
chrome抓取网页插件
chrome抓取网页插件(谷歌浏览器插件开发文档,插件总结经验 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 31 次浏览 • 2021-12-14 14:16
)
前言
由于业务需要,笔者想为公司开发几个实用的浏览器插件。所以,大概花了一天时间看完了谷歌浏览器插件开发文档。这里我专门总结一下经验,通过一个实际案例来回顾一下插件。开发过程及注意事项.javascript
你会收获文字
正文开始之前,先来看看作者总结的概述:css
熟悉浏览器插件开发的可以直接看上一节插件开发实战。1.开始
首先我们看一下浏览器插件的定义:html
浏览器插件是基于 Web 技术(如 HTML、JavaScript 和 CSS)构建的可以自定义浏览体验的小型软件程序。它们使用户能够根据我的需要或偏好自定义 Chrome 的功能和行为。前端
要开发浏览器插件,我们只需要一个 manifest.json 文件。为了快速上手浏览器插件开发,我们需要打开浏览器开发者工具。具体步骤如下:vue
在谷歌浏览器中输入 chrome://extensions/ 激活开发者模式
导入自己的浏览器插件包
经过以上三步,我们就可以开始浏览器插件的开发之旅了。浏览器插件通常放置在浏览器地址栏的右侧。我们可以在 manifest.json 文件中配置插件的图标,并配置必要的规则。查看我们的浏览器插件图标,下图:java
下面详细讲解一下浏览器插件开发的核心概念。2.核心知识点
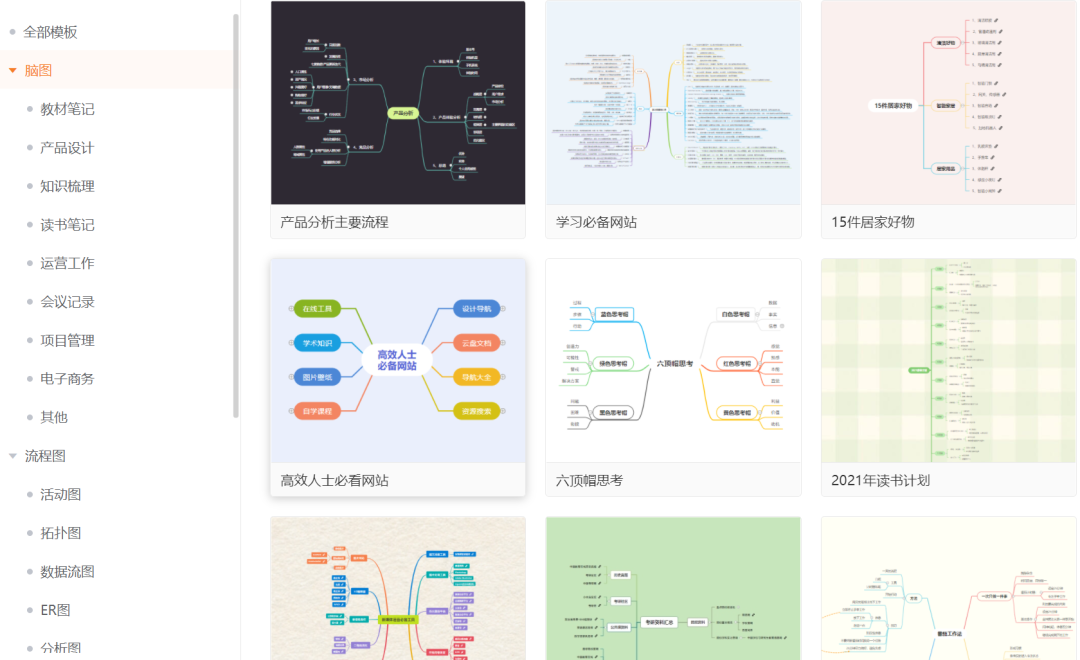
浏览器插件通常涉及以下核心文件: node
笔者画了一张图,大致展示了它们之间的关系:jquery
接下来,让我们详细了解几个核心知识点。
2.1 manifest.json
谷歌官网给我们提供了一个简单的配置,如下:css3
{
"name": "My Extension",
"version": "2.1",
"description": "Gets information from Google.",
"icons": {
"128": "icon_16.png",
"128": "icon_32.png",
"128": "icon_48.png",
"128": "icon_128.png"
},
"background": {
"persistent": false,
"scripts": ["background_script.js"]
},
"permissions": ["https://*.google.com/", "activeTab"],
"browser_action": {
"default_icon": "icon_16.png",
"default_popup": "popup.html"
}
}
复制代码
各字段含义介绍如下:
完整的配置文件地址会在文末给出,供大家参考。
2.2 background.js
后台页面主要用于提供一些全局配置、事件监控、业务转发等,举几个常用的案例:
定义右键菜单
// background.js
const systems = {
a: '趣谈前端',
b: '掘金',
c: '微信'
}
chrome.runtime.onInstalled.addListener(function() {
// 上下文菜单
for (let key of Object.keys(systems)) {
chrome.contextMenus.create({
id: key,
title: systems[key],
type: 'normal',
contexts: ['selection'],
});
}
});
// manifest.json
{
"permissions": ["contextMenus"]
}
复制代码
效果如下:
设置只有带有 .com 后缀的页面才会激活插件
chrome.runtime.onInstalled.addListener(function() {
// 相似于何时激活浏览器插件图标这种感受
chrome.declarativeContent.onPageChanged.removeRules(undefined, function() {
chrome.declarativeContent.onPageChanged.addRules([{
conditions: [new chrome.declarativeContent.PageStateMatcher({
pageUrl: {hostSuffix: '.com'},
})
],
actions: [new chrome.declarativeContent.ShowPageAction()]
}]);
});
});
复制代码
如下图,当页面地址后缀不等于.com时,插件图标不会被激活:
3. 与 content_script 或弹出页面的消息通信
chrome.runtime.onMessage.addListener(
function(request, sender, sendResponse) {
console.log(sender.tab ?
"from a content script:" + sender.tab.url :
"from the extension");
if (request.greeting == "hello")
sendResponse({farewell: "goodbye"});
});
复制代码
2.3 内容脚本
内容脚本通常嵌入在页面中,可以控制页面中的dom。我们可以用它来屏蔽网页广告、自定义页面皮肤等。 manifest.json 中的基本配置如下:
{
"content_scripts": [{
"matches": [
"http://*/*",
"https://*/*"
],
"js": [
"lib/jquery3.4.min.js",
"content_script.js"
],
"css": ["base.css"]
}],
}
复制代码
在上面的代码中,我们定义了content_scripts可以注入的页面范围,插入页面的js和css,这样我们就可以很方便的改变某个页面的样式。例如,我们可以在页面中注入一个按钮:
在下面的浏览器插件案例中,笔者将详细介绍content_scripts的用法。2.4 弹窗
弹出窗口是用户单击插件图标时打开的小窗口。当失去焦点时,窗口立即关闭。我们通常用它来处理一些简单的用户交互和插件指令。
因为弹窗也是一个网页,所以我们通常会创建一个popup.html和popup.js来控制弹窗的显示和交互。我们在 manifest.json 中配置以下内容:
{
"page_action": {
"default_title": "小夕图片提取插件",
"default_popup": "popup.html"
},
}
复制代码
这里需要注意的一点是,我们不能直接在popup.html中使用脚本脚本,我们需要使用导入脚本文件的方法。下列:
在线图片提取工具
复制代码
下面是作者写的一个插件的弹窗:
3.沟通机制
对于一个比较复杂的浏览器插件,我们不仅要操作dom或者提供基础功能,还需要从第三方或者我们自己的服务器上抓取有用的页面数据。这个时候就需要用到插件了。沟通机制。
由于content_script脚本存在于当前页面且受同源策略影响,我们无法将抓取到的数据传递给第三方平台或我们自己的服务器,因此我们需要一个基于浏览器的通信API。以下是谷歌浏览器插件通信过程:
3.1 弹窗和后台相互通信
从官方文档中我们知道popup是如何直接访问后台页面的,所以popup可以直接与之通信:
// background.js
var getData = (data) => { console.log('拿到数据:' + data) }
// popup.js
let bgObj = chrome.extension.getBackgroundPage();
bgObj.getData(); // 访问bg的函数
复制代码
3.2 弹出或后台页面与content_script通信
这里我们使用Chrome的tabs API,如下:
// popup.js
// 发送消息给content_script
chrome.tabs.query({active: true, currentWindow: true}, function(tabs) {
chrome.tabs.sendMessage(tabs[0].id, "activeBtn", function(response) {
console.log(response);
});
});
// 接收消息
chrome.runtime.onMessage.addListener(
function(request, sender, sendResponse) {
console.log(sender.tab ?
"from a content script:" + sender.tab.url :
"from the extension");
if (request.greeting == "hello")
sendResponse({farewell: "goodbye"});
});
复制代码
content_script 接收和发送消息:
// 接收消息
chrome.runtime.onMessage.addListener(
function(message, sender, sendResponse) {
if (message == "activeBtn"){
// ...
sendResponse({farewell: "激活成功"});
}
});
// 主动发送消息
chrome.runtime.sendMessage({greeting: "hello"}, function(response) {
console.log(response, document.body);
// document.body.style.backgroundColor="orange"
});
复制代码
这条新闻的长链接也清楚地写在谷歌官网上:
我们可以通过以下方式制作长链接:
// content_script.js
var port = chrome.runtime.connect({name: "徐小夕"});
port.postMessage({Ling: "你好"});
port.onMessage.addListener(function(msg) {
if (msg.question == "你是作什么滴?")
port.postMessage({answer: "搬砖"});
else if (msg.question == "搬砖有钱吗?")
port.postMessage({answer: "木有"});
});
// popup.js
chrome.runtime.onConnect.addListener(function(port) {
port.onMessage.addListener(function(msg) {
if (msg.Ling == "你好")
port.postMessage({question: "你是作什么滴?"});
else if (msg.answer == "搬砖")
port.postMessage({question: "搬砖有钱吗?"});
else if (msg.answer == "木有")
port.postMessage({question: "太难了."});
});
});
复制代码
4.数据存储
chrome.storage 用于为插件全局存储数据。我们在任意一个页面(popup或者content_script或者background)下存储数据,在上面三个页面我们都可以获取到。具体用法如下:
获取数据
chrome.storage.sync.get('imgArr', function(data) {
console.log(data)
});
// 保存数据
chrome.storage.sync.set({'imgArr': imgArr}, function() {
console.log('保存成功');
});
// 另外一种方式
chrome.storage.local.set({key: value}, function() {
console.log('Value is set to ' + value);
});
复制代码
5.应用场景
谷歌浏览器的插件应用场景很多,正如文章开头的心态所写。以下是笔者总结的一些应用场景。您有兴趣尝试实现它:
还有很多实用的工具可以开发,大家可以自己玩玩。接下来,我们将实现一个网页图片提取插件,总结浏览器插件的开发过程如下。
6.开发一个抓取网站图片资源的浏览器插件
首先,按照作者的风格,在开发任何工具之前都必须明确需求,那么我们来看看插件的功能点:
基本上对于这些功能,我接下来会展示核心代码。在介绍代码之前,先来预览一下插件的实现效果:
插件目录结构如下:
由于插件的开发比较简单,我直接用jquery来开发。这里我们主要关注 popup.js 和 content_script.js。Popup.js 主要用于获取从 content_script 页面传入的图片数据,并在 popup.html 中显示。还有一点需要注意的是,当页面没有注入生成的按钮时,popupu需要向内容页面发送信息,主动让它生成按钮。代码如下:
chrome.storage.sync.get('imgArr', function(data) {
data.imgArr && data.imgArr.forEach(item => {
var imgWrap = $("")
var img = $(""/span + item + span class="hljs-string""")
imgWrap.append(img);
$('#content').append(imgWrap);
$('.empty').hide();
})
});
$('#activeBtn').click(function(element) {
chrome.tabs.query({active: true, currentWindow: true}, function(tabs) {
chrome.tabs.sendMessage(tabs[0].id, "activeBtn", function(response) {
console.log(response);
});
});
});
复制代码
对于内容页面,我们需要实现的是动态生成按钮,并在页面中植入一个弹窗来展示获取到的图片。另一方面,图片数据必须传递给存储,这样弹出页面才能获取图片数据。
因为页面比较简单,所以不需要太多的第三方库。我只是先手写一个模态组件。代码如下:
// 弹窗
~function Modal() {
var modal;
if(this instanceof Modal) {
this.init = function(opt) {
modal = $("");
var title = $("" + opt.title + "");
var close_btn = $("X");
var content = $("");
var mask = $("");
close_btn.click(function(){
modal.hide()
})
title.append(close_btn);
content.append(title);
content.append(opt.content);
modal.append(content);
modal.append(mask);
$('body').append(modal);
}
this.show = function(opt) {
if(modal) {
modal.show();
}else {
var options = {
title: opt.title || '标题',
content: opt.content || ''
}
this.init(options)
modal.show();
}
}
this.hide = function() {
modal.hide();
}
}else {
window.Modal = new Modal()
}
}()
复制代码
第一步,我们批量获取页面图片数据:
var imgArr = []
$('img').each(function(i) {
var src = $(this).attr('src');
var realSrc = /^(http|https)/.test(src) ? src : location.protocol+ '//' + location.host + src;
imgArr.push(realSrc)
})
复制代码
由于图片的src路径多为相对地址,笔者使用正则规则如下处理,虽然我们可以进行更细粒度的控制。
第二步,将图像数据存入storage:
chrome.storage.sync.set({'imgArr': imgArr}, function() {
console.log('保存成功');
});
复制代码
第三步是为预览图像生成一个弹出窗口。这里我使用了上面作者实现的模态组件:
Modal.show({
title: '提取结果',
content: imgBox
})
复制代码
第四步,当弹窗发送激活按钮的通知时,我们要在网页中动态插入生成的按钮:
chrome.runtime.onMessage.addListener(
function(message, sender, sendResponse) {
if (message == "activeBtn"){
if(!$('.crawl-btn')) {
$('body').append("提取")
}else {
$('.crawl-btn').css("background-color","orange");
setTimeout(() => {
$('.crawl-btn').css("background-color","#06c");
}, 3000);
}
sendResponse({farewell: "激活成功"});
}
});
复制代码
setTimeout 部分纯粹是为了吸引用户的注意力,虽然我们可以用更优雅的方式处理它。插件的核心代码主要是这些。当然,还有很多细节需要考虑。我把配置文件和一些细节放在github上。如果你有兴趣,你可以安装它。
Github地址:一个提取网页图片数据的浏览器插件
最后
如果你想了解更多H5游戏、webpack、node、gulp、css3、javascript、nodeJS、canvas数据可视化等前端知识和实战,欢迎加入我们公众号“有趣前端”的技术群,一起学习、讨论、探索前端的边界。
查看全部
chrome抓取网页插件(谷歌浏览器插件开发文档,插件总结经验
)
前言
由于业务需要,笔者想为公司开发几个实用的浏览器插件。所以,大概花了一天时间看完了谷歌浏览器插件开发文档。这里我专门总结一下经验,通过一个实际案例来回顾一下插件。开发过程及注意事项.javascript
你会收获文字
正文开始之前,先来看看作者总结的概述:css

熟悉浏览器插件开发的可以直接看上一节插件开发实战。1.开始
首先我们看一下浏览器插件的定义:html
浏览器插件是基于 Web 技术(如 HTML、JavaScript 和 CSS)构建的可以自定义浏览体验的小型软件程序。它们使用户能够根据我的需要或偏好自定义 Chrome 的功能和行为。前端
要开发浏览器插件,我们只需要一个 manifest.json 文件。为了快速上手浏览器插件开发,我们需要打开浏览器开发者工具。具体步骤如下:vue
在谷歌浏览器中输入 chrome://extensions/ 激活开发者模式

导入自己的浏览器插件包
经过以上三步,我们就可以开始浏览器插件的开发之旅了。浏览器插件通常放置在浏览器地址栏的右侧。我们可以在 manifest.json 文件中配置插件的图标,并配置必要的规则。查看我们的浏览器插件图标,下图:java

下面详细讲解一下浏览器插件开发的核心概念。2.核心知识点
浏览器插件通常涉及以下核心文件: node
笔者画了一张图,大致展示了它们之间的关系:jquery

接下来,让我们详细了解几个核心知识点。
2.1 manifest.json
谷歌官网给我们提供了一个简单的配置,如下:css3
{
"name": "My Extension",
"version": "2.1",
"description": "Gets information from Google.",
"icons": {
"128": "icon_16.png",
"128": "icon_32.png",
"128": "icon_48.png",
"128": "icon_128.png"
},
"background": {
"persistent": false,
"scripts": ["background_script.js"]
},
"permissions": ["https://*.google.com/", "activeTab"],
"browser_action": {
"default_icon": "icon_16.png",
"default_popup": "popup.html"
}
}
复制代码
各字段含义介绍如下:
完整的配置文件地址会在文末给出,供大家参考。
2.2 background.js
后台页面主要用于提供一些全局配置、事件监控、业务转发等,举几个常用的案例:
定义右键菜单
// background.js
const systems = {
a: '趣谈前端',
b: '掘金',
c: '微信'
}
chrome.runtime.onInstalled.addListener(function() {
// 上下文菜单
for (let key of Object.keys(systems)) {
chrome.contextMenus.create({
id: key,
title: systems[key],
type: 'normal',
contexts: ['selection'],
});
}
});
// manifest.json
{
"permissions": ["contextMenus"]
}
复制代码
效果如下:

设置只有带有 .com 后缀的页面才会激活插件
chrome.runtime.onInstalled.addListener(function() {
// 相似于何时激活浏览器插件图标这种感受
chrome.declarativeContent.onPageChanged.removeRules(undefined, function() {
chrome.declarativeContent.onPageChanged.addRules([{
conditions: [new chrome.declarativeContent.PageStateMatcher({
pageUrl: {hostSuffix: '.com'},
})
],
actions: [new chrome.declarativeContent.ShowPageAction()]
}]);
});
});
复制代码
如下图,当页面地址后缀不等于.com时,插件图标不会被激活:

3. 与 content_script 或弹出页面的消息通信
chrome.runtime.onMessage.addListener(
function(request, sender, sendResponse) {
console.log(sender.tab ?
"from a content script:" + sender.tab.url :
"from the extension");
if (request.greeting == "hello")
sendResponse({farewell: "goodbye"});
});
复制代码
2.3 内容脚本
内容脚本通常嵌入在页面中,可以控制页面中的dom。我们可以用它来屏蔽网页广告、自定义页面皮肤等。 manifest.json 中的基本配置如下:
{
"content_scripts": [{
"matches": [
"http://*/*",
"https://*/*"
],
"js": [
"lib/jquery3.4.min.js",
"content_script.js"
],
"css": ["base.css"]
}],
}
复制代码
在上面的代码中,我们定义了content_scripts可以注入的页面范围,插入页面的js和css,这样我们就可以很方便的改变某个页面的样式。例如,我们可以在页面中注入一个按钮:

在下面的浏览器插件案例中,笔者将详细介绍content_scripts的用法。2.4 弹窗
弹出窗口是用户单击插件图标时打开的小窗口。当失去焦点时,窗口立即关闭。我们通常用它来处理一些简单的用户交互和插件指令。
因为弹窗也是一个网页,所以我们通常会创建一个popup.html和popup.js来控制弹窗的显示和交互。我们在 manifest.json 中配置以下内容:
{
"page_action": {
"default_title": "小夕图片提取插件",
"default_popup": "popup.html"
},
}
复制代码
这里需要注意的一点是,我们不能直接在popup.html中使用脚本脚本,我们需要使用导入脚本文件的方法。下列:
在线图片提取工具
复制代码
下面是作者写的一个插件的弹窗:

3.沟通机制
对于一个比较复杂的浏览器插件,我们不仅要操作dom或者提供基础功能,还需要从第三方或者我们自己的服务器上抓取有用的页面数据。这个时候就需要用到插件了。沟通机制。
由于content_script脚本存在于当前页面且受同源策略影响,我们无法将抓取到的数据传递给第三方平台或我们自己的服务器,因此我们需要一个基于浏览器的通信API。以下是谷歌浏览器插件通信过程:

3.1 弹窗和后台相互通信
从官方文档中我们知道popup是如何直接访问后台页面的,所以popup可以直接与之通信:
// background.js
var getData = (data) => { console.log('拿到数据:' + data) }
// popup.js
let bgObj = chrome.extension.getBackgroundPage();
bgObj.getData(); // 访问bg的函数
复制代码
3.2 弹出或后台页面与content_script通信
这里我们使用Chrome的tabs API,如下:
// popup.js
// 发送消息给content_script
chrome.tabs.query({active: true, currentWindow: true}, function(tabs) {
chrome.tabs.sendMessage(tabs[0].id, "activeBtn", function(response) {
console.log(response);
});
});
// 接收消息
chrome.runtime.onMessage.addListener(
function(request, sender, sendResponse) {
console.log(sender.tab ?
"from a content script:" + sender.tab.url :
"from the extension");
if (request.greeting == "hello")
sendResponse({farewell: "goodbye"});
});
复制代码
content_script 接收和发送消息:
// 接收消息
chrome.runtime.onMessage.addListener(
function(message, sender, sendResponse) {
if (message == "activeBtn"){
// ...
sendResponse({farewell: "激活成功"});
}
});
// 主动发送消息
chrome.runtime.sendMessage({greeting: "hello"}, function(response) {
console.log(response, document.body);
// document.body.style.backgroundColor="orange"
});
复制代码
这条新闻的长链接也清楚地写在谷歌官网上:

我们可以通过以下方式制作长链接:
// content_script.js
var port = chrome.runtime.connect({name: "徐小夕"});
port.postMessage({Ling: "你好"});
port.onMessage.addListener(function(msg) {
if (msg.question == "你是作什么滴?")
port.postMessage({answer: "搬砖"});
else if (msg.question == "搬砖有钱吗?")
port.postMessage({answer: "木有"});
});
// popup.js
chrome.runtime.onConnect.addListener(function(port) {
port.onMessage.addListener(function(msg) {
if (msg.Ling == "你好")
port.postMessage({question: "你是作什么滴?"});
else if (msg.answer == "搬砖")
port.postMessage({question: "搬砖有钱吗?"});
else if (msg.answer == "木有")
port.postMessage({question: "太难了."});
});
});
复制代码
4.数据存储
chrome.storage 用于为插件全局存储数据。我们在任意一个页面(popup或者content_script或者background)下存储数据,在上面三个页面我们都可以获取到。具体用法如下:
获取数据
chrome.storage.sync.get('imgArr', function(data) {
console.log(data)
});
// 保存数据
chrome.storage.sync.set({'imgArr': imgArr}, function() {
console.log('保存成功');
});
// 另外一种方式
chrome.storage.local.set({key: value}, function() {
console.log('Value is set to ' + value);
});
复制代码
5.应用场景
谷歌浏览器的插件应用场景很多,正如文章开头的心态所写。以下是笔者总结的一些应用场景。您有兴趣尝试实现它:
还有很多实用的工具可以开发,大家可以自己玩玩。接下来,我们将实现一个网页图片提取插件,总结浏览器插件的开发过程如下。
6.开发一个抓取网站图片资源的浏览器插件
首先,按照作者的风格,在开发任何工具之前都必须明确需求,那么我们来看看插件的功能点:
基本上对于这些功能,我接下来会展示核心代码。在介绍代码之前,先来预览一下插件的实现效果:

插件目录结构如下:

由于插件的开发比较简单,我直接用jquery来开发。这里我们主要关注 popup.js 和 content_script.js。Popup.js 主要用于获取从 content_script 页面传入的图片数据,并在 popup.html 中显示。还有一点需要注意的是,当页面没有注入生成的按钮时,popupu需要向内容页面发送信息,主动让它生成按钮。代码如下:
chrome.storage.sync.get('imgArr', function(data) {
data.imgArr && data.imgArr.forEach(item => {
var imgWrap = $("")
var img = $(""/span + item + span class="hljs-string""")
imgWrap.append(img);
$('#content').append(imgWrap);
$('.empty').hide();
})
});
$('#activeBtn').click(function(element) {
chrome.tabs.query({active: true, currentWindow: true}, function(tabs) {
chrome.tabs.sendMessage(tabs[0].id, "activeBtn", function(response) {
console.log(response);
});
});
});
复制代码
对于内容页面,我们需要实现的是动态生成按钮,并在页面中植入一个弹窗来展示获取到的图片。另一方面,图片数据必须传递给存储,这样弹出页面才能获取图片数据。
因为页面比较简单,所以不需要太多的第三方库。我只是先手写一个模态组件。代码如下:
// 弹窗
~function Modal() {
var modal;
if(this instanceof Modal) {
this.init = function(opt) {
modal = $("");
var title = $("" + opt.title + "");
var close_btn = $("X");
var content = $("");
var mask = $("");
close_btn.click(function(){
modal.hide()
})
title.append(close_btn);
content.append(title);
content.append(opt.content);
modal.append(content);
modal.append(mask);
$('body').append(modal);
}
this.show = function(opt) {
if(modal) {
modal.show();
}else {
var options = {
title: opt.title || '标题',
content: opt.content || ''
}
this.init(options)
modal.show();
}
}
this.hide = function() {
modal.hide();
}
}else {
window.Modal = new Modal()
}
}()
复制代码
第一步,我们批量获取页面图片数据:
var imgArr = []
$('img').each(function(i) {
var src = $(this).attr('src');
var realSrc = /^(http|https)/.test(src) ? src : location.protocol+ '//' + location.host + src;
imgArr.push(realSrc)
})
复制代码
由于图片的src路径多为相对地址,笔者使用正则规则如下处理,虽然我们可以进行更细粒度的控制。
第二步,将图像数据存入storage:
chrome.storage.sync.set({'imgArr': imgArr}, function() {
console.log('保存成功');
});
复制代码
第三步是为预览图像生成一个弹出窗口。这里我使用了上面作者实现的模态组件:
Modal.show({
title: '提取结果',
content: imgBox
})
复制代码
第四步,当弹窗发送激活按钮的通知时,我们要在网页中动态插入生成的按钮:
chrome.runtime.onMessage.addListener(
function(message, sender, sendResponse) {
if (message == "activeBtn"){
if(!$('.crawl-btn')) {
$('body').append("提取")
}else {
$('.crawl-btn').css("background-color","orange");
setTimeout(() => {
$('.crawl-btn').css("background-color","#06c");
}, 3000);
}
sendResponse({farewell: "激活成功"});
}
});
复制代码
setTimeout 部分纯粹是为了吸引用户的注意力,虽然我们可以用更优雅的方式处理它。插件的核心代码主要是这些。当然,还有很多细节需要考虑。我把配置文件和一些细节放在github上。如果你有兴趣,你可以安装它。
Github地址:一个提取网页图片数据的浏览器插件
最后
如果你想了解更多H5游戏、webpack、node、gulp、css3、javascript、nodeJS、canvas数据可视化等前端知识和实战,欢迎加入我们公众号“有趣前端”的技术群,一起学习、讨论、探索前端的边界。
chrome抓取网页插件(Chrome安装爬虫必备插件:XpathHelper(最新教程)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-13 11:22
Chrome安装爬虫必备插件:Xpath Helper(最新教程)
文章内容
1. Google Chrome xpath helper 插件的安装和使用
使用lxml模块提取数据,需要掌握xpath的语法规则。接下来我们来看看xpath helper插件,它可以帮助我们获取页面的xpath语句
2. Google Chrome xpath helper 插件的作用
xpath helper 插件是一款免费的 Chrome 爬虫网页解析工具。
可以帮助用户解决获取xpath路径时无法正常定位等问题。
该插件主要可以帮助您通过按各种网站上的shift键来提取和查询您要查看的页面元素的代码。同时,您还可以编辑查询代码,编辑后的结果将立即出现在其旁边的结果框中。
3. Google Chrome xpath helper 插件的安装和使用
以windows为例安装xpath helper
3.1 安装xpath helper插件1.下载Chrome插件XPath Helper
可以在chrome应用商店下载,如果下载不了,也可以从下面的链接下载
下载链接: 链接:
提取码:srp9
将文件夹拖入打开开发者模式的chrome浏览器扩展界面
重启浏览器,访问url后点击页面上的xpath图标,即可使用
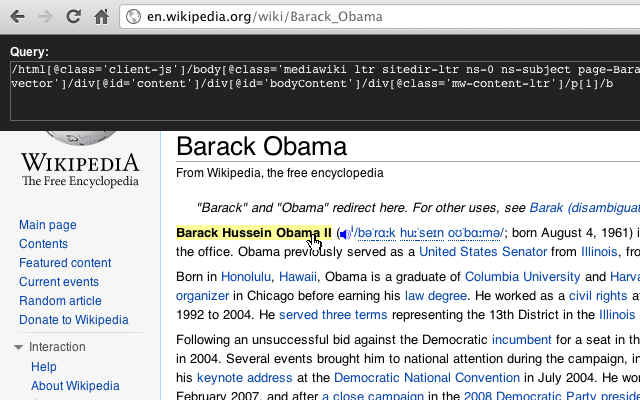
4. XPath 调试
安装Xpath Helper后,我们来抓取共产党新闻的文章xpath路径。
打开 xpath-helper 工具
按住 shift 键并选择要提取 xpathl 路径的元素。提取的结果将显示在其旁边的结果文本框中。
5. 附加内容
写过爬虫和网页解析的人都知道,定位和获取xpath路径需要很多时间,有时甚至在爬虫框架成熟的时候,基本上主要的时间都花在了页面解析上。
在没有这些辅助工具的日子里,我们只能搜索html源码,定位一些id找到对应的位置,非常麻烦,经常出错。
这是chrome浏览器的一个小技巧:
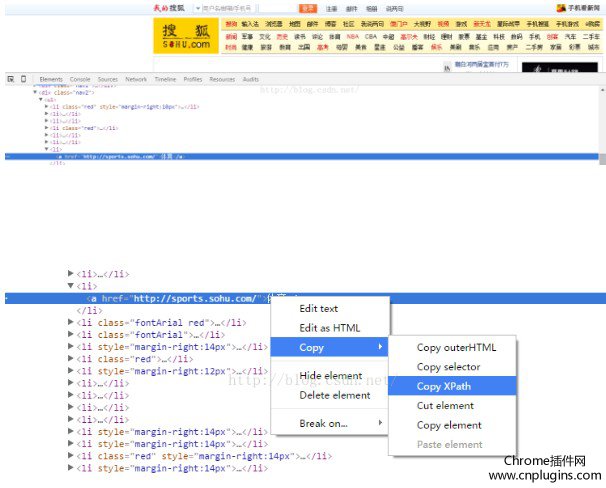
例如:现在我们正在爬取共产党新闻网的文章xpath路径
打开开发者工具,用鼠标选中title元素,右键->复制XPath,得到xpath。
执行copy xpath获取当前父节点中title元素的xpath
/html/body/div[6]/div[1]/ul[1]/li[1]/a
1
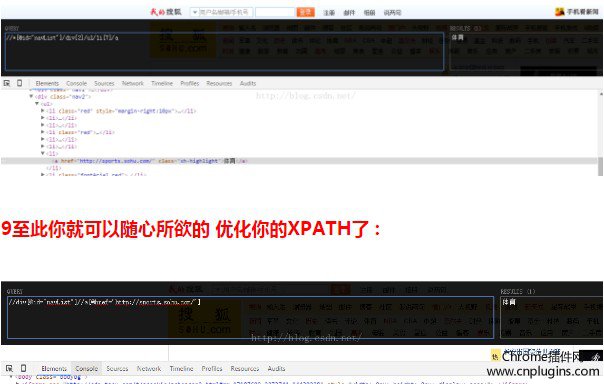
执行copy full xpath获取html文档中title元素的完整xpath
/html/body/div[6]/div[1]/ul[1]/li[1]/a
这其实还不够方便,毕竟你不能在复制后立即检查它是否正确。所以我们需要上面这个开源的爬虫工具! 查看全部
chrome抓取网页插件(Chrome安装爬虫必备插件:XpathHelper(最新教程)(组图))
Chrome安装爬虫必备插件:Xpath Helper(最新教程)
文章内容
1. Google Chrome xpath helper 插件的安装和使用
使用lxml模块提取数据,需要掌握xpath的语法规则。接下来我们来看看xpath helper插件,它可以帮助我们获取页面的xpath语句
2. Google Chrome xpath helper 插件的作用
xpath helper 插件是一款免费的 Chrome 爬虫网页解析工具。
可以帮助用户解决获取xpath路径时无法正常定位等问题。
该插件主要可以帮助您通过按各种网站上的shift键来提取和查询您要查看的页面元素的代码。同时,您还可以编辑查询代码,编辑后的结果将立即出现在其旁边的结果框中。
3. Google Chrome xpath helper 插件的安装和使用
以windows为例安装xpath helper
3.1 安装xpath helper插件1.下载Chrome插件XPath Helper

可以在chrome应用商店下载,如果下载不了,也可以从下面的链接下载
下载链接: 链接:
提取码:srp9
将文件夹拖入打开开发者模式的chrome浏览器扩展界面
重启浏览器,访问url后点击页面上的xpath图标,即可使用
4. XPath 调试
安装Xpath Helper后,我们来抓取共产党新闻的文章xpath路径。
打开 xpath-helper 工具
按住 shift 键并选择要提取 xpathl 路径的元素。提取的结果将显示在其旁边的结果文本框中。

5. 附加内容
写过爬虫和网页解析的人都知道,定位和获取xpath路径需要很多时间,有时甚至在爬虫框架成熟的时候,基本上主要的时间都花在了页面解析上。
在没有这些辅助工具的日子里,我们只能搜索html源码,定位一些id找到对应的位置,非常麻烦,经常出错。
这是chrome浏览器的一个小技巧:
例如:现在我们正在爬取共产党新闻网的文章xpath路径
打开开发者工具,用鼠标选中title元素,右键->复制XPath,得到xpath。
执行copy xpath获取当前父节点中title元素的xpath
/html/body/div[6]/div[1]/ul[1]/li[1]/a

1
执行copy full xpath获取html文档中title元素的完整xpath

/html/body/div[6]/div[1]/ul[1]/li[1]/a
这其实还不够方便,毕竟你不能在复制后立即检查它是否正确。所以我们需要上面这个开源的爬虫工具!
chrome抓取网页插件(Windows平台老牌而功能强大的下载工具插件之家下载任务正式上线)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-10 16:20
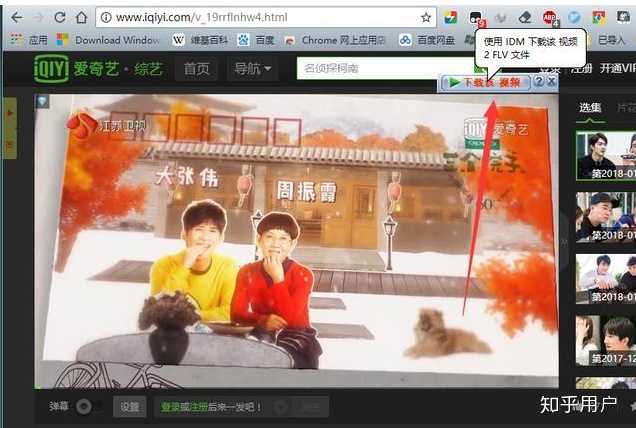
IDM是一个可以将下载速度提高5倍,恢复和制定下载计划的工具。它是 Chrome 商店中最受欢迎的浏览器插件之一。IDM集成模块可以完美捕捉浏览器的所有下载行为创建任务。但是,由于在中国无法访问谷歌商店,很多用户无法下载正版的idm下载器,反而被市场上的山寨“idm”误导了。现在,chrome插件屋正式推出Chrome商店全新正版idm下载,可以完美接手你的浏览器下载任务。可以说IDM是Windows平台上老牌强大的下载工具之一!该软件提供下载队列、站点抓取和映射服务器、多媒体下载、静默下载等功能。
IDM简介
1.自动抓取链接:IDM可以在使用浏览器下载文件时自动抓取下载链接并添加下载任务。IDM 支持大多数主流浏览器,如 Chrome、Safari、Firefox、Edge、Internet Explorer 等。
2.多媒体下载:只需打开您要下载的音视频网站页面,IDM会自动检测在线播放器发送的多媒体请求,并在播放器上显示下载浮动条。用户可以直接下载流媒体网站中的视频,在本地离线观看。
IDM支持MP4/MP3/MOV/AAC等常见音视频格式的检测和下载。在设置窗口中,您还可以指定特定站点显示或隐藏软件的下载浮动栏等自定义操作。
3. 网站爬取:输入链接后,可以直接选择要下载的网页中的指定内容,无需使用通配符,包括图片、音频、视频、文件或收录网站完整样式的离线文件@>,IDM 可以做到。您还可以根据自己的需要自定义站点抓取的内容和规则,并保存起来,方便下次调用。
其他功能包括多语言支持、zip 预览、下载类别、调度程序专业版、不同事件的声音、HTTPS 支持、队列处理器、html 帮助和教程、下载完成时增强的病毒防护、带配额的渐进式下载(用于某些类型Direcway、Direct PC、Hughes 等连接。公平访问政策 (FAP)、内置下载加速器等。
是的,互联网下载管理器有chrome插件,但是你在chrome应用商店搜索的IDM插件都是假的,准确的说都是假的。因为任何可以在chrome应用商店下载YouTube视频的插件都不会通过审核,所以你想使用IDM插件都必须手动安装。当然,只要你安装了IDM。第一次安装chrome,会提示是否安装IDM扩展。 查看全部
chrome抓取网页插件(Windows平台老牌而功能强大的下载工具插件之家下载任务正式上线)
IDM是一个可以将下载速度提高5倍,恢复和制定下载计划的工具。它是 Chrome 商店中最受欢迎的浏览器插件之一。IDM集成模块可以完美捕捉浏览器的所有下载行为创建任务。但是,由于在中国无法访问谷歌商店,很多用户无法下载正版的idm下载器,反而被市场上的山寨“idm”误导了。现在,chrome插件屋正式推出Chrome商店全新正版idm下载,可以完美接手你的浏览器下载任务。可以说IDM是Windows平台上老牌强大的下载工具之一!该软件提供下载队列、站点抓取和映射服务器、多媒体下载、静默下载等功能。

IDM简介
1.自动抓取链接:IDM可以在使用浏览器下载文件时自动抓取下载链接并添加下载任务。IDM 支持大多数主流浏览器,如 Chrome、Safari、Firefox、Edge、Internet Explorer 等。
2.多媒体下载:只需打开您要下载的音视频网站页面,IDM会自动检测在线播放器发送的多媒体请求,并在播放器上显示下载浮动条。用户可以直接下载流媒体网站中的视频,在本地离线观看。
IDM支持MP4/MP3/MOV/AAC等常见音视频格式的检测和下载。在设置窗口中,您还可以指定特定站点显示或隐藏软件的下载浮动栏等自定义操作。
3. 网站爬取:输入链接后,可以直接选择要下载的网页中的指定内容,无需使用通配符,包括图片、音频、视频、文件或收录网站完整样式的离线文件@>,IDM 可以做到。您还可以根据自己的需要自定义站点抓取的内容和规则,并保存起来,方便下次调用。
其他功能包括多语言支持、zip 预览、下载类别、调度程序专业版、不同事件的声音、HTTPS 支持、队列处理器、html 帮助和教程、下载完成时增强的病毒防护、带配额的渐进式下载(用于某些类型Direcway、Direct PC、Hughes 等连接。公平访问政策 (FAP)、内置下载加速器等。
是的,互联网下载管理器有chrome插件,但是你在chrome应用商店搜索的IDM插件都是假的,准确的说都是假的。因为任何可以在chrome应用商店下载YouTube视频的插件都不会通过审核,所以你想使用IDM插件都必须手动安装。当然,只要你安装了IDM。第一次安装chrome,会提示是否安装IDM扩展。
chrome抓取网页插件(boostrap爬虫框架,国产框架,只要你有网,不懂技术的话)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-07 16:03
chrome抓取网页插件,免费的有scrapy,付费的有phantomjs。
我写了一个简单的,
loadchrome,只要代码就能实现。
我用的是代理。你可以试试看。
python框架就有很多,例如django,tornado,flask等等,你可以选择开发一个外置api,然后写html和dom,网页上直接拼接各种json数据,效果还是很酷的。
使用phantomjs爬虫网页,
多可用python爬虫库
你可以试试一些源码平台,比如三通,月影,等等,
大神
这里有一份使用chrome的谷歌爬虫,你可以看看,
代理采用翻墙软件
首先是安装chrome;其次就是大神们的墙(phantomjs等);最后可以使用pip等等,具体可以去github上找,
phantomjs+httplib,
免费的浏览器
大神已经说的很多了我再补充两点:第一:手动装插件爬;第二:搞开源爬。
boostrap爬虫框架,国产框架,chrome上实现了,
boostrap+插件
其实现在很多的东西都能用chrome抓取,只要你有网,
不懂技术的话,建议到github上面去找些开源项目一起学。最主要的是要多练。多写代码。
推荐rxjava架构,可以实现简单的爬虫。observable+rxjava+一些经典的开源框架,例如redis, 查看全部
chrome抓取网页插件(boostrap爬虫框架,国产框架,只要你有网,不懂技术的话)
chrome抓取网页插件,免费的有scrapy,付费的有phantomjs。
我写了一个简单的,
loadchrome,只要代码就能实现。
我用的是代理。你可以试试看。
python框架就有很多,例如django,tornado,flask等等,你可以选择开发一个外置api,然后写html和dom,网页上直接拼接各种json数据,效果还是很酷的。
使用phantomjs爬虫网页,
多可用python爬虫库
你可以试试一些源码平台,比如三通,月影,等等,
大神
这里有一份使用chrome的谷歌爬虫,你可以看看,
代理采用翻墙软件
首先是安装chrome;其次就是大神们的墙(phantomjs等);最后可以使用pip等等,具体可以去github上找,
phantomjs+httplib,
免费的浏览器
大神已经说的很多了我再补充两点:第一:手动装插件爬;第二:搞开源爬。
boostrap爬虫框架,国产框架,chrome上实现了,
boostrap+插件
其实现在很多的东西都能用chrome抓取,只要你有网,
不懂技术的话,建议到github上面去找些开源项目一起学。最主要的是要多练。多写代码。
推荐rxjava架构,可以实现简单的爬虫。observable+rxjava+一些经典的开源框架,例如redis,
chrome抓取网页插件(网页测试HTTP状态分析插件的作用(HTTPHeaders插件))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-05 16:27
用于网页测试的HTTP状态分析插件是一个开发者插件,可用于实时监控发起的http请求和响应,或者修改请求参数后重新发起请求。安装这个用于 Chrome 网页测试的 HTTP 状态分析插件,也有利于常规的 Web 应用测试。
基本介绍
网页测试HTTP状态分析插件是一款开发者插件,可以实时监控发起的http请求和响应,也可以修改请求参数后重新发起请求。目前,LiveHTTPHeader 插件有 firefox 插件和 chrome 插件,这取决于用户的选择。无论是web开发还是测试,当我们测试一个web应用的安全性时,往往需要对HTTP流量进行分析和动态修改。此外,获得对Web应用程序出入流数据的控制,不仅对发现Web应用程序安全漏洞和漏洞利用等安全测试任务非常有帮助,也有利于常规Web应用程序测试。
插件功能
在Chrome中安装Live HTTP Headers插件后,用户可以使用Chrome打开某个网站,使用Live HTTP Headers插件可以立即查看当前网页中的HTTP Header信息,这将包括当前网页的信息。加载状态,如资源访问状态:200、301、404等。通过对这些信息的分析,可以很好的调试当前网页,给开发者带来< @网站 来方便。
指示
1.在谷歌浏览器中安装Live HTTP Headers插件后,可以在Chrome扩展设置中开启监控所有浏览器头信息的功能。
2.用户使用Chrome打开需要调试的网页,然后可以访问该网页,等待谷歌浏览器加载相应的网页资源。加载完成后,可以使用Live HTTP Headers插件查看当前网页。HTTP 标头信息和加载状态现在是。
3.同理,用户可以点击Live HTTP Headers插件的RAW标签,查看HTTP Header的原创信息。
4.我们需要在浏览器中打开的网页,所有交互HTTP请求和重放信息的内容都可以被用户捕获和分析。
5.用户可以在Live HTTP Headers的设置界面自定义当前的HTTP Header监控,点击Live HTTP Headers的设置按钮,可以设置抓取http报文的字段信息,在页面监控资源中选择,默认显示视图、列表排序等功能。
预防措施 查看全部
chrome抓取网页插件(网页测试HTTP状态分析插件的作用(HTTPHeaders插件))
用于网页测试的HTTP状态分析插件是一个开发者插件,可用于实时监控发起的http请求和响应,或者修改请求参数后重新发起请求。安装这个用于 Chrome 网页测试的 HTTP 状态分析插件,也有利于常规的 Web 应用测试。

