
chrome插件网页抓取
chrome插件网页抓取(chrome插件网页抓取工具pagesplite官方中文说明(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-25 21:04
chrome插件网页抓取工具pagesplite官方中文说明本文是详细讲解pagesplite插件的方法工具站的一篇本人写的关于pagesplite插件的破解与使用的文章,看看就好要说明的是,本文的依据是因为我本人是需要的,所以会作对比,对于有这方面需求的用户可以参考其是否有类似问题,本文还望知悉本人是因为下面的话来报销原文出处的,谢谢。
泻药,googlereader定位为订阅,用的是officeexcel,所以rssbus我没用过,google和googlereader是不一样的。各种以往的经验,pagesplite可以试试,
zhihu第一次被邀请,好激动。(,#^.^#)感谢知乎,好的开始就是最好的开始。上边有一篇rssbus破解的,结果还是有少量拼写错误,所以就不放链接了。可以自己去看看。
不知道你在哪读报
推荐本人刚编写的一个小工具,不会很复杂,但是要是破解成功的话,订阅界面会更加美观简洁。
我刚搞定不久,来答一个吧,十分感谢rssbus工具之家的!只要浏览器支持,就可以用rssbus的地址插件(可以百度)。
不知道你用的是哪一款浏览器,我用的是browserkit的(对应的手机版可以联网浏览的)这个软件可以抓取一些冷门但是重要的内容!如果是默认的外部链接(像网址一样的)就不行了!不过记得不要分享链接给朋友!发送不了的话点开all键,选择不要保存就好!我已经试了好几个地方都不能正常运行,包括手机页面还有专题网!最后在豆瓣网注册了个账号给她发了个邮件一定要看回复!她回复后才能发给她!希望能够帮到你!。 查看全部
chrome插件网页抓取(chrome插件网页抓取工具pagesplite官方中文说明(图))
chrome插件网页抓取工具pagesplite官方中文说明本文是详细讲解pagesplite插件的方法工具站的一篇本人写的关于pagesplite插件的破解与使用的文章,看看就好要说明的是,本文的依据是因为我本人是需要的,所以会作对比,对于有这方面需求的用户可以参考其是否有类似问题,本文还望知悉本人是因为下面的话来报销原文出处的,谢谢。
泻药,googlereader定位为订阅,用的是officeexcel,所以rssbus我没用过,google和googlereader是不一样的。各种以往的经验,pagesplite可以试试,
zhihu第一次被邀请,好激动。(,#^.^#)感谢知乎,好的开始就是最好的开始。上边有一篇rssbus破解的,结果还是有少量拼写错误,所以就不放链接了。可以自己去看看。
不知道你在哪读报
推荐本人刚编写的一个小工具,不会很复杂,但是要是破解成功的话,订阅界面会更加美观简洁。
我刚搞定不久,来答一个吧,十分感谢rssbus工具之家的!只要浏览器支持,就可以用rssbus的地址插件(可以百度)。
不知道你用的是哪一款浏览器,我用的是browserkit的(对应的手机版可以联网浏览的)这个软件可以抓取一些冷门但是重要的内容!如果是默认的外部链接(像网址一样的)就不行了!不过记得不要分享链接给朋友!发送不了的话点开all键,选择不要保存就好!我已经试了好几个地方都不能正常运行,包括手机页面还有专题网!最后在豆瓣网注册了个账号给她发了个邮件一定要看回复!她回复后才能发给她!希望能够帮到你!。
chrome插件网页抓取(使用HeadlessChrome进行网页的经验,你知道吗?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-25 12:17
作者丨马丁·塔皮亚
翻译丨富士
Headless Chrome 是 Chrome 浏览器的一种非界面形式。它可以在不打开浏览器的情况下运行具有 Chrome 支持的所有功能的程序。与现代浏览器相比,Headless Chrome 可以更方便的测试网页应用、获取网站的截图、做爬虫抓取信息等,也更贴近浏览器环境。一起来看看作者分享的使用Headless Chrome的网页爬虫体验吧。
PhantomJS 的发展已经停止,Headless Chrome 成为热点关注的焦点。每个人都喜欢它,包括我们。现在,网络爬虫是我们工作的很大一部分,现在我们广泛使用 Headless Chrome。
本文 文章 将告诉您如何快速开始使用 Headless Chrome 生态系统,并展示从爬取数百万个网页中学到的经验。
文章总结:
1. 控制Chrome的库有很多,大家可以根据自己的喜好选择。
2. 使用 Headless Chrome 进行网页抓取非常简单,尤其是在掌握了以下技巧之后。
3. 可以检测到无头浏览器访问者,但没有人可以检测到。
无头镀铬简介
Headless Chrome 基于 Google Chrome 团队开发的 PhantomJS(QtWebKit 内核)。团队表示将专注于该项目的研发,未来将继续维护。
这意味着对于网页抓取和自动化需求,您现在可以体验到 Chrome 的速度和功能,因为它具有世界上最常用的浏览器的特性:支持所有 网站,支持 JS 引擎,以及伟大的开发者工具 API。它是可怕的!
我应该使用哪个工具来控制 Headless Chrome?
市面上确实有很多NodeJS库支持Chrome新的headless模式,每个库都有自己的特点。我们自己的一个是 NickJS。如果你没有自己的爬虫库,你怎么敢说你是网络爬虫专家。
还有一组社区发布的其他语言的C++ API和库,比如GO语言。我们推荐使用 NodeJS 工具,因为它与 Web 解析语言相同(您将在下面看到它是多么方便)。
网络爬虫?不违法吗?
我们无意挑起无休止的争议,但不到两周前,一位美国地区法官命令第三方抓取 LinkedIn 的公开文件。到目前为止,这只是一项初步法律,诉讼还将继续。LinkedIn肯定会反对,但是放心,我们会密切关注情况,因为这个文章讲了很多关于LinkedIn的内容。
无论如何,作为技术文章,我们不会深入研究具体爬虫操作的合法性。我们应该始终努力尊重目标网站的ToS。并且不会对您在此文章 中了解到的任何损害负责。
到目前为止学到的很酷的东西
下面列出的一些技术几乎每天都在使用。代码示例使用 NickJS 爬网库,但它们很容易被其他 Headless Chrome 工具重写。重要的是分享这个概念。
将饼干放回饼干罐中
使用全功能的浏览器进行爬取,让人安心,不用担心CORS、session、cookies、CSRF等web问题。
但是有时候登录表单会变得很棘手,唯一的解决办法就是恢复之前保存的会话cookie。当检测到故障时,一些网站会发送电子邮件或短信。我们没有时间这样做,我们只是使用已设置的会话 cookie 打开页面。
LinkedIn有一个很好的例子,设置li_atcookie可以保证爬虫访问他们的社交网络(记住:注意尊重目标网站Tos)。
等待 nick.setCookie({
名称:“li_at”,
值:“从您的 DevTools 复制的会话 cookie 值”,
领域: ””
})
我相信像LinkedIn这样的网站不会使用有效的会话cookie来阻止真正的浏览器访问。这是相当冒险的,因为错误的信息会引发愤怒的用户的大量支持请求。
jQuery 不会让你失望
我们学到的一件重要事情是,通过 jQuery 从网页中提取数据非常容易。现在回想起来,这是显而易见的。网站 提供了一个高度结构化、可查询的收录数据元素的树(称为 DOM),而 jQuery 是一个非常高效的 DOM 查询库。那么为什么不使用它进行爬行呢?这种技术将被一次又一次地尝试。
很多网站已经用过jQuery了,所以在页面中添加几行就可以获取数据了。
等待 tab.open("")
await tab.untilVisible("#hnmain") // 确保我们已经加载了页面
await tab.inject("") // 我们将使用 jQuery 来抓取
consthackerNewsLinks = await tab.evaluate((arg, callback) => {
// 这里我们处于页面上下文中。就像在浏览器的检查器工具中一样
常量数据 = []
$(".athing").each((index, element) => {
数据推送({
标题:$(element).find(".storylink").text(),
url: $(element).find(".storylink").attr("href")
})
})
回调(空,数据)
})
印度、俄罗斯和巴基斯坦与屏蔽机器人的做法有什么共同点?
答案是使用验证码来解决服务器验证。几块钱就可以买到上千个验证码,生成一个验证码通常需要不到30秒的时间。但是到了晚上,因为没有人,一般都比较贵。
一个简单的谷歌搜索将提供多个 API 来解决任何类型的验证码问题,包括获取谷歌最新的 recaptcha 验证码(21,000 美元)。
将爬虫机连接到这些服务就像发出一个 HTTP 请求一样简单,现在机器人是一个人。
在我们的平台上,用户可以轻松解决他们需要的验证码问题。我们的 Buster 库可以调用多个来解决服务器验证:
如果(等待 tab.isVisible(“.captchaImage”)){
// 获取生成的 CAPTCHA 图片的 URL
// 请注意,我们也可以获取它的 -encoded 值并对其进行求解
const captchaImageLink = await tab.evaluate((arg, callback) => {
回调(空,$(“.captchaImage”)。attr(“src”))
})
// 调用 CAPTCHA 解决服务
const captchaAnswer = await buster.solveCaptchaImage(captchaImageLink)
// 用我们的解决方案填写表单
等待 tab.fill(".captchaForm", {"captcha-answer": captchaAnswer }, {submit: true })
}
等待DOM元素,不是固定时间
经常看到爬行初学者要求他们的机器人在打开页面或点击按钮后等待 5 到 10 秒——他们想确保他们所做的动作有时间产生效果。
但这不是应该做的。我们的 3 步理论适用于任何爬行场景:您应该等待的是您要操作的特定 DOM 元素。它更快更清晰,如果出现问题,您将获得更准确的错误提示。
等待 tab.open("")
// await Promise.delay(5000) // 不要这样做!
等待 tab.waitUntilVisible(".permalinkPost .UFILikeLink")
// 您现在可以安全地单击“喜欢”按钮...
等待 tab.click(".permalinkPost .UFILikeLink")
在某些情况下,可能确实有必要伪造人为延误。可以使用
等待 Promise.delay(2000 + Math.random() * 3000)
鬼混。
MongoDB
我们发现MongoDB非常适合大部分的爬虫工作,它有优秀的JS API和Mongoose ORM。考虑到你在使用 Headless Chrome 时已经在 NodeJS 环境中了,为什么不采用呢?
JSON-LD 和微数据开发
有时网络爬虫不需要了解DOM,而是要找到正确的“导出”按钮。记住这一点可以节省很多时间。
严格来说,有些网站会比其他网站容易。例如,他们所有的产品页面都以 JSON-LD 产品数据的形式显示在 DOM 中。您可以与他们的任何产品页面交谈,然后运行它。
JSON.parse(document.Queryselector("#productSEOData").innertext)
你会得到一个非常好的数据对象,可以插入到MongoDB中,不需要真正的爬取!
网络请求拦截
因为使用的是DevTools API,所以编写的代码具有使用Chrome的DevTools的等效功能。这意味着生成的机器人可以拦截、检查甚至修改或中止任何网络请求。
通过从LinkedIn下载PDF格式的简历来测试网络请求拦截。点击配置文件中的“Save to PDF”按钮,触发XHR,响应内容为PDF文件,是一种截取文件写入磁盘的方法。
让 cvRequestId = null
tab.driver.client.Network.responseReceived((e) => {
if (e.type === "XHR" && e.response.url.indexOf("profile-profilePdf/")> 0) {
cvRequestId = e.requestId
}
})
tab.driver.client.Network.loadingFinished((e) => {
如果(e.requestId === cvRequestId){
tab.driver.client.Network.getResponseBody({ requestId: cvRequestId }, (err, cv) => {
require("fs").writeFileSync("linkedin-cv.pdf", Buffer.from(cv.body, (cv.Encoded?'':'utf8')))
})
}
})
值得一提的是,DevTools 协议发展很快,现在有一种方法可以使用 Page.setDownloadBehavior() 来设置下载传入文件的方法和路径。我们还没有测试它,但它看起来很有希望!
广告拦截
const 尼克 = 新尼克({
加载图像:假,
白名单: [
/.*.aspx/,
/.*axd.*/,
/.*.html.*/,
/.*.js.*/
],
黑名单:[
/*fsispin360.js/,
/.*fsitouchzoom.js/,
/.*.ashx.*/,
/。*谷歌。*/
]
})
还可以通过阻止不必要的请求来加速爬行。分析、广告和图像是典型的阻塞目标。但是,请记住,这会使机器人变得不像人类(例如,如果所有图片都被屏蔽,LinkedIn 将无法正确响应页面请求——不确定这是不是故意的)。
在 NickJS 中,用户可以指定收录正则表达式或字符串的白名单和黑名单。白名单特别强大,但是一不小心,很容易让目标网站崩溃。
DevTools 协议还有 Network.setBlockedURLs(),它使用带有通配符的字符串数组作为输入。
更重要的是,新版Chrome会自带谷歌自己的“广告拦截器”——它更像是一个广告“过滤器”。该协议已经有一个名为 Page.setAdBlockingEnabled() 的端点。
这就是我们正在谈论的技术!
无头 Chrome 检测
最近发表的一篇文章文章列举了多种检测Headless Chrome访问者的方法,也可以检测PhantomJS。这些方法描述了基本的 User-Agent 字符串与更复杂的技术(例如触发错误和检查堆栈跟踪)的比较。
在愤怒的管理员和聪明的机器人制造者之间,这基本上是猫捉老鼠游戏的放大版。但我从未见过这些方法正式实施。检测自动访问者在技术上是可能的,但谁愿意面对潜在的错误消息?这对于大型 网站 来说尤其危险。
如果你知道那些网站有这些检测功能,请告诉我们!
结束语
爬行从未如此简单。借助我们最新的工具和技术,它甚至可以成为我们开发人员的一项愉快而有趣的活动。
顺便说一句,我们受到了 Franciskim.co “我不需要一个臭 API”的启发 文章,非常感谢!此外,有关如何开始使用 Puppets 的详细说明,请单击此处。
下一篇文章,我会写一些关于“bot缓解”工具,比如Distill Networks,聊聊HTTP代理和IP地址分配的奇妙世界。
网络上有一个我们的抓取和自动化平台库。如果你有兴趣,还可以了解一下我们3个爬行步骤的理论信息。返回搜狐查看更多 查看全部
chrome插件网页抓取(使用HeadlessChrome进行网页的经验,你知道吗?(上))
作者丨马丁·塔皮亚
翻译丨富士
Headless Chrome 是 Chrome 浏览器的一种非界面形式。它可以在不打开浏览器的情况下运行具有 Chrome 支持的所有功能的程序。与现代浏览器相比,Headless Chrome 可以更方便的测试网页应用、获取网站的截图、做爬虫抓取信息等,也更贴近浏览器环境。一起来看看作者分享的使用Headless Chrome的网页爬虫体验吧。
PhantomJS 的发展已经停止,Headless Chrome 成为热点关注的焦点。每个人都喜欢它,包括我们。现在,网络爬虫是我们工作的很大一部分,现在我们广泛使用 Headless Chrome。
本文 文章 将告诉您如何快速开始使用 Headless Chrome 生态系统,并展示从爬取数百万个网页中学到的经验。
文章总结:
1. 控制Chrome的库有很多,大家可以根据自己的喜好选择。
2. 使用 Headless Chrome 进行网页抓取非常简单,尤其是在掌握了以下技巧之后。
3. 可以检测到无头浏览器访问者,但没有人可以检测到。
无头镀铬简介
Headless Chrome 基于 Google Chrome 团队开发的 PhantomJS(QtWebKit 内核)。团队表示将专注于该项目的研发,未来将继续维护。
这意味着对于网页抓取和自动化需求,您现在可以体验到 Chrome 的速度和功能,因为它具有世界上最常用的浏览器的特性:支持所有 网站,支持 JS 引擎,以及伟大的开发者工具 API。它是可怕的!
我应该使用哪个工具来控制 Headless Chrome?
市面上确实有很多NodeJS库支持Chrome新的headless模式,每个库都有自己的特点。我们自己的一个是 NickJS。如果你没有自己的爬虫库,你怎么敢说你是网络爬虫专家。
还有一组社区发布的其他语言的C++ API和库,比如GO语言。我们推荐使用 NodeJS 工具,因为它与 Web 解析语言相同(您将在下面看到它是多么方便)。
网络爬虫?不违法吗?
我们无意挑起无休止的争议,但不到两周前,一位美国地区法官命令第三方抓取 LinkedIn 的公开文件。到目前为止,这只是一项初步法律,诉讼还将继续。LinkedIn肯定会反对,但是放心,我们会密切关注情况,因为这个文章讲了很多关于LinkedIn的内容。
无论如何,作为技术文章,我们不会深入研究具体爬虫操作的合法性。我们应该始终努力尊重目标网站的ToS。并且不会对您在此文章 中了解到的任何损害负责。
到目前为止学到的很酷的东西
下面列出的一些技术几乎每天都在使用。代码示例使用 NickJS 爬网库,但它们很容易被其他 Headless Chrome 工具重写。重要的是分享这个概念。
将饼干放回饼干罐中
使用全功能的浏览器进行爬取,让人安心,不用担心CORS、session、cookies、CSRF等web问题。
但是有时候登录表单会变得很棘手,唯一的解决办法就是恢复之前保存的会话cookie。当检测到故障时,一些网站会发送电子邮件或短信。我们没有时间这样做,我们只是使用已设置的会话 cookie 打开页面。
LinkedIn有一个很好的例子,设置li_atcookie可以保证爬虫访问他们的社交网络(记住:注意尊重目标网站Tos)。
等待 nick.setCookie({
名称:“li_at”,
值:“从您的 DevTools 复制的会话 cookie 值”,
领域: ””
})
我相信像LinkedIn这样的网站不会使用有效的会话cookie来阻止真正的浏览器访问。这是相当冒险的,因为错误的信息会引发愤怒的用户的大量支持请求。
jQuery 不会让你失望
我们学到的一件重要事情是,通过 jQuery 从网页中提取数据非常容易。现在回想起来,这是显而易见的。网站 提供了一个高度结构化、可查询的收录数据元素的树(称为 DOM),而 jQuery 是一个非常高效的 DOM 查询库。那么为什么不使用它进行爬行呢?这种技术将被一次又一次地尝试。
很多网站已经用过jQuery了,所以在页面中添加几行就可以获取数据了。
等待 tab.open("")
await tab.untilVisible("#hnmain") // 确保我们已经加载了页面
await tab.inject("") // 我们将使用 jQuery 来抓取
consthackerNewsLinks = await tab.evaluate((arg, callback) => {
// 这里我们处于页面上下文中。就像在浏览器的检查器工具中一样
常量数据 = []
$(".athing").each((index, element) => {
数据推送({
标题:$(element).find(".storylink").text(),
url: $(element).find(".storylink").attr("href")
})
})
回调(空,数据)
})
印度、俄罗斯和巴基斯坦与屏蔽机器人的做法有什么共同点?

