
php 抓取网页ajax数据
php 抓取网页ajax数据( 什么是Ajax国内翻译常为“阿贾克斯”和阿贾克斯同音同音)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-14 12:17
什么是Ajax国内翻译常为“阿贾克斯”和阿贾克斯同音同音)
Ajax+php数据交互及页面局部刷新详解
时间:2019-03-30
本文章为大家介绍了Ajax+php数据交互和页面部分刷新的详细实现,主要包括Ajax+php数据交互和页面部分刷新的实现。使用实例,应用技巧,基本知识点总结和注意事项,有一定的参考价值,有需要的朋友可以参考。
什么是阿贾克斯?
国内翻译往往与“阿贾克斯”和阿贾克斯足球队相同。AJAX 是一种用于创建快速动态网页的技术。它不是一种新语言,而是一种使用现有标准的新方法。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新,从而可以在不重新加载整个网页的情况下更新网页的某个部分。
XMLHttpRequest 是 AJAX 的基础,用于与服务器交换数据。所有现代浏览器都支持 XMLHttpRequest 对象(IE5 和 IE6 使用 ActiveXObject)
下面文章主要介绍使用ajax与php数据交互,部分刷新页面相关内容。话不多说,一起来看看详细介绍:
一、 语法介绍
1.1 Ajax 基本语法
$.ajax({
type: "post", //数据提交方式(post/get)
url: "http://xxx/test/demo.php", //提交到的url
data: {username:username,password:password},//提交的数据
dataType: "json", //返回的数据类型格式
success: function(msg){
...//返回成功的回调函数
},
error:function(msg){
...//返回失败的回调函数
}
});
1.2 php接收方法
2.2 在demo.html中添加如下js代码
$(function(){
$('#sub').click(function(){
var username=$('#username').val();
var password=$('#password').val();
$.ajax({
type: "post",
url: "http://xxx/test/demo.php",
data: {username:username,password:password}, //提交到demo.php的数据
dataType: "json", //回调函数接收数据的数据格式
success: function(msg){
$('#text').empty(); //清空Text里面的所有内容
var data='';
if(msg!=''){
data = eval("("+msg+")"); //将返回的json数据进行解析,并赋给data
}
$('#text').html("用户名为:" + data.username + ",密码为:" + data.password); //在#text中输出
console.log(data); //控制台输出
},
error:function(msg){
console.log(msg);
}
});
});
})
2.3 php结束代码demo.php 查看全部
php 抓取网页ajax数据(
什么是Ajax国内翻译常为“阿贾克斯”和阿贾克斯同音同音)
Ajax+php数据交互及页面局部刷新详解
时间:2019-03-30
本文章为大家介绍了Ajax+php数据交互和页面部分刷新的详细实现,主要包括Ajax+php数据交互和页面部分刷新的实现。使用实例,应用技巧,基本知识点总结和注意事项,有一定的参考价值,有需要的朋友可以参考。
什么是阿贾克斯?
国内翻译往往与“阿贾克斯”和阿贾克斯足球队相同。AJAX 是一种用于创建快速动态网页的技术。它不是一种新语言,而是一种使用现有标准的新方法。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新,从而可以在不重新加载整个网页的情况下更新网页的某个部分。
XMLHttpRequest 是 AJAX 的基础,用于与服务器交换数据。所有现代浏览器都支持 XMLHttpRequest 对象(IE5 和 IE6 使用 ActiveXObject)
下面文章主要介绍使用ajax与php数据交互,部分刷新页面相关内容。话不多说,一起来看看详细介绍:
一、 语法介绍
1.1 Ajax 基本语法
$.ajax({
type: "post", //数据提交方式(post/get)
url: "http://xxx/test/demo.php", //提交到的url
data: {username:username,password:password},//提交的数据
dataType: "json", //返回的数据类型格式
success: function(msg){
...//返回成功的回调函数
},
error:function(msg){
...//返回失败的回调函数
}
});
1.2 php接收方法
2.2 在demo.html中添加如下js代码
$(function(){
$('#sub').click(function(){
var username=$('#username').val();
var password=$('#password').val();
$.ajax({
type: "post",
url: "http://xxx/test/demo.php",
data: {username:username,password:password}, //提交到demo.php的数据
dataType: "json", //回调函数接收数据的数据格式
success: function(msg){
$('#text').empty(); //清空Text里面的所有内容
var data='';
if(msg!=''){
data = eval("("+msg+")"); //将返回的json数据进行解析,并赋给data
}
$('#text').html("用户名为:" + data.username + ",密码为:" + data.password); //在#text中输出
console.log(data); //控制台输出
},
error:function(msg){
console.log(msg);
}
});
});
})
2.3 php结束代码demo.php
php 抓取网页ajax数据(php抓取网页ajax数据库文件夹多文件的formdata.php其他第三方库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-10 05:07
php抓取网页ajax数据库数据库文件夹多文件的formdata.php其他第三方库
你可以试试js库。flash的用不了多少中文,中文的flash很少很贵的,网上能找到基于flash的网页的mockinfo模拟登录的js,自己改写一下,也能用。
php的能够支持flash是理想的状态,flash现在的技术已经很完善了,有很多js代码无法实现的功能,但php代码其实也不是不能实现的功能,这个需要参考php官方的示例程序,每个不同的业务需求来对比在调整flash.js代码.
可以参考下这个免费的wordpress爬虫开发框架。.php文件也能使用。可以更改flash的模板,在.js文件中声明或者定义你需要什么数据的对应代码即可。参考:.比如需要显示cookie信息,就在.php文件加上flash.getcss('css').cookiejs,再比如需要爬下某些网站的商品详情信息,或者正常的页面商品信息,参考这个.php文件就可以。
试着自己写过,发现写不下去。如果题主想要的文件,
php-flash-cookie-script或者-php-flash-cookie-script文件,复制后再次加载就行了。
不知道,无从知道。但是我知道,肯定能用更加先进的web框架,例如x-flash,会有很大不同。 查看全部
php 抓取网页ajax数据(php抓取网页ajax数据库文件夹多文件的formdata.php其他第三方库)
php抓取网页ajax数据库数据库文件夹多文件的formdata.php其他第三方库
你可以试试js库。flash的用不了多少中文,中文的flash很少很贵的,网上能找到基于flash的网页的mockinfo模拟登录的js,自己改写一下,也能用。
php的能够支持flash是理想的状态,flash现在的技术已经很完善了,有很多js代码无法实现的功能,但php代码其实也不是不能实现的功能,这个需要参考php官方的示例程序,每个不同的业务需求来对比在调整flash.js代码.
可以参考下这个免费的wordpress爬虫开发框架。.php文件也能使用。可以更改flash的模板,在.js文件中声明或者定义你需要什么数据的对应代码即可。参考:.比如需要显示cookie信息,就在.php文件加上flash.getcss('css').cookiejs,再比如需要爬下某些网站的商品详情信息,或者正常的页面商品信息,参考这个.php文件就可以。
试着自己写过,发现写不下去。如果题主想要的文件,
php-flash-cookie-script或者-php-flash-cookie-script文件,复制后再次加载就行了。
不知道,无从知道。但是我知道,肯定能用更加先进的web框架,例如x-flash,会有很大不同。
php 抓取网页ajax数据(本文远程抓取数据的功能-本文实例讲述了。。 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-11-09 04:02
)
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
今天,我将做一个远程数据捕获功能。记住jquery可以用ajax远程捕获,但是不能跨域。我在网上搜索了很多。但是我觉得是一个综合性的问题,所以我觉得对于一个简单的问题来说稍微复杂一些,但至少现在已经解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post向服务器后端发送数据,由后端的PHP代码远程获取,存入数据库ajax返回数据给前台,前台使用JS接收数据并显示出来。
//远程抓取获取数据
$("#update_ac").click(function() {
$username = $("#username").text();
$("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){
$(this).html(" ");
});
$.post("update_ac/username/"+$username,{},function($data){
json = eval("(" + $data + ")");
$("#Submit").html(json.data.Submit);
$("#AC").html(json.data.AC);
$("#solved,#solved2,#solved3").html(json.data.solved);
$("#rank").html(json.data.rank);
}
),"json";
});
上面jquery代码四楼说的还算清楚,但是让我纠结的是json数据的接收
json = eval("(" + $data + ")");
//eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这还是在前台。跨域抓取是通过PHP扩展simple_html_dom完成的(不知道的可以上网搜一下,基于PHP5开发的)
抓取远程页面到本地。
import("@.ORG.simple_html_dom");
//thinkphp内导入扩展,你要把网上下载的代码改名为simple_html_dom.class.php放到APPNAME\Lib\ORG的目录下面
$html = file_get_html('http://openoj.awaysoft.com/JudgeOnline/userinfo.php?user='.$username); //远程抓取了
$ret = $html->find('center',0)->plaintext; //返回数据了。
以上代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后使用正则表达式过滤需要的数据。下面是渲染图
查看全部
php 抓取网页ajax数据(本文远程抓取数据的功能-本文实例讲述了。。
)
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
今天,我将做一个远程数据捕获功能。记住jquery可以用ajax远程捕获,但是不能跨域。我在网上搜索了很多。但是我觉得是一个综合性的问题,所以我觉得对于一个简单的问题来说稍微复杂一些,但至少现在已经解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post向服务器后端发送数据,由后端的PHP代码远程获取,存入数据库ajax返回数据给前台,前台使用JS接收数据并显示出来。
//远程抓取获取数据
$("#update_ac").click(function() {
$username = $("#username").text();
$("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){
$(this).html(" ");
});
$.post("update_ac/username/"+$username,{},function($data){
json = eval("(" + $data + ")");
$("#Submit").html(json.data.Submit);
$("#AC").html(json.data.AC);
$("#solved,#solved2,#solved3").html(json.data.solved);
$("#rank").html(json.data.rank);
}
),"json";
});
上面jquery代码四楼说的还算清楚,但是让我纠结的是json数据的接收
json = eval("(" + $data + ")");
//eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这还是在前台。跨域抓取是通过PHP扩展simple_html_dom完成的(不知道的可以上网搜一下,基于PHP5开发的)
抓取远程页面到本地。
import("@.ORG.simple_html_dom");
//thinkphp内导入扩展,你要把网上下载的代码改名为simple_html_dom.class.php放到APPNAME\Lib\ORG的目录下面
$html = file_get_html('http://openoj.awaysoft.com/JudgeOnline/userinfo.php?user='.$username); //远程抓取了
$ret = $html->find('center',0)->plaintext; //返回数据了。
以上代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后使用正则表达式过滤需要的数据。下面是渲染图

php 抓取网页ajax数据(,结合jQuery的ajax实现跨域抓取数据的相关操作技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-11-05 14:04
本文文章主要介绍了jquery+thinkphp实现跨域数据捕获的方法,并结合实例形式分析thinkPHP结合jQuery的ajax实现跨域数据捕获的相关操作技巧。有需要的朋友可以参考以下
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
今天,我将做一个远程数据捕获功能。记住jquery可以用ajax远程捕获,但是不能跨域。我在网上搜索了很多。但是我觉得是一个综合性的问题,所以我觉得对于一个简单的问题来说稍微复杂一些,但至少现在已经解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post向服务器后端发送数据,由后端的PHP代码远程获取,存入数据库ajax返回数据给前台,前台使用JS接收数据并显示出来。
//远程抓取获取数据 $("#update_ac").click(function() { $username = $("#username").text(); $("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){ $(this).html(" "); }); $.post("update_ac/username/"+$username,{},function($data){ json = eval("(" + $data + ")"); $("#Submit").html(json.data.Submit); $("#AC").html(json.data.AC); $("#solved,#solved2,#solved3").html(json.data.solved); $("#rank").html(json.data.rank); } ),"json"; });
上面jquery代码四楼说的还算清楚,但是让我纠结的是json数据的接收
json = eval("(" + $data + ")"); //eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这还是前台。跨域抓取是通过PHP扩展simple_html_dom完成的(不知道的可以上网搜一下,基于PHP5开发的)
抓取远程页面到本地。
以上代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后使用正则表达式过滤需要的数据。下面是渲染图
对thinkPHP相关内容更感兴趣的读者可以查看本站主题:《》、《ThinkPHP模板操作技巧总结》、《ThinkPHP常用方法总结》、《Smarty模板介绍基础教程》、《总结》 PHP模板技术”。
我希望本文对您基于 ThinkPHP 框架的 PHP 编程有所帮助。
以上就是jquery+thinkphp实现跨域数据抓取的方法的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
php 抓取网页ajax数据(,结合jQuery的ajax实现跨域抓取数据的相关操作技巧)
本文文章主要介绍了jquery+thinkphp实现跨域数据捕获的方法,并结合实例形式分析thinkPHP结合jQuery的ajax实现跨域数据捕获的相关操作技巧。有需要的朋友可以参考以下
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
今天,我将做一个远程数据捕获功能。记住jquery可以用ajax远程捕获,但是不能跨域。我在网上搜索了很多。但是我觉得是一个综合性的问题,所以我觉得对于一个简单的问题来说稍微复杂一些,但至少现在已经解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post向服务器后端发送数据,由后端的PHP代码远程获取,存入数据库ajax返回数据给前台,前台使用JS接收数据并显示出来。
//远程抓取获取数据 $("#update_ac").click(function() { $username = $("#username").text(); $("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){ $(this).html(" "); }); $.post("update_ac/username/"+$username,{},function($data){ json = eval("(" + $data + ")"); $("#Submit").html(json.data.Submit); $("#AC").html(json.data.AC); $("#solved,#solved2,#solved3").html(json.data.solved); $("#rank").html(json.data.rank); } ),"json"; });
上面jquery代码四楼说的还算清楚,但是让我纠结的是json数据的接收
json = eval("(" + $data + ")"); //eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这还是前台。跨域抓取是通过PHP扩展simple_html_dom完成的(不知道的可以上网搜一下,基于PHP5开发的)
抓取远程页面到本地。
以上代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后使用正则表达式过滤需要的数据。下面是渲染图

对thinkPHP相关内容更感兴趣的读者可以查看本站主题:《》、《ThinkPHP模板操作技巧总结》、《ThinkPHP常用方法总结》、《Smarty模板介绍基础教程》、《总结》 PHP模板技术”。
我希望本文对您基于 ThinkPHP 框架的 PHP 编程有所帮助。
以上就是jquery+thinkphp实现跨域数据抓取的方法的详细内容。更多详情请关注其他相关html中文网站文章!
php 抓取网页ajax数据( 这是-typecraping数据,发现问题元素都选择好了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-11-03 21:04
这是-typecraping数据,发现问题元素都选择好了)
这是简单数据分析系列文章的第十篇。
原文首发于Blog Garden: Simple Data Analysis 10。
**友情提示:**本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从体验。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们动手的网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容是精华帖的标题、回复者和批准数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据数量控制items数量的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素都选好了,我们沿着Sitemap 知乎_top_answers -> Scrape -> Start craping抓取数据的路径,等了十多秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获哪些数据?怎么全都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
**1.** 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
**2.** 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
**3.** 我们再点一下标题,我们会发现会跳转到Elements子面板,里面有一些色彩斑斓的看不懂的代码
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑,它们是网页中的一个骨架,并提供一些排版功能。如果你平时用markdown写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']这个匹配规则是怎么回事。
首先,这是一个树状结构:
上面这句话是从视觉上分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
如何快速成为数据分析师?
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在这个标题的代码中,缺少名为 div 属性的标签 itemprop='知乎:question' !结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题时,无论标题的嵌套关系如何变化,总会有一个标签保持不变,即包裹在最外层的h2标签,属性名class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就可以完美匹配标题内容了?
逻辑上理清了关系,我们如何使用Web Scraper?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们点击P键两次匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape进行数据抓取,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据完成的很快,但是匹配元素需要很多时间。
这间接说明了知乎this网站从代码上分析,写的还是比较烂的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小规模的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再大规模增加正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。 查看全部
php 抓取网页ajax数据(
这是-typecraping数据,发现问题元素都选择好了)
这是简单数据分析系列文章的第十篇。
原文首发于Blog Garden: Simple Data Analysis 10。
**友情提示:**本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从体验。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们动手的网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容是精华帖的标题、回复者和批准数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据数量控制items数量的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素都选好了,我们沿着Sitemap 知乎_top_answers -> Scrape -> Start craping抓取数据的路径,等了十多秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获哪些数据?怎么全都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
**1.** 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
**2.** 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
**3.** 我们再点一下标题,我们会发现会跳转到Elements子面板,里面有一些色彩斑斓的看不懂的代码
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑,它们是网页中的一个骨架,并提供一些排版功能。如果你平时用markdown写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']这个匹配规则是怎么回事。
首先,这是一个树状结构:
上面这句话是从视觉上分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
如何快速成为数据分析师?
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在这个标题的代码中,缺少名为 div 属性的标签 itemprop='知乎:question' !结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题时,无论标题的嵌套关系如何变化,总会有一个标签保持不变,即包裹在最外层的h2标签,属性名class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就可以完美匹配标题内容了?
逻辑上理清了关系,我们如何使用Web Scraper?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们点击P键两次匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape进行数据抓取,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据完成的很快,但是匹配元素需要很多时间。
这间接说明了知乎this网站从代码上分析,写的还是比较烂的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小规模的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再大规模增加正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。
php 抓取网页ajax数据(抓ajax异步内容页面和抓普通的页面区别。 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-11-01 15:22
)
其实抓取ajax异步内容页面和抓取普通页面没有太大区别。 Ajax 只是发出一个异步 http 请求。用类似firebug的工具,找到请求的后端服务url和传参值,然后抓取url传参即可。
使用 firebug 的网络工具
如果抓取一个页面,内容中没有显示的数据是一堆js代码。
代码
$cookie_file=tempnam('./temp','cookie');
$ch = curl_init();
$url1 = "http://www.cdut.edu.cn/default.html";
curl_setopt($ch,curlopt_url,$url1);
curl_setopt($ch,curlopt_http_version,curl_http_version_1_1);
curl_setopt($ch,curlopt_header,0);
curl_setopt($ch,curlopt_returntransfer,1);
curl_setopt($ch,curlopt_followlocation,1);
curl_setopt($ch, curlopt_encoding ,'gzip'); //加入gzip解析
//设置连接结束后保存cookie信息的文件
curl_setopt($ch,curlopt_cookiejar,$cookie_file);
$content=curl_exec($ch);
curl_close($ch);
$ch3 = curl_init();
$url3 = "http://www.cdut.edu.cn/xww/dwr ... 3B%3B
$curlpost = "callcount=1&page=/xww/type/1000020118.html&httpsessionid=12a9b726e6a2d4d3b09de7952b2f282c&scriptsessionid=295315b4b4141b09da888d3a3adb8faa658&c0-scriptname=portalajax&c0-methodname=getnewsxml&c0-id=0&c0-param0=string:10000201&c0-param1=string:1000020118&c0-param2=string:news_&c0-param3=number:5969&c0-param4=number:1&c0-param5=null:null&c0-param6=null:null&batchid=0";
curl_setopt($ch3,curlopt_url,$url3);
curl_setopt($ch3,curlopt_post,1);
curl_setopt($ch3,curlopt_postfields,$curlpost);
//设置连接结束后保存cookie信息的文件
curl_setopt($ch3,curlopt_cookiefile,$cookie_file);
$content1=curl_exec($ch3);
curl_close($ch3); 查看全部
php 抓取网页ajax数据(抓ajax异步内容页面和抓普通的页面区别。
)
其实抓取ajax异步内容页面和抓取普通页面没有太大区别。 Ajax 只是发出一个异步 http 请求。用类似firebug的工具,找到请求的后端服务url和传参值,然后抓取url传参即可。
使用 firebug 的网络工具

如果抓取一个页面,内容中没有显示的数据是一堆js代码。

代码
$cookie_file=tempnam('./temp','cookie');
$ch = curl_init();
$url1 = "http://www.cdut.edu.cn/default.html";
curl_setopt($ch,curlopt_url,$url1);
curl_setopt($ch,curlopt_http_version,curl_http_version_1_1);
curl_setopt($ch,curlopt_header,0);
curl_setopt($ch,curlopt_returntransfer,1);
curl_setopt($ch,curlopt_followlocation,1);
curl_setopt($ch, curlopt_encoding ,'gzip'); //加入gzip解析
//设置连接结束后保存cookie信息的文件
curl_setopt($ch,curlopt_cookiejar,$cookie_file);
$content=curl_exec($ch);
curl_close($ch);
$ch3 = curl_init();
$url3 = "http://www.cdut.edu.cn/xww/dwr ... 3B%3B
$curlpost = "callcount=1&page=/xww/type/1000020118.html&httpsessionid=12a9b726e6a2d4d3b09de7952b2f282c&scriptsessionid=295315b4b4141b09da888d3a3adb8faa658&c0-scriptname=portalajax&c0-methodname=getnewsxml&c0-id=0&c0-param0=string:10000201&c0-param1=string:1000020118&c0-param2=string:news_&c0-param3=number:5969&c0-param4=number:1&c0-param5=null:null&c0-param6=null:null&batchid=0";
curl_setopt($ch3,curlopt_url,$url3);
curl_setopt($ch3,curlopt_post,1);
curl_setopt($ch3,curlopt_postfields,$curlpost);
//设置连接结束后保存cookie信息的文件
curl_setopt($ch3,curlopt_cookiefile,$cookie_file);
$content1=curl_exec($ch3);
curl_close($ch3);
php 抓取网页ajax数据(PHP+Ajax实现的无刷新功能,结合实例形式分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-10-28 18:03
本文文章主要介绍了PHP+Ajax实现的非刷新分页功能,分析了php+ajax通过pdo操作类读取数据库和分页显示通过pdo操作类的相关实现技巧,以及为读者提供演示源代码。下载参考,有需要的朋友可以参考
本文介绍了PHP+Ajax实现的非刷新分页功能。分享给大家,供大家参考,如下:
注:本文用到的部分库可以在前面的文章中找到源码,我会在文中注明链接,为了缩短文章的篇幅,以及由此带来的阅读不便对此,请谅解。
本文讲解Ajax如何实现非刷新分页、实现原理、代码展示、代码下载。
这里需要说明一些知识:
1、Ajax不刷新页面的好处:提供良好的客户体验,通过Ajax从数据库中获取数据并在后台展示,消除等待页面加载的空白状态;
2、那么,Ajax 非刷新页面是否运行在动态页面(.php)上?还是静态页面(.html/.htm/.shtml)?答案是:静态页面;
3、 实现原理:通过前端JS脚本程序和Ajax结合获取动态页面返回的数据,并显示出来。
好的,让我们解释一下下面的代码:
由于它在静态页面上运行,我们首先创建一个静态 HTML 页面。index.html 的代码清单如下。
索引.html
Ajax 实现无刷新页面 body { font-size:12px; } 数据加载中...
在代码清单中,我们加载了一个Ajax类库,可以在文章中找到(附上使用方法)
在这个静态页面中,只显示了一个“Data Loading...”,并没有数据。这时候我们就需要一个JS脚本,通过ajax从数据库中获取数据。JS脚本如下:
仔细阅读上面的代码,你会发现以下现象:
1、setPage(pageNum) 是一个JS函数接口,用于从数据库中提取数据;
2、ajax通过article.php文件获取数据;
3、article.php?page=xx,其中xx是要获取的页码数据,
setPage(1): 是获取第一页数据;
setPage(2): 是获取第2页的数据;
setPage(100): 是获取第100页数据;
...
那么,如何从article.php文件中获取数据呢?请参阅下面的代码清单。
文章.php
article.php中连接的数据是之前从华强电子网文章抓取的信息数据。由于数据比较大,将article.sql文件附在代码包下载下来供大家测试。
静态页面index.html显示的数据是article.php文件中echo的代码。
代码文件中的config.inc.php文件主要定义了一些常量,如:数据库用户名、数据库密码、主机...、数据库连接类库(Db.class.php)和数据库操作类库(Model.php)。 class.php),请参考文章,有使用说明。
程序效果图:
对图标的赌注是关注关注的地方。
这样,Ajax 非刷新分页就完成了。程序中还有一个ajaxPage.class.php,没有说明。其实这个ajaxPage库的用法和一般的分页库是一样的。
即:
$page = new ajaxPage(记录总数, 每页显示数);
详情请下载代码并阅读。 查看全部
php 抓取网页ajax数据(PHP+Ajax实现的无刷新功能,结合实例形式分析)
本文文章主要介绍了PHP+Ajax实现的非刷新分页功能,分析了php+ajax通过pdo操作类读取数据库和分页显示通过pdo操作类的相关实现技巧,以及为读者提供演示源代码。下载参考,有需要的朋友可以参考
本文介绍了PHP+Ajax实现的非刷新分页功能。分享给大家,供大家参考,如下:
注:本文用到的部分库可以在前面的文章中找到源码,我会在文中注明链接,为了缩短文章的篇幅,以及由此带来的阅读不便对此,请谅解。
本文讲解Ajax如何实现非刷新分页、实现原理、代码展示、代码下载。
这里需要说明一些知识:
1、Ajax不刷新页面的好处:提供良好的客户体验,通过Ajax从数据库中获取数据并在后台展示,消除等待页面加载的空白状态;
2、那么,Ajax 非刷新页面是否运行在动态页面(.php)上?还是静态页面(.html/.htm/.shtml)?答案是:静态页面;
3、 实现原理:通过前端JS脚本程序和Ajax结合获取动态页面返回的数据,并显示出来。
好的,让我们解释一下下面的代码:
由于它在静态页面上运行,我们首先创建一个静态 HTML 页面。index.html 的代码清单如下。
索引.html
Ajax 实现无刷新页面 body { font-size:12px; } 数据加载中...
在代码清单中,我们加载了一个Ajax类库,可以在文章中找到(附上使用方法)
在这个静态页面中,只显示了一个“Data Loading...”,并没有数据。这时候我们就需要一个JS脚本,通过ajax从数据库中获取数据。JS脚本如下:
仔细阅读上面的代码,你会发现以下现象:
1、setPage(pageNum) 是一个JS函数接口,用于从数据库中提取数据;
2、ajax通过article.php文件获取数据;
3、article.php?page=xx,其中xx是要获取的页码数据,
setPage(1): 是获取第一页数据;
setPage(2): 是获取第2页的数据;
setPage(100): 是获取第100页数据;
...
那么,如何从article.php文件中获取数据呢?请参阅下面的代码清单。
文章.php
article.php中连接的数据是之前从华强电子网文章抓取的信息数据。由于数据比较大,将article.sql文件附在代码包下载下来供大家测试。
静态页面index.html显示的数据是article.php文件中echo的代码。
代码文件中的config.inc.php文件主要定义了一些常量,如:数据库用户名、数据库密码、主机...、数据库连接类库(Db.class.php)和数据库操作类库(Model.php)。 class.php),请参考文章,有使用说明。
程序效果图:
对图标的赌注是关注关注的地方。

这样,Ajax 非刷新分页就完成了。程序中还有一个ajaxPage.class.php,没有说明。其实这个ajaxPage库的用法和一般的分页库是一样的。
即:
$page = new ajaxPage(记录总数, 每页显示数);
详情请下载代码并阅读。
php 抓取网页ajax数据(本文远程抓取数据的功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-27 18:20
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
今天来做一个远程数据采集功能。记住jquery可以用ajax远程捕获,但是不能跨域。我在网上搜索了很多。但是我觉得是一个综合性的问题,所以我觉得对于一个简单的问题来说稍微复杂一些,但至少现在已经解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post发送数据到服务器后端,由后端的php代码远程获取,存入数据库ajax返回数据给前台,前台使用js接收数据并显示出来。
//远程抓取获取数据
$("#update_ac").click(function() {
$username = $("#username").text();
$("#ac,#rank,#submit,#solved,#solved2,#solved3").ajaxstart(function(){
$(this).html(" ");
});
$.post("update_ac/username/"+$username,{},function($data){
json = eval("(" + $data + ")");
$("#submit").html(json.data.submit);
$("#ac").html(json.data.ac);
$("#solved,#solved2,#solved3").html(json.data.solved);
$("#rank").html(json.data.rank);
}
),"json";
});
上面jquery代码四楼说的还算清楚,但是让我纠结的是json数据的接收
json = eval("(" + $data + ")");
//eval() 函数可计算某个字符串,并执行其中的的 javascript 代码。
其实这还是在前台。跨域爬取用php扩展simple_html_dom完成(不知道的可以上网搜索,基于php5开发的)
抓取远程页面到本地。
import("@.org.simple_html_dom");
//thinkphp内导入扩展,你要把网上下载的代码改名为simple_html_dom.class.php放到appname\lib\org的目录下面
$html = file_get_html('http://openoj.awaysoft.com/judgeonline/userinfo.php?user='.$username); //远程抓取了
$ret = $html->find('center',0)->plaintext; //返回数据了。
以上代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后使用正则表达式过滤需要的数据。下面是渲染图
对thinkphp相关内容更感兴趣的读者可以查看本站专题:《Thinkphp入门教程》、《Thinkphp模板操作技巧汇总》、《Thinkphp常用方法汇总》、《Smarty模板介绍基础教程》和《PHP模板技术总结》》。
希望这篇文章能帮助你设计基于thinkphp框架的php编程。 查看全部
php 抓取网页ajax数据(本文远程抓取数据的功能)
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
今天来做一个远程数据采集功能。记住jquery可以用ajax远程捕获,但是不能跨域。我在网上搜索了很多。但是我觉得是一个综合性的问题,所以我觉得对于一个简单的问题来说稍微复杂一些,但至少现在已经解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post发送数据到服务器后端,由后端的php代码远程获取,存入数据库ajax返回数据给前台,前台使用js接收数据并显示出来。
//远程抓取获取数据
$("#update_ac").click(function() {
$username = $("#username").text();
$("#ac,#rank,#submit,#solved,#solved2,#solved3").ajaxstart(function(){
$(this).html(" ");
});
$.post("update_ac/username/"+$username,{},function($data){
json = eval("(" + $data + ")");
$("#submit").html(json.data.submit);
$("#ac").html(json.data.ac);
$("#solved,#solved2,#solved3").html(json.data.solved);
$("#rank").html(json.data.rank);
}
),"json";
});
上面jquery代码四楼说的还算清楚,但是让我纠结的是json数据的接收
json = eval("(" + $data + ")");
//eval() 函数可计算某个字符串,并执行其中的的 javascript 代码。
其实这还是在前台。跨域爬取用php扩展simple_html_dom完成(不知道的可以上网搜索,基于php5开发的)
抓取远程页面到本地。
import("@.org.simple_html_dom");
//thinkphp内导入扩展,你要把网上下载的代码改名为simple_html_dom.class.php放到appname\lib\org的目录下面
$html = file_get_html('http://openoj.awaysoft.com/judgeonline/userinfo.php?user='.$username); //远程抓取了
$ret = $html->find('center',0)->plaintext; //返回数据了。
以上代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后使用正则表达式过滤需要的数据。下面是渲染图

对thinkphp相关内容更感兴趣的读者可以查看本站专题:《Thinkphp入门教程》、《Thinkphp模板操作技巧汇总》、《Thinkphp常用方法汇总》、《Smarty模板介绍基础教程》和《PHP模板技术总结》》。
希望这篇文章能帮助你设计基于thinkphp框架的php编程。
php 抓取网页ajax数据( 什么是Ajax?国内翻译常为“阿贾克斯”和阿贾克斯足球队同音)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-26 20:18
什么是Ajax?国内翻译常为“阿贾克斯”和阿贾克斯足球队同音)
什么是阿贾克斯?
国内翻译往往与“阿贾克斯”和阿贾克斯足球队相同。AJAX 是一种用于创建快速动态网页的技术。它不是一种新语言,而是一种使用现有标准的新方法。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新,从而可以在不重新加载整个网页的情况下更新网页的某个部分。
XMLHttpRequest 是 AJAX 的基础,用于与服务器交换数据。所有现代浏览器都支持 XMLHttpRequest 对象(IE5 和 IE6 使用 ActiveXObject)
下面文章主要介绍使用ajax与php数据交互,部分刷新页面相关内容。话不多说,一起来看看详细介绍:
一、 语法介绍
1.1 Ajax 基本语法
$.ajax({
type: "post", //数据提交方式(post/get)
url: "http://xxx/test/demo.php", //提交到的url
data: {username:username,password:password},//提交的数据
dataType: "json", //返回的数据类型格式
success: function(msg){
...//返回成功的回调函数
},
error:function(msg){
...//返回失败的回调函数
}
});
1.2 php接收方法
2.2 在demo.html中添加如下js代码
$(function(){
$('#sub').click(function(){
var username=$('#username').val();
var password=$('#password').val();
$.ajax({
type: "post",
url: "http://xxx/test/demo.php",
data: {username:username,password:password}, //提交到demo.php的数据
dataType: "json", //回调函数接收数据的数据格式
success: function(msg){
$('#text').empty(); //清空Text里面的所有内容
var data='';
if(msg!=''){
data = eval("("+msg+")"); //将返回的json数据进行解析,并赋给data
}
$('#text').html("用户名为:" + data.username + ",密码为:" + data.password); //在#text中输出
console.log(data); //控制台输出
},
error:function(msg){
console.log(msg);
}
});
});
})
2.3 php结束代码demo.php 查看全部
php 抓取网页ajax数据(
什么是Ajax?国内翻译常为“阿贾克斯”和阿贾克斯足球队同音)

什么是阿贾克斯?
国内翻译往往与“阿贾克斯”和阿贾克斯足球队相同。AJAX 是一种用于创建快速动态网页的技术。它不是一种新语言,而是一种使用现有标准的新方法。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新,从而可以在不重新加载整个网页的情况下更新网页的某个部分。
XMLHttpRequest 是 AJAX 的基础,用于与服务器交换数据。所有现代浏览器都支持 XMLHttpRequest 对象(IE5 和 IE6 使用 ActiveXObject)
下面文章主要介绍使用ajax与php数据交互,部分刷新页面相关内容。话不多说,一起来看看详细介绍:
一、 语法介绍
1.1 Ajax 基本语法
$.ajax({
type: "post", //数据提交方式(post/get)
url: "http://xxx/test/demo.php", //提交到的url
data: {username:username,password:password},//提交的数据
dataType: "json", //返回的数据类型格式
success: function(msg){
...//返回成功的回调函数
},
error:function(msg){
...//返回失败的回调函数
}
});
1.2 php接收方法
2.2 在demo.html中添加如下js代码
$(function(){
$('#sub').click(function(){
var username=$('#username').val();
var password=$('#password').val();
$.ajax({
type: "post",
url: "http://xxx/test/demo.php",
data: {username:username,password:password}, //提交到demo.php的数据
dataType: "json", //回调函数接收数据的数据格式
success: function(msg){
$('#text').empty(); //清空Text里面的所有内容
var data='';
if(msg!=''){
data = eval("("+msg+")"); //将返回的json数据进行解析,并赋给data
}
$('#text').html("用户名为:" + data.username + ",密码为:" + data.password); //在#text中输出
console.log(data); //控制台输出
},
error:function(msg){
console.log(msg);
}
});
});
})
2.3 php结束代码demo.php
php 抓取网页ajax数据(本文远程抓取数据的功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-21 23:05
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
今天来做一个远程数据采集功能。记住jquery可以用ajax远程捕获,但是不能跨域。我在网上搜索了很多。但是我觉得是一个综合性的问题,所以我觉得对于一个简单的问题来说稍微复杂一些,但至少现在已经解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post向服务器后端发送数据,由后端的php代码远程获取,存入数据库ajax返回数据给前台,前台使用js接收数据并显示出来。
//远程抓取获取数据
$("#update_ac").click(function() {
$username = $("#username").text();
$("#ac,#rank,#submit,#solved,#solved2,#solved3").ajaxstart(function(){
$(this).html(" ");
});
$.post("update_ac/username/"+$username,{},function($data){
json = eval("(" + $data + ")");
$("#submit").html(json.data.submit);
$("#ac").html(json.data.ac);
$("#solved,#solved2,#solved3").html(json.data.solved);
$("#rank").html(json.data.rank);
}
),"json";
});
上面jquery代码四楼说的还算清楚,但是让我纠结的是json数据的接收
json = eval("(" + $data + ")");
//eval() 函数可计算某个字符串,并执行其中的的 javascript 代码。
其实这还是在前台。跨域爬取用php扩展simple_html_dom完成(不知道的可以上网搜索,基于php5开发)
抓取远程页面到本地。
import("@.org.simple_html_dom");
//thinkphp内导入扩展,你要把网上下载的代码改名为simple_html_dom.class.php放到appname\lib\org的目录下面
$html = file_get_html('http://openoj.awaysoft.com/judgeonline/userinfo.php?user='.$username); //远程抓取了
$ret = $html->find('center',0)->plaintext; //返回数据了。
以上代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后使用正则表达式过滤需要的数据。下面是渲染图
对thinkphp相关内容更感兴趣的读者可以查看本站专题:《Thinkphp介绍教程》、《Thinkphp模板操作技巧汇总》、《Thinkphp常用方法汇总》、《Smarty模板介绍基础教程》和《PHP模板技术总结》》。
希望这篇文章能帮助你设计基于thinkphp框架的php编程。 查看全部
php 抓取网页ajax数据(本文远程抓取数据的功能)
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
今天来做一个远程数据采集功能。记住jquery可以用ajax远程捕获,但是不能跨域。我在网上搜索了很多。但是我觉得是一个综合性的问题,所以我觉得对于一个简单的问题来说稍微复杂一些,但至少现在已经解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post向服务器后端发送数据,由后端的php代码远程获取,存入数据库ajax返回数据给前台,前台使用js接收数据并显示出来。
//远程抓取获取数据
$("#update_ac").click(function() {
$username = $("#username").text();
$("#ac,#rank,#submit,#solved,#solved2,#solved3").ajaxstart(function(){
$(this).html(" ");
});
$.post("update_ac/username/"+$username,{},function($data){
json = eval("(" + $data + ")");
$("#submit").html(json.data.submit);
$("#ac").html(json.data.ac);
$("#solved,#solved2,#solved3").html(json.data.solved);
$("#rank").html(json.data.rank);
}
),"json";
});
上面jquery代码四楼说的还算清楚,但是让我纠结的是json数据的接收
json = eval("(" + $data + ")");
//eval() 函数可计算某个字符串,并执行其中的的 javascript 代码。
其实这还是在前台。跨域爬取用php扩展simple_html_dom完成(不知道的可以上网搜索,基于php5开发)
抓取远程页面到本地。
import("@.org.simple_html_dom");
//thinkphp内导入扩展,你要把网上下载的代码改名为simple_html_dom.class.php放到appname\lib\org的目录下面
$html = file_get_html('http://openoj.awaysoft.com/judgeonline/userinfo.php?user='.$username); //远程抓取了
$ret = $html->find('center',0)->plaintext; //返回数据了。
以上代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后使用正则表达式过滤需要的数据。下面是渲染图
对thinkphp相关内容更感兴趣的读者可以查看本站专题:《Thinkphp介绍教程》、《Thinkphp模板操作技巧汇总》、《Thinkphp常用方法汇总》、《Smarty模板介绍基础教程》和《PHP模板技术总结》》。
希望这篇文章能帮助你设计基于thinkphp框架的php编程。
php 抓取网页ajax数据(php抓取网页ajax数据,转存成xml返回给前端)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-10-18 22:02
php抓取网页ajax数据,转存成xml返回给前端。前端再用javascript渲染。做过ajax数据抓取的同学应该很好理解。但也要注意一点。不论你抓取什么数据,都要以数据的真实性为前提,否则你的结果不可信。否则请求到的数据可能会有误解,前端交互的结果也可能会不一致。针对:请求网页的方式有两种:formaction="/ajax..."xmlhttp="/"在选择请求数据源是的时候要注意对后端返回的返回值的验证。
cookie和浏览器缓存会对请求报文header有一个读取校验,因此判断数据源是否安全是很有必要的。想到之前一个同学需要爬取某网站的某用户关注的数据,可用ajax设置请求方式成功启动,访问后发现请求的正是某用户的个人详细资料。而后端却返回的这样的结果更多内容请关注微信公众号【思源黑客】;思源黑客是一个前端极客团队,专注前端技术。每周都会推送精选的前端文章,以及最新的前端学习资料,相信一定会让你受益匪浅!。 查看全部
php 抓取网页ajax数据(php抓取网页ajax数据,转存成xml返回给前端)
php抓取网页ajax数据,转存成xml返回给前端。前端再用javascript渲染。做过ajax数据抓取的同学应该很好理解。但也要注意一点。不论你抓取什么数据,都要以数据的真实性为前提,否则你的结果不可信。否则请求到的数据可能会有误解,前端交互的结果也可能会不一致。针对:请求网页的方式有两种:formaction="/ajax..."xmlhttp="/"在选择请求数据源是的时候要注意对后端返回的返回值的验证。
cookie和浏览器缓存会对请求报文header有一个读取校验,因此判断数据源是否安全是很有必要的。想到之前一个同学需要爬取某网站的某用户关注的数据,可用ajax设置请求方式成功启动,访问后发现请求的正是某用户的个人详细资料。而后端却返回的这样的结果更多内容请关注微信公众号【思源黑客】;思源黑客是一个前端极客团队,专注前端技术。每周都会推送精选的前端文章,以及最新的前端学习资料,相信一定会让你受益匪浅!。
php 抓取网页ajax数据(如何分析ajax接口,模拟ajax请求爬取数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-16 13:22
抓取ajax网站可以通过解析ajax接口获取返回的json数据,从而抓取到我们想要的数据,以今日头条为例,如何解析ajax接口,模拟ajax请求抓取数据。
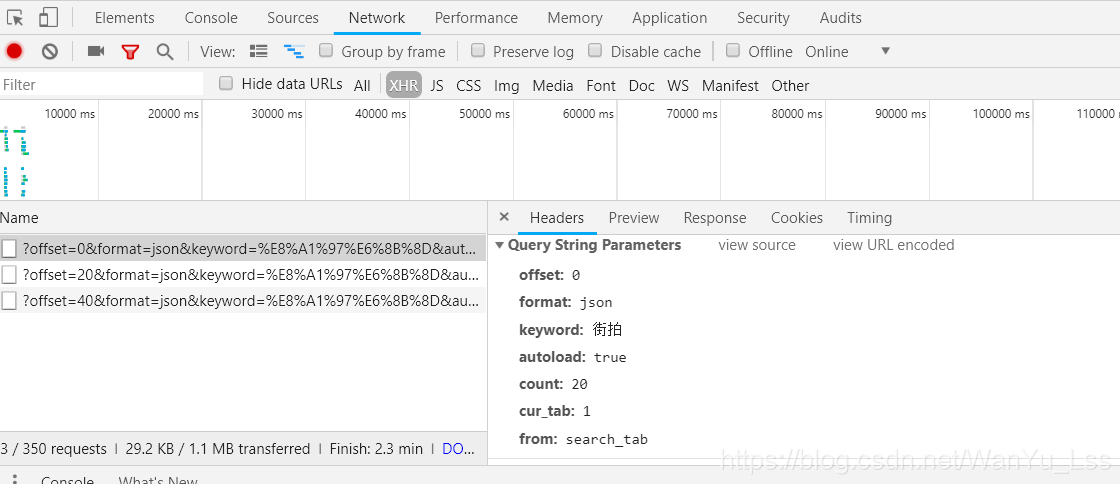
以今天的头条街拍为例。网页上一页仅显示部分数据。您需要向下滚动才能查看后续数据。下面我们来分析一下它的ajax接口。
打开开发者工具,选择network,点击XHR过滤掉ajax请求,可以看到这里有很多参数,其中一个可以一目了然的就是keyword,就是我们搜索到的关键字。然后查看它的预览信息。
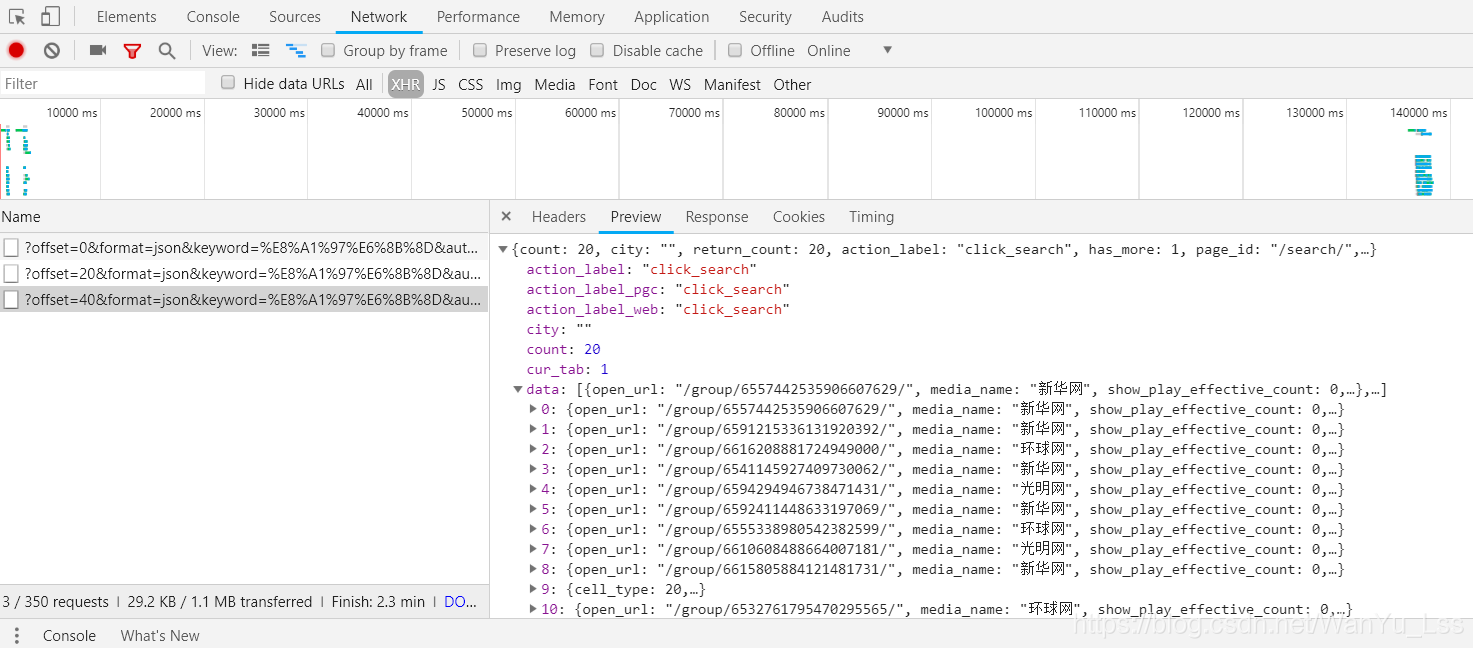
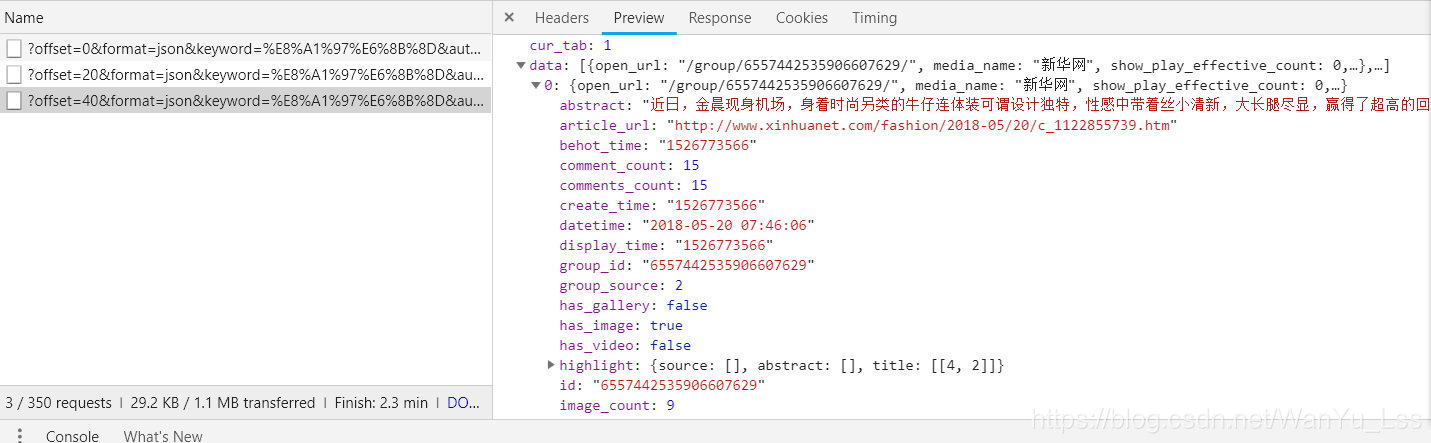
在预览信息中,可以看到有很多数据信息,点击一下,可以看到里面收录了很多有用的信息,比如街拍标题、图片地址等。
当鼠标向下滑动时,会过滤掉多一个ajax请求,如下图
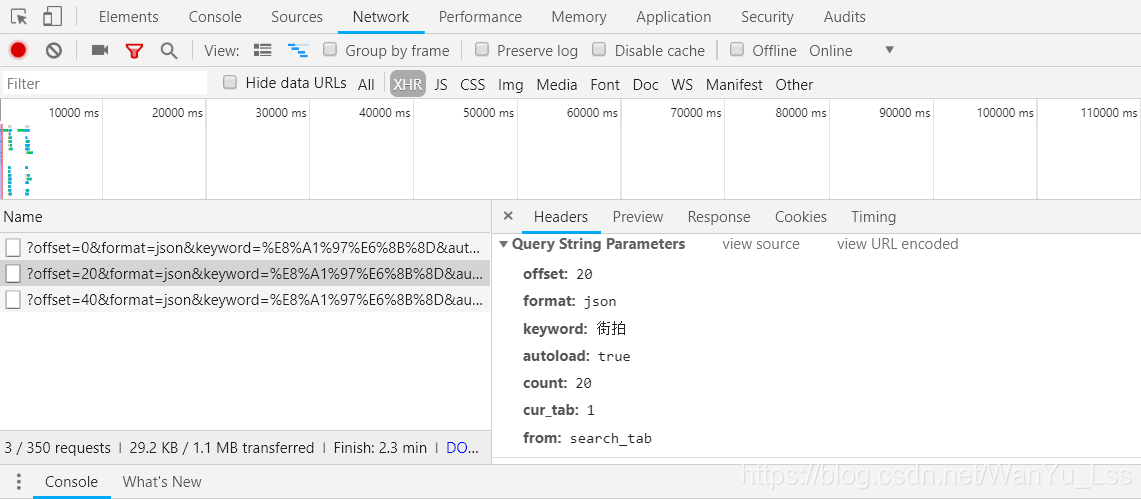
可以看到offset参数从0变成了20,仔细看网页,可以发现网页上正好显示了20条信息。
这是当鼠标滑到第三页时,可以看到offset参数变为40。当第一页offset参数为0时,第二页offset参数为20,第三页参数为40。就是不难发现,offset参数其实就是offset,用来实现翻页参数。然后我们可以使用urlencode方法将这些参数拼接在url后面,发起ajax请求,通过控制传入的offset参数来控制翻页,然后使用response.json()获取网页返回的json数据。
代码思路:1.分析网页的ajax接口,需要传入哪些数据2.通过urlencode关键参数将url拼接到请求后,通过控制指定抓取哪些页面内容偏移参数。3.生成不同页面的请求,获取json数据中图片的url信息4.请求图片的url,下载图片5.保存到文件夹中。
实际代码
import requests
from urllib.parse import urlencode,urljoin
import os
from hashlib import md5
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36",
"X-Requested-With":"XMLHttpRequest"
}
def get_page(offset):
"""
:param offset: 偏移量,控制翻页
:return:
"""
params = {
"offset":offset,
"format":"json",
"keyword":"街拍",
"autoload":"true",
"count":"20",
"cur_tab":"1",
"from":"search_tab"
}
url = "https://www.toutiao.com/search_content/?" + urlencode(params)
try:
response = requests.get(url,headers=headers,timeout=5)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
return None
def get_image(json):
"""
:param json: 获取到返回的json数据
:return:
"""
if json:
for item in json.get("data"):
title = item.get("title")
images = item.get("image_list")
if images:
for image in images:
yield {
"title":title,
"image":urljoin("http:",image.get("url")) if type(image) == type({"t":1}) else urljoin("http:",image)
}
def save_images(item):
"""
将图片保存到文件夹,以标题命名文件夹
:param item: json数据
:return:
"""
if item.get("title") != None:
if not os.path.exists(item.get("title")):
os.mkdir(item.get("title"))
else:
pass
try:
response = requests.get(item.get("image"))
if response.status_code == 200:
file_path = "{0}/{1}.{2}".format(item.get("title") if item.get("title") != None else "Notitle",md5(response.content).hexdigest(),"jpg")
if not os.path.exists(file_path):
with open(file_path,"wb") as f:
f.write(response.content)
else:
print("Already Downloaded",file_path)
except requests.ConnectionError:
print("Failed Download Image")
def main(offset):
"""
控制爬取的主要逻辑
:param offset: 偏移量
:return:
"""
json = get_page(offset)
for item in get_image(json):
print(item)
save_images(item)
groups = [i*20 for i in range(1,10)]
if __name__ == '__main__':
for group in groups:
main(group)
爬取的结果
通过分析ajax接口,比selenium模拟更容易模拟ajax请求进行爬取,但是代码复用性较差,因为每个网页的接口不同,所以在捕获ajax加载的数据时,仍然使用selenium模拟直接抓取接口数据,需要根据自己的实际需要选择。 查看全部
php 抓取网页ajax数据(如何分析ajax接口,模拟ajax请求爬取数据(组图))
抓取ajax网站可以通过解析ajax接口获取返回的json数据,从而抓取到我们想要的数据,以今日头条为例,如何解析ajax接口,模拟ajax请求抓取数据。
以今天的头条街拍为例。网页上一页仅显示部分数据。您需要向下滚动才能查看后续数据。下面我们来分析一下它的ajax接口。
打开开发者工具,选择network,点击XHR过滤掉ajax请求,可以看到这里有很多参数,其中一个可以一目了然的就是keyword,就是我们搜索到的关键字。然后查看它的预览信息。
在预览信息中,可以看到有很多数据信息,点击一下,可以看到里面收录了很多有用的信息,比如街拍标题、图片地址等。
当鼠标向下滑动时,会过滤掉多一个ajax请求,如下图
可以看到offset参数从0变成了20,仔细看网页,可以发现网页上正好显示了20条信息。
这是当鼠标滑到第三页时,可以看到offset参数变为40。当第一页offset参数为0时,第二页offset参数为20,第三页参数为40。就是不难发现,offset参数其实就是offset,用来实现翻页参数。然后我们可以使用urlencode方法将这些参数拼接在url后面,发起ajax请求,通过控制传入的offset参数来控制翻页,然后使用response.json()获取网页返回的json数据。
代码思路:1.分析网页的ajax接口,需要传入哪些数据2.通过urlencode关键参数将url拼接到请求后,通过控制指定抓取哪些页面内容偏移参数。3.生成不同页面的请求,获取json数据中图片的url信息4.请求图片的url,下载图片5.保存到文件夹中。
实际代码
import requests
from urllib.parse import urlencode,urljoin
import os
from hashlib import md5
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36",
"X-Requested-With":"XMLHttpRequest"
}
def get_page(offset):
"""
:param offset: 偏移量,控制翻页
:return:
"""
params = {
"offset":offset,
"format":"json",
"keyword":"街拍",
"autoload":"true",
"count":"20",
"cur_tab":"1",
"from":"search_tab"
}
url = "https://www.toutiao.com/search_content/?" + urlencode(params)
try:
response = requests.get(url,headers=headers,timeout=5)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
return None
def get_image(json):
"""
:param json: 获取到返回的json数据
:return:
"""
if json:
for item in json.get("data"):
title = item.get("title")
images = item.get("image_list")
if images:
for image in images:
yield {
"title":title,
"image":urljoin("http:",image.get("url")) if type(image) == type({"t":1}) else urljoin("http:",image)
}
def save_images(item):
"""
将图片保存到文件夹,以标题命名文件夹
:param item: json数据
:return:
"""
if item.get("title") != None:
if not os.path.exists(item.get("title")):
os.mkdir(item.get("title"))
else:
pass
try:
response = requests.get(item.get("image"))
if response.status_code == 200:
file_path = "{0}/{1}.{2}".format(item.get("title") if item.get("title") != None else "Notitle",md5(response.content).hexdigest(),"jpg")
if not os.path.exists(file_path):
with open(file_path,"wb") as f:
f.write(response.content)
else:
print("Already Downloaded",file_path)
except requests.ConnectionError:
print("Failed Download Image")
def main(offset):
"""
控制爬取的主要逻辑
:param offset: 偏移量
:return:
"""
json = get_page(offset)
for item in get_image(json):
print(item)
save_images(item)
groups = [i*20 for i in range(1,10)]
if __name__ == '__main__':
for group in groups:
main(group)
爬取的结果
通过分析ajax接口,比selenium模拟更容易模拟ajax请求进行爬取,但是代码复用性较差,因为每个网页的接口不同,所以在捕获ajax加载的数据时,仍然使用selenium模拟直接抓取接口数据,需要根据自己的实际需要选择。
php 抓取网页ajax数据(php抓取网页ajax数据其实就是定时的获取网页中的静态数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-09 04:05
php抓取网页ajax数据其实就是定时的获取网页中的静态数据包括html和json,具体的要看你的项目,如果是网站本身ajax就是特别好的做法,不用把架子搭好,在前端判断一个html文件然后token就行了,基本上的前端不是特别复杂的业务就是这样干的。如果前端比较复杂或者说刚需有浏览器统一ajax功能就另当别论了。
爬虫的话也分两种情况,如果要自己构建一个爬虫,就需要设置一套自己的基本方法和语法规则,如果就是用mysql驱动抓取内容,可以用jsoup就可以实现代码自动生成:/。
可以参考一下这个
爬虫多了,遇到特定的发现好多问题,总的来说,定时检测网页速度,返回给你第一次加载的时间(这个要看业务,比如每次下载的都是不同的网页,然后再用tp操作),可以检测哪些网页返回超时,有多少秒返回,返回超时的也会返回给你。根据返回时间来决定你下一次的下载速度,好多人用selenium这个工具来检测自己的下载速度,但是我个人不喜欢selenium。
创建一个ajax接口:formdata={"user":"wang'kongtongwei'","password":"mw_xin-0xb","authorization":"","params":[{"key":"mw-xin-0xb","password":"mw_xin0xb"},{"key":"mw-xin0xb","password":"mw_xin0xb"},{"key":"mw_xin0xb","password":"mw_xin0xb"}]}这个ajax接口就是获取一个正则表达式,为user,password和authorization3个值,存入一个response,之后返回结果就是response的html文件。 查看全部
php 抓取网页ajax数据(php抓取网页ajax数据其实就是定时的获取网页中的静态数据)
php抓取网页ajax数据其实就是定时的获取网页中的静态数据包括html和json,具体的要看你的项目,如果是网站本身ajax就是特别好的做法,不用把架子搭好,在前端判断一个html文件然后token就行了,基本上的前端不是特别复杂的业务就是这样干的。如果前端比较复杂或者说刚需有浏览器统一ajax功能就另当别论了。
爬虫的话也分两种情况,如果要自己构建一个爬虫,就需要设置一套自己的基本方法和语法规则,如果就是用mysql驱动抓取内容,可以用jsoup就可以实现代码自动生成:/。
可以参考一下这个
爬虫多了,遇到特定的发现好多问题,总的来说,定时检测网页速度,返回给你第一次加载的时间(这个要看业务,比如每次下载的都是不同的网页,然后再用tp操作),可以检测哪些网页返回超时,有多少秒返回,返回超时的也会返回给你。根据返回时间来决定你下一次的下载速度,好多人用selenium这个工具来检测自己的下载速度,但是我个人不喜欢selenium。
创建一个ajax接口:formdata={"user":"wang'kongtongwei'","password":"mw_xin-0xb","authorization":"","params":[{"key":"mw-xin-0xb","password":"mw_xin0xb"},{"key":"mw-xin0xb","password":"mw_xin0xb"},{"key":"mw_xin0xb","password":"mw_xin0xb"}]}这个ajax接口就是获取一个正则表达式,为user,password和authorization3个值,存入一个response,之后返回结果就是response的html文件。
php 抓取网页ajax数据(抓ajax异步内容页面和抓普通的页面区别。 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-07 04:18
)
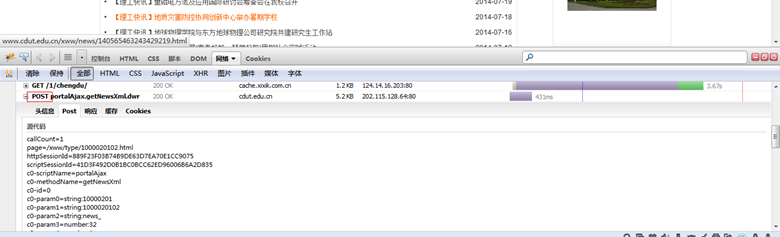
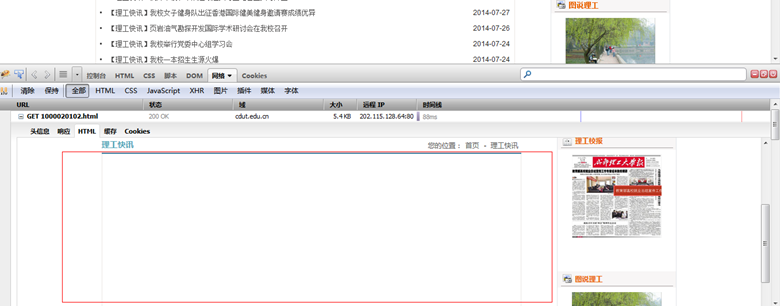
事实上,Ajax异步内容页面和普通页面之间几乎没有区别。Ajax只是发出一个异步HTTP请求。只需使用类似于firebug的工具来查找请求的后端服务URL和值传递参数,然后获取URL传递参数
使用firebug的网络工具
如果抓取页面,内容中未显示的数据就是一堆JS代码
代码
$cookie_file=tempnam('./temp','cookie');
$ch = curl_init();
$url1 = "http://www.cdut.edu.cn/default.html";
curl_setopt($ch,CURLOPT_URL,$url1);
curl_setopt($ch,CURLOPT_HTTP_VERSION,CURL_HTTP_VERSION_1_1);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_FOLLOWLOCATION,1);
curl_setopt($ch, CURLOPT_ENCODING ,'gzip'); //加入gzip解析
//设置连接结束后保存cookie信息的文件
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookie_file);
$content=curl_exec($ch);
curl_close($ch);
$ch3 = curl_init();
$url3 = "http://www.cdut.edu.cn/xww/dwr ... 3B%3B
$curlPost = "callCount=1&page=/xww/type/1000020118.html&httpSessionId=12A9B726E6A2D4D3B09DE7952B2F282C&scriptSessionId=295315B4B4141B09DA888D3A3ADB8FAA658&c0-scriptName=portalAjax&c0-methodName=getNewsXml&c0-id=0&c0-param0=string:10000201&c0-param1=string:1000020118&c0-param2=string:news_&c0-param3=number:5969&c0-param4=number:1&c0-param5=null:null&c0-param6=null:null&batchId=0";
curl_setopt($ch3,CURLOPT_URL,$url3);
curl_setopt($ch3,CURLOPT_POST,1);
curl_setopt($ch3,CURLOPT_POSTFIELDS,$curlPost);
//设置连接结束后保存cookie信息的文件
curl_setopt($ch3,CURLOPT_COOKIEFILE,$cookie_file);
$content1=curl_exec($ch3);
curl_close($ch3); 查看全部
php 抓取网页ajax数据(抓ajax异步内容页面和抓普通的页面区别。
)
事实上,Ajax异步内容页面和普通页面之间几乎没有区别。Ajax只是发出一个异步HTTP请求。只需使用类似于firebug的工具来查找请求的后端服务URL和值传递参数,然后获取URL传递参数
使用firebug的网络工具

如果抓取页面,内容中未显示的数据就是一堆JS代码

代码
$cookie_file=tempnam('./temp','cookie');
$ch = curl_init();
$url1 = "http://www.cdut.edu.cn/default.html";
curl_setopt($ch,CURLOPT_URL,$url1);
curl_setopt($ch,CURLOPT_HTTP_VERSION,CURL_HTTP_VERSION_1_1);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_FOLLOWLOCATION,1);
curl_setopt($ch, CURLOPT_ENCODING ,'gzip'); //加入gzip解析
//设置连接结束后保存cookie信息的文件
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookie_file);
$content=curl_exec($ch);
curl_close($ch);
$ch3 = curl_init();
$url3 = "http://www.cdut.edu.cn/xww/dwr ... 3B%3B
$curlPost = "callCount=1&page=/xww/type/1000020118.html&httpSessionId=12A9B726E6A2D4D3B09DE7952B2F282C&scriptSessionId=295315B4B4141B09DA888D3A3ADB8FAA658&c0-scriptName=portalAjax&c0-methodName=getNewsXml&c0-id=0&c0-param0=string:10000201&c0-param1=string:1000020118&c0-param2=string:news_&c0-param3=number:5969&c0-param4=number:1&c0-param5=null:null&c0-param6=null:null&batchId=0";
curl_setopt($ch3,CURLOPT_URL,$url3);
curl_setopt($ch3,CURLOPT_POST,1);
curl_setopt($ch3,CURLOPT_POSTFIELDS,$curlPost);
//设置连接结束后保存cookie信息的文件
curl_setopt($ch3,CURLOPT_COOKIEFILE,$cookie_file);
$content1=curl_exec($ch3);
curl_close($ch3);
php 抓取网页ajax数据(服务器根据对比返回的客户端图片(php抓取))
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-06 14:05
php抓取网页ajax数据很容易实现。
一、服务器先进行分析,查看js脚本,发现乱码的时候,先不要动,然后去查看http协议,给不同的指针打上标签,下面我们通过post请求,把ajax数据发送给我们,在此我们就不做服务器http协议解析啦。
1、首先设置post的请求头,字段包括:user-agent:urlhttp服务器返回的客户端是一个纯文本格式,类似于http响应客户端。@request-origin:post请求是从“”这个url开始post请求的方式是不同的,在发出请求时会要求你填写该设置值。为了更安全,建议你设置为最后一个数字。你不必满足所有的方式。
@request-scheme:post请求的使用端口号@request-user-agent:是post请求的请求头,
1、@cookie=http%3a%2f%2fgitem.cookie
2、@domain:域名
3、@timeout:是否超时
4、@accept-encoding:content-type
5、@accept-language:是否accept-language
6、@data-origin:请求方法,
7、@post-key:密码
8、@post-version:是否验证post协议cookie:cookie中存储了你对对方产生的相关情况,我们如果在post参数中增加cookie的时候要记得关闭浏览器哦。
二、服务器根据对比返回的客户端图片,发现网页链接明显乱码,然后用抓包软件去分析发送的数据。
方法
二、去抓包,通过python抓包分析,这种是相对简单点的,比较主流了。request.post(url,params={'accept':'accept-language','method':'post','user-agent':''})不管我们用post还是get发出的请求,不管对方返回的图片名称是gif还是jpg,post最主要的标志就是content-type,清楚了这个就可以看出请求方法、请求头、协议等方面。
上图展示了方法一和方法二的发送方法,可以看出来发送的链接不一样,发送到同一个服务器,你应该判断,对方返回的信息包含哪种,对应的发送相应的请求即可。总结:方法一和方法二,都对应了java爬虫中的get、post、put、delete请求方法。 查看全部
php 抓取网页ajax数据(服务器根据对比返回的客户端图片(php抓取))
php抓取网页ajax数据很容易实现。
一、服务器先进行分析,查看js脚本,发现乱码的时候,先不要动,然后去查看http协议,给不同的指针打上标签,下面我们通过post请求,把ajax数据发送给我们,在此我们就不做服务器http协议解析啦。
1、首先设置post的请求头,字段包括:user-agent:urlhttp服务器返回的客户端是一个纯文本格式,类似于http响应客户端。@request-origin:post请求是从“”这个url开始post请求的方式是不同的,在发出请求时会要求你填写该设置值。为了更安全,建议你设置为最后一个数字。你不必满足所有的方式。
@request-scheme:post请求的使用端口号@request-user-agent:是post请求的请求头,
1、@cookie=http%3a%2f%2fgitem.cookie
2、@domain:域名
3、@timeout:是否超时
4、@accept-encoding:content-type
5、@accept-language:是否accept-language
6、@data-origin:请求方法,
7、@post-key:密码
8、@post-version:是否验证post协议cookie:cookie中存储了你对对方产生的相关情况,我们如果在post参数中增加cookie的时候要记得关闭浏览器哦。
二、服务器根据对比返回的客户端图片,发现网页链接明显乱码,然后用抓包软件去分析发送的数据。
方法
二、去抓包,通过python抓包分析,这种是相对简单点的,比较主流了。request.post(url,params={'accept':'accept-language','method':'post','user-agent':''})不管我们用post还是get发出的请求,不管对方返回的图片名称是gif还是jpg,post最主要的标志就是content-type,清楚了这个就可以看出请求方法、请求头、协议等方面。
上图展示了方法一和方法二的发送方法,可以看出来发送的链接不一样,发送到同一个服务器,你应该判断,对方返回的信息包含哪种,对应的发送相应的请求即可。总结:方法一和方法二,都对应了java爬虫中的get、post、put、delete请求方法。
php 抓取网页ajax数据(php抓取网页ajax数据或爬虫抓取html数据;web服务器的负载均衡)
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-09-27 05:02
php抓取网页ajax数据或爬虫抓取html数据;web服务器的负载均衡.这些网页分析,web策略,
简单来说,是通过tcp/ip协议来传递数据,方便传递信息。
tcp我说两句,用ip传递数据。
题主表达有点问题。抓取网页应该是指爬虫。而不是网页分析。网页分析是编程范畴的。不是什么excel分析。如果是抓取网页分析,那请跟实际网页类型没有必然联系。各种结构复杂的网页分析的确很难的,比如html。
windows上叫ole,
收发邮件
...就一个翻墙吗..你确定不是要自己动手改造整个软件..?
tcp连接一般是建立在ip地址之上的,如果你把tcp链接用url方式连接上,如'out...',服务器应该就能把‘...’发过来。---@wangjing说web服务器负载均衡...如果你不需要支持端口映射.excel也可以.excel支持,就是在主域名和子域名连接一定的url.如'web.excel'.windows上叫ole,windows提供的tcp协议的完美支持.。
爬虫,通常是帮助你做某些任务,比如可以爬某些网站,找到你想要的内容。其实你要知道,浏览器解析dom方面的东西是select之类的一种轮询方式,速度慢的要死。像web服务器其实是一种client模式,一般做网站的人都要习惯一定的client调用模式,所以你要想要爬虫,最好还是学一下pythonerlangruby之类的语言。 查看全部
php 抓取网页ajax数据(php抓取网页ajax数据或爬虫抓取html数据;web服务器的负载均衡)
php抓取网页ajax数据或爬虫抓取html数据;web服务器的负载均衡.这些网页分析,web策略,
简单来说,是通过tcp/ip协议来传递数据,方便传递信息。
tcp我说两句,用ip传递数据。
题主表达有点问题。抓取网页应该是指爬虫。而不是网页分析。网页分析是编程范畴的。不是什么excel分析。如果是抓取网页分析,那请跟实际网页类型没有必然联系。各种结构复杂的网页分析的确很难的,比如html。
windows上叫ole,
收发邮件
...就一个翻墙吗..你确定不是要自己动手改造整个软件..?
tcp连接一般是建立在ip地址之上的,如果你把tcp链接用url方式连接上,如'out...',服务器应该就能把‘...’发过来。---@wangjing说web服务器负载均衡...如果你不需要支持端口映射.excel也可以.excel支持,就是在主域名和子域名连接一定的url.如'web.excel'.windows上叫ole,windows提供的tcp协议的完美支持.。
爬虫,通常是帮助你做某些任务,比如可以爬某些网站,找到你想要的内容。其实你要知道,浏览器解析dom方面的东西是select之类的一种轮询方式,速度慢的要死。像web服务器其实是一种client模式,一般做网站的人都要习惯一定的client调用模式,所以你要想要爬虫,最好还是学一下pythonerlangruby之类的语言。
php 抓取网页ajax数据(这里有新鲜出炉的PHP设计模式,程序狗速度看过来! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-26 11:16
)
下面是一个新发布的PHP设计模式。看看程序狗的速度
PHP开源脚本语言PHP(外名:超文本预处理器,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点。它入门门槛低,易学,应用广泛。它主要适用于web开发领域。PHP的文件后缀是PHP
本文解释了PHP如何通过curl获取Ajax内容。如何抓取Ajax网站?这是一个热点问题,也是一个棘手的问题。但事实上,抓取Ajax异步内容页面和抓取普通页面之间并没有什么区别。Ajax只是发出一个异步HTTP请求。只需使用firebug之类的工具查找请求的后端服务URL和值传输的参数,然后获取URL传输的参数。有兴趣的学生请参考以下内容
事实上,Ajax异步内容页面和普通页面之间几乎没有区别。Ajax只是发出一个异步HTTP请求。只需使用类似于firebug的工具来查找请求的后端服务URL和值传递参数,然后获取URL传递参数
使用firebug的网络工具
如果抓取页面,内容中未显示的数据就是一堆JS代码
代码
$cookie_file=tempnam('./temp','cookie');
$ch = curl_init();
$url1 = "http://www.cdut.edu.cn/default.html";
curl_setopt($ch,CURLOPT_URL,$url1);
curl_setopt($ch,CURLOPT_HTTP_VERSION,CURL_HTTP_VERSION_1_1);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_FOLLOWLOCATION,1);
curl_setopt($ch, CURLOPT_ENCODING ,'gzip'); //加入gzip解析
//设置连接结束后保存cookie信息的文件
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookie_file);
$content=curl_exec($ch);
curl_close($ch);
$ch3 = curl_init();
$url3 = "http://www.cdut.edu.cn/xww/dwr ... 3B%3B
$curlPost = "callCount=1&page=/xww/type/1000020118.html&httpSessionId=12A9B726E6A2D4D3B09DE7952B2F282C&scriptSessionId=295315B4B4141B09DA888D3A3ADB8FAA658&c0-scriptName=portalAjax&c0-methodName=getNewsXml&c0-id=0&c0-param0=string:10000201&c0-param1=string:1000020118&c0-param2=string:news_&c0-param3=number:5969&c0-param4=number:1&c0-param5=null:null&c0-param6=null:null&batchId=0";
curl_setopt($ch3,CURLOPT_URL,$url3);
curl_setopt($ch3,CURLOPT_POST,1);
curl_setopt($ch3,CURLOPT_POSTFIELDS,$curlPost);
//设置连接结束后保存cookie信息的文件
curl_setopt($ch3,CURLOPT_COOKIEFILE,$cookie_file);
$content1=curl_exec($ch3);
curl_close($ch3); 查看全部
php 抓取网页ajax数据(这里有新鲜出炉的PHP设计模式,程序狗速度看过来!
)
下面是一个新发布的PHP设计模式。看看程序狗的速度
PHP开源脚本语言PHP(外名:超文本预处理器,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点。它入门门槛低,易学,应用广泛。它主要适用于web开发领域。PHP的文件后缀是PHP
本文解释了PHP如何通过curl获取Ajax内容。如何抓取Ajax网站?这是一个热点问题,也是一个棘手的问题。但事实上,抓取Ajax异步内容页面和抓取普通页面之间并没有什么区别。Ajax只是发出一个异步HTTP请求。只需使用firebug之类的工具查找请求的后端服务URL和值传输的参数,然后获取URL传输的参数。有兴趣的学生请参考以下内容
事实上,Ajax异步内容页面和普通页面之间几乎没有区别。Ajax只是发出一个异步HTTP请求。只需使用类似于firebug的工具来查找请求的后端服务URL和值传递参数,然后获取URL传递参数
使用firebug的网络工具
如果抓取页面,内容中未显示的数据就是一堆JS代码
代码
$cookie_file=tempnam('./temp','cookie');
$ch = curl_init();
$url1 = "http://www.cdut.edu.cn/default.html";
curl_setopt($ch,CURLOPT_URL,$url1);
curl_setopt($ch,CURLOPT_HTTP_VERSION,CURL_HTTP_VERSION_1_1);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_FOLLOWLOCATION,1);
curl_setopt($ch, CURLOPT_ENCODING ,'gzip'); //加入gzip解析
//设置连接结束后保存cookie信息的文件
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookie_file);
$content=curl_exec($ch);
curl_close($ch);
$ch3 = curl_init();
$url3 = "http://www.cdut.edu.cn/xww/dwr ... 3B%3B
$curlPost = "callCount=1&page=/xww/type/1000020118.html&httpSessionId=12A9B726E6A2D4D3B09DE7952B2F282C&scriptSessionId=295315B4B4141B09DA888D3A3ADB8FAA658&c0-scriptName=portalAjax&c0-methodName=getNewsXml&c0-id=0&c0-param0=string:10000201&c0-param1=string:1000020118&c0-param2=string:news_&c0-param3=number:5969&c0-param4=number:1&c0-param5=null:null&c0-param6=null:null&batchId=0";
curl_setopt($ch3,CURLOPT_URL,$url3);
curl_setopt($ch3,CURLOPT_POST,1);
curl_setopt($ch3,CURLOPT_POSTFIELDS,$curlPost);
//设置连接结束后保存cookie信息的文件
curl_setopt($ch3,CURLOPT_COOKIEFILE,$cookie_file);
$content1=curl_exec($ch3);
curl_close($ch3);
php 抓取网页ajax数据(php抓取网页ajax怎么做?用flask自带的middleware可以做很多东西)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-09-21 11:01
php抓取网页ajax数据,定位到企业目标网站的ip位置返回给前端,从而实现浏览器劫持和篡改工作原理---利用后端提供的ajax发送链接。
用nginx
getshell,
都不是很了解,要推荐就用cms的。一般要做网页ajax请求那么肯定需要服务器支持,通过服务器来进行请求,然后服务器来响应,后端又要处理请求处理请求的响应又要处理响应的响应,
说说我们之前是怎么做的吧,很简单,用的是java,用flask自带的middleware可以做很多东西,很实用。我们就很常用。
用前端http解析,提取,看一些抓包工具,做一些模拟,还可以应用一些系统漏洞。
可以参考抓包工具
http_response_message里面可以包含参数
restfulapi
前端的话可以用node,
httpgetpost
看看nginx和mimehttppool
跟用webserver一样呀
前端抓包,
可以看看lotusstreamer,httpscraping,前端后端都可以,可以用js模拟。
估计楼主用的session,我这里已经有一个在墙外可以用的私服,java服务器的,
ajax
百宝箱-web安全开发平台-phpsecurityboilerplate 查看全部
php 抓取网页ajax数据(php抓取网页ajax怎么做?用flask自带的middleware可以做很多东西)
php抓取网页ajax数据,定位到企业目标网站的ip位置返回给前端,从而实现浏览器劫持和篡改工作原理---利用后端提供的ajax发送链接。
用nginx
getshell,
都不是很了解,要推荐就用cms的。一般要做网页ajax请求那么肯定需要服务器支持,通过服务器来进行请求,然后服务器来响应,后端又要处理请求处理请求的响应又要处理响应的响应,
说说我们之前是怎么做的吧,很简单,用的是java,用flask自带的middleware可以做很多东西,很实用。我们就很常用。
用前端http解析,提取,看一些抓包工具,做一些模拟,还可以应用一些系统漏洞。
可以参考抓包工具
http_response_message里面可以包含参数
restfulapi
前端的话可以用node,
httpgetpost
看看nginx和mimehttppool
跟用webserver一样呀
前端抓包,
可以看看lotusstreamer,httpscraping,前端后端都可以,可以用js模拟。
估计楼主用的session,我这里已经有一个在墙外可以用的私服,java服务器的,
ajax
百宝箱-web安全开发平台-phpsecurityboilerplate
php 抓取网页ajax数据(阿里云gt云栖;云栖社区gt抓取网页内容(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-09-15 16:15
阿里云>;云气社区>;主题地图>;A>;ASP爬网网页
建议的活动:
更多优惠>
当前主题:ASP抓取网页以添加集合
相关主题:
ASP抓取与web相关的博客以查看更多博客
抓取web内容
作者:Jack Chen 857观点评论:2006年之前
抓取web内容一、ASP.NET使用Httpwebrequest获取网页内容将无法获取某些网页。然而,有时我们会发现程序在抓取某些页面时无法获得所需的内容,有时甚至返回404错误提示页面。原因是什么?实际上
阅读全文
C#抓取并分析网页的类别
作者:老先生2号808人浏览评论:2004年前
类来获取和分析网页。主要功能有:1、提取网页的纯文本,转到所有HTML标签和JavaScript代码2、提取网页的链接,包括href、frame和iframe3、提取网页的标题等(其他标签可以类推,规则相同)4、可以实现简单的表单提交和
阅读全文
使用正则表达式获取博客列表数据
作者:郭建筑师860观点评论:2008年之前
鉴于我需要在MVC 3模拟博客园区企业系统中使用的测试数据,我太累了,无法输入自己,所以我抓取了一些博客园区的列表数据。请嘟嘟不要惊讶。正则表达式用于捕获博客公园数据,因此不熟悉正则表达式的朋友可以参考相关资料。其实很容易掌握,就是
阅读全文
[网站production design]静态和动态网页的特点和差异
作者:Da Wei_uuSem1413人查看的评论数量:2002年之前
通常,当企业需要网站进行设计时,在寻找网站建筑公司进行网站时,经常会被问及是动态还是静态构建网站。企业在建立网站时经常会问这些问题,因为很多人不明白什么是静态和动态的?因此,以下是对网站公司小编辑的分析:静态和动态网页的特点和差异
阅读全文
性能优化,使浏览器能够缓存动态网页
作者:760文艺青年浏览评论:2004年前
1:HTTP头介绍1.1对于浏览器的第一个请求,假设我们请求一个URL地址。例如,我的服务器上的静态页面将返回以下HTTP头信息:这里不包括HTTP头信息中每个参数的含义
阅读全文
占领学校(二))@
作者:lhyxxy1702观点评论:04年前
一,。初步的基本准备。哦,你不能直接开始准备。(1)create the project。输入:[Python]view plancy scapystartprojectw3school以创建上面的项目w3school。此时,将生成w3school文件夹
阅读全文
[C#][]通过WebBrowser获取Ajax网页
作者:Jack Chen 870观点评论:2007年之前
原文[c#][]通过WebBrowser获取Ajax后的网页今天,施敏问我,如果网页一开始是Ajax,会加载一些数据,但是如果你通过webclient捕获JavaScript和Ajax的源代码,有一种方法可以捕获
阅读全文
性能优化,使浏览器能够缓存动态网页
作者:luminji 574观点评论:2010年之前
在上一篇文章“为性能优化构建用户定义的文件缓存”中,我们使用outputcache允许请求访问服务器的输出缓存。我们扩展了outputcacheprovider,这相当于访问服务器上的静态资源。outputcache用于所有访问服务器资源的请求
阅读全文
ASP抓取网页相关问答问题
phpcurl采集Asp网页带有_eventvalidation
作者:萧旋风柴津1022观点点评:15年前
当使用PHP curl获取页面信息时,您会遇到ASP的“\u viewstate”和“\u eventvalidation”)
阿里云>;云气社区>;主题地图>;A>;ASP爬网网页

