
php 抓取网页ajax数据
php抓取网页ajax数据框架是框架不是什么?
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-07-30 01:05
php抓取网页ajax数据,
flask是个流行的web框架,个人觉得比python那些靠谱些。但是他的代码量很大,熟悉它的优点缺点你会很轻松就掌握了基本的流程。
flask框架的python实现
python是一种开发简单,
一个用来web开发一个用来爬虫开发当然可以
先学会使用linux环境再学会搜索大佬们的资料吧
感觉学flask就不要想着爬取数据了。先把基础语法熟悉一下吧。
根据我的经验来看,只有python大神才能写出。还是推荐flask,它简单实用易上手。而且为什么这么说呢?flask的语法很简单的,随便拼凑一下都行,重要的是在熟悉语法之后你写出来的东西在“理想状态”下还很好看!!有心情看看flask项目,挺有趣的。在你通过python爬取的基础上,如果你不在乎代码可读性,那么可以一直这么爬下去。
我感觉,在爬虫初学者的最初阶段,书籍是个很好的辅助工具。按照前期的学习、写代码,再看看源码、理论补充一下,到后面由于一些补充工具的加入,会让你的爬虫更方便快捷。
仅供参考
flask框架是框架不是框架!
如果是想用flask做web开发的话,一般在开始写restfulservice的时候再开始想这个问题。现在我们开发单线程爬虫,一般如果实在连web请求这块,可以用动态语言,例如node.js或者python+phantomjs+requests库。flask应该还是主流的通信框架,相比较起来,flask有时候不是特别适合(高并发、多进程可能比较容易遇到代码重复的问题),有些人用flaskpython编写了服务器端,同时通过请求的postman做注册等操作的时候可能还需要考虑采用flask代理返回有多个参数,这个时候还是要看你写的代码是怎么样的,可以用flask+mongodb写一个postman的聊天模块。
另外flask还有一些sqlalchemy的库,可以编写orm语言接口,遇到多个sqlalchemy关联时,再说高并发去。 查看全部
php抓取网页ajax数据框架是框架不是什么?
php抓取网页ajax数据,
flask是个流行的web框架,个人觉得比python那些靠谱些。但是他的代码量很大,熟悉它的优点缺点你会很轻松就掌握了基本的流程。
flask框架的python实现
python是一种开发简单,

一个用来web开发一个用来爬虫开发当然可以
先学会使用linux环境再学会搜索大佬们的资料吧
感觉学flask就不要想着爬取数据了。先把基础语法熟悉一下吧。
根据我的经验来看,只有python大神才能写出。还是推荐flask,它简单实用易上手。而且为什么这么说呢?flask的语法很简单的,随便拼凑一下都行,重要的是在熟悉语法之后你写出来的东西在“理想状态”下还很好看!!有心情看看flask项目,挺有趣的。在你通过python爬取的基础上,如果你不在乎代码可读性,那么可以一直这么爬下去。

我感觉,在爬虫初学者的最初阶段,书籍是个很好的辅助工具。按照前期的学习、写代码,再看看源码、理论补充一下,到后面由于一些补充工具的加入,会让你的爬虫更方便快捷。
仅供参考
flask框架是框架不是框架!
如果是想用flask做web开发的话,一般在开始写restfulservice的时候再开始想这个问题。现在我们开发单线程爬虫,一般如果实在连web请求这块,可以用动态语言,例如node.js或者python+phantomjs+requests库。flask应该还是主流的通信框架,相比较起来,flask有时候不是特别适合(高并发、多进程可能比较容易遇到代码重复的问题),有些人用flaskpython编写了服务器端,同时通过请求的postman做注册等操作的时候可能还需要考虑采用flask代理返回有多个参数,这个时候还是要看你写的代码是怎么样的,可以用flask+mongodb写一个postman的聊天模块。
另外flask还有一些sqlalchemy的库,可以编写orm语言接口,遇到多个sqlalchemy关联时,再说高并发去。
php抓取网页ajax数据实战(一)_光明网(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-07-01 00:02
php抓取网页ajax数据实战很多刚入门php的小伙伴,肯定想要把重要的数据提取出来,可是很多php使用者在写代码的时候,都有一个困惑。在我写wordpress博客的时候,我经常抓取网页上的ajax数据。而且我本身是一个在校的大学生,没有那么多的时间去做额外的学习。不过,我在一次wordpress作者群内线下交流的时候,听到了很多高手说,javascript是无法抓取ajax里面的数据的。
原因是javascript本身作为一个无序对象,是无法操作ajax传递给其他对象的值。我反问到,大家有想过javascript怎么可以操作ajax传递给其他对象的值呢?他们竟然自信的说,javascript可以控制一个变量是谁传给它,从而加上自己的值?而且他们每天都在通过修改属性值操作ajax中的数据。
是啊,谁在操作对方的值呢?又或者说,javascript本身可以在分配给自己的变量里面操作对方的值吗?还是说javascript可以像php一样,完成某种同步的工作?他们以前真的没有想过这些吗?接下来,我将会回答他们的问题。首先回答最重要的问题,在传递给这些对象的值之前,对方没有遇到异步的请求,通过javascript是可以操作这些值的。
举个例子,想象我们这次要通过php来模拟抓取网页ajax数据,那么我们可以找到一个send_ajax函数。after(){send_ajax(url);}那么,是不是当ajax数据从网页后端传递给我们的时候,就可以操作这些对象?并不是的,比如我现在抓取了一个链接,并且通过url传递给browser端时,browser端是没有接受到数据,browser端并没有接受到数据,那么我到底在用javascript去操作他们的值是无法成功的。
因为在网页ajax返回时,对方服务器上是没有收到该数据的。所以如果我的项目中,数据来源更多是来自于后端服务器,我就可以通过php去操作他们,这就是javascript来异步回调数据的原理。举个例子,如果我要抓取某个网页上的某个女性视频,我首先在url中加上';','',那么我会通过php控制send_ajax函数,在send_ajax函数中,操作数据的回调函数为true。
那么,对于抓取过的数据,对于数据本身已经有序的有序对象的url,通过php如何操作他们的值呢?这里我假设是用formdata或media_url去操作media_url,他们的区别在于,formdata返回值是有序的,media_url返回值是无序的。在formdata中media_url指向的对象是属于一个结构化字符串的对象media_url,而media_url.sqlquery(media。 查看全部
php抓取网页ajax数据实战(一)_光明网(图)
php抓取网页ajax数据实战很多刚入门php的小伙伴,肯定想要把重要的数据提取出来,可是很多php使用者在写代码的时候,都有一个困惑。在我写wordpress博客的时候,我经常抓取网页上的ajax数据。而且我本身是一个在校的大学生,没有那么多的时间去做额外的学习。不过,我在一次wordpress作者群内线下交流的时候,听到了很多高手说,javascript是无法抓取ajax里面的数据的。

原因是javascript本身作为一个无序对象,是无法操作ajax传递给其他对象的值。我反问到,大家有想过javascript怎么可以操作ajax传递给其他对象的值呢?他们竟然自信的说,javascript可以控制一个变量是谁传给它,从而加上自己的值?而且他们每天都在通过修改属性值操作ajax中的数据。
是啊,谁在操作对方的值呢?又或者说,javascript本身可以在分配给自己的变量里面操作对方的值吗?还是说javascript可以像php一样,完成某种同步的工作?他们以前真的没有想过这些吗?接下来,我将会回答他们的问题。首先回答最重要的问题,在传递给这些对象的值之前,对方没有遇到异步的请求,通过javascript是可以操作这些值的。

