
excelvba抓取网页数据
excelvba抓取网页数据(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-01-24 06:17
我相信所有个人网站站长都有抓取别人数据的经历。目前抓取别人的网站数据只有两种方式:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再赘述。
二、自己写程序来抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
起初,我也尝试使用第三方工具来获取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不明白怎么用,就干脆决定自己写了。嗯,现在基本上半天就能搞定网站了(只是程序开发时间,不包括数据采集时间)。
经过一段时间的数据爬取生涯,我也遇到了很多困难。最常见的一种是分页数据的爬取。原因是数据分页的形式有很多种。下面我主要介绍三种形式。抓取分页数据的方法,虽然在网上看过很多文章,但是每次拿别人的代码,总是会出现各种各样的问题。以下方式的代码都是正确的。实现,我目前正在使用它。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入正题:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具爬取这个表单也很简单。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得学第三方工具的人还是可以自己写代码来实现的;
该方法是通过循环生成数据分页的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;抓取的代码可以参考以下:
公共字符串 GetResponseString(字符串 url){
字符串 _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0(兼容;MSIE 7.0;WINDOWS NT 5.2;.NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回对应页面的html内容的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
第二种方式:可能通过网站的开发遇到,它的分页控件通过post的方式将分页信息提交给后台代码,比如.net下Gridview自带的分页功能,点击页面的时候分页号,你会发现URL地址没有变,但是页码变了,页面的内容也变了。仔细看会发现,当你把鼠标移到每个页码上的时候,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这个表格其实也不是很难,因为经过所有,有一个地方可以得到页码的规则。
我们知道提交HTTP请求有两种方式:一种是get,另一种是post,第一种是get,第二种是post。具体提交原理无需赘述,不是本文重点
爬取这类页面需要注意页面的几个重要元素
一、 __VIEWSTATE ,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现了这个东西,并且后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback 方法,这是一个页面自动生成的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将传递给这两个参数。
三、__EVENTVALIDATION 这也应该是独一无二的
不需要太在意这三样东西是干什么的,只要在自己写代码抓取页面的时候记得提交这三个元素就可以了。
和第一种方法一样,_dopostback的两个参数必须通过循环拼凑,只有收录页码信息的参数需要拼凑。这里有一点需要注意,就是每次通过Post提交下一页请求时,首先要获取当前页的__VIEWSTATE信息和__EVENTVALIDATION信息,这样第一页的分页数据就可以使用第一种方法获得。页码内容然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,然后在每一个页面爬取完成后记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一个页面发布数据使用
参考代码如下:
for (int i = 0; i < 1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是您需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1); //获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取上面需要的信息,比如当前页面对应的__VIEWSTATE,用于抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(例外前){
Console.WriteLine(ex.Message);
}
}
第三种方式:第三种方式是最麻烦最恶心的。这种页面在翻页过程中找不到任何地方的页码信息。这种方式耗费了我不少心血,后来采用了更狠的方法,用代码来模拟手动翻页。该方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,用代码逐页翻页。然后逐页抓取。
俗话说,外行看热闹,行家看门道。很多人可能看到这个,说可以通过使用Webbrowser控件来实现。是的,我遵循的方式是使用 WebBrowser 控件来实现它。其实.net下应该有这么一个类似的类,不过我没有研究过,希望有人有别的办法,可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了一个浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我想肯定不如IE和Firefox。呵呵
让我们减少八卦并切入主题:
使用WebBroser控件基本上可以实现任何可以在IE中操作网页的功能,所以当然也可以点击翻页按钮。既然可以手动点击WebBroser中的翻页按钮,自然我们也可以用程序代码来指令WebBroser。自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要抓取的页面,例如:
调用webBrowser控件的方法Navigate("");
此时,您应该在您的 WebBrowser 控件中看到您的网页信息,与您在 IE 中看到的一样;
第二步,WebBrowser控件的DocumentCompleted事件非常重要。当你访问的页面全部加载完毕,就会触发这个事件。所以我们分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取了当前打开的页面的html元素的内容,剩下的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程,大家应该会可以自己写。
第三步,重点在这第三步,因为页面快要翻了,那么第二步,解析完字符串后,还是在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("点击");
从代码的方法名应该可以理解,调用该方法后,WebBrwoser控件中的网页就会实现翻页,和手动点击翻页按钮是一样的。
重点是在翻页之后,DocumentCompleted事件也会被触发,所以第二步和第三步都在循环中,所以需要注意判断跳出循环的时机。
其实用WebBrowser可以做的事情有很多,比如自动登录、注销论坛、保存session、cockie,所以这个控件基本可以实现你对网页的任何操作,即使你想破解一个网站暴利的登录密码,当然不推荐这样。呵呵 查看全部
excelvba抓取网页数据(一下抓取别人网站数据的方式有什么作用?如何抓取)
我相信所有个人网站站长都有抓取别人数据的经历。目前抓取别人的网站数据只有两种方式:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再赘述。
二、自己写程序来抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
起初,我也尝试使用第三方工具来获取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不明白怎么用,就干脆决定自己写了。嗯,现在基本上半天就能搞定网站了(只是程序开发时间,不包括数据采集时间)。
经过一段时间的数据爬取生涯,我也遇到了很多困难。最常见的一种是分页数据的爬取。原因是数据分页的形式有很多种。下面我主要介绍三种形式。抓取分页数据的方法,虽然在网上看过很多文章,但是每次拿别人的代码,总是会出现各种各样的问题。以下方式的代码都是正确的。实现,我目前正在使用它。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入正题:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具爬取这个表单也很简单。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得学第三方工具的人还是可以自己写代码来实现的;
该方法是通过循环生成数据分页的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;抓取的代码可以参考以下:
公共字符串 GetResponseString(字符串 url){
字符串 _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0(兼容;MSIE 7.0;WINDOWS NT 5.2;.NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回对应页面的html内容的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
第二种方式:可能通过网站的开发遇到,它的分页控件通过post的方式将分页信息提交给后台代码,比如.net下Gridview自带的分页功能,点击页面的时候分页号,你会发现URL地址没有变,但是页码变了,页面的内容也变了。仔细看会发现,当你把鼠标移到每个页码上的时候,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这个表格其实也不是很难,因为经过所有,有一个地方可以得到页码的规则。
我们知道提交HTTP请求有两种方式:一种是get,另一种是post,第一种是get,第二种是post。具体提交原理无需赘述,不是本文重点
爬取这类页面需要注意页面的几个重要元素
一、 __VIEWSTATE ,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现了这个东西,并且后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback 方法,这是一个页面自动生成的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将传递给这两个参数。
三、__EVENTVALIDATION 这也应该是独一无二的
不需要太在意这三样东西是干什么的,只要在自己写代码抓取页面的时候记得提交这三个元素就可以了。
和第一种方法一样,_dopostback的两个参数必须通过循环拼凑,只有收录页码信息的参数需要拼凑。这里有一点需要注意,就是每次通过Post提交下一页请求时,首先要获取当前页的__VIEWSTATE信息和__EVENTVALIDATION信息,这样第一页的分页数据就可以使用第一种方法获得。页码内容然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,然后在每一个页面爬取完成后记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一个页面发布数据使用
参考代码如下:
for (int i = 0; i < 1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是您需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1); //获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取上面需要的信息,比如当前页面对应的__VIEWSTATE,用于抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(例外前){
Console.WriteLine(ex.Message);
}
}
第三种方式:第三种方式是最麻烦最恶心的。这种页面在翻页过程中找不到任何地方的页码信息。这种方式耗费了我不少心血,后来采用了更狠的方法,用代码来模拟手动翻页。该方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,用代码逐页翻页。然后逐页抓取。
俗话说,外行看热闹,行家看门道。很多人可能看到这个,说可以通过使用Webbrowser控件来实现。是的,我遵循的方式是使用 WebBrowser 控件来实现它。其实.net下应该有这么一个类似的类,不过我没有研究过,希望有人有别的办法,可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了一个浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我想肯定不如IE和Firefox。呵呵
让我们减少八卦并切入主题:
使用WebBroser控件基本上可以实现任何可以在IE中操作网页的功能,所以当然也可以点击翻页按钮。既然可以手动点击WebBroser中的翻页按钮,自然我们也可以用程序代码来指令WebBroser。自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要抓取的页面,例如:
调用webBrowser控件的方法Navigate("");
此时,您应该在您的 WebBrowser 控件中看到您的网页信息,与您在 IE 中看到的一样;
第二步,WebBrowser控件的DocumentCompleted事件非常重要。当你访问的页面全部加载完毕,就会触发这个事件。所以我们分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取了当前打开的页面的html元素的内容,剩下的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程,大家应该会可以自己写。
第三步,重点在这第三步,因为页面快要翻了,那么第二步,解析完字符串后,还是在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("点击");
从代码的方法名应该可以理解,调用该方法后,WebBrwoser控件中的网页就会实现翻页,和手动点击翻页按钮是一样的。
重点是在翻页之后,DocumentCompleted事件也会被触发,所以第二步和第三步都在循环中,所以需要注意判断跳出循环的时机。
其实用WebBrowser可以做的事情有很多,比如自动登录、注销论坛、保存session、cockie,所以这个控件基本可以实现你对网页的任何操作,即使你想破解一个网站暴利的登录密码,当然不推荐这样。呵呵
excelvba抓取网页数据( PowerQuery的6种常用连接方式,从工作簿从文本/CSV)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-01-18 10:22
PowerQuery的6种常用连接方式,从工作簿从文本/CSV)
Power Query有5大类40种连接方式,可以连接文件、数据库、在线服务等各种数据源。今天我们介绍6种常用的连接方式:
从工作簿从文本/CSV 从文件夹
来自网络空白查询的表格区域
要从工作簿建立连接:
Power Query 的一个基本概念是数据源隔离。无论连接到哪个数据源,连接后的所有操作都不会影响数据源。但是,如果在 Excel 数据源工作簿中建立连接,则数据源不会被修改,但在保存数据源 Excel 文件时,仍然会发生变化。数据源表转换为超级表,文件中的Power更多。查询查询。
因此,要保持数据源文件不被修改,最好的方法是与工作簿建立连接,这样就可以直接提取数据,无需打开 Excel 文件,无需对 Excel 文件进行任何更改。
步骤很简单:
从文本/CSV 连接:
有时数据源是文本文件(后缀为 TXT 或 CSV),也可以直接使用 Power Query 建立连接。步骤同上,选择文件建立连接即可。
从文件夹建立连接:
当 Power Query 从文件夹建立连接时,它可以自动合并格式相同的文件。过去,需要 VBA 来合并多个文件。使用 Power Query,多个文件合并变得更加容易。
按此按钮将自动合并文件。
前三种方法是从文件中获取数据来创建查询,后面三种方法不同。
从表区域:
在 Power Query 中创建查询的最简单方法是从表格区域创建查询。只需一步,选择数据区域并按下按钮。
这种连接方式通常用于单个文件中的数据处理。无需建立文件链接,直接在文件中进行数据处理。也是初学者最喜欢的方法,简单直接。
来自网络:
Power Query 提供了网页数据抓取的功能,有点高大上。通常,网络爬虫只能用Python等编程语言来实现功能。当然,Power Query 的网页抓取在效率和功能上都无法与网页爬虫相比,但基本的静态网页抓取是没有问题的。
复制并粘贴网络地址并选择表格。
构建一个空白查询:
Power Query 的背景是 M 语言。Power Query 提供了丰富的 M 函数,但有时仍需要自定义函数来处理特定问题。在这种情况下,您需要使用空查询。创建空查询后,打开高级编辑器,可以根据M语言的语法规范编写自定义函数。
Power Query提供了丰富的数据接口,可以根据需要进行选择,具体的数据库和在线连接操作并不复杂,只要有权限,按照向导填写所需信息,即可建立连接. 查看全部
excelvba抓取网页数据(
PowerQuery的6种常用连接方式,从工作簿从文本/CSV)
Power Query有5大类40种连接方式,可以连接文件、数据库、在线服务等各种数据源。今天我们介绍6种常用的连接方式:
从工作簿从文本/CSV 从文件夹
来自网络空白查询的表格区域
要从工作簿建立连接:
Power Query 的一个基本概念是数据源隔离。无论连接到哪个数据源,连接后的所有操作都不会影响数据源。但是,如果在 Excel 数据源工作簿中建立连接,则数据源不会被修改,但在保存数据源 Excel 文件时,仍然会发生变化。数据源表转换为超级表,文件中的Power更多。查询查询。
因此,要保持数据源文件不被修改,最好的方法是与工作簿建立连接,这样就可以直接提取数据,无需打开 Excel 文件,无需对 Excel 文件进行任何更改。
步骤很简单:
从文本/CSV 连接:
有时数据源是文本文件(后缀为 TXT 或 CSV),也可以直接使用 Power Query 建立连接。步骤同上,选择文件建立连接即可。
从文件夹建立连接:
当 Power Query 从文件夹建立连接时,它可以自动合并格式相同的文件。过去,需要 VBA 来合并多个文件。使用 Power Query,多个文件合并变得更加容易。
按此按钮将自动合并文件。
前三种方法是从文件中获取数据来创建查询,后面三种方法不同。
从表区域:
在 Power Query 中创建查询的最简单方法是从表格区域创建查询。只需一步,选择数据区域并按下按钮。
这种连接方式通常用于单个文件中的数据处理。无需建立文件链接,直接在文件中进行数据处理。也是初学者最喜欢的方法,简单直接。
来自网络:
Power Query 提供了网页数据抓取的功能,有点高大上。通常,网络爬虫只能用Python等编程语言来实现功能。当然,Power Query 的网页抓取在效率和功能上都无法与网页爬虫相比,但基本的静态网页抓取是没有问题的。
复制并粘贴网络地址并选择表格。
构建一个空白查询:
Power Query 的背景是 M 语言。Power Query 提供了丰富的 M 函数,但有时仍需要自定义函数来处理特定问题。在这种情况下,您需要使用空查询。创建空查询后,打开高级编辑器,可以根据M语言的语法规范编写自定义函数。
Power Query提供了丰富的数据接口,可以根据需要进行选择,具体的数据库和在线连接操作并不复杂,只要有权限,按照向导填写所需信息,即可建立连接.
excelvba抓取网页数据( 2017年03月13日java利用url实现网页内容抓取的示例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-15 00:20
2017年03月13日java利用url实现网页内容抓取的示例)
Java使用url抓取网页内容
更新时间:2017-03-13 09:42:31 作者:zangcunmiao
本文主要介绍java使用url实现网页内容爬取的例子。有很好的参考价值。下面就和小编一起来看看吧
我没什么事,刚学会部署git到远程服务器,也没什么事,就干脆做了一个爬网页信息的小工具。如果将其中的一些值设置为参数,扩展性能可能会更好!我希望这是一个好的开始,也让我在阅读字符串方面更加精通。值得注意的是,在JAVA1.8中使用String拼接字符串时,会自动读取你想要的字符串。拼接后的字符串由StringBulider进行处理,极大的优化了String的性能。废话不多说,展示我的XXX码~
运行结果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签,注入到LinkedHashMap中,就ok了,很简单吧!看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上就是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助,也希望对脚本之家的支持! 查看全部
excelvba抓取网页数据(
2017年03月13日java利用url实现网页内容抓取的示例)
Java使用url抓取网页内容
更新时间:2017-03-13 09:42:31 作者:zangcunmiao
本文主要介绍java使用url实现网页内容爬取的例子。有很好的参考价值。下面就和小编一起来看看吧
我没什么事,刚学会部署git到远程服务器,也没什么事,就干脆做了一个爬网页信息的小工具。如果将其中的一些值设置为参数,扩展性能可能会更好!我希望这是一个好的开始,也让我在阅读字符串方面更加精通。值得注意的是,在JAVA1.8中使用String拼接字符串时,会自动读取你想要的字符串。拼接后的字符串由StringBulider进行处理,极大的优化了String的性能。废话不多说,展示我的XXX码~
运行结果:

先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码

然后抓取你想要的标签,注入到LinkedHashMap中,就ok了,很简单吧!看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上就是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助,也希望对脚本之家的支持!
excelvba抓取网页数据(一下就是关于抓取别人网站数据的抓取问题和方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-13 10:07
我相信所有个人 网站 网站管理员都有捕获他人数据的经验。目前,获取他人网站数据的方式只有两种:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再赘述。
二、自己写程序来抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
起初,我也尝试使用第三方工具来获取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不明白怎么用,就干脆决定自己写了。嗯,现在基本上半天就能搞定一个网站(只是程序开发时间,不包括数据采集时间)。
经过一段时间的数据爬取生涯,我也遇到了很多困难。最常见的一种是分页数据的爬取。原因是数据分页的形式有很多种。下面我主要介绍三种形式。抓取分页数据的方法,虽然在网上看过很多文章,但是每次拿别人的代码,总是会出现各种各样的问题。以下方式的代码都是正确的。实现,我目前正在使用它。本文中的代码实现是用C#语言实现的。我认为其他语言的原理大致相同。
让我们切入正题:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具爬取这个表单也很简单。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得学第三方工具的人还是可以自己写代码来实现的;
该方法是通过循环生成数据分页的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;抓取的代码可以参考以下:
公共字符串 GetResponseString(字符串 url)
{
字符串 _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0(兼容;MSIE 7.0;WINDOWS NT 5.2;.NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回对应页面的html内容的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
第二种方式:可能通过网站的开发遇到,它的分页控件通过post的方式将分页信息提交给后台代码,比如.net下Gridview自带的分页功能,点击页面时分页号,你会发现URL地址没有变,但是页码变了,页面的内容也变了。仔细看会发现,当你把鼠标移到每个页码上的时候,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这个表格其实并不难,因为毕竟,有一个地方可以得到页码的规则。
我们知道提交HTTP请求有两种方式:一种是get,另一种是post,第一种是get,第二种是post。具体提交原理无需赘述,不是本文重点
爬取这类页面需要注意页面的几个重要元素
一、 __VIEWSTATE ,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现了这个东西,并且后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback 方法,这是一个页面自动生成的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将传递给这两个参数。
三、__EVENTVALIDATION 这也应该是独一无二的
不需要太在意这三样东西是干什么的,只要在自己写代码抓取页面的时候记得提交这三个元素就可以了。
和第一种方法一样,_dopostback的两个参数必须通过循环拼凑,只有收录页码信息的参数需要拼凑。这里有一点需要注意,就是每次通过Post提交下一页的请求,都应该先获取当前页的__VIEWSTATE信息和__EVENTVALIDATION信息,这样第一页的分页数据就可以使用第一种方法获得。然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,然后在每页抓取后记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页post数据用法
参考代码如下:
for (int i = 0; i < 1000; i++)
{
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是您需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取上面需要的信息,比如当前页面对应的__VIEWSTATE,用于抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}
捕捉(例外前)
{
Console.WriteLine(ex.Message);
}
}
第三种方法是最麻烦最恶心的。在这种页面中,您在翻页过程中的任何地方都找不到页码信息。这个方法花了我很多功夫。方法是使用代码来模拟手动翻页。该方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,用代码逐页翻页,然后逐页翻页。爬行。 查看全部
excelvba抓取网页数据(一下就是关于抓取别人网站数据的抓取问题和方法)
我相信所有个人 网站 网站管理员都有捕获他人数据的经验。目前,获取他人网站数据的方式只有两种:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再赘述。
二、自己写程序来抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
起初,我也尝试使用第三方工具来获取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不明白怎么用,就干脆决定自己写了。嗯,现在基本上半天就能搞定一个网站(只是程序开发时间,不包括数据采集时间)。
经过一段时间的数据爬取生涯,我也遇到了很多困难。最常见的一种是分页数据的爬取。原因是数据分页的形式有很多种。下面我主要介绍三种形式。抓取分页数据的方法,虽然在网上看过很多文章,但是每次拿别人的代码,总是会出现各种各样的问题。以下方式的代码都是正确的。实现,我目前正在使用它。本文中的代码实现是用C#语言实现的。我认为其他语言的原理大致相同。
让我们切入正题:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具爬取这个表单也很简单。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得学第三方工具的人还是可以自己写代码来实现的;
该方法是通过循环生成数据分页的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;抓取的代码可以参考以下:
公共字符串 GetResponseString(字符串 url)
{
字符串 _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0(兼容;MSIE 7.0;WINDOWS NT 5.2;.NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回对应页面的html内容的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
第二种方式:可能通过网站的开发遇到,它的分页控件通过post的方式将分页信息提交给后台代码,比如.net下Gridview自带的分页功能,点击页面时分页号,你会发现URL地址没有变,但是页码变了,页面的内容也变了。仔细看会发现,当你把鼠标移到每个页码上的时候,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这个表格其实并不难,因为毕竟,有一个地方可以得到页码的规则。
我们知道提交HTTP请求有两种方式:一种是get,另一种是post,第一种是get,第二种是post。具体提交原理无需赘述,不是本文重点
爬取这类页面需要注意页面的几个重要元素
一、 __VIEWSTATE ,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现了这个东西,并且后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback 方法,这是一个页面自动生成的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将传递给这两个参数。
三、__EVENTVALIDATION 这也应该是独一无二的
不需要太在意这三样东西是干什么的,只要在自己写代码抓取页面的时候记得提交这三个元素就可以了。
和第一种方法一样,_dopostback的两个参数必须通过循环拼凑,只有收录页码信息的参数需要拼凑。这里有一点需要注意,就是每次通过Post提交下一页的请求,都应该先获取当前页的__VIEWSTATE信息和__EVENTVALIDATION信息,这样第一页的分页数据就可以使用第一种方法获得。然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,然后在每页抓取后记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页post数据用法
参考代码如下:
for (int i = 0; i < 1000; i++)
{
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是您需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取上面需要的信息,比如当前页面对应的__VIEWSTATE,用于抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}
捕捉(例外前)
{
Console.WriteLine(ex.Message);
}
}
第三种方法是最麻烦最恶心的。在这种页面中,您在翻页过程中的任何地方都找不到页码信息。这个方法花了我很多功夫。方法是使用代码来模拟手动翻页。该方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,用代码逐页翻页,然后逐页翻页。爬行。
excelvba抓取网页数据(#如何用excel获得股票实时数据#首先找一个提供股票数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2022-01-04 09:22
#如何使用excel获取实时股票数据#
首先找到一个提供股票数据的网站。各种金融网站都有股票数据。以东方财富网为例:
沪深A股数据,我们在谷歌浏览器中查看真实网址:
找到股票数据对应的jQuery行,然后查看头文件中的URL:
复制这个网址到Excel,数据==>来自网站:
单击以确认,Power Query 编辑器将打开。如果一切顺利,数据会直接出现:
虽然不是表,但证明爬取成功。下一步是如何解析二进制文件。从谷歌浏览器看,这是一个jsoncallback数据包,比json数据多了一个函数名。我们只需要提取两个括号之间的数据就可以用json解析了。注意总数:4440,后面会用到这个值。
=Json.Document(Text.BetweenDelimiters(Text.FromBinary(Web.Contents(url)),'(',')'))
然后展开数据表:
到目前为止一切都很顺利,但我们抓取的只是一页数据,让我们看看:
pn是页码,我们抓取第3页,pz是每页20条数据,我们有两种方法抓取所有数据,一种是使用这个pz:20,然后定义函数,抓取所有页码,我在之前的爬行中反复使用了这个。今天我们尝试直接修改pz,一次性抓取所有数据。其实,你可以尝试改变查询参数。如果我们把pn改成4,抓到的数据是第4页的20项,同理,我们把pn改成200,看看能不能直接抓到200项数据。
那我们试试直接输入5000,能不能全部抢过来:
这似乎是可能的。
还有一个问题,就是数据的所有header行都以f开头,不可读。怎么会变成网页中的汉字标题行?
这个问题有点复杂,我们可能要查代码看看能不能找到替代的方法,先看html:
但这并不完整。需要自定义几列:
这些指标没有对应的 f 代码。
我们再看一下js文件:
这个文件里有对应的数据,我们直接拷贝到Power Query中,处理成列表形式供以后使用:
接下来是匹配表中的key,修改列名:
首先我们需要匹配出这样一个列表。
List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n[key])},(y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0})
然后我们可以直接使用Table.RenameColumns函数批量修改列名:
Table.RenameColumns(data,List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List. Count(n[key])},(y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0}) )
我们只是将数据加载到 Excel 中。
如果您想要最新的数据,只需刷新即可。 查看全部
excelvba抓取网页数据(#如何用excel获得股票实时数据#首先找一个提供股票数据)
#如何使用excel获取实时股票数据#
首先找到一个提供股票数据的网站。各种金融网站都有股票数据。以东方财富网为例:

沪深A股数据,我们在谷歌浏览器中查看真实网址:

找到股票数据对应的jQuery行,然后查看头文件中的URL:

复制这个网址到Excel,数据==>来自网站:

单击以确认,Power Query 编辑器将打开。如果一切顺利,数据会直接出现:

虽然不是表,但证明爬取成功。下一步是如何解析二进制文件。从谷歌浏览器看,这是一个jsoncallback数据包,比json数据多了一个函数名。我们只需要提取两个括号之间的数据就可以用json解析了。注意总数:4440,后面会用到这个值。

=Json.Document(Text.BetweenDelimiters(Text.FromBinary(Web.Contents(url)),'(',')'))

然后展开数据表:

到目前为止一切都很顺利,但我们抓取的只是一页数据,让我们看看:

pn是页码,我们抓取第3页,pz是每页20条数据,我们有两种方法抓取所有数据,一种是使用这个pz:20,然后定义函数,抓取所有页码,我在之前的爬行中反复使用了这个。今天我们尝试直接修改pz,一次性抓取所有数据。其实,你可以尝试改变查询参数。如果我们把pn改成4,抓到的数据是第4页的20项,同理,我们把pn改成200,看看能不能直接抓到200项数据。

那我们试试直接输入5000,能不能全部抢过来:

这似乎是可能的。
还有一个问题,就是数据的所有header行都以f开头,不可读。怎么会变成网页中的汉字标题行?
这个问题有点复杂,我们可能要查代码看看能不能找到替代的方法,先看html:

但这并不完整。需要自定义几列:

这些指标没有对应的 f 代码。
我们再看一下js文件:

这个文件里有对应的数据,我们直接拷贝到Power Query中,处理成列表形式供以后使用:

接下来是匹配表中的key,修改列名:

首先我们需要匹配出这样一个列表。
List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n[key])},(y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0})
然后我们可以直接使用Table.RenameColumns函数批量修改列名:

Table.RenameColumns(data,List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List. Count(n[key])},(y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0}) )
我们只是将数据加载到 Excel 中。

