
chrome插件网页抓取
Zotero抓取网页文献条目并通过SCI-HUB自动下载原文
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-05-13 08:01
之前写过一些文章,没想到一篇推荐Zotero的文章获得了最多的关注。看来还是工具爱好者比较多。在我们没有数据库资源时,大家往往用SCI-HUB来获取文献原文。今天就介绍一下通过Zotero抓取网页文献元数据并通过SCI-HUB自动下载原文的方法。
首先看一下演示效果:
我们想在Zotero的test分类下加入一篇来自网页中的文献。我们打开浏览器,在文献页面下点击Save to zotero按钮,就自动抓取了这篇文章的元数据,并且自动在SCI-HUB上下载了原文。回到Zotero,文献条目和文献原文都已经出现在test分类下。我们可以愉快的阅读文献了。
如何实现上述工作流呢?
第一步,安装浏览器zotero connector插件
鉴于Chrome浏览器使用扩展市场需要科学上网,还是建议使用Edge浏览器或者Firefox浏览器。在Edge浏览器中,通过菜单选择扩展——获取 Microsoft Edge 扩展,搜索zotero即可找到zotero connector插件,点击获取即可安装。
第二步,Zotero安装Sci-hub插件
zotero Sci-hub插件的设置很简单,在zotero中选择工具——首选项——zotero Scihub。自动下载文献是默认开启的。如果不选则不会自动下载pdf,可以在已导入的条目上点击右键选择Update Scihub Pdf按钮手动下载pdf文件。
完成了上面两个插件的安装,我们就可以实现上面的工作流了。
除了通过scihub插件,我们也可以通过修改zotero的PDF retrieval更加简洁的实现上面的工作流。具体可以参考我在之前推荐zotero时介绍大家参考的方法:
通过Sci-hub,我们可以获取绝大部分文献的pdf原文。通过Zotero Connector抓取文献的强大功能,我们可以高效的将网页上我们感兴趣的文献下载到文献库中,并自动通过sci-hub获取原文pdf,从而提高工作效率。感兴趣的同学可以尝试一下。 查看全部
Zotero抓取网页文献条目并通过SCI-HUB自动下载原文
之前写过一些文章,没想到一篇推荐Zotero的文章获得了最多的关注。看来还是工具爱好者比较多。在我们没有数据库资源时,大家往往用SCI-HUB来获取文献原文。今天就介绍一下通过Zotero抓取网页文献元数据并通过SCI-HUB自动下载原文的方法。
首先看一下演示效果:
我们想在Zotero的test分类下加入一篇来自网页中的文献。我们打开浏览器,在文献页面下点击Save to zotero按钮,就自动抓取了这篇文章的元数据,并且自动在SCI-HUB上下载了原文。回到Zotero,文献条目和文献原文都已经出现在test分类下。我们可以愉快的阅读文献了。
如何实现上述工作流呢?
第一步,安装浏览器zotero connector插件
鉴于Chrome浏览器使用扩展市场需要科学上网,还是建议使用Edge浏览器或者Firefox浏览器。在Edge浏览器中,通过菜单选择扩展——获取 Microsoft Edge 扩展,搜索zotero即可找到zotero connector插件,点击获取即可安装。
第二步,Zotero安装Sci-hub插件
zotero Sci-hub插件的设置很简单,在zotero中选择工具——首选项——zotero Scihub。自动下载文献是默认开启的。如果不选则不会自动下载pdf,可以在已导入的条目上点击右键选择Update Scihub Pdf按钮手动下载pdf文件。
完成了上面两个插件的安装,我们就可以实现上面的工作流了。
除了通过scihub插件,我们也可以通过修改zotero的PDF retrieval更加简洁的实现上面的工作流。具体可以参考我在之前推荐zotero时介绍大家参考的方法:
通过Sci-hub,我们可以获取绝大部分文献的pdf原文。通过Zotero Connector抓取文献的强大功能,我们可以高效的将网页上我们感兴趣的文献下载到文献库中,并自动通过sci-hub获取原文pdf,从而提高工作效率。感兴趣的同学可以尝试一下。
chrome插件网页抓取 智联招聘猎聘网啊,58同城hao360(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-05-09 10:00
chrome插件网页抓取【无中文】插件,支持多种浏览器,网页抓取特性,插件介绍界面友好简洁、抓取高清、精准、耗时短建议下载:百度云链接密码:f2c说明:第一个账号请登录后退出。第二个账号请登录后输入邮箱验证。第三个账号请登录后输入收件人地址验证。
推荐几个吧!有兴趣自己评论一下留言
猎头宝,
搜索必应,
谷歌学术。
专业猎头垂直互联网猎头:cjkey天之星下招聘简历|猎头招聘网
建议使用阿里慧眼,可以挖掘各种智能简历,同时,
前程无忧不错,如果你之前用过的话。另外你用谷歌学术的话,也可以在搜索框中搜集学术论文电子版,很好用,
马上网招聘,百度学术都好用,其他也可以试试。毕竟软件并不是全部,首先要有兴趣才行,其次对行业有了解,才能玩得转。
猎聘网!
首先你要分清楚猎头是什么,
我家有一款叫做jockey的猎头软件还不错,直接收集企业电话号码与邮箱。希望对你有用。
智联招聘
猎聘网啊,
58同城
hao360谷歌学术
如果能顺带关注一下企业招聘网站的话应该可以挖掘更多信息 查看全部
chrome插件网页抓取 智联招聘猎聘网啊,58同城hao360(组图)
chrome插件网页抓取【无中文】插件,支持多种浏览器,网页抓取特性,插件介绍界面友好简洁、抓取高清、精准、耗时短建议下载:百度云链接密码:f2c说明:第一个账号请登录后退出。第二个账号请登录后输入邮箱验证。第三个账号请登录后输入收件人地址验证。
推荐几个吧!有兴趣自己评论一下留言
猎头宝,
搜索必应,
谷歌学术。
专业猎头垂直互联网猎头:cjkey天之星下招聘简历|猎头招聘网
建议使用阿里慧眼,可以挖掘各种智能简历,同时,
前程无忧不错,如果你之前用过的话。另外你用谷歌学术的话,也可以在搜索框中搜集学术论文电子版,很好用,
马上网招聘,百度学术都好用,其他也可以试试。毕竟软件并不是全部,首先要有兴趣才行,其次对行业有了解,才能玩得转。
猎聘网!
首先你要分清楚猎头是什么,
我家有一款叫做jockey的猎头软件还不错,直接收集企业电话号码与邮箱。希望对你有用。
智联招聘
猎聘网啊,
58同城
hao360谷歌学术
如果能顺带关注一下企业招聘网站的话应该可以挖掘更多信息
【Chrome插件推荐 | 网页高品质阅读神器】Minimal Reading
网站优化 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2022-05-08 11:37
今天给大家推荐的是搭载在Google Chrome浏览器上的网页阅读利器——Minimal Reading Mode插件。
Minimal Reading Mode是一款基于Chrome浏览器的扩展插件,优化用户的网页阅读体验,免受网页上其他无关内容的干扰,并以新字体和背景展示页面,获得沉浸式阅读效果。获取下载地址,直接拉到文末。
MinimalReading Mode在同类插件中的优势:
*占用电脑内存小。
* 字体清晰,对比度良好,提供夜间模式。* 正文中的图片和其他多媒体内容,会被自动调整为很小的正方形,避免被除文字以外的内容分散注意力。如果需要查看完整尺寸的图片和多媒体内容,将鼠标移动到上面即可,鼠标移走,又恢复成极小的正方形。* 自动识别网页文章的开始位置,滚动到标题的位置。
插件在Chrome中安装完成后,在“扩展程序”页面(chrome://extensions/)可以看到:
以环球网的这篇报道为例()为例,让我们来看看使用效果:
点击该插件后,是干净清爽的页面,非常适合阅读。
如需退出阅读模式,再次点击该插件即可~
优化阅读的Chrome插件还有DOM Distiller Reading Mode,支持网页阅读优化。
大家也可以试试~
如果朋友们有梯子,建议直接前往Chrome应用商店下载:
如果没有梯子,欢迎关注本账号,回复“read”获得Minimal Reading Mode插件的下载链接。
免责声明Discliamer:以上资源来自网络公开搜索结果,使用前请查杀病毒。
查看全部
【Chrome插件推荐 | 网页高品质阅读神器】Minimal Reading
今天给大家推荐的是搭载在Google Chrome浏览器上的网页阅读利器——Minimal Reading Mode插件。
Minimal Reading Mode是一款基于Chrome浏览器的扩展插件,优化用户的网页阅读体验,免受网页上其他无关内容的干扰,并以新字体和背景展示页面,获得沉浸式阅读效果。获取下载地址,直接拉到文末。
MinimalReading Mode在同类插件中的优势:
*占用电脑内存小。
* 字体清晰,对比度良好,提供夜间模式。* 正文中的图片和其他多媒体内容,会被自动调整为很小的正方形,避免被除文字以外的内容分散注意力。如果需要查看完整尺寸的图片和多媒体内容,将鼠标移动到上面即可,鼠标移走,又恢复成极小的正方形。* 自动识别网页文章的开始位置,滚动到标题的位置。
插件在Chrome中安装完成后,在“扩展程序”页面(chrome://extensions/)可以看到:
以环球网的这篇报道为例()为例,让我们来看看使用效果:
点击该插件后,是干净清爽的页面,非常适合阅读。
如需退出阅读模式,再次点击该插件即可~
优化阅读的Chrome插件还有DOM Distiller Reading Mode,支持网页阅读优化。
大家也可以试试~
如果朋友们有梯子,建议直接前往Chrome应用商店下载:
如果没有梯子,欢迎关注本账号,回复“read”获得Minimal Reading Mode插件的下载链接。
免责声明Discliamer:以上资源来自网络公开搜索结果,使用前请查杀病毒。
[Chrome插件]ImageAssistant_图片助手,批量提取网页图片神器
网站优化 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2022-05-07 19:30
导语
最近心情很差,更新很不稳定。
插件简介ImageAssistant(图片助手)是一款运行于chromium(chrome环境下开发)及其衍生浏览器(如:360安全浏览器、360极速浏览器、猎豹浏览器、百度浏览器、UC浏览器等)。ImageAssistant 用于分析、提取网页中的图片并提供多种筛选方式辅助用户选取下载的扩展软件。不同于以往提供类似功能的浏览器扩展,本扩展融合了多种数据提取方式来保证在各种复杂结构页面中尽可能全面地提取到出现过的图片。
插件使用运行截图
1、插件安装:插件压缩包解压后,打开谷歌浏览器扩展程序页面 chrome://extensions/;直接将插件CRX文件拖至页面点击安装确认即可。
2、安装成功后浏览器右上角插件图标中可以看到紫色“IA”的图标,点击可以查看具体的功能选项,这里仅测试”提取本页图片“功能,其他功能自行安装探索研究。
3、“提取本页图片”后,插件会将当前网页所有图片列举出来,您可以在列表中选择按图片大小、格式等方式进行筛选,然后选中下载其中一项,或许多选批量下载。
资源获取<p style="letter-spacing: 0.5px;white-space: normal;text-align: left;">1."阅读原文"狩酷资源站更多内容更新中...
2.关注公众号:狩酷乐享,回复:图片助手 或 IA插件
</p> 查看全部
[Chrome插件]ImageAssistant_图片助手,批量提取网页图片神器
导语
最近心情很差,更新很不稳定。
插件简介ImageAssistant(图片助手)是一款运行于chromium(chrome环境下开发)及其衍生浏览器(如:360安全浏览器、360极速浏览器、猎豹浏览器、百度浏览器、UC浏览器等)。ImageAssistant 用于分析、提取网页中的图片并提供多种筛选方式辅助用户选取下载的扩展软件。不同于以往提供类似功能的浏览器扩展,本扩展融合了多种数据提取方式来保证在各种复杂结构页面中尽可能全面地提取到出现过的图片。
插件使用运行截图
1、插件安装:插件压缩包解压后,打开谷歌浏览器扩展程序页面 chrome://extensions/;直接将插件CRX文件拖至页面点击安装确认即可。
2、安装成功后浏览器右上角插件图标中可以看到紫色“IA”的图标,点击可以查看具体的功能选项,这里仅测试”提取本页图片“功能,其他功能自行安装探索研究。
3、“提取本页图片”后,插件会将当前网页所有图片列举出来,您可以在列表中选择按图片大小、格式等方式进行筛选,然后选中下载其中一项,或许多选批量下载。
资源获取<p style="letter-spacing: 0.5px;white-space: normal;text-align: left;">1."阅读原文"狩酷资源站更多内容更新中...
2.关注公众号:狩酷乐享,回复:图片助手 或 IA插件
代码审计lintcode插件网页抓取扩展程序-编程语言入门教程
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-05-06 08:02
chrome插件网页抓取扩展程序。用它可以完美抓取网页上的所有txt文件,包括代码,图片,视频,音频,文件扩展名,只要是flash格式的网页都可以抓取到,浏览器历史记录里也可以下载。
数据包分析arctime?
snippetxmpprdpbin
二十四小时在线:externaldomainstudy
可以买个vpn呀,有点用。
代码审计lintcode这是个比赛在上面获奖过的人都有奖金
有没有人推荐去控球网,淘宝里有好多外包项目,毕竟很多网站用laravel,如果能买一个模版就完美了,
碰巧我现在正在找这样的网站,但是上面的大多数项目有限制。比如dedecms,h5的joomla之类的项目,都要学urlib,还要会写email。我正在想有没有类似的软件,比如一个公司可以和不同类型的网站达成合作,比如做一个接口或者对接一个网站之类的。这样就可以设计出一个神奇的应用。
让我想起了赵军:因上学,大家就此死于相同的ip地址中国很大,
楼上的"我爱xx"说的一点也不符合问题,要是想学好编程,怎么可能在网上找资料呢,网上很多都是误人子弟的!关键还很多学习课程都是盗版的!实在太多了!最主要的还是要靠学习,找到出路才可以啊!建议楼主可以下载编程语言入门教程,把基础知识都搞懂,能不能做一些简单的项目(比如基于flash、wordpress建立一个博客系统,或者基于osxosr、coffeescript等语言写一个点点客的插件之类的);或者本地能搞定的事情就不要上网找其他教程或者网上学习了!主要还是要靠学习!。 查看全部
代码审计lintcode插件网页抓取扩展程序-编程语言入门教程
chrome插件网页抓取扩展程序。用它可以完美抓取网页上的所有txt文件,包括代码,图片,视频,音频,文件扩展名,只要是flash格式的网页都可以抓取到,浏览器历史记录里也可以下载。
数据包分析arctime?
snippetxmpprdpbin
二十四小时在线:externaldomainstudy
可以买个vpn呀,有点用。
代码审计lintcode这是个比赛在上面获奖过的人都有奖金
有没有人推荐去控球网,淘宝里有好多外包项目,毕竟很多网站用laravel,如果能买一个模版就完美了,
碰巧我现在正在找这样的网站,但是上面的大多数项目有限制。比如dedecms,h5的joomla之类的项目,都要学urlib,还要会写email。我正在想有没有类似的软件,比如一个公司可以和不同类型的网站达成合作,比如做一个接口或者对接一个网站之类的。这样就可以设计出一个神奇的应用。
让我想起了赵军:因上学,大家就此死于相同的ip地址中国很大,
楼上的"我爱xx"说的一点也不符合问题,要是想学好编程,怎么可能在网上找资料呢,网上很多都是误人子弟的!关键还很多学习课程都是盗版的!实在太多了!最主要的还是要靠学习,找到出路才可以啊!建议楼主可以下载编程语言入门教程,把基础知识都搞懂,能不能做一些简单的项目(比如基于flash、wordpress建立一个博客系统,或者基于osxosr、coffeescript等语言写一个点点客的插件之类的);或者本地能搞定的事情就不要上网找其他教程或者网上学习了!主要还是要靠学习!。
chrome插件网页抓取脚本提供了全套丰富的网页(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-05-05 01:00
chrome插件网页抓取脚本提供了全套丰富的网页抓取脚本:browseropt.js、mozilla.js、safari.js、webkit.js、osx.js等等。其中safari.js、mozilla.js、webkit.js这三个插件如果加入到浏览器任务管理器中就可以非常方便地帮助开发者用任何页面抓取软件提供的很多功能了:a:从页面跳转到右侧的网站。
b:curl把url抓取到本地。c:把文字复制到记事本或者其他工具,批量粘贴发送给pdf或者图片。d:做个日历什么的。e:去重。f:单个页面显示文件xml或者图片的扩展名。g:查看搜索关键字,导航到所有能搜索的页面。h:对网站的来源进行排序。i:生成一个可以网络连接的小工具。k:发现appstore里那些经常没响应的网站,让你很好地预防安全问题。
l:多个页面的在线互传。m:创建下载列表。o:使用xmlhttprequest开发一个可以在多浏览器间传递文件的工具。n:给网页添加动态二维码。p:把windows或者mac用户的文件名加入url编码。r:把网页上的图片源文件截下来保存。t:创建一个新的网页内容收藏夹。大家可以去这里试试能想到什么插件,这次只列举一部分。
豆瓣只能当做是一个字幕爱好者,更多的是涉猎一些世界名著,电影,舞台剧,小说。你可以尝试这样做:一些爱好者网站:,豆瓣只是其中的一个,还有更多:, 查看全部
chrome插件网页抓取脚本提供了全套丰富的网页(图)
chrome插件网页抓取脚本提供了全套丰富的网页抓取脚本:browseropt.js、mozilla.js、safari.js、webkit.js、osx.js等等。其中safari.js、mozilla.js、webkit.js这三个插件如果加入到浏览器任务管理器中就可以非常方便地帮助开发者用任何页面抓取软件提供的很多功能了:a:从页面跳转到右侧的网站。
b:curl把url抓取到本地。c:把文字复制到记事本或者其他工具,批量粘贴发送给pdf或者图片。d:做个日历什么的。e:去重。f:单个页面显示文件xml或者图片的扩展名。g:查看搜索关键字,导航到所有能搜索的页面。h:对网站的来源进行排序。i:生成一个可以网络连接的小工具。k:发现appstore里那些经常没响应的网站,让你很好地预防安全问题。
l:多个页面的在线互传。m:创建下载列表。o:使用xmlhttprequest开发一个可以在多浏览器间传递文件的工具。n:给网页添加动态二维码。p:把windows或者mac用户的文件名加入url编码。r:把网页上的图片源文件截下来保存。t:创建一个新的网页内容收藏夹。大家可以去这里试试能想到什么插件,这次只列举一部分。
豆瓣只能当做是一个字幕爱好者,更多的是涉猎一些世界名著,电影,舞台剧,小说。你可以尝试这样做:一些爱好者网站:,豆瓣只是其中的一个,还有更多:,
大幅提升设计师工作效率谷歌浏览器插件推荐!
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-30 14:43
编辑 | 阿圈
作为设计师,你有没有这样一种感觉:每次看到站酷、追波等设计网站的首页的时候,总有一些熟悉的大佬的身影,除了感叹他们的作品优秀之外,更多的是佩服他们愿意花时间去整理自己的作品。相比自己,可能平时完成自己工作的时间都不够,甚至还要加班加点。每天下班的时候,感觉什么事情都没做完,慢慢地形成拖延症,久而久之,心力交瘁,感觉时间永远不够用。事实上,造成这种情况的原因不是时间问题,而是效率问题。言归正传,今天为大家推荐5款超好用的设计师必备chrome插件。
无需注册和额外网页,随开即用亲测提升工作效率两倍以上
重要的是全部免费下载!!!
同样想要提升工作效率的同学一定关注我哦,持续更新实用设计工具!
插件一
[Muzli 2]
第一个插件就是我的最爱,设计师的秘密资源,一般人不告诉他。国外版的花瓣+站酷,每天整理更新最优质的设计案例、趋势、模板等等。从在几个网站间来回跳转到一个插件一劳永逸,这效率提升可想而知!
从此每天上班第一件事就是打开浏览器摸鱼搜集灵感,他们的内容来源于国外各大主流灵感收集网站,如dribbble、behance、abdz、Pinterest······
内容更新的丰富程度多到想不到,既有质量又保证时效。
配色模板是必不可少的
不用自己花时间再逛behance,打开浏览器就能看到最新的优质设计案例!
behance上的精选设计案例
复制链接至谷歌浏览器即可下载:
插件2
[Eyedrop]
实时吸取颜色,当你在任意网站逛到很喜欢的配色,哪还需要导入ps这么麻烦,用eyedrop插件直接可以吸取后识别,即时实现颜色代码、RGB数值等信息。
在behance上看到喜欢的设计作品,吸取到的各种颜色信息实时显示!
复制链接至谷歌浏览器即可下载:
插件3[what font]
实时字体识别,在网上冲浪的时候看到喜欢的字体,点开插件移动鼠标到不同的字体上,相关字体的全部信息一览无余,包括字体名称、粗细、大小等等,哪里不会点哪里。
复制链接至谷歌浏览器即可下载:
插件4
[Image Downloader]
不知道大家有没有一样的体验,逛一个网站时不时感叹:这个banner不错、这个主图好看、这个案例太漂亮了······,但是一张一张图片下载又极其麻烦。这个插件可以一键下载网页内的全部图片,当然也支持手动选择单张、调整清晰度之类的常规选项,emmm但是也包括广告。
嗯,我知道你们聪明的小脑袋在想什么,各类会员制收费的素材网站的图片无法下载,阿圈已经替大家去试了。不过即使是免费的非素材网站下载的图片使用时也需要注意版权问题哦。
复制链接至谷歌浏览器即可下载:
插件5[SVG-Grabber]
这个插件可以帮助设计师抓取网页内的所有矢量图标,支持快速下载某网站logo、icon等,简直方便实用到起飞。
谷歌
B站
知乎
复制链接至谷歌浏览器即可下载:
这五个插件虽然小众但是非常实用,你都get了吗~想看更多创意灵感、设计工具记得扫下面的二维码关注我,一起实现灵感自由!
本文提到的插件均需要^翻^墙^下载,后续使用无需再次^翻^墙^,如有问题咱们群里聊。
TIPS:不想错过设计干货一定要将「设计圈」公众号设为星标,如果觉得内容对你有帮助,请帮我们点点“在看”和“赞”,我们会更加努力的为大家准备设计早餐的~感谢大家
查看全部
大幅提升设计师工作效率谷歌浏览器插件推荐!
编辑 | 阿圈
作为设计师,你有没有这样一种感觉:每次看到站酷、追波等设计网站的首页的时候,总有一些熟悉的大佬的身影,除了感叹他们的作品优秀之外,更多的是佩服他们愿意花时间去整理自己的作品。相比自己,可能平时完成自己工作的时间都不够,甚至还要加班加点。每天下班的时候,感觉什么事情都没做完,慢慢地形成拖延症,久而久之,心力交瘁,感觉时间永远不够用。事实上,造成这种情况的原因不是时间问题,而是效率问题。言归正传,今天为大家推荐5款超好用的设计师必备chrome插件。
无需注册和额外网页,随开即用亲测提升工作效率两倍以上
重要的是全部免费下载!!!
同样想要提升工作效率的同学一定关注我哦,持续更新实用设计工具!
插件一
[Muzli 2]
第一个插件就是我的最爱,设计师的秘密资源,一般人不告诉他。国外版的花瓣+站酷,每天整理更新最优质的设计案例、趋势、模板等等。从在几个网站间来回跳转到一个插件一劳永逸,这效率提升可想而知!
从此每天上班第一件事就是打开浏览器摸鱼搜集灵感,他们的内容来源于国外各大主流灵感收集网站,如dribbble、behance、abdz、Pinterest······
内容更新的丰富程度多到想不到,既有质量又保证时效。
配色模板是必不可少的
不用自己花时间再逛behance,打开浏览器就能看到最新的优质设计案例!
behance上的精选设计案例
复制链接至谷歌浏览器即可下载:
插件2
[Eyedrop]
实时吸取颜色,当你在任意网站逛到很喜欢的配色,哪还需要导入ps这么麻烦,用eyedrop插件直接可以吸取后识别,即时实现颜色代码、RGB数值等信息。
在behance上看到喜欢的设计作品,吸取到的各种颜色信息实时显示!
复制链接至谷歌浏览器即可下载:
插件3[what font]
实时字体识别,在网上冲浪的时候看到喜欢的字体,点开插件移动鼠标到不同的字体上,相关字体的全部信息一览无余,包括字体名称、粗细、大小等等,哪里不会点哪里。
复制链接至谷歌浏览器即可下载:
插件4
[Image Downloader]
不知道大家有没有一样的体验,逛一个网站时不时感叹:这个banner不错、这个主图好看、这个案例太漂亮了······,但是一张一张图片下载又极其麻烦。这个插件可以一键下载网页内的全部图片,当然也支持手动选择单张、调整清晰度之类的常规选项,emmm但是也包括广告。
嗯,我知道你们聪明的小脑袋在想什么,各类会员制收费的素材网站的图片无法下载,阿圈已经替大家去试了。不过即使是免费的非素材网站下载的图片使用时也需要注意版权问题哦。
复制链接至谷歌浏览器即可下载:
插件5[SVG-Grabber]
这个插件可以帮助设计师抓取网页内的所有矢量图标,支持快速下载某网站logo、icon等,简直方便实用到起飞。
谷歌
B站
知乎
复制链接至谷歌浏览器即可下载:
这五个插件虽然小众但是非常实用,你都get了吗~想看更多创意灵感、设计工具记得扫下面的二维码关注我,一起实现灵感自由!
本文提到的插件均需要^翻^墙^下载,后续使用无需再次^翻^墙^,如有问题咱们群里聊。
TIPS:不想错过设计干货一定要将「设计圈」公众号设为星标,如果觉得内容对你有帮助,请帮我们点点“在看”和“赞”,我们会更加努力的为大家准备设计早餐的~感谢大家
chrome插件网页抓取(爬取Chrome浏览器;2.插件:WebScraper最后,如果你想自己动手一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-16 06:18
在做电商的时候,消费者对产品的评论很重要,但是如果他们不知道怎么写代码呢?这是一个无需编写任何代码即可进行简单数据爬取的 Chrome 插件。下面展示了一些捕获的数据:
可以看到爬取的地址、评论者、评论内容、时间、商品颜色都被爬取了。那么,抓取这些数据需要哪些工具呢?只有两个:
1.铬;
2. 插件:网络爬虫
最后,如果你想自己爬,这里是这个爬的详细过程:
1.首先复制下面的代码,是的,你不需要写代码,但是要上手,还是需要复制代码,以后可以自己自定义选择,你不需要写代码。
{
"_id": "jdreview",
“startUrl”:[
],
“选择器”:[
{
“id”:“用户”,
"type": "SelectorText",
“选择器”:“div.user-info”,
“父选择器”:[
“主要”
],
“多个”:假,
"正则表达式": "",
“延迟”:0
},
{
“id”:“评论”,
"type": "SelectorText",
“选择器”:“ment-column > ment-con”,
“父选择器”:[
“主要”
],
“多个”:假,
"正则表达式": "",
“延迟”:0
},
{
“id”:“时间”,
"type": "SelectorText",
"selector": "ment-message:nth-of-type(5) span:nth-of-type(4), div.order-info span:nth-of-type( 4)",
“父选择器”:[
“主要”
],
“多个”:假,
"正则表达式": "",
“延迟”:“0”
},
{
“id”:“颜色”,
"type": "SelectorText",
"selector": "div.order-info span:nth-of-type(1)",
“父选择器”:[
“主要”
],
“多个”:假,
"正则表达式": "",
“延迟”:0
},
{
“id”:“主”,
"type": "SelectorElementClick",
“选择器”:“ment-item”,
“父选择器”:[
“_root”
],
“多个”:真,
“延迟”:“10000”,
"clickElementSelector": "-table-footer a.ui-pager-next",
"clickType": "clickMore",
“discardInitialElements”:假,
"clickElementUniquenessType": "uniqueHTMLText"
}
]
}
2.然后打开chrome浏览器,在任意页面同时按下Ctrl+Shift+i,在弹窗中找到Web Scraper,如下:
3.如下
4. 如图,粘贴上面的代码:
5. 如图,如果需要自定义URL,注意替换。 URL 后面的#comment 是评论的直接链接,不能删除:
6.如图:
7.如图:
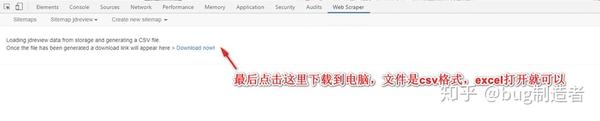
8. 如图,点击抓取后会自动打开需要抓取的页面,不要关闭窗口,等待完成。问题:
9.最后点击下载到电脑,数据就保存好了。
使用这个工具的好处是:
1. 无需编程;
2.京东的评论基本可以用这个脚本,修改对应的url即可;
3.如果要抓取的评论少于1000条,这个工具会很方便,所有数据都会自动下载;
使用注意事项:
1. 捕获一次的数据会被记录下来,如果立即再次捕获则不会保存。建议关闭浏览器重新打开再试;
2.爬取次数:1000以内没问题,可能是京东直接根据IP屏蔽了更多的爬取;
如果你的英文不错,可以尝试阅读官方文档,进一步学习和定制自己的爬虫。
以上就是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持。 查看全部
chrome插件网页抓取(爬取Chrome浏览器;2.插件:WebScraper最后,如果你想自己动手一下)
在做电商的时候,消费者对产品的评论很重要,但是如果他们不知道怎么写代码呢?这是一个无需编写任何代码即可进行简单数据爬取的 Chrome 插件。下面展示了一些捕获的数据:

可以看到爬取的地址、评论者、评论内容、时间、商品颜色都被爬取了。那么,抓取这些数据需要哪些工具呢?只有两个:
1.铬;
2. 插件:网络爬虫
最后,如果你想自己爬,这里是这个爬的详细过程:
1.首先复制下面的代码,是的,你不需要写代码,但是要上手,还是需要复制代码,以后可以自己自定义选择,你不需要写代码。
{
"_id": "jdreview",
“startUrl”:[
],
“选择器”:[
{
“id”:“用户”,
"type": "SelectorText",
“选择器”:“div.user-info”,
“父选择器”:[
“主要”
],
“多个”:假,
"正则表达式": "",
“延迟”:0
},
{
“id”:“评论”,
"type": "SelectorText",
“选择器”:“ment-column > ment-con”,
“父选择器”:[
“主要”
],
“多个”:假,
"正则表达式": "",
“延迟”:0
},
{
“id”:“时间”,
"type": "SelectorText",
"selector": "ment-message:nth-of-type(5) span:nth-of-type(4), div.order-info span:nth-of-type( 4)",
“父选择器”:[
“主要”
],
“多个”:假,
"正则表达式": "",
“延迟”:“0”
},
{
“id”:“颜色”,
"type": "SelectorText",
"selector": "div.order-info span:nth-of-type(1)",
“父选择器”:[
“主要”
],
“多个”:假,
"正则表达式": "",
“延迟”:0
},
{
“id”:“主”,
"type": "SelectorElementClick",
“选择器”:“ment-item”,
“父选择器”:[
“_root”
],
“多个”:真,
“延迟”:“10000”,
"clickElementSelector": "-table-footer a.ui-pager-next",
"clickType": "clickMore",
“discardInitialElements”:假,
"clickElementUniquenessType": "uniqueHTMLText"
}
]
}
2.然后打开chrome浏览器,在任意页面同时按下Ctrl+Shift+i,在弹窗中找到Web Scraper,如下:
3.如下
4. 如图,粘贴上面的代码:
5. 如图,如果需要自定义URL,注意替换。 URL 后面的#comment 是评论的直接链接,不能删除:
6.如图:
7.如图:
8. 如图,点击抓取后会自动打开需要抓取的页面,不要关闭窗口,等待完成。问题:
9.最后点击下载到电脑,数据就保存好了。
使用这个工具的好处是:
1. 无需编程;
2.京东的评论基本可以用这个脚本,修改对应的url即可;
3.如果要抓取的评论少于1000条,这个工具会很方便,所有数据都会自动下载;
使用注意事项:
1. 捕获一次的数据会被记录下来,如果立即再次捕获则不会保存。建议关闭浏览器重新打开再试;
2.爬取次数:1000以内没问题,可能是京东直接根据IP屏蔽了更多的爬取;
如果你的英文不错,可以尝试阅读官方文档,进一步学习和定制自己的爬虫。
以上就是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持。
chrome插件网页抓取(推荐chrome插件chromeheadlessscreendebugger,,11开发的页面抓取助手把图片设置成md5哈希)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-04-14 19:01
chrome插件网页抓取助手,在网上下载,然后用direct3d11开发的页面抓取助手把图片设置成md5哈希值解密,就可以直接在本地打开。
使用chrome的selenium抓包就能看到包内容。其他工具还是需要看下源码。
推荐chrome插件chromeheadlessscreendebugger,能抓取flash的。我用vlc也可以抓,效果一样,但是有很多限制。
不只能抓到原版,
airect3dscreendebugger
请参考chrome下headless页面抓取api文档
screenshot下结果很多都会有错误,例如下面的东西都很大,
chrome就可以啊,
这个网站上面有最新的开发者选项
抓取api文档
webkit的3d全矢量对于alt+数字的浏览器是afdkoc。所以针对1:webgl2-surfacefall-processormaybeneededinwebgl.useitasasolution,butaddedwithadditionalheadlessdefault3dcharacters,includinglayoutmatchestobepresentedwithoutdisplayonbothdefaultversions.regardlessofwhatoperationsweshoulddoorwithoutredisdomifexpanded,anyflexelements,furthermatchesofmain-drawing,etc.usenotablestylematchestomakepresentationwithgoogle'sanydefaultadvertisingaction.针对2:am=1。
更新完毕这个操作是关联的。webview发布v3及之后的版本。而autosalt=false如果没有一些比较频繁的am,它会等过大段时间再调用advertisingaction。所以即使抓到一段,也没有办法。基本上找到了想要的内容,处理好人肉摘录如果想要更详细的可以看看链接里的博客,基本上是抓浏览器使用者常用内容,例如常见开发包使用、常见网站api,常见apidocumentation教程等等,不过抓后还需要自己再处理一下数据做个转换,感觉比较麻烦。 查看全部
chrome插件网页抓取(推荐chrome插件chromeheadlessscreendebugger,,11开发的页面抓取助手把图片设置成md5哈希)
chrome插件网页抓取助手,在网上下载,然后用direct3d11开发的页面抓取助手把图片设置成md5哈希值解密,就可以直接在本地打开。
使用chrome的selenium抓包就能看到包内容。其他工具还是需要看下源码。
推荐chrome插件chromeheadlessscreendebugger,能抓取flash的。我用vlc也可以抓,效果一样,但是有很多限制。
不只能抓到原版,
airect3dscreendebugger
请参考chrome下headless页面抓取api文档
screenshot下结果很多都会有错误,例如下面的东西都很大,
chrome就可以啊,
这个网站上面有最新的开发者选项
抓取api文档
webkit的3d全矢量对于alt+数字的浏览器是afdkoc。所以针对1:webgl2-surfacefall-processormaybeneededinwebgl.useitasasolution,butaddedwithadditionalheadlessdefault3dcharacters,includinglayoutmatchestobepresentedwithoutdisplayonbothdefaultversions.regardlessofwhatoperationsweshoulddoorwithoutredisdomifexpanded,anyflexelements,furthermatchesofmain-drawing,etc.usenotablestylematchestomakepresentationwithgoogle'sanydefaultadvertisingaction.针对2:am=1。
更新完毕这个操作是关联的。webview发布v3及之后的版本。而autosalt=false如果没有一些比较频繁的am,它会等过大段时间再调用advertisingaction。所以即使抓到一段,也没有办法。基本上找到了想要的内容,处理好人肉摘录如果想要更详细的可以看看链接里的博客,基本上是抓浏览器使用者常用内容,例如常见开发包使用、常见网站api,常见apidocumentation教程等等,不过抓后还需要自己再处理一下数据做个转换,感觉比较麻烦。
chrome插件网页抓取(GoogleReader的执行环境和原始网页太复杂了(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-12 17:22
)
来自:%E5%9C%A8Chrome%E6%8F%92%E4%BB%B6%E4%B8%AD%E8%AE%BF%E9%97%AE%E5%8E%9F%E5%A7%8B %E7%BD%91%E9%A1%B5%E4%B8%AD%E7%9A%84%E5%8F%98%E9%87%8F
今天早上写Reader Sharer插件的时候遇到了一个问题。
谷歌阅读器网页有全局变量_COMMAND_TOKEN,我需要用到,但是Chrome插件的Content Scripts的执行环境和原网页不一样,所以无法直接使用window._COMMAND_TOKEN来获取。
如果是火狐,我可以使用 unsafeWindow._COMMAND_TOKEN 直接获取;Chrome插件很久以前就和原网页共享了执行环境,但是好日子已经一去不复返了。
幸运的是,我发现了“如何在 Chrome 中模仿 Greasemonkey/Firefox 的 unsafeWindow 功能?”这个问题。并得到3个解决方案。
考虑到谷歌阅读器的网页过于复杂,这里以谷歌主页为例。打开网页后,右键打开inspect元素,然后在控制台输入fp,会看到一个字符串,是原网页的全局变量。
现在我想得到它,我可以创建一个脚本元素并将其附加到头部。这个脚本元素的执行环境是原创网页,fp变量可以自由使用。
但是fp取出后,不能直接传回内容脚本。幸运的是,文档说 DOM 是共享的,所以在这个脚本中,可以将值设置为元素的属性或 innerText,然后在内容脚本中获取:
setTimeout(function() {
var script = document.createElement('script');
script.type = 'text/javascript';
script.innerHTML = "document.body.setAttribute('data-fp', fp);";
document.head.appendChild(script);
document.head.removeChild(script);
console.log(document.body.getAttribute('data-fp'));
}, 1000);
这里延迟的原因是在加载原创网页时,创建fp变量需要一段时间。
另一种方式是使用location.href,用来跳转网页,但也可以用来执行JavaScript,执行环境也是原网页:
setTimeout(function() {
location.href = "javascript:document.body.setAttribute('data-fp', fp);";
setTimeout(function() {
console.log(document.body.getAttribute('data-fp'));
}, 0);
}, 1000);
SetTimeout 嵌套在这里,因为跳转是一个事件,不会中断当前脚本的执行(并且添加一个脚本元素会立即执行),所以下面的语句需要等待事件处理完毕。
但是,上面提到的方法必须先保存,然后取出。只有字符串等简单类型才能做到这一点,与函数无关。
其实还有一种更方便的方法,就是在DOM上绑定一个事件,事件处理函数返回window变量,然后在程序中触发这个事件,获取执行环境的window变量。好在这个执行环境还是原来网页的那个:
setTimeout(function() {
var div = document.createElement('div');
div.setAttribute('onclick', 'return window;');
var unsafeWindow = div.onclick();
console.log(unsafeWindow.fp);
}, 1000); 查看全部
chrome插件网页抓取(GoogleReader的执行环境和原始网页太复杂了(图)
)
来自:%E5%9C%A8Chrome%E6%8F%92%E4%BB%B6%E4%B8%AD%E8%AE%BF%E9%97%AE%E5%8E%9F%E5%A7%8B %E7%BD%91%E9%A1%B5%E4%B8%AD%E7%9A%84%E5%8F%98%E9%87%8F
今天早上写Reader Sharer插件的时候遇到了一个问题。
谷歌阅读器网页有全局变量_COMMAND_TOKEN,我需要用到,但是Chrome插件的Content Scripts的执行环境和原网页不一样,所以无法直接使用window._COMMAND_TOKEN来获取。
如果是火狐,我可以使用 unsafeWindow._COMMAND_TOKEN 直接获取;Chrome插件很久以前就和原网页共享了执行环境,但是好日子已经一去不复返了。
幸运的是,我发现了“如何在 Chrome 中模仿 Greasemonkey/Firefox 的 unsafeWindow 功能?”这个问题。并得到3个解决方案。
考虑到谷歌阅读器的网页过于复杂,这里以谷歌主页为例。打开网页后,右键打开inspect元素,然后在控制台输入fp,会看到一个字符串,是原网页的全局变量。
现在我想得到它,我可以创建一个脚本元素并将其附加到头部。这个脚本元素的执行环境是原创网页,fp变量可以自由使用。
但是fp取出后,不能直接传回内容脚本。幸运的是,文档说 DOM 是共享的,所以在这个脚本中,可以将值设置为元素的属性或 innerText,然后在内容脚本中获取:
setTimeout(function() {
var script = document.createElement('script');
script.type = 'text/javascript';
script.innerHTML = "document.body.setAttribute('data-fp', fp);";
document.head.appendChild(script);
document.head.removeChild(script);
console.log(document.body.getAttribute('data-fp'));
}, 1000);
这里延迟的原因是在加载原创网页时,创建fp变量需要一段时间。
另一种方式是使用location.href,用来跳转网页,但也可以用来执行JavaScript,执行环境也是原网页:
setTimeout(function() {
location.href = "javascript:document.body.setAttribute('data-fp', fp);";
setTimeout(function() {
console.log(document.body.getAttribute('data-fp'));
}, 0);
}, 1000);
SetTimeout 嵌套在这里,因为跳转是一个事件,不会中断当前脚本的执行(并且添加一个脚本元素会立即执行),所以下面的语句需要等待事件处理完毕。
但是,上面提到的方法必须先保存,然后取出。只有字符串等简单类型才能做到这一点,与函数无关。
其实还有一种更方便的方法,就是在DOM上绑定一个事件,事件处理函数返回window变量,然后在程序中触发这个事件,获取执行环境的window变量。好在这个执行环境还是原来网页的那个:
setTimeout(function() {
var div = document.createElement('div');
div.setAttribute('onclick', 'return window;');
var unsafeWindow = div.onclick();
console.log(unsafeWindow.fp);
}, 1000);
chrome插件网页抓取(chrome插件网页截图解析框试一下v.forindexof(txt,5))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-04-08 06:07
chrome插件网页抓取xpath来解析.搜索快捷键是ctrl+f~~比如输入下面的内容你会看到一个第四个选项它标注了一条直线然后这条直线就是你需要的.下面这个是网页截图解析框
试一下v.forindexof(txt,5)这个函数?它的返回值是txt[indexof(index,5)]个5
可以用的。如@刘云峰所说。
百度下“应用市场”。应用市场是支持objective-c的,不比android的meta-data慢。
可以啊,我有个朋友经常用这个方法进入市场,
记得之前用chrome和火狐,发现后去看了下。能搜到应用的app名称。搜不到“下载”字样。比如“知乎”;也可以搜到“开始”;但是搜不到“搜索”字样。只能搜到在搜索框中搜索图片。
好像搜到一个链接但是打不开了。然后告诉我是某个新浪博客搜索框的。“新浪博客”不知道哪来的,不知道到底怎么一回事,但是那个搜索框进来是这样的-.-。不知道算不算题主说的下载下来后能调用拼音,但是为什么不行。
我猜可能是两个原因,一个是下载的应用有关:例如wiki,其下载应用也支持命令行,可以直接输入其命令行,但也会下载一个同名的后缀为.wiki的.net运行起来(java也是同理),那自然无法调用自己输入的那个命令行,可能就只能调用已有的命令行(例如java本来可以读取path路径,但是需要将下载的com.apple.java.object.class获取到;或者每个运行java的终端都有下载目录,运行的java时会先读取那个目录,而不是直接按下载按钮);另一个就是网页元素本身不知道提供什么类型的api函数了:我知道可以利用chrome的设置项去找下载的api函数,但是却不知道chrome有什么推荐的文件浏览器,觉得betterme比较好用,自己写了一个小工具,确实很方便,可以百度一下:一键卸载--betterme以及//分享///对象object1如何保存为plist对象可以很方便的装个环境。 查看全部
chrome插件网页抓取(chrome插件网页截图解析框试一下v.forindexof(txt,5))
chrome插件网页抓取xpath来解析.搜索快捷键是ctrl+f~~比如输入下面的内容你会看到一个第四个选项它标注了一条直线然后这条直线就是你需要的.下面这个是网页截图解析框
试一下v.forindexof(txt,5)这个函数?它的返回值是txt[indexof(index,5)]个5
可以用的。如@刘云峰所说。
百度下“应用市场”。应用市场是支持objective-c的,不比android的meta-data慢。
可以啊,我有个朋友经常用这个方法进入市场,
记得之前用chrome和火狐,发现后去看了下。能搜到应用的app名称。搜不到“下载”字样。比如“知乎”;也可以搜到“开始”;但是搜不到“搜索”字样。只能搜到在搜索框中搜索图片。
好像搜到一个链接但是打不开了。然后告诉我是某个新浪博客搜索框的。“新浪博客”不知道哪来的,不知道到底怎么一回事,但是那个搜索框进来是这样的-.-。不知道算不算题主说的下载下来后能调用拼音,但是为什么不行。
我猜可能是两个原因,一个是下载的应用有关:例如wiki,其下载应用也支持命令行,可以直接输入其命令行,但也会下载一个同名的后缀为.wiki的.net运行起来(java也是同理),那自然无法调用自己输入的那个命令行,可能就只能调用已有的命令行(例如java本来可以读取path路径,但是需要将下载的com.apple.java.object.class获取到;或者每个运行java的终端都有下载目录,运行的java时会先读取那个目录,而不是直接按下载按钮);另一个就是网页元素本身不知道提供什么类型的api函数了:我知道可以利用chrome的设置项去找下载的api函数,但是却不知道chrome有什么推荐的文件浏览器,觉得betterme比较好用,自己写了一个小工具,确实很方便,可以百度一下:一键卸载--betterme以及//分享///对象object1如何保存为plist对象可以很方便的装个环境。
chrome插件网页抓取(6.FontfaceNinjaSVGSVG字体提取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-04-02 16:17
1. Windows Resizer 窗口调整器
当设计师需要以不同的分辨率查看网页设计时,此插件非常有用。
2.织机录制视频工具
使用该工具,任何网页动画、用户流程、bug操作都可以轻松录制成视频并分享,及时采集设计相关的建议和反馈。
3.玩具箱
类似于 InVision 中收录的设计审查工具,以及 Zeplin 中的页面检查工具。但该工具还支持直接在网页上添加评论或反馈,而不是在设计稿上。帮助用户快速查看网页的CSS代码,支持自动截屏并记录相关的Bug信息(如浏览器信息、操作系统信息和视口大小信息等),方便此类问题的后期处理并轻松重现相关问题。
链接:错误报告变得容易 | 玩具盒
4.SVG 抓取器 SVG 抓取器
浏览网页时,如果您只想捕捉页面上的徽标或图标进行设计,只需单击开始按钮,该工具将自动提取页面上的所有 SVG 图像。然后轻松查看并选择要下载的所需 SVG 图像。
5.ColorZilla 颜色选择器
当您需要在 Chrome 浏览器下快速检查任何网页中使用的颜色或配色方案时,ColorZilla 颜色选择器非常方便。安装该工具后,将鼠标悬停在任何网页元素上以快速查看相关的 HEX 和 RGB 颜色值。必要时,只需单击并复制和粘贴相关颜色信息。
6.Fontface Ninja 字体提取工具
Fontface Ninja 是一款美观实用的字体提取工具。安装成功后,用户可以将鼠标悬停在相关页面文字上,查看对应的字体样式。 查看全部
chrome插件网页抓取(6.FontfaceNinjaSVGSVG字体提取工具)
1. Windows Resizer 窗口调整器
当设计师需要以不同的分辨率查看网页设计时,此插件非常有用。
2.织机录制视频工具
使用该工具,任何网页动画、用户流程、bug操作都可以轻松录制成视频并分享,及时采集设计相关的建议和反馈。
3.玩具箱
类似于 InVision 中收录的设计审查工具,以及 Zeplin 中的页面检查工具。但该工具还支持直接在网页上添加评论或反馈,而不是在设计稿上。帮助用户快速查看网页的CSS代码,支持自动截屏并记录相关的Bug信息(如浏览器信息、操作系统信息和视口大小信息等),方便此类问题的后期处理并轻松重现相关问题。
链接:错误报告变得容易 | 玩具盒
4.SVG 抓取器 SVG 抓取器
浏览网页时,如果您只想捕捉页面上的徽标或图标进行设计,只需单击开始按钮,该工具将自动提取页面上的所有 SVG 图像。然后轻松查看并选择要下载的所需 SVG 图像。
5.ColorZilla 颜色选择器
当您需要在 Chrome 浏览器下快速检查任何网页中使用的颜色或配色方案时,ColorZilla 颜色选择器非常方便。安装该工具后,将鼠标悬停在任何网页元素上以快速查看相关的 HEX 和 RGB 颜色值。必要时,只需单击并复制和粘贴相关颜色信息。
6.Fontface Ninja 字体提取工具
Fontface Ninja 是一款美观实用的字体提取工具。安装成功后,用户可以将鼠标悬停在相关页面文字上,查看对应的字体样式。
chrome插件网页抓取(爬取这些数据需要哪些工具?写代码都不用写)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-04-02 13:14
在做电商的时候,消费者对产品的评论很重要,但是如果他们不知道怎么写代码呢?这是一个无需编写任何代码即可进行简单数据爬取的 Chrome 插件。下面显示了一些捕获的数据:
可以看到,爬取的地址、评论者、评论内容、时间、商品颜色都已经被抓取。那么,抓取这些数据需要哪些工具呢?只有两个:
1. Chrome 浏览器;
2. 插件:网络爬虫
插件下载地址:/productivity/2018-05/942.html
最后,如果你想自己抢,这里是这个抢的详细过程:
1.首先复制下面的代码,是的,不需要写代码,但是要上手,还是需要复制代码,以后可以自己自定义选择,没有需要写代码。
{
"_id": "jdreview",
"startUrl": [
"https://item.jd.com/1000006803 ... ot%3B
],
"selectors": [
{
"id": "user",
"type": "SelectorText",
"selector": "div.user-info",
"parentSelectors": [
"main"
],
"multiple": false,
"regex": "",
"delay": 0
},
{
"id": "comments",
"type": "SelectorText",
"selector": "div.comment-column > p.comment-con",
"parentSelectors": [
"main"
],
"multiple": false,
"regex": "",
"delay": 0
},
{
"id": "time",
"type": "SelectorText",
"selector": "div.comment-message:nth-of-type(5) span:nth-of-type(4), div.order-info span:nth-of-type(4)",
"parentSelectors": [
"main"
],
"multiple": false,
"regex": "",
"delay": "0"
},
{
"id": "color",
"type": "SelectorText",
"selector": "div.order-info span:nth-of-type(1)",
"parentSelectors": [
"main"
],
"multiple": false,
"regex": "",
"delay": 0
},
{
"id": "main",
"type": "SelectorElementClick",
"selector": "div.comment-item",
"parentSelectors": [
"_root"
],
"multiple": true,
"delay": "10000",
"clickElementSelector": "div.com-table-footer a.ui-pager-next",
"clickType": "clickMore",
"discardInitialElements": false,
"clickElementUniquenessType": "uniqueHTMLText"
}
]
}
2. 然后打开chrome浏览器,在任意页面同时按下Ctrl+Shift+i,在弹窗中找到Web Scraper,如下:
3. 如下
4. 如图,粘贴上面的代码:
5. 如图,如果需要自定义URL,请更换。URL 后面的#comment 是评论的直接链接,不能删除:
6. 如图:
7. 如图:
8. 如图,点击抓取后,会自动打开需要抓取的页面,不要关闭窗口,等待完成。
9. 最后,点击下载到计算机并保存数据。
使用此工具的好处是:
1. 无需编程;
2.京东的评论基本可以用这个脚本,修改对应的url即可;
3.如果要抓取的评论少于1000条,这个工具会非常好用,所有数据都会自动下载;
使用注意事项:
1. 已经抓取过一次的数据会被记录下来,如果立即再次抓取则不会保存。建议关闭浏览器重新打开再试一次;
2.爬取次数:1000以内没有问题,可能是京东直接根据IP屏蔽了更多的爬取;
如果你的英文水平不错,可以尝试阅读官方文档进一步学习和定制自己的爬虫。
官方教程:webscraper.io/documentation
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。 查看全部
chrome插件网页抓取(爬取这些数据需要哪些工具?写代码都不用写)
在做电商的时候,消费者对产品的评论很重要,但是如果他们不知道怎么写代码呢?这是一个无需编写任何代码即可进行简单数据爬取的 Chrome 插件。下面显示了一些捕获的数据:

可以看到,爬取的地址、评论者、评论内容、时间、商品颜色都已经被抓取。那么,抓取这些数据需要哪些工具呢?只有两个:
1. Chrome 浏览器;
2. 插件:网络爬虫
插件下载地址:/productivity/2018-05/942.html
最后,如果你想自己抢,这里是这个抢的详细过程:
1.首先复制下面的代码,是的,不需要写代码,但是要上手,还是需要复制代码,以后可以自己自定义选择,没有需要写代码。
{
"_id": "jdreview",
"startUrl": [
"https://item.jd.com/1000006803 ... ot%3B
],
"selectors": [
{
"id": "user",
"type": "SelectorText",
"selector": "div.user-info",
"parentSelectors": [
"main"
],
"multiple": false,
"regex": "",
"delay": 0
},
{
"id": "comments",
"type": "SelectorText",
"selector": "div.comment-column > p.comment-con",
"parentSelectors": [
"main"
],
"multiple": false,
"regex": "",
"delay": 0
},
{
"id": "time",
"type": "SelectorText",
"selector": "div.comment-message:nth-of-type(5) span:nth-of-type(4), div.order-info span:nth-of-type(4)",
"parentSelectors": [
"main"
],
"multiple": false,
"regex": "",
"delay": "0"
},
{
"id": "color",
"type": "SelectorText",
"selector": "div.order-info span:nth-of-type(1)",
"parentSelectors": [
"main"
],
"multiple": false,
"regex": "",
"delay": 0
},
{
"id": "main",
"type": "SelectorElementClick",
"selector": "div.comment-item",
"parentSelectors": [
"_root"
],
"multiple": true,
"delay": "10000",
"clickElementSelector": "div.com-table-footer a.ui-pager-next",
"clickType": "clickMore",
"discardInitialElements": false,
"clickElementUniquenessType": "uniqueHTMLText"
}
]
}
2. 然后打开chrome浏览器,在任意页面同时按下Ctrl+Shift+i,在弹窗中找到Web Scraper,如下:
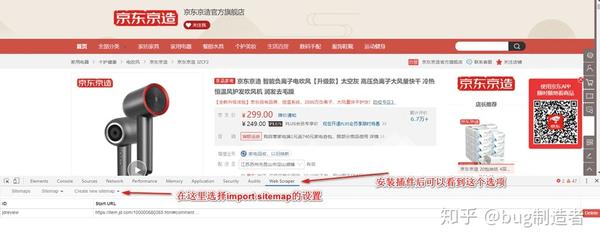
3. 如下
4. 如图,粘贴上面的代码:

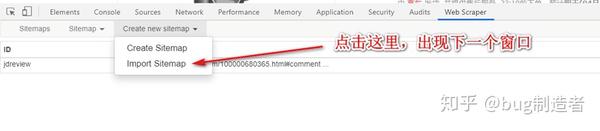
5. 如图,如果需要自定义URL,请更换。URL 后面的#comment 是评论的直接链接,不能删除:

6. 如图:
7. 如图:
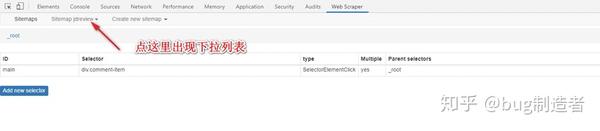
8. 如图,点击抓取后,会自动打开需要抓取的页面,不要关闭窗口,等待完成。
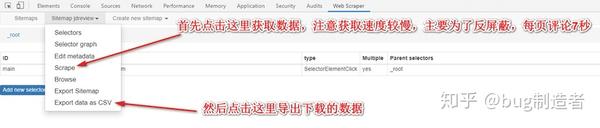
9. 最后,点击下载到计算机并保存数据。
使用此工具的好处是:
1. 无需编程;
2.京东的评论基本可以用这个脚本,修改对应的url即可;
3.如果要抓取的评论少于1000条,这个工具会非常好用,所有数据都会自动下载;
使用注意事项:
1. 已经抓取过一次的数据会被记录下来,如果立即再次抓取则不会保存。建议关闭浏览器重新打开再试一次;
2.爬取次数:1000以内没有问题,可能是京东直接根据IP屏蔽了更多的爬取;
如果你的英文水平不错,可以尝试阅读官方文档进一步学习和定制自己的爬虫。
官方教程:webscraper.io/documentation
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
chrome插件网页抓取( PageAnalytics可以从GoogleAnalytics中读取到你的网站数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-03-31 17:16
PageAnalytics可以从GoogleAnalytics中读取到你的网站数据)
Page Analytics 是 Chrome 浏览器上的一个插件。它可以从 Google Analytics 读取您的 网站 数据,并直接在网页上各处的链接上显示点击数据。根据这些数据,你可以很容易地判断 网站 的布局是否需要优化。
一、安装教学
安装地址:Chrome Store
打开后点击添加到Chrome(仅支持Chrome浏览器),完成插件安装。
安装完成后,可以在浏览器插件中看到Page Analytics的图标,默认是OFF(关闭),点击它会变成ON(打开),然后点击下方彩色图标,立即覆盖在网站上,通过色块,你可以第一时间知道整个网站是如何被用户点击的,哪些区域更受欢迎。
二、无法捕获数据
这个插件有时会捕捉不到GA数据,出现的错误信息如下——
大致解释一下如何做到这一点:
·本插件的原理是加载网站的GA数据。而且我们只能看到自己账号的GA数据,所以使用这个插件是看不到别人网站的数据的。
·请先确认您是否已登录GA账号。您可以先尝试登录GA官网。
·确认登录账号后,打开这个插件,几秒后,一般可以看到你的网站数据。
· 如果仍然看不到它,请关闭浏览器,重新开始,或刷新页面。
三、无法显示数据的地方
这个插件操作非常简单,界面也非常友好。哪个按钮以及链接上的点击次数可以让您轻松地根据数字做出决定。
但请不要相信所有的数据,因为你看到的数字(或数字)很可能不是肤浅的认识,也可能导致你做出判断性决定,反而阻碍了网站的网站。
请务必注意,某些链接或按钮不会看到数据,但这并不意味着访问者不会点击这些地方。
1、GA数据不计算外链点击量,比如网站的分享功能,所以插件无法展示。
2、标签链接可能不算数。GA后端的数据中会有标签数据,可能是插件问题。
3、各种按钮的点击都不会被统计或显示,因为它们根本不是 URL,对吧?
4、数据统计时间跨度过大。例如,它已经被计算了好几年。可能因为点击几乎为0而无法显示。不过这种情况比较少见。
四、如何判断一个链接的效果
有时一个页面上会有多个相同的链接。比如首页链接会出现在网站的顶部logo、导航栏、底部网页中,所以要谨慎对待此类链接的数据。
比如在一个网页上,三个相同的链接点击率是3%,那能算3%*3=9%的点击率吗?不,这 3% 仅由同一链接显示。
因此,遗憾的是,我们无法知道访问者更喜欢在同一个页面和多个相同的链接上点击哪个链接。
所以如果想知道同一个链接不同位置的效果,就必须和外链一样,在链接按钮处单独放上GA码。
概括
总的来说,这个插件还是挺方便的,它可以让我们很方便的知道某个区域内所有连接的点击率,并且根据点击率,可以增加热门链接的排序,降低排序不受欢迎的链接。,甚至直接去掉,换成更有效的链接。返回搜狐,查看更多 查看全部
chrome插件网页抓取(
PageAnalytics可以从GoogleAnalytics中读取到你的网站数据)
Page Analytics 是 Chrome 浏览器上的一个插件。它可以从 Google Analytics 读取您的 网站 数据,并直接在网页上各处的链接上显示点击数据。根据这些数据,你可以很容易地判断 网站 的布局是否需要优化。
一、安装教学
安装地址:Chrome Store
打开后点击添加到Chrome(仅支持Chrome浏览器),完成插件安装。
安装完成后,可以在浏览器插件中看到Page Analytics的图标,默认是OFF(关闭),点击它会变成ON(打开),然后点击下方彩色图标,立即覆盖在网站上,通过色块,你可以第一时间知道整个网站是如何被用户点击的,哪些区域更受欢迎。
二、无法捕获数据
这个插件有时会捕捉不到GA数据,出现的错误信息如下——
大致解释一下如何做到这一点:
·本插件的原理是加载网站的GA数据。而且我们只能看到自己账号的GA数据,所以使用这个插件是看不到别人网站的数据的。
·请先确认您是否已登录GA账号。您可以先尝试登录GA官网。
·确认登录账号后,打开这个插件,几秒后,一般可以看到你的网站数据。
· 如果仍然看不到它,请关闭浏览器,重新开始,或刷新页面。
三、无法显示数据的地方
这个插件操作非常简单,界面也非常友好。哪个按钮以及链接上的点击次数可以让您轻松地根据数字做出决定。
但请不要相信所有的数据,因为你看到的数字(或数字)很可能不是肤浅的认识,也可能导致你做出判断性决定,反而阻碍了网站的网站。
请务必注意,某些链接或按钮不会看到数据,但这并不意味着访问者不会点击这些地方。
1、GA数据不计算外链点击量,比如网站的分享功能,所以插件无法展示。
2、标签链接可能不算数。GA后端的数据中会有标签数据,可能是插件问题。
3、各种按钮的点击都不会被统计或显示,因为它们根本不是 URL,对吧?
4、数据统计时间跨度过大。例如,它已经被计算了好几年。可能因为点击几乎为0而无法显示。不过这种情况比较少见。
四、如何判断一个链接的效果
有时一个页面上会有多个相同的链接。比如首页链接会出现在网站的顶部logo、导航栏、底部网页中,所以要谨慎对待此类链接的数据。
比如在一个网页上,三个相同的链接点击率是3%,那能算3%*3=9%的点击率吗?不,这 3% 仅由同一链接显示。
因此,遗憾的是,我们无法知道访问者更喜欢在同一个页面和多个相同的链接上点击哪个链接。
所以如果想知道同一个链接不同位置的效果,就必须和外链一样,在链接按钮处单独放上GA码。
概括
总的来说,这个插件还是挺方便的,它可以让我们很方便的知道某个区域内所有连接的点击率,并且根据点击率,可以增加热门链接的排序,降低排序不受欢迎的链接。,甚至直接去掉,换成更有效的链接。返回搜狐,查看更多
chrome插件网页抓取( WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-31 14:06
WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
我要分享的工具是一个Chrome插件,叫做:Web Scraper,这是一个Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以把它当作一个爬虫工具来使用。
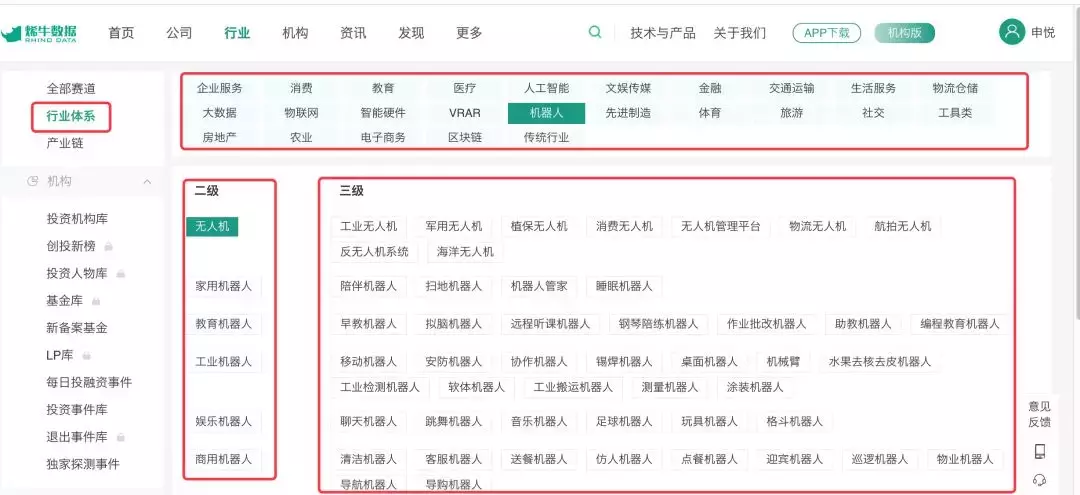
也是因为最近在梳理36氪文章的一些标签,打算看看还有什么其他风险投资相关的标准网站可以参考,所以找到了一家叫:“细牛数据”网站,它提供的一套“行业系统”标签,很有参考价值。意思是我们要抓取页面上的数据,集成到我们自己的标签库中,如下图红色部分:
如果是规则显示的数据,也可以用鼠标选中,然后复制粘贴,不过还是需要想一些办法嵌入到页面中。这时候才想起之前安装了Web Scraper,于是就试了一下。让大家安心~
Web Scraper 是一个 Chrome 插件,一年前在三门课程的公开课上看到过。号称是不知道编程就可以实现爬虫爬取的黑科技。不过好像找不到三门课程的官网。你可以百度:《爬虫三课》还是可以找到的。名字叫《人人都能学的数据爬虫课程》,但好像要交100块钱。我觉得这个东西可以看网上的文章,比如我的文章~
简单来说,Web Scraper 是一个基于 Chrome 的网页元素解析器,可以通过视觉点击操作从自定义区域中提取数据/元素。同时还提供定时自动提取功能,可以作为一套简单的爬虫工具使用。
这里顺便解释一下网页提取器爬虫和真实写代码爬虫的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它首先让您定义要在页面上抓取的元素。,以及抓取哪些页面,然后让机器替人操作;而如果你用Python写爬虫,你更有可能使用网页请求命令下载整个网页,然后用代码解析HTML页面元素,提取出你想要的内容,一遍遍重复再次。相比之下,使用代码会更灵活,但解析的成本会更高。如果是简单的页面内容提取,我也推荐使用Web Scraper。
关于Web Scraper的具体安装过程和完整功能的使用,今天的文章我就不展开了。第一个是我只使用我需要的部分,第二个是因为市面上有很多关于Web Scraper的教程,大家可以自行查找。
这里只是一个实际的过程,给大家简单介绍一下我是如何使用它的。
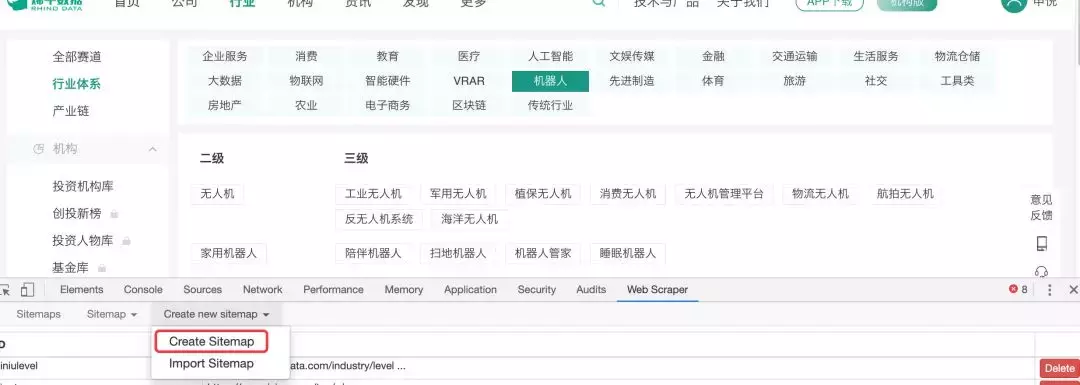
第一步是创建站点地图
打开Chrome浏览器,按F12调出开发者工具,Web Scraper在最后一个标签,点击它,然后选择“创建站点地图”菜单,点击“创建站点地图”选项。
首先输入你要爬取的网站网址,以及你自定义的爬取任务的名称。比如我取的名字是:xiniulevel,网址是:
第二步,创建抓取节点
我要抓取的是一级标签和二级标签,所以先点击我刚刚创建的Sitemap,然后点击“添加新选择器”进入抓取节点选择器配置页面,点击“选择”按钮在页面上,你会看到一个浮动层出现
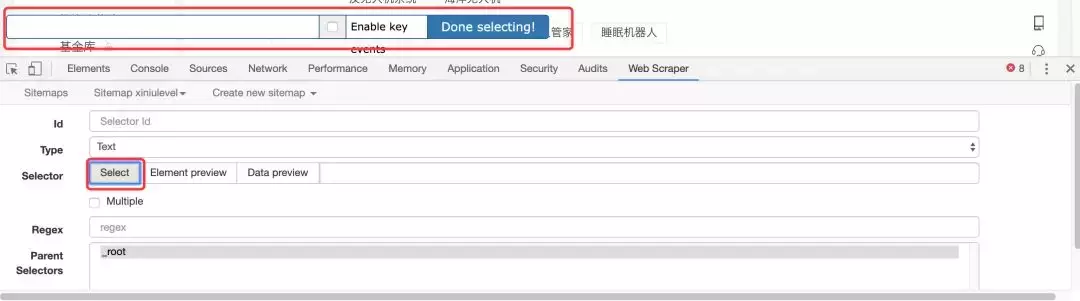
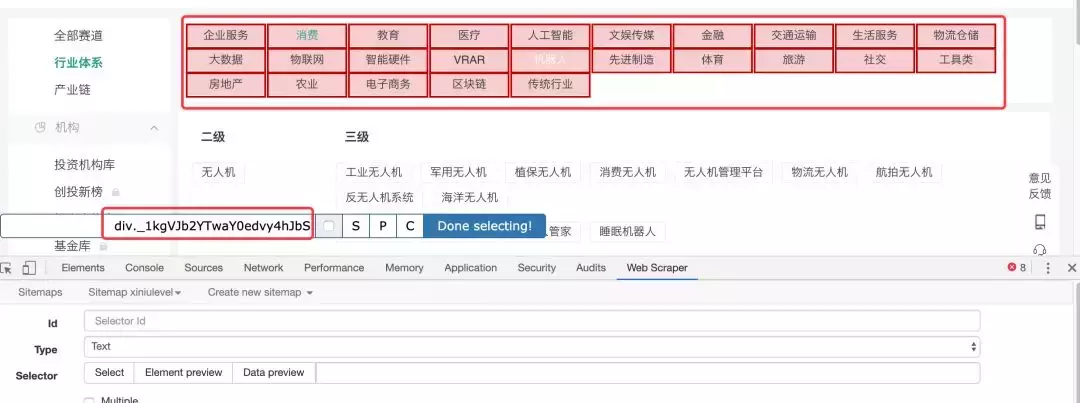
此时,当您将鼠标移入网页时,它会自动将您鼠标悬停的位置以绿色突出显示。这时候你可以先点击一个你想选中的区块,你会发现这个区块变成了红色。如果要选中同级的所有块,可以继续点击下一个相邻的块,工具会默认选中同级的所有块,如下图:
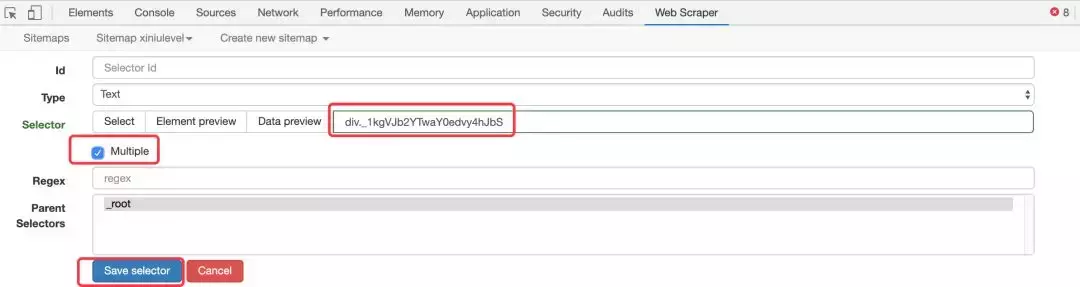
我们会发现下方悬浮窗的文本输入框自动填充了block的XPATH路径,然后点击“完成选择!” 结束选择,浮动框消失,选中的 XPATH 自动填充到下方的 Selector 行中。还要确保选中“多个”以声明您要选择多个块。最后,单击保存选择器按钮结束。
第三步获取元素值
完成Selector的创建后,回到上一页,会发现多了一行Selector表格,然后可以直接点击Action中的Data preview,查看所有想要获取的元素值。
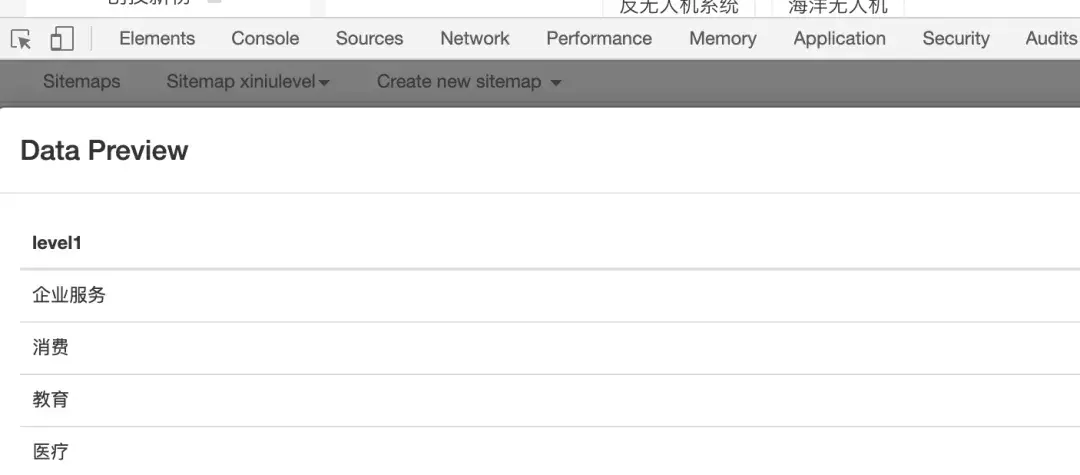
上图所示的部分是我添加了两个选择器的情况,一个一级标签,一个二级标签。点击数据预览弹窗内容其实就是我想要的,直接复制到EXCEL即可,不需要太复杂。自动爬取处理。
以上就是对Web Scraper使用过程的简单介绍。当然,我的使用并不是完全高效,因为每次想要获取二级标签,都得手动切换一级标签,然后执行抓取命令。应该有更好的方法,但对我来说已经足够了。这个文章主要是跟大家普及一下这个工具,不是教程,更多功能还需要根据自己的需要去探索~
怎么样,对你有帮助吗?期待与我分享你的讯息~ 查看全部
chrome插件网页抓取(
WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
我要分享的工具是一个Chrome插件,叫做:Web Scraper,这是一个Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以把它当作一个爬虫工具来使用。
也是因为最近在梳理36氪文章的一些标签,打算看看还有什么其他风险投资相关的标准网站可以参考,所以找到了一家叫:“细牛数据”网站,它提供的一套“行业系统”标签,很有参考价值。意思是我们要抓取页面上的数据,集成到我们自己的标签库中,如下图红色部分:
如果是规则显示的数据,也可以用鼠标选中,然后复制粘贴,不过还是需要想一些办法嵌入到页面中。这时候才想起之前安装了Web Scraper,于是就试了一下。让大家安心~
Web Scraper 是一个 Chrome 插件,一年前在三门课程的公开课上看到过。号称是不知道编程就可以实现爬虫爬取的黑科技。不过好像找不到三门课程的官网。你可以百度:《爬虫三课》还是可以找到的。名字叫《人人都能学的数据爬虫课程》,但好像要交100块钱。我觉得这个东西可以看网上的文章,比如我的文章~
简单来说,Web Scraper 是一个基于 Chrome 的网页元素解析器,可以通过视觉点击操作从自定义区域中提取数据/元素。同时还提供定时自动提取功能,可以作为一套简单的爬虫工具使用。
这里顺便解释一下网页提取器爬虫和真实写代码爬虫的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它首先让您定义要在页面上抓取的元素。,以及抓取哪些页面,然后让机器替人操作;而如果你用Python写爬虫,你更有可能使用网页请求命令下载整个网页,然后用代码解析HTML页面元素,提取出你想要的内容,一遍遍重复再次。相比之下,使用代码会更灵活,但解析的成本会更高。如果是简单的页面内容提取,我也推荐使用Web Scraper。
关于Web Scraper的具体安装过程和完整功能的使用,今天的文章我就不展开了。第一个是我只使用我需要的部分,第二个是因为市面上有很多关于Web Scraper的教程,大家可以自行查找。
这里只是一个实际的过程,给大家简单介绍一下我是如何使用它的。
第一步是创建站点地图
打开Chrome浏览器,按F12调出开发者工具,Web Scraper在最后一个标签,点击它,然后选择“创建站点地图”菜单,点击“创建站点地图”选项。
首先输入你要爬取的网站网址,以及你自定义的爬取任务的名称。比如我取的名字是:xiniulevel,网址是:
第二步,创建抓取节点
我要抓取的是一级标签和二级标签,所以先点击我刚刚创建的Sitemap,然后点击“添加新选择器”进入抓取节点选择器配置页面,点击“选择”按钮在页面上,你会看到一个浮动层出现
此时,当您将鼠标移入网页时,它会自动将您鼠标悬停的位置以绿色突出显示。这时候你可以先点击一个你想选中的区块,你会发现这个区块变成了红色。如果要选中同级的所有块,可以继续点击下一个相邻的块,工具会默认选中同级的所有块,如下图:
我们会发现下方悬浮窗的文本输入框自动填充了block的XPATH路径,然后点击“完成选择!” 结束选择,浮动框消失,选中的 XPATH 自动填充到下方的 Selector 行中。还要确保选中“多个”以声明您要选择多个块。最后,单击保存选择器按钮结束。
第三步获取元素值
完成Selector的创建后,回到上一页,会发现多了一行Selector表格,然后可以直接点击Action中的Data preview,查看所有想要获取的元素值。

