
php抓取网页json数据
php抓取网页json数据(Spark大数据分析:核心概念、技术及实践(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-18 18:10
阿里云 > 云栖社区 > 主题图 > P > php远程读取json数据库
推荐活动:
更多优惠>
当前话题:php远程读取json数据库添加到采集夹
相关话题:
php远程读取json数据库相关博客查看更多博客
云数据库产品概述
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
13款Mongodb GUI可视化管理工具,总有一款适合你
作者:徐磊 frank7237 浏览评论:02年前
MongoDB数据库默认的管理工具是(CLI)Shell命令行,专业的DBA更容易使用,但普通人使用GUI可视化工具更方便。下面介绍13个有用的MongoDB可视化工具。MongoDB官方提供社区版Compass,可独立安装使用
阅读全文
Ajax跨域请求JSON JSONP
作者:cometwo1235780 浏览评论:05年前
同源策略和跨域摘要目录:1.同源策略2.跨域3.几种跨域技术1.什么是同源策略?URL 由协议、域名、端口和路径组成。如果两个 URL 具有相同的协议、域名和端口,则它们具有相同的来源。反之,只要协议、域名、端口在其中任何一个不同,就被认为是跨域的。e
阅读全文
《Spark大数据分析:核心概念、技术与实践》大数据技术概览
作者:华章电脑 3937人浏览评论:04年前
本书摘自华章出版社《Spark大数据分析:核心概念、技术与实践》一书第一章第一节,作者Mohammed Guller 更多章节请访问云栖社区“华章计算机”公众号查看. 大数据技术一览 我们正处于大数据时代。数据不仅仅是任何组织的生命
阅读全文
一小时学会MySQL数据库
作者:张果2052 浏览评论:04年前
随着移动互联网的终结和人工智能的到来,大数据变得越来越重要,下一个成功的人应该拥有海量数据。您应该了解数据和数据库。一、数据库概要数据库(Database)是一个用于存储和管理数据的软件系统,就像存储数据的物流仓库一样。在商业领域,信息意味着商机,意味着获取信息的能力
阅读全文
1.7Hadoop的子项目“R与Hadoop大数据分析实践”
作者:华章电脑 1682人 浏览评论:04年前
本章节选自华章出版社《R与Hadoop大数据分析》一书第1章第7节,作者(印刷)Vignesh Prajapati,更多章节可在云栖社区“华章计算机”获取公众号查看1.7Hadoop的子项目Mahout是一个非常强大的数据挖掘库,其中
阅读全文
MongoDB安装
作者:技术小哥 1232人查看评论数:04年前
mongodb介绍MongoDB是一个基于分布式文件存储的数据库。它是一种文档类型。虽然它也是 NoSQL 数据库的一种,但它与 redis 和 memcached 等数据库有些不同。MongoDB 是用 C++ 语言编写的。它旨在为WEB应用程序提供可扩展的高性能数据存储解决方案。星期一
阅读全文
Android Volley 获取 json 格式的数据
作者:哼99251000 浏览评论:04年前
为了让Android能够快速接入网络,解析常见的数据格式,谷歌专门推出了Android系统网络传输的Volley库。volley 库可以轻松地从远程服务器获取图像、字符串、json 对象和 json 对象数组。当然java本身也可以访问json对象
阅读全文
Android Volley 获取 json 格式的数据
作者:沉默胜声823人查看评论:06年前
为了让Android能够快速接入网络,解析常见的数据格式,谷歌专门推出了Android系统网络传输的Volley库。volley 库可以轻松地从远程服务器获取图像、字符串、json 对象和 json 对象数组。当然java本身也可以访问json对象
阅读全文
php远程读取json数据库相关问答
【Java学习全家桶】1460道Java热点问题,百位阿里巴巴技术专家答疑解惑
作者:管理贝贝19522 浏览评论:153年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文 查看全部
php抓取网页json数据(Spark大数据分析:核心概念、技术及实践(组图))
阿里云 > 云栖社区 > 主题图 > P > php远程读取json数据库

推荐活动:
更多优惠>
当前话题:php远程读取json数据库添加到采集夹
相关话题:
php远程读取json数据库相关博客查看更多博客
云数据库产品概述

作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
13款Mongodb GUI可视化管理工具,总有一款适合你


作者:徐磊 frank7237 浏览评论:02年前
MongoDB数据库默认的管理工具是(CLI)Shell命令行,专业的DBA更容易使用,但普通人使用GUI可视化工具更方便。下面介绍13个有用的MongoDB可视化工具。MongoDB官方提供社区版Compass,可独立安装使用
阅读全文
Ajax跨域请求JSON JSONP

作者:cometwo1235780 浏览评论:05年前
同源策略和跨域摘要目录:1.同源策略2.跨域3.几种跨域技术1.什么是同源策略?URL 由协议、域名、端口和路径组成。如果两个 URL 具有相同的协议、域名和端口,则它们具有相同的来源。反之,只要协议、域名、端口在其中任何一个不同,就被认为是跨域的。e
阅读全文
《Spark大数据分析:核心概念、技术与实践》大数据技术概览

作者:华章电脑 3937人浏览评论:04年前
本书摘自华章出版社《Spark大数据分析:核心概念、技术与实践》一书第一章第一节,作者Mohammed Guller 更多章节请访问云栖社区“华章计算机”公众号查看. 大数据技术一览 我们正处于大数据时代。数据不仅仅是任何组织的生命
阅读全文
一小时学会MySQL数据库


作者:张果2052 浏览评论:04年前
随着移动互联网的终结和人工智能的到来,大数据变得越来越重要,下一个成功的人应该拥有海量数据。您应该了解数据和数据库。一、数据库概要数据库(Database)是一个用于存储和管理数据的软件系统,就像存储数据的物流仓库一样。在商业领域,信息意味着商机,意味着获取信息的能力
阅读全文
1.7Hadoop的子项目“R与Hadoop大数据分析实践”

作者:华章电脑 1682人 浏览评论:04年前
本章节选自华章出版社《R与Hadoop大数据分析》一书第1章第7节,作者(印刷)Vignesh Prajapati,更多章节可在云栖社区“华章计算机”获取公众号查看1.7Hadoop的子项目Mahout是一个非常强大的数据挖掘库,其中
阅读全文
MongoDB安装

作者:技术小哥 1232人查看评论数:04年前
mongodb介绍MongoDB是一个基于分布式文件存储的数据库。它是一种文档类型。虽然它也是 NoSQL 数据库的一种,但它与 redis 和 memcached 等数据库有些不同。MongoDB 是用 C++ 语言编写的。它旨在为WEB应用程序提供可扩展的高性能数据存储解决方案。星期一
阅读全文
Android Volley 获取 json 格式的数据
作者:哼99251000 浏览评论:04年前
为了让Android能够快速接入网络,解析常见的数据格式,谷歌专门推出了Android系统网络传输的Volley库。volley 库可以轻松地从远程服务器获取图像、字符串、json 对象和 json 对象数组。当然java本身也可以访问json对象
阅读全文
Android Volley 获取 json 格式的数据


作者:沉默胜声823人查看评论:06年前
为了让Android能够快速接入网络,解析常见的数据格式,谷歌专门推出了Android系统网络传输的Volley库。volley 库可以轻松地从远程服务器获取图像、字符串、json 对象和 json 对象数组。当然java本身也可以访问json对象
阅读全文
php远程读取json数据库相关问答
【Java学习全家桶】1460道Java热点问题,百位阿里巴巴技术专家答疑解惑


作者:管理贝贝19522 浏览评论:153年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文
php抓取网页json数据( 百度,用常规模拟登陆测试了下发现不行,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-18 09:02
百度,用常规模拟登陆测试了下发现不行,)
php中curl模拟登录用户百度知道的例子
最近弄了个工具,希望能拿到我百度网盘里的数据,但是又不想泄露数据,所以想到了模拟登录百度。我用传统的模拟登录方式对其进行了测试,发现它无法正常工作。我只是在登录期间通过抓取数据才发现的。百度在登录过程中跳转了几个页面。如果只获取一个页面的cookie是不完整的,那么只有BAIDUID的值,只有这个cookie值影响不大。
通过抓包数据分析,在实际登录过程中,页面首先被请求一次,服务器同时为浏览器设置了两个cookie,一个cookie值为BAIDUID,应该和session id有关; 另一个是
设置 Cookie:
支持=1;到期=格林威治标准时间 2021 年 8 月 19 日星期四 15:41:37;路径=/; 域=; httponly
推测这应该是百度检测浏览器是否支持cookies;
再次请求页面,获取网页数据获取登录的token值;
然后登录成功会得到BDUSS和其他相关的cookie值。以上就是登录成功了,只记录上面的cookie!
下面是简单的请求和登录函数的集合。作为基础类,可能比较简单,后面我们会改进!
代码显示如下:
这只是一个基础类,只涉及登录和请求提交数据,可以在此基础上使用,比如请求百度云网盘,代码如下:
$baidu = new baidu('用户名','密码');
$data = $baidu->request('http://pan.baidu.com/api/list% ... 39%3B,'http://pan.baidu.com');
echo $data;
也可以作为贴吧的发帖或百度空间更新工具。
教程地址:
欢迎转载!但请带上文章地址^^
/phpyy/47648.htmltrue/phpyy/47648.htmlTechArticlephp curl 模拟登录用户百度知道的例子 我最近做了一个工具,希望能得到我百度网盘里的数据但是我没有'不想泄露数据,于是想到了模拟登录百度,用常规的模拟登录测试了一下,发现不行,抢登录... 查看全部
php抓取网页json数据(
百度,用常规模拟登陆测试了下发现不行,)
php中curl模拟登录用户百度知道的例子
最近弄了个工具,希望能拿到我百度网盘里的数据,但是又不想泄露数据,所以想到了模拟登录百度。我用传统的模拟登录方式对其进行了测试,发现它无法正常工作。我只是在登录期间通过抓取数据才发现的。百度在登录过程中跳转了几个页面。如果只获取一个页面的cookie是不完整的,那么只有BAIDUID的值,只有这个cookie值影响不大。
通过抓包数据分析,在实际登录过程中,页面首先被请求一次,服务器同时为浏览器设置了两个cookie,一个cookie值为BAIDUID,应该和session id有关; 另一个是
设置 Cookie:
支持=1;到期=格林威治标准时间 2021 年 8 月 19 日星期四 15:41:37;路径=/; 域=; httponly
推测这应该是百度检测浏览器是否支持cookies;
再次请求页面,获取网页数据获取登录的token值;
然后登录成功会得到BDUSS和其他相关的cookie值。以上就是登录成功了,只记录上面的cookie!
下面是简单的请求和登录函数的集合。作为基础类,可能比较简单,后面我们会改进!
代码显示如下:
这只是一个基础类,只涉及登录和请求提交数据,可以在此基础上使用,比如请求百度云网盘,代码如下:
$baidu = new baidu('用户名','密码');
$data = $baidu->request('http://pan.baidu.com/api/list% ... 39%3B,'http://pan.baidu.com');
echo $data;
也可以作为贴吧的发帖或百度空间更新工具。
教程地址:
欢迎转载!但请带上文章地址^^
/phpyy/47648.htmltrue/phpyy/47648.htmlTechArticlephp curl 模拟登录用户百度知道的例子 我最近做了一个工具,希望能得到我百度网盘里的数据但是我没有'不想泄露数据,于是想到了模拟登录百度,用常规的模拟登录测试了一下,发现不行,抢登录...
php抓取网页json数据(【干货】逆向过程2.1分析参数(篇章中若有讲解))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-16 18:15
文章目录
内容
文章目录
前言
一、分析页面
二、逆过程
2.1 分析参数
2.2sign_code 值
2.3 折扣码
三、 请求数据,处理Json数据,本地保存图片
3.1 导入库
3.2 生成时间戳和参数
3.3 发出请求
四、附上完整代码
总结
前言
之前做的一个站最近整理了一下,写了一个文章记录,也可以给需要的朋友做个参考。(文中解释如有错误,欢迎评论区指正
目标网站: -领先的时尚摄影平台,摄影视频,摄影爱好者分享作品和技巧的首选,个人空间
一、分析页面
首先进入页面,确定我们要爬取的目标
打开页面后发现 网站 是通过惰性方式加载图片的。
PS:延迟加载是指在请求页面时,只加载可见区域的图片,不加载其他部分的图片。只有当这些图片出现在可视区域时,才会动态加载这些图片,从而节省网络带宽,提高初始加载速度。
不过我们暂时先不管它,打开f12抓包,看看这些图片在哪里。小技巧,先打开f12,清除后点击下一页。由于页面是延迟加载的,我们只需要向下滑动即可。
抓包后,下一步进入主题
二、逆过程2.1 分析参数
单纯看头信息和传入参数,直接请求数据肯定不可行,有反爬的方法。
我们来看看表头信息和传入参数(重点关注这个Form Data表单数据
把它复制出来刷新比较一下,总结出比较重要的数据的含义。
"ctime" : 时间戳(你可以使用python自己生成它
"length" : 我们要加载的张数(也可以理解为我们要抓取的张数
"sign_code" : 加密参数(最重要的一个
“works_category”:照片类型的参数(勾选是主页上的照片分类,然后是123...
2.2sign_code 值
这里我们直接使用全局搜索的方式来查找加密位置。 js文件只有一个。我们直接点进去看看吧。
一进来就可以看到sign_code的加密位置,在13479和13490的下一个断点刷新看看是怎么生成的。
分析这几行js代码
var o = JSON.stringify(e) # 只是将o转换为字符串的操作。经过多次测试,o是上面写的prama参数文章
("param":{"start":20,"length":20,"works_category":"1","time_point":1641981023})
n = t("poco_" + o + "_app"); #通过t函数加密一个字符串
n = n.substr(5, 19); # 取一部分加密数据作为sign_code值
定位到这里之后,我们根据经验可以看出这应该是加密的位置。我们可以尝试将这整个函数扣除,然后在本地运行,看看能否生成我们想要的sign_code值。
2.3 折扣码
下面是完整的js代码扣除,最后手动写了一个调用函数
function r(n, t) {
var r = (65535 & n) + (65535 & t)
, e = (n >> 16) + (t >> 16) + (r >> 16);
return e > 32 - t
}
function u(n, t, u, o, c, f) {
return r(e(r(r(t, n), r(o, f)), c), u)
}
function o(n, t, r, e, o, c, f) {
return u(t & r | ~t & e, n, t, o, c, f)
}
function c(n, t, r, e, o, c, f) {
return u(t & e | r & ~e, n, t, o, c, f)
}
function f(n, t, r, e, o, c, f) {
return u(t ^ r ^ e, n, t, o, c, f)
}
function i(n, t, r, e, o, c, f) {
return u(r ^ (t | ~e), n, t, o, c, f)
}
function a(n, t) {
n[t >> 5] |= 128 >> 9 > 5] >>> t % 32 & 255);
return r
}
function g(n) {
var t, r = [];
for (r[(n.length >> 2) - 1] = void 0,
t = 0; t < r.length; t += 1)
r[t] = 0;
for (t = 0; t < 8 * n.length; t += 8)
r[t >> 5] |= (255 & n.charCodeAt(t / 8)) 16 && (u = a(u, 8 * n.length)),
r = 0; 16 > r; r += 1)
o[r] = 909522486 ^ u[r],
c[r] = 1549556828 ^ u[r];
return e = a(o.concat(g(t)), 512 + 8 * t.length),
h(a(c.concat(e), 640))
}
function v(n) {
var t, r, e = "0123456789abcdef", u = "";
for (r = 0; r < n.length; r += 1)
t = n.charCodeAt(r),
u += e.charAt(t >>> 4 & 15) + e.charAt(15 & t);
return u
}
function s(n) {
return unescape(encodeURIComponent(n))
}
function C(n) {
return d(s(n))
}
function A(n) {
return v(C(n))
}
function m(n, t) {
return l(s(n), s(t))
}
function p(n, t) {
return v(m(n, t))
}
function b(n, t, r) {
return t ? r ? m(t, n) : p(t, n) : r ? C(n) : A(n)
};
function getsign(o){
n = b("poco_" + o + "_app");
n = n.substr(5, 19);
return n
}
经过测试,可以在本地成功运行,得到我们想要的加密数据。其实到这里已经差不多完成了90%,接下来就是请求数据并抓包了。
三、请求数据,处理Json数据,本地保存图片3.1 导入库
import requests # 请求数据
import time # 生成时间戳
import execjs # 第三方类库来执行js语句
3.2 生成时间戳和参数
time_point = int(time.time())
o = '{"start":0,"length":20,"works_category":"1","time_point":'+str(time_point)+'}'
with open('D:/poco.js', 'r', encoding='utf-8') as f: # 读取扣下来保存到本地的js代码
js_data = f.read()
js_obj = execjs.compile(js_data)
sign_code = js_obj.call('getsign',o) # 第一个参数是函数名,第二个是传入的参数
# print("sign_code")
这里的长度参数是请求的数据量。我只抓了20张,可以根据自己的需要更换。并且works_category参数也根据自己的需要而改变。
3.3 发出请求
# 把sign_code和时间戳拼接到传入的参数中
data = {
'req': '{"version":"1.1.0","app_name":"poco_photography_web","os_type":"weixin","is_enc":0,"env":"prod","ctime":'+str(int(time.time()*1000))+',"param":{"start":0,"length":20,"works_category":"1","time_point":'+str(time_point)+'},"sign_code":"'+str(sign_code)+'"}',
'host_port': 'https://photo.poco.cn'
}
由于数据是json格式,所以我们要的图片地址在img中的list下data
json数据格式可以这样取,代码如下
response = requests.post(url,headers=headers,data=data).json()['data']['list']
for i in response:
img = i['img']
urls = 'http:' + str(img) # 进行简单拼接成url格式
使用for循环将请求的图片保存到本地
with open(f'D:/POCO图库/img{num}.jpg', 'wb') as f:
print('正在下载第{}张'.format(num))
f.write(content)
你完成了
四、附上完整代码
# _*_ coding:UTF-8 _*_
# @Software : PyCharm
import requests
import time
import execjs
time_point = int(time.time())
o = '{"start":0,"length":20,"works_category":"1","time_point":'+str(time_point)+'}'
with open('D:/poco.js', 'r', encoding='utf-8') as f:
js_data = f.read()
js_obj = execjs.compile(js_data)
sign_code = js_obj.call('getsign',o)
# print(sign_code)
url = 'https://web-api.poco.cn/v1_1/rank/get_homepage_recommend_list'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'Referer': 'https://photo.poco.cn/?classify_type=1&works_type=medal',
'Origin': 'https://photo.poco.cn'
}
data = {
'req': '{"version":"1.1.0","app_name":"poco_photography_web","os_type":"weixin","is_enc":0,"env":"prod","ctime":'+str(int(time.time()*1000))+',"param":{"start":0,"length":20,"works_category":"1","time_point":'+str(time_point)+'},"sign_code":"'+str(sign_code)+'"}',
'host_port': 'https://photo.poco.cn'
}
response = requests.post(url,headers=headers,data=data).json()['data']['list']
num = 1
for i in response:
img = i['img']
urls = 'http:' + str(img)
content = requests.get(urls).content
with open(f'D:/POCO图库/img{num}.jpg', 'wb') as f:
print('正在下载第{}张'.format(num))
f.write(content)
num += 1
print('完')
总结
吐槽一下最新版的谷歌浏览器(最好用旧版更稳定),天天死机,调试js的时候死机。好在这个网站的加密不是很深。
中途扣除的js代码尝试在谷歌浏览器中运行,发现会报错,说我的方法未定义,应该是bug,然后切换到360极速浏览器,就可以正常运行了。
再次声明,本文文章仅供学习,不做任何商业用途,做一个友好的爬虫。
PS:如果觉得本章对你有帮助,请关注、评论、点赞,谢谢! 查看全部
php抓取网页json数据(【干货】逆向过程2.1分析参数(篇章中若有讲解))
文章目录
内容
文章目录
前言
一、分析页面
二、逆过程
2.1 分析参数
2.2sign_code 值
2.3 折扣码
三、 请求数据,处理Json数据,本地保存图片
3.1 导入库
3.2 生成时间戳和参数
3.3 发出请求
四、附上完整代码
总结
前言
之前做的一个站最近整理了一下,写了一个文章记录,也可以给需要的朋友做个参考。(文中解释如有错误,欢迎评论区指正
目标网站: -领先的时尚摄影平台,摄影视频,摄影爱好者分享作品和技巧的首选,个人空间
一、分析页面
首先进入页面,确定我们要爬取的目标

打开页面后发现 网站 是通过惰性方式加载图片的。
PS:延迟加载是指在请求页面时,只加载可见区域的图片,不加载其他部分的图片。只有当这些图片出现在可视区域时,才会动态加载这些图片,从而节省网络带宽,提高初始加载速度。
不过我们暂时先不管它,打开f12抓包,看看这些图片在哪里。小技巧,先打开f12,清除后点击下一页。由于页面是延迟加载的,我们只需要向下滑动即可。

抓包后,下一步进入主题
二、逆过程2.1 分析参数
单纯看头信息和传入参数,直接请求数据肯定不可行,有反爬的方法。
我们来看看表头信息和传入参数(重点关注这个Form Data表单数据

把它复制出来刷新比较一下,总结出比较重要的数据的含义。

"ctime" : 时间戳(你可以使用python自己生成它
"length" : 我们要加载的张数(也可以理解为我们要抓取的张数
"sign_code" : 加密参数(最重要的一个
“works_category”:照片类型的参数(勾选是主页上的照片分类,然后是123...
2.2sign_code 值
这里我们直接使用全局搜索的方式来查找加密位置。 js文件只有一个。我们直接点进去看看吧。


一进来就可以看到sign_code的加密位置,在13479和13490的下一个断点刷新看看是怎么生成的。

分析这几行js代码
var o = JSON.stringify(e) # 只是将o转换为字符串的操作。经过多次测试,o是上面写的prama参数文章
("param":{"start":20,"length":20,"works_category":"1","time_point":1641981023})
n = t("poco_" + o + "_app"); #通过t函数加密一个字符串
n = n.substr(5, 19); # 取一部分加密数据作为sign_code值


定位到这里之后,我们根据经验可以看出这应该是加密的位置。我们可以尝试将这整个函数扣除,然后在本地运行,看看能否生成我们想要的sign_code值。
2.3 折扣码
下面是完整的js代码扣除,最后手动写了一个调用函数
function r(n, t) {
var r = (65535 & n) + (65535 & t)
, e = (n >> 16) + (t >> 16) + (r >> 16);
return e > 32 - t
}
function u(n, t, u, o, c, f) {
return r(e(r(r(t, n), r(o, f)), c), u)
}
function o(n, t, r, e, o, c, f) {
return u(t & r | ~t & e, n, t, o, c, f)
}
function c(n, t, r, e, o, c, f) {
return u(t & e | r & ~e, n, t, o, c, f)
}
function f(n, t, r, e, o, c, f) {
return u(t ^ r ^ e, n, t, o, c, f)
}
function i(n, t, r, e, o, c, f) {
return u(r ^ (t | ~e), n, t, o, c, f)
}
function a(n, t) {
n[t >> 5] |= 128 >> 9 > 5] >>> t % 32 & 255);
return r
}
function g(n) {
var t, r = [];
for (r[(n.length >> 2) - 1] = void 0,
t = 0; t < r.length; t += 1)
r[t] = 0;
for (t = 0; t < 8 * n.length; t += 8)
r[t >> 5] |= (255 & n.charCodeAt(t / 8)) 16 && (u = a(u, 8 * n.length)),
r = 0; 16 > r; r += 1)
o[r] = 909522486 ^ u[r],
c[r] = 1549556828 ^ u[r];
return e = a(o.concat(g(t)), 512 + 8 * t.length),
h(a(c.concat(e), 640))
}
function v(n) {
var t, r, e = "0123456789abcdef", u = "";
for (r = 0; r < n.length; r += 1)
t = n.charCodeAt(r),
u += e.charAt(t >>> 4 & 15) + e.charAt(15 & t);
return u
}
function s(n) {
return unescape(encodeURIComponent(n))
}
function C(n) {
return d(s(n))
}
function A(n) {
return v(C(n))
}
function m(n, t) {
return l(s(n), s(t))
}
function p(n, t) {
return v(m(n, t))
}
function b(n, t, r) {
return t ? r ? m(t, n) : p(t, n) : r ? C(n) : A(n)
};
function getsign(o){
n = b("poco_" + o + "_app");
n = n.substr(5, 19);
return n
}

经过测试,可以在本地成功运行,得到我们想要的加密数据。其实到这里已经差不多完成了90%,接下来就是请求数据并抓包了。
三、请求数据,处理Json数据,本地保存图片3.1 导入库
import requests # 请求数据
import time # 生成时间戳
import execjs # 第三方类库来执行js语句
3.2 生成时间戳和参数
time_point = int(time.time())
o = '{"start":0,"length":20,"works_category":"1","time_point":'+str(time_point)+'}'
with open('D:/poco.js', 'r', encoding='utf-8') as f: # 读取扣下来保存到本地的js代码
js_data = f.read()
js_obj = execjs.compile(js_data)
sign_code = js_obj.call('getsign',o) # 第一个参数是函数名,第二个是传入的参数
# print("sign_code")
这里的长度参数是请求的数据量。我只抓了20张,可以根据自己的需要更换。并且works_category参数也根据自己的需要而改变。
3.3 发出请求
# 把sign_code和时间戳拼接到传入的参数中
data = {
'req': '{"version":"1.1.0","app_name":"poco_photography_web","os_type":"weixin","is_enc":0,"env":"prod","ctime":'+str(int(time.time()*1000))+',"param":{"start":0,"length":20,"works_category":"1","time_point":'+str(time_point)+'},"sign_code":"'+str(sign_code)+'"}',
'host_port': 'https://photo.poco.cn'
}
由于数据是json格式,所以我们要的图片地址在img中的list下data

json数据格式可以这样取,代码如下
response = requests.post(url,headers=headers,data=data).json()['data']['list']
for i in response:
img = i['img']
urls = 'http:' + str(img) # 进行简单拼接成url格式
使用for循环将请求的图片保存到本地
with open(f'D:/POCO图库/img{num}.jpg', 'wb') as f:
print('正在下载第{}张'.format(num))
f.write(content)

你完成了
四、附上完整代码
# _*_ coding:UTF-8 _*_
# @Software : PyCharm
import requests
import time
import execjs
time_point = int(time.time())
o = '{"start":0,"length":20,"works_category":"1","time_point":'+str(time_point)+'}'
with open('D:/poco.js', 'r', encoding='utf-8') as f:
js_data = f.read()
js_obj = execjs.compile(js_data)
sign_code = js_obj.call('getsign',o)
# print(sign_code)
url = 'https://web-api.poco.cn/v1_1/rank/get_homepage_recommend_list'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'Referer': 'https://photo.poco.cn/?classify_type=1&works_type=medal',
'Origin': 'https://photo.poco.cn'
}
data = {
'req': '{"version":"1.1.0","app_name":"poco_photography_web","os_type":"weixin","is_enc":0,"env":"prod","ctime":'+str(int(time.time()*1000))+',"param":{"start":0,"length":20,"works_category":"1","time_point":'+str(time_point)+'},"sign_code":"'+str(sign_code)+'"}',
'host_port': 'https://photo.poco.cn'
}
response = requests.post(url,headers=headers,data=data).json()['data']['list']
num = 1
for i in response:
img = i['img']
urls = 'http:' + str(img)
content = requests.get(urls).content
with open(f'D:/POCO图库/img{num}.jpg', 'wb') as f:
print('正在下载第{}张'.format(num))
f.write(content)
num += 1
print('完')
总结
吐槽一下最新版的谷歌浏览器(最好用旧版更稳定),天天死机,调试js的时候死机。好在这个网站的加密不是很深。
中途扣除的js代码尝试在谷歌浏览器中运行,发现会报错,说我的方法未定义,应该是bug,然后切换到360极速浏览器,就可以正常运行了。