举个例子,想象我们这次要通过php来模拟抓取网页ajax数据,那么我们可以找到一个send_ajax函数。after(){send_ajax(url);}那么,是不是当ajax数据从网页后端传递给我们的时候,就可以操作这些对象?并不是的,比如我现在抓取了一个链接,并且通过url传递给browser端时,browser端是没有接受到数据,browser端并没有接受到数据,那么我到底在用javascript去操作他们的值是无法成功的。
因为在网页ajax返回时,对方服务器上是没有收到该数据的。所以如果我的项目中,数据来源更多是来自于后端服务器,我就可以通过php去操作他们,这就是javascript来异步回调数据的原理。举个例子,如果我要抓取某个网页上的某个女性视频,我首先在url中加上';','',那么我会通过php控制send_ajax函数,在send_ajax函数中,操作数据的回调函数为true。
那么,对于抓取过的数据,对于数据本身已经有序的有序对象的url,通过php如何操作他们的值呢?这里我假设是用formdata或media_url去操作media_url,他们的区别在于,formdata返回值是有序的,media_url返回值是无序的。在formdata中media_url指向的对象是属于一个结构化字符串的对象media_url,而media_url.sqlquery(media。
ajax传输网页内容发起post请求传输后台数据(刷新)
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-06-16 02:01
php抓取网页ajax数据,以各种格式保存到本地,以供下次抓取。而javascript将html中的dom元素渲染成了可以解析的javascript对象,用来执行脚本。
对于普通web程序员,“ajax”这种话可能都不是什么新鲜词了。甚至比较冷门一点的站点,都会将这一词完全用在自己的站点上。但是,对于javascript来说,ajax可能是最近才提出的一个重要的概念。它的应用范围广泛,有各种各样的应用场景:ajax传输网页内容发起post请求传输网页内容传输后台数据,通过xml或者json格式发送给前端发起get请求传输后台数据,通过xml或者json格式发送给浏览器在传输过程中,网页与服务器进行通信。
传输数据之后还会返回内容:responsetext、response。而就目前而言,大多数网站,在使用ajax方式传输数据的同时,所请求的网页内容都将实际上并不在浏览器的缓存中,而是隐藏在了session中。这导致这些网页一旦被关闭,将无法再被浏览器的“重定向”,而导致页面不断刷新,用户的体验非常糟糕。
而所谓“页面刷新”,我们可以通过ajax动态生成一个重定向(刷新)链接($loading),执行这个动作后,内容就是当前正在浏览的页面,不再存在当前页面的缓存内容。这些开发者希望的情况,往往都只是能把一个很小的页面,强行生成重定向链接,并且希望用户随时都能在重定向连接中找到他们的内容。而当今所谓的ajax框架,更多地是想解决用户需求与开发者提出需求之间的冲突,最终这导致了相互撕逼的情况的出现。
而我目前在做的javascript,就是在开发一个任意比页面大很多,多个页面连续的应用程序时,执行javascript可以做到动态化发起post请求,并且动态化的返回内容在网页中。实际上,我所说的这个框架并不是这个样子的,它大概已经实现了你上面所说的这种情况。 查看全部
ajax传输网页内容发起post请求传输后台数据(刷新)
php抓取网页ajax数据,以各种格式保存到本地,以供下次抓取。而javascript将html中的dom元素渲染成了可以解析的javascript对象,用来执行脚本。
对于普通web程序员,“ajax”这种话可能都不是什么新鲜词了。甚至比较冷门一点的站点,都会将这一词完全用在自己的站点上。但是,对于javascript来说,ajax可能是最近才提出的一个重要的概念。它的应用范围广泛,有各种各样的应用场景:ajax传输网页内容发起post请求传输网页内容传输后台数据,通过xml或者json格式发送给前端发起get请求传输后台数据,通过xml或者json格式发送给浏览器在传输过程中,网页与服务器进行通信。
传输数据之后还会返回内容:responsetext、response。而就目前而言,大多数网站,在使用ajax方式传输数据的同时,所请求的网页内容都将实际上并不在浏览器的缓存中,而是隐藏在了session中。这导致这些网页一旦被关闭,将无法再被浏览器的“重定向”,而导致页面不断刷新,用户的体验非常糟糕。
而所谓“页面刷新”,我们可以通过ajax动态生成一个重定向(刷新)链接($loading),执行这个动作后,内容就是当前正在浏览的页面,不再存在当前页面的缓存内容。这些开发者希望的情况,往往都只是能把一个很小的页面,强行生成重定向链接,并且希望用户随时都能在重定向连接中找到他们的内容。而当今所谓的ajax框架,更多地是想解决用户需求与开发者提出需求之间的冲突,最终这导致了相互撕逼的情况的出现。
而我目前在做的javascript,就是在开发一个任意比页面大很多,多个页面连续的应用程序时,执行javascript可以做到动态化发起post请求,并且动态化的返回内容在网页中。实际上,我所说的这个框架并不是这个样子的,它大概已经实现了你上面所说的这种情况。
php抓取网页ajax数据,转换格式这种事情都不需要你来做了
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-06-06 06:06
php抓取网页ajax数据,转换格式这种事情都不需要你来做了。网页每秒发生n万次变化,你做不过来。反正你不要用浏览器看就是了。如果你非要做,推荐用swoole或者nodejs的cordova模块,
spine还是挺不错的,建议考虑一下。
jquery。fetch("facebook")。then("app")。then("ebay")。then("google")。then("amazon")jquery。fetch("facebook")。then("app")。then("ebay")。then("google")。then("amazon")。
可以,这个写一个websocket程序完全可以,随便哪个抓包器都可以,跨域基本上是木有问题的,传输post数据上不封锁就无限传输,
.net-json没有跨域问题.
应该不可以。除非gmail有验证,你看不到特别的ajax请求。因为这个服务不怎么安全。我想应该是服务器上缓存过,加上跨域有难度。题主可以尝试一下burpwebsocket抓包看看会不会再没有时间上实际写抓包。题主的做法是正确的,有时候要控制频率。
可以的,你把json的格式设置为xml或其他json格式,进行操作,
有两种思路,一种是在接收请求的服务器中实现解析数据,这个会比较费事,一种是在缓存中进行取数据操作,这样效率会高一些,googlegroups的数据是文本类型的,很容易拿到数据。 查看全部
php抓取网页ajax数据,转换格式这种事情都不需要你来做了
php抓取网页ajax数据,转换格式这种事情都不需要你来做了。网页每秒发生n万次变化,你做不过来。反正你不要用浏览器看就是了。如果你非要做,推荐用swoole或者nodejs的cordova模块,
spine还是挺不错的,建议考虑一下。
jquery。fetch("facebook")。then("app")。then("ebay")。then("google")。then("amazon")jquery。fetch("facebook")。then("app")。then("ebay")。then("google")。then("amazon")。
可以,这个写一个websocket程序完全可以,随便哪个抓包器都可以,跨域基本上是木有问题的,传输post数据上不封锁就无限传输,
.net-json没有跨域问题.
应该不可以。除非gmail有验证,你看不到特别的ajax请求。因为这个服务不怎么安全。我想应该是服务器上缓存过,加上跨域有难度。题主可以尝试一下burpwebsocket抓包看看会不会再没有时间上实际写抓包。题主的做法是正确的,有时候要控制频率。
可以的,你把json的格式设置为xml或其他json格式,进行操作,
有两种思路,一种是在接收请求的服务器中实现解析数据,这个会比较费事,一种是在缓存中进行取数据操作,这样效率会高一些,googlegroups的数据是文本类型的,很容易拿到数据。
web前端开发之路domopensource之旅http协议详解http服务器详解
网站优化 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2022-05-14 07:01
php抓取网页ajax数据发邮件源码ajax开发android开发web整站架构之路android中的javaweb开发入门之旅webhandle机制之旅http协议详解http服务器详解urllib1.0android环境部署之androidpackage之旅一个纯粹的android开发工程师的自我修养!web前端开发之路domopensource之旅让我们一起体验前端开发的乐趣easyweb开发之旅javascript开发之旅原生代码之旅:基于dom的ajax和pwajquery的开发之旅angularjs开发之旅vue开发之旅jquery和vueng-repeat-plot一起玩转前端开发!前端开发之路,本文转载自angularjs开发之旅,微信公众号为:angularjs之旅,angular的博客博主是阿云嘎,欢迎大家关注更多angular相关资料,欢迎点击下面地址。
angularjs之旅——router和path的理解angularjs之旅——权限管理及vue.js内部实现angularjs之旅——大家还有什么安卓开发的问题可以加群477311289一起交流!angular入门之旅零基础通过阿里巴巴出的官方开发者中心进行android开发,具体步骤如下:点击下方链接或扫描二维码。
-show/android安卓入门之旅:导航栏简单的3步搭建android中的materialdesign及vue.js可不是空手套白狼,angular应用的开发需要架构设计、上下游组件的整合与集成,更需要前端的手工制作及开发。它的架构如下:做好架构图没有什么比两者有机的结合更快速有效的建立一个完整的前端工程了:/#/material相关内容安卓入门之旅:vue和vuex异步、组件相关内容(会跟着第二步一步步介绍vuejs中间件、vuex)angular入门之旅:angularmv.js框架的整合与集成;angular2的框架结构和组件实现(异步队列、gitlab/kubernetes、spring-boot等)angular入门之旅:oc(androidstudio)开发android(更多在公众号更新,欢迎大家关注更多angular相关资料,欢迎点击下面地址)angular入门之旅:详细angularjs架构设计上下游整合与集成本文将跟着阿云嘎学习更加复杂的一个angularjs入门的整合开发,顺便理解vue.js的mvvm,我们到底该如何搭建一个简单的angularjs应用,又该如何整合和集成这些开发框架,让我们以一个前端工程的方式一起体验前端开发的乐趣。
开发环境:下载angularjs开发工具(mac环境:pkginstallergs6790d8--os--linux3.4--core/v7.3--lib9bg--http),跟我走,打开指定环境,编译angularjs到上游。这里跟大家分享一下如何打包为一个app来安装下面的开发环境。第一步:下载angularjs安装包(官方。 查看全部
web前端开发之路domopensource之旅http协议详解http服务器详解
php抓取网页ajax数据发邮件源码ajax开发android开发web整站架构之路android中的javaweb开发入门之旅webhandle机制之旅http协议详解http服务器详解urllib1.0android环境部署之androidpackage之旅一个纯粹的android开发工程师的自我修养!web前端开发之路domopensource之旅让我们一起体验前端开发的乐趣easyweb开发之旅javascript开发之旅原生代码之旅:基于dom的ajax和pwajquery的开发之旅angularjs开发之旅vue开发之旅jquery和vueng-repeat-plot一起玩转前端开发!前端开发之路,本文转载自angularjs开发之旅,微信公众号为:angularjs之旅,angular的博客博主是阿云嘎,欢迎大家关注更多angular相关资料,欢迎点击下面地址。
angularjs之旅——router和path的理解angularjs之旅——权限管理及vue.js内部实现angularjs之旅——大家还有什么安卓开发的问题可以加群477311289一起交流!angular入门之旅零基础通过阿里巴巴出的官方开发者中心进行android开发,具体步骤如下:点击下方链接或扫描二维码。
-show/android安卓入门之旅:导航栏简单的3步搭建android中的materialdesign及vue.js可不是空手套白狼,angular应用的开发需要架构设计、上下游组件的整合与集成,更需要前端的手工制作及开发。它的架构如下:做好架构图没有什么比两者有机的结合更快速有效的建立一个完整的前端工程了:/#/material相关内容安卓入门之旅:vue和vuex异步、组件相关内容(会跟着第二步一步步介绍vuejs中间件、vuex)angular入门之旅:angularmv.js框架的整合与集成;angular2的框架结构和组件实现(异步队列、gitlab/kubernetes、spring-boot等)angular入门之旅:oc(androidstudio)开发android(更多在公众号更新,欢迎大家关注更多angular相关资料,欢迎点击下面地址)angular入门之旅:详细angularjs架构设计上下游整合与集成本文将跟着阿云嘎学习更加复杂的一个angularjs入门的整合开发,顺便理解vue.js的mvvm,我们到底该如何搭建一个简单的angularjs应用,又该如何整合和集成这些开发框架,让我们以一个前端工程的方式一起体验前端开发的乐趣。
开发环境:下载angularjs开发工具(mac环境:pkginstallergs6790d8--os--linux3.4--core/v7.3--lib9bg--http),跟我走,打开指定环境,编译angularjs到上游。这里跟大家分享一下如何打包为一个app来安装下面的开发环境。第一步:下载angularjs安装包(官方。
php抓取页面时用的非常频繁的功能,我发现获取图片id的几个方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-05-10 19:01
php抓取网页ajax数据是我们php抓取页面时用的非常频繁的功能,经常用抓取手工做页面截图效率极其低下,很久之前曾经看过。它非常好用,效率却不高。在正常的一张图片的图片请求中需要为每一个帧分配一个字符串作为图片名称的缓存,另外还需要为每个图片请求为每个帧对应一个字符串做一个名称与索引作为id。在那次css2ddiv+css3的html抓取课程中,我发现获取图片id的几个方法:javascript:imgs_link=location.resolve(..);imgs_width=..;imgs_height=..;ajax:urlencodedimgs_link=location.resolve(..);filter:'lightning'class='imagefilter'extendsclass(imgs_link);requestmethod='get',timeout=500;current-reason='l';buffered-filter:'blacklevel'class='text-level'extendsclass(imgs_link);requestmethod='post',timeout=500;current-reason='s';buffered-filter:'blacklevel'class='text-level'extendsclass(imgs_link);requestmethod='post',timeout=500;current-reason='l';buffered-filter:'colorimage'class='text-colorimage'extendsclass(imgs_link);requestmethod='post',timeout=500;current-reason='s';buffered-filter:'blacklevel'class='text-colorimage'extendsclass(imgs_link);requestmethod='post',timeout=500;current-reason='s';buffered-filter:'blacklevel'class='text-level'extendsclass(imgs_link);requestmethod='post',timeout=500;requestmethod='post',timeout=500;requestmethod='post',timeout=500;requestmethod='post',timeout=500;由于http请求头中x-requested-with的值用'post'是传输二进制的方法,而'get'是传输一个字符串。
由于http响应头中的x-post方法是方法,而get方法是字符串,那么通过x-post方法我们将获取每一帧缓存,而不是同时获取每个帧对应的id。对于每一帧对应的id就有限制在一个整数范围,一个key对应一个id。而x-post是方法,通过x-post方法我们只需要关心将filter中的current-reason和request_add_request方法解码后替换为id即可。if(filter_is_has。 查看全部
php抓取页面时用的非常频繁的功能,我发现获取图片id的几个方法
php抓取网页ajax数据是我们php抓取页面时用的非常频繁的功能,经常用抓取手工做页面截图效率极其低下,很久之前曾经看过。它非常好用,效率却不高。在正常的一张图片的图片请求中需要为每一个帧分配一个字符串作为图片名称的缓存,另外还需要为每个图片请求为每个帧对应一个字符串做一个名称与索引作为id。在那次css2ddiv+css3的html抓取课程中,我发现获取图片id的几个方法:javascript:imgs_link=location.resolve(..);imgs_width=..;imgs_height=..;ajax:urlencodedimgs_link=location.resolve(..);filter:'lightning'class='imagefilter'extendsclass(imgs_link);requestmethod='get',timeout=500;current-reason='l';buffered-filter:'blacklevel'class='text-level'extendsclass(imgs_link);requestmethod='post',timeout=500;current-reason='s';buffered-filter:'blacklevel'class='text-level'extendsclass(imgs_link);requestmethod='post',timeout=500;current-reason='l';buffered-filter:'colorimage'class='text-colorimage'extendsclass(imgs_link);requestmethod='post',timeout=500;current-reason='s';buffered-filter:'blacklevel'class='text-colorimage'extendsclass(imgs_link);requestmethod='post',timeout=500;current-reason='s';buffered-filter:'blacklevel'class='text-level'extendsclass(imgs_link);requestmethod='post',timeout=500;requestmethod='post',timeout=500;requestmethod='post',timeout=500;requestmethod='post',timeout=500;由于http请求头中x-requested-with的值用'post'是传输二进制的方法,而'get'是传输一个字符串。
由于http响应头中的x-post方法是方法,而get方法是字符串,那么通过x-post方法我们将获取每一帧缓存,而不是同时获取每个帧对应的id。对于每一帧对应的id就有限制在一个整数范围,一个key对应一个id。而x-post是方法,通过x-post方法我们只需要关心将filter中的current-reason和request_add_request方法解码后替换为id即可。if(filter_is_has。
爬虫原理及反爬虫技术
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-05-06 00:12
对于大数据行业,数据的价值不言而喻,在这个信息爆炸的年代,互联网上有太多的信息数据,对于中小微公司,合理利用爬虫爬取有价值的数据,是弥补自身先天数据短板的不二选择,本文主要从爬虫原理、架构、分类以及反爬虫技术来对爬虫技术进行了总结。
1、爬虫技术概述
网络爬虫(Webcrawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题:
(1)对抓取目标的描述或定义;
(2)对网页或数据的分析与过滤;
(3)对URL的搜索策略。
2、爬虫原理
2.1网络爬虫原理
Web网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据来源。很多大型的网络搜索引擎系统都被称为基于Web数据采集的搜索引擎系统,比如Google、Baidu。由此可见Web网络爬虫系统在搜索引擎中的重要性。网页中除了包含供用户阅读的文字信息外,还包含一些超链接信息。Web网络爬虫系统正是通过网页中的超连接信息不断获得网络上的其它网页。正是因为这种采集过程像一个爬虫或者蜘蛛在网络上漫游,所以它才被称为网络爬虫系统或者网络蜘蛛系统,在英文中称为Spider或者Crawler。
2.2网络爬虫系统的工作原理
在网络爬虫的系统框架中,主过程由控制器,解析器,资源库三部分组成。控制器的主要工作是负责给多线程中的各个爬虫线程分配工作任务。解析器的主要工作是下载网页,进行页面的处理,主要是将一些JS脚本标签、CSS代码内容、空格字符、HTML标签等内容处理掉,爬虫的基本工作是由解析器完成。资源库是用来存放下载到的网页资源,一般都采用大型的数据库存储,如Oracle数据库,并对其建立索引。
控制器
控制器是网络爬虫的中央控制器,它主要是负责根据系统传过来的URL链接,分配一线程,然后启动线程调用爬虫爬取网页的过程。
解析器
解析器是负责网络爬虫的主要部分,其负责的工作主要有:下载网页的功能,对网页的文本进行处理,如过滤功能,抽取特殊HTML标签的功能,分析数据功能。
资源库
主要是用来存储网页中下载下来的数据记录的容器,并提供生成索引的目标源。中大型的数据库产品有:Oracle、SqlServer等。
Web网络爬虫系统一般会选择一些比较重要的、出度(网页中链出超链接数)较大的网站的URL作为种子URL集合。网络爬虫系统以这些种子集合作为初始URL,开始数据的抓取。因为网页中含有链接信息,通过已有网页的URL会得到一些新的URL,可以把网页之间的指向结构视为一个森林,每个种子URL对应的网页是森林中的一棵树的根节点。
这样,Web网络爬虫系统就可以根据广度优先算法或者深度优先算法遍历所有的网页。由于深度优先搜索算法可能会使爬虫系统陷入一个网站内部,不利于搜索比较靠近网站首页的网页信息,因此一般采用广度优先搜索算法采集网页。Web网络爬虫系统首先将种子URL放入下载队列,然后简单地从队首取出一个URL下载其对应的网页。得到网页的内容将其存储后,再经过解析网页中的链接信息可以得到一些新的URL,将这些URL加入下载队列。然后再取出一个URL,对其对应的网页进行下载,然后再解析,如此反复进行,直到遍历了整个网络或者满足某种条件后才会停止下来。
网络爬虫的基本工作流程如下:
1.首先选取一部分精心挑选的种子URL;
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列;
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
2.3抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面重点介绍几种常见的抓取策略:
2.3.1深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。我们以下面的图为例:
遍历的路径:A-F-GE-H-IBCD
2.3.2宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以上面的图为例:
遍历路径:A-B-C-D-E-FGHI
2.3.3反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数量。反向链接数表示的是一个网页的内容受到其他人的推荐的程度。因此,很多时候搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后顺序。
在真实的网络环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那个也的重要程度。因此,搜索引擎往往考虑一些可靠的反向链接数。
2.3.4PartialPageRank策略
PartialPageRank算法借鉴了PageRank算法的思想:对于已经下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每个页面的PageRank值,计算完之后,将待抓取URL队列中的URL按照PageRank值的大小排列,并按照该顺序抓取页面。
如果每次抓取一个页面,就重新计算PageRank值,一种折中方案是:每抓取K个页面后,重新计算一次PageRank值。但是这种情况还会有一个问题:对于已经下载下来的页面中分析出的链接,也就是我们之前提到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总,这样就形成了该未知页面的PageRank值,从而参与排序。
2.3.5OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P之后,将P的现金分摊给所有从P中分析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面按照现金数进行排序。
2.3.6大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因此叫做大站优先策略。
3、爬虫分类
开发网络爬虫应该选择Nutch、Crawler4j、WebMagic、scrapy、WebCollector还是其他的?上面说的爬虫,基本可以分3类:
(1)分布式爬虫:Nutch
(2)JAVA爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1分布式爬虫
爬虫使用分布式,主要是解决两个问题:
1)海量URL管理
2)网速
现在比较流行的分布式爬虫,是Apache的Nutch。但是对于大多数用户来说,Nutch是这几类爬虫里,最不好的选择,理由如下:
1)Nutch是为搜索引擎设计的爬虫,大多数用户是需要一个做精准数据爬取(精抽取)的爬虫。Nutch运行的一套流程里,有三分之二是为了搜索引擎而设计的。对精抽取没有太大的意义。也就是说,用Nutch做数据抽取,会浪费很多的时间在不必要的计算上。而且如果你试图通过对Nutch进行二次开发,来使得它适用于精抽取的业务,基本上就要破坏Nutch的框架,把Nutch改的面目全非,有修改Nutch的能力,真的不如自己重新写一个分布式爬虫框架了。
2)Nutch依赖hadoop运行,hadoop本身会消耗很多的时间。如果集群机器数量较少,爬取速度反而不如单机爬虫快。
3)Nutch虽然有一套插件机制,而且作为亮点宣传。可以看到一些开源的Nutch插件,提供精抽取的功能。但是开发过Nutch插件的人都知道,Nutch的插件系统有多蹩脚。利用反射的机制来加载和调用插件,使得程序的编写和调试都变得异常困难,更别说在上面开发一套复杂的精抽取系统了。而且Nutch并没有为精抽取提供相应的插件挂载点。Nutch的插件有只有五六个挂载点,而这五六个挂载点都是为了搜索引擎服务的,并没有为精抽取提供挂载点。大多数Nutch的精抽取插件,都是挂载在“页面解析”(parser)这个挂载点的,这个挂载点其实是为了解析链接(为后续爬取提供URL),以及为搜索引擎提供一些易抽取的网页信息(网页的meta信息、text文本)。
4)用Nutch进行爬虫的二次开发,爬虫的编写和调试所需的时间,往往是单机爬虫所需的十倍时间不止。了解Nutch源码的学习成本很高,何况是要让一个团队的人都读懂Nutch源码。调试过程中会出现除程序本身之外的各种问题(hadoop的问题、hbase的问题)。
5)很多人说Nutch2有gora,可以持久化数据到avro文件、hbase、mysql等。很多人其实理解错了,这里说的持久化数据,是指将URL信息(URL管理所需要的数据)存放到avro、hbase、mysql。并不是你要抽取的结构化数据。其实对大多数人来说,URL信息存在哪里无所谓。
6)Nutch2的版本目前并不适合开发。官方现在稳定的Nutch版本是nutch2.2.1,但是这个版本绑定了gora-0.3。如果想用hbase配合nutch(大多数人用nutch2就是为了用hbase),只能使用0.90版本左右的hbase,相应的就要将hadoop版本降到hadoop0.2左右。而且nutch2的官方教程比较有误导作用,Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x,这个Nutch2.x官网上写的是可以支持到hbase0.94。但是实际上,这个Nutch2.x的意思是Nutch2.3之前、Nutch2.2.1之后的一个版本,这个版本在官方的SVN中不断更新。而且非常不稳定(一直在修改)。
所以,如果你不是要做搜索引擎,尽量不要选择Nutch作为爬虫。有些团队就喜欢跟风,非要选择Nutch来开发精抽取的爬虫,其实是冲着Nutch的名气,当然最后的结果往往是项目延期完成。
如果你是要做搜索引擎,Nutch1.x是一个非常好的选择。Nutch1.x和solr或者es配合,就可以构成一套非常强大的搜索引擎了。如果非要用Nutch2的话,建议等到Nutch2.3发布再看。目前的Nutch2是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2JAVA爬虫
这里把JAVA爬虫单独分为一类,是因为JAVA在网络爬虫这块的生态圈是非常完善的。相关的资料也是最全的。这里可能有争议,我只是随便谈谈。
其实开源网络爬虫(框架)的开发非常简单,难问题和复杂的问题都被以前的人解决了(比如DOM树解析和定位、字符集检测、海量URL去重),可以说是毫无技术含量。包括Nutch,其实Nutch的技术难点是开发hadoop,本身代码非常简单。网络爬虫从某种意义来说,类似遍历本机的文件,查找文件中的信息。没有任何难度可言。之所以选择开源爬虫框架,就是为了省事。比如爬虫的URL管理、线程池之类的模块,谁都能做,但是要做稳定也是需要一段时间的调试和修改的。
对于爬虫的功能来说。用户比较关心的问题往往是:
1)爬虫支持多线程么、爬虫能用代理么、爬虫会爬取重复数据么、爬虫能爬取JS生成的信息么?
不支持多线程、不支持代理、不能过滤重复URL的,那都不叫开源爬虫,那叫循环执行http请求。
能不能爬js生成的信息和爬虫本身没有太大关系。爬虫主要是负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往需要通过模拟浏览器(htmlunit,selenium)来完成。这些模拟浏览器,往往需要耗费很多的时间来处理一个页面。所以一种策略就是,使用这些爬虫来遍历网站,遇到需要解析的页面,就将网页的相关信息提交给模拟浏览器,来完成JS生成信息的抽取。
2)爬虫可以爬取ajax信息么?
网页上有一些异步加载的数据,爬取这些数据有两种方法:使用模拟浏览器(问题1中描述过了),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果是自己生成ajax请求,使用开源爬虫的意义在哪里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我所需要的ajax请求(列表),如何用这些爬虫来对这些请求进行爬取?
爬虫往往都是设计成广度遍历或者深度遍历的模式,去遍历静态或者动态页面。爬取ajax信息属于deepweb(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方法来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的第一轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax请求作为种子,放入爬虫。用爬虫对这些种子,进行深度为1的广度遍历(默认就是广度遍历)。
3)爬虫怎么爬取要登陆的网站?
这些开源爬虫都支持在爬取时指定cookies,模拟登陆主要是靠cookies。至于cookies怎么获取,不是爬虫管的事情。你可以手动获取、用http请求模拟登陆或者用模拟浏览器自动登陆获取cookie。
4)爬虫怎么抽取网页的信息?
开源爬虫一般都会集成网页抽取工具。主要支持两种规范:CSSSELECTOR和XPATH。至于哪个好,这里不评价。
5)爬虫怎么保存网页的信息?
有一些爬虫,自带一个模块负责持久化。比如webmagic,有一个模块叫pipeline。通过简单地配置,可以将爬虫抽取到的信息,持久化到文件、数据库等。还有一些爬虫,并没有直接给用户提供数据持久化的模块。比如crawler4j和webcollector。让用户自己在网页处理模块中添加提交数据库的操作。至于使用pipeline这种模块好不好,就和操作数据库使用ORM好不好这个问题类似,取决于你的业务。
6)爬虫被网站封了怎么办?
爬虫被网站封了,一般用多代理(随机代理)就可以解决。但是这些开源爬虫一般没有直接支持随机代理的切换。所以用户往往都需要自己将获取的代理,放到一个全局数组中,自己写一个代理随机获取(从数组中)的代码。
7)网页可以调用爬虫么?
爬虫的调用是在Web的服务端调用的,平时怎么用就怎么用,这些爬虫都可以使用。
8)爬虫速度怎么样?
单机开源爬虫的速度,基本都可以讲本机的网速用到极限。爬虫的速度慢,往往是因为用户把线程数开少了、网速慢,或者在数据持久化时,和数据库的交互速度慢。而这些东西,往往都是用户的机器和二次开发的代码决定的。这些开源爬虫的速度,都很可以。
9)明明代码写对了,爬不到数据,是不是爬虫有问题,换个爬虫能解决么?
如果代码写对了,又爬不到数据,换其他爬虫也是一样爬不到。遇到这种情况,要么是网站把你封了,要么是你爬的数据是javascript生成的。爬不到数据通过换爬虫是不能解决的。
10)哪个爬虫可以判断网站是否爬完、那个爬虫可以根据主题进行爬取?
爬虫无法判断网站是否爬完,只能尽可能覆盖。
至于根据主题爬取,爬虫之后把内容爬下来才知道是什么主题。所以一般都是整个爬下来,然后再去筛选内容。如果嫌爬的太泛,可以通过限制URL正则等方式,来缩小一下范围。
11)哪个爬虫的设计模式和构架比较好?
设计模式纯属扯淡。说软件设计模式好的,都是软件开发完,然后总结出几个设计模式。设计模式对软件开发没有指导性作用。用设计模式来设计爬虫,只会使得爬虫的设计更加臃肿。
至于构架,开源爬虫目前主要是细节的数据结构的设计,比如爬取线程池、任务队列,这些大家都能控制好。爬虫的业务太简单,谈不上什么构架。
所以对于JAVA开源爬虫,我觉得,随便找一个用的顺手的就可以。如果业务复杂,拿哪个爬虫来,都是要经过复杂的二次开发,才可以满足需求。
3.3非JAVA爬虫
在非JAVA语言编写的爬虫中,有很多优秀的爬虫。这里单独提取出来作为一类,并不是针对爬虫本身的质量进行讨论,而是针对larbin、scrapy这类爬虫,对开发成本的影响。
先说python爬虫,python可以用30行代码,完成JAVA50行代码干的任务。python写代码的确快,但是在调试代码的阶段,python代码的调试往往会耗费远远多于编码阶段省下的时间。使用python开发,要保证程序的正确性和稳定性,就需要写更多的测试模块。当然如果爬取规模不大、爬取业务不复杂,使用scrapy这种爬虫也是蛮不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图,绿线是数据流向,首先从初始URL开始,Scheduler会将其交给Downloader进行下载,下载之后会交给Spider进行分析,需要保存的数据则会被送到ItemPipeline,那是对数据进行后期处理。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。因此在开发爬虫的时候,最好也先规划好各种模块。我的做法是单独规划下载模块,爬行模块,调度模块,数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本,如果软件需要团队开发或者交接,那就是很多人的学习成本了。软件的调试也不是那么容易。
还有一些ruby、php的爬虫,这里不多评价。的确有一些非常小型的数据采集任务,用ruby或者php很方便。但是选择这些语言的开源爬虫,一方面要调研一下相关的生态圈,还有就是,这些开源爬虫可能会出一些你搜不到的BUG(用的人少、资料也少)
4、反爬虫技术
因为搜索引擎的流行,网络爬虫已经成了很普及网络技术,除了专门做搜索的Google,Yahoo,微软,百度以外,几乎每个大型门户网站都有自己的搜索引擎,大大小小叫得出来名字得就几十种,还有各种不知名的几千几万种,对于一个内容型驱动的网站来说,受到网络爬虫的光顾是不可避免的。
一些智能的搜索引擎爬虫的爬取频率比较合理,对网站资源消耗比较少,但是很多糟糕的网络爬虫,对网页爬取能力很差,经常并发几十上百个请求循环重复抓取,这种爬虫对中小型网站往往是毁灭性打击,特别是一些缺乏爬虫编写经验的程序员写出来的爬虫破坏力极强,造成的网站访问压力会非常大,会导致网站访问速度缓慢,甚至无法访问。
一般网站从三个方面反爬虫:用户请求的Headers,用户行为,网站目录和数据加载方式。前两种比较容易遇到,大多数网站都从这些角度来反爬虫。第三种一些应用ajax的网站会采用,这样增大了爬取的难度。
4.1通过Headers反爬虫
从用户请求的Headers反爬虫是最常见的反爬虫策略。很多网站都会对Headers的User-Agent进行检测,还有一部分网站会对Referer进行检测(一些资源网站的防盗链就是检测Referer)。如果遇到了这类反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值修改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或者添加Headers就能很好的绕过。
[评论:往往容易被忽略,通过对请求的抓包分析,确定referer,在程序中模拟访问请求头中添加]
4.2基于用户行为反爬虫
还有一部分网站是通过检测用户行为,例如同一IP短时间内多次访问同一页面,或者同一账户短时间内多次进行相同操作。 查看全部
爬虫原理及反爬虫技术
对于大数据行业,数据的价值不言而喻,在这个信息爆炸的年代,互联网上有太多的信息数据,对于中小微公司,合理利用爬虫爬取有价值的数据,是弥补自身先天数据短板的不二选择,本文主要从爬虫原理、架构、分类以及反爬虫技术来对爬虫技术进行了总结。
1、爬虫技术概述
网络爬虫(Webcrawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题:
(1)对抓取目标的描述或定义;
(2)对网页或数据的分析与过滤;
(3)对URL的搜索策略。
2、爬虫原理
2.1网络爬虫原理
Web网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据来源。很多大型的网络搜索引擎系统都被称为基于Web数据采集的搜索引擎系统,比如Google、Baidu。由此可见Web网络爬虫系统在搜索引擎中的重要性。网页中除了包含供用户阅读的文字信息外,还包含一些超链接信息。Web网络爬虫系统正是通过网页中的超连接信息不断获得网络上的其它网页。正是因为这种采集过程像一个爬虫或者蜘蛛在网络上漫游,所以它才被称为网络爬虫系统或者网络蜘蛛系统,在英文中称为Spider或者Crawler。
2.2网络爬虫系统的工作原理
在网络爬虫的系统框架中,主过程由控制器,解析器,资源库三部分组成。控制器的主要工作是负责给多线程中的各个爬虫线程分配工作任务。解析器的主要工作是下载网页,进行页面的处理,主要是将一些JS脚本标签、CSS代码内容、空格字符、HTML标签等内容处理掉,爬虫的基本工作是由解析器完成。资源库是用来存放下载到的网页资源,一般都采用大型的数据库存储,如Oracle数据库,并对其建立索引。
控制器
控制器是网络爬虫的中央控制器,它主要是负责根据系统传过来的URL链接,分配一线程,然后启动线程调用爬虫爬取网页的过程。
解析器
解析器是负责网络爬虫的主要部分,其负责的工作主要有:下载网页的功能,对网页的文本进行处理,如过滤功能,抽取特殊HTML标签的功能,分析数据功能。
资源库
主要是用来存储网页中下载下来的数据记录的容器,并提供生成索引的目标源。中大型的数据库产品有:Oracle、SqlServer等。
Web网络爬虫系统一般会选择一些比较重要的、出度(网页中链出超链接数)较大的网站的URL作为种子URL集合。网络爬虫系统以这些种子集合作为初始URL,开始数据的抓取。因为网页中含有链接信息,通过已有网页的URL会得到一些新的URL,可以把网页之间的指向结构视为一个森林,每个种子URL对应的网页是森林中的一棵树的根节点。
这样,Web网络爬虫系统就可以根据广度优先算法或者深度优先算法遍历所有的网页。由于深度优先搜索算法可能会使爬虫系统陷入一个网站内部,不利于搜索比较靠近网站首页的网页信息,因此一般采用广度优先搜索算法采集网页。Web网络爬虫系统首先将种子URL放入下载队列,然后简单地从队首取出一个URL下载其对应的网页。得到网页的内容将其存储后,再经过解析网页中的链接信息可以得到一些新的URL,将这些URL加入下载队列。然后再取出一个URL,对其对应的网页进行下载,然后再解析,如此反复进行,直到遍历了整个网络或者满足某种条件后才会停止下来。
网络爬虫的基本工作流程如下:
1.首先选取一部分精心挑选的种子URL;
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列;
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
2.3抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面重点介绍几种常见的抓取策略:
2.3.1深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。我们以下面的图为例:
遍历的路径:A-F-GE-H-IBCD
2.3.2宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以上面的图为例:
遍历路径:A-B-C-D-E-FGHI
2.3.3反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数量。反向链接数表示的是一个网页的内容受到其他人的推荐的程度。因此,很多时候搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后顺序。
在真实的网络环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那个也的重要程度。因此,搜索引擎往往考虑一些可靠的反向链接数。
2.3.4PartialPageRank策略
PartialPageRank算法借鉴了PageRank算法的思想:对于已经下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每个页面的PageRank值,计算完之后,将待抓取URL队列中的URL按照PageRank值的大小排列,并按照该顺序抓取页面。
如果每次抓取一个页面,就重新计算PageRank值,一种折中方案是:每抓取K个页面后,重新计算一次PageRank值。但是这种情况还会有一个问题:对于已经下载下来的页面中分析出的链接,也就是我们之前提到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总,这样就形成了该未知页面的PageRank值,从而参与排序。
2.3.5OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P之后,将P的现金分摊给所有从P中分析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面按照现金数进行排序。
2.3.6大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因此叫做大站优先策略。
3、爬虫分类
开发网络爬虫应该选择Nutch、Crawler4j、WebMagic、scrapy、WebCollector还是其他的?上面说的爬虫,基本可以分3类:
(1)分布式爬虫:Nutch
(2)JAVA爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1分布式爬虫
爬虫使用分布式,主要是解决两个问题:
1)海量URL管理
2)网速
现在比较流行的分布式爬虫,是Apache的Nutch。但是对于大多数用户来说,Nutch是这几类爬虫里,最不好的选择,理由如下:
1)Nutch是为搜索引擎设计的爬虫,大多数用户是需要一个做精准数据爬取(精抽取)的爬虫。Nutch运行的一套流程里,有三分之二是为了搜索引擎而设计的。对精抽取没有太大的意义。也就是说,用Nutch做数据抽取,会浪费很多的时间在不必要的计算上。而且如果你试图通过对Nutch进行二次开发,来使得它适用于精抽取的业务,基本上就要破坏Nutch的框架,把Nutch改的面目全非,有修改Nutch的能力,真的不如自己重新写一个分布式爬虫框架了。
2)Nutch依赖hadoop运行,hadoop本身会消耗很多的时间。如果集群机器数量较少,爬取速度反而不如单机爬虫快。
3)Nutch虽然有一套插件机制,而且作为亮点宣传。可以看到一些开源的Nutch插件,提供精抽取的功能。但是开发过Nutch插件的人都知道,Nutch的插件系统有多蹩脚。利用反射的机制来加载和调用插件,使得程序的编写和调试都变得异常困难,更别说在上面开发一套复杂的精抽取系统了。而且Nutch并没有为精抽取提供相应的插件挂载点。Nutch的插件有只有五六个挂载点,而这五六个挂载点都是为了搜索引擎服务的,并没有为精抽取提供挂载点。大多数Nutch的精抽取插件,都是挂载在“页面解析”(parser)这个挂载点的,这个挂载点其实是为了解析链接(为后续爬取提供URL),以及为搜索引擎提供一些易抽取的网页信息(网页的meta信息、text文本)。
4)用Nutch进行爬虫的二次开发,爬虫的编写和调试所需的时间,往往是单机爬虫所需的十倍时间不止。了解Nutch源码的学习成本很高,何况是要让一个团队的人都读懂Nutch源码。调试过程中会出现除程序本身之外的各种问题(hadoop的问题、hbase的问题)。
5)很多人说Nutch2有gora,可以持久化数据到avro文件、hbase、mysql等。很多人其实理解错了,这里说的持久化数据,是指将URL信息(URL管理所需要的数据)存放到avro、hbase、mysql。并不是你要抽取的结构化数据。其实对大多数人来说,URL信息存在哪里无所谓。
6)Nutch2的版本目前并不适合开发。官方现在稳定的Nutch版本是nutch2.2.1,但是这个版本绑定了gora-0.3。如果想用hbase配合nutch(大多数人用nutch2就是为了用hbase),只能使用0.90版本左右的hbase,相应的就要将hadoop版本降到hadoop0.2左右。而且nutch2的官方教程比较有误导作用,Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x,这个Nutch2.x官网上写的是可以支持到hbase0.94。但是实际上,这个Nutch2.x的意思是Nutch2.3之前、Nutch2.2.1之后的一个版本,这个版本在官方的SVN中不断更新。而且非常不稳定(一直在修改)。
所以,如果你不是要做搜索引擎,尽量不要选择Nutch作为爬虫。有些团队就喜欢跟风,非要选择Nutch来开发精抽取的爬虫,其实是冲着Nutch的名气,当然最后的结果往往是项目延期完成。
如果你是要做搜索引擎,Nutch1.x是一个非常好的选择。Nutch1.x和solr或者es配合,就可以构成一套非常强大的搜索引擎了。如果非要用Nutch2的话,建议等到Nutch2.3发布再看。目前的Nutch2是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2JAVA爬虫
这里把JAVA爬虫单独分为一类,是因为JAVA在网络爬虫这块的生态圈是非常完善的。相关的资料也是最全的。这里可能有争议,我只是随便谈谈。
其实开源网络爬虫(框架)的开发非常简单,难问题和复杂的问题都被以前的人解决了(比如DOM树解析和定位、字符集检测、海量URL去重),可以说是毫无技术含量。包括Nutch,其实Nutch的技术难点是开发hadoop,本身代码非常简单。网络爬虫从某种意义来说,类似遍历本机的文件,查找文件中的信息。没有任何难度可言。之所以选择开源爬虫框架,就是为了省事。比如爬虫的URL管理、线程池之类的模块,谁都能做,但是要做稳定也是需要一段时间的调试和修改的。
对于爬虫的功能来说。用户比较关心的问题往往是:
1)爬虫支持多线程么、爬虫能用代理么、爬虫会爬取重复数据么、爬虫能爬取JS生成的信息么?
不支持多线程、不支持代理、不能过滤重复URL的,那都不叫开源爬虫,那叫循环执行http请求。
能不能爬js生成的信息和爬虫本身没有太大关系。爬虫主要是负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往需要通过模拟浏览器(htmlunit,selenium)来完成。这些模拟浏览器,往往需要耗费很多的时间来处理一个页面。所以一种策略就是,使用这些爬虫来遍历网站,遇到需要解析的页面,就将网页的相关信息提交给模拟浏览器,来完成JS生成信息的抽取。
2)爬虫可以爬取ajax信息么?
网页上有一些异步加载的数据,爬取这些数据有两种方法:使用模拟浏览器(问题1中描述过了),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果是自己生成ajax请求,使用开源爬虫的意义在哪里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我所需要的ajax请求(列表),如何用这些爬虫来对这些请求进行爬取?
