
php 抓取网页生成图片
php 抓取网页生成图片(【魔兽世界】.php)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-10-16 19:13
此方法主要是为html页面生成二维码,所以需要一个配置文件phpqrcode.php(因为内容太多,请自行到百度网盘下载,链接:提取码: r6xt。)
以下是我的控制器调用和二维码生成↓
//传的参数
$id = $_GET['id'];
$cateid = $_GET['cateid'];
//需要生成二维码的链接
$url = "http://www.***.com/?id=$id&cateid=$cateid";
require_once 'phpqrcode.php';//ci框架中引入excel类
$value = $url; //二维码内容
$errorCorrectionLevel = 'L'; //容错级别
$matrixPointSize = 5; //生成图片大小
$filename = './uploads/erweima/'.time().'.png';
QRcode::png($value,$filename , $errorCorrectionLevel, $matrixPointSize, 2);
$QR = $filename; //已经生成的原始二维码图片文件
echo base_url().$QR;die;
现在输出的是二维码的地址,然后可以通过ajax渲染到页面上。
转载于: 查看全部
php 抓取网页生成图片(【魔兽世界】.php)
此方法主要是为html页面生成二维码,所以需要一个配置文件phpqrcode.php(因为内容太多,请自行到百度网盘下载,链接:提取码: r6xt。)
以下是我的控制器调用和二维码生成↓
//传的参数
$id = $_GET['id'];
$cateid = $_GET['cateid'];
//需要生成二维码的链接
$url = "http://www.***.com/?id=$id&cateid=$cateid";
require_once 'phpqrcode.php';//ci框架中引入excel类
$value = $url; //二维码内容
$errorCorrectionLevel = 'L'; //容错级别
$matrixPointSize = 5; //生成图片大小
$filename = './uploads/erweima/'.time().'.png';
QRcode::png($value,$filename , $errorCorrectionLevel, $matrixPointSize, 2);
$QR = $filename; //已经生成的原始二维码图片文件
echo base_url().$QR;die;
现在输出的是二维码的地址,然后可以通过ajax渲染到页面上。
转载于:
php 抓取网页生成图片(PHP快速生成图片验证码并且实现验证插件1.插件(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-10-14 06:08
PHP快速生成图片验证码并实现验证插件。 1.插件功能:该插件可以快速实现网站验证码功能,包括验证码生成和验证。 2. 必需参数:CaptchaTool 类包括两个方法。 generate方法可以生成'ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890'中的四位字符,并将这些字符写入到验证码目录下的图片中,并将code值保存在session中。在和输出中,此方法不需要参数。 check方法需要用户输入的code值,返回true或false。 3. 使用方法:include这个类型的文件,实例化,用得到的对象调用对应的方法。 4. 注:使用本插件的用户可以根据自己的网站需求扩展验证码字符模板,将需要扩展的字符放在$chars中,同时需要在 for 循环中进行相应的调整。注意$bg_flie的路径文件地址是验证码背景图片的地址。验证码图片的边框颜色由imagerectangle($img, 0, 0, 144, 19, $white)中的$white决定,文字大小由imagestring()中的第二个参数决定。字符串的颜色可以根据需要分配给画布颜色,使用函数imagecolorallocate()。 查看全部
php 抓取网页生成图片(PHP快速生成图片验证码并且实现验证插件1.插件(图))
PHP快速生成图片验证码并实现验证插件。 1.插件功能:该插件可以快速实现网站验证码功能,包括验证码生成和验证。 2. 必需参数:CaptchaTool 类包括两个方法。 generate方法可以生成'ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890'中的四位字符,并将这些字符写入到验证码目录下的图片中,并将code值保存在session中。在和输出中,此方法不需要参数。 check方法需要用户输入的code值,返回true或false。 3. 使用方法:include这个类型的文件,实例化,用得到的对象调用对应的方法。 4. 注:使用本插件的用户可以根据自己的网站需求扩展验证码字符模板,将需要扩展的字符放在$chars中,同时需要在 for 循环中进行相应的调整。注意$bg_flie的路径文件地址是验证码背景图片的地址。验证码图片的边框颜色由imagerectangle($img, 0, 0, 144, 19, $white)中的$white决定,文字大小由imagestring()中的第二个参数决定。字符串的颜色可以根据需要分配给画布颜色,使用函数imagecolorallocate()。
php 抓取网页生成图片( 借助php类库及扩展完成这一需求(图)解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 397 次浏览 • 2021-10-14 06:03
借助php类库及扩展完成这一需求(图)解析)
在服务器端对编译后的html进行解析转换为图片。
由于html一般是客户端浏览器解析的,服务端无法直接解析html代码。所以我们需要使用php库和扩展来完成这个需求。
文件转换过程为html —> pdf —> png。 (推荐学习:PHP视频教程)
需要用到的类库是mPDF、imagick
pdf的官方下载地址是:(推荐在6.0虽然有点大) 这是一个可以直接下载上传到服务器的类库。里面有很多东西。新建一个html2pdf文件夹导入
include('./html2pdf/mpdf');
一个完整的函数
/*
名称 html转换为pdf图片
功能 将html页面转换为pdf图片(部分css样式无法识别)
参数数量 2个
1.必须 html代码 可以用file_get_contenth获取
2.必须 生成pdf存放位置路径
3.非必须 pdf宽
4.非必须 pdf高
返回值 图片名称
实例 code($html,'img/1.pdf');
* */
function html2pdf($html, $PATH, $w=414 ,$h=736){
//设置中文字体(很重要 它会影响到第二步中 图片生成)
$mpdf=new mPDF('utf-8');
$mpdf->autoScriptToLang = true;
$mpdf->autoLangToFont = true;
//设置pdf的尺寸
$mpdf->WriteHTML('');
//设置pdf显示方式
$mpdf->SetDisplayMode('fullpage');
//删除pdf第一页(由于设置pdf尺寸导致多出了一页)
$mpdf->DeletePages(1,1);
$mpdf->WriteHTML($html);
$pdf_name = md5(time()).'.pdf';
$mpdf->Output($PATH.$pdf_name);
return $pdf_name;
}
接下来,开始将 pdf 转换为 png 图像。这一步需要在服务器上安装ImageMagick组件
然后使用函数将生成的pdf转成png。
/*
名称 pdf转换为png图片
功能 将pdf图片转换为png图片
参数数量 2个
1.必须 html代码 可以用file_get_contenth获取
2.必须 生成pdf存放位置路径
实例 code($html,'img/1.pdf');
* */
function pdf2png($PDF, $PNG, $w=50, $h=50){
if(!extension_loaded('imagick')){
return false;
}
if(!file_exists($PDF)){
return false;
}
$im = new Imagick();
$im->setResolution($w,$h); //设置分辨率
$im->setCompressionQuality(15);//设置图片压缩的质量
$im->readImage($PDF);
$im -> resetIterator();
$imgs = $im->appendImages(true);
$imgs->setImageFormat( "png" );
$img_name = $PNG;
$imgs->writeImage($img_name);
$imgs->clear();
$imgs->destroy();
$im->clear();
$im->destroy();
return $img_name;
}
ok,简单页面的图片基本完成了,图片大小1M左右,小了看不清楚。
以上是php是否可以将页面转换为图片的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们 查看全部
php 抓取网页生成图片(
借助php类库及扩展完成这一需求(图)解析)

在服务器端对编译后的html进行解析转换为图片。
由于html一般是客户端浏览器解析的,服务端无法直接解析html代码。所以我们需要使用php库和扩展来完成这个需求。
文件转换过程为html —> pdf —> png。 (推荐学习:PHP视频教程)
需要用到的类库是mPDF、imagick
pdf的官方下载地址是:(推荐在6.0虽然有点大) 这是一个可以直接下载上传到服务器的类库。里面有很多东西。新建一个html2pdf文件夹导入
include('./html2pdf/mpdf');
一个完整的函数
/*
名称 html转换为pdf图片
功能 将html页面转换为pdf图片(部分css样式无法识别)
参数数量 2个
1.必须 html代码 可以用file_get_contenth获取
2.必须 生成pdf存放位置路径
3.非必须 pdf宽
4.非必须 pdf高
返回值 图片名称
实例 code($html,'img/1.pdf');
* */
function html2pdf($html, $PATH, $w=414 ,$h=736){
//设置中文字体(很重要 它会影响到第二步中 图片生成)
$mpdf=new mPDF('utf-8');
$mpdf->autoScriptToLang = true;
$mpdf->autoLangToFont = true;
//设置pdf的尺寸
$mpdf->WriteHTML('');
//设置pdf显示方式
$mpdf->SetDisplayMode('fullpage');
//删除pdf第一页(由于设置pdf尺寸导致多出了一页)
$mpdf->DeletePages(1,1);
$mpdf->WriteHTML($html);
$pdf_name = md5(time()).'.pdf';
$mpdf->Output($PATH.$pdf_name);
return $pdf_name;
}
接下来,开始将 pdf 转换为 png 图像。这一步需要在服务器上安装ImageMagick组件
然后使用函数将生成的pdf转成png。
/*
名称 pdf转换为png图片
功能 将pdf图片转换为png图片
参数数量 2个
1.必须 html代码 可以用file_get_contenth获取
2.必须 生成pdf存放位置路径
实例 code($html,'img/1.pdf');
* */
function pdf2png($PDF, $PNG, $w=50, $h=50){
if(!extension_loaded('imagick')){
return false;
}
if(!file_exists($PDF)){
return false;
}
$im = new Imagick();
$im->setResolution($w,$h); //设置分辨率
$im->setCompressionQuality(15);//设置图片压缩的质量
$im->readImage($PDF);
$im -> resetIterator();
$imgs = $im->appendImages(true);
$imgs->setImageFormat( "png" );
$img_name = $PNG;
$imgs->writeImage($img_name);
$imgs->clear();
$imgs->destroy();
$im->clear();
$im->destroy();
return $img_name;
}
ok,简单页面的图片基本完成了,图片大小1M左右,小了看不清楚。
以上是php是否可以将页面转换为图片的详细内容。更多详情请关注其他相关php中文网站文章!

免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们
php 抓取网页生成图片(几个单独落地页,需要分享到微信,新版的微信规则)
网站优化 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-10-14 06:02
最近做了几个单独的登陆页面,需要在微信上分享。新版微信规则很早就有了变化。
如果想分享有摘要和缩略图(强调)的页面,必须找到一个经过认证的域名公众号,并添加网站的服务器ip。
前提:
1:微信公众号认证
2:将当前网站域名加入公众号的js安全域名
3:将当前网站服务器的ip加入公众号ip白名单
如果没有,那么我不知道,我还没有测试过其他任何东西。
官方说明:微信JS-SDK文档二:编写JS-SDK文档文件
var url=window.location.href;
wx.config({
debug:false,
appId: '',
timestamp: ,
nonceStr: '',
signature: '',
url:url,
jsApiList: [
"onMenuShareTimeline", //分享给好友
"onMenuShareAppMessage", //分享到朋友圈
"onMenuShareQQ", //分享到QQ
"onMenuShareWeibo" //分享到微博
]
});
wx.ready(function (){
var shareData = {
title: '分享出去的标题',
desc: '分享出去的摘要',
link: url,
imgUrl: '分享出去的缩略图'}; //最好是300x300以上的正方形
wx.onMenuShareAppMessage(shareData);
wx.onMenuShareTimeline(shareData);
wx.onMenuShareQQ(shareData);
wx.onMenuShareWeibo(shareData);
});
尝试将代码添加到需要共享的页面的头部。
查看网页源代码,可以看到上面的段落,但是php段落是看不到的,但是会显示公众号的appid,其他随机更改。
如果您不想显示此信息,则可以将其混淆或将其加密隐藏。
本来想写一个wordpress插件的,但是网上已经想到了插件。功能更强大,让我懒得动。
它使用wordpress。如果不想自己动手,直接在后台搜索安装插件即可。 查看全部
php 抓取网页生成图片(几个单独落地页,需要分享到微信,新版的微信规则)
最近做了几个单独的登陆页面,需要在微信上分享。新版微信规则很早就有了变化。
如果想分享有摘要和缩略图(强调)的页面,必须找到一个经过认证的域名公众号,并添加网站的服务器ip。

前提:
1:微信公众号认证
2:将当前网站域名加入公众号的js安全域名
3:将当前网站服务器的ip加入公众号ip白名单
如果没有,那么我不知道,我还没有测试过其他任何东西。
官方说明:微信JS-SDK文档二:编写JS-SDK文档文件
var url=window.location.href;
wx.config({
debug:false,
appId: '',
timestamp: ,
nonceStr: '',
signature: '',
url:url,
jsApiList: [
"onMenuShareTimeline", //分享给好友
"onMenuShareAppMessage", //分享到朋友圈
"onMenuShareQQ", //分享到QQ
"onMenuShareWeibo" //分享到微博
]
});
wx.ready(function (){
var shareData = {
title: '分享出去的标题',
desc: '分享出去的摘要',
link: url,
imgUrl: '分享出去的缩略图'}; //最好是300x300以上的正方形
wx.onMenuShareAppMessage(shareData);
wx.onMenuShareTimeline(shareData);
wx.onMenuShareQQ(shareData);
wx.onMenuShareWeibo(shareData);
});
尝试将代码添加到需要共享的页面的头部。
查看网页源代码,可以看到上面的段落,但是php段落是看不到的,但是会显示公众号的appid,其他随机更改。
如果您不想显示此信息,则可以将其混淆或将其加密隐藏。
本来想写一个wordpress插件的,但是网上已经想到了插件。功能更强大,让我懒得动。
它使用wordpress。如果不想自己动手,直接在后台搜索安装插件即可。
php 抓取网页生成图片(Twitter曾经用过的方式:对于google会到抓取内容的事情)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-10-14 04:29
一、推特已经使用了该方法:
为了
twitter.com/#!/abcde
Google 将到达
twitter.com/?_escaped_fragment_=abcde
获取内容。在这里直接输出你的 Ajax 内容,Google 会收录。但是你必须为Ajax内容编写另一个api供搜索引擎使用,你展示给搜索引擎的链接也必须变成上面的形式。 . .
参考:网站管理员和开发者的 AJAX 抓取指南
二、noscript 标签
对于 /1、/2 ....
服务器做了什么:根据编号获取对应的内容,写入noscript标签,用一段js输出。
浏览器的作用:执行接收到的js,获取noscript标签中的内容,并为jQuery处理。
三、如果是单页无法刷新,则需要完整的ajax操作
使用History API,链接仍然是/1、/2的形式。 js根据数字ajax获取内容。但是还有一个步骤是将用户点击的 URL 推送到列表中
此后,如果有前进后退按钮操作,浏览器会从列表中选择URL动态改变当前地址栏,并触发popstate事件,写一个js来监听这个事件
window.addEventListener('popstate', function(e) { ajax(location.url); });
当然,ajax返回的时候还是要带noscript标签,里面塞内容。上面画一个大圈的目的就是不刷新页面。
参考资料: 查看全部
php 抓取网页生成图片(Twitter曾经用过的方式:对于google会到抓取内容的事情)
一、推特已经使用了该方法:
为了
twitter.com/#!/abcde
Google 将到达
twitter.com/?_escaped_fragment_=abcde
获取内容。在这里直接输出你的 Ajax 内容,Google 会收录。但是你必须为Ajax内容编写另一个api供搜索引擎使用,你展示给搜索引擎的链接也必须变成上面的形式。 . .
参考:网站管理员和开发者的 AJAX 抓取指南
二、noscript 标签
对于 /1、/2 ....
服务器做了什么:根据编号获取对应的内容,写入noscript标签,用一段js输出。
浏览器的作用:执行接收到的js,获取noscript标签中的内容,并为jQuery处理。
三、如果是单页无法刷新,则需要完整的ajax操作
使用History API,链接仍然是/1、/2的形式。 js根据数字ajax获取内容。但是还有一个步骤是将用户点击的 URL 推送到列表中
此后,如果有前进后退按钮操作,浏览器会从列表中选择URL动态改变当前地址栏,并触发popstate事件,写一个js来监听这个事件
window.addEventListener('popstate', function(e) { ajax(location.url); });
当然,ajax返回的时候还是要带noscript标签,里面塞内容。上面画一个大圈的目的就是不刷新页面。
参考资料:
php 抓取网页生成图片( 我看用wkhtmltopdf来实现正合适,提供Windows、Linux和Mac平台上的版本)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-10-14 04:24
我看用wkhtmltopdf来实现正合适,提供Windows、Linux和Mac平台上的版本)
使用PHP为网站生成快照图片和缩略图
因为这是网站综合信息查询所需要的
我搜索了国外的解决方案
大部分都是使用对方的API实现的
但这种方式并不好
1 会被对方加水印,缩略图加水印不好
2免费的有代数限制,收费的太贵了。通常可以生成 $1 = 10 个缩略图
像我一样,生成超过 9000 万个缩略图并不是很可靠。成本太贵,缩略图都加了水印。
最终决定使用第三方开源软件构建
这样,快照生成后,可以自动上传到云端,调用速度快
暂时测试这个方案没有问题
32位下载
wkhtmltoimage-0.11.0_rc1 Linux 静态二进制 (i368)
64位下载
wkhtmltoimage-0.11.0_rc1 Linux 静态二进制文件 (AMD64)
这是一个编译好的静态可执行文件,比较简单方便
依赖 qt4 包
解压
tar -xvf ***.tar.bz2
移动目录然后直接调用PHP
例如 /sbin/wkhtmltoimage
先测试/sbin/wkhtmltoimage g.jpg
建议设置清晰度的低点
我测试过它是否不调整
Google的页面生成的PNG大小超过1M JPG超过400K
PHP中直接exec可以调用生成然后做图片处理
然后使用 php 的 gd 或 im
php可以使用GD或IM的图片处理模块进行处理。
您可以为缩略图等添加水印。
仍在测试其他开源解决方案
可提供REST接口
那个时候更新
-------------------------------------
国外有很多网站会提供URL地址的预览功能。当鼠标移动到URL地址时,会自动显示网站的缩略图。
我觉得用wkhtmltopdf来实现比较合适,提供了Windows、Linux、Mac平台的版本。
该工具的详细参数如下:
常规选项:
--crop-h 设置裁剪高度
--crop-w 设置裁剪宽度
--crop-x 设置 x 坐标进行裁剪
--crop-y 设置 y 坐标进行裁剪
-H, --extended-help 显示更广泛的帮助,详细说明不太常见的命令开关
-f, --格式 查看全部
php 抓取网页生成图片(
我看用wkhtmltopdf来实现正合适,提供Windows、Linux和Mac平台上的版本)
使用PHP为网站生成快照图片和缩略图
因为这是网站综合信息查询所需要的
我搜索了国外的解决方案
大部分都是使用对方的API实现的
但这种方式并不好
1 会被对方加水印,缩略图加水印不好
2免费的有代数限制,收费的太贵了。通常可以生成 $1 = 10 个缩略图
像我一样,生成超过 9000 万个缩略图并不是很可靠。成本太贵,缩略图都加了水印。
最终决定使用第三方开源软件构建
这样,快照生成后,可以自动上传到云端,调用速度快
暂时测试这个方案没有问题
32位下载
wkhtmltoimage-0.11.0_rc1 Linux 静态二进制 (i368)
64位下载
wkhtmltoimage-0.11.0_rc1 Linux 静态二进制文件 (AMD64)
这是一个编译好的静态可执行文件,比较简单方便
依赖 qt4 包
解压
tar -xvf ***.tar.bz2
移动目录然后直接调用PHP
例如 /sbin/wkhtmltoimage
先测试/sbin/wkhtmltoimage g.jpg
建议设置清晰度的低点
我测试过它是否不调整
Google的页面生成的PNG大小超过1M JPG超过400K
PHP中直接exec可以调用生成然后做图片处理
然后使用 php 的 gd 或 im
php可以使用GD或IM的图片处理模块进行处理。
您可以为缩略图等添加水印。
仍在测试其他开源解决方案
可提供REST接口
那个时候更新
-------------------------------------
国外有很多网站会提供URL地址的预览功能。当鼠标移动到URL地址时,会自动显示网站的缩略图。
我觉得用wkhtmltopdf来实现比较合适,提供了Windows、Linux、Mac平台的版本。
该工具的详细参数如下:
常规选项:
--crop-h 设置裁剪高度
--crop-w 设置裁剪宽度
--crop-x 设置 x 坐标进行裁剪
--crop-y 设置 y 坐标进行裁剪
-H, --extended-help 显示更广泛的帮助,详细说明不太常见的命令开关
-f, --格式
php 抓取网页生成图片(小程序码和二维码;生成后端来生成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-10-14 04:22
小程序二维码分为小程序码和二维码;
小程序生成的二维码在文档中由后端生成。
参考小程序开发文档:
文档的参数介绍比较详细,但是没有具体的demo。也很烦人,请求接口的返回值是十六进制流(即浏览器显示一堆乱码)。这是我的代码:
//获取小程序码,这里调用的是小程序码的A接口类型
public function getQRCodeAction()
{
$data['scene'] = $this->_req->getQuery('shareId',11); //scence、page的使用要参考文档(比如:scene的值不能超过32个字符等)
$data['width'] = $this->_req->getQuery('width',220);
$data['auto_color'] = $this->_req->getQuery('auto_color');
$data['line_color'] = $this->_req->getQuery('line_color');
$data['is_hyaline'] = $this->_req->getQuery('is_hyaline',true);
$data['page'] = $this->_req->getQuery('page',""); //由这行以上代码是二维码的样式等由前端传值的形式,也可以直接在后端设置
$wxModel = new WxAuthModel();
$token = $wxModel->getAccessToken();
$res_url = "https://api.weixin.qq.com/wxa/ ... en%3D$token"; //请求微信提供的接口
header('content-type:image/png');
$data = json_encode($data);
$Qr_code = $wxModel->http_request($res_url,$data); //到这里就已经返回微信提供的返回数据了,这个时候的数据是二进制流,要处理下再返回给前端
file_put_contents('/tmp/qr_code.png', $Qr_code); //将获得的数据读到一个临时图片里
$img_string = $this->fileToBase64('/tmp/qr_code.png'); //将图片文件转化为base64
response::result($img_string);
}
//本地文件转base64
private function fileToBase64($file){
$base64_file = '';
if(file_exists($file)){
$mime_type= mime_content_type($file); //如果这里明确是图片的话我建议获取图片类型这句可以省略,直接知道了mine_type='image/png',因为我这里我虽然存的图片,但是读到的mine_type值为text/plain
$base64_data = base64_encode(file_get_contents($file));
$base64_file = 'data:'.$mime_type.';base64,'.$base64_data; //$base64_file = 'data:image/png;base64,'.$base64_data;
}
return $base64_file;
}
/*获取access_token,不需要code参数,不能用于获取用户信息的token*/
public function getAccessToken()
{
$token_file = '/dev/shm/heka2_token.json'; //由于获取token的次数存在限制,所以将一段时间内的token缓存到一个文件(注意缓存路径服务器支持可写可读),过期后再重新获取
$data = json_decode(file_get_contents($token_file));
if ($data->expire_time < time()) {
$url = "https://api.weixin.qq.com/cgi- ... id%3D$this->appId&secret=$this->appSecret";
$res = json_decode($this->http_request($url));
$access_token = $res->access_token;
if ($access_token) {
$data->expire_time = time() + 7000;
$data->access_token = $access_token;
file_put_contents($token_file, json_encode($data));
}
} else {
$access_token = $data->access_token;
}
return $access_token;
}
感觉还没找到完整的PHP实现代码,这个自己用就好了。如有不妥之处请指出~_ 查看全部
php 抓取网页生成图片(小程序码和二维码;生成后端来生成)
小程序二维码分为小程序码和二维码;
小程序生成的二维码在文档中由后端生成。
参考小程序开发文档:
文档的参数介绍比较详细,但是没有具体的demo。也很烦人,请求接口的返回值是十六进制流(即浏览器显示一堆乱码)。这是我的代码:
//获取小程序码,这里调用的是小程序码的A接口类型
public function getQRCodeAction()
{
$data['scene'] = $this->_req->getQuery('shareId',11); //scence、page的使用要参考文档(比如:scene的值不能超过32个字符等)
$data['width'] = $this->_req->getQuery('width',220);
$data['auto_color'] = $this->_req->getQuery('auto_color');
$data['line_color'] = $this->_req->getQuery('line_color');
$data['is_hyaline'] = $this->_req->getQuery('is_hyaline',true);
$data['page'] = $this->_req->getQuery('page',""); //由这行以上代码是二维码的样式等由前端传值的形式,也可以直接在后端设置
$wxModel = new WxAuthModel();
$token = $wxModel->getAccessToken();
$res_url = "https://api.weixin.qq.com/wxa/ ... en%3D$token"; //请求微信提供的接口
header('content-type:image/png');
$data = json_encode($data);
$Qr_code = $wxModel->http_request($res_url,$data); //到这里就已经返回微信提供的返回数据了,这个时候的数据是二进制流,要处理下再返回给前端
file_put_contents('/tmp/qr_code.png', $Qr_code); //将获得的数据读到一个临时图片里
$img_string = $this->fileToBase64('/tmp/qr_code.png'); //将图片文件转化为base64
response::result($img_string);
}
//本地文件转base64
private function fileToBase64($file){
$base64_file = '';
if(file_exists($file)){
$mime_type= mime_content_type($file); //如果这里明确是图片的话我建议获取图片类型这句可以省略,直接知道了mine_type='image/png',因为我这里我虽然存的图片,但是读到的mine_type值为text/plain
$base64_data = base64_encode(file_get_contents($file));
$base64_file = 'data:'.$mime_type.';base64,'.$base64_data; //$base64_file = 'data:image/png;base64,'.$base64_data;
}
return $base64_file;
}
/*获取access_token,不需要code参数,不能用于获取用户信息的token*/
public function getAccessToken()
{
$token_file = '/dev/shm/heka2_token.json'; //由于获取token的次数存在限制,所以将一段时间内的token缓存到一个文件(注意缓存路径服务器支持可写可读),过期后再重新获取
$data = json_decode(file_get_contents($token_file));
if ($data->expire_time < time()) {
$url = "https://api.weixin.qq.com/cgi- ... id%3D$this->appId&secret=$this->appSecret";
$res = json_decode($this->http_request($url));
$access_token = $res->access_token;
if ($access_token) {
$data->expire_time = time() + 7000;
$data->access_token = $access_token;
file_put_contents($token_file, json_encode($data));
}
} else {
$access_token = $data->access_token;
}
return $access_token;
}
感觉还没找到完整的PHP实现代码,这个自己用就好了。如有不妥之处请指出~_
php 抓取网页生成图片(PHP脚本与动态页面的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-10-13 21:15
首先,有人会问:为什么要生成静态页面?
说一下静态页面的好处,方便搜索引擎收录,加快网站访问速度等,不用从数据库中提取,从而减轻服务器压力
让我们先回顾一些基本概念。
一、PHP 脚本和动态页面。
PHP脚本是一种服务器端脚本程序,可以通过嵌入方式与HTML文件混合,也可以以类、函数封装等形式使用,以模板的形式处理用户请求。不管怎样,它的基本原理是这样的。客户端发出请求请求某个页面----->Web服务器引入指定的对应脚本进行处理----->脚本加载到服务器中----->指定的PHP解析器服务器匹配脚本Analyze to form HTML language form ----> 将解析后的HTML语句以包的形式传回浏览器。不难看出,页面发送到浏览器后,PHP 不复存在,已经被转换解析为 HTML 语句。客户端请求是一个动态文件。事实上,那里不存在真正的文件。由PHP解析形成相应的页面,然后发送回浏览器。这种类型的页面处理称为“动态页面”。
二、静态页面。
静态页面是指只收录服务器端确实存在的 HTML、JS、CSS 和其他客户端脚本的页面。它的处理方式是。客户端发出请求请求某个页面---->WEB服务器确认并加载某个页面->WEB服务器将该页面以包的形式返回给浏览器。从这个过程,我们来对比一下动态页面就知道了。动态页面需要通过web服务器的PHP解析器进行解析,通常需要连接数据库进行数据库访问操作,然后形成HTML语言信息包;而静态页面不需要解析,不需要连接数据库,直接发送即可。降低服务器压力,提高服务器负载能力,大幅提升页面打开速度和网站整体打开速度。
三、模板和模板分析。
模板尚未填充内容 html 文件。例如:
临时文件
代码:
以下是引用的片段:
{标题}
这是一个 {file} 文件的模板
PHP处理:
以下是引用的片段:
模板测试.php
代码:
$title = "惠普发烧友测试模板";
$file = "TwoMax Inter 测试模板,
作者:舍伊”;
$fp = fopen("temp.html","r");
$content = fread ($fp,filesize ("temp.html"));
$content .= str_replace("{文件}",$file,$content);
$content .= str_replace ("{title }",$title,$content);
回声$内容;
模板解析过程是将PHP脚本解析过程得到的结果填充(内容)到模板中的过程。通常在模板类的帮助下。目前比较流行的模板解析类有phplib、smarty、fastsmarty等。模板分析处理的原则通常是替换。也有程序员习惯于将判断、循环等处理放入模板文件中,使用解析处理。典型的应用是块概念,它只是一个循环处理。PHP 脚本指定循环次数、如何循环替换等,然后模板解析类实现这些操作。
好了,对比了静态页面和动态页面的优劣,现在来说说如何用PHP生成静态文件。
PHP生成的静态页面并不是指PHP的动态分析和HTML页面的输出,而是用PHP创建HTML页面。同时,由于 HTML 的不可写性,如果我们创建的 HTML 被修改,则需要删除并重新生成。(当然你也可以选择用正则化来修改,但个人认为还是删掉,快点重新生成比较好,有些得不偿失。)
离家较近。用过PHP文件操作函数的PHP爱好者都知道,PHP中有一个文件操作函数fopen,就是打开文件。如果该文件不存在,请尝试创建它。这是 PHP 可以用来创建 HTML 文件的理论基础。只要存放HTML文件的文件夹有写权限(即权限定义0777),就可以创建文件。(对于UNIX系统,Win系统不需要考虑。)以上面的例子为例一个例子,如果我们修改最后一句,并指定在test目录下生成一个名为test.html的静态文件:
代码:
以下是引用的片段:
$title = "Tomac 国际测试模板";
$file = "TwoMax Inter 测试模板,
author:_Max">Matrix@Two_Max";
$fp = fopen("temp.html","r");
$content = fread ($fp,filesize ("temp.html"));
$content .= str_replace("{文件}",$file,$content);
$content .= str_replace ("{title }",$title,$content);
// 回声 $content;
$filename = "test/test.html";
$handle = fopen($filename,"w"); //打开文件指针并创建文件
/*
检查文件是否已创建并可写
*/
if (!is_writable ($filename)){
die("File:".$filename." 不可写,请检查其属性并重试!");
}
if (!fwrite ($handle,$content)){ //将信息写入文件
die("生成文件".$filename."失败!");
}
fclose ($handle); //关闭指针
die("创建文件".$filename."成功!");
实际应用中常见问题的解决方法参考:
一、文章列表问题:
在数据库中创建一个字段,记录文件名,每次生成文件时将自动生成的文件名存入数据库。对于推荐的文章,只要指向指定存放静态文件的文件夹中的页面即可。使用PHP操作处理文章列表,保存为字符串,生成页面时替换此字符串。比如在页面上放置文章列表表添加标签{articletable},在PHP处理文件中:
代码:
以下是引用的片段:
$title = "Tomac 国际测试模板";
$file = "TwoMax Inter 测试模板,
author:_Max">Matrix@Two_Max";
$fp = fopen("temp.html","r");
$content = fread ($fp,filesize ("temp.html"));
$content .= str_replace("{文件}",$file,$content);
$content .= str_replace ("{title }",$title,$content);
// 开始生成列表
$list ='''''''';
$sql = "从文章中选择 id,title,filename";
$query = mysql_query ($sql);
while ($result = mysql_fetch_array ($query)){
$list .=''''''''.$result[''''title''''].''''
'''';
}
$content .= str_replace("{文章表}",$list,$content);
//生成列表结束
// 回声 $content;
$filename = "test/test.html";
$handle = fopen($filename,"w"); //打开文件指针并创建文件
/*
检查文件是否已创建并可写
*/
if (!is_writable ($filename)){
die("File:".$filename." 不可写,请检查其属性并重试!");
}
if (!fwrite ($handle,$content)){ //将信息写入文件
die("生成文件".$filename."失败!");
}
fclose ($handle); //关闭指针
die("创建文件".$filename."成功!");
二、 分页问题。
例如,当我们指定分页时,每页有 20 篇文章。查询数据库后,某个子频道列表中文章的个数为45。首先我们通过查询得到如下参数:1、总页数;2、每页文章数。第二步,for($i = 0; $i <allpages; $i++),页面元素获取、分析、文章生成都在这个循环中执行。不同的是,die("create file".$filename."success!";把这句话去掉,放在循环后的显示中,因为这句话会暂停程序的执行。例如:
代码:
以下是引用的片段:
$fp = fopen("temp.html","r");
$content = fread ($fp,filesize ("temp.html"));
$onepage =''''20'''';
$sql = "select id from article where channel='''$channelid''''";
$query = mysql_query ($sql);
$num = mysql_num_rows ($query);
$allpages = ceil ($num / $onepage);
对于 ($i = 0;$i
大体思路是这样,其中其他数据生成、数据输入输出检查、页面内容指向等都可以酌情添加到页面中。
在文章系统的实际处理中,还有很多问题需要考虑。与动态页面不同,还有很多需要注意的地方。但是大体思路是一样的,其他方面可以互相推导。 查看全部
php 抓取网页生成图片(PHP脚本与动态页面的区别)
首先,有人会问:为什么要生成静态页面?
说一下静态页面的好处,方便搜索引擎收录,加快网站访问速度等,不用从数据库中提取,从而减轻服务器压力
让我们先回顾一些基本概念。
一、PHP 脚本和动态页面。
PHP脚本是一种服务器端脚本程序,可以通过嵌入方式与HTML文件混合,也可以以类、函数封装等形式使用,以模板的形式处理用户请求。不管怎样,它的基本原理是这样的。客户端发出请求请求某个页面----->Web服务器引入指定的对应脚本进行处理----->脚本加载到服务器中----->指定的PHP解析器服务器匹配脚本Analyze to form HTML language form ----> 将解析后的HTML语句以包的形式传回浏览器。不难看出,页面发送到浏览器后,PHP 不复存在,已经被转换解析为 HTML 语句。客户端请求是一个动态文件。事实上,那里不存在真正的文件。由PHP解析形成相应的页面,然后发送回浏览器。这种类型的页面处理称为“动态页面”。
二、静态页面。
静态页面是指只收录服务器端确实存在的 HTML、JS、CSS 和其他客户端脚本的页面。它的处理方式是。客户端发出请求请求某个页面---->WEB服务器确认并加载某个页面->WEB服务器将该页面以包的形式返回给浏览器。从这个过程,我们来对比一下动态页面就知道了。动态页面需要通过web服务器的PHP解析器进行解析,通常需要连接数据库进行数据库访问操作,然后形成HTML语言信息包;而静态页面不需要解析,不需要连接数据库,直接发送即可。降低服务器压力,提高服务器负载能力,大幅提升页面打开速度和网站整体打开速度。
三、模板和模板分析。
模板尚未填充内容 html 文件。例如:
临时文件
代码:
以下是引用的片段:
{标题}
这是一个 {file} 文件的模板
PHP处理:
以下是引用的片段:
模板测试.php
代码:
$title = "惠普发烧友测试模板";
$file = "TwoMax Inter 测试模板,
作者:舍伊”;
$fp = fopen("temp.html","r");
$content = fread ($fp,filesize ("temp.html"));
$content .= str_replace("{文件}",$file,$content);
$content .= str_replace ("{title }",$title,$content);
回声$内容;
模板解析过程是将PHP脚本解析过程得到的结果填充(内容)到模板中的过程。通常在模板类的帮助下。目前比较流行的模板解析类有phplib、smarty、fastsmarty等。模板分析处理的原则通常是替换。也有程序员习惯于将判断、循环等处理放入模板文件中,使用解析处理。典型的应用是块概念,它只是一个循环处理。PHP 脚本指定循环次数、如何循环替换等,然后模板解析类实现这些操作。
好了,对比了静态页面和动态页面的优劣,现在来说说如何用PHP生成静态文件。
PHP生成的静态页面并不是指PHP的动态分析和HTML页面的输出,而是用PHP创建HTML页面。同时,由于 HTML 的不可写性,如果我们创建的 HTML 被修改,则需要删除并重新生成。(当然你也可以选择用正则化来修改,但个人认为还是删掉,快点重新生成比较好,有些得不偿失。)
离家较近。用过PHP文件操作函数的PHP爱好者都知道,PHP中有一个文件操作函数fopen,就是打开文件。如果该文件不存在,请尝试创建它。这是 PHP 可以用来创建 HTML 文件的理论基础。只要存放HTML文件的文件夹有写权限(即权限定义0777),就可以创建文件。(对于UNIX系统,Win系统不需要考虑。)以上面的例子为例一个例子,如果我们修改最后一句,并指定在test目录下生成一个名为test.html的静态文件:
代码:
以下是引用的片段:
$title = "Tomac 国际测试模板";
$file = "TwoMax Inter 测试模板,
author:_Max">Matrix@Two_Max";
$fp = fopen("temp.html","r");
$content = fread ($fp,filesize ("temp.html"));
$content .= str_replace("{文件}",$file,$content);
$content .= str_replace ("{title }",$title,$content);
// 回声 $content;
$filename = "test/test.html";
$handle = fopen($filename,"w"); //打开文件指针并创建文件
/*
检查文件是否已创建并可写
*/
if (!is_writable ($filename)){
die("File:".$filename." 不可写,请检查其属性并重试!");
}
if (!fwrite ($handle,$content)){ //将信息写入文件
die("生成文件".$filename."失败!");
}
fclose ($handle); //关闭指针
die("创建文件".$filename."成功!");
实际应用中常见问题的解决方法参考:
一、文章列表问题:
在数据库中创建一个字段,记录文件名,每次生成文件时将自动生成的文件名存入数据库。对于推荐的文章,只要指向指定存放静态文件的文件夹中的页面即可。使用PHP操作处理文章列表,保存为字符串,生成页面时替换此字符串。比如在页面上放置文章列表表添加标签{articletable},在PHP处理文件中:
代码:
以下是引用的片段:
$title = "Tomac 国际测试模板";
$file = "TwoMax Inter 测试模板,
author:_Max">Matrix@Two_Max";
$fp = fopen("temp.html","r");
$content = fread ($fp,filesize ("temp.html"));
$content .= str_replace("{文件}",$file,$content);
$content .= str_replace ("{title }",$title,$content);
// 开始生成列表
$list ='''''''';
$sql = "从文章中选择 id,title,filename";
$query = mysql_query ($sql);
while ($result = mysql_fetch_array ($query)){
$list .=''''''''.$result[''''title''''].''''
'''';
}
$content .= str_replace("{文章表}",$list,$content);
//生成列表结束
// 回声 $content;
$filename = "test/test.html";
$handle = fopen($filename,"w"); //打开文件指针并创建文件
/*
检查文件是否已创建并可写
*/
if (!is_writable ($filename)){
die("File:".$filename." 不可写,请检查其属性并重试!");
}
if (!fwrite ($handle,$content)){ //将信息写入文件
die("生成文件".$filename."失败!");
}
fclose ($handle); //关闭指针
die("创建文件".$filename."成功!");
二、 分页问题。
例如,当我们指定分页时,每页有 20 篇文章。查询数据库后,某个子频道列表中文章的个数为45。首先我们通过查询得到如下参数:1、总页数;2、每页文章数。第二步,for($i = 0; $i <allpages; $i++),页面元素获取、分析、文章生成都在这个循环中执行。不同的是,die("create file".$filename."success!";把这句话去掉,放在循环后的显示中,因为这句话会暂停程序的执行。例如:
代码:
以下是引用的片段:
$fp = fopen("temp.html","r");
$content = fread ($fp,filesize ("temp.html"));
$onepage =''''20'''';
$sql = "select id from article where channel='''$channelid''''";
$query = mysql_query ($sql);
$num = mysql_num_rows ($query);
$allpages = ceil ($num / $onepage);
对于 ($i = 0;$i
大体思路是这样,其中其他数据生成、数据输入输出检查、页面内容指向等都可以酌情添加到页面中。
在文章系统的实际处理中,还有很多问题需要考虑。与动态页面不同,还有很多需要注意的地方。但是大体思路是一样的,其他方面可以互相推导。
php 抓取网页生成图片(Google需要同一时间抓取您的WordPress网站的更新网址吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-10 00:04
最近,我们的一位读者问是否可以让 Google 重新抓取特定的网址?如果您的网站是新的网站,那么Google需要一些时间来抓取并显示新页面或搜索结果的变化。在本文中,我们将向您展示如何让 Google 重新抓取您的 WordPress网站 URL。
Google 何时以及为何需要重新抓取该网址?
当您在 WordPress网站 中添加页面和帖子时,Google 会花适当的时间来抓取这些新链接。Google 需要同时抓取您的 WordPress网站 更新 URL。
当您手动要求 Google 重新抓取您的网址时,它会将您的新链接放入队列以在 Google 上编入索引。谷歌搜索机器人将开始一一重新抓取您的链接,并将它们显示在搜索结果中。
请求 Google 重新抓取网址的一些常见原因是:
当您添加新帖子或页面时 当您对现有帖子或页面进行更改时 如果您认为某个网页应该在 Google 中编入索引,但您找不到它
对于上面提到的前两个选项,您可以使用 XML 站点地图来自动执行此过程。Google 非常擅长索引 网站,因为这是他们的业务。
但是,我们已经看到 Google 缺少特定页面(无缘无故)。有时只是要求谷歌重新抓取会立即显示页面。
话虽如此,让我们来看看如何让 Google 重新抓取您的 WordPress网站 URL 并将其显示在搜索结果中。
要求 Google 重新抓取您的 WordPress 网站 URL
首先,您需要在 Google 上列出您的 网站,然后 Google 会自动开始抓取您的网址。但是,对于我们上面讨论的任何情况,您也可以请求 Google 重新抓取新链接。
您可以按照以下步骤要求 Google 重新抓取您的 WordPress网站 URL。
第 1 步:使用 URL 检查工具重新抓取 URL
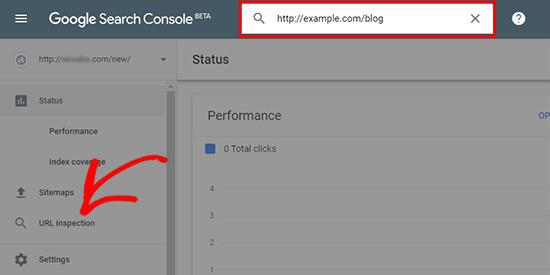
URL 检查工具在新的和更新的 Google Search Console(以前称为 Google网站管理员工具)中可用。此工具可帮助您确定与网址相关的问题,并提供解决方案以将您的 Google 链接编入索引。
它还可以帮助您解决常见的 WordPress URL 错误和其他 URL 索引问题。
在新的 Google 搜索控制台中,您需要选择您的属性或 网站 来检查 URL 索引状态。
注意:如果您没有在 Google 的 网站Administrator Tools 中列出 网站,您首先需要将其添加为新属性才能继续使用 URL 检查工具。
选择属性后,您需要转到左侧菜单中的 URL 检查工具,并在要检查的搜索字段中添加您的 URL。
它将获取有关您的 URL 的数据并将其显示在 Google Search Console 仪表板中。
如果您的网址在 Google 上,那么您会看到一条成功消息,其中收录有关您的链接的有用信息。您可以展开调查结果,看看是否还有其他问题需要解决。如果没有,那么您将看到来自 Google 的提交请求,要求重新抓取您的网址并将其编入索引。
但是,如果该链接不在 Google 上,那么它会向您显示在 Google 上索引您的 URL 的错误和可能的解决方案。
您可以解决问题并再次检查 URL,直到收到成功消息。之后,将启动重新抓取您的网址的请求。只需对您希望 Google 重新抓取的所有网址重复相同的操作即可。
第 2 步:提交 XML 站点地图以重新抓取 URL
如果您仍然不确定在 Google 上为 URL 编制索引,那么您只需将收录新 URL 的更新 XML网站 映射提交给 Google网站管理员工具。站点地图是索引新 URL 的最快方法。
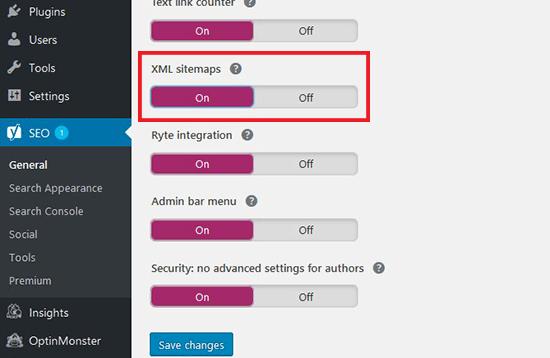
对于这一步,我们建议使用 Yoast SEO 插件,它收录灵活的选项,可以在 WordPress 中正确设置 XML 站点地图。
在您的 WordPress 管理区域,您需要转到 SEO»General 页面。在“功能”部分下,您需要打开 XML 站点地图设置。
不要忘记单击保存更改按钮。荀彧。
接下来,您可以通过单击 XML 站点地图标题旁边的问号图标来查看更新的站点地图。如果您的新链接在此站点地图文件中可见,您可以继续将其提交到 Google网站管理员工具。
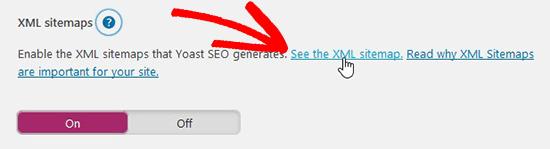
要提交 XML 站点地图,您需要访问新的 Google 搜索控制台并转到左侧菜单中的站点地图。只需添加您的 XML 站点地图链接并单击提交按钮。荀彧。
更新后的站点地图需要 Google 漫游器快速重新抓取您的新网址并将其显示在搜索结果中。
注意:您只需上传站点地图一次。Google 会定期重新抓取您的站点地图,并在添加站点地图后快速添加更新的帖子。
我们希望本文能帮助您了解如何让 Google 重新抓取您的 WordPress网站 URL。您可能还想查看我们关于如何改进 WordPress SEO 的终极指南。
----本页内容已结束,喜欢请分享---- 查看全部
php 抓取网页生成图片(Google需要同一时间抓取您的WordPress网站的更新网址吗?)
最近,我们的一位读者问是否可以让 Google 重新抓取特定的网址?如果您的网站是新的网站,那么Google需要一些时间来抓取并显示新页面或搜索结果的变化。在本文中,我们将向您展示如何让 Google 重新抓取您的 WordPress网站 URL。

Google 何时以及为何需要重新抓取该网址?
当您在 WordPress网站 中添加页面和帖子时,Google 会花适当的时间来抓取这些新链接。Google 需要同时抓取您的 WordPress网站 更新 URL。
当您手动要求 Google 重新抓取您的网址时,它会将您的新链接放入队列以在 Google 上编入索引。谷歌搜索机器人将开始一一重新抓取您的链接,并将它们显示在搜索结果中。
请求 Google 重新抓取网址的一些常见原因是:
当您添加新帖子或页面时 当您对现有帖子或页面进行更改时 如果您认为某个网页应该在 Google 中编入索引,但您找不到它
对于上面提到的前两个选项,您可以使用 XML 站点地图来自动执行此过程。Google 非常擅长索引 网站,因为这是他们的业务。
但是,我们已经看到 Google 缺少特定页面(无缘无故)。有时只是要求谷歌重新抓取会立即显示页面。
话虽如此,让我们来看看如何让 Google 重新抓取您的 WordPress网站 URL 并将其显示在搜索结果中。
要求 Google 重新抓取您的 WordPress 网站 URL
首先,您需要在 Google 上列出您的 网站,然后 Google 会自动开始抓取您的网址。但是,对于我们上面讨论的任何情况,您也可以请求 Google 重新抓取新链接。
您可以按照以下步骤要求 Google 重新抓取您的 WordPress网站 URL。
第 1 步:使用 URL 检查工具重新抓取 URL
URL 检查工具在新的和更新的 Google Search Console(以前称为 Google网站管理员工具)中可用。此工具可帮助您确定与网址相关的问题,并提供解决方案以将您的 Google 链接编入索引。
它还可以帮助您解决常见的 WordPress URL 错误和其他 URL 索引问题。
在新的 Google 搜索控制台中,您需要选择您的属性或 网站 来检查 URL 索引状态。
注意:如果您没有在 Google 的 网站Administrator Tools 中列出 网站,您首先需要将其添加为新属性才能继续使用 URL 检查工具。
选择属性后,您需要转到左侧菜单中的 URL 检查工具,并在要检查的搜索字段中添加您的 URL。
它将获取有关您的 URL 的数据并将其显示在 Google Search Console 仪表板中。
如果您的网址在 Google 上,那么您会看到一条成功消息,其中收录有关您的链接的有用信息。您可以展开调查结果,看看是否还有其他问题需要解决。如果没有,那么您将看到来自 Google 的提交请求,要求重新抓取您的网址并将其编入索引。
但是,如果该链接不在 Google 上,那么它会向您显示在 Google 上索引您的 URL 的错误和可能的解决方案。
您可以解决问题并再次检查 URL,直到收到成功消息。之后,将启动重新抓取您的网址的请求。只需对您希望 Google 重新抓取的所有网址重复相同的操作即可。
第 2 步:提交 XML 站点地图以重新抓取 URL
如果您仍然不确定在 Google 上为 URL 编制索引,那么您只需将收录新 URL 的更新 XML网站 映射提交给 Google网站管理员工具。站点地图是索引新 URL 的最快方法。
对于这一步,我们建议使用 Yoast SEO 插件,它收录灵活的选项,可以在 WordPress 中正确设置 XML 站点地图。
在您的 WordPress 管理区域,您需要转到 SEO»General 页面。在“功能”部分下,您需要打开 XML 站点地图设置。
不要忘记单击保存更改按钮。荀彧。
接下来,您可以通过单击 XML 站点地图标题旁边的问号图标来查看更新的站点地图。如果您的新链接在此站点地图文件中可见,您可以继续将其提交到 Google网站管理员工具。
要提交 XML 站点地图,您需要访问新的 Google 搜索控制台并转到左侧菜单中的站点地图。只需添加您的 XML 站点地图链接并单击提交按钮。荀彧。
更新后的站点地图需要 Google 漫游器快速重新抓取您的新网址并将其显示在搜索结果中。
注意:您只需上传站点地图一次。Google 会定期重新抓取您的站点地图,并在添加站点地图后快速添加更新的帖子。
我们希望本文能帮助您了解如何让 Google 重新抓取您的 WordPress网站 URL。您可能还想查看我们关于如何改进 WordPress SEO 的终极指南。
----本页内容已结束,喜欢请分享----
php 抓取网页生成图片( 2016年10月21日10:57:34投稿:微信头像图片没有后缀名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-08 18:00
2016年10月21日10:57:34投稿:微信头像图片没有后缀名)
PHP捕获远程图片(包括不带后缀)教程详解
更新时间:2016年10月21日10:57:34 投稿:雏菊
最近在做微信登录开发的时候,发现微信头像没有后缀。传统的图像捕获方法不起作用,需要进行特殊的捕获处理。所以,后来结合各种情况,封装成一个类,分享给大家。如果你有兴趣,我们一起来看看。
一、创建项目
作为演示,我们在www根目录下创建一个项目grabimg,创建一个类GrabImage.php和一个index.php。
二、编写类代码
我们定义一个与文件同名的类:GrabImage
class GrabImage{
}
三、属性
接下来,定义几个需要用到的属性。
1、首先定义一个需要抓取的图片地址:$img_url
2、再定义一个$file_name来存放文件名,但是不带扩展名,因为可能会涉及到扩展名的替换,所以这里是定义
3、 后跟扩展名 $extension
4、然后我们定义一个$file_dir。该属性的作用是远程镜像捕获后本地存储的目录,一般以PHP入口文件的位置为起点。但是路径一般不会保存到数据库中。
5、最后我们定义一个$save_dir,顾名思义,这个路径就是要直接保存的数据库的目录。这里说明一下,我们不直接将文件保存路径存储到数据库中,一般是为了方便以后系统迁移时更改路径。我们这里的$save_dir一般是日期+文件名,如果使用的时候需要取出来,把需要的路径放在前面。
四、方法
属性说完了,接下来我们就正式开始爬取工作了。
首先,我们定义了一个open方法getInstances来获取一些数据,比如抓拍图片的地址,本地保存路径等。同时把它放在属性中。
public function getInstances($img_url , $base_dir)
{
$this->img_url = $img_url;
$this->save_dir = date("Ym").'/'.date("d").'/'; // 比如:201610/19/
$this->file_dir = $base_dir.'/'.$this->save_dir.'/'; // 比如:./uploads/image/2016/10/19/
}
图片保存路径已拼接。接下来需要注意一个问题,目录是否存在。日期一天天过去,但目录不会自动创建。因此,在保存图片之前,您需要先检查一下,如果当前目录不存在,我们需要立即创建它。
我们创建 setDir 方法来设置目录。我们将财产设为私密、安全
/**
* 检查图片需要保持的目录是否存在
* 如果不存在,则立即创建一个目录
* @return bool
*/
private function setDir()
{
if(!file_exists($this->file_dir))
{
mkdir($this->file_dir,0777,TRUE);
}
$this->file_name = uniqid().rand(10000,99999);// 文件名,这里只是演示,实际项目中请使用自己的唯一文件名生成方法
return true;
}
下一步就是抓取核心代码
第一步是解决问题。我们需要抓取的图片可能没有后缀。按照传统的抓图方式,先抓图,再截取后缀名是行不通的。
我们必须通过其他方法获取图片类型。方式是从文件流信息中获取文件头信息,然后判断文件mime信息,即可知道文件后缀名。
为方便起见,首先定义一个 mime 和文件扩展名映射。
$mimes=array(
'image/bmp'=>'bmp',
'image/gif'=>'gif',
'image/jpeg'=>'jpg',
'image/png'=>'png',
'image/x-icon'=>'ico'
);
这样,当我得到类型 image/gif 时,我可以知道它是一个 .gif 图像。
使用php函数get_headers获取文件流头信息。当它的值不为 false 时,我们将它分配给变量 $headers
取出Content-Type的值作为mime的值。
if(($headers=get_headers($this->img_url, 1))!==false){
// 获取响应的类型
$type=$headers['Content-Type'];
}
使用我们上面定义的映射表,我们可以很容易地得到后缀名。
$this->extension=$mimes[$type];
当然,上面得到的$type可能不存在于我们的映射表中,说明这种类型的文件不是我们想要的,放弃它,忽略它。
以下步骤与传统的文件抓取相同。
$file_path = $this->file_dir.$this->file_name.".".$this->extension;
// 获取数据并保存
$contents=file_get_contents($this->img_url);
if(file_put_contents($file_path , $contents))
{
// 这里返回出去的值是直接保存到数据库的路径 + 文件名,形如:201610/19/57feefd7e2a7aY5p7LsPqaI-lY1BF.jpg
return $this->save_dir.$this->file_name.".".$this->extension;
}
先获取本地保存图片的全路径$file_path,然后用file_get_contents抓取数据,再用file_put_contents保存到刚才的文件路径。
最后,我们返回一个可以直接保存到数据库的路径,而不是文件存储路径。
完整版的爬取方法为:
private function getRemoteImg()
{
// mime 和 扩展名 的映射
$mimes=array(
'image/bmp'=>'bmp',
'image/gif'=>'gif',
'image/jpeg'=>'jpg',
'image/png'=>'png',
'image/x-icon'=>'ico'
);
// 获取响应头
if(($headers=get_headers($this->img_url, 1))!==false)
{
// 获取响应的类型
$type=$headers['Content-Type'];
// 如果符合我们要的类型
if(isset($mimes[$type]))
{
$this->extension=$mimes[$type];
$file_path = $this->file_dir.$this->file_name.".".$this->extension;
// 获取数据并保存
$contents=file_get_contents($this->img_url);
if(file_put_contents($file_path , $contents))
{
// 这里返回出去的值是直接保存到数据库的路径 + 文件名,形如:201610/19/57feefd7e2a7aY5p7LsPqaI-lY1BF.jpg
return $this->save_dir.$this->file_name.".".$this->extension;
}
}
}
return false;
}
最后,为了简单起见,我们希望在别处调用这些方法之一来完成爬网。所以我们直接把抓取动作放到getInstances里面,配置好路径后,直接抓取。因此,我们将代码添加到初始配置方法 getInstances 中。
if($this->setDir())
{
return $this->getRemoteImg();
}
else
{
return false;
}
测试
让我们在刚刚创建的 index.php 文件中尝试一下。
确实抢到了
完整代码
<p> 查看全部
php 抓取网页生成图片(
2016年10月21日10:57:34投稿:微信头像图片没有后缀名)
PHP捕获远程图片(包括不带后缀)教程详解
更新时间:2016年10月21日10:57:34 投稿:雏菊
最近在做微信登录开发的时候,发现微信头像没有后缀。传统的图像捕获方法不起作用,需要进行特殊的捕获处理。所以,后来结合各种情况,封装成一个类,分享给大家。如果你有兴趣,我们一起来看看。
一、创建项目
作为演示,我们在www根目录下创建一个项目grabimg,创建一个类GrabImage.php和一个index.php。
二、编写类代码
我们定义一个与文件同名的类:GrabImage
class GrabImage{
}
三、属性
接下来,定义几个需要用到的属性。
1、首先定义一个需要抓取的图片地址:$img_url
2、再定义一个$file_name来存放文件名,但是不带扩展名,因为可能会涉及到扩展名的替换,所以这里是定义
3、 后跟扩展名 $extension
4、然后我们定义一个$file_dir。该属性的作用是远程镜像捕获后本地存储的目录,一般以PHP入口文件的位置为起点。但是路径一般不会保存到数据库中。
5、最后我们定义一个$save_dir,顾名思义,这个路径就是要直接保存的数据库的目录。这里说明一下,我们不直接将文件保存路径存储到数据库中,一般是为了方便以后系统迁移时更改路径。我们这里的$save_dir一般是日期+文件名,如果使用的时候需要取出来,把需要的路径放在前面。
四、方法
属性说完了,接下来我们就正式开始爬取工作了。
首先,我们定义了一个open方法getInstances来获取一些数据,比如抓拍图片的地址,本地保存路径等。同时把它放在属性中。
public function getInstances($img_url , $base_dir)
{
$this->img_url = $img_url;
$this->save_dir = date("Ym").'/'.date("d").'/'; // 比如:201610/19/
$this->file_dir = $base_dir.'/'.$this->save_dir.'/'; // 比如:./uploads/image/2016/10/19/
}
图片保存路径已拼接。接下来需要注意一个问题,目录是否存在。日期一天天过去,但目录不会自动创建。因此,在保存图片之前,您需要先检查一下,如果当前目录不存在,我们需要立即创建它。
我们创建 setDir 方法来设置目录。我们将财产设为私密、安全
/**
* 检查图片需要保持的目录是否存在
* 如果不存在,则立即创建一个目录
* @return bool
*/
private function setDir()
{
if(!file_exists($this->file_dir))
{
mkdir($this->file_dir,0777,TRUE);
}
$this->file_name = uniqid().rand(10000,99999);// 文件名,这里只是演示,实际项目中请使用自己的唯一文件名生成方法
return true;
}
下一步就是抓取核心代码
第一步是解决问题。我们需要抓取的图片可能没有后缀。按照传统的抓图方式,先抓图,再截取后缀名是行不通的。
我们必须通过其他方法获取图片类型。方式是从文件流信息中获取文件头信息,然后判断文件mime信息,即可知道文件后缀名。
为方便起见,首先定义一个 mime 和文件扩展名映射。
$mimes=array(
'image/bmp'=>'bmp',
'image/gif'=>'gif',
'image/jpeg'=>'jpg',
'image/png'=>'png',
'image/x-icon'=>'ico'
);
这样,当我得到类型 image/gif 时,我可以知道它是一个 .gif 图像。
使用php函数get_headers获取文件流头信息。当它的值不为 false 时,我们将它分配给变量 $headers
取出Content-Type的值作为mime的值。
if(($headers=get_headers($this->img_url, 1))!==false){
// 获取响应的类型
$type=$headers['Content-Type'];
}
使用我们上面定义的映射表,我们可以很容易地得到后缀名。
$this->extension=$mimes[$type];
当然,上面得到的$type可能不存在于我们的映射表中,说明这种类型的文件不是我们想要的,放弃它,忽略它。
以下步骤与传统的文件抓取相同。
$file_path = $this->file_dir.$this->file_name.".".$this->extension;
// 获取数据并保存
$contents=file_get_contents($this->img_url);
if(file_put_contents($file_path , $contents))
{
// 这里返回出去的值是直接保存到数据库的路径 + 文件名,形如:201610/19/57feefd7e2a7aY5p7LsPqaI-lY1BF.jpg
return $this->save_dir.$this->file_name.".".$this->extension;
}
先获取本地保存图片的全路径$file_path,然后用file_get_contents抓取数据,再用file_put_contents保存到刚才的文件路径。
最后,我们返回一个可以直接保存到数据库的路径,而不是文件存储路径。
完整版的爬取方法为:
private function getRemoteImg()
{
// mime 和 扩展名 的映射
$mimes=array(
'image/bmp'=>'bmp',
'image/gif'=>'gif',
'image/jpeg'=>'jpg',
'image/png'=>'png',
'image/x-icon'=>'ico'
);
// 获取响应头
if(($headers=get_headers($this->img_url, 1))!==false)
{
// 获取响应的类型
$type=$headers['Content-Type'];
// 如果符合我们要的类型
if(isset($mimes[$type]))
{
$this->extension=$mimes[$type];
$file_path = $this->file_dir.$this->file_name.".".$this->extension;
// 获取数据并保存
$contents=file_get_contents($this->img_url);
if(file_put_contents($file_path , $contents))
{
// 这里返回出去的值是直接保存到数据库的路径 + 文件名,形如:201610/19/57feefd7e2a7aY5p7LsPqaI-lY1BF.jpg
return $this->save_dir.$this->file_name.".".$this->extension;
}
}
}
return false;
}
最后,为了简单起见,我们希望在别处调用这些方法之一来完成爬网。所以我们直接把抓取动作放到getInstances里面,配置好路径后,直接抓取。因此,我们将代码添加到初始配置方法 getInstances 中。
if($this->setDir())
{
return $this->getRemoteImg();
}
else
{
return false;
}
测试
让我们在刚刚创建的 index.php 文件中尝试一下。
确实抢到了

完整代码
<p>
php 抓取网页生成图片(每天都会推送一张很漂亮的图片,如何?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-08 00:33
发表于 2020-04-05, 17:28-admin
必应搜索首页每天都会推送一张非常漂亮的图片。如何使用PHP获取Bing搜索日常图片?
我们使用的界面是
注意,有几个GET参数,它们的作用是:
这里设置n为1、格式为js,idx为0发送GET请求【推荐一个Getman在线版:】,返回数据如下:
{
"images": [
{
"startdate": "20200404",
"fullstartdate": "202004041600",
"enddate": "20200405",
"url": "/th?id=OHR.KissimmeeFrog_ZH-CN8379824947_1920x1080.jpg&rf=LaDigue_1920x1080.jpg&pid=hp",
"urlbase": "/th?id=OHR.KissimmeeFrog_ZH-CN8379824947",
"copyright": "基西米湖中的绿色树蛙和紫色睡莲,佛罗里达州 (© Joanne Williams/Danita Delimont)",
"copyrightlink": "https://www.bing.com/search%3F ... ot%3B,
"title": "",
"quiz": "/search?q=Bing+homepage+quiz&filters=WQOskey:%22HPQuiz_20200404_KissimmeeFrog%22&FORM=HPQUIZ",
"wp": true,
"hsh": "759031457bf9d3d144d511a09e80d227",
"drk": 1,
"top": 1,
"bot": 1,
"hs": []
}
],
"tooltips": {
"loading": "正在加载...",
"previous": "上一个图像",
"next": "下一个图像",
"walle": "此图片不能下载用作壁纸。",
"walls": "下载今日美图。仅限用作桌面壁纸。"
}
}
“images”节点下的“url”值就是我们要获取的图片的地址。我们取出来,加上Bing的URL前缀(),构成一个完整的图片地址。比如上面返回数据的完整图片地址是这样的:
th?id=OHR.KissimmeeFrog_EN-CN8379824947_1920x1080.jpg&rf=LaDigue_1920x1080.jpg&pid=hp
知道了如何获取背景图片,接下来就是使用PHP动态抓取了。
如果只是想作为网页背景使用,只需要创建一个php文件,在里面粘贴如下代码即可:
然后将php文件上传到你的服务器,你应该可以看到访问php文件时被重定向到Bing的图片。
使用方法:直接将php文件的绝对地址作为图片放入网页中。
比如你的php地址是“”,那么你可以在自己网页的css中写这个,作为背景:
body{
width:100%;
height:100%;
background: url(https://hao.defcon.cn/bing.php) no-repeat;
-moz-background-size: cover; /*背景图片拉伸以铺满全屏*/
-ms-background-size: cover;
-webkit-background-size: cover;
background-size: cover;
}
上面的方法只是一个简单的跳转。如果您想抓取这张图片并将其保存到服务器怎么办?直接把代码贴在这里:
<p> 查看全部
php 抓取网页生成图片(每天都会推送一张很漂亮的图片,如何?(图))
发表于 2020-04-05, 17:28-admin

必应搜索首页每天都会推送一张非常漂亮的图片。如何使用PHP获取Bing搜索日常图片?
我们使用的界面是
注意,有几个GET参数,它们的作用是:
这里设置n为1、格式为js,idx为0发送GET请求【推荐一个Getman在线版:】,返回数据如下:
{
"images": [
{
"startdate": "20200404",
"fullstartdate": "202004041600",
"enddate": "20200405",
"url": "/th?id=OHR.KissimmeeFrog_ZH-CN8379824947_1920x1080.jpg&rf=LaDigue_1920x1080.jpg&pid=hp",
"urlbase": "/th?id=OHR.KissimmeeFrog_ZH-CN8379824947",
"copyright": "基西米湖中的绿色树蛙和紫色睡莲,佛罗里达州 (© Joanne Williams/Danita Delimont)",
"copyrightlink": "https://www.bing.com/search%3F ... ot%3B,
"title": "",
"quiz": "/search?q=Bing+homepage+quiz&filters=WQOskey:%22HPQuiz_20200404_KissimmeeFrog%22&FORM=HPQUIZ",
"wp": true,
"hsh": "759031457bf9d3d144d511a09e80d227",
"drk": 1,
"top": 1,
"bot": 1,
"hs": []
}
],
"tooltips": {
"loading": "正在加载...",
"previous": "上一个图像",
"next": "下一个图像",
"walle": "此图片不能下载用作壁纸。",
"walls": "下载今日美图。仅限用作桌面壁纸。"
}
}
“images”节点下的“url”值就是我们要获取的图片的地址。我们取出来,加上Bing的URL前缀(),构成一个完整的图片地址。比如上面返回数据的完整图片地址是这样的:
th?id=OHR.KissimmeeFrog_EN-CN8379824947_1920x1080.jpg&rf=LaDigue_1920x1080.jpg&pid=hp
知道了如何获取背景图片,接下来就是使用PHP动态抓取了。
如果只是想作为网页背景使用,只需要创建一个php文件,在里面粘贴如下代码即可:
然后将php文件上传到你的服务器,你应该可以看到访问php文件时被重定向到Bing的图片。
使用方法:直接将php文件的绝对地址作为图片放入网页中。
比如你的php地址是“”,那么你可以在自己网页的css中写这个,作为背景:
body{
width:100%;
height:100%;
background: url(https://hao.defcon.cn/bing.php) no-repeat;
-moz-background-size: cover; /*背景图片拉伸以铺满全屏*/
-ms-background-size: cover;
-webkit-background-size: cover;
background-size: cover;
}
上面的方法只是一个简单的跳转。如果您想抓取这张图片并将其保存到服务器怎么办?直接把代码贴在这里:
<p>
php 抓取网页生成图片(去年做过一个项目,要把用户上传的图像文件列出文字清单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-06 20:29
去年做了一个项目,列出用户上传的图片文件。当用户单击文件名时,可以显示图像。因为需要考虑对各种图片格式的兼容性,所以使用了GD库。找出具体的图片文件(MINE),然后调用对应的图片生成函数imagecreatefromXXX()生成一个img,然后将img以jpeg格式输出到浏览器。虽然完成了,但总觉得不满意。今天我有机会重新考虑这个功能。我在php手册中找到了几行代码。它简洁明了。完全可以实现我想要的功能。我不需要 GD 库来复制代码。代码如下:
代码量不到我原来的1/10,速度快了N倍。
TAG标签:PHP实现提取图片文件并在浏览器上显示的代码
易白网是国内知名的建站品牌服务商。我们拥有九年网站建设、网站制作、网页设计、PHP开发、域名注册和虚拟主机服务经验,提供自助建站服务。享誉全国。近年来,整合团队优势,自主研发了可视化多用户“点云建站系统”3.0平台版,拖放排版网站制作设计,简单易用实现pc站、手机微网站、小程序、APP一体化全网营销网站建设,已成功为全国数百家在线企业提供自助平台建设服务。
上一篇:PHP代码生成本地唯一识别码LUID | 下一篇:PHP中3种生成XML文件的方法速度和效率对比 查看全部
php 抓取网页生成图片(去年做过一个项目,要把用户上传的图像文件列出文字清单)
去年做了一个项目,列出用户上传的图片文件。当用户单击文件名时,可以显示图像。因为需要考虑对各种图片格式的兼容性,所以使用了GD库。找出具体的图片文件(MINE),然后调用对应的图片生成函数imagecreatefromXXX()生成一个img,然后将img以jpeg格式输出到浏览器。虽然完成了,但总觉得不满意。今天我有机会重新考虑这个功能。我在php手册中找到了几行代码。它简洁明了。完全可以实现我想要的功能。我不需要 GD 库来复制代码。代码如下:
代码量不到我原来的1/10,速度快了N倍。
TAG标签:PHP实现提取图片文件并在浏览器上显示的代码
易白网是国内知名的建站品牌服务商。我们拥有九年网站建设、网站制作、网页设计、PHP开发、域名注册和虚拟主机服务经验,提供自助建站服务。享誉全国。近年来,整合团队优势,自主研发了可视化多用户“点云建站系统”3.0平台版,拖放排版网站制作设计,简单易用实现pc站、手机微网站、小程序、APP一体化全网营销网站建设,已成功为全国数百家在线企业提供自助平台建设服务。
上一篇:PHP代码生成本地唯一识别码LUID | 下一篇:PHP中3种生成XML文件的方法速度和效率对比
php 抓取网页生成图片(下午仿照网上例子写了个抓取网页中图片并保存到本地的例子)
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-10-06 07:09
下午模仿网上的例子,写了一个从网页抓取图片保存到本地Python的例子。很好奇google上有没有类似的在线抓图插件工具。
然后我找到了这个文章-Pseric写的Image Cyborg,可以一键下载并存储网页上的所有图片
—————————————————————————————————————————————————————————
如果要抓取网页中的所有图片,您知道怎么做最快吗?或许你之前从未安装过类似的扩展,因为有些插件可以批量下载并保存网页中的所有图片。如果你不使用插件,你实际上可以使用在线工具来完成。本文即将介绍一种可以快速下载并存储网页中所有图片的服务。只需输入网址,无需安装附加软件,非常方便!
Image Cyborg 是一个免费的在线工具,提供批量下载和备份网络图像。它可以批量下载、提取和打包您输入的 URL 中的所有图像到一个压缩文件中。隐私是其最大的特点。网站 不会记录和跟踪用户下载数据。Image Cyborg 支持数据URI Scheme格式的图片(使用一段Base64编码处理图片,减少带宽,提高网站加载效率技术),以及延迟加载和动态生成图片,一般无法通过插件。
此服务支持的图像格式包括:.bmp、.eps、.gif、.jpeg、.jpg、.icns、.im、.mps、.pcx、.png、.ppm、.spider、.tiff、.webp ,.xbm,.svg,只要输入要下载图片的原创网址,它就会自动抓取网页中的所有图片,打包成压缩文件供用户下载。
网站名称:Image Cyborg
网站 链接:
使用步骤
第1步
打开Image Cyborg的官网——可以看到如下图所示的页面。将复制的网址直接粘贴到首页,点击“下载图片”开始处理。
第2步
需要一段时间来处理。Image Cyborg 网站 将显示当前进度。经过几次测试,我发现速度相当快。下载一个收录 10 张图片的网页需要将近 30 秒的处理时间。
第 3 步
处理完成后,Image Cyborg 会弹出文件下载提示,下载一个名为[].zip 的压缩包。
将下载的压缩文件解压后,即可得到网页中所有的原创图片文件。不仅如此,它还会自动修改图片文件名,在前面添加源URL和随机字符串。
值得一试的三个理由: 输入网站 URL,所有图片会自动打包下载。支持数据URI Scheme,延迟或动态加载图片,无需额外下载插件,跨平台
—————————————————————————————————————————————————————————
按照上面三个步骤,我找到了一个链接来测试下载:
原网页如下图有6张图中红色箭头标出的图片:
得到的[].zip压缩包解压后依次得到如下6张图片:
总结:
image-cyborg 是一个很好的在线抓取网页图片的工具。 查看全部
php 抓取网页生成图片(下午仿照网上例子写了个抓取网页中图片并保存到本地的例子)
下午模仿网上的例子,写了一个从网页抓取图片保存到本地Python的例子。很好奇google上有没有类似的在线抓图插件工具。
然后我找到了这个文章-Pseric写的Image Cyborg,可以一键下载并存储网页上的所有图片
—————————————————————————————————————————————————————————
如果要抓取网页中的所有图片,您知道怎么做最快吗?或许你之前从未安装过类似的扩展,因为有些插件可以批量下载并保存网页中的所有图片。如果你不使用插件,你实际上可以使用在线工具来完成。本文即将介绍一种可以快速下载并存储网页中所有图片的服务。只需输入网址,无需安装附加软件,非常方便!
Image Cyborg 是一个免费的在线工具,提供批量下载和备份网络图像。它可以批量下载、提取和打包您输入的 URL 中的所有图像到一个压缩文件中。隐私是其最大的特点。网站 不会记录和跟踪用户下载数据。Image Cyborg 支持数据URI Scheme格式的图片(使用一段Base64编码处理图片,减少带宽,提高网站加载效率技术),以及延迟加载和动态生成图片,一般无法通过插件。
此服务支持的图像格式包括:.bmp、.eps、.gif、.jpeg、.jpg、.icns、.im、.mps、.pcx、.png、.ppm、.spider、.tiff、.webp ,.xbm,.svg,只要输入要下载图片的原创网址,它就会自动抓取网页中的所有图片,打包成压缩文件供用户下载。
网站名称:Image Cyborg
网站 链接:
使用步骤
第1步
打开Image Cyborg的官网——可以看到如下图所示的页面。将复制的网址直接粘贴到首页,点击“下载图片”开始处理。
第2步
需要一段时间来处理。Image Cyborg 网站 将显示当前进度。经过几次测试,我发现速度相当快。下载一个收录 10 张图片的网页需要将近 30 秒的处理时间。
第 3 步
处理完成后,Image Cyborg 会弹出文件下载提示,下载一个名为[].zip 的压缩包。
将下载的压缩文件解压后,即可得到网页中所有的原创图片文件。不仅如此,它还会自动修改图片文件名,在前面添加源URL和随机字符串。
值得一试的三个理由: 输入网站 URL,所有图片会自动打包下载。支持数据URI Scheme,延迟或动态加载图片,无需额外下载插件,跨平台
—————————————————————————————————————————————————————————
按照上面三个步骤,我找到了一个链接来测试下载:
原网页如下图有6张图中红色箭头标出的图片:
得到的[].zip压缩包解压后依次得到如下6张图片:
总结:
image-cyborg 是一个很好的在线抓取网页图片的工具。
php 抓取网页生成图片(什么是代理?什么情况下会用到代理IP?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-10-06 07:06
)
什么是代理?什么情况下会使用代理IP?
Proxy Server,它的作用是代表用户获取网络信息,然后返回给用户。形象地说:它是网络信息的中转站。通过代理IP访问目标站,可以隐藏用户的真实IP。
比如你要抓取一段网站的数据,网站有100万条内容。他们设置了IP限制,每个IP每小时只能抢1000个。如果因为限制使用单个IP去抢 完成采集大约需要40天。如果使用代理IP,不断切换IP,可以突破每小时1000的频率限制,从而提高效率。
其他想要切换IP或者隐藏身份的场景也会用到代理IP,比如SEO。
代理IP有开放代理和私有代理。开放代理从全网扫描,不稳定,不适合爬取。随便用就好了。使用爬虫抓取数据,最好使用私有代理。网上私人代理的供应商很多,稳定性参差不齐。现在我们公司使用的是“可变IP”提供的私有代理。
我们公司有一个项目,抓取亚马逊数据分析销售、评论等,使用PHP抓取。爬取亚马逊时要特别注意header,否则输出数据为空。还有一种方法,可以用PHP通过shell_exec调用curl命令来抓取。
PHP如果是使用curl函数来抓取,主要设置下面几项即可。
curl_setopt($ch, CURLOPT_PROXY, 'proxy.baibianip.com'); //代理服务器地址
curl_setopt($ch, CURLOPT_PROXYPORT, '8000'); //代理服务器端口
如果是抓取HTTPS,把下面两项设置为false:
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); //抓HTTPS可以把此项设置为false
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); //抓HTTPS可以把此项设置为false<br />
方法一:完整示例代码如下,下面提供两种方式来调用:
<p> 查看全部
php 抓取网页生成图片(什么是代理?什么情况下会用到代理IP?(图)
)
什么是代理?什么情况下会使用代理IP?
Proxy Server,它的作用是代表用户获取网络信息,然后返回给用户。形象地说:它是网络信息的中转站。通过代理IP访问目标站,可以隐藏用户的真实IP。
比如你要抓取一段网站的数据,网站有100万条内容。他们设置了IP限制,每个IP每小时只能抢1000个。如果因为限制使用单个IP去抢 完成采集大约需要40天。如果使用代理IP,不断切换IP,可以突破每小时1000的频率限制,从而提高效率。
其他想要切换IP或者隐藏身份的场景也会用到代理IP,比如SEO。
代理IP有开放代理和私有代理。开放代理从全网扫描,不稳定,不适合爬取。随便用就好了。使用爬虫抓取数据,最好使用私有代理。网上私人代理的供应商很多,稳定性参差不齐。现在我们公司使用的是“可变IP”提供的私有代理。
我们公司有一个项目,抓取亚马逊数据分析销售、评论等,使用PHP抓取。爬取亚马逊时要特别注意header,否则输出数据为空。还有一种方法,可以用PHP通过shell_exec调用curl命令来抓取。
PHP如果是使用curl函数来抓取,主要设置下面几项即可。
curl_setopt($ch, CURLOPT_PROXY, 'proxy.baibianip.com'); //代理服务器地址
curl_setopt($ch, CURLOPT_PROXYPORT, '8000'); //代理服务器端口
如果是抓取HTTPS,把下面两项设置为false:
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); //抓HTTPS可以把此项设置为false
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); //抓HTTPS可以把此项设置为false<br />
方法一:完整示例代码如下,下面提供两种方式来调用:
<p>
php 抓取网页生成图片( PHP脚本与动态页面教程(图)!(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-03 17:12
PHP脚本与动态页面教程(图)!(组图)
)
更详细的PHP生成静态页面教程
更新时间:2012年1月10日13:46:27 作者:
PHP生成静态页面教程,先复习一些基本概念
一、PHP脚本和动态页面。
PHP脚本是一种服务器端脚本程序,可以通过嵌入方式与HTML文件混合,也可以以类、函数封装等形式使用,以模板的形式处理用户请求。不管怎样,它的基本原理是这样的。客户端发出请求,请求某个页面----->WEB服务器引入指定的对应脚本进行处理----->脚本加载到服务器中----->指定的PHP解析器服务器匹配脚本Analyze to form HTML language form ----> 将解析后的HTML语句以包的形式传回浏览器。不难看出,页面发送到浏览器后,PHP 不复存在,已经被转换解析为 HTML 语句。客户端请求是一个动态文件。事实上,那里不存在真正的文件。由PHP解析形成相应的页面,然后发送回浏览器。这种类型的页面处理称为“动态页面”。
二、静态页面。
静态页面是指只收录服务器端确实存在的 HTML、JS、CSS 和其他客户端脚本的页面。它的处理方式是。客户端发出请求请求某个页面---->WEB服务器确认并加载某个页面---->WEB服务器将该页面以包的形式返回给浏览器。从这个过程中,我们可以比较动态页面。动态页面需要通过WEB服务器的PHP解析器进行解析,通常需要连接数据库进行数据库访问操作,然后形成HTML语言信息包;而静态页面不需要解析,不需要连接数据库,直接发送即可。降低服务器压力,提高服务器负载能力,大幅提升页面打开速度和网站整体打开速度。
三、模板和模板分析。
模板尚未填充内容 html 文件。例如:
临时文件
代码:
复制代码代码如下:
{标题}
这是一个 {file} 文件的模板
PHP处理:
模板测试.php
代码:
$title = "Tomac 国际测试模板";
$file = "TwoMax Inter 测试模板,
作者:Matrix@Two_Max”;
$fp = fopen("temp.html","r");
$content = fread ($fp,filesize ("temp.html"));
$content .= str_replace("{文件}",$file,$content);
$content .= str_replace ("{title }",$title,$content);
回声$内容;
模板解析过程是将PHP脚本解析过程得到的结果填充(内容)到模板中的过程。通常在模板类的帮助下。目前比较流行的模板解析类有phplib、smarty、fastsmarty等。模板分析处理的原则通常是替换。也有程序员习惯于将判断、循环等处理放入模板文件中,使用解析处理。典型的应用是块概念,它只是一个循环处理。PHP 脚本指定循环次数、如何循环替换等,然后模板解析类实现这些操作。
好了,对比了静态页面和动态页面的优劣,现在来说说如何用PHP生成静态文件。
PHP生成的静态页面并不是指PHP的动态分析和HTML页面的输出,而是用PHP创建HTML页面。同时,由于 HTML 的不可写性,如果我们创建的 HTML 被修改,则需要删除并重新生成。(当然你也可以选择用正则化来修改,但个人认为还是删掉,快点重新生成比较好,有些得不偿失。)
离家较近。用过PHP文件操作函数的PHP爱好者都知道,PHP中有一个文件操作函数fopen,就是打开文件。如果该文件不存在,请尝试创建它。这是 PHP 可以用来创建 HTML 文件的理论基础。只要存放HTML文件的文件夹有写权限(即权限定义0777),就可以创建文件。(对于UNIX系统,Win系统不需要考虑。)以上面的例子为例一个例子,如果我们修改最后一句,并指定在test目录下生成一个名为test.html的静态文件:
代码:
复制代码代码如下:
实际应用中常见问题的解决方法参考:
1. 文章 列表问题:
在数据库中创建一个字段,记录文件名,每次生成文件时将自动生成的文件名存入数据库。对于推荐的文章,只要指向指定存放静态文件的文件夹中的页面即可。使用PHP操作处理文章列表,保存为字符串,生成页面时替换此字符串。比如在页面上放置文章列表表添加标签{articletable},在PHP处理文件中:
代码:
复制代码代码如下:
第二,分页问题。
例如,当我们指定分页时,每页有 20 篇文章。某个子频道列表中文章的数量已经被数据库查询到了45个,那么首先我们通过查询得到如下参数:1、总页数;2、每页文章数。第二步,对于($i = 0; $i
代码:
复制代码代码如下:
$fp = fopen("temp.html","r");
$content = fread ($fp,filesize ("temp.html"));
$onepage = '20';
$sql = "select id from article where channel='$channelid'";
$query = mysql_query ($sql);
$num = mysql_num_rows ($query);
$allpages = ceil ($num / $onepage);
对于 ($i = 0;$i
大体思路是这样,其中其他数据生成、数据输入输出检查、页面内容指向等都可以酌情添加到页面中。
在文章系统的实际处理中,还有很多问题需要考虑。与动态页面不同,还有很多需要注意的地方。但是大体思路是一样的,其他方面可以互相推导。
使用PHP制作网站的静态模板框架
模板可以改进网站的结构。这篇文章讲解了如何使用PHP 4的新函数和模板类巧妙地使用模板来控制由大量静态HTML页面组成的网站中的页面布局。
大纲:
====================================
独立的功能和布局
避免重复页面元素
网站 的静态模板框架
====================================
独立的功能和布局
首先,我们来看看应用模板的两个主要目的:
分离功能 (PHP) 和布局 (HTML)
避免重复页面元素
第一个目的是谈论最多的目的。它设想了这样一种情况,一组程序员编写 PHP 脚本来生成页面内容,而另一组设计人员设计 HTML 和图形来控制页面的最终外观。功能和布局分离的基本思路是让这两组人能够编写和使用一组独立的文件:程序员只需要关心那些只收录PHP代码的文件,而不是页面的外观。
; 而且页面设计者可以使用他们最熟悉的可视化编辑器来设计页面布局,而不必担心破坏页面中嵌入的任何 PHP 代码。
如果您看过一些关于 PHP 模板的教程,那么您应该已经了解模板的工作原理。考虑一个简单的页面部分:页面顶部是页眉,左侧是导航栏,其余部分是内容区域。这种类型的 网站 可以有以下模板文件:
复制代码代码如下:
{头}
{左导航}
{内容}
富
酒吧
您可以看到页面是如何从这些模板构建的:主模板控制整个页面的布局;header 模板和 leftnav 模板控制页面的公共元素。花括号“{}”内的标识符是内容占位符。使用模板的主要好处是界面设计者可以根据自己的意愿编辑这些文件,比如设置字体、修改颜色和图形,或者完全改变页面的布局。界面设计者可以使用任何普通的 HTML 编辑器或可视化工具来编辑这些页面,因为这些文件只收录 HTML 代码,没有任何 PHP 代码。
PHP 代码全部保存在一个单独的文件中,该文件是页面 URL 实际调用的文件。Web 服务器通过 PHP 引擎解析文件,然后将结果返回给浏览器。通常,PHP 代码总是动态生成页面内容,例如查询数据库或执行某些计算。下面是一个例子:
复制代码代码如下:
这里我们使用流行的 FastTemplate 模板类,但基本思想与许多其他模板类相同。首先你实例化一个类,告诉它去哪里找模板文件,哪个模板文件对应页面的哪个部分;接下来是生成页面内容,并将结果赋给内容标识;然后,依次解析每个模板文件,模板类会进行必要的替换操作;最后将分析结果输出到浏览器。
这个文件完全由PHP代码组成,不收录任何HTML代码,这是它最大的优势。现在,PHP 程序员可以专注于编写生成页面内容的代码,而不必担心如何生成 HTML 以正确设置最终页面的格式。
可以用这个方法和上面的文件构造一个完整的网站。如果PHP代码根据URL中的查询字符串生成页面内容,例如,您可以基于此构造一个完整的杂志网站。
很容易看出使用模板还有第二个好处。如上例所示,页面左侧的导航栏单独保存为一个文件,我们只需要编辑该模板文件即可更改所有页面左侧的导航栏网站。
避免重复页面元素
“这真是太好了”,你可能会想,“我的网站主要是由大量的静态页面组成的,现在我可以从所有页面中删除它们的公共部分。更新这些公共部分太麻烦了. 将来,我可以使用模板来创建易于维护的统一页面布局。” 但事情并没有那么简单。“大量静态页面”说明问题。
请考虑上面的例子。这个例子实际上只有一个example.php 页面。之所以能生成整个网站的所有页面,是因为它利用URL中的查询字符串,从数据库等信息源动态构建页面。
我们大多数人运行的 网站 不一定有数据库支持。我们的大部分网站都是由静态页面组成的,然后用PHP到处添加一些动态的功能,比如搜索引擎,反馈表等等。 那么,如何将模板应用到这种网站?
最简单的方法是为每个页面复制一个PHP文件,
然后将表示 PHP 代码中内容的变量设置为每个页面中相应的页面内容。例如,假设有主页、关于、产品三个页面,我们可以使用三个文件分别生成它们。这三个文件的内容如下:
复制代码代码如下:
很明显,这种方法存在三个问题:我们必须为每个页面复制这些涉及模板的复杂PHP代码,这使得页面难以维护,就像重复常见的页面元素一样;现在文件与 HTML 和 PHP 代码混合在一起;内容变量赋值会变得非常困难,因为我们要处理大量的特殊字符。
解决这个问题的关键是将PHP代码和HTML内容分开。虽然我们无法从文件中删除所有 HTML 内容,但可以删除大部分 PHP 代码。
网站 的静态模板框架
首先,我们像以前一样为页面的所有公共元素和页面的整体布局编写模板文件;然后删除所有页面的公共部分,只留下页面内容;然后在每个页面添加三行PHP代码,如下:
复制代码代码如下:
你好
欢迎参观
查看全部
php 抓取网页生成图片(
PHP脚本与动态页面教程(图)!(组图)
)
更详细的PHP生成静态页面教程
更新时间:2012年1月10日13:46:27 作者:
PHP生成静态页面教程,先复习一些基本概念
一、PHP脚本和动态页面。
PHP脚本是一种服务器端脚本程序,可以通过嵌入方式与HTML文件混合,也可以以类、函数封装等形式使用,以模板的形式处理用户请求。不管怎样,它的基本原理是这样的。客户端发出请求,请求某个页面----->WEB服务器引入指定的对应脚本进行处理----->脚本加载到服务器中----->指定的PHP解析器服务器匹配脚本Analyze to form HTML language form ----> 将解析后的HTML语句以包的形式传回浏览器。不难看出,页面发送到浏览器后,PHP 不复存在,已经被转换解析为 HTML 语句。客户端请求是一个动态文件。事实上,那里不存在真正的文件。由PHP解析形成相应的页面,然后发送回浏览器。这种类型的页面处理称为“动态页面”。
二、静态页面。
静态页面是指只收录服务器端确实存在的 HTML、JS、CSS 和其他客户端脚本的页面。它的处理方式是。客户端发出请求请求某个页面---->WEB服务器确认并加载某个页面---->WEB服务器将该页面以包的形式返回给浏览器。从这个过程中,我们可以比较动态页面。动态页面需要通过WEB服务器的PHP解析器进行解析,通常需要连接数据库进行数据库访问操作,然后形成HTML语言信息包;而静态页面不需要解析,不需要连接数据库,直接发送即可。降低服务器压力,提高服务器负载能力,大幅提升页面打开速度和网站整体打开速度。
三、模板和模板分析。
模板尚未填充内容 html 文件。例如:
临时文件
代码:
复制代码代码如下:
{标题}
这是一个 {file} 文件的模板
PHP处理:
模板测试.php
代码:
$title = "Tomac 国际测试模板";
$file = "TwoMax Inter 测试模板,
作者:Matrix@Two_Max”;
$fp = fopen("temp.html","r");
$content = fread ($fp,filesize ("temp.html"));
$content .= str_replace("{文件}",$file,$content);
$content .= str_replace ("{title }",$title,$content);
回声$内容;
模板解析过程是将PHP脚本解析过程得到的结果填充(内容)到模板中的过程。通常在模板类的帮助下。目前比较流行的模板解析类有phplib、smarty、fastsmarty等。模板分析处理的原则通常是替换。也有程序员习惯于将判断、循环等处理放入模板文件中,使用解析处理。典型的应用是块概念,它只是一个循环处理。PHP 脚本指定循环次数、如何循环替换等,然后模板解析类实现这些操作。
好了,对比了静态页面和动态页面的优劣,现在来说说如何用PHP生成静态文件。
PHP生成的静态页面并不是指PHP的动态分析和HTML页面的输出,而是用PHP创建HTML页面。同时,由于 HTML 的不可写性,如果我们创建的 HTML 被修改,则需要删除并重新生成。(当然你也可以选择用正则化来修改,但个人认为还是删掉,快点重新生成比较好,有些得不偿失。)
离家较近。用过PHP文件操作函数的PHP爱好者都知道,PHP中有一个文件操作函数fopen,就是打开文件。如果该文件不存在,请尝试创建它。这是 PHP 可以用来创建 HTML 文件的理论基础。只要存放HTML文件的文件夹有写权限(即权限定义0777),就可以创建文件。(对于UNIX系统,Win系统不需要考虑。)以上面的例子为例一个例子,如果我们修改最后一句,并指定在test目录下生成一个名为test.html的静态文件:
代码:
复制代码代码如下:
实际应用中常见问题的解决方法参考:
1. 文章 列表问题:
在数据库中创建一个字段,记录文件名,每次生成文件时将自动生成的文件名存入数据库。对于推荐的文章,只要指向指定存放静态文件的文件夹中的页面即可。使用PHP操作处理文章列表,保存为字符串,生成页面时替换此字符串。比如在页面上放置文章列表表添加标签{articletable},在PHP处理文件中:
代码:
复制代码代码如下:
第二,分页问题。
例如,当我们指定分页时,每页有 20 篇文章。某个子频道列表中文章的数量已经被数据库查询到了45个,那么首先我们通过查询得到如下参数:1、总页数;2、每页文章数。第二步,对于($i = 0; $i
代码:
复制代码代码如下:
$fp = fopen("temp.html","r");
$content = fread ($fp,filesize ("temp.html"));
$onepage = '20';
$sql = "select id from article where channel='$channelid'";
$query = mysql_query ($sql);
$num = mysql_num_rows ($query);
$allpages = ceil ($num / $onepage);
对于 ($i = 0;$i
大体思路是这样,其中其他数据生成、数据输入输出检查、页面内容指向等都可以酌情添加到页面中。
在文章系统的实际处理中,还有很多问题需要考虑。与动态页面不同,还有很多需要注意的地方。但是大体思路是一样的,其他方面可以互相推导。
使用PHP制作网站的静态模板框架
模板可以改进网站的结构。这篇文章讲解了如何使用PHP 4的新函数和模板类巧妙地使用模板来控制由大量静态HTML页面组成的网站中的页面布局。
大纲:
====================================
独立的功能和布局
避免重复页面元素
网站 的静态模板框架
====================================
独立的功能和布局
首先,我们来看看应用模板的两个主要目的:
分离功能 (PHP) 和布局 (HTML)
避免重复页面元素
第一个目的是谈论最多的目的。它设想了这样一种情况,一组程序员编写 PHP 脚本来生成页面内容,而另一组设计人员设计 HTML 和图形来控制页面的最终外观。功能和布局分离的基本思路是让这两组人能够编写和使用一组独立的文件:程序员只需要关心那些只收录PHP代码的文件,而不是页面的外观。
; 而且页面设计者可以使用他们最熟悉的可视化编辑器来设计页面布局,而不必担心破坏页面中嵌入的任何 PHP 代码。
如果您看过一些关于 PHP 模板的教程,那么您应该已经了解模板的工作原理。考虑一个简单的页面部分:页面顶部是页眉,左侧是导航栏,其余部分是内容区域。这种类型的 网站 可以有以下模板文件:
复制代码代码如下:
{头}
{左导航}
{内容}

富
酒吧
您可以看到页面是如何从这些模板构建的:主模板控制整个页面的布局;header 模板和 leftnav 模板控制页面的公共元素。花括号“{}”内的标识符是内容占位符。使用模板的主要好处是界面设计者可以根据自己的意愿编辑这些文件,比如设置字体、修改颜色和图形,或者完全改变页面的布局。界面设计者可以使用任何普通的 HTML 编辑器或可视化工具来编辑这些页面,因为这些文件只收录 HTML 代码,没有任何 PHP 代码。
PHP 代码全部保存在一个单独的文件中,该文件是页面 URL 实际调用的文件。Web 服务器通过 PHP 引擎解析文件,然后将结果返回给浏览器。通常,PHP 代码总是动态生成页面内容,例如查询数据库或执行某些计算。下面是一个例子:
复制代码代码如下:
这里我们使用流行的 FastTemplate 模板类,但基本思想与许多其他模板类相同。首先你实例化一个类,告诉它去哪里找模板文件,哪个模板文件对应页面的哪个部分;接下来是生成页面内容,并将结果赋给内容标识;然后,依次解析每个模板文件,模板类会进行必要的替换操作;最后将分析结果输出到浏览器。
这个文件完全由PHP代码组成,不收录任何HTML代码,这是它最大的优势。现在,PHP 程序员可以专注于编写生成页面内容的代码,而不必担心如何生成 HTML 以正确设置最终页面的格式。
可以用这个方法和上面的文件构造一个完整的网站。如果PHP代码根据URL中的查询字符串生成页面内容,例如,您可以基于此构造一个完整的杂志网站。
很容易看出使用模板还有第二个好处。如上例所示,页面左侧的导航栏单独保存为一个文件,我们只需要编辑该模板文件即可更改所有页面左侧的导航栏网站。
避免重复页面元素
“这真是太好了”,你可能会想,“我的网站主要是由大量的静态页面组成的,现在我可以从所有页面中删除它们的公共部分。更新这些公共部分太麻烦了. 将来,我可以使用模板来创建易于维护的统一页面布局。” 但事情并没有那么简单。“大量静态页面”说明问题。
请考虑上面的例子。这个例子实际上只有一个example.php 页面。之所以能生成整个网站的所有页面,是因为它利用URL中的查询字符串,从数据库等信息源动态构建页面。
我们大多数人运行的 网站 不一定有数据库支持。我们的大部分网站都是由静态页面组成的,然后用PHP到处添加一些动态的功能,比如搜索引擎,反馈表等等。 那么,如何将模板应用到这种网站?
最简单的方法是为每个页面复制一个PHP文件,
然后将表示 PHP 代码中内容的变量设置为每个页面中相应的页面内容。例如,假设有主页、关于、产品三个页面,我们可以使用三个文件分别生成它们。这三个文件的内容如下:
复制代码代码如下:
很明显,这种方法存在三个问题:我们必须为每个页面复制这些涉及模板的复杂PHP代码,这使得页面难以维护,就像重复常见的页面元素一样;现在文件与 HTML 和 PHP 代码混合在一起;内容变量赋值会变得非常困难,因为我们要处理大量的特殊字符。
解决这个问题的关键是将PHP代码和HTML内容分开。虽然我们无法从文件中删除所有 HTML 内容,但可以删除大部分 PHP 代码。
网站 的静态模板框架
首先,我们像以前一样为页面的所有公共元素和页面的整体布局编写模板文件;然后删除所有页面的公共部分,只留下页面内容;然后在每个页面添加三行PHP代码,如下:
复制代码代码如下:
你好
欢迎参观

php 抓取网页生成图片(用php执行系统命令的时候发现无法执行,但是可以执行CutyCapt)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-03 11:21
制作网站屏幕截图时,使用服务器的工具cutycapt。您可以通过服务器上的命令直接获取它,以生成指定URL的图片。但是,在使用PHP执行系统命令时,发现无法执行该命令,但是可以执行收录帮助信息的命令,例如cutycapt(“/usr/local/cutycapt/cutycapt/xvfb run.Sh--help”),但无法成功执行调用系统变量的脚本。有人怀疑这是一个许可问题。后来发现cutycapt权限设置为www。后来发现这是因为nginx服务器在执行命令时会调用shell脚本。此时,它将遇到权限问题
可爱的
屏幕截图中使用的系统命令:
/usr/bin/sudo/usr/local/cutycapt/cutycapt/xvfb-run.sh/usr/local/cutycapt/cutycapt/cutycapt--url=--out=/tmp/insert.jpg
1、设置sudo配置文件可写权限
chmod u+w/etc/sudoers
2、增加WWW用户执行cutycapt脚本的权限(添加要运行的脚本和命令的权限):
www ALL=(root)NOPASSWD:/bin/sh、/usr/local/cutycapt/cutycapt/xvfb-run.sh、/usr/local/cutycapt/cutycapt/cutycapt
3、关闭[强制控制台登录]以执行或允许www用户在不使用控制台的情况下登录
修改内容:
注意:需要默认值
更好的修改方法(更安全):
仅添加:默认值:www!要求(WWW用户不使用控制台登录)
4使用PHP执行
系统('/usr/bin/sudo/usr/local/cutycapt/cutycapt/xvfb-run.sh/usr/local/cutycapt/cutycapt/cutycapt-url=--out=/tmp/insert2.jpg',m)
注(更安全的方式):
系统('sudo/usr/local/cutycapt/cutycapt/xvfb-run.sh/usr/local/cutycapt/cutycapt/cutycapt-url=--out=/tmp/insert2.jpg',m)
Nginx重启:
同样,增加WWW用户执行nginx脚本的权限 查看全部
php 抓取网页生成图片(用php执行系统命令的时候发现无法执行,但是可以执行CutyCapt)
制作网站屏幕截图时,使用服务器的工具cutycapt。您可以通过服务器上的命令直接获取它,以生成指定URL的图片。但是,在使用PHP执行系统命令时,发现无法执行该命令,但是可以执行收录帮助信息的命令,例如cutycapt(“/usr/local/cutycapt/cutycapt/xvfb run.Sh--help”),但无法成功执行调用系统变量的脚本。有人怀疑这是一个许可问题。后来发现cutycapt权限设置为www。后来发现这是因为nginx服务器在执行命令时会调用shell脚本。此时,它将遇到权限问题
可爱的
屏幕截图中使用的系统命令:
/usr/bin/sudo/usr/local/cutycapt/cutycapt/xvfb-run.sh/usr/local/cutycapt/cutycapt/cutycapt--url=--out=/tmp/insert.jpg
1、设置sudo配置文件可写权限
chmod u+w/etc/sudoers
2、增加WWW用户执行cutycapt脚本的权限(添加要运行的脚本和命令的权限):
www ALL=(root)NOPASSWD:/bin/sh、/usr/local/cutycapt/cutycapt/xvfb-run.sh、/usr/local/cutycapt/cutycapt/cutycapt
3、关闭[强制控制台登录]以执行或允许www用户在不使用控制台的情况下登录
修改内容:
注意:需要默认值
更好的修改方法(更安全):
仅添加:默认值:www!要求(WWW用户不使用控制台登录)
4使用PHP执行
系统('/usr/bin/sudo/usr/local/cutycapt/cutycapt/xvfb-run.sh/usr/local/cutycapt/cutycapt/cutycapt-url=--out=/tmp/insert2.jpg',m)
注(更安全的方式):
系统('sudo/usr/local/cutycapt/cutycapt/xvfb-run.sh/usr/local/cutycapt/cutycapt/cutycapt-url=--out=/tmp/insert2.jpg',m)
Nginx重启:
同样,增加WWW用户执行nginx脚本的权限
php 抓取网页生成图片([博物馆]())
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-02 15:19
黄聪:Python访问和抓取网页的常用命令(本地保存图片、模拟post、get、中文编码)
简单网络爬网:
import urllib.request
url="http://google.cn/"
response=urllib.request.urlopen(url) #返回文件对象
page=response.read()
将URL直接保存为本地文件:
import urllib.request
url="http://www.xxxx.com/1.jpg"
urllib.request.urlretrieve(url,r"d:\temp\1.jpg")
发布模式:
import urllib.parse
import urllib.request
url="http://liuxin-blog.appspot.com ... ot%3B
values={"content":"命令行发出网页请求测试"}
data=urllib.parse.urlencode(values)
#创建请求对象
req=urllib.request.Request(url,data)
#获得服务器返回的数据
response=urllib.request.urlopen(req)
#处理数据
page=response.read()
获取方法:
import urllib.parse
import urllib.request
url="http://www.google.cn/webhp"
values={"rls":"ig"}
data=urllib.parse.urlencode(values)
theurl=url+"?"+data
#创建请求对象
req=urllib.request.Request(theurl)
#获得服务器返回的数据
response=urllib.request.urlopen(req)
#处理数据
page=response.read()
有两种常用方法,geturl(),info()
Geturl()设置为标识是否存在服务器端URL重定向,而info()收录一系列信息
Encode()编码和解码()将用于处理中文问题: 查看全部
php 抓取网页生成图片([博物馆]())
黄聪:Python访问和抓取网页的常用命令(本地保存图片、模拟post、get、中文编码)
简单网络爬网:
import urllib.request
url="http://google.cn/"
response=urllib.request.urlopen(url) #返回文件对象
page=response.read()
将URL直接保存为本地文件:
import urllib.request
url="http://www.xxxx.com/1.jpg"
urllib.request.urlretrieve(url,r"d:\temp\1.jpg")
发布模式:
import urllib.parse
import urllib.request
url="http://liuxin-blog.appspot.com ... ot%3B
values={"content":"命令行发出网页请求测试"}
data=urllib.parse.urlencode(values)
#创建请求对象
req=urllib.request.Request(url,data)
#获得服务器返回的数据
response=urllib.request.urlopen(req)
#处理数据
page=response.read()
获取方法:
import urllib.parse
import urllib.request
url="http://www.google.cn/webhp"
values={"rls":"ig"}
data=urllib.parse.urlencode(values)
theurl=url+"?"+data
#创建请求对象
req=urllib.request.Request(theurl)
#获得服务器返回的数据
response=urllib.request.urlopen(req)
#处理数据
page=response.read()
有两种常用方法,geturl(),info()
Geturl()设置为标识是否存在服务器端URL重定向,而info()收录一系列信息
Encode()编码和解码()将用于处理中文问题:
php 抓取网页生成图片( 一下PHP生成静态页面的原理是什么?HTML5设计原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-02 15:17
一下PHP生成静态页面的原理是什么?HTML5设计原理)
php入门教程:生成静态html页面的原理
经常操作网站后端的人都知道,目前大部分网站系统,如dedecms、phpcms、Empire等知名的内容管理系统,提供静态页面生成。该功能不仅有利于搜索引擎的抓取,还能有效降低服务器压力,所以这是一个非常流行和实用的功能。
对于正在学习PHP,即将从事WEB网站开发的人来说,了解这个功能是必不可少的。因此,我们来分享一下PHP生成静态页面的原理。
一、 思路分析
其实实现静态页面生成功能的原理很简单。它主要使用几种常用的PHP文件操作函数来操作文件。思考过程如下:
生成静态页面流程图
二、功能实现
设置example.html为模板文件,然后根据这个模板文件生成article-1.html~article-5.html进行简单的演示。代码如下:
注解:
fopen(文件名,打开方法),打开文件功能,如果没有文件,就创建。返回值为资源类型;
fread(文件名,读取字节数),读取文件内容及对应的字节数;
str_replace(指定要搜索的'值,替换被搜索值的值,被搜索的字符串),替换函数;
fclose(文件名),关闭文件;
fwrite(要写入的打开文件,要写入打开文件的字符串,要写入的最大字节数)。
三、终于
原理比较简单。作为一个php初学者,一定要把每一个基础知识都学好,每天坚持写代码,形成条件反射。其次,根据工作需要设定阶段目标。我相信您的 PHP 之路一定会如此。风光无限,互相鼓励!
【PHP简介:生成静态html页面的原理】相关文章:
1.PHP入门教程
2.网站静态生成html有什么好处
3.静态页面生成方案介绍
4.HTML5 设计原则
5.PHP.NET 简介
6.简单的HTML5初级入门教程
7.关于HTML 30分钟入门教程
8.html5 入口设计原则 查看全部
php 抓取网页生成图片(
一下PHP生成静态页面的原理是什么?HTML5设计原理)
php入门教程:生成静态html页面的原理
经常操作网站后端的人都知道,目前大部分网站系统,如dedecms、phpcms、Empire等知名的内容管理系统,提供静态页面生成。该功能不仅有利于搜索引擎的抓取,还能有效降低服务器压力,所以这是一个非常流行和实用的功能。
对于正在学习PHP,即将从事WEB网站开发的人来说,了解这个功能是必不可少的。因此,我们来分享一下PHP生成静态页面的原理。
一、 思路分析
其实实现静态页面生成功能的原理很简单。它主要使用几种常用的PHP文件操作函数来操作文件。思考过程如下:

生成静态页面流程图
二、功能实现
设置example.html为模板文件,然后根据这个模板文件生成article-1.html~article-5.html进行简单的演示。代码如下:
注解:
fopen(文件名,打开方法),打开文件功能,如果没有文件,就创建。返回值为资源类型;
fread(文件名,读取字节数),读取文件内容及对应的字节数;
str_replace(指定要搜索的'值,替换被搜索值的值,被搜索的字符串),替换函数;
fclose(文件名),关闭文件;
fwrite(要写入的打开文件,要写入打开文件的字符串,要写入的最大字节数)。
三、终于
原理比较简单。作为一个php初学者,一定要把每一个基础知识都学好,每天坚持写代码,形成条件反射。其次,根据工作需要设定阶段目标。我相信您的 PHP 之路一定会如此。风光无限,互相鼓励!
【PHP简介:生成静态html页面的原理】相关文章:
1.PHP入门教程
2.网站静态生成html有什么好处
3.静态页面生成方案介绍
4.HTML5 设计原则
5.PHP.NET 简介
6.简单的HTML5初级入门教程
7.关于HTML 30分钟入门教程
8.html5 入口设计原则
php 抓取网页生成图片(PHP快速生成图片验证码并且实现验证插件1.插件(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-01 10:07
PHP快速生成图片验证码并实现验证插件1.插件功能:该插件可以快速实现网站验证码功能,包括验证码的生成和验证2.所需参数:captchatool类收录两种方法。生成方法可以实现生成';ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890';并将这些字符写入captcha目录中的图片。同时,在会话中保存代码值并将其输出。此方法不需要参数。Check方法,需要用户输入代码值并返回true或false3.使用方法:包括这些文件,实例化它们,并使用获取的对象调用相应的方法4.注意事项:使用此插件,用户可以根据其网站扩展验证代码字符的示例文本,将要展开的字符放在$chars中,并在for循环中进行相应的调整。小心确保flie的路径文件地址$BG_uu是验证代码背景图片的地址。验证码图像的边框颜色由imagerectangle($img,0,0,144,19,$white)中的$white确定,文本大小由imagestring()中的第二个参数确定。字符串颜色可用于根据需要分配画布颜色。使用函数imagecolorallocate() 查看全部
php 抓取网页生成图片(PHP快速生成图片验证码并且实现验证插件1.插件(图))
PHP快速生成图片验证码并实现验证插件1.插件功能:该插件可以快速实现网站验证码功能,包括验证码的生成和验证2.所需参数:captchatool类收录两种方法。生成方法可以实现生成';ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890';并将这些字符写入captcha目录中的图片。同时,在会话中保存代码值并将其输出。此方法不需要参数。Check方法,需要用户输入代码值并返回true或false3.使用方法:包括这些文件,实例化它们,并使用获取的对象调用相应的方法4.注意事项:使用此插件,用户可以根据其网站扩展验证代码字符的示例文本,将要展开的字符放在$chars中,并在for循环中进行相应的调整。小心确保flie的路径文件地址$BG_uu是验证代码背景图片的地址。验证码图像的边框颜色由imagerectangle($img,0,0,144,19,$white)中的$white确定,文本大小由imagestring()中的第二个参数确定。字符串颜色可用于根据需要分配画布颜色。使用函数imagecolorallocate()
php 抓取网页生成图片( www根目录创建项目实现步骤:属性接下来:创建步骤 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-09-26 11:07
www根目录创建项目实现步骤:属性接下来:创建步骤
)
具体实现步骤如下:
创建项目
作为演示,我们在www根目录下创建一个项目grabimg,创建一个类GrabImage.php和一个index.php。
编写类代码
我们定义一个与文件同名的类:GrabImage
class GrabImage{
}
属性
接下来,定义几个需要用到的属性。
1、首先定义一个需要抓取的图片地址:$img_url
2、再定义一个$file_name来存放文件名,但是不带扩展名,因为可能会涉及到扩展名的替换,所以这里是定义
3、 后跟扩展名 $extension
4、 然后我们定义一个$file_dir。该属性的作用是远程镜像捕获后本地存储的目录,一般以PHP入口文件的位置为起点。但是路径一般不会保存到数据库中。
5、最后我们定义了一个$save_dir,顾名思义,这个路径就是要直接保存的数据库的目录。这里说明一下,我们不直接将文件保存路径存储到数据库中,一般是为以后系统迁移时更改路径做准备。我们这里的$save_dir一般是日期文件名,如果使用的时候需要取出来,把需要的路径放在前面。
(免费学习视频教程分享:php视频教程)
方法
属性说完了,接下来我们就正式开始爬取工作了。
首先,我们定义了一个open方法getInstances来获取一些数据,比如抓拍图片的地址,本地保存路径等。同时把它放在属性中。
public function getInstances($img_url , $base_dir)
{
$this->img_url = $img_url;
$this->save_dir = date("Ym").'/'.date("d").'/'; // 比如:201610/19/
$this->file_dir = $base_dir.'/'.$this->save_dir.'/'; // 比如:./uploads/image/2016/10/19/
}
图片保存路径已拼接。接下来需要注意一个问题,目录是否存在。日期一天天过去,但目录不会自动创建。因此,在保存图片之前,您需要先检查一下,如果当前目录不存在,我们需要立即创建它。
我们创建 setDir 方法来设置目录。我们将财产设为私密、安全
下一步就是抓取核心代码
第一步是解决问题。我们需要抓取的图片可能没有后缀。按照传统的抓图方式,先抓图,再截取后缀名是行不通的。
我们必须通过其他方法获取图片类型。方式是从文件流信息中获取文件头信息,然后判断文件mime信息,即可知道文件后缀名。
为方便起见,首先定义一个 mime 和文件扩展名映射。
$mimes=array(
'image/bmp'=>'bmp',
'image/gif'=>'gif',
'image/jpeg'=>'jpg',
'image/png'=>'png',
'image/x-icon'=>'ico'
);
这样,当我得到类型 image/gif 时,我可以知道它是一个 .gif 图像。
使用php函数get_headers获取文件流头信息。当它的值不为 false 时,我们将它分配给变量 $headers
取出Content-Type的值作为mime的值。
if(($headers=get_headers($this->img_url, 1))!==false){
// 获取响应的类型
$type=$headers['Content-Type'];
}
使用我们上面定义的映射表,我们可以很容易地得到后缀名。
$this->extension=$mimes[$type];
当然,上面得到的$type可能不存在于我们的映射表中,说明这种类型的文件不是我们想要的,放弃它,忽略它。
以下步骤与传统的文件抓取相同。
$file_path = $this->file_dir.$this->file_name.".".$this->extension;
// 获取数据并保存
$contents=file_get_contents($this->img_url);
if(file_put_contents($file_path , $contents))
{
// 这里返回出去的值是直接保存到数据库的路径 文件名,形如:201610/19/57feefd7e2a7aY5p7LsPqaI-lY1BF.jpg
return $this->save_dir.$this->file_name.".".$this->extension;
}
先获取本地保存图片的全路径$file_path,然后用file_get_contents抓取数据,再用file_put_contents保存到刚才的文件路径。
最后,我们返回一个可以直接保存到数据库的路径,而不是文件存储路径。
完整的获取方法如下:
private function getRemoteImg()
{
// mime 和 扩展名 的映射
$mimes=array(
'image/bmp'=>'bmp',
'image/gif'=>'gif',
'image/jpeg'=>'jpg',
'image/png'=>'png',
'image/x-icon'=>'ico'
);
// 获取响应头
if(($headers=get_headers($this->img_url, 1))!==false)
{
// 获取响应的类型
$type=$headers['Content-Type'];
// 如果符合我们要的类型
if(isset($mimes[$type]))
{
$this->extension=$mimes[$type];
$file_path = $this->file_dir.$this->file_name.".".$this->extension;
// 获取数据并保存
$contents=file_get_contents($this->img_url);
if(file_put_contents($file_path , $contents))
{
// 这里返回出去的值是直接保存到数据库的路径 文件名,形如:201610/19/57feefd7e2a7aY5p7LsPqaI-lY1BF.jpg
return $this->save_dir.$this->file_name.".".$this->extension;
}
}
}
return false;
}
最后,为了简单起见,我们希望在别处调用这些方法之一来完成爬网。所以我们直接把抓取动作放到getInstances里面,配置好路径后,直接抓取。因此,我们将代码添加到初始配置方法 getInstances 中。
if($this->setDir())
{
return $this->getRemoteImg();
}
else
{
return false;
}
测试
让我们在刚刚创建的 index.php 文件中尝试一下。
完整代码如下:
<p> 查看全部
php 抓取网页生成图片(
www根目录创建项目实现步骤:属性接下来:创建步骤
)

具体实现步骤如下:
创建项目
作为演示,我们在www根目录下创建一个项目grabimg,创建一个类GrabImage.php和一个index.php。
编写类代码
我们定义一个与文件同名的类:GrabImage
class GrabImage{
}
属性
接下来,定义几个需要用到的属性。
1、首先定义一个需要抓取的图片地址:$img_url
2、再定义一个$file_name来存放文件名,但是不带扩展名,因为可能会涉及到扩展名的替换,所以这里是定义
3、 后跟扩展名 $extension
4、 然后我们定义一个$file_dir。该属性的作用是远程镜像捕获后本地存储的目录,一般以PHP入口文件的位置为起点。但是路径一般不会保存到数据库中。
5、最后我们定义了一个$save_dir,顾名思义,这个路径就是要直接保存的数据库的目录。这里说明一下,我们不直接将文件保存路径存储到数据库中,一般是为以后系统迁移时更改路径做准备。我们这里的$save_dir一般是日期文件名,如果使用的时候需要取出来,把需要的路径放在前面。
(免费学习视频教程分享:php视频教程)
方法
属性说完了,接下来我们就正式开始爬取工作了。
首先,我们定义了一个open方法getInstances来获取一些数据,比如抓拍图片的地址,本地保存路径等。同时把它放在属性中。
public function getInstances($img_url , $base_dir)
{
$this->img_url = $img_url;
$this->save_dir = date("Ym").'/'.date("d").'/'; // 比如:201610/19/
$this->file_dir = $base_dir.'/'.$this->save_dir.'/'; // 比如:./uploads/image/2016/10/19/
}
图片保存路径已拼接。接下来需要注意一个问题,目录是否存在。日期一天天过去,但目录不会自动创建。因此,在保存图片之前,您需要先检查一下,如果当前目录不存在,我们需要立即创建它。
我们创建 setDir 方法来设置目录。我们将财产设为私密、安全

下一步就是抓取核心代码
第一步是解决问题。我们需要抓取的图片可能没有后缀。按照传统的抓图方式,先抓图,再截取后缀名是行不通的。
我们必须通过其他方法获取图片类型。方式是从文件流信息中获取文件头信息,然后判断文件mime信息,即可知道文件后缀名。
为方便起见,首先定义一个 mime 和文件扩展名映射。
$mimes=array(
'image/bmp'=>'bmp',
'image/gif'=>'gif',
'image/jpeg'=>'jpg',
'image/png'=>'png',
'image/x-icon'=>'ico'
);
这样,当我得到类型 image/gif 时,我可以知道它是一个 .gif 图像。
使用php函数get_headers获取文件流头信息。当它的值不为 false 时,我们将它分配给变量 $headers
取出Content-Type的值作为mime的值。
if(($headers=get_headers($this->img_url, 1))!==false){
// 获取响应的类型
$type=$headers['Content-Type'];
}
使用我们上面定义的映射表,我们可以很容易地得到后缀名。
$this->extension=$mimes[$type];
当然,上面得到的$type可能不存在于我们的映射表中,说明这种类型的文件不是我们想要的,放弃它,忽略它。
以下步骤与传统的文件抓取相同。
$file_path = $this->file_dir.$this->file_name.".".$this->extension;
// 获取数据并保存
$contents=file_get_contents($this->img_url);
if(file_put_contents($file_path , $contents))
{
// 这里返回出去的值是直接保存到数据库的路径 文件名,形如:201610/19/57feefd7e2a7aY5p7LsPqaI-lY1BF.jpg
return $this->save_dir.$this->file_name.".".$this->extension;
}
先获取本地保存图片的全路径$file_path,然后用file_get_contents抓取数据,再用file_put_contents保存到刚才的文件路径。
最后,我们返回一个可以直接保存到数据库的路径,而不是文件存储路径。
完整的获取方法如下:
private function getRemoteImg()
{
// mime 和 扩展名 的映射
$mimes=array(
'image/bmp'=>'bmp',
'image/gif'=>'gif',
'image/jpeg'=>'jpg',
'image/png'=>'png',
'image/x-icon'=>'ico'
);
// 获取响应头
if(($headers=get_headers($this->img_url, 1))!==false)
{
// 获取响应的类型
$type=$headers['Content-Type'];
// 如果符合我们要的类型
if(isset($mimes[$type]))
{
$this->extension=$mimes[$type];
$file_path = $this->file_dir.$this->file_name.".".$this->extension;
// 获取数据并保存
$contents=file_get_contents($this->img_url);
if(file_put_contents($file_path , $contents))
{
// 这里返回出去的值是直接保存到数据库的路径 文件名,形如:201610/19/57feefd7e2a7aY5p7LsPqaI-lY1BF.jpg
return $this->save_dir.$this->file_name.".".$this->extension;
}
}
}
return false;
}
最后,为了简单起见,我们希望在别处调用这些方法之一来完成爬网。所以我们直接把抓取动作放到getInstances里面,配置好路径后,直接抓取。因此,我们将代码添加到初始配置方法 getInstances 中。
if($this->setDir())
{
return $this->getRemoteImg();
}
else
{
return false;
}
测试
让我们在刚刚创建的 index.php 文件中尝试一下。
完整代码如下:
<p>
php 抓取网页生成图片(【魔兽世界】.php)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-10-16 19:13
此方法主要是为html页面生成二维码,所以需要一个配置文件phpqrcode.php(因为内容太多,请自行到百度网盘下载,链接:提取码: r6xt。)
以下是我的控制器调用和二维码生成↓
//传的参数
$id = $_GET['id'];
$cateid = $_GET['cateid'];
//需要生成二维码的链接
$url = "http://www.***.com/?id=$id&cateid=$cateid";
require_once 'phpqrcode.php';//ci框架中引入excel类
$value = $url; //二维码内容
$errorCorrectionLevel = 'L'; //容错级别
$matrixPointSize = 5; //生成图片大小
$filename = './uploads/erweima/'.time().'.png';
QRcode::png($value,$filename , $errorCorrectionLevel, $matrixPointSize, 2);
$QR = $filename; //已经生成的原始二维码图片文件
echo base_url().$QR;die;
现在输出的是二维码的地址,然后可以通过ajax渲染到页面上。
转载于: 查看全部
php 抓取网页生成图片(【魔兽世界】.php)
此方法主要是为html页面生成二维码,所以需要一个配置文件phpqrcode.php(因为内容太多,请自行到百度网盘下载,链接:提取码: r6xt。)
以下是我的控制器调用和二维码生成↓
//传的参数
$id = $_GET['id'];
$cateid = $_GET['cateid'];
//需要生成二维码的链接
$url = "http://www.***.com/?id=$id&cateid=$cateid";
require_once 'phpqrcode.php';//ci框架中引入excel类
$value = $url; //二维码内容
$errorCorrectionLevel = 'L'; //容错级别
$matrixPointSize = 5; //生成图片大小
$filename = './uploads/erweima/'.time().'.png';
QRcode::png($value,$filename , $errorCorrectionLevel, $matrixPointSize, 2);
$QR = $filename; //已经生成的原始二维码图片文件
echo base_url().$QR;die;
现在输出的是二维码的地址,然后可以通过ajax渲染到页面上。
转载于:
php 抓取网页生成图片(PHP快速生成图片验证码并且实现验证插件1.插件(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-10-14 06:08
PHP快速生成图片验证码并实现验证插件。 1.插件功能:该插件可以快速实现网站验证码功能,包括验证码生成和验证。 2. 必需参数:CaptchaTool 类包括两个方法。 generate方法可以生成'ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890'中的四位字符,并将这些字符写入到验证码目录下的图片中,并将code值保存在session中。在和输出中,此方法不需要参数。 check方法需要用户输入的code值,返回true或false。 3. 使用方法:include这个类型的文件,实例化,用得到的对象调用对应的方法。 4. 注:使用本插件的用户可以根据自己的网站需求扩展验证码字符模板,将需要扩展的字符放在$chars中,同时需要在 for 循环中进行相应的调整。注意$bg_flie的路径文件地址是验证码背景图片的地址。验证码图片的边框颜色由imagerectangle($img, 0, 0, 144, 19, $white)中的$white决定,文字大小由imagestring()中的第二个参数决定。字符串的颜色可以根据需要分配给画布颜色,使用函数imagecolorallocate()。 查看全部
php 抓取网页生成图片(PHP快速生成图片验证码并且实现验证插件1.插件(图))
PHP快速生成图片验证码并实现验证插件。 1.插件功能:该插件可以快速实现网站验证码功能,包括验证码生成和验证。 2. 必需参数:CaptchaTool 类包括两个方法。 generate方法可以生成'ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890'中的四位字符,并将这些字符写入到验证码目录下的图片中,并将code值保存在session中。在和输出中,此方法不需要参数。 check方法需要用户输入的code值,返回true或false。 3. 使用方法:include这个类型的文件,实例化,用得到的对象调用对应的方法。 4. 注:使用本插件的用户可以根据自己的网站需求扩展验证码字符模板,将需要扩展的字符放在$chars中,同时需要在 for 循环中进行相应的调整。注意$bg_flie的路径文件地址是验证码背景图片的地址。验证码图片的边框颜色由imagerectangle($img, 0, 0, 144, 19, $white)中的$white决定,文字大小由imagestring()中的第二个参数决定。字符串的颜色可以根据需要分配给画布颜色,使用函数imagecolorallocate()。
php 抓取网页生成图片( 借助php类库及扩展完成这一需求(图)解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 397 次浏览 • 2021-10-14 06:03
借助php类库及扩展完成这一需求(图)解析)
在服务器端对编译后的html进行解析转换为图片。
由于html一般是客户端浏览器解析的,服务端无法直接解析html代码。所以我们需要使用php库和扩展来完成这个需求。
文件转换过程为html —> pdf —> png。 (推荐学习:PHP视频教程)
需要用到的类库是mPDF、imagick
pdf的官方下载地址是:(推荐在6.0虽然有点大) 这是一个可以直接下载上传到服务器的类库。里面有很多东西。新建一个html2pdf文件夹导入
include('./html2pdf/mpdf');
一个完整的函数
/*
名称 html转换为pdf图片
功能 将html页面转换为pdf图片(部分css样式无法识别)
参数数量 2个
1.必须 html代码 可以用file_get_contenth获取
2.必须 生成pdf存放位置路径
3.非必须 pdf宽
4.非必须 pdf高
返回值 图片名称
实例 code($html,'img/1.pdf');
* */
function html2pdf($html, $PATH, $w=414 ,$h=736){
//设置中文字体(很重要 它会影响到第二步中 图片生成)
$mpdf=new mPDF('utf-8');
$mpdf->autoScriptToLang = true;
$mpdf->autoLangToFont = true;
//设置pdf的尺寸
$mpdf->WriteHTML('');
//设置pdf显示方式
$mpdf->SetDisplayMode('fullpage');
//删除pdf第一页(由于设置pdf尺寸导致多出了一页)
$mpdf->DeletePages(1,1);
$mpdf->WriteHTML($html);
$pdf_name = md5(time()).'.pdf';
$mpdf->Output($PATH.$pdf_name);
return $pdf_name;
}
接下来,开始将 pdf 转换为 png 图像。这一步需要在服务器上安装ImageMagick组件
然后使用函数将生成的pdf转成png。
/*
名称 pdf转换为png图片
功能 将pdf图片转换为png图片
参数数量 2个
1.必须 html代码 可以用file_get_contenth获取
2.必须 生成pdf存放位置路径
实例 code($html,'img/1.pdf');
* */
function pdf2png($PDF, $PNG, $w=50, $h=50){
if(!extension_loaded('imagick')){
return false;
}
if(!file_exists($PDF)){
return false;
}
$im = new Imagick();
$im->setResolution($w,$h); //设置分辨率
$im->setCompressionQuality(15);//设置图片压缩的质量
$im->readImage($PDF);
$im -> resetIterator();
$imgs = $im->appendImages(true);
$imgs->setImageFormat( "png" );
$img_name = $PNG;
$imgs->writeImage($img_name);
$imgs->clear();
$imgs->destroy();
$im->clear();
$im->destroy();
return $img_name;
}
ok,简单页面的图片基本完成了,图片大小1M左右,小了看不清楚。
以上是php是否可以将页面转换为图片的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们 查看全部
php 抓取网页生成图片(
借助php类库及扩展完成这一需求(图)解析)
在服务器端对编译后的html进行解析转换为图片。
由于html一般是客户端浏览器解析的,服务端无法直接解析html代码。所以我们需要使用php库和扩展来完成这个需求。
文件转换过程为html —> pdf —> png。 (推荐学习:PHP视频教程)
需要用到的类库是mPDF、imagick
pdf的官方下载地址是:(推荐在6.0虽然有点大) 这是一个可以直接下载上传到服务器的类库。里面有很多东西。新建一个html2pdf文件夹导入
include('./html2pdf/mpdf');
一个完整的函数
/*
名称 html转换为pdf图片
功能 将html页面转换为pdf图片(部分css样式无法识别)
参数数量 2个
1.必须 html代码 可以用file_get_contenth获取
2.必须 生成pdf存放位置路径
3.非必须 pdf宽
4.非必须 pdf高
返回值 图片名称
实例 code($html,'img/1.pdf');
* */
function html2pdf($html, $PATH, $w=414 ,$h=736){
//设置中文字体(很重要 它会影响到第二步中 图片生成)
$mpdf=new mPDF('utf-8');
$mpdf->autoScriptToLang = true;
$mpdf->autoLangToFont = true;
//设置pdf的尺寸
$mpdf->WriteHTML('');
//设置pdf显示方式
$mpdf->SetDisplayMode('fullpage');
//删除pdf第一页(由于设置pdf尺寸导致多出了一页)
$mpdf->DeletePages(1,1);
$mpdf->WriteHTML($html);
$pdf_name = md5(time()).'.pdf';
$mpdf->Output($PATH.$pdf_name);
return $pdf_name;
}
接下来,开始将 pdf 转换为 png 图像。这一步需要在服务器上安装ImageMagick组件
然后使用函数将生成的pdf转成png。
/*
名称 pdf转换为png图片
功能 将pdf图片转换为png图片
参数数量 2个
1.必须 html代码 可以用file_get_contenth获取
2.必须 生成pdf存放位置路径
实例 code($html,'img/1.pdf');
* */
function pdf2png($PDF, $PNG, $w=50, $h=50){
if(!extension_loaded('imagick')){
return false;
}
if(!file_exists($PDF)){
return false;
}
$im = new Imagick();
$im->setResolution($w,$h); //设置分辨率
$im->setCompressionQuality(15);//设置图片压缩的质量
$im->readImage($PDF);
$im -> resetIterator();
$imgs = $im->appendImages(true);
$imgs->setImageFormat( "png" );
$img_name = $PNG;
$imgs->writeImage($img_name);
$imgs->clear();
$imgs->destroy();
$im->clear();
$im->destroy();
return $img_name;
}
ok,简单页面的图片基本完成了,图片大小1M左右,小了看不清楚。
以上是php是否可以将页面转换为图片的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们
php 抓取网页生成图片(几个单独落地页,需要分享到微信,新版的微信规则)
网站优化 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-10-14 06:02
最近做了几个单独的登陆页面,需要在微信上分享。新版微信规则很早就有了变化。
如果想分享有摘要和缩略图(强调)的页面,必须找到一个经过认证的域名公众号,并添加网站的服务器ip。
前提:
1:微信公众号认证
2:将当前网站域名加入公众号的js安全域名
3:将当前网站服务器的ip加入公众号ip白名单
如果没有,那么我不知道,我还没有测试过其他任何东西。
官方说明:微信JS-SDK文档二:编写JS-SDK文档文件
var url=window.location.href;
wx.config({
debug:false,
appId: '',
timestamp: ,
nonceStr: '',
signature: '',
url:url,
jsApiList: [
"onMenuShareTimeline", //分享给好友
"onMenuShareAppMessage", //分享到朋友圈
"onMenuShareQQ", //分享到QQ
"onMenuShareWeibo" //分享到微博
]
});
wx.ready(function (){
var shareData = {
title: '分享出去的标题',
desc: '分享出去的摘要',
link: url,
imgUrl: '分享出去的缩略图'}; //最好是300x300以上的正方形
wx.onMenuShareAppMessage(shareData);
wx.onMenuShareTimeline(shareData);
wx.onMenuShareQQ(shareData);
wx.onMenuShareWeibo(shareData);
});
尝试将代码添加到需要共享的页面的头部。
查看网页源代码,可以看到上面的段落,但是php段落是看不到的,但是会显示公众号的appid,其他随机更改。
如果您不想显示此信息,则可以将其混淆或将其加密隐藏。
本来想写一个wordpress插件的,但是网上已经想到了插件。功能更强大,让我懒得动。
它使用wordpress。如果不想自己动手,直接在后台搜索安装插件即可。 查看全部
php 抓取网页生成图片(几个单独落地页,需要分享到微信,新版的微信规则)
最近做了几个单独的登陆页面,需要在微信上分享。新版微信规则很早就有了变化。
如果想分享有摘要和缩略图(强调)的页面,必须找到一个经过认证的域名公众号,并添加网站的服务器ip。
前提:
1:微信公众号认证
2:将当前网站域名加入公众号的js安全域名
3:将当前网站服务器的ip加入公众号ip白名单
如果没有,那么我不知道,我还没有测试过其他任何东西。
官方说明:微信JS-SDK文档二:编写JS-SDK文档文件
var url=window.location.href;
wx.config({
debug:false,
appId: '',
timestamp: ,
nonceStr: '',
signature: '',
url:url,
jsApiList: [
"onMenuShareTimeline", //分享给好友
"onMenuShareAppMessage", //分享到朋友圈
"onMenuShareQQ", //分享到QQ
"onMenuShareWeibo" //分享到微博
]
});
wx.ready(function (){
var shareData = {
title: '分享出去的标题',
desc: '分享出去的摘要',
link: url,
imgUrl: '分享出去的缩略图'}; //最好是300x300以上的正方形
wx.onMenuShareAppMessage(shareData);
wx.onMenuShareTimeline(shareData);
wx.onMenuShareQQ(shareData);
wx.onMenuShareWeibo(shareData);
});
尝试将代码添加到需要共享的页面的头部。
查看网页源代码,可以看到上面的段落,但是php段落是看不到的,但是会显示公众号的appid,其他随机更改。
如果您不想显示此信息,则可以将其混淆或将其加密隐藏。
本来想写一个wordpress插件的,但是网上已经想到了插件。功能更强大,让我懒得动。
它使用wordpress。如果不想自己动手,直接在后台搜索安装插件即可。
php 抓取网页生成图片(Twitter曾经用过的方式:对于google会到抓取内容的事情)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-10-14 04:29
一、推特已经使用了该方法:
为了
twitter.com/#!/abcde
Google 将到达
twitter.com/?_escaped_fragment_=abcde
获取内容。在这里直接输出你的 Ajax 内容,Google 会收录。但是你必须为Ajax内容编写另一个api供搜索引擎使用,你展示给搜索引擎的链接也必须变成上面的形式。 . .
参考:网站管理员和开发者的 AJAX 抓取指南
二、noscript 标签
对于 /1、/2 ....
服务器做了什么:根据编号获取对应的内容,写入noscript标签,用一段js输出。
浏览器的作用:执行接收到的js,获取noscript标签中的内容,并为jQuery处理。
三、如果是单页无法刷新,则需要完整的ajax操作
使用History API,链接仍然是/1、/2的形式。 js根据数字ajax获取内容。但是还有一个步骤是将用户点击的 URL 推送到列表中
此后,如果有前进后退按钮操作,浏览器会从列表中选择URL动态改变当前地址栏,并触发popstate事件,写一个js来监听这个事件
window.addEventListener('popstate', function(e) { ajax(location.url); });
当然,ajax返回的时候还是要带noscript标签,里面塞内容。上面画一个大圈的目的就是不刷新页面。
参考资料: 查看全部
php 抓取网页生成图片(Twitter曾经用过的方式:对于google会到抓取内容的事情)
一、推特已经使用了该方法:
为了
twitter.com/#!/abcde
Google 将到达
twitter.com/?_escaped_fragment_=abcde
获取内容。在这里直接输出你的 Ajax 内容,Google 会收录。但是你必须为Ajax内容编写另一个api供搜索引擎使用,你展示给搜索引擎的链接也必须变成上面的形式。 . .
参考:网站管理员和开发者的 AJAX 抓取指南
二、noscript 标签
对于 /1、/2 ....
服务器做了什么:根据编号获取对应的内容,写入noscript标签,用一段js输出。
浏览器的作用:执行接收到的js,获取noscript标签中的内容,并为jQuery处理。
三、如果是单页无法刷新,则需要完整的ajax操作
使用History API,链接仍然是/1、/2的形式。 js根据数字ajax获取内容。但是还有一个步骤是将用户点击的 URL 推送到列表中
此后,如果有前进后退按钮操作,浏览器会从列表中选择URL动态改变当前地址栏,并触发popstate事件,写一个js来监听这个事件
window.addEventListener('popstate', function(e) { ajax(location.url); });
当然,ajax返回的时候还是要带noscript标签,里面塞内容。上面画一个大圈的目的就是不刷新页面。
参考资料:
php 抓取网页生成图片( 我看用wkhtmltopdf来实现正合适,提供Windows、Linux和Mac平台上的版本)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-10-14 04:24
我看用wkhtmltopdf来实现正合适,提供Windows、Linux和Mac平台上的版本)
使用PHP为网站生成快照图片和缩略图
因为这是网站综合信息查询所需要的
我搜索了国外的解决方案
大部分都是使用对方的API实现的
但这种方式并不好
1 会被对方加水印,缩略图加水印不好
2免费的有代数限制,收费的太贵了。通常可以生成 $1 = 10 个缩略图
像我一样,生成超过 9000 万个缩略图并不是很可靠。成本太贵,缩略图都加了水印。
最终决定使用第三方开源软件构建
这样,快照生成后,可以自动上传到云端,调用速度快
暂时测试这个方案没有问题
32位下载
wkhtmltoimage-0.11.0_rc1 Linux 静态二进制 (i368)
64位下载
wkhtmltoimage-0.11.0_rc1 Linux 静态二进制文件 (AMD64)
这是一个编译好的静态可执行文件,比较简单方便
依赖 qt4 包
解压
tar -xvf ***.tar.bz2
移动目录然后直接调用PHP
例如 /sbin/wkhtmltoimage
先测试/sbin/wkhtmltoimage g.jpg
建议设置清晰度的低点
我测试过它是否不调整
Google的页面生成的PNG大小超过1M JPG超过400K
PHP中直接exec可以调用生成然后做图片处理
然后使用 php 的 gd 或 im
php可以使用GD或IM的图片处理模块进行处理。
您可以为缩略图等添加水印。
仍在测试其他开源解决方案
可提供REST接口
那个时候更新
-------------------------------------
国外有很多网站会提供URL地址的预览功能。当鼠标移动到URL地址时,会自动显示网站的缩略图。
我觉得用wkhtmltopdf来实现比较合适,提供了Windows、Linux、Mac平台的版本。
该工具的详细参数如下:
常规选项:
--crop-h 设置裁剪高度
--crop-w 设置裁剪宽度
--crop-x 设置 x 坐标进行裁剪
--crop-y 设置 y 坐标进行裁剪
-H, --extended-help 显示更广泛的帮助,详细说明不太常见的命令开关
-f, --格式 查看全部
php 抓取网页生成图片(
我看用wkhtmltopdf来实现正合适,提供Windows、Linux和Mac平台上的版本)
使用PHP为网站生成快照图片和缩略图
因为这是网站综合信息查询所需要的
我搜索了国外的解决方案
大部分都是使用对方的API实现的
但这种方式并不好
1 会被对方加水印,缩略图加水印不好
2免费的有代数限制,收费的太贵了。通常可以生成 $1 = 10 个缩略图
像我一样,生成超过 9000 万个缩略图并不是很可靠。成本太贵,缩略图都加了水印。
最终决定使用第三方开源软件构建
这样,快照生成后,可以自动上传到云端,调用速度快
暂时测试这个方案没有问题
32位下载
wkhtmltoimage-0.11.0_rc1 Linux 静态二进制 (i368)
64位下载
wkhtmltoimage-0.11.0_rc1 Linux 静态二进制文件 (AMD64)
这是一个编译好的静态可执行文件,比较简单方便
依赖 qt4 包
解压
tar -xvf ***.tar.bz2
移动目录然后直接调用PHP
例如 /sbin/wkhtmltoimage
先测试/sbin/wkhtmltoimage g.jpg
建议设置清晰度的低点
我测试过它是否不调整
Google的页面生成的PNG大小超过1M JPG超过400K
PHP中直接exec可以调用生成然后做图片处理
然后使用 php 的 gd 或 im
php可以使用GD或IM的图片处理模块进行处理。
您可以为缩略图等添加水印。
仍在测试其他开源解决方案
可提供REST接口
那个时候更新
-------------------------------------
国外有很多网站会提供URL地址的预览功能。当鼠标移动到URL地址时,会自动显示网站的缩略图。
我觉得用wkhtmltopdf来实现比较合适,提供了Windows、Linux、Mac平台的版本。
该工具的详细参数如下:
常规选项:
--crop-h 设置裁剪高度
--crop-w 设置裁剪宽度
--crop-x 设置 x 坐标进行裁剪
--crop-y 设置 y 坐标进行裁剪
-H, --extended-help 显示更广泛的帮助,详细说明不太常见的命令开关
-f, --格式
php 抓取网页生成图片(小程序码和二维码;生成后端来生成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-10-14 04:22
小程序二维码分为小程序码和二维码;
小程序生成的二维码在文档中由后端生成。
参考小程序开发文档:
文档的参数介绍比较详细,但是没有具体的demo。也很烦人,请求接口的返回值是十六进制流(即浏览器显示一堆乱码)。这是我的代码:
//获取小程序码,这里调用的是小程序码的A接口类型
public function getQRCodeAction()
{
$data['scene'] = $this->_req->getQuery('shareId',11); //scence、page的使用要参考文档(比如:scene的值不能超过32个字符等)
$data['width'] = $this->_req->getQuery('width',220);
$data['auto_color'] = $this->_req->getQuery('auto_color');
$data['line_color'] = $this->_req->getQuery('line_color');
$data['is_hyaline'] = $this->_req->getQuery('is_hyaline',true);
$data['page'] = $this->_req->getQuery('page',""); //由这行以上代码是二维码的样式等由前端传值的形式,也可以直接在后端设置
$wxModel = new WxAuthModel();
$token = $wxModel->getAccessToken();
$res_url = "https://api.weixin.qq.com/wxa/ ... en%3D$token"; //请求微信提供的接口
header('content-type:image/png');
$data = json_encode($data);
$Qr_code = $wxModel->http_request($res_url,$data); //到这里就已经返回微信提供的返回数据了,这个时候的数据是二进制流,要处理下再返回给前端
file_put_contents('/tmp/qr_code.png', $Qr_code); //将获得的数据读到一个临时图片里
$img_string = $this->fileToBase64('/tmp/qr_code.png'); //将图片文件转化为base64
response::result($img_string);
}
//本地文件转base64
private function fileToBase64($file){
$base64_file = '';
if(file_exists($file)){
$mime_type= mime_content_type($file); //如果这里明确是图片的话我建议获取图片类型这句可以省略,直接知道了mine_type='image/png',因为我这里我虽然存的图片,但是读到的mine_type值为text/plain
$base64_data = base64_encode(file_get_contents($file));
$base64_file = 'data:'.$mime_type.';base64,'.$base64_data; //$base64_file = 'data:image/png;base64,'.$base64_data;
}
return $base64_file;
}
/*获取access_token,不需要code参数,不能用于获取用户信息的token*/
public function getAccessToken()
{
$token_file = '/dev/shm/heka2_token.json'; //由于获取token的次数存在限制,所以将一段时间内的token缓存到一个文件(注意缓存路径服务器支持可写可读),过期后再重新获取
$data = json_decode(file_get_contents($token_file));
if ($data->expire_time < time()) {
$url = "https://api.weixin.qq.com/cgi- ... id%3D$this->appId&secret=$this->appSecret";
$res = json_decode($this->http_request($url));
$access_token = $res->access_token;
if ($access_token) {
$data->expire_time = time() + 7000;
$data->access_token = $access_token;
file_put_contents($token_file, json_encode($data));
}
} else {
$access_token = $data->access_token;
}
return $access_token;
}
感觉还没找到完整的PHP实现代码,这个自己用就好了。如有不妥之处请指出~_ 查看全部
php 抓取网页生成图片(小程序码和二维码;生成后端来生成)
小程序二维码分为小程序码和二维码;
小程序生成的二维码在文档中由后端生成。
参考小程序开发文档:
文档的参数介绍比较详细,但是没有具体的demo。也很烦人,请求接口的返回值是十六进制流(即浏览器显示一堆乱码)。这是我的代码:
//获取小程序码,这里调用的是小程序码的A接口类型
public function getQRCodeAction()
{
$data['scene'] = $this->_req->getQuery('shareId',11); //scence、page的使用要参考文档(比如:scene的值不能超过32个字符等)
$data['width'] = $this->_req->getQuery('width',220);
$data['auto_color'] = $this->_req->getQuery('auto_color');
$data['line_color'] = $this->_req->getQuery('line_color');
$data['is_hyaline'] = $this->_req->getQuery('is_hyaline',true);
$data['page'] = $this->_req->getQuery('page',""); //由这行以上代码是二维码的样式等由前端传值的形式,也可以直接在后端设置
$wxModel = new WxAuthModel();
$token = $wxModel->getAccessToken();
$res_url = "https://api.weixin.qq.com/wxa/ ... en%3D$token"; //请求微信提供的接口
header('content-type:image/png');
$data = json_encode($data);
$Qr_code = $wxModel->http_request($res_url,$data); //到这里就已经返回微信提供的返回数据了,这个时候的数据是二进制流,要处理下再返回给前端
file_put_contents('/tmp/qr_code.png', $Qr_code); //将获得的数据读到一个临时图片里
$img_string = $this->fileToBase64('/tmp/qr_code.png'); //将图片文件转化为base64
response::result($img_string);
}
//本地文件转base64
private function fileToBase64($file){
$base64_file = '';
if(file_exists($file)){
$mime_type= mime_content_type($file); //如果这里明确是图片的话我建议获取图片类型这句可以省略,直接知道了mine_type='image/png',因为我这里我虽然存的图片,但是读到的mine_type值为text/plain
$base64_data = base64_encode(file_get_contents($file));
$base64_file = 'data:'.$mime_type.';base64,'.$base64_data; //$base64_file = 'data:image/png;base64,'.$base64_data;
}
return $base64_file;
}
/*获取access_token,不需要code参数,不能用于获取用户信息的token*/
public function getAccessToken()
{
$token_file = '/dev/shm/heka2_token.json'; //由于获取token的次数存在限制,所以将一段时间内的token缓存到一个文件(注意缓存路径服务器支持可写可读),过期后再重新获取
$data = json_decode(file_get_contents($token_file));
if ($data->expire_time < time()) {
$url = "https://api.weixin.qq.com/cgi- ... id%3D$this->appId&secret=$this->appSecret";
$res = json_decode($this->http_request($url));
$access_token = $res->access_token;
if ($access_token) {
$data->expire_time = time() + 7000;
$data->access_token = $access_token;
file_put_contents($token_file, json_encode($data));
}
} else {
$access_token = $data->access_token;
}
return $access_token;
}
感觉还没找到完整的PHP实现代码,这个自己用就好了。如有不妥之处请指出~_
php 抓取网页生成图片(PHP脚本与动态页面的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-10-13 21:15
首先,有人会问:为什么要生成静态页面?
说一下静态页面的好处,方便搜索引擎收录,加快网站访问速度等,不用从数据库中提取,从而减轻服务器压力
让我们先回顾一些基本概念。
一、PHP 脚本和动态页面。
PHP脚本是一种服务器端脚本程序,可以通过嵌入方式与HTML文件混合,也可以以类、函数封装等形式使用,以模板的形式处理用户请求。不管怎样,它的基本原理是这样的。客户端发出请求请求某个页面----->Web服务器引入指定的对应脚本进行处理----->脚本加载到服务器中----->指定的PHP解析器服务器匹配脚本Analyze to form HTML language form ----> 将解析后的HTML语句以包的形式传回浏览器。不难看出,页面发送到浏览器后,PHP 不复存在,已经被转换解析为 HTML 语句。客户端请求是一个动态文件。事实上,那里不存在真正的文件。由PHP解析形成相应的页面,然后发送回浏览器。这种类型的页面处理称为“动态页面”。
二、静态页面。
静态页面是指只收录服务器端确实存在的 HTML、JS、CSS 和其他客户端脚本的页面。它的处理方式是。客户端发出请求请求某个页面---->WEB服务器确认并加载某个页面->WEB服务器将该页面以包的形式返回给浏览器。从这个过程,我们来对比一下动态页面就知道了。动态页面需要通过web服务器的PHP解析器进行解析,通常需要连接数据库进行数据库访问操作,然后形成HTML语言信息包;而静态页面不需要解析,不需要连接数据库,直接发送即可。降低服务器压力,提高服务器负载能力,大幅提升页面打开速度和网站整体打开速度。
三、模板和模板分析。
模板尚未填充内容 html 文件。例如:
临时文件
代码:
以下是引用的片段:
{标题}
这是一个 {file} 文件的模板
PHP处理:
以下是引用的片段:
模板测试.php
代码:
$title = "惠普发烧友测试模板";
$file = "TwoMax Inter 测试模板,
作者:舍伊”;
$fp = fopen("temp.html","r");
$content = fread ($fp,filesize ("temp.html"));
$content .= str_replace("{文件}",$file,$content);
$content .= str_replace ("{title }",$title,$content);
回声$内容;
模板解析过程是将PHP脚本解析过程得到的结果填充(内容)到模板中的过程。通常在模板类的帮助下。目前比较流行的模板解析类有phplib、smarty、fastsmarty等。模板分析处理的原则通常是替换。也有程序员习惯于将判断、循环等处理放入模板文件中,使用解析处理。典型的应用是块概念,它只是一个循环处理。PHP 脚本指定循环次数、如何循环替换等,然后模板解析类实现这些操作。
好了,对比了静态页面和动态页面的优劣,现在来说说如何用PHP生成静态文件。
PHP生成的静态页面并不是指PHP的动态分析和HTML页面的输出,而是用PHP创建HTML页面。同时,由于 HTML 的不可写性,如果我们创建的 HTML 被修改,则需要删除并重新生成。(当然你也可以选择用正则化来修改,但个人认为还是删掉,快点重新生成比较好,有些得不偿失。)
离家较近。用过PHP文件操作函数的PHP爱好者都知道,PHP中有一个文件操作函数fopen,就是打开文件。如果该文件不存在,请尝试创建它。这是 PHP 可以用来创建 HTML 文件的理论基础。只要存放HTML文件的文件夹有写权限(即权限定义0777),就可以创建文件。(对于UNIX系统,Win系统不需要考虑。)以上面的例子为例一个例子,如果我们修改最后一句,并指定在test目录下生成一个名为test.html的静态文件:
代码:
以下是引用的片段:
$title = "Tomac 国际测试模板";
$file = "TwoMax Inter 测试模板,
author:_Max">Matrix@Two_Max";
$fp = fopen("temp.html","r");
$content = fread ($fp,filesize ("temp.html"));
$content .= str_replace("{文件}",$file,$content);
$content .= str_replace ("{title }",$title,$content);
// 回声 $content;
$filename = "test/test.html";
$handle = fopen($filename,"w"); //打开文件指针并创建文件
/*
检查文件是否已创建并可写
*/
if (!is_writable ($filename)){
die("File:".$filename." 不可写,请检查其属性并重试!");
}
if (!fwrite ($handle,$content)){ //将信息写入文件
die("生成文件".$filename."失败!");
}
fclose ($handle); //关闭指针
die("创建文件".$filename."成功!");
实际应用中常见问题的解决方法参考:
一、文章列表问题:
在数据库中创建一个字段,记录文件名,每次生成文件时将自动生成的文件名存入数据库。对于推荐的文章,只要指向指定存放静态文件的文件夹中的页面即可。使用PHP操作处理文章列表,保存为字符串,生成页面时替换此字符串。比如在页面上放置文章列表表添加标签{articletable},在PHP处理文件中:
代码:
以下是引用的片段:
$title = "Tomac 国际测试模板";
$file = "TwoMax Inter 测试模板,
author:_Max">Matrix@Two_Max";
$fp = fopen("temp.html","r");
$content = fread ($fp,filesize ("temp.html"));
$content .= str_replace("{文件}",$file,$content);
$content .= str_replace ("{title }",$title,$content);
// 开始生成列表
$list ='''''''';
$sql = "从文章中选择 id,title,filename";
$query = mysql_query ($sql);
while ($result = mysql_fetch_array ($query)){
$list .=''''''''.$result[''''title''''].''''
'''';
}
$content .= str_replace("{文章表}",$list,$content);
//生成列表结束
// 回声 $content;
$filename = "test/test.html";
$handle = fopen($filename,"w"); //打开文件指针并创建文件
/*
检查文件是否已创建并可写
*/
if (!is_writable ($filename)){
die("File:".$filename." 不可写,请检查其属性并重试!");
}
if (!fwrite ($handle,$content)){ //将信息写入文件
die("生成文件".$filename."失败!");
}
fclose ($handle); //关闭指针
die("创建文件".$filename."成功!");
二、 分页问题。
例如,当我们指定分页时,每页有 20 篇文章。查询数据库后,某个子频道列表中文章的个数为45。首先我们通过查询得到如下参数:1、总页数;2、每页文章数。第二步,for($i = 0; $i <allpages; $i++),页面元素获取、分析、文章生成都在这个循环中执行。不同的是,die("create file".$filename."success!";把这句话去掉,放在循环后的显示中,因为这句话会暂停程序的执行。例如:
代码:
以下是引用的片段:
$fp = fopen("temp.html","r");
$content = fread ($fp,filesize ("temp.html"));
$onepage =''''20'''';
$sql = "select id from article where channel='''$channelid''''";
$query = mysql_query ($sql);
$num = mysql_num_rows ($query);
$allpages = ceil ($num / $onepage);
对于 ($i = 0;$i
大体思路是这样,其中其他数据生成、数据输入输出检查、页面内容指向等都可以酌情添加到页面中。
在文章系统的实际处理中,还有很多问题需要考虑。与动态页面不同,还有很多需要注意的地方。但是大体思路是一样的,其他方面可以互相推导。 查看全部
php 抓取网页生成图片(PHP脚本与动态页面的区别)
首先,有人会问:为什么要生成静态页面?
说一下静态页面的好处,方便搜索引擎收录,加快网站访问速度等,不用从数据库中提取,从而减轻服务器压力
让我们先回顾一些基本概念。
一、PHP 脚本和动态页面。
PHP脚本是一种服务器端脚本程序,可以通过嵌入方式与HTML文件混合,也可以以类、函数封装等形式使用,以模板的形式处理用户请求。不管怎样,它的基本原理是这样的。客户端发出请求请求某个页面----->Web服务器引入指定的对应脚本进行处理----->脚本加载到服务器中----->指定的PHP解析器服务器匹配脚本Analyze to form HTML language form ----> 将解析后的HTML语句以包的形式传回浏览器。不难看出,页面发送到浏览器后,PHP 不复存在,已经被转换解析为 HTML 语句。客户端请求是一个动态文件。事实上,那里不存在真正的文件。由PHP解析形成相应的页面,然后发送回浏览器。这种类型的页面处理称为“动态页面”。
二、静态页面。
静态页面是指只收录服务器端确实存在的 HTML、JS、CSS 和其他客户端脚本的页面。它的处理方式是。客户端发出请求请求某个页面---->WEB服务器确认并加载某个页面->WEB服务器将该页面以包的形式返回给浏览器。从这个过程,我们来对比一下动态页面就知道了。动态页面需要通过web服务器的PHP解析器进行解析,通常需要连接数据库进行数据库访问操作,然后形成HTML语言信息包;而静态页面不需要解析,不需要连接数据库,直接发送即可。降低服务器压力,提高服务器负载能力,大幅提升页面打开速度和网站整体打开速度。
三、模板和模板分析。
模板尚未填充内容 html 文件。例如:
临时文件
代码:
以下是引用的片段:
{标题}
这是一个 {file} 文件的模板
PHP处理:
以下是引用的片段:
模板测试.php
代码:
$title = "惠普发烧友测试模板";
$file = "TwoMax Inter 测试模板,
作者:舍伊”;
$fp = fopen("temp.html","r");
$content = fread ($fp,filesize ("temp.html"));
$content .= str_replace("{文件}",$file,$content);
$content .= str_replace ("{title }",$title,$content);
回声$内容;
模板解析过程是将PHP脚本解析过程得到的结果填充(内容)到模板中的过程。通常在模板类的帮助下。目前比较流行的模板解析类有phplib、smarty、fastsmarty等。模板分析处理的原则通常是替换。也有程序员习惯于将判断、循环等处理放入模板文件中,使用解析处理。典型的应用是块概念,它只是一个循环处理。PHP 脚本指定循环次数、如何循环替换等,然后模板解析类实现这些操作。
好了,对比了静态页面和动态页面的优劣,现在来说说如何用PHP生成静态文件。
PHP生成的静态页面并不是指PHP的动态分析和HTML页面的输出,而是用PHP创建HTML页面。同时,由于 HTML 的不可写性,如果我们创建的 HTML 被修改,则需要删除并重新生成。(当然你也可以选择用正则化来修改,但个人认为还是删掉,快点重新生成比较好,有些得不偿失。)
离家较近。用过PHP文件操作函数的PHP爱好者都知道,PHP中有一个文件操作函数fopen,就是打开文件。如果该文件不存在,请尝试创建它。这是 PHP 可以用来创建 HTML 文件的理论基础。只要存放HTML文件的文件夹有写权限(即权限定义0777),就可以创建文件。(对于UNIX系统,Win系统不需要考虑。)以上面的例子为例一个例子,如果我们修改最后一句,并指定在test目录下生成一个名为test.html的静态文件:
代码:
以下是引用的片段:
$title = "Tomac 国际测试模板";
$file = "TwoMax Inter 测试模板,
author:_Max">Matrix@Two_Max";
$fp = fopen("temp.html","r");
$content = fread ($fp,filesize ("temp.html"));
$content .= str_replace("{文件}",$file,$content);
$content .= str_replace ("{title }",$title,$content);
// 回声 $content;
$filename = "test/test.html";
$handle = fopen($filename,"w"); //打开文件指针并创建文件
/*
检查文件是否已创建并可写
*/
if (!is_writable ($filename)){
die("File:".$filename." 不可写,请检查其属性并重试!");
}
if (!fwrite ($handle,$content)){ //将信息写入文件
die("生成文件".$filename."失败!");
}
fclose ($handle); //关闭指针
die("创建文件".$filename."成功!");
实际应用中常见问题的解决方法参考:
一、文章列表问题:
在数据库中创建一个字段,记录文件名,每次生成文件时将自动生成的文件名存入数据库。对于推荐的文章,只要指向指定存放静态文件的文件夹中的页面即可。使用PHP操作处理文章列表,保存为字符串,生成页面时替换此字符串。比如在页面上放置文章列表表添加标签{articletable},在PHP处理文件中:
代码:
以下是引用的片段:
$title = "Tomac 国际测试模板";
$file = "TwoMax Inter 测试模板,
author:_Max">Matrix@Two_Max";
$fp = fopen("temp.html","r");
$content = fread ($fp,filesize ("temp.html"));
$content .= str_replace("{文件}",$file,$content);
$content .= str_replace ("{title }",$title,$content);
// 开始生成列表
$list ='''''''';
$sql = "从文章中选择 id,title,filename";
$query = mysql_query ($sql);
while ($result = mysql_fetch_array ($query)){
$list .=''''''''.$result[''''title''''].''''
'''';
}
$content .= str_replace("{文章表}",$list,$content);
//生成列表结束
// 回声 $content;
$filename = "test/test.html";
$handle = fopen($filename,"w"); //打开文件指针并创建文件
/*
检查文件是否已创建并可写
*/
if (!is_writable ($filename)){
die("File:".$filename." 不可写,请检查其属性并重试!");
}
if (!fwrite ($handle,$content)){ //将信息写入文件
die("生成文件".$filename."失败!");
}
fclose ($handle); //关闭指针
die("创建文件".$filename."成功!");
二、 分页问题。
例如,当我们指定分页时,每页有 20 篇文章。查询数据库后,某个子频道列表中文章的个数为45。首先我们通过查询得到如下参数:1、总页数;2、每页文章数。第二步,for($i = 0; $i <allpages; $i++),页面元素获取、分析、文章生成都在这个循环中执行。不同的是,die("create file".$filename."success!";把这句话去掉,放在循环后的显示中,因为这句话会暂停程序的执行。例如:
代码:
以下是引用的片段:
$fp = fopen("temp.html","r");
$content = fread ($fp,filesize ("temp.html"));
$onepage =''''20'''';
$sql = "select id from article where channel='''$channelid''''";
$query = mysql_query ($sql);
$num = mysql_num_rows ($query);
$allpages = ceil ($num / $onepage);
对于 ($i = 0;$i
大体思路是这样,其中其他数据生成、数据输入输出检查、页面内容指向等都可以酌情添加到页面中。
在文章系统的实际处理中,还有很多问题需要考虑。与动态页面不同,还有很多需要注意的地方。但是大体思路是一样的,其他方面可以互相推导。
php 抓取网页生成图片(Google需要同一时间抓取您的WordPress网站的更新网址吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-10 00:04
最近,我们的一位读者问是否可以让 Google 重新抓取特定的网址?如果您的网站是新的网站,那么Google需要一些时间来抓取并显示新页面或搜索结果的变化。在本文中,我们将向您展示如何让 Google 重新抓取您的 WordPress网站 URL。
Google 何时以及为何需要重新抓取该网址?
当您在 WordPress网站 中添加页面和帖子时,Google 会花适当的时间来抓取这些新链接。Google 需要同时抓取您的 WordPress网站 更新 URL。
当您手动要求 Google 重新抓取您的网址时,它会将您的新链接放入队列以在 Google 上编入索引。谷歌搜索机器人将开始一一重新抓取您的链接,并将它们显示在搜索结果中。
请求 Google 重新抓取网址的一些常见原因是:
当您添加新帖子或页面时 当您对现有帖子或页面进行更改时 如果您认为某个网页应该在 Google 中编入索引,但您找不到它
对于上面提到的前两个选项,您可以使用 XML 站点地图来自动执行此过程。Google 非常擅长索引 网站,因为这是他们的业务。
但是,我们已经看到 Google 缺少特定页面(无缘无故)。有时只是要求谷歌重新抓取会立即显示页面。
话虽如此,让我们来看看如何让 Google 重新抓取您的 WordPress网站 URL 并将其显示在搜索结果中。
要求 Google 重新抓取您的 WordPress 网站 URL
首先,您需要在 Google 上列出您的 网站,然后 Google 会自动开始抓取您的网址。但是,对于我们上面讨论的任何情况,您也可以请求 Google 重新抓取新链接。
您可以按照以下步骤要求 Google 重新抓取您的 WordPress网站 URL。
第 1 步:使用 URL 检查工具重新抓取 URL
URL 检查工具在新的和更新的 Google Search Console(以前称为 Google网站管理员工具)中可用。此工具可帮助您确定与网址相关的问题,并提供解决方案以将您的 Google 链接编入索引。
它还可以帮助您解决常见的 WordPress URL 错误和其他 URL 索引问题。
在新的 Google 搜索控制台中,您需要选择您的属性或 网站 来检查 URL 索引状态。
注意:如果您没有在 Google 的 网站Administrator Tools 中列出 网站,您首先需要将其添加为新属性才能继续使用 URL 检查工具。
选择属性后,您需要转到左侧菜单中的 URL 检查工具,并在要检查的搜索字段中添加您的 URL。
它将获取有关您的 URL 的数据并将其显示在 Google Search Console 仪表板中。
如果您的网址在 Google 上,那么您会看到一条成功消息,其中收录有关您的链接的有用信息。您可以展开调查结果,看看是否还有其他问题需要解决。如果没有,那么您将看到来自 Google 的提交请求,要求重新抓取您的网址并将其编入索引。
但是,如果该链接不在 Google 上,那么它会向您显示在 Google 上索引您的 URL 的错误和可能的解决方案。
您可以解决问题并再次检查 URL,直到收到成功消息。之后,将启动重新抓取您的网址的请求。只需对您希望 Google 重新抓取的所有网址重复相同的操作即可。
第 2 步:提交 XML 站点地图以重新抓取 URL
如果您仍然不确定在 Google 上为 URL 编制索引,那么您只需将收录新 URL 的更新 XML网站 映射提交给 Google网站管理员工具。站点地图是索引新 URL 的最快方法。
对于这一步,我们建议使用 Yoast SEO 插件,它收录灵活的选项,可以在 WordPress 中正确设置 XML 站点地图。
在您的 WordPress 管理区域,您需要转到 SEO»General 页面。在“功能”部分下,您需要打开 XML 站点地图设置。
不要忘记单击保存更改按钮。荀彧。
接下来,您可以通过单击 XML 站点地图标题旁边的问号图标来查看更新的站点地图。如果您的新链接在此站点地图文件中可见,您可以继续将其提交到 Google网站管理员工具。
要提交 XML 站点地图,您需要访问新的 Google 搜索控制台并转到左侧菜单中的站点地图。只需添加您的 XML 站点地图链接并单击提交按钮。荀彧。
更新后的站点地图需要 Google 漫游器快速重新抓取您的新网址并将其显示在搜索结果中。
注意:您只需上传站点地图一次。Google 会定期重新抓取您的站点地图,并在添加站点地图后快速添加更新的帖子。
我们希望本文能帮助您了解如何让 Google 重新抓取您的 WordPress网站 URL。您可能还想查看我们关于如何改进 WordPress SEO 的终极指南。
----本页内容已结束,喜欢请分享---- 查看全部
php 抓取网页生成图片(Google需要同一时间抓取您的WordPress网站的更新网址吗?)
最近,我们的一位读者问是否可以让 Google 重新抓取特定的网址?如果您的网站是新的网站,那么Google需要一些时间来抓取并显示新页面或搜索结果的变化。在本文中,我们将向您展示如何让 Google 重新抓取您的 WordPress网站 URL。
Google 何时以及为何需要重新抓取该网址?
当您在 WordPress网站 中添加页面和帖子时,Google 会花适当的时间来抓取这些新链接。Google 需要同时抓取您的 WordPress网站 更新 URL。
当您手动要求 Google 重新抓取您的网址时,它会将您的新链接放入队列以在 Google 上编入索引。谷歌搜索机器人将开始一一重新抓取您的链接,并将它们显示在搜索结果中。
请求 Google 重新抓取网址的一些常见原因是:
当您添加新帖子或页面时 当您对现有帖子或页面进行更改时 如果您认为某个网页应该在 Google 中编入索引,但您找不到它
对于上面提到的前两个选项,您可以使用 XML 站点地图来自动执行此过程。Google 非常擅长索引 网站,因为这是他们的业务。
但是,我们已经看到 Google 缺少特定页面(无缘无故)。有时只是要求谷歌重新抓取会立即显示页面。
话虽如此,让我们来看看如何让 Google 重新抓取您的 WordPress网站 URL 并将其显示在搜索结果中。
要求 Google 重新抓取您的 WordPress 网站 URL
首先,您需要在 Google 上列出您的 网站,然后 Google 会自动开始抓取您的网址。但是,对于我们上面讨论的任何情况,您也可以请求 Google 重新抓取新链接。
您可以按照以下步骤要求 Google 重新抓取您的 WordPress网站 URL。
第 1 步:使用 URL 检查工具重新抓取 URL
URL 检查工具在新的和更新的 Google Search Console(以前称为 Google网站管理员工具)中可用。此工具可帮助您确定与网址相关的问题,并提供解决方案以将您的 Google 链接编入索引。
它还可以帮助您解决常见的 WordPress URL 错误和其他 URL 索引问题。
在新的 Google 搜索控制台中,您需要选择您的属性或 网站 来检查 URL 索引状态。
注意:如果您没有在 Google 的 网站Administrator Tools 中列出 网站,您首先需要将其添加为新属性才能继续使用 URL 检查工具。
选择属性后,您需要转到左侧菜单中的 URL 检查工具,并在要检查的搜索字段中添加您的 URL。
它将获取有关您的 URL 的数据并将其显示在 Google Search Console 仪表板中。
如果您的网址在 Google 上,那么您会看到一条成功消息,其中收录有关您的链接的有用信息。您可以展开调查结果,看看是否还有其他问题需要解决。如果没有,那么您将看到来自 Google 的提交请求,要求重新抓取您的网址并将其编入索引。
但是,如果该链接不在 Google 上,那么它会向您显示在 Google 上索引您的 URL 的错误和可能的解决方案。
您可以解决问题并再次检查 URL,直到收到成功消息。之后,将启动重新抓取您的网址的请求。只需对您希望 Google 重新抓取的所有网址重复相同的操作即可。
第 2 步:提交 XML 站点地图以重新抓取 URL
如果您仍然不确定在 Google 上为 URL 编制索引,那么您只需将收录新 URL 的更新 XML网站 映射提交给 Google网站管理员工具。站点地图是索引新 URL 的最快方法。
对于这一步,我们建议使用 Yoast SEO 插件,它收录灵活的选项,可以在 WordPress 中正确设置 XML 站点地图。
在您的 WordPress 管理区域,您需要转到 SEO»General 页面。在“功能”部分下,您需要打开 XML 站点地图设置。
不要忘记单击保存更改按钮。荀彧。
接下来,您可以通过单击 XML 站点地图标题旁边的问号图标来查看更新的站点地图。如果您的新链接在此站点地图文件中可见,您可以继续将其提交到 Google网站管理员工具。
要提交 XML 站点地图,您需要访问新的 Google 搜索控制台并转到左侧菜单中的站点地图。只需添加您的 XML 站点地图链接并单击提交按钮。荀彧。
更新后的站点地图需要 Google 漫游器快速重新抓取您的新网址并将其显示在搜索结果中。
注意:您只需上传站点地图一次。Google 会定期重新抓取您的站点地图,并在添加站点地图后快速添加更新的帖子。
我们希望本文能帮助您了解如何让 Google 重新抓取您的 WordPress网站 URL。您可能还想查看我们关于如何改进 WordPress SEO 的终极指南。
----本页内容已结束,喜欢请分享----
php 抓取网页生成图片( 2016年10月21日10:57:34投稿:微信头像图片没有后缀名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-08 18:00
2016年10月21日10:57:34投稿:微信头像图片没有后缀名)
PHP捕获远程图片(包括不带后缀)教程详解
更新时间:2016年10月21日10:57:34 投稿:雏菊
最近在做微信登录开发的时候,发现微信头像没有后缀。传统的图像捕获方法不起作用,需要进行特殊的捕获处理。所以,后来结合各种情况,封装成一个类,分享给大家。如果你有兴趣,我们一起来看看。
一、创建项目
作为演示,我们在www根目录下创建一个项目grabimg,创建一个类GrabImage.php和一个index.php。
二、编写类代码
我们定义一个与文件同名的类:GrabImage
class GrabImage{
}
三、属性
接下来,定义几个需要用到的属性。
1、首先定义一个需要抓取的图片地址:$img_url
2、再定义一个$file_name来存放文件名,但是不带扩展名,因为可能会涉及到扩展名的替换,所以这里是定义
3、 后跟扩展名 $extension
4、然后我们定义一个$file_dir。该属性的作用是远程镜像捕获后本地存储的目录,一般以PHP入口文件的位置为起点。但是路径一般不会保存到数据库中。
5、最后我们定义一个$save_dir,顾名思义,这个路径就是要直接保存的数据库的目录。这里说明一下,我们不直接将文件保存路径存储到数据库中,一般是为了方便以后系统迁移时更改路径。我们这里的$save_dir一般是日期+文件名,如果使用的时候需要取出来,把需要的路径放在前面。
四、方法
属性说完了,接下来我们就正式开始爬取工作了。
首先,我们定义了一个open方法getInstances来获取一些数据,比如抓拍图片的地址,本地保存路径等。同时把它放在属性中。
public function getInstances($img_url , $base_dir)
{
$this->img_url = $img_url;
$this->save_dir = date("Ym").'/'.date("d").'/'; // 比如:201610/19/
$this->file_dir = $base_dir.'/'.$this->save_dir.'/'; // 比如:./uploads/image/2016/10/19/
}
图片保存路径已拼接。接下来需要注意一个问题,目录是否存在。日期一天天过去,但目录不会自动创建。因此,在保存图片之前,您需要先检查一下,如果当前目录不存在,我们需要立即创建它。
我们创建 setDir 方法来设置目录。我们将财产设为私密、安全
/**
* 检查图片需要保持的目录是否存在
* 如果不存在,则立即创建一个目录
* @return bool
*/
private function setDir()
{
if(!file_exists($this->file_dir))
{
mkdir($this->file_dir,0777,TRUE);
}
$this->file_name = uniqid().rand(10000,99999);// 文件名,这里只是演示,实际项目中请使用自己的唯一文件名生成方法
return true;
}
下一步就是抓取核心代码
第一步是解决问题。我们需要抓取的图片可能没有后缀。按照传统的抓图方式,先抓图,再截取后缀名是行不通的。
我们必须通过其他方法获取图片类型。方式是从文件流信息中获取文件头信息,然后判断文件mime信息,即可知道文件后缀名。
为方便起见,首先定义一个 mime 和文件扩展名映射。
$mimes=array(
'image/bmp'=>'bmp',
'image/gif'=>'gif',
'image/jpeg'=>'jpg',
'image/png'=>'png',
'image/x-icon'=>'ico'
);
这样,当我得到类型 image/gif 时,我可以知道它是一个 .gif 图像。
使用php函数get_headers获取文件流头信息。当它的值不为 false 时,我们将它分配给变量 $headers
取出Content-Type的值作为mime的值。
if(($headers=get_headers($this->img_url, 1))!==false){
// 获取响应的类型
$type=$headers['Content-Type'];
}
使用我们上面定义的映射表,我们可以很容易地得到后缀名。
$this->extension=$mimes[$type];
当然,上面得到的$type可能不存在于我们的映射表中,说明这种类型的文件不是我们想要的,放弃它,忽略它。
以下步骤与传统的文件抓取相同。
$file_path = $this->file_dir.$this->file_name.".".$this->extension;
// 获取数据并保存
$contents=file_get_contents($this->img_url);
if(file_put_contents($file_path , $contents))
{
// 这里返回出去的值是直接保存到数据库的路径 + 文件名,形如:201610/19/57feefd7e2a7aY5p7LsPqaI-lY1BF.jpg
return $this->save_dir.$this->file_name.".".$this->extension;
}
先获取本地保存图片的全路径$file_path,然后用file_get_contents抓取数据,再用file_put_contents保存到刚才的文件路径。
最后,我们返回一个可以直接保存到数据库的路径,而不是文件存储路径。
完整版的爬取方法为:
private function getRemoteImg()
{
// mime 和 扩展名 的映射
$mimes=array(
'image/bmp'=>'bmp',
'image/gif'=>'gif',
'image/jpeg'=>'jpg',
'image/png'=>'png',
'image/x-icon'=>'ico'
);
// 获取响应头
if(($headers=get_headers($this->img_url, 1))!==false)
{
// 获取响应的类型
$type=$headers['Content-Type'];
// 如果符合我们要的类型
if(isset($mimes[$type]))
{
$this->extension=$mimes[$type];
$file_path = $this->file_dir.$this->file_name.".".$this->extension;
// 获取数据并保存
$contents=file_get_contents($this->img_url);
if(file_put_contents($file_path , $contents))
{
// 这里返回出去的值是直接保存到数据库的路径 + 文件名,形如:201610/19/57feefd7e2a7aY5p7LsPqaI-lY1BF.jpg
return $this->save_dir.$this->file_name.".".$this->extension;
}
}
}
return false;
}
最后,为了简单起见,我们希望在别处调用这些方法之一来完成爬网。所以我们直接把抓取动作放到getInstances里面,配置好路径后,直接抓取。因此,我们将代码添加到初始配置方法 getInstances 中。
if($this->setDir())
{
return $this->getRemoteImg();
}
else
{
return false;
}
测试
让我们在刚刚创建的 index.php 文件中尝试一下。
确实抢到了
完整代码
<p> 查看全部
php 抓取网页生成图片(
2016年10月21日10:57:34投稿:微信头像图片没有后缀名)
PHP捕获远程图片(包括不带后缀)教程详解
更新时间:2016年10月21日10:57:34 投稿:雏菊
最近在做微信登录开发的时候,发现微信头像没有后缀。传统的图像捕获方法不起作用,需要进行特殊的捕获处理。所以,后来结合各种情况,封装成一个类,分享给大家。如果你有兴趣,我们一起来看看。
一、创建项目
作为演示,我们在www根目录下创建一个项目grabimg,创建一个类GrabImage.php和一个index.php。
二、编写类代码
我们定义一个与文件同名的类:GrabImage
class GrabImage{
}
三、属性
接下来,定义几个需要用到的属性。
1、首先定义一个需要抓取的图片地址:$img_url
2、再定义一个$file_name来存放文件名,但是不带扩展名,因为可能会涉及到扩展名的替换,所以这里是定义
3、 后跟扩展名 $extension
4、然后我们定义一个$file_dir。该属性的作用是远程镜像捕获后本地存储的目录,一般以PHP入口文件的位置为起点。但是路径一般不会保存到数据库中。
5、最后我们定义一个$save_dir,顾名思义,这个路径就是要直接保存的数据库的目录。这里说明一下,我们不直接将文件保存路径存储到数据库中,一般是为了方便以后系统迁移时更改路径。我们这里的$save_dir一般是日期+文件名,如果使用的时候需要取出来,把需要的路径放在前面。
四、方法
属性说完了,接下来我们就正式开始爬取工作了。
首先,我们定义了一个open方法getInstances来获取一些数据,比如抓拍图片的地址,本地保存路径等。同时把它放在属性中。
public function getInstances($img_url , $base_dir)
{
$this->img_url = $img_url;
$this->save_dir = date("Ym").'/'.date("d").'/'; // 比如:201610/19/
$this->file_dir = $base_dir.'/'.$this->save_dir.'/'; // 比如:./uploads/image/2016/10/19/
}
图片保存路径已拼接。接下来需要注意一个问题,目录是否存在。日期一天天过去,但目录不会自动创建。因此,在保存图片之前,您需要先检查一下,如果当前目录不存在,我们需要立即创建它。
我们创建 setDir 方法来设置目录。我们将财产设为私密、安全
/**
* 检查图片需要保持的目录是否存在
* 如果不存在,则立即创建一个目录
* @return bool
*/
private function setDir()
{
if(!file_exists($this->file_dir))
{
mkdir($this->file_dir,0777,TRUE);
}
$this->file_name = uniqid().rand(10000,99999);// 文件名,这里只是演示,实际项目中请使用自己的唯一文件名生成方法
return true;
}
下一步就是抓取核心代码
第一步是解决问题。我们需要抓取的图片可能没有后缀。按照传统的抓图方式,先抓图,再截取后缀名是行不通的。
我们必须通过其他方法获取图片类型。方式是从文件流信息中获取文件头信息,然后判断文件mime信息,即可知道文件后缀名。
为方便起见,首先定义一个 mime 和文件扩展名映射。
$mimes=array(
'image/bmp'=>'bmp',
'image/gif'=>'gif',
'image/jpeg'=>'jpg',
'image/png'=>'png',
'image/x-icon'=>'ico'
);
这样,当我得到类型 image/gif 时,我可以知道它是一个 .gif 图像。
使用php函数get_headers获取文件流头信息。当它的值不为 false 时,我们将它分配给变量 $headers
取出Content-Type的值作为mime的值。
if(($headers=get_headers($this->img_url, 1))!==false){
// 获取响应的类型
$type=$headers['Content-Type'];
}
使用我们上面定义的映射表,我们可以很容易地得到后缀名。
$this->extension=$mimes[$type];
当然,上面得到的$type可能不存在于我们的映射表中,说明这种类型的文件不是我们想要的,放弃它,忽略它。
以下步骤与传统的文件抓取相同。
$file_path = $this->file_dir.$this->file_name.".".$this->extension;
// 获取数据并保存
$contents=file_get_contents($this->img_url);
if(file_put_contents($file_path , $contents))
{
// 这里返回出去的值是直接保存到数据库的路径 + 文件名,形如:201610/19/57feefd7e2a7aY5p7LsPqaI-lY1BF.jpg
return $this->save_dir.$this->file_name.".".$this->extension;
}
先获取本地保存图片的全路径$file_path,然后用file_get_contents抓取数据,再用file_put_contents保存到刚才的文件路径。
最后,我们返回一个可以直接保存到数据库的路径,而不是文件存储路径。
完整版的爬取方法为:
private function getRemoteImg()
{
// mime 和 扩展名 的映射
$mimes=array(
'image/bmp'=>'bmp',
'image/gif'=>'gif',
'image/jpeg'=>'jpg',
'image/png'=>'png',
'image/x-icon'=>'ico'
);
// 获取响应头
if(($headers=get_headers($this->img_url, 1))!==false)
{
// 获取响应的类型
$type=$headers['Content-Type'];
// 如果符合我们要的类型
if(isset($mimes[$type]))
{
$this->extension=$mimes[$type];
$file_path = $this->file_dir.$this->file_name.".".$this->extension;
// 获取数据并保存
$contents=file_get_contents($this->img_url);
if(file_put_contents($file_path , $contents))
{
// 这里返回出去的值是直接保存到数据库的路径 + 文件名,形如:201610/19/57feefd7e2a7aY5p7LsPqaI-lY1BF.jpg
return $this->save_dir.$this->file_name.".".$this->extension;
}
}
}
return false;
}
最后,为了简单起见,我们希望在别处调用这些方法之一来完成爬网。所以我们直接把抓取动作放到getInstances里面,配置好路径后,直接抓取。因此,我们将代码添加到初始配置方法 getInstances 中。
if($this->setDir())
{
return $this->getRemoteImg();
}
else
{
return false;
}
测试
让我们在刚刚创建的 index.php 文件中尝试一下。
确实抢到了
完整代码
<p>
php 抓取网页生成图片(每天都会推送一张很漂亮的图片,如何?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-08 00:33
发表于 2020-04-05, 17:28-admin
必应搜索首页每天都会推送一张非常漂亮的图片。如何使用PHP获取Bing搜索日常图片?
我们使用的界面是
注意,有几个GET参数,它们的作用是:
这里设置n为1、格式为js,idx为0发送GET请求【推荐一个Getman在线版:】,返回数据如下:
{
"images": [
{
"startdate": "20200404",
"fullstartdate": "202004041600",
"enddate": "20200405",
"url": "/th?id=OHR.KissimmeeFrog_ZH-CN8379824947_1920x1080.jpg&rf=LaDigue_1920x1080.jpg&pid=hp",
"urlbase": "/th?id=OHR.KissimmeeFrog_ZH-CN8379824947",
"copyright": "基西米湖中的绿色树蛙和紫色睡莲,佛罗里达州 (© Joanne Williams/Danita Delimont)",
"copyrightlink": "https://www.bing.com/search%3F ... ot%3B,
"title": "",
"quiz": "/search?q=Bing+homepage+quiz&filters=WQOskey:%22HPQuiz_20200404_KissimmeeFrog%22&FORM=HPQUIZ",
"wp": true,
"hsh": "759031457bf9d3d144d511a09e80d227",
"drk": 1,
"top": 1,
"bot": 1,
"hs": []
}
],
"tooltips": {
"loading": "正在加载...",
"previous": "上一个图像",
"next": "下一个图像",
"walle": "此图片不能下载用作壁纸。",
"walls": "下载今日美图。仅限用作桌面壁纸。"
}
}
“images”节点下的“url”值就是我们要获取的图片的地址。我们取出来,加上Bing的URL前缀(),构成一个完整的图片地址。比如上面返回数据的完整图片地址是这样的:
th?id=OHR.KissimmeeFrog_EN-CN8379824947_1920x1080.jpg&rf=LaDigue_1920x1080.jpg&pid=hp
知道了如何获取背景图片,接下来就是使用PHP动态抓取了。
如果只是想作为网页背景使用,只需要创建一个php文件,在里面粘贴如下代码即可:
然后将php文件上传到你的服务器,你应该可以看到访问php文件时被重定向到Bing的图片。
使用方法:直接将php文件的绝对地址作为图片放入网页中。
比如你的php地址是“”,那么你可以在自己网页的css中写这个,作为背景:
body{
width:100%;
height:100%;
background: url(https://hao.defcon.cn/bing.php) no-repeat;
-moz-background-size: cover; /*背景图片拉伸以铺满全屏*/
-ms-background-size: cover;
-webkit-background-size: cover;
background-size: cover;
}
上面的方法只是一个简单的跳转。如果您想抓取这张图片并将其保存到服务器怎么办?直接把代码贴在这里:
<p> 查看全部
php 抓取网页生成图片(每天都会推送一张很漂亮的图片,如何?(图))
发表于 2020-04-05, 17:28-admin
必应搜索首页每天都会推送一张非常漂亮的图片。如何使用PHP获取Bing搜索日常图片?
我们使用的界面是
注意,有几个GET参数,它们的作用是:
这里设置n为1、格式为js,idx为0发送GET请求【推荐一个Getman在线版:】,返回数据如下:
{
"images": [
{
"startdate": "20200404",
"fullstartdate": "202004041600",
"enddate": "20200405",
"url": "/th?id=OHR.KissimmeeFrog_ZH-CN8379824947_1920x1080.jpg&rf=LaDigue_1920x1080.jpg&pid=hp",
"urlbase": "/th?id=OHR.KissimmeeFrog_ZH-CN8379824947",
"copyright": "基西米湖中的绿色树蛙和紫色睡莲,佛罗里达州 (© Joanne Williams/Danita Delimont)",
"copyrightlink": "https://www.bing.com/search%3F ... ot%3B,
"title": "",
"quiz": "/search?q=Bing+homepage+quiz&filters=WQOskey:%22HPQuiz_20200404_KissimmeeFrog%22&FORM=HPQUIZ",
"wp": true,
"hsh": "759031457bf9d3d144d511a09e80d227",
"drk": 1,
"top": 1,
"bot": 1,
"hs": []
}
],
"tooltips": {
"loading": "正在加载...",
"previous": "上一个图像",
"next": "下一个图像",
"walle": "此图片不能下载用作壁纸。",
"walls": "下载今日美图。仅限用作桌面壁纸。"
}
}
“images”节点下的“url”值就是我们要获取的图片的地址。我们取出来,加上Bing的URL前缀(),构成一个完整的图片地址。比如上面返回数据的完整图片地址是这样的:
th?id=OHR.KissimmeeFrog_EN-CN8379824947_1920x1080.jpg&rf=LaDigue_1920x1080.jpg&pid=hp
知道了如何获取背景图片,接下来就是使用PHP动态抓取了。
如果只是想作为网页背景使用,只需要创建一个php文件,在里面粘贴如下代码即可:
然后将php文件上传到你的服务器,你应该可以看到访问php文件时被重定向到Bing的图片。
使用方法:直接将php文件的绝对地址作为图片放入网页中。
比如你的php地址是“”,那么你可以在自己网页的css中写这个,作为背景:
body{
width:100%;
height:100%;
background: url(https://hao.defcon.cn/bing.php) no-repeat;
-moz-background-size: cover; /*背景图片拉伸以铺满全屏*/
-ms-background-size: cover;
-webkit-background-size: cover;
background-size: cover;
}
上面的方法只是一个简单的跳转。如果您想抓取这张图片并将其保存到服务器怎么办?直接把代码贴在这里:
<p>
php 抓取网页生成图片(去年做过一个项目,要把用户上传的图像文件列出文字清单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-06 20:29
去年做了一个项目,列出用户上传的图片文件。当用户单击文件名时,可以显示图像。因为需要考虑对各种图片格式的兼容性,所以使用了GD库。找出具体的图片文件(MINE),然后调用对应的图片生成函数imagecreatefromXXX()生成一个img,然后将img以jpeg格式输出到浏览器。虽然完成了,但总觉得不满意。今天我有机会重新考虑这个功能。我在php手册中找到了几行代码。它简洁明了。完全可以实现我想要的功能。我不需要 GD 库来复制代码。代码如下:
代码量不到我原来的1/10,速度快了N倍。
TAG标签:PHP实现提取图片文件并在浏览器上显示的代码
易白网是国内知名的建站品牌服务商。我们拥有九年网站建设、网站制作、网页设计、PHP开发、域名注册和虚拟主机服务经验,提供自助建站服务。享誉全国。近年来,整合团队优势,自主研发了可视化多用户“点云建站系统”3.0平台版,拖放排版网站制作设计,简单易用实现pc站、手机微网站、小程序、APP一体化全网营销网站建设,已成功为全国数百家在线企业提供自助平台建设服务。
上一篇:PHP代码生成本地唯一识别码LUID | 下一篇:PHP中3种生成XML文件的方法速度和效率对比 查看全部
php 抓取网页生成图片(去年做过一个项目,要把用户上传的图像文件列出文字清单)
去年做了一个项目,列出用户上传的图片文件。当用户单击文件名时,可以显示图像。因为需要考虑对各种图片格式的兼容性,所以使用了GD库。找出具体的图片文件(MINE),然后调用对应的图片生成函数imagecreatefromXXX()生成一个img,然后将img以jpeg格式输出到浏览器。虽然完成了,但总觉得不满意。今天我有机会重新考虑这个功能。我在php手册中找到了几行代码。它简洁明了。完全可以实现我想要的功能。我不需要 GD 库来复制代码。代码如下:
代码量不到我原来的1/10,速度快了N倍。
TAG标签:PHP实现提取图片文件并在浏览器上显示的代码
易白网是国内知名的建站品牌服务商。我们拥有九年网站建设、网站制作、网页设计、PHP开发、域名注册和虚拟主机服务经验,提供自助建站服务。享誉全国。近年来,整合团队优势,自主研发了可视化多用户“点云建站系统”3.0平台版,拖放排版网站制作设计,简单易用实现pc站、手机微网站、小程序、APP一体化全网营销网站建设,已成功为全国数百家在线企业提供自助平台建设服务。
上一篇:PHP代码生成本地唯一识别码LUID | 下一篇:PHP中3种生成XML文件的方法速度和效率对比
php 抓取网页生成图片(下午仿照网上例子写了个抓取网页中图片并保存到本地的例子)
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-10-06 07:09
下午模仿网上的例子,写了一个从网页抓取图片保存到本地Python的例子。很好奇google上有没有类似的在线抓图插件工具。
然后我找到了这个文章-Pseric写的Image Cyborg,可以一键下载并存储网页上的所有图片
—————————————————————————————————————————————————————————
如果要抓取网页中的所有图片,您知道怎么做最快吗?或许你之前从未安装过类似的扩展,因为有些插件可以批量下载并保存网页中的所有图片。如果你不使用插件,你实际上可以使用在线工具来完成。本文即将介绍一种可以快速下载并存储网页中所有图片的服务。只需输入网址,无需安装附加软件,非常方便!
Image Cyborg 是一个免费的在线工具,提供批量下载和备份网络图像。它可以批量下载、提取和打包您输入的 URL 中的所有图像到一个压缩文件中。隐私是其最大的特点。网站 不会记录和跟踪用户下载数据。Image Cyborg 支持数据URI Scheme格式的图片(使用一段Base64编码处理图片,减少带宽,提高网站加载效率技术),以及延迟加载和动态生成图片,一般无法通过插件。
此服务支持的图像格式包括:.bmp、.eps、.gif、.jpeg、.jpg、.icns、.im、.mps、.pcx、.png、.ppm、.spider、.tiff、.webp ,.xbm,.svg,只要输入要下载图片的原创网址,它就会自动抓取网页中的所有图片,打包成压缩文件供用户下载。
网站名称:Image Cyborg
网站 链接:
使用步骤
第1步
打开Image Cyborg的官网——可以看到如下图所示的页面。将复制的网址直接粘贴到首页,点击“下载图片”开始处理。
第2步
需要一段时间来处理。Image Cyborg 网站 将显示当前进度。经过几次测试,我发现速度相当快。下载一个收录 10 张图片的网页需要将近 30 秒的处理时间。
第 3 步
处理完成后,Image Cyborg 会弹出文件下载提示,下载一个名为[].zip 的压缩包。
将下载的压缩文件解压后,即可得到网页中所有的原创图片文件。不仅如此,它还会自动修改图片文件名,在前面添加源URL和随机字符串。
值得一试的三个理由: 输入网站 URL,所有图片会自动打包下载。支持数据URI Scheme,延迟或动态加载图片,无需额外下载插件,跨平台
—————————————————————————————————————————————————————————
按照上面三个步骤,我找到了一个链接来测试下载:
原网页如下图有6张图中红色箭头标出的图片:
得到的[].zip压缩包解压后依次得到如下6张图片:
总结:
image-cyborg 是一个很好的在线抓取网页图片的工具。 查看全部
php 抓取网页生成图片(下午仿照网上例子写了个抓取网页中图片并保存到本地的例子)
下午模仿网上的例子,写了一个从网页抓取图片保存到本地Python的例子。很好奇google上有没有类似的在线抓图插件工具。
然后我找到了这个文章-Pseric写的Image Cyborg,可以一键下载并存储网页上的所有图片
—————————————————————————————————————————————————————————
如果要抓取网页中的所有图片,您知道怎么做最快吗?或许你之前从未安装过类似的扩展,因为有些插件可以批量下载并保存网页中的所有图片。如果你不使用插件,你实际上可以使用在线工具来完成。本文即将介绍一种可以快速下载并存储网页中所有图片的服务。只需输入网址,无需安装附加软件,非常方便!
Image Cyborg 是一个免费的在线工具,提供批量下载和备份网络图像。它可以批量下载、提取和打包您输入的 URL 中的所有图像到一个压缩文件中。隐私是其最大的特点。网站 不会记录和跟踪用户下载数据。Image Cyborg 支持数据URI Scheme格式的图片(使用一段Base64编码处理图片,减少带宽,提高网站加载效率技术),以及延迟加载和动态生成图片,一般无法通过插件。
此服务支持的图像格式包括:.bmp、.eps、.gif、.jpeg、.jpg、.icns、.im、.mps、.pcx、.png、.ppm、.spider、.tiff、.webp ,.xbm,.svg,只要输入要下载图片的原创网址,它就会自动抓取网页中的所有图片,打包成压缩文件供用户下载。
网站名称:Image Cyborg
网站 链接:
使用步骤
第1步
打开Image Cyborg的官网——可以看到如下图所示的页面。将复制的网址直接粘贴到首页,点击“下载图片”开始处理。
第2步
需要一段时间来处理。Image Cyborg 网站 将显示当前进度。经过几次测试,我发现速度相当快。下载一个收录 10 张图片的网页需要将近 30 秒的处理时间。
第 3 步
处理完成后,Image Cyborg 会弹出文件下载提示,下载一个名为[].zip 的压缩包。
将下载的压缩文件解压后,即可得到网页中所有的原创图片文件。不仅如此,它还会自动修改图片文件名,在前面添加源URL和随机字符串。
值得一试的三个理由: 输入网站 URL,所有图片会自动打包下载。支持数据URI Scheme,延迟或动态加载图片,无需额外下载插件,跨平台
—————————————————————————————————————————————————————————
按照上面三个步骤,我找到了一个链接来测试下载:
原网页如下图有6张图中红色箭头标出的图片:
得到的[].zip压缩包解压后依次得到如下6张图片:
总结:
image-cyborg 是一个很好的在线抓取网页图片的工具。
php 抓取网页生成图片(什么是代理?什么情况下会用到代理IP?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-10-06 07:06
)
什么是代理?什么情况下会使用代理IP?
Proxy Server,它的作用是代表用户获取网络信息,然后返回给用户。形象地说:它是网络信息的中转站。通过代理IP访问目标站,可以隐藏用户的真实IP。
比如你要抓取一段网站的数据,网站有100万条内容。他们设置了IP限制,每个IP每小时只能抢1000个。如果因为限制使用单个IP去抢 完成采集大约需要40天。如果使用代理IP,不断切换IP,可以突破每小时1000的频率限制,从而提高效率。
其他想要切换IP或者隐藏身份的场景也会用到代理IP,比如SEO。
代理IP有开放代理和私有代理。开放代理从全网扫描,不稳定,不适合爬取。随便用就好了。使用爬虫抓取数据,最好使用私有代理。网上私人代理的供应商很多,稳定性参差不齐。现在我们公司使用的是“可变IP”提供的私有代理。
我们公司有一个项目,抓取亚马逊数据分析销售、评论等,使用PHP抓取。爬取亚马逊时要特别注意header,否则输出数据为空。还有一种方法,可以用PHP通过shell_exec调用curl命令来抓取。
PHP如果是使用curl函数来抓取,主要设置下面几项即可。
curl_setopt($ch, CURLOPT_PROXY, 'proxy.baibianip.com'); //代理服务器地址
curl_setopt($ch, CURLOPT_PROXYPORT, '8000'); //代理服务器端口
如果是抓取HTTPS,把下面两项设置为false:
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); //抓HTTPS可以把此项设置为false
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); //抓HTTPS可以把此项设置为false<br />
方法一:完整示例代码如下,下面提供两种方式来调用:
<p> 查看全部
php 抓取网页生成图片(什么是代理?什么情况下会用到代理IP?(图)
)
什么是代理?什么情况下会使用代理IP?
Proxy Server,它的作用是代表用户获取网络信息,然后返回给用户。形象地说:它是网络信息的中转站。通过代理IP访问目标站,可以隐藏用户的真实IP。
比如你要抓取一段网站的数据,网站有100万条内容。他们设置了IP限制,每个IP每小时只能抢1000个。如果因为限制使用单个IP去抢 完成采集大约需要40天。如果使用代理IP,不断切换IP,可以突破每小时1000的频率限制,从而提高效率。
其他想要切换IP或者隐藏身份的场景也会用到代理IP,比如SEO。
代理IP有开放代理和私有代理。开放代理从全网扫描,不稳定,不适合爬取。随便用就好了。使用爬虫抓取数据,最好使用私有代理。网上私人代理的供应商很多,稳定性参差不齐。现在我们公司使用的是“可变IP”提供的私有代理。
我们公司有一个项目,抓取亚马逊数据分析销售、评论等,使用PHP抓取。爬取亚马逊时要特别注意header,否则输出数据为空。还有一种方法,可以用PHP通过shell_exec调用curl命令来抓取。
PHP如果是使用curl函数来抓取,主要设置下面几项即可。
curl_setopt($ch, CURLOPT_PROXY, 'proxy.baibianip.com'); //代理服务器地址
curl_setopt($ch, CURLOPT_PROXYPORT, '8000'); //代理服务器端口
如果是抓取HTTPS,把下面两项设置为false:
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); //抓HTTPS可以把此项设置为false
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); //抓HTTPS可以把此项设置为false<br />
方法一:完整示例代码如下,下面提供两种方式来调用:
<p>
php 抓取网页生成图片( PHP脚本与动态页面教程(图)!(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-03 17:12
PHP脚本与动态页面教程(图)!(组图)
)
更详细的PHP生成静态页面教程
更新时间:2012年1月10日13:46:27 作者:
PHP生成静态页面教程,先复习一些基本概念
一、PHP脚本和动态页面。
PHP脚本是一种服务器端脚本程序,可以通过嵌入方式与HTML文件混合,也可以以类、函数封装等形式使用,以模板的形式处理用户请求。不管怎样,它的基本原理是这样的。客户端发出请求,请求某个页面----->WEB服务器引入指定的对应脚本进行处理----->脚本加载到服务器中----->指定的PHP解析器服务器匹配脚本Analyze to form HTML language form ----> 将解析后的HTML语句以包的形式传回浏览器。不难看出,页面发送到浏览器后,PHP 不复存在,已经被转换解析为 HTML 语句。客户端请求是一个动态文件。事实上,那里不存在真正的文件。由PHP解析形成相应的页面,然后发送回浏览器。这种类型的页面处理称为“动态页面”。
二、静态页面。
静态页面是指只收录服务器端确实存在的 HTML、JS、CSS 和其他客户端脚本的页面。它的处理方式是。客户端发出请求请求某个页面---->WEB服务器确认并加载某个页面---->WEB服务器将该页面以包的形式返回给浏览器。从这个过程中,我们可以比较动态页面。动态页面需要通过WEB服务器的PHP解析器进行解析,通常需要连接数据库进行数据库访问操作,然后形成HTML语言信息包;而静态页面不需要解析,不需要连接数据库,直接发送即可。降低服务器压力,提高服务器负载能力,大幅提升页面打开速度和网站整体打开速度。
三、模板和模板分析。
模板尚未填充内容 html 文件。例如:
临时文件
代码:
复制代码代码如下:
{标题}
这是一个 {file} 文件的模板
PHP处理:
模板测试.php
代码:
$title = "Tomac 国际测试模板";
$file = "TwoMax Inter 测试模板,
作者:Matrix@Two_Max”;
$fp = fopen("temp.html","r");
$content = fread ($fp,filesize ("temp.html"));
$content .= str_replace("{文件}",$file,$content);
$content .= str_replace ("{title }",$title,$content);
回声$内容;
模板解析过程是将PHP脚本解析过程得到的结果填充(内容)到模板中的过程。通常在模板类的帮助下。目前比较流行的模板解析类有phplib、smarty、fastsmarty等。模板分析处理的原则通常是替换。也有程序员习惯于将判断、循环等处理放入模板文件中,使用解析处理。典型的应用是块概念,它只是一个循环处理。PHP 脚本指定循环次数、如何循环替换等,然后模板解析类实现这些操作。
好了,对比了静态页面和动态页面的优劣,现在来说说如何用PHP生成静态文件。
PHP生成的静态页面并不是指PHP的动态分析和HTML页面的输出,而是用PHP创建HTML页面。同时,由于 HTML 的不可写性,如果我们创建的 HTML 被修改,则需要删除并重新生成。(当然你也可以选择用正则化来修改,但个人认为还是删掉,快点重新生成比较好,有些得不偿失。)
离家较近。用过PHP文件操作函数的PHP爱好者都知道,PHP中有一个文件操作函数fopen,就是打开文件。如果该文件不存在,请尝试创建它。这是 PHP 可以用来创建 HTML 文件的理论基础。只要存放HTML文件的文件夹有写权限(即权限定义0777),就可以创建文件。(对于UNIX系统,Win系统不需要考虑。)以上面的例子为例一个例子,如果我们修改最后一句,并指定在test目录下生成一个名为test.html的静态文件:
代码:
复制代码代码如下:
实际应用中常见问题的解决方法参考:
1. 文章 列表问题:
在数据库中创建一个字段,记录文件名,每次生成文件时将自动生成的文件名存入数据库。对于推荐的文章,只要指向指定存放静态文件的文件夹中的页面即可。使用PHP操作处理文章列表,保存为字符串,生成页面时替换此字符串。比如在页面上放置文章列表表添加标签{articletable},在PHP处理文件中:
代码:
复制代码代码如下:
第二,分页问题。
例如,当我们指定分页时,每页有 20 篇文章。某个子频道列表中文章的数量已经被数据库查询到了45个,那么首先我们通过查询得到如下参数:1、总页数;2、每页文章数。第二步,对于($i = 0; $i
代码:
复制代码代码如下:
$fp = fopen("temp.html","r");
$content = fread ($fp,filesize ("temp.html"));
$onepage = '20';
$sql = "select id from article where channel='$channelid'";
$query = mysql_query ($sql);
$num = mysql_num_rows ($query);
$allpages = ceil ($num / $onepage);
对于 ($i = 0;$i
大体思路是这样,其中其他数据生成、数据输入输出检查、页面内容指向等都可以酌情添加到页面中。
在文章系统的实际处理中,还有很多问题需要考虑。与动态页面不同,还有很多需要注意的地方。但是大体思路是一样的,其他方面可以互相推导。
使用PHP制作网站的静态模板框架
模板可以改进网站的结构。这篇文章讲解了如何使用PHP 4的新函数和模板类巧妙地使用模板来控制由大量静态HTML页面组成的网站中的页面布局。
大纲:
====================================
独立的功能和布局
避免重复页面元素
网站 的静态模板框架
====================================
独立的功能和布局
首先,我们来看看应用模板的两个主要目的:
分离功能 (PHP) 和布局 (HTML)
避免重复页面元素
第一个目的是谈论最多的目的。它设想了这样一种情况,一组程序员编写 PHP 脚本来生成页面内容,而另一组设计人员设计 HTML 和图形来控制页面的最终外观。功能和布局分离的基本思路是让这两组人能够编写和使用一组独立的文件:程序员只需要关心那些只收录PHP代码的文件,而不是页面的外观。
; 而且页面设计者可以使用他们最熟悉的可视化编辑器来设计页面布局,而不必担心破坏页面中嵌入的任何 PHP 代码。
如果您看过一些关于 PHP 模板的教程,那么您应该已经了解模板的工作原理。考虑一个简单的页面部分:页面顶部是页眉,左侧是导航栏,其余部分是内容区域。这种类型的 网站 可以有以下模板文件:
复制代码代码如下:
{头}
{左导航}
{内容}
富
酒吧
您可以看到页面是如何从这些模板构建的:主模板控制整个页面的布局;header 模板和 leftnav 模板控制页面的公共元素。花括号“{}”内的标识符是内容占位符。使用模板的主要好处是界面设计者可以根据自己的意愿编辑这些文件,比如设置字体、修改颜色和图形,或者完全改变页面的布局。界面设计者可以使用任何普通的 HTML 编辑器或可视化工具来编辑这些页面,因为这些文件只收录 HTML 代码,没有任何 PHP 代码。
PHP 代码全部保存在一个单独的文件中,该文件是页面 URL 实际调用的文件。Web 服务器通过 PHP 引擎解析文件,然后将结果返回给浏览器。通常,PHP 代码总是动态生成页面内容,例如查询数据库或执行某些计算。下面是一个例子:
复制代码代码如下:
这里我们使用流行的 FastTemplate 模板类,但基本思想与许多其他模板类相同。首先你实例化一个类,告诉它去哪里找模板文件,哪个模板文件对应页面的哪个部分;接下来是生成页面内容,并将结果赋给内容标识;然后,依次解析每个模板文件,模板类会进行必要的替换操作;最后将分析结果输出到浏览器。
这个文件完全由PHP代码组成,不收录任何HTML代码,这是它最大的优势。现在,PHP 程序员可以专注于编写生成页面内容的代码,而不必担心如何生成 HTML 以正确设置最终页面的格式。
可以用这个方法和上面的文件构造一个完整的网站。如果PHP代码根据URL中的查询字符串生成页面内容,例如,您可以基于此构造一个完整的杂志网站。
很容易看出使用模板还有第二个好处。如上例所示,页面左侧的导航栏单独保存为一个文件,我们只需要编辑该模板文件即可更改所有页面左侧的导航栏网站。
避免重复页面元素
“这真是太好了”,你可能会想,“我的网站主要是由大量的静态页面组成的,现在我可以从所有页面中删除它们的公共部分。更新这些公共部分太麻烦了. 将来,我可以使用模板来创建易于维护的统一页面布局。” 但事情并没有那么简单。“大量静态页面”说明问题。
请考虑上面的例子。这个例子实际上只有一个example.php 页面。之所以能生成整个网站的所有页面,是因为它利用URL中的查询字符串,从数据库等信息源动态构建页面。
我们大多数人运行的 网站 不一定有数据库支持。我们的大部分网站都是由静态页面组成的,然后用PHP到处添加一些动态的功能,比如搜索引擎,反馈表等等。 那么,如何将模板应用到这种网站?
最简单的方法是为每个页面复制一个PHP文件,
然后将表示 PHP 代码中内容的变量设置为每个页面中相应的页面内容。例如,假设有主页、关于、产品三个页面,我们可以使用三个文件分别生成它们。这三个文件的内容如下:
复制代码代码如下:
很明显,这种方法存在三个问题:我们必须为每个页面复制这些涉及模板的复杂PHP代码,这使得页面难以维护,就像重复常见的页面元素一样;现在文件与 HTML 和 PHP 代码混合在一起;内容变量赋值会变得非常困难,因为我们要处理大量的特殊字符。
解决这个问题的关键是将PHP代码和HTML内容分开。虽然我们无法从文件中删除所有 HTML 内容,但可以删除大部分 PHP 代码。
网站 的静态模板框架
首先,我们像以前一样为页面的所有公共元素和页面的整体布局编写模板文件;然后删除所有页面的公共部分,只留下页面内容;然后在每个页面添加三行PHP代码,如下:
复制代码代码如下:
你好
欢迎参观
查看全部
php 抓取网页生成图片(
PHP脚本与动态页面教程(图)!(组图)
)
更详细的PHP生成静态页面教程
更新时间:2012年1月10日13:46:27 作者:
PHP生成静态页面教程,先复习一些基本概念
一、PHP脚本和动态页面。
PHP脚本是一种服务器端脚本程序,可以通过嵌入方式与HTML文件混合,也可以以类、函数封装等形式使用,以模板的形式处理用户请求。不管怎样,它的基本原理是这样的。客户端发出请求,请求某个页面----->WEB服务器引入指定的对应脚本进行处理----->脚本加载到服务器中----->指定的PHP解析器服务器匹配脚本Analyze to form HTML language form ----> 将解析后的HTML语句以包的形式传回浏览器。不难看出,页面发送到浏览器后,PHP 不复存在,已经被转换解析为 HTML 语句。客户端请求是一个动态文件。事实上,那里不存在真正的文件。由PHP解析形成相应的页面,然后发送回浏览器。这种类型的页面处理称为“动态页面”。
二、静态页面。
静态页面是指只收录服务器端确实存在的 HTML、JS、CSS 和其他客户端脚本的页面。它的处理方式是。客户端发出请求请求某个页面---->WEB服务器确认并加载某个页面---->WEB服务器将该页面以包的形式返回给浏览器。从这个过程中,我们可以比较动态页面。动态页面需要通过WEB服务器的PHP解析器进行解析,通常需要连接数据库进行数据库访问操作,然后形成HTML语言信息包;而静态页面不需要解析,不需要连接数据库,直接发送即可。降低服务器压力,提高服务器负载能力,大幅提升页面打开速度和网站整体打开速度。
三、模板和模板分析。
模板尚未填充内容 html 文件。例如:
临时文件
代码:
复制代码代码如下:
{标题}
这是一个 {file} 文件的模板
PHP处理:
模板测试.php
代码:
$title = "Tomac 国际测试模板";
$file = "TwoMax Inter 测试模板,
作者:Matrix@Two_Max”;
$fp = fopen("temp.html","r");
$content = fread ($fp,filesize ("temp.html"));
$content .= str_replace("{文件}",$file,$content);
$content .= str_replace ("{title }",$title,$content);
回声$内容;
模板解析过程是将PHP脚本解析过程得到的结果填充(内容)到模板中的过程。通常在模板类的帮助下。目前比较流行的模板解析类有phplib、smarty、fastsmarty等。模板分析处理的原则通常是替换。也有程序员习惯于将判断、循环等处理放入模板文件中,使用解析处理。典型的应用是块概念,它只是一个循环处理。PHP 脚本指定循环次数、如何循环替换等,然后模板解析类实现这些操作。
好了,对比了静态页面和动态页面的优劣,现在来说说如何用PHP生成静态文件。
PHP生成的静态页面并不是指PHP的动态分析和HTML页面的输出,而是用PHP创建HTML页面。同时,由于 HTML 的不可写性,如果我们创建的 HTML 被修改,则需要删除并重新生成。(当然你也可以选择用正则化来修改,但个人认为还是删掉,快点重新生成比较好,有些得不偿失。)
离家较近。用过PHP文件操作函数的PHP爱好者都知道,PHP中有一个文件操作函数fopen,就是打开文件。如果该文件不存在,请尝试创建它。这是 PHP 可以用来创建 HTML 文件的理论基础。只要存放HTML文件的文件夹有写权限(即权限定义0777),就可以创建文件。(对于UNIX系统,Win系统不需要考虑。)以上面的例子为例一个例子,如果我们修改最后一句,并指定在test目录下生成一个名为test.html的静态文件:
代码:
复制代码代码如下:
实际应用中常见问题的解决方法参考:
1. 文章 列表问题:
在数据库中创建一个字段,记录文件名,每次生成文件时将自动生成的文件名存入数据库。对于推荐的文章,只要指向指定存放静态文件的文件夹中的页面即可。使用PHP操作处理文章列表,保存为字符串,生成页面时替换此字符串。比如在页面上放置文章列表表添加标签{articletable},在PHP处理文件中:
代码:
复制代码代码如下:
第二,分页问题。
例如,当我们指定分页时,每页有 20 篇文章。某个子频道列表中文章的数量已经被数据库查询到了45个,那么首先我们通过查询得到如下参数:1、总页数;2、每页文章数。第二步,对于($i = 0; $i
代码:
复制代码代码如下:
$fp = fopen("temp.html","r");
$content = fread ($fp,filesize ("temp.html"));
$onepage = '20';
$sql = "select id from article where channel='$channelid'";
$query = mysql_query ($sql);
$num = mysql_num_rows ($query);
$allpages = ceil ($num / $onepage);
对于 ($i = 0;$i
大体思路是这样,其中其他数据生成、数据输入输出检查、页面内容指向等都可以酌情添加到页面中。
在文章系统的实际处理中,还有很多问题需要考虑。与动态页面不同,还有很多需要注意的地方。但是大体思路是一样的,其他方面可以互相推导。
使用PHP制作网站的静态模板框架
模板可以改进网站的结构。这篇文章讲解了如何使用PHP 4的新函数和模板类巧妙地使用模板来控制由大量静态HTML页面组成的网站中的页面布局。
大纲:
====================================
独立的功能和布局
避免重复页面元素
网站 的静态模板框架
====================================
独立的功能和布局
首先,我们来看看应用模板的两个主要目的:
分离功能 (PHP) 和布局 (HTML)
避免重复页面元素
第一个目的是谈论最多的目的。它设想了这样一种情况,一组程序员编写 PHP 脚本来生成页面内容,而另一组设计人员设计 HTML 和图形来控制页面的最终外观。功能和布局分离的基本思路是让这两组人能够编写和使用一组独立的文件:程序员只需要关心那些只收录PHP代码的文件,而不是页面的外观。
; 而且页面设计者可以使用他们最熟悉的可视化编辑器来设计页面布局,而不必担心破坏页面中嵌入的任何 PHP 代码。
如果您看过一些关于 PHP 模板的教程,那么您应该已经了解模板的工作原理。考虑一个简单的页面部分:页面顶部是页眉,左侧是导航栏,其余部分是内容区域。这种类型的 网站 可以有以下模板文件:
复制代码代码如下:
{头}
{左导航}
{内容}
富
酒吧
您可以看到页面是如何从这些模板构建的:主模板控制整个页面的布局;header 模板和 leftnav 模板控制页面的公共元素。花括号“{}”内的标识符是内容占位符。使用模板的主要好处是界面设计者可以根据自己的意愿编辑这些文件,比如设置字体、修改颜色和图形,或者完全改变页面的布局。界面设计者可以使用任何普通的 HTML 编辑器或可视化工具来编辑这些页面,因为这些文件只收录 HTML 代码,没有任何 PHP 代码。
PHP 代码全部保存在一个单独的文件中,该文件是页面 URL 实际调用的文件。Web 服务器通过 PHP 引擎解析文件,然后将结果返回给浏览器。通常,PHP 代码总是动态生成页面内容,例如查询数据库或执行某些计算。下面是一个例子:
复制代码代码如下:
这里我们使用流行的 FastTemplate 模板类,但基本思想与许多其他模板类相同。首先你实例化一个类,告诉它去哪里找模板文件,哪个模板文件对应页面的哪个部分;接下来是生成页面内容,并将结果赋给内容标识;然后,依次解析每个模板文件,模板类会进行必要的替换操作;最后将分析结果输出到浏览器。
这个文件完全由PHP代码组成,不收录任何HTML代码,这是它最大的优势。现在,PHP 程序员可以专注于编写生成页面内容的代码,而不必担心如何生成 HTML 以正确设置最终页面的格式。
可以用这个方法和上面的文件构造一个完整的网站。如果PHP代码根据URL中的查询字符串生成页面内容,例如,您可以基于此构造一个完整的杂志网站。
很容易看出使用模板还有第二个好处。如上例所示,页面左侧的导航栏单独保存为一个文件,我们只需要编辑该模板文件即可更改所有页面左侧的导航栏网站。
避免重复页面元素
“这真是太好了”,你可能会想,“我的网站主要是由大量的静态页面组成的,现在我可以从所有页面中删除它们的公共部分。更新这些公共部分太麻烦了. 将来,我可以使用模板来创建易于维护的统一页面布局。” 但事情并没有那么简单。“大量静态页面”说明问题。
请考虑上面的例子。这个例子实际上只有一个example.php 页面。之所以能生成整个网站的所有页面,是因为它利用URL中的查询字符串,从数据库等信息源动态构建页面。
我们大多数人运行的 网站 不一定有数据库支持。我们的大部分网站都是由静态页面组成的,然后用PHP到处添加一些动态的功能,比如搜索引擎,反馈表等等。 那么,如何将模板应用到这种网站?
最简单的方法是为每个页面复制一个PHP文件,
然后将表示 PHP 代码中内容的变量设置为每个页面中相应的页面内容。例如,假设有主页、关于、产品三个页面,我们可以使用三个文件分别生成它们。这三个文件的内容如下:
复制代码代码如下:
很明显,这种方法存在三个问题:我们必须为每个页面复制这些涉及模板的复杂PHP代码,这使得页面难以维护,就像重复常见的页面元素一样;现在文件与 HTML 和 PHP 代码混合在一起;内容变量赋值会变得非常困难,因为我们要处理大量的特殊字符。
解决这个问题的关键是将PHP代码和HTML内容分开。虽然我们无法从文件中删除所有 HTML 内容,但可以删除大部分 PHP 代码。
网站 的静态模板框架
首先,我们像以前一样为页面的所有公共元素和页面的整体布局编写模板文件;然后删除所有页面的公共部分,只留下页面内容;然后在每个页面添加三行PHP代码,如下:
复制代码代码如下:
你好
欢迎参观
php 抓取网页生成图片(用php执行系统命令的时候发现无法执行,但是可以执行CutyCapt)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-03 11:21
制作网站屏幕截图时,使用服务器的工具cutycapt。您可以通过服务器上的命令直接获取它,以生成指定URL的图片。但是,在使用PHP执行系统命令时,发现无法执行该命令,但是可以执行收录帮助信息的命令,例如cutycapt(“/usr/local/cutycapt/cutycapt/xvfb run.Sh--help”),但无法成功执行调用系统变量的脚本。有人怀疑这是一个许可问题。后来发现cutycapt权限设置为www。后来发现这是因为nginx服务器在执行命令时会调用shell脚本。此时,它将遇到权限问题
可爱的
屏幕截图中使用的系统命令:
/usr/bin/sudo/usr/local/cutycapt/cutycapt/xvfb-run.sh/usr/local/cutycapt/cutycapt/cutycapt--url=--out=/tmp/insert.jpg
1、设置sudo配置文件可写权限
chmod u+w/etc/sudoers
2、增加WWW用户执行cutycapt脚本的权限(添加要运行的脚本和命令的权限):
www ALL=(root)NOPASSWD:/bin/sh、/usr/local/cutycapt/cutycapt/xvfb-run.sh、/usr/local/cutycapt/cutycapt/cutycapt
3、关闭[强制控制台登录]以执行或允许www用户在不使用控制台的情况下登录
修改内容:
注意:需要默认值
更好的修改方法(更安全):
仅添加:默认值:www!要求(WWW用户不使用控制台登录)
4使用PHP执行
系统('/usr/bin/sudo/usr/local/cutycapt/cutycapt/xvfb-run.sh/usr/local/cutycapt/cutycapt/cutycapt-url=--out=/tmp/insert2.jpg',m)
注(更安全的方式):
系统('sudo/usr/local/cutycapt/cutycapt/xvfb-run.sh/usr/local/cutycapt/cutycapt/cutycapt-url=--out=/tmp/insert2.jpg',m)
Nginx重启:
同样,增加WWW用户执行nginx脚本的权限 查看全部
php 抓取网页生成图片(用php执行系统命令的时候发现无法执行,但是可以执行CutyCapt)
制作网站屏幕截图时,使用服务器的工具cutycapt。您可以通过服务器上的命令直接获取它,以生成指定URL的图片。但是,在使用PHP执行系统命令时,发现无法执行该命令,但是可以执行收录帮助信息的命令,例如cutycapt(“/usr/local/cutycapt/cutycapt/xvfb run.Sh--help”),但无法成功执行调用系统变量的脚本。有人怀疑这是一个许可问题。后来发现cutycapt权限设置为www。后来发现这是因为nginx服务器在执行命令时会调用shell脚本。此时,它将遇到权限问题
可爱的
屏幕截图中使用的系统命令:
/usr/bin/sudo/usr/local/cutycapt/cutycapt/xvfb-run.sh/usr/local/cutycapt/cutycapt/cutycapt--url=--out=/tmp/insert.jpg
1、设置sudo配置文件可写权限
chmod u+w/etc/sudoers
2、增加WWW用户执行cutycapt脚本的权限(添加要运行的脚本和命令的权限):
www ALL=(root)NOPASSWD:/bin/sh、/usr/local/cutycapt/cutycapt/xvfb-run.sh、/usr/local/cutycapt/cutycapt/cutycapt
3、关闭[强制控制台登录]以执行或允许www用户在不使用控制台的情况下登录
修改内容:
注意:需要默认值
更好的修改方法(更安全):
仅添加:默认值:www!要求(WWW用户不使用控制台登录)
4使用PHP执行
系统('/usr/bin/sudo/usr/local/cutycapt/cutycapt/xvfb-run.sh/usr/local/cutycapt/cutycapt/cutycapt-url=--out=/tmp/insert2.jpg',m)
注(更安全的方式):
系统('sudo/usr/local/cutycapt/cutycapt/xvfb-run.sh/usr/local/cutycapt/cutycapt/cutycapt-url=--out=/tmp/insert2.jpg',m)
Nginx重启:
同样,增加WWW用户执行nginx脚本的权限
php 抓取网页生成图片([博物馆]())
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-02 15:19
黄聪:Python访问和抓取网页的常用命令(本地保存图片、模拟post、get、中文编码)
简单网络爬网:
import urllib.request
url="http://google.cn/"
response=urllib.request.urlopen(url) #返回文件对象
page=response.read()
将URL直接保存为本地文件:
import urllib.request
url="http://www.xxxx.com/1.jpg"
urllib.request.urlretrieve(url,r"d:\temp\1.jpg")
发布模式:
import urllib.parse
import urllib.request
url="http://liuxin-blog.appspot.com ... ot%3B
values={"content":"命令行发出网页请求测试"}
data=urllib.parse.urlencode(values)
#创建请求对象
req=urllib.request.Request(url,data)
#获得服务器返回的数据
response=urllib.request.urlopen(req)
#处理数据
page=response.read()
获取方法:
import urllib.parse
import urllib.request
url="http://www.google.cn/webhp"
values={"rls":"ig"}
data=urllib.parse.urlencode(values)
theurl=url+"?"+data
#创建请求对象
req=urllib.request.Request(theurl)
#获得服务器返回的数据
response=urllib.request.urlopen(req)
#处理数据
page=response.read()
有两种常用方法,geturl(),info()
Geturl()设置为标识是否存在服务器端URL重定向,而info()收录一系列信息
Encode()编码和解码()将用于处理中文问题: 查看全部
php 抓取网页生成图片([博物馆]())
黄聪:Python访问和抓取网页的常用命令(本地保存图片、模拟post、get、中文编码)
简单网络爬网:
import urllib.request
url="http://google.cn/"
response=urllib.request.urlopen(url) #返回文件对象
page=response.read()
将URL直接保存为本地文件:
import urllib.request
url="http://www.xxxx.com/1.jpg"
urllib.request.urlretrieve(url,r"d:\temp\1.jpg")
发布模式:
import urllib.parse
import urllib.request
url="http://liuxin-blog.appspot.com ... ot%3B
values={"content":"命令行发出网页请求测试"}
data=urllib.parse.urlencode(values)
#创建请求对象
req=urllib.request.Request(url,data)
#获得服务器返回的数据
response=urllib.request.urlopen(req)
#处理数据
page=response.read()
获取方法:
import urllib.parse
import urllib.request
url="http://www.google.cn/webhp"
values={"rls":"ig"}
data=urllib.parse.urlencode(values)
theurl=url+"?"+data
#创建请求对象
req=urllib.request.Request(theurl)
#获得服务器返回的数据
response=urllib.request.urlopen(req)
#处理数据
page=response.read()
有两种常用方法,geturl(),info()
Geturl()设置为标识是否存在服务器端URL重定向,而info()收录一系列信息
Encode()编码和解码()将用于处理中文问题:
php 抓取网页生成图片( 一下PHP生成静态页面的原理是什么?HTML5设计原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-02 15:17
一下PHP生成静态页面的原理是什么?HTML5设计原理)
php入门教程:生成静态html页面的原理
经常操作网站后端的人都知道,目前大部分网站系统,如dedecms、phpcms、Empire等知名的内容管理系统,提供静态页面生成。该功能不仅有利于搜索引擎的抓取,还能有效降低服务器压力,所以这是一个非常流行和实用的功能。
对于正在学习PHP,即将从事WEB网站开发的人来说,了解这个功能是必不可少的。因此,我们来分享一下PHP生成静态页面的原理。
一、 思路分析
其实实现静态页面生成功能的原理很简单。它主要使用几种常用的PHP文件操作函数来操作文件。思考过程如下:
生成静态页面流程图
二、功能实现
设置example.html为模板文件,然后根据这个模板文件生成article-1.html~article-5.html进行简单的演示。代码如下:
注解:
fopen(文件名,打开方法),打开文件功能,如果没有文件,就创建。返回值为资源类型;
fread(文件名,读取字节数),读取文件内容及对应的字节数;
str_replace(指定要搜索的'值,替换被搜索值的值,被搜索的字符串),替换函数;
fclose(文件名),关闭文件;
fwrite(要写入的打开文件,要写入打开文件的字符串,要写入的最大字节数)。
三、终于
原理比较简单。作为一个php初学者,一定要把每一个基础知识都学好,每天坚持写代码,形成条件反射。其次,根据工作需要设定阶段目标。我相信您的 PHP 之路一定会如此。风光无限,互相鼓励!
【PHP简介:生成静态html页面的原理】相关文章:
1.PHP入门教程
2.网站静态生成html有什么好处
3.静态页面生成方案介绍
4.HTML5 设计原则
5.PHP.NET 简介
6.简单的HTML5初级入门教程
7.关于HTML 30分钟入门教程
8.html5 入口设计原则 查看全部
php 抓取网页生成图片(
一下PHP生成静态页面的原理是什么?HTML5设计原理)
php入门教程:生成静态html页面的原理
经常操作网站后端的人都知道,目前大部分网站系统,如dedecms、phpcms、Empire等知名的内容管理系统,提供静态页面生成。该功能不仅有利于搜索引擎的抓取,还能有效降低服务器压力,所以这是一个非常流行和实用的功能。
对于正在学习PHP,即将从事WEB网站开发的人来说,了解这个功能是必不可少的。因此,我们来分享一下PHP生成静态页面的原理。
一、 思路分析
其实实现静态页面生成功能的原理很简单。它主要使用几种常用的PHP文件操作函数来操作文件。思考过程如下:
生成静态页面流程图
二、功能实现
设置example.html为模板文件,然后根据这个模板文件生成article-1.html~article-5.html进行简单的演示。代码如下:
注解:
fopen(文件名,打开方法),打开文件功能,如果没有文件,就创建。返回值为资源类型;
fread(文件名,读取字节数),读取文件内容及对应的字节数;
str_replace(指定要搜索的'值,替换被搜索值的值,被搜索的字符串),替换函数;
fclose(文件名),关闭文件;
fwrite(要写入的打开文件,要写入打开文件的字符串,要写入的最大字节数)。
三、终于
原理比较简单。作为一个php初学者,一定要把每一个基础知识都学好,每天坚持写代码,形成条件反射。其次,根据工作需要设定阶段目标。我相信您的 PHP 之路一定会如此。风光无限,互相鼓励!
【PHP简介:生成静态html页面的原理】相关文章:
1.PHP入门教程
2.网站静态生成html有什么好处
3.静态页面生成方案介绍
4.HTML5 设计原则
5.PHP.NET 简介
6.简单的HTML5初级入门教程
7.关于HTML 30分钟入门教程
8.html5 入口设计原则
php 抓取网页生成图片(PHP快速生成图片验证码并且实现验证插件1.插件(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-01 10:07
PHP快速生成图片验证码并实现验证插件1.插件功能:该插件可以快速实现网站验证码功能,包括验证码的生成和验证2.所需参数:captchatool类收录两种方法。生成方法可以实现生成';ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890';并将这些字符写入captcha目录中的图片。同时,在会话中保存代码值并将其输出。此方法不需要参数。Check方法,需要用户输入代码值并返回true或false3.使用方法:包括这些文件,实例化它们,并使用获取的对象调用相应的方法4.注意事项:使用此插件,用户可以根据其网站扩展验证代码字符的示例文本,将要展开的字符放在$chars中,并在for循环中进行相应的调整。小心确保flie的路径文件地址$BG_uu是验证代码背景图片的地址。验证码图像的边框颜色由imagerectangle($img,0,0,144,19,$white)中的$white确定,文本大小由imagestring()中的第二个参数确定。字符串颜色可用于根据需要分配画布颜色。使用函数imagecolorallocate() 查看全部
php 抓取网页生成图片(PHP快速生成图片验证码并且实现验证插件1.插件(图))
PHP快速生成图片验证码并实现验证插件1.插件功能:该插件可以快速实现网站验证码功能,包括验证码的生成和验证2.所需参数:captchatool类收录两种方法。生成方法可以实现生成';ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890';并将这些字符写入captcha目录中的图片。同时,在会话中保存代码值并将其输出。此方法不需要参数。Check方法,需要用户输入代码值并返回true或false3.使用方法:包括这些文件,实例化它们,并使用获取的对象调用相应的方法4.注意事项:使用此插件,用户可以根据其网站扩展验证代码字符的示例文本,将要展开的字符放在$chars中,并在for循环中进行相应的调整。小心确保flie的路径文件地址$BG_uu是验证代码背景图片的地址。验证码图像的边框颜色由imagerectangle($img,0,0,144,19,$white)中的$white确定,文本大小由imagestring()中的第二个参数确定。字符串颜色可用于根据需要分配画布颜色。使用函数imagecolorallocate()
php 抓取网页生成图片( www根目录创建项目实现步骤:属性接下来:创建步骤 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-09-26 11:07
www根目录创建项目实现步骤:属性接下来:创建步骤
)
具体实现步骤如下:
创建项目
作为演示,我们在www根目录下创建一个项目grabimg,创建一个类GrabImage.php和一个index.php。
编写类代码
我们定义一个与文件同名的类:GrabImage
class GrabImage{
}
属性
接下来,定义几个需要用到的属性。
1、首先定义一个需要抓取的图片地址:$img_url
2、再定义一个$file_name来存放文件名,但是不带扩展名,因为可能会涉及到扩展名的替换,所以这里是定义
3、 后跟扩展名 $extension
4、 然后我们定义一个$file_dir。该属性的作用是远程镜像捕获后本地存储的目录,一般以PHP入口文件的位置为起点。但是路径一般不会保存到数据库中。
5、最后我们定义了一个$save_dir,顾名思义,这个路径就是要直接保存的数据库的目录。这里说明一下,我们不直接将文件保存路径存储到数据库中,一般是为以后系统迁移时更改路径做准备。我们这里的$save_dir一般是日期文件名,如果使用的时候需要取出来,把需要的路径放在前面。
(免费学习视频教程分享:php视频教程)
方法
属性说完了,接下来我们就正式开始爬取工作了。
首先,我们定义了一个open方法getInstances来获取一些数据,比如抓拍图片的地址,本地保存路径等。同时把它放在属性中。
public function getInstances($img_url , $base_dir)
{
$this->img_url = $img_url;
$this->save_dir = date("Ym").'/'.date("d").'/'; // 比如:201610/19/
$this->file_dir = $base_dir.'/'.$this->save_dir.'/'; // 比如:./uploads/image/2016/10/19/
}
图片保存路径已拼接。接下来需要注意一个问题,目录是否存在。日期一天天过去,但目录不会自动创建。因此,在保存图片之前,您需要先检查一下,如果当前目录不存在,我们需要立即创建它。
我们创建 setDir 方法来设置目录。我们将财产设为私密、安全
下一步就是抓取核心代码
第一步是解决问题。我们需要抓取的图片可能没有后缀。按照传统的抓图方式,先抓图,再截取后缀名是行不通的。
我们必须通过其他方法获取图片类型。方式是从文件流信息中获取文件头信息,然后判断文件mime信息,即可知道文件后缀名。
为方便起见,首先定义一个 mime 和文件扩展名映射。
$mimes=array(
'image/bmp'=>'bmp',
'image/gif'=>'gif',
'image/jpeg'=>'jpg',
'image/png'=>'png',
'image/x-icon'=>'ico'
);
这样,当我得到类型 image/gif 时,我可以知道它是一个 .gif 图像。
使用php函数get_headers获取文件流头信息。当它的值不为 false 时,我们将它分配给变量 $headers
取出Content-Type的值作为mime的值。
if(($headers=get_headers($this->img_url, 1))!==false){
// 获取响应的类型
$type=$headers['Content-Type'];
}
使用我们上面定义的映射表,我们可以很容易地得到后缀名。
$this->extension=$mimes[$type];
当然,上面得到的$type可能不存在于我们的映射表中,说明这种类型的文件不是我们想要的,放弃它,忽略它。
以下步骤与传统的文件抓取相同。
$file_path = $this->file_dir.$this->file_name.".".$this->extension;
// 获取数据并保存
$contents=file_get_contents($this->img_url);
if(file_put_contents($file_path , $contents))
{
// 这里返回出去的值是直接保存到数据库的路径 文件名,形如:201610/19/57feefd7e2a7aY5p7LsPqaI-lY1BF.jpg
return $this->save_dir.$this->file_name.".".$this->extension;
}
先获取本地保存图片的全路径$file_path,然后用file_get_contents抓取数据,再用file_put_contents保存到刚才的文件路径。
最后,我们返回一个可以直接保存到数据库的路径,而不是文件存储路径。
完整的获取方法如下:
private function getRemoteImg()
{
// mime 和 扩展名 的映射
$mimes=array(
'image/bmp'=>'bmp',
'image/gif'=>'gif',
'image/jpeg'=>'jpg',
'image/png'=>'png',
'image/x-icon'=>'ico'
);
// 获取响应头
if(($headers=get_headers($this->img_url, 1))!==false)
{
// 获取响应的类型
$type=$headers['Content-Type'];
// 如果符合我们要的类型
if(isset($mimes[$type]))
{
$this->extension=$mimes[$type];
$file_path = $this->file_dir.$this->file_name.".".$this->extension;
// 获取数据并保存
$contents=file_get_contents($this->img_url);
if(file_put_contents($file_path , $contents))
{
// 这里返回出去的值是直接保存到数据库的路径 文件名,形如:201610/19/57feefd7e2a7aY5p7LsPqaI-lY1BF.jpg
return $this->save_dir.$this->file_name.".".$this->extension;
}
}
}
return false;
}
最后,为了简单起见,我们希望在别处调用这些方法之一来完成爬网。所以我们直接把抓取动作放到getInstances里面,配置好路径后,直接抓取。因此,我们将代码添加到初始配置方法 getInstances 中。
if($this->setDir())
{
return $this->getRemoteImg();
}
else
{
return false;
}
测试
让我们在刚刚创建的 index.php 文件中尝试一下。
完整代码如下:
<p> 查看全部
php 抓取网页生成图片(
www根目录创建项目实现步骤:属性接下来:创建步骤
)
具体实现步骤如下:
创建项目
作为演示,我们在www根目录下创建一个项目grabimg,创建一个类GrabImage.php和一个index.php。
编写类代码
我们定义一个与文件同名的类:GrabImage
class GrabImage{
}
属性
接下来,定义几个需要用到的属性。
1、首先定义一个需要抓取的图片地址:$img_url
2、再定义一个$file_name来存放文件名,但是不带扩展名,因为可能会涉及到扩展名的替换,所以这里是定义
3、 后跟扩展名 $extension
4、 然后我们定义一个$file_dir。该属性的作用是远程镜像捕获后本地存储的目录,一般以PHP入口文件的位置为起点。但是路径一般不会保存到数据库中。
5、最后我们定义了一个$save_dir,顾名思义,这个路径就是要直接保存的数据库的目录。这里说明一下,我们不直接将文件保存路径存储到数据库中,一般是为以后系统迁移时更改路径做准备。我们这里的$save_dir一般是日期文件名,如果使用的时候需要取出来,把需要的路径放在前面。
(免费学习视频教程分享:php视频教程)
方法
属性说完了,接下来我们就正式开始爬取工作了。
首先,我们定义了一个open方法getInstances来获取一些数据,比如抓拍图片的地址,本地保存路径等。同时把它放在属性中。
public function getInstances($img_url , $base_dir)
{
$this->img_url = $img_url;
$this->save_dir = date("Ym").'/'.date("d").'/'; // 比如:201610/19/
$this->file_dir = $base_dir.'/'.$this->save_dir.'/'; // 比如:./uploads/image/2016/10/19/
}
图片保存路径已拼接。接下来需要注意一个问题,目录是否存在。日期一天天过去,但目录不会自动创建。因此,在保存图片之前,您需要先检查一下,如果当前目录不存在,我们需要立即创建它。
我们创建 setDir 方法来设置目录。我们将财产设为私密、安全
下一步就是抓取核心代码
第一步是解决问题。我们需要抓取的图片可能没有后缀。按照传统的抓图方式,先抓图,再截取后缀名是行不通的。
我们必须通过其他方法获取图片类型。方式是从文件流信息中获取文件头信息,然后判断文件mime信息,即可知道文件后缀名。
为方便起见,首先定义一个 mime 和文件扩展名映射。
$mimes=array(
'image/bmp'=>'bmp',
'image/gif'=>'gif',
'image/jpeg'=>'jpg',
'image/png'=>'png',
'image/x-icon'=>'ico'
);
这样,当我得到类型 image/gif 时,我可以知道它是一个 .gif 图像。
使用php函数get_headers获取文件流头信息。当它的值不为 false 时,我们将它分配给变量 $headers
取出Content-Type的值作为mime的值。
if(($headers=get_headers($this->img_url, 1))!==false){
// 获取响应的类型
$type=$headers['Content-Type'];
}
使用我们上面定义的映射表,我们可以很容易地得到后缀名。
$this->extension=$mimes[$type];
当然,上面得到的$type可能不存在于我们的映射表中,说明这种类型的文件不是我们想要的,放弃它,忽略它。
以下步骤与传统的文件抓取相同。
$file_path = $this->file_dir.$this->file_name.".".$this->extension;
// 获取数据并保存
$contents=file_get_contents($this->img_url);
if(file_put_contents($file_path , $contents))
{
// 这里返回出去的值是直接保存到数据库的路径 文件名,形如:201610/19/57feefd7e2a7aY5p7LsPqaI-lY1BF.jpg
return $this->save_dir.$this->file_name.".".$this->extension;
}
先获取本地保存图片的全路径$file_path,然后用file_get_contents抓取数据,再用file_put_contents保存到刚才的文件路径。
最后,我们返回一个可以直接保存到数据库的路径,而不是文件存储路径。
完整的获取方法如下:
private function getRemoteImg()
{
// mime 和 扩展名 的映射
$mimes=array(
'image/bmp'=>'bmp',
'image/gif'=>'gif',
'image/jpeg'=>'jpg',
'image/png'=>'png',
'image/x-icon'=>'ico'
);
// 获取响应头
if(($headers=get_headers($this->img_url, 1))!==false)
{
// 获取响应的类型
$type=$headers['Content-Type'];
// 如果符合我们要的类型
if(isset($mimes[$type]))
{
$this->extension=$mimes[$type];
$file_path = $this->file_dir.$this->file_name.".".$this->extension;
// 获取数据并保存
$contents=file_get_contents($this->img_url);
if(file_put_contents($file_path , $contents))
{
// 这里返回出去的值是直接保存到数据库的路径 文件名,形如:201610/19/57feefd7e2a7aY5p7LsPqaI-lY1BF.jpg
return $this->save_dir.$this->file_name.".".$this->extension;
}
}
}
return false;
}
最后,为了简单起见,我们希望在别处调用这些方法之一来完成爬网。所以我们直接把抓取动作放到getInstances里面,配置好路径后,直接抓取。因此,我们将代码添加到初始配置方法 getInstances 中。
if($this->setDir())
{
return $this->getRemoteImg();
}
else
{
return false;
}
测试
让我们在刚刚创建的 index.php 文件中尝试一下。
完整代码如下:
<p>