再次声明,本文文章仅供学习,不做任何商业用途,做一个友好的爬虫。
PS:如果觉得本章对你有帮助,请关注、评论、点赞,谢谢!
php抓取网页json数据(Python抓取今日头条街拍图片结构(2)分析(2))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-05 17:12
内容
(1) 抢今日头条街拍
(2)今日头条街拍的照片结构解析
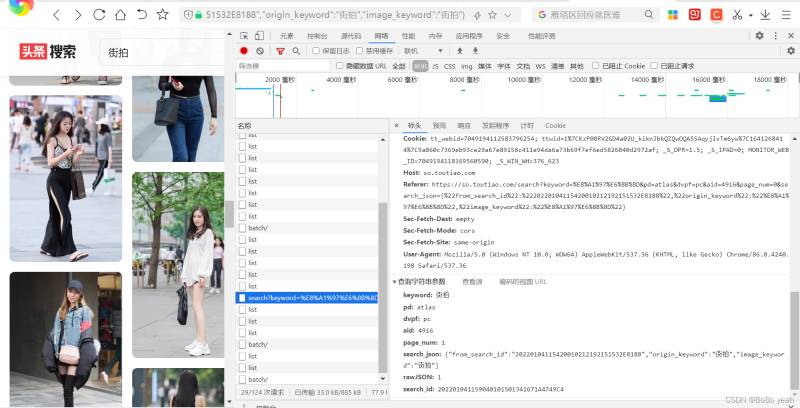
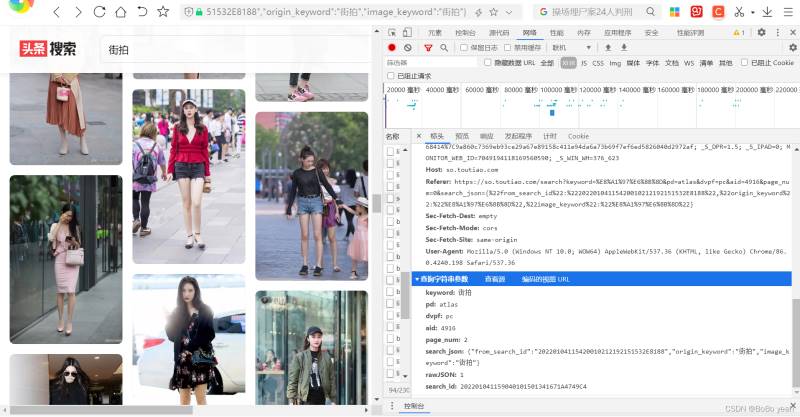
keyword: 街拍
pd: atlas
dvpf: pc
aid: 4916
page_num: 1
search_json: {"from_search_id":"20220104115420010212192151532E8188","origin_keyword":"街拍","image_keyword":"街拍"}
rawJSON: 1
search_id: 202201041159040101501341671A4749C4
可以找到规律,page_num从1开始累加,其他参数不变
(3) 根据不同的功能编写不同的方法组织代码
获取网页json格式数据
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search?keyword=%E8%A1%97%E6%8B%8D&pd=atlas&dvpf=pc&aid=4916&page_num=0&search_json={%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
从json格式数据中提取街道照片
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
用它的md5代码命名街拍图片并保存图片
实现一个 save_image() 方法来保存图像,其中 item 是前面的 get_images() 方法返回的字典。该方法中,首先根据item的标题创建一个文件夹,然后请求图片的链接,获取图片的二进制数据,以二进制形式写入文件。图片名称可以使用其内容的MD5值,可以消除重复。相关代码如下:
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
main() 调用其他函数
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
(4) 抓20页今日头条街图片资料
这里定义了分页的起始页和结束页号,分别是GROUP_START和GROUP_END,同样使用了多线程线程池,调用其map()方法实现多线程下载。
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
import requests
from urllib.parse import urlencode
from hashlib import md5
from multiprocessing.pool import Pool
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search?keyword=%E8%A1%97%E6%8B%8D&pd=atlas&dvpf=pc&aid=4916&page_num=0&search_json={%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
至此这篇关于Python抓取今日头条图片数据的文章介绍到这里。更多Python相关抓拍今日头条图片内容,请搜索之前的文章或继续浏览下方相关文章希望大家以后多多支持! 查看全部
php抓取网页json数据(Python抓取今日头条街拍图片结构(2)分析(2))
内容
(1) 抢今日头条街拍
(2)今日头条街拍的照片结构解析
keyword: 街拍
pd: atlas
dvpf: pc
aid: 4916
page_num: 1
search_json: {"from_search_id":"20220104115420010212192151532E8188","origin_keyword":"街拍","image_keyword":"街拍"}
rawJSON: 1
search_id: 202201041159040101501341671A4749C4
可以找到规律,page_num从1开始累加,其他参数不变
(3) 根据不同的功能编写不同的方法组织代码
获取网页json格式数据
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search?keyword=%E8%A1%97%E6%8B%8D&pd=atlas&dvpf=pc&aid=4916&page_num=0&search_json={%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
从json格式数据中提取街道照片
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
用它的md5代码命名街拍图片并保存图片
实现一个 save_image() 方法来保存图像,其中 item 是前面的 get_images() 方法返回的字典。该方法中,首先根据item的标题创建一个文件夹,然后请求图片的链接,获取图片的二进制数据,以二进制形式写入文件。图片名称可以使用其内容的MD5值,可以消除重复。相关代码如下:
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
main() 调用其他函数
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
(4) 抓20页今日头条街图片资料
这里定义了分页的起始页和结束页号,分别是GROUP_START和GROUP_END,同样使用了多线程线程池,调用其map()方法实现多线程下载。
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
import requests
from urllib.parse import urlencode
from hashlib import md5
from multiprocessing.pool import Pool
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search?keyword=%E8%A1%97%E6%8B%8D&pd=atlas&dvpf=pc&aid=4916&page_num=0&search_json={%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
至此这篇关于Python抓取今日头条图片数据的文章介绍到这里。更多Python相关抓拍今日头条图片内容,请搜索之前的文章或继续浏览下方相关文章希望大家以后多多支持!
php抓取网页json数据(JSON西装一样采集的日志样本图(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-01-01 21:07
记录和监控就像托尼·斯塔克和他的钢铁侠套装。两者需要搭配使用才能发挥最大功效,因为它们相得益彰。
日志一直是应用和基础框架性能和故障诊断的重要手段,但现在我们意识到日志不仅可以用于故障诊断,还可以用于大数据分析、业务可视化和性能分析等..
因此,记录应用程序日志非常非常重要。
为什么要使用 JSON 格式
为了了解 JSON 日志记录的优势,我们先来了解一段 Anuj(系统工程师)和 Kartik(业务分析师)之间的对话。
但几天后,Kartik 发现 Web 界面已关闭。 Anuj摸着头看了看日志,发现开发者在日志中多加了一个字段,破坏了他自定义的日志解析器。
相信很多童鞋都遇到过类似的情况吧?
这种情况下,如果开发者把应用设计成JSON格式的日志,那么Anuj定义的解析器就很简单了,然后根据JSON键搜索字段就够了,你不用需要关心它是否在日志中的新字段已被修改。
使用JSON格式的日志最大的好处就是结构化,让我们分析应用日志非常方便。不仅可以轻松读取日志,还可以通过各个字段进行日志查询,几乎所有编程语言都可以轻松解析。
JSON 日志魔术
最近,我们创建了一个 Golang 示例应用程序,以在代码构建、测试和部署阶段获取一些相关信息。我们使用 JSON 格式的日志进行记录。
采集的日志样本如下:
使用ELK进行日志采集时,我们只需要在Logstash中添加如下日志分析即可:
filter {
json {
source => "message"
}
}
我们不需要任何额外的解析步骤,即使新的字段被添加到日志中。 采集日志到达如下图:
我们可以看到,在Kibana中,JSON日志的key已经被自动解析为ES属性,比如employee_name、employee_city等字段。我们不需要在 Logstash 或其他工具中添加一些非常复杂的解析。现在我们可以很容易地使用这些数据来创建一些 Dashboards 进行数据分析。
结论
从文本日志迁移到 JSON 日志格式不会花费太长时间。大多数编程语言都有相应的 JSON 日志库。我非常确定 JSON 日志格式将为您当前的日志采集系统提供更大的灵活性。性。
以下是一些支持 JSON 日志格式的流行库:
希望大家现在对 JSON 格式的日志有了更好的了解。
原文:
翻译: 查看全部
php抓取网页json数据(JSON西装一样采集的日志样本图(上))
记录和监控就像托尼·斯塔克和他的钢铁侠套装。两者需要搭配使用才能发挥最大功效,因为它们相得益彰。
日志一直是应用和基础框架性能和故障诊断的重要手段,但现在我们意识到日志不仅可以用于故障诊断,还可以用于大数据分析、业务可视化和性能分析等..
因此,记录应用程序日志非常非常重要。
为什么要使用 JSON 格式
为了了解 JSON 日志记录的优势,我们先来了解一段 Anuj(系统工程师)和 Kartik(业务分析师)之间的对话。
但几天后,Kartik 发现 Web 界面已关闭。 Anuj摸着头看了看日志,发现开发者在日志中多加了一个字段,破坏了他自定义的日志解析器。
相信很多童鞋都遇到过类似的情况吧?
这种情况下,如果开发者把应用设计成JSON格式的日志,那么Anuj定义的解析器就很简单了,然后根据JSON键搜索字段就够了,你不用需要关心它是否在日志中的新字段已被修改。
使用JSON格式的日志最大的好处就是结构化,让我们分析应用日志非常方便。不仅可以轻松读取日志,还可以通过各个字段进行日志查询,几乎所有编程语言都可以轻松解析。
JSON 日志魔术
最近,我们创建了一个 Golang 示例应用程序,以在代码构建、测试和部署阶段获取一些相关信息。我们使用 JSON 格式的日志进行记录。
采集的日志样本如下:
使用ELK进行日志采集时,我们只需要在Logstash中添加如下日志分析即可:
filter {
json {
source => "message"
}
}
我们不需要任何额外的解析步骤,即使新的字段被添加到日志中。 采集日志到达如下图:
我们可以看到,在Kibana中,JSON日志的key已经被自动解析为ES属性,比如employee_name、employee_city等字段。我们不需要在 Logstash 或其他工具中添加一些非常复杂的解析。现在我们可以很容易地使用这些数据来创建一些 Dashboards 进行数据分析。
结论
从文本日志迁移到 JSON 日志格式不会花费太长时间。大多数编程语言都有相应的 JSON 日志库。我非常确定 JSON 日志格式将为您当前的日志采集系统提供更大的灵活性。性。
以下是一些支持 JSON 日志格式的流行库:
希望大家现在对 JSON 格式的日志有了更好的了解。
原文:
翻译:
php抓取网页json数据( ,涉及php针对json格式数据及文件相关操作技巧汇总)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-28 10:00
,涉及php针对json格式数据及文件相关操作技巧汇总)
PHP生成和获取JSON文件的方法
更新时间:2016-08-23 12:15:26 作者:onestopweb
本文主要介绍PHP生成和获取JSON文件的方法,涉及PHP的JSON格式数据和文件相关的操作技巧。有需要的朋友可以参考以下
本文介绍如何通过 PHP 生成和获取 JSON 文件。分享给大家,供大家参考,如下:
先定义一个数组,然后遍历数据表,将对应的数据放入数组中,最后通过json_encode()转换数组
json_encode() 函数的作用是将值转换为JSON数据存储格式。
putjson.php:
如果有同名的 JSON 文件,则会被覆盖,如果没有 JSON 文件,则会创建。
生成或覆盖的 JSON 如下:
复制代码代码如下:
[["1","\u811A\u672C\u4E4B\u5BB6",""],["2","\u7F16\u7A0B\u5F00\u53D1",""]]
然后,将 JSON 文件中的数据读入 PHP 变量。
getjson.php:
效果图:
PS:这里有一些比较实用的json在线工具供大家参考:
在线JSON代码检查、检查、美化和格式化工具:
JSON在线格式化工具:
在线 XML/JSON 转换工具:
json代码在线格式化/美化/压缩/编辑/转换工具:
C语言风格/HTML/CSS/json代码格式化和美化工具:
对PHP相关内容感兴趣的读者可以查看本站主题:《PHP中JSON格式数据操作技巧总结》、《PHP XML文件操作技巧总结》、《PHP基本语法介绍》、《 PHP数组(数组)操作技巧,《php字符串(字符串)使用总结》、《php+mysql数据库操作入门教程》、《php常用数据库操作技巧总结》
我希望这篇文章能帮助你进行 PHP 编程。 查看全部
php抓取网页json数据(
,涉及php针对json格式数据及文件相关操作技巧汇总)
PHP生成和获取JSON文件的方法
更新时间:2016-08-23 12:15:26 作者:onestopweb
本文主要介绍PHP生成和获取JSON文件的方法,涉及PHP的JSON格式数据和文件相关的操作技巧。有需要的朋友可以参考以下
本文介绍如何通过 PHP 生成和获取 JSON 文件。分享给大家,供大家参考,如下:
先定义一个数组,然后遍历数据表,将对应的数据放入数组中,最后通过json_encode()转换数组
json_encode() 函数的作用是将值转换为JSON数据存储格式。
putjson.php:
如果有同名的 JSON 文件,则会被覆盖,如果没有 JSON 文件,则会创建。
生成或覆盖的 JSON 如下:
复制代码代码如下:
[["1","\u811A\u672C\u4E4B\u5BB6",""],["2","\u7F16\u7A0B\u5F00\u53D1",""]]
然后,将 JSON 文件中的数据读入 PHP 变量。
getjson.php:
效果图:
PS:这里有一些比较实用的json在线工具供大家参考:
在线JSON代码检查、检查、美化和格式化工具:
JSON在线格式化工具:
在线 XML/JSON 转换工具:
json代码在线格式化/美化/压缩/编辑/转换工具:
C语言风格/HTML/CSS/json代码格式化和美化工具:
对PHP相关内容感兴趣的读者可以查看本站主题:《PHP中JSON格式数据操作技巧总结》、《PHP XML文件操作技巧总结》、《PHP基本语法介绍》、《 PHP数组(数组)操作技巧,《php字符串(字符串)使用总结》、《php+mysql数据库操作入门教程》、《php常用数据库操作技巧总结》
我希望这篇文章能帮助你进行 PHP 编程。
php抓取网页json数据(ajax读取Json数据的注意事项有哪些,就是实战案例分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-27 03:07
这次给大家带来Ajax读取Json数据的方法。 Ajax读取Json数据有哪些注意事项?下面是一个实际案例。我们来看看。
本文将与大家分享如何使用ajax读取Json中的数据。
一、基础知识
什么是json?
JSON 指的是 JavaScript Object Notation(JavaScript Object Notation)
JSON 是一种轻量级的文本数据交换格式
JSON 独立于语言 *
JSON 具有自我描述性且更易于理解
JSON 使用 JavaScript 语法来描述数据对象,但 JSON 仍然独立于语言和平台。 JSON 解析器和 JSON 库支持多种不同的编程语言。
JSON-转换为 JavaScript 对象
JSON 文本格式在语法上与创建 JavaScript 对象的代码相同。
由于这种相似性,不需要解析器,JavaScript 程序可以使用内置的 eval() 函数从 JSON 数据生成原生 JavaScript 对象。
二、在 Json 中读取数据
首先我写了一个收录
内容的 Json 文件。注意格式。
图1 编写json文件
然后,编写html代码并引用ajax。
使用AJAX异步读取json
window.onload=function()
{
/*获得按钮*/
var aBtn=document.getElementById('btn1');
//给按钮添加点击事件
aBtn.onclick=function()
{
//调用ajax函数
ajax('data.json',function(str){
//将JSON 数据来生成原生的 JavaScript 对象
var arr=eval(str);
alert(arr[0].b);
});
};
};
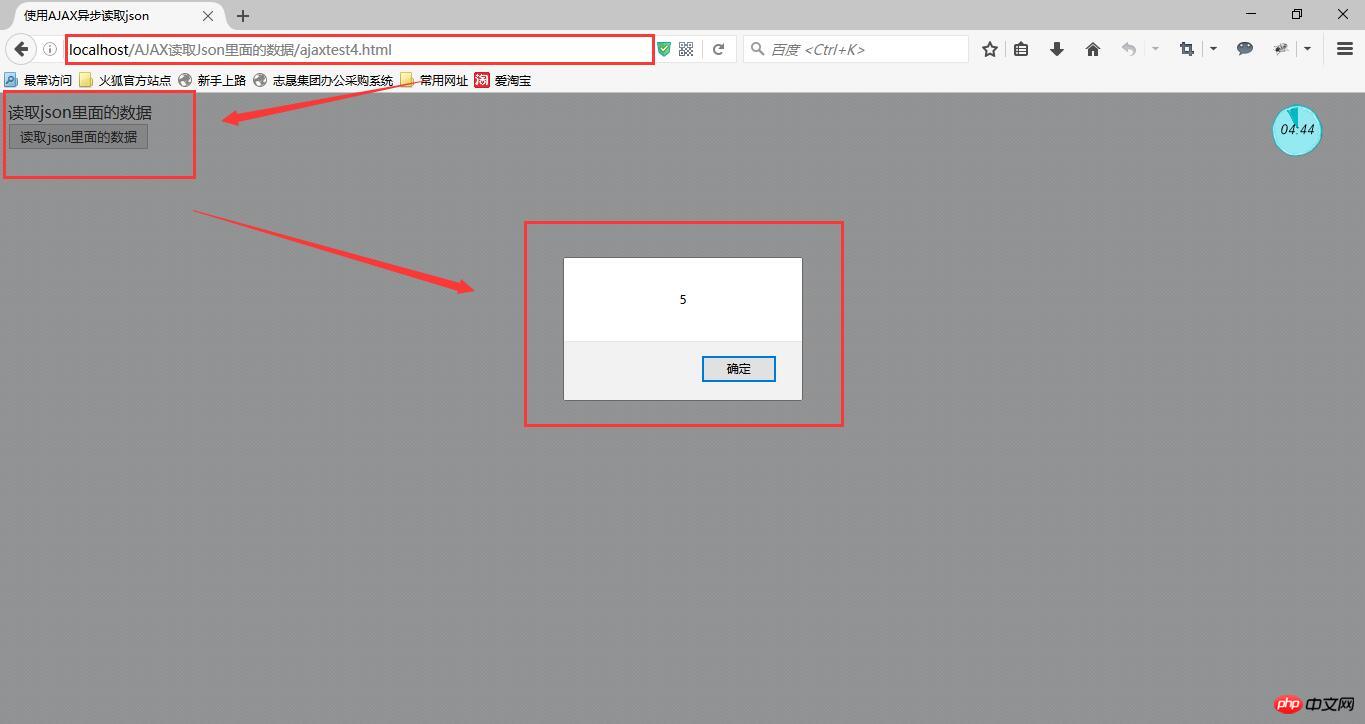
读取json里面的数据 <br />
封装的AJAX函数代码如下:
/*
AJAX封装函数
url:系统要读取文件的地址
fnSucc:一个函数,文件取过来,加载完会调用
*/
function ajax(url, fnSucc, fnFaild)
{
//1.创建Ajax对象
var oAjax=null;
if(window.XMLHttpRequest)
{
oAjax=new XMLHttpRequest();
}
else
{
oAjax=new ActiveXObject("Microsoft.XMLHTTP");
}
//2.连接服务器
oAjax.open('GET', url, true);
//3.发送请求
oAjax.send();
//4.接收服务器的返回
oAjax.onreadystatechange=function ()
{
if(oAjax.readyState==4) //完成
{
if(oAjax.status==200) //成功
{
fnSucc(oAjax.responseText);
}
else
{
if(fnFaild)
fnFaild(oAjax.status);
}
}
};
}
下一步是读取文件的内容。在此之前,有一点需要说明的是,AJAX 从服务器读取文件,因此将写入的 JSON 文件放在服务器的路径中。学者们接触过的唯一服务器是IIS。其文件路径为 C:\inetpub\wwwroot\aspnet_client\system_web。把Json放在这个路径下,使用localhost访问服务器即可。
相信看完本文的案例你已经掌握了方法。更多精彩请关注php中文网其他相关文章! 查看全部
php抓取网页json数据(ajax读取Json数据的注意事项有哪些,就是实战案例分享)
这次给大家带来Ajax读取Json数据的方法。 Ajax读取Json数据有哪些注意事项?下面是一个实际案例。我们来看看。
本文将与大家分享如何使用ajax读取Json中的数据。
一、基础知识
什么是json?
JSON 指的是 JavaScript Object Notation(JavaScript Object Notation)
JSON 是一种轻量级的文本数据交换格式
JSON 独立于语言 *
JSON 具有自我描述性且更易于理解
JSON 使用 JavaScript 语法来描述数据对象,但 JSON 仍然独立于语言和平台。 JSON 解析器和 JSON 库支持多种不同的编程语言。
JSON-转换为 JavaScript 对象
JSON 文本格式在语法上与创建 JavaScript 对象的代码相同。
由于这种相似性,不需要解析器,JavaScript 程序可以使用内置的 eval() 函数从 JSON 数据生成原生 JavaScript 对象。
二、在 Json 中读取数据
首先我写了一个收录
内容的 Json 文件。注意格式。
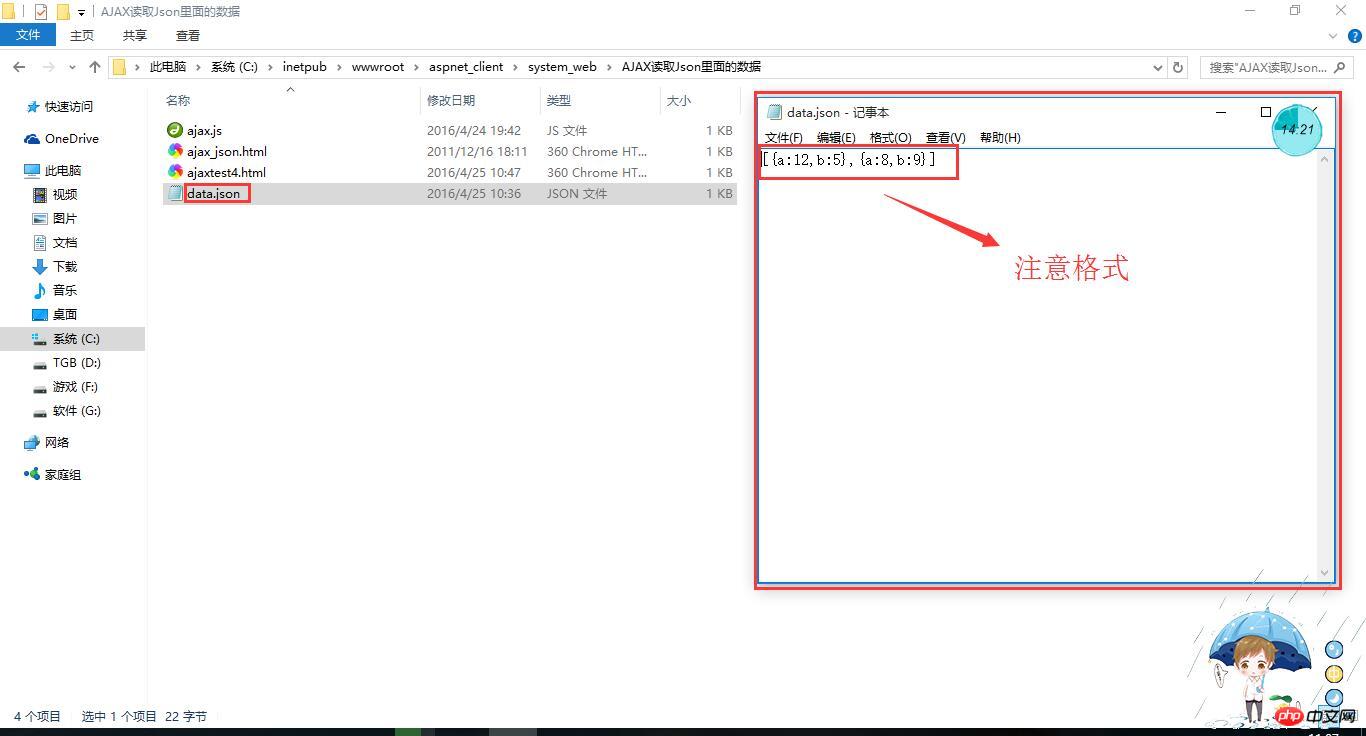
图1 编写json文件
然后,编写html代码并引用ajax。
使用AJAX异步读取json
window.onload=function()
{
/*获得按钮*/
var aBtn=document.getElementById('btn1');
//给按钮添加点击事件
aBtn.onclick=function()
{
//调用ajax函数
ajax('data.json',function(str){
//将JSON 数据来生成原生的 JavaScript 对象
var arr=eval(str);
alert(arr[0].b);
});
};
};
读取json里面的数据 <br />
封装的AJAX函数代码如下:
/*
AJAX封装函数
url:系统要读取文件的地址
fnSucc:一个函数,文件取过来,加载完会调用
*/
function ajax(url, fnSucc, fnFaild)
{
//1.创建Ajax对象
var oAjax=null;
if(window.XMLHttpRequest)
{
oAjax=new XMLHttpRequest();
}
else
{
oAjax=new ActiveXObject("Microsoft.XMLHTTP");
}
//2.连接服务器
oAjax.open('GET', url, true);
//3.发送请求
oAjax.send();
//4.接收服务器的返回
oAjax.onreadystatechange=function ()
{
if(oAjax.readyState==4) //完成
{
if(oAjax.status==200) //成功
{
fnSucc(oAjax.responseText);
}
else
{
if(fnFaild)
fnFaild(oAjax.status);
}
}
};
}
下一步是读取文件的内容。在此之前,有一点需要说明的是,AJAX 从服务器读取文件,因此将写入的 JSON 文件放在服务器的路径中。学者们接触过的唯一服务器是IIS。其文件路径为 C:\inetpub\wwwroot\aspnet_client\system_web。把Json放在这个路径下,使用localhost访问服务器即可。
相信看完本文的案例你已经掌握了方法。更多精彩请关注php中文网其他相关文章!
php抓取网页json数据(从php获取json数据使用js读取显示到网页笔记笔记)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-24 10:00
从php获取json数据,用js读取并显示到web笔记
php代码
"hellojson","age" => 23,"sex"=>"M");//定义php数组
$res=json_encode($array);
//var_dump($res);
echo $res;//输出结果到页面
HTML 代码
$(function(){
$(document).on("click",'.test',function(){
var id=$(this).attr("id");
var data={id:id}
//var aaa=[{"0":"1","id":"1","1":"hello","name":"hello","2":"","密码":""},{"0":"2","id":"2","1"
// :"world","name":"world","2":"","password":""},{"0":"3","id":"3", "1":"helloworld","name":"helloworld"
// ,"2":"","password":""}]
// alert(aaa[2].name)
$.ajax({
输入:“GET”,
数据:数据,
url:'xml.php',
数据类型:"json",
成功:功能(味精){
if(msg){
var res=eval(msg);//php返回的数据如果不能直接使用可以转换,可以使用eval()函数来实现转换。
//alert(res.username)
alert(res[1].name)//弹出要获取的数据
//console.log(res)
}
}
});
})
})
在原生js中,也可以使用JSON.parse()函数转换为json格式。在php中已经转成json格式,可以直接获取。
alert(msg[0].name)//msg为返回的json格式
从php中获取json数据,用js读取并显示web笔记的php代码? php//json与数组转换 $array = array(username = hellojson,age = 23, sex=M);//定义php数组$ res=json_encode(... 查看全部
php抓取网页json数据(从php获取json数据使用js读取显示到网页笔记笔记)
从php获取json数据,用js读取并显示到web笔记
php代码
"hellojson","age" => 23,"sex"=>"M");//定义php数组
$res=json_encode($array);
//var_dump($res);
echo $res;//输出结果到页面
HTML 代码
$(function(){
$(document).on("click",'.test',function(){
var id=$(this).attr("id");
var data={id:id}
//var aaa=[{"0":"1","id":"1","1":"hello","name":"hello","2":"","密码":""},{"0":"2","id":"2","1"
// :"world","name":"world","2":"","password":""},{"0":"3","id":"3", "1":"helloworld","name":"helloworld"
// ,"2":"","password":""}]
// alert(aaa[2].name)
$.ajax({
输入:“GET”,
数据:数据,
url:'xml.php',
数据类型:"json",
成功:功能(味精){
if(msg){
var res=eval(msg);//php返回的数据如果不能直接使用可以转换,可以使用eval()函数来实现转换。
//alert(res.username)
alert(res[1].name)//弹出要获取的数据
//console.log(res)
}
}
});
})
})
在原生js中,也可以使用JSON.parse()函数转换为json格式。在php中已经转成json格式,可以直接获取。
alert(msg[0].name)//msg为返回的json格式
从php中获取json数据,用js读取并显示web笔记的php代码? php//json与数组转换 $array = array(username = hellojson,age = 23, sex=M);//定义php数组$ res=json_encode(...
php抓取网页json数据(类似:UncaughtTypeErrortosearchfor‘’inJSONstring前端jsamp;php笔记正文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-20 18:11
类似:Uncaught TypeError:无法使用‘in’操作符在JSON字符串中搜索‘’前端js&php笔记
身体:
在html页面中,通过$.get()方法请求php页面,回调函数返回json数据,但是获取不到数据点中的数据,代码如下:
js 代码:
$("#button1").click(function(){
$.get("index.php",{username:$("#username").val(),password:$("#password").val(),tel:$("#tel").val()},function(data,textStatus){ //get方法请求数据
$("#response").html("用户名:"+data.name+"
密码:"+data.pwd+"
手机号码:"+data.tell);
alert(data); //能够显示数据
})
})
php 代码:
运行后:
能够返回数据
无法检索返回的数据
解决方案:
创建一个对象,将json数据转换成一个对象
ajaxData=$.parseJSON(data) //将json数据转换为js对象
注意:
无法在程序中运行,在程序中运行时无法解释php页面,必须在appserv程序下的www文件夹下运行(运行时不能是ftp地址,而是像“:82” /unit07/index.html”地址) 查看全部
php抓取网页json数据(类似:UncaughtTypeErrortosearchfor‘’inJSONstring前端jsamp;php笔记正文)
类似:Uncaught TypeError:无法使用‘in’操作符在JSON字符串中搜索‘’前端js&php笔记
身体:
在html页面中,通过$.get()方法请求php页面,回调函数返回json数据,但是获取不到数据点中的数据,代码如下:
js 代码:
$("#button1").click(function(){
$.get("index.php",{username:$("#username").val(),password:$("#password").val(),tel:$("#tel").val()},function(data,textStatus){ //get方法请求数据
$("#response").html("用户名:"+data.name+"
密码:"+data.pwd+"
手机号码:"+data.tell);
alert(data); //能够显示数据
})
})
php 代码:
运行后:
能够返回数据