爬虫往往都是设计成广度遍历或者深度遍历的模式,去遍历静态或者动态页面。爬取ajax信息属于deepweb(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方法来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的第一轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax请求作为种子,放入爬虫。用爬虫对这些种子,进行深度为1的广度遍历(默认就是广度遍历)。
3)爬虫怎么爬取要登陆的网站?
这些开源爬虫都支持在爬取时指定cookies,模拟登陆主要是靠cookies。至于cookies怎么获取,不是爬虫管的事情。你可以手动获取、用http请求模拟登陆或者用模拟浏览器自动登陆获取cookie。
4)爬虫怎么抽取网页的信息?
开源爬虫一般都会集成网页抽取工具。主要支持两种规范:CSSSELECTOR和XPATH。至于哪个好,这里不评价。
5)爬虫怎么保存网页的信息?
有一些爬虫,自带一个模块负责持久化。比如webmagic,有一个模块叫pipeline。通过简单地配置,可以将爬虫抽取到的信息,持久化到文件、数据库等。还有一些爬虫,并没有直接给用户提供数据持久化的模块。比如crawler4j和webcollector。让用户自己在网页处理模块中添加提交数据库的操作。至于使用pipeline这种模块好不好,就和操作数据库使用ORM好不好这个问题类似,取决于你的业务。
6)爬虫被网站封了怎么办?
爬虫被网站封了,一般用多代理(随机代理)就可以解决。但是这些开源爬虫一般没有直接支持随机代理的切换。所以用户往往都需要自己将获取的代理,放到一个全局数组中,自己写一个代理随机获取(从数组中)的代码。
7)网页可以调用爬虫么?
爬虫的调用是在Web的服务端调用的,平时怎么用就怎么用,这些爬虫都可以使用。
8)爬虫速度怎么样?
单机开源爬虫的速度,基本都可以讲本机的网速用到极限。爬虫的速度慢,往往是因为用户把线程数开少了、网速慢,或者在数据持久化时,和数据库的交互速度慢。而这些东西,往往都是用户的机器和二次开发的代码决定的。这些开源爬虫的速度,都很可以。
9)明明代码写对了,爬不到数据,是不是爬虫有问题,换个爬虫能解决么?
如果代码写对了,又爬不到数据,换其他爬虫也是一样爬不到。遇到这种情况,要么是网站把你封了,要么是你爬的数据是javascript生成的。爬不到数据通过换爬虫是不能解决的。
10)哪个爬虫可以判断网站是否爬完、那个爬虫可以根据主题进行爬取?
爬虫无法判断网站是否爬完,只能尽可能覆盖。
至于根据主题爬取,爬虫之后把内容爬下来才知道是什么主题。所以一般都是整个爬下来,然后再去筛选内容。如果嫌爬的太泛,可以通过限制URL正则等方式,来缩小一下范围。
11)哪个爬虫的设计模式和构架比较好?
设计模式纯属扯淡。说软件设计模式好的,都是软件开发完,然后总结出几个设计模式。设计模式对软件开发没有指导性作用。用设计模式来设计爬虫,只会使得爬虫的设计更加臃肿。
至于构架,开源爬虫目前主要是细节的数据结构的设计,比如爬取线程池、任务队列,这些大家都能控制好。爬虫的业务太简单,谈不上什么构架。
所以对于JAVA开源爬虫,我觉得,随便找一个用的顺手的就可以。如果业务复杂,拿哪个爬虫来,都是要经过复杂的二次开发,才可以满足需求。
3.3非JAVA爬虫
在非JAVA语言编写的爬虫中,有很多优秀的爬虫。这里单独提取出来作为一类,并不是针对爬虫本身的质量进行讨论,而是针对larbin、scrapy这类爬虫,对开发成本的影响。
先说python爬虫,python可以用30行代码,完成JAVA50行代码干的任务。python写代码的确快,但是在调试代码的阶段,python代码的调试往往会耗费远远多于编码阶段省下的时间。使用python开发,要保证程序的正确性和稳定性,就需要写更多的测试模块。当然如果爬取规模不大、爬取业务不复杂,使用scrapy这种爬虫也是蛮不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图,绿线是数据流向,首先从初始URL开始,Scheduler会将其交给Downloader进行下载,下载之后会交给Spider进行分析,需要保存的数据则会被送到ItemPipeline,那是对数据进行后期处理。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。因此在开发爬虫的时候,最好也先规划好各种模块。我的做法是单独规划下载模块,爬行模块,调度模块,数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本,如果软件需要团队开发或者交接,那就是很多人的学习成本了。软件的调试也不是那么容易。
还有一些ruby、php的爬虫,这里不多评价。的确有一些非常小型的数据采集任务,用ruby或者php很方便。但是选择这些语言的开源爬虫,一方面要调研一下相关的生态圈,还有就是,这些开源爬虫可能会出一些你搜不到的BUG(用的人少、资料也少)
4、反爬虫技术
因为搜索引擎的流行,网络爬虫已经成了很普及网络技术,除了专门做搜索的Google,Yahoo,微软,百度以外,几乎每个大型门户网站都有自己的搜索引擎,大大小小叫得出来名字得就几十种,还有各种不知名的几千几万种,对于一个内容型驱动的网站来说,受到网络爬虫的光顾是不可避免的。
一些智能的搜索引擎爬虫的爬取频率比较合理,对网站资源消耗比较少,但是很多糟糕的网络爬虫,对网页爬取能力很差,经常并发几十上百个请求循环重复抓取,这种爬虫对中小型网站往往是毁灭性打击,特别是一些缺乏爬虫编写经验的程序员写出来的爬虫破坏力极强,造成的网站访问压力会非常大,会导致网站访问速度缓慢,甚至无法访问。
一般网站从三个方面反爬虫:用户请求的Headers,用户行为,网站目录和数据加载方式。前两种比较容易遇到,大多数网站都从这些角度来反爬虫。第三种一些应用ajax的网站会采用,这样增大了爬取的难度。
4.1通过Headers反爬虫
从用户请求的Headers反爬虫是最常见的反爬虫策略。很多网站都会对Headers的User-Agent进行检测,还有一部分网站会对Referer进行检测(一些资源网站的防盗链就是检测Referer)。如果遇到了这类反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值修改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或者添加Headers就能很好的绕过。
[评论:往往容易被忽略,通过对请求的抓包分析,确定referer,在程序中模拟访问请求头中添加]
4.2基于用户行为反爬虫
还有一部分网站是通过检测用户行为,例如同一IP短时间内多次访问同一页面,或者同一账户短时间内多次进行相同操作。
网络爬虫技术总结
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-05-06 00:10
对于大数据行业,数据的价值不言而喻,在这个信息爆炸的年代,互联网上有太多的信息数据,对于中小微公司,合理利用爬虫爬取有价值的数据,是弥补自身先天数据短板的不二选择,本文主要从爬虫原理、架构、分类以及反爬虫技术来对爬虫技术进行了总结。
1、爬虫技术概述
网络爬虫(Webcrawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题:
(1)对抓取目标的描述或定义;
(2)对网页或数据的分析与过滤;
(3)对URL的搜索策略。
2、爬虫原理
2.1网络爬虫原理
Web网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据来源。很多大型的网络搜索引擎系统都被称为基于Web数据采集的搜索引擎系统,比如Google、Baidu。由此可见Web网络爬虫系统在搜索引擎中的重要性。网页中除了包含供用户阅读的文字信息外,还包含一些超链接信息。Web网络爬虫系统正是通过网页中的超连接信息不断获得网络上的其它网页。正是因为这种采集过程像一个爬虫或者蜘蛛在网络上漫游,所以它才被称为网络爬虫系统或者网络蜘蛛系统,在英文中称为Spider或者Crawler。
2.2网络爬虫系统的工作原理
在网络爬虫的系统框架中,主过程由控制器,解析器,资源库三部分组成。控制器的主要工作是负责给多线程中的各个爬虫线程分配工作任务。解析器的主要工作是下载网页,进行页面的处理,主要是将一些JS脚本标签、CSS代码内容、空格字符、HTML标签等内容处理掉,爬虫的基本工作是由解析器完成。资源库是用来存放下载到的网页资源,一般都采用大型的数据库存储,如Oracle数据库,并对其建立索引。
控制器
控制器是网络爬虫的中央控制器,它主要是负责根据系统传过来的URL链接,分配一线程,然后启动线程调用爬虫爬取网页的过程。
解析器
解析器是负责网络爬虫的主要部分,其负责的工作主要有:下载网页的功能,对网页的文本进行处理,如过滤功能,抽取特殊HTML标签的功能,分析数据功能。
资源库
主要是用来存储网页中下载下来的数据记录的容器,并提供生成索引的目标源。中大型的数据库产品有:Oracle、SqlServer等。
Web网络爬虫系统一般会选择一些比较重要的、出度(网页中链出超链接数)较大的网站的URL作为种子URL集合。网络爬虫系统以这些种子集合作为初始URL,开始数据的抓取。因为网页中含有链接信息,通过已有网页的URL会得到一些新的URL,可以把网页之间的指向结构视为一个森林,每个种子URL对应的网页是森林中的一棵树的根节点。
这样,Web网络爬虫系统就可以根据广度优先算法或者深度优先算法遍历所有的网页。由于深度优先搜索算法可能会使爬虫系统陷入一个网站内部,不利于搜索比较靠近网站首页的网页信息,因此一般采用广度优先搜索算法采集网页。Web网络爬虫系统首先将种子URL放入下载队列,然后简单地从队首取出一个URL下载其对应的网页。得到网页的内容将其存储后,再经过解析网页中的链接信息可以得到一些新的URL,将这些URL加入下载队列。然后再取出一个URL,对其对应的网页进行下载,然后再解析,如此反复进行,直到遍历了整个网络或者满足某种条件后才会停止下来。
网络爬虫的基本工作流程如下:
1.首先选取一部分精心挑选的种子URL;
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列;
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
2.3抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面重点介绍几种常见的抓取策略:
2.3.1深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。我们以下面的图为例:
遍历的路径:A-F-GE-H-IBCD
2.3.2宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以上面的图为例:
遍历路径:A-B-C-D-E-FGHI
2.3.3反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数量。反向链接数表示的是一个网页的内容受到其他人的推荐的程度。因此,很多时候搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后顺序。
在真实的网络环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那个也的重要程度。因此,搜索引擎往往考虑一些可靠的反向链接数。
2.3.4PartialPageRank策略
PartialPageRank算法借鉴了PageRank算法的思想:对于已经下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每个页面的PageRank值,计算完之后,将待抓取URL队列中的URL按照PageRank值的大小排列,并按照该顺序抓取页面。
如果每次抓取一个页面,就重新计算PageRank值,一种折中方案是:每抓取K个页面后,重新计算一次PageRank值。但是这种情况还会有一个问题:对于已经下载下来的页面中分析出的链接,也就是我们之前提到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总,这样就形成了该未知页面的PageRank值,从而参与排序。
2.3.5OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P之后,将P的现金分摊给所有从P中分析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面按照现金数进行排序。
2.3.6大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因此叫做大站优先策略。
3、爬虫分类
开发网络爬虫应该选择Nutch、Crawler4j、WebMagic、scrapy、WebCollector还是其他的?上面说的爬虫,基本可以分3类:
(1)分布式爬虫:Nutch
(2)JAVA爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1分布式爬虫
爬虫使用分布式,主要是解决两个问题:
1)海量URL管理
2)网速
现在比较流行的分布式爬虫,是Apache的Nutch。但是对于大多数用户来说,Nutch是这几类爬虫里,最不好的选择,理由如下:
1)Nutch是为搜索引擎设计的爬虫,大多数用户是需要一个做精准数据爬取(精抽取)的爬虫。Nutch运行的一套流程里,有三分之二是为了搜索引擎而设计的。对精抽取没有太大的意义。也就是说,用Nutch做数据抽取,会浪费很多的时间在不必要的计算上。而且如果你试图通过对Nutch进行二次开发,来使得它适用于精抽取的业务,基本上就要破坏Nutch的框架,把Nutch改的面目全非,有修改Nutch的能力,真的不如自己重新写一个分布式爬虫框架了。
2)Nutch依赖hadoop运行,hadoop本身会消耗很多的时间。如果集群机器数量较少,爬取速度反而不如单机爬虫快。
3)Nutch虽然有一套插件机制,而且作为亮点宣传。可以看到一些开源的Nutch插件,提供精抽取的功能。但是开发过Nutch插件的人都知道,Nutch的插件系统有多蹩脚。利用反射的机制来加载和调用插件,使得程序的编写和调试都变得异常困难,更别说在上面开发一套复杂的精抽取系统了。而且Nutch并没有为精抽取提供相应的插件挂载点。Nutch的插件有只有五六个挂载点,而这五六个挂载点都是为了搜索引擎服务的,并没有为精抽取提供挂载点。大多数Nutch的精抽取插件,都是挂载在“页面解析”(parser)这个挂载点的,这个挂载点其实是为了解析链接(为后续爬取提供URL),以及为搜索引擎提供一些易抽取的网页信息(网页的meta信息、text文本)。
4)用Nutch进行爬虫的二次开发,爬虫的编写和调试所需的时间,往往是单机爬虫所需的十倍时间不止。了解Nutch源码的学习成本很高,何况是要让一个团队的人都读懂Nutch源码。调试过程中会出现除程序本身之外的各种问题(hadoop的问题、hbase的问题)。
5)很多人说Nutch2有gora,可以持久化数据到avro文件、hbase、mysql等。很多人其实理解错了,这里说的持久化数据,是指将URL信息(URL管理所需要的数据)存放到avro、hbase、mysql。并不是你要抽取的结构化数据。其实对大多数人来说,URL信息存在哪里无所谓。
6)Nutch2的版本目前并不适合开发。官方现在稳定的Nutch版本是nutch2.2.1,但是这个版本绑定了gora-0.3。如果想用hbase配合nutch(大多数人用nutch2就是为了用hbase),只能使用0.90版本左右的hbase,相应的就要将hadoop版本降到hadoop0.2左右。而且nutch2的官方教程比较有误导作用,Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x,这个Nutch2.x官网上写的是可以支持到hbase0.94。但是实际上,这个Nutch2.x的意思是Nutch2.3之前、Nutch2.2.1之后的一个版本,这个版本在官方的SVN中不断更新。而且非常不稳定(一直在修改)。
所以,如果你不是要做搜索引擎,尽量不要选择Nutch作为爬虫。有些团队就喜欢跟风,非要选择Nutch来开发精抽取的爬虫,其实是冲着Nutch的名气,当然最后的结果往往是项目延期完成。
如果你是要做搜索引擎,Nutch1.x是一个非常好的选择。Nutch1.x和solr或者es配合,就可以构成一套非常强大的搜索引擎了。如果非要用Nutch2的话,建议等到Nutch2.3发布再看。目前的Nutch2是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2JAVA爬虫
这里把JAVA爬虫单独分为一类,是因为JAVA在网络爬虫这块的生态圈是非常完善的。相关的资料也是最全的。这里可能有争议,我只是随便谈谈。
其实开源网络爬虫(框架)的开发非常简单,难问题和复杂的问题都被以前的人解决了(比如DOM树解析和定位、字符集检测、海量URL去重),可以说是毫无技术含量。包括Nutch,其实Nutch的技术难点是开发hadoop,本身代码非常简单。网络爬虫从某种意义来说,类似遍历本机的文件,查找文件中的信息。没有任何难度可言。之所以选择开源爬虫框架,就是为了省事。比如爬虫的URL管理、线程池之类的模块,谁都能做,但是要做稳定也是需要一段时间的调试和修改的。
对于爬虫的功能来说。用户比较关心的问题往往是:
1)爬虫支持多线程么、爬虫能用代理么、爬虫会爬取重复数据么、爬虫能爬取JS生成的信息么?
不支持多线程、不支持代理、不能过滤重复URL的,那都不叫开源爬虫,那叫循环执行http请求。
能不能爬js生成的信息和爬虫本身没有太大关系。爬虫主要是负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往需要通过模拟浏览器(htmlunit,selenium)来完成。这些模拟浏览器,往往需要耗费很多的时间来处理一个页面。所以一种策略就是,使用这些爬虫来遍历网站,遇到需要解析的页面,就将网页的相关信息提交给模拟浏览器,来完成JS生成信息的抽取。
2)爬虫可以爬取ajax信息么?
网页上有一些异步加载的数据,爬取这些数据有两种方法:使用模拟浏览器(问题1中描述过了),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果是自己生成ajax请求,使用开源爬虫的意义在哪里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我所需要的ajax请求(列表),如何用这些爬虫来对这些请求进行爬取?
爬虫往往都是设计成广度遍历或者深度遍历的模式,去遍历静态或者动态页面。爬取ajax信息属于deepweb(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方法来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的第一轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax请求作为种子,放入爬虫。用爬虫对这些种子,进行深度为1的广度遍历(默认就是广度遍历)。
3)爬虫怎么爬取要登陆的网站?
这些开源爬虫都支持在爬取时指定cookies,模拟登陆主要是靠cookies。至于cookies怎么获取,不是爬虫管的事情。你可以手动获取、用http请求模拟登陆或者用模拟浏览器自动登陆获取cookie。
4)爬虫怎么抽取网页的信息?
开源爬虫一般都会集成网页抽取工具。主要支持两种规范:CSSSELECTOR和XPATH。至于哪个好,这里不评价。
5)爬虫怎么保存网页的信息?
有一些爬虫,自带一个模块负责持久化。比如webmagic,有一个模块叫pipeline。通过简单地配置,可以将爬虫抽取到的信息,持久化到文件、数据库等。还有一些爬虫,并没有直接给用户提供数据持久化的模块。比如crawler4j和webcollector。让用户自己在网页处理模块中添加提交数据库的操作。至于使用pipeline这种模块好不好,就和操作数据库使用ORM好不好这个问题类似,取决于你的业务。
6)爬虫被网站封了怎么办?
爬虫被网站封了,一般用多代理(随机代理)就可以解决。但是这些开源爬虫一般没有直接支持随机代理的切换。所以用户往往都需要自己将获取的代理,放到一个全局数组中,自己写一个代理随机获取(从数组中)的代码。
7)网页可以调用爬虫么?
爬虫的调用是在Web的服务端调用的,平时怎么用就怎么用,这些爬虫都可以使用。
8)爬虫速度怎么样?
单机开源爬虫的速度,基本都可以讲本机的网速用到极限。爬虫的速度慢,往往是因为用户把线程数开少了、网速慢,或者在数据持久化时,和数据库的交互速度慢。而这些东西,往往都是用户的机器和二次开发的代码决定的。这些开源爬虫的速度,都很可以。
9)明明代码写对了,爬不到数据,是不是爬虫有问题,换个爬虫能解决么?
如果代码写对了,又爬不到数据,换其他爬虫也是一样爬不到。遇到这种情况,要么是网站把你封了,要么是你爬的数据是javascript生成的。爬不到数据通过换爬虫是不能解决的。
10)哪个爬虫可以判断网站是否爬完、那个爬虫可以根据主题进行爬取?
爬虫无法判断网站是否爬完,只能尽可能覆盖。
至于根据主题爬取,爬虫之后把内容爬下来才知道是什么主题。所以一般都是整个爬下来,然后再去筛选内容。如果嫌爬的太泛,可以通过限制URL正则等方式,来缩小一下范围。
11)哪个爬虫的设计模式和构架比较好?
设计模式纯属扯淡。说软件设计模式好的,都是软件开发完,然后总结出几个设计模式。设计模式对软件开发没有指导性作用。用设计模式来设计爬虫,只会使得爬虫的设计更加臃肿。
至于构架,开源爬虫目前主要是细节的数据结构的设计,比如爬取线程池、任务队列,这些大家都能控制好。爬虫的业务太简单,谈不上什么构架。
所以对于JAVA开源爬虫,我觉得,随便找一个用的顺手的就可以。如果业务复杂,拿哪个爬虫来,都是要经过复杂的二次开发,才可以满足需求。
3.3非JAVA爬虫
在非JAVA语言编写的爬虫中,有很多优秀的爬虫。这里单独提取出来作为一类,并不是针对爬虫本身的质量进行讨论,而是针对larbin、scrapy这类爬虫,对开发成本的影响。
先说python爬虫,python可以用30行代码,完成JAVA50行代码干的任务。python写代码的确快,但是在调试代码的阶段,python代码的调试往往会耗费远远多于编码阶段省下的时间。使用python开发,要保证程序的正确性和稳定性,就需要写更多的测试模块。当然如果爬取规模不大、爬取业务不复杂,使用scrapy这种爬虫也是蛮不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图,绿线是数据流向,首先从初始URL开始,Scheduler会将其交给Downloader进行下载,下载之后会交给Spider进行分析,需要保存的数据则会被送到ItemPipeline,那是对数据进行后期处理。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。因此在开发爬虫的时候,最好也先规划好各种模块。我的做法是单独规划下载模块,爬行模块,调度模块,数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本,如果软件需要团队开发或者交接,那就是很多人的学习成本了。软件的调试也不是那么容易。
还有一些ruby、php的爬虫,这里不多评价。的确有一些非常小型的数据采集任务,用ruby或者php很方便。但是选择这些语言的开源爬虫,一方面要调研一下相关的生态圈,还有就是,这些开源爬虫可能会出一些你搜不到的BUG(用的人少、资料也少)
4、反爬虫技术
因为搜索引擎的流行,网络爬虫已经成了很普及网络技术,除了专门做搜索的Google,Yahoo,微软,百度以外,几乎每个大型门户网站都有自己的搜索引擎,大大小小叫得出来名字得就几十种,还有各种不知名的几千几万种,对于一个内容型驱动的网站来说,受到网络爬虫的光顾是不可避免的。
一些智能的搜索引擎爬虫的爬取频率比较合理,对网站资源消耗比较少,但是很多糟糕的网络爬虫,对网页爬取能力很差,经常并发几十上百个请求循环重复抓取,这种爬虫对中小型网站往往是毁灭性打击,特别是一些缺乏爬虫编写经验的程序员写出来的爬虫破坏力极强,造成的网站访问压力会非常大,会导致网站访问速度缓慢,甚至无法访问。
一般网站从三个方面反爬虫:用户请求的Headers,用户行为,网站目录和数据加载方式。前两种比较容易遇到,大多数网站都从这些角度来反爬虫。第三种一些应用ajax的网站会采用,这样增大了爬取的难度。
4.1通过Headers反爬虫
从用户请求的Headers反爬虫是最常见的反爬虫策略。很多网站都会对Headers的User-Agent进行检测,还有一部分网站会对Referer进行检测(一些资源网站的防盗链就是检测Referer)。如果遇到了这类反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值修改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或者添加Headers就能很好的绕过。
[评论:往往容易被忽略,通过对请求的抓包分析,确定referer,在程序中模拟访问请求头中添加]
4.2基于用户行为反爬虫
还有一部分网站是通过检测用户行为,例如同一IP短时间内多次访问同一页面,或者同一账户短时间内多次进行相同操作。 查看全部
网络爬虫技术总结
对于大数据行业,数据的价值不言而喻,在这个信息爆炸的年代,互联网上有太多的信息数据,对于中小微公司,合理利用爬虫爬取有价值的数据,是弥补自身先天数据短板的不二选择,本文主要从爬虫原理、架构、分类以及反爬虫技术来对爬虫技术进行了总结。
1、爬虫技术概述
网络爬虫(Webcrawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题:
(1)对抓取目标的描述或定义;
(2)对网页或数据的分析与过滤;
(3)对URL的搜索策略。
2、爬虫原理
2.1网络爬虫原理
Web网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据来源。很多大型的网络搜索引擎系统都被称为基于Web数据采集的搜索引擎系统,比如Google、Baidu。由此可见Web网络爬虫系统在搜索引擎中的重要性。网页中除了包含供用户阅读的文字信息外,还包含一些超链接信息。Web网络爬虫系统正是通过网页中的超连接信息不断获得网络上的其它网页。正是因为这种采集过程像一个爬虫或者蜘蛛在网络上漫游,所以它才被称为网络爬虫系统或者网络蜘蛛系统,在英文中称为Spider或者Crawler。
2.2网络爬虫系统的工作原理
在网络爬虫的系统框架中,主过程由控制器,解析器,资源库三部分组成。控制器的主要工作是负责给多线程中的各个爬虫线程分配工作任务。解析器的主要工作是下载网页,进行页面的处理,主要是将一些JS脚本标签、CSS代码内容、空格字符、HTML标签等内容处理掉,爬虫的基本工作是由解析器完成。资源库是用来存放下载到的网页资源,一般都采用大型的数据库存储,如Oracle数据库,并对其建立索引。
控制器
控制器是网络爬虫的中央控制器,它主要是负责根据系统传过来的URL链接,分配一线程,然后启动线程调用爬虫爬取网页的过程。
解析器
解析器是负责网络爬虫的主要部分,其负责的工作主要有:下载网页的功能,对网页的文本进行处理,如过滤功能,抽取特殊HTML标签的功能,分析数据功能。
资源库
主要是用来存储网页中下载下来的数据记录的容器,并提供生成索引的目标源。中大型的数据库产品有:Oracle、SqlServer等。
Web网络爬虫系统一般会选择一些比较重要的、出度(网页中链出超链接数)较大的网站的URL作为种子URL集合。网络爬虫系统以这些种子集合作为初始URL,开始数据的抓取。因为网页中含有链接信息,通过已有网页的URL会得到一些新的URL,可以把网页之间的指向结构视为一个森林,每个种子URL对应的网页是森林中的一棵树的根节点。
这样,Web网络爬虫系统就可以根据广度优先算法或者深度优先算法遍历所有的网页。由于深度优先搜索算法可能会使爬虫系统陷入一个网站内部,不利于搜索比较靠近网站首页的网页信息,因此一般采用广度优先搜索算法采集网页。Web网络爬虫系统首先将种子URL放入下载队列,然后简单地从队首取出一个URL下载其对应的网页。得到网页的内容将其存储后,再经过解析网页中的链接信息可以得到一些新的URL,将这些URL加入下载队列。然后再取出一个URL,对其对应的网页进行下载,然后再解析,如此反复进行,直到遍历了整个网络或者满足某种条件后才会停止下来。
网络爬虫的基本工作流程如下:
1.首先选取一部分精心挑选的种子URL;
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列;
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
2.3抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面重点介绍几种常见的抓取策略:
2.3.1深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。我们以下面的图为例:
遍历的路径:A-F-GE-H-IBCD
2.3.2宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以上面的图为例:
遍历路径:A-B-C-D-E-FGHI
2.3.3反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数量。反向链接数表示的是一个网页的内容受到其他人的推荐的程度。因此,很多时候搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后顺序。
在真实的网络环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那个也的重要程度。因此,搜索引擎往往考虑一些可靠的反向链接数。
2.3.4PartialPageRank策略
PartialPageRank算法借鉴了PageRank算法的思想:对于已经下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每个页面的PageRank值,计算完之后,将待抓取URL队列中的URL按照PageRank值的大小排列,并按照该顺序抓取页面。
如果每次抓取一个页面,就重新计算PageRank值,一种折中方案是:每抓取K个页面后,重新计算一次PageRank值。但是这种情况还会有一个问题:对于已经下载下来的页面中分析出的链接,也就是我们之前提到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总,这样就形成了该未知页面的PageRank值,从而参与排序。
2.3.5OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P之后,将P的现金分摊给所有从P中分析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面按照现金数进行排序。
2.3.6大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因此叫做大站优先策略。
3、爬虫分类
开发网络爬虫应该选择Nutch、Crawler4j、WebMagic、scrapy、WebCollector还是其他的?上面说的爬虫,基本可以分3类:
(1)分布式爬虫:Nutch
(2)JAVA爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1分布式爬虫
爬虫使用分布式,主要是解决两个问题:
1)海量URL管理
2)网速
现在比较流行的分布式爬虫,是Apache的Nutch。但是对于大多数用户来说,Nutch是这几类爬虫里,最不好的选择,理由如下:
1)Nutch是为搜索引擎设计的爬虫,大多数用户是需要一个做精准数据爬取(精抽取)的爬虫。Nutch运行的一套流程里,有三分之二是为了搜索引擎而设计的。对精抽取没有太大的意义。也就是说,用Nutch做数据抽取,会浪费很多的时间在不必要的计算上。而且如果你试图通过对Nutch进行二次开发,来使得它适用于精抽取的业务,基本上就要破坏Nutch的框架,把Nutch改的面目全非,有修改Nutch的能力,真的不如自己重新写一个分布式爬虫框架了。
2)Nutch依赖hadoop运行,hadoop本身会消耗很多的时间。如果集群机器数量较少,爬取速度反而不如单机爬虫快。
3)Nutch虽然有一套插件机制,而且作为亮点宣传。可以看到一些开源的Nutch插件,提供精抽取的功能。但是开发过Nutch插件的人都知道,Nutch的插件系统有多蹩脚。利用反射的机制来加载和调用插件,使得程序的编写和调试都变得异常困难,更别说在上面开发一套复杂的精抽取系统了。而且Nutch并没有为精抽取提供相应的插件挂载点。Nutch的插件有只有五六个挂载点,而这五六个挂载点都是为了搜索引擎服务的,并没有为精抽取提供挂载点。大多数Nutch的精抽取插件,都是挂载在“页面解析”(parser)这个挂载点的,这个挂载点其实是为了解析链接(为后续爬取提供URL),以及为搜索引擎提供一些易抽取的网页信息(网页的meta信息、text文本)。
4)用Nutch进行爬虫的二次开发,爬虫的编写和调试所需的时间,往往是单机爬虫所需的十倍时间不止。了解Nutch源码的学习成本很高,何况是要让一个团队的人都读懂Nutch源码。调试过程中会出现除程序本身之外的各种问题(hadoop的问题、hbase的问题)。
5)很多人说Nutch2有gora,可以持久化数据到avro文件、hbase、mysql等。很多人其实理解错了,这里说的持久化数据,是指将URL信息(URL管理所需要的数据)存放到avro、hbase、mysql。并不是你要抽取的结构化数据。其实对大多数人来说,URL信息存在哪里无所谓。
6)Nutch2的版本目前并不适合开发。官方现在稳定的Nutch版本是nutch2.2.1,但是这个版本绑定了gora-0.3。如果想用hbase配合nutch(大多数人用nutch2就是为了用hbase),只能使用0.90版本左右的hbase,相应的就要将hadoop版本降到hadoop0.2左右。而且nutch2的官方教程比较有误导作用,Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x,这个Nutch2.x官网上写的是可以支持到hbase0.94。但是实际上,这个Nutch2.x的意思是Nutch2.3之前、Nutch2.2.1之后的一个版本,这个版本在官方的SVN中不断更新。而且非常不稳定(一直在修改)。
所以,如果你不是要做搜索引擎,尽量不要选择Nutch作为爬虫。有些团队就喜欢跟风,非要选择Nutch来开发精抽取的爬虫,其实是冲着Nutch的名气,当然最后的结果往往是项目延期完成。
如果你是要做搜索引擎,Nutch1.x是一个非常好的选择。Nutch1.x和solr或者es配合,就可以构成一套非常强大的搜索引擎了。如果非要用Nutch2的话,建议等到Nutch2.3发布再看。目前的Nutch2是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2JAVA爬虫
这里把JAVA爬虫单独分为一类,是因为JAVA在网络爬虫这块的生态圈是非常完善的。相关的资料也是最全的。这里可能有争议,我只是随便谈谈。
其实开源网络爬虫(框架)的开发非常简单,难问题和复杂的问题都被以前的人解决了(比如DOM树解析和定位、字符集检测、海量URL去重),可以说是毫无技术含量。包括Nutch,其实Nutch的技术难点是开发hadoop,本身代码非常简单。网络爬虫从某种意义来说,类似遍历本机的文件,查找文件中的信息。没有任何难度可言。之所以选择开源爬虫框架,就是为了省事。比如爬虫的URL管理、线程池之类的模块,谁都能做,但是要做稳定也是需要一段时间的调试和修改的。
对于爬虫的功能来说。用户比较关心的问题往往是:
1)爬虫支持多线程么、爬虫能用代理么、爬虫会爬取重复数据么、爬虫能爬取JS生成的信息么?
不支持多线程、不支持代理、不能过滤重复URL的,那都不叫开源爬虫,那叫循环执行http请求。
能不能爬js生成的信息和爬虫本身没有太大关系。爬虫主要是负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往需要通过模拟浏览器(htmlunit,selenium)来完成。这些模拟浏览器,往往需要耗费很多的时间来处理一个页面。所以一种策略就是,使用这些爬虫来遍历网站,遇到需要解析的页面,就将网页的相关信息提交给模拟浏览器,来完成JS生成信息的抽取。
2)爬虫可以爬取ajax信息么?
网页上有一些异步加载的数据,爬取这些数据有两种方法:使用模拟浏览器(问题1中描述过了),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果是自己生成ajax请求,使用开源爬虫的意义在哪里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我所需要的ajax请求(列表),如何用这些爬虫来对这些请求进行爬取?
爬虫往往都是设计成广度遍历或者深度遍历的模式,去遍历静态或者动态页面。爬取ajax信息属于deepweb(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方法来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的第一轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax请求作为种子,放入爬虫。用爬虫对这些种子,进行深度为1的广度遍历(默认就是广度遍历)。
3)爬虫怎么爬取要登陆的网站?
这些开源爬虫都支持在爬取时指定cookies,模拟登陆主要是靠cookies。至于cookies怎么获取,不是爬虫管的事情。你可以手动获取、用http请求模拟登陆或者用模拟浏览器自动登陆获取cookie。
4)爬虫怎么抽取网页的信息?
开源爬虫一般都会集成网页抽取工具。主要支持两种规范:CSSSELECTOR和XPATH。至于哪个好,这里不评价。
5)爬虫怎么保存网页的信息?
有一些爬虫,自带一个模块负责持久化。比如webmagic,有一个模块叫pipeline。通过简单地配置,可以将爬虫抽取到的信息,持久化到文件、数据库等。还有一些爬虫,并没有直接给用户提供数据持久化的模块。比如crawler4j和webcollector。让用户自己在网页处理模块中添加提交数据库的操作。至于使用pipeline这种模块好不好,就和操作数据库使用ORM好不好这个问题类似,取决于你的业务。
6)爬虫被网站封了怎么办?
爬虫被网站封了,一般用多代理(随机代理)就可以解决。但是这些开源爬虫一般没有直接支持随机代理的切换。所以用户往往都需要自己将获取的代理,放到一个全局数组中,自己写一个代理随机获取(从数组中)的代码。
7)网页可以调用爬虫么?
爬虫的调用是在Web的服务端调用的,平时怎么用就怎么用,这些爬虫都可以使用。
8)爬虫速度怎么样?
单机开源爬虫的速度,基本都可以讲本机的网速用到极限。爬虫的速度慢,往往是因为用户把线程数开少了、网速慢,或者在数据持久化时,和数据库的交互速度慢。而这些东西,往往都是用户的机器和二次开发的代码决定的。这些开源爬虫的速度,都很可以。
9)明明代码写对了,爬不到数据,是不是爬虫有问题,换个爬虫能解决么?
如果代码写对了,又爬不到数据,换其他爬虫也是一样爬不到。遇到这种情况,要么是网站把你封了,要么是你爬的数据是javascript生成的。爬不到数据通过换爬虫是不能解决的。
10)哪个爬虫可以判断网站是否爬完、那个爬虫可以根据主题进行爬取?
爬虫无法判断网站是否爬完,只能尽可能覆盖。
至于根据主题爬取,爬虫之后把内容爬下来才知道是什么主题。所以一般都是整个爬下来,然后再去筛选内容。如果嫌爬的太泛,可以通过限制URL正则等方式,来缩小一下范围。
11)哪个爬虫的设计模式和构架比较好?
设计模式纯属扯淡。说软件设计模式好的,都是软件开发完,然后总结出几个设计模式。设计模式对软件开发没有指导性作用。用设计模式来设计爬虫,只会使得爬虫的设计更加臃肿。
至于构架,开源爬虫目前主要是细节的数据结构的设计,比如爬取线程池、任务队列,这些大家都能控制好。爬虫的业务太简单,谈不上什么构架。
所以对于JAVA开源爬虫,我觉得,随便找一个用的顺手的就可以。如果业务复杂,拿哪个爬虫来,都是要经过复杂的二次开发,才可以满足需求。
3.3非JAVA爬虫
在非JAVA语言编写的爬虫中,有很多优秀的爬虫。这里单独提取出来作为一类,并不是针对爬虫本身的质量进行讨论,而是针对larbin、scrapy这类爬虫,对开发成本的影响。
先说python爬虫,python可以用30行代码,完成JAVA50行代码干的任务。python写代码的确快,但是在调试代码的阶段,python代码的调试往往会耗费远远多于编码阶段省下的时间。使用python开发,要保证程序的正确性和稳定性,就需要写更多的测试模块。当然如果爬取规模不大、爬取业务不复杂,使用scrapy这种爬虫也是蛮不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图,绿线是数据流向,首先从初始URL开始,Scheduler会将其交给Downloader进行下载,下载之后会交给Spider进行分析,需要保存的数据则会被送到ItemPipeline,那是对数据进行后期处理。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。因此在开发爬虫的时候,最好也先规划好各种模块。我的做法是单独规划下载模块,爬行模块,调度模块,数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本,如果软件需要团队开发或者交接,那就是很多人的学习成本了。软件的调试也不是那么容易。
还有一些ruby、php的爬虫,这里不多评价。的确有一些非常小型的数据采集任务,用ruby或者php很方便。但是选择这些语言的开源爬虫,一方面要调研一下相关的生态圈,还有就是,这些开源爬虫可能会出一些你搜不到的BUG(用的人少、资料也少)
4、反爬虫技术
因为搜索引擎的流行,网络爬虫已经成了很普及网络技术,除了专门做搜索的Google,Yahoo,微软,百度以外,几乎每个大型门户网站都有自己的搜索引擎,大大小小叫得出来名字得就几十种,还有各种不知名的几千几万种,对于一个内容型驱动的网站来说,受到网络爬虫的光顾是不可避免的。
一些智能的搜索引擎爬虫的爬取频率比较合理,对网站资源消耗比较少,但是很多糟糕的网络爬虫,对网页爬取能力很差,经常并发几十上百个请求循环重复抓取,这种爬虫对中小型网站往往是毁灭性打击,特别是一些缺乏爬虫编写经验的程序员写出来的爬虫破坏力极强,造成的网站访问压力会非常大,会导致网站访问速度缓慢,甚至无法访问。
一般网站从三个方面反爬虫:用户请求的Headers,用户行为,网站目录和数据加载方式。前两种比较容易遇到,大多数网站都从这些角度来反爬虫。第三种一些应用ajax的网站会采用,这样增大了爬取的难度。
4.1通过Headers反爬虫
从用户请求的Headers反爬虫是最常见的反爬虫策略。很多网站都会对Headers的User-Agent进行检测,还有一部分网站会对Referer进行检测(一些资源网站的防盗链就是检测Referer)。如果遇到了这类反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值修改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或者添加Headers就能很好的绕过。
[评论:往往容易被忽略,通过对请求的抓包分析,确定referer,在程序中模拟访问请求头中添加]
4.2基于用户行为反爬虫
还有一部分网站是通过检测用户行为,例如同一IP短时间内多次访问同一页面,或者同一账户短时间内多次进行相同操作。
php 抓取网页ajax数据(这里有新鲜出炉的精品教程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-04-20 18:39
这里有新鲜出炉的精品教程,看看程序狗速!
ThinkPHP开源PHP框架 ThinkPHP是一个开源PHP框架,为简化企业级应用开发和敏捷WEB应用开发而生。ThinkPHP可以支持windows/Unix/Liunx等服务器环境。正式版需要PHP5.0或以上,支持MySql、PgSQL、Sqlite、PDO等多种数据库。
本篇文章主要介绍jquery+thinkphp实现跨域数据抓取的方法,分析thinkPHP结合jQuery的ajax实现跨域数据抓取的相关操作技巧。有需要的朋友可以参考以下
本文示例介绍jquery+thinkphp实现跨域数据抓取的方法。分享给大家参考,详情如下:
今天,我将做一个远程获取数据的功能。请记住,jquery 可以使用 Ajax 获取远程数据,但不能跨域。我在网上找到了很多。但我觉得还是综合,所以我觉得对于一个简单的问题来说有点复杂,但至少现在解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post发送数据到服务器后台,后台的php代码执行远程抓取,存入数据库ajax并返回数据到前台,前台用js接受数据并显示。
//远程抓取获取数据
$("#update_ac").click(function() {
$username = $("#username").text();
$("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){
$(this).html(" ");
});
$.post("update_ac/username/"+$username,{},function($data){
json = eval("(" + $data + ")");
$("#Submit").html(json.data.Submit);
$("#AC").html(json.data.AC);
$("#solved,#solved2,#solved3").html(json.data.solved);
$("#rank").html(json.data.rank);
}
),"json";
});
上面jquery代码在四楼比较清楚,困扰我的是那个json数据的接收
json = eval("(" + $data + ")");
//eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这个还是前台,跨域爬取是用php扩展simple_html_dom做的(如果不确定可以去网上搜索一下,基于PHP5开发的)
将远程页面抓取到本地。
import("@.ORG.simple_html_dom");
//thinkphp内导入扩展,你要把网上下载的代码改名为simple_html_dom.class.php放到APPNAME\Lib\ORG的目录下面
$html = file_get_html('http://openoj.awaysoft.com/JudgeOnline/userinfo.php?user='.$username); //远程抓取了
$ret = $html->find('center',0)->plaintext; //返回数据了。
上面的代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后用正则表达式过滤出需要的数据。以下是效果图
希望这篇文章对大家基于ThinkPHP框架的PHP编程有所帮助。 查看全部
php 抓取网页ajax数据(这里有新鲜出炉的精品教程,程序狗速度看过来!)
这里有新鲜出炉的精品教程,看看程序狗速!
ThinkPHP开源PHP框架 ThinkPHP是一个开源PHP框架,为简化企业级应用开发和敏捷WEB应用开发而生。ThinkPHP可以支持windows/Unix/Liunx等服务器环境。正式版需要PHP5.0或以上,支持MySql、PgSQL、Sqlite、PDO等多种数据库。
本篇文章主要介绍jquery+thinkphp实现跨域数据抓取的方法,分析thinkPHP结合jQuery的ajax实现跨域数据抓取的相关操作技巧。有需要的朋友可以参考以下
本文示例介绍jquery+thinkphp实现跨域数据抓取的方法。分享给大家参考,详情如下:
今天,我将做一个远程获取数据的功能。请记住,jquery 可以使用 Ajax 获取远程数据,但不能跨域。我在网上找到了很多。但我觉得还是综合,所以我觉得对于一个简单的问题来说有点复杂,但至少现在解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post发送数据到服务器后台,后台的php代码执行远程抓取,存入数据库ajax并返回数据到前台,前台用js接受数据并显示。
//远程抓取获取数据
$("#update_ac").click(function() {
$username = $("#username").text();
$("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){
$(this).html(" ");
});
$.post("update_ac/username/"+$username,{},function($data){
json = eval("(" + $data + ")");
$("#Submit").html(json.data.Submit);
$("#AC").html(json.data.AC);
$("#solved,#solved2,#solved3").html(json.data.solved);
$("#rank").html(json.data.rank);
}
),"json";
});
上面jquery代码在四楼比较清楚,困扰我的是那个json数据的接收
json = eval("(" + $data + ")");
//eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这个还是前台,跨域爬取是用php扩展simple_html_dom做的(如果不确定可以去网上搜索一下,基于PHP5开发的)
将远程页面抓取到本地。
import("@.ORG.simple_html_dom");
//thinkphp内导入扩展,你要把网上下载的代码改名为simple_html_dom.class.php放到APPNAME\Lib\ORG的目录下面
$html = file_get_html('http://openoj.awaysoft.com/JudgeOnline/userinfo.php?user='.$username); //远程抓取了
$ret = $html->find('center',0)->plaintext; //返回数据了。
上面的代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后用正则表达式过滤出需要的数据。以下是效果图