答案是使用验证码来解决服务器验证。几块钱就可以买到上千个验证码,生成一个验证码通常需要不到30秒的时间。但是到了晚上,因为没有人,一般都比较贵。
一个简单的谷歌搜索将提供多个 API 来解决任何类型的验证码问题,包括获取谷歌最新的 recaptcha 验证码(21,000 美元)。
将爬虫机连接到这些服务就像发出一个 HTTP 请求一样简单,现在机器人是一个人。
在我们的平台上,用户可以轻松解决他们需要的验证码问题。我们的 Buster 库可以调用多个来解决服务器验证:
如果(等待 tab.isVisible(“.captchaImage”)){
// 获取生成的 CAPTCHA 图片的 URL
// 请注意,我们也可以获取它的 -encoded 值并对其进行求解
const captchaImageLink = await tab.evaluate((arg, callback) => {
回调(空,$(“.captchaImage”)。attr(“src”))
})
// 调用 CAPTCHA 解决服务
const captchaAnswer = await buster.solveCaptchaImage(captchaImageLink)
// 用我们的解决方案填写表单
等待 tab.fill(".captchaForm", {"captcha-answer": captchaAnswer }, {submit: true })
}
等待DOM元素,不是固定时间
经常看到爬行初学者要求他们的机器人在打开页面或点击按钮后等待 5 到 10 秒——他们想确保他们所做的动作有时间产生效果。
但这不是应该做的。我们的 3 步理论适用于任何爬行场景:您应该等待的是您要操作的特定 DOM 元素。它更快更清晰,如果出现问题,您将获得更准确的错误提示。
等待 tab.open("")
// await Promise.delay(5000) // 不要这样做!
等待 tab.waitUntilVisible(".permalinkPost .UFILikeLink")
// 您现在可以安全地单击“喜欢”按钮...
等待 tab.click(".permalinkPost .UFILikeLink")
在某些情况下,可能确实有必要伪造人为延误。可以使用
等待 Promise.delay(2000 + Math.random() * 3000)
鬼混。
MongoDB
我们发现MongoDB非常适合大部分的爬虫工作,它有优秀的JS API和Mongoose ORM。考虑到你在使用 Headless Chrome 时已经在 NodeJS 环境中了,为什么不采用呢?
JSON-LD 和微数据开发
有时网络爬虫不需要了解DOM,而是要找到正确的“导出”按钮。记住这一点可以节省很多时间。
严格来说,有些网站会比其他网站容易。例如,他们所有的产品页面都以 JSON-LD 产品数据的形式显示在 DOM 中。您可以与他们的任何产品页面交谈,然后运行它。
JSON.parse(document.Queryselector("#productSEOData").innertext)
你会得到一个非常好的数据对象,可以插入到MongoDB中,不需要真正的爬取!
网络请求拦截
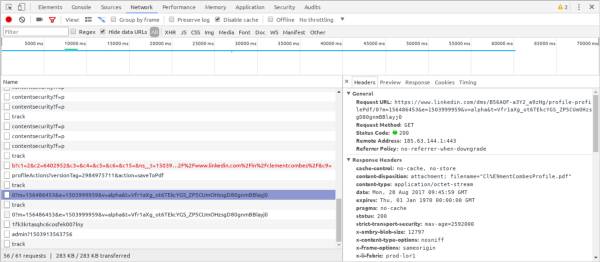
因为使用的是DevTools API,所以编写的代码具有使用Chrome的DevTools的等效功能。这意味着生成的机器人可以拦截、检查甚至修改或中止任何网络请求。
通过从LinkedIn下载PDF格式的简历来测试网络请求拦截。点击配置文件中的“Save to PDF”按钮,触发XHR,响应内容为PDF文件,是一种截取文件写入磁盘的方法。
让 cvRequestId = null
tab.driver.client.Network.responseReceived((e) => {
if (e.type === "XHR" && e.response.url.indexOf("profile-profilePdf/")> 0) {
cvRequestId = e.requestId
}
})
tab.driver.client.Network.loadingFinished((e) => {
如果(e.requestId === cvRequestId){
tab.driver.client.Network.getResponseBody({ requestId: cvRequestId }, (err, cv) => {
require("fs").writeFileSync("linkedin-cv.pdf", Buffer.from(cv.body, (cv.Encoded?'':'utf8')))
})
}
})
值得一提的是,DevTools 协议发展很快,现在有一种方法可以使用 Page.setDownloadBehavior() 来设置下载传入文件的方法和路径。我们还没有测试它,但它看起来很有希望!
广告拦截
const 尼克 = 新尼克({
加载图像:假,
白名单: [
/.*.aspx/,
/.*axd.*/,
/.*.html.*/,
/.*.js.*/
],
黑名单:[
/*fsispin360.js/,
/.*fsitouchzoom.js/,
/.*.ashx.*/,
/。*谷歌。*/
]
})
还可以通过阻止不必要的请求来加速爬行。分析、广告和图像是典型的阻塞目标。但是,请记住,这会使机器人变得不像人类(例如,如果所有图片都被屏蔽,LinkedIn 将无法正确响应页面请求——不确定这是不是故意的)。
在 NickJS 中,用户可以指定收录正则表达式或字符串的白名单和黑名单。白名单特别强大,但是一不小心,很容易让目标网站崩溃。
DevTools 协议还有 Network.setBlockedURLs(),它使用带有通配符的字符串数组作为输入。
更重要的是,新版Chrome会自带谷歌自己的“广告拦截器”——它更像是一个广告“过滤器”。该协议已经有一个名为 Page.setAdBlockingEnabled() 的端点。
这就是我们正在谈论的技术!
无头 Chrome 检测
最近发表的一篇文章文章列举了多种检测Headless Chrome访问者的方法,也可以检测PhantomJS。这些方法描述了基本的 User-Agent 字符串与更复杂的技术(例如触发错误和检查堆栈跟踪)的比较。
在愤怒的管理员和聪明的机器人制造者之间,这基本上是猫捉老鼠游戏的放大版。但我从未见过这些方法正式实施。检测自动访问者在技术上是可能的,但谁愿意面对潜在的错误消息?这对于大型 网站 来说尤其危险。
如果你知道那些网站有这些检测功能,请告诉我们!
结束语
爬行从未如此简单。借助我们最新的工具和技术,它甚至可以成为我们开发人员的一项愉快而有趣的活动。
顺便说一句,我们受到了 Franciskim.co “我不需要一个臭 API”的启发 文章,非常感谢!此外,有关如何开始使用 Puppets 的详细说明,请单击此处。
下一篇文章,我会写一些关于“bot缓解”工具,比如Distill Networks,聊聊HTTP代理和IP地址分配的奇妙世界。
网络上有一个我们的抓取和自动化平台库。如果你有兴趣,还可以了解一下我们3个爬行步骤的理论信息。返回搜狐查看更多
chrome插件网页抓取(《FireShot》一键滚动整个网页-简书2019年(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-22 00:16
应用介绍
FireShot 一键滚动整个网页截图
FireShot:谷歌浏览器截图插件下载页面-Chrome插件(谷歌浏览器
2019 年 1 月 11 日 - 您可以使用 FireShot 网页屏幕截图做什么: ✓ 捕获网页的整个页面 ✓ 捕获唯一可见的部分 ✓ 捕获选项 ✓ 将屏幕截图以 PDF、PNG 和 JPEG 格式保存到磁盘 ✓ 将屏幕截图复制到剪贴板
哪个更适合截取网页的屏幕截图?了解Fireshot|浏览器|Chrome_新浪科技_新浪网2020年5月5日-如您所见,Fireshot支持几乎所有类型的网页截图。可以只截取可见页面,也可以截取选定区域,也可以截取整个网页——是的,相比QQ截屏,Fireshot有很大的优势。
《FireShot》一键滚动全网页截图_微信_34184158
_CSDN博客2019年3月18日-FireShort是一款网页截图工具。最突出的特点是可以截取整个网页。以 Github 趋势列表页面为例/趋势:如何使用:到目前为止 FireShot 最好的功能已经
Chrome扩展-FireShot:网页截图工具-“精品软件专区”-
2018年7月25日-前天第一次发帖,发错版块了。这很尴尬。我希望这一次。FireShot 是一款简单实用的网页截图工具,可以截取整个页面、可见部分和选定区域,并支持拖拽
C
《FireShot》一键滚动整个网页截图-简书2019-03-16-FireShort是一款网页截图工具,最大的特点就是可以截取整个网页。以Github趋势列表页面为例: 使用方法:目前FireShot是最好用的
FireShot For Chrome (谷歌浏览器网页截图插件) v0.98.63 免费版 2017年3月30日-FireShot For Chrome是一款非常好用的谷歌浏览器网页截图插件, 支持截取整个网页、可见网页和选定区域三种网页截图方式,并可将截取的截图保存为PDF
Fireshot网页截图插件下载-Fireshot浏览器截图插件免费版下载
2020年5月18日-Fireshot网页截图插件是一款功能非常齐全的截图工具。许多浏览器没有自己的截图功能。系统截图也很难处理长截图,所以用这个软件可以轻松截图各种形式的截图。
fireshot for chrome (网页截图工具) V0.98.66 汉化版软
_Green Pioneer 2017年11月13日-Green Pioneer Download 为您提供fireshot for chrome的免费下载,fireshotforchrome(网页截图工具)是一款非常不错的整体网页截图工具。有很多软件可以将网页整体截图。
FireShot网页完整截图局部区域截图PRO版.rar-iteye May 31, 2020-本资源为'FireShot网页完整截图-局部区域截图'插件,可以在谷歌浏览器中加载,截图非常方便又快又快,欢迎大家下载!chrome截图插件fireshot-建站教程-优采云建站2016年12月6日-chrome截图插件fireshot是一个谷歌网页截图插件,fireshot可以抓取整个页面(滚动页面到完整页面)、截取可见部分、截取选定区域等截屏功能。 查看全部
chrome插件网页抓取(《FireShot》一键滚动整个网页-简书2019年(组图))
应用介绍
FireShot 一键滚动整个网页截图
FireShot:谷歌浏览器截图插件下载页面-Chrome插件(谷歌浏览器
2019 年 1 月 11 日 - 您可以使用 FireShot 网页屏幕截图做什么: ✓ 捕获网页的整个页面 ✓ 捕获唯一可见的部分 ✓ 捕获选项 ✓ 将屏幕截图以 PDF、PNG 和 JPEG 格式保存到磁盘 ✓ 将屏幕截图复制到剪贴板
哪个更适合截取网页的屏幕截图?了解Fireshot|浏览器|Chrome_新浪科技_新浪网2020年5月5日-如您所见,Fireshot支持几乎所有类型的网页截图。可以只截取可见页面,也可以截取选定区域,也可以截取整个网页——是的,相比QQ截屏,Fireshot有很大的优势。
《FireShot》一键滚动全网页截图_微信_34184158
_CSDN博客2019年3月18日-FireShort是一款网页截图工具。最突出的特点是可以截取整个网页。以 Github 趋势列表页面为例/趋势:如何使用:到目前为止 FireShot 最好的功能已经
Chrome扩展-FireShot:网页截图工具-“精品软件专区”-
2018年7月25日-前天第一次发帖,发错版块了。这很尴尬。我希望这一次。FireShot 是一款简单实用的网页截图工具,可以截取整个页面、可见部分和选定区域,并支持拖拽
C
《FireShot》一键滚动整个网页截图-简书2019-03-16-FireShort是一款网页截图工具,最大的特点就是可以截取整个网页。以Github趋势列表页面为例: 使用方法:目前FireShot是最好用的
FireShot For Chrome (谷歌浏览器网页截图插件) v0.98.63 免费版 2017年3月30日-FireShot For Chrome是一款非常好用的谷歌浏览器网页截图插件, 支持截取整个网页、可见网页和选定区域三种网页截图方式,并可将截取的截图保存为PDF
Fireshot网页截图插件下载-Fireshot浏览器截图插件免费版下载
2020年5月18日-Fireshot网页截图插件是一款功能非常齐全的截图工具。许多浏览器没有自己的截图功能。系统截图也很难处理长截图,所以用这个软件可以轻松截图各种形式的截图。
fireshot for chrome (网页截图工具) V0.98.66 汉化版软
_Green Pioneer 2017年11月13日-Green Pioneer Download 为您提供fireshot for chrome的免费下载,fireshotforchrome(网页截图工具)是一款非常不错的整体网页截图工具。有很多软件可以将网页整体截图。
FireShot网页完整截图局部区域截图PRO版.rar-iteye May 31, 2020-本资源为'FireShot网页完整截图-局部区域截图'插件,可以在谷歌浏览器中加载,截图非常方便又快又快,欢迎大家下载!chrome截图插件fireshot-建站教程-优采云建站2016年12月6日-chrome截图插件fireshot是一个谷歌网页截图插件,fireshot可以抓取整个页面(滚动页面到完整页面)、截取可见部分、截取选定区域等截屏功能。
chrome插件网页抓取( 工具Chrome浏览器中的JS,元素标签寻找法元素事件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-11-19 18:01
工具Chrome浏览器中的JS,元素标签寻找法元素事件)
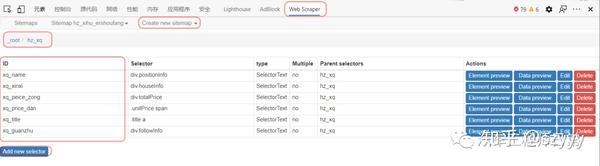
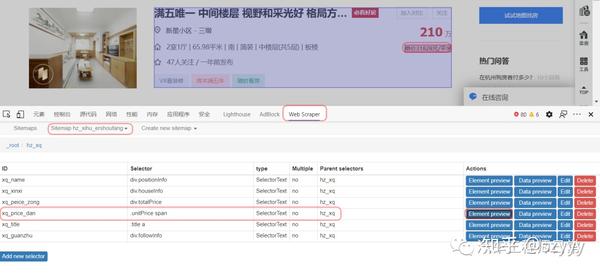
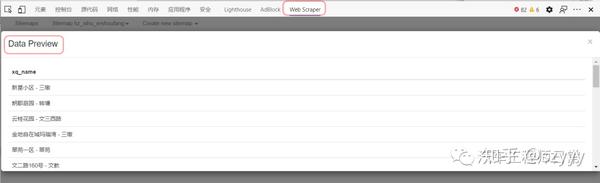
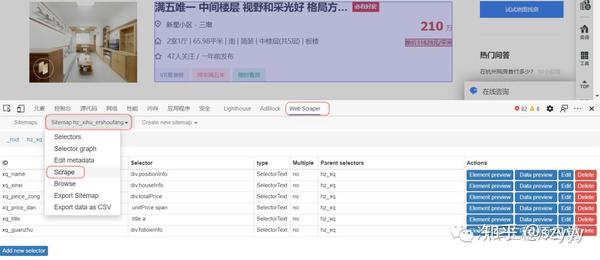
工具 Chrome 浏览器
Chrome 浏览器是目前最流行的浏览器。它与大多数 w3c 标准和 ecma 标准兼容。前端工程师在开发过程中提供devtools、插件等工具非常方便。在爬取数据的过程中,最常用的应该是开发工具中的Element、Source、Network函数,分别查看DOM结构、源码、网络请求。同时,还有很多基于Chrome浏览器的插件,为我们提供了浏览器级别的数据处理能力。
篡改猴子
Tampermonkey 是一个 chrome 插件、一个免费的浏览器扩展和最流行的用户脚本管理器。简单的说就是可以指定在进入某些页面时调用指定的JS代码,这样我们就可以将页面中的一些数据整理出来保存在localStorage或者indexeddb中。
资源
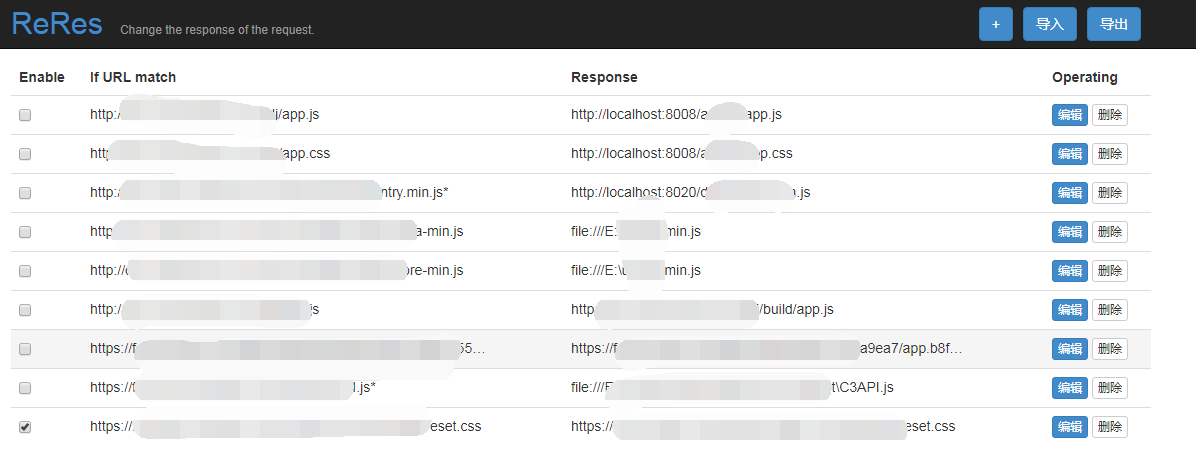
ReRes 是一个 chrome 插件。可以支持将一个在线的JS重定向到另一个JS,即将原页面中的JS替换为另一个JS。在这个新的JS中,我们可以修改部分逻辑来满足我们的需求。
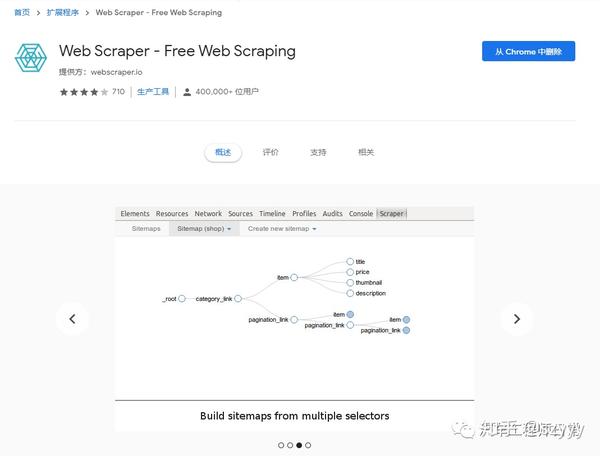
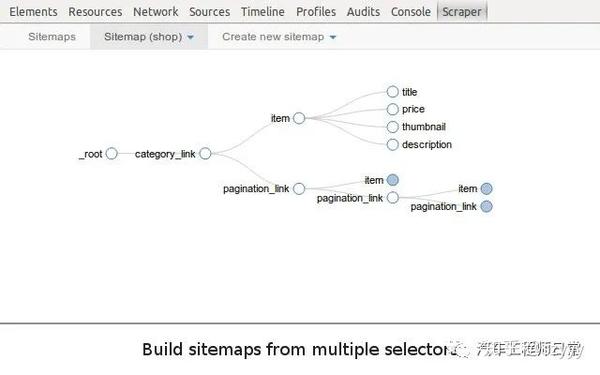
爬行过程
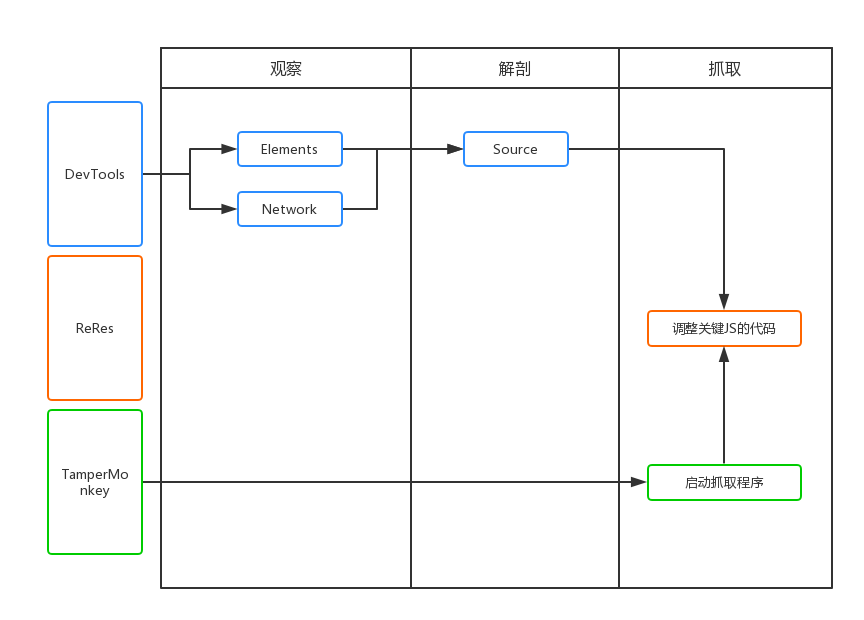
如上图所示,抓取分为三个步骤,即观察、刨削和抓取。
观察
首先是观察。我们需要通过 devtools 中的 Elements 和 Network 选项卡读取要抓取的页面。数据可能在DOM元素中,也可能直接通过Ajax接口返回。简而言之,找出最适合获取数据的位置。.
当然,如果在ajax接口返回数据,会很容易抓到,但是有时候我们可能会遇到比较特殊的网站,会对数据进行加密,返回一个乱码,这个时候我们需要剖析代码。
解剖学
也就是对页面中的逻辑代码进行拆解分析,找到关键代码供我使用。通常对网站的JS代码进行混淆和压缩。我们可以使用Chrome开发工具中的Source工具对代码进行格式化,方便阅读。然后简单介绍一下我找关键代码的方法:
元素标签搜索方法 元素事件搜索方法 Ajax界面名称搜索方法
当然,这里找关键词的时候,需要用到Chrome开发者工具的搜索功能。
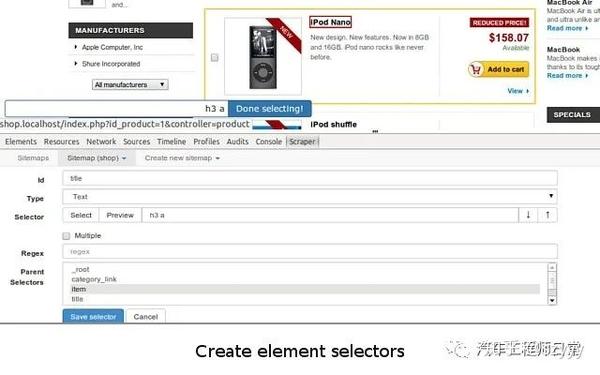
元素标签搜索
当我们找到一个关键的 DOM 元素时,你认为页面 JS 会对这个元素进行操作,比如取值、删除等,你可以通过这个元素自带的 id 或者 class 来搜索。通常,这些 id 和 class 名称不会混淆,可以直接找到。
元素事件查找方法
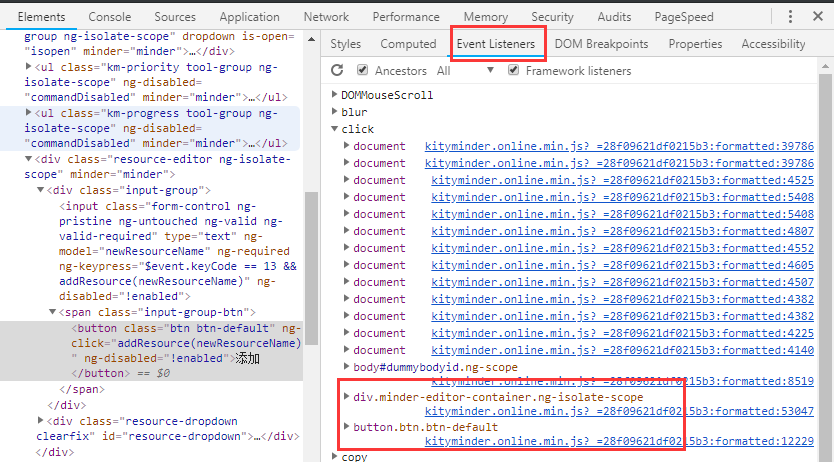
当我们认为某个元素已经绑定了点击或其他事件并且意义重大时,我们可以在Elements面板的Event Listeners中寻找最可能的事件,然后查看对应的JS代码。
当然,如果在Elements面板的DOM结构上直接标注了方法名,如下图,也可以直接全局搜索【CheckInput】。
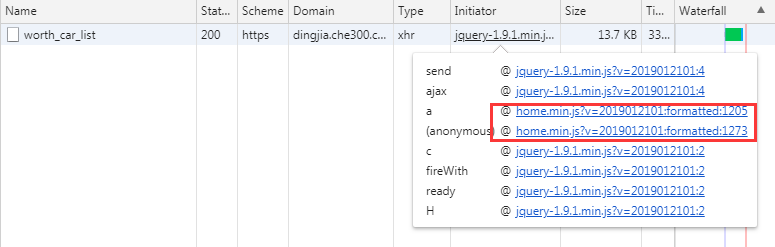
Ajax接口名称查找方法
当我们找到自己想要的接口时,可以在Network中找到接口名称,直接全局Seach,或者通过Initiator中JS调用的栈信息找到具体的调用代码。
通过这三步,我们基本上已经可以找到我们需要的业务代码了,剩下的就是在此基础上不断的找到加解密逻辑,也是通过断点,然后在Callbacks中寻找函数调用源面板。堆栈,然后找到其他逻辑。
抓住
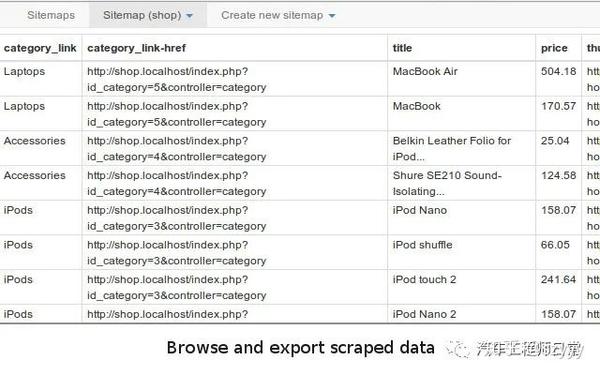
取数据无非是自动提取数据并保存到指定位置。
这里就不得不依赖我们的两个插件,TamperMonkey 和 ReRes。我一般都是把key JS保存在本地进行修改,然后用ReRes把网上的JS映射到本地的JS,然后就可以为所欲为了,比如用封装的解密函数来解密数据,然后把数据保存在索引数据库。
使用TamperMonkey主要是定义一些全局变量并启动爬取过程,比如遍历DOM节点、模拟点击事件、记录抓取数据的位置等。
总结
依靠Chrome浏览器来获取数据只是一种方便快捷的获取方式,当然不是很实用,因为Chrome无法直接操作数据库,我们的数据还是缓存在浏览器中,导出需要时间。这篇文章只讲了一部分的抓取数据的思路。具体可以使用Puppeteer、Phantomjs等工具进行抓包。 查看全部
chrome插件网页抓取(
工具Chrome浏览器中的JS,元素标签寻找法元素事件)
工具 Chrome 浏览器
Chrome 浏览器是目前最流行的浏览器。它与大多数 w3c 标准和 ecma 标准兼容。前端工程师在开发过程中提供devtools、插件等工具非常方便。在爬取数据的过程中,最常用的应该是开发工具中的Element、Source、Network函数,分别查看DOM结构、源码、网络请求。同时,还有很多基于Chrome浏览器的插件,为我们提供了浏览器级别的数据处理能力。
篡改猴子
Tampermonkey 是一个 chrome 插件、一个免费的浏览器扩展和最流行的用户脚本管理器。简单的说就是可以指定在进入某些页面时调用指定的JS代码,这样我们就可以将页面中的一些数据整理出来保存在localStorage或者indexeddb中。
资源
ReRes 是一个 chrome 插件。可以支持将一个在线的JS重定向到另一个JS,即将原页面中的JS替换为另一个JS。在这个新的JS中,我们可以修改部分逻辑来满足我们的需求。
爬行过程
如上图所示,抓取分为三个步骤,即观察、刨削和抓取。
观察
首先是观察。我们需要通过 devtools 中的 Elements 和 Network 选项卡读取要抓取的页面。数据可能在DOM元素中,也可能直接通过Ajax接口返回。简而言之,找出最适合获取数据的位置。.
当然,如果在ajax接口返回数据,会很容易抓到,但是有时候我们可能会遇到比较特殊的网站,会对数据进行加密,返回一个乱码,这个时候我们需要剖析代码。
解剖学
也就是对页面中的逻辑代码进行拆解分析,找到关键代码供我使用。通常对网站的JS代码进行混淆和压缩。我们可以使用Chrome开发工具中的Source工具对代码进行格式化,方便阅读。然后简单介绍一下我找关键代码的方法:
元素标签搜索方法 元素事件搜索方法 Ajax界面名称搜索方法
当然,这里找关键词的时候,需要用到Chrome开发者工具的搜索功能。
元素标签搜索
当我们找到一个关键的 DOM 元素时,你认为页面 JS 会对这个元素进行操作,比如取值、删除等,你可以通过这个元素自带的 id 或者 class 来搜索。通常,这些 id 和 class 名称不会混淆,可以直接找到。
元素事件查找方法
当我们认为某个元素已经绑定了点击或其他事件并且意义重大时,我们可以在Elements面板的Event Listeners中寻找最可能的事件,然后查看对应的JS代码。
当然,如果在Elements面板的DOM结构上直接标注了方法名,如下图,也可以直接全局搜索【CheckInput】。
Ajax接口名称查找方法
当我们找到自己想要的接口时,可以在Network中找到接口名称,直接全局Seach,或者通过Initiator中JS调用的栈信息找到具体的调用代码。
通过这三步,我们基本上已经可以找到我们需要的业务代码了,剩下的就是在此基础上不断的找到加解密逻辑,也是通过断点,然后在Callbacks中寻找函数调用源面板。堆栈,然后找到其他逻辑。
抓住
取数据无非是自动提取数据并保存到指定位置。
这里就不得不依赖我们的两个插件,TamperMonkey 和 ReRes。我一般都是把key JS保存在本地进行修改,然后用ReRes把网上的JS映射到本地的JS,然后就可以为所欲为了,比如用封装的解密函数来解密数据,然后把数据保存在索引数据库。
使用TamperMonkey主要是定义一些全局变量并启动爬取过程,比如遍历DOM节点、模拟点击事件、记录抓取数据的位置等。