无法检索返回的数据

解决方案:
创建一个对象,将json数据转换成一个对象

ajaxData=$.parseJSON(data) //将json数据转换为js对象
注意:
无法在程序中运行,在程序中运行时无法解释php页面,必须在appserv程序下的www文件夹下运行(运行时不能是ftp地址,而是像“:82” /unit07/index.html”地址)
php抓取网页json数据(对以上的url进行爬取importrequests=requests.get)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-16 16:20
URL列表=[]
#将地址拼接到爬网
对于范围(1,5)2)>:
url=urlbase+str(i)+“&;=49”url列表。附加(url)
#循环获取列表页面信息
2、使用请求对上述URL进行爬网
导入请求
内容=请求。获取(url,headers=headers)。内容
在爬网过程中,考虑到模拟真实用户的需要,需要添加cookie或头参数
(二)。对爬行JSON格式数据的分析
到目前为止,数据已经被抓取下来并存储在内容中,但是如何提出关键数据是非常重要的
为了在浏览器中轻松浏览JSON格式的数据,建议在chrome中添加扩展jsonview,以实现JSON格式数据的结构化显示。例如,人人贷款的数据如下所示
有两种方法可以解析此数据
1、正则表达式解析
例如,如果我们想获取“金额”的内容,可以通过以下方式获取:
进口
##使用regular提取金额字段amount=re findall(r'“amount”:(.*),(内容)
哪里的内容是爬下来的内容
2、基于JSON格式获取
事实上,JSON的数据格式与Python的dict非常相似。Python的importjson包中提供了两种经典的预处理方法:
导入json
格言={1:2,3:4,“55”:“66”}
#测试json。倾倒
打印类型(dict),dict_
json_u;str=json。转储(dict_)
打印“json.dumps(dict)返回:”
打印类型(json_str),json_str
#测试json。装载
打印“\njson.loads(str)返回”
dict_u2=json。加载(json_str)
打印类型(dict_2)@>,dict_2
输出为:
计划结果:
{'55':'66',1:2,3:4}
json。转储(dict)返回:
{“55”:“66”,“1”:2,“3”:4}
json。负载(str)返回
{u'55':u'66',u'1':2,u'3':4}
从上述示例可以看出,转储和加载的功能如下:
json。倾倒
:将ptyhon的Dict转换为str
json。加载:将STR转换为Python的dict类型
有了以上基础知识,可以通过以下方式直接对人人贷款数据进行处理:
FORURLINURLIST:
//得到满足
内容=请求。获取(url,headers=headers)。内容
//使用JSON,loads方法将STR转换为dict类型
con=json。Loads(content)#获取评论列表,因为以前不需要很多其他东西
//直接使用Python中dict的数据采集方法获取贷款列表,然后直接获取每个数据
commentList=con[“数据”][“贷款”]
对于commentList中的项目:
loanId=项目['loanId']
标题=项目['title']
金额=项目[“金额”]
利息=项目[“利息”]
月数=项目[“月数”]
备注:
使用第二种方法时,应注意返回的数据是否为标准JSON格式。如果不是标准JSON格式,则可能需要额外处理。例如,京东产品的审查数据
这是中国联通的苹果iphone7plus(a166)128G亮黑色4G手机的评论数据
直接打开上面的链接后,您会发现jsonview下没有正式的JSON格式数据显示。对于这种数据类型,可以通过正则表达式获取,也可以将JSON转换为dict
仔细分析攀爬数据:
原文页:
我们想要抓取的是用户评论数据,而我们抓取的内容不是标准JSON格式的数据。如上图所示,我们抓取的内容是将数据放入fetchjson_Comment98vv52063(),括号中的数据是标准JSON格式的数据
因此,对于这类数据,我们应该首先用括号正则表示数据,然后使用loads方法将其转换为Python的dict类型数据进行处理
源代码如下:
#爬行
URL列表中的forurl:
cont=请求。获取(url,headers=headers,cookies=cookie)。内容
#这是非常重要的。这里的正则表达式以数字或字母开头,后跟()
content=rex。Findall(cont)[0]#去掉括号中的内容,这是一种标准的JSON格式数据
con=json。加载(内容,“gbk”)
#进入评论列表,因为之前还有很多不需要的东西
commentList=con['comments']
对于列表中的项目:
id=项目['id']
内容=项目['content']。条带()
referenceName=项目['referenceName']
productColor=项目['productColor']
技巧:您可以尝试将()中的数据提交给一些在线JSON解析网站(),以查看JSON数据的排列格式,从而更清楚地了解如何提取数据
(三)参考文献:
1、使用Python-urllib捕获和分析数据
:
二, 查看全部
php抓取网页json数据(对以上的url进行爬取importrequests=requests.get)
URL列表=[]
#将地址拼接到爬网
对于范围(1,5)2)>:
url=urlbase+str(i)+“&;=49”url列表。附加(url)
#循环获取列表页面信息
2、使用请求对上述URL进行爬网
导入请求
内容=请求。获取(url,headers=headers)。内容
在爬网过程中,考虑到模拟真实用户的需要,需要添加cookie或头参数
(二)。对爬行JSON格式数据的分析
到目前为止,数据已经被抓取下来并存储在内容中,但是如何提出关键数据是非常重要的
为了在浏览器中轻松浏览JSON格式的数据,建议在chrome中添加扩展jsonview,以实现JSON格式数据的结构化显示。例如,人人贷款的数据如下所示

有两种方法可以解析此数据
1、正则表达式解析
例如,如果我们想获取“金额”的内容,可以通过以下方式获取:
进口
##使用regular提取金额字段amount=re findall(r'“amount”:(.*),(内容)
哪里的内容是爬下来的内容
2、基于JSON格式获取
事实上,JSON的数据格式与Python的dict非常相似。Python的importjson包中提供了两种经典的预处理方法:
导入json
格言={1:2,3:4,“55”:“66”}
#测试json。倾倒
打印类型(dict),dict_
json_u;str=json。转储(dict_)
打印“json.dumps(dict)返回:”
打印类型(json_str),json_str
#测试json。装载
打印“\njson.loads(str)返回”
dict_u2=json。加载(json_str)
打印类型(dict_2)@>,dict_2
输出为:
计划结果:
{'55':'66',1:2,3:4}
json。转储(dict)返回:
{“55”:“66”,“1”:2,“3”:4}
json。负载(str)返回
{u'55':u'66',u'1':2,u'3':4}
从上述示例可以看出,转储和加载的功能如下:
json。倾倒
:将ptyhon的Dict转换为str
json。加载:将STR转换为Python的dict类型
有了以上基础知识,可以通过以下方式直接对人人贷款数据进行处理:
FORURLINURLIST:
//得到满足
内容=请求。获取(url,headers=headers)。内容
//使用JSON,loads方法将STR转换为dict类型
con=json。Loads(content)#获取评论列表,因为以前不需要很多其他东西
//直接使用Python中dict的数据采集方法获取贷款列表,然后直接获取每个数据
commentList=con[“数据”][“贷款”]
对于commentList中的项目:
loanId=项目['loanId']
标题=项目['title']
金额=项目[“金额”]
利息=项目[“利息”]
月数=项目[“月数”]
备注:
使用第二种方法时,应注意返回的数据是否为标准JSON格式。如果不是标准JSON格式,则可能需要额外处理。例如,京东产品的审查数据
这是中国联通的苹果iphone7plus(a166)128G亮黑色4G手机的评论数据
直接打开上面的链接后,您会发现jsonview下没有正式的JSON格式数据显示。对于这种数据类型,可以通过正则表达式获取,也可以将JSON转换为dict
仔细分析攀爬数据:
原文页:
我们想要抓取的是用户评论数据,而我们抓取的内容不是标准JSON格式的数据。如上图所示,我们抓取的内容是将数据放入fetchjson_Comment98vv52063(),括号中的数据是标准JSON格式的数据
因此,对于这类数据,我们应该首先用括号正则表示数据,然后使用loads方法将其转换为Python的dict类型数据进行处理
源代码如下:
#爬行
URL列表中的forurl:
cont=请求。获取(url,headers=headers,cookies=cookie)。内容
#这是非常重要的。这里的正则表达式以数字或字母开头,后跟()
content=rex。Findall(cont)[0]#去掉括号中的内容,这是一种标准的JSON格式数据
con=json。加载(内容,“gbk”)
#进入评论列表,因为之前还有很多不需要的东西
commentList=con['comments']
对于列表中的项目:
id=项目['id']
内容=项目['content']。条带()
referenceName=项目['referenceName']
productColor=项目['productColor']
技巧:您可以尝试将()中的数据提交给一些在线JSON解析网站(),以查看JSON数据的排列格式,从而更清楚地了解如何提取数据
(三)参考文献:
1、使用Python-urllib捕获和分析数据
:
二,
php抓取网页json数据(Python网络爬虫findfind动态网页的两种技术:1.使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-15 17:19
由于主流的网站都使用JavaScript来展示网页内容,不像之前的静态网页简单爬行,使用JavaScript的时候很多内容没有出现在HTML源代码中,而是放在了HTML源代码中代码。一段JavaScript代码,最后呈现的数据是由JavaScript提取出来的,提取出服务器返回的数据,加载到源代码中进行呈现。因此,抓取静态网页的技术可能无法正常工作。因此,我们需要使用两种技术进行动态网页爬取:
1.通过浏览器评论元素分析真实网页地址;
2.使用selenium模拟浏览器。
我们这里先介绍第一种方法。
以《Python Web Crawler:从入门到实践》作者的个人博客评论为例。网址:1)“抓包”:找到真实数据地址
右键单击“检查”,单击“网络”,然后选择“js”。刷新页面,选择数据列表?回调...这个页面刷新时返回的js文件。选择右侧的标题。如图:
其中Request URL为真实数据地址。
在此状态下,滚动鼠标滚轮以找到 User-Agent。
2)相关代码:
import requests
import json
headers={\'User-Agent\':\'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36\'}
link="https://api-zero.livere.com/v1 ... ot%3B
r=requests.get(link,headers=headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find(\'{\'):-2]
json_data=json.loads(json_string)
comment_list=json_data[\'results\'][\'parents\']
for eachone in comment_list:
message=eachone[\'content\']
print(message)
输出是:
现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?
为何静态网页抓取不了?
奇怪了,我按照书上的方法来操作,XHR也是空的啊
XHR没有显示任何东西啊。奇怪。
找到原因了
caps["marionette"] = True
作者可以解释一下这句话是干什么的吗
我用的是 pycham IDE,按照作者的写法写的,怎么不行
对火狐版本有要求吗
4.3.1 打开Hello World,代码用的作者的,火狐地址我也设置了,为啥运行没反应
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps = webdriver.DesiredCapabilities().FIREFOX
caps["marionette"] = False
binary = FirefoxBinary(r\'C:\\Program Files\\Mozilla Firefox\\firefox.exe\')
#把上述地址改成你电脑中Firefox程序的地址
driver = webdriver.Firefox(firefox_binary=binary, capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
我是番茄
为什么刷新没有XHR数据,评论明明加载出来了
代码分析:
1)对于代码json_string.find() api解析为:
Docstring:
S.find(sub[, start[, end]]) -> int
Return the lowest index in S where substring sub is found,
such that sub is contained within S[start:end]. Optional
arguments start and end are interpreted as in slice notation.
Return -1 on failure.
Type: method_descriptor
所以代码 json_string.find(\'{\') 返回的是“{”在json_string字符串中的索引位置。
2) 如果在代码中加一句代码print json_string,这句话的输出结果是(由于输出内容太多,只截取了开头和结尾,关键位置用红色标出):
/**/ typeof jQuery112405600294326674093_1523687034324 === \'function\' && jQuery112405600294326674093_1523687034324({"results":{"parents":[{"replySeq":33365104,"name":"骨犬","memberId":"B9E06FBF9013D49CADBB5B623E8226C8","memberIcon":"http://q.qlogo.cn/qqapp/101256 ... ot%3B,"memberUrl":"https://qq.com/","memberDomain":"qq","good":0,"bad":0,"police":0,"parentSeq":33365104,"directSeq":0,"shortUrl":null,"title":"Hello world! - 数据科学@唐松
Santos","site":"http://www.santostang.com/2017 ... ot%3B,"email":null,"ipAddress":"27.210.192.241","isMobile":"0","agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.108 Safari/537.36 2345Explorer/8.8.3.16721","septSns":null,"targetService":null,"targetUserName":null,"info1":null,"info2":null,"info3":null,"image1":null,"image2":null,"image3":null,"link1":null,"link2":null,"link3":null,"isSecret":0,"isModified":0,"confirm":0,"subCount":1,"regdate":"2018-01-01T06:27:50.000Z","deletedDate":null,"file1":null,"file2":null,"file3":null,"additionalSeq":0,"content":"现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?"
。。。。。。。。。 tent":"我的也是提示火狐版本不匹配,你解决了吗","quotationSeq":null,"quotationContent":null,"consumerSeq":1020,"livereSeq":28583,"repSeq":3871836,"memberGroupSeq":26828779,"memberSeq":27312353,"status":0,"repGroupSeq":0,"adminSeq":25413747,"deleteReason":null,"sticker":0,"version":null}],"quotations":[]},"resultCode":200,"resultMessage":"Okay, livere"});
从上面的输出结果,我们可以看出在代码中加入 json_string = json_string[json_string.find(\'{\'):-2] 的重要性。
如果不加json_string.find(\'{\'),则结果不是合法的json格式,无法成功形成json文件;如果没有截取到倒数第二个位置,则结果收录冗余);也不能构成合法的 json 格式。
3)代码comment_list=json_data[\'results\'][\'parents\']和message=eachone[\'content\']中括号中字符串类型的标签定位,可以上面2)中的关键部分搜索,即截取后合法的json文件同时收录在“results”和“parents”中,所以用两个括号一层一层定位,因为我们是爬取评论,其内容在json文件的“content”标签中,所以使用[“content”]定位。
观察到实际数据地址中的偏移量是页数。 查看全部
php抓取网页json数据(Python网络爬虫findfind动态网页的两种技术:1.使用)
由于主流的网站都使用JavaScript来展示网页内容,不像之前的静态网页简单爬行,使用JavaScript的时候很多内容没有出现在HTML源代码中,而是放在了HTML源代码中代码。一段JavaScript代码,最后呈现的数据是由JavaScript提取出来的,提取出服务器返回的数据,加载到源代码中进行呈现。因此,抓取静态网页的技术可能无法正常工作。因此,我们需要使用两种技术进行动态网页爬取:
1.通过浏览器评论元素分析真实网页地址;
2.使用selenium模拟浏览器。
我们这里先介绍第一种方法。
以《Python Web Crawler:从入门到实践》作者的个人博客评论为例。网址:1)“抓包”:找到真实数据地址
右键单击“检查”,单击“网络”,然后选择“js”。刷新页面,选择数据列表?回调...这个页面刷新时返回的js文件。选择右侧的标题。如图:

其中Request URL为真实数据地址。
在此状态下,滚动鼠标滚轮以找到 User-Agent。

2)相关代码:
import requests
import json
headers={\'User-Agent\':\'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36\'}
link="https://api-zero.livere.com/v1 ... ot%3B
r=requests.get(link,headers=headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find(\'{\'):-2]
json_data=json.loads(json_string)
comment_list=json_data[\'results\'][\'parents\']
for eachone in comment_list:
message=eachone[\'content\']
print(message)
输出是:
现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?
为何静态网页抓取不了?
奇怪了,我按照书上的方法来操作,XHR也是空的啊
XHR没有显示任何东西啊。奇怪。
找到原因了
caps["marionette"] = True
作者可以解释一下这句话是干什么的吗
我用的是 pycham IDE,按照作者的写法写的,怎么不行
对火狐版本有要求吗
4.3.1 打开Hello World,代码用的作者的,火狐地址我也设置了,为啥运行没反应
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps = webdriver.DesiredCapabilities().FIREFOX
caps["marionette"] = False
binary = FirefoxBinary(r\'C:\\Program Files\\Mozilla Firefox\\firefox.exe\')
#把上述地址改成你电脑中Firefox程序的地址
driver = webdriver.Firefox(firefox_binary=binary, capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
我是番茄
为什么刷新没有XHR数据,评论明明加载出来了
代码分析:
1)对于代码json_string.find() api解析为:
Docstring:
S.find(sub[, start[, end]]) -> int
Return the lowest index in S where substring sub is found,
such that sub is contained within S[start:end]. Optional
arguments start and end are interpreted as in slice notation.
Return -1 on failure.
Type: method_descriptor
所以代码 json_string.find(\'{\') 返回的是“{”在json_string字符串中的索引位置。
2) 如果在代码中加一句代码print json_string,这句话的输出结果是(由于输出内容太多,只截取了开头和结尾,关键位置用红色标出):
/**/ typeof jQuery112405600294326674093_1523687034324 === \'function\' && jQuery112405600294326674093_1523687034324({"results":{"parents":[{"replySeq":33365104,"name":"骨犬","memberId":"B9E06FBF9013D49CADBB5B623E8226C8","memberIcon":"http://q.qlogo.cn/qqapp/101256 ... ot%3B,"memberUrl":"https://qq.com/","memberDomain":"qq","good":0,"bad":0,"police":0,"parentSeq":33365104,"directSeq":0,"shortUrl":null,"title":"Hello world! - 数据科学@唐松
Santos","site":"http://www.santostang.com/2017 ... ot%3B,"email":null,"ipAddress":"27.210.192.241","isMobile":"0","agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.108 Safari/537.36 2345Explorer/8.8.3.16721","septSns":null,"targetService":null,"targetUserName":null,"info1":null,"info2":null,"info3":null,"image1":null,"image2":null,"image3":null,"link1":null,"link2":null,"link3":null,"isSecret":0,"isModified":0,"confirm":0,"subCount":1,"regdate":"2018-01-01T06:27:50.000Z","deletedDate":null,"file1":null,"file2":null,"file3":null,"additionalSeq":0,"content":"现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?"
。。。。。。。。。 tent":"我的也是提示火狐版本不匹配,你解决了吗","quotationSeq":null,"quotationContent":null,"consumerSeq":1020,"livereSeq":28583,"repSeq":3871836,"memberGroupSeq":26828779,"memberSeq":27312353,"status":0,"repGroupSeq":0,"adminSeq":25413747,"deleteReason":null,"sticker":0,"version":null}],"quotations":[]},"resultCode":200,"resultMessage":"Okay, livere"});
从上面的输出结果,我们可以看出在代码中加入 json_string = json_string[json_string.find(\'{\'):-2] 的重要性。
如果不加json_string.find(\'{\'),则结果不是合法的json格式,无法成功形成json文件;如果没有截取到倒数第二个位置,则结果收录冗余);也不能构成合法的 json 格式。
3)代码comment_list=json_data[\'results\'][\'parents\']和message=eachone[\'content\']中括号中字符串类型的标签定位,可以上面2)中的关键部分搜索,即截取后合法的json文件同时收录在“results”和“parents”中,所以用两个括号一层一层定位,因为我们是爬取评论,其内容在json文件的“content”标签中,所以使用[“content”]定位。
观察到实际数据地址中的偏移量是页数。
php抓取网页json数据(PHP应用JSON形式数组和访问普通的对象属性(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 37 次浏览 • 2021-12-15 17:09
PHP 一直受到程序开发人员的青睐,不仅因为它的高效,还因为它的灵活性和便利性。很多服务器返回的数据都是json格式的,而json数据的形式多种多样,这就要求我们的php程序能够处理不同形式的json数据。
PHP应用JSON的相关函数为: json_encode($PHP_string);
而使用PHP解析JSON的函数是: json_decode($json_string);
在学习这个文章之前,我们需要知道什么是json数据。
PHP 提供了特殊的函数来生成和解析 JSON 格式的数据。PHP解析出来的数据与原创Javascript数据含义相同,即Javascript对象解析为PHP对象,Javascript数组解析为PHP数组。我们使用php中的json_decode()函数来解析json数据。
JSON的形式有很多种,不同的形式被PHP解释后会有不同的形式。
JSON 格式一:
它完全以对象的形式存在。这种形式的数据在 Javascript 中也称为关联数组。与一般数组的区别在于可以通过字符串作为索引来访问(使用“[]”或“.”表示级别)
$json='{
"item1":{
"item11":{
"n":"chenling",
"m":"llll"
},&
quot;sex":"男",
"age":"25"
},
"item2":{
"item21":"ling",
"sex":"女",
"age":"24"
}
}';
$J=json_decode($json);
print_r($J);
输出数据为:
stdClass Object
(
[item1] => stdClass Object
(
[item11] => stdClass Object
(
[n] => chenling
[m] => llll
)
[sex] => 男
[age] => 25
)
[item2] => stdClass Object
(
[item21] => ling
[sex] => 女
[age] => 24
)
)
比如我想获取值为chenling的属性,应该这样访问: $J->item1->item11->n;
这将获得属性 n 的值:chenling。
其实这种访问方式类似于访问普通对象的属性,相当于访问一个3维数组。
JSON形式二:混合对象和数组
$json='{"item1":[{"name":[{"chen":<br />
"chenling","ling":"chenli"}],"sex":<br />
"男","age":"25"},{"name":"sun","sex":<br />
"女","age":"24"}]}';
$J=json_decode($json);
print_r($J);
输出数据为:
stdClass Object
(
[item1] => Array
(
[0] => stdClass Object
(
[name] => Array
(
[0] => stdClass Object
(
[chen] => chenling
[ling] => chenli
)
)
[sex] => 男
[age] => 25
)
[1] => stdClass Object
(
[name] => sun
[sex] => 女
[age] => 24
)
)
)
比如我想获取值为chenling的元素,应该这样访问: $J->item1[0]->name[0]->chen;
这将得到元素chen的值:chenling。
其实这个PHP应用JSON格式结合了对象和数组的访问方式,相当于访问了一个5维数组。
JSON形式三:完整数组形式
$json='[["item1","item11"],[
"n","chenling"],["m","llll"]]';
$J=json_decode($json);
print_r($J);
输出数据为:
Array
(
[0] => Array
(
[0] => item1
[1] => item11
)
[1] => Array
(
[0] => n
[1] => chenling
)
[2] => Array
(
[0] => m
[1] => llll
)
)
比如我想获取值为chenling的元素,就应该这样访问: $J[0][1];
这将获得元素值为chenling的元素。
但是,使用这种方法有一个缺点,就是不能使用字符串作为索引。您只能使用一个数字。这个问题可以用完整对象的形式来解决。其实这种访问方式就是数组的访问方式,相当于访问一个二维数组。.
PHP解析不同形式的JSON数据汇总:
从上面的 PHP 应用 JSON 例子可以看出,JSON 有点类似于 XML,而且结构化数据也可以在 PHP 和 Javascript 之间传递,使用起来非常方便。需要注意的是,每个属性和属性值都用引号“”括起来。
免责声明:如需转载请注明出处并保留原文链接: 查看全部
php抓取网页json数据(PHP应用JSON形式数组和访问普通的对象属性(图))
PHP 一直受到程序开发人员的青睐,不仅因为它的高效,还因为它的灵活性和便利性。很多服务器返回的数据都是json格式的,而json数据的形式多种多样,这就要求我们的php程序能够处理不同形式的json数据。
PHP应用JSON的相关函数为: json_encode($PHP_string);
而使用PHP解析JSON的函数是: json_decode($json_string);
在学习这个文章之前,我们需要知道什么是json数据。
PHP 提供了特殊的函数来生成和解析 JSON 格式的数据。PHP解析出来的数据与原创Javascript数据含义相同,即Javascript对象解析为PHP对象,Javascript数组解析为PHP数组。我们使用php中的json_decode()函数来解析json数据。
JSON的形式有很多种,不同的形式被PHP解释后会有不同的形式。

