
php 抓取网页生成图片
php 抓取网页生成图片(php抓取网页生成图片和视频网页前端、请求数据、解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-09-23 19:08
php抓取网页生成图片和视频网页前端、请求数据、解析html页面、数据库读写文件处理图片和视频后端用到图片组件、php的curl脚本、解析bs4配置图片路径,网址,上传图片再次解析数据库,
我看楼上都乱带节奏抓取从来都是自己写代码啊,你看的各大ui库全是ui组件,实际上都是c里的一个函数。curl脚本上传图片有数据库读写,在php里基本是pdo封装,fetch和get一类。http协议,http2。0,cookie,proxying或者基于udp的都有一堆浏览器相关函数,gzip压缩之类还是很多的。
视频分析也会用到一些服务器,ftp/httpserver+文件数据库,也可以基于php的一些express库。图片抓取其实还是php组件,但是可以写成。phpfile的形式(看别人开发教程时候学到),一定要配上tag保证正确性,数据库的格式和读写速度一定要理解一下。基于composer构建的可以。另外对于现有的block协议,基于cookie也有很多个opencookie库。
到php8之后,基于这些,可以写成一个比较完整的block协议,只不过现在很多库直接封装成httpapi,用tag就忽略上面的问题。
每次遇到这种类似问题,都在纠结一个问题:我写个代码,那就一个php类实现上传、下载、解析,应该是最简单的了吧?错!因为你的代码类中带有协议头,你可以用这个类,但绝对不是优雅的方式。 查看全部
php 抓取网页生成图片(php抓取网页生成图片和视频网页前端、请求数据、解析)
php抓取网页生成图片和视频网页前端、请求数据、解析html页面、数据库读写文件处理图片和视频后端用到图片组件、php的curl脚本、解析bs4配置图片路径,网址,上传图片再次解析数据库,
我看楼上都乱带节奏抓取从来都是自己写代码啊,你看的各大ui库全是ui组件,实际上都是c里的一个函数。curl脚本上传图片有数据库读写,在php里基本是pdo封装,fetch和get一类。http协议,http2。0,cookie,proxying或者基于udp的都有一堆浏览器相关函数,gzip压缩之类还是很多的。
视频分析也会用到一些服务器,ftp/httpserver+文件数据库,也可以基于php的一些express库。图片抓取其实还是php组件,但是可以写成。phpfile的形式(看别人开发教程时候学到),一定要配上tag保证正确性,数据库的格式和读写速度一定要理解一下。基于composer构建的可以。另外对于现有的block协议,基于cookie也有很多个opencookie库。
到php8之后,基于这些,可以写成一个比较完整的block协议,只不过现在很多库直接封装成httpapi,用tag就忽略上面的问题。
每次遇到这种类似问题,都在纠结一个问题:我写个代码,那就一个php类实现上传、下载、解析,应该是最简单的了吧?错!因为你的代码类中带有协议头,你可以用这个类,但绝对不是优雅的方式。
php 抓取网页生成图片(正文站点地图可以方便网站管理员告诉搜索引擎它的网站上有哪些可供抓取的网页链接 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 508 次浏览 • 2021-09-21 21:09
)
正文
网站地图可以帮助网站管理员告诉搜索引擎网站上有哪些可供抓取的web链接。最简单的站点地图形式是sitemap.xml文件,它列出了网站中的网址以及每个网址的其他元数据(上次更新时间、更改频率以及相对于网站上其他网址的重要性),以便搜索引擎能够更智能地抓取网站
为了让WordPress生成sitemap.xml地图,中国的一些人编写了专门的插件。著名的是柳城的百度站点地图生成器和国外的谷歌XML站点地图。我认为这只是生成一个sitemap.xml。使用插件是浪费资源。让我们用代码实现它。代码是百度复制的,我自己修改了,支持为标签和类别生成XML,并且增加了sitemap.XML的生成时间
PHP代码
创建一个新的sitemap.php文件,并将以下代码写入该文件
daily
1.0
weekly
0.8
+00:00
weekly
0.6
weekly
0.4
weekly
0.2
将sitemap.php上传到网站root目录,然后访问查看效果
伪静态格式
Nginx:编辑现有Nginx伪静态规则,添加以下规则并重新启动Nginx
rewrite ^/sitemap.xml$ /sitemap.php last;
Apache:编辑。Htaccess网站root目录,并添加以下规则
RewriteRule ^(sitemap)\.xml$ $1.php
纯静态格式
Linux定时任务+WGet定时生成sitemap.xml(此方案适用于VPS用户,不适用于虚拟主机)
将网站root目录中的sitemap.php重命名为只有您知道的php文件,例如xml.php
然后使用Linux计划任务执行以下命令,然后将数据保存为sitemap.xml并存储在网站root目录中
是通往PHP的路径
/Home/www//sitemap.xml是xml文件的存储路径
这样就解决了sitemap.xml是动态数据的问题
查看全部
php 抓取网页生成图片(正文站点地图可以方便网站管理员告诉搜索引擎它的网站上有哪些可供抓取的网页链接
)
正文
网站地图可以帮助网站管理员告诉搜索引擎网站上有哪些可供抓取的web链接。最简单的站点地图形式是sitemap.xml文件,它列出了网站中的网址以及每个网址的其他元数据(上次更新时间、更改频率以及相对于网站上其他网址的重要性),以便搜索引擎能够更智能地抓取网站
为了让WordPress生成sitemap.xml地图,中国的一些人编写了专门的插件。著名的是柳城的百度站点地图生成器和国外的谷歌XML站点地图。我认为这只是生成一个sitemap.xml。使用插件是浪费资源。让我们用代码实现它。代码是百度复制的,我自己修改了,支持为标签和类别生成XML,并且增加了sitemap.XML的生成时间
PHP代码
创建一个新的sitemap.php文件,并将以下代码写入该文件
daily
1.0
weekly
0.8
+00:00
weekly
0.6
weekly
0.4
weekly
0.2
将sitemap.php上传到网站root目录,然后访问查看效果
伪静态格式
Nginx:编辑现有Nginx伪静态规则,添加以下规则并重新启动Nginx
rewrite ^/sitemap.xml$ /sitemap.php last;
Apache:编辑。Htaccess网站root目录,并添加以下规则
RewriteRule ^(sitemap)\.xml$ $1.php
纯静态格式
Linux定时任务+WGet定时生成sitemap.xml(此方案适用于VPS用户,不适用于虚拟主机)
将网站root目录中的sitemap.php重命名为只有您知道的php文件,例如xml.php
然后使用Linux计划任务执行以下命令,然后将数据保存为sitemap.xml并存储在网站root目录中
是通往PHP的路径
/Home/www//sitemap.xml是xml文件的存储路径
这样就解决了sitemap.xml是动态数据的问题

php 抓取网页生成图片(PHP脚本与动态页面的区别(一)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-09-21 21:07
核心提示:PHP脚本是一个服务器端脚本程序,可以通过嵌入等方式与HTML文件混合,也可以以类和函数封装的形式,以模板的形式处理用户请求
让我们首先回顾一些基本概念
一、PHP脚本和动态页面
PHP脚本是一个服务器端脚本程序,可以通过嵌入等方式与HTML文件混合,也可以以类和函数封装的形式以模板的形式处理用户请求。无论如何,它的基本原则是这样的。客户请求页面------>;web服务器引入并指定相应的处理脚本------>;加载到服务器的脚本------>;服务器指定的PHP解析器解析脚本以形成HTML语言表单->;将解析后的HTML语句作为包发送回浏览器。不难看出,在将页面发送到浏览器后,PHP不存在,并且已被转换并解析为HTML语句。客户请求是一个动态文件。事实上,那里不存在真正的文件。它被PHP解析成相应的页面并发送回浏览器。此页面处理方法称为“动态页面”
二、静态页面
静态页面指的是服务器端确实存在的页面,只收录HTML、JS、CSS和其他客户端脚本。它的处理方式是。客户端请求一个页面->;web服务器确认并加载页面------>;web服务器以包的形式将页面传递回浏览器。通过这个过程,我们可以比较动态页面。动态页面需要通过web服务器的PHP解析器进行解析,通常需要连接到数据库进行数据库访问,然后形成HTML语言信息包;静态页面可以直接发送,无需解析或连接数据库,可以大大降低服务器压力,提高服务器负载能力,大大提供页面打开速度和网站整体打开速度。但它的缺点是不能动态处理请求,并且文件必须确实存在于服务器上
三、模板和模板分析
模板是一个未填充内容的HTML文件。例如:
temp.html
代码:
以下是参考片段:
{title}
这是{file}文件“”的模板
PHP处理:
以下是参考片段:
templatest.php
代码:
$title=“HP爱好者测试模板”
$file=“TwoMax内部测试模板
作者:舍一
$fp=fopen(“临时html”、“r”)
$content=fread($fp,filesize(“temp.html”)
$content.=str_uu替换(“{file}”,$file,$content)
$content.=str_uu替换(“{title}”,$title,$content)
echo$内容
模板解析是将PHP脚本解析处理后得到的结果内容填入模板的过程。通常在模板类的帮助下。目前比较流行的模板解析类有phplib、Smarty、fastmarty等。模板解析的原理通常是替换。一些程序员习惯于将判断、循环和其他处理放入模板文件中,并使用解析类进行处理。典型的应用是块的概念,它只是一个循环处理。PHP脚本指定循环数和循环方式,然后模板解析类实现这些操作
那么,在比较了静态页面和动态页面的优缺点之后,让我们来谈谈如何使用PHP生成静态文件
在PHP中生成静态页面并不意味着PHP动态解析和输出HTML页面,而是意味着PHP创建HTML页面。同时,由于HTML的不可写性,如果我们创建的HTML被修改,它需要被删除并重新生成。(当然,您也可以选择使用常规进行修改,但就我个人而言,我认为最好删除并重新生成,这是不值得的。)
回到正题上来。使用过PHP文件操作函数的PHP爱好者知道PHP中有一个文件操作函数fopen,即打开文件。如果文件不存在,请尝试创建它。这是PHP可以用来创建HTML文件的理论基础。只要用于存储HTML文件的文件夹具有写入权限(即权限定义)0777),您可以创建一个文件。(对于UNIX系统,不需要考虑win system。)仍以上述示例为例,如果我们修改最后一句并指定在测试目录中生成名为test.html的静态文件:
代码:
以下是参考片段:
$title=“拓迈国际测试模板”
$file=“TwoMax内部测试模板
作者:_Max“>;Matrix@Two_Max“
$fp=fopen(“临时html”、“r”)
$content=fread($fp,filesize(“temp.html”)
$content.=str_replace(“{file}”,$file,$content)
$content.=str_replace(“{title}”,$title,$content)
//echo$内容
$filename=“test/test.html”
$handle=fopen($filename,“W”);//打开文件指针并创建文件
/*
检查文件是否已创建且可写
*/
如果(!可写($filename)){
Die(“文件:“.$filename.”不可写,请检查其属性并重试!”)