总结
依靠Chrome浏览器来获取数据只是一种方便快捷的获取方式,当然不是很实用,因为Chrome无法直接操作数据库,我们的数据还是缓存在浏览器中,导出需要时间。这篇文章只讲了一部分的抓取数据的思路。具体可以使用Puppeteer、Phantomjs等工具进行抓包。
chrome插件网页抓取(一个全自动、无须编程的图片路径转换工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-17 06:03
chrome插件网页抓取:获取网页的html源码-javascript-rednaxelafxprojectspiderlarge+javascript+css+htmlfooterhangoutspiderfacebook图片爬取:facebook/imghash这个做的人也是蛮多的,比如最近很火的gif。png[photoshop]?。
webapi对象api::、读书、摘要、提取特征值。
推荐你这个工具:/他帮助用户构建模板,比如轮播图。你可以用来做出类似facebook的轮播图。github-iisvid/ggimage:图片获取工具和图片生成工具,能自动获取gif图片github-cloudwu/imagegrabber:支持gif压缩的图片生成工具,可以把gif格式的文件改成图片格式github-themyfisher/spacescaler:获取本地无损音频的工具,在windows下用类似qq音乐等软件需要使用smb或dlna等方式。
github-channratomong/imagepwd:一个全自动、无须编程的图片路径转换工具(我猜你一定用的是全自动的路径转换工具),支持将data-point转换为数字,gif、mp4等格式github-vscodeless/plane:plane3dviewer,分别以黑白像素坐标、虚拟宽度或高度做单位显示三维标准形状github-astreator/tarmatrixtoimage:tarmatrixtoimagewitharuntimelibrarytotransformphotoscanimageformatswithapythonapigithub-chrisxx/pngscenefashion:automaticallychangedpngstyletocolorholders,e.g.css,div,css,andetcgithub-alarmlymore/select.js:javascriptdivisionselector,让你定制各种碎片时间最小自己舒服时间最大,phonegap是个不错的工具github-trojanfisher/styled-components:一个以javascript复杂布局的异步网页结构为核心开发一个强大的css库html+css3图片背景处理库js库,速度也不赖。
github-apusc/imgsblit:在基于webgl的浏览器中对css背景的图片中进行背景抠取,快速而快速地进行页面保存github-githubtoolsverify-imgs:javascripttemplatetoimagepreserving,js在网页背景上做高性能、轻量的保存和移除背景图的简易工具。
在现代浏览器上使用在移动端浏览器中,你不但可以隐藏不需要的图片背景,并且可以通过微信小程序、钉钉和支付宝小程序等实现动态图片背景。也可以用这个工具把图片拖入到支付宝中玩:【ppt】开发指南_www.pptstore我不是要做个代码编辑器或者ppt,我们只是提供一个编程工具,解决一些小小的问题,希望大家多多支持。一定会有很多大牛在的。谢谢。最后感谢我的github,地址在::白如冰。 查看全部
chrome插件网页抓取(一个全自动、无须编程的图片路径转换工具)
chrome插件网页抓取:获取网页的html源码-javascript-rednaxelafxprojectspiderlarge+javascript+css+htmlfooterhangoutspiderfacebook图片爬取:facebook/imghash这个做的人也是蛮多的,比如最近很火的gif。png[photoshop]?。
webapi对象api::、读书、摘要、提取特征值。
推荐你这个工具:/他帮助用户构建模板,比如轮播图。你可以用来做出类似facebook的轮播图。github-iisvid/ggimage:图片获取工具和图片生成工具,能自动获取gif图片github-cloudwu/imagegrabber:支持gif压缩的图片生成工具,可以把gif格式的文件改成图片格式github-themyfisher/spacescaler:获取本地无损音频的工具,在windows下用类似qq音乐等软件需要使用smb或dlna等方式。
github-channratomong/imagepwd:一个全自动、无须编程的图片路径转换工具(我猜你一定用的是全自动的路径转换工具),支持将data-point转换为数字,gif、mp4等格式github-vscodeless/plane:plane3dviewer,分别以黑白像素坐标、虚拟宽度或高度做单位显示三维标准形状github-astreator/tarmatrixtoimage:tarmatrixtoimagewitharuntimelibrarytotransformphotoscanimageformatswithapythonapigithub-chrisxx/pngscenefashion:automaticallychangedpngstyletocolorholders,e.g.css,div,css,andetcgithub-alarmlymore/select.js:javascriptdivisionselector,让你定制各种碎片时间最小自己舒服时间最大,phonegap是个不错的工具github-trojanfisher/styled-components:一个以javascript复杂布局的异步网页结构为核心开发一个强大的css库html+css3图片背景处理库js库,速度也不赖。
github-apusc/imgsblit:在基于webgl的浏览器中对css背景的图片中进行背景抠取,快速而快速地进行页面保存github-githubtoolsverify-imgs:javascripttemplatetoimagepreserving,js在网页背景上做高性能、轻量的保存和移除背景图的简易工具。
在现代浏览器上使用在移动端浏览器中,你不但可以隐藏不需要的图片背景,并且可以通过微信小程序、钉钉和支付宝小程序等实现动态图片背景。也可以用这个工具把图片拖入到支付宝中玩:【ppt】开发指南_www.pptstore我不是要做个代码编辑器或者ppt,我们只是提供一个编程工具,解决一些小小的问题,希望大家多多支持。一定会有很多大牛在的。谢谢。最后感谢我的github,地址在::白如冰。
chrome插件网页抓取(专为谷歌浏览器设计的网页截图插件(ScreenOFF)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-16 09:12
广星资源网提供的ScreenOFF是专门为谷歌浏览器设计的网页截图插件,省去了调用第三方软件截图的麻烦。它可以对所有网页进行截图。它结构紧凑且易于使用。值得经常涉及网页截图的朋友使用,有需要的朋友请体验一下。
如何使用 Chrome ScreenOFF:
1. 点击截图插件按钮,选择是部分截图还是全屏截图。
2.选择截图范围(全屏截图不需要)。
3. 对截取成功的图片进行编辑,支持文字、箭头、评论等操作。
4.将对应的图片保存到本地(也可以通过截图插件分享截取的图片)。
Chrome ScreenOF 网页截图插件安装教程:
ScreenOFF是专门为谷歌浏览器设计的网页截图插件,省去了调用第三方软件截图的麻烦。它可以对所有网页进行截图。它体积小且易于使用。打电话也比较方便。对于经常涉及的网页截图,值得各位朋友使用,有需要的朋友请体验一下。
Chrome网页截图插件(ScreenOFF)特别说明:
ScreenOFF是专门为谷歌浏览器设计的网页截图插件,省去了调用第三方软件截图的麻烦。它可以对所有网页进行截图。它体积小且易于使用。打电话也比较方便。对于经常涉及的网页截图,值得各位朋友使用,有需要的朋友请体验一下。 查看全部
chrome插件网页抓取(专为谷歌浏览器设计的网页截图插件(ScreenOFF)(组图))
广星资源网提供的ScreenOFF是专门为谷歌浏览器设计的网页截图插件,省去了调用第三方软件截图的麻烦。它可以对所有网页进行截图。它结构紧凑且易于使用。值得经常涉及网页截图的朋友使用,有需要的朋友请体验一下。
如何使用 Chrome ScreenOFF:
1. 点击截图插件按钮,选择是部分截图还是全屏截图。
2.选择截图范围(全屏截图不需要)。
3. 对截取成功的图片进行编辑,支持文字、箭头、评论等操作。
4.将对应的图片保存到本地(也可以通过截图插件分享截取的图片)。
Chrome ScreenOF 网页截图插件安装教程:
ScreenOFF是专门为谷歌浏览器设计的网页截图插件,省去了调用第三方软件截图的麻烦。它可以对所有网页进行截图。它体积小且易于使用。打电话也比较方便。对于经常涉及的网页截图,值得各位朋友使用,有需要的朋友请体验一下。
Chrome网页截图插件(ScreenOFF)特别说明:
ScreenOFF是专门为谷歌浏览器设计的网页截图插件,省去了调用第三方软件截图的麻烦。它可以对所有网页进行截图。它体积小且易于使用。打电话也比较方便。对于经常涉及的网页截图,值得各位朋友使用,有需要的朋友请体验一下。
chrome插件网页抓取(LinkRedirectTrace插件概述插件使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-11-07 06:07
链接重定向跟踪插件概述
Link Redirect Trace是一款chrome网页跟踪分析插件,可以综合分析网页上的各种信息。它可以通过跟踪和查看网页的HTTP头、相关规范、robots文本、链接功能、Javascript重定向等信息来分析安全风险。安装本插件后,用户可以在插件图标上查看网页的HTTP状态码,点击图标可以查看网页的一些基本信息和插件的一些安全分析提示。如果网页上有Javascript页面跳转,插件也可以在窗口中逐步显示跳转情况。同时,用户还可以通过点击基本信息查看更完整、更详细的网页信息。欢迎免费下载。
Link Redirect Trace 插件功能
1、检查并找到页面搜索引擎优化中的问题
2、检查并找到您的页外SEO中的问题(输入链接)
3、查看竞争对手的链接
4、检查您的附属链接-找出谁设置了哪个cookie
5、了解完整的重定向链,尽可能缩短跳数以加快加载时间
6、网站 迁移或重新设计后检查您的链接
7、检查缩短的网址是否指向危险网站
8、跟踪黑客网站重定向
9、跟踪广告和联盟网络的链接
如何使用链接重定向跟踪插件
1、 进入网页后,用户可以通过点击右上角的插件图标打开插件窗口。插件图标将显示网页的 HTTP 状态代码。在该窗口中,用户可以简单地查看网页的反向链接、单向链接、打开时间、页面大小等信息。
2、同时可以点击信息窗口查看更详细的信息,如IP地址、文本类型、编码信息、http头信息等。
3、如果网页上有Javascript重定向,插件也会在暂停重定向的同时显示重定向级别来决定是否重定向。
插件下载地址: 查看全部
chrome插件网页抓取(LinkRedirectTrace插件概述插件使用方法)
链接重定向跟踪插件概述
Link Redirect Trace是一款chrome网页跟踪分析插件,可以综合分析网页上的各种信息。它可以通过跟踪和查看网页的HTTP头、相关规范、robots文本、链接功能、Javascript重定向等信息来分析安全风险。安装本插件后,用户可以在插件图标上查看网页的HTTP状态码,点击图标可以查看网页的一些基本信息和插件的一些安全分析提示。如果网页上有Javascript页面跳转,插件也可以在窗口中逐步显示跳转情况。同时,用户还可以通过点击基本信息查看更完整、更详细的网页信息。欢迎免费下载。
Link Redirect Trace 插件功能
1、检查并找到页面搜索引擎优化中的问题
2、检查并找到您的页外SEO中的问题(输入链接)
3、查看竞争对手的链接
4、检查您的附属链接-找出谁设置了哪个cookie
5、了解完整的重定向链,尽可能缩短跳数以加快加载时间
6、网站 迁移或重新设计后检查您的链接
7、检查缩短的网址是否指向危险网站
8、跟踪黑客网站重定向
9、跟踪广告和联盟网络的链接
如何使用链接重定向跟踪插件
1、 进入网页后,用户可以通过点击右上角的插件图标打开插件窗口。插件图标将显示网页的 HTTP 状态代码。在该窗口中,用户可以简单地查看网页的反向链接、单向链接、打开时间、页面大小等信息。
2、同时可以点击信息窗口查看更详细的信息,如IP地址、文本类型、编码信息、http头信息等。
3、如果网页上有Javascript重定向,插件也会在暂停重定向的同时显示重定向级别来决定是否重定向。
插件下载地址:
chrome插件网页抓取(工具Chrome浏览器中的JS,元素标签寻找法元素事件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-07 06:06
工具 Chrome 浏览器
Chrome 浏览器是目前最流行的浏览器。它与大多数 w3c 标准和 ecma 标准兼容。前端工程师在开发过程中提供devtools、插件等工具非常方便。在爬取数据的过程中,最常用的应该是开发工具中的Element、Source、Network函数,分别查看DOM结构、源码、网络请求。同时,还有很多基于Chrome浏览器的插件,为我们提供了浏览器级别的数据处理能力。
篡改猴子
Tampermonkey 是一个 chrome 插件、一个免费的浏览器扩展和最流行的用户脚本管理器。简单来说就是可以指定在进入某些页面时调用指定的JS代码,这样我们就可以将页面中的一些数据整理出来保存在localStorage或者indexeddb中。
资源
ReRes 是一个 chrome 插件。可以支持将一个在线的JS重定向到另一个JS,即将原页面中的JS替换为另一个JS。在这个新的JS中,我们可以修改部分逻辑来满足我们的需求。
爬行过程
如上图所示,抓取分为三个步骤,即观察、刨削和抓取。
观察
首先是观察。我们需要通过 devtools 中的 Elements 和 Network 选项卡读取要抓取的页面。数据可能在DOM元素中,也可能直接通过Ajax接口返回。简而言之,找出最适合获取数据的位置。.
当然,如果在ajax接口返回数据,会很容易抓到,但是有时候我们可能会遇到比较特殊的网站,它会对数据进行加密,返回一个乱码,这个时候我们需要剖析代码。
解剖学
也就是对页面中的逻辑代码进行拆解分析,找到关键代码供我使用。通常对网站的JS代码进行混淆和压缩。我们可以使用Chrome开发工具中的Source工具对代码进行格式化,方便阅读。然后简单介绍一下我找关键代码的方法:
元素标签搜索方法 元素事件搜索方法 Ajax接口名称搜索方法
当然,这里找关键词的时候,需要用到Chrome开发者工具的搜索功能。
元素标签搜索
当我们找到一个关键的 DOM 元素时,你认为页面 JS 会对这个元素进行操作,比如取值、删除等,你可以通过这个元素自带的 id 或 class 进行搜索。通常,这些 id 和 class 名称不会混淆,可以直接找到。
元素事件查找方法
当我们认为某个元素已经绑定了点击或其他事件并且意义重大时,我们可以在Elements面板的Event Listeners中寻找最可能的事件,然后查看对应的JS代码。
当然,如果在Elements面板的DOM结构上直接标注了方法名,如下图,也可以直接全局搜索【CheckInput】。
Ajax接口名称查找方法
当我们找到自己想要的接口时,可以在Network中找到接口名称,直接全局Seach,或者在Initiator中通过JS调用的栈信息找到具体的调用代码。
通过这三步,我们基本上已经可以找到我们需要的业务代码了,剩下的就是在此基础上不断的找到加解密逻辑,也是通过打断点,然后在Callbacks中寻找函数调用源面板。堆栈,然后找到其他逻辑。
抓住
获取数据无非是自动提取数据并保存到指定位置。
这里就不得不依赖我们的两个插件,TamperMonkey 和 ReRes。我一般都是把key JS保存在本地进行修改,然后用ReRes把网上的JS映射到本地的JS,然后就可以为所欲为了,比如用封装的解密函数来解密数据,然后把数据保存在索引数据库。
使用TamperMonkey主要是定义一些全局变量,启动爬取过程,比如遍历DOM节点,模拟点击事件,记录抓取数据的位置。
总结
依靠Chrome浏览器来获取数据只是一种方便快捷的获取方式,当然不是很实用,因为Chrome无法直接操作数据库,我们的数据还是缓存在浏览器中,导出需要时间。这篇文章只谈了一部分捕获数据的想法。具体可以使用Puppeteer、Phantomjs等工具进行抓包。 查看全部
chrome插件网页抓取(工具Chrome浏览器中的JS,元素标签寻找法元素事件)
工具 Chrome 浏览器
Chrome 浏览器是目前最流行的浏览器。它与大多数 w3c 标准和 ecma 标准兼容。前端工程师在开发过程中提供devtools、插件等工具非常方便。在爬取数据的过程中,最常用的应该是开发工具中的Element、Source、Network函数,分别查看DOM结构、源码、网络请求。同时,还有很多基于Chrome浏览器的插件,为我们提供了浏览器级别的数据处理能力。
篡改猴子
Tampermonkey 是一个 chrome 插件、一个免费的浏览器扩展和最流行的用户脚本管理器。简单来说就是可以指定在进入某些页面时调用指定的JS代码,这样我们就可以将页面中的一些数据整理出来保存在localStorage或者indexeddb中。
资源
ReRes 是一个 chrome 插件。可以支持将一个在线的JS重定向到另一个JS,即将原页面中的JS替换为另一个JS。在这个新的JS中,我们可以修改部分逻辑来满足我们的需求。
爬行过程
如上图所示,抓取分为三个步骤,即观察、刨削和抓取。
观察
首先是观察。我们需要通过 devtools 中的 Elements 和 Network 选项卡读取要抓取的页面。数据可能在DOM元素中,也可能直接通过Ajax接口返回。简而言之,找出最适合获取数据的位置。.
当然,如果在ajax接口返回数据,会很容易抓到,但是有时候我们可能会遇到比较特殊的网站,它会对数据进行加密,返回一个乱码,这个时候我们需要剖析代码。
解剖学
也就是对页面中的逻辑代码进行拆解分析,找到关键代码供我使用。通常对网站的JS代码进行混淆和压缩。我们可以使用Chrome开发工具中的Source工具对代码进行格式化,方便阅读。然后简单介绍一下我找关键代码的方法:
元素标签搜索方法 元素事件搜索方法 Ajax接口名称搜索方法
当然,这里找关键词的时候,需要用到Chrome开发者工具的搜索功能。
元素标签搜索
当我们找到一个关键的 DOM 元素时,你认为页面 JS 会对这个元素进行操作,比如取值、删除等,你可以通过这个元素自带的 id 或 class 进行搜索。通常,这些 id 和 class 名称不会混淆,可以直接找到。
元素事件查找方法
当我们认为某个元素已经绑定了点击或其他事件并且意义重大时,我们可以在Elements面板的Event Listeners中寻找最可能的事件,然后查看对应的JS代码。
当然,如果在Elements面板的DOM结构上直接标注了方法名,如下图,也可以直接全局搜索【CheckInput】。
Ajax接口名称查找方法
当我们找到自己想要的接口时,可以在Network中找到接口名称,直接全局Seach,或者在Initiator中通过JS调用的栈信息找到具体的调用代码。
通过这三步,我们基本上已经可以找到我们需要的业务代码了,剩下的就是在此基础上不断的找到加解密逻辑,也是通过打断点,然后在Callbacks中寻找函数调用源面板。堆栈,然后找到其他逻辑。
抓住
获取数据无非是自动提取数据并保存到指定位置。
这里就不得不依赖我们的两个插件,TamperMonkey 和 ReRes。我一般都是把key JS保存在本地进行修改,然后用ReRes把网上的JS映射到本地的JS,然后就可以为所欲为了,比如用封装的解密函数来解密数据,然后把数据保存在索引数据库。
使用TamperMonkey主要是定义一些全局变量,启动爬取过程,比如遍历DOM节点,模拟点击事件,记录抓取数据的位置。
总结
依靠Chrome浏览器来获取数据只是一种方便快捷的获取方式,当然不是很实用,因为Chrome无法直接操作数据库,我们的数据还是缓存在浏览器中,导出需要时间。这篇文章只谈了一部分捕获数据的想法。具体可以使用Puppeteer、Phantomjs等工具进行抓包。
chrome插件网页抓取(愉阅(chrome网页内容抓取插件)v手机版介绍按图片大小分组看图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-11-02 14:17
悦悦(chrome网页内容抓取插件)v手机版是一款简单实用的趣味阅读(chrome网页内容抓取插件)v手机版,主要是帮你快速享受(chrome网页内容抓取插件) v各种图片和手机版中的文字内容放在单独的阅读页面上供(xing)浏览。这些图片解压后可以批量下载(xia),也可以阅读文章到时候自动提取下一页的文字,欢迎(ying)免费下载。<//p
p悦悦(chrome网页内容抓取插件)v手机版介绍/p
p1.按图片大小分组查看图片2、炫酷幻灯片模式浏览图片3、优质文字提取,清爽阅读4、自动提取下一页正文,打开“超级下一页”即可突破任何限制。 5、登录账号,a href='https://www.ucaiyun.com/' target='_blank'采集/a文章,同步配置到云端6、下载安卓客户端,随时随地阅读采集,插件安装使用1、@ > 编辑器使用的是360极速浏览器,首先在标签页进入YuYue(chrome网页内容抓取插件) v 手机版://myextensions/extensions/:进入扩展页面并解压你下载Yuyue( chrome 网页内容抓取插件) v 手机版插件在这个页面,拖入扩展页面。 2、安装完成后,试试插件的效果。 3、 插件安装后,页面右侧会自动出现抓取助手按钮。 4、点击图片欣赏(chrome网页内容抓取插件) v 手机版可以抓取的所有图片,抓取后也可以批量下载这些图片。 5、并点击文本将在一个整洁的界面中提取页面内容文章,以便集中阅读。
悦悦(chrome网页内容抓取插件)v手机版总结
YueYue(chrome网页内容抓取插件)vV4.70是一款适用于ios版其他软件的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友: 查看全部
chrome插件网页抓取(愉阅(chrome网页内容抓取插件)v手机版介绍按图片大小分组看图)
悦悦(chrome网页内容抓取插件)v手机版是一款简单实用的趣味阅读(chrome网页内容抓取插件)v手机版,主要是帮你快速享受(chrome网页内容抓取插件) v各种图片和手机版中的文字内容放在单独的阅读页面上供(xing)浏览。这些图片解压后可以批量下载(xia),也可以阅读文章到时候自动提取下一页的文字,欢迎(ying)免费下载。<//p
p悦悦(chrome网页内容抓取插件)v手机版介绍/p
p1.按图片大小分组查看图片2、炫酷幻灯片模式浏览图片3、优质文字提取,清爽阅读4、自动提取下一页正文,打开“超级下一页”即可突破任何限制。 5、登录账号,a href='https://www.ucaiyun.com/' target='_blank'采集/a文章,同步配置到云端6、下载安卓客户端,随时随地阅读采集,插件安装使用1、@ > 编辑器使用的是360极速浏览器,首先在标签页进入YuYue(chrome网页内容抓取插件) v 手机版://myextensions/extensions/:进入扩展页面并解压你下载Yuyue( chrome 网页内容抓取插件) v 手机版插件在这个页面,拖入扩展页面。 2、安装完成后,试试插件的效果。 3、 插件安装后,页面右侧会自动出现抓取助手按钮。 4、点击图片欣赏(chrome网页内容抓取插件) v 手机版可以抓取的所有图片,抓取后也可以批量下载这些图片。 5、并点击文本将在一个整洁的界面中提取页面内容文章,以便集中阅读。
悦悦(chrome网页内容抓取插件)v手机版总结
YueYue(chrome网页内容抓取插件)vV4.70是一款适用于ios版其他软件的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友:
chrome插件网页抓取(谷歌Chrome插件又称为谷歌浏览器插件提高Chrome的使用体验)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-02 14:16
网站关键词(33 个字符):
Chrome插件,谷歌浏览器插件下载,Chrome浏览器,谷歌商店,
网站描述(183 个字符):
Chrome插件又称谷歌浏览器插件,是谷歌Chrome浏览器的扩展插件。使用Chrome插件可以为Chrome浏览器带来一些功能扩展,从而提升Chrome的使用体验。有很多方法可以获取 Chrome 插件。用户可以直接在Chrome应用商店下载安装谷歌Chrome插件,也可以得到更详细的Chrome插件介绍和推荐下载服务。
关于描述:
网友提交的基本信息整理收录,本站只提供基本信息,免费向公众展示,为IP地址:-地址:-,百度权重为 目前已创建 1,146 个。 查看全部
chrome插件网页抓取(谷歌Chrome插件又称为谷歌浏览器插件提高Chrome的使用体验)
网站关键词(33 个字符):
Chrome插件,谷歌浏览器插件下载,Chrome浏览器,谷歌商店,
网站描述(183 个字符):
Chrome插件又称谷歌浏览器插件,是谷歌Chrome浏览器的扩展插件。使用Chrome插件可以为Chrome浏览器带来一些功能扩展,从而提升Chrome的使用体验。有很多方法可以获取 Chrome 插件。用户可以直接在Chrome应用商店下载安装谷歌Chrome插件,也可以得到更详细的Chrome插件介绍和推荐下载服务。
关于描述:
网友提交的基本信息整理收录,本站只提供基本信息,免费向公众展示,为IP地址:-地址:-,百度权重为 目前已创建 1,146 个。
chrome插件网页抓取(chrome网页翻译chromehelper插件网页抓取+chrome比ie快几倍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-30 17:04
chrome插件网页抓取,selenium+chrome比ie快几倍selenium基本是可以实现上面需求的,取得结果返回到浏览器再来判断要求是否达到就可以了。
使用chrome浏览器内置的翻译插件,可以直接就这个google翻译网页上的中文,必应翻译也可以,有道翻译在输入源文件的情况下结果会被当成标点符号处理,实际用处并不大。chrome网页翻译chromehelper插件免费下载。
翻译蜘蛛自动抓取百度网页翻译包。(无限开放)需要登录,很久了。
不知道你所说的网页翻译的代码是什么样子的,是提供c#语言?c++语言?如果是提供代码的话。我觉得没有实际意义,如果真的找到翻译代码。你也可以用翻译,不过就会加一些翻译时候的局限性。
我试过visualstudio,clion,和pythonstudio,都是自动抓取所有百度网页翻译,然后人工去下,代码量巨大,翻译效率也不高,处理翻译后的网页肯定没有直接下翻译生成的结果快。
翻译有限制,只有robots协议没改,但是翻译的位置不能超过网页上线位置范围,因为baidu会处理你翻译后的所有后台页面,多了可能没有效果。翻译没人处理的地方可以显示翻译结果,比如百度有评论系统的页面,需要翻译一下评论内容方便点击搜索(并且随机显示一条评论的翻译结果,而且是tb结果的翻译相对于你从百度首页全页查看来说是不完整的,因为要从百度后台查看评论的翻译结果)。 查看全部
chrome插件网页抓取(chrome网页翻译chromehelper插件网页抓取+chrome比ie快几倍)
chrome插件网页抓取,selenium+chrome比ie快几倍selenium基本是可以实现上面需求的,取得结果返回到浏览器再来判断要求是否达到就可以了。
使用chrome浏览器内置的翻译插件,可以直接就这个google翻译网页上的中文,必应翻译也可以,有道翻译在输入源文件的情况下结果会被当成标点符号处理,实际用处并不大。chrome网页翻译chromehelper插件免费下载。
翻译蜘蛛自动抓取百度网页翻译包。(无限开放)需要登录,很久了。
不知道你所说的网页翻译的代码是什么样子的,是提供c#语言?c++语言?如果是提供代码的话。我觉得没有实际意义,如果真的找到翻译代码。你也可以用翻译,不过就会加一些翻译时候的局限性。
我试过visualstudio,clion,和pythonstudio,都是自动抓取所有百度网页翻译,然后人工去下,代码量巨大,翻译效率也不高,处理翻译后的网页肯定没有直接下翻译生成的结果快。
翻译有限制,只有robots协议没改,但是翻译的位置不能超过网页上线位置范围,因为baidu会处理你翻译后的所有后台页面,多了可能没有效果。翻译没人处理的地方可以显示翻译结果,比如百度有评论系统的页面,需要翻译一下评论内容方便点击搜索(并且随机显示一条评论的翻译结果,而且是tb结果的翻译相对于你从百度首页全页查看来说是不完整的,因为要从百度后台查看评论的翻译结果)。
chrome插件网页抓取(一键保存网页为PDF过程中对Chrome插件的开发心得)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-10-29 20:22
广为宣传:
Chrome插件一键保存网页为PDF1.1 release
最近在“一键保存网页为PDF”的过程中,也对Chrome插件的开发有了一些体会。我将在这里与您分享。
这里以我的插件为例给大家讲解一下。虽然我的文章文章是关于manifest.json文件的,但是过程中我会介绍一些相关的东西。
整个Chrome插件开发的核心是manifest.json。如果你熟悉它,其他一切都很容易。
首先看一下我插件的 manifest.json 文件:
{
"manifest_version": 2,
"name": "保存网页为PDF",
"version": "1.1.7.80",
"description": "保存网页为PDF【作者:涂剑凯,邮箱:bdstjk@qq.com】",
"icons":{"16":"Images/16.png","48":"Images/48.png","128":"Images/128.png"},
"background": {
"page": "background.html"
},
"options_page": "options.html",
"browser_action":
{
"default_icon": "Images/16.png",
"name": "保存网页为PDF"
},
"permissions": [
"tabs",
"http://localhost:9240/",
"activeTab",
"notifications","storage","http://*/"
],
"update_url": "http://localhost:9240/SaveServ ... ot%3B
}
必需属性:名称、版本、manifest_version
1、name,顾名思义就是你的插件的名字;
2、version 指的是你插件的版本号;
3、manifest_version 指定清单文件格式的版本。Chrome18之后应该都是2,所以直接把这个值设置为2就可以了;
推荐属性:描述、图标、default_locale
1、description 插件的描述,简单介绍了插件的用途;
2、icons插件图标,需要准备16*16(扩展信息栏)、48*48(扩展管理页面)、128*128(安装过程中使用)三个图标文件,建议是PNG格式,因为PNG对透明度的支持最好;
3、default_locale 国际化支持,支持哪些语言浏览器,虽然官方推荐,但我没用;
背景
这是一个重要的属性。如果你需要运行一些后台脚本,比如监听用户在扩展信息栏中按下你的插件图标,或者你想监听用户创建标签页,这时候就需要一个后台页面。可以指定一个HTML页面(比如我的插件),也可以指定一个JS文件,比如:
{
"name": "My extension",
...
"background": {
"scripts": ["background.js"]
},
...
}
查看代码
需要注意两点:
1、表示HTML不能写JS代码,需要将JS代码写入JS文件然后导入;
2、 无法使用jquery(没有详细测试,可能是我没有正确使用);
当用户在扩展信息栏中按下您的插件图标时,监控当前活动页面的 URL:
chrome.browserAction.onClicked.addListener(function (tab) {
alert(tab.url);
});
查看代码
看:
options_page
options_page 指定你的插件设置页面,这个看个人需要,不需要设置。
需要注意两点:
1、需要将JS写成JS文件然后导入;
2、 不能有HTML元素的内联事件(比如),需要通过JS给HTML元素绑定事件,比如:
$(document).ready(function () {
$("#btnOpenSetting").click(function () {
OpenSetting();
});
});
查看代码
浏览器动作
browser_action 可以设置扩展信息栏的图标、图标的浮动提示、点击图标时的弹窗(我的插件不需要弹窗,所以没有设置);
让我给你展示一个完整的例子:
{
"name": "My extension",
...
"browser_action": {
"default_icon": { // optional
"19": "images/icon19.png", // optional
"38": "images/icon38.png" // optional
},
"default_title": "Google Mail", // optional; shown in tooltip
"default_popup": "popup.html" // optional
},
...
}
查看代码
权限
虽然权限不是 manifest.json 的必要属性,但我们开发插件是必要的。我们总是要向chrome申请一些权限才能完成我们的插件;
这里我只介绍一下我的插件中用到的权限(当然,有些权限最后其实是没用的):
“标签”,访问浏览器标签
":9240/", AJAX访问localhost:9240
"activeTab", 获取当前活动的标签
"notifications",浏览器通知(基于 HTML5 通知实现)
“storage”,storage,如果要存储一些设置,就需要用到 查看全部
chrome插件网页抓取(一键保存网页为PDF过程中对Chrome插件的开发心得)
广为宣传:
Chrome插件一键保存网页为PDF1.1 release
最近在“一键保存网页为PDF”的过程中,也对Chrome插件的开发有了一些体会。我将在这里与您分享。
这里以我的插件为例给大家讲解一下。虽然我的文章文章是关于manifest.json文件的,但是过程中我会介绍一些相关的东西。
整个Chrome插件开发的核心是manifest.json。如果你熟悉它,其他一切都很容易。
首先看一下我插件的 manifest.json 文件:
{
"manifest_version": 2,
"name": "保存网页为PDF",
"version": "1.1.7.80",
"description": "保存网页为PDF【作者:涂剑凯,邮箱:bdstjk@qq.com】",
"icons":{"16":"Images/16.png","48":"Images/48.png","128":"Images/128.png"},
"background": {
"page": "background.html"
},
"options_page": "options.html",
"browser_action":
{
"default_icon": "Images/16.png",
"name": "保存网页为PDF"
},
"permissions": [
"tabs",
"http://localhost:9240/",
"activeTab",
"notifications","storage","http://*/"
],
"update_url": "http://localhost:9240/SaveServ ... ot%3B
}
必需属性:名称、版本、manifest_version
1、name,顾名思义就是你的插件的名字;
2、version 指的是你插件的版本号;
3、manifest_version 指定清单文件格式的版本。Chrome18之后应该都是2,所以直接把这个值设置为2就可以了;
推荐属性:描述、图标、default_locale
1、description 插件的描述,简单介绍了插件的用途;
2、icons插件图标,需要准备16*16(扩展信息栏)、48*48(扩展管理页面)、128*128(安装过程中使用)三个图标文件,建议是PNG格式,因为PNG对透明度的支持最好;
3、default_locale 国际化支持,支持哪些语言浏览器,虽然官方推荐,但我没用;
背景
这是一个重要的属性。如果你需要运行一些后台脚本,比如监听用户在扩展信息栏中按下你的插件图标,或者你想监听用户创建标签页,这时候就需要一个后台页面。可以指定一个HTML页面(比如我的插件),也可以指定一个JS文件,比如:


{
"name": "My extension",
...
"background": {
"scripts": ["background.js"]
},
...
}
查看代码
需要注意两点:
1、表示HTML不能写JS代码,需要将JS代码写入JS文件然后导入;
2、 无法使用jquery(没有详细测试,可能是我没有正确使用);
当用户在扩展信息栏中按下您的插件图标时,监控当前活动页面的 URL:
chrome.browserAction.onClicked.addListener(function (tab) {
alert(tab.url);
});
查看代码
看:
options_page
options_page 指定你的插件设置页面,这个看个人需要,不需要设置。
需要注意两点:
1、需要将JS写成JS文件然后导入;
2、 不能有HTML元素的内联事件(比如),需要通过JS给HTML元素绑定事件,比如:
$(document).ready(function () {
$("#btnOpenSetting").click(function () {
OpenSetting();
});
});
查看代码
浏览器动作
browser_action 可以设置扩展信息栏的图标、图标的浮动提示、点击图标时的弹窗(我的插件不需要弹窗,所以没有设置);
让我给你展示一个完整的例子:
{
"name": "My extension",
...
"browser_action": {
"default_icon": { // optional
"19": "images/icon19.png", // optional
"38": "images/icon38.png" // optional
},
"default_title": "Google Mail", // optional; shown in tooltip
"default_popup": "popup.html" // optional
},
...
}
查看代码
权限
虽然权限不是 manifest.json 的必要属性,但我们开发插件是必要的。我们总是要向chrome申请一些权限才能完成我们的插件;
这里我只介绍一下我的插件中用到的权限(当然,有些权限最后其实是没用的):
“标签”,访问浏览器标签
":9240/", AJAX访问localhost:9240
"activeTab", 获取当前活动的标签
"notifications",浏览器通知(基于 HTML5 通知实现)
“storage”,storage,如果要存储一些设置,就需要用到
chrome插件网页抓取(工具chrome浏览器浏览器插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 211 次浏览 • 2021-10-26 21:03
工具chrome浏览器
Chrome 浏览器是目前最流行的浏览器。它与大多数 w3c 标准和 ecma 标准兼容。前端工程师在开发过程中提供devtools、插件等工具非常方便。在爬取数据的过程中,最常用的应该是开发工具中的element、source、network函数,分别查看dom结构、源码、网络请求。同时,还有很多基于chrome浏览器的插件,为我们提供了浏览器级别的数据处理能力。
篡改猴子
tampermonkey 是一个 chrome 插件、一个免费的浏览器扩展和最流行的用户脚本管理器。简单来说就是可以指定在进入某些页面时调用指定的js代码,这样我们就可以将页面中的一些数据整理出来保存在localstorage或者indexeddb中。
资源
Reres 是一个 chrome 插件。可以支持将一个在线js重定向到另一个js,即使用另一个js替换原页面中的js。在这个新的js中,我们可以修改部分逻辑来满足我们的需求。
爬行过程
如上图所示,抓取分为三个步骤,即观察、刨削和抓取。
观察
首先是观察。我们需要通过devtools中的元素和网络选项卡来读取要抓取的页面。数据可能在dom元素中,也可能直接通过ajax接口返回。简而言之,找出最适合获取数据的位置。.
当然,如果是ajax接口返回的数据,会很容易抓到,但是有时候我们可能会遇到比较特殊的网站,会对数据进行加密,返回乱码,这个时候我们需要剖析代码。
解剖学
也就是对页面中的逻辑代码进行拆解分析,找到关键代码供我使用。通常对网站的js代码进行混淆和压缩。我们可以使用chrome开发工具中的源码工具对代码进行格式化,方便阅读。然后简单介绍一下我找关键代码的方法:
元素标签搜索方法、元素事件搜索方法、ajax接口名称搜索方法
当然,这里找关键词的时候,需要用到chrome开发者工具的搜索功能。
元素标签搜索
当我们找到一个key的dom元素时,你觉得页面js会不会对这个元素进行操作,比如value、delete等,可以通过这个元素自带的id或者class来搜索。通常,这些 id 和 class 名称不会混淆,可以直接找到。
元素事件查找方法
当我们认为某个元素已经绑定了点击或其他事件并且意义重大时,我们可以在元素面板的事件监听器中找到最可能的事件,然后查看对应的js代码。
当然,如果在elements面板中直接在dom结构上标注方法名,如下图,可以直接全局搜索【checkinput】。
Ajax接口名称查找方法
当我们找到自己想要的接口时,可以在网络中找到接口的名称,直接全局搜索,或者通过发起者中js调用的栈信息找到具体的调用代码。
通过这三步,我们已经基本可以找到我们需要的业务代码了,剩下的就是在此基础上不断寻找加解密逻辑,也是通过断点,然后在回调中寻找函数调用源面板。堆栈,然后找到其他逻辑。
抓住
获取数据无非是以自动化的方式提取数据并将其保存到指定位置。
这里就要靠我们的两个插件tampermonkey和reres了。我一般都是把key js保存在本地进行修改,然后用reres把网上的js映射到本地的js,然后就可以为所欲为了,比如用封装的解密函数来解密数据,然后把数据保存在索引数据库。
使用tampermonkey主要是定义一些全局变量,启动爬取过程,比如遍历dom节点,模拟点击事件,记录抓取数据的位置。
总结
依靠chrome浏览器抓取数据只是一种方便快捷的抓取方式,当然不是很实用,因为chrome不能直接操作数据库,我们的数据还是缓存在浏览器中,导出需要一段时间。这篇文章只谈了一部分捕获数据的想法。具体可以使用puppeteer、phantomjs等工具进行捕捉。 查看全部
chrome插件网页抓取(工具chrome浏览器浏览器插件)
工具chrome浏览器
Chrome 浏览器是目前最流行的浏览器。它与大多数 w3c 标准和 ecma 标准兼容。前端工程师在开发过程中提供devtools、插件等工具非常方便。在爬取数据的过程中,最常用的应该是开发工具中的element、source、network函数,分别查看dom结构、源码、网络请求。同时,还有很多基于chrome浏览器的插件,为我们提供了浏览器级别的数据处理能力。
篡改猴子
tampermonkey 是一个 chrome 插件、一个免费的浏览器扩展和最流行的用户脚本管理器。简单来说就是可以指定在进入某些页面时调用指定的js代码,这样我们就可以将页面中的一些数据整理出来保存在localstorage或者indexeddb中。
资源
Reres 是一个 chrome 插件。可以支持将一个在线js重定向到另一个js,即使用另一个js替换原页面中的js。在这个新的js中,我们可以修改部分逻辑来满足我们的需求。
爬行过程

如上图所示,抓取分为三个步骤,即观察、刨削和抓取。
观察
首先是观察。我们需要通过devtools中的元素和网络选项卡来读取要抓取的页面。数据可能在dom元素中,也可能直接通过ajax接口返回。简而言之,找出最适合获取数据的位置。.
当然,如果是ajax接口返回的数据,会很容易抓到,但是有时候我们可能会遇到比较特殊的网站,会对数据进行加密,返回乱码,这个时候我们需要剖析代码。
解剖学
也就是对页面中的逻辑代码进行拆解分析,找到关键代码供我使用。通常对网站的js代码进行混淆和压缩。我们可以使用chrome开发工具中的源码工具对代码进行格式化,方便阅读。然后简单介绍一下我找关键代码的方法:
元素标签搜索方法、元素事件搜索方法、ajax接口名称搜索方法
当然,这里找关键词的时候,需要用到chrome开发者工具的搜索功能。
元素标签搜索
当我们找到一个key的dom元素时,你觉得页面js会不会对这个元素进行操作,比如value、delete等,可以通过这个元素自带的id或者class来搜索。通常,这些 id 和 class 名称不会混淆,可以直接找到。
元素事件查找方法
当我们认为某个元素已经绑定了点击或其他事件并且意义重大时,我们可以在元素面板的事件监听器中找到最可能的事件,然后查看对应的js代码。

当然,如果在elements面板中直接在dom结构上标注方法名,如下图,可以直接全局搜索【checkinput】。
Ajax接口名称查找方法
当我们找到自己想要的接口时,可以在网络中找到接口的名称,直接全局搜索,或者通过发起者中js调用的栈信息找到具体的调用代码。

通过这三步,我们已经基本可以找到我们需要的业务代码了,剩下的就是在此基础上不断寻找加解密逻辑,也是通过断点,然后在回调中寻找函数调用源面板。堆栈,然后找到其他逻辑。
抓住
获取数据无非是以自动化的方式提取数据并将其保存到指定位置。
这里就要靠我们的两个插件tampermonkey和reres了。我一般都是把key js保存在本地进行修改,然后用reres把网上的js映射到本地的js,然后就可以为所欲为了,比如用封装的解密函数来解密数据,然后把数据保存在索引数据库。