JSON 格式一:
它完全以对象的形式存在。这种形式的数据在 Javascript 中也称为关联数组。与一般数组的区别在于可以通过字符串作为索引来访问(使用“[]”或“.”表示级别)
$json='{
"item1":{
"item11":{
"n":"chenling",
"m":"llll"
},&
quot;sex":"男",
"age":"25"
},
"item2":{
"item21":"ling",
"sex":"女",
"age":"24"
}
}';
$J=json_decode($json);
print_r($J);
输出数据为:
stdClass Object
(
[item1] => stdClass Object
(
[item11] => stdClass Object
(
[n] => chenling
[m] => llll
)
[sex] => 男
[age] => 25
)
[item2] => stdClass Object
(
[item21] => ling
[sex] => 女
[age] => 24
)
)
比如我想获取值为chenling的属性,应该这样访问: $J->item1->item11->n;
这将获得属性 n 的值:chenling。
其实这种访问方式类似于访问普通对象的属性,相当于访问一个3维数组。
JSON形式二:混合对象和数组
$json='{"item1":[{"name":[{"chen":<br />
"chenling","ling":"chenli"}],"sex":<br />
"男","age":"25"},{"name":"sun","sex":<br />
"女","age":"24"}]}';
$J=json_decode($json);
print_r($J);
输出数据为:
stdClass Object
(
[item1] => Array
(
[0] => stdClass Object
(
[name] => Array
(
[0] => stdClass Object
(
[chen] => chenling
[ling] => chenli
)
)
[sex] => 男
[age] => 25
)
[1] => stdClass Object
(
[name] => sun
[sex] => 女
[age] => 24
)
)
)
比如我想获取值为chenling的元素,应该这样访问: $J->item1[0]->name[0]->chen;
这将得到元素chen的值:chenling。
其实这个PHP应用JSON格式结合了对象和数组的访问方式,相当于访问了一个5维数组。
JSON形式三:完整数组形式
$json='[["item1","item11"],[
"n","chenling"],["m","llll"]]';
$J=json_decode($json);
print_r($J);
输出数据为:
Array
(
[0] => Array
(
[0] => item1
[1] => item11
)
[1] => Array
(
[0] => n
[1] => chenling
)
[2] => Array
(
[0] => m
[1] => llll
)
)
比如我想获取值为chenling的元素,就应该这样访问: $J[0][1];
这将获得元素值为chenling的元素。
但是,使用这种方法有一个缺点,就是不能使用字符串作为索引。您只能使用一个数字。这个问题可以用完整对象的形式来解决。其实这种访问方式就是数组的访问方式,相当于访问一个二维数组。.
PHP解析不同形式的JSON数据汇总:
从上面的 PHP 应用 JSON 例子可以看出,JSON 有点类似于 XML,而且结构化数据也可以在 PHP 和 Javascript 之间传递,使用起来非常方便。需要注意的是,每个属性和属性值都用引号“”括起来。
免责声明:如需转载请注明出处并保留原文链接:
php抓取网页json数据( 一种轻量格式的格式及其使用方法和使用技巧介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-15 03:30
一种轻量格式的格式及其使用方法和使用技巧介绍)
JSON 数据格式
JSON 是 JavaScript ObjectNotation 的缩写,是一种轻量级的数据表示方法。json格式使用key:value来记录数据,非常直观,比XML简单,所以很流行
在介绍json格式之前,我们先来看看XML格式。显然,XML 受到了相当多的关注(正面和负面评价),并在 Ajax 应用程序中得到了广泛的应用:
Brett
McLaughlin
brett@newInstance.com
这里的数据和我们之前看到的一样,但这次是 XML 格式。这没什么了不起的;它只是另一种允许我们使用 XML 而不是纯文本和名称/值对的数据格式。
本文讨论另一种数据格式,JavaScript Object Notation (JSON)。JSON 看起来既熟悉又陌生。它提供了另一种选择,拥有更广泛的选择总是一件好事。
添加JSON
使用名称/值对或 XML 时,实际上是使用 JavaScript 从应用程序获取数据并将数据转换为另一种数据格式。在这些情况下,JavaScript 主要用作数据操作语言来移动和操作来自 Web 表单的数据,并将数据转换为适合发送到服务器端程序的格式。
但是,有时 JavaScript 不仅仅用作格式化语言。在这些情况下,JavaScript 语言中的对象实际上是用来表示数据的,而不仅仅是将来自 Web 表单的数据放入请求中。在这些情况下,从 JavaScript 对象中提取数据,然后将数据放入名称/值对或 XML 中有点多余。这时候,使用 JSON 比较合适:JSON 允许将 JavaScript 对象轻松转换为可以随请求发送的数据(同步或异步)。
JSON 不是灵丹妙药;但是,对于一些非常特殊的情况,它是一个不错的选择。
简单地说,JSON 可以将 JavaScript 对象中表示的一组数据转换为字符串,然后您可以轻松地在函数之间传递这个字符串,或者在异步应用程序中将字符串从 Web 客户端传递到服务器。结束程序。这个字符串看起来有点奇怪(稍后你会看到几个例子),但 JavaScript 很容易解释它,而且 JSON 可以表示比名称/值对更复杂的结构。例如,您可以表示数组和复杂对象,而不仅仅是键和值的简单列表。JSON 基础知识
简单的 JSON 示例
在最简单的形式中,您可以使用以下 JSON 来表示名称/值对:
{ "firstName": "Brett" }
这个例子非常基础,实际上比等效的纯文本名称/值对占用更多的空间:
firstName="Brett"
但是,当多个名称/值对串在一起时,JSON 将反映其值。首先,您可以创建收录多个名称/值对的记录,例如:
{
"firstName": "Brett",
"lastName":"McLaughlin",
"email": "brett@newInstance.com"
}
从语法的角度来看,与名称/值对相比,这并不是一个很大的优势,但在这种情况下,JSON 更易于使用且更具可读性。例如,明确表示以上三个值都是同一个记录的一部分;花括号让这些值有一定的联系。
值数组
当需要表示一组值时,JSON 不仅可以提高可读性,还可以降低复杂度。例如,假设您想表示一个人名列表。在 XML 中,需要许多开始和结束标记;如果使用典型的名称/值对(如本系列前面文章中看到的名称/值对),那么必须建立特殊的一些数据格式,或者将键名修改为person1等形式-名。
如果你使用 JSON,你只需要用花括号将多条记录组合在一起:
{ "people": [
{ "firstName": "Brett", "lastName":"McLaughlin", "email": "brett@newInstance.com" },
{ "firstName": "Jason", "lastName":"Hunter", "email": "jason@servlets.com" },
{ "firstName": "Elliotte", "lastName":"Harold", "email": "elharo@macfaq.com" }
]}
这不难理解。在这个例子中,只有一个名为 people 的变量,其值是一个收录三个条目的数组,每个条目是一个人的记录,其中收录名字、姓氏和电子邮件地址。上面的示例演示了如何使用括号将记录合并为一个值。当然,您可以使用相同的语法来表示多个值(每个值收录多条记录):
{ "programmers": [
{ "firstName": "Brett", "lastName":"McLaughlin", "email": "brett@newInstance.com" },
{ "firstName": "Jason", "lastName":"Hunter", "email": "jason@servlets.com" },
{ "firstName": "Elliotte", "lastName":"Harold", "email": "elharo@macfaq.com" }
],
"authors": [
{ "firstName": "Isaac", "lastName": "Asimov", "genre": "science fiction" },
{ "firstName": "Tad", "lastName": "Williams", "genre": "fantasy" },
{ "firstName": "Frank", "lastName": "Peretti", "genre": "christian fiction" }
],
"musicians": [
{ "firstName": "Eric", "lastName": "Clapton", "instrument": "guitar" },
{ "firstName": "Sergei", "lastName": "Rachmaninoff", "instrument": "piano" }
]
}
这里最值得注意的是它可以表示多个值,而每个值又收录多个值。但还应该注意的是,记录中的实际名称/值对在不同的主要项目(程序员、作者和音乐家)之间可能会有所不同。JSON 是完全动态的,允许在 JSON 结构中间更改表示数据的方式。
在处理 JSON 格式的数据时,没有需要遵守的预定义约束。因此,在同一个数据结构中,可以改变数据的表示方式,甚至可以用不同的方式表示相同的事物。
将 JSON 数据赋值给变量 掌握了 JSON 格式后,在 JavaScript 中使用就非常简单了。JSON 是一种 JavaScript 原生格式,这意味着在 JavaScript 中处理 JSON 数据不需要任何特殊的 API 或工具包。在 JavaScript 中使用 JSON
例如,您可以创建一个新的 JavaScript 变量,然后直接为其分配一个 JSON 格式的数据字符串:
var people =
{ "programmers": [
{ "firstName": "Brett", "lastName":"McLaughlin", "email": "brett@newInstance.com" },
{ "firstName": "Jason", "lastName":"Hunter", "email": "jason@servlets.com" },
{ "firstName": "Elliotte", "lastName":"Harold", "email": "elharo@macfaq.com" }
],
"authors": [
{ "firstName": "Isaac", "lastName": "Asimov", "genre": "science fiction" },
{ "firstName": "Tad", "lastName": "Williams", "genre": "fantasy" },
{ "firstName": "Frank", "lastName": "Peretti", "genre": "christian fiction" }
],
"musicians": [
{ "firstName": "Eric", "lastName": "Clapton", "instrument": "guitar" },
{ "firstName": "Sergei", "lastName": "Rachmaninoff", "instrument": "piano" }
]
}
这很简单;现在人们收录我们之前看到的 JSON 格式的数据。然而,这还不够,因为访问数据的方式似乎还不是很明显。
访问数据
虽然看起来并不明显,但上面的长字符串实际上只是一个数组;将此数组放入 JavaScript 变量后,您可以轻松访问它。实际上,您只需要使用点表示法来表示数组元素。因此,要访问程序员列表中第一个条目的姓氏,只需在 JavaScript 中使用以下代码:
people.programmers[0].lastName;
请注意,数组索引从零开始。所以,这行代码首先访问了people变量中的数据;然后它移动到名为程序员的条目,然后移动到第一条记录([0]);最后,它访问 lastName 键的值。结果是字符串值“McLaughlin”。
以下是使用相同变量的几个示例。
people.authors[1].genre // Value is "fantasy"
people.musicians[3].lastName // Undefined. This refers to the fourth entry, and there isn't one
people.programmers.[2].firstName // Value is "Elliotte"
使用此语法,您可以处理 JSON 格式的任何数据,而无需使用任何额外的 JavaScript 工具包或 API。
修改 JSON 数据
正如您可以使用点和括号访问数据一样,您也可以使用相同的方式轻松修改数据:
people.musicians[1].lastName = "Rachmaninov";
将字符串转换为 JavaScript 对象后,您可以像这样修改变量中的数据。
转换回字符串
当然,如果对象不能轻易转换回本文提到的文本格式,那么所有的数据修改都没有什么价值。这种转换在 JavaScript 中也很简单:
String newJSONtext = people.toJSONString();
没关系!现在您有了一个可以在任何地方使用的文本字符串,例如,它可以在 Ajax 应用程序中用作请求字符串。
更重要的是,任何 JavaScript 对象都可以转换为 JSON 文本。这不仅仅是处理最初用 JSON 字符串分配的变量。为了转换名为 myObject 的对象,您只需要执行相同形式的命令:
String myObjectInJSON = myObject.toJSONString();
这是 JSON 与本系列中讨论的其他数据格式之间的最大区别。如果使用JSON,只需要调用一个简单的函数即可获取格式化后的数据,直接使用即可。对于其他数据格式,需要在原创数据和格式化数据之间进行转换。即使你使用像文档对象模型这样的 API(提供一个函数将你自己的数据结构转换成文本),你也需要学习这个 API 并使用 API 的对象,而不是使用原生的 JavaScript 对象和语法。
最后的结论是,如果你正在处理大量的 JavaScript 对象,那么 JSON 几乎肯定是一个不错的选择,这样你就可以很容易地将数据转换成可以在请求中发送给服务器端程序的格式. 查看全部
php抓取网页json数据(
一种轻量格式的格式及其使用方法和使用技巧介绍)
JSON 数据格式
JSON 是 JavaScript ObjectNotation 的缩写,是一种轻量级的数据表示方法。json格式使用key:value来记录数据,非常直观,比XML简单,所以很流行
在介绍json格式之前,我们先来看看XML格式。显然,XML 受到了相当多的关注(正面和负面评价),并在 Ajax 应用程序中得到了广泛的应用:
Brett
McLaughlin
brett@newInstance.com
这里的数据和我们之前看到的一样,但这次是 XML 格式。这没什么了不起的;它只是另一种允许我们使用 XML 而不是纯文本和名称/值对的数据格式。
本文讨论另一种数据格式,JavaScript Object Notation (JSON)。JSON 看起来既熟悉又陌生。它提供了另一种选择,拥有更广泛的选择总是一件好事。
添加JSON
使用名称/值对或 XML 时,实际上是使用 JavaScript 从应用程序获取数据并将数据转换为另一种数据格式。在这些情况下,JavaScript 主要用作数据操作语言来移动和操作来自 Web 表单的数据,并将数据转换为适合发送到服务器端程序的格式。
但是,有时 JavaScript 不仅仅用作格式化语言。在这些情况下,JavaScript 语言中的对象实际上是用来表示数据的,而不仅仅是将来自 Web 表单的数据放入请求中。在这些情况下,从 JavaScript 对象中提取数据,然后将数据放入名称/值对或 XML 中有点多余。这时候,使用 JSON 比较合适:JSON 允许将 JavaScript 对象轻松转换为可以随请求发送的数据(同步或异步)。
JSON 不是灵丹妙药;但是,对于一些非常特殊的情况,它是一个不错的选择。
简单地说,JSON 可以将 JavaScript 对象中表示的一组数据转换为字符串,然后您可以轻松地在函数之间传递这个字符串,或者在异步应用程序中将字符串从 Web 客户端传递到服务器。结束程序。这个字符串看起来有点奇怪(稍后你会看到几个例子),但 JavaScript 很容易解释它,而且 JSON 可以表示比名称/值对更复杂的结构。例如,您可以表示数组和复杂对象,而不仅仅是键和值的简单列表。JSON 基础知识
简单的 JSON 示例
在最简单的形式中,您可以使用以下 JSON 来表示名称/值对:
{ "firstName": "Brett" }
这个例子非常基础,实际上比等效的纯文本名称/值对占用更多的空间:
firstName="Brett"
但是,当多个名称/值对串在一起时,JSON 将反映其值。首先,您可以创建收录多个名称/值对的记录,例如:
{
"firstName": "Brett",
"lastName":"McLaughlin",
"email": "brett@newInstance.com"
}
从语法的角度来看,与名称/值对相比,这并不是一个很大的优势,但在这种情况下,JSON 更易于使用且更具可读性。例如,明确表示以上三个值都是同一个记录的一部分;花括号让这些值有一定的联系。
值数组
当需要表示一组值时,JSON 不仅可以提高可读性,还可以降低复杂度。例如,假设您想表示一个人名列表。在 XML 中,需要许多开始和结束标记;如果使用典型的名称/值对(如本系列前面文章中看到的名称/值对),那么必须建立特殊的一些数据格式,或者将键名修改为person1等形式-名。
如果你使用 JSON,你只需要用花括号将多条记录组合在一起:
{ "people": [
{ "firstName": "Brett", "lastName":"McLaughlin", "email": "brett@newInstance.com" },
{ "firstName": "Jason", "lastName":"Hunter", "email": "jason@servlets.com" },
{ "firstName": "Elliotte", "lastName":"Harold", "email": "elharo@macfaq.com" }
]}
这不难理解。在这个例子中,只有一个名为 people 的变量,其值是一个收录三个条目的数组,每个条目是一个人的记录,其中收录名字、姓氏和电子邮件地址。上面的示例演示了如何使用括号将记录合并为一个值。当然,您可以使用相同的语法来表示多个值(每个值收录多条记录):
{ "programmers": [
{ "firstName": "Brett", "lastName":"McLaughlin", "email": "brett@newInstance.com" },
{ "firstName": "Jason", "lastName":"Hunter", "email": "jason@servlets.com" },
{ "firstName": "Elliotte", "lastName":"Harold", "email": "elharo@macfaq.com" }
],
"authors": [
{ "firstName": "Isaac", "lastName": "Asimov", "genre": "science fiction" },
{ "firstName": "Tad", "lastName": "Williams", "genre": "fantasy" },
{ "firstName": "Frank", "lastName": "Peretti", "genre": "christian fiction" }
],
"musicians": [
{ "firstName": "Eric", "lastName": "Clapton", "instrument": "guitar" },
{ "firstName": "Sergei", "lastName": "Rachmaninoff", "instrument": "piano" }
]
}
这里最值得注意的是它可以表示多个值,而每个值又收录多个值。但还应该注意的是,记录中的实际名称/值对在不同的主要项目(程序员、作者和音乐家)之间可能会有所不同。JSON 是完全动态的,允许在 JSON 结构中间更改表示数据的方式。
在处理 JSON 格式的数据时,没有需要遵守的预定义约束。因此,在同一个数据结构中,可以改变数据的表示方式,甚至可以用不同的方式表示相同的事物。
将 JSON 数据赋值给变量 掌握了 JSON 格式后,在 JavaScript 中使用就非常简单了。JSON 是一种 JavaScript 原生格式,这意味着在 JavaScript 中处理 JSON 数据不需要任何特殊的 API 或工具包。在 JavaScript 中使用 JSON
例如,您可以创建一个新的 JavaScript 变量,然后直接为其分配一个 JSON 格式的数据字符串:
var people =
{ "programmers": [
{ "firstName": "Brett", "lastName":"McLaughlin", "email": "brett@newInstance.com" },
{ "firstName": "Jason", "lastName":"Hunter", "email": "jason@servlets.com" },
{ "firstName": "Elliotte", "lastName":"Harold", "email": "elharo@macfaq.com" }
],
"authors": [
{ "firstName": "Isaac", "lastName": "Asimov", "genre": "science fiction" },
{ "firstName": "Tad", "lastName": "Williams", "genre": "fantasy" },
{ "firstName": "Frank", "lastName": "Peretti", "genre": "christian fiction" }
],
"musicians": [
{ "firstName": "Eric", "lastName": "Clapton", "instrument": "guitar" },
{ "firstName": "Sergei", "lastName": "Rachmaninoff", "instrument": "piano" }
]
}
这很简单;现在人们收录我们之前看到的 JSON 格式的数据。然而,这还不够,因为访问数据的方式似乎还不是很明显。
访问数据
虽然看起来并不明显,但上面的长字符串实际上只是一个数组;将此数组放入 JavaScript 变量后,您可以轻松访问它。实际上,您只需要使用点表示法来表示数组元素。因此,要访问程序员列表中第一个条目的姓氏,只需在 JavaScript 中使用以下代码:
people.programmers[0].lastName;
请注意,数组索引从零开始。所以,这行代码首先访问了people变量中的数据;然后它移动到名为程序员的条目,然后移动到第一条记录([0]);最后,它访问 lastName 键的值。结果是字符串值“McLaughlin”。
以下是使用相同变量的几个示例。
people.authors[1].genre // Value is "fantasy"
people.musicians[3].lastName // Undefined. This refers to the fourth entry, and there isn't one
people.programmers.[2].firstName // Value is "Elliotte"
使用此语法,您可以处理 JSON 格式的任何数据,而无需使用任何额外的 JavaScript 工具包或 API。
修改 JSON 数据
正如您可以使用点和括号访问数据一样,您也可以使用相同的方式轻松修改数据:
people.musicians[1].lastName = "Rachmaninov";
将字符串转换为 JavaScript 对象后,您可以像这样修改变量中的数据。
转换回字符串
当然,如果对象不能轻易转换回本文提到的文本格式,那么所有的数据修改都没有什么价值。这种转换在 JavaScript 中也很简单:
String newJSONtext = people.toJSONString();
没关系!现在您有了一个可以在任何地方使用的文本字符串,例如,它可以在 Ajax 应用程序中用作请求字符串。
更重要的是,任何 JavaScript 对象都可以转换为 JSON 文本。这不仅仅是处理最初用 JSON 字符串分配的变量。为了转换名为 myObject 的对象,您只需要执行相同形式的命令:
String myObjectInJSON = myObject.toJSONString();
这是 JSON 与本系列中讨论的其他数据格式之间的最大区别。如果使用JSON,只需要调用一个简单的函数即可获取格式化后的数据,直接使用即可。对于其他数据格式,需要在原创数据和格式化数据之间进行转换。即使你使用像文档对象模型这样的 API(提供一个函数将你自己的数据结构转换成文本),你也需要学习这个 API 并使用 API 的对象,而不是使用原生的 JavaScript 对象和语法。
最后的结论是,如果你正在处理大量的 JavaScript 对象,那么 JSON 几乎肯定是一个不错的选择,这样你就可以很容易地将数据转换成可以在请求中发送给服务器端程序的格式.
php抓取网页json数据(这是你如何做到这一点:这个链接会告诉你)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-15 03:24
所以你可以这样做:
这个链接会告诉你更详细的操作方法:
$(document).ready(function(){
$("#button").click(function(){
$.getJSON("http://example.com/",function(result){
$.each(result, function(i, field){
$("#myDiv").append(""+i + " " + field.name + "" + field.description + "");
});
});
});
});
此链接正是您想要关注的内容:
$(document).ready(function(){
$("#button").click(function(){
$.getJSON("http://example.com/",function(result){
$.each(result, function(i, field){
$("#myDiv").append("" + field.name + "<p>" + field.description + "");
});
});
});
});
</p>
你必须使用 AJAX &。 getJSON 基本上是一种从 url 中获取字段的方法。然后我将您的 json 中的表格附加到 div。
如果你向你的 json 添加更多数据,那么你可以通过 field.[json-field-name] 获取它并通过为它提供 'id' 为你提供任何样式,然后以 css 样式创建它。我跟踪 json 文件中的元素数量。
希望这有助于
更多文档:
使用 jQuery 插件的 Ajax 需要嵌入到页面的 .getJSON 方法中才能工作。 查看全部
php抓取网页json数据(这是你如何做到这一点:这个链接会告诉你)
所以你可以这样做:
这个链接会告诉你更详细的操作方法:
$(document).ready(function(){
$("#button").click(function(){
$.getJSON("http://example.com/",function(result){
$.each(result, function(i, field){
$("#myDiv").append(""+i + " " + field.name + "" + field.description + "");
});
});
});
});
此链接正是您想要关注的内容:
$(document).ready(function(){
$("#button").click(function(){
$.getJSON("http://example.com/",function(result){
$.each(result, function(i, field){
$("#myDiv").append("" + field.name + "<p>" + field.description + "");
});
});
});
});
</p>
你必须使用 AJAX &。 getJSON 基本上是一种从 url 中获取字段的方法。然后我将您的 json 中的表格附加到 div。
如果你向你的 json 添加更多数据,那么你可以通过 field.[json-field-name] 获取它并通过为它提供 'id' 为你提供任何样式,然后以 css 样式创建它。我跟踪 json 文件中的元素数量。
希望这有助于
更多文档:
使用 jQuery 插件的 Ajax 需要嵌入到页面的 .getJSON 方法中才能工作。
php抓取网页json数据(一个在python中使用模块来解析XML文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-03 17:30
乔斯
我想从 [0]name=type&facets[0]value=software&mediatype=xml 获取一些数据
我需要的是每条记录的“标题”和“GetCapabilitiesUrl”。我曾尝试使用 BeautifulSoup,但找不到获取所需数据的正确方法。
有人知道如何进行吗?
谢谢。
Gbox4
您发布的链接看起来像一个 JSON 文件,而不是一个 XML 文件。你可以在这里看到不同之处。你可以使用python中的json模块来解析这些数据。
从网站获取收录数据的字符串后,可以使用json.loads()将收录JSON对象的字符串转换为python对象。
下面的代码片段将把所有标题放在一个名为 titles 的变量中,并在其中添加一个 url。网址
import json
import urllib.request
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
raw_json_string = urllib.request.urlopen("https://kartkatalog.geonorge.n ... 6quot;).read()
json_object = json.loads(raw_json_string)
titles = []
urls = []
for record in json_object["Results"]:
titles.append(record["Title"])
try:
urls.append(record["GetCapabilitiesUrl"])
except:
pass
在编写代码时,您可以使用在线 JSON 查看器来帮助您确定字典和列表的元素。 查看全部
php抓取网页json数据(一个在python中使用模块来解析XML文件)
乔斯
我想从 [0]name=type&facets[0]value=software&mediatype=xml 获取一些数据
我需要的是每条记录的“标题”和“GetCapabilitiesUrl”。我曾尝试使用 BeautifulSoup,但找不到获取所需数据的正确方法。
有人知道如何进行吗?
谢谢。
Gbox4
您发布的链接看起来像一个 JSON 文件,而不是一个 XML 文件。你可以在这里看到不同之处。你可以使用python中的json模块来解析这些数据。
从网站获取收录数据的字符串后,可以使用json.loads()将收录JSON对象的字符串转换为python对象。
下面的代码片段将把所有标题放在一个名为 titles 的变量中,并在其中添加一个 url。网址
import json
import urllib.request
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
raw_json_string = urllib.request.urlopen("https://kartkatalog.geonorge.n ... 6quot;).read()
json_object = json.loads(raw_json_string)
titles = []
urls = []
for record in json_object["Results"]:
titles.append(record["Title"])
try:
urls.append(record["GetCapabilitiesUrl"])
except:
pass
在编写代码时,您可以使用在线 JSON 查看器来帮助您确定字典和列表的元素。
php抓取网页json数据(PHP获取接口内容api内容介绍(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-02 11:08
)
PHP 获取界面内容
如果要解析JSON数据并显示在页面上,首先必须要获取JSON接口文件的内容。 PHP中获取页面内容,可以使用fopen()函数远程访问页面,然后使用fread()函数循环获取内容。
假设接口文件页面是:,那么我们可以用下面的语句来获取这个接口文件的内容:
$handle = fopen(“http://www.qttc.net/api.php%3F ... ot%3B,"rb“);
$content = “”;
while (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
这样保存的内容就是JSON api内容。
PHP 解析 JSON 并显示
原创内容不能直接调用,必须经过PHP进一步处理后才能调用显示在网页上。在PHP5.2及以后的版本中,使用json_decode()函数解析JSON数据并转换成PHP可以调用的数据格式。例如:
$content = json_decode($content);
$content = json_decode($content);
foreach ($content->data as $key) {
echo ‘<a target=”_blank” href=”‘.$key->b_url.’”>’.$key->b_title.’</a>’;
} 查看全部
php抓取网页json数据(PHP获取接口内容api内容介绍(图)
)
PHP 获取界面内容
如果要解析JSON数据并显示在页面上,首先必须要获取JSON接口文件的内容。 PHP中获取页面内容,可以使用fopen()函数远程访问页面,然后使用fread()函数循环获取内容。
假设接口文件页面是:,那么我们可以用下面的语句来获取这个接口文件的内容:
$handle = fopen(“http://www.qttc.net/api.php%3F ... ot%3B,"rb“);
$content = “”;
while (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
这样保存的内容就是JSON api内容。
PHP 解析 JSON 并显示
原创内容不能直接调用,必须经过PHP进一步处理后才能调用显示在网页上。在PHP5.2及以后的版本中,使用json_decode()函数解析JSON数据并转换成PHP可以调用的数据格式。例如:
$content = json_decode($content);
$content = json_decode($content);
foreach ($content->data as $key) {
echo ‘<a target=”_blank” href=”‘.$key->b_url.’”>’.$key->b_title.’</a>’;
}
php抓取网页json数据(PHP代码是模仿菜鸟教程上的“PHP数据库”PHP教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-11-30 16:15
写在前面
我的需求是微信小程序访问网站发布页面的php,php登录数据库获取数据。但是问题是服务器返回的数据是string类型的,不想做string处理,所以想把返回的数据做成json格式。
PHP
代码是模仿菜鸟教程上的《PHP数据库》PHP数据库教程编写的。网页截图如下:
根据我的项目,我写了如下php:
其实上面的json_encode()可以将数组转成json格式输出。假设单个echo的输出为{...},那么服务器响应给客户端返回的数据为{...},为json格式;但是经过多次回显,响应数据为{...}{...}{...},数据以“{...}{...}”的字符串形式传递给客户端{...}”,如下图所示。 (图片没有截断,但可以看出不是json格式,是一串“{…}{…}{…}”)
了解问题后,我的方案是:
1.先定义一个空数组:$row1=array();
2.在每个循环中将 $row 推入数组 $row1: array_push( $row1, $row[“code”]);
3.最后:echo json_encode( $row1);
变化如下:
if ($result->num_rows > 0) {
$row1=array();
while($row = $result->fetch_assoc()) {
array_push($row1,$row);
}
echo json_encode($row1);
} else {
echo "0 ";
}
理论上,数据的形式是[{…},{…},{…}]。然后看小程序控制台的输出:
嘿,我觉得很舒服。其实很简单,但是对于没有PHP基础的我来说,从知道json_encode()函数到解决问题花了将近一个下午的时间。
附上下午找到的一些链接:
php 数组:
MySQLi 官方手册: 查看全部
php抓取网页json数据(PHP代码是模仿菜鸟教程上的“PHP数据库”PHP教程)
写在前面
我的需求是微信小程序访问网站发布页面的php,php登录数据库获取数据。但是问题是服务器返回的数据是string类型的,不想做string处理,所以想把返回的数据做成json格式。
PHP
代码是模仿菜鸟教程上的《PHP数据库》PHP数据库教程编写的。网页截图如下:

根据我的项目,我写了如下php:
其实上面的json_encode()可以将数组转成json格式输出。假设单个echo的输出为{...},那么服务器响应给客户端返回的数据为{...},为json格式;但是经过多次回显,响应数据为{...}{...}{...},数据以“{...}{...}”的字符串形式传递给客户端{...}”,如下图所示。 (图片没有截断,但可以看出不是json格式,是一串“{…}{…}{…}”)

了解问题后,我的方案是:
1.先定义一个空数组:$row1=array();
2.在每个循环中将 $row 推入数组 $row1: array_push( $row1, $row[“code”]);
3.最后:echo json_encode( $row1);
变化如下:
if ($result->num_rows > 0) {
$row1=array();
while($row = $result->fetch_assoc()) {
array_push($row1,$row);
}
echo json_encode($row1);
} else {
echo "0 ";
}
理论上,数据的形式是[{…},{…},{…}]。然后看小程序控制台的输出:

嘿,我觉得很舒服。其实很简单,但是对于没有PHP基础的我来说,从知道json_encode()函数到解决问题花了将近一个下午的时间。
附上下午找到的一些链接:
php 数组:
MySQLi 官方手册:
php抓取网页json数据(阿里云gtgt;云栖社区版的Compass可视化工具(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-26 22:03
阿里云>云栖社区>主题图>P>php远程读取json数据库
推荐活动:
更多优惠>
当前主题:php远程读取json数据库添加到采集夹
相关话题:
php远程读取json数据库相关博客查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
13款Mongodb GUI可视化管理工具,总有一款适合你
作者:徐雷弗兰克7237人浏览评论:02年前
MongoDB数据库默认的管理工具是(CLI)Shell命令行,专业的DBA更容易使用,但是普通人的GUI可视化工具使用起来更方便。下面介绍13个有用的MongoDB可视化工具。MongoDB官方提供社区版Compass,可独立安装使用
阅读全文
MongoDB安装
作者:技术小哥 1232人浏览评论:04年前
mongodb 简介 MongoDB 是一个基于分布式文件存储的数据库。它是一种文档类型。虽然也是NoSQL数据库的一种,但与redis、memcached等数据库有些不同。MongoDB 是用 C++ 语言编写的。旨在为WEB应用提供可扩展的高性能数据存储解决方案。星期一
阅读全文
Android Volley 获取json格式的数据
作者:呵呵 99251000人浏览评论:04年前
为了让Android能够快速接入网络,解析常用数据格式,谷歌专门推出了Android系统网络传输的Volley库。volley 库可以方便的获取远程服务器的图片、字符串、json 对象、json 对象数组。当然java本身也可以访问json对象
阅读全文
《R与Hadoop大数据分析实战》1.7Hadoop子项目
作者:华章电脑1682人浏览评论:04年前
本节摘自华章出版社《R与Hadoop大数据分析实战》一书第1章1.7节,作者(印刷)Vignesh Prajapati,更多章节可在云栖社区找到《华章电脑》公众号查看1.7Hadoop的子项目Mahout是一个非常强大的数据挖掘库,其中
阅读全文
《Spark大数据分析:核心概念、技术与实践》大数据技术概述
作者:华章电脑 3937人浏览评论:04年前
本节摘自华章出版社《Spark大数据分析:核心概念、技术与实践》一书第一章和第一节。作者穆罕默德·古勒(Mohammed Guller)更多章节可以访问云栖。社区“华章电脑”公众号查看。大数据技术概览 我们正处于大数据时代。数据不仅是任何组织的生命
阅读全文
一小时了解MySQL数据库
作者:张国2052人浏览评论:04年前
随着移动互联网的终结和人工智能的到来,大数据变得越来越重要。下一个赢家应该是拥有大量数据的人。您应该了解数据和数据库。一、数据库汇总数据库(Database)是一个存储和管理数据的软件系统,就像一个存储数据的物流仓库。在商业领域,信息意味着商机。
阅读全文
Ajax 跨域请求 JSON JSONP
作者:cometwo1235780人浏览评论:05年前
同源策略和跨域汇总目录:1.同源策略2.跨域3.几种跨域技术1.什么是同源政策?URL 由协议、域名、端口和路径组成。如果两个 URL 的协议、域名、端口都相同,则说明它们是同源的。反之,只要协议、域名、端口不同,就视为跨域。电子
阅读全文
Android Volley 获取json格式的数据
作者:无声胜有生 823人浏览评论:06年前
为了让Android能够快速接入网络,解析常用数据格式,谷歌专门推出了Android系统网络传输的Volley库。volley 库可以方便的获取远程服务器的图片、字符串、json 对象、json 对象数组。当然java本身也可以访问json对象
阅读全文
php远程读取json数据库相关问答
【Java学习全家桶】1460道Java热点题,百位阿里巴巴技术专家答疑解惑
作者:管理贝贝19522人浏览评论:153年前
阿里极客公益活动:或许你选择为一个问题夜战,或许你迷茫只是寻求答案,或许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来云栖为您解答技术问题。他们使用自己手中的技术来帮助用户成长。本次活动邀请了数百位阿里巴巴技术
阅读全文 查看全部
php抓取网页json数据(阿里云gtgt;云栖社区版的Compass可视化工具(组图))
阿里云>云栖社区>主题图>P>php远程读取json数据库
推荐活动:
更多优惠>
当前主题:php远程读取json数据库添加到采集夹
相关话题:
php远程读取json数据库相关博客查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
13款Mongodb GUI可视化管理工具,总有一款适合你
作者:徐雷弗兰克7237人浏览评论:02年前
MongoDB数据库默认的管理工具是(CLI)Shell命令行,专业的DBA更容易使用,但是普通人的GUI可视化工具使用起来更方便。下面介绍13个有用的MongoDB可视化工具。MongoDB官方提供社区版Compass,可独立安装使用
阅读全文
MongoDB安装
作者:技术小哥 1232人浏览评论:04年前
mongodb 简介 MongoDB 是一个基于分布式文件存储的数据库。它是一种文档类型。虽然也是NoSQL数据库的一种,但与redis、memcached等数据库有些不同。MongoDB 是用 C++ 语言编写的。旨在为WEB应用提供可扩展的高性能数据存储解决方案。星期一
阅读全文
Android Volley 获取json格式的数据
作者:呵呵 99251000人浏览评论:04年前
为了让Android能够快速接入网络,解析常用数据格式,谷歌专门推出了Android系统网络传输的Volley库。volley 库可以方便的获取远程服务器的图片、字符串、json 对象、json 对象数组。当然java本身也可以访问json对象
阅读全文
《R与Hadoop大数据分析实战》1.7Hadoop子项目
作者:华章电脑1682人浏览评论:04年前
本节摘自华章出版社《R与Hadoop大数据分析实战》一书第1章1.7节,作者(印刷)Vignesh Prajapati,更多章节可在云栖社区找到《华章电脑》公众号查看1.7Hadoop的子项目Mahout是一个非常强大的数据挖掘库,其中
阅读全文
《Spark大数据分析:核心概念、技术与实践》大数据技术概述
作者:华章电脑 3937人浏览评论:04年前
本节摘自华章出版社《Spark大数据分析:核心概念、技术与实践》一书第一章和第一节。作者穆罕默德·古勒(Mohammed Guller)更多章节可以访问云栖。社区“华章电脑”公众号查看。大数据技术概览 我们正处于大数据时代。数据不仅是任何组织的生命
阅读全文
一小时了解MySQL数据库
作者:张国2052人浏览评论:04年前
随着移动互联网的终结和人工智能的到来,大数据变得越来越重要。下一个赢家应该是拥有大量数据的人。您应该了解数据和数据库。一、数据库汇总数据库(Database)是一个存储和管理数据的软件系统,就像一个存储数据的物流仓库。在商业领域,信息意味着商机。
阅读全文
Ajax 跨域请求 JSON JSONP
作者:cometwo1235780人浏览评论:05年前
同源策略和跨域汇总目录:1.同源策略2.跨域3.几种跨域技术1.什么是同源政策?URL 由协议、域名、端口和路径组成。如果两个 URL 的协议、域名、端口都相同,则说明它们是同源的。反之,只要协议、域名、端口不同,就视为跨域。电子
阅读全文
Android Volley 获取json格式的数据
作者:无声胜有生 823人浏览评论:06年前
为了让Android能够快速接入网络,解析常用数据格式,谷歌专门推出了Android系统网络传输的Volley库。volley 库可以方便的获取远程服务器的图片、字符串、json 对象、json 对象数组。当然java本身也可以访问json对象
阅读全文
php远程读取json数据库相关问答
【Java学习全家桶】1460道Java热点题,百位阿里巴巴技术专家答疑解惑
作者:管理贝贝19522人浏览评论:153年前
阿里极客公益活动:或许你选择为一个问题夜战,或许你迷茫只是寻求答案,或许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来云栖为您解答技术问题。他们使用自己手中的技术来帮助用户成长。本次活动邀请了数百位阿里巴巴技术
阅读全文
php抓取网页json数据(从php获取json数据使用js读取显示到网页笔记笔记)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-19 20:15
从php获取json数据,用js读取并显示到web笔记
php代码
"hellojson","age" => 23,"sex"=>"M");//定义php数组
$res=json_encode($array);
//var_dump($res);
echo $res;//输出结果到页面
HTML 代码
$(function(){
$(document).on("click",'.test',function(){
var id=$(this).attr("id");
var data={id:id}
//var aaa=[{"0":"1","id":"1","1":"hello","name":"hello","2":"","密码":""},{"0":"2","id":"2","1"
// :"world","name":"world","2":"","password":""},{"0":"3","id":"3", "1":"helloworld","name":"helloworld"
// ,"2":"","password":""}]
// alert(aaa[2].name)
$.ajax({
输入:“GET”,
数据:数据,
url:'xml.php',
数据类型:"json",
成功:功能(味精){
if(msg){
var res=eval(msg);//php返回的数据如果不能直接使用可以转换,可以使用eval()函数来实现转换。
//alert(res.username)
alert(res[1].name)//弹出要获取的数据
//console.log(res)
}
}
});
})
})
在原生js中,也可以使用JSON.parse()函数转换为json格式。 php中已经转成json格式了,可以直接获取
alert(msg[0].name)//msg为返回的json格式
从php中获取json数据,用js读取并显示web笔记的php代码? php//json与数组转换 $array = array(username = hellojson,age = 23, sex=M);//定义php数组$ res=json_encode(... 查看全部
php抓取网页json数据(从php获取json数据使用js读取显示到网页笔记笔记)
从php获取json数据,用js读取并显示到web笔记
php代码
"hellojson","age" => 23,"sex"=>"M");//定义php数组
$res=json_encode($array);
//var_dump($res);
echo $res;//输出结果到页面
HTML 代码
$(function(){
$(document).on("click",'.test',function(){
var id=$(this).attr("id");
var data={id:id}
//var aaa=[{"0":"1","id":"1","1":"hello","name":"hello","2":"","密码":""},{"0":"2","id":"2","1"
// :"world","name":"world","2":"","password":""},{"0":"3","id":"3", "1":"helloworld","name":"helloworld"
// ,"2":"","password":""}]
// alert(aaa[2].name)
$.ajax({
输入:“GET”,
数据:数据,
url:'xml.php',
数据类型:"json",
成功:功能(味精){
if(msg){
var res=eval(msg);//php返回的数据如果不能直接使用可以转换,可以使用eval()函数来实现转换。
//alert(res.username)
alert(res[1].name)//弹出要获取的数据
//console.log(res)
}
}
});
})
})
在原生js中,也可以使用JSON.parse()函数转换为json格式。 php中已经转成json格式了,可以直接获取
alert(msg[0].name)//msg为返回的json格式
从php中获取json数据,用js读取并显示web笔记的php代码? php//json与数组转换 $array = array(username = hellojson,age = 23, sex=M);//定义php数组$ res=json_encode(...
php抓取网页json数据(这里有新鲜出炉的PHP教程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-11 18:02
这里有新鲜的PHP教程,看看程序狗的速度!
PHP 开源脚本语言 PHP(外文名:Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,入门门槛低,易学,应用广泛。主要适用于Web开发领域。PHP 的文件扩展名为 php。
本文文章主要介绍PHP采集静态页面以及保存页面css、img、js的方法,可以实现简单的网页爬取功能,有一定的参考价值,有需要的朋友可以参考下面
本文介绍了PHP采集静态页面的方法以及保存页面css、img、js的方法。分享给大家,供大家参考。具体分析如下:
这是一个可以获取网页的html代码和css、js、字体和img资源的小工具。主要用于快速获取模板。如果来不及设计UI或者看到好的模板,可以用这个工具抓取网页并提取资源文件,提取的内容会按照相对路径保存资源,这样你就不用了担心资源文件的URL导入错误。
首页index.php,代码如下:
代码显示如下:
网络抓取器
网址
得到
保存全部
列表
抓取页面代码grab.php,代码如下:
代码显示如下: 查看全部
php抓取网页json数据(这里有新鲜出炉的PHP教程,程序狗速度看过来!)
这里有新鲜的PHP教程,看看程序狗的速度!
PHP 开源脚本语言 PHP(外文名:Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,入门门槛低,易学,应用广泛。主要适用于Web开发领域。PHP 的文件扩展名为 php。
本文文章主要介绍PHP采集静态页面以及保存页面css、img、js的方法,可以实现简单的网页爬取功能,有一定的参考价值,有需要的朋友可以参考下面
本文介绍了PHP采集静态页面的方法以及保存页面css、img、js的方法。分享给大家,供大家参考。具体分析如下:
这是一个可以获取网页的html代码和css、js、字体和img资源的小工具。主要用于快速获取模板。如果来不及设计UI或者看到好的模板,可以用这个工具抓取网页并提取资源文件,提取的内容会按照相对路径保存资源,这样你就不用了担心资源文件的URL导入错误。
首页index.php,代码如下:
代码显示如下:
网络抓取器
网址
得到
保存全部
列表
抓取页面代码grab.php,代码如下:
代码显示如下:
php抓取网页json数据(Spark大数据分析:核心概念、技术及实践(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-18 18:10
阿里云 > 云栖社区 > 主题图 > P > php远程读取json数据库
推荐活动:
更多优惠>
当前话题:php远程读取json数据库添加到采集夹
相关话题:
php远程读取json数据库相关博客查看更多博客
云数据库产品概述
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
13款Mongodb GUI可视化管理工具,总有一款适合你
作者:徐磊 frank7237 浏览评论:02年前
MongoDB数据库默认的管理工具是(CLI)Shell命令行,专业的DBA更容易使用,但普通人使用GUI可视化工具更方便。下面介绍13个有用的MongoDB可视化工具。MongoDB官方提供社区版Compass,可独立安装使用
阅读全文
Ajax跨域请求JSON JSONP
作者:cometwo1235780 浏览评论:05年前
同源策略和跨域摘要目录:1.同源策略2.跨域3.几种跨域技术1.什么是同源策略?URL 由协议、域名、端口和路径组成。如果两个 URL 具有相同的协议、域名和端口,则它们具有相同的来源。反之,只要协议、域名、端口在其中任何一个不同,就被认为是跨域的。e
阅读全文
《Spark大数据分析:核心概念、技术与实践》大数据技术概览
作者:华章电脑 3937人浏览评论:04年前
本书摘自华章出版社《Spark大数据分析:核心概念、技术与实践》一书第一章第一节,作者Mohammed Guller 更多章节请访问云栖社区“华章计算机”公众号查看. 大数据技术一览 我们正处于大数据时代。数据不仅仅是任何组织的生命
阅读全文
一小时学会MySQL数据库
作者:张果2052 浏览评论:04年前
随着移动互联网的终结和人工智能的到来,大数据变得越来越重要,下一个成功的人应该拥有海量数据。您应该了解数据和数据库。一、数据库概要数据库(Database)是一个用于存储和管理数据的软件系统,就像存储数据的物流仓库一样。在商业领域,信息意味着商机,意味着获取信息的能力
阅读全文
1.7Hadoop的子项目“R与Hadoop大数据分析实践”
作者:华章电脑 1682人 浏览评论:04年前
本章节选自华章出版社《R与Hadoop大数据分析》一书第1章第7节,作者(印刷)Vignesh Prajapati,更多章节可在云栖社区“华章计算机”获取公众号查看1.7Hadoop的子项目Mahout是一个非常强大的数据挖掘库,其中
阅读全文
MongoDB安装
作者:技术小哥 1232人查看评论数:04年前
mongodb介绍MongoDB是一个基于分布式文件存储的数据库。它是一种文档类型。虽然它也是 NoSQL 数据库的一种,但它与 redis 和 memcached 等数据库有些不同。MongoDB 是用 C++ 语言编写的。它旨在为WEB应用程序提供可扩展的高性能数据存储解决方案。星期一
阅读全文
Android Volley 获取 json 格式的数据
作者:哼99251000 浏览评论:04年前
为了让Android能够快速接入网络,解析常见的数据格式,谷歌专门推出了Android系统网络传输的Volley库。volley 库可以轻松地从远程服务器获取图像、字符串、json 对象和 json 对象数组。当然java本身也可以访问json对象
阅读全文
Android Volley 获取 json 格式的数据
作者:沉默胜声823人查看评论:06年前
为了让Android能够快速接入网络,解析常见的数据格式,谷歌专门推出了Android系统网络传输的Volley库。volley 库可以轻松地从远程服务器获取图像、字符串、json 对象和 json 对象数组。当然java本身也可以访问json对象
阅读全文
php远程读取json数据库相关问答
【Java学习全家桶】1460道Java热点问题,百位阿里巴巴技术专家答疑解惑
作者:管理贝贝19522 浏览评论:153年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文 查看全部
php抓取网页json数据(Spark大数据分析:核心概念、技术及实践(组图))
阿里云 > 云栖社区 > 主题图 > P > php远程读取json数据库
推荐活动:
更多优惠>
当前话题:php远程读取json数据库添加到采集夹
相关话题:
php远程读取json数据库相关博客查看更多博客
云数据库产品概述
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
13款Mongodb GUI可视化管理工具,总有一款适合你
作者:徐磊 frank7237 浏览评论:02年前
MongoDB数据库默认的管理工具是(CLI)Shell命令行,专业的DBA更容易使用,但普通人使用GUI可视化工具更方便。下面介绍13个有用的MongoDB可视化工具。MongoDB官方提供社区版Compass,可独立安装使用
阅读全文
Ajax跨域请求JSON JSONP
作者:cometwo1235780 浏览评论:05年前
同源策略和跨域摘要目录:1.同源策略2.跨域3.几种跨域技术1.什么是同源策略?URL 由协议、域名、端口和路径组成。如果两个 URL 具有相同的协议、域名和端口,则它们具有相同的来源。反之,只要协议、域名、端口在其中任何一个不同,就被认为是跨域的。e
阅读全文
《Spark大数据分析:核心概念、技术与实践》大数据技术概览
作者:华章电脑 3937人浏览评论:04年前
本书摘自华章出版社《Spark大数据分析:核心概念、技术与实践》一书第一章第一节,作者Mohammed Guller 更多章节请访问云栖社区“华章计算机”公众号查看. 大数据技术一览 我们正处于大数据时代。数据不仅仅是任何组织的生命
阅读全文
一小时学会MySQL数据库
作者:张果2052 浏览评论:04年前
随着移动互联网的终结和人工智能的到来,大数据变得越来越重要,下一个成功的人应该拥有海量数据。您应该了解数据和数据库。一、数据库概要数据库(Database)是一个用于存储和管理数据的软件系统,就像存储数据的物流仓库一样。在商业领域,信息意味着商机,意味着获取信息的能力
阅读全文
1.7Hadoop的子项目“R与Hadoop大数据分析实践”
作者:华章电脑 1682人 浏览评论:04年前
本章节选自华章出版社《R与Hadoop大数据分析》一书第1章第7节,作者(印刷)Vignesh Prajapati,更多章节可在云栖社区“华章计算机”获取公众号查看1.7Hadoop的子项目Mahout是一个非常强大的数据挖掘库,其中
阅读全文
MongoDB安装
作者:技术小哥 1232人查看评论数:04年前
mongodb介绍MongoDB是一个基于分布式文件存储的数据库。它是一种文档类型。虽然它也是 NoSQL 数据库的一种,但它与 redis 和 memcached 等数据库有些不同。MongoDB 是用 C++ 语言编写的。它旨在为WEB应用程序提供可扩展的高性能数据存储解决方案。星期一
阅读全文
Android Volley 获取 json 格式的数据
作者:哼99251000 浏览评论:04年前
为了让Android能够快速接入网络,解析常见的数据格式,谷歌专门推出了Android系统网络传输的Volley库。volley 库可以轻松地从远程服务器获取图像、字符串、json 对象和 json 对象数组。当然java本身也可以访问json对象
阅读全文
Android Volley 获取 json 格式的数据
作者:沉默胜声823人查看评论:06年前
为了让Android能够快速接入网络,解析常见的数据格式,谷歌专门推出了Android系统网络传输的Volley库。volley 库可以轻松地从远程服务器获取图像、字符串、json 对象和 json 对象数组。当然java本身也可以访问json对象
阅读全文
php远程读取json数据库相关问答
【Java学习全家桶】1460道Java热点问题,百位阿里巴巴技术专家答疑解惑
作者:管理贝贝19522 浏览评论:153年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文
php抓取网页json数据( 百度,用常规模拟登陆测试了下发现不行,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-18 09:02
百度,用常规模拟登陆测试了下发现不行,)
php中curl模拟登录用户百度知道的例子
最近弄了个工具,希望能拿到我百度网盘里的数据,但是又不想泄露数据,所以想到了模拟登录百度。我用传统的模拟登录方式对其进行了测试,发现它无法正常工作。我只是在登录期间通过抓取数据才发现的。百度在登录过程中跳转了几个页面。如果只获取一个页面的cookie是不完整的,那么只有BAIDUID的值,只有这个cookie值影响不大。
通过抓包数据分析,在实际登录过程中,页面首先被请求一次,服务器同时为浏览器设置了两个cookie,一个cookie值为BAIDUID,应该和session id有关; 另一个是
设置 Cookie:
支持=1;到期=格林威治标准时间 2021 年 8 月 19 日星期四 15:41:37;路径=/; 域=; httponly
推测这应该是百度检测浏览器是否支持cookies;
再次请求页面,获取网页数据获取登录的token值;
然后登录成功会得到BDUSS和其他相关的cookie值。以上就是登录成功了,只记录上面的cookie!
下面是简单的请求和登录函数的集合。作为基础类,可能比较简单,后面我们会改进!
代码显示如下:
这只是一个基础类,只涉及登录和请求提交数据,可以在此基础上使用,比如请求百度云网盘,代码如下:
$baidu = new baidu('用户名','密码');
$data = $baidu->request('http://pan.baidu.com/api/list% ... 39%3B,'http://pan.baidu.com');
echo $data;
也可以作为贴吧的发帖或百度空间更新工具。
教程地址:
欢迎转载!但请带上文章地址^^
/phpyy/47648.htmltrue/phpyy/47648.htmlTechArticlephp curl 模拟登录用户百度知道的例子 我最近做了一个工具,希望能得到我百度网盘里的数据但是我没有'不想泄露数据,于是想到了模拟登录百度,用常规的模拟登录测试了一下,发现不行,抢登录... 查看全部
php抓取网页json数据(
百度,用常规模拟登陆测试了下发现不行,)
php中curl模拟登录用户百度知道的例子
最近弄了个工具,希望能拿到我百度网盘里的数据,但是又不想泄露数据,所以想到了模拟登录百度。我用传统的模拟登录方式对其进行了测试,发现它无法正常工作。我只是在登录期间通过抓取数据才发现的。百度在登录过程中跳转了几个页面。如果只获取一个页面的cookie是不完整的,那么只有BAIDUID的值,只有这个cookie值影响不大。
通过抓包数据分析,在实际登录过程中,页面首先被请求一次,服务器同时为浏览器设置了两个cookie,一个cookie值为BAIDUID,应该和session id有关; 另一个是
设置 Cookie:
支持=1;到期=格林威治标准时间 2021 年 8 月 19 日星期四 15:41:37;路径=/; 域=; httponly
推测这应该是百度检测浏览器是否支持cookies;
再次请求页面,获取网页数据获取登录的token值;
然后登录成功会得到BDUSS和其他相关的cookie值。以上就是登录成功了,只记录上面的cookie!
下面是简单的请求和登录函数的集合。作为基础类,可能比较简单,后面我们会改进!
代码显示如下:
这只是一个基础类,只涉及登录和请求提交数据,可以在此基础上使用,比如请求百度云网盘,代码如下:
$baidu = new baidu('用户名','密码');
$data = $baidu->request('http://pan.baidu.com/api/list% ... 39%3B,'http://pan.baidu.com');
echo $data;
也可以作为贴吧的发帖或百度空间更新工具。
教程地址:
欢迎转载!但请带上文章地址^^
/phpyy/47648.htmltrue/phpyy/47648.htmlTechArticlephp curl 模拟登录用户百度知道的例子 我最近做了一个工具,希望能得到我百度网盘里的数据但是我没有'不想泄露数据,于是想到了模拟登录百度,用常规的模拟登录测试了一下,发现不行,抢登录...
php抓取网页json数据(【干货】逆向过程2.1分析参数(篇章中若有讲解))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-16 18:15
文章目录
内容
文章目录
前言
一、分析页面
二、逆过程
2.1 分析参数
2.2sign_code 值
2.3 折扣码
三、 请求数据,处理Json数据,本地保存图片
3.1 导入库
3.2 生成时间戳和参数
3.3 发出请求
四、附上完整代码
总结
前言
之前做的一个站最近整理了一下,写了一个文章记录,也可以给需要的朋友做个参考。(文中解释如有错误,欢迎评论区指正
目标网站: -领先的时尚摄影平台,摄影视频,摄影爱好者分享作品和技巧的首选,个人空间
一、分析页面
首先进入页面,确定我们要爬取的目标
打开页面后发现 网站 是通过惰性方式加载图片的。
PS:延迟加载是指在请求页面时,只加载可见区域的图片,不加载其他部分的图片。只有当这些图片出现在可视区域时,才会动态加载这些图片,从而节省网络带宽,提高初始加载速度。
不过我们暂时先不管它,打开f12抓包,看看这些图片在哪里。小技巧,先打开f12,清除后点击下一页。由于页面是延迟加载的,我们只需要向下滑动即可。
抓包后,下一步进入主题
二、逆过程2.1 分析参数
单纯看头信息和传入参数,直接请求数据肯定不可行,有反爬的方法。
我们来看看表头信息和传入参数(重点关注这个Form Data表单数据
把它复制出来刷新比较一下,总结出比较重要的数据的含义。
"ctime" : 时间戳(你可以使用python自己生成它
"length" : 我们要加载的张数(也可以理解为我们要抓取的张数
"sign_code" : 加密参数(最重要的一个
“works_category”:照片类型的参数(勾选是主页上的照片分类,然后是123...
2.2sign_code 值
这里我们直接使用全局搜索的方式来查找加密位置。 js文件只有一个。我们直接点进去看看吧。
一进来就可以看到sign_code的加密位置,在13479和13490的下一个断点刷新看看是怎么生成的。
分析这几行js代码
var o = JSON.stringify(e) # 只是将o转换为字符串的操作。经过多次测试,o是上面写的prama参数文章
("param":{"start":20,"length":20,"works_category":"1","time_point":1641981023})
n = t("poco_" + o + "_app"); #通过t函数加密一个字符串
n = n.substr(5, 19); # 取一部分加密数据作为sign_code值
定位到这里之后,我们根据经验可以看出这应该是加密的位置。我们可以尝试将这整个函数扣除,然后在本地运行,看看能否生成我们想要的sign_code值。
2.3 折扣码
下面是完整的js代码扣除,最后手动写了一个调用函数
function r(n, t) {
var r = (65535 & n) + (65535 & t)
, e = (n >> 16) + (t >> 16) + (r >> 16);
return e > 32 - t
}
function u(n, t, u, o, c, f) {
return r(e(r(r(t, n), r(o, f)), c), u)
}
function o(n, t, r, e, o, c, f) {
return u(t & r | ~t & e, n, t, o, c, f)
}
function c(n, t, r, e, o, c, f) {
return u(t & e | r & ~e, n, t, o, c, f)
}
function f(n, t, r, e, o, c, f) {
return u(t ^ r ^ e, n, t, o, c, f)
}
function i(n, t, r, e, o, c, f) {
return u(r ^ (t | ~e), n, t, o, c, f)
}
function a(n, t) {
n[t >> 5] |= 128 >> 9 > 5] >>> t % 32 & 255);
return r
}
function g(n) {
var t, r = [];
for (r[(n.length >> 2) - 1] = void 0,
t = 0; t < r.length; t += 1)
r[t] = 0;
for (t = 0; t < 8 * n.length; t += 8)
r[t >> 5] |= (255 & n.charCodeAt(t / 8)) 16 && (u = a(u, 8 * n.length)),
r = 0; 16 > r; r += 1)
o[r] = 909522486 ^ u[r],
c[r] = 1549556828 ^ u[r];
return e = a(o.concat(g(t)), 512 + 8 * t.length),
h(a(c.concat(e), 640))
}
function v(n) {
var t, r, e = "0123456789abcdef", u = "";
for (r = 0; r < n.length; r += 1)
t = n.charCodeAt(r),
u += e.charAt(t >>> 4 & 15) + e.charAt(15 & t);
return u
}
function s(n) {
return unescape(encodeURIComponent(n))
}
function C(n) {
return d(s(n))
}
function A(n) {
return v(C(n))
}
function m(n, t) {
return l(s(n), s(t))
}
function p(n, t) {
return v(m(n, t))
}
function b(n, t, r) {
return t ? r ? m(t, n) : p(t, n) : r ? C(n) : A(n)
};
function getsign(o){
n = b("poco_" + o + "_app");
n = n.substr(5, 19);
return n
}
经过测试,可以在本地成功运行,得到我们想要的加密数据。其实到这里已经差不多完成了90%,接下来就是请求数据并抓包了。
三、请求数据,处理Json数据,本地保存图片3.1 导入库
import requests # 请求数据
import time # 生成时间戳
import execjs # 第三方类库来执行js语句
3.2 生成时间戳和参数
time_point = int(time.time())
o = '{"start":0,"length":20,"works_category":"1","time_point":'+str(time_point)+'}'
with open('D:/poco.js', 'r', encoding='utf-8') as f: # 读取扣下来保存到本地的js代码
js_data = f.read()
js_obj = execjs.compile(js_data)
sign_code = js_obj.call('getsign',o) # 第一个参数是函数名,第二个是传入的参数
# print("sign_code")
这里的长度参数是请求的数据量。我只抓了20张,可以根据自己的需要更换。并且works_category参数也根据自己的需要而改变。
3.3 发出请求
# 把sign_code和时间戳拼接到传入的参数中
data = {
'req': '{"version":"1.1.0","app_name":"poco_photography_web","os_type":"weixin","is_enc":0,"env":"prod","ctime":'+str(int(time.time()*1000))+',"param":{"start":0,"length":20,"works_category":"1","time_point":'+str(time_point)+'},"sign_code":"'+str(sign_code)+'"}',
'host_port': 'https://photo.poco.cn'
}
由于数据是json格式,所以我们要的图片地址在img中的list下data
json数据格式可以这样取,代码如下
response = requests.post(url,headers=headers,data=data).json()['data']['list']
for i in response:
img = i['img']
urls = 'http:' + str(img) # 进行简单拼接成url格式
使用for循环将请求的图片保存到本地
with open(f'D:/POCO图库/img{num}.jpg', 'wb') as f:
print('正在下载第{}张'.format(num))
f.write(content)
你完成了
四、附上完整代码
# _*_ coding:UTF-8 _*_
# @Software : PyCharm
import requests
import time
import execjs
time_point = int(time.time())
o = '{"start":0,"length":20,"works_category":"1","time_point":'+str(time_point)+'}'
with open('D:/poco.js', 'r', encoding='utf-8') as f:
js_data = f.read()
js_obj = execjs.compile(js_data)
sign_code = js_obj.call('getsign',o)
# print(sign_code)
url = 'https://web-api.poco.cn/v1_1/rank/get_homepage_recommend_list'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'Referer': 'https://photo.poco.cn/?classify_type=1&works_type=medal',
'Origin': 'https://photo.poco.cn'
}
data = {
'req': '{"version":"1.1.0","app_name":"poco_photography_web","os_type":"weixin","is_enc":0,"env":"prod","ctime":'+str(int(time.time()*1000))+',"param":{"start":0,"length":20,"works_category":"1","time_point":'+str(time_point)+'},"sign_code":"'+str(sign_code)+'"}',
'host_port': 'https://photo.poco.cn'
}
response = requests.post(url,headers=headers,data=data).json()['data']['list']
num = 1
for i in response:
img = i['img']
urls = 'http:' + str(img)
content = requests.get(urls).content
with open(f'D:/POCO图库/img{num}.jpg', 'wb') as f:
print('正在下载第{}张'.format(num))
f.write(content)
num += 1
print('完')
总结
吐槽一下最新版的谷歌浏览器(最好用旧版更稳定),天天死机,调试js的时候死机。好在这个网站的加密不是很深。
中途扣除的js代码尝试在谷歌浏览器中运行,发现会报错,说我的方法未定义,应该是bug,然后切换到360极速浏览器,就可以正常运行了。
再次声明,本文文章仅供学习,不做任何商业用途,做一个友好的爬虫。
PS:如果觉得本章对你有帮助,请关注、评论、点赞,谢谢! 查看全部
php抓取网页json数据(【干货】逆向过程2.1分析参数(篇章中若有讲解))
文章目录
内容
文章目录
前言
一、分析页面
二、逆过程
2.1 分析参数
2.2sign_code 值
2.3 折扣码
三、 请求数据,处理Json数据,本地保存图片
3.1 导入库
3.2 生成时间戳和参数
3.3 发出请求
四、附上完整代码
总结
前言
之前做的一个站最近整理了一下,写了一个文章记录,也可以给需要的朋友做个参考。(文中解释如有错误,欢迎评论区指正
目标网站: -领先的时尚摄影平台,摄影视频,摄影爱好者分享作品和技巧的首选,个人空间
一、分析页面
首先进入页面,确定我们要爬取的目标
打开页面后发现 网站 是通过惰性方式加载图片的。
PS:延迟加载是指在请求页面时,只加载可见区域的图片,不加载其他部分的图片。只有当这些图片出现在可视区域时,才会动态加载这些图片,从而节省网络带宽,提高初始加载速度。
不过我们暂时先不管它,打开f12抓包,看看这些图片在哪里。小技巧,先打开f12,清除后点击下一页。由于页面是延迟加载的,我们只需要向下滑动即可。
抓包后,下一步进入主题
二、逆过程2.1 分析参数
单纯看头信息和传入参数,直接请求数据肯定不可行,有反爬的方法。
我们来看看表头信息和传入参数(重点关注这个Form Data表单数据
把它复制出来刷新比较一下,总结出比较重要的数据的含义。
"ctime" : 时间戳(你可以使用python自己生成它
"length" : 我们要加载的张数(也可以理解为我们要抓取的张数
"sign_code" : 加密参数(最重要的一个
“works_category”:照片类型的参数(勾选是主页上的照片分类,然后是123...
2.2sign_code 值
这里我们直接使用全局搜索的方式来查找加密位置。 js文件只有一个。我们直接点进去看看吧。
一进来就可以看到sign_code的加密位置,在13479和13490的下一个断点刷新看看是怎么生成的。
分析这几行js代码
var o = JSON.stringify(e) # 只是将o转换为字符串的操作。经过多次测试,o是上面写的prama参数文章
("param":{"start":20,"length":20,"works_category":"1","time_point":1641981023})
n = t("poco_" + o + "_app"); #通过t函数加密一个字符串
n = n.substr(5, 19); # 取一部分加密数据作为sign_code值
定位到这里之后,我们根据经验可以看出这应该是加密的位置。我们可以尝试将这整个函数扣除,然后在本地运行,看看能否生成我们想要的sign_code值。
2.3 折扣码