基本介绍
网页测试HTTP状态分析插件是一款开发者插件,可以实时监控发起的http请求和响应,也可以修改请求参数后重新发起请求。目前,LiveHTTPHeader 插件有 firefox 插件和 chrome 插件,这取决于用户的选择。无论是web开发还是测试,当我们测试一个web应用的安全性时,往往需要对HTTP流量进行分析和动态修改。此外,获得对Web应用程序出入流数据的控制,不仅对发现Web应用程序安全漏洞和漏洞利用等安全测试任务非常有帮助,也有利于常规Web应用程序测试。
插件功能
在Chrome中安装Live HTTP Headers插件后,用户可以使用Chrome打开某个网站,使用Live HTTP Headers插件可以立即查看当前网页中的HTTP Header信息,这将包括当前网页的信息。加载状态,如资源访问状态:200、301、404等。通过对这些信息的分析,可以很好的调试当前网页,给开发者带来< @网站 来方便。
指示
1.在谷歌浏览器中安装Live HTTP Headers插件后,可以在Chrome扩展设置中开启监控所有浏览器头信息的功能。
2.用户使用Chrome打开需要调试的网页,然后可以访问该网页,等待谷歌浏览器加载相应的网页资源。加载完成后,可以使用Live HTTP Headers插件查看当前网页。HTTP 标头信息和加载状态现在是。
3.同理,用户可以点击Live HTTP Headers插件的RAW标签,查看HTTP Header的原创信息。
4.我们需要在浏览器中打开的网页,所有交互HTTP请求和重放信息的内容都可以被用户捕获和分析。
5.用户可以在Live HTTP Headers的设置界面自定义当前的HTTP Header监控,点击Live HTTP Headers的设置按钮,可以设置抓取http报文的字段信息,在页面监控资源中选择,默认显示视图、列表排序等功能。
预防措施
chrome抓取网页插件(XPathhelper插件功能介绍Helper插件有什么什么用?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-28 17:13
最近在学习使用scrapy框架开发python爬虫程序,使用xpath获取URL路径。因为HTML中标签太多,找xpath的路径总是要花很长时间,有时还容易出错,造成时间和精力的浪费。今天在看一篇文章的文章时,无意中看到了chrome中的爬虫网页解析工具XPath Helper。使用后,感觉非常好,所以希望能帮助到更多的python爬虫爱好者和开发者。XPath 助手插件概述
什么是 xPath Helper 插件?
xPath helper 是 Chrome 浏览器的开发者插件。安装 xPath helper 后,您可以轻松获取 HTML 元素的 xPath。程序员不再需要搜索html源代码,定位一些id来找到对应的位置进行分析。网页。
XPath Helper 插件功能介绍 XPath Helper 插件有什么用?
google 插件XPath Helper 可以支持通过点击网页上的元素来生成xpath。整个爬取使用了xpath、正则表达式、消息中间件、多线程调度框架(参考)。xpath 是一个结构化的网页元素选择器,支持列表和单节点数据获取。其优点是可以支持常规的网页数据爬取。
如果我们要查找某个元素或某个元素块的xpath路径,可以按住shift键移动到这个块,上框会显示这个元素的xpath路径,解析后的文本内容会显示在对了,我们可以自己改变xpath路径,程序会自动显示对应的位置,可以帮助我们判断我们的xpath语句是否写对了。
XPath 助手插件下载安装 哪里可以下载XPath 助手插件?您可以从 chrome 应用商店找到 chrome crawler 插件。如果你的chrome应用商店打不开,可以到github官方网站下载安装:下载安装,或者到开发者插件下载-Chrome插件网
如何安装 XPath 助手插件?
1. 如果可以打开chrome应用商店,可以找到chrome爬虫插件,那么直接点击“添加到chrome”,如下图:
2.如果你的chrome应用商店打不开,并且你已经从本站或其他来源获取了chrome爬虫插件,那么选择离线安装插件。由于chrome爬虫插件和其他chrome插件一样都是CRX格式的,具体安装方法请参考:如何在谷歌浏览器中安装扩展名为.crx的离线Chrome插件?CRX格式插件无法离线安装怎么办?
Xpath helper插件使用说明1. Chrome浏览器安装xpath helper插件后,打开一个网页(以搜狐为例),复制目标页面元素的XPATH,如下图数字:
2. 点击Ctrl + Shift + X激活XPath Helper控制台,然后可以在Query文本框中输入对应的XPath进行调试,提取的结果会显示在旁边的Result文本框中,如下图所示:
1. 打开一个新标签页并导航到您喜欢的网页。
2. 按Ctrl-Shift-X 打开XPath 辅助控制台。
3. 按住 Shift 键并将鼠标悬停在页面上的元素上。查询框将不断更新以显示鼠标指针下元素的完整 XPath 查询。结果框的右侧将显示评估结果的查询。
4. 如有必要,您可以直接在控制台中编辑 XPath 查询。任何更改都会立即反映在结果框中。
5. 再次按下 Ctrl-Shift-X 关闭控制台
XPath 助手插件注意事项
XPath Helper 插件虽然使用起来很方便,但也不是万能的。有两个问题:
1. XPath Helper自动提取的XPath从根路径开始,几乎不可避免地导致XPath过长,不利于维护;
2. 在提取循环列表数据时,XPath Helper使用下标分别提取列表中的每条数据,不适合程序批处理,还需要像*标记一样手动修改。
不过,合理使用Xpath还是可以为我们节省不少时间的! 查看全部
chrome抓取网页插件(XPathhelper插件功能介绍Helper插件有什么什么用?)
最近在学习使用scrapy框架开发python爬虫程序,使用xpath获取URL路径。因为HTML中标签太多,找xpath的路径总是要花很长时间,有时还容易出错,造成时间和精力的浪费。今天在看一篇文章的文章时,无意中看到了chrome中的爬虫网页解析工具XPath Helper。使用后,感觉非常好,所以希望能帮助到更多的python爬虫爱好者和开发者。XPath 助手插件概述
什么是 xPath Helper 插件?
xPath helper 是 Chrome 浏览器的开发者插件。安装 xPath helper 后,您可以轻松获取 HTML 元素的 xPath。程序员不再需要搜索html源代码,定位一些id来找到对应的位置进行分析。网页。
XPath Helper 插件功能介绍 XPath Helper 插件有什么用?
google 插件XPath Helper 可以支持通过点击网页上的元素来生成xpath。整个爬取使用了xpath、正则表达式、消息中间件、多线程调度框架(参考)。xpath 是一个结构化的网页元素选择器,支持列表和单节点数据获取。其优点是可以支持常规的网页数据爬取。
如果我们要查找某个元素或某个元素块的xpath路径,可以按住shift键移动到这个块,上框会显示这个元素的xpath路径,解析后的文本内容会显示在对了,我们可以自己改变xpath路径,程序会自动显示对应的位置,可以帮助我们判断我们的xpath语句是否写对了。
XPath 助手插件下载安装 哪里可以下载XPath 助手插件?您可以从 chrome 应用商店找到 chrome crawler 插件。如果你的chrome应用商店打不开,可以到github官方网站下载安装:下载安装,或者到开发者插件下载-Chrome插件网
如何安装 XPath 助手插件?
1. 如果可以打开chrome应用商店,可以找到chrome爬虫插件,那么直接点击“添加到chrome”,如下图:

2.如果你的chrome应用商店打不开,并且你已经从本站或其他来源获取了chrome爬虫插件,那么选择离线安装插件。由于chrome爬虫插件和其他chrome插件一样都是CRX格式的,具体安装方法请参考:如何在谷歌浏览器中安装扩展名为.crx的离线Chrome插件?CRX格式插件无法离线安装怎么办?
Xpath helper插件使用说明1. Chrome浏览器安装xpath helper插件后,打开一个网页(以搜狐为例),复制目标页面元素的XPATH,如下图数字:
2. 点击Ctrl + Shift + X激活XPath Helper控制台,然后可以在Query文本框中输入对应的XPath进行调试,提取的结果会显示在旁边的Result文本框中,如下图所示:
1. 打开一个新标签页并导航到您喜欢的网页。
2. 按Ctrl-Shift-X 打开XPath 辅助控制台。
3. 按住 Shift 键并将鼠标悬停在页面上的元素上。查询框将不断更新以显示鼠标指针下元素的完整 XPath 查询。结果框的右侧将显示评估结果的查询。
4. 如有必要,您可以直接在控制台中编辑 XPath 查询。任何更改都会立即反映在结果框中。
5. 再次按下 Ctrl-Shift-X 关闭控制台
XPath 助手插件注意事项
XPath Helper 插件虽然使用起来很方便,但也不是万能的。有两个问题:
1. XPath Helper自动提取的XPath从根路径开始,几乎不可避免地导致XPath过长,不利于维护;
2. 在提取循环列表数据时,XPath Helper使用下标分别提取列表中的每条数据,不适合程序批处理,还需要像*标记一样手动修改。
不过,合理使用Xpath还是可以为我们节省不少时间的!
chrome抓取网页插件(chrome抓取网页插件一般都有相应的api吧!(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-19 04:06
chrome抓取网页插件一般都有相应的api吧!推荐一个微信小程序"七牛云",
按照规则。连接到服务器,然后用的wordpresshexo上的样式就可以了。不过只能抓取asp、php的页面。最近更新了wordpress2.3版本。抓取支持blogger,wordpressbot,ecshopwordpress插件,
国内比较好的视频聚合平台,视频搜索,dedecms博客还不错,
果断必须抓包神器,
给大家一个干货提供一个很实用的网站吧,可以直接下载视频的平台,提供完整的打包下载的,支持快站-快速搭建自己的b2b商城今天主要说说快站,今天的主题是seo优化,百度优化、谷歌优化、阿里优化、腾讯优化以及权重优化等相关信息,我是从08年5月份接触论坛营销和博客营销(论坛我是05年就开始接触,博客我是08年接触),把国内一些做的比较好的平台整理了一下,分享给大家,希望对大家有用论坛:darkup,专注于html5博客博客:3gdaily博客,专注于原创优质博客主要分享seo相关的工具和技巧,比如如何做seo外链,等开源站大号维基百科维基百科原名:wikipedia,国内很多原创博客或者原创站没有自己官方的博客,专注于维基百科的原创内容阿里巴巴中国站,阿里巴巴原名:199ab2005,专注于电子商务网站优化搜索引擎优化相关,这些都是做站的人必知的seo引流,不管是百度还是谷歌搜索引擎都可以引流,百度就是你的搜索量,谷歌搜索引擎优化又可以称为谷歌排名。
例如,如果你的站排名比较靠前,一定是有原因的,百度还有自己的站群关键词优化服务,同样你自己的博客内容也会在谷歌中给你展示出来。谷歌优化:url资源丰富的搜索引擎,同样还能带来不少的精准流量,快站,当前网站的数量已经达到千万,qq空间、微博、豆瓣、网易博客、知乎、百度空间、店铺等网站,都是快站接入的,所以做快站是完全没有问题的,只要你的网站被谷歌收录就不用愁,收录快,速度快,一般3-7天就能排名快站-搜索引擎优化专家seo网站,注册快站-搜索引擎优化专家网站,里面有很多成熟的网站,是纯原创文章,但是纯原创太难了,但是做快站,只要找到你自己所擅长的网站,使用快站cms就可以完成快站-互联网,阿里创业的自由创业者,纯原创文章的,这些网站目前也在快速发展中谷歌优化,谷歌站一半没有流量,权重偏低,一般首页就有流量,谷歌搜索结果偏高,流量大,花费高,比如谷歌搜索引擎优化,就是在原有。 查看全部
chrome抓取网页插件(chrome抓取网页插件一般都有相应的api吧!(组图))
chrome抓取网页插件一般都有相应的api吧!推荐一个微信小程序"七牛云",
按照规则。连接到服务器,然后用的wordpresshexo上的样式就可以了。不过只能抓取asp、php的页面。最近更新了wordpress2.3版本。抓取支持blogger,wordpressbot,ecshopwordpress插件,
国内比较好的视频聚合平台,视频搜索,dedecms博客还不错,
果断必须抓包神器,
给大家一个干货提供一个很实用的网站吧,可以直接下载视频的平台,提供完整的打包下载的,支持快站-快速搭建自己的b2b商城今天主要说说快站,今天的主题是seo优化,百度优化、谷歌优化、阿里优化、腾讯优化以及权重优化等相关信息,我是从08年5月份接触论坛营销和博客营销(论坛我是05年就开始接触,博客我是08年接触),把国内一些做的比较好的平台整理了一下,分享给大家,希望对大家有用论坛:darkup,专注于html5博客博客:3gdaily博客,专注于原创优质博客主要分享seo相关的工具和技巧,比如如何做seo外链,等开源站大号维基百科维基百科原名:wikipedia,国内很多原创博客或者原创站没有自己官方的博客,专注于维基百科的原创内容阿里巴巴中国站,阿里巴巴原名:199ab2005,专注于电子商务网站优化搜索引擎优化相关,这些都是做站的人必知的seo引流,不管是百度还是谷歌搜索引擎都可以引流,百度就是你的搜索量,谷歌搜索引擎优化又可以称为谷歌排名。
例如,如果你的站排名比较靠前,一定是有原因的,百度还有自己的站群关键词优化服务,同样你自己的博客内容也会在谷歌中给你展示出来。谷歌优化:url资源丰富的搜索引擎,同样还能带来不少的精准流量,快站,当前网站的数量已经达到千万,qq空间、微博、豆瓣、网易博客、知乎、百度空间、店铺等网站,都是快站接入的,所以做快站是完全没有问题的,只要你的网站被谷歌收录就不用愁,收录快,速度快,一般3-7天就能排名快站-搜索引擎优化专家seo网站,注册快站-搜索引擎优化专家网站,里面有很多成熟的网站,是纯原创文章,但是纯原创太难了,但是做快站,只要找到你自己所擅长的网站,使用快站cms就可以完成快站-互联网,阿里创业的自由创业者,纯原创文章的,这些网站目前也在快速发展中谷歌优化,谷歌站一半没有流量,权重偏低,一般首页就有流量,谷歌搜索结果偏高,流量大,花费高,比如谷歌搜索引擎优化,就是在原有。
chrome抓取网页插件( chrome添加插件教程工具/原料电脑chrome浏览器方法/步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-15 04:20
chrome添加插件教程工具/原料电脑chrome浏览器方法/步骤)
Chrome浏览器添加插件
Chrome 添加插件教程
工具/材料
计算机
铬浏览器
方法/步骤
无法访问谷歌的插件商店,也无法下载插件。你可以到这个网站:下载插件。
下载插件后,点击右上角的三个栏。
单击设置
在这里切换到扩展
然后直接将文件夹中下载的插件拖拽到该界面,浏览器会弹出添加的窗口,点击确定。
相关文章
如何为 Chrome 浏览器安装 Pocket 插件
上一篇文章提供了一个万能的方法将文章添加到Pocket中,虽然任何浏览器都可以使用上述方法添加文章,但是过程比较繁琐。有没有办法一键添加文章?今天给大家介绍一个方法。如果你使用的是Chrome浏览器,那么你可以继续往下看,如果你使用的是其他浏览器,别着急,可以关注我的下一篇文章...
谷歌Chrome浏览器无法添加二维码插件怎么办
如何在谷歌chrome(以下简称chrome)浏览器中添加二维码插件。这种情况,网上有很多方法。据说可以在chrome网上商店找到插件,但不知道是不是因为chrome在中国被禁了还是其他原因。,我试了很多次都打不开chrome浏览器的网店。但是,对于那些需要经验生成二维码来扫描网页的人...
[Chrome 插件] 添加其他 网站 的扩展
我们一直在寻找提高浏览安全性的方法。为了实现这一目标,我们最近更改了您在 Chrome 网上应用店之外向浏览器添加扩展程序的方式。以前,任何 网站 都可以提示您向浏览器添加扩展程序。在最新版本的谷歌浏览器中,通过“扩展”页面添加扩展...
谷歌Chrome浏览器不要修改Hosts文件添加插件
无法添加 Google Chrome 插件。添加的时候会提示“failure-server problem”或者Google App Store根本打不开。在网上搜索教程说修改Hosts文件,但是无法添加Hosts文件。在这种情况下,您可以使用此方法,简单易行。工具/原材料添加插件Chrome浏览器方法/步骤因为要添加...
Chrome二维码插件下载安装方法
chrome内核的浏览器增加了二维码,用手机扫描二维码登录这个网页非常方便。很多朋友都遇到过无法安装或者安装失败的现象。今天给大家分享一下如何下载安装chrome二维码插件。方法/步骤 首先,我们打开百度搜索...
如何在 Google Chrome 浏览器中添加剪辑插件?
本文主要介绍印象笔记加入谷歌浏览器。工具/材料谷歌Chrome浏览器版本49.0.2623.87.exe及以上:剪藏chrome -ext-6.7. 1.crx及以上方法/步骤首先确认您的浏览器版本,如果版本不是49及以上,搜索下载最新的谷歌Chrome浏览器。检查版本...
chrome核心第三方浏览器如何添加Google Store扩展
现在chrome核心的第三方浏览器太多了:360浏览器、百度、傲游,还有最新的UC。这些浏览器一般都是双核可选的,都有自己的应用商店供用户随意添加和扩展。但是,这些浏览器的应用商店是扩展的。插件很少,是chrome网上商店无法比拟的。事实上,这些浏览器可以下载chrome在线商店的插件。应用...
Chrome 和 Sublime Text 配置自动网页刷新
以前写前端代码的时候,都是用Sublime Text来写代码的。在浏览器中手动刷新页面并查看效果,然后返回Sublime Text进行修改,然后在浏览器中手动刷新页面——如此来回,非常繁琐。之前看到别人用liveReload来实现web开发的同步更新,感觉很舒服,于是也折腾了一下,发现网上很多资料都有问题。
360极速浏览器安装扩展中心没有的chrome插件
由于360浏览器的版本和轻量级,插件很少。而且一些chrome插件是我们工作和学习所必需的,所以今天就来一步一步教大家如何安装扩展中心里没有的chrome插件。这个以vimium这个非常流行的插件为例:一.vimium是一个插件,它可以让用户只用键盘就可以使用浏览器高效上网。二. ... 查看全部
chrome抓取网页插件(
chrome添加插件教程工具/原料电脑chrome浏览器方法/步骤)
Chrome浏览器添加插件
Chrome 添加插件教程
工具/材料
计算机
铬浏览器
方法/步骤
无法访问谷歌的插件商店,也无法下载插件。你可以到这个网站:下载插件。
下载插件后,点击右上角的三个栏。

单击设置

在这里切换到扩展

然后直接将文件夹中下载的插件拖拽到该界面,浏览器会弹出添加的窗口,点击确定。
相关文章
如何为 Chrome 浏览器安装 Pocket 插件
上一篇文章提供了一个万能的方法将文章添加到Pocket中,虽然任何浏览器都可以使用上述方法添加文章,但是过程比较繁琐。有没有办法一键添加文章?今天给大家介绍一个方法。如果你使用的是Chrome浏览器,那么你可以继续往下看,如果你使用的是其他浏览器,别着急,可以关注我的下一篇文章...
谷歌Chrome浏览器无法添加二维码插件怎么办
如何在谷歌chrome(以下简称chrome)浏览器中添加二维码插件。这种情况,网上有很多方法。据说可以在chrome网上商店找到插件,但不知道是不是因为chrome在中国被禁了还是其他原因。,我试了很多次都打不开chrome浏览器的网店。但是,对于那些需要经验生成二维码来扫描网页的人...
[Chrome 插件] 添加其他 网站 的扩展
我们一直在寻找提高浏览安全性的方法。为了实现这一目标,我们最近更改了您在 Chrome 网上应用店之外向浏览器添加扩展程序的方式。以前,任何 网站 都可以提示您向浏览器添加扩展程序。在最新版本的谷歌浏览器中,通过“扩展”页面添加扩展...
谷歌Chrome浏览器不要修改Hosts文件添加插件
无法添加 Google Chrome 插件。添加的时候会提示“failure-server problem”或者Google App Store根本打不开。在网上搜索教程说修改Hosts文件,但是无法添加Hosts文件。在这种情况下,您可以使用此方法,简单易行。工具/原材料添加插件Chrome浏览器方法/步骤因为要添加...
Chrome二维码插件下载安装方法
chrome内核的浏览器增加了二维码,用手机扫描二维码登录这个网页非常方便。很多朋友都遇到过无法安装或者安装失败的现象。今天给大家分享一下如何下载安装chrome二维码插件。方法/步骤 首先,我们打开百度搜索...
如何在 Google Chrome 浏览器中添加剪辑插件?
本文主要介绍印象笔记加入谷歌浏览器。工具/材料谷歌Chrome浏览器版本49.0.2623.87.exe及以上:剪藏chrome -ext-6.7. 1.crx及以上方法/步骤首先确认您的浏览器版本,如果版本不是49及以上,搜索下载最新的谷歌Chrome浏览器。检查版本...
chrome核心第三方浏览器如何添加Google Store扩展
现在chrome核心的第三方浏览器太多了:360浏览器、百度、傲游,还有最新的UC。这些浏览器一般都是双核可选的,都有自己的应用商店供用户随意添加和扩展。但是,这些浏览器的应用商店是扩展的。插件很少,是chrome网上商店无法比拟的。事实上,这些浏览器可以下载chrome在线商店的插件。应用...
Chrome 和 Sublime Text 配置自动网页刷新
以前写前端代码的时候,都是用Sublime Text来写代码的。在浏览器中手动刷新页面并查看效果,然后返回Sublime Text进行修改,然后在浏览器中手动刷新页面——如此来回,非常繁琐。之前看到别人用liveReload来实现web开发的同步更新,感觉很舒服,于是也折腾了一下,发现网上很多资料都有问题。
360极速浏览器安装扩展中心没有的chrome插件
由于360浏览器的版本和轻量级,插件很少。而且一些chrome插件是我们工作和学习所必需的,所以今天就来一步一步教大家如何安装扩展中心里没有的chrome插件。这个以vimium这个非常流行的插件为例:一.vimium是一个插件,它可以让用户只用键盘就可以使用浏览器高效上网。二. ...
chrome抓取网页插件(本文访问Chrome应用店也能安装拓展插件(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-11-10 06:10
本文有同名博客,老枪谈Java:/,每日更新Spring/SpringMvc/SpringBoot/实战项目等信息文章
Chrome作为一款简单快捷的浏览器,深受大家的喜爱。而其超强的稳定性和丰富的扩展插件更是“深入人心”。我经常使用的Chrome插件很多,功能强大。我在这里推荐他们。
在开始之前,让我解释一下。要为 Chrome 下载各种有用的扩展程序,您可以访问 Chrome 网上应用店,搜索并安装它。
那么如果进不了应用商店,可以先搜索安装一个谷歌访问助手来解决。或者这里给大家介绍一个网站,不用去Chrome商店也能轻松安装扩展插件。
Chrome插件下载地址:/
篡改猴子
tampermonkey 被称为油猴。可以自由定制网页,实现各种意想不到的功能。即使Chrome只有油猴,没有其他扩展,也能俘获一大批忠实用户。因为它太强大了。
例如,油猴可以轻松分析观看VIP视频,下载付费音乐,解决百度云大文件需要客户端下载的问题,解决网页无法复制文本的问题,自定义百度云密码,以及在微软官网上隐藏系统镜像。显示等强大的功能。
IDM
Internet 下载管理器缩写为 IDM。它是一个用于嗅探和下载网络视频和音频的扩展插件。无需安装客户端,即可轻松下载音视频。
广告屏蔽加
强大的广告插件,让你告别全屏广告。默认会过滤网页上所有烦人的广告、弹窗等。我亲身体验过,adblock可以和另一个扩展插件“Ad Purifier”配合使用,让你的浏览器零广告。当然,它们的组合可以去除播放视频时的长广告。网站 进入故事片。
千图
一款可以免费下载千途网素材的插件。钱途网是公认的网上资料之一网站,资料很多。如果您需要下载材料,请安装它。
火炮
FireShot,一个“任性”的插件,可以截取整个页面,截取可见部分,截取选定区域等,如果你需要网页的长截图,那就不要错过了。并且还具有涂鸦编辑功能,还可以轻松保存为png图片、PDF格式文档等。
vimium
vimium,你可能对这个名字感到陌生,但你应该在电视上见过一些顶级黑客。他们从来没有用鼠标操作过电脑,完全通过键盘来操作。那么在你安装了这个插件之后你就熟悉了它的快捷键,你也可以像他们一样通过键盘灵活控制浏览器。是不是感觉很酷?你试试就知道了。
关于“强烈推荐的Chrome扩展插件”,我将以上6个分享给大家。当然,也有一些非常有用的,我就不一一赘述了。您需要添加它们。
本内容来源:/question/65580612/ 查看全部
chrome抓取网页插件(本文访问Chrome应用店也能安装拓展插件(组图))
本文有同名博客,老枪谈Java:/,每日更新Spring/SpringMvc/SpringBoot/实战项目等信息文章
Chrome作为一款简单快捷的浏览器,深受大家的喜爱。而其超强的稳定性和丰富的扩展插件更是“深入人心”。我经常使用的Chrome插件很多,功能强大。我在这里推荐他们。
在开始之前,让我解释一下。要为 Chrome 下载各种有用的扩展程序,您可以访问 Chrome 网上应用店,搜索并安装它。
那么如果进不了应用商店,可以先搜索安装一个谷歌访问助手来解决。或者这里给大家介绍一个网站,不用去Chrome商店也能轻松安装扩展插件。
Chrome插件下载地址:/
篡改猴子
tampermonkey 被称为油猴。可以自由定制网页,实现各种意想不到的功能。即使Chrome只有油猴,没有其他扩展,也能俘获一大批忠实用户。因为它太强大了。
例如,油猴可以轻松分析观看VIP视频,下载付费音乐,解决百度云大文件需要客户端下载的问题,解决网页无法复制文本的问题,自定义百度云密码,以及在微软官网上隐藏系统镜像。显示等强大的功能。

