
php抓取网页json数据
php抓取网页json数据(json数据1.json的作用让不同编程语言之间可以进行有效的数据交流 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-11 18:01
)
json 数据 1. json 的作用
实现不同编程语言之间的有效数据通信(几乎所有高级语言都支持json数据格式)
2. 什么是 json
一个有效的json只有一个数据,唯一的数据必须是json支持的数据类型。
json 支持的数据类型:
直接写数字,例如:100、+23、-45、12.5、3e4
String-双引号,只有双引号,例如:"yuting"、"Chongqing"、"abc\n123"
Boolean-only 两个值,true 和 false
空值-null
数组(列表)——相当于一个 Python 列表:[元素 1,元素 2,元素 3,...]
Dictionary-key 必须是字符串:{key 1: value 1, key 2: value 2,...}
3. json 数据分析
1)如果通过requests发送请求得到的数据是json数据,可以直接使用response.json()将json数据转换成Python数据。
2)非json接口提供的json数据解析。
系统模块:json -> 提供两个功能:将json数据转换为Python数据和将Python数据转换为json数据。
json.loads(json格式的字符串)-将json转换为Python,返回值的类型会因字符串的内容不同而不同。
json.dumps(python data)-将python数据转为json格式的字符串,返回值为字符串。
说明:json格式的字符串——字符串的内容为json格式的数据,例如:‘100’、‘"abc"’、‘{"a": 100}’
int、float、str、bool、list、dict、None、tuple-可以转成json数据
import json
# json转换python
result = json.loads('100')
print(result, type(result)) # 100
result = json.loads('"abc"')
print(result, type(result)) # abc
result = json.loads('{"a": 100}')
print(result, type(result)) # {'a': 100}
result = json.loads('[100, "abc", true, null]')
print(result, type(result)) # [100, 'abc', True, None]
# python转json
result = json.dumps(100)
print(result, type(result)) # 100
result = json.dumps('abc')
print(result, type(result)) # "abc"
result = json.dumps([100, 12.4, True, None, 'hello', [10, 'a'], {10: 20}, (100, 200)])
print(result, type(result)) # '[100, 12.4, true, null, "hello", [10, "a"], {"10": 20}, [100, 200]]'
获取多页数据
# https://movie.douban.com/top25 ... er%3D
# https://movie.douban.com/top25 ... er%3D
# https://movie.douban.com/top25 ... er%3D
import requests
def get_html(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'
}
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
return r.text
def get_all_data():
for x in range(0, 226, 25):
url = f'https://movie.douban.com/top250?start={x}&filter='
get_html(url)
xpath 数据分析
运行环境:from lxml import etree
lxml:可以通过xpath方法解析html数据和xml数据
1. 创建树结构并获取根节点
etree.HTML(html代码)-将html页面创建成树状结构并返回树的根节点。
html_node = etree.HTML(open('files/网页.html', encoding='utf-8').read())
print(html_node) #
2.根据路径获取指定标签
node object.xpath(path)-返回值是一个列表,列表中的元素都是根据路径找到的结果
1) 绝对路径-/从根节点写全路径
注意:绝对写法和搜索方式与谁去了前面的.xpath无关
h1_node = html_node.xpath('/html/body/div/h1')[0]
print(h1_node) #
p_nodes = html_node.xpath('/html/body/div/p')
print(p_nodes) # [, ]
div_node_2 = html_node.xpath('/html/body/div')[-1]
result = div_node_2.xpath('/html/body/div/p')
print(result)
2) 相对路径:./path,. ./路径
使用。表示当前节点(谁去.xpath,谁是当前节点)
用..表示当前节点的上层节点
result = html_node.xpath('./body/div/p')
print(result) # [, ]
result = div_node_2.xpath('./p/text()')
print(result) # []
result = div_node_2.xpath('../div/h1/text()')
print(result)
3) 全局搜索://
//路径
<p>result = html_node.xpath('//img')
print(result) # [, , , , ]
result = html_node.xpath('//div/img')
print(result) # [, 查看全部
php抓取网页json数据(json数据1.json的作用让不同编程语言之间可以进行有效的数据交流
)
json 数据 1. json 的作用
实现不同编程语言之间的有效数据通信(几乎所有高级语言都支持json数据格式)
2. 什么是 json
一个有效的json只有一个数据,唯一的数据必须是json支持的数据类型。
json 支持的数据类型:
直接写数字,例如:100、+23、-45、12.5、3e4
String-双引号,只有双引号,例如:"yuting"、"Chongqing"、"abc\n123"
Boolean-only 两个值,true 和 false
空值-null
数组(列表)——相当于一个 Python 列表:[元素 1,元素 2,元素 3,...]
Dictionary-key 必须是字符串:{key 1: value 1, key 2: value 2,...}
3. json 数据分析
1)如果通过requests发送请求得到的数据是json数据,可以直接使用response.json()将json数据转换成Python数据。
2)非json接口提供的json数据解析。
系统模块:json -> 提供两个功能:将json数据转换为Python数据和将Python数据转换为json数据。
json.loads(json格式的字符串)-将json转换为Python,返回值的类型会因字符串的内容不同而不同。
json.dumps(python data)-将python数据转为json格式的字符串,返回值为字符串。
说明:json格式的字符串——字符串的内容为json格式的数据,例如:‘100’、‘"abc"’、‘{"a": 100}’
int、float、str、bool、list、dict、None、tuple-可以转成json数据
import json
# json转换python
result = json.loads('100')
print(result, type(result)) # 100
result = json.loads('"abc"')
print(result, type(result)) # abc
result = json.loads('{"a": 100}')
print(result, type(result)) # {'a': 100}
result = json.loads('[100, "abc", true, null]')
print(result, type(result)) # [100, 'abc', True, None]
# python转json
result = json.dumps(100)
print(result, type(result)) # 100
result = json.dumps('abc')
print(result, type(result)) # "abc"
result = json.dumps([100, 12.4, True, None, 'hello', [10, 'a'], {10: 20}, (100, 200)])
print(result, type(result)) # '[100, 12.4, true, null, "hello", [10, "a"], {"10": 20}, [100, 200]]'
获取多页数据
# https://movie.douban.com/top25 ... er%3D
# https://movie.douban.com/top25 ... er%3D
# https://movie.douban.com/top25 ... er%3D
import requests
def get_html(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'
}
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
return r.text
def get_all_data():
for x in range(0, 226, 25):
url = f'https://movie.douban.com/top250?start={x}&filter='
get_html(url)
xpath 数据分析
运行环境:from lxml import etree
lxml:可以通过xpath方法解析html数据和xml数据
1. 创建树结构并获取根节点
etree.HTML(html代码)-将html页面创建成树状结构并返回树的根节点。
html_node = etree.HTML(open('files/网页.html', encoding='utf-8').read())
print(html_node) #
2.根据路径获取指定标签
node object.xpath(path)-返回值是一个列表,列表中的元素都是根据路径找到的结果
1) 绝对路径-/从根节点写全路径
注意:绝对写法和搜索方式与谁去了前面的.xpath无关
h1_node = html_node.xpath('/html/body/div/h1')[0]
print(h1_node) #
p_nodes = html_node.xpath('/html/body/div/p')
print(p_nodes) # [, ]
div_node_2 = html_node.xpath('/html/body/div')[-1]
result = div_node_2.xpath('/html/body/div/p')
print(result)
2) 相对路径:./path,. ./路径
使用。表示当前节点(谁去.xpath,谁是当前节点)
用..表示当前节点的上层节点
result = html_node.xpath('./body/div/p')
print(result) # [, ]
result = div_node_2.xpath('./p/text()')
print(result) # []
result = div_node_2.xpath('../div/h1/text()')
print(result)
3) 全局搜索://
//路径
<p>result = html_node.xpath('//img')
print(result) # [, , , , ]
result = html_node.xpath('//div/img')
print(result) # [,
php抓取网页json数据(之前我写过一遍php外挂python脚本处理视频的文章 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-10 01:00
)
之前我写了一个php插件python脚本来处理视频文章。今天给大家分享一下php插件python实现关键字搜索的脚本。
先来分析一波网站:
我们可以看到,普通的爬取网站已经不能满足我们的需求了。这个 网站 使用了第二次数据采集。再来看看头部;
可以看到数据是通过ajax获取的。我们把拿到的链接放到浏览器中直接打开,报错了。有些网站可以通过获取链接直接获取数据,但是很明显,这个接口使用的是post接口请求
让我们先请求一个 wave:
代码开始:
# -*- coding: utf-8 -*-
# @Time : 2019/9/4 14:43
# @Author : wujf
# @Email : 1028540310@qq.com
# @File : 爬取ajax数据.py
# @Software: PyCharm
'''
json.loads(json_str) json字符串转换成字典
json.dumps(dict) 字典转换成json字符串
'''
import requests
import json
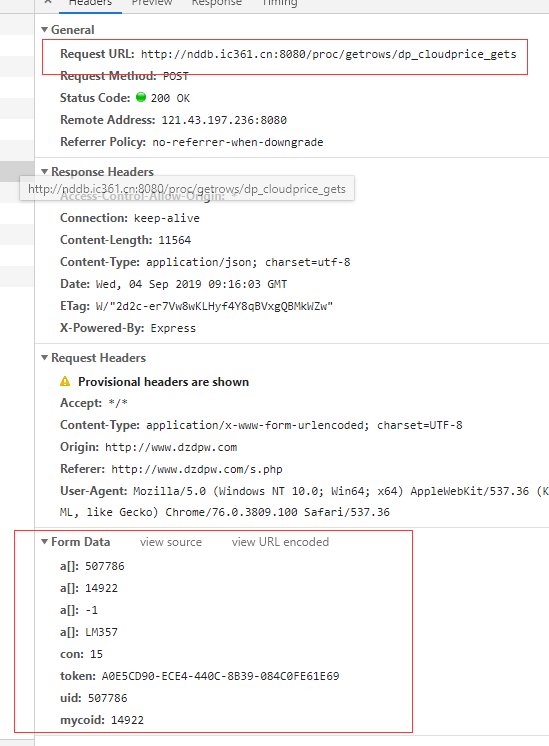
url = "http://nddb.ic361.cn:8080/proc ... ot%3B
seach = input("请输入您要搜索的内容:")
list = ['507786','14922','-1']
list.append(seach)
d = {
'token':'A0E5CD90-ECE4-440C-8B39-084C0FE61E69',
'uid':'507786',
'mycoid':'14922',
'con':'15',
'a':list
}
果然可以得到数据。
然后就很简单了:
关于代码--------
import requests
import json
import sys
url = "http://nddb.ic361.cn:8080/proc ... ot%3B
seach = sys.argv[1]
#seach1 = sys.argv[2]
#item = seach+'-'+seach1
# with open(r'D:\\phpStudy_server\\PHPTutorial\\WWW\\demo\\log.txt','a') as f:
# try:
# f.write(seach)
# except Exception as e:
# print(e)
# seach = input("请输入您要搜索的内容:")
list = ['507786','14922','-1']
list.append(seach)
d = {
'token':'A0E5CD90-ECE4-440C-8B39-084C0FE61E69',
'uid':'507786',
'mycoid':'14922',
'con':'15',
'a':list
}
r = requests.post(url,data=d)
dic = r.json()
print(json.dumps(dic))
接下来我们看一下打印结果:
查看全部
php抓取网页json数据(之前我写过一遍php外挂python脚本处理视频的文章
)
之前我写了一个php插件python脚本来处理视频文章。今天给大家分享一下php插件python实现关键字搜索的脚本。
先来分析一波网站:
我们可以看到,普通的爬取网站已经不能满足我们的需求了。这个 网站 使用了第二次数据采集。再来看看头部;
可以看到数据是通过ajax获取的。我们把拿到的链接放到浏览器中直接打开,报错了。有些网站可以通过获取链接直接获取数据,但是很明显,这个接口使用的是post接口请求
让我们先请求一个 wave:
代码开始:
# -*- coding: utf-8 -*-
# @Time : 2019/9/4 14:43
# @Author : wujf
# @Email : 1028540310@qq.com
# @File : 爬取ajax数据.py
# @Software: PyCharm
'''
json.loads(json_str) json字符串转换成字典
json.dumps(dict) 字典转换成json字符串
'''
import requests
import json
url = "http://nddb.ic361.cn:8080/proc ... ot%3B
seach = input("请输入您要搜索的内容:")
list = ['507786','14922','-1']
list.append(seach)
d = {
'token':'A0E5CD90-ECE4-440C-8B39-084C0FE61E69',
'uid':'507786',
'mycoid':'14922',
'con':'15',
'a':list
}

果然可以得到数据。
然后就很简单了:
关于代码--------
import requests
import json
import sys
url = "http://nddb.ic361.cn:8080/proc ... ot%3B
seach = sys.argv[1]
#seach1 = sys.argv[2]
#item = seach+'-'+seach1
# with open(r'D:\\phpStudy_server\\PHPTutorial\\WWW\\demo\\log.txt','a') as f:
# try:
# f.write(seach)
# except Exception as e:
# print(e)
# seach = input("请输入您要搜索的内容:")
list = ['507786','14922','-1']
list.append(seach)
d = {
'token':'A0E5CD90-ECE4-440C-8B39-084C0FE61E69',
'uid':'507786',
'mycoid':'14922',
'con':'15',
'a':list
}
r = requests.post(url,data=d)
dic = r.json()
print(json.dumps(dic))
接下来我们看一下打印结果:

php抓取网页json数据(PHP获取内容、PHP解析JSONPHP(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-09 03:05
好久没有为PHP写文章了,好久没用PHP了。我差点忘了怎么做。JSON是现在比较流行的数据通信方式,比XML更流行,一般用作数据获取和通信的api接口。
就文章的标题而言,本文介绍了两个小点:PHP获取内容,PHP解析JSON并显示。
PHP获取界面内容
如果要解析JSON数据并显示在页面上,首先必须要获取JSON接口文件的内容。在 PHP 中要获取页面的内容,可以使用 fopen() 函数远程访问页面,然后使用 fread() 函数循环获取内容。
$handle = fopen(";only_recommend=1&limit=5","rb");
$content = "";
而 (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
这样,内容保存的内容就是JSON api内容。
PHP解析JSON并显示
原创内容不能直接调用,必须经过PHP进一步处理后才能调用显示在网页上。在PHP5.2及以后的版本中,使用json_decode()函数解析JSON数据并转换成PHP可以调用的数据格式。例如:
$content = json_decode($content);
解析后,我们可以像调用PHP中的数组数据一样调用JSON中的数据。这个调用方法需要根据具体的JSON数据格式来编写,演示请看下面。关于json_decode函数的使用,详见PHP手册,这里不再赘述:
实战中调用琼台博客的api
细心的朋友会发现,潜行者m博客的侧边栏底部多了一个“好友推荐”模块,推荐了一些琼台博客的文章。
友情推荐是琼泰博客提出的一种博客之间的交流方式,比传统友情链接更有效,同时实现了博客内容的互补。由于琼台博客的博客程序是自己写的,所以提供了JSON api接口,获取最新的推荐文章。
我使用 PHP 来获取这个 JSON 接口并将其输出到我的博客的侧边栏。让我们付诸行动。
第一步是检查api是如何调用的
调用前一定要查看对方的api调用手册,包括调用地址、调用方式、数据输出格式等。琼台博客api描述地址如下:.
第二步获取api结构数据
很简单,如上所述,具体代码如下:
$handle = fopen(";only_recommend=1&limit=5","rb");
$content = "";
而 (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
首先打开数据文件,然后将所有内容保存在content变量中。因为可以确定api数据不会超过10000个字符,所以使用10000作为fread函数的第二个参数。这样,api 返回的 JSON 数据就存储在 content 变量中。
第三步,解析并输出内容
使用以下代码解析数据,然后调用输出
$content = json_decode($content);
foreach ($content->data as $key) {
回声'
';
}
首先对content变量中的JSON数据进行处理,然后将其转化为PHP可以调用的数据,然后使用foreach遍历输出这5条内容,按照我需要的HTML格式将内容插入进去。
再加上样式修改,这样就完成了JSON的获取解析并展示在页面上。调用其他api数据的方法类似。 查看全部
php抓取网页json数据(PHP获取内容、PHP解析JSONPHP(组图))
好久没有为PHP写文章了,好久没用PHP了。我差点忘了怎么做。JSON是现在比较流行的数据通信方式,比XML更流行,一般用作数据获取和通信的api接口。
就文章的标题而言,本文介绍了两个小点:PHP获取内容,PHP解析JSON并显示。
PHP获取界面内容
如果要解析JSON数据并显示在页面上,首先必须要获取JSON接口文件的内容。在 PHP 中要获取页面的内容,可以使用 fopen() 函数远程访问页面,然后使用 fread() 函数循环获取内容。
$handle = fopen(";only_recommend=1&limit=5","rb");
$content = "";
而 (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
这样,内容保存的内容就是JSON api内容。
PHP解析JSON并显示
原创内容不能直接调用,必须经过PHP进一步处理后才能调用显示在网页上。在PHP5.2及以后的版本中,使用json_decode()函数解析JSON数据并转换成PHP可以调用的数据格式。例如:
$content = json_decode($content);
解析后,我们可以像调用PHP中的数组数据一样调用JSON中的数据。这个调用方法需要根据具体的JSON数据格式来编写,演示请看下面。关于json_decode函数的使用,详见PHP手册,这里不再赘述:
实战中调用琼台博客的api
细心的朋友会发现,潜行者m博客的侧边栏底部多了一个“好友推荐”模块,推荐了一些琼台博客的文章。

友情推荐是琼泰博客提出的一种博客之间的交流方式,比传统友情链接更有效,同时实现了博客内容的互补。由于琼台博客的博客程序是自己写的,所以提供了JSON api接口,获取最新的推荐文章。
我使用 PHP 来获取这个 JSON 接口并将其输出到我的博客的侧边栏。让我们付诸行动。
第一步是检查api是如何调用的
调用前一定要查看对方的api调用手册,包括调用地址、调用方式、数据输出格式等。琼台博客api描述地址如下:.
第二步获取api结构数据
很简单,如上所述,具体代码如下:
$handle = fopen(";only_recommend=1&limit=5","rb");
$content = "";
而 (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
首先打开数据文件,然后将所有内容保存在content变量中。因为可以确定api数据不会超过10000个字符,所以使用10000作为fread函数的第二个参数。这样,api 返回的 JSON 数据就存储在 content 变量中。
第三步,解析并输出内容
使用以下代码解析数据,然后调用输出
$content = json_decode($content);
foreach ($content->data as $key) {
回声'
';
}
首先对content变量中的JSON数据进行处理,然后将其转化为PHP可以调用的数据,然后使用foreach遍历输出这5条内容,按照我需要的HTML格式将内容插入进去。
再加上样式修改,这样就完成了JSON的获取解析并展示在页面上。调用其他api数据的方法类似。
php抓取网页json数据(PHP解析JSON接口内容()函数循环获取内容介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-08 01:06
)
PHP访问界面内容
如果要解析JSON数据并显示在页面上,首先必须要获取JSON接口文件的内容。 PHP 中获取页面内容,可以使用 fopen() 函数远程访问页面,然后使用 fread() 函数循环获取内容。
假设接口文件页面是:,那么我们可以用下面的语句来获取这个接口文件的内容:
$handle = fopen(“http://www.qttc.net/api.php%3F ... ot%3B,"rb“);<br />$content = “”;<br />while (!feof($handle)) {<br /> $content .= fread($handle, 10000);<br />}<br />fclose($handle);
这样保存的内容就是JSON api内容。
PHP 解析 JSON 并显示
原创内容不能直接调用,必须经过PHP进一步处理后才能调用显示在网页上。在PHP5.2及以后的版本中,使用json_decode()函数解析JSON数据并转换成PHP可以调用的数据格式。例如:
$content = json_decode($content);
$content = json_decode($content);<br />foreach ($content->data as $key) {<br /> echo ‘<a target=”_blank” href=”‘.$key->b_url.’”>’.$key->b_title.’</a>’;<br />} 查看全部
php抓取网页json数据(PHP解析JSON接口内容()函数循环获取内容介绍
)
PHP访问界面内容
如果要解析JSON数据并显示在页面上,首先必须要获取JSON接口文件的内容。 PHP 中获取页面内容,可以使用 fopen() 函数远程访问页面,然后使用 fread() 函数循环获取内容。
假设接口文件页面是:,那么我们可以用下面的语句来获取这个接口文件的内容:
$handle = fopen(“http://www.qttc.net/api.php%3F ... ot%3B,"rb“);<br />$content = “”;<br />while (!feof($handle)) {<br /> $content .= fread($handle, 10000);<br />}<br />fclose($handle);
这样保存的内容就是JSON api内容。
PHP 解析 JSON 并显示
原创内容不能直接调用,必须经过PHP进一步处理后才能调用显示在网页上。在PHP5.2及以后的版本中,使用json_decode()函数解析JSON数据并转换成PHP可以调用的数据格式。例如:
$content = json_decode($content);
$content = json_decode($content);<br />foreach ($content->data as $key) {<br /> echo ‘<a target=”_blank” href=”‘.$key->b_url.’”>’.$key->b_title.’</a>’;<br />}
php抓取网页json数据(几个自己研究出来的抓数据的技术,欢迎大家指正补充哈哈!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-01 03:09
还有一个关于数据抓取的小研究。现在我分享一些我研究过的数据抓取技术。可能有很多缺点。欢迎大家指正并补充哈哈!
方法一:直接抓取网页源码
优点:速度快。
缺点: 1、由于速度快,容易被服务器检测,可能会限制当前的ip抓取。为此,您可以尝试使用 ip 代码来解决它。
2、如果要抓取的数据是在网页加载后,js修改了网页元素,无法抓取。
3、遇到一些大规模的网站抓取,如果登录后需要抓取页面,可能需要破解服务器端账号加密算法和各种加密算法,测试技术性。
适用场景:网页是完全静态的,第一次加载网页时就加载了你要抓取的数据。涉及登录或权限操作的类似页面未加密或简单加密。
当然,如果你为这个网页抓取的数据是通过接口获取的json,那你会更开心,直接抓取json页面即可。
对于一个登录页面,我们如何获取他的登录页面背后的源代码?
首先,我想介绍一下,当会话保存帐户信息时,服务器如何确定用户的身份。
首先,用户登录成功后,服务器会在session中保存用户当前的session信息,每个session都有一个唯一的标识sessionId。当用户访问该页面时,会话创建后,服务器返回的 sessionId 会被接收并保存在 cookie 中。因此,我们可以用chrome浏览器打开勾选项,查看当前页面的jsessionId。用户下次访问需要登录的页面时,用户发送的请求头会附加这个sessionId,服务器端可以通过这个sessionId来判断用户的身份。
在这里,我搭建了一个简单的jsp登录页面,登录后的账户信息保存在服务端会话中。
思路:1.登录。2.登录成功后获取cookies。3. 将cookie放入请求头,向登录页面发送请求。
附上java版本代码和python
爪哇版:
package craw;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintStream;
import java.io.PrintWriter;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.List;
import java.util.Map;
public class CrawTest {
//获得网页源代码
private static String getHtml(String urlString,String charset,String cookie){
StringBuffer html = new StringBuffer();
try {
URL url = new URL(urlString);
HttpURLConnection urlConn = (HttpURLConnection) url.openConnection();
urlConn.setRequestProperty("Cookie", cookie);
BufferedReader br = new BufferedReader(new InputStreamReader(urlConn.getInputStream(),charset));
String str;
while((str=br.readLine())!=null){
html.append(str);
}
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return html.toString();
}
//发送post请求,并返回请求后的cookie
private static String postGetCookie(String urlString,String params,String charset){
String cookies=null;
try {
URL url = new URL(urlString);
URLConnection urlConn = url.openConnection();
urlConn.setDoInput(true);
urlConn.setDoOutput(true);
PrintWriter out = new PrintWriter(urlConn.getOutputStream());
out.print(params);
out.flush();
cookies = urlConn.getHeaderFields().get("Set-Cookie").get(0);
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return cookies;
}
public static void main(String[] args) {
String cookie = postGetCookie("http://localhost:8080/loginDemo/login",
"username=admin&password=123456","utf-8");
String html = getHtml("http://localhost:8080/loginDemo/index.jsp", "utf-8", cookie);
System.out.println(html);//这里我们就可能输出登录后的网页源代码了
}
}
蟒蛇版本:
#encoding:utf-8
import urllib
import urllib2
data={\'username\':\'admin\',\'password\':\'123456\'}
data=urllib.urlencode(data)
response = urllib2.urlopen(\'http://localhost:8080/loginDemo/login\',data=data)//登录
cookie = response.info()[\'set-cookie\']//获得登录后的cookie
jsessionId = cookie.split(\';\')[0].split(\'=\')[-1]//从cookie获得sessionId
html = response.read()
if html==\'error\':
print(\'用户名密码错误!\')
elif html==\'success\':
headers = {\'Cookie\':\'JSESSIONID=\'+jsessionId}//请求头
request =urllib2.Request(\'http://localhost:8080/loginDemo/index.jsp\',headers=headers)
html = urllib2.urlopen(request).read()
print(html)//输出登录后的页面源码
我们可以很明显的看到python的优势,至少会比java少写一半的代码量。当然,这是java的优点,也是java的缺点。优点是更加灵活,程序员可以更好地控制底层代码的实现。,缺点是使用不方便,需要的技术太多。因此,如果您是数据抓取的新手,我强烈建议您学习python。
方法二:模拟浏览器操作
优点: 1. 类似于用户操作,不易被服务器检测到。
2、对于登录的网站,即使是N层加密,也无需考虑其加密算法。
3、可随时获取当前页面各元素的最新状态。
缺点: 1. 稍慢。
这里有一些很好的模拟浏览器操作的库:
C#webbrower 控件:
如果你学过c#winform,相信你对webbrower控件永远不会陌生。是浏览器,内部驱动其实就是IE驱动。
他可以随时在dom模式下解析当前文档(网页文档对象),不仅可以获取相关的Element对象,还可以修改元素对象,甚至调用方法,比如onclick方法,onsubmit等,或者直接调用页面js方法。
web浏览器的C#操作代码:
webBrowser1.Navigate("https://localhost//index.html");//加载一个页面
需要注意的是:不要直接执行以下代码,因为网页加载需要时间,建议以下代码写到webBrowser1_DocumentCompleted(加载完成)事件中:
webBrowser1.Document.GetElementById("username").InnerText="admin";//在网页中找到id为username的元素,设置其文本为admin
webBrowser1.Document.GetElementById("password").InnerText = "123456";//在网页中找到id为password的元素,设置其文本为123456
webBrowser1.Document.InvokeScript("loginEncrypt");//调用网页js函数:loginEncrypt.
因为有些页面可能不够友好,或者IE版本太低,甚至安全证书等问题,那么这个解决方案可能会通过。
我们可以直接使用selenium库来操作操作系统中真实的浏览器,比如chrome浏览器,selenuim支持多语言开发,以python调用selenium为例,selenium就是直接操作我们系统中的浏览器,但是我们需要确保浏览器安装了相应的Drive。
但是,在实际开发中,有时我们可能不想看到这样的浏览器界面。这里可以给大家推荐一个后台浏览器,直接在cmd里面操作。没有接口,就是phantomjs。
这样我们就可以用python+selenium+phantomjs在不看界面的情况下模拟浏览器的操作。由于phantomjs没有界面,所以会比普通浏览器快很多。
网上资料很多,一时无法解释,这里就不过多解释了,大家可以看看:
三、Fidderscript:
fidder 是一个非常强大的数据捕获工具。它不仅可以捕获当前系统中的http请求,还可以提供安全证书。所以,有时候,如果我们在爬取的过程中遇到安全证书错误,我们不妨打开fidder,让他给你提供一个证书,说不定你就快成功了。
更强大的是fidderscript,它可以在捕获请求后执行系统操作,例如将请求的数据保存到硬盘。或者在请求之前修改请求头,可以说是一个强大的抓取工具。这样我们之前用fdder配合各种方法,相信大部分问题都可以解决。而且他的语法和Clike系列的语法差不多,类库和c#大同小异,相信熟悉C#的同学会很快上手fiddlerscript。
附注: 查看全部
php抓取网页json数据(几个自己研究出来的抓数据的技术,欢迎大家指正补充哈哈!)
还有一个关于数据抓取的小研究。现在我分享一些我研究过的数据抓取技术。可能有很多缺点。欢迎大家指正并补充哈哈!
