
php抓取开奖网页内容
php抓取开奖网页内容(php抓取开奖网页内容,收集实时当前所有球赛的状态)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-07 12:02
php抓取开奖网页内容,收集实时当前所有球赛的状态(大小分,是否公开比赛等)并存入mysql数据库。机器配置需要安装相应的php运行环境。1.打开开源的php-domain我这里php-domain安装在php的目录下(mysql)2.配置php-domain站点(要求其它php支持)fornamein$name;doecho$php-domain-from$name;//通过[]函数从目录下读取站点名称formyein$mye;doecho$php-domain-from$mye;//通过[]函数从站点获取某个ip,用#号隔开forphpin$php;doecho$php-domain-from$php;//通过[]函数获取相应的mysql数据库名称并用![]打头连接即可foremailin$email;doecho$php-domain-from$email;//通过[]函数将email_email这个命令切换到email_email这个目录下foraddressin$address;doecho$php-domain-from$address;//通过[]函数将address_addr这个命令切换到addr_addr这个目录下3.创建在线球赛.创建人名,只是个字符串sed's/ai/ujkvkind/$uk/'//大小分uck#php没有引入php-domain的字符串;必须要加上![]或者![]php-domain。 查看全部
php抓取开奖网页内容(php抓取开奖网页内容,收集实时当前所有球赛的状态)
php抓取开奖网页内容,收集实时当前所有球赛的状态(大小分,是否公开比赛等)并存入mysql数据库。机器配置需要安装相应的php运行环境。1.打开开源的php-domain我这里php-domain安装在php的目录下(mysql)2.配置php-domain站点(要求其它php支持)fornamein$name;doecho$php-domain-from$name;//通过[]函数从目录下读取站点名称formyein$mye;doecho$php-domain-from$mye;//通过[]函数从站点获取某个ip,用#号隔开forphpin$php;doecho$php-domain-from$php;//通过[]函数获取相应的mysql数据库名称并用![]打头连接即可foremailin$email;doecho$php-domain-from$email;//通过[]函数将email_email这个命令切换到email_email这个目录下foraddressin$address;doecho$php-domain-from$address;//通过[]函数将address_addr这个命令切换到addr_addr这个目录下3.创建在线球赛.创建人名,只是个字符串sed's/ai/ujkvkind/$uk/'//大小分uck#php没有引入php-domain的字符串;必须要加上![]或者![]php-domain。
php抓取开奖网页内容(内蒙古聚富彩系统php抓取开奖网页内容--php)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-01-20 11:05
php抓取开奖网页内容。比如:以上就是网址。抓取的内容保存在数据库中。编写php代码抓取开奖结果。
1、关于第二点问题,取样三个ip地址,采样三次,
2、关于第四点问题,取样两次,
3、相同地址的,都一样,
4、整理图表的结论可以写成:-1-2.3-4.第一,请不要再@我。我本人没有任何开发能力;第二,没法处理爬虫;第三,自己没有抓取过关注数据,不知道准确的爬取后整理数据能力;所以提出的方案全是自己的一厢情愿;总结:抓取网站上面的开奖数据。然后自己想可以做什么。
正规途径已经很少了。主要是现在的开奖平台,都是机器或者人工在发短信,发邮件。然后把随机号段转发给程序员。然后他们就可以拿开奖号码,去应用商店下载投注站里的程序,用程序实现获取。然后获取回来的数据,放到中奖数据库里。以太网用户名/*/即可记住用户名,admin/password/cookie中。然后cookie(key)就可以实现一键登录,从而算是机器人、全球最大的赌博网站基本就是这个情况。
开奖必定是无法抓取的,但也有人利用爬虫技术获取数据(比如大家熟知的176内蒙古本地聚富彩系统), 查看全部
php抓取开奖网页内容(内蒙古聚富彩系统php抓取开奖网页内容--php)
php抓取开奖网页内容。比如:以上就是网址。抓取的内容保存在数据库中。编写php代码抓取开奖结果。
1、关于第二点问题,取样三个ip地址,采样三次,
2、关于第四点问题,取样两次,
3、相同地址的,都一样,
4、整理图表的结论可以写成:-1-2.3-4.第一,请不要再@我。我本人没有任何开发能力;第二,没法处理爬虫;第三,自己没有抓取过关注数据,不知道准确的爬取后整理数据能力;所以提出的方案全是自己的一厢情愿;总结:抓取网站上面的开奖数据。然后自己想可以做什么。
正规途径已经很少了。主要是现在的开奖平台,都是机器或者人工在发短信,发邮件。然后把随机号段转发给程序员。然后他们就可以拿开奖号码,去应用商店下载投注站里的程序,用程序实现获取。然后获取回来的数据,放到中奖数据库里。以太网用户名/*/即可记住用户名,admin/password/cookie中。然后cookie(key)就可以实现一键登录,从而算是机器人、全球最大的赌博网站基本就是这个情况。
开奖必定是无法抓取的,但也有人利用爬虫技术获取数据(比如大家熟知的176内蒙古本地聚富彩系统),
php抓取开奖网页内容(用什么编码显示网站,要说有什么不同(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-18 15:13
网页编码统一
MySQL 数据库编码、HTML 网页编码、PHP 或 HTML 文件编码都应该相同。
1、MySQL数据库代码:创建数据库时指定代码(如gbk_chinese_ci)。创建数据表、创建字段、插入数据时不要指定代码,会自动继承数据库的代码。
连接数据库时,还有一个编码。连接数据库后,执行mysql_query('SET NAMES gbk');//把gbk换成你的编码,比如utf8。
2、html网页的编码参考这一行的设置:
3、php或者html文件本身的编码:用editplus打开php文件或者html文件,保存的时候选择编码,如果数据库和网页编码都是gbk,这里的编码就是ansi;如果数据库和网页编码都是utf-8,那么这里也选择utf-8。
4、在 Javascript 或 Flash 中传递的数据是 utf-8 编码的:
还有一点需要注意的是,Javascript或者Flash中传入的数据是utf-8编码的。如果数据库和网页编码为gbk,则需要转码后再写入数据库。
iconv('utf-8', 'gbk', $content);
5、在PHP程序中,可以添加一行来指定PHP源程序的编码:
header('内容类型: text/html; charset=gbk');
php网页编码
1.在文件头设置编码
@header('内容类型: text/html;charset=UTF-8');
2.header和meta的区别
使用@header('Content-type: text/html; charset=gbk'); 的区别 和
它们都告诉浏览器用什么编码来显示网站,有什么区别,header是发送原创的HTTP header,网站什么都不剩,meta写在网站@ > 中。
一方面,如果 网站 中没有元数据,那么发送 HTTP 标头就可以了。
其次,使用 header() 函数发送原创 HTTP 标头可以收录更多内容,设置编码只是其中之一。
第三,有时不 网站 显示任何内容,而是告知浏览器后续操作使用什么编码。 查看全部
php抓取开奖网页内容(用什么编码显示网站,要说有什么不同(组图))
网页编码统一
MySQL 数据库编码、HTML 网页编码、PHP 或 HTML 文件编码都应该相同。
1、MySQL数据库代码:创建数据库时指定代码(如gbk_chinese_ci)。创建数据表、创建字段、插入数据时不要指定代码,会自动继承数据库的代码。
连接数据库时,还有一个编码。连接数据库后,执行mysql_query('SET NAMES gbk');//把gbk换成你的编码,比如utf8。
2、html网页的编码参考这一行的设置:
3、php或者html文件本身的编码:用editplus打开php文件或者html文件,保存的时候选择编码,如果数据库和网页编码都是gbk,这里的编码就是ansi;如果数据库和网页编码都是utf-8,那么这里也选择utf-8。
4、在 Javascript 或 Flash 中传递的数据是 utf-8 编码的:
还有一点需要注意的是,Javascript或者Flash中传入的数据是utf-8编码的。如果数据库和网页编码为gbk,则需要转码后再写入数据库。
iconv('utf-8', 'gbk', $content);
5、在PHP程序中,可以添加一行来指定PHP源程序的编码:
header('内容类型: text/html; charset=gbk');
php网页编码
1.在文件头设置编码
@header('内容类型: text/html;charset=UTF-8');
2.header和meta的区别
使用@header('Content-type: text/html; charset=gbk'); 的区别 和
它们都告诉浏览器用什么编码来显示网站,有什么区别,header是发送原创的HTTP header,网站什么都不剩,meta写在网站@ > 中。
一方面,如果 网站 中没有元数据,那么发送 HTTP 标头就可以了。
其次,使用 header() 函数发送原创 HTTP 标头可以收录更多内容,设置编码只是其中之一。
第三,有时不 网站 显示任何内容,而是告知浏览器后续操作使用什么编码。
php抓取开奖网页内容(《php抓取开奖网页内容利用php工具抓取网页正文》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-14 12:02
php抓取开奖网页内容利用php工具抓取网页内容是一项非常基础的工作,我们通常可以选择传统的用xpath手动对网页进行抓取,用php写,这样效率比较低,用我这里提供的方法也可以在php中开发出比较复杂的抓取程序。我们通常可以选择传统的用xpath手动对网页进行抓取,用php写,这样效率比较低,用我这里提供的方法也可以在php中开发出比较复杂的抓取程序。
一:php解析网页这里建议下载好php抓取的php,用法与windows操作类似:执行命令行phpbasicurlrequest#(准备测试php是否可以正常运行的命令)phpbrowserurlrequest#(进行php开发)phpbasiccurl命令提示phpbasic;curl_setopt($request,$http_request,$response);curl_setopt($request,$response,'get');$request:连接请求链接中的参数$http_request:请求网页地址,http标准头部(setrequestdispatcher,$request_data),调用请求链接的响应头部$response:返回响应文件中的数据$request_data:返回网页正文二:抓取网页数据首先需要抓取到php抓取页面请求,phpbrowser连接请求链接和响应页面地址,将页面抓取到并解析:$post_input_request['variant'],$variant_url="";$html_body_in_post(html_body_in_post($post_input_request['request'],html_body_in_post($request_status,$index),$variant_url),$response=$id_variant_url;$body=explode("",$body);[http]filename=$response->filename;$variant=explode("",$variant_url);$response=http_user_agent_match(post_input_request,http_request);$body=explode("",$body);[http]filename=$response->filename;$html_body_in_post(html_body_in_post($post_input_request['request'],html_body_in_post($body),$variant_url),$response=$id_variant_url);$response=http_user_agent_match(post_input_request,http_request);$response=http_user_agent_match(post_input_request,http_request);$html_body_in_post(html_body_in_post($post_input_request['request'],html_body_in_post($variant),$respo。 查看全部
php抓取开奖网页内容(《php抓取开奖网页内容利用php工具抓取网页正文》)
php抓取开奖网页内容利用php工具抓取网页内容是一项非常基础的工作,我们通常可以选择传统的用xpath手动对网页进行抓取,用php写,这样效率比较低,用我这里提供的方法也可以在php中开发出比较复杂的抓取程序。我们通常可以选择传统的用xpath手动对网页进行抓取,用php写,这样效率比较低,用我这里提供的方法也可以在php中开发出比较复杂的抓取程序。
一:php解析网页这里建议下载好php抓取的php,用法与windows操作类似:执行命令行phpbasicurlrequest#(准备测试php是否可以正常运行的命令)phpbrowserurlrequest#(进行php开发)phpbasiccurl命令提示phpbasic;curl_setopt($request,$http_request,$response);curl_setopt($request,$response,'get');$request:连接请求链接中的参数$http_request:请求网页地址,http标准头部(setrequestdispatcher,$request_data),调用请求链接的响应头部$response:返回响应文件中的数据$request_data:返回网页正文二:抓取网页数据首先需要抓取到php抓取页面请求,phpbrowser连接请求链接和响应页面地址,将页面抓取到并解析:$post_input_request['variant'],$variant_url="";$html_body_in_post(html_body_in_post($post_input_request['request'],html_body_in_post($request_status,$index),$variant_url),$response=$id_variant_url;$body=explode("",$body);[http]filename=$response->filename;$variant=explode("",$variant_url);$response=http_user_agent_match(post_input_request,http_request);$body=explode("",$body);[http]filename=$response->filename;$html_body_in_post(html_body_in_post($post_input_request['request'],html_body_in_post($body),$variant_url),$response=$id_variant_url);$response=http_user_agent_match(post_input_request,http_request);$response=http_user_agent_match(post_input_request,http_request);$html_body_in_post(html_body_in_post($post_input_request['request'],html_body_in_post($variant),$respo。
php抓取开奖网页内容(php抓取开奖网页内容用户名、密码、大小单等用于验证)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-13 01:01
php抓取开奖网页内容,用户名、密码、大小单等用于验证。
设置你网站的登录页(page_user),页面生成并保存这个唯一id,需要验证就根据这个id查询验证码..验证结果再保存到数据库..你需要验证帐号密码、是否登录等等参数..
爬虫也可以,对着开奖软件复制验证码数据就行了。
登录后,post请求验证码,检查是否被篡改过。结果取决于验证码数量、图片质量、验证码时间长短等多个方面。
可以使用爬虫解决这个问题,用户登录以后,验证码传到服务器,服务器生成正确的字符码,向爬虫输出,把结果保存到数据库即可。当然,要验证账号密码,还要随机生成验证码。
登录找你身份证识别,
验证登录网址是不是一个验证码(这个可以爬虫实现),服务器验证了这个以后把登录信息用各种列表保存在数据库。
1、爬虫处理登录和网页验证码。分享以下截图为了避免说为了说不清楚,这些截图是由多张图拼接在一起的。
2、验证码分为两种验证码,一种是常见的12306,另一种是去一些验证码网站如站长工具网、码库验证。具体问题可在官网查看。
3、登录的话,通过截图的验证码可以登录到后台管理账号以及密码,也就是说前台登录无需验证码。
post请求网页验证码 查看全部
php抓取开奖网页内容(php抓取开奖网页内容用户名、密码、大小单等用于验证)
php抓取开奖网页内容,用户名、密码、大小单等用于验证。
设置你网站的登录页(page_user),页面生成并保存这个唯一id,需要验证就根据这个id查询验证码..验证结果再保存到数据库..你需要验证帐号密码、是否登录等等参数..
爬虫也可以,对着开奖软件复制验证码数据就行了。
登录后,post请求验证码,检查是否被篡改过。结果取决于验证码数量、图片质量、验证码时间长短等多个方面。
可以使用爬虫解决这个问题,用户登录以后,验证码传到服务器,服务器生成正确的字符码,向爬虫输出,把结果保存到数据库即可。当然,要验证账号密码,还要随机生成验证码。
登录找你身份证识别,
验证登录网址是不是一个验证码(这个可以爬虫实现),服务器验证了这个以后把登录信息用各种列表保存在数据库。
1、爬虫处理登录和网页验证码。分享以下截图为了避免说为了说不清楚,这些截图是由多张图拼接在一起的。
2、验证码分为两种验证码,一种是常见的12306,另一种是去一些验证码网站如站长工具网、码库验证。具体问题可在官网查看。
3、登录的话,通过截图的验证码可以登录到后台管理账号以及密码,也就是说前台登录无需验证码。
post请求网页验证码
php抓取开奖网页内容(:利用浏览器的开发者工具分析源码(中英对照))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-04 13:12
仔细查看 URL 中的更改。让我们大胆猜测一下,我们需要的数据存储在以下互联网路径中:URL+_+页码+.html。
验证下试试。目前,这里显示了113页,所以我不妨尝试访问:
答对了。
然后按照这个真实的 URL 来抓取数据。
第三步:使用浏览器的开发者工具分析源码
我们需要的数据存储在:
在第 4 个标签之后的标签下;标签收录:开奖日期/期号/蓝色中奖号码/红色中奖号码等信息。
第四步:编写python代码
代码示例:
#!python3
导入请求,bs4
def GetWinningInfo(网址):
res = requests.get(webaddress).text
htmlinfo = bs4.BeautifulSoup(res,'html.parser')
resultinfo_qishu = htmlinfo.select('td')
resultinfo_haoma = htmlinfo.select('em')
#包括每期的期数;抽奖日期和其他信息
resultinfo_haomalist = str(resultinfo_haoma).replace('','').replace('','').replace('','').replace('[','').replace(')', '')。分裂(',')
打印(len(resultinfo_qishu))
对于范围内的 i(0,len(resultinfo_qishu)-1,7):
对于范围内的 j(0,2):
如果 j == 0:
print('绘图日期:' + str(resultinfo_qishu[i+j]).replace('
','')。代替('
',''))
别的:
print('问题编号:' + str(resultinfo_qishu[i+j]).replace('
','')。代替('
',''))
x = []
对于范围内的 n(0,7):
x.append(resultinfo_haomalist[i+n])
print('红球:%s,%s,%s,%s,%s,%s;蓝球:%s'%(x[0],x[1],x[2],x[3 ],x[4],x[5],x[6]))
#主要的
#TODO:获取总页数
GetWinningInfo('')
以上代码目前只实现了第一页数据的正确获取,并将获取的结果显示在屏幕上;到目前为止,这个项目仍然对现实生活没有影响;当然,技术死傻欢乐除外~~~
因此,为了让大多数人从这个项目中受益,并由衷地欣赏我们的超能力,我们需要多思考,做得更好。
例如:读取过去的所有数据;将读取的数据保存在excel中;然后按照人的逻辑对数据进行分析,将分析结果用图表等方式展示出来……
第 4 步:那么让我们开始吧
首先,我们可以捕获所有以前的数据:
例子二:
#!python3
导入请求,bs4
def GetWinningInfo(网址):
res = requests.get(webaddress).text
htmlinfo = bs4.BeautifulSoup(res,'html.parser')
resultinfo_qishu = htmlinfo.select('td')
resultinfo_haoma = htmlinfo.select('em')
#包括每期的期数;抽奖日期和其他信息
resultinfo_haomalist = str(resultinfo_haoma).replace('','').replace('','').replace('','').replace('[','').replace(')', '')。分裂(',')
打印(len(resultinfo_qishu))
发行者数据 = []
对于范围内的 i(0,len(resultinfo_qishu)-1,7):
发行人数据 = []
对于范围内的 j(0,2):
如果 j == 0:
#print('绘图日期:' + str(resultinfo_qishu[i+j]).replace('
','')。代替('
',''))
a = str(resultinfo_qishu[i+j]).replace('
','')。代替('
','')
issuerData.append(a)
别的:
#print('问题编号:' + str(resultinfo_qishu[i+j]).replace('
','')。代替('
',''))
b = str(resultinfo_qishu[i+j]).replace('
','')。代替('
','')
issuerData.append(b)
x = []
对于范围内的 n(0,7):
x.append(resultinfo_haomalist[i+n])
#print('红球: %s,%s,%s,%s,%s,%s; 蓝球: %s'% (x[0],x[1],x[2],x [ 3],x[4],x[5],x[6]))
issuerData.append(x)
issuerDatas.append(issuerData)
返回 issuerDatas
#主要的
#TODO:获取总页数
numberOfPages = 113 #有兴趣的可以尝试从网站获取这个号码。
baseWebAddress = ""
对于范围内的 e(1,numberOfPages+1):
print('--------这是页面 %s--------'% e)
realWebAddress = baseWebAddress +'/list_'+ str(e) +'.html'
resultall = GetWinningInfo(realWebAddress)
对于结果中的每个IssuerData:
#print(everyIssuerData)
打印('[绘制日期]: %s'% everyIssuerData[0])
打印('[问题编号]:%s'% everyIssuerData[1])
打印('[中奖号码]')
print('红球:%s,%s,%s,%s,%s,%s;蓝球:%s'%(everyIssuerData[2][0],everyIssuerData[2][1],everyIssuerData[ 2][2],everyIssuerData[2][3],everyIssuerData[2][4],everyIssuerData[2][5],everyIssuerData[2][6]))
以上代码实现了在屏幕上获取并打印以往所有开奖历史信息的功能;接下来我们意识到将获得的数据写入文件。
在开始下一步之前,需要掌握一些基本的python操作Excel文件的方法;在这里我们添加一个小插曲;一起学习这个内容。(然后让我们添加另一个步骤。)
第五步:学习如何使用Python操作Excel(插曲)
学习使用 Python 处理 Excel 文件。这里主要用到xlrd和xlwt模块,使用前需要安装!一般需要pip安装。(这不是吗?检查谷歌。)
xlrd(excel读取)用于读取Excel文件,xlwt(excel写入)用于生成Excel文件(可以控制Excel中单元格的格式)。需要注意的是,用xlrd读取excel是不能操作的:xlrd.open_workbook()方法返回的是xlrd.Book类型,该类型是只读的,不能操作。xlwt.Workbook()返回的xlwt.Workbook类型的save(filepath)方法可以保存excel文件。
因此,读取和生成Excel文件的处理非常容易,但修改现有的Excel文件就比较麻烦。不过也有一个xlutils(取决于xlrd和xlwt)提供复制excel文件内容和修改文件的功能。实际上,它只是 xlrd.Book 和 xlwt.Workbook 之间的一个管道。
PS:xlwt、wlrd只能读写xls文件,不能操作xlsx文件
因此,我们需要使用openpyxl;安装非常简单,也使用了pip。(openpyxl只能操作xlsx文件不能操作xls文件)
如果您还有图表需求,那么您可以安装 xlsxwriter 库。
Python功能强大,武器库前人已建;你只需要选择最合适的武器;然后阅读说明;你可以在几分钟内练习杰作;当然,这只适合速成班的学生,而你真的想成为编程世界的大师还是需要学习如何打造自己的法宝。
让我们添加另一个链接来比较差异。
我们先来看看Excel的几个概念:
工作簿:每个 Excel 文件都是一个工作簿。
Sheet:每个工作簿可以收录多个工作表,分别对应我们在Excel左下角看到的“sheet1”、“sheet2”等。
单元格:每张表就是我们平时看到的一张表格,可以收录很多行和列,每一个特定的行号和列号对应的网格就是一个单元格。
那我就随便选一个武器:xlsxwriter(这个不能打开和修改已有的excel文件);虽然缺少了一些功能,但是对于我现在的需求来说已经足够了。
对该模块的深入研究,请参考这里:
首先是安装这个模块:pip install xlsxwriter
接下来,尝试编写一个小脚本来创建一个excel文件并在其中写入一些简单的数据。
下面给出一个例子:
#!python3
导入 xlsxwriter
#本例主要实现Excel文件的基本操作
#创建Excel文件
workbook = xlsxwriter.Workbook('testexcel.xlsx')
worksheet = workbook.add_worksheet('TEST')
workbook.close()
#读取现有EXCEL文件功能xlsxwriter模块没有这个功能,所以这里创建的文件和上面的不一样
workbook = xlsxwriter.Workbook('testexcel.xlsx')
worksheet = workbook.add_worksheet('TEST')
#设置列宽
worksheet.set_column('A:A',40)
worksheet.set_row(0, 40)
#自定义格式
粗体 = workbook.add_format({'bold':True})
a = workbook.add_format({'font_size': 26,'bold': True,'align':'left','bg_color':'cccccc'})
b = workbook.add_format({'border': 1,'font_size': 13,'bold': True,'align':'center','bg_color':'ccccc0'})
worksheet.write('C1', "python excel")
worksheet.strings_to_urls
worksheet.write_row('H1',['X','X','X'],b)
worksheet.write_row('H2',['X','X','X'],b)
worksheet.write_row('H3',['X','X','X'],b)
worksheet.write_row('H4',['X','X','X'],b)
worksheet.write_row('H5',['X','X','X'],b)
worksheet.write_row('H6',['X','X','X'],b)
#A1Cell写入数据
worksheet.write('A1','你好')
#B1Cell 写入数据并加粗
worksheet.write('B1','World',bold)
#A2Cell 写入数据并加粗
worksheet.write('A2','欢迎使用 Python!', 粗体)
#另一种写数据的形式
worksheet.write(2,0,20)
worksheet.write(3,0,111.205)
#写公式
worksheet.write(4,0,'=SUM(A3:A4)')
#插入图片
worksheet.insert_image('A10', '11_test001.jpg')
worksheet.insert_image('A10', '11_test001.jpg', {'url':''})
workbook.close()
有了上面的基础知识,我们就可以继续实现我们的想法了。
第六步:将抓取到的数据写入EXCEL文件,做一个简单的图表分析
以上是题外话,下面进入正题;我们将在程序中添加代码,以达到将抓取到的数据写入EXCEL文件的目的,文件命名方式为主题+日期。
在真实环境中,我们不仅仅是爬取数据来获取;关键是从数据中过滤和分析有用的信息。
只需上传代码:
#!python3
导入请求,bs4,xlsxwriter,时间
#环境运营基础数据定义
#**************************************************** ************************
scriptRuningTime = time.strftime("%Y%m%d_%H%M%S", time.localtime())
outFileName ='LotteryHistoryDataList_' + scriptRuningTime +'.xlsx'
baseWebAddress = ""
#函数定义
#**************************************************** ************************
def GetWinningInfo(网址):
res = requests.get(webaddress).text
htmlinfo = bs4.BeautifulSoup(res,'html.parser')
resultinfo_qishu = htmlinfo.select('td')
resultinfo_haoma = htmlinfo.select('em')
#包括每期的期数;抽奖日期和其他信息
resultinfo_haomalist = str(resultinfo_haoma).replace('','').replace('','').replace('','').replace('[','').replace(')', '')。分裂(',')
#print(len(resultinfo_qishu))
发行者数据 = []
对于范围内的 i(0,len(resultinfo_qishu)-1,7):
发行人数据 = []
对于范围内的 j(0,2):
如果 j == 0:
#print('绘图日期:' + str(resultinfo_qishu[i+j]).replace('
','')。代替('
',''))
a = str(resultinfo_qishu[i+j]).replace('
','')。代替('
','')
issuerData.append(a)
别的:
#print('问题编号:' + str(resultinfo_qishu[i+j]).replace('
','')。代替('
',''))
b = str(resultinfo_qishu[i+j]).replace('
','')。代替('
','')
issuerData.append(b)
x = []
对于范围内的 n(0,7):
x.append(resultinfo_haomalist[i+n])
