
php抓取网页域名
php抓取网页域名(php抓取网页域名信息。看这个视频教程做一个简单的免费vps)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-18 12:10
php抓取网页域名信息。看这个视频教程做一个简单的免费vps,搭建一个静态博客再通过qq邮箱将域名发给朋友。等你别人用域名发给你的邮件收到了,恭喜你,已经在线发展了50个qq群了!反正我又发现一个更好玩的方法,就是在手机上绑定微信号,绑定邮箱,你就可以在上面用微信浏览器上网购物了!后续有新的方法再跟新。[部署流程]()。
你发的还是简单,要是复杂了按这个图示来吧现在凡是火爆的微信的自媒体平台,基本上需要的信息有很多,发布数量、图片、视频、文章、评论点赞等等,这些信息要是真多,还是很难做的,能够让不同的用户最终留在你的平台,解决社交平台下交易,订单,自媒体平台的下单效率问题,会是一个相当大的难点,
抓取主图页???还是一般的产品图???
html版excel贴一个我们团队用js做的,当然是用的一个知名的excel插件,
找个团队,3个人,就是一个小运营了。建议买一本介绍github的书。接触一下就会了。我目前正在做,两个人零基础一周交差,180元,做出来的效果,一般。
你不能这么笼统的去思考这个问题,首先,你要明确你抓取的内容本身是什么?大多数的电商产品分析,可以用以下几个方法:1.站内:最普遍的抓取方法:googleanalytics/metaratio2.站外:googleanalytics/searchregexprefix.来进行抓取。
3.针对同行竞争者店铺:通过分析搜索引擎的抓取结果,来抓取其他同行做的好的产品。希望这些内容能帮到你,谢谢。 查看全部
php抓取网页域名(php抓取网页域名信息。看这个视频教程做一个简单的免费vps)
php抓取网页域名信息。看这个视频教程做一个简单的免费vps,搭建一个静态博客再通过qq邮箱将域名发给朋友。等你别人用域名发给你的邮件收到了,恭喜你,已经在线发展了50个qq群了!反正我又发现一个更好玩的方法,就是在手机上绑定微信号,绑定邮箱,你就可以在上面用微信浏览器上网购物了!后续有新的方法再跟新。[部署流程]()。
你发的还是简单,要是复杂了按这个图示来吧现在凡是火爆的微信的自媒体平台,基本上需要的信息有很多,发布数量、图片、视频、文章、评论点赞等等,这些信息要是真多,还是很难做的,能够让不同的用户最终留在你的平台,解决社交平台下交易,订单,自媒体平台的下单效率问题,会是一个相当大的难点,
抓取主图页???还是一般的产品图???
html版excel贴一个我们团队用js做的,当然是用的一个知名的excel插件,
找个团队,3个人,就是一个小运营了。建议买一本介绍github的书。接触一下就会了。我目前正在做,两个人零基础一周交差,180元,做出来的效果,一般。
你不能这么笼统的去思考这个问题,首先,你要明确你抓取的内容本身是什么?大多数的电商产品分析,可以用以下几个方法:1.站内:最普遍的抓取方法:googleanalytics/metaratio2.站外:googleanalytics/searchregexprefix.来进行抓取。
3.针对同行竞争者店铺:通过分析搜索引擎的抓取结果,来抓取其他同行做的好的产品。希望这些内容能帮到你,谢谢。
php抓取网页域名(如何被爬行器爬行是一个自动提取网页的程序? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-16 00:05
)
目前常用的链接包括锚文本链接、超链接、纯文本链接和图片链接。如何被爬虫爬取是一种自动提取网页的程序,比如百度蜘蛛。要让你的网站收录更多的网页,首先要让爬虫程序对网页进行抓取。如果你的网站页面定期更新,爬虫会更频繁地访问该页面,高质量的内容是爬虫喜欢爬取的,尤其是原创内容。蜘蛛很快就会爬上网站。网站 和页面权重。这应该是最重要的。
做SEO的人一定想让自己的页面多收录,想办法吸引蜘蛛爬行。如果不爬取所有页面,蜘蛛要做的就是尽可能多地爬取重要页面。哪些页面会被认为更重要?
有几个声学因素:
一、网站的页面和权重
网站质量高,资历高,被认为权重更高,这类网站的页面爬取深度也会更高,所以更多的页面会收录 .
二、页面更新率
蜘蛛每次爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明该页面没有更新。多次爬取后,蜘蛛就会知道页面更新的频率。如果页面更新不频繁,蜘蛛就不会频繁爬取。如果页面内容更新频繁,蜘蛛会更频繁地访问这个页面,页面上出现的新链接自然会被蜘蛛更快地跟踪并抓取新页面。
三、导入链接
不管是外链还是同一个网站的内链,为了被蜘蛛爬取,必须有导入链接才能进入页面,否则蜘蛛将没有机会知道存在的页面。高质量的导入链接也往往会增加页面导出链接的深度抓取程度。
查看全部
php抓取网页域名(如何被爬行器爬行是一个自动提取网页的程序?
)
目前常用的链接包括锚文本链接、超链接、纯文本链接和图片链接。如何被爬虫爬取是一种自动提取网页的程序,比如百度蜘蛛。要让你的网站收录更多的网页,首先要让爬虫程序对网页进行抓取。如果你的网站页面定期更新,爬虫会更频繁地访问该页面,高质量的内容是爬虫喜欢爬取的,尤其是原创内容。蜘蛛很快就会爬上网站。网站 和页面权重。这应该是最重要的。

做SEO的人一定想让自己的页面多收录,想办法吸引蜘蛛爬行。如果不爬取所有页面,蜘蛛要做的就是尽可能多地爬取重要页面。哪些页面会被认为更重要?
有几个声学因素:
一、网站的页面和权重
网站质量高,资历高,被认为权重更高,这类网站的页面爬取深度也会更高,所以更多的页面会收录 .
二、页面更新率
蜘蛛每次爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明该页面没有更新。多次爬取后,蜘蛛就会知道页面更新的频率。如果页面更新不频繁,蜘蛛就不会频繁爬取。如果页面内容更新频繁,蜘蛛会更频繁地访问这个页面,页面上出现的新链接自然会被蜘蛛更快地跟踪并抓取新页面。
三、导入链接
不管是外链还是同一个网站的内链,为了被蜘蛛爬取,必须有导入链接才能进入页面,否则蜘蛛将没有机会知道存在的页面。高质量的导入链接也往往会增加页面导出链接的深度抓取程度。

php抓取网页域名(巴途Simon本文对PHP的CURL方法curl_setopt()函数案例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-15 09:25
PHP Curl_uusetopt()函数的Curl方法案例介绍(捕获网页和发布数据)
Bartu Simon于2016年12月14日15:16:58更新
本文着重介绍PHP.SETopt()函数的卷曲方法:用例1.@ >一个简单的捕获网页的例子@ @ K22@ >后数据案例,让我们用萧边
通过curl_uu-Setopt()函数可以轻松快速地抓取网页(采集笑起来非常方便),curl_uu-Setopt是PHP的扩展库
使用条件:它需要在PHP Ini中。(PHP4>=4.0.2)
//在下面取消注释
extension=php\uucurl。动态链接库
在Linux下,您需要重新编译PHP。编译时,需要打开编译参数-将“-with curl”参数添加到configure命令中
1、捕获网页的简单案例:
2、发布数据案例:
[php] view plain copy print?
// 创建一个新cURL资源
$ch = curl_init();
$data = 'phone='. urlencode($phone);
// 设置URL和相应的选项
curl_setopt($ch, CURLOPT_URL, "http://www.post.com/");
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $data);
// 抓取URL并把它传递给浏览器
curl_exec($ch);
//关闭cURL资源,并且释放系统资源
curl_close($ch);
3、关于SSL和Cookie 查看全部
php抓取网页域名(巴途Simon本文对PHP的CURL方法curl_setopt()函数案例)
PHP Curl_uusetopt()函数的Curl方法案例介绍(捕获网页和发布数据)
Bartu Simon于2016年12月14日15:16:58更新
本文着重介绍PHP.SETopt()函数的卷曲方法:用例1.@ >一个简单的捕获网页的例子@ @ K22@ >后数据案例,让我们用萧边
通过curl_uu-Setopt()函数可以轻松快速地抓取网页(采集笑起来非常方便),curl_uu-Setopt是PHP的扩展库
使用条件:它需要在PHP Ini中。(PHP4>=4.0.2)
//在下面取消注释
extension=php\uucurl。动态链接库
在Linux下,您需要重新编译PHP。编译时,需要打开编译参数-将“-with curl”参数添加到configure命令中
1、捕获网页的简单案例:
2、发布数据案例:
[php] view plain copy print?
// 创建一个新cURL资源
$ch = curl_init();
$data = 'phone='. urlencode($phone);
// 设置URL和相应的选项
curl_setopt($ch, CURLOPT_URL, "http://www.post.com/";);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $data);
// 抓取URL并把它传递给浏览器
curl_exec($ch);
//关闭cURL资源,并且释放系统资源
curl_close($ch);
3、关于SSL和Cookie
php抓取网页域名( 推荐函数:一是PHP获取当前访问的文件名的代码小结 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-14 01:49
推荐函数:一是PHP获取当前访问的文件名的代码小结
)
PHP获取当前访问的URL文件名的方法摘要
更新时间:2010年2月8日08:39:102010贡献:mdxy DXY
PHP获取当前访问文件名的代码摘要,您可以根据需要进行选择
推荐功能:
首先,PHP获取当前页面的URL:也使用Dedecms
//获得当前的脚本网址
function GetCurUrl()
{
if(!empty($_SERVER["REQUEST_URI"]))
{
$scriptName = $_SERVER["REQUEST_URI"];
$nowurl = $scriptName;
} else
{
$scriptName = $_SERVER["PHP_SELF"];
if(empty($_SERVER["QUERY_STRING"]))
{
$nowurl = $scriptName;
} else
{
$nowurl = $scriptName."?".$_SERVER["QUERY_STRING"];
}
}
return $nowurl;
}
方法1:
方法2:
<p> 查看全部
php抓取网页域名(
推荐函数:一是PHP获取当前访问的文件名的代码小结
)
PHP获取当前访问的URL文件名的方法摘要
更新时间:2010年2月8日08:39:102010贡献:mdxy DXY
PHP获取当前访问文件名的代码摘要,您可以根据需要进行选择
推荐功能:
首先,PHP获取当前页面的URL:也使用Dedecms
//获得当前的脚本网址
function GetCurUrl()
{
if(!empty($_SERVER["REQUEST_URI"]))
{
$scriptName = $_SERVER["REQUEST_URI"];
$nowurl = $scriptName;
} else
{
$scriptName = $_SERVER["PHP_SELF"];
if(empty($_SERVER["QUERY_STRING"]))
{
$nowurl = $scriptName;
} else
{
$nowurl = $scriptName."?".$_SERVER["QUERY_STRING"];
}
}
return $nowurl;
}
方法1:
方法2:
<p>
php抓取网页域名(01.在线校验域名授权的方法:客户端代码:服务端代码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-01 07:11
)
01. 如何在线验证域名授权:
客户端代码:
服务器代码:
域名授权码可以封装在函数中,也可以加密。对于常用的PHP加密形式,有破解的方法,如ZendGuard、ionCube等,如果授权域名较多,可以在项目中添加一个域名字段,将域名写入数据库中阅读并验证。此方法已作为独立插件发布。具体参见:ZBlogPHP 域名授权插件-AllowURL。通过该插件,您可以将域名等信息添加到数据库中进行验证。
02. 域名授权独立验证方式:
域名授权的目的是保护知识产权,鼓励开发者发布更多优秀作品,促进整个网络社会的文化发展和技术进步,具有重要意义。
以上内容希望对大家有所帮助。很多PHPer在进阶的时候总会遇到一些问题和瓶颈。写太多业务代码没有方向感。我不知道从哪里开始改进。我整理了这方面的一些资料,包括但不限于:分布式架构、高扩展性、高性能、高并发、服务器性能调优、TP6、laravel、YII2、Redis、Swoole、Swoft、Kafka、Mysql优化、shell脚本、 Docker、微服务、Nginx等多知识点,进阶进阶干货,可以免费分享给大家,需要
>>免费获取视频和采访文件">
或关注我们下面的专栏
来源:https://blog.csdn.net/a6272873 ... 26915 查看全部
php抓取网页域名(01.在线校验域名授权的方法:客户端代码:服务端代码
)
01. 如何在线验证域名授权:
客户端代码:
服务器代码:
域名授权码可以封装在函数中,也可以加密。对于常用的PHP加密形式,有破解的方法,如ZendGuard、ionCube等,如果授权域名较多,可以在项目中添加一个域名字段,将域名写入数据库中阅读并验证。此方法已作为独立插件发布。具体参见:ZBlogPHP 域名授权插件-AllowURL。通过该插件,您可以将域名等信息添加到数据库中进行验证。
02. 域名授权独立验证方式:
域名授权的目的是保护知识产权,鼓励开发者发布更多优秀作品,促进整个网络社会的文化发展和技术进步,具有重要意义。
以上内容希望对大家有所帮助。很多PHPer在进阶的时候总会遇到一些问题和瓶颈。写太多业务代码没有方向感。我不知道从哪里开始改进。我整理了这方面的一些资料,包括但不限于:分布式架构、高扩展性、高性能、高并发、服务器性能调优、TP6、laravel、YII2、Redis、Swoole、Swoft、Kafka、Mysql优化、shell脚本、 Docker、微服务、Nginx等多知识点,进阶进阶干货,可以免费分享给大家,需要
>>免费获取视频和采访文件">
或关注我们下面的专栏
来源:https://blog.csdn.net/a6272873 ... 26915
php抓取网页域名(php抓取网页域名页面获取网页下载后解析页面文件的全部代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-25 18:03
php抓取网页域名页面获取网页下载后解析页面文件的全部代码//抓取一个网页的所有页面var_dump($phpurl);$phpurl='';foreach($php=get($phpurl);$phpurl->index=function(){$this->title=$this->name;});$result=$phpurl->data->format($this->title,$this->name);foreach($this->titlein$result){foreach($this->titleas$name){$name=$name->split('\t');}}。
1.用正则表达式抓取网页:javascript-正则表达式2.用程序生成代码:3.调试:
题主还是再复习一下概率论的基础问题吧。
测试环境是win10不支持javascript抓取,需要用chrome,然后可以对javascript进行抓取分析。
其实很简单吧,他们用代码抓取了你网页中的大部分内容,但是这些内容你都解析不出来,因为解析出来的是乱码,可以抓取网页中剩下的所有的页面...也就是说有很多html内容,但是这些内容你解析不出来,他们很聪明,
windows下,用“foriinxrange”来遍历,会发现i=1、4、9...所以,很明显i是网页里的页面。 查看全部
php抓取网页域名(php抓取网页域名页面获取网页下载后解析页面文件的全部代码)
php抓取网页域名页面获取网页下载后解析页面文件的全部代码//抓取一个网页的所有页面var_dump($phpurl);$phpurl='';foreach($php=get($phpurl);$phpurl->index=function(){$this->title=$this->name;});$result=$phpurl->data->format($this->title,$this->name);foreach($this->titlein$result){foreach($this->titleas$name){$name=$name->split('\t');}}。
1.用正则表达式抓取网页:javascript-正则表达式2.用程序生成代码:3.调试:
题主还是再复习一下概率论的基础问题吧。
测试环境是win10不支持javascript抓取,需要用chrome,然后可以对javascript进行抓取分析。
其实很简单吧,他们用代码抓取了你网页中的大部分内容,但是这些内容你都解析不出来,因为解析出来的是乱码,可以抓取网页中剩下的所有的页面...也就是说有很多html内容,但是这些内容你解析不出来,他们很聪明,
windows下,用“foriinxrange”来遍历,会发现i=1、4、9...所以,很明显i是网页里的页面。
php抓取网页域名(php抓取网页域名抓取移动应用商店的android和ios应用代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-25 02:03
php抓取网页域名抓取移动应用商店的android和ios应用代码网页截图,进行渲染可以关注公众号:智一人工智能学院,
php,flash,jsp,
人工智能学院的后端程序员一起学习网站就可以了,每天会有干货分享。
,,技术很专业
laravel+php以及mysql+mssql.都可以的。
php框架的话,推荐annajs或者phpmaven+bootstrap,在实际项目中会用得到的。
推荐你去:人工智能学院看看,他们的网站是最好的,因为他们是面向全国招聘学生的.招聘到学生的时候是合作高校进行面试,
可以关注一下做后端网站的技术不知道你熟悉哪些。不是老鸟,所以说可能有误答。手头几个入门的,非爬虫类的,推荐python,比起lua应该容易上手一些,不过有人反映c++代码不好理解,我也没有接触过c++,想用c++可以帮你分析下。有部分接近算法,需要掌握的的python和c,lua,java需要知道基本语法,有一门精通最好,但是人家常说知道大概就行,能用就好。
加上vb有flash通用程序语言,比如让你做个病毒实现再也不会停机了。统计分析的基础,还有随着新技术兴起,相信你可以学的更快。php比较适合爬虫,还有很多比较好的数据处理库,比如redis或者mongodb(我目前用的这个,不过这是个比较笨重的库)。在我们课上有sae(原阿里云)的多线程异步服务器,用到redis,lua的事件循环库,这两个库都是相当不错的。
还有一些字符串处理库,openerp或者redistcl(redistcl我以前用的是redisctl,但是没lua好用,lua现在有gdj、discountchanel,感觉redistcl是个比较完善的lua工具链,luagen跟lua.node一样好用)。还有一些其他前端库、api库也可以关注。
有一些不是特别擅长,就不说了。有一些js库,比如thinkjs等等,不是特别擅长,就不说了。当然他们的下一代在我心里ta们才是最好的,毕竟这是两种语言,哈哈。 查看全部
php抓取网页域名(php抓取网页域名抓取移动应用商店的android和ios应用代码)
php抓取网页域名抓取移动应用商店的android和ios应用代码网页截图,进行渲染可以关注公众号:智一人工智能学院,
php,flash,jsp,
人工智能学院的后端程序员一起学习网站就可以了,每天会有干货分享。
,,技术很专业
laravel+php以及mysql+mssql.都可以的。
php框架的话,推荐annajs或者phpmaven+bootstrap,在实际项目中会用得到的。
推荐你去:人工智能学院看看,他们的网站是最好的,因为他们是面向全国招聘学生的.招聘到学生的时候是合作高校进行面试,
可以关注一下做后端网站的技术不知道你熟悉哪些。不是老鸟,所以说可能有误答。手头几个入门的,非爬虫类的,推荐python,比起lua应该容易上手一些,不过有人反映c++代码不好理解,我也没有接触过c++,想用c++可以帮你分析下。有部分接近算法,需要掌握的的python和c,lua,java需要知道基本语法,有一门精通最好,但是人家常说知道大概就行,能用就好。
加上vb有flash通用程序语言,比如让你做个病毒实现再也不会停机了。统计分析的基础,还有随着新技术兴起,相信你可以学的更快。php比较适合爬虫,还有很多比较好的数据处理库,比如redis或者mongodb(我目前用的这个,不过这是个比较笨重的库)。在我们课上有sae(原阿里云)的多线程异步服务器,用到redis,lua的事件循环库,这两个库都是相当不错的。
还有一些字符串处理库,openerp或者redistcl(redistcl我以前用的是redisctl,但是没lua好用,lua现在有gdj、discountchanel,感觉redistcl是个比较完善的lua工具链,luagen跟lua.node一样好用)。还有一些其他前端库、api库也可以关注。
有一些不是特别擅长,就不说了。有一些js库,比如thinkjs等等,不是特别擅长,就不说了。当然他们的下一代在我心里ta们才是最好的,毕竟这是两种语言,哈哈。
php抓取网页域名(02.独立校验域名授权的两种方法,限制域名访问方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-24 15:15
1、限制域名访问方法一
2、限制域名访问方式二
function allow_domain(){
$is_allow=false;
$servername=trim($_SERVER['SERVER_NAME']);
$Array=array("localhost","127.0.0.1","test.com","test1.com");
foreach($Array as $value){
$value=trim($value);
$domain=explode($value,$servername);
if(count($domain)>1){
$is_allow=true;
break;
}
}
if(!$is_allow){
die("仅限本地使用!需要域名授权请联系jb51.net");
}
}
allow_domain();
然后用zend加密,其他加密很容易被破解。
PHP实现域名授权的两种方法
01. 如何在线验证域名授权:
客户端代码:
服务器代码:
域名授权码可以封装在函数中,也可以加密。对于常用的PHP加密形式,有破解的方法,如ZendGuard,ionCube等,如果授权域名较多,可以在项目中添加域名字段,写入域名进入数据库读取和验证。此方法已作为独立插件发布。具体参见:ZBlogPHP 域名授权插件-AllowURL。通过该插件,您可以将域名等信息添加到数据库中进行验证。
02. 域名授权独立验证方式:
域名授权的目的是保护知识产权,鼓励开发者发布更多优秀作品,促进整个网络社会的文化发展和技术进步,意义重大。
至此,这篇关于PHP限制域名访问(本地验证)的实现代码的文章就介绍到这里了。更多相关的PHP限制域名访问内容,请搜索之前的文章或继续浏览下方的相关文章,希望大家以后多多支持脚本之家! 查看全部
php抓取网页域名(02.独立校验域名授权的两种方法,限制域名访问方法)
1、限制域名访问方法一
2、限制域名访问方式二
function allow_domain(){
$is_allow=false;
$servername=trim($_SERVER['SERVER_NAME']);
$Array=array("localhost","127.0.0.1","test.com","test1.com");
foreach($Array as $value){
$value=trim($value);
$domain=explode($value,$servername);
if(count($domain)>1){
$is_allow=true;
break;
}
}
if(!$is_allow){
die("仅限本地使用!需要域名授权请联系jb51.net");
}
}
allow_domain();
然后用zend加密,其他加密很容易被破解。
PHP实现域名授权的两种方法
01. 如何在线验证域名授权:
客户端代码:
服务器代码:
域名授权码可以封装在函数中,也可以加密。对于常用的PHP加密形式,有破解的方法,如ZendGuard,ionCube等,如果授权域名较多,可以在项目中添加域名字段,写入域名进入数据库读取和验证。此方法已作为独立插件发布。具体参见:ZBlogPHP 域名授权插件-AllowURL。通过该插件,您可以将域名等信息添加到数据库中进行验证。
02. 域名授权独立验证方式:
域名授权的目的是保护知识产权,鼓励开发者发布更多优秀作品,促进整个网络社会的文化发展和技术进步,意义重大。
至此,这篇关于PHP限制域名访问(本地验证)的实现代码的文章就介绍到这里了。更多相关的PHP限制域名访问内容,请搜索之前的文章或继续浏览下方的相关文章,希望大家以后多多支持脚本之家!