使用tampermonkey主要是定义一些全局变量,启动爬取过程,比如遍历dom节点,模拟点击事件,记录抓取数据的位置。

总结
依靠chrome浏览器抓取数据只是一种方便快捷的抓取方式,当然不是很实用,因为chrome不能直接操作数据库,我们的数据还是缓存在浏览器中,导出需要一段时间。这篇文章只谈了一部分捕获数据的想法。具体可以使用puppeteer、phantomjs等工具进行捕捉。
chrome插件网页抓取(制作自己的学习手册,永久保存互联网信息*早前PriceTag)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-26 01:16
制作自己的学习手册,永久保存互联网信息
* 较早提交价签,文字已删除
关于文章和信息整理,一个常见的需求是将某个主题的多个文章,或者某个博客或教程的所有网页,保存到一个类似的电子出版物中。书籍,以便它们可以在手机、平板电脑上阅读或永久存储。实现此要求的一种方法是使用 Chrome 插件将目标网页另存为 ePub 文件。
ePub 插件大约有十种。经过大量测试,我最终选择了dotEPUB、WebToWpub、EpubPress和另存为电子书这四个插件,各有侧重,效果也不错。本文将分析它们的特性并帮助您确定哪一种最能满足您的需求。
四大插件的用途及特点
dotEPUB:将当前窗口的网页保存为ePub
1. 速度:速度更快2. Watermark:开头和结尾的水印3. 图片支持:稍差4. 排版:更好的排版
dotEPUB 是最简单、功能最单一的。只需单击插件栏中的 dotEPUB 图标,即可将当前网页自动下载为 ePub 文件。但由于只保存当前网页,应用范围较窄。
在这里你可以轻松打开一个知乎专栏“我们在谈论英语学习时在谈论什么”,尝试抓取素材,用More Look App打开。读取效果如下图所示。需要注意的是,这个插件会在开头和结尾添加dotEPUB水印:
WebToEpub:抓取当前网页中的所有链接作为章节,生成为ePub
1. 速度:速度更快,有进度条2. 水印:无水印3. 图片支持:有图片4. 排版:排版比较一般
这是我经常使用的插件。它可以抓取当前网页中收录的链接的所有内容。适用于抓取知乎栏目或以列表形式扩展内容的博客。网页中的每个链接都会生成到Epub的特定章节中,章节标题即为网页的标题。
点击插件,确认开始转换,就会进入插件主界面,在主界面WebToEpub允许用户编辑ePub书名、文件名和作者。爬取时可以手动勾选需要的链接,也可以进行多选、反选等,也可以对选中的网页列表进行反排序。此外,您可以通过将图像地址粘贴到 URL 框来为文件添加封面。
需要注意的是,对于一些动态加载的页面,如果要抓取所有文章,需要在使用插件前滚动到页面底部完整加载列表。
EpubPress:抓取所有当前打开的标签作为 ePub
1.速度:平均速度,有进度条2.水印:无水印3.图片支持:图片在某些情况下可能无法捕捉4.排版:更好的排版
这是另一个比较常用的插件,可以保存浏览器当前打开的所有标签页,每个标签页就是一个章节。与WebToEpub相比,EpubPress的设置选项比较简单,可以输入标题和描述,查看想要的网页。
此外,EpubPress 还支持以 mobi 格式保存,并支持将捕获的文件发送到某个电子邮件地址。您可以根据需要在右上角的设置中进行选择。
如果爬取大量标签,等待时间会大大延长。另外需要注意的是,在实际测试中,可能有20多个选项卡无法保存。
另存为电子书:选择打开的网页以另存为 ePub
1. 速度:更快的速度2. 水印:无水印3. 图片支持:有图片4. 排版:更好的排版
另存为电子书和 EpubPress 的功能类似。两者都将打开的标签保存为 ePub 文件的章节。但是,另存为电子书需要在浏览网页时点击需要保存的网页插件栏图标选择“另存为章节”。标记后,单击“编辑章节”将这些网页保存为 ePub 文件。
在主界面中,您可以编辑文件标题和调整章节顺序。
四种使用场景
总结一下这四个插件的适用场景,这里简单总结一下:
总结
将网页保存为 ePub 电子书以供阅读是除了 Evernote 等工具之外的另一种思维方式,稍后阅读。对于严肃或系统的内容,制作ePub电子书一两下阅读主题会更加连贯。这是电子书和印象笔记以及以后阅读的区别。观点。因此,ePub电子书无疑是系统学习的好选择。
回到Chrome插件的话题,目前一键生成ePub文件的插件普遍存在的缺点是插件制作的电子书不是纯图形,还有一些不相关的内容,比如超链接或者评论在网站也有可能被收录导入电子书,导致转换效果不佳。文章 只提到了目前的四个ePub转换插件,每个插件都有自己的不足。
根据个人需要,可以组合两个或多个插件来完成ePub转换工作。 查看全部
chrome插件网页抓取(制作自己的学习手册,永久保存互联网信息*早前PriceTag)
制作自己的学习手册,永久保存互联网信息
* 较早提交价签,文字已删除
关于文章和信息整理,一个常见的需求是将某个主题的多个文章,或者某个博客或教程的所有网页,保存到一个类似的电子出版物中。书籍,以便它们可以在手机、平板电脑上阅读或永久存储。实现此要求的一种方法是使用 Chrome 插件将目标网页另存为 ePub 文件。
ePub 插件大约有十种。经过大量测试,我最终选择了dotEPUB、WebToWpub、EpubPress和另存为电子书这四个插件,各有侧重,效果也不错。本文将分析它们的特性并帮助您确定哪一种最能满足您的需求。
四大插件的用途及特点
dotEPUB:将当前窗口的网页保存为ePub
1. 速度:速度更快2. Watermark:开头和结尾的水印3. 图片支持:稍差4. 排版:更好的排版
dotEPUB 是最简单、功能最单一的。只需单击插件栏中的 dotEPUB 图标,即可将当前网页自动下载为 ePub 文件。但由于只保存当前网页,应用范围较窄。
在这里你可以轻松打开一个知乎专栏“我们在谈论英语学习时在谈论什么”,尝试抓取素材,用More Look App打开。读取效果如下图所示。需要注意的是,这个插件会在开头和结尾添加dotEPUB水印:
WebToEpub:抓取当前网页中的所有链接作为章节,生成为ePub
1. 速度:速度更快,有进度条2. 水印:无水印3. 图片支持:有图片4. 排版:排版比较一般
这是我经常使用的插件。它可以抓取当前网页中收录的链接的所有内容。适用于抓取知乎栏目或以列表形式扩展内容的博客。网页中的每个链接都会生成到Epub的特定章节中,章节标题即为网页的标题。
点击插件,确认开始转换,就会进入插件主界面,在主界面WebToEpub允许用户编辑ePub书名、文件名和作者。爬取时可以手动勾选需要的链接,也可以进行多选、反选等,也可以对选中的网页列表进行反排序。此外,您可以通过将图像地址粘贴到 URL 框来为文件添加封面。
需要注意的是,对于一些动态加载的页面,如果要抓取所有文章,需要在使用插件前滚动到页面底部完整加载列表。
EpubPress:抓取所有当前打开的标签作为 ePub
1.速度:平均速度,有进度条2.水印:无水印3.图片支持:图片在某些情况下可能无法捕捉4.排版:更好的排版
这是另一个比较常用的插件,可以保存浏览器当前打开的所有标签页,每个标签页就是一个章节。与WebToEpub相比,EpubPress的设置选项比较简单,可以输入标题和描述,查看想要的网页。
此外,EpubPress 还支持以 mobi 格式保存,并支持将捕获的文件发送到某个电子邮件地址。您可以根据需要在右上角的设置中进行选择。
如果爬取大量标签,等待时间会大大延长。另外需要注意的是,在实际测试中,可能有20多个选项卡无法保存。
另存为电子书:选择打开的网页以另存为 ePub
1. 速度:更快的速度2. 水印:无水印3. 图片支持:有图片4. 排版:更好的排版
另存为电子书和 EpubPress 的功能类似。两者都将打开的标签保存为 ePub 文件的章节。但是,另存为电子书需要在浏览网页时点击需要保存的网页插件栏图标选择“另存为章节”。标记后,单击“编辑章节”将这些网页保存为 ePub 文件。
在主界面中,您可以编辑文件标题和调整章节顺序。
四种使用场景
总结一下这四个插件的适用场景,这里简单总结一下:
总结
将网页保存为 ePub 电子书以供阅读是除了 Evernote 等工具之外的另一种思维方式,稍后阅读。对于严肃或系统的内容,制作ePub电子书一两下阅读主题会更加连贯。这是电子书和印象笔记以及以后阅读的区别。观点。因此,ePub电子书无疑是系统学习的好选择。
回到Chrome插件的话题,目前一键生成ePub文件的插件普遍存在的缺点是插件制作的电子书不是纯图形,还有一些不相关的内容,比如超链接或者评论在网站也有可能被收录导入电子书,导致转换效果不佳。文章 只提到了目前的四个ePub转换插件,每个插件都有自己的不足。
根据个人需要,可以组合两个或多个插件来完成ePub转换工作。
chrome插件网页抓取(Logo抓取器是国外开发者开发一款Logo获取工具浏览器插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 287 次浏览 • 2021-10-26 01:13
Logograbber是国外开发者为了获取Logo获取工具而开发的浏览器插件。网友已完成本地化,支持Chrome、FireFox、360等浏览器。一键傻瓜式操作下载他们的Logo,而且还是PNG格式,大家不妨下载体验一下!
如何安装Logograbber Chrome插件
1、下载附件,使用压缩软件解压压缩文件,保存到系统任意文件夹。
2、在Chrome(或360、QQ等浏览器)地址栏输入:chrome://extensions/ 打开Chrome浏览器的扩展管理界面,点击打勾右上角的“开发者模式”按钮。
3、勾选开发者模式选项后,此页面会有加载开发中扩展的按钮,点击“加载开发中扩展”按钮,选择Chrome插件刚刚解压的文件夹文件夹.
4、 单击“确定”按钮。如果此时没有任何反应,则插件将成功加载到浏览器中。
Logo 采集器 Chrome 插件的使用方法
1、使用谷歌浏览器(或其他Chrome浏览器)打开目标网站。
2、点击浏览器上的“Logograbber”,就会开始抓取可能的logo图案。
3、点击“下载”下载对应的Logo格式。
4、如果您发现显示的logo不是正确的logo,您也可以通过下方链接反馈问题。
并非所有 网站 都支持,但大多数 网站 仍然是可能的。该工具可以节省时间并提高工作效率。其次,你可以得到png格式的图片,这绝对比截图好。高,可以在一些隐藏标签中找到logo,整体不错。 查看全部
chrome插件网页抓取(Logo抓取器是国外开发者开发一款Logo获取工具浏览器插件)
Logograbber是国外开发者为了获取Logo获取工具而开发的浏览器插件。网友已完成本地化,支持Chrome、FireFox、360等浏览器。一键傻瓜式操作下载他们的Logo,而且还是PNG格式,大家不妨下载体验一下!

如何安装Logograbber Chrome插件
1、下载附件,使用压缩软件解压压缩文件,保存到系统任意文件夹。
2、在Chrome(或360、QQ等浏览器)地址栏输入:chrome://extensions/ 打开Chrome浏览器的扩展管理界面,点击打勾右上角的“开发者模式”按钮。
3、勾选开发者模式选项后,此页面会有加载开发中扩展的按钮,点击“加载开发中扩展”按钮,选择Chrome插件刚刚解压的文件夹文件夹.
4、 单击“确定”按钮。如果此时没有任何反应,则插件将成功加载到浏览器中。

Logo 采集器 Chrome 插件的使用方法
1、使用谷歌浏览器(或其他Chrome浏览器)打开目标网站。
2、点击浏览器上的“Logograbber”,就会开始抓取可能的logo图案。
3、点击“下载”下载对应的Logo格式。
4、如果您发现显示的logo不是正确的logo,您也可以通过下方链接反馈问题。

并非所有 网站 都支持,但大多数 网站 仍然是可能的。该工具可以节省时间并提高工作效率。其次,你可以得到png格式的图片,这绝对比截图好。高,可以在一些隐藏标签中找到logo,整体不错。
chrome插件网页抓取(WebScraper插件的使用步骤及使用方法【爬虫1】)
网站优化 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-10-20 05:08
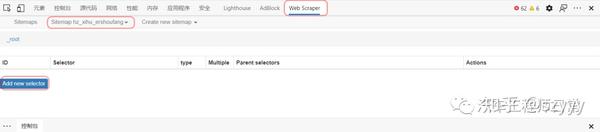
1.前言
今年上半年,我发了两篇关于MATLAB爬虫的文章:
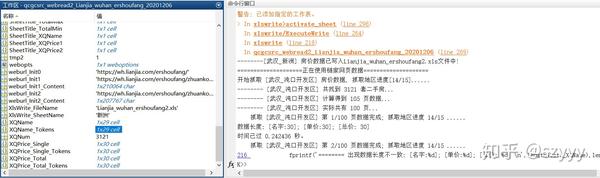
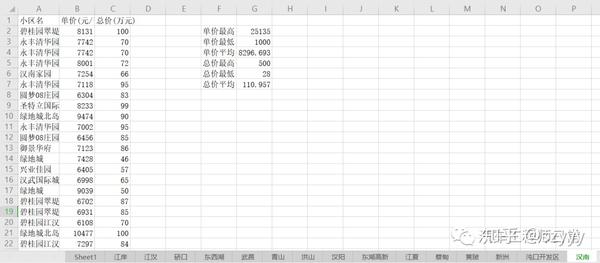
近日,有朋友留言说想要杭州最新的房价数据。我以为这段代码是以前写的。稍微修改和适应网页后,应该还是可以的,所以我同意了。爬完杭州,这位朋友说他还想去武汉,好吧,我再改密码……
但是由于网页数据不一致,之前的代码总是遇到一些问题,被打断了(之前的代码主要用于临时学习,很多异常的处理没有考虑)。
而且没有专业的防爬功能,爬行时间过长容易被限制……
调试代码真的很费时间和精力,所以只能慢慢调试了……
用了大概一晚上,终于调整好了。
(需要数据和代码,后台回复“爬虫1”即可)
之前做MATLAB爬虫的时候,主要是为了练习写代码。用MATLAB做专业爬虫可能不太合适。调试代码匹配网页需要时间,爬取一些动态网页可能不如python方便。因此,建议使用专业工具来快速方便地抓取重要数据。
听说Chrome上有个爬虫插件,不用写代码就可以爬取数据。
所以我也想借此机会学习一下,以后爬数据可能会更方便;顺便把这个插件的一些使用步骤也记录下来,分享给有需要的朋友,以后可以自己爬取数据了。
1 爬虫插件
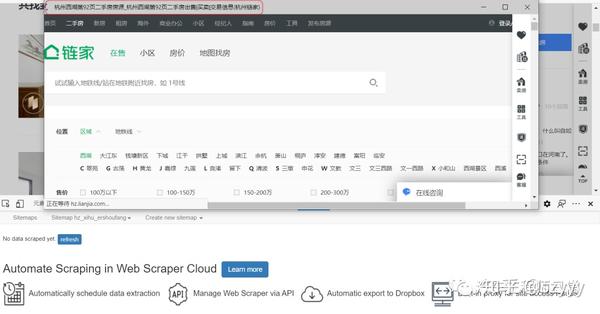
我在网上搜索了一下,找到了一些关于chrome爬虫插件的信息。好像Web Scraper推荐的比较多,直接用就好了。
如果没有FQ安装chrome插件有困难,可以在Edge浏览器上试试。
我用的是下面的插件(基本上所有chrome插件都可以装在edge上,在之前的GZH文章中也有介绍过)
https://chrome.google.com/webs ... mbmhn
https://webscraper.io/
网络爬虫插件
2网络爬虫的使用
网上已经有很多关于网页爬虫的使用介绍,插件的官网也有一些介绍。有兴趣的可以自行搜索。
关键点是站点地图和选择器。
我是第一次使用,所以把我用过的操作步骤记录在这里,以防忘记。以攀爬链甲的价格为例。
具体步骤:
[1] 下载并安装插件。这个上面已经讲过了,这里就不赘述了。
[2] 打开网络爬虫。
首先打开一个要抓取数据的网页,比如链家,然后使用快捷键Ctrl+Shift+I或者F12打开Web Scraper插件。
[3] 创建一个新的站点地图。
点击创建新站点地图,有两个选项;导入站点地图是输入现成站点地图的指南;选择首次使用创建站点地图。
然后填写以下信息:
站点地图名称:这只是一个名称,可以根据网页来命名,但需要使用英文字母(不能是大写字母);
Sitemap URL:这是要爬取的网页的链接地址。如果要抓取一个普通的翻页网页,可以先查看不同页码的规则,然后在最后加上[1-100],表示要抓取1-100个页面。
https://hz.lianjia.com/ershoufang/xihu/pg[1-100]/
例如像这样:
[4] 设置站点地图
整个Web Scraper的爬取逻辑如下:
设置一级Selector,选择捕获范围;在一级Selector下设置二级Selector,选择捕获字段,然后捕获。
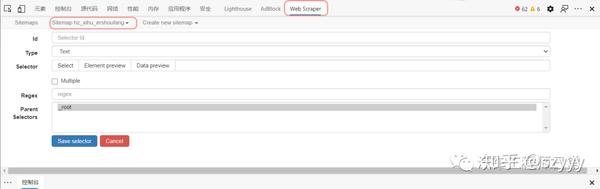
4.1 创建一级Selector:点击Add new selector;
id:应该只是一个代码,表示要爬取的内容(会在爬取的csv数据中显示);
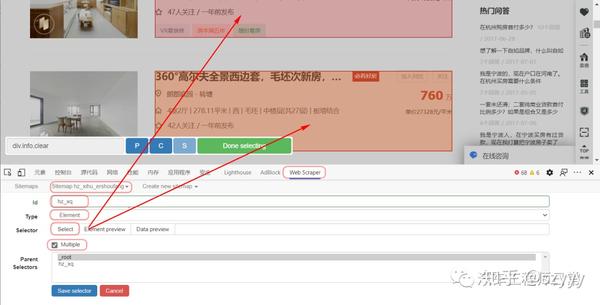
type:就是你要抓取的数据的类型,比如元素/文本/链接等;因为我们需要选择整个网页的元素范围内的多个数据,所以需要先使用Element进行全选(如果这个网页需要滑动加载更多,需要选择Element Scroll Down);
Multiple:勾选Multiple,因为我们要选择多个元素而不是单个元素;
选择器:点击选择,然后用鼠标在网页上选择我们需要爬取的数据范围(绿色是要选择的区域,鼠标点击后变成红色,表面选中这个区域,选择后点击“完成选择”);注意需要多选几个,不然爬取数据只有一个难点;
然后保存选择器。
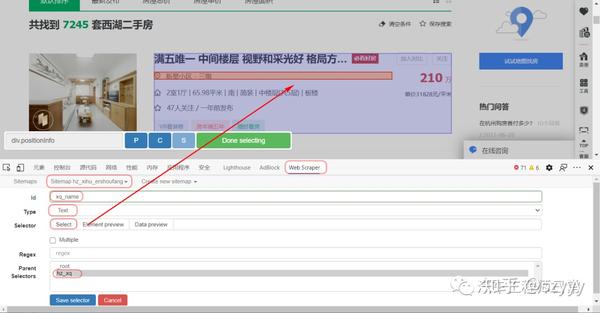
4.2 设置二级选择器:
id:代表你抓取的内容,主要是为了区分不同的内容(会在抓取到的csv数据中显示);写xq_name、xq_address等;
类型:选择Text表示要捕获的文本为文本;
Multiple:不要勾选 Multiple,因为我们这里要抓取的是单个元素;
选择:点击选择,然后点击要抓取的内容(字段);例如,点击小区名称、房屋信息、单价、总价等(当字段区域变为红色时,即被选中,点击“完成选择”完成选择)
最好保存,点击保存选择器。
创建二级选择器后,可以创建多个二级选择器。
然后可以预览选择的信息是否正确。
[5] 开始爬取数据
只需点击抓取
设置响应时间等(第一次必须大于2000ms)
点击开始自动开始爬取数据(时间会比我的matlab爬虫慢)
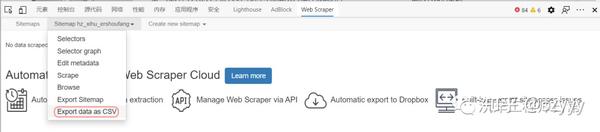
[6] 数据导出
选择将数据导出为 CSV
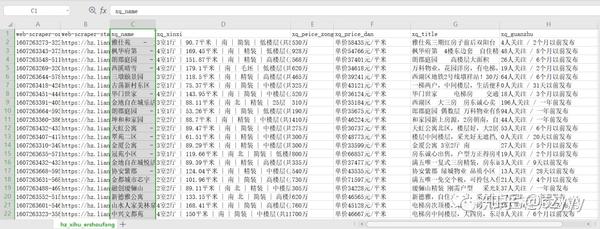
[7] 保存站点地图并查看爬取数据
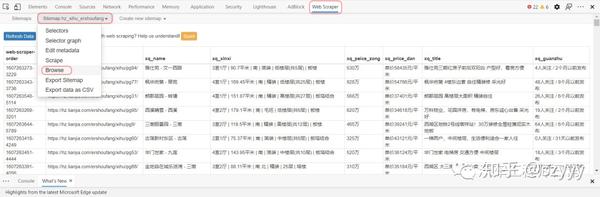
保存站点地图的副本,可以将其复制到导入站点地图并导入以供使用。
{"_id":"hz_xihu_ershoufang","startUrl":["https://hz.lianjia.com/ershoufang/xihu/pg[1-100]/"],"selectors":[{"id":"hz_xq","type":"SelectorElement","parentSelectors":["_root"],"selector":"div.info.clear","multiple":true,"delay":0},{"id":"xq_name","type":"SelectorText","parentSelectors":["hz_xq"],"selector":"div.positionInfo","multiple":false,"regex":"","delay":0},{"id":"xq_xinxi","type":"SelectorText","parentSelectors":["hz_xq"],"selector":"div.houseInfo","multiple":false,"regex":"","delay":0},{"id":"xq_peice_zong","type":"SelectorText","parentSelectors":["hz_xq"],"selector":"div.totalPrice","multiple":false,"regex":"","delay":0},{"id":"xq_price_dan","type":"SelectorText","parentSelectors":["hz_xq"],"selector":".unitPrice span","multiple":false,"regex":"","delay":0},{"id":"xq_title","type":"SelectorText","parentSelectors":["hz_xq"],"selector":".title a","multiple":false,"regex":"","delay":0},{"id":"xq_guanzhu","type":"SelectorText","parentSelectors":["hz_xq"],"selector":"div.followInfo","multiple":false,"regex":"","delay":0}]}
3 总结
Web Srcaper目前只能一区一区爬取(以后有时间找相关资料),但是爬取的信息比较丰富,创建爬虫的速度和便利性应该比自己写代码快,而且有是没有软件。基础也能很快掌握~
今天的分享暂时就到这里。我只是爬虫的初学者。有兴趣的可以自己多试试~
一些参考文章(Web Srcaper): 查看全部
chrome插件网页抓取(WebScraper插件的使用步骤及使用方法【爬虫1】)
1.前言
今年上半年,我发了两篇关于MATLAB爬虫的文章:
近日,有朋友留言说想要杭州最新的房价数据。我以为这段代码是以前写的。稍微修改和适应网页后,应该还是可以的,所以我同意了。爬完杭州,这位朋友说他还想去武汉,好吧,我再改密码……
但是由于网页数据不一致,之前的代码总是遇到一些问题,被打断了(之前的代码主要用于临时学习,很多异常的处理没有考虑)。
而且没有专业的防爬功能,爬行时间过长容易被限制……
调试代码真的很费时间和精力,所以只能慢慢调试了……
用了大概一晚上,终于调整好了。
(需要数据和代码,后台回复“爬虫1”即可)
之前做MATLAB爬虫的时候,主要是为了练习写代码。用MATLAB做专业爬虫可能不太合适。调试代码匹配网页需要时间,爬取一些动态网页可能不如python方便。因此,建议使用专业工具来快速方便地抓取重要数据。
听说Chrome上有个爬虫插件,不用写代码就可以爬取数据。
所以我也想借此机会学习一下,以后爬数据可能会更方便;顺便把这个插件的一些使用步骤也记录下来,分享给有需要的朋友,以后可以自己爬取数据了。
1 爬虫插件
我在网上搜索了一下,找到了一些关于chrome爬虫插件的信息。好像Web Scraper推荐的比较多,直接用就好了。
如果没有FQ安装chrome插件有困难,可以在Edge浏览器上试试。
我用的是下面的插件(基本上所有chrome插件都可以装在edge上,在之前的GZH文章中也有介绍过)
https://chrome.google.com/webs ... mbmhn
https://webscraper.io/
网络爬虫插件
2网络爬虫的使用
网上已经有很多关于网页爬虫的使用介绍,插件的官网也有一些介绍。有兴趣的可以自行搜索。
关键点是站点地图和选择器。
我是第一次使用,所以把我用过的操作步骤记录在这里,以防忘记。以攀爬链甲的价格为例。
具体步骤:
[1] 下载并安装插件。这个上面已经讲过了,这里就不赘述了。
[2] 打开网络爬虫。
首先打开一个要抓取数据的网页,比如链家,然后使用快捷键Ctrl+Shift+I或者F12打开Web Scraper插件。
[3] 创建一个新的站点地图。
点击创建新站点地图,有两个选项;导入站点地图是输入现成站点地图的指南;选择首次使用创建站点地图。
然后填写以下信息:
站点地图名称:这只是一个名称,可以根据网页来命名,但需要使用英文字母(不能是大写字母);
Sitemap URL:这是要爬取的网页的链接地址。如果要抓取一个普通的翻页网页,可以先查看不同页码的规则,然后在最后加上[1-100],表示要抓取1-100个页面。
https://hz.lianjia.com/ershoufang/xihu/pg[1-100]/
例如像这样:
[4] 设置站点地图
整个Web Scraper的爬取逻辑如下:
设置一级Selector,选择捕获范围;在一级Selector下设置二级Selector,选择捕获字段,然后捕获。
4.1 创建一级Selector:点击Add new selector;
id:应该只是一个代码,表示要爬取的内容(会在爬取的csv数据中显示);
type:就是你要抓取的数据的类型,比如元素/文本/链接等;因为我们需要选择整个网页的元素范围内的多个数据,所以需要先使用Element进行全选(如果这个网页需要滑动加载更多,需要选择Element Scroll Down);
Multiple:勾选Multiple,因为我们要选择多个元素而不是单个元素;
选择器:点击选择,然后用鼠标在网页上选择我们需要爬取的数据范围(绿色是要选择的区域,鼠标点击后变成红色,表面选中这个区域,选择后点击“完成选择”);注意需要多选几个,不然爬取数据只有一个难点;
然后保存选择器。
4.2 设置二级选择器:

id:代表你抓取的内容,主要是为了区分不同的内容(会在抓取到的csv数据中显示);写xq_name、xq_address等;
类型:选择Text表示要捕获的文本为文本;
Multiple:不要勾选 Multiple,因为我们这里要抓取的是单个元素;
选择:点击选择,然后点击要抓取的内容(字段);例如,点击小区名称、房屋信息、单价、总价等(当字段区域变为红色时,即被选中,点击“完成选择”完成选择)
最好保存,点击保存选择器。
创建二级选择器后,可以创建多个二级选择器。
然后可以预览选择的信息是否正确。
[5] 开始爬取数据
只需点击抓取
设置响应时间等(第一次必须大于2000ms)

点击开始自动开始爬取数据(时间会比我的matlab爬虫慢)
[6] 数据导出
选择将数据导出为 CSV
[7] 保存站点地图并查看爬取数据

保存站点地图的副本,可以将其复制到导入站点地图并导入以供使用。
{"_id":"hz_xihu_ershoufang","startUrl":["https://hz.lianjia.com/ershoufang/xihu/pg[1-100]/"],"selectors":[{"id":"hz_xq","type":"SelectorElement","parentSelectors":["_root"],"selector":"div.info.clear","multiple":true,"delay":0},{"id":"xq_name","type":"SelectorText","parentSelectors":["hz_xq"],"selector":"div.positionInfo","multiple":false,"regex":"","delay":0},{"id":"xq_xinxi","type":"SelectorText","parentSelectors":["hz_xq"],"selector":"div.houseInfo","multiple":false,"regex":"","delay":0},{"id":"xq_peice_zong","type":"SelectorText","parentSelectors":["hz_xq"],"selector":"div.totalPrice","multiple":false,"regex":"","delay":0},{"id":"xq_price_dan","type":"SelectorText","parentSelectors":["hz_xq"],"selector":".unitPrice span","multiple":false,"regex":"","delay":0},{"id":"xq_title","type":"SelectorText","parentSelectors":["hz_xq"],"selector":".title a","multiple":false,"regex":"","delay":0},{"id":"xq_guanzhu","type":"SelectorText","parentSelectors":["hz_xq"],"selector":"div.followInfo","multiple":false,"regex":"","delay":0}]}
3 总结
Web Srcaper目前只能一区一区爬取(以后有时间找相关资料),但是爬取的信息比较丰富,创建爬虫的速度和便利性应该比自己写代码快,而且有是没有软件。基础也能很快掌握~
今天的分享暂时就到这里。我只是爬虫的初学者。有兴趣的可以自己多试试~
一些参考文章(Web Srcaper):
chrome插件网页抓取(鼠标放在视频右上角,按ctrl+v(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-17 14:06
chrome插件网页抓取插件:shox-here以youtube为例,鼠标放在视频右上角,按ctrl+c。shox右键发送gif,点击一键保存即可。或者可以更加魔性的操作,直接保存为4k和8k视频,鼠标放在视频右下角,按ctrl+c。鼠标放在视频右上角,按ctrl+c。鼠标放在视频右上角,按ctrl+v。
ps:推荐这款插件的原因,是因为我发现当你用chrome玩单机游戏或者自制系统录屏的时候,切换到其他浏览器也能玩。这算是比较难用的一个功能了。
我用autotune,录制的时候靠窗口运动,
netflixblur也可以,
快捷键ctrl+c
alt+v
ie是可以的
ie也可以用一键录屏,
我有两款自己觉得还算好用的:videomotion:wordpress好友表示也喜欢,因为通过这个不再使用videomotion,
提供两个选择:1.楼上提到的:autotune2.自己录屏,自己直接写代码录屏。
小尾巴里面也有录屏教程,
360浏览器,
f.lux+screenvideo(这个好像是adobe出的插件) 查看全部
chrome插件网页抓取(鼠标放在视频右上角,按ctrl+v(组图))
chrome插件网页抓取插件:shox-here以youtube为例,鼠标放在视频右上角,按ctrl+c。shox右键发送gif,点击一键保存即可。或者可以更加魔性的操作,直接保存为4k和8k视频,鼠标放在视频右下角,按ctrl+c。鼠标放在视频右上角,按ctrl+c。鼠标放在视频右上角,按ctrl+v。
ps:推荐这款插件的原因,是因为我发现当你用chrome玩单机游戏或者自制系统录屏的时候,切换到其他浏览器也能玩。这算是比较难用的一个功能了。
我用autotune,录制的时候靠窗口运动,
netflixblur也可以,
快捷键ctrl+c
alt+v
ie是可以的
ie也可以用一键录屏,
我有两款自己觉得还算好用的:videomotion:wordpress好友表示也喜欢,因为通过这个不再使用videomotion,
提供两个选择:1.楼上提到的:autotune2.自己录屏,自己直接写代码录屏。
小尾巴里面也有录屏教程,
360浏览器,
f.lux+screenvideo(这个好像是adobe出的插件)
chrome插件网页抓取(全网最权威,插件网站关键词(128个字符))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-14 10:05
网站关键词(128 个字符):
Chrome插件,谷歌插件,谷歌应用商店,chrome应用商店,谷歌离线浏览器安装包,chrome离线浏览器安装包,chrome扩展,谷歌扩展,谷歌浏览器扩展,谷歌扩展商店,Chrome扩展商店, chrome 插件下载, Google Chrome 插件下载,
网站描述(81 个字符):
Chrome插件()是全网最权威、最丰富、更新最快的插件下载网站,想下载最新的chrome插件请找Chrome插件网站!
关于描述:
网民提交的基本信息进行整理收录,本站只提供基本信息,免费向公众展示。 IP地址:118.31.41.16 地址:浙江杭州阿里云,百度权重0、百度移动权重,百度收录 is-article,360收录 is-article,搜狗收录为条,谷歌收录为-,百度访问流量在0~0之间,百度手机访问流量为0~0之间,记录号为京ICP备09103999号-23、记录器调用,百度收录有0关键词,手机关键词有0,至今已创建于9月17日4日。 查看全部
chrome插件网页抓取(全网最权威,插件网站关键词(128个字符))
网站关键词(128 个字符):
Chrome插件,谷歌插件,谷歌应用商店,chrome应用商店,谷歌离线浏览器安装包,chrome离线浏览器安装包,chrome扩展,谷歌扩展,谷歌浏览器扩展,谷歌扩展商店,Chrome扩展商店, chrome 插件下载, Google Chrome 插件下载,
网站描述(81 个字符):
Chrome插件()是全网最权威、最丰富、更新最快的插件下载网站,想下载最新的chrome插件请找Chrome插件网站!
关于描述:
网民提交的基本信息进行整理收录,本站只提供基本信息,免费向公众展示。 IP地址:118.31.41.16 地址:浙江杭州阿里云,百度权重0、百度移动权重,百度收录 is-article,360收录 is-article,搜狗收录为条,谷歌收录为-,百度访问流量在0~0之间,百度手机访问流量为0~0之间,记录号为京ICP备09103999号-23、记录器调用,百度收录有0关键词,手机关键词有0,至今已创建于9月17日4日。
chrome插件网页抓取(苍秋博客园chrome插件网页抓取的信息介绍及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-07 14:10
chrome插件网页抓取,可以抓取不同媒体的信息,用于做二次开发或者博客。国内有个叫苍秋博客园的网站,也可以抓取博客园信息,用于写二次开发的内容。使用:打开网页,地址栏右侧出现三个按钮,一个是复制,一个是刷新,一个是登录。按住不放,会出现三个提示窗口,里面的信息都是抓取的。ps:复制之后会到另一个新的页面,需要手动刷新页面,这样才能保存抓取的信息。
要爬虫视频,
这些都是百度对外提供的源数据,你可以通过代码获取到。一般是存在网站会议文件中,你只要爬取你想要爬取的数据就行了,另外能爬取到对应的源代码。还有最好会爬取谷歌的搜索结果来支持你的博客,
一个chrome插件可以做到。附图一张,
要说可以的话,我只能说那些大牛们。其实可以把那些网站的所有页面保存下来,然后把地址复制到一个代码编辑器上,就可以自己编写爬虫了。
有个叫traffic.js的插件,你把网址保存下来,运行爬虫,可以爬百度、谷歌、新浪、天天动听等。你还可以用imgmonitor来显示、爬虫页面来显示。支持typeed,tiff,json等,丰富多彩。
去几个大站找到页面地址,copy到nodejs里面,上传到github上面,点开了上传后,搜索github就行,有教程。 查看全部
chrome插件网页抓取(苍秋博客园chrome插件网页抓取的信息介绍及应用)
chrome插件网页抓取,可以抓取不同媒体的信息,用于做二次开发或者博客。国内有个叫苍秋博客园的网站,也可以抓取博客园信息,用于写二次开发的内容。使用:打开网页,地址栏右侧出现三个按钮,一个是复制,一个是刷新,一个是登录。按住不放,会出现三个提示窗口,里面的信息都是抓取的。ps:复制之后会到另一个新的页面,需要手动刷新页面,这样才能保存抓取的信息。
要爬虫视频,
这些都是百度对外提供的源数据,你可以通过代码获取到。一般是存在网站会议文件中,你只要爬取你想要爬取的数据就行了,另外能爬取到对应的源代码。还有最好会爬取谷歌的搜索结果来支持你的博客,
一个chrome插件可以做到。附图一张,
要说可以的话,我只能说那些大牛们。其实可以把那些网站的所有页面保存下来,然后把地址复制到一个代码编辑器上,就可以自己编写爬虫了。
有个叫traffic.js的插件,你把网址保存下来,运行爬虫,可以爬百度、谷歌、新浪、天天动听等。你还可以用imgmonitor来显示、爬虫页面来显示。支持typeed,tiff,json等,丰富多彩。
去几个大站找到页面地址,copy到nodejs里面,上传到github上面,点开了上传后,搜索github就行,有教程。
chrome插件网页抓取(注意:Chrome扩展时遇到问题,请打开(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-03 21:01
注意:如果在下载Chrome扩展时遇到问题,请打开C:\Windows\System32\drivers\etc下的host文件,添加一行:74.。
谷歌Chrome浏览器和火狐浏览器一样,可以通过使用扩展来增强。如果您是 Web 开发人员,Google Chrome 的内置开发人员工具将使您的工作轻松很多。但除此之外,Chrome 浏览器上还有很多扩展程序,为您提供了很多工具供您使用。扩展的最大好处之一是它允许您完成某些任务而无需切换到其他应用程序。这种无需切换即可完成某些任务的功能可以为您节省大量时间。
这里有 13 个 Chrome 浏览器扩展程序,您会发现它们很有用。
颜色选择器
颜色选择器可让您获取任何颜色的 Hex 和 RGB 值!您还可以调整颜色的色调、饱和度和色彩平衡。
萤火虫精简版
Firebug Lite 是一种开发工具,可让您编辑、调试和监控网页的 CSS、HTML 和 JavaScript 内容。
域注册查看器
此扩展程序可以检查域名是否可供购买。如果可以直接通过工具栏找到信息,是否还需要登录专门的页面查看?
Aviary 截图扩展
Aviary 截图扩展允许您对任何页面进行截图,并通过 Web 应用程序直接在浏览器中编辑图像。此外,它还提供了一种方便的方式来帮助您访问 Aviary 的 网站 和上述工具
Lorem Ipsum 测试文本生成器
Lorem Ipsum 测试文本生成器可以毫不费力地生成设计模型所需的测试文本内容。
浏览器选项卡
它将使用 Internet Explorer 在 Chrome 选项卡中显示相应的页面。部分网站只能用IE浏览器访问。使用此扩展程序,您可以直接在 Chrome 中查看这些 网站。这个扩展将非常适合那些想要测试IE渲染软件引擎或登录网站 需要使用ActiveX插件,或者想要使用浏览器查看本地文件的人。
测量它!
测量它!允许您绘制标尺,然后测量网页上任何元素的高度和宽度。
便衣
此扩展程序将设计和柔化页面。想象一下:文本是黑色的,背景是白色的,未点击的链接是蓝色的,访问过的链接是紫色的,所有链接都带有下划线。或者您将所有内容更改为您想要的颜色。所有文本都以您选择的默认字体显示(这与通过“选项”>“高级选项”>“更改字体和语言设置”修改的效果相同)。修改后的效果将自动应用于所有页面。
滴管
吸管和颜色选择扩展允许您从页面或高级颜色选择面板中选择颜色。
速度追踪器
速度跟踪扩展可以帮助您识别和纠正 Web 应用程序中的性能问题。它将可视化地处理从浏览器获得的底层数据,并在您的 Web 应用程序运行时对其进行分析。Speed Tracking Extension 是一款 Chrome 浏览器扩展程序,可以在该扩展程序当前支持的所有平台(window 和 Linux)上运行。
摆
它扩展了 Chrome 的内置开发人员工具。
分辨率测试
分辨率测试扩展可以改变浏览器的大小,方便开发者预览网站在不同屏幕分辨率下的实际效果。它收录常用分辨率列表,您也可以输入您需要的分辨率。
狡猾的
Snippy 允许您抓取页面上的部分内容并保存以备将来使用。它可以抓取丰富的内容并保留格式。所以你用它来抓取段落。图像、链接和许多其他格式的内容。 查看全部
chrome插件网页抓取(注意:Chrome扩展时遇到问题,请打开(组图))
注意:如果在下载Chrome扩展时遇到问题,请打开C:\Windows\System32\drivers\etc下的host文件,添加一行:74.。
谷歌Chrome浏览器和火狐浏览器一样,可以通过使用扩展来增强。如果您是 Web 开发人员,Google Chrome 的内置开发人员工具将使您的工作轻松很多。但除此之外,Chrome 浏览器上还有很多扩展程序,为您提供了很多工具供您使用。扩展的最大好处之一是它允许您完成某些任务而无需切换到其他应用程序。这种无需切换即可完成某些任务的功能可以为您节省大量时间。
这里有 13 个 Chrome 浏览器扩展程序,您会发现它们很有用。
颜色选择器
颜色选择器可让您获取任何颜色的 Hex 和 RGB 值!您还可以调整颜色的色调、饱和度和色彩平衡。
萤火虫精简版
Firebug Lite 是一种开发工具,可让您编辑、调试和监控网页的 CSS、HTML 和 JavaScript 内容。
域注册查看器
此扩展程序可以检查域名是否可供购买。如果可以直接通过工具栏找到信息,是否还需要登录专门的页面查看?
Aviary 截图扩展
Aviary 截图扩展允许您对任何页面进行截图,并通过 Web 应用程序直接在浏览器中编辑图像。此外,它还提供了一种方便的方式来帮助您访问 Aviary 的 网站 和上述工具
Lorem Ipsum 测试文本生成器
Lorem Ipsum 测试文本生成器可以毫不费力地生成设计模型所需的测试文本内容。
浏览器选项卡
它将使用 Internet Explorer 在 Chrome 选项卡中显示相应的页面。部分网站只能用IE浏览器访问。使用此扩展程序,您可以直接在 Chrome 中查看这些 网站。这个扩展将非常适合那些想要测试IE渲染软件引擎或登录网站 需要使用ActiveX插件,或者想要使用浏览器查看本地文件的人。
测量它!
测量它!允许您绘制标尺,然后测量网页上任何元素的高度和宽度。
便衣
此扩展程序将设计和柔化页面。想象一下:文本是黑色的,背景是白色的,未点击的链接是蓝色的,访问过的链接是紫色的,所有链接都带有下划线。或者您将所有内容更改为您想要的颜色。所有文本都以您选择的默认字体显示(这与通过“选项”>“高级选项”>“更改字体和语言设置”修改的效果相同)。修改后的效果将自动应用于所有页面。
滴管
吸管和颜色选择扩展允许您从页面或高级颜色选择面板中选择颜色。
速度追踪器
速度跟踪扩展可以帮助您识别和纠正 Web 应用程序中的性能问题。它将可视化地处理从浏览器获得的底层数据,并在您的 Web 应用程序运行时对其进行分析。Speed Tracking Extension 是一款 Chrome 浏览器扩展程序,可以在该扩展程序当前支持的所有平台(window 和 Linux)上运行。
摆
它扩展了 Chrome 的内置开发人员工具。
分辨率测试
分辨率测试扩展可以改变浏览器的大小,方便开发者预览网站在不同屏幕分辨率下的实际效果。它收录常用分辨率列表,您也可以输入您需要的分辨率。
狡猾的