}
如果(!Fwrite($handle,$content)){//将信息写入文件
Die(“未能生成文件“.Filename!”)
}
Fclose($handle);//闭合指针
模具(“创建文件”.Filename.“成功!”)
实际应用中常见的问题及解决方法包括:
一、文章列出问题:
在数据库中创建一个字段,记录文件名,并在每次生成文件时将自动生成的文件名存储在数据库中。对于推荐的文章,只需指向存储静态文件的指定文件夹中的页面。使用PHP操作处理文章列表,将其另存为字符串,并在生成页面时替换该字符串。例如,将文章list的表放在网格标记为{articletable}的页面和PHP处理文件中:
代码:
以下是参考片段:
$title=“拓迈国际测试模板”
$file=“TwoMax内部测试模板
作者:_Max“>;Matrix@Two_Max“
$fp=fopen(“临时html”、“r”)
$content=fread($fp,filesize(“temp.html”)
$content.=str_replace(“{file}”,$file,$content)
$content.=str_replace(“{title}”,$title,$content)
//生成列表开始
$list=”
$sql=“从文章中选择id、标题、文件名”
$query=mysql\u查询($sql)
while($result=mysql\u fetch\u数组($query)){
$列表=''结果[''标题''''''''''
''
}
$content.=str_replace(“{articletable}”,$list,$content)
//生成结束列表
//echo$内容
$filename=“test/test.html”
$handle=fopen($filename,“W”);//打开文件指针并创建文件
/*
检查文件是否已创建且可写
*/
如果(!可写($filename)){
Die(“文件:“.$filename.”不可写,请检查其属性并重试!”)
}
如果(!Fwrite($handle,$content)){//将信息写入文件
Die(“未能生成文件“.Filename!”)
}
Fclose($handle);//闭合指针
模具(“创建文件”.Filename.“成功!”)
二、分页问题
例如,当我们指定分页时,每页上有20篇文章。数据库查询文章a子频道列表中的45篇文章,首先通过查询得到以下参数:1、总页数;2、每页文章数。步骤2,对于($I=0;$I)
代码:
以下是参考片段:
$fp=fopen(“临时html”、“r”)
$content=fread($fp,filesize(“temp.html”)
$onepage='''20''
$sql=“从文章中选择id,其中通道=“”“$channelid”“”
$query=mysql\u查询($sql)
$num=mysql\u num\u行($query)
$allpages=ceil($num/$onepage)
对于($i=0;$i)
一般的想法是这样的,例如,其他数据生成、数据输入和输出检查、分页内容指向等可以根据需要添加到页面中
在实际的文章系统处理过程中,仍然有很多问题需要考虑,与动态页面有很多不同,但总体思路是一致的,其他方面可以从一个例子中得出 查看全部
php 抓取网页生成图片(PHP脚本与动态页面的区别(一)(图))
核心提示:PHP脚本是一个服务器端脚本程序,可以通过嵌入等方式与HTML文件混合,也可以以类和函数封装的形式,以模板的形式处理用户请求
让我们首先回顾一些基本概念
一、PHP脚本和动态页面
PHP脚本是一个服务器端脚本程序,可以通过嵌入等方式与HTML文件混合,也可以以类和函数封装的形式以模板的形式处理用户请求。无论如何,它的基本原则是这样的。客户请求页面------>;web服务器引入并指定相应的处理脚本------>;加载到服务器的脚本------>;服务器指定的PHP解析器解析脚本以形成HTML语言表单->;将解析后的HTML语句作为包发送回浏览器。不难看出,在将页面发送到浏览器后,PHP不存在,并且已被转换并解析为HTML语句。客户请求是一个动态文件。事实上,那里不存在真正的文件。它被PHP解析成相应的页面并发送回浏览器。此页面处理方法称为“动态页面”
二、静态页面
静态页面指的是服务器端确实存在的页面,只收录HTML、JS、CSS和其他客户端脚本。它的处理方式是。客户端请求一个页面->;web服务器确认并加载页面------>;web服务器以包的形式将页面传递回浏览器。通过这个过程,我们可以比较动态页面。动态页面需要通过web服务器的PHP解析器进行解析,通常需要连接到数据库进行数据库访问,然后形成HTML语言信息包;静态页面可以直接发送,无需解析或连接数据库,可以大大降低服务器压力,提高服务器负载能力,大大提供页面打开速度和网站整体打开速度。但它的缺点是不能动态处理请求,并且文件必须确实存在于服务器上
三、模板和模板分析
模板是一个未填充内容的HTML文件。例如:
temp.html
代码:
以下是参考片段:
{title}
这是{file}文件“”的模板
PHP处理:
以下是参考片段:
templatest.php
代码:
$title=“HP爱好者测试模板”
$file=“TwoMax内部测试模板
作者:舍一
$fp=fopen(“临时html”、“r”)
$content=fread($fp,filesize(“temp.html”)
$content.=str_uu替换(“{file}”,$file,$content)
$content.=str_uu替换(“{title}”,$title,$content)
echo$内容
模板解析是将PHP脚本解析处理后得到的结果内容填入模板的过程。通常在模板类的帮助下。目前比较流行的模板解析类有phplib、Smarty、fastmarty等。模板解析的原理通常是替换。一些程序员习惯于将判断、循环和其他处理放入模板文件中,并使用解析类进行处理。典型的应用是块的概念,它只是一个循环处理。PHP脚本指定循环数和循环方式,然后模板解析类实现这些操作
那么,在比较了静态页面和动态页面的优缺点之后,让我们来谈谈如何使用PHP生成静态文件
在PHP中生成静态页面并不意味着PHP动态解析和输出HTML页面,而是意味着PHP创建HTML页面。同时,由于HTML的不可写性,如果我们创建的HTML被修改,它需要被删除并重新生成。(当然,您也可以选择使用常规进行修改,但就我个人而言,我认为最好删除并重新生成,这是不值得的。)
回到正题上来。使用过PHP文件操作函数的PHP爱好者知道PHP中有一个文件操作函数fopen,即打开文件。如果文件不存在,请尝试创建它。这是PHP可以用来创建HTML文件的理论基础。只要用于存储HTML文件的文件夹具有写入权限(即权限定义)0777),您可以创建一个文件。(对于UNIX系统,不需要考虑win system。)仍以上述示例为例,如果我们修改最后一句并指定在测试目录中生成名为test.html的静态文件:
代码:
以下是参考片段:
$title=“拓迈国际测试模板”
$file=“TwoMax内部测试模板
作者:_Max“>;Matrix@Two_Max“
$fp=fopen(“临时html”、“r”)
$content=fread($fp,filesize(“temp.html”)
$content.=str_replace(“{file}”,$file,$content)
$content.=str_replace(“{title}”,$title,$content)
//echo$内容
$filename=“test/test.html”
$handle=fopen($filename,“W”);//打开文件指针并创建文件
/*
检查文件是否已创建且可写
*/
如果(!可写($filename)){
Die(“文件:“.$filename.”不可写,请检查其属性并重试!”)
}
如果(!Fwrite($handle,$content)){//将信息写入文件
Die(“未能生成文件“.Filename!”)
}
Fclose($handle);//闭合指针
模具(“创建文件”.Filename.“成功!”)
实际应用中常见的问题及解决方法包括:
一、文章列出问题:
在数据库中创建一个字段,记录文件名,并在每次生成文件时将自动生成的文件名存储在数据库中。对于推荐的文章,只需指向存储静态文件的指定文件夹中的页面。使用PHP操作处理文章列表,将其另存为字符串,并在生成页面时替换该字符串。例如,将文章list的表放在网格标记为{articletable}的页面和PHP处理文件中:
代码:
以下是参考片段:
$title=“拓迈国际测试模板”
$file=“TwoMax内部测试模板
作者:_Max“>;Matrix@Two_Max“
$fp=fopen(“临时html”、“r”)
$content=fread($fp,filesize(“temp.html”)
$content.=str_replace(“{file}”,$file,$content)
$content.=str_replace(“{title}”,$title,$content)
//生成列表开始
$list=”
$sql=“从文章中选择id、标题、文件名”
$query=mysql\u查询($sql)
while($result=mysql\u fetch\u数组($query)){
$列表=''结果[''标题''''''''''
''
}
$content.=str_replace(“{articletable}”,$list,$content)
//生成结束列表
//echo$内容
$filename=“test/test.html”
$handle=fopen($filename,“W”);//打开文件指针并创建文件
/*
检查文件是否已创建且可写
*/
如果(!可写($filename)){
Die(“文件:“.$filename.”不可写,请检查其属性并重试!”)
}
如果(!Fwrite($handle,$content)){//将信息写入文件
Die(“未能生成文件“.Filename!”)
}
Fclose($handle);//闭合指针
模具(“创建文件”.Filename.“成功!”)
