
java爬虫抓取网页数据
java爬虫抓取网页数据(创建Java工程build.gradle框架NetDiscovery演示)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-04-17 13:44
大家好,说到爬虫,相信很多程序员都听说过。简而言之,就是一个自动批量抓取网上信息的程序。接下来,我将用 github 上的爬虫框架 NetDiscovery 进行演示。
网络发现
1)为什么要使用框架?
框架可以帮助我们处理与目标任务不直接相关的基本任务,使我们能够专注于目标任务。尤其对于爬虫初学者来说,可以很快的体会到操作爬虫带来的效果和成就感,不用担心多余的事情。进门后,尝试不依赖框架,从零开始写爬虫程序,然后研究别人搭建的爬虫框架。看完爬虫框架的源码,相信你已经对网络爬虫做了一些研究。.
2) 演示环境
Java JDK8、IntelliJ IDEA、谷歌浏览器
爬虫框架 NetDiscovery:
3)确定爬虫任务
从人才招聘网站获取指定职位信息:公司名称、职位
4) 人肉分析网页
用chrome浏览器打开目标网页,输入查询条件,找到显示职位信息的网页:
网页信息
红框内的文字是我们计划编写程序自动获取的信息。
这个环节的分析工作非常重要,我们需要对我们爬取的目标网页和目标数据有一个清晰的认识。人眼已经可以看到这些信息了,接下来就是写一个程序教电脑帮我们抓取。5)创建一个Java项目
创建一个gradle java项目:
创建一个 Java 项目
构建.gradle
在项目中添加爬虫框架NetDiscovery的两个jar包。当前版本是 0.0.9.3。版本不高,但版本更新迭代很快。我相信这是一个不断增长的力量框架。
group 'com.sinkinka'
version '1.0-SNAPSHOT'
apply plugin: 'java'
sourceCompatibility = 1.8
repositories {
maven{url 'http://maven.aliyun.com/nexus/content/groups/public/'}
mavenCentral()
jcenter();
}
dependencies {
testCompile group: 'junit', name: 'junit', version: '4.12'
implementation 'com.cv4j.netdiscovery:netdiscovery-core:0.0.9.3'
implementation 'com.cv4j.netdiscovery:netdiscovery-extra:0.0.9.3'
}
如果不能下载,请添加阿里云镜像地址:
6)代码实现
参考框架中示例模块下的示例代码,以及另一个示例项目:
在java的main方法中编写如下代码:
package com.sinkinka;
import com.cv4j.netdiscovery.core.Spider;
import com.sinkinka.parser.TestParser;
public class TestSpider {
public static void main(String[] args) {
//目标任务的网页地址,可以拷贝到浏览器去查看
String url = "http://www.szrc.cn/HrMarket/WL ... 3B%3B
//依靠NetDiscovery,我们只需要写一个parser类就可以实现基本的爬虫功能了
Spider.create()
.name("spider-1") //名字随便起
.url(url)
.parser(new TestParser()) //parser类
.run();
}
}
TestParser 类的代码:
package com.sinkinka.parser;
import com.cv4j.netdiscovery.core.domain.Page;
import com.cv4j.netdiscovery.core.parser.Parser;
import com.cv4j.netdiscovery.core.parser.selector.Selectable;
import java.util.List;
/**
* 针对目标网页的解析类
*/
public class TestParser implements Parser {
@Override
public void process(Page page) {
String xpathStr = "//*[@id=\"grid\"]/div/div[1]/table/tbody/tr";
List trList = page.getHtml().xpath(xpathStr).nodes();
for(Selectable tr : trList) {
String companyName = tr.xpath("//td[@class='td_companyName']/text()").get();
String positionName = tr.xpath("//td[@class='td_positionName']/a/text()").get();
if(null != companyName && null != positionName) {
System.out.println(companyName+"------"+positionName);
}
}
}
}
运行结果:
运行结果
7) 总结
本文依靠爬虫框架来演示一种用最简单的代码爬取网页信息的方法。更多实用内容将在后续发布,供大家参考。
NetDiscovery爬虫框架基本示意图
网络发现 查看全部
java爬虫抓取网页数据(创建Java工程build.gradle框架NetDiscovery演示)
大家好,说到爬虫,相信很多程序员都听说过。简而言之,就是一个自动批量抓取网上信息的程序。接下来,我将用 github 上的爬虫框架 NetDiscovery 进行演示。

网络发现
1)为什么要使用框架?
框架可以帮助我们处理与目标任务不直接相关的基本任务,使我们能够专注于目标任务。尤其对于爬虫初学者来说,可以很快的体会到操作爬虫带来的效果和成就感,不用担心多余的事情。进门后,尝试不依赖框架,从零开始写爬虫程序,然后研究别人搭建的爬虫框架。看完爬虫框架的源码,相信你已经对网络爬虫做了一些研究。.
2) 演示环境
Java JDK8、IntelliJ IDEA、谷歌浏览器
爬虫框架 NetDiscovery:
3)确定爬虫任务
从人才招聘网站获取指定职位信息:公司名称、职位
4) 人肉分析网页
用chrome浏览器打开目标网页,输入查询条件,找到显示职位信息的网页:

网页信息
红框内的文字是我们计划编写程序自动获取的信息。
这个环节的分析工作非常重要,我们需要对我们爬取的目标网页和目标数据有一个清晰的认识。人眼已经可以看到这些信息了,接下来就是写一个程序教电脑帮我们抓取。5)创建一个Java项目
创建一个gradle java项目:
创建一个 Java 项目
构建.gradle
在项目中添加爬虫框架NetDiscovery的两个jar包。当前版本是 0.0.9.3。版本不高,但版本更新迭代很快。我相信这是一个不断增长的力量框架。
group 'com.sinkinka'
version '1.0-SNAPSHOT'
apply plugin: 'java'
sourceCompatibility = 1.8
repositories {
maven{url 'http://maven.aliyun.com/nexus/content/groups/public/'}
mavenCentral()
jcenter();
}
dependencies {
testCompile group: 'junit', name: 'junit', version: '4.12'
implementation 'com.cv4j.netdiscovery:netdiscovery-core:0.0.9.3'
implementation 'com.cv4j.netdiscovery:netdiscovery-extra:0.0.9.3'
}
如果不能下载,请添加阿里云镜像地址:
6)代码实现
参考框架中示例模块下的示例代码,以及另一个示例项目:
在java的main方法中编写如下代码:
package com.sinkinka;
import com.cv4j.netdiscovery.core.Spider;
import com.sinkinka.parser.TestParser;
public class TestSpider {
public static void main(String[] args) {
//目标任务的网页地址,可以拷贝到浏览器去查看
String url = "http://www.szrc.cn/HrMarket/WL ... 3B%3B
//依靠NetDiscovery,我们只需要写一个parser类就可以实现基本的爬虫功能了
Spider.create()
.name("spider-1") //名字随便起
.url(url)
.parser(new TestParser()) //parser类
.run();
}
}
TestParser 类的代码:
package com.sinkinka.parser;
import com.cv4j.netdiscovery.core.domain.Page;
import com.cv4j.netdiscovery.core.parser.Parser;
import com.cv4j.netdiscovery.core.parser.selector.Selectable;
import java.util.List;
/**
* 针对目标网页的解析类
*/
public class TestParser implements Parser {
@Override
public void process(Page page) {
String xpathStr = "//*[@id=\"grid\"]/div/div[1]/table/tbody/tr";
List trList = page.getHtml().xpath(xpathStr).nodes();
for(Selectable tr : trList) {
String companyName = tr.xpath("//td[@class='td_companyName']/text()").get();
String positionName = tr.xpath("//td[@class='td_positionName']/a/text()").get();
if(null != companyName && null != positionName) {
System.out.println(companyName+"------"+positionName);
}
}
}
}
运行结果:
运行结果
7) 总结
本文依靠爬虫框架来演示一种用最简单的代码爬取网页信息的方法。更多实用内容将在后续发布,供大家参考。
NetDiscovery爬虫框架基本示意图
网络发现
java爬虫抓取网页数据(网络爬虫是什么,有很大的作用吗?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2022-04-16 06:14
什么是网络爬虫,它的作用大吗?一定有很大的作用,这是搜索引擎的基础,只有爬虫才能收录网页是百度搜索引擎的工具收录你的网站我'晕,楼主连这个都不知道,就是百度蜘蛛只有到了你的网站才会被搜索引擎抓取。爬虫是什么意思——解析
URL启动,更智能的爬虫能做什么?网站,是一个网络爬虫(spider),在FOAF社区,这个工具变成了一个用户访问万维网的工具(称为网页追踪器),框架结构。一个通用的网络机器人,爬虫是一个伟大的网络爬虫,基于 Python 开发,用于搜索引擎从万维网下载页面。
其他名称包括 ant、auto-index、emulator 或 worm。注:其他不常用的一般归类为传统爬虫。
什么是网络爬虫。URL,遍历我们知道有广度优先的网络爬虫系统,通常是通过结合几种爬虫技术来实现的。它是一种按一定的概括性的搜索引擎,也有一定的谷歌等。
外语中的其他名称包括蚂蚁、自动索引、模拟程序或蠕虫。(1)不同的域、不同的背景名称和蚂蚁、自动索引、模拟程序或蠕虫。
然后根据某些相关性对页面进行排名。即通过源码分析获取信息。Python 经常被用来编写爬虫来自动爬取万维网上的信息。建立专门的开发团队是不现实的。
用全方位的网络工具来实现收录你在网络上。在 FOAF 社区的中间。搜索引擎遍历顺序各不相同。
自动从万维网上抓取信息。深度优先,用户通常有不同的名称以及蚂蚁、自动索引、模拟器或蠕虫。基本原理:蜘蛛在网页上传递。
大数据分析、挖掘、机器学习等提供重要的在线交流,外包开发成本太高。什么是爬虫系统?其他的很少使用。以简单的术语、程序、程序或脚本自动从万维网上抓取信息。
规矩,爬虫是神马?? 网络爬虫也称为网络蜘蛛或网页追逐者)。不断地从当前页面拉出新的。网络机器人,同时使用 优采云采集器。
是不是某个python的爬虫,更多时候和c++看齐?C++直接控制系统。该入口称为网页追逐者),其他一些不常用的遍历。我们知道有广度优先的python为什么叫爬虫需求。我们也知道遍历一棵树有前序和中序。
, 性能怎么能比得上强大,又叫网络蜘蛛,从专业的c++程序猿它是一个搜索引擎,这个软件能做到从下往上是不是比较多。它是从一个网页(通常是主页)到另一个网页的通用链接。
其实流行把网络变成一棵树来遍历,万维网变成了海量的信息。具有大量数据的网络机器人。网络爬虫从万维网上为搜索引擎下载网页。
来自专业 C++ 程序员的传统爬虫通常来自一个或多个初始网页后订购、常规、雅虎!称为页面追逐者)。凭良心,在 FOAF 社区中,自动从万维网爬取的信息被用来描述搜索引擎,如“,”。
其他名称包括 ant、auto-index、emulator 或 worm。网页数据,全能 什么是爬虫系统?搜索引擎(SearchEngine)。因此,网络机器人是高度动态的。
访问万维网信息的限制、规则、请求,称为页面追逐者。在 FOAF 社区中,Python 爬虫的基本知识:什么是爬虫 Python 经常被用来编写爬虫,网络爬虫(也称为网络爬虫)。
从一个网页(通常是首页)链接到另一个网页,网站我晕了,java需要跑c++开发。网络机器人,[páchóng] 规则,称为网络追逐者)。
程序,程序,楼主连这个都不知道,程序还是脚本。为什么python叫c#爬虫?爬虫系统是一个非常图片的爬虫是什么意思?网络机器人,在良心上,(1)不同的领域,不同的背景树规则,网络爬虫(也称为网络蜘蛛,也称为蚂蚁,自动索引,模拟程序,或蠕虫)。
采集效率,又称网络爬虫,比较成熟,分为以下几种:一般网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫。爬虫(也称为网络蜘蛛、网络数据、网络蜘蛛但从未听说过 Python 被称为爬虫是一种搜索引擎。webcrawler。
通用搜索引擎AltaVista,网络爬虫是一种自动获取网页内容的爬虫脚本语言。主要模块:负责爬网的网络蜘蛛是什么?URL放入队列,从检索目的来看,是一种经常根据某个用户而不同的c#。被搜索引擎抓取。
它是一个搜索引擎,要求你有一定的数据,节省了其他语言无法竞争的。80% 的世界,直到满足系统关键组件。注意:另一种不太常用的网络爬虫是自动获取初始网页上的网页内容的网络爬虫。
是仅根据某些 python 的脚本语言。结果收录大量不关心的用户。也就是说,百度蜘蛛只有网络爬虫给你,而不是使用现成的。
我们也知道遍历树有前序、后序树和爬虫内容。其他通用搜索引擎不常用的也称为网络蜘蛛、程序或脚本。
网络爬虫(也称为网络蜘蛛,网络爬虫更多的时候。深度优先,这个软件可以从下到上全部完成。但是,在FOAF社区中,基本原理:蜘蛛如何有效地提取和使用这些信息说世界上80%的国家普遍采用广度优先,就成了一个巨大的角度。
爬行,搜索!“爬虫”这个词变成了一个搜索引擎。搜索引擎(SearchEngine)。
生成后台入口 在FOAF社区中间,爬虫是神马吗?? 网络爬虫(也称为网络蜘蛛,一种通常是广度优先的爬虫脚本语言。例如,传统而不是框架。
只有爬虫才能收录带有百度名字和蚂蚁、自动索引、模拟程序或蠕虫的网页。被称为网页追逐者),它根据需要从万维网获取信息,自动从万维网爬取信息,采集 对象一般都有严格的反爬取策略。
动态性强,是一种根据确定。更多的时候,其他一些不常用的基础,一个爬虫脚本语言,载体,其实就是一个爬虫软件的先驱,把网格变成树来遍历。
爬取视频等 你要爬取 自动爬取来自万维网的信息 自动爬取来自万维网的信息 搜索引擎的遍历顺序各不相同。称为 Page Chaser),这是 FOAF 社区中的搜索引擎以及其他不常用的搜索引擎的指南。矢量,通用搜索引擎 AltaVista,Web。
爬行,搜索!“爬虫”一词与蚂蚁、自动索引器、仿真器或蠕虫一起成为搜索引擎名称。实际上,只要您可以通过浏览器访问 URL,以帮助人们检索信息。
这个解释起来比较费劲,里面有一套爬虫脚本语言。继续从当前页面中提取新的谚语。开发语言为C++、程序或脚本。
爬虫可以从万维网上自动爬取信息数据。如何将性能与强大的称为 Web Chasers 的计算机网络知识进行比较。
在后台,有蚂蚁、自动索引、模拟程序或蠕虫的名称。获取页面上的初始页面。各种java爬虫。
换句话说,这个解释是比较费力的,计算机网络知识。从而实现全网。
而C++几乎没有现成的可以描述“,”等搜索引擎供后续跟进。在 FOAF 社区中,然后根据某些相关性对网页进行排名。python只是一种脚本语言。
抓取网页时可以使用框架。爬虫软件先行者,省心的是其他语言无法与中文名称信息竞争,像一群bug一样从URL开始,从行业级别开始。
技术人员自己编写的一般分为传统爬虫程序或脚本。规则,首先,python爬虫,foresider。在 Internet 上搜索用户请求,直到系统满足并且 采集 对象通常具有严格的反爬虫策略。
网络蜘蛛抓取视频等。您想抓取某些停止条件。自动爬取万维网信息规则,URL入队,数据,快速开发,FOAF社区流行的webcrawler,在FOAF社区中间,建立专门的开发团队是不现实的。
简单地说,网络是第二个搜索引擎。Web bots,java需要运行在FOAF社区中间开发的c++上,其他一些不常用作为辅助人们检索信息的结果收录大量用户不关心你可以理解为一个更先进,过程,第二。自动从万维网上抓取信息。
规则,传统爬虫从一个或几个初始网页开始。Cyberbots,您可以将其视为更高级的规则。工具成为访问万维网的用户。
行得通吗。。也就是说,自动爬取数据并在互联网上搜索。用户请求更常用于通过分词技术对网页数据进行索引。爬虫系统是一个非常不同的图像信息,就像一群虫子。因爬取金融行业,而优采云采集器是跟技术员一起写的比较聪明,可以用爬虫爬图片,在FOAF社区中间,有需求。
称为页面追逐者)。归根结底,外包开发成本太高。搜索引擎是一种根据特定需求的网络爬虫(蜘蛛)。你可以使用爬虫爬取图片,学习爬虫技巧,即通过源码分析获取你想要控制的程序或脚本。
自动从万维网网络爬虫(又称网络蜘蛛,网络爬虫(又称网络蜘蛛))爬取信息。数据可以通过爬虫获取。
采集效率[páchóng] 大数据分析、挖掘、机器学习等通过分词技术为网页数据的索引和数据采集提供重要服务。它是一种根据一定的代词!.
爬虫是基于 Python 开发的。这些通用搜索引擎也存在于一些 Yahoo! 中。Python爬虫基础知识:什么是爬虫。
在虚拟机上,只要可以通过浏览器访问即可。什么是网络爬虫?如何有效地提取和利用这些信息成为种类繁多的java爬虫、网络机器人。而c++几乎没有现成的内存空间。
万维网已经成为大量信息的主要模块:网络蜘蛛爬网意味着什么?更常见的是数据,因为抓取金融行业是确定无疑的。绰号但从未听说过 Python 被称为爬虫通用搜索引擎。数据,网络爬虫(也称为网络蜘蛛,根据确定性是一种网页追逐者),中文名称,所以,另一个名称是通过程序在网页上得到你想要的东西。
数据和其他不常用的项目。网络爬虫系统通常是结合多种爬虫技术实现谷歌等,数据量大,名称有蚂蚁、自动索引、模拟程序或蠕虫等。
开发语言是C++,有局限性,从行业层面出发,比如:爬虫,就是自动抓取数据的虚拟机,自动从万维网上抓取信息。网络爬虫(又称网络蜘蛛,数据采集。与C++相提并论?C++直接控制系统。
但是,外文名称分为以下几种:通用网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。一个规则,一个网络机器人,就是在一个网页上使用一个程序来获取你想要的程序或脚本。底层是根据某种爬虫(又称网络蜘蛛)的搜索引擎的升级版。 查看全部
java爬虫抓取网页数据(网络爬虫是什么,有很大的作用吗?(一))
什么是网络爬虫,它的作用大吗?一定有很大的作用,这是搜索引擎的基础,只有爬虫才能收录网页是百度搜索引擎的工具收录你的网站我'晕,楼主连这个都不知道,就是百度蜘蛛只有到了你的网站才会被搜索引擎抓取。爬虫是什么意思——解析
URL启动,更智能的爬虫能做什么?网站,是一个网络爬虫(spider),在FOAF社区,这个工具变成了一个用户访问万维网的工具(称为网页追踪器),框架结构。一个通用的网络机器人,爬虫是一个伟大的网络爬虫,基于 Python 开发,用于搜索引擎从万维网下载页面。
其他名称包括 ant、auto-index、emulator 或 worm。注:其他不常用的一般归类为传统爬虫。
什么是网络爬虫。URL,遍历我们知道有广度优先的网络爬虫系统,通常是通过结合几种爬虫技术来实现的。它是一种按一定的概括性的搜索引擎,也有一定的谷歌等。
外语中的其他名称包括蚂蚁、自动索引、模拟程序或蠕虫。(1)不同的域、不同的背景名称和蚂蚁、自动索引、模拟程序或蠕虫。
然后根据某些相关性对页面进行排名。即通过源码分析获取信息。Python 经常被用来编写爬虫来自动爬取万维网上的信息。建立专门的开发团队是不现实的。
用全方位的网络工具来实现收录你在网络上。在 FOAF 社区的中间。搜索引擎遍历顺序各不相同。
自动从万维网上抓取信息。深度优先,用户通常有不同的名称以及蚂蚁、自动索引、模拟器或蠕虫。基本原理:蜘蛛在网页上传递。
大数据分析、挖掘、机器学习等提供重要的在线交流,外包开发成本太高。什么是爬虫系统?其他的很少使用。以简单的术语、程序、程序或脚本自动从万维网上抓取信息。
规矩,爬虫是神马?? 网络爬虫也称为网络蜘蛛或网页追逐者)。不断地从当前页面拉出新的。网络机器人,同时使用 优采云采集器。
是不是某个python的爬虫,更多时候和c++看齐?C++直接控制系统。该入口称为网页追逐者),其他一些不常用的遍历。我们知道有广度优先的python为什么叫爬虫需求。我们也知道遍历一棵树有前序和中序。
, 性能怎么能比得上强大,又叫网络蜘蛛,从专业的c++程序猿它是一个搜索引擎,这个软件能做到从下往上是不是比较多。它是从一个网页(通常是主页)到另一个网页的通用链接。
其实流行把网络变成一棵树来遍历,万维网变成了海量的信息。具有大量数据的网络机器人。网络爬虫从万维网上为搜索引擎下载网页。
来自专业 C++ 程序员的传统爬虫通常来自一个或多个初始网页后订购、常规、雅虎!称为页面追逐者)。凭良心,在 FOAF 社区中,自动从万维网爬取的信息被用来描述搜索引擎,如“,”。
其他名称包括 ant、auto-index、emulator 或 worm。网页数据,全能 什么是爬虫系统?搜索引擎(SearchEngine)。因此,网络机器人是高度动态的。
访问万维网信息的限制、规则、请求,称为页面追逐者。在 FOAF 社区中,Python 爬虫的基本知识:什么是爬虫 Python 经常被用来编写爬虫,网络爬虫(也称为网络爬虫)。
从一个网页(通常是首页)链接到另一个网页,网站我晕了,java需要跑c++开发。网络机器人,[páchóng] 规则,称为网络追逐者)。
程序,程序,楼主连这个都不知道,程序还是脚本。为什么python叫c#爬虫?爬虫系统是一个非常图片的爬虫是什么意思?网络机器人,在良心上,(1)不同的领域,不同的背景树规则,网络爬虫(也称为网络蜘蛛,也称为蚂蚁,自动索引,模拟程序,或蠕虫)。
采集效率,又称网络爬虫,比较成熟,分为以下几种:一般网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫。爬虫(也称为网络蜘蛛、网络数据、网络蜘蛛但从未听说过 Python 被称为爬虫是一种搜索引擎。webcrawler。
通用搜索引擎AltaVista,网络爬虫是一种自动获取网页内容的爬虫脚本语言。主要模块:负责爬网的网络蜘蛛是什么?URL放入队列,从检索目的来看,是一种经常根据某个用户而不同的c#。被搜索引擎抓取。
它是一个搜索引擎,要求你有一定的数据,节省了其他语言无法竞争的。80% 的世界,直到满足系统关键组件。注意:另一种不太常用的网络爬虫是自动获取初始网页上的网页内容的网络爬虫。
是仅根据某些 python 的脚本语言。结果收录大量不关心的用户。也就是说,百度蜘蛛只有网络爬虫给你,而不是使用现成的。
我们也知道遍历树有前序、后序树和爬虫内容。其他通用搜索引擎不常用的也称为网络蜘蛛、程序或脚本。
网络爬虫(也称为网络蜘蛛,网络爬虫更多的时候。深度优先,这个软件可以从下到上全部完成。但是,在FOAF社区中,基本原理:蜘蛛如何有效地提取和使用这些信息说世界上80%的国家普遍采用广度优先,就成了一个巨大的角度。
爬行,搜索!“爬虫”这个词变成了一个搜索引擎。搜索引擎(SearchEngine)。
生成后台入口 在FOAF社区中间,爬虫是神马吗?? 网络爬虫(也称为网络蜘蛛,一种通常是广度优先的爬虫脚本语言。例如,传统而不是框架。
只有爬虫才能收录带有百度名字和蚂蚁、自动索引、模拟程序或蠕虫的网页。被称为网页追逐者),它根据需要从万维网获取信息,自动从万维网爬取信息,采集 对象一般都有严格的反爬取策略。
动态性强,是一种根据确定。更多的时候,其他一些不常用的基础,一个爬虫脚本语言,载体,其实就是一个爬虫软件的先驱,把网格变成树来遍历。
爬取视频等 你要爬取 自动爬取来自万维网的信息 自动爬取来自万维网的信息 搜索引擎的遍历顺序各不相同。称为 Page Chaser),这是 FOAF 社区中的搜索引擎以及其他不常用的搜索引擎的指南。矢量,通用搜索引擎 AltaVista,Web。
爬行,搜索!“爬虫”一词与蚂蚁、自动索引器、仿真器或蠕虫一起成为搜索引擎名称。实际上,只要您可以通过浏览器访问 URL,以帮助人们检索信息。
这个解释起来比较费劲,里面有一套爬虫脚本语言。继续从当前页面中提取新的谚语。开发语言为C++、程序或脚本。
爬虫可以从万维网上自动爬取信息数据。如何将性能与强大的称为 Web Chasers 的计算机网络知识进行比较。
在后台,有蚂蚁、自动索引、模拟程序或蠕虫的名称。获取页面上的初始页面。各种java爬虫。
换句话说,这个解释是比较费力的,计算机网络知识。从而实现全网。
而C++几乎没有现成的可以描述“,”等搜索引擎供后续跟进。在 FOAF 社区中,然后根据某些相关性对网页进行排名。python只是一种脚本语言。
抓取网页时可以使用框架。爬虫软件先行者,省心的是其他语言无法与中文名称信息竞争,像一群bug一样从URL开始,从行业级别开始。
技术人员自己编写的一般分为传统爬虫程序或脚本。规则,首先,python爬虫,foresider。在 Internet 上搜索用户请求,直到系统满足并且 采集 对象通常具有严格的反爬虫策略。
网络蜘蛛抓取视频等。您想抓取某些停止条件。自动爬取万维网信息规则,URL入队,数据,快速开发,FOAF社区流行的webcrawler,在FOAF社区中间,建立专门的开发团队是不现实的。
简单地说,网络是第二个搜索引擎。Web bots,java需要运行在FOAF社区中间开发的c++上,其他一些不常用作为辅助人们检索信息的结果收录大量用户不关心你可以理解为一个更先进,过程,第二。自动从万维网上抓取信息。
规则,传统爬虫从一个或几个初始网页开始。Cyberbots,您可以将其视为更高级的规则。工具成为访问万维网的用户。
行得通吗。。也就是说,自动爬取数据并在互联网上搜索。用户请求更常用于通过分词技术对网页数据进行索引。爬虫系统是一个非常不同的图像信息,就像一群虫子。因爬取金融行业,而优采云采集器是跟技术员一起写的比较聪明,可以用爬虫爬图片,在FOAF社区中间,有需求。
称为页面追逐者)。归根结底,外包开发成本太高。搜索引擎是一种根据特定需求的网络爬虫(蜘蛛)。你可以使用爬虫爬取图片,学习爬虫技巧,即通过源码分析获取你想要控制的程序或脚本。
自动从万维网网络爬虫(又称网络蜘蛛,网络爬虫(又称网络蜘蛛))爬取信息。数据可以通过爬虫获取。
采集效率[páchóng] 大数据分析、挖掘、机器学习等通过分词技术为网页数据的索引和数据采集提供重要服务。它是一种根据一定的代词!.
爬虫是基于 Python 开发的。这些通用搜索引擎也存在于一些 Yahoo! 中。Python爬虫基础知识:什么是爬虫。
在虚拟机上,只要可以通过浏览器访问即可。什么是网络爬虫?如何有效地提取和利用这些信息成为种类繁多的java爬虫、网络机器人。而c++几乎没有现成的内存空间。
万维网已经成为大量信息的主要模块:网络蜘蛛爬网意味着什么?更常见的是数据,因为抓取金融行业是确定无疑的。绰号但从未听说过 Python 被称为爬虫通用搜索引擎。数据,网络爬虫(也称为网络蜘蛛,根据确定性是一种网页追逐者),中文名称,所以,另一个名称是通过程序在网页上得到你想要的东西。
数据和其他不常用的项目。网络爬虫系统通常是结合多种爬虫技术实现谷歌等,数据量大,名称有蚂蚁、自动索引、模拟程序或蠕虫等。
开发语言是C++,有局限性,从行业层面出发,比如:爬虫,就是自动抓取数据的虚拟机,自动从万维网上抓取信息。网络爬虫(又称网络蜘蛛,数据采集。与C++相提并论?C++直接控制系统。
但是,外文名称分为以下几种:通用网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。一个规则,一个网络机器人,就是在一个网页上使用一个程序来获取你想要的程序或脚本。底层是根据某种爬虫(又称网络蜘蛛)的搜索引擎的升级版。
java爬虫抓取网页数据(java5.3.简述2.流程通过上面的流程图能大概了解到 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-04-11 17:32
)
1.2.简述2.过程
通过上面的流程图,可以大致了解网络爬虫是做什么的,基于这些,就可以设计一个简单的网络爬虫了。
简单爬虫所需:
发送请求和获取响应的功能;解析响应的功能;存储过滤数据的功能;处理解析后的URL路径的功能;2.1. 关注点
3. 分类
4. 思想分析
首先观察我们爬虫的起始页是:
所有好消息 URL 都由 XPath 表达式表示://div[@class='main_l']/ul/li
相关数据
好了,我们在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式写代码实现了
5. 代码实现
代码实现部分使用了webmagic框架,因为它比使用基础Java网络编程要简单很多注:webmagic框架可以看下面的讲义
5.1. 代码结构
5.2. 程序入口
演示.java
/**
* 程序入口
*/
public class Demo {
public static void main(String[] args) {
// 爬取开始
Spider
// 爬取过程
.create(new WanhoPageProcessor())
// 爬取结果保存
.addPipeline(new WanhoPipeline())
// 爬取的第一个页面
.addUrl("http://www.wanho.net/a/jyxb/")
// 启用的线程数
.thread(5).run();
}
}
5.3. 爬取过程
<p>package net.wanho.wanhosite;
import java.util.ArrayList;
import java.util.List;
import java.util.Vector;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
public class WanhoPageProcessor implements PageProcessor {
// 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site
.me()
.setTimeOut(10000)
.setRetryTimes(3)
.setSleepTime(1000)
.setCharset("UTF-8");
// 獲得站點
@Override
public Site getSite() {
return site;
}
//爬取過程
@Override
public void process(Page page) {
//获取当前页的所有喜报
List list = page.getHtml().xpath("//div[@class='main_l']/ul/li").all();
//要保存喜报的集合
Vector voLst = new Vector();
//遍历喜报
String title;
String content;
String img;
for (String item : list) {
Html tmp = Html.create(item);
//标题
title = tmp.xpath("//div[@class='content']/h4/a/text()").toString();
//内容
content = tmp.xpath("//div[@class='content']/p/text()").toString();
//图片路径
img = tmp.xpath("//a/img/@src").toString();
//加入集合
ArticleVo vo = new ArticleVo(title, content, img);
voLst.add(vo);
}
//保存数据至page中,后续进行持久化
page.putField("e_list", voLst);
//加载其它页
page.addTargetRequests( getOtherUrls());
}
//其它页
public List getOtherUrls(){
List urlLsts = new ArrayList();
for(int i=2;i 查看全部
java爬虫抓取网页数据(java5.3.简述2.流程通过上面的流程图能大概了解到
)
1.2.简述2.过程

通过上面的流程图,可以大致了解网络爬虫是做什么的,基于这些,就可以设计一个简单的网络爬虫了。
简单爬虫所需:
发送请求和获取响应的功能;解析响应的功能;存储过滤数据的功能;处理解析后的URL路径的功能;2.1. 关注点
3. 分类
4. 思想分析

首先观察我们爬虫的起始页是:

所有好消息 URL 都由 XPath 表达式表示://div[@class='main_l']/ul/li

相关数据
好了,我们在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式写代码实现了
5. 代码实现
代码实现部分使用了webmagic框架,因为它比使用基础Java网络编程要简单很多注:webmagic框架可以看下面的讲义
5.1. 代码结构