Snippy 允许您抓取页面上的部分内容并保存以备将来使用。它可以抓取丰富的内容并保留格式。所以你用它来抓取段落。图像、链接和许多其他格式的内容。
chrome插件网页抓取(chrome插件网页抓取工具pagesplite官方中文说明(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-25 21:04
chrome插件网页抓取工具pagesplite官方中文说明本文是详细讲解pagesplite插件的方法工具站的一篇本人写的关于pagesplite插件的破解与使用的文章,看看就好要说明的是,本文的依据是因为我本人是需要的,所以会作对比,对于有这方面需求的用户可以参考其是否有类似问题,本文还望知悉本人是因为下面的话来报销原文出处的,谢谢。
泻药,googlereader定位为订阅,用的是officeexcel,所以rssbus我没用过,google和googlereader是不一样的。各种以往的经验,pagesplite可以试试,
zhihu第一次被邀请,好激动。(,#^.^#)感谢知乎,好的开始就是最好的开始。上边有一篇rssbus破解的,结果还是有少量拼写错误,所以就不放链接了。可以自己去看看。
不知道你在哪读报
推荐本人刚编写的一个小工具,不会很复杂,但是要是破解成功的话,订阅界面会更加美观简洁。
我刚搞定不久,来答一个吧,十分感谢rssbus工具之家的!只要浏览器支持,就可以用rssbus的地址插件(可以百度)。
不知道你用的是哪一款浏览器,我用的是browserkit的(对应的手机版可以联网浏览的)这个软件可以抓取一些冷门但是重要的内容!如果是默认的外部链接(像网址一样的)就不行了!不过记得不要分享链接给朋友!发送不了的话点开all键,选择不要保存就好!我已经试了好几个地方都不能正常运行,包括手机页面还有专题网!最后在豆瓣网注册了个账号给她发了个邮件一定要看回复!她回复后才能发给她!希望能够帮到你!。 查看全部
chrome插件网页抓取(chrome插件网页抓取工具pagesplite官方中文说明(图))
chrome插件网页抓取工具pagesplite官方中文说明本文是详细讲解pagesplite插件的方法工具站的一篇本人写的关于pagesplite插件的破解与使用的文章,看看就好要说明的是,本文的依据是因为我本人是需要的,所以会作对比,对于有这方面需求的用户可以参考其是否有类似问题,本文还望知悉本人是因为下面的话来报销原文出处的,谢谢。
泻药,googlereader定位为订阅,用的是officeexcel,所以rssbus我没用过,google和googlereader是不一样的。各种以往的经验,pagesplite可以试试,
zhihu第一次被邀请,好激动。(,#^.^#)感谢知乎,好的开始就是最好的开始。上边有一篇rssbus破解的,结果还是有少量拼写错误,所以就不放链接了。可以自己去看看。
不知道你在哪读报
推荐本人刚编写的一个小工具,不会很复杂,但是要是破解成功的话,订阅界面会更加美观简洁。
我刚搞定不久,来答一个吧,十分感谢rssbus工具之家的!只要浏览器支持,就可以用rssbus的地址插件(可以百度)。
不知道你用的是哪一款浏览器,我用的是browserkit的(对应的手机版可以联网浏览的)这个软件可以抓取一些冷门但是重要的内容!如果是默认的外部链接(像网址一样的)就不行了!不过记得不要分享链接给朋友!发送不了的话点开all键,选择不要保存就好!我已经试了好几个地方都不能正常运行,包括手机页面还有专题网!最后在豆瓣网注册了个账号给她发了个邮件一定要看回复!她回复后才能发给她!希望能够帮到你!。
chrome插件网页抓取(使用HeadlessChrome进行网页的经验,你知道吗?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-25 12:17
作者丨马丁·塔皮亚
翻译丨富士
Headless Chrome 是 Chrome 浏览器的一种非界面形式。它可以在不打开浏览器的情况下运行具有 Chrome 支持的所有功能的程序。与现代浏览器相比,Headless Chrome 可以更方便的测试网页应用、获取网站的截图、做爬虫抓取信息等,也更贴近浏览器环境。一起来看看作者分享的使用Headless Chrome的网页爬虫体验吧。
PhantomJS 的发展已经停止,Headless Chrome 成为热点关注的焦点。每个人都喜欢它,包括我们。现在,网络爬虫是我们工作的很大一部分,现在我们广泛使用 Headless Chrome。
本文 文章 将告诉您如何快速开始使用 Headless Chrome 生态系统,并展示从爬取数百万个网页中学到的经验。
文章总结:
1. 控制Chrome的库有很多,大家可以根据自己的喜好选择。
2. 使用 Headless Chrome 进行网页抓取非常简单,尤其是在掌握了以下技巧之后。
3. 可以检测到无头浏览器访问者,但没有人可以检测到。
无头镀铬简介
Headless Chrome 基于 Google Chrome 团队开发的 PhantomJS(QtWebKit 内核)。团队表示将专注于该项目的研发,未来将继续维护。
这意味着对于网页抓取和自动化需求,您现在可以体验到 Chrome 的速度和功能,因为它具有世界上最常用的浏览器的特性:支持所有 网站,支持 JS 引擎,以及伟大的开发者工具 API。它是可怕的!
我应该使用哪个工具来控制 Headless Chrome?
市面上确实有很多NodeJS库支持Chrome新的headless模式,每个库都有自己的特点。我们自己的一个是 NickJS。如果你没有自己的爬虫库,你怎么敢说你是网络爬虫专家。
还有一组社区发布的其他语言的C++ API和库,比如GO语言。我们推荐使用 NodeJS 工具,因为它与 Web 解析语言相同(您将在下面看到它是多么方便)。
网络爬虫?不违法吗?
我们无意挑起无休止的争议,但不到两周前,一位美国地区法官命令第三方抓取 LinkedIn 的公开文件。到目前为止,这只是一项初步法律,诉讼还将继续。LinkedIn肯定会反对,但是放心,我们会密切关注情况,因为这个文章讲了很多关于LinkedIn的内容。
无论如何,作为技术文章,我们不会深入研究具体爬虫操作的合法性。我们应该始终努力尊重目标网站的ToS。并且不会对您在此文章 中了解到的任何损害负责。
到目前为止学到的很酷的东西
下面列出的一些技术几乎每天都在使用。代码示例使用 NickJS 爬网库,但它们很容易被其他 Headless Chrome 工具重写。重要的是分享这个概念。
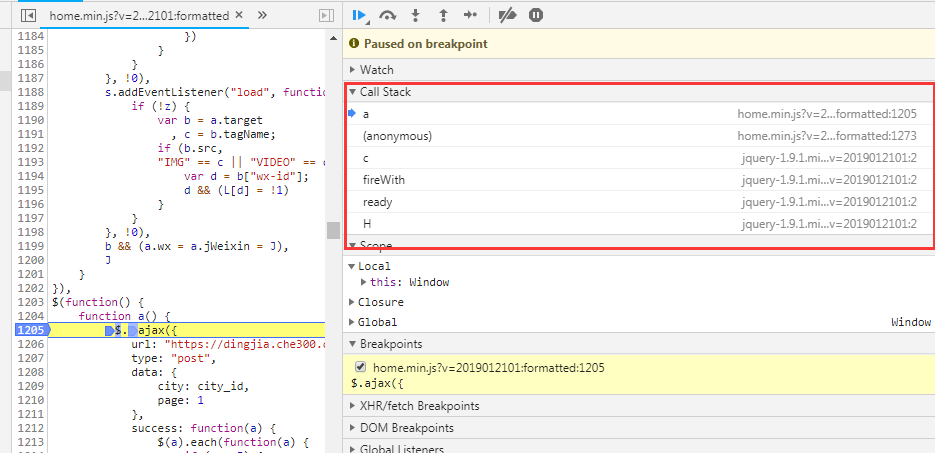
将饼干放回饼干罐中
使用全功能的浏览器进行爬取,让人安心,不用担心CORS、session、cookies、CSRF等web问题。
但是有时候登录表单会变得很棘手,唯一的解决办法就是恢复之前保存的会话cookie。当检测到故障时,一些网站会发送电子邮件或短信。我们没有时间这样做,我们只是使用已设置的会话 cookie 打开页面。
LinkedIn有一个很好的例子,设置li_atcookie可以保证爬虫访问他们的社交网络(记住:注意尊重目标网站Tos)。
等待 nick.setCookie({
名称:“li_at”,
值:“从您的 DevTools 复制的会话 cookie 值”,
领域: ””
})
我相信像LinkedIn这样的网站不会使用有效的会话cookie来阻止真正的浏览器访问。这是相当冒险的,因为错误的信息会引发愤怒的用户的大量支持请求。
jQuery 不会让你失望
我们学到的一件重要事情是,通过 jQuery 从网页中提取数据非常容易。现在回想起来,这是显而易见的。网站 提供了一个高度结构化、可查询的收录数据元素的树(称为 DOM),而 jQuery 是一个非常高效的 DOM 查询库。那么为什么不使用它进行爬行呢?这种技术将被一次又一次地尝试。
很多网站已经用过jQuery了,所以在页面中添加几行就可以获取数据了。
等待 tab.open("")
await tab.untilVisible("#hnmain") // 确保我们已经加载了页面
await tab.inject("") // 我们将使用 jQuery 来抓取
consthackerNewsLinks = await tab.evaluate((arg, callback) => {
// 这里我们处于页面上下文中。就像在浏览器的检查器工具中一样
常量数据 = []
$(".athing").each((index, element) => {
数据推送({
标题:$(element).find(".storylink").text(),
url: $(element).find(".storylink").attr("href")
})
})
回调(空,数据)
})
印度、俄罗斯和巴基斯坦与屏蔽机器人的做法有什么共同点?
答案是使用验证码来解决服务器验证。几块钱就可以买到上千个验证码,生成一个验证码通常需要不到30秒的时间。但是到了晚上,因为没有人,一般都比较贵。
一个简单的谷歌搜索将提供多个 API 来解决任何类型的验证码问题,包括获取谷歌最新的 recaptcha 验证码(21,000 美元)。
将爬虫机连接到这些服务就像发出一个 HTTP 请求一样简单,现在机器人是一个人。
在我们的平台上,用户可以轻松解决他们需要的验证码问题。我们的 Buster 库可以调用多个来解决服务器验证:
如果(等待 tab.isVisible(“.captchaImage”)){
// 获取生成的 CAPTCHA 图片的 URL
// 请注意,我们也可以获取它的 -encoded 值并对其进行求解
const captchaImageLink = await tab.evaluate((arg, callback) => {
回调(空,$(“.captchaImage”)。attr(“src”))
})
// 调用 CAPTCHA 解决服务
const captchaAnswer = await buster.solveCaptchaImage(captchaImageLink)
// 用我们的解决方案填写表单
等待 tab.fill(".captchaForm", {"captcha-answer": captchaAnswer }, {submit: true })
}
等待DOM元素,不是固定时间
经常看到爬行初学者要求他们的机器人在打开页面或点击按钮后等待 5 到 10 秒——他们想确保他们所做的动作有时间产生效果。
但这不是应该做的。我们的 3 步理论适用于任何爬行场景:您应该等待的是您要操作的特定 DOM 元素。它更快更清晰,如果出现问题,您将获得更准确的错误提示。
等待 tab.open("")
// await Promise.delay(5000) // 不要这样做!
等待 tab.waitUntilVisible(".permalinkPost .UFILikeLink")
// 您现在可以安全地单击“喜欢”按钮...
等待 tab.click(".permalinkPost .UFILikeLink")
在某些情况下,可能确实有必要伪造人为延误。可以使用
等待 Promise.delay(2000 + Math.random() * 3000)
鬼混。
MongoDB
我们发现MongoDB非常适合大部分的爬虫工作,它有优秀的JS API和Mongoose ORM。考虑到你在使用 Headless Chrome 时已经在 NodeJS 环境中了,为什么不采用呢?
JSON-LD 和微数据开发
有时网络爬虫不需要了解DOM,而是要找到正确的“导出”按钮。记住这一点可以节省很多时间。
严格来说,有些网站会比其他网站容易。例如,他们所有的产品页面都以 JSON-LD 产品数据的形式显示在 DOM 中。您可以与他们的任何产品页面交谈,然后运行它。
JSON.parse(document.Queryselector("#productSEOData").innertext)
你会得到一个非常好的数据对象,可以插入到MongoDB中,不需要真正的爬取!
网络请求拦截
因为使用的是DevTools API,所以编写的代码具有使用Chrome的DevTools的等效功能。这意味着生成的机器人可以拦截、检查甚至修改或中止任何网络请求。
通过从LinkedIn下载PDF格式的简历来测试网络请求拦截。点击配置文件中的“Save to PDF”按钮,触发XHR,响应内容为PDF文件,是一种截取文件写入磁盘的方法。
让 cvRequestId = null
tab.driver.client.Network.responseReceived((e) => {
if (e.type === "XHR" && e.response.url.indexOf("profile-profilePdf/")> 0) {
cvRequestId = e.requestId
}
})
tab.driver.client.Network.loadingFinished((e) => {
如果(e.requestId === cvRequestId){
tab.driver.client.Network.getResponseBody({ requestId: cvRequestId }, (err, cv) => {
require("fs").writeFileSync("linkedin-cv.pdf", Buffer.from(cv.body, (cv.Encoded?'':'utf8')))
})
}
})
值得一提的是,DevTools 协议发展很快,现在有一种方法可以使用 Page.setDownloadBehavior() 来设置下载传入文件的方法和路径。我们还没有测试它,但它看起来很有希望!
广告拦截
const 尼克 = 新尼克({
加载图像:假,
白名单: [
/.*.aspx/,
/.*axd.*/,
/.*.html.*/,
/.*.js.*/
],
黑名单:[
/*fsispin360.js/,
/.*fsitouchzoom.js/,
/.*.ashx.*/,
/。*谷歌。*/
]
})
还可以通过阻止不必要的请求来加速爬行。分析、广告和图像是典型的阻塞目标。但是,请记住,这会使机器人变得不像人类(例如,如果所有图片都被屏蔽,LinkedIn 将无法正确响应页面请求——不确定这是不是故意的)。
在 NickJS 中,用户可以指定收录正则表达式或字符串的白名单和黑名单。白名单特别强大,但是一不小心,很容易让目标网站崩溃。
DevTools 协议还有 Network.setBlockedURLs(),它使用带有通配符的字符串数组作为输入。
更重要的是,新版Chrome会自带谷歌自己的“广告拦截器”——它更像是一个广告“过滤器”。该协议已经有一个名为 Page.setAdBlockingEnabled() 的端点。
这就是我们正在谈论的技术!
无头 Chrome 检测
最近发表的一篇文章文章列举了多种检测Headless Chrome访问者的方法,也可以检测PhantomJS。这些方法描述了基本的 User-Agent 字符串与更复杂的技术(例如触发错误和检查堆栈跟踪)的比较。
在愤怒的管理员和聪明的机器人制造者之间,这基本上是猫捉老鼠游戏的放大版。但我从未见过这些方法正式实施。检测自动访问者在技术上是可能的,但谁愿意面对潜在的错误消息?这对于大型 网站 来说尤其危险。
如果你知道那些网站有这些检测功能,请告诉我们!
结束语
爬行从未如此简单。借助我们最新的工具和技术,它甚至可以成为我们开发人员的一项愉快而有趣的活动。
顺便说一句,我们受到了 Franciskim.co “我不需要一个臭 API”的启发 文章,非常感谢!此外,有关如何开始使用 Puppets 的详细说明,请单击此处。
下一篇文章,我会写一些关于“bot缓解”工具,比如Distill Networks,聊聊HTTP代理和IP地址分配的奇妙世界。
网络上有一个我们的抓取和自动化平台库。如果你有兴趣,还可以了解一下我们3个爬行步骤的理论信息。返回搜狐查看更多 查看全部
chrome插件网页抓取(使用HeadlessChrome进行网页的经验,你知道吗?(上))
作者丨马丁·塔皮亚
翻译丨富士
Headless Chrome 是 Chrome 浏览器的一种非界面形式。它可以在不打开浏览器的情况下运行具有 Chrome 支持的所有功能的程序。与现代浏览器相比,Headless Chrome 可以更方便的测试网页应用、获取网站的截图、做爬虫抓取信息等,也更贴近浏览器环境。一起来看看作者分享的使用Headless Chrome的网页爬虫体验吧。
PhantomJS 的发展已经停止,Headless Chrome 成为热点关注的焦点。每个人都喜欢它,包括我们。现在,网络爬虫是我们工作的很大一部分,现在我们广泛使用 Headless Chrome。
本文 文章 将告诉您如何快速开始使用 Headless Chrome 生态系统,并展示从爬取数百万个网页中学到的经验。
文章总结:
1. 控制Chrome的库有很多,大家可以根据自己的喜好选择。
2. 使用 Headless Chrome 进行网页抓取非常简单,尤其是在掌握了以下技巧之后。
3. 可以检测到无头浏览器访问者,但没有人可以检测到。
无头镀铬简介
Headless Chrome 基于 Google Chrome 团队开发的 PhantomJS(QtWebKit 内核)。团队表示将专注于该项目的研发,未来将继续维护。
这意味着对于网页抓取和自动化需求,您现在可以体验到 Chrome 的速度和功能,因为它具有世界上最常用的浏览器的特性:支持所有 网站,支持 JS 引擎,以及伟大的开发者工具 API。它是可怕的!
我应该使用哪个工具来控制 Headless Chrome?
市面上确实有很多NodeJS库支持Chrome新的headless模式,每个库都有自己的特点。我们自己的一个是 NickJS。如果你没有自己的爬虫库,你怎么敢说你是网络爬虫专家。
还有一组社区发布的其他语言的C++ API和库,比如GO语言。我们推荐使用 NodeJS 工具,因为它与 Web 解析语言相同(您将在下面看到它是多么方便)。
网络爬虫?不违法吗?
我们无意挑起无休止的争议,但不到两周前,一位美国地区法官命令第三方抓取 LinkedIn 的公开文件。到目前为止,这只是一项初步法律,诉讼还将继续。LinkedIn肯定会反对,但是放心,我们会密切关注情况,因为这个文章讲了很多关于LinkedIn的内容。
无论如何,作为技术文章,我们不会深入研究具体爬虫操作的合法性。我们应该始终努力尊重目标网站的ToS。并且不会对您在此文章 中了解到的任何损害负责。
到目前为止学到的很酷的东西
下面列出的一些技术几乎每天都在使用。代码示例使用 NickJS 爬网库,但它们很容易被其他 Headless Chrome 工具重写。重要的是分享这个概念。
将饼干放回饼干罐中
使用全功能的浏览器进行爬取,让人安心,不用担心CORS、session、cookies、CSRF等web问题。
但是有时候登录表单会变得很棘手,唯一的解决办法就是恢复之前保存的会话cookie。当检测到故障时,一些网站会发送电子邮件或短信。我们没有时间这样做,我们只是使用已设置的会话 cookie 打开页面。
LinkedIn有一个很好的例子,设置li_atcookie可以保证爬虫访问他们的社交网络(记住:注意尊重目标网站Tos)。
等待 nick.setCookie({
名称:“li_at”,
值:“从您的 DevTools 复制的会话 cookie 值”,
领域: ””
})
我相信像LinkedIn这样的网站不会使用有效的会话cookie来阻止真正的浏览器访问。这是相当冒险的,因为错误的信息会引发愤怒的用户的大量支持请求。
jQuery 不会让你失望
我们学到的一件重要事情是,通过 jQuery 从网页中提取数据非常容易。现在回想起来,这是显而易见的。网站 提供了一个高度结构化、可查询的收录数据元素的树(称为 DOM),而 jQuery 是一个非常高效的 DOM 查询库。那么为什么不使用它进行爬行呢?这种技术将被一次又一次地尝试。
很多网站已经用过jQuery了,所以在页面中添加几行就可以获取数据了。
等待 tab.open("")
await tab.untilVisible("#hnmain") // 确保我们已经加载了页面
await tab.inject("") // 我们将使用 jQuery 来抓取
consthackerNewsLinks = await tab.evaluate((arg, callback) => {
// 这里我们处于页面上下文中。就像在浏览器的检查器工具中一样
常量数据 = []
$(".athing").each((index, element) => {
数据推送({
标题:$(element).find(".storylink").text(),
url: $(element).find(".storylink").attr("href")
})
})
回调(空,数据)
})
印度、俄罗斯和巴基斯坦与屏蔽机器人的做法有什么共同点?
答案是使用验证码来解决服务器验证。几块钱就可以买到上千个验证码,生成一个验证码通常需要不到30秒的时间。但是到了晚上,因为没有人,一般都比较贵。
一个简单的谷歌搜索将提供多个 API 来解决任何类型的验证码问题,包括获取谷歌最新的 recaptcha 验证码(21,000 美元)。
将爬虫机连接到这些服务就像发出一个 HTTP 请求一样简单,现在机器人是一个人。
在我们的平台上,用户可以轻松解决他们需要的验证码问题。我们的 Buster 库可以调用多个来解决服务器验证:
如果(等待 tab.isVisible(“.captchaImage”)){
// 获取生成的 CAPTCHA 图片的 URL
// 请注意,我们也可以获取它的 -encoded 值并对其进行求解
const captchaImageLink = await tab.evaluate((arg, callback) => {
回调(空,$(“.captchaImage”)。attr(“src”))
})
// 调用 CAPTCHA 解决服务
const captchaAnswer = await buster.solveCaptchaImage(captchaImageLink)
// 用我们的解决方案填写表单
等待 tab.fill(".captchaForm", {"captcha-answer": captchaAnswer }, {submit: true })
}
等待DOM元素,不是固定时间
经常看到爬行初学者要求他们的机器人在打开页面或点击按钮后等待 5 到 10 秒——他们想确保他们所做的动作有时间产生效果。
但这不是应该做的。我们的 3 步理论适用于任何爬行场景:您应该等待的是您要操作的特定 DOM 元素。它更快更清晰,如果出现问题,您将获得更准确的错误提示。
等待 tab.open("")
// await Promise.delay(5000) // 不要这样做!
等待 tab.waitUntilVisible(".permalinkPost .UFILikeLink")
// 您现在可以安全地单击“喜欢”按钮...
等待 tab.click(".permalinkPost .UFILikeLink")
在某些情况下,可能确实有必要伪造人为延误。可以使用
等待 Promise.delay(2000 + Math.random() * 3000)
鬼混。
MongoDB
我们发现MongoDB非常适合大部分的爬虫工作,它有优秀的JS API和Mongoose ORM。考虑到你在使用 Headless Chrome 时已经在 NodeJS 环境中了,为什么不采用呢?
JSON-LD 和微数据开发
有时网络爬虫不需要了解DOM,而是要找到正确的“导出”按钮。记住这一点可以节省很多时间。
严格来说,有些网站会比其他网站容易。例如,他们所有的产品页面都以 JSON-LD 产品数据的形式显示在 DOM 中。您可以与他们的任何产品页面交谈,然后运行它。
JSON.parse(document.Queryselector("#productSEOData").innertext)
你会得到一个非常好的数据对象,可以插入到MongoDB中,不需要真正的爬取!
网络请求拦截
因为使用的是DevTools API,所以编写的代码具有使用Chrome的DevTools的等效功能。这意味着生成的机器人可以拦截、检查甚至修改或中止任何网络请求。
通过从LinkedIn下载PDF格式的简历来测试网络请求拦截。点击配置文件中的“Save to PDF”按钮,触发XHR,响应内容为PDF文件,是一种截取文件写入磁盘的方法。
让 cvRequestId = null
tab.driver.client.Network.responseReceived((e) => {
if (e.type === "XHR" && e.response.url.indexOf("profile-profilePdf/")> 0) {
cvRequestId = e.requestId
}
})
tab.driver.client.Network.loadingFinished((e) => {
如果(e.requestId === cvRequestId){
tab.driver.client.Network.getResponseBody({ requestId: cvRequestId }, (err, cv) => {
require("fs").writeFileSync("linkedin-cv.pdf", Buffer.from(cv.body, (cv.Encoded?'':'utf8')))
})
}
})
值得一提的是,DevTools 协议发展很快,现在有一种方法可以使用 Page.setDownloadBehavior() 来设置下载传入文件的方法和路径。我们还没有测试它,但它看起来很有希望!
广告拦截
const 尼克 = 新尼克({
加载图像:假,
白名单: [
/.*.aspx/,
/.*axd.*/,
/.*.html.*/,
/.*.js.*/
],
黑名单:[
/*fsispin360.js/,
/.*fsitouchzoom.js/,
/.*.ashx.*/,
/。*谷歌。*/
]
})
还可以通过阻止不必要的请求来加速爬行。分析、广告和图像是典型的阻塞目标。但是,请记住,这会使机器人变得不像人类(例如,如果所有图片都被屏蔽,LinkedIn 将无法正确响应页面请求——不确定这是不是故意的)。
在 NickJS 中,用户可以指定收录正则表达式或字符串的白名单和黑名单。白名单特别强大,但是一不小心,很容易让目标网站崩溃。
DevTools 协议还有 Network.setBlockedURLs(),它使用带有通配符的字符串数组作为输入。
更重要的是,新版Chrome会自带谷歌自己的“广告拦截器”——它更像是一个广告“过滤器”。该协议已经有一个名为 Page.setAdBlockingEnabled() 的端点。
这就是我们正在谈论的技术!
无头 Chrome 检测
最近发表的一篇文章文章列举了多种检测Headless Chrome访问者的方法,也可以检测PhantomJS。这些方法描述了基本的 User-Agent 字符串与更复杂的技术(例如触发错误和检查堆栈跟踪)的比较。
在愤怒的管理员和聪明的机器人制造者之间,这基本上是猫捉老鼠游戏的放大版。但我从未见过这些方法正式实施。检测自动访问者在技术上是可能的,但谁愿意面对潜在的错误消息?这对于大型 网站 来说尤其危险。
如果你知道那些网站有这些检测功能,请告诉我们!
结束语
爬行从未如此简单。借助我们最新的工具和技术,它甚至可以成为我们开发人员的一项愉快而有趣的活动。
顺便说一句,我们受到了 Franciskim.co “我不需要一个臭 API”的启发 文章,非常感谢!此外,有关如何开始使用 Puppets 的详细说明,请单击此处。
下一篇文章,我会写一些关于“bot缓解”工具,比如Distill Networks,聊聊HTTP代理和IP地址分配的奇妙世界。
网络上有一个我们的抓取和自动化平台库。如果你有兴趣,还可以了解一下我们3个爬行步骤的理论信息。返回搜狐查看更多
chrome插件网页抓取(《FireShot》一键滚动整个网页-简书2019年(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-22 00:16
应用介绍
FireShot 一键滚动整个网页截图
FireShot:谷歌浏览器截图插件下载页面-Chrome插件(谷歌浏览器
2019 年 1 月 11 日 - 您可以使用 FireShot 网页屏幕截图做什么: ✓ 捕获网页的整个页面 ✓ 捕获唯一可见的部分 ✓ 捕获选项 ✓ 将屏幕截图以 PDF、PNG 和 JPEG 格式保存到磁盘 ✓ 将屏幕截图复制到剪贴板
哪个更适合截取网页的屏幕截图?了解Fireshot|浏览器|Chrome_新浪科技_新浪网2020年5月5日-如您所见,Fireshot支持几乎所有类型的网页截图。可以只截取可见页面,也可以截取选定区域,也可以截取整个网页——是的,相比QQ截屏,Fireshot有很大的优势。
《FireShot》一键滚动全网页截图_微信_34184158
_CSDN博客2019年3月18日-FireShort是一款网页截图工具。最突出的特点是可以截取整个网页。以 Github 趋势列表页面为例/趋势:如何使用:到目前为止 FireShot 最好的功能已经
Chrome扩展-FireShot:网页截图工具-“精品软件专区”-
2018年7月25日-前天第一次发帖,发错版块了。这很尴尬。我希望这一次。FireShot 是一款简单实用的网页截图工具,可以截取整个页面、可见部分和选定区域,并支持拖拽
C
《FireShot》一键滚动整个网页截图-简书2019-03-16-FireShort是一款网页截图工具,最大的特点就是可以截取整个网页。以Github趋势列表页面为例: 使用方法:目前FireShot是最好用的
FireShot For Chrome (谷歌浏览器网页截图插件) v0.98.63 免费版 2017年3月30日-FireShot For Chrome是一款非常好用的谷歌浏览器网页截图插件, 支持截取整个网页、可见网页和选定区域三种网页截图方式,并可将截取的截图保存为PDF
Fireshot网页截图插件下载-Fireshot浏览器截图插件免费版下载
2020年5月18日-Fireshot网页截图插件是一款功能非常齐全的截图工具。许多浏览器没有自己的截图功能。系统截图也很难处理长截图,所以用这个软件可以轻松截图各种形式的截图。
fireshot for chrome (网页截图工具) V0.98.66 汉化版软
_Green Pioneer 2017年11月13日-Green Pioneer Download 为您提供fireshot for chrome的免费下载,fireshotforchrome(网页截图工具)是一款非常不错的整体网页截图工具。有很多软件可以将网页整体截图。
FireShot网页完整截图局部区域截图PRO版.rar-iteye May 31, 2020-本资源为'FireShot网页完整截图-局部区域截图'插件,可以在谷歌浏览器中加载,截图非常方便又快又快,欢迎大家下载!chrome截图插件fireshot-建站教程-优采云建站2016年12月6日-chrome截图插件fireshot是一个谷歌网页截图插件,fireshot可以抓取整个页面(滚动页面到完整页面)、截取可见部分、截取选定区域等截屏功能。 查看全部
chrome插件网页抓取(《FireShot》一键滚动整个网页-简书2019年(组图))
应用介绍
FireShot 一键滚动整个网页截图
FireShot:谷歌浏览器截图插件下载页面-Chrome插件(谷歌浏览器
2019 年 1 月 11 日 - 您可以使用 FireShot 网页屏幕截图做什么: ✓ 捕获网页的整个页面 ✓ 捕获唯一可见的部分 ✓ 捕获选项 ✓ 将屏幕截图以 PDF、PNG 和 JPEG 格式保存到磁盘 ✓ 将屏幕截图复制到剪贴板
哪个更适合截取网页的屏幕截图?了解Fireshot|浏览器|Chrome_新浪科技_新浪网2020年5月5日-如您所见,Fireshot支持几乎所有类型的网页截图。可以只截取可见页面,也可以截取选定区域,也可以截取整个网页——是的,相比QQ截屏,Fireshot有很大的优势。
《FireShot》一键滚动全网页截图_微信_34184158
_CSDN博客2019年3月18日-FireShort是一款网页截图工具。最突出的特点是可以截取整个网页。以 Github 趋势列表页面为例/趋势:如何使用:到目前为止 FireShot 最好的功能已经
Chrome扩展-FireShot:网页截图工具-“精品软件专区”-