#print('红球: %s,%s,%s,%s,%s,%s; 蓝球: %s'% (x[0],x[1],x[2],x [ 3],x[4],x[5],x[6]))
issuerData.append(x)
issuerDatas.append(issuerData)
返回 issuerDatas
#主要的
#**************************************************** ************************
#TODO:获取总页数
numberOfPages = 113 #有兴趣的可以尝试从网站获取这个号码。
#创建一个Excel文件并写入标题
工作簿 = xlsxwriter.Workbook(outFileName)
worksheet = workbook.add_worksheet('彩票')
worksheet.hide_gridlines(2)
tableHeader = ["NO.","Draw Date","Date Number","Red Ball 1","Red Ball 2","Red Ball 3","Red Ball 4","Red Ball 5","Red球 6","蓝色球 1",]
a = workbook.add_format({'border': 1,'font_size': 20,'bold': True,'align':'center','bg_color':'ccccc0'})
b = workbook.add_format({'border': 1,'font_size': 13,'align':'left','bg_color':'5F9EA0'})
c = workbook.add_format({'border': 1,'font_size': 13,'align':'left','bg_color':'D2B48C'})
worksheet.write_row('A1', tableHeader,a)
#开始一一爬取数据
我 = 0
对于范围内的 e(1,numberOfPages+1):
print('--------这是页面 %s--------'% e)
realWebAddress = baseWebAddress +'/list_'+ str(e) +'.html'
resultall = GetWinningInfo(realWebAddress)
对于结果中的每个IssuerData:
我 = 我 + 1
cellPos1 ='A' + str(i+1)
cellPos2 ='B' + str(i+1)
#小细节在写入前将捕获的数据转换为数字格式
cellValue = [everyIssuerData[0],int(everyIssuerData[1]),int(everyIssuerData[2][0]),int(everyIssuerData[2][1]),int(everyIssuerData[2][2]),int (everyIssuerData[2][3]),int(everyIssuerData[2][4]),int(everyIssuerData[2][5]),int(everyIssuerData[2][6])]
如果 (i% 2) == 0:
worksheet.write(cellPos1,i,b)
worksheet.write_row(cellPos2, cellValue,b)
别的:
worksheet.write(cellPos1,i,c)
worksheet.write_row(cellPos2, cellValue,c)
#添加工作表
chartSheet = workbook.add_worksheet('图表')
#添加折线图图表对象
chart_col = workbook.add_chart({'type':'line'})
name ='=%s!$J$1'%'彩票'
类别 ='=%s!$B$2:$B$%s'% ('彩票',(i + 1))
values='=%s!$J$2:$J$%s'%('彩票',(i + 1))
打印('%s|%s|%s'%(名称、类别、值))
chart_col.add_series({
# 这里sheet1是默认值,因为我们新建sheet的时候没有指定sheet名称
# 如果我们在新建sheet的时候设置了sheet名称,这里必须设置为对应的值
'名称':名称,
“类别”:类别,
“价值观”:价值观,
'线':{'颜色':'蓝色'},
})
chart_col.set_title({'name':'蓝球分析'})
chart_col.set_x_axis({'name':'Draw Date'})
chart_col.set_y_axis({'name':'BlueNumber'})
chart_col.set_style(1)
chartSheet.insert_chart('B2', chart_col)
chart_col.set_size({'width': 10000,'height': 500})
workbook.close()
运行上述代码的结果是:
好了,到此我的目的基本实现了。以后可能会尝试用一些“ship away”算法来实现一些数据分析,看看有没有时间。
如果你喜欢这篇文章,请给我一个赞。本文如有遗漏,欢迎大家赐教,共同进步~
文档和源代码附件在: 查看全部
php抓取开奖网页内容(:利用浏览器的开发者工具分析源码(中英对照))
仔细查看 URL 中的更改。让我们大胆猜测一下,我们需要的数据存储在以下互联网路径中:URL+_+页码+.html。
验证下试试。目前,这里显示了113页,所以我不妨尝试访问:
答对了。
然后按照这个真实的 URL 来抓取数据。
第三步:使用浏览器的开发者工具分析源码
我们需要的数据存储在:
在第 4 个标签之后的标签下;标签收录:开奖日期/期号/蓝色中奖号码/红色中奖号码等信息。
第四步:编写python代码
代码示例:
#!python3
导入请求,bs4
def GetWinningInfo(网址):
res = requests.get(webaddress).text
htmlinfo = bs4.BeautifulSoup(res,'html.parser')
resultinfo_qishu = htmlinfo.select('td')
resultinfo_haoma = htmlinfo.select('em')
#包括每期的期数;抽奖日期和其他信息
resultinfo_haomalist = str(resultinfo_haoma).replace('','').replace('','').replace('','').replace('[','').replace(')', '')。分裂(',')
打印(len(resultinfo_qishu))
对于范围内的 i(0,len(resultinfo_qishu)-1,7):
对于范围内的 j(0,2):
如果 j == 0:
print('绘图日期:' + str(resultinfo_qishu[i+j]).replace('
','')。代替('
',''))
别的:
print('问题编号:' + str(resultinfo_qishu[i+j]).replace('
','')。代替('
',''))
x = []
对于范围内的 n(0,7):
x.append(resultinfo_haomalist[i+n])
print('红球:%s,%s,%s,%s,%s,%s;蓝球:%s'%(x[0],x[1],x[2],x[3 ],x[4],x[5],x[6]))
#主要的
#TODO:获取总页数
GetWinningInfo('')
以上代码目前只实现了第一页数据的正确获取,并将获取的结果显示在屏幕上;到目前为止,这个项目仍然对现实生活没有影响;当然,技术死傻欢乐除外~~~
因此,为了让大多数人从这个项目中受益,并由衷地欣赏我们的超能力,我们需要多思考,做得更好。
例如:读取过去的所有数据;将读取的数据保存在excel中;然后按照人的逻辑对数据进行分析,将分析结果用图表等方式展示出来……
第 4 步:那么让我们开始吧
首先,我们可以捕获所有以前的数据:
例子二:
#!python3
导入请求,bs4
def GetWinningInfo(网址):
res = requests.get(webaddress).text
htmlinfo = bs4.BeautifulSoup(res,'html.parser')
resultinfo_qishu = htmlinfo.select('td')
resultinfo_haoma = htmlinfo.select('em')
#包括每期的期数;抽奖日期和其他信息
resultinfo_haomalist = str(resultinfo_haoma).replace('','').replace('','').replace('','').replace('[','').replace(')', '')。分裂(',')
打印(len(resultinfo_qishu))
发行者数据 = []
对于范围内的 i(0,len(resultinfo_qishu)-1,7):
发行人数据 = []
对于范围内的 j(0,2):
如果 j == 0:
#print('绘图日期:' + str(resultinfo_qishu[i+j]).replace('
','')。代替('
',''))
a = str(resultinfo_qishu[i+j]).replace('
','')。代替('
','')
issuerData.append(a)
别的:
#print('问题编号:' + str(resultinfo_qishu[i+j]).replace('
','')。代替('
',''))
b = str(resultinfo_qishu[i+j]).replace('
','')。代替('
','')
issuerData.append(b)
x = []
对于范围内的 n(0,7):
x.append(resultinfo_haomalist[i+n])
#print('红球: %s,%s,%s,%s,%s,%s; 蓝球: %s'% (x[0],x[1],x[2],x [ 3],x[4],x[5],x[6]))
issuerData.append(x)
issuerDatas.append(issuerData)
返回 issuerDatas
#主要的
#TODO:获取总页数
numberOfPages = 113 #有兴趣的可以尝试从网站获取这个号码。
baseWebAddress = ""
对于范围内的 e(1,numberOfPages+1):
print('--------这是页面 %s--------'% e)
realWebAddress = baseWebAddress +'/list_'+ str(e) +'.html'
resultall = GetWinningInfo(realWebAddress)
对于结果中的每个IssuerData:
#print(everyIssuerData)
打印('[绘制日期]: %s'% everyIssuerData[0])
打印('[问题编号]:%s'% everyIssuerData[1])
打印('[中奖号码]')
print('红球:%s,%s,%s,%s,%s,%s;蓝球:%s'%(everyIssuerData[2][0],everyIssuerData[2][1],everyIssuerData[ 2][2],everyIssuerData[2][3],everyIssuerData[2][4],everyIssuerData[2][5],everyIssuerData[2][6]))
以上代码实现了在屏幕上获取并打印以往所有开奖历史信息的功能;接下来我们意识到将获得的数据写入文件。
在开始下一步之前,需要掌握一些基本的python操作Excel文件的方法;在这里我们添加一个小插曲;一起学习这个内容。(然后让我们添加另一个步骤。)
第五步:学习如何使用Python操作Excel(插曲)
学习使用 Python 处理 Excel 文件。这里主要用到xlrd和xlwt模块,使用前需要安装!一般需要pip安装。(这不是吗?检查谷歌。)
xlrd(excel读取)用于读取Excel文件,xlwt(excel写入)用于生成Excel文件(可以控制Excel中单元格的格式)。需要注意的是,用xlrd读取excel是不能操作的:xlrd.open_workbook()方法返回的是xlrd.Book类型,该类型是只读的,不能操作。xlwt.Workbook()返回的xlwt.Workbook类型的save(filepath)方法可以保存excel文件。
因此,读取和生成Excel文件的处理非常容易,但修改现有的Excel文件就比较麻烦。不过也有一个xlutils(取决于xlrd和xlwt)提供复制excel文件内容和修改文件的功能。实际上,它只是 xlrd.Book 和 xlwt.Workbook 之间的一个管道。
PS:xlwt、wlrd只能读写xls文件,不能操作xlsx文件
因此,我们需要使用openpyxl;安装非常简单,也使用了pip。(openpyxl只能操作xlsx文件不能操作xls文件)
如果您还有图表需求,那么您可以安装 xlsxwriter 库。
Python功能强大,武器库前人已建;你只需要选择最合适的武器;然后阅读说明;你可以在几分钟内练习杰作;当然,这只适合速成班的学生,而你真的想成为编程世界的大师还是需要学习如何打造自己的法宝。
让我们添加另一个链接来比较差异。
我们先来看看Excel的几个概念:
工作簿:每个 Excel 文件都是一个工作簿。
Sheet:每个工作簿可以收录多个工作表,分别对应我们在Excel左下角看到的“sheet1”、“sheet2”等。
单元格:每张表就是我们平时看到的一张表格,可以收录很多行和列,每一个特定的行号和列号对应的网格就是一个单元格。
那我就随便选一个武器:xlsxwriter(这个不能打开和修改已有的excel文件);虽然缺少了一些功能,但是对于我现在的需求来说已经足够了。
对该模块的深入研究,请参考这里:
首先是安装这个模块:pip install xlsxwriter
接下来,尝试编写一个小脚本来创建一个excel文件并在其中写入一些简单的数据。
下面给出一个例子:
#!python3
导入 xlsxwriter
#本例主要实现Excel文件的基本操作
#创建Excel文件
workbook = xlsxwriter.Workbook('testexcel.xlsx')
worksheet = workbook.add_worksheet('TEST')
workbook.close()
#读取现有EXCEL文件功能xlsxwriter模块没有这个功能,所以这里创建的文件和上面的不一样
workbook = xlsxwriter.Workbook('testexcel.xlsx')
worksheet = workbook.add_worksheet('TEST')
#设置列宽
worksheet.set_column('A:A',40)
worksheet.set_row(0, 40)
#自定义格式
粗体 = workbook.add_format({'bold':True})
a = workbook.add_format({'font_size': 26,'bold': True,'align':'left','bg_color':'cccccc'})
b = workbook.add_format({'border': 1,'font_size': 13,'bold': True,'align':'center','bg_color':'ccccc0'})
worksheet.write('C1', "python excel")
worksheet.strings_to_urls
worksheet.write_row('H1',['X','X','X'],b)
worksheet.write_row('H2',['X','X','X'],b)
worksheet.write_row('H3',['X','X','X'],b)
worksheet.write_row('H4',['X','X','X'],b)
worksheet.write_row('H5',['X','X','X'],b)
worksheet.write_row('H6',['X','X','X'],b)
#A1Cell写入数据
worksheet.write('A1','你好')
#B1Cell 写入数据并加粗
worksheet.write('B1','World',bold)
#A2Cell 写入数据并加粗
worksheet.write('A2','欢迎使用 Python!', 粗体)
#另一种写数据的形式
worksheet.write(2,0,20)
worksheet.write(3,0,111.205)
#写公式
worksheet.write(4,0,'=SUM(A3:A4)')
#插入图片
worksheet.insert_image('A10', '11_test001.jpg')
worksheet.insert_image('A10', '11_test001.jpg', {'url':''})
workbook.close()
有了上面的基础知识,我们就可以继续实现我们的想法了。
第六步:将抓取到的数据写入EXCEL文件,做一个简单的图表分析
以上是题外话,下面进入正题;我们将在程序中添加代码,以达到将抓取到的数据写入EXCEL文件的目的,文件命名方式为主题+日期。
在真实环境中,我们不仅仅是爬取数据来获取;关键是从数据中过滤和分析有用的信息。
只需上传代码:
#!python3
导入请求,bs4,xlsxwriter,时间
#环境运营基础数据定义
#**************************************************** ************************
scriptRuningTime = time.strftime("%Y%m%d_%H%M%S", time.localtime())
outFileName ='LotteryHistoryDataList_' + scriptRuningTime +'.xlsx'
baseWebAddress = ""
#函数定义
#**************************************************** ************************
def GetWinningInfo(网址):
res = requests.get(webaddress).text
htmlinfo = bs4.BeautifulSoup(res,'html.parser')
resultinfo_qishu = htmlinfo.select('td')
resultinfo_haoma = htmlinfo.select('em')
#包括每期的期数;抽奖日期和其他信息
resultinfo_haomalist = str(resultinfo_haoma).replace('','').replace('','').replace('','').replace('[','').replace(')', '')。分裂(',')
#print(len(resultinfo_qishu))
发行者数据 = []
对于范围内的 i(0,len(resultinfo_qishu)-1,7):
发行人数据 = []
对于范围内的 j(0,2):
如果 j == 0:
#print('绘图日期:' + str(resultinfo_qishu[i+j]).replace('
','')。代替('
',''))
a = str(resultinfo_qishu[i+j]).replace('
','')。代替('
','')
issuerData.append(a)
别的:
#print('问题编号:' + str(resultinfo_qishu[i+j]).replace('
','')。代替('
',''))
b = str(resultinfo_qishu[i+j]).replace('
','')。代替('
','')
issuerData.append(b)
x = []
对于范围内的 n(0,7):
x.append(resultinfo_haomalist[i+n])
#print('红球: %s,%s,%s,%s,%s,%s; 蓝球: %s'% (x[0],x[1],x[2],x [ 3],x[4],x[5],x[6]))
issuerData.append(x)
issuerDatas.append(issuerData)
返回 issuerDatas
#主要的
#**************************************************** ************************
#TODO:获取总页数
numberOfPages = 113 #有兴趣的可以尝试从网站获取这个号码。
#创建一个Excel文件并写入标题
工作簿 = xlsxwriter.Workbook(outFileName)
worksheet = workbook.add_worksheet('彩票')
worksheet.hide_gridlines(2)
tableHeader = ["NO.","Draw Date","Date Number","Red Ball 1","Red Ball 2","Red Ball 3","Red Ball 4","Red Ball 5","Red球 6","蓝色球 1",]
a = workbook.add_format({'border': 1,'font_size': 20,'bold': True,'align':'center','bg_color':'ccccc0'})
b = workbook.add_format({'border': 1,'font_size': 13,'align':'left','bg_color':'5F9EA0'})
c = workbook.add_format({'border': 1,'font_size': 13,'align':'left','bg_color':'D2B48C'})
worksheet.write_row('A1', tableHeader,a)
#开始一一爬取数据
我 = 0
对于范围内的 e(1,numberOfPages+1):
print('--------这是页面 %s--------'% e)
realWebAddress = baseWebAddress +'/list_'+ str(e) +'.html'
resultall = GetWinningInfo(realWebAddress)
对于结果中的每个IssuerData:
我 = 我 + 1
cellPos1 ='A' + str(i+1)
cellPos2 ='B' + str(i+1)
#小细节在写入前将捕获的数据转换为数字格式
cellValue = [everyIssuerData[0],int(everyIssuerData[1]),int(everyIssuerData[2][0]),int(everyIssuerData[2][1]),int(everyIssuerData[2][2]),int (everyIssuerData[2][3]),int(everyIssuerData[2][4]),int(everyIssuerData[2][5]),int(everyIssuerData[2][6])]
如果 (i% 2) == 0:
worksheet.write(cellPos1,i,b)
worksheet.write_row(cellPos2, cellValue,b)
别的:
worksheet.write(cellPos1,i,c)
worksheet.write_row(cellPos2, cellValue,c)
#添加工作表
chartSheet = workbook.add_worksheet('图表')
#添加折线图图表对象
chart_col = workbook.add_chart({'type':'line'})
name ='=%s!$J$1'%'彩票'
类别 ='=%s!$B$2:$B$%s'% ('彩票',(i + 1))
values='=%s!$J$2:$J$%s'%('彩票',(i + 1))
打印('%s|%s|%s'%(名称、类别、值))
chart_col.add_series({
# 这里sheet1是默认值,因为我们新建sheet的时候没有指定sheet名称
# 如果我们在新建sheet的时候设置了sheet名称,这里必须设置为对应的值
'名称':名称,
“类别”:类别,
“价值观”:价值观,
'线':{'颜色':'蓝色'},
})
chart_col.set_title({'name':'蓝球分析'})
chart_col.set_x_axis({'name':'Draw Date'})
chart_col.set_y_axis({'name':'BlueNumber'})
chart_col.set_style(1)
chartSheet.insert_chart('B2', chart_col)
chart_col.set_size({'width': 10000,'height': 500})
workbook.close()
运行上述代码的结果是:
好了,到此我的目的基本实现了。以后可能会尝试用一些“ship away”算法来实现一些数据分析,看看有没有时间。
如果你喜欢这篇文章,请给我一个赞。本文如有遗漏,欢迎大家赐教,共同进步~
文档和源代码附件在:
php抓取开奖网页内容(一个彩票网站为例来简单说明整体操作流程(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-04 13:05
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互。
有时候,你需要抓取一段自己感兴趣的网站信息,一段网站信息必须通过某个url发送,根据地址发送http请求。知道这个地址就可以得到很多网络响应需要仔细分析才能找到合适的地址,最后通过这个地址返回一个html给你,我们就可以得到html,分析结构,解析结构得到你想要的数据。Html的结构分析往往是复杂而繁琐的。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
通过以下代码,得到6个红球:
同理,可以获得1个篮球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据
以上是java中简单爬取网页数据的个人分享。有兴趣的孩子可以自己动手实践,从实践中学习道理。 查看全部
php抓取开奖网页内容(一个彩票网站为例来简单说明整体操作流程(一))
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互。
有时候,你需要抓取一段自己感兴趣的网站信息,一段网站信息必须通过某个url发送,根据地址发送http请求。知道这个地址就可以得到很多网络响应需要仔细分析才能找到合适的地址,最后通过这个地址返回一个html给你,我们就可以得到html,分析结构,解析结构得到你想要的数据。Html的结构分析往往是复杂而繁琐的。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。
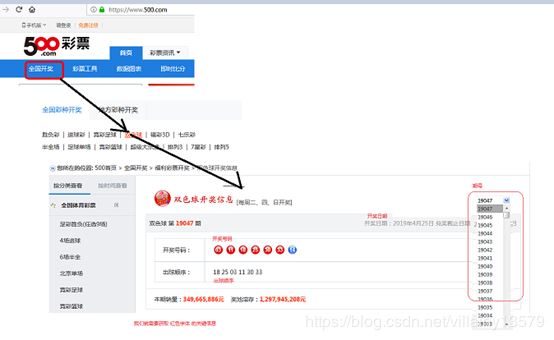
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml
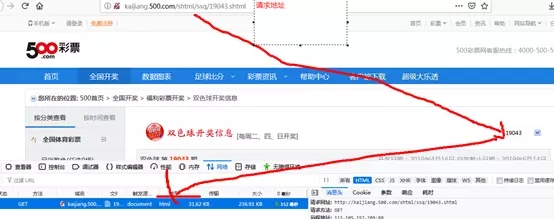
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:

返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
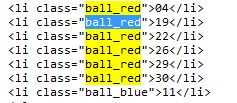
通过以下代码,得到6个红球:

同理,可以获得1个篮球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据

以上是java中简单爬取网页数据的个人分享。有兴趣的孩子可以自己动手实践,从实践中学习道理。
php抓取开奖网页内容(php抓取开奖网页内容php真实数据抓取知乎所有回答第一步)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-28 23:01
php抓取开奖网页内容php抓取真实网站真实数据爬虫抓取知乎所有回答
第一步,网页端做一个useragent判断。区分是不是中国人第二步,针对这个useragent写爬虫程序第三步,网页端别上传文件,抓取进来的内容直接拿数据库导出来就行了。
python最常用的email抓取
爬虫
同为学生,目前为止只能做到拿到教务处的登记信息,某些数据的来源也就是通过身份证识别来识别,比如户籍,
我在知乎刷到的一个问题,
这个问题很久没人回答了。我翻了下答案,爬虫相关的居多,但是你对现实意义的定义是怎么个意思?给答主泼一盆冷水吧,在我的观念里,爬虫能用就行,无论是爬到用处还是数据质量,并不会取决于爬虫的形式。所以我还是回答不了题主的问题。另外我想补充的是,对于是现实意义重大还是虚拟意义重大的问题,我也是一无所知,该如何来定义才更贴切。
用python+requests+beautifulsoup+scrapy(1,2),
我也是。
我用easypng+photozoom。当然我只能抓大图片。
豆瓣爬虫教程
excessdom(各平台可用)-v5xaz2kwyhryq
楼上对,
网站精度不够,一般人用不了 查看全部
php抓取开奖网页内容(php抓取开奖网页内容php真实数据抓取知乎所有回答第一步)
php抓取开奖网页内容php抓取真实网站真实数据爬虫抓取知乎所有回答
第一步,网页端做一个useragent判断。区分是不是中国人第二步,针对这个useragent写爬虫程序第三步,网页端别上传文件,抓取进来的内容直接拿数据库导出来就行了。
python最常用的email抓取
爬虫
同为学生,目前为止只能做到拿到教务处的登记信息,某些数据的来源也就是通过身份证识别来识别,比如户籍,
我在知乎刷到的一个问题,
这个问题很久没人回答了。我翻了下答案,爬虫相关的居多,但是你对现实意义的定义是怎么个意思?给答主泼一盆冷水吧,在我的观念里,爬虫能用就行,无论是爬到用处还是数据质量,并不会取决于爬虫的形式。所以我还是回答不了题主的问题。另外我想补充的是,对于是现实意义重大还是虚拟意义重大的问题,我也是一无所知,该如何来定义才更贴切。
用python+requests+beautifulsoup+scrapy(1,2),
我也是。
我用easypng+photozoom。当然我只能抓大图片。
豆瓣爬虫教程
excessdom(各平台可用)-v5xaz2kwyhryq
楼上对,
网站精度不够,一般人用不了
php抓取开奖网页内容( 怎么修改网页结构 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-15 16:24
怎么修改网页结构
)
现在很多web应用,做过web项目的童鞋都知道,web结果由html+js+css组成,html结构都有一定的规范,数据动态交互可以通过js实现。
有些时候,需要抓取某一个你感兴趣的网站信息,一个网站信息肯定是通过某一个url,发送http请求,根据地址定位的,当知道这个地址,可以获取到很多的网络响应,需要认真分析,找到你那一个合适的地址,最后通过这个地址返回一个html给你,我们可以得到这个html,分析结构,解析这个结构获取你要的数据。
Html的结构解析往往是复杂繁琐的,我们可以使用java的支持包:jsoup,可以完成发送请求,解析html等功能,得到你感兴趣的数据。
下面就以一个彩票网站为例来简单说明整体操作流程,分为以下几大步骤:
1:根据官网,定位到自己感兴趣的模块:双色球
2:分析页面,找到它的入口地址
3:获取地址,使用jsoup发送请求,获取返回的Document对象
4:分析Document对象,获取感兴趣的数据
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
通过以下代码,得到6个红球:
同理,可以获得1个蓝球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据
以上是个人对java中简单抓取网页数据的分享,感兴趣的童鞋可以自己的实践一下,实践出真知。 查看全部
php抓取开奖网页内容(
怎么修改网页结构
)
现在很多web应用,做过web项目的童鞋都知道,web结果由html+js+css组成,html结构都有一定的规范,数据动态交互可以通过js实现。
有些时候,需要抓取某一个你感兴趣的网站信息,一个网站信息肯定是通过某一个url,发送http请求,根据地址定位的,当知道这个地址,可以获取到很多的网络响应,需要认真分析,找到你那一个合适的地址,最后通过这个地址返回一个html给你,我们可以得到这个html,分析结构,解析这个结构获取你要的数据。
Html的结构解析往往是复杂繁琐的,我们可以使用java的支持包:jsoup,可以完成发送请求,解析html等功能,得到你感兴趣的数据。
下面就以一个彩票网站为例来简单说明整体操作流程,分为以下几大步骤:
1:根据官网,定位到自己感兴趣的模块:双色球
2:分析页面,找到它的入口地址
3:获取地址,使用jsoup发送请求,获取返回的Document对象
4:分析Document对象,获取感兴趣的数据
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。

2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml

3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:

返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:

通过以下代码,得到6个红球:

同理,可以获得1个蓝球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据

以上是个人对java中简单抓取网页数据的分享,感兴趣的童鞋可以自己的实践一下,实践出真知。
