSocket-for-Python - Python 2和3以及PyPy的WebSocket客户端和服务器库。DNS解析
dnsyo -在全球超过1 500个的DNS服务器.上检测你的DNS。
pycares - c-ares的插口。c-ares是 进行DNS恳求和异步名称决议的C语言库。
计算机视觉
SimpleCV -用于照相机、图像处理、特征提取、格式转换的简介,可读性强的插口(基于OpenCV)。
Flask是一个轻量级的Web应用框架,使用Python编撰。基于WerkzeugWSGI工具箱和Jinja2模板引擎。使用BSD授权。
Flask也被称为"microframework" ,因为它使用简单的核心,用extension降低其他功能。Flask没有默认使用的数据库、窗体验证工具。然而,Flask保留了扩增的弹性,可以用Flask-extension加入这种功能: ORM、窗体验证工具、文件上传、各种开放式身分验证技术。
Web2py是一个用Python语言 编写的免费的开源Web框架,旨在敏捷快速的开发Web应用,具有快速、可扩充、安全以及可移植的数据库驱动的应用,遵循LGPLv3开 源合同。
Web2py提供一站式的解决方案,整个开发过程都可以在浏览器上进行,提供了Web版的在线开发,HTML模版编撰,静态文件的上传,数据库的编撰的功能。其它的还有日志功能,以及一个自动化的admin插口。
4.Tornado
Tornado即是一.个Web server(对此本文不作阐述)python分布式爬虫框架,同时又是一个类web.py的micro-framework,作为框架Tornado的思想主要来源于Web.py,大家在Web.py的网站首页也可以见到Tornado的大鳄Bret Taylor的那么一段话(他这儿说的FriendFeed用的框架跟Tornado可以看作是一个东西) :
"[web.pyinspired the] Web framework we useat FriendFeed [and] the webapp frameworkthat ships with App Engin...”
因为有这层关系,后面不再单独讨论Tornado。
5.CherryPy
CherryPy是一种用于Python的、简单而特别有用的Web框架,其主要作用是以尽可能少的操作将Web服务器与Python代码联接,其功能包括外置的剖析功能、灵活的插件系统以及一次运行多个HTTP服务器的功能python分布式爬虫框架,可与运行在最新版本的Python、Jython、 Android上。 查看全部
urlib -网络库(stdlib)。requests -网络库。
grab -网络库(基于pycurl)。pycurl -网络库(绑定libcurl)
ullib3 - Python HTTP库,安全连接池、支持文件post、可用性高。httplib2一网络库。
RoboBrowser -一个简单的、极具Python风格的Python库,无需独立的浏览器即可浏览网页。
MechanicalSoup一个与网站自动交互Python库。
mechanize -有状态、可编程的Web浏览库。socket -底层网路插口(stdlib)。
Unirest for Python - Unirest是一套可用于 多种语言的轻量级的HTTP库。
hyper - Python的HTTP/2客户端。
PySocks - SocksiPy更新并积极维护的版本,包括错误修补和一些其他的特点。作为socket模块的直接替换。
网络爬虫框架
grab -网络爬虫框架(基 于pycur/multicur)。
scrapy -网络爬虫框架(基 于twisted), 不支持Python3。
pyspider -一个强悍的爬虫系统。cola-一个分布式爬虫框架。其他
portia -基于Scrapy的可视化爬虫。
restkit - Python的HTTP资源工具包。它可以使你轻松地访问HTTP资源,并围绕它完善的对象。
demiurge -基于PyQuery的爬虫微框架。HTML/XML解析器
lxml - C语言编撰高效HTML/ XML处理库。支持XPath。
cssselect -解析DOM树和CSS选择器。pyquery -解析DOM树和jQuery选择器。
BeautIFulSoup -低效HTML/ XML处理库,纯Python实现。
html5lib -根据WHATWG规范生成HTML/ XML文档的DOM。该规范被用在现今所有的浏览器上。
feedparser一解析RSS/ATOM feeds。
MarkupSafe -为XML/HTML/XHTML提供了安全通配符的字符串。
xmltodict-一个可以使你在处理XML时觉得象在处理JSON一样的Python模块。
xhtml2pdf -将HTML/CSS转换为PDF。
untangle -轻松实现将XML文件转换为Python对象。清理
Bleach -清理HTML (需要html5lib)。sanitize -为混乱的数据世界带来端午。文本处理
用于解析和操作简单文本的库。
difflib - (Python标准库) 帮助进行差异化比较。
Levenshtein一快速估算L evenshtein距离和字符串相似度。
fuzzywuzzy -模糊字符串匹配。esmre -正则表达式加速器。
ftfy-自动整理Unicode文本,减少碎片化。.自然语言处理
处理人类语言问题的库。
NLTK -编写Python程序来处理人类语言数据的最好平台。
Pattern一Python的网路挖掘模块。他有自然语言处理工具,机器学习以及其它。