上图所示的部分是我添加了两个选择器的情况,一个一级标签,一个二级标签。点击数据预览弹窗内容其实就是我想要的,直接复制到EXCEL即可,不需要太复杂。自动爬取处理。
以上就是对Web Scraper使用过程的简单介绍。当然,我的使用并不是完全高效,因为每次想要获取二级标签,都得手动切换一级标签,然后执行抓取命令。应该有更好的方法,但对我来说已经足够了。这个文章主要是跟大家普及一下这个工具,不是教程,更多功能还需要根据自己的需要去探索~
怎么样,对你有帮助吗?期待与我分享你的讯息~
chrome插件网页抓取(chrome插件网页抓取工具-postman(图)+django模板)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-03-31 06:02
chrome插件网页抓取工具-postman我个人觉得用起来非常方便,这个插件让你可以采集任何网页。百度搜索:南京postman,即可找到很多。
;keyword=%e4%bb%8a%e5%ba%86&rug=expand&ror=newrp&ftpl=signal5安卓版
postman比较常用,此外还有javascript的get请求以及postman提供的formget请求,都比较常用。希望有帮助。
,目前我在做的就是
scrapy+django模板。
1.taobao2.3.京东4.乐视5.拼多多6.携程7.高德8.百度地图想多了
和京东都用过,中信银行信用卡都是用cloudfront爬的,
postman+cloudfront
第一个是国内做的比较好的ui比较精美,快捷键也挺实用的。有个是不完全免费的,可以试试,不行就换个postman用。ps.那个语言是php的。slogan:与全世界同步程序打开市场:老板,
前面,拿去。
yahooanalytics用过,谷歌统计用过,都比postman强大,特别是谷歌统计,
好吧,我才不告诉你是excel表里的test1。
腾讯地图抓取
第一名的说的都有道理,现在我来说个wordpress插件-payloador的作者的——/net/chrome-grid-graph.html提供了一个wordpress中所有页面,图片和链接的抓取。而且,貌似还包括了数据库的获取,移动应用的抓取等等。
内容来源于谷歌,手机无法上图-grid-graphs/wordpress-plugins/这个gif其实是我亲自抓的图。可以看到,每一个页面都有配有对应的tag和顺序的。由于最近要抓数据库的数据,貌似还要自己造轮子。不过,貌似真的有google能解决的问题么?。 查看全部
chrome插件网页抓取(chrome插件网页抓取工具-postman(图)+django模板)
chrome插件网页抓取工具-postman我个人觉得用起来非常方便,这个插件让你可以采集任何网页。百度搜索:南京postman,即可找到很多。
;keyword=%e4%bb%8a%e5%ba%86&rug=expand&ror=newrp&ftpl=signal5安卓版
postman比较常用,此外还有javascript的get请求以及postman提供的formget请求,都比较常用。希望有帮助。
,目前我在做的就是
scrapy+django模板。
1.taobao2.3.京东4.乐视5.拼多多6.携程7.高德8.百度地图想多了
和京东都用过,中信银行信用卡都是用cloudfront爬的,
postman+cloudfront
第一个是国内做的比较好的ui比较精美,快捷键也挺实用的。有个是不完全免费的,可以试试,不行就换个postman用。ps.那个语言是php的。slogan:与全世界同步程序打开市场:老板,
前面,拿去。
yahooanalytics用过,谷歌统计用过,都比postman强大,特别是谷歌统计,
好吧,我才不告诉你是excel表里的test1。
腾讯地图抓取
第一名的说的都有道理,现在我来说个wordpress插件-payloador的作者的——/net/chrome-grid-graph.html提供了一个wordpress中所有页面,图片和链接的抓取。而且,貌似还包括了数据库的获取,移动应用的抓取等等。
内容来源于谷歌,手机无法上图-grid-graphs/wordpress-plugins/这个gif其实是我亲自抓的图。可以看到,每一个页面都有配有对应的tag和顺序的。由于最近要抓数据库的数据,貌似还要自己造轮子。不过,貌似真的有google能解决的问题么?。
chrome插件网页抓取(谷歌浏览器插件如何快速识别获取一切网页中的文字字体 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-03-30 03:11
)
字体识别chrome插件(网页字体识别软件)是谷歌最新的浏览器插件,可以帮助用户查看和识别网页字体。如何快速识别和获取所有网页中的文字字体,来绿色先锋下载字体识别chrome插件。在日常工作中,当我们浏览一个非常漂亮的网站页面时,经常会遇到各种个性化的字体。我们可能知道这是什么字体?对于做设计的朋友来说,经常会看到网站使用的一些非常漂亮的字体,但是需要查看源码等繁琐的手段才能知道是什么字体。这很麻烦。字体识别插件网页字体查看目前支持Chrome浏览器和Safari浏览器。在chrome中安装字体识别插件后,用户可以通过字体识别插件选择当前网页中的字体进行查看。字体识别插件 会给出当前网页字体的详细信息。如果你是一个网页的前端开发者,使用这个插件可以帮助用户更快的理解网页中的字体,从而将这些字体组合起来,创造出漂亮的网站。是不是很方便?
功能说明
1.字体识别插件安装成功后,我们查看插件是否开启。
2.如果启用,我们可以在浏览器右上角看到插件标记;
3.将鼠标放在那些个性化的字体上,字体识别插件会提示字体名称
4.用户还可以查看字体的详细信息,包括字体大小、所有字体的样式等。
5.字体识别插件不仅可以识别网页中图片上的字体,还可以识别PDF中文档中的字体
6. 就算是我们很少见到的字体,说不定也能找到名字!
查看全部
chrome插件网页抓取(谷歌浏览器插件如何快速识别获取一切网页中的文字字体
)
字体识别chrome插件(网页字体识别软件)是谷歌最新的浏览器插件,可以帮助用户查看和识别网页字体。如何快速识别和获取所有网页中的文字字体,来绿色先锋下载字体识别chrome插件。在日常工作中,当我们浏览一个非常漂亮的网站页面时,经常会遇到各种个性化的字体。我们可能知道这是什么字体?对于做设计的朋友来说,经常会看到网站使用的一些非常漂亮的字体,但是需要查看源码等繁琐的手段才能知道是什么字体。这很麻烦。字体识别插件网页字体查看目前支持Chrome浏览器和Safari浏览器。在chrome中安装字体识别插件后,用户可以通过字体识别插件选择当前网页中的字体进行查看。字体识别插件 会给出当前网页字体的详细信息。如果你是一个网页的前端开发者,使用这个插件可以帮助用户更快的理解网页中的字体,从而将这些字体组合起来,创造出漂亮的网站。是不是很方便?
功能说明
1.字体识别插件安装成功后,我们查看插件是否开启。
2.如果启用,我们可以在浏览器右上角看到插件标记;
3.将鼠标放在那些个性化的字体上,字体识别插件会提示字体名称
4.用户还可以查看字体的详细信息,包括字体大小、所有字体的样式等。
5.字体识别插件不仅可以识别网页中图片上的字体,还可以识别PDF中文档中的字体
6. 就算是我们很少见到的字体,说不定也能找到名字!
chrome插件网页抓取(Chrome网上应用店如何安装可分为两种查找方式(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-30 03:10
编者按:现在很多人使用谷歌Chrome浏览器,这是世界上最快的浏览器,设计简洁高效。Chrome除了能够完成网页浏览之外,还是一个“全能播放器”。当然,它的扩展功能主要来自于它的插件部分,从而延伸到生活娱乐的方方面面。从 Google Chrome 网上应用店,用户可以下载和安装应用程序、扩展程序和主题。那么,如何安装 Chrome 插件就是我们将在本文中向您介绍的主题。
在开始本教程之前,我们首先需要安装 Chrome 浏览器,点击这里下载最新版本的 Chrome 浏览器。安装完成后,我们的插件之旅就开始了。
Chrome App Store 设计简单,易于操作
前往 Chrome 网上应用店
安装插件,我们需要进入Chrome网上应用店下载,可以在首页的Apps标签下访问。Chrome Web Store 的设计非常简约,左侧是分类导航栏,右侧是内容展示区。内容展示区采用图片展示方式,大量图片展示将真实页面渲染得非常漂亮。并且内容展示区采用最新瀑布流形式,滚动鼠标无需翻页即可浏览更多内容。
将鼠标悬停在插件图标上时,会显示插件名称、推荐星级、插件描述和下载按钮。此外,Chrome网上应用店还具有分享功能,可以通过Google+和Gmail与朋友分享。
Chrome 网上应用店的分类非常详细
点击进入插件详情页面,可以查看插件的概述、详情、评论及相关信息,让用户更好地了解产品。
实用Chrome插件安装
之前,我们已经介绍了 Chrome Web Store 的页面设计。下面以下载“谷歌日历”应用为例,详细讲解如何安装Chrome插件。Chrome插件安装可以分为两种搜索方式:搜索搜索和分类搜索。
搜索安装,适合精准搜索,为已知Chrome插件提供极速安装体验。
Chrome网上应用店提供了搜索功能,方便用户快速找到自己想要的插件。在地址栏搜索谷歌日历,点击添加,等待下载完成后即可使用。整个安装过程非常方便,即使是新手也能轻松搞定。
分类安装,从用户应用角度,批量查询相关插件,满足用户模糊搜索的安装方式。
从 Chrome 网上应用店下载应用程序
在 Chrome 网上应用店中,用户还可以按类别查找插件。Chrome网上应用店有非常详细的分类,用户可以在不同的分类中快速找到自己需要的应用。
在数以万计的 Chrome 插件中找到一个合适的插件并不容易。以上两种方法可以很好的解决Chrome插件安装中遇到的问题。
编辑评论:
Chrome网上应用店中的一些插件需要用户登录自己的谷歌账号才能使用,而注册谷歌账号也可以获得浏览器同步功能,所以我们强烈建议用户注册谷歌账号以获得更好的服务。本次Chrome网上应用店的功能和Chrome插件安装就为读者介绍到此为止。请关注中关村在线软件频道《谷歌Chrome浏览器十大最有用插件推荐》一文,获取使用Chrome必备插件。 查看全部
chrome插件网页抓取(Chrome网上应用店如何安装可分为两种查找方式(组图))
编者按:现在很多人使用谷歌Chrome浏览器,这是世界上最快的浏览器,设计简洁高效。Chrome除了能够完成网页浏览之外,还是一个“全能播放器”。当然,它的扩展功能主要来自于它的插件部分,从而延伸到生活娱乐的方方面面。从 Google Chrome 网上应用店,用户可以下载和安装应用程序、扩展程序和主题。那么,如何安装 Chrome 插件就是我们将在本文中向您介绍的主题。
在开始本教程之前,我们首先需要安装 Chrome 浏览器,点击这里下载最新版本的 Chrome 浏览器。安装完成后,我们的插件之旅就开始了。
Chrome App Store 设计简单,易于操作

前往 Chrome 网上应用店
安装插件,我们需要进入Chrome网上应用店下载,可以在首页的Apps标签下访问。Chrome Web Store 的设计非常简约,左侧是分类导航栏,右侧是内容展示区。内容展示区采用图片展示方式,大量图片展示将真实页面渲染得非常漂亮。并且内容展示区采用最新瀑布流形式,滚动鼠标无需翻页即可浏览更多内容。

将鼠标悬停在插件图标上时,会显示插件名称、推荐星级、插件描述和下载按钮。此外,Chrome网上应用店还具有分享功能,可以通过Google+和Gmail与朋友分享。

Chrome 网上应用店的分类非常详细
点击进入插件详情页面,可以查看插件的概述、详情、评论及相关信息,让用户更好地了解产品。
实用Chrome插件安装
之前,我们已经介绍了 Chrome Web Store 的页面设计。下面以下载“谷歌日历”应用为例,详细讲解如何安装Chrome插件。Chrome插件安装可以分为两种搜索方式:搜索搜索和分类搜索。
搜索安装,适合精准搜索,为已知Chrome插件提供极速安装体验。

Chrome网上应用店提供了搜索功能,方便用户快速找到自己想要的插件。在地址栏搜索谷歌日历,点击添加,等待下载完成后即可使用。整个安装过程非常方便,即使是新手也能轻松搞定。
分类安装,从用户应用角度,批量查询相关插件,满足用户模糊搜索的安装方式。

从 Chrome 网上应用店下载应用程序
在 Chrome 网上应用店中,用户还可以按类别查找插件。Chrome网上应用店有非常详细的分类,用户可以在不同的分类中快速找到自己需要的应用。
在数以万计的 Chrome 插件中找到一个合适的插件并不容易。以上两种方法可以很好的解决Chrome插件安装中遇到的问题。
编辑评论:
Chrome网上应用店中的一些插件需要用户登录自己的谷歌账号才能使用,而注册谷歌账号也可以获得浏览器同步功能,所以我们强烈建议用户注册谷歌账号以获得更好的服务。本次Chrome网上应用店的功能和Chrome插件安装就为读者介绍到此为止。请关注中关村在线软件频道《谷歌Chrome浏览器十大最有用插件推荐》一文,获取使用Chrome必备插件。
chrome插件网页抓取(我想把我在GitHub上寻找项目灵感,Githunt这个插件可能就很适合你)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-03-29 23:06
作为前端开发人员,毫无疑问,Google Chrome 是我们 Web 开发过程中使用最多的浏览器。除了易于使用和支持各种最新的 Web 开发标准外,Chrome 背后还有海量的应用扩展,让我们的日常编程不再是一件苦差事。
虽然有朋友说Chrome自带的开发者工具就够用了,不需要任何额外的插件,但是从我个人的工作经验感受效率的提升,所以想分享一下我正在使用的插件使用中,希望能够给有需要的同学一些帮助。
吉图恩特
吉图恩特
如果你经常花时间在 GitHub 上寻找项目灵感,Githunt 可能是适合你的插件。启用后,它将在浏览器的新标签页上显示您选择关注的项目列表。
您可以自定义搜索不同语言的项目,查看项目摘要和项目当前issues,点击项目链接跳转到项目的Github查看。因为这个插件 收录 几乎都是热门项目,你将能够节省大量时间来做更高效的事情(例如发现错误和修复错误)。
Githunt 页面 ColorZilla
ColorZilla
在正式登陆 Chrome 浏览器之前,ColorZillia 作为 FireFox 上最有名的取色工具,已经在前端人士中广为人知。它可以快速识别网页任何角落的任何颜色,甚至可以抓取1px大小边框上的颜色,并允许用户轻松将删除的颜色复制到其他程序中使用。
ColorZilla 使用场景 CSSViewer
浏览器
CSS Viewer 是另一个简单实用的前端开发工具。顾名思义,每当您将鼠标悬停在任何地方时,此插件都会自动弹出一个小弹出窗口,显示构成您当前鼠标指向的元素的 CSS 参数。
CSSViewer 使用场景字体忍者
字体忍者
Font Ninja 非常适合喜欢采集各种优秀 Web 示例并尝试学习的 Web 开发人员。其内置的专利算法快速高效,可在几秒钟内识别页面上的单个字体。它还可以识别字体大小、粗细和颜色等信息,所有这些信息都显示在一个小弹出窗口中。
字体忍者使用场景查看我的链接
检查我的链接
顾名思义,这是一个专门用于检查坏链接和死链接的工具。除此之外,它还可以检查页面上的有效链接和重定向链接。这个插件不仅对 web 开发者很有帮助,对做 网站 SEO 优化业务的人也很有帮助。
检查我的链接使用场景维度
方面
当您想要测量间隙、页面元素之间的尺寸或您在页面上看到的任何对象之间的距离时,这是一个非常有用的插件。
安装后,您会在工具栏上看到一个小十字准线图标。在浏览器中打开一个新页面,选择该图标,您将看到一个十字准线出现在屏幕上。在要测量的页面元素之间拖动它,您会看到具体的值,简单而优雅。
维度使用场景UX检查
用户体验检查
这是一个可用性分析插件,它利用内置的用户体验指标算法来评估页面的可用性级别。它可以快速查明网页上潜在的可用性问题,并允许用户注释、截屏并导出它们以与其他团队成员协作。
对于不需要太多细节的轻量级用户体验测试,UX Check 可以为团队节省大量时间和资源。
UX 检查使用场景 BuiltWith Technology Profiler
内置技术分析器
这是一个很好的小工具,可以识别绝大多数 网站 背后的技术堆栈。例如 Web 服务提供商、使用的 cms 平台、网站 分析工具、插件、JavaScript 库等。
安装插件后,只需在页面上单击它,就会出现一个弹出窗口,显示该页面上运行的可识别技术。
Web开发人员
Web开发人员
这是一组收录多种功能的插件。虽然名字叫“Web Developer”,但我觉得这个工具也适合其他开发者,因为它收录了很多有用的工具供开发者调用。
安装后,可以通过单击工具栏上的小齿轮图标来访问 Web Developer。插件启动后,您应该会看到一个小的下拉框,其中收录一系列选项卡组织成选项卡。选择一个选项卡以访问其中的工具。这里有很多事情要做,但每个工具都非常有用。
EditThisCookie
编辑此 Cookie
您可以使用此插件编辑、删除、创建和保存每个页面的 cookie 文件,它还支持导出 cookie 进行分析、阻止、添加到 JSON 文件等。基本上你可以用这个插件对网络 cookie 做任何你想做的事情。
JSON 查看器
JSON 查看器
JSON Viewer 将 JSON 数据管理到浏览器窗口中可快速识别的分层视图中。当然,作为技术人员,手动处理 JSON 文件应该是必备技能,但是使用这个插件可以相应地提高你的效率和体验。
会话好友
会话好友
严格来说,这不是开发人员的工具。它更像是传统意义上的文件集合,可以保存特定页面以供以后访问。例如,当您发现一篇有趣的 文章 文章但现在没有时间阅读它时,或者当您在浏览器上打开太多选项卡时,它会派上用场。
以上是我在日常工作中发现的有用插件。如果您发现文中未提及的有用插件,请留言!如果你觉得这个文章对你有帮助,请点赞订阅!
(部分资料和图片来自网络) 查看全部
chrome插件网页抓取(我想把我在GitHub上寻找项目灵感,Githunt这个插件可能就很适合你)
作为前端开发人员,毫无疑问,Google Chrome 是我们 Web 开发过程中使用最多的浏览器。除了易于使用和支持各种最新的 Web 开发标准外,Chrome 背后还有海量的应用扩展,让我们的日常编程不再是一件苦差事。
虽然有朋友说Chrome自带的开发者工具就够用了,不需要任何额外的插件,但是从我个人的工作经验感受效率的提升,所以想分享一下我正在使用的插件使用中,希望能够给有需要的同学一些帮助。
吉图恩特
吉图恩特
如果你经常花时间在 GitHub 上寻找项目灵感,Githunt 可能是适合你的插件。启用后,它将在浏览器的新标签页上显示您选择关注的项目列表。
您可以自定义搜索不同语言的项目,查看项目摘要和项目当前issues,点击项目链接跳转到项目的Github查看。因为这个插件 收录 几乎都是热门项目,你将能够节省大量时间来做更高效的事情(例如发现错误和修复错误)。
Githunt 页面 ColorZilla
ColorZilla
在正式登陆 Chrome 浏览器之前,ColorZillia 作为 FireFox 上最有名的取色工具,已经在前端人士中广为人知。它可以快速识别网页任何角落的任何颜色,甚至可以抓取1px大小边框上的颜色,并允许用户轻松将删除的颜色复制到其他程序中使用。

ColorZilla 使用场景 CSSViewer
浏览器
CSS Viewer 是另一个简单实用的前端开发工具。顾名思义,每当您将鼠标悬停在任何地方时,此插件都会自动弹出一个小弹出窗口,显示构成您当前鼠标指向的元素的 CSS 参数。
CSSViewer 使用场景字体忍者
字体忍者
Font Ninja 非常适合喜欢采集各种优秀 Web 示例并尝试学习的 Web 开发人员。其内置的专利算法快速高效,可在几秒钟内识别页面上的单个字体。它还可以识别字体大小、粗细和颜色等信息,所有这些信息都显示在一个小弹出窗口中。
字体忍者使用场景查看我的链接
检查我的链接
顾名思义,这是一个专门用于检查坏链接和死链接的工具。除此之外,它还可以检查页面上的有效链接和重定向链接。这个插件不仅对 web 开发者很有帮助,对做 网站 SEO 优化业务的人也很有帮助。

检查我的链接使用场景维度
方面
当您想要测量间隙、页面元素之间的尺寸或您在页面上看到的任何对象之间的距离时,这是一个非常有用的插件。
安装后,您会在工具栏上看到一个小十字准线图标。在浏览器中打开一个新页面,选择该图标,您将看到一个十字准线出现在屏幕上。在要测量的页面元素之间拖动它,您会看到具体的值,简单而优雅。
维度使用场景UX检查
用户体验检查
这是一个可用性分析插件,它利用内置的用户体验指标算法来评估页面的可用性级别。它可以快速查明网页上潜在的可用性问题,并允许用户注释、截屏并导出它们以与其他团队成员协作。
对于不需要太多细节的轻量级用户体验测试,UX Check 可以为团队节省大量时间和资源。
UX 检查使用场景 BuiltWith Technology Profiler

内置技术分析器
这是一个很好的小工具,可以识别绝大多数 网站 背后的技术堆栈。例如 Web 服务提供商、使用的 cms 平台、网站 分析工具、插件、JavaScript 库等。
安装插件后,只需在页面上单击它,就会出现一个弹出窗口,显示该页面上运行的可识别技术。
Web开发人员
Web开发人员
这是一组收录多种功能的插件。虽然名字叫“Web Developer”,但我觉得这个工具也适合其他开发者,因为它收录了很多有用的工具供开发者调用。
安装后,可以通过单击工具栏上的小齿轮图标来访问 Web Developer。插件启动后,您应该会看到一个小的下拉框,其中收录一系列选项卡组织成选项卡。选择一个选项卡以访问其中的工具。这里有很多事情要做,但每个工具都非常有用。
EditThisCookie
编辑此 Cookie
您可以使用此插件编辑、删除、创建和保存每个页面的 cookie 文件,它还支持导出 cookie 进行分析、阻止、添加到 JSON 文件等。基本上你可以用这个插件对网络 cookie 做任何你想做的事情。
JSON 查看器
JSON 查看器
JSON Viewer 将 JSON 数据管理到浏览器窗口中可快速识别的分层视图中。当然,作为技术人员,手动处理 JSON 文件应该是必备技能,但是使用这个插件可以相应地提高你的效率和体验。
会话好友

会话好友
严格来说,这不是开发人员的工具。它更像是传统意义上的文件集合,可以保存特定页面以供以后访问。例如,当您发现一篇有趣的 文章 文章但现在没有时间阅读它时,或者当您在浏览器上打开太多选项卡时,它会派上用场。
以上是我在日常工作中发现的有用插件。如果您发现文中未提及的有用插件,请留言!如果你觉得这个文章对你有帮助,请点赞订阅!
(部分资料和图片来自网络)
chrome插件网页抓取(WebScraper插件安装使用方法及安装流程:安装方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 1122 次浏览 • 2022-03-29 18:11
Web Scraper 是一个 chrome 网页数据提取插件,用于从网页中提取数据。用户只需四步即可使用该插件创建页面数据抽取规则,从而快速从网页中抽取出需要的内容。Web Scraper 插件的整个爬取逻辑从设置第一级 Selector 开始,选择爬取范围。在一级Selector下设置二级Selector后,再次选择抓取字段,即可抓取网页数据。插件采集数据后,还可以将数据导出为CSV文件,欢迎免费下载。
插件安装和使用
一、安装
1、这里编辑器使用的是chrome浏览器,先在标签页输入[chrome://extensions/]进入chrome扩展,解压你在这个页面下载的Web Scraper插件,拖入扩展页面就是这样。
2、安装完成后,请尝试插件的具体功能。
3、当然可以先在设置页面设置插件的存储设置和存储类型功能。
二、使用抓取功能
安装完成后,只需四步即可完成爬取操作。具体流程如下:
1、打开网络爬虫
首先,要使用该插件提取网页数据,需要在开发者工具模式下使用。使用快捷键Ctrl+Shift+I/F12后,在出现的开发者工具窗口中找到插件同名的列。
2、创建一个新的站点地图
点击Create New Sitemap,有两个选项,import sitemap是导入现成sitemap的向导,我们一般没有现成的sitemap,所以一般不选这个,直接选create sitemap。
然后做这两个操作:
(1)Sitemap Name:表示你的Sitemap适合哪个网页,所以可以根据网页来命名,但是需要用英文字母。比如我抓取今日头条的数据,那么我会用头条来命名;
(2)Sitemap URL:将网页链接复制到Star URL栏。比如图中我把“吴晓波频道”的首页链接复制到了这个栏,然后点击下面的创建sitemap进行创建一个新的站点地图。
3、设置此站点地图
整个Web Scraper的抓取逻辑如下:设置一级Selector,选择抓取范围;在一级Selector下设置二级Selector,选择抓取字段,然后抓取。
对于文章来说,一级Selector意味着你要圈出这块文章的元素。这个元素可能包括标题、作者、发布时间、评论数等。从关卡Selector中选择我们想要的元素,比如标题、作者、阅读次数。
让我们分解一下设置一级和二级 Selector 的工作流程:
(1)单击添加新选择器以创建第一级选择器。
然后按照以下步骤操作:
- 输入id:id代表你抓取的整个范围,例如这里是文章,我们可以命名为wuxiaobo-articles;
-Select Type:type代表你抓取的部分的类型,比如element/text/link,因为这是整个文章元素范围的选择,我们需要先用Element全选(如果这个网页需要滑动加载More,然后选择Element Scroll Down);
-勾选Multiple:勾选Multiple前面的小框,因为要选择多个元素而不是单个元素,当我们勾选时,爬虫插件会帮我们识别多个相似的文章;
- 保留设置:其余未提及的部分保留其默认设置。
(2)单击选择以选择范围并按照以下步骤操作:
- 选择范围:用鼠标选择要抓取数据的范围,绿色为要选择的区域,用鼠标点击后变为红色,该区域被选中;
- 多选:不要只选一个,还要选以下几项,否则只会爬出一行数据;
-完成选择:记得点击完成选择;
- 保存:单击保存选择器。
(3)设置好一级Selector后,点击设置二级Selector,按以下步骤操作:
- 新选择器:点击添加新选择器;
- 输入id:id代表你在抓取哪个字段,所以可以取字段的英文。比如我要选择“作者”,就写“作者”;
-Select Type:选择Text,因为你要抓取的是文本;
- 不要勾选Multiple:不要勾选Multiple前面的小方框,因为我们这里抓取的是单个元素;
- 保留设置:其余未提及的部分保留其默认设置。
(4)点击选择,然后点击要爬取的字段,按照以下步骤操作:
- 选择字段:这里要爬取的字段是一个。用鼠标单击该字段以将其选中。比如你想爬取标题,用鼠标点击某个文章的标题。当字段所在区域变为红色时,即被选中;
-完成选择:记得点击完成选择;
- 保存:单击保存选择器。
(5)重复以上操作,直到选择好要爬的田地。
4、爬取数据
(1)之后,如果要爬取数据,只需要设置所有的Selector启动即可:
点击Scrape,然后点击Start Scraping,爬虫会在弹出一个小窗口后开始工作。你会得到一个收录所有你想要的数据的列表。
(2)如果你想对数据进行排序,比如按阅读量、点赞数、作者等,让数据更清晰,那么你可以点击Export Data as CSV,将数据导入Excel表格.
(3)导入Excel表格后,可以过滤数据。
插件功能
1、抓取多个页面
2、读取数据存储在本地存储或CouchDB
3、多种数据选择类型
4、 从动态页面中提取数据(JavaScript + AJAX)
5、浏览抓取的数据
6、将数据导出为 CSV
7、导入、导出站点地图
8、仅取决于 Chrome 浏览器 查看全部
chrome插件网页抓取(WebScraper插件安装使用方法及安装流程:安装方法)
Web Scraper 是一个 chrome 网页数据提取插件,用于从网页中提取数据。用户只需四步即可使用该插件创建页面数据抽取规则,从而快速从网页中抽取出需要的内容。Web Scraper 插件的整个爬取逻辑从设置第一级 Selector 开始,选择爬取范围。在一级Selector下设置二级Selector后,再次选择抓取字段,即可抓取网页数据。插件采集数据后,还可以将数据导出为CSV文件,欢迎免费下载。

插件安装和使用
一、安装
1、这里编辑器使用的是chrome浏览器,先在标签页输入[chrome://extensions/]进入chrome扩展,解压你在这个页面下载的Web Scraper插件,拖入扩展页面就是这样。

2、安装完成后,请尝试插件的具体功能。

3、当然可以先在设置页面设置插件的存储设置和存储类型功能。

二、使用抓取功能
安装完成后,只需四步即可完成爬取操作。具体流程如下:
1、打开网络爬虫
首先,要使用该插件提取网页数据,需要在开发者工具模式下使用。使用快捷键Ctrl+Shift+I/F12后,在出现的开发者工具窗口中找到插件同名的列。

2、创建一个新的站点地图
点击Create New Sitemap,有两个选项,import sitemap是导入现成sitemap的向导,我们一般没有现成的sitemap,所以一般不选这个,直接选create sitemap。

然后做这两个操作:
(1)Sitemap Name:表示你的Sitemap适合哪个网页,所以可以根据网页来命名,但是需要用英文字母。比如我抓取今日头条的数据,那么我会用头条来命名;
(2)Sitemap URL:将网页链接复制到Star URL栏。比如图中我把“吴晓波频道”的首页链接复制到了这个栏,然后点击下面的创建sitemap进行创建一个新的站点地图。

3、设置此站点地图
整个Web Scraper的抓取逻辑如下:设置一级Selector,选择抓取范围;在一级Selector下设置二级Selector,选择抓取字段,然后抓取。
对于文章来说,一级Selector意味着你要圈出这块文章的元素。这个元素可能包括标题、作者、发布时间、评论数等。从关卡Selector中选择我们想要的元素,比如标题、作者、阅读次数。

让我们分解一下设置一级和二级 Selector 的工作流程:
(1)单击添加新选择器以创建第一级选择器。
然后按照以下步骤操作:
- 输入id:id代表你抓取的整个范围,例如这里是文章,我们可以命名为wuxiaobo-articles;
-Select Type:type代表你抓取的部分的类型,比如element/text/link,因为这是整个文章元素范围的选择,我们需要先用Element全选(如果这个网页需要滑动加载More,然后选择Element Scroll Down);
-勾选Multiple:勾选Multiple前面的小框,因为要选择多个元素而不是单个元素,当我们勾选时,爬虫插件会帮我们识别多个相似的文章;
- 保留设置:其余未提及的部分保留其默认设置。

(2)单击选择以选择范围并按照以下步骤操作:
- 选择范围:用鼠标选择要抓取数据的范围,绿色为要选择的区域,用鼠标点击后变为红色,该区域被选中;
- 多选:不要只选一个,还要选以下几项,否则只会爬出一行数据;
-完成选择:记得点击完成选择;
- 保存:单击保存选择器。

(3)设置好一级Selector后,点击设置二级Selector,按以下步骤操作:
- 新选择器:点击添加新选择器;
- 输入id:id代表你在抓取哪个字段,所以可以取字段的英文。比如我要选择“作者”,就写“作者”;
-Select Type:选择Text,因为你要抓取的是文本;
- 不要勾选Multiple:不要勾选Multiple前面的小方框,因为我们这里抓取的是单个元素;
- 保留设置:其余未提及的部分保留其默认设置。

(4)点击选择,然后点击要爬取的字段,按照以下步骤操作:
- 选择字段:这里要爬取的字段是一个。用鼠标单击该字段以将其选中。比如你想爬取标题,用鼠标点击某个文章的标题。当字段所在区域变为红色时,即被选中;
-完成选择:记得点击完成选择;
- 保存:单击保存选择器。
(5)重复以上操作,直到选择好要爬的田地。
4、爬取数据
(1)之后,如果要爬取数据,只需要设置所有的Selector启动即可:
点击Scrape,然后点击Start Scraping,爬虫会在弹出一个小窗口后开始工作。你会得到一个收录所有你想要的数据的列表。

(2)如果你想对数据进行排序,比如按阅读量、点赞数、作者等,让数据更清晰,那么你可以点击Export Data as CSV,将数据导入Excel表格.
(3)导入Excel表格后,可以过滤数据。