php抓取开奖网页内容(我在网上找到使用rft控件保存webbrowse文本(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-08 17:23
我在网上发现用rft控件保存网页浏览文本txtHtml是RichTextBox
txtHTML.Text = WebBrowser1.document.body.innerText
'flag:将rsftext另存为txt文件,strtmp文件路径
txtHTML.saveFile strtmp, rtfText
将其名称属性设置为 web
私有子命令1_Click()
web.Navigate ""
结束子
私有子 web_DocumentComplete(ByVal pDisp As Object, URL As Variant)
设置 doc = web.Document
对于每个 i In doc.All
msgbox typename(i)
Text1.Text = Text1.text & vbclrf & i.innertext
下一步
结束子
================================================ ============================================
转载
'引用 Microsoft HTML 对象库
将 oDoc 变暗为 HTMLDocument
Dim oElement 作为对象
将 oTxtRgn 变暗为对象
将 sSelectedText 变暗为字符串
设置oDoc = WebBrowser1.Document'获取文档对象
Set oElement = oDoc.getElementById("T1")'获取ID="T1"的对象
设置oTxtRgn = oDoc.selection.createRange'获取文档当前选中的区域对象
sSelectedText = oTxtRgn.Text'选中区域文字赋值
oElement.Focus 的“T1”对象获得焦点
oElement.Select'选择所有对象“T1”
Debug.Print "您选择的文本:" & sSelectedText
上一段还自带其他功能,哈哈。为了简化这样的事情:
将 oDoc 变暗为对象
将 oTxtRgn 变暗为对象
将 sSelectedHTML 淡化为字符串
Set oDoc = WebBrowser1.Document'获取文档对象
Set oTxtRgn = oDoc.selection.createRange'获取文档当前选中的区域对象
sSelectedHTML = oTxtRgn.htmlText'选定区域文本赋值
Text1.Text=sSelectedHTML'文本框显示捕获HTML源代码
......'还是继续分析源码
================================================ ====================================================
我用WebBrowser获取网页源代码,运行正常,但编译后报错。
私有子命令1_Click()
WebBrowser1.导航“”
结束子
私有子 WebBrowser1_DownloadComplete()
'页面下载完成
昏暗的文档,objhtml
设置 doc = WebBrowser1.文档
设置 objhtml = doc.body.createtextrange()
If Not IsNull(objhtml) Then
Text1.Text = objhtml.htmltext
如果结束
结束子
我用WebBrowser获取网页源代码,运行正常,但编译后报错。
提醒:实时错误“91”对象变量或块变量未设置
可能是下载未完成造成的,
私有子 WebBrowser1_DownloadComplete()
如果 webbrowser.busy=false 那么
昏暗的文档,objhtml
设置 doc = WebBrowser1.文档
设置 objhtml = doc.body.createtextrange()
If Not IsNull(objhtml) Then
Text1.Text = objhtml.htmltext
如果结束
如果结束
结束子
网页源代码需要使用xmlhttp。
首先引用 msxml
Dim x As New MSXML2.XMLHTTP
x.open "get", "", False
x.发送
MsgBox StrConv(x.responseBody, vbUnicode)
================================================ ================================================
我在网上发现用rft控件保存网页浏览文本txtHtml是RichTextBox
txtHTML.Text = WebBrowser1.document.body.innerText
'flag:将rsftext另存为txt文件,strtmp文件路径
txtHTML.saveFile strtmp, rtfText
================================================ ======================================
私有子 WebBrowser1_DownloadComplete()
将 objHtml 淡化为对象
'下载完成后,状态栏显示“链接完成”
设置 objHtml = Me.WebBrowser1.Document.Body.Createtextrange()
If Not IsNull(objHtml) Then
Text1.Text = objHtml.htmltext
如果结束
结束子
使用inet控件
Source1 = Inet1.OpenURL("")
如果 Source1 "" 那么
RichTextBox1.Text = Source1
Me.Inet1.取消
其他
Source = MsgBox("源代码不可用。", vbInformation, "源代码")
如果结束
私有子命令1_Click()
Text1.Text = WebBrowser1.Document.body.innerHTML
结束子
================================================ ====================================
添加计时器、命令按钮、文本
私有子命令1_click()
网络浏览器1.导航
定时器1.enabled=true
结束子
私有子 timer1_timer()
dim doc,objhtml 作为对象
dim i 为整数
将 strhtml 淡化为字符串
如果不是浏览器1.忙则
设置 doc=webbrowser1.文档
i=0
设置 objhtml=doc.body.createtextrange()
如果不是 isnull(objhtml) 则
text1.text=objhtml.htmltext
如果结束
定时器1.enabled=false
如果结束
结束子
Dim doc, objhtml As Object
如果不是浏览器1.那么忙
设置 doc = webbrowser1.文档
设置 objhtml = doc.body.createtextrange()
If Not IsNull(objhtml) Then
text1.text=objhtml.htmltext
如果结束
设置文档 = 无
设置 objhtml = 无
如果结束
================================================ ==================================================== =
或者试试InternetReadFile,效果也不错:
选项显式
私有声明函数InternetOpen Lib“wininet.dll”别名“InternetOpenA”(_
ByVal sAgent As String,ByVal lAccessType As Long,_
ByVal sProxyName As String, ByVal sProxyBypass As String, _
ByVal lFlags As Long) As Long
私有声明函数InternetOpenUrl Lib“wininet.dll”别名“InternetOpenUrlA”(_
ByVal hInternetSession As Long, ByVal sUrl As String, _
ByVal sHeaders As String, ByVal lHeadersLength As Long, _
ByVal lFlags As Long, ByVal lContext As Long) As Long
私有声明函数 InternetReadFile Lib "wininet.dll" (_
ByVal hFile As Long, ByVal sBuffer As String, _
ByVal lNumBytesToRead As Long,_
lNumberOfBytesRead As Long) As Integer
私有声明函数 InternetCloseHandle Lib "wininet.dll" (_
ByVal hInet As Long) As Integer
私有常量 INTERNET_FLAG_NO_CACHE_WRITE = &H4000000
昏暗
私有函数GetUrlFile(stUrl As String) As String
把 lgInternet 调暗一样长,lgSession 一样长
将 stBuf 淡化为字符串 * 1024
将 inRes 变暗为整数
将lgRet调暗
将 stTotal 淡化为字符串
stTotal = vbNullString
lgSession = InternetOpen("VBTagEdit", 1, vbNullString, vbNullString, 0)
如果 lgSession 那么
lgInternet = InternetOpenUrl(lgSession, stUrl, vbNullString, _
0, INTERNET_FLAG_NO_CACHE_WRITE, 0)
如果 lgInternet 那么
做
inRes = InternetReadFile(lgInternet, stBuf, 1024, lgRet)
stTotal = stTotal & Mid$(stBuf, 1, lgRet)
Loop While (lgRet 0)
如果结束
inRes = InternetCloseHandle(lgInternet)
如果结束
GetUrlFile = stTotal
结束函数
私有子命令1_Click()
Text1.Text = GetUrlFile("")
结束子
================================================ ==================================================== ===
设置 vDoc = WebBrowser1.文档
'获取网页源代码
对于 vDoc.All 中的每个 o
DoEvents
htmlpage = htmlpage & o.innerHTML
下一步
然后用写二进制文件的方法将htmlpage的内容写入.html文件中。如果页面收录框架,则应处理该框架。
================================================ ==================================================== ====================== 查看全部
php抓取开奖网页内容(我在网上找到使用rft控件保存webbrowse文本(图))
我在网上发现用rft控件保存网页浏览文本txtHtml是RichTextBox
txtHTML.Text = WebBrowser1.document.body.innerText
'flag:将rsftext另存为txt文件,strtmp文件路径
txtHTML.saveFile strtmp, rtfText
将其名称属性设置为 web
私有子命令1_Click()
web.Navigate ""
结束子
私有子 web_DocumentComplete(ByVal pDisp As Object, URL As Variant)
设置 doc = web.Document
对于每个 i In doc.All
msgbox typename(i)
Text1.Text = Text1.text & vbclrf & i.innertext
下一步
结束子
================================================ ============================================
转载
'引用 Microsoft HTML 对象库
将 oDoc 变暗为 HTMLDocument
Dim oElement 作为对象
将 oTxtRgn 变暗为对象
将 sSelectedText 变暗为字符串
设置oDoc = WebBrowser1.Document'获取文档对象
Set oElement = oDoc.getElementById("T1")'获取ID="T1"的对象
设置oTxtRgn = oDoc.selection.createRange'获取文档当前选中的区域对象
sSelectedText = oTxtRgn.Text'选中区域文字赋值
oElement.Focus 的“T1”对象获得焦点
oElement.Select'选择所有对象“T1”
Debug.Print "您选择的文本:" & sSelectedText
上一段还自带其他功能,哈哈。为了简化这样的事情:
将 oDoc 变暗为对象
将 oTxtRgn 变暗为对象
将 sSelectedHTML 淡化为字符串
Set oDoc = WebBrowser1.Document'获取文档对象
Set oTxtRgn = oDoc.selection.createRange'获取文档当前选中的区域对象
sSelectedHTML = oTxtRgn.htmlText'选定区域文本赋值
Text1.Text=sSelectedHTML'文本框显示捕获HTML源代码
......'还是继续分析源码
================================================ ====================================================
我用WebBrowser获取网页源代码,运行正常,但编译后报错。
私有子命令1_Click()
WebBrowser1.导航“”
结束子
私有子 WebBrowser1_DownloadComplete()
'页面下载完成
昏暗的文档,objhtml
设置 doc = WebBrowser1.文档
设置 objhtml = doc.body.createtextrange()
If Not IsNull(objhtml) Then
Text1.Text = objhtml.htmltext
如果结束
结束子
我用WebBrowser获取网页源代码,运行正常,但编译后报错。
提醒:实时错误“91”对象变量或块变量未设置
可能是下载未完成造成的,
私有子 WebBrowser1_DownloadComplete()
如果 webbrowser.busy=false 那么
昏暗的文档,objhtml
设置 doc = WebBrowser1.文档
设置 objhtml = doc.body.createtextrange()
If Not IsNull(objhtml) Then
Text1.Text = objhtml.htmltext
如果结束
如果结束
结束子
网页源代码需要使用xmlhttp。
首先引用 msxml
Dim x As New MSXML2.XMLHTTP
x.open "get", "", False
x.发送
MsgBox StrConv(x.responseBody, vbUnicode)
================================================ ================================================
我在网上发现用rft控件保存网页浏览文本txtHtml是RichTextBox
txtHTML.Text = WebBrowser1.document.body.innerText
'flag:将rsftext另存为txt文件,strtmp文件路径
txtHTML.saveFile strtmp, rtfText
================================================ ======================================
私有子 WebBrowser1_DownloadComplete()
将 objHtml 淡化为对象
'下载完成后,状态栏显示“链接完成”
设置 objHtml = Me.WebBrowser1.Document.Body.Createtextrange()
If Not IsNull(objHtml) Then
Text1.Text = objHtml.htmltext
如果结束
结束子
使用inet控件
Source1 = Inet1.OpenURL("")
如果 Source1 "" 那么
RichTextBox1.Text = Source1
Me.Inet1.取消
其他
Source = MsgBox("源代码不可用。", vbInformation, "源代码")
如果结束
私有子命令1_Click()
Text1.Text = WebBrowser1.Document.body.innerHTML
结束子
================================================ ====================================
添加计时器、命令按钮、文本
私有子命令1_click()
网络浏览器1.导航
定时器1.enabled=true
结束子
私有子 timer1_timer()
dim doc,objhtml 作为对象
dim i 为整数
将 strhtml 淡化为字符串
如果不是浏览器1.忙则
设置 doc=webbrowser1.文档
i=0
设置 objhtml=doc.body.createtextrange()
如果不是 isnull(objhtml) 则
text1.text=objhtml.htmltext
如果结束
定时器1.enabled=false
如果结束
结束子
Dim doc, objhtml As Object
如果不是浏览器1.那么忙
设置 doc = webbrowser1.文档
设置 objhtml = doc.body.createtextrange()
If Not IsNull(objhtml) Then
text1.text=objhtml.htmltext
如果结束
设置文档 = 无
设置 objhtml = 无
如果结束
================================================ ==================================================== =
或者试试InternetReadFile,效果也不错:
选项显式
私有声明函数InternetOpen Lib“wininet.dll”别名“InternetOpenA”(_
ByVal sAgent As String,ByVal lAccessType As Long,_
ByVal sProxyName As String, ByVal sProxyBypass As String, _
ByVal lFlags As Long) As Long
私有声明函数InternetOpenUrl Lib“wininet.dll”别名“InternetOpenUrlA”(_
ByVal hInternetSession As Long, ByVal sUrl As String, _
ByVal sHeaders As String, ByVal lHeadersLength As Long, _
ByVal lFlags As Long, ByVal lContext As Long) As Long
私有声明函数 InternetReadFile Lib "wininet.dll" (_
ByVal hFile As Long, ByVal sBuffer As String, _
ByVal lNumBytesToRead As Long,_
lNumberOfBytesRead As Long) As Integer
私有声明函数 InternetCloseHandle Lib "wininet.dll" (_
ByVal hInet As Long) As Integer
私有常量 INTERNET_FLAG_NO_CACHE_WRITE = &H4000000
昏暗
私有函数GetUrlFile(stUrl As String) As String
把 lgInternet 调暗一样长,lgSession 一样长
将 stBuf 淡化为字符串 * 1024
将 inRes 变暗为整数
将lgRet调暗
将 stTotal 淡化为字符串
stTotal = vbNullString
lgSession = InternetOpen("VBTagEdit", 1, vbNullString, vbNullString, 0)
如果 lgSession 那么
lgInternet = InternetOpenUrl(lgSession, stUrl, vbNullString, _
0, INTERNET_FLAG_NO_CACHE_WRITE, 0)
如果 lgInternet 那么
做
inRes = InternetReadFile(lgInternet, stBuf, 1024, lgRet)
stTotal = stTotal & Mid$(stBuf, 1, lgRet)
Loop While (lgRet 0)
如果结束
inRes = InternetCloseHandle(lgInternet)
如果结束
GetUrlFile = stTotal
结束函数
私有子命令1_Click()
Text1.Text = GetUrlFile("")
结束子
================================================ ==================================================== ===
设置 vDoc = WebBrowser1.文档
'获取网页源代码
对于 vDoc.All 中的每个 o
DoEvents
htmlpage = htmlpage & o.innerHTML
下一步
然后用写二进制文件的方法将htmlpage的内容写入.html文件中。如果页面收录框架,则应处理该框架。
================================================ ==================================================== ======================
php抓取开奖网页内容(抓取自己公众号文章的还是最基本的,比较困难)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-20 22:03
php抓取开奖网页内容,进行数据筛选,去重分析,处理数据,生成excel,之后分析网站流量,地区,
有很多可以提取隐藏转发的。其实抓取外部公众号推送文章的还是最基本的,如果只是抓取抓取自己公众号文章的,比较困难,毕竟公众号太多了。可以先用模拟推送功能来推送有需要的文章,再推送消息,如果是抓取整个大号公众号的,就会好过多了。
到脉脉找
在刚刚过去的国庆中秋节,全国人民都过了一个“小长假”。大部分地区路不通,车不走,飞机票不一定买得到,朋友圈在美滋滋晒出了旅游的一瞬间——几个月前,发图回到老家过年;但在看着美滋滋的同时,有人在想,我们应该准备好哪些资料回家?怎么才能收获一个合适的旅行目的地?你问对人了!我最近听到了一个珍贵的消息,不一定要出去走走,但是可以收集一些国庆家乡的资料!这里要安利一个叫做“酒城故事”的公众号,他们会发布很多有意思、有价值的资料。
这个号主做了一个很有意思的事情:做一个小程序,在每一年的国庆节里,把自己知道的关于国庆的事情、故事、图片、文章在小程序里一并呈现出来,让你直接回家!如果你看到了什么,还想发挥你的想象力和创造力,欢迎联系!。
从微信公众号文章中就可以找到 查看全部
php抓取开奖网页内容(抓取自己公众号文章的还是最基本的,比较困难)
php抓取开奖网页内容,进行数据筛选,去重分析,处理数据,生成excel,之后分析网站流量,地区,
有很多可以提取隐藏转发的。其实抓取外部公众号推送文章的还是最基本的,如果只是抓取抓取自己公众号文章的,比较困难,毕竟公众号太多了。可以先用模拟推送功能来推送有需要的文章,再推送消息,如果是抓取整个大号公众号的,就会好过多了。
到脉脉找
在刚刚过去的国庆中秋节,全国人民都过了一个“小长假”。大部分地区路不通,车不走,飞机票不一定买得到,朋友圈在美滋滋晒出了旅游的一瞬间——几个月前,发图回到老家过年;但在看着美滋滋的同时,有人在想,我们应该准备好哪些资料回家?怎么才能收获一个合适的旅行目的地?你问对人了!我最近听到了一个珍贵的消息,不一定要出去走走,但是可以收集一些国庆家乡的资料!这里要安利一个叫做“酒城故事”的公众号,他们会发布很多有意思、有价值的资料。
这个号主做了一个很有意思的事情:做一个小程序,在每一年的国庆节里,把自己知道的关于国庆的事情、故事、图片、文章在小程序里一并呈现出来,让你直接回家!如果你看到了什么,还想发挥你的想象力和创造力,欢迎联系!。
从微信公众号文章中就可以找到
php抓取开奖网页内容(超级站群5.5版本(未加密版本)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-19 05:15
超级站群5.5版(未加密版)
一、泛分析模式 泛分析是网络上最火的模式!据说他走红是因为模特创造了神话!2012年造了7天重8,一直持续到2013年底,百度开始封杀。直到2014年底才慢慢恢复收录!但是收录的效果比之前差了很多!但是 10 个域名 收录 10,000 个条目就可以了!建议:此模式适用于长尾关键词。没有大批量竞争关键词!比如我卖手机!我们要批量挖掘手机的长尾关键词,比如北京手机便宜的网店卖的苹果手机等等,这些术语基本没有竞争!百度的收录之后 泛解析二级域名!有50%的几率进入百度前2页!你可能会问这个词基本上没有人搜索它!我想告诉你的是!搜索这个词的人并不多!基本上3天就遇到了一个搜索者!你可以数出来!如果一般分析站群收录有10000个页面,那么10000个关键词页面也有几十个!即使每天有 100 个 关键词 页面中的 1 个人访问我们的页面!每天有100个IP流量!泛解析方式1.需要批量的长尾没有竞争关键词越多越好2.需要批量的大量域名,因为一个域名收录是约1000个域名。一点效果都没有!二、 什么是蜘蛛池模式?蜘蛛就是我们所说的百度爬取网站地下IP,我们通常称它们为蜘蛛!看名字就知道蜘蛛池就是我们用批量域名搭建站群,让这些域名生成网站,所有的轮子都链在一起,蜘蛛爬行我们的< @站群,一直循环生成页面,蜘蛛是我们养的!蜘蛛池的作用:蜘蛛池的使用非常简单。比如我要让我的网站这个页面收录!我只需要覆盖链接并放入我们的站群!蜘蛛被引导到这个页面爬行!爬完百度就会收录!现在很多人用蜘蛛池来推断它是什么!外推是互联网上的一些高特权网站。如果他们的网站乱发一则垃圾,就算没有文章页面,也会立马被百度收录,别给排名!我们要做的外推就是在我们的关键词中加入我们的联系方式访问或者网站,并在这些大网站上留下页面痕迹,然后把这个页面的链接提交给我们的蜘蛛,让蜘蛛抓取这个页面!大家访问网站,右击选择源代码。我们可以在代码中看到这是页面的标题!我们程序蜘蛛池中的链接在哪里提交,然后百度蜘蛛爬取收录!有一定几率别人会搜索关键词 站群,你看我留下的东西会被推广!以上是我的解释!具体来说,那些大站可以是收录 排名需要自己搜索资源!三、什么是短网址模式?这是正确的。缩短我们的 网站 页面或 URL。当其他人访问这个短网址时,他们看到的是我们网站页面或网址的内容!我们的理论和上面解释的一样!使用工具生成我们泛分析生成的二级域名的短网址!然后链上依靠百度蜘蛛来收录这些短网址和排名!网上最火的就是最近出了问题,惹来不少麻烦收录!建议你找其他短网址来操作!有68个短网址生成器我们点赞数量增加了,大家可以看看!还有你从百度下载的短网址自己找相关网站!看看那些可以< @收录,大家好好学习!四、爱站 外推方式与上面提到的外推方式相同,但这是自动的。您可以选择加密版本的方式,并且不能修改帐户密码。点赞后发送完整程序!可以修改账号密码!第一步是批量域名解析到你的VPS或服务器!第二步:将站群程序上传到VPS或服务器!第三步:环境配置如果你的服务有php环境,则无需配置。如果没有,请下载php环境配置包!如果您不明白,请联系您的服务器提供商!但这是自动的。您可以选择加密版本的方式,并且不能修改帐户密码。点赞后发送完整程序!可以修改账号密码!第一步是批量域名解析到你的VPS或服务器!第二步:将站群程序上传到VPS或服务器!第三步:环境配置如果你的服务有php环境,则无需配置。如果没有,请下载php环境配置包!如果您不明白,请联系您的服务器提供商!但这是自动的。您可以选择加密版本的方式,并且不能修改帐户密码。点赞后发送完整程序!可以修改账号密码!第一步是批量域名解析到你的VPS或服务器!第二步:将站群程序上传到VPS或服务器!第三步:环境配置如果你的服务有php环境,则无需配置。如果没有,请下载php环境配置包!如果您不明白,请联系您的服务器提供商!程序到 VPS 或服务器!第三步:环境配置如果你的服务有php环境,则无需配置。如果没有,请下载php环境配置包!如果您不明白,请联系您的服务器提供商!程序到 VPS 或服务器!第三步:环境配置如果你的服务有php环境,则无需配置。如果没有,请下载php环境配置包!如果您不明白,请联系您的服务器提供商!
现在就下载 查看全部
php抓取开奖网页内容(超级站群5.5版本(未加密版本)(组图))
超级站群5.5版(未加密版)
一、泛分析模式 泛分析是网络上最火的模式!据说他走红是因为模特创造了神话!2012年造了7天重8,一直持续到2013年底,百度开始封杀。直到2014年底才慢慢恢复收录!但是收录的效果比之前差了很多!但是 10 个域名 收录 10,000 个条目就可以了!建议:此模式适用于长尾关键词。没有大批量竞争关键词!比如我卖手机!我们要批量挖掘手机的长尾关键词,比如北京手机便宜的网店卖的苹果手机等等,这些术语基本没有竞争!百度的收录之后 泛解析二级域名!有50%的几率进入百度前2页!你可能会问这个词基本上没有人搜索它!我想告诉你的是!搜索这个词的人并不多!基本上3天就遇到了一个搜索者!你可以数出来!如果一般分析站群收录有10000个页面,那么10000个关键词页面也有几十个!即使每天有 100 个 关键词 页面中的 1 个人访问我们的页面!每天有100个IP流量!泛解析方式1.需要批量的长尾没有竞争关键词越多越好2.需要批量的大量域名,因为一个域名收录是约1000个域名。一点效果都没有!二、 什么是蜘蛛池模式?蜘蛛就是我们所说的百度爬取网站地下IP,我们通常称它们为蜘蛛!看名字就知道蜘蛛池就是我们用批量域名搭建站群,让这些域名生成网站,所有的轮子都链在一起,蜘蛛爬行我们的< @站群,一直循环生成页面,蜘蛛是我们养的!蜘蛛池的作用:蜘蛛池的使用非常简单。比如我要让我的网站这个页面收录!我只需要覆盖链接并放入我们的站群!蜘蛛被引导到这个页面爬行!爬完百度就会收录!现在很多人用蜘蛛池来推断它是什么!外推是互联网上的一些高特权网站。如果他们的网站乱发一则垃圾,就算没有文章页面,也会立马被百度收录,别给排名!我们要做的外推就是在我们的关键词中加入我们的联系方式访问或者网站,并在这些大网站上留下页面痕迹,然后把这个页面的链接提交给我们的蜘蛛,让蜘蛛抓取这个页面!大家访问网站,右击选择源代码。我们可以在代码中看到这是页面的标题!我们程序蜘蛛池中的链接在哪里提交,然后百度蜘蛛爬取收录!有一定几率别人会搜索关键词 站群,你看我留下的东西会被推广!以上是我的解释!具体来说,那些大站可以是收录 排名需要自己搜索资源!三、什么是短网址模式?这是正确的。缩短我们的 网站 页面或 URL。当其他人访问这个短网址时,他们看到的是我们网站页面或网址的内容!我们的理论和上面解释的一样!使用工具生成我们泛分析生成的二级域名的短网址!然后链上依靠百度蜘蛛来收录这些短网址和排名!网上最火的就是最近出了问题,惹来不少麻烦收录!建议你找其他短网址来操作!有68个短网址生成器我们点赞数量增加了,大家可以看看!还有你从百度下载的短网址自己找相关网站!看看那些可以< @收录,大家好好学习!四、爱站 外推方式与上面提到的外推方式相同,但这是自动的。您可以选择加密版本的方式,并且不能修改帐户密码。点赞后发送完整程序!可以修改账号密码!第一步是批量域名解析到你的VPS或服务器!第二步:将站群程序上传到VPS或服务器!第三步:环境配置如果你的服务有php环境,则无需配置。如果没有,请下载php环境配置包!如果您不明白,请联系您的服务器提供商!但这是自动的。您可以选择加密版本的方式,并且不能修改帐户密码。点赞后发送完整程序!可以修改账号密码!第一步是批量域名解析到你的VPS或服务器!第二步:将站群程序上传到VPS或服务器!第三步:环境配置如果你的服务有php环境,则无需配置。如果没有,请下载php环境配置包!如果您不明白,请联系您的服务器提供商!但这是自动的。您可以选择加密版本的方式,并且不能修改帐户密码。点赞后发送完整程序!可以修改账号密码!第一步是批量域名解析到你的VPS或服务器!第二步:将站群程序上传到VPS或服务器!第三步:环境配置如果你的服务有php环境,则无需配置。如果没有,请下载php环境配置包!如果您不明白,请联系您的服务器提供商!程序到 VPS 或服务器!第三步:环境配置如果你的服务有php环境,则无需配置。如果没有,请下载php环境配置包!如果您不明白,请联系您的服务器提供商!程序到 VPS 或服务器!第三步:环境配置如果你的服务有php环境,则无需配置。如果没有,请下载php环境配置包!如果您不明白,请联系您的服务器提供商!