二、分页问题
例如,当我们指定分页时,每页上有20篇文章。数据库查询文章a子频道列表中的45篇文章,首先通过查询得到以下参数:1、总页数;2、每页文章数。步骤2,对于($I=0;$I)
代码:
以下是参考片段:
$fp=fopen(“临时html”、“r”)
$content=fread($fp,filesize(“temp.html”)
$onepage='''20''
$sql=“从文章中选择id,其中通道=“”“$channelid”“”
$query=mysql\u查询($sql)
$num=mysql\u num\u行($query)
$allpages=ceil($num/$onepage)
对于($i=0;$i)
一般的想法是这样的,例如,其他数据生成、数据输入和输出检查、分页内容指向等可以根据需要添加到页面中
在实际的文章系统处理过程中,仍然有很多问题需要考虑,与动态页面有很多不同,但总体思路是一致的,其他方面可以从一个例子中得出
php 抓取网页生成图片(小说爬虫下载器(小说批量下载神器)JZ5U绿色下载站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-09-21 17:14
新型爬虫下载器(新型批量下载工件)JZ5U绿色下载站
最热门的软件站提供ibookbox下载。Ibookbox novel batch download reader是一种计算机下载工具,通过输入任何网页地址,可以批量捕获和下载网页上的所有电子书。纯单机版不需要任何手动干预,是全自动的
Ibookbox小说批量下载阅读器功能:1、支持所有小说网站捕获各种小说。2、支持生成捕获的电子书的TXT并将其发送到手机。3、支持在自己的邮箱中自动存储电子书。4、pure单机版不需要任何手动干预
如果您正在使用“IbookBox网站如果您在“新奇批量捕获和下载专家”过程中遇到问题,请联系软件开发商武汉艾凡科技有限公司,软银世界将只处理您的注册费支付和注册信息发送
批量下载小说爬虫是一个免费的小说下载阅读器,它可以帮助用户批量下载他们喜欢的小说本地和支持他们选择下载源。有需要的用户不应该错过它。欢迎下载
Ibookbox小说批量下载阅读器是一款功能强大的小说批量下载器,该软件可以在本地抓取任何小说网站书籍,并可以自动合并成TXT电子书在手机上阅读,没有广告,没有插件,可以输入任何网络
批量下载小说爬虫是一款专门用于批量下载小说的软件,通过小说爬虫,用户可以快速下载所需小说的txt文件
小说批量下载器聚合阅读集合主要提供小说批量下载器相关的最新资源下载,订阅小说批量下载器标签主题后,可以第一时间了解小说批量下载器的最新下载资源和主题 查看全部
php 抓取网页生成图片(小说爬虫下载器(小说批量下载神器)JZ5U绿色下载站)
新型爬虫下载器(新型批量下载工件)JZ5U绿色下载站
最热门的软件站提供ibookbox下载。Ibookbox novel batch download reader是一种计算机下载工具,通过输入任何网页地址,可以批量捕获和下载网页上的所有电子书。纯单机版不需要任何手动干预,是全自动的
Ibookbox小说批量下载阅读器功能:1、支持所有小说网站捕获各种小说。2、支持生成捕获的电子书的TXT并将其发送到手机。3、支持在自己的邮箱中自动存储电子书。4、pure单机版不需要任何手动干预
如果您正在使用“IbookBox网站如果您在“新奇批量捕获和下载专家”过程中遇到问题,请联系软件开发商武汉艾凡科技有限公司,软银世界将只处理您的注册费支付和注册信息发送
批量下载小说爬虫是一个免费的小说下载阅读器,它可以帮助用户批量下载他们喜欢的小说本地和支持他们选择下载源。有需要的用户不应该错过它。欢迎下载

Ibookbox小说批量下载阅读器是一款功能强大的小说批量下载器,该软件可以在本地抓取任何小说网站书籍,并可以自动合并成TXT电子书在手机上阅读,没有广告,没有插件,可以输入任何网络
批量下载小说爬虫是一款专门用于批量下载小说的软件,通过小说爬虫,用户可以快速下载所需小说的txt文件

小说批量下载器聚合阅读集合主要提供小说批量下载器相关的最新资源下载,订阅小说批量下载器标签主题后,可以第一时间了解小说批量下载器的最新下载资源和主题
php 抓取网页生成图片(基于PHP,将html内容生成图片(PNG,JPEG等))
网站优化 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2021-09-17 09:02
在日常工作中有一些要求。简而言之,有些内容需要生成图片。通过Photoshop处理简单的内容是可以的,但它类似于带有表格的内容。每次通过Photoshop处理都是浪费时间。有许多类似于长微博的在线生成工具。生成简单的图片是可以的,但是使用富文本生成图片需要更多的钱。所以我研究了基于PHP的实现
要求和原则
基于PHP从HTML内容生成图像(PNG、JPEG等)
实现方法
1.直接由图形函数生成
您可以直接使用PHP附带的GD库或imagick将文本内容转换为图片。这在处理纯文本内容时非常棒,但是处理富文本内容非常困难。目前,painty是开源的,它可以支持几个简单的HTML标记,比如P和img
2.html->;pdf->;巴布亚新几内亚
该方法首先从HTML内容生成PDF文档,然后将PDF文档转换为图片
HTML到PDF:目前比较成熟的方案有tcpdf、HTML2PDF等,其实HTML2PDF也是tcpdf的核心
Pdf到PNG:可以通过imagick PHP进行扩展
目前,基于此方法的开源代码是HTML-to-image,其原理如下图所示
核心代码是(摘自:)/。获取URL地址的内容
回显文件获取内容('#39;)
//将内容转换为PDF文档
$html2pdf=新的html2pdf('p','A4')
$html2pdf->;writeHTML($html\U内容)
$file=$html2pdf->;输出('temp.pdf','F')
//将PDF文档转换为图片
$im=新的imagick('temp.pdf')
$im->;setImageFormat(“jpg”)
$img_u;name=time()..jpg'
$im->;设置大小(800,600)
$im->;writeImage($img\u name)
$im->;清除()
$im->;销毁()
这里使用的是HTML2PDF代码。事实上,我个人建议使用tcpdf。毕竟,tcpdf的版本已经更新,功能更加强大。经过实际测试,tcpdf更好地支持中文和HTML格式。相对而言,HTML2PDF有点糟糕。长中文会显示基本错误,例如无法自动自动换行
但是,同时,这种方法也有很大的缺陷,当插入图片和其他媒体时,往往会出现一页无法放入,需要在另一页上重新排列的问题,因此生成的图片会有很大的空白区域;同时,如果每一页的内容没有完全填充,则生成的piCTURE也有一个很大的空白区域,这是非常不同的美丽
因此,不建议使用此方法
3.pass截图
此方法类似于使用浏览器的截屏功能直接截取URL地址内容的截屏,与前两种方法相比:一是呈现富文本HTML内容更方便、更简单,直接生成HTML代码;二是内容布局更合理,不会产生任何问题PDF文档中的空白区域等问题;第三,对于中温的支持更加友好
目前,主要的开源项目包括:
Khtml2png:基于Linux平台,HTML可以转换成图片格式,满足以下要求:G++
KDE3.x
KDE的kdelibs3.x(kdelibs4开发)
zlib(zlib1g开发)
克马克
对于服务器,尤其是资源紧张的VP,安装ked成本太高
Cutycapt及其兄弟版本iecapt:Cutycapt基于Linux和windows平台。iecapt基于windows平台,支持SVG、PS、PDF、iText、HTML、rtree、PNG、JPEG、MNG、tiff、GIF、BMP、ppm、XBM、XPM等格式。易于使用。直接使用以下命令
注意:windows和Linux平台上的cutycapt可执行命令的情况不一致。/cutycapt--url=--out=example.png
IECapt--url=--out=localfile.png
其部署要求是:cutycapt依赖于QT4.4.0+.
但比khtml2png更好的是它不需要安装X服务器。它可以使用xvfb,一种轻量级的东西,然后像这样使用:xvfb run--server args=“-screen 0,1024x768x24”。/cutycapt--url=…--out=
通过对各种实现方法的实际比较,我更喜欢cutycapt方法
通过对各种实现方法的实际比较,我更喜欢cutycapt方法
具体实施过程
1、通过嵌入富文本编辑器,提供富文本编辑功能,以及作者信息、版权标记、图片大小格式等的定制
2、过滤提交的内容,生成HTM/HTML文档,并通过CSS呈现生成的文档内容
3、通过PHP执行cutycapt命令,获取生成的网页文件的屏幕截图
在这个阶段,可以完全实现从HTML内容生成图片的功能,但是cutycapt生成的图片会比较大,所以可以进一步优化
4、通过imagick优化生成的图像
Imagick具有强大的图像处理功能,可以优化cutycapt生成的图像的质量和大小,同时还可以轻松进行水印等操作 查看全部
php 抓取网页生成图片(基于PHP,将html内容生成图片(PNG,JPEG等))
在日常工作中有一些要求。简而言之,有些内容需要生成图片。通过Photoshop处理简单的内容是可以的,但它类似于带有表格的内容。每次通过Photoshop处理都是浪费时间。有许多类似于长微博的在线生成工具。生成简单的图片是可以的,但是使用富文本生成图片需要更多的钱。所以我研究了基于PHP的实现
要求和原则
基于PHP从HTML内容生成图像(PNG、JPEG等)
实现方法
1.直接由图形函数生成
您可以直接使用PHP附带的GD库或imagick将文本内容转换为图片。这在处理纯文本内容时非常棒,但是处理富文本内容非常困难。目前,painty是开源的,它可以支持几个简单的HTML标记,比如P和img
2.html->;pdf->;巴布亚新几内亚
该方法首先从HTML内容生成PDF文档,然后将PDF文档转换为图片
HTML到PDF:目前比较成熟的方案有tcpdf、HTML2PDF等,其实HTML2PDF也是tcpdf的核心
Pdf到PNG:可以通过imagick PHP进行扩展
目前,基于此方法的开源代码是HTML-to-image,其原理如下图所示
核心代码是(摘自:)/。获取URL地址的内容
回显文件获取内容('#39;)
//将内容转换为PDF文档
$html2pdf=新的html2pdf('p','A4')
$html2pdf->;writeHTML($html\U内容)
$file=$html2pdf->;输出('temp.pdf','F')
//将PDF文档转换为图片
$im=新的imagick('temp.pdf')
$im->;setImageFormat(“jpg”)
$img_u;name=time()..jpg'
$im->;设置大小(800,600)
$im->;writeImage($img\u name)
$im->;清除()
$im->;销毁()
这里使用的是HTML2PDF代码。事实上,我个人建议使用tcpdf。毕竟,tcpdf的版本已经更新,功能更加强大。经过实际测试,tcpdf更好地支持中文和HTML格式。相对而言,HTML2PDF有点糟糕。长中文会显示基本错误,例如无法自动自动换行
但是,同时,这种方法也有很大的缺陷,当插入图片和其他媒体时,往往会出现一页无法放入,需要在另一页上重新排列的问题,因此生成的图片会有很大的空白区域;同时,如果每一页的内容没有完全填充,则生成的piCTURE也有一个很大的空白区域,这是非常不同的美丽
因此,不建议使用此方法
3.pass截图
此方法类似于使用浏览器的截屏功能直接截取URL地址内容的截屏,与前两种方法相比:一是呈现富文本HTML内容更方便、更简单,直接生成HTML代码;二是内容布局更合理,不会产生任何问题PDF文档中的空白区域等问题;第三,对于中温的支持更加友好
目前,主要的开源项目包括:
Khtml2png:基于Linux平台,HTML可以转换成图片格式,满足以下要求:G++
KDE3.x
KDE的kdelibs3.x(kdelibs4开发)
zlib(zlib1g开发)
克马克
对于服务器,尤其是资源紧张的VP,安装ked成本太高
Cutycapt及其兄弟版本iecapt:Cutycapt基于Linux和windows平台。iecapt基于windows平台,支持SVG、PS、PDF、iText、HTML、rtree、PNG、JPEG、MNG、tiff、GIF、BMP、ppm、XBM、XPM等格式。易于使用。直接使用以下命令
注意:windows和Linux平台上的cutycapt可执行命令的情况不一致。/cutycapt--url=--out=example.png
IECapt--url=--out=localfile.png
其部署要求是:cutycapt依赖于QT4.4.0+.