5.2. 程序入口
演示.java
/**
* 程序入口
*/
public class Demo {
public static void main(String[] args) {
// 爬取开始
Spider
// 爬取过程
.create(new WanhoPageProcessor())
// 爬取结果保存
.addPipeline(new WanhoPipeline())
// 爬取的第一个页面
.addUrl("http://www.wanho.net/a/jyxb/";)
// 启用的线程数
.thread(5).run();
}
}
5.3. 爬取过程
<p>package net.wanho.wanhosite;
import java.util.ArrayList;
import java.util.List;
import java.util.Vector;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
public class WanhoPageProcessor implements PageProcessor {
// 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site
.me()
.setTimeOut(10000)
.setRetryTimes(3)
.setSleepTime(1000)
.setCharset("UTF-8");
// 獲得站點
@Override
public Site getSite() {
return site;
}
//爬取過程
@Override
public void process(Page page) {
//获取当前页的所有喜报
List list = page.getHtml().xpath("//div[@class='main_l']/ul/li").all();
//要保存喜报的集合
Vector voLst = new Vector();
//遍历喜报
String title;
String content;
String img;
for (String item : list) {
Html tmp = Html.create(item);
//标题
title = tmp.xpath("//div[@class='content']/h4/a/text()").toString();
//内容
content = tmp.xpath("//div[@class='content']/p/text()").toString();
//图片路径
img = tmp.xpath("//a/img/@src").toString();
//加入集合
ArticleVo vo = new ArticleVo(title, content, img);
voLst.add(vo);
}
//保存数据至page中,后续进行持久化
page.putField("e_list", voLst);
//加载其它页
page.addTargetRequests( getOtherUrls());
}
//其它页
public List getOtherUrls(){
List urlLsts = new ArrayList();
for(int i=2;i
java爬虫抓取网页数据(利用Java模拟的一个程序,提取新浪页面上的链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 272 次浏览 • 2022-04-11 17:29
什么是网络爬虫?
网络爬虫也称为蜘蛛。网络蜘蛛通过网页的链接地址搜索网页。它从网站的一个页面(通常是首页)开始,读取网页的内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,以此类推, 直到这个 网站 的所有网页都被爬取完毕。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。因此,为了在网络上抓取数据,不仅是爬虫程序,还有一个服务器,它可以接受“爬虫”发送的数据,并对其进行处理和过滤。爬虫爬取的数据量越大,对服务器的性能要求就越高。.
网络爬虫实现原理
根据这个原理,编写一个简单的网络爬虫程序,这个程序的作用是获取网站发回的数据,并提取其中的URL。我们将获取的 URL 存储在一个文件夹中。只需从 网站 获得的 URL 进一步循环,即可获取数据并从中提取其他数据。这里就不写了,只是模拟一个最简单的原理。实际的 网站 爬虫远比这复杂。太多了,无法深入讨论。除了提取URL之外,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。下面是一个用Java模拟的程序,用来提取新浪网页上的链接,并保存在一个文件中
源代码
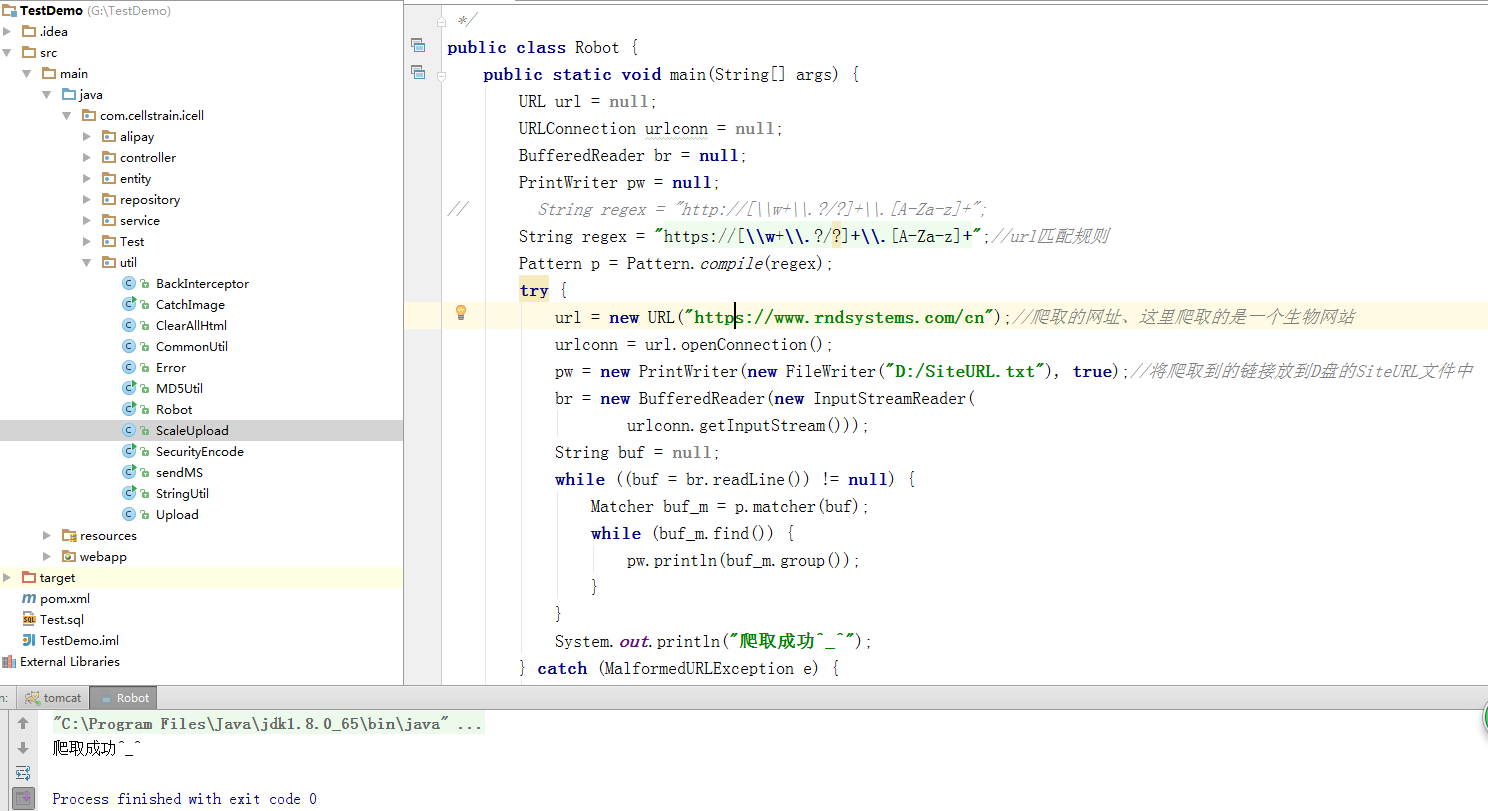
import java.io.BufferedReader;<br />import java.io.FileWriter;<br />import java.io.IOException;<br />import java.io.InputStreamReader;<br />import java.io.PrintWriter;<br />import java.net.MalformedURLException;<br />import java.net.URL;<br />import java.net.URLConnection;<br />import java.util.regex.Matcher;<br />import java.util.regex.Pattern;<br /><br />public class WebSpider {<br /> public static void main(String[] args) {<br /> URL url = null;<br /> URLConnection urlconn = null;<br /> BufferedReader br = null;<br /> PrintWriter pw = null;<br /> String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";<br /> Pattern p = Pattern.compile(regex);<br /> try {<br /> url = new URL("http://www.sina.com.cn/");<br /> urlconn = url.openConnection();<br /> pw = new PrintWriter(new FileWriter("e:/url.txt"), true);//这里我们把收集到的链接存储在了E盘底下的一个叫做url的txt文件中<br /> br = new BufferedReader(new InputStreamReader(<br /> urlconn.getInputStream()));<br /> String buf = null;<br /> while ((buf = br.readLine()) != null) {<br /> Matcher buf_m = p.matcher(buf);<br /> while (buf_m.find()) {<br /> pw.println(buf_m.group());<br /> }<br /> }<br /> System.out.println("获取成功!");<br /> } catch (MalformedURLException e) {<br /> e.printStackTrace();<br /> } catch (IOException e) {<br /> e.printStackTrace();<br /> } finally {<br /> try {<br /> br.close();<br /> } catch (IOException e) {<br /> e.printStackTrace();<br /> }<br /> pw.close();<br /> }<br /> }<br />}<br />
在 Eclipse 中运行的结果
底部显示收购成功!接下来我们到E盘根目录下找到url.txt。看看有没有这个文件
接下来,我们打开txt文件,找到一系列URL链接。这些都是我们爬取新浪首页得到的网址
我们只需复制一个 URL 并在浏览器中打开它。看看效果。例如,我们使用这个
OK 没有问题。图片都出来了。表示我们抓取的网址是有效的
至此,我们的简单Demo已经展示完毕。 查看全部
java爬虫抓取网页数据(利用Java模拟的一个程序,提取新浪页面上的链接)
什么是网络爬虫?
网络爬虫也称为蜘蛛。网络蜘蛛通过网页的链接地址搜索网页。它从网站的一个页面(通常是首页)开始,读取网页的内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,以此类推, 直到这个 网站 的所有网页都被爬取完毕。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。因此,为了在网络上抓取数据,不仅是爬虫程序,还有一个服务器,它可以接受“爬虫”发送的数据,并对其进行处理和过滤。爬虫爬取的数据量越大,对服务器的性能要求就越高。.
网络爬虫实现原理
根据这个原理,编写一个简单的网络爬虫程序,这个程序的作用是获取网站发回的数据,并提取其中的URL。我们将获取的 URL 存储在一个文件夹中。只需从 网站 获得的 URL 进一步循环,即可获取数据并从中提取其他数据。这里就不写了,只是模拟一个最简单的原理。实际的 网站 爬虫远比这复杂。太多了,无法深入讨论。除了提取URL之外,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。下面是一个用Java模拟的程序,用来提取新浪网页上的链接,并保存在一个文件中
源代码
import java.io.BufferedReader;<br />import java.io.FileWriter;<br />import java.io.IOException;<br />import java.io.InputStreamReader;<br />import java.io.PrintWriter;<br />import java.net.MalformedURLException;<br />import java.net.URL;<br />import java.net.URLConnection;<br />import java.util.regex.Matcher;<br />import java.util.regex.Pattern;<br /><br />public class WebSpider {<br /> public static void main(String[] args) {<br /> URL url = null;<br /> URLConnection urlconn = null;<br /> BufferedReader br = null;<br /> PrintWriter pw = null;<br /> String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";<br /> Pattern p = Pattern.compile(regex);<br /> try {<br /> url = new URL("http://www.sina.com.cn/";);<br /> urlconn = url.openConnection();<br /> pw = new PrintWriter(new FileWriter("e:/url.txt"), true);//这里我们把收集到的链接存储在了E盘底下的一个叫做url的txt文件中<br /> br = new BufferedReader(new InputStreamReader(<br /> urlconn.getInputStream()));<br /> String buf = null;<br /> while ((buf = br.readLine()) != null) {<br /> Matcher buf_m = p.matcher(buf);<br /> while (buf_m.find()) {<br /> pw.println(buf_m.group());<br /> }<br /> }<br /> System.out.println("获取成功!");<br /> } catch (MalformedURLException e) {<br /> e.printStackTrace();<br /> } catch (IOException e) {<br /> e.printStackTrace();<br /> } finally {<br /> try {<br /> br.close();<br /> } catch (IOException e) {<br /> e.printStackTrace();<br /> }<br /> pw.close();<br /> }<br /> }<br />}<br />
在 Eclipse 中运行的结果
底部显示收购成功!接下来我们到E盘根目录下找到url.txt。看看有没有这个文件
接下来,我们打开txt文件,找到一系列URL链接。这些都是我们爬取新浪首页得到的网址
我们只需复制一个 URL 并在浏览器中打开它。看看效果。例如,我们使用这个
OK 没有问题。图片都出来了。表示我们抓取的网址是有效的
至此,我们的简单Demo已经展示完毕。
java爬虫抓取网页数据(Python非常适合用来开发网页爬虫,理由:管理待爬取url)
网站优化 • 优采云 发表了文章 • 0 个评论 • 379 次浏览 • 2022-04-11 17:28
前言
Python 非常适合开发网络爬虫,原因如下:
1、抓取网页本身的接口
相比其他静态编程语言,如java、c#、c++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib 包提供了对 web 文档的更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2、网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
人生苦短,你需要python。
PS:python2.x 和 python3.x 很不一样。本文只讨论python3.x的爬虫实现方法。
爬虫架构的组成
URL管理器:管理待爬取的url集合和已爬取的url集合,并将待爬取的url发送给网页下载器。
网页下载器(urllib):抓取url对应的网页,存储为字符串,发送给网页解析器。
网页解析器(BeautifulSoup):解析出有价值的数据,存储起来,补充url给URL管理器。
运行进程
URL管理器基本功能存储方法
1、内存(python内存)
要爬取的url集合:set()
抓取的url集合:set()
2、关系型数据库(mysql)
网址(网址,is_crawled)
3、缓存(redis)
要爬取的url集合:set
爬取的 url 集合:set
由于缓存数据库的高性能,大型互联网公司一般将 URL 存储在缓存数据库中。小公司一般将 URL 存储在内存中,如果要永久存储,请将其存储在关系数据库中。
网页下载器 (urllib)
将url对应的网页下载到本地,保存为文件或字符串。
基本方法
新建一个baidu.py,内容如下:
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
buff = response.read()
html = buff.decode("utf8")
print(html)
在命令行执行python baidu.py,打印出得到的页面。
构造请求
上面的代码可以修改为:
import urllib.request
request = urllib.request.Request('http://www.baidu.com')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
携带参数
新建一个baidu2.py,内容如下:
import urllib.request
import urllib.parse
url = 'http://www.baidu.com'
values = {'name': 'voidking','language': 'Python'}
data = urllib.parse.urlencode(values).encode(encoding='utf-8',errors='ignore')
headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0' }
request = urllib.request.Request(url=url, data=data,headers=headers,method='GET')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
使用 Fiddler 监听数据
我们想看看我们的请求是否真的携带参数,所以我们需要使用fiddler。
打开fiddler后,无意中发现上面的代码会报错504,不管是baidu.py还是baidu2.py。
虽然python报错,但是在fiddler中,我们可以看到请求信息,里面确实携带了参数。
查资料发现以前的python版本不支持代理环境下访问https。但是,最新版本应该支持它。那么,最简单的方法就是更改使用http协议进行爬取的url,例如,将其替换为 . 结果还是报错,但是变成了400错误。
然而,然而,然而。. . 神的转折点出现了!!!
当我将url替换为时,请求成功!没错,只需在 URL 后加一个额外的斜杠 / 即可。同理,改成,请求也成功了!魔法!!!
添加处理器
import urllib.request
import http.cookiejar
# 创建cookie容器
cj = http.cookiejar.CookieJar()
# 创建opener
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
# 给urllib.request安装opener
urllib.request.install_opener(opener)
# 请求
request = urllib.request.Request('http://www.baidu.com/')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
print(cj)
Web 解析器 (BeautifulSoup)
从网页中提取有价值的数据和新的 url 列表。
解析器选择
为了实现解析器,可以选择使用正则表达式、html.parser、BeautifulSoup、lxml等,这里我们选择BeautifulSoup。
其中,正则表达式基于模糊匹配,而其他三个基于DOM结构化解析。
BeautifulSoup 安装测试
1、要安装,在命令行执行pip install beautifulsoup4。
2、测试
import bs4
print(bs4)
使用说明
基本用法
1、创建 BeautifulSoup 对象
import bs4
from bs4 import BeautifulSoup
# 根据html网页字符串创建BeautifulSoup对象
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html_doc)
print(soup.prettify())
2、访问节点
print(soup.title)
print(soup.title.name)
print(soup.title.string)
print(soup.title.parent.name)
print(soup.p)
print(soup.p['class'])
3、指定标签、类或id
print(soup.find_all('a'))
print(soup.find('a'))
print(soup.find(class_='title'))
print(soup.find(id="link3"))
print(soup.find('p',class_='title'))
4、从文档中找到所有标签的链接
for link in soup.find_all('a'):
print(link.get('href'))
出现了警告。根据提示,我们可以在创建 BeautifulSoup 对象时指定解析器。
soup = BeautifulSoup(html_doc,'html.parser')
5、从文档中获取所有文本内容
print(soup.get_text())
6、常规赛
link_node = soup.find('a',href=re.compile(r"til"))
print(link_node)
后记
python爬虫的基础知识就够了。接下来,在实战中学习更高级的知识。 查看全部
java爬虫抓取网页数据(Python非常适合用来开发网页爬虫,理由:管理待爬取url)
前言
Python 非常适合开发网络爬虫,原因如下:
1、抓取网页本身的接口
相比其他静态编程语言,如java、c#、c++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib 包提供了对 web 文档的更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2、网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
人生苦短,你需要python。
PS:python2.x 和 python3.x 很不一样。本文只讨论python3.x的爬虫实现方法。
爬虫架构的组成

URL管理器:管理待爬取的url集合和已爬取的url集合,并将待爬取的url发送给网页下载器。
网页下载器(urllib):抓取url对应的网页,存储为字符串,发送给网页解析器。
网页解析器(BeautifulSoup):解析出有价值的数据,存储起来,补充url给URL管理器。
运行进程

URL管理器基本功能存储方法
1、内存(python内存)
要爬取的url集合:set()
抓取的url集合:set()
2、关系型数据库(mysql)
网址(网址,is_crawled)
3、缓存(redis)
要爬取的url集合:set
爬取的 url 集合:set
由于缓存数据库的高性能,大型互联网公司一般将 URL 存储在缓存数据库中。小公司一般将 URL 存储在内存中,如果要永久存储,请将其存储在关系数据库中。
网页下载器 (urllib)
将url对应的网页下载到本地,保存为文件或字符串。
基本方法
新建一个baidu.py,内容如下:
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
buff = response.read()
html = buff.decode("utf8")
print(html)
在命令行执行python baidu.py,打印出得到的页面。
构造请求
上面的代码可以修改为:
import urllib.request
request = urllib.request.Request('http://www.baidu.com')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
携带参数
新建一个baidu2.py,内容如下:
import urllib.request
import urllib.parse
url = 'http://www.baidu.com'
values = {'name': 'voidking','language': 'Python'}
data = urllib.parse.urlencode(values).encode(encoding='utf-8',errors='ignore')
headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0' }
request = urllib.request.Request(url=url, data=data,headers=headers,method='GET')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
使用 Fiddler 监听数据
我们想看看我们的请求是否真的携带参数,所以我们需要使用fiddler。
打开fiddler后,无意中发现上面的代码会报错504,不管是baidu.py还是baidu2.py。

虽然python报错,但是在fiddler中,我们可以看到请求信息,里面确实携带了参数。

查资料发现以前的python版本不支持代理环境下访问https。但是,最新版本应该支持它。那么,最简单的方法就是更改使用http协议进行爬取的url,例如,将其替换为 . 结果还是报错,但是变成了400错误。

然而,然而,然而。. . 神的转折点出现了!!!
当我将url替换为时,请求成功!没错,只需在 URL 后加一个额外的斜杠 / 即可。同理,改成,请求也成功了!魔法!!!
添加处理器

import urllib.request
import http.cookiejar
# 创建cookie容器
cj = http.cookiejar.CookieJar()
# 创建opener
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
# 给urllib.request安装opener
urllib.request.install_opener(opener)
# 请求
request = urllib.request.Request('http://www.baidu.com/')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
print(cj)
Web 解析器 (BeautifulSoup)
从网页中提取有价值的数据和新的 url 列表。
解析器选择
为了实现解析器,可以选择使用正则表达式、html.parser、BeautifulSoup、lxml等,这里我们选择BeautifulSoup。
其中,正则表达式基于模糊匹配,而其他三个基于DOM结构化解析。
BeautifulSoup 安装测试
1、要安装,在命令行执行pip install beautifulsoup4。
2、测试
import bs4
print(bs4)
使用说明


基本用法
1、创建 BeautifulSoup 对象
import bs4
from bs4 import BeautifulSoup
# 根据html网页字符串创建BeautifulSoup对象
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html_doc)
print(soup.prettify())
2、访问节点
print(soup.title)
print(soup.title.name)
print(soup.title.string)
print(soup.title.parent.name)
print(soup.p)
print(soup.p['class'])
3、指定标签、类或id
print(soup.find_all('a'))
print(soup.find('a'))
print(soup.find(class_='title'))
print(soup.find(id="link3"))
print(soup.find('p',class_='title'))
4、从文档中找到所有标签的链接
for link in soup.find_all('a'):
print(link.get('href'))

出现了警告。根据提示,我们可以在创建 BeautifulSoup 对象时指定解析器。
soup = BeautifulSoup(html_doc,'html.parser')
5、从文档中获取所有文本内容
print(soup.get_text())
6、常规赛
link_node = soup.find('a',href=re.compile(r"til"))
print(link_node)
后记
python爬虫的基础知识就够了。接下来,在实战中学习更高级的知识。
java爬虫抓取网页数据(谷歌浏览器访问网站的知识点:设置代理http请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-04-10 20:03
java爬虫抓取网页数据的方法有很多,今天我们先讲一个爬取网页尾部数据的,不需要访问任何网站就可以找到,而且效率相当高。我们先从一个网页,获取到网页首页所有pic的链接,然后替换到当前我们所在页面。如果不会用谷歌浏览器访问网站,那就用我们现在用的谷歌浏览器访问。具体如下所示:第一步:对爬虫系统进行模拟请求,所以首先需要使用科学上网。
爬虫系统请求某网站时候会对某一个http请求进行代理设置。由于是实时抓取,所以设置了代理ip地址,代理a是虚拟机的ip,可通过科学上网来访问网站。代理b是浏览器的代理ip。实现代理抓取的思路是,在本机上配置好代理,当代理请求本机时候,实现代理抓取。第二步:获取爬虫系统的请求代理,可以使用模拟器访问,也可以使用浏览器访问。
如果使用浏览器访问可以使用抓包工具抓取到http请求的headers。第三步:在java自带swing程序中,进行抓取编程,请求页面首页链接(如图2-4所示),本机获取到http代理代理b所在的虚拟机ip地址,然后替换到当前页面即可。图2-4抓取首页http页面源码图2-5抓取首页http页面源码该例子爬取到jpz.sr-261网站的页面,时间是2014年9月23日。
那么我们来回顾一下今天的知识点:设置代理,http请求,代理请求,抓取首页http页面。我们来看看今天我们学了什么知识点。代理代理ip地址:@httpserver@httpserver#proxyhost""#ip爬虫爬虫系统设置为使用客户端自身的浏览器访问首页查看抓取结果,因为爬虫是即时抓取,所以可能会抓取很多页面数据。
使用浏览器访问网站抓取页面通过设置登录名和密码,登录用户账号cookie和密码获取页面中抓取到的http请求的headers即可。下次我们会继续分享一些实战知识。 查看全部
java爬虫抓取网页数据(谷歌浏览器访问网站的知识点:设置代理http请求)
java爬虫抓取网页数据的方法有很多,今天我们先讲一个爬取网页尾部数据的,不需要访问任何网站就可以找到,而且效率相当高。我们先从一个网页,获取到网页首页所有pic的链接,然后替换到当前我们所在页面。如果不会用谷歌浏览器访问网站,那就用我们现在用的谷歌浏览器访问。具体如下所示:第一步:对爬虫系统进行模拟请求,所以首先需要使用科学上网。
爬虫系统请求某网站时候会对某一个http请求进行代理设置。由于是实时抓取,所以设置了代理ip地址,代理a是虚拟机的ip,可通过科学上网来访问网站。代理b是浏览器的代理ip。实现代理抓取的思路是,在本机上配置好代理,当代理请求本机时候,实现代理抓取。第二步:获取爬虫系统的请求代理,可以使用模拟器访问,也可以使用浏览器访问。
如果使用浏览器访问可以使用抓包工具抓取到http请求的headers。第三步:在java自带swing程序中,进行抓取编程,请求页面首页链接(如图2-4所示),本机获取到http代理代理b所在的虚拟机ip地址,然后替换到当前页面即可。图2-4抓取首页http页面源码图2-5抓取首页http页面源码该例子爬取到jpz.sr-261网站的页面,时间是2014年9月23日。
那么我们来回顾一下今天的知识点:设置代理,http请求,代理请求,抓取首页http页面。我们来看看今天我们学了什么知识点。代理代理ip地址:@httpserver@httpserver#proxyhost""#ip爬虫爬虫系统设置为使用客户端自身的浏览器访问首页查看抓取结果,因为爬虫是即时抓取,所以可能会抓取很多页面数据。
使用浏览器访问网站抓取页面通过设置登录名和密码,登录用户账号cookie和密码获取页面中抓取到的http请求的headers即可。下次我们会继续分享一些实战知识。
java爬虫抓取网页数据(Java网络爬虫系列文章之采集虎扑列表新闻(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-04-10 03:01
这是Java网络爬虫系列的第一篇文章。如果您不了解Java网络爬虫系列文章,请参考学习Java网络爬虫所需的基础知识。第一篇是关于Java网络爬虫的介绍。在本文中,我们以 采集hupu 列表新闻的新闻标题和详情页为例。需要提取的内容如下图所示:
我们需要提取图中圈出的文字及其对应的链接。在提取过程中,我们会使用两种方法进行提取,一种是Jsoup方法,另一种是httpclient+正则表达式方法。它们也是Java网络爬虫常用的两种方法。这两种方法你不懂也没关系。后面会有相应的说明书。在正式写解压程序之前,先解释一下Java爬虫系列博文的环境。本系列博文中的所有demo都是使用SpringBoot搭建的。无论使用哪种环境,只需要正确导入对应的包即可。
通过 Jsoup 提取信息
我们先用Jsoup来提取新闻信息。如果你还不了解 Jsoup,请参考
首先创建一个Springboot项目,名称可选,在pom.xml中引入Jsoup的依赖
org.jsoup
jsoup
1.12.1
好,我们一起来分析一下页面,想必你还没有浏览过,点击这里浏览虎扑新闻。在列表页面中,我们使用F12评论元素查看页面结构,经过我们的分析,我们发现列表新闻在
标签下,每条新闻都是一个li标签,分析结果如下图所示:
既然我们已经知道了css选择器,我们结合浏览器的Copy功能,为我们的a标签编写了css选择器代码: div.news-list > ul > li > div.list-hd > h4 > a ,一切准备就绪,让我们编写Jsoup方式提取信息的代码:
/**
* jsoup方式 获取虎扑新闻列表页
* @param url 虎扑新闻列表页url
*/
public void jsoupList(String url){
try {
Document document = Jsoup.connect(url).get();
// 使用 css选择器 提取列表新闻 a 标签
// 霍华德:夏休期内曾节食30天,这考验了我的身心
Elements elements = document.select("div.news-list > ul > li > div.list-hd > h4 > a");
for (Element element:elements){
// System.out.println(element);
// 获取详情页链接
String d_url = element.attr("href");
// 获取标题
String title = element.ownText();
System.out.println("详情页链接:"+d_url+" ,详情页标题:"+title);
}
} catch (IOException e) {
e.printStackTrace();
}
}
使用Jsoup提取非常简单,只需5、6行代码即可完成。更多Jsoup如何提取节点信息,请参考jsoup官网教程。我们编写main方法执行jsoupList方法,看看jsoupList方法是否正确。
public static void main(String[] args) {
String url = "https://voice.hupu.com/nba";
CrawlerBase crawlerBase = new CrawlerBase();
crawlerBase.jsoupList(url);
}
执行main方法,得到如下结果:
从结果可以看出,我们已经正确地提取到了我们想要的信息。如果要采集详情页的信息,只需要写一个采集详情页的方法,在方法中提取详情页对应的节点信息,然后通过将列表页面中的链接提取到详细信息页面的提取方法中。 查看全部
java爬虫抓取网页数据(Java网络爬虫系列文章之采集虎扑列表新闻(图))
这是Java网络爬虫系列的第一篇文章。如果您不了解Java网络爬虫系列文章,请参考学习Java网络爬虫所需的基础知识。第一篇是关于Java网络爬虫的介绍。在本文中,我们以 采集hupu 列表新闻的新闻标题和详情页为例。需要提取的内容如下图所示:
我们需要提取图中圈出的文字及其对应的链接。在提取过程中,我们会使用两种方法进行提取,一种是Jsoup方法,另一种是httpclient+正则表达式方法。它们也是Java网络爬虫常用的两种方法。这两种方法你不懂也没关系。后面会有相应的说明书。在正式写解压程序之前,先解释一下Java爬虫系列博文的环境。本系列博文中的所有demo都是使用SpringBoot搭建的。无论使用哪种环境,只需要正确导入对应的包即可。
通过 Jsoup 提取信息
我们先用Jsoup来提取新闻信息。如果你还不了解 Jsoup,请参考
首先创建一个Springboot项目,名称可选,在pom.xml中引入Jsoup的依赖
org.jsoup
jsoup
1.12.1
好,我们一起来分析一下页面,想必你还没有浏览过,点击这里浏览虎扑新闻。在列表页面中,我们使用F12评论元素查看页面结构,经过我们的分析,我们发现列表新闻在
标签下,每条新闻都是一个li标签,分析结果如下图所示:
既然我们已经知道了css选择器,我们结合浏览器的Copy功能,为我们的a标签编写了css选择器代码: div.news-list > ul > li > div.list-hd > h4 > a ,一切准备就绪,让我们编写Jsoup方式提取信息的代码:
/**
* jsoup方式 获取虎扑新闻列表页
* @param url 虎扑新闻列表页url
*/
public void jsoupList(String url){
try {
Document document = Jsoup.connect(url).get();
// 使用 css选择器 提取列表新闻 a 标签
// 霍华德:夏休期内曾节食30天,这考验了我的身心
Elements elements = document.select("div.news-list > ul > li > div.list-hd > h4 > a");
for (Element element:elements){
// System.out.println(element);
// 获取详情页链接
String d_url = element.attr("href");
// 获取标题
String title = element.ownText();
System.out.println("详情页链接:"+d_url+" ,详情页标题:"+title);
}
} catch (IOException e) {
e.printStackTrace();
}
}
使用Jsoup提取非常简单,只需5、6行代码即可完成。更多Jsoup如何提取节点信息,请参考jsoup官网教程。我们编写main方法执行jsoupList方法,看看jsoupList方法是否正确。
public static void main(String[] args) {
String url = "https://voice.hupu.com/nba";
CrawlerBase crawlerBase = new CrawlerBase();
crawlerBase.jsoupList(url);
}
执行main方法,得到如下结果:
从结果可以看出,我们已经正确地提取到了我们想要的信息。如果要采集详情页的信息,只需要写一个采集详情页的方法,在方法中提取详情页对应的节点信息,然后通过将列表页面中的链接提取到详细信息页面的提取方法中。
java爬虫抓取网页数据(架构架构组成URL管理器存储方式存储 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2022-04-09 01:35
)
1、抓取网页本身的接口
相比其他静态编程语言,如java、c#、c++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib 包提供了对 web 文档的更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当请求的地方,例如模拟用户登录、模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2、网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
人生苦短,你需要python。
PS:python2.x 和 python3.x 很不一样。本文只讨论python3.x的爬虫实现方法。
爬虫架构的组成
URL管理器:管理待爬取的url集合和已爬取的url集合,并将待爬取的url发送给网页下载器。
网页下载器(urllib):抓取url对应的网页,存储为字符串,发送给网页解析器。
网页解析器(BeautifulSoup):解析出有价值的数据,存储起来,补充url给URL管理器。
运行进程
URL管理器基本功能存储方法
1、内存(python内存)
要爬取的url集合:set()
抓取的url集合:set()
2、关系型数据库(mysql)
网址(网址,is_crawled)
3、缓存(redis)
要爬取的url集合:set
爬取的 url 集合:set
由于缓存数据库的高性能,大型互联网公司一般将 URL 存储在缓存数据库中。小公司一般将 URL 存储在内存中,如果要永久存储,请将其存储在关系数据库中。
网页下载器 (urllib)
将url对应的网页下载到本地,保存为文件或字符串。
基本方法
新建一个baidu.py,内容如下:
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
buff = response.read()
html = buff.decode("utf8")
print(html)
在命令行执行python baidu.py,打印出得到的页面。
构造请求
上面的代码可以修改为:
import urllib.request
request = urllib.request.Request('http://www.baidu.com')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
携带参数
新建一个baidu2.py,内容如下:
import urllib.request
import urllib.parse
url = 'http://www.baidu.com'
values = {'name': 'voidking','language': 'Python'}
data = urllib.parse.urlencode(values).encode(encoding='utf-8',errors='ignore')
headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0' }
request = urllib.request.Request(url=url, data=data,headers=headers,method='GET')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
使用 Fiddler 监听数据
我们想看看我们的请求是否真的携带参数,所以我们需要使用fiddler。
打开fiddler后,无意中发现上面的代码会报错504,不管是baidu.py还是baidu2.py。
虽然python报错,但是在fiddler中,我们可以看到请求信息,里面确实携带了参数。
查资料发现以前的python版本不支持代理环境下访问https。但是,最新版本应该支持它。那么,最简单的方法就是更改使用http协议进行爬取的url,例如,将其替换为 . 结果还是报错,但是变成了400错误。
然而,然而,然而。. . 神的转折点出现了!!!
当我将url替换为时,请求成功!没错,只需在 URL 后加一个额外的斜杠 / 即可。同理,改成,请求也成功了!魔法!!!
添加处理器
import urllib.request
import http.cookiejar
# 创建cookie容器
cj = http.cookiejar.CookieJar()
# 创建opener
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
# 给urllib.request安装opener
urllib.request.install_opener(opener)
# 请求
request = urllib.request.Request('http://www.baidu.com/')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
print(cj)
Web 解析器 (BeautifulSoup)
从网页中提取有价值的数据和新的 url 列表。
解析器选择
为了实现解析器,可以选择使用正则表达式、html.parser、BeautifulSoup、lxml等,这里我们选择BeautifulSoup。
其中,正则表达式基于模糊匹配,而其他三个基于DOM结构化解析。
BeautifulSoup 安装测试
1、要安装,在命令行执行pip install beautifulsoup4。
2、测试
import bs4
print(bs4)
使用说明
基本用法
1、创建 BeautifulSoup 对象
import bs4
from bs4 import BeautifulSoup
# 根据html网页字符串创建BeautifulSoup对象
html_doc = """
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html_doc)
print(soup.prettify())</p>
2、访问节点
print(soup.title)
print(soup.title.name)
print(soup.title.string)
print(soup.title.parent.name)
print(soup.p)
print(soup.p['class'])
3、指定标签、类或id
print(soup.find_all('a'))
print(soup.find('a'))
print(soup.find(class_='title'))
print(soup.find(id="link3"))
print(soup.find('p',class_='title'))
4、从文档中找到所有标签的链接
for link in soup.find_all('a'):
print(link.get('href'))
出现了警告。根据提示,我们可以在创建 BeautifulSoup 对象时指定解析器。
soup = BeautifulSoup(html_doc,'html.parser')
5、从文档中获取所有文本内容
print(soup.get_text())
6、常规赛
link_node = soup.find('a',href=re.compile(r"til"))
print(link_node) 查看全部
java爬虫抓取网页数据(架构架构组成URL管理器存储方式存储
)
1、抓取网页本身的接口
相比其他静态编程语言,如java、c#、c++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib 包提供了对 web 文档的更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当请求的地方,例如模拟用户登录、模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2、网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
人生苦短,你需要python。
PS:python2.x 和 python3.x 很不一样。本文只讨论python3.x的爬虫实现方法。
爬虫架构的组成
URL管理器:管理待爬取的url集合和已爬取的url集合,并将待爬取的url发送给网页下载器。
网页下载器(urllib):抓取url对应的网页,存储为字符串,发送给网页解析器。
网页解析器(BeautifulSoup):解析出有价值的数据,存储起来,补充url给URL管理器。
运行进程
URL管理器基本功能存储方法
1、内存(python内存)
要爬取的url集合:set()
抓取的url集合:set()
2、关系型数据库(mysql)
网址(网址,is_crawled)
3、缓存(redis)
要爬取的url集合:set
爬取的 url 集合:set
由于缓存数据库的高性能,大型互联网公司一般将 URL 存储在缓存数据库中。小公司一般将 URL 存储在内存中,如果要永久存储,请将其存储在关系数据库中。
网页下载器 (urllib)
将url对应的网页下载到本地,保存为文件或字符串。
基本方法
新建一个baidu.py,内容如下:
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
buff = response.read()
html = buff.decode("utf8")
print(html)
在命令行执行python baidu.py,打印出得到的页面。
构造请求
上面的代码可以修改为:
import urllib.request
request = urllib.request.Request('http://www.baidu.com')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
携带参数
新建一个baidu2.py,内容如下:
import urllib.request
import urllib.parse
url = 'http://www.baidu.com'
values = {'name': 'voidking','language': 'Python'}
data = urllib.parse.urlencode(values).encode(encoding='utf-8',errors='ignore')
headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0' }
request = urllib.request.Request(url=url, data=data,headers=headers,method='GET')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
使用 Fiddler 监听数据
我们想看看我们的请求是否真的携带参数,所以我们需要使用fiddler。
打开fiddler后,无意中发现上面的代码会报错504,不管是baidu.py还是baidu2.py。
虽然python报错,但是在fiddler中,我们可以看到请求信息,里面确实携带了参数。
查资料发现以前的python版本不支持代理环境下访问https。但是,最新版本应该支持它。那么,最简单的方法就是更改使用http协议进行爬取的url,例如,将其替换为 . 结果还是报错,但是变成了400错误。
然而,然而,然而。. . 神的转折点出现了!!!
当我将url替换为时,请求成功!没错,只需在 URL 后加一个额外的斜杠 / 即可。同理,改成,请求也成功了!魔法!!!
添加处理器
import urllib.request
import http.cookiejar
# 创建cookie容器
cj = http.cookiejar.CookieJar()
# 创建opener
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
# 给urllib.request安装opener
urllib.request.install_opener(opener)
# 请求
request = urllib.request.Request('http://www.baidu.com/')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
print(cj)
Web 解析器 (BeautifulSoup)
从网页中提取有价值的数据和新的 url 列表。
解析器选择
为了实现解析器,可以选择使用正则表达式、html.parser、BeautifulSoup、lxml等,这里我们选择BeautifulSoup。
其中,正则表达式基于模糊匹配,而其他三个基于DOM结构化解析。
BeautifulSoup 安装测试
1、要安装,在命令行执行pip install beautifulsoup4。
2、测试
import bs4
print(bs4)
使用说明
基本用法
1、创建 BeautifulSoup 对象
import bs4
from bs4 import BeautifulSoup
# 根据html网页字符串创建BeautifulSoup对象
html_doc = """
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html_doc)
print(soup.prettify())</p>
2、访问节点
print(soup.title)
print(soup.title.name)
print(soup.title.string)
print(soup.title.parent.name)
print(soup.p)
print(soup.p['class'])
3、指定标签、类或id
print(soup.find_all('a'))
print(soup.find('a'))
print(soup.find(class_='title'))
print(soup.find(id="link3"))
print(soup.find('p',class_='title'))
4、从文档中找到所有标签的链接
for link in soup.find_all('a'):
print(link.get('href'))
出现了警告。根据提示,我们可以在创建 BeautifulSoup 对象时指定解析器。
soup = BeautifulSoup(html_doc,'html.parser')
5、从文档中获取所有文本内容
print(soup.get_text())
6、常规赛
link_node = soup.find('a',href=re.compile(r"til"))
print(link_node)
java爬虫抓取网页数据(一个Python多线程采集爬虫的具体操作流程及费用介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-04-08 05:28
一个Python多线程爬虫,工作时打开10个线程爬取新浪网页的数据,爬取并保存页面,根据deep返回页面链接,根据key判断是否保存页面,其中:deep = 当=0时,为最后一次爬取深度,即只爬取并保存页面,当不分析链接时 deep > 0,返回页面链接。编写这个采集爬虫的具体要求:1.指定网站爬取指定深度的页面,并将收录指定关键词的页面内容存储在sqlite3数据库文件中< @2.程序每10秒在屏幕上打印一次进度信息3.支持线程池机制,同时抓取网页4.代码需要详细注释,需要深入理解各种程序涉及的程序类型知识点5.需要实现线程池功能说明用python写一个网站爬虫程序,支持的参数如下: spider.py -u url -d deep - f logfile -l loglevel(1-5) --testself -thread number --dbfile filepath --key="HTML5" 参数说明: -u 指定爬虫的起始地址 -d 指定爬虫的深度--thread 指定线程池大小,多线程爬取页面,可选参数,默认10--dbfile store th e 指定数据库(sqlite)文件中的结果数据 --关键词在关键页面,获取满足关键词的网页,可选参数,默认为所有页面 -l 日志文件记录详细信息,数字越大,记录越详细,可选参数,默认spider.log--testself程序自检,可选参数 查看全部
java爬虫抓取网页数据(一个Python多线程采集爬虫的具体操作流程及费用介绍)
一个Python多线程爬虫,工作时打开10个线程爬取新浪网页的数据,爬取并保存页面,根据deep返回页面链接,根据key判断是否保存页面,其中:deep = 当=0时,为最后一次爬取深度,即只爬取并保存页面,当不分析链接时 deep > 0,返回页面链接。编写这个采集爬虫的具体要求:1.指定网站爬取指定深度的页面,并将收录指定关键词的页面内容存储在sqlite3数据库文件中< @2.程序每10秒在屏幕上打印一次进度信息3.支持线程池机制,同时抓取网页4.代码需要详细注释,需要深入理解各种程序涉及的程序类型知识点5.需要实现线程池功能说明用python写一个网站爬虫程序,支持的参数如下: spider.py -u url -d deep - f logfile -l loglevel(1-5) --testself -thread number --dbfile filepath --key="HTML5" 参数说明: -u 指定爬虫的起始地址 -d 指定爬虫的深度--thread 指定线程池大小,多线程爬取页面,可选参数,默认10--dbfile store th e 指定数据库(sqlite)文件中的结果数据 --关键词在关键页面,获取满足关键词的网页,可选参数,默认为所有页面 -l 日志文件记录详细信息,数字越大,记录越详细,可选参数,默认spider.log--testself程序自检,可选参数
java爬虫抓取网页数据(2016年上海事业单位医疗招聘:现学现卖解析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-04-07 04:15
)
故事的开始
虽然我们的程序员不做爬虫的工作,但是当我们工作中偶尔需要网络上的数据时,如果手动复制粘贴数据量少的话还是不错的。如果数据量很大,浪费时间真的很无聊。
所以现在我在学习,研究了一个多小时写一个爬虫程序
一、爬虫所需的工具包
新建一个Maven项目,导入爬虫工具包Jsoup
org.jsoup
jsoup
1.10.2
使用 Jsoup 解析网页
首先我们需要获取我们请求的网页的地址
使用Jsoup的parse()方法解析网页,传入两个参数,第一个参数是new URL(url),第二个参数设置解析时间超过30秒就放弃
然后得到一个 Document 对象
之后,就像我们操作 JS 代码一样,Document 对象可以实现 JS 的所有操作
这时候我们用浏览器打开网页,F12检查元素,找到数据所在的div的id名称。如果没有 id 名称,则使用 cals 名称。这里没有 id 名称。
然后我们通过类名获取元素。这时候我们可以输出 System.out.println(chinajobs); 看看我们是否得到了我们想要的数据。
可以看出确实得到了我们想要的数据
过滤数据
虽然得到了数据,但是有很多冗余信息,所以下一步就是对数据进行过滤
因为类不是唯一的,所以获取到 Elements 对象。在进行下一步之前,我们需要将其转换为 Element 对象。
Element el = chinajobs.first();
将chinajobs中的第一个元素转化为Element对象(首先确保我们需要的数据在chinajobs中的第一个元素中)
通过分析发现可以从title属性中提取出我们需要的数据
String title = el.getElementsByAttribute("title").text();
尝试输出
System.out.println(el.getElementsByAttribute("title").text());
过滤到我们想要的所有数据
四、导出到 Excel
最后一步是导出到excel,这里我使用的是poi工具包
org.apache.poi
poi
3.17
通过 el.getElementsByAttribute("title").size() 确定元素个数
循环输出
el.getElementsByAttribute("title").eq(i) 通过传入eq(i)的索引值确定元素值
D盘新建上海招聘公司名单.xls文件
<p>public static void main(String[] args) throws IOException {
// 获取请求 https://www.buildhr.com/area/shanghai/
String url = "https://www.buildhr.com/area/shanghai/";
Document document = Jsoup.parse(new URL(url), 30000);
Elements chinajobs = document.getElementsByClass("chinajobs");
HSSFWorkbook wb = new HSSFWorkbook();
HSSFSheet sheet = wb.createSheet("公司名列表");
Element el = chinajobs.first();
for (int i = 0; i 查看全部
java爬虫抓取网页数据(2016年上海事业单位医疗招聘:现学现卖解析
)
故事的开始

虽然我们的程序员不做爬虫的工作,但是当我们工作中偶尔需要网络上的数据时,如果手动复制粘贴数据量少的话还是不错的。如果数据量很大,浪费时间真的很无聊。
所以现在我在学习,研究了一个多小时写一个爬虫程序
一、爬虫所需的工具包
新建一个Maven项目,导入爬虫工具包Jsoup
org.jsoup
jsoup
1.10.2

使用 Jsoup 解析网页
首先我们需要获取我们请求的网页的地址
使用Jsoup的parse()方法解析网页,传入两个参数,第一个参数是new URL(url),第二个参数设置解析时间超过30秒就放弃
然后得到一个 Document 对象
之后,就像我们操作 JS 代码一样,Document 对象可以实现 JS 的所有操作

这时候我们用浏览器打开网页,F12检查元素,找到数据所在的div的id名称。如果没有 id 名称,则使用 cals 名称。这里没有 id 名称。

然后我们通过类名获取元素。这时候我们可以输出 System.out.println(chinajobs); 看看我们是否得到了我们想要的数据。

可以看出确实得到了我们想要的数据

过滤数据
虽然得到了数据,但是有很多冗余信息,所以下一步就是对数据进行过滤
因为类不是唯一的,所以获取到 Elements 对象。在进行下一步之前,我们需要将其转换为 Element 对象。
Element el = chinajobs.first();
将chinajobs中的第一个元素转化为Element对象(首先确保我们需要的数据在chinajobs中的第一个元素中)
通过分析发现可以从title属性中提取出我们需要的数据

String title = el.getElementsByAttribute("title").text();
尝试输出
System.out.println(el.getElementsByAttribute("title").text());
过滤到我们想要的所有数据