下面是完整的js代码扣除,最后手动写了一个调用函数
function r(n, t) {
var r = (65535 & n) + (65535 & t)
, e = (n >> 16) + (t >> 16) + (r >> 16);
return e > 32 - t
}
function u(n, t, u, o, c, f) {
return r(e(r(r(t, n), r(o, f)), c), u)
}
function o(n, t, r, e, o, c, f) {
return u(t & r | ~t & e, n, t, o, c, f)
}
function c(n, t, r, e, o, c, f) {
return u(t & e | r & ~e, n, t, o, c, f)
}
function f(n, t, r, e, o, c, f) {
return u(t ^ r ^ e, n, t, o, c, f)
}
function i(n, t, r, e, o, c, f) {
return u(r ^ (t | ~e), n, t, o, c, f)
}
function a(n, t) {
n[t >> 5] |= 128 >> 9 > 5] >>> t % 32 & 255);
return r
}
function g(n) {
var t, r = [];
for (r[(n.length >> 2) - 1] = void 0,
t = 0; t < r.length; t += 1)
r[t] = 0;
for (t = 0; t < 8 * n.length; t += 8)
r[t >> 5] |= (255 & n.charCodeAt(t / 8)) 16 && (u = a(u, 8 * n.length)),
r = 0; 16 > r; r += 1)
o[r] = 909522486 ^ u[r],
c[r] = 1549556828 ^ u[r];
return e = a(o.concat(g(t)), 512 + 8 * t.length),
h(a(c.concat(e), 640))
}
function v(n) {
var t, r, e = "0123456789abcdef", u = "";
for (r = 0; r < n.length; r += 1)
t = n.charCodeAt(r),
u += e.charAt(t >>> 4 & 15) + e.charAt(15 & t);
return u
}
function s(n) {
return unescape(encodeURIComponent(n))
}
function C(n) {
return d(s(n))
}
function A(n) {
return v(C(n))
}
function m(n, t) {
return l(s(n), s(t))
}
function p(n, t) {
return v(m(n, t))
}
function b(n, t, r) {
return t ? r ? m(t, n) : p(t, n) : r ? C(n) : A(n)
};
function getsign(o){
n = b("poco_" + o + "_app");
n = n.substr(5, 19);
return n
}
经过测试,可以在本地成功运行,得到我们想要的加密数据。其实到这里已经差不多完成了90%,接下来就是请求数据并抓包了。
三、请求数据,处理Json数据,本地保存图片3.1 导入库
import requests # 请求数据
import time # 生成时间戳
import execjs # 第三方类库来执行js语句
3.2 生成时间戳和参数
time_point = int(time.time())
o = '{"start":0,"length":20,"works_category":"1","time_point":'+str(time_point)+'}'
with open('D:/poco.js', 'r', encoding='utf-8') as f: # 读取扣下来保存到本地的js代码
js_data = f.read()
js_obj = execjs.compile(js_data)
sign_code = js_obj.call('getsign',o) # 第一个参数是函数名,第二个是传入的参数
# print("sign_code")
这里的长度参数是请求的数据量。我只抓了20张,可以根据自己的需要更换。并且works_category参数也根据自己的需要而改变。
3.3 发出请求
# 把sign_code和时间戳拼接到传入的参数中
data = {
'req': '{"version":"1.1.0","app_name":"poco_photography_web","os_type":"weixin","is_enc":0,"env":"prod","ctime":'+str(int(time.time()*1000))+',"param":{"start":0,"length":20,"works_category":"1","time_point":'+str(time_point)+'},"sign_code":"'+str(sign_code)+'"}',
'host_port': 'https://photo.poco.cn'
}
由于数据是json格式,所以我们要的图片地址在img中的list下data
json数据格式可以这样取,代码如下
response = requests.post(url,headers=headers,data=data).json()['data']['list']
for i in response:
img = i['img']
urls = 'http:' + str(img) # 进行简单拼接成url格式
使用for循环将请求的图片保存到本地
with open(f'D:/POCO图库/img{num}.jpg', 'wb') as f:
print('正在下载第{}张'.format(num))
f.write(content)
你完成了
四、附上完整代码
# _*_ coding:UTF-8 _*_
# @Software : PyCharm
import requests
import time
import execjs
time_point = int(time.time())
o = '{"start":0,"length":20,"works_category":"1","time_point":'+str(time_point)+'}'
with open('D:/poco.js', 'r', encoding='utf-8') as f:
js_data = f.read()
js_obj = execjs.compile(js_data)
sign_code = js_obj.call('getsign',o)
# print(sign_code)
url = 'https://web-api.poco.cn/v1_1/rank/get_homepage_recommend_list'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'Referer': 'https://photo.poco.cn/?classify_type=1&works_type=medal',
'Origin': 'https://photo.poco.cn'
}
data = {
'req': '{"version":"1.1.0","app_name":"poco_photography_web","os_type":"weixin","is_enc":0,"env":"prod","ctime":'+str(int(time.time()*1000))+',"param":{"start":0,"length":20,"works_category":"1","time_point":'+str(time_point)+'},"sign_code":"'+str(sign_code)+'"}',
'host_port': 'https://photo.poco.cn'
}
response = requests.post(url,headers=headers,data=data).json()['data']['list']
num = 1
for i in response:
img = i['img']
urls = 'http:' + str(img)
content = requests.get(urls).content
with open(f'D:/POCO图库/img{num}.jpg', 'wb') as f:
print('正在下载第{}张'.format(num))
f.write(content)
num += 1
print('完')
总结
吐槽一下最新版的谷歌浏览器(最好用旧版更稳定),天天死机,调试js的时候死机。好在这个网站的加密不是很深。
中途扣除的js代码尝试在谷歌浏览器中运行,发现会报错,说我的方法未定义,应该是bug,然后切换到360极速浏览器,就可以正常运行了。
再次声明,本文文章仅供学习,不做任何商业用途,做一个友好的爬虫。
PS:如果觉得本章对你有帮助,请关注、评论、点赞,谢谢!
php抓取网页json数据(Python抓取今日头条街拍图片结构(2)分析(2))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-05 17:12
内容
(1) 抢今日头条街拍
(2)今日头条街拍的照片结构解析
keyword: 街拍
pd: atlas
dvpf: pc
aid: 4916
page_num: 1
search_json: {"from_search_id":"20220104115420010212192151532E8188","origin_keyword":"街拍","image_keyword":"街拍"}
rawJSON: 1
search_id: 202201041159040101501341671A4749C4
可以找到规律,page_num从1开始累加,其他参数不变
(3) 根据不同的功能编写不同的方法组织代码
获取网页json格式数据
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search?keyword=%E8%A1%97%E6%8B%8D&pd=atlas&dvpf=pc&aid=4916&page_num=0&search_json={%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
从json格式数据中提取街道照片
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
用它的md5代码命名街拍图片并保存图片
实现一个 save_image() 方法来保存图像,其中 item 是前面的 get_images() 方法返回的字典。该方法中,首先根据item的标题创建一个文件夹,然后请求图片的链接,获取图片的二进制数据,以二进制形式写入文件。图片名称可以使用其内容的MD5值,可以消除重复。相关代码如下:
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
main() 调用其他函数
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
(4) 抓20页今日头条街图片资料
这里定义了分页的起始页和结束页号,分别是GROUP_START和GROUP_END,同样使用了多线程线程池,调用其map()方法实现多线程下载。
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
import requests
from urllib.parse import urlencode
from hashlib import md5
from multiprocessing.pool import Pool
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search?keyword=%E8%A1%97%E6%8B%8D&pd=atlas&dvpf=pc&aid=4916&page_num=0&search_json={%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
至此这篇关于Python抓取今日头条图片数据的文章介绍到这里。更多Python相关抓拍今日头条图片内容,请搜索之前的文章或继续浏览下方相关文章希望大家以后多多支持! 查看全部
php抓取网页json数据(Python抓取今日头条街拍图片结构(2)分析(2))
内容
(1) 抢今日头条街拍
(2)今日头条街拍的照片结构解析
keyword: 街拍
pd: atlas
dvpf: pc
aid: 4916
page_num: 1
search_json: {"from_search_id":"20220104115420010212192151532E8188","origin_keyword":"街拍","image_keyword":"街拍"}
rawJSON: 1
search_id: 202201041159040101501341671A4749C4
可以找到规律,page_num从1开始累加,其他参数不变
(3) 根据不同的功能编写不同的方法组织代码
获取网页json格式数据
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search?keyword=%E8%A1%97%E6%8B%8D&pd=atlas&dvpf=pc&aid=4916&page_num=0&search_json={%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
从json格式数据中提取街道照片
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
用它的md5代码命名街拍图片并保存图片
实现一个 save_image() 方法来保存图像,其中 item 是前面的 get_images() 方法返回的字典。该方法中,首先根据item的标题创建一个文件夹,然后请求图片的链接,获取图片的二进制数据,以二进制形式写入文件。图片名称可以使用其内容的MD5值,可以消除重复。相关代码如下:
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
main() 调用其他函数
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
(4) 抓20页今日头条街图片资料
这里定义了分页的起始页和结束页号,分别是GROUP_START和GROUP_END,同样使用了多线程线程池,调用其map()方法实现多线程下载。
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
import requests
from urllib.parse import urlencode
from hashlib import md5
from multiprocessing.pool import Pool
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search?keyword=%E8%A1%97%E6%8B%8D&pd=atlas&dvpf=pc&aid=4916&page_num=0&search_json={%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
至此这篇关于Python抓取今日头条图片数据的文章介绍到这里。更多Python相关抓拍今日头条图片内容,请搜索之前的文章或继续浏览下方相关文章希望大家以后多多支持!
php抓取网页json数据(JSON西装一样采集的日志样本图(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-01-01 21:07
记录和监控就像托尼·斯塔克和他的钢铁侠套装。两者需要搭配使用才能发挥最大功效,因为它们相得益彰。
日志一直是应用和基础框架性能和故障诊断的重要手段,但现在我们意识到日志不仅可以用于故障诊断,还可以用于大数据分析、业务可视化和性能分析等..
因此,记录应用程序日志非常非常重要。
为什么要使用 JSON 格式
为了了解 JSON 日志记录的优势,我们先来了解一段 Anuj(系统工程师)和 Kartik(业务分析师)之间的对话。
但几天后,Kartik 发现 Web 界面已关闭。 Anuj摸着头看了看日志,发现开发者在日志中多加了一个字段,破坏了他自定义的日志解析器。
相信很多童鞋都遇到过类似的情况吧?
这种情况下,如果开发者把应用设计成JSON格式的日志,那么Anuj定义的解析器就很简单了,然后根据JSON键搜索字段就够了,你不用需要关心它是否在日志中的新字段已被修改。
使用JSON格式的日志最大的好处就是结构化,让我们分析应用日志非常方便。不仅可以轻松读取日志,还可以通过各个字段进行日志查询,几乎所有编程语言都可以轻松解析。
JSON 日志魔术
最近,我们创建了一个 Golang 示例应用程序,以在代码构建、测试和部署阶段获取一些相关信息。我们使用 JSON 格式的日志进行记录。
采集的日志样本如下:
使用ELK进行日志采集时,我们只需要在Logstash中添加如下日志分析即可:
filter {
json {
source => "message"
}
}
我们不需要任何额外的解析步骤,即使新的字段被添加到日志中。 采集日志到达如下图:
我们可以看到,在Kibana中,JSON日志的key已经被自动解析为ES属性,比如employee_name、employee_city等字段。我们不需要在 Logstash 或其他工具中添加一些非常复杂的解析。现在我们可以很容易地使用这些数据来创建一些 Dashboards 进行数据分析。
结论
从文本日志迁移到 JSON 日志格式不会花费太长时间。大多数编程语言都有相应的 JSON 日志库。我非常确定 JSON 日志格式将为您当前的日志采集系统提供更大的灵活性。性。
以下是一些支持 JSON 日志格式的流行库:
希望大家现在对 JSON 格式的日志有了更好的了解。
原文:
翻译: 查看全部
php抓取网页json数据(JSON西装一样采集的日志样本图(上))
记录和监控就像托尼·斯塔克和他的钢铁侠套装。两者需要搭配使用才能发挥最大功效,因为它们相得益彰。
日志一直是应用和基础框架性能和故障诊断的重要手段,但现在我们意识到日志不仅可以用于故障诊断,还可以用于大数据分析、业务可视化和性能分析等..
因此,记录应用程序日志非常非常重要。
为什么要使用 JSON 格式
为了了解 JSON 日志记录的优势,我们先来了解一段 Anuj(系统工程师)和 Kartik(业务分析师)之间的对话。
但几天后,Kartik 发现 Web 界面已关闭。 Anuj摸着头看了看日志,发现开发者在日志中多加了一个字段,破坏了他自定义的日志解析器。
相信很多童鞋都遇到过类似的情况吧?
这种情况下,如果开发者把应用设计成JSON格式的日志,那么Anuj定义的解析器就很简单了,然后根据JSON键搜索字段就够了,你不用需要关心它是否在日志中的新字段已被修改。
使用JSON格式的日志最大的好处就是结构化,让我们分析应用日志非常方便。不仅可以轻松读取日志,还可以通过各个字段进行日志查询,几乎所有编程语言都可以轻松解析。
JSON 日志魔术
最近,我们创建了一个 Golang 示例应用程序,以在代码构建、测试和部署阶段获取一些相关信息。我们使用 JSON 格式的日志进行记录。
采集的日志样本如下:
使用ELK进行日志采集时,我们只需要在Logstash中添加如下日志分析即可:
filter {
json {
source => "message"
}
}
我们不需要任何额外的解析步骤,即使新的字段被添加到日志中。 采集日志到达如下图:
我们可以看到,在Kibana中,JSON日志的key已经被自动解析为ES属性,比如employee_name、employee_city等字段。我们不需要在 Logstash 或其他工具中添加一些非常复杂的解析。现在我们可以很容易地使用这些数据来创建一些 Dashboards 进行数据分析。
结论
从文本日志迁移到 JSON 日志格式不会花费太长时间。大多数编程语言都有相应的 JSON 日志库。我非常确定 JSON 日志格式将为您当前的日志采集系统提供更大的灵活性。性。
以下是一些支持 JSON 日志格式的流行库:
希望大家现在对 JSON 格式的日志有了更好的了解。
原文:
翻译:
php抓取网页json数据( ,涉及php针对json格式数据及文件相关操作技巧汇总)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-28 10:00
,涉及php针对json格式数据及文件相关操作技巧汇总)
PHP生成和获取JSON文件的方法
更新时间:2016-08-23 12:15:26 作者:onestopweb
本文主要介绍PHP生成和获取JSON文件的方法,涉及PHP的JSON格式数据和文件相关的操作技巧。有需要的朋友可以参考以下
本文介绍如何通过 PHP 生成和获取 JSON 文件。分享给大家,供大家参考,如下:
先定义一个数组,然后遍历数据表,将对应的数据放入数组中,最后通过json_encode()转换数组
json_encode() 函数的作用是将值转换为JSON数据存储格式。
putjson.php:
如果有同名的 JSON 文件,则会被覆盖,如果没有 JSON 文件,则会创建。
生成或覆盖的 JSON 如下:
复制代码代码如下:
[["1","\u811A\u672C\u4E4B\u5BB6",""],["2","\u7F16\u7A0B\u5F00\u53D1",""]]
然后,将 JSON 文件中的数据读入 PHP 变量。
getjson.php:
效果图:
PS:这里有一些比较实用的json在线工具供大家参考:
在线JSON代码检查、检查、美化和格式化工具:
JSON在线格式化工具:
在线 XML/JSON 转换工具:
json代码在线格式化/美化/压缩/编辑/转换工具:
C语言风格/HTML/CSS/json代码格式化和美化工具:
对PHP相关内容感兴趣的读者可以查看本站主题:《PHP中JSON格式数据操作技巧总结》、《PHP XML文件操作技巧总结》、《PHP基本语法介绍》、《 PHP数组(数组)操作技巧,《php字符串(字符串)使用总结》、《php+mysql数据库操作入门教程》、《php常用数据库操作技巧总结》
我希望这篇文章能帮助你进行 PHP 编程。 查看全部
php抓取网页json数据(
,涉及php针对json格式数据及文件相关操作技巧汇总)
PHP生成和获取JSON文件的方法
更新时间:2016-08-23 12:15:26 作者:onestopweb
本文主要介绍PHP生成和获取JSON文件的方法,涉及PHP的JSON格式数据和文件相关的操作技巧。有需要的朋友可以参考以下
本文介绍如何通过 PHP 生成和获取 JSON 文件。分享给大家,供大家参考,如下:
先定义一个数组,然后遍历数据表,将对应的数据放入数组中,最后通过json_encode()转换数组
json_encode() 函数的作用是将值转换为JSON数据存储格式。
putjson.php:
如果有同名的 JSON 文件,则会被覆盖,如果没有 JSON 文件,则会创建。
生成或覆盖的 JSON 如下:
复制代码代码如下:
[["1","\u811A\u672C\u4E4B\u5BB6",""],["2","\u7F16\u7A0B\u5F00\u53D1",""]]
然后,将 JSON 文件中的数据读入 PHP 变量。
getjson.php:
效果图:
PS:这里有一些比较实用的json在线工具供大家参考:
在线JSON代码检查、检查、美化和格式化工具:
JSON在线格式化工具:
在线 XML/JSON 转换工具:
json代码在线格式化/美化/压缩/编辑/转换工具:
C语言风格/HTML/CSS/json代码格式化和美化工具:
对PHP相关内容感兴趣的读者可以查看本站主题:《PHP中JSON格式数据操作技巧总结》、《PHP XML文件操作技巧总结》、《PHP基本语法介绍》、《 PHP数组(数组)操作技巧,《php字符串(字符串)使用总结》、《php+mysql数据库操作入门教程》、《php常用数据库操作技巧总结》
我希望这篇文章能帮助你进行 PHP 编程。
php抓取网页json数据(ajax读取Json数据的注意事项有哪些,就是实战案例分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-27 03:07
这次给大家带来Ajax读取Json数据的方法。 Ajax读取Json数据有哪些注意事项?下面是一个实际案例。我们来看看。
本文将与大家分享如何使用ajax读取Json中的数据。
一、基础知识
什么是json?
JSON 指的是 JavaScript Object Notation(JavaScript Object Notation)
JSON 是一种轻量级的文本数据交换格式
JSON 独立于语言 *
JSON 具有自我描述性且更易于理解
JSON 使用 JavaScript 语法来描述数据对象,但 JSON 仍然独立于语言和平台。 JSON 解析器和 JSON 库支持多种不同的编程语言。
JSON-转换为 JavaScript 对象
JSON 文本格式在语法上与创建 JavaScript 对象的代码相同。
由于这种相似性,不需要解析器,JavaScript 程序可以使用内置的 eval() 函数从 JSON 数据生成原生 JavaScript 对象。
二、在 Json 中读取数据
首先我写了一个收录
内容的 Json 文件。注意格式。
图1 编写json文件
然后,编写html代码并引用ajax。
使用AJAX异步读取json
window.onload=function()
{
/*获得按钮*/
var aBtn=document.getElementById('btn1');
//给按钮添加点击事件
aBtn.onclick=function()
{
//调用ajax函数
ajax('data.json',function(str){
//将JSON 数据来生成原生的 JavaScript 对象
var arr=eval(str);
alert(arr[0].b);
});
};
};
读取json里面的数据 <br />
封装的AJAX函数代码如下:
/*
AJAX封装函数
url:系统要读取文件的地址
fnSucc:一个函数,文件取过来,加载完会调用
*/
function ajax(url, fnSucc, fnFaild)
{
//1.创建Ajax对象
var oAjax=null;
if(window.XMLHttpRequest)
{
oAjax=new XMLHttpRequest();
}
else
{
oAjax=new ActiveXObject("Microsoft.XMLHTTP");
}
//2.连接服务器
oAjax.open('GET', url, true);
//3.发送请求
oAjax.send();
//4.接收服务器的返回
oAjax.onreadystatechange=function ()
{
if(oAjax.readyState==4) //完成
{
if(oAjax.status==200) //成功
{
fnSucc(oAjax.responseText);
}
else
{
if(fnFaild)
fnFaild(oAjax.status);
}
}
};
}
下一步是读取文件的内容。在此之前,有一点需要说明的是,AJAX 从服务器读取文件,因此将写入的 JSON 文件放在服务器的路径中。学者们接触过的唯一服务器是IIS。其文件路径为 C:\inetpub\wwwroot\aspnet_client\system_web。把Json放在这个路径下,使用localhost访问服务器即可。
相信看完本文的案例你已经掌握了方法。更多精彩请关注php中文网其他相关文章! 查看全部
php抓取网页json数据(ajax读取Json数据的注意事项有哪些,就是实战案例分享)
这次给大家带来Ajax读取Json数据的方法。 Ajax读取Json数据有哪些注意事项?下面是一个实际案例。我们来看看。
本文将与大家分享如何使用ajax读取Json中的数据。
一、基础知识
什么是json?
JSON 指的是 JavaScript Object Notation(JavaScript Object Notation)
JSON 是一种轻量级的文本数据交换格式
JSON 独立于语言 *
JSON 具有自我描述性且更易于理解
JSON 使用 JavaScript 语法来描述数据对象,但 JSON 仍然独立于语言和平台。 JSON 解析器和 JSON 库支持多种不同的编程语言。
JSON-转换为 JavaScript 对象
JSON 文本格式在语法上与创建 JavaScript 对象的代码相同。
由于这种相似性,不需要解析器,JavaScript 程序可以使用内置的 eval() 函数从 JSON 数据生成原生 JavaScript 对象。
二、在 Json 中读取数据
首先我写了一个收录
内容的 Json 文件。注意格式。
图1 编写json文件
然后,编写html代码并引用ajax。
使用AJAX异步读取json
window.onload=function()
{
/*获得按钮*/
var aBtn=document.getElementById('btn1');
//给按钮添加点击事件
aBtn.onclick=function()
{
//调用ajax函数
ajax('data.json',function(str){
//将JSON 数据来生成原生的 JavaScript 对象
var arr=eval(str);
alert(arr[0].b);
});
};
};
读取json里面的数据 <br />
封装的AJAX函数代码如下:
/*
AJAX封装函数
url:系统要读取文件的地址
fnSucc:一个函数,文件取过来,加载完会调用
*/
function ajax(url, fnSucc, fnFaild)
{
//1.创建Ajax对象
var oAjax=null;
if(window.XMLHttpRequest)
{
oAjax=new XMLHttpRequest();
}
else
{
oAjax=new ActiveXObject("Microsoft.XMLHTTP");
}
//2.连接服务器
oAjax.open('GET', url, true);
//3.发送请求
oAjax.send();
//4.接收服务器的返回
oAjax.onreadystatechange=function ()
{
if(oAjax.readyState==4) //完成
{
if(oAjax.status==200) //成功
{
fnSucc(oAjax.responseText);
}
else
{
if(fnFaild)
fnFaild(oAjax.status);
}
}
};
}
下一步是读取文件的内容。在此之前,有一点需要说明的是,AJAX 从服务器读取文件,因此将写入的 JSON 文件放在服务器的路径中。学者们接触过的唯一服务器是IIS。其文件路径为 C:\inetpub\wwwroot\aspnet_client\system_web。把Json放在这个路径下,使用localhost访问服务器即可。
相信看完本文的案例你已经掌握了方法。更多精彩请关注php中文网其他相关文章!
php抓取网页json数据(从php获取json数据使用js读取显示到网页笔记笔记)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-24 10:00
从php获取json数据,用js读取并显示到web笔记
php代码
"hellojson","age" => 23,"sex"=>"M");//定义php数组
$res=json_encode($array);
//var_dump($res);
echo $res;//输出结果到页面
HTML 代码
$(function(){
$(document).on("click",'.test',function(){
var id=$(this).attr("id");
var data={id:id}
//var aaa=[{"0":"1","id":"1","1":"hello","name":"hello","2":"","密码":""},{"0":"2","id":"2","1"
// :"world","name":"world","2":"","password":""},{"0":"3","id":"3", "1":"helloworld","name":"helloworld"
// ,"2":"","password":""}]
// alert(aaa[2].name)
$.ajax({
输入:“GET”,
数据:数据,
url:'xml.php',
数据类型:"json",
成功:功能(味精){
if(msg){
var res=eval(msg);//php返回的数据如果不能直接使用可以转换,可以使用eval()函数来实现转换。
//alert(res.username)
alert(res[1].name)//弹出要获取的数据
//console.log(res)
}
}
});
})
})
在原生js中,也可以使用JSON.parse()函数转换为json格式。在php中已经转成json格式,可以直接获取。
alert(msg[0].name)//msg为返回的json格式
从php中获取json数据,用js读取并显示web笔记的php代码? php//json与数组转换 $array = array(username = hellojson,age = 23, sex=M);//定义php数组$ res=json_encode(... 查看全部
php抓取网页json数据(从php获取json数据使用js读取显示到网页笔记笔记)
从php获取json数据,用js读取并显示到web笔记
php代码
"hellojson","age" => 23,"sex"=>"M");//定义php数组
$res=json_encode($array);
//var_dump($res);
echo $res;//输出结果到页面
HTML 代码
$(function(){
$(document).on("click",'.test',function(){
var id=$(this).attr("id");
var data={id:id}
//var aaa=[{"0":"1","id":"1","1":"hello","name":"hello","2":"","密码":""},{"0":"2","id":"2","1"
// :"world","name":"world","2":"","password":""},{"0":"3","id":"3", "1":"helloworld","name":"helloworld"
// ,"2":"","password":""}]
// alert(aaa[2].name)
$.ajax({
输入:“GET”,
数据:数据,
url:'xml.php',
数据类型:"json",
成功:功能(味精){
if(msg){
var res=eval(msg);//php返回的数据如果不能直接使用可以转换,可以使用eval()函数来实现转换。
//alert(res.username)
alert(res[1].name)//弹出要获取的数据
//console.log(res)
}
}
});
})
})
在原生js中,也可以使用JSON.parse()函数转换为json格式。在php中已经转成json格式,可以直接获取。
alert(msg[0].name)//msg为返回的json格式
从php中获取json数据,用js读取并显示web笔记的php代码? php//json与数组转换 $array = array(username = hellojson,age = 23, sex=M);//定义php数组$ res=json_encode(...
php抓取网页json数据(类似:UncaughtTypeErrortosearchfor‘’inJSONstring前端jsamp;php笔记正文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-20 18:11
类似:Uncaught TypeError:无法使用‘in’操作符在JSON字符串中搜索‘’前端js&php笔记
身体:
在html页面中,通过$.get()方法请求php页面,回调函数返回json数据,但是获取不到数据点中的数据,代码如下:
js 代码:
$("#button1").click(function(){
$.get("index.php",{username:$("#username").val(),password:$("#password").val(),tel:$("#tel").val()},function(data,textStatus){ //get方法请求数据
$("#response").html("用户名:"+data.name+"
密码:"+data.pwd+"
手机号码:"+data.tell);
alert(data); //能够显示数据
})
})
php 代码:
运行后:
能够返回数据
无法检索返回的数据
解决方案:
创建一个对象,将json数据转换成一个对象
ajaxData=$.parseJSON(data) //将json数据转换为js对象
注意:
无法在程序中运行,在程序中运行时无法解释php页面,必须在appserv程序下的www文件夹下运行(运行时不能是ftp地址,而是像“:82” /unit07/index.html”地址) 查看全部
php抓取网页json数据(类似:UncaughtTypeErrortosearchfor‘’inJSONstring前端jsamp;php笔记正文)
类似:Uncaught TypeError:无法使用‘in’操作符在JSON字符串中搜索‘’前端js&php笔记
身体:
在html页面中,通过$.get()方法请求php页面,回调函数返回json数据,但是获取不到数据点中的数据,代码如下:
js 代码:
$("#button1").click(function(){
$.get("index.php",{username:$("#username").val(),password:$("#password").val(),tel:$("#tel").val()},function(data,textStatus){ //get方法请求数据
$("#response").html("用户名:"+data.name+"
密码:"+data.pwd+"
手机号码:"+data.tell);
alert(data); //能够显示数据
})
})
php 代码:
运行后:
能够返回数据
无法检索返回的数据
解决方案:
创建一个对象,将json数据转换成一个对象
ajaxData=$.parseJSON(data) //将json数据转换为js对象
注意:
无法在程序中运行,在程序中运行时无法解释php页面,必须在appserv程序下的www文件夹下运行(运行时不能是ftp地址,而是像“:82” /unit07/index.html”地址)
php抓取网页json数据(对以上的url进行爬取importrequests=requests.get)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-16 16:20
URL列表=[]
#将地址拼接到爬网
对于范围(1,5)2)>:
url=urlbase+str(i)+“&;=49”url列表。附加(url)
#循环获取列表页面信息
2、使用请求对上述URL进行爬网
导入请求
内容=请求。获取(url,headers=headers)。内容
在爬网过程中,考虑到模拟真实用户的需要,需要添加cookie或头参数
(二)。对爬行JSON格式数据的分析
到目前为止,数据已经被抓取下来并存储在内容中,但是如何提出关键数据是非常重要的
为了在浏览器中轻松浏览JSON格式的数据,建议在chrome中添加扩展jsonview,以实现JSON格式数据的结构化显示。例如,人人贷款的数据如下所示
有两种方法可以解析此数据
1、正则表达式解析
例如,如果我们想获取“金额”的内容,可以通过以下方式获取:
进口
##使用regular提取金额字段amount=re findall(r'“amount”:(.*),(内容)
哪里的内容是爬下来的内容
2、基于JSON格式获取
事实上,JSON的数据格式与Python的dict非常相似。Python的importjson包中提供了两种经典的预处理方法:
导入json
格言={1:2,3:4,“55”:“66”}
#测试json。倾倒
打印类型(dict),dict_
json_u;str=json。转储(dict_)
打印“json.dumps(dict)返回:”
打印类型(json_str),json_str
#测试json。装载
打印“\njson.loads(str)返回”
dict_u2=json。加载(json_str)
打印类型(dict_2)@>,dict_2
输出为:
计划结果:
{'55':'66',1:2,3:4}
json。转储(dict)返回:
{“55”:“66”,“1”:2,“3”:4}
json。负载(str)返回
{u'55':u'66',u'1':2,u'3':4}
从上述示例可以看出,转储和加载的功能如下:
json。倾倒
:将ptyhon的Dict转换为str
json。加载:将STR转换为Python的dict类型
有了以上基础知识,可以通过以下方式直接对人人贷款数据进行处理:
FORURLINURLIST:
//得到满足
内容=请求。获取(url,headers=headers)。内容
//使用JSON,loads方法将STR转换为dict类型
con=json。Loads(content)#获取评论列表,因为以前不需要很多其他东西
//直接使用Python中dict的数据采集方法获取贷款列表,然后直接获取每个数据
commentList=con[“数据”][“贷款”]
对于commentList中的项目:
loanId=项目['loanId']
标题=项目['title']
金额=项目[“金额”]
利息=项目[“利息”]
月数=项目[“月数”]
备注:
使用第二种方法时,应注意返回的数据是否为标准JSON格式。如果不是标准JSON格式,则可能需要额外处理。例如,京东产品的审查数据
这是中国联通的苹果iphone7plus(a166)128G亮黑色4G手机的评论数据
直接打开上面的链接后,您会发现jsonview下没有正式的JSON格式数据显示。对于这种数据类型,可以通过正则表达式获取,也可以将JSON转换为dict