现在就下载
php抓取开奖网页内容(php抓取开奖网页内容,解析字段值,比如验证码:basketball,等等,然后拼接或者翻页,短短两句话,想到)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-14 00:00
php抓取开奖网页内容,解析字段值,比如验证码:basketball,all-onepatches等等,然后拼接或者翻页,
短短两句话,想到的是vba+cookie,不过同事是直接用微软系列vb。中途会跳转其他页面,
对你这种刚毕业的人应该不难实现
<p>想到一种,文件目录下,php目录下,找到banner.php文件,然后通过 查看全部
php抓取开奖网页内容(php抓取开奖网页内容,解析字段值,比如验证码:basketball,等等,然后拼接或者翻页,短短两句话,想到)
php抓取开奖网页内容,解析字段值,比如验证码:basketball,all-onepatches等等,然后拼接或者翻页,
短短两句话,想到的是vba+cookie,不过同事是直接用微软系列vb。中途会跳转其他页面,
对你这种刚毕业的人应该不难实现
<p>想到一种,文件目录下,php目录下,找到banner.php文件,然后通过
php抓取开奖网页内容(很好用!app的返利有没有,多少??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-06 17:03
php抓取开奖网页内容,用于推送程序出售。用http协议,通过id找到本期开奖号码的期望值。0号以0开头,1号以1开头,2号以2开头。如果你不知道,就能从我的文章里获取。
大部分的站长都有自己搭建返利网站,然后把网站挂在各种百度联盟。百度都会拿返利来作为广告联盟的出价。别家站点的站长自己搭建返利网站,
返利app后台是做为推广app的跳板,而推广app本身是需要推广费用的。
app有,返利是可以定金返,押金返,现金返。甚至返全返。返利网站是站长接入返利返的网站,自己搭建返利站点,定时上活动,自然定期返利出来。自己定时上活动,自然要收费,这个是合理的。
大家都懂的我只说一句话,只有大app才会返利,
我是用户!!!很好用!
app的返利有没有,多少?返利网的返利有没有,多少?我没有去看过,不好说。但是可以说下我了解到的情况。返利一般针对的都是老用户,而且是相对较高的用户,相对来说是一条不断升级、不断强大、不断持续增长的好产品!这点相信大家也深有体会!另外,我是用返利app,很好用,很方便,也不用担心漏发了或者少发了,收到的返利都在服务号上,很方便。 查看全部
php抓取开奖网页内容(很好用!app的返利有没有,多少??)
php抓取开奖网页内容,用于推送程序出售。用http协议,通过id找到本期开奖号码的期望值。0号以0开头,1号以1开头,2号以2开头。如果你不知道,就能从我的文章里获取。
大部分的站长都有自己搭建返利网站,然后把网站挂在各种百度联盟。百度都会拿返利来作为广告联盟的出价。别家站点的站长自己搭建返利网站,
返利app后台是做为推广app的跳板,而推广app本身是需要推广费用的。
app有,返利是可以定金返,押金返,现金返。甚至返全返。返利网站是站长接入返利返的网站,自己搭建返利站点,定时上活动,自然定期返利出来。自己定时上活动,自然要收费,这个是合理的。
大家都懂的我只说一句话,只有大app才会返利,
我是用户!!!很好用!
app的返利有没有,多少?返利网的返利有没有,多少?我没有去看过,不好说。但是可以说下我了解到的情况。返利一般针对的都是老用户,而且是相对较高的用户,相对来说是一条不断升级、不断强大、不断持续增长的好产品!这点相信大家也深有体会!另外,我是用返利app,很好用,很方便,也不用担心漏发了或者少发了,收到的返利都在服务号上,很方便。
php抓取开奖网页内容(python代码解析题目+beautifulsoup加代理池就可以了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-03 02:03
php抓取开奖网页内容免费分析,解析关键词,提取题目,下载题目等等。scrapy前端自动代理,实现代理转发,python代码解析,将提取到的关键词,上传到某网站,返回给seoer。python后端程序用selenium或者lxml解析抓取信息,对关键词进行下载,然后上传到某网站。
tornado基于urllib2,解析url并生成booklet,然后循环抓取的文件。
python代码解析题目
requests+beautifulsoup应该可以吧,
看样子应该是抓取了几千关键词组成的文档然后用这些关键词生成文档内容然后再从文档中提取你要的这个没事抓个零零碎碎的总行吧
理论上是可以的,可以爬虫只爬那些简单的,或者走简单的中转站高阶代理,比如借助防火墙绕过代理而跳转,或者用代理池。
支持!探寻终极大招,从金融入手,好像主要是金融经济类,但这个方向已经有大量的案例,目标是银行,券商等,bfs、boost等爬虫系统即可。
python加boost加代理池就可以了啊
如果是个人理解的是,那么从python抓手写一个爬虫程序,单机就可以抓取相关网站页面数据,解析出题目内容,document文件提交到系统进行统计或分析等, 查看全部
php抓取开奖网页内容(python代码解析题目+beautifulsoup加代理池就可以了)
php抓取开奖网页内容免费分析,解析关键词,提取题目,下载题目等等。scrapy前端自动代理,实现代理转发,python代码解析,将提取到的关键词,上传到某网站,返回给seoer。python后端程序用selenium或者lxml解析抓取信息,对关键词进行下载,然后上传到某网站。
tornado基于urllib2,解析url并生成booklet,然后循环抓取的文件。
python代码解析题目
requests+beautifulsoup应该可以吧,
看样子应该是抓取了几千关键词组成的文档然后用这些关键词生成文档内容然后再从文档中提取你要的这个没事抓个零零碎碎的总行吧
理论上是可以的,可以爬虫只爬那些简单的,或者走简单的中转站高阶代理,比如借助防火墙绕过代理而跳转,或者用代理池。
支持!探寻终极大招,从金融入手,好像主要是金融经济类,但这个方向已经有大量的案例,目标是银行,券商等,bfs、boost等爬虫系统即可。
python加boost加代理池就可以了啊
如果是个人理解的是,那么从python抓手写一个爬虫程序,单机就可以抓取相关网站页面数据,解析出题目内容,document文件提交到系统进行统计或分析等,
php抓取开奖网页内容(全国第一大框架,wordpresswordpress,框架下载-慕课网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-02 22:03
php抓取开奖网页内容:javascript抓取js文件:
..
现在基本都用requests了吧,get方法的效率太低,又不安全。selenium不也用不安全吗,在服务器上存也麻烦。fiddler代理也不稳定,还是要使用selenium。laravel的trimjs解析php代码也不方便,那肯定是selenium最好。
简单的看看这个
mysql和sqlserver都行,不过最终都会通过httpapilibrarylibmgrr里去拿,楼上说的很详细了,现在开源社区也比较成熟了,基本不用自己写了。
推荐自己写laravel
可以的,现在采用比较多的是requests,具体的laravel项目-laravel,hibernate,mybatis,struts框架的全国第一大php框架,wordpress框架下载-慕课网,我目前用的是tap的。
我觉得可以postman比起一般爬虫肯定是方便,但是比如需要用到事务的就不方便了,比如订单的就不方便,
这种要看你是做什么方面了我简单介绍下我自己的个人经验shopify有配套的抓取工具包,postman比较流行,
不太同意第一个答案看来是没有在github或者其他地方看到过python爬虫框架... 查看全部
php抓取开奖网页内容(全国第一大框架,wordpresswordpress,框架下载-慕课网)
php抓取开奖网页内容:javascript抓取js文件:
..
现在基本都用requests了吧,get方法的效率太低,又不安全。selenium不也用不安全吗,在服务器上存也麻烦。fiddler代理也不稳定,还是要使用selenium。laravel的trimjs解析php代码也不方便,那肯定是selenium最好。
简单的看看这个
mysql和sqlserver都行,不过最终都会通过httpapilibrarylibmgrr里去拿,楼上说的很详细了,现在开源社区也比较成熟了,基本不用自己写了。
推荐自己写laravel
可以的,现在采用比较多的是requests,具体的laravel项目-laravel,hibernate,mybatis,struts框架的全国第一大php框架,wordpress框架下载-慕课网,我目前用的是tap的。
我觉得可以postman比起一般爬虫肯定是方便,但是比如需要用到事务的就不方便了,比如订单的就不方便,
这种要看你是做什么方面了我简单介绍下我自己的个人经验shopify有配套的抓取工具包,postman比较流行,
不太同意第一个答案看来是没有在github或者其他地方看到过python爬虫框架...
php抓取开奖网页内容(中国体育彩票超级大乐透爬取代码grab500_dlt.py.dlt)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-30 14:05
经调研发现,中国福彩双色球每周21:15开奖二、四、,中国体彩超级乐透每周六21:30开奖一、< @三、 ,而我们要完成的目标是:
1、自动完成安装工作
2、每周晚23:00二、四、,爬取每周晚23:00中福彩票双色球开奖数据一、< @三、 抓取中国体彩超级乐透开奖数据。
1、工具
2、具体方法1、使用python2.7写爬虫脚本
除了正常的爬取操作,这里还增加了独立的参数设置。如果没有参数,则抓取到的数据在当前目录;如果有参数,可以设置保存目录和保存文件名后缀。在这种情况下,此脚本可以单独使用,也可以与 sh 计时任务结合使用。
二色球爬行的grab500_ssq.py代码内容:
# -*- coding:utf-8 -*-
import re
import urllib
import time
import sys
datapath = sys.path[0]
datasuffix = 'txt'
if (len(sys.argv)>1):
datapath = sys.argv[1]
datasuffix = sys.argv[2]
def getHtml(url):
html = urllib.urlopen(url)
return html.read()
html = getHtml("http://zx.500.com/ssq/")
reg = ['([0-9]\d*).*']
reg.append('([0-9]\d*)')
reg.append('([0-9]\d*)')
outstr = "";
for i in range(len(reg)):
page = re.compile(reg[i])
rs = re.findall(page,html)
for j in range(len(rs)):
outstr+= rs[j] + ","
#print time.strftime('%Y-%m-%d',time.localtime(time.time()))+":"+outstr[:-1]
with open(datapath+'/lot_500_ssq.'+datasuffix, 'a') as f:
f.write(time.strftime('%Y-%m-%d',time.localtime(time.time()))+":"+outstr[:-1]+'\n')
DaLotto爬取代码grab500_dlt.py内容:
# -*- coding:utf-8 -*-
import re
import urllib
import time
import sys
datapath = sys.path[0]
datasuffix ='txt'
if(len(sys.argv)>1):
datapath = sys.argv[1]
datasuffix = sys.argv[2]
defgetHtml(url):
html = urllib.urlopen(url)
return html.read()
html = getHtml("http://zx.500.com/dlt/")
reg =['([0-9]\d*).*']
reg.append('([0-9]\d*)')
reg.append('([0-9]\d*)')
outstr ="";
for i in range(len(reg)):
page = re.compile(reg[i])
rs = re.findall(page,html)
for j in range(len(rs)):
outstr+= rs[j]+","
#print time.strftime('%Y-%m-%d',time.localtime(time.time()))+":"+outstr[:-1]
with open(datapath+'/lot_500_dlt.'+datasuffix,'a')as f:
f.write(time.strftime('%Y-%m-%d',time.localtime(time.time()))+":"+outstr[:-1]+'\n')
2、编写一个可执行的sh脚本
我们需要编写执行python的sh脚本bwb_lottery_everyday.sh。需要注意的是sh date得到的星期日值是0而不是7,crontab可以设置为0或7。
#!/bin/sh
basepath=$(cd `dirname $0`; pwd) #shell's dir
datapath=$basepath'/lotterydata' #shell's datadir
datasuffix='txt' #datasuffix
a=`date -d "${date}" +%w`
if [ $a -eq 1 ] || [ $a -eq 3 ] || [ $a -eq 6 ]; then
python "${basepath}/grab500_ssq.py" $datapath $datasuffix
elif [ $a -eq 2 ] || [ $a -eq 4 ] || [ $a -eq 0 ]; then
python "${basepath}/grab500_dlt.py" $datapath $datasuffix
fi
3、写一个主sh脚本
编写一个主 sh 脚本 bwb_lottery_main.sh 来执行清理和设置任务。需要注意的是,这里直接使用系统的/etc/crontab文件来达到周期性执行的目的,不是很好,但是crontab -e方法很难自动化,所以只能设置为系统任务。
#!/bin/sh
cronfile="/etc/crontab" #debian cronfile
basepath=$(cd `dirname $0`; pwd) #shell's dir
datapath=$basepath'/lotterydata' #shell's datadir
datasuffix='txt' #datasuffix
crontaskname="bwb_lottery_everyday.sh" #shell's name
crontasktime="0 23\t* * 1-4,6-7" #crontab task run time,default everyday except friday 23:00
echo "checking..."
if [ ! -f ${cronfile} ]; then
echo "crontab file $cronfile doesn't exsits.\nplease check file or modify shell setting and run shell again."
exit 1
fi
pyver=`python -V 2>&1|awk '{print $2}'|awk -F '.' '{print $1}'`
if [ $pyver != '2' ]; then
echo "python2(.7) is needed."
exit 1
fi
echo "writing crontab file..."
if [ `grep -c "${crontaskname}" ${cronfile}` -eq '0' ]; then
echo "${crontasktime}\troot\t${basepath}/${crontaskname}">>${cronfile}
else
sed -i "s#^.*${crontaskname}.*#${crontasktime}\troot\t${basepath}/${crontaskname}#" ${cronfile}
fi
/etc/init.d/cron restart
echo "making data dir..."
if [ ! -d "${datapath}" ]; then
mkdir ${datapath}
else
if [ ! -d "${datapath}/bak" ]; then
mkdir "${datapath}/bak"
else
mv ${datapath}/*.${datasuffix} ${datapath}/bak/ 2>/dev/null
fi
fi
echo "changing permission..."
chmod +x "$basepath/$crontaskname"
chmod +w -R $datapath
echo "finished!"
最后,我们只需要执行这个主脚本,就可以一键自动完成彩票爬虫的布局。
完整的项目代码已经上传到github~
/BEWINDOWEB/lotterygrabber
欢迎提交 watch、star、fork 质量三元组并提交 issue。 查看全部
php抓取开奖网页内容(中国体育彩票超级大乐透爬取代码grab500_dlt.py.dlt)
经调研发现,中国福彩双色球每周21:15开奖二、四、,中国体彩超级乐透每周六21:30开奖一、< @三、 ,而我们要完成的目标是:
1、自动完成安装工作
2、每周晚23:00二、四、,爬取每周晚23:00中福彩票双色球开奖数据一、< @三、 抓取中国体彩超级乐透开奖数据。
1、工具

2、具体方法1、使用python2.7写爬虫脚本
除了正常的爬取操作,这里还增加了独立的参数设置。如果没有参数,则抓取到的数据在当前目录;如果有参数,可以设置保存目录和保存文件名后缀。在这种情况下,此脚本可以单独使用,也可以与 sh 计时任务结合使用。
二色球爬行的grab500_ssq.py代码内容:
# -*- coding:utf-8 -*-
import re
import urllib
import time
import sys
datapath = sys.path[0]
datasuffix = 'txt'
if (len(sys.argv)>1):
datapath = sys.argv[1]
datasuffix = sys.argv[2]
def getHtml(url):
html = urllib.urlopen(url)
return html.read()
html = getHtml("http://zx.500.com/ssq/";)
reg = ['([0-9]\d*).*']
reg.append('([0-9]\d*)')
reg.append('([0-9]\d*)')
outstr = "";
for i in range(len(reg)):
page = re.compile(reg[i])
rs = re.findall(page,html)
for j in range(len(rs)):
outstr+= rs[j] + ","
#print time.strftime('%Y-%m-%d',time.localtime(time.time()))+":"+outstr[:-1]
with open(datapath+'/lot_500_ssq.'+datasuffix, 'a') as f:
f.write(time.strftime('%Y-%m-%d',time.localtime(time.time()))+":"+outstr[:-1]+'\n')
DaLotto爬取代码grab500_dlt.py内容:
# -*- coding:utf-8 -*-
import re
import urllib
import time
import sys
datapath = sys.path[0]
datasuffix ='txt'
if(len(sys.argv)>1):
datapath = sys.argv[1]
datasuffix = sys.argv[2]
defgetHtml(url):
html = urllib.urlopen(url)
return html.read()
html = getHtml("http://zx.500.com/dlt/";)
reg =['([0-9]\d*).*']
reg.append('([0-9]\d*)')
reg.append('([0-9]\d*)')
outstr ="";
for i in range(len(reg)):
page = re.compile(reg[i])
rs = re.findall(page,html)
for j in range(len(rs)):
outstr+= rs[j]+","
#print time.strftime('%Y-%m-%d',time.localtime(time.time()))+":"+outstr[:-1]
with open(datapath+'/lot_500_dlt.'+datasuffix,'a')as f:
f.write(time.strftime('%Y-%m-%d',time.localtime(time.time()))+":"+outstr[:-1]+'\n')
2、编写一个可执行的sh脚本
我们需要编写执行python的sh脚本bwb_lottery_everyday.sh。需要注意的是sh date得到的星期日值是0而不是7,crontab可以设置为0或7。
#!/bin/sh
basepath=$(cd `dirname $0`; pwd) #shell's dir
datapath=$basepath'/lotterydata' #shell's datadir
datasuffix='txt' #datasuffix
a=`date -d "${date}" +%w`
if [ $a -eq 1 ] || [ $a -eq 3 ] || [ $a -eq 6 ]; then
python "${basepath}/grab500_ssq.py" $datapath $datasuffix
elif [ $a -eq 2 ] || [ $a -eq 4 ] || [ $a -eq 0 ]; then
python "${basepath}/grab500_dlt.py" $datapath $datasuffix
fi
3、写一个主sh脚本
编写一个主 sh 脚本 bwb_lottery_main.sh 来执行清理和设置任务。需要注意的是,这里直接使用系统的/etc/crontab文件来达到周期性执行的目的,不是很好,但是crontab -e方法很难自动化,所以只能设置为系统任务。
#!/bin/sh
cronfile="/etc/crontab" #debian cronfile
basepath=$(cd `dirname $0`; pwd) #shell's dir
datapath=$basepath'/lotterydata' #shell's datadir
datasuffix='txt' #datasuffix
crontaskname="bwb_lottery_everyday.sh" #shell's name
crontasktime="0 23\t* * 1-4,6-7" #crontab task run time,default everyday except friday 23:00
echo "checking..."
if [ ! -f ${cronfile} ]; then
echo "crontab file $cronfile doesn't exsits.\nplease check file or modify shell setting and run shell again."
exit 1
fi
pyver=`python -V 2>&1|awk '{print $2}'|awk -F '.' '{print $1}'`
if [ $pyver != '2' ]; then
echo "python2(.7) is needed."
exit 1
fi
echo "writing crontab file..."
if [ `grep -c "${crontaskname}" ${cronfile}` -eq '0' ]; then
echo "${crontasktime}\troot\t${basepath}/${crontaskname}">>${cronfile}
else
sed -i "s#^.*${crontaskname}.*#${crontasktime}\troot\t${basepath}/${crontaskname}#" ${cronfile}
fi
/etc/init.d/cron restart
echo "making data dir..."
if [ ! -d "${datapath}" ]; then
mkdir ${datapath}
else
if [ ! -d "${datapath}/bak" ]; then
mkdir "${datapath}/bak"
else
mv ${datapath}/*.${datasuffix} ${datapath}/bak/ 2>/dev/null
fi
fi
echo "changing permission..."
chmod +x "$basepath/$crontaskname"
chmod +w -R $datapath
echo "finished!"
最后,我们只需要执行这个主脚本,就可以一键自动完成彩票爬虫的布局。
完整的项目代码已经上传到github~
/BEWINDOWEB/lotterygrabber
欢迎提交 watch、star、fork 质量三元组并提交 issue。
php抓取开奖网页内容(如何提高PHP表单的安全性?(实例运行实例分析))
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-28 08:13
实例
Name:
E-mail:
运行实例
“welcome_get.php”是这样的:
Welcome
Your email address is:
上面的代码非常简单。然而,最重要的内容被遗漏了。您需要验证表单数据以防止脚本中出现漏洞。
注意:处理PHP表单时请注意安全!
此页面不收录任何表单验证器,它仅向我们展示如何发送和接收表单数据。
但是后面的章节会讲解如何提高PHP表单的安全性!表单的正确安全验证对于防御黑客攻击和垃圾邮件非常重要!
GET 与 POST
GET 和 POST 都创建数组(例如,array( key => value, key2 => value2, key3 => value3, ...))。该数组收录键/值对,其中键是表单控件的名称,值是来自用户的输入数据。
GET 和 POST 被视为 $_GET 和 $_POST。它们是超全局变量,这意味着它们可以被访问而无需考虑作用域——无需任何特殊代码,您可以从任何函数、类或文件访问它们。
$_GET 是通过 URL 参数传递给当前脚本的变量数组。
$_POST 是通过 HTTP POST 传递给当前脚本的变量数组。
什么时候使用 GET?
通过 GET 方法从表单发送的信息对任何人都是可见的(所有变量名和值都显示在 URL 中)。GET 对发送的信息量也有限制。限制为大约 2000 个字符。但是,由于该变量显示在 URL 中,因此将页面添加到书签中也更加方便。
GET 可用于发送非敏感数据。
注意:切勿使用 GET 发送密码或其他敏感信息!
什么时候使用POST?
表单通过POST方式发送的信息对其他人是不可见的(所有的名称/值都会嵌入到HTTP请求的正文中),发送的信息量没有限制。
此外,POST 支持高级功能,例如上传文件到服务器时的多部分二进制输入。
但是,由于该变量未显示在 URL 中,因此无法为该页面添加书签。
提示:开发人员更喜欢 POST 发送表单数据。
接下来让我们看看如何安全地处理PHP表单! 查看全部
php抓取开奖网页内容(如何提高PHP表单的安全性?(实例运行实例分析))
实例
Name:
E-mail:
运行实例
“welcome_get.php”是这样的:
Welcome
Your email address is:
上面的代码非常简单。然而,最重要的内容被遗漏了。您需要验证表单数据以防止脚本中出现漏洞。
注意:处理PHP表单时请注意安全!
此页面不收录任何表单验证器,它仅向我们展示如何发送和接收表单数据。
但是后面的章节会讲解如何提高PHP表单的安全性!表单的正确安全验证对于防御黑客攻击和垃圾邮件非常重要!
GET 与 POST
GET 和 POST 都创建数组(例如,array( key => value, key2 => value2, key3 => value3, ...))。该数组收录键/值对,其中键是表单控件的名称,值是来自用户的输入数据。
GET 和 POST 被视为 $_GET 和 $_POST。它们是超全局变量,这意味着它们可以被访问而无需考虑作用域——无需任何特殊代码,您可以从任何函数、类或文件访问它们。
$_GET 是通过 URL 参数传递给当前脚本的变量数组。
$_POST 是通过 HTTP POST 传递给当前脚本的变量数组。
什么时候使用 GET?
通过 GET 方法从表单发送的信息对任何人都是可见的(所有变量名和值都显示在 URL 中)。GET 对发送的信息量也有限制。限制为大约 2000 个字符。但是,由于该变量显示在 URL 中,因此将页面添加到书签中也更加方便。
GET 可用于发送非敏感数据。
注意:切勿使用 GET 发送密码或其他敏感信息!
什么时候使用POST?
表单通过POST方式发送的信息对其他人是不可见的(所有的名称/值都会嵌入到HTTP请求的正文中),发送的信息量没有限制。
此外,POST 支持高级功能,例如上传文件到服务器时的多部分二进制输入。
但是,由于该变量未显示在 URL 中,因此无法为该页面添加书签。
提示:开发人员更喜欢 POST 发送表单数据。
接下来让我们看看如何安全地处理PHP表单!
php抓取开奖网页内容(我想从网页的script标记中获取特定内容内容。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-26 12:11
我想从网页的脚本标签中获取特定内容。
这是一个 HTML 页面。
//some other srcipt code
//some other srcipt code
var abc = {"asld":"asdjk","thisone":"https:\/\/www.example.com\/$N.jpg|#1000#M$M#JSuL8|1000#M$M#fW4EC0jcOl8kUY_QBZbOASsF8t0","user_gender":"m"};
我只想得到这个值 fW4EC0jcOl8kUY_QBZbOASsF8t0,它位于脚本变量 thisone 中 var abc 的最后一个属性中。
我可以使用 PHP HTML DOM 来做到这一点吗?如果没有,我该怎么办
最佳答案
您可以使用正则表达式轻松获取它
"thisone":".*#(.*)",
假设页面是,
$data = file_get_contents('http://example.com');
preg_match_all("/\"thisone\":\".*#(.*)\",/", $data, $output);
echo $output[1][0]; // prints fW4EC0jcOl8kUY_QBZbOASsF8t0
希望有帮助!
关于javascript-using PHP to get script content from web pages,我们在Stack Overflow上发现了一个类似的问题: 查看全部
php抓取开奖网页内容(我想从网页的script标记中获取特定内容内容。)
我想从网页的脚本标签中获取特定内容。
这是一个 HTML 页面。
//some other srcipt code
//some other srcipt code
var abc = {"asld":"asdjk","thisone":"https:\/\/www.example.com\/$N.jpg|#1000#M$M#JSuL8|1000#M$M#fW4EC0jcOl8kUY_QBZbOASsF8t0","user_gender":"m"};
我只想得到这个值 fW4EC0jcOl8kUY_QBZbOASsF8t0,它位于脚本变量 thisone 中 var abc 的最后一个属性中。
我可以使用 PHP HTML DOM 来做到这一点吗?如果没有,我该怎么办
最佳答案
您可以使用正则表达式轻松获取它
"thisone":".*#(.*)",
假设页面是,
$data = file_get_contents('http://example.com');
preg_match_all("/\"thisone\":\".*#(.*)\",/", $data, $output);
echo $output[1][0]; // prints fW4EC0jcOl8kUY_QBZbOASsF8t0
希望有帮助!
关于javascript-using PHP to get script content from web pages,我们在Stack Overflow上发现了一个类似的问题:
php抓取开奖网页内容(php抓取开奖网页内容,然后用php去拼接就可以了,获取效率很高!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-10-14 05:03
php抓取开奖网页内容,然后用php去拼接就可以了,获取效率很高!比简单爬虫快n多倍.5万个点中5个,获取100万个点的奖组信息,用这个爬虫真的要下很大功夫!如果觉得我解答得也还受用,也欢迎加入我新开的wx群,我们一帮人在里面交流基金投资心得,每周周末都会分享基金投资的知识和经验。
1.点一下鼠标2.按住鼠标左键不放3.摇一摇鼠标4.选中所有的内容。也可以用来做数据分析。
http请求抓取
刚刚在下载一次软件,还是的软件,说需要两个对象,需要把一个软件可能生成的内容都用一个对象记录下来,然后转换成html格式的话,也就是要从各个数据库字段进行转换,也就是要查找有没有库可以进行数据查询,因为我用的是phpweb开发语言。
python,php我就是这么下载抓取数据的。你这么问就是嫌简单。
加粗那条,
知乎不是百度知道,百度上搜半天只是皮毛,你不嫌复杂,你就去找个比这难一点的。如果你实在想找个没有这个框框的方案,给你个思路。1.找到任何一个你想抓取的页面,然后打开看看2.这页你看见了什么?从哪个网站过来?下一页就是什么?3.看起来你啥都不知道,就去搜索下,看看知乎上是否也有人有一样的问题?总结一下:想快速下载任何内容,首先你要明白你要抓取什么内容。
对于你所说的几十秒获取50w个登录数据,我想应该不是登录数据,只是普通的页面下载数据。简单有效的快速下载方案:登录次数:1秒快速下载页数:50w这样来看,你离快速下载和查看都比较远,如果你愿意折腾的话。 查看全部
php抓取开奖网页内容(php抓取开奖网页内容,然后用php去拼接就可以了,获取效率很高!)
php抓取开奖网页内容,然后用php去拼接就可以了,获取效率很高!比简单爬虫快n多倍.5万个点中5个,获取100万个点的奖组信息,用这个爬虫真的要下很大功夫!如果觉得我解答得也还受用,也欢迎加入我新开的wx群,我们一帮人在里面交流基金投资心得,每周周末都会分享基金投资的知识和经验。
1.点一下鼠标2.按住鼠标左键不放3.摇一摇鼠标4.选中所有的内容。也可以用来做数据分析。
http请求抓取
刚刚在下载一次软件,还是的软件,说需要两个对象,需要把一个软件可能生成的内容都用一个对象记录下来,然后转换成html格式的话,也就是要从各个数据库字段进行转换,也就是要查找有没有库可以进行数据查询,因为我用的是phpweb开发语言。
python,php我就是这么下载抓取数据的。你这么问就是嫌简单。
加粗那条,
知乎不是百度知道,百度上搜半天只是皮毛,你不嫌复杂,你就去找个比这难一点的。如果你实在想找个没有这个框框的方案,给你个思路。1.找到任何一个你想抓取的页面,然后打开看看2.这页你看见了什么?从哪个网站过来?下一页就是什么?3.看起来你啥都不知道,就去搜索下,看看知乎上是否也有人有一样的问题?总结一下:想快速下载任何内容,首先你要明白你要抓取什么内容。
对于你所说的几十秒获取50w个登录数据,我想应该不是登录数据,只是普通的页面下载数据。简单有效的快速下载方案:登录次数:1秒快速下载页数:50w这样来看,你离快速下载和查看都比较远,如果你愿意折腾的话。
php抓取开奖网页内容(php抓取开奖网页内容,收集实时当前所有球赛的状态)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-07 12:02
php抓取开奖网页内容,收集实时当前所有球赛的状态(大小分,是否公开比赛等)并存入mysql数据库。机器配置需要安装相应的php运行环境。1.打开开源的php-domain我这里php-domain安装在php的目录下(mysql)2.配置php-domain站点(要求其它php支持)fornamein$name;doecho$php-domain-from$name;//通过[]函数从目录下读取站点名称formyein$mye;doecho$php-domain-from$mye;//通过[]函数从站点获取某个ip,用#号隔开forphpin$php;doecho$php-domain-from$php;//通过[]函数获取相应的mysql数据库名称并用![]打头连接即可foremailin$email;doecho$php-domain-from$email;//通过[]函数将email_email这个命令切换到email_email这个目录下foraddressin$address;doecho$php-domain-from$address;//通过[]函数将address_addr这个命令切换到addr_addr这个目录下3.创建在线球赛.创建人名,只是个字符串sed's/ai/ujkvkind/$uk/'//大小分uck#php没有引入php-domain的字符串;必须要加上![]或者![]php-domain。 查看全部
php抓取开奖网页内容(php抓取开奖网页内容,收集实时当前所有球赛的状态)
php抓取开奖网页内容,收集实时当前所有球赛的状态(大小分,是否公开比赛等)并存入mysql数据库。机器配置需要安装相应的php运行环境。1.打开开源的php-domain我这里php-domain安装在php的目录下(mysql)2.配置php-domain站点(要求其它php支持)fornamein$name;doecho$php-domain-from$name;//通过[]函数从目录下读取站点名称formyein$mye;doecho$php-domain-from$mye;//通过[]函数从站点获取某个ip,用#号隔开forphpin$php;doecho$php-domain-from$php;//通过[]函数获取相应的mysql数据库名称并用![]打头连接即可foremailin$email;doecho$php-domain-from$email;//通过[]函数将email_email这个命令切换到email_email这个目录下foraddressin$address;doecho$php-domain-from$address;//通过[]函数将address_addr这个命令切换到addr_addr这个目录下3.创建在线球赛.创建人名,只是个字符串sed's/ai/ujkvkind/$uk/'//大小分uck#php没有引入php-domain的字符串;必须要加上![]或者![]php-domain。
php抓取开奖网页内容(内蒙古聚富彩系统php抓取开奖网页内容--php)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-01-20 11:05
php抓取开奖网页内容。比如:以上就是网址。抓取的内容保存在数据库中。编写php代码抓取开奖结果。
1、关于第二点问题,取样三个ip地址,采样三次,
2、关于第四点问题,取样两次,
3、相同地址的,都一样,
4、整理图表的结论可以写成:-1-2.3-4.第一,请不要再@我。我本人没有任何开发能力;第二,没法处理爬虫;第三,自己没有抓取过关注数据,不知道准确的爬取后整理数据能力;所以提出的方案全是自己的一厢情愿;总结:抓取网站上面的开奖数据。然后自己想可以做什么。
正规途径已经很少了。主要是现在的开奖平台,都是机器或者人工在发短信,发邮件。然后把随机号段转发给程序员。然后他们就可以拿开奖号码,去应用商店下载投注站里的程序,用程序实现获取。然后获取回来的数据,放到中奖数据库里。以太网用户名/*/即可记住用户名,admin/password/cookie中。然后cookie(key)就可以实现一键登录,从而算是机器人、全球最大的赌博网站基本就是这个情况。
开奖必定是无法抓取的,但也有人利用爬虫技术获取数据(比如大家熟知的176内蒙古本地聚富彩系统), 查看全部
php抓取开奖网页内容(内蒙古聚富彩系统php抓取开奖网页内容--php)
php抓取开奖网页内容。比如:以上就是网址。抓取的内容保存在数据库中。编写php代码抓取开奖结果。
1、关于第二点问题,取样三个ip地址,采样三次,
2、关于第四点问题,取样两次,
3、相同地址的,都一样,
4、整理图表的结论可以写成:-1-2.3-4.第一,请不要再@我。我本人没有任何开发能力;第二,没法处理爬虫;第三,自己没有抓取过关注数据,不知道准确的爬取后整理数据能力;所以提出的方案全是自己的一厢情愿;总结:抓取网站上面的开奖数据。然后自己想可以做什么。
正规途径已经很少了。主要是现在的开奖平台,都是机器或者人工在发短信,发邮件。然后把随机号段转发给程序员。然后他们就可以拿开奖号码,去应用商店下载投注站里的程序,用程序实现获取。然后获取回来的数据,放到中奖数据库里。以太网用户名/*/即可记住用户名,admin/password/cookie中。然后cookie(key)就可以实现一键登录,从而算是机器人、全球最大的赌博网站基本就是这个情况。
开奖必定是无法抓取的,但也有人利用爬虫技术获取数据(比如大家熟知的176内蒙古本地聚富彩系统),
php抓取开奖网页内容(用什么编码显示网站,要说有什么不同(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-18 15:13
网页编码统一
MySQL 数据库编码、HTML 网页编码、PHP 或 HTML 文件编码都应该相同。
1、MySQL数据库代码:创建数据库时指定代码(如gbk_chinese_ci)。创建数据表、创建字段、插入数据时不要指定代码,会自动继承数据库的代码。
连接数据库时,还有一个编码。连接数据库后,执行mysql_query('SET NAMES gbk');//把gbk换成你的编码,比如utf8。
2、html网页的编码参考这一行的设置:
3、php或者html文件本身的编码:用editplus打开php文件或者html文件,保存的时候选择编码,如果数据库和网页编码都是gbk,这里的编码就是ansi;如果数据库和网页编码都是utf-8,那么这里也选择utf-8。
4、在 Javascript 或 Flash 中传递的数据是 utf-8 编码的:
还有一点需要注意的是,Javascript或者Flash中传入的数据是utf-8编码的。如果数据库和网页编码为gbk,则需要转码后再写入数据库。
iconv('utf-8', 'gbk', $content);
5、在PHP程序中,可以添加一行来指定PHP源程序的编码:
header('内容类型: text/html; charset=gbk');
php网页编码
1.在文件头设置编码
@header('内容类型: text/html;charset=UTF-8');
2.header和meta的区别
使用@header('Content-type: text/html; charset=gbk'); 的区别 和
它们都告诉浏览器用什么编码来显示网站,有什么区别,header是发送原创的HTTP header,网站什么都不剩,meta写在网站@ > 中。
一方面,如果 网站 中没有元数据,那么发送 HTTP 标头就可以了。
其次,使用 header() 函数发送原创 HTTP 标头可以收录更多内容,设置编码只是其中之一。
第三,有时不 网站 显示任何内容,而是告知浏览器后续操作使用什么编码。 查看全部
php抓取开奖网页内容(用什么编码显示网站,要说有什么不同(组图))
网页编码统一
MySQL 数据库编码、HTML 网页编码、PHP 或 HTML 文件编码都应该相同。
1、MySQL数据库代码:创建数据库时指定代码(如gbk_chinese_ci)。创建数据表、创建字段、插入数据时不要指定代码,会自动继承数据库的代码。
连接数据库时,还有一个编码。连接数据库后,执行mysql_query('SET NAMES gbk');//把gbk换成你的编码,比如utf8。
2、html网页的编码参考这一行的设置:
3、php或者html文件本身的编码:用editplus打开php文件或者html文件,保存的时候选择编码,如果数据库和网页编码都是gbk,这里的编码就是ansi;如果数据库和网页编码都是utf-8,那么这里也选择utf-8。
4、在 Javascript 或 Flash 中传递的数据是 utf-8 编码的:
还有一点需要注意的是,Javascript或者Flash中传入的数据是utf-8编码的。如果数据库和网页编码为gbk,则需要转码后再写入数据库。
iconv('utf-8', 'gbk', $content);
5、在PHP程序中,可以添加一行来指定PHP源程序的编码:
header('内容类型: text/html; charset=gbk');
php网页编码
1.在文件头设置编码
@header('内容类型: text/html;charset=UTF-8');
2.header和meta的区别
使用@header('Content-type: text/html; charset=gbk'); 的区别 和
它们都告诉浏览器用什么编码来显示网站,有什么区别,header是发送原创的HTTP header,网站什么都不剩,meta写在网站@ > 中。
一方面,如果 网站 中没有元数据,那么发送 HTTP 标头就可以了。
其次,使用 header() 函数发送原创 HTTP 标头可以收录更多内容,设置编码只是其中之一。
第三,有时不 网站 显示任何内容,而是告知浏览器后续操作使用什么编码。
php抓取开奖网页内容(《php抓取开奖网页内容利用php工具抓取网页正文》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-14 12:02
php抓取开奖网页内容利用php工具抓取网页内容是一项非常基础的工作,我们通常可以选择传统的用xpath手动对网页进行抓取,用php写,这样效率比较低,用我这里提供的方法也可以在php中开发出比较复杂的抓取程序。我们通常可以选择传统的用xpath手动对网页进行抓取,用php写,这样效率比较低,用我这里提供的方法也可以在php中开发出比较复杂的抓取程序。
一:php解析网页这里建议下载好php抓取的php,用法与windows操作类似:执行命令行phpbasicurlrequest#(准备测试php是否可以正常运行的命令)phpbrowserurlrequest#(进行php开发)phpbasiccurl命令提示phpbasic;curl_setopt($request,$http_request,$response);curl_setopt($request,$response,'get');$request:连接请求链接中的参数$http_request:请求网页地址,http标准头部(setrequestdispatcher,$request_data),调用请求链接的响应头部$response:返回响应文件中的数据$request_data:返回网页正文二:抓取网页数据首先需要抓取到php抓取页面请求,phpbrowser连接请求链接和响应页面地址,将页面抓取到并解析:$post_input_request['variant'],$variant_url="";$html_body_in_post(html_body_in_post($post_input_request['request'],html_body_in_post($request_status,$index),$variant_url),$response=$id_variant_url;$body=explode("",$body);[http]filename=$response->filename;$variant=explode("",$variant_url);$response=http_user_agent_match(post_input_request,http_request);$body=explode("",$body);[http]filename=$response->filename;$html_body_in_post(html_body_in_post($post_input_request['request'],html_body_in_post($body),$variant_url),$response=$id_variant_url);$response=http_user_agent_match(post_input_request,http_request);$response=http_user_agent_match(post_input_request,http_request);$html_body_in_post(html_body_in_post($post_input_request['request'],html_body_in_post($variant),$respo。 查看全部
php抓取开奖网页内容(《php抓取开奖网页内容利用php工具抓取网页正文》)
php抓取开奖网页内容利用php工具抓取网页内容是一项非常基础的工作,我们通常可以选择传统的用xpath手动对网页进行抓取,用php写,这样效率比较低,用我这里提供的方法也可以在php中开发出比较复杂的抓取程序。我们通常可以选择传统的用xpath手动对网页进行抓取,用php写,这样效率比较低,用我这里提供的方法也可以在php中开发出比较复杂的抓取程序。
一:php解析网页这里建议下载好php抓取的php,用法与windows操作类似:执行命令行phpbasicurlrequest#(准备测试php是否可以正常运行的命令)phpbrowserurlrequest#(进行php开发)phpbasiccurl命令提示phpbasic;curl_setopt($request,$http_request,$response);curl_setopt($request,$response,'get');$request:连接请求链接中的参数$http_request:请求网页地址,http标准头部(setrequestdispatcher,$request_data),调用请求链接的响应头部$response:返回响应文件中的数据$request_data:返回网页正文二:抓取网页数据首先需要抓取到php抓取页面请求,phpbrowser连接请求链接和响应页面地址,将页面抓取到并解析:$post_input_request['variant'],$variant_url="";$html_body_in_post(html_body_in_post($post_input_request['request'],html_body_in_post($request_status,$index),$variant_url),$response=$id_variant_url;$body=explode("",$body);[http]filename=$response->filename;$variant=explode("",$variant_url);$response=http_user_agent_match(post_input_request,http_request);$body=explode("",$body);[http]filename=$response->filename;$html_body_in_post(html_body_in_post($post_input_request['request'],html_body_in_post($body),$variant_url),$response=$id_variant_url);$response=http_user_agent_match(post_input_request,http_request);$response=http_user_agent_match(post_input_request,http_request);$html_body_in_post(html_body_in_post($post_input_request['request'],html_body_in_post($variant),$respo。
php抓取开奖网页内容(php抓取开奖网页内容用户名、密码、大小单等用于验证)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-13 01:01
php抓取开奖网页内容,用户名、密码、大小单等用于验证。
设置你网站的登录页(page_user),页面生成并保存这个唯一id,需要验证就根据这个id查询验证码..验证结果再保存到数据库..你需要验证帐号密码、是否登录等等参数..
爬虫也可以,对着开奖软件复制验证码数据就行了。
登录后,post请求验证码,检查是否被篡改过。结果取决于验证码数量、图片质量、验证码时间长短等多个方面。
可以使用爬虫解决这个问题,用户登录以后,验证码传到服务器,服务器生成正确的字符码,向爬虫输出,把结果保存到数据库即可。当然,要验证账号密码,还要随机生成验证码。
登录找你身份证识别,
验证登录网址是不是一个验证码(这个可以爬虫实现),服务器验证了这个以后把登录信息用各种列表保存在数据库。
1、爬虫处理登录和网页验证码。分享以下截图为了避免说为了说不清楚,这些截图是由多张图拼接在一起的。
2、验证码分为两种验证码,一种是常见的12306,另一种是去一些验证码网站如站长工具网、码库验证。具体问题可在官网查看。
3、登录的话,通过截图的验证码可以登录到后台管理账号以及密码,也就是说前台登录无需验证码。
post请求网页验证码 查看全部
php抓取开奖网页内容(php抓取开奖网页内容用户名、密码、大小单等用于验证)
php抓取开奖网页内容,用户名、密码、大小单等用于验证。
设置你网站的登录页(page_user),页面生成并保存这个唯一id,需要验证就根据这个id查询验证码..验证结果再保存到数据库..你需要验证帐号密码、是否登录等等参数..
爬虫也可以,对着开奖软件复制验证码数据就行了。
登录后,post请求验证码,检查是否被篡改过。结果取决于验证码数量、图片质量、验证码时间长短等多个方面。
可以使用爬虫解决这个问题,用户登录以后,验证码传到服务器,服务器生成正确的字符码,向爬虫输出,把结果保存到数据库即可。当然,要验证账号密码,还要随机生成验证码。
登录找你身份证识别,
验证登录网址是不是一个验证码(这个可以爬虫实现),服务器验证了这个以后把登录信息用各种列表保存在数据库。
1、爬虫处理登录和网页验证码。分享以下截图为了避免说为了说不清楚,这些截图是由多张图拼接在一起的。
2、验证码分为两种验证码,一种是常见的12306,另一种是去一些验证码网站如站长工具网、码库验证。具体问题可在官网查看。
3、登录的话,通过截图的验证码可以登录到后台管理账号以及密码,也就是说前台登录无需验证码。
post请求网页验证码
php抓取开奖网页内容(:利用浏览器的开发者工具分析源码(中英对照))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-04 13:12
仔细查看 URL 中的更改。让我们大胆猜测一下,我们需要的数据存储在以下互联网路径中:URL+_+页码+.html。
验证下试试。目前,这里显示了113页,所以我不妨尝试访问:
答对了。
然后按照这个真实的 URL 来抓取数据。
第三步:使用浏览器的开发者工具分析源码
我们需要的数据存储在:
在第 4 个标签之后的标签下;标签收录:开奖日期/期号/蓝色中奖号码/红色中奖号码等信息。
第四步:编写python代码
代码示例:
#!python3
导入请求,bs4
def GetWinningInfo(网址):
res = requests.get(webaddress).text
htmlinfo = bs4.BeautifulSoup(res,'html.parser')
resultinfo_qishu = htmlinfo.select('td')
resultinfo_haoma = htmlinfo.select('em')
#包括每期的期数;抽奖日期和其他信息
resultinfo_haomalist = str(resultinfo_haoma).replace('','').replace('','').replace('','').replace('[','').replace(')', '')。分裂(',')
打印(len(resultinfo_qishu))
对于范围内的 i(0,len(resultinfo_qishu)-1,7):
对于范围内的 j(0,2):
如果 j == 0:
print('绘图日期:' + str(resultinfo_qishu[i+j]).replace('
','')。代替('
',''))
别的:
print('问题编号:' + str(resultinfo_qishu[i+j]).replace('
','')。代替('
',''))
x = []
对于范围内的 n(0,7):
x.append(resultinfo_haomalist[i+n])
print('红球:%s,%s,%s,%s,%s,%s;蓝球:%s'%(x[0],x[1],x[2],x[3 ],x[4],x[5],x[6]))
#主要的
#TODO:获取总页数
GetWinningInfo('')
以上代码目前只实现了第一页数据的正确获取,并将获取的结果显示在屏幕上;到目前为止,这个项目仍然对现实生活没有影响;当然,技术死傻欢乐除外~~~
因此,为了让大多数人从这个项目中受益,并由衷地欣赏我们的超能力,我们需要多思考,做得更好。
例如:读取过去的所有数据;将读取的数据保存在excel中;然后按照人的逻辑对数据进行分析,将分析结果用图表等方式展示出来……
第 4 步:那么让我们开始吧
首先,我们可以捕获所有以前的数据:
例子二:
#!python3
导入请求,bs4
def GetWinningInfo(网址):
res = requests.get(webaddress).text
htmlinfo = bs4.BeautifulSoup(res,'html.parser')
resultinfo_qishu = htmlinfo.select('td')
resultinfo_haoma = htmlinfo.select('em')
#包括每期的期数;抽奖日期和其他信息
resultinfo_haomalist = str(resultinfo_haoma).replace('','').replace('','').replace('','').replace('[','').replace(')', '')。分裂(',')
打印(len(resultinfo_qishu))
发行者数据 = []
对于范围内的 i(0,len(resultinfo_qishu)-1,7):
发行人数据 = []
对于范围内的 j(0,2):
如果 j == 0:
#print('绘图日期:' + str(resultinfo_qishu[i+j]).replace('
','')。代替('
',''))
a = str(resultinfo_qishu[i+j]).replace('
','')。代替('
','')
issuerData.append(a)
别的:
#print('问题编号:' + str(resultinfo_qishu[i+j]).replace('
','')。代替('
',''))
b = str(resultinfo_qishu[i+j]).replace('
','')。代替('
','')
issuerData.append(b)
x = []
对于范围内的 n(0,7):
x.append(resultinfo_haomalist[i+n])
#print('红球: %s,%s,%s,%s,%s,%s; 蓝球: %s'% (x[0],x[1],x[2],x [ 3],x[4],x[5],x[6]))
issuerData.append(x)
issuerDatas.append(issuerData)
返回 issuerDatas
#主要的
#TODO:获取总页数
numberOfPages = 113 #有兴趣的可以尝试从网站获取这个号码。
baseWebAddress = ""
对于范围内的 e(1,numberOfPages+1):
print('--------这是页面 %s--------'% e)
realWebAddress = baseWebAddress +'/list_'+ str(e) +'.html'
resultall = GetWinningInfo(realWebAddress)
对于结果中的每个IssuerData:
#print(everyIssuerData)
打印('[绘制日期]: %s'% everyIssuerData[0])
打印('[问题编号]:%s'% everyIssuerData[1])
打印('[中奖号码]')
print('红球:%s,%s,%s,%s,%s,%s;蓝球:%s'%(everyIssuerData[2][0],everyIssuerData[2][1],everyIssuerData[ 2][2],everyIssuerData[2][3],everyIssuerData[2][4],everyIssuerData[2][5],everyIssuerData[2][6]))
以上代码实现了在屏幕上获取并打印以往所有开奖历史信息的功能;接下来我们意识到将获得的数据写入文件。
在开始下一步之前,需要掌握一些基本的python操作Excel文件的方法;在这里我们添加一个小插曲;一起学习这个内容。(然后让我们添加另一个步骤。)
第五步:学习如何使用Python操作Excel(插曲)
学习使用 Python 处理 Excel 文件。这里主要用到xlrd和xlwt模块,使用前需要安装!一般需要pip安装。(这不是吗?检查谷歌。)
xlrd(excel读取)用于读取Excel文件,xlwt(excel写入)用于生成Excel文件(可以控制Excel中单元格的格式)。需要注意的是,用xlrd读取excel是不能操作的:xlrd.open_workbook()方法返回的是xlrd.Book类型,该类型是只读的,不能操作。xlwt.Workbook()返回的xlwt.Workbook类型的save(filepath)方法可以保存excel文件。
因此,读取和生成Excel文件的处理非常容易,但修改现有的Excel文件就比较麻烦。不过也有一个xlutils(取决于xlrd和xlwt)提供复制excel文件内容和修改文件的功能。实际上,它只是 xlrd.Book 和 xlwt.Workbook 之间的一个管道。
PS:xlwt、wlrd只能读写xls文件,不能操作xlsx文件
因此,我们需要使用openpyxl;安装非常简单,也使用了pip。(openpyxl只能操作xlsx文件不能操作xls文件)
如果您还有图表需求,那么您可以安装 xlsxwriter 库。
Python功能强大,武器库前人已建;你只需要选择最合适的武器;然后阅读说明;你可以在几分钟内练习杰作;当然,这只适合速成班的学生,而你真的想成为编程世界的大师还是需要学习如何打造自己的法宝。
让我们添加另一个链接来比较差异。
我们先来看看Excel的几个概念:
工作簿:每个 Excel 文件都是一个工作簿。
Sheet:每个工作簿可以收录多个工作表,分别对应我们在Excel左下角看到的“sheet1”、“sheet2”等。
单元格:每张表就是我们平时看到的一张表格,可以收录很多行和列,每一个特定的行号和列号对应的网格就是一个单元格。
那我就随便选一个武器:xlsxwriter(这个不能打开和修改已有的excel文件);虽然缺少了一些功能,但是对于我现在的需求来说已经足够了。
对该模块的深入研究,请参考这里:
首先是安装这个模块:pip install xlsxwriter
接下来,尝试编写一个小脚本来创建一个excel文件并在其中写入一些简单的数据。
下面给出一个例子:
#!python3
导入 xlsxwriter
#本例主要实现Excel文件的基本操作
#创建Excel文件
workbook = xlsxwriter.Workbook('testexcel.xlsx')
worksheet = workbook.add_worksheet('TEST')
workbook.close()
#读取现有EXCEL文件功能xlsxwriter模块没有这个功能,所以这里创建的文件和上面的不一样
workbook = xlsxwriter.Workbook('testexcel.xlsx')
worksheet = workbook.add_worksheet('TEST')
#设置列宽
worksheet.set_column('A:A',40)
worksheet.set_row(0, 40)
#自定义格式
粗体 = workbook.add_format({'bold':True})
a = workbook.add_format({'font_size': 26,'bold': True,'align':'left','bg_color':'cccccc'})
b = workbook.add_format({'border': 1,'font_size': 13,'bold': True,'align':'center','bg_color':'ccccc0'})
worksheet.write('C1', "python excel")
worksheet.strings_to_urls
worksheet.write_row('H1',['X','X','X'],b)
worksheet.write_row('H2',['X','X','X'],b)
worksheet.write_row('H3',['X','X','X'],b)
worksheet.write_row('H4',['X','X','X'],b)
worksheet.write_row('H5',['X','X','X'],b)
worksheet.write_row('H6',['X','X','X'],b)
#A1Cell写入数据
worksheet.write('A1','你好')
#B1Cell 写入数据并加粗
worksheet.write('B1','World',bold)
#A2Cell 写入数据并加粗
worksheet.write('A2','欢迎使用 Python!', 粗体)
#另一种写数据的形式
worksheet.write(2,0,20)
worksheet.write(3,0,111.205)
#写公式
worksheet.write(4,0,'=SUM(A3:A4)')
#插入图片
worksheet.insert_image('A10', '11_test001.jpg')
worksheet.insert_image('A10', '11_test001.jpg', {'url':''})
workbook.close()
有了上面的基础知识,我们就可以继续实现我们的想法了。
第六步:将抓取到的数据写入EXCEL文件,做一个简单的图表分析
以上是题外话,下面进入正题;我们将在程序中添加代码,以达到将抓取到的数据写入EXCEL文件的目的,文件命名方式为主题+日期。
在真实环境中,我们不仅仅是爬取数据来获取;关键是从数据中过滤和分析有用的信息。
只需上传代码:
#!python3
导入请求,bs4,xlsxwriter,时间
#环境运营基础数据定义
#**************************************************** ************************
scriptRuningTime = time.strftime("%Y%m%d_%H%M%S", time.localtime())
outFileName ='LotteryHistoryDataList_' + scriptRuningTime +'.xlsx'
baseWebAddress = ""
#函数定义
#**************************************************** ************************
def GetWinningInfo(网址):
res = requests.get(webaddress).text
htmlinfo = bs4.BeautifulSoup(res,'html.parser')
resultinfo_qishu = htmlinfo.select('td')
resultinfo_haoma = htmlinfo.select('em')
#包括每期的期数;抽奖日期和其他信息
resultinfo_haomalist = str(resultinfo_haoma).replace('','').replace('','').replace('','').replace('[','').replace(')', '')。分裂(',')
#print(len(resultinfo_qishu))
发行者数据 = []
对于范围内的 i(0,len(resultinfo_qishu)-1,7):
发行人数据 = []
对于范围内的 j(0,2):
如果 j == 0:
#print('绘图日期:' + str(resultinfo_qishu[i+j]).replace('
','')。代替('
',''))
a = str(resultinfo_qishu[i+j]).replace('
','')。代替('
','')
issuerData.append(a)
别的:
#print('问题编号:' + str(resultinfo_qishu[i+j]).replace('
','')。代替('
',''))
b = str(resultinfo_qishu[i+j]).replace('
','')。代替('
','')
issuerData.append(b)
x = []
对于范围内的 n(0,7):
x.append(resultinfo_haomalist[i+n])
#print('红球: %s,%s,%s,%s,%s,%s; 蓝球: %s'% (x[0],x[1],x[2],x [ 3],x[4],x[5],x[6]))
issuerData.append(x)
issuerDatas.append(issuerData)
返回 issuerDatas
#主要的
#**************************************************** ************************
#TODO:获取总页数
numberOfPages = 113 #有兴趣的可以尝试从网站获取这个号码。
#创建一个Excel文件并写入标题
工作簿 = xlsxwriter.Workbook(outFileName)
worksheet = workbook.add_worksheet('彩票')
worksheet.hide_gridlines(2)
tableHeader = ["NO.","Draw Date","Date Number","Red Ball 1","Red Ball 2","Red Ball 3","Red Ball 4","Red Ball 5","Red球 6","蓝色球 1",]
a = workbook.add_format({'border': 1,'font_size': 20,'bold': True,'align':'center','bg_color':'ccccc0'})
b = workbook.add_format({'border': 1,'font_size': 13,'align':'left','bg_color':'5F9EA0'})
c = workbook.add_format({'border': 1,'font_size': 13,'align':'left','bg_color':'D2B48C'})
worksheet.write_row('A1', tableHeader,a)
#开始一一爬取数据
我 = 0
对于范围内的 e(1,numberOfPages+1):
print('--------这是页面 %s--------'% e)
realWebAddress = baseWebAddress +'/list_'+ str(e) +'.html'
resultall = GetWinningInfo(realWebAddress)
对于结果中的每个IssuerData:
我 = 我 + 1
cellPos1 ='A' + str(i+1)
cellPos2 ='B' + str(i+1)
#小细节在写入前将捕获的数据转换为数字格式
cellValue = [everyIssuerData[0],int(everyIssuerData[1]),int(everyIssuerData[2][0]),int(everyIssuerData[2][1]),int(everyIssuerData[2][2]),int (everyIssuerData[2][3]),int(everyIssuerData[2][4]),int(everyIssuerData[2][5]),int(everyIssuerData[2][6])]
如果 (i% 2) == 0:
worksheet.write(cellPos1,i,b)
worksheet.write_row(cellPos2, cellValue,b)
别的:
worksheet.write(cellPos1,i,c)
worksheet.write_row(cellPos2, cellValue,c)
#添加工作表
chartSheet = workbook.add_worksheet('图表')
#添加折线图图表对象
chart_col = workbook.add_chart({'type':'line'})
name ='=%s!$J$1'%'彩票'
类别 ='=%s!$B$2:$B$%s'% ('彩票',(i + 1))
values='=%s!$J$2:$J$%s'%('彩票',(i + 1))
打印('%s|%s|%s'%(名称、类别、值))
chart_col.add_series({
# 这里sheet1是默认值,因为我们新建sheet的时候没有指定sheet名称
# 如果我们在新建sheet的时候设置了sheet名称,这里必须设置为对应的值
'名称':名称,
“类别”:类别,
“价值观”:价值观,
'线':{'颜色':'蓝色'},
})
chart_col.set_title({'name':'蓝球分析'})
chart_col.set_x_axis({'name':'Draw Date'})
chart_col.set_y_axis({'name':'BlueNumber'})
chart_col.set_style(1)
chartSheet.insert_chart('B2', chart_col)
chart_col.set_size({'width': 10000,'height': 500})
workbook.close()
运行上述代码的结果是:
好了,到此我的目的基本实现了。以后可能会尝试用一些“ship away”算法来实现一些数据分析,看看有没有时间。
如果你喜欢这篇文章,请给我一个赞。本文如有遗漏,欢迎大家赐教,共同进步~
文档和源代码附件在: 查看全部
php抓取开奖网页内容(:利用浏览器的开发者工具分析源码(中英对照))
仔细查看 URL 中的更改。让我们大胆猜测一下,我们需要的数据存储在以下互联网路径中:URL+_+页码+.html。
验证下试试。目前,这里显示了113页,所以我不妨尝试访问:
答对了。
然后按照这个真实的 URL 来抓取数据。
第三步:使用浏览器的开发者工具分析源码
我们需要的数据存储在:
在第 4 个标签之后的标签下;标签收录:开奖日期/期号/蓝色中奖号码/红色中奖号码等信息。
第四步:编写python代码
代码示例:
#!python3
导入请求,bs4
def GetWinningInfo(网址):
res = requests.get(webaddress).text
htmlinfo = bs4.BeautifulSoup(res,'html.parser')
resultinfo_qishu = htmlinfo.select('td')
resultinfo_haoma = htmlinfo.select('em')
#包括每期的期数;抽奖日期和其他信息
resultinfo_haomalist = str(resultinfo_haoma).replace('','').replace('','').replace('','').replace('[','').replace(')', '')。分裂(',')
打印(len(resultinfo_qishu))
对于范围内的 i(0,len(resultinfo_qishu)-1,7):
对于范围内的 j(0,2):
如果 j == 0:
print('绘图日期:' + str(resultinfo_qishu[i+j]).replace('
','')。代替('
',''))
别的:
print('问题编号:' + str(resultinfo_qishu[i+j]).replace('
','')。代替('
',''))
x = []
对于范围内的 n(0,7):
x.append(resultinfo_haomalist[i+n])
print('红球:%s,%s,%s,%s,%s,%s;蓝球:%s'%(x[0],x[1],x[2],x[3 ],x[4],x[5],x[6]))
#主要的
#TODO:获取总页数
GetWinningInfo('')
以上代码目前只实现了第一页数据的正确获取,并将获取的结果显示在屏幕上;到目前为止,这个项目仍然对现实生活没有影响;当然,技术死傻欢乐除外~~~
因此,为了让大多数人从这个项目中受益,并由衷地欣赏我们的超能力,我们需要多思考,做得更好。
例如:读取过去的所有数据;将读取的数据保存在excel中;然后按照人的逻辑对数据进行分析,将分析结果用图表等方式展示出来……
第 4 步:那么让我们开始吧
首先,我们可以捕获所有以前的数据:
例子二:
#!python3
导入请求,bs4
def GetWinningInfo(网址):
res = requests.get(webaddress).text
htmlinfo = bs4.BeautifulSoup(res,'html.parser')
resultinfo_qishu = htmlinfo.select('td')
resultinfo_haoma = htmlinfo.select('em')
#包括每期的期数;抽奖日期和其他信息
resultinfo_haomalist = str(resultinfo_haoma).replace('','').replace('','').replace('','').replace('[','').replace(')', '')。分裂(',')
打印(len(resultinfo_qishu))
发行者数据 = []
对于范围内的 i(0,len(resultinfo_qishu)-1,7):
发行人数据 = []
对于范围内的 j(0,2):
如果 j == 0:
#print('绘图日期:' + str(resultinfo_qishu[i+j]).replace('
','')。代替('
',''))
a = str(resultinfo_qishu[i+j]).replace('
','')。代替('
','')
issuerData.append(a)
别的:
#print('问题编号:' + str(resultinfo_qishu[i+j]).replace('
','')。代替('
',''))
b = str(resultinfo_qishu[i+j]).replace('
','')。代替('
','')
issuerData.append(b)
x = []
对于范围内的 n(0,7):
x.append(resultinfo_haomalist[i+n])
#print('红球: %s,%s,%s,%s,%s,%s; 蓝球: %s'% (x[0],x[1],x[2],x [ 3],x[4],x[5],x[6]))
issuerData.append(x)
issuerDatas.append(issuerData)
返回 issuerDatas
#主要的
#TODO:获取总页数
numberOfPages = 113 #有兴趣的可以尝试从网站获取这个号码。
baseWebAddress = ""
对于范围内的 e(1,numberOfPages+1):
print('--------这是页面 %s--------'% e)
realWebAddress = baseWebAddress +'/list_'+ str(e) +'.html'
resultall = GetWinningInfo(realWebAddress)
对于结果中的每个IssuerData:
#print(everyIssuerData)
打印('[绘制日期]: %s'% everyIssuerData[0])
打印('[问题编号]:%s'% everyIssuerData[1])
打印('[中奖号码]')
print('红球:%s,%s,%s,%s,%s,%s;蓝球:%s'%(everyIssuerData[2][0],everyIssuerData[2][1],everyIssuerData[ 2][2],everyIssuerData[2][3],everyIssuerData[2][4],everyIssuerData[2][5],everyIssuerData[2][6]))
以上代码实现了在屏幕上获取并打印以往所有开奖历史信息的功能;接下来我们意识到将获得的数据写入文件。
在开始下一步之前,需要掌握一些基本的python操作Excel文件的方法;在这里我们添加一个小插曲;一起学习这个内容。(然后让我们添加另一个步骤。)
第五步:学习如何使用Python操作Excel(插曲)
学习使用 Python 处理 Excel 文件。这里主要用到xlrd和xlwt模块,使用前需要安装!一般需要pip安装。(这不是吗?检查谷歌。)
xlrd(excel读取)用于读取Excel文件,xlwt(excel写入)用于生成Excel文件(可以控制Excel中单元格的格式)。需要注意的是,用xlrd读取excel是不能操作的:xlrd.open_workbook()方法返回的是xlrd.Book类型,该类型是只读的,不能操作。xlwt.Workbook()返回的xlwt.Workbook类型的save(filepath)方法可以保存excel文件。
因此,读取和生成Excel文件的处理非常容易,但修改现有的Excel文件就比较麻烦。不过也有一个xlutils(取决于xlrd和xlwt)提供复制excel文件内容和修改文件的功能。实际上,它只是 xlrd.Book 和 xlwt.Workbook 之间的一个管道。
PS:xlwt、wlrd只能读写xls文件,不能操作xlsx文件
因此,我们需要使用openpyxl;安装非常简单,也使用了pip。(openpyxl只能操作xlsx文件不能操作xls文件)
如果您还有图表需求,那么您可以安装 xlsxwriter 库。
Python功能强大,武器库前人已建;你只需要选择最合适的武器;然后阅读说明;你可以在几分钟内练习杰作;当然,这只适合速成班的学生,而你真的想成为编程世界的大师还是需要学习如何打造自己的法宝。
让我们添加另一个链接来比较差异。
我们先来看看Excel的几个概念:
工作簿:每个 Excel 文件都是一个工作簿。
Sheet:每个工作簿可以收录多个工作表,分别对应我们在Excel左下角看到的“sheet1”、“sheet2”等。
单元格:每张表就是我们平时看到的一张表格,可以收录很多行和列,每一个特定的行号和列号对应的网格就是一个单元格。
那我就随便选一个武器:xlsxwriter(这个不能打开和修改已有的excel文件);虽然缺少了一些功能,但是对于我现在的需求来说已经足够了。
对该模块的深入研究,请参考这里:
首先是安装这个模块:pip install xlsxwriter
接下来,尝试编写一个小脚本来创建一个excel文件并在其中写入一些简单的数据。
下面给出一个例子:
#!python3
导入 xlsxwriter
#本例主要实现Excel文件的基本操作
#创建Excel文件
workbook = xlsxwriter.Workbook('testexcel.xlsx')
worksheet = workbook.add_worksheet('TEST')
workbook.close()
#读取现有EXCEL文件功能xlsxwriter模块没有这个功能,所以这里创建的文件和上面的不一样
workbook = xlsxwriter.Workbook('testexcel.xlsx')
worksheet = workbook.add_worksheet('TEST')
#设置列宽
worksheet.set_column('A:A',40)
worksheet.set_row(0, 40)
#自定义格式
粗体 = workbook.add_format({'bold':True})
a = workbook.add_format({'font_size': 26,'bold': True,'align':'left','bg_color':'cccccc'})
b = workbook.add_format({'border': 1,'font_size': 13,'bold': True,'align':'center','bg_color':'ccccc0'})
worksheet.write('C1', "python excel")
worksheet.strings_to_urls
worksheet.write_row('H1',['X','X','X'],b)
worksheet.write_row('H2',['X','X','X'],b)
worksheet.write_row('H3',['X','X','X'],b)
worksheet.write_row('H4',['X','X','X'],b)
worksheet.write_row('H5',['X','X','X'],b)
worksheet.write_row('H6',['X','X','X'],b)
#A1Cell写入数据
worksheet.write('A1','你好')
#B1Cell 写入数据并加粗
worksheet.write('B1','World',bold)
#A2Cell 写入数据并加粗
worksheet.write('A2','欢迎使用 Python!', 粗体)
#另一种写数据的形式
worksheet.write(2,0,20)
worksheet.write(3,0,111.205)
#写公式
worksheet.write(4,0,'=SUM(A3:A4)')
#插入图片
worksheet.insert_image('A10', '11_test001.jpg')
worksheet.insert_image('A10', '11_test001.jpg', {'url':''})
workbook.close()
有了上面的基础知识,我们就可以继续实现我们的想法了。
第六步:将抓取到的数据写入EXCEL文件,做一个简单的图表分析
以上是题外话,下面进入正题;我们将在程序中添加代码,以达到将抓取到的数据写入EXCEL文件的目的,文件命名方式为主题+日期。
在真实环境中,我们不仅仅是爬取数据来获取;关键是从数据中过滤和分析有用的信息。
只需上传代码:
#!python3
导入请求,bs4,xlsxwriter,时间
#环境运营基础数据定义
#**************************************************** ************************
scriptRuningTime = time.strftime("%Y%m%d_%H%M%S", time.localtime())
outFileName ='LotteryHistoryDataList_' + scriptRuningTime +'.xlsx'
baseWebAddress = ""
#函数定义
#**************************************************** ************************
def GetWinningInfo(网址):
res = requests.get(webaddress).text
htmlinfo = bs4.BeautifulSoup(res,'html.parser')
resultinfo_qishu = htmlinfo.select('td')
resultinfo_haoma = htmlinfo.select('em')
#包括每期的期数;抽奖日期和其他信息
resultinfo_haomalist = str(resultinfo_haoma).replace('','').replace('','').replace('','').replace('[','').replace(')', '')。分裂(',')
#print(len(resultinfo_qishu))
发行者数据 = []
对于范围内的 i(0,len(resultinfo_qishu)-1,7):
发行人数据 = []
对于范围内的 j(0,2):
如果 j == 0:
#print('绘图日期:' + str(resultinfo_qishu[i+j]).replace('
','')。代替('
',''))
a = str(resultinfo_qishu[i+j]).replace('
','')。代替('
','')
issuerData.append(a)
别的:
#print('问题编号:' + str(resultinfo_qishu[i+j]).replace('
','')。代替('
',''))
b = str(resultinfo_qishu[i+j]).replace('
','')。代替('
','')
issuerData.append(b)
x = []
对于范围内的 n(0,7):
x.append(resultinfo_haomalist[i+n])
#print('红球: %s,%s,%s,%s,%s,%s; 蓝球: %s'% (x[0],x[1],x[2],x [ 3],x[4],x[5],x[6]))
issuerData.append(x)
issuerDatas.append(issuerData)
返回 issuerDatas
#主要的
#**************************************************** ************************
#TODO:获取总页数
numberOfPages = 113 #有兴趣的可以尝试从网站获取这个号码。
#创建一个Excel文件并写入标题
工作簿 = xlsxwriter.Workbook(outFileName)
worksheet = workbook.add_worksheet('彩票')
worksheet.hide_gridlines(2)
tableHeader = ["NO.","Draw Date","Date Number","Red Ball 1","Red Ball 2","Red Ball 3","Red Ball 4","Red Ball 5","Red球 6","蓝色球 1",]
a = workbook.add_format({'border': 1,'font_size': 20,'bold': True,'align':'center','bg_color':'ccccc0'})
b = workbook.add_format({'border': 1,'font_size': 13,'align':'left','bg_color':'5F9EA0'})
c = workbook.add_format({'border': 1,'font_size': 13,'align':'left','bg_color':'D2B48C'})
worksheet.write_row('A1', tableHeader,a)
#开始一一爬取数据
我 = 0
对于范围内的 e(1,numberOfPages+1):
print('--------这是页面 %s--------'% e)
realWebAddress = baseWebAddress +'/list_'+ str(e) +'.html'
resultall = GetWinningInfo(realWebAddress)
对于结果中的每个IssuerData:
我 = 我 + 1
cellPos1 ='A' + str(i+1)
cellPos2 ='B' + str(i+1)
#小细节在写入前将捕获的数据转换为数字格式
cellValue = [everyIssuerData[0],int(everyIssuerData[1]),int(everyIssuerData[2][0]),int(everyIssuerData[2][1]),int(everyIssuerData[2][2]),int (everyIssuerData[2][3]),int(everyIssuerData[2][4]),int(everyIssuerData[2][5]),int(everyIssuerData[2][6])]
如果 (i% 2) == 0:
worksheet.write(cellPos1,i,b)
worksheet.write_row(cellPos2, cellValue,b)
别的:
worksheet.write(cellPos1,i,c)
worksheet.write_row(cellPos2, cellValue,c)
#添加工作表
chartSheet = workbook.add_worksheet('图表')
#添加折线图图表对象
chart_col = workbook.add_chart({'type':'line'})
name ='=%s!$J$1'%'彩票'
类别 ='=%s!$B$2:$B$%s'% ('彩票',(i + 1))
values='=%s!$J$2:$J$%s'%('彩票',(i + 1))
打印('%s|%s|%s'%(名称、类别、值))
chart_col.add_series({
# 这里sheet1是默认值,因为我们新建sheet的时候没有指定sheet名称
# 如果我们在新建sheet的时候设置了sheet名称,这里必须设置为对应的值
'名称':名称,
“类别”:类别,
“价值观”:价值观,
'线':{'颜色':'蓝色'},
})
chart_col.set_title({'name':'蓝球分析'})
chart_col.set_x_axis({'name':'Draw Date'})
chart_col.set_y_axis({'name':'BlueNumber'})
chart_col.set_style(1)
chartSheet.insert_chart('B2', chart_col)
chart_col.set_size({'width': 10000,'height': 500})
workbook.close()
运行上述代码的结果是:
好了,到此我的目的基本实现了。以后可能会尝试用一些“ship away”算法来实现一些数据分析,看看有没有时间。
如果你喜欢这篇文章,请给我一个赞。本文如有遗漏,欢迎大家赐教,共同进步~
文档和源代码附件在:
php抓取开奖网页内容(一个彩票网站为例来简单说明整体操作流程(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-04 13:05
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互。
有时候,你需要抓取一段自己感兴趣的网站信息,一段网站信息必须通过某个url发送,根据地址发送http请求。知道这个地址就可以得到很多网络响应需要仔细分析才能找到合适的地址,最后通过这个地址返回一个html给你,我们就可以得到html,分析结构,解析结构得到你想要的数据。Html的结构分析往往是复杂而繁琐的。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
通过以下代码,得到6个红球:
同理,可以获得1个篮球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据
以上是java中简单爬取网页数据的个人分享。有兴趣的孩子可以自己动手实践,从实践中学习道理。 查看全部
php抓取开奖网页内容(一个彩票网站为例来简单说明整体操作流程(一))
前言
现在很多web应用和做过web项目的童鞋都知道web结果是由html+js+css组成的,html结构有一定的规范,可以通过js实现动态数据交互。
有时候,你需要抓取一段自己感兴趣的网站信息,一段网站信息必须通过某个url发送,根据地址发送http请求。知道这个地址就可以得到很多网络响应需要仔细分析才能找到合适的地址,最后通过这个地址返回一个html给你,我们就可以得到html,分析结构,解析结构得到你想要的数据。Html的结构分析往往是复杂而繁琐的。我们可以使用java支持包:jsoup,它可以完成发送请求、解析html、获取你感兴趣的数据等功能。
我们以一张彩票网站为例简单说明一下整体的操作流程,分为以下几个主要步骤:
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
通过以下代码,得到6个红球:
同理,可以获得1个篮球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据
以上是java中简单爬取网页数据的个人分享。有兴趣的孩子可以自己动手实践,从实践中学习道理。
php抓取开奖网页内容(php抓取开奖网页内容php真实数据抓取知乎所有回答第一步)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-28 23:01
php抓取开奖网页内容php抓取真实网站真实数据爬虫抓取知乎所有回答
第一步,网页端做一个useragent判断。区分是不是中国人第二步,针对这个useragent写爬虫程序第三步,网页端别上传文件,抓取进来的内容直接拿数据库导出来就行了。
python最常用的email抓取
爬虫
同为学生,目前为止只能做到拿到教务处的登记信息,某些数据的来源也就是通过身份证识别来识别,比如户籍,
我在知乎刷到的一个问题,
这个问题很久没人回答了。我翻了下答案,爬虫相关的居多,但是你对现实意义的定义是怎么个意思?给答主泼一盆冷水吧,在我的观念里,爬虫能用就行,无论是爬到用处还是数据质量,并不会取决于爬虫的形式。所以我还是回答不了题主的问题。另外我想补充的是,对于是现实意义重大还是虚拟意义重大的问题,我也是一无所知,该如何来定义才更贴切。
用python+requests+beautifulsoup+scrapy(1,2),
我也是。
我用easypng+photozoom。当然我只能抓大图片。
豆瓣爬虫教程
excessdom(各平台可用)-v5xaz2kwyhryq
楼上对,
网站精度不够,一般人用不了 查看全部
php抓取开奖网页内容(php抓取开奖网页内容php真实数据抓取知乎所有回答第一步)
php抓取开奖网页内容php抓取真实网站真实数据爬虫抓取知乎所有回答
第一步,网页端做一个useragent判断。区分是不是中国人第二步,针对这个useragent写爬虫程序第三步,网页端别上传文件,抓取进来的内容直接拿数据库导出来就行了。
python最常用的email抓取
爬虫
同为学生,目前为止只能做到拿到教务处的登记信息,某些数据的来源也就是通过身份证识别来识别,比如户籍,
我在知乎刷到的一个问题,
这个问题很久没人回答了。我翻了下答案,爬虫相关的居多,但是你对现实意义的定义是怎么个意思?给答主泼一盆冷水吧,在我的观念里,爬虫能用就行,无论是爬到用处还是数据质量,并不会取决于爬虫的形式。所以我还是回答不了题主的问题。另外我想补充的是,对于是现实意义重大还是虚拟意义重大的问题,我也是一无所知,该如何来定义才更贴切。
用python+requests+beautifulsoup+scrapy(1,2),
我也是。
我用easypng+photozoom。当然我只能抓大图片。
豆瓣爬虫教程
excessdom(各平台可用)-v5xaz2kwyhryq
楼上对,
网站精度不够,一般人用不了
php抓取开奖网页内容( 怎么修改网页结构 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-15 16:24
怎么修改网页结构
)
现在很多web应用,做过web项目的童鞋都知道,web结果由html+js+css组成,html结构都有一定的规范,数据动态交互可以通过js实现。
有些时候,需要抓取某一个你感兴趣的网站信息,一个网站信息肯定是通过某一个url,发送http请求,根据地址定位的,当知道这个地址,可以获取到很多的网络响应,需要认真分析,找到你那一个合适的地址,最后通过这个地址返回一个html给你,我们可以得到这个html,分析结构,解析这个结构获取你要的数据。
Html的结构解析往往是复杂繁琐的,我们可以使用java的支持包:jsoup,可以完成发送请求,解析html等功能,得到你感兴趣的数据。
下面就以一个彩票网站为例来简单说明整体操作流程,分为以下几大步骤:
1:根据官网,定位到自己感兴趣的模块:双色球
2:分析页面,找到它的入口地址
3:获取地址,使用jsoup发送请求,获取返回的Document对象
4:分析Document对象,获取感兴趣的数据
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
通过以下代码,得到6个红球:
同理,可以获得1个蓝球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据
以上是个人对java中简单抓取网页数据的分享,感兴趣的童鞋可以自己的实践一下,实践出真知。 查看全部
php抓取开奖网页内容(
怎么修改网页结构
)
现在很多web应用,做过web项目的童鞋都知道,web结果由html+js+css组成,html结构都有一定的规范,数据动态交互可以通过js实现。
有些时候,需要抓取某一个你感兴趣的网站信息,一个网站信息肯定是通过某一个url,发送http请求,根据地址定位的,当知道这个地址,可以获取到很多的网络响应,需要认真分析,找到你那一个合适的地址,最后通过这个地址返回一个html给你,我们可以得到这个html,分析结构,解析这个结构获取你要的数据。
Html的结构解析往往是复杂繁琐的,我们可以使用java的支持包:jsoup,可以完成发送请求,解析html等功能,得到你感兴趣的数据。
下面就以一个彩票网站为例来简单说明整体操作流程,分为以下几大步骤:
1:根据官网,定位到自己感兴趣的模块:双色球
2:分析页面,找到它的入口地址
3:获取地址,使用jsoup发送请求,获取返回的Document对象
4:分析Document对象,获取感兴趣的数据
1:根据官网,找到您感兴趣的模块:双色球:
我选的500彩票网站:请按照以下步骤找到双色球版块。
2:分析页面,找到它的入口地址
发现右边有个下拉选择框,这是历史双色球开奖日期。改变这个值,浏览器会重新请求这个时期的彩票信息,并确定地址为:
选择问题编号.shtml
3:获取地址,使用jsoup发送请求,获取返回的Document对象
创建一个maven项目并导入jsoup的依赖:在你的java类中,向2个地址发送请求:获取返回的页面数据:
返回的html页面内容较多,这里就不贴了。下面我就直接分析这个页面(特别是每个html的结构不是一成不变的。有可能读者看到这个文章,网站修改了网页结构,那你就需要重新-分析一下。当然,估计网站修改网页结构的可能性比较小...)