四、导出到 Excel
最后一步是导出到excel,这里我使用的是poi工具包
org.apache.poi
poi
3.17
通过 el.getElementsByAttribute("title").size() 确定元素个数
循环输出
el.getElementsByAttribute("title").eq(i) 通过传入eq(i)的索引值确定元素值
D盘新建上海招聘公司名单.xls文件
<p>public static void main(String[] args) throws IOException {
// 获取请求 https://www.buildhr.com/area/shanghai/
String url = "https://www.buildhr.com/area/shanghai/";
Document document = Jsoup.parse(new URL(url), 30000);
Elements chinajobs = document.getElementsByClass("chinajobs");
HSSFWorkbook wb = new HSSFWorkbook();
HSSFSheet sheet = wb.createSheet("公司名列表");
Element el = chinajobs.first();
for (int i = 0; i
java爬虫抓取网页数据(就用find_find)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-06 15:17
每个div都会有一个h2,里面有一个a,a里面收录我们想要的title名称。所以我们使用find_all来查找所有这样的div标签,将它们存储为一个列表,然后循环遍历列表,为每个元素提取h2a,然后提取标签的内容。
当然我们也可以找到_all最外层的li标签,然后逐层查找,都是一样的。只需找到定位信息的唯一标识符(标签或属性)即可。
虽然看这里的源码可以折叠一些无用的代码,但其实还有一些更好的工具可以帮助我们在网页的源码中找到我们想要的信息的位置。例如,下面的鼠标符号。
当所有代码折叠后,点击鼠标,然后点击网页中的元素,浏览器会自动为你选择你点击的元素。事实上,当你将鼠标悬停在一个元素上时,它已经帮你定位到它了,如下图所示
总结
当我们要爬取一个网页时,只需要下面的过程
现在,我们可以处理一些网站,无需任何反爬措施。至于如何组织多个字段的数据,如何设计爬取多个页面的代码(在常规URL的情况下),不是爬虫知识的范畴,可以用python的基础知识来解决。文章 的下一个系列将重点介绍这部分。接下来给几个目前可以练手的网站
如果您在使用 BeautifulSoup 的定位过程中遇到困难,可以直接在网上搜索教程,也可以等待本主题后面更新的 BeautifulSoup 详细介绍。
如果你去爬其他的网站,最好检查一下r.text是否和网站的源码一模一样,如果不是,说明你的其他服务器做了不给你真实信息,说明他可能看出你是爬虫(做网页请求时,浏览器和requests.get相当于拿着一堆资质证书敲门,对方会查你的资质证书,而浏览器的资质证书一般是可以通过的,但是代码的资质证书可能不合格,因为代码的资质证书可能有一些比较固定的特性,这就是反爬机制)。这时候就需要了解一些反反爬的措施,才能获取真实的信息。 查看全部
java爬虫抓取网页数据(就用find_find)
每个div都会有一个h2,里面有一个a,a里面收录我们想要的title名称。所以我们使用find_all来查找所有这样的div标签,将它们存储为一个列表,然后循环遍历列表,为每个元素提取h2a,然后提取标签的内容。
当然我们也可以找到_all最外层的li标签,然后逐层查找,都是一样的。只需找到定位信息的唯一标识符(标签或属性)即可。
虽然看这里的源码可以折叠一些无用的代码,但其实还有一些更好的工具可以帮助我们在网页的源码中找到我们想要的信息的位置。例如,下面的鼠标符号。

当所有代码折叠后,点击鼠标,然后点击网页中的元素,浏览器会自动为你选择你点击的元素。事实上,当你将鼠标悬停在一个元素上时,它已经帮你定位到它了,如下图所示

总结
当我们要爬取一个网页时,只需要下面的过程
现在,我们可以处理一些网站,无需任何反爬措施。至于如何组织多个字段的数据,如何设计爬取多个页面的代码(在常规URL的情况下),不是爬虫知识的范畴,可以用python的基础知识来解决。文章 的下一个系列将重点介绍这部分。接下来给几个目前可以练手的网站
如果您在使用 BeautifulSoup 的定位过程中遇到困难,可以直接在网上搜索教程,也可以等待本主题后面更新的 BeautifulSoup 详细介绍。
如果你去爬其他的网站,最好检查一下r.text是否和网站的源码一模一样,如果不是,说明你的其他服务器做了不给你真实信息,说明他可能看出你是爬虫(做网页请求时,浏览器和requests.get相当于拿着一堆资质证书敲门,对方会查你的资质证书,而浏览器的资质证书一般是可以通过的,但是代码的资质证书可能不合格,因为代码的资质证书可能有一些比较固定的特性,这就是反爬机制)。这时候就需要了解一些反反爬的措施,才能获取真实的信息。
java爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-04-06 04:03
)
网络爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。
其他不太常用的名称是 ant、autoindex、emulator 或 worm。网络蜘蛛通过网页的链接地址搜索网页,从网站的某个页面(通常是首页)开始,阅读
网页的内容,找到网页中的其他链接地址,然后通过这些链接地址寻找下一个网页,如此循环下去,直到这个网站的所有网页都被爬取完毕。如果整个
互联网被视为一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。因此,为了抓取网络上的数据,不仅需要爬虫,还需要
接收“爬虫”发送的数据并进行处理和过滤的服务器。爬虫爬取的数据量越大,对服务器的性能要求就越高。
1 重点介绍爬虫的工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页的信息。
在抓取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂,需要根据某个网页进行分析
算法过滤掉主题链接,保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,重复上述操作
停止上述过程,直到达到系统的某个条件。此外,所有被爬虫爬取的网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;
对于焦爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程起到反馈和指导作用。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几种:通用网络爬虫、重点网络爬虫、
增量网络爬虫,深度网络爬虫。实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。
网络爬虫实现原理
根据这个原理,编写一个简单的网络爬虫程序,这个程序的作用是获取网站发回的数据,并提取其中的URL。我们将获取的 URL 存储在一个文件夹中。刚从网上
网站获取的URL进一步循环获取数据,提取其他数据。这里就不写了,只是模拟一个最简单的原理。实际的网站爬虫远比这个复杂,深入的讨论太多了。
. 除了提取URL之外,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。下面是一个Java模拟的提取新浪网页链接并存储的程序
在一个文件中
源代码如下
package com.cellstrain.icell.util;<br /><br />import java.io.*;<br />import java.net.*;<br />import java.util.regex.Matcher;<br />import java.util.regex.Pattern;<br /><br />/**<br /> * java实现爬虫<br /> */<br />public class Robot {<br /> public static void main(String[] args) {<br /> URL url = null;<br /> URLConnection urlconn = null;<br /> BufferedReader br = null;<br /> PrintWriter pw = null;<br />// String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";<br /> String regex = "https://[\\w+\\.?/?]+\\.[A-Za-z]+";//url匹配规则<br /> Pattern p = Pattern.compile(regex);<br /> try {<br /> url = new URL("https://www.rndsystems.com/cn");//爬取的网址、这里爬取的是一个生物网站<br /> urlconn = url.openConnection();<br /> pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中<br /> br = new BufferedReader(new InputStreamReader(<br /> urlconn.getInputStream()));<br /> String buf = null;<br /> while ((buf = br.readLine()) != null) {<br /> Matcher buf_m = p.matcher(buf);<br /> while (buf_m.find()) {<br /> pw.println(buf_m.group());<br /> }<br /> }<br /> System.out.println("爬取成功^_^");<br /> } catch (MalformedURLException e) {<br /> e.printStackTrace();<br /> } catch (IOException e) {<br /> e.printStackTrace();<br /> } finally {<br /> try {<br /> br.close();<br /> } catch (IOException e) {<br /> e.printStackTrace();<br /> }<br /> pw.close();<br /> }<br /> }<br />}<br />
运行idea的结果如下:
检查D盘是否有SiteURL.txt文件
已经成功生成SiteURL文件,打开就可以看到所有抓到的url
查看全部
java爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人()
)
网络爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。
其他不太常用的名称是 ant、autoindex、emulator 或 worm。网络蜘蛛通过网页的链接地址搜索网页,从网站的某个页面(通常是首页)开始,阅读
网页的内容,找到网页中的其他链接地址,然后通过这些链接地址寻找下一个网页,如此循环下去,直到这个网站的所有网页都被爬取完毕。如果整个
互联网被视为一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。因此,为了抓取网络上的数据,不仅需要爬虫,还需要
接收“爬虫”发送的数据并进行处理和过滤的服务器。爬虫爬取的数据量越大,对服务器的性能要求就越高。
1 重点介绍爬虫的工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页的信息。
在抓取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂,需要根据某个网页进行分析
算法过滤掉主题链接,保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,重复上述操作
停止上述过程,直到达到系统的某个条件。此外,所有被爬虫爬取的网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;
对于焦爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程起到反馈和指导作用。

与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几种:通用网络爬虫、重点网络爬虫、
增量网络爬虫,深度网络爬虫。实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。
网络爬虫实现原理
根据这个原理,编写一个简单的网络爬虫程序,这个程序的作用是获取网站发回的数据,并提取其中的URL。我们将获取的 URL 存储在一个文件夹中。刚从网上
网站获取的URL进一步循环获取数据,提取其他数据。这里就不写了,只是模拟一个最简单的原理。实际的网站爬虫远比这个复杂,深入的讨论太多了。
. 除了提取URL之外,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。下面是一个Java模拟的提取新浪网页链接并存储的程序
在一个文件中
源代码如下
package com.cellstrain.icell.util;<br /><br />import java.io.*;<br />import java.net.*;<br />import java.util.regex.Matcher;<br />import java.util.regex.Pattern;<br /><br />/**<br /> * java实现爬虫<br /> */<br />public class Robot {<br /> public static void main(String[] args) {<br /> URL url = null;<br /> URLConnection urlconn = null;<br /> BufferedReader br = null;<br /> PrintWriter pw = null;<br />// String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";<br /> String regex = "https://[\\w+\\.?/?]+\\.[A-Za-z]+";//url匹配规则<br /> Pattern p = Pattern.compile(regex);<br /> try {<br /> url = new URL("https://www.rndsystems.com/cn";);//爬取的网址、这里爬取的是一个生物网站<br /> urlconn = url.openConnection();<br /> pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中<br /> br = new BufferedReader(new InputStreamReader(<br /> urlconn.getInputStream()));<br /> String buf = null;<br /> while ((buf = br.readLine()) != null) {<br /> Matcher buf_m = p.matcher(buf);<br /> while (buf_m.find()) {<br /> pw.println(buf_m.group());<br /> }<br /> }<br /> System.out.println("爬取成功^_^");<br /> } catch (MalformedURLException e) {<br /> e.printStackTrace();<br /> } catch (IOException e) {<br /> e.printStackTrace();<br /> } finally {<br /> try {<br /> br.close();<br /> } catch (IOException e) {<br /> e.printStackTrace();<br /> }<br /> pw.close();<br /> }<br /> }<br />}<br />
运行idea的结果如下:
检查D盘是否有SiteURL.txt文件

已经成功生成SiteURL文件,打开就可以看到所有抓到的url

java爬虫抓取网页数据(爬虫入门程序urllib2实现下载网页的三种方式:入门 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-04 02:10
)
爬虫入口程序
urllib2实现了三种下载网页的方式:
第一个:
import cookielib
import urllib2
url = "http://www.baidu.com"
response1 = urllib2.urlopen(url)
print "第一种方法"
#获取状态码,200表示成功
print response1.getcode()
#获取网页内容的长度
print len(response1.read())
第二:
request = urllib2.Request(url)
#模拟Mozilla浏览器进行爬虫
request.add_header("user-agent","Mozilla/5.0")
response2 = urllib2.urlopen(request)
print response2.getcode()
print len(response2.read())
第三:
cookie = cookielib.CookieJar()
#加入urllib2处理cookie的能力
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
urllib2.install_opener(opener)
response3 = urllib2.urlopen(url)
print response3.getcode()
print len(response3.read())
print cookie
爬虫添加数据、标头,然后发布请求
import urllib
import urllib2
url = 'http://www.server.com/login'
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
values = {'username' : 'cqc', 'password' : 'XXXX' }
headers = { 'User-Agent' : user_agent }
data = urllib.urlencode(values)
request = urllib2.Request(url, data, headers)
response = urllib2.urlopen(request)
page = response.read()
爬虫添加 cookie
为什么要添加 cookie?
Cookie,是指存储在用户本地终端上的一些网站数据(通常是加密的),用于识别用户身份和进行会话跟踪。比如有些网站需要登录才能访问某个页面,在登录之前,你想抓取一个页面内容是不允许的。然后我们就可以使用Urllib2库来保存我们登录的cookies,然后爬取其他页面来达到目的
获取 cookie 并将其保存到变量中
首先我们用CookieJar对象来实现获取cookies的功能,存储在变量中,先体验一下
import urllib2
import cookielib
#声明一个CookieJar对象实例来保存cookie
cookie = cookielib.CookieJar()
#利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器
handler=urllib2.HTTPCookieProcessor(cookie)
#通过handler来构建opener
opener = urllib2.build_opener(handler)
#此处的open方法同urllib2的urlopen方法,也可以传入request
response = opener.open('http://www.baidu.com')
for item in cookie:
print 'Name = '+item.name
print 'Value = '+item.value
我们用上面的方法将cookie保存到一个变量中,然后打印出cookie中的值,结果如下
Name = BAIDUID
Value = B07B663B645729F11F659C02AAE65B4C:FG=1
Name = BAIDUPSID
Value = B07B663B645729F11F659C02AAE65B4C
Name = H_PS_PSSID
Value = 12527_11076_1438_10633
Name = BDSVRTM
Value = 0
Name = BD_HOME
Value = 0
将 cookie 保存到文件
在上述方法中,我们将cookie保存到cookie变量中。如果我们想将 cookie 保存到文件中怎么办?这时候,我们将使用 FileCookieJar 对象,这里我们使用它的子类 MozillaCookieJar 来保存 cookie
mport cookielib
import urllib2
#设置保存cookie的文件,同级目录下的cookie.txt
filename = 'cookie.txt'
#声明一个MozillaCookieJar对象实例来保存cookie,之后写入文件
cookie = cookielib.MozillaCookieJar(filename)
#利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器
handler = urllib2.HTTPCookieProcessor(cookie)
#通过handler来构建opener
opener = urllib2.build_opener(handler)
#创建一个请求,原理同urllib2的urlopen
response = opener.open("http://www.baidu.com")
#保存cookie到文件
cookie.save(ignore_discard=True, ignore_expires=True)
正则表达式的正则表达式语法规则
查看全部
java爬虫抓取网页数据(爬虫入门程序urllib2实现下载网页的三种方式:入门
)
爬虫入口程序
urllib2实现了三种下载网页的方式:
第一个:
import cookielib
import urllib2
url = "http://www.baidu.com"
response1 = urllib2.urlopen(url)
print "第一种方法"
#获取状态码,200表示成功
print response1.getcode()
#获取网页内容的长度
print len(response1.read())
第二:
request = urllib2.Request(url)
#模拟Mozilla浏览器进行爬虫
request.add_header("user-agent","Mozilla/5.0")
response2 = urllib2.urlopen(request)
print response2.getcode()
print len(response2.read())
第三:
cookie = cookielib.CookieJar()
#加入urllib2处理cookie的能力
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
urllib2.install_opener(opener)
response3 = urllib2.urlopen(url)
print response3.getcode()
print len(response3.read())
print cookie
爬虫添加数据、标头,然后发布请求
import urllib
import urllib2
url = 'http://www.server.com/login'
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
values = {'username' : 'cqc', 'password' : 'XXXX' }
headers = { 'User-Agent' : user_agent }
data = urllib.urlencode(values)
request = urllib2.Request(url, data, headers)
response = urllib2.urlopen(request)
page = response.read()
爬虫添加 cookie
为什么要添加 cookie?
Cookie,是指存储在用户本地终端上的一些网站数据(通常是加密的),用于识别用户身份和进行会话跟踪。比如有些网站需要登录才能访问某个页面,在登录之前,你想抓取一个页面内容是不允许的。然后我们就可以使用Urllib2库来保存我们登录的cookies,然后爬取其他页面来达到目的
获取 cookie 并将其保存到变量中
首先我们用CookieJar对象来实现获取cookies的功能,存储在变量中,先体验一下
import urllib2
import cookielib
#声明一个CookieJar对象实例来保存cookie
cookie = cookielib.CookieJar()
#利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器
handler=urllib2.HTTPCookieProcessor(cookie)
#通过handler来构建opener
opener = urllib2.build_opener(handler)
#此处的open方法同urllib2的urlopen方法,也可以传入request
response = opener.open('http://www.baidu.com')
for item in cookie:
print 'Name = '+item.name
print 'Value = '+item.value
我们用上面的方法将cookie保存到一个变量中,然后打印出cookie中的值,结果如下
Name = BAIDUID
Value = B07B663B645729F11F659C02AAE65B4C:FG=1
Name = BAIDUPSID
Value = B07B663B645729F11F659C02AAE65B4C
Name = H_PS_PSSID
Value = 12527_11076_1438_10633
Name = BDSVRTM
Value = 0
Name = BD_HOME
Value = 0
将 cookie 保存到文件
在上述方法中,我们将cookie保存到cookie变量中。如果我们想将 cookie 保存到文件中怎么办?这时候,我们将使用 FileCookieJar 对象,这里我们使用它的子类 MozillaCookieJar 来保存 cookie
mport cookielib
import urllib2
#设置保存cookie的文件,同级目录下的cookie.txt
filename = 'cookie.txt'
#声明一个MozillaCookieJar对象实例来保存cookie,之后写入文件
cookie = cookielib.MozillaCookieJar(filename)
#利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器
handler = urllib2.HTTPCookieProcessor(cookie)
#通过handler来构建opener
opener = urllib2.build_opener(handler)
#创建一个请求,原理同urllib2的urlopen
response = opener.open("http://www.baidu.com";)
#保存cookie到文件
cookie.save(ignore_discard=True, ignore_expires=True)
正则表达式的正则表达式语法规则


java爬虫抓取网页数据(分布式网络新闻抓取系统的设计与实现(一)-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-04-01 14:26
1 项目介绍
本项目的主要内容是分布式网络新闻抓取系统的设计与实现。主要有以下几个部分要介绍:
(1)深入分析网络新闻爬虫特点,设计分布式网络新闻爬虫系统爬取策略、爬取领域、动态网络爬取方式、分布式结构、系统监控和数据存储六大关键功能。
(2)结合程序代码分解讲解分布式网络新闻爬虫系统的实现过程。包括爬虫编写、爬虫规避、动态网页数据爬取、分布式爬虫部署、系统监控,共六个内容,结合腾讯新闻数据的实际针对性抓取,通过测试来测试系统性能。
(3)规划设计了一个数据处理模块,包括数据清洗、代码转换、数据分类、对象添加等功能。
2. 分布式网络新闻抓取系统设计
2.1 整体系统架构设计
系统采用分布式主从结构,一台Master服务器和多台Slave服务器。Master 管理 Redis 数据库并分发下载任务。Slave 部署 Scrapy 抓取网页,解析提取项目数据。服务器的基本环境是Ubuntu操作系统,Master服务器安装Redis数据库服务器和Graphite,
Slave 安装 Scrapy 和 Redis 客户端。系统按功能可分为两大模块,一是数据采集模块,二是数据处理模块。数据抓取模块包括浏览器调用、网页下载、字段提取、爬虫规避、数据存储和系统监控六大功能;数据处理模块包括数据清洗、对象添加、编码转换和数据分类四个功能。
2.2 爬取策略设计
本项目的网络爬虫采用深度优先的爬取策略,根据设置下载网页数据。网页链接处理流程如下:
1.手动设置初始下载地址,一般是网站导航地址。
2.爬虫开始运行,从初始地址抓取第一个网页链接。
3、爬虫根据正则表达式识别新链接中的目录页地址和新闻内容页地址,将识别出的新地址加入待下载队列,等待被爬取,无法识别的网页地址为定义为无用的链接并丢弃。
4.爬虫依次取出要下载的网页链接,从待下载队列中提取数据。
5、下载队列为空,爬虫停止爬取。
新闻网站的导航页数是有限的,这个规则决定了新闻导航页的url在一定的人工参与下很容易获得,并作为爬虫系统的初始url。
2.3 爬取字段的设计
本项目的目的是捕捉网络新闻数据,因此内容必须能够客观、准确地反映网络新闻的特点。
以腾讯在线新闻数据的爬取为例,通过分析网页结构,确定了两步爬取步骤。第一步,抓取新闻内容页,获取新闻标题、新闻来源、新闻内容、发表时间、评论数、评论地址、相关搜索、用户仍喜欢的新闻、点赞数等9项内容;第二步,在获取评论地址后,抓取评论页面,获取评论者ID、评论者昵称、评论者性别、评论者所在地区、评论时间、评论内容、单条评论支持人数、回复数一条评论。
2.4 动态网页抓取方法设计
腾讯新闻网页使用Java生成动态网页内容。一些 JS 事件触发页面内容在打开时会发生变化,而一些网页在没有 JS 支持的情况下根本无法工作。普通爬虫根本无法从这些页面获取数据。解决Java动态网页爬取问题的方法有四种:
1、编写代码模拟相关的JS逻辑。
2. 调用带有界面的浏览器,类似于那些广泛用于测试的浏览器,例如 Selenium。
3、使用无界面浏览器,各种基于Webkit的,如Casperjs、Phantomjs等。
4.结合JS执行引擎,实现轻量级浏览器。
由于本项目是基于Python作为主要语言编写的,所以使用Selenium来处理JS
动态新闻页面。它的优点是简单和易于实施。使用Python代码模拟用户对浏览器的操作,首先将网页加载到浏览器中打开,然后从浏览器缓存中获取网页数据,传递给spider进行解析提取,最后将目标数据传递给项目频道。
2.5 爬虫分布式设计
使用Redis数据库实现分布式爬取。基本思路是Scrapy爬虫获取到的urls(request)
都放在一个 Redis Queue 中,所有爬虫也从指定的 Redis Queue 中获取请求(url)。
Scrapy-Redis 默认使用 Spider Priority Queue 来确定 url 的顺序,由 sorted set 决定
实现了非 FIFO 和 LIFO 方法。
Redis 存储了 Scrapy 项目的 request 和 stats 信息,根据这些信息可以掌握任务
情况和爬虫状态,在分配任务时很容易平衡系统负载,有助于克服爬虫的性能瓶颈。同时
利用 Redis 的高性能和易扩展性,可以轻松实现高效下载。当 Redis 存储或
当访问速度遇到问题时,可以通过增加 Redis 集群和爬虫集群的数量来提高。Scrapy-Redis
分布式解决方案解决了间歇性爬取和重复数据删除的问题。爬虫重启后会和Redis进行比较。
抓取队列中的url,已经抓取的url会被自动过滤掉。
2.6 基于Graphite系统的监控组件设计
使用Graphite监控系统运行状态,实现了一个分布式系统的statscollector,
系统的统计信息以图表的形式实时动态显示,即实时监控。Graphite监控的信息包括:系统下载信息、日志信息、文件数、调度信息、爬虫运行信息、爬虫异常信息、文件数、获取的项目数、最大请求深度、收到的响应数。
2.7 数据存储模块设计
Scrapy 支持 json、csv 和 xml 等文本格式的数据存储。用户可以在运行爬虫时设置,例如:scrapy crawlspider –o items.json –t json,或者在Scrapy项目文件的Item Pipeline中
在文件中定义。除此之外,Scrapy 还提供了多种数据库 API 来支持数据库存储。比如 MongoDB,
雷迪斯等人。数据存储分为两部分,一是网页链接的存储,二是项目数据的存储。网络链接存储
存储在Redis数据库中,用于实现分布式爬虫的下载管理;项目数据包括新闻数据和评论数据,以JSON格式保存为文本文件,方便处理。评论数据以评论url中收录的评论ID命名存储,这是一种将新闻数据与评论数据相关联的方式。
3 项目总结 查看全部
java爬虫抓取网页数据(分布式网络新闻抓取系统的设计与实现(一)-上海怡健医学)
1 项目介绍
本项目的主要内容是分布式网络新闻抓取系统的设计与实现。主要有以下几个部分要介绍:
(1)深入分析网络新闻爬虫特点,设计分布式网络新闻爬虫系统爬取策略、爬取领域、动态网络爬取方式、分布式结构、系统监控和数据存储六大关键功能。
(2)结合程序代码分解讲解分布式网络新闻爬虫系统的实现过程。包括爬虫编写、爬虫规避、动态网页数据爬取、分布式爬虫部署、系统监控,共六个内容,结合腾讯新闻数据的实际针对性抓取,通过测试来测试系统性能。
(3)规划设计了一个数据处理模块,包括数据清洗、代码转换、数据分类、对象添加等功能。
2. 分布式网络新闻抓取系统设计
2.1 整体系统架构设计
系统采用分布式主从结构,一台Master服务器和多台Slave服务器。Master 管理 Redis 数据库并分发下载任务。Slave 部署 Scrapy 抓取网页,解析提取项目数据。服务器的基本环境是Ubuntu操作系统,Master服务器安装Redis数据库服务器和Graphite,
Slave 安装 Scrapy 和 Redis 客户端。系统按功能可分为两大模块,一是数据采集模块,二是数据处理模块。数据抓取模块包括浏览器调用、网页下载、字段提取、爬虫规避、数据存储和系统监控六大功能;数据处理模块包括数据清洗、对象添加、编码转换和数据分类四个功能。
2.2 爬取策略设计
本项目的网络爬虫采用深度优先的爬取策略,根据设置下载网页数据。网页链接处理流程如下:
1.手动设置初始下载地址,一般是网站导航地址。
2.爬虫开始运行,从初始地址抓取第一个网页链接。
3、爬虫根据正则表达式识别新链接中的目录页地址和新闻内容页地址,将识别出的新地址加入待下载队列,等待被爬取,无法识别的网页地址为定义为无用的链接并丢弃。
4.爬虫依次取出要下载的网页链接,从待下载队列中提取数据。
5、下载队列为空,爬虫停止爬取。
新闻网站的导航页数是有限的,这个规则决定了新闻导航页的url在一定的人工参与下很容易获得,并作为爬虫系统的初始url。
2.3 爬取字段的设计
本项目的目的是捕捉网络新闻数据,因此内容必须能够客观、准确地反映网络新闻的特点。
以腾讯在线新闻数据的爬取为例,通过分析网页结构,确定了两步爬取步骤。第一步,抓取新闻内容页,获取新闻标题、新闻来源、新闻内容、发表时间、评论数、评论地址、相关搜索、用户仍喜欢的新闻、点赞数等9项内容;第二步,在获取评论地址后,抓取评论页面,获取评论者ID、评论者昵称、评论者性别、评论者所在地区、评论时间、评论内容、单条评论支持人数、回复数一条评论。
2.4 动态网页抓取方法设计
腾讯新闻网页使用Java生成动态网页内容。一些 JS 事件触发页面内容在打开时会发生变化,而一些网页在没有 JS 支持的情况下根本无法工作。普通爬虫根本无法从这些页面获取数据。解决Java动态网页爬取问题的方法有四种:
1、编写代码模拟相关的JS逻辑。
2. 调用带有界面的浏览器,类似于那些广泛用于测试的浏览器,例如 Selenium。
3、使用无界面浏览器,各种基于Webkit的,如Casperjs、Phantomjs等。
4.结合JS执行引擎,实现轻量级浏览器。
由于本项目是基于Python作为主要语言编写的,所以使用Selenium来处理JS
动态新闻页面。它的优点是简单和易于实施。使用Python代码模拟用户对浏览器的操作,首先将网页加载到浏览器中打开,然后从浏览器缓存中获取网页数据,传递给spider进行解析提取,最后将目标数据传递给项目频道。
2.5 爬虫分布式设计
使用Redis数据库实现分布式爬取。基本思路是Scrapy爬虫获取到的urls(request)
都放在一个 Redis Queue 中,所有爬虫也从指定的 Redis Queue 中获取请求(url)。
Scrapy-Redis 默认使用 Spider Priority Queue 来确定 url 的顺序,由 sorted set 决定
实现了非 FIFO 和 LIFO 方法。
Redis 存储了 Scrapy 项目的 request 和 stats 信息,根据这些信息可以掌握任务
情况和爬虫状态,在分配任务时很容易平衡系统负载,有助于克服爬虫的性能瓶颈。同时
利用 Redis 的高性能和易扩展性,可以轻松实现高效下载。当 Redis 存储或
当访问速度遇到问题时,可以通过增加 Redis 集群和爬虫集群的数量来提高。Scrapy-Redis
分布式解决方案解决了间歇性爬取和重复数据删除的问题。爬虫重启后会和Redis进行比较。
抓取队列中的url,已经抓取的url会被自动过滤掉。
2.6 基于Graphite系统的监控组件设计
使用Graphite监控系统运行状态,实现了一个分布式系统的statscollector,
系统的统计信息以图表的形式实时动态显示,即实时监控。Graphite监控的信息包括:系统下载信息、日志信息、文件数、调度信息、爬虫运行信息、爬虫异常信息、文件数、获取的项目数、最大请求深度、收到的响应数。
2.7 数据存储模块设计
Scrapy 支持 json、csv 和 xml 等文本格式的数据存储。用户可以在运行爬虫时设置,例如:scrapy crawlspider –o items.json –t json,或者在Scrapy项目文件的Item Pipeline中
在文件中定义。除此之外,Scrapy 还提供了多种数据库 API 来支持数据库存储。比如 MongoDB,
雷迪斯等人。数据存储分为两部分,一是网页链接的存储,二是项目数据的存储。网络链接存储
存储在Redis数据库中,用于实现分布式爬虫的下载管理;项目数据包括新闻数据和评论数据,以JSON格式保存为文本文件,方便处理。评论数据以评论url中收录的评论ID命名存储,这是一种将新闻数据与评论数据相关联的方式。
3 项目总结
java爬虫抓取网页数据(Python即时网络爬虫GitHub源7,文档修改历史(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-31 22:15
)
1 简介
本文介绍了如何使用 GooSeeker API 下载 Java 和 JavaScript 中的内容提取器。这是一个示例程序。什么是内容提取器?为什么要用这种方式?来自 Python Instant Web Crawler 开源项目:通过生成内容提取器来节省程序员的时间。详情请参阅“内容提取器的定义”。
2.用Java下载内容提取器
这是一系列示例程序之一。就目前编程语言的发展而言,Java并不适合提取网页内容。除了语言的不灵活和方便外,整个生态系统还不够活跃,可选类库增长缓慢。此外,要从 JavaScript 动态网页中提取内容,Java 也很不方便,需要 JavaScript 引擎。使用 JavaScript 下载内容提取器以直接跳到第 3 部分的内容。
执行
注解:
源代码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613 ... 3B%3B // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
返回结果如下:
3. 使用 JavaScript 下载内容提取器
请注意,如果本示例中的 JavaScript 代码运行在网页上,由于跨域问题,无法抓取非本地网页的内容。因此,需要在特权JavaScript引擎上运行,例如浏览器扩展、自研浏览器、自身程序中的JavaScript引擎等。
为了实验的方便,这个例子还在网页上运行。为了绕过跨域问题,保存并修改目标网页,并在其中插入JavaScript。这么多手动操作只是为了实验,正式使用时还需要考虑其他手段。
执行
注解:
这是源代码:
返回结果截图如下
4、展望
您还可以使用 Python 来获取指定网页的内容。我觉得Python的语法更简洁。以后我会添加 Python 语言的例子。有兴趣的朋友可以加入研究。
五、相关文件
Python Instant Web Crawler:API 说明
6.Jisouke GooSeeker开源代码下载源
GooSeeker 开源 Python 网络爬虫 GitHub 源码
7.文档修改历史
2016-06-20: V1.0
如有疑问,您可以或
查看全部
java爬虫抓取网页数据(Python即时网络爬虫GitHub源7,文档修改历史(组图)
)
1 简介
本文介绍了如何使用 GooSeeker API 下载 Java 和 JavaScript 中的内容提取器。这是一个示例程序。什么是内容提取器?为什么要用这种方式?来自 Python Instant Web Crawler 开源项目:通过生成内容提取器来节省程序员的时间。详情请参阅“内容提取器的定义”。
2.用Java下载内容提取器
这是一系列示例程序之一。就目前编程语言的发展而言,Java并不适合提取网页内容。除了语言的不灵活和方便外,整个生态系统还不够活跃,可选类库增长缓慢。此外,要从 JavaScript 动态网页中提取内容,Java 也很不方便,需要 JavaScript 引擎。使用 JavaScript 下载内容提取器以直接跳到第 3 部分的内容。
执行
注解:
源代码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613 ... 3B%3B // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
返回结果如下:

3. 使用 JavaScript 下载内容提取器
请注意,如果本示例中的 JavaScript 代码运行在网页上,由于跨域问题,无法抓取非本地网页的内容。因此,需要在特权JavaScript引擎上运行,例如浏览器扩展、自研浏览器、自身程序中的JavaScript引擎等。
为了实验的方便,这个例子还在网页上运行。为了绕过跨域问题,保存并修改目标网页,并在其中插入JavaScript。这么多手动操作只是为了实验,正式使用时还需要考虑其他手段。
执行
注解:
这是源代码:
返回结果截图如下

4、展望
您还可以使用 Python 来获取指定网页的内容。我觉得Python的语法更简洁。以后我会添加 Python 语言的例子。有兴趣的朋友可以加入研究。
五、相关文件
Python Instant Web Crawler:API 说明
6.Jisouke GooSeeker开源代码下载源
GooSeeker 开源 Python 网络爬虫 GitHub 源码
7.文档修改历史
2016-06-20: V1.0
如有疑问,您可以或

java爬虫抓取网页数据(Java爬虫实战(一):爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2022-03-28 19:27
爬取java爬虫相关博客
Java爬虫,信息爬取(传输)的实现
转载请注明出处: 今天公司有个需求,要抓到指定网站查询后的数据,所以抽时间写了一个demo来演示使用。这个想法很简单:它是通过 Ja
developerguy6 年前1569
超级简单的java爬虫
最简单的爬虫,不需要设置代理服务器,不需要设置cookie,不需要http连接池,使用httpget方法,只需要获取html代码……嗯,符合这个要求的爬虫应该是最基本的爬虫了。当然,这也是制作复杂爬虫的基础。使用了httpclient4的相关API。
爱丹7 年前803
Java爬虫实战(一):抓取一个网站上的所有链接
算法介绍 程序采用idea中的广度优先算法,对未遍历的链接逐一发起GET请求,然后用正则表达式解析返回的页面,取出未遍历的新链接已找到,并将它们添加到集合中。迭代下一个循环。具体实现使用Map,键值对是链接和
技术哥 4年前 962
简单的Java爬虫制作
一、文章芮雨本来最近任务挺多的,今天想放松一下,正好比尔喜欢玩英文配音,配音全在配音云上软件,想全部搞定,所以写了一个爬虫,然后就有了这个爬虫教程~~二、爬虫!!爬虫!!首先我们要搞清楚什么是爬虫~~网络爬虫(又称网络蜘蛛、网络机器
this_is_bill6 年前 1692
一个分布式java爬虫框架JLiteSpider
一个精简的分布式 Java 蜘蛛框架。这是一个轻量级的分布式 Java 蜘蛛框架。特点 这是一个强大但轻量级的分布式蜘蛛框架。jlitespider本质上是分布式的,每个worker需要传递一个或多个消息
建筑之路 3年前 1955
一个分布式java爬虫框架JLiteSpider
JLiteSpider 一个精简的分布式 Java 蜘蛛框架。这是一个轻量级的分布式 Java 蜘蛛框架。特点 这是一个强大但轻量级的分布式蜘蛛框架。jlitespider 本质上是分布式的,并且在工人之间
建筑之路 3年前 1207
Java爬虫-微博热搜
前言由于写了文章关于Lifecycle的内容,还没有找到其他有趣的源码,所以决定看一下写后台代码,一波试试。百度了一周左右,SSM框架基本完成。一时兴起,我打算采集各种热搜。最先想到的肯定是微博热搜,那么,让我们一起爬下微博热搜吧!工具
ksuu3 年前 1826
函数计算实战-java爬虫从指定网站获取图片并存入对象存储的例子
前段时间,阿里云函数计算推出了Java8版本的编译环境。我结合一门Java语言完成了函数计算的代码编写。本例主要模拟一个网站图片爬虫,并指定指定的网站。获取页面的所有图片并保存到对象存储中,绘制简单的架构图如下: 流程说明:用户输入某个网站地址,爬取
文一4年前3399
爬取java爬虫相关问答
请问Java_crawler,Js如何爬取动态生成数据的页面?
很多网站使用`js`或者`jquery`生成数据,后台获取数据后,使用`document.write()`或者`("#id").html=""`的时候写入页面,此时用浏览器查看源代码是看不到数据的。`HttpClient` 将不起作用
爵士 6 年前 2752
如何使用 crawler4j 作为网络爬虫来爬取特定的标题和发布时间
如何使用 crawler4j 进行网页爬取
野蛮人 1235 年前 913
爬虫数据管理【问答合集】
互联网爬虫的自然语言处理目前前景如何?artTemplate:arttemplate生成的页面可以爬取到数据吗?
我是管理员 3 年前 28342
MongoDB吃内存,怎么办?
我最近使用爬虫来捕获数据。刚开始java和mysql的时候,发现mysql的插入速度有点慢,所以换成了mongodb。速度提升了很多,但是问题出来了,怎么控制mongodb的内存,完全吃光了不能配置一个最大内存使用量吗?我有大量的数据,每天都需要抓取新的数据。
花开 6年前 1127
MongoDB这么吃内存,怎么存。
我最近使用爬虫来捕获数据。刚开始java和mysql的时候,发现mysql的插入速度有点慢,于是换成了mongodb,速度提升了很多,但是问题就出来了。,完全吃光了,不能配置一个最大内存使用量吗?我的数据量很大,每天都需要获取新数据。
a1234566785 前 741
MongoDB这么吃内存,怎么存。
我最近使用爬虫来捕获数据。刚开始java和mysql的时候,发现mysql的插入速度有点慢,于是换成了mongodb,速度提升了很多,但是问题就出来了。,完全吃光了,不能配置一个最大内存使用量吗?我的数据量很大,每天都需要获取新数据。
小旋风柴进6年前830 查看全部
java爬虫抓取网页数据(Java爬虫实战(一):爬虫)
爬取java爬虫相关博客
Java爬虫,信息爬取(传输)的实现

转载请注明出处: 今天公司有个需求,要抓到指定网站查询后的数据,所以抽时间写了一个demo来演示使用。这个想法很简单:它是通过 Ja

developerguy6 年前1569
超级简单的java爬虫

最简单的爬虫,不需要设置代理服务器,不需要设置cookie,不需要http连接池,使用httpget方法,只需要获取html代码……嗯,符合这个要求的爬虫应该是最基本的爬虫了。当然,这也是制作复杂爬虫的基础。使用了httpclient4的相关API。

爱丹7 年前803
Java爬虫实战(一):抓取一个网站上的所有链接

算法介绍 程序采用idea中的广度优先算法,对未遍历的链接逐一发起GET请求,然后用正则表达式解析返回的页面,取出未遍历的新链接已找到,并将它们添加到集合中。迭代下一个循环。具体实现使用Map,键值对是链接和
技术哥 4年前 962
简单的Java爬虫制作

一、文章芮雨本来最近任务挺多的,今天想放松一下,正好比尔喜欢玩英文配音,配音全在配音云上软件,想全部搞定,所以写了一个爬虫,然后就有了这个爬虫教程~~二、爬虫!!爬虫!!首先我们要搞清楚什么是爬虫~~网络爬虫(又称网络蜘蛛、网络机器
this_is_bill6 年前 1692
一个分布式java爬虫框架JLiteSpider

一个精简的分布式 Java 蜘蛛框架。这是一个轻量级的分布式 Java 蜘蛛框架。特点 这是一个强大但轻量级的分布式蜘蛛框架。jlitespider本质上是分布式的,每个worker需要传递一个或多个消息

建筑之路 3年前 1955
一个分布式java爬虫框架JLiteSpider

JLiteSpider 一个精简的分布式 Java 蜘蛛框架。这是一个轻量级的分布式 Java 蜘蛛框架。特点 这是一个强大但轻量级的分布式蜘蛛框架。jlitespider 本质上是分布式的,并且在工人之间
建筑之路 3年前 1207
Java爬虫-微博热搜

前言由于写了文章关于Lifecycle的内容,还没有找到其他有趣的源码,所以决定看一下写后台代码,一波试试。百度了一周左右,SSM框架基本完成。一时兴起,我打算采集各种热搜。最先想到的肯定是微博热搜,那么,让我们一起爬下微博热搜吧!工具
ksuu3 年前 1826
函数计算实战-java爬虫从指定网站获取图片并存入对象存储的例子

前段时间,阿里云函数计算推出了Java8版本的编译环境。我结合一门Java语言完成了函数计算的代码编写。本例主要模拟一个网站图片爬虫,并指定指定的网站。获取页面的所有图片并保存到对象存储中,绘制简单的架构图如下: 流程说明:用户输入某个网站地址,爬取

文一4年前3399
爬取java爬虫相关问答
请问Java_crawler,Js如何爬取动态生成数据的页面?

很多网站使用`js`或者`jquery`生成数据,后台获取数据后,使用`document.write()`或者`("#id").html=""`的时候写入页面,此时用浏览器查看源代码是看不到数据的。`HttpClient` 将不起作用

爵士 6 年前 2752
如何使用 crawler4j 作为网络爬虫来爬取特定的标题和发布时间
如何使用 crawler4j 进行网页爬取

野蛮人 1235 年前 913
爬虫数据管理【问答合集】

互联网爬虫的自然语言处理目前前景如何?artTemplate:arttemplate生成的页面可以爬取到数据吗?