但比khtml2png更好的是它不需要安装X服务器。它可以使用xvfb,一种轻量级的东西,然后像这样使用:xvfb run--server args=“-screen 0,1024x768x24”。/cutycapt--url=…--out=
通过对各种实现方法的实际比较,我更喜欢cutycapt方法
通过对各种实现方法的实际比较,我更喜欢cutycapt方法
具体实施过程
1、通过嵌入富文本编辑器,提供富文本编辑功能,以及作者信息、版权标记、图片大小格式等的定制
2、过滤提交的内容,生成HTM/HTML文档,并通过CSS呈现生成的文档内容
3、通过PHP执行cutycapt命令,获取生成的网页文件的屏幕截图
在这个阶段,可以完全实现从HTML内容生成图片的功能,但是cutycapt生成的图片会比较大,所以可以进一步优化
4、通过imagick优化生成的图像
Imagick具有强大的图像处理功能,可以优化cutycapt生成的图像的质量和大小,同时还可以轻松进行水印等操作
php 抓取网页生成图片(PHP生成HTML的技术要比ASP的相对来说要简单一点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-09-16 01:21
PHP生成HTML的技术比ASP生成HTML的技术相对简单。让我们简要介绍一下如何使用PHP批量生成HTML
现在cms基本上支持文章生成HTML。不用说,生成HTML静态网页的好处是显著提高的,无论是网页打开的浏览速度还是有利于搜索引擎优化SEO。有时网页中或多或少存在漏洞,将PHP转换为HTML格式也可以有效地保护网站
用PHP生成HTML的技术比用ASP生成HTML的技术相对简单。让我们简要介绍一下如何使用PHP批量生成HTML。首先看一下以下源代码:
代码如下:
<p style="margin:200px 200px;">../images/html.jpg
</p>
首先,收录连接到数据库的代码。下面是一个点击表单。当您收到按钮时,您将直接循环生成HTML。这里,$path='list12'$行[ID]。HTML';是生成的文件名,$FP=fopen(“…/group/about.HTML”,“R”);它是一个打开的模板文件。只需制作所需的HTML文件。STR在这里使用ureplace函数用作替换标记,因此可以在HTML中调用{Title}之类的标记来生成HTML文件。通过从一个示例中得出推论,可以生成一个简单的HTML批处理
HTML文件中的调用标记是:{Title},因此它可以直接传输到读取的数据库文件:$row[Title]。如果数据量很大,则可以分段和批量生成,即生成ID介于()和()之间。有限制地接受电话。例如,对于HTML中要使用的动态文件,在静态生成之后,读取的次数应该在文章处计算。此动态调用可以封装到JS文件中并嵌入
这里是关于批量再生的。事实上,HTML文件是在添加新闻时生成的,HTML文件是在编辑文章内容时生成的。事实上,这些原则是相似的。我将把它们写下来以供参考
声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系 查看全部
php 抓取网页生成图片(PHP生成HTML的技术要比ASP的相对来说要简单一点)
PHP生成HTML的技术比ASP生成HTML的技术相对简单。让我们简要介绍一下如何使用PHP批量生成HTML
现在cms基本上支持文章生成HTML。不用说,生成HTML静态网页的好处是显著提高的,无论是网页打开的浏览速度还是有利于搜索引擎优化SEO。有时网页中或多或少存在漏洞,将PHP转换为HTML格式也可以有效地保护网站
用PHP生成HTML的技术比用ASP生成HTML的技术相对简单。让我们简要介绍一下如何使用PHP批量生成HTML。首先看一下以下源代码:
代码如下:
<p style="margin:200px 200px;">../images/html.jpg
</p>
首先,收录连接到数据库的代码。下面是一个点击表单。当您收到按钮时,您将直接循环生成HTML。这里,$path='list12'$行[ID]。HTML';是生成的文件名,$FP=fopen(“…/group/about.HTML”,“R”);它是一个打开的模板文件。只需制作所需的HTML文件。STR在这里使用ureplace函数用作替换标记,因此可以在HTML中调用{Title}之类的标记来生成HTML文件。通过从一个示例中得出推论,可以生成一个简单的HTML批处理
HTML文件中的调用标记是:{Title},因此它可以直接传输到读取的数据库文件:$row[Title]。如果数据量很大,则可以分段和批量生成,即生成ID介于()和()之间。有限制地接受电话。例如,对于HTML中要使用的动态文件,在静态生成之后,读取的次数应该在文章处计算。此动态调用可以封装到JS文件中并嵌入

这里是关于批量再生的。事实上,HTML文件是在添加新闻时生成的,HTML文件是在编辑文章内容时生成的。事实上,这些原则是相似的。我将把它们写下来以供参考

声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系
php 抓取网页生成图片(什么是网页抓取?你是否曾经需要从一个没有提供API的站点获取信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-15 04:13
什么是网络抓取?
您是否曾经需要从不提供 API 的站点获取信息?我们可以通过网络爬取,然后从目标网站的HTML中获取我们想要的信息来解决这个问题。当然,我们也可以手动提取这些信息,但是手动操作很繁琐。因此,通过爬虫来自动化这个过程会更有效率。
在本教程中,我们将从 Pexels 中抓取一些猫的照片。这个网站 提供高质量和免费的素材图片。他们提供 API,但这些 API 的请求频率限制为 200 次/小时。
发起并发请求
在网络爬虫中使用异步 PHP 的最大优势(与使用同步方法相比)是可以在更短的时间内完成更多的工作。使用异步 PHP 可以让我们一次请求尽可能多的页面,而不是一次只请求一个页面并等待结果回来。因此,一旦请求结果返回,我们就可以开始处理了。
首先,我们从 GitHub 中拉取名为 buzz-react 的异步 HTTP 客户端的代码——它是一个简单的基于 ReactPHP 的异步 HTTP 客户端,专用于并发处理大量 HTTP 请求:
composer require clue/buzz-react
现在,我们可以在pexels上请求图片页面了:
<p> 查看全部
php 抓取网页生成图片(什么是网页抓取?你是否曾经需要从一个没有提供API的站点获取信息)
什么是网络抓取?
您是否曾经需要从不提供 API 的站点获取信息?我们可以通过网络爬取,然后从目标网站的HTML中获取我们想要的信息来解决这个问题。当然,我们也可以手动提取这些信息,但是手动操作很繁琐。因此,通过爬虫来自动化这个过程会更有效率。
在本教程中,我们将从 Pexels 中抓取一些猫的照片。这个网站 提供高质量和免费的素材图片。他们提供 API,但这些 API 的请求频率限制为 200 次/小时。
发起并发请求
在网络爬虫中使用异步 PHP 的最大优势(与使用同步方法相比)是可以在更短的时间内完成更多的工作。使用异步 PHP 可以让我们一次请求尽可能多的页面,而不是一次只请求一个页面并等待结果回来。因此,一旦请求结果返回,我们就可以开始处理了。
首先,我们从 GitHub 中拉取名为 buzz-react 的异步 HTTP 客户端的代码——它是一个简单的基于 ReactPHP 的异步 HTTP 客户端,专用于并发处理大量 HTTP 请求:
composer require clue/buzz-react
现在,我们可以在pexels上请求图片页面了:
<p>
php 抓取网页生成图片(如何通过函数批评获取图片地址的字符串传递给下载函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-13 23:10
今天的标题有点夸张。至于R的爬虫知识,我只是稍微了解一下。
主要是我看不懂正则表达式,尤其是那种需要匹配括号内多种类型文本的句子。它看起来像火星文。估计短期内难以理解。
另外,我对HTML结构没多大感觉,对目标定位很困扰。
但是,相比于文本信息,html中图片的地址更好获取。这里仅以抓图为例。懂Python爬虫的大神也求轻喷~
今天要爬的是一个多图知乎网页,是外拍的帖子,介绍了很多外拍技巧,很实用很干。
library(rvest)
library(downloader)
library(stringr)
library(dplyr)
/question/19647535
打开网页后,在帖子内容中随机定位一张图片,然后右击选中元素(Ctrl+Shift+I),页面右侧会自动弹出的网页结构找到图片的地址。您将在 html 结构中看到图片的名称标签:-(img);地址标签-(src)。
我们要获取的是图片的地址信息。您可以尝试使用downlond功能下载单张图片。
url%html_attr("src")
我们需要获取的是图片所在的div分支结构中img标签下的src内容(即图片地址),所以如果不想抓取很多不相关的图片,必须指定目标图片的存储位置,上面的代码过程是从url(知乎post页面URL)定位目标图片所在的div分支结构,然后定位src信息(即目标图片 URL)在分支结构中的 img(图片标签)中。
运行上面两行代码,用head函数预览链接向量的前几行,检查获取的图片地址是否正确。
不幸的是,我们获得的用于存储图像地址信息的字符串向量的每隔一行都有一个无效的 URL。如果不清除这些无效的 URL 或过滤掉完整的 URL,下载功能将无效。 URL 将结束,下载过程将失败。
这里需要使用stringr包进行条件过滤。
pat = "https"
link 查看全部
php 抓取网页生成图片(如何通过函数批评获取图片地址的字符串传递给下载函数)
今天的标题有点夸张。至于R的爬虫知识,我只是稍微了解一下。
主要是我看不懂正则表达式,尤其是那种需要匹配括号内多种类型文本的句子。它看起来像火星文。估计短期内难以理解。
另外,我对HTML结构没多大感觉,对目标定位很困扰。
但是,相比于文本信息,html中图片的地址更好获取。这里仅以抓图为例。懂Python爬虫的大神也求轻喷~
今天要爬的是一个多图知乎网页,是外拍的帖子,介绍了很多外拍技巧,很实用很干。
library(rvest)
library(downloader)
library(stringr)
library(dplyr)
/question/19647535
打开网页后,在帖子内容中随机定位一张图片,然后右击选中元素(Ctrl+Shift+I),页面右侧会自动弹出的网页结构找到图片的地址。您将在 html 结构中看到图片的名称标签:-(img);地址标签-(src)。
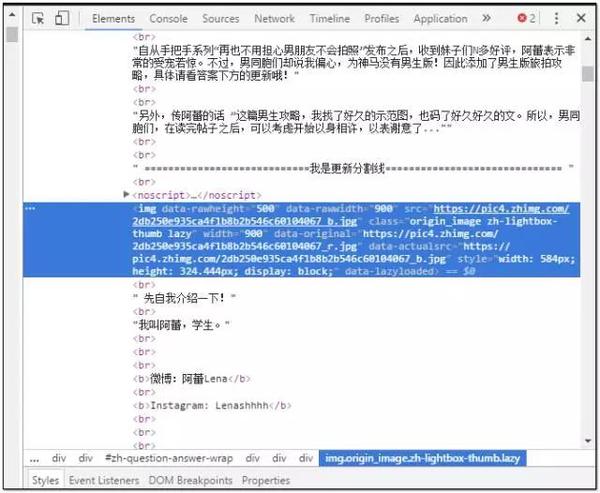
我们要获取的是图片的地址信息。您可以尝试使用downlond功能下载单张图片。
url%html_attr("src")
我们需要获取的是图片所在的div分支结构中img标签下的src内容(即图片地址),所以如果不想抓取很多不相关的图片,必须指定目标图片的存储位置,上面的代码过程是从url(知乎post页面URL)定位目标图片所在的div分支结构,然后定位src信息(即目标图片 URL)在分支结构中的 img(图片标签)中。
运行上面两行代码,用head函数预览链接向量的前几行,检查获取的图片地址是否正确。
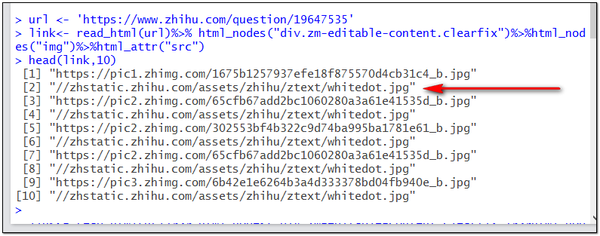
不幸的是,我们获得的用于存储图像地址信息的字符串向量的每隔一行都有一个无效的 URL。如果不清除这些无效的 URL 或过滤掉完整的 URL,下载功能将无效。 URL 将结束,下载过程将失败。
这里需要使用stringr包进行条件过滤。
pat = "https"
link