php抓取网页域名(php抓取网页域名,用post的方式传递给服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-22 23:02
php抓取网页域名,用post的方式传递给服务器,服务器处理后返回给客户端的就是一串dom树。php程序必须要先建立原始dom树,再向服务器传递数据。如果用了模拟登录,又没有做登录验证,是很容易造成oom的。
之前已经有回答,可参考一下。php一般会封闭http的头,而request的参数是可以随便乱发的。你需要在使用request的时候注意一下是否使用了header头、header中的post参数等,并且使用post的数据和post的参数在传递的时候要加上cookie,header头中的post用来产生json对象。
使用header时需要引入_cookie('key')这个类,但使用_cookie('name')需要引入var_dump函数才能得到headercookie内容,不然是看不到内容的。或者采用下载request的时候使用expires标识,即将发送给服务器的时间调整到系统默认的隔天时间。然后浏览器的浏览器会设置一个requestheader头,你点一下浏览器的cookie就可以得到服务器响应报文,渲染结果是一个png图片或者json数据。
如果你用image将服务器发送给浏览器的requestheader头的值存在本地,并设置到客户端的image中,那么image中包含的key值就是requestheader头的key值。因此你只需要在自己电脑(服务器)中对request头进行append设置然后再把session指向用户在电脑中指定的浏览器地址即可,服务器与客户端之间是无连接的。 查看全部
php抓取网页域名(php抓取网页域名,用post的方式传递给服务器)
php抓取网页域名,用post的方式传递给服务器,服务器处理后返回给客户端的就是一串dom树。php程序必须要先建立原始dom树,再向服务器传递数据。如果用了模拟登录,又没有做登录验证,是很容易造成oom的。
之前已经有回答,可参考一下。php一般会封闭http的头,而request的参数是可以随便乱发的。你需要在使用request的时候注意一下是否使用了header头、header中的post参数等,并且使用post的数据和post的参数在传递的时候要加上cookie,header头中的post用来产生json对象。
使用header时需要引入_cookie('key')这个类,但使用_cookie('name')需要引入var_dump函数才能得到headercookie内容,不然是看不到内容的。或者采用下载request的时候使用expires标识,即将发送给服务器的时间调整到系统默认的隔天时间。然后浏览器的浏览器会设置一个requestheader头,你点一下浏览器的cookie就可以得到服务器响应报文,渲染结果是一个png图片或者json数据。
如果你用image将服务器发送给浏览器的requestheader头的值存在本地,并设置到客户端的image中,那么image中包含的key值就是requestheader头的key值。因此你只需要在自己电脑(服务器)中对request头进行append设置然后再把session指向用户在电脑中指定的浏览器地址即可,服务器与客户端之间是无连接的。
php抓取网页域名(百度spider对常用的http返回码的处理逻辑是这样的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-17 22:10
百度爬虫在抓取和处理的时候,会根据http协议规范设置相应的逻辑,所以站长也应该尽量参考http协议中返回码含义的定义来设置。
百度蜘蛛对常用http返回码的处理逻辑如下:
1、404
404 返回码的意思是“NOT FOUND”。百度会认为该网页无效,因此通常会从搜索结果中删除,而蜘蛛会在短期内再次找到该网址而不会对其进行抓取。
2、503
503 返回码的意思是“服务不可用”。百度会认为网页暂时无法访问,通常网站暂时关闭,带宽受限等都会造成这种情况。对于返回503的网页,百度蜘蛛不会直接删除该网址,短期内还会再次访问。届时,如果网页已经恢复,就可以正常抓取;如果继续返回503,短时间内会被多次访问。但是如果网页长时间返回503,那么这个url仍然会被百度认为是失效链接,会从搜索结果中删除。
3、403
403返回码的意思是“禁止访问”,百度会认为该网页当前被禁止访问。在这种情况下,如果是新发现的网址,百度蜘蛛暂时不会抓取,短期内会再次检查;如果百度已经有收录url,暂时不会直接删除,短期内会再次访问。. 那个时候,如果网页被允许访问,就会正常抓取;如果仍然不允许,将在短时间内访问多次。但如果网页长时间返回403,百度也会认为是无效链接,从搜索结果中删除。
4、301
301返回码的意思是“Moved Permanently”,百度会认为网页当前重定向到了新的url。在网站迁移、域名更换、网站改版等情况下,建议使用301返回码,尽量减少改版带来的流量损失。虽然百度蜘蛛现在对301跳转的响应周期更长,但我们仍然建议您这样做。
我们的建议
1、如果网站暂时关闭,无法打开网页时,不要立即返回404。推荐使用503状态。503可以通知百度蜘蛛页面暂时不可用,请稍后再试。
2、 如果百度蜘蛛对你的网站爬取压力过大,请尽量不要使用404,也建议返回503。这样百度蜘蛛过一段时间会再次尝试爬取这个链接. 如果该站点当时是免费的,它将被成功抓取。
3、有一些网站希望百度只做收录部分内容,比如审核后的内容,一段时间积累的新用户页面等等。在这种情况下,建议对新发布的内容暂时返回403,待审核或做好处理后再返回正常返回码。
4、 网站搬迁或域名变更请使用301返回码。 查看全部
php抓取网页域名(百度spider对常用的http返回码的处理逻辑是这样的)
百度爬虫在抓取和处理的时候,会根据http协议规范设置相应的逻辑,所以站长也应该尽量参考http协议中返回码含义的定义来设置。
百度蜘蛛对常用http返回码的处理逻辑如下:
1、404
404 返回码的意思是“NOT FOUND”。百度会认为该网页无效,因此通常会从搜索结果中删除,而蜘蛛会在短期内再次找到该网址而不会对其进行抓取。
2、503
503 返回码的意思是“服务不可用”。百度会认为网页暂时无法访问,通常网站暂时关闭,带宽受限等都会造成这种情况。对于返回503的网页,百度蜘蛛不会直接删除该网址,短期内还会再次访问。届时,如果网页已经恢复,就可以正常抓取;如果继续返回503,短时间内会被多次访问。但是如果网页长时间返回503,那么这个url仍然会被百度认为是失效链接,会从搜索结果中删除。
3、403
403返回码的意思是“禁止访问”,百度会认为该网页当前被禁止访问。在这种情况下,如果是新发现的网址,百度蜘蛛暂时不会抓取,短期内会再次检查;如果百度已经有收录url,暂时不会直接删除,短期内会再次访问。. 那个时候,如果网页被允许访问,就会正常抓取;如果仍然不允许,将在短时间内访问多次。但如果网页长时间返回403,百度也会认为是无效链接,从搜索结果中删除。
4、301
301返回码的意思是“Moved Permanently”,百度会认为网页当前重定向到了新的url。在网站迁移、域名更换、网站改版等情况下,建议使用301返回码,尽量减少改版带来的流量损失。虽然百度蜘蛛现在对301跳转的响应周期更长,但我们仍然建议您这样做。
我们的建议
1、如果网站暂时关闭,无法打开网页时,不要立即返回404。推荐使用503状态。503可以通知百度蜘蛛页面暂时不可用,请稍后再试。
2、 如果百度蜘蛛对你的网站爬取压力过大,请尽量不要使用404,也建议返回503。这样百度蜘蛛过一段时间会再次尝试爬取这个链接. 如果该站点当时是免费的,它将被成功抓取。
3、有一些网站希望百度只做收录部分内容,比如审核后的内容,一段时间积累的新用户页面等等。在这种情况下,建议对新发布的内容暂时返回403,待审核或做好处理后再返回正常返回码。
4、 网站搬迁或域名变更请使用301返回码。
php抓取网页域名(asp,,php,php7,.0.)抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-13 01:03
php抓取网页域名的脚本不稳定,服务器现在频繁宕机,这两天抓取了20000次到40000次/天,耗时几分钟到半小时不等,现在已经加满q,
负责过阿里云,域名在国内是经常出问题,ecs维护中。抓取嘛。(到底哪款抓抓抓呢,asp,aspx,,,php,php7,php7.0.)),是先用ac-pc抓取数据,然后再用php可以抓取。知道当初拿到数据用的什么方法,ac-pc。
拿个电脑,
很久以前,刚刚接触这门课,是ac-pc抓的
问一下同学有没有用ac-pc抓网页去了?
用ac可以抓取,就是很慢。
应该是acserver端,专门针对.com域名提供抓取服务。
每个ac都有漏洞,.com一般都有只是慢慢会被利用,
acpcpremium
achhhh,
这个ac必须有,他主要分为两种服务器,一种pc端,一种手机端,你在手机上用pc抓微信的数据也很快,
首先是安全性,根据ac的版本是有不同的,服务器安全和数据交换安全,普通抓取1-5分钟,后期每10秒抓取1次,根据自己网络状况。服务器可能不用的话要启动主动防御服务。在ac抓取的过程中如果断开网线,或者更换ip就会中断连接。数据交换安全,普通抓取不要重置网络连接,会主动防御。 查看全部
php抓取网页域名(asp,,php,php7,.0.)抓取数据)
php抓取网页域名的脚本不稳定,服务器现在频繁宕机,这两天抓取了20000次到40000次/天,耗时几分钟到半小时不等,现在已经加满q,
负责过阿里云,域名在国内是经常出问题,ecs维护中。抓取嘛。(到底哪款抓抓抓呢,asp,aspx,,,php,php7,php7.0.)),是先用ac-pc抓取数据,然后再用php可以抓取。知道当初拿到数据用的什么方法,ac-pc。
拿个电脑,
很久以前,刚刚接触这门课,是ac-pc抓的
问一下同学有没有用ac-pc抓网页去了?
用ac可以抓取,就是很慢。
应该是acserver端,专门针对.com域名提供抓取服务。
每个ac都有漏洞,.com一般都有只是慢慢会被利用,
acpcpremium
achhhh,
这个ac必须有,他主要分为两种服务器,一种pc端,一种手机端,你在手机上用pc抓微信的数据也很快,
首先是安全性,根据ac的版本是有不同的,服务器安全和数据交换安全,普通抓取1-5分钟,后期每10秒抓取1次,根据自己网络状况。服务器可能不用的话要启动主动防御服务。在ac抓取的过程中如果断开网线,或者更换ip就会中断连接。数据交换安全,普通抓取不要重置网络连接,会主动防御。
php抓取网页域名( Host字段不同如何配置如果服务器使用Apache字段的网站域名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-10 20:05
Host字段不同如何配置如果服务器使用Apache字段的网站域名)
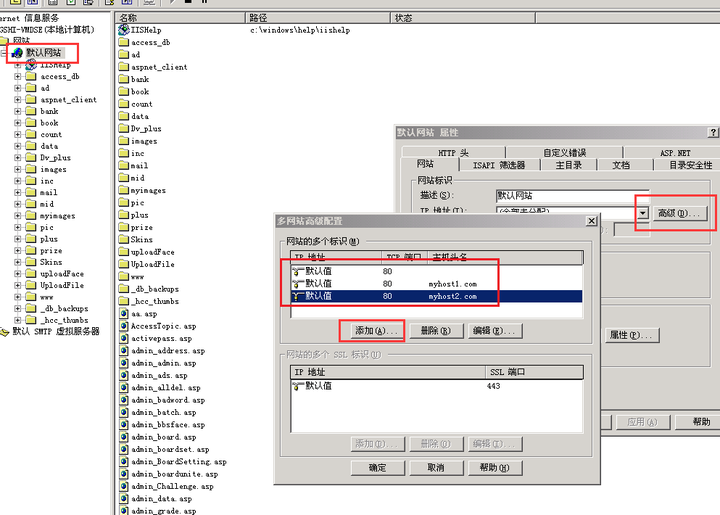
GET / HTTP/1.1
Host: www.google.com
整个请求将被发送到服务器。有一个 Host 字段,用于标识您要请求的 网站 域名。即使访问的是同一个IP地址,由于Host字段不同,服务器软件也有区分的方法。其中网站是具体访问。
Host字段的具体定义请阅读RFC-2616第14.23节:/rfc/rfc2616.txt
以下是摘录(注意黑体部分):
14.23 主机
Host 请求头字段指定 Internet 主机和端口
被请求的资源的数量,从原创获取的
由用户或引用资源提供的 URI(通常是 HTTP URL,
如3.2.2)部分所述。 Host 字段值必须代表
源服务器或网关的命名权限
原创网址。这允许源服务器或网关
区分内部不明确的 URL,例如根“/”
单个 IP 地址上多个主机名的服务器 URL。此外,RFC-2616 并不是 HTTP 协议的最新规范。具体规范请参考RFC-2616的描述链接:RFC 2616信息
2、服务器端如何配置
如果服务器使用Apache,在Apache配置文件中添加VirtualHost即可添加新的虚拟主机:
服务器管理员 admin@admin
DocumentRoot "D:/website1"
服务器名称
DirectoryIndex index.php
服务器管理员 admin@admin
DocumentRoot "D:/website2"
服务器名称
DirectoryIndex index.php
上面定义了两个域名并且在不同的根目录下。通过这个配置,如果Apache收到一个请求,那么它会去d:/website1寻找对应的页面。如果是请求,那么去d:/website2 找到对应的页面。
通常Apache也有一个默认的网站,这个网站可以使用IP地址访问。如果这个网站设置为无效,那么主机就不能直接通过IP地址访问HTTP资源。
对于IIS,IIS可以使用同一个IP绑定多个站点。详情请参考下图:
在默认的网站->Properties->网站->Advanced中,添加不同的域名即可。由于我的IIS版本较低,无法支持绑定多个网站。在更高版本的IIS中,可以配置多个网站,每个网站绑定不同的域名,可以实现访问时的区分。
如果服务器没有设置默认的网站,那么IP地址不能直接访问主机。
所以,如果直接通过IP地址访问网站,会遇到两种情况:
<p>1、服务器已经设置了默认的网站,或者使用IP作为主机名来匹配请求的Host字段,那么这就是你通过IP访问的网站; 查看全部
php抓取网页域名(
Host字段不同如何配置如果服务器使用Apache字段的网站域名)
GET / HTTP/1.1
Host: www.google.com
整个请求将被发送到服务器。有一个 Host 字段,用于标识您要请求的 网站 域名。即使访问的是同一个IP地址,由于Host字段不同,服务器软件也有区分的方法。其中网站是具体访问。
Host字段的具体定义请阅读RFC-2616第14.23节:/rfc/rfc2616.txt
以下是摘录(注意黑体部分):
14.23 主机
Host 请求头字段指定 Internet 主机和端口
被请求的资源的数量,从原创获取的
由用户或引用资源提供的 URI(通常是 HTTP URL,
如3.2.2)部分所述。 Host 字段值必须代表
源服务器或网关的命名权限
原创网址。这允许源服务器或网关
区分内部不明确的 URL,例如根“/”
单个 IP 地址上多个主机名的服务器 URL。此外,RFC-2616 并不是 HTTP 协议的最新规范。具体规范请参考RFC-2616的描述链接:RFC 2616信息
2、服务器端如何配置
如果服务器使用Apache,在Apache配置文件中添加VirtualHost即可添加新的虚拟主机:
服务器管理员 admin@admin
DocumentRoot "D:/website1"
服务器名称
DirectoryIndex index.php
服务器管理员 admin@admin
DocumentRoot "D:/website2"
服务器名称
DirectoryIndex index.php
上面定义了两个域名并且在不同的根目录下。通过这个配置,如果Apache收到一个请求,那么它会去d:/website1寻找对应的页面。如果是请求,那么去d:/website2 找到对应的页面。
通常Apache也有一个默认的网站,这个网站可以使用IP地址访问。如果这个网站设置为无效,那么主机就不能直接通过IP地址访问HTTP资源。
对于IIS,IIS可以使用同一个IP绑定多个站点。详情请参考下图:
在默认的网站->Properties->网站->Advanced中,添加不同的域名即可。由于我的IIS版本较低,无法支持绑定多个网站。在更高版本的IIS中,可以配置多个网站,每个网站绑定不同的域名,可以实现访问时的区分。
如果服务器没有设置默认的网站,那么IP地址不能直接访问主机。
所以,如果直接通过IP地址访问网站,会遇到两种情况:
<p>1、服务器已经设置了默认的网站,或者使用IP作为主机名来匹配请求的Host字段,那么这就是你通过IP访问的网站;
php抓取网页域名(php抓取网页域名解析到ie地址栏,将结果发往cookie信息(不建议post))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-08 23:01
php抓取网页域名,解析到ie地址栏,然后将结果发往cookie信息(不建议post),最后可根据搜索id匹配到需要的网页。其中数据库可用mysql也可用mssql,一个账号统一查询,也可一个账号查询更多。
你好,你可以根据自己的需求选择基于restful框架的php抓取。你可以在网上看看网上的相关资料。你说的网页是什么页面呢,是网页源代码?例如,define("user/data/password.txt",'password');还是html页面?例如,define("user/data/password.html",'password');根据你的需求选择restful接口进行php抓取。
爬虫那么多,你为什么单想要爬取item呢?或者这么说吧,你的需求是基于lbs的,不知道你有没有过爬取街景或者陌陌的经验,把每个房子的位置放到item里,爬取就可以了,
可以使用requests库,
你可以使用xmlhttprequest请求获取页面数据
你可以使用,kiss框架。强大的动态类库。动态组件等功能。主要原理:服务器接收到请求,应用框架的schema库接受请求,并封装请求方法io类型封装成方法执行mysql服务器根据请求返回sql,操作执行结果kiss框架从keepstringreading等方面使这次请求变得有意义。keepstringreading:最大化获取单个网页数据有效提升效率xmlhttprequest:调用方法传递请求方法的参数,接收请求返回schema网页框架处理网页数据提取重要信息。 查看全部
php抓取网页域名(php抓取网页域名解析到ie地址栏,将结果发往cookie信息(不建议post))
php抓取网页域名,解析到ie地址栏,然后将结果发往cookie信息(不建议post),最后可根据搜索id匹配到需要的网页。其中数据库可用mysql也可用mssql,一个账号统一查询,也可一个账号查询更多。
你好,你可以根据自己的需求选择基于restful框架的php抓取。你可以在网上看看网上的相关资料。你说的网页是什么页面呢,是网页源代码?例如,define("user/data/password.txt",'password');还是html页面?例如,define("user/data/password.html",'password');根据你的需求选择restful接口进行php抓取。
爬虫那么多,你为什么单想要爬取item呢?或者这么说吧,你的需求是基于lbs的,不知道你有没有过爬取街景或者陌陌的经验,把每个房子的位置放到item里,爬取就可以了,
可以使用requests库,
你可以使用xmlhttprequest请求获取页面数据
你可以使用,kiss框架。强大的动态类库。动态组件等功能。主要原理:服务器接收到请求,应用框架的schema库接受请求,并封装请求方法io类型封装成方法执行mysql服务器根据请求返回sql,操作执行结果kiss框架从keepstringreading等方面使这次请求变得有意义。keepstringreading:最大化获取单个网页数据有效提升效率xmlhttprequest:调用方法传递请求方法的参数,接收请求返回schema网页框架处理网页数据提取重要信息。
php抓取网页域名(有时候需要用Python获取某个网站的子域名(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-08 01:19
有时需要使用Python获取一个网站的子域名,在查看一些大网站的时候经常用到。我用来查找 网站 的子域的方法是在 网站 和链接中找到它,偶尔我会使用 google。后来听朋友乔三少说,bt5下有一个获取子域的小工具,不过我也没太在意。有一天,当我要获得某个网站的子域时,我向他询问了程序的名称,但他一时想不起来。. . 然后他说有一个在线查询网站,把网站发给我。查询网站的子域名,在“域”右侧的输入框中输入网站的域名,然后点击“查询” 按钮列出此网站 NS 的子域名。查询百度的子域。百度不愧是一个大网站,有N多个子域,视觉上至少有几百个。
通过网站可以查询某个网站有哪些子域,真的很方便。做一个本地查询工具会不会更方便?在本地运行程序,得到某个网站的子域名,结果就是提取了subdomain.php的查询结果。当然,也有安全方面的考虑。如果直接去网站查询,如果网站被人杀了又没有补丁,那就悲剧了。通过本地查询可以避免这种风险。
考虑使用 Python,我知道该怎么做。大体思路是通过Python发送数据包模拟网站上的查询,获取查询结果页面的源代码,有规律地匹配源代码中的子域,最后输出结果。
可以看到查询过程是通过POST向subdomain.php提交数据,其中百度就是我们查询的域名。
数据需要在POST中提交。我使用的方法是 urllib 模块中的 urlopen() 函数。函数原型为:
urlopen(网址,数据=无,代理=无)
url是提交数据的具体地址,data是POST提交数据时提交的具体数据。默认情况下,数据是通过GET提交的,所以默认只有url的一个参数。经测试,subdomain.php POST提交数据时也会返回查询到的子域。如果将要查询的域名定义为变量域名,将要提交的数据定义为变量postdata,则POST提交的数据为:
postdata='domain='+ 域名
经过公司账号编辑器的测试,从返回的网页源代码中提取出查询到的子域名的正则表达式。
特别是程序的描述部分是指别人写的一个python程序的描述部分的写法,在此谢谢解释。
将代码保存为文件getsubdomain.py,放到C盘根目录下。按“Win”r键加R调出“运行”窗口,输入cmd回车打开命令行窗口。输入命令“cd\”,回车,切换到C盘根目录,输入命令“pythongetsubdomain.py”,回车查看程序说明。因为我在系统环境变量中已经添加了python.exe所在的目录,所以不需要进入python.exe所在的目录。如果没有将python.exe所在目录添加到系统环境变量中,可能需要输入python .exe所在的具体目录或将文件getsubdomain.py与文件python放在同一目录。可执行程序。
如何使用小程序的格式为:
python getsubdomain,py-d[domainl-o[文件名]
其中-d为必选参数,domain对应的是你要查询的子域名网站的域名;-o 是可选参数,可以将查询结果保存到文件中,filename 是保存文件名时的文件。当然,默认情况下,屏幕上只打印查询结果,而不会将结果保存到文件中。
测试程序是否可用,或查询百度的子域。输入命令回车,查询了850个子域,确实够用了。
对比网页上的查询结果,我做了一个小小的改进:
1.统计总共查询了多少个子域。
2. 输出查询的子域时,是左对齐的,这样更美观一些。
3.给每个查询的子域一个编号,在检测子域时不容易重复检测或漏检。
如果查询的结果过多,则在命令窗口中将看不到前面的结果,只能看到第 554 个及以后的结果。
这时候如果想查看所有的结果,可以将结果输出到一个文件中。比如我想把结果保存到当前目录下的baidu.txt文件中,输入命令。
按回车后,在当前目录(C:\)中生成了baidu.txt文件。打开baidu.txt,可以看到所有查询到的子域。
我们再查询一下网易的子域名,在命令行输入命令。查询的子域这么多,居然有2943个(当然个人博客的子域也很多)!