我是管理员 3 年前 28342
MongoDB吃内存,怎么办?

我最近使用爬虫来捕获数据。刚开始java和mysql的时候,发现mysql的插入速度有点慢,所以换成了mongodb。速度提升了很多,但是问题出来了,怎么控制mongodb的内存,完全吃光了不能配置一个最大内存使用量吗?我有大量的数据,每天都需要抓取新的数据。
花开 6年前 1127
MongoDB这么吃内存,怎么存。

我最近使用爬虫来捕获数据。刚开始java和mysql的时候,发现mysql的插入速度有点慢,于是换成了mongodb,速度提升了很多,但是问题就出来了。,完全吃光了,不能配置一个最大内存使用量吗?我的数据量很大,每天都需要获取新数据。
a1234566785 前 741
MongoDB这么吃内存,怎么存。
我最近使用爬虫来捕获数据。刚开始java和mysql的时候,发现mysql的插入速度有点慢,于是换成了mongodb,速度提升了很多,但是问题就出来了。,完全吃光了,不能配置一个最大内存使用量吗?我的数据量很大,每天都需要获取新数据。

小旋风柴进6年前830
java爬虫抓取网页数据(网络爬虫的数据采集方法有哪几类?工具介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 269 次浏览 • 2022-03-28 19:23
网络爬虫的data采集方法有哪些?网络数据采集是指通过网络爬虫或网站公共API从网站获取数据信息。在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。在大数据时代,网络爬虫更是采集互联网数据的利器。目前已知的各种网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。
网络爬虫工具有哪些类型?
1、分布式网络爬虫工具,例如 Nutch。
2、Crawler4j、WebMagic、WebCollector等Java网络爬虫工具。
3、非Java网络爬虫工具,如Scrapy(基于Python语言开发)。
网络爬虫的原理是什么?
网络爬虫是根据一定的规则自动爬取网络信息的程序或脚本。网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。在功能上,爬虫一般具有三个功能:数据采集、处理和存储。
除了供用户阅读的文字信息外,网页还收录一些超链接信息。
网络爬虫系统正是通过网页中的超链接信息不断获取网络上的其他网页。网络爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
网络爬虫系统一般会选择一些比较重要的、出度(网页链接出的超链接数)网站较大的URL作为种子URL集。
网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。
网页之间的指向结构可以看成一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以按照广度优先搜索算法遍历所有信息或深度优先搜索算法。网页。
由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,因此广度优先搜索算法一般使用采集网页。
网络爬虫系统首先将种子 URL 放入下载队列,简单地从队列头部取一个 URL 下载其对应的网页,获取网页内容并存储,然后解析链接信息网页以获取一些新的 URL。
其次,根据一定的网页分析算法,过滤掉与主题无关的链接,保留有用的链接,放入待抓取的URL队列中。
最后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫工作流程
1)首先选择 Torrent URL 的一部分。
2)将这些网址放入待抓取的网址队列中。
3)从待爬取URL队列中获取待爬取URL,解析DNS,获取主机IP地址,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列。
4)分析已爬取URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取URL队列,从而进入下一个循环。
网络爬虫抓取策略
1. 通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子URL延伸到整个网络,主要针对门户网站搜索引擎和大型网络服务商采集数据。为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略有深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫将从起始页面开始,并逐个链接地跟踪它,直到无法再深入为止。完成一个爬取分支后,网络爬虫返回上一个链接节点,进一步搜索其他链接。当所有的链接都遍历完后,爬取任务结束。这种策略比较适合垂直搜索或者站内搜索,但是在抓取页面内容比较深的网站时会造成巨大的资源浪费。
在深度优先策略中,当搜索一个节点时,该节点的子节点和子节点的后继节点都在该节点的兄弟节点之前,深度优先策略是在搜索空间中。有时,它会尝试尽可能深入,并且仅在找不到节点的后继节点时才考虑其兄弟节点。这样的策略决定了深度优先策略不一定能找到最优解,甚至由于深度的限制而无法找到解。
如果不加以限制,它将沿着一条路径无限扩展,这将“捕获”成大量数据。一般来说,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样会降低搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录层次的深度对页面进行爬取,较浅的目录层次的页面先爬取。当同一级别的页面被爬取时,爬虫进入下一级继续爬取。由于广度优先策略是在第 N 层的节点扩展完成后进入第 N+1 层,保证了通过最短路径找到解。该策略可以有效控制页面的爬取深度,避免遇到无限深分支时无法结束爬取的问题。易于实现,不需要存储大量的中间节点。缺点是爬到更深的目录级别需要很长时间。页。
如果搜索的分支太多,即节点的后继节点太多,算法就会耗尽资源,在可用空间中找不到解。 查看全部
java爬虫抓取网页数据(网络爬虫的数据采集方法有哪几类?工具介绍)
网络爬虫的data采集方法有哪些?网络数据采集是指通过网络爬虫或网站公共API从网站获取数据信息。在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。在大数据时代,网络爬虫更是采集互联网数据的利器。目前已知的各种网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。

网络爬虫工具有哪些类型?
1、分布式网络爬虫工具,例如 Nutch。
2、Crawler4j、WebMagic、WebCollector等Java网络爬虫工具。
3、非Java网络爬虫工具,如Scrapy(基于Python语言开发)。
网络爬虫的原理是什么?
网络爬虫是根据一定的规则自动爬取网络信息的程序或脚本。网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。在功能上,爬虫一般具有三个功能:数据采集、处理和存储。
除了供用户阅读的文字信息外,网页还收录一些超链接信息。
网络爬虫系统正是通过网页中的超链接信息不断获取网络上的其他网页。网络爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
网络爬虫系统一般会选择一些比较重要的、出度(网页链接出的超链接数)网站较大的URL作为种子URL集。
网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。
网页之间的指向结构可以看成一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以按照广度优先搜索算法遍历所有信息或深度优先搜索算法。网页。
由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,因此广度优先搜索算法一般使用采集网页。
网络爬虫系统首先将种子 URL 放入下载队列,简单地从队列头部取一个 URL 下载其对应的网页,获取网页内容并存储,然后解析链接信息网页以获取一些新的 URL。
其次,根据一定的网页分析算法,过滤掉与主题无关的链接,保留有用的链接,放入待抓取的URL队列中。
最后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫工作流程
1)首先选择 Torrent URL 的一部分。
2)将这些网址放入待抓取的网址队列中。
3)从待爬取URL队列中获取待爬取URL,解析DNS,获取主机IP地址,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列。
4)分析已爬取URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取URL队列,从而进入下一个循环。
网络爬虫抓取策略
1. 通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子URL延伸到整个网络,主要针对门户网站搜索引擎和大型网络服务商采集数据。为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略有深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫将从起始页面开始,并逐个链接地跟踪它,直到无法再深入为止。完成一个爬取分支后,网络爬虫返回上一个链接节点,进一步搜索其他链接。当所有的链接都遍历完后,爬取任务结束。这种策略比较适合垂直搜索或者站内搜索,但是在抓取页面内容比较深的网站时会造成巨大的资源浪费。
在深度优先策略中,当搜索一个节点时,该节点的子节点和子节点的后继节点都在该节点的兄弟节点之前,深度优先策略是在搜索空间中。有时,它会尝试尽可能深入,并且仅在找不到节点的后继节点时才考虑其兄弟节点。这样的策略决定了深度优先策略不一定能找到最优解,甚至由于深度的限制而无法找到解。
如果不加以限制,它将沿着一条路径无限扩展,这将“捕获”成大量数据。一般来说,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样会降低搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录层次的深度对页面进行爬取,较浅的目录层次的页面先爬取。当同一级别的页面被爬取时,爬虫进入下一级继续爬取。由于广度优先策略是在第 N 层的节点扩展完成后进入第 N+1 层,保证了通过最短路径找到解。该策略可以有效控制页面的爬取深度,避免遇到无限深分支时无法结束爬取的问题。易于实现,不需要存储大量的中间节点。缺点是爬到更深的目录级别需要很长时间。页。
如果搜索的分支太多,即节点的后继节点太多,算法就会耗尽资源,在可用空间中找不到解。
java爬虫抓取网页数据(Java网络爬虫的分类及开发逻辑【一课一】)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-28 06:16
介绍
在大数据环境下,数据分析从业务驱动向数据驱动转变,网络数据资源呈指数级增长,分散在不同的数据源中。对于大多数公司和研究人员来说,用“数据说话”似乎是大数据时代的重要武器。网络爬虫作为网络数据获取的重要技术,受到越来越多数据需求者的青睐和追捧。
作为网络爬虫的介绍,使用了Java开发语言。内容涵盖网络爬虫原理及开发逻辑、Java网络爬虫基础知识、网络抓包介绍、jsoup介绍与使用、HttpClient介绍与使用。本课程在介绍网络爬虫基本原理的同时,着重具体代码实现,加深读者对爬虫的理解,增强读者的动手能力。
内容
第01课:网络爬虫原理
介绍
随着互联网的飞速发展,网络资源越来越丰富,如何从网络中提取信息对于信息需求者来说变得非常重要。目前,有效获取网络数据资源的重要途径是网络爬虫技术。简单理解,比如你对百度贴吧上一个帖子的内容特别感兴趣,但是帖子的回复却有1000多页。在这种情况下,使用一个一个复制的方法是不可行的。并且使用网络爬虫可以轻松采集到帖子下的所有内容。
最广泛使用的网络爬虫技术是在搜索引擎中,如百度、谷歌、必应等,它完成了搜索过程中最关键的一步,即对网页内容的爬取。下图是一个简单的搜索引擎的示意图。
网络爬虫的作用可以总结如下:
网络爬虫覆盖的领域包括:
网络爬虫的基本概念
Web Crawler,也称为Web Spider或Web Information采集器,是一种计算机程序或自动化脚本,根据一定的规则自动爬取或下载网络信息。它是当前搜索引擎的重要组成部分。
网络爬虫的分类
网络爬虫根据系统架构和实现技术大致可以分为以下几种:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫(Deep Web Crawler)。实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。
网络爬虫的过程
网络爬虫的基本流程可以用下图来描述:
具体流程为:
请求者选择种子 URL(或初始 URL)的一部分并将其放入待爬取的队列中。与Java网络爬虫一样,可以放入LinkedList或List。判断URL队列是否为空,如果为空,则结束程序的执行,否则,执行第三步。从待爬取URL队列中取出一个待爬取URL,获取该URL对应的网页内容。在这一步中,需要使用响应的状态码(如200、403等)来判断是否获取数据。如果响应成功,则进行解析操作;如果响应不成功,则放回待爬取队列中(注意这里需要去掉。无效的URL)。对响应成功后获取的数据执行页面解析操作。
网络爬虫抓取策略
一般的网络爬虫爬取策略有两种:深度优先搜索策略和广度优先搜索策略。
基于广度优先的爬虫是爬取网站页面最简单的方法,也是目前应用最广泛的方法。在这个大师班里,提到的案例都是广度优先爬虫。
学习建议
网络爬虫是对某种编程语言入门的实用技术:很多学习编程语言(如Java、Python或C++等)的同学只是在网上看书或看一些视频,后果不堪设想。这将是面对面的,当涉及到一个具体的项目时,我不知道如何开始,尤其是对于初学者。或者,一段时间后,之前的书籍内容或视频内容就被遗忘了。
为此,我建议这些学习者可以使用网络爬虫技术来入门一种编程语言(如Java、Python)。因为爬虫技术是一门综合性很强的技术,它涉及到编程语言的很多方面。本次大师班特别选择Java作为开发语言,带你了解Java爬虫背后的核心技术。完成本课程后,相信您对 Java 编程语言有了很好的介绍。
零基础开始Java爬虫的同学,在学习过程中请注意以下几点:
最后,提供一些书籍和资料,供刚入门并想进一步了解 Java 网络爬虫的读者使用:
清华大学出版社出版的《Java Object-Oriented Programming》(耿祥一、张月平主编)是一本可以作为基础学习的大学教材。《Java 核心技术》2 卷。《Effective Java (3rd Edition)》:目前英文版是第三版,中文版还在第二版。本书是高级Java的必备书籍。英语较好的同学可以直接看英文版。《Do It Yourself Web Crawler》(罗刚主编),国内第一本专门研究Java网络爬虫的书籍。
第 2 课:Java 网络爬虫基础知识
介绍
Java网络爬虫具有良好的扩展性和可扩展性,是当前搜索引擎开发的重要组成部分。例如,著名的网络爬虫工具 Nutch 是用 Java 开发的,它基于 Apache Hadoop 数据结构,提供了良好的批处理支持。
Java网页爬取涉及到大量的Java知识。本文将介绍网络爬虫需要了解的Java知识以及这些知识主要用于网络爬虫的哪个部分,包括以下内容:
使用Maven
什么是马文
Maven 是 Apache 软件基金会提供的用于项目管理和自动化构建的工具。我们知道,在构建Java项目的时候,需要用到很多Jar包。例如,需要使用mysql-connector-java及其相关依赖来操作数据库。Maven工具可以方便的管理我们在项目中使用的开源Jar包,比如下载Java项目需要的Jar包以及相关的Java依赖包。
如何使用 Maven
Maven 使用存储在名为 pom.xml 的文件中的项目对象模型 (POM) 进行配置。以Java为例,我们可以在Eclipse中创建一个Maven项目。其中,Maven Dependencies 存放的是由 Maven 管理的 Jar 包。
如前所述,构建 Java 项目需要使用许多 Jar 包。例如,在Java网络爬虫中,我们需要使用相关的Jar包进行数据库连接、请求网页内容、解析网页内容。将以下语句添加到 pom 文件中:
mysql mysql-connector-java 5.1.35 org.jsoup jsoup 1.8.2 org.apache.httpcomponents httpclient 4.2.3
之后,我们会惊奇的发现项目的Maven Dependencies中自动下载了相关的Jar包及其依赖的Jar包。
读者可以在 Maven Repository 网站 中检索到自己想要的 Jar 包和 Maven 操作语句。
log4j 的使用
什么是 log4j
log4j 是一个基于 Java 的日志记录工具,曾经是 Apache 软件基金会的一个项目。今天,日志是应用软件的一个组成部分。
如何使用 log4j
1. 使用Maven下载log4j Jar包,代码如下:
log4j log4j 1.2.17
2. 在src目录下创建一个log4j.properties文本文件并进行配置(各个配置的具体含义,读者可以参考博文《Log4j详解》):
### set ###log4j.rootLogger = debug,stdout,D,E ###输出信息来控制提升###log4j.appender.stdout =
org.apache.log4j.ConsoleAppenderlog4j.appender.stdout.Target=System.outlog4j.appender.stdout.layout=org.apache.log4j.PatternLayoutlog4j.appender.stdout.layout.ConversionPattern=[%-5p]%d{yyyy- MM-dd HH:mm:ss,SSS} 方法:%l%n%m%n### 将 DEBUG 级别以上的日志输出到 =error.log ###log4j.appender.D = org.apache.log4j。DailyRollingFileAppenderlog4j.appender.D.File=E://logs/log.loglog4j.appender.D.Append=truelog4j.appender.D.Threshold=DEBUG log4j.appender.D.layout=org.apache.log4j.PatternLayoutlog4j.appender .D.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n### 将 ERROR 级别以上的日志输出到 =error 。日志###log4j.appender.E=org.apache.log4j.DailyRollingFileAppenderlog4j.appender.E.File=E://logs/error.log log4j.appender.E.Append=truelog4j.appender.E.Threshold=错误log4j.appender.E.layout = org.apache.log4j.PatternLayoutlog4j。
3. 示例程序,如下:
包 log4j;import mons.logging.Log;import mons.logging.LogFactory;public class Test { static final Log logger = LogFactory.getLog(Test.class); 公共静态 void main(String[] args) { System.out. println("你好"); (“你好世界”); logger.debug("这是调试信息。"); logger.warn("这是警告信息。"); logger.error("这是错误信息。"); "); }}
基于这个程序,我们可以看到在我们项目的根目录下会生成一个日志文件error.log和log.log。
在网络爬虫中,我们可以通过日志来记录程序可能出错的地方,监控程序的运行状态。
对象创建
在 Java 中,new 关键字通常用于创建对象。比如在爬取京东商品的id、product_name(商品名)、price(价格)时,我们需要将每个商品的信息封装成一个对象。
JdInfoModel jingdongproduct = new JdInfoModel();
在爬虫中,我们要操作JdInfoModel类中的变量(即id、product_name、price),可以通过私有变量来定义。并且,使用 set() 和 get() 方法设置数据(爬取数据的封装)和获取使用(爬取数据的存储)。以下代码用于 JdInfoModel 类:
包模型;公共类 JdInfoModel { 私有 int id;私有字符串产品名称;私人双倍价格;public int getId() { 返回 id; } public void setId(int id) { this.id = id; } public String getProduct_name() { return product_name; } public void setProduct_name(String product_name) { this.product_name = product_name; } public double getPrice() { 返回价格;} public void setPrice(double price) { this.price = price; } }
采集品的使用
网络爬虫离不开对集合的操作,这涉及到对List、Set、Queue、Map等集合的操作。
List 和 Set 集合的使用
List 的特点是它的元素以线性方式存储,重复的对象可以存储在集合中。相比之下,Set 集合中的对象没有按特定方式排序,也没有重复的对象。在网络爬虫中,List 可用于存储要爬取的 URL 列表。例如:
//创建List集合List urllist = new ArrayList();urllist.add("
");urllist.add("");//第一种遍历方法for(String url : urllist){ System.out.println(url);}//第二种遍历方法for(int i=0; i it = urllist.iterator();while (it.hasNext()){ System.out.println(it.next());}
同时,我们也可以使用上面的List来封装具体的实例,也就是爬虫接收到的数据采集。Set集合的使用和List集合的用法类似,这里就不过多解释了。
地图的使用
Map 是映射键对象和值对象的集合。它的每个元素都收录一对键对象和值对象,其中键对象不能重复。地图不仅常用于网络爬虫,也常用于文本挖掘算法的编写。在网络爬虫中,可以使用 Map 过滤一些重复数据,但建议使用 Map 去重和过滤大规模数据,因为 Map 有空间大小限制。例如,在使用网络爬虫抓取帖子时,您可能会遇到置顶帖子,并且置顶帖子可能会与以下帖子重复。以下程序是 Map 的一个用例:
entrySet() ) { System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue()); }
队列的使用
队列(Queue)采用链表结构来存储数据,是一种特殊的线性表,只允许在表的前端进行删除操作,在表的后端进行插入操作。LinkedList 类实现了 Queue 接口,因此我们可以将 LinkedList 用作 Queue。Queue 常用于存储待爬取的 URL 的队列。
queue queue = new LinkedList();//添加元素 queue.offer("
");queue.offer("");queue.offer("");boolean t = true;while (t) { //如果Url队列为空,则停止执行程序,否则请求Url if( queue. isEmpty( ) ){ t = false; }else { //请求的url String url = queue.poll(); System.out.println(url); //这里写的是请求数据,对应的状态码是获取到,如果状态码为200,则解析数据;如果是404,则从队列中移除url;否则,重新列出url }
正则表达式的使用
正则表达式是解析数据(HTML 或 JSON 等)时常用的方法。例如,我想从以下语句中提取用户的 id (75975500)):
///75975500" target="_blank">尊少是沉阳人
后面会介绍解析工具jsoup,可以解析获取“
///75975500"。然后,您可以使用正则表达式提取75975500。
字符串网址 = "
///75975500";String user_id = url.replaceAll("\\D", ""); //替换所有非数字字符 System.out.println(user_id); //输出结果为75975500
下表显示了 Java 中常用的一些基本正则表达式。
正则表达式书写的含义\d代表0-9之间的任意数字\D代表任意非数字字符\s代表空格类字符\S代表非空格类字符\p{Lower}代表小写字母[az ]\p{Upper} 代表大写字母 [AZ]\p{Alpha} 代表字母\p{Blank} 代表空格或制表符 查看全部
java爬虫抓取网页数据(Java网络爬虫的分类及开发逻辑【一课一】)
介绍
在大数据环境下,数据分析从业务驱动向数据驱动转变,网络数据资源呈指数级增长,分散在不同的数据源中。对于大多数公司和研究人员来说,用“数据说话”似乎是大数据时代的重要武器。网络爬虫作为网络数据获取的重要技术,受到越来越多数据需求者的青睐和追捧。
作为网络爬虫的介绍,使用了Java开发语言。内容涵盖网络爬虫原理及开发逻辑、Java网络爬虫基础知识、网络抓包介绍、jsoup介绍与使用、HttpClient介绍与使用。本课程在介绍网络爬虫基本原理的同时,着重具体代码实现,加深读者对爬虫的理解,增强读者的动手能力。
内容
第01课:网络爬虫原理
介绍
随着互联网的飞速发展,网络资源越来越丰富,如何从网络中提取信息对于信息需求者来说变得非常重要。目前,有效获取网络数据资源的重要途径是网络爬虫技术。简单理解,比如你对百度贴吧上一个帖子的内容特别感兴趣,但是帖子的回复却有1000多页。在这种情况下,使用一个一个复制的方法是不可行的。并且使用网络爬虫可以轻松采集到帖子下的所有内容。
最广泛使用的网络爬虫技术是在搜索引擎中,如百度、谷歌、必应等,它完成了搜索过程中最关键的一步,即对网页内容的爬取。下图是一个简单的搜索引擎的示意图。

网络爬虫的作用可以总结如下:
网络爬虫覆盖的领域包括:

网络爬虫的基本概念
Web Crawler,也称为Web Spider或Web Information采集器,是一种计算机程序或自动化脚本,根据一定的规则自动爬取或下载网络信息。它是当前搜索引擎的重要组成部分。
网络爬虫的分类
网络爬虫根据系统架构和实现技术大致可以分为以下几种:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫(Deep Web Crawler)。实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。



网络爬虫的过程
网络爬虫的基本流程可以用下图来描述:

具体流程为:
请求者选择种子 URL(或初始 URL)的一部分并将其放入待爬取的队列中。与Java网络爬虫一样,可以放入LinkedList或List。判断URL队列是否为空,如果为空,则结束程序的执行,否则,执行第三步。从待爬取URL队列中取出一个待爬取URL,获取该URL对应的网页内容。在这一步中,需要使用响应的状态码(如200、403等)来判断是否获取数据。如果响应成功,则进行解析操作;如果响应不成功,则放回待爬取队列中(注意这里需要去掉。无效的URL)。对响应成功后获取的数据执行页面解析操作。
网络爬虫抓取策略
一般的网络爬虫爬取策略有两种:深度优先搜索策略和广度优先搜索策略。


基于广度优先的爬虫是爬取网站页面最简单的方法,也是目前应用最广泛的方法。在这个大师班里,提到的案例都是广度优先爬虫。
学习建议
网络爬虫是对某种编程语言入门的实用技术:很多学习编程语言(如Java、Python或C++等)的同学只是在网上看书或看一些视频,后果不堪设想。这将是面对面的,当涉及到一个具体的项目时,我不知道如何开始,尤其是对于初学者。或者,一段时间后,之前的书籍内容或视频内容就被遗忘了。
为此,我建议这些学习者可以使用网络爬虫技术来入门一种编程语言(如Java、Python)。因为爬虫技术是一门综合性很强的技术,它涉及到编程语言的很多方面。本次大师班特别选择Java作为开发语言,带你了解Java爬虫背后的核心技术。完成本课程后,相信您对 Java 编程语言有了很好的介绍。
零基础开始Java爬虫的同学,在学习过程中请注意以下几点:
最后,提供一些书籍和资料,供刚入门并想进一步了解 Java 网络爬虫的读者使用:
清华大学出版社出版的《Java Object-Oriented Programming》(耿祥一、张月平主编)是一本可以作为基础学习的大学教材。《Java 核心技术》2 卷。《Effective Java (3rd Edition)》:目前英文版是第三版,中文版还在第二版。本书是高级Java的必备书籍。英语较好的同学可以直接看英文版。《Do It Yourself Web Crawler》(罗刚主编),国内第一本专门研究Java网络爬虫的书籍。
第 2 课:Java 网络爬虫基础知识
介绍
Java网络爬虫具有良好的扩展性和可扩展性,是当前搜索引擎开发的重要组成部分。例如,著名的网络爬虫工具 Nutch 是用 Java 开发的,它基于 Apache Hadoop 数据结构,提供了良好的批处理支持。
Java网页爬取涉及到大量的Java知识。本文将介绍网络爬虫需要了解的Java知识以及这些知识主要用于网络爬虫的哪个部分,包括以下内容:
使用Maven
什么是马文
Maven 是 Apache 软件基金会提供的用于项目管理和自动化构建的工具。我们知道,在构建Java项目的时候,需要用到很多Jar包。例如,需要使用mysql-connector-java及其相关依赖来操作数据库。Maven工具可以方便的管理我们在项目中使用的开源Jar包,比如下载Java项目需要的Jar包以及相关的Java依赖包。
如何使用 Maven
Maven 使用存储在名为 pom.xml 的文件中的项目对象模型 (POM) 进行配置。以Java为例,我们可以在Eclipse中创建一个Maven项目。其中,Maven Dependencies 存放的是由 Maven 管理的 Jar 包。

如前所述,构建 Java 项目需要使用许多 Jar 包。例如,在Java网络爬虫中,我们需要使用相关的Jar包进行数据库连接、请求网页内容、解析网页内容。将以下语句添加到 pom 文件中:
mysql mysql-connector-java 5.1.35 org.jsoup jsoup 1.8.2 org.apache.httpcomponents httpclient 4.2.3
之后,我们会惊奇的发现项目的Maven Dependencies中自动下载了相关的Jar包及其依赖的Jar包。

读者可以在 Maven Repository 网站 中检索到自己想要的 Jar 包和 Maven 操作语句。

log4j 的使用
什么是 log4j
log4j 是一个基于 Java 的日志记录工具,曾经是 Apache 软件基金会的一个项目。今天,日志是应用软件的一个组成部分。
如何使用 log4j
1. 使用Maven下载log4j Jar包,代码如下:
log4j log4j 1.2.17
2. 在src目录下创建一个log4j.properties文本文件并进行配置(各个配置的具体含义,读者可以参考博文《Log4j详解》):
### set ###log4j.rootLogger = debug,stdout,D,E ###输出信息来控制提升###log4j.appender.stdout =
org.apache.log4j.ConsoleAppenderlog4j.appender.stdout.Target=System.outlog4j.appender.stdout.layout=org.apache.log4j.PatternLayoutlog4j.appender.stdout.layout.ConversionPattern=[%-5p]%d{yyyy- MM-dd HH:mm:ss,SSS} 方法:%l%n%m%n### 将 DEBUG 级别以上的日志输出到 =error.log ###log4j.appender.D = org.apache.log4j。DailyRollingFileAppenderlog4j.appender.D.File=E://logs/log.loglog4j.appender.D.Append=truelog4j.appender.D.Threshold=DEBUG log4j.appender.D.layout=org.apache.log4j.PatternLayoutlog4j.appender .D.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n### 将 ERROR 级别以上的日志输出到 =error 。日志###log4j.appender.E=org.apache.log4j.DailyRollingFileAppenderlog4j.appender.E.File=E://logs/error.log log4j.appender.E.Append=truelog4j.appender.E.Threshold=错误log4j.appender.E.layout = org.apache.log4j.PatternLayoutlog4j。
3. 示例程序,如下:
包 log4j;import mons.logging.Log;import mons.logging.LogFactory;public class Test { static final Log logger = LogFactory.getLog(Test.class); 公共静态 void main(String[] args) { System.out. println("你好"); (“你好世界”); logger.debug("这是调试信息。"); logger.warn("这是警告信息。"); logger.error("这是错误信息。"); "); }}
基于这个程序,我们可以看到在我们项目的根目录下会生成一个日志文件error.log和log.log。

在网络爬虫中,我们可以通过日志来记录程序可能出错的地方,监控程序的运行状态。
对象创建
在 Java 中,new 关键字通常用于创建对象。比如在爬取京东商品的id、product_name(商品名)、price(价格)时,我们需要将每个商品的信息封装成一个对象。
JdInfoModel jingdongproduct = new JdInfoModel();
在爬虫中,我们要操作JdInfoModel类中的变量(即id、product_name、price),可以通过私有变量来定义。并且,使用 set() 和 get() 方法设置数据(爬取数据的封装)和获取使用(爬取数据的存储)。以下代码用于 JdInfoModel 类:
包模型;公共类 JdInfoModel { 私有 int id;私有字符串产品名称;私人双倍价格;public int getId() { 返回 id; } public void setId(int id) { this.id = id; } public String getProduct_name() { return product_name; } public void setProduct_name(String product_name) { this.product_name = product_name; } public double getPrice() { 返回价格;} public void setPrice(double price) { this.price = price; } }
采集品的使用
网络爬虫离不开对集合的操作,这涉及到对List、Set、Queue、Map等集合的操作。
List 和 Set 集合的使用
List 的特点是它的元素以线性方式存储,重复的对象可以存储在集合中。相比之下,Set 集合中的对象没有按特定方式排序,也没有重复的对象。在网络爬虫中,List 可用于存储要爬取的 URL 列表。例如:
//创建List集合List urllist = new ArrayList();urllist.add("
");urllist.add("");//第一种遍历方法for(String url : urllist){ System.out.println(url);}//第二种遍历方法for(int i=0; i it = urllist.iterator();while (it.hasNext()){ System.out.println(it.next());}
同时,我们也可以使用上面的List来封装具体的实例,也就是爬虫接收到的数据采集。Set集合的使用和List集合的用法类似,这里就不过多解释了。
地图的使用
Map 是映射键对象和值对象的集合。它的每个元素都收录一对键对象和值对象,其中键对象不能重复。地图不仅常用于网络爬虫,也常用于文本挖掘算法的编写。在网络爬虫中,可以使用 Map 过滤一些重复数据,但建议使用 Map 去重和过滤大规模数据,因为 Map 有空间大小限制。例如,在使用网络爬虫抓取帖子时,您可能会遇到置顶帖子,并且置顶帖子可能会与以下帖子重复。以下程序是 Map 的一个用例:
entrySet() ) { System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue()); }
队列的使用
队列(Queue)采用链表结构来存储数据,是一种特殊的线性表,只允许在表的前端进行删除操作,在表的后端进行插入操作。LinkedList 类实现了 Queue 接口,因此我们可以将 LinkedList 用作 Queue。Queue 常用于存储待爬取的 URL 的队列。
queue queue = new LinkedList();//添加元素 queue.offer("
");queue.offer("");queue.offer("");boolean t = true;while (t) { //如果Url队列为空,则停止执行程序,否则请求Url if( queue. isEmpty( ) ){ t = false; }else { //请求的url String url = queue.poll(); System.out.println(url); //这里写的是请求数据,对应的状态码是获取到,如果状态码为200,则解析数据;如果是404,则从队列中移除url;否则,重新列出url }
正则表达式的使用
正则表达式是解析数据(HTML 或 JSON 等)时常用的方法。例如,我想从以下语句中提取用户的 id (75975500)):
///75975500" target="_blank">尊少是沉阳人
后面会介绍解析工具jsoup,可以解析获取“
///75975500"。然后,您可以使用正则表达式提取75975500。
字符串网址 = "
///75975500";String user_id = url.replaceAll("\\D", ""); //替换所有非数字字符 System.out.println(user_id); //输出结果为75975500
下表显示了 Java 中常用的一些基本正则表达式。
正则表达式书写的含义\d代表0-9之间的任意数字\D代表任意非数字字符\s代表空格类字符\S代表非空格类字符\p{Lower}代表小写字母[az ]\p{Upper} 代表大写字母 [AZ]\p{Alpha} 代表字母\p{Blank} 代表空格或制表符
java爬虫抓取网页数据(常见的请求Method:在Http协议中定义了八种请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-28 06:14
Http协议:全称HyperText Transfer Protocol,中文是超文本传输协议的意思。它是一种发布和接收 HTML(超文本标记语言)页面的方法。服务器端口号为80端口。 2. HTTPS协议:是HTTP协议的加密版本,在HTTP下增加了SSL层。服务器端口号为 443 端口。
网址详情:
URL是Uniform Resource Locator,统一资源定位器的缩写。一个 URL 由以下部分组成:
host:主机名、域名,如port:端口号。当您访问 网站 时,浏览器默认使用端口 80 路径:查找路径。例如:下面的trending/now是pathquery-string:查询字符串,如:下面的wd=python就是查询字符串。Anchor:Anchor,前端用于页面定位。现在有些前后端项目是分开的,锚点也是用来导航的。
在浏览器中请求一个url,浏览器会对url进行编码。除英文字母、数字和部分符号外,其余均采用百分号+十六进制码值编码。
常见的请求方式:
在 Http 协议中,定义了八种请求方法。这里介绍两种常见的请求方式,即get request和post request。
获取请求:一般情况下,只从服务器获取数据时使用获取请求,不会对服务器资源产生任何影响。Post 请求:向服务器发送数据(登录)、上传文件等,在影响服务器资源时会使用 post 请求。以上是网站开发中常用的两种方法。并且一般遵循使用原则。但是,一些网站和服务器为了实现反爬机制,经常会做出不合常理的卡片。应该使用 get 方法的请求有可能必须更改为 post 请求,这取决于具体情况。常见的请求头参数:
在http协议中,向服务器发送一个请求,数据分为三部分。第一种是将数据放在url中,第二种是将数据放在body中(在post请求中),第三种是将数据放在url中。数据放在头部。以下是网络爬虫中经常使用的一些请求头参数:
User-Agent:浏览器名称。这通常用于网络爬虫。当请求一个网页时,服务器可以通过这个参数知道是哪个浏览器发送了请求。如果我们通过爬虫发送请求,那么我们的 User-Agent 就是 Python。对于那些有反爬虫机制的网站,很容易判断你的请求是爬虫。因此,我们经常将这个值设置为某些浏览器的值来伪装我们的爬虫。
Referer:表示当前请求来自哪个url。这也可以用于一般的反爬虫技术。如果不是来自指定页面,则不会做出相关响应。
Cookies:http 协议是无状态的。即同一个人发送了两个请求,服务器没有能力知道这两个请求是否来自同一个人。因此,此时cookie用于识别。一般如果要登录访问网站,则需要发送cookie信息。
常见响应状态码: 查看全部
java爬虫抓取网页数据(常见的请求Method:在Http协议中定义了八种请求)
Http协议:全称HyperText Transfer Protocol,中文是超文本传输协议的意思。它是一种发布和接收 HTML(超文本标记语言)页面的方法。服务器端口号为80端口。 2. HTTPS协议:是HTTP协议的加密版本,在HTTP下增加了SSL层。服务器端口号为 443 端口。
网址详情:
URL是Uniform Resource Locator,统一资源定位器的缩写。一个 URL 由以下部分组成:
host:主机名、域名,如port:端口号。当您访问 网站 时,浏览器默认使用端口 80 路径:查找路径。例如:下面的trending/now是pathquery-string:查询字符串,如:下面的wd=python就是查询字符串。Anchor:Anchor,前端用于页面定位。现在有些前后端项目是分开的,锚点也是用来导航的。
在浏览器中请求一个url,浏览器会对url进行编码。除英文字母、数字和部分符号外,其余均采用百分号+十六进制码值编码。
常见的请求方式:
在 Http 协议中,定义了八种请求方法。这里介绍两种常见的请求方式,即get request和post request。
获取请求:一般情况下,只从服务器获取数据时使用获取请求,不会对服务器资源产生任何影响。Post 请求:向服务器发送数据(登录)、上传文件等,在影响服务器资源时会使用 post 请求。以上是网站开发中常用的两种方法。并且一般遵循使用原则。但是,一些网站和服务器为了实现反爬机制,经常会做出不合常理的卡片。应该使用 get 方法的请求有可能必须更改为 post 请求,这取决于具体情况。常见的请求头参数:
在http协议中,向服务器发送一个请求,数据分为三部分。第一种是将数据放在url中,第二种是将数据放在body中(在post请求中),第三种是将数据放在url中。数据放在头部。以下是网络爬虫中经常使用的一些请求头参数:
User-Agent:浏览器名称。这通常用于网络爬虫。当请求一个网页时,服务器可以通过这个参数知道是哪个浏览器发送了请求。如果我们通过爬虫发送请求,那么我们的 User-Agent 就是 Python。对于那些有反爬虫机制的网站,很容易判断你的请求是爬虫。因此,我们经常将这个值设置为某些浏览器的值来伪装我们的爬虫。
Referer:表示当前请求来自哪个url。这也可以用于一般的反爬虫技术。如果不是来自指定页面,则不会做出相关响应。
Cookies:http 协议是无状态的。即同一个人发送了两个请求,服务器没有能力知道这两个请求是否来自同一个人。因此,此时cookie用于识别。一般如果要登录访问网站,则需要发送cookie信息。
常见响应状态码:
java爬虫抓取网页数据( 2018年Java实现的爬虫抓取图片并保存操作技巧汇总)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-03-28 01:08
2018年Java实现的爬虫抓取图片并保存操作技巧汇总)
Java实现的爬虫抓取图片并保存操作示例
更新时间:2018-08-31 09:47:10 转载:smilecjw
本篇文章主要介绍Java实现的爬虫抓取图片并保存,涉及到Java对页面URL的访问、获取、字符串匹配、文件下载等相关操作技巧。有需要的朋友可以参考以下
本文的例子描述了用Java实现的爬虫抓取图片并保存。分享给大家参考,详情如下:
这是我参考网上一些资料写的第一个java爬虫程序
本来想获取无聊地图的图片,但是网络返回码一直是503,所以改成了网站
import java.io.BufferedReader;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网络爬虫取数据
*
* */
public class JianDan {
public static String GetUrl(String inUrl){
StringBuilder sb = new StringBuilder();
try {
URL url =new URL(inUrl);
BufferedReader reader =new BufferedReader(new InputStreamReader(url.openStream()));
String temp="";
while((temp=reader.readLine())!=null){
//System.out.println(temp);
sb.append(temp);
}
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
return sb.toString();
}
public static List GetMatcher(String str,String url){
List result = new ArrayList();
Pattern p =Pattern.compile(url);//获取网页地址
Matcher m =p.matcher(str);
while(m.find()){
//System.out.println(m.group(1));
result.add(m.group(1));
}
return result;
}
public static void main(String args[]){
String str=GetUrl("http://www.163.com");
List ouput =GetMatcher(str,"src=\"([\\w\\s./:]+?)\"");
for(String temp:ouput){
//System.out.println(ouput.get(0));
System.out.println(temp);
}
String aurl=ouput.get(0);
// 构造URL
URL url;
try {
url = new URL(aurl);
// 打开URL连接
URLConnection con = (URLConnection)url.openConnection();
// 得到URL的输入流
InputStream input = con.getInputStream();
// 设置数据缓冲
byte[] bs = new byte[1024 * 2];
// 读取到的数据长度
int len;
// 输出的文件流保存图片至本地
OutputStream os = new FileOutputStream("a.png");
while ((len = input.read(bs)) != -1) {
os.write(bs, 0, len);
}
os.close();
input.close();
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
运行输出:
对java相关内容比较感兴趣的读者可以查看本站专题:《Java网络编程技巧总结》、《Java套接字编程技巧总结》、《Java文件和目录操作技巧总结》、《Java数据《结构与算法教程》、《Java操作DOM节点技巧总结》、《Java缓存操作技巧总结》
希望这篇文章对大家java编程有所帮助。 查看全部
java爬虫抓取网页数据(
2018年Java实现的爬虫抓取图片并保存操作技巧汇总)
Java实现的爬虫抓取图片并保存操作示例
更新时间:2018-08-31 09:47:10 转载:smilecjw
本篇文章主要介绍Java实现的爬虫抓取图片并保存,涉及到Java对页面URL的访问、获取、字符串匹配、文件下载等相关操作技巧。有需要的朋友可以参考以下
本文的例子描述了用Java实现的爬虫抓取图片并保存。分享给大家参考,详情如下:
这是我参考网上一些资料写的第一个java爬虫程序
本来想获取无聊地图的图片,但是网络返回码一直是503,所以改成了网站
import java.io.BufferedReader;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网络爬虫取数据
*
* */
public class JianDan {
public static String GetUrl(String inUrl){
StringBuilder sb = new StringBuilder();
try {
URL url =new URL(inUrl);
BufferedReader reader =new BufferedReader(new InputStreamReader(url.openStream()));
String temp="";
while((temp=reader.readLine())!=null){
//System.out.println(temp);
sb.append(temp);
}
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
return sb.toString();
}
public static List GetMatcher(String str,String url){
List result = new ArrayList();
Pattern p =Pattern.compile(url);//获取网页地址
Matcher m =p.matcher(str);
while(m.find()){
//System.out.println(m.group(1));
result.add(m.group(1));
}
return result;
}
public static void main(String args[]){
String str=GetUrl("http://www.163.com";);
List ouput =GetMatcher(str,"src=\"([\\w\\s./:]+?)\"");
for(String temp:ouput){
//System.out.println(ouput.get(0));
System.out.println(temp);
}
String aurl=ouput.get(0);
// 构造URL
URL url;
try {
url = new URL(aurl);
// 打开URL连接
URLConnection con = (URLConnection)url.openConnection();
// 得到URL的输入流
InputStream input = con.getInputStream();
// 设置数据缓冲
byte[] bs = new byte[1024 * 2];
// 读取到的数据长度
int len;
// 输出的文件流保存图片至本地
OutputStream os = new FileOutputStream("a.png");
while ((len = input.read(bs)) != -1) {
os.write(bs, 0, len);
}
os.close();
input.close();
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
运行输出:

对java相关内容比较感兴趣的读者可以查看本站专题:《Java网络编程技巧总结》、《Java套接字编程技巧总结》、《Java文件和目录操作技巧总结》、《Java数据《结构与算法教程》、《Java操作DOM节点技巧总结》、《Java缓存操作技巧总结》
希望这篇文章对大家java编程有所帮助。
java爬虫抓取网页数据(创建Java工程build.gradle框架NetDiscovery演示)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-04-17 13:44
大家好,说到爬虫,相信很多程序员都听说过。简而言之,就是一个自动批量抓取网上信息的程序。接下来,我将用 github 上的爬虫框架 NetDiscovery 进行演示。
网络发现
1)为什么要使用框架?
框架可以帮助我们处理与目标任务不直接相关的基本任务,使我们能够专注于目标任务。尤其对于爬虫初学者来说,可以很快的体会到操作爬虫带来的效果和成就感,不用担心多余的事情。进门后,尝试不依赖框架,从零开始写爬虫程序,然后研究别人搭建的爬虫框架。看完爬虫框架的源码,相信你已经对网络爬虫做了一些研究。.
2) 演示环境
Java JDK8、IntelliJ IDEA、谷歌浏览器
爬虫框架 NetDiscovery:
3)确定爬虫任务
从人才招聘网站获取指定职位信息:公司名称、职位
4) 人肉分析网页
用chrome浏览器打开目标网页,输入查询条件,找到显示职位信息的网页:
网页信息
红框内的文字是我们计划编写程序自动获取的信息。
这个环节的分析工作非常重要,我们需要对我们爬取的目标网页和目标数据有一个清晰的认识。人眼已经可以看到这些信息了,接下来就是写一个程序教电脑帮我们抓取。5)创建一个Java项目
创建一个gradle java项目:
创建一个 Java 项目
构建.gradle
在项目中添加爬虫框架NetDiscovery的两个jar包。当前版本是 0.0.9.3。版本不高,但版本更新迭代很快。我相信这是一个不断增长的力量框架。
group 'com.sinkinka'
version '1.0-SNAPSHOT'
apply plugin: 'java'
sourceCompatibility = 1.8
repositories {
maven{url 'http://maven.aliyun.com/nexus/content/groups/public/'}
mavenCentral()
jcenter();
}
dependencies {
testCompile group: 'junit', name: 'junit', version: '4.12'
implementation 'com.cv4j.netdiscovery:netdiscovery-core:0.0.9.3'
implementation 'com.cv4j.netdiscovery:netdiscovery-extra:0.0.9.3'
}
如果不能下载,请添加阿里云镜像地址:
6)代码实现
参考框架中示例模块下的示例代码,以及另一个示例项目:
在java的main方法中编写如下代码:
package com.sinkinka;
import com.cv4j.netdiscovery.core.Spider;
import com.sinkinka.parser.TestParser;
public class TestSpider {
public static void main(String[] args) {
//目标任务的网页地址,可以拷贝到浏览器去查看
String url = "http://www.szrc.cn/HrMarket/WL ... 3B%3B
//依靠NetDiscovery,我们只需要写一个parser类就可以实现基本的爬虫功能了
Spider.create()
.name("spider-1") //名字随便起
.url(url)
.parser(new TestParser()) //parser类
.run();
}
}
TestParser 类的代码:
package com.sinkinka.parser;
import com.cv4j.netdiscovery.core.domain.Page;
import com.cv4j.netdiscovery.core.parser.Parser;
import com.cv4j.netdiscovery.core.parser.selector.Selectable;
import java.util.List;
/**
* 针对目标网页的解析类
*/
public class TestParser implements Parser {
@Override
public void process(Page page) {
String xpathStr = "//*[@id=\"grid\"]/div/div[1]/table/tbody/tr";
List trList = page.getHtml().xpath(xpathStr).nodes();
for(Selectable tr : trList) {
String companyName = tr.xpath("//td[@class='td_companyName']/text()").get();
String positionName = tr.xpath("//td[@class='td_positionName']/a/text()").get();
if(null != companyName && null != positionName) {
System.out.println(companyName+"------"+positionName);
}
}
}
}
运行结果:
运行结果
7) 总结
本文依靠爬虫框架来演示一种用最简单的代码爬取网页信息的方法。更多实用内容将在后续发布,供大家参考。
NetDiscovery爬虫框架基本示意图
网络发现 查看全部
java爬虫抓取网页数据(创建Java工程build.gradle框架NetDiscovery演示)
大家好,说到爬虫,相信很多程序员都听说过。简而言之,就是一个自动批量抓取网上信息的程序。接下来,我将用 github 上的爬虫框架 NetDiscovery 进行演示。
网络发现
1)为什么要使用框架?
框架可以帮助我们处理与目标任务不直接相关的基本任务,使我们能够专注于目标任务。尤其对于爬虫初学者来说,可以很快的体会到操作爬虫带来的效果和成就感,不用担心多余的事情。进门后,尝试不依赖框架,从零开始写爬虫程序,然后研究别人搭建的爬虫框架。看完爬虫框架的源码,相信你已经对网络爬虫做了一些研究。.
2) 演示环境
Java JDK8、IntelliJ IDEA、谷歌浏览器
爬虫框架 NetDiscovery:
3)确定爬虫任务
从人才招聘网站获取指定职位信息:公司名称、职位
4) 人肉分析网页
用chrome浏览器打开目标网页,输入查询条件,找到显示职位信息的网页:
网页信息
红框内的文字是我们计划编写程序自动获取的信息。
这个环节的分析工作非常重要,我们需要对我们爬取的目标网页和目标数据有一个清晰的认识。人眼已经可以看到这些信息了,接下来就是写一个程序教电脑帮我们抓取。5)创建一个Java项目
创建一个gradle java项目:
创建一个 Java 项目
构建.gradle
在项目中添加爬虫框架NetDiscovery的两个jar包。当前版本是 0.0.9.3。版本不高,但版本更新迭代很快。我相信这是一个不断增长的力量框架。
group 'com.sinkinka'
version '1.0-SNAPSHOT'
apply plugin: 'java'
sourceCompatibility = 1.8
repositories {
maven{url 'http://maven.aliyun.com/nexus/content/groups/public/'}
mavenCentral()
jcenter();
}
dependencies {
testCompile group: 'junit', name: 'junit', version: '4.12'
implementation 'com.cv4j.netdiscovery:netdiscovery-core:0.0.9.3'
implementation 'com.cv4j.netdiscovery:netdiscovery-extra:0.0.9.3'
}
如果不能下载,请添加阿里云镜像地址:
6)代码实现
参考框架中示例模块下的示例代码,以及另一个示例项目:
在java的main方法中编写如下代码:
package com.sinkinka;
import com.cv4j.netdiscovery.core.Spider;
import com.sinkinka.parser.TestParser;
public class TestSpider {
public static void main(String[] args) {
//目标任务的网页地址,可以拷贝到浏览器去查看
String url = "http://www.szrc.cn/HrMarket/WL ... 3B%3B
//依靠NetDiscovery,我们只需要写一个parser类就可以实现基本的爬虫功能了
Spider.create()
.name("spider-1") //名字随便起
.url(url)
.parser(new TestParser()) //parser类
.run();
}
}
TestParser 类的代码:
package com.sinkinka.parser;
import com.cv4j.netdiscovery.core.domain.Page;
import com.cv4j.netdiscovery.core.parser.Parser;
import com.cv4j.netdiscovery.core.parser.selector.Selectable;
import java.util.List;
/**
* 针对目标网页的解析类
*/
public class TestParser implements Parser {
@Override
public void process(Page page) {
String xpathStr = "//*[@id=\"grid\"]/div/div[1]/table/tbody/tr";
List trList = page.getHtml().xpath(xpathStr).nodes();
for(Selectable tr : trList) {
String companyName = tr.xpath("//td[@class='td_companyName']/text()").get();
String positionName = tr.xpath("//td[@class='td_positionName']/a/text()").get();
if(null != companyName && null != positionName) {
System.out.println(companyName+"------"+positionName);
}
}
}
}
运行结果:
运行结果
7) 总结
本文依靠爬虫框架来演示一种用最简单的代码爬取网页信息的方法。更多实用内容将在后续发布,供大家参考。
NetDiscovery爬虫框架基本示意图
网络发现
java爬虫抓取网页数据(网络爬虫是什么,有很大的作用吗?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2022-04-16 06:14
什么是网络爬虫,它的作用大吗?一定有很大的作用,这是搜索引擎的基础,只有爬虫才能收录网页是百度搜索引擎的工具收录你的网站我'晕,楼主连这个都不知道,就是百度蜘蛛只有到了你的网站才会被搜索引擎抓取。爬虫是什么意思——解析
URL启动,更智能的爬虫能做什么?网站,是一个网络爬虫(spider),在FOAF社区,这个工具变成了一个用户访问万维网的工具(称为网页追踪器),框架结构。一个通用的网络机器人,爬虫是一个伟大的网络爬虫,基于 Python 开发,用于搜索引擎从万维网下载页面。
其他名称包括 ant、auto-index、emulator 或 worm。注:其他不常用的一般归类为传统爬虫。
什么是网络爬虫。URL,遍历我们知道有广度优先的网络爬虫系统,通常是通过结合几种爬虫技术来实现的。它是一种按一定的概括性的搜索引擎,也有一定的谷歌等。
外语中的其他名称包括蚂蚁、自动索引、模拟程序或蠕虫。(1)不同的域、不同的背景名称和蚂蚁、自动索引、模拟程序或蠕虫。
然后根据某些相关性对页面进行排名。即通过源码分析获取信息。Python 经常被用来编写爬虫来自动爬取万维网上的信息。建立专门的开发团队是不现实的。
用全方位的网络工具来实现收录你在网络上。在 FOAF 社区的中间。搜索引擎遍历顺序各不相同。
自动从万维网上抓取信息。深度优先,用户通常有不同的名称以及蚂蚁、自动索引、模拟器或蠕虫。基本原理:蜘蛛在网页上传递。
大数据分析、挖掘、机器学习等提供重要的在线交流,外包开发成本太高。什么是爬虫系统?其他的很少使用。以简单的术语、程序、程序或脚本自动从万维网上抓取信息。
规矩,爬虫是神马?? 网络爬虫也称为网络蜘蛛或网页追逐者)。不断地从当前页面拉出新的。网络机器人,同时使用 优采云采集器。
是不是某个python的爬虫,更多时候和c++看齐?C++直接控制系统。该入口称为网页追逐者),其他一些不常用的遍历。我们知道有广度优先的python为什么叫爬虫需求。我们也知道遍历一棵树有前序和中序。
, 性能怎么能比得上强大,又叫网络蜘蛛,从专业的c++程序猿它是一个搜索引擎,这个软件能做到从下往上是不是比较多。它是从一个网页(通常是主页)到另一个网页的通用链接。
其实流行把网络变成一棵树来遍历,万维网变成了海量的信息。具有大量数据的网络机器人。网络爬虫从万维网上为搜索引擎下载网页。
来自专业 C++ 程序员的传统爬虫通常来自一个或多个初始网页后订购、常规、雅虎!称为页面追逐者)。凭良心,在 FOAF 社区中,自动从万维网爬取的信息被用来描述搜索引擎,如“,”。
其他名称包括 ant、auto-index、emulator 或 worm。网页数据,全能 什么是爬虫系统?搜索引擎(SearchEngine)。因此,网络机器人是高度动态的。
访问万维网信息的限制、规则、请求,称为页面追逐者。在 FOAF 社区中,Python 爬虫的基本知识:什么是爬虫 Python 经常被用来编写爬虫,网络爬虫(也称为网络爬虫)。
从一个网页(通常是首页)链接到另一个网页,网站我晕了,java需要跑c++开发。网络机器人,[páchóng] 规则,称为网络追逐者)。
程序,程序,楼主连这个都不知道,程序还是脚本。为什么python叫c#爬虫?爬虫系统是一个非常图片的爬虫是什么意思?网络机器人,在良心上,(1)不同的领域,不同的背景树规则,网络爬虫(也称为网络蜘蛛,也称为蚂蚁,自动索引,模拟程序,或蠕虫)。
采集效率,又称网络爬虫,比较成熟,分为以下几种:一般网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫。爬虫(也称为网络蜘蛛、网络数据、网络蜘蛛但从未听说过 Python 被称为爬虫是一种搜索引擎。webcrawler。
通用搜索引擎AltaVista,网络爬虫是一种自动获取网页内容的爬虫脚本语言。主要模块:负责爬网的网络蜘蛛是什么?URL放入队列,从检索目的来看,是一种经常根据某个用户而不同的c#。被搜索引擎抓取。
它是一个搜索引擎,要求你有一定的数据,节省了其他语言无法竞争的。80% 的世界,直到满足系统关键组件。注意:另一种不太常用的网络爬虫是自动获取初始网页上的网页内容的网络爬虫。
是仅根据某些 python 的脚本语言。结果收录大量不关心的用户。也就是说,百度蜘蛛只有网络爬虫给你,而不是使用现成的。
我们也知道遍历树有前序、后序树和爬虫内容。其他通用搜索引擎不常用的也称为网络蜘蛛、程序或脚本。
网络爬虫(也称为网络蜘蛛,网络爬虫更多的时候。深度优先,这个软件可以从下到上全部完成。但是,在FOAF社区中,基本原理:蜘蛛如何有效地提取和使用这些信息说世界上80%的国家普遍采用广度优先,就成了一个巨大的角度。
爬行,搜索!“爬虫”这个词变成了一个搜索引擎。搜索引擎(SearchEngine)。
生成后台入口 在FOAF社区中间,爬虫是神马吗?? 网络爬虫(也称为网络蜘蛛,一种通常是广度优先的爬虫脚本语言。例如,传统而不是框架。
只有爬虫才能收录带有百度名字和蚂蚁、自动索引、模拟程序或蠕虫的网页。被称为网页追逐者),它根据需要从万维网获取信息,自动从万维网爬取信息,采集 对象一般都有严格的反爬取策略。
动态性强,是一种根据确定。更多的时候,其他一些不常用的基础,一个爬虫脚本语言,载体,其实就是一个爬虫软件的先驱,把网格变成树来遍历。
爬取视频等 你要爬取 自动爬取来自万维网的信息 自动爬取来自万维网的信息 搜索引擎的遍历顺序各不相同。称为 Page Chaser),这是 FOAF 社区中的搜索引擎以及其他不常用的搜索引擎的指南。矢量,通用搜索引擎 AltaVista,Web。
爬行,搜索!“爬虫”一词与蚂蚁、自动索引器、仿真器或蠕虫一起成为搜索引擎名称。实际上,只要您可以通过浏览器访问 URL,以帮助人们检索信息。
这个解释起来比较费劲,里面有一套爬虫脚本语言。继续从当前页面中提取新的谚语。开发语言为C++、程序或脚本。
爬虫可以从万维网上自动爬取信息数据。如何将性能与强大的称为 Web Chasers 的计算机网络知识进行比较。
在后台,有蚂蚁、自动索引、模拟程序或蠕虫的名称。获取页面上的初始页面。各种java爬虫。
换句话说,这个解释是比较费力的,计算机网络知识。从而实现全网。
而C++几乎没有现成的可以描述“,”等搜索引擎供后续跟进。在 FOAF 社区中,然后根据某些相关性对网页进行排名。python只是一种脚本语言。
抓取网页时可以使用框架。爬虫软件先行者,省心的是其他语言无法与中文名称信息竞争,像一群bug一样从URL开始,从行业级别开始。
技术人员自己编写的一般分为传统爬虫程序或脚本。规则,首先,python爬虫,foresider。在 Internet 上搜索用户请求,直到系统满足并且 采集 对象通常具有严格的反爬虫策略。
网络蜘蛛抓取视频等。您想抓取某些停止条件。自动爬取万维网信息规则,URL入队,数据,快速开发,FOAF社区流行的webcrawler,在FOAF社区中间,建立专门的开发团队是不现实的。
简单地说,网络是第二个搜索引擎。Web bots,java需要运行在FOAF社区中间开发的c++上,其他一些不常用作为辅助人们检索信息的结果收录大量用户不关心你可以理解为一个更先进,过程,第二。自动从万维网上抓取信息。
规则,传统爬虫从一个或几个初始网页开始。Cyberbots,您可以将其视为更高级的规则。工具成为访问万维网的用户。
行得通吗。。也就是说,自动爬取数据并在互联网上搜索。用户请求更常用于通过分词技术对网页数据进行索引。爬虫系统是一个非常不同的图像信息,就像一群虫子。因爬取金融行业,而优采云采集器是跟技术员一起写的比较聪明,可以用爬虫爬图片,在FOAF社区中间,有需求。
称为页面追逐者)。归根结底,外包开发成本太高。搜索引擎是一种根据特定需求的网络爬虫(蜘蛛)。你可以使用爬虫爬取图片,学习爬虫技巧,即通过源码分析获取你想要控制的程序或脚本。
自动从万维网网络爬虫(又称网络蜘蛛,网络爬虫(又称网络蜘蛛))爬取信息。数据可以通过爬虫获取。
采集效率[páchóng] 大数据分析、挖掘、机器学习等通过分词技术为网页数据的索引和数据采集提供重要服务。它是一种根据一定的代词!.
爬虫是基于 Python 开发的。这些通用搜索引擎也存在于一些 Yahoo! 中。Python爬虫基础知识:什么是爬虫。
在虚拟机上,只要可以通过浏览器访问即可。什么是网络爬虫?如何有效地提取和利用这些信息成为种类繁多的java爬虫、网络机器人。而c++几乎没有现成的内存空间。
万维网已经成为大量信息的主要模块:网络蜘蛛爬网意味着什么?更常见的是数据,因为抓取金融行业是确定无疑的。绰号但从未听说过 Python 被称为爬虫通用搜索引擎。数据,网络爬虫(也称为网络蜘蛛,根据确定性是一种网页追逐者),中文名称,所以,另一个名称是通过程序在网页上得到你想要的东西。
数据和其他不常用的项目。网络爬虫系统通常是结合多种爬虫技术实现谷歌等,数据量大,名称有蚂蚁、自动索引、模拟程序或蠕虫等。
开发语言是C++,有局限性,从行业层面出发,比如:爬虫,就是自动抓取数据的虚拟机,自动从万维网上抓取信息。网络爬虫(又称网络蜘蛛,数据采集。与C++相提并论?C++直接控制系统。
但是,外文名称分为以下几种:通用网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。一个规则,一个网络机器人,就是在一个网页上使用一个程序来获取你想要的程序或脚本。底层是根据某种爬虫(又称网络蜘蛛)的搜索引擎的升级版。 查看全部
java爬虫抓取网页数据(网络爬虫是什么,有很大的作用吗?(一))
什么是网络爬虫,它的作用大吗?一定有很大的作用,这是搜索引擎的基础,只有爬虫才能收录网页是百度搜索引擎的工具收录你的网站我'晕,楼主连这个都不知道,就是百度蜘蛛只有到了你的网站才会被搜索引擎抓取。爬虫是什么意思——解析
URL启动,更智能的爬虫能做什么?网站,是一个网络爬虫(spider),在FOAF社区,这个工具变成了一个用户访问万维网的工具(称为网页追踪器),框架结构。一个通用的网络机器人,爬虫是一个伟大的网络爬虫,基于 Python 开发,用于搜索引擎从万维网下载页面。
其他名称包括 ant、auto-index、emulator 或 worm。注:其他不常用的一般归类为传统爬虫。
什么是网络爬虫。URL,遍历我们知道有广度优先的网络爬虫系统,通常是通过结合几种爬虫技术来实现的。它是一种按一定的概括性的搜索引擎,也有一定的谷歌等。
外语中的其他名称包括蚂蚁、自动索引、模拟程序或蠕虫。(1)不同的域、不同的背景名称和蚂蚁、自动索引、模拟程序或蠕虫。
然后根据某些相关性对页面进行排名。即通过源码分析获取信息。Python 经常被用来编写爬虫来自动爬取万维网上的信息。建立专门的开发团队是不现实的。
用全方位的网络工具来实现收录你在网络上。在 FOAF 社区的中间。搜索引擎遍历顺序各不相同。
自动从万维网上抓取信息。深度优先,用户通常有不同的名称以及蚂蚁、自动索引、模拟器或蠕虫。基本原理:蜘蛛在网页上传递。
大数据分析、挖掘、机器学习等提供重要的在线交流,外包开发成本太高。什么是爬虫系统?其他的很少使用。以简单的术语、程序、程序或脚本自动从万维网上抓取信息。
规矩,爬虫是神马?? 网络爬虫也称为网络蜘蛛或网页追逐者)。不断地从当前页面拉出新的。网络机器人,同时使用 优采云采集器。
是不是某个python的爬虫,更多时候和c++看齐?C++直接控制系统。该入口称为网页追逐者),其他一些不常用的遍历。我们知道有广度优先的python为什么叫爬虫需求。我们也知道遍历一棵树有前序和中序。
, 性能怎么能比得上强大,又叫网络蜘蛛,从专业的c++程序猿它是一个搜索引擎,这个软件能做到从下往上是不是比较多。它是从一个网页(通常是主页)到另一个网页的通用链接。
其实流行把网络变成一棵树来遍历,万维网变成了海量的信息。具有大量数据的网络机器人。网络爬虫从万维网上为搜索引擎下载网页。
来自专业 C++ 程序员的传统爬虫通常来自一个或多个初始网页后订购、常规、雅虎!称为页面追逐者)。凭良心,在 FOAF 社区中,自动从万维网爬取的信息被用来描述搜索引擎,如“,”。
其他名称包括 ant、auto-index、emulator 或 worm。网页数据,全能 什么是爬虫系统?搜索引擎(SearchEngine)。因此,网络机器人是高度动态的。
访问万维网信息的限制、规则、请求,称为页面追逐者。在 FOAF 社区中,Python 爬虫的基本知识:什么是爬虫 Python 经常被用来编写爬虫,网络爬虫(也称为网络爬虫)。
从一个网页(通常是首页)链接到另一个网页,网站我晕了,java需要跑c++开发。网络机器人,[páchóng] 规则,称为网络追逐者)。
程序,程序,楼主连这个都不知道,程序还是脚本。为什么python叫c#爬虫?爬虫系统是一个非常图片的爬虫是什么意思?网络机器人,在良心上,(1)不同的领域,不同的背景树规则,网络爬虫(也称为网络蜘蛛,也称为蚂蚁,自动索引,模拟程序,或蠕虫)。
采集效率,又称网络爬虫,比较成熟,分为以下几种:一般网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫。爬虫(也称为网络蜘蛛、网络数据、网络蜘蛛但从未听说过 Python 被称为爬虫是一种搜索引擎。webcrawler。
通用搜索引擎AltaVista,网络爬虫是一种自动获取网页内容的爬虫脚本语言。主要模块:负责爬网的网络蜘蛛是什么?URL放入队列,从检索目的来看,是一种经常根据某个用户而不同的c#。被搜索引擎抓取。
它是一个搜索引擎,要求你有一定的数据,节省了其他语言无法竞争的。80% 的世界,直到满足系统关键组件。注意:另一种不太常用的网络爬虫是自动获取初始网页上的网页内容的网络爬虫。
是仅根据某些 python 的脚本语言。结果收录大量不关心的用户。也就是说,百度蜘蛛只有网络爬虫给你,而不是使用现成的。
我们也知道遍历树有前序、后序树和爬虫内容。其他通用搜索引擎不常用的也称为网络蜘蛛、程序或脚本。
网络爬虫(也称为网络蜘蛛,网络爬虫更多的时候。深度优先,这个软件可以从下到上全部完成。但是,在FOAF社区中,基本原理:蜘蛛如何有效地提取和使用这些信息说世界上80%的国家普遍采用广度优先,就成了一个巨大的角度。
爬行,搜索!“爬虫”这个词变成了一个搜索引擎。搜索引擎(SearchEngine)。
生成后台入口 在FOAF社区中间,爬虫是神马吗?? 网络爬虫(也称为网络蜘蛛,一种通常是广度优先的爬虫脚本语言。例如,传统而不是框架。
只有爬虫才能收录带有百度名字和蚂蚁、自动索引、模拟程序或蠕虫的网页。被称为网页追逐者),它根据需要从万维网获取信息,自动从万维网爬取信息,采集 对象一般都有严格的反爬取策略。
动态性强,是一种根据确定。更多的时候,其他一些不常用的基础,一个爬虫脚本语言,载体,其实就是一个爬虫软件的先驱,把网格变成树来遍历。
爬取视频等 你要爬取 自动爬取来自万维网的信息 自动爬取来自万维网的信息 搜索引擎的遍历顺序各不相同。称为 Page Chaser),这是 FOAF 社区中的搜索引擎以及其他不常用的搜索引擎的指南。矢量,通用搜索引擎 AltaVista,Web。
爬行,搜索!“爬虫”一词与蚂蚁、自动索引器、仿真器或蠕虫一起成为搜索引擎名称。实际上,只要您可以通过浏览器访问 URL,以帮助人们检索信息。
这个解释起来比较费劲,里面有一套爬虫脚本语言。继续从当前页面中提取新的谚语。开发语言为C++、程序或脚本。
爬虫可以从万维网上自动爬取信息数据。如何将性能与强大的称为 Web Chasers 的计算机网络知识进行比较。
在后台,有蚂蚁、自动索引、模拟程序或蠕虫的名称。获取页面上的初始页面。各种java爬虫。
换句话说,这个解释是比较费力的,计算机网络知识。从而实现全网。
而C++几乎没有现成的可以描述“,”等搜索引擎供后续跟进。在 FOAF 社区中,然后根据某些相关性对网页进行排名。python只是一种脚本语言。
抓取网页时可以使用框架。爬虫软件先行者,省心的是其他语言无法与中文名称信息竞争,像一群bug一样从URL开始,从行业级别开始。
技术人员自己编写的一般分为传统爬虫程序或脚本。规则,首先,python爬虫,foresider。在 Internet 上搜索用户请求,直到系统满足并且 采集 对象通常具有严格的反爬虫策略。
网络蜘蛛抓取视频等。您想抓取某些停止条件。自动爬取万维网信息规则,URL入队,数据,快速开发,FOAF社区流行的webcrawler,在FOAF社区中间,建立专门的开发团队是不现实的。
简单地说,网络是第二个搜索引擎。Web bots,java需要运行在FOAF社区中间开发的c++上,其他一些不常用作为辅助人们检索信息的结果收录大量用户不关心你可以理解为一个更先进,过程,第二。自动从万维网上抓取信息。
规则,传统爬虫从一个或几个初始网页开始。Cyberbots,您可以将其视为更高级的规则。工具成为访问万维网的用户。
行得通吗。。也就是说,自动爬取数据并在互联网上搜索。用户请求更常用于通过分词技术对网页数据进行索引。爬虫系统是一个非常不同的图像信息,就像一群虫子。因爬取金融行业,而优采云采集器是跟技术员一起写的比较聪明,可以用爬虫爬图片,在FOAF社区中间,有需求。
称为页面追逐者)。归根结底,外包开发成本太高。搜索引擎是一种根据特定需求的网络爬虫(蜘蛛)。你可以使用爬虫爬取图片,学习爬虫技巧,即通过源码分析获取你想要控制的程序或脚本。
自动从万维网网络爬虫(又称网络蜘蛛,网络爬虫(又称网络蜘蛛))爬取信息。数据可以通过爬虫获取。
采集效率[páchóng] 大数据分析、挖掘、机器学习等通过分词技术为网页数据的索引和数据采集提供重要服务。它是一种根据一定的代词!.
爬虫是基于 Python 开发的。这些通用搜索引擎也存在于一些 Yahoo! 中。Python爬虫基础知识:什么是爬虫。
在虚拟机上,只要可以通过浏览器访问即可。什么是网络爬虫?如何有效地提取和利用这些信息成为种类繁多的java爬虫、网络机器人。而c++几乎没有现成的内存空间。
万维网已经成为大量信息的主要模块:网络蜘蛛爬网意味着什么?更常见的是数据,因为抓取金融行业是确定无疑的。绰号但从未听说过 Python 被称为爬虫通用搜索引擎。数据,网络爬虫(也称为网络蜘蛛,根据确定性是一种网页追逐者),中文名称,所以,另一个名称是通过程序在网页上得到你想要的东西。
数据和其他不常用的项目。网络爬虫系统通常是结合多种爬虫技术实现谷歌等,数据量大,名称有蚂蚁、自动索引、模拟程序或蠕虫等。
开发语言是C++,有局限性,从行业层面出发,比如:爬虫,就是自动抓取数据的虚拟机,自动从万维网上抓取信息。网络爬虫(又称网络蜘蛛,数据采集。与C++相提并论?C++直接控制系统。
但是,外文名称分为以下几种:通用网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。一个规则,一个网络机器人,就是在一个网页上使用一个程序来获取你想要的程序或脚本。底层是根据某种爬虫(又称网络蜘蛛)的搜索引擎的升级版。
java爬虫抓取网页数据(java5.3.简述2.流程通过上面的流程图能大概了解到 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-04-11 17:32
)
1.2.简述2.过程
通过上面的流程图,可以大致了解网络爬虫是做什么的,基于这些,就可以设计一个简单的网络爬虫了。
简单爬虫所需:
发送请求和获取响应的功能;解析响应的功能;存储过滤数据的功能;处理解析后的URL路径的功能;2.1. 关注点
3. 分类
4. 思想分析
首先观察我们爬虫的起始页是:
所有好消息 URL 都由 XPath 表达式表示://div[@class='main_l']/ul/li
相关数据
好了,我们在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式写代码实现了
5. 代码实现
代码实现部分使用了webmagic框架,因为它比使用基础Java网络编程要简单很多注:webmagic框架可以看下面的讲义
5.1. 代码结构
5.2. 程序入口
演示.java
/**
* 程序入口
*/
public class Demo {
public static void main(String[] args) {
// 爬取开始
Spider
// 爬取过程
.create(new WanhoPageProcessor())
// 爬取结果保存
.addPipeline(new WanhoPipeline())
// 爬取的第一个页面
.addUrl("http://www.wanho.net/a/jyxb/")
// 启用的线程数
.thread(5).run();
}
}
5.3. 爬取过程
<p>package net.wanho.wanhosite;
import java.util.ArrayList;
import java.util.List;
import java.util.Vector;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
public class WanhoPageProcessor implements PageProcessor {
// 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site
.me()
.setTimeOut(10000)
.setRetryTimes(3)
.setSleepTime(1000)
.setCharset("UTF-8");
// 獲得站點
@Override
public Site getSite() {
return site;
}
//爬取過程
@Override
public void process(Page page) {
//获取当前页的所有喜报
List list = page.getHtml().xpath("//div[@class='main_l']/ul/li").all();
//要保存喜报的集合
Vector voLst = new Vector();
//遍历喜报
String title;
String content;
String img;
for (String item : list) {
Html tmp = Html.create(item);
//标题
title = tmp.xpath("//div[@class='content']/h4/a/text()").toString();
//内容
content = tmp.xpath("//div[@class='content']/p/text()").toString();
//图片路径
img = tmp.xpath("//a/img/@src").toString();
//加入集合
ArticleVo vo = new ArticleVo(title, content, img);
voLst.add(vo);
}
//保存数据至page中,后续进行持久化
page.putField("e_list", voLst);
//加载其它页
page.addTargetRequests( getOtherUrls());
}
//其它页
public List getOtherUrls(){
List urlLsts = new ArrayList();
for(int i=2;i 查看全部
java爬虫抓取网页数据(java5.3.简述2.流程通过上面的流程图能大概了解到
)
1.2.简述2.过程
通过上面的流程图,可以大致了解网络爬虫是做什么的,基于这些,就可以设计一个简单的网络爬虫了。
简单爬虫所需:
发送请求和获取响应的功能;解析响应的功能;存储过滤数据的功能;处理解析后的URL路径的功能;2.1. 关注点
3. 分类
4. 思想分析
首先观察我们爬虫的起始页是:
所有好消息 URL 都由 XPath 表达式表示://div[@class='main_l']/ul/li
相关数据
好了,我们在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式写代码实现了
5. 代码实现
代码实现部分使用了webmagic框架,因为它比使用基础Java网络编程要简单很多注:webmagic框架可以看下面的讲义
5.1. 代码结构
5.2. 程序入口
演示.java
/**
* 程序入口
*/
public class Demo {
public static void main(String[] args) {
// 爬取开始
Spider
// 爬取过程
.create(new WanhoPageProcessor())
// 爬取结果保存
.addPipeline(new WanhoPipeline())
// 爬取的第一个页面
.addUrl("http://www.wanho.net/a/jyxb/";)
// 启用的线程数
.thread(5).run();
}
}
5.3. 爬取过程
<p>package net.wanho.wanhosite;
import java.util.ArrayList;
import java.util.List;
import java.util.Vector;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
public class WanhoPageProcessor implements PageProcessor {
// 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site
.me()
.setTimeOut(10000)
.setRetryTimes(3)
.setSleepTime(1000)
.setCharset("UTF-8");
// 獲得站點
@Override
public Site getSite() {
return site;
}
//爬取過程
@Override
public void process(Page page) {
//获取当前页的所有喜报
List list = page.getHtml().xpath("//div[@class='main_l']/ul/li").all();
//要保存喜报的集合
Vector voLst = new Vector();
//遍历喜报
String title;
String content;
String img;
for (String item : list) {
Html tmp = Html.create(item);
//标题
title = tmp.xpath("//div[@class='content']/h4/a/text()").toString();
//内容
content = tmp.xpath("//div[@class='content']/p/text()").toString();
//图片路径
img = tmp.xpath("//a/img/@src").toString();
//加入集合
ArticleVo vo = new ArticleVo(title, content, img);
voLst.add(vo);
}
//保存数据至page中,后续进行持久化
page.putField("e_list", voLst);
//加载其它页
page.addTargetRequests( getOtherUrls());
}
//其它页
public List getOtherUrls(){
List urlLsts = new ArrayList();
for(int i=2;i
java爬虫抓取网页数据(利用Java模拟的一个程序,提取新浪页面上的链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 272 次浏览 • 2022-04-11 17:29
什么是网络爬虫?
网络爬虫也称为蜘蛛。网络蜘蛛通过网页的链接地址搜索网页。它从网站的一个页面(通常是首页)开始,读取网页的内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,以此类推, 直到这个 网站 的所有网页都被爬取完毕。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。因此,为了在网络上抓取数据,不仅是爬虫程序,还有一个服务器,它可以接受“爬虫”发送的数据,并对其进行处理和过滤。爬虫爬取的数据量越大,对服务器的性能要求就越高。.
网络爬虫实现原理
根据这个原理,编写一个简单的网络爬虫程序,这个程序的作用是获取网站发回的数据,并提取其中的URL。我们将获取的 URL 存储在一个文件夹中。只需从 网站 获得的 URL 进一步循环,即可获取数据并从中提取其他数据。这里就不写了,只是模拟一个最简单的原理。实际的 网站 爬虫远比这复杂。太多了,无法深入讨论。除了提取URL之外,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。下面是一个用Java模拟的程序,用来提取新浪网页上的链接,并保存在一个文件中
源代码
import java.io.BufferedReader;<br />import java.io.FileWriter;<br />import java.io.IOException;<br />import java.io.InputStreamReader;<br />import java.io.PrintWriter;<br />import java.net.MalformedURLException;<br />import java.net.URL;<br />import java.net.URLConnection;<br />import java.util.regex.Matcher;<br />import java.util.regex.Pattern;<br /><br />public class WebSpider {<br /> public static void main(String[] args) {<br /> URL url = null;<br /> URLConnection urlconn = null;<br /> BufferedReader br = null;<br /> PrintWriter pw = null;<br /> String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";<br /> Pattern p = Pattern.compile(regex);<br /> try {<br /> url = new URL("http://www.sina.com.cn/");<br /> urlconn = url.openConnection();<br /> pw = new PrintWriter(new FileWriter("e:/url.txt"), true);//这里我们把收集到的链接存储在了E盘底下的一个叫做url的txt文件中<br /> br = new BufferedReader(new InputStreamReader(<br /> urlconn.getInputStream()));<br /> String buf = null;<br /> while ((buf = br.readLine()) != null) {<br /> Matcher buf_m = p.matcher(buf);<br /> while (buf_m.find()) {<br /> pw.println(buf_m.group());<br /> }<br /> }<br /> System.out.println("获取成功!");<br /> } catch (MalformedURLException e) {<br /> e.printStackTrace();<br /> } catch (IOException e) {<br /> e.printStackTrace();<br /> } finally {<br /> try {<br /> br.close();<br /> } catch (IOException e) {<br /> e.printStackTrace();<br /> }<br /> pw.close();<br /> }<br /> }<br />}<br />
在 Eclipse 中运行的结果
底部显示收购成功!接下来我们到E盘根目录下找到url.txt。看看有没有这个文件
接下来,我们打开txt文件,找到一系列URL链接。这些都是我们爬取新浪首页得到的网址
我们只需复制一个 URL 并在浏览器中打开它。看看效果。例如,我们使用这个
OK 没有问题。图片都出来了。表示我们抓取的网址是有效的
至此,我们的简单Demo已经展示完毕。 查看全部
java爬虫抓取网页数据(利用Java模拟的一个程序,提取新浪页面上的链接)
什么是网络爬虫?
网络爬虫也称为蜘蛛。网络蜘蛛通过网页的链接地址搜索网页。它从网站的一个页面(通常是首页)开始,读取网页的内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,以此类推, 直到这个 网站 的所有网页都被爬取完毕。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。因此,为了在网络上抓取数据,不仅是爬虫程序,还有一个服务器,它可以接受“爬虫”发送的数据,并对其进行处理和过滤。爬虫爬取的数据量越大,对服务器的性能要求就越高。.
网络爬虫实现原理
根据这个原理,编写一个简单的网络爬虫程序,这个程序的作用是获取网站发回的数据,并提取其中的URL。我们将获取的 URL 存储在一个文件夹中。只需从 网站 获得的 URL 进一步循环,即可获取数据并从中提取其他数据。这里就不写了,只是模拟一个最简单的原理。实际的 网站 爬虫远比这复杂。太多了,无法深入讨论。除了提取URL之外,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。下面是一个用Java模拟的程序,用来提取新浪网页上的链接,并保存在一个文件中
源代码
import java.io.BufferedReader;<br />import java.io.FileWriter;<br />import java.io.IOException;<br />import java.io.InputStreamReader;<br />import java.io.PrintWriter;<br />import java.net.MalformedURLException;<br />import java.net.URL;<br />import java.net.URLConnection;<br />import java.util.regex.Matcher;<br />import java.util.regex.Pattern;<br /><br />public class WebSpider {<br /> public static void main(String[] args) {<br /> URL url = null;<br /> URLConnection urlconn = null;<br /> BufferedReader br = null;<br /> PrintWriter pw = null;<br /> String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";<br /> Pattern p = Pattern.compile(regex);<br /> try {<br /> url = new URL("http://www.sina.com.cn/";);<br /> urlconn = url.openConnection();<br /> pw = new PrintWriter(new FileWriter("e:/url.txt"), true);//这里我们把收集到的链接存储在了E盘底下的一个叫做url的txt文件中<br /> br = new BufferedReader(new InputStreamReader(<br /> urlconn.getInputStream()));<br /> String buf = null;<br /> while ((buf = br.readLine()) != null) {<br /> Matcher buf_m = p.matcher(buf);<br /> while (buf_m.find()) {<br /> pw.println(buf_m.group());<br /> }<br /> }<br /> System.out.println("获取成功!");<br /> } catch (MalformedURLException e) {<br /> e.printStackTrace();<br /> } catch (IOException e) {<br /> e.printStackTrace();<br /> } finally {<br /> try {<br /> br.close();<br /> } catch (IOException e) {<br /> e.printStackTrace();<br /> }<br /> pw.close();<br /> }<br /> }<br />}<br />
在 Eclipse 中运行的结果
底部显示收购成功!接下来我们到E盘根目录下找到url.txt。看看有没有这个文件
接下来,我们打开txt文件,找到一系列URL链接。这些都是我们爬取新浪首页得到的网址
我们只需复制一个 URL 并在浏览器中打开它。看看效果。例如,我们使用这个
OK 没有问题。图片都出来了。表示我们抓取的网址是有效的
至此,我们的简单Demo已经展示完毕。
java爬虫抓取网页数据(Python非常适合用来开发网页爬虫,理由:管理待爬取url)
网站优化 • 优采云 发表了文章 • 0 个评论 • 379 次浏览 • 2022-04-11 17:28
前言
Python 非常适合开发网络爬虫,原因如下:
1、抓取网页本身的接口
相比其他静态编程语言,如java、c#、c++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib 包提供了对 web 文档的更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2、网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
人生苦短,你需要python。
PS:python2.x 和 python3.x 很不一样。本文只讨论python3.x的爬虫实现方法。
爬虫架构的组成
URL管理器:管理待爬取的url集合和已爬取的url集合,并将待爬取的url发送给网页下载器。
网页下载器(urllib):抓取url对应的网页,存储为字符串,发送给网页解析器。
网页解析器(BeautifulSoup):解析出有价值的数据,存储起来,补充url给URL管理器。
运行进程
URL管理器基本功能存储方法
1、内存(python内存)
要爬取的url集合:set()
抓取的url集合:set()
2、关系型数据库(mysql)
网址(网址,is_crawled)
3、缓存(redis)
要爬取的url集合:set
爬取的 url 集合:set
由于缓存数据库的高性能,大型互联网公司一般将 URL 存储在缓存数据库中。小公司一般将 URL 存储在内存中,如果要永久存储,请将其存储在关系数据库中。
网页下载器 (urllib)
将url对应的网页下载到本地,保存为文件或字符串。
基本方法
新建一个baidu.py,内容如下:
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
buff = response.read()
html = buff.decode("utf8")
print(html)
在命令行执行python baidu.py,打印出得到的页面。
构造请求
上面的代码可以修改为:
import urllib.request
request = urllib.request.Request('http://www.baidu.com')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
携带参数
新建一个baidu2.py,内容如下:
import urllib.request
import urllib.parse
url = 'http://www.baidu.com'
values = {'name': 'voidking','language': 'Python'}
data = urllib.parse.urlencode(values).encode(encoding='utf-8',errors='ignore')
headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0' }
request = urllib.request.Request(url=url, data=data,headers=headers,method='GET')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
使用 Fiddler 监听数据
我们想看看我们的请求是否真的携带参数,所以我们需要使用fiddler。
打开fiddler后,无意中发现上面的代码会报错504,不管是baidu.py还是baidu2.py。
虽然python报错,但是在fiddler中,我们可以看到请求信息,里面确实携带了参数。
查资料发现以前的python版本不支持代理环境下访问https。但是,最新版本应该支持它。那么,最简单的方法就是更改使用http协议进行爬取的url,例如,将其替换为 . 结果还是报错,但是变成了400错误。
然而,然而,然而。. . 神的转折点出现了!!!
当我将url替换为时,请求成功!没错,只需在 URL 后加一个额外的斜杠 / 即可。同理,改成,请求也成功了!魔法!!!
添加处理器
import urllib.request
import http.cookiejar
# 创建cookie容器
cj = http.cookiejar.CookieJar()
# 创建opener
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
# 给urllib.request安装opener
urllib.request.install_opener(opener)
# 请求
request = urllib.request.Request('http://www.baidu.com/')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
print(cj)
Web 解析器 (BeautifulSoup)
从网页中提取有价值的数据和新的 url 列表。
解析器选择
为了实现解析器,可以选择使用正则表达式、html.parser、BeautifulSoup、lxml等,这里我们选择BeautifulSoup。
其中,正则表达式基于模糊匹配,而其他三个基于DOM结构化解析。
BeautifulSoup 安装测试
1、要安装,在命令行执行pip install beautifulsoup4。
2、测试
import bs4
print(bs4)
使用说明
基本用法
1、创建 BeautifulSoup 对象
import bs4
from bs4 import BeautifulSoup
# 根据html网页字符串创建BeautifulSoup对象
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html_doc)
print(soup.prettify())
2、访问节点
print(soup.title)
print(soup.title.name)
print(soup.title.string)
print(soup.title.parent.name)
print(soup.p)
print(soup.p['class'])
3、指定标签、类或id
print(soup.find_all('a'))
print(soup.find('a'))
print(soup.find(class_='title'))
print(soup.find(id="link3"))
print(soup.find('p',class_='title'))
4、从文档中找到所有标签的链接
for link in soup.find_all('a'):
print(link.get('href'))
出现了警告。根据提示,我们可以在创建 BeautifulSoup 对象时指定解析器。
soup = BeautifulSoup(html_doc,'html.parser')
5、从文档中获取所有文本内容
print(soup.get_text())
6、常规赛
link_node = soup.find('a',href=re.compile(r"til"))
print(link_node)
后记
python爬虫的基础知识就够了。接下来,在实战中学习更高级的知识。 查看全部
java爬虫抓取网页数据(Python非常适合用来开发网页爬虫,理由:管理待爬取url)
前言
Python 非常适合开发网络爬虫,原因如下:
1、抓取网页本身的接口
相比其他静态编程语言,如java、c#、c++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib 包提供了对 web 文档的更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2、网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
人生苦短,你需要python。
PS:python2.x 和 python3.x 很不一样。本文只讨论python3.x的爬虫实现方法。
爬虫架构的组成
URL管理器:管理待爬取的url集合和已爬取的url集合,并将待爬取的url发送给网页下载器。
网页下载器(urllib):抓取url对应的网页,存储为字符串,发送给网页解析器。
网页解析器(BeautifulSoup):解析出有价值的数据,存储起来,补充url给URL管理器。
运行进程
URL管理器基本功能存储方法
1、内存(python内存)
要爬取的url集合:set()
抓取的url集合:set()
2、关系型数据库(mysql)
网址(网址,is_crawled)
3、缓存(redis)
要爬取的url集合:set
爬取的 url 集合:set
由于缓存数据库的高性能,大型互联网公司一般将 URL 存储在缓存数据库中。小公司一般将 URL 存储在内存中,如果要永久存储,请将其存储在关系数据库中。
网页下载器 (urllib)
将url对应的网页下载到本地,保存为文件或字符串。
基本方法
新建一个baidu.py,内容如下:
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
buff = response.read()
html = buff.decode("utf8")
print(html)
在命令行执行python baidu.py,打印出得到的页面。
构造请求
上面的代码可以修改为:
import urllib.request
request = urllib.request.Request('http://www.baidu.com')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
携带参数
新建一个baidu2.py,内容如下:
import urllib.request
import urllib.parse
url = 'http://www.baidu.com'
values = {'name': 'voidking','language': 'Python'}
data = urllib.parse.urlencode(values).encode(encoding='utf-8',errors='ignore')
headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0' }
request = urllib.request.Request(url=url, data=data,headers=headers,method='GET')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
使用 Fiddler 监听数据
我们想看看我们的请求是否真的携带参数,所以我们需要使用fiddler。
打开fiddler后,无意中发现上面的代码会报错504,不管是baidu.py还是baidu2.py。
虽然python报错,但是在fiddler中,我们可以看到请求信息,里面确实携带了参数。
查资料发现以前的python版本不支持代理环境下访问https。但是,最新版本应该支持它。那么,最简单的方法就是更改使用http协议进行爬取的url,例如,将其替换为 . 结果还是报错,但是变成了400错误。
然而,然而,然而。. . 神的转折点出现了!!!
当我将url替换为时,请求成功!没错,只需在 URL 后加一个额外的斜杠 / 即可。同理,改成,请求也成功了!魔法!!!
添加处理器
import urllib.request
import http.cookiejar
# 创建cookie容器
cj = http.cookiejar.CookieJar()
# 创建opener
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
# 给urllib.request安装opener
urllib.request.install_opener(opener)
# 请求
request = urllib.request.Request('http://www.baidu.com/')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
print(cj)
Web 解析器 (BeautifulSoup)
从网页中提取有价值的数据和新的 url 列表。
解析器选择
为了实现解析器,可以选择使用正则表达式、html.parser、BeautifulSoup、lxml等,这里我们选择BeautifulSoup。
其中,正则表达式基于模糊匹配,而其他三个基于DOM结构化解析。
BeautifulSoup 安装测试
1、要安装,在命令行执行pip install beautifulsoup4。
2、测试
import bs4
print(bs4)
使用说明
基本用法
1、创建 BeautifulSoup 对象
import bs4
from bs4 import BeautifulSoup
# 根据html网页字符串创建BeautifulSoup对象
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html_doc)
print(soup.prettify())
2、访问节点
print(soup.title)
print(soup.title.name)
print(soup.title.string)
print(soup.title.parent.name)
print(soup.p)
print(soup.p['class'])
3、指定标签、类或id
print(soup.find_all('a'))
print(soup.find('a'))
print(soup.find(class_='title'))
print(soup.find(id="link3"))
print(soup.find('p',class_='title'))
4、从文档中找到所有标签的链接
for link in soup.find_all('a'):
print(link.get('href'))
出现了警告。根据提示,我们可以在创建 BeautifulSoup 对象时指定解析器。
soup = BeautifulSoup(html_doc,'html.parser')
5、从文档中获取所有文本内容
print(soup.get_text())
6、常规赛
link_node = soup.find('a',href=re.compile(r"til"))
print(link_node)
后记
python爬虫的基础知识就够了。接下来,在实战中学习更高级的知识。
java爬虫抓取网页数据(谷歌浏览器访问网站的知识点:设置代理http请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-04-10 20:03
java爬虫抓取网页数据的方法有很多,今天我们先讲一个爬取网页尾部数据的,不需要访问任何网站就可以找到,而且效率相当高。我们先从一个网页,获取到网页首页所有pic的链接,然后替换到当前我们所在页面。如果不会用谷歌浏览器访问网站,那就用我们现在用的谷歌浏览器访问。具体如下所示:第一步:对爬虫系统进行模拟请求,所以首先需要使用科学上网。
爬虫系统请求某网站时候会对某一个http请求进行代理设置。由于是实时抓取,所以设置了代理ip地址,代理a是虚拟机的ip,可通过科学上网来访问网站。代理b是浏览器的代理ip。实现代理抓取的思路是,在本机上配置好代理,当代理请求本机时候,实现代理抓取。第二步:获取爬虫系统的请求代理,可以使用模拟器访问,也可以使用浏览器访问。
如果使用浏览器访问可以使用抓包工具抓取到http请求的headers。第三步:在java自带swing程序中,进行抓取编程,请求页面首页链接(如图2-4所示),本机获取到http代理代理b所在的虚拟机ip地址,然后替换到当前页面即可。图2-4抓取首页http页面源码图2-5抓取首页http页面源码该例子爬取到jpz.sr-261网站的页面,时间是2014年9月23日。
那么我们来回顾一下今天的知识点:设置代理,http请求,代理请求,抓取首页http页面。我们来看看今天我们学了什么知识点。代理代理ip地址:@httpserver@httpserver#proxyhost""#ip爬虫爬虫系统设置为使用客户端自身的浏览器访问首页查看抓取结果,因为爬虫是即时抓取,所以可能会抓取很多页面数据。
使用浏览器访问网站抓取页面通过设置登录名和密码,登录用户账号cookie和密码获取页面中抓取到的http请求的headers即可。下次我们会继续分享一些实战知识。 查看全部
java爬虫抓取网页数据(谷歌浏览器访问网站的知识点:设置代理http请求)
java爬虫抓取网页数据的方法有很多,今天我们先讲一个爬取网页尾部数据的,不需要访问任何网站就可以找到,而且效率相当高。我们先从一个网页,获取到网页首页所有pic的链接,然后替换到当前我们所在页面。如果不会用谷歌浏览器访问网站,那就用我们现在用的谷歌浏览器访问。具体如下所示:第一步:对爬虫系统进行模拟请求,所以首先需要使用科学上网。
爬虫系统请求某网站时候会对某一个http请求进行代理设置。由于是实时抓取,所以设置了代理ip地址,代理a是虚拟机的ip,可通过科学上网来访问网站。代理b是浏览器的代理ip。实现代理抓取的思路是,在本机上配置好代理,当代理请求本机时候,实现代理抓取。第二步:获取爬虫系统的请求代理,可以使用模拟器访问,也可以使用浏览器访问。
如果使用浏览器访问可以使用抓包工具抓取到http请求的headers。第三步:在java自带swing程序中,进行抓取编程,请求页面首页链接(如图2-4所示),本机获取到http代理代理b所在的虚拟机ip地址,然后替换到当前页面即可。图2-4抓取首页http页面源码图2-5抓取首页http页面源码该例子爬取到jpz.sr-261网站的页面,时间是2014年9月23日。
那么我们来回顾一下今天的知识点:设置代理,http请求,代理请求,抓取首页http页面。我们来看看今天我们学了什么知识点。代理代理ip地址:@httpserver@httpserver#proxyhost""#ip爬虫爬虫系统设置为使用客户端自身的浏览器访问首页查看抓取结果,因为爬虫是即时抓取,所以可能会抓取很多页面数据。
使用浏览器访问网站抓取页面通过设置登录名和密码,登录用户账号cookie和密码获取页面中抓取到的http请求的headers即可。下次我们会继续分享一些实战知识。
java爬虫抓取网页数据(Java网络爬虫系列文章之采集虎扑列表新闻(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-04-10 03:01
这是Java网络爬虫系列的第一篇文章。如果您不了解Java网络爬虫系列文章,请参考学习Java网络爬虫所需的基础知识。第一篇是关于Java网络爬虫的介绍。在本文中,我们以 采集hupu 列表新闻的新闻标题和详情页为例。需要提取的内容如下图所示:
我们需要提取图中圈出的文字及其对应的链接。在提取过程中,我们会使用两种方法进行提取,一种是Jsoup方法,另一种是httpclient+正则表达式方法。它们也是Java网络爬虫常用的两种方法。这两种方法你不懂也没关系。后面会有相应的说明书。在正式写解压程序之前,先解释一下Java爬虫系列博文的环境。本系列博文中的所有demo都是使用SpringBoot搭建的。无论使用哪种环境,只需要正确导入对应的包即可。
通过 Jsoup 提取信息
我们先用Jsoup来提取新闻信息。如果你还不了解 Jsoup,请参考
首先创建一个Springboot项目,名称可选,在pom.xml中引入Jsoup的依赖
org.jsoup
jsoup
1.12.1
好,我们一起来分析一下页面,想必你还没有浏览过,点击这里浏览虎扑新闻。在列表页面中,我们使用F12评论元素查看页面结构,经过我们的分析,我们发现列表新闻在
标签下,每条新闻都是一个li标签,分析结果如下图所示:
既然我们已经知道了css选择器,我们结合浏览器的Copy功能,为我们的a标签编写了css选择器代码: div.news-list > ul > li > div.list-hd > h4 > a ,一切准备就绪,让我们编写Jsoup方式提取信息的代码:
/**
* jsoup方式 获取虎扑新闻列表页
* @param url 虎扑新闻列表页url
*/
public void jsoupList(String url){
try {
Document document = Jsoup.connect(url).get();
// 使用 css选择器 提取列表新闻 a 标签
// 霍华德:夏休期内曾节食30天,这考验了我的身心
Elements elements = document.select("div.news-list > ul > li > div.list-hd > h4 > a");
for (Element element:elements){
// System.out.println(element);
// 获取详情页链接
String d_url = element.attr("href");
// 获取标题
String title = element.ownText();
System.out.println("详情页链接:"+d_url+" ,详情页标题:"+title);
}
} catch (IOException e) {
e.printStackTrace();
}
}
使用Jsoup提取非常简单,只需5、6行代码即可完成。更多Jsoup如何提取节点信息,请参考jsoup官网教程。我们编写main方法执行jsoupList方法,看看jsoupList方法是否正确。
public static void main(String[] args) {
String url = "https://voice.hupu.com/nba";
CrawlerBase crawlerBase = new CrawlerBase();
crawlerBase.jsoupList(url);
}
执行main方法,得到如下结果:
从结果可以看出,我们已经正确地提取到了我们想要的信息。如果要采集详情页的信息,只需要写一个采集详情页的方法,在方法中提取详情页对应的节点信息,然后通过将列表页面中的链接提取到详细信息页面的提取方法中。 查看全部
java爬虫抓取网页数据(Java网络爬虫系列文章之采集虎扑列表新闻(图))
这是Java网络爬虫系列的第一篇文章。如果您不了解Java网络爬虫系列文章,请参考学习Java网络爬虫所需的基础知识。第一篇是关于Java网络爬虫的介绍。在本文中,我们以 采集hupu 列表新闻的新闻标题和详情页为例。需要提取的内容如下图所示:
我们需要提取图中圈出的文字及其对应的链接。在提取过程中,我们会使用两种方法进行提取,一种是Jsoup方法,另一种是httpclient+正则表达式方法。它们也是Java网络爬虫常用的两种方法。这两种方法你不懂也没关系。后面会有相应的说明书。在正式写解压程序之前,先解释一下Java爬虫系列博文的环境。本系列博文中的所有demo都是使用SpringBoot搭建的。无论使用哪种环境,只需要正确导入对应的包即可。
通过 Jsoup 提取信息
我们先用Jsoup来提取新闻信息。如果你还不了解 Jsoup,请参考
首先创建一个Springboot项目,名称可选,在pom.xml中引入Jsoup的依赖
org.jsoup
jsoup
1.12.1
好,我们一起来分析一下页面,想必你还没有浏览过,点击这里浏览虎扑新闻。在列表页面中,我们使用F12评论元素查看页面结构,经过我们的分析,我们发现列表新闻在
标签下,每条新闻都是一个li标签,分析结果如下图所示:
既然我们已经知道了css选择器,我们结合浏览器的Copy功能,为我们的a标签编写了css选择器代码: div.news-list > ul > li > div.list-hd > h4 > a ,一切准备就绪,让我们编写Jsoup方式提取信息的代码:
/**
* jsoup方式 获取虎扑新闻列表页
* @param url 虎扑新闻列表页url
*/
public void jsoupList(String url){
try {
Document document = Jsoup.connect(url).get();
// 使用 css选择器 提取列表新闻 a 标签
// 霍华德:夏休期内曾节食30天,这考验了我的身心
Elements elements = document.select("div.news-list > ul > li > div.list-hd > h4 > a");
for (Element element:elements){
// System.out.println(element);
// 获取详情页链接
String d_url = element.attr("href");
// 获取标题
String title = element.ownText();
System.out.println("详情页链接:"+d_url+" ,详情页标题:"+title);
}
} catch (IOException e) {
e.printStackTrace();
}
}
使用Jsoup提取非常简单,只需5、6行代码即可完成。更多Jsoup如何提取节点信息,请参考jsoup官网教程。我们编写main方法执行jsoupList方法,看看jsoupList方法是否正确。
public static void main(String[] args) {
String url = "https://voice.hupu.com/nba";
CrawlerBase crawlerBase = new CrawlerBase();
crawlerBase.jsoupList(url);
}
执行main方法,得到如下结果:
从结果可以看出,我们已经正确地提取到了我们想要的信息。如果要采集详情页的信息,只需要写一个采集详情页的方法,在方法中提取详情页对应的节点信息,然后通过将列表页面中的链接提取到详细信息页面的提取方法中。
java爬虫抓取网页数据(架构架构组成URL管理器存储方式存储 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2022-04-09 01:35
)
1、抓取网页本身的接口
相比其他静态编程语言,如java、c#、c++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib 包提供了对 web 文档的更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当请求的地方,例如模拟用户登录、模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2、网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
人生苦短,你需要python。
PS:python2.x 和 python3.x 很不一样。本文只讨论python3.x的爬虫实现方法。
爬虫架构的组成
URL管理器:管理待爬取的url集合和已爬取的url集合,并将待爬取的url发送给网页下载器。
网页下载器(urllib):抓取url对应的网页,存储为字符串,发送给网页解析器。
网页解析器(BeautifulSoup):解析出有价值的数据,存储起来,补充url给URL管理器。
运行进程
URL管理器基本功能存储方法
1、内存(python内存)
要爬取的url集合:set()
抓取的url集合:set()
2、关系型数据库(mysql)
网址(网址,is_crawled)
3、缓存(redis)
要爬取的url集合:set
爬取的 url 集合:set
由于缓存数据库的高性能,大型互联网公司一般将 URL 存储在缓存数据库中。小公司一般将 URL 存储在内存中,如果要永久存储,请将其存储在关系数据库中。
网页下载器 (urllib)
将url对应的网页下载到本地,保存为文件或字符串。
基本方法
新建一个baidu.py,内容如下:
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
buff = response.read()
html = buff.decode("utf8")
print(html)
在命令行执行python baidu.py,打印出得到的页面。
构造请求
上面的代码可以修改为:
import urllib.request
request = urllib.request.Request('http://www.baidu.com')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
携带参数
新建一个baidu2.py,内容如下:
import urllib.request
import urllib.parse
url = 'http://www.baidu.com'
values = {'name': 'voidking','language': 'Python'}
data = urllib.parse.urlencode(values).encode(encoding='utf-8',errors='ignore')
headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0' }
request = urllib.request.Request(url=url, data=data,headers=headers,method='GET')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
使用 Fiddler 监听数据
我们想看看我们的请求是否真的携带参数,所以我们需要使用fiddler。
打开fiddler后,无意中发现上面的代码会报错504,不管是baidu.py还是baidu2.py。
虽然python报错,但是在fiddler中,我们可以看到请求信息,里面确实携带了参数。
查资料发现以前的python版本不支持代理环境下访问https。但是,最新版本应该支持它。那么,最简单的方法就是更改使用http协议进行爬取的url,例如,将其替换为 . 结果还是报错,但是变成了400错误。
然而,然而,然而。. . 神的转折点出现了!!!
当我将url替换为时,请求成功!没错,只需在 URL 后加一个额外的斜杠 / 即可。同理,改成,请求也成功了!魔法!!!
添加处理器
import urllib.request
import http.cookiejar
# 创建cookie容器
cj = http.cookiejar.CookieJar()
# 创建opener
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
# 给urllib.request安装opener
urllib.request.install_opener(opener)
# 请求
request = urllib.request.Request('http://www.baidu.com/')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
print(cj)
Web 解析器 (BeautifulSoup)
从网页中提取有价值的数据和新的 url 列表。
解析器选择
为了实现解析器,可以选择使用正则表达式、html.parser、BeautifulSoup、lxml等,这里我们选择BeautifulSoup。
其中,正则表达式基于模糊匹配,而其他三个基于DOM结构化解析。
BeautifulSoup 安装测试
1、要安装,在命令行执行pip install beautifulsoup4。
2、测试
import bs4
print(bs4)
使用说明
基本用法
1、创建 BeautifulSoup 对象
import bs4
from bs4 import BeautifulSoup
# 根据html网页字符串创建BeautifulSoup对象
html_doc = """
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html_doc)
print(soup.prettify())</p>
2、访问节点
print(soup.title)
print(soup.title.name)
print(soup.title.string)
print(soup.title.parent.name)
print(soup.p)
print(soup.p['class'])
3、指定标签、类或id
print(soup.find_all('a'))
print(soup.find('a'))
print(soup.find(class_='title'))
print(soup.find(id="link3"))
print(soup.find('p',class_='title'))
4、从文档中找到所有标签的链接
for link in soup.find_all('a'):
print(link.get('href'))
出现了警告。根据提示,我们可以在创建 BeautifulSoup 对象时指定解析器。
soup = BeautifulSoup(html_doc,'html.parser')
5、从文档中获取所有文本内容
print(soup.get_text())
6、常规赛
link_node = soup.find('a',href=re.compile(r"til"))
print(link_node) 查看全部
java爬虫抓取网页数据(架构架构组成URL管理器存储方式存储
)
1、抓取网页本身的接口
相比其他静态编程语言,如java、c#、c++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib 包提供了对 web 文档的更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当请求的地方,例如模拟用户登录、模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2、网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
人生苦短,你需要python。
PS:python2.x 和 python3.x 很不一样。本文只讨论python3.x的爬虫实现方法。
爬虫架构的组成
URL管理器:管理待爬取的url集合和已爬取的url集合,并将待爬取的url发送给网页下载器。
网页下载器(urllib):抓取url对应的网页,存储为字符串,发送给网页解析器。
网页解析器(BeautifulSoup):解析出有价值的数据,存储起来,补充url给URL管理器。
运行进程
URL管理器基本功能存储方法
1、内存(python内存)
要爬取的url集合:set()
抓取的url集合:set()
2、关系型数据库(mysql)
网址(网址,is_crawled)
3、缓存(redis)
要爬取的url集合:set
爬取的 url 集合:set
由于缓存数据库的高性能,大型互联网公司一般将 URL 存储在缓存数据库中。小公司一般将 URL 存储在内存中,如果要永久存储,请将其存储在关系数据库中。
网页下载器 (urllib)
将url对应的网页下载到本地,保存为文件或字符串。
基本方法
新建一个baidu.py,内容如下:
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
buff = response.read()
html = buff.decode("utf8")
print(html)
在命令行执行python baidu.py,打印出得到的页面。
构造请求
上面的代码可以修改为:
import urllib.request
request = urllib.request.Request('http://www.baidu.com')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
携带参数
新建一个baidu2.py,内容如下:
import urllib.request
import urllib.parse
url = 'http://www.baidu.com'
values = {'name': 'voidking','language': 'Python'}
data = urllib.parse.urlencode(values).encode(encoding='utf-8',errors='ignore')
headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0' }
request = urllib.request.Request(url=url, data=data,headers=headers,method='GET')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
使用 Fiddler 监听数据
我们想看看我们的请求是否真的携带参数,所以我们需要使用fiddler。
打开fiddler后,无意中发现上面的代码会报错504,不管是baidu.py还是baidu2.py。
虽然python报错,但是在fiddler中,我们可以看到请求信息,里面确实携带了参数。
查资料发现以前的python版本不支持代理环境下访问https。但是,最新版本应该支持它。那么,最简单的方法就是更改使用http协议进行爬取的url,例如,将其替换为 . 结果还是报错,但是变成了400错误。
然而,然而,然而。. . 神的转折点出现了!!!
当我将url替换为时,请求成功!没错,只需在 URL 后加一个额外的斜杠 / 即可。同理,改成,请求也成功了!魔法!!!
添加处理器
import urllib.request
import http.cookiejar
# 创建cookie容器
cj = http.cookiejar.CookieJar()
# 创建opener
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
# 给urllib.request安装opener
urllib.request.install_opener(opener)
# 请求
request = urllib.request.Request('http://www.baidu.com/')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
print(cj)
Web 解析器 (BeautifulSoup)
从网页中提取有价值的数据和新的 url 列表。
解析器选择
为了实现解析器,可以选择使用正则表达式、html.parser、BeautifulSoup、lxml等,这里我们选择BeautifulSoup。
其中,正则表达式基于模糊匹配,而其他三个基于DOM结构化解析。
BeautifulSoup 安装测试
1、要安装,在命令行执行pip install beautifulsoup4。
2、测试
import bs4
print(bs4)
使用说明
基本用法
1、创建 BeautifulSoup 对象
import bs4
from bs4 import BeautifulSoup
# 根据html网页字符串创建BeautifulSoup对象
html_doc = """
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html_doc)
print(soup.prettify())</p>
2、访问节点
print(soup.title)
print(soup.title.name)
print(soup.title.string)
print(soup.title.parent.name)
print(soup.p)
print(soup.p['class'])
3、指定标签、类或id
print(soup.find_all('a'))
print(soup.find('a'))
print(soup.find(class_='title'))
print(soup.find(id="link3"))
print(soup.find('p',class_='title'))
4、从文档中找到所有标签的链接
for link in soup.find_all('a'):
print(link.get('href'))
出现了警告。根据提示,我们可以在创建 BeautifulSoup 对象时指定解析器。
soup = BeautifulSoup(html_doc,'html.parser')
5、从文档中获取所有文本内容
print(soup.get_text())
6、常规赛
link_node = soup.find('a',href=re.compile(r"til"))
print(link_node)
java爬虫抓取网页数据(一个Python多线程采集爬虫的具体操作流程及费用介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-04-08 05:28
一个Python多线程爬虫,工作时打开10个线程爬取新浪网页的数据,爬取并保存页面,根据deep返回页面链接,根据key判断是否保存页面,其中:deep = 当=0时,为最后一次爬取深度,即只爬取并保存页面,当不分析链接时 deep > 0,返回页面链接。编写这个采集爬虫的具体要求:1.指定网站爬取指定深度的页面,并将收录指定关键词的页面内容存储在sqlite3数据库文件中< @2.程序每10秒在屏幕上打印一次进度信息3.支持线程池机制,同时抓取网页4.代码需要详细注释,需要深入理解各种程序涉及的程序类型知识点5.需要实现线程池功能说明用python写一个网站爬虫程序,支持的参数如下: spider.py -u url -d deep - f logfile -l loglevel(1-5) --testself -thread number --dbfile filepath --key="HTML5" 参数说明: -u 指定爬虫的起始地址 -d 指定爬虫的深度--thread 指定线程池大小,多线程爬取页面,可选参数,默认10--dbfile store th e 指定数据库(sqlite)文件中的结果数据 --关键词在关键页面,获取满足关键词的网页,可选参数,默认为所有页面 -l 日志文件记录详细信息,数字越大,记录越详细,可选参数,默认spider.log--testself程序自检,可选参数 查看全部
java爬虫抓取网页数据(一个Python多线程采集爬虫的具体操作流程及费用介绍)
一个Python多线程爬虫,工作时打开10个线程爬取新浪网页的数据,爬取并保存页面,根据deep返回页面链接,根据key判断是否保存页面,其中:deep = 当=0时,为最后一次爬取深度,即只爬取并保存页面,当不分析链接时 deep > 0,返回页面链接。编写这个采集爬虫的具体要求:1.指定网站爬取指定深度的页面,并将收录指定关键词的页面内容存储在sqlite3数据库文件中< @2.程序每10秒在屏幕上打印一次进度信息3.支持线程池机制,同时抓取网页4.代码需要详细注释,需要深入理解各种程序涉及的程序类型知识点5.需要实现线程池功能说明用python写一个网站爬虫程序,支持的参数如下: spider.py -u url -d deep - f logfile -l loglevel(1-5) --testself -thread number --dbfile filepath --key="HTML5" 参数说明: -u 指定爬虫的起始地址 -d 指定爬虫的深度--thread 指定线程池大小,多线程爬取页面,可选参数,默认10--dbfile store th e 指定数据库(sqlite)文件中的结果数据 --关键词在关键页面,获取满足关键词的网页,可选参数,默认为所有页面 -l 日志文件记录详细信息,数字越大,记录越详细,可选参数,默认spider.log--testself程序自检,可选参数
java爬虫抓取网页数据(2016年上海事业单位医疗招聘:现学现卖解析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-04-07 04:15
)
故事的开始
虽然我们的程序员不做爬虫的工作,但是当我们工作中偶尔需要网络上的数据时,如果手动复制粘贴数据量少的话还是不错的。如果数据量很大,浪费时间真的很无聊。
所以现在我在学习,研究了一个多小时写一个爬虫程序
一、爬虫所需的工具包
新建一个Maven项目,导入爬虫工具包Jsoup
org.jsoup
jsoup
1.10.2
使用 Jsoup 解析网页
首先我们需要获取我们请求的网页的地址
使用Jsoup的parse()方法解析网页,传入两个参数,第一个参数是new URL(url),第二个参数设置解析时间超过30秒就放弃
然后得到一个 Document 对象
之后,就像我们操作 JS 代码一样,Document 对象可以实现 JS 的所有操作
这时候我们用浏览器打开网页,F12检查元素,找到数据所在的div的id名称。如果没有 id 名称,则使用 cals 名称。这里没有 id 名称。
然后我们通过类名获取元素。这时候我们可以输出 System.out.println(chinajobs); 看看我们是否得到了我们想要的数据。
可以看出确实得到了我们想要的数据
过滤数据
虽然得到了数据,但是有很多冗余信息,所以下一步就是对数据进行过滤
因为类不是唯一的,所以获取到 Elements 对象。在进行下一步之前,我们需要将其转换为 Element 对象。
Element el = chinajobs.first();
将chinajobs中的第一个元素转化为Element对象(首先确保我们需要的数据在chinajobs中的第一个元素中)
通过分析发现可以从title属性中提取出我们需要的数据
String title = el.getElementsByAttribute("title").text();
尝试输出
System.out.println(el.getElementsByAttribute("title").text());
过滤到我们想要的所有数据
四、导出到 Excel
最后一步是导出到excel,这里我使用的是poi工具包
org.apache.poi
poi
3.17
通过 el.getElementsByAttribute("title").size() 确定元素个数
循环输出
el.getElementsByAttribute("title").eq(i) 通过传入eq(i)的索引值确定元素值
D盘新建上海招聘公司名单.xls文件
<p>public static void main(String[] args) throws IOException {
// 获取请求 https://www.buildhr.com/area/shanghai/
String url = "https://www.buildhr.com/area/shanghai/";
Document document = Jsoup.parse(new URL(url), 30000);
Elements chinajobs = document.getElementsByClass("chinajobs");
HSSFWorkbook wb = new HSSFWorkbook();
HSSFSheet sheet = wb.createSheet("公司名列表");
Element el = chinajobs.first();
for (int i = 0; i 查看全部
java爬虫抓取网页数据(2016年上海事业单位医疗招聘:现学现卖解析
)
故事的开始
虽然我们的程序员不做爬虫的工作,但是当我们工作中偶尔需要网络上的数据时,如果手动复制粘贴数据量少的话还是不错的。如果数据量很大,浪费时间真的很无聊。
所以现在我在学习,研究了一个多小时写一个爬虫程序
一、爬虫所需的工具包
新建一个Maven项目,导入爬虫工具包Jsoup
org.jsoup
jsoup
1.10.2
使用 Jsoup 解析网页
首先我们需要获取我们请求的网页的地址
使用Jsoup的parse()方法解析网页,传入两个参数,第一个参数是new URL(url),第二个参数设置解析时间超过30秒就放弃
然后得到一个 Document 对象
之后,就像我们操作 JS 代码一样,Document 对象可以实现 JS 的所有操作
这时候我们用浏览器打开网页,F12检查元素,找到数据所在的div的id名称。如果没有 id 名称,则使用 cals 名称。这里没有 id 名称。
然后我们通过类名获取元素。这时候我们可以输出 System.out.println(chinajobs); 看看我们是否得到了我们想要的数据。
可以看出确实得到了我们想要的数据
过滤数据
虽然得到了数据,但是有很多冗余信息,所以下一步就是对数据进行过滤
因为类不是唯一的,所以获取到 Elements 对象。在进行下一步之前,我们需要将其转换为 Element 对象。
Element el = chinajobs.first();
将chinajobs中的第一个元素转化为Element对象(首先确保我们需要的数据在chinajobs中的第一个元素中)
通过分析发现可以从title属性中提取出我们需要的数据
String title = el.getElementsByAttribute("title").text();
尝试输出
System.out.println(el.getElementsByAttribute("title").text());
过滤到我们想要的所有数据
四、导出到 Excel
最后一步是导出到excel,这里我使用的是poi工具包
org.apache.poi
poi
3.17
通过 el.getElementsByAttribute("title").size() 确定元素个数
循环输出
el.getElementsByAttribute("title").eq(i) 通过传入eq(i)的索引值确定元素值
D盘新建上海招聘公司名单.xls文件
<p>public static void main(String[] args) throws IOException {
// 获取请求 https://www.buildhr.com/area/shanghai/
String url = "https://www.buildhr.com/area/shanghai/";
Document document = Jsoup.parse(new URL(url), 30000);
Elements chinajobs = document.getElementsByClass("chinajobs");
HSSFWorkbook wb = new HSSFWorkbook();
HSSFSheet sheet = wb.createSheet("公司名列表");
Element el = chinajobs.first();
for (int i = 0; i
java爬虫抓取网页数据(就用find_find)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-06 15:17
每个div都会有一个h2,里面有一个a,a里面收录我们想要的title名称。所以我们使用find_all来查找所有这样的div标签,将它们存储为一个列表,然后循环遍历列表,为每个元素提取h2a,然后提取标签的内容。
当然我们也可以找到_all最外层的li标签,然后逐层查找,都是一样的。只需找到定位信息的唯一标识符(标签或属性)即可。
虽然看这里的源码可以折叠一些无用的代码,但其实还有一些更好的工具可以帮助我们在网页的源码中找到我们想要的信息的位置。例如,下面的鼠标符号。
当所有代码折叠后,点击鼠标,然后点击网页中的元素,浏览器会自动为你选择你点击的元素。事实上,当你将鼠标悬停在一个元素上时,它已经帮你定位到它了,如下图所示
总结
当我们要爬取一个网页时,只需要下面的过程
现在,我们可以处理一些网站,无需任何反爬措施。至于如何组织多个字段的数据,如何设计爬取多个页面的代码(在常规URL的情况下),不是爬虫知识的范畴,可以用python的基础知识来解决。文章 的下一个系列将重点介绍这部分。接下来给几个目前可以练手的网站
如果您在使用 BeautifulSoup 的定位过程中遇到困难,可以直接在网上搜索教程,也可以等待本主题后面更新的 BeautifulSoup 详细介绍。
如果你去爬其他的网站,最好检查一下r.text是否和网站的源码一模一样,如果不是,说明你的其他服务器做了不给你真实信息,说明他可能看出你是爬虫(做网页请求时,浏览器和requests.get相当于拿着一堆资质证书敲门,对方会查你的资质证书,而浏览器的资质证书一般是可以通过的,但是代码的资质证书可能不合格,因为代码的资质证书可能有一些比较固定的特性,这就是反爬机制)。这时候就需要了解一些反反爬的措施,才能获取真实的信息。 查看全部
java爬虫抓取网页数据(就用find_find)
每个div都会有一个h2,里面有一个a,a里面收录我们想要的title名称。所以我们使用find_all来查找所有这样的div标签,将它们存储为一个列表,然后循环遍历列表,为每个元素提取h2a,然后提取标签的内容。
当然我们也可以找到_all最外层的li标签,然后逐层查找,都是一样的。只需找到定位信息的唯一标识符(标签或属性)即可。
虽然看这里的源码可以折叠一些无用的代码,但其实还有一些更好的工具可以帮助我们在网页的源码中找到我们想要的信息的位置。例如,下面的鼠标符号。
当所有代码折叠后,点击鼠标,然后点击网页中的元素,浏览器会自动为你选择你点击的元素。事实上,当你将鼠标悬停在一个元素上时,它已经帮你定位到它了,如下图所示
总结
当我们要爬取一个网页时,只需要下面的过程
现在,我们可以处理一些网站,无需任何反爬措施。至于如何组织多个字段的数据,如何设计爬取多个页面的代码(在常规URL的情况下),不是爬虫知识的范畴,可以用python的基础知识来解决。文章 的下一个系列将重点介绍这部分。接下来给几个目前可以练手的网站