4:分析Document对象,获取感兴趣的数据
双色球由6个红球和1个篮球组成。通过分析网页,它是用类来表示的。网页源代码如下:
通过以下代码,得到6个红球:
同理,可以获得1个蓝球。
根据这个原则,你可以得到你想要的数据:以下是我得到的数据
以上是个人对java中简单抓取网页数据的分享,感兴趣的童鞋可以自己的实践一下,实践出真知。
php抓取开奖网页内容(我在网上找到使用rft控件保存webbrowse文本(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-08 17:23
我在网上发现用rft控件保存网页浏览文本txtHtml是RichTextBox
txtHTML.Text = WebBrowser1.document.body.innerText
'flag:将rsftext另存为txt文件,strtmp文件路径
txtHTML.saveFile strtmp, rtfText
将其名称属性设置为 web
私有子命令1_Click()
web.Navigate ""
结束子
私有子 web_DocumentComplete(ByVal pDisp As Object, URL As Variant)
设置 doc = web.Document
对于每个 i In doc.All
msgbox typename(i)
Text1.Text = Text1.text & vbclrf & i.innertext
下一步
结束子
================================================ ============================================
转载
'引用 Microsoft HTML 对象库
将 oDoc 变暗为 HTMLDocument
Dim oElement 作为对象
将 oTxtRgn 变暗为对象
将 sSelectedText 变暗为字符串
设置oDoc = WebBrowser1.Document'获取文档对象
Set oElement = oDoc.getElementById("T1")'获取ID="T1"的对象
设置oTxtRgn = oDoc.selection.createRange'获取文档当前选中的区域对象
sSelectedText = oTxtRgn.Text'选中区域文字赋值
oElement.Focus 的“T1”对象获得焦点
oElement.Select'选择所有对象“T1”
Debug.Print "您选择的文本:" & sSelectedText
上一段还自带其他功能,哈哈。为了简化这样的事情:
将 oDoc 变暗为对象
将 oTxtRgn 变暗为对象
将 sSelectedHTML 淡化为字符串
Set oDoc = WebBrowser1.Document'获取文档对象
Set oTxtRgn = oDoc.selection.createRange'获取文档当前选中的区域对象
sSelectedHTML = oTxtRgn.htmlText'选定区域文本赋值
Text1.Text=sSelectedHTML'文本框显示捕获HTML源代码
......'还是继续分析源码
================================================ ====================================================
我用WebBrowser获取网页源代码,运行正常,但编译后报错。
私有子命令1_Click()
WebBrowser1.导航“”
结束子
私有子 WebBrowser1_DownloadComplete()
'页面下载完成
昏暗的文档,objhtml
设置 doc = WebBrowser1.文档
设置 objhtml = doc.body.createtextrange()
If Not IsNull(objhtml) Then
Text1.Text = objhtml.htmltext
如果结束
结束子
我用WebBrowser获取网页源代码,运行正常,但编译后报错。
提醒:实时错误“91”对象变量或块变量未设置
可能是下载未完成造成的,
私有子 WebBrowser1_DownloadComplete()
如果 webbrowser.busy=false 那么
昏暗的文档,objhtml
设置 doc = WebBrowser1.文档
设置 objhtml = doc.body.createtextrange()
If Not IsNull(objhtml) Then
Text1.Text = objhtml.htmltext
如果结束
如果结束
结束子
网页源代码需要使用xmlhttp。
首先引用 msxml
Dim x As New MSXML2.XMLHTTP
x.open "get", "", False
x.发送
MsgBox StrConv(x.responseBody, vbUnicode)
================================================ ================================================
我在网上发现用rft控件保存网页浏览文本txtHtml是RichTextBox
txtHTML.Text = WebBrowser1.document.body.innerText
'flag:将rsftext另存为txt文件,strtmp文件路径
txtHTML.saveFile strtmp, rtfText
================================================ ======================================
私有子 WebBrowser1_DownloadComplete()
将 objHtml 淡化为对象
'下载完成后,状态栏显示“链接完成”
设置 objHtml = Me.WebBrowser1.Document.Body.Createtextrange()
If Not IsNull(objHtml) Then
Text1.Text = objHtml.htmltext
如果结束
结束子
使用inet控件
Source1 = Inet1.OpenURL("")
如果 Source1 "" 那么
RichTextBox1.Text = Source1
Me.Inet1.取消
其他
Source = MsgBox("源代码不可用。", vbInformation, "源代码")
如果结束
私有子命令1_Click()
Text1.Text = WebBrowser1.Document.body.innerHTML
结束子
================================================ ====================================
添加计时器、命令按钮、文本
私有子命令1_click()
网络浏览器1.导航
定时器1.enabled=true
结束子
私有子 timer1_timer()
dim doc,objhtml 作为对象
dim i 为整数
将 strhtml 淡化为字符串
如果不是浏览器1.忙则
设置 doc=webbrowser1.文档
i=0
设置 objhtml=doc.body.createtextrange()
如果不是 isnull(objhtml) 则
text1.text=objhtml.htmltext
如果结束
定时器1.enabled=false
如果结束
结束子
Dim doc, objhtml As Object
如果不是浏览器1.那么忙
设置 doc = webbrowser1.文档
设置 objhtml = doc.body.createtextrange()
If Not IsNull(objhtml) Then
text1.text=objhtml.htmltext
如果结束
设置文档 = 无
设置 objhtml = 无
如果结束
================================================ ==================================================== =
或者试试InternetReadFile,效果也不错:
选项显式
私有声明函数InternetOpen Lib“wininet.dll”别名“InternetOpenA”(_
ByVal sAgent As String,ByVal lAccessType As Long,_
ByVal sProxyName As String, ByVal sProxyBypass As String, _
ByVal lFlags As Long) As Long
私有声明函数InternetOpenUrl Lib“wininet.dll”别名“InternetOpenUrlA”(_
ByVal hInternetSession As Long, ByVal sUrl As String, _
ByVal sHeaders As String, ByVal lHeadersLength As Long, _
ByVal lFlags As Long, ByVal lContext As Long) As Long
私有声明函数 InternetReadFile Lib "wininet.dll" (_
ByVal hFile As Long, ByVal sBuffer As String, _
ByVal lNumBytesToRead As Long,_
lNumberOfBytesRead As Long) As Integer
私有声明函数 InternetCloseHandle Lib "wininet.dll" (_
ByVal hInet As Long) As Integer
私有常量 INTERNET_FLAG_NO_CACHE_WRITE = &H4000000
昏暗
私有函数GetUrlFile(stUrl As String) As String
把 lgInternet 调暗一样长,lgSession 一样长
将 stBuf 淡化为字符串 * 1024
将 inRes 变暗为整数
将lgRet调暗
将 stTotal 淡化为字符串
stTotal = vbNullString
lgSession = InternetOpen("VBTagEdit", 1, vbNullString, vbNullString, 0)
如果 lgSession 那么
lgInternet = InternetOpenUrl(lgSession, stUrl, vbNullString, _
0, INTERNET_FLAG_NO_CACHE_WRITE, 0)
如果 lgInternet 那么
做
inRes = InternetReadFile(lgInternet, stBuf, 1024, lgRet)
stTotal = stTotal & Mid$(stBuf, 1, lgRet)
Loop While (lgRet 0)
如果结束
inRes = InternetCloseHandle(lgInternet)
如果结束
GetUrlFile = stTotal
结束函数
私有子命令1_Click()
Text1.Text = GetUrlFile("")
结束子
================================================ ==================================================== ===
设置 vDoc = WebBrowser1.文档
'获取网页源代码
对于 vDoc.All 中的每个 o
DoEvents
htmlpage = htmlpage & o.innerHTML
下一步
然后用写二进制文件的方法将htmlpage的内容写入.html文件中。如果页面收录框架,则应处理该框架。
================================================ ==================================================== ====================== 查看全部
php抓取开奖网页内容(我在网上找到使用rft控件保存webbrowse文本(图))
我在网上发现用rft控件保存网页浏览文本txtHtml是RichTextBox
txtHTML.Text = WebBrowser1.document.body.innerText
'flag:将rsftext另存为txt文件,strtmp文件路径
txtHTML.saveFile strtmp, rtfText
将其名称属性设置为 web
私有子命令1_Click()
web.Navigate ""
结束子
私有子 web_DocumentComplete(ByVal pDisp As Object, URL As Variant)
设置 doc = web.Document
对于每个 i In doc.All
msgbox typename(i)
Text1.Text = Text1.text & vbclrf & i.innertext
下一步
结束子
================================================ ============================================
转载
'引用 Microsoft HTML 对象库
将 oDoc 变暗为 HTMLDocument
Dim oElement 作为对象
将 oTxtRgn 变暗为对象
将 sSelectedText 变暗为字符串
设置oDoc = WebBrowser1.Document'获取文档对象
Set oElement = oDoc.getElementById("T1")'获取ID="T1"的对象
设置oTxtRgn = oDoc.selection.createRange'获取文档当前选中的区域对象
sSelectedText = oTxtRgn.Text'选中区域文字赋值
oElement.Focus 的“T1”对象获得焦点
oElement.Select'选择所有对象“T1”
Debug.Print "您选择的文本:" & sSelectedText
上一段还自带其他功能,哈哈。为了简化这样的事情:
将 oDoc 变暗为对象
将 oTxtRgn 变暗为对象
将 sSelectedHTML 淡化为字符串
Set oDoc = WebBrowser1.Document'获取文档对象
Set oTxtRgn = oDoc.selection.createRange'获取文档当前选中的区域对象
sSelectedHTML = oTxtRgn.htmlText'选定区域文本赋值
Text1.Text=sSelectedHTML'文本框显示捕获HTML源代码
......'还是继续分析源码
================================================ ====================================================
我用WebBrowser获取网页源代码,运行正常,但编译后报错。
私有子命令1_Click()
WebBrowser1.导航“”
结束子
私有子 WebBrowser1_DownloadComplete()
'页面下载完成
昏暗的文档,objhtml
设置 doc = WebBrowser1.文档
设置 objhtml = doc.body.createtextrange()
If Not IsNull(objhtml) Then
Text1.Text = objhtml.htmltext
如果结束
结束子
我用WebBrowser获取网页源代码,运行正常,但编译后报错。
提醒:实时错误“91”对象变量或块变量未设置
可能是下载未完成造成的,
私有子 WebBrowser1_DownloadComplete()
如果 webbrowser.busy=false 那么
昏暗的文档,objhtml
设置 doc = WebBrowser1.文档
设置 objhtml = doc.body.createtextrange()
If Not IsNull(objhtml) Then
Text1.Text = objhtml.htmltext
如果结束
如果结束
结束子
网页源代码需要使用xmlhttp。
首先引用 msxml
Dim x As New MSXML2.XMLHTTP
x.open "get", "", False
x.发送
MsgBox StrConv(x.responseBody, vbUnicode)
================================================ ================================================
我在网上发现用rft控件保存网页浏览文本txtHtml是RichTextBox
txtHTML.Text = WebBrowser1.document.body.innerText
'flag:将rsftext另存为txt文件,strtmp文件路径
txtHTML.saveFile strtmp, rtfText
================================================ ======================================
私有子 WebBrowser1_DownloadComplete()
将 objHtml 淡化为对象
'下载完成后,状态栏显示“链接完成”
设置 objHtml = Me.WebBrowser1.Document.Body.Createtextrange()
If Not IsNull(objHtml) Then
Text1.Text = objHtml.htmltext
如果结束
结束子
使用inet控件
Source1 = Inet1.OpenURL("")
如果 Source1 "" 那么
RichTextBox1.Text = Source1
Me.Inet1.取消
其他
Source = MsgBox("源代码不可用。", vbInformation, "源代码")
如果结束
私有子命令1_Click()
Text1.Text = WebBrowser1.Document.body.innerHTML
结束子
================================================ ====================================
添加计时器、命令按钮、文本
私有子命令1_click()
网络浏览器1.导航
定时器1.enabled=true
结束子
私有子 timer1_timer()
dim doc,objhtml 作为对象
dim i 为整数
将 strhtml 淡化为字符串
如果不是浏览器1.忙则
设置 doc=webbrowser1.文档
i=0
设置 objhtml=doc.body.createtextrange()
如果不是 isnull(objhtml) 则
text1.text=objhtml.htmltext
如果结束
定时器1.enabled=false
如果结束
结束子
Dim doc, objhtml As Object
如果不是浏览器1.那么忙
设置 doc = webbrowser1.文档
设置 objhtml = doc.body.createtextrange()
If Not IsNull(objhtml) Then
text1.text=objhtml.htmltext
如果结束
设置文档 = 无
设置 objhtml = 无
如果结束
================================================ ==================================================== =
或者试试InternetReadFile,效果也不错:
选项显式
私有声明函数InternetOpen Lib“wininet.dll”别名“InternetOpenA”(_
ByVal sAgent As String,ByVal lAccessType As Long,_
ByVal sProxyName As String, ByVal sProxyBypass As String, _
ByVal lFlags As Long) As Long
私有声明函数InternetOpenUrl Lib“wininet.dll”别名“InternetOpenUrlA”(_
ByVal hInternetSession As Long, ByVal sUrl As String, _
ByVal sHeaders As String, ByVal lHeadersLength As Long, _
ByVal lFlags As Long, ByVal lContext As Long) As Long
私有声明函数 InternetReadFile Lib "wininet.dll" (_
ByVal hFile As Long, ByVal sBuffer As String, _
ByVal lNumBytesToRead As Long,_
lNumberOfBytesRead As Long) As Integer
私有声明函数 InternetCloseHandle Lib "wininet.dll" (_
ByVal hInet As Long) As Integer
私有常量 INTERNET_FLAG_NO_CACHE_WRITE = &H4000000
昏暗
私有函数GetUrlFile(stUrl As String) As String
把 lgInternet 调暗一样长,lgSession 一样长
将 stBuf 淡化为字符串 * 1024
将 inRes 变暗为整数
将lgRet调暗
将 stTotal 淡化为字符串
stTotal = vbNullString
lgSession = InternetOpen("VBTagEdit", 1, vbNullString, vbNullString, 0)
如果 lgSession 那么
lgInternet = InternetOpenUrl(lgSession, stUrl, vbNullString, _
0, INTERNET_FLAG_NO_CACHE_WRITE, 0)
如果 lgInternet 那么
做
inRes = InternetReadFile(lgInternet, stBuf, 1024, lgRet)
stTotal = stTotal & Mid$(stBuf, 1, lgRet)
Loop While (lgRet 0)
如果结束
inRes = InternetCloseHandle(lgInternet)
如果结束
GetUrlFile = stTotal
结束函数
私有子命令1_Click()
Text1.Text = GetUrlFile("")
结束子
================================================ ==================================================== ===
设置 vDoc = WebBrowser1.文档
'获取网页源代码
对于 vDoc.All 中的每个 o
DoEvents
htmlpage = htmlpage & o.innerHTML
下一步
然后用写二进制文件的方法将htmlpage的内容写入.html文件中。如果页面收录框架,则应处理该框架。
================================================ ==================================================== ======================
php抓取开奖网页内容(抓取自己公众号文章的还是最基本的,比较困难)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-20 22:03
php抓取开奖网页内容,进行数据筛选,去重分析,处理数据,生成excel,之后分析网站流量,地区,
有很多可以提取隐藏转发的。其实抓取外部公众号推送文章的还是最基本的,如果只是抓取抓取自己公众号文章的,比较困难,毕竟公众号太多了。可以先用模拟推送功能来推送有需要的文章,再推送消息,如果是抓取整个大号公众号的,就会好过多了。
到脉脉找
在刚刚过去的国庆中秋节,全国人民都过了一个“小长假”。大部分地区路不通,车不走,飞机票不一定买得到,朋友圈在美滋滋晒出了旅游的一瞬间——几个月前,发图回到老家过年;但在看着美滋滋的同时,有人在想,我们应该准备好哪些资料回家?怎么才能收获一个合适的旅行目的地?你问对人了!我最近听到了一个珍贵的消息,不一定要出去走走,但是可以收集一些国庆家乡的资料!这里要安利一个叫做“酒城故事”的公众号,他们会发布很多有意思、有价值的资料。
这个号主做了一个很有意思的事情:做一个小程序,在每一年的国庆节里,把自己知道的关于国庆的事情、故事、图片、文章在小程序里一并呈现出来,让你直接回家!如果你看到了什么,还想发挥你的想象力和创造力,欢迎联系!。
从微信公众号文章中就可以找到 查看全部
php抓取开奖网页内容(抓取自己公众号文章的还是最基本的,比较困难)
php抓取开奖网页内容,进行数据筛选,去重分析,处理数据,生成excel,之后分析网站流量,地区,
有很多可以提取隐藏转发的。其实抓取外部公众号推送文章的还是最基本的,如果只是抓取抓取自己公众号文章的,比较困难,毕竟公众号太多了。可以先用模拟推送功能来推送有需要的文章,再推送消息,如果是抓取整个大号公众号的,就会好过多了。
到脉脉找
在刚刚过去的国庆中秋节,全国人民都过了一个“小长假”。大部分地区路不通,车不走,飞机票不一定买得到,朋友圈在美滋滋晒出了旅游的一瞬间——几个月前,发图回到老家过年;但在看着美滋滋的同时,有人在想,我们应该准备好哪些资料回家?怎么才能收获一个合适的旅行目的地?你问对人了!我最近听到了一个珍贵的消息,不一定要出去走走,但是可以收集一些国庆家乡的资料!这里要安利一个叫做“酒城故事”的公众号,他们会发布很多有意思、有价值的资料。
这个号主做了一个很有意思的事情:做一个小程序,在每一年的国庆节里,把自己知道的关于国庆的事情、故事、图片、文章在小程序里一并呈现出来,让你直接回家!如果你看到了什么,还想发挥你的想象力和创造力,欢迎联系!。
从微信公众号文章中就可以找到
php抓取开奖网页内容(超级站群5.5版本(未加密版本)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-19 05:15
超级站群5.5版(未加密版)
一、泛分析模式 泛分析是网络上最火的模式!据说他走红是因为模特创造了神话!2012年造了7天重8,一直持续到2013年底,百度开始封杀。直到2014年底才慢慢恢复收录!但是收录的效果比之前差了很多!但是 10 个域名 收录 10,000 个条目就可以了!建议:此模式适用于长尾关键词。没有大批量竞争关键词!比如我卖手机!我们要批量挖掘手机的长尾关键词,比如北京手机便宜的网店卖的苹果手机等等,这些术语基本没有竞争!百度的收录之后 泛解析二级域名!有50%的几率进入百度前2页!你可能会问这个词基本上没有人搜索它!我想告诉你的是!搜索这个词的人并不多!基本上3天就遇到了一个搜索者!你可以数出来!如果一般分析站群收录有10000个页面,那么10000个关键词页面也有几十个!即使每天有 100 个 关键词 页面中的 1 个人访问我们的页面!每天有100个IP流量!泛解析方式1.需要批量的长尾没有竞争关键词越多越好2.需要批量的大量域名,因为一个域名收录是约1000个域名。一点效果都没有!二、 什么是蜘蛛池模式?蜘蛛就是我们所说的百度爬取网站地下IP,我们通常称它们为蜘蛛!看名字就知道蜘蛛池就是我们用批量域名搭建站群,让这些域名生成网站,所有的轮子都链在一起,蜘蛛爬行我们的< @站群,一直循环生成页面,蜘蛛是我们养的!蜘蛛池的作用:蜘蛛池的使用非常简单。比如我要让我的网站这个页面收录!我只需要覆盖链接并放入我们的站群!蜘蛛被引导到这个页面爬行!爬完百度就会收录!现在很多人用蜘蛛池来推断它是什么!外推是互联网上的一些高特权网站。如果他们的网站乱发一则垃圾,就算没有文章页面,也会立马被百度收录,别给排名!我们要做的外推就是在我们的关键词中加入我们的联系方式访问或者网站,并在这些大网站上留下页面痕迹,然后把这个页面的链接提交给我们的蜘蛛,让蜘蛛抓取这个页面!大家访问网站,右击选择源代码。我们可以在代码中看到这是页面的标题!我们程序蜘蛛池中的链接在哪里提交,然后百度蜘蛛爬取收录!有一定几率别人会搜索关键词 站群,你看我留下的东西会被推广!以上是我的解释!具体来说,那些大站可以是收录 排名需要自己搜索资源!三、什么是短网址模式?这是正确的。缩短我们的 网站 页面或 URL。当其他人访问这个短网址时,他们看到的是我们网站页面或网址的内容!我们的理论和上面解释的一样!使用工具生成我们泛分析生成的二级域名的短网址!然后链上依靠百度蜘蛛来收录这些短网址和排名!网上最火的就是最近出了问题,惹来不少麻烦收录!建议你找其他短网址来操作!有68个短网址生成器我们点赞数量增加了,大家可以看看!还有你从百度下载的短网址自己找相关网站!看看那些可以< @收录,大家好好学习!四、爱站 外推方式与上面提到的外推方式相同,但这是自动的。您可以选择加密版本的方式,并且不能修改帐户密码。点赞后发送完整程序!可以修改账号密码!第一步是批量域名解析到你的VPS或服务器!第二步:将站群程序上传到VPS或服务器!第三步:环境配置如果你的服务有php环境,则无需配置。如果没有,请下载php环境配置包!如果您不明白,请联系您的服务器提供商!但这是自动的。您可以选择加密版本的方式,并且不能修改帐户密码。点赞后发送完整程序!可以修改账号密码!第一步是批量域名解析到你的VPS或服务器!第二步:将站群程序上传到VPS或服务器!第三步:环境配置如果你的服务有php环境,则无需配置。如果没有,请下载php环境配置包!如果您不明白,请联系您的服务器提供商!但这是自动的。您可以选择加密版本的方式,并且不能修改帐户密码。点赞后发送完整程序!可以修改账号密码!第一步是批量域名解析到你的VPS或服务器!第二步:将站群程序上传到VPS或服务器!第三步:环境配置如果你的服务有php环境,则无需配置。如果没有,请下载php环境配置包!如果您不明白,请联系您的服务器提供商!程序到 VPS 或服务器!第三步:环境配置如果你的服务有php环境,则无需配置。如果没有,请下载php环境配置包!如果您不明白,请联系您的服务器提供商!程序到 VPS 或服务器!第三步:环境配置如果你的服务有php环境,则无需配置。如果没有,请下载php环境配置包!如果您不明白,请联系您的服务器提供商!
现在就下载 查看全部
php抓取开奖网页内容(超级站群5.5版本(未加密版本)(组图))
超级站群5.5版(未加密版)
一、泛分析模式 泛分析是网络上最火的模式!据说他走红是因为模特创造了神话!2012年造了7天重8,一直持续到2013年底,百度开始封杀。直到2014年底才慢慢恢复收录!但是收录的效果比之前差了很多!但是 10 个域名 收录 10,000 个条目就可以了!建议:此模式适用于长尾关键词。没有大批量竞争关键词!比如我卖手机!我们要批量挖掘手机的长尾关键词,比如北京手机便宜的网店卖的苹果手机等等,这些术语基本没有竞争!百度的收录之后 泛解析二级域名!有50%的几率进入百度前2页!你可能会问这个词基本上没有人搜索它!我想告诉你的是!搜索这个词的人并不多!基本上3天就遇到了一个搜索者!你可以数出来!如果一般分析站群收录有10000个页面,那么10000个关键词页面也有几十个!即使每天有 100 个 关键词 页面中的 1 个人访问我们的页面!每天有100个IP流量!泛解析方式1.需要批量的长尾没有竞争关键词越多越好2.需要批量的大量域名,因为一个域名收录是约1000个域名。一点效果都没有!二、 什么是蜘蛛池模式?蜘蛛就是我们所说的百度爬取网站地下IP,我们通常称它们为蜘蛛!看名字就知道蜘蛛池就是我们用批量域名搭建站群,让这些域名生成网站,所有的轮子都链在一起,蜘蛛爬行我们的< @站群,一直循环生成页面,蜘蛛是我们养的!蜘蛛池的作用:蜘蛛池的使用非常简单。比如我要让我的网站这个页面收录!我只需要覆盖链接并放入我们的站群!蜘蛛被引导到这个页面爬行!爬完百度就会收录!现在很多人用蜘蛛池来推断它是什么!外推是互联网上的一些高特权网站。如果他们的网站乱发一则垃圾,就算没有文章页面,也会立马被百度收录,别给排名!我们要做的外推就是在我们的关键词中加入我们的联系方式访问或者网站,并在这些大网站上留下页面痕迹,然后把这个页面的链接提交给我们的蜘蛛,让蜘蛛抓取这个页面!大家访问网站,右击选择源代码。我们可以在代码中看到这是页面的标题!我们程序蜘蛛池中的链接在哪里提交,然后百度蜘蛛爬取收录!有一定几率别人会搜索关键词 站群,你看我留下的东西会被推广!以上是我的解释!具体来说,那些大站可以是收录 排名需要自己搜索资源!三、什么是短网址模式?这是正确的。缩短我们的 网站 页面或 URL。当其他人访问这个短网址时,他们看到的是我们网站页面或网址的内容!我们的理论和上面解释的一样!使用工具生成我们泛分析生成的二级域名的短网址!然后链上依靠百度蜘蛛来收录这些短网址和排名!网上最火的就是最近出了问题,惹来不少麻烦收录!建议你找其他短网址来操作!有68个短网址生成器我们点赞数量增加了,大家可以看看!还有你从百度下载的短网址自己找相关网站!看看那些可以< @收录,大家好好学习!四、爱站 外推方式与上面提到的外推方式相同,但这是自动的。您可以选择加密版本的方式,并且不能修改帐户密码。点赞后发送完整程序!可以修改账号密码!第一步是批量域名解析到你的VPS或服务器!第二步:将站群程序上传到VPS或服务器!第三步:环境配置如果你的服务有php环境,则无需配置。如果没有,请下载php环境配置包!如果您不明白,请联系您的服务器提供商!但这是自动的。您可以选择加密版本的方式,并且不能修改帐户密码。点赞后发送完整程序!可以修改账号密码!第一步是批量域名解析到你的VPS或服务器!第二步:将站群程序上传到VPS或服务器!第三步:环境配置如果你的服务有php环境,则无需配置。如果没有,请下载php环境配置包!如果您不明白,请联系您的服务器提供商!但这是自动的。您可以选择加密版本的方式,并且不能修改帐户密码。点赞后发送完整程序!可以修改账号密码!第一步是批量域名解析到你的VPS或服务器!第二步:将站群程序上传到VPS或服务器!第三步:环境配置如果你的服务有php环境,则无需配置。如果没有,请下载php环境配置包!如果您不明白,请联系您的服务器提供商!程序到 VPS 或服务器!第三步:环境配置如果你的服务有php环境,则无需配置。如果没有,请下载php环境配置包!如果您不明白,请联系您的服务器提供商!程序到 VPS 或服务器!第三步:环境配置如果你的服务有php环境,则无需配置。如果没有,请下载php环境配置包!如果您不明白,请联系您的服务器提供商!
现在就下载
php抓取开奖网页内容(php抓取开奖网页内容,解析字段值,比如验证码:basketball,等等,然后拼接或者翻页,短短两句话,想到)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-14 00:00
php抓取开奖网页内容,解析字段值,比如验证码:basketball,all-onepatches等等,然后拼接或者翻页,
短短两句话,想到的是vba+cookie,不过同事是直接用微软系列vb。中途会跳转其他页面,
对你这种刚毕业的人应该不难实现
<p>想到一种,文件目录下,php目录下,找到banner.php文件,然后通过 查看全部
php抓取开奖网页内容(php抓取开奖网页内容,解析字段值,比如验证码:basketball,等等,然后拼接或者翻页,短短两句话,想到)
php抓取开奖网页内容,解析字段值,比如验证码:basketball,all-onepatches等等,然后拼接或者翻页,
短短两句话,想到的是vba+cookie,不过同事是直接用微软系列vb。中途会跳转其他页面,
对你这种刚毕业的人应该不难实现
<p>想到一种,文件目录下,php目录下,找到banner.php文件,然后通过
php抓取开奖网页内容(很好用!app的返利有没有,多少??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-06 17:03
php抓取开奖网页内容,用于推送程序出售。用http协议,通过id找到本期开奖号码的期望值。0号以0开头,1号以1开头,2号以2开头。如果你不知道,就能从我的文章里获取。
大部分的站长都有自己搭建返利网站,然后把网站挂在各种百度联盟。百度都会拿返利来作为广告联盟的出价。别家站点的站长自己搭建返利网站,
返利app后台是做为推广app的跳板,而推广app本身是需要推广费用的。
app有,返利是可以定金返,押金返,现金返。甚至返全返。返利网站是站长接入返利返的网站,自己搭建返利站点,定时上活动,自然定期返利出来。自己定时上活动,自然要收费,这个是合理的。
大家都懂的我只说一句话,只有大app才会返利,
我是用户!!!很好用!
app的返利有没有,多少?返利网的返利有没有,多少?我没有去看过,不好说。但是可以说下我了解到的情况。返利一般针对的都是老用户,而且是相对较高的用户,相对来说是一条不断升级、不断强大、不断持续增长的好产品!这点相信大家也深有体会!另外,我是用返利app,很好用,很方便,也不用担心漏发了或者少发了,收到的返利都在服务号上,很方便。 查看全部
php抓取开奖网页内容(很好用!app的返利有没有,多少??)
php抓取开奖网页内容,用于推送程序出售。用http协议,通过id找到本期开奖号码的期望值。0号以0开头,1号以1开头,2号以2开头。如果你不知道,就能从我的文章里获取。
大部分的站长都有自己搭建返利网站,然后把网站挂在各种百度联盟。百度都会拿返利来作为广告联盟的出价。别家站点的站长自己搭建返利网站,
返利app后台是做为推广app的跳板,而推广app本身是需要推广费用的。
app有,返利是可以定金返,押金返,现金返。甚至返全返。返利网站是站长接入返利返的网站,自己搭建返利站点,定时上活动,自然定期返利出来。自己定时上活动,自然要收费,这个是合理的。
大家都懂的我只说一句话,只有大app才会返利,
我是用户!!!很好用!
app的返利有没有,多少?返利网的返利有没有,多少?我没有去看过,不好说。但是可以说下我了解到的情况。返利一般针对的都是老用户,而且是相对较高的用户,相对来说是一条不断升级、不断强大、不断持续增长的好产品!这点相信大家也深有体会!另外,我是用返利app,很好用,很方便,也不用担心漏发了或者少发了,收到的返利都在服务号上,很方便。
php抓取开奖网页内容(python代码解析题目+beautifulsoup加代理池就可以了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-03 02:03
php抓取开奖网页内容免费分析,解析关键词,提取题目,下载题目等等。scrapy前端自动代理,实现代理转发,python代码解析,将提取到的关键词,上传到某网站,返回给seoer。python后端程序用selenium或者lxml解析抓取信息,对关键词进行下载,然后上传到某网站。
tornado基于urllib2,解析url并生成booklet,然后循环抓取的文件。
python代码解析题目
requests+beautifulsoup应该可以吧,
看样子应该是抓取了几千关键词组成的文档然后用这些关键词生成文档内容然后再从文档中提取你要的这个没事抓个零零碎碎的总行吧
理论上是可以的,可以爬虫只爬那些简单的,或者走简单的中转站高阶代理,比如借助防火墙绕过代理而跳转,或者用代理池。
支持!探寻终极大招,从金融入手,好像主要是金融经济类,但这个方向已经有大量的案例,目标是银行,券商等,bfs、boost等爬虫系统即可。
python加boost加代理池就可以了啊
如果是个人理解的是,那么从python抓手写一个爬虫程序,单机就可以抓取相关网站页面数据,解析出题目内容,document文件提交到系统进行统计或分析等, 查看全部
php抓取开奖网页内容(python代码解析题目+beautifulsoup加代理池就可以了)
php抓取开奖网页内容免费分析,解析关键词,提取题目,下载题目等等。scrapy前端自动代理,实现代理转发,python代码解析,将提取到的关键词,上传到某网站,返回给seoer。python后端程序用selenium或者lxml解析抓取信息,对关键词进行下载,然后上传到某网站。
tornado基于urllib2,解析url并生成booklet,然后循环抓取的文件。
python代码解析题目
requests+beautifulsoup应该可以吧,
看样子应该是抓取了几千关键词组成的文档然后用这些关键词生成文档内容然后再从文档中提取你要的这个没事抓个零零碎碎的总行吧
理论上是可以的,可以爬虫只爬那些简单的,或者走简单的中转站高阶代理,比如借助防火墙绕过代理而跳转,或者用代理池。
支持!探寻终极大招,从金融入手,好像主要是金融经济类,但这个方向已经有大量的案例,目标是银行,券商等,bfs、boost等爬虫系统即可。
python加boost加代理池就可以了啊
如果是个人理解的是,那么从python抓手写一个爬虫程序,单机就可以抓取相关网站页面数据,解析出题目内容,document文件提交到系统进行统计或分析等,
php抓取开奖网页内容(全国第一大框架,wordpresswordpress,框架下载-慕课网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-02 22:03
php抓取开奖网页内容:javascript抓取js文件:
..
现在基本都用requests了吧,get方法的效率太低,又不安全。selenium不也用不安全吗,在服务器上存也麻烦。fiddler代理也不稳定,还是要使用selenium。laravel的trimjs解析php代码也不方便,那肯定是selenium最好。
简单的看看这个
mysql和sqlserver都行,不过最终都会通过httpapilibrarylibmgrr里去拿,楼上说的很详细了,现在开源社区也比较成熟了,基本不用自己写了。
推荐自己写laravel
可以的,现在采用比较多的是requests,具体的laravel项目-laravel,hibernate,mybatis,struts框架的全国第一大php框架,wordpress框架下载-慕课网,我目前用的是tap的。
我觉得可以postman比起一般爬虫肯定是方便,但是比如需要用到事务的就不方便了,比如订单的就不方便,
这种要看你是做什么方面了我简单介绍下我自己的个人经验shopify有配套的抓取工具包,postman比较流行,
不太同意第一个答案看来是没有在github或者其他地方看到过python爬虫框架... 查看全部
php抓取开奖网页内容(全国第一大框架,wordpresswordpress,框架下载-慕课网)
php抓取开奖网页内容:javascript抓取js文件:
..
现在基本都用requests了吧,get方法的效率太低,又不安全。selenium不也用不安全吗,在服务器上存也麻烦。fiddler代理也不稳定,还是要使用selenium。laravel的trimjs解析php代码也不方便,那肯定是selenium最好。
简单的看看这个
mysql和sqlserver都行,不过最终都会通过httpapilibrarylibmgrr里去拿,楼上说的很详细了,现在开源社区也比较成熟了,基本不用自己写了。
推荐自己写laravel
可以的,现在采用比较多的是requests,具体的laravel项目-laravel,hibernate,mybatis,struts框架的全国第一大php框架,wordpress框架下载-慕课网,我目前用的是tap的。
我觉得可以postman比起一般爬虫肯定是方便,但是比如需要用到事务的就不方便了,比如订单的就不方便,
这种要看你是做什么方面了我简单介绍下我自己的个人经验shopify有配套的抓取工具包,postman比较流行,
不太同意第一个答案看来是没有在github或者其他地方看到过python爬虫框架...
php抓取开奖网页内容(中国体育彩票超级大乐透爬取代码grab500_dlt.py.dlt)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-30 14:05
经调研发现,中国福彩双色球每周21:15开奖二、四、,中国体彩超级乐透每周六21:30开奖一、< @三、 ,而我们要完成的目标是:
1、自动完成安装工作
2、每周晚23:00二、四、,爬取每周晚23:00中福彩票双色球开奖数据一、< @三、 抓取中国体彩超级乐透开奖数据。
1、工具
2、具体方法1、使用python2.7写爬虫脚本
除了正常的爬取操作,这里还增加了独立的参数设置。如果没有参数,则抓取到的数据在当前目录;如果有参数,可以设置保存目录和保存文件名后缀。在这种情况下,此脚本可以单独使用,也可以与 sh 计时任务结合使用。
二色球爬行的grab500_ssq.py代码内容:
# -*- coding:utf-8 -*-
import re
import urllib
import time
import sys
datapath = sys.path[0]
datasuffix = 'txt'
if (len(sys.argv)>1):
datapath = sys.argv[1]
datasuffix = sys.argv[2]
def getHtml(url):
html = urllib.urlopen(url)
return html.read()
html = getHtml("http://zx.500.com/ssq/")
reg = ['([0-9]\d*).*']
reg.append('([0-9]\d*)')
reg.append('([0-9]\d*)')
outstr = "";
for i in range(len(reg)):
page = re.compile(reg[i])
rs = re.findall(page,html)
for j in range(len(rs)):
outstr+= rs[j] + ","
#print time.strftime('%Y-%m-%d',time.localtime(time.time()))+":"+outstr[:-1]
with open(datapath+'/lot_500_ssq.'+datasuffix, 'a') as f:
f.write(time.strftime('%Y-%m-%d',time.localtime(time.time()))+":"+outstr[:-1]+'\n')
DaLotto爬取代码grab500_dlt.py内容:
# -*- coding:utf-8 -*-
import re
import urllib
import time
import sys
datapath = sys.path[0]
datasuffix ='txt'
if(len(sys.argv)>1):
datapath = sys.argv[1]
datasuffix = sys.argv[2]
defgetHtml(url):
html = urllib.urlopen(url)
return html.read()
html = getHtml("http://zx.500.com/dlt/")
reg =['([0-9]\d*).*']
reg.append('([0-9]\d*)')
reg.append('([0-9]\d*)')
outstr ="";
for i in range(len(reg)):
page = re.compile(reg[i])
rs = re.findall(page,html)
for j in range(len(rs)):
outstr+= rs[j]+","
#print time.strftime('%Y-%m-%d',time.localtime(time.time()))+":"+outstr[:-1]
with open(datapath+'/lot_500_dlt.'+datasuffix,'a')as f:
f.write(time.strftime('%Y-%m-%d',time.localtime(time.time()))+":"+outstr[:-1]+'\n')
2、编写一个可执行的sh脚本
我们需要编写执行python的sh脚本bwb_lottery_everyday.sh。需要注意的是sh date得到的星期日值是0而不是7,crontab可以设置为0或7。
#!/bin/sh
basepath=$(cd `dirname $0`; pwd) #shell's dir
datapath=$basepath'/lotterydata' #shell's datadir
datasuffix='txt' #datasuffix
a=`date -d "${date}" +%w`
if [ $a -eq 1 ] || [ $a -eq 3 ] || [ $a -eq 6 ]; then
python "${basepath}/grab500_ssq.py" $datapath $datasuffix
elif [ $a -eq 2 ] || [ $a -eq 4 ] || [ $a -eq 0 ]; then
python "${basepath}/grab500_dlt.py" $datapath $datasuffix
fi
3、写一个主sh脚本
编写一个主 sh 脚本 bwb_lottery_main.sh 来执行清理和设置任务。需要注意的是,这里直接使用系统的/etc/crontab文件来达到周期性执行的目的,不是很好,但是crontab -e方法很难自动化,所以只能设置为系统任务。
#!/bin/sh
cronfile="/etc/crontab" #debian cronfile
basepath=$(cd `dirname $0`; pwd) #shell's dir
datapath=$basepath'/lotterydata' #shell's datadir
datasuffix='txt' #datasuffix
crontaskname="bwb_lottery_everyday.sh" #shell's name
crontasktime="0 23\t* * 1-4,6-7" #crontab task run time,default everyday except friday 23:00
echo "checking..."
if [ ! -f ${cronfile} ]; then
echo "crontab file $cronfile doesn't exsits.\nplease check file or modify shell setting and run shell again."
exit 1
fi
pyver=`python -V 2>&1|awk '{print $2}'|awk -F '.' '{print $1}'`
if [ $pyver != '2' ]; then
echo "python2(.7) is needed."
exit 1
fi
echo "writing crontab file..."
if [ `grep -c "${crontaskname}" ${cronfile}` -eq '0' ]; then
echo "${crontasktime}\troot\t${basepath}/${crontaskname}">>${cronfile}
else
sed -i "s#^.*${crontaskname}.*#${crontasktime}\troot\t${basepath}/${crontaskname}#" ${cronfile}
fi
/etc/init.d/cron restart
echo "making data dir..."
if [ ! -d "${datapath}" ]; then
mkdir ${datapath}
else
if [ ! -d "${datapath}/bak" ]; then
mkdir "${datapath}/bak"
else
mv ${datapath}/*.${datasuffix} ${datapath}/bak/ 2>/dev/null
fi
fi
echo "changing permission..."
chmod +x "$basepath/$crontaskname"
chmod +w -R $datapath
echo "finished!"
最后,我们只需要执行这个主脚本,就可以一键自动完成彩票爬虫的布局。
完整的项目代码已经上传到github~
/BEWINDOWEB/lotterygrabber
欢迎提交 watch、star、fork 质量三元组并提交 issue。 查看全部
php抓取开奖网页内容(中国体育彩票超级大乐透爬取代码grab500_dlt.py.dlt)
经调研发现,中国福彩双色球每周21:15开奖二、四、,中国体彩超级乐透每周六21:30开奖一、< @三、 ,而我们要完成的目标是:
1、自动完成安装工作
2、每周晚23:00二、四、,爬取每周晚23:00中福彩票双色球开奖数据一、< @三、 抓取中国体彩超级乐透开奖数据。
1、工具
2、具体方法1、使用python2.7写爬虫脚本
除了正常的爬取操作,这里还增加了独立的参数设置。如果没有参数,则抓取到的数据在当前目录;如果有参数,可以设置保存目录和保存文件名后缀。在这种情况下,此脚本可以单独使用,也可以与 sh 计时任务结合使用。
二色球爬行的grab500_ssq.py代码内容:
# -*- coding:utf-8 -*-
import re
import urllib
import time
import sys
datapath = sys.path[0]
datasuffix = 'txt'
if (len(sys.argv)>1):
datapath = sys.argv[1]
datasuffix = sys.argv[2]
def getHtml(url):
html = urllib.urlopen(url)
return html.read()
html = getHtml("http://zx.500.com/ssq/";)
reg = ['([0-9]\d*).*']
reg.append('([0-9]\d*)')
reg.append('([0-9]\d*)')
outstr = "";
for i in range(len(reg)):
page = re.compile(reg[i])
rs = re.findall(page,html)
for j in range(len(rs)):
outstr+= rs[j] + ","
#print time.strftime('%Y-%m-%d',time.localtime(time.time()))+":"+outstr[:-1]
with open(datapath+'/lot_500_ssq.'+datasuffix, 'a') as f:
f.write(time.strftime('%Y-%m-%d',time.localtime(time.time()))+":"+outstr[:-1]+'\n')
DaLotto爬取代码grab500_dlt.py内容:
# -*- coding:utf-8 -*-
import re
import urllib
import time
import sys
datapath = sys.path[0]
datasuffix ='txt'
if(len(sys.argv)>1):
datapath = sys.argv[1]
datasuffix = sys.argv[2]
defgetHtml(url):
html = urllib.urlopen(url)
return html.read()
html = getHtml("http://zx.500.com/dlt/";)
reg =['([0-9]\d*).*']
reg.append('([0-9]\d*)')
reg.append('([0-9]\d*)')
outstr ="";
for i in range(len(reg)):
page = re.compile(reg[i])
rs = re.findall(page,html)
for j in range(len(rs)):
outstr+= rs[j]+","
#print time.strftime('%Y-%m-%d',time.localtime(time.time()))+":"+outstr[:-1]
with open(datapath+'/lot_500_dlt.'+datasuffix,'a')as f:
f.write(time.strftime('%Y-%m-%d',time.localtime(time.time()))+":"+outstr[:-1]+'\n')
2、编写一个可执行的sh脚本
我们需要编写执行python的sh脚本bwb_lottery_everyday.sh。需要注意的是sh date得到的星期日值是0而不是7,crontab可以设置为0或7。
#!/bin/sh
basepath=$(cd `dirname $0`; pwd) #shell's dir
datapath=$basepath'/lotterydata' #shell's datadir
datasuffix='txt' #datasuffix
a=`date -d "${date}" +%w`
if [ $a -eq 1 ] || [ $a -eq 3 ] || [ $a -eq 6 ]; then
python "${basepath}/grab500_ssq.py" $datapath $datasuffix
elif [ $a -eq 2 ] || [ $a -eq 4 ] || [ $a -eq 0 ]; then
python "${basepath}/grab500_dlt.py" $datapath $datasuffix
fi
3、写一个主sh脚本
编写一个主 sh 脚本 bwb_lottery_main.sh 来执行清理和设置任务。需要注意的是,这里直接使用系统的/etc/crontab文件来达到周期性执行的目的,不是很好,但是crontab -e方法很难自动化,所以只能设置为系统任务。
#!/bin/sh
cronfile="/etc/crontab" #debian cronfile
basepath=$(cd `dirname $0`; pwd) #shell's dir
datapath=$basepath'/lotterydata' #shell's datadir
datasuffix='txt' #datasuffix
crontaskname="bwb_lottery_everyday.sh" #shell's name
crontasktime="0 23\t* * 1-4,6-7" #crontab task run time,default everyday except friday 23:00
echo "checking..."
if [ ! -f ${cronfile} ]; then
echo "crontab file $cronfile doesn't exsits.\nplease check file or modify shell setting and run shell again."
exit 1
fi
pyver=`python -V 2>&1|awk '{print $2}'|awk -F '.' '{print $1}'`
if [ $pyver != '2' ]; then
echo "python2(.7) is needed."
exit 1
fi
echo "writing crontab file..."
if [ `grep -c "${crontaskname}" ${cronfile}` -eq '0' ]; then
echo "${crontasktime}\troot\t${basepath}/${crontaskname}">>${cronfile}
else
sed -i "s#^.*${crontaskname}.*#${crontasktime}\troot\t${basepath}/${crontaskname}#" ${cronfile}
fi
/etc/init.d/cron restart
echo "making data dir..."
if [ ! -d "${datapath}" ]; then
mkdir ${datapath}
else
if [ ! -d "${datapath}/bak" ]; then
mkdir "${datapath}/bak"
else
mv ${datapath}/*.${datasuffix} ${datapath}/bak/ 2>/dev/null
fi
fi
echo "changing permission..."
chmod +x "$basepath/$crontaskname"
chmod +w -R $datapath
echo "finished!"
最后,我们只需要执行这个主脚本,就可以一键自动完成彩票爬虫的布局。
完整的项目代码已经上传到github~
/BEWINDOWEB/lotterygrabber
欢迎提交 watch、star、fork 质量三元组并提交 issue。
php抓取开奖网页内容(如何提高PHP表单的安全性?(实例运行实例分析))
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-28 08:13
实例
Name:
E-mail:
运行实例
“welcome_get.php”是这样的:
Welcome
Your email address is:
上面的代码非常简单。然而,最重要的内容被遗漏了。您需要验证表单数据以防止脚本中出现漏洞。
注意:处理PHP表单时请注意安全!
此页面不收录任何表单验证器,它仅向我们展示如何发送和接收表单数据。
但是后面的章节会讲解如何提高PHP表单的安全性!表单的正确安全验证对于防御黑客攻击和垃圾邮件非常重要!
GET 与 POST
GET 和 POST 都创建数组(例如,array( key => value, key2 => value2, key3 => value3, ...))。该数组收录键/值对,其中键是表单控件的名称,值是来自用户的输入数据。
GET 和 POST 被视为 $_GET 和 $_POST。它们是超全局变量,这意味着它们可以被访问而无需考虑作用域——无需任何特殊代码,您可以从任何函数、类或文件访问它们。
$_GET 是通过 URL 参数传递给当前脚本的变量数组。
$_POST 是通过 HTTP POST 传递给当前脚本的变量数组。
什么时候使用 GET?
通过 GET 方法从表单发送的信息对任何人都是可见的(所有变量名和值都显示在 URL 中)。GET 对发送的信息量也有限制。限制为大约 2000 个字符。但是,由于该变量显示在 URL 中,因此将页面添加到书签中也更加方便。
GET 可用于发送非敏感数据。
注意:切勿使用 GET 发送密码或其他敏感信息!
什么时候使用POST?
表单通过POST方式发送的信息对其他人是不可见的(所有的名称/值都会嵌入到HTTP请求的正文中),发送的信息量没有限制。
此外,POST 支持高级功能,例如上传文件到服务器时的多部分二进制输入。
但是,由于该变量未显示在 URL 中,因此无法为该页面添加书签。
提示:开发人员更喜欢 POST 发送表单数据。
接下来让我们看看如何安全地处理PHP表单! 查看全部
php抓取开奖网页内容(如何提高PHP表单的安全性?(实例运行实例分析))
实例
Name:
E-mail:
运行实例
“welcome_get.php”是这样的:
Welcome
Your email address is:
上面的代码非常简单。然而,最重要的内容被遗漏了。您需要验证表单数据以防止脚本中出现漏洞。
注意:处理PHP表单时请注意安全!
此页面不收录任何表单验证器,它仅向我们展示如何发送和接收表单数据。
但是后面的章节会讲解如何提高PHP表单的安全性!表单的正确安全验证对于防御黑客攻击和垃圾邮件非常重要!
GET 与 POST
GET 和 POST 都创建数组(例如,array( key => value, key2 => value2, key3 => value3, ...))。该数组收录键/值对,其中键是表单控件的名称,值是来自用户的输入数据。
GET 和 POST 被视为 $_GET 和 $_POST。它们是超全局变量,这意味着它们可以被访问而无需考虑作用域——无需任何特殊代码,您可以从任何函数、类或文件访问它们。
$_GET 是通过 URL 参数传递给当前脚本的变量数组。
$_POST 是通过 HTTP POST 传递给当前脚本的变量数组。
什么时候使用 GET?
通过 GET 方法从表单发送的信息对任何人都是可见的(所有变量名和值都显示在 URL 中)。GET 对发送的信息量也有限制。限制为大约 2000 个字符。但是,由于该变量显示在 URL 中,因此将页面添加到书签中也更加方便。
GET 可用于发送非敏感数据。
注意:切勿使用 GET 发送密码或其他敏感信息!
什么时候使用POST?
表单通过POST方式发送的信息对其他人是不可见的(所有的名称/值都会嵌入到HTTP请求的正文中),发送的信息量没有限制。
此外,POST 支持高级功能,例如上传文件到服务器时的多部分二进制输入。
但是,由于该变量未显示在 URL 中,因此无法为该页面添加书签。
提示:开发人员更喜欢 POST 发送表单数据。
接下来让我们看看如何安全地处理PHP表单!
php抓取开奖网页内容(我想从网页的script标记中获取特定内容内容。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-26 12:11
我想从网页的脚本标签中获取特定内容。
这是一个 HTML 页面。
//some other srcipt code
//some other srcipt code
var abc = {"asld":"asdjk","thisone":"https:\/\/www.example.com\/$N.jpg|#1000#M$M#JSuL8|1000#M$M#fW4EC0jcOl8kUY_QBZbOASsF8t0","user_gender":"m"};
我只想得到这个值 fW4EC0jcOl8kUY_QBZbOASsF8t0,它位于脚本变量 thisone 中 var abc 的最后一个属性中。
我可以使用 PHP HTML DOM 来做到这一点吗?如果没有,我该怎么办
最佳答案
您可以使用正则表达式轻松获取它
"thisone":".*#(.*)",
假设页面是,
$data = file_get_contents('http://example.com');
preg_match_all("/\"thisone\":\".*#(.*)\",/", $data, $output);
echo $output[1][0]; // prints fW4EC0jcOl8kUY_QBZbOASsF8t0
希望有帮助!
关于javascript-using PHP to get script content from web pages,我们在Stack Overflow上发现了一个类似的问题: 查看全部
php抓取开奖网页内容(我想从网页的script标记中获取特定内容内容。)
我想从网页的脚本标签中获取特定内容。
这是一个 HTML 页面。
//some other srcipt code
//some other srcipt code
var abc = {"asld":"asdjk","thisone":"https:\/\/www.example.com\/$N.jpg|#1000#M$M#JSuL8|1000#M$M#fW4EC0jcOl8kUY_QBZbOASsF8t0","user_gender":"m"};
我只想得到这个值 fW4EC0jcOl8kUY_QBZbOASsF8t0,它位于脚本变量 thisone 中 var abc 的最后一个属性中。
我可以使用 PHP HTML DOM 来做到这一点吗?如果没有,我该怎么办
最佳答案
您可以使用正则表达式轻松获取它
"thisone":".*#(.*)",
假设页面是,
$data = file_get_contents('http://example.com');
preg_match_all("/\"thisone\":\".*#(.*)\",/", $data, $output);
echo $output[1][0]; // prints fW4EC0jcOl8kUY_QBZbOASsF8t0
希望有帮助!
关于javascript-using PHP to get script content from web pages,我们在Stack Overflow上发现了一个类似的问题:
php抓取开奖网页内容(php抓取开奖网页内容,然后用php去拼接就可以了,获取效率很高!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-10-14 05:03
php抓取开奖网页内容,然后用php去拼接就可以了,获取效率很高!比简单爬虫快n多倍.5万个点中5个,获取100万个点的奖组信息,用这个爬虫真的要下很大功夫!如果觉得我解答得也还受用,也欢迎加入我新开的wx群,我们一帮人在里面交流基金投资心得,每周周末都会分享基金投资的知识和经验。
1.点一下鼠标2.按住鼠标左键不放3.摇一摇鼠标4.选中所有的内容。也可以用来做数据分析。
http请求抓取
刚刚在下载一次软件,还是的软件,说需要两个对象,需要把一个软件可能生成的内容都用一个对象记录下来,然后转换成html格式的话,也就是要从各个数据库字段进行转换,也就是要查找有没有库可以进行数据查询,因为我用的是phpweb开发语言。
python,php我就是这么下载抓取数据的。你这么问就是嫌简单。
加粗那条,
知乎不是百度知道,百度上搜半天只是皮毛,你不嫌复杂,你就去找个比这难一点的。如果你实在想找个没有这个框框的方案,给你个思路。1.找到任何一个你想抓取的页面,然后打开看看2.这页你看见了什么?从哪个网站过来?下一页就是什么?3.看起来你啥都不知道,就去搜索下,看看知乎上是否也有人有一样的问题?总结一下:想快速下载任何内容,首先你要明白你要抓取什么内容。
对于你所说的几十秒获取50w个登录数据,我想应该不是登录数据,只是普通的页面下载数据。简单有效的快速下载方案:登录次数:1秒快速下载页数:50w这样来看,你离快速下载和查看都比较远,如果你愿意折腾的话。 查看全部
php抓取开奖网页内容(php抓取开奖网页内容,然后用php去拼接就可以了,获取效率很高!)
php抓取开奖网页内容,然后用php去拼接就可以了,获取效率很高!比简单爬虫快n多倍.5万个点中5个,获取100万个点的奖组信息,用这个爬虫真的要下很大功夫!如果觉得我解答得也还受用,也欢迎加入我新开的wx群,我们一帮人在里面交流基金投资心得,每周周末都会分享基金投资的知识和经验。
1.点一下鼠标2.按住鼠标左键不放3.摇一摇鼠标4.选中所有的内容。也可以用来做数据分析。
http请求抓取
刚刚在下载一次软件,还是的软件,说需要两个对象,需要把一个软件可能生成的内容都用一个对象记录下来,然后转换成html格式的话,也就是要从各个数据库字段进行转换,也就是要查找有没有库可以进行数据查询,因为我用的是phpweb开发语言。
python,php我就是这么下载抓取数据的。你这么问就是嫌简单。
加粗那条,
知乎不是百度知道,百度上搜半天只是皮毛,你不嫌复杂,你就去找个比这难一点的。如果你实在想找个没有这个框框的方案,给你个思路。1.找到任何一个你想抓取的页面,然后打开看看2.这页你看见了什么?从哪个网站过来?下一页就是什么?3.看起来你啥都不知道,就去搜索下,看看知乎上是否也有人有一样的问题?总结一下:想快速下载任何内容,首先你要明白你要抓取什么内容。
对于你所说的几十秒获取50w个登录数据,我想应该不是登录数据,只是普通的页面下载数据。简单有效的快速下载方案:登录次数:1秒快速下载页数:50w这样来看,你离快速下载和查看都比较远,如果你愿意折腾的话。