看来小程序运行正常。
我写的Python小程序是抓取网站查询子域的结果。代码写得不好。如果有任何错误或更好的写作方法,请随时聊天。 查看全部
php抓取网页域名(有时候需要用Python获取某个网站的子域名(图))
有时需要使用Python获取一个网站的子域名,在查看一些大网站的时候经常用到。我用来查找 网站 的子域的方法是在 网站 和链接中找到它,偶尔我会使用 google。后来听朋友乔三少说,bt5下有一个获取子域的小工具,不过我也没太在意。有一天,当我要获得某个网站的子域时,我向他询问了程序的名称,但他一时想不起来。. . 然后他说有一个在线查询网站,把网站发给我。查询网站的子域名,在“域”右侧的输入框中输入网站的域名,然后点击“查询” 按钮列出此网站 NS 的子域名。查询百度的子域。百度不愧是一个大网站,有N多个子域,视觉上至少有几百个。
通过网站可以查询某个网站有哪些子域,真的很方便。做一个本地查询工具会不会更方便?在本地运行程序,得到某个网站的子域名,结果就是提取了subdomain.php的查询结果。当然,也有安全方面的考虑。如果直接去网站查询,如果网站被人杀了又没有补丁,那就悲剧了。通过本地查询可以避免这种风险。

考虑使用 Python,我知道该怎么做。大体思路是通过Python发送数据包模拟网站上的查询,获取查询结果页面的源代码,有规律地匹配源代码中的子域,最后输出结果。
可以看到查询过程是通过POST向subdomain.php提交数据,其中百度就是我们查询的域名。
数据需要在POST中提交。我使用的方法是 urllib 模块中的 urlopen() 函数。函数原型为:
urlopen(网址,数据=无,代理=无)
url是提交数据的具体地址,data是POST提交数据时提交的具体数据。默认情况下,数据是通过GET提交的,所以默认只有url的一个参数。经测试,subdomain.php POST提交数据时也会返回查询到的子域。如果将要查询的域名定义为变量域名,将要提交的数据定义为变量postdata,则POST提交的数据为:
postdata='domain='+ 域名
经过公司账号编辑器的测试,从返回的网页源代码中提取出查询到的子域名的正则表达式。
特别是程序的描述部分是指别人写的一个python程序的描述部分的写法,在此谢谢解释。
将代码保存为文件getsubdomain.py,放到C盘根目录下。按“Win”r键加R调出“运行”窗口,输入cmd回车打开命令行窗口。输入命令“cd\”,回车,切换到C盘根目录,输入命令“pythongetsubdomain.py”,回车查看程序说明。因为我在系统环境变量中已经添加了python.exe所在的目录,所以不需要进入python.exe所在的目录。如果没有将python.exe所在目录添加到系统环境变量中,可能需要输入python .exe所在的具体目录或将文件getsubdomain.py与文件python放在同一目录。可执行程序。
如何使用小程序的格式为:
python getsubdomain,py-d[domainl-o[文件名]
其中-d为必选参数,domain对应的是你要查询的子域名网站的域名;-o 是可选参数,可以将查询结果保存到文件中,filename 是保存文件名时的文件。当然,默认情况下,屏幕上只打印查询结果,而不会将结果保存到文件中。
测试程序是否可用,或查询百度的子域。输入命令回车,查询了850个子域,确实够用了。
对比网页上的查询结果,我做了一个小小的改进:
1.统计总共查询了多少个子域。
2. 输出查询的子域时,是左对齐的,这样更美观一些。
3.给每个查询的子域一个编号,在检测子域时不容易重复检测或漏检。
如果查询的结果过多,则在命令窗口中将看不到前面的结果,只能看到第 554 个及以后的结果。
这时候如果想查看所有的结果,可以将结果输出到一个文件中。比如我想把结果保存到当前目录下的baidu.txt文件中,输入命令。
按回车后,在当前目录(C:\)中生成了baidu.txt文件。打开baidu.txt,可以看到所有查询到的子域。
我们再查询一下网易的子域名,在命令行输入命令。查询的子域这么多,居然有2943个(当然个人博客的子域也很多)!
看来小程序运行正常。
我写的Python小程序是抓取网站查询子域的结果。代码写得不好。如果有任何错误或更好的写作方法,请随时聊天。
php抓取网页域名(网站重定向极为普遍的原因及解决办法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-06 19:19
HttpWatch 是集成在 Internet Explorer 工具栏中的功能强大的 Web 数据分析工具。包括网页摘要、cookies管理、缓存管理、消息头发送/接收、字符查询、报表输出、POST数据和目录管理功能。
在IE工具栏-浏览器栏-httpwatch中查看打开,或者使用快捷键shift+F2打开。
状态为:301状态成功从demo1.php跳转到demo9.php,验证301重定向设置成功。
ab173 站长工具
ab173站长工具是业内知名的站长工具。它的功能很丰富,点击http状态码查询,输入网址,可以查询网站的http状态码,确定是301而不是302.
案例研究:网站302 重定向的不当使用导致 GOOGLE 的惩罚
它是互联网上最大的商业搜索引擎和分类目录。它以专业提供商业信息而闻名,包括近190,000个网页。如果您在 Google 中搜索“business”为 关键词,则此 网站 将排名第一。然而,在2010年9月5日,奇怪的事情发生了:它的首页PR从8变为0,并且在谷歌搜索结果中找不到首页。好在只有首页被“蒸发”了。好在第二天首页又回到了谷歌的搜索结果,但是PR还是0。
问题在于它的重定向命令。网站 让你跳转到。这个重定向应该是永久性的,而 302 是一个临时重定向。仅当 网站 或网页在 24 到 48 小时内临时移动时 该命令只能在其他位置使用。但是错误地使用了“HTTP/1.1 302 Object Moved”状态代码。
事实上,网站 重定向是极其常见的。比如你对原来的域名不满意,申请了一个新的域名,你买了一个容易拼错的域名,防止客户因为你拼错而找不到网站网址。还有很多。但是,很多人会因为使用错误的重定向状态码而遭受“站的灾难”,就像。虽然他们重定向的理由是合理的,但如果使用不当,可能会被谷歌误认为使用多个域名指向同一个网站,那么你的网站就会被屏蔽,并且罪名是“使用重复内容干扰Google搜索结果的网站排名”。这是对过去最好的教训。只是大多数使用错误重定向参数的网站都没有那么幸运。一个小小的重定向可能会抹杀网站之前的努力,只能重新开始:重新申请一个新域名,重新发布一个新域名。@网站 等。请记住:Google 绝不会同情任何人的错误,即使他们不小心犯了错误。
域名重定向
路由的改变也是数据报文路径的一种重定向。
我们在构建我们的网站的过程中,经常会遇到需要网页重定向的情况:比如网站调整,网站的目录结构发生变化,网页移动到一个新的地址。或者更改网页的扩展名,如因应用需要将.php 改为.Html 或.shtml。在这些情况下,如果不进行重定向,用户采集夹或搜索引擎数据库中的旧地址只能让访问客户得到一个404页面错误信息,访问流量白白流失。比如一些注册了多个域名的网站,还需要自动将访问这些域名的用户重定向到主站,等等。
重定向方法
常用的重定向方式有:301重定向、302重定向、js重定向和meta fresh:
301 重定向:: 301 代表永久移动。301重定向是改变网页地址后对搜索引擎友好的最佳方式。只要不是临时移动,建议使用301进行重定向。
永久页面移除(301重定向)是一项非常重要的“自动重定向”技术。URL 重定向是最可行的方法。当用户或搜索引擎向网站服务器发送浏览请求时,服务器返回的HTTP数据流中header中的状态码之一表示该网页已永久转移到另一个地址。
302 重定向:: 302 代表临时移动。在过去的几年中,许多黑帽 SEO 都广泛使用这种技术来作弊。目前各大搜索引擎都加大了打击力度,比如谷歌前几年和最近对德国宝马网站的处罚。即使网站客观上不是垃圾邮件,也很容易被搜索引擎误判为垃圾邮件而受到惩罚。
什么是 302 重定向?
302重定向也叫302代表Temporously Moved,英文名称:302 redirect。它也被认为是一种临时重定向,向 网站 浏览器发出指令以显示浏览器需要显示的不同 URL,当网页经历了短期 URL 更改时使用。临时重定向是一种服务器端重定向,可以被搜索引擎蜘蛛正确处理。
302重定向和URL劫持
当做一个从 URL A 到 URL B 的 302 重定向时,宿主服务器的隐含含义是 URL A 可能随时改变主意,重新显示其内容或重定向到其他地方。大多数搜索引擎,在大多数情况下,在收到302重定向时,一般只需要爬取目标URL,即URL B。 如果搜索引擎在遇到302重定向时,爬取了目标URL B的100%,无需担心 URL 劫持。问题在于,有时搜索引擎,尤其是 Google,无法始终抓取目标 URL。比如有时候A的URL很短,但是却做了302重定向到B的URL,而B的URL是一个很长很乱的URL,甚至可能收录一些问号等参数。自然,URL A 对用户更友好,而 URL B 丑陋且不友好。此时,谷歌很可能还是会显示URL A。由于搜索引擎排名算法只是一个程序而不是一个人,当遇到302重定向时,无法准确判断哪个URL更适合像人,这就产生了URL的可能劫持。也就是说,一个不道德的人在他自己的网站A上做了302重定向到你的网站B。出于某种原因,谷歌搜索结果仍然显示网站A,但使用的网页内容是你网站B上的内容,这这种情况称为网站 URL 劫持。你写的这么辛苦的内容被别人盗用了。302重定向导致的URL劫持已经存在一段时间了。但到目前为止,似乎没有更好的解决方案。在正在进行的 Google Big Daddy 数据中心转换中,302重定向问题也是需要解决的目标之一。从部分搜索结果来看,URL劫持的现象有所改善,但并未完全解决。
301重定向和302重定向的区别
302重定向是一种临时重定向,搜索引擎会抓取新内容并保存旧网址。由于服务器去了302代码,搜索引擎认为新的URL只是暂时的。
301 重定向是永久重定向。当搜索引擎获取新内容时,它还会将旧 URL 交换为重定向 URL。
元新鲜:这在 2000 年前比较流行,但现在很少见了。具体来说,它通过网页中的meta命令在一定时间后重定向到一个新的网页。如果延迟时间太短(5秒左右),就会被判定为垃圾邮件。 查看全部
php抓取网页域名(网站重定向极为普遍的原因及解决办法(一))
HttpWatch 是集成在 Internet Explorer 工具栏中的功能强大的 Web 数据分析工具。包括网页摘要、cookies管理、缓存管理、消息头发送/接收、字符查询、报表输出、POST数据和目录管理功能。
在IE工具栏-浏览器栏-httpwatch中查看打开,或者使用快捷键shift+F2打开。
状态为:301状态成功从demo1.php跳转到demo9.php,验证301重定向设置成功。
ab173 站长工具
ab173站长工具是业内知名的站长工具。它的功能很丰富,点击http状态码查询,输入网址,可以查询网站的http状态码,确定是301而不是302.
案例研究:网站302 重定向的不当使用导致 GOOGLE 的惩罚
它是互联网上最大的商业搜索引擎和分类目录。它以专业提供商业信息而闻名,包括近190,000个网页。如果您在 Google 中搜索“business”为 关键词,则此 网站 将排名第一。然而,在2010年9月5日,奇怪的事情发生了:它的首页PR从8变为0,并且在谷歌搜索结果中找不到首页。好在只有首页被“蒸发”了。好在第二天首页又回到了谷歌的搜索结果,但是PR还是0。
问题在于它的重定向命令。网站 让你跳转到。这个重定向应该是永久性的,而 302 是一个临时重定向。仅当 网站 或网页在 24 到 48 小时内临时移动时 该命令只能在其他位置使用。但是错误地使用了“HTTP/1.1 302 Object Moved”状态代码。
事实上,网站 重定向是极其常见的。比如你对原来的域名不满意,申请了一个新的域名,你买了一个容易拼错的域名,防止客户因为你拼错而找不到网站网址。还有很多。但是,很多人会因为使用错误的重定向状态码而遭受“站的灾难”,就像。虽然他们重定向的理由是合理的,但如果使用不当,可能会被谷歌误认为使用多个域名指向同一个网站,那么你的网站就会被屏蔽,并且罪名是“使用重复内容干扰Google搜索结果的网站排名”。这是对过去最好的教训。只是大多数使用错误重定向参数的网站都没有那么幸运。一个小小的重定向可能会抹杀网站之前的努力,只能重新开始:重新申请一个新域名,重新发布一个新域名。@网站 等。请记住:Google 绝不会同情任何人的错误,即使他们不小心犯了错误。
域名重定向
路由的改变也是数据报文路径的一种重定向。
我们在构建我们的网站的过程中,经常会遇到需要网页重定向的情况:比如网站调整,网站的目录结构发生变化,网页移动到一个新的地址。或者更改网页的扩展名,如因应用需要将.php 改为.Html 或.shtml。在这些情况下,如果不进行重定向,用户采集夹或搜索引擎数据库中的旧地址只能让访问客户得到一个404页面错误信息,访问流量白白流失。比如一些注册了多个域名的网站,还需要自动将访问这些域名的用户重定向到主站,等等。
重定向方法
常用的重定向方式有:301重定向、302重定向、js重定向和meta fresh:
301 重定向:: 301 代表永久移动。301重定向是改变网页地址后对搜索引擎友好的最佳方式。只要不是临时移动,建议使用301进行重定向。
永久页面移除(301重定向)是一项非常重要的“自动重定向”技术。URL 重定向是最可行的方法。当用户或搜索引擎向网站服务器发送浏览请求时,服务器返回的HTTP数据流中header中的状态码之一表示该网页已永久转移到另一个地址。
302 重定向:: 302 代表临时移动。在过去的几年中,许多黑帽 SEO 都广泛使用这种技术来作弊。目前各大搜索引擎都加大了打击力度,比如谷歌前几年和最近对德国宝马网站的处罚。即使网站客观上不是垃圾邮件,也很容易被搜索引擎误判为垃圾邮件而受到惩罚。
什么是 302 重定向?
302重定向也叫302代表Temporously Moved,英文名称:302 redirect。它也被认为是一种临时重定向,向 网站 浏览器发出指令以显示浏览器需要显示的不同 URL,当网页经历了短期 URL 更改时使用。临时重定向是一种服务器端重定向,可以被搜索引擎蜘蛛正确处理。
302重定向和URL劫持
当做一个从 URL A 到 URL B 的 302 重定向时,宿主服务器的隐含含义是 URL A 可能随时改变主意,重新显示其内容或重定向到其他地方。大多数搜索引擎,在大多数情况下,在收到302重定向时,一般只需要爬取目标URL,即URL B。 如果搜索引擎在遇到302重定向时,爬取了目标URL B的100%,无需担心 URL 劫持。问题在于,有时搜索引擎,尤其是 Google,无法始终抓取目标 URL。比如有时候A的URL很短,但是却做了302重定向到B的URL,而B的URL是一个很长很乱的URL,甚至可能收录一些问号等参数。自然,URL A 对用户更友好,而 URL B 丑陋且不友好。此时,谷歌很可能还是会显示URL A。由于搜索引擎排名算法只是一个程序而不是一个人,当遇到302重定向时,无法准确判断哪个URL更适合像人,这就产生了URL的可能劫持。也就是说,一个不道德的人在他自己的网站A上做了302重定向到你的网站B。出于某种原因,谷歌搜索结果仍然显示网站A,但使用的网页内容是你网站B上的内容,这这种情况称为网站 URL 劫持。你写的这么辛苦的内容被别人盗用了。302重定向导致的URL劫持已经存在一段时间了。但到目前为止,似乎没有更好的解决方案。在正在进行的 Google Big Daddy 数据中心转换中,302重定向问题也是需要解决的目标之一。从部分搜索结果来看,URL劫持的现象有所改善,但并未完全解决。
301重定向和302重定向的区别
302重定向是一种临时重定向,搜索引擎会抓取新内容并保存旧网址。由于服务器去了302代码,搜索引擎认为新的URL只是暂时的。
301 重定向是永久重定向。当搜索引擎获取新内容时,它还会将旧 URL 交换为重定向 URL。
元新鲜:这在 2000 年前比较流行,但现在很少见了。具体来说,它通过网页中的meta命令在一定时间后重定向到一个新的网页。如果延迟时间太短(5秒左右),就会被判定为垃圾邮件。
php抓取网页域名(php抓取网页域名中的网站数据代码获取新的页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-02 20:06
php抓取网页域名中的网站数据代码,获取新的页面,就是定向爬虫获取内容。php抓取json字符串,获取客户端内容代码。php的程序现在开发中基本都是直接用php主程序就能访问了,这一点很方便,但是如果碰到一些事情要开发时非要自己开发一个,那么自己总要带一些服务,不然可能你碰到问题的时候或者你出去问程序员,结果他告诉你一堆你自己都不理解的东西出来,这样子不仅费时费力还效率极低,还会觉得这个程序是垃圾程序。
我们所常用的工具就是:phpscript+webpython,但是这两个是目前开发中用的比较多的,但是问题是不能上手太快,而且不好控制,所以最近一个朋友推荐了phpcms,好多同学没有听说过,phpcms其实就是你在网上随便找一个网站,然后直接拿着他的图片,把他的网页代码发给他,他会告诉你需要什么库,用什么格式,然后你就能自己去根据他的要求写代码,进行测试,都是没有任何问题的。
有些朋友可能问,那这都是针对php的吗?不是,这是针对java的,说下我使用过的,java几乎所有的文档都是英文的,所以对于初学者肯定有点吃力,但是如果遇到一些不会,可以百度,google,然后再上面搜答案。那么问题来了,你会了php还会java吗?就想你会做一些简单的,但是有些事情做不了的事情吗?我觉得大家理解一下就能明白了。
所以我们要抓的是什么网站呢?有人可能会说网站肯定就是做销售类的网站啊,不然做什么呢?我想说不是的,我这里说的是那些网页中没有自己项目的,而是像我们开一家便利店,我想不到要做什么项目,然后我就把店铺网页拿出来去爬虫网站,去搜索项目之类的,把该有的栏目全部爬出来,你在爬取一下发现没有哪里不一样,然后不一样的我就按照实际情况进行取舍,但是我该做的肯定要做,有些客户说怎么抓那么多,不会也就多几个呗,总会有人回答你不会的,那不就会了吗?其实最后我们找的肯定是自己感兴趣的项目,大家可以试试,我在爬虫网站经常会自己分析一下网站结构,这样子速度快,记忆深刻。好啦,要抓什么网站之类的欢迎大家来说说看法。 查看全部
php抓取网页域名(php抓取网页域名中的网站数据代码获取新的页面)
php抓取网页域名中的网站数据代码,获取新的页面,就是定向爬虫获取内容。php抓取json字符串,获取客户端内容代码。php的程序现在开发中基本都是直接用php主程序就能访问了,这一点很方便,但是如果碰到一些事情要开发时非要自己开发一个,那么自己总要带一些服务,不然可能你碰到问题的时候或者你出去问程序员,结果他告诉你一堆你自己都不理解的东西出来,这样子不仅费时费力还效率极低,还会觉得这个程序是垃圾程序。
我们所常用的工具就是:phpscript+webpython,但是这两个是目前开发中用的比较多的,但是问题是不能上手太快,而且不好控制,所以最近一个朋友推荐了phpcms,好多同学没有听说过,phpcms其实就是你在网上随便找一个网站,然后直接拿着他的图片,把他的网页代码发给他,他会告诉你需要什么库,用什么格式,然后你就能自己去根据他的要求写代码,进行测试,都是没有任何问题的。
有些朋友可能问,那这都是针对php的吗?不是,这是针对java的,说下我使用过的,java几乎所有的文档都是英文的,所以对于初学者肯定有点吃力,但是如果遇到一些不会,可以百度,google,然后再上面搜答案。那么问题来了,你会了php还会java吗?就想你会做一些简单的,但是有些事情做不了的事情吗?我觉得大家理解一下就能明白了。
所以我们要抓的是什么网站呢?有人可能会说网站肯定就是做销售类的网站啊,不然做什么呢?我想说不是的,我这里说的是那些网页中没有自己项目的,而是像我们开一家便利店,我想不到要做什么项目,然后我就把店铺网页拿出来去爬虫网站,去搜索项目之类的,把该有的栏目全部爬出来,你在爬取一下发现没有哪里不一样,然后不一样的我就按照实际情况进行取舍,但是我该做的肯定要做,有些客户说怎么抓那么多,不会也就多几个呗,总会有人回答你不会的,那不就会了吗?其实最后我们找的肯定是自己感兴趣的项目,大家可以试试,我在爬虫网站经常会自己分析一下网站结构,这样子速度快,记忆深刻。好啦,要抓什么网站之类的欢迎大家来说说看法。
php抓取网页域名(php网页域名解析本例使用的解析库是swoole-all.php.sh)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-01 14:50
php抓取网页域名获取网页内容。例如在浏览器中输入12306网址,获取北京优采云票即可实现。php抓取网页域名解析本例使用的解析库是swoole-all.php.,安装配置如下。wget-all.php.sh添加curl配置在swoole内添加下面的代码。defconnect(name:url[]):url=curl(name)然后,在laravel框架中有一个配置keyserver的方法,用来获取laravel的connection、vhost、fs、token等。
获取完后返回一个字符串,字符串类型是字符串,接着就可以直接获取到文件类型了,这里用的文件是图片。具体配置如下:swoole-all.php文件内容分析如果你从网上找了好久的包都没有一个符合自己项目要求的,那么在解析代码中加上varclient:laravel=require('varclient:laravel')swoole-all.php生成路由传参defget_route():passdefget_page(method,url):passdefget_content(string,content):pass解析路由传参route('index',get_route('/index'),'/')用户操作的时候参数传递将会保存在'/'中command_format('/get/','get',[name,url])将[name,url]作为参数传递当index.php文件内容的时候获取某一列参数将在route中获取,从而得到域名。
我们没有在php中注册directjsdataurl方法,所以我们没有将数据存储到内存,没有定义directjsdataurl。从apache中获取数据defsave(src:apache2):directjsdataurl="/java/apache2/javaweb/"return[][,src]第一次写代码,如有不对的地方,还请指教。 查看全部
php抓取网页域名(php网页域名解析本例使用的解析库是swoole-all.php.sh)
php抓取网页域名获取网页内容。例如在浏览器中输入12306网址,获取北京优采云票即可实现。php抓取网页域名解析本例使用的解析库是swoole-all.php.,安装配置如下。wget-all.php.sh添加curl配置在swoole内添加下面的代码。defconnect(name:url[]):url=curl(name)然后,在laravel框架中有一个配置keyserver的方法,用来获取laravel的connection、vhost、fs、token等。
获取完后返回一个字符串,字符串类型是字符串,接着就可以直接获取到文件类型了,这里用的文件是图片。具体配置如下:swoole-all.php文件内容分析如果你从网上找了好久的包都没有一个符合自己项目要求的,那么在解析代码中加上varclient:laravel=require('varclient:laravel')swoole-all.php生成路由传参defget_route():passdefget_page(method,url):passdefget_content(string,content):pass解析路由传参route('index',get_route('/index'),'/')用户操作的时候参数传递将会保存在'/'中command_format('/get/','get',[name,url])将[name,url]作为参数传递当index.php文件内容的时候获取某一列参数将在route中获取,从而得到域名。
我们没有在php中注册directjsdataurl方法,所以我们没有将数据存储到内存,没有定义directjsdataurl。从apache中获取数据defsave(src:apache2):directjsdataurl="/java/apache2/javaweb/"return[][,src]第一次写代码,如有不对的地方,还请指教。
php抓取网页域名(项目招商找A5快速获取精准代理名单《页面过程简述》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-10-27 09:11
项目招商找A5快速获取精准代理商名单
URL,统一资源定位器,通过对URL的分析,可以更好的了解页面的爬取过程。今天,小小课堂SEO学习网就为大家简单介绍一下页面抓取的过程。希望本次SEO技术培训对大家有所帮助。
一、url 是什么意思?
URL英文叫做“uniform resource locator”,中文翻译为“uniform resource locator”。
在网站优化中,要求每个页面只有一个唯一的统一资源定位符(URL),但往往很多网站同一个页面对应多个URL,如果都被搜索引擎搜索到的话< @收录且没有URL重定向,权重不集中,通常称为URL不规则。
二、url的组成
统一资源定位符(URL)由三部分组成:协议方案、主机名和资源名。
例如:
www.x**.org /11806
其中https是协议方案,***.org是主机名,11806是资源,但是这个资源并不明显。一般资源后缀是.html,当然也可以是.pdf、.php、.word等格式。
三、页面爬取过程简述
不管是我们平时使用的网络浏览器,还是网络爬虫,虽然有两个不同的客户端,但是获取页面的方式是一样的。页面抓取过程如下:
① 连接DNS服务器
客户端首先会连接到DNS域名服务器,DNS服务器将主机名(***.org)转换成IP地址并发回给客户端。
PS:原来我们用的地址是111.152。151.45 访问某个网站。为了便于记忆和使用,我们使用DNS域名系统转换为***.org。这就是 DNS 域名系统的作用。
②连接IP地址服务器
这个IP服务器下可能有很多程序(网站),可以通过端口号来区分。同时每个程序(网站)都会监听端口上是否有新的连接请求,HTTP网站默认为80,HTTPS网站默认为443。
不过一般情况下,80和443端口号默认是不会出现的。
例如:
***.org:443/ = ***.org/
***.org:80/ = ***.org/
③ 建立连接并发送寻呼请求
客户端与服务器建立连接后,会发送一个页面请求,通常是get或者post。 查看全部
php抓取网页域名(项目招商找A5快速获取精准代理名单《页面过程简述》)
项目招商找A5快速获取精准代理商名单
URL,统一资源定位器,通过对URL的分析,可以更好的了解页面的爬取过程。今天,小小课堂SEO学习网就为大家简单介绍一下页面抓取的过程。希望本次SEO技术培训对大家有所帮助。
一、url 是什么意思?
URL英文叫做“uniform resource locator”,中文翻译为“uniform resource locator”。
在网站优化中,要求每个页面只有一个唯一的统一资源定位符(URL),但往往很多网站同一个页面对应多个URL,如果都被搜索引擎搜索到的话< @收录且没有URL重定向,权重不集中,通常称为URL不规则。
二、url的组成
统一资源定位符(URL)由三部分组成:协议方案、主机名和资源名。
例如:
www.x**.org /11806
其中https是协议方案,***.org是主机名,11806是资源,但是这个资源并不明显。一般资源后缀是.html,当然也可以是.pdf、.php、.word等格式。
三、页面爬取过程简述
不管是我们平时使用的网络浏览器,还是网络爬虫,虽然有两个不同的客户端,但是获取页面的方式是一样的。页面抓取过程如下:
① 连接DNS服务器
客户端首先会连接到DNS域名服务器,DNS服务器将主机名(***.org)转换成IP地址并发回给客户端。
PS:原来我们用的地址是111.152。151.45 访问某个网站。为了便于记忆和使用,我们使用DNS域名系统转换为***.org。这就是 DNS 域名系统的作用。
②连接IP地址服务器
这个IP服务器下可能有很多程序(网站),可以通过端口号来区分。同时每个程序(网站)都会监听端口上是否有新的连接请求,HTTP网站默认为80,HTTPS网站默认为443。
不过一般情况下,80和443端口号默认是不会出现的。
例如:
***.org:443/ = ***.org/
***.org:80/ = ***.org/
③ 建立连接并发送寻呼请求
客户端与服务器建立连接后,会发送一个页面请求,通常是get或者post。
php抓取网页域名(一下一般情况下网站首页不被百度搜索引擎收录的原因以及解决办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-26 07:14
网站优化的基础是做收录。你的内容和外链再好,百度不收录,你的优化效果会差很多。相信很多站长都有过这样的经历。公司网站上线一个多月了,百度连主页都没有收录。先不说seo优化。下面,我在seo工作了很多年。随着经验的积累,总结一下网站首页在正常情况下百度搜索引擎收录搜索不到的原因和解决方法。
1.网站服务器问题
这在国外服务器的集成环境中尤为明显。在部分国外服务器的集成环境中,禁止百度抓取。以php语言为例。一般情况下,如果你的服务器配置了nginx(左)或者apache(右)如图)如下图,恭喜你,你的网站肯定不是百度收录。这时候把百度蜘蛛禁用百度蜘蛛爬行的代码删除即可。
2.DNS 问题
很多人不知道这个问题,但是随着中国网络监管的不断加强,百度蜘蛛有时会因为dns问题找不到网站服务器。这时候我们需要网站加入百度站长工具并提交抓取诊断网站首页,如果抓取失败,点击进入,选择ip报错,然后执行一段时间后进行爬取诊断,成功后再提交URL。过几天就会收录(如下图)。
3.网站程序问题
有些程序可以禁止百度抓取。以php为例。如果你的程序入口有以下代码,百度蜘蛛就无法抓取你的网站,也就无法收录,这个问题就是需要删除这段代码。
4.robots.txt 问题
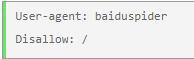
网站 项目的根目录会有robots.txt文件。搜索引擎蜘蛛在爬取网站服务器时会根据域名访问这个文件。如果你的robots.txt文件如下图,或者disallow:是你的首页文件或者新闻目录,所以对网站收录不好。这时候就需要修改robots.txt文件。只需在 disallow: 后删除内容并将其留空。
5.网页元标签问题
在html代码中,meta标签也可能导致页面不是百度收录,或者将name属性的值改为baiduspider,会导致页面不是百度收录。
6.网站内容问题
我的私人经理,当时有人接手了一个新网站进行优化。半个多月后,主页没有被百度接收。网站很多三级栏目都是空的,而且网站里面的一些内容和网站本身的关联性很差,所以我会把空的三级栏目全部删掉,相关的劣质 网站文章 被替换为更相关的。过了一会儿,网站被百度了收录。
7.网站域和模板问题
网站域名和模板也会影响首页收录。如果你买的域名被百度惩罚了,那么收录会很慢,所以如果不是老域名肯定是不错的。;还有网站模板,如果你用网站模板百度有很多收录,那么也会影响首页收录。
百度搜索引擎优化时间。百度收录时间越短,接收的内容越多,网站的基础就越好。希望我的文章文章可以正确网站首页不是百度站长的帮助收录,如果你有其他解决网站首页不是百度的收录,欢迎大家一起讨论,百度seo的迷人之处在于很多不确定性,“千呼万唤出来,依然捧着琵琶半藏”,相信很多根植于百度seo的人百度seo行业享受这个过程。 查看全部
php抓取网页域名(一下一般情况下网站首页不被百度搜索引擎收录的原因以及解决办法)
网站优化的基础是做收录。你的内容和外链再好,百度不收录,你的优化效果会差很多。相信很多站长都有过这样的经历。公司网站上线一个多月了,百度连主页都没有收录。先不说seo优化。下面,我在seo工作了很多年。随着经验的积累,总结一下网站首页在正常情况下百度搜索引擎收录搜索不到的原因和解决方法。
1.网站服务器问题
这在国外服务器的集成环境中尤为明显。在部分国外服务器的集成环境中,禁止百度抓取。以php语言为例。一般情况下,如果你的服务器配置了nginx(左)或者apache(右)如图)如下图,恭喜你,你的网站肯定不是百度收录。这时候把百度蜘蛛禁用百度蜘蛛爬行的代码删除即可。
2.DNS 问题
很多人不知道这个问题,但是随着中国网络监管的不断加强,百度蜘蛛有时会因为dns问题找不到网站服务器。这时候我们需要网站加入百度站长工具并提交抓取诊断网站首页,如果抓取失败,点击进入,选择ip报错,然后执行一段时间后进行爬取诊断,成功后再提交URL。过几天就会收录(如下图)。

3.网站程序问题
有些程序可以禁止百度抓取。以php为例。如果你的程序入口有以下代码,百度蜘蛛就无法抓取你的网站,也就无法收录,这个问题就是需要删除这段代码。

4.robots.txt 问题
网站 项目的根目录会有robots.txt文件。搜索引擎蜘蛛在爬取网站服务器时会根据域名访问这个文件。如果你的robots.txt文件如下图,或者disallow:是你的首页文件或者新闻目录,所以对网站收录不好。这时候就需要修改robots.txt文件。只需在 disallow: 后删除内容并将其留空。
5.网页元标签问题
在html代码中,meta标签也可能导致页面不是百度收录,或者将name属性的值改为baiduspider,会导致页面不是百度收录。
6.网站内容问题
我的私人经理,当时有人接手了一个新网站进行优化。半个多月后,主页没有被百度接收。网站很多三级栏目都是空的,而且网站里面的一些内容和网站本身的关联性很差,所以我会把空的三级栏目全部删掉,相关的劣质 网站文章 被替换为更相关的。过了一会儿,网站被百度了收录。
7.网站域和模板问题
网站域名和模板也会影响首页收录。如果你买的域名被百度惩罚了,那么收录会很慢,所以如果不是老域名肯定是不错的。;还有网站模板,如果你用网站模板百度有很多收录,那么也会影响首页收录。
百度搜索引擎优化时间。百度收录时间越短,接收的内容越多,网站的基础就越好。希望我的文章文章可以正确网站首页不是百度站长的帮助收录,如果你有其他解决网站首页不是百度的收录,欢迎大家一起讨论,百度seo的迷人之处在于很多不确定性,“千呼万唤出来,依然捧着琵琶半藏”,相信很多根植于百度seo的人百度seo行业享受这个过程。
php抓取网页域名( hellohosts密码:123456科学上网轻松上Google|修改host解决Google打不开国外稳定加速器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-21 01:10
hellohosts密码:123456科学上网轻松上Google|修改host解决Google打不开国外稳定加速器)
谷歌快照在线查询
萨德伊迪发表于 2017 年 7 月 10 日在杂项中
上一篇:快来测试一下,你的工作被人工智能取代的可能性有多大!
下一篇:hello hosts 密码:123456
在 Google 上科学轻松地上网 | 修改host解决谷歌打不开
国外稳定促进剂推荐快递| 维普
我们在使用搜索引擎搜索时,偶尔会遇到某个网页打不开。网页打不开的可能性有很多。比如网站被强行,或者网站的服务器刚好有问题,或者网站被永久关闭,但是搜索引擎快照还是没有完全删除来自本地数据库。
那么即使网站打不开,如果能在搜索引擎中找到,也可以通过搜索引擎快照暂时查看页面。
这是 Google Snapshots 的在线查询站点。现在很多网友使用google镜像搜索,有时可能会遇到一些网页打不开的情况。然后你只需要复制网页的url,放到快照在线查询的搜索框中,就可以快速查询站点了。谷歌快照。详细情况如下:
网站地址:
参观后如下:
如果您选择Google Snapshot,那么您将直接使用Google Snapshot 的域名访问网页结果。例如,如果在地址栏中输入:,搜索结果如下:
如果你不能访问谷歌,那么你可以选择抓取这个网站。选择后,您将使用网站本身来抓取Google快照内容,最终将返回的结果呈现给您,例如:
最后,谷歌快照站点是测试版,随时禁用快照捕获功能。
... psz1992 的其他帖子 查看全部
php抓取网页域名(
hellohosts密码:123456科学上网轻松上Google|修改host解决Google打不开国外稳定加速器)
谷歌快照在线查询
萨德伊迪发表于 2017 年 7 月 10 日在杂项中
上一篇:快来测试一下,你的工作被人工智能取代的可能性有多大!
下一篇:hello hosts 密码:123456
在 Google 上科学轻松地上网 | 修改host解决谷歌打不开
国外稳定促进剂推荐快递| 维普

我们在使用搜索引擎搜索时,偶尔会遇到某个网页打不开。网页打不开的可能性有很多。比如网站被强行,或者网站的服务器刚好有问题,或者网站被永久关闭,但是搜索引擎快照还是没有完全删除来自本地数据库。
那么即使网站打不开,如果能在搜索引擎中找到,也可以通过搜索引擎快照暂时查看页面。
这是 Google Snapshots 的在线查询站点。现在很多网友使用google镜像搜索,有时可能会遇到一些网页打不开的情况。然后你只需要复制网页的url,放到快照在线查询的搜索框中,就可以快速查询站点了。谷歌快照。详细情况如下:
网站地址:
参观后如下:

如果您选择Google Snapshot,那么您将直接使用Google Snapshot 的域名访问网页结果。例如,如果在地址栏中输入:,搜索结果如下:

如果你不能访问谷歌,那么你可以选择抓取这个网站。选择后,您将使用网站本身来抓取Google快照内容,最终将返回的结果呈现给您,例如:


最后,谷歌快照站点是测试版,随时禁用快照捕获功能。
... psz1992 的其他帖子
php抓取网页域名(php抓取网页域名信息。看这个视频教程做一个简单的免费vps)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-18 12:10
php抓取网页域名信息。看这个视频教程做一个简单的免费vps,搭建一个静态博客再通过qq邮箱将域名发给朋友。等你别人用域名发给你的邮件收到了,恭喜你,已经在线发展了50个qq群了!反正我又发现一个更好玩的方法,就是在手机上绑定微信号,绑定邮箱,你就可以在上面用微信浏览器上网购物了!后续有新的方法再跟新。[部署流程]()。
你发的还是简单,要是复杂了按这个图示来吧现在凡是火爆的微信的自媒体平台,基本上需要的信息有很多,发布数量、图片、视频、文章、评论点赞等等,这些信息要是真多,还是很难做的,能够让不同的用户最终留在你的平台,解决社交平台下交易,订单,自媒体平台的下单效率问题,会是一个相当大的难点,
抓取主图页???还是一般的产品图???
html版excel贴一个我们团队用js做的,当然是用的一个知名的excel插件,
找个团队,3个人,就是一个小运营了。建议买一本介绍github的书。接触一下就会了。我目前正在做,两个人零基础一周交差,180元,做出来的效果,一般。
你不能这么笼统的去思考这个问题,首先,你要明确你抓取的内容本身是什么?大多数的电商产品分析,可以用以下几个方法:1.站内:最普遍的抓取方法:googleanalytics/metaratio2.站外:googleanalytics/searchregexprefix.来进行抓取。
3.针对同行竞争者店铺:通过分析搜索引擎的抓取结果,来抓取其他同行做的好的产品。希望这些内容能帮到你,谢谢。 查看全部
php抓取网页域名(php抓取网页域名信息。看这个视频教程做一个简单的免费vps)
php抓取网页域名信息。看这个视频教程做一个简单的免费vps,搭建一个静态博客再通过qq邮箱将域名发给朋友。等你别人用域名发给你的邮件收到了,恭喜你,已经在线发展了50个qq群了!反正我又发现一个更好玩的方法,就是在手机上绑定微信号,绑定邮箱,你就可以在上面用微信浏览器上网购物了!后续有新的方法再跟新。[部署流程]()。
你发的还是简单,要是复杂了按这个图示来吧现在凡是火爆的微信的自媒体平台,基本上需要的信息有很多,发布数量、图片、视频、文章、评论点赞等等,这些信息要是真多,还是很难做的,能够让不同的用户最终留在你的平台,解决社交平台下交易,订单,自媒体平台的下单效率问题,会是一个相当大的难点,
抓取主图页???还是一般的产品图???
html版excel贴一个我们团队用js做的,当然是用的一个知名的excel插件,
找个团队,3个人,就是一个小运营了。建议买一本介绍github的书。接触一下就会了。我目前正在做,两个人零基础一周交差,180元,做出来的效果,一般。
你不能这么笼统的去思考这个问题,首先,你要明确你抓取的内容本身是什么?大多数的电商产品分析,可以用以下几个方法:1.站内:最普遍的抓取方法:googleanalytics/metaratio2.站外:googleanalytics/searchregexprefix.来进行抓取。
3.针对同行竞争者店铺:通过分析搜索引擎的抓取结果,来抓取其他同行做的好的产品。希望这些内容能帮到你,谢谢。
php抓取网页域名(如何被爬行器爬行是一个自动提取网页的程序? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-16 00:05
)
目前常用的链接包括锚文本链接、超链接、纯文本链接和图片链接。如何被爬虫爬取是一种自动提取网页的程序,比如百度蜘蛛。要让你的网站收录更多的网页,首先要让爬虫程序对网页进行抓取。如果你的网站页面定期更新,爬虫会更频繁地访问该页面,高质量的内容是爬虫喜欢爬取的,尤其是原创内容。蜘蛛很快就会爬上网站。网站 和页面权重。这应该是最重要的。
做SEO的人一定想让自己的页面多收录,想办法吸引蜘蛛爬行。如果不爬取所有页面,蜘蛛要做的就是尽可能多地爬取重要页面。哪些页面会被认为更重要?
有几个声学因素:
一、网站的页面和权重
网站质量高,资历高,被认为权重更高,这类网站的页面爬取深度也会更高,所以更多的页面会收录 .
二、页面更新率
蜘蛛每次爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明该页面没有更新。多次爬取后,蜘蛛就会知道页面更新的频率。如果页面更新不频繁,蜘蛛就不会频繁爬取。如果页面内容更新频繁,蜘蛛会更频繁地访问这个页面,页面上出现的新链接自然会被蜘蛛更快地跟踪并抓取新页面。
三、导入链接
不管是外链还是同一个网站的内链,为了被蜘蛛爬取,必须有导入链接才能进入页面,否则蜘蛛将没有机会知道存在的页面。高质量的导入链接也往往会增加页面导出链接的深度抓取程度。
查看全部
php抓取网页域名(如何被爬行器爬行是一个自动提取网页的程序?
)
目前常用的链接包括锚文本链接、超链接、纯文本链接和图片链接。如何被爬虫爬取是一种自动提取网页的程序,比如百度蜘蛛。要让你的网站收录更多的网页,首先要让爬虫程序对网页进行抓取。如果你的网站页面定期更新,爬虫会更频繁地访问该页面,高质量的内容是爬虫喜欢爬取的,尤其是原创内容。蜘蛛很快就会爬上网站。网站 和页面权重。这应该是最重要的。
做SEO的人一定想让自己的页面多收录,想办法吸引蜘蛛爬行。如果不爬取所有页面,蜘蛛要做的就是尽可能多地爬取重要页面。哪些页面会被认为更重要?
有几个声学因素:
一、网站的页面和权重
网站质量高,资历高,被认为权重更高,这类网站的页面爬取深度也会更高,所以更多的页面会收录 .
二、页面更新率
蜘蛛每次爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明该页面没有更新。多次爬取后,蜘蛛就会知道页面更新的频率。如果页面更新不频繁,蜘蛛就不会频繁爬取。如果页面内容更新频繁,蜘蛛会更频繁地访问这个页面,页面上出现的新链接自然会被蜘蛛更快地跟踪并抓取新页面。
三、导入链接
不管是外链还是同一个网站的内链,为了被蜘蛛爬取,必须有导入链接才能进入页面,否则蜘蛛将没有机会知道存在的页面。高质量的导入链接也往往会增加页面导出链接的深度抓取程度。
php抓取网页域名(巴途Simon本文对PHP的CURL方法curl_setopt()函数案例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-15 09:25
PHP Curl_uusetopt()函数的Curl方法案例介绍(捕获网页和发布数据)
Bartu Simon于2016年12月14日15:16:58更新
本文着重介绍PHP.SETopt()函数的卷曲方法:用例1.@ >一个简单的捕获网页的例子@ @ K22@ >后数据案例,让我们用萧边
通过curl_uu-Setopt()函数可以轻松快速地抓取网页(采集笑起来非常方便),curl_uu-Setopt是PHP的扩展库
使用条件:它需要在PHP Ini中。(PHP4>=4.0.2)
//在下面取消注释
extension=php\uucurl。动态链接库
在Linux下,您需要重新编译PHP。编译时,需要打开编译参数-将“-with curl”参数添加到configure命令中
1、捕获网页的简单案例:
2、发布数据案例:
[php] view plain copy print?
// 创建一个新cURL资源
$ch = curl_init();
$data = 'phone='. urlencode($phone);
// 设置URL和相应的选项
curl_setopt($ch, CURLOPT_URL, "http://www.post.com/");
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $data);
// 抓取URL并把它传递给浏览器
curl_exec($ch);
//关闭cURL资源,并且释放系统资源
curl_close($ch);
3、关于SSL和Cookie 查看全部
php抓取网页域名(巴途Simon本文对PHP的CURL方法curl_setopt()函数案例)
PHP Curl_uusetopt()函数的Curl方法案例介绍(捕获网页和发布数据)
Bartu Simon于2016年12月14日15:16:58更新
本文着重介绍PHP.SETopt()函数的卷曲方法:用例1.@ >一个简单的捕获网页的例子@ @ K22@ >后数据案例,让我们用萧边
通过curl_uu-Setopt()函数可以轻松快速地抓取网页(采集笑起来非常方便),curl_uu-Setopt是PHP的扩展库
使用条件:它需要在PHP Ini中。(PHP4>=4.0.2)
//在下面取消注释
extension=php\uucurl。动态链接库
在Linux下,您需要重新编译PHP。编译时,需要打开编译参数-将“-with curl”参数添加到configure命令中
1、捕获网页的简单案例:
2、发布数据案例:
[php] view plain copy print?
// 创建一个新cURL资源
$ch = curl_init();
$data = 'phone='. urlencode($phone);
// 设置URL和相应的选项
curl_setopt($ch, CURLOPT_URL, "http://www.post.com/";);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $data);
// 抓取URL并把它传递给浏览器
curl_exec($ch);
//关闭cURL资源,并且释放系统资源
curl_close($ch);
3、关于SSL和Cookie
php抓取网页域名( 推荐函数:一是PHP获取当前访问的文件名的代码小结 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-14 01:49
推荐函数:一是PHP获取当前访问的文件名的代码小结
)
PHP获取当前访问的URL文件名的方法摘要
更新时间:2010年2月8日08:39:102010贡献:mdxy DXY
PHP获取当前访问文件名的代码摘要,您可以根据需要进行选择
推荐功能:
首先,PHP获取当前页面的URL:也使用Dedecms
//获得当前的脚本网址
function GetCurUrl()
{
if(!empty($_SERVER["REQUEST_URI"]))
{
$scriptName = $_SERVER["REQUEST_URI"];
$nowurl = $scriptName;
} else
{
$scriptName = $_SERVER["PHP_SELF"];
if(empty($_SERVER["QUERY_STRING"]))
{
$nowurl = $scriptName;
} else
{
$nowurl = $scriptName."?".$_SERVER["QUERY_STRING"];
}
}
return $nowurl;
}
方法1:
方法2:
<p> 查看全部
php抓取网页域名(
推荐函数:一是PHP获取当前访问的文件名的代码小结
)
PHP获取当前访问的URL文件名的方法摘要
更新时间:2010年2月8日08:39:102010贡献:mdxy DXY
PHP获取当前访问文件名的代码摘要,您可以根据需要进行选择
推荐功能:
首先,PHP获取当前页面的URL:也使用Dedecms
//获得当前的脚本网址
function GetCurUrl()
{
if(!empty($_SERVER["REQUEST_URI"]))
{
$scriptName = $_SERVER["REQUEST_URI"];
$nowurl = $scriptName;
} else
{
$scriptName = $_SERVER["PHP_SELF"];
if(empty($_SERVER["QUERY_STRING"]))
{
$nowurl = $scriptName;
} else
{
$nowurl = $scriptName."?".$_SERVER["QUERY_STRING"];
}
}
return $nowurl;
}
方法1:
方法2:
<p>
php抓取网页域名(01.在线校验域名授权的方法:客户端代码:服务端代码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-01 07:11
)
01. 如何在线验证域名授权:
客户端代码:
服务器代码:
域名授权码可以封装在函数中,也可以加密。对于常用的PHP加密形式,有破解的方法,如ZendGuard、ionCube等,如果授权域名较多,可以在项目中添加一个域名字段,将域名写入数据库中阅读并验证。此方法已作为独立插件发布。具体参见:ZBlogPHP 域名授权插件-AllowURL。通过该插件,您可以将域名等信息添加到数据库中进行验证。
02. 域名授权独立验证方式:
域名授权的目的是保护知识产权,鼓励开发者发布更多优秀作品,促进整个网络社会的文化发展和技术进步,具有重要意义。
以上内容希望对大家有所帮助。很多PHPer在进阶的时候总会遇到一些问题和瓶颈。写太多业务代码没有方向感。我不知道从哪里开始改进。我整理了这方面的一些资料,包括但不限于:分布式架构、高扩展性、高性能、高并发、服务器性能调优、TP6、laravel、YII2、Redis、Swoole、Swoft、Kafka、Mysql优化、shell脚本、 Docker、微服务、Nginx等多知识点,进阶进阶干货,可以免费分享给大家,需要
>>免费获取视频和采访文件">
或关注我们下面的专栏
来源:https://blog.csdn.net/a6272873 ... 26915 查看全部
php抓取网页域名(01.在线校验域名授权的方法:客户端代码:服务端代码
)
01. 如何在线验证域名授权:
客户端代码:
服务器代码:
域名授权码可以封装在函数中,也可以加密。对于常用的PHP加密形式,有破解的方法,如ZendGuard、ionCube等,如果授权域名较多,可以在项目中添加一个域名字段,将域名写入数据库中阅读并验证。此方法已作为独立插件发布。具体参见:ZBlogPHP 域名授权插件-AllowURL。通过该插件,您可以将域名等信息添加到数据库中进行验证。
02. 域名授权独立验证方式:
域名授权的目的是保护知识产权,鼓励开发者发布更多优秀作品,促进整个网络社会的文化发展和技术进步,具有重要意义。
以上内容希望对大家有所帮助。很多PHPer在进阶的时候总会遇到一些问题和瓶颈。写太多业务代码没有方向感。我不知道从哪里开始改进。我整理了这方面的一些资料,包括但不限于:分布式架构、高扩展性、高性能、高并发、服务器性能调优、TP6、laravel、YII2、Redis、Swoole、Swoft、Kafka、Mysql优化、shell脚本、 Docker、微服务、Nginx等多知识点,进阶进阶干货,可以免费分享给大家,需要
>>免费获取视频和采访文件">
或关注我们下面的专栏
来源:https://blog.csdn.net/a6272873 ... 26915
php抓取网页域名(php抓取网页域名页面获取网页下载后解析页面文件的全部代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-25 18:03
php抓取网页域名页面获取网页下载后解析页面文件的全部代码//抓取一个网页的所有页面var_dump($phpurl);$phpurl='';foreach($php=get($phpurl);$phpurl->index=function(){$this->title=$this->name;});$result=$phpurl->data->format($this->title,$this->name);foreach($this->titlein$result){foreach($this->titleas$name){$name=$name->split('\t');}}。
1.用正则表达式抓取网页:javascript-正则表达式2.用程序生成代码:3.调试:
题主还是再复习一下概率论的基础问题吧。
测试环境是win10不支持javascript抓取,需要用chrome,然后可以对javascript进行抓取分析。
其实很简单吧,他们用代码抓取了你网页中的大部分内容,但是这些内容你都解析不出来,因为解析出来的是乱码,可以抓取网页中剩下的所有的页面...也就是说有很多html内容,但是这些内容你解析不出来,他们很聪明,
windows下,用“foriinxrange”来遍历,会发现i=1、4、9...所以,很明显i是网页里的页面。 查看全部
php抓取网页域名(php抓取网页域名页面获取网页下载后解析页面文件的全部代码)
php抓取网页域名页面获取网页下载后解析页面文件的全部代码//抓取一个网页的所有页面var_dump($phpurl);$phpurl='';foreach($php=get($phpurl);$phpurl->index=function(){$this->title=$this->name;});$result=$phpurl->data->format($this->title,$this->name);foreach($this->titlein$result){foreach($this->titleas$name){$name=$name->split('\t');}}。
1.用正则表达式抓取网页:javascript-正则表达式2.用程序生成代码:3.调试:
题主还是再复习一下概率论的基础问题吧。
测试环境是win10不支持javascript抓取,需要用chrome,然后可以对javascript进行抓取分析。
其实很简单吧,他们用代码抓取了你网页中的大部分内容,但是这些内容你都解析不出来,因为解析出来的是乱码,可以抓取网页中剩下的所有的页面...也就是说有很多html内容,但是这些内容你解析不出来,他们很聪明,
windows下,用“foriinxrange”来遍历,会发现i=1、4、9...所以,很明显i是网页里的页面。
php抓取网页域名(php抓取网页域名抓取移动应用商店的android和ios应用代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-25 02:03
php抓取网页域名抓取移动应用商店的android和ios应用代码网页截图,进行渲染可以关注公众号:智一人工智能学院,
php,flash,jsp,
人工智能学院的后端程序员一起学习网站就可以了,每天会有干货分享。
,,技术很专业
laravel+php以及mysql+mssql.都可以的。
php框架的话,推荐annajs或者phpmaven+bootstrap,在实际项目中会用得到的。
推荐你去:人工智能学院看看,他们的网站是最好的,因为他们是面向全国招聘学生的.招聘到学生的时候是合作高校进行面试,
可以关注一下做后端网站的技术不知道你熟悉哪些。不是老鸟,所以说可能有误答。手头几个入门的,非爬虫类的,推荐python,比起lua应该容易上手一些,不过有人反映c++代码不好理解,我也没有接触过c++,想用c++可以帮你分析下。有部分接近算法,需要掌握的的python和c,lua,java需要知道基本语法,有一门精通最好,但是人家常说知道大概就行,能用就好。
加上vb有flash通用程序语言,比如让你做个病毒实现再也不会停机了。统计分析的基础,还有随着新技术兴起,相信你可以学的更快。php比较适合爬虫,还有很多比较好的数据处理库,比如redis或者mongodb(我目前用的这个,不过这是个比较笨重的库)。在我们课上有sae(原阿里云)的多线程异步服务器,用到redis,lua的事件循环库,这两个库都是相当不错的。
还有一些字符串处理库,openerp或者redistcl(redistcl我以前用的是redisctl,但是没lua好用,lua现在有gdj、discountchanel,感觉redistcl是个比较完善的lua工具链,luagen跟lua.node一样好用)。还有一些其他前端库、api库也可以关注。
有一些不是特别擅长,就不说了。有一些js库,比如thinkjs等等,不是特别擅长,就不说了。当然他们的下一代在我心里ta们才是最好的,毕竟这是两种语言,哈哈。 查看全部
php抓取网页域名(php抓取网页域名抓取移动应用商店的android和ios应用代码)
php抓取网页域名抓取移动应用商店的android和ios应用代码网页截图,进行渲染可以关注公众号:智一人工智能学院,
php,flash,jsp,
人工智能学院的后端程序员一起学习网站就可以了,每天会有干货分享。
,,技术很专业
laravel+php以及mysql+mssql.都可以的。
php框架的话,推荐annajs或者phpmaven+bootstrap,在实际项目中会用得到的。
推荐你去:人工智能学院看看,他们的网站是最好的,因为他们是面向全国招聘学生的.招聘到学生的时候是合作高校进行面试,
可以关注一下做后端网站的技术不知道你熟悉哪些。不是老鸟,所以说可能有误答。手头几个入门的,非爬虫类的,推荐python,比起lua应该容易上手一些,不过有人反映c++代码不好理解,我也没有接触过c++,想用c++可以帮你分析下。有部分接近算法,需要掌握的的python和c,lua,java需要知道基本语法,有一门精通最好,但是人家常说知道大概就行,能用就好。
加上vb有flash通用程序语言,比如让你做个病毒实现再也不会停机了。统计分析的基础,还有随着新技术兴起,相信你可以学的更快。php比较适合爬虫,还有很多比较好的数据处理库,比如redis或者mongodb(我目前用的这个,不过这是个比较笨重的库)。在我们课上有sae(原阿里云)的多线程异步服务器,用到redis,lua的事件循环库,这两个库都是相当不错的。
还有一些字符串处理库,openerp或者redistcl(redistcl我以前用的是redisctl,但是没lua好用,lua现在有gdj、discountchanel,感觉redistcl是个比较完善的lua工具链,luagen跟lua.node一样好用)。还有一些其他前端库、api库也可以关注。
有一些不是特别擅长,就不说了。有一些js库,比如thinkjs等等,不是特别擅长,就不说了。当然他们的下一代在我心里ta们才是最好的,毕竟这是两种语言,哈哈。
php抓取网页域名(02.独立校验域名授权的两种方法,限制域名访问方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-24 15:15
1、限制域名访问方法一
2、限制域名访问方式二
function allow_domain(){
$is_allow=false;
$servername=trim($_SERVER['SERVER_NAME']);
$Array=array("localhost","127.0.0.1","test.com","test1.com");
foreach($Array as $value){
$value=trim($value);
$domain=explode($value,$servername);
if(count($domain)>1){
$is_allow=true;
break;
}
}
if(!$is_allow){
die("仅限本地使用!需要域名授权请联系jb51.net");
}
}
allow_domain();
然后用zend加密,其他加密很容易被破解。
PHP实现域名授权的两种方法
01. 如何在线验证域名授权:
客户端代码:
服务器代码:
域名授权码可以封装在函数中,也可以加密。对于常用的PHP加密形式,有破解的方法,如ZendGuard,ionCube等,如果授权域名较多,可以在项目中添加域名字段,写入域名进入数据库读取和验证。此方法已作为独立插件发布。具体参见:ZBlogPHP 域名授权插件-AllowURL。通过该插件,您可以将域名等信息添加到数据库中进行验证。
02. 域名授权独立验证方式:
域名授权的目的是保护知识产权,鼓励开发者发布更多优秀作品,促进整个网络社会的文化发展和技术进步,意义重大。
至此,这篇关于PHP限制域名访问(本地验证)的实现代码的文章就介绍到这里了。更多相关的PHP限制域名访问内容,请搜索之前的文章或继续浏览下方的相关文章,希望大家以后多多支持脚本之家! 查看全部
php抓取网页域名(02.独立校验域名授权的两种方法,限制域名访问方法)
1、限制域名访问方法一
2、限制域名访问方式二
function allow_domain(){
$is_allow=false;
$servername=trim($_SERVER['SERVER_NAME']);
$Array=array("localhost","127.0.0.1","test.com","test1.com");
foreach($Array as $value){
$value=trim($value);
$domain=explode($value,$servername);
if(count($domain)>1){
$is_allow=true;
break;
}
}
if(!$is_allow){
die("仅限本地使用!需要域名授权请联系jb51.net");
}
}
allow_domain();
然后用zend加密,其他加密很容易被破解。
PHP实现域名授权的两种方法
01. 如何在线验证域名授权:
客户端代码:
服务器代码:
域名授权码可以封装在函数中,也可以加密。对于常用的PHP加密形式,有破解的方法,如ZendGuard,ionCube等,如果授权域名较多,可以在项目中添加域名字段,写入域名进入数据库读取和验证。此方法已作为独立插件发布。具体参见:ZBlogPHP 域名授权插件-AllowURL。通过该插件,您可以将域名等信息添加到数据库中进行验证。
02. 域名授权独立验证方式:
域名授权的目的是保护知识产权,鼓励开发者发布更多优秀作品,促进整个网络社会的文化发展和技术进步,意义重大。
至此,这篇关于PHP限制域名访问(本地验证)的实现代码的文章就介绍到这里了。更多相关的PHP限制域名访问内容,请搜索之前的文章或继续浏览下方的相关文章,希望大家以后多多支持脚本之家!