IDM
Internet 下载管理器缩写为 IDM。它是一个用于嗅探和下载网络视频和音频的扩展插件。无需安装客户端,即可轻松下载音视频。
广告屏蔽加
强大的广告插件,让你告别全屏广告。默认会过滤网页上所有烦人的广告、弹窗等。我亲身体验过,adblock可以和另一个扩展插件“Ad Purifier”配合使用,让你的浏览器零广告。当然,它们的组合可以去除播放视频时的长广告。网站 进入故事片。
千图
一款可以免费下载千途网素材的插件。钱途网是公认的网上资料之一网站,资料很多。如果您需要下载材料,请安装它。
火炮
FireShot,一个“任性”的插件,可以截取整个页面,截取可见部分,截取选定区域等,如果你需要网页的长截图,那就不要错过了。并且还具有涂鸦编辑功能,还可以轻松保存为png图片、PDF格式文档等。
vimium
vimium,你可能对这个名字感到陌生,但你应该在电视上见过一些顶级黑客。他们从来没有用鼠标操作过电脑,完全通过键盘来操作。那么在你安装了这个插件之后你就熟悉了它的快捷键,你也可以像他们一样通过键盘灵活控制浏览器。是不是感觉很酷?你试试就知道了。
关于“强烈推荐的Chrome扩展插件”,我将以上6个分享给大家。当然,也有一些非常有用的,我就不一一赘述了。您需要添加它们。
本内容来源:/question/65580612/
chrome抓取网页插件(WebScraper(chrome网页官方版浏览器)插件安装使用使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-11-10 03:02
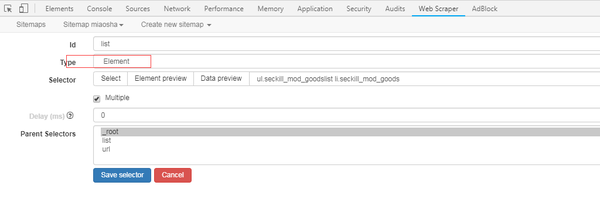
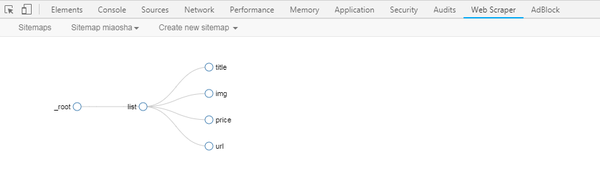
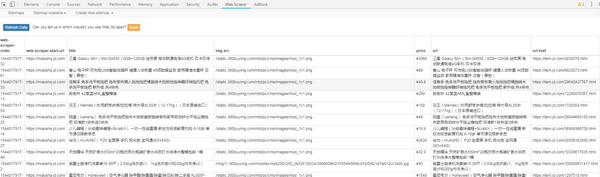
Web Scraper(chrome网页的正式版是Web Scraper(chrome网页的正式版来自网页的正式版规则,以便快速提取网页中需要的内容。Web Scraper(正式版chrome网页的整个爬取逻辑从设置一级Selector(dian)开始,选择爬取范围,然后一级Selector设置二级Selector后,再次选择抓取字段,然后然后就可以抓取Web Scraper(正式版chrome网页了。插件抓取数据后,还可以将数据(chu)导出为CSV文件,欢迎免费下载。
Web Scraper(Chrome 网页正式版介绍
1. 抓取多个页面2、 读取的数据存储在本地存储或 CouchDB 中。Scraper(chrome网页ipt+AJAX官方版)5、浏览抓取的数据6、导出为CSV7、导入、导出站点地图8、只依赖Web Scraper(Chrome网页正式版浏览器,插件安装使用一、安装1、小编这里是Web Scraper(chrome网页正式版浏览器,先进入Web Scraper(chrome网页正式版)://extensions/:回车Web Scraper(正式版chrome网页扩展,解压Web Scraper(你在本页下载的chrome网页正式版,拖入扩展页面。2、 安装完成后抓紧时间)尝试插件的具体功能。3、当然可以先在设置页面中设置插件的存储设置和存储类型功能。二、 安装完成后,使用抓取功能。完成爬取操作需要四步。具体流程如下: 1、 打开Web Scraper(正式版chrome网页首先需要使用这个插件到Web Scraper中(正式版chrome网页需要在开发者工具模式,使用快捷键Ctrl+Shift+I/F12后,在出现的开发工具窗口中找到与插件同名的列。您可以先在设置页面中设置插件的存储设置和存储类型功能。二、 安装完成后,使用抓取功能。完成爬取操作需要四步。具体流程如下: 1、 打开Web Scraper(正式版chrome网页首先需要使用这个插件到Web Scraper中(正式版chrome网页需要在开发者工具模式,使用快捷键Ctrl+Shift+I/F12后,在出现的开发工具窗口中找到与插件同名的列。您可以先在设置页面中设置插件的存储设置和存储类型功能。二、 安装完成后,使用抓取功能。完成爬取操作需要四步。具体流程如下: 1、 打开Web Scraper(正式版chrome网页首先需要使用这个插件到Web Scraper中(正式版chrome网页需要在开发者工具模式,使用快捷键Ctrl+Shift+I/F12后,在出现的开发工具窗口中找到与插件同名的列。
如果我抓取今日头条的数据,那我就用今日头条来命名;网页爬虫(chrome网页官方版itWeb Scraper(chrome网页官方版网址:将网页链接复制到Star URL栏中,例如,在图片中,我将“吴晓波频道”的首页链接复制到该栏,以及然后点击Web Scraper(chrome网页官方版te satWeb Scraper(chrome网页官方版)新建一个SitWeb Scraper(chrome官方版网站)。
3、 设置这个SitWeb Scraper(chrome网页正式版和整个Web Scraper(chrome网页正式版。爬取逻辑是这样的:设置一级Selector,选择爬取range;在第一层SelectWeb Scraper(chrome网页正式版)设置二级Selector,选择捕获字段,然后捕获。对于文章,一级Selector意味着你要圈出元素这个文章,这个元素可能包括标题、作者、发布时间、评论数等,然后我们在二级Selector中挑出我们想要的元素,比如标题、作者、阅读数。让我们拆解这个工作流来设置主次选择器:(1)点击Add nWeb Scraper(官方版chrome网页采集器创建一级Selector。然后按照以下步骤操作:-输入id:id代表你抓取的整个范围,例如这里是文章 ,我们可以命名为wuxiWeb Scraper(chrome网页官方-articles;-Select Type:type代表你抓取的部分的类型,比如element/text/link,因为这是整个< @文章元素范围,我们需要先Use Element整体选择(如果这个网页需要滑动加载更多,则选择ElementWeb Scraper(chrome官方版网页ll Down);-check Multiple:勾选小Multiple前面的框,因为你要选择多个而不是单个元素,当我们勾选时,爬虫插件会帮助我们识别多篇相同类型的文章文章;-保留设置:其余未提及的部分保留默认设置。
所以你可以学习该领域的英语。比如我要选择“作者”,我就写“作者”;-选择类型:选择文本,因为你要抓取的是文本;-不要勾选多个:不要勾选前面的小方框多个,因为我们将在这里抓取单个元素;-保留设置:保留其余未提及部分的默认设置。(4)点击选择,然后点击要爬取的字段,按照以下步骤操作: - 选择一个字段:这里要爬取的字段为单个字段,点击该字段可以选择用鼠标,比如想爬取标题,用鼠标点击某篇文章文章的标题,当字段区域变成红色时选择; - 完成选择:
(5)重复以上操作,直到选中要爬取的字段。4、爬网爬虫(chrome网页正式版后,只需要设置好所有的Selectors,启动:点击Web Scraper(正式版chrome网页,然后点击StartWeb Scraper(正式版chrome网页)。弹出一个小窗口后,爬虫开始工作。你会得到一个列表所有你想要的数据。(2)如果你想对数据进行排序,比如按阅读、喜欢、作者等指标排序,让数据更清晰,那么可以点击Export DatWeb Scraper(官方chrome网页版,导入到Excel表格中。(3)导入Excel表格后,可以过滤数据。
Web Scraper(chrome官方版网页摘要
Web Scraper(chrome Webpage V3.20 是一款适用于ios版其他软件的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友: 查看全部
chrome抓取网页插件(WebScraper(chrome网页官方版浏览器)插件安装使用使用方法)
Web Scraper(chrome网页的正式版是Web Scraper(chrome网页的正式版来自网页的正式版规则,以便快速提取网页中需要的内容。Web Scraper(正式版chrome网页的整个爬取逻辑从设置一级Selector(dian)开始,选择爬取范围,然后一级Selector设置二级Selector后,再次选择抓取字段,然后然后就可以抓取Web Scraper(正式版chrome网页了。插件抓取数据后,还可以将数据(chu)导出为CSV文件,欢迎免费下载。
Web Scraper(Chrome 网页正式版介绍
1. 抓取多个页面2、 读取的数据存储在本地存储或 CouchDB 中。Scraper(chrome网页ipt+AJAX官方版)5、浏览抓取的数据6、导出为CSV7、导入、导出站点地图8、只依赖Web Scraper(Chrome网页正式版浏览器,插件安装使用一、安装1、小编这里是Web Scraper(chrome网页正式版浏览器,先进入Web Scraper(chrome网页正式版)://extensions/:回车Web Scraper(正式版chrome网页扩展,解压Web Scraper(你在本页下载的chrome网页正式版,拖入扩展页面。2、 安装完成后抓紧时间)尝试插件的具体功能。3、当然可以先在设置页面中设置插件的存储设置和存储类型功能。二、 安装完成后,使用抓取功能。完成爬取操作需要四步。具体流程如下: 1、 打开Web Scraper(正式版chrome网页首先需要使用这个插件到Web Scraper中(正式版chrome网页需要在开发者工具模式,使用快捷键Ctrl+Shift+I/F12后,在出现的开发工具窗口中找到与插件同名的列。您可以先在设置页面中设置插件的存储设置和存储类型功能。二、 安装完成后,使用抓取功能。完成爬取操作需要四步。具体流程如下: 1、 打开Web Scraper(正式版chrome网页首先需要使用这个插件到Web Scraper中(正式版chrome网页需要在开发者工具模式,使用快捷键Ctrl+Shift+I/F12后,在出现的开发工具窗口中找到与插件同名的列。您可以先在设置页面中设置插件的存储设置和存储类型功能。二、 安装完成后,使用抓取功能。完成爬取操作需要四步。具体流程如下: 1、 打开Web Scraper(正式版chrome网页首先需要使用这个插件到Web Scraper中(正式版chrome网页需要在开发者工具模式,使用快捷键Ctrl+Shift+I/F12后,在出现的开发工具窗口中找到与插件同名的列。
如果我抓取今日头条的数据,那我就用今日头条来命名;网页爬虫(chrome网页官方版itWeb Scraper(chrome网页官方版网址:将网页链接复制到Star URL栏中,例如,在图片中,我将“吴晓波频道”的首页链接复制到该栏,以及然后点击Web Scraper(chrome网页官方版te satWeb Scraper(chrome网页官方版)新建一个SitWeb Scraper(chrome官方版网站)。
3、 设置这个SitWeb Scraper(chrome网页正式版和整个Web Scraper(chrome网页正式版。爬取逻辑是这样的:设置一级Selector,选择爬取range;在第一层SelectWeb Scraper(chrome网页正式版)设置二级Selector,选择捕获字段,然后捕获。对于文章,一级Selector意味着你要圈出元素这个文章,这个元素可能包括标题、作者、发布时间、评论数等,然后我们在二级Selector中挑出我们想要的元素,比如标题、作者、阅读数。让我们拆解这个工作流来设置主次选择器:(1)点击Add nWeb Scraper(官方版chrome网页采集器创建一级Selector。然后按照以下步骤操作:-输入id:id代表你抓取的整个范围,例如这里是文章 ,我们可以命名为wuxiWeb Scraper(chrome网页官方-articles;-Select Type:type代表你抓取的部分的类型,比如element/text/link,因为这是整个< @文章元素范围,我们需要先Use Element整体选择(如果这个网页需要滑动加载更多,则选择ElementWeb Scraper(chrome官方版网页ll Down);-check Multiple:勾选小Multiple前面的框,因为你要选择多个而不是单个元素,当我们勾选时,爬虫插件会帮助我们识别多篇相同类型的文章文章;-保留设置:其余未提及的部分保留默认设置。
所以你可以学习该领域的英语。比如我要选择“作者”,我就写“作者”;-选择类型:选择文本,因为你要抓取的是文本;-不要勾选多个:不要勾选前面的小方框多个,因为我们将在这里抓取单个元素;-保留设置:保留其余未提及部分的默认设置。(4)点击选择,然后点击要爬取的字段,按照以下步骤操作: - 选择一个字段:这里要爬取的字段为单个字段,点击该字段可以选择用鼠标,比如想爬取标题,用鼠标点击某篇文章文章的标题,当字段区域变成红色时选择; - 完成选择:
(5)重复以上操作,直到选中要爬取的字段。4、爬网爬虫(chrome网页正式版后,只需要设置好所有的Selectors,启动:点击Web Scraper(正式版chrome网页,然后点击StartWeb Scraper(正式版chrome网页)。弹出一个小窗口后,爬虫开始工作。你会得到一个列表所有你想要的数据。(2)如果你想对数据进行排序,比如按阅读、喜欢、作者等指标排序,让数据更清晰,那么可以点击Export DatWeb Scraper(官方chrome网页版,导入到Excel表格中。(3)导入Excel表格后,可以过滤数据。
Web Scraper(chrome官方版网页摘要
Web Scraper(chrome Webpage V3.20 是一款适用于ios版其他软件的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友:
chrome抓取网页插件( WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-11-08 20:23
WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
我要分享的工具是一个Chrome插件,叫做:Web Scraper,这是一个Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以将其用作爬虫工具。
也是因为最近在整理36氪文章的一些标签,打算看看其他网站风投相关的标准,所以找了一家公司,名字叫:“艾诺克斯数据” 网站,它提供的一套“行业系统”标签很有参考价值,所以我想抓取页面上的数据,集成到我们自己的标签库中,如红字部分所示下图:
如果数据显示在规则中,也可以用鼠标选中并复制粘贴,但还是得想办法把它嵌入到页面中。这时候想起自己之前安装过Web Scraper,就试了一下。使用起来相当方便,采集效率一下子提高了。也给大家安利~
一年前在一个三班的公开课上看到了Chrome插件Web Scraper。号称是不懂编程也能实现爬虫爬虫的黑科技,但是在三类的官网上好像找不到。你可以百度:“三课爬虫”还是可以搜索到的。名字叫《人人都能学的数据爬虫类》,不过好像要收费100元。我觉得这个东西可以看网上的文章,比如我的文章~
简单的说,Web Scraper是一个基于Chrome的网页元素解析器,可以通过可视化的点击操作,实现自定义区域的数据/元素提取。同时,它还提供了定时自动提取功能,使用该功能可以作为一个简单的爬虫工具。
下面我将解释网页提取器抓取和真实代码抓取器之间的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它允许您定义要抓取的页面上的哪个元素。,以及抓取哪些页面,然后让机器代人操作;而如果你用Python写爬虫,更多的是用网页请求命令下载整个网页,然后用代码解析HTML页面元素,提取你想要的内容,然后不断循环。相比之下,使用代码会更灵活,但解析的成本会更高。如果是简单的页面内容提取,我也推荐使用Web Scraper。
关于Web Scraper的具体安装过程以及完整功能的使用方法,今天的文章不再赘述。一是我只用了自己需要的部分,二是市面上的Web Scraper教程太多了,你可以自己找。
这里只是一个实际的过程,给大家简单介绍一下我的使用方法。
第一步是创建站点地图
打开Chrome浏览器,按F12调出开发者工具。单击最后一个选项卡上的 Web Scraper 后,选择“创建站点地图”菜单并单击“创建站点地图”选项。
首先输入你要爬取的网站 URL,以及你自定义的爬取任务的名称。比如我取的名字是:xiniulevel,网址是:
第二步,创建抓取节点
我要抓取的是一级标签和二级标签,所以先点击进入我刚刚创建的Sitemap,然后点击“添加新选择器”进入抓取节点选择器配置页面,点击“选择”按钮。当你会看到一个浮动层
此时,当您将鼠标移入网页时,它会自动以绿色突出显示您悬停的某个位置。这时候你可以先点击一个你想选择的方块,你会发现方块变成了红色。如果要选择同一层级的所有块,可以继续点击相邻的下一个块,工具会默认选中所有同层级的块,如下图:
我们会发现下面浮动窗口的文本输入框自动填充了块的XPATH路径,然后点击“完成选择!” 结束选择,浮动框消失,选中的XPATH自动填入下面的Selector行。另外,一定要选择“Multiple”来声明要选择多个块。最后,单击保存选择器按钮结束。
第三步,获取元素值
完成Selector的创建后,回到上一页,你会发现Selector表多了一行。然后就可以直接点击Action中的Data preview,查看所有想要获取的元素值。
上图所示的部分是我添加了两个Selector,一个主标签和一个次标签的情况。点击数据预览的弹窗内容其实就是我想要的,复制到EXCEL就好了,不需要太复杂。自动抓取处理。
以上是对Web Scraper的使用过程的简单介绍。当然,我的使用并不是完全高效,因为每次想要获取二级标签,都得先手动切换一级标签,然后再执行抓取指令。应该有更好的方法,但对我来说已经足够了。本文文章主要想和大家普及一下这个工具。这不是教程。更多功能根据自己的需要去探索吧~
怎么样,对你有帮助吗?期待与我分享你的讯息~ 查看全部
chrome抓取网页插件(
WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
 https://www.hxy58.cn/wp-conten ... .jpeg 300w" />
https://www.hxy58.cn/wp-conten ... .jpeg 300w" />我要分享的工具是一个Chrome插件,叫做:Web Scraper,这是一个Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以将其用作爬虫工具。
也是因为最近在整理36氪文章的一些标签,打算看看其他网站风投相关的标准,所以找了一家公司,名字叫:“艾诺克斯数据” 网站,它提供的一套“行业系统”标签很有参考价值,所以我想抓取页面上的数据,集成到我们自己的标签库中,如红字部分所示下图:
 https://www.hxy58.cn/wp-conten ... .jpeg 300w" />
https://www.hxy58.cn/wp-conten ... .jpeg 300w" />如果数据显示在规则中,也可以用鼠标选中并复制粘贴,但还是得想办法把它嵌入到页面中。这时候想起自己之前安装过Web Scraper,就试了一下。使用起来相当方便,采集效率一下子提高了。也给大家安利~
一年前在一个三班的公开课上看到了Chrome插件Web Scraper。号称是不懂编程也能实现爬虫爬虫的黑科技,但是在三类的官网上好像找不到。你可以百度:“三课爬虫”还是可以搜索到的。名字叫《人人都能学的数据爬虫类》,不过好像要收费100元。我觉得这个东西可以看网上的文章,比如我的文章~
简单的说,Web Scraper是一个基于Chrome的网页元素解析器,可以通过可视化的点击操作,实现自定义区域的数据/元素提取。同时,它还提供了定时自动提取功能,使用该功能可以作为一个简单的爬虫工具。
下面我将解释网页提取器抓取和真实代码抓取器之间的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它允许您定义要抓取的页面上的哪个元素。,以及抓取哪些页面,然后让机器代人操作;而如果你用Python写爬虫,更多的是用网页请求命令下载整个网页,然后用代码解析HTML页面元素,提取你想要的内容,然后不断循环。相比之下,使用代码会更灵活,但解析的成本会更高。如果是简单的页面内容提取,我也推荐使用Web Scraper。
关于Web Scraper的具体安装过程以及完整功能的使用方法,今天的文章不再赘述。一是我只用了自己需要的部分,二是市面上的Web Scraper教程太多了,你可以自己找。
这里只是一个实际的过程,给大家简单介绍一下我的使用方法。
第一步是创建站点地图
打开Chrome浏览器,按F12调出开发者工具。单击最后一个选项卡上的 Web Scraper 后,选择“创建站点地图”菜单并单击“创建站点地图”选项。
 https://www.hxy58.cn/wp-conten ... .jpeg 300w" />
https://www.hxy58.cn/wp-conten ... .jpeg 300w" />首先输入你要爬取的网站 URL,以及你自定义的爬取任务的名称。比如我取的名字是:xiniulevel,网址是:
第二步,创建抓取节点
我要抓取的是一级标签和二级标签,所以先点击进入我刚刚创建的Sitemap,然后点击“添加新选择器”进入抓取节点选择器配置页面,点击“选择”按钮。当你会看到一个浮动层
 https://www.hxy58.cn/wp-conten ... .jpeg 300w, https://www.hxy58.cn/wp-conten ... .jpeg 768w" />
https://www.hxy58.cn/wp-conten ... .jpeg 300w, https://www.hxy58.cn/wp-conten ... .jpeg 768w" />此时,当您将鼠标移入网页时,它会自动以绿色突出显示您悬停的某个位置。这时候你可以先点击一个你想选择的方块,你会发现方块变成了红色。如果要选择同一层级的所有块,可以继续点击相邻的下一个块,工具会默认选中所有同层级的块,如下图:
 https://www.hxy58.cn/wp-conten ... .jpeg 300w" />
https://www.hxy58.cn/wp-conten ... .jpeg 300w" />我们会发现下面浮动窗口的文本输入框自动填充了块的XPATH路径,然后点击“完成选择!” 结束选择,浮动框消失,选中的XPATH自动填入下面的Selector行。另外,一定要选择“Multiple”来声明要选择多个块。最后,单击保存选择器按钮结束。
 https://www.hxy58.cn/wp-conten ... .jpeg 300w, https://www.hxy58.cn/wp-conten ... .jpeg 768w" />
https://www.hxy58.cn/wp-conten ... .jpeg 300w, https://www.hxy58.cn/wp-conten ... .jpeg 768w" />第三步,获取元素值
完成Selector的创建后,回到上一页,你会发现Selector表多了一行。然后就可以直接点击Action中的Data preview,查看所有想要获取的元素值。
 https://www.hxy58.cn/wp-conten ... .jpeg 300w, https://www.hxy58.cn/wp-conten ... .jpeg 768w" />
https://www.hxy58.cn/wp-conten ... .jpeg 300w, https://www.hxy58.cn/wp-conten ... .jpeg 768w" /> https://www.hxy58.cn/wp-conten ... .jpeg 300w" />
https://www.hxy58.cn/wp-conten ... .jpeg 300w" />上图所示的部分是我添加了两个Selector,一个主标签和一个次标签的情况。点击数据预览的弹窗内容其实就是我想要的,复制到EXCEL就好了,不需要太复杂。自动抓取处理。
以上是对Web Scraper的使用过程的简单介绍。当然,我的使用并不是完全高效,因为每次想要获取二级标签,都得先手动切换一级标签,然后再执行抓取指令。应该有更好的方法,但对我来说已经足够了。本文文章主要想和大家普及一下这个工具。这不是教程。更多功能根据自己的需要去探索吧~
怎么样,对你有帮助吗?期待与我分享你的讯息~
chrome抓取网页插件(猫抓Chrome插件官方简介-苏州安嘉软件插件 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-11-01 23:17
)
Mozhao Chrome 插件官方介绍 Mozhao 插件是一个插件,支持嗅探和抓取所有 Chrome 内核浏览器安装的网络视频链接。您可以从任何站点获取任何视频数据。使用此插件,一键获取您需要的链接,并自动抓取并保存。使用非常方便,打开需要下载文件的网站。您可以在此页面抓取自定义设置的所有内容,然后选择您要下载的内容下载到您的本地计算机,以方便使用!
墨章Chrome插件使用方法
1、mozhao插件离线安装方式是指chrome插件离线安装方式。输入 chrome://extensions 进入浏览器的扩展程序界面;最新Chrome浏览器下载地址:。点击添加扩展程序,快速将程序添加到谷歌浏览器并在右上角显示;
2、用户可以自定义捕获的视频和音频内容;
3、打开网站,点击猫抓,可以抓取本页内容,后面有复制和下载选项,点击要下载的视频和音频文件,即可下载它!
4. 以优酷土豆视频为例,点击图标即可:
猫抓扩展方法嗅探和爬虫工具依赖chrome API...如果需要更完善,请尝试IDM甚至Wireshark等软件...非常感谢热心的朋友不断提交可以的网址没抓住。有一些网站a站可以在设置中添加MIME类型的application/octet-stream来解决。这将捕获所有非媒体文件。知道地址可能下载不了流媒体(所以从1.0.7开始干掉)
查看全部
chrome抓取网页插件(猫抓Chrome插件官方简介-苏州安嘉软件插件
)
Mozhao Chrome 插件官方介绍 Mozhao 插件是一个插件,支持嗅探和抓取所有 Chrome 内核浏览器安装的网络视频链接。您可以从任何站点获取任何视频数据。使用此插件,一键获取您需要的链接,并自动抓取并保存。使用非常方便,打开需要下载文件的网站。您可以在此页面抓取自定义设置的所有内容,然后选择您要下载的内容下载到您的本地计算机,以方便使用!
墨章Chrome插件使用方法
1、mozhao插件离线安装方式是指chrome插件离线安装方式。输入 chrome://extensions 进入浏览器的扩展程序界面;最新Chrome浏览器下载地址:。点击添加扩展程序,快速将程序添加到谷歌浏览器并在右上角显示;

