
htmlunit 抓取网页
htmlunit 抓取网页(网页获取和解析速度和性能的应用场景详解! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-21 22:09
)
(4)支持代理
(5)支持自动cookie管理等。
Java爬虫开发是应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;import org.apache.http.client.HttpClient;import org.apache.http.client.ResponseHandler;import org.apache.http.client.methods.HttpGet;import org.apache.http.impl.client.BasicResponseHandler;import org.apache.http.impl.client.DefaultHttpClient;/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHttpClientTest{
publicstaticvoid main(String[] args)throwsException{
//目标页面String url ="http://www.yshjava.cn";//创建一个默认的HttpClientHttpClient httpclient =newDefaultHttpClient();try{
//以get方式请求网页http://www.yshjava.cnHttpGet httpget =newHttpGet(url);//打印请求地址System.out.println("executing request "+ httpget.getURI());//创建响应处理器处理服务器响应内容ResponseHandlerresponseHandler=newBasicResponseHandler();//执行请求并获取结果String responseBody = httpclient.execute(httpget, responseHandler);System.out.println("----------------------------------------");System.out.println(responseBody);System.out.println("----------------------------------------");}finally{
//关闭连接管理器
httpclient.getConnectionManager().shutdown();}}}
汤
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
示例代码如下:
package cn.ysh.studio.crawler.jsoup;import java.io.IOException;import org.jsoup.Jsoup;/**
* 基于Jsoup抓取网页内容
* @author www.yshjava.cn
*/publicclassJsoupTest{
publicstaticvoid main(String[] args)throwsIOException{
//目标页面String url ="http://www.yshjava.cn";//使用Jsoup连接目标页面,并执行请求,获取服务器响应内容String html =Jsoup.connect(url).execute().body();//打印页面内容System.out.println(html);}}
html单元
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取和解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;import com.gargoylesoftware.htmlunit.BrowserVersion;import com.gargoylesoftware.htmlunit.Page;import com.gargoylesoftware.htmlunit.WebClient;/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlUnitSpider{
publicstaticvoid main(String[] s)throwsException{
//目标网页String url ="http://www.yshjava.cn";//模拟特定浏览器FIREFOX_3WebClient spider =newWebClient(BrowserVersion.FIREFOX_3);//获取目标网页Page page = spider.getPage(url);//打印网页内容System.out.println(page.getWebResponse().getContentAsString());//关闭所有窗口
spider.closeAllWindows();}}
瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
示例代码如下:
package cn.ysh.studio.crawler.ie;import watij.runtime.ie.IE;/**
* 基于Watij抓取网页内容,仅限Windows平台
*
* @author www.yshjava.cn
*/publicclassWatijTest{
publicstaticvoid main(String[] s){
//目标页面String url ="http://www.yshjava.cn";//实例化IE浏览器对象
IE ie =new IE();try{
//启动浏览器
ie.start();//转到目标网页
ie.goTo(url);//等待网页加载就绪
ie.waitUntilReady();//打印页面内容System.out.println(ie.html());}catch(Exception e){
e.printStackTrace();}finally{
try{
//关闭IE浏览器
ie.close();}catch(Exception e){
}}}}
硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;import org.openqa.selenium.htmlunit.HtmlUnitDriver;/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlDriverTest{
publicstaticvoid main(String[] s){
//目标网页String url ="http://www.yshjava.cn";HtmlUnitDriver driver =newHtmlUnitDriver();try{
//禁用JS脚本功能
driver.setJavascriptEnabled(false);//打开目标网页
driver.get(url);//获取当前网页源码String html = driver.getPageSource();//打印网页源码System.out.println(html);}catch(Exception e){
//打印堆栈信息
e.printStackTrace();}finally{
try{
//关闭并退出
driver.close();
driver.quit();}catch(Exception e){
}}}}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;import org.watij.webspec.dsl.WebSpec;/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/publicclassWebspecTest{
publicstaticvoid main(String[] s){
//目标网页String url ="http://www.yshjava.cn";//实例化浏览器对象WebSpec spec =newWebSpec().mozilla();//隐藏浏览器窗体
spec.hide();//打开目标页面
spec.open(url);//打印网页源码System.out.println(spec.source());//关闭所有窗口
spec.closeAll();}} 查看全部
htmlunit 抓取网页(网页获取和解析速度和性能的应用场景详解!
)
(4)支持代理
(5)支持自动cookie管理等。
Java爬虫开发是应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;import org.apache.http.client.HttpClient;import org.apache.http.client.ResponseHandler;import org.apache.http.client.methods.HttpGet;import org.apache.http.impl.client.BasicResponseHandler;import org.apache.http.impl.client.DefaultHttpClient;/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHttpClientTest{
publicstaticvoid main(String[] args)throwsException{
//目标页面String url ="http://www.yshjava.cn";//创建一个默认的HttpClientHttpClient httpclient =newDefaultHttpClient();try{
//以get方式请求网页http://www.yshjava.cnHttpGet httpget =newHttpGet(url);//打印请求地址System.out.println("executing request "+ httpget.getURI());//创建响应处理器处理服务器响应内容ResponseHandlerresponseHandler=newBasicResponseHandler();//执行请求并获取结果String responseBody = httpclient.execute(httpget, responseHandler);System.out.println("----------------------------------------");System.out.println(responseBody);System.out.println("----------------------------------------");}finally{
//关闭连接管理器
httpclient.getConnectionManager().shutdown();}}}
汤
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
示例代码如下:
package cn.ysh.studio.crawler.jsoup;import java.io.IOException;import org.jsoup.Jsoup;/**
* 基于Jsoup抓取网页内容
* @author www.yshjava.cn
*/publicclassJsoupTest{
publicstaticvoid main(String[] args)throwsIOException{
//目标页面String url ="http://www.yshjava.cn";//使用Jsoup连接目标页面,并执行请求,获取服务器响应内容String html =Jsoup.connect(url).execute().body();//打印页面内容System.out.println(html);}}
html单元
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取和解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;import com.gargoylesoftware.htmlunit.BrowserVersion;import com.gargoylesoftware.htmlunit.Page;import com.gargoylesoftware.htmlunit.WebClient;/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlUnitSpider{
publicstaticvoid main(String[] s)throwsException{
//目标网页String url ="http://www.yshjava.cn";//模拟特定浏览器FIREFOX_3WebClient spider =newWebClient(BrowserVersion.FIREFOX_3);//获取目标网页Page page = spider.getPage(url);//打印网页内容System.out.println(page.getWebResponse().getContentAsString());//关闭所有窗口
spider.closeAllWindows();}}
瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
示例代码如下:
package cn.ysh.studio.crawler.ie;import watij.runtime.ie.IE;/**
* 基于Watij抓取网页内容,仅限Windows平台
*
* @author www.yshjava.cn
*/publicclassWatijTest{
publicstaticvoid main(String[] s){
//目标页面String url ="http://www.yshjava.cn";//实例化IE浏览器对象
IE ie =new IE();try{
//启动浏览器
ie.start();//转到目标网页
ie.goTo(url);//等待网页加载就绪
ie.waitUntilReady();//打印页面内容System.out.println(ie.html());}catch(Exception e){
e.printStackTrace();}finally{
try{
//关闭IE浏览器
ie.close();}catch(Exception e){
}}}}
硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;import org.openqa.selenium.htmlunit.HtmlUnitDriver;/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlDriverTest{
publicstaticvoid main(String[] s){
//目标网页String url ="http://www.yshjava.cn";HtmlUnitDriver driver =newHtmlUnitDriver();try{
//禁用JS脚本功能
driver.setJavascriptEnabled(false);//打开目标网页
driver.get(url);//获取当前网页源码String html = driver.getPageSource();//打印网页源码System.out.println(html);}catch(Exception e){
//打印堆栈信息
e.printStackTrace();}finally{
try{
//关闭并退出
driver.close();
driver.quit();}catch(Exception e){
}}}}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;import org.watij.webspec.dsl.WebSpec;/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/publicclassWebspecTest{
publicstaticvoid main(String[] s){
//目标网页String url ="http://www.yshjava.cn";//实例化浏览器对象WebSpec spec =newWebSpec().mozilla();//隐藏浏览器窗体
spec.hide();//打开目标页面
spec.open(url);//打印网页源码System.out.println(spec.source());//关闭所有窗口
spec.closeAll();}}
htmlunit 抓取网页(htmlunit网络工具一个没有没有 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-19 11:16
)
1:背景
本来想用jsoup抓取一个页面,但是抓取的数据总是不完整,然后发现页面执行js后,页面上渲染了一些数据,也就是说数据页是只在js执行后显示。数据会显示出来,但是jsoup无法实现执行页面的js。
2:解决
经过搜索,发现htmlunit网络工具可以实现js。它相当于一个没有页面的浏览器。解决方法是先用htmlUnit发送网络请求,执行js获取页面,然后用jsoup转换成Document页面对象。然后使用jsoup分析页面读取数据。
3:htmlUnit发送请求
1 public static Document getDocument() throws IOException, InterruptedException{
2 /*String url="https://www.marklines.com/cn/v ... 3B%3B
3 Connection connect = Jsoup.connect(url).userAgent("")
4 .header("Cookie", "PLAY_LANG=cn; _plh=b9289d0a863a8fc9c79fb938f15372f7731d13fb; PLATFORM_SESSION=39034d07000717c664134556ad39869771aabc04-_ldi=520275&_lsh=8cf91cdbcbbb255adff5cba6061f561b642f5157&csrfToken=209f20c8473bc0518413c226f898ff79cd69c3ff-1539926671235-b853a6a63c77dd8fcc364a58&_lpt=%2Fcn%2Fvehicle_sales%2Fsearch&_lsi=1646321; _ga=GA1.2.2146952143.1539926675; _gid=GA1.2.1032787565.1539926675; _plh_notime=8cf91cdbcbbb255adff5cba6061f561b642f5157")
5 .timeout(360000000);
6 Document document = connect.get();*/
7 WebClient wc = new WebClient(BrowserVersion.CHROME);
8 //是否使用不安全的SSL
9 wc.getOptions().setUseInsecureSSL(true);
10 //启用JS解释器,默认为true
11 wc.getOptions().setJavaScriptEnabled(true);
12 //禁用CSS
13 wc.getOptions().setCssEnabled(false);
14 //js运行错误时,是否抛出异常
15 wc.getOptions().setThrowExceptionOnScriptError(false);
16 //状态码错误时,是否抛出异常
17 wc.getOptions().setThrowExceptionOnFailingStatusCode(false);
18 //是否允许使用ActiveX
19 wc.getOptions().setActiveXNative(false);
20 //等待js时间
21 wc.waitForBackgroundJavaScript(600*1000);
22 //设置Ajax异步处理控制器即启用Ajax支持
23 wc.setAjaxController(new NicelyResynchronizingAjaxController());
24 //设置超时时间
25 wc.getOptions().setTimeout(1000000);
26 //不跟踪抓取
27 wc.getOptions().setDoNotTrackEnabled(false);
28 WebRequest request=new WebRequest(new URL("https://www.marklines.com/cn/v ... 6quot;));
29 request.setAdditionalHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:62.0) Gecko/20100101 Firefox/62.0");
30 request.setAdditionalHeader("Cookie","PLAY_LANG=cn; _plh=b9289d0a863a8fc9c79fb938f15372f7731d13fb; PLATFORM_SESSION=39034d07000717c664134556ad39869771aabc04-_ldi=520275&_lsh=8cf91cdbcbbb255adff5cba6061f561b642f5157&csrfToken=209f20c8473bc0518413c226f898ff79cd69c3ff-1539926671235-b853a6a63c77dd8fcc364a58&_lpt=%2Fcn%2Fvehicle_sales%2Fsearch&_lsi=1646321; _ga=GA1.2.2146952143.1539926675; _gid=GA1.2.1032787565.1539926675; _plh_notime=8cf91cdbcbbb255adff5cba6061f561b642f5157");
31 try {
32 //模拟浏览器打开一个目标网址
33 HtmlPage htmlPage = wc.getPage(request);
34 //为了获取js执行的数据 线程开始沉睡等待
35 Thread.sleep(1000);//这个线程的等待 因为js加载需要时间的
36 //以xml形式获取响应文本
37 String xml = htmlPage.asXml();
38 //并转为Document对象return
39 return Jsoup.parse(xml);
40 //System.out.println(xml.contains("结果.xls"));//false
41 } catch (FailingHttpStatusCodeException e) {
42 e.printStackTrace();
43 } catch (MalformedURLException e) {
44 e.printStackTrace();
45 } catch (IOException e) {
46 e.printStackTrace();
47 }
48 return null;
49 }
4:返回的Document对象交给jsoup处理
这里只做一个简单的输出,看看数据是否全部渲染完毕。
1 Document doc=getDocument();
2 Element table=doc.select("table.table.table-bordered.aggregate_table").get(0);//获取到表格
3 Element tableContext=table.getElementsByTag("tbody").get(0);
4 Elements contextTrs=tableContext.getElementsByTag("tr");
5 System.out.println(contextTrs.size());
6
7
8 String context=doc.toString();
9 OutputStreamWriter pw = null;
10 pw = new OutputStreamWriter(new FileOutputStream("D:/test.txt"),"GBK");
11 pw.write(context);
12 pw.close(); 查看全部
htmlunit 抓取网页(htmlunit网络工具一个没有没有
)
1:背景
本来想用jsoup抓取一个页面,但是抓取的数据总是不完整,然后发现页面执行js后,页面上渲染了一些数据,也就是说数据页是只在js执行后显示。数据会显示出来,但是jsoup无法实现执行页面的js。
2:解决
经过搜索,发现htmlunit网络工具可以实现js。它相当于一个没有页面的浏览器。解决方法是先用htmlUnit发送网络请求,执行js获取页面,然后用jsoup转换成Document页面对象。然后使用jsoup分析页面读取数据。
3:htmlUnit发送请求
1 public static Document getDocument() throws IOException, InterruptedException{
2 /*String url="https://www.marklines.com/cn/v ... 3B%3B
3 Connection connect = Jsoup.connect(url).userAgent("")
4 .header("Cookie", "PLAY_LANG=cn; _plh=b9289d0a863a8fc9c79fb938f15372f7731d13fb; PLATFORM_SESSION=39034d07000717c664134556ad39869771aabc04-_ldi=520275&_lsh=8cf91cdbcbbb255adff5cba6061f561b642f5157&csrfToken=209f20c8473bc0518413c226f898ff79cd69c3ff-1539926671235-b853a6a63c77dd8fcc364a58&_lpt=%2Fcn%2Fvehicle_sales%2Fsearch&_lsi=1646321; _ga=GA1.2.2146952143.1539926675; _gid=GA1.2.1032787565.1539926675; _plh_notime=8cf91cdbcbbb255adff5cba6061f561b642f5157")
5 .timeout(360000000);
6 Document document = connect.get();*/
7 WebClient wc = new WebClient(BrowserVersion.CHROME);
8 //是否使用不安全的SSL
9 wc.getOptions().setUseInsecureSSL(true);
10 //启用JS解释器,默认为true
11 wc.getOptions().setJavaScriptEnabled(true);
12 //禁用CSS
13 wc.getOptions().setCssEnabled(false);
14 //js运行错误时,是否抛出异常
15 wc.getOptions().setThrowExceptionOnScriptError(false);
16 //状态码错误时,是否抛出异常
17 wc.getOptions().setThrowExceptionOnFailingStatusCode(false);
18 //是否允许使用ActiveX
19 wc.getOptions().setActiveXNative(false);
20 //等待js时间
21 wc.waitForBackgroundJavaScript(600*1000);
22 //设置Ajax异步处理控制器即启用Ajax支持
23 wc.setAjaxController(new NicelyResynchronizingAjaxController());
24 //设置超时时间
25 wc.getOptions().setTimeout(1000000);
26 //不跟踪抓取
27 wc.getOptions().setDoNotTrackEnabled(false);
28 WebRequest request=new WebRequest(new URL("https://www.marklines.com/cn/v ... 6quot;));
29 request.setAdditionalHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:62.0) Gecko/20100101 Firefox/62.0");
30 request.setAdditionalHeader("Cookie","PLAY_LANG=cn; _plh=b9289d0a863a8fc9c79fb938f15372f7731d13fb; PLATFORM_SESSION=39034d07000717c664134556ad39869771aabc04-_ldi=520275&_lsh=8cf91cdbcbbb255adff5cba6061f561b642f5157&csrfToken=209f20c8473bc0518413c226f898ff79cd69c3ff-1539926671235-b853a6a63c77dd8fcc364a58&_lpt=%2Fcn%2Fvehicle_sales%2Fsearch&_lsi=1646321; _ga=GA1.2.2146952143.1539926675; _gid=GA1.2.1032787565.1539926675; _plh_notime=8cf91cdbcbbb255adff5cba6061f561b642f5157");
31 try {
32 //模拟浏览器打开一个目标网址
33 HtmlPage htmlPage = wc.getPage(request);
34 //为了获取js执行的数据 线程开始沉睡等待
35 Thread.sleep(1000);//这个线程的等待 因为js加载需要时间的
36 //以xml形式获取响应文本
37 String xml = htmlPage.asXml();
38 //并转为Document对象return
39 return Jsoup.parse(xml);
40 //System.out.println(xml.contains("结果.xls"));//false
41 } catch (FailingHttpStatusCodeException e) {
42 e.printStackTrace();
43 } catch (MalformedURLException e) {
44 e.printStackTrace();
45 } catch (IOException e) {
46 e.printStackTrace();
47 }
48 return null;
49 }
4:返回的Document对象交给jsoup处理
这里只做一个简单的输出,看看数据是否全部渲染完毕。
1 Document doc=getDocument();
2 Element table=doc.select("table.table.table-bordered.aggregate_table").get(0);//获取到表格
3 Element tableContext=table.getElementsByTag("tbody").get(0);
4 Elements contextTrs=tableContext.getElementsByTag("tr");
5 System.out.println(contextTrs.size());
6
7
8 String context=doc.toString();
9 OutputStreamWriter pw = null;
10 pw = new OutputStreamWriter(new FileOutputStream("D:/test.txt"),"GBK");
11 pw.write(context);
12 pw.close();
htmlunit 抓取网页(编程之家为你收集整理的全部内容解决方法())
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-13 21:25
概述 当使用 htmlunit 抓取网页时,我偶尔会注意到这些警告充斥着控制台输出。 2011 年 7 月 24 日 5:12:59 PM
在使用 htmlunit 抓取网页时,我偶尔会注意到这些警告淹没了控制台输出。
Jul 24,2011 5:12:59 PM com.gargoylesoftware.htmlunit.javascript.StrictErrorReporter warning
WARNING: warning: message=[Calling eval() with anything other than a primitive string value
will simply return the value. Is this what you intended?] sourceName=[http://ad.doubleclick.net/adj/ ... 40%3F] line=[356] lineSource=[null] lineOffset=[0]
有没有办法让htmlunit忽略javascript
> .*
> .*
就算了
>
>
同样,有没有办法让 htmlunit 只解释收录特定子字符串或匹配正则表达式的网页上的 javascript?
解决方案
您可以通过实现自己的 javascript 来删除不需要的 JavaScript
.您的 ScriptPreProcessor 可以检测到您不想执行的 jsvascript,而不是将其从 网站 中删除。
我还没有尝试过,但它可能会起作用。
总结
以上是编程之家为您采集的全部内容。希望文章可以帮助你解决你遇到的程序开发问题。
如果你觉得编程之家网站的内容还不错,欢迎你把编程之家网站推荐给你的程序员朋友。 查看全部
htmlunit 抓取网页(编程之家为你收集整理的全部内容解决方法())
概述 当使用 htmlunit 抓取网页时,我偶尔会注意到这些警告充斥着控制台输出。 2011 年 7 月 24 日 5:12:59 PM
在使用 htmlunit 抓取网页时,我偶尔会注意到这些警告淹没了控制台输出。
Jul 24,2011 5:12:59 PM com.gargoylesoftware.htmlunit.javascript.StrictErrorReporter warning
WARNING: warning: message=[Calling eval() with anything other than a primitive string value
will simply return the value. Is this what you intended?] sourceName=[http://ad.doubleclick.net/adj/ ... 40%3F] line=[356] lineSource=[null] lineOffset=[0]
有没有办法让htmlunit忽略javascript
> .*
> .*
就算了
>
>
同样,有没有办法让 htmlunit 只解释收录特定子字符串或匹配正则表达式的网页上的 javascript?
解决方案
您可以通过实现自己的 javascript 来删除不需要的 JavaScript
.您的 ScriptPreProcessor 可以检测到您不想执行的 jsvascript,而不是将其从 网站 中删除。
我还没有尝试过,但它可能会起作用。
总结
以上是编程之家为您采集的全部内容。希望文章可以帮助你解决你遇到的程序开发问题。
如果你觉得编程之家网站的内容还不错,欢迎你把编程之家网站推荐给你的程序员朋友。
htmlunit 抓取网页(和java自带的网络API进行结合,怎么做?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-22 16:24
HtmlUnit结合了HttpClient和java自带的网络API,更容易抓取数据,更容易操作。HtmlUnit底层还是封装了HttpClient,但是封装之后,解析出来的内容更像是一个网页,而不是抽象的请求和响应,所以更方便开发者上手。
// [1] new一个WebClient,在其中定义一种浏览器
WebClient webClent = new WebClient(BrowserVersion.FIREFOX_17);
// [2] 设置网页解析的内容
WebClientOptions options=webClent.getOptions();
options.setCssEnabled(false);
options.setJavaScriptEnabled(true);
options.setActiveXNative(false);
options.setAppletEnabled(false);
options.setRedirectEnabled(true);
options.setThrowExceptionOnFailingStatusCode(false);
options.setThrowExceptionOnScriptError(false);
options.setDoNotTrackEnabled(false);
options.setGeolocationEnabled(false);
// [3] 访问指定的页面,并将其赋予HtmlPage
HtmlPage htmlPage=webClent.getPage(url);
// [4] 获得的HtmlPage并不易于阅读,所以有需要可以通过Jsoup将其转换为Document对象
Document document = Jsoup.parseBodyFragment(htmlPage.asXml());
// [5]关闭
webClent.closeAllWindows();
HtmlPage 非常方便在获取到按钮后进行赋值和操作点击事件。常用方法getElementByName根据名称获取指定的标签(HtmlElement),类型可以设置为标签。
在 Document 对象中经常使用 select("") 方法,通过该方法可以获取到具体的 Element,然后通过解析内容得到需要的数据。
HtmlUnit很容易爬取,但是因为它模拟了网页的点击事件,所以响应返回的所有内容都会很臃肿。如果需要的数据量很小,效率会有点低。 查看全部
htmlunit 抓取网页(和java自带的网络API进行结合,怎么做?)
HtmlUnit结合了HttpClient和java自带的网络API,更容易抓取数据,更容易操作。HtmlUnit底层还是封装了HttpClient,但是封装之后,解析出来的内容更像是一个网页,而不是抽象的请求和响应,所以更方便开发者上手。
// [1] new一个WebClient,在其中定义一种浏览器
WebClient webClent = new WebClient(BrowserVersion.FIREFOX_17);
// [2] 设置网页解析的内容
WebClientOptions options=webClent.getOptions();
options.setCssEnabled(false);
options.setJavaScriptEnabled(true);
options.setActiveXNative(false);
options.setAppletEnabled(false);
options.setRedirectEnabled(true);
options.setThrowExceptionOnFailingStatusCode(false);
options.setThrowExceptionOnScriptError(false);
options.setDoNotTrackEnabled(false);
options.setGeolocationEnabled(false);
// [3] 访问指定的页面,并将其赋予HtmlPage
HtmlPage htmlPage=webClent.getPage(url);
// [4] 获得的HtmlPage并不易于阅读,所以有需要可以通过Jsoup将其转换为Document对象
Document document = Jsoup.parseBodyFragment(htmlPage.asXml());
// [5]关闭
webClent.closeAllWindows();
HtmlPage 非常方便在获取到按钮后进行赋值和操作点击事件。常用方法getElementByName根据名称获取指定的标签(HtmlElement),类型可以设置为标签。
在 Document 对象中经常使用 select("") 方法,通过该方法可以获取到具体的 Element,然后通过解析内容得到需要的数据。
HtmlUnit很容易爬取,但是因为它模拟了网页的点击事件,所以响应返回的所有内容都会很臃肿。如果需要的数据量很小,效率会有点低。
htmlunit 抓取网页(抓一个今日头条的首页内容解决方案-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-22 16:23
不知道大家在使用jsoup的过程中是否遇到过爬取内容,发现有些网页中的内容是通过javascript异步加载的,导致我们的爬虫空手返回(只抓到一个网页的外框) .
当我第一次遇到这个问题时,我想到了两个解决方案:
在等待网页异步加载后,使用类似于 Python 中延迟加载的方法对异步加载的网页进行爬取。使用一种特殊的方法来模拟被爬取的网页框架内的 JavaScript 代码的执行,最终到达完整的网页。
在搜索引擎的帮助下,决定使用方案二来解决这个问题。解决方案1中没有搜索到更好的第三方库。在java中使用解决方案1解决此问题的朋友希望与下一个讨论,非常感谢。
案例很简单,抓取一条今日头条的首页内容。你可以看一下今日头条的首页,里面的内容是异步加载的。
添加jsoup和htmlunit依赖
org.jsoup
jsoup
1.10.2
net.sourceforge.htmlunit
htmlunit
2.25
首先,我们单独使用jsoup来解析今日头条的首页
String url = "https://www.toutiao.com/";
Connection connect = Jsoup.connect(url);
Document document = connect.get();
System.out.println(document);
↑ 这里只能获取网页的框架内容,不能获取首页的新闻内容
接下来,我们使用htmlunit来尝试
//构造一个webClient 模拟Chrome 浏览器
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//屏蔽日志信息
LogFactory.getFactory().setAttribute("org.apache.commons.logging.Log",
"org.apache.commons.logging.impl.NoOpLog");
java.util.logging.Logger.getLogger("com.gargoylesoftware").setLevel(Level.OFF);
//支持JavaScript
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setTimeout(5000);
HtmlPage rootPage = webClient.getPage(url);
//设置一个运行JavaScript的时间
webClient.waitForBackgroundJavaScript(5000);
String html = rootPage.asXml();
Document document = Jsoup.parse(html);
这为我们提供了运行 JavaScript 的完整源页面 查看全部
htmlunit 抓取网页(抓一个今日头条的首页内容解决方案-苏州安嘉)
不知道大家在使用jsoup的过程中是否遇到过爬取内容,发现有些网页中的内容是通过javascript异步加载的,导致我们的爬虫空手返回(只抓到一个网页的外框) .
当我第一次遇到这个问题时,我想到了两个解决方案:
在等待网页异步加载后,使用类似于 Python 中延迟加载的方法对异步加载的网页进行爬取。使用一种特殊的方法来模拟被爬取的网页框架内的 JavaScript 代码的执行,最终到达完整的网页。
在搜索引擎的帮助下,决定使用方案二来解决这个问题。解决方案1中没有搜索到更好的第三方库。在java中使用解决方案1解决此问题的朋友希望与下一个讨论,非常感谢。
案例很简单,抓取一条今日头条的首页内容。你可以看一下今日头条的首页,里面的内容是异步加载的。
添加jsoup和htmlunit依赖
org.jsoup
jsoup
1.10.2
net.sourceforge.htmlunit
htmlunit
2.25
首先,我们单独使用jsoup来解析今日头条的首页
String url = "https://www.toutiao.com/";
Connection connect = Jsoup.connect(url);
Document document = connect.get();
System.out.println(document);
↑ 这里只能获取网页的框架内容,不能获取首页的新闻内容
接下来,我们使用htmlunit来尝试
//构造一个webClient 模拟Chrome 浏览器
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//屏蔽日志信息
LogFactory.getFactory().setAttribute("org.apache.commons.logging.Log",
"org.apache.commons.logging.impl.NoOpLog");
java.util.logging.Logger.getLogger("com.gargoylesoftware").setLevel(Level.OFF);
//支持JavaScript
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setTimeout(5000);
HtmlPage rootPage = webClient.getPage(url);
//设置一个运行JavaScript的时间
webClient.waitForBackgroundJavaScript(5000);
String html = rootPage.asXml();
Document document = Jsoup.parse(html);
这为我们提供了运行 JavaScript 的完整源页面
htmlunit 抓取网页(java页面分析工具是什么?是怎么做的? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-22 10:14
)
一、什么是 HtmlUnit?
1、htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这是一个没有界面但运行速度很快的浏览器。
2、 使用 Rhinojs 引擎。模拟js运行
3、一般来说,这个项目可以用来测试页面和自动化网页测试,(包括JS)
4、但是一般来说,在小型爬虫项目中,这种框架是非常常用的,它可以有效的分析DOM标签,有效的运行页面上的js来获取一些需要执行的js来获得价值。
二、应用:获取百度API返回的详情url,从详情url中抓取图片url
maven 依赖:
net.sourceforge.htmlunit
htmlunit-core-js
2.23
net.sourceforge.htmlunit
htmlunit
2.23
xml-apis
xml-apis
1.4.01
服务器代码:
/**
* 从百度POI详情页获取图片url
* @param poiUid
* @return
*/
public static List grabImgUrl(String poiUid) {
if (StringUtils.isBlank(poiUid)) {
return null;
}
final String IMG_LIST_URL = "http://map.baidu.com/detail%3F ... 3B%3B
String detailUrl = IMG_LIST_URL + poiUid;
log.info("grabImgUrl. detailUrl=" + detailUrl);
final String DIV_ID = "photoContainer";
final String TAG_IMG = "img";
final String IMG_SRC = "src";
try (final WebClient webClient = new WebClient()) {
final HtmlPage page = webClient.getPage(detailUrl);
if (page != null && page.isHtmlPage()) {
Thread.sleep(40000); // 等待页面加载完成。
final HtmlDivision div = page.getHtmlElementById(DIV_ID);
DomNodeList eleList = div.getElementsByTagName(TAG_IMG);
List imgUrlList = new ArrayList();
for (HtmlElement hele : eleList) {
String imgUrl = hele.getAttribute(IMG_SRC);
if (StringUtils.isNotBlank(imgUrl)) {
log.info("imgUrl=" + imgUrl);
imgUrlList.add(imgUrl);
}
}
return imgUrlList;
}
} catch (Exception e) {
log.error("grabImgUrl error.", e);
}
return null;
}
页面显示:
设为封面
× 查看全部
htmlunit 抓取网页(java页面分析工具是什么?是怎么做的?
)
一、什么是 HtmlUnit?
1、htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这是一个没有界面但运行速度很快的浏览器。
2、 使用 Rhinojs 引擎。模拟js运行
3、一般来说,这个项目可以用来测试页面和自动化网页测试,(包括JS)
4、但是一般来说,在小型爬虫项目中,这种框架是非常常用的,它可以有效的分析DOM标签,有效的运行页面上的js来获取一些需要执行的js来获得价值。
二、应用:获取百度API返回的详情url,从详情url中抓取图片url
maven 依赖:
net.sourceforge.htmlunit
htmlunit-core-js
2.23
net.sourceforge.htmlunit
htmlunit
2.23
xml-apis
xml-apis
1.4.01
服务器代码:
/**
* 从百度POI详情页获取图片url
* @param poiUid
* @return
*/
public static List grabImgUrl(String poiUid) {
if (StringUtils.isBlank(poiUid)) {
return null;
}
final String IMG_LIST_URL = "http://map.baidu.com/detail%3F ... 3B%3B
String detailUrl = IMG_LIST_URL + poiUid;
log.info("grabImgUrl. detailUrl=" + detailUrl);
final String DIV_ID = "photoContainer";
final String TAG_IMG = "img";
final String IMG_SRC = "src";
try (final WebClient webClient = new WebClient()) {
final HtmlPage page = webClient.getPage(detailUrl);
if (page != null && page.isHtmlPage()) {
Thread.sleep(40000); // 等待页面加载完成。
final HtmlDivision div = page.getHtmlElementById(DIV_ID);
DomNodeList eleList = div.getElementsByTagName(TAG_IMG);
List imgUrlList = new ArrayList();
for (HtmlElement hele : eleList) {
String imgUrl = hele.getAttribute(IMG_SRC);
if (StringUtils.isNotBlank(imgUrl)) {
log.info("imgUrl=" + imgUrl);
imgUrlList.add(imgUrl);
}
}
return imgUrlList;
}
} catch (Exception e) {
log.error("grabImgUrl error.", e);
}
return null;
}
页面显示:
设为封面
×
htmlunit 抓取网页(网页获取和解析速度和性能的应用场景详解! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 364 次浏览 • 2022-01-22 10:12
)
(4)支持代理
(5)支持自动cookie管理等。
Java爬虫开发中应用最广泛的网页获取技术之一,速度和性能一流。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;
import org.apache.http.client.HttpClient;
import org.apache.http.client.ResponseHandler;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.BasicResponseHandler;
import org.apache.http.impl.client.DefaultHttpClient;
/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/
public class HttpClientTest {
public static void main(String[] args) throws Exception {
//目标页面
String url = "http://www.yshjava.cn";
//创建一个默认的HttpClient
HttpClient httpclient = new DefaultHttpClient();
try {
//以get方式请求网页http://www.yshjava.cn
HttpGet httpget = new HttpGet(url);
//打印请求地址
System.out.println("executing request " + httpget.getURI());
//创建响应处理器处理服务器响应内容
ResponseHandlerresponseHandler = new BasicResponseHandler();
//执行请求并获取结果
String responseBody = httpclient.execute(httpget, responseHandler);
System.out.println("----------------------------------------");
System.out.println(responseBody);
System.out.println("----------------------------------------");
} finally {
//关闭连接管理器
httpclient.getConnectionManager().shutdown();
}
}
}
汤
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
示例代码如下:
package cn.ysh.studio.crawler.jsoup;
import java.io.IOException;
import org.jsoup.Jsoup;
/**
* 基于Jsoup抓取网页内容
* @author www.yshjava.cn
*/
public class JsoupTest {
public static void main(String[] args) throws IOException {
//目标页面
String url = "http://www.yshjava.cn";
//使用Jsoup连接目标页面,并执行请求,获取服务器响应内容
String html = Jsoup.connect(url).execute().body();
//打印页面内容
System.out.println(html);
}
}
html单元
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取和解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.Page;
import com.gargoylesoftware.htmlunit.WebClient;
/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlUnitSpider {
public static void main(String[] s) throws Exception {
//目标网页
String url = "http://www.yshjava.cn";
//模拟特定浏览器FIREFOX_3
WebClient spider = new WebClient(BrowserVersion.FIREFOX_3);
//获取目标网页
Page page = spider.getPage(url);
//打印网页内容
System.out.println(page.getWebResponse().getContentAsString());
//关闭所有窗口
spider.closeAllWindows();
}
}
瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
示例代码如下:
package cn.ysh.studio.crawler.ie;
import watij.runtime.ie.IE;
/**
* 基于Watij抓取网页内容,仅限Windows平台
*
* @author www.yshjava.cn
*/
public class WatijTest {
public static void main(String[] s) {
//目标页面
String url = "http://www.yshjava.cn";
//实例化IE浏览器对象
IE ie = new IE();
try {
//启动浏览器
ie.start();
//转到目标网页
ie.goTo(url);
//等待网页加载就绪
ie.waitUntilReady();
//打印页面内容
System.out.println(ie.html());
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
//关闭IE浏览器
ie.close();
} catch (Exception e) {
}
}
}
}
硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性——测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;
import org.openqa.selenium.htmlunit.HtmlUnitDriver;
/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlDriverTest {
public static void main(String[] s) {
//目标网页
String url = "http://www.yshjava.cn";
HtmlUnitDriver driver = new HtmlUnitDriver();
try {
//禁用JS脚本功能
driver.setJavascriptEnabled(false);
//打开目标网页
driver.get(url);
//获取当前网页源码
String html = driver.getPageSource();
//打印网页源码
System.out.println(html);
} catch (Exception e) {
//打印堆栈信息
e.printStackTrace();
} finally {
try {
//关闭并退出
driver.close();
driver.quit();
} catch (Exception e) {
}
}
}
}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;
import org.watij.webspec.dsl.WebSpec;
/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/
public class WebspecTest {
public static void main(String[] s) {
//目标网页
String url = "http://www.yshjava.cn";
//实例化浏览器对象
WebSpec spec = new WebSpec().mozilla();
//隐藏浏览器窗体
spec.hide();
//打开目标页面
spec.open(url);
//打印网页源码
System.out.println(spec.source());
//关闭所有窗口
spec.closeAll();
}
} 查看全部
htmlunit 抓取网页(网页获取和解析速度和性能的应用场景详解!
)
(4)支持代理
(5)支持自动cookie管理等。
Java爬虫开发中应用最广泛的网页获取技术之一,速度和性能一流。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;
import org.apache.http.client.HttpClient;
import org.apache.http.client.ResponseHandler;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.BasicResponseHandler;
import org.apache.http.impl.client.DefaultHttpClient;
/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/
public class HttpClientTest {
public static void main(String[] args) throws Exception {
//目标页面
String url = "http://www.yshjava.cn";
//创建一个默认的HttpClient
HttpClient httpclient = new DefaultHttpClient();
try {
//以get方式请求网页http://www.yshjava.cn
HttpGet httpget = new HttpGet(url);
//打印请求地址
System.out.println("executing request " + httpget.getURI());
//创建响应处理器处理服务器响应内容
ResponseHandlerresponseHandler = new BasicResponseHandler();
//执行请求并获取结果
String responseBody = httpclient.execute(httpget, responseHandler);
System.out.println("----------------------------------------");
System.out.println(responseBody);
System.out.println("----------------------------------------");
} finally {
//关闭连接管理器
httpclient.getConnectionManager().shutdown();
}
}
}
汤
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
示例代码如下:
package cn.ysh.studio.crawler.jsoup;
import java.io.IOException;
import org.jsoup.Jsoup;
/**
* 基于Jsoup抓取网页内容
* @author www.yshjava.cn
*/
public class JsoupTest {
public static void main(String[] args) throws IOException {
//目标页面
String url = "http://www.yshjava.cn";
//使用Jsoup连接目标页面,并执行请求,获取服务器响应内容
String html = Jsoup.connect(url).execute().body();
//打印页面内容
System.out.println(html);
}
}
html单元
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取和解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.Page;
import com.gargoylesoftware.htmlunit.WebClient;
/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlUnitSpider {
public static void main(String[] s) throws Exception {
//目标网页
String url = "http://www.yshjava.cn";
//模拟特定浏览器FIREFOX_3
WebClient spider = new WebClient(BrowserVersion.FIREFOX_3);
//获取目标网页
Page page = spider.getPage(url);
//打印网页内容
System.out.println(page.getWebResponse().getContentAsString());
//关闭所有窗口
spider.closeAllWindows();
}
}
瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
示例代码如下:
package cn.ysh.studio.crawler.ie;
import watij.runtime.ie.IE;
/**
* 基于Watij抓取网页内容,仅限Windows平台
*
* @author www.yshjava.cn
*/
public class WatijTest {
public static void main(String[] s) {
//目标页面
String url = "http://www.yshjava.cn";
//实例化IE浏览器对象
IE ie = new IE();
try {
//启动浏览器
ie.start();
//转到目标网页
ie.goTo(url);
//等待网页加载就绪
ie.waitUntilReady();
//打印页面内容
System.out.println(ie.html());
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
//关闭IE浏览器
ie.close();
} catch (Exception e) {
}
}
}
}
硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性——测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;
import org.openqa.selenium.htmlunit.HtmlUnitDriver;
/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlDriverTest {
public static void main(String[] s) {
//目标网页
String url = "http://www.yshjava.cn";
HtmlUnitDriver driver = new HtmlUnitDriver();
try {
//禁用JS脚本功能
driver.setJavascriptEnabled(false);
//打开目标网页
driver.get(url);
//获取当前网页源码
String html = driver.getPageSource();
//打印网页源码
System.out.println(html);
} catch (Exception e) {
//打印堆栈信息
e.printStackTrace();
} finally {
try {
//关闭并退出
driver.close();
driver.quit();
} catch (Exception e) {
}
}
}
}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;
import org.watij.webspec.dsl.WebSpec;
/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/
public class WebspecTest {
public static void main(String[] s) {
//目标网页
String url = "http://www.yshjava.cn";
//实例化浏览器对象
WebSpec spec = new WebSpec().mozilla();
//隐藏浏览器窗体
spec.hide();
//打开目标页面
spec.open(url);
//打印网页源码
System.out.println(spec.source());
//关闭所有窗口
spec.closeAll();
}
}
htmlunit 抓取网页(抓一个今日头条的首页内容解决方案-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-01-22 10:09
不知道大家在使用jsoup的过程中是否遇到过爬取内容,发现有些网页中的内容是通过javascript异步加载的,导致我们的爬虫空手返回(只抓到一个网页的外框) .
当我第一次遇到这个问题时,我想到了两个解决方案:
在等待网页异步加载后,使用类似于 Python 中延迟加载的方法对异步加载的网页进行爬取。使用一种特殊的方法来模拟被爬取的网页框架内的 JavaScript 代码的执行,最终到达完整的网页。
在搜索引擎的帮助下,决定使用方案二来解决这个问题。解决方案1中没有搜索到更好的第三方库。在java中使用解决方案1解决此问题的朋友希望与下一个讨论,非常感谢。
案例很简单,抓取一条今日头条的首页内容。你可以看一下今日头条的首页,里面的内容是异步加载的。
添加jsoup和htmlunit依赖
org.jsoup
jsoup
1.10.2
net.sourceforge.htmlunit
htmlunit
2.25
首先,我们单独使用jsoup来解析今日头条的首页
String url = "https://www.toutiao.com/";
Connection connect = Jsoup.connect(url);
Document document = connect.get();
System.out.println(document);
↑ 这里只能获取网页的框架内容,不能获取首页的新闻内容
接下来,我们使用htmlunit来尝试
//构造一个webClient 模拟Chrome 浏览器
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//屏蔽日志信息
LogFactory.getFactory().setAttribute("org.apache.commons.logging.Log",
"org.apache.commons.logging.impl.NoOpLog");
java.util.logging.Logger.getLogger("com.gargoylesoftware").setLevel(Level.OFF);
//支持JavaScript
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setTimeout(5000);
HtmlPage rootPage = webClient.getPage(url);
//设置一个运行JavaScript的时间
webClient.waitForBackgroundJavaScript(5000);
String html = rootPage.asXml();
Document document = Jsoup.parse(html);
这为我们提供了运行 JavaScript 的完整源页面 查看全部
htmlunit 抓取网页(抓一个今日头条的首页内容解决方案-苏州安嘉)
不知道大家在使用jsoup的过程中是否遇到过爬取内容,发现有些网页中的内容是通过javascript异步加载的,导致我们的爬虫空手返回(只抓到一个网页的外框) .
当我第一次遇到这个问题时,我想到了两个解决方案:
在等待网页异步加载后,使用类似于 Python 中延迟加载的方法对异步加载的网页进行爬取。使用一种特殊的方法来模拟被爬取的网页框架内的 JavaScript 代码的执行,最终到达完整的网页。
在搜索引擎的帮助下,决定使用方案二来解决这个问题。解决方案1中没有搜索到更好的第三方库。在java中使用解决方案1解决此问题的朋友希望与下一个讨论,非常感谢。
案例很简单,抓取一条今日头条的首页内容。你可以看一下今日头条的首页,里面的内容是异步加载的。
添加jsoup和htmlunit依赖
org.jsoup
jsoup
1.10.2
net.sourceforge.htmlunit
htmlunit
2.25
首先,我们单独使用jsoup来解析今日头条的首页
String url = "https://www.toutiao.com/";
Connection connect = Jsoup.connect(url);
Document document = connect.get();
System.out.println(document);
↑ 这里只能获取网页的框架内容,不能获取首页的新闻内容
接下来,我们使用htmlunit来尝试
//构造一个webClient 模拟Chrome 浏览器
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//屏蔽日志信息
LogFactory.getFactory().setAttribute("org.apache.commons.logging.Log",
"org.apache.commons.logging.impl.NoOpLog");
java.util.logging.Logger.getLogger("com.gargoylesoftware").setLevel(Level.OFF);
//支持JavaScript
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setTimeout(5000);
HtmlPage rootPage = webClient.getPage(url);
//设置一个运行JavaScript的时间
webClient.waitForBackgroundJavaScript(5000);
String html = rootPage.asXml();
Document document = Jsoup.parse(html);
这为我们提供了运行 JavaScript 的完整源页面
htmlunit 抓取网页(介绍常用爬虫开源项目和腾讯微博爬虫的问题总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-22 08:08
介绍
常用爬虫开源项目
新浪微博爬虫和腾讯微博爬虫
新浪爬虫问题
总结
介绍
相关介绍
即网络爬虫是一种自动获取网页内容的程序。它是搜索引擎的重要组成部分,因此搜索引擎优化主要针对爬虫进行优化。
主要分类
网络爬虫从万维网上为搜索引擎下载网页。一般分为传统爬虫和专注爬虫。
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某个停止条件。通俗的讲,就是通过源码分析得到想要的内容。
焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
反爬虫:KS-WAF将爬虫行为分为搜索引擎爬虫和扫描爬虫,可以屏蔽特定搜索引擎爬虫以节省带宽和性能,也可以屏蔽扫描爬虫防止网站被恶意爬取。
常用爬虫开源项目
Nutch 标志 搜索引擎 Nutch
Nutch 是一个搜索引擎的开源 Java 实现。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫。
尽管网络搜索是漫游 Internet 的基本要求,但现有网络搜索引擎的数量正在下降。而这很可能会演变成一家为其商业利益垄断几乎所有网络搜索的公司。这显然对绝大多数网民不利。
现在所有主要的搜索引擎都使用专有的排名算法,这些算法不能解释为什么一个页面被排在一个特定的位置。另外,有些搜索引擎按网站付费,而不是按自己的值排序。
Apache Nutch 项目(一个网络搜索引擎)。当 Nutch 发展到一定程度时,遇到了可扩展性的问题,即当存储的网页数量达到 1 亿的水平时,Nutch 原有的结构很难达到高效率。就在整个团队不知所措的时候,救星谷歌出现了。Google 在 2003 年发布了 Google 使用的分布式文件存储系统文章(The Google File System),Nutch 开发者意识到可以将 Nutch 放在 GFS 上实现,所以经过一年的发展,NDFS(Nutch Distributed文件系统)出现。在解决了瓶颈问题之后,Nutch 有了很大的发展,而就在 2004 年,Google 发布了 MapReduce 的想法,因此尝到甜头的 Nutch 开发者们毫不犹豫地将 MapReduce 模型应用到了 Nutch 系统中。
但是在 Nutch 加入 GFS 和 MapReduce 之后,Nutch 变得太大了,超出了网络搜索引擎的范围,所以在 2006 年分别移植了 NDFS 和 MapReduce,形成了一个新的项目,叫做 Hadoop。
Java 多线程网络爬虫 Crawler4j
Crawler4j 是一个开源的 Java 类库,它提供了一个简单的网页爬取接口。它可以用来构建一个多线程的网络爬虫。
crawler4j的使用主要分为两步:
1. 实现一个继承自WebCrawler的爬虫类;
2.调用CrawlController实现的爬虫类。
WebCrawler 是一个抽象类,继承它必须实现两个方法:shouldVisit 和 visit。在:
shouldVisit 是判断当前URL是否应该被爬取(visited);
visit 是抓取URL指向的页面的数据,传入的参数是网页所有数据的封装对象Page。
Crawler.CrawController 控制爬虫,先添加seed,然后开启多个爬虫,不断监控每个爬虫的生存状态。
Crawler.WebCrawler 爬虫
1. Run():不断循环,每次从Frontier取50个url,对每个url进行processPage(curUrl)。
2. processPage(curURL):使用 PageFetcher.fetch 抓取网页。如果curURL被重定向,则将重定向url的url添加到Frontier,稍后调度;如果爬取正常,则先解析,生成Page,然后将新的url下降到Frontier(此时确定新增url的深度),调用visit(Page){用户自定义操作} .
Crawler.Configurations 读取 crawler4j.properties 中的信息
Crawler.PageFetcher 启动 IdleConnectionMonitorThread 并使用 fetch(Page, ignoreIfBinary) 抓取单个 Page 页面。是一个静态类。
Crawler.Page 一个页面
Crawler.PageFetchStatus 单页爬取的配置,如返回的爬取状态号的含义等。
Crawler.HTMLParser 解析 HTML 源代码并将其存储在 Page 中。
Crawler.LinkExtractor 提取 HTML 页面中收录的所有链接。
Crawler.IdleConnectionMonitorThread 用于监控连接(用于发送get请求,获取页面),其connMgr负责发送HTML请求。
HTML单元
HtmlUnitHtmlUnit 是“Java 程序的无 GUI 浏览器”。它对 HTML 文档进行建模并提供一个 API,允许您调用页面、填写表单、单击链接等……就像您在“普通”浏览器中所做的一样。
HtmlUnit的使用: 简介:HtmlUnit是一个浏览器,用Java编写,没有界面。因为它没有接口,所以执行速度仍然可以下降。HtmlUnit提供了一系列的API,这些API可以做很多功能,比如表单填写、表单提交、模拟点击链接,并且由于内置了Rhinojs引擎,可以执行Javascript
1、模拟特定浏览器,也可以指定浏览器对应版本(HtmlUnit最新版本2.13现在可以模拟Chrome/FireFox/IE)
WebClient webClient=new WebClient(BrowserVersion.FIREFOX_24);
2、查找特定元素,可以通过get或者XPath从HtmlPage中获取特定的Html元素。例如;
DomElement plc_main=page.getElementById("plc_main");
DomElement code_box=(DomElement) pl_common_sassfilter.getByXPath("//div[@class='code_box clearfix']").get(0);
3. 模拟表单的提交显示在用于登录的代码中;
HtmlForm loginform = logonPage.getFormByName("loginform");
HtmlTextInput uid = loginform.getInputByName("u");
uid.click();//点击获取焦点
uid.type(Config.getAccount());
HtmlPasswordInput pwd = loginform.getInputByName("p");
pwd.click();
pwd.type(Config.getPassword());
4、获取新浪微博等微博内容等信息。
DomNodeList dls = pl_weibo_direct.getElementsByTagName("dl");
DomElement dl= dls.get(0);
整数索引 = 0;
而(DL!=空){
DomElement em=feed_list_content.getElementsByTagName("em").get(0);
字符串内容 = em.getTextContent();
newlist.add(内容);
索引++;
dl = dls.get(索引);}
2.模拟登录,找到微博内容的位置。
3.获取微博数据并存入数据库,数据库使用MYSQL
逻辑其实很简单。需要熟悉HTMLunit提供的一些类,然后是XPath语法,再熟悉一些基础的数据库知识,就可以完成微博的爬取。
腾讯微博也有同样的想法。一些区别是
1.页面解析不同。
2.URL 的某些特征是不同的。
新浪爬虫问题总结
新浪微博爬虫的一些问题:
首先是微博数量的限制,从搜索页关键词开始,只能搜索到50页的微博数据。那么每页有20条,只能搜到1000条,这肯定跟实时微博的数量不匹配。
所以你可以使用高级搜索从2009年开始搜索,这需要不断的实验,看看时间可以弥补50页的微博。因为无论我搜索什么,新浪微博都只能显示50页的数据。
以本田雅阁为例,可以分为五次搜索,第一次是2009年到2010年,这个时间段只有33页数据,然后是2010年1.1到2011.1.1有50页数据,然后往下推。在某些时期,建立50页数据只需要五六个月。简而言之,这不是常规模式。大概,时间越长,微博越多。. 所以当这个编程达到50页时,url链接的下一页就没有了。这是一个限制。
第二个问题是微博内容重复。如果连接是
%25E6%259C%25AC%25E7%2594%25B0%25E9%259B%2585%25E9%2598%2581&xsort=time&scope=ori×cope=custom:2013-01-01-0:2014-04-23-0&page=8
以本田雅阁为例,这个页面上的微博基本上都是一样的内容。据我观察,这个品牌的微博更像是一个营销和广告的微博。当然,你可以用微博来验证这个方法来刷选。但真正有意义的是,原创的微博,是一个少得可怜的数字。只有几百个大小。
还是有一些方法可以删除同一个微博。最近在数据库下操作比较有效,使用select distinct content from weibo where program='Honda Accord' into outfile 'D:/Honda Accord.txt';仍然可以删除其中大部分重复推文。
或者对于几乎相同的情况,只有 URL 不同。您可以使用删除微博内容 LIKE '%铃木“大型车”将与本田雅阁同级%';或其他一些具有特别明显特征的词或短语。
第三个问题是,虽然新浪只提供了这么多数据,但还是处处受限。当程序运行到20页时,会出现需要手动输入验证码以防止爬虫影响其服务器的问题。这个方案是通过模仿登录验证码的方法来解决的。就是拿到需要输入的验证码,把imageReader拿出来变成一个JFrame,手动输入,点一下,基本上就可以解决问题了。
第四个问题是微博内容在页面中体现不规则。例如,所有微博内容合二为一,只需 em.getTextContent()。因为不规则,有的em像点赞、空格等,解决方法是通过判断发现em只要不是真实的内容就没有任何属性。否则会有一个类属性。使用判断 hasAttribute() 踢掉点赞和空格。
第五个问题是不同id定位的问题。使用通用搜索时,定位ID为pl_weibo_direct,使用高级搜索时,微博内容定位ID为pl_wb_feedlist。
,当然是一些细节。
总结:
虽然还有很多问题,但是爬取数据的效果不是很好。不过可以肯定的是,新浪微博上的大部分数据还是可以通过网址找到的,新浪不可能大规模删除。假设像我这样的用户很久以前在2009年发了一条支持本田雅阁的微博,我可以通过我的微博链接看到与本田雅阁相关的微博内容。因此,与关键字相关的微博仍然存在于页面上,但新浪微博本身提供的搜索功能并不强大且有限。 查看全部
htmlunit 抓取网页(介绍常用爬虫开源项目和腾讯微博爬虫的问题总结)
介绍
常用爬虫开源项目
新浪微博爬虫和腾讯微博爬虫
新浪爬虫问题
总结
介绍
相关介绍
即网络爬虫是一种自动获取网页内容的程序。它是搜索引擎的重要组成部分,因此搜索引擎优化主要针对爬虫进行优化。
主要分类
网络爬虫从万维网上为搜索引擎下载网页。一般分为传统爬虫和专注爬虫。
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某个停止条件。通俗的讲,就是通过源码分析得到想要的内容。
焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
反爬虫:KS-WAF将爬虫行为分为搜索引擎爬虫和扫描爬虫,可以屏蔽特定搜索引擎爬虫以节省带宽和性能,也可以屏蔽扫描爬虫防止网站被恶意爬取。
常用爬虫开源项目
Nutch 标志 搜索引擎 Nutch
Nutch 是一个搜索引擎的开源 Java 实现。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫。
尽管网络搜索是漫游 Internet 的基本要求,但现有网络搜索引擎的数量正在下降。而这很可能会演变成一家为其商业利益垄断几乎所有网络搜索的公司。这显然对绝大多数网民不利。
现在所有主要的搜索引擎都使用专有的排名算法,这些算法不能解释为什么一个页面被排在一个特定的位置。另外,有些搜索引擎按网站付费,而不是按自己的值排序。
Apache Nutch 项目(一个网络搜索引擎)。当 Nutch 发展到一定程度时,遇到了可扩展性的问题,即当存储的网页数量达到 1 亿的水平时,Nutch 原有的结构很难达到高效率。就在整个团队不知所措的时候,救星谷歌出现了。Google 在 2003 年发布了 Google 使用的分布式文件存储系统文章(The Google File System),Nutch 开发者意识到可以将 Nutch 放在 GFS 上实现,所以经过一年的发展,NDFS(Nutch Distributed文件系统)出现。在解决了瓶颈问题之后,Nutch 有了很大的发展,而就在 2004 年,Google 发布了 MapReduce 的想法,因此尝到甜头的 Nutch 开发者们毫不犹豫地将 MapReduce 模型应用到了 Nutch 系统中。
但是在 Nutch 加入 GFS 和 MapReduce 之后,Nutch 变得太大了,超出了网络搜索引擎的范围,所以在 2006 年分别移植了 NDFS 和 MapReduce,形成了一个新的项目,叫做 Hadoop。
Java 多线程网络爬虫 Crawler4j
Crawler4j 是一个开源的 Java 类库,它提供了一个简单的网页爬取接口。它可以用来构建一个多线程的网络爬虫。
crawler4j的使用主要分为两步:
1. 实现一个继承自WebCrawler的爬虫类;
2.调用CrawlController实现的爬虫类。
WebCrawler 是一个抽象类,继承它必须实现两个方法:shouldVisit 和 visit。在:
shouldVisit 是判断当前URL是否应该被爬取(visited);
visit 是抓取URL指向的页面的数据,传入的参数是网页所有数据的封装对象Page。
Crawler.CrawController 控制爬虫,先添加seed,然后开启多个爬虫,不断监控每个爬虫的生存状态。
Crawler.WebCrawler 爬虫
1. Run():不断循环,每次从Frontier取50个url,对每个url进行processPage(curUrl)。
2. processPage(curURL):使用 PageFetcher.fetch 抓取网页。如果curURL被重定向,则将重定向url的url添加到Frontier,稍后调度;如果爬取正常,则先解析,生成Page,然后将新的url下降到Frontier(此时确定新增url的深度),调用visit(Page){用户自定义操作} .
Crawler.Configurations 读取 crawler4j.properties 中的信息
Crawler.PageFetcher 启动 IdleConnectionMonitorThread 并使用 fetch(Page, ignoreIfBinary) 抓取单个 Page 页面。是一个静态类。
Crawler.Page 一个页面
Crawler.PageFetchStatus 单页爬取的配置,如返回的爬取状态号的含义等。
Crawler.HTMLParser 解析 HTML 源代码并将其存储在 Page 中。
Crawler.LinkExtractor 提取 HTML 页面中收录的所有链接。
Crawler.IdleConnectionMonitorThread 用于监控连接(用于发送get请求,获取页面),其connMgr负责发送HTML请求。
HTML单元
HtmlUnitHtmlUnit 是“Java 程序的无 GUI 浏览器”。它对 HTML 文档进行建模并提供一个 API,允许您调用页面、填写表单、单击链接等……就像您在“普通”浏览器中所做的一样。
HtmlUnit的使用: 简介:HtmlUnit是一个浏览器,用Java编写,没有界面。因为它没有接口,所以执行速度仍然可以下降。HtmlUnit提供了一系列的API,这些API可以做很多功能,比如表单填写、表单提交、模拟点击链接,并且由于内置了Rhinojs引擎,可以执行Javascript
1、模拟特定浏览器,也可以指定浏览器对应版本(HtmlUnit最新版本2.13现在可以模拟Chrome/FireFox/IE)
WebClient webClient=new WebClient(BrowserVersion.FIREFOX_24);
2、查找特定元素,可以通过get或者XPath从HtmlPage中获取特定的Html元素。例如;
DomElement plc_main=page.getElementById("plc_main");
DomElement code_box=(DomElement) pl_common_sassfilter.getByXPath("//div[@class='code_box clearfix']").get(0);
3. 模拟表单的提交显示在用于登录的代码中;
HtmlForm loginform = logonPage.getFormByName("loginform");
HtmlTextInput uid = loginform.getInputByName("u");
uid.click();//点击获取焦点
uid.type(Config.getAccount());
HtmlPasswordInput pwd = loginform.getInputByName("p");
pwd.click();
pwd.type(Config.getPassword());
4、获取新浪微博等微博内容等信息。
DomNodeList dls = pl_weibo_direct.getElementsByTagName("dl");
DomElement dl= dls.get(0);
整数索引 = 0;
而(DL!=空){
DomElement em=feed_list_content.getElementsByTagName("em").get(0);
字符串内容 = em.getTextContent();
newlist.add(内容);
索引++;
dl = dls.get(索引);}
2.模拟登录,找到微博内容的位置。
3.获取微博数据并存入数据库,数据库使用MYSQL
逻辑其实很简单。需要熟悉HTMLunit提供的一些类,然后是XPath语法,再熟悉一些基础的数据库知识,就可以完成微博的爬取。
腾讯微博也有同样的想法。一些区别是
1.页面解析不同。
2.URL 的某些特征是不同的。
新浪爬虫问题总结
新浪微博爬虫的一些问题:
首先是微博数量的限制,从搜索页关键词开始,只能搜索到50页的微博数据。那么每页有20条,只能搜到1000条,这肯定跟实时微博的数量不匹配。
所以你可以使用高级搜索从2009年开始搜索,这需要不断的实验,看看时间可以弥补50页的微博。因为无论我搜索什么,新浪微博都只能显示50页的数据。
以本田雅阁为例,可以分为五次搜索,第一次是2009年到2010年,这个时间段只有33页数据,然后是2010年1.1到2011.1.1有50页数据,然后往下推。在某些时期,建立50页数据只需要五六个月。简而言之,这不是常规模式。大概,时间越长,微博越多。. 所以当这个编程达到50页时,url链接的下一页就没有了。这是一个限制。
第二个问题是微博内容重复。如果连接是
%25E6%259C%25AC%25E7%2594%25B0%25E9%259B%2585%25E9%2598%2581&xsort=time&scope=ori×cope=custom:2013-01-01-0:2014-04-23-0&page=8
以本田雅阁为例,这个页面上的微博基本上都是一样的内容。据我观察,这个品牌的微博更像是一个营销和广告的微博。当然,你可以用微博来验证这个方法来刷选。但真正有意义的是,原创的微博,是一个少得可怜的数字。只有几百个大小。
还是有一些方法可以删除同一个微博。最近在数据库下操作比较有效,使用select distinct content from weibo where program='Honda Accord' into outfile 'D:/Honda Accord.txt';仍然可以删除其中大部分重复推文。
或者对于几乎相同的情况,只有 URL 不同。您可以使用删除微博内容 LIKE '%铃木“大型车”将与本田雅阁同级%';或其他一些具有特别明显特征的词或短语。
第三个问题是,虽然新浪只提供了这么多数据,但还是处处受限。当程序运行到20页时,会出现需要手动输入验证码以防止爬虫影响其服务器的问题。这个方案是通过模仿登录验证码的方法来解决的。就是拿到需要输入的验证码,把imageReader拿出来变成一个JFrame,手动输入,点一下,基本上就可以解决问题了。
第四个问题是微博内容在页面中体现不规则。例如,所有微博内容合二为一,只需 em.getTextContent()。因为不规则,有的em像点赞、空格等,解决方法是通过判断发现em只要不是真实的内容就没有任何属性。否则会有一个类属性。使用判断 hasAttribute() 踢掉点赞和空格。
第五个问题是不同id定位的问题。使用通用搜索时,定位ID为pl_weibo_direct,使用高级搜索时,微博内容定位ID为pl_wb_feedlist。
,当然是一些细节。
总结:
虽然还有很多问题,但是爬取数据的效果不是很好。不过可以肯定的是,新浪微博上的大部分数据还是可以通过网址找到的,新浪不可能大规模删除。假设像我这样的用户很久以前在2009年发了一条支持本田雅阁的微博,我可以通过我的微博链接看到与本田雅阁相关的微博内容。因此,与关键字相关的微博仍然存在于页面上,但新浪微博本身提供的搜索功能并不强大且有限。
htmlunit 抓取网页(介绍两种使用Java进行Web的工具,即无头模式! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-11 13:17
)
在之前的 文章 中,我向您介绍了两个使用 Java 进行网页抓取的工具。第一个 文章 中的 HtmlUnit 和 文章 中的 PhantomJS 关于处理 Javascript-heavy 网站。
这一次,我们将介绍 Chrome 的一项新功能,即无头模式。有传言称谷歌使用特殊版本的 Chrome 来满足其抓取需求。我不知道这是否属实,但谷歌几个月前为 Chrome 59 引入了无头模式。
PhantomJS 是该领域的领导者,它已经(并且仍然)大量用于浏览器自动化和测试。在听说 Headless Chrome 之后,PhantomJS 的维护者说他辞去了维护者的职务,因为我引用了“Google Chrome 比 PhantomJS 更快、更稳定 [...]”
在浏览器自动化和处理 Java-heavy网站 方面,Chrome 无头似乎正在成为一种选择。
HtmlUnit、PhantomJS 和其他无头浏览器是非常有用的工具,问题是它们不如 Chrome 稳定,有时你会得到 Chrome 没有的 Javascript 错误。
先决条件
org.seleniumhq.selenium
selenium-java
3.8.1
如果你没有安装谷歌浏览器,你可以在这里下载
要安装 Chromedriver,您可以在 MacOS 上使用 brew:
brew install chromedriver
或使用以下链接下载。
版本比较多,建议大家使用最新版的Chrome和chromedriver。
让我们登录黑客新闻
在这一部分中,我们将登录 Hacker News 并在登录后进行截图。我们不需要 Chrome 无头来执行此任务,但本文的目的只是向您展示如何使用 Selenium 运行无头 Chrome。
我们要做的第一件事是创建一个 WebDriver 对象并设置 chromedriver 路径和一些参数:
的
option is needed on Windows systems, according to the [documentation](https://developers.google.com/ ... chrome)
Chromedriver should automatically find the Google Chrome executable path, if you have a special installation, or if you want to use a different version of Chrome, you can do it with :
```java
options.setBinary("/Path/to/specific/version/of/Google Chrome");
如果您想了解有关不同选项的更多信息,请参阅 Chromedriver 文档
下一步是对 Hacker News 登录表单执行 GET 请求,选择用户名和密码字段,用我们的凭据填写它们,然后单击登录按钮。然后我们必须检查凭据错误,如果登录,我们可以截屏。
查看全部
htmlunit 抓取网页(介绍两种使用Java进行Web的工具,即无头模式!
)
在之前的 文章 中,我向您介绍了两个使用 Java 进行网页抓取的工具。第一个 文章 中的 HtmlUnit 和 文章 中的 PhantomJS 关于处理 Javascript-heavy 网站。
这一次,我们将介绍 Chrome 的一项新功能,即无头模式。有传言称谷歌使用特殊版本的 Chrome 来满足其抓取需求。我不知道这是否属实,但谷歌几个月前为 Chrome 59 引入了无头模式。
PhantomJS 是该领域的领导者,它已经(并且仍然)大量用于浏览器自动化和测试。在听说 Headless Chrome 之后,PhantomJS 的维护者说他辞去了维护者的职务,因为我引用了“Google Chrome 比 PhantomJS 更快、更稳定 [...]”
在浏览器自动化和处理 Java-heavy网站 方面,Chrome 无头似乎正在成为一种选择。
HtmlUnit、PhantomJS 和其他无头浏览器是非常有用的工具,问题是它们不如 Chrome 稳定,有时你会得到 Chrome 没有的 Javascript 错误。
先决条件
org.seleniumhq.selenium
selenium-java
3.8.1
如果你没有安装谷歌浏览器,你可以在这里下载
要安装 Chromedriver,您可以在 MacOS 上使用 brew:
brew install chromedriver
或使用以下链接下载。
版本比较多,建议大家使用最新版的Chrome和chromedriver。
让我们登录黑客新闻
在这一部分中,我们将登录 Hacker News 并在登录后进行截图。我们不需要 Chrome 无头来执行此任务,但本文的目的只是向您展示如何使用 Selenium 运行无头 Chrome。
我们要做的第一件事是创建一个 WebDriver 对象并设置 chromedriver 路径和一些参数:
的
option is needed on Windows systems, according to the [documentation](https://developers.google.com/ ... chrome)
Chromedriver should automatically find the Google Chrome executable path, if you have a special installation, or if you want to use a different version of Chrome, you can do it with :
```java
options.setBinary("/Path/to/specific/version/of/Google Chrome");
如果您想了解有关不同选项的更多信息,请参阅 Chromedriver 文档
下一步是对 Hacker News 登录表单执行 GET 请求,选择用户名和密码字段,用我们的凭据填写它们,然后单击登录按钮。然后我们必须检查凭据错误,如果登录,我们可以截屏。
htmlunit 抓取网页(1.通用网络爬虫的基本结构和工作有所实现时要)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-01-08 08:04
有趣~~
网络爬虫简介
【可爱的脸孔】
前言
爬虫这个词在互联网高度发达的今天,也许你我不再陌生。互联网上每天都会产生海量的数据,如何帮助人们准确找到自己想要的信息一直是相关从业者努力改进的问题。其中,以搜索引擎为代表的应用系统是我们日常生活中最常见的表现形式。爬虫是否有助于测试工作?带着这个问题,我们先来了解一下爬虫的基本概念和原理:参考360百科就知道,网络爬虫,又称网络蜘蛛、网络机器人,是一种遵循一定规则的网络爬虫。,一种自动从万维网上抓取信息的程序或脚本。
爬虫?? 有趣~~
网络爬虫的基本结构和工作流程
在实践中,一个通用的网络爬虫可以通过多种不同的方式实现,但总体原理是相同的。以下是笔者接触过的框架,笔者以此为背景与大家分享。
1. 通用网络爬虫框架图:
基本工作流程如下——将种子 URL(即开始爬取的入口 URL)和配置文件交给控制器。配置文件可以收录爬取深度、文件类型、使用的账号信息以及线程数、机器人数等。 - 控制器会从待处理的URL中获取一定数量的URL,交给空闲线程去抓取对应的网页内容——每个网页处理线程在下载对应的URL中间的内容后,会将当前的URL放入已处理的URL表中。同时,处理线程将获取当前内容中的所有链接地址并与处理后的URL表进行比较,将未处理的URL放入待处理的URL表中。
2. 实现爬虫需要注意几个方面:
判断返回页面的状态码,需要针对有跳转的页面跟踪跳转后的URL(以下代码截取自开源java爬虫工具crawler4j)
处理js动态加载:由于js在浏览器中执行后才能看到内容,所以爬虫获取时不执行,指定html标签下的内容必须为空。内容的js代码字符串,然后通过正则表达式获取对应的内容,而不是解析HTML标签。在收录以下 js 片段的页面中提取“分数”值:
未通过带有“id=result”的标签找到,但可以通过正则表达式分数匹配:(\d+)。
Ajax异步请求,在今天的网站中经常使用,一般需要用户进行交互才能返回内容。在这种情况下,可以使用一些模拟浏览器的工具,比如HtmlUnit,通过模拟用户点击操作来获取想要的数据。这种方式可能会导致系统资源消耗严重,稳定性差。另一种方式是直接拼接ajax接口参数的url来完成数据抓取。
对于设计用于大规模网络的爬虫,还需要考虑完成所有页面爬取所需的时间和存储资源。在这种情况下,爬虫设计应该采用分布式应用架构。这里不讨论这个。
三、测试领域的应用
因为我们在做测试,所以我们也想探索爬虫在自动化测试中可以拥有哪些应用程序。目前可以预见的尝试以下几个方面: - 使用爬虫遍历web服务的每个URL,检查是否有损坏的链接 - 结合selenium webdriver进行随机测试(如crawjax) - 定期更新web对象仓库UI自动化测试
四、结束语
我们刚刚开始对网络爬虫的研究和研究,期待在新的体验之后与您分享更多相关内容。最后附上一个开源的java爬虫工具crawler4j(下载地址:)。这个项目也是我用来学习爬虫的项目。之前的网页上有例子,有兴趣的同学可以使用。
看不够~
忍不住哭了~~
Qtest之道
遵循Qtest的方式 查看全部
htmlunit 抓取网页(1.通用网络爬虫的基本结构和工作有所实现时要)
有趣~~


网络爬虫简介
【可爱的脸孔】
前言
爬虫这个词在互联网高度发达的今天,也许你我不再陌生。互联网上每天都会产生海量的数据,如何帮助人们准确找到自己想要的信息一直是相关从业者努力改进的问题。其中,以搜索引擎为代表的应用系统是我们日常生活中最常见的表现形式。爬虫是否有助于测试工作?带着这个问题,我们先来了解一下爬虫的基本概念和原理:参考360百科就知道,网络爬虫,又称网络蜘蛛、网络机器人,是一种遵循一定规则的网络爬虫。,一种自动从万维网上抓取信息的程序或脚本。
爬虫?? 有趣~~

网络爬虫的基本结构和工作流程
在实践中,一个通用的网络爬虫可以通过多种不同的方式实现,但总体原理是相同的。以下是笔者接触过的框架,笔者以此为背景与大家分享。
1. 通用网络爬虫框架图:

基本工作流程如下——将种子 URL(即开始爬取的入口 URL)和配置文件交给控制器。配置文件可以收录爬取深度、文件类型、使用的账号信息以及线程数、机器人数等。 - 控制器会从待处理的URL中获取一定数量的URL,交给空闲线程去抓取对应的网页内容——每个网页处理线程在下载对应的URL中间的内容后,会将当前的URL放入已处理的URL表中。同时,处理线程将获取当前内容中的所有链接地址并与处理后的URL表进行比较,将未处理的URL放入待处理的URL表中。
2. 实现爬虫需要注意几个方面:
判断返回页面的状态码,需要针对有跳转的页面跟踪跳转后的URL(以下代码截取自开源java爬虫工具crawler4j)

处理js动态加载:由于js在浏览器中执行后才能看到内容,所以爬虫获取时不执行,指定html标签下的内容必须为空。内容的js代码字符串,然后通过正则表达式获取对应的内容,而不是解析HTML标签。在收录以下 js 片段的页面中提取“分数”值:

未通过带有“id=result”的标签找到,但可以通过正则表达式分数匹配:(\d+)。
Ajax异步请求,在今天的网站中经常使用,一般需要用户进行交互才能返回内容。在这种情况下,可以使用一些模拟浏览器的工具,比如HtmlUnit,通过模拟用户点击操作来获取想要的数据。这种方式可能会导致系统资源消耗严重,稳定性差。另一种方式是直接拼接ajax接口参数的url来完成数据抓取。
对于设计用于大规模网络的爬虫,还需要考虑完成所有页面爬取所需的时间和存储资源。在这种情况下,爬虫设计应该采用分布式应用架构。这里不讨论这个。
三、测试领域的应用
因为我们在做测试,所以我们也想探索爬虫在自动化测试中可以拥有哪些应用程序。目前可以预见的尝试以下几个方面: - 使用爬虫遍历web服务的每个URL,检查是否有损坏的链接 - 结合selenium webdriver进行随机测试(如crawjax) - 定期更新web对象仓库UI自动化测试
四、结束语
我们刚刚开始对网络爬虫的研究和研究,期待在新的体验之后与您分享更多相关内容。最后附上一个开源的java爬虫工具crawler4j(下载地址:)。这个项目也是我用来学习爬虫的项目。之前的网页上有例子,有兴趣的同学可以使用。
看不够~
忍不住哭了~~

Qtest之道

遵循Qtest的方式
htmlunit 抓取网页(Htmlunit模拟浏览页面内容的java框架,具有js解析引擎(rhino))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-06 00:19
Htmlunit 是一个模拟浏览和抓取页面内容的java框架。自带js解析引擎(rhino),可以解析页面的js脚本,得到完整的页面内容,特别适合这种不完整页面的站点抓取。
以下使用的是htmlunit版本:
net.sourceforge.htmlunit
htmlunit
2.14
代码的实现很简单,主要分为两种常见的场景:解析页面的js和不解析页面的js
public class CrawlPage {
public static void main(String[] args) throws Exception {
CrawlPage crawl = new CrawlPage();
String url = "http://www.baidu.com/";
System.out.println("----------------------抓取页面时不解析js-----------------");
crawl.crawlPageWithoutAnalyseJs(url);
System.out.println("----------------------抓取页面时解析js-------------------");
crawl.crawlPageWithAnalyseJs(url);
}
/**
* 功能描述:抓取页面时不解析页面的js
* @param url
* @throws Exception
*/
public void crawlPageWithoutAnalyseJs(String url) throws Exception{
//1.创建连接client
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//2.设置连接的相关选项
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setTimeout(10000);
//3.抓取页面
HtmlPage page = webClient.getPage(url);
System.out.println(page.asXml());
//4.关闭模拟窗口
webClient.closeAllWindows();
}
/**
* 功能描述:抓取页面时并解析页面的js
* @param url
* @throws Exception
*/
public void crawlPageWithAnalyseJs(String url) throws Exception{
//1.创建连接client
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//2.设置连接的相关选项
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true); //需要解析js
webClient.getOptions().setThrowExceptionOnScriptError(false); //解析js出错时不抛异常
webClient.getOptions().setTimeout(10000); //超时时间 ms
//3.抓取页面
HtmlPage page = webClient.getPage(url);
//4.将页面转成指定格式
webClient.waitForBackgroundJavaScript(10000); //等侍js脚本执行完成
System.out.println(page.asXml());
//5.关闭模拟的窗口
webClient.closeAllWindows();
}
}
主要关注webClient几个选项的配置,
webClient.getOptions().setJavaScriptEnabled(true); //需要解析js
webClient.getOptions().setThrowExceptionOnScriptError(false); //解析js出错时不抛异常
默认需要打开这两个开关来解析页面的js和css渲染。因为爬虫本身没有接口,所以不需要这部分,即如下配置:
webClient.getOptions().setCssEnabled(false);
Htmlunit 在解析 js 时也可能会失败。此篇未深入研究,后续使用中遇到问题记录
抓到的内容默认以xml的形式获取,即page.asXml(),因为这样可以通过jsoup解析html页面数据,jsoup是一个更方便简洁的工具,后续有follow -up 关于jsoup的使用实践,欢迎大家来打砖~~
相关文件:
htmlunit官网-
jsoup官网- 查看全部
htmlunit 抓取网页(Htmlunit模拟浏览页面内容的java框架,具有js解析引擎(rhino))
Htmlunit 是一个模拟浏览和抓取页面内容的java框架。自带js解析引擎(rhino),可以解析页面的js脚本,得到完整的页面内容,特别适合这种不完整页面的站点抓取。
以下使用的是htmlunit版本:
net.sourceforge.htmlunit
htmlunit
2.14
代码的实现很简单,主要分为两种常见的场景:解析页面的js和不解析页面的js
public class CrawlPage {
public static void main(String[] args) throws Exception {
CrawlPage crawl = new CrawlPage();
String url = "http://www.baidu.com/";
System.out.println("----------------------抓取页面时不解析js-----------------");
crawl.crawlPageWithoutAnalyseJs(url);
System.out.println("----------------------抓取页面时解析js-------------------");
crawl.crawlPageWithAnalyseJs(url);
}
/**
* 功能描述:抓取页面时不解析页面的js
* @param url
* @throws Exception
*/
public void crawlPageWithoutAnalyseJs(String url) throws Exception{
//1.创建连接client
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//2.设置连接的相关选项
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setTimeout(10000);
//3.抓取页面
HtmlPage page = webClient.getPage(url);
System.out.println(page.asXml());
//4.关闭模拟窗口
webClient.closeAllWindows();
}
/**
* 功能描述:抓取页面时并解析页面的js
* @param url
* @throws Exception
*/
public void crawlPageWithAnalyseJs(String url) throws Exception{
//1.创建连接client
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//2.设置连接的相关选项
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true); //需要解析js
webClient.getOptions().setThrowExceptionOnScriptError(false); //解析js出错时不抛异常
webClient.getOptions().setTimeout(10000); //超时时间 ms
//3.抓取页面
HtmlPage page = webClient.getPage(url);
//4.将页面转成指定格式
webClient.waitForBackgroundJavaScript(10000); //等侍js脚本执行完成
System.out.println(page.asXml());
//5.关闭模拟的窗口
webClient.closeAllWindows();
}
}
主要关注webClient几个选项的配置,
webClient.getOptions().setJavaScriptEnabled(true); //需要解析js
webClient.getOptions().setThrowExceptionOnScriptError(false); //解析js出错时不抛异常
默认需要打开这两个开关来解析页面的js和css渲染。因为爬虫本身没有接口,所以不需要这部分,即如下配置:
webClient.getOptions().setCssEnabled(false);
Htmlunit 在解析 js 时也可能会失败。此篇未深入研究,后续使用中遇到问题记录
抓到的内容默认以xml的形式获取,即page.asXml(),因为这样可以通过jsoup解析html页面数据,jsoup是一个更方便简洁的工具,后续有follow -up 关于jsoup的使用实践,欢迎大家来打砖~~
相关文件:
htmlunit官网-
jsoup官网-
htmlunit 抓取网页(普通web网站的信息,用URL的HTML源代码的方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-01-06 00:03
普通的web网站信息通过下载URL的HTML源代码就可以满足基本需求,但是现在有更多的网站使用web2.0技术,比如一些电子商务网站、SNS网站等,抓取网页的部分信息时,如评论、滚动、延迟加载等,直接下载HTML源代码不能满足需求,而且很多ajax规则需要自定义,通过多个请求完成一个页面信息的采集。在这种情况下,爬虫代码定制更加复杂,开发和维护难度增加。
找了一些支持ajax爬取的开源工具,比如Crawlajax(?),它是基于webdriver技术的,需要一个接口来辅助,但是爬虫最好没有接口,以减少加载时间,降低复杂度,增加程序的便利性和稳定性 经过一番搜索,有一个开源工具可以基本满足需求,那就是HtmlUnit。
该工具集成了 Rhino 的 javascript 引擎,可以解析 HTML 并模拟 js 的执行。通过HtmlUnit打开网页后,可以获取当前的DOM结构,执行js,点击链接,提交表单。最大的优点是它没有接口。
import java.net.URL;import com.gargoylesoftware.htmlunit.WebClient;import com.gargoylesoftware.htmlunit.html.HtmlElement;import com.gargoylesoftware.htmlunit.html.HtmlPage;public class Sample {/** * @param args */public static void main(String[] args) throws Exception{// TODO Auto-generated method stub//设置访问ChromeDriver的路径 final WebClient webClient = new WebClient(); // 构造一个URL,指向需要测试的URL,如http://www.javaeye.com URL url = new URL("http://item.jd.com/754320.html"); // 通过getPage()方法,返回相应的页面 webClient.getCurrentWindow().setInnerHeight(60000); webClient.setCssEnabled(false); HtmlPage page = (HtmlPage) webClient.getPage(url); System.out.println("InnerHeight:"+webClient.getCurrentWindow().getInnerHeight()); //System.out.println(page.getTitleText()); System.out.println(page.asText()); }}
特别说明:HtmlUnit 不支持滚动消息。一些网页在加载时滚动。执行js语句将webcontrol滚动到底部是无效的。国外也有人提出了这个问题,但没有给出解决方案。找了半天,终于找到了绕过的办法,就是把页面的高度设置为60000,一个可以容纳所有页面可见范围的大值,这样就可以满足滚动加载的需要(也就是页面不需要滚动。没关系)。 查看全部
htmlunit 抓取网页(普通web网站的信息,用URL的HTML源代码的方式)
普通的web网站信息通过下载URL的HTML源代码就可以满足基本需求,但是现在有更多的网站使用web2.0技术,比如一些电子商务网站、SNS网站等,抓取网页的部分信息时,如评论、滚动、延迟加载等,直接下载HTML源代码不能满足需求,而且很多ajax规则需要自定义,通过多个请求完成一个页面信息的采集。在这种情况下,爬虫代码定制更加复杂,开发和维护难度增加。
找了一些支持ajax爬取的开源工具,比如Crawlajax(?),它是基于webdriver技术的,需要一个接口来辅助,但是爬虫最好没有接口,以减少加载时间,降低复杂度,增加程序的便利性和稳定性 经过一番搜索,有一个开源工具可以基本满足需求,那就是HtmlUnit。
该工具集成了 Rhino 的 javascript 引擎,可以解析 HTML 并模拟 js 的执行。通过HtmlUnit打开网页后,可以获取当前的DOM结构,执行js,点击链接,提交表单。最大的优点是它没有接口。
import java.net.URL;import com.gargoylesoftware.htmlunit.WebClient;import com.gargoylesoftware.htmlunit.html.HtmlElement;import com.gargoylesoftware.htmlunit.html.HtmlPage;public class Sample {/** * @param args */public static void main(String[] args) throws Exception{// TODO Auto-generated method stub//设置访问ChromeDriver的路径 final WebClient webClient = new WebClient(); // 构造一个URL,指向需要测试的URL,如http://www.javaeye.com URL url = new URL("http://item.jd.com/754320.html";); // 通过getPage()方法,返回相应的页面 webClient.getCurrentWindow().setInnerHeight(60000); webClient.setCssEnabled(false); HtmlPage page = (HtmlPage) webClient.getPage(url); System.out.println("InnerHeight:"+webClient.getCurrentWindow().getInnerHeight()); //System.out.println(page.getTitleText()); System.out.println(page.asText()); }}
特别说明:HtmlUnit 不支持滚动消息。一些网页在加载时滚动。执行js语句将webcontrol滚动到底部是无效的。国外也有人提出了这个问题,但没有给出解决方案。找了半天,终于找到了绕过的办法,就是把页面的高度设置为60000,一个可以容纳所有页面可见范围的大值,这样就可以满足滚动加载的需要(也就是页面不需要滚动。没关系)。
htmlunit 抓取网页(和java自带的网络API进行结合,怎么做?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-05 04:01
HtmlUnit 结合了 HttpClient 和 java 自带的网络 API,操作起来更加简单方便。HtmlUnit底层依然封装了HttpClient,但是封装之后解析出来的内容更像是一个网页,而不是抽象的请求和响应,所以更方便开发者上手。
// [1] new一个WebClient,在其中定义一种浏览器
WebClient webClent = new WebClient(BrowserVersion.FIREFOX_17);
// [2] 设置网页解析的内容
WebClientOptions options=webClent.getOptions();
options.setCssEnabled(false);
options.setJavaScriptEnabled(true);
options.setActiveXNative(false);
options.setAppletEnabled(false);
options.setRedirectEnabled(true);
options.setThrowExceptionOnFailingStatusCode(false);
options.setThrowExceptionOnScriptError(false);
options.setDoNotTrackEnabled(false);
options.setGeolocationEnabled(false);
// [3] 访问指定的页面,并将其赋予HtmlPage
HtmlPage htmlPage=webClent.getPage(url);
// [4] 获得的HtmlPage并不易于阅读,所以有需要可以通过Jsoup将其转换为Document对象
Document document = Jsoup.parseBodyFragment(htmlPage.asXml());
// [5]关闭
webClent.closeAllWindows();
HtmlPage对于获取按钮后赋值和操作点击事件非常方便。常用方法getElementByName根据名称获取指定的标签(HtmlElement),可以为标签设置类型。
select("") 方法经常用在 Document 对象中。通过这个方法可以得到一个特定的Element,然后通过解析内容就可以得到需要的数据。
HtmlUnit方便抓取,但是因为它模拟了网页点击事件,所以所有的响应内容都会变得臃肿。如果需要的数据量很小,效率会有点低。 查看全部
htmlunit 抓取网页(和java自带的网络API进行结合,怎么做?)
HtmlUnit 结合了 HttpClient 和 java 自带的网络 API,操作起来更加简单方便。HtmlUnit底层依然封装了HttpClient,但是封装之后解析出来的内容更像是一个网页,而不是抽象的请求和响应,所以更方便开发者上手。
// [1] new一个WebClient,在其中定义一种浏览器
WebClient webClent = new WebClient(BrowserVersion.FIREFOX_17);
// [2] 设置网页解析的内容
WebClientOptions options=webClent.getOptions();
options.setCssEnabled(false);
options.setJavaScriptEnabled(true);
options.setActiveXNative(false);
options.setAppletEnabled(false);
options.setRedirectEnabled(true);
options.setThrowExceptionOnFailingStatusCode(false);
options.setThrowExceptionOnScriptError(false);
options.setDoNotTrackEnabled(false);
options.setGeolocationEnabled(false);
// [3] 访问指定的页面,并将其赋予HtmlPage
HtmlPage htmlPage=webClent.getPage(url);
// [4] 获得的HtmlPage并不易于阅读,所以有需要可以通过Jsoup将其转换为Document对象
Document document = Jsoup.parseBodyFragment(htmlPage.asXml());
// [5]关闭
webClent.closeAllWindows();
HtmlPage对于获取按钮后赋值和操作点击事件非常方便。常用方法getElementByName根据名称获取指定的标签(HtmlElement),可以为标签设置类型。
select("") 方法经常用在 Document 对象中。通过这个方法可以得到一个特定的Element,然后通过解析内容就可以得到需要的数据。
HtmlUnit方便抓取,但是因为它模拟了网页点击事件,所以所有的响应内容都会变得臃肿。如果需要的数据量很小,效率会有点低。
htmlunit 抓取网页(搜索引擎如何将频次分配给网站的机制以及提高网站排名和有机流量的技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-23 04:00
爬行频率更像是一个 SEO 概念。大多数情况下,站长并不关心百度蜘蛛的抓取频率,因为抓取频率对中小企业几乎没有影响网站。
尽管大多数 网站 管理员不必担心抓取频率,但如果您正在运行大型 网站,抓取频率是我们可以(并且应该)优化的 SEO 因素。
当然,随着 SEO 的发展,爬取频率和排名的关系并不简单,爬取本身并不是一个排名因素,但是从某种角度来说,爬取频率对搜索引擎优化有着间接的影响(这也是造成搜索引擎优化的原因)蜘蛛池的流行)。
在本指南中,我将讲解相关的爬取概念,搜索引擎如何将爬取频率分配给网站的机制,以及如何充分利用爬取频率来最大化网站的排名和排名的技巧为有机交通。
内容
网络蜘蛛的好与坏
网络蜘蛛、爬虫或机器人是不断“访问”和抓取网页以采集某些信息的计算机程序。
根据爬行的目的,可以区分以下几种蜘蛛:
搜索引擎蜘蛛
网络服务蜘蛛;
黑客蜘蛛
搜索引擎蜘蛛由百度、谷歌或360等搜索引擎管理。这些蜘蛛可以抓取互联网上的所有页面(前提是可以找到)并提供给搜索引擎的索引库。
许多网络服务,如搜索引擎优化工具、购物、旅游和优惠券,都有自己的网络索引和蜘蛛。例如,WebMeUp 有一个名为 Blexbot 的蜘蛛,每天可以抓取数百亿个页面。采集反向链接数据并将此数据提供给其链接索引(SEO SpyGlass 中使用的链接索引)。
黑客也喜欢繁殖蜘蛛。他们使用蜘蛛来测试各种 网站 漏洞。一旦发现漏洞,他们可能会尝试访问您的 网站 或服务器。
你可能会听到人们谈论好蜘蛛和坏蜘蛛,我是这样区分的:任何旨在为非法目的采集信息的蜘蛛都是坏的,其余的都是好的。
大多数蜘蛛在用户代理字符串的帮助下识别自己,并提供 URL,您可以在其中了解有关蜘蛛的更多信息:
在本文中,我将重点介绍搜索引擎蜘蛛以及它们如何抓取 网站。
了解抓取频率
抓取频率是搜索引擎蜘蛛在一定时间内点击网站的次数。例如,百度通常每月点击我的网站 1000 次。我可以说1K是百度每个月的爬虫频率,请注意这些爬虫的数量和频率没有一般限制;。
为什么抓取频率很重要?
从逻辑上讲,你应该注意抓取频率,因为你想让百度在网站上发现尽可能多的重要网页,也希望它能在你的网站上快速找到新的内容和抓取频率越高,这种情况发生的速度就越快。
确定爬取频率
您可以在百度网站管理员工具中查看您的网站抓取频率。比如你需要确定自己的百度爬取频率,登录百度站长账号,进入数据监控->爬取频率,这里会看到每天的爬取频率。
从上面的报告中可以看出,百度平均每天抓取我大约30次。由此可以看出,我每月的爬取频率是30*30=900。
当然,这个数字很容易变化和波动,但它会为你提供一个可靠的想法,你可以在特定时间段内抓取你的网站的页面数量。
如果需要更详细地查看每个页面的爬取统计信息,则必须分析服务器日志。日志文件的位置取决于服务器配置。
如果您不确定如何访问服务器日志,请向您的系统管理员或托管服务提供商寻求帮助。
原创日志文件难以阅读和分析。要理解这些,您需要绝对水平的正则表达式技能或专门的工具。我更喜欢使用光年日志分析工具进行分析。
如何分配抓取频率?
对于搜索引擎优化,我们并不完全了解搜索引擎是如何形成网站的抓取频率的。所有博主对网络内容进行梳理,搜索引擎使用以下两个因素来确定抓取频率:
人气——越流行的网页会被更频繁地抓取;
过时-百度不会使有关网页的信息过时。对于网站管理员来说,这意味着如果网页内容更新频繁,百度会更频繁地尝试抓取网页。
假设一个网站的抓取频率与反向链接的数量和网站在百度眼中的重要性成正比——百度希望确保最重要的网页保持最新的索引。
内部链接呢?您能否通过指向更多内部链接来提高特定页面的抓取速度?
为了回答这些问题,我决定检查一下内链和外链的相关性和爬取统计。我采集了网站的11条数据,进行了简单的分析。简而言之,这是我完成的。
我为 11 个将要分析的站点创建了项目。我计算了每个 网站 网页的内部链接数量。接下来,我运行了 SEO Spyglass 并为相同的 11 个站点创建了项目。在每个项目中,我检查了统计数据并复制了每个页面的外部链接数量的锚点 URL。
然后,我分析了服务器日志中的爬取统计数据,以了解百度访问每个网页的频率。最后,我把所有这些数据放到一个电子表格中,计算出内链和爬虫预算、外链和爬虫预算的相关性。
我发现了一件非常有趣的事情。这是我分析的 网站 的示例电子表格之一:
我的数据集证明,蜘蛛访问次数与外部链接数之间存在很强的相关性(0,978)。同时,蜘蛛命中数与内部链接之间的相关性被证明非常弱(0 ,154),说明反向链接比网站链接更重要。
这是否意味着增加抓取频率的唯一方法是建立链接和发布新内容?如果我们讨论整个网站的朱雀频率,我会说是的:添加链接并经常更新网站,网站的抓取频率会成比例地增加。
但是,当我们单独取一个页面时,它会变得更有趣,正如您在下面的介绍中看到的那样,您甚至可能会在不知不觉中浪费大量的抓取频率。通过巧妙地管理频率,您通常可以使单个网页的抓取次数增加一倍——但它仍然会与每个网页的反向链接数量成正比。
如何充分利用抓取频率
现在,我们已经发现爬行很重要,是不是要花更多的时间来管理爬行频率?
你应该(或不应该)做很多事情来让搜索蜘蛛消耗更多的 网站 页面。以下是最大化爬取频率特征的操作列表:
1.保证重要页面可以被抓取,如果搜索到的内容不提供价值,就会被屏蔽。
.htaccess 和 robots.txt 不应阻塞 网站 的重要页面。机器人应该能够访问 CSS 和 Javascript 文件。同时,应该屏蔽不想在搜索中显示的内容,屏蔽“正在建设中的网站”区域和动态生成的网址等。
请记住,搜索引擎蜘蛛并不总是遵循 robots.txt 中收录的说明。你有没有在百度搜索结果中看到过这样的片段?
Robots.txt 不保证网页不会出现在搜索结果中:百度仍然可以根据外部信息(如传入链接)确定其相关性,如果您想明确阻止页面被索引,您应该使用 noindex robots 元标记或 X-Robots-Tag HTTP 标头,在这种情况下,您不应在 robots.txt 中禁止该页面,因为必须抓取该页面才能看到并符合该标记。 查看全部
htmlunit 抓取网页(搜索引擎如何将频次分配给网站的机制以及提高网站排名和有机流量的技巧)
爬行频率更像是一个 SEO 概念。大多数情况下,站长并不关心百度蜘蛛的抓取频率,因为抓取频率对中小企业几乎没有影响网站。
尽管大多数 网站 管理员不必担心抓取频率,但如果您正在运行大型 网站,抓取频率是我们可以(并且应该)优化的 SEO 因素。
当然,随着 SEO 的发展,爬取频率和排名的关系并不简单,爬取本身并不是一个排名因素,但是从某种角度来说,爬取频率对搜索引擎优化有着间接的影响(这也是造成搜索引擎优化的原因)蜘蛛池的流行)。
在本指南中,我将讲解相关的爬取概念,搜索引擎如何将爬取频率分配给网站的机制,以及如何充分利用爬取频率来最大化网站的排名和排名的技巧为有机交通。
内容
网络蜘蛛的好与坏
网络蜘蛛、爬虫或机器人是不断“访问”和抓取网页以采集某些信息的计算机程序。
根据爬行的目的,可以区分以下几种蜘蛛:
搜索引擎蜘蛛
网络服务蜘蛛;
黑客蜘蛛
搜索引擎蜘蛛由百度、谷歌或360等搜索引擎管理。这些蜘蛛可以抓取互联网上的所有页面(前提是可以找到)并提供给搜索引擎的索引库。
许多网络服务,如搜索引擎优化工具、购物、旅游和优惠券,都有自己的网络索引和蜘蛛。例如,WebMeUp 有一个名为 Blexbot 的蜘蛛,每天可以抓取数百亿个页面。采集反向链接数据并将此数据提供给其链接索引(SEO SpyGlass 中使用的链接索引)。
黑客也喜欢繁殖蜘蛛。他们使用蜘蛛来测试各种 网站 漏洞。一旦发现漏洞,他们可能会尝试访问您的 网站 或服务器。
你可能会听到人们谈论好蜘蛛和坏蜘蛛,我是这样区分的:任何旨在为非法目的采集信息的蜘蛛都是坏的,其余的都是好的。
大多数蜘蛛在用户代理字符串的帮助下识别自己,并提供 URL,您可以在其中了解有关蜘蛛的更多信息:
 https://www.simcf.cc/wp-conten ... 4.jpg 300w, https://www.simcf.cc/wp-conten ... 9.jpg 768w" />
https://www.simcf.cc/wp-conten ... 4.jpg 300w, https://www.simcf.cc/wp-conten ... 9.jpg 768w" />在本文中,我将重点介绍搜索引擎蜘蛛以及它们如何抓取 网站。
了解抓取频率
抓取频率是搜索引擎蜘蛛在一定时间内点击网站的次数。例如,百度通常每月点击我的网站 1000 次。我可以说1K是百度每个月的爬虫频率,请注意这些爬虫的数量和频率没有一般限制;。
为什么抓取频率很重要?
从逻辑上讲,你应该注意抓取频率,因为你想让百度在网站上发现尽可能多的重要网页,也希望它能在你的网站上快速找到新的内容和抓取频率越高,这种情况发生的速度就越快。
确定爬取频率
您可以在百度网站管理员工具中查看您的网站抓取频率。比如你需要确定自己的百度爬取频率,登录百度站长账号,进入数据监控->爬取频率,这里会看到每天的爬取频率。
 https://www.simcf.cc/wp-conten ... 2.jpg 300w, https://www.simcf.cc/wp-conten ... 1.jpg 768w, https://www.simcf.cc/wp-conten ... h.jpg 1159w" />
https://www.simcf.cc/wp-conten ... 2.jpg 300w, https://www.simcf.cc/wp-conten ... 1.jpg 768w, https://www.simcf.cc/wp-conten ... h.jpg 1159w" />从上面的报告中可以看出,百度平均每天抓取我大约30次。由此可以看出,我每月的爬取频率是30*30=900。
当然,这个数字很容易变化和波动,但它会为你提供一个可靠的想法,你可以在特定时间段内抓取你的网站的页面数量。
如果需要更详细地查看每个页面的爬取统计信息,则必须分析服务器日志。日志文件的位置取决于服务器配置。
如果您不确定如何访问服务器日志,请向您的系统管理员或托管服务提供商寻求帮助。
原创日志文件难以阅读和分析。要理解这些,您需要绝对水平的正则表达式技能或专门的工具。我更喜欢使用光年日志分析工具进行分析。
如何分配抓取频率?
对于搜索引擎优化,我们并不完全了解搜索引擎是如何形成网站的抓取频率的。所有博主对网络内容进行梳理,搜索引擎使用以下两个因素来确定抓取频率:
人气——越流行的网页会被更频繁地抓取;
过时-百度不会使有关网页的信息过时。对于网站管理员来说,这意味着如果网页内容更新频繁,百度会更频繁地尝试抓取网页。
假设一个网站的抓取频率与反向链接的数量和网站在百度眼中的重要性成正比——百度希望确保最重要的网页保持最新的索引。
内部链接呢?您能否通过指向更多内部链接来提高特定页面的抓取速度?
为了回答这些问题,我决定检查一下内链和外链的相关性和爬取统计。我采集了网站的11条数据,进行了简单的分析。简而言之,这是我完成的。
我为 11 个将要分析的站点创建了项目。我计算了每个 网站 网页的内部链接数量。接下来,我运行了 SEO Spyglass 并为相同的 11 个站点创建了项目。在每个项目中,我检查了统计数据并复制了每个页面的外部链接数量的锚点 URL。
然后,我分析了服务器日志中的爬取统计数据,以了解百度访问每个网页的频率。最后,我把所有这些数据放到一个电子表格中,计算出内链和爬虫预算、外链和爬虫预算的相关性。
我发现了一件非常有趣的事情。这是我分析的 网站 的示例电子表格之一:
 https://www.simcf.cc/wp-conten ... 5.png 300w" />
https://www.simcf.cc/wp-conten ... 5.png 300w" />我的数据集证明,蜘蛛访问次数与外部链接数之间存在很强的相关性(0,978)。同时,蜘蛛命中数与内部链接之间的相关性被证明非常弱(0 ,154),说明反向链接比网站链接更重要。
这是否意味着增加抓取频率的唯一方法是建立链接和发布新内容?如果我们讨论整个网站的朱雀频率,我会说是的:添加链接并经常更新网站,网站的抓取频率会成比例地增加。
但是,当我们单独取一个页面时,它会变得更有趣,正如您在下面的介绍中看到的那样,您甚至可能会在不知不觉中浪费大量的抓取频率。通过巧妙地管理频率,您通常可以使单个网页的抓取次数增加一倍——但它仍然会与每个网页的反向链接数量成正比。
 https://www.simcf.cc/wp-conten ... 0.png 300w" />
https://www.simcf.cc/wp-conten ... 0.png 300w" />如何充分利用抓取频率
现在,我们已经发现爬行很重要,是不是要花更多的时间来管理爬行频率?
你应该(或不应该)做很多事情来让搜索蜘蛛消耗更多的 网站 页面。以下是最大化爬取频率特征的操作列表:
1.保证重要页面可以被抓取,如果搜索到的内容不提供价值,就会被屏蔽。
.htaccess 和 robots.txt 不应阻塞 网站 的重要页面。机器人应该能够访问 CSS 和 Javascript 文件。同时,应该屏蔽不想在搜索中显示的内容,屏蔽“正在建设中的网站”区域和动态生成的网址等。
请记住,搜索引擎蜘蛛并不总是遵循 robots.txt 中收录的说明。你有没有在百度搜索结果中看到过这样的片段?
Robots.txt 不保证网页不会出现在搜索结果中:百度仍然可以根据外部信息(如传入链接)确定其相关性,如果您想明确阻止页面被索引,您应该使用 noindex robots 元标记或 X-Robots-Tag HTTP 标头,在这种情况下,您不应在 robots.txt 中禁止该页面,因为必须抓取该页面才能看到并符合该标记。
htmlunit 抓取网页(个人感觉java原生支持的方式友好,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-22 00:17
以上四种方法都是下载http资源。htmlunit 功能稍微强大一些。它还可以加载js和css。不过对于爬虫来说,加载css是没有意义的,但是有时候加载js还是很有必要的。
无论哪种方式都可以,这取决于您如何选择。个人感觉java原生的支持方式不够友好,但是不需要加载很多依赖。其他方法都非常好用,调用过程也很简单。下载组件通常以util的形式出现,写入后很少修改,除非http请求有bug,所以一旦写入完成,基本什么都没有。使用任何一种方法都可以。
解析组件
我们经常写爬虫不是为了像谷歌、百度这样的搜索引擎,而是为了获取特定的信息,这需要页面分析。比如我们爬取csdn的博客,那么我们需要的就是博客。博客的标题、作者、内容不需要其他内容,所以这时候我们需要解析html页面,获取我们需要的文本内容。
推荐两个工具,一个是htmlCleaner,一个是JSOUP。
HTMLCleaner 支持 XPATH。如果想了解更多关于xpath的内容,可以自行百度。XPATH 是一种支持 XML 节点定位的语言。HTML 可以理解为 XML 的一种。通过XPATH,我们可以定位我们的资源。
JSOUP和HTMLCleaner的作用是一样的,都是解析HTML文本,获取我们需要的问题的内容。
持久化组件
这很容易理解。我们爬取的内容一定要保存,否则爬虫就没有意义了。这需要一个持久化组件,目的是存储数据。至于mysq、hbase、redis的存储,就看你的了。达到了。
重复数据删除组件
爬虫必须对爬取过程中被爬取的内容进行重复数据删除。否则,可想而知,爬虫经常在做无意义的死循环。重复下载和分析爬取的内容是没有意义的。去重的目的是对爬取的链接做一个记录,实现的方法有很多种。如果只抓到一个网站,并且网站不大,可以用java用一个SET来完成。如果数据量很大,可以使用 REDIS、Memeched 等内存库进行过滤。对于繁重的工作,还有一个bloomfilter,非常适合这种场景。
工具:
1. JAVA SET
2. Redis,MEMCACHED
3. 过滤器
工艺梳理
总结
爬虫系统可以用java基础实现。最重要的是满足自己的需求,当需求增加时可以快速扩展。目前JAVA有很多非常好的开源爬虫系统。 查看全部
htmlunit 抓取网页(个人感觉java原生支持的方式友好,你知道吗?)
以上四种方法都是下载http资源。htmlunit 功能稍微强大一些。它还可以加载js和css。不过对于爬虫来说,加载css是没有意义的,但是有时候加载js还是很有必要的。
无论哪种方式都可以,这取决于您如何选择。个人感觉java原生的支持方式不够友好,但是不需要加载很多依赖。其他方法都非常好用,调用过程也很简单。下载组件通常以util的形式出现,写入后很少修改,除非http请求有bug,所以一旦写入完成,基本什么都没有。使用任何一种方法都可以。
解析组件
我们经常写爬虫不是为了像谷歌、百度这样的搜索引擎,而是为了获取特定的信息,这需要页面分析。比如我们爬取csdn的博客,那么我们需要的就是博客。博客的标题、作者、内容不需要其他内容,所以这时候我们需要解析html页面,获取我们需要的文本内容。
推荐两个工具,一个是htmlCleaner,一个是JSOUP。
HTMLCleaner 支持 XPATH。如果想了解更多关于xpath的内容,可以自行百度。XPATH 是一种支持 XML 节点定位的语言。HTML 可以理解为 XML 的一种。通过XPATH,我们可以定位我们的资源。
JSOUP和HTMLCleaner的作用是一样的,都是解析HTML文本,获取我们需要的问题的内容。
持久化组件
这很容易理解。我们爬取的内容一定要保存,否则爬虫就没有意义了。这需要一个持久化组件,目的是存储数据。至于mysq、hbase、redis的存储,就看你的了。达到了。
重复数据删除组件
爬虫必须对爬取过程中被爬取的内容进行重复数据删除。否则,可想而知,爬虫经常在做无意义的死循环。重复下载和分析爬取的内容是没有意义的。去重的目的是对爬取的链接做一个记录,实现的方法有很多种。如果只抓到一个网站,并且网站不大,可以用java用一个SET来完成。如果数据量很大,可以使用 REDIS、Memeched 等内存库进行过滤。对于繁重的工作,还有一个bloomfilter,非常适合这种场景。
工具:
1. JAVA SET
2. Redis,MEMCACHED
3. 过滤器
工艺梳理
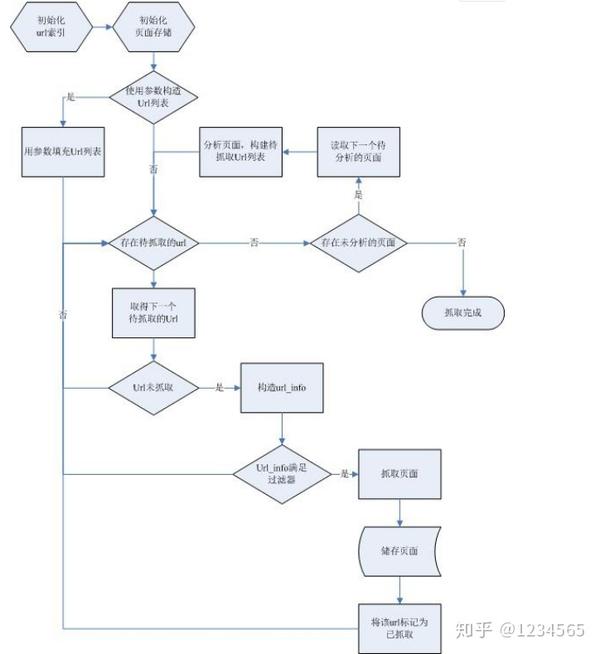
总结
爬虫系统可以用java基础实现。最重要的是满足自己的需求,当需求增加时可以快速扩展。目前JAVA有很多非常好的开源爬虫系统。
htmlunit 抓取网页(遇到一个网页数据抓取的任务,给大家分享下!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-19 08:03
遇到一个爬取网页数据的任务,分享给大家。
说到网页信息抓取,相信Jsoup基本上是首选工具。完整的类似JQuery的操作让人感觉很舒服。不过,今天我们要说说Jsoup的缺点。
这是某网站的搜索栏,填写一些格式化数据进行经纬度转换,初始化是这样的,然后用jsoup捕获的代码如下:
当我们添加数据时,抓取的页面信息保持不变。这就是Jsoup的缺点。如果Jsoup抓取页面,页面加载后的所有数据,ajax加载的异步数据是不会抓取的。到达的。
这里再给大家介绍一个开源项目:HttpUnit,这个名字是用来测试的,但是爬取数据也不错,是一个完美的解决方案。HttpUnit其实相当于一个没有UI的浏览器,可以让页面上的js执行完成后,再次抓取信息。
有时我们使用requests抓取页面时,得到的结果可能与浏览器中看到的不同:在浏览器中可以看到正常显示的页面数据,但是使用requests得到的结果却不是。这是因为获取的请求都是原创的 HTML 文档,浏览器中的页面是 JavaScript 处理数据后生成的结果。这些数据的来源有很多,可能是通过Ajax加载的,可能是收录在HTML中的,也可能是通过JavaScript和特定算法计算后生成的文档中的文档。
在第一种情况下,数据加载是一种异步加载方法。原创页面最初不会收录一些数据。原创页面加载完成后,会向服务器请求一个接口来获取数据,然后对数据进行处理和呈现。在网页上,这实际上是一个 Ajax 请求。
根据Web的发展趋势,这种形式的页面越来越多。网页的原创 HTML 文档不收录任何数据。数据通过Ajax统一加载后呈现,从而在Web开发中实现前后端分离,减少服务器直接渲染页面带来的压力。
因此,如果遇到这样的页面,可以直接使用requests等库来抓取原创页面,无法获取有效数据。这时候就需要从网页后台分析发送到界面的Ajax请求。如果可以使用requests来模拟ajax请求,那么就可以成功爬取。
但是我没有使用这个测试框架:我解决问题的想法是
总结:ajax数据的爬取过程:
分析网页信息,抓取网页
1. 提交我们的搜索时,会加载这部分内容,并且会有表单数据生成,
体现在节目中:
2.服务器加载这个页面,我们输入表单信息,这个表单信息就是我们的搜索条件,例如:
体现在节目中:
3.js返回加载的页面,并在该页面添加信息
jsoup 可以解析页面。
4.模拟登录部分:
静态网页:jsoup
ajax 网页:webdriver+selenium+jsoup 查看全部
htmlunit 抓取网页(遇到一个网页数据抓取的任务,给大家分享下!)
遇到一个爬取网页数据的任务,分享给大家。
说到网页信息抓取,相信Jsoup基本上是首选工具。完整的类似JQuery的操作让人感觉很舒服。不过,今天我们要说说Jsoup的缺点。
这是某网站的搜索栏,填写一些格式化数据进行经纬度转换,初始化是这样的,然后用jsoup捕获的代码如下:

当我们添加数据时,抓取的页面信息保持不变。这就是Jsoup的缺点。如果Jsoup抓取页面,页面加载后的所有数据,ajax加载的异步数据是不会抓取的。到达的。


这里再给大家介绍一个开源项目:HttpUnit,这个名字是用来测试的,但是爬取数据也不错,是一个完美的解决方案。HttpUnit其实相当于一个没有UI的浏览器,可以让页面上的js执行完成后,再次抓取信息。
有时我们使用requests抓取页面时,得到的结果可能与浏览器中看到的不同:在浏览器中可以看到正常显示的页面数据,但是使用requests得到的结果却不是。这是因为获取的请求都是原创的 HTML 文档,浏览器中的页面是 JavaScript 处理数据后生成的结果。这些数据的来源有很多,可能是通过Ajax加载的,可能是收录在HTML中的,也可能是通过JavaScript和特定算法计算后生成的文档中的文档。
在第一种情况下,数据加载是一种异步加载方法。原创页面最初不会收录一些数据。原创页面加载完成后,会向服务器请求一个接口来获取数据,然后对数据进行处理和呈现。在网页上,这实际上是一个 Ajax 请求。
根据Web的发展趋势,这种形式的页面越来越多。网页的原创 HTML 文档不收录任何数据。数据通过Ajax统一加载后呈现,从而在Web开发中实现前后端分离,减少服务器直接渲染页面带来的压力。
因此,如果遇到这样的页面,可以直接使用requests等库来抓取原创页面,无法获取有效数据。这时候就需要从网页后台分析发送到界面的Ajax请求。如果可以使用requests来模拟ajax请求,那么就可以成功爬取。
但是我没有使用这个测试框架:我解决问题的想法是
总结:ajax数据的爬取过程:
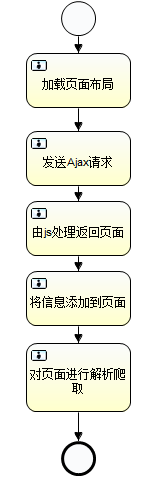
分析网页信息,抓取网页
1. 提交我们的搜索时,会加载这部分内容,并且会有表单数据生成,
体现在节目中:
2.服务器加载这个页面,我们输入表单信息,这个表单信息就是我们的搜索条件,例如:
体现在节目中:

3.js返回加载的页面,并在该页面添加信息
jsoup 可以解析页面。
4.模拟登录部分:

静态网页:jsoup
ajax 网页:webdriver+selenium+jsoup
htmlunit 抓取网页(Python开发的一个快速、高层次的优点及解决办法!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 238 次浏览 • 2021-12-19 07:20
(1),Scrapy:
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还提供了多种爬虫的基类,如BaseSpider、站点地图爬虫等,最新版本还提供了web2.0爬虫支持。
废料意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2. 社区人数比较多,文档比较齐全。
3.URL 去重采用 Bloom filter 方案。
4. 可以处理不完整的 HTML,Scrapy 提供了选择器(一个基于 lxml 的更高级的接口),
可以高效处理不完整的HTML代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
Pyspider是一个用python实现的强大的网络爬虫系统。可以在浏览器界面实时编写脚本、调度函数和查看爬取结果。后端使用常用的数据库来存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2. 完全可视化,非常人性化:WEB界面编写调试脚本、启停脚本、监控执行状态、查看活动历史、获取结果。
3.简单,五分钟就能上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL去重使用数据库代替Bloom过滤器,数亿存储的db io会导致效率急剧下降。
2. 用户友好性牺牲了灵活性并降低了定制能力。
(3)Apache Nutch(更高)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。在 Nutch 运行的一组进程中,三分之二是为搜索引擎设计的。
Nutch的框架需要Hadoop运行,Hadoop需要开集群。对于那些想快速上手爬虫的人来说,我很沮丧......
这里列出了一些资源地址,也许以后会学到。
纳奇官网
1.Nutch支持分布式爬取,并且有Hadoop支持,可以进行多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。因为有了这个框架,Nutch的插件开发非常容易,第三方插件也层出不穷,大大提升了Nutch的功能和口碑。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的API,可以快速上手
2.模块化结构,易于扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), WebCollector
WebCollector是一个不需要配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,可以用少量的代码实现强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
优势:
1.基于文本密度自动提取网页正文
2.支持断点重爬
3.支持代理
缺点:
1. 不支持分布式,只支持单机
2.无URL优先调度
3.不是很活跃
(6), Heritrix3
Heritrix是一个由java开发的开源网络爬虫,用户可以使用它从网上抓取自己想要的资源
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫不能相互配合。
2. 在机器资源有限的情况下,需要复杂的操作。
3. 仅官方支持,仅在 Linux 上测试。
4.每个爬虫独立工作,更新没有任何修改。
5. 在发生硬件和系统故障时,恢复能力较差。
6. 花在优化性能上的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,没有搜索引擎。如果要对爬取的站点进行排序,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j是一个基于Java的轻量级独立开源爬虫框架
优势
1.多线程采集
2. 内置Url过滤机制,BerkeleyDB用于url过滤。
3. 可以扩展支持网页字段的结构化提取,可以作为一个垂直的采集
缺点
1. 不支持动态网页爬取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,我做了一个框架优缺点对比图,如下:
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期培训老师讲解的框架。几乎有完整的文档介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过这个框架有一个优势,它有非常强大的网页解析功能。
Jsoup中文教程
selenium(多位谷歌高管参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,是真正的模拟浏览器。GitHub1.4w+star,你没看错,有几万个。但我只是没有一个好的环境。入门Demo就是不能成功运行,所以放弃了。
硒官方GitHub
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器,就是这样。
基本介绍:
HtmlUnit的优点是可以轻松抓取静态网民;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染出来的网页;缺点是需要配备环境变量等。
两者结合,相互学习,cdp4j可用。
选择它的原因是真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名也有名。我在学习软件工程的时候,一直在想,我为什么要写文档?我的程序能不能实现它的功能不重要吗?如今,看着如此详细的文件,我留下了激动和遗憾的泪水……
cdp4j 有很多功能:
一个。获取渲染网页的源代码
湾 模拟浏览器点击事件
C。下载网页上可用的文件
d. 截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以在以下三个地址中找到:
【cdp4j官网地址】
【Github 仓库】
[演示列表] 查看全部
htmlunit 抓取网页(Python开发的一个快速、高层次的优点及解决办法!)
(1),Scrapy:

Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还提供了多种爬虫的基类,如BaseSpider、站点地图爬虫等,最新版本还提供了web2.0爬虫支持。
废料意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2. 社区人数比较多,文档比较齐全。
3.URL 去重采用 Bloom filter 方案。
4. 可以处理不完整的 HTML,Scrapy 提供了选择器(一个基于 lxml 的更高级的接口),
可以高效处理不完整的HTML代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
Pyspider是一个用python实现的强大的网络爬虫系统。可以在浏览器界面实时编写脚本、调度函数和查看爬取结果。后端使用常用的数据库来存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2. 完全可视化,非常人性化:WEB界面编写调试脚本、启停脚本、监控执行状态、查看活动历史、获取结果。
3.简单,五分钟就能上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL去重使用数据库代替Bloom过滤器,数亿存储的db io会导致效率急剧下降。
2. 用户友好性牺牲了灵活性并降低了定制能力。
(3)Apache Nutch(更高)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。在 Nutch 运行的一组进程中,三分之二是为搜索引擎设计的。
Nutch的框架需要Hadoop运行,Hadoop需要开集群。对于那些想快速上手爬虫的人来说,我很沮丧......
这里列出了一些资源地址,也许以后会学到。
纳奇官网
1.Nutch支持分布式爬取,并且有Hadoop支持,可以进行多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。因为有了这个框架,Nutch的插件开发非常容易,第三方插件也层出不穷,大大提升了Nutch的功能和口碑。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的API,可以快速上手
2.模块化结构,易于扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), WebCollector
WebCollector是一个不需要配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,可以用少量的代码实现强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
优势:
1.基于文本密度自动提取网页正文
2.支持断点重爬
3.支持代理
缺点:
1. 不支持分布式,只支持单机
2.无URL优先调度
3.不是很活跃
(6), Heritrix3
Heritrix是一个由java开发的开源网络爬虫,用户可以使用它从网上抓取自己想要的资源
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫不能相互配合。
2. 在机器资源有限的情况下,需要复杂的操作。
3. 仅官方支持,仅在 Linux 上测试。
4.每个爬虫独立工作,更新没有任何修改。
5. 在发生硬件和系统故障时,恢复能力较差。
6. 花在优化性能上的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,没有搜索引擎。如果要对爬取的站点进行排序,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j是一个基于Java的轻量级独立开源爬虫框架
优势
1.多线程采集
2. 内置Url过滤机制,BerkeleyDB用于url过滤。
3. 可以扩展支持网页字段的结构化提取,可以作为一个垂直的采集
缺点
1. 不支持动态网页爬取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,我做了一个框架优缺点对比图,如下:
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期培训老师讲解的框架。几乎有完整的文档介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过这个框架有一个优势,它有非常强大的网页解析功能。
Jsoup中文教程
selenium(多位谷歌高管参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,是真正的模拟浏览器。GitHub1.4w+star,你没看错,有几万个。但我只是没有一个好的环境。入门Demo就是不能成功运行,所以放弃了。
硒官方GitHub
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器,就是这样。
基本介绍:
HtmlUnit的优点是可以轻松抓取静态网民;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染出来的网页;缺点是需要配备环境变量等。
两者结合,相互学习,cdp4j可用。
选择它的原因是真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名也有名。我在学习软件工程的时候,一直在想,我为什么要写文档?我的程序能不能实现它的功能不重要吗?如今,看着如此详细的文件,我留下了激动和遗憾的泪水……
cdp4j 有很多功能:
一个。获取渲染网页的源代码
湾 模拟浏览器点击事件
C。下载网页上可用的文件
d. 截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以在以下三个地址中找到:
【cdp4j官网地址】
【Github 仓库】
[演示列表]
htmlunit 抓取网页(如何用Python爬虫“爬”到解析出来的链接?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-16 21:41
可能你觉得这个文章太简单了,满足不了你的要求。
文章只展示了如何从一个网页中抓取信息,但您必须处理数千个网页。
别担心。
本质上,抓取一个网页与抓取 10,000 个网页是一样的。
而且,根据我们的示例,您是否已经尝试过获取链接?
以链接为基础,您可以滚雪球,让 Python 爬虫“爬行”到已解析的链接以进行进一步处理。
以后在实际场景中,你可能要处理一些棘手的问题:
这些问题的解决方法,希望在以后的教程中与大家一一分享。
需要注意的是,虽然网络爬虫抓取数据的能力很强,但是学习和实践也有一定的门槛。
当您面临数据采集任务时,您应该首先查看此列表:
如果答案是否定的,则需要自己编写脚本并调动爬虫来抓取它。
为了巩固你所学的知识,请切换到另一个网页,根据我们的代码进行修改,抓取你感兴趣的内容。
如果能记录下自己爬的过程,在评论区把记录链接分享给大家就更好了。
因为刻意练习是掌握实践技能的最佳途径,而教学是最好的学习。
祝你好运!
思考
已经解释了本文的主要内容。
这里有一个问题供您思考:
我们解析和存储的链接实际上是重复的:
这不是因为我们的代码有问题,而是在《如何使用“玉树智兰”开始数据科学?"文章中,我多次引用了一些文章,所以重复的链接都被抓了 查看全部
htmlunit 抓取网页(如何用Python爬虫“爬”到解析出来的链接?)
可能你觉得这个文章太简单了,满足不了你的要求。
文章只展示了如何从一个网页中抓取信息,但您必须处理数千个网页。
别担心。
本质上,抓取一个网页与抓取 10,000 个网页是一样的。
而且,根据我们的示例,您是否已经尝试过获取链接?
以链接为基础,您可以滚雪球,让 Python 爬虫“爬行”到已解析的链接以进行进一步处理。
以后在实际场景中,你可能要处理一些棘手的问题:
这些问题的解决方法,希望在以后的教程中与大家一一分享。
需要注意的是,虽然网络爬虫抓取数据的能力很强,但是学习和实践也有一定的门槛。
当您面临数据采集任务时,您应该首先查看此列表:
如果答案是否定的,则需要自己编写脚本并调动爬虫来抓取它。
为了巩固你所学的知识,请切换到另一个网页,根据我们的代码进行修改,抓取你感兴趣的内容。
如果能记录下自己爬的过程,在评论区把记录链接分享给大家就更好了。
因为刻意练习是掌握实践技能的最佳途径,而教学是最好的学习。
祝你好运!
思考
已经解释了本文的主要内容。
这里有一个问题供您思考:
我们解析和存储的链接实际上是重复的:

这不是因为我们的代码有问题,而是在《如何使用“玉树智兰”开始数据科学?"文章中,我多次引用了一些文章,所以重复的链接都被抓了
htmlunit 抓取网页(1.maven依赖引入2.Java代码3.其他功能总结(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-14 00:34
通常我们使用Java提供的HttpURLConnection或者Apache的HttpClient来获取网页源码,直观可见,代码内容与网页内容一致,在浏览器上右击查看网页的源代码。
但是现在越来越多的网站使用Js动态生成内容来提高相应的速度,而HttpClient在后端只返回相应响应的请求体,并没有返回浏览器生成的网页,所以对于 Js 生成的内容 HttpClient 不可用。
获取Js生成的网页,我们主要是模拟浏览器的操作,渲染响应的请求体,最终得到对应的内容。通过浏览器右键->点击check/view元素得到的内容与网页内容一致。
我们这里讲的模拟方法大致有两种:
抓取目标
我们这次的目标是获取bilibili动态生成的动画列表。左上角是获取到的目标列表,左下角是浏览器渲染的html内容,右边是服务器返回的响应正文。通过对比,我们可以看到目标列表是由Js生成的。
使用 Selenium 获取页面
Selenium 是一种用于 Web 应用程序自动化测试的工具。更多介绍是谷歌。这里我们主要用来模拟页面的操作并返回结果。网页截图的功能也是可行的。
Selenium 支持模拟很多浏览器,但我们这里只模拟 PhantomJS,因为 PhantomJS 是一个脚本化的、无界面的 WebKit,它使用 JavaScript 作为脚本语言来实现各种功能。因为它没有接口,所以速度性能会更好。
1.下载
使用PhantomJS需要到官网下载最新的客户端,这里使用phantomjs-2.1.1-windows.zip
2.maven 依赖介绍:
org.seleniumhq.selenium
selenium-java
2.53.0
com.codeborne
phantomjsdriver
1.2.1
org.seleniumhq.selenium
selenium-remote-driver
org.seleniumhq.selenium
selenium-java
3.示例代码
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriverService;
import org.openqa.selenium.remote.DesiredCapabilities;
import java.util.ArrayList;
/**
* @author GinPonson
*/
public class TestSelenium {
static final String HOST = "127.0.0.1";
static final String PORT = "80";
static final String USER = "gin";
static final String PWD = "12345";
public static void main(String[] args){
System.setProperty("phantomjs.binary.path", "D:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe");
DesiredCapabilities capabilities = DesiredCapabilities.phantomjs();
//设置代理或者其他参数
ArrayList cliArgsCap = new ArrayList();
//cliArgsCap.add("--proxy=http://"+HOST+":"+PORT);
//cliArgsCap.add("--proxy-auth=" + USER + ":" + PWD);
//cliArgsCap.add("--proxy-type=http");
capabilities.setCapability(PhantomJSDriverService.PHANTOMJS_CLI_ARGS, cliArgsCap);
//capabilities.setCapability("phantomjs.page.settings.userAgent", "");
WebDriver driver = new PhantomJSDriver(capabilities);
driver.get("http://www.bilibili.com/video/ ... 6quot;);
System.out.println(driver.getPageSource());
driver.quit();
}
}
4.其他功能
使用 HtmlUnit 获取页面
HtmlUnit 在功能上是 Selenium 的子集,Selenium 有相应的 HtmlUnit 实现。HtmlUnit 是一个用 Java 编写的无界面浏览器。因为没有接口,所以执行速度还可以。
1.maven 依赖介绍
net.sourceforge.htmlunit
htmlunit
2.25
2.Java 代码
/**
* @author GinPonson
*/
public class TestHtmlUnit {
static final String HOST = "127.0.0.1";
static final String PORT = "80";
static final String USER = "gin";
static final String PWD = "12345";
public static void main(String[] args) throws Exception{
WebClient webClient = new WebClient();
//设置代理
//ProxyConfig proxyConfig = webClient.getOptions().getProxyConfig();
//proxyConfig.setProxyHost(HOST);
//proxyConfig.setProxyPort(Integer.valueOf(PORT));
//DefaultCredentialsProvider credentialsProvider = (DefaultCredentialsProvider) webClient.getCredentialsProvider();
//credentialsProvider.addCredentials(USER, PWD);
//设置参数
//webClient.getOptions().setCssEnabled(false);
//webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
HtmlPage page = webClient.getPage("http://www.bilibili.com/video/ ... 6quot;);
System.out.println(page.asXml());
webClient.close();
}
}
3.其他功能
总结
PhantomJS 和 HtmlUnit 都模拟了浏览器页面生成功能。PhantomJS 是一个非接口的 WebKit。页面渲染功能非常齐全,并且具有浏览器截图功能,可以模拟登录操作。HtmlUnit 使用 Rhino 引擎解析 Js。有时解析速度很慢。就像上面的例子一样,需要很长时间,但是HtmlUnit可以获取页面并解析一组元素。(当然最好用Jsoup来解析元素)。不错的工具。
HtmlUnit遇到错误后,处理前后相差7分钟。可能是我没用QAQ
欢迎补充:) 查看全部
htmlunit 抓取网页(1.maven依赖引入2.Java代码3.其他功能总结(组图))
通常我们使用Java提供的HttpURLConnection或者Apache的HttpClient来获取网页源码,直观可见,代码内容与网页内容一致,在浏览器上右击查看网页的源代码。
但是现在越来越多的网站使用Js动态生成内容来提高相应的速度,而HttpClient在后端只返回相应响应的请求体,并没有返回浏览器生成的网页,所以对于 Js 生成的内容 HttpClient 不可用。
获取Js生成的网页,我们主要是模拟浏览器的操作,渲染响应的请求体,最终得到对应的内容。通过浏览器右键->点击check/view元素得到的内容与网页内容一致。
我们这里讲的模拟方法大致有两种:
抓取目标
我们这次的目标是获取bilibili动态生成的动画列表。左上角是获取到的目标列表,左下角是浏览器渲染的html内容,右边是服务器返回的响应正文。通过对比,我们可以看到目标列表是由Js生成的。
使用 Selenium 获取页面
Selenium 是一种用于 Web 应用程序自动化测试的工具。更多介绍是谷歌。这里我们主要用来模拟页面的操作并返回结果。网页截图的功能也是可行的。
Selenium 支持模拟很多浏览器,但我们这里只模拟 PhantomJS,因为 PhantomJS 是一个脚本化的、无界面的 WebKit,它使用 JavaScript 作为脚本语言来实现各种功能。因为它没有接口,所以速度性能会更好。
1.下载
使用PhantomJS需要到官网下载最新的客户端,这里使用phantomjs-2.1.1-windows.zip
2.maven 依赖介绍:
org.seleniumhq.selenium
selenium-java
2.53.0
com.codeborne
phantomjsdriver
1.2.1
org.seleniumhq.selenium
selenium-remote-driver
org.seleniumhq.selenium
selenium-java
3.示例代码
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriverService;
import org.openqa.selenium.remote.DesiredCapabilities;
import java.util.ArrayList;
/**
* @author GinPonson
*/
public class TestSelenium {
static final String HOST = "127.0.0.1";
static final String PORT = "80";
static final String USER = "gin";
static final String PWD = "12345";
public static void main(String[] args){
System.setProperty("phantomjs.binary.path", "D:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe");
DesiredCapabilities capabilities = DesiredCapabilities.phantomjs();
//设置代理或者其他参数
ArrayList cliArgsCap = new ArrayList();
//cliArgsCap.add("--proxy=http://"+HOST+":"+PORT);
//cliArgsCap.add("--proxy-auth=" + USER + ":" + PWD);
//cliArgsCap.add("--proxy-type=http");
capabilities.setCapability(PhantomJSDriverService.PHANTOMJS_CLI_ARGS, cliArgsCap);
//capabilities.setCapability("phantomjs.page.settings.userAgent", "");
WebDriver driver = new PhantomJSDriver(capabilities);
driver.get("http://www.bilibili.com/video/ ... 6quot;);
System.out.println(driver.getPageSource());
driver.quit();
}
}
4.其他功能
使用 HtmlUnit 获取页面
HtmlUnit 在功能上是 Selenium 的子集,Selenium 有相应的 HtmlUnit 实现。HtmlUnit 是一个用 Java 编写的无界面浏览器。因为没有接口,所以执行速度还可以。
1.maven 依赖介绍
net.sourceforge.htmlunit
htmlunit
2.25
2.Java 代码
/**
* @author GinPonson
*/
public class TestHtmlUnit {
static final String HOST = "127.0.0.1";
static final String PORT = "80";
static final String USER = "gin";
static final String PWD = "12345";
public static void main(String[] args) throws Exception{
WebClient webClient = new WebClient();
//设置代理
//ProxyConfig proxyConfig = webClient.getOptions().getProxyConfig();
//proxyConfig.setProxyHost(HOST);
//proxyConfig.setProxyPort(Integer.valueOf(PORT));
//DefaultCredentialsProvider credentialsProvider = (DefaultCredentialsProvider) webClient.getCredentialsProvider();
//credentialsProvider.addCredentials(USER, PWD);
//设置参数
//webClient.getOptions().setCssEnabled(false);
//webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
HtmlPage page = webClient.getPage("http://www.bilibili.com/video/ ... 6quot;);
System.out.println(page.asXml());
webClient.close();
}
}
3.其他功能
总结
PhantomJS 和 HtmlUnit 都模拟了浏览器页面生成功能。PhantomJS 是一个非接口的 WebKit。页面渲染功能非常齐全,并且具有浏览器截图功能,可以模拟登录操作。HtmlUnit 使用 Rhino 引擎解析 Js。有时解析速度很慢。就像上面的例子一样,需要很长时间,但是HtmlUnit可以获取页面并解析一组元素。(当然最好用Jsoup来解析元素)。不错的工具。
HtmlUnit遇到错误后,处理前后相差7分钟。可能是我没用QAQ

欢迎补充:)
htmlunit 抓取网页(网页获取和解析速度和性能的应用场景详解! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-21 22:09
)
(4)支持代理
(5)支持自动cookie管理等。
Java爬虫开发是应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;import org.apache.http.client.HttpClient;import org.apache.http.client.ResponseHandler;import org.apache.http.client.methods.HttpGet;import org.apache.http.impl.client.BasicResponseHandler;import org.apache.http.impl.client.DefaultHttpClient;/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHttpClientTest{
publicstaticvoid main(String[] args)throwsException{
//目标页面String url ="http://www.yshjava.cn";//创建一个默认的HttpClientHttpClient httpclient =newDefaultHttpClient();try{
//以get方式请求网页http://www.yshjava.cnHttpGet httpget =newHttpGet(url);//打印请求地址System.out.println("executing request "+ httpget.getURI());//创建响应处理器处理服务器响应内容ResponseHandlerresponseHandler=newBasicResponseHandler();//执行请求并获取结果String responseBody = httpclient.execute(httpget, responseHandler);System.out.println("----------------------------------------");System.out.println(responseBody);System.out.println("----------------------------------------");}finally{
//关闭连接管理器
httpclient.getConnectionManager().shutdown();}}}
汤
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
示例代码如下:
package cn.ysh.studio.crawler.jsoup;import java.io.IOException;import org.jsoup.Jsoup;/**
* 基于Jsoup抓取网页内容
* @author www.yshjava.cn
*/publicclassJsoupTest{
publicstaticvoid main(String[] args)throwsIOException{
//目标页面String url ="http://www.yshjava.cn";//使用Jsoup连接目标页面,并执行请求,获取服务器响应内容String html =Jsoup.connect(url).execute().body();//打印页面内容System.out.println(html);}}
html单元
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取和解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;import com.gargoylesoftware.htmlunit.BrowserVersion;import com.gargoylesoftware.htmlunit.Page;import com.gargoylesoftware.htmlunit.WebClient;/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlUnitSpider{
publicstaticvoid main(String[] s)throwsException{
//目标网页String url ="http://www.yshjava.cn";//模拟特定浏览器FIREFOX_3WebClient spider =newWebClient(BrowserVersion.FIREFOX_3);//获取目标网页Page page = spider.getPage(url);//打印网页内容System.out.println(page.getWebResponse().getContentAsString());//关闭所有窗口
spider.closeAllWindows();}}
瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
示例代码如下:
package cn.ysh.studio.crawler.ie;import watij.runtime.ie.IE;/**
* 基于Watij抓取网页内容,仅限Windows平台
*
* @author www.yshjava.cn
*/publicclassWatijTest{
publicstaticvoid main(String[] s){
//目标页面String url ="http://www.yshjava.cn";//实例化IE浏览器对象
IE ie =new IE();try{
//启动浏览器
ie.start();//转到目标网页
ie.goTo(url);//等待网页加载就绪
ie.waitUntilReady();//打印页面内容System.out.println(ie.html());}catch(Exception e){
e.printStackTrace();}finally{
try{
//关闭IE浏览器
ie.close();}catch(Exception e){
}}}}
硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;import org.openqa.selenium.htmlunit.HtmlUnitDriver;/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlDriverTest{
publicstaticvoid main(String[] s){
//目标网页String url ="http://www.yshjava.cn";HtmlUnitDriver driver =newHtmlUnitDriver();try{
//禁用JS脚本功能
driver.setJavascriptEnabled(false);//打开目标网页
driver.get(url);//获取当前网页源码String html = driver.getPageSource();//打印网页源码System.out.println(html);}catch(Exception e){
//打印堆栈信息
e.printStackTrace();}finally{
try{
//关闭并退出
driver.close();
driver.quit();}catch(Exception e){
}}}}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;import org.watij.webspec.dsl.WebSpec;/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/publicclassWebspecTest{
publicstaticvoid main(String[] s){
//目标网页String url ="http://www.yshjava.cn";//实例化浏览器对象WebSpec spec =newWebSpec().mozilla();//隐藏浏览器窗体
spec.hide();//打开目标页面
spec.open(url);//打印网页源码System.out.println(spec.source());//关闭所有窗口
spec.closeAll();}} 查看全部
htmlunit 抓取网页(网页获取和解析速度和性能的应用场景详解!
)
(4)支持代理
(5)支持自动cookie管理等。
Java爬虫开发是应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;import org.apache.http.client.HttpClient;import org.apache.http.client.ResponseHandler;import org.apache.http.client.methods.HttpGet;import org.apache.http.impl.client.BasicResponseHandler;import org.apache.http.impl.client.DefaultHttpClient;/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHttpClientTest{
publicstaticvoid main(String[] args)throwsException{
//目标页面String url ="http://www.yshjava.cn";//创建一个默认的HttpClientHttpClient httpclient =newDefaultHttpClient();try{
//以get方式请求网页http://www.yshjava.cnHttpGet httpget =newHttpGet(url);//打印请求地址System.out.println("executing request "+ httpget.getURI());//创建响应处理器处理服务器响应内容ResponseHandlerresponseHandler=newBasicResponseHandler();//执行请求并获取结果String responseBody = httpclient.execute(httpget, responseHandler);System.out.println("----------------------------------------");System.out.println(responseBody);System.out.println("----------------------------------------");}finally{
//关闭连接管理器
httpclient.getConnectionManager().shutdown();}}}
汤
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
示例代码如下:
package cn.ysh.studio.crawler.jsoup;import java.io.IOException;import org.jsoup.Jsoup;/**
* 基于Jsoup抓取网页内容
* @author www.yshjava.cn
*/publicclassJsoupTest{
publicstaticvoid main(String[] args)throwsIOException{
//目标页面String url ="http://www.yshjava.cn";//使用Jsoup连接目标页面,并执行请求,获取服务器响应内容String html =Jsoup.connect(url).execute().body();//打印页面内容System.out.println(html);}}
html单元
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取和解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;import com.gargoylesoftware.htmlunit.BrowserVersion;import com.gargoylesoftware.htmlunit.Page;import com.gargoylesoftware.htmlunit.WebClient;/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlUnitSpider{
publicstaticvoid main(String[] s)throwsException{
//目标网页String url ="http://www.yshjava.cn";//模拟特定浏览器FIREFOX_3WebClient spider =newWebClient(BrowserVersion.FIREFOX_3);//获取目标网页Page page = spider.getPage(url);//打印网页内容System.out.println(page.getWebResponse().getContentAsString());//关闭所有窗口
spider.closeAllWindows();}}
瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
示例代码如下:
package cn.ysh.studio.crawler.ie;import watij.runtime.ie.IE;/**
* 基于Watij抓取网页内容,仅限Windows平台
*
* @author www.yshjava.cn
*/publicclassWatijTest{
publicstaticvoid main(String[] s){
//目标页面String url ="http://www.yshjava.cn";//实例化IE浏览器对象
IE ie =new IE();try{
//启动浏览器
ie.start();//转到目标网页
ie.goTo(url);//等待网页加载就绪
ie.waitUntilReady();//打印页面内容System.out.println(ie.html());}catch(Exception e){
e.printStackTrace();}finally{
try{
//关闭IE浏览器
ie.close();}catch(Exception e){
}}}}
硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;import org.openqa.selenium.htmlunit.HtmlUnitDriver;/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlDriverTest{
publicstaticvoid main(String[] s){
//目标网页String url ="http://www.yshjava.cn";HtmlUnitDriver driver =newHtmlUnitDriver();try{
//禁用JS脚本功能
driver.setJavascriptEnabled(false);//打开目标网页
driver.get(url);//获取当前网页源码String html = driver.getPageSource();//打印网页源码System.out.println(html);}catch(Exception e){
//打印堆栈信息
e.printStackTrace();}finally{
try{
//关闭并退出
driver.close();
driver.quit();}catch(Exception e){
}}}}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;import org.watij.webspec.dsl.WebSpec;/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/publicclassWebspecTest{
publicstaticvoid main(String[] s){
//目标网页String url ="http://www.yshjava.cn";//实例化浏览器对象WebSpec spec =newWebSpec().mozilla();//隐藏浏览器窗体
spec.hide();//打开目标页面
spec.open(url);//打印网页源码System.out.println(spec.source());//关闭所有窗口
spec.closeAll();}}
htmlunit 抓取网页(htmlunit网络工具一个没有没有 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-19 11:16
)
1:背景
本来想用jsoup抓取一个页面,但是抓取的数据总是不完整,然后发现页面执行js后,页面上渲染了一些数据,也就是说数据页是只在js执行后显示。数据会显示出来,但是jsoup无法实现执行页面的js。
2:解决
经过搜索,发现htmlunit网络工具可以实现js。它相当于一个没有页面的浏览器。解决方法是先用htmlUnit发送网络请求,执行js获取页面,然后用jsoup转换成Document页面对象。然后使用jsoup分析页面读取数据。
3:htmlUnit发送请求
1 public static Document getDocument() throws IOException, InterruptedException{
2 /*String url="https://www.marklines.com/cn/v ... 3B%3B
3 Connection connect = Jsoup.connect(url).userAgent("")
4 .header("Cookie", "PLAY_LANG=cn; _plh=b9289d0a863a8fc9c79fb938f15372f7731d13fb; PLATFORM_SESSION=39034d07000717c664134556ad39869771aabc04-_ldi=520275&_lsh=8cf91cdbcbbb255adff5cba6061f561b642f5157&csrfToken=209f20c8473bc0518413c226f898ff79cd69c3ff-1539926671235-b853a6a63c77dd8fcc364a58&_lpt=%2Fcn%2Fvehicle_sales%2Fsearch&_lsi=1646321; _ga=GA1.2.2146952143.1539926675; _gid=GA1.2.1032787565.1539926675; _plh_notime=8cf91cdbcbbb255adff5cba6061f561b642f5157")
5 .timeout(360000000);
6 Document document = connect.get();*/
7 WebClient wc = new WebClient(BrowserVersion.CHROME);
8 //是否使用不安全的SSL
9 wc.getOptions().setUseInsecureSSL(true);
10 //启用JS解释器,默认为true
11 wc.getOptions().setJavaScriptEnabled(true);
12 //禁用CSS
13 wc.getOptions().setCssEnabled(false);
14 //js运行错误时,是否抛出异常
15 wc.getOptions().setThrowExceptionOnScriptError(false);
16 //状态码错误时,是否抛出异常
17 wc.getOptions().setThrowExceptionOnFailingStatusCode(false);
18 //是否允许使用ActiveX
19 wc.getOptions().setActiveXNative(false);
20 //等待js时间
21 wc.waitForBackgroundJavaScript(600*1000);
22 //设置Ajax异步处理控制器即启用Ajax支持
23 wc.setAjaxController(new NicelyResynchronizingAjaxController());
24 //设置超时时间
25 wc.getOptions().setTimeout(1000000);
26 //不跟踪抓取
27 wc.getOptions().setDoNotTrackEnabled(false);
28 WebRequest request=new WebRequest(new URL("https://www.marklines.com/cn/v ... 6quot;));
29 request.setAdditionalHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:62.0) Gecko/20100101 Firefox/62.0");
30 request.setAdditionalHeader("Cookie","PLAY_LANG=cn; _plh=b9289d0a863a8fc9c79fb938f15372f7731d13fb; PLATFORM_SESSION=39034d07000717c664134556ad39869771aabc04-_ldi=520275&_lsh=8cf91cdbcbbb255adff5cba6061f561b642f5157&csrfToken=209f20c8473bc0518413c226f898ff79cd69c3ff-1539926671235-b853a6a63c77dd8fcc364a58&_lpt=%2Fcn%2Fvehicle_sales%2Fsearch&_lsi=1646321; _ga=GA1.2.2146952143.1539926675; _gid=GA1.2.1032787565.1539926675; _plh_notime=8cf91cdbcbbb255adff5cba6061f561b642f5157");
31 try {
32 //模拟浏览器打开一个目标网址
33 HtmlPage htmlPage = wc.getPage(request);
34 //为了获取js执行的数据 线程开始沉睡等待
35 Thread.sleep(1000);//这个线程的等待 因为js加载需要时间的
36 //以xml形式获取响应文本
37 String xml = htmlPage.asXml();
38 //并转为Document对象return
39 return Jsoup.parse(xml);
40 //System.out.println(xml.contains("结果.xls"));//false
41 } catch (FailingHttpStatusCodeException e) {
42 e.printStackTrace();
43 } catch (MalformedURLException e) {
44 e.printStackTrace();
45 } catch (IOException e) {
46 e.printStackTrace();
47 }
48 return null;
49 }
4:返回的Document对象交给jsoup处理
这里只做一个简单的输出,看看数据是否全部渲染完毕。
1 Document doc=getDocument();
2 Element table=doc.select("table.table.table-bordered.aggregate_table").get(0);//获取到表格
3 Element tableContext=table.getElementsByTag("tbody").get(0);
4 Elements contextTrs=tableContext.getElementsByTag("tr");
5 System.out.println(contextTrs.size());
6
7
8 String context=doc.toString();
9 OutputStreamWriter pw = null;
10 pw = new OutputStreamWriter(new FileOutputStream("D:/test.txt"),"GBK");
11 pw.write(context);
12 pw.close(); 查看全部
htmlunit 抓取网页(htmlunit网络工具一个没有没有
)
1:背景
本来想用jsoup抓取一个页面,但是抓取的数据总是不完整,然后发现页面执行js后,页面上渲染了一些数据,也就是说数据页是只在js执行后显示。数据会显示出来,但是jsoup无法实现执行页面的js。
2:解决
经过搜索,发现htmlunit网络工具可以实现js。它相当于一个没有页面的浏览器。解决方法是先用htmlUnit发送网络请求,执行js获取页面,然后用jsoup转换成Document页面对象。然后使用jsoup分析页面读取数据。
3:htmlUnit发送请求
1 public static Document getDocument() throws IOException, InterruptedException{
2 /*String url="https://www.marklines.com/cn/v ... 3B%3B
3 Connection connect = Jsoup.connect(url).userAgent("")
4 .header("Cookie", "PLAY_LANG=cn; _plh=b9289d0a863a8fc9c79fb938f15372f7731d13fb; PLATFORM_SESSION=39034d07000717c664134556ad39869771aabc04-_ldi=520275&_lsh=8cf91cdbcbbb255adff5cba6061f561b642f5157&csrfToken=209f20c8473bc0518413c226f898ff79cd69c3ff-1539926671235-b853a6a63c77dd8fcc364a58&_lpt=%2Fcn%2Fvehicle_sales%2Fsearch&_lsi=1646321; _ga=GA1.2.2146952143.1539926675; _gid=GA1.2.1032787565.1539926675; _plh_notime=8cf91cdbcbbb255adff5cba6061f561b642f5157")
5 .timeout(360000000);
6 Document document = connect.get();*/
7 WebClient wc = new WebClient(BrowserVersion.CHROME);
8 //是否使用不安全的SSL
9 wc.getOptions().setUseInsecureSSL(true);
10 //启用JS解释器,默认为true
11 wc.getOptions().setJavaScriptEnabled(true);
12 //禁用CSS
13 wc.getOptions().setCssEnabled(false);
14 //js运行错误时,是否抛出异常
15 wc.getOptions().setThrowExceptionOnScriptError(false);
16 //状态码错误时,是否抛出异常
17 wc.getOptions().setThrowExceptionOnFailingStatusCode(false);
18 //是否允许使用ActiveX
19 wc.getOptions().setActiveXNative(false);
20 //等待js时间
21 wc.waitForBackgroundJavaScript(600*1000);
22 //设置Ajax异步处理控制器即启用Ajax支持
23 wc.setAjaxController(new NicelyResynchronizingAjaxController());
24 //设置超时时间
25 wc.getOptions().setTimeout(1000000);
26 //不跟踪抓取
27 wc.getOptions().setDoNotTrackEnabled(false);
28 WebRequest request=new WebRequest(new URL("https://www.marklines.com/cn/v ... 6quot;));
29 request.setAdditionalHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:62.0) Gecko/20100101 Firefox/62.0");
30 request.setAdditionalHeader("Cookie","PLAY_LANG=cn; _plh=b9289d0a863a8fc9c79fb938f15372f7731d13fb; PLATFORM_SESSION=39034d07000717c664134556ad39869771aabc04-_ldi=520275&_lsh=8cf91cdbcbbb255adff5cba6061f561b642f5157&csrfToken=209f20c8473bc0518413c226f898ff79cd69c3ff-1539926671235-b853a6a63c77dd8fcc364a58&_lpt=%2Fcn%2Fvehicle_sales%2Fsearch&_lsi=1646321; _ga=GA1.2.2146952143.1539926675; _gid=GA1.2.1032787565.1539926675; _plh_notime=8cf91cdbcbbb255adff5cba6061f561b642f5157");
31 try {
32 //模拟浏览器打开一个目标网址
33 HtmlPage htmlPage = wc.getPage(request);
34 //为了获取js执行的数据 线程开始沉睡等待
35 Thread.sleep(1000);//这个线程的等待 因为js加载需要时间的
36 //以xml形式获取响应文本
37 String xml = htmlPage.asXml();
38 //并转为Document对象return
39 return Jsoup.parse(xml);
40 //System.out.println(xml.contains("结果.xls"));//false
41 } catch (FailingHttpStatusCodeException e) {
42 e.printStackTrace();
43 } catch (MalformedURLException e) {
44 e.printStackTrace();
45 } catch (IOException e) {
46 e.printStackTrace();
47 }
48 return null;
49 }
4:返回的Document对象交给jsoup处理
这里只做一个简单的输出,看看数据是否全部渲染完毕。
1 Document doc=getDocument();
2 Element table=doc.select("table.table.table-bordered.aggregate_table").get(0);//获取到表格
3 Element tableContext=table.getElementsByTag("tbody").get(0);
4 Elements contextTrs=tableContext.getElementsByTag("tr");
5 System.out.println(contextTrs.size());
6
7
8 String context=doc.toString();
9 OutputStreamWriter pw = null;
10 pw = new OutputStreamWriter(new FileOutputStream("D:/test.txt"),"GBK");
11 pw.write(context);
12 pw.close();
htmlunit 抓取网页(编程之家为你收集整理的全部内容解决方法())
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-13 21:25
概述 当使用 htmlunit 抓取网页时,我偶尔会注意到这些警告充斥着控制台输出。 2011 年 7 月 24 日 5:12:59 PM
在使用 htmlunit 抓取网页时,我偶尔会注意到这些警告淹没了控制台输出。
Jul 24,2011 5:12:59 PM com.gargoylesoftware.htmlunit.javascript.StrictErrorReporter warning
WARNING: warning: message=[Calling eval() with anything other than a primitive string value
will simply return the value. Is this what you intended?] sourceName=[http://ad.doubleclick.net/adj/ ... 40%3F] line=[356] lineSource=[null] lineOffset=[0]
有没有办法让htmlunit忽略javascript
> .*
> .*
就算了
>
>
同样,有没有办法让 htmlunit 只解释收录特定子字符串或匹配正则表达式的网页上的 javascript?
解决方案
您可以通过实现自己的 javascript 来删除不需要的 JavaScript
.您的 ScriptPreProcessor 可以检测到您不想执行的 jsvascript,而不是将其从 网站 中删除。
我还没有尝试过,但它可能会起作用。
总结
以上是编程之家为您采集的全部内容。希望文章可以帮助你解决你遇到的程序开发问题。
如果你觉得编程之家网站的内容还不错,欢迎你把编程之家网站推荐给你的程序员朋友。 查看全部
htmlunit 抓取网页(编程之家为你收集整理的全部内容解决方法())
概述 当使用 htmlunit 抓取网页时,我偶尔会注意到这些警告充斥着控制台输出。 2011 年 7 月 24 日 5:12:59 PM
在使用 htmlunit 抓取网页时,我偶尔会注意到这些警告淹没了控制台输出。
Jul 24,2011 5:12:59 PM com.gargoylesoftware.htmlunit.javascript.StrictErrorReporter warning
WARNING: warning: message=[Calling eval() with anything other than a primitive string value
will simply return the value. Is this what you intended?] sourceName=[http://ad.doubleclick.net/adj/ ... 40%3F] line=[356] lineSource=[null] lineOffset=[0]
有没有办法让htmlunit忽略javascript
> .*
> .*
就算了
>
>
同样,有没有办法让 htmlunit 只解释收录特定子字符串或匹配正则表达式的网页上的 javascript?
解决方案
您可以通过实现自己的 javascript 来删除不需要的 JavaScript
.您的 ScriptPreProcessor 可以检测到您不想执行的 jsvascript,而不是将其从 网站 中删除。
我还没有尝试过,但它可能会起作用。
总结
以上是编程之家为您采集的全部内容。希望文章可以帮助你解决你遇到的程序开发问题。
如果你觉得编程之家网站的内容还不错,欢迎你把编程之家网站推荐给你的程序员朋友。
htmlunit 抓取网页(和java自带的网络API进行结合,怎么做?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-22 16:24
HtmlUnit结合了HttpClient和java自带的网络API,更容易抓取数据,更容易操作。HtmlUnit底层还是封装了HttpClient,但是封装之后,解析出来的内容更像是一个网页,而不是抽象的请求和响应,所以更方便开发者上手。
// [1] new一个WebClient,在其中定义一种浏览器
WebClient webClent = new WebClient(BrowserVersion.FIREFOX_17);
// [2] 设置网页解析的内容
WebClientOptions options=webClent.getOptions();
options.setCssEnabled(false);
options.setJavaScriptEnabled(true);
options.setActiveXNative(false);
options.setAppletEnabled(false);
options.setRedirectEnabled(true);
options.setThrowExceptionOnFailingStatusCode(false);
options.setThrowExceptionOnScriptError(false);
options.setDoNotTrackEnabled(false);
options.setGeolocationEnabled(false);
// [3] 访问指定的页面,并将其赋予HtmlPage
HtmlPage htmlPage=webClent.getPage(url);
// [4] 获得的HtmlPage并不易于阅读,所以有需要可以通过Jsoup将其转换为Document对象
Document document = Jsoup.parseBodyFragment(htmlPage.asXml());
// [5]关闭
webClent.closeAllWindows();
HtmlPage 非常方便在获取到按钮后进行赋值和操作点击事件。常用方法getElementByName根据名称获取指定的标签(HtmlElement),类型可以设置为标签。
在 Document 对象中经常使用 select("") 方法,通过该方法可以获取到具体的 Element,然后通过解析内容得到需要的数据。
HtmlUnit很容易爬取,但是因为它模拟了网页的点击事件,所以响应返回的所有内容都会很臃肿。如果需要的数据量很小,效率会有点低。 查看全部
htmlunit 抓取网页(和java自带的网络API进行结合,怎么做?)
HtmlUnit结合了HttpClient和java自带的网络API,更容易抓取数据,更容易操作。HtmlUnit底层还是封装了HttpClient,但是封装之后,解析出来的内容更像是一个网页,而不是抽象的请求和响应,所以更方便开发者上手。
// [1] new一个WebClient,在其中定义一种浏览器
WebClient webClent = new WebClient(BrowserVersion.FIREFOX_17);
// [2] 设置网页解析的内容
WebClientOptions options=webClent.getOptions();
options.setCssEnabled(false);
options.setJavaScriptEnabled(true);
options.setActiveXNative(false);
options.setAppletEnabled(false);
options.setRedirectEnabled(true);
options.setThrowExceptionOnFailingStatusCode(false);
options.setThrowExceptionOnScriptError(false);
options.setDoNotTrackEnabled(false);
options.setGeolocationEnabled(false);
// [3] 访问指定的页面,并将其赋予HtmlPage
HtmlPage htmlPage=webClent.getPage(url);
// [4] 获得的HtmlPage并不易于阅读,所以有需要可以通过Jsoup将其转换为Document对象
Document document = Jsoup.parseBodyFragment(htmlPage.asXml());
// [5]关闭
webClent.closeAllWindows();
HtmlPage 非常方便在获取到按钮后进行赋值和操作点击事件。常用方法getElementByName根据名称获取指定的标签(HtmlElement),类型可以设置为标签。
在 Document 对象中经常使用 select("") 方法,通过该方法可以获取到具体的 Element,然后通过解析内容得到需要的数据。
HtmlUnit很容易爬取,但是因为它模拟了网页的点击事件,所以响应返回的所有内容都会很臃肿。如果需要的数据量很小,效率会有点低。
htmlunit 抓取网页(抓一个今日头条的首页内容解决方案-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-22 16:23
不知道大家在使用jsoup的过程中是否遇到过爬取内容,发现有些网页中的内容是通过javascript异步加载的,导致我们的爬虫空手返回(只抓到一个网页的外框) .
当我第一次遇到这个问题时,我想到了两个解决方案:
在等待网页异步加载后,使用类似于 Python 中延迟加载的方法对异步加载的网页进行爬取。使用一种特殊的方法来模拟被爬取的网页框架内的 JavaScript 代码的执行,最终到达完整的网页。
在搜索引擎的帮助下,决定使用方案二来解决这个问题。解决方案1中没有搜索到更好的第三方库。在java中使用解决方案1解决此问题的朋友希望与下一个讨论,非常感谢。
案例很简单,抓取一条今日头条的首页内容。你可以看一下今日头条的首页,里面的内容是异步加载的。
添加jsoup和htmlunit依赖
org.jsoup
jsoup
1.10.2
net.sourceforge.htmlunit
htmlunit
2.25
首先,我们单独使用jsoup来解析今日头条的首页
String url = "https://www.toutiao.com/";
Connection connect = Jsoup.connect(url);
Document document = connect.get();
System.out.println(document);
↑ 这里只能获取网页的框架内容,不能获取首页的新闻内容
接下来,我们使用htmlunit来尝试
//构造一个webClient 模拟Chrome 浏览器
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//屏蔽日志信息
LogFactory.getFactory().setAttribute("org.apache.commons.logging.Log",
"org.apache.commons.logging.impl.NoOpLog");
java.util.logging.Logger.getLogger("com.gargoylesoftware").setLevel(Level.OFF);
//支持JavaScript
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setTimeout(5000);
HtmlPage rootPage = webClient.getPage(url);
//设置一个运行JavaScript的时间
webClient.waitForBackgroundJavaScript(5000);
String html = rootPage.asXml();
Document document = Jsoup.parse(html);
这为我们提供了运行 JavaScript 的完整源页面 查看全部
htmlunit 抓取网页(抓一个今日头条的首页内容解决方案-苏州安嘉)
不知道大家在使用jsoup的过程中是否遇到过爬取内容,发现有些网页中的内容是通过javascript异步加载的,导致我们的爬虫空手返回(只抓到一个网页的外框) .
当我第一次遇到这个问题时,我想到了两个解决方案:
在等待网页异步加载后,使用类似于 Python 中延迟加载的方法对异步加载的网页进行爬取。使用一种特殊的方法来模拟被爬取的网页框架内的 JavaScript 代码的执行,最终到达完整的网页。
在搜索引擎的帮助下,决定使用方案二来解决这个问题。解决方案1中没有搜索到更好的第三方库。在java中使用解决方案1解决此问题的朋友希望与下一个讨论,非常感谢。
案例很简单,抓取一条今日头条的首页内容。你可以看一下今日头条的首页,里面的内容是异步加载的。
添加jsoup和htmlunit依赖
org.jsoup
jsoup
1.10.2
net.sourceforge.htmlunit
htmlunit
2.25
首先,我们单独使用jsoup来解析今日头条的首页
String url = "https://www.toutiao.com/";
Connection connect = Jsoup.connect(url);
Document document = connect.get();
System.out.println(document);
↑ 这里只能获取网页的框架内容,不能获取首页的新闻内容
接下来,我们使用htmlunit来尝试
//构造一个webClient 模拟Chrome 浏览器
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//屏蔽日志信息
LogFactory.getFactory().setAttribute("org.apache.commons.logging.Log",
"org.apache.commons.logging.impl.NoOpLog");
java.util.logging.Logger.getLogger("com.gargoylesoftware").setLevel(Level.OFF);
//支持JavaScript
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setTimeout(5000);
HtmlPage rootPage = webClient.getPage(url);
//设置一个运行JavaScript的时间
webClient.waitForBackgroundJavaScript(5000);
String html = rootPage.asXml();
Document document = Jsoup.parse(html);
这为我们提供了运行 JavaScript 的完整源页面
htmlunit 抓取网页(java页面分析工具是什么?是怎么做的? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-22 10:14
)
一、什么是 HtmlUnit?
1、htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这是一个没有界面但运行速度很快的浏览器。
2、 使用 Rhinojs 引擎。模拟js运行
3、一般来说,这个项目可以用来测试页面和自动化网页测试,(包括JS)
4、但是一般来说,在小型爬虫项目中,这种框架是非常常用的,它可以有效的分析DOM标签,有效的运行页面上的js来获取一些需要执行的js来获得价值。
二、应用:获取百度API返回的详情url,从详情url中抓取图片url
maven 依赖:
net.sourceforge.htmlunit
htmlunit-core-js
2.23
net.sourceforge.htmlunit
htmlunit
2.23
xml-apis
xml-apis
1.4.01
服务器代码:
/**
* 从百度POI详情页获取图片url
* @param poiUid
* @return
*/
public static List grabImgUrl(String poiUid) {
if (StringUtils.isBlank(poiUid)) {
return null;
}
final String IMG_LIST_URL = "http://map.baidu.com/detail%3F ... 3B%3B
String detailUrl = IMG_LIST_URL + poiUid;
log.info("grabImgUrl. detailUrl=" + detailUrl);
final String DIV_ID = "photoContainer";
final String TAG_IMG = "img";
final String IMG_SRC = "src";
try (final WebClient webClient = new WebClient()) {
final HtmlPage page = webClient.getPage(detailUrl);
if (page != null && page.isHtmlPage()) {
Thread.sleep(40000); // 等待页面加载完成。
final HtmlDivision div = page.getHtmlElementById(DIV_ID);
DomNodeList eleList = div.getElementsByTagName(TAG_IMG);
List imgUrlList = new ArrayList();
for (HtmlElement hele : eleList) {
String imgUrl = hele.getAttribute(IMG_SRC);
if (StringUtils.isNotBlank(imgUrl)) {
log.info("imgUrl=" + imgUrl);
imgUrlList.add(imgUrl);
}
}
return imgUrlList;
}
} catch (Exception e) {
log.error("grabImgUrl error.", e);
}
return null;
}
页面显示:
设为封面
× 查看全部
htmlunit 抓取网页(java页面分析工具是什么?是怎么做的?
)
一、什么是 HtmlUnit?
1、htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这是一个没有界面但运行速度很快的浏览器。
2、 使用 Rhinojs 引擎。模拟js运行
3、一般来说,这个项目可以用来测试页面和自动化网页测试,(包括JS)
4、但是一般来说,在小型爬虫项目中,这种框架是非常常用的,它可以有效的分析DOM标签,有效的运行页面上的js来获取一些需要执行的js来获得价值。
二、应用:获取百度API返回的详情url,从详情url中抓取图片url
maven 依赖:
net.sourceforge.htmlunit
htmlunit-core-js
2.23
net.sourceforge.htmlunit
htmlunit
2.23
xml-apis
xml-apis
1.4.01
服务器代码:
/**
* 从百度POI详情页获取图片url
* @param poiUid
* @return
*/
public static List grabImgUrl(String poiUid) {
if (StringUtils.isBlank(poiUid)) {
return null;
}
final String IMG_LIST_URL = "http://map.baidu.com/detail%3F ... 3B%3B
String detailUrl = IMG_LIST_URL + poiUid;
log.info("grabImgUrl. detailUrl=" + detailUrl);
final String DIV_ID = "photoContainer";
final String TAG_IMG = "img";
final String IMG_SRC = "src";
try (final WebClient webClient = new WebClient()) {
final HtmlPage page = webClient.getPage(detailUrl);
if (page != null && page.isHtmlPage()) {
Thread.sleep(40000); // 等待页面加载完成。
final HtmlDivision div = page.getHtmlElementById(DIV_ID);
DomNodeList eleList = div.getElementsByTagName(TAG_IMG);
List imgUrlList = new ArrayList();
for (HtmlElement hele : eleList) {
String imgUrl = hele.getAttribute(IMG_SRC);
if (StringUtils.isNotBlank(imgUrl)) {
log.info("imgUrl=" + imgUrl);
imgUrlList.add(imgUrl);
}
}
return imgUrlList;
}
} catch (Exception e) {
log.error("grabImgUrl error.", e);
}
return null;
}
页面显示:
设为封面
×
htmlunit 抓取网页(网页获取和解析速度和性能的应用场景详解! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 364 次浏览 • 2022-01-22 10:12
)
(4)支持代理
(5)支持自动cookie管理等。
Java爬虫开发中应用最广泛的网页获取技术之一,速度和性能一流。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;
import org.apache.http.client.HttpClient;
import org.apache.http.client.ResponseHandler;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.BasicResponseHandler;
import org.apache.http.impl.client.DefaultHttpClient;
/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/
public class HttpClientTest {
public static void main(String[] args) throws Exception {
//目标页面
String url = "http://www.yshjava.cn";
//创建一个默认的HttpClient
HttpClient httpclient = new DefaultHttpClient();
try {
//以get方式请求网页http://www.yshjava.cn
HttpGet httpget = new HttpGet(url);
//打印请求地址
System.out.println("executing request " + httpget.getURI());
//创建响应处理器处理服务器响应内容
ResponseHandlerresponseHandler = new BasicResponseHandler();
//执行请求并获取结果
String responseBody = httpclient.execute(httpget, responseHandler);
System.out.println("----------------------------------------");
System.out.println(responseBody);
System.out.println("----------------------------------------");
} finally {
//关闭连接管理器
httpclient.getConnectionManager().shutdown();
}
}
}
汤
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
示例代码如下:
package cn.ysh.studio.crawler.jsoup;
import java.io.IOException;
import org.jsoup.Jsoup;
/**
* 基于Jsoup抓取网页内容
* @author www.yshjava.cn
*/
public class JsoupTest {
public static void main(String[] args) throws IOException {
//目标页面
String url = "http://www.yshjava.cn";
//使用Jsoup连接目标页面,并执行请求,获取服务器响应内容
String html = Jsoup.connect(url).execute().body();
//打印页面内容
System.out.println(html);
}
}
html单元
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取和解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.Page;
import com.gargoylesoftware.htmlunit.WebClient;
/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlUnitSpider {
public static void main(String[] s) throws Exception {
//目标网页
String url = "http://www.yshjava.cn";
//模拟特定浏览器FIREFOX_3
WebClient spider = new WebClient(BrowserVersion.FIREFOX_3);
//获取目标网页
Page page = spider.getPage(url);
//打印网页内容
System.out.println(page.getWebResponse().getContentAsString());
//关闭所有窗口
spider.closeAllWindows();
}
}
瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
示例代码如下:
package cn.ysh.studio.crawler.ie;
import watij.runtime.ie.IE;
/**
* 基于Watij抓取网页内容,仅限Windows平台
*
* @author www.yshjava.cn
*/
public class WatijTest {
public static void main(String[] s) {
//目标页面
String url = "http://www.yshjava.cn";
//实例化IE浏览器对象
IE ie = new IE();
try {
//启动浏览器
ie.start();
//转到目标网页
ie.goTo(url);
//等待网页加载就绪
ie.waitUntilReady();
//打印页面内容
System.out.println(ie.html());
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
//关闭IE浏览器
ie.close();
} catch (Exception e) {
}
}
}
}
硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性——测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;
import org.openqa.selenium.htmlunit.HtmlUnitDriver;
/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlDriverTest {
public static void main(String[] s) {
//目标网页
String url = "http://www.yshjava.cn";
HtmlUnitDriver driver = new HtmlUnitDriver();
try {
//禁用JS脚本功能
driver.setJavascriptEnabled(false);
//打开目标网页
driver.get(url);
//获取当前网页源码
String html = driver.getPageSource();
//打印网页源码
System.out.println(html);
} catch (Exception e) {
//打印堆栈信息
e.printStackTrace();
} finally {
try {
//关闭并退出
driver.close();
driver.quit();
} catch (Exception e) {
}
}
}
}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;
import org.watij.webspec.dsl.WebSpec;
/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/
public class WebspecTest {
public static void main(String[] s) {
//目标网页
String url = "http://www.yshjava.cn";
//实例化浏览器对象
WebSpec spec = new WebSpec().mozilla();
//隐藏浏览器窗体
spec.hide();
//打开目标页面
spec.open(url);
//打印网页源码
System.out.println(spec.source());
//关闭所有窗口
spec.closeAll();
}
} 查看全部
htmlunit 抓取网页(网页获取和解析速度和性能的应用场景详解!
)
(4)支持代理
(5)支持自动cookie管理等。
Java爬虫开发中应用最广泛的网页获取技术之一,速度和性能一流。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;
import org.apache.http.client.HttpClient;
import org.apache.http.client.ResponseHandler;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.BasicResponseHandler;
import org.apache.http.impl.client.DefaultHttpClient;
/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/
public class HttpClientTest {
public static void main(String[] args) throws Exception {
//目标页面
String url = "http://www.yshjava.cn";
//创建一个默认的HttpClient
HttpClient httpclient = new DefaultHttpClient();
try {
//以get方式请求网页http://www.yshjava.cn
HttpGet httpget = new HttpGet(url);
//打印请求地址
System.out.println("executing request " + httpget.getURI());
//创建响应处理器处理服务器响应内容
ResponseHandlerresponseHandler = new BasicResponseHandler();
//执行请求并获取结果
String responseBody = httpclient.execute(httpget, responseHandler);
System.out.println("----------------------------------------");
System.out.println(responseBody);
System.out.println("----------------------------------------");
} finally {
//关闭连接管理器
httpclient.getConnectionManager().shutdown();
}
}
}
汤
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
示例代码如下:
package cn.ysh.studio.crawler.jsoup;
import java.io.IOException;
import org.jsoup.Jsoup;
/**
* 基于Jsoup抓取网页内容
* @author www.yshjava.cn
*/
public class JsoupTest {
public static void main(String[] args) throws IOException {
//目标页面
String url = "http://www.yshjava.cn";
//使用Jsoup连接目标页面,并执行请求,获取服务器响应内容
String html = Jsoup.connect(url).execute().body();
//打印页面内容
System.out.println(html);
}
}
html单元
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取和解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.Page;
import com.gargoylesoftware.htmlunit.WebClient;
/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlUnitSpider {
public static void main(String[] s) throws Exception {
//目标网页
String url = "http://www.yshjava.cn";
//模拟特定浏览器FIREFOX_3
WebClient spider = new WebClient(BrowserVersion.FIREFOX_3);
//获取目标网页
Page page = spider.getPage(url);
//打印网页内容
System.out.println(page.getWebResponse().getContentAsString());
//关闭所有窗口
spider.closeAllWindows();
}
}
瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
示例代码如下:
package cn.ysh.studio.crawler.ie;
import watij.runtime.ie.IE;
/**
* 基于Watij抓取网页内容,仅限Windows平台
*
* @author www.yshjava.cn
*/
public class WatijTest {
public static void main(String[] s) {
//目标页面
String url = "http://www.yshjava.cn";
//实例化IE浏览器对象
IE ie = new IE();
try {
//启动浏览器
ie.start();
//转到目标网页
ie.goTo(url);
//等待网页加载就绪
ie.waitUntilReady();
//打印页面内容
System.out.println(ie.html());
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
//关闭IE浏览器
ie.close();
} catch (Exception e) {
}
}
}
}
硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性——测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;
import org.openqa.selenium.htmlunit.HtmlUnitDriver;
/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlDriverTest {
public static void main(String[] s) {
//目标网页
String url = "http://www.yshjava.cn";
HtmlUnitDriver driver = new HtmlUnitDriver();
try {
//禁用JS脚本功能
driver.setJavascriptEnabled(false);
//打开目标网页
driver.get(url);
//获取当前网页源码
String html = driver.getPageSource();
//打印网页源码
System.out.println(html);
} catch (Exception e) {
//打印堆栈信息
e.printStackTrace();
} finally {
try {
//关闭并退出
driver.close();
driver.quit();
} catch (Exception e) {
}
}
}
}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;
import org.watij.webspec.dsl.WebSpec;
/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/
public class WebspecTest {
public static void main(String[] s) {
//目标网页
String url = "http://www.yshjava.cn";
//实例化浏览器对象
WebSpec spec = new WebSpec().mozilla();
//隐藏浏览器窗体
spec.hide();
//打开目标页面
spec.open(url);
//打印网页源码
System.out.println(spec.source());
//关闭所有窗口
spec.closeAll();
}
}
htmlunit 抓取网页(抓一个今日头条的首页内容解决方案-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-01-22 10:09
不知道大家在使用jsoup的过程中是否遇到过爬取内容,发现有些网页中的内容是通过javascript异步加载的,导致我们的爬虫空手返回(只抓到一个网页的外框) .
当我第一次遇到这个问题时,我想到了两个解决方案:
在等待网页异步加载后,使用类似于 Python 中延迟加载的方法对异步加载的网页进行爬取。使用一种特殊的方法来模拟被爬取的网页框架内的 JavaScript 代码的执行,最终到达完整的网页。
在搜索引擎的帮助下,决定使用方案二来解决这个问题。解决方案1中没有搜索到更好的第三方库。在java中使用解决方案1解决此问题的朋友希望与下一个讨论,非常感谢。
案例很简单,抓取一条今日头条的首页内容。你可以看一下今日头条的首页,里面的内容是异步加载的。
添加jsoup和htmlunit依赖
org.jsoup
jsoup
1.10.2
net.sourceforge.htmlunit
htmlunit
2.25
首先,我们单独使用jsoup来解析今日头条的首页
String url = "https://www.toutiao.com/";
Connection connect = Jsoup.connect(url);
Document document = connect.get();
System.out.println(document);
↑ 这里只能获取网页的框架内容,不能获取首页的新闻内容
接下来,我们使用htmlunit来尝试
//构造一个webClient 模拟Chrome 浏览器
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//屏蔽日志信息
LogFactory.getFactory().setAttribute("org.apache.commons.logging.Log",
"org.apache.commons.logging.impl.NoOpLog");
java.util.logging.Logger.getLogger("com.gargoylesoftware").setLevel(Level.OFF);
//支持JavaScript
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setTimeout(5000);
HtmlPage rootPage = webClient.getPage(url);
//设置一个运行JavaScript的时间
webClient.waitForBackgroundJavaScript(5000);
String html = rootPage.asXml();
Document document = Jsoup.parse(html);
这为我们提供了运行 JavaScript 的完整源页面 查看全部
htmlunit 抓取网页(抓一个今日头条的首页内容解决方案-苏州安嘉)
不知道大家在使用jsoup的过程中是否遇到过爬取内容,发现有些网页中的内容是通过javascript异步加载的,导致我们的爬虫空手返回(只抓到一个网页的外框) .
当我第一次遇到这个问题时,我想到了两个解决方案:
在等待网页异步加载后,使用类似于 Python 中延迟加载的方法对异步加载的网页进行爬取。使用一种特殊的方法来模拟被爬取的网页框架内的 JavaScript 代码的执行,最终到达完整的网页。
在搜索引擎的帮助下,决定使用方案二来解决这个问题。解决方案1中没有搜索到更好的第三方库。在java中使用解决方案1解决此问题的朋友希望与下一个讨论,非常感谢。
案例很简单,抓取一条今日头条的首页内容。你可以看一下今日头条的首页,里面的内容是异步加载的。
添加jsoup和htmlunit依赖
org.jsoup
jsoup
1.10.2
net.sourceforge.htmlunit
htmlunit
2.25
首先,我们单独使用jsoup来解析今日头条的首页
String url = "https://www.toutiao.com/";
Connection connect = Jsoup.connect(url);
Document document = connect.get();
System.out.println(document);
↑ 这里只能获取网页的框架内容,不能获取首页的新闻内容
接下来,我们使用htmlunit来尝试
//构造一个webClient 模拟Chrome 浏览器
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//屏蔽日志信息
LogFactory.getFactory().setAttribute("org.apache.commons.logging.Log",
"org.apache.commons.logging.impl.NoOpLog");
java.util.logging.Logger.getLogger("com.gargoylesoftware").setLevel(Level.OFF);
//支持JavaScript
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setTimeout(5000);
HtmlPage rootPage = webClient.getPage(url);
//设置一个运行JavaScript的时间
webClient.waitForBackgroundJavaScript(5000);
String html = rootPage.asXml();
Document document = Jsoup.parse(html);
这为我们提供了运行 JavaScript 的完整源页面
htmlunit 抓取网页(介绍常用爬虫开源项目和腾讯微博爬虫的问题总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-22 08:08
介绍
常用爬虫开源项目
新浪微博爬虫和腾讯微博爬虫
新浪爬虫问题
总结
介绍
相关介绍
即网络爬虫是一种自动获取网页内容的程序。它是搜索引擎的重要组成部分,因此搜索引擎优化主要针对爬虫进行优化。
主要分类
网络爬虫从万维网上为搜索引擎下载网页。一般分为传统爬虫和专注爬虫。
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某个停止条件。通俗的讲,就是通过源码分析得到想要的内容。
焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
反爬虫:KS-WAF将爬虫行为分为搜索引擎爬虫和扫描爬虫,可以屏蔽特定搜索引擎爬虫以节省带宽和性能,也可以屏蔽扫描爬虫防止网站被恶意爬取。
常用爬虫开源项目
Nutch 标志 搜索引擎 Nutch
Nutch 是一个搜索引擎的开源 Java 实现。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫。
尽管网络搜索是漫游 Internet 的基本要求,但现有网络搜索引擎的数量正在下降。而这很可能会演变成一家为其商业利益垄断几乎所有网络搜索的公司。这显然对绝大多数网民不利。
现在所有主要的搜索引擎都使用专有的排名算法,这些算法不能解释为什么一个页面被排在一个特定的位置。另外,有些搜索引擎按网站付费,而不是按自己的值排序。
Apache Nutch 项目(一个网络搜索引擎)。当 Nutch 发展到一定程度时,遇到了可扩展性的问题,即当存储的网页数量达到 1 亿的水平时,Nutch 原有的结构很难达到高效率。就在整个团队不知所措的时候,救星谷歌出现了。Google 在 2003 年发布了 Google 使用的分布式文件存储系统文章(The Google File System),Nutch 开发者意识到可以将 Nutch 放在 GFS 上实现,所以经过一年的发展,NDFS(Nutch Distributed文件系统)出现。在解决了瓶颈问题之后,Nutch 有了很大的发展,而就在 2004 年,Google 发布了 MapReduce 的想法,因此尝到甜头的 Nutch 开发者们毫不犹豫地将 MapReduce 模型应用到了 Nutch 系统中。
但是在 Nutch 加入 GFS 和 MapReduce 之后,Nutch 变得太大了,超出了网络搜索引擎的范围,所以在 2006 年分别移植了 NDFS 和 MapReduce,形成了一个新的项目,叫做 Hadoop。
Java 多线程网络爬虫 Crawler4j
Crawler4j 是一个开源的 Java 类库,它提供了一个简单的网页爬取接口。它可以用来构建一个多线程的网络爬虫。
crawler4j的使用主要分为两步:
1. 实现一个继承自WebCrawler的爬虫类;
2.调用CrawlController实现的爬虫类。
WebCrawler 是一个抽象类,继承它必须实现两个方法:shouldVisit 和 visit。在:
shouldVisit 是判断当前URL是否应该被爬取(visited);
visit 是抓取URL指向的页面的数据,传入的参数是网页所有数据的封装对象Page。
Crawler.CrawController 控制爬虫,先添加seed,然后开启多个爬虫,不断监控每个爬虫的生存状态。
Crawler.WebCrawler 爬虫
1. Run():不断循环,每次从Frontier取50个url,对每个url进行processPage(curUrl)。
2. processPage(curURL):使用 PageFetcher.fetch 抓取网页。如果curURL被重定向,则将重定向url的url添加到Frontier,稍后调度;如果爬取正常,则先解析,生成Page,然后将新的url下降到Frontier(此时确定新增url的深度),调用visit(Page){用户自定义操作} .
Crawler.Configurations 读取 crawler4j.properties 中的信息
Crawler.PageFetcher 启动 IdleConnectionMonitorThread 并使用 fetch(Page, ignoreIfBinary) 抓取单个 Page 页面。是一个静态类。
Crawler.Page 一个页面
Crawler.PageFetchStatus 单页爬取的配置,如返回的爬取状态号的含义等。
Crawler.HTMLParser 解析 HTML 源代码并将其存储在 Page 中。
Crawler.LinkExtractor 提取 HTML 页面中收录的所有链接。
Crawler.IdleConnectionMonitorThread 用于监控连接(用于发送get请求,获取页面),其connMgr负责发送HTML请求。
HTML单元
HtmlUnitHtmlUnit 是“Java 程序的无 GUI 浏览器”。它对 HTML 文档进行建模并提供一个 API,允许您调用页面、填写表单、单击链接等……就像您在“普通”浏览器中所做的一样。
HtmlUnit的使用: 简介:HtmlUnit是一个浏览器,用Java编写,没有界面。因为它没有接口,所以执行速度仍然可以下降。HtmlUnit提供了一系列的API,这些API可以做很多功能,比如表单填写、表单提交、模拟点击链接,并且由于内置了Rhinojs引擎,可以执行Javascript
1、模拟特定浏览器,也可以指定浏览器对应版本(HtmlUnit最新版本2.13现在可以模拟Chrome/FireFox/IE)
WebClient webClient=new WebClient(BrowserVersion.FIREFOX_24);
2、查找特定元素,可以通过get或者XPath从HtmlPage中获取特定的Html元素。例如;
DomElement plc_main=page.getElementById("plc_main");
DomElement code_box=(DomElement) pl_common_sassfilter.getByXPath("//div[@class='code_box clearfix']").get(0);
3. 模拟表单的提交显示在用于登录的代码中;
HtmlForm loginform = logonPage.getFormByName("loginform");
HtmlTextInput uid = loginform.getInputByName("u");
uid.click();//点击获取焦点
uid.type(Config.getAccount());
HtmlPasswordInput pwd = loginform.getInputByName("p");
pwd.click();
pwd.type(Config.getPassword());
4、获取新浪微博等微博内容等信息。
DomNodeList dls = pl_weibo_direct.getElementsByTagName("dl");
DomElement dl= dls.get(0);
整数索引 = 0;
而(DL!=空){
DomElement em=feed_list_content.getElementsByTagName("em").get(0);
字符串内容 = em.getTextContent();
newlist.add(内容);
索引++;
dl = dls.get(索引);}
2.模拟登录,找到微博内容的位置。
3.获取微博数据并存入数据库,数据库使用MYSQL
逻辑其实很简单。需要熟悉HTMLunit提供的一些类,然后是XPath语法,再熟悉一些基础的数据库知识,就可以完成微博的爬取。
腾讯微博也有同样的想法。一些区别是
1.页面解析不同。
2.URL 的某些特征是不同的。
新浪爬虫问题总结
新浪微博爬虫的一些问题:
首先是微博数量的限制,从搜索页关键词开始,只能搜索到50页的微博数据。那么每页有20条,只能搜到1000条,这肯定跟实时微博的数量不匹配。
所以你可以使用高级搜索从2009年开始搜索,这需要不断的实验,看看时间可以弥补50页的微博。因为无论我搜索什么,新浪微博都只能显示50页的数据。
以本田雅阁为例,可以分为五次搜索,第一次是2009年到2010年,这个时间段只有33页数据,然后是2010年1.1到2011.1.1有50页数据,然后往下推。在某些时期,建立50页数据只需要五六个月。简而言之,这不是常规模式。大概,时间越长,微博越多。. 所以当这个编程达到50页时,url链接的下一页就没有了。这是一个限制。
第二个问题是微博内容重复。如果连接是
%25E6%259C%25AC%25E7%2594%25B0%25E9%259B%2585%25E9%2598%2581&xsort=time&scope=ori×cope=custom:2013-01-01-0:2014-04-23-0&page=8
以本田雅阁为例,这个页面上的微博基本上都是一样的内容。据我观察,这个品牌的微博更像是一个营销和广告的微博。当然,你可以用微博来验证这个方法来刷选。但真正有意义的是,原创的微博,是一个少得可怜的数字。只有几百个大小。
还是有一些方法可以删除同一个微博。最近在数据库下操作比较有效,使用select distinct content from weibo where program='Honda Accord' into outfile 'D:/Honda Accord.txt';仍然可以删除其中大部分重复推文。
或者对于几乎相同的情况,只有 URL 不同。您可以使用删除微博内容 LIKE '%铃木“大型车”将与本田雅阁同级%';或其他一些具有特别明显特征的词或短语。
第三个问题是,虽然新浪只提供了这么多数据,但还是处处受限。当程序运行到20页时,会出现需要手动输入验证码以防止爬虫影响其服务器的问题。这个方案是通过模仿登录验证码的方法来解决的。就是拿到需要输入的验证码,把imageReader拿出来变成一个JFrame,手动输入,点一下,基本上就可以解决问题了。
第四个问题是微博内容在页面中体现不规则。例如,所有微博内容合二为一,只需 em.getTextContent()。因为不规则,有的em像点赞、空格等,解决方法是通过判断发现em只要不是真实的内容就没有任何属性。否则会有一个类属性。使用判断 hasAttribute() 踢掉点赞和空格。
第五个问题是不同id定位的问题。使用通用搜索时,定位ID为pl_weibo_direct,使用高级搜索时,微博内容定位ID为pl_wb_feedlist。
,当然是一些细节。
总结:
虽然还有很多问题,但是爬取数据的效果不是很好。不过可以肯定的是,新浪微博上的大部分数据还是可以通过网址找到的,新浪不可能大规模删除。假设像我这样的用户很久以前在2009年发了一条支持本田雅阁的微博,我可以通过我的微博链接看到与本田雅阁相关的微博内容。因此,与关键字相关的微博仍然存在于页面上,但新浪微博本身提供的搜索功能并不强大且有限。 查看全部
htmlunit 抓取网页(介绍常用爬虫开源项目和腾讯微博爬虫的问题总结)
介绍
常用爬虫开源项目
新浪微博爬虫和腾讯微博爬虫
新浪爬虫问题
总结
介绍
相关介绍
即网络爬虫是一种自动获取网页内容的程序。它是搜索引擎的重要组成部分,因此搜索引擎优化主要针对爬虫进行优化。
主要分类
网络爬虫从万维网上为搜索引擎下载网页。一般分为传统爬虫和专注爬虫。
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某个停止条件。通俗的讲,就是通过源码分析得到想要的内容。
焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
反爬虫:KS-WAF将爬虫行为分为搜索引擎爬虫和扫描爬虫,可以屏蔽特定搜索引擎爬虫以节省带宽和性能,也可以屏蔽扫描爬虫防止网站被恶意爬取。
常用爬虫开源项目
Nutch 标志 搜索引擎 Nutch
Nutch 是一个搜索引擎的开源 Java 实现。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫。
尽管网络搜索是漫游 Internet 的基本要求,但现有网络搜索引擎的数量正在下降。而这很可能会演变成一家为其商业利益垄断几乎所有网络搜索的公司。这显然对绝大多数网民不利。
现在所有主要的搜索引擎都使用专有的排名算法,这些算法不能解释为什么一个页面被排在一个特定的位置。另外,有些搜索引擎按网站付费,而不是按自己的值排序。
Apache Nutch 项目(一个网络搜索引擎)。当 Nutch 发展到一定程度时,遇到了可扩展性的问题,即当存储的网页数量达到 1 亿的水平时,Nutch 原有的结构很难达到高效率。就在整个团队不知所措的时候,救星谷歌出现了。Google 在 2003 年发布了 Google 使用的分布式文件存储系统文章(The Google File System),Nutch 开发者意识到可以将 Nutch 放在 GFS 上实现,所以经过一年的发展,NDFS(Nutch Distributed文件系统)出现。在解决了瓶颈问题之后,Nutch 有了很大的发展,而就在 2004 年,Google 发布了 MapReduce 的想法,因此尝到甜头的 Nutch 开发者们毫不犹豫地将 MapReduce 模型应用到了 Nutch 系统中。
但是在 Nutch 加入 GFS 和 MapReduce 之后,Nutch 变得太大了,超出了网络搜索引擎的范围,所以在 2006 年分别移植了 NDFS 和 MapReduce,形成了一个新的项目,叫做 Hadoop。
Java 多线程网络爬虫 Crawler4j
Crawler4j 是一个开源的 Java 类库,它提供了一个简单的网页爬取接口。它可以用来构建一个多线程的网络爬虫。
crawler4j的使用主要分为两步:
1. 实现一个继承自WebCrawler的爬虫类;
2.调用CrawlController实现的爬虫类。
WebCrawler 是一个抽象类,继承它必须实现两个方法:shouldVisit 和 visit。在:
shouldVisit 是判断当前URL是否应该被爬取(visited);
visit 是抓取URL指向的页面的数据,传入的参数是网页所有数据的封装对象Page。
Crawler.CrawController 控制爬虫,先添加seed,然后开启多个爬虫,不断监控每个爬虫的生存状态。
Crawler.WebCrawler 爬虫
1. Run():不断循环,每次从Frontier取50个url,对每个url进行processPage(curUrl)。
2. processPage(curURL):使用 PageFetcher.fetch 抓取网页。如果curURL被重定向,则将重定向url的url添加到Frontier,稍后调度;如果爬取正常,则先解析,生成Page,然后将新的url下降到Frontier(此时确定新增url的深度),调用visit(Page){用户自定义操作} .
Crawler.Configurations 读取 crawler4j.properties 中的信息
Crawler.PageFetcher 启动 IdleConnectionMonitorThread 并使用 fetch(Page, ignoreIfBinary) 抓取单个 Page 页面。是一个静态类。
Crawler.Page 一个页面
Crawler.PageFetchStatus 单页爬取的配置,如返回的爬取状态号的含义等。
Crawler.HTMLParser 解析 HTML 源代码并将其存储在 Page 中。
Crawler.LinkExtractor 提取 HTML 页面中收录的所有链接。
Crawler.IdleConnectionMonitorThread 用于监控连接(用于发送get请求,获取页面),其connMgr负责发送HTML请求。
HTML单元
HtmlUnitHtmlUnit 是“Java 程序的无 GUI 浏览器”。它对 HTML 文档进行建模并提供一个 API,允许您调用页面、填写表单、单击链接等……就像您在“普通”浏览器中所做的一样。
HtmlUnit的使用: 简介:HtmlUnit是一个浏览器,用Java编写,没有界面。因为它没有接口,所以执行速度仍然可以下降。HtmlUnit提供了一系列的API,这些API可以做很多功能,比如表单填写、表单提交、模拟点击链接,并且由于内置了Rhinojs引擎,可以执行Javascript
1、模拟特定浏览器,也可以指定浏览器对应版本(HtmlUnit最新版本2.13现在可以模拟Chrome/FireFox/IE)
WebClient webClient=new WebClient(BrowserVersion.FIREFOX_24);
2、查找特定元素,可以通过get或者XPath从HtmlPage中获取特定的Html元素。例如;
DomElement plc_main=page.getElementById("plc_main");
DomElement code_box=(DomElement) pl_common_sassfilter.getByXPath("//div[@class='code_box clearfix']").get(0);
3. 模拟表单的提交显示在用于登录的代码中;
HtmlForm loginform = logonPage.getFormByName("loginform");
HtmlTextInput uid = loginform.getInputByName("u");
uid.click();//点击获取焦点
uid.type(Config.getAccount());
HtmlPasswordInput pwd = loginform.getInputByName("p");
pwd.click();
pwd.type(Config.getPassword());
4、获取新浪微博等微博内容等信息。
DomNodeList dls = pl_weibo_direct.getElementsByTagName("dl");
DomElement dl= dls.get(0);
整数索引 = 0;
而(DL!=空){
DomElement em=feed_list_content.getElementsByTagName("em").get(0);
字符串内容 = em.getTextContent();
newlist.add(内容);
索引++;
dl = dls.get(索引);}
2.模拟登录,找到微博内容的位置。
3.获取微博数据并存入数据库,数据库使用MYSQL
逻辑其实很简单。需要熟悉HTMLunit提供的一些类,然后是XPath语法,再熟悉一些基础的数据库知识,就可以完成微博的爬取。
腾讯微博也有同样的想法。一些区别是
1.页面解析不同。
2.URL 的某些特征是不同的。
新浪爬虫问题总结
新浪微博爬虫的一些问题:
首先是微博数量的限制,从搜索页关键词开始,只能搜索到50页的微博数据。那么每页有20条,只能搜到1000条,这肯定跟实时微博的数量不匹配。
所以你可以使用高级搜索从2009年开始搜索,这需要不断的实验,看看时间可以弥补50页的微博。因为无论我搜索什么,新浪微博都只能显示50页的数据。
以本田雅阁为例,可以分为五次搜索,第一次是2009年到2010年,这个时间段只有33页数据,然后是2010年1.1到2011.1.1有50页数据,然后往下推。在某些时期,建立50页数据只需要五六个月。简而言之,这不是常规模式。大概,时间越长,微博越多。. 所以当这个编程达到50页时,url链接的下一页就没有了。这是一个限制。
第二个问题是微博内容重复。如果连接是
%25E6%259C%25AC%25E7%2594%25B0%25E9%259B%2585%25E9%2598%2581&xsort=time&scope=ori×cope=custom:2013-01-01-0:2014-04-23-0&page=8
以本田雅阁为例,这个页面上的微博基本上都是一样的内容。据我观察,这个品牌的微博更像是一个营销和广告的微博。当然,你可以用微博来验证这个方法来刷选。但真正有意义的是,原创的微博,是一个少得可怜的数字。只有几百个大小。
还是有一些方法可以删除同一个微博。最近在数据库下操作比较有效,使用select distinct content from weibo where program='Honda Accord' into outfile 'D:/Honda Accord.txt';仍然可以删除其中大部分重复推文。
或者对于几乎相同的情况,只有 URL 不同。您可以使用删除微博内容 LIKE '%铃木“大型车”将与本田雅阁同级%';或其他一些具有特别明显特征的词或短语。
第三个问题是,虽然新浪只提供了这么多数据,但还是处处受限。当程序运行到20页时,会出现需要手动输入验证码以防止爬虫影响其服务器的问题。这个方案是通过模仿登录验证码的方法来解决的。就是拿到需要输入的验证码,把imageReader拿出来变成一个JFrame,手动输入,点一下,基本上就可以解决问题了。
第四个问题是微博内容在页面中体现不规则。例如,所有微博内容合二为一,只需 em.getTextContent()。因为不规则,有的em像点赞、空格等,解决方法是通过判断发现em只要不是真实的内容就没有任何属性。否则会有一个类属性。使用判断 hasAttribute() 踢掉点赞和空格。
第五个问题是不同id定位的问题。使用通用搜索时,定位ID为pl_weibo_direct,使用高级搜索时,微博内容定位ID为pl_wb_feedlist。
,当然是一些细节。
总结:
虽然还有很多问题,但是爬取数据的效果不是很好。不过可以肯定的是,新浪微博上的大部分数据还是可以通过网址找到的,新浪不可能大规模删除。假设像我这样的用户很久以前在2009年发了一条支持本田雅阁的微博,我可以通过我的微博链接看到与本田雅阁相关的微博内容。因此,与关键字相关的微博仍然存在于页面上,但新浪微博本身提供的搜索功能并不强大且有限。
htmlunit 抓取网页(介绍两种使用Java进行Web的工具,即无头模式! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-11 13:17
)
在之前的 文章 中,我向您介绍了两个使用 Java 进行网页抓取的工具。第一个 文章 中的 HtmlUnit 和 文章 中的 PhantomJS 关于处理 Javascript-heavy 网站。
这一次,我们将介绍 Chrome 的一项新功能,即无头模式。有传言称谷歌使用特殊版本的 Chrome 来满足其抓取需求。我不知道这是否属实,但谷歌几个月前为 Chrome 59 引入了无头模式。
PhantomJS 是该领域的领导者,它已经(并且仍然)大量用于浏览器自动化和测试。在听说 Headless Chrome 之后,PhantomJS 的维护者说他辞去了维护者的职务,因为我引用了“Google Chrome 比 PhantomJS 更快、更稳定 [...]”
在浏览器自动化和处理 Java-heavy网站 方面,Chrome 无头似乎正在成为一种选择。
HtmlUnit、PhantomJS 和其他无头浏览器是非常有用的工具,问题是它们不如 Chrome 稳定,有时你会得到 Chrome 没有的 Javascript 错误。
先决条件
org.seleniumhq.selenium
selenium-java
3.8.1
如果你没有安装谷歌浏览器,你可以在这里下载
要安装 Chromedriver,您可以在 MacOS 上使用 brew:
brew install chromedriver
或使用以下链接下载。
版本比较多,建议大家使用最新版的Chrome和chromedriver。
让我们登录黑客新闻
在这一部分中,我们将登录 Hacker News 并在登录后进行截图。我们不需要 Chrome 无头来执行此任务,但本文的目的只是向您展示如何使用 Selenium 运行无头 Chrome。
我们要做的第一件事是创建一个 WebDriver 对象并设置 chromedriver 路径和一些参数:
的
option is needed on Windows systems, according to the [documentation](https://developers.google.com/ ... chrome)
Chromedriver should automatically find the Google Chrome executable path, if you have a special installation, or if you want to use a different version of Chrome, you can do it with :
```java
options.setBinary("/Path/to/specific/version/of/Google Chrome");
如果您想了解有关不同选项的更多信息,请参阅 Chromedriver 文档
下一步是对 Hacker News 登录表单执行 GET 请求,选择用户名和密码字段,用我们的凭据填写它们,然后单击登录按钮。然后我们必须检查凭据错误,如果登录,我们可以截屏。
查看全部
htmlunit 抓取网页(介绍两种使用Java进行Web的工具,即无头模式!
)
在之前的 文章 中,我向您介绍了两个使用 Java 进行网页抓取的工具。第一个 文章 中的 HtmlUnit 和 文章 中的 PhantomJS 关于处理 Javascript-heavy 网站。
这一次,我们将介绍 Chrome 的一项新功能,即无头模式。有传言称谷歌使用特殊版本的 Chrome 来满足其抓取需求。我不知道这是否属实,但谷歌几个月前为 Chrome 59 引入了无头模式。
PhantomJS 是该领域的领导者,它已经(并且仍然)大量用于浏览器自动化和测试。在听说 Headless Chrome 之后,PhantomJS 的维护者说他辞去了维护者的职务,因为我引用了“Google Chrome 比 PhantomJS 更快、更稳定 [...]”
在浏览器自动化和处理 Java-heavy网站 方面,Chrome 无头似乎正在成为一种选择。
HtmlUnit、PhantomJS 和其他无头浏览器是非常有用的工具,问题是它们不如 Chrome 稳定,有时你会得到 Chrome 没有的 Javascript 错误。
先决条件
org.seleniumhq.selenium
selenium-java
3.8.1
如果你没有安装谷歌浏览器,你可以在这里下载
要安装 Chromedriver,您可以在 MacOS 上使用 brew:
brew install chromedriver
或使用以下链接下载。
版本比较多,建议大家使用最新版的Chrome和chromedriver。
让我们登录黑客新闻
在这一部分中,我们将登录 Hacker News 并在登录后进行截图。我们不需要 Chrome 无头来执行此任务,但本文的目的只是向您展示如何使用 Selenium 运行无头 Chrome。
我们要做的第一件事是创建一个 WebDriver 对象并设置 chromedriver 路径和一些参数:
的
option is needed on Windows systems, according to the [documentation](https://developers.google.com/ ... chrome)
Chromedriver should automatically find the Google Chrome executable path, if you have a special installation, or if you want to use a different version of Chrome, you can do it with :
```java
options.setBinary("/Path/to/specific/version/of/Google Chrome");
如果您想了解有关不同选项的更多信息,请参阅 Chromedriver 文档
下一步是对 Hacker News 登录表单执行 GET 请求,选择用户名和密码字段,用我们的凭据填写它们,然后单击登录按钮。然后我们必须检查凭据错误,如果登录,我们可以截屏。
htmlunit 抓取网页(1.通用网络爬虫的基本结构和工作有所实现时要)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-01-08 08:04
有趣~~
网络爬虫简介
【可爱的脸孔】
前言
爬虫这个词在互联网高度发达的今天,也许你我不再陌生。互联网上每天都会产生海量的数据,如何帮助人们准确找到自己想要的信息一直是相关从业者努力改进的问题。其中,以搜索引擎为代表的应用系统是我们日常生活中最常见的表现形式。爬虫是否有助于测试工作?带着这个问题,我们先来了解一下爬虫的基本概念和原理:参考360百科就知道,网络爬虫,又称网络蜘蛛、网络机器人,是一种遵循一定规则的网络爬虫。,一种自动从万维网上抓取信息的程序或脚本。
爬虫?? 有趣~~
网络爬虫的基本结构和工作流程
在实践中,一个通用的网络爬虫可以通过多种不同的方式实现,但总体原理是相同的。以下是笔者接触过的框架,笔者以此为背景与大家分享。
1. 通用网络爬虫框架图:
基本工作流程如下——将种子 URL(即开始爬取的入口 URL)和配置文件交给控制器。配置文件可以收录爬取深度、文件类型、使用的账号信息以及线程数、机器人数等。 - 控制器会从待处理的URL中获取一定数量的URL,交给空闲线程去抓取对应的网页内容——每个网页处理线程在下载对应的URL中间的内容后,会将当前的URL放入已处理的URL表中。同时,处理线程将获取当前内容中的所有链接地址并与处理后的URL表进行比较,将未处理的URL放入待处理的URL表中。
2. 实现爬虫需要注意几个方面:
判断返回页面的状态码,需要针对有跳转的页面跟踪跳转后的URL(以下代码截取自开源java爬虫工具crawler4j)
处理js动态加载:由于js在浏览器中执行后才能看到内容,所以爬虫获取时不执行,指定html标签下的内容必须为空。内容的js代码字符串,然后通过正则表达式获取对应的内容,而不是解析HTML标签。在收录以下 js 片段的页面中提取“分数”值:
未通过带有“id=result”的标签找到,但可以通过正则表达式分数匹配:(\d+)。
Ajax异步请求,在今天的网站中经常使用,一般需要用户进行交互才能返回内容。在这种情况下,可以使用一些模拟浏览器的工具,比如HtmlUnit,通过模拟用户点击操作来获取想要的数据。这种方式可能会导致系统资源消耗严重,稳定性差。另一种方式是直接拼接ajax接口参数的url来完成数据抓取。
对于设计用于大规模网络的爬虫,还需要考虑完成所有页面爬取所需的时间和存储资源。在这种情况下,爬虫设计应该采用分布式应用架构。这里不讨论这个。
三、测试领域的应用
因为我们在做测试,所以我们也想探索爬虫在自动化测试中可以拥有哪些应用程序。目前可以预见的尝试以下几个方面: - 使用爬虫遍历web服务的每个URL,检查是否有损坏的链接 - 结合selenium webdriver进行随机测试(如crawjax) - 定期更新web对象仓库UI自动化测试
四、结束语
我们刚刚开始对网络爬虫的研究和研究,期待在新的体验之后与您分享更多相关内容。最后附上一个开源的java爬虫工具crawler4j(下载地址:)。这个项目也是我用来学习爬虫的项目。之前的网页上有例子,有兴趣的同学可以使用。
看不够~
忍不住哭了~~
Qtest之道
遵循Qtest的方式 查看全部
htmlunit 抓取网页(1.通用网络爬虫的基本结构和工作有所实现时要)
有趣~~
网络爬虫简介
【可爱的脸孔】
前言
爬虫这个词在互联网高度发达的今天,也许你我不再陌生。互联网上每天都会产生海量的数据,如何帮助人们准确找到自己想要的信息一直是相关从业者努力改进的问题。其中,以搜索引擎为代表的应用系统是我们日常生活中最常见的表现形式。爬虫是否有助于测试工作?带着这个问题,我们先来了解一下爬虫的基本概念和原理:参考360百科就知道,网络爬虫,又称网络蜘蛛、网络机器人,是一种遵循一定规则的网络爬虫。,一种自动从万维网上抓取信息的程序或脚本。
爬虫?? 有趣~~
网络爬虫的基本结构和工作流程
在实践中,一个通用的网络爬虫可以通过多种不同的方式实现,但总体原理是相同的。以下是笔者接触过的框架,笔者以此为背景与大家分享。
1. 通用网络爬虫框架图:
基本工作流程如下——将种子 URL(即开始爬取的入口 URL)和配置文件交给控制器。配置文件可以收录爬取深度、文件类型、使用的账号信息以及线程数、机器人数等。 - 控制器会从待处理的URL中获取一定数量的URL,交给空闲线程去抓取对应的网页内容——每个网页处理线程在下载对应的URL中间的内容后,会将当前的URL放入已处理的URL表中。同时,处理线程将获取当前内容中的所有链接地址并与处理后的URL表进行比较,将未处理的URL放入待处理的URL表中。
2. 实现爬虫需要注意几个方面:
判断返回页面的状态码,需要针对有跳转的页面跟踪跳转后的URL(以下代码截取自开源java爬虫工具crawler4j)
处理js动态加载:由于js在浏览器中执行后才能看到内容,所以爬虫获取时不执行,指定html标签下的内容必须为空。内容的js代码字符串,然后通过正则表达式获取对应的内容,而不是解析HTML标签。在收录以下 js 片段的页面中提取“分数”值:
未通过带有“id=result”的标签找到,但可以通过正则表达式分数匹配:(\d+)。
Ajax异步请求,在今天的网站中经常使用,一般需要用户进行交互才能返回内容。在这种情况下,可以使用一些模拟浏览器的工具,比如HtmlUnit,通过模拟用户点击操作来获取想要的数据。这种方式可能会导致系统资源消耗严重,稳定性差。另一种方式是直接拼接ajax接口参数的url来完成数据抓取。
对于设计用于大规模网络的爬虫,还需要考虑完成所有页面爬取所需的时间和存储资源。在这种情况下,爬虫设计应该采用分布式应用架构。这里不讨论这个。
三、测试领域的应用
因为我们在做测试,所以我们也想探索爬虫在自动化测试中可以拥有哪些应用程序。目前可以预见的尝试以下几个方面: - 使用爬虫遍历web服务的每个URL,检查是否有损坏的链接 - 结合selenium webdriver进行随机测试(如crawjax) - 定期更新web对象仓库UI自动化测试
四、结束语
我们刚刚开始对网络爬虫的研究和研究,期待在新的体验之后与您分享更多相关内容。最后附上一个开源的java爬虫工具crawler4j(下载地址:)。这个项目也是我用来学习爬虫的项目。之前的网页上有例子,有兴趣的同学可以使用。
看不够~
忍不住哭了~~
Qtest之道
遵循Qtest的方式
htmlunit 抓取网页(Htmlunit模拟浏览页面内容的java框架,具有js解析引擎(rhino))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-06 00:19
Htmlunit 是一个模拟浏览和抓取页面内容的java框架。自带js解析引擎(rhino),可以解析页面的js脚本,得到完整的页面内容,特别适合这种不完整页面的站点抓取。
以下使用的是htmlunit版本:
net.sourceforge.htmlunit
htmlunit
2.14
代码的实现很简单,主要分为两种常见的场景:解析页面的js和不解析页面的js
public class CrawlPage {
public static void main(String[] args) throws Exception {
CrawlPage crawl = new CrawlPage();
String url = "http://www.baidu.com/";
System.out.println("----------------------抓取页面时不解析js-----------------");
crawl.crawlPageWithoutAnalyseJs(url);
System.out.println("----------------------抓取页面时解析js-------------------");
crawl.crawlPageWithAnalyseJs(url);
}
/**
* 功能描述:抓取页面时不解析页面的js
* @param url
* @throws Exception
*/
public void crawlPageWithoutAnalyseJs(String url) throws Exception{
//1.创建连接client
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//2.设置连接的相关选项
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setTimeout(10000);
//3.抓取页面
HtmlPage page = webClient.getPage(url);
System.out.println(page.asXml());
//4.关闭模拟窗口
webClient.closeAllWindows();
}
/**
* 功能描述:抓取页面时并解析页面的js
* @param url
* @throws Exception
*/
public void crawlPageWithAnalyseJs(String url) throws Exception{
//1.创建连接client
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//2.设置连接的相关选项
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true); //需要解析js
webClient.getOptions().setThrowExceptionOnScriptError(false); //解析js出错时不抛异常
webClient.getOptions().setTimeout(10000); //超时时间 ms
//3.抓取页面
HtmlPage page = webClient.getPage(url);
//4.将页面转成指定格式
webClient.waitForBackgroundJavaScript(10000); //等侍js脚本执行完成
System.out.println(page.asXml());
//5.关闭模拟的窗口
webClient.closeAllWindows();
}
}
主要关注webClient几个选项的配置,
webClient.getOptions().setJavaScriptEnabled(true); //需要解析js
webClient.getOptions().setThrowExceptionOnScriptError(false); //解析js出错时不抛异常
默认需要打开这两个开关来解析页面的js和css渲染。因为爬虫本身没有接口,所以不需要这部分,即如下配置:
webClient.getOptions().setCssEnabled(false);
Htmlunit 在解析 js 时也可能会失败。此篇未深入研究,后续使用中遇到问题记录
抓到的内容默认以xml的形式获取,即page.asXml(),因为这样可以通过jsoup解析html页面数据,jsoup是一个更方便简洁的工具,后续有follow -up 关于jsoup的使用实践,欢迎大家来打砖~~
相关文件:
htmlunit官网-
jsoup官网- 查看全部
htmlunit 抓取网页(Htmlunit模拟浏览页面内容的java框架,具有js解析引擎(rhino))
Htmlunit 是一个模拟浏览和抓取页面内容的java框架。自带js解析引擎(rhino),可以解析页面的js脚本,得到完整的页面内容,特别适合这种不完整页面的站点抓取。
以下使用的是htmlunit版本:
net.sourceforge.htmlunit
htmlunit
2.14
代码的实现很简单,主要分为两种常见的场景:解析页面的js和不解析页面的js
public class CrawlPage {
public static void main(String[] args) throws Exception {
CrawlPage crawl = new CrawlPage();
String url = "http://www.baidu.com/";
System.out.println("----------------------抓取页面时不解析js-----------------");
crawl.crawlPageWithoutAnalyseJs(url);
System.out.println("----------------------抓取页面时解析js-------------------");
crawl.crawlPageWithAnalyseJs(url);
}
/**
* 功能描述:抓取页面时不解析页面的js
* @param url
* @throws Exception
*/
public void crawlPageWithoutAnalyseJs(String url) throws Exception{
//1.创建连接client
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//2.设置连接的相关选项
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setTimeout(10000);
//3.抓取页面
HtmlPage page = webClient.getPage(url);
System.out.println(page.asXml());
//4.关闭模拟窗口
webClient.closeAllWindows();
}
/**
* 功能描述:抓取页面时并解析页面的js
* @param url
* @throws Exception
*/
public void crawlPageWithAnalyseJs(String url) throws Exception{
//1.创建连接client
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//2.设置连接的相关选项
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(true); //需要解析js
webClient.getOptions().setThrowExceptionOnScriptError(false); //解析js出错时不抛异常
webClient.getOptions().setTimeout(10000); //超时时间 ms
//3.抓取页面
HtmlPage page = webClient.getPage(url);
//4.将页面转成指定格式
webClient.waitForBackgroundJavaScript(10000); //等侍js脚本执行完成
System.out.println(page.asXml());
//5.关闭模拟的窗口
webClient.closeAllWindows();
}
}
主要关注webClient几个选项的配置,
webClient.getOptions().setJavaScriptEnabled(true); //需要解析js
webClient.getOptions().setThrowExceptionOnScriptError(false); //解析js出错时不抛异常
默认需要打开这两个开关来解析页面的js和css渲染。因为爬虫本身没有接口,所以不需要这部分,即如下配置:
webClient.getOptions().setCssEnabled(false);
Htmlunit 在解析 js 时也可能会失败。此篇未深入研究,后续使用中遇到问题记录
抓到的内容默认以xml的形式获取,即page.asXml(),因为这样可以通过jsoup解析html页面数据,jsoup是一个更方便简洁的工具,后续有follow -up 关于jsoup的使用实践,欢迎大家来打砖~~
相关文件:
htmlunit官网-
jsoup官网-
htmlunit 抓取网页(普通web网站的信息,用URL的HTML源代码的方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-01-06 00:03
普通的web网站信息通过下载URL的HTML源代码就可以满足基本需求,但是现在有更多的网站使用web2.0技术,比如一些电子商务网站、SNS网站等,抓取网页的部分信息时,如评论、滚动、延迟加载等,直接下载HTML源代码不能满足需求,而且很多ajax规则需要自定义,通过多个请求完成一个页面信息的采集。在这种情况下,爬虫代码定制更加复杂,开发和维护难度增加。
找了一些支持ajax爬取的开源工具,比如Crawlajax(?),它是基于webdriver技术的,需要一个接口来辅助,但是爬虫最好没有接口,以减少加载时间,降低复杂度,增加程序的便利性和稳定性 经过一番搜索,有一个开源工具可以基本满足需求,那就是HtmlUnit。
该工具集成了 Rhino 的 javascript 引擎,可以解析 HTML 并模拟 js 的执行。通过HtmlUnit打开网页后,可以获取当前的DOM结构,执行js,点击链接,提交表单。最大的优点是它没有接口。
import java.net.URL;import com.gargoylesoftware.htmlunit.WebClient;import com.gargoylesoftware.htmlunit.html.HtmlElement;import com.gargoylesoftware.htmlunit.html.HtmlPage;public class Sample {/** * @param args */public static void main(String[] args) throws Exception{// TODO Auto-generated method stub//设置访问ChromeDriver的路径 final WebClient webClient = new WebClient(); // 构造一个URL,指向需要测试的URL,如http://www.javaeye.com URL url = new URL("http://item.jd.com/754320.html"); // 通过getPage()方法,返回相应的页面 webClient.getCurrentWindow().setInnerHeight(60000); webClient.setCssEnabled(false); HtmlPage page = (HtmlPage) webClient.getPage(url); System.out.println("InnerHeight:"+webClient.getCurrentWindow().getInnerHeight()); //System.out.println(page.getTitleText()); System.out.println(page.asText()); }}
特别说明:HtmlUnit 不支持滚动消息。一些网页在加载时滚动。执行js语句将webcontrol滚动到底部是无效的。国外也有人提出了这个问题,但没有给出解决方案。找了半天,终于找到了绕过的办法,就是把页面的高度设置为60000,一个可以容纳所有页面可见范围的大值,这样就可以满足滚动加载的需要(也就是页面不需要滚动。没关系)。 查看全部
htmlunit 抓取网页(普通web网站的信息,用URL的HTML源代码的方式)
普通的web网站信息通过下载URL的HTML源代码就可以满足基本需求,但是现在有更多的网站使用web2.0技术,比如一些电子商务网站、SNS网站等,抓取网页的部分信息时,如评论、滚动、延迟加载等,直接下载HTML源代码不能满足需求,而且很多ajax规则需要自定义,通过多个请求完成一个页面信息的采集。在这种情况下,爬虫代码定制更加复杂,开发和维护难度增加。
找了一些支持ajax爬取的开源工具,比如Crawlajax(?),它是基于webdriver技术的,需要一个接口来辅助,但是爬虫最好没有接口,以减少加载时间,降低复杂度,增加程序的便利性和稳定性 经过一番搜索,有一个开源工具可以基本满足需求,那就是HtmlUnit。
该工具集成了 Rhino 的 javascript 引擎,可以解析 HTML 并模拟 js 的执行。通过HtmlUnit打开网页后,可以获取当前的DOM结构,执行js,点击链接,提交表单。最大的优点是它没有接口。
import java.net.URL;import com.gargoylesoftware.htmlunit.WebClient;import com.gargoylesoftware.htmlunit.html.HtmlElement;import com.gargoylesoftware.htmlunit.html.HtmlPage;public class Sample {/** * @param args */public static void main(String[] args) throws Exception{// TODO Auto-generated method stub//设置访问ChromeDriver的路径 final WebClient webClient = new WebClient(); // 构造一个URL,指向需要测试的URL,如http://www.javaeye.com URL url = new URL("http://item.jd.com/754320.html";); // 通过getPage()方法,返回相应的页面 webClient.getCurrentWindow().setInnerHeight(60000); webClient.setCssEnabled(false); HtmlPage page = (HtmlPage) webClient.getPage(url); System.out.println("InnerHeight:"+webClient.getCurrentWindow().getInnerHeight()); //System.out.println(page.getTitleText()); System.out.println(page.asText()); }}
特别说明:HtmlUnit 不支持滚动消息。一些网页在加载时滚动。执行js语句将webcontrol滚动到底部是无效的。国外也有人提出了这个问题,但没有给出解决方案。找了半天,终于找到了绕过的办法,就是把页面的高度设置为60000,一个可以容纳所有页面可见范围的大值,这样就可以满足滚动加载的需要(也就是页面不需要滚动。没关系)。
htmlunit 抓取网页(和java自带的网络API进行结合,怎么做?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-05 04:01
HtmlUnit 结合了 HttpClient 和 java 自带的网络 API,操作起来更加简单方便。HtmlUnit底层依然封装了HttpClient,但是封装之后解析出来的内容更像是一个网页,而不是抽象的请求和响应,所以更方便开发者上手。
// [1] new一个WebClient,在其中定义一种浏览器
WebClient webClent = new WebClient(BrowserVersion.FIREFOX_17);
// [2] 设置网页解析的内容
WebClientOptions options=webClent.getOptions();
options.setCssEnabled(false);
options.setJavaScriptEnabled(true);
options.setActiveXNative(false);
options.setAppletEnabled(false);
options.setRedirectEnabled(true);
options.setThrowExceptionOnFailingStatusCode(false);
options.setThrowExceptionOnScriptError(false);
options.setDoNotTrackEnabled(false);
options.setGeolocationEnabled(false);
// [3] 访问指定的页面,并将其赋予HtmlPage
HtmlPage htmlPage=webClent.getPage(url);
// [4] 获得的HtmlPage并不易于阅读,所以有需要可以通过Jsoup将其转换为Document对象
Document document = Jsoup.parseBodyFragment(htmlPage.asXml());
// [5]关闭
webClent.closeAllWindows();
HtmlPage对于获取按钮后赋值和操作点击事件非常方便。常用方法getElementByName根据名称获取指定的标签(HtmlElement),可以为标签设置类型。
select("") 方法经常用在 Document 对象中。通过这个方法可以得到一个特定的Element,然后通过解析内容就可以得到需要的数据。
HtmlUnit方便抓取,但是因为它模拟了网页点击事件,所以所有的响应内容都会变得臃肿。如果需要的数据量很小,效率会有点低。 查看全部
htmlunit 抓取网页(和java自带的网络API进行结合,怎么做?)
HtmlUnit 结合了 HttpClient 和 java 自带的网络 API,操作起来更加简单方便。HtmlUnit底层依然封装了HttpClient,但是封装之后解析出来的内容更像是一个网页,而不是抽象的请求和响应,所以更方便开发者上手。
// [1] new一个WebClient,在其中定义一种浏览器
WebClient webClent = new WebClient(BrowserVersion.FIREFOX_17);
// [2] 设置网页解析的内容
WebClientOptions options=webClent.getOptions();
options.setCssEnabled(false);
options.setJavaScriptEnabled(true);
options.setActiveXNative(false);
options.setAppletEnabled(false);
options.setRedirectEnabled(true);
options.setThrowExceptionOnFailingStatusCode(false);
options.setThrowExceptionOnScriptError(false);
options.setDoNotTrackEnabled(false);
options.setGeolocationEnabled(false);
// [3] 访问指定的页面,并将其赋予HtmlPage
HtmlPage htmlPage=webClent.getPage(url);
// [4] 获得的HtmlPage并不易于阅读,所以有需要可以通过Jsoup将其转换为Document对象
Document document = Jsoup.parseBodyFragment(htmlPage.asXml());
// [5]关闭
webClent.closeAllWindows();
HtmlPage对于获取按钮后赋值和操作点击事件非常方便。常用方法getElementByName根据名称获取指定的标签(HtmlElement),可以为标签设置类型。
select("") 方法经常用在 Document 对象中。通过这个方法可以得到一个特定的Element,然后通过解析内容就可以得到需要的数据。
HtmlUnit方便抓取,但是因为它模拟了网页点击事件,所以所有的响应内容都会变得臃肿。如果需要的数据量很小,效率会有点低。
htmlunit 抓取网页(搜索引擎如何将频次分配给网站的机制以及提高网站排名和有机流量的技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-23 04:00
爬行频率更像是一个 SEO 概念。大多数情况下,站长并不关心百度蜘蛛的抓取频率,因为抓取频率对中小企业几乎没有影响网站。
尽管大多数 网站 管理员不必担心抓取频率,但如果您正在运行大型 网站,抓取频率是我们可以(并且应该)优化的 SEO 因素。
当然,随着 SEO 的发展,爬取频率和排名的关系并不简单,爬取本身并不是一个排名因素,但是从某种角度来说,爬取频率对搜索引擎优化有着间接的影响(这也是造成搜索引擎优化的原因)蜘蛛池的流行)。
在本指南中,我将讲解相关的爬取概念,搜索引擎如何将爬取频率分配给网站的机制,以及如何充分利用爬取频率来最大化网站的排名和排名的技巧为有机交通。
内容
网络蜘蛛的好与坏
网络蜘蛛、爬虫或机器人是不断“访问”和抓取网页以采集某些信息的计算机程序。
根据爬行的目的,可以区分以下几种蜘蛛:
搜索引擎蜘蛛
网络服务蜘蛛;
黑客蜘蛛
搜索引擎蜘蛛由百度、谷歌或360等搜索引擎管理。这些蜘蛛可以抓取互联网上的所有页面(前提是可以找到)并提供给搜索引擎的索引库。
许多网络服务,如搜索引擎优化工具、购物、旅游和优惠券,都有自己的网络索引和蜘蛛。例如,WebMeUp 有一个名为 Blexbot 的蜘蛛,每天可以抓取数百亿个页面。采集反向链接数据并将此数据提供给其链接索引(SEO SpyGlass 中使用的链接索引)。
黑客也喜欢繁殖蜘蛛。他们使用蜘蛛来测试各种 网站 漏洞。一旦发现漏洞,他们可能会尝试访问您的 网站 或服务器。
你可能会听到人们谈论好蜘蛛和坏蜘蛛,我是这样区分的:任何旨在为非法目的采集信息的蜘蛛都是坏的,其余的都是好的。
大多数蜘蛛在用户代理字符串的帮助下识别自己,并提供 URL,您可以在其中了解有关蜘蛛的更多信息:
在本文中,我将重点介绍搜索引擎蜘蛛以及它们如何抓取 网站。
了解抓取频率
抓取频率是搜索引擎蜘蛛在一定时间内点击网站的次数。例如,百度通常每月点击我的网站 1000 次。我可以说1K是百度每个月的爬虫频率,请注意这些爬虫的数量和频率没有一般限制;。
为什么抓取频率很重要?
从逻辑上讲,你应该注意抓取频率,因为你想让百度在网站上发现尽可能多的重要网页,也希望它能在你的网站上快速找到新的内容和抓取频率越高,这种情况发生的速度就越快。
确定爬取频率
您可以在百度网站管理员工具中查看您的网站抓取频率。比如你需要确定自己的百度爬取频率,登录百度站长账号,进入数据监控->爬取频率,这里会看到每天的爬取频率。
从上面的报告中可以看出,百度平均每天抓取我大约30次。由此可以看出,我每月的爬取频率是30*30=900。
当然,这个数字很容易变化和波动,但它会为你提供一个可靠的想法,你可以在特定时间段内抓取你的网站的页面数量。
如果需要更详细地查看每个页面的爬取统计信息,则必须分析服务器日志。日志文件的位置取决于服务器配置。
如果您不确定如何访问服务器日志,请向您的系统管理员或托管服务提供商寻求帮助。
原创日志文件难以阅读和分析。要理解这些,您需要绝对水平的正则表达式技能或专门的工具。我更喜欢使用光年日志分析工具进行分析。
如何分配抓取频率?
对于搜索引擎优化,我们并不完全了解搜索引擎是如何形成网站的抓取频率的。所有博主对网络内容进行梳理,搜索引擎使用以下两个因素来确定抓取频率:
人气——越流行的网页会被更频繁地抓取;
过时-百度不会使有关网页的信息过时。对于网站管理员来说,这意味着如果网页内容更新频繁,百度会更频繁地尝试抓取网页。
假设一个网站的抓取频率与反向链接的数量和网站在百度眼中的重要性成正比——百度希望确保最重要的网页保持最新的索引。
内部链接呢?您能否通过指向更多内部链接来提高特定页面的抓取速度?
为了回答这些问题,我决定检查一下内链和外链的相关性和爬取统计。我采集了网站的11条数据,进行了简单的分析。简而言之,这是我完成的。
我为 11 个将要分析的站点创建了项目。我计算了每个 网站 网页的内部链接数量。接下来,我运行了 SEO Spyglass 并为相同的 11 个站点创建了项目。在每个项目中,我检查了统计数据并复制了每个页面的外部链接数量的锚点 URL。
然后,我分析了服务器日志中的爬取统计数据,以了解百度访问每个网页的频率。最后,我把所有这些数据放到一个电子表格中,计算出内链和爬虫预算、外链和爬虫预算的相关性。
我发现了一件非常有趣的事情。这是我分析的 网站 的示例电子表格之一:
我的数据集证明,蜘蛛访问次数与外部链接数之间存在很强的相关性(0,978)。同时,蜘蛛命中数与内部链接之间的相关性被证明非常弱(0 ,154),说明反向链接比网站链接更重要。
这是否意味着增加抓取频率的唯一方法是建立链接和发布新内容?如果我们讨论整个网站的朱雀频率,我会说是的:添加链接并经常更新网站,网站的抓取频率会成比例地增加。
但是,当我们单独取一个页面时,它会变得更有趣,正如您在下面的介绍中看到的那样,您甚至可能会在不知不觉中浪费大量的抓取频率。通过巧妙地管理频率,您通常可以使单个网页的抓取次数增加一倍——但它仍然会与每个网页的反向链接数量成正比。
如何充分利用抓取频率
现在,我们已经发现爬行很重要,是不是要花更多的时间来管理爬行频率?
你应该(或不应该)做很多事情来让搜索蜘蛛消耗更多的 网站 页面。以下是最大化爬取频率特征的操作列表:
1.保证重要页面可以被抓取,如果搜索到的内容不提供价值,就会被屏蔽。
.htaccess 和 robots.txt 不应阻塞 网站 的重要页面。机器人应该能够访问 CSS 和 Javascript 文件。同时,应该屏蔽不想在搜索中显示的内容,屏蔽“正在建设中的网站”区域和动态生成的网址等。
请记住,搜索引擎蜘蛛并不总是遵循 robots.txt 中收录的说明。你有没有在百度搜索结果中看到过这样的片段?
Robots.txt 不保证网页不会出现在搜索结果中:百度仍然可以根据外部信息(如传入链接)确定其相关性,如果您想明确阻止页面被索引,您应该使用 noindex robots 元标记或 X-Robots-Tag HTTP 标头,在这种情况下,您不应在 robots.txt 中禁止该页面,因为必须抓取该页面才能看到并符合该标记。 查看全部
htmlunit 抓取网页(搜索引擎如何将频次分配给网站的机制以及提高网站排名和有机流量的技巧)
爬行频率更像是一个 SEO 概念。大多数情况下,站长并不关心百度蜘蛛的抓取频率,因为抓取频率对中小企业几乎没有影响网站。
尽管大多数 网站 管理员不必担心抓取频率,但如果您正在运行大型 网站,抓取频率是我们可以(并且应该)优化的 SEO 因素。
当然,随着 SEO 的发展,爬取频率和排名的关系并不简单,爬取本身并不是一个排名因素,但是从某种角度来说,爬取频率对搜索引擎优化有着间接的影响(这也是造成搜索引擎优化的原因)蜘蛛池的流行)。
在本指南中,我将讲解相关的爬取概念,搜索引擎如何将爬取频率分配给网站的机制,以及如何充分利用爬取频率来最大化网站的排名和排名的技巧为有机交通。
内容
网络蜘蛛的好与坏
网络蜘蛛、爬虫或机器人是不断“访问”和抓取网页以采集某些信息的计算机程序。
根据爬行的目的,可以区分以下几种蜘蛛:
搜索引擎蜘蛛
网络服务蜘蛛;
黑客蜘蛛
搜索引擎蜘蛛由百度、谷歌或360等搜索引擎管理。这些蜘蛛可以抓取互联网上的所有页面(前提是可以找到)并提供给搜索引擎的索引库。
许多网络服务,如搜索引擎优化工具、购物、旅游和优惠券,都有自己的网络索引和蜘蛛。例如,WebMeUp 有一个名为 Blexbot 的蜘蛛,每天可以抓取数百亿个页面。采集反向链接数据并将此数据提供给其链接索引(SEO SpyGlass 中使用的链接索引)。
黑客也喜欢繁殖蜘蛛。他们使用蜘蛛来测试各种 网站 漏洞。一旦发现漏洞,他们可能会尝试访问您的 网站 或服务器。
你可能会听到人们谈论好蜘蛛和坏蜘蛛,我是这样区分的:任何旨在为非法目的采集信息的蜘蛛都是坏的,其余的都是好的。
大多数蜘蛛在用户代理字符串的帮助下识别自己,并提供 URL,您可以在其中了解有关蜘蛛的更多信息:
https://www.simcf.cc/wp-conten ... 4.jpg 300w, https://www.simcf.cc/wp-conten ... 9.jpg 768w" />在本文中,我将重点介绍搜索引擎蜘蛛以及它们如何抓取 网站。
了解抓取频率
抓取频率是搜索引擎蜘蛛在一定时间内点击网站的次数。例如,百度通常每月点击我的网站 1000 次。我可以说1K是百度每个月的爬虫频率,请注意这些爬虫的数量和频率没有一般限制;。
为什么抓取频率很重要?
从逻辑上讲,你应该注意抓取频率,因为你想让百度在网站上发现尽可能多的重要网页,也希望它能在你的网站上快速找到新的内容和抓取频率越高,这种情况发生的速度就越快。
确定爬取频率
您可以在百度网站管理员工具中查看您的网站抓取频率。比如你需要确定自己的百度爬取频率,登录百度站长账号,进入数据监控->爬取频率,这里会看到每天的爬取频率。
https://www.simcf.cc/wp-conten ... 2.jpg 300w, https://www.simcf.cc/wp-conten ... 1.jpg 768w, https://www.simcf.cc/wp-conten ... h.jpg 1159w" />从上面的报告中可以看出,百度平均每天抓取我大约30次。由此可以看出,我每月的爬取频率是30*30=900。
当然,这个数字很容易变化和波动,但它会为你提供一个可靠的想法,你可以在特定时间段内抓取你的网站的页面数量。
如果需要更详细地查看每个页面的爬取统计信息,则必须分析服务器日志。日志文件的位置取决于服务器配置。
如果您不确定如何访问服务器日志,请向您的系统管理员或托管服务提供商寻求帮助。
原创日志文件难以阅读和分析。要理解这些,您需要绝对水平的正则表达式技能或专门的工具。我更喜欢使用光年日志分析工具进行分析。
如何分配抓取频率?
对于搜索引擎优化,我们并不完全了解搜索引擎是如何形成网站的抓取频率的。所有博主对网络内容进行梳理,搜索引擎使用以下两个因素来确定抓取频率:
人气——越流行的网页会被更频繁地抓取;
过时-百度不会使有关网页的信息过时。对于网站管理员来说,这意味着如果网页内容更新频繁,百度会更频繁地尝试抓取网页。
假设一个网站的抓取频率与反向链接的数量和网站在百度眼中的重要性成正比——百度希望确保最重要的网页保持最新的索引。
内部链接呢?您能否通过指向更多内部链接来提高特定页面的抓取速度?
为了回答这些问题,我决定检查一下内链和外链的相关性和爬取统计。我采集了网站的11条数据,进行了简单的分析。简而言之,这是我完成的。
我为 11 个将要分析的站点创建了项目。我计算了每个 网站 网页的内部链接数量。接下来,我运行了 SEO Spyglass 并为相同的 11 个站点创建了项目。在每个项目中,我检查了统计数据并复制了每个页面的外部链接数量的锚点 URL。
然后,我分析了服务器日志中的爬取统计数据,以了解百度访问每个网页的频率。最后,我把所有这些数据放到一个电子表格中,计算出内链和爬虫预算、外链和爬虫预算的相关性。
我发现了一件非常有趣的事情。这是我分析的 网站 的示例电子表格之一:
https://www.simcf.cc/wp-conten ... 5.png 300w" />我的数据集证明,蜘蛛访问次数与外部链接数之间存在很强的相关性(0,978)。同时,蜘蛛命中数与内部链接之间的相关性被证明非常弱(0 ,154),说明反向链接比网站链接更重要。
这是否意味着增加抓取频率的唯一方法是建立链接和发布新内容?如果我们讨论整个网站的朱雀频率,我会说是的:添加链接并经常更新网站,网站的抓取频率会成比例地增加。
但是,当我们单独取一个页面时,它会变得更有趣,正如您在下面的介绍中看到的那样,您甚至可能会在不知不觉中浪费大量的抓取频率。通过巧妙地管理频率,您通常可以使单个网页的抓取次数增加一倍——但它仍然会与每个网页的反向链接数量成正比。
https://www.simcf.cc/wp-conten ... 0.png 300w" />如何充分利用抓取频率
现在,我们已经发现爬行很重要,是不是要花更多的时间来管理爬行频率?
你应该(或不应该)做很多事情来让搜索蜘蛛消耗更多的 网站 页面。以下是最大化爬取频率特征的操作列表:
1.保证重要页面可以被抓取,如果搜索到的内容不提供价值,就会被屏蔽。
.htaccess 和 robots.txt 不应阻塞 网站 的重要页面。机器人应该能够访问 CSS 和 Javascript 文件。同时,应该屏蔽不想在搜索中显示的内容,屏蔽“正在建设中的网站”区域和动态生成的网址等。
请记住,搜索引擎蜘蛛并不总是遵循 robots.txt 中收录的说明。你有没有在百度搜索结果中看到过这样的片段?
Robots.txt 不保证网页不会出现在搜索结果中:百度仍然可以根据外部信息(如传入链接)确定其相关性,如果您想明确阻止页面被索引,您应该使用 noindex robots 元标记或 X-Robots-Tag HTTP 标头,在这种情况下,您不应在 robots.txt 中禁止该页面,因为必须抓取该页面才能看到并符合该标记。
htmlunit 抓取网页(个人感觉java原生支持的方式友好,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-22 00:17
以上四种方法都是下载http资源。htmlunit 功能稍微强大一些。它还可以加载js和css。不过对于爬虫来说,加载css是没有意义的,但是有时候加载js还是很有必要的。
无论哪种方式都可以,这取决于您如何选择。个人感觉java原生的支持方式不够友好,但是不需要加载很多依赖。其他方法都非常好用,调用过程也很简单。下载组件通常以util的形式出现,写入后很少修改,除非http请求有bug,所以一旦写入完成,基本什么都没有。使用任何一种方法都可以。
解析组件
我们经常写爬虫不是为了像谷歌、百度这样的搜索引擎,而是为了获取特定的信息,这需要页面分析。比如我们爬取csdn的博客,那么我们需要的就是博客。博客的标题、作者、内容不需要其他内容,所以这时候我们需要解析html页面,获取我们需要的文本内容。
推荐两个工具,一个是htmlCleaner,一个是JSOUP。
HTMLCleaner 支持 XPATH。如果想了解更多关于xpath的内容,可以自行百度。XPATH 是一种支持 XML 节点定位的语言。HTML 可以理解为 XML 的一种。通过XPATH,我们可以定位我们的资源。
JSOUP和HTMLCleaner的作用是一样的,都是解析HTML文本,获取我们需要的问题的内容。
持久化组件
这很容易理解。我们爬取的内容一定要保存,否则爬虫就没有意义了。这需要一个持久化组件,目的是存储数据。至于mysq、hbase、redis的存储,就看你的了。达到了。
重复数据删除组件
爬虫必须对爬取过程中被爬取的内容进行重复数据删除。否则,可想而知,爬虫经常在做无意义的死循环。重复下载和分析爬取的内容是没有意义的。去重的目的是对爬取的链接做一个记录,实现的方法有很多种。如果只抓到一个网站,并且网站不大,可以用java用一个SET来完成。如果数据量很大,可以使用 REDIS、Memeched 等内存库进行过滤。对于繁重的工作,还有一个bloomfilter,非常适合这种场景。
工具:
1. JAVA SET
2. Redis,MEMCACHED
3. 过滤器
工艺梳理
总结
爬虫系统可以用java基础实现。最重要的是满足自己的需求,当需求增加时可以快速扩展。目前JAVA有很多非常好的开源爬虫系统。 查看全部
htmlunit 抓取网页(个人感觉java原生支持的方式友好,你知道吗?)
以上四种方法都是下载http资源。htmlunit 功能稍微强大一些。它还可以加载js和css。不过对于爬虫来说,加载css是没有意义的,但是有时候加载js还是很有必要的。
无论哪种方式都可以,这取决于您如何选择。个人感觉java原生的支持方式不够友好,但是不需要加载很多依赖。其他方法都非常好用,调用过程也很简单。下载组件通常以util的形式出现,写入后很少修改,除非http请求有bug,所以一旦写入完成,基本什么都没有。使用任何一种方法都可以。
解析组件
我们经常写爬虫不是为了像谷歌、百度这样的搜索引擎,而是为了获取特定的信息,这需要页面分析。比如我们爬取csdn的博客,那么我们需要的就是博客。博客的标题、作者、内容不需要其他内容,所以这时候我们需要解析html页面,获取我们需要的文本内容。
推荐两个工具,一个是htmlCleaner,一个是JSOUP。
HTMLCleaner 支持 XPATH。如果想了解更多关于xpath的内容,可以自行百度。XPATH 是一种支持 XML 节点定位的语言。HTML 可以理解为 XML 的一种。通过XPATH,我们可以定位我们的资源。
JSOUP和HTMLCleaner的作用是一样的,都是解析HTML文本,获取我们需要的问题的内容。
持久化组件
这很容易理解。我们爬取的内容一定要保存,否则爬虫就没有意义了。这需要一个持久化组件,目的是存储数据。至于mysq、hbase、redis的存储,就看你的了。达到了。
重复数据删除组件
爬虫必须对爬取过程中被爬取的内容进行重复数据删除。否则,可想而知,爬虫经常在做无意义的死循环。重复下载和分析爬取的内容是没有意义的。去重的目的是对爬取的链接做一个记录,实现的方法有很多种。如果只抓到一个网站,并且网站不大,可以用java用一个SET来完成。如果数据量很大,可以使用 REDIS、Memeched 等内存库进行过滤。对于繁重的工作,还有一个bloomfilter,非常适合这种场景。
工具:
1. JAVA SET
2. Redis,MEMCACHED
3. 过滤器
工艺梳理
总结
爬虫系统可以用java基础实现。最重要的是满足自己的需求,当需求增加时可以快速扩展。目前JAVA有很多非常好的开源爬虫系统。
htmlunit 抓取网页(遇到一个网页数据抓取的任务,给大家分享下!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-19 08:03
遇到一个爬取网页数据的任务,分享给大家。
说到网页信息抓取,相信Jsoup基本上是首选工具。完整的类似JQuery的操作让人感觉很舒服。不过,今天我们要说说Jsoup的缺点。
这是某网站的搜索栏,填写一些格式化数据进行经纬度转换,初始化是这样的,然后用jsoup捕获的代码如下:
当我们添加数据时,抓取的页面信息保持不变。这就是Jsoup的缺点。如果Jsoup抓取页面,页面加载后的所有数据,ajax加载的异步数据是不会抓取的。到达的。
这里再给大家介绍一个开源项目:HttpUnit,这个名字是用来测试的,但是爬取数据也不错,是一个完美的解决方案。HttpUnit其实相当于一个没有UI的浏览器,可以让页面上的js执行完成后,再次抓取信息。
有时我们使用requests抓取页面时,得到的结果可能与浏览器中看到的不同:在浏览器中可以看到正常显示的页面数据,但是使用requests得到的结果却不是。这是因为获取的请求都是原创的 HTML 文档,浏览器中的页面是 JavaScript 处理数据后生成的结果。这些数据的来源有很多,可能是通过Ajax加载的,可能是收录在HTML中的,也可能是通过JavaScript和特定算法计算后生成的文档中的文档。
在第一种情况下,数据加载是一种异步加载方法。原创页面最初不会收录一些数据。原创页面加载完成后,会向服务器请求一个接口来获取数据,然后对数据进行处理和呈现。在网页上,这实际上是一个 Ajax 请求。
根据Web的发展趋势,这种形式的页面越来越多。网页的原创 HTML 文档不收录任何数据。数据通过Ajax统一加载后呈现,从而在Web开发中实现前后端分离,减少服务器直接渲染页面带来的压力。
因此,如果遇到这样的页面,可以直接使用requests等库来抓取原创页面,无法获取有效数据。这时候就需要从网页后台分析发送到界面的Ajax请求。如果可以使用requests来模拟ajax请求,那么就可以成功爬取。
但是我没有使用这个测试框架:我解决问题的想法是
总结:ajax数据的爬取过程:
分析网页信息,抓取网页
1. 提交我们的搜索时,会加载这部分内容,并且会有表单数据生成,
体现在节目中:
2.服务器加载这个页面,我们输入表单信息,这个表单信息就是我们的搜索条件,例如:
体现在节目中:
3.js返回加载的页面,并在该页面添加信息
jsoup 可以解析页面。
4.模拟登录部分:
静态网页:jsoup
ajax 网页:webdriver+selenium+jsoup 查看全部
htmlunit 抓取网页(遇到一个网页数据抓取的任务,给大家分享下!)
遇到一个爬取网页数据的任务,分享给大家。
说到网页信息抓取,相信Jsoup基本上是首选工具。完整的类似JQuery的操作让人感觉很舒服。不过,今天我们要说说Jsoup的缺点。
这是某网站的搜索栏,填写一些格式化数据进行经纬度转换,初始化是这样的,然后用jsoup捕获的代码如下:
当我们添加数据时,抓取的页面信息保持不变。这就是Jsoup的缺点。如果Jsoup抓取页面,页面加载后的所有数据,ajax加载的异步数据是不会抓取的。到达的。
这里再给大家介绍一个开源项目:HttpUnit,这个名字是用来测试的,但是爬取数据也不错,是一个完美的解决方案。HttpUnit其实相当于一个没有UI的浏览器,可以让页面上的js执行完成后,再次抓取信息。
有时我们使用requests抓取页面时,得到的结果可能与浏览器中看到的不同:在浏览器中可以看到正常显示的页面数据,但是使用requests得到的结果却不是。这是因为获取的请求都是原创的 HTML 文档,浏览器中的页面是 JavaScript 处理数据后生成的结果。这些数据的来源有很多,可能是通过Ajax加载的,可能是收录在HTML中的,也可能是通过JavaScript和特定算法计算后生成的文档中的文档。
在第一种情况下,数据加载是一种异步加载方法。原创页面最初不会收录一些数据。原创页面加载完成后,会向服务器请求一个接口来获取数据,然后对数据进行处理和呈现。在网页上,这实际上是一个 Ajax 请求。
根据Web的发展趋势,这种形式的页面越来越多。网页的原创 HTML 文档不收录任何数据。数据通过Ajax统一加载后呈现,从而在Web开发中实现前后端分离,减少服务器直接渲染页面带来的压力。
因此,如果遇到这样的页面,可以直接使用requests等库来抓取原创页面,无法获取有效数据。这时候就需要从网页后台分析发送到界面的Ajax请求。如果可以使用requests来模拟ajax请求,那么就可以成功爬取。
但是我没有使用这个测试框架:我解决问题的想法是
总结:ajax数据的爬取过程:
分析网页信息,抓取网页
1. 提交我们的搜索时,会加载这部分内容,并且会有表单数据生成,
体现在节目中:
2.服务器加载这个页面,我们输入表单信息,这个表单信息就是我们的搜索条件,例如:
体现在节目中:
3.js返回加载的页面,并在该页面添加信息
jsoup 可以解析页面。
4.模拟登录部分:
静态网页:jsoup
ajax 网页:webdriver+selenium+jsoup
htmlunit 抓取网页(Python开发的一个快速、高层次的优点及解决办法!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 238 次浏览 • 2021-12-19 07:20
(1),Scrapy:
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还提供了多种爬虫的基类,如BaseSpider、站点地图爬虫等,最新版本还提供了web2.0爬虫支持。
废料意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2. 社区人数比较多,文档比较齐全。
3.URL 去重采用 Bloom filter 方案。
4. 可以处理不完整的 HTML,Scrapy 提供了选择器(一个基于 lxml 的更高级的接口),
可以高效处理不完整的HTML代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
Pyspider是一个用python实现的强大的网络爬虫系统。可以在浏览器界面实时编写脚本、调度函数和查看爬取结果。后端使用常用的数据库来存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2. 完全可视化,非常人性化:WEB界面编写调试脚本、启停脚本、监控执行状态、查看活动历史、获取结果。
3.简单,五分钟就能上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL去重使用数据库代替Bloom过滤器,数亿存储的db io会导致效率急剧下降。
2. 用户友好性牺牲了灵活性并降低了定制能力。
(3)Apache Nutch(更高)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。在 Nutch 运行的一组进程中,三分之二是为搜索引擎设计的。
Nutch的框架需要Hadoop运行,Hadoop需要开集群。对于那些想快速上手爬虫的人来说,我很沮丧......
这里列出了一些资源地址,也许以后会学到。
纳奇官网
1.Nutch支持分布式爬取,并且有Hadoop支持,可以进行多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。因为有了这个框架,Nutch的插件开发非常容易,第三方插件也层出不穷,大大提升了Nutch的功能和口碑。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的API,可以快速上手
2.模块化结构,易于扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), WebCollector
WebCollector是一个不需要配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,可以用少量的代码实现强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
优势:
1.基于文本密度自动提取网页正文
2.支持断点重爬
3.支持代理
缺点:
1. 不支持分布式,只支持单机
2.无URL优先调度
3.不是很活跃
(6), Heritrix3
Heritrix是一个由java开发的开源网络爬虫,用户可以使用它从网上抓取自己想要的资源
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫不能相互配合。
2. 在机器资源有限的情况下,需要复杂的操作。
3. 仅官方支持,仅在 Linux 上测试。
4.每个爬虫独立工作,更新没有任何修改。
5. 在发生硬件和系统故障时,恢复能力较差。
6. 花在优化性能上的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,没有搜索引擎。如果要对爬取的站点进行排序,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j是一个基于Java的轻量级独立开源爬虫框架
优势
1.多线程采集
2. 内置Url过滤机制,BerkeleyDB用于url过滤。
3. 可以扩展支持网页字段的结构化提取,可以作为一个垂直的采集
缺点
1. 不支持动态网页爬取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,我做了一个框架优缺点对比图,如下:
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期培训老师讲解的框架。几乎有完整的文档介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过这个框架有一个优势,它有非常强大的网页解析功能。
Jsoup中文教程
selenium(多位谷歌高管参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,是真正的模拟浏览器。GitHub1.4w+star,你没看错,有几万个。但我只是没有一个好的环境。入门Demo就是不能成功运行,所以放弃了。
硒官方GitHub
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器,就是这样。
基本介绍:
HtmlUnit的优点是可以轻松抓取静态网民;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染出来的网页;缺点是需要配备环境变量等。
两者结合,相互学习,cdp4j可用。
选择它的原因是真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名也有名。我在学习软件工程的时候,一直在想,我为什么要写文档?我的程序能不能实现它的功能不重要吗?如今,看着如此详细的文件,我留下了激动和遗憾的泪水……
cdp4j 有很多功能:
一个。获取渲染网页的源代码
湾 模拟浏览器点击事件
C。下载网页上可用的文件
d. 截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以在以下三个地址中找到:
【cdp4j官网地址】
【Github 仓库】
[演示列表] 查看全部
htmlunit 抓取网页(Python开发的一个快速、高层次的优点及解决办法!)
(1),Scrapy:
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还提供了多种爬虫的基类,如BaseSpider、站点地图爬虫等,最新版本还提供了web2.0爬虫支持。
废料意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2. 社区人数比较多,文档比较齐全。
3.URL 去重采用 Bloom filter 方案。
4. 可以处理不完整的 HTML,Scrapy 提供了选择器(一个基于 lxml 的更高级的接口),
可以高效处理不完整的HTML代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
Pyspider是一个用python实现的强大的网络爬虫系统。可以在浏览器界面实时编写脚本、调度函数和查看爬取结果。后端使用常用的数据库来存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2. 完全可视化,非常人性化:WEB界面编写调试脚本、启停脚本、监控执行状态、查看活动历史、获取结果。
3.简单,五分钟就能上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL去重使用数据库代替Bloom过滤器,数亿存储的db io会导致效率急剧下降。
2. 用户友好性牺牲了灵活性并降低了定制能力。
(3)Apache Nutch(更高)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。在 Nutch 运行的一组进程中,三分之二是为搜索引擎设计的。
Nutch的框架需要Hadoop运行,Hadoop需要开集群。对于那些想快速上手爬虫的人来说,我很沮丧......
这里列出了一些资源地址,也许以后会学到。
纳奇官网
1.Nutch支持分布式爬取,并且有Hadoop支持,可以进行多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。因为有了这个框架,Nutch的插件开发非常容易,第三方插件也层出不穷,大大提升了Nutch的功能和口碑。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的API,可以快速上手
2.模块化结构,易于扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), WebCollector
WebCollector是一个不需要配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,可以用少量的代码实现强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
优势:
1.基于文本密度自动提取网页正文
2.支持断点重爬
3.支持代理
缺点:
1. 不支持分布式,只支持单机
2.无URL优先调度
3.不是很活跃
(6), Heritrix3
Heritrix是一个由java开发的开源网络爬虫,用户可以使用它从网上抓取自己想要的资源
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫不能相互配合。
2. 在机器资源有限的情况下,需要复杂的操作。
3. 仅官方支持,仅在 Linux 上测试。
4.每个爬虫独立工作,更新没有任何修改。
5. 在发生硬件和系统故障时,恢复能力较差。
6. 花在优化性能上的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,没有搜索引擎。如果要对爬取的站点进行排序,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j是一个基于Java的轻量级独立开源爬虫框架
优势
1.多线程采集
2. 内置Url过滤机制,BerkeleyDB用于url过滤。
3. 可以扩展支持网页字段的结构化提取,可以作为一个垂直的采集
缺点
1. 不支持动态网页爬取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,我做了一个框架优缺点对比图,如下:
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期培训老师讲解的框架。几乎有完整的文档介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过这个框架有一个优势,它有非常强大的网页解析功能。
Jsoup中文教程
selenium(多位谷歌高管参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,是真正的模拟浏览器。GitHub1.4w+star,你没看错,有几万个。但我只是没有一个好的环境。入门Demo就是不能成功运行,所以放弃了。
硒官方GitHub
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器,就是这样。
基本介绍:
HtmlUnit的优点是可以轻松抓取静态网民;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染出来的网页;缺点是需要配备环境变量等。
两者结合,相互学习,cdp4j可用。
选择它的原因是真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名也有名。我在学习软件工程的时候,一直在想,我为什么要写文档?我的程序能不能实现它的功能不重要吗?如今,看着如此详细的文件,我留下了激动和遗憾的泪水……
cdp4j 有很多功能:
一个。获取渲染网页的源代码
湾 模拟浏览器点击事件
C。下载网页上可用的文件
d. 截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以在以下三个地址中找到:
【cdp4j官网地址】
【Github 仓库】
[演示列表]
htmlunit 抓取网页(如何用Python爬虫“爬”到解析出来的链接?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-16 21:41
可能你觉得这个文章太简单了,满足不了你的要求。
文章只展示了如何从一个网页中抓取信息,但您必须处理数千个网页。
别担心。
本质上,抓取一个网页与抓取 10,000 个网页是一样的。
而且,根据我们的示例,您是否已经尝试过获取链接?
以链接为基础,您可以滚雪球,让 Python 爬虫“爬行”到已解析的链接以进行进一步处理。
以后在实际场景中,你可能要处理一些棘手的问题:
这些问题的解决方法,希望在以后的教程中与大家一一分享。
需要注意的是,虽然网络爬虫抓取数据的能力很强,但是学习和实践也有一定的门槛。
当您面临数据采集任务时,您应该首先查看此列表:
如果答案是否定的,则需要自己编写脚本并调动爬虫来抓取它。
为了巩固你所学的知识,请切换到另一个网页,根据我们的代码进行修改,抓取你感兴趣的内容。
如果能记录下自己爬的过程,在评论区把记录链接分享给大家就更好了。
因为刻意练习是掌握实践技能的最佳途径,而教学是最好的学习。
祝你好运!
思考
已经解释了本文的主要内容。
这里有一个问题供您思考:
我们解析和存储的链接实际上是重复的:
这不是因为我们的代码有问题,而是在《如何使用“玉树智兰”开始数据科学?"文章中,我多次引用了一些文章,所以重复的链接都被抓了 查看全部
htmlunit 抓取网页(如何用Python爬虫“爬”到解析出来的链接?)
可能你觉得这个文章太简单了,满足不了你的要求。
文章只展示了如何从一个网页中抓取信息,但您必须处理数千个网页。
别担心。
本质上,抓取一个网页与抓取 10,000 个网页是一样的。
而且,根据我们的示例,您是否已经尝试过获取链接?
以链接为基础,您可以滚雪球,让 Python 爬虫“爬行”到已解析的链接以进行进一步处理。
以后在实际场景中,你可能要处理一些棘手的问题:
这些问题的解决方法,希望在以后的教程中与大家一一分享。
需要注意的是,虽然网络爬虫抓取数据的能力很强,但是学习和实践也有一定的门槛。
当您面临数据采集任务时,您应该首先查看此列表:
如果答案是否定的,则需要自己编写脚本并调动爬虫来抓取它。
为了巩固你所学的知识,请切换到另一个网页,根据我们的代码进行修改,抓取你感兴趣的内容。
如果能记录下自己爬的过程,在评论区把记录链接分享给大家就更好了。
因为刻意练习是掌握实践技能的最佳途径,而教学是最好的学习。
祝你好运!
思考
已经解释了本文的主要内容。
这里有一个问题供您思考:
我们解析和存储的链接实际上是重复的:
这不是因为我们的代码有问题,而是在《如何使用“玉树智兰”开始数据科学?"文章中,我多次引用了一些文章,所以重复的链接都被抓了
htmlunit 抓取网页(1.maven依赖引入2.Java代码3.其他功能总结(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-14 00:34
通常我们使用Java提供的HttpURLConnection或者Apache的HttpClient来获取网页源码,直观可见,代码内容与网页内容一致,在浏览器上右击查看网页的源代码。
但是现在越来越多的网站使用Js动态生成内容来提高相应的速度,而HttpClient在后端只返回相应响应的请求体,并没有返回浏览器生成的网页,所以对于 Js 生成的内容 HttpClient 不可用。
获取Js生成的网页,我们主要是模拟浏览器的操作,渲染响应的请求体,最终得到对应的内容。通过浏览器右键->点击check/view元素得到的内容与网页内容一致。
我们这里讲的模拟方法大致有两种:
抓取目标
我们这次的目标是获取bilibili动态生成的动画列表。左上角是获取到的目标列表,左下角是浏览器渲染的html内容,右边是服务器返回的响应正文。通过对比,我们可以看到目标列表是由Js生成的。
使用 Selenium 获取页面
Selenium 是一种用于 Web 应用程序自动化测试的工具。更多介绍是谷歌。这里我们主要用来模拟页面的操作并返回结果。网页截图的功能也是可行的。
Selenium 支持模拟很多浏览器,但我们这里只模拟 PhantomJS,因为 PhantomJS 是一个脚本化的、无界面的 WebKit,它使用 JavaScript 作为脚本语言来实现各种功能。因为它没有接口,所以速度性能会更好。
1.下载
使用PhantomJS需要到官网下载最新的客户端,这里使用phantomjs-2.1.1-windows.zip
2.maven 依赖介绍:
org.seleniumhq.selenium
selenium-java
2.53.0
com.codeborne
phantomjsdriver
1.2.1
org.seleniumhq.selenium
selenium-remote-driver
org.seleniumhq.selenium
selenium-java
3.示例代码
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriverService;
import org.openqa.selenium.remote.DesiredCapabilities;
import java.util.ArrayList;
/**
* @author GinPonson
*/
public class TestSelenium {
static final String HOST = "127.0.0.1";
static final String PORT = "80";
static final String USER = "gin";
static final String PWD = "12345";
public static void main(String[] args){
System.setProperty("phantomjs.binary.path", "D:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe");
DesiredCapabilities capabilities = DesiredCapabilities.phantomjs();
//设置代理或者其他参数
ArrayList cliArgsCap = new ArrayList();
//cliArgsCap.add("--proxy=http://"+HOST+":"+PORT);
//cliArgsCap.add("--proxy-auth=" + USER + ":" + PWD);
//cliArgsCap.add("--proxy-type=http");
capabilities.setCapability(PhantomJSDriverService.PHANTOMJS_CLI_ARGS, cliArgsCap);
//capabilities.setCapability("phantomjs.page.settings.userAgent", "");
WebDriver driver = new PhantomJSDriver(capabilities);
driver.get("http://www.bilibili.com/video/ ... 6quot;);
System.out.println(driver.getPageSource());
driver.quit();
}
}
4.其他功能
使用 HtmlUnit 获取页面
HtmlUnit 在功能上是 Selenium 的子集,Selenium 有相应的 HtmlUnit 实现。HtmlUnit 是一个用 Java 编写的无界面浏览器。因为没有接口,所以执行速度还可以。
1.maven 依赖介绍
net.sourceforge.htmlunit
htmlunit
2.25
2.Java 代码
/**
* @author GinPonson
*/
public class TestHtmlUnit {
static final String HOST = "127.0.0.1";
static final String PORT = "80";
static final String USER = "gin";
static final String PWD = "12345";
public static void main(String[] args) throws Exception{
WebClient webClient = new WebClient();
//设置代理
//ProxyConfig proxyConfig = webClient.getOptions().getProxyConfig();
//proxyConfig.setProxyHost(HOST);
//proxyConfig.setProxyPort(Integer.valueOf(PORT));
//DefaultCredentialsProvider credentialsProvider = (DefaultCredentialsProvider) webClient.getCredentialsProvider();
//credentialsProvider.addCredentials(USER, PWD);
//设置参数
//webClient.getOptions().setCssEnabled(false);
//webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
HtmlPage page = webClient.getPage("http://www.bilibili.com/video/ ... 6quot;);
System.out.println(page.asXml());
webClient.close();
}
}
3.其他功能
总结
PhantomJS 和 HtmlUnit 都模拟了浏览器页面生成功能。PhantomJS 是一个非接口的 WebKit。页面渲染功能非常齐全,并且具有浏览器截图功能,可以模拟登录操作。HtmlUnit 使用 Rhino 引擎解析 Js。有时解析速度很慢。就像上面的例子一样,需要很长时间,但是HtmlUnit可以获取页面并解析一组元素。(当然最好用Jsoup来解析元素)。不错的工具。
HtmlUnit遇到错误后,处理前后相差7分钟。可能是我没用QAQ
欢迎补充:) 查看全部
htmlunit 抓取网页(1.maven依赖引入2.Java代码3.其他功能总结(组图))
通常我们使用Java提供的HttpURLConnection或者Apache的HttpClient来获取网页源码,直观可见,代码内容与网页内容一致,在浏览器上右击查看网页的源代码。
但是现在越来越多的网站使用Js动态生成内容来提高相应的速度,而HttpClient在后端只返回相应响应的请求体,并没有返回浏览器生成的网页,所以对于 Js 生成的内容 HttpClient 不可用。
获取Js生成的网页,我们主要是模拟浏览器的操作,渲染响应的请求体,最终得到对应的内容。通过浏览器右键->点击check/view元素得到的内容与网页内容一致。
我们这里讲的模拟方法大致有两种:
抓取目标
我们这次的目标是获取bilibili动态生成的动画列表。左上角是获取到的目标列表,左下角是浏览器渲染的html内容,右边是服务器返回的响应正文。通过对比,我们可以看到目标列表是由Js生成的。
使用 Selenium 获取页面
Selenium 是一种用于 Web 应用程序自动化测试的工具。更多介绍是谷歌。这里我们主要用来模拟页面的操作并返回结果。网页截图的功能也是可行的。
Selenium 支持模拟很多浏览器,但我们这里只模拟 PhantomJS,因为 PhantomJS 是一个脚本化的、无界面的 WebKit,它使用 JavaScript 作为脚本语言来实现各种功能。因为它没有接口,所以速度性能会更好。
1.下载
使用PhantomJS需要到官网下载最新的客户端,这里使用phantomjs-2.1.1-windows.zip
2.maven 依赖介绍:
org.seleniumhq.selenium
selenium-java
2.53.0
com.codeborne
phantomjsdriver
1.2.1
org.seleniumhq.selenium
selenium-remote-driver
org.seleniumhq.selenium
selenium-java
3.示例代码
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriverService;
import org.openqa.selenium.remote.DesiredCapabilities;
import java.util.ArrayList;
/**
* @author GinPonson
*/
public class TestSelenium {
static final String HOST = "127.0.0.1";
static final String PORT = "80";
static final String USER = "gin";
static final String PWD = "12345";
public static void main(String[] args){
System.setProperty("phantomjs.binary.path", "D:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe");
DesiredCapabilities capabilities = DesiredCapabilities.phantomjs();
//设置代理或者其他参数
ArrayList cliArgsCap = new ArrayList();
//cliArgsCap.add("--proxy=http://"+HOST+":"+PORT);
//cliArgsCap.add("--proxy-auth=" + USER + ":" + PWD);
//cliArgsCap.add("--proxy-type=http");
capabilities.setCapability(PhantomJSDriverService.PHANTOMJS_CLI_ARGS, cliArgsCap);
//capabilities.setCapability("phantomjs.page.settings.userAgent", "");
WebDriver driver = new PhantomJSDriver(capabilities);
driver.get("http://www.bilibili.com/video/ ... 6quot;);
System.out.println(driver.getPageSource());
driver.quit();
}
}
4.其他功能
使用 HtmlUnit 获取页面
HtmlUnit 在功能上是 Selenium 的子集,Selenium 有相应的 HtmlUnit 实现。HtmlUnit 是一个用 Java 编写的无界面浏览器。因为没有接口,所以执行速度还可以。
1.maven 依赖介绍
net.sourceforge.htmlunit
htmlunit
2.25
2.Java 代码
/**
* @author GinPonson
*/
public class TestHtmlUnit {
static final String HOST = "127.0.0.1";
static final String PORT = "80";
static final String USER = "gin";
static final String PWD = "12345";
public static void main(String[] args) throws Exception{
WebClient webClient = new WebClient();
//设置代理
//ProxyConfig proxyConfig = webClient.getOptions().getProxyConfig();
//proxyConfig.setProxyHost(HOST);
//proxyConfig.setProxyPort(Integer.valueOf(PORT));
//DefaultCredentialsProvider credentialsProvider = (DefaultCredentialsProvider) webClient.getCredentialsProvider();
//credentialsProvider.addCredentials(USER, PWD);
//设置参数
//webClient.getOptions().setCssEnabled(false);
//webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
HtmlPage page = webClient.getPage("http://www.bilibili.com/video/ ... 6quot;);
System.out.println(page.asXml());
webClient.close();
}
}
3.其他功能
总结
PhantomJS 和 HtmlUnit 都模拟了浏览器页面生成功能。PhantomJS 是一个非接口的 WebKit。页面渲染功能非常齐全,并且具有浏览器截图功能,可以模拟登录操作。HtmlUnit 使用 Rhino 引擎解析 Js。有时解析速度很慢。就像上面的例子一样,需要很长时间,但是HtmlUnit可以获取页面并解析一组元素。(当然最好用Jsoup来解析元素)。不错的工具。
HtmlUnit遇到错误后,处理前后相差7分钟。可能是我没用QAQ
欢迎补充:)