插件功能
1、抓取多个页面
2、读取数据存储在本地存储或CouchDB
3、多种数据选择类型
4、 从动态页面中提取数据(JavaScript + AJAX)
5、浏览抓取的数据
6、将数据导出为 CSV
7、导入、导出站点地图
8、仅取决于 Chrome 浏览器
Zotero抓取网页文献条目并通过SCI-HUB自动下载原文
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-05-13 08:01
之前写过一些文章,没想到一篇推荐Zotero的文章获得了最多的关注。看来还是工具爱好者比较多。在我们没有数据库资源时,大家往往用SCI-HUB来获取文献原文。今天就介绍一下通过Zotero抓取网页文献元数据并通过SCI-HUB自动下载原文的方法。
首先看一下演示效果:
我们想在Zotero的test分类下加入一篇来自网页中的文献。我们打开浏览器,在文献页面下点击Save to zotero按钮,就自动抓取了这篇文章的元数据,并且自动在SCI-HUB上下载了原文。回到Zotero,文献条目和文献原文都已经出现在test分类下。我们可以愉快的阅读文献了。
如何实现上述工作流呢?
第一步,安装浏览器zotero connector插件
鉴于Chrome浏览器使用扩展市场需要科学上网,还是建议使用Edge浏览器或者Firefox浏览器。在Edge浏览器中,通过菜单选择扩展——获取 Microsoft Edge 扩展,搜索zotero即可找到zotero connector插件,点击获取即可安装。
第二步,Zotero安装Sci-hub插件
zotero Sci-hub插件的设置很简单,在zotero中选择工具——首选项——zotero Scihub。自动下载文献是默认开启的。如果不选则不会自动下载pdf,可以在已导入的条目上点击右键选择Update Scihub Pdf按钮手动下载pdf文件。
完成了上面两个插件的安装,我们就可以实现上面的工作流了。
除了通过scihub插件,我们也可以通过修改zotero的PDF retrieval更加简洁的实现上面的工作流。具体可以参考我在之前推荐zotero时介绍大家参考的方法:
通过Sci-hub,我们可以获取绝大部分文献的pdf原文。通过Zotero Connector抓取文献的强大功能,我们可以高效的将网页上我们感兴趣的文献下载到文献库中,并自动通过sci-hub获取原文pdf,从而提高工作效率。感兴趣的同学可以尝试一下。 查看全部
Zotero抓取网页文献条目并通过SCI-HUB自动下载原文
之前写过一些文章,没想到一篇推荐Zotero的文章获得了最多的关注。看来还是工具爱好者比较多。在我们没有数据库资源时,大家往往用SCI-HUB来获取文献原文。今天就介绍一下通过Zotero抓取网页文献元数据并通过SCI-HUB自动下载原文的方法。
首先看一下演示效果:
我们想在Zotero的test分类下加入一篇来自网页中的文献。我们打开浏览器,在文献页面下点击Save to zotero按钮,就自动抓取了这篇文章的元数据,并且自动在SCI-HUB上下载了原文。回到Zotero,文献条目和文献原文都已经出现在test分类下。我们可以愉快的阅读文献了。
如何实现上述工作流呢?
第一步,安装浏览器zotero connector插件
鉴于Chrome浏览器使用扩展市场需要科学上网,还是建议使用Edge浏览器或者Firefox浏览器。在Edge浏览器中,通过菜单选择扩展——获取 Microsoft Edge 扩展,搜索zotero即可找到zotero connector插件,点击获取即可安装。
第二步,Zotero安装Sci-hub插件
zotero Sci-hub插件的设置很简单,在zotero中选择工具——首选项——zotero Scihub。自动下载文献是默认开启的。如果不选则不会自动下载pdf,可以在已导入的条目上点击右键选择Update Scihub Pdf按钮手动下载pdf文件。
完成了上面两个插件的安装,我们就可以实现上面的工作流了。
除了通过scihub插件,我们也可以通过修改zotero的PDF retrieval更加简洁的实现上面的工作流。具体可以参考我在之前推荐zotero时介绍大家参考的方法:
通过Sci-hub,我们可以获取绝大部分文献的pdf原文。通过Zotero Connector抓取文献的强大功能,我们可以高效的将网页上我们感兴趣的文献下载到文献库中,并自动通过sci-hub获取原文pdf,从而提高工作效率。感兴趣的同学可以尝试一下。
chrome插件网页抓取 智联招聘猎聘网啊,58同城hao360(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-05-09 10:00
chrome插件网页抓取【无中文】插件,支持多种浏览器,网页抓取特性,插件介绍界面友好简洁、抓取高清、精准、耗时短建议下载:百度云链接密码:f2c说明:第一个账号请登录后退出。第二个账号请登录后输入邮箱验证。第三个账号请登录后输入收件人地址验证。
推荐几个吧!有兴趣自己评论一下留言
猎头宝,
搜索必应,
谷歌学术。
专业猎头垂直互联网猎头:cjkey天之星下招聘简历|猎头招聘网
建议使用阿里慧眼,可以挖掘各种智能简历,同时,
前程无忧不错,如果你之前用过的话。另外你用谷歌学术的话,也可以在搜索框中搜集学术论文电子版,很好用,
马上网招聘,百度学术都好用,其他也可以试试。毕竟软件并不是全部,首先要有兴趣才行,其次对行业有了解,才能玩得转。
猎聘网!
首先你要分清楚猎头是什么,
我家有一款叫做jockey的猎头软件还不错,直接收集企业电话号码与邮箱。希望对你有用。
智联招聘
猎聘网啊,
58同城
hao360谷歌学术
如果能顺带关注一下企业招聘网站的话应该可以挖掘更多信息 查看全部
chrome插件网页抓取 智联招聘猎聘网啊,58同城hao360(组图)
chrome插件网页抓取【无中文】插件,支持多种浏览器,网页抓取特性,插件介绍界面友好简洁、抓取高清、精准、耗时短建议下载:百度云链接密码:f2c说明:第一个账号请登录后退出。第二个账号请登录后输入邮箱验证。第三个账号请登录后输入收件人地址验证。
推荐几个吧!有兴趣自己评论一下留言
猎头宝,
搜索必应,
谷歌学术。
专业猎头垂直互联网猎头:cjkey天之星下招聘简历|猎头招聘网
建议使用阿里慧眼,可以挖掘各种智能简历,同时,
前程无忧不错,如果你之前用过的话。另外你用谷歌学术的话,也可以在搜索框中搜集学术论文电子版,很好用,
马上网招聘,百度学术都好用,其他也可以试试。毕竟软件并不是全部,首先要有兴趣才行,其次对行业有了解,才能玩得转。
猎聘网!
首先你要分清楚猎头是什么,
我家有一款叫做jockey的猎头软件还不错,直接收集企业电话号码与邮箱。希望对你有用。
智联招聘
猎聘网啊,
58同城
hao360谷歌学术
如果能顺带关注一下企业招聘网站的话应该可以挖掘更多信息
【Chrome插件推荐 | 网页高品质阅读神器】Minimal Reading
网站优化 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2022-05-08 11:37
今天给大家推荐的是搭载在Google Chrome浏览器上的网页阅读利器——Minimal Reading Mode插件。
Minimal Reading Mode是一款基于Chrome浏览器的扩展插件,优化用户的网页阅读体验,免受网页上其他无关内容的干扰,并以新字体和背景展示页面,获得沉浸式阅读效果。获取下载地址,直接拉到文末。
MinimalReading Mode在同类插件中的优势:
*占用电脑内存小。
* 字体清晰,对比度良好,提供夜间模式。* 正文中的图片和其他多媒体内容,会被自动调整为很小的正方形,避免被除文字以外的内容分散注意力。如果需要查看完整尺寸的图片和多媒体内容,将鼠标移动到上面即可,鼠标移走,又恢复成极小的正方形。* 自动识别网页文章的开始位置,滚动到标题的位置。
插件在Chrome中安装完成后,在“扩展程序”页面(chrome://extensions/)可以看到:
以环球网的这篇报道为例()为例,让我们来看看使用效果:
点击该插件后,是干净清爽的页面,非常适合阅读。
如需退出阅读模式,再次点击该插件即可~
优化阅读的Chrome插件还有DOM Distiller Reading Mode,支持网页阅读优化。
大家也可以试试~
如果朋友们有梯子,建议直接前往Chrome应用商店下载:
如果没有梯子,欢迎关注本账号,回复“read”获得Minimal Reading Mode插件的下载链接。
免责声明Discliamer:以上资源来自网络公开搜索结果,使用前请查杀病毒。
查看全部
【Chrome插件推荐 | 网页高品质阅读神器】Minimal Reading
今天给大家推荐的是搭载在Google Chrome浏览器上的网页阅读利器——Minimal Reading Mode插件。
Minimal Reading Mode是一款基于Chrome浏览器的扩展插件,优化用户的网页阅读体验,免受网页上其他无关内容的干扰,并以新字体和背景展示页面,获得沉浸式阅读效果。获取下载地址,直接拉到文末。
MinimalReading Mode在同类插件中的优势:
*占用电脑内存小。
* 字体清晰,对比度良好,提供夜间模式。* 正文中的图片和其他多媒体内容,会被自动调整为很小的正方形,避免被除文字以外的内容分散注意力。如果需要查看完整尺寸的图片和多媒体内容,将鼠标移动到上面即可,鼠标移走,又恢复成极小的正方形。* 自动识别网页文章的开始位置,滚动到标题的位置。
插件在Chrome中安装完成后,在“扩展程序”页面(chrome://extensions/)可以看到:
以环球网的这篇报道为例()为例,让我们来看看使用效果:
点击该插件后,是干净清爽的页面,非常适合阅读。
如需退出阅读模式,再次点击该插件即可~
优化阅读的Chrome插件还有DOM Distiller Reading Mode,支持网页阅读优化。
大家也可以试试~
如果朋友们有梯子,建议直接前往Chrome应用商店下载:
如果没有梯子,欢迎关注本账号,回复“read”获得Minimal Reading Mode插件的下载链接。
免责声明Discliamer:以上资源来自网络公开搜索结果,使用前请查杀病毒。
[Chrome插件]ImageAssistant_图片助手,批量提取网页图片神器
网站优化 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2022-05-07 19:30
导语
最近心情很差,更新很不稳定。
插件简介ImageAssistant(图片助手)是一款运行于chromium(chrome环境下开发)及其衍生浏览器(如:360安全浏览器、360极速浏览器、猎豹浏览器、百度浏览器、UC浏览器等)。ImageAssistant 用于分析、提取网页中的图片并提供多种筛选方式辅助用户选取下载的扩展软件。不同于以往提供类似功能的浏览器扩展,本扩展融合了多种数据提取方式来保证在各种复杂结构页面中尽可能全面地提取到出现过的图片。
插件使用运行截图
1、插件安装:插件压缩包解压后,打开谷歌浏览器扩展程序页面 chrome://extensions/;直接将插件CRX文件拖至页面点击安装确认即可。
2、安装成功后浏览器右上角插件图标中可以看到紫色“IA”的图标,点击可以查看具体的功能选项,这里仅测试”提取本页图片“功能,其他功能自行安装探索研究。
3、“提取本页图片”后,插件会将当前网页所有图片列举出来,您可以在列表中选择按图片大小、格式等方式进行筛选,然后选中下载其中一项,或许多选批量下载。
资源获取<p style="letter-spacing: 0.5px;white-space: normal;text-align: left;">1."阅读原文"狩酷资源站更多内容更新中...
2.关注公众号:狩酷乐享,回复:图片助手 或 IA插件
</p> 查看全部
[Chrome插件]ImageAssistant_图片助手,批量提取网页图片神器
导语
最近心情很差,更新很不稳定。
插件简介ImageAssistant(图片助手)是一款运行于chromium(chrome环境下开发)及其衍生浏览器(如:360安全浏览器、360极速浏览器、猎豹浏览器、百度浏览器、UC浏览器等)。ImageAssistant 用于分析、提取网页中的图片并提供多种筛选方式辅助用户选取下载的扩展软件。不同于以往提供类似功能的浏览器扩展,本扩展融合了多种数据提取方式来保证在各种复杂结构页面中尽可能全面地提取到出现过的图片。
插件使用运行截图
1、插件安装:插件压缩包解压后,打开谷歌浏览器扩展程序页面 chrome://extensions/;直接将插件CRX文件拖至页面点击安装确认即可。
2、安装成功后浏览器右上角插件图标中可以看到紫色“IA”的图标,点击可以查看具体的功能选项,这里仅测试”提取本页图片“功能,其他功能自行安装探索研究。
3、“提取本页图片”后,插件会将当前网页所有图片列举出来,您可以在列表中选择按图片大小、格式等方式进行筛选,然后选中下载其中一项,或许多选批量下载。
资源获取<p style="letter-spacing: 0.5px;white-space: normal;text-align: left;">1."阅读原文"狩酷资源站更多内容更新中...
2.关注公众号:狩酷乐享,回复:图片助手 或 IA插件
代码审计lintcode插件网页抓取扩展程序-编程语言入门教程
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-05-06 08:02
chrome插件网页抓取扩展程序。用它可以完美抓取网页上的所有txt文件,包括代码,图片,视频,音频,文件扩展名,只要是flash格式的网页都可以抓取到,浏览器历史记录里也可以下载。
数据包分析arctime?
snippetxmpprdpbin
二十四小时在线:externaldomainstudy
可以买个vpn呀,有点用。
代码审计lintcode这是个比赛在上面获奖过的人都有奖金
有没有人推荐去控球网,淘宝里有好多外包项目,毕竟很多网站用laravel,如果能买一个模版就完美了,
碰巧我现在正在找这样的网站,但是上面的大多数项目有限制。比如dedecms,h5的joomla之类的项目,都要学urlib,还要会写email。我正在想有没有类似的软件,比如一个公司可以和不同类型的网站达成合作,比如做一个接口或者对接一个网站之类的。这样就可以设计出一个神奇的应用。
让我想起了赵军:因上学,大家就此死于相同的ip地址中国很大,
楼上的"我爱xx"说的一点也不符合问题,要是想学好编程,怎么可能在网上找资料呢,网上很多都是误人子弟的!关键还很多学习课程都是盗版的!实在太多了!最主要的还是要靠学习,找到出路才可以啊!建议楼主可以下载编程语言入门教程,把基础知识都搞懂,能不能做一些简单的项目(比如基于flash、wordpress建立一个博客系统,或者基于osxosr、coffeescript等语言写一个点点客的插件之类的);或者本地能搞定的事情就不要上网找其他教程或者网上学习了!主要还是要靠学习!。 查看全部
代码审计lintcode插件网页抓取扩展程序-编程语言入门教程
chrome插件网页抓取扩展程序。用它可以完美抓取网页上的所有txt文件,包括代码,图片,视频,音频,文件扩展名,只要是flash格式的网页都可以抓取到,浏览器历史记录里也可以下载。
数据包分析arctime?
snippetxmpprdpbin
二十四小时在线:externaldomainstudy
可以买个vpn呀,有点用。
代码审计lintcode这是个比赛在上面获奖过的人都有奖金
有没有人推荐去控球网,淘宝里有好多外包项目,毕竟很多网站用laravel,如果能买一个模版就完美了,
碰巧我现在正在找这样的网站,但是上面的大多数项目有限制。比如dedecms,h5的joomla之类的项目,都要学urlib,还要会写email。我正在想有没有类似的软件,比如一个公司可以和不同类型的网站达成合作,比如做一个接口或者对接一个网站之类的。这样就可以设计出一个神奇的应用。
让我想起了赵军:因上学,大家就此死于相同的ip地址中国很大,
楼上的"我爱xx"说的一点也不符合问题,要是想学好编程,怎么可能在网上找资料呢,网上很多都是误人子弟的!关键还很多学习课程都是盗版的!实在太多了!最主要的还是要靠学习,找到出路才可以啊!建议楼主可以下载编程语言入门教程,把基础知识都搞懂,能不能做一些简单的项目(比如基于flash、wordpress建立一个博客系统,或者基于osxosr、coffeescript等语言写一个点点客的插件之类的);或者本地能搞定的事情就不要上网找其他教程或者网上学习了!主要还是要靠学习!。
chrome插件网页抓取脚本提供了全套丰富的网页(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-05-05 01:00
chrome插件网页抓取脚本提供了全套丰富的网页抓取脚本:browseropt.js、mozilla.js、safari.js、webkit.js、osx.js等等。其中safari.js、mozilla.js、webkit.js这三个插件如果加入到浏览器任务管理器中就可以非常方便地帮助开发者用任何页面抓取软件提供的很多功能了:a:从页面跳转到右侧的网站。
b:curl把url抓取到本地。c:把文字复制到记事本或者其他工具,批量粘贴发送给pdf或者图片。d:做个日历什么的。e:去重。f:单个页面显示文件xml或者图片的扩展名。g:查看搜索关键字,导航到所有能搜索的页面。h:对网站的来源进行排序。i:生成一个可以网络连接的小工具。k:发现appstore里那些经常没响应的网站,让你很好地预防安全问题。
l:多个页面的在线互传。m:创建下载列表。o:使用xmlhttprequest开发一个可以在多浏览器间传递文件的工具。n:给网页添加动态二维码。p:把windows或者mac用户的文件名加入url编码。r:把网页上的图片源文件截下来保存。t:创建一个新的网页内容收藏夹。大家可以去这里试试能想到什么插件,这次只列举一部分。
豆瓣只能当做是一个字幕爱好者,更多的是涉猎一些世界名著,电影,舞台剧,小说。你可以尝试这样做:一些爱好者网站:,豆瓣只是其中的一个,还有更多:, 查看全部
chrome插件网页抓取脚本提供了全套丰富的网页(图)
chrome插件网页抓取脚本提供了全套丰富的网页抓取脚本:browseropt.js、mozilla.js、safari.js、webkit.js、osx.js等等。其中safari.js、mozilla.js、webkit.js这三个插件如果加入到浏览器任务管理器中就可以非常方便地帮助开发者用任何页面抓取软件提供的很多功能了:a:从页面跳转到右侧的网站。
b:curl把url抓取到本地。c:把文字复制到记事本或者其他工具,批量粘贴发送给pdf或者图片。d:做个日历什么的。e:去重。f:单个页面显示文件xml或者图片的扩展名。g:查看搜索关键字,导航到所有能搜索的页面。h:对网站的来源进行排序。i:生成一个可以网络连接的小工具。k:发现appstore里那些经常没响应的网站,让你很好地预防安全问题。
l:多个页面的在线互传。m:创建下载列表。o:使用xmlhttprequest开发一个可以在多浏览器间传递文件的工具。n:给网页添加动态二维码。p:把windows或者mac用户的文件名加入url编码。r:把网页上的图片源文件截下来保存。t:创建一个新的网页内容收藏夹。大家可以去这里试试能想到什么插件,这次只列举一部分。
豆瓣只能当做是一个字幕爱好者,更多的是涉猎一些世界名著,电影,舞台剧,小说。你可以尝试这样做:一些爱好者网站:,豆瓣只是其中的一个,还有更多:,
大幅提升设计师工作效率谷歌浏览器插件推荐!
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-30 14:43
编辑 | 阿圈
作为设计师,你有没有这样一种感觉:每次看到站酷、追波等设计网站的首页的时候,总有一些熟悉的大佬的身影,除了感叹他们的作品优秀之外,更多的是佩服他们愿意花时间去整理自己的作品。相比自己,可能平时完成自己工作的时间都不够,甚至还要加班加点。每天下班的时候,感觉什么事情都没做完,慢慢地形成拖延症,久而久之,心力交瘁,感觉时间永远不够用。事实上,造成这种情况的原因不是时间问题,而是效率问题。言归正传,今天为大家推荐5款超好用的设计师必备chrome插件。
无需注册和额外网页,随开即用亲测提升工作效率两倍以上
重要的是全部免费下载!!!
同样想要提升工作效率的同学一定关注我哦,持续更新实用设计工具!
插件一
[Muzli 2]
第一个插件就是我的最爱,设计师的秘密资源,一般人不告诉他。国外版的花瓣+站酷,每天整理更新最优质的设计案例、趋势、模板等等。从在几个网站间来回跳转到一个插件一劳永逸,这效率提升可想而知!
从此每天上班第一件事就是打开浏览器摸鱼搜集灵感,他们的内容来源于国外各大主流灵感收集网站,如dribbble、behance、abdz、Pinterest······
内容更新的丰富程度多到想不到,既有质量又保证时效。
配色模板是必不可少的
不用自己花时间再逛behance,打开浏览器就能看到最新的优质设计案例!
behance上的精选设计案例
复制链接至谷歌浏览器即可下载:
插件2
[Eyedrop]
实时吸取颜色,当你在任意网站逛到很喜欢的配色,哪还需要导入ps这么麻烦,用eyedrop插件直接可以吸取后识别,即时实现颜色代码、RGB数值等信息。
在behance上看到喜欢的设计作品,吸取到的各种颜色信息实时显示!
复制链接至谷歌浏览器即可下载:
插件3[what font]
实时字体识别,在网上冲浪的时候看到喜欢的字体,点开插件移动鼠标到不同的字体上,相关字体的全部信息一览无余,包括字体名称、粗细、大小等等,哪里不会点哪里。
复制链接至谷歌浏览器即可下载:
插件4
[Image Downloader]
不知道大家有没有一样的体验,逛一个网站时不时感叹:这个banner不错、这个主图好看、这个案例太漂亮了······,但是一张一张图片下载又极其麻烦。这个插件可以一键下载网页内的全部图片,当然也支持手动选择单张、调整清晰度之类的常规选项,emmm但是也包括广告。
嗯,我知道你们聪明的小脑袋在想什么,各类会员制收费的素材网站的图片无法下载,阿圈已经替大家去试了。不过即使是免费的非素材网站下载的图片使用时也需要注意版权问题哦。
复制链接至谷歌浏览器即可下载:
插件5[SVG-Grabber]
这个插件可以帮助设计师抓取网页内的所有矢量图标,支持快速下载某网站logo、icon等,简直方便实用到起飞。
谷歌
B站
知乎
复制链接至谷歌浏览器即可下载:
这五个插件虽然小众但是非常实用,你都get了吗~想看更多创意灵感、设计工具记得扫下面的二维码关注我,一起实现灵感自由!
本文提到的插件均需要^翻^墙^下载,后续使用无需再次^翻^墙^,如有问题咱们群里聊。
TIPS:不想错过设计干货一定要将「设计圈」公众号设为星标,如果觉得内容对你有帮助,请帮我们点点“在看”和“赞”,我们会更加努力的为大家准备设计早餐的~感谢大家
查看全部
大幅提升设计师工作效率谷歌浏览器插件推荐!
编辑 | 阿圈
作为设计师,你有没有这样一种感觉:每次看到站酷、追波等设计网站的首页的时候,总有一些熟悉的大佬的身影,除了感叹他们的作品优秀之外,更多的是佩服他们愿意花时间去整理自己的作品。相比自己,可能平时完成自己工作的时间都不够,甚至还要加班加点。每天下班的时候,感觉什么事情都没做完,慢慢地形成拖延症,久而久之,心力交瘁,感觉时间永远不够用。事实上,造成这种情况的原因不是时间问题,而是效率问题。言归正传,今天为大家推荐5款超好用的设计师必备chrome插件。
无需注册和额外网页,随开即用亲测提升工作效率两倍以上
重要的是全部免费下载!!!
同样想要提升工作效率的同学一定关注我哦,持续更新实用设计工具!
插件一
[Muzli 2]
第一个插件就是我的最爱,设计师的秘密资源,一般人不告诉他。国外版的花瓣+站酷,每天整理更新最优质的设计案例、趋势、模板等等。从在几个网站间来回跳转到一个插件一劳永逸,这效率提升可想而知!
从此每天上班第一件事就是打开浏览器摸鱼搜集灵感,他们的内容来源于国外各大主流灵感收集网站,如dribbble、behance、abdz、Pinterest······
内容更新的丰富程度多到想不到,既有质量又保证时效。
配色模板是必不可少的
不用自己花时间再逛behance,打开浏览器就能看到最新的优质设计案例!
behance上的精选设计案例
复制链接至谷歌浏览器即可下载:
插件2
[Eyedrop]
实时吸取颜色,当你在任意网站逛到很喜欢的配色,哪还需要导入ps这么麻烦,用eyedrop插件直接可以吸取后识别,即时实现颜色代码、RGB数值等信息。
在behance上看到喜欢的设计作品,吸取到的各种颜色信息实时显示!
复制链接至谷歌浏览器即可下载:
插件3[what font]
实时字体识别,在网上冲浪的时候看到喜欢的字体,点开插件移动鼠标到不同的字体上,相关字体的全部信息一览无余,包括字体名称、粗细、大小等等,哪里不会点哪里。
复制链接至谷歌浏览器即可下载:
插件4
[Image Downloader]
不知道大家有没有一样的体验,逛一个网站时不时感叹:这个banner不错、这个主图好看、这个案例太漂亮了······,但是一张一张图片下载又极其麻烦。这个插件可以一键下载网页内的全部图片,当然也支持手动选择单张、调整清晰度之类的常规选项,emmm但是也包括广告。
嗯,我知道你们聪明的小脑袋在想什么,各类会员制收费的素材网站的图片无法下载,阿圈已经替大家去试了。不过即使是免费的非素材网站下载的图片使用时也需要注意版权问题哦。
复制链接至谷歌浏览器即可下载:
插件5[SVG-Grabber]
这个插件可以帮助设计师抓取网页内的所有矢量图标,支持快速下载某网站logo、icon等,简直方便实用到起飞。
谷歌
B站
知乎
复制链接至谷歌浏览器即可下载:
这五个插件虽然小众但是非常实用,你都get了吗~想看更多创意灵感、设计工具记得扫下面的二维码关注我,一起实现灵感自由!
本文提到的插件均需要^翻^墙^下载,后续使用无需再次^翻^墙^,如有问题咱们群里聊。
TIPS:不想错过设计干货一定要将「设计圈」公众号设为星标,如果觉得内容对你有帮助,请帮我们点点“在看”和“赞”,我们会更加努力的为大家准备设计早餐的~感谢大家
chrome插件网页抓取(爬取Chrome浏览器;2.插件:WebScraper最后,如果你想自己动手一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-16 06:18
在做电商的时候,消费者对产品的评论很重要,但是如果他们不知道怎么写代码呢?这是一个无需编写任何代码即可进行简单数据爬取的 Chrome 插件。下面展示了一些捕获的数据:
可以看到爬取的地址、评论者、评论内容、时间、商品颜色都被爬取了。那么,抓取这些数据需要哪些工具呢?只有两个:
1.铬;
2. 插件:网络爬虫
最后,如果你想自己爬,这里是这个爬的详细过程:
1.首先复制下面的代码,是的,你不需要写代码,但是要上手,还是需要复制代码,以后可以自己自定义选择,你不需要写代码。
{
"_id": "jdreview",
“startUrl”:[
],
“选择器”:[
{
“id”:“用户”,
"type": "SelectorText",
“选择器”:“div.user-info”,
“父选择器”:[
“主要”
],
“多个”:假,
"正则表达式": "",
“延迟”:0
},
{
“id”:“评论”,
"type": "SelectorText",
“选择器”:“ment-column > ment-con”,
“父选择器”:[
“主要”
],
“多个”:假,
"正则表达式": "",
“延迟”:0
},
{
“id”:“时间”,
"type": "SelectorText",
"selector": "ment-message:nth-of-type(5) span:nth-of-type(4), div.order-info span:nth-of-type( 4)",
“父选择器”:[
“主要”
],
“多个”:假,
"正则表达式": "",
“延迟”:“0”
},
{
“id”:“颜色”,
"type": "SelectorText",
"selector": "div.order-info span:nth-of-type(1)",
“父选择器”:[
“主要”
],
“多个”:假,
"正则表达式": "",
“延迟”:0
},
{
“id”:“主”,
"type": "SelectorElementClick",
“选择器”:“ment-item”,
“父选择器”:[
“_root”
],
“多个”:真,
“延迟”:“10000”,
"clickElementSelector": "-table-footer a.ui-pager-next",
"clickType": "clickMore",
“discardInitialElements”:假,
"clickElementUniquenessType": "uniqueHTMLText"
}
]
}
2.然后打开chrome浏览器,在任意页面同时按下Ctrl+Shift+i,在弹窗中找到Web Scraper,如下:
3.如下
4. 如图,粘贴上面的代码:
5. 如图,如果需要自定义URL,注意替换。 URL 后面的#comment 是评论的直接链接,不能删除:
6.如图:
7.如图:
8. 如图,点击抓取后会自动打开需要抓取的页面,不要关闭窗口,等待完成。问题:
9.最后点击下载到电脑,数据就保存好了。
使用这个工具的好处是:
1. 无需编程;
2.京东的评论基本可以用这个脚本,修改对应的url即可;
3.如果要抓取的评论少于1000条,这个工具会很方便,所有数据都会自动下载;
使用注意事项:
1. 捕获一次的数据会被记录下来,如果立即再次捕获则不会保存。建议关闭浏览器重新打开再试;
2.爬取次数:1000以内没问题,可能是京东直接根据IP屏蔽了更多的爬取;
如果你的英文不错,可以尝试阅读官方文档,进一步学习和定制自己的爬虫。
以上就是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持。 查看全部
chrome插件网页抓取(爬取Chrome浏览器;2.插件:WebScraper最后,如果你想自己动手一下)
在做电商的时候,消费者对产品的评论很重要,但是如果他们不知道怎么写代码呢?这是一个无需编写任何代码即可进行简单数据爬取的 Chrome 插件。下面展示了一些捕获的数据:
可以看到爬取的地址、评论者、评论内容、时间、商品颜色都被爬取了。那么,抓取这些数据需要哪些工具呢?只有两个:
1.铬;
2. 插件:网络爬虫
最后,如果你想自己爬,这里是这个爬的详细过程:
1.首先复制下面的代码,是的,你不需要写代码,但是要上手,还是需要复制代码,以后可以自己自定义选择,你不需要写代码。
{
"_id": "jdreview",
“startUrl”:[
],
“选择器”:[
{
“id”:“用户”,
"type": "SelectorText",
“选择器”:“div.user-info”,
“父选择器”:[
“主要”
],
“多个”:假,
"正则表达式": "",
“延迟”:0
},
{
“id”:“评论”,
"type": "SelectorText",
“选择器”:“ment-column > ment-con”,
“父选择器”:[
“主要”
],
“多个”:假,
"正则表达式": "",
“延迟”:0
},
{
“id”:“时间”,
"type": "SelectorText",
"selector": "ment-message:nth-of-type(5) span:nth-of-type(4), div.order-info span:nth-of-type( 4)",
“父选择器”:[
“主要”
],
“多个”:假,
"正则表达式": "",
“延迟”:“0”
},
{
“id”:“颜色”,
"type": "SelectorText",
"selector": "div.order-info span:nth-of-type(1)",
“父选择器”:[
“主要”
],
“多个”:假,
"正则表达式": "",
“延迟”:0
},
{
“id”:“主”,
"type": "SelectorElementClick",
“选择器”:“ment-item”,
“父选择器”:[
“_root”
],
“多个”:真,
“延迟”:“10000”,
"clickElementSelector": "-table-footer a.ui-pager-next",
"clickType": "clickMore",
“discardInitialElements”:假,
"clickElementUniquenessType": "uniqueHTMLText"
}
]
}
2.然后打开chrome浏览器,在任意页面同时按下Ctrl+Shift+i,在弹窗中找到Web Scraper,如下:
3.如下
4. 如图,粘贴上面的代码:
5. 如图,如果需要自定义URL,注意替换。 URL 后面的#comment 是评论的直接链接,不能删除:
6.如图:
7.如图:
8. 如图,点击抓取后会自动打开需要抓取的页面,不要关闭窗口,等待完成。问题:
9.最后点击下载到电脑,数据就保存好了。
使用这个工具的好处是:
1. 无需编程;
2.京东的评论基本可以用这个脚本,修改对应的url即可;
3.如果要抓取的评论少于1000条,这个工具会很方便,所有数据都会自动下载;
使用注意事项:
1. 捕获一次的数据会被记录下来,如果立即再次捕获则不会保存。建议关闭浏览器重新打开再试;
2.爬取次数:1000以内没问题,可能是京东直接根据IP屏蔽了更多的爬取;
如果你的英文不错,可以尝试阅读官方文档,进一步学习和定制自己的爬虫。
以上就是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持。
chrome插件网页抓取(推荐chrome插件chromeheadlessscreendebugger,,11开发的页面抓取助手把图片设置成md5哈希)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-04-14 19:01
chrome插件网页抓取助手,在网上下载,然后用direct3d11开发的页面抓取助手把图片设置成md5哈希值解密,就可以直接在本地打开。
使用chrome的selenium抓包就能看到包内容。其他工具还是需要看下源码。
推荐chrome插件chromeheadlessscreendebugger,能抓取flash的。我用vlc也可以抓,效果一样,但是有很多限制。
不只能抓到原版,
airect3dscreendebugger
请参考chrome下headless页面抓取api文档
screenshot下结果很多都会有错误,例如下面的东西都很大,
chrome就可以啊,
这个网站上面有最新的开发者选项
抓取api文档
webkit的3d全矢量对于alt+数字的浏览器是afdkoc。所以针对1:webgl2-surfacefall-processormaybeneededinwebgl.useitasasolution,butaddedwithadditionalheadlessdefault3dcharacters,includinglayoutmatchestobepresentedwithoutdisplayonbothdefaultversions.regardlessofwhatoperationsweshoulddoorwithoutredisdomifexpanded,anyflexelements,furthermatchesofmain-drawing,etc.usenotablestylematchestomakepresentationwithgoogle'sanydefaultadvertisingaction.针对2:am=1。
更新完毕这个操作是关联的。webview发布v3及之后的版本。而autosalt=false如果没有一些比较频繁的am,它会等过大段时间再调用advertisingaction。所以即使抓到一段,也没有办法。基本上找到了想要的内容,处理好人肉摘录如果想要更详细的可以看看链接里的博客,基本上是抓浏览器使用者常用内容,例如常见开发包使用、常见网站api,常见apidocumentation教程等等,不过抓后还需要自己再处理一下数据做个转换,感觉比较麻烦。 查看全部
chrome插件网页抓取(推荐chrome插件chromeheadlessscreendebugger,,11开发的页面抓取助手把图片设置成md5哈希)
chrome插件网页抓取助手,在网上下载,然后用direct3d11开发的页面抓取助手把图片设置成md5哈希值解密,就可以直接在本地打开。
使用chrome的selenium抓包就能看到包内容。其他工具还是需要看下源码。
推荐chrome插件chromeheadlessscreendebugger,能抓取flash的。我用vlc也可以抓,效果一样,但是有很多限制。
不只能抓到原版,
airect3dscreendebugger
请参考chrome下headless页面抓取api文档
screenshot下结果很多都会有错误,例如下面的东西都很大,
chrome就可以啊,
这个网站上面有最新的开发者选项
抓取api文档
webkit的3d全矢量对于alt+数字的浏览器是afdkoc。所以针对1:webgl2-surfacefall-processormaybeneededinwebgl.useitasasolution,butaddedwithadditionalheadlessdefault3dcharacters,includinglayoutmatchestobepresentedwithoutdisplayonbothdefaultversions.regardlessofwhatoperationsweshoulddoorwithoutredisdomifexpanded,anyflexelements,furthermatchesofmain-drawing,etc.usenotablestylematchestomakepresentationwithgoogle'sanydefaultadvertisingaction.针对2:am=1。
更新完毕这个操作是关联的。webview发布v3及之后的版本。而autosalt=false如果没有一些比较频繁的am,它会等过大段时间再调用advertisingaction。所以即使抓到一段,也没有办法。基本上找到了想要的内容,处理好人肉摘录如果想要更详细的可以看看链接里的博客,基本上是抓浏览器使用者常用内容,例如常见开发包使用、常见网站api,常见apidocumentation教程等等,不过抓后还需要自己再处理一下数据做个转换,感觉比较麻烦。
chrome插件网页抓取(GoogleReader的执行环境和原始网页太复杂了(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-12 17:22
)
来自:%E5%9C%A8Chrome%E6%8F%92%E4%BB%B6%E4%B8%AD%E8%AE%BF%E9%97%AE%E5%8E%9F%E5%A7%8B %E7%BD%91%E9%A1%B5%E4%B8%AD%E7%9A%84%E5%8F%98%E9%87%8F
今天早上写Reader Sharer插件的时候遇到了一个问题。
谷歌阅读器网页有全局变量_COMMAND_TOKEN,我需要用到,但是Chrome插件的Content Scripts的执行环境和原网页不一样,所以无法直接使用window._COMMAND_TOKEN来获取。
如果是火狐,我可以使用 unsafeWindow._COMMAND_TOKEN 直接获取;Chrome插件很久以前就和原网页共享了执行环境,但是好日子已经一去不复返了。
幸运的是,我发现了“如何在 Chrome 中模仿 Greasemonkey/Firefox 的 unsafeWindow 功能?”这个问题。并得到3个解决方案。
考虑到谷歌阅读器的网页过于复杂,这里以谷歌主页为例。打开网页后,右键打开inspect元素,然后在控制台输入fp,会看到一个字符串,是原网页的全局变量。
现在我想得到它,我可以创建一个脚本元素并将其附加到头部。这个脚本元素的执行环境是原创网页,fp变量可以自由使用。
但是fp取出后,不能直接传回内容脚本。幸运的是,文档说 DOM 是共享的,所以在这个脚本中,可以将值设置为元素的属性或 innerText,然后在内容脚本中获取:
setTimeout(function() {
var script = document.createElement('script');
script.type = 'text/javascript';
script.innerHTML = "document.body.setAttribute('data-fp', fp);";
document.head.appendChild(script);
document.head.removeChild(script);
console.log(document.body.getAttribute('data-fp'));
}, 1000);
这里延迟的原因是在加载原创网页时,创建fp变量需要一段时间。
另一种方式是使用location.href,用来跳转网页,但也可以用来执行JavaScript,执行环境也是原网页:
setTimeout(function() {
location.href = "javascript:document.body.setAttribute('data-fp', fp);";
setTimeout(function() {
console.log(document.body.getAttribute('data-fp'));
}, 0);
}, 1000);
SetTimeout 嵌套在这里,因为跳转是一个事件,不会中断当前脚本的执行(并且添加一个脚本元素会立即执行),所以下面的语句需要等待事件处理完毕。
但是,上面提到的方法必须先保存,然后取出。只有字符串等简单类型才能做到这一点,与函数无关。
其实还有一种更方便的方法,就是在DOM上绑定一个事件,事件处理函数返回window变量,然后在程序中触发这个事件,获取执行环境的window变量。好在这个执行环境还是原来网页的那个:
setTimeout(function() {
var div = document.createElement('div');
div.setAttribute('onclick', 'return window;');
var unsafeWindow = div.onclick();
console.log(unsafeWindow.fp);
}, 1000); 查看全部
chrome插件网页抓取(GoogleReader的执行环境和原始网页太复杂了(图)
)
来自:%E5%9C%A8Chrome%E6%8F%92%E4%BB%B6%E4%B8%AD%E8%AE%BF%E9%97%AE%E5%8E%9F%E5%A7%8B %E7%BD%91%E9%A1%B5%E4%B8%AD%E7%9A%84%E5%8F%98%E9%87%8F
今天早上写Reader Sharer插件的时候遇到了一个问题。
谷歌阅读器网页有全局变量_COMMAND_TOKEN,我需要用到,但是Chrome插件的Content Scripts的执行环境和原网页不一样,所以无法直接使用window._COMMAND_TOKEN来获取。
如果是火狐,我可以使用 unsafeWindow._COMMAND_TOKEN 直接获取;Chrome插件很久以前就和原网页共享了执行环境,但是好日子已经一去不复返了。
幸运的是,我发现了“如何在 Chrome 中模仿 Greasemonkey/Firefox 的 unsafeWindow 功能?”这个问题。并得到3个解决方案。
考虑到谷歌阅读器的网页过于复杂,这里以谷歌主页为例。打开网页后,右键打开inspect元素,然后在控制台输入fp,会看到一个字符串,是原网页的全局变量。
现在我想得到它,我可以创建一个脚本元素并将其附加到头部。这个脚本元素的执行环境是原创网页,fp变量可以自由使用。
但是fp取出后,不能直接传回内容脚本。幸运的是,文档说 DOM 是共享的,所以在这个脚本中,可以将值设置为元素的属性或 innerText,然后在内容脚本中获取:
setTimeout(function() {
var script = document.createElement('script');
script.type = 'text/javascript';
script.innerHTML = "document.body.setAttribute('data-fp', fp);";
document.head.appendChild(script);
document.head.removeChild(script);
console.log(document.body.getAttribute('data-fp'));
}, 1000);
这里延迟的原因是在加载原创网页时,创建fp变量需要一段时间。
另一种方式是使用location.href,用来跳转网页,但也可以用来执行JavaScript,执行环境也是原网页:
setTimeout(function() {
location.href = "javascript:document.body.setAttribute('data-fp', fp);";
setTimeout(function() {
console.log(document.body.getAttribute('data-fp'));
}, 0);
}, 1000);
SetTimeout 嵌套在这里,因为跳转是一个事件,不会中断当前脚本的执行(并且添加一个脚本元素会立即执行),所以下面的语句需要等待事件处理完毕。
但是,上面提到的方法必须先保存,然后取出。只有字符串等简单类型才能做到这一点,与函数无关。
其实还有一种更方便的方法,就是在DOM上绑定一个事件,事件处理函数返回window变量,然后在程序中触发这个事件,获取执行环境的window变量。好在这个执行环境还是原来网页的那个:
setTimeout(function() {
var div = document.createElement('div');
div.setAttribute('onclick', 'return window;');
var unsafeWindow = div.onclick();
console.log(unsafeWindow.fp);
}, 1000);
chrome插件网页抓取(chrome插件网页截图解析框试一下v.forindexof(txt,5))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-04-08 06:07
chrome插件网页抓取xpath来解析.搜索快捷键是ctrl+f~~比如输入下面的内容你会看到一个第四个选项它标注了一条直线然后这条直线就是你需要的.下面这个是网页截图解析框
试一下v.forindexof(txt,5)这个函数?它的返回值是txt[indexof(index,5)]个5
可以用的。如@刘云峰所说。
百度下“应用市场”。应用市场是支持objective-c的,不比android的meta-data慢。
可以啊,我有个朋友经常用这个方法进入市场,
记得之前用chrome和火狐,发现后去看了下。能搜到应用的app名称。搜不到“下载”字样。比如“知乎”;也可以搜到“开始”;但是搜不到“搜索”字样。只能搜到在搜索框中搜索图片。
好像搜到一个链接但是打不开了。然后告诉我是某个新浪博客搜索框的。“新浪博客”不知道哪来的,不知道到底怎么一回事,但是那个搜索框进来是这样的-.-。不知道算不算题主说的下载下来后能调用拼音,但是为什么不行。
我猜可能是两个原因,一个是下载的应用有关:例如wiki,其下载应用也支持命令行,可以直接输入其命令行,但也会下载一个同名的后缀为.wiki的.net运行起来(java也是同理),那自然无法调用自己输入的那个命令行,可能就只能调用已有的命令行(例如java本来可以读取path路径,但是需要将下载的com.apple.java.object.class获取到;或者每个运行java的终端都有下载目录,运行的java时会先读取那个目录,而不是直接按下载按钮);另一个就是网页元素本身不知道提供什么类型的api函数了:我知道可以利用chrome的设置项去找下载的api函数,但是却不知道chrome有什么推荐的文件浏览器,觉得betterme比较好用,自己写了一个小工具,确实很方便,可以百度一下:一键卸载--betterme以及//分享///对象object1如何保存为plist对象可以很方便的装个环境。 查看全部
chrome插件网页抓取(chrome插件网页截图解析框试一下v.forindexof(txt,5))
chrome插件网页抓取xpath来解析.搜索快捷键是ctrl+f~~比如输入下面的内容你会看到一个第四个选项它标注了一条直线然后这条直线就是你需要的.下面这个是网页截图解析框
试一下v.forindexof(txt,5)这个函数?它的返回值是txt[indexof(index,5)]个5
可以用的。如@刘云峰所说。
百度下“应用市场”。应用市场是支持objective-c的,不比android的meta-data慢。
可以啊,我有个朋友经常用这个方法进入市场,
记得之前用chrome和火狐,发现后去看了下。能搜到应用的app名称。搜不到“下载”字样。比如“知乎”;也可以搜到“开始”;但是搜不到“搜索”字样。只能搜到在搜索框中搜索图片。
好像搜到一个链接但是打不开了。然后告诉我是某个新浪博客搜索框的。“新浪博客”不知道哪来的,不知道到底怎么一回事,但是那个搜索框进来是这样的-.-。不知道算不算题主说的下载下来后能调用拼音,但是为什么不行。
我猜可能是两个原因,一个是下载的应用有关:例如wiki,其下载应用也支持命令行,可以直接输入其命令行,但也会下载一个同名的后缀为.wiki的.net运行起来(java也是同理),那自然无法调用自己输入的那个命令行,可能就只能调用已有的命令行(例如java本来可以读取path路径,但是需要将下载的com.apple.java.object.class获取到;或者每个运行java的终端都有下载目录,运行的java时会先读取那个目录,而不是直接按下载按钮);另一个就是网页元素本身不知道提供什么类型的api函数了:我知道可以利用chrome的设置项去找下载的api函数,但是却不知道chrome有什么推荐的文件浏览器,觉得betterme比较好用,自己写了一个小工具,确实很方便,可以百度一下:一键卸载--betterme以及//分享///对象object1如何保存为plist对象可以很方便的装个环境。
chrome插件网页抓取(6.FontfaceNinjaSVGSVG字体提取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-04-02 16:17
1. Windows Resizer 窗口调整器
当设计师需要以不同的分辨率查看网页设计时,此插件非常有用。
2.织机录制视频工具
使用该工具,任何网页动画、用户流程、bug操作都可以轻松录制成视频并分享,及时采集设计相关的建议和反馈。
3.玩具箱
类似于 InVision 中收录的设计审查工具,以及 Zeplin 中的页面检查工具。但该工具还支持直接在网页上添加评论或反馈,而不是在设计稿上。帮助用户快速查看网页的CSS代码,支持自动截屏并记录相关的Bug信息(如浏览器信息、操作系统信息和视口大小信息等),方便此类问题的后期处理并轻松重现相关问题。
链接:错误报告变得容易 | 玩具盒
4.SVG 抓取器 SVG 抓取器
浏览网页时,如果您只想捕捉页面上的徽标或图标进行设计,只需单击开始按钮,该工具将自动提取页面上的所有 SVG 图像。然后轻松查看并选择要下载的所需 SVG 图像。
5.ColorZilla 颜色选择器
当您需要在 Chrome 浏览器下快速检查任何网页中使用的颜色或配色方案时,ColorZilla 颜色选择器非常方便。安装该工具后,将鼠标悬停在任何网页元素上以快速查看相关的 HEX 和 RGB 颜色值。必要时,只需单击并复制和粘贴相关颜色信息。
6.Fontface Ninja 字体提取工具
Fontface Ninja 是一款美观实用的字体提取工具。安装成功后,用户可以将鼠标悬停在相关页面文字上,查看对应的字体样式。 查看全部
chrome插件网页抓取(6.FontfaceNinjaSVGSVG字体提取工具)
1. Windows Resizer 窗口调整器
当设计师需要以不同的分辨率查看网页设计时,此插件非常有用。
2.织机录制视频工具
使用该工具,任何网页动画、用户流程、bug操作都可以轻松录制成视频并分享,及时采集设计相关的建议和反馈。
3.玩具箱
类似于 InVision 中收录的设计审查工具,以及 Zeplin 中的页面检查工具。但该工具还支持直接在网页上添加评论或反馈,而不是在设计稿上。帮助用户快速查看网页的CSS代码,支持自动截屏并记录相关的Bug信息(如浏览器信息、操作系统信息和视口大小信息等),方便此类问题的后期处理并轻松重现相关问题。
链接:错误报告变得容易 | 玩具盒
4.SVG 抓取器 SVG 抓取器
浏览网页时,如果您只想捕捉页面上的徽标或图标进行设计,只需单击开始按钮,该工具将自动提取页面上的所有 SVG 图像。然后轻松查看并选择要下载的所需 SVG 图像。
5.ColorZilla 颜色选择器
当您需要在 Chrome 浏览器下快速检查任何网页中使用的颜色或配色方案时,ColorZilla 颜色选择器非常方便。安装该工具后,将鼠标悬停在任何网页元素上以快速查看相关的 HEX 和 RGB 颜色值。必要时,只需单击并复制和粘贴相关颜色信息。
6.Fontface Ninja 字体提取工具
Fontface Ninja 是一款美观实用的字体提取工具。安装成功后,用户可以将鼠标悬停在相关页面文字上,查看对应的字体样式。
chrome插件网页抓取(爬取这些数据需要哪些工具?写代码都不用写)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-04-02 13:14
在做电商的时候,消费者对产品的评论很重要,但是如果他们不知道怎么写代码呢?这是一个无需编写任何代码即可进行简单数据爬取的 Chrome 插件。下面显示了一些捕获的数据:
可以看到,爬取的地址、评论者、评论内容、时间、商品颜色都已经被抓取。那么,抓取这些数据需要哪些工具呢?只有两个:
1. Chrome 浏览器;
2. 插件:网络爬虫
插件下载地址:/productivity/2018-05/942.html
最后,如果你想自己抢,这里是这个抢的详细过程:
1.首先复制下面的代码,是的,不需要写代码,但是要上手,还是需要复制代码,以后可以自己自定义选择,没有需要写代码。
{
"_id": "jdreview",
"startUrl": [
"https://item.jd.com/1000006803 ... ot%3B
],
"selectors": [
{
"id": "user",
"type": "SelectorText",
"selector": "div.user-info",
"parentSelectors": [
"main"
],
"multiple": false,
"regex": "",
"delay": 0
},
{
"id": "comments",
"type": "SelectorText",
"selector": "div.comment-column > p.comment-con",
"parentSelectors": [
"main"
],
"multiple": false,
"regex": "",
"delay": 0
},
{
"id": "time",
"type": "SelectorText",
"selector": "div.comment-message:nth-of-type(5) span:nth-of-type(4), div.order-info span:nth-of-type(4)",
"parentSelectors": [
"main"
],
"multiple": false,
"regex": "",
"delay": "0"
},
{
"id": "color",
"type": "SelectorText",
"selector": "div.order-info span:nth-of-type(1)",
"parentSelectors": [
"main"
],
"multiple": false,
"regex": "",
"delay": 0
},
{
"id": "main",
"type": "SelectorElementClick",
"selector": "div.comment-item",
"parentSelectors": [
"_root"
],
"multiple": true,
"delay": "10000",
"clickElementSelector": "div.com-table-footer a.ui-pager-next",
"clickType": "clickMore",
"discardInitialElements": false,
"clickElementUniquenessType": "uniqueHTMLText"
}
]
}
2. 然后打开chrome浏览器,在任意页面同时按下Ctrl+Shift+i,在弹窗中找到Web Scraper,如下:
3. 如下
4. 如图,粘贴上面的代码:
5. 如图,如果需要自定义URL,请更换。URL 后面的#comment 是评论的直接链接,不能删除:
6. 如图:
7. 如图:
8. 如图,点击抓取后,会自动打开需要抓取的页面,不要关闭窗口,等待完成。
9. 最后,点击下载到计算机并保存数据。
使用此工具的好处是:
1. 无需编程;
2.京东的评论基本可以用这个脚本,修改对应的url即可;
3.如果要抓取的评论少于1000条,这个工具会非常好用,所有数据都会自动下载;
使用注意事项:
1. 已经抓取过一次的数据会被记录下来,如果立即再次抓取则不会保存。建议关闭浏览器重新打开再试一次;
2.爬取次数:1000以内没有问题,可能是京东直接根据IP屏蔽了更多的爬取;
如果你的英文水平不错,可以尝试阅读官方文档进一步学习和定制自己的爬虫。
官方教程:webscraper.io/documentation
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。 查看全部
chrome插件网页抓取(爬取这些数据需要哪些工具?写代码都不用写)
在做电商的时候,消费者对产品的评论很重要,但是如果他们不知道怎么写代码呢?这是一个无需编写任何代码即可进行简单数据爬取的 Chrome 插件。下面显示了一些捕获的数据:
可以看到,爬取的地址、评论者、评论内容、时间、商品颜色都已经被抓取。那么,抓取这些数据需要哪些工具呢?只有两个:
1. Chrome 浏览器;
2. 插件:网络爬虫
插件下载地址:/productivity/2018-05/942.html
最后,如果你想自己抢,这里是这个抢的详细过程:
1.首先复制下面的代码,是的,不需要写代码,但是要上手,还是需要复制代码,以后可以自己自定义选择,没有需要写代码。
{
"_id": "jdreview",
"startUrl": [
"https://item.jd.com/1000006803 ... ot%3B
],
"selectors": [
{
"id": "user",
"type": "SelectorText",
"selector": "div.user-info",
"parentSelectors": [
"main"
],
"multiple": false,
"regex": "",
"delay": 0
},
{
"id": "comments",
"type": "SelectorText",
"selector": "div.comment-column > p.comment-con",
"parentSelectors": [
"main"
],
"multiple": false,
"regex": "",
"delay": 0
},
{
"id": "time",
"type": "SelectorText",
"selector": "div.comment-message:nth-of-type(5) span:nth-of-type(4), div.order-info span:nth-of-type(4)",
"parentSelectors": [
"main"
],
"multiple": false,
"regex": "",
"delay": "0"
},
{
"id": "color",
"type": "SelectorText",
"selector": "div.order-info span:nth-of-type(1)",
"parentSelectors": [
"main"
],
"multiple": false,
"regex": "",
"delay": 0
},
{
"id": "main",
"type": "SelectorElementClick",
"selector": "div.comment-item",
"parentSelectors": [
"_root"
],
"multiple": true,
"delay": "10000",
"clickElementSelector": "div.com-table-footer a.ui-pager-next",
"clickType": "clickMore",
"discardInitialElements": false,
"clickElementUniquenessType": "uniqueHTMLText"
}
]
}
2. 然后打开chrome浏览器,在任意页面同时按下Ctrl+Shift+i,在弹窗中找到Web Scraper,如下:
3. 如下
4. 如图,粘贴上面的代码:
5. 如图,如果需要自定义URL,请更换。URL 后面的#comment 是评论的直接链接,不能删除:
6. 如图:
7. 如图:
8. 如图,点击抓取后,会自动打开需要抓取的页面,不要关闭窗口,等待完成。
9. 最后,点击下载到计算机并保存数据。
使用此工具的好处是:
1. 无需编程;
2.京东的评论基本可以用这个脚本,修改对应的url即可;
3.如果要抓取的评论少于1000条,这个工具会非常好用,所有数据都会自动下载;
使用注意事项:
1. 已经抓取过一次的数据会被记录下来,如果立即再次抓取则不会保存。建议关闭浏览器重新打开再试一次;
2.爬取次数:1000以内没有问题,可能是京东直接根据IP屏蔽了更多的爬取;
如果你的英文水平不错,可以尝试阅读官方文档进一步学习和定制自己的爬虫。
官方教程:webscraper.io/documentation
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
chrome插件网页抓取( PageAnalytics可以从GoogleAnalytics中读取到你的网站数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-03-31 17:16
PageAnalytics可以从GoogleAnalytics中读取到你的网站数据)
Page Analytics 是 Chrome 浏览器上的一个插件。它可以从 Google Analytics 读取您的 网站 数据,并直接在网页上各处的链接上显示点击数据。根据这些数据,你可以很容易地判断 网站 的布局是否需要优化。
一、安装教学
安装地址:Chrome Store
打开后点击添加到Chrome(仅支持Chrome浏览器),完成插件安装。
安装完成后,可以在浏览器插件中看到Page Analytics的图标,默认是OFF(关闭),点击它会变成ON(打开),然后点击下方彩色图标,立即覆盖在网站上,通过色块,你可以第一时间知道整个网站是如何被用户点击的,哪些区域更受欢迎。
二、无法捕获数据
这个插件有时会捕捉不到GA数据,出现的错误信息如下——
大致解释一下如何做到这一点:
·本插件的原理是加载网站的GA数据。而且我们只能看到自己账号的GA数据,所以使用这个插件是看不到别人网站的数据的。
·请先确认您是否已登录GA账号。您可以先尝试登录GA官网。
·确认登录账号后,打开这个插件,几秒后,一般可以看到你的网站数据。
· 如果仍然看不到它,请关闭浏览器,重新开始,或刷新页面。
三、无法显示数据的地方
这个插件操作非常简单,界面也非常友好。哪个按钮以及链接上的点击次数可以让您轻松地根据数字做出决定。
但请不要相信所有的数据,因为你看到的数字(或数字)很可能不是肤浅的认识,也可能导致你做出判断性决定,反而阻碍了网站的网站。
请务必注意,某些链接或按钮不会看到数据,但这并不意味着访问者不会点击这些地方。
1、GA数据不计算外链点击量,比如网站的分享功能,所以插件无法展示。
2、标签链接可能不算数。GA后端的数据中会有标签数据,可能是插件问题。
3、各种按钮的点击都不会被统计或显示,因为它们根本不是 URL,对吧?
4、数据统计时间跨度过大。例如,它已经被计算了好几年。可能因为点击几乎为0而无法显示。不过这种情况比较少见。
四、如何判断一个链接的效果
有时一个页面上会有多个相同的链接。比如首页链接会出现在网站的顶部logo、导航栏、底部网页中,所以要谨慎对待此类链接的数据。
比如在一个网页上,三个相同的链接点击率是3%,那能算3%*3=9%的点击率吗?不,这 3% 仅由同一链接显示。
因此,遗憾的是,我们无法知道访问者更喜欢在同一个页面和多个相同的链接上点击哪个链接。
所以如果想知道同一个链接不同位置的效果,就必须和外链一样,在链接按钮处单独放上GA码。
概括
总的来说,这个插件还是挺方便的,它可以让我们很方便的知道某个区域内所有连接的点击率,并且根据点击率,可以增加热门链接的排序,降低排序不受欢迎的链接。,甚至直接去掉,换成更有效的链接。返回搜狐,查看更多 查看全部
chrome插件网页抓取(
PageAnalytics可以从GoogleAnalytics中读取到你的网站数据)
Page Analytics 是 Chrome 浏览器上的一个插件。它可以从 Google Analytics 读取您的 网站 数据,并直接在网页上各处的链接上显示点击数据。根据这些数据,你可以很容易地判断 网站 的布局是否需要优化。
一、安装教学
安装地址:Chrome Store
打开后点击添加到Chrome(仅支持Chrome浏览器),完成插件安装。
安装完成后,可以在浏览器插件中看到Page Analytics的图标,默认是OFF(关闭),点击它会变成ON(打开),然后点击下方彩色图标,立即覆盖在网站上,通过色块,你可以第一时间知道整个网站是如何被用户点击的,哪些区域更受欢迎。
二、无法捕获数据
这个插件有时会捕捉不到GA数据,出现的错误信息如下——
大致解释一下如何做到这一点:
·本插件的原理是加载网站的GA数据。而且我们只能看到自己账号的GA数据,所以使用这个插件是看不到别人网站的数据的。
·请先确认您是否已登录GA账号。您可以先尝试登录GA官网。
·确认登录账号后,打开这个插件,几秒后,一般可以看到你的网站数据。
· 如果仍然看不到它,请关闭浏览器,重新开始,或刷新页面。
三、无法显示数据的地方
这个插件操作非常简单,界面也非常友好。哪个按钮以及链接上的点击次数可以让您轻松地根据数字做出决定。
但请不要相信所有的数据,因为你看到的数字(或数字)很可能不是肤浅的认识,也可能导致你做出判断性决定,反而阻碍了网站的网站。
请务必注意,某些链接或按钮不会看到数据,但这并不意味着访问者不会点击这些地方。
1、GA数据不计算外链点击量,比如网站的分享功能,所以插件无法展示。
2、标签链接可能不算数。GA后端的数据中会有标签数据,可能是插件问题。
3、各种按钮的点击都不会被统计或显示,因为它们根本不是 URL,对吧?
4、数据统计时间跨度过大。例如,它已经被计算了好几年。可能因为点击几乎为0而无法显示。不过这种情况比较少见。
四、如何判断一个链接的效果
有时一个页面上会有多个相同的链接。比如首页链接会出现在网站的顶部logo、导航栏、底部网页中,所以要谨慎对待此类链接的数据。
比如在一个网页上,三个相同的链接点击率是3%,那能算3%*3=9%的点击率吗?不,这 3% 仅由同一链接显示。
因此,遗憾的是,我们无法知道访问者更喜欢在同一个页面和多个相同的链接上点击哪个链接。
所以如果想知道同一个链接不同位置的效果,就必须和外链一样,在链接按钮处单独放上GA码。
概括
总的来说,这个插件还是挺方便的,它可以让我们很方便的知道某个区域内所有连接的点击率,并且根据点击率,可以增加热门链接的排序,降低排序不受欢迎的链接。,甚至直接去掉,换成更有效的链接。返回搜狐,查看更多
chrome插件网页抓取( WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-31 14:06
WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
我要分享的工具是一个Chrome插件,叫做:Web Scraper,这是一个Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以把它当作一个爬虫工具来使用。
也是因为最近在梳理36氪文章的一些标签,打算看看还有什么其他风险投资相关的标准网站可以参考,所以找到了一家叫:“细牛数据”网站,它提供的一套“行业系统”标签,很有参考价值。意思是我们要抓取页面上的数据,集成到我们自己的标签库中,如下图红色部分:
如果是规则显示的数据,也可以用鼠标选中,然后复制粘贴,不过还是需要想一些办法嵌入到页面中。这时候才想起之前安装了Web Scraper,于是就试了一下。让大家安心~
Web Scraper 是一个 Chrome 插件,一年前在三门课程的公开课上看到过。号称是不知道编程就可以实现爬虫爬取的黑科技。不过好像找不到三门课程的官网。你可以百度:《爬虫三课》还是可以找到的。名字叫《人人都能学的数据爬虫课程》,但好像要交100块钱。我觉得这个东西可以看网上的文章,比如我的文章~
简单来说,Web Scraper 是一个基于 Chrome 的网页元素解析器,可以通过视觉点击操作从自定义区域中提取数据/元素。同时还提供定时自动提取功能,可以作为一套简单的爬虫工具使用。
这里顺便解释一下网页提取器爬虫和真实写代码爬虫的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它首先让您定义要在页面上抓取的元素。,以及抓取哪些页面,然后让机器替人操作;而如果你用Python写爬虫,你更有可能使用网页请求命令下载整个网页,然后用代码解析HTML页面元素,提取出你想要的内容,一遍遍重复再次。相比之下,使用代码会更灵活,但解析的成本会更高。如果是简单的页面内容提取,我也推荐使用Web Scraper。
关于Web Scraper的具体安装过程和完整功能的使用,今天的文章我就不展开了。第一个是我只使用我需要的部分,第二个是因为市面上有很多关于Web Scraper的教程,大家可以自行查找。
这里只是一个实际的过程,给大家简单介绍一下我是如何使用它的。
第一步是创建站点地图
打开Chrome浏览器,按F12调出开发者工具,Web Scraper在最后一个标签,点击它,然后选择“创建站点地图”菜单,点击“创建站点地图”选项。
首先输入你要爬取的网站网址,以及你自定义的爬取任务的名称。比如我取的名字是:xiniulevel,网址是:
第二步,创建抓取节点
我要抓取的是一级标签和二级标签,所以先点击我刚刚创建的Sitemap,然后点击“添加新选择器”进入抓取节点选择器配置页面,点击“选择”按钮在页面上,你会看到一个浮动层出现
此时,当您将鼠标移入网页时,它会自动将您鼠标悬停的位置以绿色突出显示。这时候你可以先点击一个你想选中的区块,你会发现这个区块变成了红色。如果要选中同级的所有块,可以继续点击下一个相邻的块,工具会默认选中同级的所有块,如下图:
我们会发现下方悬浮窗的文本输入框自动填充了block的XPATH路径,然后点击“完成选择!” 结束选择,浮动框消失,选中的 XPATH 自动填充到下方的 Selector 行中。还要确保选中“多个”以声明您要选择多个块。最后,单击保存选择器按钮结束。
第三步获取元素值
完成Selector的创建后,回到上一页,会发现多了一行Selector表格,然后可以直接点击Action中的Data preview,查看所有想要获取的元素值。
上图所示的部分是我添加了两个选择器的情况,一个一级标签,一个二级标签。点击数据预览弹窗内容其实就是我想要的,直接复制到EXCEL即可,不需要太复杂。自动爬取处理。
以上就是对Web Scraper使用过程的简单介绍。当然,我的使用并不是完全高效,因为每次想要获取二级标签,都得手动切换一级标签,然后执行抓取命令。应该有更好的方法,但对我来说已经足够了。这个文章主要是跟大家普及一下这个工具,不是教程,更多功能还需要根据自己的需要去探索~
怎么样,对你有帮助吗?期待与我分享你的讯息~ 查看全部
chrome插件网页抓取(
WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
我要分享的工具是一个Chrome插件,叫做:Web Scraper,这是一个Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以把它当作一个爬虫工具来使用。
也是因为最近在梳理36氪文章的一些标签,打算看看还有什么其他风险投资相关的标准网站可以参考,所以找到了一家叫:“细牛数据”网站,它提供的一套“行业系统”标签,很有参考价值。意思是我们要抓取页面上的数据,集成到我们自己的标签库中,如下图红色部分:
如果是规则显示的数据,也可以用鼠标选中,然后复制粘贴,不过还是需要想一些办法嵌入到页面中。这时候才想起之前安装了Web Scraper,于是就试了一下。让大家安心~
Web Scraper 是一个 Chrome 插件,一年前在三门课程的公开课上看到过。号称是不知道编程就可以实现爬虫爬取的黑科技。不过好像找不到三门课程的官网。你可以百度:《爬虫三课》还是可以找到的。名字叫《人人都能学的数据爬虫课程》,但好像要交100块钱。我觉得这个东西可以看网上的文章,比如我的文章~
简单来说,Web Scraper 是一个基于 Chrome 的网页元素解析器,可以通过视觉点击操作从自定义区域中提取数据/元素。同时还提供定时自动提取功能,可以作为一套简单的爬虫工具使用。
这里顺便解释一下网页提取器爬虫和真实写代码爬虫的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它首先让您定义要在页面上抓取的元素。,以及抓取哪些页面,然后让机器替人操作;而如果你用Python写爬虫,你更有可能使用网页请求命令下载整个网页,然后用代码解析HTML页面元素,提取出你想要的内容,一遍遍重复再次。相比之下,使用代码会更灵活,但解析的成本会更高。如果是简单的页面内容提取,我也推荐使用Web Scraper。
关于Web Scraper的具体安装过程和完整功能的使用,今天的文章我就不展开了。第一个是我只使用我需要的部分,第二个是因为市面上有很多关于Web Scraper的教程,大家可以自行查找。
这里只是一个实际的过程,给大家简单介绍一下我是如何使用它的。
第一步是创建站点地图
打开Chrome浏览器,按F12调出开发者工具,Web Scraper在最后一个标签,点击它,然后选择“创建站点地图”菜单,点击“创建站点地图”选项。
首先输入你要爬取的网站网址,以及你自定义的爬取任务的名称。比如我取的名字是:xiniulevel,网址是:
第二步,创建抓取节点
我要抓取的是一级标签和二级标签,所以先点击我刚刚创建的Sitemap,然后点击“添加新选择器”进入抓取节点选择器配置页面,点击“选择”按钮在页面上,你会看到一个浮动层出现
此时,当您将鼠标移入网页时,它会自动将您鼠标悬停的位置以绿色突出显示。这时候你可以先点击一个你想选中的区块,你会发现这个区块变成了红色。如果要选中同级的所有块,可以继续点击下一个相邻的块,工具会默认选中同级的所有块,如下图:
我们会发现下方悬浮窗的文本输入框自动填充了block的XPATH路径,然后点击“完成选择!” 结束选择,浮动框消失,选中的 XPATH 自动填充到下方的 Selector 行中。还要确保选中“多个”以声明您要选择多个块。最后,单击保存选择器按钮结束。
第三步获取元素值
完成Selector的创建后,回到上一页,会发现多了一行Selector表格,然后可以直接点击Action中的Data preview,查看所有想要获取的元素值。
上图所示的部分是我添加了两个选择器的情况,一个一级标签,一个二级标签。点击数据预览弹窗内容其实就是我想要的,直接复制到EXCEL即可,不需要太复杂。自动爬取处理。
以上就是对Web Scraper使用过程的简单介绍。当然,我的使用并不是完全高效,因为每次想要获取二级标签,都得手动切换一级标签,然后执行抓取命令。应该有更好的方法,但对我来说已经足够了。这个文章主要是跟大家普及一下这个工具,不是教程,更多功能还需要根据自己的需要去探索~
怎么样,对你有帮助吗?期待与我分享你的讯息~
chrome插件网页抓取(chrome插件网页抓取工具-postman(图)+django模板)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-03-31 06:02
chrome插件网页抓取工具-postman我个人觉得用起来非常方便,这个插件让你可以采集任何网页。百度搜索:南京postman,即可找到很多。
;keyword=%e4%bb%8a%e5%ba%86&rug=expand&ror=newrp&ftpl=signal5安卓版
postman比较常用,此外还有javascript的get请求以及postman提供的formget请求,都比较常用。希望有帮助。
,目前我在做的就是
scrapy+django模板。
1.taobao2.3.京东4.乐视5.拼多多6.携程7.高德8.百度地图想多了
和京东都用过,中信银行信用卡都是用cloudfront爬的,
postman+cloudfront
第一个是国内做的比较好的ui比较精美,快捷键也挺实用的。有个是不完全免费的,可以试试,不行就换个postman用。ps.那个语言是php的。slogan:与全世界同步程序打开市场:老板,
前面,拿去。
yahooanalytics用过,谷歌统计用过,都比postman强大,特别是谷歌统计,
好吧,我才不告诉你是excel表里的test1。
腾讯地图抓取
第一名的说的都有道理,现在我来说个wordpress插件-payloador的作者的——/net/chrome-grid-graph.html提供了一个wordpress中所有页面,图片和链接的抓取。而且,貌似还包括了数据库的获取,移动应用的抓取等等。
内容来源于谷歌,手机无法上图-grid-graphs/wordpress-plugins/这个gif其实是我亲自抓的图。可以看到,每一个页面都有配有对应的tag和顺序的。由于最近要抓数据库的数据,貌似还要自己造轮子。不过,貌似真的有google能解决的问题么?。 查看全部
chrome插件网页抓取(chrome插件网页抓取工具-postman(图)+django模板)
chrome插件网页抓取工具-postman我个人觉得用起来非常方便,这个插件让你可以采集任何网页。百度搜索:南京postman,即可找到很多。
;keyword=%e4%bb%8a%e5%ba%86&rug=expand&ror=newrp&ftpl=signal5安卓版
postman比较常用,此外还有javascript的get请求以及postman提供的formget请求,都比较常用。希望有帮助。
,目前我在做的就是
scrapy+django模板。
1.taobao2.3.京东4.乐视5.拼多多6.携程7.高德8.百度地图想多了
和京东都用过,中信银行信用卡都是用cloudfront爬的,
postman+cloudfront
第一个是国内做的比较好的ui比较精美,快捷键也挺实用的。有个是不完全免费的,可以试试,不行就换个postman用。ps.那个语言是php的。slogan:与全世界同步程序打开市场:老板,
前面,拿去。
yahooanalytics用过,谷歌统计用过,都比postman强大,特别是谷歌统计,
好吧,我才不告诉你是excel表里的test1。
腾讯地图抓取
第一名的说的都有道理,现在我来说个wordpress插件-payloador的作者的——/net/chrome-grid-graph.html提供了一个wordpress中所有页面,图片和链接的抓取。而且,貌似还包括了数据库的获取,移动应用的抓取等等。
内容来源于谷歌,手机无法上图-grid-graphs/wordpress-plugins/这个gif其实是我亲自抓的图。可以看到,每一个页面都有配有对应的tag和顺序的。由于最近要抓数据库的数据,貌似还要自己造轮子。不过,貌似真的有google能解决的问题么?。
chrome插件网页抓取(谷歌浏览器插件如何快速识别获取一切网页中的文字字体 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-03-30 03:11
)
字体识别chrome插件(网页字体识别软件)是谷歌最新的浏览器插件,可以帮助用户查看和识别网页字体。如何快速识别和获取所有网页中的文字字体,来绿色先锋下载字体识别chrome插件。在日常工作中,当我们浏览一个非常漂亮的网站页面时,经常会遇到各种个性化的字体。我们可能知道这是什么字体?对于做设计的朋友来说,经常会看到网站使用的一些非常漂亮的字体,但是需要查看源码等繁琐的手段才能知道是什么字体。这很麻烦。字体识别插件网页字体查看目前支持Chrome浏览器和Safari浏览器。在chrome中安装字体识别插件后,用户可以通过字体识别插件选择当前网页中的字体进行查看。字体识别插件 会给出当前网页字体的详细信息。如果你是一个网页的前端开发者,使用这个插件可以帮助用户更快的理解网页中的字体,从而将这些字体组合起来,创造出漂亮的网站。是不是很方便?
功能说明
1.字体识别插件安装成功后,我们查看插件是否开启。
2.如果启用,我们可以在浏览器右上角看到插件标记;
3.将鼠标放在那些个性化的字体上,字体识别插件会提示字体名称
4.用户还可以查看字体的详细信息,包括字体大小、所有字体的样式等。
5.字体识别插件不仅可以识别网页中图片上的字体,还可以识别PDF中文档中的字体
6. 就算是我们很少见到的字体,说不定也能找到名字!
查看全部
chrome插件网页抓取(谷歌浏览器插件如何快速识别获取一切网页中的文字字体
)
字体识别chrome插件(网页字体识别软件)是谷歌最新的浏览器插件,可以帮助用户查看和识别网页字体。如何快速识别和获取所有网页中的文字字体,来绿色先锋下载字体识别chrome插件。在日常工作中,当我们浏览一个非常漂亮的网站页面时,经常会遇到各种个性化的字体。我们可能知道这是什么字体?对于做设计的朋友来说,经常会看到网站使用的一些非常漂亮的字体,但是需要查看源码等繁琐的手段才能知道是什么字体。这很麻烦。字体识别插件网页字体查看目前支持Chrome浏览器和Safari浏览器。在chrome中安装字体识别插件后,用户可以通过字体识别插件选择当前网页中的字体进行查看。字体识别插件 会给出当前网页字体的详细信息。如果你是一个网页的前端开发者,使用这个插件可以帮助用户更快的理解网页中的字体,从而将这些字体组合起来,创造出漂亮的网站。是不是很方便?
功能说明
1.字体识别插件安装成功后,我们查看插件是否开启。
2.如果启用,我们可以在浏览器右上角看到插件标记;
3.将鼠标放在那些个性化的字体上,字体识别插件会提示字体名称
4.用户还可以查看字体的详细信息,包括字体大小、所有字体的样式等。
5.字体识别插件不仅可以识别网页中图片上的字体,还可以识别PDF中文档中的字体
6. 就算是我们很少见到的字体,说不定也能找到名字!
chrome插件网页抓取(Chrome网上应用店如何安装可分为两种查找方式(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-30 03:10
编者按:现在很多人使用谷歌Chrome浏览器,这是世界上最快的浏览器,设计简洁高效。Chrome除了能够完成网页浏览之外,还是一个“全能播放器”。当然,它的扩展功能主要来自于它的插件部分,从而延伸到生活娱乐的方方面面。从 Google Chrome 网上应用店,用户可以下载和安装应用程序、扩展程序和主题。那么,如何安装 Chrome 插件就是我们将在本文中向您介绍的主题。
在开始本教程之前,我们首先需要安装 Chrome 浏览器,点击这里下载最新版本的 Chrome 浏览器。安装完成后,我们的插件之旅就开始了。
Chrome App Store 设计简单,易于操作
前往 Chrome 网上应用店
安装插件,我们需要进入Chrome网上应用店下载,可以在首页的Apps标签下访问。Chrome Web Store 的设计非常简约,左侧是分类导航栏,右侧是内容展示区。内容展示区采用图片展示方式,大量图片展示将真实页面渲染得非常漂亮。并且内容展示区采用最新瀑布流形式,滚动鼠标无需翻页即可浏览更多内容。
将鼠标悬停在插件图标上时,会显示插件名称、推荐星级、插件描述和下载按钮。此外,Chrome网上应用店还具有分享功能,可以通过Google+和Gmail与朋友分享。
Chrome 网上应用店的分类非常详细
点击进入插件详情页面,可以查看插件的概述、详情、评论及相关信息,让用户更好地了解产品。
实用Chrome插件安装
之前,我们已经介绍了 Chrome Web Store 的页面设计。下面以下载“谷歌日历”应用为例,详细讲解如何安装Chrome插件。Chrome插件安装可以分为两种搜索方式:搜索搜索和分类搜索。
搜索安装,适合精准搜索,为已知Chrome插件提供极速安装体验。
Chrome网上应用店提供了搜索功能,方便用户快速找到自己想要的插件。在地址栏搜索谷歌日历,点击添加,等待下载完成后即可使用。整个安装过程非常方便,即使是新手也能轻松搞定。
分类安装,从用户应用角度,批量查询相关插件,满足用户模糊搜索的安装方式。
从 Chrome 网上应用店下载应用程序
在 Chrome 网上应用店中,用户还可以按类别查找插件。Chrome网上应用店有非常详细的分类,用户可以在不同的分类中快速找到自己需要的应用。
在数以万计的 Chrome 插件中找到一个合适的插件并不容易。以上两种方法可以很好的解决Chrome插件安装中遇到的问题。
编辑评论:
Chrome网上应用店中的一些插件需要用户登录自己的谷歌账号才能使用,而注册谷歌账号也可以获得浏览器同步功能,所以我们强烈建议用户注册谷歌账号以获得更好的服务。本次Chrome网上应用店的功能和Chrome插件安装就为读者介绍到此为止。请关注中关村在线软件频道《谷歌Chrome浏览器十大最有用插件推荐》一文,获取使用Chrome必备插件。 查看全部
chrome插件网页抓取(Chrome网上应用店如何安装可分为两种查找方式(组图))
编者按:现在很多人使用谷歌Chrome浏览器,这是世界上最快的浏览器,设计简洁高效。Chrome除了能够完成网页浏览之外,还是一个“全能播放器”。当然,它的扩展功能主要来自于它的插件部分,从而延伸到生活娱乐的方方面面。从 Google Chrome 网上应用店,用户可以下载和安装应用程序、扩展程序和主题。那么,如何安装 Chrome 插件就是我们将在本文中向您介绍的主题。
在开始本教程之前,我们首先需要安装 Chrome 浏览器,点击这里下载最新版本的 Chrome 浏览器。安装完成后,我们的插件之旅就开始了。
Chrome App Store 设计简单,易于操作
前往 Chrome 网上应用店
安装插件,我们需要进入Chrome网上应用店下载,可以在首页的Apps标签下访问。Chrome Web Store 的设计非常简约,左侧是分类导航栏,右侧是内容展示区。内容展示区采用图片展示方式,大量图片展示将真实页面渲染得非常漂亮。并且内容展示区采用最新瀑布流形式,滚动鼠标无需翻页即可浏览更多内容。
将鼠标悬停在插件图标上时,会显示插件名称、推荐星级、插件描述和下载按钮。此外,Chrome网上应用店还具有分享功能,可以通过Google+和Gmail与朋友分享。
Chrome 网上应用店的分类非常详细
点击进入插件详情页面,可以查看插件的概述、详情、评论及相关信息,让用户更好地了解产品。
实用Chrome插件安装
之前,我们已经介绍了 Chrome Web Store 的页面设计。下面以下载“谷歌日历”应用为例,详细讲解如何安装Chrome插件。Chrome插件安装可以分为两种搜索方式:搜索搜索和分类搜索。
搜索安装,适合精准搜索,为已知Chrome插件提供极速安装体验。
Chrome网上应用店提供了搜索功能,方便用户快速找到自己想要的插件。在地址栏搜索谷歌日历,点击添加,等待下载完成后即可使用。整个安装过程非常方便,即使是新手也能轻松搞定。
分类安装,从用户应用角度,批量查询相关插件,满足用户模糊搜索的安装方式。
从 Chrome 网上应用店下载应用程序
在 Chrome 网上应用店中,用户还可以按类别查找插件。Chrome网上应用店有非常详细的分类,用户可以在不同的分类中快速找到自己需要的应用。
在数以万计的 Chrome 插件中找到一个合适的插件并不容易。以上两种方法可以很好的解决Chrome插件安装中遇到的问题。
编辑评论:
Chrome网上应用店中的一些插件需要用户登录自己的谷歌账号才能使用,而注册谷歌账号也可以获得浏览器同步功能,所以我们强烈建议用户注册谷歌账号以获得更好的服务。本次Chrome网上应用店的功能和Chrome插件安装就为读者介绍到此为止。请关注中关村在线软件频道《谷歌Chrome浏览器十大最有用插件推荐》一文,获取使用Chrome必备插件。
chrome插件网页抓取(我想把我在GitHub上寻找项目灵感,Githunt这个插件可能就很适合你)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-03-29 23:06
作为前端开发人员,毫无疑问,Google Chrome 是我们 Web 开发过程中使用最多的浏览器。除了易于使用和支持各种最新的 Web 开发标准外,Chrome 背后还有海量的应用扩展,让我们的日常编程不再是一件苦差事。
虽然有朋友说Chrome自带的开发者工具就够用了,不需要任何额外的插件,但是从我个人的工作经验感受效率的提升,所以想分享一下我正在使用的插件使用中,希望能够给有需要的同学一些帮助。
吉图恩特
吉图恩特
如果你经常花时间在 GitHub 上寻找项目灵感,Githunt 可能是适合你的插件。启用后,它将在浏览器的新标签页上显示您选择关注的项目列表。
您可以自定义搜索不同语言的项目,查看项目摘要和项目当前issues,点击项目链接跳转到项目的Github查看。因为这个插件 收录 几乎都是热门项目,你将能够节省大量时间来做更高效的事情(例如发现错误和修复错误)。
Githunt 页面 ColorZilla
ColorZilla
在正式登陆 Chrome 浏览器之前,ColorZillia 作为 FireFox 上最有名的取色工具,已经在前端人士中广为人知。它可以快速识别网页任何角落的任何颜色,甚至可以抓取1px大小边框上的颜色,并允许用户轻松将删除的颜色复制到其他程序中使用。
ColorZilla 使用场景 CSSViewer
浏览器
CSS Viewer 是另一个简单实用的前端开发工具。顾名思义,每当您将鼠标悬停在任何地方时,此插件都会自动弹出一个小弹出窗口,显示构成您当前鼠标指向的元素的 CSS 参数。
CSSViewer 使用场景字体忍者
字体忍者
Font Ninja 非常适合喜欢采集各种优秀 Web 示例并尝试学习的 Web 开发人员。其内置的专利算法快速高效,可在几秒钟内识别页面上的单个字体。它还可以识别字体大小、粗细和颜色等信息,所有这些信息都显示在一个小弹出窗口中。
字体忍者使用场景查看我的链接
检查我的链接
顾名思义,这是一个专门用于检查坏链接和死链接的工具。除此之外,它还可以检查页面上的有效链接和重定向链接。这个插件不仅对 web 开发者很有帮助,对做 网站 SEO 优化业务的人也很有帮助。
检查我的链接使用场景维度
方面
当您想要测量间隙、页面元素之间的尺寸或您在页面上看到的任何对象之间的距离时,这是一个非常有用的插件。
安装后,您会在工具栏上看到一个小十字准线图标。在浏览器中打开一个新页面,选择该图标,您将看到一个十字准线出现在屏幕上。在要测量的页面元素之间拖动它,您会看到具体的值,简单而优雅。
维度使用场景UX检查
用户体验检查
这是一个可用性分析插件,它利用内置的用户体验指标算法来评估页面的可用性级别。它可以快速查明网页上潜在的可用性问题,并允许用户注释、截屏并导出它们以与其他团队成员协作。
对于不需要太多细节的轻量级用户体验测试,UX Check 可以为团队节省大量时间和资源。
UX 检查使用场景 BuiltWith Technology Profiler
内置技术分析器
这是一个很好的小工具,可以识别绝大多数 网站 背后的技术堆栈。例如 Web 服务提供商、使用的 cms 平台、网站 分析工具、插件、JavaScript 库等。
安装插件后,只需在页面上单击它,就会出现一个弹出窗口,显示该页面上运行的可识别技术。
Web开发人员
Web开发人员
这是一组收录多种功能的插件。虽然名字叫“Web Developer”,但我觉得这个工具也适合其他开发者,因为它收录了很多有用的工具供开发者调用。
安装后,可以通过单击工具栏上的小齿轮图标来访问 Web Developer。插件启动后,您应该会看到一个小的下拉框,其中收录一系列选项卡组织成选项卡。选择一个选项卡以访问其中的工具。这里有很多事情要做,但每个工具都非常有用。
EditThisCookie
编辑此 Cookie
您可以使用此插件编辑、删除、创建和保存每个页面的 cookie 文件,它还支持导出 cookie 进行分析、阻止、添加到 JSON 文件等。基本上你可以用这个插件对网络 cookie 做任何你想做的事情。
JSON 查看器
JSON 查看器
JSON Viewer 将 JSON 数据管理到浏览器窗口中可快速识别的分层视图中。当然,作为技术人员,手动处理 JSON 文件应该是必备技能,但是使用这个插件可以相应地提高你的效率和体验。
会话好友
会话好友
严格来说,这不是开发人员的工具。它更像是传统意义上的文件集合,可以保存特定页面以供以后访问。例如,当您发现一篇有趣的 文章 文章但现在没有时间阅读它时,或者当您在浏览器上打开太多选项卡时,它会派上用场。
以上是我在日常工作中发现的有用插件。如果您发现文中未提及的有用插件,请留言!如果你觉得这个文章对你有帮助,请点赞订阅!
(部分资料和图片来自网络) 查看全部
chrome插件网页抓取(我想把我在GitHub上寻找项目灵感,Githunt这个插件可能就很适合你)
作为前端开发人员,毫无疑问,Google Chrome 是我们 Web 开发过程中使用最多的浏览器。除了易于使用和支持各种最新的 Web 开发标准外,Chrome 背后还有海量的应用扩展,让我们的日常编程不再是一件苦差事。
虽然有朋友说Chrome自带的开发者工具就够用了,不需要任何额外的插件,但是从我个人的工作经验感受效率的提升,所以想分享一下我正在使用的插件使用中,希望能够给有需要的同学一些帮助。
吉图恩特
吉图恩特
如果你经常花时间在 GitHub 上寻找项目灵感,Githunt 可能是适合你的插件。启用后,它将在浏览器的新标签页上显示您选择关注的项目列表。
您可以自定义搜索不同语言的项目,查看项目摘要和项目当前issues,点击项目链接跳转到项目的Github查看。因为这个插件 收录 几乎都是热门项目,你将能够节省大量时间来做更高效的事情(例如发现错误和修复错误)。
Githunt 页面 ColorZilla
ColorZilla
在正式登陆 Chrome 浏览器之前,ColorZillia 作为 FireFox 上最有名的取色工具,已经在前端人士中广为人知。它可以快速识别网页任何角落的任何颜色,甚至可以抓取1px大小边框上的颜色,并允许用户轻松将删除的颜色复制到其他程序中使用。
ColorZilla 使用场景 CSSViewer
浏览器
CSS Viewer 是另一个简单实用的前端开发工具。顾名思义,每当您将鼠标悬停在任何地方时,此插件都会自动弹出一个小弹出窗口,显示构成您当前鼠标指向的元素的 CSS 参数。
CSSViewer 使用场景字体忍者
字体忍者
Font Ninja 非常适合喜欢采集各种优秀 Web 示例并尝试学习的 Web 开发人员。其内置的专利算法快速高效,可在几秒钟内识别页面上的单个字体。它还可以识别字体大小、粗细和颜色等信息,所有这些信息都显示在一个小弹出窗口中。
字体忍者使用场景查看我的链接
检查我的链接
顾名思义,这是一个专门用于检查坏链接和死链接的工具。除此之外,它还可以检查页面上的有效链接和重定向链接。这个插件不仅对 web 开发者很有帮助,对做 网站 SEO 优化业务的人也很有帮助。
检查我的链接使用场景维度
方面
当您想要测量间隙、页面元素之间的尺寸或您在页面上看到的任何对象之间的距离时,这是一个非常有用的插件。
安装后,您会在工具栏上看到一个小十字准线图标。在浏览器中打开一个新页面,选择该图标,您将看到一个十字准线出现在屏幕上。在要测量的页面元素之间拖动它,您会看到具体的值,简单而优雅。
维度使用场景UX检查
用户体验检查
这是一个可用性分析插件,它利用内置的用户体验指标算法来评估页面的可用性级别。它可以快速查明网页上潜在的可用性问题,并允许用户注释、截屏并导出它们以与其他团队成员协作。
对于不需要太多细节的轻量级用户体验测试,UX Check 可以为团队节省大量时间和资源。
UX 检查使用场景 BuiltWith Technology Profiler
内置技术分析器
这是一个很好的小工具,可以识别绝大多数 网站 背后的技术堆栈。例如 Web 服务提供商、使用的 cms 平台、网站 分析工具、插件、JavaScript 库等。
安装插件后,只需在页面上单击它,就会出现一个弹出窗口,显示该页面上运行的可识别技术。
Web开发人员
Web开发人员
这是一组收录多种功能的插件。虽然名字叫“Web Developer”,但我觉得这个工具也适合其他开发者,因为它收录了很多有用的工具供开发者调用。
安装后,可以通过单击工具栏上的小齿轮图标来访问 Web Developer。插件启动后,您应该会看到一个小的下拉框,其中收录一系列选项卡组织成选项卡。选择一个选项卡以访问其中的工具。这里有很多事情要做,但每个工具都非常有用。
EditThisCookie
编辑此 Cookie
您可以使用此插件编辑、删除、创建和保存每个页面的 cookie 文件,它还支持导出 cookie 进行分析、阻止、添加到 JSON 文件等。基本上你可以用这个插件对网络 cookie 做任何你想做的事情。
JSON 查看器
JSON 查看器
JSON Viewer 将 JSON 数据管理到浏览器窗口中可快速识别的分层视图中。当然,作为技术人员,手动处理 JSON 文件应该是必备技能,但是使用这个插件可以相应地提高你的效率和体验。
会话好友
会话好友
严格来说,这不是开发人员的工具。它更像是传统意义上的文件集合,可以保存特定页面以供以后访问。例如,当您发现一篇有趣的 文章 文章但现在没有时间阅读它时,或者当您在浏览器上打开太多选项卡时,它会派上用场。
以上是我在日常工作中发现的有用插件。如果您发现文中未提及的有用插件,请留言!如果你觉得这个文章对你有帮助,请点赞订阅!
(部分资料和图片来自网络)
chrome插件网页抓取(WebScraper插件安装使用方法及安装流程:安装方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 1122 次浏览 • 2022-03-29 18:11
Web Scraper 是一个 chrome 网页数据提取插件,用于从网页中提取数据。用户只需四步即可使用该插件创建页面数据抽取规则,从而快速从网页中抽取出需要的内容。Web Scraper 插件的整个爬取逻辑从设置第一级 Selector 开始,选择爬取范围。在一级Selector下设置二级Selector后,再次选择抓取字段,即可抓取网页数据。插件采集数据后,还可以将数据导出为CSV文件,欢迎免费下载。
插件安装和使用
一、安装
1、这里编辑器使用的是chrome浏览器,先在标签页输入[chrome://extensions/]进入chrome扩展,解压你在这个页面下载的Web Scraper插件,拖入扩展页面就是这样。
2、安装完成后,请尝试插件的具体功能。
3、当然可以先在设置页面设置插件的存储设置和存储类型功能。
二、使用抓取功能
安装完成后,只需四步即可完成爬取操作。具体流程如下:
1、打开网络爬虫
首先,要使用该插件提取网页数据,需要在开发者工具模式下使用。使用快捷键Ctrl+Shift+I/F12后,在出现的开发者工具窗口中找到插件同名的列。
2、创建一个新的站点地图
点击Create New Sitemap,有两个选项,import sitemap是导入现成sitemap的向导,我们一般没有现成的sitemap,所以一般不选这个,直接选create sitemap。
然后做这两个操作:
(1)Sitemap Name:表示你的Sitemap适合哪个网页,所以可以根据网页来命名,但是需要用英文字母。比如我抓取今日头条的数据,那么我会用头条来命名;
(2)Sitemap URL:将网页链接复制到Star URL栏。比如图中我把“吴晓波频道”的首页链接复制到了这个栏,然后点击下面的创建sitemap进行创建一个新的站点地图。
3、设置此站点地图
整个Web Scraper的抓取逻辑如下:设置一级Selector,选择抓取范围;在一级Selector下设置二级Selector,选择抓取字段,然后抓取。
对于文章来说,一级Selector意味着你要圈出这块文章的元素。这个元素可能包括标题、作者、发布时间、评论数等。从关卡Selector中选择我们想要的元素,比如标题、作者、阅读次数。
让我们分解一下设置一级和二级 Selector 的工作流程:
(1)单击添加新选择器以创建第一级选择器。
然后按照以下步骤操作:
- 输入id:id代表你抓取的整个范围,例如这里是文章,我们可以命名为wuxiaobo-articles;
-Select Type:type代表你抓取的部分的类型,比如element/text/link,因为这是整个文章元素范围的选择,我们需要先用Element全选(如果这个网页需要滑动加载More,然后选择Element Scroll Down);
-勾选Multiple:勾选Multiple前面的小框,因为要选择多个元素而不是单个元素,当我们勾选时,爬虫插件会帮我们识别多个相似的文章;
- 保留设置:其余未提及的部分保留其默认设置。
(2)单击选择以选择范围并按照以下步骤操作:
- 选择范围:用鼠标选择要抓取数据的范围,绿色为要选择的区域,用鼠标点击后变为红色,该区域被选中;
- 多选:不要只选一个,还要选以下几项,否则只会爬出一行数据;
-完成选择:记得点击完成选择;
- 保存:单击保存选择器。
(3)设置好一级Selector后,点击设置二级Selector,按以下步骤操作:
- 新选择器:点击添加新选择器;
- 输入id:id代表你在抓取哪个字段,所以可以取字段的英文。比如我要选择“作者”,就写“作者”;
-Select Type:选择Text,因为你要抓取的是文本;
- 不要勾选Multiple:不要勾选Multiple前面的小方框,因为我们这里抓取的是单个元素;
- 保留设置:其余未提及的部分保留其默认设置。
(4)点击选择,然后点击要爬取的字段,按照以下步骤操作:
- 选择字段:这里要爬取的字段是一个。用鼠标单击该字段以将其选中。比如你想爬取标题,用鼠标点击某个文章的标题。当字段所在区域变为红色时,即被选中;
-完成选择:记得点击完成选择;
- 保存:单击保存选择器。
(5)重复以上操作,直到选择好要爬的田地。
4、爬取数据
(1)之后,如果要爬取数据,只需要设置所有的Selector启动即可:
点击Scrape,然后点击Start Scraping,爬虫会在弹出一个小窗口后开始工作。你会得到一个收录所有你想要的数据的列表。
(2)如果你想对数据进行排序,比如按阅读量、点赞数、作者等,让数据更清晰,那么你可以点击Export Data as CSV,将数据导入Excel表格.
(3)导入Excel表格后,可以过滤数据。
插件功能
1、抓取多个页面
2、读取数据存储在本地存储或CouchDB
3、多种数据选择类型
4、 从动态页面中提取数据(JavaScript + AJAX)
5、浏览抓取的数据
6、将数据导出为 CSV
7、导入、导出站点地图
8、仅取决于 Chrome 浏览器 查看全部
chrome插件网页抓取(WebScraper插件安装使用方法及安装流程:安装方法)
Web Scraper 是一个 chrome 网页数据提取插件,用于从网页中提取数据。用户只需四步即可使用该插件创建页面数据抽取规则,从而快速从网页中抽取出需要的内容。Web Scraper 插件的整个爬取逻辑从设置第一级 Selector 开始,选择爬取范围。在一级Selector下设置二级Selector后,再次选择抓取字段,即可抓取网页数据。插件采集数据后,还可以将数据导出为CSV文件,欢迎免费下载。
插件安装和使用
一、安装
1、这里编辑器使用的是chrome浏览器,先在标签页输入[chrome://extensions/]进入chrome扩展,解压你在这个页面下载的Web Scraper插件,拖入扩展页面就是这样。
2、安装完成后,请尝试插件的具体功能。
3、当然可以先在设置页面设置插件的存储设置和存储类型功能。
二、使用抓取功能
安装完成后,只需四步即可完成爬取操作。具体流程如下:
1、打开网络爬虫
首先,要使用该插件提取网页数据,需要在开发者工具模式下使用。使用快捷键Ctrl+Shift+I/F12后,在出现的开发者工具窗口中找到插件同名的列。
2、创建一个新的站点地图
点击Create New Sitemap,有两个选项,import sitemap是导入现成sitemap的向导,我们一般没有现成的sitemap,所以一般不选这个,直接选create sitemap。
然后做这两个操作:
(1)Sitemap Name:表示你的Sitemap适合哪个网页,所以可以根据网页来命名,但是需要用英文字母。比如我抓取今日头条的数据,那么我会用头条来命名;
(2)Sitemap URL:将网页链接复制到Star URL栏。比如图中我把“吴晓波频道”的首页链接复制到了这个栏,然后点击下面的创建sitemap进行创建一个新的站点地图。
3、设置此站点地图
整个Web Scraper的抓取逻辑如下:设置一级Selector,选择抓取范围;在一级Selector下设置二级Selector,选择抓取字段,然后抓取。
对于文章来说,一级Selector意味着你要圈出这块文章的元素。这个元素可能包括标题、作者、发布时间、评论数等。从关卡Selector中选择我们想要的元素,比如标题、作者、阅读次数。
让我们分解一下设置一级和二级 Selector 的工作流程:
(1)单击添加新选择器以创建第一级选择器。
然后按照以下步骤操作:
- 输入id:id代表你抓取的整个范围,例如这里是文章,我们可以命名为wuxiaobo-articles;
-Select Type:type代表你抓取的部分的类型,比如element/text/link,因为这是整个文章元素范围的选择,我们需要先用Element全选(如果这个网页需要滑动加载More,然后选择Element Scroll Down);
-勾选Multiple:勾选Multiple前面的小框,因为要选择多个元素而不是单个元素,当我们勾选时,爬虫插件会帮我们识别多个相似的文章;
- 保留设置:其余未提及的部分保留其默认设置。
(2)单击选择以选择范围并按照以下步骤操作:
- 选择范围:用鼠标选择要抓取数据的范围,绿色为要选择的区域,用鼠标点击后变为红色,该区域被选中;
- 多选:不要只选一个,还要选以下几项,否则只会爬出一行数据;
-完成选择:记得点击完成选择;
- 保存:单击保存选择器。
(3)设置好一级Selector后,点击设置二级Selector,按以下步骤操作:
- 新选择器:点击添加新选择器;
- 输入id:id代表你在抓取哪个字段,所以可以取字段的英文。比如我要选择“作者”,就写“作者”;
-Select Type:选择Text,因为你要抓取的是文本;
- 不要勾选Multiple:不要勾选Multiple前面的小方框,因为我们这里抓取的是单个元素;
- 保留设置:其余未提及的部分保留其默认设置。
(4)点击选择,然后点击要爬取的字段,按照以下步骤操作:
- 选择字段:这里要爬取的字段是一个。用鼠标单击该字段以将其选中。比如你想爬取标题,用鼠标点击某个文章的标题。当字段所在区域变为红色时,即被选中;
-完成选择:记得点击完成选择;
- 保存:单击保存选择器。
(5)重复以上操作,直到选择好要爬的田地。
4、爬取数据
(1)之后,如果要爬取数据,只需要设置所有的Selector启动即可:
点击Scrape,然后点击Start Scraping,爬虫会在弹出一个小窗口后开始工作。你会得到一个收录所有你想要的数据的列表。
(2)如果你想对数据进行排序,比如按阅读量、点赞数、作者等,让数据更清晰,那么你可以点击Export Data as CSV,将数据导入Excel表格.
(3)导入Excel表格后,可以过滤数据。
插件功能
1、抓取多个页面
2、读取数据存储在本地存储或CouchDB
3、多种数据选择类型
4、 从动态页面中提取数据(JavaScript + AJAX)
5、浏览抓取的数据
6、将数据导出为 CSV
7、导入、导出站点地图
8、仅取决于 Chrome 浏览器