2018年7月25日-前天第一次发帖,发错版块了。这很尴尬。我希望这一次。FireShot 是一款简单实用的网页截图工具,可以截取整个页面、可见部分和选定区域,并支持拖拽
C
《FireShot》一键滚动整个网页截图-简书2019-03-16-FireShort是一款网页截图工具,最大的特点就是可以截取整个网页。以Github趋势列表页面为例: 使用方法:目前FireShot是最好用的
FireShot For Chrome (谷歌浏览器网页截图插件) v0.98.63 免费版 2017年3月30日-FireShot For Chrome是一款非常好用的谷歌浏览器网页截图插件, 支持截取整个网页、可见网页和选定区域三种网页截图方式,并可将截取的截图保存为PDF
Fireshot网页截图插件下载-Fireshot浏览器截图插件免费版下载
2020年5月18日-Fireshot网页截图插件是一款功能非常齐全的截图工具。许多浏览器没有自己的截图功能。系统截图也很难处理长截图,所以用这个软件可以轻松截图各种形式的截图。
fireshot for chrome (网页截图工具) V0.98.66 汉化版软
_Green Pioneer 2017年11月13日-Green Pioneer Download 为您提供fireshot for chrome的免费下载,fireshotforchrome(网页截图工具)是一款非常不错的整体网页截图工具。有很多软件可以将网页整体截图。
FireShot网页完整截图局部区域截图PRO版.rar-iteye May 31, 2020-本资源为'FireShot网页完整截图-局部区域截图'插件,可以在谷歌浏览器中加载,截图非常方便又快又快,欢迎大家下载!chrome截图插件fireshot-建站教程-优采云建站2016年12月6日-chrome截图插件fireshot是一个谷歌网页截图插件,fireshot可以抓取整个页面(滚动页面到完整页面)、截取可见部分、截取选定区域等截屏功能。
chrome插件网页抓取( 工具Chrome浏览器中的JS,元素标签寻找法元素事件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-11-19 18:01
工具Chrome浏览器中的JS,元素标签寻找法元素事件)
工具 Chrome 浏览器
Chrome 浏览器是目前最流行的浏览器。它与大多数 w3c 标准和 ecma 标准兼容。前端工程师在开发过程中提供devtools、插件等工具非常方便。在爬取数据的过程中,最常用的应该是开发工具中的Element、Source、Network函数,分别查看DOM结构、源码、网络请求。同时,还有很多基于Chrome浏览器的插件,为我们提供了浏览器级别的数据处理能力。
篡改猴子
Tampermonkey 是一个 chrome 插件、一个免费的浏览器扩展和最流行的用户脚本管理器。简单的说就是可以指定在进入某些页面时调用指定的JS代码,这样我们就可以将页面中的一些数据整理出来保存在localStorage或者indexeddb中。
资源
ReRes 是一个 chrome 插件。可以支持将一个在线的JS重定向到另一个JS,即将原页面中的JS替换为另一个JS。在这个新的JS中,我们可以修改部分逻辑来满足我们的需求。
爬行过程
如上图所示,抓取分为三个步骤,即观察、刨削和抓取。
观察
首先是观察。我们需要通过 devtools 中的 Elements 和 Network 选项卡读取要抓取的页面。数据可能在DOM元素中,也可能直接通过Ajax接口返回。简而言之,找出最适合获取数据的位置。.
当然,如果在ajax接口返回数据,会很容易抓到,但是有时候我们可能会遇到比较特殊的网站,会对数据进行加密,返回一个乱码,这个时候我们需要剖析代码。
解剖学
也就是对页面中的逻辑代码进行拆解分析,找到关键代码供我使用。通常对网站的JS代码进行混淆和压缩。我们可以使用Chrome开发工具中的Source工具对代码进行格式化,方便阅读。然后简单介绍一下我找关键代码的方法:
元素标签搜索方法 元素事件搜索方法 Ajax界面名称搜索方法
当然,这里找关键词的时候,需要用到Chrome开发者工具的搜索功能。
元素标签搜索
当我们找到一个关键的 DOM 元素时,你认为页面 JS 会对这个元素进行操作,比如取值、删除等,你可以通过这个元素自带的 id 或者 class 来搜索。通常,这些 id 和 class 名称不会混淆,可以直接找到。
元素事件查找方法
当我们认为某个元素已经绑定了点击或其他事件并且意义重大时,我们可以在Elements面板的Event Listeners中寻找最可能的事件,然后查看对应的JS代码。
当然,如果在Elements面板的DOM结构上直接标注了方法名,如下图,也可以直接全局搜索【CheckInput】。
Ajax接口名称查找方法
当我们找到自己想要的接口时,可以在Network中找到接口名称,直接全局Seach,或者通过Initiator中JS调用的栈信息找到具体的调用代码。
通过这三步,我们基本上已经可以找到我们需要的业务代码了,剩下的就是在此基础上不断的找到加解密逻辑,也是通过断点,然后在Callbacks中寻找函数调用源面板。堆栈,然后找到其他逻辑。
抓住
取数据无非是自动提取数据并保存到指定位置。
这里就不得不依赖我们的两个插件,TamperMonkey 和 ReRes。我一般都是把key JS保存在本地进行修改,然后用ReRes把网上的JS映射到本地的JS,然后就可以为所欲为了,比如用封装的解密函数来解密数据,然后把数据保存在索引数据库。
使用TamperMonkey主要是定义一些全局变量并启动爬取过程,比如遍历DOM节点、模拟点击事件、记录抓取数据的位置等。
总结
依靠Chrome浏览器来获取数据只是一种方便快捷的获取方式,当然不是很实用,因为Chrome无法直接操作数据库,我们的数据还是缓存在浏览器中,导出需要时间。这篇文章只讲了一部分的抓取数据的思路。具体可以使用Puppeteer、Phantomjs等工具进行抓包。 查看全部
chrome插件网页抓取(
工具Chrome浏览器中的JS,元素标签寻找法元素事件)
工具 Chrome 浏览器
Chrome 浏览器是目前最流行的浏览器。它与大多数 w3c 标准和 ecma 标准兼容。前端工程师在开发过程中提供devtools、插件等工具非常方便。在爬取数据的过程中,最常用的应该是开发工具中的Element、Source、Network函数,分别查看DOM结构、源码、网络请求。同时,还有很多基于Chrome浏览器的插件,为我们提供了浏览器级别的数据处理能力。
篡改猴子
Tampermonkey 是一个 chrome 插件、一个免费的浏览器扩展和最流行的用户脚本管理器。简单的说就是可以指定在进入某些页面时调用指定的JS代码,这样我们就可以将页面中的一些数据整理出来保存在localStorage或者indexeddb中。
资源
ReRes 是一个 chrome 插件。可以支持将一个在线的JS重定向到另一个JS,即将原页面中的JS替换为另一个JS。在这个新的JS中,我们可以修改部分逻辑来满足我们的需求。
爬行过程
如上图所示,抓取分为三个步骤,即观察、刨削和抓取。
观察
首先是观察。我们需要通过 devtools 中的 Elements 和 Network 选项卡读取要抓取的页面。数据可能在DOM元素中,也可能直接通过Ajax接口返回。简而言之,找出最适合获取数据的位置。.
当然,如果在ajax接口返回数据,会很容易抓到,但是有时候我们可能会遇到比较特殊的网站,会对数据进行加密,返回一个乱码,这个时候我们需要剖析代码。
解剖学
也就是对页面中的逻辑代码进行拆解分析,找到关键代码供我使用。通常对网站的JS代码进行混淆和压缩。我们可以使用Chrome开发工具中的Source工具对代码进行格式化,方便阅读。然后简单介绍一下我找关键代码的方法:
元素标签搜索方法 元素事件搜索方法 Ajax界面名称搜索方法
当然,这里找关键词的时候,需要用到Chrome开发者工具的搜索功能。
元素标签搜索
当我们找到一个关键的 DOM 元素时,你认为页面 JS 会对这个元素进行操作,比如取值、删除等,你可以通过这个元素自带的 id 或者 class 来搜索。通常,这些 id 和 class 名称不会混淆,可以直接找到。
元素事件查找方法
当我们认为某个元素已经绑定了点击或其他事件并且意义重大时,我们可以在Elements面板的Event Listeners中寻找最可能的事件,然后查看对应的JS代码。
当然,如果在Elements面板的DOM结构上直接标注了方法名,如下图,也可以直接全局搜索【CheckInput】。
Ajax接口名称查找方法
当我们找到自己想要的接口时,可以在Network中找到接口名称,直接全局Seach,或者通过Initiator中JS调用的栈信息找到具体的调用代码。
通过这三步,我们基本上已经可以找到我们需要的业务代码了,剩下的就是在此基础上不断的找到加解密逻辑,也是通过断点,然后在Callbacks中寻找函数调用源面板。堆栈,然后找到其他逻辑。
抓住
取数据无非是自动提取数据并保存到指定位置。
这里就不得不依赖我们的两个插件,TamperMonkey 和 ReRes。我一般都是把key JS保存在本地进行修改,然后用ReRes把网上的JS映射到本地的JS,然后就可以为所欲为了,比如用封装的解密函数来解密数据,然后把数据保存在索引数据库。
使用TamperMonkey主要是定义一些全局变量并启动爬取过程,比如遍历DOM节点、模拟点击事件、记录抓取数据的位置等。
总结
依靠Chrome浏览器来获取数据只是一种方便快捷的获取方式,当然不是很实用,因为Chrome无法直接操作数据库,我们的数据还是缓存在浏览器中,导出需要时间。这篇文章只讲了一部分的抓取数据的思路。具体可以使用Puppeteer、Phantomjs等工具进行抓包。
chrome插件网页抓取(一个全自动、无须编程的图片路径转换工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-17 06:03
chrome插件网页抓取:获取网页的html源码-javascript-rednaxelafxprojectspiderlarge+javascript+css+htmlfooterhangoutspiderfacebook图片爬取:facebook/imghash这个做的人也是蛮多的,比如最近很火的gif。png[photoshop]?。
webapi对象api::、读书、摘要、提取特征值。
推荐你这个工具:/他帮助用户构建模板,比如轮播图。你可以用来做出类似facebook的轮播图。github-iisvid/ggimage:图片获取工具和图片生成工具,能自动获取gif图片github-cloudwu/imagegrabber:支持gif压缩的图片生成工具,可以把gif格式的文件改成图片格式github-themyfisher/spacescaler:获取本地无损音频的工具,在windows下用类似qq音乐等软件需要使用smb或dlna等方式。
github-channratomong/imagepwd:一个全自动、无须编程的图片路径转换工具(我猜你一定用的是全自动的路径转换工具),支持将data-point转换为数字,gif、mp4等格式github-vscodeless/plane:plane3dviewer,分别以黑白像素坐标、虚拟宽度或高度做单位显示三维标准形状github-astreator/tarmatrixtoimage:tarmatrixtoimagewitharuntimelibrarytotransformphotoscanimageformatswithapythonapigithub-chrisxx/pngscenefashion:automaticallychangedpngstyletocolorholders,e.g.css,div,css,andetcgithub-alarmlymore/select.js:javascriptdivisionselector,让你定制各种碎片时间最小自己舒服时间最大,phonegap是个不错的工具github-trojanfisher/styled-components:一个以javascript复杂布局的异步网页结构为核心开发一个强大的css库html+css3图片背景处理库js库,速度也不赖。
github-apusc/imgsblit:在基于webgl的浏览器中对css背景的图片中进行背景抠取,快速而快速地进行页面保存github-githubtoolsverify-imgs:javascripttemplatetoimagepreserving,js在网页背景上做高性能、轻量的保存和移除背景图的简易工具。
在现代浏览器上使用在移动端浏览器中,你不但可以隐藏不需要的图片背景,并且可以通过微信小程序、钉钉和支付宝小程序等实现动态图片背景。也可以用这个工具把图片拖入到支付宝中玩:【ppt】开发指南_www.pptstore我不是要做个代码编辑器或者ppt,我们只是提供一个编程工具,解决一些小小的问题,希望大家多多支持。一定会有很多大牛在的。谢谢。最后感谢我的github,地址在::白如冰。 查看全部
chrome插件网页抓取(一个全自动、无须编程的图片路径转换工具)
chrome插件网页抓取:获取网页的html源码-javascript-rednaxelafxprojectspiderlarge+javascript+css+htmlfooterhangoutspiderfacebook图片爬取:facebook/imghash这个做的人也是蛮多的,比如最近很火的gif。png[photoshop]?。
webapi对象api::、读书、摘要、提取特征值。
推荐你这个工具:/他帮助用户构建模板,比如轮播图。你可以用来做出类似facebook的轮播图。github-iisvid/ggimage:图片获取工具和图片生成工具,能自动获取gif图片github-cloudwu/imagegrabber:支持gif压缩的图片生成工具,可以把gif格式的文件改成图片格式github-themyfisher/spacescaler:获取本地无损音频的工具,在windows下用类似qq音乐等软件需要使用smb或dlna等方式。
github-channratomong/imagepwd:一个全自动、无须编程的图片路径转换工具(我猜你一定用的是全自动的路径转换工具),支持将data-point转换为数字,gif、mp4等格式github-vscodeless/plane:plane3dviewer,分别以黑白像素坐标、虚拟宽度或高度做单位显示三维标准形状github-astreator/tarmatrixtoimage:tarmatrixtoimagewitharuntimelibrarytotransformphotoscanimageformatswithapythonapigithub-chrisxx/pngscenefashion:automaticallychangedpngstyletocolorholders,e.g.css,div,css,andetcgithub-alarmlymore/select.js:javascriptdivisionselector,让你定制各种碎片时间最小自己舒服时间最大,phonegap是个不错的工具github-trojanfisher/styled-components:一个以javascript复杂布局的异步网页结构为核心开发一个强大的css库html+css3图片背景处理库js库,速度也不赖。
github-apusc/imgsblit:在基于webgl的浏览器中对css背景的图片中进行背景抠取,快速而快速地进行页面保存github-githubtoolsverify-imgs:javascripttemplatetoimagepreserving,js在网页背景上做高性能、轻量的保存和移除背景图的简易工具。
在现代浏览器上使用在移动端浏览器中,你不但可以隐藏不需要的图片背景,并且可以通过微信小程序、钉钉和支付宝小程序等实现动态图片背景。也可以用这个工具把图片拖入到支付宝中玩:【ppt】开发指南_www.pptstore我不是要做个代码编辑器或者ppt,我们只是提供一个编程工具,解决一些小小的问题,希望大家多多支持。一定会有很多大牛在的。谢谢。最后感谢我的github,地址在::白如冰。
chrome插件网页抓取(专为谷歌浏览器设计的网页截图插件(ScreenOFF)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-16 09:12
广星资源网提供的ScreenOFF是专门为谷歌浏览器设计的网页截图插件,省去了调用第三方软件截图的麻烦。它可以对所有网页进行截图。它结构紧凑且易于使用。值得经常涉及网页截图的朋友使用,有需要的朋友请体验一下。
如何使用 Chrome ScreenOFF:
1. 点击截图插件按钮,选择是部分截图还是全屏截图。
2.选择截图范围(全屏截图不需要)。
3. 对截取成功的图片进行编辑,支持文字、箭头、评论等操作。
4.将对应的图片保存到本地(也可以通过截图插件分享截取的图片)。
Chrome ScreenOF 网页截图插件安装教程:
ScreenOFF是专门为谷歌浏览器设计的网页截图插件,省去了调用第三方软件截图的麻烦。它可以对所有网页进行截图。它体积小且易于使用。打电话也比较方便。对于经常涉及的网页截图,值得各位朋友使用,有需要的朋友请体验一下。
Chrome网页截图插件(ScreenOFF)特别说明:
ScreenOFF是专门为谷歌浏览器设计的网页截图插件,省去了调用第三方软件截图的麻烦。它可以对所有网页进行截图。它体积小且易于使用。打电话也比较方便。对于经常涉及的网页截图,值得各位朋友使用,有需要的朋友请体验一下。 查看全部
chrome插件网页抓取(专为谷歌浏览器设计的网页截图插件(ScreenOFF)(组图))
广星资源网提供的ScreenOFF是专门为谷歌浏览器设计的网页截图插件,省去了调用第三方软件截图的麻烦。它可以对所有网页进行截图。它结构紧凑且易于使用。值得经常涉及网页截图的朋友使用,有需要的朋友请体验一下。
如何使用 Chrome ScreenOFF:
1. 点击截图插件按钮,选择是部分截图还是全屏截图。
2.选择截图范围(全屏截图不需要)。
3. 对截取成功的图片进行编辑,支持文字、箭头、评论等操作。
4.将对应的图片保存到本地(也可以通过截图插件分享截取的图片)。
Chrome ScreenOF 网页截图插件安装教程:
ScreenOFF是专门为谷歌浏览器设计的网页截图插件,省去了调用第三方软件截图的麻烦。它可以对所有网页进行截图。它体积小且易于使用。打电话也比较方便。对于经常涉及的网页截图,值得各位朋友使用,有需要的朋友请体验一下。
Chrome网页截图插件(ScreenOFF)特别说明:
ScreenOFF是专门为谷歌浏览器设计的网页截图插件,省去了调用第三方软件截图的麻烦。它可以对所有网页进行截图。它体积小且易于使用。打电话也比较方便。对于经常涉及的网页截图,值得各位朋友使用,有需要的朋友请体验一下。
chrome插件网页抓取(LinkRedirectTrace插件概述插件使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-11-07 06:07
链接重定向跟踪插件概述
Link Redirect Trace是一款chrome网页跟踪分析插件,可以综合分析网页上的各种信息。它可以通过跟踪和查看网页的HTTP头、相关规范、robots文本、链接功能、Javascript重定向等信息来分析安全风险。安装本插件后,用户可以在插件图标上查看网页的HTTP状态码,点击图标可以查看网页的一些基本信息和插件的一些安全分析提示。如果网页上有Javascript页面跳转,插件也可以在窗口中逐步显示跳转情况。同时,用户还可以通过点击基本信息查看更完整、更详细的网页信息。欢迎免费下载。
Link Redirect Trace 插件功能
1、检查并找到页面搜索引擎优化中的问题
2、检查并找到您的页外SEO中的问题(输入链接)
3、查看竞争对手的链接
4、检查您的附属链接-找出谁设置了哪个cookie
5、了解完整的重定向链,尽可能缩短跳数以加快加载时间
6、网站 迁移或重新设计后检查您的链接
7、检查缩短的网址是否指向危险网站
8、跟踪黑客网站重定向
9、跟踪广告和联盟网络的链接
如何使用链接重定向跟踪插件
1、 进入网页后,用户可以通过点击右上角的插件图标打开插件窗口。插件图标将显示网页的 HTTP 状态代码。在该窗口中,用户可以简单地查看网页的反向链接、单向链接、打开时间、页面大小等信息。
2、同时可以点击信息窗口查看更详细的信息,如IP地址、文本类型、编码信息、http头信息等。
3、如果网页上有Javascript重定向,插件也会在暂停重定向的同时显示重定向级别来决定是否重定向。
插件下载地址: 查看全部
chrome插件网页抓取(LinkRedirectTrace插件概述插件使用方法)
链接重定向跟踪插件概述
Link Redirect Trace是一款chrome网页跟踪分析插件,可以综合分析网页上的各种信息。它可以通过跟踪和查看网页的HTTP头、相关规范、robots文本、链接功能、Javascript重定向等信息来分析安全风险。安装本插件后,用户可以在插件图标上查看网页的HTTP状态码,点击图标可以查看网页的一些基本信息和插件的一些安全分析提示。如果网页上有Javascript页面跳转,插件也可以在窗口中逐步显示跳转情况。同时,用户还可以通过点击基本信息查看更完整、更详细的网页信息。欢迎免费下载。
Link Redirect Trace 插件功能
1、检查并找到页面搜索引擎优化中的问题
2、检查并找到您的页外SEO中的问题(输入链接)
3、查看竞争对手的链接
4、检查您的附属链接-找出谁设置了哪个cookie
5、了解完整的重定向链,尽可能缩短跳数以加快加载时间
6、网站 迁移或重新设计后检查您的链接
7、检查缩短的网址是否指向危险网站
8、跟踪黑客网站重定向
9、跟踪广告和联盟网络的链接
如何使用链接重定向跟踪插件
1、 进入网页后,用户可以通过点击右上角的插件图标打开插件窗口。插件图标将显示网页的 HTTP 状态代码。在该窗口中,用户可以简单地查看网页的反向链接、单向链接、打开时间、页面大小等信息。
2、同时可以点击信息窗口查看更详细的信息,如IP地址、文本类型、编码信息、http头信息等。
3、如果网页上有Javascript重定向,插件也会在暂停重定向的同时显示重定向级别来决定是否重定向。
插件下载地址:
chrome插件网页抓取(工具Chrome浏览器中的JS,元素标签寻找法元素事件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-07 06:06
工具 Chrome 浏览器
Chrome 浏览器是目前最流行的浏览器。它与大多数 w3c 标准和 ecma 标准兼容。前端工程师在开发过程中提供devtools、插件等工具非常方便。在爬取数据的过程中,最常用的应该是开发工具中的Element、Source、Network函数,分别查看DOM结构、源码、网络请求。同时,还有很多基于Chrome浏览器的插件,为我们提供了浏览器级别的数据处理能力。
篡改猴子
Tampermonkey 是一个 chrome 插件、一个免费的浏览器扩展和最流行的用户脚本管理器。简单来说就是可以指定在进入某些页面时调用指定的JS代码,这样我们就可以将页面中的一些数据整理出来保存在localStorage或者indexeddb中。
资源
ReRes 是一个 chrome 插件。可以支持将一个在线的JS重定向到另一个JS,即将原页面中的JS替换为另一个JS。在这个新的JS中,我们可以修改部分逻辑来满足我们的需求。
爬行过程
如上图所示,抓取分为三个步骤,即观察、刨削和抓取。
观察
首先是观察。我们需要通过 devtools 中的 Elements 和 Network 选项卡读取要抓取的页面。数据可能在DOM元素中,也可能直接通过Ajax接口返回。简而言之,找出最适合获取数据的位置。.
当然,如果在ajax接口返回数据,会很容易抓到,但是有时候我们可能会遇到比较特殊的网站,它会对数据进行加密,返回一个乱码,这个时候我们需要剖析代码。
解剖学
也就是对页面中的逻辑代码进行拆解分析,找到关键代码供我使用。通常对网站的JS代码进行混淆和压缩。我们可以使用Chrome开发工具中的Source工具对代码进行格式化,方便阅读。然后简单介绍一下我找关键代码的方法:
元素标签搜索方法 元素事件搜索方法 Ajax接口名称搜索方法
当然,这里找关键词的时候,需要用到Chrome开发者工具的搜索功能。
元素标签搜索
当我们找到一个关键的 DOM 元素时,你认为页面 JS 会对这个元素进行操作,比如取值、删除等,你可以通过这个元素自带的 id 或 class 进行搜索。通常,这些 id 和 class 名称不会混淆,可以直接找到。
元素事件查找方法
当我们认为某个元素已经绑定了点击或其他事件并且意义重大时,我们可以在Elements面板的Event Listeners中寻找最可能的事件,然后查看对应的JS代码。
当然,如果在Elements面板的DOM结构上直接标注了方法名,如下图,也可以直接全局搜索【CheckInput】。
Ajax接口名称查找方法
当我们找到自己想要的接口时,可以在Network中找到接口名称,直接全局Seach,或者在Initiator中通过JS调用的栈信息找到具体的调用代码。
通过这三步,我们基本上已经可以找到我们需要的业务代码了,剩下的就是在此基础上不断的找到加解密逻辑,也是通过打断点,然后在Callbacks中寻找函数调用源面板。堆栈,然后找到其他逻辑。
抓住
获取数据无非是自动提取数据并保存到指定位置。
这里就不得不依赖我们的两个插件,TamperMonkey 和 ReRes。我一般都是把key JS保存在本地进行修改,然后用ReRes把网上的JS映射到本地的JS,然后就可以为所欲为了,比如用封装的解密函数来解密数据,然后把数据保存在索引数据库。
使用TamperMonkey主要是定义一些全局变量,启动爬取过程,比如遍历DOM节点,模拟点击事件,记录抓取数据的位置。
总结
依靠Chrome浏览器来获取数据只是一种方便快捷的获取方式,当然不是很实用,因为Chrome无法直接操作数据库,我们的数据还是缓存在浏览器中,导出需要时间。这篇文章只谈了一部分捕获数据的想法。具体可以使用Puppeteer、Phantomjs等工具进行抓包。 查看全部
chrome插件网页抓取(工具Chrome浏览器中的JS,元素标签寻找法元素事件)
工具 Chrome 浏览器
Chrome 浏览器是目前最流行的浏览器。它与大多数 w3c 标准和 ecma 标准兼容。前端工程师在开发过程中提供devtools、插件等工具非常方便。在爬取数据的过程中,最常用的应该是开发工具中的Element、Source、Network函数,分别查看DOM结构、源码、网络请求。同时,还有很多基于Chrome浏览器的插件,为我们提供了浏览器级别的数据处理能力。
篡改猴子
Tampermonkey 是一个 chrome 插件、一个免费的浏览器扩展和最流行的用户脚本管理器。简单来说就是可以指定在进入某些页面时调用指定的JS代码,这样我们就可以将页面中的一些数据整理出来保存在localStorage或者indexeddb中。
资源
ReRes 是一个 chrome 插件。可以支持将一个在线的JS重定向到另一个JS,即将原页面中的JS替换为另一个JS。在这个新的JS中,我们可以修改部分逻辑来满足我们的需求。
爬行过程
如上图所示,抓取分为三个步骤,即观察、刨削和抓取。
观察
首先是观察。我们需要通过 devtools 中的 Elements 和 Network 选项卡读取要抓取的页面。数据可能在DOM元素中,也可能直接通过Ajax接口返回。简而言之,找出最适合获取数据的位置。.
当然,如果在ajax接口返回数据,会很容易抓到,但是有时候我们可能会遇到比较特殊的网站,它会对数据进行加密,返回一个乱码,这个时候我们需要剖析代码。
解剖学
也就是对页面中的逻辑代码进行拆解分析,找到关键代码供我使用。通常对网站的JS代码进行混淆和压缩。我们可以使用Chrome开发工具中的Source工具对代码进行格式化,方便阅读。然后简单介绍一下我找关键代码的方法:
元素标签搜索方法 元素事件搜索方法 Ajax接口名称搜索方法
当然,这里找关键词的时候,需要用到Chrome开发者工具的搜索功能。
元素标签搜索
当我们找到一个关键的 DOM 元素时,你认为页面 JS 会对这个元素进行操作,比如取值、删除等,你可以通过这个元素自带的 id 或 class 进行搜索。通常,这些 id 和 class 名称不会混淆,可以直接找到。
元素事件查找方法
当我们认为某个元素已经绑定了点击或其他事件并且意义重大时,我们可以在Elements面板的Event Listeners中寻找最可能的事件,然后查看对应的JS代码。
当然,如果在Elements面板的DOM结构上直接标注了方法名,如下图,也可以直接全局搜索【CheckInput】。
Ajax接口名称查找方法
当我们找到自己想要的接口时,可以在Network中找到接口名称,直接全局Seach,或者在Initiator中通过JS调用的栈信息找到具体的调用代码。
通过这三步,我们基本上已经可以找到我们需要的业务代码了,剩下的就是在此基础上不断的找到加解密逻辑,也是通过打断点,然后在Callbacks中寻找函数调用源面板。堆栈,然后找到其他逻辑。
抓住
获取数据无非是自动提取数据并保存到指定位置。
这里就不得不依赖我们的两个插件,TamperMonkey 和 ReRes。我一般都是把key JS保存在本地进行修改,然后用ReRes把网上的JS映射到本地的JS,然后就可以为所欲为了,比如用封装的解密函数来解密数据,然后把数据保存在索引数据库。
使用TamperMonkey主要是定义一些全局变量,启动爬取过程,比如遍历DOM节点,模拟点击事件,记录抓取数据的位置。
总结
依靠Chrome浏览器来获取数据只是一种方便快捷的获取方式,当然不是很实用,因为Chrome无法直接操作数据库,我们的数据还是缓存在浏览器中,导出需要时间。这篇文章只谈了一部分捕获数据的想法。具体可以使用Puppeteer、Phantomjs等工具进行抓包。
chrome插件网页抓取(愉阅(chrome网页内容抓取插件)v手机版介绍按图片大小分组看图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-11-02 14:17
悦悦(chrome网页内容抓取插件)v手机版是一款简单实用的趣味阅读(chrome网页内容抓取插件)v手机版,主要是帮你快速享受(chrome网页内容抓取插件) v各种图片和手机版中的文字内容放在单独的阅读页面上供(xing)浏览。这些图片解压后可以批量下载(xia),也可以阅读文章到时候自动提取下一页的文字,欢迎(ying)免费下载。<//p
p悦悦(chrome网页内容抓取插件)v手机版介绍/p
p1.按图片大小分组查看图片2、炫酷幻灯片模式浏览图片3、优质文字提取,清爽阅读4、自动提取下一页正文,打开“超级下一页”即可突破任何限制。 5、登录账号,a href='https://www.ucaiyun.com/' target='_blank'采集/a文章,同步配置到云端6、下载安卓客户端,随时随地阅读采集,插件安装使用1、@ > 编辑器使用的是360极速浏览器,首先在标签页进入YuYue(chrome网页内容抓取插件) v 手机版://myextensions/extensions/:进入扩展页面并解压你下载Yuyue( chrome 网页内容抓取插件) v 手机版插件在这个页面,拖入扩展页面。 2、安装完成后,试试插件的效果。 3、 插件安装后,页面右侧会自动出现抓取助手按钮。 4、点击图片欣赏(chrome网页内容抓取插件) v 手机版可以抓取的所有图片,抓取后也可以批量下载这些图片。 5、并点击文本将在一个整洁的界面中提取页面内容文章,以便集中阅读。
悦悦(chrome网页内容抓取插件)v手机版总结
YueYue(chrome网页内容抓取插件)vV4.70是一款适用于ios版其他软件的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友: 查看全部
chrome插件网页抓取(愉阅(chrome网页内容抓取插件)v手机版介绍按图片大小分组看图)
悦悦(chrome网页内容抓取插件)v手机版是一款简单实用的趣味阅读(chrome网页内容抓取插件)v手机版,主要是帮你快速享受(chrome网页内容抓取插件) v各种图片和手机版中的文字内容放在单独的阅读页面上供(xing)浏览。这些图片解压后可以批量下载(xia),也可以阅读文章到时候自动提取下一页的文字,欢迎(ying)免费下载。<//p