仔细分析攀爬数据:
原文页:
我们想要抓取的是用户评论数据,而我们抓取的内容不是标准JSON格式的数据。如上图所示,我们抓取的内容是将数据放入fetchjson_Comment98vv52063(),括号中的数据是标准JSON格式的数据
因此,对于这类数据,我们应该首先用括号正则表示数据,然后使用loads方法将其转换为Python的dict类型数据进行处理
源代码如下:
#爬行
URL列表中的forurl:
cont=请求。获取(url,headers=headers,cookies=cookie)。内容
#这是非常重要的。这里的正则表达式以数字或字母开头,后跟()
content=rex。Findall(cont)[0]#去掉括号中的内容,这是一种标准的JSON格式数据
con=json。加载(内容,“gbk”)
#进入评论列表,因为之前还有很多不需要的东西
commentList=con['comments']
对于列表中的项目:
id=项目['id']
内容=项目['content']。条带()
referenceName=项目['referenceName']
productColor=项目['productColor']
技巧:您可以尝试将()中的数据提交给一些在线JSON解析网站(),以查看JSON数据的排列格式,从而更清楚地了解如何提取数据
(三)参考文献:
1、使用Python-urllib捕获和分析数据
:
二, 查看全部
php抓取网页json数据(对以上的url进行爬取importrequests=requests.get)
URL列表=[]
#将地址拼接到爬网
对于范围(1,5)2)>:
url=urlbase+str(i)+“&;=49”url列表。附加(url)
#循环获取列表页面信息
2、使用请求对上述URL进行爬网
导入请求
内容=请求。获取(url,headers=headers)。内容
在爬网过程中,考虑到模拟真实用户的需要,需要添加cookie或头参数
(二)。对爬行JSON格式数据的分析
到目前为止,数据已经被抓取下来并存储在内容中,但是如何提出关键数据是非常重要的
为了在浏览器中轻松浏览JSON格式的数据,建议在chrome中添加扩展jsonview,以实现JSON格式数据的结构化显示。例如,人人贷款的数据如下所示
有两种方法可以解析此数据
1、正则表达式解析
例如,如果我们想获取“金额”的内容,可以通过以下方式获取:
进口
##使用regular提取金额字段amount=re findall(r'“amount”:(.*),(内容)
哪里的内容是爬下来的内容
2、基于JSON格式获取
事实上,JSON的数据格式与Python的dict非常相似。Python的importjson包中提供了两种经典的预处理方法:
导入json
格言={1:2,3:4,“55”:“66”}
#测试json。倾倒
打印类型(dict),dict_
json_u;str=json。转储(dict_)
打印“json.dumps(dict)返回:”
打印类型(json_str),json_str
#测试json。装载
打印“\njson.loads(str)返回”
dict_u2=json。加载(json_str)
打印类型(dict_2)@>,dict_2
输出为:
计划结果:
{'55':'66',1:2,3:4}
json。转储(dict)返回:
{“55”:“66”,“1”:2,“3”:4}
json。负载(str)返回
{u'55':u'66',u'1':2,u'3':4}
从上述示例可以看出,转储和加载的功能如下:
json。倾倒
:将ptyhon的Dict转换为str
json。加载:将STR转换为Python的dict类型
有了以上基础知识,可以通过以下方式直接对人人贷款数据进行处理:
FORURLINURLIST:
//得到满足
内容=请求。获取(url,headers=headers)。内容
//使用JSON,loads方法将STR转换为dict类型
con=json。Loads(content)#获取评论列表,因为以前不需要很多其他东西
//直接使用Python中dict的数据采集方法获取贷款列表,然后直接获取每个数据
commentList=con[“数据”][“贷款”]
对于commentList中的项目:
loanId=项目['loanId']
标题=项目['title']
金额=项目[“金额”]
利息=项目[“利息”]
月数=项目[“月数”]
备注:
使用第二种方法时,应注意返回的数据是否为标准JSON格式。如果不是标准JSON格式,则可能需要额外处理。例如,京东产品的审查数据
这是中国联通的苹果iphone7plus(a166)128G亮黑色4G手机的评论数据
直接打开上面的链接后,您会发现jsonview下没有正式的JSON格式数据显示。对于这种数据类型,可以通过正则表达式获取,也可以将JSON转换为dict
仔细分析攀爬数据:
原文页:
我们想要抓取的是用户评论数据,而我们抓取的内容不是标准JSON格式的数据。如上图所示,我们抓取的内容是将数据放入fetchjson_Comment98vv52063(),括号中的数据是标准JSON格式的数据
因此,对于这类数据,我们应该首先用括号正则表示数据,然后使用loads方法将其转换为Python的dict类型数据进行处理
源代码如下:
#爬行
URL列表中的forurl:
cont=请求。获取(url,headers=headers,cookies=cookie)。内容
#这是非常重要的。这里的正则表达式以数字或字母开头,后跟()
content=rex。Findall(cont)[0]#去掉括号中的内容,这是一种标准的JSON格式数据
con=json。加载(内容,“gbk”)
#进入评论列表,因为之前还有很多不需要的东西
commentList=con['comments']
对于列表中的项目:
id=项目['id']
内容=项目['content']。条带()
referenceName=项目['referenceName']
productColor=项目['productColor']
技巧:您可以尝试将()中的数据提交给一些在线JSON解析网站(),以查看JSON数据的排列格式,从而更清楚地了解如何提取数据
(三)参考文献:
1、使用Python-urllib捕获和分析数据
:
二,
php抓取网页json数据(Python网络爬虫findfind动态网页的两种技术:1.使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-15 17:19
由于主流的网站都使用JavaScript来展示网页内容,不像之前的静态网页简单爬行,使用JavaScript的时候很多内容没有出现在HTML源代码中,而是放在了HTML源代码中代码。一段JavaScript代码,最后呈现的数据是由JavaScript提取出来的,提取出服务器返回的数据,加载到源代码中进行呈现。因此,抓取静态网页的技术可能无法正常工作。因此,我们需要使用两种技术进行动态网页爬取:
1.通过浏览器评论元素分析真实网页地址;
2.使用selenium模拟浏览器。
我们这里先介绍第一种方法。
以《Python Web Crawler:从入门到实践》作者的个人博客评论为例。网址:1)“抓包”:找到真实数据地址
右键单击“检查”,单击“网络”,然后选择“js”。刷新页面,选择数据列表?回调...这个页面刷新时返回的js文件。选择右侧的标题。如图:
其中Request URL为真实数据地址。
在此状态下,滚动鼠标滚轮以找到 User-Agent。
2)相关代码:
import requests
import json
headers={\'User-Agent\':\'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36\'}
link="https://api-zero.livere.com/v1 ... ot%3B
r=requests.get(link,headers=headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find(\'{\'):-2]
json_data=json.loads(json_string)
comment_list=json_data[\'results\'][\'parents\']
for eachone in comment_list:
message=eachone[\'content\']
print(message)
输出是:
现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?
为何静态网页抓取不了?
奇怪了,我按照书上的方法来操作,XHR也是空的啊
XHR没有显示任何东西啊。奇怪。
找到原因了
caps["marionette"] = True
作者可以解释一下这句话是干什么的吗
我用的是 pycham IDE,按照作者的写法写的,怎么不行
对火狐版本有要求吗
4.3.1 打开Hello World,代码用的作者的,火狐地址我也设置了,为啥运行没反应
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps = webdriver.DesiredCapabilities().FIREFOX
caps["marionette"] = False
binary = FirefoxBinary(r\'C:\\Program Files\\Mozilla Firefox\\firefox.exe\')
#把上述地址改成你电脑中Firefox程序的地址
driver = webdriver.Firefox(firefox_binary=binary, capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
我是番茄
为什么刷新没有XHR数据,评论明明加载出来了
代码分析:
1)对于代码json_string.find() api解析为:
Docstring:
S.find(sub[, start[, end]]) -> int
Return the lowest index in S where substring sub is found,
such that sub is contained within S[start:end]. Optional
arguments start and end are interpreted as in slice notation.
Return -1 on failure.
Type: method_descriptor
所以代码 json_string.find(\'{\') 返回的是“{”在json_string字符串中的索引位置。
2) 如果在代码中加一句代码print json_string,这句话的输出结果是(由于输出内容太多,只截取了开头和结尾,关键位置用红色标出):
/**/ typeof jQuery112405600294326674093_1523687034324 === \'function\' && jQuery112405600294326674093_1523687034324({"results":{"parents":[{"replySeq":33365104,"name":"骨犬","memberId":"B9E06FBF9013D49CADBB5B623E8226C8","memberIcon":"http://q.qlogo.cn/qqapp/101256 ... ot%3B,"memberUrl":"https://qq.com/","memberDomain":"qq","good":0,"bad":0,"police":0,"parentSeq":33365104,"directSeq":0,"shortUrl":null,"title":"Hello world! - 数据科学@唐松
Santos","site":"http://www.santostang.com/2017 ... ot%3B,"email":null,"ipAddress":"27.210.192.241","isMobile":"0","agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.108 Safari/537.36 2345Explorer/8.8.3.16721","septSns":null,"targetService":null,"targetUserName":null,"info1":null,"info2":null,"info3":null,"image1":null,"image2":null,"image3":null,"link1":null,"link2":null,"link3":null,"isSecret":0,"isModified":0,"confirm":0,"subCount":1,"regdate":"2018-01-01T06:27:50.000Z","deletedDate":null,"file1":null,"file2":null,"file3":null,"additionalSeq":0,"content":"现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?"
。。。。。。。。。 tent":"我的也是提示火狐版本不匹配,你解决了吗","quotationSeq":null,"quotationContent":null,"consumerSeq":1020,"livereSeq":28583,"repSeq":3871836,"memberGroupSeq":26828779,"memberSeq":27312353,"status":0,"repGroupSeq":0,"adminSeq":25413747,"deleteReason":null,"sticker":0,"version":null}],"quotations":[]},"resultCode":200,"resultMessage":"Okay, livere"});
从上面的输出结果,我们可以看出在代码中加入 json_string = json_string[json_string.find(\'{\'):-2] 的重要性。
如果不加json_string.find(\'{\'),则结果不是合法的json格式,无法成功形成json文件;如果没有截取到倒数第二个位置,则结果收录冗余);也不能构成合法的 json 格式。
3)代码comment_list=json_data[\'results\'][\'parents\']和message=eachone[\'content\']中括号中字符串类型的标签定位,可以上面2)中的关键部分搜索,即截取后合法的json文件同时收录在“results”和“parents”中,所以用两个括号一层一层定位,因为我们是爬取评论,其内容在json文件的“content”标签中,所以使用[“content”]定位。
观察到实际数据地址中的偏移量是页数。 查看全部
php抓取网页json数据(Python网络爬虫findfind动态网页的两种技术:1.使用)
由于主流的网站都使用JavaScript来展示网页内容,不像之前的静态网页简单爬行,使用JavaScript的时候很多内容没有出现在HTML源代码中,而是放在了HTML源代码中代码。一段JavaScript代码,最后呈现的数据是由JavaScript提取出来的,提取出服务器返回的数据,加载到源代码中进行呈现。因此,抓取静态网页的技术可能无法正常工作。因此,我们需要使用两种技术进行动态网页爬取:
1.通过浏览器评论元素分析真实网页地址;
2.使用selenium模拟浏览器。
我们这里先介绍第一种方法。
以《Python Web Crawler:从入门到实践》作者的个人博客评论为例。网址:1)“抓包”:找到真实数据地址
右键单击“检查”,单击“网络”,然后选择“js”。刷新页面,选择数据列表?回调...这个页面刷新时返回的js文件。选择右侧的标题。如图:
其中Request URL为真实数据地址。
在此状态下,滚动鼠标滚轮以找到 User-Agent。
2)相关代码:
import requests
import json
headers={\'User-Agent\':\'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36\'}
link="https://api-zero.livere.com/v1 ... ot%3B
r=requests.get(link,headers=headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find(\'{\'):-2]
json_data=json.loads(json_string)
comment_list=json_data[\'results\'][\'parents\']
for eachone in comment_list:
message=eachone[\'content\']
print(message)
输出是:
现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?
为何静态网页抓取不了?
奇怪了,我按照书上的方法来操作,XHR也是空的啊
XHR没有显示任何东西啊。奇怪。
找到原因了
caps["marionette"] = True
作者可以解释一下这句话是干什么的吗
我用的是 pycham IDE,按照作者的写法写的,怎么不行
对火狐版本有要求吗
4.3.1 打开Hello World,代码用的作者的,火狐地址我也设置了,为啥运行没反应
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps = webdriver.DesiredCapabilities().FIREFOX
caps["marionette"] = False
binary = FirefoxBinary(r\'C:\\Program Files\\Mozilla Firefox\\firefox.exe\')
#把上述地址改成你电脑中Firefox程序的地址
driver = webdriver.Firefox(firefox_binary=binary, capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
我是番茄
为什么刷新没有XHR数据,评论明明加载出来了
代码分析:
1)对于代码json_string.find() api解析为:
Docstring:
S.find(sub[, start[, end]]) -> int
Return the lowest index in S where substring sub is found,
such that sub is contained within S[start:end]. Optional
arguments start and end are interpreted as in slice notation.
Return -1 on failure.
Type: method_descriptor
所以代码 json_string.find(\'{\') 返回的是“{”在json_string字符串中的索引位置。
2) 如果在代码中加一句代码print json_string,这句话的输出结果是(由于输出内容太多,只截取了开头和结尾,关键位置用红色标出):
/**/ typeof jQuery112405600294326674093_1523687034324 === \'function\' && jQuery112405600294326674093_1523687034324({"results":{"parents":[{"replySeq":33365104,"name":"骨犬","memberId":"B9E06FBF9013D49CADBB5B623E8226C8","memberIcon":"http://q.qlogo.cn/qqapp/101256 ... ot%3B,"memberUrl":"https://qq.com/","memberDomain":"qq","good":0,"bad":0,"police":0,"parentSeq":33365104,"directSeq":0,"shortUrl":null,"title":"Hello world! - 数据科学@唐松
Santos","site":"http://www.santostang.com/2017 ... ot%3B,"email":null,"ipAddress":"27.210.192.241","isMobile":"0","agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.108 Safari/537.36 2345Explorer/8.8.3.16721","septSns":null,"targetService":null,"targetUserName":null,"info1":null,"info2":null,"info3":null,"image1":null,"image2":null,"image3":null,"link1":null,"link2":null,"link3":null,"isSecret":0,"isModified":0,"confirm":0,"subCount":1,"regdate":"2018-01-01T06:27:50.000Z","deletedDate":null,"file1":null,"file2":null,"file3":null,"additionalSeq":0,"content":"现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?"
。。。。。。。。。 tent":"我的也是提示火狐版本不匹配,你解决了吗","quotationSeq":null,"quotationContent":null,"consumerSeq":1020,"livereSeq":28583,"repSeq":3871836,"memberGroupSeq":26828779,"memberSeq":27312353,"status":0,"repGroupSeq":0,"adminSeq":25413747,"deleteReason":null,"sticker":0,"version":null}],"quotations":[]},"resultCode":200,"resultMessage":"Okay, livere"});
从上面的输出结果,我们可以看出在代码中加入 json_string = json_string[json_string.find(\'{\'):-2] 的重要性。
如果不加json_string.find(\'{\'),则结果不是合法的json格式,无法成功形成json文件;如果没有截取到倒数第二个位置,则结果收录冗余);也不能构成合法的 json 格式。
3)代码comment_list=json_data[\'results\'][\'parents\']和message=eachone[\'content\']中括号中字符串类型的标签定位,可以上面2)中的关键部分搜索,即截取后合法的json文件同时收录在“results”和“parents”中,所以用两个括号一层一层定位,因为我们是爬取评论,其内容在json文件的“content”标签中,所以使用[“content”]定位。
观察到实际数据地址中的偏移量是页数。
php抓取网页json数据(PHP应用JSON形式数组和访问普通的对象属性(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 37 次浏览 • 2021-12-15 17:09
PHP 一直受到程序开发人员的青睐,不仅因为它的高效,还因为它的灵活性和便利性。很多服务器返回的数据都是json格式的,而json数据的形式多种多样,这就要求我们的php程序能够处理不同形式的json数据。
PHP应用JSON的相关函数为: json_encode($PHP_string);
而使用PHP解析JSON的函数是: json_decode($json_string);
在学习这个文章之前,我们需要知道什么是json数据。
PHP 提供了特殊的函数来生成和解析 JSON 格式的数据。PHP解析出来的数据与原创Javascript数据含义相同,即Javascript对象解析为PHP对象,Javascript数组解析为PHP数组。我们使用php中的json_decode()函数来解析json数据。
JSON的形式有很多种,不同的形式被PHP解释后会有不同的形式。
JSON 格式一:
它完全以对象的形式存在。这种形式的数据在 Javascript 中也称为关联数组。与一般数组的区别在于可以通过字符串作为索引来访问(使用“[]”或“.”表示级别)
$json='{
"item1":{
"item11":{
"n":"chenling",
"m":"llll"
},&
quot;sex":"男",
"age":"25"
},
"item2":{
"item21":"ling",
"sex":"女",
"age":"24"
}
}';
$J=json_decode($json);
print_r($J);
输出数据为:
stdClass Object
(
[item1] => stdClass Object
(
[item11] => stdClass Object
(
[n] => chenling
[m] => llll
)
[sex] => 男
[age] => 25
)
[item2] => stdClass Object
(
[item21] => ling
[sex] => 女
[age] => 24
)
)
比如我想获取值为chenling的属性,应该这样访问: $J->item1->item11->n;
这将获得属性 n 的值:chenling。
其实这种访问方式类似于访问普通对象的属性,相当于访问一个3维数组。
JSON形式二:混合对象和数组
$json='{"item1":[{"name":[{"chen":<br />
"chenling","ling":"chenli"}],"sex":<br />
"男","age":"25"},{"name":"sun","sex":<br />
"女","age":"24"}]}';
$J=json_decode($json);
print_r($J);
输出数据为:
stdClass Object
(
[item1] => Array
(
[0] => stdClass Object
(
[name] => Array
(
[0] => stdClass Object
(
[chen] => chenling
[ling] => chenli
)
)
[sex] => 男
[age] => 25
)
[1] => stdClass Object
(
[name] => sun
[sex] => 女
[age] => 24
)
)
)
比如我想获取值为chenling的元素,应该这样访问: $J->item1[0]->name[0]->chen;
这将得到元素chen的值:chenling。
其实这个PHP应用JSON格式结合了对象和数组的访问方式,相当于访问了一个5维数组。
JSON形式三:完整数组形式
$json='[["item1","item11"],[
"n","chenling"],["m","llll"]]';
$J=json_decode($json);
print_r($J);
输出数据为:
Array
(
[0] => Array
(
[0] => item1
[1] => item11
)
[1] => Array
(
[0] => n
[1] => chenling
)
[2] => Array
(
[0] => m
[1] => llll
)
)
比如我想获取值为chenling的元素,就应该这样访问: $J[0][1];
这将获得元素值为chenling的元素。
但是,使用这种方法有一个缺点,就是不能使用字符串作为索引。您只能使用一个数字。这个问题可以用完整对象的形式来解决。其实这种访问方式就是数组的访问方式,相当于访问一个二维数组。.
PHP解析不同形式的JSON数据汇总:
从上面的 PHP 应用 JSON 例子可以看出,JSON 有点类似于 XML,而且结构化数据也可以在 PHP 和 Javascript 之间传递,使用起来非常方便。需要注意的是,每个属性和属性值都用引号“”括起来。
免责声明:如需转载请注明出处并保留原文链接: 查看全部
php抓取网页json数据(PHP应用JSON形式数组和访问普通的对象属性(图))
PHP 一直受到程序开发人员的青睐,不仅因为它的高效,还因为它的灵活性和便利性。很多服务器返回的数据都是json格式的,而json数据的形式多种多样,这就要求我们的php程序能够处理不同形式的json数据。
PHP应用JSON的相关函数为: json_encode($PHP_string);
而使用PHP解析JSON的函数是: json_decode($json_string);
在学习这个文章之前,我们需要知道什么是json数据。
PHP 提供了特殊的函数来生成和解析 JSON 格式的数据。PHP解析出来的数据与原创Javascript数据含义相同,即Javascript对象解析为PHP对象,Javascript数组解析为PHP数组。我们使用php中的json_decode()函数来解析json数据。
JSON的形式有很多种,不同的形式被PHP解释后会有不同的形式。
JSON 格式一:
它完全以对象的形式存在。这种形式的数据在 Javascript 中也称为关联数组。与一般数组的区别在于可以通过字符串作为索引来访问(使用“[]”或“.”表示级别)
$json='{
"item1":{
"item11":{
"n":"chenling",
"m":"llll"
},&
quot;sex":"男",
"age":"25"
},
"item2":{
"item21":"ling",
"sex":"女",
"age":"24"
}
}';
$J=json_decode($json);
print_r($J);
输出数据为:
stdClass Object
(
[item1] => stdClass Object
(
[item11] => stdClass Object
(
[n] => chenling
[m] => llll
)
[sex] => 男
[age] => 25
)
[item2] => stdClass Object
(
[item21] => ling
[sex] => 女
[age] => 24
)
)
比如我想获取值为chenling的属性,应该这样访问: $J->item1->item11->n;
这将获得属性 n 的值:chenling。
其实这种访问方式类似于访问普通对象的属性,相当于访问一个3维数组。
JSON形式二:混合对象和数组
$json='{"item1":[{"name":[{"chen":<br />
"chenling","ling":"chenli"}],"sex":<br />
"男","age":"25"},{"name":"sun","sex":<br />
"女","age":"24"}]}';
$J=json_decode($json);
print_r($J);
输出数据为:
stdClass Object
(
[item1] => Array
(
[0] => stdClass Object
(
[name] => Array
(
[0] => stdClass Object
(
[chen] => chenling
[ling] => chenli
)
)
[sex] => 男
[age] => 25
)
[1] => stdClass Object
(
[name] => sun
[sex] => 女
[age] => 24
)
)
)
比如我想获取值为chenling的元素,应该这样访问: $J->item1[0]->name[0]->chen;
这将得到元素chen的值:chenling。
其实这个PHP应用JSON格式结合了对象和数组的访问方式,相当于访问了一个5维数组。
JSON形式三:完整数组形式
$json='[["item1","item11"],[
"n","chenling"],["m","llll"]]';
$J=json_decode($json);
print_r($J);
输出数据为:
Array
(
[0] => Array
(
[0] => item1
[1] => item11
)
[1] => Array
(
[0] => n
[1] => chenling
)
[2] => Array
(
[0] => m
[1] => llll
)
)
比如我想获取值为chenling的元素,就应该这样访问: $J[0][1];
这将获得元素值为chenling的元素。
但是,使用这种方法有一个缺点,就是不能使用字符串作为索引。您只能使用一个数字。这个问题可以用完整对象的形式来解决。其实这种访问方式就是数组的访问方式,相当于访问一个二维数组。.
PHP解析不同形式的JSON数据汇总:
从上面的 PHP 应用 JSON 例子可以看出,JSON 有点类似于 XML,而且结构化数据也可以在 PHP 和 Javascript 之间传递,使用起来非常方便。需要注意的是,每个属性和属性值都用引号“”括起来。
免责声明:如需转载请注明出处并保留原文链接:
php抓取网页json数据( 一种轻量格式的格式及其使用方法和使用技巧介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-15 03:30
一种轻量格式的格式及其使用方法和使用技巧介绍)
JSON 数据格式
JSON 是 JavaScript ObjectNotation 的缩写,是一种轻量级的数据表示方法。json格式使用key:value来记录数据,非常直观,比XML简单,所以很流行
在介绍json格式之前,我们先来看看XML格式。显然,XML 受到了相当多的关注(正面和负面评价),并在 Ajax 应用程序中得到了广泛的应用:
Brett
McLaughlin
brett@newInstance.com
这里的数据和我们之前看到的一样,但这次是 XML 格式。这没什么了不起的;它只是另一种允许我们使用 XML 而不是纯文本和名称/值对的数据格式。
本文讨论另一种数据格式,JavaScript Object Notation (JSON)。JSON 看起来既熟悉又陌生。它提供了另一种选择,拥有更广泛的选择总是一件好事。
添加JSON
使用名称/值对或 XML 时,实际上是使用 JavaScript 从应用程序获取数据并将数据转换为另一种数据格式。在这些情况下,JavaScript 主要用作数据操作语言来移动和操作来自 Web 表单的数据,并将数据转换为适合发送到服务器端程序的格式。
但是,有时 JavaScript 不仅仅用作格式化语言。在这些情况下,JavaScript 语言中的对象实际上是用来表示数据的,而不仅仅是将来自 Web 表单的数据放入请求中。在这些情况下,从 JavaScript 对象中提取数据,然后将数据放入名称/值对或 XML 中有点多余。这时候,使用 JSON 比较合适:JSON 允许将 JavaScript 对象轻松转换为可以随请求发送的数据(同步或异步)。
JSON 不是灵丹妙药;但是,对于一些非常特殊的情况,它是一个不错的选择。
简单地说,JSON 可以将 JavaScript 对象中表示的一组数据转换为字符串,然后您可以轻松地在函数之间传递这个字符串,或者在异步应用程序中将字符串从 Web 客户端传递到服务器。结束程序。这个字符串看起来有点奇怪(稍后你会看到几个例子),但 JavaScript 很容易解释它,而且 JSON 可以表示比名称/值对更复杂的结构。例如,您可以表示数组和复杂对象,而不仅仅是键和值的简单列表。JSON 基础知识
简单的 JSON 示例
在最简单的形式中,您可以使用以下 JSON 来表示名称/值对:
{ "firstName": "Brett" }
这个例子非常基础,实际上比等效的纯文本名称/值对占用更多的空间:
firstName="Brett"
但是,当多个名称/值对串在一起时,JSON 将反映其值。首先,您可以创建收录多个名称/值对的记录,例如:
{
"firstName": "Brett",
"lastName":"McLaughlin",
"email": "brett@newInstance.com"
}
从语法的角度来看,与名称/值对相比,这并不是一个很大的优势,但在这种情况下,JSON 更易于使用且更具可读性。例如,明确表示以上三个值都是同一个记录的一部分;花括号让这些值有一定的联系。
值数组
当需要表示一组值时,JSON 不仅可以提高可读性,还可以降低复杂度。例如,假设您想表示一个人名列表。在 XML 中,需要许多开始和结束标记;如果使用典型的名称/值对(如本系列前面文章中看到的名称/值对),那么必须建立特殊的一些数据格式,或者将键名修改为person1等形式-名。
如果你使用 JSON,你只需要用花括号将多条记录组合在一起:
{ "people": [
{ "firstName": "Brett", "lastName":"McLaughlin", "email": "brett@newInstance.com" },
{ "firstName": "Jason", "lastName":"Hunter", "email": "jason@servlets.com" },
{ "firstName": "Elliotte", "lastName":"Harold", "email": "elharo@macfaq.com" }
]}
这不难理解。在这个例子中,只有一个名为 people 的变量,其值是一个收录三个条目的数组,每个条目是一个人的记录,其中收录名字、姓氏和电子邮件地址。上面的示例演示了如何使用括号将记录合并为一个值。当然,您可以使用相同的语法来表示多个值(每个值收录多条记录):
{ "programmers": [
{ "firstName": "Brett", "lastName":"McLaughlin", "email": "brett@newInstance.com" },
{ "firstName": "Jason", "lastName":"Hunter", "email": "jason@servlets.com" },
{ "firstName": "Elliotte", "lastName":"Harold", "email": "elharo@macfaq.com" }
],
"authors": [
{ "firstName": "Isaac", "lastName": "Asimov", "genre": "science fiction" },
{ "firstName": "Tad", "lastName": "Williams", "genre": "fantasy" },
{ "firstName": "Frank", "lastName": "Peretti", "genre": "christian fiction" }
],
"musicians": [
{ "firstName": "Eric", "lastName": "Clapton", "instrument": "guitar" },
{ "firstName": "Sergei", "lastName": "Rachmaninoff", "instrument": "piano" }
]
}
这里最值得注意的是它可以表示多个值,而每个值又收录多个值。但还应该注意的是,记录中的实际名称/值对在不同的主要项目(程序员、作者和音乐家)之间可能会有所不同。JSON 是完全动态的,允许在 JSON 结构中间更改表示数据的方式。
在处理 JSON 格式的数据时,没有需要遵守的预定义约束。因此,在同一个数据结构中,可以改变数据的表示方式,甚至可以用不同的方式表示相同的事物。
将 JSON 数据赋值给变量 掌握了 JSON 格式后,在 JavaScript 中使用就非常简单了。JSON 是一种 JavaScript 原生格式,这意味着在 JavaScript 中处理 JSON 数据不需要任何特殊的 API 或工具包。在 JavaScript 中使用 JSON
例如,您可以创建一个新的 JavaScript 变量,然后直接为其分配一个 JSON 格式的数据字符串:
var people =
{ "programmers": [
{ "firstName": "Brett", "lastName":"McLaughlin", "email": "brett@newInstance.com" },
{ "firstName": "Jason", "lastName":"Hunter", "email": "jason@servlets.com" },
{ "firstName": "Elliotte", "lastName":"Harold", "email": "elharo@macfaq.com" }
],
"authors": [
{ "firstName": "Isaac", "lastName": "Asimov", "genre": "science fiction" },
{ "firstName": "Tad", "lastName": "Williams", "genre": "fantasy" },
{ "firstName": "Frank", "lastName": "Peretti", "genre": "christian fiction" }
],
"musicians": [
{ "firstName": "Eric", "lastName": "Clapton", "instrument": "guitar" },
{ "firstName": "Sergei", "lastName": "Rachmaninoff", "instrument": "piano" }
]
}
这很简单;现在人们收录我们之前看到的 JSON 格式的数据。然而,这还不够,因为访问数据的方式似乎还不是很明显。
访问数据
虽然看起来并不明显,但上面的长字符串实际上只是一个数组;将此数组放入 JavaScript 变量后,您可以轻松访问它。实际上,您只需要使用点表示法来表示数组元素。因此,要访问程序员列表中第一个条目的姓氏,只需在 JavaScript 中使用以下代码:
people.programmers[0].lastName;
请注意,数组索引从零开始。所以,这行代码首先访问了people变量中的数据;然后它移动到名为程序员的条目,然后移动到第一条记录([0]);最后,它访问 lastName 键的值。结果是字符串值“McLaughlin”。
以下是使用相同变量的几个示例。
people.authors[1].genre // Value is "fantasy"
people.musicians[3].lastName // Undefined. This refers to the fourth entry, and there isn't one
people.programmers.[2].firstName // Value is "Elliotte"
使用此语法,您可以处理 JSON 格式的任何数据,而无需使用任何额外的 JavaScript 工具包或 API。
修改 JSON 数据
正如您可以使用点和括号访问数据一样,您也可以使用相同的方式轻松修改数据:
people.musicians[1].lastName = "Rachmaninov";
将字符串转换为 JavaScript 对象后,您可以像这样修改变量中的数据。
转换回字符串
当然,如果对象不能轻易转换回本文提到的文本格式,那么所有的数据修改都没有什么价值。这种转换在 JavaScript 中也很简单:
String newJSONtext = people.toJSONString();
没关系!现在您有了一个可以在任何地方使用的文本字符串,例如,它可以在 Ajax 应用程序中用作请求字符串。
更重要的是,任何 JavaScript 对象都可以转换为 JSON 文本。这不仅仅是处理最初用 JSON 字符串分配的变量。为了转换名为 myObject 的对象,您只需要执行相同形式的命令:
String myObjectInJSON = myObject.toJSONString();
这是 JSON 与本系列中讨论的其他数据格式之间的最大区别。如果使用JSON,只需要调用一个简单的函数即可获取格式化后的数据,直接使用即可。对于其他数据格式,需要在原创数据和格式化数据之间进行转换。即使你使用像文档对象模型这样的 API(提供一个函数将你自己的数据结构转换成文本),你也需要学习这个 API 并使用 API 的对象,而不是使用原生的 JavaScript 对象和语法。
最后的结论是,如果你正在处理大量的 JavaScript 对象,那么 JSON 几乎肯定是一个不错的选择,这样你就可以很容易地将数据转换成可以在请求中发送给服务器端程序的格式. 查看全部
php抓取网页json数据(
一种轻量格式的格式及其使用方法和使用技巧介绍)
JSON 数据格式
JSON 是 JavaScript ObjectNotation 的缩写,是一种轻量级的数据表示方法。json格式使用key:value来记录数据,非常直观,比XML简单,所以很流行
在介绍json格式之前,我们先来看看XML格式。显然,XML 受到了相当多的关注(正面和负面评价),并在 Ajax 应用程序中得到了广泛的应用:
Brett
McLaughlin
brett@newInstance.com
这里的数据和我们之前看到的一样,但这次是 XML 格式。这没什么了不起的;它只是另一种允许我们使用 XML 而不是纯文本和名称/值对的数据格式。
本文讨论另一种数据格式,JavaScript Object Notation (JSON)。JSON 看起来既熟悉又陌生。它提供了另一种选择,拥有更广泛的选择总是一件好事。
添加JSON
使用名称/值对或 XML 时,实际上是使用 JavaScript 从应用程序获取数据并将数据转换为另一种数据格式。在这些情况下,JavaScript 主要用作数据操作语言来移动和操作来自 Web 表单的数据,并将数据转换为适合发送到服务器端程序的格式。
但是,有时 JavaScript 不仅仅用作格式化语言。在这些情况下,JavaScript 语言中的对象实际上是用来表示数据的,而不仅仅是将来自 Web 表单的数据放入请求中。在这些情况下,从 JavaScript 对象中提取数据,然后将数据放入名称/值对或 XML 中有点多余。这时候,使用 JSON 比较合适:JSON 允许将 JavaScript 对象轻松转换为可以随请求发送的数据(同步或异步)。
JSON 不是灵丹妙药;但是,对于一些非常特殊的情况,它是一个不错的选择。
简单地说,JSON 可以将 JavaScript 对象中表示的一组数据转换为字符串,然后您可以轻松地在函数之间传递这个字符串,或者在异步应用程序中将字符串从 Web 客户端传递到服务器。结束程序。这个字符串看起来有点奇怪(稍后你会看到几个例子),但 JavaScript 很容易解释它,而且 JSON 可以表示比名称/值对更复杂的结构。例如,您可以表示数组和复杂对象,而不仅仅是键和值的简单列表。JSON 基础知识
简单的 JSON 示例
在最简单的形式中,您可以使用以下 JSON 来表示名称/值对:
{ "firstName": "Brett" }
这个例子非常基础,实际上比等效的纯文本名称/值对占用更多的空间:
firstName="Brett"
但是,当多个名称/值对串在一起时,JSON 将反映其值。首先,您可以创建收录多个名称/值对的记录,例如:
{
"firstName": "Brett",
"lastName":"McLaughlin",
"email": "brett@newInstance.com"
}
从语法的角度来看,与名称/值对相比,这并不是一个很大的优势,但在这种情况下,JSON 更易于使用且更具可读性。例如,明确表示以上三个值都是同一个记录的一部分;花括号让这些值有一定的联系。
值数组
当需要表示一组值时,JSON 不仅可以提高可读性,还可以降低复杂度。例如,假设您想表示一个人名列表。在 XML 中,需要许多开始和结束标记;如果使用典型的名称/值对(如本系列前面文章中看到的名称/值对),那么必须建立特殊的一些数据格式,或者将键名修改为person1等形式-名。
如果你使用 JSON,你只需要用花括号将多条记录组合在一起:
{ "people": [
{ "firstName": "Brett", "lastName":"McLaughlin", "email": "brett@newInstance.com" },
{ "firstName": "Jason", "lastName":"Hunter", "email": "jason@servlets.com" },
{ "firstName": "Elliotte", "lastName":"Harold", "email": "elharo@macfaq.com" }
]}
这不难理解。在这个例子中,只有一个名为 people 的变量,其值是一个收录三个条目的数组,每个条目是一个人的记录,其中收录名字、姓氏和电子邮件地址。上面的示例演示了如何使用括号将记录合并为一个值。当然,您可以使用相同的语法来表示多个值(每个值收录多条记录):
{ "programmers": [
{ "firstName": "Brett", "lastName":"McLaughlin", "email": "brett@newInstance.com" },
{ "firstName": "Jason", "lastName":"Hunter", "email": "jason@servlets.com" },
{ "firstName": "Elliotte", "lastName":"Harold", "email": "elharo@macfaq.com" }
],
"authors": [
{ "firstName": "Isaac", "lastName": "Asimov", "genre": "science fiction" },
{ "firstName": "Tad", "lastName": "Williams", "genre": "fantasy" },
{ "firstName": "Frank", "lastName": "Peretti", "genre": "christian fiction" }
],
"musicians": [
{ "firstName": "Eric", "lastName": "Clapton", "instrument": "guitar" },
{ "firstName": "Sergei", "lastName": "Rachmaninoff", "instrument": "piano" }
]
}
这里最值得注意的是它可以表示多个值,而每个值又收录多个值。但还应该注意的是,记录中的实际名称/值对在不同的主要项目(程序员、作者和音乐家)之间可能会有所不同。JSON 是完全动态的,允许在 JSON 结构中间更改表示数据的方式。
在处理 JSON 格式的数据时,没有需要遵守的预定义约束。因此,在同一个数据结构中,可以改变数据的表示方式,甚至可以用不同的方式表示相同的事物。
将 JSON 数据赋值给变量 掌握了 JSON 格式后,在 JavaScript 中使用就非常简单了。JSON 是一种 JavaScript 原生格式,这意味着在 JavaScript 中处理 JSON 数据不需要任何特殊的 API 或工具包。在 JavaScript 中使用 JSON
例如,您可以创建一个新的 JavaScript 变量,然后直接为其分配一个 JSON 格式的数据字符串:
var people =
{ "programmers": [
{ "firstName": "Brett", "lastName":"McLaughlin", "email": "brett@newInstance.com" },
{ "firstName": "Jason", "lastName":"Hunter", "email": "jason@servlets.com" },
{ "firstName": "Elliotte", "lastName":"Harold", "email": "elharo@macfaq.com" }
],
"authors": [
{ "firstName": "Isaac", "lastName": "Asimov", "genre": "science fiction" },
{ "firstName": "Tad", "lastName": "Williams", "genre": "fantasy" },
{ "firstName": "Frank", "lastName": "Peretti", "genre": "christian fiction" }
],
"musicians": [
{ "firstName": "Eric", "lastName": "Clapton", "instrument": "guitar" },
{ "firstName": "Sergei", "lastName": "Rachmaninoff", "instrument": "piano" }
]
}
这很简单;现在人们收录我们之前看到的 JSON 格式的数据。然而,这还不够,因为访问数据的方式似乎还不是很明显。
访问数据
虽然看起来并不明显,但上面的长字符串实际上只是一个数组;将此数组放入 JavaScript 变量后,您可以轻松访问它。实际上,您只需要使用点表示法来表示数组元素。因此,要访问程序员列表中第一个条目的姓氏,只需在 JavaScript 中使用以下代码:
people.programmers[0].lastName;
请注意,数组索引从零开始。所以,这行代码首先访问了people变量中的数据;然后它移动到名为程序员的条目,然后移动到第一条记录([0]);最后,它访问 lastName 键的值。结果是字符串值“McLaughlin”。
以下是使用相同变量的几个示例。
people.authors[1].genre // Value is "fantasy"
people.musicians[3].lastName // Undefined. This refers to the fourth entry, and there isn't one
people.programmers.[2].firstName // Value is "Elliotte"
使用此语法,您可以处理 JSON 格式的任何数据,而无需使用任何额外的 JavaScript 工具包或 API。
修改 JSON 数据
正如您可以使用点和括号访问数据一样,您也可以使用相同的方式轻松修改数据:
people.musicians[1].lastName = "Rachmaninov";
将字符串转换为 JavaScript 对象后,您可以像这样修改变量中的数据。
转换回字符串
当然,如果对象不能轻易转换回本文提到的文本格式,那么所有的数据修改都没有什么价值。这种转换在 JavaScript 中也很简单:
String newJSONtext = people.toJSONString();
没关系!现在您有了一个可以在任何地方使用的文本字符串,例如,它可以在 Ajax 应用程序中用作请求字符串。
更重要的是,任何 JavaScript 对象都可以转换为 JSON 文本。这不仅仅是处理最初用 JSON 字符串分配的变量。为了转换名为 myObject 的对象,您只需要执行相同形式的命令:
String myObjectInJSON = myObject.toJSONString();
这是 JSON 与本系列中讨论的其他数据格式之间的最大区别。如果使用JSON,只需要调用一个简单的函数即可获取格式化后的数据,直接使用即可。对于其他数据格式,需要在原创数据和格式化数据之间进行转换。即使你使用像文档对象模型这样的 API(提供一个函数将你自己的数据结构转换成文本),你也需要学习这个 API 并使用 API 的对象,而不是使用原生的 JavaScript 对象和语法。
最后的结论是,如果你正在处理大量的 JavaScript 对象,那么 JSON 几乎肯定是一个不错的选择,这样你就可以很容易地将数据转换成可以在请求中发送给服务器端程序的格式.
php抓取网页json数据(这是你如何做到这一点:这个链接会告诉你)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-15 03:24
所以你可以这样做:
这个链接会告诉你更详细的操作方法:
$(document).ready(function(){
$("#button").click(function(){
$.getJSON("http://example.com/",function(result){
$.each(result, function(i, field){
$("#myDiv").append(""+i + " " + field.name + "" + field.description + "");
});
});
});
});
此链接正是您想要关注的内容:
$(document).ready(function(){
$("#button").click(function(){
$.getJSON("http://example.com/",function(result){
$.each(result, function(i, field){
$("#myDiv").append("" + field.name + "<p>" + field.description + "");
});
});
});
});
</p>
你必须使用 AJAX &。 getJSON 基本上是一种从 url 中获取字段的方法。然后我将您的 json 中的表格附加到 div。
如果你向你的 json 添加更多数据,那么你可以通过 field.[json-field-name] 获取它并通过为它提供 'id' 为你提供任何样式,然后以 css 样式创建它。我跟踪 json 文件中的元素数量。
希望这有助于
更多文档:
使用 jQuery 插件的 Ajax 需要嵌入到页面的 .getJSON 方法中才能工作。 查看全部
php抓取网页json数据(这是你如何做到这一点:这个链接会告诉你)
所以你可以这样做:
这个链接会告诉你更详细的操作方法:
$(document).ready(function(){
$("#button").click(function(){
$.getJSON("http://example.com/",function(result){
$.each(result, function(i, field){
$("#myDiv").append(""+i + " " + field.name + "" + field.description + "");
});
});
});
});
此链接正是您想要关注的内容:
$(document).ready(function(){
$("#button").click(function(){
$.getJSON("http://example.com/",function(result){
$.each(result, function(i, field){
$("#myDiv").append("" + field.name + "<p>" + field.description + "");
});
});
});
});
</p>
你必须使用 AJAX &。 getJSON 基本上是一种从 url 中获取字段的方法。然后我将您的 json 中的表格附加到 div。
如果你向你的 json 添加更多数据,那么你可以通过 field.[json-field-name] 获取它并通过为它提供 'id' 为你提供任何样式,然后以 css 样式创建它。我跟踪 json 文件中的元素数量。
希望这有助于
更多文档:
使用 jQuery 插件的 Ajax 需要嵌入到页面的 .getJSON 方法中才能工作。
php抓取网页json数据(一个在python中使用模块来解析XML文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-03 17:30
乔斯
我想从 [0]name=type&facets[0]value=software&mediatype=xml 获取一些数据
我需要的是每条记录的“标题”和“GetCapabilitiesUrl”。我曾尝试使用 BeautifulSoup,但找不到获取所需数据的正确方法。
有人知道如何进行吗?
谢谢。
Gbox4
您发布的链接看起来像一个 JSON 文件,而不是一个 XML 文件。你可以在这里看到不同之处。你可以使用python中的json模块来解析这些数据。
从网站获取收录数据的字符串后,可以使用json.loads()将收录JSON对象的字符串转换为python对象。
下面的代码片段将把所有标题放在一个名为 titles 的变量中,并在其中添加一个 url。网址
import json
import urllib.request
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
raw_json_string = urllib.request.urlopen("https://kartkatalog.geonorge.n ... 6quot;).read()
json_object = json.loads(raw_json_string)
titles = []
urls = []
for record in json_object["Results"]:
titles.append(record["Title"])
try:
urls.append(record["GetCapabilitiesUrl"])
except:
pass
在编写代码时,您可以使用在线 JSON 查看器来帮助您确定字典和列表的元素。 查看全部
php抓取网页json数据(一个在python中使用模块来解析XML文件)
乔斯
我想从 [0]name=type&facets[0]value=software&mediatype=xml 获取一些数据
我需要的是每条记录的“标题”和“GetCapabilitiesUrl”。我曾尝试使用 BeautifulSoup,但找不到获取所需数据的正确方法。
有人知道如何进行吗?
谢谢。
Gbox4
您发布的链接看起来像一个 JSON 文件,而不是一个 XML 文件。你可以在这里看到不同之处。你可以使用python中的json模块来解析这些数据。
从网站获取收录数据的字符串后,可以使用json.loads()将收录JSON对象的字符串转换为python对象。
下面的代码片段将把所有标题放在一个名为 titles 的变量中,并在其中添加一个 url。网址
import json
import urllib.request
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
raw_json_string = urllib.request.urlopen("https://kartkatalog.geonorge.n ... 6quot;).read()
json_object = json.loads(raw_json_string)
titles = []
urls = []
for record in json_object["Results"]:
titles.append(record["Title"])
try:
urls.append(record["GetCapabilitiesUrl"])
except:
pass
在编写代码时,您可以使用在线 JSON 查看器来帮助您确定字典和列表的元素。
php抓取网页json数据(PHP获取接口内容api内容介绍(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-02 11:08
)
PHP 获取界面内容
如果要解析JSON数据并显示在页面上,首先必须要获取JSON接口文件的内容。 PHP中获取页面内容,可以使用fopen()函数远程访问页面,然后使用fread()函数循环获取内容。
假设接口文件页面是:,那么我们可以用下面的语句来获取这个接口文件的内容:
$handle = fopen(“http://www.qttc.net/api.php%3F ... ot%3B,"rb“);
$content = “”;
while (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
这样保存的内容就是JSON api内容。
PHP 解析 JSON 并显示
原创内容不能直接调用,必须经过PHP进一步处理后才能调用显示在网页上。在PHP5.2及以后的版本中,使用json_decode()函数解析JSON数据并转换成PHP可以调用的数据格式。例如:
$content = json_decode($content);
$content = json_decode($content);
foreach ($content->data as $key) {
echo ‘<a target=”_blank” href=”‘.$key->b_url.’”>’.$key->b_title.’</a>’;
} 查看全部
php抓取网页json数据(PHP获取接口内容api内容介绍(图)
)
PHP 获取界面内容
如果要解析JSON数据并显示在页面上,首先必须要获取JSON接口文件的内容。 PHP中获取页面内容,可以使用fopen()函数远程访问页面,然后使用fread()函数循环获取内容。
假设接口文件页面是:,那么我们可以用下面的语句来获取这个接口文件的内容:
$handle = fopen(“http://www.qttc.net/api.php%3F ... ot%3B,"rb“);
$content = “”;
while (!feof($handle)) {
$content .= fread($handle, 10000);
}
fclose($handle);
这样保存的内容就是JSON api内容。
PHP 解析 JSON 并显示
原创内容不能直接调用,必须经过PHP进一步处理后才能调用显示在网页上。在PHP5.2及以后的版本中,使用json_decode()函数解析JSON数据并转换成PHP可以调用的数据格式。例如:
$content = json_decode($content);
$content = json_decode($content);
foreach ($content->data as $key) {
echo ‘<a target=”_blank” href=”‘.$key->b_url.’”>’.$key->b_title.’</a>’;
}
php抓取网页json数据(PHP代码是模仿菜鸟教程上的“PHP数据库”PHP教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-11-30 16:15
写在前面
我的需求是微信小程序访问网站发布页面的php,php登录数据库获取数据。但是问题是服务器返回的数据是string类型的,不想做string处理,所以想把返回的数据做成json格式。
PHP
代码是模仿菜鸟教程上的《PHP数据库》PHP数据库教程编写的。网页截图如下:
根据我的项目,我写了如下php:
其实上面的json_encode()可以将数组转成json格式输出。假设单个echo的输出为{...},那么服务器响应给客户端返回的数据为{...},为json格式;但是经过多次回显,响应数据为{...}{...}{...},数据以“{...}{...}”的字符串形式传递给客户端{...}”,如下图所示。 (图片没有截断,但可以看出不是json格式,是一串“{…}{…}{…}”)
了解问题后,我的方案是:
1.先定义一个空数组:$row1=array();
2.在每个循环中将 $row 推入数组 $row1: array_push( $row1, $row[“code”]);
3.最后:echo json_encode( $row1);
变化如下:
if ($result->num_rows > 0) {
$row1=array();
while($row = $result->fetch_assoc()) {
array_push($row1,$row);
}
echo json_encode($row1);
} else {
echo "0 ";
}
理论上,数据的形式是[{…},{…},{…}]。然后看小程序控制台的输出:
嘿,我觉得很舒服。其实很简单,但是对于没有PHP基础的我来说,从知道json_encode()函数到解决问题花了将近一个下午的时间。
附上下午找到的一些链接:
php 数组:
MySQLi 官方手册: 查看全部
php抓取网页json数据(PHP代码是模仿菜鸟教程上的“PHP数据库”PHP教程)
写在前面
我的需求是微信小程序访问网站发布页面的php,php登录数据库获取数据。但是问题是服务器返回的数据是string类型的,不想做string处理,所以想把返回的数据做成json格式。
PHP
代码是模仿菜鸟教程上的《PHP数据库》PHP数据库教程编写的。网页截图如下:
根据我的项目,我写了如下php:
其实上面的json_encode()可以将数组转成json格式输出。假设单个echo的输出为{...},那么服务器响应给客户端返回的数据为{...},为json格式;但是经过多次回显,响应数据为{...}{...}{...},数据以“{...}{...}”的字符串形式传递给客户端{...}”,如下图所示。 (图片没有截断,但可以看出不是json格式,是一串“{…}{…}{…}”)
了解问题后,我的方案是:
1.先定义一个空数组:$row1=array();
2.在每个循环中将 $row 推入数组 $row1: array_push( $row1, $row[“code”]);
3.最后:echo json_encode( $row1);
变化如下:
if ($result->num_rows > 0) {
$row1=array();
while($row = $result->fetch_assoc()) {
array_push($row1,$row);
}
echo json_encode($row1);
} else {
echo "0 ";
}
理论上,数据的形式是[{…},{…},{…}]。然后看小程序控制台的输出:
嘿,我觉得很舒服。其实很简单,但是对于没有PHP基础的我来说,从知道json_encode()函数到解决问题花了将近一个下午的时间。
附上下午找到的一些链接:
php 数组:
MySQLi 官方手册:
php抓取网页json数据(阿里云gtgt;云栖社区版的Compass可视化工具(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-26 22:03
阿里云>云栖社区>主题图>P>php远程读取json数据库
推荐活动:
更多优惠>
当前主题:php远程读取json数据库添加到采集夹
相关话题:
php远程读取json数据库相关博客查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
13款Mongodb GUI可视化管理工具,总有一款适合你
作者:徐雷弗兰克7237人浏览评论:02年前
MongoDB数据库默认的管理工具是(CLI)Shell命令行,专业的DBA更容易使用,但是普通人的GUI可视化工具使用起来更方便。下面介绍13个有用的MongoDB可视化工具。MongoDB官方提供社区版Compass,可独立安装使用
阅读全文
MongoDB安装
作者:技术小哥 1232人浏览评论:04年前
mongodb 简介 MongoDB 是一个基于分布式文件存储的数据库。它是一种文档类型。虽然也是NoSQL数据库的一种,但与redis、memcached等数据库有些不同。MongoDB 是用 C++ 语言编写的。旨在为WEB应用提供可扩展的高性能数据存储解决方案。星期一
阅读全文
Android Volley 获取json格式的数据
作者:呵呵 99251000人浏览评论:04年前
为了让Android能够快速接入网络,解析常用数据格式,谷歌专门推出了Android系统网络传输的Volley库。volley 库可以方便的获取远程服务器的图片、字符串、json 对象、json 对象数组。当然java本身也可以访问json对象
阅读全文
《R与Hadoop大数据分析实战》1.7Hadoop子项目
作者:华章电脑1682人浏览评论:04年前
本节摘自华章出版社《R与Hadoop大数据分析实战》一书第1章1.7节,作者(印刷)Vignesh Prajapati,更多章节可在云栖社区找到《华章电脑》公众号查看1.7Hadoop的子项目Mahout是一个非常强大的数据挖掘库,其中
阅读全文
《Spark大数据分析:核心概念、技术与实践》大数据技术概述
作者:华章电脑 3937人浏览评论:04年前
本节摘自华章出版社《Spark大数据分析:核心概念、技术与实践》一书第一章和第一节。作者穆罕默德·古勒(Mohammed Guller)更多章节可以访问云栖。社区“华章电脑”公众号查看。大数据技术概览 我们正处于大数据时代。数据不仅是任何组织的生命
阅读全文
一小时了解MySQL数据库
作者:张国2052人浏览评论:04年前
随着移动互联网的终结和人工智能的到来,大数据变得越来越重要。下一个赢家应该是拥有大量数据的人。您应该了解数据和数据库。一、数据库汇总数据库(Database)是一个存储和管理数据的软件系统,就像一个存储数据的物流仓库。在商业领域,信息意味着商机。
阅读全文
Ajax 跨域请求 JSON JSONP
作者:cometwo1235780人浏览评论:05年前
同源策略和跨域汇总目录:1.同源策略2.跨域3.几种跨域技术1.什么是同源政策?URL 由协议、域名、端口和路径组成。如果两个 URL 的协议、域名、端口都相同,则说明它们是同源的。反之,只要协议、域名、端口不同,就视为跨域。电子
阅读全文
Android Volley 获取json格式的数据
作者:无声胜有生 823人浏览评论:06年前
为了让Android能够快速接入网络,解析常用数据格式,谷歌专门推出了Android系统网络传输的Volley库。volley 库可以方便的获取远程服务器的图片、字符串、json 对象、json 对象数组。当然java本身也可以访问json对象
阅读全文
php远程读取json数据库相关问答
【Java学习全家桶】1460道Java热点题,百位阿里巴巴技术专家答疑解惑
作者:管理贝贝19522人浏览评论:153年前
阿里极客公益活动:或许你选择为一个问题夜战,或许你迷茫只是寻求答案,或许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来云栖为您解答技术问题。他们使用自己手中的技术来帮助用户成长。本次活动邀请了数百位阿里巴巴技术
阅读全文 查看全部
php抓取网页json数据(阿里云gtgt;云栖社区版的Compass可视化工具(组图))
阿里云>云栖社区>主题图>P>php远程读取json数据库
推荐活动:
更多优惠>
当前主题:php远程读取json数据库添加到采集夹
相关话题:
php远程读取json数据库相关博客查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
13款Mongodb GUI可视化管理工具,总有一款适合你
作者:徐雷弗兰克7237人浏览评论:02年前
MongoDB数据库默认的管理工具是(CLI)Shell命令行,专业的DBA更容易使用,但是普通人的GUI可视化工具使用起来更方便。下面介绍13个有用的MongoDB可视化工具。MongoDB官方提供社区版Compass,可独立安装使用
阅读全文
MongoDB安装
作者:技术小哥 1232人浏览评论:04年前
mongodb 简介 MongoDB 是一个基于分布式文件存储的数据库。它是一种文档类型。虽然也是NoSQL数据库的一种,但与redis、memcached等数据库有些不同。MongoDB 是用 C++ 语言编写的。旨在为WEB应用提供可扩展的高性能数据存储解决方案。星期一
阅读全文
Android Volley 获取json格式的数据
作者:呵呵 99251000人浏览评论:04年前
为了让Android能够快速接入网络,解析常用数据格式,谷歌专门推出了Android系统网络传输的Volley库。volley 库可以方便的获取远程服务器的图片、字符串、json 对象、json 对象数组。当然java本身也可以访问json对象
阅读全文
《R与Hadoop大数据分析实战》1.7Hadoop子项目
作者:华章电脑1682人浏览评论:04年前
本节摘自华章出版社《R与Hadoop大数据分析实战》一书第1章1.7节,作者(印刷)Vignesh Prajapati,更多章节可在云栖社区找到《华章电脑》公众号查看1.7Hadoop的子项目Mahout是一个非常强大的数据挖掘库,其中
阅读全文
《Spark大数据分析:核心概念、技术与实践》大数据技术概述
作者:华章电脑 3937人浏览评论:04年前
本节摘自华章出版社《Spark大数据分析:核心概念、技术与实践》一书第一章和第一节。作者穆罕默德·古勒(Mohammed Guller)更多章节可以访问云栖。社区“华章电脑”公众号查看。大数据技术概览 我们正处于大数据时代。数据不仅是任何组织的生命
阅读全文
一小时了解MySQL数据库
作者:张国2052人浏览评论:04年前
随着移动互联网的终结和人工智能的到来,大数据变得越来越重要。下一个赢家应该是拥有大量数据的人。您应该了解数据和数据库。一、数据库汇总数据库(Database)是一个存储和管理数据的软件系统,就像一个存储数据的物流仓库。在商业领域,信息意味着商机。
阅读全文
Ajax 跨域请求 JSON JSONP
作者:cometwo1235780人浏览评论:05年前
同源策略和跨域汇总目录:1.同源策略2.跨域3.几种跨域技术1.什么是同源政策?URL 由协议、域名、端口和路径组成。如果两个 URL 的协议、域名、端口都相同,则说明它们是同源的。反之,只要协议、域名、端口不同,就视为跨域。电子
阅读全文
Android Volley 获取json格式的数据
作者:无声胜有生 823人浏览评论:06年前
为了让Android能够快速接入网络,解析常用数据格式,谷歌专门推出了Android系统网络传输的Volley库。volley 库可以方便的获取远程服务器的图片、字符串、json 对象、json 对象数组。当然java本身也可以访问json对象
阅读全文
php远程读取json数据库相关问答
【Java学习全家桶】1460道Java热点题,百位阿里巴巴技术专家答疑解惑
作者:管理贝贝19522人浏览评论:153年前
阿里极客公益活动:或许你选择为一个问题夜战,或许你迷茫只是寻求答案,或许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来云栖为您解答技术问题。他们使用自己手中的技术来帮助用户成长。本次活动邀请了数百位阿里巴巴技术
阅读全文
php抓取网页json数据(从php获取json数据使用js读取显示到网页笔记笔记)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-19 20:15
从php获取json数据,用js读取并显示到web笔记
php代码
"hellojson","age" => 23,"sex"=>"M");//定义php数组
$res=json_encode($array);
//var_dump($res);
echo $res;//输出结果到页面
HTML 代码
$(function(){
$(document).on("click",'.test',function(){
var id=$(this).attr("id");
var data={id:id}
//var aaa=[{"0":"1","id":"1","1":"hello","name":"hello","2":"","密码":""},{"0":"2","id":"2","1"
// :"world","name":"world","2":"","password":""},{"0":"3","id":"3", "1":"helloworld","name":"helloworld"
// ,"2":"","password":""}]
// alert(aaa[2].name)
$.ajax({
输入:“GET”,
数据:数据,
url:'xml.php',
数据类型:"json",
成功:功能(味精){
if(msg){
var res=eval(msg);//php返回的数据如果不能直接使用可以转换,可以使用eval()函数来实现转换。
//alert(res.username)
alert(res[1].name)//弹出要获取的数据
//console.log(res)
}
}
});
})
})
在原生js中,也可以使用JSON.parse()函数转换为json格式。 php中已经转成json格式了,可以直接获取
alert(msg[0].name)//msg为返回的json格式
从php中获取json数据,用js读取并显示web笔记的php代码? php//json与数组转换 $array = array(username = hellojson,age = 23, sex=M);//定义php数组$ res=json_encode(... 查看全部
php抓取网页json数据(从php获取json数据使用js读取显示到网页笔记笔记)
从php获取json数据,用js读取并显示到web笔记
php代码
"hellojson","age" => 23,"sex"=>"M");//定义php数组
$res=json_encode($array);
//var_dump($res);
echo $res;//输出结果到页面
HTML 代码
$(function(){
$(document).on("click",'.test',function(){
var id=$(this).attr("id");
var data={id:id}
//var aaa=[{"0":"1","id":"1","1":"hello","name":"hello","2":"","密码":""},{"0":"2","id":"2","1"
// :"world","name":"world","2":"","password":""},{"0":"3","id":"3", "1":"helloworld","name":"helloworld"
// ,"2":"","password":""}]
// alert(aaa[2].name)
$.ajax({
输入:“GET”,
数据:数据,
url:'xml.php',
数据类型:"json",
成功:功能(味精){
if(msg){
var res=eval(msg);//php返回的数据如果不能直接使用可以转换,可以使用eval()函数来实现转换。
//alert(res.username)
alert(res[1].name)//弹出要获取的数据
//console.log(res)
}
}
});
})
})
在原生js中,也可以使用JSON.parse()函数转换为json格式。 php中已经转成json格式了,可以直接获取
alert(msg[0].name)//msg为返回的json格式
从php中获取json数据,用js读取并显示web笔记的php代码? php//json与数组转换 $array = array(username = hellojson,age = 23, sex=M);//定义php数组$ res=json_encode(...
php抓取网页json数据(这里有新鲜出炉的PHP教程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-11 18:02
这里有新鲜的PHP教程,看看程序狗的速度!
PHP 开源脚本语言 PHP(外文名:Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,入门门槛低,易学,应用广泛。主要适用于Web开发领域。PHP 的文件扩展名为 php。
本文文章主要介绍PHP采集静态页面以及保存页面css、img、js的方法,可以实现简单的网页爬取功能,有一定的参考价值,有需要的朋友可以参考下面
本文介绍了PHP采集静态页面的方法以及保存页面css、img、js的方法。分享给大家,供大家参考。具体分析如下:
这是一个可以获取网页的html代码和css、js、字体和img资源的小工具。主要用于快速获取模板。如果来不及设计UI或者看到好的模板,可以用这个工具抓取网页并提取资源文件,提取的内容会按照相对路径保存资源,这样你就不用了担心资源文件的URL导入错误。
首页index.php,代码如下:
代码显示如下:
网络抓取器
网址
得到
保存全部
列表
抓取页面代码grab.php,代码如下:
代码显示如下: 查看全部
php抓取网页json数据(这里有新鲜出炉的PHP教程,程序狗速度看过来!)
这里有新鲜的PHP教程,看看程序狗的速度!
PHP 开源脚本语言 PHP(外文名:Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,入门门槛低,易学,应用广泛。主要适用于Web开发领域。PHP 的文件扩展名为 php。
本文文章主要介绍PHP采集静态页面以及保存页面css、img、js的方法,可以实现简单的网页爬取功能,有一定的参考价值,有需要的朋友可以参考下面
本文介绍了PHP采集静态页面的方法以及保存页面css、img、js的方法。分享给大家,供大家参考。具体分析如下:
这是一个可以获取网页的html代码和css、js、字体和img资源的小工具。主要用于快速获取模板。如果来不及设计UI或者看到好的模板,可以用这个工具抓取网页并提取资源文件,提取的内容会按照相对路径保存资源,这样你就不用了担心资源文件的URL导入错误。
首页index.php,代码如下:
代码显示如下:
网络抓取器
网址
得到
保存全部
列表
抓取页面代码grab.php,代码如下:
代码显示如下:

