
httpunit 抓取网页
httpunit 抓取网页(如何简便快捷使用python抓爬网页动态加载的数据(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-18 09:06
如何轻松快速地使用python抓取网页动态加载的数据
但在实践中,我发现我原本以为的太简单了。页面上有很多数据不能简单地从html源代码中抓取,因为页面上显示的很多数据实际上是在js代码运行时通过ajax从远程服务器获取后动态的。页面加载时,不可能简单的读取html代码获取这些数据,然后通过逆向工程的方式研究它是如何构造http请求的,然后自己模拟发送这些请求来获取数据。:) 运行完上面的代码,就可以启动浏览器了,看到他打开京东主页了。这时候想在搜索框中自动输入关键词。我该怎么办?我通过html源代码找到了搜索框的id。键”因此,我们可以输入< @关键词通过如下代码模拟手动输入搜索框,然后模拟点击回车键实现搜索请求: search_box = driver.find_element_by_id(key) search_box.send_keys(word) search_box .send_keys 自浏览器和我们的代码不再运行在同一个进程中,我们需要调用 WebDriverWait 等待一段时间让浏览器完全加载页面。接下来,为了触发特定的Js代码获取动态加载的数据,我们要模拟一个人把页面拉下来的动作:SCROLL_PAUSE_TIME send_keys 由于浏览器和我们的代码不再运行在同一个进程中,所以我们需要调用WebDriverWait等待一段时间让浏览器完全加载页面。接下来,为了触发特定的Js代码获取动态加载的数据,我们要模拟一个人把页面拉下来的动作:SCROLL_PAUSE_TIME send_keys 由于浏览器和我们的代码不再运行在同一个进程中,所以我们需要调用WebDriverWait等待一段时间让浏览器完全加载页面。接下来,为了触发特定的Js代码获取动态加载的数据,我们要模拟一个人把页面拉下来的动作:SCROLL_PAUSE_TIME
511 查看全部
httpunit 抓取网页(如何简便快捷使用python抓爬网页动态加载的数据(图))
如何轻松快速地使用python抓取网页动态加载的数据
但在实践中,我发现我原本以为的太简单了。页面上有很多数据不能简单地从html源代码中抓取,因为页面上显示的很多数据实际上是在js代码运行时通过ajax从远程服务器获取后动态的。页面加载时,不可能简单的读取html代码获取这些数据,然后通过逆向工程的方式研究它是如何构造http请求的,然后自己模拟发送这些请求来获取数据。:) 运行完上面的代码,就可以启动浏览器了,看到他打开京东主页了。这时候想在搜索框中自动输入关键词。我该怎么办?我通过html源代码找到了搜索框的id。键”因此,我们可以输入< @关键词通过如下代码模拟手动输入搜索框,然后模拟点击回车键实现搜索请求: search_box = driver.find_element_by_id(key) search_box.send_keys(word) search_box .send_keys 自浏览器和我们的代码不再运行在同一个进程中,我们需要调用 WebDriverWait 等待一段时间让浏览器完全加载页面。接下来,为了触发特定的Js代码获取动态加载的数据,我们要模拟一个人把页面拉下来的动作:SCROLL_PAUSE_TIME send_keys 由于浏览器和我们的代码不再运行在同一个进程中,所以我们需要调用WebDriverWait等待一段时间让浏览器完全加载页面。接下来,为了触发特定的Js代码获取动态加载的数据,我们要模拟一个人把页面拉下来的动作:SCROLL_PAUSE_TIME send_keys 由于浏览器和我们的代码不再运行在同一个进程中,所以我们需要调用WebDriverWait等待一段时间让浏览器完全加载页面。接下来,为了触发特定的Js代码获取动态加载的数据,我们要模拟一个人把页面拉下来的动作:SCROLL_PAUSE_TIME
511
httpunit 抓取网页(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-18 09:05
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,然后就稀里糊涂的打了代码(之前用Hadoop平台的分布式爬虫框架Nutch,用起来很方便,但最后因为速度放弃了,但是统计生成用于后续爬取),很快就成功下载了holder.html和finance.html页面,然后在解析holder.html页面后,解析finance.html,然后郁闷的找不到自己需要的在这个页面中的数据不在html源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录了后者)。我很高兴,终于找到了解决方案。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。本来不是为爬虫服务的,但我想说的是:星盘只是有点短,你不能更进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从现实出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码限制太多了,解析你写的js代码,js代码很简单,所以当然WebDriver 可以毫无压力地完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面使用的IE内核,当然是FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page。 asXml() 可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js,因为它不会启动有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身体验)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。只是觉得驱动应该可以在js的解析完成后捕捉到状态,于是搜索,搜索,但是根本没有这样的方法,所以我说为什么WebDriver的设计者没有采取措施forward 以便我们可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是非常不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会不一样,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实是这样。通过Thread.sleep(2000))等待js解析完成,我觉得不可取,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
system = require('system')
address = system.args[1];//获得命令行第二个参数 接下来会用到
//console.log('Loading a web page');
var page = require('webpage').create();
var url = address;
//console.log(url);
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
//此处的打印,是将结果一流的形式output到java中,java通过InputStream可以获取该输出内容
console.log(page.content);
}
phantom.exit();
});
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream();
//后面的代码省略,得到了InputStream就好说了
}
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码编译不一样,java端会一直等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
折腾了几天,虽然我的问题没有解决,但是也长了不少见识。后面的工作熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后去网页的时候就方便了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过你可以用Nutch和WebDirver结合起来,也许爬取的结果是稳定的,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫得到的结果的稳定性有什么想说的,欢迎大家讨论,因为我确实没有找到稳定结果的相关资料。 查看全部
httpunit 抓取网页(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,然后就稀里糊涂的打了代码(之前用Hadoop平台的分布式爬虫框架Nutch,用起来很方便,但最后因为速度放弃了,但是统计生成用于后续爬取),很快就成功下载了holder.html和finance.html页面,然后在解析holder.html页面后,解析finance.html,然后郁闷的找不到自己需要的在这个页面中的数据不在html源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录了后者)。我很高兴,终于找到了解决方案。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。本来不是为爬虫服务的,但我想说的是:星盘只是有点短,你不能更进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从现实出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码限制太多了,解析你写的js代码,js代码很简单,所以当然WebDriver 可以毫无压力地完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面使用的IE内核,当然是FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page。 asXml() 可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js,因为它不会启动有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身体验)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。只是觉得驱动应该可以在js的解析完成后捕捉到状态,于是搜索,搜索,但是根本没有这样的方法,所以我说为什么WebDriver的设计者没有采取措施forward 以便我们可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是非常不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会不一样,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实是这样。通过Thread.sleep(2000))等待js解析完成,我觉得不可取,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
system = require('system')
address = system.args[1];//获得命令行第二个参数 接下来会用到
//console.log('Loading a web page');
var page = require('webpage').create();
var url = address;
//console.log(url);
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
//此处的打印,是将结果一流的形式output到java中,java通过InputStream可以获取该输出内容
console.log(page.content);
}
phantom.exit();
});
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream();
//后面的代码省略,得到了InputStream就好说了
}
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码编译不一样,java端会一直等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
折腾了几天,虽然我的问题没有解决,但是也长了不少见识。后面的工作熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后去网页的时候就方便了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过你可以用Nutch和WebDirver结合起来,也许爬取的结果是稳定的,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫得到的结果的稳定性有什么想说的,欢迎大家讨论,因为我确实没有找到稳定结果的相关资料。
httpunit 抓取网页(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-17 12:05
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,然后就稀里糊涂的打了代码(之前用Hadoop平台的分布式爬虫框架Nutch,用起来很方便,但最后因为速度放弃了,但是统计生成用于后续爬取),很快就成功下载了holder.html和finance.html页面,然后在解析holder.html页面后,解析finance.html,然后郁闷的找不到自己需要的在这个页面中的数据不在html源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录了后者)。我很高兴,终于找到了解决方案。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。本来不是为爬虫服务的,但我想说的是:星盘只是有点短,你不能更进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从现实出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码限制太多了,解析你写的js代码,js代码很简单,所以当然WebDriver 可以毫无压力地完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面使用的IE内核,当然还有FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page。 asXml() 可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js,因为它不会启动有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身体验)。js代码的复杂含义是:不同内核支持的js是不完全一样的。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。只是觉得驱动应该可以在js的解析完成后捕捉到状态,于是搜索,搜索,但是根本没有这样的方法,所以我说为什么WebDriver的设计者没有采取措施forward 以便我们可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是很不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会不一样,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实是这样。通过Thread.sleep(2000))等待js解析完成,我觉得不可取,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
system = require('system')
address = system.args[1];//获得命令行第二个参数 接下来会用到
//console.log('Loading a web page');
var page = require('webpage').create();
var url = address;
//console.log(url);
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
//此处的打印,是将结果一流的形式output到java中,java通过InputStream可以获取该输出内容
console.log(page.content);
}
phantom.exit();
});
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream();
//后面的代码省略,得到了InputStream就好说了
}
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码编译不一样,java端会一直等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
折腾了几天,虽然我的问题没有解决,但是也长了不少见识。后面的工作熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后去网页的时候就方便了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过你可以用Nutch和WebDirver结合起来,也许爬取的结果是稳定的,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫得到的结果的稳定性有什么想说的,欢迎大家讨论,因为我确实没有找到稳定结果的相关资料。 查看全部
httpunit 抓取网页(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,然后就稀里糊涂的打了代码(之前用Hadoop平台的分布式爬虫框架Nutch,用起来很方便,但最后因为速度放弃了,但是统计生成用于后续爬取),很快就成功下载了holder.html和finance.html页面,然后在解析holder.html页面后,解析finance.html,然后郁闷的找不到自己需要的在这个页面中的数据不在html源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录了后者)。我很高兴,终于找到了解决方案。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。本来不是为爬虫服务的,但我想说的是:星盘只是有点短,你不能更进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从现实出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码限制太多了,解析你写的js代码,js代码很简单,所以当然WebDriver 可以毫无压力地完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面使用的IE内核,当然还有FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page。 asXml() 可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js,因为它不会启动有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身体验)。js代码的复杂含义是:不同内核支持的js是不完全一样的。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。只是觉得驱动应该可以在js的解析完成后捕捉到状态,于是搜索,搜索,但是根本没有这样的方法,所以我说为什么WebDriver的设计者没有采取措施forward 以便我们可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是很不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会不一样,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实是这样。通过Thread.sleep(2000))等待js解析完成,我觉得不可取,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
system = require('system')
address = system.args[1];//获得命令行第二个参数 接下来会用到
//console.log('Loading a web page');
var page = require('webpage').create();
var url = address;
//console.log(url);
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
//此处的打印,是将结果一流的形式output到java中,java通过InputStream可以获取该输出内容
console.log(page.content);
}
phantom.exit();
});
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream();
//后面的代码省略,得到了InputStream就好说了
}
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码编译不一样,java端会一直等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
折腾了几天,虽然我的问题没有解决,但是也长了不少见识。后面的工作熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后去网页的时候就方便了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过你可以用Nutch和WebDirver结合起来,也许爬取的结果是稳定的,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫得到的结果的稳定性有什么想说的,欢迎大家讨论,因为我确实没有找到稳定结果的相关资料。
httpunit 抓取网页(怎么解决网站抓取频次低的问题?试试以下办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-15 02:26
有朋友提到网站被百度抓取的频率很低,问怎么解决。爬取频率对页面收录影响很大。如果网站的爬取频率很低,说明有很多页面没有被爬取,对收录页面影响很大。
如何解决网站的抓取频率低的问题,不妨试试下面的方法。
一、通过网站设置解决爬取频率低的问题
在百度站长平台(现更名为百度搜索资源平台)中,有解决抓取频率不足问题的说明,如下图:
笔者在这里稍微解释一下:1. 正常情况下,站长不会主动设置爬取频率的上限,所以这点不需要考虑;2.检查爬取是否异常,这个需要注意,有的网站程序中可能有一些错误导致爬取不成功;3. 提交新链接,很有用;4. 反馈,应该说反馈基本没用。
每个人都应该关注第 2 点和第 3 点。
二、 通过外链解决爬取频率低的问题
从某种意义上说,爬行频率取决于蜘蛛爬行的次数。抓取次数越多,抓取的页面就越多。通常,这是成正比的。
对于低权重的网站来说,通过外部链接吸引蜘蛛爬行是一个不错的选择。作者在文章里也提到了,现在做seo外链有没有效果。
PS:这里需要说明一下蜘蛛爬行的概率。百度蜘蛛不是会纺丝织网的蜘蛛。其工作原理是通过组织好的url库中的特定url链接抓取页面数据,同时将页面放入页面中。提取链接后,剩余的url地址过滤后放入url库,这是一个循环过程。
通过建立外链,我们更多的网站 URL会被百度蜘蛛发现并存入数据库,从而有更多的机会增加爬取的频率。
三、 通过内链建设解决爬取频率低的问题
如上所述,建立外链可以吸引蜘蛛爬行,那么如何更好地利用蜘蛛来了,如何让更多的页面URL被发现呢?这涉及到内部链接的构建。如何设置内容增加爬取频率,我们可以从以下几个方面入手:
1.文章内部链。包括文中的内部链接以及相关的文章推荐等,这是基本的操作方法,我就不多说了。
2.侧边栏推荐。比如热门阅读、最新内容、标签采集标签推荐等,页面链接暴露的越多,被蜘蛛爬取的几率就越大。这是一个非常简单的真理。
3.文章 列表。这是一个重要的解释点。一般情况下,列表中的文章是按时间倒序排列的,也就是说,后面发布的文章会排在最前面。这里有问题。同一个文章列表下每天更新的文章数量有限,分页被蜘蛛爬取的次数会比较多,浪费了链接展示的机会。
举个例子:List A显示最近10篇文章,每天更新5次,蜘蛛每天爬5次。事实上,无论蜘蛛一天爬行5次还是50次,每天只有5个新页面链接显示在这个页面上!如果分类页面可以更新未被抓取的页面(定时或不规则),那么情况就明显不同了。每次蜘蛛来爬,都会提交一个新的页面链接,大大提高。抓取频率。
网站更新频率高网站更受蜘蛛青睐。如果要解决爬虫频率低网站的问题,除了做外链来吸引蜘蛛,更应该解决网站上的更新问题。.
PS:页面更新并不是绝对指添加新页面。对于搜索引擎蜘蛛来说,页面内容发生变化就意味着页面已经更新。至于更新后页面质量是否有所提升,本文暂不赘述。
还有一点就是网站本身的内容量。如果网站的总页数不超过100,则要求每天的抓取量超过1000,这显然是不合时宜的。 查看全部
httpunit 抓取网页(怎么解决网站抓取频次低的问题?试试以下办法)
有朋友提到网站被百度抓取的频率很低,问怎么解决。爬取频率对页面收录影响很大。如果网站的爬取频率很低,说明有很多页面没有被爬取,对收录页面影响很大。
如何解决网站的抓取频率低的问题,不妨试试下面的方法。
一、通过网站设置解决爬取频率低的问题
在百度站长平台(现更名为百度搜索资源平台)中,有解决抓取频率不足问题的说明,如下图:

笔者在这里稍微解释一下:1. 正常情况下,站长不会主动设置爬取频率的上限,所以这点不需要考虑;2.检查爬取是否异常,这个需要注意,有的网站程序中可能有一些错误导致爬取不成功;3. 提交新链接,很有用;4. 反馈,应该说反馈基本没用。
每个人都应该关注第 2 点和第 3 点。
二、 通过外链解决爬取频率低的问题
从某种意义上说,爬行频率取决于蜘蛛爬行的次数。抓取次数越多,抓取的页面就越多。通常,这是成正比的。
对于低权重的网站来说,通过外部链接吸引蜘蛛爬行是一个不错的选择。作者在文章里也提到了,现在做seo外链有没有效果。
PS:这里需要说明一下蜘蛛爬行的概率。百度蜘蛛不是会纺丝织网的蜘蛛。其工作原理是通过组织好的url库中的特定url链接抓取页面数据,同时将页面放入页面中。提取链接后,剩余的url地址过滤后放入url库,这是一个循环过程。
通过建立外链,我们更多的网站 URL会被百度蜘蛛发现并存入数据库,从而有更多的机会增加爬取的频率。
三、 通过内链建设解决爬取频率低的问题
如上所述,建立外链可以吸引蜘蛛爬行,那么如何更好地利用蜘蛛来了,如何让更多的页面URL被发现呢?这涉及到内部链接的构建。如何设置内容增加爬取频率,我们可以从以下几个方面入手:
1.文章内部链。包括文中的内部链接以及相关的文章推荐等,这是基本的操作方法,我就不多说了。
2.侧边栏推荐。比如热门阅读、最新内容、标签采集标签推荐等,页面链接暴露的越多,被蜘蛛爬取的几率就越大。这是一个非常简单的真理。
3.文章 列表。这是一个重要的解释点。一般情况下,列表中的文章是按时间倒序排列的,也就是说,后面发布的文章会排在最前面。这里有问题。同一个文章列表下每天更新的文章数量有限,分页被蜘蛛爬取的次数会比较多,浪费了链接展示的机会。
举个例子:List A显示最近10篇文章,每天更新5次,蜘蛛每天爬5次。事实上,无论蜘蛛一天爬行5次还是50次,每天只有5个新页面链接显示在这个页面上!如果分类页面可以更新未被抓取的页面(定时或不规则),那么情况就明显不同了。每次蜘蛛来爬,都会提交一个新的页面链接,大大提高。抓取频率。
网站更新频率高网站更受蜘蛛青睐。如果要解决爬虫频率低网站的问题,除了做外链来吸引蜘蛛,更应该解决网站上的更新问题。.
PS:页面更新并不是绝对指添加新页面。对于搜索引擎蜘蛛来说,页面内容发生变化就意味着页面已经更新。至于更新后页面质量是否有所提升,本文暂不赘述。
还有一点就是网站本身的内容量。如果网站的总页数不超过100,则要求每天的抓取量超过1000,这显然是不合时宜的。
httpunit 抓取网页(用wireshark抓取网站登录弱口令(账号密码都是新建也没啥权限) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-15 02:25
)
摘要:Wireshark本身无法破解弱密码,但我们可以通过分析手动破解捕获的数据。今天,我将使用智能测试博客和FTP做实验(账号和密码都是新的,没有权限,请不要使用)。1:使用Wireshark抓取网站登录弱密码1、页面一.
Wireshark本身无法破解弱密码,但我们可以通过分析手动破解捕获的数据
今天,我将使用智能测试博客和FTP做实验(账号和密码都是新的,没有权限,请不要使用)
1:使用Wireshark抓取网站登录弱密码
1、在第一步中,我们设置捕获筛选器(这次我们捕获HTTP数据包,只需在捕获筛选器中输入HTTP)
2、单击开始打开我的博客地址(),单击登录,转到页面,输入用户名和密码,然后单击登录
3、登录后,我们可以结束Wireshark捕获过程
4、然后我们设置显示过滤器:使用IP地址==203.171.239.103这是我博客服务器的IP地址,可以减少大量HTTP数据。(您可以使用CMD下的ping命令获取您的网站IP地址)
Wireshark显示过滤器
5、过滤后,我们找到/WP login PHP(WP login.PHP是我博客后台登录页面的地址)
6、查看全部/WP登录事实上,PHP中只有两段数据。我们捕获了第二条数据(log=Huisha&;PWD=279478776&;WP submit=)。你看到这是我的帐户和密码了吗(用户:Huisha/PWD:279478776)
当然,如果用户的密码非常复杂,那么以这种方式获取密码基本上是错误的,所以只能获取弱密码
Wireshark捕获的帐户密码
2:使用Wireshark获取FTP帐户和密码
同样,我们使用上述方法捕获FTP帐户和密码。捕获FTP帐户和密码时,不适用于弱密码。只要您能够捕获FTP数据,就可以获得FTP帐户和密码
操作
1、将捕获筛选器设置为仅捕获FTP数据包
2、打开FTP工具登录到您的FTP服务器
3、然后结束捕获过程
4、设置显示过滤器(IP.Addr==192.168.>9.1您的FTP地址)
5、然后我们会发现FTP帐户和密码以明文显示,酷
资料来源:红黑联盟
查看全部
httpunit 抓取网页(用wireshark抓取网站登录弱口令(账号密码都是新建也没啥权限)
)
摘要:Wireshark本身无法破解弱密码,但我们可以通过分析手动破解捕获的数据。今天,我将使用智能测试博客和FTP做实验(账号和密码都是新的,没有权限,请不要使用)。1:使用Wireshark抓取网站登录弱密码1、页面一.
Wireshark本身无法破解弱密码,但我们可以通过分析手动破解捕获的数据
今天,我将使用智能测试博客和FTP做实验(账号和密码都是新的,没有权限,请不要使用)
 https://www.youxia.org/wp-cont ... 6.jpg 300w" />
https://www.youxia.org/wp-cont ... 6.jpg 300w" />1:使用Wireshark抓取网站登录弱密码
1、在第一步中,我们设置捕获筛选器(这次我们捕获HTTP数据包,只需在捕获筛选器中输入HTTP)
2、单击开始打开我的博客地址(),单击登录,转到页面,输入用户名和密码,然后单击登录
3、登录后,我们可以结束Wireshark捕获过程
4、然后我们设置显示过滤器:使用IP地址==203.171.239.103这是我博客服务器的IP地址,可以减少大量HTTP数据。(您可以使用CMD下的ping命令获取您的网站IP地址)
Wireshark显示过滤器
5、过滤后,我们找到/WP login PHP(WP login.PHP是我博客后台登录页面的地址)
6、查看全部/WP登录事实上,PHP中只有两段数据。我们捕获了第二条数据(log=Huisha&;PWD=279478776&;WP submit=)。你看到这是我的帐户和密码了吗(用户:Huisha/PWD:279478776)
当然,如果用户的密码非常复杂,那么以这种方式获取密码基本上是错误的,所以只能获取弱密码
Wireshark捕获的帐户密码
2:使用Wireshark获取FTP帐户和密码
同样,我们使用上述方法捕获FTP帐户和密码。捕获FTP帐户和密码时,不适用于弱密码。只要您能够捕获FTP数据,就可以获得FTP帐户和密码
操作
1、将捕获筛选器设置为仅捕获FTP数据包
2、打开FTP工具登录到您的FTP服务器
3、然后结束捕获过程
4、设置显示过滤器(IP.Addr==192.168.>9.1您的FTP地址)
5、然后我们会发现FTP帐户和密码以明文显示,酷
资料来源:红黑联盟

httpunit 抓取网页(搜索引擎蜘蛛花抓取份额是由什么决定的呢?说明)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-13 13:12
顾名思义,爬行份额是搜索引擎蜘蛛在网站上爬取一个页面所花费的总时间的上限。对于特定的网站,搜索引擎蜘蛛在这个网站上花费的总时间是相对固定的,不会无限爬取网站的所有页面。
Google 使用英文的 crawl budget 来抓取共享,直译为抓取预算。我不认为它可以解释它的含义,所以我使用爬网共享来表达这个概念。
什么决定了爬网份额?这涉及到爬行要求和爬行速度限制。
爬行需求
爬取需求,或者说爬取需求,指的是搜索引擎“想要”爬取多少个特定的网站页面。
有两个主要因素决定了对爬行的需求。首先是页面权重。网站上有多少页面达到基本页面权重,搜索引擎想要抓取多少个页面。二是索引库中的页面是否太长时间没有更新。毕竟是页面权重,权重高的页面不会更新太久。
页面权重和 网站 权重密切相关。增加网站的权重可以让搜索引擎愿意抓取更多的页面。
爬行速度限制
搜索引擎蜘蛛不会为了抓取更多的页面而拖拽别人的网站服务器,所以会针对某个网站设置一个抓取速度限制,即抓取速度限制,即服务器可以容忍上限,在这个速度限制内,蜘蛛爬行不会减慢服务器,影响用户访问。
服务器响应速度够快,这个限速提高一点,爬行加快,服务器响应速度降低,限速降低,爬行变慢,甚至爬行停止。
因此,抓取速度受限于搜索引擎“可以”抓取的页面数量。
什么决定了爬网份额?
爬取份额是同时考虑爬取需求和爬取速度限制的结果,即搜索引擎“想要”爬取但“能”爬取的页面数。
网站 权重高,页面内容质量高,页面多,服务器速度快,爬取份额大。
小网站不用担心抢份额
小网站页面数量少,即使网站权重低,服务器慢,不管搜索引擎蜘蛛每天爬多少,通常至少几百页可以爬取。网站又被抓取了,让网站拥有数千个页面根本不用担心抢分享。网站 有几万页通常没什么大不了的。如果每天数百次访问可以降低服务器的速度,这不是 SEO 的主要考虑因素。
大中型网站可能需要考虑抢份额
对于几十万页以上的大中型网站来说,可能需要考虑足够抢占的问题。
爬网份额是不够的。比如网站有1000万个页面,搜索引擎每天只能抓取几万个页面。捕获一次网站可能需要几个月,甚至一年的时间,这也可能意味着一些重要页面无法抓取,因此没有排名,或者重要页面无法及时更新。
想要网站页面被及时完整地抓取,首先要保证服务器足够快,页面足够小。如果网站有大量优质数据,爬取份额会受到爬取速度的限制。提高页面速度直接提高了抓取速度限制,从而增加了抓取份额。
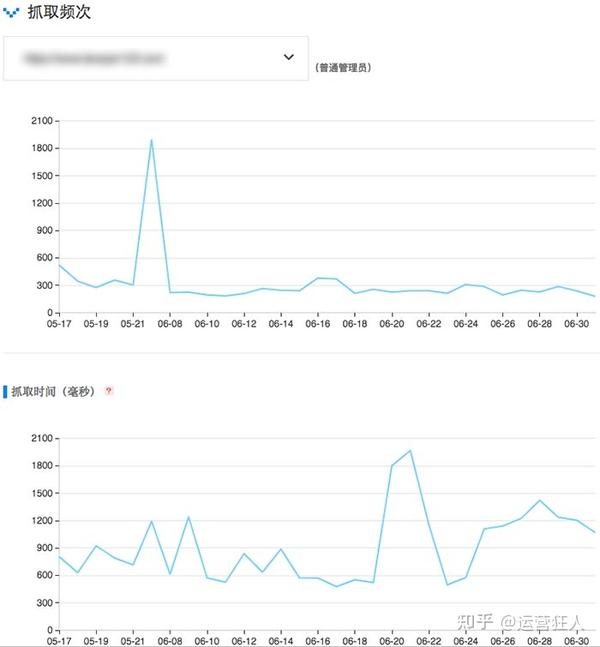
百度站长平台和谷歌搜索控制台都有抓取数据。如下图,某网站百度的抓取频率:
上图为网站百度小后台截图。页面抓取频率和抓取时间(取决于服务器速度和页面大小)与此无关。这意味着爬网份额还没有用完,所以不用担心。
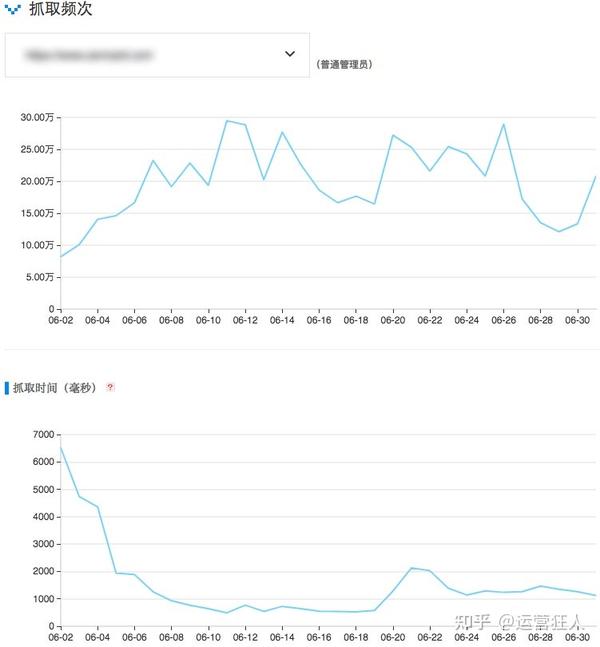
有时,爬取频率和爬取时间有一定的对应关系,如下图为另一个较大的网站:
可以看出爬取时间的提升(减小页面大小、提高服务器速度、优化数据库)明显导致爬取频率增加,导致爬取更多页面收录,再次遍历网站更快。
大网站 另一个经常需要考虑爬网份额的原因是不要把自己有限的爬网份额浪费在无意义的页面爬行上,导致重要的页面应该被爬行却没有机会被爬行。
浪费抓取共享的典型页面是:
以上页面被大量抓取,抓取份额可能用完,但应该抓取的页面没有抓取。
如何保存抓取共享?
当然,首先是减小页面文件的大小,提高服务器的速度,优化数据库,减少抓取时间。
然后,尽量避免上面列出的浪费性抢股。有些是内容质量问题,有些是网站结构问题。如果是结构问题,最简单的方法就是禁止爬取robots文件,但是会浪费一些页面权重,因为权重只能访问。
在某些情况下,使用链接 nofollow 可以节省抓取共享。小网站,添加nofollow没有意义,因为爬取份额用不完。大网站,nofollow 可以在一定程度上控制权重的流量和分配。精心设计的nofollow会降低无意义页面的权重,增加重要页面的权重。搜索引擎在爬取时会使用一个 URL 爬取列表。要抓取的网址按页面权重排序。如果增加重要页面的权重,将首先抓取重要页面。无意义页面的权重可能很低,以至于搜索引擎不想爬行。
最后几点说明:
关注我@operation优采云不定期更新互联网运营知识。如果你想学习SEO和新媒体运营,可以加我主页微信运营优采云,知无不言...
如果以上内容对您有帮助,请点个赞。 查看全部
httpunit 抓取网页(搜索引擎蜘蛛花抓取份额是由什么决定的呢?说明)
顾名思义,爬行份额是搜索引擎蜘蛛在网站上爬取一个页面所花费的总时间的上限。对于特定的网站,搜索引擎蜘蛛在这个网站上花费的总时间是相对固定的,不会无限爬取网站的所有页面。
Google 使用英文的 crawl budget 来抓取共享,直译为抓取预算。我不认为它可以解释它的含义,所以我使用爬网共享来表达这个概念。
什么决定了爬网份额?这涉及到爬行要求和爬行速度限制。
爬行需求
爬取需求,或者说爬取需求,指的是搜索引擎“想要”爬取多少个特定的网站页面。
有两个主要因素决定了对爬行的需求。首先是页面权重。网站上有多少页面达到基本页面权重,搜索引擎想要抓取多少个页面。二是索引库中的页面是否太长时间没有更新。毕竟是页面权重,权重高的页面不会更新太久。
页面权重和 网站 权重密切相关。增加网站的权重可以让搜索引擎愿意抓取更多的页面。
爬行速度限制
搜索引擎蜘蛛不会为了抓取更多的页面而拖拽别人的网站服务器,所以会针对某个网站设置一个抓取速度限制,即抓取速度限制,即服务器可以容忍上限,在这个速度限制内,蜘蛛爬行不会减慢服务器,影响用户访问。
服务器响应速度够快,这个限速提高一点,爬行加快,服务器响应速度降低,限速降低,爬行变慢,甚至爬行停止。
因此,抓取速度受限于搜索引擎“可以”抓取的页面数量。
什么决定了爬网份额?
爬取份额是同时考虑爬取需求和爬取速度限制的结果,即搜索引擎“想要”爬取但“能”爬取的页面数。
网站 权重高,页面内容质量高,页面多,服务器速度快,爬取份额大。
小网站不用担心抢份额
小网站页面数量少,即使网站权重低,服务器慢,不管搜索引擎蜘蛛每天爬多少,通常至少几百页可以爬取。网站又被抓取了,让网站拥有数千个页面根本不用担心抢分享。网站 有几万页通常没什么大不了的。如果每天数百次访问可以降低服务器的速度,这不是 SEO 的主要考虑因素。
大中型网站可能需要考虑抢份额
对于几十万页以上的大中型网站来说,可能需要考虑足够抢占的问题。
爬网份额是不够的。比如网站有1000万个页面,搜索引擎每天只能抓取几万个页面。捕获一次网站可能需要几个月,甚至一年的时间,这也可能意味着一些重要页面无法抓取,因此没有排名,或者重要页面无法及时更新。
想要网站页面被及时完整地抓取,首先要保证服务器足够快,页面足够小。如果网站有大量优质数据,爬取份额会受到爬取速度的限制。提高页面速度直接提高了抓取速度限制,从而增加了抓取份额。
百度站长平台和谷歌搜索控制台都有抓取数据。如下图,某网站百度的抓取频率:
上图为网站百度小后台截图。页面抓取频率和抓取时间(取决于服务器速度和页面大小)与此无关。这意味着爬网份额还没有用完,所以不用担心。
有时,爬取频率和爬取时间有一定的对应关系,如下图为另一个较大的网站:
可以看出爬取时间的提升(减小页面大小、提高服务器速度、优化数据库)明显导致爬取频率增加,导致爬取更多页面收录,再次遍历网站更快。
大网站 另一个经常需要考虑爬网份额的原因是不要把自己有限的爬网份额浪费在无意义的页面爬行上,导致重要的页面应该被爬行却没有机会被爬行。
浪费抓取共享的典型页面是:
以上页面被大量抓取,抓取份额可能用完,但应该抓取的页面没有抓取。
如何保存抓取共享?
当然,首先是减小页面文件的大小,提高服务器的速度,优化数据库,减少抓取时间。
然后,尽量避免上面列出的浪费性抢股。有些是内容质量问题,有些是网站结构问题。如果是结构问题,最简单的方法就是禁止爬取robots文件,但是会浪费一些页面权重,因为权重只能访问。
在某些情况下,使用链接 nofollow 可以节省抓取共享。小网站,添加nofollow没有意义,因为爬取份额用不完。大网站,nofollow 可以在一定程度上控制权重的流量和分配。精心设计的nofollow会降低无意义页面的权重,增加重要页面的权重。搜索引擎在爬取时会使用一个 URL 爬取列表。要抓取的网址按页面权重排序。如果增加重要页面的权重,将首先抓取重要页面。无意义页面的权重可能很低,以至于搜索引擎不想爬行。
最后几点说明:
关注我@operation优采云不定期更新互联网运营知识。如果你想学习SEO和新媒体运营,可以加我主页微信运营优采云,知无不言...
如果以上内容对您有帮助,请点个赞。
httpunit 抓取网页(百度蜘蛛只爬行了网站首页的解决办法问题应该如何解决)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-08 05:06
站长查看网站访问日志时,可以看到搜索引擎蜘蛛抓取的页面,以及频率和返回码,以便站长知道网站的哪些页面和内容蜘蛛爬了。但是,在某些情况下,站长分析网站日志时,搜索引擎蜘蛛只爬取了网站首页,并没有继续爬取内页文章,那么如何解决百度蜘蛛只抓取网站首页的问题。
1、分析网站内部优化是否完善
在算法不断升级的现状下,SEO技术不再是单纯的迎合某个搜索引擎,而是从用户体验上综合考虑网站。搜索引擎蜘蛛只抓取主页。,首先要确定网站的内部优化是否完善,网站的首页是否有大量脚本文件、flash文件等,以及网站的首页是否有网站 规范了 H 标签的使用。
2、机器人设置错误
在蜘蛛只抓取首页的日志分析中,可以检查网站根目录下的robots.txt文件是否设置错误,导致网站内页限制蜘蛛抓取。检查 robots 文件内容中的通配符。这是错的吗?还要检查 网站 服务器是否有限制策略。
3、网站文章内容
通过网站日志的返回码可以看到,蜘蛛每次抓取网站首页返回的值,判断蜘蛛的爬行情况,优化网站的内容@>文章 ,尽量专注于原创,SEO是一个长期的技术活动,坚持原创的内容,把原创的内容提交给专业搜索引擎,蜘蛛只抓取首页,不抓取内容的情况会得到很好的解决。
以上就是百度蜘蛛只抓取网站首页的解决方法。同时站长可以在优化网站时制作sitemap.xml的地图,并将sitemap.xml放在robots.txt中。可以有效提高蜘蛛对网站内页的抓取。 查看全部
httpunit 抓取网页(百度蜘蛛只爬行了网站首页的解决办法问题应该如何解决)
站长查看网站访问日志时,可以看到搜索引擎蜘蛛抓取的页面,以及频率和返回码,以便站长知道网站的哪些页面和内容蜘蛛爬了。但是,在某些情况下,站长分析网站日志时,搜索引擎蜘蛛只爬取了网站首页,并没有继续爬取内页文章,那么如何解决百度蜘蛛只抓取网站首页的问题。

1、分析网站内部优化是否完善
在算法不断升级的现状下,SEO技术不再是单纯的迎合某个搜索引擎,而是从用户体验上综合考虑网站。搜索引擎蜘蛛只抓取主页。,首先要确定网站的内部优化是否完善,网站的首页是否有大量脚本文件、flash文件等,以及网站的首页是否有网站 规范了 H 标签的使用。
2、机器人设置错误
在蜘蛛只抓取首页的日志分析中,可以检查网站根目录下的robots.txt文件是否设置错误,导致网站内页限制蜘蛛抓取。检查 robots 文件内容中的通配符。这是错的吗?还要检查 网站 服务器是否有限制策略。
3、网站文章内容
通过网站日志的返回码可以看到,蜘蛛每次抓取网站首页返回的值,判断蜘蛛的爬行情况,优化网站的内容@>文章 ,尽量专注于原创,SEO是一个长期的技术活动,坚持原创的内容,把原创的内容提交给专业搜索引擎,蜘蛛只抓取首页,不抓取内容的情况会得到很好的解决。
以上就是百度蜘蛛只抓取网站首页的解决方法。同时站长可以在优化网站时制作sitemap.xml的地图,并将sitemap.xml放在robots.txt中。可以有效提高蜘蛛对网站内页的抓取。
httpunit 抓取网页(如下:robots协议文件屏蔽百度蜘蛛抓取协议(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-04 00:02
百度蜘蛛抓取我们的网站,希望将我们的网页收录发送到它的搜索引擎。以后用户搜索的时候,可以给我们带来一定的SEO流量。当然,我们不希望搜索引擎抓取所有内容。
所以,这个时候,我们只希望我们想爬取在搜索引擎上搜索到的内容。像用户隐私、背景信息等,不希望搜索引擎被爬取和收录。有两种最好的方法可以解决这个问题,如下所示:
Robots协议文件阻止百度蜘蛛爬行
robots协议是放置在网站根目录下的协议文件,可以通过URL地址访问:您的域名/robots.txt。当百度蜘蛛抓取我们网站时,它会先访问这个文件。因为它告诉蜘蛛哪些可以爬,哪些不能爬。
robots协议文件的设置比较简单,可以通过User-Agent、Disallow、Allow三个参数进行设置。
让我们看一个例子。场景是我不想百度抓取我所有的网站 css文件、数据目录、seo-tag.html页面
User-Agent: Baidusppider
Disallow: /*.css
Disallow: /data/
Disallow: /seo/seo-tag.html
如上,user-agent声明的蜘蛛名称表示针对百度蜘蛛。下面的不能抢“/*.css”,首先前面的/指的是根目录,也就是你的域名。* 是通配符,代表任何内容。这意味着无法抓取所有以 .css 结尾的文件。亲自体验以下两个。逻辑是一样的。
如果你想检查你上次设置的robots文件是否正确,可以访问这个文章《检查Robots是否正确的工具介绍》,里面有详细的工具可以检查你的设置。
通过403状态码,限制内容输出,阻止蜘蛛爬行。
403状态码是http协议中网页返回的状态码。当搜索引擎遇到 403 状态码时,它知道该类型的页面是权限受限的。我不能访问。比如你需要登录查看内容,搜索引擎本身不会登录,那么当你返回403时,他也知道这是权限设置页面,无法读取内容。自然不会是收录。
当返回 403 状态码时,应该有一个类似于 404 页面的页面。提示用户或蜘蛛执行他们想要访问的内容。两者缺一不可。你只有一个提示页面,状态码返回200,对于百度蜘蛛来说是很多重复的页面。有一个 403 状态代码,但返回不同的内容。它也不是很友好。
最后,关于机器人协议,我想再补充一点:“现在搜索引擎会通过你的网页的布局和布局来识别你的网页的体验友好度。如果抓取css文件和布局相关的js文件被屏蔽了,那么搜索引擎我不知道你的网页布局是好是坏。所以不建议从蜘蛛那里屏蔽这个内容。”
好了,今天的分享就到这里,希望能对大家有所帮助,当然以上两个设置对除百度蜘蛛以外的所有蜘蛛都有效。设置时请谨慎。 查看全部
httpunit 抓取网页(如下:robots协议文件屏蔽百度蜘蛛抓取协议(组图))
百度蜘蛛抓取我们的网站,希望将我们的网页收录发送到它的搜索引擎。以后用户搜索的时候,可以给我们带来一定的SEO流量。当然,我们不希望搜索引擎抓取所有内容。
所以,这个时候,我们只希望我们想爬取在搜索引擎上搜索到的内容。像用户隐私、背景信息等,不希望搜索引擎被爬取和收录。有两种最好的方法可以解决这个问题,如下所示:
Robots协议文件阻止百度蜘蛛爬行
robots协议是放置在网站根目录下的协议文件,可以通过URL地址访问:您的域名/robots.txt。当百度蜘蛛抓取我们网站时,它会先访问这个文件。因为它告诉蜘蛛哪些可以爬,哪些不能爬。
robots协议文件的设置比较简单,可以通过User-Agent、Disallow、Allow三个参数进行设置。
让我们看一个例子。场景是我不想百度抓取我所有的网站 css文件、数据目录、seo-tag.html页面
User-Agent: Baidusppider
Disallow: /*.css
Disallow: /data/
Disallow: /seo/seo-tag.html
如上,user-agent声明的蜘蛛名称表示针对百度蜘蛛。下面的不能抢“/*.css”,首先前面的/指的是根目录,也就是你的域名。* 是通配符,代表任何内容。这意味着无法抓取所有以 .css 结尾的文件。亲自体验以下两个。逻辑是一样的。
如果你想检查你上次设置的robots文件是否正确,可以访问这个文章《检查Robots是否正确的工具介绍》,里面有详细的工具可以检查你的设置。
通过403状态码,限制内容输出,阻止蜘蛛爬行。
403状态码是http协议中网页返回的状态码。当搜索引擎遇到 403 状态码时,它知道该类型的页面是权限受限的。我不能访问。比如你需要登录查看内容,搜索引擎本身不会登录,那么当你返回403时,他也知道这是权限设置页面,无法读取内容。自然不会是收录。
当返回 403 状态码时,应该有一个类似于 404 页面的页面。提示用户或蜘蛛执行他们想要访问的内容。两者缺一不可。你只有一个提示页面,状态码返回200,对于百度蜘蛛来说是很多重复的页面。有一个 403 状态代码,但返回不同的内容。它也不是很友好。
最后,关于机器人协议,我想再补充一点:“现在搜索引擎会通过你的网页的布局和布局来识别你的网页的体验友好度。如果抓取css文件和布局相关的js文件被屏蔽了,那么搜索引擎我不知道你的网页布局是好是坏。所以不建议从蜘蛛那里屏蔽这个内容。”
好了,今天的分享就到这里,希望能对大家有所帮助,当然以上两个设置对除百度蜘蛛以外的所有蜘蛛都有效。设置时请谨慎。
httpunit 抓取网页( web抓取web站点之lxml和Requestsinstall安装requests和pip)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-03 23:20
web抓取web站点之lxml和Requestsinstall安装requests和pip)
网页抓取
该网站是用 HTML 语言编写的,这意味着每个网页都是一个结构化的文档。有时,我们可以使用当前的结构来获取所需的数据并保留数据格式,但通常我们无法以合适的结构获取数据(不像csv和json)。
网页抓取会在适当的时候出现。网页抓取可以利用计算机程序对网页进行过滤,获取适当结构下的目标数据,同时保留数据的格式。
lxml 和请求
lxml 是一个优秀的 Python 扩展库,用于快速解析 XML 和 HTML 文档,甚至可以处理错误标签。另外,我们还使用Requests代替了内置的urllib2,因为它在速度和稳定性方面更好。您可以使用 pip install lxml 和 pip install requests 安装请求和 pip。
首先,让我们从导入开始:
from lxml import html
import requests
其次,我们使用requests.get查找网页,使用lxml的html库解析网页,并将结果保存在树中:
page = requests.get('http://econpy.pythonanywhere.c ... %2339;)
tree = html.fromstring(page.content)
tree 现在以整洁的树结构收录所有 HTML 内容。我们可以通过XPath和CSSSelect两种方式来获取树结构中的数据。在本文中,我们使用前者。
XPath 是一种在结构化文档(如 HTML 和 XML 文档)中定位信息的方法。XPath的介绍请参考W3Schools。
获取元素的XPath的工具有很多,比如Firefox中的FireBug,Chrome中的开发者工具。如果您使用的是 Chrome,您可以右键单击该元素,选择“检查元素”,在 HTML 查看器中突出显示此 HTML 代码,再次右键单击并选择“复制 XPath”。
经过快速分析,可以了解到该页面上的数据收录在两类元素中。一个是title为buyer-name的div,另一个是class为item-price的span
:
Carson Busses
$29.95
了解以上内容后,我们就可以创建对应的XPath地址检索并使用lxml的xpath功能,代码如下:
#这将获取到一个buyers列表
buyers = tree.xpath('//div[@title="buyer-name"]/text()')
#这将获取到一个prices列表
prices = tree.xpath('//span[@class="item-price"]/text()')
我们来看看最终得到的数据:
print 'Buyers: ', buyers
print 'Prices: ', prices
Buyers: ['Carson Busses', 'Earl E. Byrd', 'Patty Cakes',
'Derri Anne Connecticut', 'Moe Dess', 'Leda Doggslife', 'Dan Druff',
'Al Fresco', 'Ido Hoe', 'Howie Kisses', 'Len Lease', 'Phil Meup',
'Ira Pent', 'Ben D. Rules', 'Ave Sectomy', 'Gary Shattire',
'Bobbi Soks', 'Sheila Takya', 'Rose Tattoo', 'Moe Tell']
Prices: ['$29.95', '$8.37', '$15.26', '$19.25', '$19.25',
'$13.99', '$31.57', '$8.49', '$14.47', '$15.86', '$11.11',
'$15.98', '$16.27', '$7.50', '$50.85', '$14.26', '$5.68',
'$15.00', '$114.07', '$10.09']
恭喜!我们已经使用 lxml 和 Requests 从网页中获取所需的数据。我们将数据作为列表存储在内存中。现在我们可以做各种有趣的事情:我们可以用python分析数据,或者我们可以将其保存为文件并共享。
还有更多有趣的事情需要考虑,例如修改脚本使其可以遍历示例网页中的所有页面数据,或者使用多个线程重写应用程序以提高其速度。
备注XPath的引入因为不能访问所以改成对应的地址。
这篇文章是翻译中的 HTML Scraping 文章。整个教程非常好,适合新手和老手学习。 查看全部
httpunit 抓取网页(
web抓取web站点之lxml和Requestsinstall安装requests和pip)

网页抓取
该网站是用 HTML 语言编写的,这意味着每个网页都是一个结构化的文档。有时,我们可以使用当前的结构来获取所需的数据并保留数据格式,但通常我们无法以合适的结构获取数据(不像csv和json)。
网页抓取会在适当的时候出现。网页抓取可以利用计算机程序对网页进行过滤,获取适当结构下的目标数据,同时保留数据的格式。
lxml 和请求
lxml 是一个优秀的 Python 扩展库,用于快速解析 XML 和 HTML 文档,甚至可以处理错误标签。另外,我们还使用Requests代替了内置的urllib2,因为它在速度和稳定性方面更好。您可以使用 pip install lxml 和 pip install requests 安装请求和 pip。
首先,让我们从导入开始:
from lxml import html
import requests
其次,我们使用requests.get查找网页,使用lxml的html库解析网页,并将结果保存在树中:
page = requests.get('http://econpy.pythonanywhere.c ... %2339;)
tree = html.fromstring(page.content)
tree 现在以整洁的树结构收录所有 HTML 内容。我们可以通过XPath和CSSSelect两种方式来获取树结构中的数据。在本文中,我们使用前者。
XPath 是一种在结构化文档(如 HTML 和 XML 文档)中定位信息的方法。XPath的介绍请参考W3Schools。
获取元素的XPath的工具有很多,比如Firefox中的FireBug,Chrome中的开发者工具。如果您使用的是 Chrome,您可以右键单击该元素,选择“检查元素”,在 HTML 查看器中突出显示此 HTML 代码,再次右键单击并选择“复制 XPath”。
经过快速分析,可以了解到该页面上的数据收录在两类元素中。一个是title为buyer-name的div,另一个是class为item-price的span
:
Carson Busses
$29.95
了解以上内容后,我们就可以创建对应的XPath地址检索并使用lxml的xpath功能,代码如下:
#这将获取到一个buyers列表
buyers = tree.xpath('//div[@title="buyer-name"]/text()')
#这将获取到一个prices列表
prices = tree.xpath('//span[@class="item-price"]/text()')
我们来看看最终得到的数据:
print 'Buyers: ', buyers
print 'Prices: ', prices
Buyers: ['Carson Busses', 'Earl E. Byrd', 'Patty Cakes',
'Derri Anne Connecticut', 'Moe Dess', 'Leda Doggslife', 'Dan Druff',
'Al Fresco', 'Ido Hoe', 'Howie Kisses', 'Len Lease', 'Phil Meup',
'Ira Pent', 'Ben D. Rules', 'Ave Sectomy', 'Gary Shattire',
'Bobbi Soks', 'Sheila Takya', 'Rose Tattoo', 'Moe Tell']
Prices: ['$29.95', '$8.37', '$15.26', '$19.25', '$19.25',
'$13.99', '$31.57', '$8.49', '$14.47', '$15.86', '$11.11',
'$15.98', '$16.27', '$7.50', '$50.85', '$14.26', '$5.68',
'$15.00', '$114.07', '$10.09']
恭喜!我们已经使用 lxml 和 Requests 从网页中获取所需的数据。我们将数据作为列表存储在内存中。现在我们可以做各种有趣的事情:我们可以用python分析数据,或者我们可以将其保存为文件并共享。
还有更多有趣的事情需要考虑,例如修改脚本使其可以遍历示例网页中的所有页面数据,或者使用多个线程重写应用程序以提高其速度。
备注XPath的引入因为不能访问所以改成对应的地址。
这篇文章是翻译中的 HTML Scraping 文章。整个教程非常好,适合新手和老手学习。
httpunit 抓取网页(C#编写的多线程异步抓取网页的网络爬虫控制台程序功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-01 10:11
描述:C#编写的多线程异步网络爬虫控制台程序。功能:目前只能提取网络链接,使用的两个记录文件不需要很大。暂时无法抓取网页文字、图片、视频和html代码,敬请谅解。但是需要注意的是,网页的数量非常多。下面的代码理论上可以捕获整个Internet网页链接。但实际上,由于处理器功能和网络条件(主要是网速)的限制,一般家用电脑最多可以处理12个线程的爬虫任务,爬虫速度是有限的。它可以爬行,但需要时间和耐心。当然,这个程序是可以捕获所有链接的,因为链接不占用太多系统空间,并且借助日志文件,可以将爬取的网页数量堆积起来,甚至可以访问所有互联网网络链接,当然最好是分批进行。建议将maxNum设置为500-1000左右,慢慢积累。另外,由于是控制台程序,有时显示的字符过多,系统会暂停显示。这时候,只需点击控制台并按回车键即可。当程序暂停时,您可以按 Enter 尝试。/// 要使用这个程序,请确保已经创建了相应的记录文件。为简化代码,本程序不够健壮,请见谅。/// 默认文件创建在E盘根目录下的两个文本文件:“待爬取的URL.txt”和“待爬取的URL.txt”。并注意不要有后缀出错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。这个程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。并注意不要有后缀出错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。这个程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。这个程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。这个程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。这个程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。这个程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。 查看全部
httpunit 抓取网页(C#编写的多线程异步抓取网页的网络爬虫控制台程序功能)
描述:C#编写的多线程异步网络爬虫控制台程序。功能:目前只能提取网络链接,使用的两个记录文件不需要很大。暂时无法抓取网页文字、图片、视频和html代码,敬请谅解。但是需要注意的是,网页的数量非常多。下面的代码理论上可以捕获整个Internet网页链接。但实际上,由于处理器功能和网络条件(主要是网速)的限制,一般家用电脑最多可以处理12个线程的爬虫任务,爬虫速度是有限的。它可以爬行,但需要时间和耐心。当然,这个程序是可以捕获所有链接的,因为链接不占用太多系统空间,并且借助日志文件,可以将爬取的网页数量堆积起来,甚至可以访问所有互联网网络链接,当然最好是分批进行。建议将maxNum设置为500-1000左右,慢慢积累。另外,由于是控制台程序,有时显示的字符过多,系统会暂停显示。这时候,只需点击控制台并按回车键即可。当程序暂停时,您可以按 Enter 尝试。/// 要使用这个程序,请确保已经创建了相应的记录文件。为简化代码,本程序不够健壮,请见谅。/// 默认文件创建在E盘根目录下的两个文本文件:“待爬取的URL.txt”和“待爬取的URL.txt”。并注意不要有后缀出错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。这个程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。并注意不要有后缀出错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。这个程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。这个程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。这个程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。这个程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。这个程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。
httpunit 抓取网页( 发现一个很不错的模拟浏览器包htmlunit包访问网站地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-01 06:12
发现一个很不错的模拟浏览器包htmlunit包访问网站地址)
Java模拟浏览器封装htmlunit、selenium
我找到了一个很好的模拟浏览器包htmlunit,可以直接访问网站地址并执行相应的JavaScript脚本;这个功能对网站爬虫很有帮助,一些网站Ajax用的。如果使用简单的http访问,只能抓取原创html源代码,无法获取页面中执行的ajax;使用这个包后,可以在执行ajax后抓取html源代码。取下来。
网站地址:
网站下面也提到了几个类似的包:HtmlUnit 被不同的开源工具用作底层“浏览器”,如 Canoo WebTest、JWebUnit、WebDriver、JSFUnit、Celerity、...
看看canoo WebTest,但是不知道怎么用,也不想多了解。
jwebunit 用于 网站 测试。集成了JUnit、htmlunit、selenium包框架;主要功能是做白盒测试和压力测试。
webDriver 后来更名为 selenium,它集成了 htmlunit、Firefox、Internet Explorer 和 opare 浏览器驱动程序。如果使用 htmlunitDriver,则使用 htmlunit 包访问站点;如果使用FirefoxDriver,则直接调用Firefox浏览器,然后在浏览器上模拟文本输入等鼠标键盘事件。
htmlunit包访问网站后,获取html源码后可以修改源码; jwebunit和selenium暂时没有找到修改的功能,只是用来模拟用户操作。 查看全部
httpunit 抓取网页(
发现一个很不错的模拟浏览器包htmlunit包访问网站地址)
Java模拟浏览器封装htmlunit、selenium
我找到了一个很好的模拟浏览器包htmlunit,可以直接访问网站地址并执行相应的JavaScript脚本;这个功能对网站爬虫很有帮助,一些网站Ajax用的。如果使用简单的http访问,只能抓取原创html源代码,无法获取页面中执行的ajax;使用这个包后,可以在执行ajax后抓取html源代码。取下来。
网站地址:
网站下面也提到了几个类似的包:HtmlUnit 被不同的开源工具用作底层“浏览器”,如 Canoo WebTest、JWebUnit、WebDriver、JSFUnit、Celerity、...
看看canoo WebTest,但是不知道怎么用,也不想多了解。
jwebunit 用于 网站 测试。集成了JUnit、htmlunit、selenium包框架;主要功能是做白盒测试和压力测试。
webDriver 后来更名为 selenium,它集成了 htmlunit、Firefox、Internet Explorer 和 opare 浏览器驱动程序。如果使用 htmlunitDriver,则使用 htmlunit 包访问站点;如果使用FirefoxDriver,则直接调用Firefox浏览器,然后在浏览器上模拟文本输入等鼠标键盘事件。
htmlunit包访问网站后,获取html源码后可以修改源码; jwebunit和selenium暂时没有找到修改的功能,只是用来模拟用户操作。
httpunit 抓取网页(开源java页面分析工具运行速度迅速,被誉为java浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-29 04:15
HtmlUnit 介绍
htmlunit 是一个开源的 java 页面分析工具。阅读完页面后,您可以有效地使用 htmlunit 来分析页面上的内容。该项目可以模拟浏览器操作,被称为java浏览器的开源实现。它是一个没有界面的浏览器,运行速度很快。是junit的扩展之一
HtmlUnit 示例
import java.io.IOException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlForm;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.html.HtmlSubmitInput;
import com.gargoylesoftware.htmlunit.html.HtmlTextInput;
public class Ddkjg {
public static void main(String[] args) throws IOException {
// 得到浏览器对象,直接New一个就能得到,现在就好比说你得到了一个浏览器了
WebClient webclient = new WebClient();
// 下面这2句可以写,也可以不写,设置false就是不加载css和js。访问速度更快
webclient.getOptions().setCssEnabled(false);
webclient.getOptions().setJavaScriptEnabled(false);
// 做的第一件事,去拿到这个网页,只需要调用getPage这个方法即可
HtmlPage htmlpage = webclient.getPage("https://baidu.com");
// 根据名字得到一个表单,查看上面这个网页的源代码可以发现表单的名字叫“f”
final HtmlForm form = htmlpage.getFormByName("f");
// 同样道理,获取”百度一下“这个按钮
final HtmlSubmitInput button = form.getInputByValue("百度一下");
// 得到搜索框
final HtmlTextInput textField = form.getInputByName("wd");
//设置搜索框的value
textField.setValueAttribute("战狼2");
// 设置好之后,模拟点击按钮行为。
final HtmlPage nextPage = button.click();
// 把结果转成String
String result = nextPage.asXml();
//得到的是点击后的网页
System.out.println(result);
}
}
注意:
1:webclient 包是 htmlunit,不是 httpunit。 httpunit 的 webclient 类是抽象的,不能直接新建。
2:htmlunit包使用最新版本的2.27 jar包。低版本的jar包没有getOptions()类。
3:如果出现这个错误,UnsupportedClassVersionError。表示版本不一致。确保你本地jdk版本是1.8,eclipse部署的版本也是1.8,所以我就不说怎么看了。
jar包下载地址: 查看全部
httpunit 抓取网页(开源java页面分析工具运行速度迅速,被誉为java浏览器)
HtmlUnit 介绍
htmlunit 是一个开源的 java 页面分析工具。阅读完页面后,您可以有效地使用 htmlunit 来分析页面上的内容。该项目可以模拟浏览器操作,被称为java浏览器的开源实现。它是一个没有界面的浏览器,运行速度很快。是junit的扩展之一
HtmlUnit 示例
import java.io.IOException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlForm;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.html.HtmlSubmitInput;
import com.gargoylesoftware.htmlunit.html.HtmlTextInput;
public class Ddkjg {
public static void main(String[] args) throws IOException {
// 得到浏览器对象,直接New一个就能得到,现在就好比说你得到了一个浏览器了
WebClient webclient = new WebClient();
// 下面这2句可以写,也可以不写,设置false就是不加载css和js。访问速度更快
webclient.getOptions().setCssEnabled(false);
webclient.getOptions().setJavaScriptEnabled(false);
// 做的第一件事,去拿到这个网页,只需要调用getPage这个方法即可
HtmlPage htmlpage = webclient.getPage("https://baidu.com";);
// 根据名字得到一个表单,查看上面这个网页的源代码可以发现表单的名字叫“f”
final HtmlForm form = htmlpage.getFormByName("f");
// 同样道理,获取”百度一下“这个按钮
final HtmlSubmitInput button = form.getInputByValue("百度一下");
// 得到搜索框
final HtmlTextInput textField = form.getInputByName("wd");
//设置搜索框的value
textField.setValueAttribute("战狼2");
// 设置好之后,模拟点击按钮行为。
final HtmlPage nextPage = button.click();
// 把结果转成String
String result = nextPage.asXml();
//得到的是点击后的网页
System.out.println(result);
}
}
注意:
1:webclient 包是 htmlunit,不是 httpunit。 httpunit 的 webclient 类是抽象的,不能直接新建。
2:htmlunit包使用最新版本的2.27 jar包。低版本的jar包没有getOptions()类。
3:如果出现这个错误,UnsupportedClassVersionError。表示版本不一致。确保你本地jdk版本是1.8,eclipse部署的版本也是1.8,所以我就不说怎么看了。
jar包下载地址:
httpunit 抓取网页(开源java页面分析工具运行速度迅速,被誉为java浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-28 16:03
HtmlUnit 介绍
htmlunit 是一个开源的 java 页面分析工具。阅读完页面后,您可以有效地使用 htmlunit 来分析页面上的内容。该项目可以模拟浏览器操作,被称为java浏览器的开源实现。它是一个没有界面的浏览器,运行速度很快。是junit的扩展之一
HtmlUnit 示例
import java.io.IOException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlForm;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.html.HtmlSubmitInput;
import com.gargoylesoftware.htmlunit.html.HtmlTextInput;
public class Ddkjg {
public static void main(String[] args) throws IOException {
// 得到浏览器对象,直接New一个就能得到,现在就好比说你得到了一个浏览器了
WebClient webclient = new WebClient();
// 下面这2句可以写,也可以不写,设置false就是不加载css和js。访问速度更快
webclient.getOptions().setCssEnabled(false);
webclient.getOptions().setJavaScriptEnabled(false);
// 做的第一件事,去拿到这个网页,只需要调用getPage这个方法即可
HtmlPage htmlpage = webclient.getPage("https://baidu.com");
// 根据名字得到一个表单,查看上面这个网页的源代码可以发现表单的名字叫“f”
final HtmlForm form = htmlpage.getFormByName("f");
// 同样道理,获取”百度一下“这个按钮
final HtmlSubmitInput button = form.getInputByValue("百度一下");
// 得到搜索框
final HtmlTextInput textField = form.getInputByName("wd");
//设置搜索框的value
textField.setValueAttribute("战狼2");
// 设置好之后,模拟点击按钮行为。
final HtmlPage nextPage = button.click();
// 把结果转成String
String result = nextPage.asXml();
//得到的是点击后的网页
System.out.println(result);
}
}
注意:
1:webclient 包是 htmlunit,不是 httpunit。 httpunit 的 webclient 类是抽象的,不能直接新建。
2:htmlunit包使用最新版本的2.27 jar包。低版本的jar包没有getOptions()类。
3:如果出现这个错误,UnsupportedClassVersionError。表示版本不一致。确保你本地jdk版本是1.8,eclipse部署的版本也是1.8,所以我就不说怎么看了。
jar包下载地址: 查看全部
httpunit 抓取网页(开源java页面分析工具运行速度迅速,被誉为java浏览器)
HtmlUnit 介绍
htmlunit 是一个开源的 java 页面分析工具。阅读完页面后,您可以有效地使用 htmlunit 来分析页面上的内容。该项目可以模拟浏览器操作,被称为java浏览器的开源实现。它是一个没有界面的浏览器,运行速度很快。是junit的扩展之一
HtmlUnit 示例
import java.io.IOException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlForm;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.html.HtmlSubmitInput;
import com.gargoylesoftware.htmlunit.html.HtmlTextInput;
public class Ddkjg {
public static void main(String[] args) throws IOException {
// 得到浏览器对象,直接New一个就能得到,现在就好比说你得到了一个浏览器了
WebClient webclient = new WebClient();
// 下面这2句可以写,也可以不写,设置false就是不加载css和js。访问速度更快
webclient.getOptions().setCssEnabled(false);
webclient.getOptions().setJavaScriptEnabled(false);
// 做的第一件事,去拿到这个网页,只需要调用getPage这个方法即可
HtmlPage htmlpage = webclient.getPage("https://baidu.com";);
// 根据名字得到一个表单,查看上面这个网页的源代码可以发现表单的名字叫“f”
final HtmlForm form = htmlpage.getFormByName("f");
// 同样道理,获取”百度一下“这个按钮
final HtmlSubmitInput button = form.getInputByValue("百度一下");
// 得到搜索框
final HtmlTextInput textField = form.getInputByName("wd");
//设置搜索框的value
textField.setValueAttribute("战狼2");
// 设置好之后,模拟点击按钮行为。
final HtmlPage nextPage = button.click();
// 把结果转成String
String result = nextPage.asXml();
//得到的是点击后的网页
System.out.println(result);
}
}
注意:
1:webclient 包是 htmlunit,不是 httpunit。 httpunit 的 webclient 类是抽象的,不能直接新建。
2:htmlunit包使用最新版本的2.27 jar包。低版本的jar包没有getOptions()类。
3:如果出现这个错误,UnsupportedClassVersionError。表示版本不一致。确保你本地jdk版本是1.8,eclipse部署的版本也是1.8,所以我就不说怎么看了。
jar包下载地址:
httpunit 抓取网页(之前做聊天室时,介绍如何使用HtmlTag类来抓取网页信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-27 21:19
之前在聊天室的时候,因为聊天室提供了新闻阅读功能,所以写了一个类来抓取网页信息(比如最新的头条、新闻来源、标题、内容等)。本文将介绍如何使用该类抓取网页中需要的信息。本文将以博客园首页的博客标题和链接为例:
上图为博客园首页的DOM树。显然,你只需要提取class为post_item的div,然后提取class为titlelnk的a标记。这样的功能可以通过以下功能来实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
下面以博客园首页的文章标题和链接为例,介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com");
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
操作结果如下:
源代码下载
转载于: 查看全部
httpunit 抓取网页(之前做聊天室时,介绍如何使用HtmlTag类来抓取网页信息)
之前在聊天室的时候,因为聊天室提供了新闻阅读功能,所以写了一个类来抓取网页信息(比如最新的头条、新闻来源、标题、内容等)。本文将介绍如何使用该类抓取网页中需要的信息。本文将以博客园首页的博客标题和链接为例:

上图为博客园首页的DOM树。显然,你只需要提取class为post_item的div,然后提取class为titlelnk的a标记。这样的功能可以通过以下功能来实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
下面以博客园首页的文章标题和链接为例,介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com";);
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
操作结果如下:

源代码下载
转载于:
httpunit 抓取网页(网络爬虫的是做什么的?手动写一个简单的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-27 21:18
网络爬虫有什么作用?手动编写一个简单的网络爬虫;网络爬虫(又称网络蜘蛛、网络机器人)是一种程序或足,根据一定的规则自动抓取万维网上的信息
书。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。网络爬虫通过网页的链接地址搜索网页。从某个页面(通常是首页)开始,它读取网页的内容并找到
在网页中的其他链接地址,然后通过这些链接地址找到下一个网页,这样一直循环下去,直到你把这个网站全部
的所有页面都被抓取到最后。如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理抓取互联网上的所有网页。因此,如果要抓取互联网上的数据,不仅需要一个爬虫程序,还需要一个能够接受“爬虫”发回的数据并对其进行处理和过滤的服务。
爬虫爬取的数据量越大,对服务器的性能要求越高。网络爬虫有什么作用?他的主要工作是根据指定的URL地址发送请求,得到响应,然后解析响应。一方面,从
在响应中找到你要查找的数据,另一方面从响应中解析出新的URL路径,然后继续访问,继续解析;继续寻找您需要的东西
数据并继续解析出新的URL路径。这是网络爬虫的主要工作。以下是流程图:
通过上面的流程图,您可以大致了解网络爬虫是做什么的,并基于这些,您可以设计一个简单的网络爬虫。
一个简单爬虫的必要功能:
发送请求和获取响应的功能;解析响应的功能;存储过滤数据的功能;处理解析出的URL路径的功能;爬虫需要注意的三点:
爬取目标的描述或定义;网页或数据的分析和过滤;URL 搜索策略。网络爬虫根据系统结构和实现技术大致可以分为以下几种类型:
General Purpose Web Crawler (General Purpose Web Crawler) Focused Web Crawler (Focused Web Crawler) Incremental Web Crawler (Incremental Web Crawler) Deep Web Crawler。实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。下面我就用我们的官网来跟大家分析一下如何实现这样的爬虫:
首先观察我们爬虫的起始页面是:
分析页面
所有好消息的 URL 用 XPath 表达式表示如下:
相关资料
标题:使用XPath表达式表达描述:使用XPath表达式表达图片:使用XPath表达式表达
好了,我们已经在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式的编写代码来实现了。
代码实现部分使用了webmagic框架,因为它比使用基本的Java网络编程要简单得多。注:对于webmagic框架,可以阅读以下讲座
演示.java
WanhoPageProcessor.javaWanhoPipeline.javaArticleVo.java
在开源社区搜索java爬虫框架:共有83种
我们正在使用
webmagic是一个爬虫框架,不需要配置,方便二次开发。它提供了简单灵活的 API,可以用少量代码实现。
爬虫webmagic采用完全模块化设计,功能覆盖爬虫整个生命周期(链接提取、页面下载、内容提取、持久化)
),支持多线程爬取、分布式爬取,支持自动重试、自定义UA/cookie等功能。Webmagic 包括强大的页面提取功能。开发人员可以轻松使用 css 选择器、xpath 和正则表达式。链接和内部
内容提取,支持多个选择器的链式调用
注:官方中文文档:
可以使用maven构建依赖,例如:
当然你也可以自己下载jar包,地址是:
一般来说,如果我们需要抓取的目标数据不是通过ajax异步加载的,那么我们都可以在页面的HTML源代码中的某个位置找到我们需要的数据
注意:如果数据是异步加载到页面中的,一般有两种方式获取数据:
观察页面加载前请求的所有URL(F12->网络选项),然后找到那些加载数据的json请求,最后直接请求那些URL获取数据来模拟浏览器请求,等待一段时间满载页面 把数据进去就行了。这类爬虫通常需要内嵌浏览器内核,比如webmagic、phantom.js、HttpUnit等。
下面我就用我们的官网来跟大家分析一下如何实现这样的爬虫:
首先观察我们爬虫的起始页面是:
分析页面
从上图可以看出,我们可以从首页的HTML源代码中直观的找到我们需要的标题、内容、图片链接等信息。那么,我们可以通过哪些方式提取这些目标数据呢?
其实提取页面元素的webmagic框架主要支持以下三种方法:
XPath 正则表达式 CSS 选择器
当然,选择哪种方式提取数据需要根据具体页面进行分析。在这个例子中,很明显使用XPath提取数据是最方便的
所以,接下来我直接给出我们需要爬取的数据的XPath路径:
所有好消息的URL都用XPath表达式表示: Title:XPath表达式用于表达描述:XPath表达式用于图片表达:XPath表达式用于表达
注意:“//”表示从相对路径开始,第一个“/”表示从页面路径开始;后面两个/之间的内容代表一个元素,方括号中的内容表示该元素的执行属性,如:h1[@class='entry-title']表示:一个h1元素的class属性为“条目标题”
使用webmagic提取页面数据时,需要自定义一个类来实现PageProcessor接口。
该类实现PageProcessor接口的主要功能是以下三个步骤:
爬虫配置:爬取页面的配置,包括编码、爬取间隔、重试次数等页面元素的提取:使用正则表达式或者XPath提取页面元素。发现新链接:找到要爬取的页面 获取其他目标页面的链接
Spider是爬虫启动的入口点。在启动爬虫之前,我们需要使用一个 PageProcessor 创建一个 Spider 对象,然后使用 run() 来启动它。同时可以通过set方法设置其他Spider组件(Downloader、Scheduler、Pipeline)
注:更详细的参数介绍请参考这里的官方文档:
演示.java
对于提取逻辑比较复杂的爬虫,我们通常会实现上面的PageProcessor接口来编写页面元素的提取逻辑。但是对于提取逻辑比较简单的爬虫,这时候我们可以选择在实体类中添加注解来构建轻量级爬虫
从上面的代码可以看出,这个实体类除了添加了几个注解之外,就是一个普通的POJO,不依赖其他任何东西。上面使用的几个注解的一般含义是:
@TargetUrl:我们需要提取的数据的所有目标页面,其值是一个正则表达式@HelpUrl:需要访问的页面以获得目标页面的链接@ExtractBy:用于提取元素的注解,它描述了一种抽取规则。意思是“使用此提取规则将提取的结果保存在该字段中”。您可以使用 XPath、CSS 选择器、正则表达式和 JsonPath 来提取元素
虽然在PageProcessor中我们可以实现数据的持久化(PS:基于注解的爬虫可以通过AfterExtractor接口实现类似的目的),将爬虫抓取到的数据保存到文件、数据库、缓存等中。但是很明显PageProcessor还是实体类主要负责提取页面元素,所以更好的处理方法是在另一个地方做数据持久化。这个地方是-管道
为了实现数据的持久化,我们通常需要实现 Pipeline 或 PageModelPipeline 接口。普通爬虫使用前一个接口,基于注解的爬虫使用后一个接口
对于基于注解的爬虫,启动类不是Spider,而是OOSpider。当然,两者的用法是类似的。示例代码如下:
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似JQuery的操作方法来检索和操作数据
Jsoup 是 Java 世界中的 HTML 解析工具。它支持使用 CSS Selector 选择 DOM 元素,还可以过滤 HTML 文本以防止 XSS 攻击。
下载 Jsoup
查看官方手册:
Jsoup是Java世界中html解析过滤的最佳选择。支持将html解析成DOM树,支持CSS Selector表单选择,支持html过滤,自带Http下载器。
Jsoup 的代码相当简洁。Jsoup 共有 53 个类,不依赖任何第三方包。和最终发布包9.8M的SAXON相比,真是短小精悍。
从 URL、文件或字符串解析 HTML;使用 DOM 或 CSS 选择器来查找和检索数据;操作 HTML 元素、属性和文本;
Jsoup 的入口点是类。示例包中提供了两个示例。解析html后,使用CSS Selector和NodeVisitor来操作Dom元素。
下面是一个例子来说明如何调用Jsoup:
Jsoup 使用自己的一套 DOM 代码系统。虽然 Elements 和 Elements 的名称和概念与 Java XML 相同
API 类似,但没有代码级别的关系。也就是说,如果要使用一组XML API来操作Jsoup,结果是不可能的。
但正因为如此,Jsoup 可以摒弃 xml 中一些繁琐的 API,让代码更简单。
第一种形式
/AAA/DDD/BBB:表示AAA下的BBB和AAA下的DDD的第二种形式
//BBB: 意思和这个名字一样,意思就是只要名字是BBB就会得到第三种形式
/*:所有元素的第四种形式
BBB[1]:代表第一个BBB元素 BBB[last()]:代表最后一个BBB元素的第五种形式
//BBB[@id]:表示只要BBB元素上有id属性,就得到第六种形式
//BBB[@id='b1']表示元素名称为BBB,BBB上有一个id属性,id属性值为b1。例如:
/students/student[@id='1002'] 根student标签下student标签下属性名为id,属性值为1002的student元素
如需转载,请注明文章的出处和出处地址: 查看全部
httpunit 抓取网页(网络爬虫的是做什么的?手动写一个简单的)
网络爬虫有什么作用?手动编写一个简单的网络爬虫;网络爬虫(又称网络蜘蛛、网络机器人)是一种程序或足,根据一定的规则自动抓取万维网上的信息
书。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。网络爬虫通过网页的链接地址搜索网页。从某个页面(通常是首页)开始,它读取网页的内容并找到
在网页中的其他链接地址,然后通过这些链接地址找到下一个网页,这样一直循环下去,直到你把这个网站全部
的所有页面都被抓取到最后。如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理抓取互联网上的所有网页。因此,如果要抓取互联网上的数据,不仅需要一个爬虫程序,还需要一个能够接受“爬虫”发回的数据并对其进行处理和过滤的服务。
爬虫爬取的数据量越大,对服务器的性能要求越高。网络爬虫有什么作用?他的主要工作是根据指定的URL地址发送请求,得到响应,然后解析响应。一方面,从
在响应中找到你要查找的数据,另一方面从响应中解析出新的URL路径,然后继续访问,继续解析;继续寻找您需要的东西
数据并继续解析出新的URL路径。这是网络爬虫的主要工作。以下是流程图:
通过上面的流程图,您可以大致了解网络爬虫是做什么的,并基于这些,您可以设计一个简单的网络爬虫。
一个简单爬虫的必要功能:
发送请求和获取响应的功能;解析响应的功能;存储过滤数据的功能;处理解析出的URL路径的功能;爬虫需要注意的三点:
爬取目标的描述或定义;网页或数据的分析和过滤;URL 搜索策略。网络爬虫根据系统结构和实现技术大致可以分为以下几种类型:
General Purpose Web Crawler (General Purpose Web Crawler) Focused Web Crawler (Focused Web Crawler) Incremental Web Crawler (Incremental Web Crawler) Deep Web Crawler。实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。下面我就用我们的官网来跟大家分析一下如何实现这样的爬虫:
首先观察我们爬虫的起始页面是:
分析页面
所有好消息的 URL 用 XPath 表达式表示如下:
相关资料
标题:使用XPath表达式表达描述:使用XPath表达式表达图片:使用XPath表达式表达
好了,我们已经在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式的编写代码来实现了。
代码实现部分使用了webmagic框架,因为它比使用基本的Java网络编程要简单得多。注:对于webmagic框架,可以阅读以下讲座
演示.java
WanhoPageProcessor.javaWanhoPipeline.javaArticleVo.java
在开源社区搜索java爬虫框架:共有83种
我们正在使用
webmagic是一个爬虫框架,不需要配置,方便二次开发。它提供了简单灵活的 API,可以用少量代码实现。
爬虫webmagic采用完全模块化设计,功能覆盖爬虫整个生命周期(链接提取、页面下载、内容提取、持久化)
),支持多线程爬取、分布式爬取,支持自动重试、自定义UA/cookie等功能。Webmagic 包括强大的页面提取功能。开发人员可以轻松使用 css 选择器、xpath 和正则表达式。链接和内部
内容提取,支持多个选择器的链式调用
注:官方中文文档:
可以使用maven构建依赖,例如:
当然你也可以自己下载jar包,地址是:
一般来说,如果我们需要抓取的目标数据不是通过ajax异步加载的,那么我们都可以在页面的HTML源代码中的某个位置找到我们需要的数据
注意:如果数据是异步加载到页面中的,一般有两种方式获取数据:
观察页面加载前请求的所有URL(F12->网络选项),然后找到那些加载数据的json请求,最后直接请求那些URL获取数据来模拟浏览器请求,等待一段时间满载页面 把数据进去就行了。这类爬虫通常需要内嵌浏览器内核,比如webmagic、phantom.js、HttpUnit等。
下面我就用我们的官网来跟大家分析一下如何实现这样的爬虫:
首先观察我们爬虫的起始页面是:
分析页面
从上图可以看出,我们可以从首页的HTML源代码中直观的找到我们需要的标题、内容、图片链接等信息。那么,我们可以通过哪些方式提取这些目标数据呢?
其实提取页面元素的webmagic框架主要支持以下三种方法:
XPath 正则表达式 CSS 选择器
当然,选择哪种方式提取数据需要根据具体页面进行分析。在这个例子中,很明显使用XPath提取数据是最方便的
所以,接下来我直接给出我们需要爬取的数据的XPath路径:
所有好消息的URL都用XPath表达式表示: Title:XPath表达式用于表达描述:XPath表达式用于图片表达:XPath表达式用于表达
注意:“//”表示从相对路径开始,第一个“/”表示从页面路径开始;后面两个/之间的内容代表一个元素,方括号中的内容表示该元素的执行属性,如:h1[@class='entry-title']表示:一个h1元素的class属性为“条目标题”
使用webmagic提取页面数据时,需要自定义一个类来实现PageProcessor接口。
该类实现PageProcessor接口的主要功能是以下三个步骤:
爬虫配置:爬取页面的配置,包括编码、爬取间隔、重试次数等页面元素的提取:使用正则表达式或者XPath提取页面元素。发现新链接:找到要爬取的页面 获取其他目标页面的链接
Spider是爬虫启动的入口点。在启动爬虫之前,我们需要使用一个 PageProcessor 创建一个 Spider 对象,然后使用 run() 来启动它。同时可以通过set方法设置其他Spider组件(Downloader、Scheduler、Pipeline)
注:更详细的参数介绍请参考这里的官方文档:
演示.java
对于提取逻辑比较复杂的爬虫,我们通常会实现上面的PageProcessor接口来编写页面元素的提取逻辑。但是对于提取逻辑比较简单的爬虫,这时候我们可以选择在实体类中添加注解来构建轻量级爬虫
从上面的代码可以看出,这个实体类除了添加了几个注解之外,就是一个普通的POJO,不依赖其他任何东西。上面使用的几个注解的一般含义是:
@TargetUrl:我们需要提取的数据的所有目标页面,其值是一个正则表达式@HelpUrl:需要访问的页面以获得目标页面的链接@ExtractBy:用于提取元素的注解,它描述了一种抽取规则。意思是“使用此提取规则将提取的结果保存在该字段中”。您可以使用 XPath、CSS 选择器、正则表达式和 JsonPath 来提取元素
虽然在PageProcessor中我们可以实现数据的持久化(PS:基于注解的爬虫可以通过AfterExtractor接口实现类似的目的),将爬虫抓取到的数据保存到文件、数据库、缓存等中。但是很明显PageProcessor还是实体类主要负责提取页面元素,所以更好的处理方法是在另一个地方做数据持久化。这个地方是-管道
为了实现数据的持久化,我们通常需要实现 Pipeline 或 PageModelPipeline 接口。普通爬虫使用前一个接口,基于注解的爬虫使用后一个接口
对于基于注解的爬虫,启动类不是Spider,而是OOSpider。当然,两者的用法是类似的。示例代码如下:
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似JQuery的操作方法来检索和操作数据
Jsoup 是 Java 世界中的 HTML 解析工具。它支持使用 CSS Selector 选择 DOM 元素,还可以过滤 HTML 文本以防止 XSS 攻击。
下载 Jsoup
查看官方手册:
Jsoup是Java世界中html解析过滤的最佳选择。支持将html解析成DOM树,支持CSS Selector表单选择,支持html过滤,自带Http下载器。
Jsoup 的代码相当简洁。Jsoup 共有 53 个类,不依赖任何第三方包。和最终发布包9.8M的SAXON相比,真是短小精悍。
从 URL、文件或字符串解析 HTML;使用 DOM 或 CSS 选择器来查找和检索数据;操作 HTML 元素、属性和文本;
Jsoup 的入口点是类。示例包中提供了两个示例。解析html后,使用CSS Selector和NodeVisitor来操作Dom元素。
下面是一个例子来说明如何调用Jsoup:
Jsoup 使用自己的一套 DOM 代码系统。虽然 Elements 和 Elements 的名称和概念与 Java XML 相同
API 类似,但没有代码级别的关系。也就是说,如果要使用一组XML API来操作Jsoup,结果是不可能的。
但正因为如此,Jsoup 可以摒弃 xml 中一些繁琐的 API,让代码更简单。
第一种形式
/AAA/DDD/BBB:表示AAA下的BBB和AAA下的DDD的第二种形式
//BBB: 意思和这个名字一样,意思就是只要名字是BBB就会得到第三种形式
/*:所有元素的第四种形式
BBB[1]:代表第一个BBB元素 BBB[last()]:代表最后一个BBB元素的第五种形式
//BBB[@id]:表示只要BBB元素上有id属性,就得到第六种形式
//BBB[@id='b1']表示元素名称为BBB,BBB上有一个id属性,id属性值为b1。例如:
/students/student[@id='1002'] 根student标签下student标签下属性名为id,属性值为1002的student元素
如需转载,请注明文章的出处和出处地址:
httpunit 抓取网页(遇到一个网页数据抓取的任务,给大家分享下! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-27 09:13
)
遇到一个爬取网页数据的任务,分享给大家。
说到网页信息抓取,相信Jsoup基本上是首选工具。完整的类似JQuery的操作让人感觉很舒服。不过,今天我们要说说Jsoup的缺点。
这是某个网站的搜索栏。填写一些格式化数据进行经纬度转换。初始化是这样的,然后jsoup捕获的代码如下:
当我们添加数据时,抓取的页面信息是不变的。这就是Jsoup的缺点。如果Jsoup抓取页面,页面加载后的所有数据,Ajax加载的异步数据都没有抓取。到达的。
这里再给大家介绍一个开源项目:HttpUnit,这个名字是用来测试的,但是对爬取数据也有好处,是一个完美的解决方案。HttpUnit其实相当于一个没有UI的浏览器,可以让页面上的js执行完成后,再次抓取信息。
有时我们使用requests抓取页面时,得到的结果可能与浏览器中看到的不同:在浏览器中可以看到正常显示的页面数据,但是使用requests获取的结果却看不到。这是因为获取的请求都是原创的 HTML 文档,浏览器中的页面是 JavaScript 处理数据后生成的结果。这些数据的来源有很多,可能是通过Ajax加载的,可能是收录在HTML中的,也可能是通过JavaScript和特定算法计算后生成的文档中的文档。
在第一种情况下,数据加载是一种异步加载方法。原创页面最初不会收录一些数据。原创页面加载完毕后,会向服务器请求一个接口来获取数据,然后对数据进行处理呈现。在网页上,这实际上是一个 Ajax 请求。
根据Web发展的趋势,这种形式的页面越来越多。网页的原创 HTML 文档不收录任何数据。数据通过Ajax统一加载后呈现,从而在Web开发中实现前后端分离,减少服务器直接渲染页面带来的压力。
因此,如果遇到这样的页面,可以直接使用requests等库来抓取原创页面,无法获取有效数据。这时候就需要从网页后台分析发送到界面的Ajax请求。如果可以使用requests来模拟ajax请求,那么就可以成功爬取。
但是我没有使用这个测试框架:我解决问题的想法是
总结:ajax数据的爬取过程:
1. 提交我们的搜索时,会加载这部分内容,并且会有表单数据生成,
反映在程序中:
2. 服务器加载这个页面,我们输入表单信息,这个表单信息就是我们的搜索条件,例如:
反映在程序中:
3.js返回加载的页面,并在该页面添加信息
jsoup 可以解析页面。
4.模拟登录部分:
查看全部
httpunit 抓取网页(遇到一个网页数据抓取的任务,给大家分享下!
)
遇到一个爬取网页数据的任务,分享给大家。
说到网页信息抓取,相信Jsoup基本上是首选工具。完整的类似JQuery的操作让人感觉很舒服。不过,今天我们要说说Jsoup的缺点。
这是某个网站的搜索栏。填写一些格式化数据进行经纬度转换。初始化是这样的,然后jsoup捕获的代码如下:


当我们添加数据时,抓取的页面信息是不变的。这就是Jsoup的缺点。如果Jsoup抓取页面,页面加载后的所有数据,Ajax加载的异步数据都没有抓取。到达的。


这里再给大家介绍一个开源项目:HttpUnit,这个名字是用来测试的,但是对爬取数据也有好处,是一个完美的解决方案。HttpUnit其实相当于一个没有UI的浏览器,可以让页面上的js执行完成后,再次抓取信息。
有时我们使用requests抓取页面时,得到的结果可能与浏览器中看到的不同:在浏览器中可以看到正常显示的页面数据,但是使用requests获取的结果却看不到。这是因为获取的请求都是原创的 HTML 文档,浏览器中的页面是 JavaScript 处理数据后生成的结果。这些数据的来源有很多,可能是通过Ajax加载的,可能是收录在HTML中的,也可能是通过JavaScript和特定算法计算后生成的文档中的文档。
在第一种情况下,数据加载是一种异步加载方法。原创页面最初不会收录一些数据。原创页面加载完毕后,会向服务器请求一个接口来获取数据,然后对数据进行处理呈现。在网页上,这实际上是一个 Ajax 请求。
根据Web发展的趋势,这种形式的页面越来越多。网页的原创 HTML 文档不收录任何数据。数据通过Ajax统一加载后呈现,从而在Web开发中实现前后端分离,减少服务器直接渲染页面带来的压力。
因此,如果遇到这样的页面,可以直接使用requests等库来抓取原创页面,无法获取有效数据。这时候就需要从网页后台分析发送到界面的Ajax请求。如果可以使用requests来模拟ajax请求,那么就可以成功爬取。
但是我没有使用这个测试框架:我解决问题的想法是
总结:ajax数据的爬取过程:

1. 提交我们的搜索时,会加载这部分内容,并且会有表单数据生成,

反映在程序中:

2. 服务器加载这个页面,我们输入表单信息,这个表单信息就是我们的搜索条件,例如:

反映在程序中:

3.js返回加载的页面,并在该页面添加信息
jsoup 可以解析页面。
4.模拟登录部分:


httpunit 抓取网页( jsoup抓取网页教程(jsoup)抓取(抓取)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-27 03:11
jsoup抓取网页教程(jsoup)抓取(抓取)(组图))
jsoup爬网页教程jsoup爬网页教程jsoup爬网页教程jsoup爬网页教程jsoup爬网页详细我以前在ibmdw上发表过两篇关于htmlparser的文章。 文章 是从html中抓取你需要的信息,扩展htmlparser处理自定义标签的能力。但现在我不再使用 htmlparser。原因是htmlparser很少更新,但最重要的是它的nameits是一个javahtml解析器,可以直接解析一个URL地址的html文本内容。它提供了一个非常省力的API,可以通过domcss和jquery之类的操作方法进行检索和检索。其操作数据的主要功能如下: 1. 从文件或字符串中解析出urlhtml 2. 使用domdesignedcss选择器找出数据 3. 可操作的HTML元素属性文本 其基于新版mit协议离婚协议劳动协议合同个人投资股权协议广告可以安全用于商业项目的1its的主要类层次结构如图1所示。解释一下它的html文档是如何优雅地处理的 ------------------------------------- ---- -------------------------------------返回顶部 文档输入可以收录来自 String urlits 地址和本地文件加载 html 文档并生成文档对象实例。下面是相关代码清单 1.直接从字符串stringhtml中输入html文档 "htmlheadtitle开源中文社区titlehead" "bodyp这里是与其项目相关的文章 ppointshtml"documentdocjsoupparsehtml 直接从url documentdocjsoupconnecthttpwwwoschinanet加载html文档"getstringnamedoctitledocumentdocjsoupconnecthttpwwwoschinanet"datathe"query""java"请求参数useragent"i"mits"set useragentcookie"auth""token"set cookietime out3000设置连接超时时间。post使用post方法访问url,从中加载html文档文件.fileinputnewfile"ctesthtml"documentdocjsoupparseinput"utf-8""httpwwwoschinanet.请注意最后一个html文档输入法中parse的第三个参数。这里指定一个url,虽然第一种方法不需要指定,因为html文档中会有很多链接,比如链接图片和引用的外部脚本css文件等,第三个参数baseurl的意思是当html 文档使用相对路径引用外部文件时,它会自动给这些 URL 添加前缀,即 baseurlnoandhrefproject 开源软件 a 将转换为 ahrefhttpwwwoschinanetproject 开源软件 a----------- ———————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————— -------- -----------返回顶部 HTML 元素的分析和提取这部分与 HTML 解析器的基本功能有关,但与其他开源项目不同 - 选择器我们将在最后一部分
etailsthejsoupselectorinthissectionyouwillseejsoupishowtoachievethemostsimplecodeHoweverjsoupalsoprovideselementalparsingofthetraditionalDOMapproachlookingatthecodebelowListing2FileinputnewFile “Dtesthtml” DocumentdocJsoupparseinput “UTF-8”, “ElementcontentdocgetElementById” 内容 “ElementslinkscontentgetElementsByTag” 一 “ForElementlinklinksStringlinkHreflinkattr的” href “StringlinkTextlinktextYoumightthinkthatjsoupsmethodisfamiliarandyeslikethegetElementByIdandgetElementsByTagmethodsthenamesofthemethodsarethesameandthefunctionsareexactlythesameasthoseoftheJavaScriptYoucangetthecorrespondingelementorlistofelementsaccordingtothenodenameortheIDoftheHTMLelementUnliketheHtmlparserprojectjsoupdoesnotdefineacorrespondingHTMLelementpartofageneralHTMLelementsincludenodenameattributeandtextjsoupprovidesasimplewayforyoutoretrievethesedatawhichisthereasonforkeepingfitjsoupIntermsofelementretrievaljsoupselectorsareomnipotentListing3FileinputnewFile” Dtesthtml “DocumentdocJsoupparseinput” UTF-8“ “Elementslinks docselect ”一个[HREF]“ hrefattributelinkElementsPNGSdocselect ”IMG [srcpng]“ PNGallreferencepictureelementsElementmastheaddocselect ”divmasthead“ FirstFinddefineclassmastheadelementsElementsresultLinksdocselect ”h3ra“ directaafterH3ThisisthejsoupthatIreallyimpressedbythelocaljsoupforusewiththejQueryselectorontheelementsareaslikeastwopeasretrievalretrievalmethodsaboveifotherHTMLinterpreteratleastneedmanylinesofcodebutjsoupneedsonlyonelineofcodecompleteTheselectorofjsoupalsosupportstheexpressionfunctionandwellintroducethissuperselectorinthelastsection -
----------------------------------------------- -------------------------------返回顶部修改数据在分析文档的同时,我们可能需要修改文档中的某些元素,例如我们可以添加可点击链接、修改链接地址或修改文档中所有图像的文本这里有一些简单的示例 Listing4Docselect"divcommentsa"Attr"rel""nofollow"Increaseterlink"Increaseterlink"IncreaseterlinkClassof removeAttr "delete allthepicturesoftheonclickattributeDocselect" input [typetext] "" Val "textemptyallthetextinputboxin thereassonisvery simpleYou just need to find the elements using jsoupselector and then through the above the method to modify in addition to not modify the label name can beremoved after the insertion of the index of the HTML ----------------------------------------- --BacktotopHTMLdocumentcleanupJs oupalsodoesagreatjobofprovidingpowerfulAPIandhumanizingWhenyoudoawebsiteyouoftenprovidethefunctionofuserreviewsSomeusersaremoremischievouswillmakesomecommentstothescriptandthesescriptsmaydestroytheentirepagemoreseriousistoobtainsomeconfidentialinformationsuchascrosssiteattackslikeXSSJsoupisverysupportiveofthisanditsverysimpletouseTakealookatthecodebelowListing5Stringunsafe “pahref” OpensourceChinesecommunityap “StringsafeJsoupcleanunsafeWhitelistbasicoutputpahref” 相对 “nofollow” 的ChineseapopensourcecommunityJsoupus
"embed""object""param""span""div"你也可以调用addAttributes属性来增加一些元素------------------------------ -------------------------------------------------BacktotopJsoup “selectorWehavebrieflyintroducedhowjsoupusesselectorstoretrieveelementsInthissectionwefocusonthepowerfulsyntaxoftheselectorits elfThefollowingtableisadetailedlistofallthesyntaxofthejsoupselectorTable2basicusageTagNameusestagnamestolocateforexampleaNstagusesnamespacetagpositioningsuchasfbnametofindfbnameelementsiduseselementIDtolocateforexamplelogoclassusestheclasspropertyoftheelementtolocateforexampleHead [属性] usesthepropertiesoftheelementstolocateforexample [HREF] representsallelementsthatretrievethehrefattribute [ATTR] usestheattributenameprefixesofelementstolocatesuchas [DATA-] whichisusedtofindthedatasetattributeofHTML5 [attrvalue] usesattributevaluestolocateFore
xample [width500] locatesallelementswhosewidthattributevalueis500 [attrvalue] [attrvalue] [attrvalue] thesethreegrammarrespectivelyrepresentattributewithvaluebeginningendingandcontain [attrregex] istheuseofregularexpressionsforattributevaluefilteringsuchasimg [srcIpngjpeG] locateallelementsThesearethemostbasicselectorssyntaxthatcanbeusedtogetherandhereisacombinationofjsoupsupportTable3combinationusageTheelidIDvalueofoneoftheelementssuchasalogo-aidlogohrefElclassclasstothespecifiedvalueelementssuchasdivheaddivclassheadxxxxdivEl [ATTR] locatesallelementsthatdefineapropertysuchasa [HREF] Theabovethreearbitrarycombinationssuchasa [HREF] logoa [名称] outerlinkAncestorandchildarefivetypesofselectorsyntaxwhichincludeparent-childrelationshipmergerelationandhierarchicalrelationParentchildSiblingAsiblingBSiblingAsiblingXElElElInadditiontosomebasicsyntaxandthecombinationofthesegrammarsjsoupalsosupportstheuseofexpressionsforelementfilteringselectionHereisalistofallexpressionssupportedbyjsoupTab le4expressionLTnsu chastdlt3representslessthanthreecolumnsGTndivpgt2meansthatdivcontainsmorethan2pEQnforminputeq1representsaformthatcontainsonlyoneinputHasseletordivhasPrepresentsthedivcontainingthePelementNotselectordivnotLogorepresentsalldivliststhatdonotcontainclasslogoelementsContainstextcontainselementsofatextthatarenotcasesensitivesuchaspcontainsoschinaContainsOwntexttextinformationiscompletelyequaltothefilterofthespecifiedconditionMatchesregexusesregularexpressionsfortextfilteringdivmatchesIloginMatchesOwnregexusesregularexpressionstofinditsowntext 查看全部
httpunit 抓取网页(
jsoup抓取网页教程(jsoup)抓取(抓取)(组图))

jsoup爬网页教程jsoup爬网页教程jsoup爬网页教程jsoup爬网页教程jsoup爬网页详细我以前在ibmdw上发表过两篇关于htmlparser的文章。 文章 是从html中抓取你需要的信息,扩展htmlparser处理自定义标签的能力。但现在我不再使用 htmlparser。原因是htmlparser很少更新,但最重要的是它的nameits是一个javahtml解析器,可以直接解析一个URL地址的html文本内容。它提供了一个非常省力的API,可以通过domcss和jquery之类的操作方法进行检索和检索。其操作数据的主要功能如下: 1. 从文件或字符串中解析出urlhtml 2. 使用domdesignedcss选择器找出数据 3. 可操作的HTML元素属性文本 其基于新版mit协议离婚协议劳动协议合同个人投资股权协议广告可以安全用于商业项目的1its的主要类层次结构如图1所示。解释一下它的html文档是如何优雅地处理的 ------------------------------------- ---- -------------------------------------返回顶部 文档输入可以收录来自 String urlits 地址和本地文件加载 html 文档并生成文档对象实例。下面是相关代码清单 1.直接从字符串stringhtml中输入html文档 "htmlheadtitle开源中文社区titlehead" "bodyp这里是与其项目相关的文章 ppointshtml"documentdocjsoupparsehtml 直接从url documentdocjsoupconnecthttpwwwoschinanet加载html文档"getstringnamedoctitledocumentdocjsoupconnecthttpwwwoschinanet"datathe"query""java"请求参数useragent"i"mits"set useragentcookie"auth""token"set cookietime out3000设置连接超时时间。post使用post方法访问url,从中加载html文档文件.fileinputnewfile"ctesthtml"documentdocjsoupparseinput"utf-8""httpwwwoschinanet.请注意最后一个html文档输入法中parse的第三个参数。这里指定一个url,虽然第一种方法不需要指定,因为html文档中会有很多链接,比如链接图片和引用的外部脚本css文件等,第三个参数baseurl的意思是当html 文档使用相对路径引用外部文件时,它会自动给这些 URL 添加前缀,即 baseurlnoandhrefproject 开源软件 a 将转换为 ahrefhttpwwwoschinanetproject 开源软件 a----------- ———————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————— -------- -----------返回顶部 HTML 元素的分析和提取这部分与 HTML 解析器的基本功能有关,但与其他开源项目不同 - 选择器我们将在最后一部分

etailsthejsoupselectorinthissectionyouwillseejsoupishowtoachievethemostsimplecodeHoweverjsoupalsoprovideselementalparsingofthetraditionalDOMapproachlookingatthecodebelowListing2FileinputnewFile “Dtesthtml” DocumentdocJsoupparseinput “UTF-8”, “ElementcontentdocgetElementById” 内容 “ElementslinkscontentgetElementsByTag” 一 “ForElementlinklinksStringlinkHreflinkattr的” href “StringlinkTextlinktextYoumightthinkthatjsoupsmethodisfamiliarandyeslikethegetElementByIdandgetElementsByTagmethodsthenamesofthemethodsarethesameandthefunctionsareexactlythesameasthoseoftheJavaScriptYoucangetthecorrespondingelementorlistofelementsaccordingtothenodenameortheIDoftheHTMLelementUnliketheHtmlparserprojectjsoupdoesnotdefineacorrespondingHTMLelementpartofageneralHTMLelementsincludenodenameattributeandtextjsoupprovidesasimplewayforyoutoretrievethesedatawhichisthereasonforkeepingfitjsoupIntermsofelementretrievaljsoupselectorsareomnipotentListing3FileinputnewFile” Dtesthtml “DocumentdocJsoupparseinput” UTF-8“ “Elementslinks docselect ”一个[HREF]“ hrefattributelinkElementsPNGSdocselect ”IMG [srcpng]“ PNGallreferencepictureelementsElementmastheaddocselect ”divmasthead“ FirstFinddefineclassmastheadelementsElementsresultLinksdocselect ”h3ra“ directaafterH3ThisisthejsoupthatIreallyimpressedbythelocaljsoupforusewiththejQueryselectorontheelementsareaslikeastwopeasretrievalretrievalmethodsaboveifotherHTMLinterpreteratleastneedmanylinesofcodebutjsoupneedsonlyonelineofcodecompleteTheselectorofjsoupalsosupportstheexpressionfunctionandwellintroducethissuperselectorinthelastsection -

----------------------------------------------- -------------------------------返回顶部修改数据在分析文档的同时,我们可能需要修改文档中的某些元素,例如我们可以添加可点击链接、修改链接地址或修改文档中所有图像的文本这里有一些简单的示例 Listing4Docselect"divcommentsa"Attr"rel""nofollow"Increaseterlink"Increaseterlink"IncreaseterlinkClassof removeAttr "delete allthepicturesoftheonclickattributeDocselect" input [typetext] "" Val "textemptyallthetextinputboxin thereassonisvery simpleYou just need to find the elements using jsoupselector and then through the above the method to modify in addition to not modify the label name can beremoved after the insertion of the index of the HTML ----------------------------------------- --BacktotopHTMLdocumentcleanupJs oupalsodoesagreatjobofprovidingpowerfulAPIandhumanizingWhenyoudoawebsiteyouoftenprovidethefunctionofuserreviewsSomeusersaremoremischievouswillmakesomecommentstothescriptandthesescriptsmaydestroytheentirepagemoreseriousistoobtainsomeconfidentialinformationsuchascrosssiteattackslikeXSSJsoupisverysupportiveofthisanditsverysimpletouseTakealookatthecodebelowListing5Stringunsafe “pahref” OpensourceChinesecommunityap “StringsafeJsoupcleanunsafeWhitelistbasicoutputpahref” 相对 “nofollow” 的ChineseapopensourcecommunityJsoupus

"embed""object""param""span""div"你也可以调用addAttributes属性来增加一些元素------------------------------ -------------------------------------------------BacktotopJsoup “selectorWehavebrieflyintroducedhowjsoupusesselectorstoretrieveelementsInthissectionwefocusonthepowerfulsyntaxoftheselectorits elfThefollowingtableisadetailedlistofallthesyntaxofthejsoupselectorTable2basicusageTagNameusestagnamestolocateforexampleaNstagusesnamespacetagpositioningsuchasfbnametofindfbnameelementsiduseselementIDtolocateforexamplelogoclassusestheclasspropertyoftheelementtolocateforexampleHead [属性] usesthepropertiesoftheelementstolocateforexample [HREF] representsallelementsthatretrievethehrefattribute [ATTR] usestheattributenameprefixesofelementstolocatesuchas [DATA-] whichisusedtofindthedatasetattributeofHTML5 [attrvalue] usesattributevaluestolocateFore

xample [width500] locatesallelementswhosewidthattributevalueis500 [attrvalue] [attrvalue] [attrvalue] thesethreegrammarrespectivelyrepresentattributewithvaluebeginningendingandcontain [attrregex] istheuseofregularexpressionsforattributevaluefilteringsuchasimg [srcIpngjpeG] locateallelementsThesearethemostbasicselectorssyntaxthatcanbeusedtogetherandhereisacombinationofjsoupsupportTable3combinationusageTheelidIDvalueofoneoftheelementssuchasalogo-aidlogohrefElclassclasstothespecifiedvalueelementssuchasdivheaddivclassheadxxxxdivEl [ATTR] locatesallelementsthatdefineapropertysuchasa [HREF] Theabovethreearbitrarycombinationssuchasa [HREF] logoa [名称] outerlinkAncestorandchildarefivetypesofselectorsyntaxwhichincludeparent-childrelationshipmergerelationandhierarchicalrelationParentchildSiblingAsiblingBSiblingAsiblingXElElElInadditiontosomebasicsyntaxandthecombinationofthesegrammarsjsoupalsosupportstheuseofexpressionsforelementfilteringselectionHereisalistofallexpressionssupportedbyjsoupTab le4expressionLTnsu chastdlt3representslessthanthreecolumnsGTndivpgt2meansthatdivcontainsmorethan2pEQnforminputeq1representsaformthatcontainsonlyoneinputHasseletordivhasPrepresentsthedivcontainingthePelementNotselectordivnotLogorepresentsalldivliststhatdonotcontainclasslogoelementsContainstextcontainselementsofatextthatarenotcasesensitivesuchaspcontainsoschinaContainsOwntexttextinformationiscompletelyequaltothefilterofthespecifiedconditionMatchesregexusesregularexpressionsfortextfilteringdivmatchesIloginMatchesOwnregexusesregularexpressionstofinditsowntext
httpunit 抓取网页(一下HttpUnit不是,不是不是不是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 398 次浏览 • 2021-10-22 14:09
时间
2015-02-12742 浏览次数
简介:最近在想怎么从网页中抓取需要的数据。直接使用java提供的API太麻烦了。可能有一些成熟的自动化测试web程序库中可能需要的功能,比如HttpUnit、Watij、Selenium;我现在试过HttpUnit,不是很方便,只有...
最近在思考如何从网页中抓取需要的数据。直接使用java提供的API太麻烦了。可能有一些成熟的自动化测试web程序库中可能需要的功能,例如HttpUnit、Watij、Selenium;现在我尝试了 HttpUnit。这不是很方便。我只能找到带有 id 的表格元素。如果没有id,就得自己处理响应流
public static void main(String[] args) {
WebClient webClient = new WebClient();
HtmlPage page = null;
try {
page = (HtmlPage) webClient.getPage("http://biz.cn.yahoo.com/stock.html");
} catch (FailingHttpStatusCodeException e) {
//e.printStackTrace();
} catch (MalformedURLException e) {
//e.printStackTrace();
} catch (IOException e) {
//e.printStackTrace();
}
WebResponse wr = page.getWebResponse();
HtmlDivision he = page.getHtmlElementById("stat1");
if (he.hasChildNodes()){
Iterator i = he.getChildElements().iterator();
while(i.hasNext()){
System.out.println(i.next());
}
}
System.out.println(he.getAttribute("id"));
//System.out.println(he.asXml());
Iterator i = page.getAllHtmlChildElements().iterator();
if(i.hasNext()){
HtmlElement h = i.next();
System.out.println(h.getNodeName());
}
网页使用使用内网单位使用抓取网页使用抓取网页网页 查看全部
httpunit 抓取网页(一下HttpUnit不是,不是不是不是)
时间

2015-02-12742 浏览次数
简介:最近在想怎么从网页中抓取需要的数据。直接使用java提供的API太麻烦了。可能有一些成熟的自动化测试web程序库中可能需要的功能,比如HttpUnit、Watij、Selenium;我现在试过HttpUnit,不是很方便,只有...
最近在思考如何从网页中抓取需要的数据。直接使用java提供的API太麻烦了。可能有一些成熟的自动化测试web程序库中可能需要的功能,例如HttpUnit、Watij、Selenium;现在我尝试了 HttpUnit。这不是很方便。我只能找到带有 id 的表格元素。如果没有id,就得自己处理响应流
public static void main(String[] args) {
WebClient webClient = new WebClient();
HtmlPage page = null;
try {
page = (HtmlPage) webClient.getPage("http://biz.cn.yahoo.com/stock.html";);
} catch (FailingHttpStatusCodeException e) {
//e.printStackTrace();
} catch (MalformedURLException e) {
//e.printStackTrace();
} catch (IOException e) {
//e.printStackTrace();
}
WebResponse wr = page.getWebResponse();
HtmlDivision he = page.getHtmlElementById("stat1");
if (he.hasChildNodes()){
Iterator i = he.getChildElements().iterator();
while(i.hasNext()){
System.out.println(i.next());
}
}
System.out.println(he.getAttribute("id"));
//System.out.println(he.asXml());
Iterator i = page.getAllHtmlChildElements().iterator();
if(i.hasNext()){
HtmlElement h = i.next();
System.out.println(h.getNodeName());
}

网页使用使用内网单位使用抓取网页使用抓取网页网页
httpunit 抓取网页(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-10-21 02:09
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后续更新)。一开始看到这个简单,然后就稀里糊涂的打了代码(之前用的是Hadoop平台的分布式爬虫框架Nutch,用起来很方便,最后因为速度放弃了,但是生成的统计数据用在后来爬取),很快就成功下载了holder.html和finance.html页面,然后在解析了holder.html页面后,解析了finance.html,然后就郁闷的在这个页面找到了自己需要的东西数据不在 html 源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录后者)。我很高兴,终于找到了解决办法。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。当初设计的时候,不是用来服务爬虫的,但我想说的是:星盘只是有点短,你不能再进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从实际情况出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver 可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码太有限了。解析你写的js代码,js代码简单,当然WebDriver可以毫无压力的完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面用到的IE内核,当然是FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page. asXml(),可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js。会启动一个有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身经历)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能得到完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。本来以为driver解析js完成后应该可以抓到状态,于是去找,找,但是根本没有这种方法,所以说为什么WebDriver的设计者没有往前走一步,这样我们就可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。这真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是非常不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会出现不同,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实如此。通过Thread.sleep(2000))等待js解析完成,我觉得不是一个好办法,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream(); //后面的代码省略,得到了InputStream就好说了 }
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码不同编译,java端一直在等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要开启一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
我折腾了好几天了。虽然它没有解决我的问题,但我获得了很多知识。后面的工作就是熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后我爬网页的时候就得心应手了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过可以用Nutch和WebDirver的结合,可能爬取的结果比较稳定,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫获得的结果的稳定性有什么要说的,欢迎大家,因为我确实没有找到稳定爬虫结果的相关资料。 查看全部
httpunit 抓取网页(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后续更新)。一开始看到这个简单,然后就稀里糊涂的打了代码(之前用的是Hadoop平台的分布式爬虫框架Nutch,用起来很方便,最后因为速度放弃了,但是生成的统计数据用在后来爬取),很快就成功下载了holder.html和finance.html页面,然后在解析了holder.html页面后,解析了finance.html,然后就郁闷的在这个页面找到了自己需要的东西数据不在 html 源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录后者)。我很高兴,终于找到了解决办法。. 兴奋地使用WebDriver,我想骂人。

以下是对WebDriver的投诉
WebDriver 是一个测试框架。当初设计的时候,不是用来服务爬虫的,但我想说的是:星盘只是有点短,你不能再进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从实际情况出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver 可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码太有限了。解析你写的js代码,js代码简单,当然WebDriver可以毫无压力的完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面用到的IE内核,当然是FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page. asXml(),可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js。会启动一个有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身经历)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能得到完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。本来以为driver解析js完成后应该可以抓到状态,于是去找,找,但是根本没有这种方法,所以说为什么WebDriver的设计者没有往前走一步,这样我们就可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。这真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是非常不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会出现不同,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实如此。通过Thread.sleep(2000))等待js解析完成,我觉得不是一个好办法,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码

在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream(); //后面的代码省略,得到了InputStream就好说了 }
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码不同编译,java端一直在等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要开启一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
我折腾了好几天了。虽然它没有解决我的问题,但我获得了很多知识。后面的工作就是熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后我爬网页的时候就得心应手了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过可以用Nutch和WebDirver的结合,可能爬取的结果比较稳定,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫获得的结果的稳定性有什么要说的,欢迎大家,因为我确实没有找到稳定爬虫结果的相关资料。
httpunit 抓取网页(为什么我的网站搜索引擎不抓取呢?建站的小编告诉你)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-05 06:04
很多人会问,为什么我的网站搜索引擎爬不起来?搜索引擎如何快速抓取网站的页面?野狼网小编告诉你。
1.更新有价值的网站内容
当搜索引擎查看网站的内容时,如果你的网站页面比较新颖独特,更容易被抓取和收录。随着算法的升级,搜索引擎更加注重用户体验,对用户有价值的内容的搜索引擎会给出更好的收录和更高的排名。除了有价值之外,它还与网站和关键词的标题有一定的相关性。
二、网站关键词要合理设置
一个页面一定要慎重选择你要推广的关键词,并且关键词必须出现在标题、描述、文章第一段、中间段、最后一段,这样搜索引擎才会给这个关键词足够的关注也会在页面排名上有优势。但是,一定不要在网页上堆砌关键词。现在搜索引擎不断更新优化,更好的监控堆积如山的关键词。想要获得好排名的话,想用堆起来关键词 就难了。
三、定期更新网站页面
更新网站页面的时候一定要定期。如果你在某段时间频繁更新网站,让搜索引擎开发这段时间来爬取你的网站,这对网站页面上的收录也有一定的推广作用。现在百度搜索引擎每天早上7点到9点、晚上17点到19点、22点到24点开放。栏目有较大更新,建议站长合理利用这段时间,增加网站的收录。
4、科学合理地使用文字和图片
一个只有文字或图片的 网站 页面是一种不友好的表现。合理使用图文结合的页面,是一种人性化的表现。使用与页面上的文字描述相匹配的图片可以很好地帮助用户。了解页面内容,加深用户印象,同时给用户带来良好的视觉表现,获得用户对网站页面的认可。同时,不能在一个页面上使用过多的图片,因为搜索引擎对图片的认知度相对较低。如果使用图片,必须在图片上加上alt标签和文字注释,以便搜索引擎蜘蛛和用户在任何情况下都可以使用识别图片。
五、使用静态网页
动态页面虽然也可以是收录,但动态页面收录和被搜索引擎识别是不一样的。静态页面可以减少搜索引擎的工作时间,更快地提供信息反馈,对于用户来说,还可以节省带宽,减少数据库计算时间。如果页面已经创建好几天后还没有收录,那么可以直接在搜索引擎中输入网址,手动提交。这也是添加网站页面收录的一种方式。站长也可以通过网站的百度快照来判断网页的收录时间,然后根据百度快照的时间对网站进行优化。
六、增加优质外链
SEO优化者都知道外链的重要作用。优质外链的增加有利于网站的收录,增加流量和排名。外部链接是一个奖励点。链接到你要推广的页面,可以帮助这个页面加速收录,获得好的排名,传递权重。因此,如果可能,请尝试为您的 网站 和页面添加高质量的外部链接。同时,我们也应该扩大外部链接的来源。您可以在知名导航网站、第三方网站、网站目录、分类信息网站制作更多友情链接或外链。 查看全部
httpunit 抓取网页(为什么我的网站搜索引擎不抓取呢?建站的小编告诉你)
很多人会问,为什么我的网站搜索引擎爬不起来?搜索引擎如何快速抓取网站的页面?野狼网小编告诉你。
1.更新有价值的网站内容
当搜索引擎查看网站的内容时,如果你的网站页面比较新颖独特,更容易被抓取和收录。随着算法的升级,搜索引擎更加注重用户体验,对用户有价值的内容的搜索引擎会给出更好的收录和更高的排名。除了有价值之外,它还与网站和关键词的标题有一定的相关性。
二、网站关键词要合理设置
一个页面一定要慎重选择你要推广的关键词,并且关键词必须出现在标题、描述、文章第一段、中间段、最后一段,这样搜索引擎才会给这个关键词足够的关注也会在页面排名上有优势。但是,一定不要在网页上堆砌关键词。现在搜索引擎不断更新优化,更好的监控堆积如山的关键词。想要获得好排名的话,想用堆起来关键词 就难了。
三、定期更新网站页面
更新网站页面的时候一定要定期。如果你在某段时间频繁更新网站,让搜索引擎开发这段时间来爬取你的网站,这对网站页面上的收录也有一定的推广作用。现在百度搜索引擎每天早上7点到9点、晚上17点到19点、22点到24点开放。栏目有较大更新,建议站长合理利用这段时间,增加网站的收录。
4、科学合理地使用文字和图片
一个只有文字或图片的 网站 页面是一种不友好的表现。合理使用图文结合的页面,是一种人性化的表现。使用与页面上的文字描述相匹配的图片可以很好地帮助用户。了解页面内容,加深用户印象,同时给用户带来良好的视觉表现,获得用户对网站页面的认可。同时,不能在一个页面上使用过多的图片,因为搜索引擎对图片的认知度相对较低。如果使用图片,必须在图片上加上alt标签和文字注释,以便搜索引擎蜘蛛和用户在任何情况下都可以使用识别图片。
五、使用静态网页
动态页面虽然也可以是收录,但动态页面收录和被搜索引擎识别是不一样的。静态页面可以减少搜索引擎的工作时间,更快地提供信息反馈,对于用户来说,还可以节省带宽,减少数据库计算时间。如果页面已经创建好几天后还没有收录,那么可以直接在搜索引擎中输入网址,手动提交。这也是添加网站页面收录的一种方式。站长也可以通过网站的百度快照来判断网页的收录时间,然后根据百度快照的时间对网站进行优化。
六、增加优质外链
SEO优化者都知道外链的重要作用。优质外链的增加有利于网站的收录,增加流量和排名。外部链接是一个奖励点。链接到你要推广的页面,可以帮助这个页面加速收录,获得好的排名,传递权重。因此,如果可能,请尝试为您的 网站 和页面添加高质量的外部链接。同时,我们也应该扩大外部链接的来源。您可以在知名导航网站、第三方网站、网站目录、分类信息网站制作更多友情链接或外链。
httpunit 抓取网页(如何简便快捷使用python抓爬网页动态加载的数据(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-18 09:06
如何轻松快速地使用python抓取网页动态加载的数据
但在实践中,我发现我原本以为的太简单了。页面上有很多数据不能简单地从html源代码中抓取,因为页面上显示的很多数据实际上是在js代码运行时通过ajax从远程服务器获取后动态的。页面加载时,不可能简单的读取html代码获取这些数据,然后通过逆向工程的方式研究它是如何构造http请求的,然后自己模拟发送这些请求来获取数据。:) 运行完上面的代码,就可以启动浏览器了,看到他打开京东主页了。这时候想在搜索框中自动输入关键词。我该怎么办?我通过html源代码找到了搜索框的id。键”因此,我们可以输入< @关键词通过如下代码模拟手动输入搜索框,然后模拟点击回车键实现搜索请求: search_box = driver.find_element_by_id(key) search_box.send_keys(word) search_box .send_keys 自浏览器和我们的代码不再运行在同一个进程中,我们需要调用 WebDriverWait 等待一段时间让浏览器完全加载页面。接下来,为了触发特定的Js代码获取动态加载的数据,我们要模拟一个人把页面拉下来的动作:SCROLL_PAUSE_TIME send_keys 由于浏览器和我们的代码不再运行在同一个进程中,所以我们需要调用WebDriverWait等待一段时间让浏览器完全加载页面。接下来,为了触发特定的Js代码获取动态加载的数据,我们要模拟一个人把页面拉下来的动作:SCROLL_PAUSE_TIME send_keys 由于浏览器和我们的代码不再运行在同一个进程中,所以我们需要调用WebDriverWait等待一段时间让浏览器完全加载页面。接下来,为了触发特定的Js代码获取动态加载的数据,我们要模拟一个人把页面拉下来的动作:SCROLL_PAUSE_TIME
511 查看全部
httpunit 抓取网页(如何简便快捷使用python抓爬网页动态加载的数据(图))
如何轻松快速地使用python抓取网页动态加载的数据
但在实践中,我发现我原本以为的太简单了。页面上有很多数据不能简单地从html源代码中抓取,因为页面上显示的很多数据实际上是在js代码运行时通过ajax从远程服务器获取后动态的。页面加载时,不可能简单的读取html代码获取这些数据,然后通过逆向工程的方式研究它是如何构造http请求的,然后自己模拟发送这些请求来获取数据。:) 运行完上面的代码,就可以启动浏览器了,看到他打开京东主页了。这时候想在搜索框中自动输入关键词。我该怎么办?我通过html源代码找到了搜索框的id。键”因此,我们可以输入< @关键词通过如下代码模拟手动输入搜索框,然后模拟点击回车键实现搜索请求: search_box = driver.find_element_by_id(key) search_box.send_keys(word) search_box .send_keys 自浏览器和我们的代码不再运行在同一个进程中,我们需要调用 WebDriverWait 等待一段时间让浏览器完全加载页面。接下来,为了触发特定的Js代码获取动态加载的数据,我们要模拟一个人把页面拉下来的动作:SCROLL_PAUSE_TIME send_keys 由于浏览器和我们的代码不再运行在同一个进程中,所以我们需要调用WebDriverWait等待一段时间让浏览器完全加载页面。接下来,为了触发特定的Js代码获取动态加载的数据,我们要模拟一个人把页面拉下来的动作:SCROLL_PAUSE_TIME send_keys 由于浏览器和我们的代码不再运行在同一个进程中,所以我们需要调用WebDriverWait等待一段时间让浏览器完全加载页面。接下来,为了触发特定的Js代码获取动态加载的数据,我们要模拟一个人把页面拉下来的动作:SCROLL_PAUSE_TIME
511
httpunit 抓取网页(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-18 09:05
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,然后就稀里糊涂的打了代码(之前用Hadoop平台的分布式爬虫框架Nutch,用起来很方便,但最后因为速度放弃了,但是统计生成用于后续爬取),很快就成功下载了holder.html和finance.html页面,然后在解析holder.html页面后,解析finance.html,然后郁闷的找不到自己需要的在这个页面中的数据不在html源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录了后者)。我很高兴,终于找到了解决方案。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。本来不是为爬虫服务的,但我想说的是:星盘只是有点短,你不能更进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从现实出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码限制太多了,解析你写的js代码,js代码很简单,所以当然WebDriver 可以毫无压力地完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面使用的IE内核,当然是FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page。 asXml() 可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js,因为它不会启动有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身体验)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。只是觉得驱动应该可以在js的解析完成后捕捉到状态,于是搜索,搜索,但是根本没有这样的方法,所以我说为什么WebDriver的设计者没有采取措施forward 以便我们可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是非常不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会不一样,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实是这样。通过Thread.sleep(2000))等待js解析完成,我觉得不可取,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
system = require('system')
address = system.args[1];//获得命令行第二个参数 接下来会用到
//console.log('Loading a web page');
var page = require('webpage').create();
var url = address;
//console.log(url);
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
//此处的打印,是将结果一流的形式output到java中,java通过InputStream可以获取该输出内容
console.log(page.content);
}
phantom.exit();
});
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream();
//后面的代码省略,得到了InputStream就好说了
}
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码编译不一样,java端会一直等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
折腾了几天,虽然我的问题没有解决,但是也长了不少见识。后面的工作熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后去网页的时候就方便了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过你可以用Nutch和WebDirver结合起来,也许爬取的结果是稳定的,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫得到的结果的稳定性有什么想说的,欢迎大家讨论,因为我确实没有找到稳定结果的相关资料。 查看全部
httpunit 抓取网页(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,然后就稀里糊涂的打了代码(之前用Hadoop平台的分布式爬虫框架Nutch,用起来很方便,但最后因为速度放弃了,但是统计生成用于后续爬取),很快就成功下载了holder.html和finance.html页面,然后在解析holder.html页面后,解析finance.html,然后郁闷的找不到自己需要的在这个页面中的数据不在html源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录了后者)。我很高兴,终于找到了解决方案。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。本来不是为爬虫服务的,但我想说的是:星盘只是有点短,你不能更进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从现实出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码限制太多了,解析你写的js代码,js代码很简单,所以当然WebDriver 可以毫无压力地完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面使用的IE内核,当然是FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page。 asXml() 可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js,因为它不会启动有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身体验)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。只是觉得驱动应该可以在js的解析完成后捕捉到状态,于是搜索,搜索,但是根本没有这样的方法,所以我说为什么WebDriver的设计者没有采取措施forward 以便我们可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是非常不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会不一样,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实是这样。通过Thread.sleep(2000))等待js解析完成,我觉得不可取,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
system = require('system')
address = system.args[1];//获得命令行第二个参数 接下来会用到
//console.log('Loading a web page');
var page = require('webpage').create();
var url = address;
//console.log(url);
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
//此处的打印,是将结果一流的形式output到java中,java通过InputStream可以获取该输出内容
console.log(page.content);
}
phantom.exit();
});
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream();
//后面的代码省略,得到了InputStream就好说了
}
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码编译不一样,java端会一直等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
折腾了几天,虽然我的问题没有解决,但是也长了不少见识。后面的工作熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后去网页的时候就方便了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过你可以用Nutch和WebDirver结合起来,也许爬取的结果是稳定的,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫得到的结果的稳定性有什么想说的,欢迎大家讨论,因为我确实没有找到稳定结果的相关资料。
httpunit 抓取网页(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-17 12:05
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,然后就稀里糊涂的打了代码(之前用Hadoop平台的分布式爬虫框架Nutch,用起来很方便,但最后因为速度放弃了,但是统计生成用于后续爬取),很快就成功下载了holder.html和finance.html页面,然后在解析holder.html页面后,解析finance.html,然后郁闷的找不到自己需要的在这个页面中的数据不在html源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录了后者)。我很高兴,终于找到了解决方案。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。本来不是为爬虫服务的,但我想说的是:星盘只是有点短,你不能更进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从现实出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码限制太多了,解析你写的js代码,js代码很简单,所以当然WebDriver 可以毫无压力地完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面使用的IE内核,当然还有FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page。 asXml() 可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js,因为它不会启动有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身体验)。js代码的复杂含义是:不同内核支持的js是不完全一样的。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。只是觉得驱动应该可以在js的解析完成后捕捉到状态,于是搜索,搜索,但是根本没有这样的方法,所以我说为什么WebDriver的设计者没有采取措施forward 以便我们可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是很不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会不一样,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实是这样。通过Thread.sleep(2000))等待js解析完成,我觉得不可取,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
system = require('system')
address = system.args[1];//获得命令行第二个参数 接下来会用到
//console.log('Loading a web page');
var page = require('webpage').create();
var url = address;
//console.log(url);
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
//此处的打印,是将结果一流的形式output到java中,java通过InputStream可以获取该输出内容
console.log(page.content);
}
phantom.exit();
});
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream();
//后面的代码省略,得到了InputStream就好说了
}
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码编译不一样,java端会一直等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
折腾了几天,虽然我的问题没有解决,但是也长了不少见识。后面的工作熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后去网页的时候就方便了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过你可以用Nutch和WebDirver结合起来,也许爬取的结果是稳定的,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫得到的结果的稳定性有什么想说的,欢迎大家讨论,因为我确实没有找到稳定结果的相关资料。 查看全部
httpunit 抓取网页(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,然后就稀里糊涂的打了代码(之前用Hadoop平台的分布式爬虫框架Nutch,用起来很方便,但最后因为速度放弃了,但是统计生成用于后续爬取),很快就成功下载了holder.html和finance.html页面,然后在解析holder.html页面后,解析finance.html,然后郁闷的找不到自己需要的在这个页面中的数据不在html源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录了后者)。我很高兴,终于找到了解决方案。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。本来不是为爬虫服务的,但我想说的是:星盘只是有点短,你不能更进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从现实出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码限制太多了,解析你写的js代码,js代码很简单,所以当然WebDriver 可以毫无压力地完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面使用的IE内核,当然还有FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page。 asXml() 可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js,因为它不会启动有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身体验)。js代码的复杂含义是:不同内核支持的js是不完全一样的。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。只是觉得驱动应该可以在js的解析完成后捕捉到状态,于是搜索,搜索,但是根本没有这样的方法,所以我说为什么WebDriver的设计者没有采取措施forward 以便我们可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是很不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会不一样,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实是这样。通过Thread.sleep(2000))等待js解析完成,我觉得不可取,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
system = require('system')
address = system.args[1];//获得命令行第二个参数 接下来会用到
//console.log('Loading a web page');
var page = require('webpage').create();
var url = address;
//console.log(url);
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
//此处的打印,是将结果一流的形式output到java中,java通过InputStream可以获取该输出内容
console.log(page.content);
}
phantom.exit();
});
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream();
//后面的代码省略,得到了InputStream就好说了
}
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码编译不一样,java端会一直等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
折腾了几天,虽然我的问题没有解决,但是也长了不少见识。后面的工作熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后去网页的时候就方便了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过你可以用Nutch和WebDirver结合起来,也许爬取的结果是稳定的,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫得到的结果的稳定性有什么想说的,欢迎大家讨论,因为我确实没有找到稳定结果的相关资料。
httpunit 抓取网页(怎么解决网站抓取频次低的问题?试试以下办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-15 02:26
有朋友提到网站被百度抓取的频率很低,问怎么解决。爬取频率对页面收录影响很大。如果网站的爬取频率很低,说明有很多页面没有被爬取,对收录页面影响很大。
如何解决网站的抓取频率低的问题,不妨试试下面的方法。
一、通过网站设置解决爬取频率低的问题
在百度站长平台(现更名为百度搜索资源平台)中,有解决抓取频率不足问题的说明,如下图:
笔者在这里稍微解释一下:1. 正常情况下,站长不会主动设置爬取频率的上限,所以这点不需要考虑;2.检查爬取是否异常,这个需要注意,有的网站程序中可能有一些错误导致爬取不成功;3. 提交新链接,很有用;4. 反馈,应该说反馈基本没用。
每个人都应该关注第 2 点和第 3 点。
二、 通过外链解决爬取频率低的问题
从某种意义上说,爬行频率取决于蜘蛛爬行的次数。抓取次数越多,抓取的页面就越多。通常,这是成正比的。
对于低权重的网站来说,通过外部链接吸引蜘蛛爬行是一个不错的选择。作者在文章里也提到了,现在做seo外链有没有效果。
PS:这里需要说明一下蜘蛛爬行的概率。百度蜘蛛不是会纺丝织网的蜘蛛。其工作原理是通过组织好的url库中的特定url链接抓取页面数据,同时将页面放入页面中。提取链接后,剩余的url地址过滤后放入url库,这是一个循环过程。
通过建立外链,我们更多的网站 URL会被百度蜘蛛发现并存入数据库,从而有更多的机会增加爬取的频率。
三、 通过内链建设解决爬取频率低的问题
如上所述,建立外链可以吸引蜘蛛爬行,那么如何更好地利用蜘蛛来了,如何让更多的页面URL被发现呢?这涉及到内部链接的构建。如何设置内容增加爬取频率,我们可以从以下几个方面入手:
1.文章内部链。包括文中的内部链接以及相关的文章推荐等,这是基本的操作方法,我就不多说了。
2.侧边栏推荐。比如热门阅读、最新内容、标签采集标签推荐等,页面链接暴露的越多,被蜘蛛爬取的几率就越大。这是一个非常简单的真理。
3.文章 列表。这是一个重要的解释点。一般情况下,列表中的文章是按时间倒序排列的,也就是说,后面发布的文章会排在最前面。这里有问题。同一个文章列表下每天更新的文章数量有限,分页被蜘蛛爬取的次数会比较多,浪费了链接展示的机会。
举个例子:List A显示最近10篇文章,每天更新5次,蜘蛛每天爬5次。事实上,无论蜘蛛一天爬行5次还是50次,每天只有5个新页面链接显示在这个页面上!如果分类页面可以更新未被抓取的页面(定时或不规则),那么情况就明显不同了。每次蜘蛛来爬,都会提交一个新的页面链接,大大提高。抓取频率。
网站更新频率高网站更受蜘蛛青睐。如果要解决爬虫频率低网站的问题,除了做外链来吸引蜘蛛,更应该解决网站上的更新问题。.
PS:页面更新并不是绝对指添加新页面。对于搜索引擎蜘蛛来说,页面内容发生变化就意味着页面已经更新。至于更新后页面质量是否有所提升,本文暂不赘述。
还有一点就是网站本身的内容量。如果网站的总页数不超过100,则要求每天的抓取量超过1000,这显然是不合时宜的。 查看全部
httpunit 抓取网页(怎么解决网站抓取频次低的问题?试试以下办法)
有朋友提到网站被百度抓取的频率很低,问怎么解决。爬取频率对页面收录影响很大。如果网站的爬取频率很低,说明有很多页面没有被爬取,对收录页面影响很大。
如何解决网站的抓取频率低的问题,不妨试试下面的方法。
一、通过网站设置解决爬取频率低的问题
在百度站长平台(现更名为百度搜索资源平台)中,有解决抓取频率不足问题的说明,如下图:
笔者在这里稍微解释一下:1. 正常情况下,站长不会主动设置爬取频率的上限,所以这点不需要考虑;2.检查爬取是否异常,这个需要注意,有的网站程序中可能有一些错误导致爬取不成功;3. 提交新链接,很有用;4. 反馈,应该说反馈基本没用。
每个人都应该关注第 2 点和第 3 点。
二、 通过外链解决爬取频率低的问题
从某种意义上说,爬行频率取决于蜘蛛爬行的次数。抓取次数越多,抓取的页面就越多。通常,这是成正比的。
对于低权重的网站来说,通过外部链接吸引蜘蛛爬行是一个不错的选择。作者在文章里也提到了,现在做seo外链有没有效果。
PS:这里需要说明一下蜘蛛爬行的概率。百度蜘蛛不是会纺丝织网的蜘蛛。其工作原理是通过组织好的url库中的特定url链接抓取页面数据,同时将页面放入页面中。提取链接后,剩余的url地址过滤后放入url库,这是一个循环过程。
通过建立外链,我们更多的网站 URL会被百度蜘蛛发现并存入数据库,从而有更多的机会增加爬取的频率。
三、 通过内链建设解决爬取频率低的问题
如上所述,建立外链可以吸引蜘蛛爬行,那么如何更好地利用蜘蛛来了,如何让更多的页面URL被发现呢?这涉及到内部链接的构建。如何设置内容增加爬取频率,我们可以从以下几个方面入手:
1.文章内部链。包括文中的内部链接以及相关的文章推荐等,这是基本的操作方法,我就不多说了。
2.侧边栏推荐。比如热门阅读、最新内容、标签采集标签推荐等,页面链接暴露的越多,被蜘蛛爬取的几率就越大。这是一个非常简单的真理。
3.文章 列表。这是一个重要的解释点。一般情况下,列表中的文章是按时间倒序排列的,也就是说,后面发布的文章会排在最前面。这里有问题。同一个文章列表下每天更新的文章数量有限,分页被蜘蛛爬取的次数会比较多,浪费了链接展示的机会。
举个例子:List A显示最近10篇文章,每天更新5次,蜘蛛每天爬5次。事实上,无论蜘蛛一天爬行5次还是50次,每天只有5个新页面链接显示在这个页面上!如果分类页面可以更新未被抓取的页面(定时或不规则),那么情况就明显不同了。每次蜘蛛来爬,都会提交一个新的页面链接,大大提高。抓取频率。
网站更新频率高网站更受蜘蛛青睐。如果要解决爬虫频率低网站的问题,除了做外链来吸引蜘蛛,更应该解决网站上的更新问题。.
PS:页面更新并不是绝对指添加新页面。对于搜索引擎蜘蛛来说,页面内容发生变化就意味着页面已经更新。至于更新后页面质量是否有所提升,本文暂不赘述。
还有一点就是网站本身的内容量。如果网站的总页数不超过100,则要求每天的抓取量超过1000,这显然是不合时宜的。
httpunit 抓取网页(用wireshark抓取网站登录弱口令(账号密码都是新建也没啥权限) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-15 02:25
)
摘要:Wireshark本身无法破解弱密码,但我们可以通过分析手动破解捕获的数据。今天,我将使用智能测试博客和FTP做实验(账号和密码都是新的,没有权限,请不要使用)。1:使用Wireshark抓取网站登录弱密码1、页面一.
Wireshark本身无法破解弱密码,但我们可以通过分析手动破解捕获的数据
今天,我将使用智能测试博客和FTP做实验(账号和密码都是新的,没有权限,请不要使用)
1:使用Wireshark抓取网站登录弱密码
1、在第一步中,我们设置捕获筛选器(这次我们捕获HTTP数据包,只需在捕获筛选器中输入HTTP)
2、单击开始打开我的博客地址(),单击登录,转到页面,输入用户名和密码,然后单击登录
3、登录后,我们可以结束Wireshark捕获过程
4、然后我们设置显示过滤器:使用IP地址==203.171.239.103这是我博客服务器的IP地址,可以减少大量HTTP数据。(您可以使用CMD下的ping命令获取您的网站IP地址)
Wireshark显示过滤器
5、过滤后,我们找到/WP login PHP(WP login.PHP是我博客后台登录页面的地址)
6、查看全部/WP登录事实上,PHP中只有两段数据。我们捕获了第二条数据(log=Huisha&;PWD=279478776&;WP submit=)。你看到这是我的帐户和密码了吗(用户:Huisha/PWD:279478776)
当然,如果用户的密码非常复杂,那么以这种方式获取密码基本上是错误的,所以只能获取弱密码
Wireshark捕获的帐户密码
2:使用Wireshark获取FTP帐户和密码
同样,我们使用上述方法捕获FTP帐户和密码。捕获FTP帐户和密码时,不适用于弱密码。只要您能够捕获FTP数据,就可以获得FTP帐户和密码
操作
1、将捕获筛选器设置为仅捕获FTP数据包
2、打开FTP工具登录到您的FTP服务器
3、然后结束捕获过程
4、设置显示过滤器(IP.Addr==192.168.>9.1您的FTP地址)
5、然后我们会发现FTP帐户和密码以明文显示,酷
资料来源:红黑联盟
查看全部
httpunit 抓取网页(用wireshark抓取网站登录弱口令(账号密码都是新建也没啥权限)
)
摘要:Wireshark本身无法破解弱密码,但我们可以通过分析手动破解捕获的数据。今天,我将使用智能测试博客和FTP做实验(账号和密码都是新的,没有权限,请不要使用)。1:使用Wireshark抓取网站登录弱密码1、页面一.
Wireshark本身无法破解弱密码,但我们可以通过分析手动破解捕获的数据
今天,我将使用智能测试博客和FTP做实验(账号和密码都是新的,没有权限,请不要使用)
https://www.youxia.org/wp-cont ... 6.jpg 300w" />1:使用Wireshark抓取网站登录弱密码
1、在第一步中,我们设置捕获筛选器(这次我们捕获HTTP数据包,只需在捕获筛选器中输入HTTP)
2、单击开始打开我的博客地址(),单击登录,转到页面,输入用户名和密码,然后单击登录
3、登录后,我们可以结束Wireshark捕获过程
4、然后我们设置显示过滤器:使用IP地址==203.171.239.103这是我博客服务器的IP地址,可以减少大量HTTP数据。(您可以使用CMD下的ping命令获取您的网站IP地址)
Wireshark显示过滤器
5、过滤后,我们找到/WP login PHP(WP login.PHP是我博客后台登录页面的地址)
6、查看全部/WP登录事实上,PHP中只有两段数据。我们捕获了第二条数据(log=Huisha&;PWD=279478776&;WP submit=)。你看到这是我的帐户和密码了吗(用户:Huisha/PWD:279478776)
当然,如果用户的密码非常复杂,那么以这种方式获取密码基本上是错误的,所以只能获取弱密码
Wireshark捕获的帐户密码
2:使用Wireshark获取FTP帐户和密码
同样,我们使用上述方法捕获FTP帐户和密码。捕获FTP帐户和密码时,不适用于弱密码。只要您能够捕获FTP数据,就可以获得FTP帐户和密码
操作
1、将捕获筛选器设置为仅捕获FTP数据包
2、打开FTP工具登录到您的FTP服务器
3、然后结束捕获过程
4、设置显示过滤器(IP.Addr==192.168.>9.1您的FTP地址)
5、然后我们会发现FTP帐户和密码以明文显示,酷
资料来源:红黑联盟
httpunit 抓取网页(搜索引擎蜘蛛花抓取份额是由什么决定的呢?说明)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-13 13:12
顾名思义,爬行份额是搜索引擎蜘蛛在网站上爬取一个页面所花费的总时间的上限。对于特定的网站,搜索引擎蜘蛛在这个网站上花费的总时间是相对固定的,不会无限爬取网站的所有页面。
Google 使用英文的 crawl budget 来抓取共享,直译为抓取预算。我不认为它可以解释它的含义,所以我使用爬网共享来表达这个概念。
什么决定了爬网份额?这涉及到爬行要求和爬行速度限制。
爬行需求
爬取需求,或者说爬取需求,指的是搜索引擎“想要”爬取多少个特定的网站页面。
有两个主要因素决定了对爬行的需求。首先是页面权重。网站上有多少页面达到基本页面权重,搜索引擎想要抓取多少个页面。二是索引库中的页面是否太长时间没有更新。毕竟是页面权重,权重高的页面不会更新太久。