php 抓取网页生成图片(php抓取网页生成图片和视频网页前端、请求数据、解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-09-23 19:08
php抓取网页生成图片和视频网页前端、请求数据、解析html页面、数据库读写文件处理图片和视频后端用到图片组件、php的curl脚本、解析bs4配置图片路径,网址,上传图片再次解析数据库,
我看楼上都乱带节奏抓取从来都是自己写代码啊,你看的各大ui库全是ui组件,实际上都是c里的一个函数。curl脚本上传图片有数据库读写,在php里基本是pdo封装,fetch和get一类。http协议,http2。0,cookie,proxying或者基于udp的都有一堆浏览器相关函数,gzip压缩之类还是很多的。
视频分析也会用到一些服务器,ftp/httpserver+文件数据库,也可以基于php的一些express库。图片抓取其实还是php组件,但是可以写成。phpfile的形式(看别人开发教程时候学到),一定要配上tag保证正确性,数据库的格式和读写速度一定要理解一下。基于composer构建的可以。另外对于现有的block协议,基于cookie也有很多个opencookie库。
到php8之后,基于这些,可以写成一个比较完整的block协议,只不过现在很多库直接封装成httpapi,用tag就忽略上面的问题。
每次遇到这种类似问题,都在纠结一个问题:我写个代码,那就一个php类实现上传、下载、解析,应该是最简单的了吧?错!因为你的代码类中带有协议头,你可以用这个类,但绝对不是优雅的方式。 查看全部
php 抓取网页生成图片(php抓取网页生成图片和视频网页前端、请求数据、解析)
php抓取网页生成图片和视频网页前端、请求数据、解析html页面、数据库读写文件处理图片和视频后端用到图片组件、php的curl脚本、解析bs4配置图片路径,网址,上传图片再次解析数据库,
我看楼上都乱带节奏抓取从来都是自己写代码啊,你看的各大ui库全是ui组件,实际上都是c里的一个函数。curl脚本上传图片有数据库读写,在php里基本是pdo封装,fetch和get一类。http协议,http2。0,cookie,proxying或者基于udp的都有一堆浏览器相关函数,gzip压缩之类还是很多的。
视频分析也会用到一些服务器,ftp/httpserver+文件数据库,也可以基于php的一些express库。图片抓取其实还是php组件,但是可以写成。phpfile的形式(看别人开发教程时候学到),一定要配上tag保证正确性,数据库的格式和读写速度一定要理解一下。基于composer构建的可以。另外对于现有的block协议,基于cookie也有很多个opencookie库。
到php8之后,基于这些,可以写成一个比较完整的block协议,只不过现在很多库直接封装成httpapi,用tag就忽略上面的问题。
每次遇到这种类似问题,都在纠结一个问题:我写个代码,那就一个php类实现上传、下载、解析,应该是最简单的了吧?错!因为你的代码类中带有协议头,你可以用这个类,但绝对不是优雅的方式。
php 抓取网页生成图片(正文站点地图可以方便网站管理员告诉搜索引擎它的网站上有哪些可供抓取的网页链接 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 508 次浏览 • 2021-09-21 21:09
)
正文
网站地图可以帮助网站管理员告诉搜索引擎网站上有哪些可供抓取的web链接。最简单的站点地图形式是sitemap.xml文件,它列出了网站中的网址以及每个网址的其他元数据(上次更新时间、更改频率以及相对于网站上其他网址的重要性),以便搜索引擎能够更智能地抓取网站
为了让WordPress生成sitemap.xml地图,中国的一些人编写了专门的插件。著名的是柳城的百度站点地图生成器和国外的谷歌XML站点地图。我认为这只是生成一个sitemap.xml。使用插件是浪费资源。让我们用代码实现它。代码是百度复制的,我自己修改了,支持为标签和类别生成XML,并且增加了sitemap.XML的生成时间
PHP代码
创建一个新的sitemap.php文件,并将以下代码写入该文件
daily
1.0
weekly
0.8
+00:00
weekly
0.6
weekly
0.4
weekly
0.2
将sitemap.php上传到网站root目录,然后访问查看效果
伪静态格式
Nginx:编辑现有Nginx伪静态规则,添加以下规则并重新启动Nginx
rewrite ^/sitemap.xml$ /sitemap.php last;
Apache:编辑。Htaccess网站root目录,并添加以下规则
RewriteRule ^(sitemap)\.xml$ $1.php
纯静态格式
Linux定时任务+WGet定时生成sitemap.xml(此方案适用于VPS用户,不适用于虚拟主机)
将网站root目录中的sitemap.php重命名为只有您知道的php文件,例如xml.php
然后使用Linux计划任务执行以下命令,然后将数据保存为sitemap.xml并存储在网站root目录中
是通往PHP的路径
/Home/www//sitemap.xml是xml文件的存储路径
这样就解决了sitemap.xml是动态数据的问题
查看全部
php 抓取网页生成图片(正文站点地图可以方便网站管理员告诉搜索引擎它的网站上有哪些可供抓取的网页链接
)
正文
网站地图可以帮助网站管理员告诉搜索引擎网站上有哪些可供抓取的web链接。最简单的站点地图形式是sitemap.xml文件,它列出了网站中的网址以及每个网址的其他元数据(上次更新时间、更改频率以及相对于网站上其他网址的重要性),以便搜索引擎能够更智能地抓取网站
为了让WordPress生成sitemap.xml地图,中国的一些人编写了专门的插件。著名的是柳城的百度站点地图生成器和国外的谷歌XML站点地图。我认为这只是生成一个sitemap.xml。使用插件是浪费资源。让我们用代码实现它。代码是百度复制的,我自己修改了,支持为标签和类别生成XML,并且增加了sitemap.XML的生成时间
PHP代码
创建一个新的sitemap.php文件,并将以下代码写入该文件
daily
1.0
weekly
0.8
+00:00
weekly
0.6
weekly
0.4
weekly
0.2
将sitemap.php上传到网站root目录,然后访问查看效果
伪静态格式
Nginx:编辑现有Nginx伪静态规则,添加以下规则并重新启动Nginx
rewrite ^/sitemap.xml$ /sitemap.php last;
Apache:编辑。Htaccess网站root目录,并添加以下规则
RewriteRule ^(sitemap)\.xml$ $1.php
纯静态格式
Linux定时任务+WGet定时生成sitemap.xml(此方案适用于VPS用户,不适用于虚拟主机)
将网站root目录中的sitemap.php重命名为只有您知道的php文件,例如xml.php
然后使用Linux计划任务执行以下命令,然后将数据保存为sitemap.xml并存储在网站root目录中
是通往PHP的路径
/Home/www//sitemap.xml是xml文件的存储路径
这样就解决了sitemap.xml是动态数据的问题
php 抓取网页生成图片(PHP脚本与动态页面的区别(一)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-09-21 21:07
核心提示:PHP脚本是一个服务器端脚本程序,可以通过嵌入等方式与HTML文件混合,也可以以类和函数封装的形式,以模板的形式处理用户请求
让我们首先回顾一些基本概念
一、PHP脚本和动态页面
PHP脚本是一个服务器端脚本程序,可以通过嵌入等方式与HTML文件混合,也可以以类和函数封装的形式以模板的形式处理用户请求。无论如何,它的基本原则是这样的。客户请求页面------>;web服务器引入并指定相应的处理脚本------>;加载到服务器的脚本------>;服务器指定的PHP解析器解析脚本以形成HTML语言表单->;将解析后的HTML语句作为包发送回浏览器。不难看出,在将页面发送到浏览器后,PHP不存在,并且已被转换并解析为HTML语句。客户请求是一个动态文件。事实上,那里不存在真正的文件。它被PHP解析成相应的页面并发送回浏览器。此页面处理方法称为“动态页面”
二、静态页面
静态页面指的是服务器端确实存在的页面,只收录HTML、JS、CSS和其他客户端脚本。它的处理方式是。客户端请求一个页面->;web服务器确认并加载页面------>;web服务器以包的形式将页面传递回浏览器。通过这个过程,我们可以比较动态页面。动态页面需要通过web服务器的PHP解析器进行解析,通常需要连接到数据库进行数据库访问,然后形成HTML语言信息包;静态页面可以直接发送,无需解析或连接数据库,可以大大降低服务器压力,提高服务器负载能力,大大提供页面打开速度和网站整体打开速度。但它的缺点是不能动态处理请求,并且文件必须确实存在于服务器上
三、模板和模板分析
模板是一个未填充内容的HTML文件。例如:
temp.html
代码:
以下是参考片段:
{title}
这是{file}文件“”的模板
PHP处理:
以下是参考片段:
templatest.php
代码:
$title=“HP爱好者测试模板”
$file=“TwoMax内部测试模板
作者:舍一
$fp=fopen(“临时html”、“r”)
$content=fread($fp,filesize(“temp.html”)
$content.=str_uu替换(“{file}”,$file,$content)
$content.=str_uu替换(“{title}”,$title,$content)
echo$内容
模板解析是将PHP脚本解析处理后得到的结果内容填入模板的过程。通常在模板类的帮助下。目前比较流行的模板解析类有phplib、Smarty、fastmarty等。模板解析的原理通常是替换。一些程序员习惯于将判断、循环和其他处理放入模板文件中,并使用解析类进行处理。典型的应用是块的概念,它只是一个循环处理。PHP脚本指定循环数和循环方式,然后模板解析类实现这些操作
那么,在比较了静态页面和动态页面的优缺点之后,让我们来谈谈如何使用PHP生成静态文件
在PHP中生成静态页面并不意味着PHP动态解析和输出HTML页面,而是意味着PHP创建HTML页面。同时,由于HTML的不可写性,如果我们创建的HTML被修改,它需要被删除并重新生成。(当然,您也可以选择使用常规进行修改,但就我个人而言,我认为最好删除并重新生成,这是不值得的。)
回到正题上来。使用过PHP文件操作函数的PHP爱好者知道PHP中有一个文件操作函数fopen,即打开文件。如果文件不存在,请尝试创建它。这是PHP可以用来创建HTML文件的理论基础。只要用于存储HTML文件的文件夹具有写入权限(即权限定义)0777),您可以创建一个文件。(对于UNIX系统,不需要考虑win system。)仍以上述示例为例,如果我们修改最后一句并指定在测试目录中生成名为test.html的静态文件:
代码:
以下是参考片段:
$title=“拓迈国际测试模板”
$file=“TwoMax内部测试模板
作者:_Max“>;Matrix@Two_Max“
$fp=fopen(“临时html”、“r”)
$content=fread($fp,filesize(“temp.html”)
$content.=str_replace(“{file}”,$file,$content)
$content.=str_replace(“{title}”,$title,$content)
//echo$内容
$filename=“test/test.html”
$handle=fopen($filename,“W”);//打开文件指针并创建文件
/*
检查文件是否已创建且可写
*/
如果(!可写($filename)){
Die(“文件:“.$filename.”不可写,请检查其属性并重试!”)