方法一:直接抓取网页源码
优点:速度快。
缺点: 1、由于速度快,容易被服务器检测,可能会限制当前的ip抓取。为此,您可以尝试使用 ip 代码来解决它。
2、如果要抓取的数据是在网页加载后,js修改了网页元素,无法抓取。
3、遇到一些大规模的网站抓取,如果登录后需要抓取页面,可能需要破解服务器端账号加密算法和各种加密算法,测试技术性。
适用场景:网页是完全静态的,第一次加载网页时就加载了你要抓取的数据。涉及登录或权限操作的类似页面未加密或简单加密。
当然,如果你为这个网页抓取的数据是通过接口获取的json,那你会更开心,直接抓取json页面即可。
对于一个登录页面,我们如何获取他的登录页面背后的源代码?
首先,我想介绍一下,当会话保存帐户信息时,服务器如何确定用户的身份。
首先,用户登录成功后,服务器会在session中保存用户当前的session信息,每个session都有一个唯一的标识sessionId。当用户访问该页面时,会话创建后,服务器返回的 sessionId 会被接收并保存在 cookie 中。因此,我们可以用chrome浏览器打开勾选项,查看当前页面的jsessionId。用户下次访问需要登录的页面时,用户发送的请求头会附加这个sessionId,服务器端可以通过这个sessionId来判断用户的身份。
在这里,我搭建了一个简单的jsp登录页面,登录后的账户信息保存在服务端会话中。
思路:1.登录。2.登录成功后获取cookies。3. 将cookie放入请求头,向登录页面发送请求。
附上java版本代码和python
爪哇版:
package craw;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintStream;
import java.io.PrintWriter;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.List;
import java.util.Map;
public class CrawTest {
//获得网页源代码
private static String getHtml(String urlString,String charset,String cookie){
StringBuffer html = new StringBuffer();
try {
URL url = new URL(urlString);
HttpURLConnection urlConn = (HttpURLConnection) url.openConnection();
urlConn.setRequestProperty("Cookie", cookie);
BufferedReader br = new BufferedReader(new InputStreamReader(urlConn.getInputStream(),charset));
String str;
while((str=br.readLine())!=null){
html.append(str);
}
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return html.toString();
}
//发送post请求,并返回请求后的cookie
private static String postGetCookie(String urlString,String params,String charset){
String cookies=null;
try {
URL url = new URL(urlString);
URLConnection urlConn = url.openConnection();
urlConn.setDoInput(true);
urlConn.setDoOutput(true);
PrintWriter out = new PrintWriter(urlConn.getOutputStream());
out.print(params);
out.flush();
cookies = urlConn.getHeaderFields().get("Set-Cookie").get(0);
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return cookies;
}
public static void main(String[] args) {
String cookie = postGetCookie("http://localhost:8080/loginDemo/login",
"username=admin&password=123456","utf-8");
String html = getHtml("http://localhost:8080/loginDemo/index.jsp", "utf-8", cookie);
System.out.println(html);//这里我们就可能输出登录后的网页源代码了
}
}
蟒蛇版本:
#encoding:utf-8
import urllib
import urllib2
data={\'username\':\'admin\',\'password\':\'123456\'}
data=urllib.urlencode(data)
response = urllib2.urlopen(\'http://localhost:8080/loginDemo/login\',data=data)//登录
cookie = response.info()[\'set-cookie\']//获得登录后的cookie
jsessionId = cookie.split(\';\')[0].split(\'=\')[-1]//从cookie获得sessionId
html = response.read()
if html==\'error\':
print(\'用户名密码错误!\')
elif html==\'success\':
headers = {\'Cookie\':\'JSESSIONID=\'+jsessionId}//请求头
request =urllib2.Request(\'http://localhost:8080/loginDemo/index.jsp\',headers=headers)
html = urllib2.urlopen(request).read()
print(html)//输出登录后的页面源码
我们可以很明显的看到python的优势,至少会比java少写一半的代码量。当然,这是java的优点,也是java的缺点。优点是更加灵活,程序员可以更好地控制底层代码的实现。,缺点是使用不方便,需要的技术太多。因此,如果您是数据抓取的新手,我强烈建议您学习python。
方法二:模拟浏览器操作
优点: 1. 类似于用户操作,不易被服务器检测到。
2、对于登录的网站,即使是N层加密,也无需考虑其加密算法。
3、可随时获取当前页面各元素的最新状态。
缺点: 1. 稍慢。
这里有一些很好的模拟浏览器操作的库:
C#webbrower 控件:
如果你学过c#winform,相信你对webbrower控件永远不会陌生。是浏览器,内部驱动其实就是IE驱动。
他可以随时在dom模式下解析当前文档(网页文档对象),不仅可以获取相关的Element对象,还可以修改元素对象,甚至调用方法,比如onclick方法,onsubmit等,或者直接调用页面js方法。
web浏览器的C#操作代码:
webBrowser1.Navigate("https://localhost//index.html";);//加载一个页面
需要注意的是:不要直接执行以下代码,因为网页加载需要时间,建议以下代码写到webBrowser1_DocumentCompleted(加载完成)事件中:
webBrowser1.Document.GetElementById("username").InnerText="admin";//在网页中找到id为username的元素,设置其文本为admin
webBrowser1.Document.GetElementById("password").InnerText = "123456";//在网页中找到id为password的元素,设置其文本为123456
webBrowser1.Document.InvokeScript("loginEncrypt");//调用网页js函数:loginEncrypt.
因为有些页面可能不够友好,或者IE版本太低,甚至安全证书等问题,那么这个解决方案可能会通过。
我们可以直接使用selenium库来操作操作系统中真实的浏览器,比如chrome浏览器,selenuim支持多语言开发,以python调用selenium为例,selenium就是直接操作我们系统中的浏览器,但是我们需要确保浏览器安装了相应的Drive。
但是,在实际开发中,有时我们可能不想看到这样的浏览器界面。这里可以给大家推荐一个后台浏览器,直接在cmd里面操作。没有接口,就是phantomjs。
这样我们就可以用python+selenium+phantomjs在不看界面的情况下模拟浏览器的操作。由于phantomjs没有界面,所以会比普通浏览器快很多。
网上资料很多,一时无法解释,这里就不过多解释了,大家可以看看:
三、Fidderscript:
fidder 是一个非常强大的数据捕获工具。它不仅可以捕获当前系统中的http请求,还可以提供安全证书。所以,有时候,如果我们在爬取的过程中遇到安全证书错误,我们不妨打开fidder,让他给你提供一个证书,说不定你就快成功了。
更强大的是fidderscript,它可以在捕获请求后执行系统操作,例如将请求的数据保存到硬盘。或者在请求之前修改请求头,可以说是一个强大的抓取工具。这样我们之前用fdder配合各种方法,相信大部分问题都可以解决。而且他的语法和Clike系列的语法差不多,类库和c#大同小异,相信熟悉C#的同学会很快上手fiddlerscript。
附注:
php抓取网页json数据( javajar修改servletjava代码代码使用方法代码详解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-30 22:15
javajar修改servletjava代码代码使用方法代码详解)
JS中Json数据的处理和解析JSON数据的方法详解
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript 的一个子集。JSON 使用完全独立于语言的文本格式,但也使用类似于 C 语言家族(包括 C、C++、C#、Java、JavaScript、Perl、Python 等)的习惯。这些特性使 JSON 成为一种理想的数据交换语言。便于人读写,也便于机器解析生成(通常用于提高网络传输速率)。
JSON 的规则很简单:对象是“名称/值对”的无序集合。对象以“{”(左括号)开头,以“}”(右括号)结尾。每个“名称”后跟一个“:”(冒号);“'name/value' 对”由“,”(逗号)分隔。具体细节参考
举个简单的例子:
js代码
function showJSON() {
var user =
{
"username":"andy",
"age":20,
"info": { "tel": "123456", "cellphone": "98765"},
"address":
[
{"city":"beijing","postcode":"222333"},
{"city":"newyork","postcode":"555666"}
]
}
alert(user.username);
alert(user.age);
alert(user.info.cellphone);
alert(user.address[0].city);
alert(user.address[0].postcode);
}
这表示具有用户名、年龄、信息、地址等属性的用户对象。
也可以用JSON简单的修改数据,修改上面的例子
js代码
function showJSON() {
var user =
{
"username":"andy",
"age":20,
"info": { "tel": "123456", "cellphone": "98765"},
"address":
[
{"city":"beijing","postcode":"222333"},
{"city":"newyork","postcode":"555666"}
]
}
alert(user.username);
alert(user.age);
alert(user.info.cellphone);
alert(user.address[0].city);
alert(user.address[0].postcode);
user.username = "Tom";
alert(user.username);
}
JSON 提供了 json.js 包。下载后,导入它,然后简单地使用 object.toJSONString() 将其转换为 JSON 数据。
js代码
function showCar() {
var carr = new Car("Dodge", "Coronet R/T", 1968, "yellow");
alert(carr.toJSONString());
}
function Car(make, model, year, color) {
this.make = make;
this.model = model;
this.year = year;
this.color = color;
}
您可以使用 eval 将 JSON 字符转换为 Object
js代码
function myEval() {
var str = '{ "name": "Violet", "occupation": "character" }';
var obj = eval('(' + str + ')');
alert(obj.toJSONString());
}
或者使用 parseJSON() 方法
js代码
function myEval() {
var str = '{ "name": "Violet", "occupation": "character" }';
var obj = str.parseJSON();
alert(obj.toJSONString());
}
下面用prototype写一个JSON ajax例子。
先写一个servlet(我的是servlet.ajax.JSONTest1.java),写一句
代码
response.getWriter().print("{ \"name\": \"Violet\", \"occupation\": \"character\" }");
在页面中写一个ajax请求
js代码
function sendRequest() {
var url = "/MyWebApp/JSONTest1";
var mailAjax = new Ajax.Request(
url,
{
method: 'get',
onComplete: jsonResponse
}
);
}
function jsonResponse(originalRequest) {
alert(originalRequest.responseText);
var myobj = originalRequest.responseText.parseJSON();
alert(myobj.name);
}
Prototype-1.5.1.js 提供了JSON方法,String.evalJSON(),不使用json.js也可以修改上面的方法
js代码
function jsonResponse(originalRequest) {
alert(originalRequest.responseText);
var myobj = originalRequest.responseText.evalJSON(true);
alert(myobj.name);
}
JSON也提供了java jar包API也很简单,这里举个例子
在javascript中填写请求参数
js代码
function sendRequest() {
var carr = new Car("Dodge", "Coronet R/T", 1968, "yellow");
var pars = "car=" + carr.toJSONString();
var url = "/MyWebApp/JSONTest1";
var mailAjax = new Ajax.Request(
url,
{
method: 'get',
parameters: pars,
onComplete: jsonResponse
}
);
}
使用JSON请求字符串,可以简单的生成解析JSONObject,修改servlet添加JSON处理(使用json.jar)
代码
private void doService(HttpServletRequest request, HttpServletResponse response) throws IOException {
String s3 = request.getParameter("car");
try {
JSONObject jsonObj = new JSONObject(s3);
System.out.println(jsonObj.getString("model"));
System.out.println(jsonObj.getInt("year"));
} catch (JSONException e) {
e.printStackTrace();
}
response.getWriter().print("{ \"name\": \"Violet\", \"occupation\": \"character\" }");
}
您还可以使用 JSONObject 生成 JSON 字符串和修改 servlet
代码
private void doService(HttpServletRequest request, HttpServletResponse response) throws IOException {
String s3 = request.getParameter("car");
try {
JSONObject jsonObj = new JSONObject(s3);
System.out.println(jsonObj.getString("model"));
System.out.println(jsonObj.getInt("year"));
} catch (JSONException e) {
e.printStackTrace();
}
JSONObject resultJSON = new JSONObject();
try {
resultJSON.append("name", "Violet")
.append("occupation", "developer")
.append("age", new Integer(22));
System.out.println(resultJSON.toString());
} catch (JSONException e) {
e.printStackTrace();
}
response.getWriter().print(resultJSON.toString());
}
js代码
function jsonResponse(originalRequest) {
alert(originalRequest.responseText);
var myobj = originalRequest.responseText.evalJSON(true);
alert(myobj.name);
alert(myobj.age);
}
下面重点介绍JS中json数据的处理
1、 json 数据结构(对象和数组)
json 对象:var obj = {"name":"xiao","age":12};
json 数组:var objArray = [{"name":"xiao","age":12},{"name":"xiao","age":12}];
2、 处理json数据,依赖文件为:jQuery.js
3、注:在数据传输过程中,json数据以文本形式存在,即字符串格式;
JS 语言操作 JS 对象;
所以json字符串和JS对象的转换是关键;
4、数据格式
json字符串:var json_str ='{"name":"xiao","age":12}';
Josn 对象:var obj = {"name":"xiao","age":12};
JS对象:对象{名称:“xiao”,年龄:12}
5、类型转换
Json字符串——>JS对象,使用方法:
笔记:
json_str 和 obj 代表本文副标题 4 中的数据类型;
obj = JSON.parse(json_str);
obj = jQuery.parseJSON(json_str);
注意:如果传入格式错误的json字符串(例如:'{name:"xiao",age:12}'),会抛出异常;
Json 字符串格式,严格格式:'{"name":"xiao","age":12}'
JS 对象 -> Json 字符串:
json_str = JSON。字符串化(对象);
笔记:
1、eval()是JS原生函数,使用这种形式:eval('('+'{name:"xiao",age:12}'+')'),不安全,不能保证类型转换是一个JS对象;
2、 以上3种方法均已通过chrome浏览器测试,以下为测试结果截图;
Json 字符串 -> JS 对象;
JS 对象 -> Json 字符串: 查看全部
php抓取网页json数据(
javajar修改servletjava代码代码使用方法代码详解)
JS中Json数据的处理和解析JSON数据的方法详解
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript 的一个子集。JSON 使用完全独立于语言的文本格式,但也使用类似于 C 语言家族(包括 C、C++、C#、Java、JavaScript、Perl、Python 等)的习惯。这些特性使 JSON 成为一种理想的数据交换语言。便于人读写,也便于机器解析生成(通常用于提高网络传输速率)。
JSON 的规则很简单:对象是“名称/值对”的无序集合。对象以“{”(左括号)开头,以“}”(右括号)结尾。每个“名称”后跟一个“:”(冒号);“'name/value' 对”由“,”(逗号)分隔。具体细节参考
举个简单的例子:
js代码
function showJSON() {
var user =
{
"username":"andy",
"age":20,
"info": { "tel": "123456", "cellphone": "98765"},
"address":
[
{"city":"beijing","postcode":"222333"},
{"city":"newyork","postcode":"555666"}
]
}
alert(user.username);
alert(user.age);
alert(user.info.cellphone);
alert(user.address[0].city);
alert(user.address[0].postcode);
}
这表示具有用户名、年龄、信息、地址等属性的用户对象。
也可以用JSON简单的修改数据,修改上面的例子
js代码
function showJSON() {
var user =
{
"username":"andy",
"age":20,
"info": { "tel": "123456", "cellphone": "98765"},
"address":
[
{"city":"beijing","postcode":"222333"},
{"city":"newyork","postcode":"555666"}
]
}
alert(user.username);
alert(user.age);
alert(user.info.cellphone);
alert(user.address[0].city);
alert(user.address[0].postcode);
user.username = "Tom";
alert(user.username);
}
JSON 提供了 json.js 包。下载后,导入它,然后简单地使用 object.toJSONString() 将其转换为 JSON 数据。
js代码
function showCar() {
var carr = new Car("Dodge", "Coronet R/T", 1968, "yellow");
alert(carr.toJSONString());
}
function Car(make, model, year, color) {
this.make = make;
this.model = model;
this.year = year;
this.color = color;
}
您可以使用 eval 将 JSON 字符转换为 Object
js代码
function myEval() {
var str = '{ "name": "Violet", "occupation": "character" }';
var obj = eval('(' + str + ')');
alert(obj.toJSONString());
}
或者使用 parseJSON() 方法
js代码
function myEval() {
var str = '{ "name": "Violet", "occupation": "character" }';
var obj = str.parseJSON();
alert(obj.toJSONString());
}
下面用prototype写一个JSON ajax例子。
先写一个servlet(我的是servlet.ajax.JSONTest1.java),写一句
代码
response.getWriter().print("{ \"name\": \"Violet\", \"occupation\": \"character\" }");
在页面中写一个ajax请求
js代码
function sendRequest() {
var url = "/MyWebApp/JSONTest1";
var mailAjax = new Ajax.Request(
url,
{
method: 'get',
onComplete: jsonResponse
}
);
}
function jsonResponse(originalRequest) {
alert(originalRequest.responseText);
var myobj = originalRequest.responseText.parseJSON();
alert(myobj.name);
}
Prototype-1.5.1.js 提供了JSON方法,String.evalJSON(),不使用json.js也可以修改上面的方法
js代码
function jsonResponse(originalRequest) {
alert(originalRequest.responseText);
var myobj = originalRequest.responseText.evalJSON(true);
alert(myobj.name);
}
JSON也提供了java jar包API也很简单,这里举个例子
在javascript中填写请求参数
js代码
function sendRequest() {
var carr = new Car("Dodge", "Coronet R/T", 1968, "yellow");
var pars = "car=" + carr.toJSONString();
var url = "/MyWebApp/JSONTest1";
var mailAjax = new Ajax.Request(
url,
{
method: 'get',
parameters: pars,
onComplete: jsonResponse
}
);
}
使用JSON请求字符串,可以简单的生成解析JSONObject,修改servlet添加JSON处理(使用json.jar)
代码
private void doService(HttpServletRequest request, HttpServletResponse response) throws IOException {
String s3 = request.getParameter("car");
try {
JSONObject jsonObj = new JSONObject(s3);
System.out.println(jsonObj.getString("model"));
System.out.println(jsonObj.getInt("year"));
} catch (JSONException e) {
e.printStackTrace();
}
response.getWriter().print("{ \"name\": \"Violet\", \"occupation\": \"character\" }");
}
您还可以使用 JSONObject 生成 JSON 字符串和修改 servlet
代码
private void doService(HttpServletRequest request, HttpServletResponse response) throws IOException {
String s3 = request.getParameter("car");
try {
JSONObject jsonObj = new JSONObject(s3);
System.out.println(jsonObj.getString("model"));
System.out.println(jsonObj.getInt("year"));
} catch (JSONException e) {
e.printStackTrace();
}
JSONObject resultJSON = new JSONObject();
try {
resultJSON.append("name", "Violet")
.append("occupation", "developer")
.append("age", new Integer(22));
System.out.println(resultJSON.toString());
} catch (JSONException e) {
e.printStackTrace();
}
response.getWriter().print(resultJSON.toString());
}
js代码
function jsonResponse(originalRequest) {
alert(originalRequest.responseText);
var myobj = originalRequest.responseText.evalJSON(true);
alert(myobj.name);
alert(myobj.age);
}
下面重点介绍JS中json数据的处理
1、 json 数据结构(对象和数组)
json 对象:var obj = {"name":"xiao","age":12};
json 数组:var objArray = [{"name":"xiao","age":12},{"name":"xiao","age":12}];
2、 处理json数据,依赖文件为:jQuery.js
3、注:在数据传输过程中,json数据以文本形式存在,即字符串格式;
JS 语言操作 JS 对象;
所以json字符串和JS对象的转换是关键;
4、数据格式
json字符串:var json_str ='{"name":"xiao","age":12}';
Josn 对象:var obj = {"name":"xiao","age":12};
JS对象:对象{名称:“xiao”,年龄:12}
5、类型转换
Json字符串——>JS对象,使用方法:
笔记:
json_str 和 obj 代表本文副标题 4 中的数据类型;
obj = JSON.parse(json_str);
obj = jQuery.parseJSON(json_str);
注意:如果传入格式错误的json字符串(例如:'{name:"xiao",age:12}'),会抛出异常;
Json 字符串格式,严格格式:'{"name":"xiao","age":12}'
JS 对象 -> Json 字符串:
json_str = JSON。字符串化(对象);
笔记:
1、eval()是JS原生函数,使用这种形式:eval('('+'{name:"xiao",age:12}'+')'),不安全,不能保证类型转换是一个JS对象;
2、 以上3种方法均已通过chrome浏览器测试,以下为测试结果截图;
Json 字符串 -> JS 对象;
JS 对象 -> Json 字符串:
php抓取网页json数据(这里有新鲜出炉的PHP教程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-28 20:04
这里有新鲜的PHP教程,看看程序狗的速度!
PHP 开源脚本语言 PHP(外文名:Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,入门门槛低,易学,应用广泛。主要适用于Web开发领域。PHP 的文件扩展名为 php。
我最近在百度阅读上购买了一本电子书《永恒的尽头》,但发现只能在网上或手机端阅读,无法下载并放入kindle。所以我试着看看我是否可以下载这个文章。有需要的朋友可以参考参考,一起来看看吧。
前言
本文文章主要介绍如何使用PHP抓取百度阅读。话不多说,一起来看看吧。
爬取方法如下
首先在浏览器中打开阅读页面,查看源码,发现页面上并没有直接写小说的内容,也就是说小说的内容是异步加载的。
所以把chrome开发者工具切到网络专栏,刷新阅读页面,重点关注XHR和脚本两大类。
经过排查,发现脚本类下有一个jsonp请求,更像是小说内容,请求地址为
返回的是一个jsonp字符串,然后我发现如果去掉地址中的callback=wenku7,返回的是一个json字符串,这样解析起来更容易,可以直接在php中转成数组。
我们再来分析一下返回数据的结构。返回的json字符串为树状结构后,每个节点都有at属性和ac属性。t属性用于指定节点的标签,如h2 div等,c属性是内容,但是有两种可能,一种是字符串,另一种是数组,每个元素的数组是一个节点。
这个结构最好解析,它可以通过递归来完成。
最终代码如下:
<p> 查看全部
php抓取网页json数据(这里有新鲜出炉的PHP教程,程序狗速度看过来!)
这里有新鲜的PHP教程,看看程序狗的速度!
PHP 开源脚本语言 PHP(外文名:Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,入门门槛低,易学,应用广泛。主要适用于Web开发领域。PHP 的文件扩展名为 php。
我最近在百度阅读上购买了一本电子书《永恒的尽头》,但发现只能在网上或手机端阅读,无法下载并放入kindle。所以我试着看看我是否可以下载这个文章。有需要的朋友可以参考参考,一起来看看吧。
前言
本文文章主要介绍如何使用PHP抓取百度阅读。话不多说,一起来看看吧。
爬取方法如下
首先在浏览器中打开阅读页面,查看源码,发现页面上并没有直接写小说的内容,也就是说小说的内容是异步加载的。
所以把chrome开发者工具切到网络专栏,刷新阅读页面,重点关注XHR和脚本两大类。
经过排查,发现脚本类下有一个jsonp请求,更像是小说内容,请求地址为
返回的是一个jsonp字符串,然后我发现如果去掉地址中的callback=wenku7,返回的是一个json字符串,这样解析起来更容易,可以直接在php中转成数组。
我们再来分析一下返回数据的结构。返回的json字符串为树状结构后,每个节点都有at属性和ac属性。t属性用于指定节点的标签,如h2 div等,c属性是内容,但是有两种可能,一种是字符串,另一种是数组,每个元素的数组是一个节点。
这个结构最好解析,它可以通过递归来完成。
最终代码如下:
<p>
php抓取网页json数据( 如何利用PHP抓取百度阅读的方法看能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-28 11:16
如何利用PHP抓取百度阅读的方法看能)
如何用PHP抓取百度阅读的例子
更新时间:2016年12月18日11:06:49投稿:雏菊
我最近在百度阅读上购买了一本电子书《永恒的尽头》,但发现只能在网上或手机端阅读,无法下载并放入kindle。所以我试着看看我是否可以下载这个文章。有需要的朋友可以参考参考,一起来看看吧。
前言
本文文章主要介绍如何使用PHP抓取百度阅读。话不多说,一起来看看吧。
爬取方法如下
首先在浏览器中打开阅读页面,查看源码,发现页面上并没有直接写小说的内容,也就是说小说的内容是异步加载的。
所以把chrome开发者工具切到网络专栏,刷新阅读页面,重点关注XHR和脚本两大类。
经过排查,发现脚本类下有一个jsonp请求,更像是小说内容,请求地址为
返回的是一个jsonp字符串,然后我发现如果去掉地址中的callback=wenku7,返回的是一个json字符串,这样解析起来更容易,可以直接在php中转成数组。
我们再来分析一下返回数据的结构。返回的json字符串为树状结构后,每个节点都有at属性和ac属性。t属性用于指定节点的标签,如h2 div等,c属性是内容,但是有两种可能,一种是字符串,另一种是数组,每个元素的数组是一个节点。
这个结构最好解析,它可以通过递归来完成。
最终代码如下:
<p> 查看全部
php抓取网页json数据(
如何利用PHP抓取百度阅读的方法看能)
如何用PHP抓取百度阅读的例子
更新时间:2016年12月18日11:06:49投稿:雏菊
我最近在百度阅读上购买了一本电子书《永恒的尽头》,但发现只能在网上或手机端阅读,无法下载并放入kindle。所以我试着看看我是否可以下载这个文章。有需要的朋友可以参考参考,一起来看看吧。
前言
本文文章主要介绍如何使用PHP抓取百度阅读。话不多说,一起来看看吧。
爬取方法如下
首先在浏览器中打开阅读页面,查看源码,发现页面上并没有直接写小说的内容,也就是说小说的内容是异步加载的。
所以把chrome开发者工具切到网络专栏,刷新阅读页面,重点关注XHR和脚本两大类。
经过排查,发现脚本类下有一个jsonp请求,更像是小说内容,请求地址为
返回的是一个jsonp字符串,然后我发现如果去掉地址中的callback=wenku7,返回的是一个json字符串,这样解析起来更容易,可以直接在php中转成数组。
我们再来分析一下返回数据的结构。返回的json字符串为树状结构后,每个节点都有at属性和ac属性。t属性用于指定节点的标签,如h2 div等,c属性是内容,但是有两种可能,一种是字符串,另一种是数组,每个元素的数组是一个节点。
这个结构最好解析,它可以通过递归来完成。
最终代码如下:
<p>
php抓取网页json数据(5.正则提取我们去网页看一下真实的源码(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-10-23 20:08
下面用代码实现,先抓取第一页的内容。我们实现了 get_one_page() 方法并将 url 参数传递给他。然后返回获取的页面结果,然后调用main()方法。初步代码如下:
import requests
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
return None
def main():
url = 'http://maoyan.com/board/4'
html = get_one_page(url)
print(html)
main()
运行后就可以成功获取主页的源码了。获取到之后,需要对页面进行解析,提取出我们想要的信息。
5.常规提取
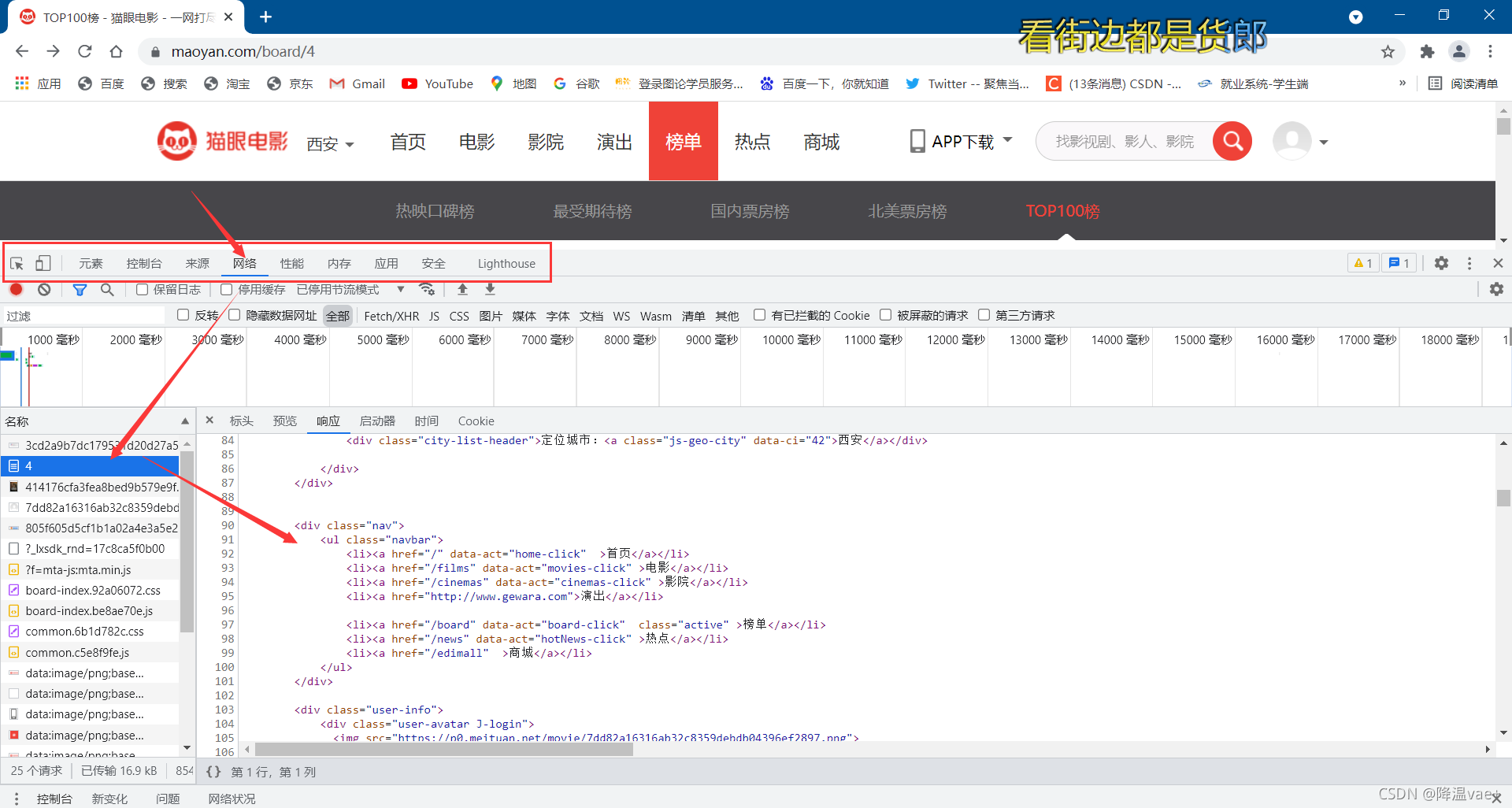
让我们去网页看看真正的源代码。在开发者模式下查看Network monitor组件中的源码,如图
注意这里不要直接进入Elements选项卡查看,因为这里的源码可能与通过JavaScript操作的原创请求不同,但是需要查看来自Network的原创请求才能获取源码。让我们分析其中一项。
可以看出,一个电影信息对应的源代码是一个dd节点,我们使用正则表达式提取其中的一些信息。首先是排名信息。它的排名在类别为 board-index 的 i-node 中。这里使用非贪婪匹配来提取 i-node 中的信息。正则表达式写成:
.*?board-index.*?>(.*?)
