
httpunit 抓取网页
httpunit 抓取网页(热图主流的实现方式一般实现热图显示需要经过如下阶段)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-30 06:17
主流热图的实现
一般来说,热图展示的实现需要经过以下几个阶段:
获取网站页面,获取处理后的用户数据,绘制热图。本文主要针对stage 1,详细介绍获取热图中网站页面的主流实现。使用iframe直接嵌入用户网站 抓取用户页面并保存在本地,通过iframe嵌入本地资源(这里所谓的本地资源被认为是分析工具端)
这两种方法各有优缺点。首先,第一种方法直接嵌入用户网站。这有一定的限制。比如用户网站阻止了iframe劫持,则不允许嵌套iframe(设置meta X-FRAME-OPTIONS为sameorgin或者直接设置http header,甚至直接通过js控制
if(window.top !== window.self){ window.top.location = window.location;}
)。在这种情况下,客户网站需要做一部分工作才能被分析工具的iframe加载。使用起来可能不太方便,因为并不是所有需要检测分析的网站用户都可以做Manage 网站。
第二种方式是直接抓取网站页面到本地服务器,然后在本地服务器上浏览抓取的页面。在这种情况下,页面已经来了,我们可以为所欲为。首先我们绕过X-FRAME-OPTIONS是同源问题,只需要解决js控件的问题,对于抓取到的页面,我们可以通过特殊的对应来处理(比如去掉对应的js控件,或者添加我们自己的js); 但是这种方法也有很多缺点:1、不能抓取spa页面,不能抓取需要用户登录授权的页面,不能抓取用户白白设置的页面等等。
这两种方法都有 https 和 http 资源。同源策略带来的另一个问题是https站无法加载http资源。因此,为了获得最佳的兼容性,热图分析工具需要与http协议一起应用。当然,可以根据详细信息进行访问。对客户网站及具体分站优化。
如何优化网站页面的抓取
这里我们针对爬取网站页面遇到的问题,基于puppeteer做了一些优化,增加爬取成功的概率,主要优化了以下两个页面:
spa页面spa页面在当前页面被认为是主流,但一直都知道对搜索引擎不友好;通常的页面爬虫程序其实就是一个简单的爬虫程序,过程通常是向User 网站(应该是user 网站 server)发起http get请求。这种爬取方式本身就会有问题。首先,直接请求用户服务器。用户服务器对非浏览器代理应该有很多限制,需要绕过处理;其次,请求返回原创内容,需要处理。浏览器中js渲染的部分无法获取(当然嵌入iframe后,js的执行还是会一定程度上弥补这个问题的)。最后,如果页面是spa页面,那么此时只获取到模板,在热图中间的显示效果非常不友好。针对这种情况,如果是基于puppeteer的,流程就变成了puppeteer启动浏览器打开用户网站-->页面渲染-->返回渲染结果,简单的用伪代码实现为如下:
const puppeteer = require('puppeteer');
async getHtml = (url) =>{
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
return await page.content();
}
这样我们得到的内容就是渲染出来的内容,不管页面是怎么渲染的(客户端渲染还是服务端)
需要登录的页面
需要登录页面的情况其实有很多:
const puppeteer = require("puppeteer");
async autoLogin =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.waitForNavigation();
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,需要保证redirect 跳转到请求的页面
await page.waitForNavigation();
return await page.content();
}
这种情况会更容易处理,你可以简单地认为是以下步骤:
通过puppeteer启动浏览器打开请求页面-->点击登录按钮-->输入用户名密码登录-->重新加载页面
基本代码如下:
const puppeteer = require("puppeteer");
async autoLoginV2 =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.click('#btn_show_login');
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,是否需要reload 根据实际情况来确定
await page.reload();
return await page.content();
}
总结
明天总结,今天下班了。
补充(偿还昨天的债务):puppeteer虽然可以友好地抓取页面内容,但也有很多限制
抓取的内容是渲染后的原创html,即资源路径(css、image、javascript)等都是相对路径,本地保存后无法正常显示。需要特殊处理(js不需要特殊处理,甚至可以去掉。因为渲染的结构已经完成) 通过puppeteer爬取页面的性能会比直接http get的性能差,因为渲染进程也不能保证页面的完整性,但是完整性的概率大大提高,虽然通过页面对象提供的各种wait方法可以解决这个问题,但是网站不同,处理方法会不同,不能重复使用。 查看全部
httpunit 抓取网页(热图主流的实现方式一般实现热图显示需要经过如下阶段)
主流热图的实现
一般来说,热图展示的实现需要经过以下几个阶段:
获取网站页面,获取处理后的用户数据,绘制热图。本文主要针对stage 1,详细介绍获取热图中网站页面的主流实现。使用iframe直接嵌入用户网站 抓取用户页面并保存在本地,通过iframe嵌入本地资源(这里所谓的本地资源被认为是分析工具端)
这两种方法各有优缺点。首先,第一种方法直接嵌入用户网站。这有一定的限制。比如用户网站阻止了iframe劫持,则不允许嵌套iframe(设置meta X-FRAME-OPTIONS为sameorgin或者直接设置http header,甚至直接通过js控制
if(window.top !== window.self){ window.top.location = window.location;}
)。在这种情况下,客户网站需要做一部分工作才能被分析工具的iframe加载。使用起来可能不太方便,因为并不是所有需要检测分析的网站用户都可以做Manage 网站。
第二种方式是直接抓取网站页面到本地服务器,然后在本地服务器上浏览抓取的页面。在这种情况下,页面已经来了,我们可以为所欲为。首先我们绕过X-FRAME-OPTIONS是同源问题,只需要解决js控件的问题,对于抓取到的页面,我们可以通过特殊的对应来处理(比如去掉对应的js控件,或者添加我们自己的js); 但是这种方法也有很多缺点:1、不能抓取spa页面,不能抓取需要用户登录授权的页面,不能抓取用户白白设置的页面等等。
这两种方法都有 https 和 http 资源。同源策略带来的另一个问题是https站无法加载http资源。因此,为了获得最佳的兼容性,热图分析工具需要与http协议一起应用。当然,可以根据详细信息进行访问。对客户网站及具体分站优化。
如何优化网站页面的抓取
这里我们针对爬取网站页面遇到的问题,基于puppeteer做了一些优化,增加爬取成功的概率,主要优化了以下两个页面:
spa页面spa页面在当前页面被认为是主流,但一直都知道对搜索引擎不友好;通常的页面爬虫程序其实就是一个简单的爬虫程序,过程通常是向User 网站(应该是user 网站 server)发起http get请求。这种爬取方式本身就会有问题。首先,直接请求用户服务器。用户服务器对非浏览器代理应该有很多限制,需要绕过处理;其次,请求返回原创内容,需要处理。浏览器中js渲染的部分无法获取(当然嵌入iframe后,js的执行还是会一定程度上弥补这个问题的)。最后,如果页面是spa页面,那么此时只获取到模板,在热图中间的显示效果非常不友好。针对这种情况,如果是基于puppeteer的,流程就变成了puppeteer启动浏览器打开用户网站-->页面渲染-->返回渲染结果,简单的用伪代码实现为如下:
const puppeteer = require('puppeteer');
async getHtml = (url) =>{
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
return await page.content();
}
这样我们得到的内容就是渲染出来的内容,不管页面是怎么渲染的(客户端渲染还是服务端)
需要登录的页面
需要登录页面的情况其实有很多:
const puppeteer = require("puppeteer");
async autoLogin =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.waitForNavigation();
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,需要保证redirect 跳转到请求的页面
await page.waitForNavigation();
return await page.content();
}
这种情况会更容易处理,你可以简单地认为是以下步骤:
通过puppeteer启动浏览器打开请求页面-->点击登录按钮-->输入用户名密码登录-->重新加载页面
基本代码如下:
const puppeteer = require("puppeteer");
async autoLoginV2 =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.click('#btn_show_login');
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,是否需要reload 根据实际情况来确定
await page.reload();
return await page.content();
}
总结
明天总结,今天下班了。
补充(偿还昨天的债务):puppeteer虽然可以友好地抓取页面内容,但也有很多限制
抓取的内容是渲染后的原创html,即资源路径(css、image、javascript)等都是相对路径,本地保存后无法正常显示。需要特殊处理(js不需要特殊处理,甚至可以去掉。因为渲染的结构已经完成) 通过puppeteer爬取页面的性能会比直接http get的性能差,因为渲染进程也不能保证页面的完整性,但是完整性的概率大大提高,虽然通过页面对象提供的各种wait方法可以解决这个问题,但是网站不同,处理方法会不同,不能重复使用。
httpunit 抓取网页(Java语言中应用一个工具类的应用工具实战步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-09-25 10:18
jsoup最大的优点是可以快速抓取静态页面,并且可以快速识别静态页面中的标签,解析页面标签内容的速度和jquery一样快。
Jsoup在处理动态页面时遇到了一些弊端,因为动态页面的内容是通过ajax通过浏览器动态访问后端服务器,返回内容后使用js脚本解析页面上的内容。Jsoup 无法解析动态内容。
httpunit 只是填补了 jsoup 的不足。可以动态模拟浏览器访问URL,然后动态获取URL上的内容进行分析,从而完成动态爬虫的爬取功能。
四、爬虫模拟点击按钮代码了解httpunit的api
大家都知道,在Java语言中应用一个工具或者工具类时,首先需要创建工具类的一个对象,然后调用该对象的方法来完成一些业务,httpunit也不例外。下面是创建对象的代码:
final WebClient webClient=new WebClient();
爬虫需要传入一个页面的url来做爬取功能,然后获取该url的page对象,代码如下:
final HtmlPage page=webClient.getPage("");
获取代表页面的页面对象后,就可以解析页面元素,可以以txt文本方式或xml文件方式显示页面。代码如下:
System.out.println(page.asXml());
System.out.println(page.asText());
完成页面内容分析后不要忘记销毁模拟工具对象。api代码如下:
webClient.closeAllWindows();
爬虫模拟百度搜索框点击按钮实战
第一步:创建webClient浏览器模拟对象,调用getPage方法方法和百度主页url地址,获取代表主页的htmlpage对象。由于我们是模拟静态页面,需要关闭js解析,而爬虫不需要样式,所以我们还需要关闭css样式设置,具体代码如下图所示:
第二步:由于我们是用爬虫模拟百度搜索框点击搜索,所以首先要得到百度首页的form表单,代码如下:
最终的 HtmlForm 表单 = htmlpage.getFormByName("f");
拿到表单ID后,再百度一下这个蓝色点击按钮的ID,代码如下:
final HtmlSubmitInput button = form.getInputByValue("百度点击");
最后获取百度搜索框的ID,以便以后模拟点击,代码如下:
final HtmlTextInput textField = form.getInputByName("q1");
第三步:准备工作已经完成,获取到的ID已经获取。接下来,我们可以在搜索框中模拟手动输入。然后点击按钮完成搜索,具体代码如下图所示:
获取到的搜索结果页面的数据以xml格式显示。XML 文件格式更规则,标签更完整。在解析内容的时候,一个标签中的大部分内容都被解析了,所以xml格式相比txt更加优雅。
最后解析数据时,我们推荐使用jsoup作为工具。通过jsoup解析静态页面的标签更方便简洁,使用更方便。 查看全部
httpunit 抓取网页(Java语言中应用一个工具类的应用工具实战步骤)
jsoup最大的优点是可以快速抓取静态页面,并且可以快速识别静态页面中的标签,解析页面标签内容的速度和jquery一样快。
Jsoup在处理动态页面时遇到了一些弊端,因为动态页面的内容是通过ajax通过浏览器动态访问后端服务器,返回内容后使用js脚本解析页面上的内容。Jsoup 无法解析动态内容。
httpunit 只是填补了 jsoup 的不足。可以动态模拟浏览器访问URL,然后动态获取URL上的内容进行分析,从而完成动态爬虫的爬取功能。
四、爬虫模拟点击按钮代码了解httpunit的api
大家都知道,在Java语言中应用一个工具或者工具类时,首先需要创建工具类的一个对象,然后调用该对象的方法来完成一些业务,httpunit也不例外。下面是创建对象的代码:
final WebClient webClient=new WebClient();
爬虫需要传入一个页面的url来做爬取功能,然后获取该url的page对象,代码如下:
final HtmlPage page=webClient.getPage("");
获取代表页面的页面对象后,就可以解析页面元素,可以以txt文本方式或xml文件方式显示页面。代码如下:
System.out.println(page.asXml());
System.out.println(page.asText());
完成页面内容分析后不要忘记销毁模拟工具对象。api代码如下:
webClient.closeAllWindows();
爬虫模拟百度搜索框点击按钮实战
第一步:创建webClient浏览器模拟对象,调用getPage方法方法和百度主页url地址,获取代表主页的htmlpage对象。由于我们是模拟静态页面,需要关闭js解析,而爬虫不需要样式,所以我们还需要关闭css样式设置,具体代码如下图所示:
 http://www.itjcw123.cn/wp-cont ... 4.png 150w" />
http://www.itjcw123.cn/wp-cont ... 4.png 150w" />第二步:由于我们是用爬虫模拟百度搜索框点击搜索,所以首先要得到百度首页的form表单,代码如下:
最终的 HtmlForm 表单 = htmlpage.getFormByName("f");
拿到表单ID后,再百度一下这个蓝色点击按钮的ID,代码如下:
final HtmlSubmitInput button = form.getInputByValue("百度点击");
最后获取百度搜索框的ID,以便以后模拟点击,代码如下:
final HtmlTextInput textField = form.getInputByName("q1");
第三步:准备工作已经完成,获取到的ID已经获取。接下来,我们可以在搜索框中模拟手动输入。然后点击按钮完成搜索,具体代码如下图所示:
 http://www.itjcw123.cn/wp-cont ... 5.png 150w" />
http://www.itjcw123.cn/wp-cont ... 5.png 150w" />获取到的搜索结果页面的数据以xml格式显示。XML 文件格式更规则,标签更完整。在解析内容的时候,一个标签中的大部分内容都被解析了,所以xml格式相比txt更加优雅。
最后解析数据时,我们推荐使用jsoup作为工具。通过jsoup解析静态页面的标签更方便简洁,使用更方便。
httpunit 抓取网页(农业信息网的小小的规律总结:1.什么是爬虫? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-09-25 10:18
)
由于项目需要,我们需要用到爬虫。自己摸索了一下,总结了一些小规则,现总结如下:
1.什么是爬虫?
网络爬虫是一种自动获取网页内容的程序,是搜索引擎的重要组成部分。
传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。对于垂直搜索,聚焦爬虫,即针对特定主题抓取网页的爬虫更合适。
2. 爬虫的实现
package com.demo;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test {
public static List findList(String url) throws IOException{ //输入某个网站查找所有新闻的地址
Connection conn = Jsoup.connect(url); //使用Jsoup获得url连接
Document doc = conn.post(); // 请求返回整个文档对象
//System.out.println(doc.html());
Elements e=doc.select("a[class=newsgray a_space2]"); //返回所有的<a>超链接标签
List list=new ArrayList();
News news=null;
for(Element element:e){
news=new News();
String title=element.toString().substring(78);
String temp=title.substring(0, title.length()-4);//新闻标题
news.setTitle(temp);
String path=element.absUrl("href"); //新闻所在路径
String content=urlToHtml(path);
news.setContent(content);
news.setUrl(path);
list.add(news);
}
return list;
}
public static String urlToHtml(String url) throws IOException{
Connection conn = Jsoup.connect(url); //使用Jsoup获得url连接
Document doc = conn.post(); // 请求返回整个文档对象
StringBuilder sb=new StringBuilder();
Elements e=doc.select("p");
for(Element element:e){
String content=element.toString();
sb.append(content);
}
return sb.toString();
}
public static void main(String[] args) throws IOException {
List list=findList("http://news.aweb.com.cn/china/hyxw/");
for(News news:list){
System.out.println(news.getContent());
}
}
}
新闻.java
package com.demo;
public class News {
private String title;
private String content;
private String url;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
}
比如我们想在农业信息网捕捉最新的农业新闻
查看全部
httpunit 抓取网页(农业信息网的小小的规律总结:1.什么是爬虫?
)
由于项目需要,我们需要用到爬虫。自己摸索了一下,总结了一些小规则,现总结如下:
1.什么是爬虫?
网络爬虫是一种自动获取网页内容的程序,是搜索引擎的重要组成部分。
传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。对于垂直搜索,聚焦爬虫,即针对特定主题抓取网页的爬虫更合适。
2. 爬虫的实现
package com.demo;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test {
public static List findList(String url) throws IOException{ //输入某个网站查找所有新闻的地址
Connection conn = Jsoup.connect(url); //使用Jsoup获得url连接
Document doc = conn.post(); // 请求返回整个文档对象
//System.out.println(doc.html());
Elements e=doc.select("a[class=newsgray a_space2]"); //返回所有的<a>超链接标签
List list=new ArrayList();
News news=null;
for(Element element:e){
news=new News();
String title=element.toString().substring(78);
String temp=title.substring(0, title.length()-4);//新闻标题
news.setTitle(temp);
String path=element.absUrl("href"); //新闻所在路径
String content=urlToHtml(path);
news.setContent(content);
news.setUrl(path);
list.add(news);
}
return list;
}
public static String urlToHtml(String url) throws IOException{
Connection conn = Jsoup.connect(url); //使用Jsoup获得url连接
Document doc = conn.post(); // 请求返回整个文档对象
StringBuilder sb=new StringBuilder();
Elements e=doc.select("p");
for(Element element:e){
String content=element.toString();
sb.append(content);
}
return sb.toString();
}
public static void main(String[] args) throws IOException {
List list=findList("http://news.aweb.com.cn/china/hyxw/";);
for(News news:list){
System.out.println(news.getContent());
}
}
}
新闻.java
package com.demo;
public class News {
private String title;
private String content;
private String url;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
}
比如我们想在农业信息网捕捉最新的农业新闻

httpunit 抓取网页(网络书籍抓取器是一款功能非常强大的网页小说下载工具方法教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-09-24 22:13
网络图书抓取器是一个非常强大的网络图书下载工具。我们可以通过这个软件在网上下载一些小说。相信喜欢看小说的用户都知道,有些网络小说是可以付费观看的。然后通过这个小说下载器,你就可以下载网络小说的各个章节并合并成一个TXT文件,这样你就可以免费获得小说供浏览了。由于还有一些用户没有使用过这个软件,不知道怎么操作,那么我就给大家分享一下具体的操作方法。有兴趣的可以看看小编分享的这个方法教程。,希望能帮到大家。
方法步骤
1.首先,第一步打开软件后,在软件界面,请输入网址框,将你要下载的网络小说的网址复制粘贴进去。
<p>2. 将目标小说网页的链接复制到软件后,下一步我们需要点击适用的网站选项右侧的下拉列表,选择小说 查看全部
httpunit 抓取网页(网络书籍抓取器是一款功能非常强大的网页小说下载工具方法教程)
网络图书抓取器是一个非常强大的网络图书下载工具。我们可以通过这个软件在网上下载一些小说。相信喜欢看小说的用户都知道,有些网络小说是可以付费观看的。然后通过这个小说下载器,你就可以下载网络小说的各个章节并合并成一个TXT文件,这样你就可以免费获得小说供浏览了。由于还有一些用户没有使用过这个软件,不知道怎么操作,那么我就给大家分享一下具体的操作方法。有兴趣的可以看看小编分享的这个方法教程。,希望能帮到大家。
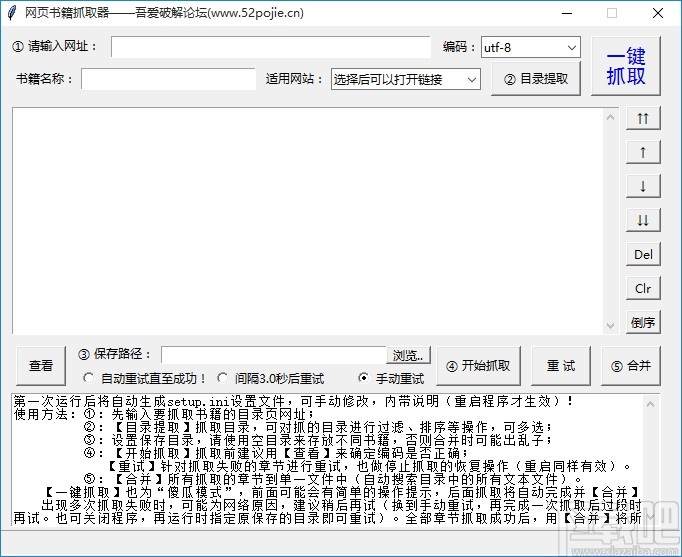
方法步骤
1.首先,第一步打开软件后,在软件界面,请输入网址框,将你要下载的网络小说的网址复制粘贴进去。
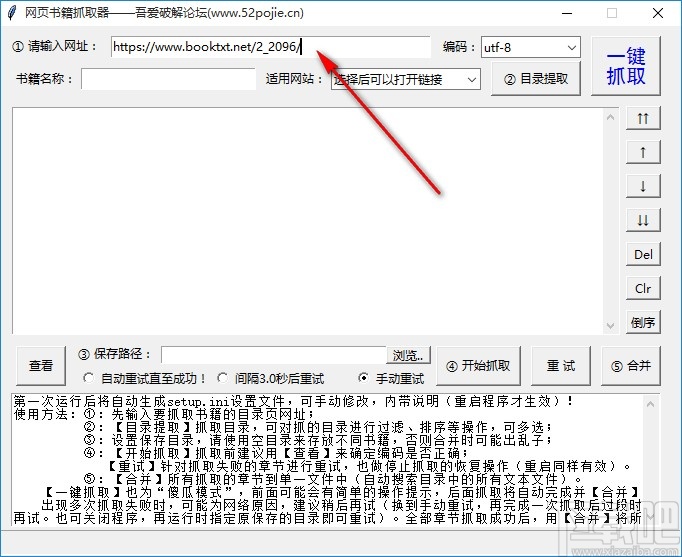
<p>2. 将目标小说网页的链接复制到软件后,下一步我们需要点击适用的网站选项右侧的下拉列表,选择小说
httpunit 抓取网页(3.去除主界面的图片链接,点击不会打开使用说明!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-12 12:02
3.去掉主界面的图片链接,点击打不开
网页FLASH爬虫使用说明
1、先进入FLASH动画网站,播放自己喜欢的FLASH。
2、点击“搜索”按钮,你刚刚播放的FLASH会出现在左上角的列表中。
3、 单击“另存为”按钮将 FLASH 保存到您的计算机。
4、点击“采集夹”按钮,将FLASH添加到“采集夹”集中管理。
5、“采集夹”默认路径为“C:MyFlashh”,可以通过点击“操作”→“更改采集夹”进行修改。
6、点击“打开”按钮播放硬盘中的FLASH。
7、本软件只抓取大于50KB文件的FLASH过滤FLASH广告。
后缀不是“.swf”的FLASH文件8、本软件无法抓取。
同类软件对比
PClawer 是一款功能强大的网络爬虫工具,具有高级定制功能,但前提是它只适合高级用户。此工具需要正则表达式。
WebSpider 蓝蜘蛛网络爬虫工具可以爬取互联网上的任何网页,wap网站,包括登录后可以访问的页面。分析爬取的页面内容,获取结构化信息,如新闻标题、作者、 source、body等,支持列表页自动翻页抓取,文本页多页合并,图片和文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。
华军编辑推荐:
网页FLASH抓取器无需安装、注册或写入垃圾文件,即可批量抓取网页中的Flash。 {zhandian}编辑推荐您下载网页版FLASH爬虫。编辑器会亲自测试,因此您可以放心使用。如有需要,请下载并试用!风雨小编等你! 查看全部
httpunit 抓取网页(3.去除主界面的图片链接,点击不会打开使用说明!)
3.去掉主界面的图片链接,点击打不开
网页FLASH爬虫使用说明
1、先进入FLASH动画网站,播放自己喜欢的FLASH。
2、点击“搜索”按钮,你刚刚播放的FLASH会出现在左上角的列表中。
3、 单击“另存为”按钮将 FLASH 保存到您的计算机。
4、点击“采集夹”按钮,将FLASH添加到“采集夹”集中管理。
5、“采集夹”默认路径为“C:MyFlashh”,可以通过点击“操作”→“更改采集夹”进行修改。
6、点击“打开”按钮播放硬盘中的FLASH。
7、本软件只抓取大于50KB文件的FLASH过滤FLASH广告。
后缀不是“.swf”的FLASH文件8、本软件无法抓取。
同类软件对比
PClawer 是一款功能强大的网络爬虫工具,具有高级定制功能,但前提是它只适合高级用户。此工具需要正则表达式。
WebSpider 蓝蜘蛛网络爬虫工具可以爬取互联网上的任何网页,wap网站,包括登录后可以访问的页面。分析爬取的页面内容,获取结构化信息,如新闻标题、作者、 source、body等,支持列表页自动翻页抓取,文本页多页合并,图片和文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。
华军编辑推荐:
网页FLASH抓取器无需安装、注册或写入垃圾文件,即可批量抓取网页中的Flash。 {zhandian}编辑推荐您下载网页版FLASH爬虫。编辑器会亲自测试,因此您可以放心使用。如有需要,请下载并试用!风雨小编等你!
httpunit 抓取网页(热图主流的实现方式一般实现热图显示需要经过如下阶段)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-30 06:17
主流热图的实现
一般来说,热图展示的实现需要经过以下几个阶段:
获取网站页面,获取处理后的用户数据,绘制热图。本文主要针对stage 1,详细介绍获取热图中网站页面的主流实现。使用iframe直接嵌入用户网站 抓取用户页面并保存在本地,通过iframe嵌入本地资源(这里所谓的本地资源被认为是分析工具端)
这两种方法各有优缺点。首先,第一种方法直接嵌入用户网站。这有一定的限制。比如用户网站阻止了iframe劫持,则不允许嵌套iframe(设置meta X-FRAME-OPTIONS为sameorgin或者直接设置http header,甚至直接通过js控制
if(window.top !== window.self){ window.top.location = window.location;}
)。在这种情况下,客户网站需要做一部分工作才能被分析工具的iframe加载。使用起来可能不太方便,因为并不是所有需要检测分析的网站用户都可以做Manage 网站。
第二种方式是直接抓取网站页面到本地服务器,然后在本地服务器上浏览抓取的页面。在这种情况下,页面已经来了,我们可以为所欲为。首先我们绕过X-FRAME-OPTIONS是同源问题,只需要解决js控件的问题,对于抓取到的页面,我们可以通过特殊的对应来处理(比如去掉对应的js控件,或者添加我们自己的js); 但是这种方法也有很多缺点:1、不能抓取spa页面,不能抓取需要用户登录授权的页面,不能抓取用户白白设置的页面等等。
这两种方法都有 https 和 http 资源。同源策略带来的另一个问题是https站无法加载http资源。因此,为了获得最佳的兼容性,热图分析工具需要与http协议一起应用。当然,可以根据详细信息进行访问。对客户网站及具体分站优化。
如何优化网站页面的抓取
这里我们针对爬取网站页面遇到的问题,基于puppeteer做了一些优化,增加爬取成功的概率,主要优化了以下两个页面:
spa页面spa页面在当前页面被认为是主流,但一直都知道对搜索引擎不友好;通常的页面爬虫程序其实就是一个简单的爬虫程序,过程通常是向User 网站(应该是user 网站 server)发起http get请求。这种爬取方式本身就会有问题。首先,直接请求用户服务器。用户服务器对非浏览器代理应该有很多限制,需要绕过处理;其次,请求返回原创内容,需要处理。浏览器中js渲染的部分无法获取(当然嵌入iframe后,js的执行还是会一定程度上弥补这个问题的)。最后,如果页面是spa页面,那么此时只获取到模板,在热图中间的显示效果非常不友好。针对这种情况,如果是基于puppeteer的,流程就变成了puppeteer启动浏览器打开用户网站-->页面渲染-->返回渲染结果,简单的用伪代码实现为如下:
const puppeteer = require('puppeteer');
async getHtml = (url) =>{
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
return await page.content();
}
这样我们得到的内容就是渲染出来的内容,不管页面是怎么渲染的(客户端渲染还是服务端)
需要登录的页面
需要登录页面的情况其实有很多:
const puppeteer = require("puppeteer");
async autoLogin =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.waitForNavigation();
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,需要保证redirect 跳转到请求的页面
await page.waitForNavigation();
return await page.content();
}
这种情况会更容易处理,你可以简单地认为是以下步骤:
通过puppeteer启动浏览器打开请求页面-->点击登录按钮-->输入用户名密码登录-->重新加载页面
基本代码如下:
const puppeteer = require("puppeteer");
async autoLoginV2 =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.click('#btn_show_login');
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,是否需要reload 根据实际情况来确定
await page.reload();
return await page.content();
}
总结
明天总结,今天下班了。
补充(偿还昨天的债务):puppeteer虽然可以友好地抓取页面内容,但也有很多限制
抓取的内容是渲染后的原创html,即资源路径(css、image、javascript)等都是相对路径,本地保存后无法正常显示。需要特殊处理(js不需要特殊处理,甚至可以去掉。因为渲染的结构已经完成) 通过puppeteer爬取页面的性能会比直接http get的性能差,因为渲染进程也不能保证页面的完整性,但是完整性的概率大大提高,虽然通过页面对象提供的各种wait方法可以解决这个问题,但是网站不同,处理方法会不同,不能重复使用。 查看全部
httpunit 抓取网页(热图主流的实现方式一般实现热图显示需要经过如下阶段)
主流热图的实现
一般来说,热图展示的实现需要经过以下几个阶段:
获取网站页面,获取处理后的用户数据,绘制热图。本文主要针对stage 1,详细介绍获取热图中网站页面的主流实现。使用iframe直接嵌入用户网站 抓取用户页面并保存在本地,通过iframe嵌入本地资源(这里所谓的本地资源被认为是分析工具端)
这两种方法各有优缺点。首先,第一种方法直接嵌入用户网站。这有一定的限制。比如用户网站阻止了iframe劫持,则不允许嵌套iframe(设置meta X-FRAME-OPTIONS为sameorgin或者直接设置http header,甚至直接通过js控制
if(window.top !== window.self){ window.top.location = window.location;}
)。在这种情况下,客户网站需要做一部分工作才能被分析工具的iframe加载。使用起来可能不太方便,因为并不是所有需要检测分析的网站用户都可以做Manage 网站。
第二种方式是直接抓取网站页面到本地服务器,然后在本地服务器上浏览抓取的页面。在这种情况下,页面已经来了,我们可以为所欲为。首先我们绕过X-FRAME-OPTIONS是同源问题,只需要解决js控件的问题,对于抓取到的页面,我们可以通过特殊的对应来处理(比如去掉对应的js控件,或者添加我们自己的js); 但是这种方法也有很多缺点:1、不能抓取spa页面,不能抓取需要用户登录授权的页面,不能抓取用户白白设置的页面等等。
这两种方法都有 https 和 http 资源。同源策略带来的另一个问题是https站无法加载http资源。因此,为了获得最佳的兼容性,热图分析工具需要与http协议一起应用。当然,可以根据详细信息进行访问。对客户网站及具体分站优化。
如何优化网站页面的抓取
这里我们针对爬取网站页面遇到的问题,基于puppeteer做了一些优化,增加爬取成功的概率,主要优化了以下两个页面:
spa页面spa页面在当前页面被认为是主流,但一直都知道对搜索引擎不友好;通常的页面爬虫程序其实就是一个简单的爬虫程序,过程通常是向User 网站(应该是user 网站 server)发起http get请求。这种爬取方式本身就会有问题。首先,直接请求用户服务器。用户服务器对非浏览器代理应该有很多限制,需要绕过处理;其次,请求返回原创内容,需要处理。浏览器中js渲染的部分无法获取(当然嵌入iframe后,js的执行还是会一定程度上弥补这个问题的)。最后,如果页面是spa页面,那么此时只获取到模板,在热图中间的显示效果非常不友好。针对这种情况,如果是基于puppeteer的,流程就变成了puppeteer启动浏览器打开用户网站-->页面渲染-->返回渲染结果,简单的用伪代码实现为如下:
const puppeteer = require('puppeteer');
async getHtml = (url) =>{
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
return await page.content();
}
这样我们得到的内容就是渲染出来的内容,不管页面是怎么渲染的(客户端渲染还是服务端)
需要登录的页面
需要登录页面的情况其实有很多:
const puppeteer = require("puppeteer");
async autoLogin =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.waitForNavigation();
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,需要保证redirect 跳转到请求的页面
await page.waitForNavigation();
return await page.content();
}
这种情况会更容易处理,你可以简单地认为是以下步骤:
通过puppeteer启动浏览器打开请求页面-->点击登录按钮-->输入用户名密码登录-->重新加载页面
基本代码如下:
const puppeteer = require("puppeteer");
async autoLoginV2 =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.click('#btn_show_login');
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,是否需要reload 根据实际情况来确定
await page.reload();
return await page.content();
}
总结
明天总结,今天下班了。
补充(偿还昨天的债务):puppeteer虽然可以友好地抓取页面内容,但也有很多限制
抓取的内容是渲染后的原创html,即资源路径(css、image、javascript)等都是相对路径,本地保存后无法正常显示。需要特殊处理(js不需要特殊处理,甚至可以去掉。因为渲染的结构已经完成) 通过puppeteer爬取页面的性能会比直接http get的性能差,因为渲染进程也不能保证页面的完整性,但是完整性的概率大大提高,虽然通过页面对象提供的各种wait方法可以解决这个问题,但是网站不同,处理方法会不同,不能重复使用。
httpunit 抓取网页(Java语言中应用一个工具类的应用工具实战步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-09-25 10:18
jsoup最大的优点是可以快速抓取静态页面,并且可以快速识别静态页面中的标签,解析页面标签内容的速度和jquery一样快。
Jsoup在处理动态页面时遇到了一些弊端,因为动态页面的内容是通过ajax通过浏览器动态访问后端服务器,返回内容后使用js脚本解析页面上的内容。Jsoup 无法解析动态内容。
httpunit 只是填补了 jsoup 的不足。可以动态模拟浏览器访问URL,然后动态获取URL上的内容进行分析,从而完成动态爬虫的爬取功能。
四、爬虫模拟点击按钮代码了解httpunit的api
大家都知道,在Java语言中应用一个工具或者工具类时,首先需要创建工具类的一个对象,然后调用该对象的方法来完成一些业务,httpunit也不例外。下面是创建对象的代码:
final WebClient webClient=new WebClient();
爬虫需要传入一个页面的url来做爬取功能,然后获取该url的page对象,代码如下:
final HtmlPage page=webClient.getPage("");
获取代表页面的页面对象后,就可以解析页面元素,可以以txt文本方式或xml文件方式显示页面。代码如下:
System.out.println(page.asXml());
System.out.println(page.asText());
完成页面内容分析后不要忘记销毁模拟工具对象。api代码如下:
webClient.closeAllWindows();
爬虫模拟百度搜索框点击按钮实战
第一步:创建webClient浏览器模拟对象,调用getPage方法方法和百度主页url地址,获取代表主页的htmlpage对象。由于我们是模拟静态页面,需要关闭js解析,而爬虫不需要样式,所以我们还需要关闭css样式设置,具体代码如下图所示:
第二步:由于我们是用爬虫模拟百度搜索框点击搜索,所以首先要得到百度首页的form表单,代码如下:
最终的 HtmlForm 表单 = htmlpage.getFormByName("f");
拿到表单ID后,再百度一下这个蓝色点击按钮的ID,代码如下:
final HtmlSubmitInput button = form.getInputByValue("百度点击");
最后获取百度搜索框的ID,以便以后模拟点击,代码如下:
final HtmlTextInput textField = form.getInputByName("q1");
第三步:准备工作已经完成,获取到的ID已经获取。接下来,我们可以在搜索框中模拟手动输入。然后点击按钮完成搜索,具体代码如下图所示:
获取到的搜索结果页面的数据以xml格式显示。XML 文件格式更规则,标签更完整。在解析内容的时候,一个标签中的大部分内容都被解析了,所以xml格式相比txt更加优雅。
最后解析数据时,我们推荐使用jsoup作为工具。通过jsoup解析静态页面的标签更方便简洁,使用更方便。 查看全部
httpunit 抓取网页(Java语言中应用一个工具类的应用工具实战步骤)
jsoup最大的优点是可以快速抓取静态页面,并且可以快速识别静态页面中的标签,解析页面标签内容的速度和jquery一样快。
Jsoup在处理动态页面时遇到了一些弊端,因为动态页面的内容是通过ajax通过浏览器动态访问后端服务器,返回内容后使用js脚本解析页面上的内容。Jsoup 无法解析动态内容。
httpunit 只是填补了 jsoup 的不足。可以动态模拟浏览器访问URL,然后动态获取URL上的内容进行分析,从而完成动态爬虫的爬取功能。
四、爬虫模拟点击按钮代码了解httpunit的api
大家都知道,在Java语言中应用一个工具或者工具类时,首先需要创建工具类的一个对象,然后调用该对象的方法来完成一些业务,httpunit也不例外。下面是创建对象的代码:
final WebClient webClient=new WebClient();
爬虫需要传入一个页面的url来做爬取功能,然后获取该url的page对象,代码如下:
final HtmlPage page=webClient.getPage("");
获取代表页面的页面对象后,就可以解析页面元素,可以以txt文本方式或xml文件方式显示页面。代码如下:
System.out.println(page.asXml());
System.out.println(page.asText());
完成页面内容分析后不要忘记销毁模拟工具对象。api代码如下:
webClient.closeAllWindows();
爬虫模拟百度搜索框点击按钮实战
第一步:创建webClient浏览器模拟对象,调用getPage方法方法和百度主页url地址,获取代表主页的htmlpage对象。由于我们是模拟静态页面,需要关闭js解析,而爬虫不需要样式,所以我们还需要关闭css样式设置,具体代码如下图所示:
http://www.itjcw123.cn/wp-cont ... 4.png 150w" />第二步:由于我们是用爬虫模拟百度搜索框点击搜索,所以首先要得到百度首页的form表单,代码如下:
最终的 HtmlForm 表单 = htmlpage.getFormByName("f");
拿到表单ID后,再百度一下这个蓝色点击按钮的ID,代码如下:
final HtmlSubmitInput button = form.getInputByValue("百度点击");
最后获取百度搜索框的ID,以便以后模拟点击,代码如下:
final HtmlTextInput textField = form.getInputByName("q1");
第三步:准备工作已经完成,获取到的ID已经获取。接下来,我们可以在搜索框中模拟手动输入。然后点击按钮完成搜索,具体代码如下图所示:
http://www.itjcw123.cn/wp-cont ... 5.png 150w" />获取到的搜索结果页面的数据以xml格式显示。XML 文件格式更规则,标签更完整。在解析内容的时候,一个标签中的大部分内容都被解析了,所以xml格式相比txt更加优雅。
最后解析数据时,我们推荐使用jsoup作为工具。通过jsoup解析静态页面的标签更方便简洁,使用更方便。
httpunit 抓取网页(农业信息网的小小的规律总结:1.什么是爬虫? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-09-25 10:18
)
由于项目需要,我们需要用到爬虫。自己摸索了一下,总结了一些小规则,现总结如下:
1.什么是爬虫?
网络爬虫是一种自动获取网页内容的程序,是搜索引擎的重要组成部分。
传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。对于垂直搜索,聚焦爬虫,即针对特定主题抓取网页的爬虫更合适。
2. 爬虫的实现
package com.demo;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test {
public static List findList(String url) throws IOException{ //输入某个网站查找所有新闻的地址
Connection conn = Jsoup.connect(url); //使用Jsoup获得url连接
Document doc = conn.post(); // 请求返回整个文档对象
//System.out.println(doc.html());
Elements e=doc.select("a[class=newsgray a_space2]"); //返回所有的<a>超链接标签
List list=new ArrayList();
News news=null;
for(Element element:e){
news=new News();
String title=element.toString().substring(78);
String temp=title.substring(0, title.length()-4);//新闻标题
news.setTitle(temp);
String path=element.absUrl("href"); //新闻所在路径
String content=urlToHtml(path);
news.setContent(content);
news.setUrl(path);
list.add(news);
}
return list;
}
public static String urlToHtml(String url) throws IOException{
Connection conn = Jsoup.connect(url); //使用Jsoup获得url连接
Document doc = conn.post(); // 请求返回整个文档对象
StringBuilder sb=new StringBuilder();
Elements e=doc.select("p");
for(Element element:e){
String content=element.toString();
sb.append(content);
}
return sb.toString();
}
public static void main(String[] args) throws IOException {
List list=findList("http://news.aweb.com.cn/china/hyxw/");
for(News news:list){
System.out.println(news.getContent());
}
}
}
新闻.java
package com.demo;
public class News {
private String title;
private String content;
private String url;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
}
比如我们想在农业信息网捕捉最新的农业新闻
查看全部
httpunit 抓取网页(农业信息网的小小的规律总结:1.什么是爬虫?
)
由于项目需要,我们需要用到爬虫。自己摸索了一下,总结了一些小规则,现总结如下:
1.什么是爬虫?
网络爬虫是一种自动获取网页内容的程序,是搜索引擎的重要组成部分。
传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。对于垂直搜索,聚焦爬虫,即针对特定主题抓取网页的爬虫更合适。
2. 爬虫的实现
package com.demo;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test {
public static List findList(String url) throws IOException{ //输入某个网站查找所有新闻的地址
Connection conn = Jsoup.connect(url); //使用Jsoup获得url连接
Document doc = conn.post(); // 请求返回整个文档对象
//System.out.println(doc.html());
Elements e=doc.select("a[class=newsgray a_space2]"); //返回所有的<a>超链接标签
List list=new ArrayList();
News news=null;
for(Element element:e){
news=new News();
String title=element.toString().substring(78);
String temp=title.substring(0, title.length()-4);//新闻标题
news.setTitle(temp);
String path=element.absUrl("href"); //新闻所在路径
String content=urlToHtml(path);
news.setContent(content);
news.setUrl(path);
list.add(news);
}
return list;
}
public static String urlToHtml(String url) throws IOException{
Connection conn = Jsoup.connect(url); //使用Jsoup获得url连接
Document doc = conn.post(); // 请求返回整个文档对象
StringBuilder sb=new StringBuilder();
Elements e=doc.select("p");
for(Element element:e){
String content=element.toString();
sb.append(content);
}
return sb.toString();
}
public static void main(String[] args) throws IOException {
List list=findList("http://news.aweb.com.cn/china/hyxw/";);
for(News news:list){
System.out.println(news.getContent());
}
}
}
新闻.java
package com.demo;
public class News {
private String title;
private String content;
private String url;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
}
比如我们想在农业信息网捕捉最新的农业新闻
httpunit 抓取网页(网络书籍抓取器是一款功能非常强大的网页小说下载工具方法教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-09-24 22:13
网络图书抓取器是一个非常强大的网络图书下载工具。我们可以通过这个软件在网上下载一些小说。相信喜欢看小说的用户都知道,有些网络小说是可以付费观看的。然后通过这个小说下载器,你就可以下载网络小说的各个章节并合并成一个TXT文件,这样你就可以免费获得小说供浏览了。由于还有一些用户没有使用过这个软件,不知道怎么操作,那么我就给大家分享一下具体的操作方法。有兴趣的可以看看小编分享的这个方法教程。,希望能帮到大家。
方法步骤
1.首先,第一步打开软件后,在软件界面,请输入网址框,将你要下载的网络小说的网址复制粘贴进去。
<p>2. 将目标小说网页的链接复制到软件后,下一步我们需要点击适用的网站选项右侧的下拉列表,选择小说 查看全部
httpunit 抓取网页(网络书籍抓取器是一款功能非常强大的网页小说下载工具方法教程)
网络图书抓取器是一个非常强大的网络图书下载工具。我们可以通过这个软件在网上下载一些小说。相信喜欢看小说的用户都知道,有些网络小说是可以付费观看的。然后通过这个小说下载器,你就可以下载网络小说的各个章节并合并成一个TXT文件,这样你就可以免费获得小说供浏览了。由于还有一些用户没有使用过这个软件,不知道怎么操作,那么我就给大家分享一下具体的操作方法。有兴趣的可以看看小编分享的这个方法教程。,希望能帮到大家。
方法步骤
1.首先,第一步打开软件后,在软件界面,请输入网址框,将你要下载的网络小说的网址复制粘贴进去。
<p>2. 将目标小说网页的链接复制到软件后,下一步我们需要点击适用的网站选项右侧的下拉列表,选择小说
httpunit 抓取网页(3.去除主界面的图片链接,点击不会打开使用说明!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-12 12:02
3.去掉主界面的图片链接,点击打不开
网页FLASH爬虫使用说明
1、先进入FLASH动画网站,播放自己喜欢的FLASH。
2、点击“搜索”按钮,你刚刚播放的FLASH会出现在左上角的列表中。
3、 单击“另存为”按钮将 FLASH 保存到您的计算机。
4、点击“采集夹”按钮,将FLASH添加到“采集夹”集中管理。
5、“采集夹”默认路径为“C:MyFlashh”,可以通过点击“操作”→“更改采集夹”进行修改。
6、点击“打开”按钮播放硬盘中的FLASH。
7、本软件只抓取大于50KB文件的FLASH过滤FLASH广告。
后缀不是“.swf”的FLASH文件8、本软件无法抓取。
同类软件对比
PClawer 是一款功能强大的网络爬虫工具,具有高级定制功能,但前提是它只适合高级用户。此工具需要正则表达式。
WebSpider 蓝蜘蛛网络爬虫工具可以爬取互联网上的任何网页,wap网站,包括登录后可以访问的页面。分析爬取的页面内容,获取结构化信息,如新闻标题、作者、 source、body等,支持列表页自动翻页抓取,文本页多页合并,图片和文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。
华军编辑推荐:
网页FLASH抓取器无需安装、注册或写入垃圾文件,即可批量抓取网页中的Flash。 {zhandian}编辑推荐您下载网页版FLASH爬虫。编辑器会亲自测试,因此您可以放心使用。如有需要,请下载并试用!风雨小编等你! 查看全部
httpunit 抓取网页(3.去除主界面的图片链接,点击不会打开使用说明!)
3.去掉主界面的图片链接,点击打不开
网页FLASH爬虫使用说明
1、先进入FLASH动画网站,播放自己喜欢的FLASH。
2、点击“搜索”按钮,你刚刚播放的FLASH会出现在左上角的列表中。
3、 单击“另存为”按钮将 FLASH 保存到您的计算机。
4、点击“采集夹”按钮,将FLASH添加到“采集夹”集中管理。
5、“采集夹”默认路径为“C:MyFlashh”,可以通过点击“操作”→“更改采集夹”进行修改。
6、点击“打开”按钮播放硬盘中的FLASH。
7、本软件只抓取大于50KB文件的FLASH过滤FLASH广告。
后缀不是“.swf”的FLASH文件8、本软件无法抓取。
同类软件对比
PClawer 是一款功能强大的网络爬虫工具,具有高级定制功能,但前提是它只适合高级用户。此工具需要正则表达式。
WebSpider 蓝蜘蛛网络爬虫工具可以爬取互联网上的任何网页,wap网站,包括登录后可以访问的页面。分析爬取的页面内容,获取结构化信息,如新闻标题、作者、 source、body等,支持列表页自动翻页抓取,文本页多页合并,图片和文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。
华军编辑推荐:
网页FLASH抓取器无需安装、注册或写入垃圾文件,即可批量抓取网页中的Flash。 {zhandian}编辑推荐您下载网页版FLASH爬虫。编辑器会亲自测试,因此您可以放心使用。如有需要,请下载并试用!风雨小编等你!