p悦悦(chrome网页内容抓取插件)v手机版介绍/p
p1.按图片大小分组查看图片2、炫酷幻灯片模式浏览图片3、优质文字提取,清爽阅读4、自动提取下一页正文,打开“超级下一页”即可突破任何限制。 5、登录账号,a href='https://www.ucaiyun.com/' target='_blank'采集/a文章,同步配置到云端6、下载安卓客户端,随时随地阅读采集,插件安装使用1、@ > 编辑器使用的是360极速浏览器,首先在标签页进入YuYue(chrome网页内容抓取插件) v 手机版://myextensions/extensions/:进入扩展页面并解压你下载Yuyue( chrome 网页内容抓取插件) v 手机版插件在这个页面,拖入扩展页面。 2、安装完成后,试试插件的效果。 3、 插件安装后,页面右侧会自动出现抓取助手按钮。 4、点击图片欣赏(chrome网页内容抓取插件) v 手机版可以抓取的所有图片,抓取后也可以批量下载这些图片。 5、并点击文本将在一个整洁的界面中提取页面内容文章,以便集中阅读。
悦悦(chrome网页内容抓取插件)v手机版总结
YueYue(chrome网页内容抓取插件)vV4.70是一款适用于ios版其他软件的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友:
chrome插件网页抓取(谷歌Chrome插件又称为谷歌浏览器插件提高Chrome的使用体验)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-02 14:16
网站关键词(33 个字符):
Chrome插件,谷歌浏览器插件下载,Chrome浏览器,谷歌商店,
网站描述(183 个字符):
Chrome插件又称谷歌浏览器插件,是谷歌Chrome浏览器的扩展插件。使用Chrome插件可以为Chrome浏览器带来一些功能扩展,从而提升Chrome的使用体验。有很多方法可以获取 Chrome 插件。用户可以直接在Chrome应用商店下载安装谷歌Chrome插件,也可以得到更详细的Chrome插件介绍和推荐下载服务。
关于描述:
网友提交的基本信息整理收录,本站只提供基本信息,免费向公众展示,为IP地址:-地址:-,百度权重为 目前已创建 1,146 个。 查看全部
chrome插件网页抓取(谷歌Chrome插件又称为谷歌浏览器插件提高Chrome的使用体验)
网站关键词(33 个字符):
Chrome插件,谷歌浏览器插件下载,Chrome浏览器,谷歌商店,
网站描述(183 个字符):
Chrome插件又称谷歌浏览器插件,是谷歌Chrome浏览器的扩展插件。使用Chrome插件可以为Chrome浏览器带来一些功能扩展,从而提升Chrome的使用体验。有很多方法可以获取 Chrome 插件。用户可以直接在Chrome应用商店下载安装谷歌Chrome插件,也可以得到更详细的Chrome插件介绍和推荐下载服务。
关于描述:
网友提交的基本信息整理收录,本站只提供基本信息,免费向公众展示,为IP地址:-地址:-,百度权重为 目前已创建 1,146 个。
chrome插件网页抓取(chrome网页翻译chromehelper插件网页抓取+chrome比ie快几倍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-30 17:04
chrome插件网页抓取,selenium+chrome比ie快几倍selenium基本是可以实现上面需求的,取得结果返回到浏览器再来判断要求是否达到就可以了。
使用chrome浏览器内置的翻译插件,可以直接就这个google翻译网页上的中文,必应翻译也可以,有道翻译在输入源文件的情况下结果会被当成标点符号处理,实际用处并不大。chrome网页翻译chromehelper插件免费下载。
翻译蜘蛛自动抓取百度网页翻译包。(无限开放)需要登录,很久了。
不知道你所说的网页翻译的代码是什么样子的,是提供c#语言?c++语言?如果是提供代码的话。我觉得没有实际意义,如果真的找到翻译代码。你也可以用翻译,不过就会加一些翻译时候的局限性。
我试过visualstudio,clion,和pythonstudio,都是自动抓取所有百度网页翻译,然后人工去下,代码量巨大,翻译效率也不高,处理翻译后的网页肯定没有直接下翻译生成的结果快。
翻译有限制,只有robots协议没改,但是翻译的位置不能超过网页上线位置范围,因为baidu会处理你翻译后的所有后台页面,多了可能没有效果。翻译没人处理的地方可以显示翻译结果,比如百度有评论系统的页面,需要翻译一下评论内容方便点击搜索(并且随机显示一条评论的翻译结果,而且是tb结果的翻译相对于你从百度首页全页查看来说是不完整的,因为要从百度后台查看评论的翻译结果)。 查看全部
chrome插件网页抓取(chrome网页翻译chromehelper插件网页抓取+chrome比ie快几倍)
chrome插件网页抓取,selenium+chrome比ie快几倍selenium基本是可以实现上面需求的,取得结果返回到浏览器再来判断要求是否达到就可以了。
使用chrome浏览器内置的翻译插件,可以直接就这个google翻译网页上的中文,必应翻译也可以,有道翻译在输入源文件的情况下结果会被当成标点符号处理,实际用处并不大。chrome网页翻译chromehelper插件免费下载。
翻译蜘蛛自动抓取百度网页翻译包。(无限开放)需要登录,很久了。
不知道你所说的网页翻译的代码是什么样子的,是提供c#语言?c++语言?如果是提供代码的话。我觉得没有实际意义,如果真的找到翻译代码。你也可以用翻译,不过就会加一些翻译时候的局限性。
我试过visualstudio,clion,和pythonstudio,都是自动抓取所有百度网页翻译,然后人工去下,代码量巨大,翻译效率也不高,处理翻译后的网页肯定没有直接下翻译生成的结果快。
翻译有限制,只有robots协议没改,但是翻译的位置不能超过网页上线位置范围,因为baidu会处理你翻译后的所有后台页面,多了可能没有效果。翻译没人处理的地方可以显示翻译结果,比如百度有评论系统的页面,需要翻译一下评论内容方便点击搜索(并且随机显示一条评论的翻译结果,而且是tb结果的翻译相对于你从百度首页全页查看来说是不完整的,因为要从百度后台查看评论的翻译结果)。
chrome插件网页抓取(一键保存网页为PDF过程中对Chrome插件的开发心得)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-10-29 20:22
广为宣传:
Chrome插件一键保存网页为PDF1.1 release
最近在“一键保存网页为PDF”的过程中,也对Chrome插件的开发有了一些体会。我将在这里与您分享。
这里以我的插件为例给大家讲解一下。虽然我的文章文章是关于manifest.json文件的,但是过程中我会介绍一些相关的东西。
整个Chrome插件开发的核心是manifest.json。如果你熟悉它,其他一切都很容易。
首先看一下我插件的 manifest.json 文件:
{
"manifest_version": 2,
"name": "保存网页为PDF",
"version": "1.1.7.80",
"description": "保存网页为PDF【作者:涂剑凯,邮箱:bdstjk@qq.com】",
"icons":{"16":"Images/16.png","48":"Images/48.png","128":"Images/128.png"},
"background": {
"page": "background.html"
},
"options_page": "options.html",
"browser_action":
{
"default_icon": "Images/16.png",
"name": "保存网页为PDF"
},
"permissions": [
"tabs",
"http://localhost:9240/",
"activeTab",
"notifications","storage","http://*/"
],
"update_url": "http://localhost:9240/SaveServ ... ot%3B
}
必需属性:名称、版本、manifest_version
1、name,顾名思义就是你的插件的名字;
2、version 指的是你插件的版本号;
3、manifest_version 指定清单文件格式的版本。Chrome18之后应该都是2,所以直接把这个值设置为2就可以了;
推荐属性:描述、图标、default_locale
1、description 插件的描述,简单介绍了插件的用途;
2、icons插件图标,需要准备16*16(扩展信息栏)、48*48(扩展管理页面)、128*128(安装过程中使用)三个图标文件,建议是PNG格式,因为PNG对透明度的支持最好;
3、default_locale 国际化支持,支持哪些语言浏览器,虽然官方推荐,但我没用;
背景
这是一个重要的属性。如果你需要运行一些后台脚本,比如监听用户在扩展信息栏中按下你的插件图标,或者你想监听用户创建标签页,这时候就需要一个后台页面。可以指定一个HTML页面(比如我的插件),也可以指定一个JS文件,比如:
{
"name": "My extension",
...
"background": {
"scripts": ["background.js"]
},
...
}
查看代码
需要注意两点:
1、表示HTML不能写JS代码,需要将JS代码写入JS文件然后导入;
2、 无法使用jquery(没有详细测试,可能是我没有正确使用);
当用户在扩展信息栏中按下您的插件图标时,监控当前活动页面的 URL:
chrome.browserAction.onClicked.addListener(function (tab) {
alert(tab.url);
});
查看代码
看:
options_page
options_page 指定你的插件设置页面,这个看个人需要,不需要设置。
需要注意两点:
1、需要将JS写成JS文件然后导入;
2、 不能有HTML元素的内联事件(比如),需要通过JS给HTML元素绑定事件,比如:
$(document).ready(function () {
$("#btnOpenSetting").click(function () {
OpenSetting();
});
});
查看代码
浏览器动作
browser_action 可以设置扩展信息栏的图标、图标的浮动提示、点击图标时的弹窗(我的插件不需要弹窗,所以没有设置);
让我给你展示一个完整的例子:
{
"name": "My extension",
...
"browser_action": {
"default_icon": { // optional
"19": "images/icon19.png", // optional
"38": "images/icon38.png" // optional
},
"default_title": "Google Mail", // optional; shown in tooltip
"default_popup": "popup.html" // optional
},
...
}
查看代码
权限
虽然权限不是 manifest.json 的必要属性,但我们开发插件是必要的。我们总是要向chrome申请一些权限才能完成我们的插件;
这里我只介绍一下我的插件中用到的权限(当然,有些权限最后其实是没用的):
“标签”,访问浏览器标签
":9240/", AJAX访问localhost:9240
"activeTab", 获取当前活动的标签
"notifications",浏览器通知(基于 HTML5 通知实现)
“storage”,storage,如果要存储一些设置,就需要用到 查看全部
chrome插件网页抓取(一键保存网页为PDF过程中对Chrome插件的开发心得)
广为宣传:
Chrome插件一键保存网页为PDF1.1 release
最近在“一键保存网页为PDF”的过程中,也对Chrome插件的开发有了一些体会。我将在这里与您分享。
这里以我的插件为例给大家讲解一下。虽然我的文章文章是关于manifest.json文件的,但是过程中我会介绍一些相关的东西。
整个Chrome插件开发的核心是manifest.json。如果你熟悉它,其他一切都很容易。
首先看一下我插件的 manifest.json 文件:
{
"manifest_version": 2,
"name": "保存网页为PDF",
"version": "1.1.7.80",
"description": "保存网页为PDF【作者:涂剑凯,邮箱:bdstjk@qq.com】",
"icons":{"16":"Images/16.png","48":"Images/48.png","128":"Images/128.png"},
"background": {
"page": "background.html"
},
"options_page": "options.html",
"browser_action":
{
"default_icon": "Images/16.png",
"name": "保存网页为PDF"
},
"permissions": [
"tabs",
"http://localhost:9240/",
"activeTab",
"notifications","storage","http://*/"
],
"update_url": "http://localhost:9240/SaveServ ... ot%3B
}
必需属性:名称、版本、manifest_version
1、name,顾名思义就是你的插件的名字;
2、version 指的是你插件的版本号;
3、manifest_version 指定清单文件格式的版本。Chrome18之后应该都是2,所以直接把这个值设置为2就可以了;
推荐属性:描述、图标、default_locale
1、description 插件的描述,简单介绍了插件的用途;
2、icons插件图标,需要准备16*16(扩展信息栏)、48*48(扩展管理页面)、128*128(安装过程中使用)三个图标文件,建议是PNG格式,因为PNG对透明度的支持最好;
3、default_locale 国际化支持,支持哪些语言浏览器,虽然官方推荐,但我没用;
背景
这是一个重要的属性。如果你需要运行一些后台脚本,比如监听用户在扩展信息栏中按下你的插件图标,或者你想监听用户创建标签页,这时候就需要一个后台页面。可以指定一个HTML页面(比如我的插件),也可以指定一个JS文件,比如:
{
"name": "My extension",
...
"background": {
"scripts": ["background.js"]
},
...
}
查看代码
需要注意两点:
1、表示HTML不能写JS代码,需要将JS代码写入JS文件然后导入;
2、 无法使用jquery(没有详细测试,可能是我没有正确使用);
当用户在扩展信息栏中按下您的插件图标时,监控当前活动页面的 URL:
chrome.browserAction.onClicked.addListener(function (tab) {
alert(tab.url);
});
查看代码
看:
options_page
options_page 指定你的插件设置页面,这个看个人需要,不需要设置。
需要注意两点:
1、需要将JS写成JS文件然后导入;
2、 不能有HTML元素的内联事件(比如),需要通过JS给HTML元素绑定事件,比如:
$(document).ready(function () {
$("#btnOpenSetting").click(function () {
OpenSetting();
});
});
查看代码
浏览器动作
browser_action 可以设置扩展信息栏的图标、图标的浮动提示、点击图标时的弹窗(我的插件不需要弹窗,所以没有设置);
让我给你展示一个完整的例子:
{
"name": "My extension",
...
"browser_action": {
"default_icon": { // optional
"19": "images/icon19.png", // optional
"38": "images/icon38.png" // optional
},
"default_title": "Google Mail", // optional; shown in tooltip
"default_popup": "popup.html" // optional
},
...
}
查看代码
权限
虽然权限不是 manifest.json 的必要属性,但我们开发插件是必要的。我们总是要向chrome申请一些权限才能完成我们的插件;
这里我只介绍一下我的插件中用到的权限(当然,有些权限最后其实是没用的):
“标签”,访问浏览器标签
":9240/", AJAX访问localhost:9240
"activeTab", 获取当前活动的标签
"notifications",浏览器通知(基于 HTML5 通知实现)
“storage”,storage,如果要存储一些设置,就需要用到
chrome插件网页抓取(工具chrome浏览器浏览器插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 211 次浏览 • 2021-10-26 21:03
工具chrome浏览器
Chrome 浏览器是目前最流行的浏览器。它与大多数 w3c 标准和 ecma 标准兼容。前端工程师在开发过程中提供devtools、插件等工具非常方便。在爬取数据的过程中,最常用的应该是开发工具中的element、source、network函数,分别查看dom结构、源码、网络请求。同时,还有很多基于chrome浏览器的插件,为我们提供了浏览器级别的数据处理能力。
篡改猴子
tampermonkey 是一个 chrome 插件、一个免费的浏览器扩展和最流行的用户脚本管理器。简单来说就是可以指定在进入某些页面时调用指定的js代码,这样我们就可以将页面中的一些数据整理出来保存在localstorage或者indexeddb中。
资源
Reres 是一个 chrome 插件。可以支持将一个在线js重定向到另一个js,即使用另一个js替换原页面中的js。在这个新的js中,我们可以修改部分逻辑来满足我们的需求。
爬行过程
如上图所示,抓取分为三个步骤,即观察、刨削和抓取。
观察
首先是观察。我们需要通过devtools中的元素和网络选项卡来读取要抓取的页面。数据可能在dom元素中,也可能直接通过ajax接口返回。简而言之,找出最适合获取数据的位置。.
当然,如果是ajax接口返回的数据,会很容易抓到,但是有时候我们可能会遇到比较特殊的网站,会对数据进行加密,返回乱码,这个时候我们需要剖析代码。
解剖学
也就是对页面中的逻辑代码进行拆解分析,找到关键代码供我使用。通常对网站的js代码进行混淆和压缩。我们可以使用chrome开发工具中的源码工具对代码进行格式化,方便阅读。然后简单介绍一下我找关键代码的方法:
元素标签搜索方法、元素事件搜索方法、ajax接口名称搜索方法
当然,这里找关键词的时候,需要用到chrome开发者工具的搜索功能。
元素标签搜索
当我们找到一个key的dom元素时,你觉得页面js会不会对这个元素进行操作,比如value、delete等,可以通过这个元素自带的id或者class来搜索。通常,这些 id 和 class 名称不会混淆,可以直接找到。
元素事件查找方法
当我们认为某个元素已经绑定了点击或其他事件并且意义重大时,我们可以在元素面板的事件监听器中找到最可能的事件,然后查看对应的js代码。
当然,如果在elements面板中直接在dom结构上标注方法名,如下图,可以直接全局搜索【checkinput】。
Ajax接口名称查找方法
当我们找到自己想要的接口时,可以在网络中找到接口的名称,直接全局搜索,或者通过发起者中js调用的栈信息找到具体的调用代码。
通过这三步,我们已经基本可以找到我们需要的业务代码了,剩下的就是在此基础上不断寻找加解密逻辑,也是通过断点,然后在回调中寻找函数调用源面板。堆栈,然后找到其他逻辑。
抓住
获取数据无非是以自动化的方式提取数据并将其保存到指定位置。
这里就要靠我们的两个插件tampermonkey和reres了。我一般都是把key js保存在本地进行修改,然后用reres把网上的js映射到本地的js,然后就可以为所欲为了,比如用封装的解密函数来解密数据,然后把数据保存在索引数据库。
使用tampermonkey主要是定义一些全局变量,启动爬取过程,比如遍历dom节点,模拟点击事件,记录抓取数据的位置。
总结
依靠chrome浏览器抓取数据只是一种方便快捷的抓取方式,当然不是很实用,因为chrome不能直接操作数据库,我们的数据还是缓存在浏览器中,导出需要一段时间。这篇文章只谈了一部分捕获数据的想法。具体可以使用puppeteer、phantomjs等工具进行捕捉。 查看全部
chrome插件网页抓取(工具chrome浏览器浏览器插件)
工具chrome浏览器
Chrome 浏览器是目前最流行的浏览器。它与大多数 w3c 标准和 ecma 标准兼容。前端工程师在开发过程中提供devtools、插件等工具非常方便。在爬取数据的过程中,最常用的应该是开发工具中的element、source、network函数,分别查看dom结构、源码、网络请求。同时,还有很多基于chrome浏览器的插件,为我们提供了浏览器级别的数据处理能力。
篡改猴子
tampermonkey 是一个 chrome 插件、一个免费的浏览器扩展和最流行的用户脚本管理器。简单来说就是可以指定在进入某些页面时调用指定的js代码,这样我们就可以将页面中的一些数据整理出来保存在localstorage或者indexeddb中。
资源
Reres 是一个 chrome 插件。可以支持将一个在线js重定向到另一个js,即使用另一个js替换原页面中的js。在这个新的js中,我们可以修改部分逻辑来满足我们的需求。
爬行过程
如上图所示,抓取分为三个步骤,即观察、刨削和抓取。
观察
首先是观察。我们需要通过devtools中的元素和网络选项卡来读取要抓取的页面。数据可能在dom元素中,也可能直接通过ajax接口返回。简而言之,找出最适合获取数据的位置。.
当然,如果是ajax接口返回的数据,会很容易抓到,但是有时候我们可能会遇到比较特殊的网站,会对数据进行加密,返回乱码,这个时候我们需要剖析代码。
解剖学
也就是对页面中的逻辑代码进行拆解分析,找到关键代码供我使用。通常对网站的js代码进行混淆和压缩。我们可以使用chrome开发工具中的源码工具对代码进行格式化,方便阅读。然后简单介绍一下我找关键代码的方法:
元素标签搜索方法、元素事件搜索方法、ajax接口名称搜索方法
当然,这里找关键词的时候,需要用到chrome开发者工具的搜索功能。
元素标签搜索
当我们找到一个key的dom元素时,你觉得页面js会不会对这个元素进行操作,比如value、delete等,可以通过这个元素自带的id或者class来搜索。通常,这些 id 和 class 名称不会混淆,可以直接找到。
元素事件查找方法
当我们认为某个元素已经绑定了点击或其他事件并且意义重大时,我们可以在元素面板的事件监听器中找到最可能的事件,然后查看对应的js代码。
当然,如果在elements面板中直接在dom结构上标注方法名,如下图,可以直接全局搜索【checkinput】。
Ajax接口名称查找方法
当我们找到自己想要的接口时,可以在网络中找到接口的名称,直接全局搜索,或者通过发起者中js调用的栈信息找到具体的调用代码。
通过这三步,我们已经基本可以找到我们需要的业务代码了,剩下的就是在此基础上不断寻找加解密逻辑,也是通过断点,然后在回调中寻找函数调用源面板。堆栈,然后找到其他逻辑。
抓住
获取数据无非是以自动化的方式提取数据并将其保存到指定位置。
这里就要靠我们的两个插件tampermonkey和reres了。我一般都是把key js保存在本地进行修改,然后用reres把网上的js映射到本地的js,然后就可以为所欲为了,比如用封装的解密函数来解密数据,然后把数据保存在索引数据库。
使用tampermonkey主要是定义一些全局变量,启动爬取过程,比如遍历dom节点,模拟点击事件,记录抓取数据的位置。
总结
依靠chrome浏览器抓取数据只是一种方便快捷的抓取方式,当然不是很实用,因为chrome不能直接操作数据库,我们的数据还是缓存在浏览器中,导出需要一段时间。这篇文章只谈了一部分捕获数据的想法。具体可以使用puppeteer、phantomjs等工具进行捕捉。
chrome插件网页抓取(制作自己的学习手册,永久保存互联网信息*早前PriceTag)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-26 01:16
制作自己的学习手册,永久保存互联网信息
* 较早提交价签,文字已删除
关于文章和信息整理,一个常见的需求是将某个主题的多个文章,或者某个博客或教程的所有网页,保存到一个类似的电子出版物中。书籍,以便它们可以在手机、平板电脑上阅读或永久存储。实现此要求的一种方法是使用 Chrome 插件将目标网页另存为 ePub 文件。
ePub 插件大约有十种。经过大量测试,我最终选择了dotEPUB、WebToWpub、EpubPress和另存为电子书这四个插件,各有侧重,效果也不错。本文将分析它们的特性并帮助您确定哪一种最能满足您的需求。
四大插件的用途及特点
dotEPUB:将当前窗口的网页保存为ePub
1. 速度:速度更快2. Watermark:开头和结尾的水印3. 图片支持:稍差4. 排版:更好的排版
dotEPUB 是最简单、功能最单一的。只需单击插件栏中的 dotEPUB 图标,即可将当前网页自动下载为 ePub 文件。但由于只保存当前网页,应用范围较窄。
在这里你可以轻松打开一个知乎专栏“我们在谈论英语学习时在谈论什么”,尝试抓取素材,用More Look App打开。读取效果如下图所示。需要注意的是,这个插件会在开头和结尾添加dotEPUB水印:
WebToEpub:抓取当前网页中的所有链接作为章节,生成为ePub
1. 速度:速度更快,有进度条2. 水印:无水印3. 图片支持:有图片4. 排版:排版比较一般
这是我经常使用的插件。它可以抓取当前网页中收录的链接的所有内容。适用于抓取知乎栏目或以列表形式扩展内容的博客。网页中的每个链接都会生成到Epub的特定章节中,章节标题即为网页的标题。
点击插件,确认开始转换,就会进入插件主界面,在主界面WebToEpub允许用户编辑ePub书名、文件名和作者。爬取时可以手动勾选需要的链接,也可以进行多选、反选等,也可以对选中的网页列表进行反排序。此外,您可以通过将图像地址粘贴到 URL 框来为文件添加封面。
需要注意的是,对于一些动态加载的页面,如果要抓取所有文章,需要在使用插件前滚动到页面底部完整加载列表。
EpubPress:抓取所有当前打开的标签作为 ePub
1.速度:平均速度,有进度条2.水印:无水印3.图片支持:图片在某些情况下可能无法捕捉4.排版:更好的排版
这是另一个比较常用的插件,可以保存浏览器当前打开的所有标签页,每个标签页就是一个章节。与WebToEpub相比,EpubPress的设置选项比较简单,可以输入标题和描述,查看想要的网页。
此外,EpubPress 还支持以 mobi 格式保存,并支持将捕获的文件发送到某个电子邮件地址。您可以根据需要在右上角的设置中进行选择。
如果爬取大量标签,等待时间会大大延长。另外需要注意的是,在实际测试中,可能有20多个选项卡无法保存。
另存为电子书:选择打开的网页以另存为 ePub
1. 速度:更快的速度2. 水印:无水印3. 图片支持:有图片4. 排版:更好的排版
另存为电子书和 EpubPress 的功能类似。两者都将打开的标签保存为 ePub 文件的章节。但是,另存为电子书需要在浏览网页时点击需要保存的网页插件栏图标选择“另存为章节”。标记后,单击“编辑章节”将这些网页保存为 ePub 文件。
在主界面中,您可以编辑文件标题和调整章节顺序。
四种使用场景
总结一下这四个插件的适用场景,这里简单总结一下:
总结
将网页保存为 ePub 电子书以供阅读是除了 Evernote 等工具之外的另一种思维方式,稍后阅读。对于严肃或系统的内容,制作ePub电子书一两下阅读主题会更加连贯。这是电子书和印象笔记以及以后阅读的区别。观点。因此,ePub电子书无疑是系统学习的好选择。
回到Chrome插件的话题,目前一键生成ePub文件的插件普遍存在的缺点是插件制作的电子书不是纯图形,还有一些不相关的内容,比如超链接或者评论在网站也有可能被收录导入电子书,导致转换效果不佳。文章 只提到了目前的四个ePub转换插件,每个插件都有自己的不足。
根据个人需要,可以组合两个或多个插件来完成ePub转换工作。 查看全部
chrome插件网页抓取(制作自己的学习手册,永久保存互联网信息*早前PriceTag)
制作自己的学习手册,永久保存互联网信息
* 较早提交价签,文字已删除
关于文章和信息整理,一个常见的需求是将某个主题的多个文章,或者某个博客或教程的所有网页,保存到一个类似的电子出版物中。书籍,以便它们可以在手机、平板电脑上阅读或永久存储。实现此要求的一种方法是使用 Chrome 插件将目标网页另存为 ePub 文件。
ePub 插件大约有十种。经过大量测试,我最终选择了dotEPUB、WebToWpub、EpubPress和另存为电子书这四个插件,各有侧重,效果也不错。本文将分析它们的特性并帮助您确定哪一种最能满足您的需求。
四大插件的用途及特点
dotEPUB:将当前窗口的网页保存为ePub
1. 速度:速度更快2. Watermark:开头和结尾的水印3. 图片支持:稍差4. 排版:更好的排版
dotEPUB 是最简单、功能最单一的。只需单击插件栏中的 dotEPUB 图标,即可将当前网页自动下载为 ePub 文件。但由于只保存当前网页,应用范围较窄。
在这里你可以轻松打开一个知乎专栏“我们在谈论英语学习时在谈论什么”,尝试抓取素材,用More Look App打开。读取效果如下图所示。需要注意的是,这个插件会在开头和结尾添加dotEPUB水印:
WebToEpub:抓取当前网页中的所有链接作为章节,生成为ePub
1. 速度:速度更快,有进度条2. 水印:无水印3. 图片支持:有图片4. 排版:排版比较一般
这是我经常使用的插件。它可以抓取当前网页中收录的链接的所有内容。适用于抓取知乎栏目或以列表形式扩展内容的博客。网页中的每个链接都会生成到Epub的特定章节中,章节标题即为网页的标题。
点击插件,确认开始转换,就会进入插件主界面,在主界面WebToEpub允许用户编辑ePub书名、文件名和作者。爬取时可以手动勾选需要的链接,也可以进行多选、反选等,也可以对选中的网页列表进行反排序。此外,您可以通过将图像地址粘贴到 URL 框来为文件添加封面。
需要注意的是,对于一些动态加载的页面,如果要抓取所有文章,需要在使用插件前滚动到页面底部完整加载列表。
EpubPress:抓取所有当前打开的标签作为 ePub
1.速度:平均速度,有进度条2.水印:无水印3.图片支持:图片在某些情况下可能无法捕捉4.排版:更好的排版
这是另一个比较常用的插件,可以保存浏览器当前打开的所有标签页,每个标签页就是一个章节。与WebToEpub相比,EpubPress的设置选项比较简单,可以输入标题和描述,查看想要的网页。
此外,EpubPress 还支持以 mobi 格式保存,并支持将捕获的文件发送到某个电子邮件地址。您可以根据需要在右上角的设置中进行选择。
如果爬取大量标签,等待时间会大大延长。另外需要注意的是,在实际测试中,可能有20多个选项卡无法保存。
另存为电子书:选择打开的网页以另存为 ePub
1. 速度:更快的速度2. 水印:无水印3. 图片支持:有图片4. 排版:更好的排版
另存为电子书和 EpubPress 的功能类似。两者都将打开的标签保存为 ePub 文件的章节。但是,另存为电子书需要在浏览网页时点击需要保存的网页插件栏图标选择“另存为章节”。标记后,单击“编辑章节”将这些网页保存为 ePub 文件。
在主界面中,您可以编辑文件标题和调整章节顺序。
四种使用场景
总结一下这四个插件的适用场景,这里简单总结一下:
总结
将网页保存为 ePub 电子书以供阅读是除了 Evernote 等工具之外的另一种思维方式,稍后阅读。对于严肃或系统的内容,制作ePub电子书一两下阅读主题会更加连贯。这是电子书和印象笔记以及以后阅读的区别。观点。因此,ePub电子书无疑是系统学习的好选择。
回到Chrome插件的话题,目前一键生成ePub文件的插件普遍存在的缺点是插件制作的电子书不是纯图形,还有一些不相关的内容,比如超链接或者评论在网站也有可能被收录导入电子书,导致转换效果不佳。文章 只提到了目前的四个ePub转换插件,每个插件都有自己的不足。
根据个人需要,可以组合两个或多个插件来完成ePub转换工作。
chrome插件网页抓取(Logo抓取器是国外开发者开发一款Logo获取工具浏览器插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 287 次浏览 • 2021-10-26 01:13
Logograbber是国外开发者为了获取Logo获取工具而开发的浏览器插件。网友已完成本地化,支持Chrome、FireFox、360等浏览器。一键傻瓜式操作下载他们的Logo,而且还是PNG格式,大家不妨下载体验一下!
如何安装Logograbber Chrome插件
1、下载附件,使用压缩软件解压压缩文件,保存到系统任意文件夹。
2、在Chrome(或360、QQ等浏览器)地址栏输入:chrome://extensions/ 打开Chrome浏览器的扩展管理界面,点击打勾右上角的“开发者模式”按钮。
3、勾选开发者模式选项后,此页面会有加载开发中扩展的按钮,点击“加载开发中扩展”按钮,选择Chrome插件刚刚解压的文件夹文件夹.
4、 单击“确定”按钮。如果此时没有任何反应,则插件将成功加载到浏览器中。
Logo 采集器 Chrome 插件的使用方法
1、使用谷歌浏览器(或其他Chrome浏览器)打开目标网站。
2、点击浏览器上的“Logograbber”,就会开始抓取可能的logo图案。
3、点击“下载”下载对应的Logo格式。
4、如果您发现显示的logo不是正确的logo,您也可以通过下方链接反馈问题。
并非所有 网站 都支持,但大多数 网站 仍然是可能的。该工具可以节省时间并提高工作效率。其次,你可以得到png格式的图片,这绝对比截图好。高,可以在一些隐藏标签中找到logo,整体不错。 查看全部
chrome插件网页抓取(Logo抓取器是国外开发者开发一款Logo获取工具浏览器插件)
Logograbber是国外开发者为了获取Logo获取工具而开发的浏览器插件。网友已完成本地化,支持Chrome、FireFox、360等浏览器。一键傻瓜式操作下载他们的Logo,而且还是PNG格式,大家不妨下载体验一下!
如何安装Logograbber Chrome插件
1、下载附件,使用压缩软件解压压缩文件,保存到系统任意文件夹。
2、在Chrome(或360、QQ等浏览器)地址栏输入:chrome://extensions/ 打开Chrome浏览器的扩展管理界面,点击打勾右上角的“开发者模式”按钮。
3、勾选开发者模式选项后,此页面会有加载开发中扩展的按钮,点击“加载开发中扩展”按钮,选择Chrome插件刚刚解压的文件夹文件夹.
4、 单击“确定”按钮。如果此时没有任何反应,则插件将成功加载到浏览器中。
Logo 采集器 Chrome 插件的使用方法
1、使用谷歌浏览器(或其他Chrome浏览器)打开目标网站。
2、点击浏览器上的“Logograbber”,就会开始抓取可能的logo图案。
3、点击“下载”下载对应的Logo格式。
4、如果您发现显示的logo不是正确的logo,您也可以通过下方链接反馈问题。
并非所有 网站 都支持,但大多数 网站 仍然是可能的。该工具可以节省时间并提高工作效率。其次,你可以得到png格式的图片,这绝对比截图好。高,可以在一些隐藏标签中找到logo,整体不错。
chrome插件网页抓取(WebScraper插件的使用步骤及使用方法【爬虫1】)
网站优化 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-10-20 05:08
1.前言
今年上半年,我发了两篇关于MATLAB爬虫的文章:
近日,有朋友留言说想要杭州最新的房价数据。我以为这段代码是以前写的。稍微修改和适应网页后,应该还是可以的,所以我同意了。爬完杭州,这位朋友说他还想去武汉,好吧,我再改密码……
但是由于网页数据不一致,之前的代码总是遇到一些问题,被打断了(之前的代码主要用于临时学习,很多异常的处理没有考虑)。
而且没有专业的防爬功能,爬行时间过长容易被限制……
调试代码真的很费时间和精力,所以只能慢慢调试了……
用了大概一晚上,终于调整好了。
(需要数据和代码,后台回复“爬虫1”即可)
之前做MATLAB爬虫的时候,主要是为了练习写代码。用MATLAB做专业爬虫可能不太合适。调试代码匹配网页需要时间,爬取一些动态网页可能不如python方便。因此,建议使用专业工具来快速方便地抓取重要数据。
听说Chrome上有个爬虫插件,不用写代码就可以爬取数据。
所以我也想借此机会学习一下,以后爬数据可能会更方便;顺便把这个插件的一些使用步骤也记录下来,分享给有需要的朋友,以后可以自己爬取数据了。
1 爬虫插件
我在网上搜索了一下,找到了一些关于chrome爬虫插件的信息。好像Web Scraper推荐的比较多,直接用就好了。
如果没有FQ安装chrome插件有困难,可以在Edge浏览器上试试。
我用的是下面的插件(基本上所有chrome插件都可以装在edge上,在之前的GZH文章中也有介绍过)
https://chrome.google.com/webs ... mbmhn
https://webscraper.io/
网络爬虫插件
2网络爬虫的使用
网上已经有很多关于网页爬虫的使用介绍,插件的官网也有一些介绍。有兴趣的可以自行搜索。
关键点是站点地图和选择器。
我是第一次使用,所以把我用过的操作步骤记录在这里,以防忘记。以攀爬链甲的价格为例。
具体步骤:
[1] 下载并安装插件。这个上面已经讲过了,这里就不赘述了。
[2] 打开网络爬虫。
首先打开一个要抓取数据的网页,比如链家,然后使用快捷键Ctrl+Shift+I或者F12打开Web Scraper插件。
[3] 创建一个新的站点地图。
点击创建新站点地图,有两个选项;导入站点地图是输入现成站点地图的指南;选择首次使用创建站点地图。
然后填写以下信息:
站点地图名称:这只是一个名称,可以根据网页来命名,但需要使用英文字母(不能是大写字母);
Sitemap URL:这是要爬取的网页的链接地址。如果要抓取一个普通的翻页网页,可以先查看不同页码的规则,然后在最后加上[1-100],表示要抓取1-100个页面。
https://hz.lianjia.com/ershoufang/xihu/pg[1-100]/
例如像这样:
[4] 设置站点地图
整个Web Scraper的爬取逻辑如下:
设置一级Selector,选择捕获范围;在一级Selector下设置二级Selector,选择捕获字段,然后捕获。
4.1 创建一级Selector:点击Add new selector;
id:应该只是一个代码,表示要爬取的内容(会在爬取的csv数据中显示);
type:就是你要抓取的数据的类型,比如元素/文本/链接等;因为我们需要选择整个网页的元素范围内的多个数据,所以需要先使用Element进行全选(如果这个网页需要滑动加载更多,需要选择Element Scroll Down);
Multiple:勾选Multiple,因为我们要选择多个元素而不是单个元素;
选择器:点击选择,然后用鼠标在网页上选择我们需要爬取的数据范围(绿色是要选择的区域,鼠标点击后变成红色,表面选中这个区域,选择后点击“完成选择”);注意需要多选几个,不然爬取数据只有一个难点;
然后保存选择器。
4.2 设置二级选择器:
id:代表你抓取的内容,主要是为了区分不同的内容(会在抓取到的csv数据中显示);写xq_name、xq_address等;
类型:选择Text表示要捕获的文本为文本;
Multiple:不要勾选 Multiple,因为我们这里要抓取的是单个元素;
选择:点击选择,然后点击要抓取的内容(字段);例如,点击小区名称、房屋信息、单价、总价等(当字段区域变为红色时,即被选中,点击“完成选择”完成选择)
最好保存,点击保存选择器。
创建二级选择器后,可以创建多个二级选择器。
然后可以预览选择的信息是否正确。
[5] 开始爬取数据
只需点击抓取
设置响应时间等(第一次必须大于2000ms)
点击开始自动开始爬取数据(时间会比我的matlab爬虫慢)
[6] 数据导出
选择将数据导出为 CSV
[7] 保存站点地图并查看爬取数据
保存站点地图的副本,可以将其复制到导入站点地图并导入以供使用。
{"_id":"hz_xihu_ershoufang","startUrl":["https://hz.lianjia.com/ershoufang/xihu/pg[1-100]/"],"selectors":[{"id":"hz_xq","type":"SelectorElement","parentSelectors":["_root"],"selector":"div.info.clear","multiple":true,"delay":0},{"id":"xq_name","type":"SelectorText","parentSelectors":["hz_xq"],"selector":"div.positionInfo","multiple":false,"regex":"","delay":0},{"id":"xq_xinxi","type":"SelectorText","parentSelectors":["hz_xq"],"selector":"div.houseInfo","multiple":false,"regex":"","delay":0},{"id":"xq_peice_zong","type":"SelectorText","parentSelectors":["hz_xq"],"selector":"div.totalPrice","multiple":false,"regex":"","delay":0},{"id":"xq_price_dan","type":"SelectorText","parentSelectors":["hz_xq"],"selector":".unitPrice span","multiple":false,"regex":"","delay":0},{"id":"xq_title","type":"SelectorText","parentSelectors":["hz_xq"],"selector":".title a","multiple":false,"regex":"","delay":0},{"id":"xq_guanzhu","type":"SelectorText","parentSelectors":["hz_xq"],"selector":"div.followInfo","multiple":false,"regex":"","delay":0}]}
3 总结
Web Srcaper目前只能一区一区爬取(以后有时间找相关资料),但是爬取的信息比较丰富,创建爬虫的速度和便利性应该比自己写代码快,而且有是没有软件。基础也能很快掌握~
今天的分享暂时就到这里。我只是爬虫的初学者。有兴趣的可以自己多试试~
一些参考文章(Web Srcaper): 查看全部
chrome插件网页抓取(WebScraper插件的使用步骤及使用方法【爬虫1】)
1.前言
今年上半年,我发了两篇关于MATLAB爬虫的文章:
近日,有朋友留言说想要杭州最新的房价数据。我以为这段代码是以前写的。稍微修改和适应网页后,应该还是可以的,所以我同意了。爬完杭州,这位朋友说他还想去武汉,好吧,我再改密码……
但是由于网页数据不一致,之前的代码总是遇到一些问题,被打断了(之前的代码主要用于临时学习,很多异常的处理没有考虑)。
而且没有专业的防爬功能,爬行时间过长容易被限制……
调试代码真的很费时间和精力,所以只能慢慢调试了……
用了大概一晚上,终于调整好了。
(需要数据和代码,后台回复“爬虫1”即可)
之前做MATLAB爬虫的时候,主要是为了练习写代码。用MATLAB做专业爬虫可能不太合适。调试代码匹配网页需要时间,爬取一些动态网页可能不如python方便。因此,建议使用专业工具来快速方便地抓取重要数据。
听说Chrome上有个爬虫插件,不用写代码就可以爬取数据。
所以我也想借此机会学习一下,以后爬数据可能会更方便;顺便把这个插件的一些使用步骤也记录下来,分享给有需要的朋友,以后可以自己爬取数据了。
1 爬虫插件
我在网上搜索了一下,找到了一些关于chrome爬虫插件的信息。好像Web Scraper推荐的比较多,直接用就好了。
如果没有FQ安装chrome插件有困难,可以在Edge浏览器上试试。
我用的是下面的插件(基本上所有chrome插件都可以装在edge上,在之前的GZH文章中也有介绍过)
https://chrome.google.com/webs ... mbmhn
https://webscraper.io/
网络爬虫插件
2网络爬虫的使用
网上已经有很多关于网页爬虫的使用介绍,插件的官网也有一些介绍。有兴趣的可以自行搜索。
关键点是站点地图和选择器。
我是第一次使用,所以把我用过的操作步骤记录在这里,以防忘记。以攀爬链甲的价格为例。
具体步骤:
[1] 下载并安装插件。这个上面已经讲过了,这里就不赘述了。
[2] 打开网络爬虫。
首先打开一个要抓取数据的网页,比如链家,然后使用快捷键Ctrl+Shift+I或者F12打开Web Scraper插件。
[3] 创建一个新的站点地图。
点击创建新站点地图,有两个选项;导入站点地图是输入现成站点地图的指南;选择首次使用创建站点地图。
然后填写以下信息:
站点地图名称:这只是一个名称,可以根据网页来命名,但需要使用英文字母(不能是大写字母);
Sitemap URL:这是要爬取的网页的链接地址。如果要抓取一个普通的翻页网页,可以先查看不同页码的规则,然后在最后加上[1-100],表示要抓取1-100个页面。
https://hz.lianjia.com/ershoufang/xihu/pg[1-100]/
例如像这样:
[4] 设置站点地图
整个Web Scraper的爬取逻辑如下:
设置一级Selector,选择捕获范围;在一级Selector下设置二级Selector,选择捕获字段,然后捕获。
4.1 创建一级Selector:点击Add new selector;
id:应该只是一个代码,表示要爬取的内容(会在爬取的csv数据中显示);
type:就是你要抓取的数据的类型,比如元素/文本/链接等;因为我们需要选择整个网页的元素范围内的多个数据,所以需要先使用Element进行全选(如果这个网页需要滑动加载更多,需要选择Element Scroll Down);
Multiple:勾选Multiple,因为我们要选择多个元素而不是单个元素;
选择器:点击选择,然后用鼠标在网页上选择我们需要爬取的数据范围(绿色是要选择的区域,鼠标点击后变成红色,表面选中这个区域,选择后点击“完成选择”);注意需要多选几个,不然爬取数据只有一个难点;
然后保存选择器。
4.2 设置二级选择器:
id:代表你抓取的内容,主要是为了区分不同的内容(会在抓取到的csv数据中显示);写xq_name、xq_address等;
类型:选择Text表示要捕获的文本为文本;
Multiple:不要勾选 Multiple,因为我们这里要抓取的是单个元素;
选择:点击选择,然后点击要抓取的内容(字段);例如,点击小区名称、房屋信息、单价、总价等(当字段区域变为红色时,即被选中,点击“完成选择”完成选择)
最好保存,点击保存选择器。
创建二级选择器后,可以创建多个二级选择器。
然后可以预览选择的信息是否正确。
[5] 开始爬取数据
只需点击抓取
设置响应时间等(第一次必须大于2000ms)
点击开始自动开始爬取数据(时间会比我的matlab爬虫慢)
[6] 数据导出
选择将数据导出为 CSV
[7] 保存站点地图并查看爬取数据
保存站点地图的副本,可以将其复制到导入站点地图并导入以供使用。
{"_id":"hz_xihu_ershoufang","startUrl":["https://hz.lianjia.com/ershoufang/xihu/pg[1-100]/"],"selectors":[{"id":"hz_xq","type":"SelectorElement","parentSelectors":["_root"],"selector":"div.info.clear","multiple":true,"delay":0},{"id":"xq_name","type":"SelectorText","parentSelectors":["hz_xq"],"selector":"div.positionInfo","multiple":false,"regex":"","delay":0},{"id":"xq_xinxi","type":"SelectorText","parentSelectors":["hz_xq"],"selector":"div.houseInfo","multiple":false,"regex":"","delay":0},{"id":"xq_peice_zong","type":"SelectorText","parentSelectors":["hz_xq"],"selector":"div.totalPrice","multiple":false,"regex":"","delay":0},{"id":"xq_price_dan","type":"SelectorText","parentSelectors":["hz_xq"],"selector":".unitPrice span","multiple":false,"regex":"","delay":0},{"id":"xq_title","type":"SelectorText","parentSelectors":["hz_xq"],"selector":".title a","multiple":false,"regex":"","delay":0},{"id":"xq_guanzhu","type":"SelectorText","parentSelectors":["hz_xq"],"selector":"div.followInfo","multiple":false,"regex":"","delay":0}]}
3 总结
Web Srcaper目前只能一区一区爬取(以后有时间找相关资料),但是爬取的信息比较丰富,创建爬虫的速度和便利性应该比自己写代码快,而且有是没有软件。基础也能很快掌握~
今天的分享暂时就到这里。我只是爬虫的初学者。有兴趣的可以自己多试试~
一些参考文章(Web Srcaper):
chrome插件网页抓取(鼠标放在视频右上角,按ctrl+v(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-17 14:06
chrome插件网页抓取插件:shox-here以youtube为例,鼠标放在视频右上角,按ctrl+c。shox右键发送gif,点击一键保存即可。或者可以更加魔性的操作,直接保存为4k和8k视频,鼠标放在视频右下角,按ctrl+c。鼠标放在视频右上角,按ctrl+c。鼠标放在视频右上角,按ctrl+v。
ps:推荐这款插件的原因,是因为我发现当你用chrome玩单机游戏或者自制系统录屏的时候,切换到其他浏览器也能玩。这算是比较难用的一个功能了。
我用autotune,录制的时候靠窗口运动,
netflixblur也可以,
快捷键ctrl+c
alt+v
ie是可以的
ie也可以用一键录屏,
我有两款自己觉得还算好用的:videomotion:wordpress好友表示也喜欢,因为通过这个不再使用videomotion,
提供两个选择:1.楼上提到的:autotune2.自己录屏,自己直接写代码录屏。
小尾巴里面也有录屏教程,
360浏览器,
f.lux+screenvideo(这个好像是adobe出的插件) 查看全部
chrome插件网页抓取(鼠标放在视频右上角,按ctrl+v(组图))
chrome插件网页抓取插件:shox-here以youtube为例,鼠标放在视频右上角,按ctrl+c。shox右键发送gif,点击一键保存即可。或者可以更加魔性的操作,直接保存为4k和8k视频,鼠标放在视频右下角,按ctrl+c。鼠标放在视频右上角,按ctrl+c。鼠标放在视频右上角,按ctrl+v。
ps:推荐这款插件的原因,是因为我发现当你用chrome玩单机游戏或者自制系统录屏的时候,切换到其他浏览器也能玩。这算是比较难用的一个功能了。
我用autotune,录制的时候靠窗口运动,
netflixblur也可以,
快捷键ctrl+c
alt+v
ie是可以的
ie也可以用一键录屏,
我有两款自己觉得还算好用的:videomotion:wordpress好友表示也喜欢,因为通过这个不再使用videomotion,
提供两个选择:1.楼上提到的:autotune2.自己录屏,自己直接写代码录屏。
小尾巴里面也有录屏教程,
360浏览器,
f.lux+screenvideo(这个好像是adobe出的插件)
chrome插件网页抓取(全网最权威,插件网站关键词(128个字符))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-14 10:05
网站关键词(128 个字符):
Chrome插件,谷歌插件,谷歌应用商店,chrome应用商店,谷歌离线浏览器安装包,chrome离线浏览器安装包,chrome扩展,谷歌扩展,谷歌浏览器扩展,谷歌扩展商店,Chrome扩展商店, chrome 插件下载, Google Chrome 插件下载,
网站描述(81 个字符):
Chrome插件()是全网最权威、最丰富、更新最快的插件下载网站,想下载最新的chrome插件请找Chrome插件网站!
关于描述:
网民提交的基本信息进行整理收录,本站只提供基本信息,免费向公众展示。 IP地址:118.31.41.16 地址:浙江杭州阿里云,百度权重0、百度移动权重,百度收录 is-article,360收录 is-article,搜狗收录为条,谷歌收录为-,百度访问流量在0~0之间,百度手机访问流量为0~0之间,记录号为京ICP备09103999号-23、记录器调用,百度收录有0关键词,手机关键词有0,至今已创建于9月17日4日。 查看全部
chrome插件网页抓取(全网最权威,插件网站关键词(128个字符))
网站关键词(128 个字符):
Chrome插件,谷歌插件,谷歌应用商店,chrome应用商店,谷歌离线浏览器安装包,chrome离线浏览器安装包,chrome扩展,谷歌扩展,谷歌浏览器扩展,谷歌扩展商店,Chrome扩展商店, chrome 插件下载, Google Chrome 插件下载,
网站描述(81 个字符):
Chrome插件()是全网最权威、最丰富、更新最快的插件下载网站,想下载最新的chrome插件请找Chrome插件网站!
关于描述:
网民提交的基本信息进行整理收录,本站只提供基本信息,免费向公众展示。 IP地址:118.31.41.16 地址:浙江杭州阿里云,百度权重0、百度移动权重,百度收录 is-article,360收录 is-article,搜狗收录为条,谷歌收录为-,百度访问流量在0~0之间,百度手机访问流量为0~0之间,记录号为京ICP备09103999号-23、记录器调用,百度收录有0关键词,手机关键词有0,至今已创建于9月17日4日。
chrome插件网页抓取(苍秋博客园chrome插件网页抓取的信息介绍及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-07 14:10
chrome插件网页抓取,可以抓取不同媒体的信息,用于做二次开发或者博客。国内有个叫苍秋博客园的网站,也可以抓取博客园信息,用于写二次开发的内容。使用:打开网页,地址栏右侧出现三个按钮,一个是复制,一个是刷新,一个是登录。按住不放,会出现三个提示窗口,里面的信息都是抓取的。ps:复制之后会到另一个新的页面,需要手动刷新页面,这样才能保存抓取的信息。
要爬虫视频,
这些都是百度对外提供的源数据,你可以通过代码获取到。一般是存在网站会议文件中,你只要爬取你想要爬取的数据就行了,另外能爬取到对应的源代码。还有最好会爬取谷歌的搜索结果来支持你的博客,
一个chrome插件可以做到。附图一张,
要说可以的话,我只能说那些大牛们。其实可以把那些网站的所有页面保存下来,然后把地址复制到一个代码编辑器上,就可以自己编写爬虫了。
有个叫traffic.js的插件,你把网址保存下来,运行爬虫,可以爬百度、谷歌、新浪、天天动听等。你还可以用imgmonitor来显示、爬虫页面来显示。支持typeed,tiff,json等,丰富多彩。
去几个大站找到页面地址,copy到nodejs里面,上传到github上面,点开了上传后,搜索github就行,有教程。 查看全部
chrome插件网页抓取(苍秋博客园chrome插件网页抓取的信息介绍及应用)
chrome插件网页抓取,可以抓取不同媒体的信息,用于做二次开发或者博客。国内有个叫苍秋博客园的网站,也可以抓取博客园信息,用于写二次开发的内容。使用:打开网页,地址栏右侧出现三个按钮,一个是复制,一个是刷新,一个是登录。按住不放,会出现三个提示窗口,里面的信息都是抓取的。ps:复制之后会到另一个新的页面,需要手动刷新页面,这样才能保存抓取的信息。
要爬虫视频,
这些都是百度对外提供的源数据,你可以通过代码获取到。一般是存在网站会议文件中,你只要爬取你想要爬取的数据就行了,另外能爬取到对应的源代码。还有最好会爬取谷歌的搜索结果来支持你的博客,
一个chrome插件可以做到。附图一张,
要说可以的话,我只能说那些大牛们。其实可以把那些网站的所有页面保存下来,然后把地址复制到一个代码编辑器上,就可以自己编写爬虫了。
有个叫traffic.js的插件,你把网址保存下来,运行爬虫,可以爬百度、谷歌、新浪、天天动听等。你还可以用imgmonitor来显示、爬虫页面来显示。支持typeed,tiff,json等,丰富多彩。
去几个大站找到页面地址,copy到nodejs里面,上传到github上面,点开了上传后,搜索github就行,有教程。
chrome插件网页抓取(注意:Chrome扩展时遇到问题,请打开(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-03 21:01
注意:如果在下载Chrome扩展时遇到问题,请打开C:\Windows\System32\drivers\etc下的host文件,添加一行:74.。
谷歌Chrome浏览器和火狐浏览器一样,可以通过使用扩展来增强。如果您是 Web 开发人员,Google Chrome 的内置开发人员工具将使您的工作轻松很多。但除此之外,Chrome 浏览器上还有很多扩展程序,为您提供了很多工具供您使用。扩展的最大好处之一是它允许您完成某些任务而无需切换到其他应用程序。这种无需切换即可完成某些任务的功能可以为您节省大量时间。
这里有 13 个 Chrome 浏览器扩展程序,您会发现它们很有用。
颜色选择器
颜色选择器可让您获取任何颜色的 Hex 和 RGB 值!您还可以调整颜色的色调、饱和度和色彩平衡。
萤火虫精简版
Firebug Lite 是一种开发工具,可让您编辑、调试和监控网页的 CSS、HTML 和 JavaScript 内容。
域注册查看器
此扩展程序可以检查域名是否可供购买。如果可以直接通过工具栏找到信息,是否还需要登录专门的页面查看?
Aviary 截图扩展
Aviary 截图扩展允许您对任何页面进行截图,并通过 Web 应用程序直接在浏览器中编辑图像。此外,它还提供了一种方便的方式来帮助您访问 Aviary 的 网站 和上述工具
Lorem Ipsum 测试文本生成器
Lorem Ipsum 测试文本生成器可以毫不费力地生成设计模型所需的测试文本内容。
浏览器选项卡
它将使用 Internet Explorer 在 Chrome 选项卡中显示相应的页面。部分网站只能用IE浏览器访问。使用此扩展程序,您可以直接在 Chrome 中查看这些 网站。这个扩展将非常适合那些想要测试IE渲染软件引擎或登录网站 需要使用ActiveX插件,或者想要使用浏览器查看本地文件的人。
测量它!
测量它!允许您绘制标尺,然后测量网页上任何元素的高度和宽度。
便衣
此扩展程序将设计和柔化页面。想象一下:文本是黑色的,背景是白色的,未点击的链接是蓝色的,访问过的链接是紫色的,所有链接都带有下划线。或者您将所有内容更改为您想要的颜色。所有文本都以您选择的默认字体显示(这与通过“选项”>“高级选项”>“更改字体和语言设置”修改的效果相同)。修改后的效果将自动应用于所有页面。
滴管
吸管和颜色选择扩展允许您从页面或高级颜色选择面板中选择颜色。
速度追踪器
速度跟踪扩展可以帮助您识别和纠正 Web 应用程序中的性能问题。它将可视化地处理从浏览器获得的底层数据,并在您的 Web 应用程序运行时对其进行分析。Speed Tracking Extension 是一款 Chrome 浏览器扩展程序,可以在该扩展程序当前支持的所有平台(window 和 Linux)上运行。
摆
它扩展了 Chrome 的内置开发人员工具。
分辨率测试
分辨率测试扩展可以改变浏览器的大小,方便开发者预览网站在不同屏幕分辨率下的实际效果。它收录常用分辨率列表,您也可以输入您需要的分辨率。
狡猾的
Snippy 允许您抓取页面上的部分内容并保存以备将来使用。它可以抓取丰富的内容并保留格式。所以你用它来抓取段落。图像、链接和许多其他格式的内容。 查看全部
chrome插件网页抓取(注意:Chrome扩展时遇到问题,请打开(组图))
注意:如果在下载Chrome扩展时遇到问题,请打开C:\Windows\System32\drivers\etc下的host文件,添加一行:74.。
谷歌Chrome浏览器和火狐浏览器一样,可以通过使用扩展来增强。如果您是 Web 开发人员,Google Chrome 的内置开发人员工具将使您的工作轻松很多。但除此之外,Chrome 浏览器上还有很多扩展程序,为您提供了很多工具供您使用。扩展的最大好处之一是它允许您完成某些任务而无需切换到其他应用程序。这种无需切换即可完成某些任务的功能可以为您节省大量时间。
这里有 13 个 Chrome 浏览器扩展程序,您会发现它们很有用。
颜色选择器
颜色选择器可让您获取任何颜色的 Hex 和 RGB 值!您还可以调整颜色的色调、饱和度和色彩平衡。
萤火虫精简版
Firebug Lite 是一种开发工具,可让您编辑、调试和监控网页的 CSS、HTML 和 JavaScript 内容。
域注册查看器
此扩展程序可以检查域名是否可供购买。如果可以直接通过工具栏找到信息,是否还需要登录专门的页面查看?
Aviary 截图扩展
Aviary 截图扩展允许您对任何页面进行截图,并通过 Web 应用程序直接在浏览器中编辑图像。此外,它还提供了一种方便的方式来帮助您访问 Aviary 的 网站 和上述工具
Lorem Ipsum 测试文本生成器
Lorem Ipsum 测试文本生成器可以毫不费力地生成设计模型所需的测试文本内容。
浏览器选项卡
它将使用 Internet Explorer 在 Chrome 选项卡中显示相应的页面。部分网站只能用IE浏览器访问。使用此扩展程序,您可以直接在 Chrome 中查看这些 网站。这个扩展将非常适合那些想要测试IE渲染软件引擎或登录网站 需要使用ActiveX插件,或者想要使用浏览器查看本地文件的人。
测量它!
测量它!允许您绘制标尺,然后测量网页上任何元素的高度和宽度。
便衣
此扩展程序将设计和柔化页面。想象一下:文本是黑色的,背景是白色的,未点击的链接是蓝色的,访问过的链接是紫色的,所有链接都带有下划线。或者您将所有内容更改为您想要的颜色。所有文本都以您选择的默认字体显示(这与通过“选项”>“高级选项”>“更改字体和语言设置”修改的效果相同)。修改后的效果将自动应用于所有页面。
滴管
吸管和颜色选择扩展允许您从页面或高级颜色选择面板中选择颜色。
速度追踪器
速度跟踪扩展可以帮助您识别和纠正 Web 应用程序中的性能问题。它将可视化地处理从浏览器获得的底层数据,并在您的 Web 应用程序运行时对其进行分析。Speed Tracking Extension 是一款 Chrome 浏览器扩展程序,可以在该扩展程序当前支持的所有平台(window 和 Linux)上运行。
摆
它扩展了 Chrome 的内置开发人员工具。
分辨率测试
分辨率测试扩展可以改变浏览器的大小,方便开发者预览网站在不同屏幕分辨率下的实际效果。它收录常用分辨率列表,您也可以输入您需要的分辨率。
狡猾的
Snippy 允许您抓取页面上的部分内容并保存以备将来使用。它可以抓取丰富的内容并保留格式。所以你用它来抓取段落。图像、链接和许多其他格式的内容。