php抓取网页域名(php抓取网页域名,用post的方式传递给服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-22 23:02
php抓取网页域名,用post的方式传递给服务器,服务器处理后返回给客户端的就是一串dom树。php程序必须要先建立原始dom树,再向服务器传递数据。如果用了模拟登录,又没有做登录验证,是很容易造成oom的。
之前已经有回答,可参考一下。php一般会封闭http的头,而request的参数是可以随便乱发的。你需要在使用request的时候注意一下是否使用了header头、header中的post参数等,并且使用post的数据和post的参数在传递的时候要加上cookie,header头中的post用来产生json对象。
使用header时需要引入_cookie('key')这个类,但使用_cookie('name')需要引入var_dump函数才能得到headercookie内容,不然是看不到内容的。或者采用下载request的时候使用expires标识,即将发送给服务器的时间调整到系统默认的隔天时间。然后浏览器的浏览器会设置一个requestheader头,你点一下浏览器的cookie就可以得到服务器响应报文,渲染结果是一个png图片或者json数据。
如果你用image将服务器发送给浏览器的requestheader头的值存在本地,并设置到客户端的image中,那么image中包含的key值就是requestheader头的key值。因此你只需要在自己电脑(服务器)中对request头进行append设置然后再把session指向用户在电脑中指定的浏览器地址即可,服务器与客户端之间是无连接的。 查看全部
php抓取网页域名(php抓取网页域名,用post的方式传递给服务器)
php抓取网页域名,用post的方式传递给服务器,服务器处理后返回给客户端的就是一串dom树。php程序必须要先建立原始dom树,再向服务器传递数据。如果用了模拟登录,又没有做登录验证,是很容易造成oom的。
之前已经有回答,可参考一下。php一般会封闭http的头,而request的参数是可以随便乱发的。你需要在使用request的时候注意一下是否使用了header头、header中的post参数等,并且使用post的数据和post的参数在传递的时候要加上cookie,header头中的post用来产生json对象。
使用header时需要引入_cookie('key')这个类,但使用_cookie('name')需要引入var_dump函数才能得到headercookie内容,不然是看不到内容的。或者采用下载request的时候使用expires标识,即将发送给服务器的时间调整到系统默认的隔天时间。然后浏览器的浏览器会设置一个requestheader头,你点一下浏览器的cookie就可以得到服务器响应报文,渲染结果是一个png图片或者json数据。
如果你用image将服务器发送给浏览器的requestheader头的值存在本地,并设置到客户端的image中,那么image中包含的key值就是requestheader头的key值。因此你只需要在自己电脑(服务器)中对request头进行append设置然后再把session指向用户在电脑中指定的浏览器地址即可,服务器与客户端之间是无连接的。
php抓取网页域名(百度spider对常用的http返回码的处理逻辑是这样的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-17 22:10
百度爬虫在抓取和处理的时候,会根据http协议规范设置相应的逻辑,所以站长也应该尽量参考http协议中返回码含义的定义来设置。
百度蜘蛛对常用http返回码的处理逻辑如下:
1、404
404 返回码的意思是“NOT FOUND”。百度会认为该网页无效,因此通常会从搜索结果中删除,而蜘蛛会在短期内再次找到该网址而不会对其进行抓取。
2、503
503 返回码的意思是“服务不可用”。百度会认为网页暂时无法访问,通常网站暂时关闭,带宽受限等都会造成这种情况。对于返回503的网页,百度蜘蛛不会直接删除该网址,短期内还会再次访问。届时,如果网页已经恢复,就可以正常抓取;如果继续返回503,短时间内会被多次访问。但是如果网页长时间返回503,那么这个url仍然会被百度认为是失效链接,会从搜索结果中删除。
3、403
403返回码的意思是“禁止访问”,百度会认为该网页当前被禁止访问。在这种情况下,如果是新发现的网址,百度蜘蛛暂时不会抓取,短期内会再次检查;如果百度已经有收录url,暂时不会直接删除,短期内会再次访问。. 那个时候,如果网页被允许访问,就会正常抓取;如果仍然不允许,将在短时间内访问多次。但如果网页长时间返回403,百度也会认为是无效链接,从搜索结果中删除。
4、301
301返回码的意思是“Moved Permanently”,百度会认为网页当前重定向到了新的url。在网站迁移、域名更换、网站改版等情况下,建议使用301返回码,尽量减少改版带来的流量损失。虽然百度蜘蛛现在对301跳转的响应周期更长,但我们仍然建议您这样做。
我们的建议
1、如果网站暂时关闭,无法打开网页时,不要立即返回404。推荐使用503状态。503可以通知百度蜘蛛页面暂时不可用,请稍后再试。
2、 如果百度蜘蛛对你的网站爬取压力过大,请尽量不要使用404,也建议返回503。这样百度蜘蛛过一段时间会再次尝试爬取这个链接. 如果该站点当时是免费的,它将被成功抓取。
3、有一些网站希望百度只做收录部分内容,比如审核后的内容,一段时间积累的新用户页面等等。在这种情况下,建议对新发布的内容暂时返回403,待审核或做好处理后再返回正常返回码。
4、 网站搬迁或域名变更请使用301返回码。 查看全部
php抓取网页域名(百度spider对常用的http返回码的处理逻辑是这样的)
百度爬虫在抓取和处理的时候,会根据http协议规范设置相应的逻辑,所以站长也应该尽量参考http协议中返回码含义的定义来设置。
百度蜘蛛对常用http返回码的处理逻辑如下:
1、404
404 返回码的意思是“NOT FOUND”。百度会认为该网页无效,因此通常会从搜索结果中删除,而蜘蛛会在短期内再次找到该网址而不会对其进行抓取。
2、503
503 返回码的意思是“服务不可用”。百度会认为网页暂时无法访问,通常网站暂时关闭,带宽受限等都会造成这种情况。对于返回503的网页,百度蜘蛛不会直接删除该网址,短期内还会再次访问。届时,如果网页已经恢复,就可以正常抓取;如果继续返回503,短时间内会被多次访问。但是如果网页长时间返回503,那么这个url仍然会被百度认为是失效链接,会从搜索结果中删除。
3、403
403返回码的意思是“禁止访问”,百度会认为该网页当前被禁止访问。在这种情况下,如果是新发现的网址,百度蜘蛛暂时不会抓取,短期内会再次检查;如果百度已经有收录url,暂时不会直接删除,短期内会再次访问。. 那个时候,如果网页被允许访问,就会正常抓取;如果仍然不允许,将在短时间内访问多次。但如果网页长时间返回403,百度也会认为是无效链接,从搜索结果中删除。
4、301
301返回码的意思是“Moved Permanently”,百度会认为网页当前重定向到了新的url。在网站迁移、域名更换、网站改版等情况下,建议使用301返回码,尽量减少改版带来的流量损失。虽然百度蜘蛛现在对301跳转的响应周期更长,但我们仍然建议您这样做。
我们的建议
1、如果网站暂时关闭,无法打开网页时,不要立即返回404。推荐使用503状态。503可以通知百度蜘蛛页面暂时不可用,请稍后再试。
2、 如果百度蜘蛛对你的网站爬取压力过大,请尽量不要使用404,也建议返回503。这样百度蜘蛛过一段时间会再次尝试爬取这个链接. 如果该站点当时是免费的,它将被成功抓取。
3、有一些网站希望百度只做收录部分内容,比如审核后的内容,一段时间积累的新用户页面等等。在这种情况下,建议对新发布的内容暂时返回403,待审核或做好处理后再返回正常返回码。
4、 网站搬迁或域名变更请使用301返回码。
php抓取网页域名(asp,,php,php7,.0.)抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-13 01:03
php抓取网页域名的脚本不稳定,服务器现在频繁宕机,这两天抓取了20000次到40000次/天,耗时几分钟到半小时不等,现在已经加满q,
负责过阿里云,域名在国内是经常出问题,ecs维护中。抓取嘛。(到底哪款抓抓抓呢,asp,aspx,,,php,php7,php7.0.)),是先用ac-pc抓取数据,然后再用php可以抓取。知道当初拿到数据用的什么方法,ac-pc。
拿个电脑,
很久以前,刚刚接触这门课,是ac-pc抓的
问一下同学有没有用ac-pc抓网页去了?
用ac可以抓取,就是很慢。
应该是acserver端,专门针对.com域名提供抓取服务。
每个ac都有漏洞,.com一般都有只是慢慢会被利用,
acpcpremium
achhhh,
这个ac必须有,他主要分为两种服务器,一种pc端,一种手机端,你在手机上用pc抓微信的数据也很快,
首先是安全性,根据ac的版本是有不同的,服务器安全和数据交换安全,普通抓取1-5分钟,后期每10秒抓取1次,根据自己网络状况。服务器可能不用的话要启动主动防御服务。在ac抓取的过程中如果断开网线,或者更换ip就会中断连接。数据交换安全,普通抓取不要重置网络连接,会主动防御。 查看全部
php抓取网页域名(asp,,php,php7,.0.)抓取数据)
php抓取网页域名的脚本不稳定,服务器现在频繁宕机,这两天抓取了20000次到40000次/天,耗时几分钟到半小时不等,现在已经加满q,
负责过阿里云,域名在国内是经常出问题,ecs维护中。抓取嘛。(到底哪款抓抓抓呢,asp,aspx,,,php,php7,php7.0.)),是先用ac-pc抓取数据,然后再用php可以抓取。知道当初拿到数据用的什么方法,ac-pc。
拿个电脑,
很久以前,刚刚接触这门课,是ac-pc抓的
问一下同学有没有用ac-pc抓网页去了?
用ac可以抓取,就是很慢。
应该是acserver端,专门针对.com域名提供抓取服务。
每个ac都有漏洞,.com一般都有只是慢慢会被利用,
acpcpremium
achhhh,
这个ac必须有,他主要分为两种服务器,一种pc端,一种手机端,你在手机上用pc抓微信的数据也很快,
首先是安全性,根据ac的版本是有不同的,服务器安全和数据交换安全,普通抓取1-5分钟,后期每10秒抓取1次,根据自己网络状况。服务器可能不用的话要启动主动防御服务。在ac抓取的过程中如果断开网线,或者更换ip就会中断连接。数据交换安全,普通抓取不要重置网络连接,会主动防御。
php抓取网页域名( Host字段不同如何配置如果服务器使用Apache字段的网站域名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-10 20:05
Host字段不同如何配置如果服务器使用Apache字段的网站域名)
GET / HTTP/1.1
Host: www.google.com
整个请求将被发送到服务器。有一个 Host 字段,用于标识您要请求的 网站 域名。即使访问的是同一个IP地址,由于Host字段不同,服务器软件也有区分的方法。其中网站是具体访问。
Host字段的具体定义请阅读RFC-2616第14.23节:/rfc/rfc2616.txt
以下是摘录(注意黑体部分):
14.23 主机
Host 请求头字段指定 Internet 主机和端口
被请求的资源的数量,从原创获取的
由用户或引用资源提供的 URI(通常是 HTTP URL,
如3.2.2)部分所述。 Host 字段值必须代表
源服务器或网关的命名权限
原创网址。这允许源服务器或网关
区分内部不明确的 URL,例如根“/”
单个 IP 地址上多个主机名的服务器 URL。此外,RFC-2616 并不是 HTTP 协议的最新规范。具体规范请参考RFC-2616的描述链接:RFC 2616信息
2、服务器端如何配置
如果服务器使用Apache,在Apache配置文件中添加VirtualHost即可添加新的虚拟主机:
服务器管理员 admin@admin
DocumentRoot "D:/website1"
服务器名称
DirectoryIndex index.php
服务器管理员 admin@admin
DocumentRoot "D:/website2"
服务器名称
DirectoryIndex index.php
上面定义了两个域名并且在不同的根目录下。通过这个配置,如果Apache收到一个请求,那么它会去d:/website1寻找对应的页面。如果是请求,那么去d:/website2 找到对应的页面。
通常Apache也有一个默认的网站,这个网站可以使用IP地址访问。如果这个网站设置为无效,那么主机就不能直接通过IP地址访问HTTP资源。
对于IIS,IIS可以使用同一个IP绑定多个站点。详情请参考下图:
在默认的网站->Properties->网站->Advanced中,添加不同的域名即可。由于我的IIS版本较低,无法支持绑定多个网站。在更高版本的IIS中,可以配置多个网站,每个网站绑定不同的域名,可以实现访问时的区分。
如果服务器没有设置默认的网站,那么IP地址不能直接访问主机。
所以,如果直接通过IP地址访问网站,会遇到两种情况:
<p>1、服务器已经设置了默认的网站,或者使用IP作为主机名来匹配请求的Host字段,那么这就是你通过IP访问的网站; 查看全部
php抓取网页域名(
Host字段不同如何配置如果服务器使用Apache字段的网站域名)
GET / HTTP/1.1
Host: www.google.com
整个请求将被发送到服务器。有一个 Host 字段,用于标识您要请求的 网站 域名。即使访问的是同一个IP地址,由于Host字段不同,服务器软件也有区分的方法。其中网站是具体访问。
Host字段的具体定义请阅读RFC-2616第14.23节:/rfc/rfc2616.txt
以下是摘录(注意黑体部分):
14.23 主机
Host 请求头字段指定 Internet 主机和端口
被请求的资源的数量,从原创获取的
由用户或引用资源提供的 URI(通常是 HTTP URL,
如3.2.2)部分所述。 Host 字段值必须代表
源服务器或网关的命名权限
原创网址。这允许源服务器或网关
区分内部不明确的 URL,例如根“/”
单个 IP 地址上多个主机名的服务器 URL。此外,RFC-2616 并不是 HTTP 协议的最新规范。具体规范请参考RFC-2616的描述链接:RFC 2616信息
2、服务器端如何配置
如果服务器使用Apache,在Apache配置文件中添加VirtualHost即可添加新的虚拟主机:
服务器管理员 admin@admin
DocumentRoot "D:/website1"
服务器名称
DirectoryIndex index.php
服务器管理员 admin@admin
DocumentRoot "D:/website2"
服务器名称
DirectoryIndex index.php
上面定义了两个域名并且在不同的根目录下。通过这个配置,如果Apache收到一个请求,那么它会去d:/website1寻找对应的页面。如果是请求,那么去d:/website2 找到对应的页面。
通常Apache也有一个默认的网站,这个网站可以使用IP地址访问。如果这个网站设置为无效,那么主机就不能直接通过IP地址访问HTTP资源。
对于IIS,IIS可以使用同一个IP绑定多个站点。详情请参考下图:
在默认的网站->Properties->网站->Advanced中,添加不同的域名即可。由于我的IIS版本较低,无法支持绑定多个网站。在更高版本的IIS中,可以配置多个网站,每个网站绑定不同的域名,可以实现访问时的区分。
如果服务器没有设置默认的网站,那么IP地址不能直接访问主机。
所以,如果直接通过IP地址访问网站,会遇到两种情况:
<p>1、服务器已经设置了默认的网站,或者使用IP作为主机名来匹配请求的Host字段,那么这就是你通过IP访问的网站;
php抓取网页域名(php抓取网页域名解析到ie地址栏,将结果发往cookie信息(不建议post))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-08 23:01
php抓取网页域名,解析到ie地址栏,然后将结果发往cookie信息(不建议post),最后可根据搜索id匹配到需要的网页。其中数据库可用mysql也可用mssql,一个账号统一查询,也可一个账号查询更多。
你好,你可以根据自己的需求选择基于restful框架的php抓取。你可以在网上看看网上的相关资料。你说的网页是什么页面呢,是网页源代码?例如,define("user/data/password.txt",'password');还是html页面?例如,define("user/data/password.html",'password');根据你的需求选择restful接口进行php抓取。
爬虫那么多,你为什么单想要爬取item呢?或者这么说吧,你的需求是基于lbs的,不知道你有没有过爬取街景或者陌陌的经验,把每个房子的位置放到item里,爬取就可以了,
可以使用requests库,
你可以使用xmlhttprequest请求获取页面数据
你可以使用,kiss框架。强大的动态类库。动态组件等功能。主要原理:服务器接收到请求,应用框架的schema库接受请求,并封装请求方法io类型封装成方法执行mysql服务器根据请求返回sql,操作执行结果kiss框架从keepstringreading等方面使这次请求变得有意义。keepstringreading:最大化获取单个网页数据有效提升效率xmlhttprequest:调用方法传递请求方法的参数,接收请求返回schema网页框架处理网页数据提取重要信息。 查看全部
php抓取网页域名(php抓取网页域名解析到ie地址栏,将结果发往cookie信息(不建议post))
php抓取网页域名,解析到ie地址栏,然后将结果发往cookie信息(不建议post),最后可根据搜索id匹配到需要的网页。其中数据库可用mysql也可用mssql,一个账号统一查询,也可一个账号查询更多。
你好,你可以根据自己的需求选择基于restful框架的php抓取。你可以在网上看看网上的相关资料。你说的网页是什么页面呢,是网页源代码?例如,define("user/data/password.txt",'password');还是html页面?例如,define("user/data/password.html",'password');根据你的需求选择restful接口进行php抓取。
爬虫那么多,你为什么单想要爬取item呢?或者这么说吧,你的需求是基于lbs的,不知道你有没有过爬取街景或者陌陌的经验,把每个房子的位置放到item里,爬取就可以了,
可以使用requests库,
你可以使用xmlhttprequest请求获取页面数据
你可以使用,kiss框架。强大的动态类库。动态组件等功能。主要原理:服务器接收到请求,应用框架的schema库接受请求,并封装请求方法io类型封装成方法执行mysql服务器根据请求返回sql,操作执行结果kiss框架从keepstringreading等方面使这次请求变得有意义。keepstringreading:最大化获取单个网页数据有效提升效率xmlhttprequest:调用方法传递请求方法的参数,接收请求返回schema网页框架处理网页数据提取重要信息。
php抓取网页域名(有时候需要用Python获取某个网站的子域名(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-08 01:19
有时需要使用Python获取一个网站的子域名,在查看一些大网站的时候经常用到。我用来查找 网站 的子域的方法是在 网站 和链接中找到它,偶尔我会使用 google。后来听朋友乔三少说,bt5下有一个获取子域的小工具,不过我也没太在意。有一天,当我要获得某个网站的子域时,我向他询问了程序的名称,但他一时想不起来。. . 然后他说有一个在线查询网站,把网站发给我。查询网站的子域名,在“域”右侧的输入框中输入网站的域名,然后点击“查询” 按钮列出此网站 NS 的子域名。查询百度的子域。百度不愧是一个大网站,有N多个子域,视觉上至少有几百个。
通过网站可以查询某个网站有哪些子域,真的很方便。做一个本地查询工具会不会更方便?在本地运行程序,得到某个网站的子域名,结果就是提取了subdomain.php的查询结果。当然,也有安全方面的考虑。如果直接去网站查询,如果网站被人杀了又没有补丁,那就悲剧了。通过本地查询可以避免这种风险。
考虑使用 Python,我知道该怎么做。大体思路是通过Python发送数据包模拟网站上的查询,获取查询结果页面的源代码,有规律地匹配源代码中的子域,最后输出结果。
可以看到查询过程是通过POST向subdomain.php提交数据,其中百度就是我们查询的域名。
数据需要在POST中提交。我使用的方法是 urllib 模块中的 urlopen() 函数。函数原型为:
urlopen(网址,数据=无,代理=无)
url是提交数据的具体地址,data是POST提交数据时提交的具体数据。默认情况下,数据是通过GET提交的,所以默认只有url的一个参数。经测试,subdomain.php POST提交数据时也会返回查询到的子域。如果将要查询的域名定义为变量域名,将要提交的数据定义为变量postdata,则POST提交的数据为:
postdata='domain='+ 域名
经过公司账号编辑器的测试,从返回的网页源代码中提取出查询到的子域名的正则表达式。
特别是程序的描述部分是指别人写的一个python程序的描述部分的写法,在此谢谢解释。
将代码保存为文件getsubdomain.py,放到C盘根目录下。按“Win”r键加R调出“运行”窗口,输入cmd回车打开命令行窗口。输入命令“cd\”,回车,切换到C盘根目录,输入命令“pythongetsubdomain.py”,回车查看程序说明。因为我在系统环境变量中已经添加了python.exe所在的目录,所以不需要进入python.exe所在的目录。如果没有将python.exe所在目录添加到系统环境变量中,可能需要输入python .exe所在的具体目录或将文件getsubdomain.py与文件python放在同一目录。可执行程序。
如何使用小程序的格式为:
python getsubdomain,py-d[domainl-o[文件名]
其中-d为必选参数,domain对应的是你要查询的子域名网站的域名;-o 是可选参数,可以将查询结果保存到文件中,filename 是保存文件名时的文件。当然,默认情况下,屏幕上只打印查询结果,而不会将结果保存到文件中。
测试程序是否可用,或查询百度的子域。输入命令回车,查询了850个子域,确实够用了。
对比网页上的查询结果,我做了一个小小的改进:
1.统计总共查询了多少个子域。
2. 输出查询的子域时,是左对齐的,这样更美观一些。
3.给每个查询的子域一个编号,在检测子域时不容易重复检测或漏检。
如果查询的结果过多,则在命令窗口中将看不到前面的结果,只能看到第 554 个及以后的结果。
这时候如果想查看所有的结果,可以将结果输出到一个文件中。比如我想把结果保存到当前目录下的baidu.txt文件中,输入命令。
按回车后,在当前目录(C:\)中生成了baidu.txt文件。打开baidu.txt,可以看到所有查询到的子域。
我们再查询一下网易的子域名,在命令行输入命令。查询的子域这么多,居然有2943个(当然个人博客的子域也很多)!