希望这篇文章对大家基于ThinkPHP框架的PHP编程有所帮助。
php 抓取网页ajax数据(PHP代码执行远程抓取数据的功能讲述simple_html_dom扩展 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-04-14 12:00
)
本文示例介绍jquery+thinkphp实现跨域数据抓取的方法。分享给大家参考,详情如下:
今天,我将做一个远程获取数据的功能。请记住,jquery 可以使用 Ajax 获取远程数据,但不能跨域。我在网上找到了很多。但我觉得还是综合,所以我觉得对于一个简单的问题来说有点复杂,但至少现在解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post发送数据到服务器后台,后台的php代码执行远程抓取,存入数据库ajax并返回数据到前台,前台用js接受数据并显示。
//远程抓取获取数据
$("#update_ac").click(function() {
$username = $("#username").text();
$("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){
$(this).html(" ");
});
$.post("update_ac/username/"+$username,{},function($data){
json = eval("(" + $data + ")");
$("#Submit").html(json.data.Submit);
$("#AC").html(json.data.AC);
$("#solved,#solved2,#solved3").html(json.data.solved);
$("#rank").html(json.data.rank);
}
),"json";
});
上面jquery代码在四楼比较清楚,困扰我的是那个json数据的接收
json = eval("(" + $data + ")");
//eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这个还是前台,跨域爬取是用php扩展simple_html_dom做的(不确定可以去网上搜索一下,基于PHP5开发的)
将远程页面抓取到本地。
import("@.ORG.simple_html_dom");
//thinkphp内导入扩展,你要把网上下载的代码改名为simple_html_dom.class.php放到APPNAME\Lib\ORG的目录下面
$html = file_get_html('http://openoj.awaysoft.com/JudgeOnline/userinfo.php?user='.$username); //远程抓取了
$ret = $html->find('center',0)->plaintext; //返回数据了。
上面的代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后用正则表达式过滤出需要的数据。以下是效果图
查看全部
php 抓取网页ajax数据(PHP代码执行远程抓取数据的功能讲述simple_html_dom扩展
)
本文示例介绍jquery+thinkphp实现跨域数据抓取的方法。分享给大家参考,详情如下:
今天,我将做一个远程获取数据的功能。请记住,jquery 可以使用 Ajax 获取远程数据,但不能跨域。我在网上找到了很多。但我觉得还是综合,所以我觉得对于一个简单的问题来说有点复杂,但至少现在解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post发送数据到服务器后台,后台的php代码执行远程抓取,存入数据库ajax并返回数据到前台,前台用js接受数据并显示。
//远程抓取获取数据
$("#update_ac").click(function() {
$username = $("#username").text();
$("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){
$(this).html(" ");
});
$.post("update_ac/username/"+$username,{},function($data){
json = eval("(" + $data + ")");
$("#Submit").html(json.data.Submit);
$("#AC").html(json.data.AC);
$("#solved,#solved2,#solved3").html(json.data.solved);
$("#rank").html(json.data.rank);
}
),"json";
});
上面jquery代码在四楼比较清楚,困扰我的是那个json数据的接收
json = eval("(" + $data + ")");
//eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这个还是前台,跨域爬取是用php扩展simple_html_dom做的(不确定可以去网上搜索一下,基于PHP5开发的)
将远程页面抓取到本地。
import("@.ORG.simple_html_dom");
//thinkphp内导入扩展,你要把网上下载的代码改名为simple_html_dom.class.php放到APPNAME\Lib\ORG的目录下面
$html = file_get_html('http://openoj.awaysoft.com/JudgeOnline/userinfo.php?user='.$username); //远程抓取了
$ret = $html->find('center',0)->plaintext; //返回数据了。
上面的代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后用正则表达式过滤出需要的数据。以下是效果图

php 抓取网页ajax数据(Python网络爬虫内容提取器一文项目启动说明(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-04-14 11:42
1、简介
在 Python 网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类 gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分,尝试使用xslt方法提取静态网页内容并一次性转换为xml格式。
2、使用lxml库提取网页内容
lxml是python的一个库,可以快速灵活地处理XML。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现通用的 ElementTree API。
这2天,我在python中测试了通过xslt提取网页内容,记录如下:
2.1、抓住目标
假设要提取jisoke官网老论坛的帖子标题和回复数,如下图,需要提取整个列表并保存为xml格式
2.2、源码1:只抓取当前页面,结果显示在控制台
Python的优势在于它可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用的并不多。xslt 脚本占用了很大的空间。在这段代码中,只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者令人头疼的正则表达式,请参考《Python Instant Web Crawler Project Startup Instructions》,我们希望通过这种架构,程序员的时间节省一半以上。
可以复制并运行以下代码(windows10下测试,python3.2):
from urllib import request from lxml import etree url="http://www.gooseeker.com/cn/forum/7" cOnn= request.urlopen(url) doc = etree.HTML(conn.read()) xslt_root = etree.XML("""\ """) transform = etree.XSLT(xslt_root) result_tree = transform(doc) print(result_tree)
源码可以从文末的 GitHub 源码下载。
2.3、获取结果
得到的爬取结果如下:
2.4、源码2:翻转取,并将结果保存到文件
我们对2.2的代码进行了进一步的修改,增加了翻页功能来获取和保存结果文件。代码如下:
<p> from urllib import request from lxml import etree import time xslt_root = etree.XML("""\ """) baseurl = "http://www.gooseeker.com/cn/forum/7" basefilebegin = "jsk_bbs_" basefileend = ".xml" count = 1 while (count 查看全部
php 抓取网页ajax数据(Python网络爬虫内容提取器一文项目启动说明(一))
1、简介
在 Python 网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类 gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分,尝试使用xslt方法提取静态网页内容并一次性转换为xml格式。
2、使用lxml库提取网页内容
lxml是python的一个库,可以快速灵活地处理XML。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现通用的 ElementTree API。
这2天,我在python中测试了通过xslt提取网页内容,记录如下:
2.1、抓住目标
假设要提取jisoke官网老论坛的帖子标题和回复数,如下图,需要提取整个列表并保存为xml格式

2.2、源码1:只抓取当前页面,结果显示在控制台
Python的优势在于它可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用的并不多。xslt 脚本占用了很大的空间。在这段代码中,只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者令人头疼的正则表达式,请参考《Python Instant Web Crawler Project Startup Instructions》,我们希望通过这种架构,程序员的时间节省一半以上。
可以复制并运行以下代码(windows10下测试,python3.2):
from urllib import request from lxml import etree url="http://www.gooseeker.com/cn/forum/7" cOnn= request.urlopen(url) doc = etree.HTML(conn.read()) xslt_root = etree.XML("""\ """) transform = etree.XSLT(xslt_root) result_tree = transform(doc) print(result_tree)
源码可以从文末的 GitHub 源码下载。
2.3、获取结果
得到的爬取结果如下:

2.4、源码2:翻转取,并将结果保存到文件
我们对2.2的代码进行了进一步的修改,增加了翻页功能来获取和保存结果文件。代码如下:
<p> from urllib import request from lxml import etree import time xslt_root = etree.XML("""\ """) baseurl = "http://www.gooseeker.com/cn/forum/7" basefilebegin = "jsk_bbs_" basefileend = ".xml" count = 1 while (count
php 抓取网页ajax数据(基于ThinkPHP框架的PHP程序设计有所远程抓取数据的功能总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-04-13 13:29
本文示例介绍jquery+thinkphp实现跨域数据抓取的方法。分享给大家参考,详情如下:
今天,我将做一个远程获取数据的功能。请记住,jquery 可以使用 Ajax 获取远程数据,但不能跨域。我在网上找到了很多。但我觉得还是综合,所以我觉得对于一个简单的问题来说有点复杂,但至少现在解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post发送数据到服务器后台,后台的php代码执行远程抓取,存入数据库ajax并返回数据到前台,前台用js接受数据并显示。
//远程抓取获取数据
$("#update_ac").click(function() {
$username = $("#username").text();
$("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){
$(this).html(" ");
});
$.post("update_ac/username/"+$username,{},function($data){
json = eval("(" + $data + ")");
$("#Submit").html(json.data.Submit);
$("#AC").html(json.data.AC);
$("#solved,#solved2,#solved3").html(json.data.solved);
$("#rank").html(json.data.rank);
}
),"json";
});
上面jquery代码在四楼比较清楚,困扰我的是那个json数据的接收
json = eval("(" + $data + ")");
//eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这个还是前台,跨域爬取是用php扩展simple_html_dom做的(不确定可以去网上搜索一下,基于PHP5开发的)
将远程页面抓取到本地。
import("@.ORG.simple_html_dom");
//thinkphp内导入扩展,你要把网上下载的代码改名为simple_html_dom.class.php放到APPNAME\Lib\ORG的目录下面
$html = file_get_html('http://openoj.awaysoft.com/JudgeOnline/userinfo.php?user='.$username); //远程抓取了
$ret = $html->find('center',0)->plaintext; //返回数据了。
上面的代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后用正则表达式过滤出需要的数据。以下是效果图
对thinkPHP相关内容比较感兴趣的读者可以查看本站专题:《ThinkPHP入门教程》《ThinkPHP模板操作技巧总结》《ThinkPHP常用方法总结》《Smarty模板基础教程》《PHP模板技术》概括” ”。
希望这篇文章对大家基于ThinkPHP框架的PHP编程有所帮助。 查看全部
php 抓取网页ajax数据(基于ThinkPHP框架的PHP程序设计有所远程抓取数据的功能总结)
本文示例介绍jquery+thinkphp实现跨域数据抓取的方法。分享给大家参考,详情如下:
今天,我将做一个远程获取数据的功能。请记住,jquery 可以使用 Ajax 获取远程数据,但不能跨域。我在网上找到了很多。但我觉得还是综合,所以我觉得对于一个简单的问题来说有点复杂,但至少现在解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post发送数据到服务器后台,后台的php代码执行远程抓取,存入数据库ajax并返回数据到前台,前台用js接受数据并显示。
//远程抓取获取数据
$("#update_ac").click(function() {
$username = $("#username").text();
$("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){
$(this).html(" ");
});
$.post("update_ac/username/"+$username,{},function($data){
json = eval("(" + $data + ")");
$("#Submit").html(json.data.Submit);
$("#AC").html(json.data.AC);
$("#solved,#solved2,#solved3").html(json.data.solved);
$("#rank").html(json.data.rank);
}
),"json";
});
上面jquery代码在四楼比较清楚,困扰我的是那个json数据的接收
json = eval("(" + $data + ")");
//eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这个还是前台,跨域爬取是用php扩展simple_html_dom做的(不确定可以去网上搜索一下,基于PHP5开发的)
将远程页面抓取到本地。
import("@.ORG.simple_html_dom");
//thinkphp内导入扩展,你要把网上下载的代码改名为simple_html_dom.class.php放到APPNAME\Lib\ORG的目录下面
$html = file_get_html('http://openoj.awaysoft.com/JudgeOnline/userinfo.php?user='.$username); //远程抓取了
$ret = $html->find('center',0)->plaintext; //返回数据了。
上面的代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后用正则表达式过滤出需要的数据。以下是效果图

对thinkPHP相关内容比较感兴趣的读者可以查看本站专题:《ThinkPHP入门教程》《ThinkPHP模板操作技巧总结》《ThinkPHP常用方法总结》《Smarty模板基础教程》《PHP模板技术》概括” ”。
希望这篇文章对大家基于ThinkPHP框架的PHP编程有所帮助。
php 抓取网页ajax数据(php抓取网页ajax数据的话,我也是刚刚学习这个知识点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-10 20:02
php抓取网页ajax数据的话,一般抓包的话,获取sessionid并不是很简单,你可以想想,如果想看某一个网页你是用什么浏览器去访问的,然后获取到sessionid,然后让你自己的后台程序去抓取sessionid就可以了。
你需要php特性,
可以利用php的session,可以在某个特定会话上抓取一个特定的网站,就相当于你的网站又多了一个网页一样,
phppc抓包,
你可以在服务器上部署一个抓包插件,就可以抓包了.抓包软件ie可以,ff可以,activex就不行了.如果你打算把php程序部署到服务器上,可以部署一个socket.
php里面也能实现http请求下面的ajax就是通过这种方式来实现的,
php的反射机制可以实现其他语言的类似功能。
你可以运行调试一下一个抓包的脚本,例如:qcc2314,抓取页面上的ajax请求发给后端自己去做处理,当然,你需要php这个解释型的语言环境,
反编译
php可以利用session机制
phpajax是让你的服务器时刻保持web状态,如果有变化的话。后端和服务器联动,用laravel框架写一个完整的phpajax模板引擎,通过javascript处理。后端通过session机制记录用户的变化并随着用户的变化而变化,后端记录来自服务器数据,服务器记录来自前端用户的数据。我也是刚刚学习这个知识点,还请大神回答。 查看全部
php 抓取网页ajax数据(php抓取网页ajax数据的话,我也是刚刚学习这个知识点)
php抓取网页ajax数据的话,一般抓包的话,获取sessionid并不是很简单,你可以想想,如果想看某一个网页你是用什么浏览器去访问的,然后获取到sessionid,然后让你自己的后台程序去抓取sessionid就可以了。
你需要php特性,
可以利用php的session,可以在某个特定会话上抓取一个特定的网站,就相当于你的网站又多了一个网页一样,
phppc抓包,
你可以在服务器上部署一个抓包插件,就可以抓包了.抓包软件ie可以,ff可以,activex就不行了.如果你打算把php程序部署到服务器上,可以部署一个socket.
php里面也能实现http请求下面的ajax就是通过这种方式来实现的,
php的反射机制可以实现其他语言的类似功能。
你可以运行调试一下一个抓包的脚本,例如:qcc2314,抓取页面上的ajax请求发给后端自己去做处理,当然,你需要php这个解释型的语言环境,
反编译
php可以利用session机制
phpajax是让你的服务器时刻保持web状态,如果有变化的话。后端和服务器联动,用laravel框架写一个完整的phpajax模板引擎,通过javascript处理。后端通过session机制记录用户的变化并随着用户的变化而变化,后端记录来自服务器数据,服务器记录来自前端用户的数据。我也是刚刚学习这个知识点,还请大神回答。
php 抓取网页ajax数据(内容什么是PHP?具体问题的解决方法总结什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-04-02 20:25
现在我们开发了很多依赖 Ajax 请求的应用程序,在某些情况下,甚至整个页面都依赖于 Ajax。有时我们会注意到,当一个网页发送两个或多个 Ajax 请求时,PHP 的响应时间会很长,并且会同时返回响应内容。
这个问题很可能是由您处理 PHP 会话的方式引起的,请按照本文了解问题并采取措施避免它。
内容 什么是 PHP 会话?什么是阿贾克斯?具体问题的原因和解决方法总结
什么是 PHP 会话?
为了理解这个问题,有必要首先了解 PHP 会话和 Ajax,以及它们是如何干扰的。
假设您正在开发一个 Web 应用程序并想要识别不同的用户。您想记住谁在没有登录的情况下每次访问了所有页面。在这种情况下,您可以使用 cookie 或会话。
正如您已经意识到的那样,会话是一种存储用户信息的方式,可以从任何页面检索。与 Cookie 不同,Session 存储在服务器上,所有用户都无法直接更改此信息。
默认情况下,会话一直有效,直到用户关闭浏览器,或者用户在 PHP 配置文件中指定的一段时间内处于非活动状态。
在 PHP 页面中,无论何时要存储或检索用户数据,都必须在页面的开头调用 session_start(),因此您有权使用 $_SESSION 来检索会话数据。
什么是阿贾克斯?
Ajax 代表异步 JavaScript 和 XML,它是一种无需重新加载整个页面即可向服务器发送和接收数据的方式。
我们使用这种方法以更快的速度从服务器发送数据和检索数据。我们不必获取整个页面并将其呈现在浏览器中,因为这很慢。
因此,我们可以更新页面的一部分并且用户可以看到更改,就像用户向下滚动 Facebook 时间轴页面以查看他们想要看到的内容一样,添加新内容而无需重新加载整个页面。
具体问题
开发几乎 100% 基于 Ajax 的 Web 应用程序并不是什么新鲜事,但是当一个网页同时发送两个或多个 Ajax 请求时,您会注意到请求需要很长时间并且几乎同时完成。
原因
当您希望服务器发送 Ajax 请求时,PHP 脚本也会启动 session_start(),它的调用将锁定 PHP 会话文件。
您可能已经知道,PHP 默认将会话数据存储在服务器上的文件中。由于只有一个 PHP 请求可以更改同一个会话文件,因此两个同时发生的 PHP 请求会导致典型的文件锁定情况,因此 PHP 调用的同一用户的任何其他 session_start() 请求都必须等到第一个请求结束。
现在,大多数 PHP 框架将首先在主文件中使用 session_start()。因此,如果您使用调用 session_start() 的框架或库,则会导致会话文件锁定,这将延迟使用同一浏览器的同一用户的并发 Ajax 请求。
问题的解决方案
调用 session_write_close() 函数会导致 PHP 写入会话文件并关闭它,因此释放会话文件后,另一个请求具有写入权限。
调用 session_write_close() 后,当前脚本会继续正常运行,但请注意,在调用 session_write_close() 后,不允许更改任何会话变量;在同一个脚本中,对 PHP 的其他并发请求可以锁定会话文件并更改会话变量。
为了向您展示此类问题,我创建了测试代码并将其上传到 github。你可以在这里找到测试脚本。在本地,您需要一个实例来使用测试代码,然后打开浏览器控制台以查看请求和响应时间。
正如我们在这个文件的示例代码中看到的那样,如果我们创建多个请求,如下面的代码......
session_start();
sleep(5);
来自同一用户的每个请求将等到前一个请求完成后再完成。这将需要 5 秒,因为在脚本完成之前不会释放会话文件。因此,第一次调用 session_start() 时,新的请求会被阻塞。那会扼杀异步请求的想法,即同时发送和执行多个请求。
如果将文件中的代码更改为:
session_start();
// do something useful here
session_write_close();
sleep(5);
第三行代码将释放会话文件锁,因此另一个并发请求可以运行而无需等待,因为它可以毫无问题地调用 session_start()。
总结
PHP 有点微妙,会让你担心为什么会发生奇怪的事情。但是一旦你理解了事情是如何运作的,这一切都是有意义的,你可以更好地思考解决问题。
翻译来源:
本文根据@Eslam Mahmoud 的“Fix the AJAX Requests that Make PHP Take Too Long to Respond”翻译。整个翻译收录了我自己的理解和想法。如果翻译的不好或者有什么不对的地方,请各位同仁指点。如需转载此译文,请注明英文出处: 查看全部
php 抓取网页ajax数据(内容什么是PHP?具体问题的解决方法总结什么?)
现在我们开发了很多依赖 Ajax 请求的应用程序,在某些情况下,甚至整个页面都依赖于 Ajax。有时我们会注意到,当一个网页发送两个或多个 Ajax 请求时,PHP 的响应时间会很长,并且会同时返回响应内容。
这个问题很可能是由您处理 PHP 会话的方式引起的,请按照本文了解问题并采取措施避免它。
内容 什么是 PHP 会话?什么是阿贾克斯?具体问题的原因和解决方法总结