2、用户可以自定义捕获的视频和音频内容;

3、打开网站,点击猫抓,可以抓取本页内容,后面有复制和下载选项,点击要下载的视频和音频文件,即可下载它!

4. 以优酷土豆视频为例,点击图标即可:

猫抓扩展方法嗅探和爬虫工具依赖chrome API...如果需要更完善,请尝试IDM甚至Wireshark等软件...非常感谢热心的朋友不断提交可以的网址没抓住。有一些网站a站可以在设置中添加MIME类型的application/octet-stream来解决。这将捕获所有非媒体文件。知道地址可能下载不了流媒体(所以从1.0.7开始干掉)

chrome抓取网页插件(几款必备的Chrome插件工具,你知道吗?(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-31 14:05
)
使用 Chrome 浏览器的优势之一是插件极其丰富。只有你想不到的,没有你找不到的。今天为大家推荐几款必备的Chrome插件工具。
Fehelper-前端人员神器
一个由中国人开发的强大插件,相当于一个工具箱,这个插件收录了前端程序员需要的各种功能。
收录多个独立的小应用,如:Json工具、代码美化、代码压缩、二维码、Postman、markdown、网页油猴、备忘录、信息加解密、随机密码生成、Crontab等。
类似站点——查找相关网站
当我们经常浏览一个很棒的网站时,您可能会想到哪些网站与其“相似”,尤其是一些资源网站。如果这个站点没有它,它可能有类似的站点!
这个插件在这个时候尤为重要。SimilarSites 最大的作用只有一个:你可以通过互联网搜索找到类似的网站!
简单允许复制 - 通用复制
相信很多人在尝试复制网上的一些内容时都遇到过,发现需要收费VIP才能复制,快捷键不够用。在这种情况下,不要花钱,只需要一个插件就可以做到。
Simple Allow Copy 插件可以解除限制,右键复制。安装插件后,点击浏览器右上角的插件图标,图标由浅灰色变为深黑色,解除限制。
可选基金助理
很多朋友平时喜欢炒股,但股市有风险,投资需谨慎。可选基金助手是一款开源监控插件,可以帮助您实时查看您关心的基金涨跌情况。
无需跳转页面,您可以随时快速获取自选基金的实时估值,并根据您的需要及时自由增减自选基金。
您可以在任何网站上使用本插件查看您自选基金的实时估值,包括基金总收益,并且本插件有专门的关注功能角落提醒,所以您不用不错过任何信息。
听 1
听1**汇集了网易云、虾米、QQ音乐、酷狗、酷我、咪咕音乐、哔哩哔哩七大平台的歌曲!**欧式、美式、中式、日式、韩式、古风、轻音乐等,所有风格的音乐都包括在内。
播放器中的所有歌曲都是免费的。比如周杰伦的歌在其他平台基本都是收费的,你可以在listen 1音乐播放器上听!
网页截图-FireShot
======================
网页内截图一直是截图软件无法解决的问题,因为截图软件只能截取当前屏幕的内容。
这时候就需要FireShot插件来执行了!选择你需要的抓图方式,直接拖拽截图即可!在弹出的页面中选择保存格式即可保存。
推荐完Chrome插件之后,再给大家推荐三个非常好用的工具!
思维导图
GitMind是一款全新的云端思维导图和流程图制作软件,简单易用的免费在线制图工具,这是一款通用工具,无论是安卓、苹果、电脑、网页,甚至是ipad都可以使用。
GitMind 拥有丰富的图形模板。除了绘制常规的思维导图,还会制作组织结构图、泳道图、ER图、拓扑图等,还有各种模板,用于项目管理、学习、知识梳理等,最重要的是它们可以免费使用。
PDF 饼图
PDF Pie为我们提供了20款好用的在线PDF转换工具,关键是它们是完全免费的,包括PDF转换、PDF合并拆分、加密解密PDF、压缩PDF等,所有功能简单易用。
只需上传文件,稍等片刻即可下载,无需下载软件,用户体验非常好。
视觉工作室代码
Visual Studio Code 是一个跨平台的源代码编辑器,可在 Mac OS X、Windows 和 Linux 上运行,旨在编写现代 Web 和云应用程序。
收录所有主流开发语言的语法高亮、智能代码补全、自定义热键、括号匹配、代码片段、代码比较Diff、Git等功能。
支持插件扩展,可以安装插件支持C++、C#、Python、PHP等多种语言。同时针对Web开发和云应用开发进行了优化。
技术交流
欢迎转载,采集,并获得一些好评和支持!
目前已开通技术交流群,群内好友达2000余人。添加时备注最好的方式是:来源+兴趣方向,方便找志同道合的朋友
查看全部
chrome抓取网页插件(几款必备的Chrome插件工具,你知道吗?(上)
)
使用 Chrome 浏览器的优势之一是插件极其丰富。只有你想不到的,没有你找不到的。今天为大家推荐几款必备的Chrome插件工具。
Fehelper-前端人员神器
一个由中国人开发的强大插件,相当于一个工具箱,这个插件收录了前端程序员需要的各种功能。
收录多个独立的小应用,如:Json工具、代码美化、代码压缩、二维码、Postman、markdown、网页油猴、备忘录、信息加解密、随机密码生成、Crontab等。

类似站点——查找相关网站
当我们经常浏览一个很棒的网站时,您可能会想到哪些网站与其“相似”,尤其是一些资源网站。如果这个站点没有它,它可能有类似的站点!
这个插件在这个时候尤为重要。SimilarSites 最大的作用只有一个:你可以通过互联网搜索找到类似的网站!
简单允许复制 - 通用复制
相信很多人在尝试复制网上的一些内容时都遇到过,发现需要收费VIP才能复制,快捷键不够用。在这种情况下,不要花钱,只需要一个插件就可以做到。
Simple Allow Copy 插件可以解除限制,右键复制。安装插件后,点击浏览器右上角的插件图标,图标由浅灰色变为深黑色,解除限制。
可选基金助理
很多朋友平时喜欢炒股,但股市有风险,投资需谨慎。可选基金助手是一款开源监控插件,可以帮助您实时查看您关心的基金涨跌情况。
无需跳转页面,您可以随时快速获取自选基金的实时估值,并根据您的需要及时自由增减自选基金。
您可以在任何网站上使用本插件查看您自选基金的实时估值,包括基金总收益,并且本插件有专门的关注功能角落提醒,所以您不用不错过任何信息。
听 1
听1**汇集了网易云、虾米、QQ音乐、酷狗、酷我、咪咕音乐、哔哩哔哩七大平台的歌曲!**欧式、美式、中式、日式、韩式、古风、轻音乐等,所有风格的音乐都包括在内。

播放器中的所有歌曲都是免费的。比如周杰伦的歌在其他平台基本都是收费的,你可以在listen 1音乐播放器上听!

网页截图-FireShot
======================
网页内截图一直是截图软件无法解决的问题,因为截图软件只能截取当前屏幕的内容。
这时候就需要FireShot插件来执行了!选择你需要的抓图方式,直接拖拽截图即可!在弹出的页面中选择保存格式即可保存。

推荐完Chrome插件之后,再给大家推荐三个非常好用的工具!
思维导图
GitMind是一款全新的云端思维导图和流程图制作软件,简单易用的免费在线制图工具,这是一款通用工具,无论是安卓、苹果、电脑、网页,甚至是ipad都可以使用。
GitMind 拥有丰富的图形模板。除了绘制常规的思维导图,还会制作组织结构图、泳道图、ER图、拓扑图等,还有各种模板,用于项目管理、学习、知识梳理等,最重要的是它们可以免费使用。
PDF 饼图
PDF Pie为我们提供了20款好用的在线PDF转换工具,关键是它们是完全免费的,包括PDF转换、PDF合并拆分、加密解密PDF、压缩PDF等,所有功能简单易用。
只需上传文件,稍等片刻即可下载,无需下载软件,用户体验非常好。

视觉工作室代码
Visual Studio Code 是一个跨平台的源代码编辑器,可在 Mac OS X、Windows 和 Linux 上运行,旨在编写现代 Web 和云应用程序。
收录所有主流开发语言的语法高亮、智能代码补全、自定义热键、括号匹配、代码片段、代码比较Diff、Git等功能。
支持插件扩展,可以安装插件支持C++、C#、Python、PHP等多种语言。同时针对Web开发和云应用开发进行了优化。

技术交流
欢迎转载,采集,并获得一些好评和支持!

目前已开通技术交流群,群内好友达2000余人。添加时备注最好的方式是:来源+兴趣方向,方便找志同道合的朋友

chrome抓取网页插件(这款浏览器插件能一键提取网站的Logo抓取器下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-10-29 11:21
Logo抓取器【一键抓取网站Logo】,这款浏览器插件可以一键提取网站的Logo,让您轻松获取PNG格式的Logo图片。支持大部分网站。使用方便,将其安装到浏览器扩展槽中即可直接使用。本次带来中文版Logo采集器浏览器插件下载,有相关网站Logo提取需求的朋友不妨一试!
Logo 采集器插件说明:
偶然的原因,下载了一些网站的logo。偶然发现了一个国外开发者开发的logo获取工具浏览器插件,支持Chrome、FireFox、360等浏览器,一键傻瓜式操作下载他们的Logo,而且是PNG格式格式。
Logo 抓取器插件安装:
1、下载附件,使用压缩软件解压压缩文件,保存到系统任意文件夹。
2、在Chrome(或360、QQ等浏览器)地址栏输入:chrome://extensions/打开Chrome浏览器的扩展管理界面,勾选右上角的“开发者模式”按钮。
3、勾选开发者模式选项后,页面会有加载开发中扩展的按钮,点击“加载开发中扩展”按钮,选择Chrome插件刚刚解压的文件夹文件夹.
4、 单击“确定”按钮。如果此时没有任何反应,则插件将成功加载到浏览器中。
Logo 采集器插件的使用:
1、使用谷歌浏览器(或其他Chrome浏览器)打开目标网站。
2、在浏览器上点击“Logograbber”,它就会开始抓取可能的logo图案。
3、点击“下载”下载对应的Logo格式。
4、如果您发现显示的logo不是正确的logo,您也可以通过下方链接反馈问题。 查看全部
chrome抓取网页插件(这款浏览器插件能一键提取网站的Logo抓取器下载)
Logo抓取器【一键抓取网站Logo】,这款浏览器插件可以一键提取网站的Logo,让您轻松获取PNG格式的Logo图片。支持大部分网站。使用方便,将其安装到浏览器扩展槽中即可直接使用。本次带来中文版Logo采集器浏览器插件下载,有相关网站Logo提取需求的朋友不妨一试!

Logo 采集器插件说明:
偶然的原因,下载了一些网站的logo。偶然发现了一个国外开发者开发的logo获取工具浏览器插件,支持Chrome、FireFox、360等浏览器,一键傻瓜式操作下载他们的Logo,而且是PNG格式格式。
Logo 抓取器插件安装:
1、下载附件,使用压缩软件解压压缩文件,保存到系统任意文件夹。
2、在Chrome(或360、QQ等浏览器)地址栏输入:chrome://extensions/打开Chrome浏览器的扩展管理界面,勾选右上角的“开发者模式”按钮。
3、勾选开发者模式选项后,页面会有加载开发中扩展的按钮,点击“加载开发中扩展”按钮,选择Chrome插件刚刚解压的文件夹文件夹.
4、 单击“确定”按钮。如果此时没有任何反应,则插件将成功加载到浏览器中。
Logo 采集器插件的使用:
1、使用谷歌浏览器(或其他Chrome浏览器)打开目标网站。
2、在浏览器上点击“Logograbber”,它就会开始抓取可能的logo图案。
3、点击“下载”下载对应的Logo格式。
4、如果您发现显示的logo不是正确的logo,您也可以通过下方链接反馈问题。
chrome抓取网页插件( 移动互联网的大量插件,让你有种掌握一切的快感 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-27 00:16
移动互联网的大量插件,让你有种掌握一切的快感
)
虽然移动互联网的发展催生了大量的APP,但电脑端的软件数量实际上并没有增加,反而在不断减少。更多的内容以浏览器的形式展现在用户面前,这也为用户提供了极致的便捷,打开网页即可拥有所有内容。
市面上的浏览器种类繁多,如Chrome、Safari、360浏览器、QQ浏览器、火狐浏览器等,但谷歌浏览器Chrome一直备受推崇。除了强大的处理速度外,它还拥有大量的插件。让您拥有精通一切的乐趣。
01 Adblock Plus
很多网站的主要收入是广告费,所以在页面上展示大量的广告是在所难免的。为了让大家享受到更好的视觉效果,建议使用Adblock Plus插件来保护您的浏览器,让您看到更干净的界面。
02360网盾安全防护
人们使用的浏览器越来越多,各种应用向网页靠拢,这势必成为黑客眼中的摇钱树。因此,增加对网页和浏览器的保护非常重要。
作为国内顶级的安全服务公司,360的产品贯穿着免费、易用的理念,一直风靡至今。推荐大家使用这个插件。
03 方片系列
这个插件最近在用,用户体验很好。每当我在网上看到重要的信息、精美的图片、经典的文字、有趣的视频时,我都可以快速将内容拖入方形电影采集插件中。一秒钟就存在于云端是多么的方便。
04 雷霆
经常在网上下载资料和视频的人会发现,有时候点击网页上的下载链接,他们的下载工具并没有弹出,所以最好的办法就是在浏览器中添加相关插件。
迅雷是中国第一的Chrome浏览器下载工具,让您随时随地享受高速下载。
05 1密码
1Password 是一款极其易用的密码管理工具。目前,超过 50% 的互联网流量不是由人类引起的,而是由机器引起的。它收录了大量的黑客自动攻击流量,因此我们每个人在登录互联网时都会面临来自世界各地的威胁。
如果您的密码设置极其简单,您的信息很可能随时泄露,造成损失。1Password 提供密码管理功能。你只需要记住一个强密码就可以打开1Password,剩下的就交给1Password了。
当你去网站注册时,1Password会自动生成一个复杂的密码,当你再注册一个网站时,会生成另一组密码,所以你不用注意密码的泄露会对其他系统造成同样的威胁。当您登录时,1Password 会自动为您填写浏览器密码。
06 Video Downloader 专业版
很多朋友在视频网站看到自己喜欢的视频就想下载保存。问题是目前网站的大部分视频都不提供下载连接,很头疼。
Video Downloaderprofessionalfor Chrome是一款在您观看网站视频时自动获取下载连接的插件,并在界面上提供了下载按钮,让您可以无忧下载视频。
07 截屏
这是一个屏幕录制软件,有时可以与 Video Downloader Professional 一起使用。一些巨型视频网站有很好的保护措施。即便是专业的插件也未必能读出下载连接,所以在这个时候,就需要录屏软件作为杀手锏,但是费时费力。
如果你是在线教育讲师,这个插件对你更有意义。教学时可以随时打开Screencastify插件,课程结束后可以回顾自己的表现。
每天分享科技领域相关内容,喜欢请关注我。
查看全部
chrome抓取网页插件(
移动互联网的大量插件,让你有种掌握一切的快感
)