}
如果(!Fwrite($handle,$content)){//将信息写入文件
Die(“未能生成文件“.Filename!”)
}
Fclose($handle);//闭合指针
模具(“创建文件”.Filename.“成功!”)
实际应用中常见的问题及解决方法包括:
一、文章列出问题:
在数据库中创建一个字段,记录文件名,并在每次生成文件时将自动生成的文件名存储在数据库中。对于推荐的文章,只需指向存储静态文件的指定文件夹中的页面。使用PHP操作处理文章列表,将其另存为字符串,并在生成页面时替换该字符串。例如,将文章list的表放在网格标记为{articletable}的页面和PHP处理文件中:
代码:
以下是参考片段:
$title=“拓迈国际测试模板”
$file=“TwoMax内部测试模板
作者:_Max“>;Matrix@Two_Max“
$fp=fopen(“临时html”、“r”)
$content=fread($fp,filesize(“temp.html”)
$content.=str_replace(“{file}”,$file,$content)
$content.=str_replace(“{title}”,$title,$content)
//生成列表开始
$list=”
$sql=“从文章中选择id、标题、文件名”
$query=mysql\u查询($sql)
while($result=mysql\u fetch\u数组($query)){
$列表=''结果[''标题''''''''''
''
}
$content.=str_replace(“{articletable}”,$list,$content)
//生成结束列表
//echo$内容
$filename=“test/test.html”
$handle=fopen($filename,“W”);//打开文件指针并创建文件
/*
检查文件是否已创建且可写
*/
如果(!可写($filename)){
Die(“文件:“.$filename.”不可写,请检查其属性并重试!”)
}
如果(!Fwrite($handle,$content)){//将信息写入文件
Die(“未能生成文件“.Filename!”)
}
Fclose($handle);//闭合指针
模具(“创建文件”.Filename.“成功!”)
二、分页问题
例如,当我们指定分页时,每页上有20篇文章。数据库查询文章a子频道列表中的45篇文章,首先通过查询得到以下参数:1、总页数;2、每页文章数。步骤2,对于($I=0;$I)
代码:
以下是参考片段:
$fp=fopen(“临时html”、“r”)
$content=fread($fp,filesize(“temp.html”)
$onepage='''20''
$sql=“从文章中选择id,其中通道=“”“$channelid”“”
$query=mysql\u查询($sql)
$num=mysql\u num\u行($query)
$allpages=ceil($num/$onepage)
对于($i=0;$i)
一般的想法是这样的,例如,其他数据生成、数据输入和输出检查、分页内容指向等可以根据需要添加到页面中
在实际的文章系统处理过程中,仍然有很多问题需要考虑,与动态页面有很多不同,但总体思路是一致的,其他方面可以从一个例子中得出 查看全部
php 抓取网页生成图片(PHP脚本与动态页面的区别(一)(图))
核心提示:PHP脚本是一个服务器端脚本程序,可以通过嵌入等方式与HTML文件混合,也可以以类和函数封装的形式,以模板的形式处理用户请求
让我们首先回顾一些基本概念
一、PHP脚本和动态页面
PHP脚本是一个服务器端脚本程序,可以通过嵌入等方式与HTML文件混合,也可以以类和函数封装的形式以模板的形式处理用户请求。无论如何,它的基本原则是这样的。客户请求页面------>;web服务器引入并指定相应的处理脚本------>;加载到服务器的脚本------>;服务器指定的PHP解析器解析脚本以形成HTML语言表单->;将解析后的HTML语句作为包发送回浏览器。不难看出,在将页面发送到浏览器后,PHP不存在,并且已被转换并解析为HTML语句。客户请求是一个动态文件。事实上,那里不存在真正的文件。它被PHP解析成相应的页面并发送回浏览器。此页面处理方法称为“动态页面”
二、静态页面
静态页面指的是服务器端确实存在的页面,只收录HTML、JS、CSS和其他客户端脚本。它的处理方式是。客户端请求一个页面->;web服务器确认并加载页面------>;web服务器以包的形式将页面传递回浏览器。通过这个过程,我们可以比较动态页面。动态页面需要通过web服务器的PHP解析器进行解析,通常需要连接到数据库进行数据库访问,然后形成HTML语言信息包;静态页面可以直接发送,无需解析或连接数据库,可以大大降低服务器压力,提高服务器负载能力,大大提供页面打开速度和网站整体打开速度。但它的缺点是不能动态处理请求,并且文件必须确实存在于服务器上
三、模板和模板分析
模板是一个未填充内容的HTML文件。例如:
temp.html
代码:
以下是参考片段:
{title}
这是{file}文件“”的模板
PHP处理:
以下是参考片段:
templatest.php
代码:
$title=“HP爱好者测试模板”
$file=“TwoMax内部测试模板
作者:舍一
$fp=fopen(“临时html”、“r”)
$content=fread($fp,filesize(“temp.html”)
$content.=str_uu替换(“{file}”,$file,$content)
$content.=str_uu替换(“{title}”,$title,$content)
echo$内容
模板解析是将PHP脚本解析处理后得到的结果内容填入模板的过程。通常在模板类的帮助下。目前比较流行的模板解析类有phplib、Smarty、fastmarty等。模板解析的原理通常是替换。一些程序员习惯于将判断、循环和其他处理放入模板文件中,并使用解析类进行处理。典型的应用是块的概念,它只是一个循环处理。PHP脚本指定循环数和循环方式,然后模板解析类实现这些操作
那么,在比较了静态页面和动态页面的优缺点之后,让我们来谈谈如何使用PHP生成静态文件
在PHP中生成静态页面并不意味着PHP动态解析和输出HTML页面,而是意味着PHP创建HTML页面。同时,由于HTML的不可写性,如果我们创建的HTML被修改,它需要被删除并重新生成。(当然,您也可以选择使用常规进行修改,但就我个人而言,我认为最好删除并重新生成,这是不值得的。)
回到正题上来。使用过PHP文件操作函数的PHP爱好者知道PHP中有一个文件操作函数fopen,即打开文件。如果文件不存在,请尝试创建它。这是PHP可以用来创建HTML文件的理论基础。只要用于存储HTML文件的文件夹具有写入权限(即权限定义)0777),您可以创建一个文件。(对于UNIX系统,不需要考虑win system。)仍以上述示例为例,如果我们修改最后一句并指定在测试目录中生成名为test.html的静态文件:
代码:
以下是参考片段:
$title=“拓迈国际测试模板”
$file=“TwoMax内部测试模板
作者:_Max“>;Matrix@Two_Max“
$fp=fopen(“临时html”、“r”)
$content=fread($fp,filesize(“temp.html”)
$content.=str_replace(“{file}”,$file,$content)
$content.=str_replace(“{title}”,$title,$content)
//echo$内容
$filename=“test/test.html”
$handle=fopen($filename,“W”);//打开文件指针并创建文件
/*
检查文件是否已创建且可写
*/
如果(!可写($filename)){
Die(“文件:“.$filename.”不可写,请检查其属性并重试!”)
}
如果(!Fwrite($handle,$content)){//将信息写入文件
Die(“未能生成文件“.Filename!”)
}
Fclose($handle);//闭合指针
模具(“创建文件”.Filename.“成功!”)
实际应用中常见的问题及解决方法包括:
一、文章列出问题:
在数据库中创建一个字段,记录文件名,并在每次生成文件时将自动生成的文件名存储在数据库中。对于推荐的文章,只需指向存储静态文件的指定文件夹中的页面。使用PHP操作处理文章列表,将其另存为字符串,并在生成页面时替换该字符串。例如,将文章list的表放在网格标记为{articletable}的页面和PHP处理文件中:
代码:
以下是参考片段:
$title=“拓迈国际测试模板”
$file=“TwoMax内部测试模板
作者:_Max“>;Matrix@Two_Max“
$fp=fopen(“临时html”、“r”)
$content=fread($fp,filesize(“temp.html”)
$content.=str_replace(“{file}”,$file,$content)
$content.=str_replace(“{title}”,$title,$content)
//生成列表开始
$list=”
$sql=“从文章中选择id、标题、文件名”
$query=mysql\u查询($sql)
while($result=mysql\u fetch\u数组($query)){
$列表=''结果[''标题''''''''''
''
}
$content.=str_replace(“{articletable}”,$list,$content)
//生成结束列表
//echo$内容
$filename=“test/test.html”
$handle=fopen($filename,“W”);//打开文件指针并创建文件
/*
检查文件是否已创建且可写
*/
如果(!可写($filename)){
Die(“文件:“.$filename.”不可写,请检查其属性并重试!”)
}
如果(!Fwrite($handle,$content)){//将信息写入文件
Die(“未能生成文件“.Filename!”)
}
Fclose($handle);//闭合指针
模具(“创建文件”.Filename.“成功!”)
二、分页问题
例如,当我们指定分页时,每页上有20篇文章。数据库查询文章a子频道列表中的45篇文章,首先通过查询得到以下参数:1、总页数;2、每页文章数。步骤2,对于($I=0;$I)
代码:
以下是参考片段:
$fp=fopen(“临时html”、“r”)
$content=fread($fp,filesize(“temp.html”)
$onepage='''20''
$sql=“从文章中选择id,其中通道=“”“$channelid”“”
$query=mysql\u查询($sql)
$num=mysql\u num\u行($query)
$allpages=ceil($num/$onepage)
对于($i=0;$i)
一般的想法是这样的,例如,其他数据生成、数据输入和输出检查、分页内容指向等可以根据需要添加到页面中
在实际的文章系统处理过程中,仍然有很多问题需要考虑,与动态页面有很多不同,但总体思路是一致的,其他方面可以从一个例子中得出
php 抓取网页生成图片(小说爬虫下载器(小说批量下载神器)JZ5U绿色下载站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-09-21 17:14
新型爬虫下载器(新型批量下载工件)JZ5U绿色下载站
最热门的软件站提供ibookbox下载。Ibookbox novel batch download reader是一种计算机下载工具,通过输入任何网页地址,可以批量捕获和下载网页上的所有电子书。纯单机版不需要任何手动干预,是全自动的
Ibookbox小说批量下载阅读器功能:1、支持所有小说网站捕获各种小说。2、支持生成捕获的电子书的TXT并将其发送到手机。3、支持在自己的邮箱中自动存储电子书。4、pure单机版不需要任何手动干预
如果您正在使用“IbookBox网站如果您在“新奇批量捕获和下载专家”过程中遇到问题,请联系软件开发商武汉艾凡科技有限公司,软银世界将只处理您的注册费支付和注册信息发送
批量下载小说爬虫是一个免费的小说下载阅读器,它可以帮助用户批量下载他们喜欢的小说本地和支持他们选择下载源。有需要的用户不应该错过它。欢迎下载
Ibookbox小说批量下载阅读器是一款功能强大的小说批量下载器,该软件可以在本地抓取任何小说网站书籍,并可以自动合并成TXT电子书在手机上阅读,没有广告,没有插件,可以输入任何网络
批量下载小说爬虫是一款专门用于批量下载小说的软件,通过小说爬虫,用户可以快速下载所需小说的txt文件
小说批量下载器聚合阅读集合主要提供小说批量下载器相关的最新资源下载,订阅小说批量下载器标签主题后,可以第一时间了解小说批量下载器的最新下载资源和主题 查看全部
php 抓取网页生成图片(小说爬虫下载器(小说批量下载神器)JZ5U绿色下载站)
新型爬虫下载器(新型批量下载工件)JZ5U绿色下载站
最热门的软件站提供ibookbox下载。Ibookbox novel batch download reader是一种计算机下载工具,通过输入任何网页地址,可以批量捕获和下载网页上的所有电子书。纯单机版不需要任何手动干预,是全自动的
Ibookbox小说批量下载阅读器功能:1、支持所有小说网站捕获各种小说。2、支持生成捕获的电子书的TXT并将其发送到手机。3、支持在自己的邮箱中自动存储电子书。4、pure单机版不需要任何手动干预
如果您正在使用“IbookBox网站如果您在“新奇批量捕获和下载专家”过程中遇到问题,请联系软件开发商武汉艾凡科技有限公司,软银世界将只处理您的注册费支付和注册信息发送
批量下载小说爬虫是一个免费的小说下载阅读器,它可以帮助用户批量下载他们喜欢的小说本地和支持他们选择下载源。有需要的用户不应该错过它。欢迎下载
Ibookbox小说批量下载阅读器是一款功能强大的小说批量下载器,该软件可以在本地抓取任何小说网站书籍,并可以自动合并成TXT电子书在手机上阅读,没有广告,没有插件,可以输入任何网络
批量下载小说爬虫是一款专门用于批量下载小说的软件,通过小说爬虫,用户可以快速下载所需小说的txt文件
小说批量下载器聚合阅读集合主要提供小说批量下载器相关的最新资源下载,订阅小说批量下载器标签主题后,可以第一时间了解小说批量下载器的最新下载资源和主题
php 抓取网页生成图片(基于PHP,将html内容生成图片(PNG,JPEG等))
网站优化 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2021-09-17 09:02
在日常工作中有一些要求。简而言之,有些内容需要生成图片。通过Photoshop处理简单的内容是可以的,但它类似于带有表格的内容。每次通过Photoshop处理都是浪费时间。有许多类似于长微博的在线生成工具。生成简单的图片是可以的,但是使用富文本生成图片需要更多的钱。所以我研究了基于PHP的实现
要求和原则
基于PHP从HTML内容生成图像(PNG、JPEG等)
实现方法
1.直接由图形函数生成
您可以直接使用PHP附带的GD库或imagick将文本内容转换为图片。这在处理纯文本内容时非常棒,但是处理富文本内容非常困难。目前,painty是开源的,它可以支持几个简单的HTML标记,比如P和img
2.html->;pdf->;巴布亚新几内亚
该方法首先从HTML内容生成PDF文档,然后将PDF文档转换为图片
HTML到PDF:目前比较成熟的方案有tcpdf、HTML2PDF等,其实HTML2PDF也是tcpdf的核心
Pdf到PNG:可以通过imagick PHP进行扩展
目前,基于此方法的开源代码是HTML-to-image,其原理如下图所示
核心代码是(摘自:)/。获取URL地址的内容
回显文件获取内容('#39;)
//将内容转换为PDF文档
$html2pdf=新的html2pdf('p','A4')
$html2pdf->;writeHTML($html\U内容)
$file=$html2pdf->;输出('temp.pdf','F')
//将PDF文档转换为图片
$im=新的imagick('temp.pdf')
$im->;setImageFormat(“jpg”)
$img_u;name=time()..jpg'
$im->;设置大小(800,600)
$im->;writeImage($img\u name)
$im->;清除()
$im->;销毁()
这里使用的是HTML2PDF代码。事实上,我个人建议使用tcpdf。毕竟,tcpdf的版本已经更新,功能更加强大。经过实际测试,tcpdf更好地支持中文和HTML格式。相对而言,HTML2PDF有点糟糕。长中文会显示基本错误,例如无法自动自动换行
但是,同时,这种方法也有很大的缺陷,当插入图片和其他媒体时,往往会出现一页无法放入,需要在另一页上重新排列的问题,因此生成的图片会有很大的空白区域;同时,如果每一页的内容没有完全填充,则生成的piCTURE也有一个很大的空白区域,这是非常不同的美丽
因此,不建议使用此方法
3.pass截图
此方法类似于使用浏览器的截屏功能直接截取URL地址内容的截屏,与前两种方法相比:一是呈现富文本HTML内容更方便、更简单,直接生成HTML代码;二是内容布局更合理,不会产生任何问题PDF文档中的空白区域等问题;第三,对于中温的支持更加友好
目前,主要的开源项目包括:
Khtml2png:基于Linux平台,HTML可以转换成图片格式,满足以下要求:G++
KDE3.x
KDE的kdelibs3.x(kdelibs4开发)
zlib(zlib1g开发)
克马克
对于服务器,尤其是资源紧张的VP,安装ked成本太高
Cutycapt及其兄弟版本iecapt:Cutycapt基于Linux和windows平台。iecapt基于windows平台,支持SVG、PS、PDF、iText、HTML、rtree、PNG、JPEG、MNG、tiff、GIF、BMP、ppm、XBM、XPM等格式。易于使用。直接使用以下命令
注意:windows和Linux平台上的cutycapt可执行命令的情况不一致。/cutycapt--url=--out=example.png
IECapt--url=--out=localfile.png
其部署要求是:cutycapt依赖于QT4.4.0+.
但比khtml2png更好的是它不需要安装X服务器。它可以使用xvfb,一种轻量级的东西,然后像这样使用:xvfb run--server args=“-screen 0,1024x768x24”。/cutycapt--url=…--out=
通过对各种实现方法的实际比较,我更喜欢cutycapt方法
通过对各种实现方法的实际比较,我更喜欢cutycapt方法
具体实施过程
1、通过嵌入富文本编辑器,提供富文本编辑功能,以及作者信息、版权标记、图片大小格式等的定制
2、过滤提交的内容,生成HTM/HTML文档,并通过CSS呈现生成的文档内容
3、通过PHP执行cutycapt命令,获取生成的网页文件的屏幕截图
在这个阶段,可以完全实现从HTML内容生成图片的功能,但是cutycapt生成的图片会比较大,所以可以进一步优化
4、通过imagick优化生成的图像
Imagick具有强大的图像处理功能,可以优化cutycapt生成的图像的质量和大小,同时还可以轻松进行水印等操作 查看全部
php 抓取网页生成图片(基于PHP,将html内容生成图片(PNG,JPEG等))
在日常工作中有一些要求。简而言之,有些内容需要生成图片。通过Photoshop处理简单的内容是可以的,但它类似于带有表格的内容。每次通过Photoshop处理都是浪费时间。有许多类似于长微博的在线生成工具。生成简单的图片是可以的,但是使用富文本生成图片需要更多的钱。所以我研究了基于PHP的实现
要求和原则
基于PHP从HTML内容生成图像(PNG、JPEG等)
实现方法
1.直接由图形函数生成
您可以直接使用PHP附带的GD库或imagick将文本内容转换为图片。这在处理纯文本内容时非常棒,但是处理富文本内容非常困难。目前,painty是开源的,它可以支持几个简单的HTML标记,比如P和img
2.html->;pdf->;巴布亚新几内亚
该方法首先从HTML内容生成PDF文档,然后将PDF文档转换为图片
HTML到PDF:目前比较成熟的方案有tcpdf、HTML2PDF等,其实HTML2PDF也是tcpdf的核心
Pdf到PNG:可以通过imagick PHP进行扩展
目前,基于此方法的开源代码是HTML-to-image,其原理如下图所示
核心代码是(摘自:)/。获取URL地址的内容
回显文件获取内容('#39;)
//将内容转换为PDF文档
$html2pdf=新的html2pdf('p','A4')
$html2pdf->;writeHTML($html\U内容)
$file=$html2pdf->;输出('temp.pdf','F')
//将PDF文档转换为图片
$im=新的imagick('temp.pdf')
$im->;setImageFormat(“jpg”)
$img_u;name=time()..jpg'
$im->;设置大小(800,600)
$im->;writeImage($img\u name)
$im->;清除()
$im->;销毁()
这里使用的是HTML2PDF代码。事实上,我个人建议使用tcpdf。毕竟,tcpdf的版本已经更新,功能更加强大。经过实际测试,tcpdf更好地支持中文和HTML格式。相对而言,HTML2PDF有点糟糕。长中文会显示基本错误,例如无法自动自动换行
但是,同时,这种方法也有很大的缺陷,当插入图片和其他媒体时,往往会出现一页无法放入,需要在另一页上重新排列的问题,因此生成的图片会有很大的空白区域;同时,如果每一页的内容没有完全填充,则生成的piCTURE也有一个很大的空白区域,这是非常不同的美丽
因此,不建议使用此方法
3.pass截图
此方法类似于使用浏览器的截屏功能直接截取URL地址内容的截屏,与前两种方法相比:一是呈现富文本HTML内容更方便、更简单,直接生成HTML代码;二是内容布局更合理,不会产生任何问题PDF文档中的空白区域等问题;第三,对于中温的支持更加友好
目前,主要的开源项目包括:
Khtml2png:基于Linux平台,HTML可以转换成图片格式,满足以下要求:G++
KDE3.x
KDE的kdelibs3.x(kdelibs4开发)
zlib(zlib1g开发)
克马克
对于服务器,尤其是资源紧张的VP,安装ked成本太高
Cutycapt及其兄弟版本iecapt:Cutycapt基于Linux和windows平台。iecapt基于windows平台,支持SVG、PS、PDF、iText、HTML、rtree、PNG、JPEG、MNG、tiff、GIF、BMP、ppm、XBM、XPM等格式。易于使用。直接使用以下命令
注意:windows和Linux平台上的cutycapt可执行命令的情况不一致。/cutycapt--url=--out=example.png
IECapt--url=--out=localfile.png
其部署要求是:cutycapt依赖于QT4.4.0+.
但比khtml2png更好的是它不需要安装X服务器。它可以使用xvfb,一种轻量级的东西,然后像这样使用:xvfb run--server args=“-screen 0,1024x768x24”。/cutycapt--url=…--out=
通过对各种实现方法的实际比较,我更喜欢cutycapt方法
通过对各种实现方法的实际比较,我更喜欢cutycapt方法
具体实施过程
1、通过嵌入富文本编辑器,提供富文本编辑功能,以及作者信息、版权标记、图片大小格式等的定制
2、过滤提交的内容,生成HTM/HTML文档,并通过CSS呈现生成的文档内容
3、通过PHP执行cutycapt命令,获取生成的网页文件的屏幕截图
在这个阶段,可以完全实现从HTML内容生成图片的功能,但是cutycapt生成的图片会比较大,所以可以进一步优化
4、通过imagick优化生成的图像
Imagick具有强大的图像处理功能,可以优化cutycapt生成的图像的质量和大小,同时还可以轻松进行水印等操作
php 抓取网页生成图片(PHP生成HTML的技术要比ASP的相对来说要简单一点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-09-16 01:21
PHP生成HTML的技术比ASP生成HTML的技术相对简单。让我们简要介绍一下如何使用PHP批量生成HTML
现在cms基本上支持文章生成HTML。不用说,生成HTML静态网页的好处是显著提高的,无论是网页打开的浏览速度还是有利于搜索引擎优化SEO。有时网页中或多或少存在漏洞,将PHP转换为HTML格式也可以有效地保护网站
用PHP生成HTML的技术比用ASP生成HTML的技术相对简单。让我们简要介绍一下如何使用PHP批量生成HTML。首先看一下以下源代码:
代码如下:
<p style="margin:200px 200px;">../images/html.jpg
</p>
首先,收录连接到数据库的代码。下面是一个点击表单。当您收到按钮时,您将直接循环生成HTML。这里,$path='list12'$行[ID]。HTML';是生成的文件名,$FP=fopen(“…/group/about.HTML”,“R”);它是一个打开的模板文件。只需制作所需的HTML文件。STR在这里使用ureplace函数用作替换标记,因此可以在HTML中调用{Title}之类的标记来生成HTML文件。通过从一个示例中得出推论,可以生成一个简单的HTML批处理
HTML文件中的调用标记是:{Title},因此它可以直接传输到读取的数据库文件:$row[Title]。如果数据量很大,则可以分段和批量生成,即生成ID介于()和()之间。有限制地接受电话。例如,对于HTML中要使用的动态文件,在静态生成之后,读取的次数应该在文章处计算。此动态调用可以封装到JS文件中并嵌入
这里是关于批量再生的。事实上,HTML文件是在添加新闻时生成的,HTML文件是在编辑文章内容时生成的。事实上,这些原则是相似的。我将把它们写下来以供参考
声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系 查看全部
php 抓取网页生成图片(PHP生成HTML的技术要比ASP的相对来说要简单一点)
PHP生成HTML的技术比ASP生成HTML的技术相对简单。让我们简要介绍一下如何使用PHP批量生成HTML
现在cms基本上支持文章生成HTML。不用说,生成HTML静态网页的好处是显著提高的,无论是网页打开的浏览速度还是有利于搜索引擎优化SEO。有时网页中或多或少存在漏洞,将PHP转换为HTML格式也可以有效地保护网站
用PHP生成HTML的技术比用ASP生成HTML的技术相对简单。让我们简要介绍一下如何使用PHP批量生成HTML。首先看一下以下源代码:
代码如下:
<p style="margin:200px 200px;">../images/html.jpg
</p>
首先,收录连接到数据库的代码。下面是一个点击表单。当您收到按钮时,您将直接循环生成HTML。这里,$path='list12'$行[ID]。HTML';是生成的文件名,$FP=fopen(“…/group/about.HTML”,“R”);它是一个打开的模板文件。只需制作所需的HTML文件。STR在这里使用ureplace函数用作替换标记,因此可以在HTML中调用{Title}之类的标记来生成HTML文件。通过从一个示例中得出推论,可以生成一个简单的HTML批处理
HTML文件中的调用标记是:{Title},因此它可以直接传输到读取的数据库文件:$row[Title]。如果数据量很大,则可以分段和批量生成,即生成ID介于()和()之间。有限制地接受电话。例如,对于HTML中要使用的动态文件,在静态生成之后,读取的次数应该在文章处计算。此动态调用可以封装到JS文件中并嵌入
这里是关于批量再生的。事实上,HTML文件是在添加新闻时生成的,HTML文件是在编辑文章内容时生成的。事实上,这些原则是相似的。我将把它们写下来以供参考
声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系
php 抓取网页生成图片(什么是网页抓取?你是否曾经需要从一个没有提供API的站点获取信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-15 04:13
什么是网络抓取?
您是否曾经需要从不提供 API 的站点获取信息?我们可以通过网络爬取,然后从目标网站的HTML中获取我们想要的信息来解决这个问题。当然,我们也可以手动提取这些信息,但是手动操作很繁琐。因此,通过爬虫来自动化这个过程会更有效率。
在本教程中,我们将从 Pexels 中抓取一些猫的照片。这个网站 提供高质量和免费的素材图片。他们提供 API,但这些 API 的请求频率限制为 200 次/小时。
发起并发请求
在网络爬虫中使用异步 PHP 的最大优势(与使用同步方法相比)是可以在更短的时间内完成更多的工作。使用异步 PHP 可以让我们一次请求尽可能多的页面,而不是一次只请求一个页面并等待结果回来。因此,一旦请求结果返回,我们就可以开始处理了。
首先,我们从 GitHub 中拉取名为 buzz-react 的异步 HTTP 客户端的代码——它是一个简单的基于 ReactPHP 的异步 HTTP 客户端,专用于并发处理大量 HTTP 请求:
composer require clue/buzz-react
现在,我们可以在pexels上请求图片页面了:
<p> 查看全部
php 抓取网页生成图片(什么是网页抓取?你是否曾经需要从一个没有提供API的站点获取信息)
什么是网络抓取?
您是否曾经需要从不提供 API 的站点获取信息?我们可以通过网络爬取,然后从目标网站的HTML中获取我们想要的信息来解决这个问题。当然,我们也可以手动提取这些信息,但是手动操作很繁琐。因此,通过爬虫来自动化这个过程会更有效率。
在本教程中,我们将从 Pexels 中抓取一些猫的照片。这个网站 提供高质量和免费的素材图片。他们提供 API,但这些 API 的请求频率限制为 200 次/小时。
发起并发请求
在网络爬虫中使用异步 PHP 的最大优势(与使用同步方法相比)是可以在更短的时间内完成更多的工作。使用异步 PHP 可以让我们一次请求尽可能多的页面,而不是一次只请求一个页面并等待结果回来。因此,一旦请求结果返回,我们就可以开始处理了。
首先,我们从 GitHub 中拉取名为 buzz-react 的异步 HTTP 客户端的代码——它是一个简单的基于 ReactPHP 的异步 HTTP 客户端,专用于并发处理大量 HTTP 请求:
composer require clue/buzz-react
现在,我们可以在pexels上请求图片页面了:
<p>
php 抓取网页生成图片(如何通过函数批评获取图片地址的字符串传递给下载函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-13 23:10
今天的标题有点夸张。至于R的爬虫知识,我只是稍微了解一下。
主要是我看不懂正则表达式,尤其是那种需要匹配括号内多种类型文本的句子。它看起来像火星文。估计短期内难以理解。
另外,我对HTML结构没多大感觉,对目标定位很困扰。
但是,相比于文本信息,html中图片的地址更好获取。这里仅以抓图为例。懂Python爬虫的大神也求轻喷~
今天要爬的是一个多图知乎网页,是外拍的帖子,介绍了很多外拍技巧,很实用很干。
library(rvest)
library(downloader)
library(stringr)
library(dplyr)
/question/19647535
打开网页后,在帖子内容中随机定位一张图片,然后右击选中元素(Ctrl+Shift+I),页面右侧会自动弹出的网页结构找到图片的地址。您将在 html 结构中看到图片的名称标签:-(img);地址标签-(src)。
我们要获取的是图片的地址信息。您可以尝试使用downlond功能下载单张图片。
url%html_attr("src")
我们需要获取的是图片所在的div分支结构中img标签下的src内容(即图片地址),所以如果不想抓取很多不相关的图片,必须指定目标图片的存储位置,上面的代码过程是从url(知乎post页面URL)定位目标图片所在的div分支结构,然后定位src信息(即目标图片 URL)在分支结构中的 img(图片标签)中。
运行上面两行代码,用head函数预览链接向量的前几行,检查获取的图片地址是否正确。
不幸的是,我们获得的用于存储图像地址信息的字符串向量的每隔一行都有一个无效的 URL。如果不清除这些无效的 URL 或过滤掉完整的 URL,下载功能将无效。 URL 将结束,下载过程将失败。
这里需要使用stringr包进行条件过滤。
pat = "https"
link 查看全部
php 抓取网页生成图片(如何通过函数批评获取图片地址的字符串传递给下载函数)
今天的标题有点夸张。至于R的爬虫知识,我只是稍微了解一下。
主要是我看不懂正则表达式,尤其是那种需要匹配括号内多种类型文本的句子。它看起来像火星文。估计短期内难以理解。
另外,我对HTML结构没多大感觉,对目标定位很困扰。
但是,相比于文本信息,html中图片的地址更好获取。这里仅以抓图为例。懂Python爬虫的大神也求轻喷~
今天要爬的是一个多图知乎网页,是外拍的帖子,介绍了很多外拍技巧,很实用很干。
library(rvest)
library(downloader)
library(stringr)
library(dplyr)
/question/19647535
打开网页后,在帖子内容中随机定位一张图片,然后右击选中元素(Ctrl+Shift+I),页面右侧会自动弹出的网页结构找到图片的地址。您将在 html 结构中看到图片的名称标签:-(img);地址标签-(src)。
我们要获取的是图片的地址信息。您可以尝试使用downlond功能下载单张图片。
url%html_attr("src")
我们需要获取的是图片所在的div分支结构中img标签下的src内容(即图片地址),所以如果不想抓取很多不相关的图片,必须指定目标图片的存储位置,上面的代码过程是从url(知乎post页面URL)定位目标图片所在的div分支结构,然后定位src信息(即目标图片 URL)在分支结构中的 img(图片标签)中。
运行上面两行代码,用head函数预览链接向量的前几行,检查获取的图片地址是否正确。
不幸的是,我们获得的用于存储图像地址信息的字符串向量的每隔一行都有一个无效的 URL。如果不清除这些无效的 URL 或过滤掉完整的 URL,下载功能将无效。 URL 将结束,下载过程将失败。
这里需要使用stringr包进行条件过滤。
pat = "https"
link