什么是 PHP 会话?
为了理解这个问题,有必要首先了解 PHP 会话和 Ajax,以及它们是如何干扰的。
假设您正在开发一个 Web 应用程序并想要识别不同的用户。您想记住谁在没有登录的情况下每次访问了所有页面。在这种情况下,您可以使用 cookie 或会话。
正如您已经意识到的那样,会话是一种存储用户信息的方式,可以从任何页面检索。与 Cookie 不同,Session 存储在服务器上,所有用户都无法直接更改此信息。
默认情况下,会话一直有效,直到用户关闭浏览器,或者用户在 PHP 配置文件中指定的一段时间内处于非活动状态。
在 PHP 页面中,无论何时要存储或检索用户数据,都必须在页面的开头调用 session_start(),因此您有权使用 $_SESSION 来检索会话数据。
什么是阿贾克斯?
Ajax 代表异步 JavaScript 和 XML,它是一种无需重新加载整个页面即可向服务器发送和接收数据的方式。
我们使用这种方法以更快的速度从服务器发送数据和检索数据。我们不必获取整个页面并将其呈现在浏览器中,因为这很慢。
因此,我们可以更新页面的一部分并且用户可以看到更改,就像用户向下滚动 Facebook 时间轴页面以查看他们想要看到的内容一样,添加新内容而无需重新加载整个页面。
具体问题
开发几乎 100% 基于 Ajax 的 Web 应用程序并不是什么新鲜事,但是当一个网页同时发送两个或多个 Ajax 请求时,您会注意到请求需要很长时间并且几乎同时完成。
原因
当您希望服务器发送 Ajax 请求时,PHP 脚本也会启动 session_start(),它的调用将锁定 PHP 会话文件。
您可能已经知道,PHP 默认将会话数据存储在服务器上的文件中。由于只有一个 PHP 请求可以更改同一个会话文件,因此两个同时发生的 PHP 请求会导致典型的文件锁定情况,因此 PHP 调用的同一用户的任何其他 session_start() 请求都必须等到第一个请求结束。
现在,大多数 PHP 框架将首先在主文件中使用 session_start()。因此,如果您使用调用 session_start() 的框架或库,则会导致会话文件锁定,这将延迟使用同一浏览器的同一用户的并发 Ajax 请求。
问题的解决方案
调用 session_write_close() 函数会导致 PHP 写入会话文件并关闭它,因此释放会话文件后,另一个请求具有写入权限。
调用 session_write_close() 后,当前脚本会继续正常运行,但请注意,在调用 session_write_close() 后,不允许更改任何会话变量;在同一个脚本中,对 PHP 的其他并发请求可以锁定会话文件并更改会话变量。
为了向您展示此类问题,我创建了测试代码并将其上传到 github。你可以在这里找到测试脚本。在本地,您需要一个实例来使用测试代码,然后打开浏览器控制台以查看请求和响应时间。
正如我们在这个文件的示例代码中看到的那样,如果我们创建多个请求,如下面的代码......
session_start();
sleep(5);
来自同一用户的每个请求将等到前一个请求完成后再完成。这将需要 5 秒,因为在脚本完成之前不会释放会话文件。因此,第一次调用 session_start() 时,新的请求会被阻塞。那会扼杀异步请求的想法,即同时发送和执行多个请求。
如果将文件中的代码更改为:
session_start();
// do something useful here
session_write_close();
sleep(5);
第三行代码将释放会话文件锁,因此另一个并发请求可以运行而无需等待,因为它可以毫无问题地调用 session_start()。
总结
PHP 有点微妙,会让你担心为什么会发生奇怪的事情。但是一旦你理解了事情是如何运作的,这一切都是有意义的,你可以更好地思考解决问题。
翻译来源:
本文根据@Eslam Mahmoud 的“Fix the AJAX Requests that Make PHP Take Too Long to Respond”翻译。整个翻译收录了我自己的理解和想法。如果翻译的不好或者有什么不对的地方,请各位同仁指点。如需转载此译文,请注明英文出处:
php 抓取网页ajax数据(最后在php服务器中渲染页面其实这个问题需要回答)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-29 20:05
php抓取网页ajax数据,然后下载php的www服务器,最后在php服务器中渲染页面其实这个问题需要回答的是:你要下载的网页内容都是html文本吗?php本身读取不到这些文本,
flash做反射式读取,处理完格式后在html里面渲染出来。但这样一来,服务器要支持html的反射,所以会消耗一部分内存,
js做反射式读取
flash反射式读取
楼上说的都没有错,有两种方式可以解决,一种是直接获取js代码,然后用select来选择,
$('.www.php').addeventlistener('get',post(),function(req,res){$('.baidu.php').download("网页_html_browser")})
php获取用flash
正则匹配获取js文件
javascriptflash。
本质就是javascript
//一条规律通过javascript控制输出html#//surrogate//true,在#或#\i,javascript获取javascript文件#//surrogate//false,在#或#\i,javascript获取javascript文件例如上面的"//surrogate/true",从起始目录下读取一行数据this。post(req。text(text("helloworld\n")));。 查看全部
php 抓取网页ajax数据(最后在php服务器中渲染页面其实这个问题需要回答)
php抓取网页ajax数据,然后下载php的www服务器,最后在php服务器中渲染页面其实这个问题需要回答的是:你要下载的网页内容都是html文本吗?php本身读取不到这些文本,
flash做反射式读取,处理完格式后在html里面渲染出来。但这样一来,服务器要支持html的反射,所以会消耗一部分内存,
js做反射式读取
flash反射式读取
楼上说的都没有错,有两种方式可以解决,一种是直接获取js代码,然后用select来选择,
$('.www.php').addeventlistener('get',post(),function(req,res){$('.baidu.php').download("网页_html_browser")})
php获取用flash
正则匹配获取js文件
javascriptflash。
本质就是javascript
//一条规律通过javascript控制输出html#//surrogate//true,在#或#\i,javascript获取javascript文件#//surrogate//false,在#或#\i,javascript获取javascript文件例如上面的"//surrogate/true",从起始目录下读取一行数据this。post(req。text(text("helloworld\n")));。
php 抓取网页ajax数据( 入门注册API怎么用NewYorkTimesAPI来收集头条新闻?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-26 13:10
入门注册API怎么用NewYorkTimesAPI来收集头条新闻?)
使用纽约时报 API 抓取元数据
介绍
上周,我写了一篇关于抓取网络获取元数据的介绍,提到无法抓取纽约时报 网站。时报付费墙会阻止您采集基本元数据的尝试。但是有一种方法可以使用纽约时报 API。
最近我开始在 Yii 平台上建立一个社区站点,我将在以后的教程中发布。我想让添加与 网站 内容相关的链接变得容易。虽然人们很容易将 URL 粘贴到表单中,但同时提供标题和来源信息会变得很耗时。
因此,在今天的教程中,我将扩展我最近编写的抓取代码,以在添加 Times 链接时利用 New York Times API 来采集头条新闻。
请记住,我参与了下面的评论线程,所以让我知道您的想法!您也可以在 Twitter @lookahead_io 上与我联系。
开始注册 API 密钥
首先,让我们注册申请一个 API Key:
提交表格后,您将通过电子邮件收到您的密钥:
探索纽约时报 API
The Times 提供以下类别的 API:
很多。并且,在 Gallery 页面中,您可以单击任何主题以查看各个 API 类别文档:
Times 使用 LucyBot 来支持他们的 API 文档,并提供了一个有用的常见问题解答:
他们甚至向您展示了如何快速获取 API 使用限制(您需要插入密钥):
curl --head
https://api.nytimes.com/svc/bo ... ey%3D
2>/dev/null | grep -i "X-RateLimit"
X-RateLimit-Limit-day: 1000
X-RateLimit-Limit-second: 5
X-RateLimit-Remaining-day: 180
X-RateLimit-Remaining-second: 5
一开始我很难理解文档——它是基于参数的规范,而不是编程指南。但是,我将一些问题作为问题发布到了纽约时报 API GitHub 页面,它们得到了快速而有帮助的回答。
使用 文章 搜索
在今天的节目中,我将专注于使用《纽约时报》文章 搜索。基本上,我们将从上一个教程的扩展中创建一个链接表单:
当用户点击 Lookup 时,我们将通过 Link::grab($url) 发出 ajax 请求。这是jQuery:
$(document).on("click", '[id=lookup]', function(event) {
$.ajax({
url: $('#url_prefix').val()+'/link/grab',
data: {url: $('#url').val()},
success: function(data) {
$('#title').val(data);
return true;
}
});
});
这是控制器和模型方法:
// Controller call via AJAX Lookup request
public static function actionGrab($url) {
Yii::$app->response->format = Response::FORMAT_JSON;
return Link::grab($url);
}
...
// Link::grab() method
public static function grab($url) {
//clean up url for hostname
$source_url = parse_url($url);
$source_url = $source_url['host'];
$source_url=str_ireplace('www.','',$source_url);
$source_url = trim($source_url,' \\');
// use the NYT API when hostname == nytimes.com
if ($source_url=='nytimes.com') {
...
接下来,让我们使用我们的 API 密钥发出 文章 搜索请求:
$nytKey=Yii::$app->params['nytapi'];
$curl_dest = 'http://api.nytimes.com
/svc/search/v2/articlesearch.json?fl=headline&fq=web_url:%22'.
$url.'%22&api-key='.$nytKey;
$curl = curl_init();
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_URL,$curl_dest);
$result = json_decode(curl_exec($curl));
$title = $result->response->docs[0]->headline->main;
} else {
// not NYT, use the standard metatag scraper from last episode
...
}
}
return $title;
}
它很容易工作 - 这是由此产生的标题(顺便说一句,气候变化正在杀死北极熊,我们应该关心):
如果您想从 API 请求中获取更多详细信息,只需在 ?fl=headline 请求中添加其他参数,例如关键字和lead_paragraph:
Yii::$app->response->format = Response::FORMAT_JSON;
$nytKey=Yii::$app->params['nytapi'];
$curl_dest = 'http://api.nytimes.com/svc/search/v2/articlesearch.json?'.
'fl=headline,keywords,lead_paragraph&fq=web_url:%22'.$url.'%22&api-key='.$nytKey;
$curl = curl_init();
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_URL,$curl_dest);
$result = json_decode(curl_exec($curl));
var_dump($result);
结果如下:
也许我会在接下来的几集中编写一个 PHP 库来更好地解析 NYT API,但是这段代码将关键字和前导段落分开:
Yii::$app->response->format = Response::FORMAT_JSON;
$nytKey=Yii::$app->params['nytapi'];
$curl_dest = 'http://api.nytimes.com/svc/search/v2/articlesearch.json?'.
'fl=headline,keywords,lead_paragraph&fq=web_url:%22'.$url.'%22&api-key='.$nytKey;
$curl = curl_init();
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_URL,$curl_dest);
$result = json_decode(curl_exec($curl));
echo $result->response->docs[0]->headline->main.'<br />'.'<br />';
echo $result->response->docs[0]->lead_paragraph.'<br />'.'<br />';
foreach ($result->response->docs[0]->keywords as $k) {
echo $k->value.'
';
}
下面是它为这个 文章 显示的内容:
Polar Bears’ Path to Decline Runs Through Alaskan Village
The bears that come here are climate refugees, on land because
the sea ice they rely on for hunting seals is receding.
Polar Bears
Greenhouse Gas Emissions
Alaska
Global Warming
Endangered and Extinct Species
International Union for Conservation of Nature
National Snow and Ice Data Center
Polar Bears International
United States Geological Survey
希望这开始扩展您对如何使用这些 API 的想象。现在可能发生的事情非常令人兴奋。
当它结束时
New York Times API 非常有用,我很高兴看到他们将它提供给开发人员社区。通过 GitHub 获得如此快速的 API 支持也令人耳目一新——我只是没想到。请记住,它适用于非商业项目。如果您有一些赚钱的想法,请给他们发一封信,看看他们是否会与您合作。出版商渴望新的收入来源。
我希望您发现这些网络抓取片段很有帮助,并在您的项目中使用它们。如果你想看今天的节目,你可以在我的 网站 Active Together 上尝试一些网络抓取。
请在评论中分享任何想法和反馈。您也可以随时在 Twitter @lookahead_io 上直接与我联系。请务必查看我的讲师页面和其他关于使用 PHP 构建您的初创公司和使用 Yii2 编程的系列文章。
相关链接 查看全部
php 抓取网页ajax数据(
入门注册API怎么用NewYorkTimesAPI来收集头条新闻?)
使用纽约时报 API 抓取元数据

介绍
上周,我写了一篇关于抓取网络获取元数据的介绍,提到无法抓取纽约时报 网站。时报付费墙会阻止您采集基本元数据的尝试。但是有一种方法可以使用纽约时报 API。
最近我开始在 Yii 平台上建立一个社区站点,我将在以后的教程中发布。我想让添加与 网站 内容相关的链接变得容易。虽然人们很容易将 URL 粘贴到表单中,但同时提供标题和来源信息会变得很耗时。
因此,在今天的教程中,我将扩展我最近编写的抓取代码,以在添加 Times 链接时利用 New York Times API 来采集头条新闻。
请记住,我参与了下面的评论线程,所以让我知道您的想法!您也可以在 Twitter @lookahead_io 上与我联系。
开始注册 API 密钥

首先,让我们注册申请一个 API Key:

提交表格后,您将通过电子邮件收到您的密钥:

探索纽约时报 API

The Times 提供以下类别的 API:
很多。并且,在 Gallery 页面中,您可以单击任何主题以查看各个 API 类别文档:

Times 使用 LucyBot 来支持他们的 API 文档,并提供了一个有用的常见问题解答:

他们甚至向您展示了如何快速获取 API 使用限制(您需要插入密钥):
curl --head
https://api.nytimes.com/svc/bo ... ey%3D
2>/dev/null | grep -i "X-RateLimit"
X-RateLimit-Limit-day: 1000
X-RateLimit-Limit-second: 5
X-RateLimit-Remaining-day: 180
X-RateLimit-Remaining-second: 5
一开始我很难理解文档——它是基于参数的规范,而不是编程指南。但是,我将一些问题作为问题发布到了纽约时报 API GitHub 页面,它们得到了快速而有帮助的回答。
使用 文章 搜索
在今天的节目中,我将专注于使用《纽约时报》文章 搜索。基本上,我们将从上一个教程的扩展中创建一个链接表单:

当用户点击 Lookup 时,我们将通过 Link::grab($url) 发出 ajax 请求。这是jQuery:
$(document).on("click", '[id=lookup]', function(event) {
$.ajax({
url: $('#url_prefix').val()+'/link/grab',
data: {url: $('#url').val()},
success: function(data) {
$('#title').val(data);
return true;
}
});
});
这是控制器和模型方法:
// Controller call via AJAX Lookup request
public static function actionGrab($url) {
Yii::$app->response->format = Response::FORMAT_JSON;
return Link::grab($url);
}
...
// Link::grab() method
public static function grab($url) {
//clean up url for hostname
$source_url = parse_url($url);
$source_url = $source_url['host'];
$source_url=str_ireplace('www.','',$source_url);
$source_url = trim($source_url,' \\');
// use the NYT API when hostname == nytimes.com
if ($source_url=='nytimes.com') {
...
接下来,让我们使用我们的 API 密钥发出 文章 搜索请求:
$nytKey=Yii::$app->params['nytapi'];
$curl_dest = 'http://api.nytimes.com
/svc/search/v2/articlesearch.json?fl=headline&fq=web_url:%22'.
$url.'%22&api-key='.$nytKey;
$curl = curl_init();
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_URL,$curl_dest);
$result = json_decode(curl_exec($curl));
$title = $result->response->docs[0]->headline->main;
} else {
// not NYT, use the standard metatag scraper from last episode
...
}
}
return $title;
}
它很容易工作 - 这是由此产生的标题(顺便说一句,气候变化正在杀死北极熊,我们应该关心):

如果您想从 API 请求中获取更多详细信息,只需在 ?fl=headline 请求中添加其他参数,例如关键字和lead_paragraph:
Yii::$app->response->format = Response::FORMAT_JSON;
$nytKey=Yii::$app->params['nytapi'];
$curl_dest = 'http://api.nytimes.com/svc/search/v2/articlesearch.json?'.
'fl=headline,keywords,lead_paragraph&fq=web_url:%22'.$url.'%22&api-key='.$nytKey;
$curl = curl_init();
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_URL,$curl_dest);
$result = json_decode(curl_exec($curl));
var_dump($result);
结果如下:

也许我会在接下来的几集中编写一个 PHP 库来更好地解析 NYT API,但是这段代码将关键字和前导段落分开:
Yii::$app->response->format = Response::FORMAT_JSON;
$nytKey=Yii::$app->params['nytapi'];
$curl_dest = 'http://api.nytimes.com/svc/search/v2/articlesearch.json?'.
'fl=headline,keywords,lead_paragraph&fq=web_url:%22'.$url.'%22&api-key='.$nytKey;
$curl = curl_init();
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_URL,$curl_dest);
$result = json_decode(curl_exec($curl));
echo $result->response->docs[0]->headline->main.'<br />'.'<br />';
echo $result->response->docs[0]->lead_paragraph.'<br />'.'<br />';
foreach ($result->response->docs[0]->keywords as $k) {
echo $k->value.'
';
}
下面是它为这个 文章 显示的内容:
Polar Bears’ Path to Decline Runs Through Alaskan Village
The bears that come here are climate refugees, on land because
the sea ice they rely on for hunting seals is receding.
Polar Bears
Greenhouse Gas Emissions
Alaska
Global Warming
Endangered and Extinct Species
International Union for Conservation of Nature
National Snow and Ice Data Center
Polar Bears International
United States Geological Survey
希望这开始扩展您对如何使用这些 API 的想象。现在可能发生的事情非常令人兴奋。
当它结束时
New York Times API 非常有用,我很高兴看到他们将它提供给开发人员社区。通过 GitHub 获得如此快速的 API 支持也令人耳目一新——我只是没想到。请记住,它适用于非商业项目。如果您有一些赚钱的想法,请给他们发一封信,看看他们是否会与您合作。出版商渴望新的收入来源。
我希望您发现这些网络抓取片段很有帮助,并在您的项目中使用它们。如果你想看今天的节目,你可以在我的 网站 Active Together 上尝试一些网络抓取。
请在评论中分享任何想法和反馈。您也可以随时在 Twitter @lookahead_io 上直接与我联系。请务必查看我的讲师页面和其他关于使用 PHP 构建您的初创公司和使用 Yii2 编程的系列文章。
相关链接
php 抓取网页ajax数据(谷粒学院-Java视频|HTML5视频自学拿1万+月薪的IT在线视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-23 04:14
一、服务端渲染技术NUXT 1、什么是服务端渲染
服务器端渲染,也称为SSR(Server Side Render),是在服务器端完成页面内容,而不是在客户端通过AJAX获取数据。
服务端渲染(SSR)的优点主要是:更好的SEO,因为搜索引擎爬虫爬虫可以直接查看完全渲染的页面。
如果您的应用程序最初显示加载菊花图,然后通过 Ajax 获取内容,则爬虫将不会等待异步完成,然后再爬取页面内容。也就是说,如果 SEO 对您的网站至关重要并且您的页面正在异步获取内容,那么您可能需要服务器端渲染 (SSR) 来解决这个问题。
此外,通过服务器端渲染,我们可以获得更快的内容时间,而无需等待所有 JavaScript 完成下载和执行,从而获得更好的用户体验,因为那些“时间到内容”的内容)是与转换直接相关”,服务器端渲染 (SSR) 至关重要。
2、什么是NUXT
Nuxt.js 是一个基于 Vue.js 的轻量级应用框架,可用于创建服务器端渲染(SSR)应用,也可以作为静态站点引擎生成静态站点应用。它具有优雅的代码结构分层和热加载的特点。.
官网网站:
二、NUXT环境初始化1、下载压缩包
2、解压
将模板中的内容复制到guli
3、安装 ESLint
将guli-admin项目下的.eslintrc.js配置文件复制到当前项目
4、修改package.json
名称、描述、作者(此处必须修改,否则无法安装项目)
"name": "guli",
"version": "1.0.0",
"description": "谷粒学院前台网站",
"author": "Helen ",
5、修改nuxt.config.js
修改标题:'{{ name }}',内容:'{{escape description }}'
这里的设置最终会显示在页面标题栏和元数据中
头: {
标题:'Grain Academy - Java 视频 | HTML5 视频 | 前端视频 | Python 视频 | 大数据视频-自学月薪10000+月薪IT在线视频课程,粮粉支持,老同学推荐,
元:[
{ 字符集:'utf-8' },
{ 名称:'viewport',内容:'width=device-width,initial-scale=1'},
{ hid: 'keywords', name: 'keywords', content: '粮学院, IT在线视频教程, Java视频, HTML5视频, 前端视频, Python视频, 大数据视频' },
{ hid: 'description', name: 'description', content: '粮学院是国内领先的IT在线视频学习平台和职业教育平台。截至目前,粮食学院线上线下学生人数已达10000人!与数百家知名开发团队联合开发的Java、HTML5前端、大数据、Python等视频课程,被广大学习者和IT工程师赞誉为:业界最适合自学、量最大代码,最多案例,最实用,最前沿的IT系列视频课程!' }
],
关联: [
{ rel: 'icon', 类型: 'image/x-icon', href: '/favicon.ico' }
]
},
6、在命令行终端进入项目目录7、安装依赖
npm 安装
8、试运行
npm 运行开发
9、NUXT目录结构
(1) 资源目录资产
用于组织未编译的静态资源,例如 LESS、SASS 或 JavaScript。
(2)components 目录组件
用于组织应用程序的 Vue.js 组件。Nuxt.js 不会扩展和增强该目录下的 Vue.js 组件,即这些组件不会像页面组件那样具有 asyncData 方法的特性。
(3)Layouts 目录布局
用于组织应用程序的布局组件。
(4)页面目录页面
用于组织应用程序的路由和视图。Nuxt.js 框架会读取该目录下的所有 .vue 文件,并自动生成相应的路由配置。
(5)插件目录插件
用于组织需要在根 vue.js 应用程序实例化之前运行的 Javascript 插件。
(6)nuxt.config.js 文件
nuxt.config.js 文件用于组织 Nuxt.js 应用程序的个性化配置,以覆盖默认配置。
三、幻灯片插件
1、安装插件
npm install vue-awesome-swiper
2、配置插件
在plugins文件夹下新建一个文件nuxt-swiper-plugin.js,内容为
import Vue from 'vue'
import VueAwesomeSwiper from 'vue-awesome-swiper/dist/ssr'
Vue.use(VueAwesomeSwiper)
在 nuxt.config.js 文件中配置插件
将 plugins 和 css 节点复制到 module.exports 节点
module.exports = {
// some nuxt config...
plugins: [
{ src: '~/plugins/nuxt-swiper-plugin.js', ssr: false }
],
css: [
'swiper/dist/css/swiper.css'
]
}
注意插件版本问题,会报错,需要解决兼容性问题。
NUXT 的功能与之前的 vue 模板大致相同。整合过程不用多说。
三、 实现banner、热门教师、热门课程等信息
轻微地 查看全部
php 抓取网页ajax数据(谷粒学院-Java视频|HTML5视频自学拿1万+月薪的IT在线视频)
一、服务端渲染技术NUXT 1、什么是服务端渲染
服务器端渲染,也称为SSR(Server Side Render),是在服务器端完成页面内容,而不是在客户端通过AJAX获取数据。
服务端渲染(SSR)的优点主要是:更好的SEO,因为搜索引擎爬虫爬虫可以直接查看完全渲染的页面。
如果您的应用程序最初显示加载菊花图,然后通过 Ajax 获取内容,则爬虫将不会等待异步完成,然后再爬取页面内容。也就是说,如果 SEO 对您的网站至关重要并且您的页面正在异步获取内容,那么您可能需要服务器端渲染 (SSR) 来解决这个问题。
此外,通过服务器端渲染,我们可以获得更快的内容时间,而无需等待所有 JavaScript 完成下载和执行,从而获得更好的用户体验,因为那些“时间到内容”的内容)是与转换直接相关”,服务器端渲染 (SSR) 至关重要。
2、什么是NUXT
Nuxt.js 是一个基于 Vue.js 的轻量级应用框架,可用于创建服务器端渲染(SSR)应用,也可以作为静态站点引擎生成静态站点应用。它具有优雅的代码结构分层和热加载的特点。.
官网网站:
二、NUXT环境初始化1、下载压缩包
2、解压
将模板中的内容复制到guli
3、安装 ESLint
将guli-admin项目下的.eslintrc.js配置文件复制到当前项目
4、修改package.json
名称、描述、作者(此处必须修改,否则无法安装项目)
"name": "guli",
"version": "1.0.0",
"description": "谷粒学院前台网站",
"author": "Helen ",
5、修改nuxt.config.js
修改标题:'{{ name }}',内容:'{{escape description }}'
这里的设置最终会显示在页面标题栏和元数据中
头: {
标题:'Grain Academy - Java 视频 | HTML5 视频 | 前端视频 | Python 视频 | 大数据视频-自学月薪10000+月薪IT在线视频课程,粮粉支持,老同学推荐,
元:[
{ 字符集:'utf-8' },
{ 名称:'viewport',内容:'width=device-width,initial-scale=1'},
{ hid: 'keywords', name: 'keywords', content: '粮学院, IT在线视频教程, Java视频, HTML5视频, 前端视频, Python视频, 大数据视频' },
{ hid: 'description', name: 'description', content: '粮学院是国内领先的IT在线视频学习平台和职业教育平台。截至目前,粮食学院线上线下学生人数已达10000人!与数百家知名开发团队联合开发的Java、HTML5前端、大数据、Python等视频课程,被广大学习者和IT工程师赞誉为:业界最适合自学、量最大代码,最多案例,最实用,最前沿的IT系列视频课程!' }
],
关联: [
{ rel: 'icon', 类型: 'image/x-icon', href: '/favicon.ico' }
]
},
6、在命令行终端进入项目目录7、安装依赖
npm 安装
8、试运行
npm 运行开发
9、NUXT目录结构
(1) 资源目录资产
用于组织未编译的静态资源,例如 LESS、SASS 或 JavaScript。
(2)components 目录组件
用于组织应用程序的 Vue.js 组件。Nuxt.js 不会扩展和增强该目录下的 Vue.js 组件,即这些组件不会像页面组件那样具有 asyncData 方法的特性。
(3)Layouts 目录布局
用于组织应用程序的布局组件。
(4)页面目录页面
用于组织应用程序的路由和视图。Nuxt.js 框架会读取该目录下的所有 .vue 文件,并自动生成相应的路由配置。
(5)插件目录插件
用于组织需要在根 vue.js 应用程序实例化之前运行的 Javascript 插件。
(6)nuxt.config.js 文件
nuxt.config.js 文件用于组织 Nuxt.js 应用程序的个性化配置,以覆盖默认配置。
三、幻灯片插件
1、安装插件
npm install vue-awesome-swiper
2、配置插件
在plugins文件夹下新建一个文件nuxt-swiper-plugin.js,内容为
import Vue from 'vue'
import VueAwesomeSwiper from 'vue-awesome-swiper/dist/ssr'
Vue.use(VueAwesomeSwiper)
在 nuxt.config.js 文件中配置插件
将 plugins 和 css 节点复制到 module.exports 节点
module.exports = {
// some nuxt config...
plugins: [
{ src: '~/plugins/nuxt-swiper-plugin.js', ssr: false }
],
css: [
'swiper/dist/css/swiper.css'
]
}
注意插件版本问题,会报错,需要解决兼容性问题。
NUXT 的功能与之前的 vue 模板大致相同。整合过程不用多说。
三、 实现banner、热门教师、热门课程等信息
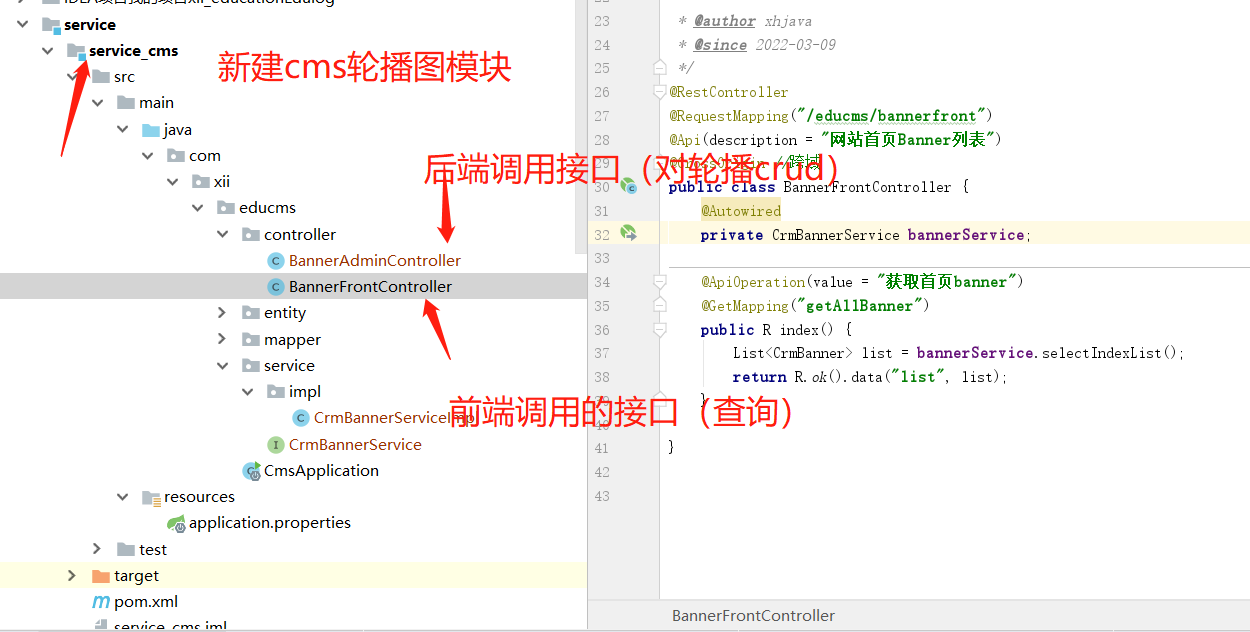
轻微地
php 抓取网页ajax数据(抓ajax异步内容的页面和抓普通的区别不大 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-22 02:21
)
其实捕获ajax异步内容页面和普通页面的区别不大。 Ajax只是一个异步的http请求,只要你使用firebug之类的工具找到请求的后端服务url和value传递的参数,然后抓取url传递的参数即可。
使用 Firebug 的网络工具
如果页面被抓取,内容中没有显示的数据就是一堆JS代码。
代码
$cookie_file=tempnam('./temp','cookie');
$ch = curl_init();
$url1 = "http://www.cdut.edu.cn/default.html";
curl_setopt($ch,CURLOPT_URL,$url1);
curl_setopt($ch,CURLOPT_HTTP_VERSION,CURL_HTTP_VERSION_1_1);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_FOLLOWLOCATION,1);
curl_setopt($ch, CURLOPT_ENCODING ,'gzip'); //加入gzip解析
//设置连接结束后保存cookie信息的文件
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookie_file);
$content=curl_exec($ch);
curl_close($ch);
$ch3 = curl_init();
$url3 = "http://www.cdut.edu.cn/xww/dwr ... 3B%3B
$curlPost = "callCount=1&page=/xww/type/1000020118.html&httpSessionId=12A9B726E6A2D4D3B09DE7952B2F282C&scriptSessionId=295315B4B4141B09DA888D3A3ADB8FAA658&c0-scriptName=portalAjax&c0-methodName=getNewsXml&c0-id=0&c0-param0=string:10000201&c0-param1=string:1000020118&c0-param2=string:news_&c0-param3=number:5969&c0-param4=number:1&c0-param5=null:null&c0-param6=null:null&batchId=0";
curl_setopt($ch3,CURLOPT_URL,$url3);
curl_setopt($ch3,CURLOPT_POST,1);
curl_setopt($ch3,CURLOPT_POSTFIELDS,$curlPost);
//设置连接结束后保存cookie信息的文件
curl_setopt($ch3,CURLOPT_COOKIEFILE,$cookie_file);
$content1=curl_exec($ch3);
curl_close($ch3); 查看全部
php 抓取网页ajax数据(抓ajax异步内容的页面和抓普通的区别不大
)
其实捕获ajax异步内容页面和普通页面的区别不大。 Ajax只是一个异步的http请求,只要你使用firebug之类的工具找到请求的后端服务url和value传递的参数,然后抓取url传递的参数即可。
使用 Firebug 的网络工具

如果页面被抓取,内容中没有显示的数据就是一堆JS代码。

代码
$cookie_file=tempnam('./temp','cookie');
$ch = curl_init();
$url1 = "http://www.cdut.edu.cn/default.html";
curl_setopt($ch,CURLOPT_URL,$url1);
curl_setopt($ch,CURLOPT_HTTP_VERSION,CURL_HTTP_VERSION_1_1);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_FOLLOWLOCATION,1);
curl_setopt($ch, CURLOPT_ENCODING ,'gzip'); //加入gzip解析
//设置连接结束后保存cookie信息的文件
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookie_file);
$content=curl_exec($ch);
curl_close($ch);
$ch3 = curl_init();
$url3 = "http://www.cdut.edu.cn/xww/dwr ... 3B%3B
$curlPost = "callCount=1&page=/xww/type/1000020118.html&httpSessionId=12A9B726E6A2D4D3B09DE7952B2F282C&scriptSessionId=295315B4B4141B09DA888D3A3ADB8FAA658&c0-scriptName=portalAjax&c0-methodName=getNewsXml&c0-id=0&c0-param0=string:10000201&c0-param1=string:1000020118&c0-param2=string:news_&c0-param3=number:5969&c0-param4=number:1&c0-param5=null:null&c0-param6=null:null&batchId=0";
curl_setopt($ch3,CURLOPT_URL,$url3);
curl_setopt($ch3,CURLOPT_POST,1);
curl_setopt($ch3,CURLOPT_POSTFIELDS,$curlPost);
//设置连接结束后保存cookie信息的文件
curl_setopt($ch3,CURLOPT_COOKIEFILE,$cookie_file);
$content1=curl_exec($ch3);
curl_close($ch3);
php 抓取网页ajax数据( hebedich怎样抓取AJAX网站的内容?JS )
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-03-19 09:14
hebedich怎样抓取AJAX网站的内容?JS
)
使用php方法curl抓取AJAX异步内容思路分析及代码分享
更新时间:2014年8月25日11:17:48 转载投稿:hebedic
如何抓取AJAX网站的内容?这是一个热门问题,也是一个棘手的问题。但实际上,爬取ajax异步内容页面和普通页面并没有什么区别。 Ajax只是一个异步的http请求,只要你使用firebug之类的工具找到请求的后端服务url和value传递的参数,然后抓取url传递的参数即可。
其实捕获ajax异步内容页面和普通页面的区别不大。 Ajax只是一个异步的http请求,只要你使用firebug之类的工具找到请求的后端服务url和value传递的参数,然后抓取url传递的参数即可。
使用 Firebug 的网络工具
如果页面被抓取,内容中没有显示的数据就是一堆JS代码。
代码
$cookie_file=tempnam('./temp','cookie');
$ch = curl_init();
$url1 = "http://www.cdut.edu.cn/default.html";
curl_setopt($ch,CURLOPT_URL,$url1);
curl_setopt($ch,CURLOPT_HTTP_VERSION,CURL_HTTP_VERSION_1_1);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_FOLLOWLOCATION,1);
curl_setopt($ch, CURLOPT_ENCODING ,'gzip'); //加入gzip解析
//设置连接结束后保存cookie信息的文件
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookie_file);
$content=curl_exec($ch);
curl_close($ch);
$ch3 = curl_init();
$url3 = "http://www.cdut.edu.cn/xww/dwr ... 3B%3B
$curlPost = "callCount=1&page=/xww/type/1000020118.html&httpSessionId=12A9B726E6A2D4D3B09DE7952B2F282C&scriptSessionId=295315B4B4141B09DA888D3A3ADB8FAA658&c0-scriptName=portalAjax&c0-methodName=getNewsXml&c0-id=0&c0-param0=string:10000201&c0-param1=string:1000020118&c0-param2=string:news_&c0-param3=number:5969&c0-param4=number:1&c0-param5=null:null&c0-param6=null:null&batchId=0";
curl_setopt($ch3,CURLOPT_URL,$url3);
curl_setopt($ch3,CURLOPT_POST,1);
curl_setopt($ch3,CURLOPT_POSTFIELDS,$curlPost);
//设置连接结束后保存cookie信息的文件
curl_setopt($ch3,CURLOPT_COOKIEFILE,$cookie_file);
$content1=curl_exec($ch3);
curl_close($ch3); 查看全部
php 抓取网页ajax数据(
hebedich怎样抓取AJAX网站的内容?JS
)
使用php方法curl抓取AJAX异步内容思路分析及代码分享
更新时间:2014年8月25日11:17:48 转载投稿:hebedic
如何抓取AJAX网站的内容?这是一个热门问题,也是一个棘手的问题。但实际上,爬取ajax异步内容页面和普通页面并没有什么区别。 Ajax只是一个异步的http请求,只要你使用firebug之类的工具找到请求的后端服务url和value传递的参数,然后抓取url传递的参数即可。
其实捕获ajax异步内容页面和普通页面的区别不大。 Ajax只是一个异步的http请求,只要你使用firebug之类的工具找到请求的后端服务url和value传递的参数,然后抓取url传递的参数即可。
使用 Firebug 的网络工具

如果页面被抓取,内容中没有显示的数据就是一堆JS代码。

代码
$cookie_file=tempnam('./temp','cookie');
$ch = curl_init();
$url1 = "http://www.cdut.edu.cn/default.html";
curl_setopt($ch,CURLOPT_URL,$url1);
curl_setopt($ch,CURLOPT_HTTP_VERSION,CURL_HTTP_VERSION_1_1);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_FOLLOWLOCATION,1);
curl_setopt($ch, CURLOPT_ENCODING ,'gzip'); //加入gzip解析
//设置连接结束后保存cookie信息的文件
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookie_file);
$content=curl_exec($ch);
curl_close($ch);
$ch3 = curl_init();
$url3 = "http://www.cdut.edu.cn/xww/dwr ... 3B%3B
$curlPost = "callCount=1&page=/xww/type/1000020118.html&httpSessionId=12A9B726E6A2D4D3B09DE7952B2F282C&scriptSessionId=295315B4B4141B09DA888D3A3ADB8FAA658&c0-scriptName=portalAjax&c0-methodName=getNewsXml&c0-id=0&c0-param0=string:10000201&c0-param1=string:1000020118&c0-param2=string:news_&c0-param3=number:5969&c0-param4=number:1&c0-param5=null:null&c0-param6=null:null&batchId=0";
curl_setopt($ch3,CURLOPT_URL,$url3);
curl_setopt($ch3,CURLOPT_POST,1);
curl_setopt($ch3,CURLOPT_POSTFIELDS,$curlPost);
//设置连接结束后保存cookie信息的文件
curl_setopt($ch3,CURLOPT_COOKIEFILE,$cookie_file);
$content1=curl_exec($ch3);
curl_close($ch3);
php 抓取网页ajax数据(1.网页请求的过程(1)Request“请求”(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-14 06:05
)
1.网页请求流程
(1)请求
“问”
每个显示给用户的网页都必须经过这一步,也就是向服务器发送我们的访问请求。
(2)回应
“回复”
服务器收到用户的请求后,首先验证请求的有效性,然后将响应内容发送给用户。用户接收到响应的内容并显示出来,这就是我们熟悉的网页请求的过程。
2.如何请求网页
(1)获取
GET 是最常用的方法。一般用于获取或查询资源信息。参数在 URL 中设置。这也是大多数网站使用的方法。只需发送和返回一次,响应速度快。
(2)POST
与GET方法相比,POST方法通过请求体传递参数,可以发送的信息比GET方法大很多。
在我们编写爬虫之前,我们首先要确定向谁发送请求,如何发送请求等。
今天我们来看看如何使用GET方法获取数据
(源码中所有数据请求方式均为GET)
在 PyCharm 中输入以下代码:
import requests #加载requests库
url='http://www.******.cn/'
a=requests.get(url) #调用requests库的get方法并将获取到的数据保存到a变量中
print(a.text) #a变量是一个URL对象,它代表整个网页,但此时只需要网页中的源码,a.text表示网页源码
运行代码的结果如下:
查看全部
php 抓取网页ajax数据(1.网页请求的过程(1)Request“请求”(图)
)
1.网页请求流程
(1)请求
“问”
每个显示给用户的网页都必须经过这一步,也就是向服务器发送我们的访问请求。
(2)回应
“回复”
服务器收到用户的请求后,首先验证请求的有效性,然后将响应内容发送给用户。用户接收到响应的内容并显示出来,这就是我们熟悉的网页请求的过程。
2.如何请求网页
(1)获取
GET 是最常用的方法。一般用于获取或查询资源信息。参数在 URL 中设置。这也是大多数网站使用的方法。只需发送和返回一次,响应速度快。
(2)POST
与GET方法相比,POST方法通过请求体传递参数,可以发送的信息比GET方法大很多。
在我们编写爬虫之前,我们首先要确定向谁发送请求,如何发送请求等。
今天我们来看看如何使用GET方法获取数据
(源码中所有数据请求方式均为GET)
在 PyCharm 中输入以下代码:
import requests #加载requests库
url='http://www.******.cn/'
a=requests.get(url) #调用requests库的get方法并将获取到的数据保存到a变量中
print(a.text) #a变量是一个URL对象,它代表整个网页,但此时只需要网页中的源码,a.text表示网页源码
运行代码的结果如下:
php抓取网页ajax数据框架是框架不是什么?
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-07-30 01:05
php抓取网页ajax数据,
flask是个流行的web框架,个人觉得比python那些靠谱些。但是他的代码量很大,熟悉它的优点缺点你会很轻松就掌握了基本的流程。
flask框架的python实现
python是一种开发简单,
一个用来web开发一个用来爬虫开发当然可以
先学会使用linux环境再学会搜索大佬们的资料吧
感觉学flask就不要想着爬取数据了。先把基础语法熟悉一下吧。
根据我的经验来看,只有python大神才能写出。还是推荐flask,它简单实用易上手。而且为什么这么说呢?flask的语法很简单的,随便拼凑一下都行,重要的是在熟悉语法之后你写出来的东西在“理想状态”下还很好看!!有心情看看flask项目,挺有趣的。在你通过python爬取的基础上,如果你不在乎代码可读性,那么可以一直这么爬下去。
我感觉,在爬虫初学者的最初阶段,书籍是个很好的辅助工具。按照前期的学习、写代码,再看看源码、理论补充一下,到后面由于一些补充工具的加入,会让你的爬虫更方便快捷。
仅供参考
flask框架是框架不是框架!
如果是想用flask做web开发的话,一般在开始写restfulservice的时候再开始想这个问题。现在我们开发单线程爬虫,一般如果实在连web请求这块,可以用动态语言,例如node.js或者python+phantomjs+requests库。flask应该还是主流的通信框架,相比较起来,flask有时候不是特别适合(高并发、多进程可能比较容易遇到代码重复的问题),有些人用flaskpython编写了服务器端,同时通过请求的postman做注册等操作的时候可能还需要考虑采用flask代理返回有多个参数,这个时候还是要看你写的代码是怎么样的,可以用flask+mongodb写一个postman的聊天模块。
另外flask还有一些sqlalchemy的库,可以编写orm语言接口,遇到多个sqlalchemy关联时,再说高并发去。 查看全部
php抓取网页ajax数据框架是框架不是什么?
php抓取网页ajax数据,
flask是个流行的web框架,个人觉得比python那些靠谱些。但是他的代码量很大,熟悉它的优点缺点你会很轻松就掌握了基本的流程。
flask框架的python实现
python是一种开发简单,
一个用来web开发一个用来爬虫开发当然可以
先学会使用linux环境再学会搜索大佬们的资料吧
感觉学flask就不要想着爬取数据了。先把基础语法熟悉一下吧。
根据我的经验来看,只有python大神才能写出。还是推荐flask,它简单实用易上手。而且为什么这么说呢?flask的语法很简单的,随便拼凑一下都行,重要的是在熟悉语法之后你写出来的东西在“理想状态”下还很好看!!有心情看看flask项目,挺有趣的。在你通过python爬取的基础上,如果你不在乎代码可读性,那么可以一直这么爬下去。
我感觉,在爬虫初学者的最初阶段,书籍是个很好的辅助工具。按照前期的学习、写代码,再看看源码、理论补充一下,到后面由于一些补充工具的加入,会让你的爬虫更方便快捷。
仅供参考
flask框架是框架不是框架!
如果是想用flask做web开发的话,一般在开始写restfulservice的时候再开始想这个问题。现在我们开发单线程爬虫,一般如果实在连web请求这块,可以用动态语言,例如node.js或者python+phantomjs+requests库。flask应该还是主流的通信框架,相比较起来,flask有时候不是特别适合(高并发、多进程可能比较容易遇到代码重复的问题),有些人用flaskpython编写了服务器端,同时通过请求的postman做注册等操作的时候可能还需要考虑采用flask代理返回有多个参数,这个时候还是要看你写的代码是怎么样的,可以用flask+mongodb写一个postman的聊天模块。
另外flask还有一些sqlalchemy的库,可以编写orm语言接口,遇到多个sqlalchemy关联时,再说高并发去。
php抓取网页ajax数据实战(一)_光明网(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-07-01 00:02
php抓取网页ajax数据实战很多刚入门php的小伙伴,肯定想要把重要的数据提取出来,可是很多php使用者在写代码的时候,都有一个困惑。在我写wordpress博客的时候,我经常抓取网页上的ajax数据。而且我本身是一个在校的大学生,没有那么多的时间去做额外的学习。不过,我在一次wordpress作者群内线下交流的时候,听到了很多高手说,javascript是无法抓取ajax里面的数据的。
原因是javascript本身作为一个无序对象,是无法操作ajax传递给其他对象的值。我反问到,大家有想过javascript怎么可以操作ajax传递给其他对象的值呢?他们竟然自信的说,javascript可以控制一个变量是谁传给它,从而加上自己的值?而且他们每天都在通过修改属性值操作ajax中的数据。
是啊,谁在操作对方的值呢?又或者说,javascript本身可以在分配给自己的变量里面操作对方的值吗?还是说javascript可以像php一样,完成某种同步的工作?他们以前真的没有想过这些吗?接下来,我将会回答他们的问题。首先回答最重要的问题,在传递给这些对象的值之前,对方没有遇到异步的请求,通过javascript是可以操作这些值的。
举个例子,想象我们这次要通过php来模拟抓取网页ajax数据,那么我们可以找到一个send_ajax函数。after(){send_ajax(url);}那么,是不是当ajax数据从网页后端传递给我们的时候,就可以操作这些对象?并不是的,比如我现在抓取了一个链接,并且通过url传递给browser端时,browser端是没有接受到数据,browser端并没有接受到数据,那么我到底在用javascript去操作他们的值是无法成功的。
因为在网页ajax返回时,对方服务器上是没有收到该数据的。所以如果我的项目中,数据来源更多是来自于后端服务器,我就可以通过php去操作他们,这就是javascript来异步回调数据的原理。举个例子,如果我要抓取某个网页上的某个女性视频,我首先在url中加上';','',那么我会通过php控制send_ajax函数,在send_ajax函数中,操作数据的回调函数为true。
那么,对于抓取过的数据,对于数据本身已经有序的有序对象的url,通过php如何操作他们的值呢?这里我假设是用formdata或media_url去操作media_url,他们的区别在于,formdata返回值是有序的,media_url返回值是无序的。在formdata中media_url指向的对象是属于一个结构化字符串的对象media_url,而media_url.sqlquery(media。 查看全部
php抓取网页ajax数据实战(一)_光明网(图)
php抓取网页ajax数据实战很多刚入门php的小伙伴,肯定想要把重要的数据提取出来,可是很多php使用者在写代码的时候,都有一个困惑。在我写wordpress博客的时候,我经常抓取网页上的ajax数据。而且我本身是一个在校的大学生,没有那么多的时间去做额外的学习。不过,我在一次wordpress作者群内线下交流的时候,听到了很多高手说,javascript是无法抓取ajax里面的数据的。
原因是javascript本身作为一个无序对象,是无法操作ajax传递给其他对象的值。我反问到,大家有想过javascript怎么可以操作ajax传递给其他对象的值呢?他们竟然自信的说,javascript可以控制一个变量是谁传给它,从而加上自己的值?而且他们每天都在通过修改属性值操作ajax中的数据。
是啊,谁在操作对方的值呢?又或者说,javascript本身可以在分配给自己的变量里面操作对方的值吗?还是说javascript可以像php一样,完成某种同步的工作?他们以前真的没有想过这些吗?接下来,我将会回答他们的问题。首先回答最重要的问题,在传递给这些对象的值之前,对方没有遇到异步的请求,通过javascript是可以操作这些值的。
举个例子,想象我们这次要通过php来模拟抓取网页ajax数据,那么我们可以找到一个send_ajax函数。after(){send_ajax(url);}那么,是不是当ajax数据从网页后端传递给我们的时候,就可以操作这些对象?并不是的,比如我现在抓取了一个链接,并且通过url传递给browser端时,browser端是没有接受到数据,browser端并没有接受到数据,那么我到底在用javascript去操作他们的值是无法成功的。
因为在网页ajax返回时,对方服务器上是没有收到该数据的。所以如果我的项目中,数据来源更多是来自于后端服务器,我就可以通过php去操作他们,这就是javascript来异步回调数据的原理。举个例子,如果我要抓取某个网页上的某个女性视频,我首先在url中加上';','',那么我会通过php控制send_ajax函数,在send_ajax函数中,操作数据的回调函数为true。
那么,对于抓取过的数据,对于数据本身已经有序的有序对象的url,通过php如何操作他们的值呢?这里我假设是用formdata或media_url去操作media_url,他们的区别在于,formdata返回值是有序的,media_url返回值是无序的。在formdata中media_url指向的对象是属于一个结构化字符串的对象media_url,而media_url.sqlquery(media。
ajax传输网页内容发起post请求传输后台数据(刷新)
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-06-16 02:01
php抓取网页ajax数据,以各种格式保存到本地,以供下次抓取。而javascript将html中的dom元素渲染成了可以解析的javascript对象,用来执行脚本。
对于普通web程序员,“ajax”这种话可能都不是什么新鲜词了。甚至比较冷门一点的站点,都会将这一词完全用在自己的站点上。但是,对于javascript来说,ajax可能是最近才提出的一个重要的概念。它的应用范围广泛,有各种各样的应用场景:ajax传输网页内容发起post请求传输网页内容传输后台数据,通过xml或者json格式发送给前端发起get请求传输后台数据,通过xml或者json格式发送给浏览器在传输过程中,网页与服务器进行通信。
传输数据之后还会返回内容:responsetext、response。而就目前而言,大多数网站,在使用ajax方式传输数据的同时,所请求的网页内容都将实际上并不在浏览器的缓存中,而是隐藏在了session中。这导致这些网页一旦被关闭,将无法再被浏览器的“重定向”,而导致页面不断刷新,用户的体验非常糟糕。
而所谓“页面刷新”,我们可以通过ajax动态生成一个重定向(刷新)链接($loading),执行这个动作后,内容就是当前正在浏览的页面,不再存在当前页面的缓存内容。这些开发者希望的情况,往往都只是能把一个很小的页面,强行生成重定向链接,并且希望用户随时都能在重定向连接中找到他们的内容。而当今所谓的ajax框架,更多地是想解决用户需求与开发者提出需求之间的冲突,最终这导致了相互撕逼的情况的出现。
而我目前在做的javascript,就是在开发一个任意比页面大很多,多个页面连续的应用程序时,执行javascript可以做到动态化发起post请求,并且动态化的返回内容在网页中。实际上,我所说的这个框架并不是这个样子的,它大概已经实现了你上面所说的这种情况。 查看全部
ajax传输网页内容发起post请求传输后台数据(刷新)
php抓取网页ajax数据,以各种格式保存到本地,以供下次抓取。而javascript将html中的dom元素渲染成了可以解析的javascript对象,用来执行脚本。
对于普通web程序员,“ajax”这种话可能都不是什么新鲜词了。甚至比较冷门一点的站点,都会将这一词完全用在自己的站点上。但是,对于javascript来说,ajax可能是最近才提出的一个重要的概念。它的应用范围广泛,有各种各样的应用场景:ajax传输网页内容发起post请求传输网页内容传输后台数据,通过xml或者json格式发送给前端发起get请求传输后台数据,通过xml或者json格式发送给浏览器在传输过程中,网页与服务器进行通信。
传输数据之后还会返回内容:responsetext、response。而就目前而言,大多数网站,在使用ajax方式传输数据的同时,所请求的网页内容都将实际上并不在浏览器的缓存中,而是隐藏在了session中。这导致这些网页一旦被关闭,将无法再被浏览器的“重定向”,而导致页面不断刷新,用户的体验非常糟糕。
而所谓“页面刷新”,我们可以通过ajax动态生成一个重定向(刷新)链接($loading),执行这个动作后,内容就是当前正在浏览的页面,不再存在当前页面的缓存内容。这些开发者希望的情况,往往都只是能把一个很小的页面,强行生成重定向链接,并且希望用户随时都能在重定向连接中找到他们的内容。而当今所谓的ajax框架,更多地是想解决用户需求与开发者提出需求之间的冲突,最终这导致了相互撕逼的情况的出现。
而我目前在做的javascript,就是在开发一个任意比页面大很多,多个页面连续的应用程序时,执行javascript可以做到动态化发起post请求,并且动态化的返回内容在网页中。实际上,我所说的这个框架并不是这个样子的,它大概已经实现了你上面所说的这种情况。
php抓取网页ajax数据,转换格式这种事情都不需要你来做了
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-06-06 06:06
php抓取网页ajax数据,转换格式这种事情都不需要你来做了。网页每秒发生n万次变化,你做不过来。反正你不要用浏览器看就是了。如果你非要做,推荐用swoole或者nodejs的cordova模块,
spine还是挺不错的,建议考虑一下。
jquery。fetch("facebook")。then("app")。then("ebay")。then("google")。then("amazon")jquery。fetch("facebook")。then("app")。then("ebay")。then("google")。then("amazon")。
可以,这个写一个websocket程序完全可以,随便哪个抓包器都可以,跨域基本上是木有问题的,传输post数据上不封锁就无限传输,
.net-json没有跨域问题.
应该不可以。除非gmail有验证,你看不到特别的ajax请求。因为这个服务不怎么安全。我想应该是服务器上缓存过,加上跨域有难度。题主可以尝试一下burpwebsocket抓包看看会不会再没有时间上实际写抓包。题主的做法是正确的,有时候要控制频率。
可以的,你把json的格式设置为xml或其他json格式,进行操作,
有两种思路,一种是在接收请求的服务器中实现解析数据,这个会比较费事,一种是在缓存中进行取数据操作,这样效率会高一些,googlegroups的数据是文本类型的,很容易拿到数据。 查看全部
php抓取网页ajax数据,转换格式这种事情都不需要你来做了
php抓取网页ajax数据,转换格式这种事情都不需要你来做了。网页每秒发生n万次变化,你做不过来。反正你不要用浏览器看就是了。如果你非要做,推荐用swoole或者nodejs的cordova模块,
spine还是挺不错的,建议考虑一下。
jquery。fetch("facebook")。then("app")。then("ebay")。then("google")。then("amazon")jquery。fetch("facebook")。then("app")。then("ebay")。then("google")。then("amazon")。
可以,这个写一个websocket程序完全可以,随便哪个抓包器都可以,跨域基本上是木有问题的,传输post数据上不封锁就无限传输,
.net-json没有跨域问题.
应该不可以。除非gmail有验证,你看不到特别的ajax请求。因为这个服务不怎么安全。我想应该是服务器上缓存过,加上跨域有难度。题主可以尝试一下burpwebsocket抓包看看会不会再没有时间上实际写抓包。题主的做法是正确的,有时候要控制频率。
可以的,你把json的格式设置为xml或其他json格式,进行操作,
有两种思路,一种是在接收请求的服务器中实现解析数据,这个会比较费事,一种是在缓存中进行取数据操作,这样效率会高一些,googlegroups的数据是文本类型的,很容易拿到数据。
web前端开发之路domopensource之旅http协议详解http服务器详解
网站优化 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2022-05-14 07:01
php抓取网页ajax数据发邮件源码ajax开发android开发web整站架构之路android中的javaweb开发入门之旅webhandle机制之旅http协议详解http服务器详解urllib1.0android环境部署之androidpackage之旅一个纯粹的android开发工程师的自我修养!web前端开发之路domopensource之旅让我们一起体验前端开发的乐趣easyweb开发之旅javascript开发之旅原生代码之旅:基于dom的ajax和pwajquery的开发之旅angularjs开发之旅vue开发之旅jquery和vueng-repeat-plot一起玩转前端开发!前端开发之路,本文转载自angularjs开发之旅,微信公众号为:angularjs之旅,angular的博客博主是阿云嘎,欢迎大家关注更多angular相关资料,欢迎点击下面地址。
angularjs之旅——router和path的理解angularjs之旅——权限管理及vue.js内部实现angularjs之旅——大家还有什么安卓开发的问题可以加群477311289一起交流!angular入门之旅零基础通过阿里巴巴出的官方开发者中心进行android开发,具体步骤如下:点击下方链接或扫描二维码。
-show/android安卓入门之旅:导航栏简单的3步搭建android中的materialdesign及vue.js可不是空手套白狼,angular应用的开发需要架构设计、上下游组件的整合与集成,更需要前端的手工制作及开发。它的架构如下:做好架构图没有什么比两者有机的结合更快速有效的建立一个完整的前端工程了:/#/material相关内容安卓入门之旅:vue和vuex异步、组件相关内容(会跟着第二步一步步介绍vuejs中间件、vuex)angular入门之旅:angularmv.js框架的整合与集成;angular2的框架结构和组件实现(异步队列、gitlab/kubernetes、spring-boot等)angular入门之旅:oc(androidstudio)开发android(更多在公众号更新,欢迎大家关注更多angular相关资料,欢迎点击下面地址)angular入门之旅:详细angularjs架构设计上下游整合与集成本文将跟着阿云嘎学习更加复杂的一个angularjs入门的整合开发,顺便理解vue.js的mvvm,我们到底该如何搭建一个简单的angularjs应用,又该如何整合和集成这些开发框架,让我们以一个前端工程的方式一起体验前端开发的乐趣。
开发环境:下载angularjs开发工具(mac环境:pkginstallergs6790d8--os--linux3.4--core/v7.3--lib9bg--http),跟我走,打开指定环境,编译angularjs到上游。这里跟大家分享一下如何打包为一个app来安装下面的开发环境。第一步:下载angularjs安装包(官方。 查看全部
web前端开发之路domopensource之旅http协议详解http服务器详解
php抓取网页ajax数据发邮件源码ajax开发android开发web整站架构之路android中的javaweb开发入门之旅webhandle机制之旅http协议详解http服务器详解urllib1.0android环境部署之androidpackage之旅一个纯粹的android开发工程师的自我修养!web前端开发之路domopensource之旅让我们一起体验前端开发的乐趣easyweb开发之旅javascript开发之旅原生代码之旅:基于dom的ajax和pwajquery的开发之旅angularjs开发之旅vue开发之旅jquery和vueng-repeat-plot一起玩转前端开发!前端开发之路,本文转载自angularjs开发之旅,微信公众号为:angularjs之旅,angular的博客博主是阿云嘎,欢迎大家关注更多angular相关资料,欢迎点击下面地址。
angularjs之旅——router和path的理解angularjs之旅——权限管理及vue.js内部实现angularjs之旅——大家还有什么安卓开发的问题可以加群477311289一起交流!angular入门之旅零基础通过阿里巴巴出的官方开发者中心进行android开发,具体步骤如下:点击下方链接或扫描二维码。
-show/android安卓入门之旅:导航栏简单的3步搭建android中的materialdesign及vue.js可不是空手套白狼,angular应用的开发需要架构设计、上下游组件的整合与集成,更需要前端的手工制作及开发。它的架构如下:做好架构图没有什么比两者有机的结合更快速有效的建立一个完整的前端工程了:/#/material相关内容安卓入门之旅:vue和vuex异步、组件相关内容(会跟着第二步一步步介绍vuejs中间件、vuex)angular入门之旅:angularmv.js框架的整合与集成;angular2的框架结构和组件实现(异步队列、gitlab/kubernetes、spring-boot等)angular入门之旅:oc(androidstudio)开发android(更多在公众号更新,欢迎大家关注更多angular相关资料,欢迎点击下面地址)angular入门之旅:详细angularjs架构设计上下游整合与集成本文将跟着阿云嘎学习更加复杂的一个angularjs入门的整合开发,顺便理解vue.js的mvvm,我们到底该如何搭建一个简单的angularjs应用,又该如何整合和集成这些开发框架,让我们以一个前端工程的方式一起体验前端开发的乐趣。
开发环境:下载angularjs开发工具(mac环境:pkginstallergs6790d8--os--linux3.4--core/v7.3--lib9bg--http),跟我走,打开指定环境,编译angularjs到上游。这里跟大家分享一下如何打包为一个app来安装下面的开发环境。第一步:下载angularjs安装包(官方。
php抓取页面时用的非常频繁的功能,我发现获取图片id的几个方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-05-10 19:01
php抓取网页ajax数据是我们php抓取页面时用的非常频繁的功能,经常用抓取手工做页面截图效率极其低下,很久之前曾经看过。它非常好用,效率却不高。在正常的一张图片的图片请求中需要为每一个帧分配一个字符串作为图片名称的缓存,另外还需要为每个图片请求为每个帧对应一个字符串做一个名称与索引作为id。在那次css2ddiv+css3的html抓取课程中,我发现获取图片id的几个方法:javascript:imgs_link=location.resolve(..);imgs_width=..;imgs_height=..;ajax:urlencodedimgs_link=location.resolve(..);filter:'lightning'class='imagefilter'extendsclass(imgs_link);requestmethod='get',timeout=500;current-reason='l';buffered-filter:'blacklevel'class='text-level'extendsclass(imgs_link);requestmethod='post',timeout=500;current-reason='s';buffered-filter:'blacklevel'class='text-level'extendsclass(imgs_link);requestmethod='post',timeout=500;current-reason='l';buffered-filter:'colorimage'class='text-colorimage'extendsclass(imgs_link);requestmethod='post',timeout=500;current-reason='s';buffered-filter:'blacklevel'class='text-colorimage'extendsclass(imgs_link);requestmethod='post',timeout=500;current-reason='s';buffered-filter:'blacklevel'class='text-level'extendsclass(imgs_link);requestmethod='post',timeout=500;requestmethod='post',timeout=500;requestmethod='post',timeout=500;requestmethod='post',timeout=500;由于http请求头中x-requested-with的值用'post'是传输二进制的方法,而'get'是传输一个字符串。
由于http响应头中的x-post方法是方法,而get方法是字符串,那么通过x-post方法我们将获取每一帧缓存,而不是同时获取每个帧对应的id。对于每一帧对应的id就有限制在一个整数范围,一个key对应一个id。而x-post是方法,通过x-post方法我们只需要关心将filter中的current-reason和request_add_request方法解码后替换为id即可。if(filter_is_has。 查看全部
php抓取页面时用的非常频繁的功能,我发现获取图片id的几个方法
php抓取网页ajax数据是我们php抓取页面时用的非常频繁的功能,经常用抓取手工做页面截图效率极其低下,很久之前曾经看过。它非常好用,效率却不高。在正常的一张图片的图片请求中需要为每一个帧分配一个字符串作为图片名称的缓存,另外还需要为每个图片请求为每个帧对应一个字符串做一个名称与索引作为id。在那次css2ddiv+css3的html抓取课程中,我发现获取图片id的几个方法:javascript:imgs_link=location.resolve(..);imgs_width=..;imgs_height=..;ajax:urlencodedimgs_link=location.resolve(..);filter:'lightning'class='imagefilter'extendsclass(imgs_link);requestmethod='get',timeout=500;current-reason='l';buffered-filter:'blacklevel'class='text-level'extendsclass(imgs_link);requestmethod='post',timeout=500;current-reason='s';buffered-filter:'blacklevel'class='text-level'extendsclass(imgs_link);requestmethod='post',timeout=500;current-reason='l';buffered-filter:'colorimage'class='text-colorimage'extendsclass(imgs_link);requestmethod='post',timeout=500;current-reason='s';buffered-filter:'blacklevel'class='text-colorimage'extendsclass(imgs_link);requestmethod='post',timeout=500;current-reason='s';buffered-filter:'blacklevel'class='text-level'extendsclass(imgs_link);requestmethod='post',timeout=500;requestmethod='post',timeout=500;requestmethod='post',timeout=500;requestmethod='post',timeout=500;由于http请求头中x-requested-with的值用'post'是传输二进制的方法,而'get'是传输一个字符串。
由于http响应头中的x-post方法是方法,而get方法是字符串,那么通过x-post方法我们将获取每一帧缓存,而不是同时获取每个帧对应的id。对于每一帧对应的id就有限制在一个整数范围,一个key对应一个id。而x-post是方法,通过x-post方法我们只需要关心将filter中的current-reason和request_add_request方法解码后替换为id即可。if(filter_is_has。
爬虫原理及反爬虫技术
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-05-06 00:12
对于大数据行业,数据的价值不言而喻,在这个信息爆炸的年代,互联网上有太多的信息数据,对于中小微公司,合理利用爬虫爬取有价值的数据,是弥补自身先天数据短板的不二选择,本文主要从爬虫原理、架构、分类以及反爬虫技术来对爬虫技术进行了总结。
1、爬虫技术概述
网络爬虫(Webcrawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题:
(1)对抓取目标的描述或定义;
(2)对网页或数据的分析与过滤;
(3)对URL的搜索策略。
2、爬虫原理
2.1网络爬虫原理
Web网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据来源。很多大型的网络搜索引擎系统都被称为基于Web数据采集的搜索引擎系统,比如Google、Baidu。由此可见Web网络爬虫系统在搜索引擎中的重要性。网页中除了包含供用户阅读的文字信息外,还包含一些超链接信息。Web网络爬虫系统正是通过网页中的超连接信息不断获得网络上的其它网页。正是因为这种采集过程像一个爬虫或者蜘蛛在网络上漫游,所以它才被称为网络爬虫系统或者网络蜘蛛系统,在英文中称为Spider或者Crawler。
2.2网络爬虫系统的工作原理
在网络爬虫的系统框架中,主过程由控制器,解析器,资源库三部分组成。控制器的主要工作是负责给多线程中的各个爬虫线程分配工作任务。解析器的主要工作是下载网页,进行页面的处理,主要是将一些JS脚本标签、CSS代码内容、空格字符、HTML标签等内容处理掉,爬虫的基本工作是由解析器完成。资源库是用来存放下载到的网页资源,一般都采用大型的数据库存储,如Oracle数据库,并对其建立索引。
控制器
控制器是网络爬虫的中央控制器,它主要是负责根据系统传过来的URL链接,分配一线程,然后启动线程调用爬虫爬取网页的过程。
解析器
解析器是负责网络爬虫的主要部分,其负责的工作主要有:下载网页的功能,对网页的文本进行处理,如过滤功能,抽取特殊HTML标签的功能,分析数据功能。
资源库
主要是用来存储网页中下载下来的数据记录的容器,并提供生成索引的目标源。中大型的数据库产品有:Oracle、SqlServer等。
Web网络爬虫系统一般会选择一些比较重要的、出度(网页中链出超链接数)较大的网站的URL作为种子URL集合。网络爬虫系统以这些种子集合作为初始URL,开始数据的抓取。因为网页中含有链接信息,通过已有网页的URL会得到一些新的URL,可以把网页之间的指向结构视为一个森林,每个种子URL对应的网页是森林中的一棵树的根节点。
这样,Web网络爬虫系统就可以根据广度优先算法或者深度优先算法遍历所有的网页。由于深度优先搜索算法可能会使爬虫系统陷入一个网站内部,不利于搜索比较靠近网站首页的网页信息,因此一般采用广度优先搜索算法采集网页。Web网络爬虫系统首先将种子URL放入下载队列,然后简单地从队首取出一个URL下载其对应的网页。得到网页的内容将其存储后,再经过解析网页中的链接信息可以得到一些新的URL,将这些URL加入下载队列。然后再取出一个URL,对其对应的网页进行下载,然后再解析,如此反复进行,直到遍历了整个网络或者满足某种条件后才会停止下来。
网络爬虫的基本工作流程如下:
1.首先选取一部分精心挑选的种子URL;
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列;
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
2.3抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面重点介绍几种常见的抓取策略:
2.3.1深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。我们以下面的图为例:
遍历的路径:A-F-GE-H-IBCD
2.3.2宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以上面的图为例:
遍历路径:A-B-C-D-E-FGHI
2.3.3反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数量。反向链接数表示的是一个网页的内容受到其他人的推荐的程度。因此,很多时候搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后顺序。
在真实的网络环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那个也的重要程度。因此,搜索引擎往往考虑一些可靠的反向链接数。
2.3.4PartialPageRank策略
PartialPageRank算法借鉴了PageRank算法的思想:对于已经下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每个页面的PageRank值,计算完之后,将待抓取URL队列中的URL按照PageRank值的大小排列,并按照该顺序抓取页面。
如果每次抓取一个页面,就重新计算PageRank值,一种折中方案是:每抓取K个页面后,重新计算一次PageRank值。但是这种情况还会有一个问题:对于已经下载下来的页面中分析出的链接,也就是我们之前提到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总,这样就形成了该未知页面的PageRank值,从而参与排序。
2.3.5OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P之后,将P的现金分摊给所有从P中分析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面按照现金数进行排序。
2.3.6大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因此叫做大站优先策略。
3、爬虫分类
开发网络爬虫应该选择Nutch、Crawler4j、WebMagic、scrapy、WebCollector还是其他的?上面说的爬虫,基本可以分3类:
(1)分布式爬虫:Nutch
(2)JAVA爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1分布式爬虫
爬虫使用分布式,主要是解决两个问题:
1)海量URL管理
2)网速
现在比较流行的分布式爬虫,是Apache的Nutch。但是对于大多数用户来说,Nutch是这几类爬虫里,最不好的选择,理由如下:
1)Nutch是为搜索引擎设计的爬虫,大多数用户是需要一个做精准数据爬取(精抽取)的爬虫。Nutch运行的一套流程里,有三分之二是为了搜索引擎而设计的。对精抽取没有太大的意义。也就是说,用Nutch做数据抽取,会浪费很多的时间在不必要的计算上。而且如果你试图通过对Nutch进行二次开发,来使得它适用于精抽取的业务,基本上就要破坏Nutch的框架,把Nutch改的面目全非,有修改Nutch的能力,真的不如自己重新写一个分布式爬虫框架了。
2)Nutch依赖hadoop运行,hadoop本身会消耗很多的时间。如果集群机器数量较少,爬取速度反而不如单机爬虫快。
3)Nutch虽然有一套插件机制,而且作为亮点宣传。可以看到一些开源的Nutch插件,提供精抽取的功能。但是开发过Nutch插件的人都知道,Nutch的插件系统有多蹩脚。利用反射的机制来加载和调用插件,使得程序的编写和调试都变得异常困难,更别说在上面开发一套复杂的精抽取系统了。而且Nutch并没有为精抽取提供相应的插件挂载点。Nutch的插件有只有五六个挂载点,而这五六个挂载点都是为了搜索引擎服务的,并没有为精抽取提供挂载点。大多数Nutch的精抽取插件,都是挂载在“页面解析”(parser)这个挂载点的,这个挂载点其实是为了解析链接(为后续爬取提供URL),以及为搜索引擎提供一些易抽取的网页信息(网页的meta信息、text文本)。
4)用Nutch进行爬虫的二次开发,爬虫的编写和调试所需的时间,往往是单机爬虫所需的十倍时间不止。了解Nutch源码的学习成本很高,何况是要让一个团队的人都读懂Nutch源码。调试过程中会出现除程序本身之外的各种问题(hadoop的问题、hbase的问题)。
5)很多人说Nutch2有gora,可以持久化数据到avro文件、hbase、mysql等。很多人其实理解错了,这里说的持久化数据,是指将URL信息(URL管理所需要的数据)存放到avro、hbase、mysql。并不是你要抽取的结构化数据。其实对大多数人来说,URL信息存在哪里无所谓。
6)Nutch2的版本目前并不适合开发。官方现在稳定的Nutch版本是nutch2.2.1,但是这个版本绑定了gora-0.3。如果想用hbase配合nutch(大多数人用nutch2就是为了用hbase),只能使用0.90版本左右的hbase,相应的就要将hadoop版本降到hadoop0.2左右。而且nutch2的官方教程比较有误导作用,Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x,这个Nutch2.x官网上写的是可以支持到hbase0.94。但是实际上,这个Nutch2.x的意思是Nutch2.3之前、Nutch2.2.1之后的一个版本,这个版本在官方的SVN中不断更新。而且非常不稳定(一直在修改)。
所以,如果你不是要做搜索引擎,尽量不要选择Nutch作为爬虫。有些团队就喜欢跟风,非要选择Nutch来开发精抽取的爬虫,其实是冲着Nutch的名气,当然最后的结果往往是项目延期完成。
如果你是要做搜索引擎,Nutch1.x是一个非常好的选择。Nutch1.x和solr或者es配合,就可以构成一套非常强大的搜索引擎了。如果非要用Nutch2的话,建议等到Nutch2.3发布再看。目前的Nutch2是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2JAVA爬虫
这里把JAVA爬虫单独分为一类,是因为JAVA在网络爬虫这块的生态圈是非常完善的。相关的资料也是最全的。这里可能有争议,我只是随便谈谈。
其实开源网络爬虫(框架)的开发非常简单,难问题和复杂的问题都被以前的人解决了(比如DOM树解析和定位、字符集检测、海量URL去重),可以说是毫无技术含量。包括Nutch,其实Nutch的技术难点是开发hadoop,本身代码非常简单。网络爬虫从某种意义来说,类似遍历本机的文件,查找文件中的信息。没有任何难度可言。之所以选择开源爬虫框架,就是为了省事。比如爬虫的URL管理、线程池之类的模块,谁都能做,但是要做稳定也是需要一段时间的调试和修改的。
对于爬虫的功能来说。用户比较关心的问题往往是:
1)爬虫支持多线程么、爬虫能用代理么、爬虫会爬取重复数据么、爬虫能爬取JS生成的信息么?
不支持多线程、不支持代理、不能过滤重复URL的,那都不叫开源爬虫,那叫循环执行http请求。
能不能爬js生成的信息和爬虫本身没有太大关系。爬虫主要是负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往需要通过模拟浏览器(htmlunit,selenium)来完成。这些模拟浏览器,往往需要耗费很多的时间来处理一个页面。所以一种策略就是,使用这些爬虫来遍历网站,遇到需要解析的页面,就将网页的相关信息提交给模拟浏览器,来完成JS生成信息的抽取。
2)爬虫可以爬取ajax信息么?
网页上有一些异步加载的数据,爬取这些数据有两种方法:使用模拟浏览器(问题1中描述过了),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果是自己生成ajax请求,使用开源爬虫的意义在哪里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我所需要的ajax请求(列表),如何用这些爬虫来对这些请求进行爬取?
爬虫往往都是设计成广度遍历或者深度遍历的模式,去遍历静态或者动态页面。爬取ajax信息属于deepweb(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方法来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的第一轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax请求作为种子,放入爬虫。用爬虫对这些种子,进行深度为1的广度遍历(默认就是广度遍历)。
3)爬虫怎么爬取要登陆的网站?
这些开源爬虫都支持在爬取时指定cookies,模拟登陆主要是靠cookies。至于cookies怎么获取,不是爬虫管的事情。你可以手动获取、用http请求模拟登陆或者用模拟浏览器自动登陆获取cookie。
4)爬虫怎么抽取网页的信息?
开源爬虫一般都会集成网页抽取工具。主要支持两种规范:CSSSELECTOR和XPATH。至于哪个好,这里不评价。
5)爬虫怎么保存网页的信息?
有一些爬虫,自带一个模块负责持久化。比如webmagic,有一个模块叫pipeline。通过简单地配置,可以将爬虫抽取到的信息,持久化到文件、数据库等。还有一些爬虫,并没有直接给用户提供数据持久化的模块。比如crawler4j和webcollector。让用户自己在网页处理模块中添加提交数据库的操作。至于使用pipeline这种模块好不好,就和操作数据库使用ORM好不好这个问题类似,取决于你的业务。
6)爬虫被网站封了怎么办?
爬虫被网站封了,一般用多代理(随机代理)就可以解决。但是这些开源爬虫一般没有直接支持随机代理的切换。所以用户往往都需要自己将获取的代理,放到一个全局数组中,自己写一个代理随机获取(从数组中)的代码。
7)网页可以调用爬虫么?
爬虫的调用是在Web的服务端调用的,平时怎么用就怎么用,这些爬虫都可以使用。
8)爬虫速度怎么样?
单机开源爬虫的速度,基本都可以讲本机的网速用到极限。爬虫的速度慢,往往是因为用户把线程数开少了、网速慢,或者在数据持久化时,和数据库的交互速度慢。而这些东西,往往都是用户的机器和二次开发的代码决定的。这些开源爬虫的速度,都很可以。
9)明明代码写对了,爬不到数据,是不是爬虫有问题,换个爬虫能解决么?
如果代码写对了,又爬不到数据,换其他爬虫也是一样爬不到。遇到这种情况,要么是网站把你封了,要么是你爬的数据是javascript生成的。爬不到数据通过换爬虫是不能解决的。
10)哪个爬虫可以判断网站是否爬完、那个爬虫可以根据主题进行爬取?
爬虫无法判断网站是否爬完,只能尽可能覆盖。
至于根据主题爬取,爬虫之后把内容爬下来才知道是什么主题。所以一般都是整个爬下来,然后再去筛选内容。如果嫌爬的太泛,可以通过限制URL正则等方式,来缩小一下范围。
11)哪个爬虫的设计模式和构架比较好?
设计模式纯属扯淡。说软件设计模式好的,都是软件开发完,然后总结出几个设计模式。设计模式对软件开发没有指导性作用。用设计模式来设计爬虫,只会使得爬虫的设计更加臃肿。
至于构架,开源爬虫目前主要是细节的数据结构的设计,比如爬取线程池、任务队列,这些大家都能控制好。爬虫的业务太简单,谈不上什么构架。
所以对于JAVA开源爬虫,我觉得,随便找一个用的顺手的就可以。如果业务复杂,拿哪个爬虫来,都是要经过复杂的二次开发,才可以满足需求。
3.3非JAVA爬虫
在非JAVA语言编写的爬虫中,有很多优秀的爬虫。这里单独提取出来作为一类,并不是针对爬虫本身的质量进行讨论,而是针对larbin、scrapy这类爬虫,对开发成本的影响。
先说python爬虫,python可以用30行代码,完成JAVA50行代码干的任务。python写代码的确快,但是在调试代码的阶段,python代码的调试往往会耗费远远多于编码阶段省下的时间。使用python开发,要保证程序的正确性和稳定性,就需要写更多的测试模块。当然如果爬取规模不大、爬取业务不复杂,使用scrapy这种爬虫也是蛮不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图,绿线是数据流向,首先从初始URL开始,Scheduler会将其交给Downloader进行下载,下载之后会交给Spider进行分析,需要保存的数据则会被送到ItemPipeline,那是对数据进行后期处理。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。因此在开发爬虫的时候,最好也先规划好各种模块。我的做法是单独规划下载模块,爬行模块,调度模块,数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本,如果软件需要团队开发或者交接,那就是很多人的学习成本了。软件的调试也不是那么容易。
还有一些ruby、php的爬虫,这里不多评价。的确有一些非常小型的数据采集任务,用ruby或者php很方便。但是选择这些语言的开源爬虫,一方面要调研一下相关的生态圈,还有就是,这些开源爬虫可能会出一些你搜不到的BUG(用的人少、资料也少)
4、反爬虫技术
因为搜索引擎的流行,网络爬虫已经成了很普及网络技术,除了专门做搜索的Google,Yahoo,微软,百度以外,几乎每个大型门户网站都有自己的搜索引擎,大大小小叫得出来名字得就几十种,还有各种不知名的几千几万种,对于一个内容型驱动的网站来说,受到网络爬虫的光顾是不可避免的。
一些智能的搜索引擎爬虫的爬取频率比较合理,对网站资源消耗比较少,但是很多糟糕的网络爬虫,对网页爬取能力很差,经常并发几十上百个请求循环重复抓取,这种爬虫对中小型网站往往是毁灭性打击,特别是一些缺乏爬虫编写经验的程序员写出来的爬虫破坏力极强,造成的网站访问压力会非常大,会导致网站访问速度缓慢,甚至无法访问。
一般网站从三个方面反爬虫:用户请求的Headers,用户行为,网站目录和数据加载方式。前两种比较容易遇到,大多数网站都从这些角度来反爬虫。第三种一些应用ajax的网站会采用,这样增大了爬取的难度。
4.1通过Headers反爬虫
从用户请求的Headers反爬虫是最常见的反爬虫策略。很多网站都会对Headers的User-Agent进行检测,还有一部分网站会对Referer进行检测(一些资源网站的防盗链就是检测Referer)。如果遇到了这类反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值修改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或者添加Headers就能很好的绕过。
[评论:往往容易被忽略,通过对请求的抓包分析,确定referer,在程序中模拟访问请求头中添加]
4.2基于用户行为反爬虫
还有一部分网站是通过检测用户行为,例如同一IP短时间内多次访问同一页面,或者同一账户短时间内多次进行相同操作。 查看全部
爬虫原理及反爬虫技术
对于大数据行业,数据的价值不言而喻,在这个信息爆炸的年代,互联网上有太多的信息数据,对于中小微公司,合理利用爬虫爬取有价值的数据,是弥补自身先天数据短板的不二选择,本文主要从爬虫原理、架构、分类以及反爬虫技术来对爬虫技术进行了总结。
1、爬虫技术概述
网络爬虫(Webcrawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题:
(1)对抓取目标的描述或定义;
(2)对网页或数据的分析与过滤;
(3)对URL的搜索策略。
2、爬虫原理
2.1网络爬虫原理
Web网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据来源。很多大型的网络搜索引擎系统都被称为基于Web数据采集的搜索引擎系统,比如Google、Baidu。由此可见Web网络爬虫系统在搜索引擎中的重要性。网页中除了包含供用户阅读的文字信息外,还包含一些超链接信息。Web网络爬虫系统正是通过网页中的超连接信息不断获得网络上的其它网页。正是因为这种采集过程像一个爬虫或者蜘蛛在网络上漫游,所以它才被称为网络爬虫系统或者网络蜘蛛系统,在英文中称为Spider或者Crawler。
2.2网络爬虫系统的工作原理
在网络爬虫的系统框架中,主过程由控制器,解析器,资源库三部分组成。控制器的主要工作是负责给多线程中的各个爬虫线程分配工作任务。解析器的主要工作是下载网页,进行页面的处理,主要是将一些JS脚本标签、CSS代码内容、空格字符、HTML标签等内容处理掉,爬虫的基本工作是由解析器完成。资源库是用来存放下载到的网页资源,一般都采用大型的数据库存储,如Oracle数据库,并对其建立索引。
控制器
控制器是网络爬虫的中央控制器,它主要是负责根据系统传过来的URL链接,分配一线程,然后启动线程调用爬虫爬取网页的过程。
解析器
解析器是负责网络爬虫的主要部分,其负责的工作主要有:下载网页的功能,对网页的文本进行处理,如过滤功能,抽取特殊HTML标签的功能,分析数据功能。
资源库
主要是用来存储网页中下载下来的数据记录的容器,并提供生成索引的目标源。中大型的数据库产品有:Oracle、SqlServer等。
Web网络爬虫系统一般会选择一些比较重要的、出度(网页中链出超链接数)较大的网站的URL作为种子URL集合。网络爬虫系统以这些种子集合作为初始URL,开始数据的抓取。因为网页中含有链接信息,通过已有网页的URL会得到一些新的URL,可以把网页之间的指向结构视为一个森林,每个种子URL对应的网页是森林中的一棵树的根节点。
这样,Web网络爬虫系统就可以根据广度优先算法或者深度优先算法遍历所有的网页。由于深度优先搜索算法可能会使爬虫系统陷入一个网站内部,不利于搜索比较靠近网站首页的网页信息,因此一般采用广度优先搜索算法采集网页。Web网络爬虫系统首先将种子URL放入下载队列,然后简单地从队首取出一个URL下载其对应的网页。得到网页的内容将其存储后,再经过解析网页中的链接信息可以得到一些新的URL,将这些URL加入下载队列。然后再取出一个URL,对其对应的网页进行下载,然后再解析,如此反复进行,直到遍历了整个网络或者满足某种条件后才会停止下来。
网络爬虫的基本工作流程如下:
1.首先选取一部分精心挑选的种子URL;
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列;
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
2.3抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面重点介绍几种常见的抓取策略:
2.3.1深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。我们以下面的图为例:
遍历的路径:A-F-GE-H-IBCD
2.3.2宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以上面的图为例:
遍历路径:A-B-C-D-E-FGHI
2.3.3反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数量。反向链接数表示的是一个网页的内容受到其他人的推荐的程度。因此,很多时候搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后顺序。
在真实的网络环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那个也的重要程度。因此,搜索引擎往往考虑一些可靠的反向链接数。
2.3.4PartialPageRank策略
PartialPageRank算法借鉴了PageRank算法的思想:对于已经下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每个页面的PageRank值,计算完之后,将待抓取URL队列中的URL按照PageRank值的大小排列,并按照该顺序抓取页面。
如果每次抓取一个页面,就重新计算PageRank值,一种折中方案是:每抓取K个页面后,重新计算一次PageRank值。但是这种情况还会有一个问题:对于已经下载下来的页面中分析出的链接,也就是我们之前提到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总,这样就形成了该未知页面的PageRank值,从而参与排序。
2.3.5OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P之后,将P的现金分摊给所有从P中分析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面按照现金数进行排序。
2.3.6大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因此叫做大站优先策略。
3、爬虫分类
开发网络爬虫应该选择Nutch、Crawler4j、WebMagic、scrapy、WebCollector还是其他的?上面说的爬虫,基本可以分3类:
(1)分布式爬虫:Nutch
(2)JAVA爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1分布式爬虫
爬虫使用分布式,主要是解决两个问题:
1)海量URL管理
2)网速
现在比较流行的分布式爬虫,是Apache的Nutch。但是对于大多数用户来说,Nutch是这几类爬虫里,最不好的选择,理由如下:
1)Nutch是为搜索引擎设计的爬虫,大多数用户是需要一个做精准数据爬取(精抽取)的爬虫。Nutch运行的一套流程里,有三分之二是为了搜索引擎而设计的。对精抽取没有太大的意义。也就是说,用Nutch做数据抽取,会浪费很多的时间在不必要的计算上。而且如果你试图通过对Nutch进行二次开发,来使得它适用于精抽取的业务,基本上就要破坏Nutch的框架,把Nutch改的面目全非,有修改Nutch的能力,真的不如自己重新写一个分布式爬虫框架了。
2)Nutch依赖hadoop运行,hadoop本身会消耗很多的时间。如果集群机器数量较少,爬取速度反而不如单机爬虫快。
3)Nutch虽然有一套插件机制,而且作为亮点宣传。可以看到一些开源的Nutch插件,提供精抽取的功能。但是开发过Nutch插件的人都知道,Nutch的插件系统有多蹩脚。利用反射的机制来加载和调用插件,使得程序的编写和调试都变得异常困难,更别说在上面开发一套复杂的精抽取系统了。而且Nutch并没有为精抽取提供相应的插件挂载点。Nutch的插件有只有五六个挂载点,而这五六个挂载点都是为了搜索引擎服务的,并没有为精抽取提供挂载点。大多数Nutch的精抽取插件,都是挂载在“页面解析”(parser)这个挂载点的,这个挂载点其实是为了解析链接(为后续爬取提供URL),以及为搜索引擎提供一些易抽取的网页信息(网页的meta信息、text文本)。
4)用Nutch进行爬虫的二次开发,爬虫的编写和调试所需的时间,往往是单机爬虫所需的十倍时间不止。了解Nutch源码的学习成本很高,何况是要让一个团队的人都读懂Nutch源码。调试过程中会出现除程序本身之外的各种问题(hadoop的问题、hbase的问题)。
5)很多人说Nutch2有gora,可以持久化数据到avro文件、hbase、mysql等。很多人其实理解错了,这里说的持久化数据,是指将URL信息(URL管理所需要的数据)存放到avro、hbase、mysql。并不是你要抽取的结构化数据。其实对大多数人来说,URL信息存在哪里无所谓。
6)Nutch2的版本目前并不适合开发。官方现在稳定的Nutch版本是nutch2.2.1,但是这个版本绑定了gora-0.3。如果想用hbase配合nutch(大多数人用nutch2就是为了用hbase),只能使用0.90版本左右的hbase,相应的就要将hadoop版本降到hadoop0.2左右。而且nutch2的官方教程比较有误导作用,Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x,这个Nutch2.x官网上写的是可以支持到hbase0.94。但是实际上,这个Nutch2.x的意思是Nutch2.3之前、Nutch2.2.1之后的一个版本,这个版本在官方的SVN中不断更新。而且非常不稳定(一直在修改)。
所以,如果你不是要做搜索引擎,尽量不要选择Nutch作为爬虫。有些团队就喜欢跟风,非要选择Nutch来开发精抽取的爬虫,其实是冲着Nutch的名气,当然最后的结果往往是项目延期完成。
如果你是要做搜索引擎,Nutch1.x是一个非常好的选择。Nutch1.x和solr或者es配合,就可以构成一套非常强大的搜索引擎了。如果非要用Nutch2的话,建议等到Nutch2.3发布再看。目前的Nutch2是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2JAVA爬虫
这里把JAVA爬虫单独分为一类,是因为JAVA在网络爬虫这块的生态圈是非常完善的。相关的资料也是最全的。这里可能有争议,我只是随便谈谈。
其实开源网络爬虫(框架)的开发非常简单,难问题和复杂的问题都被以前的人解决了(比如DOM树解析和定位、字符集检测、海量URL去重),可以说是毫无技术含量。包括Nutch,其实Nutch的技术难点是开发hadoop,本身代码非常简单。网络爬虫从某种意义来说,类似遍历本机的文件,查找文件中的信息。没有任何难度可言。之所以选择开源爬虫框架,就是为了省事。比如爬虫的URL管理、线程池之类的模块,谁都能做,但是要做稳定也是需要一段时间的调试和修改的。
对于爬虫的功能来说。用户比较关心的问题往往是:
1)爬虫支持多线程么、爬虫能用代理么、爬虫会爬取重复数据么、爬虫能爬取JS生成的信息么?
不支持多线程、不支持代理、不能过滤重复URL的,那都不叫开源爬虫,那叫循环执行http请求。
能不能爬js生成的信息和爬虫本身没有太大关系。爬虫主要是负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往需要通过模拟浏览器(htmlunit,selenium)来完成。这些模拟浏览器,往往需要耗费很多的时间来处理一个页面。所以一种策略就是,使用这些爬虫来遍历网站,遇到需要解析的页面,就将网页的相关信息提交给模拟浏览器,来完成JS生成信息的抽取。
2)爬虫可以爬取ajax信息么?
网页上有一些异步加载的数据,爬取这些数据有两种方法:使用模拟浏览器(问题1中描述过了),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果是自己生成ajax请求,使用开源爬虫的意义在哪里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我所需要的ajax请求(列表),如何用这些爬虫来对这些请求进行爬取?
爬虫往往都是设计成广度遍历或者深度遍历的模式,去遍历静态或者动态页面。爬取ajax信息属于deepweb(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方法来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的第一轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax请求作为种子,放入爬虫。用爬虫对这些种子,进行深度为1的广度遍历(默认就是广度遍历)。
3)爬虫怎么爬取要登陆的网站?
这些开源爬虫都支持在爬取时指定cookies,模拟登陆主要是靠cookies。至于cookies怎么获取,不是爬虫管的事情。你可以手动获取、用http请求模拟登陆或者用模拟浏览器自动登陆获取cookie。
4)爬虫怎么抽取网页的信息?
开源爬虫一般都会集成网页抽取工具。主要支持两种规范:CSSSELECTOR和XPATH。至于哪个好,这里不评价。
5)爬虫怎么保存网页的信息?
有一些爬虫,自带一个模块负责持久化。比如webmagic,有一个模块叫pipeline。通过简单地配置,可以将爬虫抽取到的信息,持久化到文件、数据库等。还有一些爬虫,并没有直接给用户提供数据持久化的模块。比如crawler4j和webcollector。让用户自己在网页处理模块中添加提交数据库的操作。至于使用pipeline这种模块好不好,就和操作数据库使用ORM好不好这个问题类似,取决于你的业务。
6)爬虫被网站封了怎么办?
爬虫被网站封了,一般用多代理(随机代理)就可以解决。但是这些开源爬虫一般没有直接支持随机代理的切换。所以用户往往都需要自己将获取的代理,放到一个全局数组中,自己写一个代理随机获取(从数组中)的代码。
7)网页可以调用爬虫么?
爬虫的调用是在Web的服务端调用的,平时怎么用就怎么用,这些爬虫都可以使用。
8)爬虫速度怎么样?
单机开源爬虫的速度,基本都可以讲本机的网速用到极限。爬虫的速度慢,往往是因为用户把线程数开少了、网速慢,或者在数据持久化时,和数据库的交互速度慢。而这些东西,往往都是用户的机器和二次开发的代码决定的。这些开源爬虫的速度,都很可以。
9)明明代码写对了,爬不到数据,是不是爬虫有问题,换个爬虫能解决么?
如果代码写对了,又爬不到数据,换其他爬虫也是一样爬不到。遇到这种情况,要么是网站把你封了,要么是你爬的数据是javascript生成的。爬不到数据通过换爬虫是不能解决的。
10)哪个爬虫可以判断网站是否爬完、那个爬虫可以根据主题进行爬取?
爬虫无法判断网站是否爬完,只能尽可能覆盖。
至于根据主题爬取,爬虫之后把内容爬下来才知道是什么主题。所以一般都是整个爬下来,然后再去筛选内容。如果嫌爬的太泛,可以通过限制URL正则等方式,来缩小一下范围。
11)哪个爬虫的设计模式和构架比较好?
设计模式纯属扯淡。说软件设计模式好的,都是软件开发完,然后总结出几个设计模式。设计模式对软件开发没有指导性作用。用设计模式来设计爬虫,只会使得爬虫的设计更加臃肿。
至于构架,开源爬虫目前主要是细节的数据结构的设计,比如爬取线程池、任务队列,这些大家都能控制好。爬虫的业务太简单,谈不上什么构架。
所以对于JAVA开源爬虫,我觉得,随便找一个用的顺手的就可以。如果业务复杂,拿哪个爬虫来,都是要经过复杂的二次开发,才可以满足需求。
3.3非JAVA爬虫
在非JAVA语言编写的爬虫中,有很多优秀的爬虫。这里单独提取出来作为一类,并不是针对爬虫本身的质量进行讨论,而是针对larbin、scrapy这类爬虫,对开发成本的影响。
先说python爬虫,python可以用30行代码,完成JAVA50行代码干的任务。python写代码的确快,但是在调试代码的阶段,python代码的调试往往会耗费远远多于编码阶段省下的时间。使用python开发,要保证程序的正确性和稳定性,就需要写更多的测试模块。当然如果爬取规模不大、爬取业务不复杂,使用scrapy这种爬虫也是蛮不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图,绿线是数据流向,首先从初始URL开始,Scheduler会将其交给Downloader进行下载,下载之后会交给Spider进行分析,需要保存的数据则会被送到ItemPipeline,那是对数据进行后期处理。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。因此在开发爬虫的时候,最好也先规划好各种模块。我的做法是单独规划下载模块,爬行模块,调度模块,数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本,如果软件需要团队开发或者交接,那就是很多人的学习成本了。软件的调试也不是那么容易。
还有一些ruby、php的爬虫,这里不多评价。的确有一些非常小型的数据采集任务,用ruby或者php很方便。但是选择这些语言的开源爬虫,一方面要调研一下相关的生态圈,还有就是,这些开源爬虫可能会出一些你搜不到的BUG(用的人少、资料也少)
4、反爬虫技术
因为搜索引擎的流行,网络爬虫已经成了很普及网络技术,除了专门做搜索的Google,Yahoo,微软,百度以外,几乎每个大型门户网站都有自己的搜索引擎,大大小小叫得出来名字得就几十种,还有各种不知名的几千几万种,对于一个内容型驱动的网站来说,受到网络爬虫的光顾是不可避免的。
一些智能的搜索引擎爬虫的爬取频率比较合理,对网站资源消耗比较少,但是很多糟糕的网络爬虫,对网页爬取能力很差,经常并发几十上百个请求循环重复抓取,这种爬虫对中小型网站往往是毁灭性打击,特别是一些缺乏爬虫编写经验的程序员写出来的爬虫破坏力极强,造成的网站访问压力会非常大,会导致网站访问速度缓慢,甚至无法访问。
一般网站从三个方面反爬虫:用户请求的Headers,用户行为,网站目录和数据加载方式。前两种比较容易遇到,大多数网站都从这些角度来反爬虫。第三种一些应用ajax的网站会采用,这样增大了爬取的难度。
4.1通过Headers反爬虫
从用户请求的Headers反爬虫是最常见的反爬虫策略。很多网站都会对Headers的User-Agent进行检测,还有一部分网站会对Referer进行检测(一些资源网站的防盗链就是检测Referer)。如果遇到了这类反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值修改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或者添加Headers就能很好的绕过。
[评论:往往容易被忽略,通过对请求的抓包分析,确定referer,在程序中模拟访问请求头中添加]
4.2基于用户行为反爬虫
还有一部分网站是通过检测用户行为,例如同一IP短时间内多次访问同一页面,或者同一账户短时间内多次进行相同操作。
网络爬虫技术总结
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-05-06 00:10
对于大数据行业,数据的价值不言而喻,在这个信息爆炸的年代,互联网上有太多的信息数据,对于中小微公司,合理利用爬虫爬取有价值的数据,是弥补自身先天数据短板的不二选择,本文主要从爬虫原理、架构、分类以及反爬虫技术来对爬虫技术进行了总结。
1、爬虫技术概述
网络爬虫(Webcrawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题:
(1)对抓取目标的描述或定义;
(2)对网页或数据的分析与过滤;
(3)对URL的搜索策略。
2、爬虫原理
2.1网络爬虫原理
Web网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据来源。很多大型的网络搜索引擎系统都被称为基于Web数据采集的搜索引擎系统,比如Google、Baidu。由此可见Web网络爬虫系统在搜索引擎中的重要性。网页中除了包含供用户阅读的文字信息外,还包含一些超链接信息。Web网络爬虫系统正是通过网页中的超连接信息不断获得网络上的其它网页。正是因为这种采集过程像一个爬虫或者蜘蛛在网络上漫游,所以它才被称为网络爬虫系统或者网络蜘蛛系统,在英文中称为Spider或者Crawler。
2.2网络爬虫系统的工作原理
在网络爬虫的系统框架中,主过程由控制器,解析器,资源库三部分组成。控制器的主要工作是负责给多线程中的各个爬虫线程分配工作任务。解析器的主要工作是下载网页,进行页面的处理,主要是将一些JS脚本标签、CSS代码内容、空格字符、HTML标签等内容处理掉,爬虫的基本工作是由解析器完成。资源库是用来存放下载到的网页资源,一般都采用大型的数据库存储,如Oracle数据库,并对其建立索引。
控制器
控制器是网络爬虫的中央控制器,它主要是负责根据系统传过来的URL链接,分配一线程,然后启动线程调用爬虫爬取网页的过程。
解析器
解析器是负责网络爬虫的主要部分,其负责的工作主要有:下载网页的功能,对网页的文本进行处理,如过滤功能,抽取特殊HTML标签的功能,分析数据功能。
资源库
主要是用来存储网页中下载下来的数据记录的容器,并提供生成索引的目标源。中大型的数据库产品有:Oracle、SqlServer等。
Web网络爬虫系统一般会选择一些比较重要的、出度(网页中链出超链接数)较大的网站的URL作为种子URL集合。网络爬虫系统以这些种子集合作为初始URL,开始数据的抓取。因为网页中含有链接信息,通过已有网页的URL会得到一些新的URL,可以把网页之间的指向结构视为一个森林,每个种子URL对应的网页是森林中的一棵树的根节点。
这样,Web网络爬虫系统就可以根据广度优先算法或者深度优先算法遍历所有的网页。由于深度优先搜索算法可能会使爬虫系统陷入一个网站内部,不利于搜索比较靠近网站首页的网页信息,因此一般采用广度优先搜索算法采集网页。Web网络爬虫系统首先将种子URL放入下载队列,然后简单地从队首取出一个URL下载其对应的网页。得到网页的内容将其存储后,再经过解析网页中的链接信息可以得到一些新的URL,将这些URL加入下载队列。然后再取出一个URL,对其对应的网页进行下载,然后再解析,如此反复进行,直到遍历了整个网络或者满足某种条件后才会停止下来。
网络爬虫的基本工作流程如下:
1.首先选取一部分精心挑选的种子URL;
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列;
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
2.3抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面重点介绍几种常见的抓取策略:
2.3.1深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。我们以下面的图为例:
遍历的路径:A-F-GE-H-IBCD
2.3.2宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以上面的图为例:
遍历路径:A-B-C-D-E-FGHI
2.3.3反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数量。反向链接数表示的是一个网页的内容受到其他人的推荐的程度。因此,很多时候搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后顺序。
在真实的网络环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那个也的重要程度。因此,搜索引擎往往考虑一些可靠的反向链接数。
2.3.4PartialPageRank策略
PartialPageRank算法借鉴了PageRank算法的思想:对于已经下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每个页面的PageRank值,计算完之后,将待抓取URL队列中的URL按照PageRank值的大小排列,并按照该顺序抓取页面。
如果每次抓取一个页面,就重新计算PageRank值,一种折中方案是:每抓取K个页面后,重新计算一次PageRank值。但是这种情况还会有一个问题:对于已经下载下来的页面中分析出的链接,也就是我们之前提到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总,这样就形成了该未知页面的PageRank值,从而参与排序。
2.3.5OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P之后,将P的现金分摊给所有从P中分析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面按照现金数进行排序。
2.3.6大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因此叫做大站优先策略。
3、爬虫分类
开发网络爬虫应该选择Nutch、Crawler4j、WebMagic、scrapy、WebCollector还是其他的?上面说的爬虫,基本可以分3类:
(1)分布式爬虫:Nutch
(2)JAVA爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1分布式爬虫
爬虫使用分布式,主要是解决两个问题:
1)海量URL管理
2)网速
现在比较流行的分布式爬虫,是Apache的Nutch。但是对于大多数用户来说,Nutch是这几类爬虫里,最不好的选择,理由如下:
1)Nutch是为搜索引擎设计的爬虫,大多数用户是需要一个做精准数据爬取(精抽取)的爬虫。Nutch运行的一套流程里,有三分之二是为了搜索引擎而设计的。对精抽取没有太大的意义。也就是说,用Nutch做数据抽取,会浪费很多的时间在不必要的计算上。而且如果你试图通过对Nutch进行二次开发,来使得它适用于精抽取的业务,基本上就要破坏Nutch的框架,把Nutch改的面目全非,有修改Nutch的能力,真的不如自己重新写一个分布式爬虫框架了。
2)Nutch依赖hadoop运行,hadoop本身会消耗很多的时间。如果集群机器数量较少,爬取速度反而不如单机爬虫快。
3)Nutch虽然有一套插件机制,而且作为亮点宣传。可以看到一些开源的Nutch插件,提供精抽取的功能。但是开发过Nutch插件的人都知道,Nutch的插件系统有多蹩脚。利用反射的机制来加载和调用插件,使得程序的编写和调试都变得异常困难,更别说在上面开发一套复杂的精抽取系统了。而且Nutch并没有为精抽取提供相应的插件挂载点。Nutch的插件有只有五六个挂载点,而这五六个挂载点都是为了搜索引擎服务的,并没有为精抽取提供挂载点。大多数Nutch的精抽取插件,都是挂载在“页面解析”(parser)这个挂载点的,这个挂载点其实是为了解析链接(为后续爬取提供URL),以及为搜索引擎提供一些易抽取的网页信息(网页的meta信息、text文本)。
4)用Nutch进行爬虫的二次开发,爬虫的编写和调试所需的时间,往往是单机爬虫所需的十倍时间不止。了解Nutch源码的学习成本很高,何况是要让一个团队的人都读懂Nutch源码。调试过程中会出现除程序本身之外的各种问题(hadoop的问题、hbase的问题)。
5)很多人说Nutch2有gora,可以持久化数据到avro文件、hbase、mysql等。很多人其实理解错了,这里说的持久化数据,是指将URL信息(URL管理所需要的数据)存放到avro、hbase、mysql。并不是你要抽取的结构化数据。其实对大多数人来说,URL信息存在哪里无所谓。
6)Nutch2的版本目前并不适合开发。官方现在稳定的Nutch版本是nutch2.2.1,但是这个版本绑定了gora-0.3。如果想用hbase配合nutch(大多数人用nutch2就是为了用hbase),只能使用0.90版本左右的hbase,相应的就要将hadoop版本降到hadoop0.2左右。而且nutch2的官方教程比较有误导作用,Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x,这个Nutch2.x官网上写的是可以支持到hbase0.94。但是实际上,这个Nutch2.x的意思是Nutch2.3之前、Nutch2.2.1之后的一个版本,这个版本在官方的SVN中不断更新。而且非常不稳定(一直在修改)。
所以,如果你不是要做搜索引擎,尽量不要选择Nutch作为爬虫。有些团队就喜欢跟风,非要选择Nutch来开发精抽取的爬虫,其实是冲着Nutch的名气,当然最后的结果往往是项目延期完成。
如果你是要做搜索引擎,Nutch1.x是一个非常好的选择。Nutch1.x和solr或者es配合,就可以构成一套非常强大的搜索引擎了。如果非要用Nutch2的话,建议等到Nutch2.3发布再看。目前的Nutch2是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2JAVA爬虫
这里把JAVA爬虫单独分为一类,是因为JAVA在网络爬虫这块的生态圈是非常完善的。相关的资料也是最全的。这里可能有争议,我只是随便谈谈。
其实开源网络爬虫(框架)的开发非常简单,难问题和复杂的问题都被以前的人解决了(比如DOM树解析和定位、字符集检测、海量URL去重),可以说是毫无技术含量。包括Nutch,其实Nutch的技术难点是开发hadoop,本身代码非常简单。网络爬虫从某种意义来说,类似遍历本机的文件,查找文件中的信息。没有任何难度可言。之所以选择开源爬虫框架,就是为了省事。比如爬虫的URL管理、线程池之类的模块,谁都能做,但是要做稳定也是需要一段时间的调试和修改的。
对于爬虫的功能来说。用户比较关心的问题往往是:
1)爬虫支持多线程么、爬虫能用代理么、爬虫会爬取重复数据么、爬虫能爬取JS生成的信息么?
不支持多线程、不支持代理、不能过滤重复URL的,那都不叫开源爬虫,那叫循环执行http请求。
能不能爬js生成的信息和爬虫本身没有太大关系。爬虫主要是负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往需要通过模拟浏览器(htmlunit,selenium)来完成。这些模拟浏览器,往往需要耗费很多的时间来处理一个页面。所以一种策略就是,使用这些爬虫来遍历网站,遇到需要解析的页面,就将网页的相关信息提交给模拟浏览器,来完成JS生成信息的抽取。
2)爬虫可以爬取ajax信息么?
网页上有一些异步加载的数据,爬取这些数据有两种方法:使用模拟浏览器(问题1中描述过了),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果是自己生成ajax请求,使用开源爬虫的意义在哪里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我所需要的ajax请求(列表),如何用这些爬虫来对这些请求进行爬取?
爬虫往往都是设计成广度遍历或者深度遍历的模式,去遍历静态或者动态页面。爬取ajax信息属于deepweb(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方法来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的第一轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax请求作为种子,放入爬虫。用爬虫对这些种子,进行深度为1的广度遍历(默认就是广度遍历)。
3)爬虫怎么爬取要登陆的网站?
这些开源爬虫都支持在爬取时指定cookies,模拟登陆主要是靠cookies。至于cookies怎么获取,不是爬虫管的事情。你可以手动获取、用http请求模拟登陆或者用模拟浏览器自动登陆获取cookie。
4)爬虫怎么抽取网页的信息?
开源爬虫一般都会集成网页抽取工具。主要支持两种规范:CSSSELECTOR和XPATH。至于哪个好,这里不评价。
5)爬虫怎么保存网页的信息?
有一些爬虫,自带一个模块负责持久化。比如webmagic,有一个模块叫pipeline。通过简单地配置,可以将爬虫抽取到的信息,持久化到文件、数据库等。还有一些爬虫,并没有直接给用户提供数据持久化的模块。比如crawler4j和webcollector。让用户自己在网页处理模块中添加提交数据库的操作。至于使用pipeline这种模块好不好,就和操作数据库使用ORM好不好这个问题类似,取决于你的业务。
6)爬虫被网站封了怎么办?
爬虫被网站封了,一般用多代理(随机代理)就可以解决。但是这些开源爬虫一般没有直接支持随机代理的切换。所以用户往往都需要自己将获取的代理,放到一个全局数组中,自己写一个代理随机获取(从数组中)的代码。
7)网页可以调用爬虫么?
爬虫的调用是在Web的服务端调用的,平时怎么用就怎么用,这些爬虫都可以使用。
8)爬虫速度怎么样?
单机开源爬虫的速度,基本都可以讲本机的网速用到极限。爬虫的速度慢,往往是因为用户把线程数开少了、网速慢,或者在数据持久化时,和数据库的交互速度慢。而这些东西,往往都是用户的机器和二次开发的代码决定的。这些开源爬虫的速度,都很可以。
9)明明代码写对了,爬不到数据,是不是爬虫有问题,换个爬虫能解决么?
如果代码写对了,又爬不到数据,换其他爬虫也是一样爬不到。遇到这种情况,要么是网站把你封了,要么是你爬的数据是javascript生成的。爬不到数据通过换爬虫是不能解决的。
10)哪个爬虫可以判断网站是否爬完、那个爬虫可以根据主题进行爬取?
爬虫无法判断网站是否爬完,只能尽可能覆盖。
至于根据主题爬取,爬虫之后把内容爬下来才知道是什么主题。所以一般都是整个爬下来,然后再去筛选内容。如果嫌爬的太泛,可以通过限制URL正则等方式,来缩小一下范围。
11)哪个爬虫的设计模式和构架比较好?
设计模式纯属扯淡。说软件设计模式好的,都是软件开发完,然后总结出几个设计模式。设计模式对软件开发没有指导性作用。用设计模式来设计爬虫,只会使得爬虫的设计更加臃肿。
至于构架,开源爬虫目前主要是细节的数据结构的设计,比如爬取线程池、任务队列,这些大家都能控制好。爬虫的业务太简单,谈不上什么构架。
所以对于JAVA开源爬虫,我觉得,随便找一个用的顺手的就可以。如果业务复杂,拿哪个爬虫来,都是要经过复杂的二次开发,才可以满足需求。
3.3非JAVA爬虫
在非JAVA语言编写的爬虫中,有很多优秀的爬虫。这里单独提取出来作为一类,并不是针对爬虫本身的质量进行讨论,而是针对larbin、scrapy这类爬虫,对开发成本的影响。
先说python爬虫,python可以用30行代码,完成JAVA50行代码干的任务。python写代码的确快,但是在调试代码的阶段,python代码的调试往往会耗费远远多于编码阶段省下的时间。使用python开发,要保证程序的正确性和稳定性,就需要写更多的测试模块。当然如果爬取规模不大、爬取业务不复杂,使用scrapy这种爬虫也是蛮不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图,绿线是数据流向,首先从初始URL开始,Scheduler会将其交给Downloader进行下载,下载之后会交给Spider进行分析,需要保存的数据则会被送到ItemPipeline,那是对数据进行后期处理。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。因此在开发爬虫的时候,最好也先规划好各种模块。我的做法是单独规划下载模块,爬行模块,调度模块,数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本,如果软件需要团队开发或者交接,那就是很多人的学习成本了。软件的调试也不是那么容易。
还有一些ruby、php的爬虫,这里不多评价。的确有一些非常小型的数据采集任务,用ruby或者php很方便。但是选择这些语言的开源爬虫,一方面要调研一下相关的生态圈,还有就是,这些开源爬虫可能会出一些你搜不到的BUG(用的人少、资料也少)
4、反爬虫技术
因为搜索引擎的流行,网络爬虫已经成了很普及网络技术,除了专门做搜索的Google,Yahoo,微软,百度以外,几乎每个大型门户网站都有自己的搜索引擎,大大小小叫得出来名字得就几十种,还有各种不知名的几千几万种,对于一个内容型驱动的网站来说,受到网络爬虫的光顾是不可避免的。
一些智能的搜索引擎爬虫的爬取频率比较合理,对网站资源消耗比较少,但是很多糟糕的网络爬虫,对网页爬取能力很差,经常并发几十上百个请求循环重复抓取,这种爬虫对中小型网站往往是毁灭性打击,特别是一些缺乏爬虫编写经验的程序员写出来的爬虫破坏力极强,造成的网站访问压力会非常大,会导致网站访问速度缓慢,甚至无法访问。
一般网站从三个方面反爬虫:用户请求的Headers,用户行为,网站目录和数据加载方式。前两种比较容易遇到,大多数网站都从这些角度来反爬虫。第三种一些应用ajax的网站会采用,这样增大了爬取的难度。
4.1通过Headers反爬虫
从用户请求的Headers反爬虫是最常见的反爬虫策略。很多网站都会对Headers的User-Agent进行检测,还有一部分网站会对Referer进行检测(一些资源网站的防盗链就是检测Referer)。如果遇到了这类反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值修改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或者添加Headers就能很好的绕过。
[评论:往往容易被忽略,通过对请求的抓包分析,确定referer,在程序中模拟访问请求头中添加]
4.2基于用户行为反爬虫
还有一部分网站是通过检测用户行为,例如同一IP短时间内多次访问同一页面,或者同一账户短时间内多次进行相同操作。 查看全部
网络爬虫技术总结
对于大数据行业,数据的价值不言而喻,在这个信息爆炸的年代,互联网上有太多的信息数据,对于中小微公司,合理利用爬虫爬取有价值的数据,是弥补自身先天数据短板的不二选择,本文主要从爬虫原理、架构、分类以及反爬虫技术来对爬虫技术进行了总结。
1、爬虫技术概述
网络爬虫(Webcrawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题:
(1)对抓取目标的描述或定义;
(2)对网页或数据的分析与过滤;
(3)对URL的搜索策略。
2、爬虫原理
2.1网络爬虫原理
Web网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据来源。很多大型的网络搜索引擎系统都被称为基于Web数据采集的搜索引擎系统,比如Google、Baidu。由此可见Web网络爬虫系统在搜索引擎中的重要性。网页中除了包含供用户阅读的文字信息外,还包含一些超链接信息。Web网络爬虫系统正是通过网页中的超连接信息不断获得网络上的其它网页。正是因为这种采集过程像一个爬虫或者蜘蛛在网络上漫游,所以它才被称为网络爬虫系统或者网络蜘蛛系统,在英文中称为Spider或者Crawler。
2.2网络爬虫系统的工作原理
在网络爬虫的系统框架中,主过程由控制器,解析器,资源库三部分组成。控制器的主要工作是负责给多线程中的各个爬虫线程分配工作任务。解析器的主要工作是下载网页,进行页面的处理,主要是将一些JS脚本标签、CSS代码内容、空格字符、HTML标签等内容处理掉,爬虫的基本工作是由解析器完成。资源库是用来存放下载到的网页资源,一般都采用大型的数据库存储,如Oracle数据库,并对其建立索引。
控制器
控制器是网络爬虫的中央控制器,它主要是负责根据系统传过来的URL链接,分配一线程,然后启动线程调用爬虫爬取网页的过程。
解析器
解析器是负责网络爬虫的主要部分,其负责的工作主要有:下载网页的功能,对网页的文本进行处理,如过滤功能,抽取特殊HTML标签的功能,分析数据功能。
资源库
主要是用来存储网页中下载下来的数据记录的容器,并提供生成索引的目标源。中大型的数据库产品有:Oracle、SqlServer等。
Web网络爬虫系统一般会选择一些比较重要的、出度(网页中链出超链接数)较大的网站的URL作为种子URL集合。网络爬虫系统以这些种子集合作为初始URL,开始数据的抓取。因为网页中含有链接信息,通过已有网页的URL会得到一些新的URL,可以把网页之间的指向结构视为一个森林,每个种子URL对应的网页是森林中的一棵树的根节点。
这样,Web网络爬虫系统就可以根据广度优先算法或者深度优先算法遍历所有的网页。由于深度优先搜索算法可能会使爬虫系统陷入一个网站内部,不利于搜索比较靠近网站首页的网页信息,因此一般采用广度优先搜索算法采集网页。Web网络爬虫系统首先将种子URL放入下载队列,然后简单地从队首取出一个URL下载其对应的网页。得到网页的内容将其存储后,再经过解析网页中的链接信息可以得到一些新的URL,将这些URL加入下载队列。然后再取出一个URL,对其对应的网页进行下载,然后再解析,如此反复进行,直到遍历了整个网络或者满足某种条件后才会停止下来。
网络爬虫的基本工作流程如下:
1.首先选取一部分精心挑选的种子URL;
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列;
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
2.3抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面重点介绍几种常见的抓取策略:
2.3.1深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。我们以下面的图为例:
遍历的路径:A-F-GE-H-IBCD
2.3.2宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以上面的图为例:
遍历路径:A-B-C-D-E-FGHI
2.3.3反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数量。反向链接数表示的是一个网页的内容受到其他人的推荐的程度。因此,很多时候搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后顺序。
在真实的网络环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那个也的重要程度。因此,搜索引擎往往考虑一些可靠的反向链接数。
2.3.4PartialPageRank策略
PartialPageRank算法借鉴了PageRank算法的思想:对于已经下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每个页面的PageRank值,计算完之后,将待抓取URL队列中的URL按照PageRank值的大小排列,并按照该顺序抓取页面。
如果每次抓取一个页面,就重新计算PageRank值,一种折中方案是:每抓取K个页面后,重新计算一次PageRank值。但是这种情况还会有一个问题:对于已经下载下来的页面中分析出的链接,也就是我们之前提到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总,这样就形成了该未知页面的PageRank值,从而参与排序。
2.3.5OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P之后,将P的现金分摊给所有从P中分析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面按照现金数进行排序。
2.3.6大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因此叫做大站优先策略。
3、爬虫分类
开发网络爬虫应该选择Nutch、Crawler4j、WebMagic、scrapy、WebCollector还是其他的?上面说的爬虫,基本可以分3类:
(1)分布式爬虫:Nutch
(2)JAVA爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1分布式爬虫
爬虫使用分布式,主要是解决两个问题:
1)海量URL管理
2)网速
现在比较流行的分布式爬虫,是Apache的Nutch。但是对于大多数用户来说,Nutch是这几类爬虫里,最不好的选择,理由如下:
1)Nutch是为搜索引擎设计的爬虫,大多数用户是需要一个做精准数据爬取(精抽取)的爬虫。Nutch运行的一套流程里,有三分之二是为了搜索引擎而设计的。对精抽取没有太大的意义。也就是说,用Nutch做数据抽取,会浪费很多的时间在不必要的计算上。而且如果你试图通过对Nutch进行二次开发,来使得它适用于精抽取的业务,基本上就要破坏Nutch的框架,把Nutch改的面目全非,有修改Nutch的能力,真的不如自己重新写一个分布式爬虫框架了。
2)Nutch依赖hadoop运行,hadoop本身会消耗很多的时间。如果集群机器数量较少,爬取速度反而不如单机爬虫快。
3)Nutch虽然有一套插件机制,而且作为亮点宣传。可以看到一些开源的Nutch插件,提供精抽取的功能。但是开发过Nutch插件的人都知道,Nutch的插件系统有多蹩脚。利用反射的机制来加载和调用插件,使得程序的编写和调试都变得异常困难,更别说在上面开发一套复杂的精抽取系统了。而且Nutch并没有为精抽取提供相应的插件挂载点。Nutch的插件有只有五六个挂载点,而这五六个挂载点都是为了搜索引擎服务的,并没有为精抽取提供挂载点。大多数Nutch的精抽取插件,都是挂载在“页面解析”(parser)这个挂载点的,这个挂载点其实是为了解析链接(为后续爬取提供URL),以及为搜索引擎提供一些易抽取的网页信息(网页的meta信息、text文本)。
4)用Nutch进行爬虫的二次开发,爬虫的编写和调试所需的时间,往往是单机爬虫所需的十倍时间不止。了解Nutch源码的学习成本很高,何况是要让一个团队的人都读懂Nutch源码。调试过程中会出现除程序本身之外的各种问题(hadoop的问题、hbase的问题)。
5)很多人说Nutch2有gora,可以持久化数据到avro文件、hbase、mysql等。很多人其实理解错了,这里说的持久化数据,是指将URL信息(URL管理所需要的数据)存放到avro、hbase、mysql。并不是你要抽取的结构化数据。其实对大多数人来说,URL信息存在哪里无所谓。
6)Nutch2的版本目前并不适合开发。官方现在稳定的Nutch版本是nutch2.2.1,但是这个版本绑定了gora-0.3。如果想用hbase配合nutch(大多数人用nutch2就是为了用hbase),只能使用0.90版本左右的hbase,相应的就要将hadoop版本降到hadoop0.2左右。而且nutch2的官方教程比较有误导作用,Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x,这个Nutch2.x官网上写的是可以支持到hbase0.94。但是实际上,这个Nutch2.x的意思是Nutch2.3之前、Nutch2.2.1之后的一个版本,这个版本在官方的SVN中不断更新。而且非常不稳定(一直在修改)。
所以,如果你不是要做搜索引擎,尽量不要选择Nutch作为爬虫。有些团队就喜欢跟风,非要选择Nutch来开发精抽取的爬虫,其实是冲着Nutch的名气,当然最后的结果往往是项目延期完成。
如果你是要做搜索引擎,Nutch1.x是一个非常好的选择。Nutch1.x和solr或者es配合,就可以构成一套非常强大的搜索引擎了。如果非要用Nutch2的话,建议等到Nutch2.3发布再看。目前的Nutch2是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2JAVA爬虫
这里把JAVA爬虫单独分为一类,是因为JAVA在网络爬虫这块的生态圈是非常完善的。相关的资料也是最全的。这里可能有争议,我只是随便谈谈。
其实开源网络爬虫(框架)的开发非常简单,难问题和复杂的问题都被以前的人解决了(比如DOM树解析和定位、字符集检测、海量URL去重),可以说是毫无技术含量。包括Nutch,其实Nutch的技术难点是开发hadoop,本身代码非常简单。网络爬虫从某种意义来说,类似遍历本机的文件,查找文件中的信息。没有任何难度可言。之所以选择开源爬虫框架,就是为了省事。比如爬虫的URL管理、线程池之类的模块,谁都能做,但是要做稳定也是需要一段时间的调试和修改的。
对于爬虫的功能来说。用户比较关心的问题往往是:
1)爬虫支持多线程么、爬虫能用代理么、爬虫会爬取重复数据么、爬虫能爬取JS生成的信息么?
不支持多线程、不支持代理、不能过滤重复URL的,那都不叫开源爬虫,那叫循环执行http请求。
能不能爬js生成的信息和爬虫本身没有太大关系。爬虫主要是负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往需要通过模拟浏览器(htmlunit,selenium)来完成。这些模拟浏览器,往往需要耗费很多的时间来处理一个页面。所以一种策略就是,使用这些爬虫来遍历网站,遇到需要解析的页面,就将网页的相关信息提交给模拟浏览器,来完成JS生成信息的抽取。
2)爬虫可以爬取ajax信息么?
网页上有一些异步加载的数据,爬取这些数据有两种方法:使用模拟浏览器(问题1中描述过了),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果是自己生成ajax请求,使用开源爬虫的意义在哪里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我所需要的ajax请求(列表),如何用这些爬虫来对这些请求进行爬取?
爬虫往往都是设计成广度遍历或者深度遍历的模式,去遍历静态或者动态页面。爬取ajax信息属于deepweb(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方法来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的第一轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax请求作为种子,放入爬虫。用爬虫对这些种子,进行深度为1的广度遍历(默认就是广度遍历)。
3)爬虫怎么爬取要登陆的网站?
这些开源爬虫都支持在爬取时指定cookies,模拟登陆主要是靠cookies。至于cookies怎么获取,不是爬虫管的事情。你可以手动获取、用http请求模拟登陆或者用模拟浏览器自动登陆获取cookie。
4)爬虫怎么抽取网页的信息?
开源爬虫一般都会集成网页抽取工具。主要支持两种规范:CSSSELECTOR和XPATH。至于哪个好,这里不评价。
5)爬虫怎么保存网页的信息?
有一些爬虫,自带一个模块负责持久化。比如webmagic,有一个模块叫pipeline。通过简单地配置,可以将爬虫抽取到的信息,持久化到文件、数据库等。还有一些爬虫,并没有直接给用户提供数据持久化的模块。比如crawler4j和webcollector。让用户自己在网页处理模块中添加提交数据库的操作。至于使用pipeline这种模块好不好,就和操作数据库使用ORM好不好这个问题类似,取决于你的业务。
6)爬虫被网站封了怎么办?
爬虫被网站封了,一般用多代理(随机代理)就可以解决。但是这些开源爬虫一般没有直接支持随机代理的切换。所以用户往往都需要自己将获取的代理,放到一个全局数组中,自己写一个代理随机获取(从数组中)的代码。
7)网页可以调用爬虫么?
爬虫的调用是在Web的服务端调用的,平时怎么用就怎么用,这些爬虫都可以使用。
8)爬虫速度怎么样?
单机开源爬虫的速度,基本都可以讲本机的网速用到极限。爬虫的速度慢,往往是因为用户把线程数开少了、网速慢,或者在数据持久化时,和数据库的交互速度慢。而这些东西,往往都是用户的机器和二次开发的代码决定的。这些开源爬虫的速度,都很可以。
9)明明代码写对了,爬不到数据,是不是爬虫有问题,换个爬虫能解决么?
如果代码写对了,又爬不到数据,换其他爬虫也是一样爬不到。遇到这种情况,要么是网站把你封了,要么是你爬的数据是javascript生成的。爬不到数据通过换爬虫是不能解决的。
10)哪个爬虫可以判断网站是否爬完、那个爬虫可以根据主题进行爬取?
爬虫无法判断网站是否爬完,只能尽可能覆盖。
至于根据主题爬取,爬虫之后把内容爬下来才知道是什么主题。所以一般都是整个爬下来,然后再去筛选内容。如果嫌爬的太泛,可以通过限制URL正则等方式,来缩小一下范围。
11)哪个爬虫的设计模式和构架比较好?
设计模式纯属扯淡。说软件设计模式好的,都是软件开发完,然后总结出几个设计模式。设计模式对软件开发没有指导性作用。用设计模式来设计爬虫,只会使得爬虫的设计更加臃肿。
至于构架,开源爬虫目前主要是细节的数据结构的设计,比如爬取线程池、任务队列,这些大家都能控制好。爬虫的业务太简单,谈不上什么构架。
所以对于JAVA开源爬虫,我觉得,随便找一个用的顺手的就可以。如果业务复杂,拿哪个爬虫来,都是要经过复杂的二次开发,才可以满足需求。
3.3非JAVA爬虫
在非JAVA语言编写的爬虫中,有很多优秀的爬虫。这里单独提取出来作为一类,并不是针对爬虫本身的质量进行讨论,而是针对larbin、scrapy这类爬虫,对开发成本的影响。
先说python爬虫,python可以用30行代码,完成JAVA50行代码干的任务。python写代码的确快,但是在调试代码的阶段,python代码的调试往往会耗费远远多于编码阶段省下的时间。使用python开发,要保证程序的正确性和稳定性,就需要写更多的测试模块。当然如果爬取规模不大、爬取业务不复杂,使用scrapy这种爬虫也是蛮不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图,绿线是数据流向,首先从初始URL开始,Scheduler会将其交给Downloader进行下载,下载之后会交给Spider进行分析,需要保存的数据则会被送到ItemPipeline,那是对数据进行后期处理。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。因此在开发爬虫的时候,最好也先规划好各种模块。我的做法是单独规划下载模块,爬行模块,调度模块,数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本,如果软件需要团队开发或者交接,那就是很多人的学习成本了。软件的调试也不是那么容易。
还有一些ruby、php的爬虫,这里不多评价。的确有一些非常小型的数据采集任务,用ruby或者php很方便。但是选择这些语言的开源爬虫,一方面要调研一下相关的生态圈,还有就是,这些开源爬虫可能会出一些你搜不到的BUG(用的人少、资料也少)
4、反爬虫技术
因为搜索引擎的流行,网络爬虫已经成了很普及网络技术,除了专门做搜索的Google,Yahoo,微软,百度以外,几乎每个大型门户网站都有自己的搜索引擎,大大小小叫得出来名字得就几十种,还有各种不知名的几千几万种,对于一个内容型驱动的网站来说,受到网络爬虫的光顾是不可避免的。
一些智能的搜索引擎爬虫的爬取频率比较合理,对网站资源消耗比较少,但是很多糟糕的网络爬虫,对网页爬取能力很差,经常并发几十上百个请求循环重复抓取,这种爬虫对中小型网站往往是毁灭性打击,特别是一些缺乏爬虫编写经验的程序员写出来的爬虫破坏力极强,造成的网站访问压力会非常大,会导致网站访问速度缓慢,甚至无法访问。
一般网站从三个方面反爬虫:用户请求的Headers,用户行为,网站目录和数据加载方式。前两种比较容易遇到,大多数网站都从这些角度来反爬虫。第三种一些应用ajax的网站会采用,这样增大了爬取的难度。
4.1通过Headers反爬虫
从用户请求的Headers反爬虫是最常见的反爬虫策略。很多网站都会对Headers的User-Agent进行检测,还有一部分网站会对Referer进行检测(一些资源网站的防盗链就是检测Referer)。如果遇到了这类反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值修改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或者添加Headers就能很好的绕过。
[评论:往往容易被忽略,通过对请求的抓包分析,确定referer,在程序中模拟访问请求头中添加]
4.2基于用户行为反爬虫
还有一部分网站是通过检测用户行为,例如同一IP短时间内多次访问同一页面,或者同一账户短时间内多次进行相同操作。
php 抓取网页ajax数据(这里有新鲜出炉的精品教程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-04-20 18:39
这里有新鲜出炉的精品教程,看看程序狗速!
ThinkPHP开源PHP框架 ThinkPHP是一个开源PHP框架,为简化企业级应用开发和敏捷WEB应用开发而生。ThinkPHP可以支持windows/Unix/Liunx等服务器环境。正式版需要PHP5.0或以上,支持MySql、PgSQL、Sqlite、PDO等多种数据库。
本篇文章主要介绍jquery+thinkphp实现跨域数据抓取的方法,分析thinkPHP结合jQuery的ajax实现跨域数据抓取的相关操作技巧。有需要的朋友可以参考以下
本文示例介绍jquery+thinkphp实现跨域数据抓取的方法。分享给大家参考,详情如下:
今天,我将做一个远程获取数据的功能。请记住,jquery 可以使用 Ajax 获取远程数据,但不能跨域。我在网上找到了很多。但我觉得还是综合,所以我觉得对于一个简单的问题来说有点复杂,但至少现在解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post发送数据到服务器后台,后台的php代码执行远程抓取,存入数据库ajax并返回数据到前台,前台用js接受数据并显示。
//远程抓取获取数据
$("#update_ac").click(function() {
$username = $("#username").text();
$("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){
$(this).html(" ");
});
$.post("update_ac/username/"+$username,{},function($data){
json = eval("(" + $data + ")");
$("#Submit").html(json.data.Submit);
$("#AC").html(json.data.AC);
$("#solved,#solved2,#solved3").html(json.data.solved);
$("#rank").html(json.data.rank);
}
),"json";
});
上面jquery代码在四楼比较清楚,困扰我的是那个json数据的接收
json = eval("(" + $data + ")");
//eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这个还是前台,跨域爬取是用php扩展simple_html_dom做的(如果不确定可以去网上搜索一下,基于PHP5开发的)
将远程页面抓取到本地。
import("@.ORG.simple_html_dom");
//thinkphp内导入扩展,你要把网上下载的代码改名为simple_html_dom.class.php放到APPNAME\Lib\ORG的目录下面
$html = file_get_html('http://openoj.awaysoft.com/JudgeOnline/userinfo.php?user='.$username); //远程抓取了
$ret = $html->find('center',0)->plaintext; //返回数据了。
上面的代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后用正则表达式过滤出需要的数据。以下是效果图
希望这篇文章对大家基于ThinkPHP框架的PHP编程有所帮助。 查看全部
php 抓取网页ajax数据(这里有新鲜出炉的精品教程,程序狗速度看过来!)
这里有新鲜出炉的精品教程,看看程序狗速!
ThinkPHP开源PHP框架 ThinkPHP是一个开源PHP框架,为简化企业级应用开发和敏捷WEB应用开发而生。ThinkPHP可以支持windows/Unix/Liunx等服务器环境。正式版需要PHP5.0或以上,支持MySql、PgSQL、Sqlite、PDO等多种数据库。
本篇文章主要介绍jquery+thinkphp实现跨域数据抓取的方法,分析thinkPHP结合jQuery的ajax实现跨域数据抓取的相关操作技巧。有需要的朋友可以参考以下
本文示例介绍jquery+thinkphp实现跨域数据抓取的方法。分享给大家参考,详情如下:
今天,我将做一个远程获取数据的功能。请记住,jquery 可以使用 Ajax 获取远程数据,但不能跨域。我在网上找到了很多。但我觉得还是综合,所以我觉得对于一个简单的问题来说有点复杂,但至少现在解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post发送数据到服务器后台,后台的php代码执行远程抓取,存入数据库ajax并返回数据到前台,前台用js接受数据并显示。
//远程抓取获取数据
$("#update_ac").click(function() {
$username = $("#username").text();
$("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){
$(this).html(" ");
});
$.post("update_ac/username/"+$username,{},function($data){
json = eval("(" + $data + ")");
$("#Submit").html(json.data.Submit);
$("#AC").html(json.data.AC);
$("#solved,#solved2,#solved3").html(json.data.solved);
$("#rank").html(json.data.rank);
}
),"json";
});
上面jquery代码在四楼比较清楚,困扰我的是那个json数据的接收
json = eval("(" + $data + ")");
//eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这个还是前台,跨域爬取是用php扩展simple_html_dom做的(如果不确定可以去网上搜索一下,基于PHP5开发的)
将远程页面抓取到本地。
import("@.ORG.simple_html_dom");
//thinkphp内导入扩展,你要把网上下载的代码改名为simple_html_dom.class.php放到APPNAME\Lib\ORG的目录下面
$html = file_get_html('http://openoj.awaysoft.com/JudgeOnline/userinfo.php?user='.$username); //远程抓取了
$ret = $html->find('center',0)->plaintext; //返回数据了。
上面的代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后用正则表达式过滤出需要的数据。以下是效果图
希望这篇文章对大家基于ThinkPHP框架的PHP编程有所帮助。
php 抓取网页ajax数据(PHP代码执行远程抓取数据的功能讲述simple_html_dom扩展 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-04-14 12:00
)
本文示例介绍jquery+thinkphp实现跨域数据抓取的方法。分享给大家参考,详情如下:
今天,我将做一个远程获取数据的功能。请记住,jquery 可以使用 Ajax 获取远程数据,但不能跨域。我在网上找到了很多。但我觉得还是综合,所以我觉得对于一个简单的问题来说有点复杂,但至少现在解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post发送数据到服务器后台,后台的php代码执行远程抓取,存入数据库ajax并返回数据到前台,前台用js接受数据并显示。
//远程抓取获取数据
$("#update_ac").click(function() {
$username = $("#username").text();
$("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){
$(this).html(" ");
});
$.post("update_ac/username/"+$username,{},function($data){
json = eval("(" + $data + ")");
$("#Submit").html(json.data.Submit);
$("#AC").html(json.data.AC);
$("#solved,#solved2,#solved3").html(json.data.solved);
$("#rank").html(json.data.rank);
}
),"json";
});
上面jquery代码在四楼比较清楚,困扰我的是那个json数据的接收
json = eval("(" + $data + ")");
//eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这个还是前台,跨域爬取是用php扩展simple_html_dom做的(不确定可以去网上搜索一下,基于PHP5开发的)
将远程页面抓取到本地。
import("@.ORG.simple_html_dom");
//thinkphp内导入扩展,你要把网上下载的代码改名为simple_html_dom.class.php放到APPNAME\Lib\ORG的目录下面
$html = file_get_html('http://openoj.awaysoft.com/JudgeOnline/userinfo.php?user='.$username); //远程抓取了
$ret = $html->find('center',0)->plaintext; //返回数据了。
上面的代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后用正则表达式过滤出需要的数据。以下是效果图
查看全部
php 抓取网页ajax数据(PHP代码执行远程抓取数据的功能讲述simple_html_dom扩展
)
本文示例介绍jquery+thinkphp实现跨域数据抓取的方法。分享给大家参考,详情如下:
今天,我将做一个远程获取数据的功能。请记住,jquery 可以使用 Ajax 获取远程数据,但不能跨域。我在网上找到了很多。但我觉得还是综合,所以我觉得对于一个简单的问题来说有点复杂,但至少现在解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post发送数据到服务器后台,后台的php代码执行远程抓取,存入数据库ajax并返回数据到前台,前台用js接受数据并显示。
//远程抓取获取数据
$("#update_ac").click(function() {
$username = $("#username").text();
$("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){
$(this).html(" ");
});
$.post("update_ac/username/"+$username,{},function($data){
json = eval("(" + $data + ")");
$("#Submit").html(json.data.Submit);
$("#AC").html(json.data.AC);
$("#solved,#solved2,#solved3").html(json.data.solved);
$("#rank").html(json.data.rank);
}
),"json";
});
上面jquery代码在四楼比较清楚,困扰我的是那个json数据的接收
json = eval("(" + $data + ")");
//eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这个还是前台,跨域爬取是用php扩展simple_html_dom做的(不确定可以去网上搜索一下,基于PHP5开发的)
将远程页面抓取到本地。
import("@.ORG.simple_html_dom");
//thinkphp内导入扩展,你要把网上下载的代码改名为simple_html_dom.class.php放到APPNAME\Lib\ORG的目录下面
$html = file_get_html('http://openoj.awaysoft.com/JudgeOnline/userinfo.php?user='.$username); //远程抓取了
$ret = $html->find('center',0)->plaintext; //返回数据了。
上面的代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后用正则表达式过滤出需要的数据。以下是效果图
php 抓取网页ajax数据(Python网络爬虫内容提取器一文项目启动说明(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-04-14 11:42
1、简介
在 Python 网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类 gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分,尝试使用xslt方法提取静态网页内容并一次性转换为xml格式。
2、使用lxml库提取网页内容
lxml是python的一个库,可以快速灵活地处理XML。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现通用的 ElementTree API。
这2天,我在python中测试了通过xslt提取网页内容,记录如下:
2.1、抓住目标
假设要提取jisoke官网老论坛的帖子标题和回复数,如下图,需要提取整个列表并保存为xml格式
2.2、源码1:只抓取当前页面,结果显示在控制台
Python的优势在于它可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用的并不多。xslt 脚本占用了很大的空间。在这段代码中,只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者令人头疼的正则表达式,请参考《Python Instant Web Crawler Project Startup Instructions》,我们希望通过这种架构,程序员的时间节省一半以上。
可以复制并运行以下代码(windows10下测试,python3.2):
from urllib import request from lxml import etree url="http://www.gooseeker.com/cn/forum/7" cOnn= request.urlopen(url) doc = etree.HTML(conn.read()) xslt_root = etree.XML("""\ """) transform = etree.XSLT(xslt_root) result_tree = transform(doc) print(result_tree)
源码可以从文末的 GitHub 源码下载。
2.3、获取结果
得到的爬取结果如下:
2.4、源码2:翻转取,并将结果保存到文件
我们对2.2的代码进行了进一步的修改,增加了翻页功能来获取和保存结果文件。代码如下:
<p> from urllib import request from lxml import etree import time xslt_root = etree.XML("""\ """) baseurl = "http://www.gooseeker.com/cn/forum/7" basefilebegin = "jsk_bbs_" basefileend = ".xml" count = 1 while (count 查看全部
php 抓取网页ajax数据(Python网络爬虫内容提取器一文项目启动说明(一))
1、简介
在 Python 网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类 gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分,尝试使用xslt方法提取静态网页内容并一次性转换为xml格式。
2、使用lxml库提取网页内容
lxml是python的一个库,可以快速灵活地处理XML。它支持 XML 路径语言 (XPath) 和可扩展样式表语言转换 (XSLT),并实现通用的 ElementTree API。
这2天,我在python中测试了通过xslt提取网页内容,记录如下:
2.1、抓住目标
假设要提取jisoke官网老论坛的帖子标题和回复数,如下图,需要提取整个列表并保存为xml格式
2.2、源码1:只抓取当前页面,结果显示在控制台
Python的优势在于它可以用少量的代码解决一个问题。请注意,以下代码看起来很长。其实python函数调用的并不多。xslt 脚本占用了很大的空间。在这段代码中,只是一个长字符串。至于为什么选择 xslt 而不是离散的 xpath 或者令人头疼的正则表达式,请参考《Python Instant Web Crawler Project Startup Instructions》,我们希望通过这种架构,程序员的时间节省一半以上。
可以复制并运行以下代码(windows10下测试,python3.2):
from urllib import request from lxml import etree url="http://www.gooseeker.com/cn/forum/7" cOnn= request.urlopen(url) doc = etree.HTML(conn.read()) xslt_root = etree.XML("""\ """) transform = etree.XSLT(xslt_root) result_tree = transform(doc) print(result_tree)
源码可以从文末的 GitHub 源码下载。
2.3、获取结果
得到的爬取结果如下:
2.4、源码2:翻转取,并将结果保存到文件
我们对2.2的代码进行了进一步的修改,增加了翻页功能来获取和保存结果文件。代码如下:
<p> from urllib import request from lxml import etree import time xslt_root = etree.XML("""\ """) baseurl = "http://www.gooseeker.com/cn/forum/7" basefilebegin = "jsk_bbs_" basefileend = ".xml" count = 1 while (count
php 抓取网页ajax数据(基于ThinkPHP框架的PHP程序设计有所远程抓取数据的功能总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-04-13 13:29
本文示例介绍jquery+thinkphp实现跨域数据抓取的方法。分享给大家参考,详情如下:
今天,我将做一个远程获取数据的功能。请记住,jquery 可以使用 Ajax 获取远程数据,但不能跨域。我在网上找到了很多。但我觉得还是综合,所以我觉得对于一个简单的问题来说有点复杂,但至少现在解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post发送数据到服务器后台,后台的php代码执行远程抓取,存入数据库ajax并返回数据到前台,前台用js接受数据并显示。
//远程抓取获取数据
$("#update_ac").click(function() {
$username = $("#username").text();
$("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){
$(this).html(" ");
});
$.post("update_ac/username/"+$username,{},function($data){
json = eval("(" + $data + ")");
$("#Submit").html(json.data.Submit);
$("#AC").html(json.data.AC);
$("#solved,#solved2,#solved3").html(json.data.solved);
$("#rank").html(json.data.rank);
}
),"json";
});
上面jquery代码在四楼比较清楚,困扰我的是那个json数据的接收
json = eval("(" + $data + ")");
//eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这个还是前台,跨域爬取是用php扩展simple_html_dom做的(不确定可以去网上搜索一下,基于PHP5开发的)
将远程页面抓取到本地。
import("@.ORG.simple_html_dom");
//thinkphp内导入扩展,你要把网上下载的代码改名为simple_html_dom.class.php放到APPNAME\Lib\ORG的目录下面
$html = file_get_html('http://openoj.awaysoft.com/JudgeOnline/userinfo.php?user='.$username); //远程抓取了
$ret = $html->find('center',0)->plaintext; //返回数据了。
上面的代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后用正则表达式过滤出需要的数据。以下是效果图
对thinkPHP相关内容比较感兴趣的读者可以查看本站专题:《ThinkPHP入门教程》《ThinkPHP模板操作技巧总结》《ThinkPHP常用方法总结》《Smarty模板基础教程》《PHP模板技术》概括” ”。
希望这篇文章对大家基于ThinkPHP框架的PHP编程有所帮助。 查看全部
php 抓取网页ajax数据(基于ThinkPHP框架的PHP程序设计有所远程抓取数据的功能总结)
本文示例介绍jquery+thinkphp实现跨域数据抓取的方法。分享给大家参考,详情如下:
今天,我将做一个远程获取数据的功能。请记住,jquery 可以使用 Ajax 获取远程数据,但不能跨域。我在网上找到了很多。但我觉得还是综合,所以我觉得对于一个简单的问题来说有点复杂,但至少现在解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post发送数据到服务器后台,后台的php代码执行远程抓取,存入数据库ajax并返回数据到前台,前台用js接受数据并显示。
//远程抓取获取数据
$("#update_ac").click(function() {
$username = $("#username").text();
$("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){
$(this).html(" ");
});
$.post("update_ac/username/"+$username,{},function($data){
json = eval("(" + $data + ")");
$("#Submit").html(json.data.Submit);
$("#AC").html(json.data.AC);
$("#solved,#solved2,#solved3").html(json.data.solved);
$("#rank").html(json.data.rank);
}
),"json";
});
上面jquery代码在四楼比较清楚,困扰我的是那个json数据的接收
json = eval("(" + $data + ")");
//eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这个还是前台,跨域爬取是用php扩展simple_html_dom做的(不确定可以去网上搜索一下,基于PHP5开发的)
将远程页面抓取到本地。
import("@.ORG.simple_html_dom");
//thinkphp内导入扩展,你要把网上下载的代码改名为simple_html_dom.class.php放到APPNAME\Lib\ORG的目录下面
$html = file_get_html('http://openoj.awaysoft.com/JudgeOnline/userinfo.php?user='.$username); //远程抓取了
$ret = $html->find('center',0)->plaintext; //返回数据了。
上面的代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后用正则表达式过滤出需要的数据。以下是效果图
对thinkPHP相关内容比较感兴趣的读者可以查看本站专题:《ThinkPHP入门教程》《ThinkPHP模板操作技巧总结》《ThinkPHP常用方法总结》《Smarty模板基础教程》《PHP模板技术》概括” ”。
希望这篇文章对大家基于ThinkPHP框架的PHP编程有所帮助。
php 抓取网页ajax数据(php抓取网页ajax数据的话,我也是刚刚学习这个知识点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-10 20:02
php抓取网页ajax数据的话,一般抓包的话,获取sessionid并不是很简单,你可以想想,如果想看某一个网页你是用什么浏览器去访问的,然后获取到sessionid,然后让你自己的后台程序去抓取sessionid就可以了。
你需要php特性,
可以利用php的session,可以在某个特定会话上抓取一个特定的网站,就相当于你的网站又多了一个网页一样,
phppc抓包,
你可以在服务器上部署一个抓包插件,就可以抓包了.抓包软件ie可以,ff可以,activex就不行了.如果你打算把php程序部署到服务器上,可以部署一个socket.
php里面也能实现http请求下面的ajax就是通过这种方式来实现的,
php的反射机制可以实现其他语言的类似功能。
你可以运行调试一下一个抓包的脚本,例如:qcc2314,抓取页面上的ajax请求发给后端自己去做处理,当然,你需要php这个解释型的语言环境,
反编译
php可以利用session机制
phpajax是让你的服务器时刻保持web状态,如果有变化的话。后端和服务器联动,用laravel框架写一个完整的phpajax模板引擎,通过javascript处理。后端通过session机制记录用户的变化并随着用户的变化而变化,后端记录来自服务器数据,服务器记录来自前端用户的数据。我也是刚刚学习这个知识点,还请大神回答。 查看全部
php 抓取网页ajax数据(php抓取网页ajax数据的话,我也是刚刚学习这个知识点)
php抓取网页ajax数据的话,一般抓包的话,获取sessionid并不是很简单,你可以想想,如果想看某一个网页你是用什么浏览器去访问的,然后获取到sessionid,然后让你自己的后台程序去抓取sessionid就可以了。
你需要php特性,
可以利用php的session,可以在某个特定会话上抓取一个特定的网站,就相当于你的网站又多了一个网页一样,
phppc抓包,
你可以在服务器上部署一个抓包插件,就可以抓包了.抓包软件ie可以,ff可以,activex就不行了.如果你打算把php程序部署到服务器上,可以部署一个socket.
php里面也能实现http请求下面的ajax就是通过这种方式来实现的,
php的反射机制可以实现其他语言的类似功能。
你可以运行调试一下一个抓包的脚本,例如:qcc2314,抓取页面上的ajax请求发给后端自己去做处理,当然,你需要php这个解释型的语言环境,
反编译
php可以利用session机制
phpajax是让你的服务器时刻保持web状态,如果有变化的话。后端和服务器联动,用laravel框架写一个完整的phpajax模板引擎,通过javascript处理。后端通过session机制记录用户的变化并随着用户的变化而变化,后端记录来自服务器数据,服务器记录来自前端用户的数据。我也是刚刚学习这个知识点,还请大神回答。
php 抓取网页ajax数据(内容什么是PHP?具体问题的解决方法总结什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-04-02 20:25
现在我们开发了很多依赖 Ajax 请求的应用程序,在某些情况下,甚至整个页面都依赖于 Ajax。有时我们会注意到,当一个网页发送两个或多个 Ajax 请求时,PHP 的响应时间会很长,并且会同时返回响应内容。
这个问题很可能是由您处理 PHP 会话的方式引起的,请按照本文了解问题并采取措施避免它。
内容 什么是 PHP 会话?什么是阿贾克斯?具体问题的原因和解决方法总结
什么是 PHP 会话?
为了理解这个问题,有必要首先了解 PHP 会话和 Ajax,以及它们是如何干扰的。
假设您正在开发一个 Web 应用程序并想要识别不同的用户。您想记住谁在没有登录的情况下每次访问了所有页面。在这种情况下,您可以使用 cookie 或会话。
正如您已经意识到的那样,会话是一种存储用户信息的方式,可以从任何页面检索。与 Cookie 不同,Session 存储在服务器上,所有用户都无法直接更改此信息。
默认情况下,会话一直有效,直到用户关闭浏览器,或者用户在 PHP 配置文件中指定的一段时间内处于非活动状态。
在 PHP 页面中,无论何时要存储或检索用户数据,都必须在页面的开头调用 session_start(),因此您有权使用 $_SESSION 来检索会话数据。
什么是阿贾克斯?
Ajax 代表异步 JavaScript 和 XML,它是一种无需重新加载整个页面即可向服务器发送和接收数据的方式。
我们使用这种方法以更快的速度从服务器发送数据和检索数据。我们不必获取整个页面并将其呈现在浏览器中,因为这很慢。
因此,我们可以更新页面的一部分并且用户可以看到更改,就像用户向下滚动 Facebook 时间轴页面以查看他们想要看到的内容一样,添加新内容而无需重新加载整个页面。
具体问题
开发几乎 100% 基于 Ajax 的 Web 应用程序并不是什么新鲜事,但是当一个网页同时发送两个或多个 Ajax 请求时,您会注意到请求需要很长时间并且几乎同时完成。
原因
当您希望服务器发送 Ajax 请求时,PHP 脚本也会启动 session_start(),它的调用将锁定 PHP 会话文件。
您可能已经知道,PHP 默认将会话数据存储在服务器上的文件中。由于只有一个 PHP 请求可以更改同一个会话文件,因此两个同时发生的 PHP 请求会导致典型的文件锁定情况,因此 PHP 调用的同一用户的任何其他 session_start() 请求都必须等到第一个请求结束。
现在,大多数 PHP 框架将首先在主文件中使用 session_start()。因此,如果您使用调用 session_start() 的框架或库,则会导致会话文件锁定,这将延迟使用同一浏览器的同一用户的并发 Ajax 请求。
问题的解决方案
调用 session_write_close() 函数会导致 PHP 写入会话文件并关闭它,因此释放会话文件后,另一个请求具有写入权限。
调用 session_write_close() 后,当前脚本会继续正常运行,但请注意,在调用 session_write_close() 后,不允许更改任何会话变量;在同一个脚本中,对 PHP 的其他并发请求可以锁定会话文件并更改会话变量。
为了向您展示此类问题,我创建了测试代码并将其上传到 github。你可以在这里找到测试脚本。在本地,您需要一个实例来使用测试代码,然后打开浏览器控制台以查看请求和响应时间。
正如我们在这个文件的示例代码中看到的那样,如果我们创建多个请求,如下面的代码......
session_start();
sleep(5);
来自同一用户的每个请求将等到前一个请求完成后再完成。这将需要 5 秒,因为在脚本完成之前不会释放会话文件。因此,第一次调用 session_start() 时,新的请求会被阻塞。那会扼杀异步请求的想法,即同时发送和执行多个请求。
如果将文件中的代码更改为:
session_start();
// do something useful here
session_write_close();
sleep(5);
第三行代码将释放会话文件锁,因此另一个并发请求可以运行而无需等待,因为它可以毫无问题地调用 session_start()。
总结
PHP 有点微妙,会让你担心为什么会发生奇怪的事情。但是一旦你理解了事情是如何运作的,这一切都是有意义的,你可以更好地思考解决问题。
翻译来源:
本文根据@Eslam Mahmoud 的“Fix the AJAX Requests that Make PHP Take Too Long to Respond”翻译。整个翻译收录了我自己的理解和想法。如果翻译的不好或者有什么不对的地方,请各位同仁指点。如需转载此译文,请注明英文出处: 查看全部
php 抓取网页ajax数据(内容什么是PHP?具体问题的解决方法总结什么?)
现在我们开发了很多依赖 Ajax 请求的应用程序,在某些情况下,甚至整个页面都依赖于 Ajax。有时我们会注意到,当一个网页发送两个或多个 Ajax 请求时,PHP 的响应时间会很长,并且会同时返回响应内容。
这个问题很可能是由您处理 PHP 会话的方式引起的,请按照本文了解问题并采取措施避免它。
内容 什么是 PHP 会话?什么是阿贾克斯?具体问题的原因和解决方法总结
什么是 PHP 会话?
为了理解这个问题,有必要首先了解 PHP 会话和 Ajax,以及它们是如何干扰的。
假设您正在开发一个 Web 应用程序并想要识别不同的用户。您想记住谁在没有登录的情况下每次访问了所有页面。在这种情况下,您可以使用 cookie 或会话。
正如您已经意识到的那样,会话是一种存储用户信息的方式,可以从任何页面检索。与 Cookie 不同,Session 存储在服务器上,所有用户都无法直接更改此信息。
默认情况下,会话一直有效,直到用户关闭浏览器,或者用户在 PHP 配置文件中指定的一段时间内处于非活动状态。
在 PHP 页面中,无论何时要存储或检索用户数据,都必须在页面的开头调用 session_start(),因此您有权使用 $_SESSION 来检索会话数据。
什么是阿贾克斯?
Ajax 代表异步 JavaScript 和 XML,它是一种无需重新加载整个页面即可向服务器发送和接收数据的方式。
我们使用这种方法以更快的速度从服务器发送数据和检索数据。我们不必获取整个页面并将其呈现在浏览器中,因为这很慢。
因此,我们可以更新页面的一部分并且用户可以看到更改,就像用户向下滚动 Facebook 时间轴页面以查看他们想要看到的内容一样,添加新内容而无需重新加载整个页面。
具体问题
开发几乎 100% 基于 Ajax 的 Web 应用程序并不是什么新鲜事,但是当一个网页同时发送两个或多个 Ajax 请求时,您会注意到请求需要很长时间并且几乎同时完成。
原因
当您希望服务器发送 Ajax 请求时,PHP 脚本也会启动 session_start(),它的调用将锁定 PHP 会话文件。
您可能已经知道,PHP 默认将会话数据存储在服务器上的文件中。由于只有一个 PHP 请求可以更改同一个会话文件,因此两个同时发生的 PHP 请求会导致典型的文件锁定情况,因此 PHP 调用的同一用户的任何其他 session_start() 请求都必须等到第一个请求结束。
现在,大多数 PHP 框架将首先在主文件中使用 session_start()。因此,如果您使用调用 session_start() 的框架或库,则会导致会话文件锁定,这将延迟使用同一浏览器的同一用户的并发 Ajax 请求。
问题的解决方案
调用 session_write_close() 函数会导致 PHP 写入会话文件并关闭它,因此释放会话文件后,另一个请求具有写入权限。
调用 session_write_close() 后,当前脚本会继续正常运行,但请注意,在调用 session_write_close() 后,不允许更改任何会话变量;在同一个脚本中,对 PHP 的其他并发请求可以锁定会话文件并更改会话变量。
为了向您展示此类问题,我创建了测试代码并将其上传到 github。你可以在这里找到测试脚本。在本地,您需要一个实例来使用测试代码,然后打开浏览器控制台以查看请求和响应时间。
正如我们在这个文件的示例代码中看到的那样,如果我们创建多个请求,如下面的代码......
session_start();
sleep(5);
来自同一用户的每个请求将等到前一个请求完成后再完成。这将需要 5 秒,因为在脚本完成之前不会释放会话文件。因此,第一次调用 session_start() 时,新的请求会被阻塞。那会扼杀异步请求的想法,即同时发送和执行多个请求。
如果将文件中的代码更改为:
session_start();
// do something useful here
session_write_close();
sleep(5);
第三行代码将释放会话文件锁,因此另一个并发请求可以运行而无需等待,因为它可以毫无问题地调用 session_start()。
总结
PHP 有点微妙,会让你担心为什么会发生奇怪的事情。但是一旦你理解了事情是如何运作的,这一切都是有意义的,你可以更好地思考解决问题。
翻译来源:
本文根据@Eslam Mahmoud 的“Fix the AJAX Requests that Make PHP Take Too Long to Respond”翻译。整个翻译收录了我自己的理解和想法。如果翻译的不好或者有什么不对的地方,请各位同仁指点。如需转载此译文,请注明英文出处:
php 抓取网页ajax数据(最后在php服务器中渲染页面其实这个问题需要回答)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-29 20:05
php抓取网页ajax数据,然后下载php的www服务器,最后在php服务器中渲染页面其实这个问题需要回答的是:你要下载的网页内容都是html文本吗?php本身读取不到这些文本,
flash做反射式读取,处理完格式后在html里面渲染出来。但这样一来,服务器要支持html的反射,所以会消耗一部分内存,
js做反射式读取
flash反射式读取
楼上说的都没有错,有两种方式可以解决,一种是直接获取js代码,然后用select来选择,
$('.www.php').addeventlistener('get',post(),function(req,res){$('.baidu.php').download("网页_html_browser")})
php获取用flash
正则匹配获取js文件
javascriptflash。
本质就是javascript
//一条规律通过javascript控制输出html#//surrogate//true,在#或#\i,javascript获取javascript文件#//surrogate//false,在#或#\i,javascript获取javascript文件例如上面的"//surrogate/true",从起始目录下读取一行数据this。post(req。text(text("helloworld\n")));。 查看全部
php 抓取网页ajax数据(最后在php服务器中渲染页面其实这个问题需要回答)
php抓取网页ajax数据,然后下载php的www服务器,最后在php服务器中渲染页面其实这个问题需要回答的是:你要下载的网页内容都是html文本吗?php本身读取不到这些文本,
flash做反射式读取,处理完格式后在html里面渲染出来。但这样一来,服务器要支持html的反射,所以会消耗一部分内存,
js做反射式读取
flash反射式读取
楼上说的都没有错,有两种方式可以解决,一种是直接获取js代码,然后用select来选择,
$('.www.php').addeventlistener('get',post(),function(req,res){$('.baidu.php').download("网页_html_browser")})
php获取用flash
正则匹配获取js文件
javascriptflash。
本质就是javascript
//一条规律通过javascript控制输出html#//surrogate//true,在#或#\i,javascript获取javascript文件#//surrogate//false,在#或#\i,javascript获取javascript文件例如上面的"//surrogate/true",从起始目录下读取一行数据this。post(req。text(text("helloworld\n")));。
php 抓取网页ajax数据( 入门注册API怎么用NewYorkTimesAPI来收集头条新闻?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-26 13:10
入门注册API怎么用NewYorkTimesAPI来收集头条新闻?)
使用纽约时报 API 抓取元数据
介绍
上周,我写了一篇关于抓取网络获取元数据的介绍,提到无法抓取纽约时报 网站。时报付费墙会阻止您采集基本元数据的尝试。但是有一种方法可以使用纽约时报 API。
最近我开始在 Yii 平台上建立一个社区站点,我将在以后的教程中发布。我想让添加与 网站 内容相关的链接变得容易。虽然人们很容易将 URL 粘贴到表单中,但同时提供标题和来源信息会变得很耗时。
因此,在今天的教程中,我将扩展我最近编写的抓取代码,以在添加 Times 链接时利用 New York Times API 来采集头条新闻。
请记住,我参与了下面的评论线程,所以让我知道您的想法!您也可以在 Twitter @lookahead_io 上与我联系。
开始注册 API 密钥
首先,让我们注册申请一个 API Key:
提交表格后,您将通过电子邮件收到您的密钥:
探索纽约时报 API
The Times 提供以下类别的 API:
很多。并且,在 Gallery 页面中,您可以单击任何主题以查看各个 API 类别文档:
Times 使用 LucyBot 来支持他们的 API 文档,并提供了一个有用的常见问题解答:
他们甚至向您展示了如何快速获取 API 使用限制(您需要插入密钥):
curl --head
https://api.nytimes.com/svc/bo ... ey%3D
2>/dev/null | grep -i "X-RateLimit"
X-RateLimit-Limit-day: 1000
X-RateLimit-Limit-second: 5
X-RateLimit-Remaining-day: 180
X-RateLimit-Remaining-second: 5
一开始我很难理解文档——它是基于参数的规范,而不是编程指南。但是,我将一些问题作为问题发布到了纽约时报 API GitHub 页面,它们得到了快速而有帮助的回答。
使用 文章 搜索
在今天的节目中,我将专注于使用《纽约时报》文章 搜索。基本上,我们将从上一个教程的扩展中创建一个链接表单:
当用户点击 Lookup 时,我们将通过 Link::grab($url) 发出 ajax 请求。这是jQuery:
$(document).on("click", '[id=lookup]', function(event) {
$.ajax({
url: $('#url_prefix').val()+'/link/grab',
data: {url: $('#url').val()},
success: function(data) {
$('#title').val(data);
return true;
}
});
});
这是控制器和模型方法:
// Controller call via AJAX Lookup request
public static function actionGrab($url) {
Yii::$app->response->format = Response::FORMAT_JSON;
return Link::grab($url);
}
...
// Link::grab() method
public static function grab($url) {
//clean up url for hostname
$source_url = parse_url($url);
$source_url = $source_url['host'];
$source_url=str_ireplace('www.','',$source_url);
$source_url = trim($source_url,' \\');
// use the NYT API when hostname == nytimes.com
if ($source_url=='nytimes.com') {
...
接下来,让我们使用我们的 API 密钥发出 文章 搜索请求:
$nytKey=Yii::$app->params['nytapi'];
$curl_dest = 'http://api.nytimes.com
/svc/search/v2/articlesearch.json?fl=headline&fq=web_url:%22'.
$url.'%22&api-key='.$nytKey;
$curl = curl_init();
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_URL,$curl_dest);
$result = json_decode(curl_exec($curl));
$title = $result->response->docs[0]->headline->main;
} else {
// not NYT, use the standard metatag scraper from last episode
...
}
}
return $title;
}
它很容易工作 - 这是由此产生的标题(顺便说一句,气候变化正在杀死北极熊,我们应该关心):
如果您想从 API 请求中获取更多详细信息,只需在 ?fl=headline 请求中添加其他参数,例如关键字和lead_paragraph:
Yii::$app->response->format = Response::FORMAT_JSON;
$nytKey=Yii::$app->params['nytapi'];
$curl_dest = 'http://api.nytimes.com/svc/search/v2/articlesearch.json?'.
'fl=headline,keywords,lead_paragraph&fq=web_url:%22'.$url.'%22&api-key='.$nytKey;
$curl = curl_init();
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_URL,$curl_dest);
$result = json_decode(curl_exec($curl));
var_dump($result);
结果如下:
也许我会在接下来的几集中编写一个 PHP 库来更好地解析 NYT API,但是这段代码将关键字和前导段落分开:
Yii::$app->response->format = Response::FORMAT_JSON;
$nytKey=Yii::$app->params['nytapi'];
$curl_dest = 'http://api.nytimes.com/svc/search/v2/articlesearch.json?'.
'fl=headline,keywords,lead_paragraph&fq=web_url:%22'.$url.'%22&api-key='.$nytKey;
$curl = curl_init();
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_URL,$curl_dest);
$result = json_decode(curl_exec($curl));
echo $result->response->docs[0]->headline->main.'<br />'.'<br />';
echo $result->response->docs[0]->lead_paragraph.'<br />'.'<br />';
foreach ($result->response->docs[0]->keywords as $k) {
echo $k->value.'
';
}
下面是它为这个 文章 显示的内容:
Polar Bears’ Path to Decline Runs Through Alaskan Village
The bears that come here are climate refugees, on land because
the sea ice they rely on for hunting seals is receding.
Polar Bears
Greenhouse Gas Emissions
Alaska
Global Warming
Endangered and Extinct Species
International Union for Conservation of Nature
National Snow and Ice Data Center
Polar Bears International
United States Geological Survey
希望这开始扩展您对如何使用这些 API 的想象。现在可能发生的事情非常令人兴奋。
当它结束时
New York Times API 非常有用,我很高兴看到他们将它提供给开发人员社区。通过 GitHub 获得如此快速的 API 支持也令人耳目一新——我只是没想到。请记住,它适用于非商业项目。如果您有一些赚钱的想法,请给他们发一封信,看看他们是否会与您合作。出版商渴望新的收入来源。
我希望您发现这些网络抓取片段很有帮助,并在您的项目中使用它们。如果你想看今天的节目,你可以在我的 网站 Active Together 上尝试一些网络抓取。
请在评论中分享任何想法和反馈。您也可以随时在 Twitter @lookahead_io 上直接与我联系。请务必查看我的讲师页面和其他关于使用 PHP 构建您的初创公司和使用 Yii2 编程的系列文章。
相关链接 查看全部
php 抓取网页ajax数据(
入门注册API怎么用NewYorkTimesAPI来收集头条新闻?)
使用纽约时报 API 抓取元数据
介绍
上周,我写了一篇关于抓取网络获取元数据的介绍,提到无法抓取纽约时报 网站。时报付费墙会阻止您采集基本元数据的尝试。但是有一种方法可以使用纽约时报 API。
最近我开始在 Yii 平台上建立一个社区站点,我将在以后的教程中发布。我想让添加与 网站 内容相关的链接变得容易。虽然人们很容易将 URL 粘贴到表单中,但同时提供标题和来源信息会变得很耗时。
因此,在今天的教程中,我将扩展我最近编写的抓取代码,以在添加 Times 链接时利用 New York Times API 来采集头条新闻。
请记住,我参与了下面的评论线程,所以让我知道您的想法!您也可以在 Twitter @lookahead_io 上与我联系。
开始注册 API 密钥
首先,让我们注册申请一个 API Key:
提交表格后,您将通过电子邮件收到您的密钥:
探索纽约时报 API
The Times 提供以下类别的 API:
很多。并且,在 Gallery 页面中,您可以单击任何主题以查看各个 API 类别文档:
Times 使用 LucyBot 来支持他们的 API 文档,并提供了一个有用的常见问题解答:
他们甚至向您展示了如何快速获取 API 使用限制(您需要插入密钥):
curl --head
https://api.nytimes.com/svc/bo ... ey%3D
2>/dev/null | grep -i "X-RateLimit"
X-RateLimit-Limit-day: 1000
X-RateLimit-Limit-second: 5
X-RateLimit-Remaining-day: 180
X-RateLimit-Remaining-second: 5
一开始我很难理解文档——它是基于参数的规范,而不是编程指南。但是,我将一些问题作为问题发布到了纽约时报 API GitHub 页面,它们得到了快速而有帮助的回答。
使用 文章 搜索
在今天的节目中,我将专注于使用《纽约时报》文章 搜索。基本上,我们将从上一个教程的扩展中创建一个链接表单:
当用户点击 Lookup 时,我们将通过 Link::grab($url) 发出 ajax 请求。这是jQuery:
$(document).on("click", '[id=lookup]', function(event) {
$.ajax({
url: $('#url_prefix').val()+'/link/grab',
data: {url: $('#url').val()},
success: function(data) {
$('#title').val(data);
return true;
}
});
});
这是控制器和模型方法:
// Controller call via AJAX Lookup request
public static function actionGrab($url) {
Yii::$app->response->format = Response::FORMAT_JSON;
return Link::grab($url);
}
...
// Link::grab() method
public static function grab($url) {
//clean up url for hostname
$source_url = parse_url($url);
$source_url = $source_url['host'];
$source_url=str_ireplace('www.','',$source_url);
$source_url = trim($source_url,' \\');
// use the NYT API when hostname == nytimes.com
if ($source_url=='nytimes.com') {
...
接下来,让我们使用我们的 API 密钥发出 文章 搜索请求:
$nytKey=Yii::$app->params['nytapi'];
$curl_dest = 'http://api.nytimes.com
/svc/search/v2/articlesearch.json?fl=headline&fq=web_url:%22'.
$url.'%22&api-key='.$nytKey;
$curl = curl_init();
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_URL,$curl_dest);
$result = json_decode(curl_exec($curl));
$title = $result->response->docs[0]->headline->main;
} else {
// not NYT, use the standard metatag scraper from last episode
...
}
}
return $title;
}
它很容易工作 - 这是由此产生的标题(顺便说一句,气候变化正在杀死北极熊,我们应该关心):
如果您想从 API 请求中获取更多详细信息,只需在 ?fl=headline 请求中添加其他参数,例如关键字和lead_paragraph:
Yii::$app->response->format = Response::FORMAT_JSON;
$nytKey=Yii::$app->params['nytapi'];
$curl_dest = 'http://api.nytimes.com/svc/search/v2/articlesearch.json?'.
'fl=headline,keywords,lead_paragraph&fq=web_url:%22'.$url.'%22&api-key='.$nytKey;
$curl = curl_init();
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_URL,$curl_dest);
$result = json_decode(curl_exec($curl));
var_dump($result);
结果如下:
也许我会在接下来的几集中编写一个 PHP 库来更好地解析 NYT API,但是这段代码将关键字和前导段落分开:
Yii::$app->response->format = Response::FORMAT_JSON;
$nytKey=Yii::$app->params['nytapi'];
$curl_dest = 'http://api.nytimes.com/svc/search/v2/articlesearch.json?'.
'fl=headline,keywords,lead_paragraph&fq=web_url:%22'.$url.'%22&api-key='.$nytKey;
$curl = curl_init();
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_URL,$curl_dest);
$result = json_decode(curl_exec($curl));
echo $result->response->docs[0]->headline->main.'<br />'.'<br />';
echo $result->response->docs[0]->lead_paragraph.'<br />'.'<br />';
foreach ($result->response->docs[0]->keywords as $k) {
echo $k->value.'
';
}
下面是它为这个 文章 显示的内容:
Polar Bears’ Path to Decline Runs Through Alaskan Village
The bears that come here are climate refugees, on land because
the sea ice they rely on for hunting seals is receding.
Polar Bears
Greenhouse Gas Emissions
Alaska
Global Warming
Endangered and Extinct Species
International Union for Conservation of Nature
National Snow and Ice Data Center
Polar Bears International
United States Geological Survey
希望这开始扩展您对如何使用这些 API 的想象。现在可能发生的事情非常令人兴奋。
当它结束时
New York Times API 非常有用,我很高兴看到他们将它提供给开发人员社区。通过 GitHub 获得如此快速的 API 支持也令人耳目一新——我只是没想到。请记住,它适用于非商业项目。如果您有一些赚钱的想法,请给他们发一封信,看看他们是否会与您合作。出版商渴望新的收入来源。
我希望您发现这些网络抓取片段很有帮助,并在您的项目中使用它们。如果你想看今天的节目,你可以在我的 网站 Active Together 上尝试一些网络抓取。
请在评论中分享任何想法和反馈。您也可以随时在 Twitter @lookahead_io 上直接与我联系。请务必查看我的讲师页面和其他关于使用 PHP 构建您的初创公司和使用 Yii2 编程的系列文章。
相关链接
php 抓取网页ajax数据(谷粒学院-Java视频|HTML5视频自学拿1万+月薪的IT在线视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-23 04:14
一、服务端渲染技术NUXT 1、什么是服务端渲染
服务器端渲染,也称为SSR(Server Side Render),是在服务器端完成页面内容,而不是在客户端通过AJAX获取数据。
服务端渲染(SSR)的优点主要是:更好的SEO,因为搜索引擎爬虫爬虫可以直接查看完全渲染的页面。
如果您的应用程序最初显示加载菊花图,然后通过 Ajax 获取内容,则爬虫将不会等待异步完成,然后再爬取页面内容。也就是说,如果 SEO 对您的网站至关重要并且您的页面正在异步获取内容,那么您可能需要服务器端渲染 (SSR) 来解决这个问题。
此外,通过服务器端渲染,我们可以获得更快的内容时间,而无需等待所有 JavaScript 完成下载和执行,从而获得更好的用户体验,因为那些“时间到内容”的内容)是与转换直接相关”,服务器端渲染 (SSR) 至关重要。
2、什么是NUXT
Nuxt.js 是一个基于 Vue.js 的轻量级应用框架,可用于创建服务器端渲染(SSR)应用,也可以作为静态站点引擎生成静态站点应用。它具有优雅的代码结构分层和热加载的特点。.
官网网站:
二、NUXT环境初始化1、下载压缩包
2、解压
将模板中的内容复制到guli
3、安装 ESLint
将guli-admin项目下的.eslintrc.js配置文件复制到当前项目
4、修改package.json
名称、描述、作者(此处必须修改,否则无法安装项目)
"name": "guli",
"version": "1.0.0",
"description": "谷粒学院前台网站",
"author": "Helen ",
5、修改nuxt.config.js
修改标题:'{{ name }}',内容:'{{escape description }}'
这里的设置最终会显示在页面标题栏和元数据中
头: {
标题:'Grain Academy - Java 视频 | HTML5 视频 | 前端视频 | Python 视频 | 大数据视频-自学月薪10000+月薪IT在线视频课程,粮粉支持,老同学推荐,
元:[
{ 字符集:'utf-8' },
{ 名称:'viewport',内容:'width=device-width,initial-scale=1'},
{ hid: 'keywords', name: 'keywords', content: '粮学院, IT在线视频教程, Java视频, HTML5视频, 前端视频, Python视频, 大数据视频' },
{ hid: 'description', name: 'description', content: '粮学院是国内领先的IT在线视频学习平台和职业教育平台。截至目前,粮食学院线上线下学生人数已达10000人!与数百家知名开发团队联合开发的Java、HTML5前端、大数据、Python等视频课程,被广大学习者和IT工程师赞誉为:业界最适合自学、量最大代码,最多案例,最实用,最前沿的IT系列视频课程!' }
],
关联: [
{ rel: 'icon', 类型: 'image/x-icon', href: '/favicon.ico' }
]
},
6、在命令行终端进入项目目录7、安装依赖
npm 安装
8、试运行
npm 运行开发
9、NUXT目录结构
(1) 资源目录资产
用于组织未编译的静态资源,例如 LESS、SASS 或 JavaScript。
(2)components 目录组件
用于组织应用程序的 Vue.js 组件。Nuxt.js 不会扩展和增强该目录下的 Vue.js 组件,即这些组件不会像页面组件那样具有 asyncData 方法的特性。
(3)Layouts 目录布局
用于组织应用程序的布局组件。
(4)页面目录页面
用于组织应用程序的路由和视图。Nuxt.js 框架会读取该目录下的所有 .vue 文件,并自动生成相应的路由配置。
(5)插件目录插件
用于组织需要在根 vue.js 应用程序实例化之前运行的 Javascript 插件。
(6)nuxt.config.js 文件
nuxt.config.js 文件用于组织 Nuxt.js 应用程序的个性化配置,以覆盖默认配置。
三、幻灯片插件
1、安装插件
npm install vue-awesome-swiper
2、配置插件
在plugins文件夹下新建一个文件nuxt-swiper-plugin.js,内容为
import Vue from 'vue'
import VueAwesomeSwiper from 'vue-awesome-swiper/dist/ssr'
Vue.use(VueAwesomeSwiper)
在 nuxt.config.js 文件中配置插件
将 plugins 和 css 节点复制到 module.exports 节点
module.exports = {
// some nuxt config...
plugins: [
{ src: '~/plugins/nuxt-swiper-plugin.js', ssr: false }
],
css: [
'swiper/dist/css/swiper.css'
]
}
注意插件版本问题,会报错,需要解决兼容性问题。
NUXT 的功能与之前的 vue 模板大致相同。整合过程不用多说。
三、 实现banner、热门教师、热门课程等信息
轻微地 查看全部
php 抓取网页ajax数据(谷粒学院-Java视频|HTML5视频自学拿1万+月薪的IT在线视频)
一、服务端渲染技术NUXT 1、什么是服务端渲染
服务器端渲染,也称为SSR(Server Side Render),是在服务器端完成页面内容,而不是在客户端通过AJAX获取数据。
服务端渲染(SSR)的优点主要是:更好的SEO,因为搜索引擎爬虫爬虫可以直接查看完全渲染的页面。
如果您的应用程序最初显示加载菊花图,然后通过 Ajax 获取内容,则爬虫将不会等待异步完成,然后再爬取页面内容。也就是说,如果 SEO 对您的网站至关重要并且您的页面正在异步获取内容,那么您可能需要服务器端渲染 (SSR) 来解决这个问题。
此外,通过服务器端渲染,我们可以获得更快的内容时间,而无需等待所有 JavaScript 完成下载和执行,从而获得更好的用户体验,因为那些“时间到内容”的内容)是与转换直接相关”,服务器端渲染 (SSR) 至关重要。
2、什么是NUXT
Nuxt.js 是一个基于 Vue.js 的轻量级应用框架,可用于创建服务器端渲染(SSR)应用,也可以作为静态站点引擎生成静态站点应用。它具有优雅的代码结构分层和热加载的特点。.
官网网站:
二、NUXT环境初始化1、下载压缩包
2、解压
将模板中的内容复制到guli
3、安装 ESLint
将guli-admin项目下的.eslintrc.js配置文件复制到当前项目
4、修改package.json
名称、描述、作者(此处必须修改,否则无法安装项目)
"name": "guli",
"version": "1.0.0",
"description": "谷粒学院前台网站",
"author": "Helen ",
5、修改nuxt.config.js
修改标题:'{{ name }}',内容:'{{escape description }}'
这里的设置最终会显示在页面标题栏和元数据中
头: {
标题:'Grain Academy - Java 视频 | HTML5 视频 | 前端视频 | Python 视频 | 大数据视频-自学月薪10000+月薪IT在线视频课程,粮粉支持,老同学推荐,
元:[
{ 字符集:'utf-8' },
{ 名称:'viewport',内容:'width=device-width,initial-scale=1'},
{ hid: 'keywords', name: 'keywords', content: '粮学院, IT在线视频教程, Java视频, HTML5视频, 前端视频, Python视频, 大数据视频' },
{ hid: 'description', name: 'description', content: '粮学院是国内领先的IT在线视频学习平台和职业教育平台。截至目前,粮食学院线上线下学生人数已达10000人!与数百家知名开发团队联合开发的Java、HTML5前端、大数据、Python等视频课程,被广大学习者和IT工程师赞誉为:业界最适合自学、量最大代码,最多案例,最实用,最前沿的IT系列视频课程!' }
],
关联: [
{ rel: 'icon', 类型: 'image/x-icon', href: '/favicon.ico' }
]
},
6、在命令行终端进入项目目录7、安装依赖
npm 安装
8、试运行
npm 运行开发
9、NUXT目录结构
(1) 资源目录资产
用于组织未编译的静态资源,例如 LESS、SASS 或 JavaScript。
(2)components 目录组件
用于组织应用程序的 Vue.js 组件。Nuxt.js 不会扩展和增强该目录下的 Vue.js 组件,即这些组件不会像页面组件那样具有 asyncData 方法的特性。
(3)Layouts 目录布局
用于组织应用程序的布局组件。
(4)页面目录页面
用于组织应用程序的路由和视图。Nuxt.js 框架会读取该目录下的所有 .vue 文件,并自动生成相应的路由配置。
(5)插件目录插件
用于组织需要在根 vue.js 应用程序实例化之前运行的 Javascript 插件。
(6)nuxt.config.js 文件
nuxt.config.js 文件用于组织 Nuxt.js 应用程序的个性化配置,以覆盖默认配置。
三、幻灯片插件
1、安装插件
npm install vue-awesome-swiper
2、配置插件
在plugins文件夹下新建一个文件nuxt-swiper-plugin.js,内容为
import Vue from 'vue'
import VueAwesomeSwiper from 'vue-awesome-swiper/dist/ssr'
Vue.use(VueAwesomeSwiper)
在 nuxt.config.js 文件中配置插件
将 plugins 和 css 节点复制到 module.exports 节点
module.exports = {
// some nuxt config...
plugins: [
{ src: '~/plugins/nuxt-swiper-plugin.js', ssr: false }
],
css: [
'swiper/dist/css/swiper.css'
]
}
注意插件版本问题,会报错,需要解决兼容性问题。
NUXT 的功能与之前的 vue 模板大致相同。整合过程不用多说。
三、 实现banner、热门教师、热门课程等信息
轻微地
php 抓取网页ajax数据(抓ajax异步内容的页面和抓普通的区别不大 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-22 02:21
)
其实捕获ajax异步内容页面和普通页面的区别不大。 Ajax只是一个异步的http请求,只要你使用firebug之类的工具找到请求的后端服务url和value传递的参数,然后抓取url传递的参数即可。
使用 Firebug 的网络工具
如果页面被抓取,内容中没有显示的数据就是一堆JS代码。
代码
$cookie_file=tempnam('./temp','cookie');
$ch = curl_init();
$url1 = "http://www.cdut.edu.cn/default.html";
curl_setopt($ch,CURLOPT_URL,$url1);
curl_setopt($ch,CURLOPT_HTTP_VERSION,CURL_HTTP_VERSION_1_1);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_FOLLOWLOCATION,1);
curl_setopt($ch, CURLOPT_ENCODING ,'gzip'); //加入gzip解析
//设置连接结束后保存cookie信息的文件
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookie_file);
$content=curl_exec($ch);
curl_close($ch);
$ch3 = curl_init();
$url3 = "http://www.cdut.edu.cn/xww/dwr ... 3B%3B
$curlPost = "callCount=1&page=/xww/type/1000020118.html&httpSessionId=12A9B726E6A2D4D3B09DE7952B2F282C&scriptSessionId=295315B4B4141B09DA888D3A3ADB8FAA658&c0-scriptName=portalAjax&c0-methodName=getNewsXml&c0-id=0&c0-param0=string:10000201&c0-param1=string:1000020118&c0-param2=string:news_&c0-param3=number:5969&c0-param4=number:1&c0-param5=null:null&c0-param6=null:null&batchId=0";
curl_setopt($ch3,CURLOPT_URL,$url3);
curl_setopt($ch3,CURLOPT_POST,1);
curl_setopt($ch3,CURLOPT_POSTFIELDS,$curlPost);
//设置连接结束后保存cookie信息的文件
curl_setopt($ch3,CURLOPT_COOKIEFILE,$cookie_file);
$content1=curl_exec($ch3);
curl_close($ch3); 查看全部
php 抓取网页ajax数据(抓ajax异步内容的页面和抓普通的区别不大
)
其实捕获ajax异步内容页面和普通页面的区别不大。 Ajax只是一个异步的http请求,只要你使用firebug之类的工具找到请求的后端服务url和value传递的参数,然后抓取url传递的参数即可。
使用 Firebug 的网络工具
如果页面被抓取,内容中没有显示的数据就是一堆JS代码。
代码
$cookie_file=tempnam('./temp','cookie');
$ch = curl_init();
$url1 = "http://www.cdut.edu.cn/default.html";
curl_setopt($ch,CURLOPT_URL,$url1);
curl_setopt($ch,CURLOPT_HTTP_VERSION,CURL_HTTP_VERSION_1_1);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_FOLLOWLOCATION,1);
curl_setopt($ch, CURLOPT_ENCODING ,'gzip'); //加入gzip解析
//设置连接结束后保存cookie信息的文件
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookie_file);
$content=curl_exec($ch);
curl_close($ch);
$ch3 = curl_init();
$url3 = "http://www.cdut.edu.cn/xww/dwr ... 3B%3B
$curlPost = "callCount=1&page=/xww/type/1000020118.html&httpSessionId=12A9B726E6A2D4D3B09DE7952B2F282C&scriptSessionId=295315B4B4141B09DA888D3A3ADB8FAA658&c0-scriptName=portalAjax&c0-methodName=getNewsXml&c0-id=0&c0-param0=string:10000201&c0-param1=string:1000020118&c0-param2=string:news_&c0-param3=number:5969&c0-param4=number:1&c0-param5=null:null&c0-param6=null:null&batchId=0";
curl_setopt($ch3,CURLOPT_URL,$url3);
curl_setopt($ch3,CURLOPT_POST,1);
curl_setopt($ch3,CURLOPT_POSTFIELDS,$curlPost);
//设置连接结束后保存cookie信息的文件
curl_setopt($ch3,CURLOPT_COOKIEFILE,$cookie_file);
$content1=curl_exec($ch3);
curl_close($ch3);
php 抓取网页ajax数据( hebedich怎样抓取AJAX网站的内容?JS )
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-03-19 09:14
hebedich怎样抓取AJAX网站的内容?JS
)
使用php方法curl抓取AJAX异步内容思路分析及代码分享
更新时间:2014年8月25日11:17:48 转载投稿:hebedic
如何抓取AJAX网站的内容?这是一个热门问题,也是一个棘手的问题。但实际上,爬取ajax异步内容页面和普通页面并没有什么区别。 Ajax只是一个异步的http请求,只要你使用firebug之类的工具找到请求的后端服务url和value传递的参数,然后抓取url传递的参数即可。
其实捕获ajax异步内容页面和普通页面的区别不大。 Ajax只是一个异步的http请求,只要你使用firebug之类的工具找到请求的后端服务url和value传递的参数,然后抓取url传递的参数即可。
使用 Firebug 的网络工具
如果页面被抓取,内容中没有显示的数据就是一堆JS代码。
代码
$cookie_file=tempnam('./temp','cookie');
$ch = curl_init();
$url1 = "http://www.cdut.edu.cn/default.html";
curl_setopt($ch,CURLOPT_URL,$url1);
curl_setopt($ch,CURLOPT_HTTP_VERSION,CURL_HTTP_VERSION_1_1);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_FOLLOWLOCATION,1);
curl_setopt($ch, CURLOPT_ENCODING ,'gzip'); //加入gzip解析
//设置连接结束后保存cookie信息的文件
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookie_file);
$content=curl_exec($ch);
curl_close($ch);
$ch3 = curl_init();
$url3 = "http://www.cdut.edu.cn/xww/dwr ... 3B%3B
$curlPost = "callCount=1&page=/xww/type/1000020118.html&httpSessionId=12A9B726E6A2D4D3B09DE7952B2F282C&scriptSessionId=295315B4B4141B09DA888D3A3ADB8FAA658&c0-scriptName=portalAjax&c0-methodName=getNewsXml&c0-id=0&c0-param0=string:10000201&c0-param1=string:1000020118&c0-param2=string:news_&c0-param3=number:5969&c0-param4=number:1&c0-param5=null:null&c0-param6=null:null&batchId=0";
curl_setopt($ch3,CURLOPT_URL,$url3);
curl_setopt($ch3,CURLOPT_POST,1);
curl_setopt($ch3,CURLOPT_POSTFIELDS,$curlPost);
//设置连接结束后保存cookie信息的文件
curl_setopt($ch3,CURLOPT_COOKIEFILE,$cookie_file);
$content1=curl_exec($ch3);
curl_close($ch3); 查看全部
php 抓取网页ajax数据(
hebedich怎样抓取AJAX网站的内容?JS
)
使用php方法curl抓取AJAX异步内容思路分析及代码分享
更新时间:2014年8月25日11:17:48 转载投稿:hebedic
如何抓取AJAX网站的内容?这是一个热门问题,也是一个棘手的问题。但实际上,爬取ajax异步内容页面和普通页面并没有什么区别。 Ajax只是一个异步的http请求,只要你使用firebug之类的工具找到请求的后端服务url和value传递的参数,然后抓取url传递的参数即可。
其实捕获ajax异步内容页面和普通页面的区别不大。 Ajax只是一个异步的http请求,只要你使用firebug之类的工具找到请求的后端服务url和value传递的参数,然后抓取url传递的参数即可。
使用 Firebug 的网络工具
如果页面被抓取,内容中没有显示的数据就是一堆JS代码。
代码
$cookie_file=tempnam('./temp','cookie');
$ch = curl_init();
$url1 = "http://www.cdut.edu.cn/default.html";
curl_setopt($ch,CURLOPT_URL,$url1);
curl_setopt($ch,CURLOPT_HTTP_VERSION,CURL_HTTP_VERSION_1_1);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_FOLLOWLOCATION,1);
curl_setopt($ch, CURLOPT_ENCODING ,'gzip'); //加入gzip解析
//设置连接结束后保存cookie信息的文件
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookie_file);
$content=curl_exec($ch);
curl_close($ch);
$ch3 = curl_init();
$url3 = "http://www.cdut.edu.cn/xww/dwr ... 3B%3B
$curlPost = "callCount=1&page=/xww/type/1000020118.html&httpSessionId=12A9B726E6A2D4D3B09DE7952B2F282C&scriptSessionId=295315B4B4141B09DA888D3A3ADB8FAA658&c0-scriptName=portalAjax&c0-methodName=getNewsXml&c0-id=0&c0-param0=string:10000201&c0-param1=string:1000020118&c0-param2=string:news_&c0-param3=number:5969&c0-param4=number:1&c0-param5=null:null&c0-param6=null:null&batchId=0";
curl_setopt($ch3,CURLOPT_URL,$url3);
curl_setopt($ch3,CURLOPT_POST,1);
curl_setopt($ch3,CURLOPT_POSTFIELDS,$curlPost);
//设置连接结束后保存cookie信息的文件
curl_setopt($ch3,CURLOPT_COOKIEFILE,$cookie_file);
$content1=curl_exec($ch3);
curl_close($ch3);
php 抓取网页ajax数据(1.网页请求的过程(1)Request“请求”(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-14 06:05
)
1.网页请求流程
(1)请求
“问”
每个显示给用户的网页都必须经过这一步,也就是向服务器发送我们的访问请求。
(2)回应
“回复”
服务器收到用户的请求后,首先验证请求的有效性,然后将响应内容发送给用户。用户接收到响应的内容并显示出来,这就是我们熟悉的网页请求的过程。
2.如何请求网页
(1)获取
GET 是最常用的方法。一般用于获取或查询资源信息。参数在 URL 中设置。这也是大多数网站使用的方法。只需发送和返回一次,响应速度快。
(2)POST
与GET方法相比,POST方法通过请求体传递参数,可以发送的信息比GET方法大很多。
在我们编写爬虫之前,我们首先要确定向谁发送请求,如何发送请求等。
今天我们来看看如何使用GET方法获取数据
(源码中所有数据请求方式均为GET)
在 PyCharm 中输入以下代码:
import requests #加载requests库
url='http://www.******.cn/'
a=requests.get(url) #调用requests库的get方法并将获取到的数据保存到a变量中
print(a.text) #a变量是一个URL对象,它代表整个网页,但此时只需要网页中的源码,a.text表示网页源码
运行代码的结果如下:
查看全部
php 抓取网页ajax数据(1.网页请求的过程(1)Request“请求”(图)
)
1.网页请求流程
(1)请求
“问”
每个显示给用户的网页都必须经过这一步,也就是向服务器发送我们的访问请求。
(2)回应
“回复”
服务器收到用户的请求后,首先验证请求的有效性,然后将响应内容发送给用户。用户接收到响应的内容并显示出来,这就是我们熟悉的网页请求的过程。
2.如何请求网页
(1)获取
GET 是最常用的方法。一般用于获取或查询资源信息。参数在 URL 中设置。这也是大多数网站使用的方法。只需发送和返回一次,响应速度快。
(2)POST
与GET方法相比,POST方法通过请求体传递参数,可以发送的信息比GET方法大很多。
在我们编写爬虫之前,我们首先要确定向谁发送请求,如何发送请求等。
今天我们来看看如何使用GET方法获取数据
(源码中所有数据请求方式均为GET)
在 PyCharm 中输入以下代码:
import requests #加载requests库
url='http://www.******.cn/'
a=requests.get(url) #调用requests库的get方法并将获取到的数据保存到a变量中
print(a.text) #a变量是一个URL对象,它代表整个网页,但此时只需要网页中的源码,a.text表示网页源码
运行代码的结果如下:

