
htmlunit 抓取网页
htmlunit 抓取网页(HtmlUnit可以直接访问接口吗?的扩展之一是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-19 01:28
HttpClient 是一个用于捕获 html 页面的简单工具包。它不再维护,已被 Apache 的 HttpComponents 取代。缺陷是无法获取js获取的动态数据,导致爬取数据丢失。
org.apache.httpcomponents
httpclient
4.5.8
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
public class HttpClientTest {
/**
* 获取html页面内容
* @param url 链接地址
* @return
*/
public static String getHtmlByHttpClient(String url) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet(url);
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
return html;
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
}
二、使用 HtmlUnit
HtmlUnit可以用来模拟浏览器的操作,可以认为是没有界面的浏览器,即用代码模拟鼠标等操作来操作网页,运行速度快。
HtmlUnit 是一个开源的java页面分析工具。作为junit的扩展之一,可以模拟js运行
-> 使用htmlUnit抓取百度搜索页面
通过htmlUnit操作百度高级搜索界面,最终抓取到搜索结果的html页面内容
net.sourceforge.htmlunit
htmlunit
2.23
public static String Baidu(String keyword)throws Exception{
WebClient webclient = new WebClient();
//ssl认证
//webclient.getOptions().setUseInsecureSSL(true);
//由于有的网页js书写不规范htmlunit会报错,所以去除这种错误让程序执行完全(不影响结果)
webclient.getOptions().setThrowExceptionOnScriptError(false);
webclient.getOptions().setThrowExceptionOnFailingStatusCode(false);
//不加载css
webclient.getOptions().setCssEnabled(false);
//由于是动态网页所以一定要加载js及执行
webclient.getOptions().setJavaScriptEnabled(true);
//打开百度高级搜索的网址
HtmlPage htmlpage = webclient.getPage("http://www.baidu.com/gaoji/advanced.html");
//获取网页from控件(f1为控件name)
HtmlForm form = htmlpage.getFormByName("f1");
HtmlSubmitInput button = form.getInputByValue("百度一下");
HtmlTextInput textField = form.getInputByName("q1");
textField.setValueAttribute(keyword);
final HtmlSelect htmlSelet=form.getSelectByName("rn");
htmlSelet.setDefaultValue("10");
//隐藏值
final HtmlHiddenInput hiddenInputtn = form.getInputByName("tn");
hiddenInputtn.setDefaultValue("baiduadv");
//发送请求(相当于点击百度一下按钮)获取返回后的网页
final HtmlPage page = button.click();
//获取网页的文本信息
String result = page.asText();
//获取网页源码
//String result = page.asXml();
//System.out.println(result);
webclient.close();
return result;
}
三、捕获接口获取数据
通过前两种方式,有时可能无法得到我们想要的结果,抓取到的html页面代码可能有缺失数据,同时可能被网站监听,ip地址会被封禁,让我们无法继续获取页面数据
让我们想想数据来自哪里。一般是通过接口获取的吧?如果我们可以直接访问接口呢?这是我的想法:
虽然这种方法可以稳定的获取数据,但实际上在很多网站中我们看不到XHR请求中的接口,这是因为考虑到跨域使用jsonp,这些都可以在js中找到,如果你有兴趣,你可以了解一下 查看全部
htmlunit 抓取网页(HtmlUnit可以直接访问接口吗?的扩展之一是什么?)
HttpClient 是一个用于捕获 html 页面的简单工具包。它不再维护,已被 Apache 的 HttpComponents 取代。缺陷是无法获取js获取的动态数据,导致爬取数据丢失。
org.apache.httpcomponents
httpclient
4.5.8
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
public class HttpClientTest {
/**
* 获取html页面内容
* @param url 链接地址
* @return
*/
public static String getHtmlByHttpClient(String url) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet(url);
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
return html;
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
}
二、使用 HtmlUnit
HtmlUnit可以用来模拟浏览器的操作,可以认为是没有界面的浏览器,即用代码模拟鼠标等操作来操作网页,运行速度快。
HtmlUnit 是一个开源的java页面分析工具。作为junit的扩展之一,可以模拟js运行
-> 使用htmlUnit抓取百度搜索页面
通过htmlUnit操作百度高级搜索界面,最终抓取到搜索结果的html页面内容
net.sourceforge.htmlunit
htmlunit
2.23
public static String Baidu(String keyword)throws Exception{
WebClient webclient = new WebClient();
//ssl认证
//webclient.getOptions().setUseInsecureSSL(true);
//由于有的网页js书写不规范htmlunit会报错,所以去除这种错误让程序执行完全(不影响结果)
webclient.getOptions().setThrowExceptionOnScriptError(false);
webclient.getOptions().setThrowExceptionOnFailingStatusCode(false);
//不加载css
webclient.getOptions().setCssEnabled(false);
//由于是动态网页所以一定要加载js及执行
webclient.getOptions().setJavaScriptEnabled(true);
//打开百度高级搜索的网址
HtmlPage htmlpage = webclient.getPage("http://www.baidu.com/gaoji/advanced.html";);
//获取网页from控件(f1为控件name)
HtmlForm form = htmlpage.getFormByName("f1");
HtmlSubmitInput button = form.getInputByValue("百度一下");
HtmlTextInput textField = form.getInputByName("q1");
textField.setValueAttribute(keyword);
final HtmlSelect htmlSelet=form.getSelectByName("rn");
htmlSelet.setDefaultValue("10");
//隐藏值
final HtmlHiddenInput hiddenInputtn = form.getInputByName("tn");
hiddenInputtn.setDefaultValue("baiduadv");
//发送请求(相当于点击百度一下按钮)获取返回后的网页
final HtmlPage page = button.click();
//获取网页的文本信息
String result = page.asText();
//获取网页源码
//String result = page.asXml();
//System.out.println(result);
webclient.close();
return result;
}
三、捕获接口获取数据
通过前两种方式,有时可能无法得到我们想要的结果,抓取到的html页面代码可能有缺失数据,同时可能被网站监听,ip地址会被封禁,让我们无法继续获取页面数据
让我们想想数据来自哪里。一般是通过接口获取的吧?如果我们可以直接访问接口呢?这是我的想法:
虽然这种方法可以稳定的获取数据,但实际上在很多网站中我们看不到XHR请求中的接口,这是因为考虑到跨域使用jsonp,这些都可以在js中找到,如果你有兴趣,你可以了解一下
htmlunit 抓取网页(ApacheNutchX版本实现请访问:pageonNutchwith1.8)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-12 02:20
基于Apache Nutch和Htmlunit扩展的AJAX页面爬虫爬取解析插件------------------ ------------------------------------------------- - ----------------------- 提示:项目当前版本停止更新,最新Apache Nutch 2.X版本实现请访问:- --- ------------------------------------------------------------ --- ----------------------------------
之前提供了一个版本,直接将源代码以插件的形式放到代码库中。后来发现很多人反映集成到apache nutch中编译或者运行,遇到这样那样的问题。所以,这次基于Apache Nutch 1.8源码项目,预设了所有插件源码/依赖/操作参数,让大家可以更简洁全面的使用这个插件。
Nutch Htmlunit插件项目介绍基于Apache Nutch1.8和Htmlunit组件,实现了对AJAX加载类型页面的完整页面内容抓取和分析。根据 Apache Nutch 1.8 的实现,我们无法从收录 AJAX 请求的获取页面中获取动态 HTML 信息,因为它会忽略所有 AJAX 请求。该插件将使用 Htmlunit 通过必要的动态 AJAX 请求获取整个页面内容。它使用 Apache Nutch 1.8 开发和测试,您可以在其他 Nutch 版本上尝试它或重构源代码作为您的设计。主要功能运行体验由于Nutch运行在Unix/Linux环境下,请自行准备Unix/Linux系统或Cygwin运行环境。 git clone整个项目代码后,进入本地git下载目录: cd nutch-htmlunit/runtime/local bin/crawl urls crawl false 1 //urls参数为爬虫url文件目录; crawl 是爬虫输出目录; false应该是solr index url参数,这里设置为false,不做solr索引处理; 1是爬虫执行次数后,可以看到天猫商品页面的价格/描述/滚装图,信息已经全部获取完毕。运行日志输入示例参考:扩展插件说明 查看全部
htmlunit 抓取网页(ApacheNutchX版本实现请访问:pageonNutchwith1.8)
基于Apache Nutch和Htmlunit扩展的AJAX页面爬虫爬取解析插件------------------ ------------------------------------------------- - ----------------------- 提示:项目当前版本停止更新,最新Apache Nutch 2.X版本实现请访问:- --- ------------------------------------------------------------ --- ----------------------------------
之前提供了一个版本,直接将源代码以插件的形式放到代码库中。后来发现很多人反映集成到apache nutch中编译或者运行,遇到这样那样的问题。所以,这次基于Apache Nutch 1.8源码项目,预设了所有插件源码/依赖/操作参数,让大家可以更简洁全面的使用这个插件。
Nutch Htmlunit插件项目介绍基于Apache Nutch1.8和Htmlunit组件,实现了对AJAX加载类型页面的完整页面内容抓取和分析。根据 Apache Nutch 1.8 的实现,我们无法从收录 AJAX 请求的获取页面中获取动态 HTML 信息,因为它会忽略所有 AJAX 请求。该插件将使用 Htmlunit 通过必要的动态 AJAX 请求获取整个页面内容。它使用 Apache Nutch 1.8 开发和测试,您可以在其他 Nutch 版本上尝试它或重构源代码作为您的设计。主要功能运行体验由于Nutch运行在Unix/Linux环境下,请自行准备Unix/Linux系统或Cygwin运行环境。 git clone整个项目代码后,进入本地git下载目录: cd nutch-htmlunit/runtime/local bin/crawl urls crawl false 1 //urls参数为爬虫url文件目录; crawl 是爬虫输出目录; false应该是solr index url参数,这里设置为false,不做solr索引处理; 1是爬虫执行次数后,可以看到天猫商品页面的价格/描述/滚装图,信息已经全部获取完毕。运行日志输入示例参考:扩展插件说明
htmlunit 抓取网页(:JavaHTML解析器的基本知识点总结(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-04-10 12:23
)
(4)支持代理
(5)支持自动cookie管理等。
Java爬虫开发是应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;
import org.apache.http.client.HttpClient;
import org.apache.http.client.ResponseHandler;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.BasicResponseHandler;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.util.EntityUtils;
/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/
public class HttpClientTest {
public static void main(String[] args)throws Exception{
//目标页面
String url ="http://www.jjwxc.net/";
//创建一个默认的HttpClient
HttpClient httpclient =new DefaultHttpClient();
try{
//以get方式请求网页http://www.yshjava.cn
HttpGet httpget =new HttpGet(url);
//打印请求地址
System.out.println("executing request "+ httpget.getURI());
//创建响应处理器处理服务器响应内容
ResponseHandler responseHandler = new BasicResponseHandler();
//执行请求并获取结果
String responseBody = httpclient.execute(httpget, responseHandler);
System.out.println("----------------------------------------");
String htmlStr=null;
if(responseBody != null) {
// htmlStr=new String(EntityUtils.toString(responseBody));
// htmlStr=new String(htmlStr.getBytes("ISO-8859-1"), "gbk"); // 读取乱码解决
responseBody=new String(responseBody.getBytes("ISO-8859-1"), "gb2312");
}
System.out.println(responseBody);
System.out.println("----------------------------------------");
}finally{//关闭连接管理器
httpclient.getConnectionManager().shutdown();
}
}
}
汤
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
示例代码如下:
包cn.ysh.studio.crawler.jsoup;
导入 java.io.IOException;
导入 org.jsoup.Jsoup;
/**
* 基于 Jsoup 抓取网页内容
* @作者
*/
公共类 JsoupTest {
公共静态 void main(String[] args) 抛出 IOException{
//目标页面
字符串 url = "";
//使用Jsoup连接目标页面,执行请求,获取服务器响应内容
字符串 html =Jsoup.connect(url).execute().body();
//打印页面内容
System.out.println(html);
}
}
html单元
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取和解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.Page;
import com.gargoylesoftware.htmlunit.WebClient;
/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlUnitSpider {
public static void main(String[] s) throws Exception {
// 目标网页
String url = "http://www.jjwxc.net/";
// 模拟特定浏览器FIREFOX_3
WebClient spider = new WebClient(BrowserVersion.FIREFOX_3);
// 获取目标网页
Page page = spider.getPage(url);
// 打印网页内容
System.out.println(page.getWebResponse().getContentAsString());
// 关闭所有窗口
// spider.closeAllWindows();
spider.close();
}
}
瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
示例代码如下:
包cn.ysh.studio.crawler.ie;
导入 watij.runtime.ie.IE;
/**
* 基于 Watij 抓取网页内容,仅在 Windows 平台上
*
* @作者
*/
公共类 WatijTest {
公共静态无效主要(字符串[] s){
//目标页面
字符串 url = "";
// 实例化 IE 浏览器对象
IE 即 = 新的 IE();
尝试 {
// 启动浏览器
即.start();
// 进入登陆页面
即.goTo(url);
// 等待页面加载
即.waitUntilReady();
// 打印页面内容
System.out.println(ie.html());
} 捕捉(异常 e){
e.printStackTrace();
} 最后 {
try {//关闭IE浏览器
即关闭();
} 捕捉(异常 e){
}
}
}
}
硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;
import org.openqa.selenium.htmlunit.HtmlUnitDriver;
/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlDriverTest {
public static void main(String[] s) {
// 目标网页
String url = "http://www.jjwxc.net/";
HtmlUnitDriver driver = new HtmlUnitDriver();
try {
// 禁用JS脚本功能
driver.setJavascriptEnabled(false);
// 打开目标网页
driver.get(url);
// 获取当前网页源码
String html = driver.getPageSource();
// 打印网页源码
System.out.println(html);
} catch (Exception e) {
// 打印堆栈信息
e.printStackTrace();
} finally {
try {
// 关闭并退出
driver.close();
driver.quit();
} catch (Exception e) {
}
}
}
}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;
import org.watij.webspec.dsl.WebSpec;
/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/
public class WebspecTest {
public static void main(String[] s){
//目标网页
String url ="http://www.jjwxc.net/";
//实例化浏览器对象
WebSpec spec =new WebSpec().mozilla();
//隐藏浏览器窗体
spec.hide();
//打开目标页面
spec.open(url);
//打印网页源码
System.out.println(spec.source());
//关闭所有窗口
spec.closeAll();
}
} 查看全部
htmlunit 抓取网页(:JavaHTML解析器的基本知识点总结(一)
)
(4)支持代理
(5)支持自动cookie管理等。
Java爬虫开发是应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;
import org.apache.http.client.HttpClient;
import org.apache.http.client.ResponseHandler;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.BasicResponseHandler;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.util.EntityUtils;
/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/
public class HttpClientTest {
public static void main(String[] args)throws Exception{
//目标页面
String url ="http://www.jjwxc.net/";
//创建一个默认的HttpClient
HttpClient httpclient =new DefaultHttpClient();
try{
//以get方式请求网页http://www.yshjava.cn
HttpGet httpget =new HttpGet(url);
//打印请求地址
System.out.println("executing request "+ httpget.getURI());
//创建响应处理器处理服务器响应内容
ResponseHandler responseHandler = new BasicResponseHandler();
//执行请求并获取结果
String responseBody = httpclient.execute(httpget, responseHandler);
System.out.println("----------------------------------------");
String htmlStr=null;
if(responseBody != null) {
// htmlStr=new String(EntityUtils.toString(responseBody));
// htmlStr=new String(htmlStr.getBytes("ISO-8859-1"), "gbk"); // 读取乱码解决
responseBody=new String(responseBody.getBytes("ISO-8859-1"), "gb2312");
}
System.out.println(responseBody);
System.out.println("----------------------------------------");
}finally{//关闭连接管理器
httpclient.getConnectionManager().shutdown();
}
}
}
汤
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
示例代码如下:
包cn.ysh.studio.crawler.jsoup;
导入 java.io.IOException;
导入 org.jsoup.Jsoup;
/**
* 基于 Jsoup 抓取网页内容
* @作者
*/
公共类 JsoupTest {
公共静态 void main(String[] args) 抛出 IOException{
//目标页面
字符串 url = "";
//使用Jsoup连接目标页面,执行请求,获取服务器响应内容
字符串 html =Jsoup.connect(url).execute().body();
//打印页面内容
System.out.println(html);
}
}
html单元
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取和解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.Page;
import com.gargoylesoftware.htmlunit.WebClient;
/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlUnitSpider {
public static void main(String[] s) throws Exception {
// 目标网页
String url = "http://www.jjwxc.net/";
// 模拟特定浏览器FIREFOX_3
WebClient spider = new WebClient(BrowserVersion.FIREFOX_3);
// 获取目标网页
Page page = spider.getPage(url);
// 打印网页内容
System.out.println(page.getWebResponse().getContentAsString());
// 关闭所有窗口
// spider.closeAllWindows();
spider.close();
}
}
瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
示例代码如下:
包cn.ysh.studio.crawler.ie;
导入 watij.runtime.ie.IE;
/**
* 基于 Watij 抓取网页内容,仅在 Windows 平台上
*
* @作者
*/
公共类 WatijTest {
公共静态无效主要(字符串[] s){
//目标页面
字符串 url = "";
// 实例化 IE 浏览器对象
IE 即 = 新的 IE();
尝试 {
// 启动浏览器
即.start();
// 进入登陆页面
即.goTo(url);
// 等待页面加载
即.waitUntilReady();
// 打印页面内容
System.out.println(ie.html());
} 捕捉(异常 e){
e.printStackTrace();
} 最后 {
try {//关闭IE浏览器
即关闭();
} 捕捉(异常 e){
}
}
}
}
硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;
import org.openqa.selenium.htmlunit.HtmlUnitDriver;
/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlDriverTest {
public static void main(String[] s) {
// 目标网页
String url = "http://www.jjwxc.net/";
HtmlUnitDriver driver = new HtmlUnitDriver();
try {
// 禁用JS脚本功能
driver.setJavascriptEnabled(false);
// 打开目标网页
driver.get(url);
// 获取当前网页源码
String html = driver.getPageSource();
// 打印网页源码
System.out.println(html);
} catch (Exception e) {
// 打印堆栈信息
e.printStackTrace();
} finally {
try {
// 关闭并退出
driver.close();
driver.quit();
} catch (Exception e) {
}
}
}
}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;
import org.watij.webspec.dsl.WebSpec;
/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/
public class WebspecTest {
public static void main(String[] s){
//目标网页
String url ="http://www.jjwxc.net/";
//实例化浏览器对象
WebSpec spec =new WebSpec().mozilla();
//隐藏浏览器窗体
spec.hide();
//打开目标页面
spec.open(url);
//打印网页源码
System.out.println(spec.source());
//关闭所有窗口
spec.closeAll();
}
}
htmlunit 抓取网页(:JavaHTML解析器的基本知识点总结(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-04-10 12:20
)
(4)支持代理
(5)支持自动cookie管理等。
Java爬虫开发是应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;
import org.apache.http.client.HttpClient;
import org.apache.http.client.ResponseHandler;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.BasicResponseHandler;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.util.EntityUtils;
/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/
public class HttpClientTest {
public static void main(String[] args)throws Exception{
//目标页面
String url ="http://www.jjwxc.net/";
//创建一个默认的HttpClient
HttpClient httpclient =new DefaultHttpClient();
try{
//以get方式请求网页http://www.yshjava.cn
HttpGet httpget =new HttpGet(url);
//打印请求地址
System.out.println("executing request "+ httpget.getURI());
//创建响应处理器处理服务器响应内容
ResponseHandler responseHandler = new BasicResponseHandler();
//执行请求并获取结果
String responseBody = httpclient.execute(httpget, responseHandler);
System.out.println("----------------------------------------");
String htmlStr=null;
if(responseBody != null) {
// htmlStr=new String(EntityUtils.toString(responseBody));
// htmlStr=new String(htmlStr.getBytes("ISO-8859-1"), "gbk"); // 读取乱码解决
responseBody=new String(responseBody.getBytes("ISO-8859-1"), "gb2312");
}
System.out.println(responseBody);
System.out.println("----------------------------------------");
}finally{//关闭连接管理器
httpclient.getConnectionManager().shutdown();
}
}
}
汤
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
示例代码如下:
包cn.ysh.studio.crawler.jsoup;
导入 java.io.IOException;
导入 org.jsoup.Jsoup;
/**
* 基于 Jsoup 抓取网页内容
* @作者
*/
公共类 JsoupTest {
公共静态 void main(String[] args) 抛出 IOException{
//目标页面
字符串 url = "";
//使用Jsoup连接目标页面,执行请求,获取服务器响应内容
字符串 html =Jsoup.connect(url).execute().body();
//打印页面内容
System.out.println(html);
}
}
html单元
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取和解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.Page;
import com.gargoylesoftware.htmlunit.WebClient;
/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlUnitSpider {
public static void main(String[] s) throws Exception {
// 目标网页
String url = "http://www.jjwxc.net/";
// 模拟特定浏览器FIREFOX_3
WebClient spider = new WebClient(BrowserVersion.FIREFOX_3);
// 获取目标网页
Page page = spider.getPage(url);
// 打印网页内容
System.out.println(page.getWebResponse().getContentAsString());
// 关闭所有窗口
// spider.closeAllWindows();
spider.close();
}
}
瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
示例代码如下:
包cn.ysh.studio.crawler.ie;
导入 watij.runtime.ie.IE;
/**
* 基于 Watij 抓取网页内容,仅在 Windows 平台上
*
* @作者
*/
公共类 WatijTest {
公共静态无效主要(字符串[] s){
//目标页面
字符串 url = "";
// 实例化 IE 浏览器对象
IE 即 = 新的 IE();
尝试 {
// 启动浏览器
即.start();
// 进入登陆页面
即.goTo(url);
// 等待页面加载
即.waitUntilReady();
// 打印页面内容
System.out.println(ie.html());
} 捕捉(异常 e){
e.printStackTrace();
} 最后 {
try {//关闭IE浏览器
即关闭();
} 捕捉(异常 e){
}
}
}
}
硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;
import org.openqa.selenium.htmlunit.HtmlUnitDriver;
/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlDriverTest {
public static void main(String[] s) {
// 目标网页
String url = "http://www.jjwxc.net/";
HtmlUnitDriver driver = new HtmlUnitDriver();
try {
// 禁用JS脚本功能
driver.setJavascriptEnabled(false);
// 打开目标网页
driver.get(url);
// 获取当前网页源码
String html = driver.getPageSource();
// 打印网页源码
System.out.println(html);
} catch (Exception e) {
// 打印堆栈信息
e.printStackTrace();
} finally {
try {
// 关闭并退出
driver.close();
driver.quit();
} catch (Exception e) {
}
}
}
}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;
import org.watij.webspec.dsl.WebSpec;
/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/
public class WebspecTest {
public static void main(String[] s){
//目标网页
String url ="http://www.jjwxc.net/";
//实例化浏览器对象
WebSpec spec =new WebSpec().mozilla();
//隐藏浏览器窗体
spec.hide();
//打开目标页面
spec.open(url);
//打印网页源码
System.out.println(spec.source());
//关闭所有窗口
spec.closeAll();
}
} 查看全部
htmlunit 抓取网页(:JavaHTML解析器的基本知识点总结(一)
)
(4)支持代理
(5)支持自动cookie管理等。
Java爬虫开发是应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;
import org.apache.http.client.HttpClient;
import org.apache.http.client.ResponseHandler;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.BasicResponseHandler;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.util.EntityUtils;
/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/
public class HttpClientTest {
public static void main(String[] args)throws Exception{
//目标页面
String url ="http://www.jjwxc.net/";
//创建一个默认的HttpClient
HttpClient httpclient =new DefaultHttpClient();
try{
//以get方式请求网页http://www.yshjava.cn
HttpGet httpget =new HttpGet(url);
//打印请求地址
System.out.println("executing request "+ httpget.getURI());
//创建响应处理器处理服务器响应内容
ResponseHandler responseHandler = new BasicResponseHandler();
//执行请求并获取结果
String responseBody = httpclient.execute(httpget, responseHandler);
System.out.println("----------------------------------------");
String htmlStr=null;
if(responseBody != null) {
// htmlStr=new String(EntityUtils.toString(responseBody));
// htmlStr=new String(htmlStr.getBytes("ISO-8859-1"), "gbk"); // 读取乱码解决
responseBody=new String(responseBody.getBytes("ISO-8859-1"), "gb2312");
}
System.out.println(responseBody);
System.out.println("----------------------------------------");
}finally{//关闭连接管理器
httpclient.getConnectionManager().shutdown();
}
}
}
汤
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
示例代码如下:
包cn.ysh.studio.crawler.jsoup;
导入 java.io.IOException;
导入 org.jsoup.Jsoup;
/**
* 基于 Jsoup 抓取网页内容
* @作者
*/
公共类 JsoupTest {
公共静态 void main(String[] args) 抛出 IOException{
//目标页面
字符串 url = "";
//使用Jsoup连接目标页面,执行请求,获取服务器响应内容
字符串 html =Jsoup.connect(url).execute().body();
//打印页面内容
System.out.println(html);
}
}
html单元
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取和解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.Page;
import com.gargoylesoftware.htmlunit.WebClient;
/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlUnitSpider {
public static void main(String[] s) throws Exception {
// 目标网页
String url = "http://www.jjwxc.net/";
// 模拟特定浏览器FIREFOX_3
WebClient spider = new WebClient(BrowserVersion.FIREFOX_3);
// 获取目标网页
Page page = spider.getPage(url);
// 打印网页内容
System.out.println(page.getWebResponse().getContentAsString());
// 关闭所有窗口
// spider.closeAllWindows();
spider.close();
}
}
瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
示例代码如下:
包cn.ysh.studio.crawler.ie;
导入 watij.runtime.ie.IE;
/**
* 基于 Watij 抓取网页内容,仅在 Windows 平台上
*
* @作者
*/
公共类 WatijTest {
公共静态无效主要(字符串[] s){
//目标页面
字符串 url = "";
// 实例化 IE 浏览器对象
IE 即 = 新的 IE();
尝试 {
// 启动浏览器
即.start();
// 进入登陆页面
即.goTo(url);
// 等待页面加载
即.waitUntilReady();
// 打印页面内容
System.out.println(ie.html());
} 捕捉(异常 e){
e.printStackTrace();
} 最后 {
try {//关闭IE浏览器
即关闭();
} 捕捉(异常 e){
}
}
}
}
硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;
import org.openqa.selenium.htmlunit.HtmlUnitDriver;
/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlDriverTest {
public static void main(String[] s) {
// 目标网页
String url = "http://www.jjwxc.net/";
HtmlUnitDriver driver = new HtmlUnitDriver();
try {
// 禁用JS脚本功能
driver.setJavascriptEnabled(false);
// 打开目标网页
driver.get(url);
// 获取当前网页源码
String html = driver.getPageSource();
// 打印网页源码
System.out.println(html);
} catch (Exception e) {
// 打印堆栈信息
e.printStackTrace();
} finally {
try {
// 关闭并退出
driver.close();
driver.quit();
} catch (Exception e) {
}
}
}
}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;
import org.watij.webspec.dsl.WebSpec;
/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/
public class WebspecTest {
public static void main(String[] s){
//目标网页
String url ="http://www.jjwxc.net/";
//实例化浏览器对象
WebSpec spec =new WebSpec().mozilla();
//隐藏浏览器窗体
spec.hide();
//打开目标页面
spec.open(url);
//打印网页源码
System.out.println(spec.source());
//关闭所有窗口
spec.closeAll();
}
}
htmlunit 抓取网页(使用本文中推荐的开源工具——HtmlUnit,一款能够模拟浏览器的抓包神器!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2022-04-04 16:23
之前,一峰写过一篇关于使用Jsoup爬取网页内容的文章文章:
[Jsoup] HTML解析器,轻松获取网页内容
Jsoup提供的api非常方便,完全类似于JQuery操作,轻松抓取网页数据。但是像Jsoup这样的普通爬虫工具的缺点是不能处理js生成的内容。
做过Html开发的都知道现在很多网站都是用ajax和JavaScript来获取和处理数据,普通爬虫工具已经无法处理js中的内容了。
比如我们在本地新建一个测试web文件text.html,源码如下:
main.html a { line-height: 30px; margin: 20px; } var datas = [ { href : "http://www.jianshu.com/p/8d8edf25850d", title : "推荐一款编程字体,让代码看着更美"}, { href : "http://www.jianshu.com/p/153d9f31288d", title : "Android 利用Camera实现中轴3D卡牌翻转效果"}, { href : "http://www.jianshu.com/p/d6fb0c9c9c26", title : "【Eclipse】挖掘专属最有用的快捷键组合"}, { href : "http://www.jianshu.com/p/72d69b49d135", title : "【IIS】Windows下利用IIS建立网站并实现局域网共享"} ];window.onload = function() { var infos = document.getElementById("infos"); for( var i = 0 ; i < datas.length ; i++) { var a = document.createElement("a"); a.href = datas[i].href ; a.innerText = datas[i].title; infos.appendChild(a); infos.appendChild(document.createElement("br")) }} HtmlUnit 测试网页内容!
通过IIS发布本地网站(参考之前逸峰写的文章:【IIS】在Windows下使用IIS搭建网站实现局域网共享),网页展示的效果浏览器如下:
网页显示效果.jpg
虽然通过网页检查元素,可以看到body中收录了网页显示的文字内容:
网络评论元素.jpg
但是,它根本无法通过 Jsoup 工具获得!从网页源码中可以看出,我们需要爬取的内容是在页面显示出来后通过ajax和JavaScript加载的。
那么该怎么办?使用本文推荐的开源工具——HtmlUnit,一个可以模拟浏览器的抓包神器!
在官网下载对应的jar包,添加到项目工程的lib中。简单的测试代码如下:
import java.io.IOException;import java.net.MalformedURLException;import java.text.ParseException;import com.gargoylesoftware.htmlunit.BrowserVersion;import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;import com.gargoylesoftware.htmlunit.WebClient;import com.gargoylesoftware.htmlunit.html.DomElement;import com.gargoylesoftware.htmlunit.html.DomNodeList;import com.gargoylesoftware.htmlunit.html.HtmlPage;/** * @author 亦枫 * @created_time 2016年1月12日 * @file_user_todo Java测试类 * @blog http://www.jianshu.com/users/1 ... icles */public class JavaTest { /** * 入口函数 * @param args * @throws ParseException */ public static void main(String[] args) throws ParseException { try { WebClient webClient = new WebClient(BrowserVersion.CHROME); HtmlPage htmlPage = (HtmlPage) webClient.getPage("http://localhost/test.html"); DomNodeList domNodeList = htmlPage.getElementsByTagName("a"); for (int i = 0; i < domNodeList.size(); i++) { DomElement domElement = (DomElement) domNodeList.get(i); System.out.println(domElement.asText()); } webClient.close(); } catch (FailingHttpStatusCodeException e) { e.printStackTrace(); } catch (MalformedURLException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }}
运行后,控制台打印出结果:
HtmlUnit测试结果.jpg
可以看出,HtmlUnit 能够抓取 AJAX 和 JavaScript 加载的内容。
HtmlUnit的介绍在官网上很详细。以下内容为易峰翻译的部分内容,供大家参考:
HtmlUnit 是一个基于 Java 的浏览器程序,没有图形界面。它可以调用 HTML 文档并提供 API,使开发人员可以像在普通浏览器上一样访问 Web 内容、填写表单、单击超链接等。
它对 JavaScript 的支持非常好并且还在改进中,可以解析非常复杂的 AJAX 库,模拟不同配置下的 Chrome、Firefox 和 IE 浏览器。
HtmlUnit 通常用于测试目的和检索 网站 信息。
HtmlUnit 提供了很多测试网络请求和爬取网页内容的功能。可以去官网或者其他网站学习使用。 查看全部
htmlunit 抓取网页(使用本文中推荐的开源工具——HtmlUnit,一款能够模拟浏览器的抓包神器!)
之前,一峰写过一篇关于使用Jsoup爬取网页内容的文章文章:
[Jsoup] HTML解析器,轻松获取网页内容
Jsoup提供的api非常方便,完全类似于JQuery操作,轻松抓取网页数据。但是像Jsoup这样的普通爬虫工具的缺点是不能处理js生成的内容。
做过Html开发的都知道现在很多网站都是用ajax和JavaScript来获取和处理数据,普通爬虫工具已经无法处理js中的内容了。
比如我们在本地新建一个测试web文件text.html,源码如下:
main.html a { line-height: 30px; margin: 20px; } var datas = [ { href : "http://www.jianshu.com/p/8d8edf25850d", title : "推荐一款编程字体,让代码看着更美"}, { href : "http://www.jianshu.com/p/153d9f31288d", title : "Android 利用Camera实现中轴3D卡牌翻转效果"}, { href : "http://www.jianshu.com/p/d6fb0c9c9c26", title : "【Eclipse】挖掘专属最有用的快捷键组合"}, { href : "http://www.jianshu.com/p/72d69b49d135", title : "【IIS】Windows下利用IIS建立网站并实现局域网共享"} ];window.onload = function() { var infos = document.getElementById("infos"); for( var i = 0 ; i < datas.length ; i++) { var a = document.createElement("a"); a.href = datas[i].href ; a.innerText = datas[i].title; infos.appendChild(a); infos.appendChild(document.createElement("br")) }} HtmlUnit 测试网页内容!
通过IIS发布本地网站(参考之前逸峰写的文章:【IIS】在Windows下使用IIS搭建网站实现局域网共享),网页展示的效果浏览器如下:
网页显示效果.jpg
虽然通过网页检查元素,可以看到body中收录了网页显示的文字内容:
网络评论元素.jpg
但是,它根本无法通过 Jsoup 工具获得!从网页源码中可以看出,我们需要爬取的内容是在页面显示出来后通过ajax和JavaScript加载的。
那么该怎么办?使用本文推荐的开源工具——HtmlUnit,一个可以模拟浏览器的抓包神器!
在官网下载对应的jar包,添加到项目工程的lib中。简单的测试代码如下:
import java.io.IOException;import java.net.MalformedURLException;import java.text.ParseException;import com.gargoylesoftware.htmlunit.BrowserVersion;import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;import com.gargoylesoftware.htmlunit.WebClient;import com.gargoylesoftware.htmlunit.html.DomElement;import com.gargoylesoftware.htmlunit.html.DomNodeList;import com.gargoylesoftware.htmlunit.html.HtmlPage;/** * @author 亦枫 * @created_time 2016年1月12日 * @file_user_todo Java测试类 * @blog http://www.jianshu.com/users/1 ... icles */public class JavaTest { /** * 入口函数 * @param args * @throws ParseException */ public static void main(String[] args) throws ParseException { try { WebClient webClient = new WebClient(BrowserVersion.CHROME); HtmlPage htmlPage = (HtmlPage) webClient.getPage("http://localhost/test.html";); DomNodeList domNodeList = htmlPage.getElementsByTagName("a"); for (int i = 0; i < domNodeList.size(); i++) { DomElement domElement = (DomElement) domNodeList.get(i); System.out.println(domElement.asText()); } webClient.close(); } catch (FailingHttpStatusCodeException e) { e.printStackTrace(); } catch (MalformedURLException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }}
运行后,控制台打印出结果:
HtmlUnit测试结果.jpg
可以看出,HtmlUnit 能够抓取 AJAX 和 JavaScript 加载的内容。
HtmlUnit的介绍在官网上很详细。以下内容为易峰翻译的部分内容,供大家参考:
HtmlUnit 是一个基于 Java 的浏览器程序,没有图形界面。它可以调用 HTML 文档并提供 API,使开发人员可以像在普通浏览器上一样访问 Web 内容、填写表单、单击超链接等。
它对 JavaScript 的支持非常好并且还在改进中,可以解析非常复杂的 AJAX 库,模拟不同配置下的 Chrome、Firefox 和 IE 浏览器。
HtmlUnit 通常用于测试目的和检索 网站 信息。
HtmlUnit 提供了很多测试网络请求和爬取网页内容的功能。可以去官网或者其他网站学习使用。
htmlunit 抓取网页(使用HtmlUnit抓取百度搜索结果htmlunitjava浏览器的开源实现案例 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-04 16:19
)
使用 HtmlUnit 抓取百度搜索结果
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。相关文件下载地址:(依赖包稍微多一些
)
我的要求是使用百度的高级新闻搜索来抓取指定时间段的新闻。手动搜索设置如图:
通过htmlunit,可以方便的操作网页中的表单和各种输入控件,如HtmlSubmitInput、HtmlTextInput、HtmlRadioButtonInput、HtmlHiddenInput等,通过名称和值可以找到对应的DOM节点。一开始遇到的问题是,即使正确操作了radio Button,也无法得到正确时间段的结果。用chrome查看Http header后发现百度在表单中隐藏了两个参数。参数名称为bt和et,分别代表用户选择的两次begin_date和end_date之间的时间间隔,以及1970-1-1的时间戳。因此,需要手动添加这两个参数,才能得到对应时间段的结果。代码如下:
final WebClient webclient = new WebClient();
final HtmlPage htmlpage = webclient
.getPage("http://news.baidu.com/advanced_news.html");
webclient.setCssEnabled(false);
webclient.setJavaScriptEnabled(false);
// System.out.println(htmlpage.getTitleText());
final HtmlForm form = htmlpage.getFormByName("f");
final HtmlSubmitInput button = form.getInputByValue("百度一下");
final HtmlTextInput textField = form.getInputByName("q1");
textField.setValueAttribute(word);
final List radioButtons = form
.getRadioButtonsByName("s");
radioButtons.get(0).setChecked(false);
radioButtons.get(1).setChecked(true);// 选中限定时间段的radion button
final List titleButtons = form
.getRadioButtonsByName("tn");
titleButtons.get(0).setChecked(false);
titleButtons.get(1).setChecked(true); //选中“仅在新闻的标题中”的radion button
HtmlHiddenInput bt = form.getInputByName("bt");
bt.setValueAttribute("1167580800"); //2007-1-1的时间戳
HtmlHiddenInput et = form.getInputByName("et");
et.setValueAttribute("1199116799"); //2007-12-31的时间戳
final HtmlPage page2 = button.click();
String result = page2.asText();
Pattern pattern = Pattern.compile("找到相关新闻 约(.*) 篇");
Matcher matcher = pattern.matcher(result);
webclient.closeAllWindows();
if (matcher.find())
return matcher.group(1); 查看全部
htmlunit 抓取网页(使用HtmlUnit抓取百度搜索结果htmlunitjava浏览器的开源实现案例
)
使用 HtmlUnit 抓取百度搜索结果
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。相关文件下载地址:(依赖包稍微多一些

)
我的要求是使用百度的高级新闻搜索来抓取指定时间段的新闻。手动搜索设置如图:

通过htmlunit,可以方便的操作网页中的表单和各种输入控件,如HtmlSubmitInput、HtmlTextInput、HtmlRadioButtonInput、HtmlHiddenInput等,通过名称和值可以找到对应的DOM节点。一开始遇到的问题是,即使正确操作了radio Button,也无法得到正确时间段的结果。用chrome查看Http header后发现百度在表单中隐藏了两个参数。参数名称为bt和et,分别代表用户选择的两次begin_date和end_date之间的时间间隔,以及1970-1-1的时间戳。因此,需要手动添加这两个参数,才能得到对应时间段的结果。代码如下:
final WebClient webclient = new WebClient();
final HtmlPage htmlpage = webclient
.getPage("http://news.baidu.com/advanced_news.html";);
webclient.setCssEnabled(false);
webclient.setJavaScriptEnabled(false);
// System.out.println(htmlpage.getTitleText());
final HtmlForm form = htmlpage.getFormByName("f");
final HtmlSubmitInput button = form.getInputByValue("百度一下");
final HtmlTextInput textField = form.getInputByName("q1");
textField.setValueAttribute(word);
final List radioButtons = form
.getRadioButtonsByName("s");
radioButtons.get(0).setChecked(false);
radioButtons.get(1).setChecked(true);// 选中限定时间段的radion button
final List titleButtons = form
.getRadioButtonsByName("tn");
titleButtons.get(0).setChecked(false);
titleButtons.get(1).setChecked(true); //选中“仅在新闻的标题中”的radion button
HtmlHiddenInput bt = form.getInputByName("bt");
bt.setValueAttribute("1167580800"); //2007-1-1的时间戳
HtmlHiddenInput et = form.getInputByName("et");
et.setValueAttribute("1199116799"); //2007-12-31的时间戳
final HtmlPage page2 = button.click();
String result = page2.asText();
Pattern pattern = Pattern.compile("找到相关新闻 约(.*) 篇");
Matcher matcher = pattern.matcher(result);
webclient.closeAllWindows();
if (matcher.find())
return matcher.group(1);
htmlunit 抓取网页(和java自带的网络API进行结合,怎么做?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-04 09:13
HtmlUnit结合了HttpClient和java自带的网络API,更容易抓取数据,更容易操作。HtmlUnit底层还是封装了HttpClient,但是封装之后解析出来的内容更像是一个网页,而不是抽象的请求和响应,所以更方便开发者上手。
// [1] new一个WebClient,在其中定义一种浏览器
WebClient webClent = new WebClient(BrowserVersion.FIREFOX_17);
// [2] 设置网页解析的内容
WebClientOptions options=webClent.getOptions();
options.setCssEnabled(false);
options.setJavaScriptEnabled(true);
options.setActiveXNative(false);
options.setAppletEnabled(false);
options.setRedirectEnabled(true);
options.setThrowExceptionOnFailingStatusCode(false);
options.setThrowExceptionOnScriptError(false);
options.setDoNotTrackEnabled(false);
options.setGeolocationEnabled(false);
// [3] 访问指定的页面,并将其赋予HtmlPage
HtmlPage htmlPage=webClent.getPage(url);
// [4] 获得的HtmlPage并不易于阅读,所以有需要可以通过Jsoup将其转换为Document对象
Document document = Jsoup.parseBodyFragment(htmlPage.asXml());
// [5]关闭
webClent.closeAllWindows();
HtmlPage 非常方便在获取到按钮后进行赋值和操作点击事件。常用方法getElementByName根据名称获取指定的标签(HtmlElement),类型可以设置为标签。
select("") 方法经常用在 Document 对象中。通过这个方法可以得到具体的Element,然后通过解析内容得到需要的数据。
HtmlUnit很容易爬取,但是因为它模拟了网页的点击事件,所以响应返回的所有内容都会很臃肿。如果需要的数据量很小,效率会有点低。 查看全部
htmlunit 抓取网页(和java自带的网络API进行结合,怎么做?)
HtmlUnit结合了HttpClient和java自带的网络API,更容易抓取数据,更容易操作。HtmlUnit底层还是封装了HttpClient,但是封装之后解析出来的内容更像是一个网页,而不是抽象的请求和响应,所以更方便开发者上手。
// [1] new一个WebClient,在其中定义一种浏览器
WebClient webClent = new WebClient(BrowserVersion.FIREFOX_17);
// [2] 设置网页解析的内容
WebClientOptions options=webClent.getOptions();
options.setCssEnabled(false);
options.setJavaScriptEnabled(true);
options.setActiveXNative(false);
options.setAppletEnabled(false);
options.setRedirectEnabled(true);
options.setThrowExceptionOnFailingStatusCode(false);
options.setThrowExceptionOnScriptError(false);
options.setDoNotTrackEnabled(false);
options.setGeolocationEnabled(false);
// [3] 访问指定的页面,并将其赋予HtmlPage
HtmlPage htmlPage=webClent.getPage(url);
// [4] 获得的HtmlPage并不易于阅读,所以有需要可以通过Jsoup将其转换为Document对象
Document document = Jsoup.parseBodyFragment(htmlPage.asXml());
// [5]关闭
webClent.closeAllWindows();
HtmlPage 非常方便在获取到按钮后进行赋值和操作点击事件。常用方法getElementByName根据名称获取指定的标签(HtmlElement),类型可以设置为标签。
select("") 方法经常用在 Document 对象中。通过这个方法可以得到具体的Element,然后通过解析内容得到需要的数据。
HtmlUnit很容易爬取,但是因为它模拟了网页的点击事件,所以响应返回的所有内容都会很臃肿。如果需要的数据量很小,效率会有点低。
htmlunit 抓取网页(使用本文中推荐的开源工具——HtmlUnit,一款能够模拟浏览器的抓包神器!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-03 04:07
之前,一峰写过一篇关于使用Jsoup爬取网页内容的文章文章:
[Jsoup] HTML解析器,轻松获取网页内容
Jsoup提供的api非常方便,完全类似于JQuery操作,轻松抓取网页数据。但是像Jsoup这样的普通爬虫工具的缺点是不能处理js生成的内容。
做过Html开发的都知道现在很多网站都是用ajax和JavaScript来获取和处理数据,普通爬虫工具已经无法处理js中的内容了。
比如我们在本地新建一个测试web文件text.html,源码如下:
main.html
a {
line-height: 30px;
margin: 20px;
}
var datas = [ {
href : "http://www.jianshu.com/p/8d8edf25850d",
title : "推荐一款编程字体,让代码看着更美"
}, {
href : "http://www.jianshu.com/p/153d9f31288d",
title : "Android 利用Camera实现中轴3D卡牌翻转效果"
}, {
href : "http://www.jianshu.com/p/d6fb0c9c9c26",
title : "【Eclipse】挖掘专属最有用的快捷键组合"
}, {
href : "http://www.jianshu.com/p/72d69b49d135",
title : "【IIS】Windows下利用IIS建立网站并实现局域网共享"
} ];
window.onload = function() {
var infos = document.getElementById("infos");
for( var i = 0 ; i < datas.length ; i++)
{
var a = document.createElement("a");
a.href = datas[i].href ;
a.innerText = datas[i].title;
infos.appendChild(a);
infos.appendChild(document.createElement("br"))
}
}
HtmlUnit 测试网页内容!
通过IIS发布本地网站(参考之前逸峰写的文章:
【IIS】在Windows下使用IIS建立网站,实现局域网共享),
网页在浏览器中显示的效果如下:
网页显示效果.jpg
虽然通过网页检查元素,可以看到body中收录了网页显示的文字内容:
网络评论元素.jpg
但是,它根本无法通过 Jsoup 工具获得!从网页的源码可以看出,我们需要爬取的内容是在页面显示出来后通过ajax和JavaScript加载的。
那么该怎么办?使用本文推荐的开源工具——HtmlUnit,一个可以模拟浏览器的抓包神器!
在官网下载对应的jar包,添加到项目工程的lib中。简单的测试代码如下:
import java.io.IOException;
import java.net.MalformedURLException;
import java.text.ParseException;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.DomElement;
import com.gargoylesoftware.htmlunit.html.DomNodeList;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
/**
* @author 亦枫
* @created_time 2016年1月12日
* @file_user_todo Java测试类
* @blog http://www.jianshu.com/users/1 ... icles
*/
public class JavaTest {
/**
* 入口函数
* @param args
* @throws ParseException
*/
public static void main(String[] args) throws ParseException {
try {
WebClient webClient = new WebClient(BrowserVersion.CHROME);
HtmlPage htmlPage = (HtmlPage) webClient.getPage("http://localhost/test.html");
DomNodeList domNodeList = htmlPage.getElementsByTagName("a");
for (int i = 0; i < domNodeList.size(); i++) {
DomElement domElement = (DomElement) domNodeList.get(i);
System.out.println(domElement.asText());
}
webClient.close();
} catch (FailingHttpStatusCodeException e) {
e.printStackTrace();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行后,控制台打印出结果:
HtmlUnit测试结果.jpg
可以看出,HtmlUnit 能够抓取 AJAX 和 JavaScript 加载的内容。
HtmlUnit的介绍在官网上很详细。以下内容为易峰翻译的部分内容,供大家参考:
HtmlUnit 是一个基于 Java 的浏览器程序,没有图形界面。它可以调用 HTML 文档并提供 API,使开发人员可以像在普通浏览器上一样获取 Web 内容、填写表单、单击超链接等。
它对 JavaScript 的支持非常好并且还在改进中,可以解析非常复杂的 AJAX 库,模拟不同配置下的 Chrome、Firefox 和 IE 浏览器。
HtmlUnit 通常用于测试目的和检索 网站 信息。
HtmlUnit 提供了许多测试网络请求和爬取网页内容的功能。可以去官网或者其他网站学习使用。 查看全部
htmlunit 抓取网页(使用本文中推荐的开源工具——HtmlUnit,一款能够模拟浏览器的抓包神器!)
之前,一峰写过一篇关于使用Jsoup爬取网页内容的文章文章:
[Jsoup] HTML解析器,轻松获取网页内容
Jsoup提供的api非常方便,完全类似于JQuery操作,轻松抓取网页数据。但是像Jsoup这样的普通爬虫工具的缺点是不能处理js生成的内容。
做过Html开发的都知道现在很多网站都是用ajax和JavaScript来获取和处理数据,普通爬虫工具已经无法处理js中的内容了。
比如我们在本地新建一个测试web文件text.html,源码如下:
main.html
a {
line-height: 30px;
margin: 20px;
}
var datas = [ {
href : "http://www.jianshu.com/p/8d8edf25850d",
title : "推荐一款编程字体,让代码看着更美"
}, {
href : "http://www.jianshu.com/p/153d9f31288d",
title : "Android 利用Camera实现中轴3D卡牌翻转效果"
}, {
href : "http://www.jianshu.com/p/d6fb0c9c9c26",
title : "【Eclipse】挖掘专属最有用的快捷键组合"
}, {
href : "http://www.jianshu.com/p/72d69b49d135",
title : "【IIS】Windows下利用IIS建立网站并实现局域网共享"
} ];
window.onload = function() {
var infos = document.getElementById("infos");
for( var i = 0 ; i < datas.length ; i++)
{
var a = document.createElement("a");
a.href = datas[i].href ;
a.innerText = datas[i].title;
infos.appendChild(a);
infos.appendChild(document.createElement("br"))
}
}
HtmlUnit 测试网页内容!
通过IIS发布本地网站(参考之前逸峰写的文章:
【IIS】在Windows下使用IIS建立网站,实现局域网共享),
网页在浏览器中显示的效果如下:
网页显示效果.jpg
虽然通过网页检查元素,可以看到body中收录了网页显示的文字内容:
网络评论元素.jpg
但是,它根本无法通过 Jsoup 工具获得!从网页的源码可以看出,我们需要爬取的内容是在页面显示出来后通过ajax和JavaScript加载的。
那么该怎么办?使用本文推荐的开源工具——HtmlUnit,一个可以模拟浏览器的抓包神器!
在官网下载对应的jar包,添加到项目工程的lib中。简单的测试代码如下:
import java.io.IOException;
import java.net.MalformedURLException;
import java.text.ParseException;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.DomElement;
import com.gargoylesoftware.htmlunit.html.DomNodeList;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
/**
* @author 亦枫
* @created_time 2016年1月12日
* @file_user_todo Java测试类
* @blog http://www.jianshu.com/users/1 ... icles
*/
public class JavaTest {
/**
* 入口函数
* @param args
* @throws ParseException
*/
public static void main(String[] args) throws ParseException {
try {
WebClient webClient = new WebClient(BrowserVersion.CHROME);
HtmlPage htmlPage = (HtmlPage) webClient.getPage("http://localhost/test.html";);
DomNodeList domNodeList = htmlPage.getElementsByTagName("a");
for (int i = 0; i < domNodeList.size(); i++) {
DomElement domElement = (DomElement) domNodeList.get(i);
System.out.println(domElement.asText());
}
webClient.close();
} catch (FailingHttpStatusCodeException e) {
e.printStackTrace();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行后,控制台打印出结果:
HtmlUnit测试结果.jpg
可以看出,HtmlUnit 能够抓取 AJAX 和 JavaScript 加载的内容。
HtmlUnit的介绍在官网上很详细。以下内容为易峰翻译的部分内容,供大家参考:
HtmlUnit 是一个基于 Java 的浏览器程序,没有图形界面。它可以调用 HTML 文档并提供 API,使开发人员可以像在普通浏览器上一样获取 Web 内容、填写表单、单击超链接等。
它对 JavaScript 的支持非常好并且还在改进中,可以解析非常复杂的 AJAX 库,模拟不同配置下的 Chrome、Firefox 和 IE 浏览器。
HtmlUnit 通常用于测试目的和检索 网站 信息。
HtmlUnit 提供了许多测试网络请求和爬取网页内容的功能。可以去官网或者其他网站学习使用。
htmlunit 抓取网页(GitHub上有哪些优秀的Java爬虫项目?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-03-31 17:11
GitHub上有哪些不错的Java爬虫项目?
首先声明一下业界普遍使用python作为爬虫。当然也有很多用java语言开发的
一、nutch
由著名的 Doug Cutting 发起的爬虫项目,Apache 旗下的顶级项目,是一个开源的网络爬虫,它使用 MapReduce 以分布式的方式爬取和解析网页信息。
github地址:附上官方地址。官方的:
二、赫里特里克斯
使用java开发的开源网络爬虫系统,获取网站内容完整准确的深拷贝。扩展性强,功能齐全,文档齐全。
github地址:,里面收录文档等信息。
三、杰科
一个轻量级易用的网络爬虫框架,集成了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架。它具有极好的可扩展性。该框架基于开闭原则设计,对修改封闭,对扩展开放。
github地址:收录官网地址。
四、crawler4j
是一个开源的 Java 类库,它提供了一个简单的网页抓取界面。简单易用,支持多线程,支持代理,过滤重复URL等功能。一个多线程网络爬虫可以在几分钟内建立起来。
github地址:,收录使用文档。
其他优秀的java爬虫项目还有很多,就不一一赘述了,比如WebCollector、WebMagic、Spiderman、SeimiCrawler等等。另外,实用一点就好,没必要全部都懂。
哪个java开源网络爬虫好用?
1.nutch 地址:apache/nutch · GitHub apache下的开源爬虫程序,功能丰富,文档齐全。有用于数据捕获、分析和存储的模块。
2.Heritrix 地址:internetarchive/heritrix3 · GitHub 已经存在很久了。已经更新了很多次,也被很多人使用了。功能齐全,文档齐全,网上资料多。拥有自己的 Web 管理控制台,包括 HTTP 服务器。操作员可以通过选择爬虫命令来操作控制台。
3.crawler4j 地址:yasserg/crawler4j · GitHub 因为只有爬虫的核心功能,所以上手极其容易。你可以在几分钟内编写一个多线程爬虫程序。当然,上面提到的nutch的数据存储等功能并不代表Heritrix没有,反之亦然。需要仔细阅读文档,配合实验得出结论。还有比如 JSpider、WebEater、Java Web Crawler、WebLech、Ex-Crawler、JoBo等,这些没用过,不知道。. .
什么是爬虫软件,如果要从网上爬取一些数据,是不是得自己写代码?
这个不一定,爬虫只是一个数据获取的过程,不一定非要会编码,网上有很多现成的软件可以直接爬取数据,下面我简单介绍三个,即优采云、优采云和优采云,感兴趣的朋友可以试试:
01 简单软件—优采云采集器
这是一个非常适合小白采集器的网页,完美支持3大操作平台,完全免费供个人使用。基于人工智能技术,只需输入网页地址,软件就会自动提取和解析数据。数据预览、导出、自动翻页功能简单实用,无需配置任何规则。如果想快速获取网页数据,又不熟悉代码,可以使用这个软件,非常好学:
02 国产软件——优采云采集器
这是一款非常纯正的国产软件。与优采云采集器不同,优采云采集器目前只支持Windows平台,基本功能完全免费,高级功能需要付费,目前支持两种方式:简单的采集和自定义的采集,自带很多现成的数据采集模板,可以快速采集某宝、某东等热门网站 Data,支持数据预览和导出,对于网站Data采集也是一个不错的选择:
03 专业软件—优采云采集
这是一款非常专业且功能强大的数据采集软件。和优采云一样,目前只支持Windows平台。免费版可直接供个人使用。它自动整合来自采集的数据,从清洗到分析的全过程,你可以快速设置爬取规则来爬取网页数据(灵活、智能、强大),无需编写一行代码,如果你是对代码不熟悉,没有任何基础,只想简单的获取网页数据,可以用这个软件,也很不错:
目前就分享一下这三款爬虫软件。对于日常使用来说,完全够用了。当然,除了以上三个软件之外,还有很多其他的爬虫软件,比如神策、作数等也很不错,只要熟悉使用流程,就能掌握很快。网上也有相关的教程和资料。介绍很详细。如果你有兴趣,你可以搜索它。希望以上分享的内容对您有所帮助。也欢迎评论。,留言补充。
参考页 查看全部
htmlunit 抓取网页(GitHub上有哪些优秀的Java爬虫项目?(图))
GitHub上有哪些不错的Java爬虫项目?
首先声明一下业界普遍使用python作为爬虫。当然也有很多用java语言开发的
一、nutch
由著名的 Doug Cutting 发起的爬虫项目,Apache 旗下的顶级项目,是一个开源的网络爬虫,它使用 MapReduce 以分布式的方式爬取和解析网页信息。
github地址:附上官方地址。官方的:
二、赫里特里克斯
使用java开发的开源网络爬虫系统,获取网站内容完整准确的深拷贝。扩展性强,功能齐全,文档齐全。
github地址:,里面收录文档等信息。
三、杰科
一个轻量级易用的网络爬虫框架,集成了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架。它具有极好的可扩展性。该框架基于开闭原则设计,对修改封闭,对扩展开放。
github地址:收录官网地址。
四、crawler4j
是一个开源的 Java 类库,它提供了一个简单的网页抓取界面。简单易用,支持多线程,支持代理,过滤重复URL等功能。一个多线程网络爬虫可以在几分钟内建立起来。
github地址:,收录使用文档。
其他优秀的java爬虫项目还有很多,就不一一赘述了,比如WebCollector、WebMagic、Spiderman、SeimiCrawler等等。另外,实用一点就好,没必要全部都懂。
哪个java开源网络爬虫好用?
1.nutch 地址:apache/nutch · GitHub apache下的开源爬虫程序,功能丰富,文档齐全。有用于数据捕获、分析和存储的模块。
2.Heritrix 地址:internetarchive/heritrix3 · GitHub 已经存在很久了。已经更新了很多次,也被很多人使用了。功能齐全,文档齐全,网上资料多。拥有自己的 Web 管理控制台,包括 HTTP 服务器。操作员可以通过选择爬虫命令来操作控制台。
3.crawler4j 地址:yasserg/crawler4j · GitHub 因为只有爬虫的核心功能,所以上手极其容易。你可以在几分钟内编写一个多线程爬虫程序。当然,上面提到的nutch的数据存储等功能并不代表Heritrix没有,反之亦然。需要仔细阅读文档,配合实验得出结论。还有比如 JSpider、WebEater、Java Web Crawler、WebLech、Ex-Crawler、JoBo等,这些没用过,不知道。. .
什么是爬虫软件,如果要从网上爬取一些数据,是不是得自己写代码?
这个不一定,爬虫只是一个数据获取的过程,不一定非要会编码,网上有很多现成的软件可以直接爬取数据,下面我简单介绍三个,即优采云、优采云和优采云,感兴趣的朋友可以试试:
01 简单软件—优采云采集器
这是一个非常适合小白采集器的网页,完美支持3大操作平台,完全免费供个人使用。基于人工智能技术,只需输入网页地址,软件就会自动提取和解析数据。数据预览、导出、自动翻页功能简单实用,无需配置任何规则。如果想快速获取网页数据,又不熟悉代码,可以使用这个软件,非常好学:
02 国产软件——优采云采集器
这是一款非常纯正的国产软件。与优采云采集器不同,优采云采集器目前只支持Windows平台,基本功能完全免费,高级功能需要付费,目前支持两种方式:简单的采集和自定义的采集,自带很多现成的数据采集模板,可以快速采集某宝、某东等热门网站 Data,支持数据预览和导出,对于网站Data采集也是一个不错的选择:
03 专业软件—优采云采集
这是一款非常专业且功能强大的数据采集软件。和优采云一样,目前只支持Windows平台。免费版可直接供个人使用。它自动整合来自采集的数据,从清洗到分析的全过程,你可以快速设置爬取规则来爬取网页数据(灵活、智能、强大),无需编写一行代码,如果你是对代码不熟悉,没有任何基础,只想简单的获取网页数据,可以用这个软件,也很不错:
目前就分享一下这三款爬虫软件。对于日常使用来说,完全够用了。当然,除了以上三个软件之外,还有很多其他的爬虫软件,比如神策、作数等也很不错,只要熟悉使用流程,就能掌握很快。网上也有相关的教程和资料。介绍很详细。如果你有兴趣,你可以搜索它。希望以上分享的内容对您有所帮助。也欢迎评论。,留言补充。
参考页
htmlunit 抓取网页(的java程序是什么?答案是有哪些?? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-03-30 21:29
)
1.HtmlUnit1.1 简介
HtmlUnit 是一个用 java 编写的无界面浏览器,它可以对 html 文档进行建模、通过 API 调用页面、填写表单、单击链接等等。像普通浏览器一样运行。通常用于测试和从网页中抓取信息。
官方简介翻译:<br />
HtmlUnit是一个无界面浏览器Java程序。它为HTML文档建模,提供了调用页面、填写表单、单击链接等操作的API。就跟你在浏览器里做的操作一样。
HtmlUnit不错的JavaScript支持(不断改进),甚至可以使用相当复杂的AJAX库,根据配置的不同模拟Chrome、Firefox或Internet Explorer等浏览器。
HtmlUnit通常用于测试或从web站点检索信息。
1.2 使用场景
对于java实现的网络爬虫程序,我们一般可以使用apache的HttpClient组件来获取HTML页面信息。HttpClient实现的http请求返回的响应一般是纯文本文档页面,也就是最原创的html页面。
对于一个静态的html页面,使用httpClient就足够爬出我们需要的信息了。但是对于越来越多的动态网页,更多的数据是通过异步JS代码获取和渲染的,而初始的html页面是不收录这部分数据的。
上图中我们看到的网页在初始文档加载后并没有看到红框中的数据列表。浏览器通过执行异步JS请求,将获取到的动态数据渲染到原创文档页面中,最终变成我们看到的网页。对于这部分需要JS代码执行的数据,httpClient是无能为力的。虽然我们可以通过研究得到JS执行的请求路径,然后用java代码来获取我们需要的部分数据,不说能不能从JS脚本中分析请求路径和请求参数,只分析这部分数据源码成本已经很高了。
通过上面的介绍,我们了解到现在很大一部分动态网页都是通过异步JS请求获得的数据,然后通过JS渲染页面。那么我们能不能做这样的假设,假设我们的爬虫程序模拟一个浏览器,拿到html页面后,像浏览器一样执行异步JS代码,JS渲染好html页面后,就可以愉快的获取到节点信息了这页纸。那么有没有这样的java程序呢?
答案是肯定的。
HtmlUnit就是这样一个库,用来做界面显示的所有异步工作。没有耗时的显示工作,HtmlUnit 加载的完整网页比实际的浏览器块更多。并且根据不同的配置,HtmlUnit可以模拟市面上常见的Chrome、Firefox、IE浏览器等浏览器。
通过HtmlUnit库,加载一个完整的Html页面(图片和视频除外),然后将其转换成我们常用的字符串格式,使用Jsoup等其他工具获取元素。当然,你也可以直接从HtmlUnit提供的对象中获取网页元素,甚至可以操作按钮、表单等控件。除了不能像可见浏览器那样用鼠标和键盘浏览网页之外,我们可以使用HtmlUnit来模拟所有其他的操作,比如登录网站、写博客等都可以完成。当然,网页内容抓取是最简单的应用。
2.J4L2.1官方简介
J4L OCR 工具是一组组件,可用于在 Java 应用程序中收录 OCR 功能。这意味着您可以接收传真、PDF 文件或扫描文档并从图像中提取商业信息。主要的3个组件是:
详细使用步骤请参考这篇文章文章:Java使用J4L识别验证码
本文文章主要介绍使用HtmlUnit模拟登录
3.实际案例3.1.场景
登录页面,包括表单,需要填写用户名、登录密码、验证码,实现用户登录。
3.2操作步骤
使用htmlunit模拟登录是一个获取登录页面->找到输入框->填写用户名和密码->填写验证码->模拟点击登录的过程。
4.实现代码4.1maven引入HtmlUnit依赖
net.sourceforge.htmlunit
htmlunit
2.18
4.2 主要方法
登录类
public static void main(String[] args) throws Exception {
DoCheck();
}
public static void DoCheck() throws Exception {
WebClient webClient = new WebClient(BrowserVersion.CHROME);//设置浏览器内核
webClient.getOptions().setJavaScriptEnabled(true);// js是否可用
webClient.getOptions().setCssEnabled(true);//css 一般设置false因为影响运行速度
webClient.getOptions().setThrowExceptionOnScriptError(false);//设置js抛出异常:false
webClient.getOptions().setActiveXNative(false);
//ajax
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
webClient.getOptions().setUseInsecureSSL(false);
//允许重定向
webClient.getOptions().setRedirectEnabled(true);
//连接超时
webClient.getOptions().setTimeout(5000);
//js执行超时
webClient.setJavaScriptTimeout(10000 * 3);
//允许cookie
webClient.getCookieManager().setCookiesEnabled(true);
String url = "http://hrportalneu.cs/HRPortal ... 3B%3B
HtmlPage page = webClient.getPage(url);
webClient.waitForBackgroundJavaScript(5000);
HtmlPage newPage;
newPage = readyPage(page, webClient, "btnCheckIn1");
System.out.println("url----------------" + newPage.getUrl());
System.out.println("checkIn执行后页面:" + newPage.asXml());
IOUtils.write(newPage.asXml().getBytes(), new FileWriter(new File("D:/checkIn.txt")));
if (!newPage.asXml().contains("登录成功")) {
DoCheck();
}
webClient.close();
}
public static HtmlPage readyPage(HtmlPage page, WebClient webClient, String type) throws Exception {
//封装页面元素
HtmlForm form = page.getHtmlElementById("form1");
HtmlTextInput tbxUsername = form.getInputByName("tbxUsername");
tbxUsername.setValueAttribute("用户名*******");
HtmlPasswordInput tbxPassword = form.getInputByName("tbxPassword");
tbxPassword.setValueAttribute("密码*******");
//获取验证码图片
HtmlImage verify_img = (HtmlImage) page.getElementById("AuthCode1$codeText$img");
File file = new File("D:\\" + "check" + ".png");
//保存验证码图片
verify_img.saveAs(file);
System.out.println("验证码图片已保存!");
//保存路径
String filePath = file.getPath();
//裁剪验证码
ImageUtil.cutImage(filePath, 1, 1, 96, 34);
//自动识别验证码
OCRFacade facade = new OCRFacade();
//识别验证码
String code = facade.recognizeFile(filePath, "eng");
//处理字符串
code = code.replaceAll(" ", "");
code = code.replaceAll("\\n", "");
System.out.println("验证码:" + code);
//定位验证码输入框
HtmlTextInput verify_code = form.getInputByName("AuthCode1$codeText");
//填入自动识别出来的验证码
verify_code.setValueAttribute(code);
System.out.println("原始页面:" + page.asXml());
HtmlPage newPage = null;
//操作按钮
if (type.equals("btnCheckIn1")) {
DomElement btnCheckIn1 = page.getElementById("btnCheckIn1");
System.out.println("doCheckIn");
newPage = btnCheckIn1.click();
}
//等待js加载
webClient.waitForBackgroundJavaScript(5000);
return newPage;
}
ImageUtil.class
public class ImageUtil {
public static void cutImage(String filePath, int x, int y, int w, int h)
throws Exception {
// 首先通过ImageIo中的方法,创建一个Image + InputStream到内存
ImageInputStream iis = ImageIO
.createImageInputStream(new FileInputStream(filePath));
// 再按照指定格式构造一个Reader(Reader不能new的)
Iterator it = ImageIO.getImageReadersByFormatName("gif");
ImageReader imagereader = (ImageReader) it.next();
// 再通过ImageReader绑定 InputStream
imagereader.setInput(iis);
// 设置感兴趣的源区域。
ImageReadParam par = imagereader.getDefaultReadParam();
par.setSourceRegion(new Rectangle(x, y, w, h));
// 从 reader得到BufferImage
BufferedImage bi = imagereader.read(0, par);
// 将BuffeerImage写出通过ImageIO
ImageIO.write(bi, "png", new File(filePath));
}
} 查看全部
htmlunit 抓取网页(的java程序是什么?答案是有哪些??
)
1.HtmlUnit1.1 简介
HtmlUnit 是一个用 java 编写的无界面浏览器,它可以对 html 文档进行建模、通过 API 调用页面、填写表单、单击链接等等。像普通浏览器一样运行。通常用于测试和从网页中抓取信息。
官方简介翻译:<br />
HtmlUnit是一个无界面浏览器Java程序。它为HTML文档建模,提供了调用页面、填写表单、单击链接等操作的API。就跟你在浏览器里做的操作一样。
HtmlUnit不错的JavaScript支持(不断改进),甚至可以使用相当复杂的AJAX库,根据配置的不同模拟Chrome、Firefox或Internet Explorer等浏览器。
HtmlUnit通常用于测试或从web站点检索信息。
1.2 使用场景
对于java实现的网络爬虫程序,我们一般可以使用apache的HttpClient组件来获取HTML页面信息。HttpClient实现的http请求返回的响应一般是纯文本文档页面,也就是最原创的html页面。
对于一个静态的html页面,使用httpClient就足够爬出我们需要的信息了。但是对于越来越多的动态网页,更多的数据是通过异步JS代码获取和渲染的,而初始的html页面是不收录这部分数据的。
上图中我们看到的网页在初始文档加载后并没有看到红框中的数据列表。浏览器通过执行异步JS请求,将获取到的动态数据渲染到原创文档页面中,最终变成我们看到的网页。对于这部分需要JS代码执行的数据,httpClient是无能为力的。虽然我们可以通过研究得到JS执行的请求路径,然后用java代码来获取我们需要的部分数据,不说能不能从JS脚本中分析请求路径和请求参数,只分析这部分数据源码成本已经很高了。
通过上面的介绍,我们了解到现在很大一部分动态网页都是通过异步JS请求获得的数据,然后通过JS渲染页面。那么我们能不能做这样的假设,假设我们的爬虫程序模拟一个浏览器,拿到html页面后,像浏览器一样执行异步JS代码,JS渲染好html页面后,就可以愉快的获取到节点信息了这页纸。那么有没有这样的java程序呢?
答案是肯定的。
HtmlUnit就是这样一个库,用来做界面显示的所有异步工作。没有耗时的显示工作,HtmlUnit 加载的完整网页比实际的浏览器块更多。并且根据不同的配置,HtmlUnit可以模拟市面上常见的Chrome、Firefox、IE浏览器等浏览器。
通过HtmlUnit库,加载一个完整的Html页面(图片和视频除外),然后将其转换成我们常用的字符串格式,使用Jsoup等其他工具获取元素。当然,你也可以直接从HtmlUnit提供的对象中获取网页元素,甚至可以操作按钮、表单等控件。除了不能像可见浏览器那样用鼠标和键盘浏览网页之外,我们可以使用HtmlUnit来模拟所有其他的操作,比如登录网站、写博客等都可以完成。当然,网页内容抓取是最简单的应用。
2.J4L2.1官方简介
J4L OCR 工具是一组组件,可用于在 Java 应用程序中收录 OCR 功能。这意味着您可以接收传真、PDF 文件或扫描文档并从图像中提取商业信息。主要的3个组件是:
详细使用步骤请参考这篇文章文章:Java使用J4L识别验证码
本文文章主要介绍使用HtmlUnit模拟登录
3.实际案例3.1.场景
登录页面,包括表单,需要填写用户名、登录密码、验证码,实现用户登录。
3.2操作步骤
使用htmlunit模拟登录是一个获取登录页面->找到输入框->填写用户名和密码->填写验证码->模拟点击登录的过程。
4.实现代码4.1maven引入HtmlUnit依赖
net.sourceforge.htmlunit
htmlunit
2.18
4.2 主要方法
登录类
public static void main(String[] args) throws Exception {
DoCheck();
}
public static void DoCheck() throws Exception {
WebClient webClient = new WebClient(BrowserVersion.CHROME);//设置浏览器内核
webClient.getOptions().setJavaScriptEnabled(true);// js是否可用
webClient.getOptions().setCssEnabled(true);//css 一般设置false因为影响运行速度
webClient.getOptions().setThrowExceptionOnScriptError(false);//设置js抛出异常:false
webClient.getOptions().setActiveXNative(false);
//ajax
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
webClient.getOptions().setUseInsecureSSL(false);
//允许重定向
webClient.getOptions().setRedirectEnabled(true);
//连接超时
webClient.getOptions().setTimeout(5000);
//js执行超时
webClient.setJavaScriptTimeout(10000 * 3);
//允许cookie
webClient.getCookieManager().setCookiesEnabled(true);
String url = "http://hrportalneu.cs/HRPortal ... 3B%3B
HtmlPage page = webClient.getPage(url);
webClient.waitForBackgroundJavaScript(5000);
HtmlPage newPage;
newPage = readyPage(page, webClient, "btnCheckIn1");
System.out.println("url----------------" + newPage.getUrl());
System.out.println("checkIn执行后页面:" + newPage.asXml());
IOUtils.write(newPage.asXml().getBytes(), new FileWriter(new File("D:/checkIn.txt")));
if (!newPage.asXml().contains("登录成功")) {
DoCheck();
}
webClient.close();
}
public static HtmlPage readyPage(HtmlPage page, WebClient webClient, String type) throws Exception {
//封装页面元素
HtmlForm form = page.getHtmlElementById("form1");
HtmlTextInput tbxUsername = form.getInputByName("tbxUsername");
tbxUsername.setValueAttribute("用户名*******");
HtmlPasswordInput tbxPassword = form.getInputByName("tbxPassword");
tbxPassword.setValueAttribute("密码*******");
//获取验证码图片
HtmlImage verify_img = (HtmlImage) page.getElementById("AuthCode1$codeText$img");
File file = new File("D:\\" + "check" + ".png");
//保存验证码图片
verify_img.saveAs(file);
System.out.println("验证码图片已保存!");
//保存路径
String filePath = file.getPath();
//裁剪验证码
ImageUtil.cutImage(filePath, 1, 1, 96, 34);
//自动识别验证码
OCRFacade facade = new OCRFacade();
//识别验证码
String code = facade.recognizeFile(filePath, "eng");
//处理字符串
code = code.replaceAll(" ", "");
code = code.replaceAll("\\n", "");
System.out.println("验证码:" + code);
//定位验证码输入框
HtmlTextInput verify_code = form.getInputByName("AuthCode1$codeText");
//填入自动识别出来的验证码
verify_code.setValueAttribute(code);
System.out.println("原始页面:" + page.asXml());
HtmlPage newPage = null;
//操作按钮
if (type.equals("btnCheckIn1")) {
DomElement btnCheckIn1 = page.getElementById("btnCheckIn1");
System.out.println("doCheckIn");
newPage = btnCheckIn1.click();
}
//等待js加载
webClient.waitForBackgroundJavaScript(5000);
return newPage;
}
ImageUtil.class
public class ImageUtil {
public static void cutImage(String filePath, int x, int y, int w, int h)
throws Exception {
// 首先通过ImageIo中的方法,创建一个Image + InputStream到内存
ImageInputStream iis = ImageIO
.createImageInputStream(new FileInputStream(filePath));
// 再按照指定格式构造一个Reader(Reader不能new的)
Iterator it = ImageIO.getImageReadersByFormatName("gif");
ImageReader imagereader = (ImageReader) it.next();
// 再通过ImageReader绑定 InputStream
imagereader.setInput(iis);
// 设置感兴趣的源区域。
ImageReadParam par = imagereader.getDefaultReadParam();
par.setSourceRegion(new Rectangle(x, y, w, h));
// 从 reader得到BufferImage
BufferedImage bi = imagereader.read(0, par);
// 将BuffeerImage写出通过ImageIO
ImageIO.write(bi, "png", new File(filePath));
}
}
htmlunit 抓取网页(htmlunit网络工具一个没有没有 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-03-24 07:14
)
1:背景
本来想用jsoup抓取一个页面,但是抓取的数据总是不完整,然后发现页面执行js后,页面上渲染了一些数据,也就是说数据页是只在js执行后显示。数据会显示出来,但是jsoup无法实现执行页面的js。
2:解决
经过搜索,发现htmlunit网络工具可以实现js。它相当于一个没有页面的浏览器。解决方法是使用htmlUnit发送网络请求,执行js获取页面,然后使用jsoup转换成Document页面对象。然后使用jsoup分析页面读取数据。
3:htmlUnit发送请求
1 public static Document getDocument() throws IOException, InterruptedException{
2 /*String url="https://www.marklines.com/cn/v ... 3B%3B
3 Connection connect = Jsoup.connect(url).userAgent("")
4 .header("Cookie", "PLAY_LANG=cn; _plh=b9289d0a863a8fc9c79fb938f15372f7731d13fb; PLATFORM_SESSION=39034d07000717c664134556ad39869771aabc04-_ldi=520275&_lsh=8cf91cdbcbbb255adff5cba6061f561b642f5157&csrfToken=209f20c8473bc0518413c226f898ff79cd69c3ff-1539926671235-b853a6a63c77dd8fcc364a58&_lpt=%2Fcn%2Fvehicle_sales%2Fsearch&_lsi=1646321; _ga=GA1.2.2146952143.1539926675; _gid=GA1.2.1032787565.1539926675; _plh_notime=8cf91cdbcbbb255adff5cba6061f561b642f5157")
5 .timeout(360000000);
6 Document document = connect.get();*/
7 WebClient wc = new WebClient(BrowserVersion.CHROME);
8 //是否使用不安全的SSL
9 wc.getOptions().setUseInsecureSSL(true);
10 //启用JS解释器,默认为true
11 wc.getOptions().setJavaScriptEnabled(true);
12 //禁用CSS
13 wc.getOptions().setCssEnabled(false);
14 //js运行错误时,是否抛出异常
15 wc.getOptions().setThrowExceptionOnScriptError(false);
16 //状态码错误时,是否抛出异常
17 wc.getOptions().setThrowExceptionOnFailingStatusCode(false);
18 //是否允许使用ActiveX
19 wc.getOptions().setActiveXNative(false);
20 //等待js时间
21 wc.waitForBackgroundJavaScript(600*1000);
22 //设置Ajax异步处理控制器即启用Ajax支持
23 wc.setAjaxController(new NicelyResynchronizingAjaxController());
24 //设置超时时间
25 wc.getOptions().setTimeout(1000000);
26 //不跟踪抓取
27 wc.getOptions().setDoNotTrackEnabled(false);
28 WebRequest request=new WebRequest(new URL("https://www.marklines.com/cn/v ... 6quot;));
29 request.setAdditionalHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:62.0) Gecko/20100101 Firefox/62.0");
30 request.setAdditionalHeader("Cookie","PLAY_LANG=cn; _plh=b9289d0a863a8fc9c79fb938f15372f7731d13fb; PLATFORM_SESSION=39034d07000717c664134556ad39869771aabc04-_ldi=520275&_lsh=8cf91cdbcbbb255adff5cba6061f561b642f5157&csrfToken=209f20c8473bc0518413c226f898ff79cd69c3ff-1539926671235-b853a6a63c77dd8fcc364a58&_lpt=%2Fcn%2Fvehicle_sales%2Fsearch&_lsi=1646321; _ga=GA1.2.2146952143.1539926675; _gid=GA1.2.1032787565.1539926675; _plh_notime=8cf91cdbcbbb255adff5cba6061f561b642f5157");
31 try {
32 //模拟浏览器打开一个目标网址
33 HtmlPage htmlPage = wc.getPage(request);
34 //为了获取js执行的数据 线程开始沉睡等待
35 Thread.sleep(1000);//这个线程的等待 因为js加载需要时间的
36 //以xml形式获取响应文本
37 String xml = htmlPage.asXml();
38 //并转为Document对象return
39 return Jsoup.parse(xml);
40 //System.out.println(xml.contains("结果.xls"));//false
41 } catch (FailingHttpStatusCodeException e) {
42 e.printStackTrace();
43 } catch (MalformedURLException e) {
44 e.printStackTrace();
45 } catch (IOException e) {
46 e.printStackTrace();
47 }
48 return null;
49 }
4:返回的Document对象交给jsoup处理
这里只做一个简单的输出,看看数据是否全部渲染完毕。
1 Document doc=getDocument();
2 Element table=doc.select("table.table.table-bordered.aggregate_table").get(0);//获取到表格
3 Element tableContext=table.getElementsByTag("tbody").get(0);
4 Elements contextTrs=tableContext.getElementsByTag("tr");
5 System.out.println(contextTrs.size());
6
7
8 String context=doc.toString();
9 OutputStreamWriter pw = null;
10 pw = new OutputStreamWriter(new FileOutputStream("D:/test.txt"),"GBK");
11 pw.write(context);
12 pw.close(); 查看全部
htmlunit 抓取网页(htmlunit网络工具一个没有没有
)
1:背景
本来想用jsoup抓取一个页面,但是抓取的数据总是不完整,然后发现页面执行js后,页面上渲染了一些数据,也就是说数据页是只在js执行后显示。数据会显示出来,但是jsoup无法实现执行页面的js。
2:解决
经过搜索,发现htmlunit网络工具可以实现js。它相当于一个没有页面的浏览器。解决方法是使用htmlUnit发送网络请求,执行js获取页面,然后使用jsoup转换成Document页面对象。然后使用jsoup分析页面读取数据。
3:htmlUnit发送请求
1 public static Document getDocument() throws IOException, InterruptedException{
2 /*String url="https://www.marklines.com/cn/v ... 3B%3B
3 Connection connect = Jsoup.connect(url).userAgent("")
4 .header("Cookie", "PLAY_LANG=cn; _plh=b9289d0a863a8fc9c79fb938f15372f7731d13fb; PLATFORM_SESSION=39034d07000717c664134556ad39869771aabc04-_ldi=520275&_lsh=8cf91cdbcbbb255adff5cba6061f561b642f5157&csrfToken=209f20c8473bc0518413c226f898ff79cd69c3ff-1539926671235-b853a6a63c77dd8fcc364a58&_lpt=%2Fcn%2Fvehicle_sales%2Fsearch&_lsi=1646321; _ga=GA1.2.2146952143.1539926675; _gid=GA1.2.1032787565.1539926675; _plh_notime=8cf91cdbcbbb255adff5cba6061f561b642f5157")
5 .timeout(360000000);
6 Document document = connect.get();*/
7 WebClient wc = new WebClient(BrowserVersion.CHROME);
8 //是否使用不安全的SSL
9 wc.getOptions().setUseInsecureSSL(true);
10 //启用JS解释器,默认为true
11 wc.getOptions().setJavaScriptEnabled(true);
12 //禁用CSS
13 wc.getOptions().setCssEnabled(false);
14 //js运行错误时,是否抛出异常
15 wc.getOptions().setThrowExceptionOnScriptError(false);
16 //状态码错误时,是否抛出异常
17 wc.getOptions().setThrowExceptionOnFailingStatusCode(false);
18 //是否允许使用ActiveX
19 wc.getOptions().setActiveXNative(false);
20 //等待js时间
21 wc.waitForBackgroundJavaScript(600*1000);
22 //设置Ajax异步处理控制器即启用Ajax支持
23 wc.setAjaxController(new NicelyResynchronizingAjaxController());
24 //设置超时时间
25 wc.getOptions().setTimeout(1000000);
26 //不跟踪抓取
27 wc.getOptions().setDoNotTrackEnabled(false);
28 WebRequest request=new WebRequest(new URL("https://www.marklines.com/cn/v ... 6quot;));
29 request.setAdditionalHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:62.0) Gecko/20100101 Firefox/62.0");
30 request.setAdditionalHeader("Cookie","PLAY_LANG=cn; _plh=b9289d0a863a8fc9c79fb938f15372f7731d13fb; PLATFORM_SESSION=39034d07000717c664134556ad39869771aabc04-_ldi=520275&_lsh=8cf91cdbcbbb255adff5cba6061f561b642f5157&csrfToken=209f20c8473bc0518413c226f898ff79cd69c3ff-1539926671235-b853a6a63c77dd8fcc364a58&_lpt=%2Fcn%2Fvehicle_sales%2Fsearch&_lsi=1646321; _ga=GA1.2.2146952143.1539926675; _gid=GA1.2.1032787565.1539926675; _plh_notime=8cf91cdbcbbb255adff5cba6061f561b642f5157");
31 try {
32 //模拟浏览器打开一个目标网址
33 HtmlPage htmlPage = wc.getPage(request);
34 //为了获取js执行的数据 线程开始沉睡等待
35 Thread.sleep(1000);//这个线程的等待 因为js加载需要时间的
36 //以xml形式获取响应文本
37 String xml = htmlPage.asXml();
38 //并转为Document对象return
39 return Jsoup.parse(xml);
40 //System.out.println(xml.contains("结果.xls"));//false
41 } catch (FailingHttpStatusCodeException e) {
42 e.printStackTrace();
43 } catch (MalformedURLException e) {
44 e.printStackTrace();
45 } catch (IOException e) {
46 e.printStackTrace();
47 }
48 return null;
49 }
4:返回的Document对象交给jsoup处理
这里只做一个简单的输出,看看数据是否全部渲染完毕。
1 Document doc=getDocument();
2 Element table=doc.select("table.table.table-bordered.aggregate_table").get(0);//获取到表格
3 Element tableContext=table.getElementsByTag("tbody").get(0);
4 Elements contextTrs=tableContext.getElementsByTag("tr");
5 System.out.println(contextTrs.size());
6
7
8 String context=doc.toString();
9 OutputStreamWriter pw = null;
10 pw = new OutputStreamWriter(new FileOutputStream("D:/test.txt"),"GBK");
11 pw.write(context);
12 pw.close();
htmlunit 抓取网页(抓一个今日头条的首页内容解决方案-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2022-03-17 09:04
不知道大家有没有在使用jsoup的过程中遇到爬取内容,发现部分网页中的内容是通过javascript异步加载的,导致我们的爬虫空手返回(只抓到一个网页)框架)。
当我第一次遇到这个问题时,我想到了两个解决方案:
在等待网页异步加载后,使用类似于Python中延迟加载的方法对异步加载的网页进行爬取。使用特殊的方法,让爬取的网页的框架模拟里面的JavaScript代码的执行,最终得到完整的页面
在搜索引擎的帮助下,我决定使用方案二来解决这个问题。解决方案1中没有搜索到更好的第三方库。在java中使用解决方案1解决这个问题的朋友希望可以与以下交流,不胜感激讨论。
案例很简单,抓取一条今日头条的首页内容。你可以看一下今日头条的首页,里面的内容是异步加载的。
添加jsoup和htmlunit依赖
org.jsoup
jsoup
1.10.2
net.sourceforge.htmlunit
htmlunit
2.25
首先我们单独使用jsoup来解析今日头条的首页
String url = "https://www.toutiao.com/";
Connection connect = Jsoup.connect(url);
Document document = connect.get();
System.out.println(document);
↑这里只能获取网页的frame内容,不能获取首页的新闻内容
让我们用 htmlunit 试试吧
//构造一个webClient 模拟Chrome 浏览器
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//屏蔽日志信息
LogFactory.getFactory().setAttribute("org.apache.commons.logging.Log",
"org.apache.commons.logging.impl.NoOpLog");
java.util.logging.Logger.getLogger("com.gargoylesoftware").setLevel(Level.OFF);
//支持JavaScript
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setTimeout(5000);
HtmlPage rootPage = webClient.getPage(url);
//设置一个运行JavaScript的时间
webClient.waitForBackgroundJavaScript(5000);
String html = rootPage.asXml();
Document document = Jsoup.parse(html);
这为我们提供了一个运行 JavaScript 的完整源页面 查看全部
htmlunit 抓取网页(抓一个今日头条的首页内容解决方案-苏州安嘉)
不知道大家有没有在使用jsoup的过程中遇到爬取内容,发现部分网页中的内容是通过javascript异步加载的,导致我们的爬虫空手返回(只抓到一个网页)框架)。
当我第一次遇到这个问题时,我想到了两个解决方案:
在等待网页异步加载后,使用类似于Python中延迟加载的方法对异步加载的网页进行爬取。使用特殊的方法,让爬取的网页的框架模拟里面的JavaScript代码的执行,最终得到完整的页面
在搜索引擎的帮助下,我决定使用方案二来解决这个问题。解决方案1中没有搜索到更好的第三方库。在java中使用解决方案1解决这个问题的朋友希望可以与以下交流,不胜感激讨论。
案例很简单,抓取一条今日头条的首页内容。你可以看一下今日头条的首页,里面的内容是异步加载的。
添加jsoup和htmlunit依赖
org.jsoup
jsoup
1.10.2
net.sourceforge.htmlunit
htmlunit
2.25
首先我们单独使用jsoup来解析今日头条的首页
String url = "https://www.toutiao.com/";
Connection connect = Jsoup.connect(url);
Document document = connect.get();
System.out.println(document);
↑这里只能获取网页的frame内容,不能获取首页的新闻内容
让我们用 htmlunit 试试吧
//构造一个webClient 模拟Chrome 浏览器
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//屏蔽日志信息
LogFactory.getFactory().setAttribute("org.apache.commons.logging.Log",
"org.apache.commons.logging.impl.NoOpLog");
java.util.logging.Logger.getLogger("com.gargoylesoftware").setLevel(Level.OFF);
//支持JavaScript
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setTimeout(5000);
HtmlPage rootPage = webClient.getPage(url);
//设置一个运行JavaScript的时间
webClient.waitForBackgroundJavaScript(5000);
String html = rootPage.asXml();
Document document = Jsoup.parse(html);
这为我们提供了一个运行 JavaScript 的完整源页面
htmlunit 抓取网页(介绍常用爬虫开源项目和腾讯微博爬虫的问题总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-15 03:18
介绍
常用爬虫开源项目
新浪微博爬虫和腾讯微博爬虫
新浪爬虫问题
总结
介绍
相关介绍
即网络爬虫是一种自动获取网页内容的程序。它是搜索引擎的重要组成部分,因此搜索引擎优化主要针对爬虫进行优化。
主要分类
网络爬虫从万维网上为搜索引擎下载网页。一般分为传统爬虫和专注爬虫。
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某个停止条件。通俗的讲,就是通过源码分析得到想要的内容。
焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
反爬虫:KS-WAF将爬虫行为分为搜索引擎爬虫和扫描爬虫,可以屏蔽特定搜索引擎爬虫以节省带宽和性能,也可以屏蔽扫描爬虫防止网站被恶意爬取。
常用爬虫开源项目
Nutch 标志 搜索引擎 Nutch
Nutch 是一个搜索引擎的开源 Java 实现。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫。
尽管网络搜索是漫游 Internet 的基本要求,但现有网络搜索引擎的数量正在下降。而这很可能会演变成一家为其商业利益垄断几乎所有网络搜索的公司。这显然对绝大多数网民不利。
现在所有主要的搜索引擎都使用专有的排名算法,这些算法不能解释为什么一个页面被排在一个特定的位置。另外,有些搜索引擎按网站付费,而不是按自己的值排序。
Apache Nutch 项目(一个网络搜索引擎)。Nutch 发展到一定程度时,遇到了可扩展性的问题,即当存储的网页数量达到 1 亿的水平时,Nutch 原有的结构很难达到高效率。就在整个团队不知所措的时候,救星谷歌出现了。Google 在 2003 年发布了 Google 使用的分布式文件存储系统文章(The Google File System),Nutch 开发者意识到可以将 Nutch 放在 GFS 上实现,所以经过一年的发展,NDFS(Nutch Distributed文件系统)出现。在解决了瓶颈问题之后,Nutch 有了很大的发展,而就在 2004 年,Google 发布了 MapReduce 的想法,
但是在 Nutch 中加入 GFS 和 MapReduce 之后,Nutch 变得太大了,超出了网络搜索引擎的范围,所以在 2006 年,分别移植了 NDFS 和 MapReduce,形成了一个名为 Hadoop 的新项目。
Java 多线程网络爬虫 Crawler4j
Crawler4j 是一个开源的 Java 类库,它提供了一个简单的网页爬取接口。它可以用来构建一个多线程的网络爬虫。
crawler4j的使用主要分为两步:
1. 实现一个继承自WebCrawler的爬虫类;
2.调用CrawlController实现的爬虫类。
WebCrawler 是一个抽象类,继承它必须实现两个方法:shouldVisit 和 visit。在:
shouldVisit 是判断当前URL是否应该被爬取(visited);
visit 是抓取URL指向的页面的数据,传入的参数是网页所有数据的封装对象Page。
Crawler.CrawController 控制爬虫,先添加seed,然后开启多个爬虫,不断监控每个爬虫的生存状态。
Crawler.WebCrawler 爬虫
1. Run():不断循环,每次从Frontier取50个url,对每个url进行processPage(curUrl)。
2. processPage(curURL):使用 PageFetcher.fetch 抓取网页。如果curURL被重定向,则将重定向url的url添加到Frontier,稍后调度;如果爬取正常,则先解析,生成Page,然后将新的url下放到Frontier(此时确定新增url的深度),调用visit(Page){用户自定义操作} .
Crawler.Configurations 读取 crawler4j.properties 中的信息
Crawler.PageFetcher 启动 IdleConnectionMonitorThread 并使用 fetch(Page, ignoreIfBinary) 抓取单个 Page 页面。是一个静态类。
Crawler.Page 一个页面
Crawler.PageFetchStatus 单页爬取的配置,如返回的爬取状态号的含义等。
Crawler.HTMLParser 解析 HTML 源代码并将其存储在 Page 中。
Crawler.LinkExtractor 提取 HTML 页面中收录的所有链接。
Crawler.IdleConnectionMonitorThread 用于监控连接(用于发送get请求,获取页面),其connMgr负责发送HTML请求。
HTML单元
HtmlUnitHtmlUnit 是“Java 程序的无 GUI 浏览器”。它对 HTML 文档进行建模并提供一个 API,允许您调用页面、填写表单、单击链接等……就像您在“普通”浏览器中所做的一样。
HtmlUnit的使用: 简介:HtmlUnit是一个浏览器,用Java编写,没有界面。因为它没有接口,所以执行速度仍然可以下降。HtmlUnit提供了一系列的API,这些API可以做很多功能,比如表单填写、表单提交、模拟点击链接,并且由于内置了Rhinojs引擎,可以执行Javascript
1、模拟特定浏览器,也可以指定浏览器对应版本(HtmlUnit最新版本2.13现在可以模拟Chrome/FireFox/IE)
WebClient webClient=new WebClient(BrowserVersion.FIREFOX_24);
2、查找特定元素,可以通过get或者XPath从HtmlPage中获取特定的Html元素。例如;
DomElement plc_main=page.getElementById("plc_main");
DomElement code_box=(DomElement) pl_common_sassfilter.getByXPath("//div[@class='code_box clearfix']").get(0);
3. 模拟表单的提交显示在用于登录的代码中;
HtmlForm loginform = logonPage.getFormByName("loginform");
HtmlTextInput uid = loginform.getInputByName("u");
uid.click();//点击获取焦点
uid.type(Config.getAccount());
HtmlPasswordInput pwd = loginform.getInputByName("p");
pwd.click();
pwd.type(Config.getPassword());
4、获取新浪微博等微博内容等信息。
DomNodeList dls = pl_weibo_direct.getElementsByTagName("dl");
DomElement dl= dls.get(0);
整数索引 = 0;
而(DL!=空){
DomElement em=feed_list_content.getElementsByTagName("em").get(0);
字符串内容 = em.getTextContent();
newlist.add(内容);
索引++;
dl = dls.get(索引);}
2.模拟登录,找到微博内容的位置。
3.获取微博数据并存入数据库,数据库使用MYSQL
逻辑其实很简单。需要熟悉HTMLunit提供的一些类,然后是XPath语法,再熟悉一些基础的数据库知识,就可以完成微博的爬取。
腾讯微博也有同样的想法。一些区别是
1.页面解析不同。
2.URL 的某些特征是不同的。
新浪爬虫问题总结
新浪微博爬虫的一些问题:
首先是微博数量的限制,从搜索页关键词开始,只能搜索到50页的微博数据。那么每页有20条,只能搜到1000条,这肯定跟实时微博的数量不匹配。
所以你可以使用高级搜索从2009年开始搜索,这需要不断的实验,看看时间可以弥补50页的微博。因为无论我搜索什么,新浪微博都只能显示50页的数据。
以本田雅阁为例,可以分为5次搜索,第一次是2009年到2010年,这个时间段只有33页数据,然后是2010年1.1到2011.1.1有50页数据,然后往下推。在某些时期,建立50页数据只需要五六个月。简而言之,这没有规律性。大概是时间越久,微博的数量就越多。. 所以当这个编程达到50页时,url链接的下一页就没有了。这是一个限制。
第二个问题是微博内容重复。如果连接是
%25E6%259C%25AC%25E7%2594%25B0%25E9%259B%2585%25E9%2598%2581&xsort=time&scope=ori×cope=custom:2013-01-01-0:2014-04-23-0&page=8
以本田雅阁为例,这个页面上的微博基本上都是一样的内容。据我观察,这个品牌的微博更像是一个营销和广告的微博。当然,你可以用微博来验证这个方法来刷选。但真正有意义的是,原创的微博,是一个少得可怜的数字。只有几百个大小。
还是有一些方法可以删除同一个微博。最近在数据库下操作比较有效,使用select distinct content from weibo where program='Honda Accord' into outfile 'D:/Honda Accord.txt';仍然可以删除其中大部分重复推文。
或者对于几乎相同的情况,只有 URL 不同。您可以使用删除微博内容 LIKE '%铃木“大型车”将与本田雅阁同级%';或其他一些具有特别明显特征的词或短语。
第三个问题是,虽然新浪只提供了这么多数据,但还是处处受限。当程序运行到20页时,会出现需要手动输入验证码以防止爬虫影响其服务器的问题。这个方案是通过模仿登录验证码的方法来解决的。就是拿到需要输入的验证码,把imageReader拿出来变成一个JFrame,手动输入,点一下,基本上就可以解决问题了。
第四个问题是微博内容在页面中体现不规则。例如,所有微博内容合二为一,只需 em.getTextContent()。因为不规则,有的em像点赞、空格等,解决方法是通过判断发现em只要不是真实的内容就没有任何属性。否则会有一个类属性。使用判断 hasAttribute() 踢掉点赞和空格。
第五个问题是不同id定位的问题。使用通用搜索时,定位ID为pl_weibo_direct,使用高级搜索时,微博内容定位ID为pl_wb_feedlist。
,当然是一些细节。
总结:
虽然还有很多问题,但是爬取数据的效果不是很好。不过可以肯定的是,新浪微博上的大部分数据还是可以通过网址找到的,新浪不可能大规模删除。假设像我这样的用户很久以前在2009年发了一条支持本田雅阁的微博,我可以通过我的微博链接看到与本田雅阁相关的微博内容。因此,与关键字相关的微博仍然存在于页面上,但新浪微博本身提供的搜索功能并不强大且有限。 查看全部
htmlunit 抓取网页(介绍常用爬虫开源项目和腾讯微博爬虫的问题总结)
介绍
常用爬虫开源项目
新浪微博爬虫和腾讯微博爬虫
新浪爬虫问题
总结
介绍
相关介绍
即网络爬虫是一种自动获取网页内容的程序。它是搜索引擎的重要组成部分,因此搜索引擎优化主要针对爬虫进行优化。
主要分类
网络爬虫从万维网上为搜索引擎下载网页。一般分为传统爬虫和专注爬虫。
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某个停止条件。通俗的讲,就是通过源码分析得到想要的内容。
焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
反爬虫:KS-WAF将爬虫行为分为搜索引擎爬虫和扫描爬虫,可以屏蔽特定搜索引擎爬虫以节省带宽和性能,也可以屏蔽扫描爬虫防止网站被恶意爬取。
常用爬虫开源项目
Nutch 标志 搜索引擎 Nutch
Nutch 是一个搜索引擎的开源 Java 实现。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫。
尽管网络搜索是漫游 Internet 的基本要求,但现有网络搜索引擎的数量正在下降。而这很可能会演变成一家为其商业利益垄断几乎所有网络搜索的公司。这显然对绝大多数网民不利。
现在所有主要的搜索引擎都使用专有的排名算法,这些算法不能解释为什么一个页面被排在一个特定的位置。另外,有些搜索引擎按网站付费,而不是按自己的值排序。
Apache Nutch 项目(一个网络搜索引擎)。Nutch 发展到一定程度时,遇到了可扩展性的问题,即当存储的网页数量达到 1 亿的水平时,Nutch 原有的结构很难达到高效率。就在整个团队不知所措的时候,救星谷歌出现了。Google 在 2003 年发布了 Google 使用的分布式文件存储系统文章(The Google File System),Nutch 开发者意识到可以将 Nutch 放在 GFS 上实现,所以经过一年的发展,NDFS(Nutch Distributed文件系统)出现。在解决了瓶颈问题之后,Nutch 有了很大的发展,而就在 2004 年,Google 发布了 MapReduce 的想法,
但是在 Nutch 中加入 GFS 和 MapReduce 之后,Nutch 变得太大了,超出了网络搜索引擎的范围,所以在 2006 年,分别移植了 NDFS 和 MapReduce,形成了一个名为 Hadoop 的新项目。
Java 多线程网络爬虫 Crawler4j
Crawler4j 是一个开源的 Java 类库,它提供了一个简单的网页爬取接口。它可以用来构建一个多线程的网络爬虫。
crawler4j的使用主要分为两步:
1. 实现一个继承自WebCrawler的爬虫类;
2.调用CrawlController实现的爬虫类。
WebCrawler 是一个抽象类,继承它必须实现两个方法:shouldVisit 和 visit。在:
shouldVisit 是判断当前URL是否应该被爬取(visited);
visit 是抓取URL指向的页面的数据,传入的参数是网页所有数据的封装对象Page。
Crawler.CrawController 控制爬虫,先添加seed,然后开启多个爬虫,不断监控每个爬虫的生存状态。
Crawler.WebCrawler 爬虫
1. Run():不断循环,每次从Frontier取50个url,对每个url进行processPage(curUrl)。
2. processPage(curURL):使用 PageFetcher.fetch 抓取网页。如果curURL被重定向,则将重定向url的url添加到Frontier,稍后调度;如果爬取正常,则先解析,生成Page,然后将新的url下放到Frontier(此时确定新增url的深度),调用visit(Page){用户自定义操作} .
Crawler.Configurations 读取 crawler4j.properties 中的信息
Crawler.PageFetcher 启动 IdleConnectionMonitorThread 并使用 fetch(Page, ignoreIfBinary) 抓取单个 Page 页面。是一个静态类。
Crawler.Page 一个页面
Crawler.PageFetchStatus 单页爬取的配置,如返回的爬取状态号的含义等。
Crawler.HTMLParser 解析 HTML 源代码并将其存储在 Page 中。
Crawler.LinkExtractor 提取 HTML 页面中收录的所有链接。
Crawler.IdleConnectionMonitorThread 用于监控连接(用于发送get请求,获取页面),其connMgr负责发送HTML请求。
HTML单元
HtmlUnitHtmlUnit 是“Java 程序的无 GUI 浏览器”。它对 HTML 文档进行建模并提供一个 API,允许您调用页面、填写表单、单击链接等……就像您在“普通”浏览器中所做的一样。
HtmlUnit的使用: 简介:HtmlUnit是一个浏览器,用Java编写,没有界面。因为它没有接口,所以执行速度仍然可以下降。HtmlUnit提供了一系列的API,这些API可以做很多功能,比如表单填写、表单提交、模拟点击链接,并且由于内置了Rhinojs引擎,可以执行Javascript
1、模拟特定浏览器,也可以指定浏览器对应版本(HtmlUnit最新版本2.13现在可以模拟Chrome/FireFox/IE)
WebClient webClient=new WebClient(BrowserVersion.FIREFOX_24);
2、查找特定元素,可以通过get或者XPath从HtmlPage中获取特定的Html元素。例如;
DomElement plc_main=page.getElementById("plc_main");
DomElement code_box=(DomElement) pl_common_sassfilter.getByXPath("//div[@class='code_box clearfix']").get(0);
3. 模拟表单的提交显示在用于登录的代码中;
HtmlForm loginform = logonPage.getFormByName("loginform");
HtmlTextInput uid = loginform.getInputByName("u");
uid.click();//点击获取焦点
uid.type(Config.getAccount());
HtmlPasswordInput pwd = loginform.getInputByName("p");
pwd.click();
pwd.type(Config.getPassword());
4、获取新浪微博等微博内容等信息。
DomNodeList dls = pl_weibo_direct.getElementsByTagName("dl");
DomElement dl= dls.get(0);
整数索引 = 0;
而(DL!=空){
DomElement em=feed_list_content.getElementsByTagName("em").get(0);
字符串内容 = em.getTextContent();
newlist.add(内容);
索引++;
dl = dls.get(索引);}
2.模拟登录,找到微博内容的位置。
3.获取微博数据并存入数据库,数据库使用MYSQL
逻辑其实很简单。需要熟悉HTMLunit提供的一些类,然后是XPath语法,再熟悉一些基础的数据库知识,就可以完成微博的爬取。
腾讯微博也有同样的想法。一些区别是
1.页面解析不同。
2.URL 的某些特征是不同的。
新浪爬虫问题总结
新浪微博爬虫的一些问题:
首先是微博数量的限制,从搜索页关键词开始,只能搜索到50页的微博数据。那么每页有20条,只能搜到1000条,这肯定跟实时微博的数量不匹配。
所以你可以使用高级搜索从2009年开始搜索,这需要不断的实验,看看时间可以弥补50页的微博。因为无论我搜索什么,新浪微博都只能显示50页的数据。
以本田雅阁为例,可以分为5次搜索,第一次是2009年到2010年,这个时间段只有33页数据,然后是2010年1.1到2011.1.1有50页数据,然后往下推。在某些时期,建立50页数据只需要五六个月。简而言之,这没有规律性。大概是时间越久,微博的数量就越多。. 所以当这个编程达到50页时,url链接的下一页就没有了。这是一个限制。
第二个问题是微博内容重复。如果连接是
%25E6%259C%25AC%25E7%2594%25B0%25E9%259B%2585%25E9%2598%2581&xsort=time&scope=ori×cope=custom:2013-01-01-0:2014-04-23-0&page=8
以本田雅阁为例,这个页面上的微博基本上都是一样的内容。据我观察,这个品牌的微博更像是一个营销和广告的微博。当然,你可以用微博来验证这个方法来刷选。但真正有意义的是,原创的微博,是一个少得可怜的数字。只有几百个大小。
还是有一些方法可以删除同一个微博。最近在数据库下操作比较有效,使用select distinct content from weibo where program='Honda Accord' into outfile 'D:/Honda Accord.txt';仍然可以删除其中大部分重复推文。
或者对于几乎相同的情况,只有 URL 不同。您可以使用删除微博内容 LIKE '%铃木“大型车”将与本田雅阁同级%';或其他一些具有特别明显特征的词或短语。
第三个问题是,虽然新浪只提供了这么多数据,但还是处处受限。当程序运行到20页时,会出现需要手动输入验证码以防止爬虫影响其服务器的问题。这个方案是通过模仿登录验证码的方法来解决的。就是拿到需要输入的验证码,把imageReader拿出来变成一个JFrame,手动输入,点一下,基本上就可以解决问题了。
第四个问题是微博内容在页面中体现不规则。例如,所有微博内容合二为一,只需 em.getTextContent()。因为不规则,有的em像点赞、空格等,解决方法是通过判断发现em只要不是真实的内容就没有任何属性。否则会有一个类属性。使用判断 hasAttribute() 踢掉点赞和空格。
第五个问题是不同id定位的问题。使用通用搜索时,定位ID为pl_weibo_direct,使用高级搜索时,微博内容定位ID为pl_wb_feedlist。
,当然是一些细节。
总结:
虽然还有很多问题,但是爬取数据的效果不是很好。不过可以肯定的是,新浪微博上的大部分数据还是可以通过网址找到的,新浪不可能大规模删除。假设像我这样的用户很久以前在2009年发了一条支持本田雅阁的微博,我可以通过我的微博链接看到与本田雅阁相关的微博内容。因此,与关键字相关的微博仍然存在于页面上,但新浪微博本身提供的搜索功能并不强大且有限。
htmlunit 抓取网页(大数据行业数据价值不言而喻的技术分析及解决办法!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-03-08 20:13
对于大数据行业来说,数据的价值不言而喻。在这个信息爆炸的时代,互联网上的信息数据太多了。对于中小微企业来说,合理使用爬虫爬取有价值的数据,是为了弥补自身先天的数据短缺。板子的最佳选择,本文主要从爬虫原理、架构、分类和反爬虫技术方面总结了爬虫技术。
1、爬虫技术概述
网络爬虫是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。它们广泛应用于互联网搜索引擎或其他类似的网站,并且可以自动采集所有它可以访问的页面的内容来获取或更新这些网站的内容和检索方式. 从功能上来说,爬虫一般分为数据采集、处理、存储三部分。
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。另外,爬虫爬取的所有网页都会被系统存储,进行一定的分析、过滤和索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1)爬取目标的描述或定义;
(2)网页或数据的分析和过滤;
(3)URL 的搜索策略。
2、爬虫原理
2.1网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、SqlServer等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。.
这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,因此广度优先搜索算法一般使用采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个网址,下载其对应的网页,
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列;
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历路径:AF-GE-H-IBCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDE-FGHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4PartialPageRank 策略
PartialPageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值。计算完成后,计算待爬取的URL队列中的URL。按 PageRank 值排序并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序.
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过Nutch的二次开发使其适合提取业务,你基本上会破坏Nutch的框架,将Nutch改得面目全非,并且有能力修改Nutch,还不如自己写一个新的. 分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。事实上,这是针对Nutch的声誉。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发非常简单,前人已经解决了困难和复杂的问题(如DOM树解析定位、字符集检测、海量URL去重等),可以据说没有技术含量。. 包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于deepweb(深网)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSSSELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给Spider进行分析,将要保存的数据发送到ItemPipeline。那就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,大大小小的。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这样的反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
[评论:它经常很容易被忽视。通过对请求的抓包分析,确定referer并添加到程序中模拟访问请求的header中]
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一个IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。 查看全部
htmlunit 抓取网页(大数据行业数据价值不言而喻的技术分析及解决办法!)
对于大数据行业来说,数据的价值不言而喻。在这个信息爆炸的时代,互联网上的信息数据太多了。对于中小微企业来说,合理使用爬虫爬取有价值的数据,是为了弥补自身先天的数据短缺。板子的最佳选择,本文主要从爬虫原理、架构、分类和反爬虫技术方面总结了爬虫技术。
1、爬虫技术概述
网络爬虫是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。它们广泛应用于互联网搜索引擎或其他类似的网站,并且可以自动采集所有它可以访问的页面的内容来获取或更新这些网站的内容和检索方式. 从功能上来说,爬虫一般分为数据采集、处理、存储三部分。
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。另外,爬虫爬取的所有网页都会被系统存储,进行一定的分析、过滤和索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1)爬取目标的描述或定义;
(2)网页或数据的分析和过滤;
(3)URL 的搜索策略。
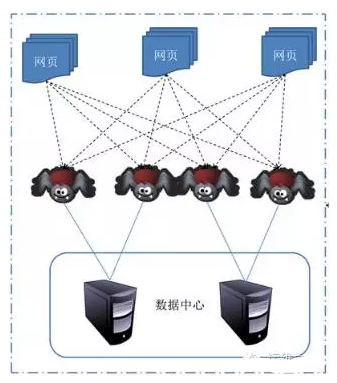
2、爬虫原理
2.1网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
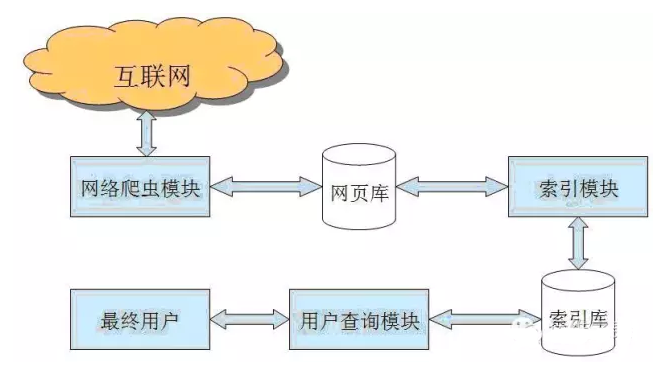
2.2网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、SqlServer等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。.
这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,因此广度优先搜索算法一般使用采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个网址,下载其对应的网页,
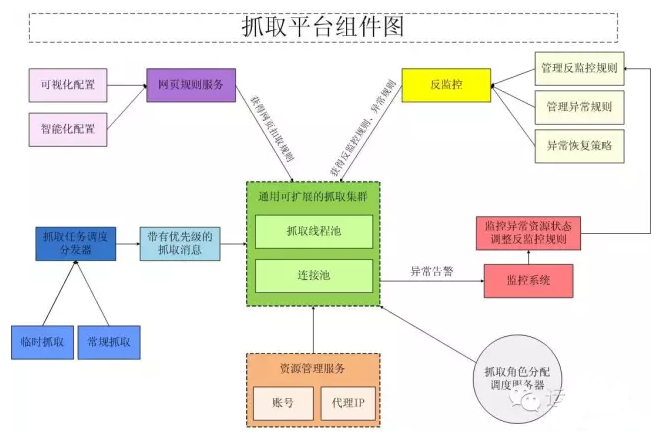
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列;
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。

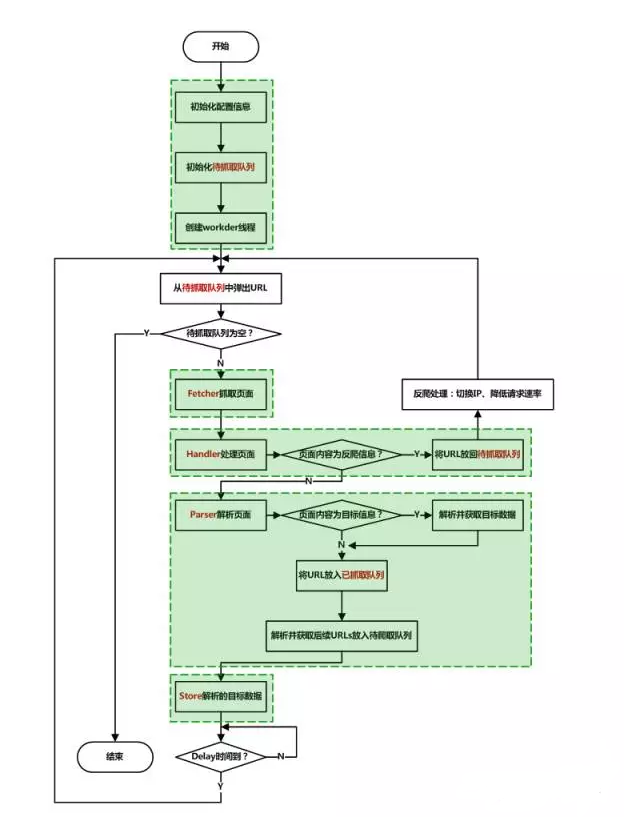
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历路径:AF-GE-H-IBCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDE-FGHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4PartialPageRank 策略
PartialPageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值。计算完成后,计算待爬取的URL队列中的URL。按 PageRank 值排序并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序.
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过Nutch的二次开发使其适合提取业务,你基本上会破坏Nutch的框架,将Nutch改得面目全非,并且有能力修改Nutch,还不如自己写一个新的. 分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。事实上,这是针对Nutch的声誉。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
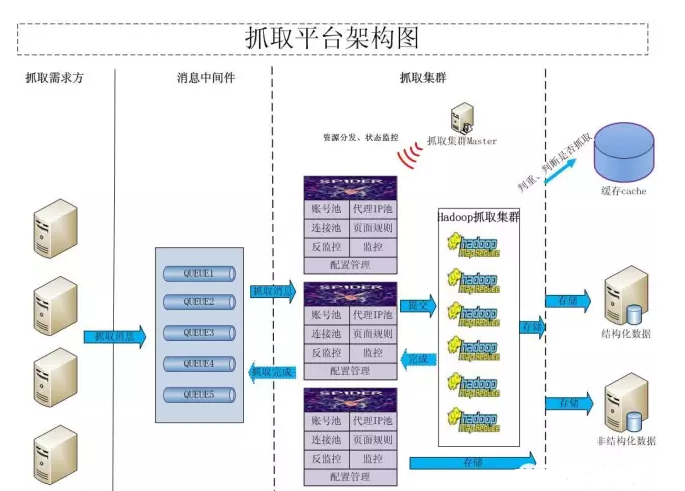
分布式爬虫平台架构图
3.2JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发非常简单,前人已经解决了困难和复杂的问题(如DOM树解析定位、字符集检测、海量URL去重等),可以据说没有技术含量。. 包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于deepweb(深网)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSSSELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
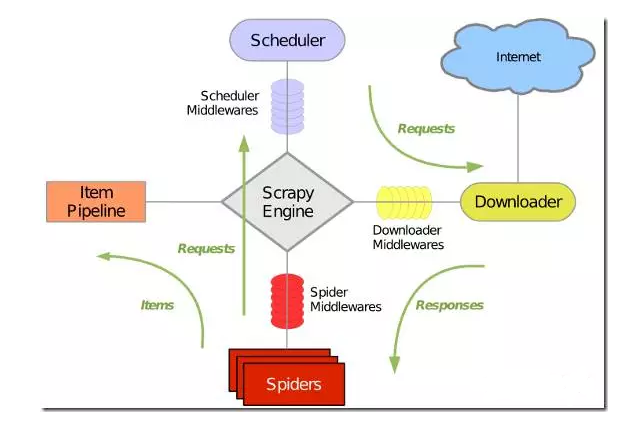
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给Spider进行分析,将要保存的数据发送到ItemPipeline。那就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,大大小小的。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这样的反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
[评论:它经常很容易被忽视。通过对请求的抓包分析,确定referer并添加到程序中模拟访问请求的header中]
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一个IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。
htmlunit 抓取网页(JavaHTML4支持代理服务器(5)支持自动的Cookies管理等 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-08 17:00
)
(4)支持代理服务器
(5)支持自动cookie管理等
Java爬虫开发中应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析渲染等准浏览器功能。推荐用于无需解析脚本和 CSS 即可获取网页的快速场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;
import org.apache.http.client.HttpClient;
import org.apache.http.client.ResponseHandler;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.BasicResponseHandler;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.util.EntityUtils;
/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/
public class HttpClientTest {
public static void main(String[] args)throws Exception{
//目标页面
String url ="http://www.jjwxc.net/";
//创建一个默认的HttpClient
HttpClient httpclient =new DefaultHttpClient();
try{
//以get方式请求网页http://www.yshjava.cn
HttpGet httpget =new HttpGet(url);
//打印请求地址
System.out.println("executing request "+ httpget.getURI());
//创建响应处理器处理服务器响应内容
ResponseHandler responseHandler = new BasicResponseHandler();
//执行请求并获取结果
String responseBody = httpclient.execute(httpget, responseHandler);
System.out.println("----------------------------------------");
String htmlStr=null;
if(responseBody != null) {
// htmlStr=new String(EntityUtils.toString(responseBody));
// htmlStr=new String(htmlStr.getBytes("ISO-8859-1"), "gbk"); // 读取乱码解决
responseBody=new String(responseBody.getBytes("ISO-8859-1"), "gb2312");
}
System.out.println(responseBody);
System.out.println("----------------------------------------");
}finally{//关闭连接管理器
httpclient.getConnectionManager().shutdown();
}
}
}
汤
jsoup 是一个Java HTML 解析器,可以直接解析一个URL 地址和HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3.可以操作HTML元素、属性、文本;
示例代码如下:
package cn.ysh.studio.crawler.jsoup;
import java.io.IOException;
import org.jsoup.Jsoup;
/**
* 基于Jsoup抓取网页内容
* @author www.yshjava.cn
*/
public class JsoupTest {
public static void main(String[] args)throws IOException{
//目标页面
String url ="http://www.jjwxc.net";
//使用Jsoup连接目标页面,并执行请求,获取服务器响应内容
String html =Jsoup.connect(url).execute().body();
//打印页面内容
System.out.println(html);
}
}
HtmlUnit
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.Page;
import com.gargoylesoftware.htmlunit.WebClient;
/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlUnitSpider {
public static void main(String[] s) throws Exception {
// 目标网页
String url = "http://www.jjwxc.net/";
// 模拟特定浏览器FIREFOX_3
WebClient spider = new WebClient(BrowserVersion.FIREFOX_3);
// 获取目标网页
Page page = spider.getPage(url);
// 打印网页内容
System.out.println(page.getWebResponse().getContentAsString());
// 关闭所有窗口
// spider.closeAllWindows();
spider.close();
}
}
瓦提
硒
Selenium 也是一个用于 Web 应用程序测试的工具。 Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性——测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。 Net、Java、Perl 和其他不同语言的测试脚本。 Selenium 是 ThoughtWorks 专门为 Web 应用编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;
import org.openqa.selenium.htmlunit.HtmlUnitDriver;
/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlDriverTest {
public static void main(String[] s) {
// 目标网页
String url = "http://www.jjwxc.net/";
HtmlUnitDriver driver = new HtmlUnitDriver();
try {
// 禁用JS脚本功能
driver.setJavascriptEnabled(false);
// 打开目标网页
driver.get(url);
// 获取当前网页源码
String html = driver.getPageSource();
// 打印网页源码
System.out.println(html);
} catch (Exception e) {
// 打印堆栈信息
e.printStackTrace();
} finally {
try {
// 关闭并退出
driver.close();
driver.quit();
} catch (Exception e) {
}
}
}
}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;
import org.watij.webspec.dsl.WebSpec;
/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/
public class WebspecTest {
public static void main(String[] s){
//目标网页
String url ="http://www.jjwxc.net/";
//实例化浏览器对象
WebSpec spec =new WebSpec().mozilla();
//隐藏浏览器窗体
spec.hide();
//打开目标页面
spec.open(url);
//打印网页源码
System.out.println(spec.source());
//关闭所有窗口
spec.closeAll();
}
} 查看全部
htmlunit 抓取网页(JavaHTML4支持代理服务器(5)支持自动的Cookies管理等
)
(4)支持代理服务器
(5)支持自动cookie管理等
Java爬虫开发中应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析渲染等准浏览器功能。推荐用于无需解析脚本和 CSS 即可获取网页的快速场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;
import org.apache.http.client.HttpClient;
import org.apache.http.client.ResponseHandler;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.BasicResponseHandler;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.util.EntityUtils;
/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/
public class HttpClientTest {
public static void main(String[] args)throws Exception{
//目标页面
String url ="http://www.jjwxc.net/";
//创建一个默认的HttpClient
HttpClient httpclient =new DefaultHttpClient();
try{
//以get方式请求网页http://www.yshjava.cn
HttpGet httpget =new HttpGet(url);
//打印请求地址
System.out.println("executing request "+ httpget.getURI());
//创建响应处理器处理服务器响应内容
ResponseHandler responseHandler = new BasicResponseHandler();
//执行请求并获取结果
String responseBody = httpclient.execute(httpget, responseHandler);
System.out.println("----------------------------------------");
String htmlStr=null;
if(responseBody != null) {
// htmlStr=new String(EntityUtils.toString(responseBody));
// htmlStr=new String(htmlStr.getBytes("ISO-8859-1"), "gbk"); // 读取乱码解决
responseBody=new String(responseBody.getBytes("ISO-8859-1"), "gb2312");
}
System.out.println(responseBody);
System.out.println("----------------------------------------");
}finally{//关闭连接管理器
httpclient.getConnectionManager().shutdown();
}
}
}
汤
jsoup 是一个Java HTML 解析器,可以直接解析一个URL 地址和HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3.可以操作HTML元素、属性、文本;
示例代码如下:
package cn.ysh.studio.crawler.jsoup;
import java.io.IOException;
import org.jsoup.Jsoup;
/**
* 基于Jsoup抓取网页内容
* @author www.yshjava.cn
*/
public class JsoupTest {
public static void main(String[] args)throws IOException{
//目标页面
String url ="http://www.jjwxc.net";
//使用Jsoup连接目标页面,并执行请求,获取服务器响应内容
String html =Jsoup.connect(url).execute().body();
//打印页面内容
System.out.println(html);
}
}
HtmlUnit
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.Page;
import com.gargoylesoftware.htmlunit.WebClient;
/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlUnitSpider {
public static void main(String[] s) throws Exception {
// 目标网页
String url = "http://www.jjwxc.net/";
// 模拟特定浏览器FIREFOX_3
WebClient spider = new WebClient(BrowserVersion.FIREFOX_3);
// 获取目标网页
Page page = spider.getPage(url);
// 打印网页内容
System.out.println(page.getWebResponse().getContentAsString());
// 关闭所有窗口
// spider.closeAllWindows();
spider.close();
}
}
瓦提
硒
Selenium 也是一个用于 Web 应用程序测试的工具。 Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性——测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。 Net、Java、Perl 和其他不同语言的测试脚本。 Selenium 是 ThoughtWorks 专门为 Web 应用编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;
import org.openqa.selenium.htmlunit.HtmlUnitDriver;
/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlDriverTest {
public static void main(String[] s) {
// 目标网页
String url = "http://www.jjwxc.net/";
HtmlUnitDriver driver = new HtmlUnitDriver();
try {
// 禁用JS脚本功能
driver.setJavascriptEnabled(false);
// 打开目标网页
driver.get(url);
// 获取当前网页源码
String html = driver.getPageSource();
// 打印网页源码
System.out.println(html);
} catch (Exception e) {
// 打印堆栈信息
e.printStackTrace();
} finally {
try {
// 关闭并退出
driver.close();
driver.quit();
} catch (Exception e) {
}
}
}
}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;
import org.watij.webspec.dsl.WebSpec;
/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/
public class WebspecTest {
public static void main(String[] s){
//目标网页
String url ="http://www.jjwxc.net/";
//实例化浏览器对象
WebSpec spec =new WebSpec().mozilla();
//隐藏浏览器窗体
spec.hide();
//打开目标页面
spec.open(url);
//打印网页源码
System.out.println(spec.source());
//关闭所有窗口
spec.closeAll();
}
}
htmlunit 抓取网页(4.网页测试您可以通过多种方式测试Web应用程序——)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-03 00:20
HtmlUnit简介一、简介
在本文中,我们将介绍 HtmlUnit,它允许我们使用 JAVA API 以编程方式交互和测试 HTML 站点。
2.关于 HtmlUnit
HtmlUnit 是一种无 GUI 浏览器 - 一种旨在以编程方式而不是由用户直接使用的浏览器。
该浏览器支持 JavaScript(通过 Mozilla Rhino 引擎),甚至可以使用具有复杂 AJAX 功能的 网站。所有这些都可以通过模拟典型的基于 GUI 的浏览器(例如 Chrome 或 Firefox)来完成。
HtmlUnit 这个名字可能会让你认为它是一个测试框架,但是虽然它绝对可以用于测试,但它可以做的远不止这些。
它还集成到 Spring 4 中,可以与 Spring MVC 测试框架无缝使用。
3.下载和Maven依赖
HtmlUnit 可以从 SourceForge 或官网下载。此外,您可以将其收录在您的构建工具(如 Maven 或 Gradle 等)中,如您在此处所见。例如,以下是您当前可以收录在项目中的 Maven 依赖项:
net.sourceforge.htmlunit
htmlunit
2.23
最新版本可以在这里找到。
4. 网络测试
您可以通过多种方式测试 Web 应用程序——其中大部分我们已经介绍过 网站 一次或多次。
使用 HtmlUnit,您可以直接解析站点的 HTML,通过浏览器与普通用户交互,检查 JavaScript 和 CSS 语法,提交表单,并解析响应以查看其 HTML 元素的内容。所有这一切,都使用纯 Java 代码。
让我们从一个简单的测试开始:创建一个 WebClient 并获取导航的第一页:
private WebClient webClient;
@Before
public void init() throws Exception {
webClient = new WebClient();
}
@After
public void close() throws Exception {
webClient.close();
}
@Test
public void givenAClient_whenEnteringBaeldung_thenPageTitleIsOk()
throws Exception {
HtmlPage page = webClient.getPage("/");
Assert.assertEquals(
"Baeldung | Java, Spring and Web Development tutorials",
page.getTitleText());
}
如果我们的 网站 有 JavaScript 或 CSS 问题,您会在运行测试时看到一些警告或错误。你应该纠正它们。
有时,如果您知道自己在做什么(例如,如果您发现唯一的错误来自不应修改的第三方 JavaScript 库),您可以通过调用 setThrowExceptionOnScriptError 来防止这些错误使您的测试失败错误的:
@Test
public void givenAClient_whenEnteringBaeldung_thenPageTitleIsCorrect()
throws Exception {
webClient.getOptions().setThrowExceptionOnScriptError(false);
HtmlPage page = webClient.getPage("/");
Assert.assertEquals(
"Baeldung | Java, Spring and Web Development tutorials",
page.getTitleText());
}
5.网页抓取
您不需要仅为您自己的 网站 使用 HtmlUnit。毕竟,它是一个浏览器:您可以使用它浏览您喜欢的任何网页,根据需要发送和检索数据。
从 网站 获取、解析、存储和分析数据的过程称为网络抓取,HtmlUnit 可以帮助您完成获取和解析部分。
前面的示例显示了我们如何输入任何 网站 并在其中导航,检索我们想要的所有信息。
例如,让我们转到 Baeldung 的完整 文章 存档,导航到最新的 文章 并检索其标题(第一个令牌)。对于我们的测试来说,这就足够了;但是,如果我们想存储更多信息,例如,我们还可以检索标题(所有标签)以了解 文章 是什么的基本概念。
通过 ID 获取元素很容易,但一般来说,如果需要查找元素,使用 XPath 语法会更方便。HtmlUnit 允许我们使用它,所以我们会。
@Test
public void givenBaeldungArchive_whenRetrievingArticle_thenHasH1()
throws Exception {
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
String url = "/full_archive";
HtmlPage page = webClient.getPage(url);
String xpath = "(//ul[@class='car-monthlisting']/li)[1]/a";
HtmlAnchor latestPostLink
= (HtmlAnchor) page.getByXPath(xpath).get(0);
HtmlPage postPage = latestPostLink.click();
List h1
= (List) postPage.getByXPath("//h1");
Assert.assertTrue(h1.size() > 0);
}
首先注意如何 - 在这种情况下,我们对 CSS 和 JavaScript 不感兴趣,我们只想解析 HTML 布局,所以我们关闭了 CSS 和 JavaScript。
在真正的网页抓取中,你可以以 h1 和 h2 标题为例,结果会是这样的:
Java Web Weekly, Issue 135
1. Spring and Java
2. Technical and Musings
3. Comics
4. Pick of the Week
您可以检查检索到的信息是否确实对应于 Baeldung 中最新的 文章:
6. AJAX 怎么样?
AJAX 功能可能是一个问题,因为 HtmlUnit 通常在 AJAX 调用完成之前检索页面。很多时候,您需要他们正确地测试您的 网站 或检索您想要的数据。有一些方法可以处理它们:
for (int i = 0; i < 20; i++) {
if (condition_to_happen_after_js_execution) {
break;
}
synchronized (page) {
page.wait(500);
}
}
WebClient webClient = new WebClient(BrowserVersion.CHROME);
7. 弹簧示例
如果我们正在测试我们自己的 Spring 应用程序,事情会变得更容易——我们不再需要一个正在运行的服务器。
让我们实现一个非常简单的示例应用程序:只是一个带有接收文本的方法的控制器和一个带有表单的 HTML 页面。用户可以在表单中输入文本,提交表单,文本会出现在表单下方。
在这种情况下,我们将为此 HTML 页面使用 Thymeleaf 模板(您可以在此处查看完整的 Thymeleaf 示例):
@RunWith(SpringJUnit4ClassRunner.class)
@WebAppConfiguration
@ContextConfiguration(classes = { TestConfig.class })
public class HtmlUnitAndSpringTest {
@Autowired
private WebApplicationContext wac;
private WebClient webClient;
@Before
public void setup() {
webClient = MockMvcWebClientBuilder
.webAppContextSetup(wac).build();
}
@Test
public void givenAMessage_whenSent_thenItShows() throws Exception {
String text = "Hello world!";
HtmlPage page;
String url = "http://localhost/message/showForm";
page = webClient.getPage(url);
HtmlTextInput messageText = page.getHtmlElementById("message");
messageText.setValueAttribute(text);
HtmlForm form = page.getForms().get(0);
HtmlSubmitInput submit = form.getOneHtmlElementByAttribute(
"input", "type", "submit");
HtmlPage newPage = submit.click();
String receivedText = newPage.getHtmlElementById("received")
.getTextContent();
Assert.assertEquals(receivedText, text);
}
}
这里的关键是使用 WebApplicationContext 中的 MockMvcWebClientBuilder 来构建 WebClient 对象。使用 WebClient,我们可以获得导航的第一页(注意它是如何由 localhost 提供的)并从那里开始浏览。
如您所见,测试解析表单输入消息(在id为“message”的字段中),提交表单,并在新页面上断言接收到的文本(id为“received”的字段)是相同的正如我们提交的文本一样。
8. 结论
HtmlUnit 是一个很棒的工具,可以让您轻松地测试您的 Web 应用程序、填写表单字段并提交它们,就像您在浏览器上使用 Web 一样。
它与 Spring 4 无缝集成,并与 Spring MVC 测试框架一起为您提供了一个非常强大的环境,即使没有 Web 服务器也可以对所有页面进行集成测试。
此外,使用 HtmlUnit,您可以自动执行任何与网页浏览相关的任务,例如获取、解析、存储和分析数据(网页抓取)。 查看全部
htmlunit 抓取网页(4.网页测试您可以通过多种方式测试Web应用程序——)
HtmlUnit简介一、简介
在本文中,我们将介绍 HtmlUnit,它允许我们使用 JAVA API 以编程方式交互和测试 HTML 站点。
2.关于 HtmlUnit
HtmlUnit 是一种无 GUI 浏览器 - 一种旨在以编程方式而不是由用户直接使用的浏览器。
该浏览器支持 JavaScript(通过 Mozilla Rhino 引擎),甚至可以使用具有复杂 AJAX 功能的 网站。所有这些都可以通过模拟典型的基于 GUI 的浏览器(例如 Chrome 或 Firefox)来完成。
HtmlUnit 这个名字可能会让你认为它是一个测试框架,但是虽然它绝对可以用于测试,但它可以做的远不止这些。
它还集成到 Spring 4 中,可以与 Spring MVC 测试框架无缝使用。
3.下载和Maven依赖
HtmlUnit 可以从 SourceForge 或官网下载。此外,您可以将其收录在您的构建工具(如 Maven 或 Gradle 等)中,如您在此处所见。例如,以下是您当前可以收录在项目中的 Maven 依赖项:
net.sourceforge.htmlunit
htmlunit
2.23
最新版本可以在这里找到。
4. 网络测试
您可以通过多种方式测试 Web 应用程序——其中大部分我们已经介绍过 网站 一次或多次。
使用 HtmlUnit,您可以直接解析站点的 HTML,通过浏览器与普通用户交互,检查 JavaScript 和 CSS 语法,提交表单,并解析响应以查看其 HTML 元素的内容。所有这一切,都使用纯 Java 代码。
让我们从一个简单的测试开始:创建一个 WebClient 并获取导航的第一页:
private WebClient webClient;
@Before
public void init() throws Exception {
webClient = new WebClient();
}
@After
public void close() throws Exception {
webClient.close();
}
@Test
public void givenAClient_whenEnteringBaeldung_thenPageTitleIsOk()
throws Exception {
HtmlPage page = webClient.getPage("/");
Assert.assertEquals(
"Baeldung | Java, Spring and Web Development tutorials",
page.getTitleText());
}
如果我们的 网站 有 JavaScript 或 CSS 问题,您会在运行测试时看到一些警告或错误。你应该纠正它们。
有时,如果您知道自己在做什么(例如,如果您发现唯一的错误来自不应修改的第三方 JavaScript 库),您可以通过调用 setThrowExceptionOnScriptError 来防止这些错误使您的测试失败错误的:
@Test
public void givenAClient_whenEnteringBaeldung_thenPageTitleIsCorrect()
throws Exception {
webClient.getOptions().setThrowExceptionOnScriptError(false);
HtmlPage page = webClient.getPage("/");
Assert.assertEquals(
"Baeldung | Java, Spring and Web Development tutorials",
page.getTitleText());
}
5.网页抓取
您不需要仅为您自己的 网站 使用 HtmlUnit。毕竟,它是一个浏览器:您可以使用它浏览您喜欢的任何网页,根据需要发送和检索数据。
从 网站 获取、解析、存储和分析数据的过程称为网络抓取,HtmlUnit 可以帮助您完成获取和解析部分。
前面的示例显示了我们如何输入任何 网站 并在其中导航,检索我们想要的所有信息。
例如,让我们转到 Baeldung 的完整 文章 存档,导航到最新的 文章 并检索其标题(第一个令牌)。对于我们的测试来说,这就足够了;但是,如果我们想存储更多信息,例如,我们还可以检索标题(所有标签)以了解 文章 是什么的基本概念。
通过 ID 获取元素很容易,但一般来说,如果需要查找元素,使用 XPath 语法会更方便。HtmlUnit 允许我们使用它,所以我们会。
@Test
public void givenBaeldungArchive_whenRetrievingArticle_thenHasH1()
throws Exception {
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
String url = "/full_archive";
HtmlPage page = webClient.getPage(url);
String xpath = "(//ul[@class='car-monthlisting']/li)[1]/a";
HtmlAnchor latestPostLink
= (HtmlAnchor) page.getByXPath(xpath).get(0);
HtmlPage postPage = latestPostLink.click();
List h1
= (List) postPage.getByXPath("//h1");
Assert.assertTrue(h1.size() > 0);
}
首先注意如何 - 在这种情况下,我们对 CSS 和 JavaScript 不感兴趣,我们只想解析 HTML 布局,所以我们关闭了 CSS 和 JavaScript。
在真正的网页抓取中,你可以以 h1 和 h2 标题为例,结果会是这样的:
Java Web Weekly, Issue 135
1. Spring and Java
2. Technical and Musings
3. Comics
4. Pick of the Week
您可以检查检索到的信息是否确实对应于 Baeldung 中最新的 文章:

6. AJAX 怎么样?
AJAX 功能可能是一个问题,因为 HtmlUnit 通常在 AJAX 调用完成之前检索页面。很多时候,您需要他们正确地测试您的 网站 或检索您想要的数据。有一些方法可以处理它们:
for (int i = 0; i < 20; i++) {
if (condition_to_happen_after_js_execution) {
break;
}
synchronized (page) {
page.wait(500);
}
}
WebClient webClient = new WebClient(BrowserVersion.CHROME);
7. 弹簧示例
如果我们正在测试我们自己的 Spring 应用程序,事情会变得更容易——我们不再需要一个正在运行的服务器。
让我们实现一个非常简单的示例应用程序:只是一个带有接收文本的方法的控制器和一个带有表单的 HTML 页面。用户可以在表单中输入文本,提交表单,文本会出现在表单下方。
在这种情况下,我们将为此 HTML 页面使用 Thymeleaf 模板(您可以在此处查看完整的 Thymeleaf 示例):
@RunWith(SpringJUnit4ClassRunner.class)
@WebAppConfiguration
@ContextConfiguration(classes = { TestConfig.class })
public class HtmlUnitAndSpringTest {
@Autowired
private WebApplicationContext wac;
private WebClient webClient;
@Before
public void setup() {
webClient = MockMvcWebClientBuilder
.webAppContextSetup(wac).build();
}
@Test
public void givenAMessage_whenSent_thenItShows() throws Exception {
String text = "Hello world!";
HtmlPage page;
String url = "http://localhost/message/showForm";
page = webClient.getPage(url);
HtmlTextInput messageText = page.getHtmlElementById("message");
messageText.setValueAttribute(text);
HtmlForm form = page.getForms().get(0);
HtmlSubmitInput submit = form.getOneHtmlElementByAttribute(
"input", "type", "submit");
HtmlPage newPage = submit.click();
String receivedText = newPage.getHtmlElementById("received")
.getTextContent();
Assert.assertEquals(receivedText, text);
}
}
这里的关键是使用 WebApplicationContext 中的 MockMvcWebClientBuilder 来构建 WebClient 对象。使用 WebClient,我们可以获得导航的第一页(注意它是如何由 localhost 提供的)并从那里开始浏览。
如您所见,测试解析表单输入消息(在id为“message”的字段中),提交表单,并在新页面上断言接收到的文本(id为“received”的字段)是相同的正如我们提交的文本一样。
8. 结论
HtmlUnit 是一个很棒的工具,可以让您轻松地测试您的 Web 应用程序、填写表单字段并提交它们,就像您在浏览器上使用 Web 一样。
它与 Spring 4 无缝集成,并与 Spring MVC 测试框架一起为您提供了一个非常强大的环境,即使没有 Web 服务器也可以对所有页面进行集成测试。
此外,使用 HtmlUnit,您可以自动执行任何与网页浏览相关的任务,例如获取、解析、存储和分析数据(网页抓取)。
htmlunit 抓取网页(的java程序是什么?答案是有哪些??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-01 04:07
1.HtmlUnit1.1 简介
HtmlUnit 是一个用 java 编写的无界面浏览器,它可以对 html 文档进行建模、通过 API 调用页面、填写表单、单击链接等等。像普通浏览器一样运行。通常用于测试和从网页中抓取信息。
官方简介翻译
HtmlUnit是一个无界面浏览器Java程序。它为HTML文档建模,提供了调用页面、填写表单、单击链接等操作的API。就跟你在浏览器里做的操作一样。
HtmlUnit不错的JavaScript支持(不断改进),甚至可以使用相当复杂的AJAX库,根据配置的不同模拟Chrome、Firefox或Internet Explorer等浏览器。
HtmlUnit通常用于测试或从web站点检索信息。
1.2 使用场景
对于java实现的网络爬虫程序,我们一般可以使用apache的HttpClient组件来获取HTML页面信息。HttpClient实现的http请求返回的响应一般是纯文本文档页面,也就是最原创的html页面。
对于一个静态的html页面,使用httpClient就足够爬出我们需要的信息了。但是对于越来越多的动态网页,更多的数据是通过异步的JS代码来获取和渲染的,而初始的html页面并没有收录这部分数据。
上图中我们看到的网页在初始文档加载后并没有看到红框中的数据列表。浏览器通过执行异步JS请求,将获取到的动态数据渲染到原创文档页面中,最终变成我们看到的网页。对于这部分需要JS代码执行的数据,httpClient是无能为力的。虽然我们可以通过研究得到JS执行的请求路径,然后用java代码来获取我们需要的部分数据,不说能不能从JS脚本中分析请求路径和请求参数,只分析这部分数据源码成本已经很高了。
通过上面的介绍,我们了解到现在很大一部分动态网页都是通过异步JS请求获取的数据,然后通过JS渲染页面。那么我们能不能做这样的假设,假设我们的爬虫程序模拟一个浏览器,拿到html页面后,像浏览器一样执行异步JS代码,JS渲染好html页面后,就可以愉快的获取到节点信息了这页纸。那么有没有这样的java程序呢?
答案是肯定的。
HtmlUnit就是这样一个库,用来做界面显示的所有异步工作。没有耗时的显示工作,HtmlUnit 加载的完整网页比实际的浏览器块更多。并且根据不同的配置,HtmlUnit可以模拟市面上常见的Chrome、Firefox、IE浏览器等浏览器。
通过HtmlUnit库,加载一个完整的Html页面(图片和视频除外),然后将其转换成我们常用的字符串格式,并使用Jsoup等其他工具获取元素。当然,你也可以直接从HtmlUnit提供的对象中获取网页元素,甚至可以操作按钮、表单等控件。除了不能像可见浏览器那样用鼠标和键盘浏览网页,我们可以使用HtmlUnit来模拟所有其他的操作,比如登录网站、写博客等等都可以完成。当然,网页内容抓取是最简单的应用。
2.J4L2.1官方简介
J4L OCR 工具是一组组件,可用于在 Java 应用程序中收录 OCR 功能。这意味着您可以接收传真、PDF 文件或扫描文档并从图像中提取商业信息。主要的3个组件是:
j4l工具的详细使用步骤请参考这篇文章文章:Java使用J4L识别验证码
本文文章主要介绍使用HtmlUnit模拟登录
3.实际案例3.1.场景
登录页面,包括表单,需要填写用户名、登录密码、验证码,实现用户登录。
3.2操作步骤
使用htmlunit模拟登录是一个获取登录页面->找到输入框->填写用户名和密码->填写验证码->模拟点击登录的过程。
4.实现代码4.1maven引入HtmlUnit依赖
net.sourceforge.htmlunit
htmlunit
2.18
4.2 主要方法
登录.java
public static void main(String[] args) throws Exception {
login();
}
public static void login() throws Exception {
WebClient webClient = new WebClient(BrowserVersion.CHROME);//设置浏览器内核
webClient.getOptions().setJavaScriptEnabled(true);// js是否可用
webClient.getOptions().setCssEnabled(true);//css 一般设置false因为影响运行速度
webClient.getOptions().setThrowExceptionOnScriptError(false);//设置js抛出异常:false
webClient.getOptions().setActiveXNative(false);
//ajax
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
webClient.getOptions().setUseInsecureSSL(false);
//允许重定向
webClient.getOptions().setRedirectEnabled(true);
//连接超时
webClient.getOptions().setTimeout(5000);
//js执行超时
webClient.setJavaScriptTimeout(10000 * 3);
//允许cookie
webClient.getCookieManager().setCookiesEnabled(true);
String url = "http://hrportalneu.cs/HRPortal ... 3B%3B
HtmlPage page = webClient.getPage(url);
webClient.waitForBackgroundJavaScript(5000);
HtmlPage newPage;
newPage = readyPage(page, webClient, "btnCheckIn1");
System.out.println("url----------------" + newPage.getUrl());
System.out.println("Login执行后页面:" + newPage.asXml());
IOUtils.write(newPage.asXml().getBytes(), new FileWriter(new File("D:/checkIn.txt")));
if (!newPage.asXml().contains("登录成功")) {
login();
}
webClient.close();
}
public static HtmlPage readyPage(HtmlPage page, WebClient webClient, String type) throws Exception {
//封装页面元素
HtmlForm form = page.getHtmlElementById("form1");
HtmlTextInput tbxUsername = form.getInputByName("tbxUsername");
tbxUsername.setValueAttribute("用户名*******");
HtmlPasswordInput tbxPassword = form.getInputByName("tbxPassword");
tbxPassword.setValueAttribute("密码*******");
//获取验证码图片
HtmlImage verify_img = (HtmlImage) page.getElementById("AuthCode1$codeText$img");
File file = new File("D:\\" + "check" + ".png");
//保存验证码图片
verify_img.saveAs(file);
System.out.println("验证码图片已保存!");
//保存路径
String filePath = file.getPath();
//裁剪验证码 这里使用原始的图片文件识别成功率不高 可以先进行裁剪
ImageUtil.cutImage(filePath, 1, 1, 96, 34);
//自动识别验证码
OCRFacade facade = new OCRFacade();
//识别验证码
String code = facade.recognizeFile(filePath, "eng");
//处理字符串
code = code.replaceAll(" ", "");
code = code.replaceAll("\\n", "");
System.out.println("验证码:" + code);
//定位验证码输入框
HtmlTextInput verify_code = form.getInputByName("AuthCode1$codeText");
//填入自动识别出来的验证码
verify_code.setValueAttribute(code);
System.out.println("原始页面:" + page.asXml());
HtmlPage newPage = null;
//操作按钮
if (type.equals("btnCheckIn1")) {
DomElement btnCheckIn1 = page.getElementById("btnCheckIn1");
System.out.println("doCheckIn");
newPage = btnCheckIn1.click();
}
//等待js加载
webClient.waitForBackgroundJavaScript(5000);
return newPage;
}
ImageUtil.java
public class ImageUtil {
public static void cutImage(String filePath, int x, int y, int w, int h)
throws Exception {
// 首先通过ImageIo中的方法,创建一个Image + InputStream到内存
ImageInputStream iis = ImageIO
.createImageInputStream(new FileInputStream(filePath));
// 再按照指定格式构造一个Reader(Reader不能new的)
Iterator it = ImageIO.getImageReadersByFormatName("gif");
ImageReader imagereader = (ImageReader) it.next();
// 再通过ImageReader绑定 InputStream
imagereader.setInput(iis);
// 设置感兴趣的源区域。
ImageReadParam par = imagereader.getDefaultReadParam();
par.setSourceRegion(new Rectangle(x, y, w, h));
// 从 reader得到BufferImage
BufferedImage bi = imagereader.read(0, par);
// 将BuffeerImage写出通过ImageIO
ImageIO.write(bi, "png", new File(filePath));
}
}
在控制台查看登录后的页面,查看是否登录成功。 查看全部
htmlunit 抓取网页(的java程序是什么?答案是有哪些??)
1.HtmlUnit1.1 简介
HtmlUnit 是一个用 java 编写的无界面浏览器,它可以对 html 文档进行建模、通过 API 调用页面、填写表单、单击链接等等。像普通浏览器一样运行。通常用于测试和从网页中抓取信息。
官方简介翻译
HtmlUnit是一个无界面浏览器Java程序。它为HTML文档建模,提供了调用页面、填写表单、单击链接等操作的API。就跟你在浏览器里做的操作一样。
HtmlUnit不错的JavaScript支持(不断改进),甚至可以使用相当复杂的AJAX库,根据配置的不同模拟Chrome、Firefox或Internet Explorer等浏览器。
HtmlUnit通常用于测试或从web站点检索信息。
1.2 使用场景
对于java实现的网络爬虫程序,我们一般可以使用apache的HttpClient组件来获取HTML页面信息。HttpClient实现的http请求返回的响应一般是纯文本文档页面,也就是最原创的html页面。
对于一个静态的html页面,使用httpClient就足够爬出我们需要的信息了。但是对于越来越多的动态网页,更多的数据是通过异步的JS代码来获取和渲染的,而初始的html页面并没有收录这部分数据。

上图中我们看到的网页在初始文档加载后并没有看到红框中的数据列表。浏览器通过执行异步JS请求,将获取到的动态数据渲染到原创文档页面中,最终变成我们看到的网页。对于这部分需要JS代码执行的数据,httpClient是无能为力的。虽然我们可以通过研究得到JS执行的请求路径,然后用java代码来获取我们需要的部分数据,不说能不能从JS脚本中分析请求路径和请求参数,只分析这部分数据源码成本已经很高了。
通过上面的介绍,我们了解到现在很大一部分动态网页都是通过异步JS请求获取的数据,然后通过JS渲染页面。那么我们能不能做这样的假设,假设我们的爬虫程序模拟一个浏览器,拿到html页面后,像浏览器一样执行异步JS代码,JS渲染好html页面后,就可以愉快的获取到节点信息了这页纸。那么有没有这样的java程序呢?
答案是肯定的。
HtmlUnit就是这样一个库,用来做界面显示的所有异步工作。没有耗时的显示工作,HtmlUnit 加载的完整网页比实际的浏览器块更多。并且根据不同的配置,HtmlUnit可以模拟市面上常见的Chrome、Firefox、IE浏览器等浏览器。
通过HtmlUnit库,加载一个完整的Html页面(图片和视频除外),然后将其转换成我们常用的字符串格式,并使用Jsoup等其他工具获取元素。当然,你也可以直接从HtmlUnit提供的对象中获取网页元素,甚至可以操作按钮、表单等控件。除了不能像可见浏览器那样用鼠标和键盘浏览网页,我们可以使用HtmlUnit来模拟所有其他的操作,比如登录网站、写博客等等都可以完成。当然,网页内容抓取是最简单的应用。
2.J4L2.1官方简介
J4L OCR 工具是一组组件,可用于在 Java 应用程序中收录 OCR 功能。这意味着您可以接收传真、PDF 文件或扫描文档并从图像中提取商业信息。主要的3个组件是:
j4l工具的详细使用步骤请参考这篇文章文章:Java使用J4L识别验证码
本文文章主要介绍使用HtmlUnit模拟登录
3.实际案例3.1.场景
登录页面,包括表单,需要填写用户名、登录密码、验证码,实现用户登录。
3.2操作步骤
使用htmlunit模拟登录是一个获取登录页面->找到输入框->填写用户名和密码->填写验证码->模拟点击登录的过程。
4.实现代码4.1maven引入HtmlUnit依赖
net.sourceforge.htmlunit
htmlunit
2.18
4.2 主要方法
登录.java
public static void main(String[] args) throws Exception {
login();
}
public static void login() throws Exception {
WebClient webClient = new WebClient(BrowserVersion.CHROME);//设置浏览器内核
webClient.getOptions().setJavaScriptEnabled(true);// js是否可用
webClient.getOptions().setCssEnabled(true);//css 一般设置false因为影响运行速度
webClient.getOptions().setThrowExceptionOnScriptError(false);//设置js抛出异常:false
webClient.getOptions().setActiveXNative(false);
//ajax
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
webClient.getOptions().setUseInsecureSSL(false);
//允许重定向
webClient.getOptions().setRedirectEnabled(true);
//连接超时
webClient.getOptions().setTimeout(5000);
//js执行超时
webClient.setJavaScriptTimeout(10000 * 3);
//允许cookie
webClient.getCookieManager().setCookiesEnabled(true);
String url = "http://hrportalneu.cs/HRPortal ... 3B%3B
HtmlPage page = webClient.getPage(url);
webClient.waitForBackgroundJavaScript(5000);
HtmlPage newPage;
newPage = readyPage(page, webClient, "btnCheckIn1");
System.out.println("url----------------" + newPage.getUrl());
System.out.println("Login执行后页面:" + newPage.asXml());
IOUtils.write(newPage.asXml().getBytes(), new FileWriter(new File("D:/checkIn.txt")));
if (!newPage.asXml().contains("登录成功")) {
login();
}
webClient.close();
}
public static HtmlPage readyPage(HtmlPage page, WebClient webClient, String type) throws Exception {
//封装页面元素
HtmlForm form = page.getHtmlElementById("form1");
HtmlTextInput tbxUsername = form.getInputByName("tbxUsername");
tbxUsername.setValueAttribute("用户名*******");
HtmlPasswordInput tbxPassword = form.getInputByName("tbxPassword");
tbxPassword.setValueAttribute("密码*******");
//获取验证码图片
HtmlImage verify_img = (HtmlImage) page.getElementById("AuthCode1$codeText$img");
File file = new File("D:\\" + "check" + ".png");
//保存验证码图片
verify_img.saveAs(file);
System.out.println("验证码图片已保存!");
//保存路径
String filePath = file.getPath();
//裁剪验证码 这里使用原始的图片文件识别成功率不高 可以先进行裁剪
ImageUtil.cutImage(filePath, 1, 1, 96, 34);
//自动识别验证码
OCRFacade facade = new OCRFacade();
//识别验证码
String code = facade.recognizeFile(filePath, "eng");
//处理字符串
code = code.replaceAll(" ", "");
code = code.replaceAll("\\n", "");
System.out.println("验证码:" + code);
//定位验证码输入框
HtmlTextInput verify_code = form.getInputByName("AuthCode1$codeText");
//填入自动识别出来的验证码
verify_code.setValueAttribute(code);
System.out.println("原始页面:" + page.asXml());
HtmlPage newPage = null;
//操作按钮
if (type.equals("btnCheckIn1")) {
DomElement btnCheckIn1 = page.getElementById("btnCheckIn1");
System.out.println("doCheckIn");
newPage = btnCheckIn1.click();
}
//等待js加载
webClient.waitForBackgroundJavaScript(5000);
return newPage;
}
ImageUtil.java
public class ImageUtil {
public static void cutImage(String filePath, int x, int y, int w, int h)
throws Exception {
// 首先通过ImageIo中的方法,创建一个Image + InputStream到内存
ImageInputStream iis = ImageIO
.createImageInputStream(new FileInputStream(filePath));
// 再按照指定格式构造一个Reader(Reader不能new的)
Iterator it = ImageIO.getImageReadersByFormatName("gif");
ImageReader imagereader = (ImageReader) it.next();
// 再通过ImageReader绑定 InputStream
imagereader.setInput(iis);
// 设置感兴趣的源区域。
ImageReadParam par = imagereader.getDefaultReadParam();
par.setSourceRegion(new Rectangle(x, y, w, h));
// 从 reader得到BufferImage
BufferedImage bi = imagereader.read(0, par);
// 将BuffeerImage写出通过ImageIO
ImageIO.write(bi, "png", new File(filePath));
}
}
在控制台查看登录后的页面,查看是否登录成功。
htmlunit 抓取网页(htmlunitjava页面分析工具模拟运行 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-28 04:02
)
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit对页面内容进行分析。
该项目可以模拟浏览器的操作,被称为java浏览器的开源实现。是没有界面的浏览器。
使用了 Rhinojs 引擎。模拟js运行。
使用htmlunit抓取网页大致可以分为以下几个步骤:
1、定义一个 WebClient 客户端。
相当于定义了一个没有界面的浏览器。
2、使用WebClient客户端从指定的URL获取HtmlPage。
HtmlPage 收录目标 URL 页面中的所有信息。
3、从 HtmlPage 中获取我们需要的指定元素。
我们来看一个例子:
1package com.fuwh;
2
3import com.gargoylesoftware.htmlunit.WebClient;
4import com.gargoylesoftware.htmlunit.html.HtmlPage;
5
6public class Demo01 {
7
8 public static void main(String[] args) {
9
10 WebClient webClient=null;
11 try {
12 webClient= new WebClient(); //定义一个默认的WebClient
13 HtmlPage page=webClient.getPage("https://www.cnblogs.com/"); //从指定URL获取HtmlPage
14 System.out.println(page.asText()); //将HtmlPage转换成字符串打印出来
15 } catch (Exception e) {
16 // TODO: handle exception
17 e.printStackTrace();
18 }finally {
19 webClient.close(); //关闭客户端
20 }
21 }
22}
23
在上面的例子中,我们创建了一个默认的WebClient实例,使用WebClient#getBrowserVersion()方法,可以看到,
默认创建Chrome版本的浏览器。
当然,我们也可以在创建时指定浏览器版本。
例子:
1package com.fuwh;
2
3import com.gargoylesoftware.htmlunit.BrowserVersion;
4import com.gargoylesoftware.htmlunit.WebClient;
5import com.gargoylesoftware.htmlunit.html.HtmlPage;
6
7public class Demo01 {
8
9 public static void main(String[] args) {
10
11 WebClient webClient=null;
12 try {
13 webClient= new WebClient(BrowserVersion.FIREFOX_45); //定义一个WebClient
14 HtmlPage page=webClient.getPage("https://www.cnblogs.com/"); //从指定URL获取HtmlPage
15 System.out.println(page.asText()); //将HtmlPage转换成字符串打印出来
16 } catch (Exception e) {
17 // TODO: handle exception
18 e.printStackTrace();
19 }finally {
20 webClient.close(); //关闭客户端
21 }
22 }
23}
24
在 BrowserVersion 中,定义了许多浏览器版本。
在获得一个 HtmlPage 之后,我们仍然希望能够找到我们想要的元素,而不是输入整个页面。
HtmlUnit 还为查找特定元素提供了丰富的支持。
支持使用 DOM、CSS 和 XPath 的方式(推荐)。
◇使用DOM方法:
1package com.fuwh;
2
3import com.gargoylesoftware.htmlunit.BrowserVersion;
4import com.gargoylesoftware.htmlunit.WebClient;
5import com.gargoylesoftware.htmlunit.html.DomElement;
6import com.gargoylesoftware.htmlunit.html.DomNodeList;
7import com.gargoylesoftware.htmlunit.html.HtmlAnchor;
8import com.gargoylesoftware.htmlunit.html.HtmlDivision;
9import com.gargoylesoftware.htmlunit.html.HtmlPage;
10
11public class Demo01 {
12
13 public static void main(String[] args) {
14
15 WebClient webClient=null;
16 try {
17 webClient= new WebClient(BrowserVersion.FIREFOX_45); //定义一个WebClient
18 final HtmlPage page=webClient.getPage("https://www.cnblogs.com/"); //从指定URL获取HtmlPage
19
20 /**
21 * DomElement 的子类:HtmlElement
22 * HtmlElemnt也有很多子类,基本上涵盖了所有的Html元素
23 * 例如:HtmlDivision,HtmlInput
24 */
25 System.out.println("=============================================");
26 //通过id获取指定DOM元素
27 HtmlDivision htmlDiv=(HtmlDivision) page.getElementById("header");
28 System.out.println(htmlDiv.asXml());
29
30 System.out.println("=============================================");
31 //通过tagName来获取元素集合
32 DomNodeList nodeList=page.getElementsByTagName("a");
33 for (DomElement domElement : nodeList) {
34 HtmlAnchor htmlAnchor=(HtmlAnchor) domElement;
35 System.out.println("标题:"+htmlAnchor.asText()+" --> 地址:"+htmlAnchor.getAttribute("href"));
36 }
37
38 } catch (Exception e) {
39 // TODO: handle exception
40 e.printStackTrace();
41 }finally {
42 webClient.close(); //关闭客户端
43 }
44 }
45}
46
◇使用CSS方法:
1package com.fuwh;
2
3import com.gargoylesoftware.htmlunit.BrowserVersion;
4import com.gargoylesoftware.htmlunit.WebClient;
5import com.gargoylesoftware.htmlunit.html.DomElement;
6import com.gargoylesoftware.htmlunit.html.DomNodeList;
7import com.gargoylesoftware.htmlunit.html.HtmlAnchor;
8import com.gargoylesoftware.htmlunit.html.HtmlDivision;
9import com.gargoylesoftware.htmlunit.html.HtmlPage;
10
11public class Demo02 {
12
13 public static void main(String[] args) {
14
15 WebClient webClient=null;
16 try {
17 webClient= new WebClient(BrowserVersion.FIREFOX_45); //定义一个WebClient
18 final HtmlPage page=webClient.getPage("https://www.cnblogs.com/"); //从指定URL获取HtmlPage
19
20 HtmlDivision htmlDiv =page.querySelector("div");//获取第一个div
21 System.out.println(htmlDiv.asXml());
22
23 System.out.println("====================================");
24
25 HtmlDivision htmlDiv2=page.querySelector("div#footer_bottom");//也可以指定多个选择器,通过‘,’隔开
26 System.out.println(htmlDiv2.asXml());
27 } catch (Exception e) {
28 // TODO: handle exception
29 e.printStackTrace();
30 }finally {
31 webClient.close(); //关闭客户端
32 }
33 }
34}
35
◇使用XPath方法:
1package com.fuwh;
2
3import java.util.List;
4
5import com.gargoylesoftware.htmlunit.BrowserVersion;
6import com.gargoylesoftware.htmlunit.WebClient;
7import com.gargoylesoftware.htmlunit.html.HtmlDivision;
8import com.gargoylesoftware.htmlunit.html.HtmlPage;
9
10public class Demo03 {
11
12 public static void main(String[] args) {
13
14 WebClient webClient=null;
15 try {
16 webClient= new WebClient(BrowserVersion.FIREFOX_45); //定义一个WebClient
17 final HtmlPage page=webClient.getPage("https://www.cnblogs.com/"); //从指定URL获取HtmlPage
18
19 List divList=page.getByXPath("//div[@id='cnblogs_a1']");
20 for (HtmlDivision htmlDivision : divList) {
21 System.out.println("***********************************************8");
22 System.out.println(htmlDivision.asXml());
23 }
24
25 } catch (Exception e) {
26 // TODO: handle exception
27 e.printStackTrace();
28 }finally {
29 webClient.close(); //关闭客户端
30 }
31 }
32}
33 查看全部
htmlunit 抓取网页(htmlunitjava页面分析工具模拟运行
)
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit对页面内容进行分析。
该项目可以模拟浏览器的操作,被称为java浏览器的开源实现。是没有界面的浏览器。
使用了 Rhinojs 引擎。模拟js运行。
使用htmlunit抓取网页大致可以分为以下几个步骤:
1、定义一个 WebClient 客户端。
相当于定义了一个没有界面的浏览器。
2、使用WebClient客户端从指定的URL获取HtmlPage。
HtmlPage 收录目标 URL 页面中的所有信息。
3、从 HtmlPage 中获取我们需要的指定元素。
我们来看一个例子:
1package com.fuwh;
2
3import com.gargoylesoftware.htmlunit.WebClient;
4import com.gargoylesoftware.htmlunit.html.HtmlPage;
5
6public class Demo01 {
7
8 public static void main(String[] args) {
9
10 WebClient webClient=null;
11 try {
12 webClient= new WebClient(); //定义一个默认的WebClient
13 HtmlPage page=webClient.getPage("https://www.cnblogs.com/";); //从指定URL获取HtmlPage
14 System.out.println(page.asText()); //将HtmlPage转换成字符串打印出来
15 } catch (Exception e) {
16 // TODO: handle exception
17 e.printStackTrace();
18 }finally {
19 webClient.close(); //关闭客户端
20 }
21 }
22}
23
在上面的例子中,我们创建了一个默认的WebClient实例,使用WebClient#getBrowserVersion()方法,可以看到,
默认创建Chrome版本的浏览器。
当然,我们也可以在创建时指定浏览器版本。
例子:
1package com.fuwh;
2
3import com.gargoylesoftware.htmlunit.BrowserVersion;
4import com.gargoylesoftware.htmlunit.WebClient;
5import com.gargoylesoftware.htmlunit.html.HtmlPage;
6
7public class Demo01 {
8
9 public static void main(String[] args) {
10
11 WebClient webClient=null;
12 try {
13 webClient= new WebClient(BrowserVersion.FIREFOX_45); //定义一个WebClient
14 HtmlPage page=webClient.getPage("https://www.cnblogs.com/";); //从指定URL获取HtmlPage
15 System.out.println(page.asText()); //将HtmlPage转换成字符串打印出来
16 } catch (Exception e) {
17 // TODO: handle exception
18 e.printStackTrace();
19 }finally {
20 webClient.close(); //关闭客户端
21 }
22 }
23}
24
在 BrowserVersion 中,定义了许多浏览器版本。
在获得一个 HtmlPage 之后,我们仍然希望能够找到我们想要的元素,而不是输入整个页面。
HtmlUnit 还为查找特定元素提供了丰富的支持。
支持使用 DOM、CSS 和 XPath 的方式(推荐)。
◇使用DOM方法:
1package com.fuwh;
2
3import com.gargoylesoftware.htmlunit.BrowserVersion;
4import com.gargoylesoftware.htmlunit.WebClient;
5import com.gargoylesoftware.htmlunit.html.DomElement;
6import com.gargoylesoftware.htmlunit.html.DomNodeList;
7import com.gargoylesoftware.htmlunit.html.HtmlAnchor;
8import com.gargoylesoftware.htmlunit.html.HtmlDivision;
9import com.gargoylesoftware.htmlunit.html.HtmlPage;
10
11public class Demo01 {
12
13 public static void main(String[] args) {
14
15 WebClient webClient=null;
16 try {
17 webClient= new WebClient(BrowserVersion.FIREFOX_45); //定义一个WebClient
18 final HtmlPage page=webClient.getPage("https://www.cnblogs.com/";); //从指定URL获取HtmlPage
19
20 /**
21 * DomElement 的子类:HtmlElement
22 * HtmlElemnt也有很多子类,基本上涵盖了所有的Html元素
23 * 例如:HtmlDivision,HtmlInput
24 */
25 System.out.println("=============================================");
26 //通过id获取指定DOM元素
27 HtmlDivision htmlDiv=(HtmlDivision) page.getElementById("header");
28 System.out.println(htmlDiv.asXml());
29
30 System.out.println("=============================================");
31 //通过tagName来获取元素集合
32 DomNodeList nodeList=page.getElementsByTagName("a");
33 for (DomElement domElement : nodeList) {
34 HtmlAnchor htmlAnchor=(HtmlAnchor) domElement;
35 System.out.println("标题:"+htmlAnchor.asText()+" --> 地址:"+htmlAnchor.getAttribute("href"));
36 }
37
38 } catch (Exception e) {
39 // TODO: handle exception
40 e.printStackTrace();
41 }finally {
42 webClient.close(); //关闭客户端
43 }
44 }
45}
46
◇使用CSS方法:
1package com.fuwh;
2
3import com.gargoylesoftware.htmlunit.BrowserVersion;
4import com.gargoylesoftware.htmlunit.WebClient;
5import com.gargoylesoftware.htmlunit.html.DomElement;
6import com.gargoylesoftware.htmlunit.html.DomNodeList;
7import com.gargoylesoftware.htmlunit.html.HtmlAnchor;
8import com.gargoylesoftware.htmlunit.html.HtmlDivision;
9import com.gargoylesoftware.htmlunit.html.HtmlPage;
10
11public class Demo02 {
12
13 public static void main(String[] args) {
14
15 WebClient webClient=null;
16 try {
17 webClient= new WebClient(BrowserVersion.FIREFOX_45); //定义一个WebClient
18 final HtmlPage page=webClient.getPage("https://www.cnblogs.com/";); //从指定URL获取HtmlPage
19
20 HtmlDivision htmlDiv =page.querySelector("div");//获取第一个div
21 System.out.println(htmlDiv.asXml());
22
23 System.out.println("====================================");
24
25 HtmlDivision htmlDiv2=page.querySelector("div#footer_bottom");//也可以指定多个选择器,通过‘,’隔开
26 System.out.println(htmlDiv2.asXml());
27 } catch (Exception e) {
28 // TODO: handle exception
29 e.printStackTrace();
30 }finally {
31 webClient.close(); //关闭客户端
32 }
33 }
34}
35
◇使用XPath方法:
1package com.fuwh;
2
3import java.util.List;
4
5import com.gargoylesoftware.htmlunit.BrowserVersion;
6import com.gargoylesoftware.htmlunit.WebClient;
7import com.gargoylesoftware.htmlunit.html.HtmlDivision;
8import com.gargoylesoftware.htmlunit.html.HtmlPage;
9
10public class Demo03 {
11
12 public static void main(String[] args) {
13
14 WebClient webClient=null;
15 try {
16 webClient= new WebClient(BrowserVersion.FIREFOX_45); //定义一个WebClient
17 final HtmlPage page=webClient.getPage("https://www.cnblogs.com/";); //从指定URL获取HtmlPage
18
19 List divList=page.getByXPath("//div[@id='cnblogs_a1']");
20 for (HtmlDivision htmlDivision : divList) {
21 System.out.println("***********************************************8");
22 System.out.println(htmlDivision.asXml());
23 }
24
25 } catch (Exception e) {
26 // TODO: handle exception
27 e.printStackTrace();
28 }finally {
29 webClient.close(); //关闭客户端
30 }
31 }
32}
33
htmlunit 抓取网页(我可以让htmlunit忽略javascript*>**)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-02-25 15:27
在使用 htmlunit 抓取网页时,我偶尔会注意到这些警告淹没了控制台输出。
Jul 24,2011 5:12:59 PM com.gargoylesoftware.htmlunit.javascript.StrictErrorReporter warning
WARNING: warning: message=[Calling eval() with anything other than a primitive string value
will simply return the value. Is this what you intended?] sourceName=[http://ad.doubleclick.net/adj/ ... 40%3F] line=[356] lineSource=[null] lineOffset=[0]
有没有办法让htmlunit忽略javascript
> *
> *
就算了
>
>
同样,有没有办法让 htmlunit 只解释收录特定子字符串或匹配正则表达式的网页上的 javascript?
解决方案
您可以通过实现自己的 javascript 来删除不需要的 JavaScript
脚本预处理器。您的 ScriptPreProcessor 可以检测到您不想执行的 jsvascript,而不是将其从 网站 中删除。
我还没有尝试过,但它可能会起作用。 查看全部
htmlunit 抓取网页(我可以让htmlunit忽略javascript*>**)
在使用 htmlunit 抓取网页时,我偶尔会注意到这些警告淹没了控制台输出。
Jul 24,2011 5:12:59 PM com.gargoylesoftware.htmlunit.javascript.StrictErrorReporter warning
WARNING: warning: message=[Calling eval() with anything other than a primitive string value
will simply return the value. Is this what you intended?] sourceName=[http://ad.doubleclick.net/adj/ ... 40%3F] line=[356] lineSource=[null] lineOffset=[0]
有没有办法让htmlunit忽略javascript
> *
> *
就算了
>
>
同样,有没有办法让 htmlunit 只解释收录特定子字符串或匹配正则表达式的网页上的 javascript?
解决方案
您可以通过实现自己的 javascript 来删除不需要的 JavaScript
脚本预处理器。您的 ScriptPreProcessor 可以检测到您不想执行的 jsvascript,而不是将其从 网站 中删除。
我还没有尝试过,但它可能会起作用。
htmlunit 抓取网页(抓一个今日头条的首页内容解决方案-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-25 11:27
不知道大家在使用jsoup的过程中是否遇到过爬取内容,发现有些网页中的内容是通过javascript异步加载的,导致我们的爬虫空手返回(只抓到一个网页的外框) .
当我第一次遇到这个问题时,我想到了两个解决方案:
在等待网页异步加载后,使用类似于 Python 中延迟加载的方法对异步加载的网页进行爬取。使用一种特殊的方法,让爬取的网页的框架模拟里面的JavaScript代码的执行,最终到达完整的网页。
在搜索引擎的帮助下,决定使用方案二来解决这个问题。没有更好的第三方库搜索解决方案1。在java中使用解决方案1解决这个问题的朋友希望与下一个讨论,不胜感激。
案例很简单,抓取一条今日头条的首页内容。你可以看一下今日头条的首页,里面的内容是异步加载的。
添加jsoup和htmlunit依赖
org.jsoup
jsoup
1.10.2
net.sourceforge.htmlunit
htmlunit
2.25
首先,我们单独使用jsoup来解析今日头条的首页
String url = "https://www.toutiao.com/";
Connection connect = Jsoup.connect(url);
Document document = connect.get();
System.out.println(document);
↑ 这里只能获取网页的框架内容,不能获取首页的新闻内容
接下来,我们使用htmlunit来尝试
//构造一个webClient 模拟Chrome 浏览器
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//屏蔽日志信息
LogFactory.getFactory().setAttribute("org.apache.commons.logging.Log",
"org.apache.commons.logging.impl.NoOpLog");
java.util.logging.Logger.getLogger("com.gargoylesoftware").setLevel(Level.OFF);
//支持JavaScript
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setTimeout(5000);
HtmlPage rootPage = webClient.getPage(url);
//设置一个运行JavaScript的时间
webClient.waitForBackgroundJavaScript(5000);
String html = rootPage.asXml();
Document document = Jsoup.parse(html);
这为我们提供了运行 JavaScript 的完整源页面 查看全部
htmlunit 抓取网页(抓一个今日头条的首页内容解决方案-苏州安嘉)
不知道大家在使用jsoup的过程中是否遇到过爬取内容,发现有些网页中的内容是通过javascript异步加载的,导致我们的爬虫空手返回(只抓到一个网页的外框) .
当我第一次遇到这个问题时,我想到了两个解决方案:
在等待网页异步加载后,使用类似于 Python 中延迟加载的方法对异步加载的网页进行爬取。使用一种特殊的方法,让爬取的网页的框架模拟里面的JavaScript代码的执行,最终到达完整的网页。
在搜索引擎的帮助下,决定使用方案二来解决这个问题。没有更好的第三方库搜索解决方案1。在java中使用解决方案1解决这个问题的朋友希望与下一个讨论,不胜感激。
案例很简单,抓取一条今日头条的首页内容。你可以看一下今日头条的首页,里面的内容是异步加载的。
添加jsoup和htmlunit依赖
org.jsoup
jsoup
1.10.2
net.sourceforge.htmlunit
htmlunit
2.25
首先,我们单独使用jsoup来解析今日头条的首页
String url = "https://www.toutiao.com/";
Connection connect = Jsoup.connect(url);
Document document = connect.get();
System.out.println(document);
↑ 这里只能获取网页的框架内容,不能获取首页的新闻内容
接下来,我们使用htmlunit来尝试
//构造一个webClient 模拟Chrome 浏览器
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//屏蔽日志信息
LogFactory.getFactory().setAttribute("org.apache.commons.logging.Log",
"org.apache.commons.logging.impl.NoOpLog");
java.util.logging.Logger.getLogger("com.gargoylesoftware").setLevel(Level.OFF);
//支持JavaScript
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setTimeout(5000);
HtmlPage rootPage = webClient.getPage(url);
//设置一个运行JavaScript的时间
webClient.waitForBackgroundJavaScript(5000);
String html = rootPage.asXml();
Document document = Jsoup.parse(html);
这为我们提供了运行 JavaScript 的完整源页面
htmlunit 抓取网页(HtmlUnit可以直接访问接口吗?的扩展之一是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-19 01:28
HttpClient 是一个用于捕获 html 页面的简单工具包。它不再维护,已被 Apache 的 HttpComponents 取代。缺陷是无法获取js获取的动态数据,导致爬取数据丢失。
org.apache.httpcomponents
httpclient
4.5.8
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
public class HttpClientTest {
/**
* 获取html页面内容
* @param url 链接地址
* @return
*/
public static String getHtmlByHttpClient(String url) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet(url);
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
return html;
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
}
二、使用 HtmlUnit
HtmlUnit可以用来模拟浏览器的操作,可以认为是没有界面的浏览器,即用代码模拟鼠标等操作来操作网页,运行速度快。
HtmlUnit 是一个开源的java页面分析工具。作为junit的扩展之一,可以模拟js运行
-> 使用htmlUnit抓取百度搜索页面
通过htmlUnit操作百度高级搜索界面,最终抓取到搜索结果的html页面内容
net.sourceforge.htmlunit
htmlunit
2.23
public static String Baidu(String keyword)throws Exception{
WebClient webclient = new WebClient();
//ssl认证
//webclient.getOptions().setUseInsecureSSL(true);
//由于有的网页js书写不规范htmlunit会报错,所以去除这种错误让程序执行完全(不影响结果)
webclient.getOptions().setThrowExceptionOnScriptError(false);
webclient.getOptions().setThrowExceptionOnFailingStatusCode(false);
//不加载css
webclient.getOptions().setCssEnabled(false);
//由于是动态网页所以一定要加载js及执行
webclient.getOptions().setJavaScriptEnabled(true);
//打开百度高级搜索的网址
HtmlPage htmlpage = webclient.getPage("http://www.baidu.com/gaoji/advanced.html");
//获取网页from控件(f1为控件name)
HtmlForm form = htmlpage.getFormByName("f1");
HtmlSubmitInput button = form.getInputByValue("百度一下");
HtmlTextInput textField = form.getInputByName("q1");
textField.setValueAttribute(keyword);
final HtmlSelect htmlSelet=form.getSelectByName("rn");
htmlSelet.setDefaultValue("10");
//隐藏值
final HtmlHiddenInput hiddenInputtn = form.getInputByName("tn");
hiddenInputtn.setDefaultValue("baiduadv");
//发送请求(相当于点击百度一下按钮)获取返回后的网页
final HtmlPage page = button.click();
//获取网页的文本信息
String result = page.asText();
//获取网页源码
//String result = page.asXml();
//System.out.println(result);
webclient.close();
return result;
}
三、捕获接口获取数据
通过前两种方式,有时可能无法得到我们想要的结果,抓取到的html页面代码可能有缺失数据,同时可能被网站监听,ip地址会被封禁,让我们无法继续获取页面数据
让我们想想数据来自哪里。一般是通过接口获取的吧?如果我们可以直接访问接口呢?这是我的想法:
虽然这种方法可以稳定的获取数据,但实际上在很多网站中我们看不到XHR请求中的接口,这是因为考虑到跨域使用jsonp,这些都可以在js中找到,如果你有兴趣,你可以了解一下 查看全部
htmlunit 抓取网页(HtmlUnit可以直接访问接口吗?的扩展之一是什么?)
HttpClient 是一个用于捕获 html 页面的简单工具包。它不再维护,已被 Apache 的 HttpComponents 取代。缺陷是无法获取js获取的动态数据,导致爬取数据丢失。
org.apache.httpcomponents
httpclient
4.5.8
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
public class HttpClientTest {
/**
* 获取html页面内容
* @param url 链接地址
* @return
*/
public static String getHtmlByHttpClient(String url) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet(url);
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
return html;
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
}
二、使用 HtmlUnit
HtmlUnit可以用来模拟浏览器的操作,可以认为是没有界面的浏览器,即用代码模拟鼠标等操作来操作网页,运行速度快。
HtmlUnit 是一个开源的java页面分析工具。作为junit的扩展之一,可以模拟js运行
-> 使用htmlUnit抓取百度搜索页面
通过htmlUnit操作百度高级搜索界面,最终抓取到搜索结果的html页面内容
net.sourceforge.htmlunit
htmlunit
2.23
public static String Baidu(String keyword)throws Exception{
WebClient webclient = new WebClient();
//ssl认证
//webclient.getOptions().setUseInsecureSSL(true);
//由于有的网页js书写不规范htmlunit会报错,所以去除这种错误让程序执行完全(不影响结果)
webclient.getOptions().setThrowExceptionOnScriptError(false);
webclient.getOptions().setThrowExceptionOnFailingStatusCode(false);
//不加载css
webclient.getOptions().setCssEnabled(false);
//由于是动态网页所以一定要加载js及执行
webclient.getOptions().setJavaScriptEnabled(true);
//打开百度高级搜索的网址
HtmlPage htmlpage = webclient.getPage("http://www.baidu.com/gaoji/advanced.html";);
//获取网页from控件(f1为控件name)
HtmlForm form = htmlpage.getFormByName("f1");
HtmlSubmitInput button = form.getInputByValue("百度一下");
HtmlTextInput textField = form.getInputByName("q1");
textField.setValueAttribute(keyword);
final HtmlSelect htmlSelet=form.getSelectByName("rn");
htmlSelet.setDefaultValue("10");
//隐藏值
final HtmlHiddenInput hiddenInputtn = form.getInputByName("tn");
hiddenInputtn.setDefaultValue("baiduadv");
//发送请求(相当于点击百度一下按钮)获取返回后的网页
final HtmlPage page = button.click();
//获取网页的文本信息
String result = page.asText();
//获取网页源码
//String result = page.asXml();
//System.out.println(result);
webclient.close();
return result;
}
三、捕获接口获取数据
通过前两种方式,有时可能无法得到我们想要的结果,抓取到的html页面代码可能有缺失数据,同时可能被网站监听,ip地址会被封禁,让我们无法继续获取页面数据
让我们想想数据来自哪里。一般是通过接口获取的吧?如果我们可以直接访问接口呢?这是我的想法:
虽然这种方法可以稳定的获取数据,但实际上在很多网站中我们看不到XHR请求中的接口,这是因为考虑到跨域使用jsonp,这些都可以在js中找到,如果你有兴趣,你可以了解一下
htmlunit 抓取网页(ApacheNutchX版本实现请访问:pageonNutchwith1.8)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-12 02:20
基于Apache Nutch和Htmlunit扩展的AJAX页面爬虫爬取解析插件------------------ ------------------------------------------------- - ----------------------- 提示:项目当前版本停止更新,最新Apache Nutch 2.X版本实现请访问:- --- ------------------------------------------------------------ --- ----------------------------------
之前提供了一个版本,直接将源代码以插件的形式放到代码库中。后来发现很多人反映集成到apache nutch中编译或者运行,遇到这样那样的问题。所以,这次基于Apache Nutch 1.8源码项目,预设了所有插件源码/依赖/操作参数,让大家可以更简洁全面的使用这个插件。
Nutch Htmlunit插件项目介绍基于Apache Nutch1.8和Htmlunit组件,实现了对AJAX加载类型页面的完整页面内容抓取和分析。根据 Apache Nutch 1.8 的实现,我们无法从收录 AJAX 请求的获取页面中获取动态 HTML 信息,因为它会忽略所有 AJAX 请求。该插件将使用 Htmlunit 通过必要的动态 AJAX 请求获取整个页面内容。它使用 Apache Nutch 1.8 开发和测试,您可以在其他 Nutch 版本上尝试它或重构源代码作为您的设计。主要功能运行体验由于Nutch运行在Unix/Linux环境下,请自行准备Unix/Linux系统或Cygwin运行环境。 git clone整个项目代码后,进入本地git下载目录: cd nutch-htmlunit/runtime/local bin/crawl urls crawl false 1 //urls参数为爬虫url文件目录; crawl 是爬虫输出目录; false应该是solr index url参数,这里设置为false,不做solr索引处理; 1是爬虫执行次数后,可以看到天猫商品页面的价格/描述/滚装图,信息已经全部获取完毕。运行日志输入示例参考:扩展插件说明 查看全部
htmlunit 抓取网页(ApacheNutchX版本实现请访问:pageonNutchwith1.8)
基于Apache Nutch和Htmlunit扩展的AJAX页面爬虫爬取解析插件------------------ ------------------------------------------------- - ----------------------- 提示:项目当前版本停止更新,最新Apache Nutch 2.X版本实现请访问:- --- ------------------------------------------------------------ --- ----------------------------------
之前提供了一个版本,直接将源代码以插件的形式放到代码库中。后来发现很多人反映集成到apache nutch中编译或者运行,遇到这样那样的问题。所以,这次基于Apache Nutch 1.8源码项目,预设了所有插件源码/依赖/操作参数,让大家可以更简洁全面的使用这个插件。
Nutch Htmlunit插件项目介绍基于Apache Nutch1.8和Htmlunit组件,实现了对AJAX加载类型页面的完整页面内容抓取和分析。根据 Apache Nutch 1.8 的实现,我们无法从收录 AJAX 请求的获取页面中获取动态 HTML 信息,因为它会忽略所有 AJAX 请求。该插件将使用 Htmlunit 通过必要的动态 AJAX 请求获取整个页面内容。它使用 Apache Nutch 1.8 开发和测试,您可以在其他 Nutch 版本上尝试它或重构源代码作为您的设计。主要功能运行体验由于Nutch运行在Unix/Linux环境下,请自行准备Unix/Linux系统或Cygwin运行环境。 git clone整个项目代码后,进入本地git下载目录: cd nutch-htmlunit/runtime/local bin/crawl urls crawl false 1 //urls参数为爬虫url文件目录; crawl 是爬虫输出目录; false应该是solr index url参数,这里设置为false,不做solr索引处理; 1是爬虫执行次数后,可以看到天猫商品页面的价格/描述/滚装图,信息已经全部获取完毕。运行日志输入示例参考:扩展插件说明
htmlunit 抓取网页(:JavaHTML解析器的基本知识点总结(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-04-10 12:23
)
(4)支持代理
(5)支持自动cookie管理等。
Java爬虫开发是应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;
import org.apache.http.client.HttpClient;
import org.apache.http.client.ResponseHandler;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.BasicResponseHandler;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.util.EntityUtils;
/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/
public class HttpClientTest {
public static void main(String[] args)throws Exception{
//目标页面
String url ="http://www.jjwxc.net/";
//创建一个默认的HttpClient
HttpClient httpclient =new DefaultHttpClient();
try{
//以get方式请求网页http://www.yshjava.cn
HttpGet httpget =new HttpGet(url);
//打印请求地址
System.out.println("executing request "+ httpget.getURI());
//创建响应处理器处理服务器响应内容
ResponseHandler responseHandler = new BasicResponseHandler();
//执行请求并获取结果
String responseBody = httpclient.execute(httpget, responseHandler);
System.out.println("----------------------------------------");
String htmlStr=null;
if(responseBody != null) {
// htmlStr=new String(EntityUtils.toString(responseBody));
// htmlStr=new String(htmlStr.getBytes("ISO-8859-1"), "gbk"); // 读取乱码解决
responseBody=new String(responseBody.getBytes("ISO-8859-1"), "gb2312");
}
System.out.println(responseBody);
System.out.println("----------------------------------------");
}finally{//关闭连接管理器
httpclient.getConnectionManager().shutdown();
}
}
}
汤
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
示例代码如下:
包cn.ysh.studio.crawler.jsoup;
导入 java.io.IOException;
导入 org.jsoup.Jsoup;
/**
* 基于 Jsoup 抓取网页内容
* @作者
*/
公共类 JsoupTest {
公共静态 void main(String[] args) 抛出 IOException{
//目标页面
字符串 url = "";
//使用Jsoup连接目标页面,执行请求,获取服务器响应内容
字符串 html =Jsoup.connect(url).execute().body();
//打印页面内容
System.out.println(html);
}
}
html单元
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取和解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.Page;
import com.gargoylesoftware.htmlunit.WebClient;
/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlUnitSpider {
public static void main(String[] s) throws Exception {
// 目标网页
String url = "http://www.jjwxc.net/";
// 模拟特定浏览器FIREFOX_3
WebClient spider = new WebClient(BrowserVersion.FIREFOX_3);
// 获取目标网页
Page page = spider.getPage(url);
// 打印网页内容
System.out.println(page.getWebResponse().getContentAsString());
// 关闭所有窗口
// spider.closeAllWindows();
spider.close();
}
}
瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
示例代码如下:
包cn.ysh.studio.crawler.ie;
导入 watij.runtime.ie.IE;
/**
* 基于 Watij 抓取网页内容,仅在 Windows 平台上
*
* @作者
*/
公共类 WatijTest {
公共静态无效主要(字符串[] s){
//目标页面
字符串 url = "";
// 实例化 IE 浏览器对象
IE 即 = 新的 IE();
尝试 {
// 启动浏览器
即.start();
// 进入登陆页面
即.goTo(url);
// 等待页面加载
即.waitUntilReady();
// 打印页面内容
System.out.println(ie.html());
} 捕捉(异常 e){
e.printStackTrace();
} 最后 {
try {//关闭IE浏览器
即关闭();
} 捕捉(异常 e){
}
}
}
}
硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;
import org.openqa.selenium.htmlunit.HtmlUnitDriver;
/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlDriverTest {
public static void main(String[] s) {
// 目标网页
String url = "http://www.jjwxc.net/";
HtmlUnitDriver driver = new HtmlUnitDriver();
try {
// 禁用JS脚本功能
driver.setJavascriptEnabled(false);
// 打开目标网页
driver.get(url);
// 获取当前网页源码
String html = driver.getPageSource();
// 打印网页源码
System.out.println(html);
} catch (Exception e) {
// 打印堆栈信息
e.printStackTrace();
} finally {
try {
// 关闭并退出
driver.close();
driver.quit();
} catch (Exception e) {
}
}
}
}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;
import org.watij.webspec.dsl.WebSpec;
/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/
public class WebspecTest {
public static void main(String[] s){
//目标网页
String url ="http://www.jjwxc.net/";
//实例化浏览器对象
WebSpec spec =new WebSpec().mozilla();
//隐藏浏览器窗体
spec.hide();
//打开目标页面
spec.open(url);
//打印网页源码
System.out.println(spec.source());
//关闭所有窗口
spec.closeAll();
}
} 查看全部
htmlunit 抓取网页(:JavaHTML解析器的基本知识点总结(一)
)
(4)支持代理
(5)支持自动cookie管理等。
Java爬虫开发是应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;
import org.apache.http.client.HttpClient;
import org.apache.http.client.ResponseHandler;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.BasicResponseHandler;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.util.EntityUtils;
/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/
public class HttpClientTest {
public static void main(String[] args)throws Exception{
//目标页面
String url ="http://www.jjwxc.net/";
//创建一个默认的HttpClient
HttpClient httpclient =new DefaultHttpClient();
try{
//以get方式请求网页http://www.yshjava.cn
HttpGet httpget =new HttpGet(url);
//打印请求地址
System.out.println("executing request "+ httpget.getURI());
//创建响应处理器处理服务器响应内容
ResponseHandler responseHandler = new BasicResponseHandler();
//执行请求并获取结果
String responseBody = httpclient.execute(httpget, responseHandler);
System.out.println("----------------------------------------");
String htmlStr=null;
if(responseBody != null) {
// htmlStr=new String(EntityUtils.toString(responseBody));
// htmlStr=new String(htmlStr.getBytes("ISO-8859-1"), "gbk"); // 读取乱码解决
responseBody=new String(responseBody.getBytes("ISO-8859-1"), "gb2312");
}
System.out.println(responseBody);
System.out.println("----------------------------------------");
}finally{//关闭连接管理器
httpclient.getConnectionManager().shutdown();
}
}
}
汤
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
示例代码如下:
包cn.ysh.studio.crawler.jsoup;
导入 java.io.IOException;
导入 org.jsoup.Jsoup;
/**
* 基于 Jsoup 抓取网页内容
* @作者
*/
公共类 JsoupTest {
公共静态 void main(String[] args) 抛出 IOException{
//目标页面
字符串 url = "";
//使用Jsoup连接目标页面,执行请求,获取服务器响应内容
字符串 html =Jsoup.connect(url).execute().body();
//打印页面内容
System.out.println(html);
}
}
html单元
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取和解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.Page;
import com.gargoylesoftware.htmlunit.WebClient;
/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlUnitSpider {
public static void main(String[] s) throws Exception {
// 目标网页
String url = "http://www.jjwxc.net/";
// 模拟特定浏览器FIREFOX_3
WebClient spider = new WebClient(BrowserVersion.FIREFOX_3);
// 获取目标网页
Page page = spider.getPage(url);
// 打印网页内容
System.out.println(page.getWebResponse().getContentAsString());
// 关闭所有窗口
// spider.closeAllWindows();
spider.close();
}
}
瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
示例代码如下:
包cn.ysh.studio.crawler.ie;
导入 watij.runtime.ie.IE;
/**
* 基于 Watij 抓取网页内容,仅在 Windows 平台上
*
* @作者
*/
公共类 WatijTest {
公共静态无效主要(字符串[] s){
//目标页面
字符串 url = "";
// 实例化 IE 浏览器对象
IE 即 = 新的 IE();
尝试 {
// 启动浏览器
即.start();
// 进入登陆页面
即.goTo(url);
// 等待页面加载
即.waitUntilReady();
// 打印页面内容
System.out.println(ie.html());
} 捕捉(异常 e){
e.printStackTrace();
} 最后 {
try {//关闭IE浏览器
即关闭();
} 捕捉(异常 e){
}
}
}
}
硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;
import org.openqa.selenium.htmlunit.HtmlUnitDriver;
/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlDriverTest {
public static void main(String[] s) {
// 目标网页
String url = "http://www.jjwxc.net/";
HtmlUnitDriver driver = new HtmlUnitDriver();
try {
// 禁用JS脚本功能
driver.setJavascriptEnabled(false);
// 打开目标网页
driver.get(url);
// 获取当前网页源码
String html = driver.getPageSource();
// 打印网页源码
System.out.println(html);
} catch (Exception e) {
// 打印堆栈信息
e.printStackTrace();
} finally {
try {
// 关闭并退出
driver.close();
driver.quit();
} catch (Exception e) {
}
}
}
}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;
import org.watij.webspec.dsl.WebSpec;
/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/
public class WebspecTest {
public static void main(String[] s){
//目标网页
String url ="http://www.jjwxc.net/";
//实例化浏览器对象
WebSpec spec =new WebSpec().mozilla();
//隐藏浏览器窗体
spec.hide();
//打开目标页面
spec.open(url);
//打印网页源码
System.out.println(spec.source());
//关闭所有窗口
spec.closeAll();
}
}
htmlunit 抓取网页(:JavaHTML解析器的基本知识点总结(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-04-10 12:20
)
(4)支持代理
(5)支持自动cookie管理等。
Java爬虫开发是应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;
import org.apache.http.client.HttpClient;
import org.apache.http.client.ResponseHandler;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.BasicResponseHandler;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.util.EntityUtils;
/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/
public class HttpClientTest {
public static void main(String[] args)throws Exception{
//目标页面
String url ="http://www.jjwxc.net/";
//创建一个默认的HttpClient
HttpClient httpclient =new DefaultHttpClient();
try{
//以get方式请求网页http://www.yshjava.cn
HttpGet httpget =new HttpGet(url);
//打印请求地址
System.out.println("executing request "+ httpget.getURI());
//创建响应处理器处理服务器响应内容
ResponseHandler responseHandler = new BasicResponseHandler();
//执行请求并获取结果
String responseBody = httpclient.execute(httpget, responseHandler);
System.out.println("----------------------------------------");
String htmlStr=null;
if(responseBody != null) {
// htmlStr=new String(EntityUtils.toString(responseBody));
// htmlStr=new String(htmlStr.getBytes("ISO-8859-1"), "gbk"); // 读取乱码解决
responseBody=new String(responseBody.getBytes("ISO-8859-1"), "gb2312");
}
System.out.println(responseBody);
System.out.println("----------------------------------------");
}finally{//关闭连接管理器
httpclient.getConnectionManager().shutdown();
}
}
}
汤
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
示例代码如下:
包cn.ysh.studio.crawler.jsoup;
导入 java.io.IOException;
导入 org.jsoup.Jsoup;
/**
* 基于 Jsoup 抓取网页内容
* @作者
*/
公共类 JsoupTest {
公共静态 void main(String[] args) 抛出 IOException{
//目标页面
字符串 url = "";
//使用Jsoup连接目标页面,执行请求,获取服务器响应内容
字符串 html =Jsoup.connect(url).execute().body();
//打印页面内容
System.out.println(html);
}
}
html单元
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取和解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.Page;
import com.gargoylesoftware.htmlunit.WebClient;
/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlUnitSpider {
public static void main(String[] s) throws Exception {
// 目标网页
String url = "http://www.jjwxc.net/";
// 模拟特定浏览器FIREFOX_3
WebClient spider = new WebClient(BrowserVersion.FIREFOX_3);
// 获取目标网页
Page page = spider.getPage(url);
// 打印网页内容
System.out.println(page.getWebResponse().getContentAsString());
// 关闭所有窗口
// spider.closeAllWindows();
spider.close();
}
}
瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
示例代码如下:
包cn.ysh.studio.crawler.ie;
导入 watij.runtime.ie.IE;
/**
* 基于 Watij 抓取网页内容,仅在 Windows 平台上
*
* @作者
*/
公共类 WatijTest {
公共静态无效主要(字符串[] s){
//目标页面
字符串 url = "";
// 实例化 IE 浏览器对象
IE 即 = 新的 IE();
尝试 {
// 启动浏览器
即.start();
// 进入登陆页面
即.goTo(url);
// 等待页面加载
即.waitUntilReady();
// 打印页面内容
System.out.println(ie.html());
} 捕捉(异常 e){
e.printStackTrace();
} 最后 {
try {//关闭IE浏览器
即关闭();
} 捕捉(异常 e){
}
}
}
}
硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;
import org.openqa.selenium.htmlunit.HtmlUnitDriver;
/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlDriverTest {
public static void main(String[] s) {
// 目标网页
String url = "http://www.jjwxc.net/";
HtmlUnitDriver driver = new HtmlUnitDriver();
try {
// 禁用JS脚本功能
driver.setJavascriptEnabled(false);
// 打开目标网页
driver.get(url);
// 获取当前网页源码
String html = driver.getPageSource();
// 打印网页源码
System.out.println(html);
} catch (Exception e) {
// 打印堆栈信息
e.printStackTrace();
} finally {
try {
// 关闭并退出
driver.close();
driver.quit();
} catch (Exception e) {
}
}
}
}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;
import org.watij.webspec.dsl.WebSpec;
/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/
public class WebspecTest {
public static void main(String[] s){
//目标网页
String url ="http://www.jjwxc.net/";
//实例化浏览器对象
WebSpec spec =new WebSpec().mozilla();
//隐藏浏览器窗体
spec.hide();
//打开目标页面
spec.open(url);
//打印网页源码
System.out.println(spec.source());
//关闭所有窗口
spec.closeAll();
}
} 查看全部
htmlunit 抓取网页(:JavaHTML解析器的基本知识点总结(一)
)
(4)支持代理
(5)支持自动cookie管理等。
Java爬虫开发是应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;
import org.apache.http.client.HttpClient;
import org.apache.http.client.ResponseHandler;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.BasicResponseHandler;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.util.EntityUtils;
/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/
public class HttpClientTest {
public static void main(String[] args)throws Exception{
//目标页面
String url ="http://www.jjwxc.net/";
//创建一个默认的HttpClient
HttpClient httpclient =new DefaultHttpClient();
try{
//以get方式请求网页http://www.yshjava.cn
HttpGet httpget =new HttpGet(url);
//打印请求地址
System.out.println("executing request "+ httpget.getURI());
//创建响应处理器处理服务器响应内容
ResponseHandler responseHandler = new BasicResponseHandler();
//执行请求并获取结果
String responseBody = httpclient.execute(httpget, responseHandler);
System.out.println("----------------------------------------");
String htmlStr=null;
if(responseBody != null) {
// htmlStr=new String(EntityUtils.toString(responseBody));
// htmlStr=new String(htmlStr.getBytes("ISO-8859-1"), "gbk"); // 读取乱码解决
responseBody=new String(responseBody.getBytes("ISO-8859-1"), "gb2312");
}
System.out.println(responseBody);
System.out.println("----------------------------------------");
}finally{//关闭连接管理器
httpclient.getConnectionManager().shutdown();
}
}
}
汤
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
示例代码如下:
包cn.ysh.studio.crawler.jsoup;
导入 java.io.IOException;
导入 org.jsoup.Jsoup;
/**
* 基于 Jsoup 抓取网页内容
* @作者
*/
公共类 JsoupTest {
公共静态 void main(String[] args) 抛出 IOException{
//目标页面
字符串 url = "";
//使用Jsoup连接目标页面,执行请求,获取服务器响应内容
字符串 html =Jsoup.connect(url).execute().body();
//打印页面内容
System.out.println(html);
}
}
html单元
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取和解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.Page;
import com.gargoylesoftware.htmlunit.WebClient;
/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlUnitSpider {
public static void main(String[] s) throws Exception {
// 目标网页
String url = "http://www.jjwxc.net/";
// 模拟特定浏览器FIREFOX_3
WebClient spider = new WebClient(BrowserVersion.FIREFOX_3);
// 获取目标网页
Page page = spider.getPage(url);
// 打印网页内容
System.out.println(page.getWebResponse().getContentAsString());
// 关闭所有窗口
// spider.closeAllWindows();
spider.close();
}
}
瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
示例代码如下:
包cn.ysh.studio.crawler.ie;
导入 watij.runtime.ie.IE;
/**
* 基于 Watij 抓取网页内容,仅在 Windows 平台上
*
* @作者
*/
公共类 WatijTest {
公共静态无效主要(字符串[] s){
//目标页面
字符串 url = "";
// 实例化 IE 浏览器对象
IE 即 = 新的 IE();
尝试 {
// 启动浏览器
即.start();
// 进入登陆页面
即.goTo(url);
// 等待页面加载
即.waitUntilReady();
// 打印页面内容
System.out.println(ie.html());
} 捕捉(异常 e){
e.printStackTrace();
} 最后 {
try {//关闭IE浏览器
即关闭();
} 捕捉(异常 e){
}
}
}
}
硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;
import org.openqa.selenium.htmlunit.HtmlUnitDriver;
/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlDriverTest {
public static void main(String[] s) {
// 目标网页
String url = "http://www.jjwxc.net/";
HtmlUnitDriver driver = new HtmlUnitDriver();
try {
// 禁用JS脚本功能
driver.setJavascriptEnabled(false);
// 打开目标网页
driver.get(url);
// 获取当前网页源码
String html = driver.getPageSource();
// 打印网页源码
System.out.println(html);
} catch (Exception e) {
// 打印堆栈信息
e.printStackTrace();
} finally {
try {
// 关闭并退出
driver.close();
driver.quit();
} catch (Exception e) {
}
}
}
}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;
import org.watij.webspec.dsl.WebSpec;
/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/
public class WebspecTest {
public static void main(String[] s){
//目标网页
String url ="http://www.jjwxc.net/";
//实例化浏览器对象
WebSpec spec =new WebSpec().mozilla();
//隐藏浏览器窗体
spec.hide();
//打开目标页面
spec.open(url);
//打印网页源码
System.out.println(spec.source());
//关闭所有窗口
spec.closeAll();
}
}
htmlunit 抓取网页(使用本文中推荐的开源工具——HtmlUnit,一款能够模拟浏览器的抓包神器!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2022-04-04 16:23
之前,一峰写过一篇关于使用Jsoup爬取网页内容的文章文章:
[Jsoup] HTML解析器,轻松获取网页内容
Jsoup提供的api非常方便,完全类似于JQuery操作,轻松抓取网页数据。但是像Jsoup这样的普通爬虫工具的缺点是不能处理js生成的内容。
做过Html开发的都知道现在很多网站都是用ajax和JavaScript来获取和处理数据,普通爬虫工具已经无法处理js中的内容了。
比如我们在本地新建一个测试web文件text.html,源码如下:
main.html a { line-height: 30px; margin: 20px; } var datas = [ { href : "http://www.jianshu.com/p/8d8edf25850d", title : "推荐一款编程字体,让代码看着更美"}, { href : "http://www.jianshu.com/p/153d9f31288d", title : "Android 利用Camera实现中轴3D卡牌翻转效果"}, { href : "http://www.jianshu.com/p/d6fb0c9c9c26", title : "【Eclipse】挖掘专属最有用的快捷键组合"}, { href : "http://www.jianshu.com/p/72d69b49d135", title : "【IIS】Windows下利用IIS建立网站并实现局域网共享"} ];window.onload = function() { var infos = document.getElementById("infos"); for( var i = 0 ; i < datas.length ; i++) { var a = document.createElement("a"); a.href = datas[i].href ; a.innerText = datas[i].title; infos.appendChild(a); infos.appendChild(document.createElement("br")) }} HtmlUnit 测试网页内容!
通过IIS发布本地网站(参考之前逸峰写的文章:【IIS】在Windows下使用IIS搭建网站实现局域网共享),网页展示的效果浏览器如下:
网页显示效果.jpg
虽然通过网页检查元素,可以看到body中收录了网页显示的文字内容:
网络评论元素.jpg
但是,它根本无法通过 Jsoup 工具获得!从网页源码中可以看出,我们需要爬取的内容是在页面显示出来后通过ajax和JavaScript加载的。
那么该怎么办?使用本文推荐的开源工具——HtmlUnit,一个可以模拟浏览器的抓包神器!
在官网下载对应的jar包,添加到项目工程的lib中。简单的测试代码如下:
import java.io.IOException;import java.net.MalformedURLException;import java.text.ParseException;import com.gargoylesoftware.htmlunit.BrowserVersion;import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;import com.gargoylesoftware.htmlunit.WebClient;import com.gargoylesoftware.htmlunit.html.DomElement;import com.gargoylesoftware.htmlunit.html.DomNodeList;import com.gargoylesoftware.htmlunit.html.HtmlPage;/** * @author 亦枫 * @created_time 2016年1月12日 * @file_user_todo Java测试类 * @blog http://www.jianshu.com/users/1 ... icles */public class JavaTest { /** * 入口函数 * @param args * @throws ParseException */ public static void main(String[] args) throws ParseException { try { WebClient webClient = new WebClient(BrowserVersion.CHROME); HtmlPage htmlPage = (HtmlPage) webClient.getPage("http://localhost/test.html"); DomNodeList domNodeList = htmlPage.getElementsByTagName("a"); for (int i = 0; i < domNodeList.size(); i++) { DomElement domElement = (DomElement) domNodeList.get(i); System.out.println(domElement.asText()); } webClient.close(); } catch (FailingHttpStatusCodeException e) { e.printStackTrace(); } catch (MalformedURLException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }}
运行后,控制台打印出结果:
HtmlUnit测试结果.jpg
可以看出,HtmlUnit 能够抓取 AJAX 和 JavaScript 加载的内容。
HtmlUnit的介绍在官网上很详细。以下内容为易峰翻译的部分内容,供大家参考:
HtmlUnit 是一个基于 Java 的浏览器程序,没有图形界面。它可以调用 HTML 文档并提供 API,使开发人员可以像在普通浏览器上一样访问 Web 内容、填写表单、单击超链接等。
它对 JavaScript 的支持非常好并且还在改进中,可以解析非常复杂的 AJAX 库,模拟不同配置下的 Chrome、Firefox 和 IE 浏览器。
HtmlUnit 通常用于测试目的和检索 网站 信息。
HtmlUnit 提供了很多测试网络请求和爬取网页内容的功能。可以去官网或者其他网站学习使用。 查看全部
htmlunit 抓取网页(使用本文中推荐的开源工具——HtmlUnit,一款能够模拟浏览器的抓包神器!)
之前,一峰写过一篇关于使用Jsoup爬取网页内容的文章文章:
[Jsoup] HTML解析器,轻松获取网页内容
Jsoup提供的api非常方便,完全类似于JQuery操作,轻松抓取网页数据。但是像Jsoup这样的普通爬虫工具的缺点是不能处理js生成的内容。
做过Html开发的都知道现在很多网站都是用ajax和JavaScript来获取和处理数据,普通爬虫工具已经无法处理js中的内容了。
比如我们在本地新建一个测试web文件text.html,源码如下:
main.html a { line-height: 30px; margin: 20px; } var datas = [ { href : "http://www.jianshu.com/p/8d8edf25850d", title : "推荐一款编程字体,让代码看着更美"}, { href : "http://www.jianshu.com/p/153d9f31288d", title : "Android 利用Camera实现中轴3D卡牌翻转效果"}, { href : "http://www.jianshu.com/p/d6fb0c9c9c26", title : "【Eclipse】挖掘专属最有用的快捷键组合"}, { href : "http://www.jianshu.com/p/72d69b49d135", title : "【IIS】Windows下利用IIS建立网站并实现局域网共享"} ];window.onload = function() { var infos = document.getElementById("infos"); for( var i = 0 ; i < datas.length ; i++) { var a = document.createElement("a"); a.href = datas[i].href ; a.innerText = datas[i].title; infos.appendChild(a); infos.appendChild(document.createElement("br")) }} HtmlUnit 测试网页内容!
通过IIS发布本地网站(参考之前逸峰写的文章:【IIS】在Windows下使用IIS搭建网站实现局域网共享),网页展示的效果浏览器如下:
网页显示效果.jpg
虽然通过网页检查元素,可以看到body中收录了网页显示的文字内容:
网络评论元素.jpg
但是,它根本无法通过 Jsoup 工具获得!从网页源码中可以看出,我们需要爬取的内容是在页面显示出来后通过ajax和JavaScript加载的。
那么该怎么办?使用本文推荐的开源工具——HtmlUnit,一个可以模拟浏览器的抓包神器!
在官网下载对应的jar包,添加到项目工程的lib中。简单的测试代码如下:
import java.io.IOException;import java.net.MalformedURLException;import java.text.ParseException;import com.gargoylesoftware.htmlunit.BrowserVersion;import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;import com.gargoylesoftware.htmlunit.WebClient;import com.gargoylesoftware.htmlunit.html.DomElement;import com.gargoylesoftware.htmlunit.html.DomNodeList;import com.gargoylesoftware.htmlunit.html.HtmlPage;/** * @author 亦枫 * @created_time 2016年1月12日 * @file_user_todo Java测试类 * @blog http://www.jianshu.com/users/1 ... icles */public class JavaTest { /** * 入口函数 * @param args * @throws ParseException */ public static void main(String[] args) throws ParseException { try { WebClient webClient = new WebClient(BrowserVersion.CHROME); HtmlPage htmlPage = (HtmlPage) webClient.getPage("http://localhost/test.html";); DomNodeList domNodeList = htmlPage.getElementsByTagName("a"); for (int i = 0; i < domNodeList.size(); i++) { DomElement domElement = (DomElement) domNodeList.get(i); System.out.println(domElement.asText()); } webClient.close(); } catch (FailingHttpStatusCodeException e) { e.printStackTrace(); } catch (MalformedURLException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }}
运行后,控制台打印出结果:
HtmlUnit测试结果.jpg
可以看出,HtmlUnit 能够抓取 AJAX 和 JavaScript 加载的内容。
HtmlUnit的介绍在官网上很详细。以下内容为易峰翻译的部分内容,供大家参考:
HtmlUnit 是一个基于 Java 的浏览器程序,没有图形界面。它可以调用 HTML 文档并提供 API,使开发人员可以像在普通浏览器上一样访问 Web 内容、填写表单、单击超链接等。
它对 JavaScript 的支持非常好并且还在改进中,可以解析非常复杂的 AJAX 库,模拟不同配置下的 Chrome、Firefox 和 IE 浏览器。
HtmlUnit 通常用于测试目的和检索 网站 信息。
HtmlUnit 提供了很多测试网络请求和爬取网页内容的功能。可以去官网或者其他网站学习使用。
htmlunit 抓取网页(使用HtmlUnit抓取百度搜索结果htmlunitjava浏览器的开源实现案例 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-04 16:19
)
使用 HtmlUnit 抓取百度搜索结果
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。相关文件下载地址:(依赖包稍微多一些
)
我的要求是使用百度的高级新闻搜索来抓取指定时间段的新闻。手动搜索设置如图:
通过htmlunit,可以方便的操作网页中的表单和各种输入控件,如HtmlSubmitInput、HtmlTextInput、HtmlRadioButtonInput、HtmlHiddenInput等,通过名称和值可以找到对应的DOM节点。一开始遇到的问题是,即使正确操作了radio Button,也无法得到正确时间段的结果。用chrome查看Http header后发现百度在表单中隐藏了两个参数。参数名称为bt和et,分别代表用户选择的两次begin_date和end_date之间的时间间隔,以及1970-1-1的时间戳。因此,需要手动添加这两个参数,才能得到对应时间段的结果。代码如下:
final WebClient webclient = new WebClient();
final HtmlPage htmlpage = webclient
.getPage("http://news.baidu.com/advanced_news.html");
webclient.setCssEnabled(false);
webclient.setJavaScriptEnabled(false);
// System.out.println(htmlpage.getTitleText());
final HtmlForm form = htmlpage.getFormByName("f");
final HtmlSubmitInput button = form.getInputByValue("百度一下");
final HtmlTextInput textField = form.getInputByName("q1");
textField.setValueAttribute(word);
final List radioButtons = form
.getRadioButtonsByName("s");
radioButtons.get(0).setChecked(false);
radioButtons.get(1).setChecked(true);// 选中限定时间段的radion button
final List titleButtons = form
.getRadioButtonsByName("tn");
titleButtons.get(0).setChecked(false);
titleButtons.get(1).setChecked(true); //选中“仅在新闻的标题中”的radion button
HtmlHiddenInput bt = form.getInputByName("bt");
bt.setValueAttribute("1167580800"); //2007-1-1的时间戳
HtmlHiddenInput et = form.getInputByName("et");
et.setValueAttribute("1199116799"); //2007-12-31的时间戳
final HtmlPage page2 = button.click();
String result = page2.asText();
Pattern pattern = Pattern.compile("找到相关新闻 约(.*) 篇");
Matcher matcher = pattern.matcher(result);
webclient.closeAllWindows();
if (matcher.find())
return matcher.group(1); 查看全部
htmlunit 抓取网页(使用HtmlUnit抓取百度搜索结果htmlunitjava浏览器的开源实现案例
)
使用 HtmlUnit 抓取百度搜索结果
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。相关文件下载地址:(依赖包稍微多一些
)
我的要求是使用百度的高级新闻搜索来抓取指定时间段的新闻。手动搜索设置如图:
通过htmlunit,可以方便的操作网页中的表单和各种输入控件,如HtmlSubmitInput、HtmlTextInput、HtmlRadioButtonInput、HtmlHiddenInput等,通过名称和值可以找到对应的DOM节点。一开始遇到的问题是,即使正确操作了radio Button,也无法得到正确时间段的结果。用chrome查看Http header后发现百度在表单中隐藏了两个参数。参数名称为bt和et,分别代表用户选择的两次begin_date和end_date之间的时间间隔,以及1970-1-1的时间戳。因此,需要手动添加这两个参数,才能得到对应时间段的结果。代码如下:
final WebClient webclient = new WebClient();
final HtmlPage htmlpage = webclient
.getPage("http://news.baidu.com/advanced_news.html";);
webclient.setCssEnabled(false);
webclient.setJavaScriptEnabled(false);
// System.out.println(htmlpage.getTitleText());
final HtmlForm form = htmlpage.getFormByName("f");
final HtmlSubmitInput button = form.getInputByValue("百度一下");
final HtmlTextInput textField = form.getInputByName("q1");
textField.setValueAttribute(word);
final List radioButtons = form
.getRadioButtonsByName("s");
radioButtons.get(0).setChecked(false);
radioButtons.get(1).setChecked(true);// 选中限定时间段的radion button
final List titleButtons = form
.getRadioButtonsByName("tn");
titleButtons.get(0).setChecked(false);
titleButtons.get(1).setChecked(true); //选中“仅在新闻的标题中”的radion button
HtmlHiddenInput bt = form.getInputByName("bt");
bt.setValueAttribute("1167580800"); //2007-1-1的时间戳
HtmlHiddenInput et = form.getInputByName("et");
et.setValueAttribute("1199116799"); //2007-12-31的时间戳
final HtmlPage page2 = button.click();
String result = page2.asText();
Pattern pattern = Pattern.compile("找到相关新闻 约(.*) 篇");
Matcher matcher = pattern.matcher(result);
webclient.closeAllWindows();
if (matcher.find())
return matcher.group(1);
htmlunit 抓取网页(和java自带的网络API进行结合,怎么做?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-04 09:13
HtmlUnit结合了HttpClient和java自带的网络API,更容易抓取数据,更容易操作。HtmlUnit底层还是封装了HttpClient,但是封装之后解析出来的内容更像是一个网页,而不是抽象的请求和响应,所以更方便开发者上手。
// [1] new一个WebClient,在其中定义一种浏览器
WebClient webClent = new WebClient(BrowserVersion.FIREFOX_17);
// [2] 设置网页解析的内容
WebClientOptions options=webClent.getOptions();
options.setCssEnabled(false);
options.setJavaScriptEnabled(true);
options.setActiveXNative(false);
options.setAppletEnabled(false);
options.setRedirectEnabled(true);
options.setThrowExceptionOnFailingStatusCode(false);
options.setThrowExceptionOnScriptError(false);
options.setDoNotTrackEnabled(false);
options.setGeolocationEnabled(false);
// [3] 访问指定的页面,并将其赋予HtmlPage
HtmlPage htmlPage=webClent.getPage(url);
// [4] 获得的HtmlPage并不易于阅读,所以有需要可以通过Jsoup将其转换为Document对象
Document document = Jsoup.parseBodyFragment(htmlPage.asXml());
// [5]关闭
webClent.closeAllWindows();
HtmlPage 非常方便在获取到按钮后进行赋值和操作点击事件。常用方法getElementByName根据名称获取指定的标签(HtmlElement),类型可以设置为标签。
select("") 方法经常用在 Document 对象中。通过这个方法可以得到具体的Element,然后通过解析内容得到需要的数据。
HtmlUnit很容易爬取,但是因为它模拟了网页的点击事件,所以响应返回的所有内容都会很臃肿。如果需要的数据量很小,效率会有点低。 查看全部
htmlunit 抓取网页(和java自带的网络API进行结合,怎么做?)
HtmlUnit结合了HttpClient和java自带的网络API,更容易抓取数据,更容易操作。HtmlUnit底层还是封装了HttpClient,但是封装之后解析出来的内容更像是一个网页,而不是抽象的请求和响应,所以更方便开发者上手。
// [1] new一个WebClient,在其中定义一种浏览器
WebClient webClent = new WebClient(BrowserVersion.FIREFOX_17);
// [2] 设置网页解析的内容
WebClientOptions options=webClent.getOptions();
options.setCssEnabled(false);
options.setJavaScriptEnabled(true);
options.setActiveXNative(false);
options.setAppletEnabled(false);
options.setRedirectEnabled(true);
options.setThrowExceptionOnFailingStatusCode(false);
options.setThrowExceptionOnScriptError(false);
options.setDoNotTrackEnabled(false);
options.setGeolocationEnabled(false);
// [3] 访问指定的页面,并将其赋予HtmlPage
HtmlPage htmlPage=webClent.getPage(url);
// [4] 获得的HtmlPage并不易于阅读,所以有需要可以通过Jsoup将其转换为Document对象
Document document = Jsoup.parseBodyFragment(htmlPage.asXml());
// [5]关闭
webClent.closeAllWindows();
HtmlPage 非常方便在获取到按钮后进行赋值和操作点击事件。常用方法getElementByName根据名称获取指定的标签(HtmlElement),类型可以设置为标签。
select("") 方法经常用在 Document 对象中。通过这个方法可以得到具体的Element,然后通过解析内容得到需要的数据。
HtmlUnit很容易爬取,但是因为它模拟了网页的点击事件,所以响应返回的所有内容都会很臃肿。如果需要的数据量很小,效率会有点低。
htmlunit 抓取网页(使用本文中推荐的开源工具——HtmlUnit,一款能够模拟浏览器的抓包神器!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-03 04:07
之前,一峰写过一篇关于使用Jsoup爬取网页内容的文章文章:
[Jsoup] HTML解析器,轻松获取网页内容
Jsoup提供的api非常方便,完全类似于JQuery操作,轻松抓取网页数据。但是像Jsoup这样的普通爬虫工具的缺点是不能处理js生成的内容。
做过Html开发的都知道现在很多网站都是用ajax和JavaScript来获取和处理数据,普通爬虫工具已经无法处理js中的内容了。
比如我们在本地新建一个测试web文件text.html,源码如下:
main.html
a {
line-height: 30px;
margin: 20px;
}
var datas = [ {
href : "http://www.jianshu.com/p/8d8edf25850d",
title : "推荐一款编程字体,让代码看着更美"
}, {
href : "http://www.jianshu.com/p/153d9f31288d",
title : "Android 利用Camera实现中轴3D卡牌翻转效果"
}, {
href : "http://www.jianshu.com/p/d6fb0c9c9c26",
title : "【Eclipse】挖掘专属最有用的快捷键组合"
}, {
href : "http://www.jianshu.com/p/72d69b49d135",
title : "【IIS】Windows下利用IIS建立网站并实现局域网共享"
} ];
window.onload = function() {
var infos = document.getElementById("infos");
for( var i = 0 ; i < datas.length ; i++)
{
var a = document.createElement("a");
a.href = datas[i].href ;
a.innerText = datas[i].title;
infos.appendChild(a);
infos.appendChild(document.createElement("br"))
}
}
HtmlUnit 测试网页内容!
通过IIS发布本地网站(参考之前逸峰写的文章:
【IIS】在Windows下使用IIS建立网站,实现局域网共享),
网页在浏览器中显示的效果如下:
网页显示效果.jpg
虽然通过网页检查元素,可以看到body中收录了网页显示的文字内容:
网络评论元素.jpg
但是,它根本无法通过 Jsoup 工具获得!从网页的源码可以看出,我们需要爬取的内容是在页面显示出来后通过ajax和JavaScript加载的。
那么该怎么办?使用本文推荐的开源工具——HtmlUnit,一个可以模拟浏览器的抓包神器!
在官网下载对应的jar包,添加到项目工程的lib中。简单的测试代码如下:
import java.io.IOException;
import java.net.MalformedURLException;
import java.text.ParseException;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.DomElement;
import com.gargoylesoftware.htmlunit.html.DomNodeList;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
/**
* @author 亦枫
* @created_time 2016年1月12日
* @file_user_todo Java测试类
* @blog http://www.jianshu.com/users/1 ... icles
*/
public class JavaTest {
/**
* 入口函数
* @param args
* @throws ParseException
*/
public static void main(String[] args) throws ParseException {
try {
WebClient webClient = new WebClient(BrowserVersion.CHROME);
HtmlPage htmlPage = (HtmlPage) webClient.getPage("http://localhost/test.html");
DomNodeList domNodeList = htmlPage.getElementsByTagName("a");
for (int i = 0; i < domNodeList.size(); i++) {
DomElement domElement = (DomElement) domNodeList.get(i);
System.out.println(domElement.asText());
}
webClient.close();
} catch (FailingHttpStatusCodeException e) {
e.printStackTrace();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行后,控制台打印出结果:
HtmlUnit测试结果.jpg
可以看出,HtmlUnit 能够抓取 AJAX 和 JavaScript 加载的内容。
HtmlUnit的介绍在官网上很详细。以下内容为易峰翻译的部分内容,供大家参考:
HtmlUnit 是一个基于 Java 的浏览器程序,没有图形界面。它可以调用 HTML 文档并提供 API,使开发人员可以像在普通浏览器上一样获取 Web 内容、填写表单、单击超链接等。
它对 JavaScript 的支持非常好并且还在改进中,可以解析非常复杂的 AJAX 库,模拟不同配置下的 Chrome、Firefox 和 IE 浏览器。
HtmlUnit 通常用于测试目的和检索 网站 信息。
HtmlUnit 提供了许多测试网络请求和爬取网页内容的功能。可以去官网或者其他网站学习使用。 查看全部
htmlunit 抓取网页(使用本文中推荐的开源工具——HtmlUnit,一款能够模拟浏览器的抓包神器!)
之前,一峰写过一篇关于使用Jsoup爬取网页内容的文章文章:
[Jsoup] HTML解析器,轻松获取网页内容
Jsoup提供的api非常方便,完全类似于JQuery操作,轻松抓取网页数据。但是像Jsoup这样的普通爬虫工具的缺点是不能处理js生成的内容。
做过Html开发的都知道现在很多网站都是用ajax和JavaScript来获取和处理数据,普通爬虫工具已经无法处理js中的内容了。
比如我们在本地新建一个测试web文件text.html,源码如下:
main.html
a {
line-height: 30px;
margin: 20px;
}
var datas = [ {
href : "http://www.jianshu.com/p/8d8edf25850d",
title : "推荐一款编程字体,让代码看着更美"
}, {
href : "http://www.jianshu.com/p/153d9f31288d",
title : "Android 利用Camera实现中轴3D卡牌翻转效果"
}, {
href : "http://www.jianshu.com/p/d6fb0c9c9c26",
title : "【Eclipse】挖掘专属最有用的快捷键组合"
}, {
href : "http://www.jianshu.com/p/72d69b49d135",
title : "【IIS】Windows下利用IIS建立网站并实现局域网共享"
} ];
window.onload = function() {
var infos = document.getElementById("infos");
for( var i = 0 ; i < datas.length ; i++)
{
var a = document.createElement("a");
a.href = datas[i].href ;
a.innerText = datas[i].title;
infos.appendChild(a);
infos.appendChild(document.createElement("br"))
}
}
HtmlUnit 测试网页内容!
通过IIS发布本地网站(参考之前逸峰写的文章:
【IIS】在Windows下使用IIS建立网站,实现局域网共享),
网页在浏览器中显示的效果如下:
网页显示效果.jpg
虽然通过网页检查元素,可以看到body中收录了网页显示的文字内容:
网络评论元素.jpg
但是,它根本无法通过 Jsoup 工具获得!从网页的源码可以看出,我们需要爬取的内容是在页面显示出来后通过ajax和JavaScript加载的。
那么该怎么办?使用本文推荐的开源工具——HtmlUnit,一个可以模拟浏览器的抓包神器!
在官网下载对应的jar包,添加到项目工程的lib中。简单的测试代码如下:
import java.io.IOException;
import java.net.MalformedURLException;
import java.text.ParseException;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.DomElement;
import com.gargoylesoftware.htmlunit.html.DomNodeList;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
/**
* @author 亦枫
* @created_time 2016年1月12日
* @file_user_todo Java测试类
* @blog http://www.jianshu.com/users/1 ... icles
*/
public class JavaTest {
/**
* 入口函数
* @param args
* @throws ParseException
*/
public static void main(String[] args) throws ParseException {
try {
WebClient webClient = new WebClient(BrowserVersion.CHROME);
HtmlPage htmlPage = (HtmlPage) webClient.getPage("http://localhost/test.html";);
DomNodeList domNodeList = htmlPage.getElementsByTagName("a");
for (int i = 0; i < domNodeList.size(); i++) {
DomElement domElement = (DomElement) domNodeList.get(i);
System.out.println(domElement.asText());
}
webClient.close();
} catch (FailingHttpStatusCodeException e) {
e.printStackTrace();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行后,控制台打印出结果:
HtmlUnit测试结果.jpg
可以看出,HtmlUnit 能够抓取 AJAX 和 JavaScript 加载的内容。
HtmlUnit的介绍在官网上很详细。以下内容为易峰翻译的部分内容,供大家参考:
HtmlUnit 是一个基于 Java 的浏览器程序,没有图形界面。它可以调用 HTML 文档并提供 API,使开发人员可以像在普通浏览器上一样获取 Web 内容、填写表单、单击超链接等。
它对 JavaScript 的支持非常好并且还在改进中,可以解析非常复杂的 AJAX 库,模拟不同配置下的 Chrome、Firefox 和 IE 浏览器。
HtmlUnit 通常用于测试目的和检索 网站 信息。
HtmlUnit 提供了许多测试网络请求和爬取网页内容的功能。可以去官网或者其他网站学习使用。
htmlunit 抓取网页(GitHub上有哪些优秀的Java爬虫项目?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-03-31 17:11
GitHub上有哪些不错的Java爬虫项目?
首先声明一下业界普遍使用python作为爬虫。当然也有很多用java语言开发的
一、nutch
由著名的 Doug Cutting 发起的爬虫项目,Apache 旗下的顶级项目,是一个开源的网络爬虫,它使用 MapReduce 以分布式的方式爬取和解析网页信息。
github地址:附上官方地址。官方的:
二、赫里特里克斯
使用java开发的开源网络爬虫系统,获取网站内容完整准确的深拷贝。扩展性强,功能齐全,文档齐全。
github地址:,里面收录文档等信息。
三、杰科
一个轻量级易用的网络爬虫框架,集成了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架。它具有极好的可扩展性。该框架基于开闭原则设计,对修改封闭,对扩展开放。
github地址:收录官网地址。
四、crawler4j
是一个开源的 Java 类库,它提供了一个简单的网页抓取界面。简单易用,支持多线程,支持代理,过滤重复URL等功能。一个多线程网络爬虫可以在几分钟内建立起来。
github地址:,收录使用文档。
其他优秀的java爬虫项目还有很多,就不一一赘述了,比如WebCollector、WebMagic、Spiderman、SeimiCrawler等等。另外,实用一点就好,没必要全部都懂。
哪个java开源网络爬虫好用?
1.nutch 地址:apache/nutch · GitHub apache下的开源爬虫程序,功能丰富,文档齐全。有用于数据捕获、分析和存储的模块。
2.Heritrix 地址:internetarchive/heritrix3 · GitHub 已经存在很久了。已经更新了很多次,也被很多人使用了。功能齐全,文档齐全,网上资料多。拥有自己的 Web 管理控制台,包括 HTTP 服务器。操作员可以通过选择爬虫命令来操作控制台。
3.crawler4j 地址:yasserg/crawler4j · GitHub 因为只有爬虫的核心功能,所以上手极其容易。你可以在几分钟内编写一个多线程爬虫程序。当然,上面提到的nutch的数据存储等功能并不代表Heritrix没有,反之亦然。需要仔细阅读文档,配合实验得出结论。还有比如 JSpider、WebEater、Java Web Crawler、WebLech、Ex-Crawler、JoBo等,这些没用过,不知道。. .
什么是爬虫软件,如果要从网上爬取一些数据,是不是得自己写代码?
这个不一定,爬虫只是一个数据获取的过程,不一定非要会编码,网上有很多现成的软件可以直接爬取数据,下面我简单介绍三个,即优采云、优采云和优采云,感兴趣的朋友可以试试:
01 简单软件—优采云采集器
这是一个非常适合小白采集器的网页,完美支持3大操作平台,完全免费供个人使用。基于人工智能技术,只需输入网页地址,软件就会自动提取和解析数据。数据预览、导出、自动翻页功能简单实用,无需配置任何规则。如果想快速获取网页数据,又不熟悉代码,可以使用这个软件,非常好学:
02 国产软件——优采云采集器
这是一款非常纯正的国产软件。与优采云采集器不同,优采云采集器目前只支持Windows平台,基本功能完全免费,高级功能需要付费,目前支持两种方式:简单的采集和自定义的采集,自带很多现成的数据采集模板,可以快速采集某宝、某东等热门网站 Data,支持数据预览和导出,对于网站Data采集也是一个不错的选择:
03 专业软件—优采云采集
这是一款非常专业且功能强大的数据采集软件。和优采云一样,目前只支持Windows平台。免费版可直接供个人使用。它自动整合来自采集的数据,从清洗到分析的全过程,你可以快速设置爬取规则来爬取网页数据(灵活、智能、强大),无需编写一行代码,如果你是对代码不熟悉,没有任何基础,只想简单的获取网页数据,可以用这个软件,也很不错:
目前就分享一下这三款爬虫软件。对于日常使用来说,完全够用了。当然,除了以上三个软件之外,还有很多其他的爬虫软件,比如神策、作数等也很不错,只要熟悉使用流程,就能掌握很快。网上也有相关的教程和资料。介绍很详细。如果你有兴趣,你可以搜索它。希望以上分享的内容对您有所帮助。也欢迎评论。,留言补充。
参考页 查看全部
htmlunit 抓取网页(GitHub上有哪些优秀的Java爬虫项目?(图))
GitHub上有哪些不错的Java爬虫项目?
首先声明一下业界普遍使用python作为爬虫。当然也有很多用java语言开发的
一、nutch
由著名的 Doug Cutting 发起的爬虫项目,Apache 旗下的顶级项目,是一个开源的网络爬虫,它使用 MapReduce 以分布式的方式爬取和解析网页信息。
github地址:附上官方地址。官方的:
二、赫里特里克斯
使用java开发的开源网络爬虫系统,获取网站内容完整准确的深拷贝。扩展性强,功能齐全,文档齐全。
github地址:,里面收录文档等信息。
三、杰科
一个轻量级易用的网络爬虫框架,集成了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架。它具有极好的可扩展性。该框架基于开闭原则设计,对修改封闭,对扩展开放。
github地址:收录官网地址。
四、crawler4j
是一个开源的 Java 类库,它提供了一个简单的网页抓取界面。简单易用,支持多线程,支持代理,过滤重复URL等功能。一个多线程网络爬虫可以在几分钟内建立起来。
github地址:,收录使用文档。
其他优秀的java爬虫项目还有很多,就不一一赘述了,比如WebCollector、WebMagic、Spiderman、SeimiCrawler等等。另外,实用一点就好,没必要全部都懂。
哪个java开源网络爬虫好用?
1.nutch 地址:apache/nutch · GitHub apache下的开源爬虫程序,功能丰富,文档齐全。有用于数据捕获、分析和存储的模块。
2.Heritrix 地址:internetarchive/heritrix3 · GitHub 已经存在很久了。已经更新了很多次,也被很多人使用了。功能齐全,文档齐全,网上资料多。拥有自己的 Web 管理控制台,包括 HTTP 服务器。操作员可以通过选择爬虫命令来操作控制台。
3.crawler4j 地址:yasserg/crawler4j · GitHub 因为只有爬虫的核心功能,所以上手极其容易。你可以在几分钟内编写一个多线程爬虫程序。当然,上面提到的nutch的数据存储等功能并不代表Heritrix没有,反之亦然。需要仔细阅读文档,配合实验得出结论。还有比如 JSpider、WebEater、Java Web Crawler、WebLech、Ex-Crawler、JoBo等,这些没用过,不知道。. .
什么是爬虫软件,如果要从网上爬取一些数据,是不是得自己写代码?
这个不一定,爬虫只是一个数据获取的过程,不一定非要会编码,网上有很多现成的软件可以直接爬取数据,下面我简单介绍三个,即优采云、优采云和优采云,感兴趣的朋友可以试试:
01 简单软件—优采云采集器
这是一个非常适合小白采集器的网页,完美支持3大操作平台,完全免费供个人使用。基于人工智能技术,只需输入网页地址,软件就会自动提取和解析数据。数据预览、导出、自动翻页功能简单实用,无需配置任何规则。如果想快速获取网页数据,又不熟悉代码,可以使用这个软件,非常好学:
02 国产软件——优采云采集器
这是一款非常纯正的国产软件。与优采云采集器不同,优采云采集器目前只支持Windows平台,基本功能完全免费,高级功能需要付费,目前支持两种方式:简单的采集和自定义的采集,自带很多现成的数据采集模板,可以快速采集某宝、某东等热门网站 Data,支持数据预览和导出,对于网站Data采集也是一个不错的选择:
03 专业软件—优采云采集
这是一款非常专业且功能强大的数据采集软件。和优采云一样,目前只支持Windows平台。免费版可直接供个人使用。它自动整合来自采集的数据,从清洗到分析的全过程,你可以快速设置爬取规则来爬取网页数据(灵活、智能、强大),无需编写一行代码,如果你是对代码不熟悉,没有任何基础,只想简单的获取网页数据,可以用这个软件,也很不错:
目前就分享一下这三款爬虫软件。对于日常使用来说,完全够用了。当然,除了以上三个软件之外,还有很多其他的爬虫软件,比如神策、作数等也很不错,只要熟悉使用流程,就能掌握很快。网上也有相关的教程和资料。介绍很详细。如果你有兴趣,你可以搜索它。希望以上分享的内容对您有所帮助。也欢迎评论。,留言补充。
参考页
htmlunit 抓取网页(的java程序是什么?答案是有哪些?? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-03-30 21:29
)
1.HtmlUnit1.1 简介
HtmlUnit 是一个用 java 编写的无界面浏览器,它可以对 html 文档进行建模、通过 API 调用页面、填写表单、单击链接等等。像普通浏览器一样运行。通常用于测试和从网页中抓取信息。
官方简介翻译:<br />
HtmlUnit是一个无界面浏览器Java程序。它为HTML文档建模,提供了调用页面、填写表单、单击链接等操作的API。就跟你在浏览器里做的操作一样。
HtmlUnit不错的JavaScript支持(不断改进),甚至可以使用相当复杂的AJAX库,根据配置的不同模拟Chrome、Firefox或Internet Explorer等浏览器。
HtmlUnit通常用于测试或从web站点检索信息。
1.2 使用场景
对于java实现的网络爬虫程序,我们一般可以使用apache的HttpClient组件来获取HTML页面信息。HttpClient实现的http请求返回的响应一般是纯文本文档页面,也就是最原创的html页面。
对于一个静态的html页面,使用httpClient就足够爬出我们需要的信息了。但是对于越来越多的动态网页,更多的数据是通过异步JS代码获取和渲染的,而初始的html页面是不收录这部分数据的。
上图中我们看到的网页在初始文档加载后并没有看到红框中的数据列表。浏览器通过执行异步JS请求,将获取到的动态数据渲染到原创文档页面中,最终变成我们看到的网页。对于这部分需要JS代码执行的数据,httpClient是无能为力的。虽然我们可以通过研究得到JS执行的请求路径,然后用java代码来获取我们需要的部分数据,不说能不能从JS脚本中分析请求路径和请求参数,只分析这部分数据源码成本已经很高了。
通过上面的介绍,我们了解到现在很大一部分动态网页都是通过异步JS请求获得的数据,然后通过JS渲染页面。那么我们能不能做这样的假设,假设我们的爬虫程序模拟一个浏览器,拿到html页面后,像浏览器一样执行异步JS代码,JS渲染好html页面后,就可以愉快的获取到节点信息了这页纸。那么有没有这样的java程序呢?
答案是肯定的。
HtmlUnit就是这样一个库,用来做界面显示的所有异步工作。没有耗时的显示工作,HtmlUnit 加载的完整网页比实际的浏览器块更多。并且根据不同的配置,HtmlUnit可以模拟市面上常见的Chrome、Firefox、IE浏览器等浏览器。
通过HtmlUnit库,加载一个完整的Html页面(图片和视频除外),然后将其转换成我们常用的字符串格式,使用Jsoup等其他工具获取元素。当然,你也可以直接从HtmlUnit提供的对象中获取网页元素,甚至可以操作按钮、表单等控件。除了不能像可见浏览器那样用鼠标和键盘浏览网页之外,我们可以使用HtmlUnit来模拟所有其他的操作,比如登录网站、写博客等都可以完成。当然,网页内容抓取是最简单的应用。
2.J4L2.1官方简介
J4L OCR 工具是一组组件,可用于在 Java 应用程序中收录 OCR 功能。这意味着您可以接收传真、PDF 文件或扫描文档并从图像中提取商业信息。主要的3个组件是:
详细使用步骤请参考这篇文章文章:Java使用J4L识别验证码
本文文章主要介绍使用HtmlUnit模拟登录
3.实际案例3.1.场景
登录页面,包括表单,需要填写用户名、登录密码、验证码,实现用户登录。
3.2操作步骤
使用htmlunit模拟登录是一个获取登录页面->找到输入框->填写用户名和密码->填写验证码->模拟点击登录的过程。
4.实现代码4.1maven引入HtmlUnit依赖
net.sourceforge.htmlunit
htmlunit
2.18
4.2 主要方法
登录类
public static void main(String[] args) throws Exception {
DoCheck();
}
public static void DoCheck() throws Exception {
WebClient webClient = new WebClient(BrowserVersion.CHROME);//设置浏览器内核
webClient.getOptions().setJavaScriptEnabled(true);// js是否可用
webClient.getOptions().setCssEnabled(true);//css 一般设置false因为影响运行速度
webClient.getOptions().setThrowExceptionOnScriptError(false);//设置js抛出异常:false
webClient.getOptions().setActiveXNative(false);
//ajax
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
webClient.getOptions().setUseInsecureSSL(false);
//允许重定向
webClient.getOptions().setRedirectEnabled(true);
//连接超时
webClient.getOptions().setTimeout(5000);
//js执行超时
webClient.setJavaScriptTimeout(10000 * 3);
//允许cookie
webClient.getCookieManager().setCookiesEnabled(true);
String url = "http://hrportalneu.cs/HRPortal ... 3B%3B
HtmlPage page = webClient.getPage(url);
webClient.waitForBackgroundJavaScript(5000);
HtmlPage newPage;
newPage = readyPage(page, webClient, "btnCheckIn1");
System.out.println("url----------------" + newPage.getUrl());
System.out.println("checkIn执行后页面:" + newPage.asXml());
IOUtils.write(newPage.asXml().getBytes(), new FileWriter(new File("D:/checkIn.txt")));
if (!newPage.asXml().contains("登录成功")) {
DoCheck();
}
webClient.close();
}
public static HtmlPage readyPage(HtmlPage page, WebClient webClient, String type) throws Exception {
//封装页面元素
HtmlForm form = page.getHtmlElementById("form1");
HtmlTextInput tbxUsername = form.getInputByName("tbxUsername");
tbxUsername.setValueAttribute("用户名*******");
HtmlPasswordInput tbxPassword = form.getInputByName("tbxPassword");
tbxPassword.setValueAttribute("密码*******");
//获取验证码图片
HtmlImage verify_img = (HtmlImage) page.getElementById("AuthCode1$codeText$img");
File file = new File("D:\\" + "check" + ".png");
//保存验证码图片
verify_img.saveAs(file);
System.out.println("验证码图片已保存!");
//保存路径
String filePath = file.getPath();
//裁剪验证码
ImageUtil.cutImage(filePath, 1, 1, 96, 34);
//自动识别验证码
OCRFacade facade = new OCRFacade();
//识别验证码
String code = facade.recognizeFile(filePath, "eng");
//处理字符串
code = code.replaceAll(" ", "");
code = code.replaceAll("\\n", "");
System.out.println("验证码:" + code);
//定位验证码输入框
HtmlTextInput verify_code = form.getInputByName("AuthCode1$codeText");
//填入自动识别出来的验证码
verify_code.setValueAttribute(code);
System.out.println("原始页面:" + page.asXml());
HtmlPage newPage = null;
//操作按钮
if (type.equals("btnCheckIn1")) {
DomElement btnCheckIn1 = page.getElementById("btnCheckIn1");
System.out.println("doCheckIn");
newPage = btnCheckIn1.click();
}
//等待js加载
webClient.waitForBackgroundJavaScript(5000);
return newPage;
}
ImageUtil.class
public class ImageUtil {
public static void cutImage(String filePath, int x, int y, int w, int h)
throws Exception {
// 首先通过ImageIo中的方法,创建一个Image + InputStream到内存
ImageInputStream iis = ImageIO
.createImageInputStream(new FileInputStream(filePath));
// 再按照指定格式构造一个Reader(Reader不能new的)
Iterator it = ImageIO.getImageReadersByFormatName("gif");
ImageReader imagereader = (ImageReader) it.next();
// 再通过ImageReader绑定 InputStream
imagereader.setInput(iis);
// 设置感兴趣的源区域。
ImageReadParam par = imagereader.getDefaultReadParam();
par.setSourceRegion(new Rectangle(x, y, w, h));
// 从 reader得到BufferImage
BufferedImage bi = imagereader.read(0, par);
// 将BuffeerImage写出通过ImageIO
ImageIO.write(bi, "png", new File(filePath));
}
} 查看全部
htmlunit 抓取网页(的java程序是什么?答案是有哪些??
)
1.HtmlUnit1.1 简介
HtmlUnit 是一个用 java 编写的无界面浏览器,它可以对 html 文档进行建模、通过 API 调用页面、填写表单、单击链接等等。像普通浏览器一样运行。通常用于测试和从网页中抓取信息。
官方简介翻译:<br />
HtmlUnit是一个无界面浏览器Java程序。它为HTML文档建模,提供了调用页面、填写表单、单击链接等操作的API。就跟你在浏览器里做的操作一样。
HtmlUnit不错的JavaScript支持(不断改进),甚至可以使用相当复杂的AJAX库,根据配置的不同模拟Chrome、Firefox或Internet Explorer等浏览器。
HtmlUnit通常用于测试或从web站点检索信息。
1.2 使用场景
对于java实现的网络爬虫程序,我们一般可以使用apache的HttpClient组件来获取HTML页面信息。HttpClient实现的http请求返回的响应一般是纯文本文档页面,也就是最原创的html页面。
对于一个静态的html页面,使用httpClient就足够爬出我们需要的信息了。但是对于越来越多的动态网页,更多的数据是通过异步JS代码获取和渲染的,而初始的html页面是不收录这部分数据的。
上图中我们看到的网页在初始文档加载后并没有看到红框中的数据列表。浏览器通过执行异步JS请求,将获取到的动态数据渲染到原创文档页面中,最终变成我们看到的网页。对于这部分需要JS代码执行的数据,httpClient是无能为力的。虽然我们可以通过研究得到JS执行的请求路径,然后用java代码来获取我们需要的部分数据,不说能不能从JS脚本中分析请求路径和请求参数,只分析这部分数据源码成本已经很高了。
通过上面的介绍,我们了解到现在很大一部分动态网页都是通过异步JS请求获得的数据,然后通过JS渲染页面。那么我们能不能做这样的假设,假设我们的爬虫程序模拟一个浏览器,拿到html页面后,像浏览器一样执行异步JS代码,JS渲染好html页面后,就可以愉快的获取到节点信息了这页纸。那么有没有这样的java程序呢?
答案是肯定的。
HtmlUnit就是这样一个库,用来做界面显示的所有异步工作。没有耗时的显示工作,HtmlUnit 加载的完整网页比实际的浏览器块更多。并且根据不同的配置,HtmlUnit可以模拟市面上常见的Chrome、Firefox、IE浏览器等浏览器。
通过HtmlUnit库,加载一个完整的Html页面(图片和视频除外),然后将其转换成我们常用的字符串格式,使用Jsoup等其他工具获取元素。当然,你也可以直接从HtmlUnit提供的对象中获取网页元素,甚至可以操作按钮、表单等控件。除了不能像可见浏览器那样用鼠标和键盘浏览网页之外,我们可以使用HtmlUnit来模拟所有其他的操作,比如登录网站、写博客等都可以完成。当然,网页内容抓取是最简单的应用。
2.J4L2.1官方简介
J4L OCR 工具是一组组件,可用于在 Java 应用程序中收录 OCR 功能。这意味着您可以接收传真、PDF 文件或扫描文档并从图像中提取商业信息。主要的3个组件是:
详细使用步骤请参考这篇文章文章:Java使用J4L识别验证码
本文文章主要介绍使用HtmlUnit模拟登录
3.实际案例3.1.场景
登录页面,包括表单,需要填写用户名、登录密码、验证码,实现用户登录。
3.2操作步骤
使用htmlunit模拟登录是一个获取登录页面->找到输入框->填写用户名和密码->填写验证码->模拟点击登录的过程。
4.实现代码4.1maven引入HtmlUnit依赖
net.sourceforge.htmlunit
htmlunit
2.18
4.2 主要方法
登录类
public static void main(String[] args) throws Exception {
DoCheck();
}
public static void DoCheck() throws Exception {
WebClient webClient = new WebClient(BrowserVersion.CHROME);//设置浏览器内核
webClient.getOptions().setJavaScriptEnabled(true);// js是否可用
webClient.getOptions().setCssEnabled(true);//css 一般设置false因为影响运行速度
webClient.getOptions().setThrowExceptionOnScriptError(false);//设置js抛出异常:false
webClient.getOptions().setActiveXNative(false);
//ajax
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
webClient.getOptions().setUseInsecureSSL(false);
//允许重定向
webClient.getOptions().setRedirectEnabled(true);
//连接超时
webClient.getOptions().setTimeout(5000);
//js执行超时
webClient.setJavaScriptTimeout(10000 * 3);
//允许cookie
webClient.getCookieManager().setCookiesEnabled(true);
String url = "http://hrportalneu.cs/HRPortal ... 3B%3B
HtmlPage page = webClient.getPage(url);
webClient.waitForBackgroundJavaScript(5000);
HtmlPage newPage;
newPage = readyPage(page, webClient, "btnCheckIn1");
System.out.println("url----------------" + newPage.getUrl());
System.out.println("checkIn执行后页面:" + newPage.asXml());
IOUtils.write(newPage.asXml().getBytes(), new FileWriter(new File("D:/checkIn.txt")));
if (!newPage.asXml().contains("登录成功")) {
DoCheck();
}
webClient.close();
}
public static HtmlPage readyPage(HtmlPage page, WebClient webClient, String type) throws Exception {
//封装页面元素
HtmlForm form = page.getHtmlElementById("form1");
HtmlTextInput tbxUsername = form.getInputByName("tbxUsername");
tbxUsername.setValueAttribute("用户名*******");
HtmlPasswordInput tbxPassword = form.getInputByName("tbxPassword");
tbxPassword.setValueAttribute("密码*******");
//获取验证码图片
HtmlImage verify_img = (HtmlImage) page.getElementById("AuthCode1$codeText$img");
File file = new File("D:\\" + "check" + ".png");
//保存验证码图片
verify_img.saveAs(file);
System.out.println("验证码图片已保存!");
//保存路径
String filePath = file.getPath();
//裁剪验证码
ImageUtil.cutImage(filePath, 1, 1, 96, 34);
//自动识别验证码
OCRFacade facade = new OCRFacade();
//识别验证码
String code = facade.recognizeFile(filePath, "eng");
//处理字符串
code = code.replaceAll(" ", "");
code = code.replaceAll("\\n", "");
System.out.println("验证码:" + code);
//定位验证码输入框
HtmlTextInput verify_code = form.getInputByName("AuthCode1$codeText");
//填入自动识别出来的验证码
verify_code.setValueAttribute(code);
System.out.println("原始页面:" + page.asXml());
HtmlPage newPage = null;
//操作按钮
if (type.equals("btnCheckIn1")) {
DomElement btnCheckIn1 = page.getElementById("btnCheckIn1");
System.out.println("doCheckIn");
newPage = btnCheckIn1.click();
}
//等待js加载
webClient.waitForBackgroundJavaScript(5000);
return newPage;
}
ImageUtil.class
public class ImageUtil {
public static void cutImage(String filePath, int x, int y, int w, int h)
throws Exception {
// 首先通过ImageIo中的方法,创建一个Image + InputStream到内存
ImageInputStream iis = ImageIO
.createImageInputStream(new FileInputStream(filePath));
// 再按照指定格式构造一个Reader(Reader不能new的)
Iterator it = ImageIO.getImageReadersByFormatName("gif");
ImageReader imagereader = (ImageReader) it.next();
// 再通过ImageReader绑定 InputStream
imagereader.setInput(iis);
// 设置感兴趣的源区域。
ImageReadParam par = imagereader.getDefaultReadParam();
par.setSourceRegion(new Rectangle(x, y, w, h));
// 从 reader得到BufferImage
BufferedImage bi = imagereader.read(0, par);
// 将BuffeerImage写出通过ImageIO
ImageIO.write(bi, "png", new File(filePath));
}
}
htmlunit 抓取网页(htmlunit网络工具一个没有没有 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-03-24 07:14
)
1:背景
本来想用jsoup抓取一个页面,但是抓取的数据总是不完整,然后发现页面执行js后,页面上渲染了一些数据,也就是说数据页是只在js执行后显示。数据会显示出来,但是jsoup无法实现执行页面的js。
2:解决
经过搜索,发现htmlunit网络工具可以实现js。它相当于一个没有页面的浏览器。解决方法是使用htmlUnit发送网络请求,执行js获取页面,然后使用jsoup转换成Document页面对象。然后使用jsoup分析页面读取数据。
3:htmlUnit发送请求
1 public static Document getDocument() throws IOException, InterruptedException{
2 /*String url="https://www.marklines.com/cn/v ... 3B%3B
3 Connection connect = Jsoup.connect(url).userAgent("")
4 .header("Cookie", "PLAY_LANG=cn; _plh=b9289d0a863a8fc9c79fb938f15372f7731d13fb; PLATFORM_SESSION=39034d07000717c664134556ad39869771aabc04-_ldi=520275&_lsh=8cf91cdbcbbb255adff5cba6061f561b642f5157&csrfToken=209f20c8473bc0518413c226f898ff79cd69c3ff-1539926671235-b853a6a63c77dd8fcc364a58&_lpt=%2Fcn%2Fvehicle_sales%2Fsearch&_lsi=1646321; _ga=GA1.2.2146952143.1539926675; _gid=GA1.2.1032787565.1539926675; _plh_notime=8cf91cdbcbbb255adff5cba6061f561b642f5157")
5 .timeout(360000000);
6 Document document = connect.get();*/
7 WebClient wc = new WebClient(BrowserVersion.CHROME);
8 //是否使用不安全的SSL
9 wc.getOptions().setUseInsecureSSL(true);
10 //启用JS解释器,默认为true
11 wc.getOptions().setJavaScriptEnabled(true);
12 //禁用CSS
13 wc.getOptions().setCssEnabled(false);
14 //js运行错误时,是否抛出异常
15 wc.getOptions().setThrowExceptionOnScriptError(false);
16 //状态码错误时,是否抛出异常
17 wc.getOptions().setThrowExceptionOnFailingStatusCode(false);
18 //是否允许使用ActiveX
19 wc.getOptions().setActiveXNative(false);
20 //等待js时间
21 wc.waitForBackgroundJavaScript(600*1000);
22 //设置Ajax异步处理控制器即启用Ajax支持
23 wc.setAjaxController(new NicelyResynchronizingAjaxController());
24 //设置超时时间
25 wc.getOptions().setTimeout(1000000);
26 //不跟踪抓取
27 wc.getOptions().setDoNotTrackEnabled(false);
28 WebRequest request=new WebRequest(new URL("https://www.marklines.com/cn/v ... 6quot;));
29 request.setAdditionalHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:62.0) Gecko/20100101 Firefox/62.0");
30 request.setAdditionalHeader("Cookie","PLAY_LANG=cn; _plh=b9289d0a863a8fc9c79fb938f15372f7731d13fb; PLATFORM_SESSION=39034d07000717c664134556ad39869771aabc04-_ldi=520275&_lsh=8cf91cdbcbbb255adff5cba6061f561b642f5157&csrfToken=209f20c8473bc0518413c226f898ff79cd69c3ff-1539926671235-b853a6a63c77dd8fcc364a58&_lpt=%2Fcn%2Fvehicle_sales%2Fsearch&_lsi=1646321; _ga=GA1.2.2146952143.1539926675; _gid=GA1.2.1032787565.1539926675; _plh_notime=8cf91cdbcbbb255adff5cba6061f561b642f5157");
31 try {
32 //模拟浏览器打开一个目标网址
33 HtmlPage htmlPage = wc.getPage(request);
34 //为了获取js执行的数据 线程开始沉睡等待
35 Thread.sleep(1000);//这个线程的等待 因为js加载需要时间的
36 //以xml形式获取响应文本
37 String xml = htmlPage.asXml();
38 //并转为Document对象return
39 return Jsoup.parse(xml);
40 //System.out.println(xml.contains("结果.xls"));//false
41 } catch (FailingHttpStatusCodeException e) {
42 e.printStackTrace();
43 } catch (MalformedURLException e) {
44 e.printStackTrace();
45 } catch (IOException e) {
46 e.printStackTrace();
47 }
48 return null;
49 }
4:返回的Document对象交给jsoup处理
这里只做一个简单的输出,看看数据是否全部渲染完毕。
1 Document doc=getDocument();
2 Element table=doc.select("table.table.table-bordered.aggregate_table").get(0);//获取到表格
3 Element tableContext=table.getElementsByTag("tbody").get(0);
4 Elements contextTrs=tableContext.getElementsByTag("tr");
5 System.out.println(contextTrs.size());
6
7
8 String context=doc.toString();
9 OutputStreamWriter pw = null;
10 pw = new OutputStreamWriter(new FileOutputStream("D:/test.txt"),"GBK");
11 pw.write(context);
12 pw.close(); 查看全部
htmlunit 抓取网页(htmlunit网络工具一个没有没有
)
1:背景
本来想用jsoup抓取一个页面,但是抓取的数据总是不完整,然后发现页面执行js后,页面上渲染了一些数据,也就是说数据页是只在js执行后显示。数据会显示出来,但是jsoup无法实现执行页面的js。
2:解决
经过搜索,发现htmlunit网络工具可以实现js。它相当于一个没有页面的浏览器。解决方法是使用htmlUnit发送网络请求,执行js获取页面,然后使用jsoup转换成Document页面对象。然后使用jsoup分析页面读取数据。
3:htmlUnit发送请求
1 public static Document getDocument() throws IOException, InterruptedException{
2 /*String url="https://www.marklines.com/cn/v ... 3B%3B
3 Connection connect = Jsoup.connect(url).userAgent("")
4 .header("Cookie", "PLAY_LANG=cn; _plh=b9289d0a863a8fc9c79fb938f15372f7731d13fb; PLATFORM_SESSION=39034d07000717c664134556ad39869771aabc04-_ldi=520275&_lsh=8cf91cdbcbbb255adff5cba6061f561b642f5157&csrfToken=209f20c8473bc0518413c226f898ff79cd69c3ff-1539926671235-b853a6a63c77dd8fcc364a58&_lpt=%2Fcn%2Fvehicle_sales%2Fsearch&_lsi=1646321; _ga=GA1.2.2146952143.1539926675; _gid=GA1.2.1032787565.1539926675; _plh_notime=8cf91cdbcbbb255adff5cba6061f561b642f5157")
5 .timeout(360000000);
6 Document document = connect.get();*/
7 WebClient wc = new WebClient(BrowserVersion.CHROME);
8 //是否使用不安全的SSL
9 wc.getOptions().setUseInsecureSSL(true);
10 //启用JS解释器,默认为true
11 wc.getOptions().setJavaScriptEnabled(true);
12 //禁用CSS
13 wc.getOptions().setCssEnabled(false);
14 //js运行错误时,是否抛出异常
15 wc.getOptions().setThrowExceptionOnScriptError(false);
16 //状态码错误时,是否抛出异常
17 wc.getOptions().setThrowExceptionOnFailingStatusCode(false);
18 //是否允许使用ActiveX
19 wc.getOptions().setActiveXNative(false);
20 //等待js时间
21 wc.waitForBackgroundJavaScript(600*1000);
22 //设置Ajax异步处理控制器即启用Ajax支持
23 wc.setAjaxController(new NicelyResynchronizingAjaxController());
24 //设置超时时间
25 wc.getOptions().setTimeout(1000000);
26 //不跟踪抓取
27 wc.getOptions().setDoNotTrackEnabled(false);
28 WebRequest request=new WebRequest(new URL("https://www.marklines.com/cn/v ... 6quot;));
29 request.setAdditionalHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:62.0) Gecko/20100101 Firefox/62.0");
30 request.setAdditionalHeader("Cookie","PLAY_LANG=cn; _plh=b9289d0a863a8fc9c79fb938f15372f7731d13fb; PLATFORM_SESSION=39034d07000717c664134556ad39869771aabc04-_ldi=520275&_lsh=8cf91cdbcbbb255adff5cba6061f561b642f5157&csrfToken=209f20c8473bc0518413c226f898ff79cd69c3ff-1539926671235-b853a6a63c77dd8fcc364a58&_lpt=%2Fcn%2Fvehicle_sales%2Fsearch&_lsi=1646321; _ga=GA1.2.2146952143.1539926675; _gid=GA1.2.1032787565.1539926675; _plh_notime=8cf91cdbcbbb255adff5cba6061f561b642f5157");
31 try {
32 //模拟浏览器打开一个目标网址
33 HtmlPage htmlPage = wc.getPage(request);
34 //为了获取js执行的数据 线程开始沉睡等待
35 Thread.sleep(1000);//这个线程的等待 因为js加载需要时间的
36 //以xml形式获取响应文本
37 String xml = htmlPage.asXml();
38 //并转为Document对象return
39 return Jsoup.parse(xml);
40 //System.out.println(xml.contains("结果.xls"));//false
41 } catch (FailingHttpStatusCodeException e) {
42 e.printStackTrace();
43 } catch (MalformedURLException e) {
44 e.printStackTrace();
45 } catch (IOException e) {
46 e.printStackTrace();
47 }
48 return null;
49 }
4:返回的Document对象交给jsoup处理
这里只做一个简单的输出,看看数据是否全部渲染完毕。
1 Document doc=getDocument();
2 Element table=doc.select("table.table.table-bordered.aggregate_table").get(0);//获取到表格
3 Element tableContext=table.getElementsByTag("tbody").get(0);
4 Elements contextTrs=tableContext.getElementsByTag("tr");
5 System.out.println(contextTrs.size());
6
7
8 String context=doc.toString();
9 OutputStreamWriter pw = null;
10 pw = new OutputStreamWriter(new FileOutputStream("D:/test.txt"),"GBK");
11 pw.write(context);
12 pw.close();
htmlunit 抓取网页(抓一个今日头条的首页内容解决方案-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2022-03-17 09:04
不知道大家有没有在使用jsoup的过程中遇到爬取内容,发现部分网页中的内容是通过javascript异步加载的,导致我们的爬虫空手返回(只抓到一个网页)框架)。
当我第一次遇到这个问题时,我想到了两个解决方案:
在等待网页异步加载后,使用类似于Python中延迟加载的方法对异步加载的网页进行爬取。使用特殊的方法,让爬取的网页的框架模拟里面的JavaScript代码的执行,最终得到完整的页面
在搜索引擎的帮助下,我决定使用方案二来解决这个问题。解决方案1中没有搜索到更好的第三方库。在java中使用解决方案1解决这个问题的朋友希望可以与以下交流,不胜感激讨论。
案例很简单,抓取一条今日头条的首页内容。你可以看一下今日头条的首页,里面的内容是异步加载的。
添加jsoup和htmlunit依赖
org.jsoup
jsoup
1.10.2
net.sourceforge.htmlunit
htmlunit
2.25
首先我们单独使用jsoup来解析今日头条的首页
String url = "https://www.toutiao.com/";
Connection connect = Jsoup.connect(url);
Document document = connect.get();
System.out.println(document);
↑这里只能获取网页的frame内容,不能获取首页的新闻内容
让我们用 htmlunit 试试吧
//构造一个webClient 模拟Chrome 浏览器
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//屏蔽日志信息
LogFactory.getFactory().setAttribute("org.apache.commons.logging.Log",
"org.apache.commons.logging.impl.NoOpLog");
java.util.logging.Logger.getLogger("com.gargoylesoftware").setLevel(Level.OFF);
//支持JavaScript
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setTimeout(5000);
HtmlPage rootPage = webClient.getPage(url);
//设置一个运行JavaScript的时间
webClient.waitForBackgroundJavaScript(5000);
String html = rootPage.asXml();
Document document = Jsoup.parse(html);
这为我们提供了一个运行 JavaScript 的完整源页面 查看全部
htmlunit 抓取网页(抓一个今日头条的首页内容解决方案-苏州安嘉)
不知道大家有没有在使用jsoup的过程中遇到爬取内容,发现部分网页中的内容是通过javascript异步加载的,导致我们的爬虫空手返回(只抓到一个网页)框架)。
当我第一次遇到这个问题时,我想到了两个解决方案:
在等待网页异步加载后,使用类似于Python中延迟加载的方法对异步加载的网页进行爬取。使用特殊的方法,让爬取的网页的框架模拟里面的JavaScript代码的执行,最终得到完整的页面
在搜索引擎的帮助下,我决定使用方案二来解决这个问题。解决方案1中没有搜索到更好的第三方库。在java中使用解决方案1解决这个问题的朋友希望可以与以下交流,不胜感激讨论。
案例很简单,抓取一条今日头条的首页内容。你可以看一下今日头条的首页,里面的内容是异步加载的。
添加jsoup和htmlunit依赖
org.jsoup
jsoup
1.10.2
net.sourceforge.htmlunit
htmlunit
2.25
首先我们单独使用jsoup来解析今日头条的首页
String url = "https://www.toutiao.com/";
Connection connect = Jsoup.connect(url);
Document document = connect.get();
System.out.println(document);
↑这里只能获取网页的frame内容,不能获取首页的新闻内容
让我们用 htmlunit 试试吧
//构造一个webClient 模拟Chrome 浏览器
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//屏蔽日志信息
LogFactory.getFactory().setAttribute("org.apache.commons.logging.Log",
"org.apache.commons.logging.impl.NoOpLog");
java.util.logging.Logger.getLogger("com.gargoylesoftware").setLevel(Level.OFF);
//支持JavaScript
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setTimeout(5000);
HtmlPage rootPage = webClient.getPage(url);
//设置一个运行JavaScript的时间
webClient.waitForBackgroundJavaScript(5000);
String html = rootPage.asXml();
Document document = Jsoup.parse(html);
这为我们提供了一个运行 JavaScript 的完整源页面
htmlunit 抓取网页(介绍常用爬虫开源项目和腾讯微博爬虫的问题总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-15 03:18
介绍
常用爬虫开源项目
新浪微博爬虫和腾讯微博爬虫
新浪爬虫问题
总结
介绍
相关介绍
即网络爬虫是一种自动获取网页内容的程序。它是搜索引擎的重要组成部分,因此搜索引擎优化主要针对爬虫进行优化。
主要分类
网络爬虫从万维网上为搜索引擎下载网页。一般分为传统爬虫和专注爬虫。
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某个停止条件。通俗的讲,就是通过源码分析得到想要的内容。
焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
反爬虫:KS-WAF将爬虫行为分为搜索引擎爬虫和扫描爬虫,可以屏蔽特定搜索引擎爬虫以节省带宽和性能,也可以屏蔽扫描爬虫防止网站被恶意爬取。
常用爬虫开源项目
Nutch 标志 搜索引擎 Nutch
Nutch 是一个搜索引擎的开源 Java 实现。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫。
尽管网络搜索是漫游 Internet 的基本要求,但现有网络搜索引擎的数量正在下降。而这很可能会演变成一家为其商业利益垄断几乎所有网络搜索的公司。这显然对绝大多数网民不利。
现在所有主要的搜索引擎都使用专有的排名算法,这些算法不能解释为什么一个页面被排在一个特定的位置。另外,有些搜索引擎按网站付费,而不是按自己的值排序。
Apache Nutch 项目(一个网络搜索引擎)。Nutch 发展到一定程度时,遇到了可扩展性的问题,即当存储的网页数量达到 1 亿的水平时,Nutch 原有的结构很难达到高效率。就在整个团队不知所措的时候,救星谷歌出现了。Google 在 2003 年发布了 Google 使用的分布式文件存储系统文章(The Google File System),Nutch 开发者意识到可以将 Nutch 放在 GFS 上实现,所以经过一年的发展,NDFS(Nutch Distributed文件系统)出现。在解决了瓶颈问题之后,Nutch 有了很大的发展,而就在 2004 年,Google 发布了 MapReduce 的想法,
但是在 Nutch 中加入 GFS 和 MapReduce 之后,Nutch 变得太大了,超出了网络搜索引擎的范围,所以在 2006 年,分别移植了 NDFS 和 MapReduce,形成了一个名为 Hadoop 的新项目。
Java 多线程网络爬虫 Crawler4j
Crawler4j 是一个开源的 Java 类库,它提供了一个简单的网页爬取接口。它可以用来构建一个多线程的网络爬虫。
crawler4j的使用主要分为两步:
1. 实现一个继承自WebCrawler的爬虫类;
2.调用CrawlController实现的爬虫类。
WebCrawler 是一个抽象类,继承它必须实现两个方法:shouldVisit 和 visit。在:
shouldVisit 是判断当前URL是否应该被爬取(visited);
visit 是抓取URL指向的页面的数据,传入的参数是网页所有数据的封装对象Page。
Crawler.CrawController 控制爬虫,先添加seed,然后开启多个爬虫,不断监控每个爬虫的生存状态。
Crawler.WebCrawler 爬虫
1. Run():不断循环,每次从Frontier取50个url,对每个url进行processPage(curUrl)。
2. processPage(curURL):使用 PageFetcher.fetch 抓取网页。如果curURL被重定向,则将重定向url的url添加到Frontier,稍后调度;如果爬取正常,则先解析,生成Page,然后将新的url下放到Frontier(此时确定新增url的深度),调用visit(Page){用户自定义操作} .
Crawler.Configurations 读取 crawler4j.properties 中的信息
Crawler.PageFetcher 启动 IdleConnectionMonitorThread 并使用 fetch(Page, ignoreIfBinary) 抓取单个 Page 页面。是一个静态类。
Crawler.Page 一个页面
Crawler.PageFetchStatus 单页爬取的配置,如返回的爬取状态号的含义等。
Crawler.HTMLParser 解析 HTML 源代码并将其存储在 Page 中。
Crawler.LinkExtractor 提取 HTML 页面中收录的所有链接。
Crawler.IdleConnectionMonitorThread 用于监控连接(用于发送get请求,获取页面),其connMgr负责发送HTML请求。
HTML单元
HtmlUnitHtmlUnit 是“Java 程序的无 GUI 浏览器”。它对 HTML 文档进行建模并提供一个 API,允许您调用页面、填写表单、单击链接等……就像您在“普通”浏览器中所做的一样。
HtmlUnit的使用: 简介:HtmlUnit是一个浏览器,用Java编写,没有界面。因为它没有接口,所以执行速度仍然可以下降。HtmlUnit提供了一系列的API,这些API可以做很多功能,比如表单填写、表单提交、模拟点击链接,并且由于内置了Rhinojs引擎,可以执行Javascript
1、模拟特定浏览器,也可以指定浏览器对应版本(HtmlUnit最新版本2.13现在可以模拟Chrome/FireFox/IE)
WebClient webClient=new WebClient(BrowserVersion.FIREFOX_24);
2、查找特定元素,可以通过get或者XPath从HtmlPage中获取特定的Html元素。例如;
DomElement plc_main=page.getElementById("plc_main");
DomElement code_box=(DomElement) pl_common_sassfilter.getByXPath("//div[@class='code_box clearfix']").get(0);
3. 模拟表单的提交显示在用于登录的代码中;
HtmlForm loginform = logonPage.getFormByName("loginform");
HtmlTextInput uid = loginform.getInputByName("u");
uid.click();//点击获取焦点
uid.type(Config.getAccount());
HtmlPasswordInput pwd = loginform.getInputByName("p");
pwd.click();
pwd.type(Config.getPassword());
4、获取新浪微博等微博内容等信息。
DomNodeList dls = pl_weibo_direct.getElementsByTagName("dl");
DomElement dl= dls.get(0);
整数索引 = 0;
而(DL!=空){
DomElement em=feed_list_content.getElementsByTagName("em").get(0);
字符串内容 = em.getTextContent();
newlist.add(内容);
索引++;
dl = dls.get(索引);}
2.模拟登录,找到微博内容的位置。
3.获取微博数据并存入数据库,数据库使用MYSQL
逻辑其实很简单。需要熟悉HTMLunit提供的一些类,然后是XPath语法,再熟悉一些基础的数据库知识,就可以完成微博的爬取。
腾讯微博也有同样的想法。一些区别是
1.页面解析不同。
2.URL 的某些特征是不同的。
新浪爬虫问题总结
新浪微博爬虫的一些问题:
首先是微博数量的限制,从搜索页关键词开始,只能搜索到50页的微博数据。那么每页有20条,只能搜到1000条,这肯定跟实时微博的数量不匹配。
所以你可以使用高级搜索从2009年开始搜索,这需要不断的实验,看看时间可以弥补50页的微博。因为无论我搜索什么,新浪微博都只能显示50页的数据。
以本田雅阁为例,可以分为5次搜索,第一次是2009年到2010年,这个时间段只有33页数据,然后是2010年1.1到2011.1.1有50页数据,然后往下推。在某些时期,建立50页数据只需要五六个月。简而言之,这没有规律性。大概是时间越久,微博的数量就越多。. 所以当这个编程达到50页时,url链接的下一页就没有了。这是一个限制。
第二个问题是微博内容重复。如果连接是
%25E6%259C%25AC%25E7%2594%25B0%25E9%259B%2585%25E9%2598%2581&xsort=time&scope=ori×cope=custom:2013-01-01-0:2014-04-23-0&page=8
以本田雅阁为例,这个页面上的微博基本上都是一样的内容。据我观察,这个品牌的微博更像是一个营销和广告的微博。当然,你可以用微博来验证这个方法来刷选。但真正有意义的是,原创的微博,是一个少得可怜的数字。只有几百个大小。
还是有一些方法可以删除同一个微博。最近在数据库下操作比较有效,使用select distinct content from weibo where program='Honda Accord' into outfile 'D:/Honda Accord.txt';仍然可以删除其中大部分重复推文。
或者对于几乎相同的情况,只有 URL 不同。您可以使用删除微博内容 LIKE '%铃木“大型车”将与本田雅阁同级%';或其他一些具有特别明显特征的词或短语。
第三个问题是,虽然新浪只提供了这么多数据,但还是处处受限。当程序运行到20页时,会出现需要手动输入验证码以防止爬虫影响其服务器的问题。这个方案是通过模仿登录验证码的方法来解决的。就是拿到需要输入的验证码,把imageReader拿出来变成一个JFrame,手动输入,点一下,基本上就可以解决问题了。
第四个问题是微博内容在页面中体现不规则。例如,所有微博内容合二为一,只需 em.getTextContent()。因为不规则,有的em像点赞、空格等,解决方法是通过判断发现em只要不是真实的内容就没有任何属性。否则会有一个类属性。使用判断 hasAttribute() 踢掉点赞和空格。
第五个问题是不同id定位的问题。使用通用搜索时,定位ID为pl_weibo_direct,使用高级搜索时,微博内容定位ID为pl_wb_feedlist。
,当然是一些细节。
总结:
虽然还有很多问题,但是爬取数据的效果不是很好。不过可以肯定的是,新浪微博上的大部分数据还是可以通过网址找到的,新浪不可能大规模删除。假设像我这样的用户很久以前在2009年发了一条支持本田雅阁的微博,我可以通过我的微博链接看到与本田雅阁相关的微博内容。因此,与关键字相关的微博仍然存在于页面上,但新浪微博本身提供的搜索功能并不强大且有限。 查看全部
htmlunit 抓取网页(介绍常用爬虫开源项目和腾讯微博爬虫的问题总结)
介绍
常用爬虫开源项目
新浪微博爬虫和腾讯微博爬虫
新浪爬虫问题
总结
介绍
相关介绍
即网络爬虫是一种自动获取网页内容的程序。它是搜索引擎的重要组成部分,因此搜索引擎优化主要针对爬虫进行优化。
主要分类
网络爬虫从万维网上为搜索引擎下载网页。一般分为传统爬虫和专注爬虫。
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某个停止条件。通俗的讲,就是通过源码分析得到想要的内容。
焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
反爬虫:KS-WAF将爬虫行为分为搜索引擎爬虫和扫描爬虫,可以屏蔽特定搜索引擎爬虫以节省带宽和性能,也可以屏蔽扫描爬虫防止网站被恶意爬取。
常用爬虫开源项目
Nutch 标志 搜索引擎 Nutch
Nutch 是一个搜索引擎的开源 Java 实现。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫。
尽管网络搜索是漫游 Internet 的基本要求,但现有网络搜索引擎的数量正在下降。而这很可能会演变成一家为其商业利益垄断几乎所有网络搜索的公司。这显然对绝大多数网民不利。
现在所有主要的搜索引擎都使用专有的排名算法,这些算法不能解释为什么一个页面被排在一个特定的位置。另外,有些搜索引擎按网站付费,而不是按自己的值排序。
Apache Nutch 项目(一个网络搜索引擎)。Nutch 发展到一定程度时,遇到了可扩展性的问题,即当存储的网页数量达到 1 亿的水平时,Nutch 原有的结构很难达到高效率。就在整个团队不知所措的时候,救星谷歌出现了。Google 在 2003 年发布了 Google 使用的分布式文件存储系统文章(The Google File System),Nutch 开发者意识到可以将 Nutch 放在 GFS 上实现,所以经过一年的发展,NDFS(Nutch Distributed文件系统)出现。在解决了瓶颈问题之后,Nutch 有了很大的发展,而就在 2004 年,Google 发布了 MapReduce 的想法,
但是在 Nutch 中加入 GFS 和 MapReduce 之后,Nutch 变得太大了,超出了网络搜索引擎的范围,所以在 2006 年,分别移植了 NDFS 和 MapReduce,形成了一个名为 Hadoop 的新项目。
Java 多线程网络爬虫 Crawler4j
Crawler4j 是一个开源的 Java 类库,它提供了一个简单的网页爬取接口。它可以用来构建一个多线程的网络爬虫。
crawler4j的使用主要分为两步:
1. 实现一个继承自WebCrawler的爬虫类;
2.调用CrawlController实现的爬虫类。
WebCrawler 是一个抽象类,继承它必须实现两个方法:shouldVisit 和 visit。在:
shouldVisit 是判断当前URL是否应该被爬取(visited);
visit 是抓取URL指向的页面的数据,传入的参数是网页所有数据的封装对象Page。
Crawler.CrawController 控制爬虫,先添加seed,然后开启多个爬虫,不断监控每个爬虫的生存状态。
Crawler.WebCrawler 爬虫
1. Run():不断循环,每次从Frontier取50个url,对每个url进行processPage(curUrl)。
2. processPage(curURL):使用 PageFetcher.fetch 抓取网页。如果curURL被重定向,则将重定向url的url添加到Frontier,稍后调度;如果爬取正常,则先解析,生成Page,然后将新的url下放到Frontier(此时确定新增url的深度),调用visit(Page){用户自定义操作} .
Crawler.Configurations 读取 crawler4j.properties 中的信息
Crawler.PageFetcher 启动 IdleConnectionMonitorThread 并使用 fetch(Page, ignoreIfBinary) 抓取单个 Page 页面。是一个静态类。
Crawler.Page 一个页面
Crawler.PageFetchStatus 单页爬取的配置,如返回的爬取状态号的含义等。
Crawler.HTMLParser 解析 HTML 源代码并将其存储在 Page 中。
Crawler.LinkExtractor 提取 HTML 页面中收录的所有链接。
Crawler.IdleConnectionMonitorThread 用于监控连接(用于发送get请求,获取页面),其connMgr负责发送HTML请求。
HTML单元
HtmlUnitHtmlUnit 是“Java 程序的无 GUI 浏览器”。它对 HTML 文档进行建模并提供一个 API,允许您调用页面、填写表单、单击链接等……就像您在“普通”浏览器中所做的一样。
HtmlUnit的使用: 简介:HtmlUnit是一个浏览器,用Java编写,没有界面。因为它没有接口,所以执行速度仍然可以下降。HtmlUnit提供了一系列的API,这些API可以做很多功能,比如表单填写、表单提交、模拟点击链接,并且由于内置了Rhinojs引擎,可以执行Javascript
1、模拟特定浏览器,也可以指定浏览器对应版本(HtmlUnit最新版本2.13现在可以模拟Chrome/FireFox/IE)
WebClient webClient=new WebClient(BrowserVersion.FIREFOX_24);
2、查找特定元素,可以通过get或者XPath从HtmlPage中获取特定的Html元素。例如;
DomElement plc_main=page.getElementById("plc_main");
DomElement code_box=(DomElement) pl_common_sassfilter.getByXPath("//div[@class='code_box clearfix']").get(0);
3. 模拟表单的提交显示在用于登录的代码中;
HtmlForm loginform = logonPage.getFormByName("loginform");
HtmlTextInput uid = loginform.getInputByName("u");
uid.click();//点击获取焦点
uid.type(Config.getAccount());
HtmlPasswordInput pwd = loginform.getInputByName("p");
pwd.click();
pwd.type(Config.getPassword());
4、获取新浪微博等微博内容等信息。
DomNodeList dls = pl_weibo_direct.getElementsByTagName("dl");
DomElement dl= dls.get(0);
整数索引 = 0;
而(DL!=空){
DomElement em=feed_list_content.getElementsByTagName("em").get(0);
字符串内容 = em.getTextContent();
newlist.add(内容);
索引++;
dl = dls.get(索引);}
2.模拟登录,找到微博内容的位置。
3.获取微博数据并存入数据库,数据库使用MYSQL
逻辑其实很简单。需要熟悉HTMLunit提供的一些类,然后是XPath语法,再熟悉一些基础的数据库知识,就可以完成微博的爬取。
腾讯微博也有同样的想法。一些区别是
1.页面解析不同。
2.URL 的某些特征是不同的。
新浪爬虫问题总结
新浪微博爬虫的一些问题:
首先是微博数量的限制,从搜索页关键词开始,只能搜索到50页的微博数据。那么每页有20条,只能搜到1000条,这肯定跟实时微博的数量不匹配。
所以你可以使用高级搜索从2009年开始搜索,这需要不断的实验,看看时间可以弥补50页的微博。因为无论我搜索什么,新浪微博都只能显示50页的数据。
以本田雅阁为例,可以分为5次搜索,第一次是2009年到2010年,这个时间段只有33页数据,然后是2010年1.1到2011.1.1有50页数据,然后往下推。在某些时期,建立50页数据只需要五六个月。简而言之,这没有规律性。大概是时间越久,微博的数量就越多。. 所以当这个编程达到50页时,url链接的下一页就没有了。这是一个限制。
第二个问题是微博内容重复。如果连接是
%25E6%259C%25AC%25E7%2594%25B0%25E9%259B%2585%25E9%2598%2581&xsort=time&scope=ori×cope=custom:2013-01-01-0:2014-04-23-0&page=8
以本田雅阁为例,这个页面上的微博基本上都是一样的内容。据我观察,这个品牌的微博更像是一个营销和广告的微博。当然,你可以用微博来验证这个方法来刷选。但真正有意义的是,原创的微博,是一个少得可怜的数字。只有几百个大小。
还是有一些方法可以删除同一个微博。最近在数据库下操作比较有效,使用select distinct content from weibo where program='Honda Accord' into outfile 'D:/Honda Accord.txt';仍然可以删除其中大部分重复推文。
或者对于几乎相同的情况,只有 URL 不同。您可以使用删除微博内容 LIKE '%铃木“大型车”将与本田雅阁同级%';或其他一些具有特别明显特征的词或短语。
第三个问题是,虽然新浪只提供了这么多数据,但还是处处受限。当程序运行到20页时,会出现需要手动输入验证码以防止爬虫影响其服务器的问题。这个方案是通过模仿登录验证码的方法来解决的。就是拿到需要输入的验证码,把imageReader拿出来变成一个JFrame,手动输入,点一下,基本上就可以解决问题了。
第四个问题是微博内容在页面中体现不规则。例如,所有微博内容合二为一,只需 em.getTextContent()。因为不规则,有的em像点赞、空格等,解决方法是通过判断发现em只要不是真实的内容就没有任何属性。否则会有一个类属性。使用判断 hasAttribute() 踢掉点赞和空格。
第五个问题是不同id定位的问题。使用通用搜索时,定位ID为pl_weibo_direct,使用高级搜索时,微博内容定位ID为pl_wb_feedlist。
,当然是一些细节。
总结:
虽然还有很多问题,但是爬取数据的效果不是很好。不过可以肯定的是,新浪微博上的大部分数据还是可以通过网址找到的,新浪不可能大规模删除。假设像我这样的用户很久以前在2009年发了一条支持本田雅阁的微博,我可以通过我的微博链接看到与本田雅阁相关的微博内容。因此,与关键字相关的微博仍然存在于页面上,但新浪微博本身提供的搜索功能并不强大且有限。
htmlunit 抓取网页(大数据行业数据价值不言而喻的技术分析及解决办法!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-03-08 20:13
对于大数据行业来说,数据的价值不言而喻。在这个信息爆炸的时代,互联网上的信息数据太多了。对于中小微企业来说,合理使用爬虫爬取有价值的数据,是为了弥补自身先天的数据短缺。板子的最佳选择,本文主要从爬虫原理、架构、分类和反爬虫技术方面总结了爬虫技术。
1、爬虫技术概述
网络爬虫是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。它们广泛应用于互联网搜索引擎或其他类似的网站,并且可以自动采集所有它可以访问的页面的内容来获取或更新这些网站的内容和检索方式. 从功能上来说,爬虫一般分为数据采集、处理、存储三部分。
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。另外,爬虫爬取的所有网页都会被系统存储,进行一定的分析、过滤和索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1)爬取目标的描述或定义;
(2)网页或数据的分析和过滤;
(3)URL 的搜索策略。
2、爬虫原理
2.1网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、SqlServer等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。.
这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,因此广度优先搜索算法一般使用采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个网址,下载其对应的网页,
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列;
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历路径:AF-GE-H-IBCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDE-FGHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4PartialPageRank 策略
PartialPageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值。计算完成后,计算待爬取的URL队列中的URL。按 PageRank 值排序并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序.
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过Nutch的二次开发使其适合提取业务,你基本上会破坏Nutch的框架,将Nutch改得面目全非,并且有能力修改Nutch,还不如自己写一个新的. 分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。事实上,这是针对Nutch的声誉。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发非常简单,前人已经解决了困难和复杂的问题(如DOM树解析定位、字符集检测、海量URL去重等),可以据说没有技术含量。. 包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于deepweb(深网)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSSSELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给Spider进行分析,将要保存的数据发送到ItemPipeline。那就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,大大小小的。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这样的反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
[评论:它经常很容易被忽视。通过对请求的抓包分析,确定referer并添加到程序中模拟访问请求的header中]
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一个IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。 查看全部
htmlunit 抓取网页(大数据行业数据价值不言而喻的技术分析及解决办法!)
对于大数据行业来说,数据的价值不言而喻。在这个信息爆炸的时代,互联网上的信息数据太多了。对于中小微企业来说,合理使用爬虫爬取有价值的数据,是为了弥补自身先天的数据短缺。板子的最佳选择,本文主要从爬虫原理、架构、分类和反爬虫技术方面总结了爬虫技术。
1、爬虫技术概述
网络爬虫是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。它们广泛应用于互联网搜索引擎或其他类似的网站,并且可以自动采集所有它可以访问的页面的内容来获取或更新这些网站的内容和检索方式. 从功能上来说,爬虫一般分为数据采集、处理、存储三部分。
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。另外,爬虫爬取的所有网页都会被系统存储,进行一定的分析、过滤和索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1)爬取目标的描述或定义;
(2)网页或数据的分析和过滤;
(3)URL 的搜索策略。
2、爬虫原理
2.1网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、SqlServer等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。.
这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,因此广度优先搜索算法一般使用采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个网址,下载其对应的网页,
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列;
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历路径:AF-GE-H-IBCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDE-FGHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4PartialPageRank 策略
PartialPageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值。计算完成后,计算待爬取的URL队列中的URL。按 PageRank 值排序并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序.
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过Nutch的二次开发使其适合提取业务,你基本上会破坏Nutch的框架,将Nutch改得面目全非,并且有能力修改Nutch,还不如自己写一个新的. 分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。事实上,这是针对Nutch的声誉。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发非常简单,前人已经解决了困难和复杂的问题(如DOM树解析定位、字符集检测、海量URL去重等),可以据说没有技术含量。. 包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于deepweb(深网)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSSSELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给Spider进行分析,将要保存的数据发送到ItemPipeline。那就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,大大小小的。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这样的反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
[评论:它经常很容易被忽视。通过对请求的抓包分析,确定referer并添加到程序中模拟访问请求的header中]
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一个IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。
htmlunit 抓取网页(JavaHTML4支持代理服务器(5)支持自动的Cookies管理等 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-08 17:00
)
(4)支持代理服务器
(5)支持自动cookie管理等
Java爬虫开发中应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析渲染等准浏览器功能。推荐用于无需解析脚本和 CSS 即可获取网页的快速场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;
import org.apache.http.client.HttpClient;
import org.apache.http.client.ResponseHandler;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.BasicResponseHandler;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.util.EntityUtils;
/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/
public class HttpClientTest {
public static void main(String[] args)throws Exception{
//目标页面
String url ="http://www.jjwxc.net/";
//创建一个默认的HttpClient
HttpClient httpclient =new DefaultHttpClient();
try{
//以get方式请求网页http://www.yshjava.cn
HttpGet httpget =new HttpGet(url);
//打印请求地址
System.out.println("executing request "+ httpget.getURI());
//创建响应处理器处理服务器响应内容
ResponseHandler responseHandler = new BasicResponseHandler();
//执行请求并获取结果
String responseBody = httpclient.execute(httpget, responseHandler);
System.out.println("----------------------------------------");
String htmlStr=null;
if(responseBody != null) {
// htmlStr=new String(EntityUtils.toString(responseBody));
// htmlStr=new String(htmlStr.getBytes("ISO-8859-1"), "gbk"); // 读取乱码解决
responseBody=new String(responseBody.getBytes("ISO-8859-1"), "gb2312");
}
System.out.println(responseBody);
System.out.println("----------------------------------------");
}finally{//关闭连接管理器
httpclient.getConnectionManager().shutdown();
}
}
}
汤
jsoup 是一个Java HTML 解析器,可以直接解析一个URL 地址和HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3.可以操作HTML元素、属性、文本;
示例代码如下:
package cn.ysh.studio.crawler.jsoup;
import java.io.IOException;
import org.jsoup.Jsoup;
/**
* 基于Jsoup抓取网页内容
* @author www.yshjava.cn
*/
public class JsoupTest {
public static void main(String[] args)throws IOException{
//目标页面
String url ="http://www.jjwxc.net";
//使用Jsoup连接目标页面,并执行请求,获取服务器响应内容
String html =Jsoup.connect(url).execute().body();
//打印页面内容
System.out.println(html);
}
}
HtmlUnit
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.Page;
import com.gargoylesoftware.htmlunit.WebClient;
/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlUnitSpider {
public static void main(String[] s) throws Exception {
// 目标网页
String url = "http://www.jjwxc.net/";
// 模拟特定浏览器FIREFOX_3
WebClient spider = new WebClient(BrowserVersion.FIREFOX_3);
// 获取目标网页
Page page = spider.getPage(url);
// 打印网页内容
System.out.println(page.getWebResponse().getContentAsString());
// 关闭所有窗口
// spider.closeAllWindows();
spider.close();
}
}
瓦提
硒
Selenium 也是一个用于 Web 应用程序测试的工具。 Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性——测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。 Net、Java、Perl 和其他不同语言的测试脚本。 Selenium 是 ThoughtWorks 专门为 Web 应用编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;
import org.openqa.selenium.htmlunit.HtmlUnitDriver;
/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlDriverTest {
public static void main(String[] s) {
// 目标网页
String url = "http://www.jjwxc.net/";
HtmlUnitDriver driver = new HtmlUnitDriver();
try {
// 禁用JS脚本功能
driver.setJavascriptEnabled(false);
// 打开目标网页
driver.get(url);
// 获取当前网页源码
String html = driver.getPageSource();
// 打印网页源码
System.out.println(html);
} catch (Exception e) {
// 打印堆栈信息
e.printStackTrace();
} finally {
try {
// 关闭并退出
driver.close();
driver.quit();
} catch (Exception e) {
}
}
}
}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;
import org.watij.webspec.dsl.WebSpec;
/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/
public class WebspecTest {
public static void main(String[] s){
//目标网页
String url ="http://www.jjwxc.net/";
//实例化浏览器对象
WebSpec spec =new WebSpec().mozilla();
//隐藏浏览器窗体
spec.hide();
//打开目标页面
spec.open(url);
//打印网页源码
System.out.println(spec.source());
//关闭所有窗口
spec.closeAll();
}
} 查看全部
htmlunit 抓取网页(JavaHTML4支持代理服务器(5)支持自动的Cookies管理等
)
(4)支持代理服务器
(5)支持自动cookie管理等
Java爬虫开发中应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析渲染等准浏览器功能。推荐用于无需解析脚本和 CSS 即可获取网页的快速场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;
import org.apache.http.client.HttpClient;
import org.apache.http.client.ResponseHandler;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.BasicResponseHandler;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.util.EntityUtils;
/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/
public class HttpClientTest {
public static void main(String[] args)throws Exception{
//目标页面
String url ="http://www.jjwxc.net/";
//创建一个默认的HttpClient
HttpClient httpclient =new DefaultHttpClient();
try{
//以get方式请求网页http://www.yshjava.cn
HttpGet httpget =new HttpGet(url);
//打印请求地址
System.out.println("executing request "+ httpget.getURI());
//创建响应处理器处理服务器响应内容
ResponseHandler responseHandler = new BasicResponseHandler();
//执行请求并获取结果
String responseBody = httpclient.execute(httpget, responseHandler);
System.out.println("----------------------------------------");
String htmlStr=null;
if(responseBody != null) {
// htmlStr=new String(EntityUtils.toString(responseBody));
// htmlStr=new String(htmlStr.getBytes("ISO-8859-1"), "gbk"); // 读取乱码解决
responseBody=new String(responseBody.getBytes("ISO-8859-1"), "gb2312");
}
System.out.println(responseBody);
System.out.println("----------------------------------------");
}finally{//关闭连接管理器
httpclient.getConnectionManager().shutdown();
}
}
}
汤
jsoup 是一个Java HTML 解析器,可以直接解析一个URL 地址和HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3.可以操作HTML元素、属性、文本;
示例代码如下:
package cn.ysh.studio.crawler.jsoup;
import java.io.IOException;
import org.jsoup.Jsoup;
/**
* 基于Jsoup抓取网页内容
* @author www.yshjava.cn
*/
public class JsoupTest {
public static void main(String[] args)throws IOException{
//目标页面
String url ="http://www.jjwxc.net";
//使用Jsoup连接目标页面,并执行请求,获取服务器响应内容
String html =Jsoup.connect(url).execute().body();
//打印页面内容
System.out.println(html);
}
}
HtmlUnit
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.Page;
import com.gargoylesoftware.htmlunit.WebClient;
/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlUnitSpider {
public static void main(String[] s) throws Exception {
// 目标网页
String url = "http://www.jjwxc.net/";
// 模拟特定浏览器FIREFOX_3
WebClient spider = new WebClient(BrowserVersion.FIREFOX_3);
// 获取目标网页
Page page = spider.getPage(url);
// 打印网页内容
System.out.println(page.getWebResponse().getContentAsString());
// 关闭所有窗口
// spider.closeAllWindows();
spider.close();
}
}
瓦提
硒
Selenium 也是一个用于 Web 应用程序测试的工具。 Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性——测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。 Net、Java、Perl 和其他不同语言的测试脚本。 Selenium 是 ThoughtWorks 专门为 Web 应用编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;
import org.openqa.selenium.htmlunit.HtmlUnitDriver;
/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/
public class HtmlDriverTest {
public static void main(String[] s) {
// 目标网页
String url = "http://www.jjwxc.net/";
HtmlUnitDriver driver = new HtmlUnitDriver();
try {
// 禁用JS脚本功能
driver.setJavascriptEnabled(false);
// 打开目标网页
driver.get(url);
// 获取当前网页源码
String html = driver.getPageSource();
// 打印网页源码
System.out.println(html);
} catch (Exception e) {
// 打印堆栈信息
e.printStackTrace();
} finally {
try {
// 关闭并退出
driver.close();
driver.quit();
} catch (Exception e) {
}
}
}
}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;
import org.watij.webspec.dsl.WebSpec;
/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/
public class WebspecTest {
public static void main(String[] s){
//目标网页
String url ="http://www.jjwxc.net/";
//实例化浏览器对象
WebSpec spec =new WebSpec().mozilla();
//隐藏浏览器窗体
spec.hide();
//打开目标页面
spec.open(url);
//打印网页源码
System.out.println(spec.source());
//关闭所有窗口
spec.closeAll();
}
}
htmlunit 抓取网页(4.网页测试您可以通过多种方式测试Web应用程序——)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-03 00:20
HtmlUnit简介一、简介
在本文中,我们将介绍 HtmlUnit,它允许我们使用 JAVA API 以编程方式交互和测试 HTML 站点。
2.关于 HtmlUnit
HtmlUnit 是一种无 GUI 浏览器 - 一种旨在以编程方式而不是由用户直接使用的浏览器。
该浏览器支持 JavaScript(通过 Mozilla Rhino 引擎),甚至可以使用具有复杂 AJAX 功能的 网站。所有这些都可以通过模拟典型的基于 GUI 的浏览器(例如 Chrome 或 Firefox)来完成。
HtmlUnit 这个名字可能会让你认为它是一个测试框架,但是虽然它绝对可以用于测试,但它可以做的远不止这些。
它还集成到 Spring 4 中,可以与 Spring MVC 测试框架无缝使用。
3.下载和Maven依赖
HtmlUnit 可以从 SourceForge 或官网下载。此外,您可以将其收录在您的构建工具(如 Maven 或 Gradle 等)中,如您在此处所见。例如,以下是您当前可以收录在项目中的 Maven 依赖项:
net.sourceforge.htmlunit
htmlunit
2.23
最新版本可以在这里找到。
4. 网络测试
您可以通过多种方式测试 Web 应用程序——其中大部分我们已经介绍过 网站 一次或多次。
使用 HtmlUnit,您可以直接解析站点的 HTML,通过浏览器与普通用户交互,检查 JavaScript 和 CSS 语法,提交表单,并解析响应以查看其 HTML 元素的内容。所有这一切,都使用纯 Java 代码。
让我们从一个简单的测试开始:创建一个 WebClient 并获取导航的第一页:
private WebClient webClient;
@Before
public void init() throws Exception {
webClient = new WebClient();
}
@After
public void close() throws Exception {
webClient.close();
}
@Test
public void givenAClient_whenEnteringBaeldung_thenPageTitleIsOk()
throws Exception {
HtmlPage page = webClient.getPage("/");
Assert.assertEquals(
"Baeldung | Java, Spring and Web Development tutorials",
page.getTitleText());
}
如果我们的 网站 有 JavaScript 或 CSS 问题,您会在运行测试时看到一些警告或错误。你应该纠正它们。
有时,如果您知道自己在做什么(例如,如果您发现唯一的错误来自不应修改的第三方 JavaScript 库),您可以通过调用 setThrowExceptionOnScriptError 来防止这些错误使您的测试失败错误的:
@Test
public void givenAClient_whenEnteringBaeldung_thenPageTitleIsCorrect()
throws Exception {
webClient.getOptions().setThrowExceptionOnScriptError(false);
HtmlPage page = webClient.getPage("/");
Assert.assertEquals(
"Baeldung | Java, Spring and Web Development tutorials",
page.getTitleText());
}
5.网页抓取
您不需要仅为您自己的 网站 使用 HtmlUnit。毕竟,它是一个浏览器:您可以使用它浏览您喜欢的任何网页,根据需要发送和检索数据。
从 网站 获取、解析、存储和分析数据的过程称为网络抓取,HtmlUnit 可以帮助您完成获取和解析部分。
前面的示例显示了我们如何输入任何 网站 并在其中导航,检索我们想要的所有信息。
例如,让我们转到 Baeldung 的完整 文章 存档,导航到最新的 文章 并检索其标题(第一个令牌)。对于我们的测试来说,这就足够了;但是,如果我们想存储更多信息,例如,我们还可以检索标题(所有标签)以了解 文章 是什么的基本概念。
通过 ID 获取元素很容易,但一般来说,如果需要查找元素,使用 XPath 语法会更方便。HtmlUnit 允许我们使用它,所以我们会。
@Test
public void givenBaeldungArchive_whenRetrievingArticle_thenHasH1()
throws Exception {
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
String url = "/full_archive";
HtmlPage page = webClient.getPage(url);
String xpath = "(//ul[@class='car-monthlisting']/li)[1]/a";
HtmlAnchor latestPostLink
= (HtmlAnchor) page.getByXPath(xpath).get(0);
HtmlPage postPage = latestPostLink.click();
List h1
= (List) postPage.getByXPath("//h1");
Assert.assertTrue(h1.size() > 0);
}
首先注意如何 - 在这种情况下,我们对 CSS 和 JavaScript 不感兴趣,我们只想解析 HTML 布局,所以我们关闭了 CSS 和 JavaScript。
在真正的网页抓取中,你可以以 h1 和 h2 标题为例,结果会是这样的:
Java Web Weekly, Issue 135
1. Spring and Java
2. Technical and Musings
3. Comics
4. Pick of the Week
您可以检查检索到的信息是否确实对应于 Baeldung 中最新的 文章:
6. AJAX 怎么样?
AJAX 功能可能是一个问题,因为 HtmlUnit 通常在 AJAX 调用完成之前检索页面。很多时候,您需要他们正确地测试您的 网站 或检索您想要的数据。有一些方法可以处理它们:
for (int i = 0; i < 20; i++) {
if (condition_to_happen_after_js_execution) {
break;
}
synchronized (page) {
page.wait(500);
}
}
WebClient webClient = new WebClient(BrowserVersion.CHROME);
7. 弹簧示例
如果我们正在测试我们自己的 Spring 应用程序,事情会变得更容易——我们不再需要一个正在运行的服务器。
让我们实现一个非常简单的示例应用程序:只是一个带有接收文本的方法的控制器和一个带有表单的 HTML 页面。用户可以在表单中输入文本,提交表单,文本会出现在表单下方。
在这种情况下,我们将为此 HTML 页面使用 Thymeleaf 模板(您可以在此处查看完整的 Thymeleaf 示例):
@RunWith(SpringJUnit4ClassRunner.class)
@WebAppConfiguration
@ContextConfiguration(classes = { TestConfig.class })
public class HtmlUnitAndSpringTest {
@Autowired
private WebApplicationContext wac;
private WebClient webClient;
@Before
public void setup() {
webClient = MockMvcWebClientBuilder
.webAppContextSetup(wac).build();
}
@Test
public void givenAMessage_whenSent_thenItShows() throws Exception {
String text = "Hello world!";
HtmlPage page;
String url = "http://localhost/message/showForm";
page = webClient.getPage(url);
HtmlTextInput messageText = page.getHtmlElementById("message");
messageText.setValueAttribute(text);
HtmlForm form = page.getForms().get(0);
HtmlSubmitInput submit = form.getOneHtmlElementByAttribute(
"input", "type", "submit");
HtmlPage newPage = submit.click();
String receivedText = newPage.getHtmlElementById("received")
.getTextContent();
Assert.assertEquals(receivedText, text);
}
}
这里的关键是使用 WebApplicationContext 中的 MockMvcWebClientBuilder 来构建 WebClient 对象。使用 WebClient,我们可以获得导航的第一页(注意它是如何由 localhost 提供的)并从那里开始浏览。
如您所见,测试解析表单输入消息(在id为“message”的字段中),提交表单,并在新页面上断言接收到的文本(id为“received”的字段)是相同的正如我们提交的文本一样。
8. 结论
HtmlUnit 是一个很棒的工具,可以让您轻松地测试您的 Web 应用程序、填写表单字段并提交它们,就像您在浏览器上使用 Web 一样。
它与 Spring 4 无缝集成,并与 Spring MVC 测试框架一起为您提供了一个非常强大的环境,即使没有 Web 服务器也可以对所有页面进行集成测试。
此外,使用 HtmlUnit,您可以自动执行任何与网页浏览相关的任务,例如获取、解析、存储和分析数据(网页抓取)。 查看全部
htmlunit 抓取网页(4.网页测试您可以通过多种方式测试Web应用程序——)
HtmlUnit简介一、简介
在本文中,我们将介绍 HtmlUnit,它允许我们使用 JAVA API 以编程方式交互和测试 HTML 站点。
2.关于 HtmlUnit
HtmlUnit 是一种无 GUI 浏览器 - 一种旨在以编程方式而不是由用户直接使用的浏览器。
该浏览器支持 JavaScript(通过 Mozilla Rhino 引擎),甚至可以使用具有复杂 AJAX 功能的 网站。所有这些都可以通过模拟典型的基于 GUI 的浏览器(例如 Chrome 或 Firefox)来完成。
HtmlUnit 这个名字可能会让你认为它是一个测试框架,但是虽然它绝对可以用于测试,但它可以做的远不止这些。
它还集成到 Spring 4 中,可以与 Spring MVC 测试框架无缝使用。
3.下载和Maven依赖
HtmlUnit 可以从 SourceForge 或官网下载。此外,您可以将其收录在您的构建工具(如 Maven 或 Gradle 等)中,如您在此处所见。例如,以下是您当前可以收录在项目中的 Maven 依赖项:
net.sourceforge.htmlunit
htmlunit
2.23
最新版本可以在这里找到。
4. 网络测试
您可以通过多种方式测试 Web 应用程序——其中大部分我们已经介绍过 网站 一次或多次。
使用 HtmlUnit,您可以直接解析站点的 HTML,通过浏览器与普通用户交互,检查 JavaScript 和 CSS 语法,提交表单,并解析响应以查看其 HTML 元素的内容。所有这一切,都使用纯 Java 代码。
让我们从一个简单的测试开始:创建一个 WebClient 并获取导航的第一页:
private WebClient webClient;
@Before
public void init() throws Exception {
webClient = new WebClient();
}
@After
public void close() throws Exception {
webClient.close();
}
@Test
public void givenAClient_whenEnteringBaeldung_thenPageTitleIsOk()
throws Exception {
HtmlPage page = webClient.getPage("/");
Assert.assertEquals(
"Baeldung | Java, Spring and Web Development tutorials",
page.getTitleText());
}
如果我们的 网站 有 JavaScript 或 CSS 问题,您会在运行测试时看到一些警告或错误。你应该纠正它们。
有时,如果您知道自己在做什么(例如,如果您发现唯一的错误来自不应修改的第三方 JavaScript 库),您可以通过调用 setThrowExceptionOnScriptError 来防止这些错误使您的测试失败错误的:
@Test
public void givenAClient_whenEnteringBaeldung_thenPageTitleIsCorrect()
throws Exception {
webClient.getOptions().setThrowExceptionOnScriptError(false);
HtmlPage page = webClient.getPage("/");
Assert.assertEquals(
"Baeldung | Java, Spring and Web Development tutorials",
page.getTitleText());
}
5.网页抓取
您不需要仅为您自己的 网站 使用 HtmlUnit。毕竟,它是一个浏览器:您可以使用它浏览您喜欢的任何网页,根据需要发送和检索数据。
从 网站 获取、解析、存储和分析数据的过程称为网络抓取,HtmlUnit 可以帮助您完成获取和解析部分。
前面的示例显示了我们如何输入任何 网站 并在其中导航,检索我们想要的所有信息。
例如,让我们转到 Baeldung 的完整 文章 存档,导航到最新的 文章 并检索其标题(第一个令牌)。对于我们的测试来说,这就足够了;但是,如果我们想存储更多信息,例如,我们还可以检索标题(所有标签)以了解 文章 是什么的基本概念。
通过 ID 获取元素很容易,但一般来说,如果需要查找元素,使用 XPath 语法会更方便。HtmlUnit 允许我们使用它,所以我们会。
@Test
public void givenBaeldungArchive_whenRetrievingArticle_thenHasH1()
throws Exception {
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
String url = "/full_archive";
HtmlPage page = webClient.getPage(url);
String xpath = "(//ul[@class='car-monthlisting']/li)[1]/a";
HtmlAnchor latestPostLink
= (HtmlAnchor) page.getByXPath(xpath).get(0);
HtmlPage postPage = latestPostLink.click();
List h1
= (List) postPage.getByXPath("//h1");
Assert.assertTrue(h1.size() > 0);
}
首先注意如何 - 在这种情况下,我们对 CSS 和 JavaScript 不感兴趣,我们只想解析 HTML 布局,所以我们关闭了 CSS 和 JavaScript。
在真正的网页抓取中,你可以以 h1 和 h2 标题为例,结果会是这样的:
Java Web Weekly, Issue 135
1. Spring and Java
2. Technical and Musings
3. Comics
4. Pick of the Week
您可以检查检索到的信息是否确实对应于 Baeldung 中最新的 文章:
6. AJAX 怎么样?
AJAX 功能可能是一个问题,因为 HtmlUnit 通常在 AJAX 调用完成之前检索页面。很多时候,您需要他们正确地测试您的 网站 或检索您想要的数据。有一些方法可以处理它们:
for (int i = 0; i < 20; i++) {
if (condition_to_happen_after_js_execution) {
break;
}
synchronized (page) {
page.wait(500);
}
}
WebClient webClient = new WebClient(BrowserVersion.CHROME);
7. 弹簧示例
如果我们正在测试我们自己的 Spring 应用程序,事情会变得更容易——我们不再需要一个正在运行的服务器。
让我们实现一个非常简单的示例应用程序:只是一个带有接收文本的方法的控制器和一个带有表单的 HTML 页面。用户可以在表单中输入文本,提交表单,文本会出现在表单下方。
在这种情况下,我们将为此 HTML 页面使用 Thymeleaf 模板(您可以在此处查看完整的 Thymeleaf 示例):
@RunWith(SpringJUnit4ClassRunner.class)
@WebAppConfiguration
@ContextConfiguration(classes = { TestConfig.class })
public class HtmlUnitAndSpringTest {
@Autowired
private WebApplicationContext wac;
private WebClient webClient;
@Before
public void setup() {
webClient = MockMvcWebClientBuilder
.webAppContextSetup(wac).build();
}
@Test
public void givenAMessage_whenSent_thenItShows() throws Exception {
String text = "Hello world!";
HtmlPage page;
String url = "http://localhost/message/showForm";
page = webClient.getPage(url);
HtmlTextInput messageText = page.getHtmlElementById("message");
messageText.setValueAttribute(text);
HtmlForm form = page.getForms().get(0);
HtmlSubmitInput submit = form.getOneHtmlElementByAttribute(
"input", "type", "submit");
HtmlPage newPage = submit.click();
String receivedText = newPage.getHtmlElementById("received")
.getTextContent();
Assert.assertEquals(receivedText, text);
}
}
这里的关键是使用 WebApplicationContext 中的 MockMvcWebClientBuilder 来构建 WebClient 对象。使用 WebClient,我们可以获得导航的第一页(注意它是如何由 localhost 提供的)并从那里开始浏览。
如您所见,测试解析表单输入消息(在id为“message”的字段中),提交表单,并在新页面上断言接收到的文本(id为“received”的字段)是相同的正如我们提交的文本一样。
8. 结论
HtmlUnit 是一个很棒的工具,可以让您轻松地测试您的 Web 应用程序、填写表单字段并提交它们,就像您在浏览器上使用 Web 一样。
它与 Spring 4 无缝集成,并与 Spring MVC 测试框架一起为您提供了一个非常强大的环境,即使没有 Web 服务器也可以对所有页面进行集成测试。
此外,使用 HtmlUnit,您可以自动执行任何与网页浏览相关的任务,例如获取、解析、存储和分析数据(网页抓取)。
htmlunit 抓取网页(的java程序是什么?答案是有哪些??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-01 04:07
1.HtmlUnit1.1 简介
HtmlUnit 是一个用 java 编写的无界面浏览器,它可以对 html 文档进行建模、通过 API 调用页面、填写表单、单击链接等等。像普通浏览器一样运行。通常用于测试和从网页中抓取信息。
官方简介翻译
HtmlUnit是一个无界面浏览器Java程序。它为HTML文档建模,提供了调用页面、填写表单、单击链接等操作的API。就跟你在浏览器里做的操作一样。
HtmlUnit不错的JavaScript支持(不断改进),甚至可以使用相当复杂的AJAX库,根据配置的不同模拟Chrome、Firefox或Internet Explorer等浏览器。
HtmlUnit通常用于测试或从web站点检索信息。
1.2 使用场景
对于java实现的网络爬虫程序,我们一般可以使用apache的HttpClient组件来获取HTML页面信息。HttpClient实现的http请求返回的响应一般是纯文本文档页面,也就是最原创的html页面。
对于一个静态的html页面,使用httpClient就足够爬出我们需要的信息了。但是对于越来越多的动态网页,更多的数据是通过异步的JS代码来获取和渲染的,而初始的html页面并没有收录这部分数据。
上图中我们看到的网页在初始文档加载后并没有看到红框中的数据列表。浏览器通过执行异步JS请求,将获取到的动态数据渲染到原创文档页面中,最终变成我们看到的网页。对于这部分需要JS代码执行的数据,httpClient是无能为力的。虽然我们可以通过研究得到JS执行的请求路径,然后用java代码来获取我们需要的部分数据,不说能不能从JS脚本中分析请求路径和请求参数,只分析这部分数据源码成本已经很高了。
通过上面的介绍,我们了解到现在很大一部分动态网页都是通过异步JS请求获取的数据,然后通过JS渲染页面。那么我们能不能做这样的假设,假设我们的爬虫程序模拟一个浏览器,拿到html页面后,像浏览器一样执行异步JS代码,JS渲染好html页面后,就可以愉快的获取到节点信息了这页纸。那么有没有这样的java程序呢?
答案是肯定的。
HtmlUnit就是这样一个库,用来做界面显示的所有异步工作。没有耗时的显示工作,HtmlUnit 加载的完整网页比实际的浏览器块更多。并且根据不同的配置,HtmlUnit可以模拟市面上常见的Chrome、Firefox、IE浏览器等浏览器。
通过HtmlUnit库,加载一个完整的Html页面(图片和视频除外),然后将其转换成我们常用的字符串格式,并使用Jsoup等其他工具获取元素。当然,你也可以直接从HtmlUnit提供的对象中获取网页元素,甚至可以操作按钮、表单等控件。除了不能像可见浏览器那样用鼠标和键盘浏览网页,我们可以使用HtmlUnit来模拟所有其他的操作,比如登录网站、写博客等等都可以完成。当然,网页内容抓取是最简单的应用。
2.J4L2.1官方简介
J4L OCR 工具是一组组件,可用于在 Java 应用程序中收录 OCR 功能。这意味着您可以接收传真、PDF 文件或扫描文档并从图像中提取商业信息。主要的3个组件是:
j4l工具的详细使用步骤请参考这篇文章文章:Java使用J4L识别验证码
本文文章主要介绍使用HtmlUnit模拟登录
3.实际案例3.1.场景
登录页面,包括表单,需要填写用户名、登录密码、验证码,实现用户登录。
3.2操作步骤
使用htmlunit模拟登录是一个获取登录页面->找到输入框->填写用户名和密码->填写验证码->模拟点击登录的过程。
4.实现代码4.1maven引入HtmlUnit依赖
net.sourceforge.htmlunit
htmlunit
2.18
4.2 主要方法
登录.java
public static void main(String[] args) throws Exception {
login();
}
public static void login() throws Exception {
WebClient webClient = new WebClient(BrowserVersion.CHROME);//设置浏览器内核
webClient.getOptions().setJavaScriptEnabled(true);// js是否可用
webClient.getOptions().setCssEnabled(true);//css 一般设置false因为影响运行速度
webClient.getOptions().setThrowExceptionOnScriptError(false);//设置js抛出异常:false
webClient.getOptions().setActiveXNative(false);
//ajax
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
webClient.getOptions().setUseInsecureSSL(false);
//允许重定向
webClient.getOptions().setRedirectEnabled(true);
//连接超时
webClient.getOptions().setTimeout(5000);
//js执行超时
webClient.setJavaScriptTimeout(10000 * 3);
//允许cookie
webClient.getCookieManager().setCookiesEnabled(true);
String url = "http://hrportalneu.cs/HRPortal ... 3B%3B
HtmlPage page = webClient.getPage(url);
webClient.waitForBackgroundJavaScript(5000);
HtmlPage newPage;
newPage = readyPage(page, webClient, "btnCheckIn1");
System.out.println("url----------------" + newPage.getUrl());
System.out.println("Login执行后页面:" + newPage.asXml());
IOUtils.write(newPage.asXml().getBytes(), new FileWriter(new File("D:/checkIn.txt")));
if (!newPage.asXml().contains("登录成功")) {
login();
}
webClient.close();
}
public static HtmlPage readyPage(HtmlPage page, WebClient webClient, String type) throws Exception {
//封装页面元素
HtmlForm form = page.getHtmlElementById("form1");
HtmlTextInput tbxUsername = form.getInputByName("tbxUsername");
tbxUsername.setValueAttribute("用户名*******");
HtmlPasswordInput tbxPassword = form.getInputByName("tbxPassword");
tbxPassword.setValueAttribute("密码*******");
//获取验证码图片
HtmlImage verify_img = (HtmlImage) page.getElementById("AuthCode1$codeText$img");
File file = new File("D:\\" + "check" + ".png");
//保存验证码图片
verify_img.saveAs(file);
System.out.println("验证码图片已保存!");
//保存路径
String filePath = file.getPath();
//裁剪验证码 这里使用原始的图片文件识别成功率不高 可以先进行裁剪
ImageUtil.cutImage(filePath, 1, 1, 96, 34);
//自动识别验证码
OCRFacade facade = new OCRFacade();
//识别验证码
String code = facade.recognizeFile(filePath, "eng");
//处理字符串
code = code.replaceAll(" ", "");
code = code.replaceAll("\\n", "");
System.out.println("验证码:" + code);
//定位验证码输入框
HtmlTextInput verify_code = form.getInputByName("AuthCode1$codeText");
//填入自动识别出来的验证码
verify_code.setValueAttribute(code);
System.out.println("原始页面:" + page.asXml());
HtmlPage newPage = null;
//操作按钮
if (type.equals("btnCheckIn1")) {
DomElement btnCheckIn1 = page.getElementById("btnCheckIn1");
System.out.println("doCheckIn");
newPage = btnCheckIn1.click();
}
//等待js加载
webClient.waitForBackgroundJavaScript(5000);
return newPage;
}
ImageUtil.java
public class ImageUtil {
public static void cutImage(String filePath, int x, int y, int w, int h)
throws Exception {
// 首先通过ImageIo中的方法,创建一个Image + InputStream到内存
ImageInputStream iis = ImageIO
.createImageInputStream(new FileInputStream(filePath));
// 再按照指定格式构造一个Reader(Reader不能new的)
Iterator it = ImageIO.getImageReadersByFormatName("gif");
ImageReader imagereader = (ImageReader) it.next();
// 再通过ImageReader绑定 InputStream
imagereader.setInput(iis);
// 设置感兴趣的源区域。
ImageReadParam par = imagereader.getDefaultReadParam();
par.setSourceRegion(new Rectangle(x, y, w, h));
// 从 reader得到BufferImage
BufferedImage bi = imagereader.read(0, par);
// 将BuffeerImage写出通过ImageIO
ImageIO.write(bi, "png", new File(filePath));
}
}
在控制台查看登录后的页面,查看是否登录成功。 查看全部
htmlunit 抓取网页(的java程序是什么?答案是有哪些??)
1.HtmlUnit1.1 简介
HtmlUnit 是一个用 java 编写的无界面浏览器,它可以对 html 文档进行建模、通过 API 调用页面、填写表单、单击链接等等。像普通浏览器一样运行。通常用于测试和从网页中抓取信息。
官方简介翻译
HtmlUnit是一个无界面浏览器Java程序。它为HTML文档建模,提供了调用页面、填写表单、单击链接等操作的API。就跟你在浏览器里做的操作一样。
HtmlUnit不错的JavaScript支持(不断改进),甚至可以使用相当复杂的AJAX库,根据配置的不同模拟Chrome、Firefox或Internet Explorer等浏览器。
HtmlUnit通常用于测试或从web站点检索信息。
1.2 使用场景
对于java实现的网络爬虫程序,我们一般可以使用apache的HttpClient组件来获取HTML页面信息。HttpClient实现的http请求返回的响应一般是纯文本文档页面,也就是最原创的html页面。
对于一个静态的html页面,使用httpClient就足够爬出我们需要的信息了。但是对于越来越多的动态网页,更多的数据是通过异步的JS代码来获取和渲染的,而初始的html页面并没有收录这部分数据。
上图中我们看到的网页在初始文档加载后并没有看到红框中的数据列表。浏览器通过执行异步JS请求,将获取到的动态数据渲染到原创文档页面中,最终变成我们看到的网页。对于这部分需要JS代码执行的数据,httpClient是无能为力的。虽然我们可以通过研究得到JS执行的请求路径,然后用java代码来获取我们需要的部分数据,不说能不能从JS脚本中分析请求路径和请求参数,只分析这部分数据源码成本已经很高了。
通过上面的介绍,我们了解到现在很大一部分动态网页都是通过异步JS请求获取的数据,然后通过JS渲染页面。那么我们能不能做这样的假设,假设我们的爬虫程序模拟一个浏览器,拿到html页面后,像浏览器一样执行异步JS代码,JS渲染好html页面后,就可以愉快的获取到节点信息了这页纸。那么有没有这样的java程序呢?
答案是肯定的。
HtmlUnit就是这样一个库,用来做界面显示的所有异步工作。没有耗时的显示工作,HtmlUnit 加载的完整网页比实际的浏览器块更多。并且根据不同的配置,HtmlUnit可以模拟市面上常见的Chrome、Firefox、IE浏览器等浏览器。
通过HtmlUnit库,加载一个完整的Html页面(图片和视频除外),然后将其转换成我们常用的字符串格式,并使用Jsoup等其他工具获取元素。当然,你也可以直接从HtmlUnit提供的对象中获取网页元素,甚至可以操作按钮、表单等控件。除了不能像可见浏览器那样用鼠标和键盘浏览网页,我们可以使用HtmlUnit来模拟所有其他的操作,比如登录网站、写博客等等都可以完成。当然,网页内容抓取是最简单的应用。
2.J4L2.1官方简介
J4L OCR 工具是一组组件,可用于在 Java 应用程序中收录 OCR 功能。这意味着您可以接收传真、PDF 文件或扫描文档并从图像中提取商业信息。主要的3个组件是:
j4l工具的详细使用步骤请参考这篇文章文章:Java使用J4L识别验证码
本文文章主要介绍使用HtmlUnit模拟登录
3.实际案例3.1.场景
登录页面,包括表单,需要填写用户名、登录密码、验证码,实现用户登录。
3.2操作步骤
使用htmlunit模拟登录是一个获取登录页面->找到输入框->填写用户名和密码->填写验证码->模拟点击登录的过程。
4.实现代码4.1maven引入HtmlUnit依赖
net.sourceforge.htmlunit
htmlunit
2.18
4.2 主要方法
登录.java
public static void main(String[] args) throws Exception {
login();
}
public static void login() throws Exception {
WebClient webClient = new WebClient(BrowserVersion.CHROME);//设置浏览器内核
webClient.getOptions().setJavaScriptEnabled(true);// js是否可用
webClient.getOptions().setCssEnabled(true);//css 一般设置false因为影响运行速度
webClient.getOptions().setThrowExceptionOnScriptError(false);//设置js抛出异常:false
webClient.getOptions().setActiveXNative(false);
//ajax
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
webClient.getOptions().setUseInsecureSSL(false);
//允许重定向
webClient.getOptions().setRedirectEnabled(true);
//连接超时
webClient.getOptions().setTimeout(5000);
//js执行超时
webClient.setJavaScriptTimeout(10000 * 3);
//允许cookie
webClient.getCookieManager().setCookiesEnabled(true);
String url = "http://hrportalneu.cs/HRPortal ... 3B%3B
HtmlPage page = webClient.getPage(url);
webClient.waitForBackgroundJavaScript(5000);
HtmlPage newPage;
newPage = readyPage(page, webClient, "btnCheckIn1");
System.out.println("url----------------" + newPage.getUrl());
System.out.println("Login执行后页面:" + newPage.asXml());
IOUtils.write(newPage.asXml().getBytes(), new FileWriter(new File("D:/checkIn.txt")));
if (!newPage.asXml().contains("登录成功")) {
login();
}
webClient.close();
}
public static HtmlPage readyPage(HtmlPage page, WebClient webClient, String type) throws Exception {
//封装页面元素
HtmlForm form = page.getHtmlElementById("form1");
HtmlTextInput tbxUsername = form.getInputByName("tbxUsername");
tbxUsername.setValueAttribute("用户名*******");
HtmlPasswordInput tbxPassword = form.getInputByName("tbxPassword");
tbxPassword.setValueAttribute("密码*******");
//获取验证码图片
HtmlImage verify_img = (HtmlImage) page.getElementById("AuthCode1$codeText$img");
File file = new File("D:\\" + "check" + ".png");
//保存验证码图片
verify_img.saveAs(file);
System.out.println("验证码图片已保存!");
//保存路径
String filePath = file.getPath();
//裁剪验证码 这里使用原始的图片文件识别成功率不高 可以先进行裁剪
ImageUtil.cutImage(filePath, 1, 1, 96, 34);
//自动识别验证码
OCRFacade facade = new OCRFacade();
//识别验证码
String code = facade.recognizeFile(filePath, "eng");
//处理字符串
code = code.replaceAll(" ", "");
code = code.replaceAll("\\n", "");
System.out.println("验证码:" + code);
//定位验证码输入框
HtmlTextInput verify_code = form.getInputByName("AuthCode1$codeText");
//填入自动识别出来的验证码
verify_code.setValueAttribute(code);
System.out.println("原始页面:" + page.asXml());
HtmlPage newPage = null;
//操作按钮
if (type.equals("btnCheckIn1")) {
DomElement btnCheckIn1 = page.getElementById("btnCheckIn1");
System.out.println("doCheckIn");
newPage = btnCheckIn1.click();
}
//等待js加载
webClient.waitForBackgroundJavaScript(5000);
return newPage;
}
ImageUtil.java
public class ImageUtil {
public static void cutImage(String filePath, int x, int y, int w, int h)
throws Exception {
// 首先通过ImageIo中的方法,创建一个Image + InputStream到内存
ImageInputStream iis = ImageIO
.createImageInputStream(new FileInputStream(filePath));
// 再按照指定格式构造一个Reader(Reader不能new的)
Iterator it = ImageIO.getImageReadersByFormatName("gif");
ImageReader imagereader = (ImageReader) it.next();
// 再通过ImageReader绑定 InputStream
imagereader.setInput(iis);
// 设置感兴趣的源区域。
ImageReadParam par = imagereader.getDefaultReadParam();
par.setSourceRegion(new Rectangle(x, y, w, h));
// 从 reader得到BufferImage
BufferedImage bi = imagereader.read(0, par);
// 将BuffeerImage写出通过ImageIO
ImageIO.write(bi, "png", new File(filePath));
}
}
在控制台查看登录后的页面,查看是否登录成功。
htmlunit 抓取网页(htmlunitjava页面分析工具模拟运行 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-28 04:02
)
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit对页面内容进行分析。
该项目可以模拟浏览器的操作,被称为java浏览器的开源实现。是没有界面的浏览器。
使用了 Rhinojs 引擎。模拟js运行。
使用htmlunit抓取网页大致可以分为以下几个步骤:
1、定义一个 WebClient 客户端。
相当于定义了一个没有界面的浏览器。
2、使用WebClient客户端从指定的URL获取HtmlPage。
HtmlPage 收录目标 URL 页面中的所有信息。
3、从 HtmlPage 中获取我们需要的指定元素。
我们来看一个例子:
1package com.fuwh;
2
3import com.gargoylesoftware.htmlunit.WebClient;
4import com.gargoylesoftware.htmlunit.html.HtmlPage;
5
6public class Demo01 {
7
8 public static void main(String[] args) {
9
10 WebClient webClient=null;
11 try {
12 webClient= new WebClient(); //定义一个默认的WebClient
13 HtmlPage page=webClient.getPage("https://www.cnblogs.com/"); //从指定URL获取HtmlPage
14 System.out.println(page.asText()); //将HtmlPage转换成字符串打印出来
15 } catch (Exception e) {
16 // TODO: handle exception
17 e.printStackTrace();
18 }finally {
19 webClient.close(); //关闭客户端
20 }
21 }
22}
23
在上面的例子中,我们创建了一个默认的WebClient实例,使用WebClient#getBrowserVersion()方法,可以看到,
默认创建Chrome版本的浏览器。
当然,我们也可以在创建时指定浏览器版本。
例子:
1package com.fuwh;
2
3import com.gargoylesoftware.htmlunit.BrowserVersion;
4import com.gargoylesoftware.htmlunit.WebClient;
5import com.gargoylesoftware.htmlunit.html.HtmlPage;
6
7public class Demo01 {
8
9 public static void main(String[] args) {
10
11 WebClient webClient=null;
12 try {
13 webClient= new WebClient(BrowserVersion.FIREFOX_45); //定义一个WebClient
14 HtmlPage page=webClient.getPage("https://www.cnblogs.com/"); //从指定URL获取HtmlPage
15 System.out.println(page.asText()); //将HtmlPage转换成字符串打印出来
16 } catch (Exception e) {
17 // TODO: handle exception
18 e.printStackTrace();
19 }finally {
20 webClient.close(); //关闭客户端
21 }
22 }
23}
24
在 BrowserVersion 中,定义了许多浏览器版本。
在获得一个 HtmlPage 之后,我们仍然希望能够找到我们想要的元素,而不是输入整个页面。
HtmlUnit 还为查找特定元素提供了丰富的支持。
支持使用 DOM、CSS 和 XPath 的方式(推荐)。
◇使用DOM方法:
1package com.fuwh;
2
3import com.gargoylesoftware.htmlunit.BrowserVersion;
4import com.gargoylesoftware.htmlunit.WebClient;
5import com.gargoylesoftware.htmlunit.html.DomElement;
6import com.gargoylesoftware.htmlunit.html.DomNodeList;
7import com.gargoylesoftware.htmlunit.html.HtmlAnchor;
8import com.gargoylesoftware.htmlunit.html.HtmlDivision;
9import com.gargoylesoftware.htmlunit.html.HtmlPage;
10
11public class Demo01 {
12
13 public static void main(String[] args) {
14
15 WebClient webClient=null;
16 try {
17 webClient= new WebClient(BrowserVersion.FIREFOX_45); //定义一个WebClient
18 final HtmlPage page=webClient.getPage("https://www.cnblogs.com/"); //从指定URL获取HtmlPage
19
20 /**
21 * DomElement 的子类:HtmlElement
22 * HtmlElemnt也有很多子类,基本上涵盖了所有的Html元素
23 * 例如:HtmlDivision,HtmlInput
24 */
25 System.out.println("=============================================");
26 //通过id获取指定DOM元素
27 HtmlDivision htmlDiv=(HtmlDivision) page.getElementById("header");
28 System.out.println(htmlDiv.asXml());
29
30 System.out.println("=============================================");
31 //通过tagName来获取元素集合
32 DomNodeList nodeList=page.getElementsByTagName("a");
33 for (DomElement domElement : nodeList) {
34 HtmlAnchor htmlAnchor=(HtmlAnchor) domElement;
35 System.out.println("标题:"+htmlAnchor.asText()+" --> 地址:"+htmlAnchor.getAttribute("href"));
36 }
37
38 } catch (Exception e) {
39 // TODO: handle exception
40 e.printStackTrace();
41 }finally {
42 webClient.close(); //关闭客户端
43 }
44 }
45}
46
◇使用CSS方法:
1package com.fuwh;
2
3import com.gargoylesoftware.htmlunit.BrowserVersion;
4import com.gargoylesoftware.htmlunit.WebClient;
5import com.gargoylesoftware.htmlunit.html.DomElement;
6import com.gargoylesoftware.htmlunit.html.DomNodeList;
7import com.gargoylesoftware.htmlunit.html.HtmlAnchor;
8import com.gargoylesoftware.htmlunit.html.HtmlDivision;
9import com.gargoylesoftware.htmlunit.html.HtmlPage;
10
11public class Demo02 {
12
13 public static void main(String[] args) {
14
15 WebClient webClient=null;
16 try {
17 webClient= new WebClient(BrowserVersion.FIREFOX_45); //定义一个WebClient
18 final HtmlPage page=webClient.getPage("https://www.cnblogs.com/"); //从指定URL获取HtmlPage
19
20 HtmlDivision htmlDiv =page.querySelector("div");//获取第一个div
21 System.out.println(htmlDiv.asXml());
22
23 System.out.println("====================================");
24
25 HtmlDivision htmlDiv2=page.querySelector("div#footer_bottom");//也可以指定多个选择器,通过‘,’隔开
26 System.out.println(htmlDiv2.asXml());
27 } catch (Exception e) {
28 // TODO: handle exception
29 e.printStackTrace();
30 }finally {
31 webClient.close(); //关闭客户端
32 }
33 }
34}
35
◇使用XPath方法:
1package com.fuwh;
2
3import java.util.List;
4
5import com.gargoylesoftware.htmlunit.BrowserVersion;
6import com.gargoylesoftware.htmlunit.WebClient;
7import com.gargoylesoftware.htmlunit.html.HtmlDivision;
8import com.gargoylesoftware.htmlunit.html.HtmlPage;
9
10public class Demo03 {
11
12 public static void main(String[] args) {
13
14 WebClient webClient=null;
15 try {
16 webClient= new WebClient(BrowserVersion.FIREFOX_45); //定义一个WebClient
17 final HtmlPage page=webClient.getPage("https://www.cnblogs.com/"); //从指定URL获取HtmlPage
18
19 List divList=page.getByXPath("//div[@id='cnblogs_a1']");
20 for (HtmlDivision htmlDivision : divList) {
21 System.out.println("***********************************************8");
22 System.out.println(htmlDivision.asXml());
23 }
24
25 } catch (Exception e) {
26 // TODO: handle exception
27 e.printStackTrace();
28 }finally {
29 webClient.close(); //关闭客户端
30 }
31 }
32}
33 查看全部
htmlunit 抓取网页(htmlunitjava页面分析工具模拟运行
)
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit对页面内容进行分析。
该项目可以模拟浏览器的操作,被称为java浏览器的开源实现。是没有界面的浏览器。
使用了 Rhinojs 引擎。模拟js运行。
使用htmlunit抓取网页大致可以分为以下几个步骤:
1、定义一个 WebClient 客户端。
相当于定义了一个没有界面的浏览器。
2、使用WebClient客户端从指定的URL获取HtmlPage。
HtmlPage 收录目标 URL 页面中的所有信息。
3、从 HtmlPage 中获取我们需要的指定元素。
我们来看一个例子:
1package com.fuwh;
2
3import com.gargoylesoftware.htmlunit.WebClient;
4import com.gargoylesoftware.htmlunit.html.HtmlPage;
5
6public class Demo01 {
7
8 public static void main(String[] args) {
9
10 WebClient webClient=null;
11 try {
12 webClient= new WebClient(); //定义一个默认的WebClient
13 HtmlPage page=webClient.getPage("https://www.cnblogs.com/";); //从指定URL获取HtmlPage
14 System.out.println(page.asText()); //将HtmlPage转换成字符串打印出来
15 } catch (Exception e) {
16 // TODO: handle exception
17 e.printStackTrace();
18 }finally {
19 webClient.close(); //关闭客户端
20 }
21 }
22}
23
在上面的例子中,我们创建了一个默认的WebClient实例,使用WebClient#getBrowserVersion()方法,可以看到,
默认创建Chrome版本的浏览器。
当然,我们也可以在创建时指定浏览器版本。
例子:
1package com.fuwh;
2
3import com.gargoylesoftware.htmlunit.BrowserVersion;
4import com.gargoylesoftware.htmlunit.WebClient;
5import com.gargoylesoftware.htmlunit.html.HtmlPage;
6
7public class Demo01 {
8
9 public static void main(String[] args) {
10
11 WebClient webClient=null;
12 try {
13 webClient= new WebClient(BrowserVersion.FIREFOX_45); //定义一个WebClient
14 HtmlPage page=webClient.getPage("https://www.cnblogs.com/";); //从指定URL获取HtmlPage
15 System.out.println(page.asText()); //将HtmlPage转换成字符串打印出来
16 } catch (Exception e) {
17 // TODO: handle exception
18 e.printStackTrace();
19 }finally {
20 webClient.close(); //关闭客户端
21 }
22 }
23}
24
在 BrowserVersion 中,定义了许多浏览器版本。
在获得一个 HtmlPage 之后,我们仍然希望能够找到我们想要的元素,而不是输入整个页面。
HtmlUnit 还为查找特定元素提供了丰富的支持。
支持使用 DOM、CSS 和 XPath 的方式(推荐)。
◇使用DOM方法:
1package com.fuwh;
2
3import com.gargoylesoftware.htmlunit.BrowserVersion;
4import com.gargoylesoftware.htmlunit.WebClient;
5import com.gargoylesoftware.htmlunit.html.DomElement;
6import com.gargoylesoftware.htmlunit.html.DomNodeList;
7import com.gargoylesoftware.htmlunit.html.HtmlAnchor;
8import com.gargoylesoftware.htmlunit.html.HtmlDivision;
9import com.gargoylesoftware.htmlunit.html.HtmlPage;
10
11public class Demo01 {
12
13 public static void main(String[] args) {
14
15 WebClient webClient=null;
16 try {
17 webClient= new WebClient(BrowserVersion.FIREFOX_45); //定义一个WebClient
18 final HtmlPage page=webClient.getPage("https://www.cnblogs.com/";); //从指定URL获取HtmlPage
19
20 /**
21 * DomElement 的子类:HtmlElement
22 * HtmlElemnt也有很多子类,基本上涵盖了所有的Html元素
23 * 例如:HtmlDivision,HtmlInput
24 */
25 System.out.println("=============================================");
26 //通过id获取指定DOM元素
27 HtmlDivision htmlDiv=(HtmlDivision) page.getElementById("header");
28 System.out.println(htmlDiv.asXml());
29
30 System.out.println("=============================================");
31 //通过tagName来获取元素集合
32 DomNodeList nodeList=page.getElementsByTagName("a");
33 for (DomElement domElement : nodeList) {
34 HtmlAnchor htmlAnchor=(HtmlAnchor) domElement;
35 System.out.println("标题:"+htmlAnchor.asText()+" --> 地址:"+htmlAnchor.getAttribute("href"));
36 }
37
38 } catch (Exception e) {
39 // TODO: handle exception
40 e.printStackTrace();
41 }finally {
42 webClient.close(); //关闭客户端
43 }
44 }
45}
46
◇使用CSS方法:
1package com.fuwh;
2
3import com.gargoylesoftware.htmlunit.BrowserVersion;
4import com.gargoylesoftware.htmlunit.WebClient;
5import com.gargoylesoftware.htmlunit.html.DomElement;
6import com.gargoylesoftware.htmlunit.html.DomNodeList;
7import com.gargoylesoftware.htmlunit.html.HtmlAnchor;
8import com.gargoylesoftware.htmlunit.html.HtmlDivision;
9import com.gargoylesoftware.htmlunit.html.HtmlPage;
10
11public class Demo02 {
12
13 public static void main(String[] args) {
14
15 WebClient webClient=null;
16 try {
17 webClient= new WebClient(BrowserVersion.FIREFOX_45); //定义一个WebClient
18 final HtmlPage page=webClient.getPage("https://www.cnblogs.com/";); //从指定URL获取HtmlPage
19
20 HtmlDivision htmlDiv =page.querySelector("div");//获取第一个div
21 System.out.println(htmlDiv.asXml());
22
23 System.out.println("====================================");
24
25 HtmlDivision htmlDiv2=page.querySelector("div#footer_bottom");//也可以指定多个选择器,通过‘,’隔开
26 System.out.println(htmlDiv2.asXml());
27 } catch (Exception e) {
28 // TODO: handle exception
29 e.printStackTrace();
30 }finally {
31 webClient.close(); //关闭客户端
32 }
33 }
34}
35
◇使用XPath方法:
1package com.fuwh;
2
3import java.util.List;
4
5import com.gargoylesoftware.htmlunit.BrowserVersion;
6import com.gargoylesoftware.htmlunit.WebClient;
7import com.gargoylesoftware.htmlunit.html.HtmlDivision;
8import com.gargoylesoftware.htmlunit.html.HtmlPage;
9
10public class Demo03 {
11
12 public static void main(String[] args) {
13
14 WebClient webClient=null;
15 try {
16 webClient= new WebClient(BrowserVersion.FIREFOX_45); //定义一个WebClient
17 final HtmlPage page=webClient.getPage("https://www.cnblogs.com/";); //从指定URL获取HtmlPage
18
19 List divList=page.getByXPath("//div[@id='cnblogs_a1']");
20 for (HtmlDivision htmlDivision : divList) {
21 System.out.println("***********************************************8");
22 System.out.println(htmlDivision.asXml());
23 }
24
25 } catch (Exception e) {
26 // TODO: handle exception
27 e.printStackTrace();
28 }finally {
29 webClient.close(); //关闭客户端
30 }
31 }
32}
33
htmlunit 抓取网页(我可以让htmlunit忽略javascript*>**)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-02-25 15:27
在使用 htmlunit 抓取网页时,我偶尔会注意到这些警告淹没了控制台输出。
Jul 24,2011 5:12:59 PM com.gargoylesoftware.htmlunit.javascript.StrictErrorReporter warning
WARNING: warning: message=[Calling eval() with anything other than a primitive string value
will simply return the value. Is this what you intended?] sourceName=[http://ad.doubleclick.net/adj/ ... 40%3F] line=[356] lineSource=[null] lineOffset=[0]
有没有办法让htmlunit忽略javascript
> *
> *
就算了
>
>
同样,有没有办法让 htmlunit 只解释收录特定子字符串或匹配正则表达式的网页上的 javascript?
解决方案
您可以通过实现自己的 javascript 来删除不需要的 JavaScript
脚本预处理器。您的 ScriptPreProcessor 可以检测到您不想执行的 jsvascript,而不是将其从 网站 中删除。
我还没有尝试过,但它可能会起作用。 查看全部
htmlunit 抓取网页(我可以让htmlunit忽略javascript*>**)
在使用 htmlunit 抓取网页时,我偶尔会注意到这些警告淹没了控制台输出。
Jul 24,2011 5:12:59 PM com.gargoylesoftware.htmlunit.javascript.StrictErrorReporter warning
WARNING: warning: message=[Calling eval() with anything other than a primitive string value
will simply return the value. Is this what you intended?] sourceName=[http://ad.doubleclick.net/adj/ ... 40%3F] line=[356] lineSource=[null] lineOffset=[0]
有没有办法让htmlunit忽略javascript
> *
> *
就算了
>
>
同样,有没有办法让 htmlunit 只解释收录特定子字符串或匹配正则表达式的网页上的 javascript?
解决方案
您可以通过实现自己的 javascript 来删除不需要的 JavaScript
脚本预处理器。您的 ScriptPreProcessor 可以检测到您不想执行的 jsvascript,而不是将其从 网站 中删除。
我还没有尝试过,但它可能会起作用。
htmlunit 抓取网页(抓一个今日头条的首页内容解决方案-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-25 11:27
不知道大家在使用jsoup的过程中是否遇到过爬取内容,发现有些网页中的内容是通过javascript异步加载的,导致我们的爬虫空手返回(只抓到一个网页的外框) .
当我第一次遇到这个问题时,我想到了两个解决方案:
在等待网页异步加载后,使用类似于 Python 中延迟加载的方法对异步加载的网页进行爬取。使用一种特殊的方法,让爬取的网页的框架模拟里面的JavaScript代码的执行,最终到达完整的网页。
在搜索引擎的帮助下,决定使用方案二来解决这个问题。没有更好的第三方库搜索解决方案1。在java中使用解决方案1解决这个问题的朋友希望与下一个讨论,不胜感激。
案例很简单,抓取一条今日头条的首页内容。你可以看一下今日头条的首页,里面的内容是异步加载的。
添加jsoup和htmlunit依赖
org.jsoup
jsoup
1.10.2
net.sourceforge.htmlunit
htmlunit
2.25
首先,我们单独使用jsoup来解析今日头条的首页
String url = "https://www.toutiao.com/";
Connection connect = Jsoup.connect(url);
Document document = connect.get();
System.out.println(document);
↑ 这里只能获取网页的框架内容,不能获取首页的新闻内容
接下来,我们使用htmlunit来尝试
//构造一个webClient 模拟Chrome 浏览器
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//屏蔽日志信息
LogFactory.getFactory().setAttribute("org.apache.commons.logging.Log",
"org.apache.commons.logging.impl.NoOpLog");
java.util.logging.Logger.getLogger("com.gargoylesoftware").setLevel(Level.OFF);
//支持JavaScript
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setTimeout(5000);
HtmlPage rootPage = webClient.getPage(url);
//设置一个运行JavaScript的时间
webClient.waitForBackgroundJavaScript(5000);
String html = rootPage.asXml();
Document document = Jsoup.parse(html);
这为我们提供了运行 JavaScript 的完整源页面 查看全部
htmlunit 抓取网页(抓一个今日头条的首页内容解决方案-苏州安嘉)
不知道大家在使用jsoup的过程中是否遇到过爬取内容,发现有些网页中的内容是通过javascript异步加载的,导致我们的爬虫空手返回(只抓到一个网页的外框) .
当我第一次遇到这个问题时,我想到了两个解决方案:
在等待网页异步加载后,使用类似于 Python 中延迟加载的方法对异步加载的网页进行爬取。使用一种特殊的方法,让爬取的网页的框架模拟里面的JavaScript代码的执行,最终到达完整的网页。
在搜索引擎的帮助下,决定使用方案二来解决这个问题。没有更好的第三方库搜索解决方案1。在java中使用解决方案1解决这个问题的朋友希望与下一个讨论,不胜感激。
案例很简单,抓取一条今日头条的首页内容。你可以看一下今日头条的首页,里面的内容是异步加载的。
添加jsoup和htmlunit依赖
org.jsoup
jsoup
1.10.2
net.sourceforge.htmlunit
htmlunit
2.25
首先,我们单独使用jsoup来解析今日头条的首页
String url = "https://www.toutiao.com/";
Connection connect = Jsoup.connect(url);
Document document = connect.get();
System.out.println(document);
↑ 这里只能获取网页的框架内容,不能获取首页的新闻内容
接下来,我们使用htmlunit来尝试
//构造一个webClient 模拟Chrome 浏览器
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//屏蔽日志信息
LogFactory.getFactory().setAttribute("org.apache.commons.logging.Log",
"org.apache.commons.logging.impl.NoOpLog");
java.util.logging.Logger.getLogger("com.gargoylesoftware").setLevel(Level.OFF);
//支持JavaScript
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setTimeout(5000);
HtmlPage rootPage = webClient.getPage(url);
//设置一个运行JavaScript的时间
webClient.waitForBackgroundJavaScript(5000);
String html = rootPage.asXml();
Document document = Jsoup.parse(html);
这为我们提供了运行 JavaScript 的完整源页面