看来小程序运行正常。
我写的Python小程序是抓取网站查询子域的结果。代码写得不好。如果有任何错误或更好的写作方法,请随时聊天。 查看全部
php抓取网页域名(有时候需要用Python获取某个网站的子域名(图))
有时需要使用Python获取一个网站的子域名,在查看一些大网站的时候经常用到。我用来查找 网站 的子域的方法是在 网站 和链接中找到它,偶尔我会使用 google。后来听朋友乔三少说,bt5下有一个获取子域的小工具,不过我也没太在意。有一天,当我要获得某个网站的子域时,我向他询问了程序的名称,但他一时想不起来。. . 然后他说有一个在线查询网站,把网站发给我。查询网站的子域名,在“域”右侧的输入框中输入网站的域名,然后点击“查询” 按钮列出此网站 NS 的子域名。查询百度的子域。百度不愧是一个大网站,有N多个子域,视觉上至少有几百个。
通过网站可以查询某个网站有哪些子域,真的很方便。做一个本地查询工具会不会更方便?在本地运行程序,得到某个网站的子域名,结果就是提取了subdomain.php的查询结果。当然,也有安全方面的考虑。如果直接去网站查询,如果网站被人杀了又没有补丁,那就悲剧了。通过本地查询可以避免这种风险。
考虑使用 Python,我知道该怎么做。大体思路是通过Python发送数据包模拟网站上的查询,获取查询结果页面的源代码,有规律地匹配源代码中的子域,最后输出结果。
可以看到查询过程是通过POST向subdomain.php提交数据,其中百度就是我们查询的域名。
数据需要在POST中提交。我使用的方法是 urllib 模块中的 urlopen() 函数。函数原型为:
urlopen(网址,数据=无,代理=无)
url是提交数据的具体地址,data是POST提交数据时提交的具体数据。默认情况下,数据是通过GET提交的,所以默认只有url的一个参数。经测试,subdomain.php POST提交数据时也会返回查询到的子域。如果将要查询的域名定义为变量域名,将要提交的数据定义为变量postdata,则POST提交的数据为:
postdata='domain='+ 域名
经过公司账号编辑器的测试,从返回的网页源代码中提取出查询到的子域名的正则表达式。
特别是程序的描述部分是指别人写的一个python程序的描述部分的写法,在此谢谢解释。
将代码保存为文件getsubdomain.py,放到C盘根目录下。按“Win”r键加R调出“运行”窗口,输入cmd回车打开命令行窗口。输入命令“cd\”,回车,切换到C盘根目录,输入命令“pythongetsubdomain.py”,回车查看程序说明。因为我在系统环境变量中已经添加了python.exe所在的目录,所以不需要进入python.exe所在的目录。如果没有将python.exe所在目录添加到系统环境变量中,可能需要输入python .exe所在的具体目录或将文件getsubdomain.py与文件python放在同一目录。可执行程序。
如何使用小程序的格式为:
python getsubdomain,py-d[domainl-o[文件名]
其中-d为必选参数,domain对应的是你要查询的子域名网站的域名;-o 是可选参数,可以将查询结果保存到文件中,filename 是保存文件名时的文件。当然,默认情况下,屏幕上只打印查询结果,而不会将结果保存到文件中。
测试程序是否可用,或查询百度的子域。输入命令回车,查询了850个子域,确实够用了。
对比网页上的查询结果,我做了一个小小的改进:
1.统计总共查询了多少个子域。
2. 输出查询的子域时,是左对齐的,这样更美观一些。
3.给每个查询的子域一个编号,在检测子域时不容易重复检测或漏检。
如果查询的结果过多,则在命令窗口中将看不到前面的结果,只能看到第 554 个及以后的结果。
这时候如果想查看所有的结果,可以将结果输出到一个文件中。比如我想把结果保存到当前目录下的baidu.txt文件中,输入命令。
按回车后,在当前目录(C:\)中生成了baidu.txt文件。打开baidu.txt,可以看到所有查询到的子域。
我们再查询一下网易的子域名,在命令行输入命令。查询的子域这么多,居然有2943个(当然个人博客的子域也很多)!
看来小程序运行正常。
我写的Python小程序是抓取网站查询子域的结果。代码写得不好。如果有任何错误或更好的写作方法,请随时聊天。
php抓取网页域名(网站重定向极为普遍的原因及解决办法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-06 19:19
HttpWatch 是集成在 Internet Explorer 工具栏中的功能强大的 Web 数据分析工具。包括网页摘要、cookies管理、缓存管理、消息头发送/接收、字符查询、报表输出、POST数据和目录管理功能。
在IE工具栏-浏览器栏-httpwatch中查看打开,或者使用快捷键shift+F2打开。
状态为:301状态成功从demo1.php跳转到demo9.php,验证301重定向设置成功。
ab173 站长工具
ab173站长工具是业内知名的站长工具。它的功能很丰富,点击http状态码查询,输入网址,可以查询网站的http状态码,确定是301而不是302.
案例研究:网站302 重定向的不当使用导致 GOOGLE 的惩罚
它是互联网上最大的商业搜索引擎和分类目录。它以专业提供商业信息而闻名,包括近190,000个网页。如果您在 Google 中搜索“business”为 关键词,则此 网站 将排名第一。然而,在2010年9月5日,奇怪的事情发生了:它的首页PR从8变为0,并且在谷歌搜索结果中找不到首页。好在只有首页被“蒸发”了。好在第二天首页又回到了谷歌的搜索结果,但是PR还是0。
问题在于它的重定向命令。网站 让你跳转到。这个重定向应该是永久性的,而 302 是一个临时重定向。仅当 网站 或网页在 24 到 48 小时内临时移动时 该命令只能在其他位置使用。但是错误地使用了“HTTP/1.1 302 Object Moved”状态代码。
事实上,网站 重定向是极其常见的。比如你对原来的域名不满意,申请了一个新的域名,你买了一个容易拼错的域名,防止客户因为你拼错而找不到网站网址。还有很多。但是,很多人会因为使用错误的重定向状态码而遭受“站的灾难”,就像。虽然他们重定向的理由是合理的,但如果使用不当,可能会被谷歌误认为使用多个域名指向同一个网站,那么你的网站就会被屏蔽,并且罪名是“使用重复内容干扰Google搜索结果的网站排名”。这是对过去最好的教训。只是大多数使用错误重定向参数的网站都没有那么幸运。一个小小的重定向可能会抹杀网站之前的努力,只能重新开始:重新申请一个新域名,重新发布一个新域名。@网站 等。请记住:Google 绝不会同情任何人的错误,即使他们不小心犯了错误。
域名重定向
路由的改变也是数据报文路径的一种重定向。
我们在构建我们的网站的过程中,经常会遇到需要网页重定向的情况:比如网站调整,网站的目录结构发生变化,网页移动到一个新的地址。或者更改网页的扩展名,如因应用需要将.php 改为.Html 或.shtml。在这些情况下,如果不进行重定向,用户采集夹或搜索引擎数据库中的旧地址只能让访问客户得到一个404页面错误信息,访问流量白白流失。比如一些注册了多个域名的网站,还需要自动将访问这些域名的用户重定向到主站,等等。
重定向方法
常用的重定向方式有:301重定向、302重定向、js重定向和meta fresh:
301 重定向:: 301 代表永久移动。301重定向是改变网页地址后对搜索引擎友好的最佳方式。只要不是临时移动,建议使用301进行重定向。
永久页面移除(301重定向)是一项非常重要的“自动重定向”技术。URL 重定向是最可行的方法。当用户或搜索引擎向网站服务器发送浏览请求时,服务器返回的HTTP数据流中header中的状态码之一表示该网页已永久转移到另一个地址。
302 重定向:: 302 代表临时移动。在过去的几年中,许多黑帽 SEO 都广泛使用这种技术来作弊。目前各大搜索引擎都加大了打击力度,比如谷歌前几年和最近对德国宝马网站的处罚。即使网站客观上不是垃圾邮件,也很容易被搜索引擎误判为垃圾邮件而受到惩罚。
什么是 302 重定向?
302重定向也叫302代表Temporously Moved,英文名称:302 redirect。它也被认为是一种临时重定向,向 网站 浏览器发出指令以显示浏览器需要显示的不同 URL,当网页经历了短期 URL 更改时使用。临时重定向是一种服务器端重定向,可以被搜索引擎蜘蛛正确处理。
302重定向和URL劫持
当做一个从 URL A 到 URL B 的 302 重定向时,宿主服务器的隐含含义是 URL A 可能随时改变主意,重新显示其内容或重定向到其他地方。大多数搜索引擎,在大多数情况下,在收到302重定向时,一般只需要爬取目标URL,即URL B。 如果搜索引擎在遇到302重定向时,爬取了目标URL B的100%,无需担心 URL 劫持。问题在于,有时搜索引擎,尤其是 Google,无法始终抓取目标 URL。比如有时候A的URL很短,但是却做了302重定向到B的URL,而B的URL是一个很长很乱的URL,甚至可能收录一些问号等参数。自然,URL A 对用户更友好,而 URL B 丑陋且不友好。此时,谷歌很可能还是会显示URL A。由于搜索引擎排名算法只是一个程序而不是一个人,当遇到302重定向时,无法准确判断哪个URL更适合像人,这就产生了URL的可能劫持。也就是说,一个不道德的人在他自己的网站A上做了302重定向到你的网站B。出于某种原因,谷歌搜索结果仍然显示网站A,但使用的网页内容是你网站B上的内容,这这种情况称为网站 URL 劫持。你写的这么辛苦的内容被别人盗用了。302重定向导致的URL劫持已经存在一段时间了。但到目前为止,似乎没有更好的解决方案。在正在进行的 Google Big Daddy 数据中心转换中,302重定向问题也是需要解决的目标之一。从部分搜索结果来看,URL劫持的现象有所改善,但并未完全解决。
301重定向和302重定向的区别
302重定向是一种临时重定向,搜索引擎会抓取新内容并保存旧网址。由于服务器去了302代码,搜索引擎认为新的URL只是暂时的。
301 重定向是永久重定向。当搜索引擎获取新内容时,它还会将旧 URL 交换为重定向 URL。
元新鲜:这在 2000 年前比较流行,但现在很少见了。具体来说,它通过网页中的meta命令在一定时间后重定向到一个新的网页。如果延迟时间太短(5秒左右),就会被判定为垃圾邮件。 查看全部
php抓取网页域名(网站重定向极为普遍的原因及解决办法(一))
HttpWatch 是集成在 Internet Explorer 工具栏中的功能强大的 Web 数据分析工具。包括网页摘要、cookies管理、缓存管理、消息头发送/接收、字符查询、报表输出、POST数据和目录管理功能。
在IE工具栏-浏览器栏-httpwatch中查看打开,或者使用快捷键shift+F2打开。
状态为:301状态成功从demo1.php跳转到demo9.php,验证301重定向设置成功。
ab173 站长工具
ab173站长工具是业内知名的站长工具。它的功能很丰富,点击http状态码查询,输入网址,可以查询网站的http状态码,确定是301而不是302.
案例研究:网站302 重定向的不当使用导致 GOOGLE 的惩罚
它是互联网上最大的商业搜索引擎和分类目录。它以专业提供商业信息而闻名,包括近190,000个网页。如果您在 Google 中搜索“business”为 关键词,则此 网站 将排名第一。然而,在2010年9月5日,奇怪的事情发生了:它的首页PR从8变为0,并且在谷歌搜索结果中找不到首页。好在只有首页被“蒸发”了。好在第二天首页又回到了谷歌的搜索结果,但是PR还是0。
问题在于它的重定向命令。网站 让你跳转到。这个重定向应该是永久性的,而 302 是一个临时重定向。仅当 网站 或网页在 24 到 48 小时内临时移动时 该命令只能在其他位置使用。但是错误地使用了“HTTP/1.1 302 Object Moved”状态代码。
事实上,网站 重定向是极其常见的。比如你对原来的域名不满意,申请了一个新的域名,你买了一个容易拼错的域名,防止客户因为你拼错而找不到网站网址。还有很多。但是,很多人会因为使用错误的重定向状态码而遭受“站的灾难”,就像。虽然他们重定向的理由是合理的,但如果使用不当,可能会被谷歌误认为使用多个域名指向同一个网站,那么你的网站就会被屏蔽,并且罪名是“使用重复内容干扰Google搜索结果的网站排名”。这是对过去最好的教训。只是大多数使用错误重定向参数的网站都没有那么幸运。一个小小的重定向可能会抹杀网站之前的努力,只能重新开始:重新申请一个新域名,重新发布一个新域名。@网站 等。请记住:Google 绝不会同情任何人的错误,即使他们不小心犯了错误。
域名重定向
路由的改变也是数据报文路径的一种重定向。
我们在构建我们的网站的过程中,经常会遇到需要网页重定向的情况:比如网站调整,网站的目录结构发生变化,网页移动到一个新的地址。或者更改网页的扩展名,如因应用需要将.php 改为.Html 或.shtml。在这些情况下,如果不进行重定向,用户采集夹或搜索引擎数据库中的旧地址只能让访问客户得到一个404页面错误信息,访问流量白白流失。比如一些注册了多个域名的网站,还需要自动将访问这些域名的用户重定向到主站,等等。
重定向方法
常用的重定向方式有:301重定向、302重定向、js重定向和meta fresh:
301 重定向:: 301 代表永久移动。301重定向是改变网页地址后对搜索引擎友好的最佳方式。只要不是临时移动,建议使用301进行重定向。
永久页面移除(301重定向)是一项非常重要的“自动重定向”技术。URL 重定向是最可行的方法。当用户或搜索引擎向网站服务器发送浏览请求时,服务器返回的HTTP数据流中header中的状态码之一表示该网页已永久转移到另一个地址。
302 重定向:: 302 代表临时移动。在过去的几年中,许多黑帽 SEO 都广泛使用这种技术来作弊。目前各大搜索引擎都加大了打击力度,比如谷歌前几年和最近对德国宝马网站的处罚。即使网站客观上不是垃圾邮件,也很容易被搜索引擎误判为垃圾邮件而受到惩罚。
什么是 302 重定向?
302重定向也叫302代表Temporously Moved,英文名称:302 redirect。它也被认为是一种临时重定向,向 网站 浏览器发出指令以显示浏览器需要显示的不同 URL,当网页经历了短期 URL 更改时使用。临时重定向是一种服务器端重定向,可以被搜索引擎蜘蛛正确处理。
302重定向和URL劫持
当做一个从 URL A 到 URL B 的 302 重定向时,宿主服务器的隐含含义是 URL A 可能随时改变主意,重新显示其内容或重定向到其他地方。大多数搜索引擎,在大多数情况下,在收到302重定向时,一般只需要爬取目标URL,即URL B。 如果搜索引擎在遇到302重定向时,爬取了目标URL B的100%,无需担心 URL 劫持。问题在于,有时搜索引擎,尤其是 Google,无法始终抓取目标 URL。比如有时候A的URL很短,但是却做了302重定向到B的URL,而B的URL是一个很长很乱的URL,甚至可能收录一些问号等参数。自然,URL A 对用户更友好,而 URL B 丑陋且不友好。此时,谷歌很可能还是会显示URL A。由于搜索引擎排名算法只是一个程序而不是一个人,当遇到302重定向时,无法准确判断哪个URL更适合像人,这就产生了URL的可能劫持。也就是说,一个不道德的人在他自己的网站A上做了302重定向到你的网站B。出于某种原因,谷歌搜索结果仍然显示网站A,但使用的网页内容是你网站B上的内容,这这种情况称为网站 URL 劫持。你写的这么辛苦的内容被别人盗用了。302重定向导致的URL劫持已经存在一段时间了。但到目前为止,似乎没有更好的解决方案。在正在进行的 Google Big Daddy 数据中心转换中,302重定向问题也是需要解决的目标之一。从部分搜索结果来看,URL劫持的现象有所改善,但并未完全解决。
301重定向和302重定向的区别
302重定向是一种临时重定向,搜索引擎会抓取新内容并保存旧网址。由于服务器去了302代码,搜索引擎认为新的URL只是暂时的。
301 重定向是永久重定向。当搜索引擎获取新内容时,它还会将旧 URL 交换为重定向 URL。
元新鲜:这在 2000 年前比较流行,但现在很少见了。具体来说,它通过网页中的meta命令在一定时间后重定向到一个新的网页。如果延迟时间太短(5秒左右),就会被判定为垃圾邮件。
php抓取网页域名(php抓取网页域名中的网站数据代码获取新的页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-02 20:06
php抓取网页域名中的网站数据代码,获取新的页面,就是定向爬虫获取内容。php抓取json字符串,获取客户端内容代码。php的程序现在开发中基本都是直接用php主程序就能访问了,这一点很方便,但是如果碰到一些事情要开发时非要自己开发一个,那么自己总要带一些服务,不然可能你碰到问题的时候或者你出去问程序员,结果他告诉你一堆你自己都不理解的东西出来,这样子不仅费时费力还效率极低,还会觉得这个程序是垃圾程序。
我们所常用的工具就是:phpscript+webpython,但是这两个是目前开发中用的比较多的,但是问题是不能上手太快,而且不好控制,所以最近一个朋友推荐了phpcms,好多同学没有听说过,phpcms其实就是你在网上随便找一个网站,然后直接拿着他的图片,把他的网页代码发给他,他会告诉你需要什么库,用什么格式,然后你就能自己去根据他的要求写代码,进行测试,都是没有任何问题的。
有些朋友可能问,那这都是针对php的吗?不是,这是针对java的,说下我使用过的,java几乎所有的文档都是英文的,所以对于初学者肯定有点吃力,但是如果遇到一些不会,可以百度,google,然后再上面搜答案。那么问题来了,你会了php还会java吗?就想你会做一些简单的,但是有些事情做不了的事情吗?我觉得大家理解一下就能明白了。
所以我们要抓的是什么网站呢?有人可能会说网站肯定就是做销售类的网站啊,不然做什么呢?我想说不是的,我这里说的是那些网页中没有自己项目的,而是像我们开一家便利店,我想不到要做什么项目,然后我就把店铺网页拿出来去爬虫网站,去搜索项目之类的,把该有的栏目全部爬出来,你在爬取一下发现没有哪里不一样,然后不一样的我就按照实际情况进行取舍,但是我该做的肯定要做,有些客户说怎么抓那么多,不会也就多几个呗,总会有人回答你不会的,那不就会了吗?其实最后我们找的肯定是自己感兴趣的项目,大家可以试试,我在爬虫网站经常会自己分析一下网站结构,这样子速度快,记忆深刻。好啦,要抓什么网站之类的欢迎大家来说说看法。 查看全部
php抓取网页域名(php抓取网页域名中的网站数据代码获取新的页面)
php抓取网页域名中的网站数据代码,获取新的页面,就是定向爬虫获取内容。php抓取json字符串,获取客户端内容代码。php的程序现在开发中基本都是直接用php主程序就能访问了,这一点很方便,但是如果碰到一些事情要开发时非要自己开发一个,那么自己总要带一些服务,不然可能你碰到问题的时候或者你出去问程序员,结果他告诉你一堆你自己都不理解的东西出来,这样子不仅费时费力还效率极低,还会觉得这个程序是垃圾程序。
我们所常用的工具就是:phpscript+webpython,但是这两个是目前开发中用的比较多的,但是问题是不能上手太快,而且不好控制,所以最近一个朋友推荐了phpcms,好多同学没有听说过,phpcms其实就是你在网上随便找一个网站,然后直接拿着他的图片,把他的网页代码发给他,他会告诉你需要什么库,用什么格式,然后你就能自己去根据他的要求写代码,进行测试,都是没有任何问题的。
有些朋友可能问,那这都是针对php的吗?不是,这是针对java的,说下我使用过的,java几乎所有的文档都是英文的,所以对于初学者肯定有点吃力,但是如果遇到一些不会,可以百度,google,然后再上面搜答案。那么问题来了,你会了php还会java吗?就想你会做一些简单的,但是有些事情做不了的事情吗?我觉得大家理解一下就能明白了。
所以我们要抓的是什么网站呢?有人可能会说网站肯定就是做销售类的网站啊,不然做什么呢?我想说不是的,我这里说的是那些网页中没有自己项目的,而是像我们开一家便利店,我想不到要做什么项目,然后我就把店铺网页拿出来去爬虫网站,去搜索项目之类的,把该有的栏目全部爬出来,你在爬取一下发现没有哪里不一样,然后不一样的我就按照实际情况进行取舍,但是我该做的肯定要做,有些客户说怎么抓那么多,不会也就多几个呗,总会有人回答你不会的,那不就会了吗?其实最后我们找的肯定是自己感兴趣的项目,大家可以试试,我在爬虫网站经常会自己分析一下网站结构,这样子速度快,记忆深刻。好啦,要抓什么网站之类的欢迎大家来说说看法。
php抓取网页域名(php网页域名解析本例使用的解析库是swoole-all.php.sh)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-01 14:50
php抓取网页域名获取网页内容。例如在浏览器中输入12306网址,获取北京优采云票即可实现。php抓取网页域名解析本例使用的解析库是swoole-all.php.,安装配置如下。wget-all.php.sh添加curl配置在swoole内添加下面的代码。defconnect(name:url[]):url=curl(name)然后,在laravel框架中有一个配置keyserver的方法,用来获取laravel的connection、vhost、fs、token等。
获取完后返回一个字符串,字符串类型是字符串,接着就可以直接获取到文件类型了,这里用的文件是图片。具体配置如下:swoole-all.php文件内容分析如果你从网上找了好久的包都没有一个符合自己项目要求的,那么在解析代码中加上varclient:laravel=require('varclient:laravel')swoole-all.php生成路由传参defget_route():passdefget_page(method,url):passdefget_content(string,content):pass解析路由传参route('index',get_route('/index'),'/')用户操作的时候参数传递将会保存在'/'中command_format('/get/','get',[name,url])将[name,url]作为参数传递当index.php文件内容的时候获取某一列参数将在route中获取,从而得到域名。
我们没有在php中注册directjsdataurl方法,所以我们没有将数据存储到内存,没有定义directjsdataurl。从apache中获取数据defsave(src:apache2):directjsdataurl="/java/apache2/javaweb/"return[][,src]第一次写代码,如有不对的地方,还请指教。 查看全部
php抓取网页域名(php网页域名解析本例使用的解析库是swoole-all.php.sh)
php抓取网页域名获取网页内容。例如在浏览器中输入12306网址,获取北京优采云票即可实现。php抓取网页域名解析本例使用的解析库是swoole-all.php.,安装配置如下。wget-all.php.sh添加curl配置在swoole内添加下面的代码。defconnect(name:url[]):url=curl(name)然后,在laravel框架中有一个配置keyserver的方法,用来获取laravel的connection、vhost、fs、token等。
获取完后返回一个字符串,字符串类型是字符串,接着就可以直接获取到文件类型了,这里用的文件是图片。具体配置如下:swoole-all.php文件内容分析如果你从网上找了好久的包都没有一个符合自己项目要求的,那么在解析代码中加上varclient:laravel=require('varclient:laravel')swoole-all.php生成路由传参defget_route():passdefget_page(method,url):passdefget_content(string,content):pass解析路由传参route('index',get_route('/index'),'/')用户操作的时候参数传递将会保存在'/'中command_format('/get/','get',[name,url])将[name,url]作为参数传递当index.php文件内容的时候获取某一列参数将在route中获取,从而得到域名。
我们没有在php中注册directjsdataurl方法,所以我们没有将数据存储到内存,没有定义directjsdataurl。从apache中获取数据defsave(src:apache2):directjsdataurl="/java/apache2/javaweb/"return[][,src]第一次写代码,如有不对的地方,还请指教。
php抓取网页域名(项目招商找A5快速获取精准代理名单《页面过程简述》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-10-27 09:11
项目招商找A5快速获取精准代理商名单
URL,统一资源定位器,通过对URL的分析,可以更好的了解页面的爬取过程。今天,小小课堂SEO学习网就为大家简单介绍一下页面抓取的过程。希望本次SEO技术培训对大家有所帮助。
一、url 是什么意思?
URL英文叫做“uniform resource locator”,中文翻译为“uniform resource locator”。
在网站优化中,要求每个页面只有一个唯一的统一资源定位符(URL),但往往很多网站同一个页面对应多个URL,如果都被搜索引擎搜索到的话< @收录且没有URL重定向,权重不集中,通常称为URL不规则。
二、url的组成
统一资源定位符(URL)由三部分组成:协议方案、主机名和资源名。
例如:
www.x**.org /11806
其中https是协议方案,***.org是主机名,11806是资源,但是这个资源并不明显。一般资源后缀是.html,当然也可以是.pdf、.php、.word等格式。
三、页面爬取过程简述
不管是我们平时使用的网络浏览器,还是网络爬虫,虽然有两个不同的客户端,但是获取页面的方式是一样的。页面抓取过程如下:
① 连接DNS服务器
客户端首先会连接到DNS域名服务器,DNS服务器将主机名(***.org)转换成IP地址并发回给客户端。
PS:原来我们用的地址是111.152。151.45 访问某个网站。为了便于记忆和使用,我们使用DNS域名系统转换为***.org。这就是 DNS 域名系统的作用。
②连接IP地址服务器
这个IP服务器下可能有很多程序(网站),可以通过端口号来区分。同时每个程序(网站)都会监听端口上是否有新的连接请求,HTTP网站默认为80,HTTPS网站默认为443。
不过一般情况下,80和443端口号默认是不会出现的。
例如:
***.org:443/ = ***.org/
***.org:80/ = ***.org/
③ 建立连接并发送寻呼请求
客户端与服务器建立连接后,会发送一个页面请求,通常是get或者post。 查看全部
php抓取网页域名(项目招商找A5快速获取精准代理名单《页面过程简述》)
项目招商找A5快速获取精准代理商名单
URL,统一资源定位器,通过对URL的分析,可以更好的了解页面的爬取过程。今天,小小课堂SEO学习网就为大家简单介绍一下页面抓取的过程。希望本次SEO技术培训对大家有所帮助。
一、url 是什么意思?
URL英文叫做“uniform resource locator”,中文翻译为“uniform resource locator”。
在网站优化中,要求每个页面只有一个唯一的统一资源定位符(URL),但往往很多网站同一个页面对应多个URL,如果都被搜索引擎搜索到的话< @收录且没有URL重定向,权重不集中,通常称为URL不规则。
二、url的组成
统一资源定位符(URL)由三部分组成:协议方案、主机名和资源名。
例如:
www.x**.org /11806
其中https是协议方案,***.org是主机名,11806是资源,但是这个资源并不明显。一般资源后缀是.html,当然也可以是.pdf、.php、.word等格式。
三、页面爬取过程简述
不管是我们平时使用的网络浏览器,还是网络爬虫,虽然有两个不同的客户端,但是获取页面的方式是一样的。页面抓取过程如下:
① 连接DNS服务器
客户端首先会连接到DNS域名服务器,DNS服务器将主机名(***.org)转换成IP地址并发回给客户端。
PS:原来我们用的地址是111.152。151.45 访问某个网站。为了便于记忆和使用,我们使用DNS域名系统转换为***.org。这就是 DNS 域名系统的作用。
②连接IP地址服务器
这个IP服务器下可能有很多程序(网站),可以通过端口号来区分。同时每个程序(网站)都会监听端口上是否有新的连接请求,HTTP网站默认为80,HTTPS网站默认为443。
不过一般情况下,80和443端口号默认是不会出现的。
例如:
***.org:443/ = ***.org/
***.org:80/ = ***.org/
③ 建立连接并发送寻呼请求
客户端与服务器建立连接后,会发送一个页面请求,通常是get或者post。
php抓取网页域名(一下一般情况下网站首页不被百度搜索引擎收录的原因以及解决办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-26 07:14
网站优化的基础是做收录。你的内容和外链再好,百度不收录,你的优化效果会差很多。相信很多站长都有过这样的经历。公司网站上线一个多月了,百度连主页都没有收录。先不说seo优化。下面,我在seo工作了很多年。随着经验的积累,总结一下网站首页在正常情况下百度搜索引擎收录搜索不到的原因和解决方法。
1.网站服务器问题
这在国外服务器的集成环境中尤为明显。在部分国外服务器的集成环境中,禁止百度抓取。以php语言为例。一般情况下,如果你的服务器配置了nginx(左)或者apache(右)如图)如下图,恭喜你,你的网站肯定不是百度收录。这时候把百度蜘蛛禁用百度蜘蛛爬行的代码删除即可。
2.DNS 问题
很多人不知道这个问题,但是随着中国网络监管的不断加强,百度蜘蛛有时会因为dns问题找不到网站服务器。这时候我们需要网站加入百度站长工具并提交抓取诊断网站首页,如果抓取失败,点击进入,选择ip报错,然后执行一段时间后进行爬取诊断,成功后再提交URL。过几天就会收录(如下图)。
3.网站程序问题
有些程序可以禁止百度抓取。以php为例。如果你的程序入口有以下代码,百度蜘蛛就无法抓取你的网站,也就无法收录,这个问题就是需要删除这段代码。
4.robots.txt 问题
网站 项目的根目录会有robots.txt文件。搜索引擎蜘蛛在爬取网站服务器时会根据域名访问这个文件。如果你的robots.txt文件如下图,或者disallow:是你的首页文件或者新闻目录,所以对网站收录不好。这时候就需要修改robots.txt文件。只需在 disallow: 后删除内容并将其留空。
5.网页元标签问题
在html代码中,meta标签也可能导致页面不是百度收录,或者将name属性的值改为baiduspider,会导致页面不是百度收录。
6.网站内容问题
我的私人经理,当时有人接手了一个新网站进行优化。半个多月后,主页没有被百度接收。网站很多三级栏目都是空的,而且网站里面的一些内容和网站本身的关联性很差,所以我会把空的三级栏目全部删掉,相关的劣质 网站文章 被替换为更相关的。过了一会儿,网站被百度了收录。
7.网站域和模板问题
网站域名和模板也会影响首页收录。如果你买的域名被百度惩罚了,那么收录会很慢,所以如果不是老域名肯定是不错的。;还有网站模板,如果你用网站模板百度有很多收录,那么也会影响首页收录。
百度搜索引擎优化时间。百度收录时间越短,接收的内容越多,网站的基础就越好。希望我的文章文章可以正确网站首页不是百度站长的帮助收录,如果你有其他解决网站首页不是百度的收录,欢迎大家一起讨论,百度seo的迷人之处在于很多不确定性,“千呼万唤出来,依然捧着琵琶半藏”,相信很多根植于百度seo的人百度seo行业享受这个过程。 查看全部
php抓取网页域名(一下一般情况下网站首页不被百度搜索引擎收录的原因以及解决办法)
网站优化的基础是做收录。你的内容和外链再好,百度不收录,你的优化效果会差很多。相信很多站长都有过这样的经历。公司网站上线一个多月了,百度连主页都没有收录。先不说seo优化。下面,我在seo工作了很多年。随着经验的积累,总结一下网站首页在正常情况下百度搜索引擎收录搜索不到的原因和解决方法。
1.网站服务器问题
这在国外服务器的集成环境中尤为明显。在部分国外服务器的集成环境中,禁止百度抓取。以php语言为例。一般情况下,如果你的服务器配置了nginx(左)或者apache(右)如图)如下图,恭喜你,你的网站肯定不是百度收录。这时候把百度蜘蛛禁用百度蜘蛛爬行的代码删除即可。
2.DNS 问题
很多人不知道这个问题,但是随着中国网络监管的不断加强,百度蜘蛛有时会因为dns问题找不到网站服务器。这时候我们需要网站加入百度站长工具并提交抓取诊断网站首页,如果抓取失败,点击进入,选择ip报错,然后执行一段时间后进行爬取诊断,成功后再提交URL。过几天就会收录(如下图)。
3.网站程序问题
有些程序可以禁止百度抓取。以php为例。如果你的程序入口有以下代码,百度蜘蛛就无法抓取你的网站,也就无法收录,这个问题就是需要删除这段代码。
4.robots.txt 问题
网站 项目的根目录会有robots.txt文件。搜索引擎蜘蛛在爬取网站服务器时会根据域名访问这个文件。如果你的robots.txt文件如下图,或者disallow:是你的首页文件或者新闻目录,所以对网站收录不好。这时候就需要修改robots.txt文件。只需在 disallow: 后删除内容并将其留空。
5.网页元标签问题
在html代码中,meta标签也可能导致页面不是百度收录,或者将name属性的值改为baiduspider,会导致页面不是百度收录。
6.网站内容问题
我的私人经理,当时有人接手了一个新网站进行优化。半个多月后,主页没有被百度接收。网站很多三级栏目都是空的,而且网站里面的一些内容和网站本身的关联性很差,所以我会把空的三级栏目全部删掉,相关的劣质 网站文章 被替换为更相关的。过了一会儿,网站被百度了收录。
7.网站域和模板问题
网站域名和模板也会影响首页收录。如果你买的域名被百度惩罚了,那么收录会很慢,所以如果不是老域名肯定是不错的。;还有网站模板,如果你用网站模板百度有很多收录,那么也会影响首页收录。
百度搜索引擎优化时间。百度收录时间越短,接收的内容越多,网站的基础就越好。希望我的文章文章可以正确网站首页不是百度站长的帮助收录,如果你有其他解决网站首页不是百度的收录,欢迎大家一起讨论,百度seo的迷人之处在于很多不确定性,“千呼万唤出来,依然捧着琵琶半藏”,相信很多根植于百度seo的人百度seo行业享受这个过程。
php抓取网页域名( hellohosts密码:123456科学上网轻松上Google|修改host解决Google打不开国外稳定加速器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-21 01:10
hellohosts密码:123456科学上网轻松上Google|修改host解决Google打不开国外稳定加速器)
谷歌快照在线查询
萨德伊迪发表于 2017 年 7 月 10 日在杂项中
上一篇:快来测试一下,你的工作被人工智能取代的可能性有多大!
下一篇:hello hosts 密码:123456
在 Google 上科学轻松地上网 | 修改host解决谷歌打不开
国外稳定促进剂推荐快递| 维普
我们在使用搜索引擎搜索时,偶尔会遇到某个网页打不开。网页打不开的可能性有很多。比如网站被强行,或者网站的服务器刚好有问题,或者网站被永久关闭,但是搜索引擎快照还是没有完全删除来自本地数据库。
那么即使网站打不开,如果能在搜索引擎中找到,也可以通过搜索引擎快照暂时查看页面。
这是 Google Snapshots 的在线查询站点。现在很多网友使用google镜像搜索,有时可能会遇到一些网页打不开的情况。然后你只需要复制网页的url,放到快照在线查询的搜索框中,就可以快速查询站点了。谷歌快照。详细情况如下:
网站地址:
参观后如下:
如果您选择Google Snapshot,那么您将直接使用Google Snapshot 的域名访问网页结果。例如,如果在地址栏中输入:,搜索结果如下:
如果你不能访问谷歌,那么你可以选择抓取这个网站。选择后,您将使用网站本身来抓取Google快照内容,最终将返回的结果呈现给您,例如:
最后,谷歌快照站点是测试版,随时禁用快照捕获功能。
... psz1992 的其他帖子 查看全部
php抓取网页域名(
hellohosts密码:123456科学上网轻松上Google|修改host解决Google打不开国外稳定加速器)
谷歌快照在线查询
萨德伊迪发表于 2017 年 7 月 10 日在杂项中
上一篇:快来测试一下,你的工作被人工智能取代的可能性有多大!
下一篇:hello hosts 密码:123456
在 Google 上科学轻松地上网 | 修改host解决谷歌打不开
国外稳定促进剂推荐快递| 维普
我们在使用搜索引擎搜索时,偶尔会遇到某个网页打不开。网页打不开的可能性有很多。比如网站被强行,或者网站的服务器刚好有问题,或者网站被永久关闭,但是搜索引擎快照还是没有完全删除来自本地数据库。
那么即使网站打不开,如果能在搜索引擎中找到,也可以通过搜索引擎快照暂时查看页面。
这是 Google Snapshots 的在线查询站点。现在很多网友使用google镜像搜索,有时可能会遇到一些网页打不开的情况。然后你只需要复制网页的url,放到快照在线查询的搜索框中,就可以快速查询站点了。谷歌快照。详细情况如下:
网站地址:
参观后如下:
如果您选择Google Snapshot,那么您将直接使用Google Snapshot 的域名访问网页结果。例如,如果在地址栏中输入:,搜索结果如下:
如果你不能访问谷歌,那么你可以选择抓取这个网站。选择后,您将使用网站本身来抓取Google快照内容,最终将返回的结果呈现给您,例如:
最后,谷歌快照站点是测试版,随时禁用快照捕获功能。
... psz1992 的其他帖子