如果您想要最新的数据,只需刷新即可。
excelvba抓取网页数据(人均985,年薪百万的知乎背后,到底有什么秘密?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-31 06:05
友情提示:文末...
一个完整的python数据分析流程是怎样的?
使用python从网站中抓取数据并保存到SQLite数据库中,然后对数据进行清洗,最后对数据进行数据可视化分析。
但是熟悉它的人应该知道,python爬取很简单,但是分析起来却非常困难。SQL 语句,Pandas 和 Matplotlib 非常繁琐,大多数人不会。
于是想到了一种更简单的数据分析方式,即python爬取+BI分析。BI是什么就不用我多介绍了。Python强大的数据采集能力,结合敏捷BI简单快速的数据可视化操作,一定能发挥出分析的效果!
那么这次我们就来看看“人均985,年薪百万”知乎,背后到底有什么秘密?话不多说,开始爬!
一、我们想要什么数据?
知乎 用户所在的学校和公司肯定是首当其冲的。我想看看这些人是编造的还是真的哈哈哈。
其次是性别、职业、地理位置、活动水平等,都是。
二、 爬取的过程
知乎 现在我用的是https请求,数据加密,不过问题不大,重要的是网页数据发生了变化,后台在请求的时候会对爬虫做一些判断,所以需要每次请求时添加请求头尽可能接近浏览器请求的样子。
获取列表页面的源码后,可以从中获取每个问题的链接:
每页有20道题,所以可以得到20道题的链接,然后是每道题的处理:
实现这一步,剩下的就是循环,判断和一些细节。
代码的最后部分如下:
import requests
import pandas as pd
import time
headers={
'authorization':'',#此处填写你自己的身份验证信息
'User-Agent':''#此处填写你自己浏览器的User-Agent
}
user_data = []
def get_user_data(page):
for i in range(page):#翻页
url = 'https://www.zhihu.com/api/v4/m ... %255B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset={}&limit=20'.format(i*20)
response = requests.get(url, headers=headers).json()['data']
user_data.extend(response) #把response数据添加进user_data
print('正在爬取第%s页' % str(i+1))
time.sleep(1) #设置爬取网页的时间间隔为1秒
if __name__ == '__main__':
get_user_data(10)
df = pd.DataFrame.from_dict(user_data)#以字典保存数据
df.to_csv('zhihu.csv',encoding='utf_8_sig')#保存到用户名为zhihu的csv文件中,encoding='utf_8_sig'参数是为了解决中文乱码的问题
print(df)
更多源码见文末!
在Python代码中,我没有使用线程池,而是使用了10个main()方法进行爬取,也就是10个进程,历时4个小时,爬取了57w+的数据。
三、使用BI进行数据可视化分析
现在我们已经到了最后一步,开始用BI进行数据可视化,揭秘知乎的时候到了。
市场上有很多种BI工具。国外的Tableau和国内的FineBI都是BI领域的佼佼者,但早就听说Tableau适合基础数据分析师,对小白很不友好。另外,前天无意中看到IDC的报告,发现帆软的市场份额是第一。为了避免返工,我选择了敏捷工具FineBI。事实证明,我的选择是对的。
首先在官网下载FineBI。虽然是企业级数据分析平台,但对个人永久免费。文末为大家准备了下载链接~
然后直接使用FineBI提供的数据配置终端的功能,添加SQL数据集(或者直接添加表)来检查验证刚刚抓取存储的数据是否已经成功存储到MySQL中。
忘了说了,FineBI 的一大特色就是自助分析。什么是自助分析?自己拖拽数据就可以了,可以和Matplotlib一样的效果,你可能也会想到Excel,但是一般都是几万行以上的数据,excel基本无能为力,很卡。但是FineBI还是可以处理大数据的,效率有可能高出几十倍、几百倍。
同时,VBA有一个致命的弱点,就是只能基于excel进行自动化,别无他法。
在写这篇文章之前,我分析了房价和销量,特地做成了一张动画图供大家参考:
四、知乎数据可视化
FineBI的仪表盘可以通过拖拽的方式调整组件的位置,并配备了各种类型的直方图、饼图和雷达图。数据可视化就是这么简单,只有你想不到,没有它你做不到。
1、哪个城市的知乎用户最多?
从云字图可以看出,越繁华的城市,知乎的用户越多(文字越大,占比越大)。因此,我们也可以看到,以北京、上海、广州、深圳四个一线城市为中心,其次是新一线城市。换句话说:知乎人多是一线城市或新一线城市,真是见多识广!
我们来看看具体的排名:
杭州位居第三。果然,互联网的优采云之一并没有被吹捧。阿里巴巴网易起到了很大的作用。你为什么这么说?看到这个职业你就明白了。
2、他们属于哪些学校?
看看,看看,这个度真的很高,谁说人均985吹的?
但是知乎专注于高智商的聚集地,学生花在手机上的时间比上班族多,这也就不足为奇了。
既然分析了学校,就要看看各个高校玩知乎的男女比例:
不用我说,你也能猜到蓝色代表男孩。女孩要么购物要么学习。低头玩手机的肯定是男生(虽然我也是男的)。
我们来看看每个地区有哪些大学是知乎重度用户。颜色越深,学校的知乎用户越多:
不说了,知乎人均是985真锤。我流下了羡慕的泪水。请问各位同学,你们是如何做到边玩边学的?如果你教我,我的高考可能更接近清华的录取分数线……
3、知乎 占有率
排除了学生之后,我们发现知乎的人都是……
产品经理最多。这是近年来最流行的职业,但是你的文档呢?需求被绘制?你对知乎的页面交互不满意吗?你为什么不去上班?
可以看出,除了一些互联网公司的共同职位外,教师和律师用户在知乎中也占据了很大的比例。
我们再用一张热图来观察知乎主流职业(前四)在各个地区的分布情况。颜色越深,该区域的职业数量越多:
总结
分析了这么多,不是要告诉你知乎的用户是什么样的,而是说如果你要做数据分析,FineBI确实是一个非常有用的工具,无论是对个人还是对公司。所以。
当然,以上只是FineBI的冰山一角,更多的东西还需要自己去探索。 查看全部
excelvba抓取网页数据(人均985,年薪百万的知乎背后,到底有什么秘密?)
友情提示:文末...
一个完整的python数据分析流程是怎样的?
使用python从网站中抓取数据并保存到SQLite数据库中,然后对数据进行清洗,最后对数据进行数据可视化分析。
但是熟悉它的人应该知道,python爬取很简单,但是分析起来却非常困难。SQL 语句,Pandas 和 Matplotlib 非常繁琐,大多数人不会。
于是想到了一种更简单的数据分析方式,即python爬取+BI分析。BI是什么就不用我多介绍了。Python强大的数据采集能力,结合敏捷BI简单快速的数据可视化操作,一定能发挥出分析的效果!
那么这次我们就来看看“人均985,年薪百万”知乎,背后到底有什么秘密?话不多说,开始爬!
一、我们想要什么数据?
知乎 用户所在的学校和公司肯定是首当其冲的。我想看看这些人是编造的还是真的哈哈哈。
其次是性别、职业、地理位置、活动水平等,都是。
二、 爬取的过程
知乎 现在我用的是https请求,数据加密,不过问题不大,重要的是网页数据发生了变化,后台在请求的时候会对爬虫做一些判断,所以需要每次请求时添加请求头尽可能接近浏览器请求的样子。
获取列表页面的源码后,可以从中获取每个问题的链接:
每页有20道题,所以可以得到20道题的链接,然后是每道题的处理:
实现这一步,剩下的就是循环,判断和一些细节。
代码的最后部分如下:
import requests
import pandas as pd
import time
headers={
'authorization':'',#此处填写你自己的身份验证信息
'User-Agent':''#此处填写你自己浏览器的User-Agent
}
user_data = []
def get_user_data(page):
for i in range(page):#翻页
url = 'https://www.zhihu.com/api/v4/m ... %255B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset={}&limit=20'.format(i*20)
response = requests.get(url, headers=headers).json()['data']
user_data.extend(response) #把response数据添加进user_data
print('正在爬取第%s页' % str(i+1))
time.sleep(1) #设置爬取网页的时间间隔为1秒
if __name__ == '__main__':
get_user_data(10)
df = pd.DataFrame.from_dict(user_data)#以字典保存数据
df.to_csv('zhihu.csv',encoding='utf_8_sig')#保存到用户名为zhihu的csv文件中,encoding='utf_8_sig'参数是为了解决中文乱码的问题
print(df)
更多源码见文末!
在Python代码中,我没有使用线程池,而是使用了10个main()方法进行爬取,也就是10个进程,历时4个小时,爬取了57w+的数据。
三、使用BI进行数据可视化分析
现在我们已经到了最后一步,开始用BI进行数据可视化,揭秘知乎的时候到了。
市场上有很多种BI工具。国外的Tableau和国内的FineBI都是BI领域的佼佼者,但早就听说Tableau适合基础数据分析师,对小白很不友好。另外,前天无意中看到IDC的报告,发现帆软的市场份额是第一。为了避免返工,我选择了敏捷工具FineBI。事实证明,我的选择是对的。
首先在官网下载FineBI。虽然是企业级数据分析平台,但对个人永久免费。文末为大家准备了下载链接~
然后直接使用FineBI提供的数据配置终端的功能,添加SQL数据集(或者直接添加表)来检查验证刚刚抓取存储的数据是否已经成功存储到MySQL中。
忘了说了,FineBI 的一大特色就是自助分析。什么是自助分析?自己拖拽数据就可以了,可以和Matplotlib一样的效果,你可能也会想到Excel,但是一般都是几万行以上的数据,excel基本无能为力,很卡。但是FineBI还是可以处理大数据的,效率有可能高出几十倍、几百倍。
同时,VBA有一个致命的弱点,就是只能基于excel进行自动化,别无他法。
在写这篇文章之前,我分析了房价和销量,特地做成了一张动画图供大家参考:
四、知乎数据可视化
FineBI的仪表盘可以通过拖拽的方式调整组件的位置,并配备了各种类型的直方图、饼图和雷达图。数据可视化就是这么简单,只有你想不到,没有它你做不到。
1、哪个城市的知乎用户最多?
从云字图可以看出,越繁华的城市,知乎的用户越多(文字越大,占比越大)。因此,我们也可以看到,以北京、上海、广州、深圳四个一线城市为中心,其次是新一线城市。换句话说:知乎人多是一线城市或新一线城市,真是见多识广!
我们来看看具体的排名:
杭州位居第三。果然,互联网的优采云之一并没有被吹捧。阿里巴巴网易起到了很大的作用。你为什么这么说?看到这个职业你就明白了。
2、他们属于哪些学校?
看看,看看,这个度真的很高,谁说人均985吹的?
但是知乎专注于高智商的聚集地,学生花在手机上的时间比上班族多,这也就不足为奇了。
既然分析了学校,就要看看各个高校玩知乎的男女比例:
不用我说,你也能猜到蓝色代表男孩。女孩要么购物要么学习。低头玩手机的肯定是男生(虽然我也是男的)。
我们来看看每个地区有哪些大学是知乎重度用户。颜色越深,学校的知乎用户越多:
不说了,知乎人均是985真锤。我流下了羡慕的泪水。请问各位同学,你们是如何做到边玩边学的?如果你教我,我的高考可能更接近清华的录取分数线……
3、知乎 占有率
排除了学生之后,我们发现知乎的人都是……
产品经理最多。这是近年来最流行的职业,但是你的文档呢?需求被绘制?你对知乎的页面交互不满意吗?你为什么不去上班?
可以看出,除了一些互联网公司的共同职位外,教师和律师用户在知乎中也占据了很大的比例。
我们再用一张热图来观察知乎主流职业(前四)在各个地区的分布情况。颜色越深,该区域的职业数量越多:
总结
分析了这么多,不是要告诉你知乎的用户是什么样的,而是说如果你要做数据分析,FineBI确实是一个非常有用的工具,无论是对个人还是对公司。所以。
当然,以上只是FineBI的冰山一角,更多的东西还需要自己去探索。
excelvba抓取网页数据(VBA基础的人来说不可能解决问题,我也不想把私信变成聊天窗 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-12-13 23:00
)
因为在知乎的一些回答里,总有私信问我怎么用VBA抓网,但是我基本没有回复。因为这个问题太大了,有基础知识的人其实很容易自己在百度或者ExcelHome论坛上找到答案。我不需要说什么。对于没有基础知识的人来说,是不可能三言两语解决问题的。我不想把私信变成聊天窗口。趁着开专栏知乎的机会,正好是仔细解释一下这个问题的好时机。
我对 Excel 和 VBA 的了解有限。我只能解决我遇到的一些问题,不一定适用于所有场景。以下内容基于对VBA基本用法和HTML语言知识的了解:
一、前期准备
据我所知,VBA 不能操作任何浏览器和网页。我们所能做的就是在IE上执行一些操作,是的,只有IE。不要告诉我电脑上没有IE,所以你可以退出Sub。就像在Python中导入,在C#中使用一样,VBA也需要引用一些库来操作IE,不过好在它是微软的产品,所以我们可以很方便的使用VBA自带的一些库。
我们需要做的第一件事是在 VBA 中引用 Micorsoft Internet Controls。这个名字会告诉我们它可以帮助我们控制 IE 页面。
二、网页操作
引用 Micorsoft Internet Controls 后,我们可以对页面做任何我们想做的事情,但是我们需要在主页上有一个页面,上帝说我们需要一个页面!
1、打开网页
我们以在百度上搜索“查虎”关键词为例:
With CreateObject("internetexplorer.application")
.Visible = True
.Navigate "https://www.baidu.com/s?wd=扯乎"
'关闭网页
' .Quit
End With
代码很简单,先创建一个IE对象,然后给一些属性赋值。Visible是可见性,是指网页操作时是否会看到网页。熟练之后可以设置为False,这样不仅可以让程序在运行时有一种神秘感(其实并没有),还能稍微加快运行速度。
但是需要注意的一点是,这个网页在我们打开后并没有关闭,这意味着程序结束后需要手动关闭它。如果网页不可见,则无法手动关闭。代码中的注释部分用于关闭网页。不用说,导航就是 URL。
我们必须等到网页完全加载后才能开始信息抓取。这时候,我们使用:(从这里开始,所有的代码都需要写在With代码块中)
While .ReadyState 4 Or .Busy
DoEvents
Wend
Busy是网页的繁忙状态,ReadyState是HTTP的五种就绪状态,对应如下:
2、获取信息
我们先抓取页面上的所有内容,稍后过滤掉有用的部分,然后慢慢添加条件到抓取中。
Set dmt = .Document
For i = 0 To dmt.all.Length - 1
Set htMent = dmt.all(i)
With ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
End With
Next i
这段代码有点类似于JS,需要从IE.Document.all中找出页面上的所有节点。还有其他几种方法:
这些更方便用于在抓取所有页面内容后帮助过滤有效信息。当然all 最好用,因为all 也有all("IDName") 和all.IDName 的用法。
上面代码部分返回的属性值都是基本的HTML内容,就不一一解释了。
3、填写信息
爬网神器当然是Python。大多数人使用Excel自动填写页面内容,直接将表格提交到网页,省去了问卷录入等大量工作。抓取页面内容后,填充起来就更容易了。你只需要直接给页面标签的Value属性赋值即可。
但是,除了文本框,可能还有其他没有Value的标签,比如下拉菜单和单选按钮。给这些内容赋值需要一些基本的HTML知识。
'下拉菜单选择
.all("select")(0).Selected = True
'单选按钮选择
.all("radio").Checked = True
'复选按钮选择
.all("checkbox").Checked = True
下拉菜单是select标签,每个选项都在一个option标签中,所以要返回一个set,需要选择一个option将对应的Selected属性修改为True。单选按钮和复选按钮都是输入标签。不同的是类型分别是radio和checkbox。要选择一个选项,您需要修改相应的 Checked 属性。
三、数据接口
有时我们可以直接获取一些API。当然,通过API返回数据比打开网页更方便快捷,使用的方法也不同。
1、请求接口
比如我得到了一个可以从网上查询到城市免费WIFI的API,用下面的代码通过Excel界面访问:(虽然是免费的,为了避免麻烦,我还是隐藏了我的AppKey)
Dim http
Set http = CreateObject("Microsoft.XMLHTTP")
http.Open "GET", "http://api.avatardata.cn/Wifi/QueryByCity", False
http.setRequestHeader "CONTENT-TYPE", "application/x-www-form-urlencoded"
http.send "key=[AppKey]&city=北京&page=1"
这时候我们创建的对象不再是IE,而是HTTP对象。这里使用ajax的Open方法,GET为数据发送方法,第二个参数为接口地址,第三个参数指定请求方法是否异步。如果这个API有账号和密码,就写在第四个和第五个参数中。
setRequestHeader是向接口发送一个HTTP协议头文件,最后发送的内容就是接口参数。当然,这个QueryString也可以直接写在URL中,发送一个空字符串即可。
2、接口返回
接口返回和获取的方式很简单:
If http.Status = 200 Then Range("A1").Value = http.responseText 查看全部
excelvba抓取网页数据(VBA基础的人来说不可能解决问题,我也不想把私信变成聊天窗
)
因为在知乎的一些回答里,总有私信问我怎么用VBA抓网,但是我基本没有回复。因为这个问题太大了,有基础知识的人其实很容易自己在百度或者ExcelHome论坛上找到答案。我不需要说什么。对于没有基础知识的人来说,是不可能三言两语解决问题的。我不想把私信变成聊天窗口。趁着开专栏知乎的机会,正好是仔细解释一下这个问题的好时机。
我对 Excel 和 VBA 的了解有限。我只能解决我遇到的一些问题,不一定适用于所有场景。以下内容基于对VBA基本用法和HTML语言知识的了解:
一、前期准备
据我所知,VBA 不能操作任何浏览器和网页。我们所能做的就是在IE上执行一些操作,是的,只有IE。不要告诉我电脑上没有IE,所以你可以退出Sub。就像在Python中导入,在C#中使用一样,VBA也需要引用一些库来操作IE,不过好在它是微软的产品,所以我们可以很方便的使用VBA自带的一些库。
我们需要做的第一件事是在 VBA 中引用 Micorsoft Internet Controls。这个名字会告诉我们它可以帮助我们控制 IE 页面。
二、网页操作
引用 Micorsoft Internet Controls 后,我们可以对页面做任何我们想做的事情,但是我们需要在主页上有一个页面,上帝说我们需要一个页面!
1、打开网页
我们以在百度上搜索“查虎”关键词为例:
With CreateObject("internetexplorer.application")
.Visible = True
.Navigate "https://www.baidu.com/s?wd=扯乎"
'关闭网页
' .Quit
End With
代码很简单,先创建一个IE对象,然后给一些属性赋值。Visible是可见性,是指网页操作时是否会看到网页。熟练之后可以设置为False,这样不仅可以让程序在运行时有一种神秘感(其实并没有),还能稍微加快运行速度。
但是需要注意的一点是,这个网页在我们打开后并没有关闭,这意味着程序结束后需要手动关闭它。如果网页不可见,则无法手动关闭。代码中的注释部分用于关闭网页。不用说,导航就是 URL。
我们必须等到网页完全加载后才能开始信息抓取。这时候,我们使用:(从这里开始,所有的代码都需要写在With代码块中)
While .ReadyState 4 Or .Busy
DoEvents
Wend
Busy是网页的繁忙状态,ReadyState是HTTP的五种就绪状态,对应如下:
2、获取信息
我们先抓取页面上的所有内容,稍后过滤掉有用的部分,然后慢慢添加条件到抓取中。
Set dmt = .Document
For i = 0 To dmt.all.Length - 1
Set htMent = dmt.all(i)
With ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
End With
Next i
这段代码有点类似于JS,需要从IE.Document.all中找出页面上的所有节点。还有其他几种方法:
这些更方便用于在抓取所有页面内容后帮助过滤有效信息。当然all 最好用,因为all 也有all("IDName") 和all.IDName 的用法。
上面代码部分返回的属性值都是基本的HTML内容,就不一一解释了。
3、填写信息
爬网神器当然是Python。大多数人使用Excel自动填写页面内容,直接将表格提交到网页,省去了问卷录入等大量工作。抓取页面内容后,填充起来就更容易了。你只需要直接给页面标签的Value属性赋值即可。
但是,除了文本框,可能还有其他没有Value的标签,比如下拉菜单和单选按钮。给这些内容赋值需要一些基本的HTML知识。
'下拉菜单选择
.all("select")(0).Selected = True
'单选按钮选择
.all("radio").Checked = True
'复选按钮选择
.all("checkbox").Checked = True
下拉菜单是select标签,每个选项都在一个option标签中,所以要返回一个set,需要选择一个option将对应的Selected属性修改为True。单选按钮和复选按钮都是输入标签。不同的是类型分别是radio和checkbox。要选择一个选项,您需要修改相应的 Checked 属性。
三、数据接口
有时我们可以直接获取一些API。当然,通过API返回数据比打开网页更方便快捷,使用的方法也不同。
1、请求接口
比如我得到了一个可以从网上查询到城市免费WIFI的API,用下面的代码通过Excel界面访问:(虽然是免费的,为了避免麻烦,我还是隐藏了我的AppKey)
Dim http
Set http = CreateObject("Microsoft.XMLHTTP")
http.Open "GET", "http://api.avatardata.cn/Wifi/QueryByCity", False
http.setRequestHeader "CONTENT-TYPE", "application/x-www-form-urlencoded"
http.send "key=[AppKey]&city=北京&page=1"
这时候我们创建的对象不再是IE,而是HTTP对象。这里使用ajax的Open方法,GET为数据发送方法,第二个参数为接口地址,第三个参数指定请求方法是否异步。如果这个API有账号和密码,就写在第四个和第五个参数中。
setRequestHeader是向接口发送一个HTTP协议头文件,最后发送的内容就是接口参数。当然,这个QueryString也可以直接写在URL中,发送一个空字符串即可。
2、接口返回
接口返回和获取的方式很简单:
If http.Status = 200 Then Range("A1").Value = http.responseText
excelvba抓取网页数据(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-11 00:18
Excel 2013及以后版本提供了WEBSERVICE和FILTERXML函数,可以用于网页数据的抓取,但是只能抓取XML格式的数据。而现在网站的很多网页或者接口都返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?今天以豆瓣图书基本资料为例,给大家介绍一下如何使用Excel API网络函数库抓取JSON格式的网页数据。第一步是找到豆瓣网的基本信息网页。第二步是安装ExcelAPI网络函数库。第三步,使用函数抓取JSON数据。
Excel 2013及以后版本提供了WEBSERVICE和FILTERXML函数,可以用于网页数据的抓取,但是只能抓取XML格式的数据。而现在网站的很多网页或者接口都返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?
今天以豆瓣图书基本资料为例,给大家介绍一下如何使用Excel API网络函数库抓取JSON格式的网页数据。
第一步是找到豆瓣网的基本信息网页。
豆瓣图书信息网站是9787111529385,网站最后一串数字是图书的ISBN号。
在火狐浏览器中,这个URL会返回如下信息,是标准的JSON格式,蓝色字体为属性名称,红色字体对应属性值。
第二步是安装ExcelAPI网络函数库。
访问ExcelAPI网络函数库官网,根据帮助文件安装函数库。
第三步,使用函数抓取JSON数据。
首先,使用函数 GetJsonSource(url,"UTF-8") 返回 JSON 原创数据。
然后,使用函数 GetJsonByPropertyName(json_source,property_name) 返回书的基本信息
使用GetJsonSource()函数一次性抓取所有数据,然后按需抓取。这样做的目的是提高爬行速度。毕竟,访问网页需要时间。 查看全部
excelvba抓取网页数据(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据?)
Excel 2013及以后版本提供了WEBSERVICE和FILTERXML函数,可以用于网页数据的抓取,但是只能抓取XML格式的数据。而现在网站的很多网页或者接口都返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?今天以豆瓣图书基本资料为例,给大家介绍一下如何使用Excel API网络函数库抓取JSON格式的网页数据。第一步是找到豆瓣网的基本信息网页。第二步是安装ExcelAPI网络函数库。第三步,使用函数抓取JSON数据。
Excel 2013及以后版本提供了WEBSERVICE和FILTERXML函数,可以用于网页数据的抓取,但是只能抓取XML格式的数据。而现在网站的很多网页或者接口都返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?
今天以豆瓣图书基本资料为例,给大家介绍一下如何使用Excel API网络函数库抓取JSON格式的网页数据。
第一步是找到豆瓣网的基本信息网页。
豆瓣图书信息网站是9787111529385,网站最后一串数字是图书的ISBN号。
在火狐浏览器中,这个URL会返回如下信息,是标准的JSON格式,蓝色字体为属性名称,红色字体对应属性值。
第二步是安装ExcelAPI网络函数库。
访问ExcelAPI网络函数库官网,根据帮助文件安装函数库。
第三步,使用函数抓取JSON数据。
首先,使用函数 GetJsonSource(url,"UTF-8") 返回 JSON 原创数据。
然后,使用函数 GetJsonByPropertyName(json_source,property_name) 返回书的基本信息
使用GetJsonSource()函数一次性抓取所有数据,然后按需抓取。这样做的目的是提高爬行速度。毕竟,访问网页需要时间。
excelvba抓取网页数据( 此控件的功能为1.对需要录入的数据进行提取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-12-03 12:27
此控件的功能为1.对需要录入的数据进行提取)
介绍:
这个控件的功能是
1. 提取需要录入的数据,排版并选择打印数量
2.针对不同的任务和根本不同的需求,清理和处理数据
3.各种辅助功能,如生成数据透视表、过滤复制数据、按指定方式粘贴数据
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●● ●●●
【配置区域】
该区域可以与内部代码进行交互,修改会直接导致功能上的相应变化。
左栏是对应的功能区,右栏是内容修改区。
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●● ●●●
【部分实际执行代码】
◆1.◆。
■代码量巨大,暂不写。
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●● ●●●
【一些小功能】
◆1.小功能一览◆。
Function ColCopy(intA%) '列数据全选
If Cells(1048576, intA).End(3).Row < 2 Then '是否空值
Cells(2, intA).Copy
Else
Range(Cells(2, intA), Cells(Cells(1048576, intA).End(3).Row, intA)).Copy
End If
End Function
■创建小列选择功能,方便不同情况下选择对应列的数据
■ 判断目标列中是否有数据,如果不存在,复制第二个网格
■判断目标列是否有数据,如果存在则复制指定列的数据,从第二个单元格开始到最后一个单元格
◆2.锁定表格/解锁表格◆。
Function LockSub() '锁定excel
With Application
.Interactive = False
.ScreenUpdating = False
End With
End Function
Function UnlockSub() '解锁excel
With Application
.Interactive = True
.ScreenUpdating = True
End With
End Function
■锁定禁止操作表格,关闭屏幕更新
■为防止误操作,优化操作效率,本内容创建为功能,随时使用
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●● ●●●
下载地址:【VBA】多功能辅助插件-VB文档资源-CSDN下载 查看全部
excelvba抓取网页数据(
此控件的功能为1.对需要录入的数据进行提取)

介绍:
这个控件的功能是
1. 提取需要录入的数据,排版并选择打印数量
2.针对不同的任务和根本不同的需求,清理和处理数据
3.各种辅助功能,如生成数据透视表、过滤复制数据、按指定方式粘贴数据
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●● ●●●

【配置区域】
该区域可以与内部代码进行交互,修改会直接导致功能上的相应变化。
左栏是对应的功能区,右栏是内容修改区。
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●● ●●●
【部分实际执行代码】
◆1.◆。
■代码量巨大,暂不写。
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●● ●●●
【一些小功能】
◆1.小功能一览◆。
Function ColCopy(intA%) '列数据全选
If Cells(1048576, intA).End(3).Row < 2 Then '是否空值
Cells(2, intA).Copy
Else
Range(Cells(2, intA), Cells(Cells(1048576, intA).End(3).Row, intA)).Copy
End If
End Function
■创建小列选择功能,方便不同情况下选择对应列的数据
■ 判断目标列中是否有数据,如果不存在,复制第二个网格
■判断目标列是否有数据,如果存在则复制指定列的数据,从第二个单元格开始到最后一个单元格
◆2.锁定表格/解锁表格◆。
Function LockSub() '锁定excel
With Application
.Interactive = False
.ScreenUpdating = False
End With
End Function
Function UnlockSub() '解锁excel
With Application
.Interactive = True
.ScreenUpdating = True
End With
End Function
■锁定禁止操作表格,关闭屏幕更新
■为防止误操作,优化操作效率,本内容创建为功能,随时使用
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●● ●●●
下载地址:【VBA】多功能辅助插件-VB文档资源-CSDN下载
excelvba抓取网页数据(获取Excel中的时间和云量/日期/2020-04-15)
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-12-03 09:12
我正在尝试从天气预报表中复制特定数据。我正在尝试从天气预报表中复制特定数据。更准确地说,我试图从类似 ,26.44/date/2020-04- 的链接中以表格格式(但现在任何格式都可以)获取 Excel 中的时间和云覆盖15. 更准确地说,我试图从这样的链接中以表格格式(但现在可以使用任何格式)获取 Excel 中的时间和云量/45.00,26.44 /日期/2020-04-15。到目前为止,我已经尝试了很多方法来获取特定数据,但我没有达到(我是使用 VBA 进行网络抓取的新手)。到目前为止,我已经尝试了很多方法来获取特定数据,但我没有达到(我是使用 VBA 进行网络抓取的新手)。使用 VBA 进行网页抓取的新手)。概念和命令对我来说非常清楚,它们适用于其他站点,但对于这个站点,我不知所措。网站,我不知所措。目前,我正在使用:目前,我正在使用:
Sub WeatherScrap()
Range("A1").Select
Dim mainlink As String Dim http As New XMLHTTP60, html As New HTMLDocument Dim CloudCover As Object
mainlink = "https://www.wunderground.com/hourly/ro/mizil/45.00,26.44/date/2020-04-15"
With http
.Open "GET", mainlink, False
.send
html.body.innerHTML = .responseText
End With
For Each CloudCover In html.getElementsByClassName("wu-value wu-value-to")
ActiveCell.Value = CloudCover.innerText
ActiveCell.Offset(1, 0).Select
Next CloudCover
End Sub
我显然没有在 html 上引用正确的类、标签或 ID(到目前为止我已经尝试了很多,但没有一个检索到所需的数据)。我显然没有在 html 上引用正确的类、标签或 ID(到目前为止我已经尝试了很多,但没有一个检索到所需的数据)。站内html元素为:网站站内html元素为:
100 %
现在,只需了解如何从表格中获取云覆盖百分比就足够了。现在,只需了解如何从表中获取 Cloud Cover 百分比就足够了。任何人都可以帮忙吗?任何人都可以帮忙吗?非常感谢!非常感谢! 查看全部
excelvba抓取网页数据(获取Excel中的时间和云量/日期/2020-04-15)
我正在尝试从天气预报表中复制特定数据。我正在尝试从天气预报表中复制特定数据。更准确地说,我试图从类似 ,26.44/date/2020-04- 的链接中以表格格式(但现在任何格式都可以)获取 Excel 中的时间和云覆盖15. 更准确地说,我试图从这样的链接中以表格格式(但现在可以使用任何格式)获取 Excel 中的时间和云量/45.00,26.44 /日期/2020-04-15。到目前为止,我已经尝试了很多方法来获取特定数据,但我没有达到(我是使用 VBA 进行网络抓取的新手)。到目前为止,我已经尝试了很多方法来获取特定数据,但我没有达到(我是使用 VBA 进行网络抓取的新手)。使用 VBA 进行网页抓取的新手)。概念和命令对我来说非常清楚,它们适用于其他站点,但对于这个站点,我不知所措。网站,我不知所措。目前,我正在使用:目前,我正在使用:
Sub WeatherScrap()
Range("A1").Select
Dim mainlink As String Dim http As New XMLHTTP60, html As New HTMLDocument Dim CloudCover As Object
mainlink = "https://www.wunderground.com/hourly/ro/mizil/45.00,26.44/date/2020-04-15"
With http
.Open "GET", mainlink, False
.send
html.body.innerHTML = .responseText
End With
For Each CloudCover In html.getElementsByClassName("wu-value wu-value-to")
ActiveCell.Value = CloudCover.innerText
ActiveCell.Offset(1, 0).Select
Next CloudCover
End Sub
我显然没有在 html 上引用正确的类、标签或 ID(到目前为止我已经尝试了很多,但没有一个检索到所需的数据)。我显然没有在 html 上引用正确的类、标签或 ID(到目前为止我已经尝试了很多,但没有一个检索到所需的数据)。站内html元素为:网站站内html元素为:
100 %
现在,只需了解如何从表格中获取云覆盖百分比就足够了。现在,只需了解如何从表中获取 Cloud Cover 百分比就足够了。任何人都可以帮忙吗?任何人都可以帮忙吗?非常感谢!非常感谢!
excelvba抓取网页数据(如何用Python爬数据?(一)Python进行爬虫抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-02 10:20
它使用 Python 抓取数据,并与 requests_html 连接。在这篇文章中文章:
如何用Python抓取数据?(一)网页抓取
在此之前,我对网页有一些了解,所以使用起来并不难,但我在理解 Python 语法方面花了一点功夫。
requests_html中的方法和方法名,可以在这里查看:
遇到的主要问题:
使用requests_html的render()时,发现会报错。错误内容:
无法在现有事件循环中使用 HTMLSession。使用 AsyncHTMLSession
一开始参考这个文章试了一下:request-htmlchromium download failed or request-html failed to download Chromium or r.html.render()导致异常错误
它仍然不起作用。这个错误让我头疼了一天,终于发现jupyter Notebook不能用这个方法。这种方法不仅会在jupyter notebook上报错,其他东西也会报错,只要在Anoconda中,比如Spyder,都会报错。
最后自己试了一下,新建了一个hello.py文件。在这个文件中,调用了render()方法,输出没问题。
这是我的代码的一部分:
from requests_html import HTMLSession
session = HTMLSession()
url = 'xxxxxxxxxxxxxxx'
sel = 'xxxxxxxxxxxxxxx'
r = session.get(url)
r.html.render(scrolldown = 4,sleep = 2)
result = r.html.find(sel)
解释render()方法的作用(虽然我自己也不是很懂)
这种方法,我认为是滚动网页。简单来说,有些网页需要加载更多的内容。触发“加载”的是用户滚动到某个位置,或者滚动多少,这样网页自己加载更多的内容,而不是刷新整个页面。
使用requests_html爬取这种网页时,爬取的是“加载更多”之前的网页,数据量往往很小。
而 render(scrolldown = 4,sleep = 2) 可以模拟用户的滚动动作,让网页有更多的内容。
一个简单易懂的例子:
使用r=session.get(url)时,print(r.html.links)捕获的链接数为:10
网页滚动后,这个页面的链接数量会增加到20个。如果不使用r.html.render(scrolldown = 4, sleep = 2)来滚动网页,数量这些链接中的总是 10 个
如果你调用这个语句:.html.render(scrolldown = 4, sleep = 2),那么当你使用print(r.html.links)时,会显示20个链接。 查看全部
excelvba抓取网页数据(如何用Python爬数据?(一)Python进行爬虫抓取数据)
它使用 Python 抓取数据,并与 requests_html 连接。在这篇文章中文章:
如何用Python抓取数据?(一)网页抓取
在此之前,我对网页有一些了解,所以使用起来并不难,但我在理解 Python 语法方面花了一点功夫。
requests_html中的方法和方法名,可以在这里查看:
遇到的主要问题:
使用requests_html的render()时,发现会报错。错误内容:
无法在现有事件循环中使用 HTMLSession。使用 AsyncHTMLSession
一开始参考这个文章试了一下:request-htmlchromium download failed or request-html failed to download Chromium or r.html.render()导致异常错误
它仍然不起作用。这个错误让我头疼了一天,终于发现jupyter Notebook不能用这个方法。这种方法不仅会在jupyter notebook上报错,其他东西也会报错,只要在Anoconda中,比如Spyder,都会报错。
最后自己试了一下,新建了一个hello.py文件。在这个文件中,调用了render()方法,输出没问题。
这是我的代码的一部分:
from requests_html import HTMLSession
session = HTMLSession()
url = 'xxxxxxxxxxxxxxx'
sel = 'xxxxxxxxxxxxxxx'
r = session.get(url)
r.html.render(scrolldown = 4,sleep = 2)
result = r.html.find(sel)
解释render()方法的作用(虽然我自己也不是很懂)
这种方法,我认为是滚动网页。简单来说,有些网页需要加载更多的内容。触发“加载”的是用户滚动到某个位置,或者滚动多少,这样网页自己加载更多的内容,而不是刷新整个页面。
使用requests_html爬取这种网页时,爬取的是“加载更多”之前的网页,数据量往往很小。
而 render(scrolldown = 4,sleep = 2) 可以模拟用户的滚动动作,让网页有更多的内容。
一个简单易懂的例子:
使用r=session.get(url)时,print(r.html.links)捕获的链接数为:10
网页滚动后,这个页面的链接数量会增加到20个。如果不使用r.html.render(scrolldown = 4, sleep = 2)来滚动网页,数量这些链接中的总是 10 个
如果你调用这个语句:.html.render(scrolldown = 4, sleep = 2),那么当你使用print(r.html.links)时,会显示20个链接。
excelvba抓取网页数据(我前一阵子用XMLHTTP的Get功能抓取邮件轨迹(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-28 17:23
)
前阵子用VBA做了一个工具,利用XMLHTTP的Get函数来抓取城市之间的距离。现在我想使用XMLHTTP的Post功能来抓取邮件踪迹。是使用Get还是Post抓数据取决于网站提交参数的方式。
1、通过分析(使用fiddler),邮件轨迹查询网站是通过post参数提交的。如下图:
上图中的“Entity”内容用于设置header。点击“TextView”可以看到传输的参数内容和邮箱号,如下图:
获取数据的代码如下:
Sub tt()
Dim HttpReq As Object
Dim pdata, http As String
Set HttpReq = CreateObject("MSXML2.XMLHTTP.6.0")
'轨迹头部数据,网址用xxx屏蔽
http = "http://10.xxx.xxx.xxx/querypus ... ot%3B
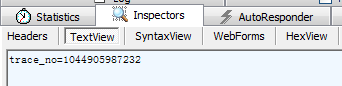
pdata = "trace_no=1044905987232"
HttpReq.Open "Post", http, False
HttpReq.setRequestHeader "Content-Length", Len(pdata)
'HttpReq.setRequestHeader "CONTENT-TYPE", "application/x-www-form-urlencoded"
HttpReq.setRequestHeader "CONTENT-TYPE", "application/x-www-form-urlencoded; charset=utf-8"
HttpReq.send pdata '"trace_nos=1194359346482"
Do Until HttpReq.readyState = 4
DoEvents
Loop
If HttpReq.Status = 200 Then
Debug.Print HttpReq.responseText
End If
End Sub
2、返回的内容为json结构化数据,可以使用fiddler查看返回内容,点击“TextView”:
点击“JSON”查看数据分析结果:
但是vba解析的时候内容是空的。对比之前json结构中返回的数据,发现这个数据缺少一个名字,因为在js函数定义的时候,指定了一个json结构数据的名字,即jscode = "function json( s ,i) {return eval('(' + s +').traces[' + i +']'); }" 在跟踪名称中。
添加后就可以解析了,即:
'要返回数据成为标准的json结构,还需要在外面加一层数据名
buf = "{""traces"":" & HttpReq.responseText & "}"
kk = get_trace(buf)
get_trace函数用于解析json数据,代码如下:
<p>Function get_trace(mystring As String) As Integer
Dim objJSx As Object, objJSy As Object
Dim m1, m2, n, j As Integer
Dim source, level, kind, sm As String
On Error Resume Next
Set objJSx = CreateObject("ScriptControl") '调用MSScriptControl.ScriptControl对象将提取的变量文本运算形成对象集合
objJSx.Language = "JavaScript" '测试发现JavaScript、javascript、JScript都可以表示JavaScript语言
'定义一个JS函数,通过计算表达式的方式引入JSON数据并解析
jscode = "function json(s,i) { return eval('(' + s + ').traces[' + i + ']'); }"
objJSx.AddCode jscode
TT = "否"
For n = 1 To 100
If objJSx.Run("json", mystring, n - 1) = "" Then Exit For
Set objJSy = objJSx.Run("json", mystring, n - 1)
For j = 1 To 11
TraceInfo(n, j) = ""
Next j
TraceInfo(n, 1) = objJSy.traceNo
TraceInfo(n, 2) = objJSy.opCode
TraceInfo(n, 3) = objJSy.opTime
TraceInfo(n, 4) = objJSy.opName
TraceInfo(n, 6) = objJSy.opOrgCode
TraceInfo(n, 7) = objJSy.opOrgSimpleName
TraceInfo(n, 8) = objJSy.operatorNo
TraceInfo(n, 9) = objJSy.operatorName
TraceInfo(n, 10) = objJSy.level
TraceInfo(n, 11) = objJSy.source
sm = objJSy.desc
'剔除数据中的HTML部分
Do While InStr(sm, " 查看全部
excelvba抓取网页数据(我前一阵子用XMLHTTP的Get功能抓取邮件轨迹(图)
)
前阵子用VBA做了一个工具,利用XMLHTTP的Get函数来抓取城市之间的距离。现在我想使用XMLHTTP的Post功能来抓取邮件踪迹。是使用Get还是Post抓数据取决于网站提交参数的方式。
1、通过分析(使用fiddler),邮件轨迹查询网站是通过post参数提交的。如下图:

上图中的“Entity”内容用于设置header。点击“TextView”可以看到传输的参数内容和邮箱号,如下图:
获取数据的代码如下:
Sub tt()
Dim HttpReq As Object
Dim pdata, http As String
Set HttpReq = CreateObject("MSXML2.XMLHTTP.6.0")
'轨迹头部数据,网址用xxx屏蔽
http = "http://10.xxx.xxx.xxx/querypus ... ot%3B
pdata = "trace_no=1044905987232"
HttpReq.Open "Post", http, False
HttpReq.setRequestHeader "Content-Length", Len(pdata)
'HttpReq.setRequestHeader "CONTENT-TYPE", "application/x-www-form-urlencoded"
HttpReq.setRequestHeader "CONTENT-TYPE", "application/x-www-form-urlencoded; charset=utf-8"
HttpReq.send pdata '"trace_nos=1194359346482"
Do Until HttpReq.readyState = 4
DoEvents
Loop
If HttpReq.Status = 200 Then
Debug.Print HttpReq.responseText
End If
End Sub
2、返回的内容为json结构化数据,可以使用fiddler查看返回内容,点击“TextView”:

点击“JSON”查看数据分析结果:

但是vba解析的时候内容是空的。对比之前json结构中返回的数据,发现这个数据缺少一个名字,因为在js函数定义的时候,指定了一个json结构数据的名字,即jscode = "function json( s ,i) {return eval('(' + s +').traces[' + i +']'); }" 在跟踪名称中。
添加后就可以解析了,即:
'要返回数据成为标准的json结构,还需要在外面加一层数据名
buf = "{""traces"":" & HttpReq.responseText & "}"
kk = get_trace(buf)
get_trace函数用于解析json数据,代码如下:
<p>Function get_trace(mystring As String) As Integer
Dim objJSx As Object, objJSy As Object
Dim m1, m2, n, j As Integer
Dim source, level, kind, sm As String
On Error Resume Next
Set objJSx = CreateObject("ScriptControl") '调用MSScriptControl.ScriptControl对象将提取的变量文本运算形成对象集合
objJSx.Language = "JavaScript" '测试发现JavaScript、javascript、JScript都可以表示JavaScript语言
'定义一个JS函数,通过计算表达式的方式引入JSON数据并解析
jscode = "function json(s,i) { return eval('(' + s + ').traces[' + i + ']'); }"
objJSx.AddCode jscode
TT = "否"
For n = 1 To 100
If objJSx.Run("json", mystring, n - 1) = "" Then Exit For
Set objJSy = objJSx.Run("json", mystring, n - 1)
For j = 1 To 11
TraceInfo(n, j) = ""
Next j
TraceInfo(n, 1) = objJSy.traceNo
TraceInfo(n, 2) = objJSy.opCode
TraceInfo(n, 3) = objJSy.opTime
TraceInfo(n, 4) = objJSy.opName
TraceInfo(n, 6) = objJSy.opOrgCode
TraceInfo(n, 7) = objJSy.opOrgSimpleName
TraceInfo(n, 8) = objJSy.operatorNo
TraceInfo(n, 9) = objJSy.operatorName
TraceInfo(n, 10) = objJSy.level
TraceInfo(n, 11) = objJSy.source
sm = objJSy.desc
'剔除数据中的HTML部分
Do While InStr(sm, "
excelvba抓取网页数据( 一个网页源文件代码写入数据集用+input的大致步骤是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-26 08:09
一个网页源文件代码写入数据集用+input的大致步骤是什么)
一般的过程是使用filename fileref url'web address'获取网页代码信息(包括要提取的数据),然后使用infile fileref将字符代码读入变量,然后对写入的进行“数据清洗”根据待提取数据的特征进行观测”,最终得到所需要的观测数据。
首先简单描述一下过程中可能出现的问题:
1.我用的SAS软件是多语言9.2版本。当我第一次开始使用 filename fileref url'web address' 和 infile fileref 运行时,出现一个不友好的显示错误:无法连接到主机。这个问题困扰了我很久。终于看到一个前辈的帖子,下载了相关的hot fix后解决了(F9BA26) from a 网站)。
2. 如果infile语句中没有加encoding='utf-8',则观察结果为乱码。
3.正则表达式不是必需的,但它们简洁明了使用。配合一些字符函数使用,绝对可以达到你想要的提取目的。
4. 大家进入网页后,右键查看源代码(部分为源文件)。这个源代码就是我们需要写入数据集的文件。首先使用filename fileref url'';
5.如何用infile+input将网页源文件代码写入数据集。但是,根据写入方式的不同,后续的数据清理流程自然也不同。由于源代码中每一行输入的形式都是!!!或者(可以观察网页的源码),我们需要的数据都在!!!而且因为一个网页收录的信息太多,所以有可能找到它!!!不收录所需的数据。为了方便“清洗”数据,这里采用了比较笨的方法。通过观察源代码中待提取数据的大致范围,例如第一个待提取字符串“黑龙江”出现在第184个输入行,最后一个“120”(澳门人均降水量)出现在第 623 条输入线。我们不 不需要其他输入线。我们可以考虑在infile语句中加入firstobs=184 obs=623。
注意:由于网页有细微改动的可能性,firstobs=和obs=的值可能不准确,可能会影响结果。建议查看源码确定对应的值。
这里有两种不同的写作方法。
一种。以'>'为分隔符,写完后,每次观察看起来像 查看全部
excelvba抓取网页数据(
一个网页源文件代码写入数据集用+input的大致步骤是什么)

一般的过程是使用filename fileref url'web address'获取网页代码信息(包括要提取的数据),然后使用infile fileref将字符代码读入变量,然后对写入的进行“数据清洗”根据待提取数据的特征进行观测”,最终得到所需要的观测数据。
首先简单描述一下过程中可能出现的问题:
1.我用的SAS软件是多语言9.2版本。当我第一次开始使用 filename fileref url'web address' 和 infile fileref 运行时,出现一个不友好的显示错误:无法连接到主机。这个问题困扰了我很久。终于看到一个前辈的帖子,下载了相关的hot fix后解决了(F9BA26) from a 网站)。
2. 如果infile语句中没有加encoding='utf-8',则观察结果为乱码。
3.正则表达式不是必需的,但它们简洁明了使用。配合一些字符函数使用,绝对可以达到你想要的提取目的。
4. 大家进入网页后,右键查看源代码(部分为源文件)。这个源代码就是我们需要写入数据集的文件。首先使用filename fileref url'';
5.如何用infile+input将网页源文件代码写入数据集。但是,根据写入方式的不同,后续的数据清理流程自然也不同。由于源代码中每一行输入的形式都是!!!或者(可以观察网页的源码),我们需要的数据都在!!!而且因为一个网页收录的信息太多,所以有可能找到它!!!不收录所需的数据。为了方便“清洗”数据,这里采用了比较笨的方法。通过观察源代码中待提取数据的大致范围,例如第一个待提取字符串“黑龙江”出现在第184个输入行,最后一个“120”(澳门人均降水量)出现在第 623 条输入线。我们不 不需要其他输入线。我们可以考虑在infile语句中加入firstobs=184 obs=623。
注意:由于网页有细微改动的可能性,firstobs=和obs=的值可能不准确,可能会影响结果。建议查看源码确定对应的值。
这里有两种不同的写作方法。
一种。以'>'为分隔符,写完后,每次观察看起来像
excelvba抓取网页数据(使用VBA宏将表格数据从多个网页提取到Excel中..! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 539 次浏览 • 2021-10-25 23:22
)
使用 VBA 宏从多个网页中提取表格数据到 Excel.. !! 目前我使用下面的链接,但我只能在代码中使用一个网页..我有一个 ulr 列表来获取数据......它必须是垂直的......!请建议我.. :)
Sub INDEXdata()
With ActiveSheet.QueryTables.Add(Connection:= _
"URL;http://recorder.maricopa.gov/r ... ot%3B _
, Destination:=Range("$A$1"))
.Name = "rec=19770000006"
.FieldNames = True
.RowNumbers = False
.FillAdjacentFormulas = False
.PreserveFormatting = True
.RefreshOnFileOpen = False
.BackgroundQuery = True
.RefreshStyle = xlInsertDeleteCells
.SavePassword = False
.SaveData = True
.AdjustColumnWidth = True
.RefreshPeriod = 0
.WebSelectionType = xlSpecifiedTables
.WebFormatting = xlWebFormattingNone
.WebTables = "2,3"
.WebPreFormattedTextToColumns = True
.WebConsecutiveDelimitersAsOne = True
.WebSingleBlockTextImport = False
.WebDisableDateRecognition = False
.WebDisableRedirections = False
.Refresh BackgroundQuery:=False
End With
End Sub
1 个回答:
答案 0:(得分:0)
好吧,我不知道您有多少编程背景,也不知道您发布的代码的哪些部分特定于该源 URL 和目标位置。
但是,这样的事情可能会有用。我假设您要提取的每个页面的 URL、目的地和名称都会更改。
我所做的是将似乎适用于所有源页面和目标的代码部分放入我自己的参数化子例程中。原创例程 IndexData 仅指定每个复制操作的 URL、目标和名称。
Sub IndexData()
GetData("http://recorder.maricopa.gov/r ... ot%3B , _
"$A$1", _
"rec=19770000006")
GetData("http://somewhereelse.com/somed ... ot%3B, _
"$A$2", _
"rec=12345")
GetData("http://anotherurl.com/etc", _
"$A$3", _
"something")
End
Sub GetData(url as string, destination as string, name as string)
With ActiveSheet.QueryTables.Add(Connection:= _
"URL;" & url , Destination:=Range(destination))
.Name = name
.FieldNames = True
.RowNumbers = False
.FillAdjacentFormulas = False
.PreserveFormatting = True
.RefreshOnFileOpen = False
.BackgroundQuery = True
.RefreshStyle = xlInsertDeleteCells
.SavePassword = False
.SaveData = True
.AdjustColumnWidth = True
.RefreshPeriod = 0
.WebSelectionType = xlSpecifiedTables
.WebFormatting = xlWebFormattingNone
.WebTables = "2,3"
.WebPreFormattedTextToColumns = True
.WebConsecutiveDelimitersAsOne = True
.WebSingleBlockTextImport = False
.WebDisableDateRecognition = False
.WebDisableRedirections = False
.Refresh BackgroundQuery:=False
End With
End Sub 查看全部
excelvba抓取网页数据(使用VBA宏将表格数据从多个网页提取到Excel中..!
)
使用 VBA 宏从多个网页中提取表格数据到 Excel.. !! 目前我使用下面的链接,但我只能在代码中使用一个网页..我有一个 ulr 列表来获取数据......它必须是垂直的......!请建议我.. :)
Sub INDEXdata()
With ActiveSheet.QueryTables.Add(Connection:= _
"URL;http://recorder.maricopa.gov/r ... ot%3B _
, Destination:=Range("$A$1"))
.Name = "rec=19770000006"
.FieldNames = True
.RowNumbers = False
.FillAdjacentFormulas = False
.PreserveFormatting = True
.RefreshOnFileOpen = False
.BackgroundQuery = True
.RefreshStyle = xlInsertDeleteCells
.SavePassword = False
.SaveData = True
.AdjustColumnWidth = True
.RefreshPeriod = 0
.WebSelectionType = xlSpecifiedTables
.WebFormatting = xlWebFormattingNone
.WebTables = "2,3"
.WebPreFormattedTextToColumns = True
.WebConsecutiveDelimitersAsOne = True
.WebSingleBlockTextImport = False
.WebDisableDateRecognition = False
.WebDisableRedirections = False
.Refresh BackgroundQuery:=False
End With
End Sub
1 个回答:
答案 0:(得分:0)
好吧,我不知道您有多少编程背景,也不知道您发布的代码的哪些部分特定于该源 URL 和目标位置。
但是,这样的事情可能会有用。我假设您要提取的每个页面的 URL、目的地和名称都会更改。
我所做的是将似乎适用于所有源页面和目标的代码部分放入我自己的参数化子例程中。原创例程 IndexData 仅指定每个复制操作的 URL、目标和名称。
Sub IndexData()
GetData("http://recorder.maricopa.gov/r ... ot%3B , _
"$A$1", _
"rec=19770000006")
GetData("http://somewhereelse.com/somed ... ot%3B, _
"$A$2", _
"rec=12345")
GetData("http://anotherurl.com/etc", _
"$A$3", _
"something")
End
Sub GetData(url as string, destination as string, name as string)
With ActiveSheet.QueryTables.Add(Connection:= _
"URL;" & url , Destination:=Range(destination))
.Name = name
.FieldNames = True
.RowNumbers = False
.FillAdjacentFormulas = False
.PreserveFormatting = True
.RefreshOnFileOpen = False
.BackgroundQuery = True
.RefreshStyle = xlInsertDeleteCells
.SavePassword = False
.SaveData = True
.AdjustColumnWidth = True
.RefreshPeriod = 0
.WebSelectionType = xlSpecifiedTables
.WebFormatting = xlWebFormattingNone
.WebTables = "2,3"
.WebPreFormattedTextToColumns = True
.WebConsecutiveDelimitersAsOne = True
.WebSingleBlockTextImport = False
.WebDisableDateRecognition = False
.WebDisableRedirections = False
.Refresh BackgroundQuery:=False
End With
End Sub
excelvba抓取网页数据(网上检索到的知识点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2021-10-25 07:10
一直忙于研究WebRequest()获取网页数据,比如myfxbook的OutLook。发现的问题是,
从网上检索到的知识点是,
使用官方的F1,可以看两个例子,方便大家理解各个参数。
本次访问myfxbook,实现过程为:
时间间隔检查;使用for循环多次使用WebRequest()访问获取网页流;
bool 下载数据(char &result[])//1-1
{
string Headers; // 服务器响应标头
string referer = NULL; // HTTP 请求标头的推荐页字段
string cookie = NULL;
char post[]; // HTTP请求信息数组
int err;
ResetLastError();
// 1000ms
if(WebRequest("GET", MyFxBookUrl, cookie, referer, Timeout, post,
0, //post[]数组大小
result, //服务器响应数据数组
Headers) < 0)
{
err = GetLastError();
Print("Error in WebRequest [",err,"]",ErrorDescription(err));
return false;
}
return true;
}
读取这个流中的有用信息,使用StringFindInArray()子函数查找关键词的地址;类似于优采云,缩小地址范围后,找到第二个关键词,然后精确定位到要抓取的数据;检查捕获数据的合规性;完成处理,例如记录上次访问时间。将合规性数据分配给全局变量或数组以供使用。
本博客中的所有文章,除非另有说明,均为原创。作者:天宏评测 查看全部
excelvba抓取网页数据(网上检索到的知识点)
一直忙于研究WebRequest()获取网页数据,比如myfxbook的OutLook。发现的问题是,
从网上检索到的知识点是,
使用官方的F1,可以看两个例子,方便大家理解各个参数。
本次访问myfxbook,实现过程为:
时间间隔检查;使用for循环多次使用WebRequest()访问获取网页流;
bool 下载数据(char &result[])//1-1
{
string Headers; // 服务器响应标头
string referer = NULL; // HTTP 请求标头的推荐页字段
string cookie = NULL;
char post[]; // HTTP请求信息数组
int err;
ResetLastError();
// 1000ms
if(WebRequest("GET", MyFxBookUrl, cookie, referer, Timeout, post,
0, //post[]数组大小
result, //服务器响应数据数组
Headers) < 0)
{
err = GetLastError();
Print("Error in WebRequest [",err,"]",ErrorDescription(err));
return false;
}
return true;
}
读取这个流中的有用信息,使用StringFindInArray()子函数查找关键词的地址;类似于优采云,缩小地址范围后,找到第二个关键词,然后精确定位到要抓取的数据;检查捕获数据的合规性;完成处理,例如记录上次访问时间。将合规性数据分配给全局变量或数组以供使用。
本博客中的所有文章,除非另有说明,均为原创。作者:天宏评测
excelvba抓取网页数据(EXCEL自带的功能,我一般的操纵过程是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-10-18 08:12
借用你的帖子,多页数据,我的一般操作过程来谈谈吧:
第一个是看。
观察网页的网址,或者使用HTTPFOX查看网址和参数。如果是POSTed,看能否用GET获取。然后试试看能不能通过URL来改变页面切换。
如果可以,那很容易。
那么,接下来,尝试看看EXCEL本身的功能,可以导入网页数据可以获取数据,如果行得通,只需记录一个宏并更改一个循环。
因为EXCEL的导入功能还是很强大的,只要页面是非跳转或者脚本编写或者框架的,直接源码有TABLE代码,直接用QUERYTABLE获取即可。
如果无法获取到QUERYTABLE的数量,那么一般的网页是动态页面或者框架页面等。那么我一般会使用HTTPFOX进一步查找网页的真实数据源(一般是第一页改成第二页试试,很容易找到),找到了,后续无非很简单,就是文本处理,可以用XMLHTTP来处理,后续无非就是调整HTTP头消息、POST 等。部分页面异常,有盗链处理。大多数 XMLHTTP 无法处理它。您需要使用 WINHTTP 对象,但该对象与 XMLHTTP 非常相似。反正无非是假的COOKIE或者REFERER或者多页跳转。我已经回答了所有的帮助请求。
最后,如果是后缀为.asp或.aspx的页面,通常是不正常的。POST 参数具有“_VIEWSTATE”。VIEWSTATE 存储在上一页中。如果你想阅读它,你必须访问以前的业务。这种页面一般比较累。有的时候用IE/WEBBROWSER来处理比较容易,原理也很简单,就是你说的DOM机制,要取数,无非就是找到数据的TABLE,然后去TR ,拿到TD,反正配合FIREBUG。只是去观察。
最后是一种非常异常的页面,是一个可以禁止跨域访问的框架页面。不管怎样,你搜索我的帖子。后来我用一些国外高手用JAVA写的函数来伪造一个容器。将框架剥离出来,然后访问读取。
简而言之,做更多的实践很重要。如果您触摸太多,您就会知道正在处理哪些页面。其实把这块拿到底,不用学太多JAVASCRIPT语言,但是好处多多。例如,如果一个脚本生成一个数据页,则可以使用网页的代码,然后使用MSScriptControl控件直接处理脚本,生成数据流,并导出。
此外,最近越来越多的页面采用 XML 格式。反正获取到XML样式后,再用XML DOM继续获取。或者,你也可以得到HTML代码,就像你说的,审查,但我使用Microsoft.XMLDOM对象或直接调用HTML文档对象,还有
LoadXML等方法可以加载代码文本,有时可以成功构造XML样式或HTML样式,也可以用来简化取数的操作。但我很少这样做。总觉得直接用IE的方式比较好。
最后,在 VBA 中处理网页实际上更加困难。如果你刚入门并且有一定的电脑背景,更建议你直接学习AAU软件。优点是库中有很多参考代码,可以导入库或者复制粘贴。发帖很方便,但前提是语法和JAVASCRIPT差不多,最好有相关语言背景。 查看全部
excelvba抓取网页数据(EXCEL自带的功能,我一般的操纵过程是什么?)
借用你的帖子,多页数据,我的一般操作过程来谈谈吧:
第一个是看。
观察网页的网址,或者使用HTTPFOX查看网址和参数。如果是POSTed,看能否用GET获取。然后试试看能不能通过URL来改变页面切换。
如果可以,那很容易。
那么,接下来,尝试看看EXCEL本身的功能,可以导入网页数据可以获取数据,如果行得通,只需记录一个宏并更改一个循环。
因为EXCEL的导入功能还是很强大的,只要页面是非跳转或者脚本编写或者框架的,直接源码有TABLE代码,直接用QUERYTABLE获取即可。
如果无法获取到QUERYTABLE的数量,那么一般的网页是动态页面或者框架页面等。那么我一般会使用HTTPFOX进一步查找网页的真实数据源(一般是第一页改成第二页试试,很容易找到),找到了,后续无非很简单,就是文本处理,可以用XMLHTTP来处理,后续无非就是调整HTTP头消息、POST 等。部分页面异常,有盗链处理。大多数 XMLHTTP 无法处理它。您需要使用 WINHTTP 对象,但该对象与 XMLHTTP 非常相似。反正无非是假的COOKIE或者REFERER或者多页跳转。我已经回答了所有的帮助请求。
最后,如果是后缀为.asp或.aspx的页面,通常是不正常的。POST 参数具有“_VIEWSTATE”。VIEWSTATE 存储在上一页中。如果你想阅读它,你必须访问以前的业务。这种页面一般比较累。有的时候用IE/WEBBROWSER来处理比较容易,原理也很简单,就是你说的DOM机制,要取数,无非就是找到数据的TABLE,然后去TR ,拿到TD,反正配合FIREBUG。只是去观察。
最后是一种非常异常的页面,是一个可以禁止跨域访问的框架页面。不管怎样,你搜索我的帖子。后来我用一些国外高手用JAVA写的函数来伪造一个容器。将框架剥离出来,然后访问读取。
简而言之,做更多的实践很重要。如果您触摸太多,您就会知道正在处理哪些页面。其实把这块拿到底,不用学太多JAVASCRIPT语言,但是好处多多。例如,如果一个脚本生成一个数据页,则可以使用网页的代码,然后使用MSScriptControl控件直接处理脚本,生成数据流,并导出。
此外,最近越来越多的页面采用 XML 格式。反正获取到XML样式后,再用XML DOM继续获取。或者,你也可以得到HTML代码,就像你说的,审查,但我使用Microsoft.XMLDOM对象或直接调用HTML文档对象,还有
LoadXML等方法可以加载代码文本,有时可以成功构造XML样式或HTML样式,也可以用来简化取数的操作。但我很少这样做。总觉得直接用IE的方式比较好。
最后,在 VBA 中处理网页实际上更加困难。如果你刚入门并且有一定的电脑背景,更建议你直接学习AAU软件。优点是库中有很多参考代码,可以导入库或者复制粘贴。发帖很方便,但前提是语法和JAVASCRIPT差不多,最好有相关语言背景。
excelvba抓取网页数据( 这是简易数据分析系列的第13篇文章教程的全盘总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-13 20:14
这是简易数据分析系列的第13篇文章教程的全盘总结)
这是简单数据分析系列文章的第13篇。
本文首发于博客园:简单数据分析13。
不知不觉写了10个网络爬虫系列教程。这10篇文章基本涵盖了Web Scraper的大部分功能。今天的内容是本系列的最后一篇。下一章,我会开一个新洞,谈谈如何使用Excel对采集到的数据进行格式化和分析。
下一篇文章我会把Web Scraper教程的完整总结放上来,今天开始我们的实战教程。
之前的课程,我们爬取的数据都是同级别的内容。我们讨论的主要问题是如何处理市场上各种类型的分页,但是没有介绍如何抓取详情页的内容数据。.
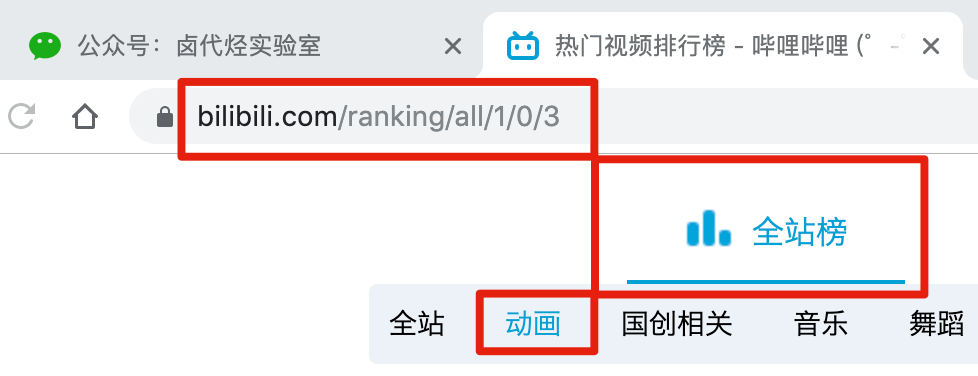
比如我们要抓取b站动画区TOP排行榜的数据:
按照之前的爬取逻辑,我们爬取了这个榜单上作品的相关数据,比如下图中的排名、作品名称、浏览量、弹幕数和作者姓名等。
经常逛B站的朋友也知道,UP主经常建议自己看视频三连操作(喜欢+投币+采集)。可以看出,这三个数据对视频的排名都有一定的影响,所以这些数据对我们也有一定的参考价值。
遗憾的是,这份排行榜没有相关数据。这些数据都在视频详情页,我们需要点击链接才能看到:
今天的教程内容就是教大家如何在爬取一级页面(列表页面)的同时,使用Web Scraper对二级页面(详情页面)的内容进行爬取。
1.创建站点地图
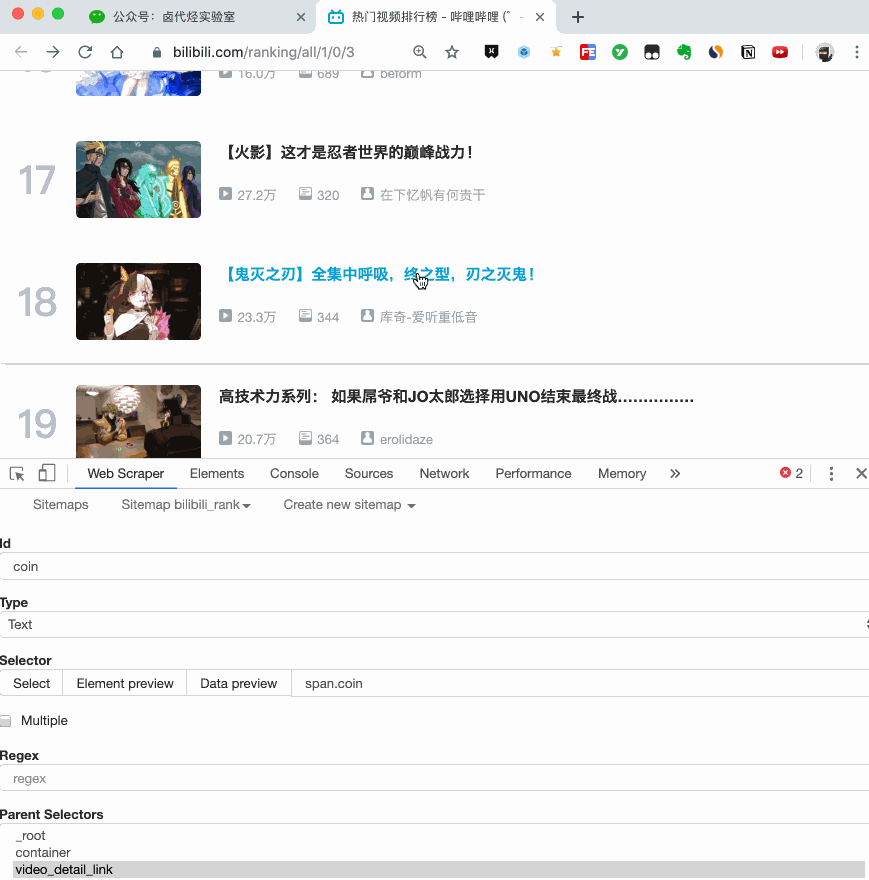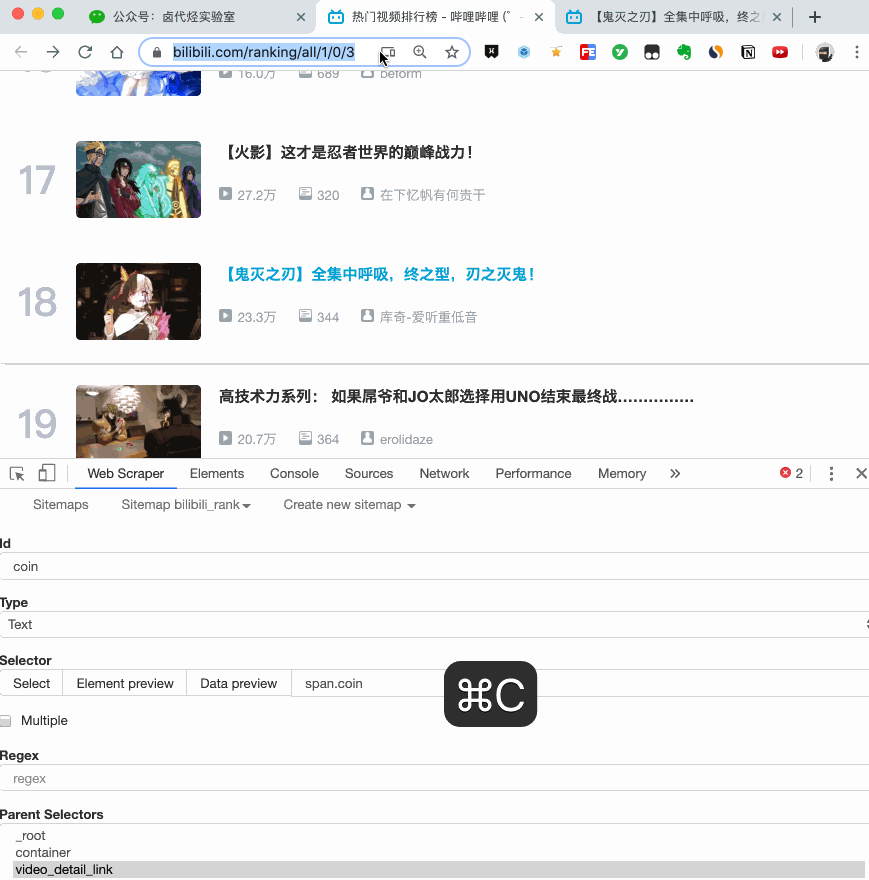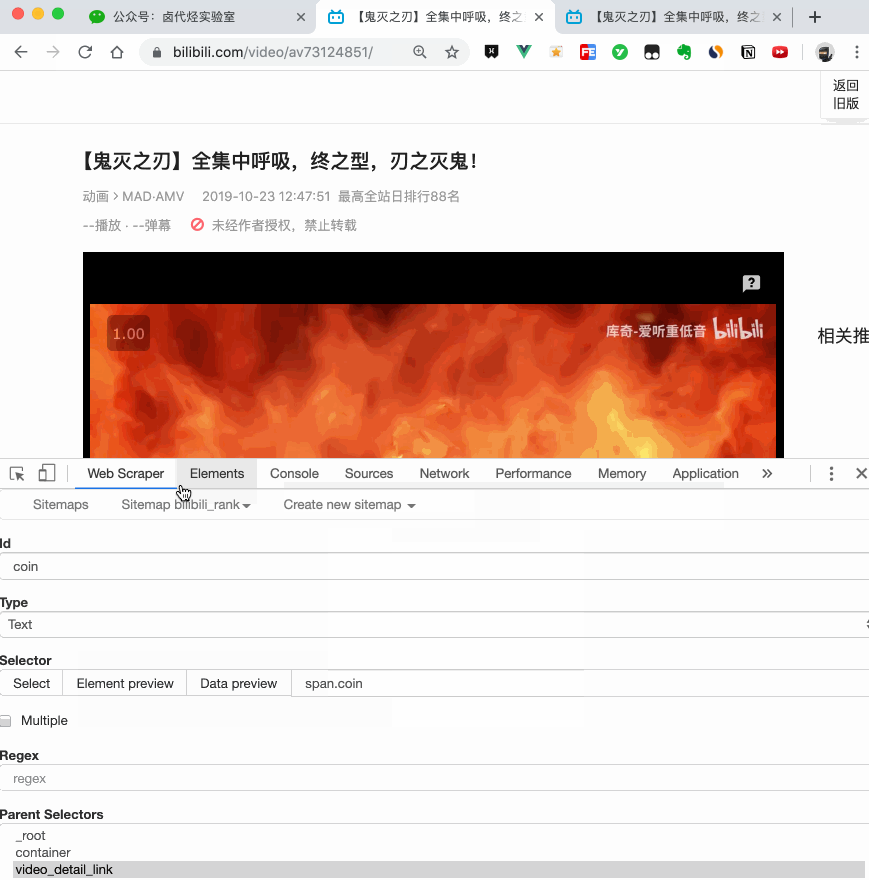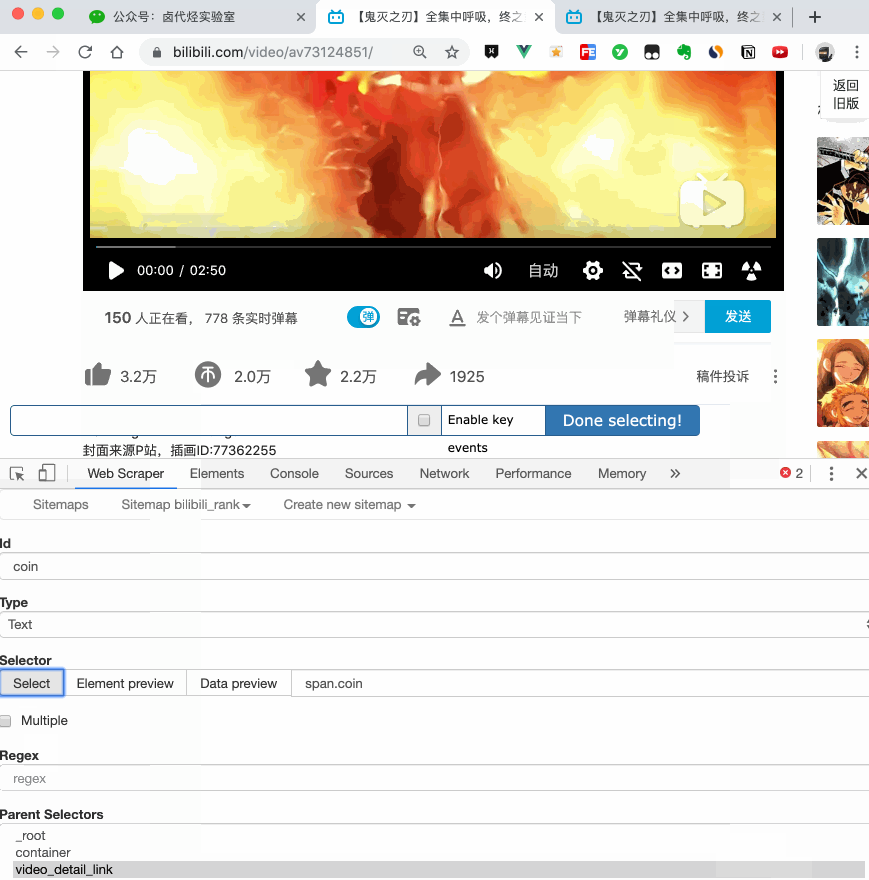
首先,我们找到要捕获的数据的位置。我在下图中的红框中标出了关键路径。你可以比较一下:
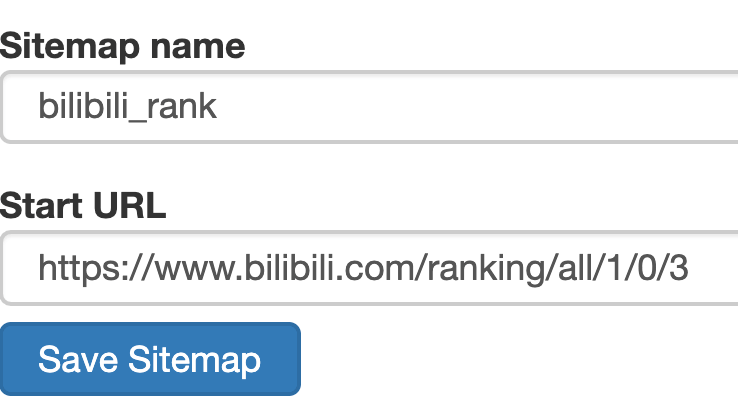
然后创建一个相关的SiteMap,这里我取了bilibili_rank的名字:
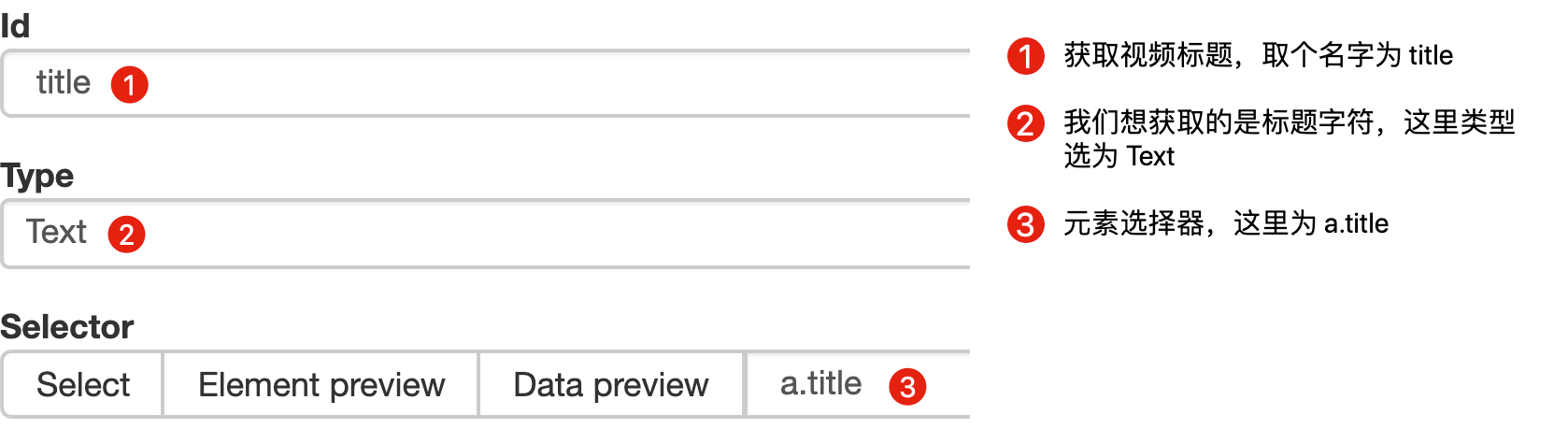
2.创建容器选择器
设置之前先看看,发现这个页面的排名数据是一次加载100条数据,不需要分页,所以这里的Type选为Element。
其他参数比较简单,就不细说了(不明白的可以看我之前的基础教程)。这是一个截图供您参考:
3.创建列表页子选择器
这次子选择器要抓取的内容如下,都比较简单。你可以参考截图:
Rank(num) 作品名称(title) 播放量(play_amount) 弹幕量(danmu_count) 作者:(author)
如果这样做,实际上可以抓取所有已知的列表数据,但本文的重点是:如何抓取二级页面(详细信息页面)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper本质上是模拟人的操作来达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实直接点击标题链接即可跳转:
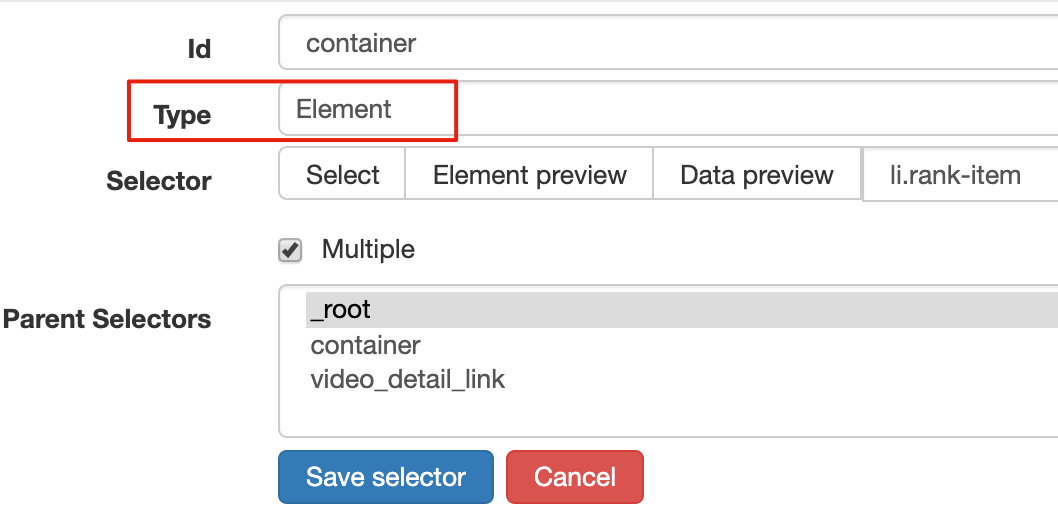
Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过示例进行比较以理解。
首先,在这种情况下,我们得到了标题的文本,此时的选择器类型为Text:
当我们想要获取一个链接时,我们必须创建另一个选择器。选中的元素是一样的,但是Type是Link:
创建成功后,我们点击Link type选择器,输入,创建相关选择器。下面我录了个动图。注意我的鼠标突出显示的导航路线部分。这可以很明显的看出几个选择器的层次关系:
4.创建详情页子选择器
当您点击链接时,您会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页打开了Web Scraper选择窗口,您无法跨页面选择所需的数据。
处理这个问题也很简单,可以复制详情页的链接,复制到列表页所在的Tab页,按回车重新加载,这样就可以在当前页面选中了。
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了4个数据,比如点赞数、硬币数、采集数和分享数。这个操作也很简单,这里就不赘述了。
所有选择器的结构图如下:
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经全部建立。
5.获取数据
终于到了激动人心的部分,我们即将开始爬取数据。但是在爬行之前,我们需要把等待时间调大一点,默认时间是2000ms,我这里改成了5000ms。
你为什么这么做?看下图你就明白了:
首先,每次打开二级页面,都是一个全新的页面。这时候浏览器加载网页需要时间;其次,我们可以观察到要捕获的喜欢数量等数据。页面刚加载时,它的值为“--”,过一会就会变成一个数字。所以,我们只等5000ms,等页面和数据加载完毕后,一起爬取。
配置好参数后,我们就可以正式抓取下载了。下图是我抓到的部分数据,特此证明这个方法有用:
6.总结
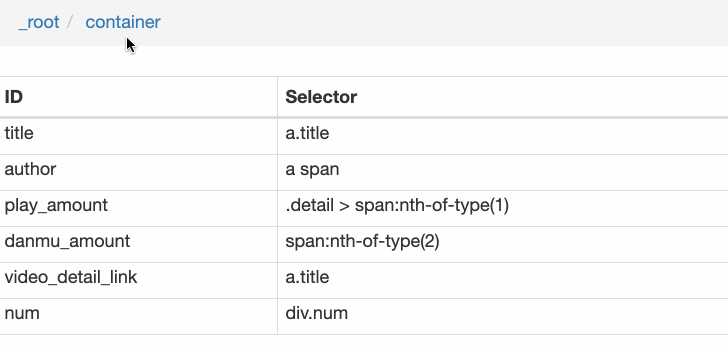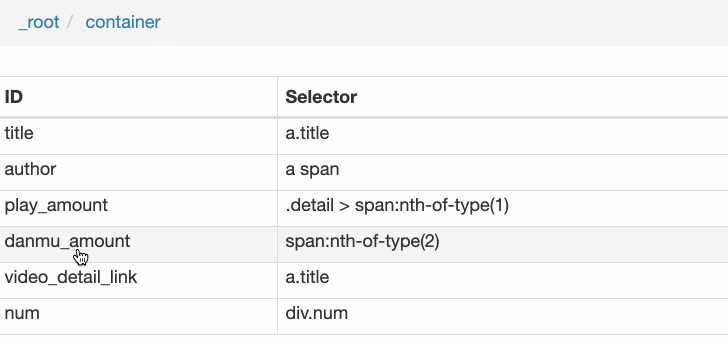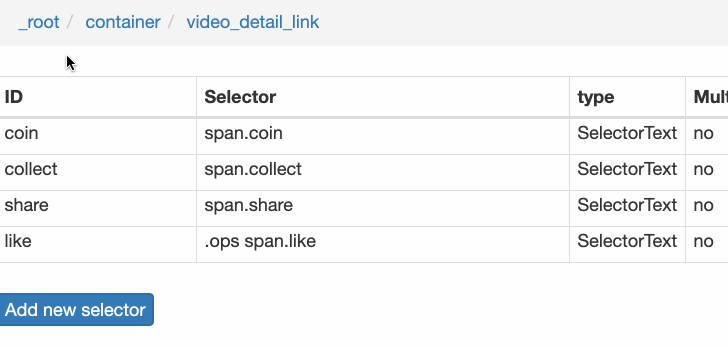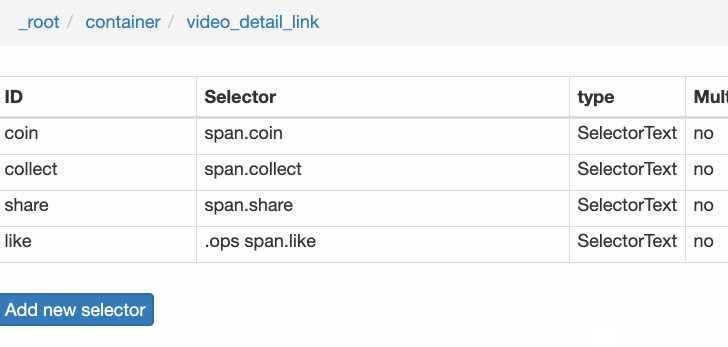
本教程可能有点困难。我将分享我的站点地图。如果在制作时遇到问题,可以参考我的配置。我在第六篇教程中详细讲解了SiteMap导入的功能。可以一起吃。:
<p>{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}</p>
一旦掌握了二级页面的抓取方式,三级、四级页面就没有问题了。因为例程是相同的:数据是在链接选择器指向的下一页上捕获的。因为原理是一样的,我就不演示了。 查看全部
excelvba抓取网页数据(
这是简易数据分析系列的第13篇文章教程的全盘总结)

这是简单数据分析系列文章的第13篇。
本文首发于博客园:简单数据分析13。
不知不觉写了10个网络爬虫系列教程。这10篇文章基本涵盖了Web Scraper的大部分功能。今天的内容是本系列的最后一篇。下一章,我会开一个新洞,谈谈如何使用Excel对采集到的数据进行格式化和分析。
下一篇文章我会把Web Scraper教程的完整总结放上来,今天开始我们的实战教程。
之前的课程,我们爬取的数据都是同级别的内容。我们讨论的主要问题是如何处理市场上各种类型的分页,但是没有介绍如何抓取详情页的内容数据。.
比如我们要抓取b站动画区TOP排行榜的数据:
按照之前的爬取逻辑,我们爬取了这个榜单上作品的相关数据,比如下图中的排名、作品名称、浏览量、弹幕数和作者姓名等。

经常逛B站的朋友也知道,UP主经常建议自己看视频三连操作(喜欢+投币+采集)。可以看出,这三个数据对视频的排名都有一定的影响,所以这些数据对我们也有一定的参考价值。

遗憾的是,这份排行榜没有相关数据。这些数据都在视频详情页,我们需要点击链接才能看到:

今天的教程内容就是教大家如何在爬取一级页面(列表页面)的同时,使用Web Scraper对二级页面(详情页面)的内容进行爬取。
1.创建站点地图
首先,我们找到要捕获的数据的位置。我在下图中的红框中标出了关键路径。你可以比较一下:
然后创建一个相关的SiteMap,这里我取了bilibili_rank的名字:
2.创建容器选择器
设置之前先看看,发现这个页面的排名数据是一次加载100条数据,不需要分页,所以这里的Type选为Element。
其他参数比较简单,就不细说了(不明白的可以看我之前的基础教程)。这是一个截图供您参考:
3.创建列表页子选择器
这次子选择器要抓取的内容如下,都比较简单。你可以参考截图:
Rank(num) 作品名称(title) 播放量(play_amount) 弹幕量(danmu_count) 作者:(author)

如果这样做,实际上可以抓取所有已知的列表数据,但本文的重点是:如何抓取二级页面(详细信息页面)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper本质上是模拟人的操作来达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实直接点击标题链接即可跳转:

Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过示例进行比较以理解。
首先,在这种情况下,我们得到了标题的文本,此时的选择器类型为Text:
当我们想要获取一个链接时,我们必须创建另一个选择器。选中的元素是一样的,但是Type是Link:

创建成功后,我们点击Link type选择器,输入,创建相关选择器。下面我录了个动图。注意我的鼠标突出显示的导航路线部分。这可以很明显的看出几个选择器的层次关系:
4.创建详情页子选择器
当您点击链接时,您会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页打开了Web Scraper选择窗口,您无法跨页面选择所需的数据。
处理这个问题也很简单,可以复制详情页的链接,复制到列表页所在的Tab页,按回车重新加载,这样就可以在当前页面选中了。
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了4个数据,比如点赞数、硬币数、采集数和分享数。这个操作也很简单,这里就不赘述了。

所有选择器的结构图如下:
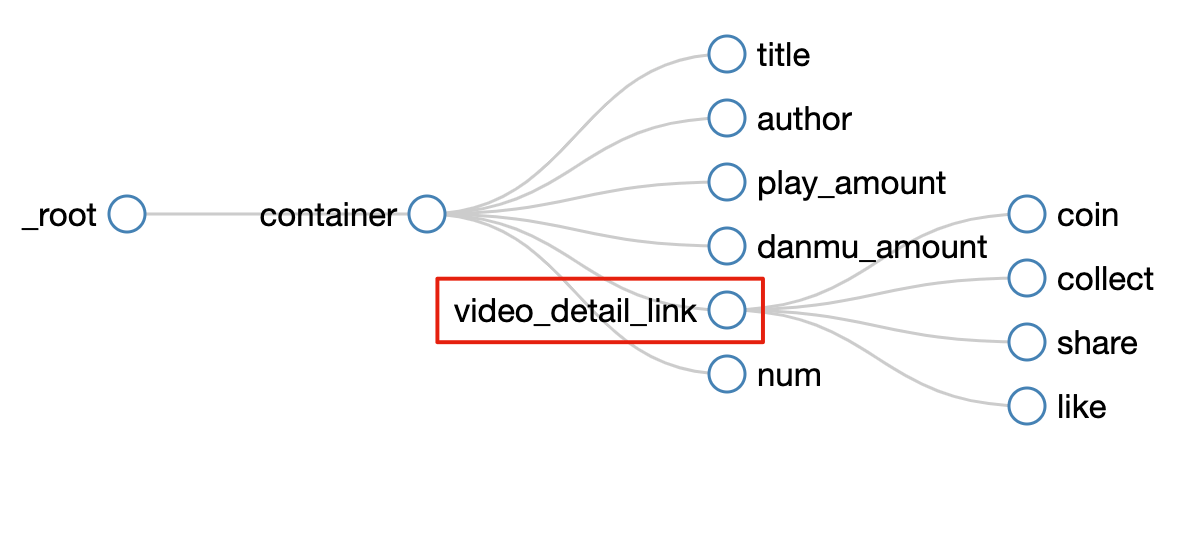
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经全部建立。
5.获取数据
终于到了激动人心的部分,我们即将开始爬取数据。但是在爬行之前,我们需要把等待时间调大一点,默认时间是2000ms,我这里改成了5000ms。

你为什么这么做?看下图你就明白了:

首先,每次打开二级页面,都是一个全新的页面。这时候浏览器加载网页需要时间;其次,我们可以观察到要捕获的喜欢数量等数据。页面刚加载时,它的值为“--”,过一会就会变成一个数字。所以,我们只等5000ms,等页面和数据加载完毕后,一起爬取。
配置好参数后,我们就可以正式抓取下载了。下图是我抓到的部分数据,特此证明这个方法有用:
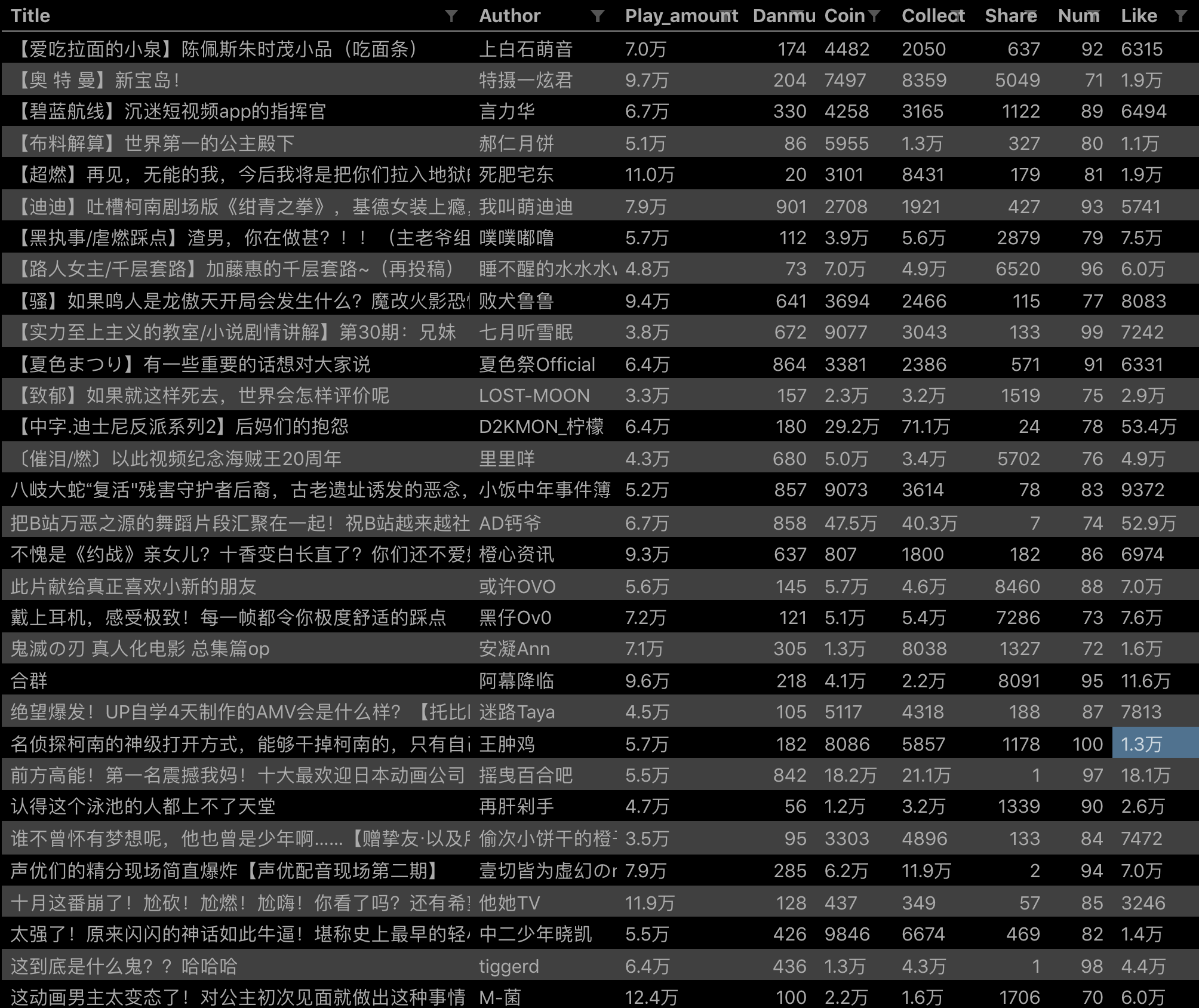
6.总结
本教程可能有点困难。我将分享我的站点地图。如果在制作时遇到问题,可以参考我的配置。我在第六篇教程中详细讲解了SiteMap导入的功能。可以一起吃。:
<p>{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}</p>
一旦掌握了二级页面的抓取方式,三级、四级页面就没有问题了。因为例程是相同的:数据是在链接选择器指向的下一页上捕获的。因为原理是一样的,我就不演示了。
excelvba抓取网页数据(网上的大多数教程,都是教给你怎么使用Excel直接获取股票数据的方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-10-12 17:57
大多数在线教程都会教您如何使用 VBA 下载股票数据。
但是最基础的下载股票数据的操作已经可以通过Excel2010之后的内置函数直接加载了。
Excel目前有四种获取股票数据的方式,包括:
1.直接从通大信等股票软件获取交易数据
2.使用Finance上提供的一些CSV格式的数据网站
3.利用EXCEL的爬虫功能爬取网络股票数据
4.使用网站的API接口获取数据等。
其中API接口,最常用的公共接口有雅虎财经、谷歌财经、新浪财经、搜狐财经等。
另外,海外Quandl和国内tushare也提供API接口,可以直接用EXCEL加载数据。
本文主要介绍如何使用Excel直接获取Quandl中的股票数据。
昆德尔介绍
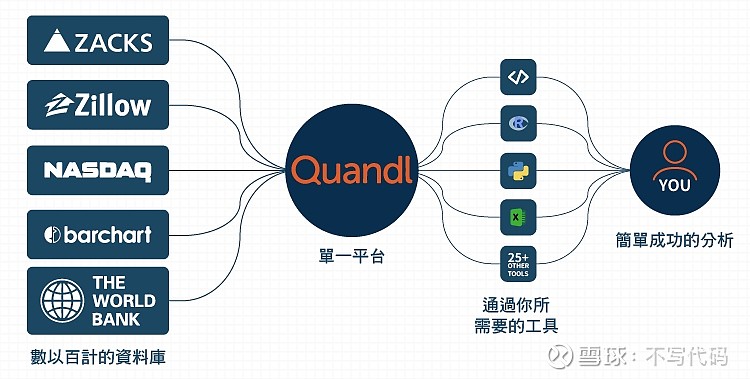
Quandl 是一个金融和经济数据平台。不仅包括昂贵的费用数据,还有很多免费的开放数据,包括我的大量A股数据。
下图展示了针对各种数据源,Quandl平台提供了多种数据输出形式供用户分析。
EXCEL从Quandl获取数据的几种方式
据介绍,Quandl 提供了 Excel 支持的 4 种数据格式,分别是
CSV文件,EXCEL插件方式,JASON和XML格式下载。
1.最简单的方法是直接下载CSV格式的数据。2.EXCEL插件,需要安装网站提供的Quandl.Excel.Addin插件
下载地址为网页链接
下载安装后,在Excel中,直接获取数据,如下图
3.JSON 和 XML 格式数据
网站 注册后,您将获得一个API key。以苹果的股票 AAPL 为例。地址是:
网页链接
第一种和第二种方法比较简单。下一篇文章将逐步演示如何使用第三种方法获取数据。
欢迎关注我的专栏“EXCEL进行量化” 查看全部
excelvba抓取网页数据(网上的大多数教程,都是教给你怎么使用Excel直接获取股票数据的方式)
大多数在线教程都会教您如何使用 VBA 下载股票数据。
但是最基础的下载股票数据的操作已经可以通过Excel2010之后的内置函数直接加载了。
Excel目前有四种获取股票数据的方式,包括:
1.直接从通大信等股票软件获取交易数据
2.使用Finance上提供的一些CSV格式的数据网站
3.利用EXCEL的爬虫功能爬取网络股票数据
4.使用网站的API接口获取数据等。
其中API接口,最常用的公共接口有雅虎财经、谷歌财经、新浪财经、搜狐财经等。
另外,海外Quandl和国内tushare也提供API接口,可以直接用EXCEL加载数据。
本文主要介绍如何使用Excel直接获取Quandl中的股票数据。
昆德尔介绍
Quandl 是一个金融和经济数据平台。不仅包括昂贵的费用数据,还有很多免费的开放数据,包括我的大量A股数据。
下图展示了针对各种数据源,Quandl平台提供了多种数据输出形式供用户分析。
EXCEL从Quandl获取数据的几种方式
据介绍,Quandl 提供了 Excel 支持的 4 种数据格式,分别是
CSV文件,EXCEL插件方式,JASON和XML格式下载。
1.最简单的方法是直接下载CSV格式的数据。2.EXCEL插件,需要安装网站提供的Quandl.Excel.Addin插件
下载地址为网页链接
下载安装后,在Excel中,直接获取数据,如下图
3.JSON 和 XML 格式数据
网站 注册后,您将获得一个API key。以苹果的股票 AAPL 为例。地址是:
网页链接
第一种和第二种方法比较简单。下一篇文章将逐步演示如何使用第三种方法获取数据。
欢迎关注我的专栏“EXCEL进行量化”
excelvba抓取网页数据(可以,只能用IE实现,引用MicrosoftInternetControls就可以)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-12 14:04
是的,只能用IE来实现。您可以通过引用 Microsoft Internet Controls 在 VBA 中操作网页上的内容。
Dim mShellwindows As New ShellWindows
Dim IE As InternetExplorer
For Each IE In mShellwindows '搜索页面
If IE.LocationURL = [URL] Then Exit For
Next
With IE.Document '在文本框填写内容
.all("[id_or_name]").Value = Sheet1.Cells(1, 1).Value
End With
基本原理如上面的代码所示。
[URL]是你要填数据的页面,先用IE浏览器打开这个页面。
[id_or_name] 是要填充数据的控件的 id 或名称。这需要提前从页面中获取。
至于其他的个性化定制内容,需要自己写~如果不想发图,再问!
顺便一提
Sub getPageInfo()
With CreateObject("internetexplorer.application")
.Visible = True
.Navigate [URL]
While .ReadyState 4 Or .Busy
DoEvents
Wend
Set dmt = .Document
For i = 0 To dmt.all.Length - 1
Set htMent = dmt.all(i)
With ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
End With
Next i
Set r = Nothing
.Quit
End With
MsgBox "获取页面信息成功!"
End Sub
这是抓取页面内容的代码...如果要登录,必须先打开页面。 查看全部
excelvba抓取网页数据(可以,只能用IE实现,引用MicrosoftInternetControls就可以)
是的,只能用IE来实现。您可以通过引用 Microsoft Internet Controls 在 VBA 中操作网页上的内容。
Dim mShellwindows As New ShellWindows
Dim IE As InternetExplorer
For Each IE In mShellwindows '搜索页面
If IE.LocationURL = [URL] Then Exit For
Next
With IE.Document '在文本框填写内容
.all("[id_or_name]").Value = Sheet1.Cells(1, 1).Value
End With
基本原理如上面的代码所示。
[URL]是你要填数据的页面,先用IE浏览器打开这个页面。
[id_or_name] 是要填充数据的控件的 id 或名称。这需要提前从页面中获取。
至于其他的个性化定制内容,需要自己写~如果不想发图,再问!
顺便一提
Sub getPageInfo()
With CreateObject("internetexplorer.application")
.Visible = True
.Navigate [URL]
While .ReadyState 4 Or .Busy
DoEvents
Wend
Set dmt = .Document
For i = 0 To dmt.all.Length - 1
Set htMent = dmt.all(i)
With ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
End With
Next i
Set r = Nothing
.Quit
End With
MsgBox "获取页面信息成功!"
End Sub
这是抓取页面内容的代码...如果要登录,必须先打开页面。
excelvba抓取网页数据( VBA·5个月前如何使用VBA网抓的,我基本都没有回复 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 459 次浏览 • 2021-10-10 14:12
VBA·5个月前如何使用VBA网抓的,我基本都没有回复
)
使用Excel+VBA操作网页
黄辰5 个月前
因为知乎里面的一些回答,最近总有私信问我怎么用VBA抓网,但是我基本没有回复。因为这个问题太大了,有基础知识的人其实很容易自己在百度或者ExcelHome论坛上找到答案。我不需要说什么。对于没有基础知识的人来说,是不可能三言两语解决问题的。我不想把私信变成聊天窗口。借开专栏知乎的机会,恰巧仔细解释了这个问题。
我对Excel和VBA的了解有限,只能解决我遇到的一些问题,不一定适用于所有场景。以下内容基于对VBA基本用法和HTML语言知识的了解:
一、前期准备
据我所知,VBA 不能操作任何浏览器和网页。我们所能做的就是在IE上执行一些操作,是的,只有IE。不要告诉我电脑上没有IE,所以你可以退出Sub。就像在Python中使用import,在C#中使用一样,VBA也需要引用一些库来操作IE,不过好在它是微软的产品,所以我们可以很方便的使用VBA自带的一些库。
我们需要做的第一件事是在 VBA 中引用 Micorsoft Internet Controls。通过查看这个名称,我们知道它可以帮助我们控制 IE 页面。
二、网页操作
引用 Micorsoft Internet Controls 后,我们可以对页面做任何我们想做的事情,但是我们需要在主页上有一个页面,上帝说我们需要一个页面!
1、打开网页
我们以在百度上搜索“查虎”关键词为例:
With CreateObject("internetexplorer.application")
.Visible = True
.Navigate "https://www.baidu.com/s?wd=扯乎"
'关闭网页
' .Quit
End With
代码很简单,先创建一个IE对象,然后给一些属性赋值。Visible就是可见性,是指网页被操作时是否会看到网页。熟练后可以设置为False,这样不仅让程序在运行时有一种神秘感(而不是),而且速度也快了一点。
但是有一点要记住,这个网页在我们打开后并没有关闭,这意味着程序结束后需要手动关闭它。如果网页不可见,则无法手动关闭。代码中的注释部分用于关闭网页。不用说,导航就是 URL。
我们必须等待网页完全加载,然后才能开始信息抓取。这时候,我们使用:(从这里开始,所有的代码都需要写在With代码块中)
While .ReadyState 4 Or .Busy
DoEvents
Wend
Busy 是网页的繁忙状态,ReadyState 是 HTTP 的五种就绪状态,对应如下:
2、获取信息
我们先抓取页面上的所有内容,稍后过滤掉有用的部分,然后慢慢添加条件到抓取中。
Set dmt = .Document
For i = 0 To dmt.all.Length - 1
Set htMent = dmt.all(i)
With ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
End With
Next i
这段代码有点类似于JS,需要从IE.Document.all中找出页面上的所有节点。还有其他几种方法:
这些更方便用于在抓取所有页面内容后帮助过滤有效信息。当然 all 最好用,因为 all 也有 all ("IDName") 和 all.IDName 的用法。
上面代码部分返回的属性值都是基本的HTML内容,就不一一解释了。
3、填写信息
爬网神器当然是Python。大多数人使用Excel自动填写页面内容,直接将表单提交到网页,省去了问卷录入等大量工作。抓取页面内容后,填充起来就更容易了。你只需要直接给页面标签的Value属性赋值即可。
但是,除了文本框,可能还有其他没有Value的标签,比如下拉菜单和单选按钮。给这些内容赋值需要一些基本的HTML知识。
'下拉菜单选择
.all("select")(0).Selected = True
'单选按钮选择
.all("radio").Checked = True
'复选按钮选择
.all("checkbox").Checked = True
下拉菜单是一个select标签,每个选项都在一个option标签中,所以要返回一个集合,需要选择一个选项,将对应的Selected属性修改为True。单选按钮和复选按钮都是输入标签。不同的是类型分别是radio和checkbox。要选择一个选项,您需要修改相应的 Checked 属性。
三、数据接口
有时我们可以直接获取一些API。当然,通过API返回数据比打开网页更方便快捷,使用的方法也有些不同。
1、请求接口
比如我得到了一个可以从网上查询到城市免费WIFI的API,我用下面的代码通过Excel界面访问:(虽然是免费的,为了避免麻烦,我还是隐藏了我的AppKey)
Dim http
Set http = CreateObject("Microsoft.XMLHTTP")
http.Open "GET", "http://api.avatardata.cn/Wifi/QueryByCity", False
http.setRequestHeader "CONTENT-TYPE", "application/x-www-form-urlencoded"
http.send "key=[AppKey]&city=北京&page=1"
这时候我们创建的对象不再是IE,而是HTTP对象。这里使用的是ajax的Open方法,GET为数据发送方法,第二个参数为接口地址,第三个参数指定请求方法是否异步。如果这个API有账号和密码,就写在第四个和第五个参数中。
setRequestHeader是向接口发送一个HTTP协议头文件,最后发送的内容就是接口参数。当然,这个QueryString也可以直接写在URL中,发送一个空字符串即可。
2、接口返回
接口返回和获取的方式很简单:
If http.Status = 200 Then Range("A1").Value = http.responseText 查看全部
excelvba抓取网页数据(
VBA·5个月前如何使用VBA网抓的,我基本都没有回复
)
使用Excel+VBA操作网页

黄辰5 个月前
因为知乎里面的一些回答,最近总有私信问我怎么用VBA抓网,但是我基本没有回复。因为这个问题太大了,有基础知识的人其实很容易自己在百度或者ExcelHome论坛上找到答案。我不需要说什么。对于没有基础知识的人来说,是不可能三言两语解决问题的。我不想把私信变成聊天窗口。借开专栏知乎的机会,恰巧仔细解释了这个问题。
我对Excel和VBA的了解有限,只能解决我遇到的一些问题,不一定适用于所有场景。以下内容基于对VBA基本用法和HTML语言知识的了解:
一、前期准备
据我所知,VBA 不能操作任何浏览器和网页。我们所能做的就是在IE上执行一些操作,是的,只有IE。不要告诉我电脑上没有IE,所以你可以退出Sub。就像在Python中使用import,在C#中使用一样,VBA也需要引用一些库来操作IE,不过好在它是微软的产品,所以我们可以很方便的使用VBA自带的一些库。
我们需要做的第一件事是在 VBA 中引用 Micorsoft Internet Controls。通过查看这个名称,我们知道它可以帮助我们控制 IE 页面。
二、网页操作
引用 Micorsoft Internet Controls 后,我们可以对页面做任何我们想做的事情,但是我们需要在主页上有一个页面,上帝说我们需要一个页面!
1、打开网页
我们以在百度上搜索“查虎”关键词为例:
With CreateObject("internetexplorer.application")
.Visible = True
.Navigate "https://www.baidu.com/s?wd=扯乎"
'关闭网页
' .Quit
End With
代码很简单,先创建一个IE对象,然后给一些属性赋值。Visible就是可见性,是指网页被操作时是否会看到网页。熟练后可以设置为False,这样不仅让程序在运行时有一种神秘感(而不是),而且速度也快了一点。
但是有一点要记住,这个网页在我们打开后并没有关闭,这意味着程序结束后需要手动关闭它。如果网页不可见,则无法手动关闭。代码中的注释部分用于关闭网页。不用说,导航就是 URL。
我们必须等待网页完全加载,然后才能开始信息抓取。这时候,我们使用:(从这里开始,所有的代码都需要写在With代码块中)
While .ReadyState 4 Or .Busy
DoEvents
Wend
Busy 是网页的繁忙状态,ReadyState 是 HTTP 的五种就绪状态,对应如下:
2、获取信息
我们先抓取页面上的所有内容,稍后过滤掉有用的部分,然后慢慢添加条件到抓取中。
Set dmt = .Document
For i = 0 To dmt.all.Length - 1
Set htMent = dmt.all(i)
With ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
End With
Next i
这段代码有点类似于JS,需要从IE.Document.all中找出页面上的所有节点。还有其他几种方法:
这些更方便用于在抓取所有页面内容后帮助过滤有效信息。当然 all 最好用,因为 all 也有 all ("IDName") 和 all.IDName 的用法。
上面代码部分返回的属性值都是基本的HTML内容,就不一一解释了。
3、填写信息
爬网神器当然是Python。大多数人使用Excel自动填写页面内容,直接将表单提交到网页,省去了问卷录入等大量工作。抓取页面内容后,填充起来就更容易了。你只需要直接给页面标签的Value属性赋值即可。
但是,除了文本框,可能还有其他没有Value的标签,比如下拉菜单和单选按钮。给这些内容赋值需要一些基本的HTML知识。
'下拉菜单选择
.all("select")(0).Selected = True
'单选按钮选择
.all("radio").Checked = True
'复选按钮选择
.all("checkbox").Checked = True
下拉菜单是一个select标签,每个选项都在一个option标签中,所以要返回一个集合,需要选择一个选项,将对应的Selected属性修改为True。单选按钮和复选按钮都是输入标签。不同的是类型分别是radio和checkbox。要选择一个选项,您需要修改相应的 Checked 属性。
三、数据接口
有时我们可以直接获取一些API。当然,通过API返回数据比打开网页更方便快捷,使用的方法也有些不同。
1、请求接口
比如我得到了一个可以从网上查询到城市免费WIFI的API,我用下面的代码通过Excel界面访问:(虽然是免费的,为了避免麻烦,我还是隐藏了我的AppKey)
Dim http
Set http = CreateObject("Microsoft.XMLHTTP")
http.Open "GET", "http://api.avatardata.cn/Wifi/QueryByCity", False
http.setRequestHeader "CONTENT-TYPE", "application/x-www-form-urlencoded"
http.send "key=[AppKey]&city=北京&page=1"
这时候我们创建的对象不再是IE,而是HTTP对象。这里使用的是ajax的Open方法,GET为数据发送方法,第二个参数为接口地址,第三个参数指定请求方法是否异步。如果这个API有账号和密码,就写在第四个和第五个参数中。
setRequestHeader是向接口发送一个HTTP协议头文件,最后发送的内容就是接口参数。当然,这个QueryString也可以直接写在URL中,发送一个空字符串即可。
2、接口返回
接口返回和获取的方式很简单:
If http.Status = 200 Then Range("A1").Value = http.responseText
excelvba抓取网页数据(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-01-24 06:17
我相信所有个人网站站长都有抓取别人数据的经历。目前抓取别人的网站数据只有两种方式:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再赘述。
二、自己写程序来抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
起初,我也尝试使用第三方工具来获取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不明白怎么用,就干脆决定自己写了。嗯,现在基本上半天就能搞定网站了(只是程序开发时间,不包括数据采集时间)。
经过一段时间的数据爬取生涯,我也遇到了很多困难。最常见的一种是分页数据的爬取。原因是数据分页的形式有很多种。下面我主要介绍三种形式。抓取分页数据的方法,虽然在网上看过很多文章,但是每次拿别人的代码,总是会出现各种各样的问题。以下方式的代码都是正确的。实现,我目前正在使用它。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入正题:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具爬取这个表单也很简单。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得学第三方工具的人还是可以自己写代码来实现的;
该方法是通过循环生成数据分页的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;抓取的代码可以参考以下:
公共字符串 GetResponseString(字符串 url){
字符串 _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0(兼容;MSIE 7.0;WINDOWS NT 5.2;.NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回对应页面的html内容的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
第二种方式:可能通过网站的开发遇到,它的分页控件通过post的方式将分页信息提交给后台代码,比如.net下Gridview自带的分页功能,点击页面的时候分页号,你会发现URL地址没有变,但是页码变了,页面的内容也变了。仔细看会发现,当你把鼠标移到每个页码上的时候,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这个表格其实也不是很难,因为经过所有,有一个地方可以得到页码的规则。
我们知道提交HTTP请求有两种方式:一种是get,另一种是post,第一种是get,第二种是post。具体提交原理无需赘述,不是本文重点
爬取这类页面需要注意页面的几个重要元素
一、 __VIEWSTATE ,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现了这个东西,并且后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback 方法,这是一个页面自动生成的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将传递给这两个参数。
三、__EVENTVALIDATION 这也应该是独一无二的
不需要太在意这三样东西是干什么的,只要在自己写代码抓取页面的时候记得提交这三个元素就可以了。
和第一种方法一样,_dopostback的两个参数必须通过循环拼凑,只有收录页码信息的参数需要拼凑。这里有一点需要注意,就是每次通过Post提交下一页请求时,首先要获取当前页的__VIEWSTATE信息和__EVENTVALIDATION信息,这样第一页的分页数据就可以使用第一种方法获得。页码内容然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,然后在每一个页面爬取完成后记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一个页面发布数据使用
参考代码如下:
for (int i = 0; i < 1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是您需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1); //获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取上面需要的信息,比如当前页面对应的__VIEWSTATE,用于抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(例外前){
Console.WriteLine(ex.Message);
}
}
第三种方式:第三种方式是最麻烦最恶心的。这种页面在翻页过程中找不到任何地方的页码信息。这种方式耗费了我不少心血,后来采用了更狠的方法,用代码来模拟手动翻页。该方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,用代码逐页翻页。然后逐页抓取。
俗话说,外行看热闹,行家看门道。很多人可能看到这个,说可以通过使用Webbrowser控件来实现。是的,我遵循的方式是使用 WebBrowser 控件来实现它。其实.net下应该有这么一个类似的类,不过我没有研究过,希望有人有别的办法,可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了一个浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我想肯定不如IE和Firefox。呵呵
让我们减少八卦并切入主题:
使用WebBroser控件基本上可以实现任何可以在IE中操作网页的功能,所以当然也可以点击翻页按钮。既然可以手动点击WebBroser中的翻页按钮,自然我们也可以用程序代码来指令WebBroser。自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要抓取的页面,例如:
调用webBrowser控件的方法Navigate("");
此时,您应该在您的 WebBrowser 控件中看到您的网页信息,与您在 IE 中看到的一样;
第二步,WebBrowser控件的DocumentCompleted事件非常重要。当你访问的页面全部加载完毕,就会触发这个事件。所以我们分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取了当前打开的页面的html元素的内容,剩下的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程,大家应该会可以自己写。
第三步,重点在这第三步,因为页面快要翻了,那么第二步,解析完字符串后,还是在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("点击");
从代码的方法名应该可以理解,调用该方法后,WebBrwoser控件中的网页就会实现翻页,和手动点击翻页按钮是一样的。
重点是在翻页之后,DocumentCompleted事件也会被触发,所以第二步和第三步都在循环中,所以需要注意判断跳出循环的时机。
其实用WebBrowser可以做的事情有很多,比如自动登录、注销论坛、保存session、cockie,所以这个控件基本可以实现你对网页的任何操作,即使你想破解一个网站暴利的登录密码,当然不推荐这样。呵呵 查看全部
excelvba抓取网页数据(一下抓取别人网站数据的方式有什么作用?如何抓取)
我相信所有个人网站站长都有抓取别人数据的经历。目前抓取别人的网站数据只有两种方式:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再赘述。
二、自己写程序来抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
起初,我也尝试使用第三方工具来获取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不明白怎么用,就干脆决定自己写了。嗯,现在基本上半天就能搞定网站了(只是程序开发时间,不包括数据采集时间)。
经过一段时间的数据爬取生涯,我也遇到了很多困难。最常见的一种是分页数据的爬取。原因是数据分页的形式有很多种。下面我主要介绍三种形式。抓取分页数据的方法,虽然在网上看过很多文章,但是每次拿别人的代码,总是会出现各种各样的问题。以下方式的代码都是正确的。实现,我目前正在使用它。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入正题:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具爬取这个表单也很简单。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得学第三方工具的人还是可以自己写代码来实现的;
该方法是通过循环生成数据分页的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;抓取的代码可以参考以下:
公共字符串 GetResponseString(字符串 url){
字符串 _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0(兼容;MSIE 7.0;WINDOWS NT 5.2;.NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回对应页面的html内容的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
第二种方式:可能通过网站的开发遇到,它的分页控件通过post的方式将分页信息提交给后台代码,比如.net下Gridview自带的分页功能,点击页面的时候分页号,你会发现URL地址没有变,但是页码变了,页面的内容也变了。仔细看会发现,当你把鼠标移到每个页码上的时候,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这个表格其实也不是很难,因为经过所有,有一个地方可以得到页码的规则。
我们知道提交HTTP请求有两种方式:一种是get,另一种是post,第一种是get,第二种是post。具体提交原理无需赘述,不是本文重点
爬取这类页面需要注意页面的几个重要元素
一、 __VIEWSTATE ,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现了这个东西,并且后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback 方法,这是一个页面自动生成的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将传递给这两个参数。
三、__EVENTVALIDATION 这也应该是独一无二的
不需要太在意这三样东西是干什么的,只要在自己写代码抓取页面的时候记得提交这三个元素就可以了。
和第一种方法一样,_dopostback的两个参数必须通过循环拼凑,只有收录页码信息的参数需要拼凑。这里有一点需要注意,就是每次通过Post提交下一页请求时,首先要获取当前页的__VIEWSTATE信息和__EVENTVALIDATION信息,这样第一页的分页数据就可以使用第一种方法获得。页码内容然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,然后在每一个页面爬取完成后记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一个页面发布数据使用
参考代码如下:
for (int i = 0; i < 1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是您需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1); //获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取上面需要的信息,比如当前页面对应的__VIEWSTATE,用于抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(例外前){
Console.WriteLine(ex.Message);
}
}
第三种方式:第三种方式是最麻烦最恶心的。这种页面在翻页过程中找不到任何地方的页码信息。这种方式耗费了我不少心血,后来采用了更狠的方法,用代码来模拟手动翻页。该方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,用代码逐页翻页。然后逐页抓取。
俗话说,外行看热闹,行家看门道。很多人可能看到这个,说可以通过使用Webbrowser控件来实现。是的,我遵循的方式是使用 WebBrowser 控件来实现它。其实.net下应该有这么一个类似的类,不过我没有研究过,希望有人有别的办法,可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了一个浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我想肯定不如IE和Firefox。呵呵
让我们减少八卦并切入主题:
使用WebBroser控件基本上可以实现任何可以在IE中操作网页的功能,所以当然也可以点击翻页按钮。既然可以手动点击WebBroser中的翻页按钮,自然我们也可以用程序代码来指令WebBroser。自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要抓取的页面,例如:
调用webBrowser控件的方法Navigate("");
此时,您应该在您的 WebBrowser 控件中看到您的网页信息,与您在 IE 中看到的一样;
第二步,WebBrowser控件的DocumentCompleted事件非常重要。当你访问的页面全部加载完毕,就会触发这个事件。所以我们分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取了当前打开的页面的html元素的内容,剩下的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程,大家应该会可以自己写。
第三步,重点在这第三步,因为页面快要翻了,那么第二步,解析完字符串后,还是在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("点击");
从代码的方法名应该可以理解,调用该方法后,WebBrwoser控件中的网页就会实现翻页,和手动点击翻页按钮是一样的。
重点是在翻页之后,DocumentCompleted事件也会被触发,所以第二步和第三步都在循环中,所以需要注意判断跳出循环的时机。
其实用WebBrowser可以做的事情有很多,比如自动登录、注销论坛、保存session、cockie,所以这个控件基本可以实现你对网页的任何操作,即使你想破解一个网站暴利的登录密码,当然不推荐这样。呵呵
excelvba抓取网页数据( PowerQuery的6种常用连接方式,从工作簿从文本/CSV)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-01-18 10:22
PowerQuery的6种常用连接方式,从工作簿从文本/CSV)
Power Query有5大类40种连接方式,可以连接文件、数据库、在线服务等各种数据源。今天我们介绍6种常用的连接方式:
从工作簿从文本/CSV 从文件夹
来自网络空白查询的表格区域
要从工作簿建立连接:
Power Query 的一个基本概念是数据源隔离。无论连接到哪个数据源,连接后的所有操作都不会影响数据源。但是,如果在 Excel 数据源工作簿中建立连接,则数据源不会被修改,但在保存数据源 Excel 文件时,仍然会发生变化。数据源表转换为超级表,文件中的Power更多。查询查询。
因此,要保持数据源文件不被修改,最好的方法是与工作簿建立连接,这样就可以直接提取数据,无需打开 Excel 文件,无需对 Excel 文件进行任何更改。
步骤很简单:
从文本/CSV 连接:
有时数据源是文本文件(后缀为 TXT 或 CSV),也可以直接使用 Power Query 建立连接。步骤同上,选择文件建立连接即可。
从文件夹建立连接:
当 Power Query 从文件夹建立连接时,它可以自动合并格式相同的文件。过去,需要 VBA 来合并多个文件。使用 Power Query,多个文件合并变得更加容易。
按此按钮将自动合并文件。
前三种方法是从文件中获取数据来创建查询,后面三种方法不同。
从表区域:
在 Power Query 中创建查询的最简单方法是从表格区域创建查询。只需一步,选择数据区域并按下按钮。
这种连接方式通常用于单个文件中的数据处理。无需建立文件链接,直接在文件中进行数据处理。也是初学者最喜欢的方法,简单直接。
来自网络:
Power Query 提供了网页数据抓取的功能,有点高大上。通常,网络爬虫只能用Python等编程语言来实现功能。当然,Power Query 的网页抓取在效率和功能上都无法与网页爬虫相比,但基本的静态网页抓取是没有问题的。
复制并粘贴网络地址并选择表格。
构建一个空白查询:
Power Query 的背景是 M 语言。Power Query 提供了丰富的 M 函数,但有时仍需要自定义函数来处理特定问题。在这种情况下,您需要使用空查询。创建空查询后,打开高级编辑器,可以根据M语言的语法规范编写自定义函数。
Power Query提供了丰富的数据接口,可以根据需要进行选择,具体的数据库和在线连接操作并不复杂,只要有权限,按照向导填写所需信息,即可建立连接. 查看全部
excelvba抓取网页数据(
PowerQuery的6种常用连接方式,从工作簿从文本/CSV)
Power Query有5大类40种连接方式,可以连接文件、数据库、在线服务等各种数据源。今天我们介绍6种常用的连接方式:
从工作簿从文本/CSV 从文件夹
来自网络空白查询的表格区域
要从工作簿建立连接:
Power Query 的一个基本概念是数据源隔离。无论连接到哪个数据源,连接后的所有操作都不会影响数据源。但是,如果在 Excel 数据源工作簿中建立连接,则数据源不会被修改,但在保存数据源 Excel 文件时,仍然会发生变化。数据源表转换为超级表,文件中的Power更多。查询查询。
因此,要保持数据源文件不被修改,最好的方法是与工作簿建立连接,这样就可以直接提取数据,无需打开 Excel 文件,无需对 Excel 文件进行任何更改。
步骤很简单:
从文本/CSV 连接:
有时数据源是文本文件(后缀为 TXT 或 CSV),也可以直接使用 Power Query 建立连接。步骤同上,选择文件建立连接即可。
从文件夹建立连接:
当 Power Query 从文件夹建立连接时,它可以自动合并格式相同的文件。过去,需要 VBA 来合并多个文件。使用 Power Query,多个文件合并变得更加容易。
按此按钮将自动合并文件。
前三种方法是从文件中获取数据来创建查询,后面三种方法不同。
从表区域:
在 Power Query 中创建查询的最简单方法是从表格区域创建查询。只需一步,选择数据区域并按下按钮。
这种连接方式通常用于单个文件中的数据处理。无需建立文件链接,直接在文件中进行数据处理。也是初学者最喜欢的方法,简单直接。
来自网络:
Power Query 提供了网页数据抓取的功能,有点高大上。通常,网络爬虫只能用Python等编程语言来实现功能。当然,Power Query 的网页抓取在效率和功能上都无法与网页爬虫相比,但基本的静态网页抓取是没有问题的。
复制并粘贴网络地址并选择表格。
构建一个空白查询:
Power Query 的背景是 M 语言。Power Query 提供了丰富的 M 函数,但有时仍需要自定义函数来处理特定问题。在这种情况下,您需要使用空查询。创建空查询后,打开高级编辑器,可以根据M语言的语法规范编写自定义函数。
Power Query提供了丰富的数据接口,可以根据需要进行选择,具体的数据库和在线连接操作并不复杂,只要有权限,按照向导填写所需信息,即可建立连接.
excelvba抓取网页数据( 2017年03月13日java利用url实现网页内容抓取的示例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-15 00:20
2017年03月13日java利用url实现网页内容抓取的示例)
Java使用url抓取网页内容
更新时间:2017-03-13 09:42:31 作者:zangcunmiao
本文主要介绍java使用url实现网页内容爬取的例子。有很好的参考价值。下面就和小编一起来看看吧
我没什么事,刚学会部署git到远程服务器,也没什么事,就干脆做了一个爬网页信息的小工具。如果将其中的一些值设置为参数,扩展性能可能会更好!我希望这是一个好的开始,也让我在阅读字符串方面更加精通。值得注意的是,在JAVA1.8中使用String拼接字符串时,会自动读取你想要的字符串。拼接后的字符串由StringBulider进行处理,极大的优化了String的性能。废话不多说,展示我的XXX码~
运行结果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签,注入到LinkedHashMap中,就ok了,很简单吧!看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上就是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助,也希望对脚本之家的支持! 查看全部
excelvba抓取网页数据(
2017年03月13日java利用url实现网页内容抓取的示例)
Java使用url抓取网页内容
更新时间:2017-03-13 09:42:31 作者:zangcunmiao
本文主要介绍java使用url实现网页内容爬取的例子。有很好的参考价值。下面就和小编一起来看看吧
我没什么事,刚学会部署git到远程服务器,也没什么事,就干脆做了一个爬网页信息的小工具。如果将其中的一些值设置为参数,扩展性能可能会更好!我希望这是一个好的开始,也让我在阅读字符串方面更加精通。值得注意的是,在JAVA1.8中使用String拼接字符串时,会自动读取你想要的字符串。拼接后的字符串由StringBulider进行处理,极大的优化了String的性能。废话不多说,展示我的XXX码~
运行结果:
先打开百度百科,搜索词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签,注入到LinkedHashMap中,就ok了,很简单吧!看代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*;
/**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch {
//储存返回结果
private LinkedHashMap mapOfBaike;
//获取搜索信息
public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
}
//通过网络链接获取信息
private static LinkedHashMap getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">";
String endNode = "";
boolean isNode = false;
String title;
String href;
String rLine;
LinkedHashMap keyMap = new LinkedHashMap();
//开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
}
//获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
}
//获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("||</a>|<a>","");
}
return result;
}
}
以上就是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助,也希望对脚本之家的支持!
excelvba抓取网页数据(一下就是关于抓取别人网站数据的抓取问题和方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-13 10:07
我相信所有个人 网站 网站管理员都有捕获他人数据的经验。目前,获取他人网站数据的方式只有两种:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再赘述。
二、自己写程序来抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
起初,我也尝试使用第三方工具来获取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不明白怎么用,就干脆决定自己写了。嗯,现在基本上半天就能搞定一个网站(只是程序开发时间,不包括数据采集时间)。
经过一段时间的数据爬取生涯,我也遇到了很多困难。最常见的一种是分页数据的爬取。原因是数据分页的形式有很多种。下面我主要介绍三种形式。抓取分页数据的方法,虽然在网上看过很多文章,但是每次拿别人的代码,总是会出现各种各样的问题。以下方式的代码都是正确的。实现,我目前正在使用它。本文中的代码实现是用C#语言实现的。我认为其他语言的原理大致相同。
让我们切入正题:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具爬取这个表单也很简单。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得学第三方工具的人还是可以自己写代码来实现的;
该方法是通过循环生成数据分页的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;抓取的代码可以参考以下:
公共字符串 GetResponseString(字符串 url)
{
字符串 _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0(兼容;MSIE 7.0;WINDOWS NT 5.2;.NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回对应页面的html内容的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
第二种方式:可能通过网站的开发遇到,它的分页控件通过post的方式将分页信息提交给后台代码,比如.net下Gridview自带的分页功能,点击页面时分页号,你会发现URL地址没有变,但是页码变了,页面的内容也变了。仔细看会发现,当你把鼠标移到每个页码上的时候,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这个表格其实并不难,因为毕竟,有一个地方可以得到页码的规则。
我们知道提交HTTP请求有两种方式:一种是get,另一种是post,第一种是get,第二种是post。具体提交原理无需赘述,不是本文重点
爬取这类页面需要注意页面的几个重要元素
一、 __VIEWSTATE ,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现了这个东西,并且后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback 方法,这是一个页面自动生成的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将传递给这两个参数。
三、__EVENTVALIDATION 这也应该是独一无二的
不需要太在意这三样东西是干什么的,只要在自己写代码抓取页面的时候记得提交这三个元素就可以了。
和第一种方法一样,_dopostback的两个参数必须通过循环拼凑,只有收录页码信息的参数需要拼凑。这里有一点需要注意,就是每次通过Post提交下一页的请求,都应该先获取当前页的__VIEWSTATE信息和__EVENTVALIDATION信息,这样第一页的分页数据就可以使用第一种方法获得。然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,然后在每页抓取后记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页post数据用法
参考代码如下:
for (int i = 0; i < 1000; i++)
{
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是您需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取上面需要的信息,比如当前页面对应的__VIEWSTATE,用于抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}
捕捉(例外前)
{
Console.WriteLine(ex.Message);
}
}
第三种方法是最麻烦最恶心的。在这种页面中,您在翻页过程中的任何地方都找不到页码信息。这个方法花了我很多功夫。方法是使用代码来模拟手动翻页。该方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,用代码逐页翻页,然后逐页翻页。爬行。 查看全部
excelvba抓取网页数据(一下就是关于抓取别人网站数据的抓取问题和方法)
我相信所有个人 网站 网站管理员都有捕获他人数据的经验。目前,获取他人网站数据的方式只有两种:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再赘述。
二、自己写程序来抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
起初,我也尝试使用第三方工具来获取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不明白怎么用,就干脆决定自己写了。嗯,现在基本上半天就能搞定一个网站(只是程序开发时间,不包括数据采集时间)。
经过一段时间的数据爬取生涯,我也遇到了很多困难。最常见的一种是分页数据的爬取。原因是数据分页的形式有很多种。下面我主要介绍三种形式。抓取分页数据的方法,虽然在网上看过很多文章,但是每次拿别人的代码,总是会出现各种各样的问题。以下方式的代码都是正确的。实现,我目前正在使用它。本文中的代码实现是用C#语言实现的。我认为其他语言的原理大致相同。
让我们切入正题:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具爬取这个表单也很简单。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得学第三方工具的人还是可以自己写代码来实现的;
该方法是通过循环生成数据分页的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;抓取的代码可以参考以下:
公共字符串 GetResponseString(字符串 url)
{
字符串 _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0(兼容;MSIE 7.0;WINDOWS NT 5.2;.NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回对应页面的html内容的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
第二种方式:可能通过网站的开发遇到,它的分页控件通过post的方式将分页信息提交给后台代码,比如.net下Gridview自带的分页功能,点击页面时分页号,你会发现URL地址没有变,但是页码变了,页面的内容也变了。仔细看会发现,当你把鼠标移到每个页码上的时候,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这个表格其实并不难,因为毕竟,有一个地方可以得到页码的规则。
我们知道提交HTTP请求有两种方式:一种是get,另一种是post,第一种是get,第二种是post。具体提交原理无需赘述,不是本文重点
爬取这类页面需要注意页面的几个重要元素
一、 __VIEWSTATE ,这应该是 .net 独有的,也是 .net 开发人员又爱又恨的东西。当你打开一个网站的页面时,如果你发现了这个东西,并且后面跟着很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback 方法,这是一个页面自动生成的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将传递给这两个参数。
三、__EVENTVALIDATION 这也应该是独一无二的
不需要太在意这三样东西是干什么的,只要在自己写代码抓取页面的时候记得提交这三个元素就可以了。
和第一种方法一样,_dopostback的两个参数必须通过循环拼凑,只有收录页码信息的参数需要拼凑。这里有一点需要注意,就是每次通过Post提交下一页的请求,都应该先获取当前页的__VIEWSTATE信息和__EVENTVALIDATION信息,这样第一页的分页数据就可以使用第一种方法获得。然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,然后在每页抓取后记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页post数据用法
参考代码如下:
for (int i = 0; i < 1000; i++)
{
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是您需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取上面需要的信息,比如当前页面对应的__VIEWSTATE,用于抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}
捕捉(例外前)
{
Console.WriteLine(ex.Message);
}
}
第三种方法是最麻烦最恶心的。在这种页面中,您在翻页过程中的任何地方都找不到页码信息。这个方法花了我很多功夫。方法是使用代码来模拟手动翻页。该方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,用代码逐页翻页,然后逐页翻页。爬行。
excelvba抓取网页数据(#如何用excel获得股票实时数据#首先找一个提供股票数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2022-01-04 09:22
#如何使用excel获取实时股票数据#
首先找到一个提供股票数据的网站。各种金融网站都有股票数据。以东方财富网为例:
沪深A股数据,我们在谷歌浏览器中查看真实网址:
找到股票数据对应的jQuery行,然后查看头文件中的URL:
复制这个网址到Excel,数据==>来自网站:
单击以确认,Power Query 编辑器将打开。如果一切顺利,数据会直接出现:
虽然不是表,但证明爬取成功。下一步是如何解析二进制文件。从谷歌浏览器看,这是一个jsoncallback数据包,比json数据多了一个函数名。我们只需要提取两个括号之间的数据就可以用json解析了。注意总数:4440,后面会用到这个值。
=Json.Document(Text.BetweenDelimiters(Text.FromBinary(Web.Contents(url)),'(',')'))
然后展开数据表:
到目前为止一切都很顺利,但我们抓取的只是一页数据,让我们看看:
pn是页码,我们抓取第3页,pz是每页20条数据,我们有两种方法抓取所有数据,一种是使用这个pz:20,然后定义函数,抓取所有页码,我在之前的爬行中反复使用了这个。今天我们尝试直接修改pz,一次性抓取所有数据。其实,你可以尝试改变查询参数。如果我们把pn改成4,抓到的数据是第4页的20项,同理,我们把pn改成200,看看能不能直接抓到200项数据。
那我们试试直接输入5000,能不能全部抢过来:
这似乎是可能的。
还有一个问题,就是数据的所有header行都以f开头,不可读。怎么会变成网页中的汉字标题行?
这个问题有点复杂,我们可能要查代码看看能不能找到替代的方法,先看html:
但这并不完整。需要自定义几列:
这些指标没有对应的 f 代码。
我们再看一下js文件:
这个文件里有对应的数据,我们直接拷贝到Power Query中,处理成列表形式供以后使用:
接下来是匹配表中的key,修改列名:
首先我们需要匹配出这样一个列表。
List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n[key])},(y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0})
然后我们可以直接使用Table.RenameColumns函数批量修改列名:
Table.RenameColumns(data,List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List. Count(n[key])},(y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0}) )
我们只是将数据加载到 Excel 中。
如果您想要最新的数据,只需刷新即可。 查看全部
excelvba抓取网页数据(#如何用excel获得股票实时数据#首先找一个提供股票数据)
#如何使用excel获取实时股票数据#
首先找到一个提供股票数据的网站。各种金融网站都有股票数据。以东方财富网为例:
沪深A股数据,我们在谷歌浏览器中查看真实网址:
找到股票数据对应的jQuery行,然后查看头文件中的URL:
复制这个网址到Excel,数据==>来自网站:
单击以确认,Power Query 编辑器将打开。如果一切顺利,数据会直接出现:
虽然不是表,但证明爬取成功。下一步是如何解析二进制文件。从谷歌浏览器看,这是一个jsoncallback数据包,比json数据多了一个函数名。我们只需要提取两个括号之间的数据就可以用json解析了。注意总数:4440,后面会用到这个值。
=Json.Document(Text.BetweenDelimiters(Text.FromBinary(Web.Contents(url)),'(',')'))
然后展开数据表:
到目前为止一切都很顺利,但我们抓取的只是一页数据,让我们看看:
pn是页码,我们抓取第3页,pz是每页20条数据,我们有两种方法抓取所有数据,一种是使用这个pz:20,然后定义函数,抓取所有页码,我在之前的爬行中反复使用了这个。今天我们尝试直接修改pz,一次性抓取所有数据。其实,你可以尝试改变查询参数。如果我们把pn改成4,抓到的数据是第4页的20项,同理,我们把pn改成200,看看能不能直接抓到200项数据。
那我们试试直接输入5000,能不能全部抢过来:
这似乎是可能的。
还有一个问题,就是数据的所有header行都以f开头,不可读。怎么会变成网页中的汉字标题行?
这个问题有点复杂,我们可能要查代码看看能不能找到替代的方法,先看html:
但这并不完整。需要自定义几列:
这些指标没有对应的 f 代码。
我们再看一下js文件:
这个文件里有对应的数据,我们直接拷贝到Power Query中,处理成列表形式供以后使用:
接下来是匹配表中的key,修改列名:
首先我们需要匹配出这样一个列表。
List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List.Count(n[key])},(y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0})
然后我们可以直接使用Table.RenameColumns函数批量修改列名:
Table.RenameColumns(data,List.RemoveNulls(List.Zip(List.Transform(Table.ColumnNames(data),(x)=>List.RemoveNulls(List.Transform({1..List. Count(n[key])},(y)=>if x=n[key]{y-1} then {x,n[title]{y-1}} else null)))){0}) )
我们只是将数据加载到 Excel 中。
如果您想要最新的数据,只需刷新即可。
excelvba抓取网页数据(人均985,年薪百万的知乎背后,到底有什么秘密?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-31 06:05
友情提示:文末...
一个完整的python数据分析流程是怎样的?
使用python从网站中抓取数据并保存到SQLite数据库中,然后对数据进行清洗,最后对数据进行数据可视化分析。
但是熟悉它的人应该知道,python爬取很简单,但是分析起来却非常困难。SQL 语句,Pandas 和 Matplotlib 非常繁琐,大多数人不会。
于是想到了一种更简单的数据分析方式,即python爬取+BI分析。BI是什么就不用我多介绍了。Python强大的数据采集能力,结合敏捷BI简单快速的数据可视化操作,一定能发挥出分析的效果!
那么这次我们就来看看“人均985,年薪百万”知乎,背后到底有什么秘密?话不多说,开始爬!
一、我们想要什么数据?
知乎 用户所在的学校和公司肯定是首当其冲的。我想看看这些人是编造的还是真的哈哈哈。
其次是性别、职业、地理位置、活动水平等,都是。
二、 爬取的过程
知乎 现在我用的是https请求,数据加密,不过问题不大,重要的是网页数据发生了变化,后台在请求的时候会对爬虫做一些判断,所以需要每次请求时添加请求头尽可能接近浏览器请求的样子。
获取列表页面的源码后,可以从中获取每个问题的链接:
每页有20道题,所以可以得到20道题的链接,然后是每道题的处理:
实现这一步,剩下的就是循环,判断和一些细节。
代码的最后部分如下:
import requests
import pandas as pd
import time
headers={
'authorization':'',#此处填写你自己的身份验证信息
'User-Agent':''#此处填写你自己浏览器的User-Agent
}
user_data = []
def get_user_data(page):
for i in range(page):#翻页
url = 'https://www.zhihu.com/api/v4/m ... %255B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset={}&limit=20'.format(i*20)
response = requests.get(url, headers=headers).json()['data']
user_data.extend(response) #把response数据添加进user_data
print('正在爬取第%s页' % str(i+1))
time.sleep(1) #设置爬取网页的时间间隔为1秒
if __name__ == '__main__':
get_user_data(10)
df = pd.DataFrame.from_dict(user_data)#以字典保存数据
df.to_csv('zhihu.csv',encoding='utf_8_sig')#保存到用户名为zhihu的csv文件中,encoding='utf_8_sig'参数是为了解决中文乱码的问题
print(df)
更多源码见文末!
在Python代码中,我没有使用线程池,而是使用了10个main()方法进行爬取,也就是10个进程,历时4个小时,爬取了57w+的数据。
三、使用BI进行数据可视化分析
现在我们已经到了最后一步,开始用BI进行数据可视化,揭秘知乎的时候到了。
市场上有很多种BI工具。国外的Tableau和国内的FineBI都是BI领域的佼佼者,但早就听说Tableau适合基础数据分析师,对小白很不友好。另外,前天无意中看到IDC的报告,发现帆软的市场份额是第一。为了避免返工,我选择了敏捷工具FineBI。事实证明,我的选择是对的。
首先在官网下载FineBI。虽然是企业级数据分析平台,但对个人永久免费。文末为大家准备了下载链接~
然后直接使用FineBI提供的数据配置终端的功能,添加SQL数据集(或者直接添加表)来检查验证刚刚抓取存储的数据是否已经成功存储到MySQL中。
忘了说了,FineBI 的一大特色就是自助分析。什么是自助分析?自己拖拽数据就可以了,可以和Matplotlib一样的效果,你可能也会想到Excel,但是一般都是几万行以上的数据,excel基本无能为力,很卡。但是FineBI还是可以处理大数据的,效率有可能高出几十倍、几百倍。
同时,VBA有一个致命的弱点,就是只能基于excel进行自动化,别无他法。
在写这篇文章之前,我分析了房价和销量,特地做成了一张动画图供大家参考:
四、知乎数据可视化
FineBI的仪表盘可以通过拖拽的方式调整组件的位置,并配备了各种类型的直方图、饼图和雷达图。数据可视化就是这么简单,只有你想不到,没有它你做不到。
1、哪个城市的知乎用户最多?
从云字图可以看出,越繁华的城市,知乎的用户越多(文字越大,占比越大)。因此,我们也可以看到,以北京、上海、广州、深圳四个一线城市为中心,其次是新一线城市。换句话说:知乎人多是一线城市或新一线城市,真是见多识广!
我们来看看具体的排名:
杭州位居第三。果然,互联网的优采云之一并没有被吹捧。阿里巴巴网易起到了很大的作用。你为什么这么说?看到这个职业你就明白了。
2、他们属于哪些学校?
看看,看看,这个度真的很高,谁说人均985吹的?
但是知乎专注于高智商的聚集地,学生花在手机上的时间比上班族多,这也就不足为奇了。
既然分析了学校,就要看看各个高校玩知乎的男女比例:
不用我说,你也能猜到蓝色代表男孩。女孩要么购物要么学习。低头玩手机的肯定是男生(虽然我也是男的)。
我们来看看每个地区有哪些大学是知乎重度用户。颜色越深,学校的知乎用户越多:
不说了,知乎人均是985真锤。我流下了羡慕的泪水。请问各位同学,你们是如何做到边玩边学的?如果你教我,我的高考可能更接近清华的录取分数线……
3、知乎 占有率
排除了学生之后,我们发现知乎的人都是……
产品经理最多。这是近年来最流行的职业,但是你的文档呢?需求被绘制?你对知乎的页面交互不满意吗?你为什么不去上班?
可以看出,除了一些互联网公司的共同职位外,教师和律师用户在知乎中也占据了很大的比例。
我们再用一张热图来观察知乎主流职业(前四)在各个地区的分布情况。颜色越深,该区域的职业数量越多:
总结
分析了这么多,不是要告诉你知乎的用户是什么样的,而是说如果你要做数据分析,FineBI确实是一个非常有用的工具,无论是对个人还是对公司。所以。
当然,以上只是FineBI的冰山一角,更多的东西还需要自己去探索。 查看全部
excelvba抓取网页数据(人均985,年薪百万的知乎背后,到底有什么秘密?)
友情提示:文末...
一个完整的python数据分析流程是怎样的?
使用python从网站中抓取数据并保存到SQLite数据库中,然后对数据进行清洗,最后对数据进行数据可视化分析。
但是熟悉它的人应该知道,python爬取很简单,但是分析起来却非常困难。SQL 语句,Pandas 和 Matplotlib 非常繁琐,大多数人不会。
于是想到了一种更简单的数据分析方式,即python爬取+BI分析。BI是什么就不用我多介绍了。Python强大的数据采集能力,结合敏捷BI简单快速的数据可视化操作,一定能发挥出分析的效果!
那么这次我们就来看看“人均985,年薪百万”知乎,背后到底有什么秘密?话不多说,开始爬!
一、我们想要什么数据?
知乎 用户所在的学校和公司肯定是首当其冲的。我想看看这些人是编造的还是真的哈哈哈。
其次是性别、职业、地理位置、活动水平等,都是。
二、 爬取的过程
知乎 现在我用的是https请求,数据加密,不过问题不大,重要的是网页数据发生了变化,后台在请求的时候会对爬虫做一些判断,所以需要每次请求时添加请求头尽可能接近浏览器请求的样子。
获取列表页面的源码后,可以从中获取每个问题的链接:
每页有20道题,所以可以得到20道题的链接,然后是每道题的处理:
实现这一步,剩下的就是循环,判断和一些细节。
代码的最后部分如下:
import requests
import pandas as pd
import time
headers={
'authorization':'',#此处填写你自己的身份验证信息
'User-Agent':''#此处填写你自己浏览器的User-Agent
}
user_data = []
def get_user_data(page):
for i in range(page):#翻页
url = 'https://www.zhihu.com/api/v4/m ... %255B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset={}&limit=20'.format(i*20)
response = requests.get(url, headers=headers).json()['data']
user_data.extend(response) #把response数据添加进user_data
print('正在爬取第%s页' % str(i+1))
time.sleep(1) #设置爬取网页的时间间隔为1秒
if __name__ == '__main__':
get_user_data(10)
df = pd.DataFrame.from_dict(user_data)#以字典保存数据
df.to_csv('zhihu.csv',encoding='utf_8_sig')#保存到用户名为zhihu的csv文件中,encoding='utf_8_sig'参数是为了解决中文乱码的问题
print(df)
更多源码见文末!
在Python代码中,我没有使用线程池,而是使用了10个main()方法进行爬取,也就是10个进程,历时4个小时,爬取了57w+的数据。
三、使用BI进行数据可视化分析
现在我们已经到了最后一步,开始用BI进行数据可视化,揭秘知乎的时候到了。
市场上有很多种BI工具。国外的Tableau和国内的FineBI都是BI领域的佼佼者,但早就听说Tableau适合基础数据分析师,对小白很不友好。另外,前天无意中看到IDC的报告,发现帆软的市场份额是第一。为了避免返工,我选择了敏捷工具FineBI。事实证明,我的选择是对的。
首先在官网下载FineBI。虽然是企业级数据分析平台,但对个人永久免费。文末为大家准备了下载链接~
然后直接使用FineBI提供的数据配置终端的功能,添加SQL数据集(或者直接添加表)来检查验证刚刚抓取存储的数据是否已经成功存储到MySQL中。
忘了说了,FineBI 的一大特色就是自助分析。什么是自助分析?自己拖拽数据就可以了,可以和Matplotlib一样的效果,你可能也会想到Excel,但是一般都是几万行以上的数据,excel基本无能为力,很卡。但是FineBI还是可以处理大数据的,效率有可能高出几十倍、几百倍。
同时,VBA有一个致命的弱点,就是只能基于excel进行自动化,别无他法。
在写这篇文章之前,我分析了房价和销量,特地做成了一张动画图供大家参考:
四、知乎数据可视化
FineBI的仪表盘可以通过拖拽的方式调整组件的位置,并配备了各种类型的直方图、饼图和雷达图。数据可视化就是这么简单,只有你想不到,没有它你做不到。
1、哪个城市的知乎用户最多?
从云字图可以看出,越繁华的城市,知乎的用户越多(文字越大,占比越大)。因此,我们也可以看到,以北京、上海、广州、深圳四个一线城市为中心,其次是新一线城市。换句话说:知乎人多是一线城市或新一线城市,真是见多识广!
我们来看看具体的排名:
杭州位居第三。果然,互联网的优采云之一并没有被吹捧。阿里巴巴网易起到了很大的作用。你为什么这么说?看到这个职业你就明白了。
2、他们属于哪些学校?
看看,看看,这个度真的很高,谁说人均985吹的?
但是知乎专注于高智商的聚集地,学生花在手机上的时间比上班族多,这也就不足为奇了。
既然分析了学校,就要看看各个高校玩知乎的男女比例:
不用我说,你也能猜到蓝色代表男孩。女孩要么购物要么学习。低头玩手机的肯定是男生(虽然我也是男的)。
我们来看看每个地区有哪些大学是知乎重度用户。颜色越深,学校的知乎用户越多:
不说了,知乎人均是985真锤。我流下了羡慕的泪水。请问各位同学,你们是如何做到边玩边学的?如果你教我,我的高考可能更接近清华的录取分数线……
3、知乎 占有率
排除了学生之后,我们发现知乎的人都是……
产品经理最多。这是近年来最流行的职业,但是你的文档呢?需求被绘制?你对知乎的页面交互不满意吗?你为什么不去上班?
可以看出,除了一些互联网公司的共同职位外,教师和律师用户在知乎中也占据了很大的比例。
我们再用一张热图来观察知乎主流职业(前四)在各个地区的分布情况。颜色越深,该区域的职业数量越多:
总结
分析了这么多,不是要告诉你知乎的用户是什么样的,而是说如果你要做数据分析,FineBI确实是一个非常有用的工具,无论是对个人还是对公司。所以。
当然,以上只是FineBI的冰山一角,更多的东西还需要自己去探索。
excelvba抓取网页数据(VBA基础的人来说不可能解决问题,我也不想把私信变成聊天窗 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-12-13 23:00
)
因为在知乎的一些回答里,总有私信问我怎么用VBA抓网,但是我基本没有回复。因为这个问题太大了,有基础知识的人其实很容易自己在百度或者ExcelHome论坛上找到答案。我不需要说什么。对于没有基础知识的人来说,是不可能三言两语解决问题的。我不想把私信变成聊天窗口。趁着开专栏知乎的机会,正好是仔细解释一下这个问题的好时机。
我对 Excel 和 VBA 的了解有限。我只能解决我遇到的一些问题,不一定适用于所有场景。以下内容基于对VBA基本用法和HTML语言知识的了解:
一、前期准备
据我所知,VBA 不能操作任何浏览器和网页。我们所能做的就是在IE上执行一些操作,是的,只有IE。不要告诉我电脑上没有IE,所以你可以退出Sub。就像在Python中导入,在C#中使用一样,VBA也需要引用一些库来操作IE,不过好在它是微软的产品,所以我们可以很方便的使用VBA自带的一些库。
我们需要做的第一件事是在 VBA 中引用 Micorsoft Internet Controls。这个名字会告诉我们它可以帮助我们控制 IE 页面。
二、网页操作
引用 Micorsoft Internet Controls 后,我们可以对页面做任何我们想做的事情,但是我们需要在主页上有一个页面,上帝说我们需要一个页面!
1、打开网页
我们以在百度上搜索“查虎”关键词为例:
With CreateObject("internetexplorer.application")
.Visible = True
.Navigate "https://www.baidu.com/s?wd=扯乎"
'关闭网页
' .Quit
End With
代码很简单,先创建一个IE对象,然后给一些属性赋值。Visible是可见性,是指网页操作时是否会看到网页。熟练之后可以设置为False,这样不仅可以让程序在运行时有一种神秘感(其实并没有),还能稍微加快运行速度。
但是需要注意的一点是,这个网页在我们打开后并没有关闭,这意味着程序结束后需要手动关闭它。如果网页不可见,则无法手动关闭。代码中的注释部分用于关闭网页。不用说,导航就是 URL。
我们必须等到网页完全加载后才能开始信息抓取。这时候,我们使用:(从这里开始,所有的代码都需要写在With代码块中)
While .ReadyState 4 Or .Busy
DoEvents
Wend
Busy是网页的繁忙状态,ReadyState是HTTP的五种就绪状态,对应如下:
2、获取信息
我们先抓取页面上的所有内容,稍后过滤掉有用的部分,然后慢慢添加条件到抓取中。
Set dmt = .Document
For i = 0 To dmt.all.Length - 1
Set htMent = dmt.all(i)
With ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
End With
Next i
这段代码有点类似于JS,需要从IE.Document.all中找出页面上的所有节点。还有其他几种方法:
这些更方便用于在抓取所有页面内容后帮助过滤有效信息。当然all 最好用,因为all 也有all("IDName") 和all.IDName 的用法。
上面代码部分返回的属性值都是基本的HTML内容,就不一一解释了。
3、填写信息
爬网神器当然是Python。大多数人使用Excel自动填写页面内容,直接将表格提交到网页,省去了问卷录入等大量工作。抓取页面内容后,填充起来就更容易了。你只需要直接给页面标签的Value属性赋值即可。
但是,除了文本框,可能还有其他没有Value的标签,比如下拉菜单和单选按钮。给这些内容赋值需要一些基本的HTML知识。
'下拉菜单选择
.all("select")(0).Selected = True
'单选按钮选择
.all("radio").Checked = True
'复选按钮选择
.all("checkbox").Checked = True
下拉菜单是select标签,每个选项都在一个option标签中,所以要返回一个set,需要选择一个option将对应的Selected属性修改为True。单选按钮和复选按钮都是输入标签。不同的是类型分别是radio和checkbox。要选择一个选项,您需要修改相应的 Checked 属性。
三、数据接口
有时我们可以直接获取一些API。当然,通过API返回数据比打开网页更方便快捷,使用的方法也不同。
1、请求接口
比如我得到了一个可以从网上查询到城市免费WIFI的API,用下面的代码通过Excel界面访问:(虽然是免费的,为了避免麻烦,我还是隐藏了我的AppKey)
Dim http
Set http = CreateObject("Microsoft.XMLHTTP")
http.Open "GET", "http://api.avatardata.cn/Wifi/QueryByCity", False
http.setRequestHeader "CONTENT-TYPE", "application/x-www-form-urlencoded"
http.send "key=[AppKey]&city=北京&page=1"
这时候我们创建的对象不再是IE,而是HTTP对象。这里使用ajax的Open方法,GET为数据发送方法,第二个参数为接口地址,第三个参数指定请求方法是否异步。如果这个API有账号和密码,就写在第四个和第五个参数中。
setRequestHeader是向接口发送一个HTTP协议头文件,最后发送的内容就是接口参数。当然,这个QueryString也可以直接写在URL中,发送一个空字符串即可。
2、接口返回
接口返回和获取的方式很简单:
If http.Status = 200 Then Range("A1").Value = http.responseText 查看全部
excelvba抓取网页数据(VBA基础的人来说不可能解决问题,我也不想把私信变成聊天窗
)
因为在知乎的一些回答里,总有私信问我怎么用VBA抓网,但是我基本没有回复。因为这个问题太大了,有基础知识的人其实很容易自己在百度或者ExcelHome论坛上找到答案。我不需要说什么。对于没有基础知识的人来说,是不可能三言两语解决问题的。我不想把私信变成聊天窗口。趁着开专栏知乎的机会,正好是仔细解释一下这个问题的好时机。
我对 Excel 和 VBA 的了解有限。我只能解决我遇到的一些问题,不一定适用于所有场景。以下内容基于对VBA基本用法和HTML语言知识的了解:
一、前期准备
据我所知,VBA 不能操作任何浏览器和网页。我们所能做的就是在IE上执行一些操作,是的,只有IE。不要告诉我电脑上没有IE,所以你可以退出Sub。就像在Python中导入,在C#中使用一样,VBA也需要引用一些库来操作IE,不过好在它是微软的产品,所以我们可以很方便的使用VBA自带的一些库。
我们需要做的第一件事是在 VBA 中引用 Micorsoft Internet Controls。这个名字会告诉我们它可以帮助我们控制 IE 页面。
二、网页操作
引用 Micorsoft Internet Controls 后,我们可以对页面做任何我们想做的事情,但是我们需要在主页上有一个页面,上帝说我们需要一个页面!
1、打开网页
我们以在百度上搜索“查虎”关键词为例:
With CreateObject("internetexplorer.application")
.Visible = True
.Navigate "https://www.baidu.com/s?wd=扯乎"
'关闭网页
' .Quit
End With
代码很简单,先创建一个IE对象,然后给一些属性赋值。Visible是可见性,是指网页操作时是否会看到网页。熟练之后可以设置为False,这样不仅可以让程序在运行时有一种神秘感(其实并没有),还能稍微加快运行速度。
但是需要注意的一点是,这个网页在我们打开后并没有关闭,这意味着程序结束后需要手动关闭它。如果网页不可见,则无法手动关闭。代码中的注释部分用于关闭网页。不用说,导航就是 URL。
我们必须等到网页完全加载后才能开始信息抓取。这时候,我们使用:(从这里开始,所有的代码都需要写在With代码块中)
While .ReadyState 4 Or .Busy
DoEvents
Wend
Busy是网页的繁忙状态,ReadyState是HTTP的五种就绪状态,对应如下:
2、获取信息
我们先抓取页面上的所有内容,稍后过滤掉有用的部分,然后慢慢添加条件到抓取中。
Set dmt = .Document
For i = 0 To dmt.all.Length - 1
Set htMent = dmt.all(i)
With ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
End With
Next i
这段代码有点类似于JS,需要从IE.Document.all中找出页面上的所有节点。还有其他几种方法:
这些更方便用于在抓取所有页面内容后帮助过滤有效信息。当然all 最好用,因为all 也有all("IDName") 和all.IDName 的用法。
上面代码部分返回的属性值都是基本的HTML内容,就不一一解释了。
3、填写信息
爬网神器当然是Python。大多数人使用Excel自动填写页面内容,直接将表格提交到网页,省去了问卷录入等大量工作。抓取页面内容后,填充起来就更容易了。你只需要直接给页面标签的Value属性赋值即可。
但是,除了文本框,可能还有其他没有Value的标签,比如下拉菜单和单选按钮。给这些内容赋值需要一些基本的HTML知识。
'下拉菜单选择
.all("select")(0).Selected = True
'单选按钮选择
.all("radio").Checked = True
'复选按钮选择
.all("checkbox").Checked = True
下拉菜单是select标签,每个选项都在一个option标签中,所以要返回一个set,需要选择一个option将对应的Selected属性修改为True。单选按钮和复选按钮都是输入标签。不同的是类型分别是radio和checkbox。要选择一个选项,您需要修改相应的 Checked 属性。
三、数据接口
有时我们可以直接获取一些API。当然,通过API返回数据比打开网页更方便快捷,使用的方法也不同。
1、请求接口
比如我得到了一个可以从网上查询到城市免费WIFI的API,用下面的代码通过Excel界面访问:(虽然是免费的,为了避免麻烦,我还是隐藏了我的AppKey)
Dim http
Set http = CreateObject("Microsoft.XMLHTTP")
http.Open "GET", "http://api.avatardata.cn/Wifi/QueryByCity", False
http.setRequestHeader "CONTENT-TYPE", "application/x-www-form-urlencoded"
http.send "key=[AppKey]&city=北京&page=1"
这时候我们创建的对象不再是IE,而是HTTP对象。这里使用ajax的Open方法,GET为数据发送方法,第二个参数为接口地址,第三个参数指定请求方法是否异步。如果这个API有账号和密码,就写在第四个和第五个参数中。
setRequestHeader是向接口发送一个HTTP协议头文件,最后发送的内容就是接口参数。当然,这个QueryString也可以直接写在URL中,发送一个空字符串即可。
2、接口返回
接口返回和获取的方式很简单:
If http.Status = 200 Then Range("A1").Value = http.responseText
excelvba抓取网页数据(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-11 00:18
Excel 2013及以后版本提供了WEBSERVICE和FILTERXML函数,可以用于网页数据的抓取,但是只能抓取XML格式的数据。而现在网站的很多网页或者接口都返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?今天以豆瓣图书基本资料为例,给大家介绍一下如何使用Excel API网络函数库抓取JSON格式的网页数据。第一步是找到豆瓣网的基本信息网页。第二步是安装ExcelAPI网络函数库。第三步,使用函数抓取JSON数据。
Excel 2013及以后版本提供了WEBSERVICE和FILTERXML函数,可以用于网页数据的抓取,但是只能抓取XML格式的数据。而现在网站的很多网页或者接口都返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?
今天以豆瓣图书基本资料为例,给大家介绍一下如何使用Excel API网络函数库抓取JSON格式的网页数据。
第一步是找到豆瓣网的基本信息网页。
豆瓣图书信息网站是9787111529385,网站最后一串数字是图书的ISBN号。
在火狐浏览器中,这个URL会返回如下信息,是标准的JSON格式,蓝色字体为属性名称,红色字体对应属性值。
第二步是安装ExcelAPI网络函数库。
访问ExcelAPI网络函数库官网,根据帮助文件安装函数库。
第三步,使用函数抓取JSON数据。
首先,使用函数 GetJsonSource(url,"UTF-8") 返回 JSON 原创数据。
然后,使用函数 GetJsonByPropertyName(json_source,property_name) 返回书的基本信息
使用GetJsonSource()函数一次性抓取所有数据,然后按需抓取。这样做的目的是提高爬行速度。毕竟,访问网页需要时间。 查看全部
excelvba抓取网页数据(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据?)
Excel 2013及以后版本提供了WEBSERVICE和FILTERXML函数,可以用于网页数据的抓取,但是只能抓取XML格式的数据。而现在网站的很多网页或者接口都返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?今天以豆瓣图书基本资料为例,给大家介绍一下如何使用Excel API网络函数库抓取JSON格式的网页数据。第一步是找到豆瓣网的基本信息网页。第二步是安装ExcelAPI网络函数库。第三步,使用函数抓取JSON数据。
Excel 2013及以后版本提供了WEBSERVICE和FILTERXML函数,可以用于网页数据的抓取,但是只能抓取XML格式的数据。而现在网站的很多网页或者接口都返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?
今天以豆瓣图书基本资料为例,给大家介绍一下如何使用Excel API网络函数库抓取JSON格式的网页数据。
第一步是找到豆瓣网的基本信息网页。
豆瓣图书信息网站是9787111529385,网站最后一串数字是图书的ISBN号。
在火狐浏览器中,这个URL会返回如下信息,是标准的JSON格式,蓝色字体为属性名称,红色字体对应属性值。
第二步是安装ExcelAPI网络函数库。
访问ExcelAPI网络函数库官网,根据帮助文件安装函数库。
第三步,使用函数抓取JSON数据。
首先,使用函数 GetJsonSource(url,"UTF-8") 返回 JSON 原创数据。
然后,使用函数 GetJsonByPropertyName(json_source,property_name) 返回书的基本信息
使用GetJsonSource()函数一次性抓取所有数据,然后按需抓取。这样做的目的是提高爬行速度。毕竟,访问网页需要时间。
excelvba抓取网页数据( 此控件的功能为1.对需要录入的数据进行提取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-12-03 12:27
此控件的功能为1.对需要录入的数据进行提取)
介绍:
这个控件的功能是
1. 提取需要录入的数据,排版并选择打印数量
2.针对不同的任务和根本不同的需求,清理和处理数据
3.各种辅助功能,如生成数据透视表、过滤复制数据、按指定方式粘贴数据
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●● ●●●
【配置区域】
该区域可以与内部代码进行交互,修改会直接导致功能上的相应变化。
左栏是对应的功能区,右栏是内容修改区。
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●● ●●●
【部分实际执行代码】
◆1.◆。
■代码量巨大,暂不写。
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●● ●●●
【一些小功能】
◆1.小功能一览◆。
Function ColCopy(intA%) '列数据全选
If Cells(1048576, intA).End(3).Row < 2 Then '是否空值
Cells(2, intA).Copy
Else
Range(Cells(2, intA), Cells(Cells(1048576, intA).End(3).Row, intA)).Copy
End If
End Function
■创建小列选择功能,方便不同情况下选择对应列的数据
■ 判断目标列中是否有数据,如果不存在,复制第二个网格
■判断目标列是否有数据,如果存在则复制指定列的数据,从第二个单元格开始到最后一个单元格
◆2.锁定表格/解锁表格◆。
Function LockSub() '锁定excel
With Application
.Interactive = False
.ScreenUpdating = False
End With
End Function
Function UnlockSub() '解锁excel
With Application
.Interactive = True
.ScreenUpdating = True
End With
End Function
■锁定禁止操作表格,关闭屏幕更新
■为防止误操作,优化操作效率,本内容创建为功能,随时使用
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●● ●●●
下载地址:【VBA】多功能辅助插件-VB文档资源-CSDN下载 查看全部
excelvba抓取网页数据(
此控件的功能为1.对需要录入的数据进行提取)
介绍:
这个控件的功能是
1. 提取需要录入的数据,排版并选择打印数量
2.针对不同的任务和根本不同的需求,清理和处理数据
3.各种辅助功能,如生成数据透视表、过滤复制数据、按指定方式粘贴数据
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●● ●●●
【配置区域】
该区域可以与内部代码进行交互,修改会直接导致功能上的相应变化。
左栏是对应的功能区,右栏是内容修改区。
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●● ●●●
【部分实际执行代码】
◆1.◆。
■代码量巨大,暂不写。
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●● ●●●
【一些小功能】
◆1.小功能一览◆。
Function ColCopy(intA%) '列数据全选
If Cells(1048576, intA).End(3).Row < 2 Then '是否空值
Cells(2, intA).Copy
Else
Range(Cells(2, intA), Cells(Cells(1048576, intA).End(3).Row, intA)).Copy
End If
End Function
■创建小列选择功能,方便不同情况下选择对应列的数据
■ 判断目标列中是否有数据,如果不存在,复制第二个网格
■判断目标列是否有数据,如果存在则复制指定列的数据,从第二个单元格开始到最后一个单元格
◆2.锁定表格/解锁表格◆。
Function LockSub() '锁定excel
With Application
.Interactive = False
.ScreenUpdating = False
End With
End Function
Function UnlockSub() '解锁excel
With Application
.Interactive = True
.ScreenUpdating = True
End With
End Function
■锁定禁止操作表格,关闭屏幕更新
■为防止误操作,优化操作效率,本内容创建为功能,随时使用
●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●● ●●●
下载地址:【VBA】多功能辅助插件-VB文档资源-CSDN下载
excelvba抓取网页数据(获取Excel中的时间和云量/日期/2020-04-15)
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-12-03 09:12
我正在尝试从天气预报表中复制特定数据。我正在尝试从天气预报表中复制特定数据。更准确地说,我试图从类似 ,26.44/date/2020-04- 的链接中以表格格式(但现在任何格式都可以)获取 Excel 中的时间和云覆盖15. 更准确地说,我试图从这样的链接中以表格格式(但现在可以使用任何格式)获取 Excel 中的时间和云量/45.00,26.44 /日期/2020-04-15。到目前为止,我已经尝试了很多方法来获取特定数据,但我没有达到(我是使用 VBA 进行网络抓取的新手)。到目前为止,我已经尝试了很多方法来获取特定数据,但我没有达到(我是使用 VBA 进行网络抓取的新手)。使用 VBA 进行网页抓取的新手)。概念和命令对我来说非常清楚,它们适用于其他站点,但对于这个站点,我不知所措。网站,我不知所措。目前,我正在使用:目前,我正在使用:
Sub WeatherScrap()
Range("A1").Select
Dim mainlink As String Dim http As New XMLHTTP60, html As New HTMLDocument Dim CloudCover As Object
mainlink = "https://www.wunderground.com/hourly/ro/mizil/45.00,26.44/date/2020-04-15"
With http
.Open "GET", mainlink, False
.send
html.body.innerHTML = .responseText
End With
For Each CloudCover In html.getElementsByClassName("wu-value wu-value-to")
ActiveCell.Value = CloudCover.innerText
ActiveCell.Offset(1, 0).Select
Next CloudCover
End Sub
我显然没有在 html 上引用正确的类、标签或 ID(到目前为止我已经尝试了很多,但没有一个检索到所需的数据)。我显然没有在 html 上引用正确的类、标签或 ID(到目前为止我已经尝试了很多,但没有一个检索到所需的数据)。站内html元素为:网站站内html元素为:
100 %
现在,只需了解如何从表格中获取云覆盖百分比就足够了。现在,只需了解如何从表中获取 Cloud Cover 百分比就足够了。任何人都可以帮忙吗?任何人都可以帮忙吗?非常感谢!非常感谢! 查看全部
excelvba抓取网页数据(获取Excel中的时间和云量/日期/2020-04-15)
我正在尝试从天气预报表中复制特定数据。我正在尝试从天气预报表中复制特定数据。更准确地说,我试图从类似 ,26.44/date/2020-04- 的链接中以表格格式(但现在任何格式都可以)获取 Excel 中的时间和云覆盖15. 更准确地说,我试图从这样的链接中以表格格式(但现在可以使用任何格式)获取 Excel 中的时间和云量/45.00,26.44 /日期/2020-04-15。到目前为止,我已经尝试了很多方法来获取特定数据,但我没有达到(我是使用 VBA 进行网络抓取的新手)。到目前为止,我已经尝试了很多方法来获取特定数据,但我没有达到(我是使用 VBA 进行网络抓取的新手)。使用 VBA 进行网页抓取的新手)。概念和命令对我来说非常清楚,它们适用于其他站点,但对于这个站点,我不知所措。网站,我不知所措。目前,我正在使用:目前,我正在使用:
Sub WeatherScrap()
Range("A1").Select
Dim mainlink As String Dim http As New XMLHTTP60, html As New HTMLDocument Dim CloudCover As Object
mainlink = "https://www.wunderground.com/hourly/ro/mizil/45.00,26.44/date/2020-04-15"
With http
.Open "GET", mainlink, False
.send
html.body.innerHTML = .responseText
End With
For Each CloudCover In html.getElementsByClassName("wu-value wu-value-to")
ActiveCell.Value = CloudCover.innerText
ActiveCell.Offset(1, 0).Select
Next CloudCover
End Sub
我显然没有在 html 上引用正确的类、标签或 ID(到目前为止我已经尝试了很多,但没有一个检索到所需的数据)。我显然没有在 html 上引用正确的类、标签或 ID(到目前为止我已经尝试了很多,但没有一个检索到所需的数据)。站内html元素为:网站站内html元素为:
100 %
现在,只需了解如何从表格中获取云覆盖百分比就足够了。现在,只需了解如何从表中获取 Cloud Cover 百分比就足够了。任何人都可以帮忙吗?任何人都可以帮忙吗?非常感谢!非常感谢!
excelvba抓取网页数据(如何用Python爬数据?(一)Python进行爬虫抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-02 10:20
它使用 Python 抓取数据,并与 requests_html 连接。在这篇文章中文章:
如何用Python抓取数据?(一)网页抓取
在此之前,我对网页有一些了解,所以使用起来并不难,但我在理解 Python 语法方面花了一点功夫。
requests_html中的方法和方法名,可以在这里查看:
遇到的主要问题:
使用requests_html的render()时,发现会报错。错误内容:
无法在现有事件循环中使用 HTMLSession。使用 AsyncHTMLSession
一开始参考这个文章试了一下:request-htmlchromium download failed or request-html failed to download Chromium or r.html.render()导致异常错误
它仍然不起作用。这个错误让我头疼了一天,终于发现jupyter Notebook不能用这个方法。这种方法不仅会在jupyter notebook上报错,其他东西也会报错,只要在Anoconda中,比如Spyder,都会报错。
最后自己试了一下,新建了一个hello.py文件。在这个文件中,调用了render()方法,输出没问题。
这是我的代码的一部分:
from requests_html import HTMLSession
session = HTMLSession()
url = 'xxxxxxxxxxxxxxx'
sel = 'xxxxxxxxxxxxxxx'
r = session.get(url)
r.html.render(scrolldown = 4,sleep = 2)
result = r.html.find(sel)
解释render()方法的作用(虽然我自己也不是很懂)
这种方法,我认为是滚动网页。简单来说,有些网页需要加载更多的内容。触发“加载”的是用户滚动到某个位置,或者滚动多少,这样网页自己加载更多的内容,而不是刷新整个页面。
使用requests_html爬取这种网页时,爬取的是“加载更多”之前的网页,数据量往往很小。
而 render(scrolldown = 4,sleep = 2) 可以模拟用户的滚动动作,让网页有更多的内容。
一个简单易懂的例子:
使用r=session.get(url)时,print(r.html.links)捕获的链接数为:10
网页滚动后,这个页面的链接数量会增加到20个。如果不使用r.html.render(scrolldown = 4, sleep = 2)来滚动网页,数量这些链接中的总是 10 个
如果你调用这个语句:.html.render(scrolldown = 4, sleep = 2),那么当你使用print(r.html.links)时,会显示20个链接。 查看全部
excelvba抓取网页数据(如何用Python爬数据?(一)Python进行爬虫抓取数据)
它使用 Python 抓取数据,并与 requests_html 连接。在这篇文章中文章:
如何用Python抓取数据?(一)网页抓取
在此之前,我对网页有一些了解,所以使用起来并不难,但我在理解 Python 语法方面花了一点功夫。
requests_html中的方法和方法名,可以在这里查看:
遇到的主要问题:
使用requests_html的render()时,发现会报错。错误内容:
无法在现有事件循环中使用 HTMLSession。使用 AsyncHTMLSession
一开始参考这个文章试了一下:request-htmlchromium download failed or request-html failed to download Chromium or r.html.render()导致异常错误
它仍然不起作用。这个错误让我头疼了一天,终于发现jupyter Notebook不能用这个方法。这种方法不仅会在jupyter notebook上报错,其他东西也会报错,只要在Anoconda中,比如Spyder,都会报错。
最后自己试了一下,新建了一个hello.py文件。在这个文件中,调用了render()方法,输出没问题。
这是我的代码的一部分:
from requests_html import HTMLSession
session = HTMLSession()
url = 'xxxxxxxxxxxxxxx'
sel = 'xxxxxxxxxxxxxxx'
r = session.get(url)
r.html.render(scrolldown = 4,sleep = 2)
result = r.html.find(sel)
解释render()方法的作用(虽然我自己也不是很懂)
这种方法,我认为是滚动网页。简单来说,有些网页需要加载更多的内容。触发“加载”的是用户滚动到某个位置,或者滚动多少,这样网页自己加载更多的内容,而不是刷新整个页面。
使用requests_html爬取这种网页时,爬取的是“加载更多”之前的网页,数据量往往很小。
而 render(scrolldown = 4,sleep = 2) 可以模拟用户的滚动动作,让网页有更多的内容。
一个简单易懂的例子:
使用r=session.get(url)时,print(r.html.links)捕获的链接数为:10
网页滚动后,这个页面的链接数量会增加到20个。如果不使用r.html.render(scrolldown = 4, sleep = 2)来滚动网页,数量这些链接中的总是 10 个
如果你调用这个语句:.html.render(scrolldown = 4, sleep = 2),那么当你使用print(r.html.links)时,会显示20个链接。
excelvba抓取网页数据(我前一阵子用XMLHTTP的Get功能抓取邮件轨迹(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-28 17:23
)
前阵子用VBA做了一个工具,利用XMLHTTP的Get函数来抓取城市之间的距离。现在我想使用XMLHTTP的Post功能来抓取邮件踪迹。是使用Get还是Post抓数据取决于网站提交参数的方式。
1、通过分析(使用fiddler),邮件轨迹查询网站是通过post参数提交的。如下图:
上图中的“Entity”内容用于设置header。点击“TextView”可以看到传输的参数内容和邮箱号,如下图:
获取数据的代码如下:
Sub tt()
Dim HttpReq As Object
Dim pdata, http As String
Set HttpReq = CreateObject("MSXML2.XMLHTTP.6.0")
'轨迹头部数据,网址用xxx屏蔽
http = "http://10.xxx.xxx.xxx/querypus ... ot%3B
pdata = "trace_no=1044905987232"
HttpReq.Open "Post", http, False
HttpReq.setRequestHeader "Content-Length", Len(pdata)
'HttpReq.setRequestHeader "CONTENT-TYPE", "application/x-www-form-urlencoded"
HttpReq.setRequestHeader "CONTENT-TYPE", "application/x-www-form-urlencoded; charset=utf-8"
HttpReq.send pdata '"trace_nos=1194359346482"
Do Until HttpReq.readyState = 4
DoEvents
Loop
If HttpReq.Status = 200 Then
Debug.Print HttpReq.responseText
End If
End Sub
2、返回的内容为json结构化数据,可以使用fiddler查看返回内容,点击“TextView”:
点击“JSON”查看数据分析结果:
但是vba解析的时候内容是空的。对比之前json结构中返回的数据,发现这个数据缺少一个名字,因为在js函数定义的时候,指定了一个json结构数据的名字,即jscode = "function json( s ,i) {return eval('(' + s +').traces[' + i +']'); }" 在跟踪名称中。
添加后就可以解析了,即:
'要返回数据成为标准的json结构,还需要在外面加一层数据名
buf = "{""traces"":" & HttpReq.responseText & "}"
kk = get_trace(buf)
get_trace函数用于解析json数据,代码如下:
<p>Function get_trace(mystring As String) As Integer
Dim objJSx As Object, objJSy As Object
Dim m1, m2, n, j As Integer
Dim source, level, kind, sm As String
On Error Resume Next
Set objJSx = CreateObject("ScriptControl") '调用MSScriptControl.ScriptControl对象将提取的变量文本运算形成对象集合
objJSx.Language = "JavaScript" '测试发现JavaScript、javascript、JScript都可以表示JavaScript语言
'定义一个JS函数,通过计算表达式的方式引入JSON数据并解析
jscode = "function json(s,i) { return eval('(' + s + ').traces[' + i + ']'); }"
objJSx.AddCode jscode
TT = "否"
For n = 1 To 100
If objJSx.Run("json", mystring, n - 1) = "" Then Exit For
Set objJSy = objJSx.Run("json", mystring, n - 1)
For j = 1 To 11
TraceInfo(n, j) = ""
Next j
TraceInfo(n, 1) = objJSy.traceNo
TraceInfo(n, 2) = objJSy.opCode
TraceInfo(n, 3) = objJSy.opTime
TraceInfo(n, 4) = objJSy.opName
TraceInfo(n, 6) = objJSy.opOrgCode
TraceInfo(n, 7) = objJSy.opOrgSimpleName
TraceInfo(n, 8) = objJSy.operatorNo
TraceInfo(n, 9) = objJSy.operatorName
TraceInfo(n, 10) = objJSy.level
TraceInfo(n, 11) = objJSy.source
sm = objJSy.desc
'剔除数据中的HTML部分
Do While InStr(sm, " 查看全部
excelvba抓取网页数据(我前一阵子用XMLHTTP的Get功能抓取邮件轨迹(图)
)
前阵子用VBA做了一个工具,利用XMLHTTP的Get函数来抓取城市之间的距离。现在我想使用XMLHTTP的Post功能来抓取邮件踪迹。是使用Get还是Post抓数据取决于网站提交参数的方式。
1、通过分析(使用fiddler),邮件轨迹查询网站是通过post参数提交的。如下图:
上图中的“Entity”内容用于设置header。点击“TextView”可以看到传输的参数内容和邮箱号,如下图:
获取数据的代码如下:
Sub tt()
Dim HttpReq As Object
Dim pdata, http As String
Set HttpReq = CreateObject("MSXML2.XMLHTTP.6.0")
'轨迹头部数据,网址用xxx屏蔽
http = "http://10.xxx.xxx.xxx/querypus ... ot%3B
pdata = "trace_no=1044905987232"
HttpReq.Open "Post", http, False
HttpReq.setRequestHeader "Content-Length", Len(pdata)
'HttpReq.setRequestHeader "CONTENT-TYPE", "application/x-www-form-urlencoded"
HttpReq.setRequestHeader "CONTENT-TYPE", "application/x-www-form-urlencoded; charset=utf-8"
HttpReq.send pdata '"trace_nos=1194359346482"
Do Until HttpReq.readyState = 4
DoEvents
Loop
If HttpReq.Status = 200 Then
Debug.Print HttpReq.responseText
End If
End Sub
2、返回的内容为json结构化数据,可以使用fiddler查看返回内容,点击“TextView”:
点击“JSON”查看数据分析结果:
但是vba解析的时候内容是空的。对比之前json结构中返回的数据,发现这个数据缺少一个名字,因为在js函数定义的时候,指定了一个json结构数据的名字,即jscode = "function json( s ,i) {return eval('(' + s +').traces[' + i +']'); }" 在跟踪名称中。
添加后就可以解析了,即:
'要返回数据成为标准的json结构,还需要在外面加一层数据名
buf = "{""traces"":" & HttpReq.responseText & "}"
kk = get_trace(buf)
get_trace函数用于解析json数据,代码如下:
<p>Function get_trace(mystring As String) As Integer
Dim objJSx As Object, objJSy As Object
Dim m1, m2, n, j As Integer
Dim source, level, kind, sm As String
On Error Resume Next
Set objJSx = CreateObject("ScriptControl") '调用MSScriptControl.ScriptControl对象将提取的变量文本运算形成对象集合
objJSx.Language = "JavaScript" '测试发现JavaScript、javascript、JScript都可以表示JavaScript语言
'定义一个JS函数,通过计算表达式的方式引入JSON数据并解析
jscode = "function json(s,i) { return eval('(' + s + ').traces[' + i + ']'); }"
objJSx.AddCode jscode
TT = "否"
For n = 1 To 100
If objJSx.Run("json", mystring, n - 1) = "" Then Exit For
Set objJSy = objJSx.Run("json", mystring, n - 1)
For j = 1 To 11
TraceInfo(n, j) = ""
Next j
TraceInfo(n, 1) = objJSy.traceNo
TraceInfo(n, 2) = objJSy.opCode
TraceInfo(n, 3) = objJSy.opTime
TraceInfo(n, 4) = objJSy.opName
TraceInfo(n, 6) = objJSy.opOrgCode
TraceInfo(n, 7) = objJSy.opOrgSimpleName
TraceInfo(n, 8) = objJSy.operatorNo
TraceInfo(n, 9) = objJSy.operatorName
TraceInfo(n, 10) = objJSy.level
TraceInfo(n, 11) = objJSy.source
sm = objJSy.desc
'剔除数据中的HTML部分
Do While InStr(sm, "
excelvba抓取网页数据( 一个网页源文件代码写入数据集用+input的大致步骤是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-26 08:09
一个网页源文件代码写入数据集用+input的大致步骤是什么)
一般的过程是使用filename fileref url'web address'获取网页代码信息(包括要提取的数据),然后使用infile fileref将字符代码读入变量,然后对写入的进行“数据清洗”根据待提取数据的特征进行观测”,最终得到所需要的观测数据。
首先简单描述一下过程中可能出现的问题:
1.我用的SAS软件是多语言9.2版本。当我第一次开始使用 filename fileref url'web address' 和 infile fileref 运行时,出现一个不友好的显示错误:无法连接到主机。这个问题困扰了我很久。终于看到一个前辈的帖子,下载了相关的hot fix后解决了(F9BA26) from a 网站)。
2. 如果infile语句中没有加encoding='utf-8',则观察结果为乱码。
3.正则表达式不是必需的,但它们简洁明了使用。配合一些字符函数使用,绝对可以达到你想要的提取目的。
4. 大家进入网页后,右键查看源代码(部分为源文件)。这个源代码就是我们需要写入数据集的文件。首先使用filename fileref url'';
5.如何用infile+input将网页源文件代码写入数据集。但是,根据写入方式的不同,后续的数据清理流程自然也不同。由于源代码中每一行输入的形式都是!!!或者(可以观察网页的源码),我们需要的数据都在!!!而且因为一个网页收录的信息太多,所以有可能找到它!!!不收录所需的数据。为了方便“清洗”数据,这里采用了比较笨的方法。通过观察源代码中待提取数据的大致范围,例如第一个待提取字符串“黑龙江”出现在第184个输入行,最后一个“120”(澳门人均降水量)出现在第 623 条输入线。我们不 不需要其他输入线。我们可以考虑在infile语句中加入firstobs=184 obs=623。
注意:由于网页有细微改动的可能性,firstobs=和obs=的值可能不准确,可能会影响结果。建议查看源码确定对应的值。
这里有两种不同的写作方法。
一种。以'>'为分隔符,写完后,每次观察看起来像 查看全部
excelvba抓取网页数据(
一个网页源文件代码写入数据集用+input的大致步骤是什么)
一般的过程是使用filename fileref url'web address'获取网页代码信息(包括要提取的数据),然后使用infile fileref将字符代码读入变量,然后对写入的进行“数据清洗”根据待提取数据的特征进行观测”,最终得到所需要的观测数据。
首先简单描述一下过程中可能出现的问题:
1.我用的SAS软件是多语言9.2版本。当我第一次开始使用 filename fileref url'web address' 和 infile fileref 运行时,出现一个不友好的显示错误:无法连接到主机。这个问题困扰了我很久。终于看到一个前辈的帖子,下载了相关的hot fix后解决了(F9BA26) from a 网站)。
2. 如果infile语句中没有加encoding='utf-8',则观察结果为乱码。
3.正则表达式不是必需的,但它们简洁明了使用。配合一些字符函数使用,绝对可以达到你想要的提取目的。
4. 大家进入网页后,右键查看源代码(部分为源文件)。这个源代码就是我们需要写入数据集的文件。首先使用filename fileref url'';
5.如何用infile+input将网页源文件代码写入数据集。但是,根据写入方式的不同,后续的数据清理流程自然也不同。由于源代码中每一行输入的形式都是!!!或者(可以观察网页的源码),我们需要的数据都在!!!而且因为一个网页收录的信息太多,所以有可能找到它!!!不收录所需的数据。为了方便“清洗”数据,这里采用了比较笨的方法。通过观察源代码中待提取数据的大致范围,例如第一个待提取字符串“黑龙江”出现在第184个输入行,最后一个“120”(澳门人均降水量)出现在第 623 条输入线。我们不 不需要其他输入线。我们可以考虑在infile语句中加入firstobs=184 obs=623。
注意:由于网页有细微改动的可能性,firstobs=和obs=的值可能不准确,可能会影响结果。建议查看源码确定对应的值。
这里有两种不同的写作方法。
一种。以'>'为分隔符,写完后,每次观察看起来像
excelvba抓取网页数据(使用VBA宏将表格数据从多个网页提取到Excel中..! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 539 次浏览 • 2021-10-25 23:22
)
使用 VBA 宏从多个网页中提取表格数据到 Excel.. !! 目前我使用下面的链接,但我只能在代码中使用一个网页..我有一个 ulr 列表来获取数据......它必须是垂直的......!请建议我.. :)
Sub INDEXdata()
With ActiveSheet.QueryTables.Add(Connection:= _
"URL;http://recorder.maricopa.gov/r ... ot%3B _
, Destination:=Range("$A$1"))
.Name = "rec=19770000006"
.FieldNames = True
.RowNumbers = False
.FillAdjacentFormulas = False
.PreserveFormatting = True
.RefreshOnFileOpen = False
.BackgroundQuery = True
.RefreshStyle = xlInsertDeleteCells
.SavePassword = False
.SaveData = True
.AdjustColumnWidth = True
.RefreshPeriod = 0
.WebSelectionType = xlSpecifiedTables
.WebFormatting = xlWebFormattingNone
.WebTables = "2,3"
.WebPreFormattedTextToColumns = True
.WebConsecutiveDelimitersAsOne = True
.WebSingleBlockTextImport = False
.WebDisableDateRecognition = False
.WebDisableRedirections = False
.Refresh BackgroundQuery:=False
End With
End Sub
1 个回答:
答案 0:(得分:0)
好吧,我不知道您有多少编程背景,也不知道您发布的代码的哪些部分特定于该源 URL 和目标位置。
但是,这样的事情可能会有用。我假设您要提取的每个页面的 URL、目的地和名称都会更改。
我所做的是将似乎适用于所有源页面和目标的代码部分放入我自己的参数化子例程中。原创例程 IndexData 仅指定每个复制操作的 URL、目标和名称。
Sub IndexData()
GetData("http://recorder.maricopa.gov/r ... ot%3B , _
"$A$1", _
"rec=19770000006")
GetData("http://somewhereelse.com/somed ... ot%3B, _
"$A$2", _
"rec=12345")
GetData("http://anotherurl.com/etc", _
"$A$3", _
"something")
End
Sub GetData(url as string, destination as string, name as string)
With ActiveSheet.QueryTables.Add(Connection:= _
"URL;" & url , Destination:=Range(destination))
.Name = name
.FieldNames = True
.RowNumbers = False
.FillAdjacentFormulas = False
.PreserveFormatting = True
.RefreshOnFileOpen = False
.BackgroundQuery = True
.RefreshStyle = xlInsertDeleteCells
.SavePassword = False
.SaveData = True
.AdjustColumnWidth = True
.RefreshPeriod = 0
.WebSelectionType = xlSpecifiedTables
.WebFormatting = xlWebFormattingNone
.WebTables = "2,3"
.WebPreFormattedTextToColumns = True
.WebConsecutiveDelimitersAsOne = True
.WebSingleBlockTextImport = False
.WebDisableDateRecognition = False
.WebDisableRedirections = False
.Refresh BackgroundQuery:=False
End With
End Sub 查看全部
excelvba抓取网页数据(使用VBA宏将表格数据从多个网页提取到Excel中..!
)
使用 VBA 宏从多个网页中提取表格数据到 Excel.. !! 目前我使用下面的链接,但我只能在代码中使用一个网页..我有一个 ulr 列表来获取数据......它必须是垂直的......!请建议我.. :)
Sub INDEXdata()
With ActiveSheet.QueryTables.Add(Connection:= _
"URL;http://recorder.maricopa.gov/r ... ot%3B _
, Destination:=Range("$A$1"))
.Name = "rec=19770000006"
.FieldNames = True
.RowNumbers = False
.FillAdjacentFormulas = False
.PreserveFormatting = True
.RefreshOnFileOpen = False
.BackgroundQuery = True
.RefreshStyle = xlInsertDeleteCells
.SavePassword = False
.SaveData = True
.AdjustColumnWidth = True
.RefreshPeriod = 0
.WebSelectionType = xlSpecifiedTables
.WebFormatting = xlWebFormattingNone
.WebTables = "2,3"
.WebPreFormattedTextToColumns = True
.WebConsecutiveDelimitersAsOne = True
.WebSingleBlockTextImport = False
.WebDisableDateRecognition = False
.WebDisableRedirections = False
.Refresh BackgroundQuery:=False
End With
End Sub
1 个回答:
答案 0:(得分:0)
好吧,我不知道您有多少编程背景,也不知道您发布的代码的哪些部分特定于该源 URL 和目标位置。
但是,这样的事情可能会有用。我假设您要提取的每个页面的 URL、目的地和名称都会更改。
我所做的是将似乎适用于所有源页面和目标的代码部分放入我自己的参数化子例程中。原创例程 IndexData 仅指定每个复制操作的 URL、目标和名称。
Sub IndexData()
GetData("http://recorder.maricopa.gov/r ... ot%3B , _
"$A$1", _
"rec=19770000006")
GetData("http://somewhereelse.com/somed ... ot%3B, _
"$A$2", _
"rec=12345")
GetData("http://anotherurl.com/etc", _
"$A$3", _
"something")
End
Sub GetData(url as string, destination as string, name as string)
With ActiveSheet.QueryTables.Add(Connection:= _
"URL;" & url , Destination:=Range(destination))
.Name = name
.FieldNames = True
.RowNumbers = False
.FillAdjacentFormulas = False
.PreserveFormatting = True
.RefreshOnFileOpen = False
.BackgroundQuery = True
.RefreshStyle = xlInsertDeleteCells
.SavePassword = False
.SaveData = True
.AdjustColumnWidth = True
.RefreshPeriod = 0
.WebSelectionType = xlSpecifiedTables
.WebFormatting = xlWebFormattingNone
.WebTables = "2,3"
.WebPreFormattedTextToColumns = True
.WebConsecutiveDelimitersAsOne = True
.WebSingleBlockTextImport = False
.WebDisableDateRecognition = False
.WebDisableRedirections = False
.Refresh BackgroundQuery:=False
End With
End Sub
excelvba抓取网页数据(网上检索到的知识点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2021-10-25 07:10
一直忙于研究WebRequest()获取网页数据,比如myfxbook的OutLook。发现的问题是,
从网上检索到的知识点是,
使用官方的F1,可以看两个例子,方便大家理解各个参数。
本次访问myfxbook,实现过程为:
时间间隔检查;使用for循环多次使用WebRequest()访问获取网页流;
bool 下载数据(char &result[])//1-1
{
string Headers; // 服务器响应标头
string referer = NULL; // HTTP 请求标头的推荐页字段
string cookie = NULL;
char post[]; // HTTP请求信息数组
int err;
ResetLastError();
// 1000ms
if(WebRequest("GET", MyFxBookUrl, cookie, referer, Timeout, post,
0, //post[]数组大小
result, //服务器响应数据数组
Headers) < 0)
{
err = GetLastError();
Print("Error in WebRequest [",err,"]",ErrorDescription(err));
return false;
}
return true;
}
读取这个流中的有用信息,使用StringFindInArray()子函数查找关键词的地址;类似于优采云,缩小地址范围后,找到第二个关键词,然后精确定位到要抓取的数据;检查捕获数据的合规性;完成处理,例如记录上次访问时间。将合规性数据分配给全局变量或数组以供使用。
本博客中的所有文章,除非另有说明,均为原创。作者:天宏评测 查看全部
excelvba抓取网页数据(网上检索到的知识点)
一直忙于研究WebRequest()获取网页数据,比如myfxbook的OutLook。发现的问题是,
从网上检索到的知识点是,
使用官方的F1,可以看两个例子,方便大家理解各个参数。
本次访问myfxbook,实现过程为:
时间间隔检查;使用for循环多次使用WebRequest()访问获取网页流;
bool 下载数据(char &result[])//1-1
{
string Headers; // 服务器响应标头
string referer = NULL; // HTTP 请求标头的推荐页字段
string cookie = NULL;
char post[]; // HTTP请求信息数组
int err;
ResetLastError();
// 1000ms
if(WebRequest("GET", MyFxBookUrl, cookie, referer, Timeout, post,
0, //post[]数组大小
result, //服务器响应数据数组
Headers) < 0)
{
err = GetLastError();
Print("Error in WebRequest [",err,"]",ErrorDescription(err));
return false;
}
return true;
}
读取这个流中的有用信息,使用StringFindInArray()子函数查找关键词的地址;类似于优采云,缩小地址范围后,找到第二个关键词,然后精确定位到要抓取的数据;检查捕获数据的合规性;完成处理,例如记录上次访问时间。将合规性数据分配给全局变量或数组以供使用。
本博客中的所有文章,除非另有说明,均为原创。作者:天宏评测
excelvba抓取网页数据(EXCEL自带的功能,我一般的操纵过程是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-10-18 08:12
借用你的帖子,多页数据,我的一般操作过程来谈谈吧:
第一个是看。
观察网页的网址,或者使用HTTPFOX查看网址和参数。如果是POSTed,看能否用GET获取。然后试试看能不能通过URL来改变页面切换。
如果可以,那很容易。
那么,接下来,尝试看看EXCEL本身的功能,可以导入网页数据可以获取数据,如果行得通,只需记录一个宏并更改一个循环。
因为EXCEL的导入功能还是很强大的,只要页面是非跳转或者脚本编写或者框架的,直接源码有TABLE代码,直接用QUERYTABLE获取即可。
如果无法获取到QUERYTABLE的数量,那么一般的网页是动态页面或者框架页面等。那么我一般会使用HTTPFOX进一步查找网页的真实数据源(一般是第一页改成第二页试试,很容易找到),找到了,后续无非很简单,就是文本处理,可以用XMLHTTP来处理,后续无非就是调整HTTP头消息、POST 等。部分页面异常,有盗链处理。大多数 XMLHTTP 无法处理它。您需要使用 WINHTTP 对象,但该对象与 XMLHTTP 非常相似。反正无非是假的COOKIE或者REFERER或者多页跳转。我已经回答了所有的帮助请求。
最后,如果是后缀为.asp或.aspx的页面,通常是不正常的。POST 参数具有“_VIEWSTATE”。VIEWSTATE 存储在上一页中。如果你想阅读它,你必须访问以前的业务。这种页面一般比较累。有的时候用IE/WEBBROWSER来处理比较容易,原理也很简单,就是你说的DOM机制,要取数,无非就是找到数据的TABLE,然后去TR ,拿到TD,反正配合FIREBUG。只是去观察。
最后是一种非常异常的页面,是一个可以禁止跨域访问的框架页面。不管怎样,你搜索我的帖子。后来我用一些国外高手用JAVA写的函数来伪造一个容器。将框架剥离出来,然后访问读取。
简而言之,做更多的实践很重要。如果您触摸太多,您就会知道正在处理哪些页面。其实把这块拿到底,不用学太多JAVASCRIPT语言,但是好处多多。例如,如果一个脚本生成一个数据页,则可以使用网页的代码,然后使用MSScriptControl控件直接处理脚本,生成数据流,并导出。
此外,最近越来越多的页面采用 XML 格式。反正获取到XML样式后,再用XML DOM继续获取。或者,你也可以得到HTML代码,就像你说的,审查,但我使用Microsoft.XMLDOM对象或直接调用HTML文档对象,还有
LoadXML等方法可以加载代码文本,有时可以成功构造XML样式或HTML样式,也可以用来简化取数的操作。但我很少这样做。总觉得直接用IE的方式比较好。
最后,在 VBA 中处理网页实际上更加困难。如果你刚入门并且有一定的电脑背景,更建议你直接学习AAU软件。优点是库中有很多参考代码,可以导入库或者复制粘贴。发帖很方便,但前提是语法和JAVASCRIPT差不多,最好有相关语言背景。 查看全部
excelvba抓取网页数据(EXCEL自带的功能,我一般的操纵过程是什么?)
借用你的帖子,多页数据,我的一般操作过程来谈谈吧:
第一个是看。
观察网页的网址,或者使用HTTPFOX查看网址和参数。如果是POSTed,看能否用GET获取。然后试试看能不能通过URL来改变页面切换。
如果可以,那很容易。
那么,接下来,尝试看看EXCEL本身的功能,可以导入网页数据可以获取数据,如果行得通,只需记录一个宏并更改一个循环。
因为EXCEL的导入功能还是很强大的,只要页面是非跳转或者脚本编写或者框架的,直接源码有TABLE代码,直接用QUERYTABLE获取即可。
如果无法获取到QUERYTABLE的数量,那么一般的网页是动态页面或者框架页面等。那么我一般会使用HTTPFOX进一步查找网页的真实数据源(一般是第一页改成第二页试试,很容易找到),找到了,后续无非很简单,就是文本处理,可以用XMLHTTP来处理,后续无非就是调整HTTP头消息、POST 等。部分页面异常,有盗链处理。大多数 XMLHTTP 无法处理它。您需要使用 WINHTTP 对象,但该对象与 XMLHTTP 非常相似。反正无非是假的COOKIE或者REFERER或者多页跳转。我已经回答了所有的帮助请求。
最后,如果是后缀为.asp或.aspx的页面,通常是不正常的。POST 参数具有“_VIEWSTATE”。VIEWSTATE 存储在上一页中。如果你想阅读它,你必须访问以前的业务。这种页面一般比较累。有的时候用IE/WEBBROWSER来处理比较容易,原理也很简单,就是你说的DOM机制,要取数,无非就是找到数据的TABLE,然后去TR ,拿到TD,反正配合FIREBUG。只是去观察。
最后是一种非常异常的页面,是一个可以禁止跨域访问的框架页面。不管怎样,你搜索我的帖子。后来我用一些国外高手用JAVA写的函数来伪造一个容器。将框架剥离出来,然后访问读取。
简而言之,做更多的实践很重要。如果您触摸太多,您就会知道正在处理哪些页面。其实把这块拿到底,不用学太多JAVASCRIPT语言,但是好处多多。例如,如果一个脚本生成一个数据页,则可以使用网页的代码,然后使用MSScriptControl控件直接处理脚本,生成数据流,并导出。
此外,最近越来越多的页面采用 XML 格式。反正获取到XML样式后,再用XML DOM继续获取。或者,你也可以得到HTML代码,就像你说的,审查,但我使用Microsoft.XMLDOM对象或直接调用HTML文档对象,还有
LoadXML等方法可以加载代码文本,有时可以成功构造XML样式或HTML样式,也可以用来简化取数的操作。但我很少这样做。总觉得直接用IE的方式比较好。
最后,在 VBA 中处理网页实际上更加困难。如果你刚入门并且有一定的电脑背景,更建议你直接学习AAU软件。优点是库中有很多参考代码,可以导入库或者复制粘贴。发帖很方便,但前提是语法和JAVASCRIPT差不多,最好有相关语言背景。
excelvba抓取网页数据( 这是简易数据分析系列的第13篇文章教程的全盘总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-13 20:14
这是简易数据分析系列的第13篇文章教程的全盘总结)
这是简单数据分析系列文章的第13篇。
本文首发于博客园:简单数据分析13。
不知不觉写了10个网络爬虫系列教程。这10篇文章基本涵盖了Web Scraper的大部分功能。今天的内容是本系列的最后一篇。下一章,我会开一个新洞,谈谈如何使用Excel对采集到的数据进行格式化和分析。
下一篇文章我会把Web Scraper教程的完整总结放上来,今天开始我们的实战教程。
之前的课程,我们爬取的数据都是同级别的内容。我们讨论的主要问题是如何处理市场上各种类型的分页,但是没有介绍如何抓取详情页的内容数据。.
比如我们要抓取b站动画区TOP排行榜的数据:
按照之前的爬取逻辑,我们爬取了这个榜单上作品的相关数据,比如下图中的排名、作品名称、浏览量、弹幕数和作者姓名等。
经常逛B站的朋友也知道,UP主经常建议自己看视频三连操作(喜欢+投币+采集)。可以看出,这三个数据对视频的排名都有一定的影响,所以这些数据对我们也有一定的参考价值。
遗憾的是,这份排行榜没有相关数据。这些数据都在视频详情页,我们需要点击链接才能看到:
今天的教程内容就是教大家如何在爬取一级页面(列表页面)的同时,使用Web Scraper对二级页面(详情页面)的内容进行爬取。
1.创建站点地图
首先,我们找到要捕获的数据的位置。我在下图中的红框中标出了关键路径。你可以比较一下:
然后创建一个相关的SiteMap,这里我取了bilibili_rank的名字:
2.创建容器选择器
设置之前先看看,发现这个页面的排名数据是一次加载100条数据,不需要分页,所以这里的Type选为Element。
其他参数比较简单,就不细说了(不明白的可以看我之前的基础教程)。这是一个截图供您参考:
3.创建列表页子选择器
这次子选择器要抓取的内容如下,都比较简单。你可以参考截图:
Rank(num) 作品名称(title) 播放量(play_amount) 弹幕量(danmu_count) 作者:(author)
如果这样做,实际上可以抓取所有已知的列表数据,但本文的重点是:如何抓取二级页面(详细信息页面)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper本质上是模拟人的操作来达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实直接点击标题链接即可跳转:
Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过示例进行比较以理解。
首先,在这种情况下,我们得到了标题的文本,此时的选择器类型为Text:
当我们想要获取一个链接时,我们必须创建另一个选择器。选中的元素是一样的,但是Type是Link:
创建成功后,我们点击Link type选择器,输入,创建相关选择器。下面我录了个动图。注意我的鼠标突出显示的导航路线部分。这可以很明显的看出几个选择器的层次关系:
4.创建详情页子选择器
当您点击链接时,您会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页打开了Web Scraper选择窗口,您无法跨页面选择所需的数据。
处理这个问题也很简单,可以复制详情页的链接,复制到列表页所在的Tab页,按回车重新加载,这样就可以在当前页面选中了。
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了4个数据,比如点赞数、硬币数、采集数和分享数。这个操作也很简单,这里就不赘述了。
所有选择器的结构图如下:
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经全部建立。
5.获取数据
终于到了激动人心的部分,我们即将开始爬取数据。但是在爬行之前,我们需要把等待时间调大一点,默认时间是2000ms,我这里改成了5000ms。
你为什么这么做?看下图你就明白了:
首先,每次打开二级页面,都是一个全新的页面。这时候浏览器加载网页需要时间;其次,我们可以观察到要捕获的喜欢数量等数据。页面刚加载时,它的值为“--”,过一会就会变成一个数字。所以,我们只等5000ms,等页面和数据加载完毕后,一起爬取。
配置好参数后,我们就可以正式抓取下载了。下图是我抓到的部分数据,特此证明这个方法有用:
6.总结
本教程可能有点困难。我将分享我的站点地图。如果在制作时遇到问题,可以参考我的配置。我在第六篇教程中详细讲解了SiteMap导入的功能。可以一起吃。:
<p>{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}</p>
一旦掌握了二级页面的抓取方式,三级、四级页面就没有问题了。因为例程是相同的:数据是在链接选择器指向的下一页上捕获的。因为原理是一样的,我就不演示了。 查看全部
excelvba抓取网页数据(
这是简易数据分析系列的第13篇文章教程的全盘总结)
这是简单数据分析系列文章的第13篇。
本文首发于博客园:简单数据分析13。
不知不觉写了10个网络爬虫系列教程。这10篇文章基本涵盖了Web Scraper的大部分功能。今天的内容是本系列的最后一篇。下一章,我会开一个新洞,谈谈如何使用Excel对采集到的数据进行格式化和分析。
下一篇文章我会把Web Scraper教程的完整总结放上来,今天开始我们的实战教程。
之前的课程,我们爬取的数据都是同级别的内容。我们讨论的主要问题是如何处理市场上各种类型的分页,但是没有介绍如何抓取详情页的内容数据。.
比如我们要抓取b站动画区TOP排行榜的数据:
按照之前的爬取逻辑,我们爬取了这个榜单上作品的相关数据,比如下图中的排名、作品名称、浏览量、弹幕数和作者姓名等。
经常逛B站的朋友也知道,UP主经常建议自己看视频三连操作(喜欢+投币+采集)。可以看出,这三个数据对视频的排名都有一定的影响,所以这些数据对我们也有一定的参考价值。
遗憾的是,这份排行榜没有相关数据。这些数据都在视频详情页,我们需要点击链接才能看到:
今天的教程内容就是教大家如何在爬取一级页面(列表页面)的同时,使用Web Scraper对二级页面(详情页面)的内容进行爬取。
1.创建站点地图
首先,我们找到要捕获的数据的位置。我在下图中的红框中标出了关键路径。你可以比较一下:
然后创建一个相关的SiteMap,这里我取了bilibili_rank的名字:
2.创建容器选择器
设置之前先看看,发现这个页面的排名数据是一次加载100条数据,不需要分页,所以这里的Type选为Element。
其他参数比较简单,就不细说了(不明白的可以看我之前的基础教程)。这是一个截图供您参考:
3.创建列表页子选择器
这次子选择器要抓取的内容如下,都比较简单。你可以参考截图:
Rank(num) 作品名称(title) 播放量(play_amount) 弹幕量(danmu_count) 作者:(author)
如果这样做,实际上可以抓取所有已知的列表数据,但本文的重点是:如何抓取二级页面(详细信息页面)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper本质上是模拟人的操作来达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实直接点击标题链接即可跳转:
Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过示例进行比较以理解。
首先,在这种情况下,我们得到了标题的文本,此时的选择器类型为Text:
当我们想要获取一个链接时,我们必须创建另一个选择器。选中的元素是一样的,但是Type是Link:
创建成功后,我们点击Link type选择器,输入,创建相关选择器。下面我录了个动图。注意我的鼠标突出显示的导航路线部分。这可以很明显的看出几个选择器的层次关系:
4.创建详情页子选择器
当您点击链接时,您会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页打开了Web Scraper选择窗口,您无法跨页面选择所需的数据。
处理这个问题也很简单,可以复制详情页的链接,复制到列表页所在的Tab页,按回车重新加载,这样就可以在当前页面选中了。
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了4个数据,比如点赞数、硬币数、采集数和分享数。这个操作也很简单,这里就不赘述了。
所有选择器的结构图如下:
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经全部建立。
5.获取数据
终于到了激动人心的部分,我们即将开始爬取数据。但是在爬行之前,我们需要把等待时间调大一点,默认时间是2000ms,我这里改成了5000ms。
你为什么这么做?看下图你就明白了:
首先,每次打开二级页面,都是一个全新的页面。这时候浏览器加载网页需要时间;其次,我们可以观察到要捕获的喜欢数量等数据。页面刚加载时,它的值为“--”,过一会就会变成一个数字。所以,我们只等5000ms,等页面和数据加载完毕后,一起爬取。
配置好参数后,我们就可以正式抓取下载了。下图是我抓到的部分数据,特此证明这个方法有用:
6.总结
本教程可能有点困难。我将分享我的站点地图。如果在制作时遇到问题,可以参考我的配置。我在第六篇教程中详细讲解了SiteMap导入的功能。可以一起吃。:
<p>{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}</p>
一旦掌握了二级页面的抓取方式,三级、四级页面就没有问题了。因为例程是相同的:数据是在链接选择器指向的下一页上捕获的。因为原理是一样的,我就不演示了。
excelvba抓取网页数据(网上的大多数教程,都是教给你怎么使用Excel直接获取股票数据的方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-10-12 17:57
大多数在线教程都会教您如何使用 VBA 下载股票数据。
但是最基础的下载股票数据的操作已经可以通过Excel2010之后的内置函数直接加载了。
Excel目前有四种获取股票数据的方式,包括:
1.直接从通大信等股票软件获取交易数据
2.使用Finance上提供的一些CSV格式的数据网站
3.利用EXCEL的爬虫功能爬取网络股票数据
4.使用网站的API接口获取数据等。
其中API接口,最常用的公共接口有雅虎财经、谷歌财经、新浪财经、搜狐财经等。
另外,海外Quandl和国内tushare也提供API接口,可以直接用EXCEL加载数据。
本文主要介绍如何使用Excel直接获取Quandl中的股票数据。
昆德尔介绍
Quandl 是一个金融和经济数据平台。不仅包括昂贵的费用数据,还有很多免费的开放数据,包括我的大量A股数据。
下图展示了针对各种数据源,Quandl平台提供了多种数据输出形式供用户分析。
EXCEL从Quandl获取数据的几种方式
据介绍,Quandl 提供了 Excel 支持的 4 种数据格式,分别是
CSV文件,EXCEL插件方式,JASON和XML格式下载。
1.最简单的方法是直接下载CSV格式的数据。2.EXCEL插件,需要安装网站提供的Quandl.Excel.Addin插件
下载地址为网页链接
下载安装后,在Excel中,直接获取数据,如下图
3.JSON 和 XML 格式数据
网站 注册后,您将获得一个API key。以苹果的股票 AAPL 为例。地址是:
网页链接
第一种和第二种方法比较简单。下一篇文章将逐步演示如何使用第三种方法获取数据。
欢迎关注我的专栏“EXCEL进行量化” 查看全部
excelvba抓取网页数据(网上的大多数教程,都是教给你怎么使用Excel直接获取股票数据的方式)
大多数在线教程都会教您如何使用 VBA 下载股票数据。
但是最基础的下载股票数据的操作已经可以通过Excel2010之后的内置函数直接加载了。
Excel目前有四种获取股票数据的方式,包括:
1.直接从通大信等股票软件获取交易数据
2.使用Finance上提供的一些CSV格式的数据网站
3.利用EXCEL的爬虫功能爬取网络股票数据
4.使用网站的API接口获取数据等。
其中API接口,最常用的公共接口有雅虎财经、谷歌财经、新浪财经、搜狐财经等。
另外,海外Quandl和国内tushare也提供API接口,可以直接用EXCEL加载数据。
本文主要介绍如何使用Excel直接获取Quandl中的股票数据。
昆德尔介绍
Quandl 是一个金融和经济数据平台。不仅包括昂贵的费用数据,还有很多免费的开放数据,包括我的大量A股数据。
下图展示了针对各种数据源,Quandl平台提供了多种数据输出形式供用户分析。
EXCEL从Quandl获取数据的几种方式
据介绍,Quandl 提供了 Excel 支持的 4 种数据格式,分别是
CSV文件,EXCEL插件方式,JASON和XML格式下载。
1.最简单的方法是直接下载CSV格式的数据。2.EXCEL插件,需要安装网站提供的Quandl.Excel.Addin插件
下载地址为网页链接
下载安装后,在Excel中,直接获取数据,如下图
3.JSON 和 XML 格式数据
网站 注册后,您将获得一个API key。以苹果的股票 AAPL 为例。地址是:
网页链接
第一种和第二种方法比较简单。下一篇文章将逐步演示如何使用第三种方法获取数据。
欢迎关注我的专栏“EXCEL进行量化”
excelvba抓取网页数据(可以,只能用IE实现,引用MicrosoftInternetControls就可以)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-12 14:04
是的,只能用IE来实现。您可以通过引用 Microsoft Internet Controls 在 VBA 中操作网页上的内容。
Dim mShellwindows As New ShellWindows
Dim IE As InternetExplorer
For Each IE In mShellwindows '搜索页面
If IE.LocationURL = [URL] Then Exit For
Next
With IE.Document '在文本框填写内容
.all("[id_or_name]").Value = Sheet1.Cells(1, 1).Value
End With
基本原理如上面的代码所示。
[URL]是你要填数据的页面,先用IE浏览器打开这个页面。
[id_or_name] 是要填充数据的控件的 id 或名称。这需要提前从页面中获取。
至于其他的个性化定制内容,需要自己写~如果不想发图,再问!
顺便一提
Sub getPageInfo()
With CreateObject("internetexplorer.application")
.Visible = True
.Navigate [URL]
While .ReadyState 4 Or .Busy
DoEvents
Wend
Set dmt = .Document
For i = 0 To dmt.all.Length - 1
Set htMent = dmt.all(i)
With ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
End With
Next i
Set r = Nothing
.Quit
End With
MsgBox "获取页面信息成功!"
End Sub
这是抓取页面内容的代码...如果要登录,必须先打开页面。 查看全部
excelvba抓取网页数据(可以,只能用IE实现,引用MicrosoftInternetControls就可以)
是的,只能用IE来实现。您可以通过引用 Microsoft Internet Controls 在 VBA 中操作网页上的内容。
Dim mShellwindows As New ShellWindows
Dim IE As InternetExplorer
For Each IE In mShellwindows '搜索页面
If IE.LocationURL = [URL] Then Exit For
Next
With IE.Document '在文本框填写内容
.all("[id_or_name]").Value = Sheet1.Cells(1, 1).Value
End With
基本原理如上面的代码所示。
[URL]是你要填数据的页面,先用IE浏览器打开这个页面。
[id_or_name] 是要填充数据的控件的 id 或名称。这需要提前从页面中获取。
至于其他的个性化定制内容,需要自己写~如果不想发图,再问!
顺便一提
Sub getPageInfo()
With CreateObject("internetexplorer.application")
.Visible = True
.Navigate [URL]
While .ReadyState 4 Or .Busy
DoEvents
Wend
Set dmt = .Document
For i = 0 To dmt.all.Length - 1
Set htMent = dmt.all(i)
With ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
End With
Next i
Set r = Nothing
.Quit
End With
MsgBox "获取页面信息成功!"
End Sub
这是抓取页面内容的代码...如果要登录,必须先打开页面。
excelvba抓取网页数据( VBA·5个月前如何使用VBA网抓的,我基本都没有回复 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 459 次浏览 • 2021-10-10 14:12
VBA·5个月前如何使用VBA网抓的,我基本都没有回复
)
使用Excel+VBA操作网页
黄辰5 个月前
因为知乎里面的一些回答,最近总有私信问我怎么用VBA抓网,但是我基本没有回复。因为这个问题太大了,有基础知识的人其实很容易自己在百度或者ExcelHome论坛上找到答案。我不需要说什么。对于没有基础知识的人来说,是不可能三言两语解决问题的。我不想把私信变成聊天窗口。借开专栏知乎的机会,恰巧仔细解释了这个问题。
我对Excel和VBA的了解有限,只能解决我遇到的一些问题,不一定适用于所有场景。以下内容基于对VBA基本用法和HTML语言知识的了解:
一、前期准备
据我所知,VBA 不能操作任何浏览器和网页。我们所能做的就是在IE上执行一些操作,是的,只有IE。不要告诉我电脑上没有IE,所以你可以退出Sub。就像在Python中使用import,在C#中使用一样,VBA也需要引用一些库来操作IE,不过好在它是微软的产品,所以我们可以很方便的使用VBA自带的一些库。
我们需要做的第一件事是在 VBA 中引用 Micorsoft Internet Controls。通过查看这个名称,我们知道它可以帮助我们控制 IE 页面。
二、网页操作
引用 Micorsoft Internet Controls 后,我们可以对页面做任何我们想做的事情,但是我们需要在主页上有一个页面,上帝说我们需要一个页面!
1、打开网页
我们以在百度上搜索“查虎”关键词为例:
With CreateObject("internetexplorer.application")
.Visible = True
.Navigate "https://www.baidu.com/s?wd=扯乎"
'关闭网页
' .Quit
End With
代码很简单,先创建一个IE对象,然后给一些属性赋值。Visible就是可见性,是指网页被操作时是否会看到网页。熟练后可以设置为False,这样不仅让程序在运行时有一种神秘感(而不是),而且速度也快了一点。
但是有一点要记住,这个网页在我们打开后并没有关闭,这意味着程序结束后需要手动关闭它。如果网页不可见,则无法手动关闭。代码中的注释部分用于关闭网页。不用说,导航就是 URL。
我们必须等待网页完全加载,然后才能开始信息抓取。这时候,我们使用:(从这里开始,所有的代码都需要写在With代码块中)
While .ReadyState 4 Or .Busy
DoEvents
Wend
Busy 是网页的繁忙状态,ReadyState 是 HTTP 的五种就绪状态,对应如下:
2、获取信息
我们先抓取页面上的所有内容,稍后过滤掉有用的部分,然后慢慢添加条件到抓取中。
Set dmt = .Document
For i = 0 To dmt.all.Length - 1
Set htMent = dmt.all(i)
With ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
End With
Next i
这段代码有点类似于JS,需要从IE.Document.all中找出页面上的所有节点。还有其他几种方法:
这些更方便用于在抓取所有页面内容后帮助过滤有效信息。当然 all 最好用,因为 all 也有 all ("IDName") 和 all.IDName 的用法。
上面代码部分返回的属性值都是基本的HTML内容,就不一一解释了。
3、填写信息
爬网神器当然是Python。大多数人使用Excel自动填写页面内容,直接将表单提交到网页,省去了问卷录入等大量工作。抓取页面内容后,填充起来就更容易了。你只需要直接给页面标签的Value属性赋值即可。
但是,除了文本框,可能还有其他没有Value的标签,比如下拉菜单和单选按钮。给这些内容赋值需要一些基本的HTML知识。
'下拉菜单选择
.all("select")(0).Selected = True
'单选按钮选择
.all("radio").Checked = True
'复选按钮选择
.all("checkbox").Checked = True
下拉菜单是一个select标签,每个选项都在一个option标签中,所以要返回一个集合,需要选择一个选项,将对应的Selected属性修改为True。单选按钮和复选按钮都是输入标签。不同的是类型分别是radio和checkbox。要选择一个选项,您需要修改相应的 Checked 属性。
三、数据接口
有时我们可以直接获取一些API。当然,通过API返回数据比打开网页更方便快捷,使用的方法也有些不同。
1、请求接口
比如我得到了一个可以从网上查询到城市免费WIFI的API,我用下面的代码通过Excel界面访问:(虽然是免费的,为了避免麻烦,我还是隐藏了我的AppKey)
Dim http
Set http = CreateObject("Microsoft.XMLHTTP")
http.Open "GET", "http://api.avatardata.cn/Wifi/QueryByCity", False
http.setRequestHeader "CONTENT-TYPE", "application/x-www-form-urlencoded"
http.send "key=[AppKey]&city=北京&page=1"
这时候我们创建的对象不再是IE,而是HTTP对象。这里使用的是ajax的Open方法,GET为数据发送方法,第二个参数为接口地址,第三个参数指定请求方法是否异步。如果这个API有账号和密码,就写在第四个和第五个参数中。
setRequestHeader是向接口发送一个HTTP协议头文件,最后发送的内容就是接口参数。当然,这个QueryString也可以直接写在URL中,发送一个空字符串即可。
2、接口返回
接口返回和获取的方式很简单:
If http.Status = 200 Then Range("A1").Value = http.responseText 查看全部
excelvba抓取网页数据(
VBA·5个月前如何使用VBA网抓的,我基本都没有回复
)
使用Excel+VBA操作网页
黄辰5 个月前
因为知乎里面的一些回答,最近总有私信问我怎么用VBA抓网,但是我基本没有回复。因为这个问题太大了,有基础知识的人其实很容易自己在百度或者ExcelHome论坛上找到答案。我不需要说什么。对于没有基础知识的人来说,是不可能三言两语解决问题的。我不想把私信变成聊天窗口。借开专栏知乎的机会,恰巧仔细解释了这个问题。
我对Excel和VBA的了解有限,只能解决我遇到的一些问题,不一定适用于所有场景。以下内容基于对VBA基本用法和HTML语言知识的了解:
一、前期准备
据我所知,VBA 不能操作任何浏览器和网页。我们所能做的就是在IE上执行一些操作,是的,只有IE。不要告诉我电脑上没有IE,所以你可以退出Sub。就像在Python中使用import,在C#中使用一样,VBA也需要引用一些库来操作IE,不过好在它是微软的产品,所以我们可以很方便的使用VBA自带的一些库。
我们需要做的第一件事是在 VBA 中引用 Micorsoft Internet Controls。通过查看这个名称,我们知道它可以帮助我们控制 IE 页面。
二、网页操作
引用 Micorsoft Internet Controls 后,我们可以对页面做任何我们想做的事情,但是我们需要在主页上有一个页面,上帝说我们需要一个页面!
1、打开网页
我们以在百度上搜索“查虎”关键词为例:
With CreateObject("internetexplorer.application")
.Visible = True
.Navigate "https://www.baidu.com/s?wd=扯乎"
'关闭网页
' .Quit
End With
代码很简单,先创建一个IE对象,然后给一些属性赋值。Visible就是可见性,是指网页被操作时是否会看到网页。熟练后可以设置为False,这样不仅让程序在运行时有一种神秘感(而不是),而且速度也快了一点。
但是有一点要记住,这个网页在我们打开后并没有关闭,这意味着程序结束后需要手动关闭它。如果网页不可见,则无法手动关闭。代码中的注释部分用于关闭网页。不用说,导航就是 URL。
我们必须等待网页完全加载,然后才能开始信息抓取。这时候,我们使用:(从这里开始,所有的代码都需要写在With代码块中)
While .ReadyState 4 Or .Busy
DoEvents
Wend
Busy 是网页的繁忙状态,ReadyState 是 HTTP 的五种就绪状态,对应如下:
2、获取信息
我们先抓取页面上的所有内容,稍后过滤掉有用的部分,然后慢慢添加条件到抓取中。
Set dmt = .Document
For i = 0 To dmt.all.Length - 1
Set htMent = dmt.all(i)
With ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
End With
Next i
这段代码有点类似于JS,需要从IE.Document.all中找出页面上的所有节点。还有其他几种方法:
这些更方便用于在抓取所有页面内容后帮助过滤有效信息。当然 all 最好用,因为 all 也有 all ("IDName") 和 all.IDName 的用法。
上面代码部分返回的属性值都是基本的HTML内容,就不一一解释了。
3、填写信息
爬网神器当然是Python。大多数人使用Excel自动填写页面内容,直接将表单提交到网页,省去了问卷录入等大量工作。抓取页面内容后,填充起来就更容易了。你只需要直接给页面标签的Value属性赋值即可。
但是,除了文本框,可能还有其他没有Value的标签,比如下拉菜单和单选按钮。给这些内容赋值需要一些基本的HTML知识。
'下拉菜单选择
.all("select")(0).Selected = True
'单选按钮选择
.all("radio").Checked = True
'复选按钮选择
.all("checkbox").Checked = True
下拉菜单是一个select标签,每个选项都在一个option标签中,所以要返回一个集合,需要选择一个选项,将对应的Selected属性修改为True。单选按钮和复选按钮都是输入标签。不同的是类型分别是radio和checkbox。要选择一个选项,您需要修改相应的 Checked 属性。
三、数据接口
有时我们可以直接获取一些API。当然,通过API返回数据比打开网页更方便快捷,使用的方法也有些不同。
1、请求接口
比如我得到了一个可以从网上查询到城市免费WIFI的API,我用下面的代码通过Excel界面访问:(虽然是免费的,为了避免麻烦,我还是隐藏了我的AppKey)
Dim http
Set http = CreateObject("Microsoft.XMLHTTP")
http.Open "GET", "http://api.avatardata.cn/Wifi/QueryByCity", False
http.setRequestHeader "CONTENT-TYPE", "application/x-www-form-urlencoded"
http.send "key=[AppKey]&city=北京&page=1"
这时候我们创建的对象不再是IE,而是HTTP对象。这里使用的是ajax的Open方法,GET为数据发送方法,第二个参数为接口地址,第三个参数指定请求方法是否异步。如果这个API有账号和密码,就写在第四个和第五个参数中。
setRequestHeader是向接口发送一个HTTP协议头文件,最后发送的内容就是接口参数。当然,这个QueryString也可以直接写在URL中,发送一个空字符串即可。
2、接口返回
接口返回和获取的方式很简单:
If http.Status = 200 Then Range("A1").Value = http.responseText