接下来需要提取的是电影图片。可以看到,后面有一个节点,里面有两个img节点。检查后发现第二个img节点的data-src属性是图片链接。这里提取第二个img节点的data-src属性,把表达式改成这样:
.*?board-index.*?>(.*?).*?data-src="(.*?)"
后面需要提取电影名称,在后面的p节点中,类为name。因此,您也可以使用name作为标志位,然后进一步提取其中的a节点的文本内容。这时正则表达式改写如下:
.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>
用同样的原理提取男主角、上映时间、收视率等,最终的正则表达式为:
.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?).*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?).*?fraction.*?>(.*?).*?
</p>
这样的正则表达式可以匹配一部电影的结果,一共有七条信息。接下来,通过调用 findall() 方法提取所有内容。
接下来我们定义一个方法parse_one_page()来解析页面,主要是通过正则表达式从结果中提取出我们想要的内容,代码如下:
def parse_one_page(html):
pattern = re.compile('.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?).*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?).*?fraction.*?>(.*?).*?',re.S)
items = re.findall(pattern,html)
print(items)
</p>
输出如下,是一个列表形式。
但是数据比较乱,所以我们先处理匹配结果,遍历提取结果生成字典,改成这样:
def parse_one_page(html):
pattern = re.compile('.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?).*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?).*?fraction.*?>(.*?).*?',re.S)
items = re.findall(pattern,html)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2].strip(),
'actor': item[3].strip()[3:] if len(item[3]) > 3 else '',
'time': item[4].strip()[5:] if len(item[3]) > 3 else '',
'score': item[5].strip() + item[6].strip()
}
</p>
这样就可以成功提取电影排名、图片、片名、演员、时间、收视率等内容,并分配到字典中,形成结构化数据。操作结果如下:
6.写入文件
随后,我们将提取的结果写入文件,这里直接写入文本文件。这里通过JSON库的dumps()方法实现字典的序列化,将ensure_ascii参数指定为False,保证输出结果是中文格式,而不是Unicode编码。代码显示如下:
def write_to_file(content):
with open('result.txt', 'a', encoding='utf-8') as f:
print(type(json.dumps(content)))
f.write(json.dumps(content, ensure_ascii=False) + '\n')
将字典写入文本文件的过程可以通过调用write_to_file()方法来实现。这里的content参数是提取结果,是一个字典。
7.集成代码
最后实现main()方法调用前面的方法,将单页电影结果写入文件。代码如下:
def main(offset):
url = 'http://maoyan.com/board/4'
html = get_one_page(url)
for item in parse_one_page(html):
write_to_file(item)
至此我们就完成了单个页面的提取。
8.页面抓取
因为我们要抓取TOP100电影,所以还需要遍历并将offset参数传递给这个链接,实现其他90部电影的抓取。这时,添加如下调用:
if __name__ == '__main__':
for i in range(10):
main(offset= i*10)
还需要修改main方法,接收一个偏移值作为偏移量,然后进行URL构建。代码显示如下:
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
至此,集成后的代码如下:
import json
import requests
from requests.exceptions import RequestException
import re
import time
import http
def get_one_page(url):
try:
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile('.*?board-index.*?>(\d+).*?data-src="(.*?)".*?name">(.*?)</a>.*?star">(.*?).*?releasetime">(.*?)</p>'
+ '.*?integer">(.*?).*?fraction">(.*?).*?', re.S)
items = re.findall(pattern, str(html))
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5] + item[6]
}
def write_to_file(content):
with open('result.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
for i in range(10):
main(offset= i*10)
time.sleep(1)
</p>
因为猫眼是有抗爬虫的,如果速度太快,就会没有反应,所以加了一个延迟。可能有人在练习的时候注意到ip被封了。其实这里最好的解决办法就是设置代理。您可以找到一些免费的代理服务器。
9.运行结果
我们运行一下代码,输出如下
我们再看一下文本文件,如图
如您所见,所有电影信息也保存在一个文本文件中。
10.本节代码
本节的代码也已经提交到GitHub,代码地址:。 查看全部
php抓取网页json数据(5.正则提取我们去网页看一下真实的源码(图))
下面用代码实现,先抓取第一页的内容。我们实现了 get_one_page() 方法并将 url 参数传递给他。然后返回获取的页面结果,然后调用main()方法。初步代码如下:
import requests
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
return None
def main():
url = 'http://maoyan.com/board/4'
html = get_one_page(url)
print(html)
main()
运行后就可以成功获取主页的源码了。获取到之后,需要对页面进行解析,提取出我们想要的信息。
5.常规提取
让我们去网页看看真正的源代码。在开发者模式下查看Network monitor组件中的源码,如图
注意这里不要直接进入Elements选项卡查看,因为这里的源码可能与通过JavaScript操作的原创请求不同,但是需要查看来自Network的原创请求才能获取源码。让我们分析其中一项。
可以看出,一个电影信息对应的源代码是一个dd节点,我们使用正则表达式提取其中的一些信息。首先是排名信息。它的排名在类别为 board-index 的 i-node 中。这里使用非贪婪匹配来提取 i-node 中的信息。正则表达式写成:
.*?board-index.*?>(.*?)
接下来需要提取的是电影图片。可以看到,后面有一个节点,里面有两个img节点。检查后发现第二个img节点的data-src属性是图片链接。这里提取第二个img节点的data-src属性,把表达式改成这样:
.*?board-index.*?>(.*?).*?data-src="(.*?)"
后面需要提取电影名称,在后面的p节点中,类为name。因此,您也可以使用name作为标志位,然后进一步提取其中的a节点的文本内容。这时正则表达式改写如下:
.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>
用同样的原理提取男主角、上映时间、收视率等,最终的正则表达式为:
.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?).*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?).*?fraction.*?>(.*?).*?
</p>
这样的正则表达式可以匹配一部电影的结果,一共有七条信息。接下来,通过调用 findall() 方法提取所有内容。
接下来我们定义一个方法parse_one_page()来解析页面,主要是通过正则表达式从结果中提取出我们想要的内容,代码如下:
def parse_one_page(html):
pattern = re.compile('.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?).*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?).*?fraction.*?>(.*?).*?',re.S)
items = re.findall(pattern,html)
print(items)
</p>
输出如下,是一个列表形式。

但是数据比较乱,所以我们先处理匹配结果,遍历提取结果生成字典,改成这样:
def parse_one_page(html):
pattern = re.compile('.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?).*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?).*?fraction.*?>(.*?).*?',re.S)
items = re.findall(pattern,html)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2].strip(),
'actor': item[3].strip()[3:] if len(item[3]) > 3 else '',
'time': item[4].strip()[5:] if len(item[3]) > 3 else '',
'score': item[5].strip() + item[6].strip()
}
</p>
这样就可以成功提取电影排名、图片、片名、演员、时间、收视率等内容,并分配到字典中,形成结构化数据。操作结果如下:
6.写入文件
随后,我们将提取的结果写入文件,这里直接写入文本文件。这里通过JSON库的dumps()方法实现字典的序列化,将ensure_ascii参数指定为False,保证输出结果是中文格式,而不是Unicode编码。代码显示如下:
def write_to_file(content):
with open('result.txt', 'a', encoding='utf-8') as f:
print(type(json.dumps(content)))
f.write(json.dumps(content, ensure_ascii=False) + '\n')
将字典写入文本文件的过程可以通过调用write_to_file()方法来实现。这里的content参数是提取结果,是一个字典。
7.集成代码
最后实现main()方法调用前面的方法,将单页电影结果写入文件。代码如下:
def main(offset):
url = 'http://maoyan.com/board/4'
html = get_one_page(url)
for item in parse_one_page(html):
write_to_file(item)
至此我们就完成了单个页面的提取。
8.页面抓取
因为我们要抓取TOP100电影,所以还需要遍历并将offset参数传递给这个链接,实现其他90部电影的抓取。这时,添加如下调用:
if __name__ == '__main__':
for i in range(10):
main(offset= i*10)
还需要修改main方法,接收一个偏移值作为偏移量,然后进行URL构建。代码显示如下:
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
至此,集成后的代码如下:
import json
import requests
from requests.exceptions import RequestException
import re
import time
import http
def get_one_page(url):
try:
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile('.*?board-index.*?>(\d+).*?data-src="(.*?)".*?name">(.*?)</a>.*?star">(.*?).*?releasetime">(.*?)</p>'
+ '.*?integer">(.*?).*?fraction">(.*?).*?', re.S)
items = re.findall(pattern, str(html))
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5] + item[6]
}
def write_to_file(content):
with open('result.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
for i in range(10):
main(offset= i*10)
time.sleep(1)
</p>
因为猫眼是有抗爬虫的,如果速度太快,就会没有反应,所以加了一个延迟。可能有人在练习的时候注意到ip被封了。其实这里最好的解决办法就是设置代理。您可以找到一些免费的代理服务器。
9.运行结果
我们运行一下代码,输出如下
我们再看一下文本文件,如图
如您所见,所有电影信息也保存在一个文本文件中。
10.本节代码
本节的代码也已经提交到GitHub,代码地址:。
php抓取网页json数据(实例如下所示:以上这篇就是小编分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 348 次浏览 • 2021-10-21 11:00
示例如下:
// 追加写入用户名下文件
$code="001";//动态数据
$json_string = file_get_contents("text.json");// 从文件中读取数据到PHP变量
$data = json_decode($json_string,true);// 把JSON字符串转成PHP数组
$data[$code]=array("a"=>"as","b"=>"bs","c"=>"cs");
$json_strings = json_encode($data);
file_put_contents("text.json",$json_strings);//写入
//修改
$json_string = file_get_contents("text.json");// 从文件中读取数据到PHP变量
$data = json_decode($json_string,true);// 把JSON字符串转成PHP数组
$data["001"]["a"]="aas";
$json_strings = json_encode($data);
file_put_contents("text.json",$json_strings);//写入
以上php读写json文件和修改json的方法是小编分享的全部内容,希望能给大家参考,希望大家多多支持。
本文链接: 查看全部
php抓取网页json数据(实例如下所示:以上这篇就是小编分享)
示例如下:
// 追加写入用户名下文件
$code="001";//动态数据
$json_string = file_get_contents("text.json");// 从文件中读取数据到PHP变量
$data = json_decode($json_string,true);// 把JSON字符串转成PHP数组
$data[$code]=array("a"=>"as","b"=>"bs","c"=>"cs");
$json_strings = json_encode($data);
file_put_contents("text.json",$json_strings);//写入
//修改
$json_string = file_get_contents("text.json");// 从文件中读取数据到PHP变量
$data = json_decode($json_string,true);// 把JSON字符串转成PHP数组
$data["001"]["a"]="aas";
$json_strings = json_encode($data);
file_put_contents("text.json",$json_strings);//写入
以上php读写json文件和修改json的方法是小编分享的全部内容,希望能给大家参考,希望大家多多支持。

本文链接:
php抓取网页json数据(PHP中json_decode函数的使用(一)_PHP手册)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-10-18 11:00
好久没有为PHP写文章了,好久没用PHP了。我差点忘了怎么做。JSON是现在比较流行的数据通信方式,比XML更流行,一般用作数据获取和通信的api接口。
就文章的标题而言,本文介绍了两个小点:PHP获取内容,PHP解析JSON并显示。
PHP获取界面内容
如果要解析JSON数据并显示在页面上,首先必须要获取JSON接口文件的内容。在 PHP 中要获取页面的内容,可以使用 fopen() 函数远程访问页面,然后使用 fread() 函数循环获取内容。
假设接口文件页面是:,那么我们可以使用下面的语句来获取这个接口文件的内容:
$handle = fopen("","rb");
$content = "";
而 (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
这样,内容保存的内容就是JSON api内容。
PHP解析JSON并显示
原创内容不能直接调用,必须经过PHP进一步处理后才能调用显示在网页上。在PHP5.2及以后的版本中,使用json_decode()函数解析JSON数据并转换成PHP可以调用的数据格式。例如:
$content = json_decode($content);
解析后,我们可以像调用PHP中的数组数据一样调用JSON中的数据。这个调用方法需要根据具体的JSON数据格式来编写,演示请看下面。关于json_decode函数的使用,详见PHP手册,这里不再赘述:
实战中调用琼台博客的api
细心的朋友会发现,潜行者m博客的侧边栏底部多了一个“好友推荐”模块,推荐了一些琼台博客的文章。
友情推荐是琼台博客提出的一种博客之间的交流方式,比传统友情链接更有效,同时实现了博客内容的互补。由于琼台博客的博客程序是自己写的,所以提供了JSON api接口,获取最新的推荐文章。
我使用 PHP 来获取这个 JSON 接口并将其输出到我的博客的侧边栏。让我们付诸行动。
第一步是检查api是如何调用的
调用前一定要阅读对方的api调用手册,包括调用地址、调用方式、数据输出格式等。琼泰博客api描述地址如下:。
根据文档,我使用了这个参数,意思是调用五个推荐的文章。
第二步获取api结构数据
很简单,如上所述,具体代码如下:
$handle = fopen("","rb");
$content = "";
而 (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
首先打开数据文件,然后将所有内容保存到内容变量中。因为可以确定api数据不会超过10000个字符,所以使用10000作为fread函数的第二个参数。这样,api 返回的 JSON 数据就存储在 content 变量中。
第三步,解析并输出内容
使用以下代码解析数据,然后调用输出
$content = json_decode($content);
foreach ($content->data as $key) {
回声'';
}
先处理content变量中的JSON数据,然后将其转化为PHP可以调用的数据,然后使用foreach遍历输出这5条内容,按照我需要的HTML格式插入内容.
再加上样式修改,这样就完成了JSON的获取解析并展示在页面上。调用其他api数据的方法类似。
原文链接: 查看全部
php抓取网页json数据(PHP中json_decode函数的使用(一)_PHP手册)
好久没有为PHP写文章了,好久没用PHP了。我差点忘了怎么做。JSON是现在比较流行的数据通信方式,比XML更流行,一般用作数据获取和通信的api接口。
就文章的标题而言,本文介绍了两个小点:PHP获取内容,PHP解析JSON并显示。
PHP获取界面内容
如果要解析JSON数据并显示在页面上,首先必须要获取JSON接口文件的内容。在 PHP 中要获取页面的内容,可以使用 fopen() 函数远程访问页面,然后使用 fread() 函数循环获取内容。
假设接口文件页面是:,那么我们可以使用下面的语句来获取这个接口文件的内容:
$handle = fopen("","rb");
$content = "";
而 (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
这样,内容保存的内容就是JSON api内容。
PHP解析JSON并显示
原创内容不能直接调用,必须经过PHP进一步处理后才能调用显示在网页上。在PHP5.2及以后的版本中,使用json_decode()函数解析JSON数据并转换成PHP可以调用的数据格式。例如:
$content = json_decode($content);
解析后,我们可以像调用PHP中的数组数据一样调用JSON中的数据。这个调用方法需要根据具体的JSON数据格式来编写,演示请看下面。关于json_decode函数的使用,详见PHP手册,这里不再赘述:
实战中调用琼台博客的api
细心的朋友会发现,潜行者m博客的侧边栏底部多了一个“好友推荐”模块,推荐了一些琼台博客的文章。
友情推荐是琼台博客提出的一种博客之间的交流方式,比传统友情链接更有效,同时实现了博客内容的互补。由于琼台博客的博客程序是自己写的,所以提供了JSON api接口,获取最新的推荐文章。
我使用 PHP 来获取这个 JSON 接口并将其输出到我的博客的侧边栏。让我们付诸行动。
第一步是检查api是如何调用的
调用前一定要阅读对方的api调用手册,包括调用地址、调用方式、数据输出格式等。琼泰博客api描述地址如下:。
根据文档,我使用了这个参数,意思是调用五个推荐的文章。
第二步获取api结构数据
很简单,如上所述,具体代码如下:
$handle = fopen("","rb");
$content = "";
而 (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
首先打开数据文件,然后将所有内容保存到内容变量中。因为可以确定api数据不会超过10000个字符,所以使用10000作为fread函数的第二个参数。这样,api 返回的 JSON 数据就存储在 content 变量中。
第三步,解析并输出内容
使用以下代码解析数据,然后调用输出
$content = json_decode($content);
foreach ($content->data as $key) {
回声'';
}
先处理content变量中的JSON数据,然后将其转化为PHP可以调用的数据,然后使用foreach遍历输出这5条内容,按照我需要的HTML格式插入内容.
再加上样式修改,这样就完成了JSON的获取解析并展示在页面上。调用其他api数据的方法类似。
原文链接:
php抓取网页json数据(()php中从数据库读取数据读取数据格式返回数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-18 10:30
)
在php中,从数据库中读取数据,并以json格式返回数据。具体方法如下:
第一步是定义相关变量
$servername = "localhost";
$username = "root";
$password = "root";
$mysqlname = "datatest";
$json = '';
$data = array();
class User {
public $id;
public $fname;
public $lname;
public $email;
public $password;
}
第二步是链接数据库,代码如下:
// 创建连接
$conn = mysqli_connect($servername, $username, $password, $mysqlname);
第三步,定义查询语句并执行。代码如下:
$sql = "SELECT * FROM userinfo";
$result = $conn->query($sql);
第四步,获取查询到的数据,放入预先声明的类中,最后以json格式输出。代码如下:
if($result) {
//echo "查询成功";
while ($row = mysqli_fetch_array($result,MYSQL_ASSOC)) {
$user = new User();
$user->id = $row["id"];
$user->fname = $row["fname"];
$user->lname = $row["lname"];
$user->email = $row["email"];
$user->password = $row["password"];
$data[]=$user;
}
//把数据转换为JSON数据.
$json = json_encode($data);
echo "{".'"user"'.":".$json."}";
} else {
echo "查询失败";
} 查看全部
php抓取网页json数据(()php中从数据库读取数据读取数据格式返回数据
)
在php中,从数据库中读取数据,并以json格式返回数据。具体方法如下:
第一步是定义相关变量
$servername = "localhost";
$username = "root";
$password = "root";
$mysqlname = "datatest";
$json = '';
$data = array();
class User {
public $id;
public $fname;
public $lname;
public $email;
public $password;
}
第二步是链接数据库,代码如下:
// 创建连接
$conn = mysqli_connect($servername, $username, $password, $mysqlname);
第三步,定义查询语句并执行。代码如下:
$sql = "SELECT * FROM userinfo";
$result = $conn->query($sql);
第四步,获取查询到的数据,放入预先声明的类中,最后以json格式输出。代码如下:
if($result) {
//echo "查询成功";
while ($row = mysqli_fetch_array($result,MYSQL_ASSOC)) {
$user = new User();
$user->id = $row["id"];
$user->fname = $row["fname"];
$user->lname = $row["lname"];
$user->email = $row["email"];
$user->password = $row["password"];
$data[]=$user;
}
//把数据转换为JSON数据.