TextBlob -为深入自然语言处理任务提供了一致的API。是基于NLTK以及Pattern的巨人之肩上发展的。
jieba-中文动词工具。
SnowNLP -中文文本处理库。
loso-另一个英文分词库。浏览器自动化与仿真
selenium一自动化真正的浏览器(Chrome浏览器,火狐浏览器,Opera浏览器, IE浏览器)。
Ghost.py -对PyQt的webkit的封装(需 要PyQT)。
Spynner -对PyQt的webkit的封装(需要PyQT),
Splinter -通用API浏览器模拟器(seleniumweb驱动,Django顾客 端,Zope) 。多重处理
threading - Python标准库的线程运行。对于I/0密集型任务太有效。对于CPU绑定的任务没用,因为python GIL。
multiprocessing -标准的Python库运行多进程。
celery -基于分布式消息传递的异步任务队列/作业队列。;
concurrent-futures一concurrent-futures模块为调用异步执行提供了一个高层次的插口。
异步网路编程库
asyncio- (在Python 3.4 +版本以上的Python标准库)异步I/O, 时间循环,协同程序和任务。
Twisted一基于风波驱动的网路引|擎框架。Tornado -一个网路框架和异步网路库。pulsar - Python风波驱动的并发框架。
diesel - Python的基于红色风波的I/O框架。gevent -一个使用greenlet的基于解释器的Python网路库。
eventlet -有WSGI支持的异步框架。
Tomorrow -异步代码的奇妙的修饰句型。队列
celery -基于分布式消息传递的异步任务队列/作业队列。
huey -小型多线程任务队列。
mrq - Mr. Queue -使用redis & Gevent的Python分布式工作任务队列。
RQ -基于Redis的轻量级任务队列管理器。simpleq--个简单的,可无限扩充,基于Amazon SQS的队列。
python-geARMan一Gearman的Python API。
云计算
picloud -云端执行Python代码。
dominoup.com -云端执行R,Python和matlab代码网页内容提取
提取网页内容的库。
HTML页面的文本和元数据
newspaper -用Python进行新闻提取、文章提I取和内容策展。
html2text -将HTML转为Markdown格式文本。
python-goose一HTML内容/文章提取器。lassie -人性化的网页内容检索工具WebSocket
用于WebSocket的库。
Crossbar -开源的应用消息传递路由器
(Python实现的用于Autobahn的WebSocket和WAMP)。
AutobahnPython -提供了WebSocket合同和WAMP合同的Python实现而且开源。
WebSocket-for-Python - Python 2和3以及PyPy的WebSocket客户端和服务器库。DNS解析
dnsyo -在全球超过1 500个的DNS服务器.上检测你的DNS。
pycares - c-ares的插口。c-ares是 进行DNS恳求和异步名称决议的C语言库。
计算机视觉
SimpleCV -用于照相机、图像处理、特征提取、格式转换的简介,可读性强的插口(基于OpenCV)。
Flask是一个轻量级的Web应用框架,使用Python编撰。基于WerkzeugWSGI工具箱和Jinja2模板引擎。使用BSD授权。
Flask也被称为"microframework" ,因为它使用简单的核心,用extension降低其他功能。Flask没有默认使用的数据库、窗体验证工具。然而,Flask保留了扩增的弹性,可以用Flask-extension加入这种功能: ORM、窗体验证工具、文件上传、各种开放式身分验证技术。
Web2py是一个用Python语言 编写的免费的开源Web框架,旨在敏捷快速的开发Web应用,具有快速、可扩充、安全以及可移植的数据库驱动的应用,遵循LGPLv3开 源合同。
Web2py提供一站式的解决方案,整个开发过程都可以在浏览器上进行,提供了Web版的在线开发,HTML模版编撰,静态文件的上传,数据库的编撰的功能。其它的还有日志功能,以及一个自动化的admin插口。
4.Tornado
Tornado即是一.个Web server(对此本文不作阐述)python分布式爬虫框架,同时又是一个类web.py的micro-framework,作为框架Tornado的思想主要来源于Web.py,大家在Web.py的网站首页也可以见到Tornado的大鳄Bret Taylor的那么一段话(他这儿说的FriendFeed用的框架跟Tornado可以看作是一个东西) :
"[web.pyinspired the] Web framework we useat FriendFeed [and] the webapp frameworkthat ships with App Engin...”
因为有这层关系,后面不再单独讨论Tornado。
5.CherryPy
CherryPy是一种用于Python的、简单而特别有用的Web框架,其主要作用是以尽可能少的操作将Web服务器与Python代码联接,其功能包括外置的剖析功能、灵活的插件系统以及一次运行多个HTTP服务器的功能python分布式爬虫框架,可与运行在最新版本的Python、Jython、 Android上。