页面权重和 网站 权重密切相关。增加网站的权重可以让搜索引擎愿意抓取更多的页面。
爬行速度限制
搜索引擎蜘蛛不会为了抓取更多的页面而拖拽别人的网站服务器,所以会针对某个网站设置一个抓取速度限制,即抓取速度限制,即服务器可以容忍上限,在这个速度限制内,蜘蛛爬行不会减慢服务器,影响用户访问。
服务器响应速度够快,这个限速提高一点,爬行加快,服务器响应速度降低,限速降低,爬行变慢,甚至爬行停止。
因此,抓取速度受限于搜索引擎“可以”抓取的页面数量。
什么决定了爬网份额?
爬取份额是同时考虑爬取需求和爬取速度限制的结果,即搜索引擎“想要”爬取但“能”爬取的页面数。
网站 权重高,页面内容质量高,页面多,服务器速度快,爬取份额大。
小网站不用担心抢份额
小网站页面数量少,即使网站权重低,服务器慢,不管搜索引擎蜘蛛每天爬多少,通常至少几百页可以爬取。网站又被抓取了,让网站拥有数千个页面根本不用担心抢分享。网站 有几万页通常没什么大不了的。如果每天数百次访问可以降低服务器的速度,这不是 SEO 的主要考虑因素。
大中型网站可能需要考虑抢份额
对于几十万页以上的大中型网站来说,可能需要考虑足够抢占的问题。
爬网份额是不够的。比如网站有1000万个页面,搜索引擎每天只能抓取几万个页面。捕获一次网站可能需要几个月,甚至一年的时间,这也可能意味着一些重要页面无法抓取,因此没有排名,或者重要页面无法及时更新。
想要网站页面被及时完整地抓取,首先要保证服务器足够快,页面足够小。如果网站有大量优质数据,爬取份额会受到爬取速度的限制。提高页面速度直接提高了抓取速度限制,从而增加了抓取份额。
百度站长平台和谷歌搜索控制台都有抓取数据。如下图,某网站百度的抓取频率:
上图为网站百度小后台截图。页面抓取频率和抓取时间(取决于服务器速度和页面大小)与此无关。这意味着爬网份额还没有用完,所以不用担心。
有时,爬取频率和爬取时间有一定的对应关系,如下图为另一个较大的网站:
可以看出爬取时间的提升(减小页面大小、提高服务器速度、优化数据库)明显导致爬取频率增加,导致爬取更多页面收录,再次遍历网站更快。
大网站 另一个经常需要考虑爬网份额的原因是不要把自己有限的爬网份额浪费在无意义的页面爬行上,导致重要的页面应该被爬行却没有机会被爬行。
浪费抓取共享的典型页面是:
以上页面被大量抓取,抓取份额可能用完,但应该抓取的页面没有抓取。
如何保存抓取共享?
当然,首先是减小页面文件的大小,提高服务器的速度,优化数据库,减少抓取时间。
然后,尽量避免上面列出的浪费性抢股。有些是内容质量问题,有些是网站结构问题。如果是结构问题,最简单的方法就是禁止爬取robots文件,但是会浪费一些页面权重,因为权重只能访问。
在某些情况下,使用链接 nofollow 可以节省抓取共享。小网站,添加nofollow没有意义,因为爬取份额用不完。大网站,nofollow 可以在一定程度上控制权重的流量和分配。精心设计的nofollow会降低无意义页面的权重,增加重要页面的权重。搜索引擎在爬取时会使用一个 URL 爬取列表。要抓取的网址按页面权重排序。如果增加重要页面的权重,将首先抓取重要页面。无意义页面的权重可能很低,以至于搜索引擎不想爬行。
最后几点说明:
关注我@operation优采云不定期更新互联网运营知识。如果你想学习SEO和新媒体运营,可以加我主页微信运营优采云,知无不言...
如果以上内容对您有帮助,请点个赞。 查看全部
httpunit 抓取网页(搜索引擎蜘蛛花抓取份额是由什么决定的呢?说明)
顾名思义,爬行份额是搜索引擎蜘蛛在网站上爬取一个页面所花费的总时间的上限。对于特定的网站,搜索引擎蜘蛛在这个网站上花费的总时间是相对固定的,不会无限爬取网站的所有页面。
Google 使用英文的 crawl budget 来抓取共享,直译为抓取预算。我不认为它可以解释它的含义,所以我使用爬网共享来表达这个概念。
什么决定了爬网份额?这涉及到爬行要求和爬行速度限制。
爬行需求
爬取需求,或者说爬取需求,指的是搜索引擎“想要”爬取多少个特定的网站页面。
有两个主要因素决定了对爬行的需求。首先是页面权重。网站上有多少页面达到基本页面权重,搜索引擎想要抓取多少个页面。二是索引库中的页面是否太长时间没有更新。毕竟是页面权重,权重高的页面不会更新太久。
页面权重和 网站 权重密切相关。增加网站的权重可以让搜索引擎愿意抓取更多的页面。
爬行速度限制
搜索引擎蜘蛛不会为了抓取更多的页面而拖拽别人的网站服务器,所以会针对某个网站设置一个抓取速度限制,即抓取速度限制,即服务器可以容忍上限,在这个速度限制内,蜘蛛爬行不会减慢服务器,影响用户访问。
服务器响应速度够快,这个限速提高一点,爬行加快,服务器响应速度降低,限速降低,爬行变慢,甚至爬行停止。
因此,抓取速度受限于搜索引擎“可以”抓取的页面数量。
什么决定了爬网份额?
爬取份额是同时考虑爬取需求和爬取速度限制的结果,即搜索引擎“想要”爬取但“能”爬取的页面数。
网站 权重高,页面内容质量高,页面多,服务器速度快,爬取份额大。
小网站不用担心抢份额
小网站页面数量少,即使网站权重低,服务器慢,不管搜索引擎蜘蛛每天爬多少,通常至少几百页可以爬取。网站又被抓取了,让网站拥有数千个页面根本不用担心抢分享。网站 有几万页通常没什么大不了的。如果每天数百次访问可以降低服务器的速度,这不是 SEO 的主要考虑因素。
大中型网站可能需要考虑抢份额
对于几十万页以上的大中型网站来说,可能需要考虑足够抢占的问题。
爬网份额是不够的。比如网站有1000万个页面,搜索引擎每天只能抓取几万个页面。捕获一次网站可能需要几个月,甚至一年的时间,这也可能意味着一些重要页面无法抓取,因此没有排名,或者重要页面无法及时更新。
想要网站页面被及时完整地抓取,首先要保证服务器足够快,页面足够小。如果网站有大量优质数据,爬取份额会受到爬取速度的限制。提高页面速度直接提高了抓取速度限制,从而增加了抓取份额。
百度站长平台和谷歌搜索控制台都有抓取数据。如下图,某网站百度的抓取频率:
上图为网站百度小后台截图。页面抓取频率和抓取时间(取决于服务器速度和页面大小)与此无关。这意味着爬网份额还没有用完,所以不用担心。
有时,爬取频率和爬取时间有一定的对应关系,如下图为另一个较大的网站:
可以看出爬取时间的提升(减小页面大小、提高服务器速度、优化数据库)明显导致爬取频率增加,导致爬取更多页面收录,再次遍历网站更快。
大网站 另一个经常需要考虑爬网份额的原因是不要把自己有限的爬网份额浪费在无意义的页面爬行上,导致重要的页面应该被爬行却没有机会被爬行。
浪费抓取共享的典型页面是:
以上页面被大量抓取,抓取份额可能用完,但应该抓取的页面没有抓取。
如何保存抓取共享?
当然,首先是减小页面文件的大小,提高服务器的速度,优化数据库,减少抓取时间。
然后,尽量避免上面列出的浪费性抢股。有些是内容质量问题,有些是网站结构问题。如果是结构问题,最简单的方法就是禁止爬取robots文件,但是会浪费一些页面权重,因为权重只能访问。
在某些情况下,使用链接 nofollow 可以节省抓取共享。小网站,添加nofollow没有意义,因为爬取份额用不完。大网站,nofollow 可以在一定程度上控制权重的流量和分配。精心设计的nofollow会降低无意义页面的权重,增加重要页面的权重。搜索引擎在爬取时会使用一个 URL 爬取列表。要抓取的网址按页面权重排序。如果增加重要页面的权重,将首先抓取重要页面。无意义页面的权重可能很低,以至于搜索引擎不想爬行。
最后几点说明:
关注我@operation优采云不定期更新互联网运营知识。如果你想学习SEO和新媒体运营,可以加我主页微信运营优采云,知无不言...
如果以上内容对您有帮助,请点个赞。
httpunit 抓取网页(百度蜘蛛只爬行了网站首页的解决办法问题应该如何解决)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-08 05:06
站长查看网站访问日志时,可以看到搜索引擎蜘蛛抓取的页面,以及频率和返回码,以便站长知道网站的哪些页面和内容蜘蛛爬了。但是,在某些情况下,站长分析网站日志时,搜索引擎蜘蛛只爬取了网站首页,并没有继续爬取内页文章,那么如何解决百度蜘蛛只抓取网站首页的问题。
1、分析网站内部优化是否完善
在算法不断升级的现状下,SEO技术不再是单纯的迎合某个搜索引擎,而是从用户体验上综合考虑网站。搜索引擎蜘蛛只抓取主页。,首先要确定网站的内部优化是否完善,网站的首页是否有大量脚本文件、flash文件等,以及网站的首页是否有网站 规范了 H 标签的使用。
2、机器人设置错误
在蜘蛛只抓取首页的日志分析中,可以检查网站根目录下的robots.txt文件是否设置错误,导致网站内页限制蜘蛛抓取。检查 robots 文件内容中的通配符。这是错的吗?还要检查 网站 服务器是否有限制策略。
3、网站文章内容
通过网站日志的返回码可以看到,蜘蛛每次抓取网站首页返回的值,判断蜘蛛的爬行情况,优化网站的内容@>文章 ,尽量专注于原创,SEO是一个长期的技术活动,坚持原创的内容,把原创的内容提交给专业搜索引擎,蜘蛛只抓取首页,不抓取内容的情况会得到很好的解决。
以上就是百度蜘蛛只抓取网站首页的解决方法。同时站长可以在优化网站时制作sitemap.xml的地图,并将sitemap.xml放在robots.txt中。可以有效提高蜘蛛对网站内页的抓取。 查看全部
httpunit 抓取网页(百度蜘蛛只爬行了网站首页的解决办法问题应该如何解决)
站长查看网站访问日志时,可以看到搜索引擎蜘蛛抓取的页面,以及频率和返回码,以便站长知道网站的哪些页面和内容蜘蛛爬了。但是,在某些情况下,站长分析网站日志时,搜索引擎蜘蛛只爬取了网站首页,并没有继续爬取内页文章,那么如何解决百度蜘蛛只抓取网站首页的问题。
1、分析网站内部优化是否完善
在算法不断升级的现状下,SEO技术不再是单纯的迎合某个搜索引擎,而是从用户体验上综合考虑网站。搜索引擎蜘蛛只抓取主页。,首先要确定网站的内部优化是否完善,网站的首页是否有大量脚本文件、flash文件等,以及网站的首页是否有网站 规范了 H 标签的使用。
2、机器人设置错误
在蜘蛛只抓取首页的日志分析中,可以检查网站根目录下的robots.txt文件是否设置错误,导致网站内页限制蜘蛛抓取。检查 robots 文件内容中的通配符。这是错的吗?还要检查 网站 服务器是否有限制策略。
3、网站文章内容
通过网站日志的返回码可以看到,蜘蛛每次抓取网站首页返回的值,判断蜘蛛的爬行情况,优化网站的内容@>文章 ,尽量专注于原创,SEO是一个长期的技术活动,坚持原创的内容,把原创的内容提交给专业搜索引擎,蜘蛛只抓取首页,不抓取内容的情况会得到很好的解决。
以上就是百度蜘蛛只抓取网站首页的解决方法。同时站长可以在优化网站时制作sitemap.xml的地图,并将sitemap.xml放在robots.txt中。可以有效提高蜘蛛对网站内页的抓取。
httpunit 抓取网页(如下:robots协议文件屏蔽百度蜘蛛抓取协议(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-04 00:02
百度蜘蛛抓取我们的网站,希望将我们的网页收录发送到它的搜索引擎。以后用户搜索的时候,可以给我们带来一定的SEO流量。当然,我们不希望搜索引擎抓取所有内容。
所以,这个时候,我们只希望我们想爬取在搜索引擎上搜索到的内容。像用户隐私、背景信息等,不希望搜索引擎被爬取和收录。有两种最好的方法可以解决这个问题,如下所示:
Robots协议文件阻止百度蜘蛛爬行
robots协议是放置在网站根目录下的协议文件,可以通过URL地址访问:您的域名/robots.txt。当百度蜘蛛抓取我们网站时,它会先访问这个文件。因为它告诉蜘蛛哪些可以爬,哪些不能爬。
robots协议文件的设置比较简单,可以通过User-Agent、Disallow、Allow三个参数进行设置。
让我们看一个例子。场景是我不想百度抓取我所有的网站 css文件、数据目录、seo-tag.html页面
User-Agent: Baidusppider
Disallow: /*.css
Disallow: /data/
Disallow: /seo/seo-tag.html
如上,user-agent声明的蜘蛛名称表示针对百度蜘蛛。下面的不能抢“/*.css”,首先前面的/指的是根目录,也就是你的域名。* 是通配符,代表任何内容。这意味着无法抓取所有以 .css 结尾的文件。亲自体验以下两个。逻辑是一样的。
如果你想检查你上次设置的robots文件是否正确,可以访问这个文章《检查Robots是否正确的工具介绍》,里面有详细的工具可以检查你的设置。
通过403状态码,限制内容输出,阻止蜘蛛爬行。
403状态码是http协议中网页返回的状态码。当搜索引擎遇到 403 状态码时,它知道该类型的页面是权限受限的。我不能访问。比如你需要登录查看内容,搜索引擎本身不会登录,那么当你返回403时,他也知道这是权限设置页面,无法读取内容。自然不会是收录。
当返回 403 状态码时,应该有一个类似于 404 页面的页面。提示用户或蜘蛛执行他们想要访问的内容。两者缺一不可。你只有一个提示页面,状态码返回200,对于百度蜘蛛来说是很多重复的页面。有一个 403 状态代码,但返回不同的内容。它也不是很友好。
最后,关于机器人协议,我想再补充一点:“现在搜索引擎会通过你的网页的布局和布局来识别你的网页的体验友好度。如果抓取css文件和布局相关的js文件被屏蔽了,那么搜索引擎我不知道你的网页布局是好是坏。所以不建议从蜘蛛那里屏蔽这个内容。”
好了,今天的分享就到这里,希望能对大家有所帮助,当然以上两个设置对除百度蜘蛛以外的所有蜘蛛都有效。设置时请谨慎。 查看全部
httpunit 抓取网页(如下:robots协议文件屏蔽百度蜘蛛抓取协议(组图))
百度蜘蛛抓取我们的网站,希望将我们的网页收录发送到它的搜索引擎。以后用户搜索的时候,可以给我们带来一定的SEO流量。当然,我们不希望搜索引擎抓取所有内容。
所以,这个时候,我们只希望我们想爬取在搜索引擎上搜索到的内容。像用户隐私、背景信息等,不希望搜索引擎被爬取和收录。有两种最好的方法可以解决这个问题,如下所示:
Robots协议文件阻止百度蜘蛛爬行
robots协议是放置在网站根目录下的协议文件,可以通过URL地址访问:您的域名/robots.txt。当百度蜘蛛抓取我们网站时,它会先访问这个文件。因为它告诉蜘蛛哪些可以爬,哪些不能爬。
robots协议文件的设置比较简单,可以通过User-Agent、Disallow、Allow三个参数进行设置。
让我们看一个例子。场景是我不想百度抓取我所有的网站 css文件、数据目录、seo-tag.html页面
User-Agent: Baidusppider
Disallow: /*.css
Disallow: /data/
Disallow: /seo/seo-tag.html
如上,user-agent声明的蜘蛛名称表示针对百度蜘蛛。下面的不能抢“/*.css”,首先前面的/指的是根目录,也就是你的域名。* 是通配符,代表任何内容。这意味着无法抓取所有以 .css 结尾的文件。亲自体验以下两个。逻辑是一样的。
如果你想检查你上次设置的robots文件是否正确,可以访问这个文章《检查Robots是否正确的工具介绍》,里面有详细的工具可以检查你的设置。
通过403状态码,限制内容输出,阻止蜘蛛爬行。
403状态码是http协议中网页返回的状态码。当搜索引擎遇到 403 状态码时,它知道该类型的页面是权限受限的。我不能访问。比如你需要登录查看内容,搜索引擎本身不会登录,那么当你返回403时,他也知道这是权限设置页面,无法读取内容。自然不会是收录。
当返回 403 状态码时,应该有一个类似于 404 页面的页面。提示用户或蜘蛛执行他们想要访问的内容。两者缺一不可。你只有一个提示页面,状态码返回200,对于百度蜘蛛来说是很多重复的页面。有一个 403 状态代码,但返回不同的内容。它也不是很友好。
最后,关于机器人协议,我想再补充一点:“现在搜索引擎会通过你的网页的布局和布局来识别你的网页的体验友好度。如果抓取css文件和布局相关的js文件被屏蔽了,那么搜索引擎我不知道你的网页布局是好是坏。所以不建议从蜘蛛那里屏蔽这个内容。”
好了,今天的分享就到这里,希望能对大家有所帮助,当然以上两个设置对除百度蜘蛛以外的所有蜘蛛都有效。设置时请谨慎。
httpunit 抓取网页( web抓取web站点之lxml和Requestsinstall安装requests和pip)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-03 23:20
web抓取web站点之lxml和Requestsinstall安装requests和pip)
网页抓取
该网站是用 HTML 语言编写的,这意味着每个网页都是一个结构化的文档。有时,我们可以使用当前的结构来获取所需的数据并保留数据格式,但通常我们无法以合适的结构获取数据(不像csv和json)。
网页抓取会在适当的时候出现。网页抓取可以利用计算机程序对网页进行过滤,获取适当结构下的目标数据,同时保留数据的格式。
lxml 和请求
lxml 是一个优秀的 Python 扩展库,用于快速解析 XML 和 HTML 文档,甚至可以处理错误标签。另外,我们还使用Requests代替了内置的urllib2,因为它在速度和稳定性方面更好。您可以使用 pip install lxml 和 pip install requests 安装请求和 pip。
首先,让我们从导入开始:
from lxml import html
import requests
其次,我们使用requests.get查找网页,使用lxml的html库解析网页,并将结果保存在树中:
page = requests.get('http://econpy.pythonanywhere.c ... %2339;)
tree = html.fromstring(page.content)
tree 现在以整洁的树结构收录所有 HTML 内容。我们可以通过XPath和CSSSelect两种方式来获取树结构中的数据。在本文中,我们使用前者。
XPath 是一种在结构化文档(如 HTML 和 XML 文档)中定位信息的方法。XPath的介绍请参考W3Schools。
获取元素的XPath的工具有很多,比如Firefox中的FireBug,Chrome中的开发者工具。如果您使用的是 Chrome,您可以右键单击该元素,选择“检查元素”,在 HTML 查看器中突出显示此 HTML 代码,再次右键单击并选择“复制 XPath”。
经过快速分析,可以了解到该页面上的数据收录在两类元素中。一个是title为buyer-name的div,另一个是class为item-price的span
:
Carson Busses
$29.95
了解以上内容后,我们就可以创建对应的XPath地址检索并使用lxml的xpath功能,代码如下:
#这将获取到一个buyers列表
buyers = tree.xpath('//div[@title="buyer-name"]/text()')
#这将获取到一个prices列表
prices = tree.xpath('//span[@class="item-price"]/text()')
我们来看看最终得到的数据:
print 'Buyers: ', buyers
print 'Prices: ', prices
Buyers: ['Carson Busses', 'Earl E. Byrd', 'Patty Cakes',
'Derri Anne Connecticut', 'Moe Dess', 'Leda Doggslife', 'Dan Druff',
'Al Fresco', 'Ido Hoe', 'Howie Kisses', 'Len Lease', 'Phil Meup',
'Ira Pent', 'Ben D. Rules', 'Ave Sectomy', 'Gary Shattire',
'Bobbi Soks', 'Sheila Takya', 'Rose Tattoo', 'Moe Tell']
Prices: ['$29.95', '$8.37', '$15.26', '$19.25', '$19.25',
'$13.99', '$31.57', '$8.49', '$14.47', '$15.86', '$11.11',
'$15.98', '$16.27', '$7.50', '$50.85', '$14.26', '$5.68',
'$15.00', '$114.07', '$10.09']
恭喜!我们已经使用 lxml 和 Requests 从网页中获取所需的数据。我们将数据作为列表存储在内存中。现在我们可以做各种有趣的事情:我们可以用python分析数据,或者我们可以将其保存为文件并共享。
还有更多有趣的事情需要考虑,例如修改脚本使其可以遍历示例网页中的所有页面数据,或者使用多个线程重写应用程序以提高其速度。
备注XPath的引入因为不能访问所以改成对应的地址。
这篇文章是翻译中的 HTML Scraping 文章。整个教程非常好,适合新手和老手学习。 查看全部
httpunit 抓取网页(
web抓取web站点之lxml和Requestsinstall安装requests和pip)
网页抓取
该网站是用 HTML 语言编写的,这意味着每个网页都是一个结构化的文档。有时,我们可以使用当前的结构来获取所需的数据并保留数据格式,但通常我们无法以合适的结构获取数据(不像csv和json)。
网页抓取会在适当的时候出现。网页抓取可以利用计算机程序对网页进行过滤,获取适当结构下的目标数据,同时保留数据的格式。
lxml 和请求
lxml 是一个优秀的 Python 扩展库,用于快速解析 XML 和 HTML 文档,甚至可以处理错误标签。另外,我们还使用Requests代替了内置的urllib2,因为它在速度和稳定性方面更好。您可以使用 pip install lxml 和 pip install requests 安装请求和 pip。
首先,让我们从导入开始:
from lxml import html
import requests
其次,我们使用requests.get查找网页,使用lxml的html库解析网页,并将结果保存在树中:
page = requests.get('http://econpy.pythonanywhere.c ... %2339;)
tree = html.fromstring(page.content)
tree 现在以整洁的树结构收录所有 HTML 内容。我们可以通过XPath和CSSSelect两种方式来获取树结构中的数据。在本文中,我们使用前者。
XPath 是一种在结构化文档(如 HTML 和 XML 文档)中定位信息的方法。XPath的介绍请参考W3Schools。
获取元素的XPath的工具有很多,比如Firefox中的FireBug,Chrome中的开发者工具。如果您使用的是 Chrome,您可以右键单击该元素,选择“检查元素”,在 HTML 查看器中突出显示此 HTML 代码,再次右键单击并选择“复制 XPath”。
经过快速分析,可以了解到该页面上的数据收录在两类元素中。一个是title为buyer-name的div,另一个是class为item-price的span
:
Carson Busses
$29.95
了解以上内容后,我们就可以创建对应的XPath地址检索并使用lxml的xpath功能,代码如下:
#这将获取到一个buyers列表
buyers = tree.xpath('//div[@title="buyer-name"]/text()')
#这将获取到一个prices列表
prices = tree.xpath('//span[@class="item-price"]/text()')
我们来看看最终得到的数据:
print 'Buyers: ', buyers
print 'Prices: ', prices
Buyers: ['Carson Busses', 'Earl E. Byrd', 'Patty Cakes',
'Derri Anne Connecticut', 'Moe Dess', 'Leda Doggslife', 'Dan Druff',
'Al Fresco', 'Ido Hoe', 'Howie Kisses', 'Len Lease', 'Phil Meup',
'Ira Pent', 'Ben D. Rules', 'Ave Sectomy', 'Gary Shattire',
'Bobbi Soks', 'Sheila Takya', 'Rose Tattoo', 'Moe Tell']
Prices: ['$29.95', '$8.37', '$15.26', '$19.25', '$19.25',
'$13.99', '$31.57', '$8.49', '$14.47', '$15.86', '$11.11',
'$15.98', '$16.27', '$7.50', '$50.85', '$14.26', '$5.68',
'$15.00', '$114.07', '$10.09']
恭喜!我们已经使用 lxml 和 Requests 从网页中获取所需的数据。我们将数据作为列表存储在内存中。现在我们可以做各种有趣的事情:我们可以用python分析数据,或者我们可以将其保存为文件并共享。
还有更多有趣的事情需要考虑,例如修改脚本使其可以遍历示例网页中的所有页面数据,或者使用多个线程重写应用程序以提高其速度。
备注XPath的引入因为不能访问所以改成对应的地址。
这篇文章是翻译中的 HTML Scraping 文章。整个教程非常好,适合新手和老手学习。
httpunit 抓取网页(C#编写的多线程异步抓取网页的网络爬虫控制台程序功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-01 10:11
描述:C#编写的多线程异步网络爬虫控制台程序。功能:目前只能提取网络链接,使用的两个记录文件不需要很大。暂时无法抓取网页文字、图片、视频和html代码,敬请谅解。但是需要注意的是,网页的数量非常多。下面的代码理论上可以捕获整个Internet网页链接。但实际上,由于处理器功能和网络条件(主要是网速)的限制,一般家用电脑最多可以处理12个线程的爬虫任务,爬虫速度是有限的。它可以爬行,但需要时间和耐心。当然,这个程序是可以捕获所有链接的,因为链接不占用太多系统空间,并且借助日志文件,可以将爬取的网页数量堆积起来,甚至可以访问所有互联网网络链接,当然最好是分批进行。建议将maxNum设置为500-1000左右,慢慢积累。另外,由于是控制台程序,有时显示的字符过多,系统会暂停显示。这时候,只需点击控制台并按回车键即可。当程序暂停时,您可以按 Enter 尝试。/// 要使用这个程序,请确保已经创建了相应的记录文件。为简化代码,本程序不够健壮,请见谅。/// 默认文件创建在E盘根目录下的两个文本文件:“待爬取的URL.txt”和“待爬取的URL.txt”。并注意不要有后缀出错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。这个程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。并注意不要有后缀出错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。这个程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。这个程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。这个程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。这个程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。这个程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。 查看全部
httpunit 抓取网页(C#编写的多线程异步抓取网页的网络爬虫控制台程序功能)
描述:C#编写的多线程异步网络爬虫控制台程序。功能:目前只能提取网络链接,使用的两个记录文件不需要很大。暂时无法抓取网页文字、图片、视频和html代码,敬请谅解。但是需要注意的是,网页的数量非常多。下面的代码理论上可以捕获整个Internet网页链接。但实际上,由于处理器功能和网络条件(主要是网速)的限制,一般家用电脑最多可以处理12个线程的爬虫任务,爬虫速度是有限的。它可以爬行,但需要时间和耐心。当然,这个程序是可以捕获所有链接的,因为链接不占用太多系统空间,并且借助日志文件,可以将爬取的网页数量堆积起来,甚至可以访问所有互联网网络链接,当然最好是分批进行。建议将maxNum设置为500-1000左右,慢慢积累。另外,由于是控制台程序,有时显示的字符过多,系统会暂停显示。这时候,只需点击控制台并按回车键即可。当程序暂停时,您可以按 Enter 尝试。/// 要使用这个程序,请确保已经创建了相应的记录文件。为简化代码,本程序不够健壮,请见谅。/// 默认文件创建在E盘根目录下的两个文本文件:“待爬取的URL.txt”和“待爬取的URL.txt”。并注意不要有后缀出错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。这个程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。并注意不要有后缀出错。这两个文件中的链接基本上都是有效链接,可以分开处理。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。这个程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。这个程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。这个爬虫程序的速度如下:10个线程最快,大约每分钟500个链接,6-8个线程最快,每分钟大约400-500个链接,2-4个线程最快,大约200-400个每分钟链接数,最快的单线程大概是每分钟70-100个链接被多线程异步爬取,完全是出于效率的考虑。这个程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。这个程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。最快的单线程大概是每分钟多线程异步爬70-100个链接,完全是出于效率考虑。这个程序的多线程同步并没有带来速度的提升,只要爬取的网页不是太重复和冗余即可。异步并不意味着错误。
httpunit 抓取网页( 发现一个很不错的模拟浏览器包htmlunit包访问网站地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-01 06:12
发现一个很不错的模拟浏览器包htmlunit包访问网站地址)
Java模拟浏览器封装htmlunit、selenium
我找到了一个很好的模拟浏览器包htmlunit,可以直接访问网站地址并执行相应的JavaScript脚本;这个功能对网站爬虫很有帮助,一些网站Ajax用的。如果使用简单的http访问,只能抓取原创html源代码,无法获取页面中执行的ajax;使用这个包后,可以在执行ajax后抓取html源代码。取下来。
网站地址:
网站下面也提到了几个类似的包:HtmlUnit 被不同的开源工具用作底层“浏览器”,如 Canoo WebTest、JWebUnit、WebDriver、JSFUnit、Celerity、...
看看canoo WebTest,但是不知道怎么用,也不想多了解。
jwebunit 用于 网站 测试。集成了JUnit、htmlunit、selenium包框架;主要功能是做白盒测试和压力测试。
webDriver 后来更名为 selenium,它集成了 htmlunit、Firefox、Internet Explorer 和 opare 浏览器驱动程序。如果使用 htmlunitDriver,则使用 htmlunit 包访问站点;如果使用FirefoxDriver,则直接调用Firefox浏览器,然后在浏览器上模拟文本输入等鼠标键盘事件。
htmlunit包访问网站后,获取html源码后可以修改源码; jwebunit和selenium暂时没有找到修改的功能,只是用来模拟用户操作。 查看全部
httpunit 抓取网页(
发现一个很不错的模拟浏览器包htmlunit包访问网站地址)
Java模拟浏览器封装htmlunit、selenium
我找到了一个很好的模拟浏览器包htmlunit,可以直接访问网站地址并执行相应的JavaScript脚本;这个功能对网站爬虫很有帮助,一些网站Ajax用的。如果使用简单的http访问,只能抓取原创html源代码,无法获取页面中执行的ajax;使用这个包后,可以在执行ajax后抓取html源代码。取下来。
网站地址:
网站下面也提到了几个类似的包:HtmlUnit 被不同的开源工具用作底层“浏览器”,如 Canoo WebTest、JWebUnit、WebDriver、JSFUnit、Celerity、...
看看canoo WebTest,但是不知道怎么用,也不想多了解。
jwebunit 用于 网站 测试。集成了JUnit、htmlunit、selenium包框架;主要功能是做白盒测试和压力测试。
webDriver 后来更名为 selenium,它集成了 htmlunit、Firefox、Internet Explorer 和 opare 浏览器驱动程序。如果使用 htmlunitDriver,则使用 htmlunit 包访问站点;如果使用FirefoxDriver,则直接调用Firefox浏览器,然后在浏览器上模拟文本输入等鼠标键盘事件。
htmlunit包访问网站后,获取html源码后可以修改源码; jwebunit和selenium暂时没有找到修改的功能,只是用来模拟用户操作。
httpunit 抓取网页(开源java页面分析工具运行速度迅速,被誉为java浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-29 04:15
HtmlUnit 介绍
htmlunit 是一个开源的 java 页面分析工具。阅读完页面后,您可以有效地使用 htmlunit 来分析页面上的内容。该项目可以模拟浏览器操作,被称为java浏览器的开源实现。它是一个没有界面的浏览器,运行速度很快。是junit的扩展之一
HtmlUnit 示例
import java.io.IOException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlForm;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.html.HtmlSubmitInput;
import com.gargoylesoftware.htmlunit.html.HtmlTextInput;
public class Ddkjg {
public static void main(String[] args) throws IOException {
// 得到浏览器对象,直接New一个就能得到,现在就好比说你得到了一个浏览器了
WebClient webclient = new WebClient();
// 下面这2句可以写,也可以不写,设置false就是不加载css和js。访问速度更快
webclient.getOptions().setCssEnabled(false);
webclient.getOptions().setJavaScriptEnabled(false);
// 做的第一件事,去拿到这个网页,只需要调用getPage这个方法即可
HtmlPage htmlpage = webclient.getPage("https://baidu.com");
// 根据名字得到一个表单,查看上面这个网页的源代码可以发现表单的名字叫“f”
final HtmlForm form = htmlpage.getFormByName("f");
// 同样道理,获取”百度一下“这个按钮
final HtmlSubmitInput button = form.getInputByValue("百度一下");
// 得到搜索框
final HtmlTextInput textField = form.getInputByName("wd");
//设置搜索框的value
textField.setValueAttribute("战狼2");
// 设置好之后,模拟点击按钮行为。
final HtmlPage nextPage = button.click();
// 把结果转成String
String result = nextPage.asXml();
//得到的是点击后的网页
System.out.println(result);
}
}
注意:
1:webclient 包是 htmlunit,不是 httpunit。 httpunit 的 webclient 类是抽象的,不能直接新建。
2:htmlunit包使用最新版本的2.27 jar包。低版本的jar包没有getOptions()类。
3:如果出现这个错误,UnsupportedClassVersionError。表示版本不一致。确保你本地jdk版本是1.8,eclipse部署的版本也是1.8,所以我就不说怎么看了。
jar包下载地址: 查看全部
httpunit 抓取网页(开源java页面分析工具运行速度迅速,被誉为java浏览器)
HtmlUnit 介绍
htmlunit 是一个开源的 java 页面分析工具。阅读完页面后,您可以有效地使用 htmlunit 来分析页面上的内容。该项目可以模拟浏览器操作,被称为java浏览器的开源实现。它是一个没有界面的浏览器,运行速度很快。是junit的扩展之一
HtmlUnit 示例
import java.io.IOException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlForm;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.html.HtmlSubmitInput;
import com.gargoylesoftware.htmlunit.html.HtmlTextInput;
public class Ddkjg {
public static void main(String[] args) throws IOException {
// 得到浏览器对象,直接New一个就能得到,现在就好比说你得到了一个浏览器了
WebClient webclient = new WebClient();
// 下面这2句可以写,也可以不写,设置false就是不加载css和js。访问速度更快
webclient.getOptions().setCssEnabled(false);
webclient.getOptions().setJavaScriptEnabled(false);
// 做的第一件事,去拿到这个网页,只需要调用getPage这个方法即可
HtmlPage htmlpage = webclient.getPage("https://baidu.com";);
// 根据名字得到一个表单,查看上面这个网页的源代码可以发现表单的名字叫“f”
final HtmlForm form = htmlpage.getFormByName("f");
// 同样道理,获取”百度一下“这个按钮
final HtmlSubmitInput button = form.getInputByValue("百度一下");
// 得到搜索框
final HtmlTextInput textField = form.getInputByName("wd");
//设置搜索框的value
textField.setValueAttribute("战狼2");
// 设置好之后,模拟点击按钮行为。
final HtmlPage nextPage = button.click();
// 把结果转成String
String result = nextPage.asXml();
//得到的是点击后的网页
System.out.println(result);
}
}
注意:
1:webclient 包是 htmlunit,不是 httpunit。 httpunit 的 webclient 类是抽象的,不能直接新建。
2:htmlunit包使用最新版本的2.27 jar包。低版本的jar包没有getOptions()类。
3:如果出现这个错误,UnsupportedClassVersionError。表示版本不一致。确保你本地jdk版本是1.8,eclipse部署的版本也是1.8,所以我就不说怎么看了。
jar包下载地址:
httpunit 抓取网页(开源java页面分析工具运行速度迅速,被誉为java浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-28 16:03
HtmlUnit 介绍
htmlunit 是一个开源的 java 页面分析工具。阅读完页面后,您可以有效地使用 htmlunit 来分析页面上的内容。该项目可以模拟浏览器操作,被称为java浏览器的开源实现。它是一个没有界面的浏览器,运行速度很快。是junit的扩展之一
HtmlUnit 示例
import java.io.IOException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlForm;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.html.HtmlSubmitInput;
import com.gargoylesoftware.htmlunit.html.HtmlTextInput;
public class Ddkjg {
public static void main(String[] args) throws IOException {
// 得到浏览器对象,直接New一个就能得到,现在就好比说你得到了一个浏览器了
WebClient webclient = new WebClient();
// 下面这2句可以写,也可以不写,设置false就是不加载css和js。访问速度更快
webclient.getOptions().setCssEnabled(false);
webclient.getOptions().setJavaScriptEnabled(false);
// 做的第一件事,去拿到这个网页,只需要调用getPage这个方法即可
HtmlPage htmlpage = webclient.getPage("https://baidu.com");
// 根据名字得到一个表单,查看上面这个网页的源代码可以发现表单的名字叫“f”
final HtmlForm form = htmlpage.getFormByName("f");
// 同样道理,获取”百度一下“这个按钮
final HtmlSubmitInput button = form.getInputByValue("百度一下");
// 得到搜索框
final HtmlTextInput textField = form.getInputByName("wd");
//设置搜索框的value
textField.setValueAttribute("战狼2");
// 设置好之后,模拟点击按钮行为。
final HtmlPage nextPage = button.click();
// 把结果转成String
String result = nextPage.asXml();
//得到的是点击后的网页
System.out.println(result);
}
}
注意:
1:webclient 包是 htmlunit,不是 httpunit。 httpunit 的 webclient 类是抽象的,不能直接新建。
2:htmlunit包使用最新版本的2.27 jar包。低版本的jar包没有getOptions()类。
3:如果出现这个错误,UnsupportedClassVersionError。表示版本不一致。确保你本地jdk版本是1.8,eclipse部署的版本也是1.8,所以我就不说怎么看了。
jar包下载地址: 查看全部
httpunit 抓取网页(开源java页面分析工具运行速度迅速,被誉为java浏览器)
HtmlUnit 介绍
htmlunit 是一个开源的 java 页面分析工具。阅读完页面后,您可以有效地使用 htmlunit 来分析页面上的内容。该项目可以模拟浏览器操作,被称为java浏览器的开源实现。它是一个没有界面的浏览器,运行速度很快。是junit的扩展之一
HtmlUnit 示例
import java.io.IOException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlForm;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.html.HtmlSubmitInput;
import com.gargoylesoftware.htmlunit.html.HtmlTextInput;
public class Ddkjg {
public static void main(String[] args) throws IOException {
// 得到浏览器对象,直接New一个就能得到,现在就好比说你得到了一个浏览器了
WebClient webclient = new WebClient();
// 下面这2句可以写,也可以不写,设置false就是不加载css和js。访问速度更快
webclient.getOptions().setCssEnabled(false);
webclient.getOptions().setJavaScriptEnabled(false);
// 做的第一件事,去拿到这个网页,只需要调用getPage这个方法即可
HtmlPage htmlpage = webclient.getPage("https://baidu.com";);
// 根据名字得到一个表单,查看上面这个网页的源代码可以发现表单的名字叫“f”
final HtmlForm form = htmlpage.getFormByName("f");
// 同样道理,获取”百度一下“这个按钮
final HtmlSubmitInput button = form.getInputByValue("百度一下");
// 得到搜索框
final HtmlTextInput textField = form.getInputByName("wd");
//设置搜索框的value
textField.setValueAttribute("战狼2");
// 设置好之后,模拟点击按钮行为。
final HtmlPage nextPage = button.click();
// 把结果转成String
String result = nextPage.asXml();
//得到的是点击后的网页
System.out.println(result);
}
}
注意:
1:webclient 包是 htmlunit,不是 httpunit。 httpunit 的 webclient 类是抽象的,不能直接新建。
2:htmlunit包使用最新版本的2.27 jar包。低版本的jar包没有getOptions()类。
3:如果出现这个错误,UnsupportedClassVersionError。表示版本不一致。确保你本地jdk版本是1.8,eclipse部署的版本也是1.8,所以我就不说怎么看了。
jar包下载地址:
httpunit 抓取网页(之前做聊天室时,介绍如何使用HtmlTag类来抓取网页信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-27 21:19
之前在聊天室的时候,因为聊天室提供了新闻阅读功能,所以写了一个类来抓取网页信息(比如最新的头条、新闻来源、标题、内容等)。本文将介绍如何使用该类抓取网页中需要的信息。本文将以博客园首页的博客标题和链接为例:
上图为博客园首页的DOM树。显然,你只需要提取class为post_item的div,然后提取class为titlelnk的a标记。这样的功能可以通过以下功能来实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
下面以博客园首页的文章标题和链接为例,介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com");
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
操作结果如下:
源代码下载
转载于: 查看全部
httpunit 抓取网页(之前做聊天室时,介绍如何使用HtmlTag类来抓取网页信息)
之前在聊天室的时候,因为聊天室提供了新闻阅读功能,所以写了一个类来抓取网页信息(比如最新的头条、新闻来源、标题、内容等)。本文将介绍如何使用该类抓取网页中需要的信息。本文将以博客园首页的博客标题和链接为例:
上图为博客园首页的DOM树。显然,你只需要提取class为post_item的div,然后提取class为titlelnk的a标记。这样的功能可以通过以下功能来实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
下面以博客园首页的文章标题和链接为例,介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com";);
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
操作结果如下:
源代码下载
转载于:
httpunit 抓取网页(网络爬虫的是做什么的?手动写一个简单的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-10-27 21:18
网络爬虫有什么作用?手动编写一个简单的网络爬虫;网络爬虫(又称网络蜘蛛、网络机器人)是一种程序或足,根据一定的规则自动抓取万维网上的信息
书。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。网络爬虫通过网页的链接地址搜索网页。从某个页面(通常是首页)开始,它读取网页的内容并找到
在网页中的其他链接地址,然后通过这些链接地址找到下一个网页,这样一直循环下去,直到你把这个网站全部
的所有页面都被抓取到最后。如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理抓取互联网上的所有网页。因此,如果要抓取互联网上的数据,不仅需要一个爬虫程序,还需要一个能够接受“爬虫”发回的数据并对其进行处理和过滤的服务。
爬虫爬取的数据量越大,对服务器的性能要求越高。网络爬虫有什么作用?他的主要工作是根据指定的URL地址发送请求,得到响应,然后解析响应。一方面,从
在响应中找到你要查找的数据,另一方面从响应中解析出新的URL路径,然后继续访问,继续解析;继续寻找您需要的东西
数据并继续解析出新的URL路径。这是网络爬虫的主要工作。以下是流程图:
通过上面的流程图,您可以大致了解网络爬虫是做什么的,并基于这些,您可以设计一个简单的网络爬虫。
一个简单爬虫的必要功能:
发送请求和获取响应的功能;解析响应的功能;存储过滤数据的功能;处理解析出的URL路径的功能;爬虫需要注意的三点:
爬取目标的描述或定义;网页或数据的分析和过滤;URL 搜索策略。网络爬虫根据系统结构和实现技术大致可以分为以下几种类型:
General Purpose Web Crawler (General Purpose Web Crawler) Focused Web Crawler (Focused Web Crawler) Incremental Web Crawler (Incremental Web Crawler) Deep Web Crawler。实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。下面我就用我们的官网来跟大家分析一下如何实现这样的爬虫:
首先观察我们爬虫的起始页面是:
分析页面
所有好消息的 URL 用 XPath 表达式表示如下:
相关资料
标题:使用XPath表达式表达描述:使用XPath表达式表达图片:使用XPath表达式表达
好了,我们已经在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式的编写代码来实现了。
代码实现部分使用了webmagic框架,因为它比使用基本的Java网络编程要简单得多。注:对于webmagic框架,可以阅读以下讲座
演示.java
WanhoPageProcessor.javaWanhoPipeline.javaArticleVo.java
在开源社区搜索java爬虫框架:共有83种
我们正在使用
webmagic是一个爬虫框架,不需要配置,方便二次开发。它提供了简单灵活的 API,可以用少量代码实现。
爬虫webmagic采用完全模块化设计,功能覆盖爬虫整个生命周期(链接提取、页面下载、内容提取、持久化)
),支持多线程爬取、分布式爬取,支持自动重试、自定义UA/cookie等功能。Webmagic 包括强大的页面提取功能。开发人员可以轻松使用 css 选择器、xpath 和正则表达式。链接和内部
内容提取,支持多个选择器的链式调用
注:官方中文文档:
可以使用maven构建依赖,例如:
当然你也可以自己下载jar包,地址是:
一般来说,如果我们需要抓取的目标数据不是通过ajax异步加载的,那么我们都可以在页面的HTML源代码中的某个位置找到我们需要的数据
注意:如果数据是异步加载到页面中的,一般有两种方式获取数据:
观察页面加载前请求的所有URL(F12->网络选项),然后找到那些加载数据的json请求,最后直接请求那些URL获取数据来模拟浏览器请求,等待一段时间满载页面 把数据进去就行了。这类爬虫通常需要内嵌浏览器内核,比如webmagic、phantom.js、HttpUnit等。
下面我就用我们的官网来跟大家分析一下如何实现这样的爬虫:
首先观察我们爬虫的起始页面是:
分析页面
从上图可以看出,我们可以从首页的HTML源代码中直观的找到我们需要的标题、内容、图片链接等信息。那么,我们可以通过哪些方式提取这些目标数据呢?
其实提取页面元素的webmagic框架主要支持以下三种方法:
XPath 正则表达式 CSS 选择器
当然,选择哪种方式提取数据需要根据具体页面进行分析。在这个例子中,很明显使用XPath提取数据是最方便的
所以,接下来我直接给出我们需要爬取的数据的XPath路径:
所有好消息的URL都用XPath表达式表示: Title:XPath表达式用于表达描述:XPath表达式用于图片表达:XPath表达式用于表达
注意:“//”表示从相对路径开始,第一个“/”表示从页面路径开始;后面两个/之间的内容代表一个元素,方括号中的内容表示该元素的执行属性,如:h1[@class='entry-title']表示:一个h1元素的class属性为“条目标题”
使用webmagic提取页面数据时,需要自定义一个类来实现PageProcessor接口。
该类实现PageProcessor接口的主要功能是以下三个步骤:
爬虫配置:爬取页面的配置,包括编码、爬取间隔、重试次数等页面元素的提取:使用正则表达式或者XPath提取页面元素。发现新链接:找到要爬取的页面 获取其他目标页面的链接
Spider是爬虫启动的入口点。在启动爬虫之前,我们需要使用一个 PageProcessor 创建一个 Spider 对象,然后使用 run() 来启动它。同时可以通过set方法设置其他Spider组件(Downloader、Scheduler、Pipeline)
注:更详细的参数介绍请参考这里的官方文档:
演示.java
对于提取逻辑比较复杂的爬虫,我们通常会实现上面的PageProcessor接口来编写页面元素的提取逻辑。但是对于提取逻辑比较简单的爬虫,这时候我们可以选择在实体类中添加注解来构建轻量级爬虫
从上面的代码可以看出,这个实体类除了添加了几个注解之外,就是一个普通的POJO,不依赖其他任何东西。上面使用的几个注解的一般含义是:
@TargetUrl:我们需要提取的数据的所有目标页面,其值是一个正则表达式@HelpUrl:需要访问的页面以获得目标页面的链接@ExtractBy:用于提取元素的注解,它描述了一种抽取规则。意思是“使用此提取规则将提取的结果保存在该字段中”。您可以使用 XPath、CSS 选择器、正则表达式和 JsonPath 来提取元素
虽然在PageProcessor中我们可以实现数据的持久化(PS:基于注解的爬虫可以通过AfterExtractor接口实现类似的目的),将爬虫抓取到的数据保存到文件、数据库、缓存等中。但是很明显PageProcessor还是实体类主要负责提取页面元素,所以更好的处理方法是在另一个地方做数据持久化。这个地方是-管道
为了实现数据的持久化,我们通常需要实现 Pipeline 或 PageModelPipeline 接口。普通爬虫使用前一个接口,基于注解的爬虫使用后一个接口
对于基于注解的爬虫,启动类不是Spider,而是OOSpider。当然,两者的用法是类似的。示例代码如下:
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似JQuery的操作方法来检索和操作数据
Jsoup 是 Java 世界中的 HTML 解析工具。它支持使用 CSS Selector 选择 DOM 元素,还可以过滤 HTML 文本以防止 XSS 攻击。
下载 Jsoup
查看官方手册:
Jsoup是Java世界中html解析过滤的最佳选择。支持将html解析成DOM树,支持CSS Selector表单选择,支持html过滤,自带Http下载器。
Jsoup 的代码相当简洁。Jsoup 共有 53 个类,不依赖任何第三方包。和最终发布包9.8M的SAXON相比,真是短小精悍。
从 URL、文件或字符串解析 HTML;使用 DOM 或 CSS 选择器来查找和检索数据;操作 HTML 元素、属性和文本;
Jsoup 的入口点是类。示例包中提供了两个示例。解析html后,使用CSS Selector和NodeVisitor来操作Dom元素。
下面是一个例子来说明如何调用Jsoup:
Jsoup 使用自己的一套 DOM 代码系统。虽然 Elements 和 Elements 的名称和概念与 Java XML 相同
API 类似,但没有代码级别的关系。也就是说,如果要使用一组XML API来操作Jsoup,结果是不可能的。
但正因为如此,Jsoup 可以摒弃 xml 中一些繁琐的 API,让代码更简单。
第一种形式
/AAA/DDD/BBB:表示AAA下的BBB和AAA下的DDD的第二种形式
//BBB: 意思和这个名字一样,意思就是只要名字是BBB就会得到第三种形式
/*:所有元素的第四种形式
BBB[1]:代表第一个BBB元素 BBB[last()]:代表最后一个BBB元素的第五种形式
//BBB[@id]:表示只要BBB元素上有id属性,就得到第六种形式
//BBB[@id='b1']表示元素名称为BBB,BBB上有一个id属性,id属性值为b1。例如:
/students/student[@id='1002'] 根student标签下student标签下属性名为id,属性值为1002的student元素
如需转载,请注明文章的出处和出处地址: 查看全部
httpunit 抓取网页(网络爬虫的是做什么的?手动写一个简单的)
网络爬虫有什么作用?手动编写一个简单的网络爬虫;网络爬虫(又称网络蜘蛛、网络机器人)是一种程序或足,根据一定的规则自动抓取万维网上的信息
书。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。网络爬虫通过网页的链接地址搜索网页。从某个页面(通常是首页)开始,它读取网页的内容并找到
在网页中的其他链接地址,然后通过这些链接地址找到下一个网页,这样一直循环下去,直到你把这个网站全部
的所有页面都被抓取到最后。如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理抓取互联网上的所有网页。因此,如果要抓取互联网上的数据,不仅需要一个爬虫程序,还需要一个能够接受“爬虫”发回的数据并对其进行处理和过滤的服务。
爬虫爬取的数据量越大,对服务器的性能要求越高。网络爬虫有什么作用?他的主要工作是根据指定的URL地址发送请求,得到响应,然后解析响应。一方面,从
在响应中找到你要查找的数据,另一方面从响应中解析出新的URL路径,然后继续访问,继续解析;继续寻找您需要的东西
数据并继续解析出新的URL路径。这是网络爬虫的主要工作。以下是流程图:
通过上面的流程图,您可以大致了解网络爬虫是做什么的,并基于这些,您可以设计一个简单的网络爬虫。
一个简单爬虫的必要功能:
发送请求和获取响应的功能;解析响应的功能;存储过滤数据的功能;处理解析出的URL路径的功能;爬虫需要注意的三点:
爬取目标的描述或定义;网页或数据的分析和过滤;URL 搜索策略。网络爬虫根据系统结构和实现技术大致可以分为以下几种类型:
General Purpose Web Crawler (General Purpose Web Crawler) Focused Web Crawler (Focused Web Crawler) Incremental Web Crawler (Incremental Web Crawler) Deep Web Crawler。实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。下面我就用我们的官网来跟大家分析一下如何实现这样的爬虫:
首先观察我们爬虫的起始页面是:
分析页面
所有好消息的 URL 用 XPath 表达式表示如下:
相关资料
标题:使用XPath表达式表达描述:使用XPath表达式表达图片:使用XPath表达式表达
好了,我们已经在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式的编写代码来实现了。
代码实现部分使用了webmagic框架,因为它比使用基本的Java网络编程要简单得多。注:对于webmagic框架,可以阅读以下讲座
演示.java
WanhoPageProcessor.javaWanhoPipeline.javaArticleVo.java
在开源社区搜索java爬虫框架:共有83种
我们正在使用
webmagic是一个爬虫框架,不需要配置,方便二次开发。它提供了简单灵活的 API,可以用少量代码实现。
爬虫webmagic采用完全模块化设计,功能覆盖爬虫整个生命周期(链接提取、页面下载、内容提取、持久化)
),支持多线程爬取、分布式爬取,支持自动重试、自定义UA/cookie等功能。Webmagic 包括强大的页面提取功能。开发人员可以轻松使用 css 选择器、xpath 和正则表达式。链接和内部
内容提取,支持多个选择器的链式调用
注:官方中文文档:
可以使用maven构建依赖,例如:
当然你也可以自己下载jar包,地址是:
一般来说,如果我们需要抓取的目标数据不是通过ajax异步加载的,那么我们都可以在页面的HTML源代码中的某个位置找到我们需要的数据
注意:如果数据是异步加载到页面中的,一般有两种方式获取数据:
观察页面加载前请求的所有URL(F12->网络选项),然后找到那些加载数据的json请求,最后直接请求那些URL获取数据来模拟浏览器请求,等待一段时间满载页面 把数据进去就行了。这类爬虫通常需要内嵌浏览器内核,比如webmagic、phantom.js、HttpUnit等。
下面我就用我们的官网来跟大家分析一下如何实现这样的爬虫:
首先观察我们爬虫的起始页面是:
分析页面
从上图可以看出,我们可以从首页的HTML源代码中直观的找到我们需要的标题、内容、图片链接等信息。那么,我们可以通过哪些方式提取这些目标数据呢?
其实提取页面元素的webmagic框架主要支持以下三种方法:
XPath 正则表达式 CSS 选择器
当然,选择哪种方式提取数据需要根据具体页面进行分析。在这个例子中,很明显使用XPath提取数据是最方便的
所以,接下来我直接给出我们需要爬取的数据的XPath路径:
所有好消息的URL都用XPath表达式表示: Title:XPath表达式用于表达描述:XPath表达式用于图片表达:XPath表达式用于表达
注意:“//”表示从相对路径开始,第一个“/”表示从页面路径开始;后面两个/之间的内容代表一个元素,方括号中的内容表示该元素的执行属性,如:h1[@class='entry-title']表示:一个h1元素的class属性为“条目标题”
使用webmagic提取页面数据时,需要自定义一个类来实现PageProcessor接口。
该类实现PageProcessor接口的主要功能是以下三个步骤:
爬虫配置:爬取页面的配置,包括编码、爬取间隔、重试次数等页面元素的提取:使用正则表达式或者XPath提取页面元素。发现新链接:找到要爬取的页面 获取其他目标页面的链接
Spider是爬虫启动的入口点。在启动爬虫之前,我们需要使用一个 PageProcessor 创建一个 Spider 对象,然后使用 run() 来启动它。同时可以通过set方法设置其他Spider组件(Downloader、Scheduler、Pipeline)
注:更详细的参数介绍请参考这里的官方文档:
演示.java
对于提取逻辑比较复杂的爬虫,我们通常会实现上面的PageProcessor接口来编写页面元素的提取逻辑。但是对于提取逻辑比较简单的爬虫,这时候我们可以选择在实体类中添加注解来构建轻量级爬虫
从上面的代码可以看出,这个实体类除了添加了几个注解之外,就是一个普通的POJO,不依赖其他任何东西。上面使用的几个注解的一般含义是:
@TargetUrl:我们需要提取的数据的所有目标页面,其值是一个正则表达式@HelpUrl:需要访问的页面以获得目标页面的链接@ExtractBy:用于提取元素的注解,它描述了一种抽取规则。意思是“使用此提取规则将提取的结果保存在该字段中”。您可以使用 XPath、CSS 选择器、正则表达式和 JsonPath 来提取元素
虽然在PageProcessor中我们可以实现数据的持久化(PS:基于注解的爬虫可以通过AfterExtractor接口实现类似的目的),将爬虫抓取到的数据保存到文件、数据库、缓存等中。但是很明显PageProcessor还是实体类主要负责提取页面元素,所以更好的处理方法是在另一个地方做数据持久化。这个地方是-管道
为了实现数据的持久化,我们通常需要实现 Pipeline 或 PageModelPipeline 接口。普通爬虫使用前一个接口,基于注解的爬虫使用后一个接口
对于基于注解的爬虫,启动类不是Spider,而是OOSpider。当然,两者的用法是类似的。示例代码如下:
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似JQuery的操作方法来检索和操作数据
Jsoup 是 Java 世界中的 HTML 解析工具。它支持使用 CSS Selector 选择 DOM 元素,还可以过滤 HTML 文本以防止 XSS 攻击。
下载 Jsoup
查看官方手册:
Jsoup是Java世界中html解析过滤的最佳选择。支持将html解析成DOM树,支持CSS Selector表单选择,支持html过滤,自带Http下载器。
Jsoup 的代码相当简洁。Jsoup 共有 53 个类,不依赖任何第三方包。和最终发布包9.8M的SAXON相比,真是短小精悍。
从 URL、文件或字符串解析 HTML;使用 DOM 或 CSS 选择器来查找和检索数据;操作 HTML 元素、属性和文本;
Jsoup 的入口点是类。示例包中提供了两个示例。解析html后,使用CSS Selector和NodeVisitor来操作Dom元素。
下面是一个例子来说明如何调用Jsoup:
Jsoup 使用自己的一套 DOM 代码系统。虽然 Elements 和 Elements 的名称和概念与 Java XML 相同
API 类似,但没有代码级别的关系。也就是说,如果要使用一组XML API来操作Jsoup,结果是不可能的。
但正因为如此,Jsoup 可以摒弃 xml 中一些繁琐的 API,让代码更简单。
第一种形式
/AAA/DDD/BBB:表示AAA下的BBB和AAA下的DDD的第二种形式
//BBB: 意思和这个名字一样,意思就是只要名字是BBB就会得到第三种形式
/*:所有元素的第四种形式
BBB[1]:代表第一个BBB元素 BBB[last()]:代表最后一个BBB元素的第五种形式
//BBB[@id]:表示只要BBB元素上有id属性,就得到第六种形式
//BBB[@id='b1']表示元素名称为BBB,BBB上有一个id属性,id属性值为b1。例如:
/students/student[@id='1002'] 根student标签下student标签下属性名为id,属性值为1002的student元素
如需转载,请注明文章的出处和出处地址:
httpunit 抓取网页(遇到一个网页数据抓取的任务,给大家分享下! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-27 09:13
)
遇到一个爬取网页数据的任务,分享给大家。
说到网页信息抓取,相信Jsoup基本上是首选工具。完整的类似JQuery的操作让人感觉很舒服。不过,今天我们要说说Jsoup的缺点。
这是某个网站的搜索栏。填写一些格式化数据进行经纬度转换。初始化是这样的,然后jsoup捕获的代码如下:
当我们添加数据时,抓取的页面信息是不变的。这就是Jsoup的缺点。如果Jsoup抓取页面,页面加载后的所有数据,Ajax加载的异步数据都没有抓取。到达的。
这里再给大家介绍一个开源项目:HttpUnit,这个名字是用来测试的,但是对爬取数据也有好处,是一个完美的解决方案。HttpUnit其实相当于一个没有UI的浏览器,可以让页面上的js执行完成后,再次抓取信息。
有时我们使用requests抓取页面时,得到的结果可能与浏览器中看到的不同:在浏览器中可以看到正常显示的页面数据,但是使用requests获取的结果却看不到。这是因为获取的请求都是原创的 HTML 文档,浏览器中的页面是 JavaScript 处理数据后生成的结果。这些数据的来源有很多,可能是通过Ajax加载的,可能是收录在HTML中的,也可能是通过JavaScript和特定算法计算后生成的文档中的文档。
在第一种情况下,数据加载是一种异步加载方法。原创页面最初不会收录一些数据。原创页面加载完毕后,会向服务器请求一个接口来获取数据,然后对数据进行处理呈现。在网页上,这实际上是一个 Ajax 请求。
根据Web发展的趋势,这种形式的页面越来越多。网页的原创 HTML 文档不收录任何数据。数据通过Ajax统一加载后呈现,从而在Web开发中实现前后端分离,减少服务器直接渲染页面带来的压力。
因此,如果遇到这样的页面,可以直接使用requests等库来抓取原创页面,无法获取有效数据。这时候就需要从网页后台分析发送到界面的Ajax请求。如果可以使用requests来模拟ajax请求,那么就可以成功爬取。
但是我没有使用这个测试框架:我解决问题的想法是
总结:ajax数据的爬取过程:
1. 提交我们的搜索时,会加载这部分内容,并且会有表单数据生成,
反映在程序中:
2. 服务器加载这个页面,我们输入表单信息,这个表单信息就是我们的搜索条件,例如:
反映在程序中:
3.js返回加载的页面,并在该页面添加信息
jsoup 可以解析页面。
4.模拟登录部分:
查看全部
httpunit 抓取网页(遇到一个网页数据抓取的任务,给大家分享下!
)
遇到一个爬取网页数据的任务,分享给大家。
说到网页信息抓取,相信Jsoup基本上是首选工具。完整的类似JQuery的操作让人感觉很舒服。不过,今天我们要说说Jsoup的缺点。
这是某个网站的搜索栏。填写一些格式化数据进行经纬度转换。初始化是这样的,然后jsoup捕获的代码如下:
当我们添加数据时,抓取的页面信息是不变的。这就是Jsoup的缺点。如果Jsoup抓取页面,页面加载后的所有数据,Ajax加载的异步数据都没有抓取。到达的。
这里再给大家介绍一个开源项目:HttpUnit,这个名字是用来测试的,但是对爬取数据也有好处,是一个完美的解决方案。HttpUnit其实相当于一个没有UI的浏览器,可以让页面上的js执行完成后,再次抓取信息。
有时我们使用requests抓取页面时,得到的结果可能与浏览器中看到的不同:在浏览器中可以看到正常显示的页面数据,但是使用requests获取的结果却看不到。这是因为获取的请求都是原创的 HTML 文档,浏览器中的页面是 JavaScript 处理数据后生成的结果。这些数据的来源有很多,可能是通过Ajax加载的,可能是收录在HTML中的,也可能是通过JavaScript和特定算法计算后生成的文档中的文档。
在第一种情况下,数据加载是一种异步加载方法。原创页面最初不会收录一些数据。原创页面加载完毕后,会向服务器请求一个接口来获取数据,然后对数据进行处理呈现。在网页上,这实际上是一个 Ajax 请求。
根据Web发展的趋势,这种形式的页面越来越多。网页的原创 HTML 文档不收录任何数据。数据通过Ajax统一加载后呈现,从而在Web开发中实现前后端分离,减少服务器直接渲染页面带来的压力。
因此,如果遇到这样的页面,可以直接使用requests等库来抓取原创页面,无法获取有效数据。这时候就需要从网页后台分析发送到界面的Ajax请求。如果可以使用requests来模拟ajax请求,那么就可以成功爬取。
但是我没有使用这个测试框架:我解决问题的想法是
总结:ajax数据的爬取过程:
1. 提交我们的搜索时,会加载这部分内容,并且会有表单数据生成,
反映在程序中:
2. 服务器加载这个页面,我们输入表单信息,这个表单信息就是我们的搜索条件,例如:
反映在程序中:
3.js返回加载的页面,并在该页面添加信息
jsoup 可以解析页面。
4.模拟登录部分:
httpunit 抓取网页( jsoup抓取网页教程(jsoup)抓取(抓取)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-27 03:11
jsoup抓取网页教程(jsoup)抓取(抓取)(组图))
jsoup爬网页教程jsoup爬网页教程jsoup爬网页教程jsoup爬网页教程jsoup爬网页详细我以前在ibmdw上发表过两篇关于htmlparser的文章。 文章 是从html中抓取你需要的信息,扩展htmlparser处理自定义标签的能力。但现在我不再使用 htmlparser。原因是htmlparser很少更新,但最重要的是它的nameits是一个javahtml解析器,可以直接解析一个URL地址的html文本内容。它提供了一个非常省力的API,可以通过domcss和jquery之类的操作方法进行检索和检索。其操作数据的主要功能如下: 1. 从文件或字符串中解析出urlhtml 2. 使用domdesignedcss选择器找出数据 3. 可操作的HTML元素属性文本 其基于新版mit协议离婚协议劳动协议合同个人投资股权协议广告可以安全用于商业项目的1its的主要类层次结构如图1所示。解释一下它的html文档是如何优雅地处理的 ------------------------------------- ---- -------------------------------------返回顶部 文档输入可以收录来自 String urlits 地址和本地文件加载 html 文档并生成文档对象实例。下面是相关代码清单 1.直接从字符串stringhtml中输入html文档 "htmlheadtitle开源中文社区titlehead" "bodyp这里是与其项目相关的文章 ppointshtml"documentdocjsoupparsehtml 直接从url documentdocjsoupconnecthttpwwwoschinanet加载html文档"getstringnamedoctitledocumentdocjsoupconnecthttpwwwoschinanet"datathe"query""java"请求参数useragent"i"mits"set useragentcookie"auth""token"set cookietime out3000设置连接超时时间。post使用post方法访问url,从中加载html文档文件.fileinputnewfile"ctesthtml"documentdocjsoupparseinput"utf-8""httpwwwoschinanet.请注意最后一个html文档输入法中parse的第三个参数。这里指定一个url,虽然第一种方法不需要指定,因为html文档中会有很多链接,比如链接图片和引用的外部脚本css文件等,第三个参数baseurl的意思是当html 文档使用相对路径引用外部文件时,它会自动给这些 URL 添加前缀,即 baseurlnoandhrefproject 开源软件 a 将转换为 ahrefhttpwwwoschinanetproject 开源软件 a----------- ———————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————— -------- -----------返回顶部 HTML 元素的分析和提取这部分与 HTML 解析器的基本功能有关,但与其他开源项目不同 - 选择器我们将在最后一部分
etailsthejsoupselectorinthissectionyouwillseejsoupishowtoachievethemostsimplecodeHoweverjsoupalsoprovideselementalparsingofthetraditionalDOMapproachlookingatthecodebelowListing2FileinputnewFile “Dtesthtml” DocumentdocJsoupparseinput “UTF-8”, “ElementcontentdocgetElementById” 内容 “ElementslinkscontentgetElementsByTag” 一 “ForElementlinklinksStringlinkHreflinkattr的” href “StringlinkTextlinktextYoumightthinkthatjsoupsmethodisfamiliarandyeslikethegetElementByIdandgetElementsByTagmethodsthenamesofthemethodsarethesameandthefunctionsareexactlythesameasthoseoftheJavaScriptYoucangetthecorrespondingelementorlistofelementsaccordingtothenodenameortheIDoftheHTMLelementUnliketheHtmlparserprojectjsoupdoesnotdefineacorrespondingHTMLelementpartofageneralHTMLelementsincludenodenameattributeandtextjsoupprovidesasimplewayforyoutoretrievethesedatawhichisthereasonforkeepingfitjsoupIntermsofelementretrievaljsoupselectorsareomnipotentListing3FileinputnewFile” Dtesthtml “DocumentdocJsoupparseinput” UTF-8“ “Elementslinks docselect ”一个[HREF]“ hrefattributelinkElementsPNGSdocselect ”IMG [srcpng]“ PNGallreferencepictureelementsElementmastheaddocselect ”divmasthead“ FirstFinddefineclassmastheadelementsElementsresultLinksdocselect ”h3ra“ directaafterH3ThisisthejsoupthatIreallyimpressedbythelocaljsoupforusewiththejQueryselectorontheelementsareaslikeastwopeasretrievalretrievalmethodsaboveifotherHTMLinterpreteratleastneedmanylinesofcodebutjsoupneedsonlyonelineofcodecompleteTheselectorofjsoupalsosupportstheexpressionfunctionandwellintroducethissuperselectorinthelastsection -
----------------------------------------------- -------------------------------返回顶部修改数据在分析文档的同时,我们可能需要修改文档中的某些元素,例如我们可以添加可点击链接、修改链接地址或修改文档中所有图像的文本这里有一些简单的示例 Listing4Docselect"divcommentsa"Attr"rel""nofollow"Increaseterlink"Increaseterlink"IncreaseterlinkClassof removeAttr "delete allthepicturesoftheonclickattributeDocselect" input [typetext] "" Val "textemptyallthetextinputboxin thereassonisvery simpleYou just need to find the elements using jsoupselector and then through the above the method to modify in addition to not modify the label name can beremoved after the insertion of the index of the HTML ----------------------------------------- --BacktotopHTMLdocumentcleanupJs oupalsodoesagreatjobofprovidingpowerfulAPIandhumanizingWhenyoudoawebsiteyouoftenprovidethefunctionofuserreviewsSomeusersaremoremischievouswillmakesomecommentstothescriptandthesescriptsmaydestroytheentirepagemoreseriousistoobtainsomeconfidentialinformationsuchascrosssiteattackslikeXSSJsoupisverysupportiveofthisanditsverysimpletouseTakealookatthecodebelowListing5Stringunsafe “pahref” OpensourceChinesecommunityap “StringsafeJsoupcleanunsafeWhitelistbasicoutputpahref” 相对 “nofollow” 的ChineseapopensourcecommunityJsoupus
"embed""object""param""span""div"你也可以调用addAttributes属性来增加一些元素------------------------------ -------------------------------------------------BacktotopJsoup “selectorWehavebrieflyintroducedhowjsoupusesselectorstoretrieveelementsInthissectionwefocusonthepowerfulsyntaxoftheselectorits elfThefollowingtableisadetailedlistofallthesyntaxofthejsoupselectorTable2basicusageTagNameusestagnamestolocateforexampleaNstagusesnamespacetagpositioningsuchasfbnametofindfbnameelementsiduseselementIDtolocateforexamplelogoclassusestheclasspropertyoftheelementtolocateforexampleHead [属性] usesthepropertiesoftheelementstolocateforexample [HREF] representsallelementsthatretrievethehrefattribute [ATTR] usestheattributenameprefixesofelementstolocatesuchas [DATA-] whichisusedtofindthedatasetattributeofHTML5 [attrvalue] usesattributevaluestolocateFore
xample [width500] locatesallelementswhosewidthattributevalueis500 [attrvalue] [attrvalue] [attrvalue] thesethreegrammarrespectivelyrepresentattributewithvaluebeginningendingandcontain [attrregex] istheuseofregularexpressionsforattributevaluefilteringsuchasimg [srcIpngjpeG] locateallelementsThesearethemostbasicselectorssyntaxthatcanbeusedtogetherandhereisacombinationofjsoupsupportTable3combinationusageTheelidIDvalueofoneoftheelementssuchasalogo-aidlogohrefElclassclasstothespecifiedvalueelementssuchasdivheaddivclassheadxxxxdivEl [ATTR] locatesallelementsthatdefineapropertysuchasa [HREF] Theabovethreearbitrarycombinationssuchasa [HREF] logoa [名称] outerlinkAncestorandchildarefivetypesofselectorsyntaxwhichincludeparent-childrelationshipmergerelationandhierarchicalrelationParentchildSiblingAsiblingBSiblingAsiblingXElElElInadditiontosomebasicsyntaxandthecombinationofthesegrammarsjsoupalsosupportstheuseofexpressionsforelementfilteringselectionHereisalistofallexpressionssupportedbyjsoupTab le4expressionLTnsu chastdlt3representslessthanthreecolumnsGTndivpgt2meansthatdivcontainsmorethan2pEQnforminputeq1representsaformthatcontainsonlyoneinputHasseletordivhasPrepresentsthedivcontainingthePelementNotselectordivnotLogorepresentsalldivliststhatdonotcontainclasslogoelementsContainstextcontainselementsofatextthatarenotcasesensitivesuchaspcontainsoschinaContainsOwntexttextinformationiscompletelyequaltothefilterofthespecifiedconditionMatchesregexusesregularexpressionsfortextfilteringdivmatchesIloginMatchesOwnregexusesregularexpressionstofinditsowntext 查看全部
httpunit 抓取网页(
jsoup抓取网页教程(jsoup)抓取(抓取)(组图))
jsoup爬网页教程jsoup爬网页教程jsoup爬网页教程jsoup爬网页教程jsoup爬网页详细我以前在ibmdw上发表过两篇关于htmlparser的文章。 文章 是从html中抓取你需要的信息,扩展htmlparser处理自定义标签的能力。但现在我不再使用 htmlparser。原因是htmlparser很少更新,但最重要的是它的nameits是一个javahtml解析器,可以直接解析一个URL地址的html文本内容。它提供了一个非常省力的API,可以通过domcss和jquery之类的操作方法进行检索和检索。其操作数据的主要功能如下: 1. 从文件或字符串中解析出urlhtml 2. 使用domdesignedcss选择器找出数据 3. 可操作的HTML元素属性文本 其基于新版mit协议离婚协议劳动协议合同个人投资股权协议广告可以安全用于商业项目的1its的主要类层次结构如图1所示。解释一下它的html文档是如何优雅地处理的 ------------------------------------- ---- -------------------------------------返回顶部 文档输入可以收录来自 String urlits 地址和本地文件加载 html 文档并生成文档对象实例。下面是相关代码清单 1.直接从字符串stringhtml中输入html文档 "htmlheadtitle开源中文社区titlehead" "bodyp这里是与其项目相关的文章 ppointshtml"documentdocjsoupparsehtml 直接从url documentdocjsoupconnecthttpwwwoschinanet加载html文档"getstringnamedoctitledocumentdocjsoupconnecthttpwwwoschinanet"datathe"query""java"请求参数useragent"i"mits"set useragentcookie"auth""token"set cookietime out3000设置连接超时时间。post使用post方法访问url,从中加载html文档文件.fileinputnewfile"ctesthtml"documentdocjsoupparseinput"utf-8""httpwwwoschinanet.请注意最后一个html文档输入法中parse的第三个参数。这里指定一个url,虽然第一种方法不需要指定,因为html文档中会有很多链接,比如链接图片和引用的外部脚本css文件等,第三个参数baseurl的意思是当html 文档使用相对路径引用外部文件时,它会自动给这些 URL 添加前缀,即 baseurlnoandhrefproject 开源软件 a 将转换为 ahrefhttpwwwoschinanetproject 开源软件 a----------- ———————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————— -------- -----------返回顶部 HTML 元素的分析和提取这部分与 HTML 解析器的基本功能有关,但与其他开源项目不同 - 选择器我们将在最后一部分
etailsthejsoupselectorinthissectionyouwillseejsoupishowtoachievethemostsimplecodeHoweverjsoupalsoprovideselementalparsingofthetraditionalDOMapproachlookingatthecodebelowListing2FileinputnewFile “Dtesthtml” DocumentdocJsoupparseinput “UTF-8”, “ElementcontentdocgetElementById” 内容 “ElementslinkscontentgetElementsByTag” 一 “ForElementlinklinksStringlinkHreflinkattr的” href “StringlinkTextlinktextYoumightthinkthatjsoupsmethodisfamiliarandyeslikethegetElementByIdandgetElementsByTagmethodsthenamesofthemethodsarethesameandthefunctionsareexactlythesameasthoseoftheJavaScriptYoucangetthecorrespondingelementorlistofelementsaccordingtothenodenameortheIDoftheHTMLelementUnliketheHtmlparserprojectjsoupdoesnotdefineacorrespondingHTMLelementpartofageneralHTMLelementsincludenodenameattributeandtextjsoupprovidesasimplewayforyoutoretrievethesedatawhichisthereasonforkeepingfitjsoupIntermsofelementretrievaljsoupselectorsareomnipotentListing3FileinputnewFile” Dtesthtml “DocumentdocJsoupparseinput” UTF-8“ “Elementslinks docselect ”一个[HREF]“ hrefattributelinkElementsPNGSdocselect ”IMG [srcpng]“ PNGallreferencepictureelementsElementmastheaddocselect ”divmasthead“ FirstFinddefineclassmastheadelementsElementsresultLinksdocselect ”h3ra“ directaafterH3ThisisthejsoupthatIreallyimpressedbythelocaljsoupforusewiththejQueryselectorontheelementsareaslikeastwopeasretrievalretrievalmethodsaboveifotherHTMLinterpreteratleastneedmanylinesofcodebutjsoupneedsonlyonelineofcodecompleteTheselectorofjsoupalsosupportstheexpressionfunctionandwellintroducethissuperselectorinthelastsection -
----------------------------------------------- -------------------------------返回顶部修改数据在分析文档的同时,我们可能需要修改文档中的某些元素,例如我们可以添加可点击链接、修改链接地址或修改文档中所有图像的文本这里有一些简单的示例 Listing4Docselect"divcommentsa"Attr"rel""nofollow"Increaseterlink"Increaseterlink"IncreaseterlinkClassof removeAttr "delete allthepicturesoftheonclickattributeDocselect" input [typetext] "" Val "textemptyallthetextinputboxin thereassonisvery simpleYou just need to find the elements using jsoupselector and then through the above the method to modify in addition to not modify the label name can beremoved after the insertion of the index of the HTML ----------------------------------------- --BacktotopHTMLdocumentcleanupJs oupalsodoesagreatjobofprovidingpowerfulAPIandhumanizingWhenyoudoawebsiteyouoftenprovidethefunctionofuserreviewsSomeusersaremoremischievouswillmakesomecommentstothescriptandthesescriptsmaydestroytheentirepagemoreseriousistoobtainsomeconfidentialinformationsuchascrosssiteattackslikeXSSJsoupisverysupportiveofthisanditsverysimpletouseTakealookatthecodebelowListing5Stringunsafe “pahref” OpensourceChinesecommunityap “StringsafeJsoupcleanunsafeWhitelistbasicoutputpahref” 相对 “nofollow” 的ChineseapopensourcecommunityJsoupus
"embed""object""param""span""div"你也可以调用addAttributes属性来增加一些元素------------------------------ -------------------------------------------------BacktotopJsoup “selectorWehavebrieflyintroducedhowjsoupusesselectorstoretrieveelementsInthissectionwefocusonthepowerfulsyntaxoftheselectorits elfThefollowingtableisadetailedlistofallthesyntaxofthejsoupselectorTable2basicusageTagNameusestagnamestolocateforexampleaNstagusesnamespacetagpositioningsuchasfbnametofindfbnameelementsiduseselementIDtolocateforexamplelogoclassusestheclasspropertyoftheelementtolocateforexampleHead [属性] usesthepropertiesoftheelementstolocateforexample [HREF] representsallelementsthatretrievethehrefattribute [ATTR] usestheattributenameprefixesofelementstolocatesuchas [DATA-] whichisusedtofindthedatasetattributeofHTML5 [attrvalue] usesattributevaluestolocateFore
xample [width500] locatesallelementswhosewidthattributevalueis500 [attrvalue] [attrvalue] [attrvalue] thesethreegrammarrespectivelyrepresentattributewithvaluebeginningendingandcontain [attrregex] istheuseofregularexpressionsforattributevaluefilteringsuchasimg [srcIpngjpeG] locateallelementsThesearethemostbasicselectorssyntaxthatcanbeusedtogetherandhereisacombinationofjsoupsupportTable3combinationusageTheelidIDvalueofoneoftheelementssuchasalogo-aidlogohrefElclassclasstothespecifiedvalueelementssuchasdivheaddivclassheadxxxxdivEl [ATTR] locatesallelementsthatdefineapropertysuchasa [HREF] Theabovethreearbitrarycombinationssuchasa [HREF] logoa [名称] outerlinkAncestorandchildarefivetypesofselectorsyntaxwhichincludeparent-childrelationshipmergerelationandhierarchicalrelationParentchildSiblingAsiblingBSiblingAsiblingXElElElInadditiontosomebasicsyntaxandthecombinationofthesegrammarsjsoupalsosupportstheuseofexpressionsforelementfilteringselectionHereisalistofallexpressionssupportedbyjsoupTab le4expressionLTnsu chastdlt3representslessthanthreecolumnsGTndivpgt2meansthatdivcontainsmorethan2pEQnforminputeq1representsaformthatcontainsonlyoneinputHasseletordivhasPrepresentsthedivcontainingthePelementNotselectordivnotLogorepresentsalldivliststhatdonotcontainclasslogoelementsContainstextcontainselementsofatextthatarenotcasesensitivesuchaspcontainsoschinaContainsOwntexttextinformationiscompletelyequaltothefilterofthespecifiedconditionMatchesregexusesregularexpressionsfortextfilteringdivmatchesIloginMatchesOwnregexusesregularexpressionstofinditsowntext
httpunit 抓取网页(一下HttpUnit不是,不是不是不是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 398 次浏览 • 2021-10-22 14:09
时间
2015-02-12742 浏览次数
简介:最近在想怎么从网页中抓取需要的数据。直接使用java提供的API太麻烦了。可能有一些成熟的自动化测试web程序库中可能需要的功能,比如HttpUnit、Watij、Selenium;我现在试过HttpUnit,不是很方便,只有...
最近在思考如何从网页中抓取需要的数据。直接使用java提供的API太麻烦了。可能有一些成熟的自动化测试web程序库中可能需要的功能,例如HttpUnit、Watij、Selenium;现在我尝试了 HttpUnit。这不是很方便。我只能找到带有 id 的表格元素。如果没有id,就得自己处理响应流
public static void main(String[] args) {
WebClient webClient = new WebClient();
HtmlPage page = null;
try {
page = (HtmlPage) webClient.getPage("http://biz.cn.yahoo.com/stock.html");
} catch (FailingHttpStatusCodeException e) {
//e.printStackTrace();
} catch (MalformedURLException e) {
//e.printStackTrace();
} catch (IOException e) {
//e.printStackTrace();
}
WebResponse wr = page.getWebResponse();
HtmlDivision he = page.getHtmlElementById("stat1");
if (he.hasChildNodes()){
Iterator i = he.getChildElements().iterator();
while(i.hasNext()){
System.out.println(i.next());
}
}
System.out.println(he.getAttribute("id"));
//System.out.println(he.asXml());
Iterator i = page.getAllHtmlChildElements().iterator();
if(i.hasNext()){
HtmlElement h = i.next();
System.out.println(h.getNodeName());
}
网页使用使用内网单位使用抓取网页使用抓取网页网页 查看全部
httpunit 抓取网页(一下HttpUnit不是,不是不是不是)
时间
2015-02-12742 浏览次数
简介:最近在想怎么从网页中抓取需要的数据。直接使用java提供的API太麻烦了。可能有一些成熟的自动化测试web程序库中可能需要的功能,比如HttpUnit、Watij、Selenium;我现在试过HttpUnit,不是很方便,只有...
最近在思考如何从网页中抓取需要的数据。直接使用java提供的API太麻烦了。可能有一些成熟的自动化测试web程序库中可能需要的功能,例如HttpUnit、Watij、Selenium;现在我尝试了 HttpUnit。这不是很方便。我只能找到带有 id 的表格元素。如果没有id,就得自己处理响应流
public static void main(String[] args) {
WebClient webClient = new WebClient();
HtmlPage page = null;
try {
page = (HtmlPage) webClient.getPage("http://biz.cn.yahoo.com/stock.html";);
} catch (FailingHttpStatusCodeException e) {
//e.printStackTrace();
} catch (MalformedURLException e) {
//e.printStackTrace();
} catch (IOException e) {
//e.printStackTrace();
}
WebResponse wr = page.getWebResponse();
HtmlDivision he = page.getHtmlElementById("stat1");
if (he.hasChildNodes()){
Iterator i = he.getChildElements().iterator();
while(i.hasNext()){
System.out.println(i.next());
}
}
System.out.println(he.getAttribute("id"));
//System.out.println(he.asXml());
Iterator i = page.getAllHtmlChildElements().iterator();
if(i.hasNext()){
HtmlElement h = i.next();
System.out.println(h.getNodeName());
}
网页使用使用内网单位使用抓取网页使用抓取网页网页
httpunit 抓取网页(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-10-21 02:09
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后续更新)。一开始看到这个简单,然后就稀里糊涂的打了代码(之前用的是Hadoop平台的分布式爬虫框架Nutch,用起来很方便,最后因为速度放弃了,但是生成的统计数据用在后来爬取),很快就成功下载了holder.html和finance.html页面,然后在解析了holder.html页面后,解析了finance.html,然后就郁闷的在这个页面找到了自己需要的东西数据不在 html 源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录后者)。我很高兴,终于找到了解决办法。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。当初设计的时候,不是用来服务爬虫的,但我想说的是:星盘只是有点短,你不能再进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从实际情况出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver 可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码太有限了。解析你写的js代码,js代码简单,当然WebDriver可以毫无压力的完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面用到的IE内核,当然是FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page. asXml(),可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js。会启动一个有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身经历)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能得到完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。本来以为driver解析js完成后应该可以抓到状态,于是去找,找,但是根本没有这种方法,所以说为什么WebDriver的设计者没有往前走一步,这样我们就可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。这真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是非常不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会出现不同,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实如此。通过Thread.sleep(2000))等待js解析完成,我觉得不是一个好办法,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream(); //后面的代码省略,得到了InputStream就好说了 }
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码不同编译,java端一直在等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要开启一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
我折腾了好几天了。虽然它没有解决我的问题,但我获得了很多知识。后面的工作就是熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后我爬网页的时候就得心应手了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过可以用Nutch和WebDirver的结合,可能爬取的结果比较稳定,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫获得的结果的稳定性有什么要说的,欢迎大家,因为我确实没有找到稳定爬虫结果的相关资料。 查看全部
httpunit 抓取网页(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后续更新)。一开始看到这个简单,然后就稀里糊涂的打了代码(之前用的是Hadoop平台的分布式爬虫框架Nutch,用起来很方便,最后因为速度放弃了,但是生成的统计数据用在后来爬取),很快就成功下载了holder.html和finance.html页面,然后在解析了holder.html页面后,解析了finance.html,然后就郁闷的在这个页面找到了自己需要的东西数据不在 html 源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录后者)。我很高兴,终于找到了解决办法。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。当初设计的时候,不是用来服务爬虫的,但我想说的是:星盘只是有点短,你不能再进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从实际情况出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver 可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码太有限了。解析你写的js代码,js代码简单,当然WebDriver可以毫无压力的完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面用到的IE内核,当然是FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page. asXml(),可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js。会启动一个有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身经历)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能得到完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。本来以为driver解析js完成后应该可以抓到状态,于是去找,找,但是根本没有这种方法,所以说为什么WebDriver的设计者没有往前走一步,这样我们就可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。这真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是非常不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会出现不同,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实如此。通过Thread.sleep(2000))等待js解析完成,我觉得不是一个好办法,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream(); //后面的代码省略,得到了InputStream就好说了 }
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码不同编译,java端一直在等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要开启一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
我折腾了好几天了。虽然它没有解决我的问题,但我获得了很多知识。后面的工作就是熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后我爬网页的时候就得心应手了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过可以用Nutch和WebDirver的结合,可能爬取的结果比较稳定,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫获得的结果的稳定性有什么要说的,欢迎大家,因为我确实没有找到稳定爬虫结果的相关资料。
httpunit 抓取网页(为什么我的网站搜索引擎不抓取呢?建站的小编告诉你)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-05 06:04
很多人会问,为什么我的网站搜索引擎爬不起来?搜索引擎如何快速抓取网站的页面?野狼网小编告诉你。
1.更新有价值的网站内容
当搜索引擎查看网站的内容时,如果你的网站页面比较新颖独特,更容易被抓取和收录。随着算法的升级,搜索引擎更加注重用户体验,对用户有价值的内容的搜索引擎会给出更好的收录和更高的排名。除了有价值之外,它还与网站和关键词的标题有一定的相关性。
二、网站关键词要合理设置
一个页面一定要慎重选择你要推广的关键词,并且关键词必须出现在标题、描述、文章第一段、中间段、最后一段,这样搜索引擎才会给这个关键词足够的关注也会在页面排名上有优势。但是,一定不要在网页上堆砌关键词。现在搜索引擎不断更新优化,更好的监控堆积如山的关键词。想要获得好排名的话,想用堆起来关键词 就难了。
三、定期更新网站页面
更新网站页面的时候一定要定期。如果你在某段时间频繁更新网站,让搜索引擎开发这段时间来爬取你的网站,这对网站页面上的收录也有一定的推广作用。现在百度搜索引擎每天早上7点到9点、晚上17点到19点、22点到24点开放。栏目有较大更新,建议站长合理利用这段时间,增加网站的收录。
4、科学合理地使用文字和图片
一个只有文字或图片的 网站 页面是一种不友好的表现。合理使用图文结合的页面,是一种人性化的表现。使用与页面上的文字描述相匹配的图片可以很好地帮助用户。了解页面内容,加深用户印象,同时给用户带来良好的视觉表现,获得用户对网站页面的认可。同时,不能在一个页面上使用过多的图片,因为搜索引擎对图片的认知度相对较低。如果使用图片,必须在图片上加上alt标签和文字注释,以便搜索引擎蜘蛛和用户在任何情况下都可以使用识别图片。
五、使用静态网页
动态页面虽然也可以是收录,但动态页面收录和被搜索引擎识别是不一样的。静态页面可以减少搜索引擎的工作时间,更快地提供信息反馈,对于用户来说,还可以节省带宽,减少数据库计算时间。如果页面已经创建好几天后还没有收录,那么可以直接在搜索引擎中输入网址,手动提交。这也是添加网站页面收录的一种方式。站长也可以通过网站的百度快照来判断网页的收录时间,然后根据百度快照的时间对网站进行优化。
六、增加优质外链
SEO优化者都知道外链的重要作用。优质外链的增加有利于网站的收录,增加流量和排名。外部链接是一个奖励点。链接到你要推广的页面,可以帮助这个页面加速收录,获得好的排名,传递权重。因此,如果可能,请尝试为您的 网站 和页面添加高质量的外部链接。同时,我们也应该扩大外部链接的来源。您可以在知名导航网站、第三方网站、网站目录、分类信息网站制作更多友情链接或外链。 查看全部
httpunit 抓取网页(为什么我的网站搜索引擎不抓取呢?建站的小编告诉你)
很多人会问,为什么我的网站搜索引擎爬不起来?搜索引擎如何快速抓取网站的页面?野狼网小编告诉你。
1.更新有价值的网站内容
当搜索引擎查看网站的内容时,如果你的网站页面比较新颖独特,更容易被抓取和收录。随着算法的升级,搜索引擎更加注重用户体验,对用户有价值的内容的搜索引擎会给出更好的收录和更高的排名。除了有价值之外,它还与网站和关键词的标题有一定的相关性。
二、网站关键词要合理设置
一个页面一定要慎重选择你要推广的关键词,并且关键词必须出现在标题、描述、文章第一段、中间段、最后一段,这样搜索引擎才会给这个关键词足够的关注也会在页面排名上有优势。但是,一定不要在网页上堆砌关键词。现在搜索引擎不断更新优化,更好的监控堆积如山的关键词。想要获得好排名的话,想用堆起来关键词 就难了。
三、定期更新网站页面
更新网站页面的时候一定要定期。如果你在某段时间频繁更新网站,让搜索引擎开发这段时间来爬取你的网站,这对网站页面上的收录也有一定的推广作用。现在百度搜索引擎每天早上7点到9点、晚上17点到19点、22点到24点开放。栏目有较大更新,建议站长合理利用这段时间,增加网站的收录。
4、科学合理地使用文字和图片
一个只有文字或图片的 网站 页面是一种不友好的表现。合理使用图文结合的页面,是一种人性化的表现。使用与页面上的文字描述相匹配的图片可以很好地帮助用户。了解页面内容,加深用户印象,同时给用户带来良好的视觉表现,获得用户对网站页面的认可。同时,不能在一个页面上使用过多的图片,因为搜索引擎对图片的认知度相对较低。如果使用图片,必须在图片上加上alt标签和文字注释,以便搜索引擎蜘蛛和用户在任何情况下都可以使用识别图片。
五、使用静态网页
动态页面虽然也可以是收录,但动态页面收录和被搜索引擎识别是不一样的。静态页面可以减少搜索引擎的工作时间,更快地提供信息反馈,对于用户来说,还可以节省带宽,减少数据库计算时间。如果页面已经创建好几天后还没有收录,那么可以直接在搜索引擎中输入网址,手动提交。这也是添加网站页面收录的一种方式。站长也可以通过网站的百度快照来判断网页的收录时间,然后根据百度快照的时间对网站进行优化。
六、增加优质外链
SEO优化者都知道外链的重要作用。优质外链的增加有利于网站的收录,增加流量和排名。外部链接是一个奖励点。链接到你要推广的页面,可以帮助这个页面加速收录,获得好的排名,传递权重。因此,如果可能,请尝试为您的 网站 和页面添加高质量的外部链接。同时,我们也应该扩大外部链接的来源。您可以在知名导航网站、第三方网站、网站目录、分类信息网站制作更多友情链接或外链。