$json = json_encode($data);
echo "{".'"user"'.":".$json."}";
} else {
echo "查询失败";
}
php抓取网页json数据( ,涉及php针对json格式数据及文件相关操作技巧汇总)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-10-14 15:12
,涉及php针对json格式数据及文件相关操作技巧汇总)
PHP生成获取JSON文件的方法
更新时间:2016-08-23 12:15:26 作者:onestopweb
本文文章主要介绍PHP生成和获取JSON文件的方法。涉及到PHP的json格式数据和文件相关的操作技巧。有需要的朋友可以参考以下
本文介绍了PHP生成和获取JSON文件的方法。分享给大家,供大家参考,如下:
先定义一个数组,然后遍历数据表,将对应的数据放入数组中,最后通过json_encode()转换数组
json_encode() 函数的作用是将值转换为JSON数据存储格式。
putjson.php:
如果有同名的 JSON 文件,则会被覆盖,如果没有 JSON 文件,则会创建。
生成或覆盖的 JSON 如下:
复制代码代码如下:
[["1","\u811A\u672C\u4E4B\u5BB6",""],["2","\u7F16\u7A0B\u5F00\u53D1",""]]
然后,将 JSON 文件中的数据读入 PHP 变量。
getjson.php:
效果图:
PS:这里有一些比较实用的json在线工具供大家参考:
在线JSON代码检查、检查、美化和格式化工具:
JSON在线格式化工具:
在线 XML/JSON 转换工具:
json代码在线格式化/美化/压缩/编辑/转换工具:
C语言风格/HTML/CSS/json代码格式化和美化工具:
对PHP相关内容感兴趣的读者可以查看本站主题:《PHP中json格式数据操作技巧总结》、《XML文件的PHP操作技巧总结》、《PHP基本语法介绍》、 《PHP数组(数组)操作技巧》、《php字符串(字符串)使用总结》、《php+mysql数据库操作入门教程》、《php常用数据库操作技巧总结》
我希望这篇文章能帮助你进行 PHP 编程。 查看全部
php抓取网页json数据(
,涉及php针对json格式数据及文件相关操作技巧汇总)
PHP生成获取JSON文件的方法
更新时间:2016-08-23 12:15:26 作者:onestopweb
本文文章主要介绍PHP生成和获取JSON文件的方法。涉及到PHP的json格式数据和文件相关的操作技巧。有需要的朋友可以参考以下
本文介绍了PHP生成和获取JSON文件的方法。分享给大家,供大家参考,如下:
先定义一个数组,然后遍历数据表,将对应的数据放入数组中,最后通过json_encode()转换数组
json_encode() 函数的作用是将值转换为JSON数据存储格式。
putjson.php:
如果有同名的 JSON 文件,则会被覆盖,如果没有 JSON 文件,则会创建。
生成或覆盖的 JSON 如下:
复制代码代码如下:
[["1","\u811A\u672C\u4E4B\u5BB6",""],["2","\u7F16\u7A0B\u5F00\u53D1",""]]
然后,将 JSON 文件中的数据读入 PHP 变量。
getjson.php:
效果图:
PS:这里有一些比较实用的json在线工具供大家参考:
在线JSON代码检查、检查、美化和格式化工具:
JSON在线格式化工具:
在线 XML/JSON 转换工具:
json代码在线格式化/美化/压缩/编辑/转换工具:
C语言风格/HTML/CSS/json代码格式化和美化工具:
对PHP相关内容感兴趣的读者可以查看本站主题:《PHP中json格式数据操作技巧总结》、《XML文件的PHP操作技巧总结》、《PHP基本语法介绍》、 《PHP数组(数组)操作技巧》、《php字符串(字符串)使用总结》、《php+mysql数据库操作入门教程》、《php常用数据库操作技巧总结》
我希望这篇文章能帮助你进行 PHP 编程。
php抓取网页json数据(一个从网络上抓取数据的一个小程序(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-11 08:29
最近做了一个小程序,从网上抓取数据。主要是关于信用,一些黑名单网站采集,从网站抓到自己的系统。
我也找到了一些资料,但我认为没有一个很好的和全面的例子。所以在这里做个笔记以提醒自己。
首先需要一个jsoup jar包,我用的是1.6.0。. 下载地址为:
1.获取网页内容(核心代码,技术有限,无封装)。
2.登录后,抓取网页数据(如何在请求中携带cookies)。
3、获取网站的ajax请求方法(返回json)。
上面三点我都会用一个class来收录(见谅,看的粗糙,直接复制代码就行了,应该可以的)
一、这个类分别有上面的1、2、3个方法,可以直接测试main方法
package com.minxinloan.black.web.utils;
import java.io.BufferedReader;
import java.io.ByteArrayOutputStream;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.io.PrintWriter;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLConnection;
import java.net.URLEncoder;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import java.util.StringTokenizer;
import net.sf.json.JSONArray;
import net.sf.json.JSONObject;
import org.jsoup.Connection;
import org.jsoup.Connection.Method;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class CookieUtil {
public final static String CONTENT_TYPE = "Content-Type";
public static void main(String[] args) {
//String loginURL = "http://www.p2peye.com/member.p ... 3B%3B
String listURL = "http://www.p2peye.com/blacklist.php?p=2";
String logURL = "http://www.p2peye.com/member.php";
//********************************需要登录的*************************************************
try {
Connection.Response res =
Jsoup.connect(logURL)
.data("mod","logging"
,"action","login"
,"loginsubmit","yes"
,"loginhash","Lsc66"
,"username","puqiuxiaomao"
,"password","a1234567")
.method(Method.POST)
.execute();
//这儿的SESSIONID需要根据要登录的目标网站设置的session Cookie名字而定
Connection con=Jsoup.connect(listURL);
//设置访问形式(电脑访问,手机访问):直接百度都参数设置
con.header("User-Agent", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)");
//把登录信息的cookies保存如map对象里面
Map map=res.cookies();
Iterator it =map.entrySet().iterator();
while(it.hasNext()){
Entry en= it.next();
//把登录的信息放入请求里面
con =con.cookie(en.getKey(), en.getValue());
}
//再次获取Document对象。
Document objectDoc = con.get();
Elements elements = objectDoc.getAllElements();//获取这个连接返回页面的源码内容(不是源码跟源码差不多)
for (Element element : elements) {
//element是迭代出来的标签:如:
Elements elements2= element.getAllElements();//
for (Element element2 : elements2) {
element2.text();
element2.attr("href");//获取标签属性。element2代表a标签:href代表属性
element2.text();//获取标签文本
}
}
//********************************不需要登录的*************************************************
String URL = "http://www.p2peye.com/blacklist.php?p=2";
Document conTemp = Jsoup.connect(URL).get();
Elements elementsTemps = conTemp.getAllElements();
for (Element elementsTemp : elementsTemps) {
elementsTemp.text();
elementsTemp.attr("href");//获取标签属性。element2代表a标签:href代表属性
elementsTemp.text();//获取标签文本
}
//********************************ajax方法获取内容。。。*************************************************。
HttpURLConnection connection = null;
BufferedReader reader = null;
try {
StringBuffer sb = new StringBuffer();
URL getUrl = new URL(URL);
connection = (HttpURLConnection)getUrl.openConnection();
reader = new BufferedReader(new InputStreamReader(
connection.getInputStream(),"utf-8"));
String lines;
while ((lines = reader.readLine()) != null) {
sb.append(lines);
};
List list = parseJSON2List(sb.toString());//json转换成list
} catch (Exception e) {
} finally{
if(reader!=null)
try {
reader.close();
} catch (IOException e) {
}
// 断开连接
connection.disconnect();
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static Map parseJSON2Map(String jsonStr){
Map map = new HashMap();
//最外层解析
JSONObject json = JSONObject.fromObject(jsonStr);
for(Object k : json.keySet()){
Object v = json.get(k);
//如果内层还是数组的话,继续解析
if(v instanceof JSONArray){
List list = new ArrayList();
Iterator it = ((JSONArray)v).iterator();
while(it.hasNext()){
JSONObject json2 = it.next();
list.add(parseJSON2Map(json2.toString()));
}
map.put(k.toString(), list);
} else {
map.put(k.toString(), v);
}
}
return map;
}
public static List parseJSON2List(String jsonStr){
JSONArray jsonArr = JSONArray.fromObject(jsonStr);
List list = new ArrayList();
Iterator it = jsonArr.iterator();
while(it.hasNext()){
JSONObject json2 = it.next();
list.add(parseJSON2Map(json2.toString()));
}
return list;
}
}
二、这是获取验证码的类,可以研究一下。(但是要分析网站的验证码的请求地址)
Java抓取网页数据,登录后抓取数据,补不扣,
Java抓取网页数据,登录后抓取数据。
原来的: 查看全部
php抓取网页json数据(一个从网络上抓取数据的一个小程序(图))
最近做了一个小程序,从网上抓取数据。主要是关于信用,一些黑名单网站采集,从网站抓到自己的系统。
我也找到了一些资料,但我认为没有一个很好的和全面的例子。所以在这里做个笔记以提醒自己。
首先需要一个jsoup jar包,我用的是1.6.0。. 下载地址为:
1.获取网页内容(核心代码,技术有限,无封装)。
2.登录后,抓取网页数据(如何在请求中携带cookies)。
3、获取网站的ajax请求方法(返回json)。
上面三点我都会用一个class来收录(见谅,看的粗糙,直接复制代码就行了,应该可以的)
一、这个类分别有上面的1、2、3个方法,可以直接测试main方法
package com.minxinloan.black.web.utils;
import java.io.BufferedReader;
import java.io.ByteArrayOutputStream;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.io.PrintWriter;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLConnection;
import java.net.URLEncoder;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import java.util.StringTokenizer;
import net.sf.json.JSONArray;
import net.sf.json.JSONObject;
import org.jsoup.Connection;
import org.jsoup.Connection.Method;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class CookieUtil {
public final static String CONTENT_TYPE = "Content-Type";
public static void main(String[] args) {
//String loginURL = "http://www.p2peye.com/member.p ... 3B%3B
String listURL = "http://www.p2peye.com/blacklist.php?p=2";
String logURL = "http://www.p2peye.com/member.php";
//********************************需要登录的*************************************************
try {
Connection.Response res =
Jsoup.connect(logURL)
.data("mod","logging"
,"action","login"
,"loginsubmit","yes"
,"loginhash","Lsc66"
,"username","puqiuxiaomao"
,"password","a1234567")
.method(Method.POST)
.execute();
//这儿的SESSIONID需要根据要登录的目标网站设置的session Cookie名字而定
Connection con=Jsoup.connect(listURL);
//设置访问形式(电脑访问,手机访问):直接百度都参数设置
con.header("User-Agent", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)");
//把登录信息的cookies保存如map对象里面
Map map=res.cookies();
Iterator it =map.entrySet().iterator();
while(it.hasNext()){
Entry en= it.next();
//把登录的信息放入请求里面
con =con.cookie(en.getKey(), en.getValue());
}
//再次获取Document对象。
Document objectDoc = con.get();
Elements elements = objectDoc.getAllElements();//获取这个连接返回页面的源码内容(不是源码跟源码差不多)
for (Element element : elements) {
//element是迭代出来的标签:如:
Elements elements2= element.getAllElements();//
for (Element element2 : elements2) {
element2.text();
element2.attr("href");//获取标签属性。element2代表a标签:href代表属性
element2.text();//获取标签文本
}
}
//********************************不需要登录的*************************************************
String URL = "http://www.p2peye.com/blacklist.php?p=2";
Document conTemp = Jsoup.connect(URL).get();
Elements elementsTemps = conTemp.getAllElements();
for (Element elementsTemp : elementsTemps) {
elementsTemp.text();
elementsTemp.attr("href");//获取标签属性。element2代表a标签:href代表属性
elementsTemp.text();//获取标签文本
}
//********************************ajax方法获取内容。。。*************************************************。
HttpURLConnection connection = null;
BufferedReader reader = null;
try {
StringBuffer sb = new StringBuffer();
URL getUrl = new URL(URL);
connection = (HttpURLConnection)getUrl.openConnection();
reader = new BufferedReader(new InputStreamReader(
connection.getInputStream(),"utf-8"));
String lines;
while ((lines = reader.readLine()) != null) {
sb.append(lines);
};
List list = parseJSON2List(sb.toString());//json转换成list
} catch (Exception e) {
} finally{
if(reader!=null)
try {
reader.close();
} catch (IOException e) {
}
// 断开连接
connection.disconnect();
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static Map parseJSON2Map(String jsonStr){
Map map = new HashMap();
//最外层解析
JSONObject json = JSONObject.fromObject(jsonStr);
for(Object k : json.keySet()){
Object v = json.get(k);
//如果内层还是数组的话,继续解析
if(v instanceof JSONArray){
List list = new ArrayList();
Iterator it = ((JSONArray)v).iterator();
while(it.hasNext()){
JSONObject json2 = it.next();
list.add(parseJSON2Map(json2.toString()));
}
map.put(k.toString(), list);
} else {
map.put(k.toString(), v);
}
}
return map;
}
public static List parseJSON2List(String jsonStr){
JSONArray jsonArr = JSONArray.fromObject(jsonStr);
List list = new ArrayList();
Iterator it = jsonArr.iterator();
while(it.hasNext()){
JSONObject json2 = it.next();
list.add(parseJSON2Map(json2.toString()));
}
return list;
}
}
二、这是获取验证码的类,可以研究一下。(但是要分析网站的验证码的请求地址)
Java抓取网页数据,登录后抓取数据,补不扣,
Java抓取网页数据,登录后抓取数据。
原来的:
php抓取网页json数据(()定义相关变量第二步:定义查询语句)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-06 16:21
在php中,从数据库中读取数据,并以json格式返回数据。具体方法如下: 第一步,定义相关变量$s
在php中,从数据库中读取数据,并以json格式返回数据。具体方法如下:
第一步,定义相关变量
$servername = "localhost";
$username = "root";
$password = "root";
$mysqlname = "datatest";
$json = '';
$data = array();
class User
{
public $id;
public $fname;
public $lname;
public $email;
public $password;
}
第二步是链接数据库,代码如下:
// 创建连接
$conn = mysqli_connect($servername, $username, $password, $mysqlname);
第三步,定义查询语句并执行。代码如下:
$sql = "SELECT * FROM userinfo";
$result = $conn->query($sql);
第四步,获取查询到的数据,放入预先声明的类中,最后以json格式输出。
代码显示如下:
if($result){
//echo "查询成功";
while ($row = mysqli_fetch_array($result,MYSQL_ASSOC))
{
$user = new User();
$user->id = $row["id"];
$user->fname = $row["fname"];
$user->lname = $row["lname"];
$user->email = $row["email"];
$user->password = $row["password"];
$data[]=$user;
}
$json = json_encode($data);//把数据转换为JSON数据.
echo "{".'"user"'.":".$json."}";
}else{
echo "查询失败";
}
以上php从数据库中读取数据并以json格式返回数据的方法是小编分享的全部内容,希望能给大家一个参考,也希望大家多多支持脚本之家。 查看全部
php抓取网页json数据(()定义相关变量第二步:定义查询语句)
在php中,从数据库中读取数据,并以json格式返回数据。具体方法如下: 第一步,定义相关变量$s
在php中,从数据库中读取数据,并以json格式返回数据。具体方法如下:
第一步,定义相关变量
$servername = "localhost";
$username = "root";
$password = "root";
$mysqlname = "datatest";
$json = '';
$data = array();
class User
{
public $id;
public $fname;
public $lname;
public $email;
public $password;
}
第二步是链接数据库,代码如下:
// 创建连接
$conn = mysqli_connect($servername, $username, $password, $mysqlname);
第三步,定义查询语句并执行。代码如下:
$sql = "SELECT * FROM userinfo";
$result = $conn->query($sql);
第四步,获取查询到的数据,放入预先声明的类中,最后以json格式输出。
代码显示如下:
if($result){
//echo "查询成功";
while ($row = mysqli_fetch_array($result,MYSQL_ASSOC))
{
$user = new User();
$user->id = $row["id"];
$user->fname = $row["fname"];
$user->lname = $row["lname"];
$user->email = $row["email"];
$user->password = $row["password"];
$data[]=$user;
}
$json = json_encode($data);//把数据转换为JSON数据.
echo "{".'"user"'.":".$json."}";
}else{
echo "查询失败";
}
以上php从数据库中读取数据并以json格式返回数据的方法是小编分享的全部内容,希望能给大家一个参考,也希望大家多多支持脚本之家。
php抓取网页json数据(PHP一个问题:用AJAX返回数据时,怎么提取其中的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-10-06 04:31
有这样一个问题:当使用Ajax返回数据时,如何提取信息并将其写入网页的不同部分?W3C学校提到,AJAX返回的数据是JSON数据格式。我使用PHP作为背景脚本。起初,我自己组装JSON数据,但效果不好。后来,我检查了数据,并在PHP_uencode()函数中使用了JSON
存在这样一个问题:使用Ajax返回数据时,如何提取信息并将其写入网页的不同部分
W3C学校提到AJAX返回的数据是JSON数据格式。我使用PHP作为背景脚本
起初,我以JSON格式组装数据,但效果不好。后来,我检查了数据,并在PHP_uencode()函数中使用了JSON
$STR是要处理的数据。使用以下语句输出JSON格式的数据
其中,JSON_uNescaped_uuUnicode指的是Unicode格式的编码
手册上说“此函数只能接受UTF-8编码的数据”,并且有多种格式
echo json_encode($row,JSON_UNESCAPED_UNICODE);
前台页面启动一个Ajax请求,核心部分是处理Ajax返回的数据xmlhttp.respondtext
使用此语句处理TXT=xmlhttp。响应文本;var obj=eval(“(“+txt+”)评估功能是关键
eval()函数使用JavaScript编译器解析JSON文本并生成JavaScript对象。文本必须用括号括起来,以避免语法错误:
Ajax请求代码如下所示:
var xmlHttp=null
function get_pic(str)
{
/*search the file in mysql table pydot and pydot_g,
then give the result to front page.start ajax request*/
xmlHttp=GetXmlHttpObject()
if (xmlHttp==null)
{
alert ("Browser does not support HTTP Request")
return
}
var url="Public/Js/json.php";
url=url+"?q="+str.innerHTML
url=url+"&sid="+Math.random()
//alert(url)
xmlHttp.onreadystatechange=stateChanged
xmlHttp.open("GET",url,true)
xmlHttp.send(null)
}
function stateChanged()
{
var txt,x;
if (xmlHttp.readyState==4 || xmlHttp.readyState=="complete")
{ txt=xmlHttp.responseText ;
//alert(txt)
var obj = eval ("(" + txt + ")");
document.getElementById("other").innerHTML=obj.other;
document.getElementById("title").innerHTML=obj.title;
}
}
function GetXmlHttpObject()
{
var xmlHttp=null;
try
{
// Firefox, Opera 8.0+, Safari
xmlHttp=new XMLHttpRequest();
}
catch (e)
{
//Internet Explorer
try
{
xmlHttp=new ActiveXObject("Msxml2.XMLHTTP");
}
catch (e)
{
xmlHttp=new ActiveXObject("Microsoft.XMLHTTP");
}
}
return xmlHttp;
}
从代码中,我们可以看到obj。Title提取返回文本中的标题信息,并将其写入页面中id='Title'的元素
声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系 查看全部
php抓取网页json数据(PHP一个问题:用AJAX返回数据时,怎么提取其中的信息)
有这样一个问题:当使用Ajax返回数据时,如何提取信息并将其写入网页的不同部分?W3C学校提到,AJAX返回的数据是JSON数据格式。我使用PHP作为背景脚本。起初,我自己组装JSON数据,但效果不好。后来,我检查了数据,并在PHP_uencode()函数中使用了JSON
存在这样一个问题:使用Ajax返回数据时,如何提取信息并将其写入网页的不同部分
W3C学校提到AJAX返回的数据是JSON数据格式。我使用PHP作为背景脚本
起初,我以JSON格式组装数据,但效果不好。后来,我检查了数据,并在PHP_uencode()函数中使用了JSON
$STR是要处理的数据。使用以下语句输出JSON格式的数据
其中,JSON_uNescaped_uuUnicode指的是Unicode格式的编码
手册上说“此函数只能接受UTF-8编码的数据”,并且有多种格式
echo json_encode($row,JSON_UNESCAPED_UNICODE);
前台页面启动一个Ajax请求,核心部分是处理Ajax返回的数据xmlhttp.respondtext
使用此语句处理TXT=xmlhttp。响应文本;var obj=eval(“(“+txt+”)评估功能是关键
eval()函数使用JavaScript编译器解析JSON文本并生成JavaScript对象。文本必须用括号括起来,以避免语法错误:
Ajax请求代码如下所示:
var xmlHttp=null
function get_pic(str)
{
/*search the file in mysql table pydot and pydot_g,
then give the result to front page.start ajax request*/
xmlHttp=GetXmlHttpObject()
if (xmlHttp==null)
{
alert ("Browser does not support HTTP Request")
return
}
var url="Public/Js/json.php";
url=url+"?q="+str.innerHTML
url=url+"&sid="+Math.random()
//alert(url)
xmlHttp.onreadystatechange=stateChanged
xmlHttp.open("GET",url,true)
xmlHttp.send(null)
}
function stateChanged()
{
var txt,x;
if (xmlHttp.readyState==4 || xmlHttp.readyState=="complete")
{ txt=xmlHttp.responseText ;
//alert(txt)
var obj = eval ("(" + txt + ")");
document.getElementById("other").innerHTML=obj.other;
document.getElementById("title").innerHTML=obj.title;
}
}
function GetXmlHttpObject()
{
var xmlHttp=null;
try
{
// Firefox, Opera 8.0+, Safari
xmlHttp=new XMLHttpRequest();
}
catch (e)
{
//Internet Explorer
try
{
xmlHttp=new ActiveXObject("Msxml2.XMLHTTP");
}
catch (e)
{
xmlHttp=new ActiveXObject("Microsoft.XMLHTTP");
}
}
return xmlHttp;
}
从代码中,我们可以看到obj。Title提取返回文本中的标题信息,并将其写入页面中id='Title'的元素

声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系
php抓取网页json数据(微信小程序的基础知识2.实现原理首先,先看一下这个请求函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-06 04:27
微信小程序基础知识
2. 实现原理
首先我们来看看请求函数 wx.request({
url:'******', //这里填写你的接口路径
header: {//这里写你返回什么类型的数据为借口,这里就是微信小程序的威力,直接帮你解析数据,再也不用找各种方式解析json、xml等数据了
'内容类型':'应用程序/json'
},
data: {//在这里写你要请求的参数
X:'',
你:''
},
成功:功能(资源){
//这里是请求成功后执行一些函数操作
控制台.log(res.data)
}
})
3.代码
分解图
一、上一段开头知乎 json格式的接口数据
"日期":"20161114",
“故事”:[
{
“图片”:[
“”
],
“类型”:0,
"id":8975316,
"ga_prefix":"111422",
"title":"小东西,我跟你一样"
},
{
“图片”:[
“”
],
“类型”:0,
"id":8977438,
"ga_prefix":"111421",
“title”:“长大了,谁说就一定要长大?”
},
索引.js
页({
数据: {
持续时间:2000,
指标点:真实,
自动播放:真实,
间隔:3000,
加载:假,
普通:假
},
加载:函数(){
var that = this//这句话不要错过,很重要
wx.request({
网址:'#39;,
标题:{
'内容类型':'应用程序/json'
},
成功:功能(资源){
//获取到的json数据会存放在这个名为知乎的数组中
那.setData({
知乎:res.data.stories,
//res代表成功函数的事件对,数据是固定的,故事就是上面json数据中的故事
})
}
})
}
})
索引.wxml
autoplay="{{autoplay}}" interval="{{interval}}" duration="{{duration}}">//这里的属性不重要,见下
{{item.title}}
看完这段代码,你会想,根据微信小程序的绑定原理,这里的代码在哪里调用了onLoad()函数,别想太多,微信小程序会为你省略这些步骤。直接调用知乎数组就行了。 查看全部
php抓取网页json数据(微信小程序的基础知识2.实现原理首先,先看一下这个请求函数)
微信小程序基础知识
2. 实现原理
首先我们来看看请求函数 wx.request({
url:'******', //这里填写你的接口路径
header: {//这里写你返回什么类型的数据为借口,这里就是微信小程序的威力,直接帮你解析数据,再也不用找各种方式解析json、xml等数据了
'内容类型':'应用程序/json'
},
data: {//在这里写你要请求的参数
X:'',
你:''
},
成功:功能(资源){
//这里是请求成功后执行一些函数操作
控制台.log(res.data)
}
})
3.代码
分解图

一、上一段开头知乎 json格式的接口数据
"日期":"20161114",
“故事”:[
{
“图片”:[
“”
],
“类型”:0,
"id":8975316,
"ga_prefix":"111422",
"title":"小东西,我跟你一样"
},
{
“图片”:[
“”
],
“类型”:0,
"id":8977438,
"ga_prefix":"111421",
“title”:“长大了,谁说就一定要长大?”
},
索引.js
页({
数据: {
持续时间:2000,
指标点:真实,
自动播放:真实,
间隔:3000,
加载:假,
普通:假
},
加载:函数(){
var that = this//这句话不要错过,很重要
wx.request({
网址:'#39;,
标题:{
'内容类型':'应用程序/json'
},
成功:功能(资源){
//获取到的json数据会存放在这个名为知乎的数组中
那.setData({
知乎:res.data.stories,
//res代表成功函数的事件对,数据是固定的,故事就是上面json数据中的故事
})
}
})
}
})
索引.wxml
autoplay="{{autoplay}}" interval="{{interval}}" duration="{{duration}}">//这里的属性不重要,见下
{{item.title}}
看完这段代码,你会想,根据微信小程序的绑定原理,这里的代码在哪里调用了onLoad()函数,别想太多,微信小程序会为你省略这些步骤。直接调用知乎数组就行了。
php抓取网页json数据(类似:UncaughtTypeErrortosearchfor‘’inJSONstring前端jsamp;php笔记正文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-02 09:12
类似:未捕获类型错误:无法使用“in”运算符搜索“in”JSON字符串前端JS&;PHP注释
正文:
在HTML页面中,通过$请求PHP页面。Get()方法,回调函数返回JSON数据,但无法通过数据点中的数据获取。代码如下:
JS代码:
$("#button1").click(function(){
$.get("index.php",{username:$("#username").val(),password:$("#password").val(),tel:$("#tel").val()},function(data,textStatus){ //get方法请求数据
$("#response").html("用户名:"+data.name+"
密码:"+data.pwd+"
手机号码:"+data.tell);
alert(data); //能够显示数据
})
})
PHP代码:
手术后:
返回数据的能力
无法检索返回的数据
解决方案:
创建一个对象以将JSON数据转换为对象
ajaxData=$.parseJSON(data) //将json数据转换为js对象
注:
它不能在程序中运行,这无法解释PHP页面。它必须在AppServ程序下的WWW文件夹中运行(运行时不能是FTP地址,而是诸如“:82/unit07/index.HTML”之类的地址) 查看全部
php抓取网页json数据(类似:UncaughtTypeErrortosearchfor‘’inJSONstring前端jsamp;php笔记正文)
类似:未捕获类型错误:无法使用“in”运算符搜索“in”JSON字符串前端JS&;PHP注释
正文:
在HTML页面中,通过$请求PHP页面。Get()方法,回调函数返回JSON数据,但无法通过数据点中的数据获取。代码如下:
JS代码:
$("#button1").click(function(){
$.get("index.php",{username:$("#username").val(),password:$("#password").val(),tel:$("#tel").val()},function(data,textStatus){ //get方法请求数据
$("#response").html("用户名:"+data.name+"
密码:"+data.pwd+"
手机号码:"+data.tell);
alert(data); //能够显示数据
})
})
PHP代码:
手术后:
返回数据的能力

无法检索返回的数据

解决方案:
创建一个对象以将JSON数据转换为对象

ajaxData=$.parseJSON(data) //将json数据转换为js对象
注:
它不能在程序中运行,这无法解释PHP页面。它必须在AppServ程序下的WWW文件夹中运行(运行时不能是FTP地址,而是诸如“:82/unit07/index.HTML”之类的地址)
php抓取网页json数据(,结合jQuery的ajax实现跨域抓取数据的相关操作技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-01 10:11
本文文章主要介绍jquery+thinkphp实现跨域数据抓取的方法,并结合实例的形式分析thinkPHP结合jQuery的ajax实现跨域数据抓取的相关操作技巧。有需要的朋友可以参考以下
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
今天,我将做一个远程数据捕获功能。记住jquery可以用ajax远程捕获,但是不能跨域。我在网上搜索了很多。但是我觉得是一个综合性的问题,所以我觉得对于一个简单的问题来说稍微复杂一些,但至少现在已经解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post向服务器后端发送数据,由后端的PHP代码远程获取,存入数据库ajax返回数据给前台,前台使用JS接收数据并显示出来。
//远程抓取获取数据 $("#update_ac").click(function() { $username = $("#username").text(); $("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){ $(this).html(" "); }); $.post("update_ac/username/"+$username,{},function($data){ json = eval("(" + $data + ")"); $("#Submit").html(json.data.Submit); $("#AC").html(json.data.AC); $("#solved,#solved2,#solved3").html(json.data.solved); $("#rank").html(json.data.rank); } ),"json"; });
上面jquery代码四楼说的还算清楚,但是让我纠结的是json数据的接收
json = eval("(" + $data + ")"); //eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这还是前台。跨域抓取是通过PHP扩展simple_html_dom完成的(不知道的可以上网搜一下,基于PHP5开发的)
抓取远程页面到本地。
以上代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后使用正则表达式过滤需要的数据。下面是渲染图
对thinkPHP相关内容更感兴趣的读者可以查看本站专题:《》、《ThinkPHP模板操作技巧总结》、《ThinkPHP常用方法总结》、《Smarty模板介绍基础教程》、《总结》 PHP模板技术”。
我希望本文对您基于 ThinkPHP 框架的 PHP 编程有所帮助。
以上就是jquery+thinkphp实现跨域数据抓取的方法的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
php抓取网页json数据(,结合jQuery的ajax实现跨域抓取数据的相关操作技巧)
本文文章主要介绍jquery+thinkphp实现跨域数据抓取的方法,并结合实例的形式分析thinkPHP结合jQuery的ajax实现跨域数据抓取的相关操作技巧。有需要的朋友可以参考以下
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
今天,我将做一个远程数据捕获功能。记住jquery可以用ajax远程捕获,但是不能跨域。我在网上搜索了很多。但是我觉得是一个综合性的问题,所以我觉得对于一个简单的问题来说稍微复杂一些,但至少现在已经解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post向服务器后端发送数据,由后端的PHP代码远程获取,存入数据库ajax返回数据给前台,前台使用JS接收数据并显示出来。
//远程抓取获取数据 $("#update_ac").click(function() { $username = $("#username").text(); $("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){ $(this).html(" "); }); $.post("update_ac/username/"+$username,{},function($data){ json = eval("(" + $data + ")"); $("#Submit").html(json.data.Submit); $("#AC").html(json.data.AC); $("#solved,#solved2,#solved3").html(json.data.solved); $("#rank").html(json.data.rank); } ),"json"; });
上面jquery代码四楼说的还算清楚,但是让我纠结的是json数据的接收
json = eval("(" + $data + ")"); //eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这还是前台。跨域抓取是通过PHP扩展simple_html_dom完成的(不知道的可以上网搜一下,基于PHP5开发的)
抓取远程页面到本地。
以上代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后使用正则表达式过滤需要的数据。下面是渲染图

对thinkPHP相关内容更感兴趣的读者可以查看本站专题:《》、《ThinkPHP模板操作技巧总结》、《ThinkPHP常用方法总结》、《Smarty模板介绍基础教程》、《总结》 PHP模板技术”。
我希望本文对您基于 ThinkPHP 框架的 PHP 编程有所帮助。
以上就是jquery+thinkphp实现跨域数据抓取的方法的详细内容。更多详情请关注其他相关html中文网站文章!
php抓取网页json数据(PHP获取接口内容(一)(1)_PHP解析JSON)
网站优化 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2021-09-20 06:22
PHP获取接口内容
如果要解析JSON数据并在页面中显示,必须首先获取JSON接口文件的内容。要在PHP中获取页面的内容,可以使用fopen()函数远程页面,然后使用FREAD()函数循环内容
假设接口文件页是API。PHP?操作=打开\uGetBlogList&;仅推荐=1&;Limit=5,则我们可以使用以下语句获取此接口文件的内容:
$handle = fopen("api.php?action=open_getBlogList&only_recommend=1&limit=5","rb");
$content = "";
while (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
通过这种方式,内容保存JSON API内容
PHP解析JSON并显示它
无法直接调用原创内容。在调用它并在网页中显示之前,它必须由PHP进一步处理。用PHP5.2在更高版本中,使用JSON。decode()函数解析JSON数据并将其转换为PHP可以调用的数据格式。例如:
$content = json_decode($content);
在解析
,我们可以在JSON中调用数据,就像在PHP中调用数组数据一样。此调用方法需要根据特定的JSON数据格式编写。请参见下面的演示。关于JSON\ PHP手册中详细介绍了解码函数的使用,此处不再重复:
实战中调用琼台博客API
细心的朋友会发现,在跟踪者m博客的边栏底部有一个“朋友文章推荐”模块,它推荐了一些琼台博客文章
友文推荐是琼台博客提出的一种博客间的交流方式。它比传统的友情链接更有效,实现了博客内容的互补性。因为琼台博客的博客程序是自己写的,所以他提供了JSON API接口来获取最新推荐的文章
我使用PHP获取JSON接口,然后将其输出到我博客的侧栏。下面是实际操作
第一步是检查API调用模式
在调用之前,您必须查看对方的API调用手册,包括调用地址、如何调用、数据输出格式等。琼台博客的API描述地址如下:openapi.html
根据文档,我使用了API。PHP?操作=打开\uGetBlogList&;仅推荐=1&;limit=5等参数表示调用五个推荐值文章
第二步是获取API结构数据
非常简单,如上所述,具体代码如下:
$handle = fopen("api.php?action=open_getBlogList&only_recommend=1&limit=5","rb");
$content = "";
while (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
首先打开数据文件,然后将所有内容保存到内容变量中。因为可以确定API数据不会超过10000个字符,所以10000被用作FREAD函数的第二个参数。这样,API返回的JSON数据保存在内容变量中
步骤3:解析并输出内容
使用以下代码解析数据,然后调用输出
$content = json_decode($content);
foreach ($content->data as $key) {
echo ''.$key->b_title.'';
}
首先,处理content变量中的JSON数据,然后将其转换为PHP可以调用的数据,然后使用foreach遍历并输出这五个内容,并根据我需要的HTML格式插入内容
通过样式修改,您可以获取和解析JSON并在页面中显示它。调用其他API数据的方法与此类似 查看全部
php抓取网页json数据(PHP获取接口内容(一)(1)_PHP解析JSON)
PHP获取接口内容
如果要解析JSON数据并在页面中显示,必须首先获取JSON接口文件的内容。要在PHP中获取页面的内容,可以使用fopen()函数远程页面,然后使用FREAD()函数循环内容
假设接口文件页是API。PHP?操作=打开\uGetBlogList&;仅推荐=1&;Limit=5,则我们可以使用以下语句获取此接口文件的内容:
$handle = fopen("api.php?action=open_getBlogList&only_recommend=1&limit=5","rb");
$content = "";
while (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
通过这种方式,内容保存JSON API内容
PHP解析JSON并显示它
无法直接调用原创内容。在调用它并在网页中显示之前,它必须由PHP进一步处理。用PHP5.2在更高版本中,使用JSON。decode()函数解析JSON数据并将其转换为PHP可以调用的数据格式。例如:
$content = json_decode($content);
在解析
,我们可以在JSON中调用数据,就像在PHP中调用数组数据一样。此调用方法需要根据特定的JSON数据格式编写。请参见下面的演示。关于JSON\ PHP手册中详细介绍了解码函数的使用,此处不再重复:
实战中调用琼台博客API
细心的朋友会发现,在跟踪者m博客的边栏底部有一个“朋友文章推荐”模块,它推荐了一些琼台博客文章

友文推荐是琼台博客提出的一种博客间的交流方式。它比传统的友情链接更有效,实现了博客内容的互补性。因为琼台博客的博客程序是自己写的,所以他提供了JSON API接口来获取最新推荐的文章
我使用PHP获取JSON接口,然后将其输出到我博客的侧栏。下面是实际操作
第一步是检查API调用模式
在调用之前,您必须查看对方的API调用手册,包括调用地址、如何调用、数据输出格式等。琼台博客的API描述地址如下:openapi.html
根据文档,我使用了API。PHP?操作=打开\uGetBlogList&;仅推荐=1&;limit=5等参数表示调用五个推荐值文章
第二步是获取API结构数据
非常简单,如上所述,具体代码如下:
$handle = fopen("api.php?action=open_getBlogList&only_recommend=1&limit=5","rb");
$content = "";
while (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
首先打开数据文件,然后将所有内容保存到内容变量中。因为可以确定API数据不会超过10000个字符,所以10000被用作FREAD函数的第二个参数。这样,API返回的JSON数据保存在内容变量中
步骤3:解析并输出内容
使用以下代码解析数据,然后调用输出
$content = json_decode($content);
foreach ($content->data as $key) {
echo ''.$key->b_title.'';
}
首先,处理content变量中的JSON数据,然后将其转换为PHP可以调用的数据,然后使用foreach遍历并输出这五个内容,并根据我需要的HTML格式插入内容
通过样式修改,您可以获取和解析JSON并在页面中显示它。调用其他API数据的方法与此类似
php抓取网页json数据(json数据1.json的作用让不同编程语言之间可以进行有效的数据交流 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-11 18:01
)
json 数据 1. json 的作用
实现不同编程语言之间的有效数据通信(几乎所有高级语言都支持json数据格式)
2. 什么是 json
一个有效的json只有一个数据,唯一的数据必须是json支持的数据类型。
json 支持的数据类型:
直接写数字,例如:100、+23、-45、12.5、3e4
String-双引号,只有双引号,例如:"yuting"、"Chongqing"、"abc\n123"
Boolean-only 两个值,true 和 false
空值-null
数组(列表)——相当于一个 Python 列表:[元素 1,元素 2,元素 3,...]