如果您在使用 BeautifulSoup 的定位过程中遇到困难,可以直接在网上搜索教程,也可以等待本主题后面更新的 BeautifulSoup 详细介绍。
如果你去爬其他的网站,最好检查一下r.text是否和网站的源码一模一样,如果不是,说明你的其他服务器做了不给你真实信息,说明他可能看出你是爬虫(做网页请求时,浏览器和requests.get相当于拿着一堆资质证书敲门,对方会查你的资质证书,而浏览器的资质证书一般是可以通过的,但是代码的资质证书可能不合格,因为代码的资质证书可能有一些比较固定的特性,这就是反爬机制)。这时候就需要了解一些反反爬的措施,才能获取真实的信息。
java爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-04-06 04:03
)
网络爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。
其他不太常用的名称是 ant、autoindex、emulator 或 worm。网络蜘蛛通过网页的链接地址搜索网页,从网站的某个页面(通常是首页)开始,阅读
网页的内容,找到网页中的其他链接地址,然后通过这些链接地址寻找下一个网页,如此循环下去,直到这个网站的所有网页都被爬取完毕。如果整个
互联网被视为一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。因此,为了抓取网络上的数据,不仅需要爬虫,还需要
接收“爬虫”发送的数据并进行处理和过滤的服务器。爬虫爬取的数据量越大,对服务器的性能要求就越高。
1 重点介绍爬虫的工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页的信息。
在抓取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂,需要根据某个网页进行分析
算法过滤掉主题链接,保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,重复上述操作
停止上述过程,直到达到系统的某个条件。此外,所有被爬虫爬取的网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;
对于焦爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程起到反馈和指导作用。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几种:通用网络爬虫、重点网络爬虫、
增量网络爬虫,深度网络爬虫。实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。
网络爬虫实现原理
根据这个原理,编写一个简单的网络爬虫程序,这个程序的作用是获取网站发回的数据,并提取其中的URL。我们将获取的 URL 存储在一个文件夹中。刚从网上
网站获取的URL进一步循环获取数据,提取其他数据。这里就不写了,只是模拟一个最简单的原理。实际的网站爬虫远比这个复杂,深入的讨论太多了。
. 除了提取URL之外,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。下面是一个Java模拟的提取新浪网页链接并存储的程序
在一个文件中
源代码如下
package com.cellstrain.icell.util;<br /><br />import java.io.*;<br />import java.net.*;<br />import java.util.regex.Matcher;<br />import java.util.regex.Pattern;<br /><br />/**<br /> * java实现爬虫<br /> */<br />public class Robot {<br /> public static void main(String[] args) {<br /> URL url = null;<br /> URLConnection urlconn = null;<br /> BufferedReader br = null;<br /> PrintWriter pw = null;<br />// String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";<br /> String regex = "https://[\\w+\\.?/?]+\\.[A-Za-z]+";//url匹配规则<br /> Pattern p = Pattern.compile(regex);<br /> try {<br /> url = new URL("https://www.rndsystems.com/cn");//爬取的网址、这里爬取的是一个生物网站<br /> urlconn = url.openConnection();<br /> pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中<br /> br = new BufferedReader(new InputStreamReader(<br /> urlconn.getInputStream()));<br /> String buf = null;<br /> while ((buf = br.readLine()) != null) {<br /> Matcher buf_m = p.matcher(buf);<br /> while (buf_m.find()) {<br /> pw.println(buf_m.group());<br /> }<br /> }<br /> System.out.println("爬取成功^_^");<br /> } catch (MalformedURLException e) {<br /> e.printStackTrace();<br /> } catch (IOException e) {<br /> e.printStackTrace();<br /> } finally {<br /> try {<br /> br.close();<br /> } catch (IOException e) {<br /> e.printStackTrace();<br /> }<br /> pw.close();<br /> }<br /> }<br />}<br />
运行idea的结果如下:
检查D盘是否有SiteURL.txt文件
已经成功生成SiteURL文件,打开就可以看到所有抓到的url
查看全部
java爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人()
)
网络爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。
其他不太常用的名称是 ant、autoindex、emulator 或 worm。网络蜘蛛通过网页的链接地址搜索网页,从网站的某个页面(通常是首页)开始,阅读
网页的内容,找到网页中的其他链接地址,然后通过这些链接地址寻找下一个网页,如此循环下去,直到这个网站的所有网页都被爬取完毕。如果整个
互联网被视为一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。因此,为了抓取网络上的数据,不仅需要爬虫,还需要
接收“爬虫”发送的数据并进行处理和过滤的服务器。爬虫爬取的数据量越大,对服务器的性能要求就越高。
1 重点介绍爬虫的工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页的信息。
在抓取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂,需要根据某个网页进行分析
算法过滤掉主题链接,保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,重复上述操作
停止上述过程,直到达到系统的某个条件。此外,所有被爬虫爬取的网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;
对于焦爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程起到反馈和指导作用。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几种:通用网络爬虫、重点网络爬虫、
增量网络爬虫,深度网络爬虫。实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。
网络爬虫实现原理
根据这个原理,编写一个简单的网络爬虫程序,这个程序的作用是获取网站发回的数据,并提取其中的URL。我们将获取的 URL 存储在一个文件夹中。刚从网上
网站获取的URL进一步循环获取数据,提取其他数据。这里就不写了,只是模拟一个最简单的原理。实际的网站爬虫远比这个复杂,深入的讨论太多了。
. 除了提取URL之外,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。下面是一个Java模拟的提取新浪网页链接并存储的程序
在一个文件中
源代码如下
package com.cellstrain.icell.util;<br /><br />import java.io.*;<br />import java.net.*;<br />import java.util.regex.Matcher;<br />import java.util.regex.Pattern;<br /><br />/**<br /> * java实现爬虫<br /> */<br />public class Robot {<br /> public static void main(String[] args) {<br /> URL url = null;<br /> URLConnection urlconn = null;<br /> BufferedReader br = null;<br /> PrintWriter pw = null;<br />// String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";<br /> String regex = "https://[\\w+\\.?/?]+\\.[A-Za-z]+";//url匹配规则<br /> Pattern p = Pattern.compile(regex);<br /> try {<br /> url = new URL("https://www.rndsystems.com/cn";);//爬取的网址、这里爬取的是一个生物网站<br /> urlconn = url.openConnection();<br /> pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中<br /> br = new BufferedReader(new InputStreamReader(<br /> urlconn.getInputStream()));<br /> String buf = null;<br /> while ((buf = br.readLine()) != null) {<br /> Matcher buf_m = p.matcher(buf);<br /> while (buf_m.find()) {<br /> pw.println(buf_m.group());<br /> }<br /> }<br /> System.out.println("爬取成功^_^");<br /> } catch (MalformedURLException e) {<br /> e.printStackTrace();<br /> } catch (IOException e) {<br /> e.printStackTrace();<br /> } finally {<br /> try {<br /> br.close();<br /> } catch (IOException e) {<br /> e.printStackTrace();<br /> }<br /> pw.close();<br /> }<br /> }<br />}<br />
运行idea的结果如下:
检查D盘是否有SiteURL.txt文件
已经成功生成SiteURL文件,打开就可以看到所有抓到的url
java爬虫抓取网页数据(爬虫入门程序urllib2实现下载网页的三种方式:入门 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-04 02:10
)
爬虫入口程序
urllib2实现了三种下载网页的方式:
第一个:
import cookielib
import urllib2
url = "http://www.baidu.com"
response1 = urllib2.urlopen(url)
print "第一种方法"
#获取状态码,200表示成功
print response1.getcode()
#获取网页内容的长度
print len(response1.read())
第二:
request = urllib2.Request(url)
#模拟Mozilla浏览器进行爬虫
request.add_header("user-agent","Mozilla/5.0")
response2 = urllib2.urlopen(request)
print response2.getcode()
print len(response2.read())
第三:
cookie = cookielib.CookieJar()
#加入urllib2处理cookie的能力
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
urllib2.install_opener(opener)
response3 = urllib2.urlopen(url)
print response3.getcode()
print len(response3.read())
print cookie
爬虫添加数据、标头,然后发布请求
import urllib
import urllib2
url = 'http://www.server.com/login'
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
values = {'username' : 'cqc', 'password' : 'XXXX' }
headers = { 'User-Agent' : user_agent }
data = urllib.urlencode(values)
request = urllib2.Request(url, data, headers)
response = urllib2.urlopen(request)
page = response.read()
爬虫添加 cookie
为什么要添加 cookie?
Cookie,是指存储在用户本地终端上的一些网站数据(通常是加密的),用于识别用户身份和进行会话跟踪。比如有些网站需要登录才能访问某个页面,在登录之前,你想抓取一个页面内容是不允许的。然后我们就可以使用Urllib2库来保存我们登录的cookies,然后爬取其他页面来达到目的
获取 cookie 并将其保存到变量中
首先我们用CookieJar对象来实现获取cookies的功能,存储在变量中,先体验一下
import urllib2
import cookielib
#声明一个CookieJar对象实例来保存cookie
cookie = cookielib.CookieJar()
#利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器
handler=urllib2.HTTPCookieProcessor(cookie)
#通过handler来构建opener
opener = urllib2.build_opener(handler)
#此处的open方法同urllib2的urlopen方法,也可以传入request
response = opener.open('http://www.baidu.com')
for item in cookie:
print 'Name = '+item.name
print 'Value = '+item.value
我们用上面的方法将cookie保存到一个变量中,然后打印出cookie中的值,结果如下
Name = BAIDUID
Value = B07B663B645729F11F659C02AAE65B4C:FG=1
Name = BAIDUPSID
Value = B07B663B645729F11F659C02AAE65B4C
Name = H_PS_PSSID
Value = 12527_11076_1438_10633
Name = BDSVRTM
Value = 0
Name = BD_HOME
Value = 0
将 cookie 保存到文件
在上述方法中,我们将cookie保存到cookie变量中。如果我们想将 cookie 保存到文件中怎么办?这时候,我们将使用 FileCookieJar 对象,这里我们使用它的子类 MozillaCookieJar 来保存 cookie
mport cookielib
import urllib2
#设置保存cookie的文件,同级目录下的cookie.txt
filename = 'cookie.txt'
#声明一个MozillaCookieJar对象实例来保存cookie,之后写入文件
cookie = cookielib.MozillaCookieJar(filename)
#利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器
handler = urllib2.HTTPCookieProcessor(cookie)
#通过handler来构建opener
opener = urllib2.build_opener(handler)
#创建一个请求,原理同urllib2的urlopen
response = opener.open("http://www.baidu.com")
#保存cookie到文件
cookie.save(ignore_discard=True, ignore_expires=True)
正则表达式的正则表达式语法规则
查看全部
java爬虫抓取网页数据(爬虫入门程序urllib2实现下载网页的三种方式:入门
)
爬虫入口程序
urllib2实现了三种下载网页的方式:
第一个:
import cookielib
import urllib2
url = "http://www.baidu.com"
response1 = urllib2.urlopen(url)
print "第一种方法"
#获取状态码,200表示成功
print response1.getcode()
#获取网页内容的长度
print len(response1.read())
第二:
request = urllib2.Request(url)
#模拟Mozilla浏览器进行爬虫
request.add_header("user-agent","Mozilla/5.0")
response2 = urllib2.urlopen(request)
print response2.getcode()
print len(response2.read())
第三:
cookie = cookielib.CookieJar()
#加入urllib2处理cookie的能力
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
urllib2.install_opener(opener)
response3 = urllib2.urlopen(url)
print response3.getcode()
print len(response3.read())
print cookie
爬虫添加数据、标头,然后发布请求
import urllib
import urllib2
url = 'http://www.server.com/login'
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
values = {'username' : 'cqc', 'password' : 'XXXX' }
headers = { 'User-Agent' : user_agent }
data = urllib.urlencode(values)
request = urllib2.Request(url, data, headers)
response = urllib2.urlopen(request)
page = response.read()
爬虫添加 cookie
为什么要添加 cookie?
Cookie,是指存储在用户本地终端上的一些网站数据(通常是加密的),用于识别用户身份和进行会话跟踪。比如有些网站需要登录才能访问某个页面,在登录之前,你想抓取一个页面内容是不允许的。然后我们就可以使用Urllib2库来保存我们登录的cookies,然后爬取其他页面来达到目的
获取 cookie 并将其保存到变量中
首先我们用CookieJar对象来实现获取cookies的功能,存储在变量中,先体验一下
import urllib2
import cookielib
#声明一个CookieJar对象实例来保存cookie
cookie = cookielib.CookieJar()
#利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器
handler=urllib2.HTTPCookieProcessor(cookie)
#通过handler来构建opener
opener = urllib2.build_opener(handler)
#此处的open方法同urllib2的urlopen方法,也可以传入request
response = opener.open('http://www.baidu.com')
for item in cookie:
print 'Name = '+item.name
print 'Value = '+item.value
我们用上面的方法将cookie保存到一个变量中,然后打印出cookie中的值,结果如下
Name = BAIDUID
Value = B07B663B645729F11F659C02AAE65B4C:FG=1
Name = BAIDUPSID
Value = B07B663B645729F11F659C02AAE65B4C
Name = H_PS_PSSID
Value = 12527_11076_1438_10633
Name = BDSVRTM
Value = 0
Name = BD_HOME
Value = 0
将 cookie 保存到文件
在上述方法中,我们将cookie保存到cookie变量中。如果我们想将 cookie 保存到文件中怎么办?这时候,我们将使用 FileCookieJar 对象,这里我们使用它的子类 MozillaCookieJar 来保存 cookie
mport cookielib
import urllib2
#设置保存cookie的文件,同级目录下的cookie.txt
filename = 'cookie.txt'
#声明一个MozillaCookieJar对象实例来保存cookie,之后写入文件
cookie = cookielib.MozillaCookieJar(filename)
#利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器
handler = urllib2.HTTPCookieProcessor(cookie)
#通过handler来构建opener
opener = urllib2.build_opener(handler)
#创建一个请求,原理同urllib2的urlopen
response = opener.open("http://www.baidu.com";)
#保存cookie到文件
cookie.save(ignore_discard=True, ignore_expires=True)
正则表达式的正则表达式语法规则
java爬虫抓取网页数据(分布式网络新闻抓取系统的设计与实现(一)-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-04-01 14:26
1 项目介绍
本项目的主要内容是分布式网络新闻抓取系统的设计与实现。主要有以下几个部分要介绍:
(1)深入分析网络新闻爬虫特点,设计分布式网络新闻爬虫系统爬取策略、爬取领域、动态网络爬取方式、分布式结构、系统监控和数据存储六大关键功能。
(2)结合程序代码分解讲解分布式网络新闻爬虫系统的实现过程。包括爬虫编写、爬虫规避、动态网页数据爬取、分布式爬虫部署、系统监控,共六个内容,结合腾讯新闻数据的实际针对性抓取,通过测试来测试系统性能。
(3)规划设计了一个数据处理模块,包括数据清洗、代码转换、数据分类、对象添加等功能。
2. 分布式网络新闻抓取系统设计
2.1 整体系统架构设计
系统采用分布式主从结构,一台Master服务器和多台Slave服务器。Master 管理 Redis 数据库并分发下载任务。Slave 部署 Scrapy 抓取网页,解析提取项目数据。服务器的基本环境是Ubuntu操作系统,Master服务器安装Redis数据库服务器和Graphite,
Slave 安装 Scrapy 和 Redis 客户端。系统按功能可分为两大模块,一是数据采集模块,二是数据处理模块。数据抓取模块包括浏览器调用、网页下载、字段提取、爬虫规避、数据存储和系统监控六大功能;数据处理模块包括数据清洗、对象添加、编码转换和数据分类四个功能。
2.2 爬取策略设计
本项目的网络爬虫采用深度优先的爬取策略,根据设置下载网页数据。网页链接处理流程如下:
1.手动设置初始下载地址,一般是网站导航地址。
2.爬虫开始运行,从初始地址抓取第一个网页链接。
3、爬虫根据正则表达式识别新链接中的目录页地址和新闻内容页地址,将识别出的新地址加入待下载队列,等待被爬取,无法识别的网页地址为定义为无用的链接并丢弃。
4.爬虫依次取出要下载的网页链接,从待下载队列中提取数据。
5、下载队列为空,爬虫停止爬取。
新闻网站的导航页数是有限的,这个规则决定了新闻导航页的url在一定的人工参与下很容易获得,并作为爬虫系统的初始url。
2.3 爬取字段的设计
本项目的目的是捕捉网络新闻数据,因此内容必须能够客观、准确地反映网络新闻的特点。
以腾讯在线新闻数据的爬取为例,通过分析网页结构,确定了两步爬取步骤。第一步,抓取新闻内容页,获取新闻标题、新闻来源、新闻内容、发表时间、评论数、评论地址、相关搜索、用户仍喜欢的新闻、点赞数等9项内容;第二步,在获取评论地址后,抓取评论页面,获取评论者ID、评论者昵称、评论者性别、评论者所在地区、评论时间、评论内容、单条评论支持人数、回复数一条评论。
2.4 动态网页抓取方法设计
腾讯新闻网页使用Java生成动态网页内容。一些 JS 事件触发页面内容在打开时会发生变化,而一些网页在没有 JS 支持的情况下根本无法工作。普通爬虫根本无法从这些页面获取数据。解决Java动态网页爬取问题的方法有四种:
1、编写代码模拟相关的JS逻辑。
2. 调用带有界面的浏览器,类似于那些广泛用于测试的浏览器,例如 Selenium。
3、使用无界面浏览器,各种基于Webkit的,如Casperjs、Phantomjs等。
4.结合JS执行引擎,实现轻量级浏览器。
由于本项目是基于Python作为主要语言编写的,所以使用Selenium来处理JS
动态新闻页面。它的优点是简单和易于实施。使用Python代码模拟用户对浏览器的操作,首先将网页加载到浏览器中打开,然后从浏览器缓存中获取网页数据,传递给spider进行解析提取,最后将目标数据传递给项目频道。
2.5 爬虫分布式设计
使用Redis数据库实现分布式爬取。基本思路是Scrapy爬虫获取到的urls(request)
都放在一个 Redis Queue 中,所有爬虫也从指定的 Redis Queue 中获取请求(url)。
Scrapy-Redis 默认使用 Spider Priority Queue 来确定 url 的顺序,由 sorted set 决定
实现了非 FIFO 和 LIFO 方法。
Redis 存储了 Scrapy 项目的 request 和 stats 信息,根据这些信息可以掌握任务
情况和爬虫状态,在分配任务时很容易平衡系统负载,有助于克服爬虫的性能瓶颈。同时
利用 Redis 的高性能和易扩展性,可以轻松实现高效下载。当 Redis 存储或
当访问速度遇到问题时,可以通过增加 Redis 集群和爬虫集群的数量来提高。Scrapy-Redis
分布式解决方案解决了间歇性爬取和重复数据删除的问题。爬虫重启后会和Redis进行比较。
抓取队列中的url,已经抓取的url会被自动过滤掉。
2.6 基于Graphite系统的监控组件设计
使用Graphite监控系统运行状态,实现了一个分布式系统的statscollector,
系统的统计信息以图表的形式实时动态显示,即实时监控。Graphite监控的信息包括:系统下载信息、日志信息、文件数、调度信息、爬虫运行信息、爬虫异常信息、文件数、获取的项目数、最大请求深度、收到的响应数。
2.7 数据存储模块设计
Scrapy 支持 json、csv 和 xml 等文本格式的数据存储。用户可以在运行爬虫时设置,例如:scrapy crawlspider –o items.json –t json,或者在Scrapy项目文件的Item Pipeline中
在文件中定义。除此之外,Scrapy 还提供了多种数据库 API 来支持数据库存储。比如 MongoDB,
雷迪斯等人。数据存储分为两部分,一是网页链接的存储,二是项目数据的存储。网络链接存储
存储在Redis数据库中,用于实现分布式爬虫的下载管理;项目数据包括新闻数据和评论数据,以JSON格式保存为文本文件,方便处理。评论数据以评论url中收录的评论ID命名存储,这是一种将新闻数据与评论数据相关联的方式。
3 项目总结 查看全部
java爬虫抓取网页数据(分布式网络新闻抓取系统的设计与实现(一)-上海怡健医学)
1 项目介绍
本项目的主要内容是分布式网络新闻抓取系统的设计与实现。主要有以下几个部分要介绍:
(1)深入分析网络新闻爬虫特点,设计分布式网络新闻爬虫系统爬取策略、爬取领域、动态网络爬取方式、分布式结构、系统监控和数据存储六大关键功能。
(2)结合程序代码分解讲解分布式网络新闻爬虫系统的实现过程。包括爬虫编写、爬虫规避、动态网页数据爬取、分布式爬虫部署、系统监控,共六个内容,结合腾讯新闻数据的实际针对性抓取,通过测试来测试系统性能。
(3)规划设计了一个数据处理模块,包括数据清洗、代码转换、数据分类、对象添加等功能。
2. 分布式网络新闻抓取系统设计
2.1 整体系统架构设计
系统采用分布式主从结构,一台Master服务器和多台Slave服务器。Master 管理 Redis 数据库并分发下载任务。Slave 部署 Scrapy 抓取网页,解析提取项目数据。服务器的基本环境是Ubuntu操作系统,Master服务器安装Redis数据库服务器和Graphite,
Slave 安装 Scrapy 和 Redis 客户端。系统按功能可分为两大模块,一是数据采集模块,二是数据处理模块。数据抓取模块包括浏览器调用、网页下载、字段提取、爬虫规避、数据存储和系统监控六大功能;数据处理模块包括数据清洗、对象添加、编码转换和数据分类四个功能。
2.2 爬取策略设计
本项目的网络爬虫采用深度优先的爬取策略,根据设置下载网页数据。网页链接处理流程如下:
1.手动设置初始下载地址,一般是网站导航地址。
2.爬虫开始运行,从初始地址抓取第一个网页链接。
3、爬虫根据正则表达式识别新链接中的目录页地址和新闻内容页地址,将识别出的新地址加入待下载队列,等待被爬取,无法识别的网页地址为定义为无用的链接并丢弃。
4.爬虫依次取出要下载的网页链接,从待下载队列中提取数据。
5、下载队列为空,爬虫停止爬取。
新闻网站的导航页数是有限的,这个规则决定了新闻导航页的url在一定的人工参与下很容易获得,并作为爬虫系统的初始url。
2.3 爬取字段的设计
本项目的目的是捕捉网络新闻数据,因此内容必须能够客观、准确地反映网络新闻的特点。
以腾讯在线新闻数据的爬取为例,通过分析网页结构,确定了两步爬取步骤。第一步,抓取新闻内容页,获取新闻标题、新闻来源、新闻内容、发表时间、评论数、评论地址、相关搜索、用户仍喜欢的新闻、点赞数等9项内容;第二步,在获取评论地址后,抓取评论页面,获取评论者ID、评论者昵称、评论者性别、评论者所在地区、评论时间、评论内容、单条评论支持人数、回复数一条评论。
2.4 动态网页抓取方法设计
腾讯新闻网页使用Java生成动态网页内容。一些 JS 事件触发页面内容在打开时会发生变化,而一些网页在没有 JS 支持的情况下根本无法工作。普通爬虫根本无法从这些页面获取数据。解决Java动态网页爬取问题的方法有四种:
1、编写代码模拟相关的JS逻辑。
2. 调用带有界面的浏览器,类似于那些广泛用于测试的浏览器,例如 Selenium。
3、使用无界面浏览器,各种基于Webkit的,如Casperjs、Phantomjs等。
4.结合JS执行引擎,实现轻量级浏览器。
由于本项目是基于Python作为主要语言编写的,所以使用Selenium来处理JS
动态新闻页面。它的优点是简单和易于实施。使用Python代码模拟用户对浏览器的操作,首先将网页加载到浏览器中打开,然后从浏览器缓存中获取网页数据,传递给spider进行解析提取,最后将目标数据传递给项目频道。
2.5 爬虫分布式设计
使用Redis数据库实现分布式爬取。基本思路是Scrapy爬虫获取到的urls(request)
都放在一个 Redis Queue 中,所有爬虫也从指定的 Redis Queue 中获取请求(url)。
Scrapy-Redis 默认使用 Spider Priority Queue 来确定 url 的顺序,由 sorted set 决定
实现了非 FIFO 和 LIFO 方法。
Redis 存储了 Scrapy 项目的 request 和 stats 信息,根据这些信息可以掌握任务
情况和爬虫状态,在分配任务时很容易平衡系统负载,有助于克服爬虫的性能瓶颈。同时
利用 Redis 的高性能和易扩展性,可以轻松实现高效下载。当 Redis 存储或
当访问速度遇到问题时,可以通过增加 Redis 集群和爬虫集群的数量来提高。Scrapy-Redis
分布式解决方案解决了间歇性爬取和重复数据删除的问题。爬虫重启后会和Redis进行比较。
抓取队列中的url,已经抓取的url会被自动过滤掉。
2.6 基于Graphite系统的监控组件设计
使用Graphite监控系统运行状态,实现了一个分布式系统的statscollector,
系统的统计信息以图表的形式实时动态显示,即实时监控。Graphite监控的信息包括:系统下载信息、日志信息、文件数、调度信息、爬虫运行信息、爬虫异常信息、文件数、获取的项目数、最大请求深度、收到的响应数。
2.7 数据存储模块设计
Scrapy 支持 json、csv 和 xml 等文本格式的数据存储。用户可以在运行爬虫时设置,例如:scrapy crawlspider –o items.json –t json,或者在Scrapy项目文件的Item Pipeline中
在文件中定义。除此之外,Scrapy 还提供了多种数据库 API 来支持数据库存储。比如 MongoDB,
雷迪斯等人。数据存储分为两部分,一是网页链接的存储,二是项目数据的存储。网络链接存储
存储在Redis数据库中,用于实现分布式爬虫的下载管理;项目数据包括新闻数据和评论数据,以JSON格式保存为文本文件,方便处理。评论数据以评论url中收录的评论ID命名存储,这是一种将新闻数据与评论数据相关联的方式。
3 项目总结
java爬虫抓取网页数据(Python即时网络爬虫GitHub源7,文档修改历史(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-31 22:15
)
1 简介
本文介绍了如何使用 GooSeeker API 下载 Java 和 JavaScript 中的内容提取器。这是一个示例程序。什么是内容提取器?为什么要用这种方式?来自 Python Instant Web Crawler 开源项目:通过生成内容提取器来节省程序员的时间。详情请参阅“内容提取器的定义”。
2.用Java下载内容提取器
这是一系列示例程序之一。就目前编程语言的发展而言,Java并不适合提取网页内容。除了语言的不灵活和方便外,整个生态系统还不够活跃,可选类库增长缓慢。此外,要从 JavaScript 动态网页中提取内容,Java 也很不方便,需要 JavaScript 引擎。使用 JavaScript 下载内容提取器以直接跳到第 3 部分的内容。
执行
注解:
源代码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613 ... 3B%3B // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
返回结果如下:
3. 使用 JavaScript 下载内容提取器
请注意,如果本示例中的 JavaScript 代码运行在网页上,由于跨域问题,无法抓取非本地网页的内容。因此,需要在特权JavaScript引擎上运行,例如浏览器扩展、自研浏览器、自身程序中的JavaScript引擎等。
为了实验的方便,这个例子还在网页上运行。为了绕过跨域问题,保存并修改目标网页,并在其中插入JavaScript。这么多手动操作只是为了实验,正式使用时还需要考虑其他手段。
执行
注解:
这是源代码:
返回结果截图如下
4、展望
您还可以使用 Python 来获取指定网页的内容。我觉得Python的语法更简洁。以后我会添加 Python 语言的例子。有兴趣的朋友可以加入研究。
五、相关文件
Python Instant Web Crawler:API 说明
6.Jisouke GooSeeker开源代码下载源
GooSeeker 开源 Python 网络爬虫 GitHub 源码
7.文档修改历史
2016-06-20: V1.0
如有疑问,您可以或
查看全部
java爬虫抓取网页数据(Python即时网络爬虫GitHub源7,文档修改历史(组图)
)
1 简介
本文介绍了如何使用 GooSeeker API 下载 Java 和 JavaScript 中的内容提取器。这是一个示例程序。什么是内容提取器?为什么要用这种方式?来自 Python Instant Web Crawler 开源项目:通过生成内容提取器来节省程序员的时间。详情请参阅“内容提取器的定义”。
2.用Java下载内容提取器
这是一系列示例程序之一。就目前编程语言的发展而言,Java并不适合提取网页内容。除了语言的不灵活和方便外,整个生态系统还不够活跃,可选类库增长缓慢。此外,要从 JavaScript 动态网页中提取内容,Java 也很不方便,需要 JavaScript 引擎。使用 JavaScript 下载内容提取器以直接跳到第 3 部分的内容。
执行
注解:
源代码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613 ... 3B%3B // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
返回结果如下:
3. 使用 JavaScript 下载内容提取器
请注意,如果本示例中的 JavaScript 代码运行在网页上,由于跨域问题,无法抓取非本地网页的内容。因此,需要在特权JavaScript引擎上运行,例如浏览器扩展、自研浏览器、自身程序中的JavaScript引擎等。
为了实验的方便,这个例子还在网页上运行。为了绕过跨域问题,保存并修改目标网页,并在其中插入JavaScript。这么多手动操作只是为了实验,正式使用时还需要考虑其他手段。
执行
注解:
这是源代码:
返回结果截图如下
4、展望
您还可以使用 Python 来获取指定网页的内容。我觉得Python的语法更简洁。以后我会添加 Python 语言的例子。有兴趣的朋友可以加入研究。
五、相关文件
Python Instant Web Crawler:API 说明
6.Jisouke GooSeeker开源代码下载源
GooSeeker 开源 Python 网络爬虫 GitHub 源码
7.文档修改历史
2016-06-20: V1.0
如有疑问,您可以或
java爬虫抓取网页数据(Java爬虫实战(一):爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2022-03-28 19:27
爬取java爬虫相关博客
Java爬虫,信息爬取(传输)的实现
转载请注明出处: 今天公司有个需求,要抓到指定网站查询后的数据,所以抽时间写了一个demo来演示使用。这个想法很简单:它是通过 Ja
developerguy6 年前1569
超级简单的java爬虫
最简单的爬虫,不需要设置代理服务器,不需要设置cookie,不需要http连接池,使用httpget方法,只需要获取html代码……嗯,符合这个要求的爬虫应该是最基本的爬虫了。当然,这也是制作复杂爬虫的基础。使用了httpclient4的相关API。
爱丹7 年前803
Java爬虫实战(一):抓取一个网站上的所有链接
算法介绍 程序采用idea中的广度优先算法,对未遍历的链接逐一发起GET请求,然后用正则表达式解析返回的页面,取出未遍历的新链接已找到,并将它们添加到集合中。迭代下一个循环。具体实现使用Map,键值对是链接和
技术哥 4年前 962
简单的Java爬虫制作
一、文章芮雨本来最近任务挺多的,今天想放松一下,正好比尔喜欢玩英文配音,配音全在配音云上软件,想全部搞定,所以写了一个爬虫,然后就有了这个爬虫教程~~二、爬虫!!爬虫!!首先我们要搞清楚什么是爬虫~~网络爬虫(又称网络蜘蛛、网络机器
this_is_bill6 年前 1692
一个分布式java爬虫框架JLiteSpider
一个精简的分布式 Java 蜘蛛框架。这是一个轻量级的分布式 Java 蜘蛛框架。特点 这是一个强大但轻量级的分布式蜘蛛框架。jlitespider本质上是分布式的,每个worker需要传递一个或多个消息
建筑之路 3年前 1955
一个分布式java爬虫框架JLiteSpider
JLiteSpider 一个精简的分布式 Java 蜘蛛框架。这是一个轻量级的分布式 Java 蜘蛛框架。特点 这是一个强大但轻量级的分布式蜘蛛框架。jlitespider 本质上是分布式的,并且在工人之间
建筑之路 3年前 1207
Java爬虫-微博热搜
前言由于写了文章关于Lifecycle的内容,还没有找到其他有趣的源码,所以决定看一下写后台代码,一波试试。百度了一周左右,SSM框架基本完成。一时兴起,我打算采集各种热搜。最先想到的肯定是微博热搜,那么,让我们一起爬下微博热搜吧!工具
ksuu3 年前 1826
函数计算实战-java爬虫从指定网站获取图片并存入对象存储的例子
前段时间,阿里云函数计算推出了Java8版本的编译环境。我结合一门Java语言完成了函数计算的代码编写。本例主要模拟一个网站图片爬虫,并指定指定的网站。获取页面的所有图片并保存到对象存储中,绘制简单的架构图如下: 流程说明:用户输入某个网站地址,爬取
文一4年前3399
爬取java爬虫相关问答
请问Java_crawler,Js如何爬取动态生成数据的页面?
很多网站使用`js`或者`jquery`生成数据,后台获取数据后,使用`document.write()`或者`("#id").html=""`的时候写入页面,此时用浏览器查看源代码是看不到数据的。`HttpClient` 将不起作用
爵士 6 年前 2752
如何使用 crawler4j 作为网络爬虫来爬取特定的标题和发布时间
如何使用 crawler4j 进行网页爬取
野蛮人 1235 年前 913
爬虫数据管理【问答合集】
互联网爬虫的自然语言处理目前前景如何?artTemplate:arttemplate生成的页面可以爬取到数据吗?
我是管理员 3 年前 28342
MongoDB吃内存,怎么办?
我最近使用爬虫来捕获数据。刚开始java和mysql的时候,发现mysql的插入速度有点慢,所以换成了mongodb。速度提升了很多,但是问题出来了,怎么控制mongodb的内存,完全吃光了不能配置一个最大内存使用量吗?我有大量的数据,每天都需要抓取新的数据。
花开 6年前 1127
MongoDB这么吃内存,怎么存。
我最近使用爬虫来捕获数据。刚开始java和mysql的时候,发现mysql的插入速度有点慢,于是换成了mongodb,速度提升了很多,但是问题就出来了。,完全吃光了,不能配置一个最大内存使用量吗?我的数据量很大,每天都需要获取新数据。
a1234566785 前 741
MongoDB这么吃内存,怎么存。
我最近使用爬虫来捕获数据。刚开始java和mysql的时候,发现mysql的插入速度有点慢,于是换成了mongodb,速度提升了很多,但是问题就出来了。,完全吃光了,不能配置一个最大内存使用量吗?我的数据量很大,每天都需要获取新数据。
小旋风柴进6年前830 查看全部
java爬虫抓取网页数据(Java爬虫实战(一):爬虫)
爬取java爬虫相关博客
Java爬虫,信息爬取(传输)的实现
转载请注明出处: 今天公司有个需求,要抓到指定网站查询后的数据,所以抽时间写了一个demo来演示使用。这个想法很简单:它是通过 Ja
developerguy6 年前1569
超级简单的java爬虫
最简单的爬虫,不需要设置代理服务器,不需要设置cookie,不需要http连接池,使用httpget方法,只需要获取html代码……嗯,符合这个要求的爬虫应该是最基本的爬虫了。当然,这也是制作复杂爬虫的基础。使用了httpclient4的相关API。
爱丹7 年前803
Java爬虫实战(一):抓取一个网站上的所有链接
算法介绍 程序采用idea中的广度优先算法,对未遍历的链接逐一发起GET请求,然后用正则表达式解析返回的页面,取出未遍历的新链接已找到,并将它们添加到集合中。迭代下一个循环。具体实现使用Map,键值对是链接和
技术哥 4年前 962
简单的Java爬虫制作
一、文章芮雨本来最近任务挺多的,今天想放松一下,正好比尔喜欢玩英文配音,配音全在配音云上软件,想全部搞定,所以写了一个爬虫,然后就有了这个爬虫教程~~二、爬虫!!爬虫!!首先我们要搞清楚什么是爬虫~~网络爬虫(又称网络蜘蛛、网络机器
this_is_bill6 年前 1692
一个分布式java爬虫框架JLiteSpider
一个精简的分布式 Java 蜘蛛框架。这是一个轻量级的分布式 Java 蜘蛛框架。特点 这是一个强大但轻量级的分布式蜘蛛框架。jlitespider本质上是分布式的,每个worker需要传递一个或多个消息
建筑之路 3年前 1955
一个分布式java爬虫框架JLiteSpider
JLiteSpider 一个精简的分布式 Java 蜘蛛框架。这是一个轻量级的分布式 Java 蜘蛛框架。特点 这是一个强大但轻量级的分布式蜘蛛框架。jlitespider 本质上是分布式的,并且在工人之间
建筑之路 3年前 1207
Java爬虫-微博热搜
前言由于写了文章关于Lifecycle的内容,还没有找到其他有趣的源码,所以决定看一下写后台代码,一波试试。百度了一周左右,SSM框架基本完成。一时兴起,我打算采集各种热搜。最先想到的肯定是微博热搜,那么,让我们一起爬下微博热搜吧!工具
ksuu3 年前 1826
函数计算实战-java爬虫从指定网站获取图片并存入对象存储的例子
前段时间,阿里云函数计算推出了Java8版本的编译环境。我结合一门Java语言完成了函数计算的代码编写。本例主要模拟一个网站图片爬虫,并指定指定的网站。获取页面的所有图片并保存到对象存储中,绘制简单的架构图如下: 流程说明:用户输入某个网站地址,爬取
文一4年前3399
爬取java爬虫相关问答
请问Java_crawler,Js如何爬取动态生成数据的页面?
很多网站使用`js`或者`jquery`生成数据,后台获取数据后,使用`document.write()`或者`("#id").html=""`的时候写入页面,此时用浏览器查看源代码是看不到数据的。`HttpClient` 将不起作用
爵士 6 年前 2752
如何使用 crawler4j 作为网络爬虫来爬取特定的标题和发布时间
如何使用 crawler4j 进行网页爬取
野蛮人 1235 年前 913
爬虫数据管理【问答合集】
互联网爬虫的自然语言处理目前前景如何?artTemplate:arttemplate生成的页面可以爬取到数据吗?
我是管理员 3 年前 28342
MongoDB吃内存,怎么办?
我最近使用爬虫来捕获数据。刚开始java和mysql的时候,发现mysql的插入速度有点慢,所以换成了mongodb。速度提升了很多,但是问题出来了,怎么控制mongodb的内存,完全吃光了不能配置一个最大内存使用量吗?我有大量的数据,每天都需要抓取新的数据。
花开 6年前 1127
MongoDB这么吃内存,怎么存。
我最近使用爬虫来捕获数据。刚开始java和mysql的时候,发现mysql的插入速度有点慢,于是换成了mongodb,速度提升了很多,但是问题就出来了。,完全吃光了,不能配置一个最大内存使用量吗?我的数据量很大,每天都需要获取新数据。
a1234566785 前 741
MongoDB这么吃内存,怎么存。
我最近使用爬虫来捕获数据。刚开始java和mysql的时候,发现mysql的插入速度有点慢,于是换成了mongodb,速度提升了很多,但是问题就出来了。,完全吃光了,不能配置一个最大内存使用量吗?我的数据量很大,每天都需要获取新数据。
小旋风柴进6年前830
java爬虫抓取网页数据(网络爬虫的数据采集方法有哪几类?工具介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 269 次浏览 • 2022-03-28 19:23
网络爬虫的data采集方法有哪些?网络数据采集是指通过网络爬虫或网站公共API从网站获取数据信息。在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。在大数据时代,网络爬虫更是采集互联网数据的利器。目前已知的各种网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。
网络爬虫工具有哪些类型?
1、分布式网络爬虫工具,例如 Nutch。
2、Crawler4j、WebMagic、WebCollector等Java网络爬虫工具。
3、非Java网络爬虫工具,如Scrapy(基于Python语言开发)。
网络爬虫的原理是什么?
网络爬虫是根据一定的规则自动爬取网络信息的程序或脚本。网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。在功能上,爬虫一般具有三个功能:数据采集、处理和存储。
除了供用户阅读的文字信息外,网页还收录一些超链接信息。
网络爬虫系统正是通过网页中的超链接信息不断获取网络上的其他网页。网络爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
网络爬虫系统一般会选择一些比较重要的、出度(网页链接出的超链接数)网站较大的URL作为种子URL集。
网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。
网页之间的指向结构可以看成一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以按照广度优先搜索算法遍历所有信息或深度优先搜索算法。网页。
由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,因此广度优先搜索算法一般使用采集网页。
网络爬虫系统首先将种子 URL 放入下载队列,简单地从队列头部取一个 URL 下载其对应的网页,获取网页内容并存储,然后解析链接信息网页以获取一些新的 URL。
其次,根据一定的网页分析算法,过滤掉与主题无关的链接,保留有用的链接,放入待抓取的URL队列中。
最后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫工作流程
1)首先选择 Torrent URL 的一部分。
2)将这些网址放入待抓取的网址队列中。
3)从待爬取URL队列中获取待爬取URL,解析DNS,获取主机IP地址,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列。
4)分析已爬取URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取URL队列,从而进入下一个循环。
网络爬虫抓取策略
1. 通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子URL延伸到整个网络,主要针对门户网站搜索引擎和大型网络服务商采集数据。为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略有深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫将从起始页面开始,并逐个链接地跟踪它,直到无法再深入为止。完成一个爬取分支后,网络爬虫返回上一个链接节点,进一步搜索其他链接。当所有的链接都遍历完后,爬取任务结束。这种策略比较适合垂直搜索或者站内搜索,但是在抓取页面内容比较深的网站时会造成巨大的资源浪费。
在深度优先策略中,当搜索一个节点时,该节点的子节点和子节点的后继节点都在该节点的兄弟节点之前,深度优先策略是在搜索空间中。有时,它会尝试尽可能深入,并且仅在找不到节点的后继节点时才考虑其兄弟节点。这样的策略决定了深度优先策略不一定能找到最优解,甚至由于深度的限制而无法找到解。
如果不加以限制,它将沿着一条路径无限扩展,这将“捕获”成大量数据。一般来说,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样会降低搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录层次的深度对页面进行爬取,较浅的目录层次的页面先爬取。当同一级别的页面被爬取时,爬虫进入下一级继续爬取。由于广度优先策略是在第 N 层的节点扩展完成后进入第 N+1 层,保证了通过最短路径找到解。该策略可以有效控制页面的爬取深度,避免遇到无限深分支时无法结束爬取的问题。易于实现,不需要存储大量的中间节点。缺点是爬到更深的目录级别需要很长时间。页。
如果搜索的分支太多,即节点的后继节点太多,算法就会耗尽资源,在可用空间中找不到解。 查看全部
java爬虫抓取网页数据(网络爬虫的数据采集方法有哪几类?工具介绍)
网络爬虫的data采集方法有哪些?网络数据采集是指通过网络爬虫或网站公共API从网站获取数据信息。在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。在大数据时代,网络爬虫更是采集互联网数据的利器。目前已知的各种网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。
网络爬虫工具有哪些类型?
1、分布式网络爬虫工具,例如 Nutch。
2、Crawler4j、WebMagic、WebCollector等Java网络爬虫工具。
3、非Java网络爬虫工具,如Scrapy(基于Python语言开发)。
网络爬虫的原理是什么?
网络爬虫是根据一定的规则自动爬取网络信息的程序或脚本。网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。在功能上,爬虫一般具有三个功能:数据采集、处理和存储。
除了供用户阅读的文字信息外,网页还收录一些超链接信息。
网络爬虫系统正是通过网页中的超链接信息不断获取网络上的其他网页。网络爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
网络爬虫系统一般会选择一些比较重要的、出度(网页链接出的超链接数)网站较大的URL作为种子URL集。
网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。
网页之间的指向结构可以看成一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以按照广度优先搜索算法遍历所有信息或深度优先搜索算法。网页。
由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,因此广度优先搜索算法一般使用采集网页。
网络爬虫系统首先将种子 URL 放入下载队列,简单地从队列头部取一个 URL 下载其对应的网页,获取网页内容并存储,然后解析链接信息网页以获取一些新的 URL。
其次,根据一定的网页分析算法,过滤掉与主题无关的链接,保留有用的链接,放入待抓取的URL队列中。
最后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫工作流程
1)首先选择 Torrent URL 的一部分。
2)将这些网址放入待抓取的网址队列中。
3)从待爬取URL队列中获取待爬取URL,解析DNS,获取主机IP地址,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列。
4)分析已爬取URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取URL队列,从而进入下一个循环。
网络爬虫抓取策略
1. 通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子URL延伸到整个网络,主要针对门户网站搜索引擎和大型网络服务商采集数据。为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略有深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫将从起始页面开始,并逐个链接地跟踪它,直到无法再深入为止。完成一个爬取分支后,网络爬虫返回上一个链接节点,进一步搜索其他链接。当所有的链接都遍历完后,爬取任务结束。这种策略比较适合垂直搜索或者站内搜索,但是在抓取页面内容比较深的网站时会造成巨大的资源浪费。
在深度优先策略中,当搜索一个节点时,该节点的子节点和子节点的后继节点都在该节点的兄弟节点之前,深度优先策略是在搜索空间中。有时,它会尝试尽可能深入,并且仅在找不到节点的后继节点时才考虑其兄弟节点。这样的策略决定了深度优先策略不一定能找到最优解,甚至由于深度的限制而无法找到解。
如果不加以限制,它将沿着一条路径无限扩展,这将“捕获”成大量数据。一般来说,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样会降低搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录层次的深度对页面进行爬取,较浅的目录层次的页面先爬取。当同一级别的页面被爬取时,爬虫进入下一级继续爬取。由于广度优先策略是在第 N 层的节点扩展完成后进入第 N+1 层,保证了通过最短路径找到解。该策略可以有效控制页面的爬取深度,避免遇到无限深分支时无法结束爬取的问题。易于实现,不需要存储大量的中间节点。缺点是爬到更深的目录级别需要很长时间。页。
如果搜索的分支太多,即节点的后继节点太多,算法就会耗尽资源,在可用空间中找不到解。
java爬虫抓取网页数据(Java网络爬虫的分类及开发逻辑【一课一】)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-28 06:16
介绍
在大数据环境下,数据分析从业务驱动向数据驱动转变,网络数据资源呈指数级增长,分散在不同的数据源中。对于大多数公司和研究人员来说,用“数据说话”似乎是大数据时代的重要武器。网络爬虫作为网络数据获取的重要技术,受到越来越多数据需求者的青睐和追捧。
作为网络爬虫的介绍,使用了Java开发语言。内容涵盖网络爬虫原理及开发逻辑、Java网络爬虫基础知识、网络抓包介绍、jsoup介绍与使用、HttpClient介绍与使用。本课程在介绍网络爬虫基本原理的同时,着重具体代码实现,加深读者对爬虫的理解,增强读者的动手能力。
内容
第01课:网络爬虫原理
介绍
随着互联网的飞速发展,网络资源越来越丰富,如何从网络中提取信息对于信息需求者来说变得非常重要。目前,有效获取网络数据资源的重要途径是网络爬虫技术。简单理解,比如你对百度贴吧上一个帖子的内容特别感兴趣,但是帖子的回复却有1000多页。在这种情况下,使用一个一个复制的方法是不可行的。并且使用网络爬虫可以轻松采集到帖子下的所有内容。
最广泛使用的网络爬虫技术是在搜索引擎中,如百度、谷歌、必应等,它完成了搜索过程中最关键的一步,即对网页内容的爬取。下图是一个简单的搜索引擎的示意图。
网络爬虫的作用可以总结如下:
网络爬虫覆盖的领域包括:
网络爬虫的基本概念
Web Crawler,也称为Web Spider或Web Information采集器,是一种计算机程序或自动化脚本,根据一定的规则自动爬取或下载网络信息。它是当前搜索引擎的重要组成部分。
网络爬虫的分类
网络爬虫根据系统架构和实现技术大致可以分为以下几种:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫(Deep Web Crawler)。实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。
网络爬虫的过程
网络爬虫的基本流程可以用下图来描述:
具体流程为:
请求者选择种子 URL(或初始 URL)的一部分并将其放入待爬取的队列中。与Java网络爬虫一样,可以放入LinkedList或List。判断URL队列是否为空,如果为空,则结束程序的执行,否则,执行第三步。从待爬取URL队列中取出一个待爬取URL,获取该URL对应的网页内容。在这一步中,需要使用响应的状态码(如200、403等)来判断是否获取数据。如果响应成功,则进行解析操作;如果响应不成功,则放回待爬取队列中(注意这里需要去掉。无效的URL)。对响应成功后获取的数据执行页面解析操作。
网络爬虫抓取策略
一般的网络爬虫爬取策略有两种:深度优先搜索策略和广度优先搜索策略。
基于广度优先的爬虫是爬取网站页面最简单的方法,也是目前应用最广泛的方法。在这个大师班里,提到的案例都是广度优先爬虫。
学习建议
网络爬虫是对某种编程语言入门的实用技术:很多学习编程语言(如Java、Python或C++等)的同学只是在网上看书或看一些视频,后果不堪设想。这将是面对面的,当涉及到一个具体的项目时,我不知道如何开始,尤其是对于初学者。或者,一段时间后,之前的书籍内容或视频内容就被遗忘了。
为此,我建议这些学习者可以使用网络爬虫技术来入门一种编程语言(如Java、Python)。因为爬虫技术是一门综合性很强的技术,它涉及到编程语言的很多方面。本次大师班特别选择Java作为开发语言,带你了解Java爬虫背后的核心技术。完成本课程后,相信您对 Java 编程语言有了很好的介绍。
零基础开始Java爬虫的同学,在学习过程中请注意以下几点:
最后,提供一些书籍和资料,供刚入门并想进一步了解 Java 网络爬虫的读者使用:
清华大学出版社出版的《Java Object-Oriented Programming》(耿祥一、张月平主编)是一本可以作为基础学习的大学教材。《Java 核心技术》2 卷。《Effective Java (3rd Edition)》:目前英文版是第三版,中文版还在第二版。本书是高级Java的必备书籍。英语较好的同学可以直接看英文版。《Do It Yourself Web Crawler》(罗刚主编),国内第一本专门研究Java网络爬虫的书籍。
第 2 课:Java 网络爬虫基础知识
介绍
Java网络爬虫具有良好的扩展性和可扩展性,是当前搜索引擎开发的重要组成部分。例如,著名的网络爬虫工具 Nutch 是用 Java 开发的,它基于 Apache Hadoop 数据结构,提供了良好的批处理支持。
Java网页爬取涉及到大量的Java知识。本文将介绍网络爬虫需要了解的Java知识以及这些知识主要用于网络爬虫的哪个部分,包括以下内容:
使用Maven
什么是马文
Maven 是 Apache 软件基金会提供的用于项目管理和自动化构建的工具。我们知道,在构建Java项目的时候,需要用到很多Jar包。例如,需要使用mysql-connector-java及其相关依赖来操作数据库。Maven工具可以方便的管理我们在项目中使用的开源Jar包,比如下载Java项目需要的Jar包以及相关的Java依赖包。
如何使用 Maven
Maven 使用存储在名为 pom.xml 的文件中的项目对象模型 (POM) 进行配置。以Java为例,我们可以在Eclipse中创建一个Maven项目。其中,Maven Dependencies 存放的是由 Maven 管理的 Jar 包。
如前所述,构建 Java 项目需要使用许多 Jar 包。例如,在Java网络爬虫中,我们需要使用相关的Jar包进行数据库连接、请求网页内容、解析网页内容。将以下语句添加到 pom 文件中:
mysql mysql-connector-java 5.1.35 org.jsoup jsoup 1.8.2 org.apache.httpcomponents httpclient 4.2.3
之后,我们会惊奇的发现项目的Maven Dependencies中自动下载了相关的Jar包及其依赖的Jar包。
读者可以在 Maven Repository 网站 中检索到自己想要的 Jar 包和 Maven 操作语句。
log4j 的使用
什么是 log4j
log4j 是一个基于 Java 的日志记录工具,曾经是 Apache 软件基金会的一个项目。今天,日志是应用软件的一个组成部分。
如何使用 log4j
1. 使用Maven下载log4j Jar包,代码如下:
log4j log4j 1.2.17
2. 在src目录下创建一个log4j.properties文本文件并进行配置(各个配置的具体含义,读者可以参考博文《Log4j详解》):
### set ###log4j.rootLogger = debug,stdout,D,E ###输出信息来控制提升###log4j.appender.stdout =
org.apache.log4j.ConsoleAppenderlog4j.appender.stdout.Target=System.outlog4j.appender.stdout.layout=org.apache.log4j.PatternLayoutlog4j.appender.stdout.layout.ConversionPattern=[%-5p]%d{yyyy- MM-dd HH:mm:ss,SSS} 方法:%l%n%m%n### 将 DEBUG 级别以上的日志输出到 =error.log ###log4j.appender.D = org.apache.log4j。DailyRollingFileAppenderlog4j.appender.D.File=E://logs/log.loglog4j.appender.D.Append=truelog4j.appender.D.Threshold=DEBUG log4j.appender.D.layout=org.apache.log4j.PatternLayoutlog4j.appender .D.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n### 将 ERROR 级别以上的日志输出到 =error 。日志###log4j.appender.E=org.apache.log4j.DailyRollingFileAppenderlog4j.appender.E.File=E://logs/error.log log4j.appender.E.Append=truelog4j.appender.E.Threshold=错误log4j.appender.E.layout = org.apache.log4j.PatternLayoutlog4j。
3. 示例程序,如下:
包 log4j;import mons.logging.Log;import mons.logging.LogFactory;public class Test { static final Log logger = LogFactory.getLog(Test.class); 公共静态 void main(String[] args) { System.out. println("你好"); (“你好世界”); logger.debug("这是调试信息。"); logger.warn("这是警告信息。"); logger.error("这是错误信息。"); "); }}
基于这个程序,我们可以看到在我们项目的根目录下会生成一个日志文件error.log和log.log。
在网络爬虫中,我们可以通过日志来记录程序可能出错的地方,监控程序的运行状态。
对象创建
在 Java 中,new 关键字通常用于创建对象。比如在爬取京东商品的id、product_name(商品名)、price(价格)时,我们需要将每个商品的信息封装成一个对象。
JdInfoModel jingdongproduct = new JdInfoModel();
在爬虫中,我们要操作JdInfoModel类中的变量(即id、product_name、price),可以通过私有变量来定义。并且,使用 set() 和 get() 方法设置数据(爬取数据的封装)和获取使用(爬取数据的存储)。以下代码用于 JdInfoModel 类:
包模型;公共类 JdInfoModel { 私有 int id;私有字符串产品名称;私人双倍价格;public int getId() { 返回 id; } public void setId(int id) { this.id = id; } public String getProduct_name() { return product_name; } public void setProduct_name(String product_name) { this.product_name = product_name; } public double getPrice() { 返回价格;} public void setPrice(double price) { this.price = price; } }
采集品的使用
网络爬虫离不开对集合的操作,这涉及到对List、Set、Queue、Map等集合的操作。
List 和 Set 集合的使用
List 的特点是它的元素以线性方式存储,重复的对象可以存储在集合中。相比之下,Set 集合中的对象没有按特定方式排序,也没有重复的对象。在网络爬虫中,List 可用于存储要爬取的 URL 列表。例如:
//创建List集合List urllist = new ArrayList();urllist.add("
");urllist.add("");//第一种遍历方法for(String url : urllist){ System.out.println(url);}//第二种遍历方法for(int i=0; i it = urllist.iterator();while (it.hasNext()){ System.out.println(it.next());}
同时,我们也可以使用上面的List来封装具体的实例,也就是爬虫接收到的数据采集。Set集合的使用和List集合的用法类似,这里就不过多解释了。
地图的使用
Map 是映射键对象和值对象的集合。它的每个元素都收录一对键对象和值对象,其中键对象不能重复。地图不仅常用于网络爬虫,也常用于文本挖掘算法的编写。在网络爬虫中,可以使用 Map 过滤一些重复数据,但建议使用 Map 去重和过滤大规模数据,因为 Map 有空间大小限制。例如,在使用网络爬虫抓取帖子时,您可能会遇到置顶帖子,并且置顶帖子可能会与以下帖子重复。以下程序是 Map 的一个用例:
entrySet() ) { System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue()); }
队列的使用
队列(Queue)采用链表结构来存储数据,是一种特殊的线性表,只允许在表的前端进行删除操作,在表的后端进行插入操作。LinkedList 类实现了 Queue 接口,因此我们可以将 LinkedList 用作 Queue。Queue 常用于存储待爬取的 URL 的队列。
queue queue = new LinkedList();//添加元素 queue.offer("
");queue.offer("");queue.offer("");boolean t = true;while (t) { //如果Url队列为空,则停止执行程序,否则请求Url if( queue. isEmpty( ) ){ t = false; }else { //请求的url String url = queue.poll(); System.out.println(url); //这里写的是请求数据,对应的状态码是获取到,如果状态码为200,则解析数据;如果是404,则从队列中移除url;否则,重新列出url }
正则表达式的使用
正则表达式是解析数据(HTML 或 JSON 等)时常用的方法。例如,我想从以下语句中提取用户的 id (75975500)):
///75975500" target="_blank">尊少是沉阳人
后面会介绍解析工具jsoup,可以解析获取“
///75975500"。然后,您可以使用正则表达式提取75975500。
字符串网址 = "
///75975500";String user_id = url.replaceAll("\\D", ""); //替换所有非数字字符 System.out.println(user_id); //输出结果为75975500
下表显示了 Java 中常用的一些基本正则表达式。
正则表达式书写的含义\d代表0-9之间的任意数字\D代表任意非数字字符\s代表空格类字符\S代表非空格类字符\p{Lower}代表小写字母[az ]\p{Upper} 代表大写字母 [AZ]\p{Alpha} 代表字母\p{Blank} 代表空格或制表符 查看全部
java爬虫抓取网页数据(Java网络爬虫的分类及开发逻辑【一课一】)
介绍
在大数据环境下,数据分析从业务驱动向数据驱动转变,网络数据资源呈指数级增长,分散在不同的数据源中。对于大多数公司和研究人员来说,用“数据说话”似乎是大数据时代的重要武器。网络爬虫作为网络数据获取的重要技术,受到越来越多数据需求者的青睐和追捧。
作为网络爬虫的介绍,使用了Java开发语言。内容涵盖网络爬虫原理及开发逻辑、Java网络爬虫基础知识、网络抓包介绍、jsoup介绍与使用、HttpClient介绍与使用。本课程在介绍网络爬虫基本原理的同时,着重具体代码实现,加深读者对爬虫的理解,增强读者的动手能力。
内容
第01课:网络爬虫原理
介绍
随着互联网的飞速发展,网络资源越来越丰富,如何从网络中提取信息对于信息需求者来说变得非常重要。目前,有效获取网络数据资源的重要途径是网络爬虫技术。简单理解,比如你对百度贴吧上一个帖子的内容特别感兴趣,但是帖子的回复却有1000多页。在这种情况下,使用一个一个复制的方法是不可行的。并且使用网络爬虫可以轻松采集到帖子下的所有内容。
最广泛使用的网络爬虫技术是在搜索引擎中,如百度、谷歌、必应等,它完成了搜索过程中最关键的一步,即对网页内容的爬取。下图是一个简单的搜索引擎的示意图。
网络爬虫的作用可以总结如下:
网络爬虫覆盖的领域包括:
网络爬虫的基本概念
Web Crawler,也称为Web Spider或Web Information采集器,是一种计算机程序或自动化脚本,根据一定的规则自动爬取或下载网络信息。它是当前搜索引擎的重要组成部分。
网络爬虫的分类
网络爬虫根据系统架构和实现技术大致可以分为以下几种:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫(Deep Web Crawler)。实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。
网络爬虫的过程
网络爬虫的基本流程可以用下图来描述:
具体流程为:
请求者选择种子 URL(或初始 URL)的一部分并将其放入待爬取的队列中。与Java网络爬虫一样,可以放入LinkedList或List。判断URL队列是否为空,如果为空,则结束程序的执行,否则,执行第三步。从待爬取URL队列中取出一个待爬取URL,获取该URL对应的网页内容。在这一步中,需要使用响应的状态码(如200、403等)来判断是否获取数据。如果响应成功,则进行解析操作;如果响应不成功,则放回待爬取队列中(注意这里需要去掉。无效的URL)。对响应成功后获取的数据执行页面解析操作。
网络爬虫抓取策略
一般的网络爬虫爬取策略有两种:深度优先搜索策略和广度优先搜索策略。
基于广度优先的爬虫是爬取网站页面最简单的方法,也是目前应用最广泛的方法。在这个大师班里,提到的案例都是广度优先爬虫。
学习建议
网络爬虫是对某种编程语言入门的实用技术:很多学习编程语言(如Java、Python或C++等)的同学只是在网上看书或看一些视频,后果不堪设想。这将是面对面的,当涉及到一个具体的项目时,我不知道如何开始,尤其是对于初学者。或者,一段时间后,之前的书籍内容或视频内容就被遗忘了。
为此,我建议这些学习者可以使用网络爬虫技术来入门一种编程语言(如Java、Python)。因为爬虫技术是一门综合性很强的技术,它涉及到编程语言的很多方面。本次大师班特别选择Java作为开发语言,带你了解Java爬虫背后的核心技术。完成本课程后,相信您对 Java 编程语言有了很好的介绍。
零基础开始Java爬虫的同学,在学习过程中请注意以下几点:
最后,提供一些书籍和资料,供刚入门并想进一步了解 Java 网络爬虫的读者使用:
清华大学出版社出版的《Java Object-Oriented Programming》(耿祥一、张月平主编)是一本可以作为基础学习的大学教材。《Java 核心技术》2 卷。《Effective Java (3rd Edition)》:目前英文版是第三版,中文版还在第二版。本书是高级Java的必备书籍。英语较好的同学可以直接看英文版。《Do It Yourself Web Crawler》(罗刚主编),国内第一本专门研究Java网络爬虫的书籍。
第 2 课:Java 网络爬虫基础知识
介绍
Java网络爬虫具有良好的扩展性和可扩展性,是当前搜索引擎开发的重要组成部分。例如,著名的网络爬虫工具 Nutch 是用 Java 开发的,它基于 Apache Hadoop 数据结构,提供了良好的批处理支持。
Java网页爬取涉及到大量的Java知识。本文将介绍网络爬虫需要了解的Java知识以及这些知识主要用于网络爬虫的哪个部分,包括以下内容:
使用Maven
什么是马文
Maven 是 Apache 软件基金会提供的用于项目管理和自动化构建的工具。我们知道,在构建Java项目的时候,需要用到很多Jar包。例如,需要使用mysql-connector-java及其相关依赖来操作数据库。Maven工具可以方便的管理我们在项目中使用的开源Jar包,比如下载Java项目需要的Jar包以及相关的Java依赖包。
如何使用 Maven
Maven 使用存储在名为 pom.xml 的文件中的项目对象模型 (POM) 进行配置。以Java为例,我们可以在Eclipse中创建一个Maven项目。其中,Maven Dependencies 存放的是由 Maven 管理的 Jar 包。
如前所述,构建 Java 项目需要使用许多 Jar 包。例如,在Java网络爬虫中,我们需要使用相关的Jar包进行数据库连接、请求网页内容、解析网页内容。将以下语句添加到 pom 文件中:
mysql mysql-connector-java 5.1.35 org.jsoup jsoup 1.8.2 org.apache.httpcomponents httpclient 4.2.3
之后,我们会惊奇的发现项目的Maven Dependencies中自动下载了相关的Jar包及其依赖的Jar包。
读者可以在 Maven Repository 网站 中检索到自己想要的 Jar 包和 Maven 操作语句。
log4j 的使用
什么是 log4j
log4j 是一个基于 Java 的日志记录工具,曾经是 Apache 软件基金会的一个项目。今天,日志是应用软件的一个组成部分。
如何使用 log4j
1. 使用Maven下载log4j Jar包,代码如下:
log4j log4j 1.2.17
2. 在src目录下创建一个log4j.properties文本文件并进行配置(各个配置的具体含义,读者可以参考博文《Log4j详解》):
### set ###log4j.rootLogger = debug,stdout,D,E ###输出信息来控制提升###log4j.appender.stdout =
org.apache.log4j.ConsoleAppenderlog4j.appender.stdout.Target=System.outlog4j.appender.stdout.layout=org.apache.log4j.PatternLayoutlog4j.appender.stdout.layout.ConversionPattern=[%-5p]%d{yyyy- MM-dd HH:mm:ss,SSS} 方法:%l%n%m%n### 将 DEBUG 级别以上的日志输出到 =error.log ###log4j.appender.D = org.apache.log4j。DailyRollingFileAppenderlog4j.appender.D.File=E://logs/log.loglog4j.appender.D.Append=truelog4j.appender.D.Threshold=DEBUG log4j.appender.D.layout=org.apache.log4j.PatternLayoutlog4j.appender .D.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n### 将 ERROR 级别以上的日志输出到 =error 。日志###log4j.appender.E=org.apache.log4j.DailyRollingFileAppenderlog4j.appender.E.File=E://logs/error.log log4j.appender.E.Append=truelog4j.appender.E.Threshold=错误log4j.appender.E.layout = org.apache.log4j.PatternLayoutlog4j。
3. 示例程序,如下:
包 log4j;import mons.logging.Log;import mons.logging.LogFactory;public class Test { static final Log logger = LogFactory.getLog(Test.class); 公共静态 void main(String[] args) { System.out. println("你好"); (“你好世界”); logger.debug("这是调试信息。"); logger.warn("这是警告信息。"); logger.error("这是错误信息。"); "); }}
基于这个程序,我们可以看到在我们项目的根目录下会生成一个日志文件error.log和log.log。
在网络爬虫中,我们可以通过日志来记录程序可能出错的地方,监控程序的运行状态。
对象创建
在 Java 中,new 关键字通常用于创建对象。比如在爬取京东商品的id、product_name(商品名)、price(价格)时,我们需要将每个商品的信息封装成一个对象。
JdInfoModel jingdongproduct = new JdInfoModel();
在爬虫中,我们要操作JdInfoModel类中的变量(即id、product_name、price),可以通过私有变量来定义。并且,使用 set() 和 get() 方法设置数据(爬取数据的封装)和获取使用(爬取数据的存储)。以下代码用于 JdInfoModel 类:
包模型;公共类 JdInfoModel { 私有 int id;私有字符串产品名称;私人双倍价格;public int getId() { 返回 id; } public void setId(int id) { this.id = id; } public String getProduct_name() { return product_name; } public void setProduct_name(String product_name) { this.product_name = product_name; } public double getPrice() { 返回价格;} public void setPrice(double price) { this.price = price; } }
采集品的使用
网络爬虫离不开对集合的操作,这涉及到对List、Set、Queue、Map等集合的操作。
List 和 Set 集合的使用
List 的特点是它的元素以线性方式存储,重复的对象可以存储在集合中。相比之下,Set 集合中的对象没有按特定方式排序,也没有重复的对象。在网络爬虫中,List 可用于存储要爬取的 URL 列表。例如:
//创建List集合List urllist = new ArrayList();urllist.add("
");urllist.add("");//第一种遍历方法for(String url : urllist){ System.out.println(url);}//第二种遍历方法for(int i=0; i it = urllist.iterator();while (it.hasNext()){ System.out.println(it.next());}
同时,我们也可以使用上面的List来封装具体的实例,也就是爬虫接收到的数据采集。Set集合的使用和List集合的用法类似,这里就不过多解释了。
地图的使用
Map 是映射键对象和值对象的集合。它的每个元素都收录一对键对象和值对象,其中键对象不能重复。地图不仅常用于网络爬虫,也常用于文本挖掘算法的编写。在网络爬虫中,可以使用 Map 过滤一些重复数据,但建议使用 Map 去重和过滤大规模数据,因为 Map 有空间大小限制。例如,在使用网络爬虫抓取帖子时,您可能会遇到置顶帖子,并且置顶帖子可能会与以下帖子重复。以下程序是 Map 的一个用例:
entrySet() ) { System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue()); }
队列的使用
队列(Queue)采用链表结构来存储数据,是一种特殊的线性表,只允许在表的前端进行删除操作,在表的后端进行插入操作。LinkedList 类实现了 Queue 接口,因此我们可以将 LinkedList 用作 Queue。Queue 常用于存储待爬取的 URL 的队列。
queue queue = new LinkedList();//添加元素 queue.offer("
");queue.offer("");queue.offer("");boolean t = true;while (t) { //如果Url队列为空,则停止执行程序,否则请求Url if( queue. isEmpty( ) ){ t = false; }else { //请求的url String url = queue.poll(); System.out.println(url); //这里写的是请求数据,对应的状态码是获取到,如果状态码为200,则解析数据;如果是404,则从队列中移除url;否则,重新列出url }
正则表达式的使用
正则表达式是解析数据(HTML 或 JSON 等)时常用的方法。例如,我想从以下语句中提取用户的 id (75975500)):
///75975500" target="_blank">尊少是沉阳人
后面会介绍解析工具jsoup,可以解析获取“
///75975500"。然后,您可以使用正则表达式提取75975500。
字符串网址 = "
///75975500";String user_id = url.replaceAll("\\D", ""); //替换所有非数字字符 System.out.println(user_id); //输出结果为75975500
下表显示了 Java 中常用的一些基本正则表达式。
正则表达式书写的含义\d代表0-9之间的任意数字\D代表任意非数字字符\s代表空格类字符\S代表非空格类字符\p{Lower}代表小写字母[az ]\p{Upper} 代表大写字母 [AZ]\p{Alpha} 代表字母\p{Blank} 代表空格或制表符
java爬虫抓取网页数据(常见的请求Method:在Http协议中定义了八种请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-28 06:14
Http协议:全称HyperText Transfer Protocol,中文是超文本传输协议的意思。它是一种发布和接收 HTML(超文本标记语言)页面的方法。服务器端口号为80端口。 2. HTTPS协议:是HTTP协议的加密版本,在HTTP下增加了SSL层。服务器端口号为 443 端口。
网址详情:
URL是Uniform Resource Locator,统一资源定位器的缩写。一个 URL 由以下部分组成:
host:主机名、域名,如port:端口号。当您访问 网站 时,浏览器默认使用端口 80 路径:查找路径。例如:下面的trending/now是pathquery-string:查询字符串,如:下面的wd=python就是查询字符串。Anchor:Anchor,前端用于页面定位。现在有些前后端项目是分开的,锚点也是用来导航的。
在浏览器中请求一个url,浏览器会对url进行编码。除英文字母、数字和部分符号外,其余均采用百分号+十六进制码值编码。
常见的请求方式:
在 Http 协议中,定义了八种请求方法。这里介绍两种常见的请求方式,即get request和post request。
获取请求:一般情况下,只从服务器获取数据时使用获取请求,不会对服务器资源产生任何影响。Post 请求:向服务器发送数据(登录)、上传文件等,在影响服务器资源时会使用 post 请求。以上是网站开发中常用的两种方法。并且一般遵循使用原则。但是,一些网站和服务器为了实现反爬机制,经常会做出不合常理的卡片。应该使用 get 方法的请求有可能必须更改为 post 请求,这取决于具体情况。常见的请求头参数:
在http协议中,向服务器发送一个请求,数据分为三部分。第一种是将数据放在url中,第二种是将数据放在body中(在post请求中),第三种是将数据放在url中。数据放在头部。以下是网络爬虫中经常使用的一些请求头参数:
User-Agent:浏览器名称。这通常用于网络爬虫。当请求一个网页时,服务器可以通过这个参数知道是哪个浏览器发送了请求。如果我们通过爬虫发送请求,那么我们的 User-Agent 就是 Python。对于那些有反爬虫机制的网站,很容易判断你的请求是爬虫。因此,我们经常将这个值设置为某些浏览器的值来伪装我们的爬虫。
Referer:表示当前请求来自哪个url。这也可以用于一般的反爬虫技术。如果不是来自指定页面,则不会做出相关响应。
Cookies:http 协议是无状态的。即同一个人发送了两个请求,服务器没有能力知道这两个请求是否来自同一个人。因此,此时cookie用于识别。一般如果要登录访问网站,则需要发送cookie信息。
常见响应状态码: 查看全部
java爬虫抓取网页数据(常见的请求Method:在Http协议中定义了八种请求)
Http协议:全称HyperText Transfer Protocol,中文是超文本传输协议的意思。它是一种发布和接收 HTML(超文本标记语言)页面的方法。服务器端口号为80端口。 2. HTTPS协议:是HTTP协议的加密版本,在HTTP下增加了SSL层。服务器端口号为 443 端口。
网址详情:
URL是Uniform Resource Locator,统一资源定位器的缩写。一个 URL 由以下部分组成:
host:主机名、域名,如port:端口号。当您访问 网站 时,浏览器默认使用端口 80 路径:查找路径。例如:下面的trending/now是pathquery-string:查询字符串,如:下面的wd=python就是查询字符串。Anchor:Anchor,前端用于页面定位。现在有些前后端项目是分开的,锚点也是用来导航的。
在浏览器中请求一个url,浏览器会对url进行编码。除英文字母、数字和部分符号外,其余均采用百分号+十六进制码值编码。
常见的请求方式:
在 Http 协议中,定义了八种请求方法。这里介绍两种常见的请求方式,即get request和post request。
获取请求:一般情况下,只从服务器获取数据时使用获取请求,不会对服务器资源产生任何影响。Post 请求:向服务器发送数据(登录)、上传文件等,在影响服务器资源时会使用 post 请求。以上是网站开发中常用的两种方法。并且一般遵循使用原则。但是,一些网站和服务器为了实现反爬机制,经常会做出不合常理的卡片。应该使用 get 方法的请求有可能必须更改为 post 请求,这取决于具体情况。常见的请求头参数:
在http协议中,向服务器发送一个请求,数据分为三部分。第一种是将数据放在url中,第二种是将数据放在body中(在post请求中),第三种是将数据放在url中。数据放在头部。以下是网络爬虫中经常使用的一些请求头参数:
User-Agent:浏览器名称。这通常用于网络爬虫。当请求一个网页时,服务器可以通过这个参数知道是哪个浏览器发送了请求。如果我们通过爬虫发送请求,那么我们的 User-Agent 就是 Python。对于那些有反爬虫机制的网站,很容易判断你的请求是爬虫。因此,我们经常将这个值设置为某些浏览器的值来伪装我们的爬虫。
Referer:表示当前请求来自哪个url。这也可以用于一般的反爬虫技术。如果不是来自指定页面,则不会做出相关响应。
Cookies:http 协议是无状态的。即同一个人发送了两个请求,服务器没有能力知道这两个请求是否来自同一个人。因此,此时cookie用于识别。一般如果要登录访问网站,则需要发送cookie信息。
常见响应状态码:
java爬虫抓取网页数据( 2018年Java实现的爬虫抓取图片并保存操作技巧汇总)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-03-28 01:08
2018年Java实现的爬虫抓取图片并保存操作技巧汇总)
Java实现的爬虫抓取图片并保存操作示例
更新时间:2018-08-31 09:47:10 转载:smilecjw
本篇文章主要介绍Java实现的爬虫抓取图片并保存,涉及到Java对页面URL的访问、获取、字符串匹配、文件下载等相关操作技巧。有需要的朋友可以参考以下
本文的例子描述了用Java实现的爬虫抓取图片并保存。分享给大家参考,详情如下:
这是我参考网上一些资料写的第一个java爬虫程序
本来想获取无聊地图的图片,但是网络返回码一直是503,所以改成了网站
import java.io.BufferedReader;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网络爬虫取数据
*
* */
public class JianDan {
public static String GetUrl(String inUrl){
StringBuilder sb = new StringBuilder();
try {
URL url =new URL(inUrl);
BufferedReader reader =new BufferedReader(new InputStreamReader(url.openStream()));
String temp="";
while((temp=reader.readLine())!=null){
//System.out.println(temp);
sb.append(temp);
}
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
return sb.toString();
}
public static List GetMatcher(String str,String url){
List result = new ArrayList();
Pattern p =Pattern.compile(url);//获取网页地址
Matcher m =p.matcher(str);
while(m.find()){
//System.out.println(m.group(1));
result.add(m.group(1));
}
return result;
}
public static void main(String args[]){
String str=GetUrl("http://www.163.com");
List ouput =GetMatcher(str,"src=\"([\\w\\s./:]+?)\"");
for(String temp:ouput){
//System.out.println(ouput.get(0));
System.out.println(temp);
}
String aurl=ouput.get(0);
// 构造URL
URL url;
try {
url = new URL(aurl);
// 打开URL连接
URLConnection con = (URLConnection)url.openConnection();
// 得到URL的输入流
InputStream input = con.getInputStream();
// 设置数据缓冲
byte[] bs = new byte[1024 * 2];
// 读取到的数据长度
int len;
// 输出的文件流保存图片至本地
OutputStream os = new FileOutputStream("a.png");
while ((len = input.read(bs)) != -1) {
os.write(bs, 0, len);
}
os.close();
input.close();
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
运行输出:
对java相关内容比较感兴趣的读者可以查看本站专题:《Java网络编程技巧总结》、《Java套接字编程技巧总结》、《Java文件和目录操作技巧总结》、《Java数据《结构与算法教程》、《Java操作DOM节点技巧总结》、《Java缓存操作技巧总结》
希望这篇文章对大家java编程有所帮助。 查看全部
java爬虫抓取网页数据(
2018年Java实现的爬虫抓取图片并保存操作技巧汇总)
Java实现的爬虫抓取图片并保存操作示例
更新时间:2018-08-31 09:47:10 转载:smilecjw
本篇文章主要介绍Java实现的爬虫抓取图片并保存,涉及到Java对页面URL的访问、获取、字符串匹配、文件下载等相关操作技巧。有需要的朋友可以参考以下
本文的例子描述了用Java实现的爬虫抓取图片并保存。分享给大家参考,详情如下:
这是我参考网上一些资料写的第一个java爬虫程序
本来想获取无聊地图的图片,但是网络返回码一直是503,所以改成了网站
import java.io.BufferedReader;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网络爬虫取数据
*
* */
public class JianDan {
public static String GetUrl(String inUrl){
StringBuilder sb = new StringBuilder();
try {
URL url =new URL(inUrl);
BufferedReader reader =new BufferedReader(new InputStreamReader(url.openStream()));
String temp="";
while((temp=reader.readLine())!=null){
//System.out.println(temp);
sb.append(temp);
}
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
return sb.toString();
}
public static List GetMatcher(String str,String url){
List result = new ArrayList();
Pattern p =Pattern.compile(url);//获取网页地址
Matcher m =p.matcher(str);
while(m.find()){
//System.out.println(m.group(1));
result.add(m.group(1));
}
return result;
}
public static void main(String args[]){
String str=GetUrl("http://www.163.com";);
List ouput =GetMatcher(str,"src=\"([\\w\\s./:]+?)\"");
for(String temp:ouput){
//System.out.println(ouput.get(0));
System.out.println(temp);
}
String aurl=ouput.get(0);
// 构造URL
URL url;
try {
url = new URL(aurl);
// 打开URL连接
URLConnection con = (URLConnection)url.openConnection();
// 得到URL的输入流
InputStream input = con.getInputStream();
// 设置数据缓冲
byte[] bs = new byte[1024 * 2];
// 读取到的数据长度
int len;
// 输出的文件流保存图片至本地
OutputStream os = new FileOutputStream("a.png");
while ((len = input.read(bs)) != -1) {
os.write(bs, 0, len);
}
os.close();
input.close();
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
运行输出:
对java相关内容比较感兴趣的读者可以查看本站专题:《Java网络编程技巧总结》、《Java套接字编程技巧总结》、《Java文件和目录操作技巧总结》、《Java数据《结构与算法教程》、《Java操作DOM节点技巧总结》、《Java缓存操作技巧总结》
希望这篇文章对大家java编程有所帮助。