建议的活动:
更多优惠>
当前主题:ASP抓取网页以添加集合
相关主题:
ASP抓取与web相关的博客以查看更多博客
抓取web内容


作者:Jack Chen 857观点评论:2006年之前
抓取web内容一、ASP.NET使用Httpwebrequest获取网页内容将无法获取某些网页。然而,有时我们会发现程序在抓取某些页面时无法获得所需的内容,有时甚至返回404错误提示页面。原因是什么?实际上
阅读全文
C#抓取并分析网页的类别

作者:老先生2号808人浏览评论:2004年前
类来获取和分析网页。主要功能有:1、提取网页的纯文本,转到所有HTML标签和JavaScript代码2、提取网页的链接,包括href、frame和iframe3、提取网页的标题等(其他标签可以类推,规则相同)4、可以实现简单的表单提交和
阅读全文
使用正则表达式获取博客列表数据


作者:郭建筑师860观点评论:2008年之前
鉴于我需要在MVC 3模拟博客园区企业系统中使用的测试数据,我太累了,无法输入自己,所以我抓取了一些博客园区的列表数据。请嘟嘟不要惊讶。正则表达式用于捕获博客公园数据,因此不熟悉正则表达式的朋友可以参考相关资料。其实很容易掌握,就是
阅读全文
[网站production design]静态和动态网页的特点和差异


作者:Da Wei_uuSem1413人查看的评论数量:2002年之前
通常,当企业需要网站进行设计时,在寻找网站建筑公司进行网站时,经常会被问及是动态还是静态构建网站。企业在建立网站时经常会问这些问题,因为很多人不明白什么是静态和动态的?因此,以下是对网站公司小编辑的分析:静态和动态网页的特点和差异
阅读全文
性能优化,使浏览器能够缓存动态网页

作者:760文艺青年浏览评论:2004年前
1:HTTP头介绍1.1对于浏览器的第一个请求,假设我们请求一个URL地址。例如,我的服务器上的静态页面将返回以下HTTP头信息:这里不包括HTTP头信息中每个参数的含义
阅读全文
占领学校(二))@


作者:lhyxxy1702观点评论:04年前
一,。初步的基本准备。哦,你不能直接开始准备。(1)create the project。输入:[Python]view plancy scapystartprojectw3school以创建上面的项目w3school。此时,将生成w3school文件夹
阅读全文
[C#][]通过WebBrowser获取Ajax网页

作者:Jack Chen 870观点评论:2007年之前
原文[c#][]通过WebBrowser获取Ajax后的网页今天,施敏问我,如果网页一开始是Ajax,会加载一些数据,但是如果你通过webclient捕获JavaScript和Ajax的源代码,有一种方法可以捕获
阅读全文
性能优化,使浏览器能够缓存动态网页


作者:luminji 574观点评论:2010年之前
在上一篇文章“为性能优化构建用户定义的文件缓存”中,我们使用outputcache允许请求访问服务器的输出缓存。我们扩展了outputcacheprovider,这相当于访问服务器上的静态资源。outputcache用于所有访问服务器资源的请求
阅读全文
ASP抓取网页相关问答问题
phpcurl采集Asp网页带有_eventvalidation


作者:萧旋风柴津1022观点点评:15年前
当使用PHP curl获取页面信息时,您会遇到ASP的“\u viewstate”和“\u eventvalidation”
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-14 12:17
什么是Ajax国内翻译常为“阿贾克斯”和阿贾克斯同音同音)
Ajax+php数据交互及页面局部刷新详解
时间:2019-03-30
本文章为大家介绍了Ajax+php数据交互和页面部分刷新的详细实现,主要包括Ajax+php数据交互和页面部分刷新的实现。使用实例,应用技巧,基本知识点总结和注意事项,有一定的参考价值,有需要的朋友可以参考。
什么是阿贾克斯?
国内翻译往往与“阿贾克斯”和阿贾克斯足球队相同。AJAX 是一种用于创建快速动态网页的技术。它不是一种新语言,而是一种使用现有标准的新方法。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新,从而可以在不重新加载整个网页的情况下更新网页的某个部分。
XMLHttpRequest 是 AJAX 的基础,用于与服务器交换数据。所有现代浏览器都支持 XMLHttpRequest 对象(IE5 和 IE6 使用 ActiveXObject)
下面文章主要介绍使用ajax与php数据交互,部分刷新页面相关内容。话不多说,一起来看看详细介绍:
一、 语法介绍
1.1 Ajax 基本语法
$.ajax({
type: "post", //数据提交方式(post/get)
url: "http://xxx/test/demo.php", //提交到的url
data: {username:username,password:password},//提交的数据
dataType: "json", //返回的数据类型格式
success: function(msg){
...//返回成功的回调函数
},
error:function(msg){
...//返回失败的回调函数
}
});
1.2 php接收方法
2.2 在demo.html中添加如下js代码
$(function(){
$('#sub').click(function(){
var username=$('#username').val();
var password=$('#password').val();
$.ajax({
type: "post",
url: "http://xxx/test/demo.php",
data: {username:username,password:password}, //提交到demo.php的数据
dataType: "json", //回调函数接收数据的数据格式
success: function(msg){
$('#text').empty(); //清空Text里面的所有内容
var data='';
if(msg!=''){
data = eval("("+msg+")"); //将返回的json数据进行解析,并赋给data
}
$('#text').html("用户名为:" + data.username + ",密码为:" + data.password); //在#text中输出
console.log(data); //控制台输出
},
error:function(msg){
console.log(msg);
}
});
});
})
2.3 php结束代码demo.php 查看全部
php 抓取网页ajax数据(
什么是Ajax国内翻译常为“阿贾克斯”和阿贾克斯同音同音)
Ajax+php数据交互及页面局部刷新详解
时间:2019-03-30
本文章为大家介绍了Ajax+php数据交互和页面部分刷新的详细实现,主要包括Ajax+php数据交互和页面部分刷新的实现。使用实例,应用技巧,基本知识点总结和注意事项,有一定的参考价值,有需要的朋友可以参考。
什么是阿贾克斯?
国内翻译往往与“阿贾克斯”和阿贾克斯足球队相同。AJAX 是一种用于创建快速动态网页的技术。它不是一种新语言,而是一种使用现有标准的新方法。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新,从而可以在不重新加载整个网页的情况下更新网页的某个部分。
XMLHttpRequest 是 AJAX 的基础,用于与服务器交换数据。所有现代浏览器都支持 XMLHttpRequest 对象(IE5 和 IE6 使用 ActiveXObject)
下面文章主要介绍使用ajax与php数据交互,部分刷新页面相关内容。话不多说,一起来看看详细介绍:
一、 语法介绍
1.1 Ajax 基本语法
$.ajax({
type: "post", //数据提交方式(post/get)
url: "http://xxx/test/demo.php", //提交到的url
data: {username:username,password:password},//提交的数据
dataType: "json", //返回的数据类型格式
success: function(msg){
...//返回成功的回调函数
},
error:function(msg){
...//返回失败的回调函数
}
});
1.2 php接收方法
2.2 在demo.html中添加如下js代码
$(function(){
$('#sub').click(function(){
var username=$('#username').val();
var password=$('#password').val();
$.ajax({
type: "post",
url: "http://xxx/test/demo.php",
data: {username:username,password:password}, //提交到demo.php的数据
dataType: "json", //回调函数接收数据的数据格式
success: function(msg){
$('#text').empty(); //清空Text里面的所有内容
var data='';
if(msg!=''){
data = eval("("+msg+")"); //将返回的json数据进行解析,并赋给data
}
$('#text').html("用户名为:" + data.username + ",密码为:" + data.password); //在#text中输出
console.log(data); //控制台输出
},
error:function(msg){
console.log(msg);
}
});
});
})
2.3 php结束代码demo.php
php 抓取网页ajax数据(php抓取网页ajax数据库文件夹多文件的formdata.php其他第三方库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-10 05:07
php抓取网页ajax数据库数据库文件夹多文件的formdata.php其他第三方库
你可以试试js库。flash的用不了多少中文,中文的flash很少很贵的,网上能找到基于flash的网页的mockinfo模拟登录的js,自己改写一下,也能用。
php的能够支持flash是理想的状态,flash现在的技术已经很完善了,有很多js代码无法实现的功能,但php代码其实也不是不能实现的功能,这个需要参考php官方的示例程序,每个不同的业务需求来对比在调整flash.js代码.
可以参考下这个免费的wordpress爬虫开发框架。.php文件也能使用。可以更改flash的模板,在.js文件中声明或者定义你需要什么数据的对应代码即可。参考:.比如需要显示cookie信息,就在.php文件加上flash.getcss('css').cookiejs,再比如需要爬下某些网站的商品详情信息,或者正常的页面商品信息,参考这个.php文件就可以。
试着自己写过,发现写不下去。如果题主想要的文件,
php-flash-cookie-script或者-php-flash-cookie-script文件,复制后再次加载就行了。
不知道,无从知道。但是我知道,肯定能用更加先进的web框架,例如x-flash,会有很大不同。 查看全部
php 抓取网页ajax数据(php抓取网页ajax数据库文件夹多文件的formdata.php其他第三方库)
php抓取网页ajax数据库数据库文件夹多文件的formdata.php其他第三方库
你可以试试js库。flash的用不了多少中文,中文的flash很少很贵的,网上能找到基于flash的网页的mockinfo模拟登录的js,自己改写一下,也能用。
php的能够支持flash是理想的状态,flash现在的技术已经很完善了,有很多js代码无法实现的功能,但php代码其实也不是不能实现的功能,这个需要参考php官方的示例程序,每个不同的业务需求来对比在调整flash.js代码.
可以参考下这个免费的wordpress爬虫开发框架。.php文件也能使用。可以更改flash的模板,在.js文件中声明或者定义你需要什么数据的对应代码即可。参考:.比如需要显示cookie信息,就在.php文件加上flash.getcss('css').cookiejs,再比如需要爬下某些网站的商品详情信息,或者正常的页面商品信息,参考这个.php文件就可以。
试着自己写过,发现写不下去。如果题主想要的文件,
php-flash-cookie-script或者-php-flash-cookie-script文件,复制后再次加载就行了。
不知道,无从知道。但是我知道,肯定能用更加先进的web框架,例如x-flash,会有很大不同。
php 抓取网页ajax数据(本文远程抓取数据的功能-本文实例讲述了。。 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-11-09 04:02
)
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
今天,我将做一个远程数据捕获功能。记住jquery可以用ajax远程捕获,但是不能跨域。我在网上搜索了很多。但是我觉得是一个综合性的问题,所以我觉得对于一个简单的问题来说稍微复杂一些,但至少现在已经解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post向服务器后端发送数据,由后端的PHP代码远程获取,存入数据库ajax返回数据给前台,前台使用JS接收数据并显示出来。
//远程抓取获取数据
$("#update_ac").click(function() {
$username = $("#username").text();
$("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){
$(this).html(" ");
});
$.post("update_ac/username/"+$username,{},function($data){
json = eval("(" + $data + ")");
$("#Submit").html(json.data.Submit);
$("#AC").html(json.data.AC);
$("#solved,#solved2,#solved3").html(json.data.solved);
$("#rank").html(json.data.rank);
}
),"json";
});
上面jquery代码四楼说的还算清楚,但是让我纠结的是json数据的接收
json = eval("(" + $data + ")");
//eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这还是在前台。跨域抓取是通过PHP扩展simple_html_dom完成的(不知道的可以上网搜一下,基于PHP5开发的)
抓取远程页面到本地。
import("@.ORG.simple_html_dom");
//thinkphp内导入扩展,你要把网上下载的代码改名为simple_html_dom.class.php放到APPNAME\Lib\ORG的目录下面
$html = file_get_html('http://openoj.awaysoft.com/JudgeOnline/userinfo.php?user='.$username); //远程抓取了
$ret = $html->find('center',0)->plaintext; //返回数据了。
以上代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后使用正则表达式过滤需要的数据。下面是渲染图
查看全部
php 抓取网页ajax数据(本文远程抓取数据的功能-本文实例讲述了。。
)
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
今天,我将做一个远程数据捕获功能。记住jquery可以用ajax远程捕获,但是不能跨域。我在网上搜索了很多。但是我觉得是一个综合性的问题,所以我觉得对于一个简单的问题来说稍微复杂一些,但至少现在已经解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post向服务器后端发送数据,由后端的PHP代码远程获取,存入数据库ajax返回数据给前台,前台使用JS接收数据并显示出来。
//远程抓取获取数据
$("#update_ac").click(function() {
$username = $("#username").text();
$("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){
$(this).html(" ");
});
$.post("update_ac/username/"+$username,{},function($data){
json = eval("(" + $data + ")");
$("#Submit").html(json.data.Submit);
$("#AC").html(json.data.AC);
$("#solved,#solved2,#solved3").html(json.data.solved);
$("#rank").html(json.data.rank);
}
),"json";
});
上面jquery代码四楼说的还算清楚,但是让我纠结的是json数据的接收
json = eval("(" + $data + ")");
//eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这还是在前台。跨域抓取是通过PHP扩展simple_html_dom完成的(不知道的可以上网搜一下,基于PHP5开发的)
抓取远程页面到本地。
import("@.ORG.simple_html_dom");
//thinkphp内导入扩展,你要把网上下载的代码改名为simple_html_dom.class.php放到APPNAME\Lib\ORG的目录下面
$html = file_get_html('http://openoj.awaysoft.com/JudgeOnline/userinfo.php?user='.$username); //远程抓取了
$ret = $html->find('center',0)->plaintext; //返回数据了。
以上代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后使用正则表达式过滤需要的数据。下面是渲染图
php 抓取网页ajax数据(,结合jQuery的ajax实现跨域抓取数据的相关操作技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-11-05 14:04
本文文章主要介绍了jquery+thinkphp实现跨域数据捕获的方法,并结合实例形式分析thinkPHP结合jQuery的ajax实现跨域数据捕获的相关操作技巧。有需要的朋友可以参考以下
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
今天,我将做一个远程数据捕获功能。记住jquery可以用ajax远程捕获,但是不能跨域。我在网上搜索了很多。但是我觉得是一个综合性的问题,所以我觉得对于一个简单的问题来说稍微复杂一些,但至少现在已经解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post向服务器后端发送数据,由后端的PHP代码远程获取,存入数据库ajax返回数据给前台,前台使用JS接收数据并显示出来。
//远程抓取获取数据 $("#update_ac").click(function() { $username = $("#username").text(); $("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){ $(this).html(" "); }); $.post("update_ac/username/"+$username,{},function($data){ json = eval("(" + $data + ")"); $("#Submit").html(json.data.Submit); $("#AC").html(json.data.AC); $("#solved,#solved2,#solved3").html(json.data.solved); $("#rank").html(json.data.rank); } ),"json"; });
上面jquery代码四楼说的还算清楚,但是让我纠结的是json数据的接收
json = eval("(" + $data + ")"); //eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这还是前台。跨域抓取是通过PHP扩展simple_html_dom完成的(不知道的可以上网搜一下,基于PHP5开发的)
抓取远程页面到本地。
以上代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后使用正则表达式过滤需要的数据。下面是渲染图
对thinkPHP相关内容更感兴趣的读者可以查看本站主题:《》、《ThinkPHP模板操作技巧总结》、《ThinkPHP常用方法总结》、《Smarty模板介绍基础教程》、《总结》 PHP模板技术”。
我希望本文对您基于 ThinkPHP 框架的 PHP 编程有所帮助。
以上就是jquery+thinkphp实现跨域数据抓取的方法的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
php 抓取网页ajax数据(,结合jQuery的ajax实现跨域抓取数据的相关操作技巧)
本文文章主要介绍了jquery+thinkphp实现跨域数据捕获的方法,并结合实例形式分析thinkPHP结合jQuery的ajax实现跨域数据捕获的相关操作技巧。有需要的朋友可以参考以下
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
今天,我将做一个远程数据捕获功能。记住jquery可以用ajax远程捕获,但是不能跨域。我在网上搜索了很多。但是我觉得是一个综合性的问题,所以我觉得对于一个简单的问题来说稍微复杂一些,但至少现在已经解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post向服务器后端发送数据,由后端的PHP代码远程获取,存入数据库ajax返回数据给前台,前台使用JS接收数据并显示出来。
//远程抓取获取数据 $("#update_ac").click(function() { $username = $("#username").text(); $("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){ $(this).html(" "); }); $.post("update_ac/username/"+$username,{},function($data){ json = eval("(" + $data + ")"); $("#Submit").html(json.data.Submit); $("#AC").html(json.data.AC); $("#solved,#solved2,#solved3").html(json.data.solved); $("#rank").html(json.data.rank); } ),"json"; });
上面jquery代码四楼说的还算清楚,但是让我纠结的是json数据的接收
json = eval("(" + $data + ")"); //eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这还是前台。跨域抓取是通过PHP扩展simple_html_dom完成的(不知道的可以上网搜一下,基于PHP5开发的)
抓取远程页面到本地。
以上代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后使用正则表达式过滤需要的数据。下面是渲染图
对thinkPHP相关内容更感兴趣的读者可以查看本站主题:《》、《ThinkPHP模板操作技巧总结》、《ThinkPHP常用方法总结》、《Smarty模板介绍基础教程》、《总结》 PHP模板技术”。
我希望本文对您基于 ThinkPHP 框架的 PHP 编程有所帮助。
以上就是jquery+thinkphp实现跨域数据抓取的方法的详细内容。更多详情请关注其他相关html中文网站文章!
php 抓取网页ajax数据( 这是-typecraping数据,发现问题元素都选择好了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-11-03 21:04
这是-typecraping数据,发现问题元素都选择好了)
这是简单数据分析系列文章的第十篇。
原文首发于Blog Garden: Simple Data Analysis 10。
**友情提示:**本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从体验。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们动手的网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容是精华帖的标题、回复者和批准数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据数量控制items数量的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素都选好了,我们沿着Sitemap 知乎_top_answers -> Scrape -> Start craping抓取数据的路径,等了十多秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获哪些数据?怎么全都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
**1.** 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
**2.** 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
**3.** 我们再点一下标题,我们会发现会跳转到Elements子面板,里面有一些色彩斑斓的看不懂的代码
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑,它们是网页中的一个骨架,并提供一些排版功能。如果你平时用markdown写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']这个匹配规则是怎么回事。
首先,这是一个树状结构:
上面这句话是从视觉上分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
如何快速成为数据分析师?
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在这个标题的代码中,缺少名为 div 属性的标签 itemprop='知乎:question' !结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题时,无论标题的嵌套关系如何变化,总会有一个标签保持不变,即包裹在最外层的h2标签,属性名class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就可以完美匹配标题内容了?
逻辑上理清了关系,我们如何使用Web Scraper?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们点击P键两次匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape进行数据抓取,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据完成的很快,但是匹配元素需要很多时间。
这间接说明了知乎this网站从代码上分析,写的还是比较烂的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小规模的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再大规模增加正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。 查看全部
php 抓取网页ajax数据(
这是-typecraping数据,发现问题元素都选择好了)
这是简单数据分析系列文章的第十篇。
原文首发于Blog Garden: Simple Data Analysis 10。
**友情提示:**本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从体验。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们动手的网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容是精华帖的标题、回复者和批准数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据数量控制items数量的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素都选好了,我们沿着Sitemap 知乎_top_answers -> Scrape -> Start craping抓取数据的路径,等了十多秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获哪些数据?怎么全都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
**1.** 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
**2.** 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
**3.** 我们再点一下标题,我们会发现会跳转到Elements子面板,里面有一些色彩斑斓的看不懂的代码
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑,它们是网页中的一个骨架,并提供一些排版功能。如果你平时用markdown写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']这个匹配规则是怎么回事。
首先,这是一个树状结构:
上面这句话是从视觉上分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
如何快速成为数据分析师?
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在这个标题的代码中,缺少名为 div 属性的标签 itemprop='知乎:question' !结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题时,无论标题的嵌套关系如何变化,总会有一个标签保持不变,即包裹在最外层的h2标签,属性名class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就可以完美匹配标题内容了?
逻辑上理清了关系,我们如何使用Web Scraper?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们点击P键两次匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape进行数据抓取,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据完成的很快,但是匹配元素需要很多时间。
这间接说明了知乎this网站从代码上分析,写的还是比较烂的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小规模的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再大规模增加正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。
php 抓取网页ajax数据(抓ajax异步内容页面和抓普通的页面区别。 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-11-01 15:22
)
其实抓取ajax异步内容页面和抓取普通页面没有太大区别。 Ajax 只是发出一个异步 http 请求。用类似firebug的工具,找到请求的后端服务url和传参值,然后抓取url传参即可。
使用 firebug 的网络工具
如果抓取一个页面,内容中没有显示的数据是一堆js代码。
代码
$cookie_file=tempnam('./temp','cookie');
$ch = curl_init();
$url1 = "http://www.cdut.edu.cn/default.html";
curl_setopt($ch,curlopt_url,$url1);
curl_setopt($ch,curlopt_http_version,curl_http_version_1_1);
curl_setopt($ch,curlopt_header,0);
curl_setopt($ch,curlopt_returntransfer,1);
curl_setopt($ch,curlopt_followlocation,1);
curl_setopt($ch, curlopt_encoding ,'gzip'); //加入gzip解析
//设置连接结束后保存cookie信息的文件
curl_setopt($ch,curlopt_cookiejar,$cookie_file);
$content=curl_exec($ch);
curl_close($ch);
$ch3 = curl_init();
$url3 = "http://www.cdut.edu.cn/xww/dwr ... 3B%3B
$curlpost = "callcount=1&page=/xww/type/1000020118.html&httpsessionid=12a9b726e6a2d4d3b09de7952b2f282c&scriptsessionid=295315b4b4141b09da888d3a3adb8faa658&c0-scriptname=portalajax&c0-methodname=getnewsxml&c0-id=0&c0-param0=string:10000201&c0-param1=string:1000020118&c0-param2=string:news_&c0-param3=number:5969&c0-param4=number:1&c0-param5=null:null&c0-param6=null:null&batchid=0";
curl_setopt($ch3,curlopt_url,$url3);
curl_setopt($ch3,curlopt_post,1);
curl_setopt($ch3,curlopt_postfields,$curlpost);
//设置连接结束后保存cookie信息的文件
curl_setopt($ch3,curlopt_cookiefile,$cookie_file);
$content1=curl_exec($ch3);
curl_close($ch3); 查看全部
php 抓取网页ajax数据(抓ajax异步内容页面和抓普通的页面区别。
)
其实抓取ajax异步内容页面和抓取普通页面没有太大区别。 Ajax 只是发出一个异步 http 请求。用类似firebug的工具,找到请求的后端服务url和传参值,然后抓取url传参即可。
使用 firebug 的网络工具
如果抓取一个页面,内容中没有显示的数据是一堆js代码。
代码
$cookie_file=tempnam('./temp','cookie');
$ch = curl_init();
$url1 = "http://www.cdut.edu.cn/default.html";
curl_setopt($ch,curlopt_url,$url1);
curl_setopt($ch,curlopt_http_version,curl_http_version_1_1);
curl_setopt($ch,curlopt_header,0);
curl_setopt($ch,curlopt_returntransfer,1);
curl_setopt($ch,curlopt_followlocation,1);
curl_setopt($ch, curlopt_encoding ,'gzip'); //加入gzip解析
//设置连接结束后保存cookie信息的文件
curl_setopt($ch,curlopt_cookiejar,$cookie_file);
$content=curl_exec($ch);
curl_close($ch);
$ch3 = curl_init();
$url3 = "http://www.cdut.edu.cn/xww/dwr ... 3B%3B
$curlpost = "callcount=1&page=/xww/type/1000020118.html&httpsessionid=12a9b726e6a2d4d3b09de7952b2f282c&scriptsessionid=295315b4b4141b09da888d3a3adb8faa658&c0-scriptname=portalajax&c0-methodname=getnewsxml&c0-id=0&c0-param0=string:10000201&c0-param1=string:1000020118&c0-param2=string:news_&c0-param3=number:5969&c0-param4=number:1&c0-param5=null:null&c0-param6=null:null&batchid=0";
curl_setopt($ch3,curlopt_url,$url3);
curl_setopt($ch3,curlopt_post,1);
curl_setopt($ch3,curlopt_postfields,$curlpost);
//设置连接结束后保存cookie信息的文件
curl_setopt($ch3,curlopt_cookiefile,$cookie_file);
$content1=curl_exec($ch3);
curl_close($ch3);
php 抓取网页ajax数据(PHP+Ajax实现的无刷新功能,结合实例形式分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-10-28 18:03
本文文章主要介绍了PHP+Ajax实现的非刷新分页功能,分析了php+ajax通过pdo操作类读取数据库和分页显示通过pdo操作类的相关实现技巧,以及为读者提供演示源代码。下载参考,有需要的朋友可以参考
本文介绍了PHP+Ajax实现的非刷新分页功能。分享给大家,供大家参考,如下:
注:本文用到的部分库可以在前面的文章中找到源码,我会在文中注明链接,为了缩短文章的篇幅,以及由此带来的阅读不便对此,请谅解。
本文讲解Ajax如何实现非刷新分页、实现原理、代码展示、代码下载。
这里需要说明一些知识:
1、Ajax不刷新页面的好处:提供良好的客户体验,通过Ajax从数据库中获取数据并在后台展示,消除等待页面加载的空白状态;
2、那么,Ajax 非刷新页面是否运行在动态页面(.php)上?还是静态页面(.html/.htm/.shtml)?答案是:静态页面;
3、 实现原理:通过前端JS脚本程序和Ajax结合获取动态页面返回的数据,并显示出来。
好的,让我们解释一下下面的代码:
由于它在静态页面上运行,我们首先创建一个静态 HTML 页面。index.html 的代码清单如下。
索引.html
Ajax 实现无刷新页面 body { font-size:12px; } 数据加载中...
在代码清单中,我们加载了一个Ajax类库,可以在文章中找到(附上使用方法)
在这个静态页面中,只显示了一个“Data Loading...”,并没有数据。这时候我们就需要一个JS脚本,通过ajax从数据库中获取数据。JS脚本如下:
仔细阅读上面的代码,你会发现以下现象:
1、setPage(pageNum) 是一个JS函数接口,用于从数据库中提取数据;
2、ajax通过article.php文件获取数据;
3、article.php?page=xx,其中xx是要获取的页码数据,
setPage(1): 是获取第一页数据;
setPage(2): 是获取第2页的数据;
setPage(100): 是获取第100页数据;
...
那么,如何从article.php文件中获取数据呢?请参阅下面的代码清单。
文章.php
article.php中连接的数据是之前从华强电子网文章抓取的信息数据。由于数据比较大,将article.sql文件附在代码包下载下来供大家测试。
静态页面index.html显示的数据是article.php文件中echo的代码。
代码文件中的config.inc.php文件主要定义了一些常量,如:数据库用户名、数据库密码、主机...、数据库连接类库(Db.class.php)和数据库操作类库(Model.php)。 class.php),请参考文章,有使用说明。
程序效果图:
对图标的赌注是关注关注的地方。
这样,Ajax 非刷新分页就完成了。程序中还有一个ajaxPage.class.php,没有说明。其实这个ajaxPage库的用法和一般的分页库是一样的。
即:
$page = new ajaxPage(记录总数, 每页显示数);
详情请下载代码并阅读。 查看全部
php 抓取网页ajax数据(PHP+Ajax实现的无刷新功能,结合实例形式分析)
本文文章主要介绍了PHP+Ajax实现的非刷新分页功能,分析了php+ajax通过pdo操作类读取数据库和分页显示通过pdo操作类的相关实现技巧,以及为读者提供演示源代码。下载参考,有需要的朋友可以参考
本文介绍了PHP+Ajax实现的非刷新分页功能。分享给大家,供大家参考,如下:
注:本文用到的部分库可以在前面的文章中找到源码,我会在文中注明链接,为了缩短文章的篇幅,以及由此带来的阅读不便对此,请谅解。
本文讲解Ajax如何实现非刷新分页、实现原理、代码展示、代码下载。
这里需要说明一些知识:
1、Ajax不刷新页面的好处:提供良好的客户体验,通过Ajax从数据库中获取数据并在后台展示,消除等待页面加载的空白状态;
2、那么,Ajax 非刷新页面是否运行在动态页面(.php)上?还是静态页面(.html/.htm/.shtml)?答案是:静态页面;
3、 实现原理:通过前端JS脚本程序和Ajax结合获取动态页面返回的数据,并显示出来。
好的,让我们解释一下下面的代码:
由于它在静态页面上运行,我们首先创建一个静态 HTML 页面。index.html 的代码清单如下。
索引.html
Ajax 实现无刷新页面 body { font-size:12px; } 数据加载中...
在代码清单中,我们加载了一个Ajax类库,可以在文章中找到(附上使用方法)
在这个静态页面中,只显示了一个“Data Loading...”,并没有数据。这时候我们就需要一个JS脚本,通过ajax从数据库中获取数据。JS脚本如下:
仔细阅读上面的代码,你会发现以下现象:
1、setPage(pageNum) 是一个JS函数接口,用于从数据库中提取数据;
2、ajax通过article.php文件获取数据;
3、article.php?page=xx,其中xx是要获取的页码数据,
setPage(1): 是获取第一页数据;
setPage(2): 是获取第2页的数据;
setPage(100): 是获取第100页数据;
...
那么,如何从article.php文件中获取数据呢?请参阅下面的代码清单。
文章.php
article.php中连接的数据是之前从华强电子网文章抓取的信息数据。由于数据比较大,将article.sql文件附在代码包下载下来供大家测试。
静态页面index.html显示的数据是article.php文件中echo的代码。
代码文件中的config.inc.php文件主要定义了一些常量,如:数据库用户名、数据库密码、主机...、数据库连接类库(Db.class.php)和数据库操作类库(Model.php)。 class.php),请参考文章,有使用说明。
程序效果图:
对图标的赌注是关注关注的地方。
这样,Ajax 非刷新分页就完成了。程序中还有一个ajaxPage.class.php,没有说明。其实这个ajaxPage库的用法和一般的分页库是一样的。
即:
$page = new ajaxPage(记录总数, 每页显示数);
详情请下载代码并阅读。
php 抓取网页ajax数据(本文远程抓取数据的功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-27 18:20
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
今天来做一个远程数据采集功能。记住jquery可以用ajax远程捕获,但是不能跨域。我在网上搜索了很多。但是我觉得是一个综合性的问题,所以我觉得对于一个简单的问题来说稍微复杂一些,但至少现在已经解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post发送数据到服务器后端,由后端的php代码远程获取,存入数据库ajax返回数据给前台,前台使用js接收数据并显示出来。
//远程抓取获取数据
$("#update_ac").click(function() {
$username = $("#username").text();
$("#ac,#rank,#submit,#solved,#solved2,#solved3").ajaxstart(function(){
$(this).html(" ");
});
$.post("update_ac/username/"+$username,{},function($data){
json = eval("(" + $data + ")");
$("#submit").html(json.data.submit);
$("#ac").html(json.data.ac);
$("#solved,#solved2,#solved3").html(json.data.solved);
$("#rank").html(json.data.rank);
}
),"json";
});
上面jquery代码四楼说的还算清楚,但是让我纠结的是json数据的接收
json = eval("(" + $data + ")");
//eval() 函数可计算某个字符串,并执行其中的的 javascript 代码。
其实这还是在前台。跨域爬取用php扩展simple_html_dom完成(不知道的可以上网搜索,基于php5开发的)
抓取远程页面到本地。
import("@.org.simple_html_dom");
//thinkphp内导入扩展,你要把网上下载的代码改名为simple_html_dom.class.php放到appname\lib\org的目录下面
$html = file_get_html('http://openoj.awaysoft.com/judgeonline/userinfo.php?user='.$username); //远程抓取了
$ret = $html->find('center',0)->plaintext; //返回数据了。
以上代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后使用正则表达式过滤需要的数据。下面是渲染图
对thinkphp相关内容更感兴趣的读者可以查看本站专题:《Thinkphp入门教程》、《Thinkphp模板操作技巧汇总》、《Thinkphp常用方法汇总》、《Smarty模板介绍基础教程》和《PHP模板技术总结》》。
希望这篇文章能帮助你设计基于thinkphp框架的php编程。 查看全部
php 抓取网页ajax数据(本文远程抓取数据的功能)
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
今天来做一个远程数据采集功能。记住jquery可以用ajax远程捕获,但是不能跨域。我在网上搜索了很多。但是我觉得是一个综合性的问题,所以我觉得对于一个简单的问题来说稍微复杂一些,但至少现在已经解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post发送数据到服务器后端,由后端的php代码远程获取,存入数据库ajax返回数据给前台,前台使用js接收数据并显示出来。
//远程抓取获取数据
$("#update_ac").click(function() {
$username = $("#username").text();
$("#ac,#rank,#submit,#solved,#solved2,#solved3").ajaxstart(function(){
$(this).html(" ");
});
$.post("update_ac/username/"+$username,{},function($data){
json = eval("(" + $data + ")");
$("#submit").html(json.data.submit);
$("#ac").html(json.data.ac);
$("#solved,#solved2,#solved3").html(json.data.solved);
$("#rank").html(json.data.rank);
}
),"json";
});
上面jquery代码四楼说的还算清楚,但是让我纠结的是json数据的接收
json = eval("(" + $data + ")");
//eval() 函数可计算某个字符串,并执行其中的的 javascript 代码。
其实这还是在前台。跨域爬取用php扩展simple_html_dom完成(不知道的可以上网搜索,基于php5开发的)
抓取远程页面到本地。
import("@.org.simple_html_dom");
//thinkphp内导入扩展,你要把网上下载的代码改名为simple_html_dom.class.php放到appname\lib\org的目录下面
$html = file_get_html('http://openoj.awaysoft.com/judgeonline/userinfo.php?user='.$username); //远程抓取了
$ret = $html->find('center',0)->plaintext; //返回数据了。
以上代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后使用正则表达式过滤需要的数据。下面是渲染图
对thinkphp相关内容更感兴趣的读者可以查看本站专题:《Thinkphp入门教程》、《Thinkphp模板操作技巧汇总》、《Thinkphp常用方法汇总》、《Smarty模板介绍基础教程》和《PHP模板技术总结》》。
希望这篇文章能帮助你设计基于thinkphp框架的php编程。
php 抓取网页ajax数据( 什么是Ajax?国内翻译常为“阿贾克斯”和阿贾克斯足球队同音)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-26 20:18
什么是Ajax?国内翻译常为“阿贾克斯”和阿贾克斯足球队同音)
什么是阿贾克斯?
国内翻译往往与“阿贾克斯”和阿贾克斯足球队相同。AJAX 是一种用于创建快速动态网页的技术。它不是一种新语言,而是一种使用现有标准的新方法。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新,从而可以在不重新加载整个网页的情况下更新网页的某个部分。
XMLHttpRequest 是 AJAX 的基础,用于与服务器交换数据。所有现代浏览器都支持 XMLHttpRequest 对象(IE5 和 IE6 使用 ActiveXObject)
下面文章主要介绍使用ajax与php数据交互,部分刷新页面相关内容。话不多说,一起来看看详细介绍:
一、 语法介绍
1.1 Ajax 基本语法
$.ajax({
type: "post", //数据提交方式(post/get)
url: "http://xxx/test/demo.php", //提交到的url
data: {username:username,password:password},//提交的数据
dataType: "json", //返回的数据类型格式
success: function(msg){
...//返回成功的回调函数
},
error:function(msg){
...//返回失败的回调函数
}
});
1.2 php接收方法
2.2 在demo.html中添加如下js代码
$(function(){
$('#sub').click(function(){
var username=$('#username').val();
var password=$('#password').val();
$.ajax({
type: "post",
url: "http://xxx/test/demo.php",
data: {username:username,password:password}, //提交到demo.php的数据
dataType: "json", //回调函数接收数据的数据格式
success: function(msg){
$('#text').empty(); //清空Text里面的所有内容
var data='';
if(msg!=''){
data = eval("("+msg+")"); //将返回的json数据进行解析,并赋给data
}
$('#text').html("用户名为:" + data.username + ",密码为:" + data.password); //在#text中输出
console.log(data); //控制台输出
},
error:function(msg){
console.log(msg);
}
});
});
})
2.3 php结束代码demo.php 查看全部
php 抓取网页ajax数据(
什么是Ajax?国内翻译常为“阿贾克斯”和阿贾克斯足球队同音)
什么是阿贾克斯?
国内翻译往往与“阿贾克斯”和阿贾克斯足球队相同。AJAX 是一种用于创建快速动态网页的技术。它不是一种新语言,而是一种使用现有标准的新方法。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新,从而可以在不重新加载整个网页的情况下更新网页的某个部分。
XMLHttpRequest 是 AJAX 的基础,用于与服务器交换数据。所有现代浏览器都支持 XMLHttpRequest 对象(IE5 和 IE6 使用 ActiveXObject)
下面文章主要介绍使用ajax与php数据交互,部分刷新页面相关内容。话不多说,一起来看看详细介绍:
一、 语法介绍
1.1 Ajax 基本语法
$.ajax({
type: "post", //数据提交方式(post/get)
url: "http://xxx/test/demo.php", //提交到的url
data: {username:username,password:password},//提交的数据
dataType: "json", //返回的数据类型格式
success: function(msg){
...//返回成功的回调函数
},
error:function(msg){
...//返回失败的回调函数
}
});
1.2 php接收方法
2.2 在demo.html中添加如下js代码
$(function(){
$('#sub').click(function(){
var username=$('#username').val();
var password=$('#password').val();
$.ajax({
type: "post",
url: "http://xxx/test/demo.php",
data: {username:username,password:password}, //提交到demo.php的数据
dataType: "json", //回调函数接收数据的数据格式
success: function(msg){
$('#text').empty(); //清空Text里面的所有内容
var data='';
if(msg!=''){
data = eval("("+msg+")"); //将返回的json数据进行解析,并赋给data
}
$('#text').html("用户名为:" + data.username + ",密码为:" + data.password); //在#text中输出
console.log(data); //控制台输出
},
error:function(msg){
console.log(msg);
}
});
});
})
2.3 php结束代码demo.php
php 抓取网页ajax数据(本文远程抓取数据的功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-21 23:05
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
今天来做一个远程数据采集功能。记住jquery可以用ajax远程捕获,但是不能跨域。我在网上搜索了很多。但是我觉得是一个综合性的问题,所以我觉得对于一个简单的问题来说稍微复杂一些,但至少现在已经解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post向服务器后端发送数据,由后端的php代码远程获取,存入数据库ajax返回数据给前台,前台使用js接收数据并显示出来。
//远程抓取获取数据
$("#update_ac").click(function() {
$username = $("#username").text();
$("#ac,#rank,#submit,#solved,#solved2,#solved3").ajaxstart(function(){
$(this).html(" ");
});
$.post("update_ac/username/"+$username,{},function($data){
json = eval("(" + $data + ")");
$("#submit").html(json.data.submit);
$("#ac").html(json.data.ac);
$("#solved,#solved2,#solved3").html(json.data.solved);
$("#rank").html(json.data.rank);
}
),"json";
});
上面jquery代码四楼说的还算清楚,但是让我纠结的是json数据的接收
json = eval("(" + $data + ")");
//eval() 函数可计算某个字符串,并执行其中的的 javascript 代码。
其实这还是在前台。跨域爬取用php扩展simple_html_dom完成(不知道的可以上网搜索,基于php5开发)
抓取远程页面到本地。
import("@.org.simple_html_dom");
//thinkphp内导入扩展,你要把网上下载的代码改名为simple_html_dom.class.php放到appname\lib\org的目录下面
$html = file_get_html('http://openoj.awaysoft.com/judgeonline/userinfo.php?user='.$username); //远程抓取了
$ret = $html->find('center',0)->plaintext; //返回数据了。
以上代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后使用正则表达式过滤需要的数据。下面是渲染图
对thinkphp相关内容更感兴趣的读者可以查看本站专题:《Thinkphp介绍教程》、《Thinkphp模板操作技巧汇总》、《Thinkphp常用方法汇总》、《Smarty模板介绍基础教程》和《PHP模板技术总结》》。
希望这篇文章能帮助你设计基于thinkphp框架的php编程。 查看全部
php 抓取网页ajax数据(本文远程抓取数据的功能)
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
今天来做一个远程数据采集功能。记住jquery可以用ajax远程捕获,但是不能跨域。我在网上搜索了很多。但是我觉得是一个综合性的问题,所以我觉得对于一个简单的问题来说稍微复杂一些,但至少现在已经解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post向服务器后端发送数据,由后端的php代码远程获取,存入数据库ajax返回数据给前台,前台使用js接收数据并显示出来。
//远程抓取获取数据
$("#update_ac").click(function() {
$username = $("#username").text();
$("#ac,#rank,#submit,#solved,#solved2,#solved3").ajaxstart(function(){
$(this).html(" ");
});
$.post("update_ac/username/"+$username,{},function($data){
json = eval("(" + $data + ")");
$("#submit").html(json.data.submit);
$("#ac").html(json.data.ac);
$("#solved,#solved2,#solved3").html(json.data.solved);
$("#rank").html(json.data.rank);
}
),"json";
});
上面jquery代码四楼说的还算清楚,但是让我纠结的是json数据的接收
json = eval("(" + $data + ")");
//eval() 函数可计算某个字符串,并执行其中的的 javascript 代码。
其实这还是在前台。跨域爬取用php扩展simple_html_dom完成(不知道的可以上网搜索,基于php5开发)
抓取远程页面到本地。
import("@.org.simple_html_dom");
//thinkphp内导入扩展,你要把网上下载的代码改名为simple_html_dom.class.php放到appname\lib\org的目录下面
$html = file_get_html('http://openoj.awaysoft.com/judgeonline/userinfo.php?user='.$username); //远程抓取了
$ret = $html->find('center',0)->plaintext; //返回数据了。
以上代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后使用正则表达式过滤需要的数据。下面是渲染图
对thinkphp相关内容更感兴趣的读者可以查看本站专题:《Thinkphp介绍教程》、《Thinkphp模板操作技巧汇总》、《Thinkphp常用方法汇总》、《Smarty模板介绍基础教程》和《PHP模板技术总结》》。
希望这篇文章能帮助你设计基于thinkphp框架的php编程。
php 抓取网页ajax数据(php抓取网页ajax数据,转存成xml返回给前端)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-10-18 22:02
php抓取网页ajax数据,转存成xml返回给前端。前端再用javascript渲染。做过ajax数据抓取的同学应该很好理解。但也要注意一点。不论你抓取什么数据,都要以数据的真实性为前提,否则你的结果不可信。否则请求到的数据可能会有误解,前端交互的结果也可能会不一致。针对:请求网页的方式有两种:formaction="/ajax..."xmlhttp="/"在选择请求数据源是的时候要注意对后端返回的返回值的验证。
cookie和浏览器缓存会对请求报文header有一个读取校验,因此判断数据源是否安全是很有必要的。想到之前一个同学需要爬取某网站的某用户关注的数据,可用ajax设置请求方式成功启动,访问后发现请求的正是某用户的个人详细资料。而后端却返回的这样的结果更多内容请关注微信公众号【思源黑客】;思源黑客是一个前端极客团队,专注前端技术。每周都会推送精选的前端文章,以及最新的前端学习资料,相信一定会让你受益匪浅!。 查看全部
php 抓取网页ajax数据(php抓取网页ajax数据,转存成xml返回给前端)
php抓取网页ajax数据,转存成xml返回给前端。前端再用javascript渲染。做过ajax数据抓取的同学应该很好理解。但也要注意一点。不论你抓取什么数据,都要以数据的真实性为前提,否则你的结果不可信。否则请求到的数据可能会有误解,前端交互的结果也可能会不一致。针对:请求网页的方式有两种:formaction="/ajax..."xmlhttp="/"在选择请求数据源是的时候要注意对后端返回的返回值的验证。
cookie和浏览器缓存会对请求报文header有一个读取校验,因此判断数据源是否安全是很有必要的。想到之前一个同学需要爬取某网站的某用户关注的数据,可用ajax设置请求方式成功启动,访问后发现请求的正是某用户的个人详细资料。而后端却返回的这样的结果更多内容请关注微信公众号【思源黑客】;思源黑客是一个前端极客团队,专注前端技术。每周都会推送精选的前端文章,以及最新的前端学习资料,相信一定会让你受益匪浅!。
php 抓取网页ajax数据(如何分析ajax接口,模拟ajax请求爬取数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-16 13:22
抓取ajax网站可以通过解析ajax接口获取返回的json数据,从而抓取到我们想要的数据,以今日头条为例,如何解析ajax接口,模拟ajax请求抓取数据。
以今天的头条街拍为例。网页上一页仅显示部分数据。您需要向下滚动才能查看后续数据。下面我们来分析一下它的ajax接口。
打开开发者工具,选择network,点击XHR过滤掉ajax请求,可以看到这里有很多参数,其中一个可以一目了然的就是keyword,就是我们搜索到的关键字。然后查看它的预览信息。
在预览信息中,可以看到有很多数据信息,点击一下,可以看到里面收录了很多有用的信息,比如街拍标题、图片地址等。
当鼠标向下滑动时,会过滤掉多一个ajax请求,如下图
可以看到offset参数从0变成了20,仔细看网页,可以发现网页上正好显示了20条信息。
这是当鼠标滑到第三页时,可以看到offset参数变为40。当第一页offset参数为0时,第二页offset参数为20,第三页参数为40。就是不难发现,offset参数其实就是offset,用来实现翻页参数。然后我们可以使用urlencode方法将这些参数拼接在url后面,发起ajax请求,通过控制传入的offset参数来控制翻页,然后使用response.json()获取网页返回的json数据。
代码思路:1.分析网页的ajax接口,需要传入哪些数据2.通过urlencode关键参数将url拼接到请求后,通过控制指定抓取哪些页面内容偏移参数。3.生成不同页面的请求,获取json数据中图片的url信息4.请求图片的url,下载图片5.保存到文件夹中。
实际代码
import requests
from urllib.parse import urlencode,urljoin
import os
from hashlib import md5
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36",
"X-Requested-With":"XMLHttpRequest"
}
def get_page(offset):
"""
:param offset: 偏移量,控制翻页
:return:
"""
params = {
"offset":offset,
"format":"json",
"keyword":"街拍",
"autoload":"true",
"count":"20",
"cur_tab":"1",
"from":"search_tab"
}
url = "https://www.toutiao.com/search_content/?" + urlencode(params)
try:
response = requests.get(url,headers=headers,timeout=5)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
return None
def get_image(json):
"""
:param json: 获取到返回的json数据
:return:
"""
if json:
for item in json.get("data"):
title = item.get("title")
images = item.get("image_list")
if images:
for image in images:
yield {
"title":title,
"image":urljoin("http:",image.get("url")) if type(image) == type({"t":1}) else urljoin("http:",image)
}
def save_images(item):
"""
将图片保存到文件夹,以标题命名文件夹
:param item: json数据
:return:
"""
if item.get("title") != None:
if not os.path.exists(item.get("title")):
os.mkdir(item.get("title"))
else:
pass
try:
response = requests.get(item.get("image"))
if response.status_code == 200:
file_path = "{0}/{1}.{2}".format(item.get("title") if item.get("title") != None else "Notitle",md5(response.content).hexdigest(),"jpg")
if not os.path.exists(file_path):
with open(file_path,"wb") as f:
f.write(response.content)
else:
print("Already Downloaded",file_path)
except requests.ConnectionError:
print("Failed Download Image")
def main(offset):
"""
控制爬取的主要逻辑
:param offset: 偏移量
:return:
"""
json = get_page(offset)
for item in get_image(json):
print(item)
save_images(item)
groups = [i*20 for i in range(1,10)]
if __name__ == '__main__':
for group in groups:
main(group)
爬取的结果
通过分析ajax接口,比selenium模拟更容易模拟ajax请求进行爬取,但是代码复用性较差,因为每个网页的接口不同,所以在捕获ajax加载的数据时,仍然使用selenium模拟直接抓取接口数据,需要根据自己的实际需要选择。 查看全部
php 抓取网页ajax数据(如何分析ajax接口,模拟ajax请求爬取数据(组图))
抓取ajax网站可以通过解析ajax接口获取返回的json数据,从而抓取到我们想要的数据,以今日头条为例,如何解析ajax接口,模拟ajax请求抓取数据。
以今天的头条街拍为例。网页上一页仅显示部分数据。您需要向下滚动才能查看后续数据。下面我们来分析一下它的ajax接口。
打开开发者工具,选择network,点击XHR过滤掉ajax请求,可以看到这里有很多参数,其中一个可以一目了然的就是keyword,就是我们搜索到的关键字。然后查看它的预览信息。
在预览信息中,可以看到有很多数据信息,点击一下,可以看到里面收录了很多有用的信息,比如街拍标题、图片地址等。
当鼠标向下滑动时,会过滤掉多一个ajax请求,如下图
可以看到offset参数从0变成了20,仔细看网页,可以发现网页上正好显示了20条信息。
这是当鼠标滑到第三页时,可以看到offset参数变为40。当第一页offset参数为0时,第二页offset参数为20,第三页参数为40。就是不难发现,offset参数其实就是offset,用来实现翻页参数。然后我们可以使用urlencode方法将这些参数拼接在url后面,发起ajax请求,通过控制传入的offset参数来控制翻页,然后使用response.json()获取网页返回的json数据。
代码思路:1.分析网页的ajax接口,需要传入哪些数据2.通过urlencode关键参数将url拼接到请求后,通过控制指定抓取哪些页面内容偏移参数。3.生成不同页面的请求,获取json数据中图片的url信息4.请求图片的url,下载图片5.保存到文件夹中。
实际代码
import requests
from urllib.parse import urlencode,urljoin
import os
from hashlib import md5
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36",
"X-Requested-With":"XMLHttpRequest"
}
def get_page(offset):
"""
:param offset: 偏移量,控制翻页
:return:
"""
params = {
"offset":offset,
"format":"json",
"keyword":"街拍",
"autoload":"true",
"count":"20",
"cur_tab":"1",
"from":"search_tab"
}
url = "https://www.toutiao.com/search_content/?" + urlencode(params)
try:
response = requests.get(url,headers=headers,timeout=5)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
return None
def get_image(json):
"""
:param json: 获取到返回的json数据
:return:
"""
if json:
for item in json.get("data"):
title = item.get("title")
images = item.get("image_list")
if images:
for image in images:
yield {
"title":title,
"image":urljoin("http:",image.get("url")) if type(image) == type({"t":1}) else urljoin("http:",image)
}
def save_images(item):
"""
将图片保存到文件夹,以标题命名文件夹
:param item: json数据
:return:
"""
if item.get("title") != None:
if not os.path.exists(item.get("title")):
os.mkdir(item.get("title"))
else:
pass
try:
response = requests.get(item.get("image"))
if response.status_code == 200:
file_path = "{0}/{1}.{2}".format(item.get("title") if item.get("title") != None else "Notitle",md5(response.content).hexdigest(),"jpg")
if not os.path.exists(file_path):
with open(file_path,"wb") as f:
f.write(response.content)
else:
print("Already Downloaded",file_path)
except requests.ConnectionError:
print("Failed Download Image")
def main(offset):
"""
控制爬取的主要逻辑
:param offset: 偏移量
:return:
"""
json = get_page(offset)
for item in get_image(json):
print(item)
save_images(item)
groups = [i*20 for i in range(1,10)]
if __name__ == '__main__':
for group in groups:
main(group)
爬取的结果
通过分析ajax接口,比selenium模拟更容易模拟ajax请求进行爬取,但是代码复用性较差,因为每个网页的接口不同,所以在捕获ajax加载的数据时,仍然使用selenium模拟直接抓取接口数据,需要根据自己的实际需要选择。
php 抓取网页ajax数据(php抓取网页ajax数据其实就是定时的获取网页中的静态数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-09 04:05
php抓取网页ajax数据其实就是定时的获取网页中的静态数据包括html和json,具体的要看你的项目,如果是网站本身ajax就是特别好的做法,不用把架子搭好,在前端判断一个html文件然后token就行了,基本上的前端不是特别复杂的业务就是这样干的。如果前端比较复杂或者说刚需有浏览器统一ajax功能就另当别论了。
爬虫的话也分两种情况,如果要自己构建一个爬虫,就需要设置一套自己的基本方法和语法规则,如果就是用mysql驱动抓取内容,可以用jsoup就可以实现代码自动生成:/。
可以参考一下这个
爬虫多了,遇到特定的发现好多问题,总的来说,定时检测网页速度,返回给你第一次加载的时间(这个要看业务,比如每次下载的都是不同的网页,然后再用tp操作),可以检测哪些网页返回超时,有多少秒返回,返回超时的也会返回给你。根据返回时间来决定你下一次的下载速度,好多人用selenium这个工具来检测自己的下载速度,但是我个人不喜欢selenium。
创建一个ajax接口:formdata={"user":"wang'kongtongwei'","password":"mw_xin-0xb","authorization":"","params":[{"key":"mw-xin-0xb","password":"mw_xin0xb"},{"key":"mw-xin0xb","password":"mw_xin0xb"},{"key":"mw_xin0xb","password":"mw_xin0xb"}]}这个ajax接口就是获取一个正则表达式,为user,password和authorization3个值,存入一个response,之后返回结果就是response的html文件。 查看全部
php 抓取网页ajax数据(php抓取网页ajax数据其实就是定时的获取网页中的静态数据)
php抓取网页ajax数据其实就是定时的获取网页中的静态数据包括html和json,具体的要看你的项目,如果是网站本身ajax就是特别好的做法,不用把架子搭好,在前端判断一个html文件然后token就行了,基本上的前端不是特别复杂的业务就是这样干的。如果前端比较复杂或者说刚需有浏览器统一ajax功能就另当别论了。
爬虫的话也分两种情况,如果要自己构建一个爬虫,就需要设置一套自己的基本方法和语法规则,如果就是用mysql驱动抓取内容,可以用jsoup就可以实现代码自动生成:/。
可以参考一下这个
爬虫多了,遇到特定的发现好多问题,总的来说,定时检测网页速度,返回给你第一次加载的时间(这个要看业务,比如每次下载的都是不同的网页,然后再用tp操作),可以检测哪些网页返回超时,有多少秒返回,返回超时的也会返回给你。根据返回时间来决定你下一次的下载速度,好多人用selenium这个工具来检测自己的下载速度,但是我个人不喜欢selenium。
创建一个ajax接口:formdata={"user":"wang'kongtongwei'","password":"mw_xin-0xb","authorization":"","params":[{"key":"mw-xin-0xb","password":"mw_xin0xb"},{"key":"mw-xin0xb","password":"mw_xin0xb"},{"key":"mw_xin0xb","password":"mw_xin0xb"}]}这个ajax接口就是获取一个正则表达式,为user,password和authorization3个值,存入一个response,之后返回结果就是response的html文件。
php 抓取网页ajax数据(抓ajax异步内容页面和抓普通的页面区别。 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-07 04:18
)
事实上,Ajax异步内容页面和普通页面之间几乎没有区别。Ajax只是发出一个异步HTTP请求。只需使用类似于firebug的工具来查找请求的后端服务URL和值传递参数,然后获取URL传递参数
使用firebug的网络工具
如果抓取页面,内容中未显示的数据就是一堆JS代码
代码
$cookie_file=tempnam('./temp','cookie');
$ch = curl_init();
$url1 = "http://www.cdut.edu.cn/default.html";
curl_setopt($ch,CURLOPT_URL,$url1);
curl_setopt($ch,CURLOPT_HTTP_VERSION,CURL_HTTP_VERSION_1_1);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_FOLLOWLOCATION,1);
curl_setopt($ch, CURLOPT_ENCODING ,'gzip'); //加入gzip解析
//设置连接结束后保存cookie信息的文件
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookie_file);
$content=curl_exec($ch);
curl_close($ch);
$ch3 = curl_init();
$url3 = "http://www.cdut.edu.cn/xww/dwr ... 3B%3B
$curlPost = "callCount=1&page=/xww/type/1000020118.html&httpSessionId=12A9B726E6A2D4D3B09DE7952B2F282C&scriptSessionId=295315B4B4141B09DA888D3A3ADB8FAA658&c0-scriptName=portalAjax&c0-methodName=getNewsXml&c0-id=0&c0-param0=string:10000201&c0-param1=string:1000020118&c0-param2=string:news_&c0-param3=number:5969&c0-param4=number:1&c0-param5=null:null&c0-param6=null:null&batchId=0";
curl_setopt($ch3,CURLOPT_URL,$url3);
curl_setopt($ch3,CURLOPT_POST,1);
curl_setopt($ch3,CURLOPT_POSTFIELDS,$curlPost);
//设置连接结束后保存cookie信息的文件
curl_setopt($ch3,CURLOPT_COOKIEFILE,$cookie_file);
$content1=curl_exec($ch3);
curl_close($ch3); 查看全部
php 抓取网页ajax数据(抓ajax异步内容页面和抓普通的页面区别。
)
事实上,Ajax异步内容页面和普通页面之间几乎没有区别。Ajax只是发出一个异步HTTP请求。只需使用类似于firebug的工具来查找请求的后端服务URL和值传递参数,然后获取URL传递参数
使用firebug的网络工具
如果抓取页面,内容中未显示的数据就是一堆JS代码
代码
$cookie_file=tempnam('./temp','cookie');
$ch = curl_init();
$url1 = "http://www.cdut.edu.cn/default.html";
curl_setopt($ch,CURLOPT_URL,$url1);
curl_setopt($ch,CURLOPT_HTTP_VERSION,CURL_HTTP_VERSION_1_1);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_FOLLOWLOCATION,1);
curl_setopt($ch, CURLOPT_ENCODING ,'gzip'); //加入gzip解析
//设置连接结束后保存cookie信息的文件
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookie_file);
$content=curl_exec($ch);
curl_close($ch);
$ch3 = curl_init();
$url3 = "http://www.cdut.edu.cn/xww/dwr ... 3B%3B
$curlPost = "callCount=1&page=/xww/type/1000020118.html&httpSessionId=12A9B726E6A2D4D3B09DE7952B2F282C&scriptSessionId=295315B4B4141B09DA888D3A3ADB8FAA658&c0-scriptName=portalAjax&c0-methodName=getNewsXml&c0-id=0&c0-param0=string:10000201&c0-param1=string:1000020118&c0-param2=string:news_&c0-param3=number:5969&c0-param4=number:1&c0-param5=null:null&c0-param6=null:null&batchId=0";
curl_setopt($ch3,CURLOPT_URL,$url3);
curl_setopt($ch3,CURLOPT_POST,1);
curl_setopt($ch3,CURLOPT_POSTFIELDS,$curlPost);
//设置连接结束后保存cookie信息的文件
curl_setopt($ch3,CURLOPT_COOKIEFILE,$cookie_file);
$content1=curl_exec($ch3);
curl_close($ch3);
php 抓取网页ajax数据(服务器根据对比返回的客户端图片(php抓取))
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-06 14:05
php抓取网页ajax数据很容易实现。
一、服务器先进行分析,查看js脚本,发现乱码的时候,先不要动,然后去查看http协议,给不同的指针打上标签,下面我们通过post请求,把ajax数据发送给我们,在此我们就不做服务器http协议解析啦。
1、首先设置post的请求头,字段包括:user-agent:urlhttp服务器返回的客户端是一个纯文本格式,类似于http响应客户端。@request-origin:post请求是从“”这个url开始post请求的方式是不同的,在发出请求时会要求你填写该设置值。为了更安全,建议你设置为最后一个数字。你不必满足所有的方式。
@request-scheme:post请求的使用端口号@request-user-agent:是post请求的请求头,
1、@cookie=http%3a%2f%2fgitem.cookie
2、@domain:域名
3、@timeout:是否超时
4、@accept-encoding:content-type
5、@accept-language:是否accept-language
6、@data-origin:请求方法,
7、@post-key:密码
8、@post-version:是否验证post协议cookie:cookie中存储了你对对方产生的相关情况,我们如果在post参数中增加cookie的时候要记得关闭浏览器哦。
二、服务器根据对比返回的客户端图片,发现网页链接明显乱码,然后用抓包软件去分析发送的数据。
方法
二、去抓包,通过python抓包分析,这种是相对简单点的,比较主流了。request.post(url,params={'accept':'accept-language','method':'post','user-agent':''})不管我们用post还是get发出的请求,不管对方返回的图片名称是gif还是jpg,post最主要的标志就是content-type,清楚了这个就可以看出请求方法、请求头、协议等方面。
上图展示了方法一和方法二的发送方法,可以看出来发送的链接不一样,发送到同一个服务器,你应该判断,对方返回的信息包含哪种,对应的发送相应的请求即可。总结:方法一和方法二,都对应了java爬虫中的get、post、put、delete请求方法。 查看全部
php 抓取网页ajax数据(服务器根据对比返回的客户端图片(php抓取))
php抓取网页ajax数据很容易实现。
一、服务器先进行分析,查看js脚本,发现乱码的时候,先不要动,然后去查看http协议,给不同的指针打上标签,下面我们通过post请求,把ajax数据发送给我们,在此我们就不做服务器http协议解析啦。
1、首先设置post的请求头,字段包括:user-agent:urlhttp服务器返回的客户端是一个纯文本格式,类似于http响应客户端。@request-origin:post请求是从“”这个url开始post请求的方式是不同的,在发出请求时会要求你填写该设置值。为了更安全,建议你设置为最后一个数字。你不必满足所有的方式。
@request-scheme:post请求的使用端口号@request-user-agent:是post请求的请求头,
1、@cookie=http%3a%2f%2fgitem.cookie
2、@domain:域名
3、@timeout:是否超时
4、@accept-encoding:content-type
5、@accept-language:是否accept-language
6、@data-origin:请求方法,
7、@post-key:密码
8、@post-version:是否验证post协议cookie:cookie中存储了你对对方产生的相关情况,我们如果在post参数中增加cookie的时候要记得关闭浏览器哦。
二、服务器根据对比返回的客户端图片,发现网页链接明显乱码,然后用抓包软件去分析发送的数据。
方法
二、去抓包,通过python抓包分析,这种是相对简单点的,比较主流了。request.post(url,params={'accept':'accept-language','method':'post','user-agent':''})不管我们用post还是get发出的请求,不管对方返回的图片名称是gif还是jpg,post最主要的标志就是content-type,清楚了这个就可以看出请求方法、请求头、协议等方面。
上图展示了方法一和方法二的发送方法,可以看出来发送的链接不一样,发送到同一个服务器,你应该判断,对方返回的信息包含哪种,对应的发送相应的请求即可。总结:方法一和方法二,都对应了java爬虫中的get、post、put、delete请求方法。
php 抓取网页ajax数据(php抓取网页ajax数据或爬虫抓取html数据;web服务器的负载均衡)
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-09-27 05:02
php抓取网页ajax数据或爬虫抓取html数据;web服务器的负载均衡.这些网页分析,web策略,
简单来说,是通过tcp/ip协议来传递数据,方便传递信息。
tcp我说两句,用ip传递数据。
题主表达有点问题。抓取网页应该是指爬虫。而不是网页分析。网页分析是编程范畴的。不是什么excel分析。如果是抓取网页分析,那请跟实际网页类型没有必然联系。各种结构复杂的网页分析的确很难的,比如html。
windows上叫ole,
收发邮件
...就一个翻墙吗..你确定不是要自己动手改造整个软件..?
tcp连接一般是建立在ip地址之上的,如果你把tcp链接用url方式连接上,如'out...',服务器应该就能把‘...’发过来。---@wangjing说web服务器负载均衡...如果你不需要支持端口映射.excel也可以.excel支持,就是在主域名和子域名连接一定的url.如'web.excel'.windows上叫ole,windows提供的tcp协议的完美支持.。
爬虫,通常是帮助你做某些任务,比如可以爬某些网站,找到你想要的内容。其实你要知道,浏览器解析dom方面的东西是select之类的一种轮询方式,速度慢的要死。像web服务器其实是一种client模式,一般做网站的人都要习惯一定的client调用模式,所以你要想要爬虫,最好还是学一下pythonerlangruby之类的语言。 查看全部
php 抓取网页ajax数据(php抓取网页ajax数据或爬虫抓取html数据;web服务器的负载均衡)
php抓取网页ajax数据或爬虫抓取html数据;web服务器的负载均衡.这些网页分析,web策略,
简单来说,是通过tcp/ip协议来传递数据,方便传递信息。
tcp我说两句,用ip传递数据。
题主表达有点问题。抓取网页应该是指爬虫。而不是网页分析。网页分析是编程范畴的。不是什么excel分析。如果是抓取网页分析,那请跟实际网页类型没有必然联系。各种结构复杂的网页分析的确很难的,比如html。
windows上叫ole,
收发邮件
...就一个翻墙吗..你确定不是要自己动手改造整个软件..?
tcp连接一般是建立在ip地址之上的,如果你把tcp链接用url方式连接上,如'out...',服务器应该就能把‘...’发过来。---@wangjing说web服务器负载均衡...如果你不需要支持端口映射.excel也可以.excel支持,就是在主域名和子域名连接一定的url.如'web.excel'.windows上叫ole,windows提供的tcp协议的完美支持.。
爬虫,通常是帮助你做某些任务,比如可以爬某些网站,找到你想要的内容。其实你要知道,浏览器解析dom方面的东西是select之类的一种轮询方式,速度慢的要死。像web服务器其实是一种client模式,一般做网站的人都要习惯一定的client调用模式,所以你要想要爬虫,最好还是学一下pythonerlangruby之类的语言。
php 抓取网页ajax数据(这里有新鲜出炉的PHP设计模式,程序狗速度看过来! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-26 11:16
)
下面是一个新发布的PHP设计模式。看看程序狗的速度
PHP开源脚本语言PHP(外名:超文本预处理器,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点。它入门门槛低,易学,应用广泛。它主要适用于web开发领域。PHP的文件后缀是PHP
本文解释了PHP如何通过curl获取Ajax内容。如何抓取Ajax网站?这是一个热点问题,也是一个棘手的问题。但事实上,抓取Ajax异步内容页面和抓取普通页面之间并没有什么区别。Ajax只是发出一个异步HTTP请求。只需使用firebug之类的工具查找请求的后端服务URL和值传输的参数,然后获取URL传输的参数。有兴趣的学生请参考以下内容
事实上,Ajax异步内容页面和普通页面之间几乎没有区别。Ajax只是发出一个异步HTTP请求。只需使用类似于firebug的工具来查找请求的后端服务URL和值传递参数,然后获取URL传递参数
使用firebug的网络工具
如果抓取页面,内容中未显示的数据就是一堆JS代码
代码
$cookie_file=tempnam('./temp','cookie');
$ch = curl_init();
$url1 = "http://www.cdut.edu.cn/default.html";
curl_setopt($ch,CURLOPT_URL,$url1);
curl_setopt($ch,CURLOPT_HTTP_VERSION,CURL_HTTP_VERSION_1_1);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_FOLLOWLOCATION,1);
curl_setopt($ch, CURLOPT_ENCODING ,'gzip'); //加入gzip解析
//设置连接结束后保存cookie信息的文件
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookie_file);
$content=curl_exec($ch);
curl_close($ch);
$ch3 = curl_init();
$url3 = "http://www.cdut.edu.cn/xww/dwr ... 3B%3B
$curlPost = "callCount=1&page=/xww/type/1000020118.html&httpSessionId=12A9B726E6A2D4D3B09DE7952B2F282C&scriptSessionId=295315B4B4141B09DA888D3A3ADB8FAA658&c0-scriptName=portalAjax&c0-methodName=getNewsXml&c0-id=0&c0-param0=string:10000201&c0-param1=string:1000020118&c0-param2=string:news_&c0-param3=number:5969&c0-param4=number:1&c0-param5=null:null&c0-param6=null:null&batchId=0";
curl_setopt($ch3,CURLOPT_URL,$url3);
curl_setopt($ch3,CURLOPT_POST,1);
curl_setopt($ch3,CURLOPT_POSTFIELDS,$curlPost);
//设置连接结束后保存cookie信息的文件
curl_setopt($ch3,CURLOPT_COOKIEFILE,$cookie_file);
$content1=curl_exec($ch3);
curl_close($ch3); 查看全部
php 抓取网页ajax数据(这里有新鲜出炉的PHP设计模式,程序狗速度看过来!
)
下面是一个新发布的PHP设计模式。看看程序狗的速度
PHP开源脚本语言PHP(外名:超文本预处理器,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点。它入门门槛低,易学,应用广泛。它主要适用于web开发领域。PHP的文件后缀是PHP
本文解释了PHP如何通过curl获取Ajax内容。如何抓取Ajax网站?这是一个热点问题,也是一个棘手的问题。但事实上,抓取Ajax异步内容页面和抓取普通页面之间并没有什么区别。Ajax只是发出一个异步HTTP请求。只需使用firebug之类的工具查找请求的后端服务URL和值传输的参数,然后获取URL传输的参数。有兴趣的学生请参考以下内容
事实上,Ajax异步内容页面和普通页面之间几乎没有区别。Ajax只是发出一个异步HTTP请求。只需使用类似于firebug的工具来查找请求的后端服务URL和值传递参数,然后获取URL传递参数
使用firebug的网络工具
如果抓取页面,内容中未显示的数据就是一堆JS代码
代码
$cookie_file=tempnam('./temp','cookie');
$ch = curl_init();
$url1 = "http://www.cdut.edu.cn/default.html";
curl_setopt($ch,CURLOPT_URL,$url1);
curl_setopt($ch,CURLOPT_HTTP_VERSION,CURL_HTTP_VERSION_1_1);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_FOLLOWLOCATION,1);
curl_setopt($ch, CURLOPT_ENCODING ,'gzip'); //加入gzip解析
//设置连接结束后保存cookie信息的文件
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookie_file);
$content=curl_exec($ch);
curl_close($ch);
$ch3 = curl_init();
$url3 = "http://www.cdut.edu.cn/xww/dwr ... 3B%3B
$curlPost = "callCount=1&page=/xww/type/1000020118.html&httpSessionId=12A9B726E6A2D4D3B09DE7952B2F282C&scriptSessionId=295315B4B4141B09DA888D3A3ADB8FAA658&c0-scriptName=portalAjax&c0-methodName=getNewsXml&c0-id=0&c0-param0=string:10000201&c0-param1=string:1000020118&c0-param2=string:news_&c0-param3=number:5969&c0-param4=number:1&c0-param5=null:null&c0-param6=null:null&batchId=0";
curl_setopt($ch3,CURLOPT_URL,$url3);
curl_setopt($ch3,CURLOPT_POST,1);
curl_setopt($ch3,CURLOPT_POSTFIELDS,$curlPost);
//设置连接结束后保存cookie信息的文件
curl_setopt($ch3,CURLOPT_COOKIEFILE,$cookie_file);
$content1=curl_exec($ch3);
curl_close($ch3);
php 抓取网页ajax数据(php抓取网页ajax怎么做?用flask自带的middleware可以做很多东西)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-09-21 11:01
php抓取网页ajax数据,定位到企业目标网站的ip位置返回给前端,从而实现浏览器劫持和篡改工作原理---利用后端提供的ajax发送链接。
用nginx
getshell,
都不是很了解,要推荐就用cms的。一般要做网页ajax请求那么肯定需要服务器支持,通过服务器来进行请求,然后服务器来响应,后端又要处理请求处理请求的响应又要处理响应的响应,
说说我们之前是怎么做的吧,很简单,用的是java,用flask自带的middleware可以做很多东西,很实用。我们就很常用。
用前端http解析,提取,看一些抓包工具,做一些模拟,还可以应用一些系统漏洞。
可以参考抓包工具
http_response_message里面可以包含参数
restfulapi
前端的话可以用node,
httpgetpost
看看nginx和mimehttppool
跟用webserver一样呀
前端抓包,
可以看看lotusstreamer,httpscraping,前端后端都可以,可以用js模拟。
估计楼主用的session,我这里已经有一个在墙外可以用的私服,java服务器的,
ajax
百宝箱-web安全开发平台-phpsecurityboilerplate 查看全部
php 抓取网页ajax数据(php抓取网页ajax怎么做?用flask自带的middleware可以做很多东西)
php抓取网页ajax数据,定位到企业目标网站的ip位置返回给前端,从而实现浏览器劫持和篡改工作原理---利用后端提供的ajax发送链接。
用nginx
getshell,
都不是很了解,要推荐就用cms的。一般要做网页ajax请求那么肯定需要服务器支持,通过服务器来进行请求,然后服务器来响应,后端又要处理请求处理请求的响应又要处理响应的响应,
说说我们之前是怎么做的吧,很简单,用的是java,用flask自带的middleware可以做很多东西,很实用。我们就很常用。
用前端http解析,提取,看一些抓包工具,做一些模拟,还可以应用一些系统漏洞。
可以参考抓包工具
http_response_message里面可以包含参数
restfulapi
前端的话可以用node,
httpgetpost
看看nginx和mimehttppool
跟用webserver一样呀
前端抓包,
可以看看lotusstreamer,httpscraping,前端后端都可以,可以用js模拟。
估计楼主用的session,我这里已经有一个在墙外可以用的私服,java服务器的,
ajax
百宝箱-web安全开发平台-phpsecurityboilerplate
php 抓取网页ajax数据(阿里云gt云栖;云栖社区gt抓取网页内容(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-09-15 16:15
阿里云>;云气社区>;主题地图>;A>;ASP爬网网页
建议的活动:
更多优惠>
当前主题:ASP抓取网页以添加集合
相关主题:
ASP抓取与web相关的博客以查看更多博客
抓取web内容
作者:Jack Chen 857观点评论:2006年之前
抓取web内容一、ASP.NET使用Httpwebrequest获取网页内容将无法获取某些网页。然而,有时我们会发现程序在抓取某些页面时无法获得所需的内容,有时甚至返回404错误提示页面。原因是什么?实际上
阅读全文
C#抓取并分析网页的类别
作者:老先生2号808人浏览评论:2004年前
类来获取和分析网页。主要功能有:1、提取网页的纯文本,转到所有HTML标签和JavaScript代码2、提取网页的链接,包括href、frame和iframe3、提取网页的标题等(其他标签可以类推,规则相同)4、可以实现简单的表单提交和
阅读全文
使用正则表达式获取博客列表数据
作者:郭建筑师860观点评论:2008年之前
鉴于我需要在MVC 3模拟博客园区企业系统中使用的测试数据,我太累了,无法输入自己,所以我抓取了一些博客园区的列表数据。请嘟嘟不要惊讶。正则表达式用于捕获博客公园数据,因此不熟悉正则表达式的朋友可以参考相关资料。其实很容易掌握,就是
阅读全文
[网站production design]静态和动态网页的特点和差异
作者:Da Wei_uuSem1413人查看的评论数量:2002年之前
通常,当企业需要网站进行设计时,在寻找网站建筑公司进行网站时,经常会被问及是动态还是静态构建网站。企业在建立网站时经常会问这些问题,因为很多人不明白什么是静态和动态的?因此,以下是对网站公司小编辑的分析:静态和动态网页的特点和差异
阅读全文
性能优化,使浏览器能够缓存动态网页
作者:760文艺青年浏览评论:2004年前
1:HTTP头介绍1.1对于浏览器的第一个请求,假设我们请求一个URL地址。例如,我的服务器上的静态页面将返回以下HTTP头信息:这里不包括HTTP头信息中每个参数的含义
阅读全文
占领学校(二))@
作者:lhyxxy1702观点评论:04年前
一,。初步的基本准备。哦,你不能直接开始准备。(1)create the project。输入:[Python]view plancy scapystartprojectw3school以创建上面的项目w3school。此时,将生成w3school文件夹
阅读全文
[C#][]通过WebBrowser获取Ajax网页
作者:Jack Chen 870观点评论:2007年之前
原文[c#][]通过WebBrowser获取Ajax后的网页今天,施敏问我,如果网页一开始是Ajax,会加载一些数据,但是如果你通过webclient捕获JavaScript和Ajax的源代码,有一种方法可以捕获
阅读全文
性能优化,使浏览器能够缓存动态网页
作者:luminji 574观点评论:2010年之前
在上一篇文章“为性能优化构建用户定义的文件缓存”中,我们使用outputcache允许请求访问服务器的输出缓存。我们扩展了outputcacheprovider,这相当于访问服务器上的静态资源。outputcache用于所有访问服务器资源的请求
阅读全文
ASP抓取网页相关问答问题
phpcurl采集Asp网页带有_eventvalidation
作者:萧旋风柴津1022观点点评:15年前
当使用PHP curl获取页面信息时,您会遇到ASP的“\u viewstate”和“\u eventvalidation”)
阿里云>;云气社区>;主题地图>;A>;ASP爬网网页
建议的活动:
更多优惠>
当前主题:ASP抓取网页以添加集合
相关主题:
ASP抓取与web相关的博客以查看更多博客
抓取web内容
作者:Jack Chen 857观点评论:2006年之前
抓取web内容一、ASP.NET使用Httpwebrequest获取网页内容将无法获取某些网页。然而,有时我们会发现程序在抓取某些页面时无法获得所需的内容,有时甚至返回404错误提示页面。原因是什么?实际上
阅读全文
C#抓取并分析网页的类别
作者:老先生2号808人浏览评论:2004年前
类来获取和分析网页。主要功能有:1、提取网页的纯文本,转到所有HTML标签和JavaScript代码2、提取网页的链接,包括href、frame和iframe3、提取网页的标题等(其他标签可以类推,规则相同)4、可以实现简单的表单提交和
阅读全文
使用正则表达式获取博客列表数据
作者:郭建筑师860观点评论:2008年之前
鉴于我需要在MVC 3模拟博客园区企业系统中使用的测试数据,我太累了,无法输入自己,所以我抓取了一些博客园区的列表数据。请嘟嘟不要惊讶。正则表达式用于捕获博客公园数据,因此不熟悉正则表达式的朋友可以参考相关资料。其实很容易掌握,就是
阅读全文
[网站production design]静态和动态网页的特点和差异
作者:Da Wei_uuSem1413人查看的评论数量:2002年之前
通常,当企业需要网站进行设计时,在寻找网站建筑公司进行网站时,经常会被问及是动态还是静态构建网站。企业在建立网站时经常会问这些问题,因为很多人不明白什么是静态和动态的?因此,以下是对网站公司小编辑的分析:静态和动态网页的特点和差异
阅读全文
性能优化,使浏览器能够缓存动态网页
作者:760文艺青年浏览评论:2004年前
1:HTTP头介绍1.1对于浏览器的第一个请求,假设我们请求一个URL地址。例如,我的服务器上的静态页面将返回以下HTTP头信息:这里不包括HTTP头信息中每个参数的含义
阅读全文
占领学校(二))@
作者:lhyxxy1702观点评论:04年前
一,。初步的基本准备。哦,你不能直接开始准备。(1)create the project。输入:[Python]view plancy scapystartprojectw3school以创建上面的项目w3school。此时,将生成w3school文件夹
阅读全文
[C#][]通过WebBrowser获取Ajax网页
作者:Jack Chen 870观点评论:2007年之前
原文[c#][]通过WebBrowser获取Ajax后的网页今天,施敏问我,如果网页一开始是Ajax,会加载一些数据,但是如果你通过webclient捕获JavaScript和Ajax的源代码,有一种方法可以捕获
阅读全文
性能优化,使浏览器能够缓存动态网页
作者:luminji 574观点评论:2010年之前
在上一篇文章“为性能优化构建用户定义的文件缓存”中,我们使用outputcache允许请求访问服务器的输出缓存。我们扩展了outputcacheprovider,这相当于访问服务器上的静态资源。outputcache用于所有访问服务器资源的请求
阅读全文
ASP抓取网页相关问答问题
phpcurl采集Asp网页带有_eventvalidation
作者:萧旋风柴津1022观点点评:15年前
当使用PHP curl获取页面信息时,您会遇到ASP的“\u viewstate”和“\u eventvalidation”