Dictionary-key 必须是字符串:{key 1: value 1, key 2: value 2,...}
3. json 数据分析
1)如果通过requests发送请求得到的数据是json数据,可以直接使用response.json()将json数据转换成Python数据。
2)非json接口提供的json数据解析。
系统模块:json -> 提供两个功能:将json数据转换为Python数据和将Python数据转换为json数据。
json.loads(json格式的字符串)-将json转换为Python,返回值的类型会因字符串的内容不同而不同。
json.dumps(python data)-将python数据转为json格式的字符串,返回值为字符串。
说明:json格式的字符串——字符串的内容为json格式的数据,例如:‘100’、‘"abc"’、‘{"a": 100}’
int、float、str、bool、list、dict、None、tuple-可以转成json数据
import json
# json转换python
result = json.loads('100')
print(result, type(result)) # 100
result = json.loads('"abc"')
print(result, type(result)) # abc
result = json.loads('{"a": 100}')
print(result, type(result)) # {'a': 100}
result = json.loads('[100, "abc", true, null]')
print(result, type(result)) # [100, 'abc', True, None]
# python转json
result = json.dumps(100)
print(result, type(result)) # 100
result = json.dumps('abc')
print(result, type(result)) # "abc"
result = json.dumps([100, 12.4, True, None, 'hello', [10, 'a'], {10: 20}, (100, 200)])
print(result, type(result)) # '[100, 12.4, true, null, "hello", [10, "a"], {"10": 20}, [100, 200]]'
获取多页数据
# https://movie.douban.com/top25 ... er%3D
# https://movie.douban.com/top25 ... er%3D
# https://movie.douban.com/top25 ... er%3D
import requests
def get_html(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'
}
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
return r.text
def get_all_data():
for x in range(0, 226, 25):
url = f'https://movie.douban.com/top250?start={x}&filter='
get_html(url)
xpath 数据分析
运行环境:from lxml import etree
lxml:可以通过xpath方法解析html数据和xml数据
1. 创建树结构并获取根节点
etree.HTML(html代码)-将html页面创建成树状结构并返回树的根节点。
html_node = etree.HTML(open('files/网页.html', encoding='utf-8').read())
print(html_node) #
2.根据路径获取指定标签
node object.xpath(path)-返回值是一个列表,列表中的元素都是根据路径找到的结果
1) 绝对路径-/从根节点写全路径
注意:绝对写法和搜索方式与谁去了前面的.xpath无关
h1_node = html_node.xpath('/html/body/div/h1')[0]
print(h1_node) #
p_nodes = html_node.xpath('/html/body/div/p')
print(p_nodes) # [, ]
div_node_2 = html_node.xpath('/html/body/div')[-1]
result = div_node_2.xpath('/html/body/div/p')
print(result)
2) 相对路径:./path,. ./路径
使用。表示当前节点(谁去.xpath,谁是当前节点)
用..表示当前节点的上层节点
result = html_node.xpath('./body/div/p')
print(result) # [, ]
result = div_node_2.xpath('./p/text()')
print(result) # []
result = div_node_2.xpath('../div/h1/text()')
print(result)
3) 全局搜索://
//路径
<p>result = html_node.xpath('//img')
print(result) # [, , , , ]
result = html_node.xpath('//div/img')
print(result) # [, 查看全部
php抓取网页json数据(json数据1.json的作用让不同编程语言之间可以进行有效的数据交流
)
json 数据 1. json 的作用
实现不同编程语言之间的有效数据通信(几乎所有高级语言都支持json数据格式)
2. 什么是 json
一个有效的json只有一个数据,唯一的数据必须是json支持的数据类型。
json 支持的数据类型:
直接写数字,例如:100、+23、-45、12.5、3e4
String-双引号,只有双引号,例如:"yuting"、"Chongqing"、"abc\n123"
Boolean-only 两个值,true 和 false
空值-null
数组(列表)——相当于一个 Python 列表:[元素 1,元素 2,元素 3,...]
Dictionary-key 必须是字符串:{key 1: value 1, key 2: value 2,...}
3. json 数据分析
1)如果通过requests发送请求得到的数据是json数据,可以直接使用response.json()将json数据转换成Python数据。
2)非json接口提供的json数据解析。
系统模块:json -> 提供两个功能:将json数据转换为Python数据和将Python数据转换为json数据。
json.loads(json格式的字符串)-将json转换为Python,返回值的类型会因字符串的内容不同而不同。
json.dumps(python data)-将python数据转为json格式的字符串,返回值为字符串。
说明:json格式的字符串——字符串的内容为json格式的数据,例如:‘100’、‘"abc"’、‘{"a": 100}’
int、float、str、bool、list、dict、None、tuple-可以转成json数据
import json
# json转换python
result = json.loads('100')
print(result, type(result)) # 100
result = json.loads('"abc"')
print(result, type(result)) # abc
result = json.loads('{"a": 100}')
print(result, type(result)) # {'a': 100}
result = json.loads('[100, "abc", true, null]')
print(result, type(result)) # [100, 'abc', True, None]
# python转json
result = json.dumps(100)
print(result, type(result)) # 100
result = json.dumps('abc')
print(result, type(result)) # "abc"
result = json.dumps([100, 12.4, True, None, 'hello', [10, 'a'], {10: 20}, (100, 200)])
print(result, type(result)) # '[100, 12.4, true, null, "hello", [10, "a"], {"10": 20}, [100, 200]]'
获取多页数据
# https://movie.douban.com/top25 ... er%3D
# https://movie.douban.com/top25 ... er%3D
# https://movie.douban.com/top25 ... er%3D
import requests
def get_html(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'
}
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
return r.text
def get_all_data():
for x in range(0, 226, 25):
url = f'https://movie.douban.com/top250?start={x}&filter='
get_html(url)
xpath 数据分析
运行环境:from lxml import etree
lxml:可以通过xpath方法解析html数据和xml数据
1. 创建树结构并获取根节点
etree.HTML(html代码)-将html页面创建成树状结构并返回树的根节点。
html_node = etree.HTML(open('files/网页.html', encoding='utf-8').read())
print(html_node) #
2.根据路径获取指定标签
node object.xpath(path)-返回值是一个列表,列表中的元素都是根据路径找到的结果
1) 绝对路径-/从根节点写全路径
注意:绝对写法和搜索方式与谁去了前面的.xpath无关
h1_node = html_node.xpath('/html/body/div/h1')[0]
print(h1_node) #
p_nodes = html_node.xpath('/html/body/div/p')
print(p_nodes) # [, ]
div_node_2 = html_node.xpath('/html/body/div')[-1]
result = div_node_2.xpath('/html/body/div/p')
print(result)
2) 相对路径:./path,. ./路径
使用。表示当前节点(谁去.xpath,谁是当前节点)
用..表示当前节点的上层节点
result = html_node.xpath('./body/div/p')
print(result) # [, ]
result = div_node_2.xpath('./p/text()')
print(result) # []
result = div_node_2.xpath('../div/h1/text()')
print(result)
3) 全局搜索://
//路径
<p>result = html_node.xpath('//img')
print(result) # [, , , , ]
result = html_node.xpath('//div/img')
print(result) # [,
php抓取网页json数据(之前我写过一遍php外挂python脚本处理视频的文章 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-10 01:00
)
之前我写了一个php插件python脚本来处理视频文章。今天给大家分享一下php插件python实现关键字搜索的脚本。
先来分析一波网站:
我们可以看到,普通的爬取网站已经不能满足我们的需求了。这个 网站 使用了第二次数据采集。再来看看头部;
可以看到数据是通过ajax获取的。我们把拿到的链接放到浏览器中直接打开,报错了。有些网站可以通过获取链接直接获取数据,但是很明显,这个接口使用的是post接口请求
让我们先请求一个 wave:
代码开始:
# -*- coding: utf-8 -*-
# @Time : 2019/9/4 14:43
# @Author : wujf
# @Email : 1028540310@qq.com
# @File : 爬取ajax数据.py
# @Software: PyCharm
'''
json.loads(json_str) json字符串转换成字典
json.dumps(dict) 字典转换成json字符串
'''
import requests
import json
url = "http://nddb.ic361.cn:8080/proc ... ot%3B
seach = input("请输入您要搜索的内容:")
list = ['507786','14922','-1']
list.append(seach)
d = {
'token':'A0E5CD90-ECE4-440C-8B39-084C0FE61E69',
'uid':'507786',
'mycoid':'14922',
'con':'15',
'a':list
}
果然可以得到数据。
然后就很简单了:
关于代码--------
import requests
import json
import sys
url = "http://nddb.ic361.cn:8080/proc ... ot%3B
seach = sys.argv[1]
#seach1 = sys.argv[2]
#item = seach+'-'+seach1
# with open(r'D:\\phpStudy_server\\PHPTutorial\\WWW\\demo\\log.txt','a') as f:
# try:
# f.write(seach)
# except Exception as e:
# print(e)
# seach = input("请输入您要搜索的内容:")
list = ['507786','14922','-1']
list.append(seach)
d = {
'token':'A0E5CD90-ECE4-440C-8B39-084C0FE61E69',
'uid':'507786',
'mycoid':'14922',
'con':'15',
'a':list
}
r = requests.post(url,data=d)
dic = r.json()
print(json.dumps(dic))
接下来我们看一下打印结果:
查看全部
php抓取网页json数据(之前我写过一遍php外挂python脚本处理视频的文章
)
之前我写了一个php插件python脚本来处理视频文章。今天给大家分享一下php插件python实现关键字搜索的脚本。
先来分析一波网站:
我们可以看到,普通的爬取网站已经不能满足我们的需求了。这个 网站 使用了第二次数据采集。再来看看头部;
可以看到数据是通过ajax获取的。我们把拿到的链接放到浏览器中直接打开,报错了。有些网站可以通过获取链接直接获取数据,但是很明显,这个接口使用的是post接口请求
让我们先请求一个 wave:
代码开始:
# -*- coding: utf-8 -*-
# @Time : 2019/9/4 14:43
# @Author : wujf
# @Email : 1028540310@qq.com
# @File : 爬取ajax数据.py
# @Software: PyCharm
'''
json.loads(json_str) json字符串转换成字典
json.dumps(dict) 字典转换成json字符串
'''
import requests
import json
url = "http://nddb.ic361.cn:8080/proc ... ot%3B
seach = input("请输入您要搜索的内容:")
list = ['507786','14922','-1']
list.append(seach)
d = {
'token':'A0E5CD90-ECE4-440C-8B39-084C0FE61E69',
'uid':'507786',
'mycoid':'14922',
'con':'15',
'a':list
}
果然可以得到数据。
然后就很简单了:
关于代码--------
import requests
import json
import sys
url = "http://nddb.ic361.cn:8080/proc ... ot%3B
seach = sys.argv[1]
#seach1 = sys.argv[2]
#item = seach+'-'+seach1
# with open(r'D:\\phpStudy_server\\PHPTutorial\\WWW\\demo\\log.txt','a') as f:
# try:
# f.write(seach)
# except Exception as e:
# print(e)
# seach = input("请输入您要搜索的内容:")
list = ['507786','14922','-1']
list.append(seach)
d = {
'token':'A0E5CD90-ECE4-440C-8B39-084C0FE61E69',
'uid':'507786',
'mycoid':'14922',
'con':'15',
'a':list
}
r = requests.post(url,data=d)
dic = r.json()
print(json.dumps(dic))
接下来我们看一下打印结果:
php抓取网页json数据(PHP获取内容、PHP解析JSONPHP(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-09 03:05
好久没有为PHP写文章了,好久没用PHP了。我差点忘了怎么做。JSON是现在比较流行的数据通信方式,比XML更流行,一般用作数据获取和通信的api接口。
就文章的标题而言,本文介绍了两个小点:PHP获取内容,PHP解析JSON并显示。
PHP获取界面内容
如果要解析JSON数据并显示在页面上,首先必须要获取JSON接口文件的内容。在 PHP 中要获取页面的内容,可以使用 fopen() 函数远程访问页面,然后使用 fread() 函数循环获取内容。
$handle = fopen(";only_recommend=1&limit=5","rb");
$content = "";
而 (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
这样,内容保存的内容就是JSON api内容。
PHP解析JSON并显示
原创内容不能直接调用,必须经过PHP进一步处理后才能调用显示在网页上。在PHP5.2及以后的版本中,使用json_decode()函数解析JSON数据并转换成PHP可以调用的数据格式。例如:
$content = json_decode($content);
解析后,我们可以像调用PHP中的数组数据一样调用JSON中的数据。这个调用方法需要根据具体的JSON数据格式来编写,演示请看下面。关于json_decode函数的使用,详见PHP手册,这里不再赘述:
实战中调用琼台博客的api
细心的朋友会发现,潜行者m博客的侧边栏底部多了一个“好友推荐”模块,推荐了一些琼台博客的文章。
友情推荐是琼泰博客提出的一种博客之间的交流方式,比传统友情链接更有效,同时实现了博客内容的互补。由于琼台博客的博客程序是自己写的,所以提供了JSON api接口,获取最新的推荐文章。
我使用 PHP 来获取这个 JSON 接口并将其输出到我的博客的侧边栏。让我们付诸行动。
第一步是检查api是如何调用的
调用前一定要查看对方的api调用手册,包括调用地址、调用方式、数据输出格式等。琼台博客api描述地址如下:.
第二步获取api结构数据
很简单,如上所述,具体代码如下:
$handle = fopen(";only_recommend=1&limit=5","rb");
$content = "";
而 (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
首先打开数据文件,然后将所有内容保存在content变量中。因为可以确定api数据不会超过10000个字符,所以使用10000作为fread函数的第二个参数。这样,api 返回的 JSON 数据就存储在 content 变量中。
第三步,解析并输出内容
使用以下代码解析数据,然后调用输出
$content = json_decode($content);
foreach ($content->data as $key) {
回声'
';
}
首先对content变量中的JSON数据进行处理,然后将其转化为PHP可以调用的数据,然后使用foreach遍历输出这5条内容,按照我需要的HTML格式将内容插入进去。
再加上样式修改,这样就完成了JSON的获取解析并展示在页面上。调用其他api数据的方法类似。 查看全部
php抓取网页json数据(PHP获取内容、PHP解析JSONPHP(组图))
好久没有为PHP写文章了,好久没用PHP了。我差点忘了怎么做。JSON是现在比较流行的数据通信方式,比XML更流行,一般用作数据获取和通信的api接口。
就文章的标题而言,本文介绍了两个小点:PHP获取内容,PHP解析JSON并显示。
PHP获取界面内容
如果要解析JSON数据并显示在页面上,首先必须要获取JSON接口文件的内容。在 PHP 中要获取页面的内容,可以使用 fopen() 函数远程访问页面,然后使用 fread() 函数循环获取内容。
$handle = fopen(";only_recommend=1&limit=5","rb");
$content = "";
而 (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
这样,内容保存的内容就是JSON api内容。
PHP解析JSON并显示
原创内容不能直接调用,必须经过PHP进一步处理后才能调用显示在网页上。在PHP5.2及以后的版本中,使用json_decode()函数解析JSON数据并转换成PHP可以调用的数据格式。例如:
$content = json_decode($content);
解析后,我们可以像调用PHP中的数组数据一样调用JSON中的数据。这个调用方法需要根据具体的JSON数据格式来编写,演示请看下面。关于json_decode函数的使用,详见PHP手册,这里不再赘述:
实战中调用琼台博客的api
细心的朋友会发现,潜行者m博客的侧边栏底部多了一个“好友推荐”模块,推荐了一些琼台博客的文章。
友情推荐是琼泰博客提出的一种博客之间的交流方式,比传统友情链接更有效,同时实现了博客内容的互补。由于琼台博客的博客程序是自己写的,所以提供了JSON api接口,获取最新的推荐文章。
我使用 PHP 来获取这个 JSON 接口并将其输出到我的博客的侧边栏。让我们付诸行动。
第一步是检查api是如何调用的
调用前一定要查看对方的api调用手册,包括调用地址、调用方式、数据输出格式等。琼台博客api描述地址如下:.
第二步获取api结构数据
很简单,如上所述,具体代码如下:
$handle = fopen(";only_recommend=1&limit=5","rb");
$content = "";
而 (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
首先打开数据文件,然后将所有内容保存在content变量中。因为可以确定api数据不会超过10000个字符,所以使用10000作为fread函数的第二个参数。这样,api 返回的 JSON 数据就存储在 content 变量中。
第三步,解析并输出内容
使用以下代码解析数据,然后调用输出
$content = json_decode($content);
foreach ($content->data as $key) {
回声'
';
}
首先对content变量中的JSON数据进行处理,然后将其转化为PHP可以调用的数据,然后使用foreach遍历输出这5条内容,按照我需要的HTML格式将内容插入进去。
再加上样式修改,这样就完成了JSON的获取解析并展示在页面上。调用其他api数据的方法类似。
php抓取网页json数据(PHP解析JSON接口内容()函数循环获取内容介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-08 01:06
)
PHP访问界面内容
如果要解析JSON数据并显示在页面上,首先必须要获取JSON接口文件的内容。 PHP 中获取页面内容,可以使用 fopen() 函数远程访问页面,然后使用 fread() 函数循环获取内容。
假设接口文件页面是:,那么我们可以用下面的语句来获取这个接口文件的内容:
$handle = fopen(“http://www.qttc.net/api.php%3F ... ot%3B,"rb“);<br />$content = “”;<br />while (!feof($handle)) {<br /> $content .= fread($handle, 10000);<br />}<br />fclose($handle);
这样保存的内容就是JSON api内容。
PHP 解析 JSON 并显示
原创内容不能直接调用,必须经过PHP进一步处理后才能调用显示在网页上。在PHP5.2及以后的版本中,使用json_decode()函数解析JSON数据并转换成PHP可以调用的数据格式。例如:
$content = json_decode($content);
$content = json_decode($content);<br />foreach ($content->data as $key) {<br /> echo ‘<a target=”_blank” href=”‘.$key->b_url.’”>’.$key->b_title.’</a>’;<br />} 查看全部
php抓取网页json数据(PHP解析JSON接口内容()函数循环获取内容介绍
)
PHP访问界面内容
如果要解析JSON数据并显示在页面上,首先必须要获取JSON接口文件的内容。 PHP 中获取页面内容,可以使用 fopen() 函数远程访问页面,然后使用 fread() 函数循环获取内容。
假设接口文件页面是:,那么我们可以用下面的语句来获取这个接口文件的内容:
$handle = fopen(“http://www.qttc.net/api.php%3F ... ot%3B,"rb“);<br />$content = “”;<br />while (!feof($handle)) {<br /> $content .= fread($handle, 10000);<br />}<br />fclose($handle);
这样保存的内容就是JSON api内容。
PHP 解析 JSON 并显示
原创内容不能直接调用,必须经过PHP进一步处理后才能调用显示在网页上。在PHP5.2及以后的版本中,使用json_decode()函数解析JSON数据并转换成PHP可以调用的数据格式。例如:
$content = json_decode($content);
$content = json_decode($content);<br />foreach ($content->data as $key) {<br /> echo ‘<a target=”_blank” href=”‘.$key->b_url.’”>’.$key->b_title.’</a>’;<br />}
php抓取网页json数据(几个自己研究出来的抓数据的技术,欢迎大家指正补充哈哈!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-01 03:09
还有一个关于数据抓取的小研究。现在我分享一些我研究过的数据抓取技术。可能有很多缺点。欢迎大家指正并补充哈哈!
方法一:直接抓取网页源码
优点:速度快。
缺点: 1、由于速度快,容易被服务器检测,可能会限制当前的ip抓取。为此,您可以尝试使用 ip 代码来解决它。
2、如果要抓取的数据是在网页加载后,js修改了网页元素,无法抓取。
3、遇到一些大规模的网站抓取,如果登录后需要抓取页面,可能需要破解服务器端账号加密算法和各种加密算法,测试技术性。
适用场景:网页是完全静态的,第一次加载网页时就加载了你要抓取的数据。涉及登录或权限操作的类似页面未加密或简单加密。
当然,如果你为这个网页抓取的数据是通过接口获取的json,那你会更开心,直接抓取json页面即可。
对于一个登录页面,我们如何获取他的登录页面背后的源代码?
首先,我想介绍一下,当会话保存帐户信息时,服务器如何确定用户的身份。
首先,用户登录成功后,服务器会在session中保存用户当前的session信息,每个session都有一个唯一的标识sessionId。当用户访问该页面时,会话创建后,服务器返回的 sessionId 会被接收并保存在 cookie 中。因此,我们可以用chrome浏览器打开勾选项,查看当前页面的jsessionId。用户下次访问需要登录的页面时,用户发送的请求头会附加这个sessionId,服务器端可以通过这个sessionId来判断用户的身份。
在这里,我搭建了一个简单的jsp登录页面,登录后的账户信息保存在服务端会话中。
思路:1.登录。2.登录成功后获取cookies。3. 将cookie放入请求头,向登录页面发送请求。
附上java版本代码和python
爪哇版:
package craw;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintStream;
import java.io.PrintWriter;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.List;
import java.util.Map;
public class CrawTest {
//获得网页源代码
private static String getHtml(String urlString,String charset,String cookie){
StringBuffer html = new StringBuffer();
try {
URL url = new URL(urlString);
HttpURLConnection urlConn = (HttpURLConnection) url.openConnection();
urlConn.setRequestProperty("Cookie", cookie);
BufferedReader br = new BufferedReader(new InputStreamReader(urlConn.getInputStream(),charset));
String str;
while((str=br.readLine())!=null){
html.append(str);
}
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return html.toString();
}
//发送post请求,并返回请求后的cookie
private static String postGetCookie(String urlString,String params,String charset){
String cookies=null;
try {
URL url = new URL(urlString);
URLConnection urlConn = url.openConnection();
urlConn.setDoInput(true);
urlConn.setDoOutput(true);
PrintWriter out = new PrintWriter(urlConn.getOutputStream());
out.print(params);
out.flush();
cookies = urlConn.getHeaderFields().get("Set-Cookie").get(0);
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return cookies;
}
public static void main(String[] args) {
String cookie = postGetCookie("http://localhost:8080/loginDemo/login",
"username=admin&password=123456","utf-8");
String html = getHtml("http://localhost:8080/loginDemo/index.jsp", "utf-8", cookie);
System.out.println(html);//这里我们就可能输出登录后的网页源代码了
}
}
蟒蛇版本:
#encoding:utf-8
import urllib
import urllib2
data={\'username\':\'admin\',\'password\':\'123456\'}
data=urllib.urlencode(data)
response = urllib2.urlopen(\'http://localhost:8080/loginDemo/login\',data=data)//登录
cookie = response.info()[\'set-cookie\']//获得登录后的cookie
jsessionId = cookie.split(\';\')[0].split(\'=\')[-1]//从cookie获得sessionId
html = response.read()
if html==\'error\':
print(\'用户名密码错误!\')
elif html==\'success\':
headers = {\'Cookie\':\'JSESSIONID=\'+jsessionId}//请求头
request =urllib2.Request(\'http://localhost:8080/loginDemo/index.jsp\',headers=headers)
html = urllib2.urlopen(request).read()
print(html)//输出登录后的页面源码
我们可以很明显的看到python的优势,至少会比java少写一半的代码量。当然,这是java的优点,也是java的缺点。优点是更加灵活,程序员可以更好地控制底层代码的实现。,缺点是使用不方便,需要的技术太多。因此,如果您是数据抓取的新手,我强烈建议您学习python。
方法二:模拟浏览器操作
优点: 1. 类似于用户操作,不易被服务器检测到。
2、对于登录的网站,即使是N层加密,也无需考虑其加密算法。
3、可随时获取当前页面各元素的最新状态。
缺点: 1. 稍慢。
这里有一些很好的模拟浏览器操作的库:
C#webbrower 控件:
如果你学过c#winform,相信你对webbrower控件永远不会陌生。是浏览器,内部驱动其实就是IE驱动。
他可以随时在dom模式下解析当前文档(网页文档对象),不仅可以获取相关的Element对象,还可以修改元素对象,甚至调用方法,比如onclick方法,onsubmit等,或者直接调用页面js方法。
web浏览器的C#操作代码:
webBrowser1.Navigate("https://localhost//index.html");//加载一个页面
需要注意的是:不要直接执行以下代码,因为网页加载需要时间,建议以下代码写到webBrowser1_DocumentCompleted(加载完成)事件中:
webBrowser1.Document.GetElementById("username").InnerText="admin";//在网页中找到id为username的元素,设置其文本为admin
webBrowser1.Document.GetElementById("password").InnerText = "123456";//在网页中找到id为password的元素,设置其文本为123456
webBrowser1.Document.InvokeScript("loginEncrypt");//调用网页js函数:loginEncrypt.
因为有些页面可能不够友好,或者IE版本太低,甚至安全证书等问题,那么这个解决方案可能会通过。
我们可以直接使用selenium库来操作操作系统中真实的浏览器,比如chrome浏览器,selenuim支持多语言开发,以python调用selenium为例,selenium就是直接操作我们系统中的浏览器,但是我们需要确保浏览器安装了相应的Drive。
但是,在实际开发中,有时我们可能不想看到这样的浏览器界面。这里可以给大家推荐一个后台浏览器,直接在cmd里面操作。没有接口,就是phantomjs。
这样我们就可以用python+selenium+phantomjs在不看界面的情况下模拟浏览器的操作。由于phantomjs没有界面,所以会比普通浏览器快很多。
网上资料很多,一时无法解释,这里就不过多解释了,大家可以看看:
三、Fidderscript:
fidder 是一个非常强大的数据捕获工具。它不仅可以捕获当前系统中的http请求,还可以提供安全证书。所以,有时候,如果我们在爬取的过程中遇到安全证书错误,我们不妨打开fidder,让他给你提供一个证书,说不定你就快成功了。
更强大的是fidderscript,它可以在捕获请求后执行系统操作,例如将请求的数据保存到硬盘。或者在请求之前修改请求头,可以说是一个强大的抓取工具。这样我们之前用fdder配合各种方法,相信大部分问题都可以解决。而且他的语法和Clike系列的语法差不多,类库和c#大同小异,相信熟悉C#的同学会很快上手fiddlerscript。
附注: 查看全部
php抓取网页json数据(几个自己研究出来的抓数据的技术,欢迎大家指正补充哈哈!)
还有一个关于数据抓取的小研究。现在我分享一些我研究过的数据抓取技术。可能有很多缺点。欢迎大家指正并补充哈哈!
方法一:直接抓取网页源码
优点:速度快。
缺点: 1、由于速度快,容易被服务器检测,可能会限制当前的ip抓取。为此,您可以尝试使用 ip 代码来解决它。
2、如果要抓取的数据是在网页加载后,js修改了网页元素,无法抓取。
3、遇到一些大规模的网站抓取,如果登录后需要抓取页面,可能需要破解服务器端账号加密算法和各种加密算法,测试技术性。
适用场景:网页是完全静态的,第一次加载网页时就加载了你要抓取的数据。涉及登录或权限操作的类似页面未加密或简单加密。
当然,如果你为这个网页抓取的数据是通过接口获取的json,那你会更开心,直接抓取json页面即可。
对于一个登录页面,我们如何获取他的登录页面背后的源代码?
首先,我想介绍一下,当会话保存帐户信息时,服务器如何确定用户的身份。
首先,用户登录成功后,服务器会在session中保存用户当前的session信息,每个session都有一个唯一的标识sessionId。当用户访问该页面时,会话创建后,服务器返回的 sessionId 会被接收并保存在 cookie 中。因此,我们可以用chrome浏览器打开勾选项,查看当前页面的jsessionId。用户下次访问需要登录的页面时,用户发送的请求头会附加这个sessionId,服务器端可以通过这个sessionId来判断用户的身份。
在这里,我搭建了一个简单的jsp登录页面,登录后的账户信息保存在服务端会话中。
思路:1.登录。2.登录成功后获取cookies。3. 将cookie放入请求头,向登录页面发送请求。
附上java版本代码和python
爪哇版:
package craw;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintStream;
import java.io.PrintWriter;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.List;
import java.util.Map;
public class CrawTest {
//获得网页源代码
private static String getHtml(String urlString,String charset,String cookie){
StringBuffer html = new StringBuffer();
try {
URL url = new URL(urlString);
HttpURLConnection urlConn = (HttpURLConnection) url.openConnection();
urlConn.setRequestProperty("Cookie", cookie);
BufferedReader br = new BufferedReader(new InputStreamReader(urlConn.getInputStream(),charset));
String str;
while((str=br.readLine())!=null){
html.append(str);
}
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return html.toString();
}
//发送post请求,并返回请求后的cookie
private static String postGetCookie(String urlString,String params,String charset){
String cookies=null;
try {
URL url = new URL(urlString);
URLConnection urlConn = url.openConnection();
urlConn.setDoInput(true);
urlConn.setDoOutput(true);
PrintWriter out = new PrintWriter(urlConn.getOutputStream());
out.print(params);
out.flush();
cookies = urlConn.getHeaderFields().get("Set-Cookie").get(0);
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return cookies;
}
public static void main(String[] args) {
String cookie = postGetCookie("http://localhost:8080/loginDemo/login",
"username=admin&password=123456","utf-8");
String html = getHtml("http://localhost:8080/loginDemo/index.jsp", "utf-8", cookie);
System.out.println(html);//这里我们就可能输出登录后的网页源代码了
}
}
蟒蛇版本:
#encoding:utf-8
import urllib
import urllib2
data={\'username\':\'admin\',\'password\':\'123456\'}
data=urllib.urlencode(data)
response = urllib2.urlopen(\'http://localhost:8080/loginDemo/login\',data=data)//登录
cookie = response.info()[\'set-cookie\']//获得登录后的cookie
jsessionId = cookie.split(\';\')[0].split(\'=\')[-1]//从cookie获得sessionId
html = response.read()
if html==\'error\':
print(\'用户名密码错误!\')
elif html==\'success\':
headers = {\'Cookie\':\'JSESSIONID=\'+jsessionId}//请求头
request =urllib2.Request(\'http://localhost:8080/loginDemo/index.jsp\',headers=headers)
html = urllib2.urlopen(request).read()
print(html)//输出登录后的页面源码
我们可以很明显的看到python的优势,至少会比java少写一半的代码量。当然,这是java的优点,也是java的缺点。优点是更加灵活,程序员可以更好地控制底层代码的实现。,缺点是使用不方便,需要的技术太多。因此,如果您是数据抓取的新手,我强烈建议您学习python。
方法二:模拟浏览器操作
优点: 1. 类似于用户操作,不易被服务器检测到。
2、对于登录的网站,即使是N层加密,也无需考虑其加密算法。
3、可随时获取当前页面各元素的最新状态。
缺点: 1. 稍慢。
这里有一些很好的模拟浏览器操作的库:
C#webbrower 控件:
如果你学过c#winform,相信你对webbrower控件永远不会陌生。是浏览器,内部驱动其实就是IE驱动。
他可以随时在dom模式下解析当前文档(网页文档对象),不仅可以获取相关的Element对象,还可以修改元素对象,甚至调用方法,比如onclick方法,onsubmit等,或者直接调用页面js方法。
web浏览器的C#操作代码:
webBrowser1.Navigate("https://localhost//index.html";);//加载一个页面
需要注意的是:不要直接执行以下代码,因为网页加载需要时间,建议以下代码写到webBrowser1_DocumentCompleted(加载完成)事件中:
webBrowser1.Document.GetElementById("username").InnerText="admin";//在网页中找到id为username的元素,设置其文本为admin
webBrowser1.Document.GetElementById("password").InnerText = "123456";//在网页中找到id为password的元素,设置其文本为123456
webBrowser1.Document.InvokeScript("loginEncrypt");//调用网页js函数:loginEncrypt.
因为有些页面可能不够友好,或者IE版本太低,甚至安全证书等问题,那么这个解决方案可能会通过。
我们可以直接使用selenium库来操作操作系统中真实的浏览器,比如chrome浏览器,selenuim支持多语言开发,以python调用selenium为例,selenium就是直接操作我们系统中的浏览器,但是我们需要确保浏览器安装了相应的Drive。
但是,在实际开发中,有时我们可能不想看到这样的浏览器界面。这里可以给大家推荐一个后台浏览器,直接在cmd里面操作。没有接口,就是phantomjs。
这样我们就可以用python+selenium+phantomjs在不看界面的情况下模拟浏览器的操作。由于phantomjs没有界面,所以会比普通浏览器快很多。
网上资料很多,一时无法解释,这里就不过多解释了,大家可以看看:
三、Fidderscript:
fidder 是一个非常强大的数据捕获工具。它不仅可以捕获当前系统中的http请求,还可以提供安全证书。所以,有时候,如果我们在爬取的过程中遇到安全证书错误,我们不妨打开fidder,让他给你提供一个证书,说不定你就快成功了。
更强大的是fidderscript,它可以在捕获请求后执行系统操作,例如将请求的数据保存到硬盘。或者在请求之前修改请求头,可以说是一个强大的抓取工具。这样我们之前用fdder配合各种方法,相信大部分问题都可以解决。而且他的语法和Clike系列的语法差不多,类库和c#大同小异,相信熟悉C#的同学会很快上手fiddlerscript。
附注:
php抓取网页json数据( javajar修改servletjava代码代码使用方法代码详解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-30 22:15
javajar修改servletjava代码代码使用方法代码详解)
JS中Json数据的处理和解析JSON数据的方法详解
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript 的一个子集。JSON 使用完全独立于语言的文本格式,但也使用类似于 C 语言家族(包括 C、C++、C#、Java、JavaScript、Perl、Python 等)的习惯。这些特性使 JSON 成为一种理想的数据交换语言。便于人读写,也便于机器解析生成(通常用于提高网络传输速率)。
JSON 的规则很简单:对象是“名称/值对”的无序集合。对象以“{”(左括号)开头,以“}”(右括号)结尾。每个“名称”后跟一个“:”(冒号);“'name/value' 对”由“,”(逗号)分隔。具体细节参考
举个简单的例子:
js代码
function showJSON() {
var user =
{
"username":"andy",
"age":20,
"info": { "tel": "123456", "cellphone": "98765"},
"address":
[
{"city":"beijing","postcode":"222333"},
{"city":"newyork","postcode":"555666"}
]
}
alert(user.username);
alert(user.age);
alert(user.info.cellphone);
alert(user.address[0].city);
alert(user.address[0].postcode);
}
这表示具有用户名、年龄、信息、地址等属性的用户对象。
也可以用JSON简单的修改数据,修改上面的例子
js代码
function showJSON() {
var user =
{
"username":"andy",
"age":20,
"info": { "tel": "123456", "cellphone": "98765"},
"address":
[
{"city":"beijing","postcode":"222333"},
{"city":"newyork","postcode":"555666"}
]
}
alert(user.username);
alert(user.age);
alert(user.info.cellphone);
alert(user.address[0].city);
alert(user.address[0].postcode);
user.username = "Tom";
alert(user.username);
}
JSON 提供了 json.js 包。下载后,导入它,然后简单地使用 object.toJSONString() 将其转换为 JSON 数据。
js代码
function showCar() {
var carr = new Car("Dodge", "Coronet R/T", 1968, "yellow");
alert(carr.toJSONString());
}
function Car(make, model, year, color) {
this.make = make;
this.model = model;
this.year = year;
this.color = color;
}
您可以使用 eval 将 JSON 字符转换为 Object
js代码
function myEval() {
var str = '{ "name": "Violet", "occupation": "character" }';
var obj = eval('(' + str + ')');
alert(obj.toJSONString());
}
或者使用 parseJSON() 方法
js代码
function myEval() {
var str = '{ "name": "Violet", "occupation": "character" }';
var obj = str.parseJSON();
alert(obj.toJSONString());
}
下面用prototype写一个JSON ajax例子。
先写一个servlet(我的是servlet.ajax.JSONTest1.java),写一句
代码
response.getWriter().print("{ \"name\": \"Violet\", \"occupation\": \"character\" }");
在页面中写一个ajax请求
js代码
function sendRequest() {
var url = "/MyWebApp/JSONTest1";
var mailAjax = new Ajax.Request(
url,
{
method: 'get',
onComplete: jsonResponse
}
);
}
function jsonResponse(originalRequest) {
alert(originalRequest.responseText);
var myobj = originalRequest.responseText.parseJSON();
alert(myobj.name);
}
Prototype-1.5.1.js 提供了JSON方法,String.evalJSON(),不使用json.js也可以修改上面的方法
js代码
function jsonResponse(originalRequest) {
alert(originalRequest.responseText);
var myobj = originalRequest.responseText.evalJSON(true);
alert(myobj.name);
}
JSON也提供了java jar包API也很简单,这里举个例子
在javascript中填写请求参数
js代码
function sendRequest() {
var carr = new Car("Dodge", "Coronet R/T", 1968, "yellow");
var pars = "car=" + carr.toJSONString();
var url = "/MyWebApp/JSONTest1";
var mailAjax = new Ajax.Request(
url,
{
method: 'get',
parameters: pars,
onComplete: jsonResponse
}
);
}
使用JSON请求字符串,可以简单的生成解析JSONObject,修改servlet添加JSON处理(使用json.jar)
代码
private void doService(HttpServletRequest request, HttpServletResponse response) throws IOException {
String s3 = request.getParameter("car");
try {
JSONObject jsonObj = new JSONObject(s3);
System.out.println(jsonObj.getString("model"));
System.out.println(jsonObj.getInt("year"));
} catch (JSONException e) {
e.printStackTrace();
}
response.getWriter().print("{ \"name\": \"Violet\", \"occupation\": \"character\" }");
}
您还可以使用 JSONObject 生成 JSON 字符串和修改 servlet
代码
private void doService(HttpServletRequest request, HttpServletResponse response) throws IOException {
String s3 = request.getParameter("car");
try {
JSONObject jsonObj = new JSONObject(s3);
System.out.println(jsonObj.getString("model"));
System.out.println(jsonObj.getInt("year"));
} catch (JSONException e) {
e.printStackTrace();
}
JSONObject resultJSON = new JSONObject();
try {
resultJSON.append("name", "Violet")
.append("occupation", "developer")
.append("age", new Integer(22));
System.out.println(resultJSON.toString());
} catch (JSONException e) {
e.printStackTrace();
}
response.getWriter().print(resultJSON.toString());
}
js代码
function jsonResponse(originalRequest) {
alert(originalRequest.responseText);
var myobj = originalRequest.responseText.evalJSON(true);
alert(myobj.name);
alert(myobj.age);
}
下面重点介绍JS中json数据的处理
1、 json 数据结构(对象和数组)
json 对象:var obj = {"name":"xiao","age":12};
json 数组:var objArray = [{"name":"xiao","age":12},{"name":"xiao","age":12}];
2、 处理json数据,依赖文件为:jQuery.js
3、注:在数据传输过程中,json数据以文本形式存在,即字符串格式;
JS 语言操作 JS 对象;
所以json字符串和JS对象的转换是关键;
4、数据格式
json字符串:var json_str ='{"name":"xiao","age":12}';
Josn 对象:var obj = {"name":"xiao","age":12};
JS对象:对象{名称:“xiao”,年龄:12}
5、类型转换
Json字符串——>JS对象,使用方法:
笔记:
json_str 和 obj 代表本文副标题 4 中的数据类型;
obj = JSON.parse(json_str);
obj = jQuery.parseJSON(json_str);
注意:如果传入格式错误的json字符串(例如:'{name:"xiao",age:12}'),会抛出异常;
Json 字符串格式,严格格式:'{"name":"xiao","age":12}'
JS 对象 -> Json 字符串:
json_str = JSON。字符串化(对象);
笔记:
1、eval()是JS原生函数,使用这种形式:eval('('+'{name:"xiao",age:12}'+')'),不安全,不能保证类型转换是一个JS对象;
2、 以上3种方法均已通过chrome浏览器测试,以下为测试结果截图;
Json 字符串 -> JS 对象;
JS 对象 -> Json 字符串: 查看全部
php抓取网页json数据(
javajar修改servletjava代码代码使用方法代码详解)
JS中Json数据的处理和解析JSON数据的方法详解
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript 的一个子集。JSON 使用完全独立于语言的文本格式,但也使用类似于 C 语言家族(包括 C、C++、C#、Java、JavaScript、Perl、Python 等)的习惯。这些特性使 JSON 成为一种理想的数据交换语言。便于人读写,也便于机器解析生成(通常用于提高网络传输速率)。
JSON 的规则很简单:对象是“名称/值对”的无序集合。对象以“{”(左括号)开头,以“}”(右括号)结尾。每个“名称”后跟一个“:”(冒号);“'name/value' 对”由“,”(逗号)分隔。具体细节参考
举个简单的例子:
js代码
function showJSON() {
var user =
{
"username":"andy",
"age":20,
"info": { "tel": "123456", "cellphone": "98765"},
"address":
[
{"city":"beijing","postcode":"222333"},
{"city":"newyork","postcode":"555666"}
]
}
alert(user.username);
alert(user.age);
alert(user.info.cellphone);
alert(user.address[0].city);
alert(user.address[0].postcode);
}
这表示具有用户名、年龄、信息、地址等属性的用户对象。
也可以用JSON简单的修改数据,修改上面的例子
js代码
function showJSON() {
var user =
{
"username":"andy",
"age":20,
"info": { "tel": "123456", "cellphone": "98765"},
"address":
[
{"city":"beijing","postcode":"222333"},
{"city":"newyork","postcode":"555666"}
]
}
alert(user.username);
alert(user.age);
alert(user.info.cellphone);
alert(user.address[0].city);
alert(user.address[0].postcode);
user.username = "Tom";
alert(user.username);
}
JSON 提供了 json.js 包。下载后,导入它,然后简单地使用 object.toJSONString() 将其转换为 JSON 数据。
js代码
function showCar() {
var carr = new Car("Dodge", "Coronet R/T", 1968, "yellow");
alert(carr.toJSONString());
}
function Car(make, model, year, color) {
this.make = make;
this.model = model;
this.year = year;
this.color = color;
}
您可以使用 eval 将 JSON 字符转换为 Object
js代码
function myEval() {
var str = '{ "name": "Violet", "occupation": "character" }';
var obj = eval('(' + str + ')');
alert(obj.toJSONString());
}
或者使用 parseJSON() 方法
js代码
function myEval() {
var str = '{ "name": "Violet", "occupation": "character" }';
var obj = str.parseJSON();
alert(obj.toJSONString());
}
下面用prototype写一个JSON ajax例子。
先写一个servlet(我的是servlet.ajax.JSONTest1.java),写一句
代码
response.getWriter().print("{ \"name\": \"Violet\", \"occupation\": \"character\" }");
在页面中写一个ajax请求
js代码
function sendRequest() {
var url = "/MyWebApp/JSONTest1";
var mailAjax = new Ajax.Request(
url,
{
method: 'get',
onComplete: jsonResponse
}
);
}
function jsonResponse(originalRequest) {
alert(originalRequest.responseText);
var myobj = originalRequest.responseText.parseJSON();
alert(myobj.name);
}
Prototype-1.5.1.js 提供了JSON方法,String.evalJSON(),不使用json.js也可以修改上面的方法
js代码
function jsonResponse(originalRequest) {
alert(originalRequest.responseText);
var myobj = originalRequest.responseText.evalJSON(true);
alert(myobj.name);
}
JSON也提供了java jar包API也很简单,这里举个例子
在javascript中填写请求参数
js代码
function sendRequest() {
var carr = new Car("Dodge", "Coronet R/T", 1968, "yellow");
var pars = "car=" + carr.toJSONString();
var url = "/MyWebApp/JSONTest1";
var mailAjax = new Ajax.Request(
url,
{
method: 'get',
parameters: pars,
onComplete: jsonResponse
}
);
}
使用JSON请求字符串,可以简单的生成解析JSONObject,修改servlet添加JSON处理(使用json.jar)
代码
private void doService(HttpServletRequest request, HttpServletResponse response) throws IOException {
String s3 = request.getParameter("car");
try {
JSONObject jsonObj = new JSONObject(s3);
System.out.println(jsonObj.getString("model"));
System.out.println(jsonObj.getInt("year"));
} catch (JSONException e) {
e.printStackTrace();
}
response.getWriter().print("{ \"name\": \"Violet\", \"occupation\": \"character\" }");
}
您还可以使用 JSONObject 生成 JSON 字符串和修改 servlet
代码
private void doService(HttpServletRequest request, HttpServletResponse response) throws IOException {
String s3 = request.getParameter("car");
try {
JSONObject jsonObj = new JSONObject(s3);
System.out.println(jsonObj.getString("model"));
System.out.println(jsonObj.getInt("year"));
} catch (JSONException e) {
e.printStackTrace();
}
JSONObject resultJSON = new JSONObject();
try {
resultJSON.append("name", "Violet")
.append("occupation", "developer")
.append("age", new Integer(22));
System.out.println(resultJSON.toString());
} catch (JSONException e) {
e.printStackTrace();
}
response.getWriter().print(resultJSON.toString());
}
js代码
function jsonResponse(originalRequest) {
alert(originalRequest.responseText);
var myobj = originalRequest.responseText.evalJSON(true);
alert(myobj.name);
alert(myobj.age);
}
下面重点介绍JS中json数据的处理
1、 json 数据结构(对象和数组)
json 对象:var obj = {"name":"xiao","age":12};
json 数组:var objArray = [{"name":"xiao","age":12},{"name":"xiao","age":12}];
2、 处理json数据,依赖文件为:jQuery.js
3、注:在数据传输过程中,json数据以文本形式存在,即字符串格式;
JS 语言操作 JS 对象;
所以json字符串和JS对象的转换是关键;
4、数据格式
json字符串:var json_str ='{"name":"xiao","age":12}';
Josn 对象:var obj = {"name":"xiao","age":12};
JS对象:对象{名称:“xiao”,年龄:12}
5、类型转换
Json字符串——>JS对象,使用方法:
笔记:
json_str 和 obj 代表本文副标题 4 中的数据类型;
obj = JSON.parse(json_str);
obj = jQuery.parseJSON(json_str);
注意:如果传入格式错误的json字符串(例如:'{name:"xiao",age:12}'),会抛出异常;
Json 字符串格式,严格格式:'{"name":"xiao","age":12}'
JS 对象 -> Json 字符串:
json_str = JSON。字符串化(对象);
笔记:
1、eval()是JS原生函数,使用这种形式:eval('('+'{name:"xiao",age:12}'+')'),不安全,不能保证类型转换是一个JS对象;
2、 以上3种方法均已通过chrome浏览器测试,以下为测试结果截图;
Json 字符串 -> JS 对象;
JS 对象 -> Json 字符串:
php抓取网页json数据(这里有新鲜出炉的PHP教程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-28 20:04
这里有新鲜的PHP教程,看看程序狗的速度!
PHP 开源脚本语言 PHP(外文名:Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,入门门槛低,易学,应用广泛。主要适用于Web开发领域。PHP 的文件扩展名为 php。
我最近在百度阅读上购买了一本电子书《永恒的尽头》,但发现只能在网上或手机端阅读,无法下载并放入kindle。所以我试着看看我是否可以下载这个文章。有需要的朋友可以参考参考,一起来看看吧。
前言
本文文章主要介绍如何使用PHP抓取百度阅读。话不多说,一起来看看吧。
爬取方法如下
首先在浏览器中打开阅读页面,查看源码,发现页面上并没有直接写小说的内容,也就是说小说的内容是异步加载的。
所以把chrome开发者工具切到网络专栏,刷新阅读页面,重点关注XHR和脚本两大类。
经过排查,发现脚本类下有一个jsonp请求,更像是小说内容,请求地址为
返回的是一个jsonp字符串,然后我发现如果去掉地址中的callback=wenku7,返回的是一个json字符串,这样解析起来更容易,可以直接在php中转成数组。
我们再来分析一下返回数据的结构。返回的json字符串为树状结构后,每个节点都有at属性和ac属性。t属性用于指定节点的标签,如h2 div等,c属性是内容,但是有两种可能,一种是字符串,另一种是数组,每个元素的数组是一个节点。
这个结构最好解析,它可以通过递归来完成。
最终代码如下:
<p> 查看全部
php抓取网页json数据(这里有新鲜出炉的PHP教程,程序狗速度看过来!)
这里有新鲜的PHP教程,看看程序狗的速度!
PHP 开源脚本语言 PHP(外文名:Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,入门门槛低,易学,应用广泛。主要适用于Web开发领域。PHP 的文件扩展名为 php。
我最近在百度阅读上购买了一本电子书《永恒的尽头》,但发现只能在网上或手机端阅读,无法下载并放入kindle。所以我试着看看我是否可以下载这个文章。有需要的朋友可以参考参考,一起来看看吧。
前言
本文文章主要介绍如何使用PHP抓取百度阅读。话不多说,一起来看看吧。
爬取方法如下
首先在浏览器中打开阅读页面,查看源码,发现页面上并没有直接写小说的内容,也就是说小说的内容是异步加载的。
所以把chrome开发者工具切到网络专栏,刷新阅读页面,重点关注XHR和脚本两大类。
经过排查,发现脚本类下有一个jsonp请求,更像是小说内容,请求地址为
返回的是一个jsonp字符串,然后我发现如果去掉地址中的callback=wenku7,返回的是一个json字符串,这样解析起来更容易,可以直接在php中转成数组。
我们再来分析一下返回数据的结构。返回的json字符串为树状结构后,每个节点都有at属性和ac属性。t属性用于指定节点的标签,如h2 div等,c属性是内容,但是有两种可能,一种是字符串,另一种是数组,每个元素的数组是一个节点。
这个结构最好解析,它可以通过递归来完成。
最终代码如下:
<p>
php抓取网页json数据( 如何利用PHP抓取百度阅读的方法看能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-28 11:16
如何利用PHP抓取百度阅读的方法看能)
如何用PHP抓取百度阅读的例子
更新时间:2016年12月18日11:06:49投稿:雏菊
我最近在百度阅读上购买了一本电子书《永恒的尽头》,但发现只能在网上或手机端阅读,无法下载并放入kindle。所以我试着看看我是否可以下载这个文章。有需要的朋友可以参考参考,一起来看看吧。
前言
本文文章主要介绍如何使用PHP抓取百度阅读。话不多说,一起来看看吧。
爬取方法如下
首先在浏览器中打开阅读页面,查看源码,发现页面上并没有直接写小说的内容,也就是说小说的内容是异步加载的。
所以把chrome开发者工具切到网络专栏,刷新阅读页面,重点关注XHR和脚本两大类。
经过排查,发现脚本类下有一个jsonp请求,更像是小说内容,请求地址为
返回的是一个jsonp字符串,然后我发现如果去掉地址中的callback=wenku7,返回的是一个json字符串,这样解析起来更容易,可以直接在php中转成数组。
我们再来分析一下返回数据的结构。返回的json字符串为树状结构后,每个节点都有at属性和ac属性。t属性用于指定节点的标签,如h2 div等,c属性是内容,但是有两种可能,一种是字符串,另一种是数组,每个元素的数组是一个节点。
这个结构最好解析,它可以通过递归来完成。
最终代码如下:
<p> 查看全部
php抓取网页json数据(
如何利用PHP抓取百度阅读的方法看能)
如何用PHP抓取百度阅读的例子
更新时间:2016年12月18日11:06:49投稿:雏菊
我最近在百度阅读上购买了一本电子书《永恒的尽头》,但发现只能在网上或手机端阅读,无法下载并放入kindle。所以我试着看看我是否可以下载这个文章。有需要的朋友可以参考参考,一起来看看吧。
前言
本文文章主要介绍如何使用PHP抓取百度阅读。话不多说,一起来看看吧。
爬取方法如下
首先在浏览器中打开阅读页面,查看源码,发现页面上并没有直接写小说的内容,也就是说小说的内容是异步加载的。
所以把chrome开发者工具切到网络专栏,刷新阅读页面,重点关注XHR和脚本两大类。
经过排查,发现脚本类下有一个jsonp请求,更像是小说内容,请求地址为
返回的是一个jsonp字符串,然后我发现如果去掉地址中的callback=wenku7,返回的是一个json字符串,这样解析起来更容易,可以直接在php中转成数组。
我们再来分析一下返回数据的结构。返回的json字符串为树状结构后,每个节点都有at属性和ac属性。t属性用于指定节点的标签,如h2 div等,c属性是内容,但是有两种可能,一种是字符串,另一种是数组,每个元素的数组是一个节点。
这个结构最好解析,它可以通过递归来完成。
最终代码如下:
<p>
php抓取网页json数据(5.正则提取我们去网页看一下真实的源码(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-10-23 20:08
下面用代码实现,先抓取第一页的内容。我们实现了 get_one_page() 方法并将 url 参数传递给他。然后返回获取的页面结果,然后调用main()方法。初步代码如下:
import requests
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
return None
def main():
url = 'http://maoyan.com/board/4'
html = get_one_page(url)
print(html)
main()
运行后就可以成功获取主页的源码了。获取到之后,需要对页面进行解析,提取出我们想要的信息。
5.常规提取
让我们去网页看看真正的源代码。在开发者模式下查看Network monitor组件中的源码,如图
注意这里不要直接进入Elements选项卡查看,因为这里的源码可能与通过JavaScript操作的原创请求不同,但是需要查看来自Network的原创请求才能获取源码。让我们分析其中一项。
可以看出,一个电影信息对应的源代码是一个dd节点,我们使用正则表达式提取其中的一些信息。首先是排名信息。它的排名在类别为 board-index 的 i-node 中。这里使用非贪婪匹配来提取 i-node 中的信息。正则表达式写成:
.*?board-index.*?>(.*?)
接下来需要提取的是电影图片。可以看到,后面有一个节点,里面有两个img节点。检查后发现第二个img节点的data-src属性是图片链接。这里提取第二个img节点的data-src属性,把表达式改成这样:
.*?board-index.*?>(.*?).*?data-src="(.*?)"
后面需要提取电影名称,在后面的p节点中,类为name。因此,您也可以使用name作为标志位,然后进一步提取其中的a节点的文本内容。这时正则表达式改写如下:
.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>
用同样的原理提取男主角、上映时间、收视率等,最终的正则表达式为:
.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?).*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?).*?fraction.*?>(.*?).*?
</p>
这样的正则表达式可以匹配一部电影的结果,一共有七条信息。接下来,通过调用 findall() 方法提取所有内容。
接下来我们定义一个方法parse_one_page()来解析页面,主要是通过正则表达式从结果中提取出我们想要的内容,代码如下:
def parse_one_page(html):
pattern = re.compile('.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?).*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?).*?fraction.*?>(.*?).*?',re.S)
items = re.findall(pattern,html)
print(items)
</p>
输出如下,是一个列表形式。
但是数据比较乱,所以我们先处理匹配结果,遍历提取结果生成字典,改成这样:
def parse_one_page(html):
pattern = re.compile('.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?).*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?).*?fraction.*?>(.*?).*?',re.S)
items = re.findall(pattern,html)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2].strip(),
'actor': item[3].strip()[3:] if len(item[3]) > 3 else '',
'time': item[4].strip()[5:] if len(item[3]) > 3 else '',
'score': item[5].strip() + item[6].strip()
}
</p>
这样就可以成功提取电影排名、图片、片名、演员、时间、收视率等内容,并分配到字典中,形成结构化数据。操作结果如下:
6.写入文件
随后,我们将提取的结果写入文件,这里直接写入文本文件。这里通过JSON库的dumps()方法实现字典的序列化,将ensure_ascii参数指定为False,保证输出结果是中文格式,而不是Unicode编码。代码显示如下:
def write_to_file(content):
with open('result.txt', 'a', encoding='utf-8') as f:
print(type(json.dumps(content)))
f.write(json.dumps(content, ensure_ascii=False) + '\n')
将字典写入文本文件的过程可以通过调用write_to_file()方法来实现。这里的content参数是提取结果,是一个字典。
7.集成代码
最后实现main()方法调用前面的方法,将单页电影结果写入文件。代码如下:
def main(offset):
url = 'http://maoyan.com/board/4'
html = get_one_page(url)
for item in parse_one_page(html):
write_to_file(item)
至此我们就完成了单个页面的提取。
8.页面抓取
因为我们要抓取TOP100电影,所以还需要遍历并将offset参数传递给这个链接,实现其他90部电影的抓取。这时,添加如下调用:
if __name__ == '__main__':
for i in range(10):
main(offset= i*10)
还需要修改main方法,接收一个偏移值作为偏移量,然后进行URL构建。代码显示如下:
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
至此,集成后的代码如下:
import json
import requests
from requests.exceptions import RequestException
import re
import time
import http
def get_one_page(url):
try:
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile('.*?board-index.*?>(\d+).*?data-src="(.*?)".*?name">(.*?)</a>.*?star">(.*?).*?releasetime">(.*?)</p>'
+ '.*?integer">(.*?).*?fraction">(.*?).*?', re.S)
items = re.findall(pattern, str(html))
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5] + item[6]
}
def write_to_file(content):
with open('result.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
for i in range(10):
main(offset= i*10)
time.sleep(1)
</p>
因为猫眼是有抗爬虫的,如果速度太快,就会没有反应,所以加了一个延迟。可能有人在练习的时候注意到ip被封了。其实这里最好的解决办法就是设置代理。您可以找到一些免费的代理服务器。
9.运行结果
我们运行一下代码,输出如下
我们再看一下文本文件,如图
如您所见,所有电影信息也保存在一个文本文件中。
10.本节代码
本节的代码也已经提交到GitHub,代码地址:。 查看全部
php抓取网页json数据(5.正则提取我们去网页看一下真实的源码(图))
下面用代码实现,先抓取第一页的内容。我们实现了 get_one_page() 方法并将 url 参数传递给他。然后返回获取的页面结果,然后调用main()方法。初步代码如下:
import requests
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
return None
def main():
url = 'http://maoyan.com/board/4'
html = get_one_page(url)
print(html)
main()
运行后就可以成功获取主页的源码了。获取到之后,需要对页面进行解析,提取出我们想要的信息。
5.常规提取
让我们去网页看看真正的源代码。在开发者模式下查看Network monitor组件中的源码,如图
注意这里不要直接进入Elements选项卡查看,因为这里的源码可能与通过JavaScript操作的原创请求不同,但是需要查看来自Network的原创请求才能获取源码。让我们分析其中一项。
可以看出,一个电影信息对应的源代码是一个dd节点,我们使用正则表达式提取其中的一些信息。首先是排名信息。它的排名在类别为 board-index 的 i-node 中。这里使用非贪婪匹配来提取 i-node 中的信息。正则表达式写成:
.*?board-index.*?>(.*?)
接下来需要提取的是电影图片。可以看到,后面有一个节点,里面有两个img节点。检查后发现第二个img节点的data-src属性是图片链接。这里提取第二个img节点的data-src属性,把表达式改成这样:
.*?board-index.*?>(.*?).*?data-src="(.*?)"
后面需要提取电影名称,在后面的p节点中,类为name。因此,您也可以使用name作为标志位,然后进一步提取其中的a节点的文本内容。这时正则表达式改写如下:
.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>
用同样的原理提取男主角、上映时间、收视率等,最终的正则表达式为:
.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?).*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?).*?fraction.*?>(.*?).*?
</p>
这样的正则表达式可以匹配一部电影的结果,一共有七条信息。接下来,通过调用 findall() 方法提取所有内容。
接下来我们定义一个方法parse_one_page()来解析页面,主要是通过正则表达式从结果中提取出我们想要的内容,代码如下:
def parse_one_page(html):
pattern = re.compile('.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?).*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?).*?fraction.*?>(.*?).*?',re.S)
items = re.findall(pattern,html)
print(items)
</p>
输出如下,是一个列表形式。
但是数据比较乱,所以我们先处理匹配结果,遍历提取结果生成字典,改成这样:
def parse_one_page(html):
pattern = re.compile('.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?).*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?).*?fraction.*?>(.*?).*?',re.S)
items = re.findall(pattern,html)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2].strip(),
'actor': item[3].strip()[3:] if len(item[3]) > 3 else '',
'time': item[4].strip()[5:] if len(item[3]) > 3 else '',
'score': item[5].strip() + item[6].strip()
}
</p>
这样就可以成功提取电影排名、图片、片名、演员、时间、收视率等内容,并分配到字典中,形成结构化数据。操作结果如下:
6.写入文件
随后,我们将提取的结果写入文件,这里直接写入文本文件。这里通过JSON库的dumps()方法实现字典的序列化,将ensure_ascii参数指定为False,保证输出结果是中文格式,而不是Unicode编码。代码显示如下:
def write_to_file(content):
with open('result.txt', 'a', encoding='utf-8') as f:
print(type(json.dumps(content)))
f.write(json.dumps(content, ensure_ascii=False) + '\n')
将字典写入文本文件的过程可以通过调用write_to_file()方法来实现。这里的content参数是提取结果,是一个字典。
7.集成代码
最后实现main()方法调用前面的方法,将单页电影结果写入文件。代码如下:
def main(offset):
url = 'http://maoyan.com/board/4'
html = get_one_page(url)
for item in parse_one_page(html):
write_to_file(item)
至此我们就完成了单个页面的提取。
8.页面抓取
因为我们要抓取TOP100电影,所以还需要遍历并将offset参数传递给这个链接,实现其他90部电影的抓取。这时,添加如下调用:
if __name__ == '__main__':
for i in range(10):
main(offset= i*10)
还需要修改main方法,接收一个偏移值作为偏移量,然后进行URL构建。代码显示如下:
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
至此,集成后的代码如下:
import json
import requests
from requests.exceptions import RequestException
import re
import time
import http
def get_one_page(url):
try:
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile('.*?board-index.*?>(\d+).*?data-src="(.*?)".*?name">(.*?)</a>.*?star">(.*?).*?releasetime">(.*?)</p>'
+ '.*?integer">(.*?).*?fraction">(.*?).*?', re.S)
items = re.findall(pattern, str(html))
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5] + item[6]
}
def write_to_file(content):
with open('result.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
for i in range(10):
main(offset= i*10)
time.sleep(1)
</p>
因为猫眼是有抗爬虫的,如果速度太快,就会没有反应,所以加了一个延迟。可能有人在练习的时候注意到ip被封了。其实这里最好的解决办法就是设置代理。您可以找到一些免费的代理服务器。
9.运行结果
我们运行一下代码,输出如下
我们再看一下文本文件,如图
如您所见,所有电影信息也保存在一个文本文件中。
10.本节代码
本节的代码也已经提交到GitHub,代码地址:。
php抓取网页json数据(实例如下所示:以上这篇就是小编分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 348 次浏览 • 2021-10-21 11:00
示例如下:
// 追加写入用户名下文件
$code="001";//动态数据
$json_string = file_get_contents("text.json");// 从文件中读取数据到PHP变量
$data = json_decode($json_string,true);// 把JSON字符串转成PHP数组
$data[$code]=array("a"=>"as","b"=>"bs","c"=>"cs");
$json_strings = json_encode($data);
file_put_contents("text.json",$json_strings);//写入
//修改
$json_string = file_get_contents("text.json");// 从文件中读取数据到PHP变量
$data = json_decode($json_string,true);// 把JSON字符串转成PHP数组
$data["001"]["a"]="aas";
$json_strings = json_encode($data);
file_put_contents("text.json",$json_strings);//写入
以上php读写json文件和修改json的方法是小编分享的全部内容,希望能给大家参考,希望大家多多支持。
本文链接: 查看全部
php抓取网页json数据(实例如下所示:以上这篇就是小编分享)
示例如下:
// 追加写入用户名下文件
$code="001";//动态数据
$json_string = file_get_contents("text.json");// 从文件中读取数据到PHP变量
$data = json_decode($json_string,true);// 把JSON字符串转成PHP数组
$data[$code]=array("a"=>"as","b"=>"bs","c"=>"cs");
$json_strings = json_encode($data);
file_put_contents("text.json",$json_strings);//写入
//修改
$json_string = file_get_contents("text.json");// 从文件中读取数据到PHP变量
$data = json_decode($json_string,true);// 把JSON字符串转成PHP数组
$data["001"]["a"]="aas";
$json_strings = json_encode($data);
file_put_contents("text.json",$json_strings);//写入
以上php读写json文件和修改json的方法是小编分享的全部内容,希望能给大家参考,希望大家多多支持。
本文链接:
php抓取网页json数据(PHP中json_decode函数的使用(一)_PHP手册)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-10-18 11:00
好久没有为PHP写文章了,好久没用PHP了。我差点忘了怎么做。JSON是现在比较流行的数据通信方式,比XML更流行,一般用作数据获取和通信的api接口。
就文章的标题而言,本文介绍了两个小点:PHP获取内容,PHP解析JSON并显示。
PHP获取界面内容
如果要解析JSON数据并显示在页面上,首先必须要获取JSON接口文件的内容。在 PHP 中要获取页面的内容,可以使用 fopen() 函数远程访问页面,然后使用 fread() 函数循环获取内容。
假设接口文件页面是:,那么我们可以使用下面的语句来获取这个接口文件的内容:
$handle = fopen("","rb");
$content = "";
而 (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
这样,内容保存的内容就是JSON api内容。
PHP解析JSON并显示
原创内容不能直接调用,必须经过PHP进一步处理后才能调用显示在网页上。在PHP5.2及以后的版本中,使用json_decode()函数解析JSON数据并转换成PHP可以调用的数据格式。例如:
$content = json_decode($content);
解析后,我们可以像调用PHP中的数组数据一样调用JSON中的数据。这个调用方法需要根据具体的JSON数据格式来编写,演示请看下面。关于json_decode函数的使用,详见PHP手册,这里不再赘述:
实战中调用琼台博客的api
细心的朋友会发现,潜行者m博客的侧边栏底部多了一个“好友推荐”模块,推荐了一些琼台博客的文章。
友情推荐是琼台博客提出的一种博客之间的交流方式,比传统友情链接更有效,同时实现了博客内容的互补。由于琼台博客的博客程序是自己写的,所以提供了JSON api接口,获取最新的推荐文章。
我使用 PHP 来获取这个 JSON 接口并将其输出到我的博客的侧边栏。让我们付诸行动。
第一步是检查api是如何调用的
调用前一定要阅读对方的api调用手册,包括调用地址、调用方式、数据输出格式等。琼泰博客api描述地址如下:。
根据文档,我使用了这个参数,意思是调用五个推荐的文章。
第二步获取api结构数据
很简单,如上所述,具体代码如下:
$handle = fopen("","rb");
$content = "";
而 (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
首先打开数据文件,然后将所有内容保存到内容变量中。因为可以确定api数据不会超过10000个字符,所以使用10000作为fread函数的第二个参数。这样,api 返回的 JSON 数据就存储在 content 变量中。
第三步,解析并输出内容
使用以下代码解析数据,然后调用输出
$content = json_decode($content);
foreach ($content->data as $key) {
回声'';
}
先处理content变量中的JSON数据,然后将其转化为PHP可以调用的数据,然后使用foreach遍历输出这5条内容,按照我需要的HTML格式插入内容.
再加上样式修改,这样就完成了JSON的获取解析并展示在页面上。调用其他api数据的方法类似。
原文链接: 查看全部
php抓取网页json数据(PHP中json_decode函数的使用(一)_PHP手册)
好久没有为PHP写文章了,好久没用PHP了。我差点忘了怎么做。JSON是现在比较流行的数据通信方式,比XML更流行,一般用作数据获取和通信的api接口。
就文章的标题而言,本文介绍了两个小点:PHP获取内容,PHP解析JSON并显示。
PHP获取界面内容
如果要解析JSON数据并显示在页面上,首先必须要获取JSON接口文件的内容。在 PHP 中要获取页面的内容,可以使用 fopen() 函数远程访问页面,然后使用 fread() 函数循环获取内容。
假设接口文件页面是:,那么我们可以使用下面的语句来获取这个接口文件的内容:
$handle = fopen("","rb");
$content = "";
而 (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
这样,内容保存的内容就是JSON api内容。
PHP解析JSON并显示
原创内容不能直接调用,必须经过PHP进一步处理后才能调用显示在网页上。在PHP5.2及以后的版本中,使用json_decode()函数解析JSON数据并转换成PHP可以调用的数据格式。例如:
$content = json_decode($content);
解析后,我们可以像调用PHP中的数组数据一样调用JSON中的数据。这个调用方法需要根据具体的JSON数据格式来编写,演示请看下面。关于json_decode函数的使用,详见PHP手册,这里不再赘述:
实战中调用琼台博客的api
细心的朋友会发现,潜行者m博客的侧边栏底部多了一个“好友推荐”模块,推荐了一些琼台博客的文章。
友情推荐是琼台博客提出的一种博客之间的交流方式,比传统友情链接更有效,同时实现了博客内容的互补。由于琼台博客的博客程序是自己写的,所以提供了JSON api接口,获取最新的推荐文章。
我使用 PHP 来获取这个 JSON 接口并将其输出到我的博客的侧边栏。让我们付诸行动。
第一步是检查api是如何调用的
调用前一定要阅读对方的api调用手册,包括调用地址、调用方式、数据输出格式等。琼泰博客api描述地址如下:。
根据文档,我使用了这个参数,意思是调用五个推荐的文章。
第二步获取api结构数据
很简单,如上所述,具体代码如下:
$handle = fopen("","rb");
$content = "";
而 (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
首先打开数据文件,然后将所有内容保存到内容变量中。因为可以确定api数据不会超过10000个字符,所以使用10000作为fread函数的第二个参数。这样,api 返回的 JSON 数据就存储在 content 变量中。
第三步,解析并输出内容
使用以下代码解析数据,然后调用输出
$content = json_decode($content);
foreach ($content->data as $key) {
回声'';
}
先处理content变量中的JSON数据,然后将其转化为PHP可以调用的数据,然后使用foreach遍历输出这5条内容,按照我需要的HTML格式插入内容.
再加上样式修改,这样就完成了JSON的获取解析并展示在页面上。调用其他api数据的方法类似。
原文链接:
php抓取网页json数据(()php中从数据库读取数据读取数据格式返回数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-18 10:30
)
在php中,从数据库中读取数据,并以json格式返回数据。具体方法如下:
第一步是定义相关变量
$servername = "localhost";
$username = "root";
$password = "root";
$mysqlname = "datatest";
$json = '';
$data = array();
class User {
public $id;
public $fname;
public $lname;
public $email;
public $password;
}
第二步是链接数据库,代码如下:
// 创建连接
$conn = mysqli_connect($servername, $username, $password, $mysqlname);
第三步,定义查询语句并执行。代码如下:
$sql = "SELECT * FROM userinfo";
$result = $conn->query($sql);
第四步,获取查询到的数据,放入预先声明的类中,最后以json格式输出。代码如下:
if($result) {
//echo "查询成功";
while ($row = mysqli_fetch_array($result,MYSQL_ASSOC)) {
$user = new User();
$user->id = $row["id"];
$user->fname = $row["fname"];
$user->lname = $row["lname"];
$user->email = $row["email"];
$user->password = $row["password"];
$data[]=$user;
}
//把数据转换为JSON数据.
$json = json_encode($data);
echo "{".'"user"'.":".$json."}";
} else {
echo "查询失败";
} 查看全部
php抓取网页json数据(()php中从数据库读取数据读取数据格式返回数据
)
在php中,从数据库中读取数据,并以json格式返回数据。具体方法如下:
第一步是定义相关变量
$servername = "localhost";
$username = "root";
$password = "root";
$mysqlname = "datatest";
$json = '';
$data = array();
class User {
public $id;
public $fname;
public $lname;
public $email;
public $password;
}
第二步是链接数据库,代码如下:
// 创建连接
$conn = mysqli_connect($servername, $username, $password, $mysqlname);
第三步,定义查询语句并执行。代码如下:
$sql = "SELECT * FROM userinfo";
$result = $conn->query($sql);
第四步,获取查询到的数据,放入预先声明的类中,最后以json格式输出。代码如下:
if($result) {
//echo "查询成功";
while ($row = mysqli_fetch_array($result,MYSQL_ASSOC)) {
$user = new User();
$user->id = $row["id"];
$user->fname = $row["fname"];
$user->lname = $row["lname"];
$user->email = $row["email"];
$user->password = $row["password"];
$data[]=$user;
}
//把数据转换为JSON数据.
$json = json_encode($data);
echo "{".'"user"'.":".$json."}";
} else {
echo "查询失败";
}
php抓取网页json数据( ,涉及php针对json格式数据及文件相关操作技巧汇总)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-10-14 15:12
,涉及php针对json格式数据及文件相关操作技巧汇总)
PHP生成获取JSON文件的方法
更新时间:2016-08-23 12:15:26 作者:onestopweb
本文文章主要介绍PHP生成和获取JSON文件的方法。涉及到PHP的json格式数据和文件相关的操作技巧。有需要的朋友可以参考以下
本文介绍了PHP生成和获取JSON文件的方法。分享给大家,供大家参考,如下:
先定义一个数组,然后遍历数据表,将对应的数据放入数组中,最后通过json_encode()转换数组
json_encode() 函数的作用是将值转换为JSON数据存储格式。
putjson.php:
如果有同名的 JSON 文件,则会被覆盖,如果没有 JSON 文件,则会创建。
生成或覆盖的 JSON 如下:
复制代码代码如下:
[["1","\u811A\u672C\u4E4B\u5BB6",""],["2","\u7F16\u7A0B\u5F00\u53D1",""]]
然后,将 JSON 文件中的数据读入 PHP 变量。
getjson.php:
效果图:
PS:这里有一些比较实用的json在线工具供大家参考:
在线JSON代码检查、检查、美化和格式化工具:
JSON在线格式化工具:
在线 XML/JSON 转换工具:
json代码在线格式化/美化/压缩/编辑/转换工具:
C语言风格/HTML/CSS/json代码格式化和美化工具:
对PHP相关内容感兴趣的读者可以查看本站主题:《PHP中json格式数据操作技巧总结》、《XML文件的PHP操作技巧总结》、《PHP基本语法介绍》、 《PHP数组(数组)操作技巧》、《php字符串(字符串)使用总结》、《php+mysql数据库操作入门教程》、《php常用数据库操作技巧总结》
我希望这篇文章能帮助你进行 PHP 编程。 查看全部
php抓取网页json数据(
,涉及php针对json格式数据及文件相关操作技巧汇总)
PHP生成获取JSON文件的方法
更新时间:2016-08-23 12:15:26 作者:onestopweb
本文文章主要介绍PHP生成和获取JSON文件的方法。涉及到PHP的json格式数据和文件相关的操作技巧。有需要的朋友可以参考以下
本文介绍了PHP生成和获取JSON文件的方法。分享给大家,供大家参考,如下:
先定义一个数组,然后遍历数据表,将对应的数据放入数组中,最后通过json_encode()转换数组
json_encode() 函数的作用是将值转换为JSON数据存储格式。
putjson.php:
如果有同名的 JSON 文件,则会被覆盖,如果没有 JSON 文件,则会创建。
生成或覆盖的 JSON 如下:
复制代码代码如下:
[["1","\u811A\u672C\u4E4B\u5BB6",""],["2","\u7F16\u7A0B\u5F00\u53D1",""]]
然后,将 JSON 文件中的数据读入 PHP 变量。
getjson.php:
效果图:
PS:这里有一些比较实用的json在线工具供大家参考:
在线JSON代码检查、检查、美化和格式化工具:
JSON在线格式化工具:
在线 XML/JSON 转换工具:
json代码在线格式化/美化/压缩/编辑/转换工具:
C语言风格/HTML/CSS/json代码格式化和美化工具:
对PHP相关内容感兴趣的读者可以查看本站主题:《PHP中json格式数据操作技巧总结》、《XML文件的PHP操作技巧总结》、《PHP基本语法介绍》、 《PHP数组(数组)操作技巧》、《php字符串(字符串)使用总结》、《php+mysql数据库操作入门教程》、《php常用数据库操作技巧总结》
我希望这篇文章能帮助你进行 PHP 编程。
php抓取网页json数据(一个从网络上抓取数据的一个小程序(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-11 08:29
最近做了一个小程序,从网上抓取数据。主要是关于信用,一些黑名单网站采集,从网站抓到自己的系统。
我也找到了一些资料,但我认为没有一个很好的和全面的例子。所以在这里做个笔记以提醒自己。
首先需要一个jsoup jar包,我用的是1.6.0。. 下载地址为:
1.获取网页内容(核心代码,技术有限,无封装)。
2.登录后,抓取网页数据(如何在请求中携带cookies)。
3、获取网站的ajax请求方法(返回json)。
上面三点我都会用一个class来收录(见谅,看的粗糙,直接复制代码就行了,应该可以的)
一、这个类分别有上面的1、2、3个方法,可以直接测试main方法
package com.minxinloan.black.web.utils;
import java.io.BufferedReader;
import java.io.ByteArrayOutputStream;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.io.PrintWriter;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLConnection;
import java.net.URLEncoder;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import java.util.StringTokenizer;
import net.sf.json.JSONArray;
import net.sf.json.JSONObject;
import org.jsoup.Connection;
import org.jsoup.Connection.Method;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class CookieUtil {
public final static String CONTENT_TYPE = "Content-Type";
public static void main(String[] args) {
//String loginURL = "http://www.p2peye.com/member.p ... 3B%3B
String listURL = "http://www.p2peye.com/blacklist.php?p=2";
String logURL = "http://www.p2peye.com/member.php";
//********************************需要登录的*************************************************
try {
Connection.Response res =
Jsoup.connect(logURL)
.data("mod","logging"
,"action","login"
,"loginsubmit","yes"
,"loginhash","Lsc66"
,"username","puqiuxiaomao"
,"password","a1234567")
.method(Method.POST)
.execute();
//这儿的SESSIONID需要根据要登录的目标网站设置的session Cookie名字而定
Connection con=Jsoup.connect(listURL);
//设置访问形式(电脑访问,手机访问):直接百度都参数设置
con.header("User-Agent", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)");
//把登录信息的cookies保存如map对象里面
Map map=res.cookies();
Iterator it =map.entrySet().iterator();
while(it.hasNext()){
Entry en= it.next();
//把登录的信息放入请求里面
con =con.cookie(en.getKey(), en.getValue());
}
//再次获取Document对象。
Document objectDoc = con.get();
Elements elements = objectDoc.getAllElements();//获取这个连接返回页面的源码内容(不是源码跟源码差不多)
for (Element element : elements) {
//element是迭代出来的标签:如:
Elements elements2= element.getAllElements();//
for (Element element2 : elements2) {
element2.text();
element2.attr("href");//获取标签属性。element2代表a标签:href代表属性
element2.text();//获取标签文本
}
}
//********************************不需要登录的*************************************************
String URL = "http://www.p2peye.com/blacklist.php?p=2";
Document conTemp = Jsoup.connect(URL).get();
Elements elementsTemps = conTemp.getAllElements();
for (Element elementsTemp : elementsTemps) {
elementsTemp.text();
elementsTemp.attr("href");//获取标签属性。element2代表a标签:href代表属性
elementsTemp.text();//获取标签文本
}
//********************************ajax方法获取内容。。。*************************************************。
HttpURLConnection connection = null;
BufferedReader reader = null;
try {
StringBuffer sb = new StringBuffer();
URL getUrl = new URL(URL);
connection = (HttpURLConnection)getUrl.openConnection();
reader = new BufferedReader(new InputStreamReader(
connection.getInputStream(),"utf-8"));
String lines;
while ((lines = reader.readLine()) != null) {
sb.append(lines);
};
List list = parseJSON2List(sb.toString());//json转换成list
} catch (Exception e) {
} finally{
if(reader!=null)
try {
reader.close();
} catch (IOException e) {
}
// 断开连接
connection.disconnect();
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static Map parseJSON2Map(String jsonStr){
Map map = new HashMap();
//最外层解析
JSONObject json = JSONObject.fromObject(jsonStr);
for(Object k : json.keySet()){
Object v = json.get(k);
//如果内层还是数组的话,继续解析
if(v instanceof JSONArray){
List list = new ArrayList();
Iterator it = ((JSONArray)v).iterator();
while(it.hasNext()){
JSONObject json2 = it.next();
list.add(parseJSON2Map(json2.toString()));
}
map.put(k.toString(), list);
} else {
map.put(k.toString(), v);
}
}
return map;
}
public static List parseJSON2List(String jsonStr){
JSONArray jsonArr = JSONArray.fromObject(jsonStr);
List list = new ArrayList();
Iterator it = jsonArr.iterator();
while(it.hasNext()){
JSONObject json2 = it.next();
list.add(parseJSON2Map(json2.toString()));
}
return list;
}
}
二、这是获取验证码的类,可以研究一下。(但是要分析网站的验证码的请求地址)
Java抓取网页数据,登录后抓取数据,补不扣,
Java抓取网页数据,登录后抓取数据。
原来的: 查看全部
php抓取网页json数据(一个从网络上抓取数据的一个小程序(图))
最近做了一个小程序,从网上抓取数据。主要是关于信用,一些黑名单网站采集,从网站抓到自己的系统。
我也找到了一些资料,但我认为没有一个很好的和全面的例子。所以在这里做个笔记以提醒自己。
首先需要一个jsoup jar包,我用的是1.6.0。. 下载地址为:
1.获取网页内容(核心代码,技术有限,无封装)。
2.登录后,抓取网页数据(如何在请求中携带cookies)。
3、获取网站的ajax请求方法(返回json)。
上面三点我都会用一个class来收录(见谅,看的粗糙,直接复制代码就行了,应该可以的)
一、这个类分别有上面的1、2、3个方法,可以直接测试main方法
package com.minxinloan.black.web.utils;
import java.io.BufferedReader;
import java.io.ByteArrayOutputStream;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.io.PrintWriter;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLConnection;
import java.net.URLEncoder;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import java.util.StringTokenizer;
import net.sf.json.JSONArray;
import net.sf.json.JSONObject;
import org.jsoup.Connection;
import org.jsoup.Connection.Method;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class CookieUtil {
public final static String CONTENT_TYPE = "Content-Type";
public static void main(String[] args) {
//String loginURL = "http://www.p2peye.com/member.p ... 3B%3B
String listURL = "http://www.p2peye.com/blacklist.php?p=2";
String logURL = "http://www.p2peye.com/member.php";
//********************************需要登录的*************************************************
try {
Connection.Response res =
Jsoup.connect(logURL)
.data("mod","logging"
,"action","login"
,"loginsubmit","yes"
,"loginhash","Lsc66"
,"username","puqiuxiaomao"
,"password","a1234567")
.method(Method.POST)
.execute();
//这儿的SESSIONID需要根据要登录的目标网站设置的session Cookie名字而定
Connection con=Jsoup.connect(listURL);
//设置访问形式(电脑访问,手机访问):直接百度都参数设置
con.header("User-Agent", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)");
//把登录信息的cookies保存如map对象里面
Map map=res.cookies();
Iterator it =map.entrySet().iterator();
while(it.hasNext()){
Entry en= it.next();
//把登录的信息放入请求里面
con =con.cookie(en.getKey(), en.getValue());
}
//再次获取Document对象。
Document objectDoc = con.get();
Elements elements = objectDoc.getAllElements();//获取这个连接返回页面的源码内容(不是源码跟源码差不多)
for (Element element : elements) {
//element是迭代出来的标签:如:
Elements elements2= element.getAllElements();//
for (Element element2 : elements2) {
element2.text();
element2.attr("href");//获取标签属性。element2代表a标签:href代表属性
element2.text();//获取标签文本
}
}
//********************************不需要登录的*************************************************
String URL = "http://www.p2peye.com/blacklist.php?p=2";
Document conTemp = Jsoup.connect(URL).get();
Elements elementsTemps = conTemp.getAllElements();
for (Element elementsTemp : elementsTemps) {
elementsTemp.text();
elementsTemp.attr("href");//获取标签属性。element2代表a标签:href代表属性
elementsTemp.text();//获取标签文本
}
//********************************ajax方法获取内容。。。*************************************************。
HttpURLConnection connection = null;
BufferedReader reader = null;
try {
StringBuffer sb = new StringBuffer();
URL getUrl = new URL(URL);
connection = (HttpURLConnection)getUrl.openConnection();
reader = new BufferedReader(new InputStreamReader(
connection.getInputStream(),"utf-8"));
String lines;
while ((lines = reader.readLine()) != null) {
sb.append(lines);
};
List list = parseJSON2List(sb.toString());//json转换成list
} catch (Exception e) {
} finally{
if(reader!=null)
try {
reader.close();
} catch (IOException e) {
}
// 断开连接
connection.disconnect();
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static Map parseJSON2Map(String jsonStr){
Map map = new HashMap();
//最外层解析
JSONObject json = JSONObject.fromObject(jsonStr);
for(Object k : json.keySet()){
Object v = json.get(k);
//如果内层还是数组的话,继续解析
if(v instanceof JSONArray){
List list = new ArrayList();
Iterator it = ((JSONArray)v).iterator();
while(it.hasNext()){
JSONObject json2 = it.next();
list.add(parseJSON2Map(json2.toString()));
}
map.put(k.toString(), list);
} else {
map.put(k.toString(), v);
}
}
return map;
}
public static List parseJSON2List(String jsonStr){
JSONArray jsonArr = JSONArray.fromObject(jsonStr);
List list = new ArrayList();
Iterator it = jsonArr.iterator();
while(it.hasNext()){
JSONObject json2 = it.next();
list.add(parseJSON2Map(json2.toString()));
}
return list;
}
}
二、这是获取验证码的类,可以研究一下。(但是要分析网站的验证码的请求地址)
Java抓取网页数据,登录后抓取数据,补不扣,
Java抓取网页数据,登录后抓取数据。
原来的:
php抓取网页json数据(()定义相关变量第二步:定义查询语句)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-06 16:21
在php中,从数据库中读取数据,并以json格式返回数据。具体方法如下: 第一步,定义相关变量$s
在php中,从数据库中读取数据,并以json格式返回数据。具体方法如下:
第一步,定义相关变量
$servername = "localhost";
$username = "root";
$password = "root";
$mysqlname = "datatest";
$json = '';
$data = array();
class User
{
public $id;
public $fname;
public $lname;
public $email;
public $password;
}
第二步是链接数据库,代码如下:
// 创建连接
$conn = mysqli_connect($servername, $username, $password, $mysqlname);
第三步,定义查询语句并执行。代码如下:
$sql = "SELECT * FROM userinfo";
$result = $conn->query($sql);
第四步,获取查询到的数据,放入预先声明的类中,最后以json格式输出。
代码显示如下:
if($result){
//echo "查询成功";
while ($row = mysqli_fetch_array($result,MYSQL_ASSOC))
{
$user = new User();
$user->id = $row["id"];
$user->fname = $row["fname"];
$user->lname = $row["lname"];
$user->email = $row["email"];
$user->password = $row["password"];
$data[]=$user;
}
$json = json_encode($data);//把数据转换为JSON数据.
echo "{".'"user"'.":".$json."}";
}else{
echo "查询失败";
}
以上php从数据库中读取数据并以json格式返回数据的方法是小编分享的全部内容,希望能给大家一个参考,也希望大家多多支持脚本之家。 查看全部
php抓取网页json数据(()定义相关变量第二步:定义查询语句)
在php中,从数据库中读取数据,并以json格式返回数据。具体方法如下: 第一步,定义相关变量$s
在php中,从数据库中读取数据,并以json格式返回数据。具体方法如下:
第一步,定义相关变量
$servername = "localhost";
$username = "root";
$password = "root";
$mysqlname = "datatest";
$json = '';
$data = array();
class User
{
public $id;
public $fname;
public $lname;
public $email;
public $password;
}
第二步是链接数据库,代码如下:
// 创建连接
$conn = mysqli_connect($servername, $username, $password, $mysqlname);
第三步,定义查询语句并执行。代码如下:
$sql = "SELECT * FROM userinfo";
$result = $conn->query($sql);
第四步,获取查询到的数据,放入预先声明的类中,最后以json格式输出。
代码显示如下:
if($result){
//echo "查询成功";
while ($row = mysqli_fetch_array($result,MYSQL_ASSOC))
{
$user = new User();
$user->id = $row["id"];
$user->fname = $row["fname"];
$user->lname = $row["lname"];
$user->email = $row["email"];
$user->password = $row["password"];
$data[]=$user;
}
$json = json_encode($data);//把数据转换为JSON数据.
echo "{".'"user"'.":".$json."}";
}else{
echo "查询失败";
}
以上php从数据库中读取数据并以json格式返回数据的方法是小编分享的全部内容,希望能给大家一个参考,也希望大家多多支持脚本之家。
php抓取网页json数据(PHP一个问题:用AJAX返回数据时,怎么提取其中的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-10-06 04:31
有这样一个问题:当使用Ajax返回数据时,如何提取信息并将其写入网页的不同部分?W3C学校提到,AJAX返回的数据是JSON数据格式。我使用PHP作为背景脚本。起初,我自己组装JSON数据,但效果不好。后来,我检查了数据,并在PHP_uencode()函数中使用了JSON
存在这样一个问题:使用Ajax返回数据时,如何提取信息并将其写入网页的不同部分
W3C学校提到AJAX返回的数据是JSON数据格式。我使用PHP作为背景脚本
起初,我以JSON格式组装数据,但效果不好。后来,我检查了数据,并在PHP_uencode()函数中使用了JSON
$STR是要处理的数据。使用以下语句输出JSON格式的数据
其中,JSON_uNescaped_uuUnicode指的是Unicode格式的编码
手册上说“此函数只能接受UTF-8编码的数据”,并且有多种格式
echo json_encode($row,JSON_UNESCAPED_UNICODE);
前台页面启动一个Ajax请求,核心部分是处理Ajax返回的数据xmlhttp.respondtext
使用此语句处理TXT=xmlhttp。响应文本;var obj=eval(“(“+txt+”)评估功能是关键
eval()函数使用JavaScript编译器解析JSON文本并生成JavaScript对象。文本必须用括号括起来,以避免语法错误:
Ajax请求代码如下所示:
var xmlHttp=null
function get_pic(str)
{
/*search the file in mysql table pydot and pydot_g,
then give the result to front page.start ajax request*/
xmlHttp=GetXmlHttpObject()
if (xmlHttp==null)
{
alert ("Browser does not support HTTP Request")
return
}
var url="Public/Js/json.php";
url=url+"?q="+str.innerHTML
url=url+"&sid="+Math.random()
//alert(url)
xmlHttp.onreadystatechange=stateChanged
xmlHttp.open("GET",url,true)
xmlHttp.send(null)
}
function stateChanged()
{
var txt,x;
if (xmlHttp.readyState==4 || xmlHttp.readyState=="complete")
{ txt=xmlHttp.responseText ;
//alert(txt)
var obj = eval ("(" + txt + ")");
document.getElementById("other").innerHTML=obj.other;
document.getElementById("title").innerHTML=obj.title;
}
}
function GetXmlHttpObject()
{
var xmlHttp=null;
try
{
// Firefox, Opera 8.0+, Safari
xmlHttp=new XMLHttpRequest();
}
catch (e)
{
//Internet Explorer
try
{
xmlHttp=new ActiveXObject("Msxml2.XMLHTTP");
}
catch (e)
{
xmlHttp=new ActiveXObject("Microsoft.XMLHTTP");
}
}
return xmlHttp;
}
从代码中,我们可以看到obj。Title提取返回文本中的标题信息,并将其写入页面中id='Title'的元素
声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系 查看全部
php抓取网页json数据(PHP一个问题:用AJAX返回数据时,怎么提取其中的信息)
有这样一个问题:当使用Ajax返回数据时,如何提取信息并将其写入网页的不同部分?W3C学校提到,AJAX返回的数据是JSON数据格式。我使用PHP作为背景脚本。起初,我自己组装JSON数据,但效果不好。后来,我检查了数据,并在PHP_uencode()函数中使用了JSON
存在这样一个问题:使用Ajax返回数据时,如何提取信息并将其写入网页的不同部分
W3C学校提到AJAX返回的数据是JSON数据格式。我使用PHP作为背景脚本
起初,我以JSON格式组装数据,但效果不好。后来,我检查了数据,并在PHP_uencode()函数中使用了JSON
$STR是要处理的数据。使用以下语句输出JSON格式的数据
其中,JSON_uNescaped_uuUnicode指的是Unicode格式的编码
手册上说“此函数只能接受UTF-8编码的数据”,并且有多种格式
echo json_encode($row,JSON_UNESCAPED_UNICODE);
前台页面启动一个Ajax请求,核心部分是处理Ajax返回的数据xmlhttp.respondtext
使用此语句处理TXT=xmlhttp。响应文本;var obj=eval(“(“+txt+”)评估功能是关键
eval()函数使用JavaScript编译器解析JSON文本并生成JavaScript对象。文本必须用括号括起来,以避免语法错误:
Ajax请求代码如下所示:
var xmlHttp=null
function get_pic(str)
{
/*search the file in mysql table pydot and pydot_g,
then give the result to front page.start ajax request*/
xmlHttp=GetXmlHttpObject()
if (xmlHttp==null)
{
alert ("Browser does not support HTTP Request")
return
}
var url="Public/Js/json.php";
url=url+"?q="+str.innerHTML
url=url+"&sid="+Math.random()
//alert(url)
xmlHttp.onreadystatechange=stateChanged
xmlHttp.open("GET",url,true)
xmlHttp.send(null)
}
function stateChanged()
{
var txt,x;
if (xmlHttp.readyState==4 || xmlHttp.readyState=="complete")
{ txt=xmlHttp.responseText ;
//alert(txt)
var obj = eval ("(" + txt + ")");
document.getElementById("other").innerHTML=obj.other;
document.getElementById("title").innerHTML=obj.title;
}
}
function GetXmlHttpObject()
{
var xmlHttp=null;
try
{
// Firefox, Opera 8.0+, Safari
xmlHttp=new XMLHttpRequest();
}
catch (e)
{
//Internet Explorer
try
{
xmlHttp=new ActiveXObject("Msxml2.XMLHTTP");
}
catch (e)
{
xmlHttp=new ActiveXObject("Microsoft.XMLHTTP");
}
}
return xmlHttp;
}
从代码中,我们可以看到obj。Title提取返回文本中的标题信息,并将其写入页面中id='Title'的元素
声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系
php抓取网页json数据(微信小程序的基础知识2.实现原理首先,先看一下这个请求函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-06 04:27
微信小程序基础知识
2. 实现原理
首先我们来看看请求函数 wx.request({
url:'******', //这里填写你的接口路径
header: {//这里写你返回什么类型的数据为借口,这里就是微信小程序的威力,直接帮你解析数据,再也不用找各种方式解析json、xml等数据了
'内容类型':'应用程序/json'
},
data: {//在这里写你要请求的参数
X:'',
你:''
},
成功:功能(资源){
//这里是请求成功后执行一些函数操作
控制台.log(res.data)
}
})
3.代码
分解图
一、上一段开头知乎 json格式的接口数据
"日期":"20161114",
“故事”:[
{
“图片”:[
“”
],
“类型”:0,
"id":8975316,
"ga_prefix":"111422",
"title":"小东西,我跟你一样"
},
{
“图片”:[
“”
],
“类型”:0,
"id":8977438,
"ga_prefix":"111421",
“title”:“长大了,谁说就一定要长大?”
},
索引.js
页({
数据: {
持续时间:2000,
指标点:真实,
自动播放:真实,
间隔:3000,
加载:假,
普通:假
},
加载:函数(){
var that = this//这句话不要错过,很重要
wx.request({
网址:'#39;,
标题:{
'内容类型':'应用程序/json'
},
成功:功能(资源){
//获取到的json数据会存放在这个名为知乎的数组中
那.setData({
知乎:res.data.stories,
//res代表成功函数的事件对,数据是固定的,故事就是上面json数据中的故事
})
}
})
}
})
索引.wxml
autoplay="{{autoplay}}" interval="{{interval}}" duration="{{duration}}">//这里的属性不重要,见下
{{item.title}}
看完这段代码,你会想,根据微信小程序的绑定原理,这里的代码在哪里调用了onLoad()函数,别想太多,微信小程序会为你省略这些步骤。直接调用知乎数组就行了。 查看全部
php抓取网页json数据(微信小程序的基础知识2.实现原理首先,先看一下这个请求函数)
微信小程序基础知识
2. 实现原理
首先我们来看看请求函数 wx.request({
url:'******', //这里填写你的接口路径
header: {//这里写你返回什么类型的数据为借口,这里就是微信小程序的威力,直接帮你解析数据,再也不用找各种方式解析json、xml等数据了
'内容类型':'应用程序/json'
},
data: {//在这里写你要请求的参数
X:'',
你:''
},
成功:功能(资源){
//这里是请求成功后执行一些函数操作
控制台.log(res.data)
}
})
3.代码
分解图
一、上一段开头知乎 json格式的接口数据
"日期":"20161114",
“故事”:[
{
“图片”:[
“”
],
“类型”:0,
"id":8975316,
"ga_prefix":"111422",
"title":"小东西,我跟你一样"
},
{
“图片”:[
“”
],
“类型”:0,
"id":8977438,
"ga_prefix":"111421",
“title”:“长大了,谁说就一定要长大?”
},
索引.js
页({
数据: {
持续时间:2000,
指标点:真实,
自动播放:真实,
间隔:3000,
加载:假,
普通:假
},
加载:函数(){
var that = this//这句话不要错过,很重要
wx.request({
网址:'#39;,
标题:{
'内容类型':'应用程序/json'
},
成功:功能(资源){
//获取到的json数据会存放在这个名为知乎的数组中
那.setData({
知乎:res.data.stories,
//res代表成功函数的事件对,数据是固定的,故事就是上面json数据中的故事
})
}
})
}
})
索引.wxml
autoplay="{{autoplay}}" interval="{{interval}}" duration="{{duration}}">//这里的属性不重要,见下
{{item.title}}
看完这段代码,你会想,根据微信小程序的绑定原理,这里的代码在哪里调用了onLoad()函数,别想太多,微信小程序会为你省略这些步骤。直接调用知乎数组就行了。
php抓取网页json数据(类似:UncaughtTypeErrortosearchfor‘’inJSONstring前端jsamp;php笔记正文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-02 09:12
类似:未捕获类型错误:无法使用“in”运算符搜索“in”JSON字符串前端JS&;PHP注释
正文:
在HTML页面中,通过$请求PHP页面。Get()方法,回调函数返回JSON数据,但无法通过数据点中的数据获取。代码如下:
JS代码:
$("#button1").click(function(){
$.get("index.php",{username:$("#username").val(),password:$("#password").val(),tel:$("#tel").val()},function(data,textStatus){ //get方法请求数据
$("#response").html("用户名:"+data.name+"
密码:"+data.pwd+"
手机号码:"+data.tell);
alert(data); //能够显示数据
})
})
PHP代码:
手术后:
返回数据的能力
无法检索返回的数据
解决方案:
创建一个对象以将JSON数据转换为对象
ajaxData=$.parseJSON(data) //将json数据转换为js对象
注:
它不能在程序中运行,这无法解释PHP页面。它必须在AppServ程序下的WWW文件夹中运行(运行时不能是FTP地址,而是诸如“:82/unit07/index.HTML”之类的地址) 查看全部
php抓取网页json数据(类似:UncaughtTypeErrortosearchfor‘’inJSONstring前端jsamp;php笔记正文)
类似:未捕获类型错误:无法使用“in”运算符搜索“in”JSON字符串前端JS&;PHP注释
正文:
在HTML页面中,通过$请求PHP页面。Get()方法,回调函数返回JSON数据,但无法通过数据点中的数据获取。代码如下:
JS代码:
$("#button1").click(function(){
$.get("index.php",{username:$("#username").val(),password:$("#password").val(),tel:$("#tel").val()},function(data,textStatus){ //get方法请求数据
$("#response").html("用户名:"+data.name+"
密码:"+data.pwd+"
手机号码:"+data.tell);
alert(data); //能够显示数据
})
})
PHP代码:
手术后:
返回数据的能力
无法检索返回的数据
解决方案:
创建一个对象以将JSON数据转换为对象
ajaxData=$.parseJSON(data) //将json数据转换为js对象
注:
它不能在程序中运行,这无法解释PHP页面。它必须在AppServ程序下的WWW文件夹中运行(运行时不能是FTP地址,而是诸如“:82/unit07/index.HTML”之类的地址)
php抓取网页json数据(,结合jQuery的ajax实现跨域抓取数据的相关操作技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-01 10:11
本文文章主要介绍jquery+thinkphp实现跨域数据抓取的方法,并结合实例的形式分析thinkPHP结合jQuery的ajax实现跨域数据抓取的相关操作技巧。有需要的朋友可以参考以下
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
今天,我将做一个远程数据捕获功能。记住jquery可以用ajax远程捕获,但是不能跨域。我在网上搜索了很多。但是我觉得是一个综合性的问题,所以我觉得对于一个简单的问题来说稍微复杂一些,但至少现在已经解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post向服务器后端发送数据,由后端的PHP代码远程获取,存入数据库ajax返回数据给前台,前台使用JS接收数据并显示出来。
//远程抓取获取数据 $("#update_ac").click(function() { $username = $("#username").text(); $("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){ $(this).html(" "); }); $.post("update_ac/username/"+$username,{},function($data){ json = eval("(" + $data + ")"); $("#Submit").html(json.data.Submit); $("#AC").html(json.data.AC); $("#solved,#solved2,#solved3").html(json.data.solved); $("#rank").html(json.data.rank); } ),"json"; });
上面jquery代码四楼说的还算清楚,但是让我纠结的是json数据的接收
json = eval("(" + $data + ")"); //eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这还是前台。跨域抓取是通过PHP扩展simple_html_dom完成的(不知道的可以上网搜一下,基于PHP5开发的)
抓取远程页面到本地。
以上代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后使用正则表达式过滤需要的数据。下面是渲染图
对thinkPHP相关内容更感兴趣的读者可以查看本站专题:《》、《ThinkPHP模板操作技巧总结》、《ThinkPHP常用方法总结》、《Smarty模板介绍基础教程》、《总结》 PHP模板技术”。
我希望本文对您基于 ThinkPHP 框架的 PHP 编程有所帮助。
以上就是jquery+thinkphp实现跨域数据抓取的方法的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
php抓取网页json数据(,结合jQuery的ajax实现跨域抓取数据的相关操作技巧)
本文文章主要介绍jquery+thinkphp实现跨域数据抓取的方法,并结合实例的形式分析thinkPHP结合jQuery的ajax实现跨域数据抓取的相关操作技巧。有需要的朋友可以参考以下
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
今天,我将做一个远程数据捕获功能。记住jquery可以用ajax远程捕获,但是不能跨域。我在网上搜索了很多。但是我觉得是一个综合性的问题,所以我觉得对于一个简单的问题来说稍微复杂一些,但至少现在已经解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post向服务器后端发送数据,由后端的PHP代码远程获取,存入数据库ajax返回数据给前台,前台使用JS接收数据并显示出来。
//远程抓取获取数据 $("#update_ac").click(function() { $username = $("#username").text(); $("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){ $(this).html(" "); }); $.post("update_ac/username/"+$username,{},function($data){ json = eval("(" + $data + ")"); $("#Submit").html(json.data.Submit); $("#AC").html(json.data.AC); $("#solved,#solved2,#solved3").html(json.data.solved); $("#rank").html(json.data.rank); } ),"json"; });
上面jquery代码四楼说的还算清楚,但是让我纠结的是json数据的接收
json = eval("(" + $data + ")"); //eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这还是前台。跨域抓取是通过PHP扩展simple_html_dom完成的(不知道的可以上网搜一下,基于PHP5开发的)
抓取远程页面到本地。
以上代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后使用正则表达式过滤需要的数据。下面是渲染图
对thinkPHP相关内容更感兴趣的读者可以查看本站专题:《》、《ThinkPHP模板操作技巧总结》、《ThinkPHP常用方法总结》、《Smarty模板介绍基础教程》、《总结》 PHP模板技术”。
我希望本文对您基于 ThinkPHP 框架的 PHP 编程有所帮助。
以上就是jquery+thinkphp实现跨域数据抓取的方法的详细内容。更多详情请关注其他相关html中文网站文章!
php抓取网页json数据(PHP获取接口内容(一)(1)_PHP解析JSON)
网站优化 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2021-09-20 06:22
PHP获取接口内容
如果要解析JSON数据并在页面中显示,必须首先获取JSON接口文件的内容。要在PHP中获取页面的内容,可以使用fopen()函数远程页面,然后使用FREAD()函数循环内容
假设接口文件页是API。PHP?操作=打开\uGetBlogList&;仅推荐=1&;Limit=5,则我们可以使用以下语句获取此接口文件的内容:
$handle = fopen("api.php?action=open_getBlogList&only_recommend=1&limit=5","rb");
$content = "";
while (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
通过这种方式,内容保存JSON API内容
PHP解析JSON并显示它
无法直接调用原创内容。在调用它并在网页中显示之前,它必须由PHP进一步处理。用PHP5.2在更高版本中,使用JSON。decode()函数解析JSON数据并将其转换为PHP可以调用的数据格式。例如:
$content = json_decode($content);
在解析
,我们可以在JSON中调用数据,就像在PHP中调用数组数据一样。此调用方法需要根据特定的JSON数据格式编写。请参见下面的演示。关于JSON\ PHP手册中详细介绍了解码函数的使用,此处不再重复:
实战中调用琼台博客API
细心的朋友会发现,在跟踪者m博客的边栏底部有一个“朋友文章推荐”模块,它推荐了一些琼台博客文章
友文推荐是琼台博客提出的一种博客间的交流方式。它比传统的友情链接更有效,实现了博客内容的互补性。因为琼台博客的博客程序是自己写的,所以他提供了JSON API接口来获取最新推荐的文章
我使用PHP获取JSON接口,然后将其输出到我博客的侧栏。下面是实际操作
第一步是检查API调用模式
在调用之前,您必须查看对方的API调用手册,包括调用地址、如何调用、数据输出格式等。琼台博客的API描述地址如下:openapi.html
根据文档,我使用了API。PHP?操作=打开\uGetBlogList&;仅推荐=1&;limit=5等参数表示调用五个推荐值文章
第二步是获取API结构数据
非常简单,如上所述,具体代码如下:
$handle = fopen("api.php?action=open_getBlogList&only_recommend=1&limit=5","rb");
$content = "";
while (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
首先打开数据文件,然后将所有内容保存到内容变量中。因为可以确定API数据不会超过10000个字符,所以10000被用作FREAD函数的第二个参数。这样,API返回的JSON数据保存在内容变量中
步骤3:解析并输出内容
使用以下代码解析数据,然后调用输出
$content = json_decode($content);
foreach ($content->data as $key) {
echo ''.$key->b_title.'';
}
首先,处理content变量中的JSON数据,然后将其转换为PHP可以调用的数据,然后使用foreach遍历并输出这五个内容,并根据我需要的HTML格式插入内容
通过样式修改,您可以获取和解析JSON并在页面中显示它。调用其他API数据的方法与此类似 查看全部
php抓取网页json数据(PHP获取接口内容(一)(1)_PHP解析JSON)
PHP获取接口内容
如果要解析JSON数据并在页面中显示,必须首先获取JSON接口文件的内容。要在PHP中获取页面的内容,可以使用fopen()函数远程页面,然后使用FREAD()函数循环内容
假设接口文件页是API。PHP?操作=打开\uGetBlogList&;仅推荐=1&;Limit=5,则我们可以使用以下语句获取此接口文件的内容:
$handle = fopen("api.php?action=open_getBlogList&only_recommend=1&limit=5","rb");
$content = "";
while (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
通过这种方式,内容保存JSON API内容
PHP解析JSON并显示它
无法直接调用原创内容。在调用它并在网页中显示之前,它必须由PHP进一步处理。用PHP5.2在更高版本中,使用JSON。decode()函数解析JSON数据并将其转换为PHP可以调用的数据格式。例如:
$content = json_decode($content);
在解析
,我们可以在JSON中调用数据,就像在PHP中调用数组数据一样。此调用方法需要根据特定的JSON数据格式编写。请参见下面的演示。关于JSON\ PHP手册中详细介绍了解码函数的使用,此处不再重复:
实战中调用琼台博客API
细心的朋友会发现,在跟踪者m博客的边栏底部有一个“朋友文章推荐”模块,它推荐了一些琼台博客文章
友文推荐是琼台博客提出的一种博客间的交流方式。它比传统的友情链接更有效,实现了博客内容的互补性。因为琼台博客的博客程序是自己写的,所以他提供了JSON API接口来获取最新推荐的文章
我使用PHP获取JSON接口,然后将其输出到我博客的侧栏。下面是实际操作
第一步是检查API调用模式
在调用之前,您必须查看对方的API调用手册,包括调用地址、如何调用、数据输出格式等。琼台博客的API描述地址如下:openapi.html
根据文档,我使用了API。PHP?操作=打开\uGetBlogList&;仅推荐=1&;limit=5等参数表示调用五个推荐值文章
第二步是获取API结构数据
非常简单,如上所述,具体代码如下:
$handle = fopen("api.php?action=open_getBlogList&only_recommend=1&limit=5","rb");
$content = "";
while (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
首先打开数据文件,然后将所有内容保存到内容变量中。因为可以确定API数据不会超过10000个字符,所以10000被用作FREAD函数的第二个参数。这样,API返回的JSON数据保存在内容变量中
步骤3:解析并输出内容
使用以下代码解析数据,然后调用输出
$content = json_decode($content);
foreach ($content->data as $key) {
echo ''.$key->b_title.'';
}
首先,处理content变量中的JSON数据,然后将其转换为PHP可以调用的数据,然后使用foreach遍历并输出这五个内容,并根据我需要的HTML格式插入内容
通过样式修改,您可以获取和解析JSON并在页面中显示它。调用其他API数据的方法与此类似