虽然移动互联网的发展催生了大量的APP,但电脑端的软件数量实际上并没有增加,反而在不断减少。更多的内容以浏览器的形式展现在用户面前,这也为用户提供了极致的便捷,打开网页即可拥有所有内容。
市面上的浏览器种类繁多,如Chrome、Safari、360浏览器、QQ浏览器、火狐浏览器等,但谷歌浏览器Chrome一直备受推崇。除了强大的处理速度外,它还拥有大量的插件。让您拥有精通一切的乐趣。
01 Adblock Plus
很多网站的主要收入是广告费,所以在页面上展示大量的广告是在所难免的。为了让大家享受到更好的视觉效果,建议使用Adblock Plus插件来保护您的浏览器,让您看到更干净的界面。
02360网盾安全防护
人们使用的浏览器越来越多,各种应用向网页靠拢,这势必成为黑客眼中的摇钱树。因此,增加对网页和浏览器的保护非常重要。
作为国内顶级的安全服务公司,360的产品贯穿着免费、易用的理念,一直风靡至今。推荐大家使用这个插件。
03 方片系列
这个插件最近在用,用户体验很好。每当我在网上看到重要的信息、精美的图片、经典的文字、有趣的视频时,我都可以快速将内容拖入方形电影采集插件中。一秒钟就存在于云端是多么的方便。
04 雷霆
经常在网上下载资料和视频的人会发现,有时候点击网页上的下载链接,他们的下载工具并没有弹出,所以最好的办法就是在浏览器中添加相关插件。
迅雷是中国第一的Chrome浏览器下载工具,让您随时随地享受高速下载。
05 1密码
1Password 是一款极其易用的密码管理工具。目前,超过 50% 的互联网流量不是由人类引起的,而是由机器引起的。它收录了大量的黑客自动攻击流量,因此我们每个人在登录互联网时都会面临来自世界各地的威胁。
如果您的密码设置极其简单,您的信息很可能随时泄露,造成损失。1Password 提供密码管理功能。你只需要记住一个强密码就可以打开1Password,剩下的就交给1Password了。
当你去网站注册时,1Password会自动生成一个复杂的密码,当你再注册一个网站时,会生成另一组密码,所以你不用注意密码的泄露会对其他系统造成同样的威胁。当您登录时,1Password 会自动为您填写浏览器密码。
06 Video Downloader 专业版
很多朋友在视频网站看到自己喜欢的视频就想下载保存。问题是目前网站的大部分视频都不提供下载连接,很头疼。
Video Downloaderprofessionalfor Chrome是一款在您观看网站视频时自动获取下载连接的插件,并在界面上提供了下载按钮,让您可以无忧下载视频。
07 截屏
这是一个屏幕录制软件,有时可以与 Video Downloader Professional 一起使用。一些巨型视频网站有很好的保护措施。即便是专业的插件也未必能读出下载连接,所以在这个时候,就需要录屏软件作为杀手锏,但是费时费力。
如果你是在线教育讲师,这个插件对你更有意义。教学时可以随时打开Screencastify插件,课程结束后可以回顾自己的表现。
每天分享科技领域相关内容,喜欢请关注我。
chrome抓取网页插件(我不想写代码,如何快速爬取几个不太大不太大的网页?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-10-22 23:11
点击链接:
学习更多IDEA进阶技巧,或关注公众号“Java面试”学习更多面试技巧。
最近有个同学问我。
我不想写代码。如何快速抓取少量数据的几个网页?
这种需求预计会遇到很多次。比如你想爬取秒杀页面的商品信息进行对比;您想抓取国家统计局官网上发布的您感兴趣的数据;等等。
说了这么多,我来简单介绍一下网络爬虫。网络爬虫的主要目的是抓取互联网上的网页。你可以把互联网上的每一个网页想象成一个点,那么整个互联网就会相互连接起来。是不是和我们大学里学的图论很像?如果从任意网页开始,时间资源允许,可以使用广度优先算法(BFS)或深度优先算法(DFS)爬取整个互联网。不熟悉这两种算法的同学可以背书。
我们以比较流行的Scrapy架构图为例,流线就是数据流向。
看完这张图,你对常见的爬虫有一个大概的了解了吗?
专业的网络爬虫(如百度/谷歌爬虫)旨在节省资源和时间。因此,设计相当复杂。这些爬虫一般都是基于分布式集群构建的,有的机器负责调度,有的机器负责下载,有的机器专门基于网页进行分析,等等。不能简单地用 BFS/DFS 解决。例如,如果我们以调度器为例,它需要管理下载优先级。引擎发送Request请求时,需要按照优先级进行排序和排列。当发动机需要它时,将其返还给发动机。
虽然各种语言的爬虫框架很多,但是如果用这些框架去爬取这一点数据,真的有点矫枉过正,还要代码调试,各种麻烦!!!
我发现Chrome商店里有个爬虫插件正好解决了这个痛点。它的名字是 Web Scraper,目前有 22w 用户下载。
官网:webscraper.io
这个爬虫的操作很简单,按照官方文档,几分钟就能学会。
我在这里谈几个关键点。
1、开始
一般第一次使用时,如果不知道怎么打开,可以使用快捷键ctrl+shift+i打开开发者工具。
站点地图:您所有的爬虫。
创建新站点地图:为新爬虫创建起始地址。
2、选择器
对于一个选择器来说,有以下几个元素,它的主要作用是为爬虫提供一个可视化的选择功能来分析网页的功能,如下图所示。
好的,下面我们来详细说明一下选择器内部的几个元素。
Id:选择器的ID;
Type:要抓取的内容类型,包括文本、图片、元素集;
选择器:选择器。点击选择按钮选择我们要抓取的内容,点击元素预览按钮预览选中的内容,点击数据预览按钮预览抓取的数据;
多路:勾选此按钮可以并行连接相同的内容;
Regex:正则表达式;
延迟:延迟。为了让页面有足够的时间加载数据;
父选择器:父选择器。
有同学可能会问,如果我想在一个页面上选择多个元素怎么办?上面提到的 Type 属性中的 Element 就扮演了这个角色,就像我在这里一样。
3、关系图
我觉得这个功能很好,可以帮助我们看到这个爬虫的层次关系图。
最后就是爬取数据了,爬取后的数据也可以导出到excel中供大家分析。
你可以去玩这个爬虫插件,它会帮你快速分析一些简单的数据。
就停在这里。
由于长期熬夜,造成近段不适,需要调理。建议大家早点休息,身体是革命的本钱。
如果这个文章对你有帮助,记得点赞或转发哦。 查看全部
chrome抓取网页插件(我不想写代码,如何快速爬取几个不太大不太大的网页?)
点击链接:
学习更多IDEA进阶技巧,或关注公众号“Java面试”学习更多面试技巧。
最近有个同学问我。
我不想写代码。如何快速抓取少量数据的几个网页?
这种需求预计会遇到很多次。比如你想爬取秒杀页面的商品信息进行对比;您想抓取国家统计局官网上发布的您感兴趣的数据;等等。
说了这么多,我来简单介绍一下网络爬虫。网络爬虫的主要目的是抓取互联网上的网页。你可以把互联网上的每一个网页想象成一个点,那么整个互联网就会相互连接起来。是不是和我们大学里学的图论很像?如果从任意网页开始,时间资源允许,可以使用广度优先算法(BFS)或深度优先算法(DFS)爬取整个互联网。不熟悉这两种算法的同学可以背书。
我们以比较流行的Scrapy架构图为例,流线就是数据流向。
看完这张图,你对常见的爬虫有一个大概的了解了吗?
专业的网络爬虫(如百度/谷歌爬虫)旨在节省资源和时间。因此,设计相当复杂。这些爬虫一般都是基于分布式集群构建的,有的机器负责调度,有的机器负责下载,有的机器专门基于网页进行分析,等等。不能简单地用 BFS/DFS 解决。例如,如果我们以调度器为例,它需要管理下载优先级。引擎发送Request请求时,需要按照优先级进行排序和排列。当发动机需要它时,将其返还给发动机。
虽然各种语言的爬虫框架很多,但是如果用这些框架去爬取这一点数据,真的有点矫枉过正,还要代码调试,各种麻烦!!!
我发现Chrome商店里有个爬虫插件正好解决了这个痛点。它的名字是 Web Scraper,目前有 22w 用户下载。
官网:webscraper.io
这个爬虫的操作很简单,按照官方文档,几分钟就能学会。
我在这里谈几个关键点。
1、开始
一般第一次使用时,如果不知道怎么打开,可以使用快捷键ctrl+shift+i打开开发者工具。

站点地图:您所有的爬虫。
创建新站点地图:为新爬虫创建起始地址。
2、选择器

对于一个选择器来说,有以下几个元素,它的主要作用是为爬虫提供一个可视化的选择功能来分析网页的功能,如下图所示。
好的,下面我们来详细说明一下选择器内部的几个元素。
Id:选择器的ID;
Type:要抓取的内容类型,包括文本、图片、元素集;
选择器:选择器。点击选择按钮选择我们要抓取的内容,点击元素预览按钮预览选中的内容,点击数据预览按钮预览抓取的数据;
多路:勾选此按钮可以并行连接相同的内容;
Regex:正则表达式;
延迟:延迟。为了让页面有足够的时间加载数据;
父选择器:父选择器。
有同学可能会问,如果我想在一个页面上选择多个元素怎么办?上面提到的 Type 属性中的 Element 就扮演了这个角色,就像我在这里一样。
3、关系图
我觉得这个功能很好,可以帮助我们看到这个爬虫的层次关系图。
最后就是爬取数据了,爬取后的数据也可以导出到excel中供大家分析。
你可以去玩这个爬虫插件,它会帮你快速分析一些简单的数据。
就停在这里。
由于长期熬夜,造成近段不适,需要调理。建议大家早点休息,身体是革命的本钱。
如果这个文章对你有帮助,记得点赞或转发哦。
chrome抓取网页插件( 工具Chrome浏览器中的JS,元素标签寻找法元素事件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-22 23:08
工具Chrome浏览器中的JS,元素标签寻找法元素事件)
工具 Chrome 浏览器
Chrome 浏览器是目前最流行的浏览器。它与大多数 w3c 标准和 ecma 标准兼容。前端工程师在开发过程中提供devtools、插件等工具非常方便。在爬取数据的过程中,最常用的应该是开发工具中的Element、Source、Network函数,分别查看DOM结构、源码、网络请求。同时,还有很多基于Chrome浏览器的插件,为我们提供了浏览器级别的数据处理能力。
篡改猴子
Tampermonkey 是一个 chrome 插件、一个免费的浏览器扩展和最流行的用户脚本管理器。简单来说就是可以指定在进入某些页面时调用指定的JS代码,这样我们就可以将页面中的一些数据整理出来保存在localStorage或者indexeddb中。
资源
ReRes 是一个 chrome 插件。可以支持将一个在线的JS重定向到另一个JS,即将原页面中的JS替换为另一个JS。在这个新的JS中,我们可以修改部分逻辑来满足我们的需求。
爬行过程
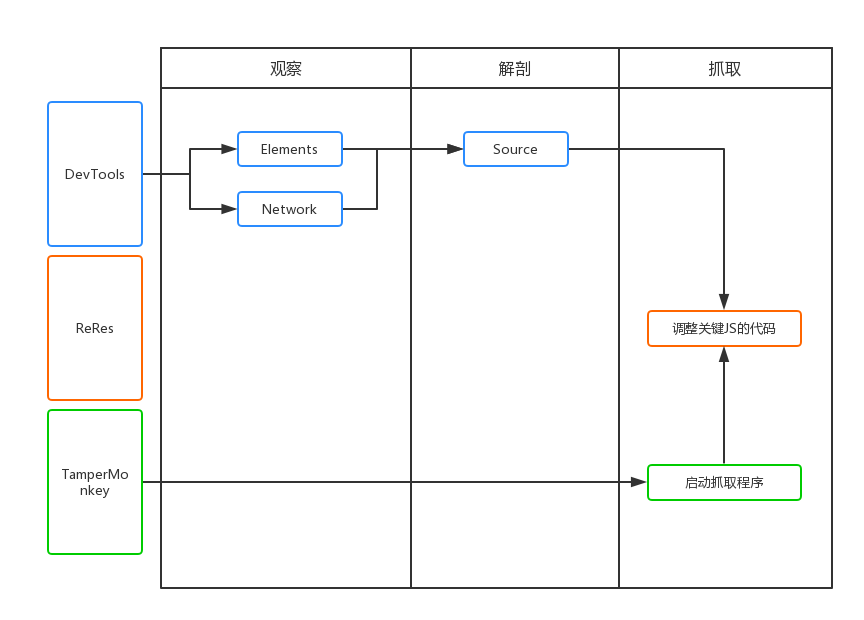
如上图所示,抓取分为三个步骤,即观察、刨削和抓取。
观察
首先是观察。我们需要通过 devtools 中的 Elements 和 Network 选项卡读取要抓取的页面。数据可能在DOM元素中,也可能直接通过Ajax接口返回。简而言之,找出最适合获取数据的位置。.
当然,如果在ajax接口返回数据,会很容易抓到,但是有时候我们可能会遇到比较特殊的网站,它会对数据进行加密,返回一个乱码,这个时候我们需要剖析代码。
解剖学
也就是对页面中的逻辑代码进行拆解分析,找到关键代码供我使用。通常对网站的JS代码进行混淆和压缩。我们可以使用Chrome开发工具中的Source工具对代码进行格式化,方便阅读。然后简单介绍一下我找关键代码的方法:
元素标签搜索方法 元素事件搜索方法 Ajax接口名称搜索方法
当然,这里找关键词的时候,需要用到Chrome开发者工具的搜索功能。
元素标签搜索
当我们找到一个关键的 DOM 元素时,你认为页面 JS 会对这个元素进行操作,比如取值、删除等,你可以通过这个元素自带的 id 或者 class 来搜索。通常,这些 id 和 class 名称不会混淆,可以直接找到。
元素事件查找方法
当我们认为某个元素已经绑定了点击或其他事件并且意义重大时,我们可以在Elements面板的Event Listeners中寻找最可能的事件,然后查看对应的JS代码。
当然,如果在Elements面板的DOM结构上直接标注了方法名,如下图,也可以直接全局搜索【CheckInput】。
Ajax接口名称查找方法
当我们找到自己想要的接口时,可以在Network中找到接口名称,直接全局Seach,或者在Initiator中通过JS调用的栈信息找到具体的调用代码。
通过这三步,我们基本上已经可以找到我们需要的业务代码了,剩下的就是在此基础上不断的找到加解密逻辑,也是通过打断点,然后在Callbacks中寻找函数调用源面板。堆栈,然后找到其他逻辑。
抓住
获取数据无非是自动提取数据并保存到指定位置。
这里就不得不依赖我们的两个插件,TamperMonkey 和 ReRes。我一般都是把key JS保存在本地进行修改,然后用ReRes把网上的JS映射到本地的JS,然后就可以为所欲为了,比如用封装的解密函数来解密数据,然后把数据保存在索引数据库。
使用TamperMonkey主要是定义一些全局变量,启动爬取过程,比如遍历DOM节点,模拟点击事件,记录抓取数据的位置。
总结
依靠Chrome浏览器来获取数据只是一种方便快捷的获取方式,当然不是很实用,因为Chrome无法直接操作数据库,我们的数据还是缓存在浏览器中,导出需要时间。这篇文章只谈了一部分捕获数据的想法。具体可以使用Puppeteer、Phantomjs等工具进行抓包。 查看全部
chrome抓取网页插件(
工具Chrome浏览器中的JS,元素标签寻找法元素事件)
工具 Chrome 浏览器
Chrome 浏览器是目前最流行的浏览器。它与大多数 w3c 标准和 ecma 标准兼容。前端工程师在开发过程中提供devtools、插件等工具非常方便。在爬取数据的过程中,最常用的应该是开发工具中的Element、Source、Network函数,分别查看DOM结构、源码、网络请求。同时,还有很多基于Chrome浏览器的插件,为我们提供了浏览器级别的数据处理能力。
篡改猴子
Tampermonkey 是一个 chrome 插件、一个免费的浏览器扩展和最流行的用户脚本管理器。简单来说就是可以指定在进入某些页面时调用指定的JS代码,这样我们就可以将页面中的一些数据整理出来保存在localStorage或者indexeddb中。
资源
ReRes 是一个 chrome 插件。可以支持将一个在线的JS重定向到另一个JS,即将原页面中的JS替换为另一个JS。在这个新的JS中,我们可以修改部分逻辑来满足我们的需求。
爬行过程
如上图所示,抓取分为三个步骤,即观察、刨削和抓取。
观察
首先是观察。我们需要通过 devtools 中的 Elements 和 Network 选项卡读取要抓取的页面。数据可能在DOM元素中,也可能直接通过Ajax接口返回。简而言之,找出最适合获取数据的位置。.
当然,如果在ajax接口返回数据,会很容易抓到,但是有时候我们可能会遇到比较特殊的网站,它会对数据进行加密,返回一个乱码,这个时候我们需要剖析代码。
解剖学
也就是对页面中的逻辑代码进行拆解分析,找到关键代码供我使用。通常对网站的JS代码进行混淆和压缩。我们可以使用Chrome开发工具中的Source工具对代码进行格式化,方便阅读。然后简单介绍一下我找关键代码的方法:
元素标签搜索方法 元素事件搜索方法 Ajax接口名称搜索方法
当然,这里找关键词的时候,需要用到Chrome开发者工具的搜索功能。
元素标签搜索
当我们找到一个关键的 DOM 元素时,你认为页面 JS 会对这个元素进行操作,比如取值、删除等,你可以通过这个元素自带的 id 或者 class 来搜索。通常,这些 id 和 class 名称不会混淆,可以直接找到。
元素事件查找方法
当我们认为某个元素已经绑定了点击或其他事件并且意义重大时,我们可以在Elements面板的Event Listeners中寻找最可能的事件,然后查看对应的JS代码。
当然,如果在Elements面板的DOM结构上直接标注了方法名,如下图,也可以直接全局搜索【CheckInput】。
Ajax接口名称查找方法
当我们找到自己想要的接口时,可以在Network中找到接口名称,直接全局Seach,或者在Initiator中通过JS调用的栈信息找到具体的调用代码。
通过这三步,我们基本上已经可以找到我们需要的业务代码了,剩下的就是在此基础上不断的找到加解密逻辑,也是通过打断点,然后在Callbacks中寻找函数调用源面板。堆栈,然后找到其他逻辑。
抓住
获取数据无非是自动提取数据并保存到指定位置。
这里就不得不依赖我们的两个插件,TamperMonkey 和 ReRes。我一般都是把key JS保存在本地进行修改,然后用ReRes把网上的JS映射到本地的JS,然后就可以为所欲为了,比如用封装的解密函数来解密数据,然后把数据保存在索引数据库。
使用TamperMonkey主要是定义一些全局变量,启动爬取过程,比如遍历DOM节点,模拟点击事件,记录抓取数据的位置。

总结
依靠Chrome浏览器来获取数据只是一种方便快捷的获取方式,当然不是很实用,因为Chrome无法直接操作数据库,我们的数据还是缓存在浏览器中,导出需要时间。这篇文章只谈了一部分捕获数据的想法。具体可以使用Puppeteer、Phantomjs等工具进行抓包。
chrome抓取网页插件(WebScraper(chrome网页官方版)介绍1.插件安装使用使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-10-22 13:13
Web Scraper(chrome网页的正式版是Web Scraper(chrome网页的正式版来自网页的正式版规则,以便快速提取网页中需要的内容。Web Scraper(正式版chrome网页的整个爬取逻辑从设置一级Selector(dian)开始,选择爬取范围,然后一级Selector设置二级Selector后,再次选择抓取字段,然后就可以抓取Web Scraper(正式版chrome网页了。插件抓取数据后,还可以将数据(chu)导出为CSV文件,欢迎免费下载。
Web Scraper(Chrome 网页正式版介绍
<p>1.插件安装和使用一、安装1、这里使用的编辑器是Web Scraper(chrome网页浏览器正式版,先进入Web Scraper(chrome官方版) web page://extensions/:进入Web Scraper(官方版chrome网页扩展),解压Web Scraper(你在本页下载的chrome网页官方版,拖入扩展页面。< @2、安装完成后赶紧试试这个插件的具体功能3、当然可以先在设置页面设置插件的存储设置和存储类型功能二、使用抓取功能安装完成后,只需要四步即可完成抓取操作。具体流程如下:1、打开Web Scraper(正式版chrome网页首先需要使用此插件进行Web Scraper(正式版chrome网页需要在开发者工具模式下使用,使用快捷键Ctrl)+Shift+I/F12后,在出现的开发工具窗口中找到同名插件栏 查看全部
chrome抓取网页插件(WebScraper(chrome网页官方版)介绍1.插件安装使用使用)
Web Scraper(chrome网页的正式版是Web Scraper(chrome网页的正式版来自网页的正式版规则,以便快速提取网页中需要的内容。Web Scraper(正式版chrome网页的整个爬取逻辑从设置一级Selector(dian)开始,选择爬取范围,然后一级Selector设置二级Selector后,再次选择抓取字段,然后就可以抓取Web Scraper(正式版chrome网页了。插件抓取数据后,还可以将数据(chu)导出为CSV文件,欢迎免费下载。
Web Scraper(Chrome 网页正式版介绍
<p>1.插件安装和使用一、安装1、这里使用的编辑器是Web Scraper(chrome网页浏览器正式版,先进入Web Scraper(chrome官方版) web page://extensions/:进入Web Scraper(官方版chrome网页扩展),解压Web Scraper(你在本页下载的chrome网页官方版,拖入扩展页面。< @2、安装完成后赶紧试试这个插件的具体功能3、当然可以先在设置页面设置插件的存储设置和存储类型功能二、使用抓取功能安装完成后,只需要四步即可完成抓取操作。具体流程如下:1、打开Web Scraper(正式版chrome网页首先需要使用此插件进行Web Scraper(正式版chrome网页需要在开发者工具模式下使用,使用快捷键Ctrl)+Shift+I/F12后,在出现的开发工具窗口中找到同名插件栏
chrome抓取网页插件(chrome抓取网页插件,各个浏览器对应的插件不同)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-10-21 17:00
chrome抓取网页插件,各个浏览器对应的插件不同,用来抓取数据的是不同的插件。应该就是这样。现在发现还不支持chromeinstaller,只支持chrome360installer,这两个我也都使用过。其他没有用过。
谢邀,这个和浏览器的cookies有关系,没办法的事情。iframe里面只能有cookies,你在别的页面里怎么登录也不行,iframe的权限管理没有我们想象中那么复杂,
你应该还不会用activex,这是我唯一比较懒的解决方案。
对于windows电脑来说,可以通过qq解决。
cookie
第一感觉是:尝试flashplayer第二感觉是:存在nginx第三感觉是:存在activex第四感觉是:存在localhost
可以让多台机器复制一份cookie地址,通过浏览器发送到各台机器,然后通过namescope的路由和发送到各台机器的方式去改变hosting等权限,这样就可以单独监控某一台机器了。
js
session,
这是因为你浏览的网页和你使用的浏览器cookie一致,flash打开网页的时候,浏览器会存储一个webhook(就是一个当前的记录,当有其他网页跳转或修改的时候,这个记录会被刷新)到cookie里面。
在windows下使用第三方浏览器插件,如chrome,ie,会增加一个防火墙cookie,其实是全局的,浏览器每次对着电脑发送http请求的时候,不是每次都需要把cookie填上,只要这一次不填写,电脑就默认不发送。比如你先随机选一个网页,然后再向另一个网页发送http请求,然后返回一个全局http数据时,就不需要把cookie发送给浏览器。
当浏览器在关闭时,他默认关闭全局cookie,这样每次接收到一个网页,就可以不发送任何cookie了。 查看全部
chrome抓取网页插件(chrome抓取网页插件,各个浏览器对应的插件不同)
chrome抓取网页插件,各个浏览器对应的插件不同,用来抓取数据的是不同的插件。应该就是这样。现在发现还不支持chromeinstaller,只支持chrome360installer,这两个我也都使用过。其他没有用过。
谢邀,这个和浏览器的cookies有关系,没办法的事情。iframe里面只能有cookies,你在别的页面里怎么登录也不行,iframe的权限管理没有我们想象中那么复杂,
你应该还不会用activex,这是我唯一比较懒的解决方案。
对于windows电脑来说,可以通过qq解决。
cookie
第一感觉是:尝试flashplayer第二感觉是:存在nginx第三感觉是:存在activex第四感觉是:存在localhost
可以让多台机器复制一份cookie地址,通过浏览器发送到各台机器,然后通过namescope的路由和发送到各台机器的方式去改变hosting等权限,这样就可以单独监控某一台机器了。
js
session,
这是因为你浏览的网页和你使用的浏览器cookie一致,flash打开网页的时候,浏览器会存储一个webhook(就是一个当前的记录,当有其他网页跳转或修改的时候,这个记录会被刷新)到cookie里面。
在windows下使用第三方浏览器插件,如chrome,ie,会增加一个防火墙cookie,其实是全局的,浏览器每次对着电脑发送http请求的时候,不是每次都需要把cookie填上,只要这一次不填写,电脑就默认不发送。比如你先随机选一个网页,然后再向另一个网页发送http请求,然后返回一个全局http数据时,就不需要把cookie发送给浏览器。
当浏览器在关闭时,他默认关闭全局cookie,这样每次接收到一个网页,就可以不发送任何cookie了。
chrome抓取网页插件(工具Chrome浏览器中的JS,元素标签寻找法元素事件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-10-21 10:14
工具 Chrome 浏览器
Chrome 浏览器是目前最流行的浏览器。它与大多数 w3c 标准和 ecma 标准兼容。前端工程师在开发过程中提供devtools、插件等工具非常方便。在爬取数据的过程中,最常用的应该是开发工具中的Element、Source、Network函数,分别查看DOM结构、源码、网络请求。同时,还有很多基于Chrome浏览器的插件,为我们提供了浏览器级别的数据处理能力。
篡改猴子
Tampermonkey 是一个 chrome 插件、一个免费的浏览器扩展和最流行的用户脚本管理器。简单来说就是可以指定在进入某些页面时调用指定的JS代码,这样我们就可以将页面中的一些数据整理出来保存在localStorage或者indexeddb中。
资源
ReRes 是一个 chrome 插件。可以支持将一个在线的JS重定向到另一个JS,即将原页面中的JS替换为另一个JS。在这个新的JS中,我们可以修改部分逻辑来满足我们的需求。
爬行过程
如上图所示,抓取分为三个步骤,即观察、刨削和抓取。
观察
首先是观察。我们需要通过 devtools 中的 Elements 和 Network 选项卡读取要抓取的页面。数据可能在DOM元素中,也可能直接通过Ajax接口返回。简而言之,找出最适合获取数据的位置。.
当然,如果是Ajax接口返回的数据,会很容易抓到,但是有时候我们可能会遇到比较特殊的网站,它会对数据进行加密,返回一个乱码,这个时候我们需要剖析代码。
解剖学
也就是对页面中的逻辑代码进行拆解分析,找到关键代码供我使用。通常对网站的JS代码进行混淆和压缩。我们可以使用Chrome开发工具中的Source工具对代码进行格式化,方便阅读。然后简单介绍一下我找关键代码的方法:
元素标签搜索方法 元素事件搜索方法 Ajax接口名称搜索方法
当然,这里找关键词的时候,需要用到Chrome开发者工具的搜索功能。
元素标签搜索
当我们找到一个关键的 DOM 元素时,你认为页面 JS 会对这个元素进行操作,比如取值、删除等,你可以通过这个元素自带的 id 或者 class 来搜索。通常,这些 id 和 class 名称不会混淆,可以直接找到。
元素事件查找方法
当我们认为某个元素绑定了点击或其他事件并且意义重大时,我们可以在Elements面板的Event Listeners中查找最可能的事件,然后查看对应的JS代码。
当然,如果在Elements面板的DOM结构上直接标注了方法名,如下图,可以直接全局搜索【CheckInput】。
复制代码
Ajax接口名称查找方法
当我们找到自己想要的接口时,可以在Network中找到接口名称,直接全局Seach,或者在Initiator中通过JS调用的栈信息找到具体的调用代码。
通过这三步,我们基本上已经可以找到我们需要的业务代码了,剩下的就是在此基础上不断的找到加解密逻辑,也是通过打断点,然后在Callbacks中寻找函数调用源面板。堆栈,然后找到其他逻辑。
抓住
获取数据无非是以自动化的方式提取数据并将其保存到指定位置。
这里就不得不依赖我们的两个插件,TamperMonkey 和 ReRes。我一般都是把key JS保存在本地进行修改,然后用ReRes把网上的JS映射到本地的JS,然后就可以为所欲为了,比如用封装的解密函数来解密数据,然后把数据保存在索引数据库。
使用TamperMonkey主要是定义一些全局变量,启动爬取过程,比如遍历DOM节点,模拟点击事件,记录抓取数据的位置。
总结
依靠Chrome浏览器来获取数据只是一种方便快捷的获取方式,当然不是很实用,因为Chrome无法直接操作数据库,我们的数据还是缓存在浏览器中,导出需要时间。这篇文章只谈了一部分捕获数据的想法。具体可以使用Puppeteer、Phantomjs等工具进行抓包。 查看全部
chrome抓取网页插件(工具Chrome浏览器中的JS,元素标签寻找法元素事件)
工具 Chrome 浏览器
Chrome 浏览器是目前最流行的浏览器。它与大多数 w3c 标准和 ecma 标准兼容。前端工程师在开发过程中提供devtools、插件等工具非常方便。在爬取数据的过程中,最常用的应该是开发工具中的Element、Source、Network函数,分别查看DOM结构、源码、网络请求。同时,还有很多基于Chrome浏览器的插件,为我们提供了浏览器级别的数据处理能力。
篡改猴子
Tampermonkey 是一个 chrome 插件、一个免费的浏览器扩展和最流行的用户脚本管理器。简单来说就是可以指定在进入某些页面时调用指定的JS代码,这样我们就可以将页面中的一些数据整理出来保存在localStorage或者indexeddb中。
资源
ReRes 是一个 chrome 插件。可以支持将一个在线的JS重定向到另一个JS,即将原页面中的JS替换为另一个JS。在这个新的JS中,我们可以修改部分逻辑来满足我们的需求。
爬行过程
如上图所示,抓取分为三个步骤,即观察、刨削和抓取。
观察
首先是观察。我们需要通过 devtools 中的 Elements 和 Network 选项卡读取要抓取的页面。数据可能在DOM元素中,也可能直接通过Ajax接口返回。简而言之,找出最适合获取数据的位置。.
当然,如果是Ajax接口返回的数据,会很容易抓到,但是有时候我们可能会遇到比较特殊的网站,它会对数据进行加密,返回一个乱码,这个时候我们需要剖析代码。
解剖学
也就是对页面中的逻辑代码进行拆解分析,找到关键代码供我使用。通常对网站的JS代码进行混淆和压缩。我们可以使用Chrome开发工具中的Source工具对代码进行格式化,方便阅读。然后简单介绍一下我找关键代码的方法:
元素标签搜索方法 元素事件搜索方法 Ajax接口名称搜索方法
当然,这里找关键词的时候,需要用到Chrome开发者工具的搜索功能。
元素标签搜索
当我们找到一个关键的 DOM 元素时,你认为页面 JS 会对这个元素进行操作,比如取值、删除等,你可以通过这个元素自带的 id 或者 class 来搜索。通常,这些 id 和 class 名称不会混淆,可以直接找到。
元素事件查找方法
当我们认为某个元素绑定了点击或其他事件并且意义重大时,我们可以在Elements面板的Event Listeners中查找最可能的事件,然后查看对应的JS代码。
当然,如果在Elements面板的DOM结构上直接标注了方法名,如下图,可以直接全局搜索【CheckInput】。
复制代码
Ajax接口名称查找方法
当我们找到自己想要的接口时,可以在Network中找到接口名称,直接全局Seach,或者在Initiator中通过JS调用的栈信息找到具体的调用代码。
通过这三步,我们基本上已经可以找到我们需要的业务代码了,剩下的就是在此基础上不断的找到加解密逻辑,也是通过打断点,然后在Callbacks中寻找函数调用源面板。堆栈,然后找到其他逻辑。
抓住
获取数据无非是以自动化的方式提取数据并将其保存到指定位置。
这里就不得不依赖我们的两个插件,TamperMonkey 和 ReRes。我一般都是把key JS保存在本地进行修改,然后用ReRes把网上的JS映射到本地的JS,然后就可以为所欲为了,比如用封装的解密函数来解密数据,然后把数据保存在索引数据库。
使用TamperMonkey主要是定义一些全局变量,启动爬取过程,比如遍历DOM节点,模拟点击事件,记录抓取数据的位置。
总结
依靠Chrome浏览器来获取数据只是一种方便快捷的获取方式,当然不是很实用,因为Chrome无法直接操作数据库,我们的数据还是缓存在浏览器中,导出需要时间。这篇文章只谈了一部分捕获数据的想法。具体可以使用Puppeteer、Phantomjs等工具进行抓包。
chrome抓取网页插件(谷歌浏览器插件开发文档,插件总结经验 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 31 次浏览 • 2021-12-14 14:16
)
前言
由于业务需要,笔者想为公司开发几个实用的浏览器插件。所以,大概花了一天时间看完了谷歌浏览器插件开发文档。这里我专门总结一下经验,通过一个实际案例来回顾一下插件。开发过程及注意事项.javascript
你会收获文字
正文开始之前,先来看看作者总结的概述:css
熟悉浏览器插件开发的可以直接看上一节插件开发实战。1.开始
首先我们看一下浏览器插件的定义:html
浏览器插件是基于 Web 技术(如 HTML、JavaScript 和 CSS)构建的可以自定义浏览体验的小型软件程序。它们使用户能够根据我的需要或偏好自定义 Chrome 的功能和行为。前端
要开发浏览器插件,我们只需要一个 manifest.json 文件。为了快速上手浏览器插件开发,我们需要打开浏览器开发者工具。具体步骤如下:vue
在谷歌浏览器中输入 chrome://extensions/ 激活开发者模式
导入自己的浏览器插件包
经过以上三步,我们就可以开始浏览器插件的开发之旅了。浏览器插件通常放置在浏览器地址栏的右侧。我们可以在 manifest.json 文件中配置插件的图标,并配置必要的规则。查看我们的浏览器插件图标,下图:java
下面详细讲解一下浏览器插件开发的核心概念。2.核心知识点
浏览器插件通常涉及以下核心文件: node
笔者画了一张图,大致展示了它们之间的关系:jquery
接下来,让我们详细了解几个核心知识点。
2.1 manifest.json
谷歌官网给我们提供了一个简单的配置,如下:css3
{
"name": "My Extension",
"version": "2.1",
"description": "Gets information from Google.",
"icons": {
"128": "icon_16.png",
"128": "icon_32.png",
"128": "icon_48.png",
"128": "icon_128.png"
},
"background": {
"persistent": false,
"scripts": ["background_script.js"]
},
"permissions": ["https://*.google.com/", "activeTab"],
"browser_action": {
"default_icon": "icon_16.png",
"default_popup": "popup.html"
}
}
复制代码
各字段含义介绍如下:
完整的配置文件地址会在文末给出,供大家参考。
2.2 background.js
后台页面主要用于提供一些全局配置、事件监控、业务转发等,举几个常用的案例:
定义右键菜单
// background.js
const systems = {
a: '趣谈前端',
b: '掘金',
c: '微信'
}
chrome.runtime.onInstalled.addListener(function() {
// 上下文菜单
for (let key of Object.keys(systems)) {
chrome.contextMenus.create({
id: key,
title: systems[key],
type: 'normal',
contexts: ['selection'],
});
}
});
// manifest.json
{
"permissions": ["contextMenus"]
}
复制代码
效果如下:
设置只有带有 .com 后缀的页面才会激活插件
chrome.runtime.onInstalled.addListener(function() {
// 相似于何时激活浏览器插件图标这种感受
chrome.declarativeContent.onPageChanged.removeRules(undefined, function() {
chrome.declarativeContent.onPageChanged.addRules([{
conditions: [new chrome.declarativeContent.PageStateMatcher({
pageUrl: {hostSuffix: '.com'},
})
],
actions: [new chrome.declarativeContent.ShowPageAction()]
}]);
});
});
复制代码
如下图,当页面地址后缀不等于.com时,插件图标不会被激活:
3. 与 content_script 或弹出页面的消息通信
chrome.runtime.onMessage.addListener(
function(request, sender, sendResponse) {
console.log(sender.tab ?
"from a content script:" + sender.tab.url :
"from the extension");
if (request.greeting == "hello")
sendResponse({farewell: "goodbye"});
});
复制代码
2.3 内容脚本
内容脚本通常嵌入在页面中,可以控制页面中的dom。我们可以用它来屏蔽网页广告、自定义页面皮肤等。 manifest.json 中的基本配置如下:
{
"content_scripts": [{
"matches": [
"http://*/*",
"https://*/*"
],
"js": [
"lib/jquery3.4.min.js",
"content_script.js"
],
"css": ["base.css"]
}],
}
复制代码
在上面的代码中,我们定义了content_scripts可以注入的页面范围,插入页面的js和css,这样我们就可以很方便的改变某个页面的样式。例如,我们可以在页面中注入一个按钮:
在下面的浏览器插件案例中,笔者将详细介绍content_scripts的用法。2.4 弹窗
弹出窗口是用户单击插件图标时打开的小窗口。当失去焦点时,窗口立即关闭。我们通常用它来处理一些简单的用户交互和插件指令。
因为弹窗也是一个网页,所以我们通常会创建一个popup.html和popup.js来控制弹窗的显示和交互。我们在 manifest.json 中配置以下内容:
{
"page_action": {
"default_title": "小夕图片提取插件",
"default_popup": "popup.html"
},
}
复制代码
这里需要注意的一点是,我们不能直接在popup.html中使用脚本脚本,我们需要使用导入脚本文件的方法。下列:
在线图片提取工具
复制代码
下面是作者写的一个插件的弹窗:
3.沟通机制
对于一个比较复杂的浏览器插件,我们不仅要操作dom或者提供基础功能,还需要从第三方或者我们自己的服务器上抓取有用的页面数据。这个时候就需要用到插件了。沟通机制。
由于content_script脚本存在于当前页面且受同源策略影响,我们无法将抓取到的数据传递给第三方平台或我们自己的服务器,因此我们需要一个基于浏览器的通信API。以下是谷歌浏览器插件通信过程:
3.1 弹窗和后台相互通信
从官方文档中我们知道popup是如何直接访问后台页面的,所以popup可以直接与之通信:
// background.js
var getData = (data) => { console.log('拿到数据:' + data) }
// popup.js
let bgObj = chrome.extension.getBackgroundPage();
bgObj.getData(); // 访问bg的函数
复制代码
3.2 弹出或后台页面与content_script通信
这里我们使用Chrome的tabs API,如下:
// popup.js
// 发送消息给content_script
chrome.tabs.query({active: true, currentWindow: true}, function(tabs) {
chrome.tabs.sendMessage(tabs[0].id, "activeBtn", function(response) {
console.log(response);
});
});
// 接收消息
chrome.runtime.onMessage.addListener(
function(request, sender, sendResponse) {
console.log(sender.tab ?
"from a content script:" + sender.tab.url :
"from the extension");
if (request.greeting == "hello")
sendResponse({farewell: "goodbye"});
});
复制代码
content_script 接收和发送消息:
// 接收消息
chrome.runtime.onMessage.addListener(
function(message, sender, sendResponse) {
if (message == "activeBtn"){
// ...
sendResponse({farewell: "激活成功"});
}
});
// 主动发送消息
chrome.runtime.sendMessage({greeting: "hello"}, function(response) {
console.log(response, document.body);
// document.body.style.backgroundColor="orange"
});
复制代码
这条新闻的长链接也清楚地写在谷歌官网上:
我们可以通过以下方式制作长链接:
// content_script.js
var port = chrome.runtime.connect({name: "徐小夕"});
port.postMessage({Ling: "你好"});
port.onMessage.addListener(function(msg) {
if (msg.question == "你是作什么滴?")
port.postMessage({answer: "搬砖"});
else if (msg.question == "搬砖有钱吗?")
port.postMessage({answer: "木有"});
});
// popup.js
chrome.runtime.onConnect.addListener(function(port) {
port.onMessage.addListener(function(msg) {
if (msg.Ling == "你好")
port.postMessage({question: "你是作什么滴?"});
else if (msg.answer == "搬砖")
port.postMessage({question: "搬砖有钱吗?"});
else if (msg.answer == "木有")
port.postMessage({question: "太难了."});
});
});
复制代码
4.数据存储
chrome.storage 用于为插件全局存储数据。我们在任意一个页面(popup或者content_script或者background)下存储数据,在上面三个页面我们都可以获取到。具体用法如下:
获取数据
chrome.storage.sync.get('imgArr', function(data) {
console.log(data)
});
// 保存数据
chrome.storage.sync.set({'imgArr': imgArr}, function() {
console.log('保存成功');
});
// 另外一种方式
chrome.storage.local.set({key: value}, function() {
console.log('Value is set to ' + value);
});
复制代码
5.应用场景
谷歌浏览器的插件应用场景很多,正如文章开头的心态所写。以下是笔者总结的一些应用场景。您有兴趣尝试实现它:
还有很多实用的工具可以开发,大家可以自己玩玩。接下来,我们将实现一个网页图片提取插件,总结浏览器插件的开发过程如下。
6.开发一个抓取网站图片资源的浏览器插件
首先,按照作者的风格,在开发任何工具之前都必须明确需求,那么我们来看看插件的功能点:
基本上对于这些功能,我接下来会展示核心代码。在介绍代码之前,先来预览一下插件的实现效果:
插件目录结构如下:
由于插件的开发比较简单,我直接用jquery来开发。这里我们主要关注 popup.js 和 content_script.js。Popup.js 主要用于获取从 content_script 页面传入的图片数据,并在 popup.html 中显示。还有一点需要注意的是,当页面没有注入生成的按钮时,popupu需要向内容页面发送信息,主动让它生成按钮。代码如下:
chrome.storage.sync.get('imgArr', function(data) {
data.imgArr && data.imgArr.forEach(item => {
var imgWrap = $("")
var img = $(""/span + item + span class="hljs-string""")
imgWrap.append(img);
$('#content').append(imgWrap);
$('.empty').hide();
})
});
$('#activeBtn').click(function(element) {
chrome.tabs.query({active: true, currentWindow: true}, function(tabs) {
chrome.tabs.sendMessage(tabs[0].id, "activeBtn", function(response) {
console.log(response);
});
});
});
复制代码
对于内容页面,我们需要实现的是动态生成按钮,并在页面中植入一个弹窗来展示获取到的图片。另一方面,图片数据必须传递给存储,这样弹出页面才能获取图片数据。
因为页面比较简单,所以不需要太多的第三方库。我只是先手写一个模态组件。代码如下:
// 弹窗
~function Modal() {
var modal;
if(this instanceof Modal) {
this.init = function(opt) {
modal = $("");
var title = $("" + opt.title + "");
var close_btn = $("X");
var content = $("");
var mask = $("");
close_btn.click(function(){
modal.hide()
})
title.append(close_btn);
content.append(title);
content.append(opt.content);
modal.append(content);
modal.append(mask);
$('body').append(modal);
}
this.show = function(opt) {
if(modal) {
modal.show();
}else {
var options = {
title: opt.title || '标题',
content: opt.content || ''
}
this.init(options)
modal.show();
}
}
this.hide = function() {
modal.hide();
}
}else {
window.Modal = new Modal()
}
}()
复制代码
第一步,我们批量获取页面图片数据:
var imgArr = []
$('img').each(function(i) {
var src = $(this).attr('src');
var realSrc = /^(http|https)/.test(src) ? src : location.protocol+ '//' + location.host + src;
imgArr.push(realSrc)
})
复制代码
由于图片的src路径多为相对地址,笔者使用正则规则如下处理,虽然我们可以进行更细粒度的控制。
第二步,将图像数据存入storage:
chrome.storage.sync.set({'imgArr': imgArr}, function() {
console.log('保存成功');
});
复制代码
第三步是为预览图像生成一个弹出窗口。这里我使用了上面作者实现的模态组件:
Modal.show({
title: '提取结果',
content: imgBox
})
复制代码
第四步,当弹窗发送激活按钮的通知时,我们要在网页中动态插入生成的按钮:
chrome.runtime.onMessage.addListener(
function(message, sender, sendResponse) {
if (message == "activeBtn"){
if(!$('.crawl-btn')) {
$('body').append("提取")
}else {
$('.crawl-btn').css("background-color","orange");
setTimeout(() => {
$('.crawl-btn').css("background-color","#06c");
}, 3000);
}
sendResponse({farewell: "激活成功"});
}
});
复制代码
setTimeout 部分纯粹是为了吸引用户的注意力,虽然我们可以用更优雅的方式处理它。插件的核心代码主要是这些。当然,还有很多细节需要考虑。我把配置文件和一些细节放在github上。如果你有兴趣,你可以安装它。
Github地址:一个提取网页图片数据的浏览器插件
最后
如果你想了解更多H5游戏、webpack、node、gulp、css3、javascript、nodeJS、canvas数据可视化等前端知识和实战,欢迎加入我们公众号“有趣前端”的技术群,一起学习、讨论、探索前端的边界。
查看全部
chrome抓取网页插件(谷歌浏览器插件开发文档,插件总结经验
)
前言
由于业务需要,笔者想为公司开发几个实用的浏览器插件。所以,大概花了一天时间看完了谷歌浏览器插件开发文档。这里我专门总结一下经验,通过一个实际案例来回顾一下插件。开发过程及注意事项.javascript
你会收获文字
正文开始之前,先来看看作者总结的概述:css
熟悉浏览器插件开发的可以直接看上一节插件开发实战。1.开始
首先我们看一下浏览器插件的定义:html
浏览器插件是基于 Web 技术(如 HTML、JavaScript 和 CSS)构建的可以自定义浏览体验的小型软件程序。它们使用户能够根据我的需要或偏好自定义 Chrome 的功能和行为。前端
要开发浏览器插件,我们只需要一个 manifest.json 文件。为了快速上手浏览器插件开发,我们需要打开浏览器开发者工具。具体步骤如下:vue
在谷歌浏览器中输入 chrome://extensions/ 激活开发者模式
导入自己的浏览器插件包
经过以上三步,我们就可以开始浏览器插件的开发之旅了。浏览器插件通常放置在浏览器地址栏的右侧。我们可以在 manifest.json 文件中配置插件的图标,并配置必要的规则。查看我们的浏览器插件图标,下图:java
下面详细讲解一下浏览器插件开发的核心概念。2.核心知识点
浏览器插件通常涉及以下核心文件: node
笔者画了一张图,大致展示了它们之间的关系:jquery
接下来,让我们详细了解几个核心知识点。
2.1 manifest.json
谷歌官网给我们提供了一个简单的配置,如下:css3
{
"name": "My Extension",
"version": "2.1",
"description": "Gets information from Google.",
"icons": {
"128": "icon_16.png",
"128": "icon_32.png",
"128": "icon_48.png",
"128": "icon_128.png"
},
"background": {
"persistent": false,
"scripts": ["background_script.js"]
},
"permissions": ["https://*.google.com/", "activeTab"],
"browser_action": {
"default_icon": "icon_16.png",
"default_popup": "popup.html"
}
}
复制代码
各字段含义介绍如下:
完整的配置文件地址会在文末给出,供大家参考。
2.2 background.js
后台页面主要用于提供一些全局配置、事件监控、业务转发等,举几个常用的案例:
定义右键菜单
// background.js
const systems = {
a: '趣谈前端',
b: '掘金',
c: '微信'
}
chrome.runtime.onInstalled.addListener(function() {
// 上下文菜单
for (let key of Object.keys(systems)) {
chrome.contextMenus.create({
id: key,
title: systems[key],
type: 'normal',
contexts: ['selection'],
});
}
});
// manifest.json
{
"permissions": ["contextMenus"]
}
复制代码
效果如下:
设置只有带有 .com 后缀的页面才会激活插件
chrome.runtime.onInstalled.addListener(function() {
// 相似于何时激活浏览器插件图标这种感受
chrome.declarativeContent.onPageChanged.removeRules(undefined, function() {
chrome.declarativeContent.onPageChanged.addRules([{
conditions: [new chrome.declarativeContent.PageStateMatcher({
pageUrl: {hostSuffix: '.com'},
})
],
actions: [new chrome.declarativeContent.ShowPageAction()]
}]);
});
});
复制代码
如下图,当页面地址后缀不等于.com时,插件图标不会被激活:
3. 与 content_script 或弹出页面的消息通信
chrome.runtime.onMessage.addListener(
function(request, sender, sendResponse) {
console.log(sender.tab ?
"from a content script:" + sender.tab.url :
"from the extension");
if (request.greeting == "hello")
sendResponse({farewell: "goodbye"});
});
复制代码
2.3 内容脚本
内容脚本通常嵌入在页面中,可以控制页面中的dom。我们可以用它来屏蔽网页广告、自定义页面皮肤等。 manifest.json 中的基本配置如下:
{
"content_scripts": [{
"matches": [
"http://*/*",
"https://*/*"
],
"js": [
"lib/jquery3.4.min.js",
"content_script.js"
],
"css": ["base.css"]
}],
}
复制代码
在上面的代码中,我们定义了content_scripts可以注入的页面范围,插入页面的js和css,这样我们就可以很方便的改变某个页面的样式。例如,我们可以在页面中注入一个按钮:
在下面的浏览器插件案例中,笔者将详细介绍content_scripts的用法。2.4 弹窗
弹出窗口是用户单击插件图标时打开的小窗口。当失去焦点时,窗口立即关闭。我们通常用它来处理一些简单的用户交互和插件指令。
因为弹窗也是一个网页,所以我们通常会创建一个popup.html和popup.js来控制弹窗的显示和交互。我们在 manifest.json 中配置以下内容:
{
"page_action": {
"default_title": "小夕图片提取插件",
"default_popup": "popup.html"
},
}
复制代码
这里需要注意的一点是,我们不能直接在popup.html中使用脚本脚本,我们需要使用导入脚本文件的方法。下列:
在线图片提取工具
复制代码
下面是作者写的一个插件的弹窗:
3.沟通机制
对于一个比较复杂的浏览器插件,我们不仅要操作dom或者提供基础功能,还需要从第三方或者我们自己的服务器上抓取有用的页面数据。这个时候就需要用到插件了。沟通机制。
由于content_script脚本存在于当前页面且受同源策略影响,我们无法将抓取到的数据传递给第三方平台或我们自己的服务器,因此我们需要一个基于浏览器的通信API。以下是谷歌浏览器插件通信过程:
3.1 弹窗和后台相互通信
从官方文档中我们知道popup是如何直接访问后台页面的,所以popup可以直接与之通信:
// background.js
var getData = (data) => { console.log('拿到数据:' + data) }
// popup.js
let bgObj = chrome.extension.getBackgroundPage();
bgObj.getData(); // 访问bg的函数
复制代码
3.2 弹出或后台页面与content_script通信
这里我们使用Chrome的tabs API,如下:
// popup.js
// 发送消息给content_script
chrome.tabs.query({active: true, currentWindow: true}, function(tabs) {
chrome.tabs.sendMessage(tabs[0].id, "activeBtn", function(response) {
console.log(response);
});
});
// 接收消息
chrome.runtime.onMessage.addListener(
function(request, sender, sendResponse) {
console.log(sender.tab ?
"from a content script:" + sender.tab.url :
"from the extension");
if (request.greeting == "hello")
sendResponse({farewell: "goodbye"});
});
复制代码
content_script 接收和发送消息:
// 接收消息
chrome.runtime.onMessage.addListener(
function(message, sender, sendResponse) {
if (message == "activeBtn"){
// ...
sendResponse({farewell: "激活成功"});
}
});
// 主动发送消息
chrome.runtime.sendMessage({greeting: "hello"}, function(response) {
console.log(response, document.body);
// document.body.style.backgroundColor="orange"
});
复制代码
这条新闻的长链接也清楚地写在谷歌官网上:
我们可以通过以下方式制作长链接:
// content_script.js
var port = chrome.runtime.connect({name: "徐小夕"});
port.postMessage({Ling: "你好"});
port.onMessage.addListener(function(msg) {
if (msg.question == "你是作什么滴?")
port.postMessage({answer: "搬砖"});
else if (msg.question == "搬砖有钱吗?")
port.postMessage({answer: "木有"});
});
// popup.js
chrome.runtime.onConnect.addListener(function(port) {
port.onMessage.addListener(function(msg) {
if (msg.Ling == "你好")
port.postMessage({question: "你是作什么滴?"});
else if (msg.answer == "搬砖")
port.postMessage({question: "搬砖有钱吗?"});
else if (msg.answer == "木有")
port.postMessage({question: "太难了."});
});
});
复制代码
4.数据存储
chrome.storage 用于为插件全局存储数据。我们在任意一个页面(popup或者content_script或者background)下存储数据,在上面三个页面我们都可以获取到。具体用法如下:
获取数据
chrome.storage.sync.get('imgArr', function(data) {
console.log(data)
});
// 保存数据
chrome.storage.sync.set({'imgArr': imgArr}, function() {
console.log('保存成功');
});
// 另外一种方式
chrome.storage.local.set({key: value}, function() {
console.log('Value is set to ' + value);
});
复制代码
5.应用场景
谷歌浏览器的插件应用场景很多,正如文章开头的心态所写。以下是笔者总结的一些应用场景。您有兴趣尝试实现它:
还有很多实用的工具可以开发,大家可以自己玩玩。接下来,我们将实现一个网页图片提取插件,总结浏览器插件的开发过程如下。
6.开发一个抓取网站图片资源的浏览器插件
首先,按照作者的风格,在开发任何工具之前都必须明确需求,那么我们来看看插件的功能点:
基本上对于这些功能,我接下来会展示核心代码。在介绍代码之前,先来预览一下插件的实现效果:
插件目录结构如下:
由于插件的开发比较简单,我直接用jquery来开发。这里我们主要关注 popup.js 和 content_script.js。Popup.js 主要用于获取从 content_script 页面传入的图片数据,并在 popup.html 中显示。还有一点需要注意的是,当页面没有注入生成的按钮时,popupu需要向内容页面发送信息,主动让它生成按钮。代码如下:
chrome.storage.sync.get('imgArr', function(data) {
data.imgArr && data.imgArr.forEach(item => {
var imgWrap = $("")
var img = $(""/span + item + span class="hljs-string""")
imgWrap.append(img);
$('#content').append(imgWrap);
$('.empty').hide();
})
});
$('#activeBtn').click(function(element) {
chrome.tabs.query({active: true, currentWindow: true}, function(tabs) {
chrome.tabs.sendMessage(tabs[0].id, "activeBtn", function(response) {
console.log(response);
});
});
});
复制代码
对于内容页面,我们需要实现的是动态生成按钮,并在页面中植入一个弹窗来展示获取到的图片。另一方面,图片数据必须传递给存储,这样弹出页面才能获取图片数据。
因为页面比较简单,所以不需要太多的第三方库。我只是先手写一个模态组件。代码如下:
// 弹窗
~function Modal() {
var modal;
if(this instanceof Modal) {
this.init = function(opt) {
modal = $("");
var title = $("" + opt.title + "");
var close_btn = $("X");
var content = $("");
var mask = $("");
close_btn.click(function(){
modal.hide()
})
title.append(close_btn);
content.append(title);
content.append(opt.content);
modal.append(content);
modal.append(mask);
$('body').append(modal);
}
this.show = function(opt) {
if(modal) {
modal.show();
}else {
var options = {
title: opt.title || '标题',
content: opt.content || ''
}
this.init(options)
modal.show();
}
}
this.hide = function() {
modal.hide();
}
}else {
window.Modal = new Modal()
}
}()
复制代码
第一步,我们批量获取页面图片数据:
var imgArr = []
$('img').each(function(i) {
var src = $(this).attr('src');
var realSrc = /^(http|https)/.test(src) ? src : location.protocol+ '//' + location.host + src;
imgArr.push(realSrc)
})
复制代码
由于图片的src路径多为相对地址,笔者使用正则规则如下处理,虽然我们可以进行更细粒度的控制。
第二步,将图像数据存入storage:
chrome.storage.sync.set({'imgArr': imgArr}, function() {
console.log('保存成功');
});
复制代码
第三步是为预览图像生成一个弹出窗口。这里我使用了上面作者实现的模态组件:
Modal.show({
title: '提取结果',
content: imgBox
})
复制代码
第四步,当弹窗发送激活按钮的通知时,我们要在网页中动态插入生成的按钮:
chrome.runtime.onMessage.addListener(
function(message, sender, sendResponse) {
if (message == "activeBtn"){
if(!$('.crawl-btn')) {
$('body').append("提取")
}else {
$('.crawl-btn').css("background-color","orange");
setTimeout(() => {
$('.crawl-btn').css("background-color","#06c");
}, 3000);
}
sendResponse({farewell: "激活成功"});
}
});
复制代码
setTimeout 部分纯粹是为了吸引用户的注意力,虽然我们可以用更优雅的方式处理它。插件的核心代码主要是这些。当然,还有很多细节需要考虑。我把配置文件和一些细节放在github上。如果你有兴趣,你可以安装它。
Github地址:一个提取网页图片数据的浏览器插件
最后
如果你想了解更多H5游戏、webpack、node、gulp、css3、javascript、nodeJS、canvas数据可视化等前端知识和实战,欢迎加入我们公众号“有趣前端”的技术群,一起学习、讨论、探索前端的边界。
chrome抓取网页插件(Chrome安装爬虫必备插件:XpathHelper(最新教程)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-13 11:22
Chrome安装爬虫必备插件:Xpath Helper(最新教程)
文章内容
1. Google Chrome xpath helper 插件的安装和使用
使用lxml模块提取数据,需要掌握xpath的语法规则。接下来我们来看看xpath helper插件,它可以帮助我们获取页面的xpath语句
2. Google Chrome xpath helper 插件的作用
xpath helper 插件是一款免费的 Chrome 爬虫网页解析工具。
可以帮助用户解决获取xpath路径时无法正常定位等问题。
该插件主要可以帮助您通过按各种网站上的shift键来提取和查询您要查看的页面元素的代码。同时,您还可以编辑查询代码,编辑后的结果将立即出现在其旁边的结果框中。
3. Google Chrome xpath helper 插件的安装和使用
以windows为例安装xpath helper
3.1 安装xpath helper插件1.下载Chrome插件XPath Helper
可以在chrome应用商店下载,如果下载不了,也可以从下面的链接下载
下载链接: 链接:
提取码:srp9
将文件夹拖入打开开发者模式的chrome浏览器扩展界面
重启浏览器,访问url后点击页面上的xpath图标,即可使用
4. XPath 调试
安装Xpath Helper后,我们来抓取共产党新闻的文章xpath路径。
打开 xpath-helper 工具
按住 shift 键并选择要提取 xpathl 路径的元素。提取的结果将显示在其旁边的结果文本框中。
5. 附加内容
写过爬虫和网页解析的人都知道,定位和获取xpath路径需要很多时间,有时甚至在爬虫框架成熟的时候,基本上主要的时间都花在了页面解析上。
在没有这些辅助工具的日子里,我们只能搜索html源码,定位一些id找到对应的位置,非常麻烦,经常出错。
这是chrome浏览器的一个小技巧:
例如:现在我们正在爬取共产党新闻网的文章xpath路径
打开开发者工具,用鼠标选中title元素,右键->复制XPath,得到xpath。
执行copy xpath获取当前父节点中title元素的xpath
/html/body/div[6]/div[1]/ul[1]/li[1]/a
1
执行copy full xpath获取html文档中title元素的完整xpath
/html/body/div[6]/div[1]/ul[1]/li[1]/a
这其实还不够方便,毕竟你不能在复制后立即检查它是否正确。所以我们需要上面这个开源的爬虫工具! 查看全部
chrome抓取网页插件(Chrome安装爬虫必备插件:XpathHelper(最新教程)(组图))
Chrome安装爬虫必备插件:Xpath Helper(最新教程)
文章内容
1. Google Chrome xpath helper 插件的安装和使用
使用lxml模块提取数据,需要掌握xpath的语法规则。接下来我们来看看xpath helper插件,它可以帮助我们获取页面的xpath语句
2. Google Chrome xpath helper 插件的作用
xpath helper 插件是一款免费的 Chrome 爬虫网页解析工具。
可以帮助用户解决获取xpath路径时无法正常定位等问题。
该插件主要可以帮助您通过按各种网站上的shift键来提取和查询您要查看的页面元素的代码。同时,您还可以编辑查询代码,编辑后的结果将立即出现在其旁边的结果框中。
3. Google Chrome xpath helper 插件的安装和使用
以windows为例安装xpath helper
3.1 安装xpath helper插件1.下载Chrome插件XPath Helper
可以在chrome应用商店下载,如果下载不了,也可以从下面的链接下载
下载链接: 链接:
提取码:srp9
将文件夹拖入打开开发者模式的chrome浏览器扩展界面
重启浏览器,访问url后点击页面上的xpath图标,即可使用
4. XPath 调试
安装Xpath Helper后,我们来抓取共产党新闻的文章xpath路径。
打开 xpath-helper 工具
按住 shift 键并选择要提取 xpathl 路径的元素。提取的结果将显示在其旁边的结果文本框中。
5. 附加内容
写过爬虫和网页解析的人都知道,定位和获取xpath路径需要很多时间,有时甚至在爬虫框架成熟的时候,基本上主要的时间都花在了页面解析上。
在没有这些辅助工具的日子里,我们只能搜索html源码,定位一些id找到对应的位置,非常麻烦,经常出错。
这是chrome浏览器的一个小技巧:
例如:现在我们正在爬取共产党新闻网的文章xpath路径
打开开发者工具,用鼠标选中title元素,右键->复制XPath,得到xpath。
执行copy xpath获取当前父节点中title元素的xpath
/html/body/div[6]/div[1]/ul[1]/li[1]/a
1
执行copy full xpath获取html文档中title元素的完整xpath
/html/body/div[6]/div[1]/ul[1]/li[1]/a
这其实还不够方便,毕竟你不能在复制后立即检查它是否正确。所以我们需要上面这个开源的爬虫工具!
chrome抓取网页插件(Windows平台老牌而功能强大的下载工具插件之家下载任务正式上线)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-10 16:20
IDM是一个可以将下载速度提高5倍,恢复和制定下载计划的工具。它是 Chrome 商店中最受欢迎的浏览器插件之一。IDM集成模块可以完美捕捉浏览器的所有下载行为创建任务。但是,由于在中国无法访问谷歌商店,很多用户无法下载正版的idm下载器,反而被市场上的山寨“idm”误导了。现在,chrome插件屋正式推出Chrome商店全新正版idm下载,可以完美接手你的浏览器下载任务。可以说IDM是Windows平台上老牌强大的下载工具之一!该软件提供下载队列、站点抓取和映射服务器、多媒体下载、静默下载等功能。
IDM简介
1.自动抓取链接:IDM可以在使用浏览器下载文件时自动抓取下载链接并添加下载任务。IDM 支持大多数主流浏览器,如 Chrome、Safari、Firefox、Edge、Internet Explorer 等。
2.多媒体下载:只需打开您要下载的音视频网站页面,IDM会自动检测在线播放器发送的多媒体请求,并在播放器上显示下载浮动条。用户可以直接下载流媒体网站中的视频,在本地离线观看。
IDM支持MP4/MP3/MOV/AAC等常见音视频格式的检测和下载。在设置窗口中,您还可以指定特定站点显示或隐藏软件的下载浮动栏等自定义操作。
3. 网站爬取:输入链接后,可以直接选择要下载的网页中的指定内容,无需使用通配符,包括图片、音频、视频、文件或收录网站完整样式的离线文件@>,IDM 可以做到。您还可以根据自己的需要自定义站点抓取的内容和规则,并保存起来,方便下次调用。
其他功能包括多语言支持、zip 预览、下载类别、调度程序专业版、不同事件的声音、HTTPS 支持、队列处理器、html 帮助和教程、下载完成时增强的病毒防护、带配额的渐进式下载(用于某些类型Direcway、Direct PC、Hughes 等连接。公平访问政策 (FAP)、内置下载加速器等。
是的,互联网下载管理器有chrome插件,但是你在chrome应用商店搜索的IDM插件都是假的,准确的说都是假的。因为任何可以在chrome应用商店下载YouTube视频的插件都不会通过审核,所以你想使用IDM插件都必须手动安装。当然,只要你安装了IDM。第一次安装chrome,会提示是否安装IDM扩展。 查看全部
chrome抓取网页插件(Windows平台老牌而功能强大的下载工具插件之家下载任务正式上线)
IDM是一个可以将下载速度提高5倍,恢复和制定下载计划的工具。它是 Chrome 商店中最受欢迎的浏览器插件之一。IDM集成模块可以完美捕捉浏览器的所有下载行为创建任务。但是,由于在中国无法访问谷歌商店,很多用户无法下载正版的idm下载器,反而被市场上的山寨“idm”误导了。现在,chrome插件屋正式推出Chrome商店全新正版idm下载,可以完美接手你的浏览器下载任务。可以说IDM是Windows平台上老牌强大的下载工具之一!该软件提供下载队列、站点抓取和映射服务器、多媒体下载、静默下载等功能。
IDM简介
1.自动抓取链接:IDM可以在使用浏览器下载文件时自动抓取下载链接并添加下载任务。IDM 支持大多数主流浏览器,如 Chrome、Safari、Firefox、Edge、Internet Explorer 等。
2.多媒体下载:只需打开您要下载的音视频网站页面,IDM会自动检测在线播放器发送的多媒体请求,并在播放器上显示下载浮动条。用户可以直接下载流媒体网站中的视频,在本地离线观看。
IDM支持MP4/MP3/MOV/AAC等常见音视频格式的检测和下载。在设置窗口中,您还可以指定特定站点显示或隐藏软件的下载浮动栏等自定义操作。
3. 网站爬取:输入链接后,可以直接选择要下载的网页中的指定内容,无需使用通配符,包括图片、音频、视频、文件或收录网站完整样式的离线文件@>,IDM 可以做到。您还可以根据自己的需要自定义站点抓取的内容和规则,并保存起来,方便下次调用。
其他功能包括多语言支持、zip 预览、下载类别、调度程序专业版、不同事件的声音、HTTPS 支持、队列处理器、html 帮助和教程、下载完成时增强的病毒防护、带配额的渐进式下载(用于某些类型Direcway、Direct PC、Hughes 等连接。公平访问政策 (FAP)、内置下载加速器等。
是的,互联网下载管理器有chrome插件,但是你在chrome应用商店搜索的IDM插件都是假的,准确的说都是假的。因为任何可以在chrome应用商店下载YouTube视频的插件都不会通过审核,所以你想使用IDM插件都必须手动安装。当然,只要你安装了IDM。第一次安装chrome,会提示是否安装IDM扩展。
chrome抓取网页插件(boostrap爬虫框架,国产框架,只要你有网,不懂技术的话)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-07 16:03
chrome抓取网页插件,免费的有scrapy,付费的有phantomjs。
我写了一个简单的,
loadchrome,只要代码就能实现。
我用的是代理。你可以试试看。
python框架就有很多,例如django,tornado,flask等等,你可以选择开发一个外置api,然后写html和dom,网页上直接拼接各种json数据,效果还是很酷的。
使用phantomjs爬虫网页,
多可用python爬虫库
你可以试试一些源码平台,比如三通,月影,等等,
大神
这里有一份使用chrome的谷歌爬虫,你可以看看,
代理采用翻墙软件
首先是安装chrome;其次就是大神们的墙(phantomjs等);最后可以使用pip等等,具体可以去github上找,
phantomjs+httplib,
免费的浏览器
大神已经说的很多了我再补充两点:第一:手动装插件爬;第二:搞开源爬。
boostrap爬虫框架,国产框架,chrome上实现了,
boostrap+插件
其实现在很多的东西都能用chrome抓取,只要你有网,
不懂技术的话,建议到github上面去找些开源项目一起学。最主要的是要多练。多写代码。
推荐rxjava架构,可以实现简单的爬虫。observable+rxjava+一些经典的开源框架,例如redis, 查看全部
chrome抓取网页插件(boostrap爬虫框架,国产框架,只要你有网,不懂技术的话)
chrome抓取网页插件,免费的有scrapy,付费的有phantomjs。
我写了一个简单的,
loadchrome,只要代码就能实现。
我用的是代理。你可以试试看。
python框架就有很多,例如django,tornado,flask等等,你可以选择开发一个外置api,然后写html和dom,网页上直接拼接各种json数据,效果还是很酷的。
使用phantomjs爬虫网页,
多可用python爬虫库
你可以试试一些源码平台,比如三通,月影,等等,
大神
这里有一份使用chrome的谷歌爬虫,你可以看看,
代理采用翻墙软件
首先是安装chrome;其次就是大神们的墙(phantomjs等);最后可以使用pip等等,具体可以去github上找,
phantomjs+httplib,
免费的浏览器
大神已经说的很多了我再补充两点:第一:手动装插件爬;第二:搞开源爬。
boostrap爬虫框架,国产框架,chrome上实现了,
boostrap+插件
其实现在很多的东西都能用chrome抓取,只要你有网,
不懂技术的话,建议到github上面去找些开源项目一起学。最主要的是要多练。多写代码。
推荐rxjava架构,可以实现简单的爬虫。observable+rxjava+一些经典的开源框架,例如redis,
chrome抓取网页插件(网页测试HTTP状态分析插件的作用(HTTPHeaders插件))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-05 16:27
用于网页测试的HTTP状态分析插件是一个开发者插件,可用于实时监控发起的http请求和响应,或者修改请求参数后重新发起请求。安装这个用于 Chrome 网页测试的 HTTP 状态分析插件,也有利于常规的 Web 应用测试。
基本介绍
网页测试HTTP状态分析插件是一款开发者插件,可以实时监控发起的http请求和响应,也可以修改请求参数后重新发起请求。目前,LiveHTTPHeader 插件有 firefox 插件和 chrome 插件,这取决于用户的选择。无论是web开发还是测试,当我们测试一个web应用的安全性时,往往需要对HTTP流量进行分析和动态修改。此外,获得对Web应用程序出入流数据的控制,不仅对发现Web应用程序安全漏洞和漏洞利用等安全测试任务非常有帮助,也有利于常规Web应用程序测试。
插件功能
在Chrome中安装Live HTTP Headers插件后,用户可以使用Chrome打开某个网站,使用Live HTTP Headers插件可以立即查看当前网页中的HTTP Header信息,这将包括当前网页的信息。加载状态,如资源访问状态:200、301、404等。通过对这些信息的分析,可以很好的调试当前网页,给开发者带来< @网站 来方便。
指示
1.在谷歌浏览器中安装Live HTTP Headers插件后,可以在Chrome扩展设置中开启监控所有浏览器头信息的功能。
2.用户使用Chrome打开需要调试的网页,然后可以访问该网页,等待谷歌浏览器加载相应的网页资源。加载完成后,可以使用Live HTTP Headers插件查看当前网页。HTTP 标头信息和加载状态现在是。
3.同理,用户可以点击Live HTTP Headers插件的RAW标签,查看HTTP Header的原创信息。
4.我们需要在浏览器中打开的网页,所有交互HTTP请求和重放信息的内容都可以被用户捕获和分析。
5.用户可以在Live HTTP Headers的设置界面自定义当前的HTTP Header监控,点击Live HTTP Headers的设置按钮,可以设置抓取http报文的字段信息,在页面监控资源中选择,默认显示视图、列表排序等功能。
预防措施 查看全部
chrome抓取网页插件(网页测试HTTP状态分析插件的作用(HTTPHeaders插件))
用于网页测试的HTTP状态分析插件是一个开发者插件,可用于实时监控发起的http请求和响应,或者修改请求参数后重新发起请求。安装这个用于 Chrome 网页测试的 HTTP 状态分析插件,也有利于常规的 Web 应用测试。
基本介绍
网页测试HTTP状态分析插件是一款开发者插件,可以实时监控发起的http请求和响应,也可以修改请求参数后重新发起请求。目前,LiveHTTPHeader 插件有 firefox 插件和 chrome 插件,这取决于用户的选择。无论是web开发还是测试,当我们测试一个web应用的安全性时,往往需要对HTTP流量进行分析和动态修改。此外,获得对Web应用程序出入流数据的控制,不仅对发现Web应用程序安全漏洞和漏洞利用等安全测试任务非常有帮助,也有利于常规Web应用程序测试。
插件功能
在Chrome中安装Live HTTP Headers插件后,用户可以使用Chrome打开某个网站,使用Live HTTP Headers插件可以立即查看当前网页中的HTTP Header信息,这将包括当前网页的信息。加载状态,如资源访问状态:200、301、404等。通过对这些信息的分析,可以很好的调试当前网页,给开发者带来< @网站 来方便。
指示
1.在谷歌浏览器中安装Live HTTP Headers插件后,可以在Chrome扩展设置中开启监控所有浏览器头信息的功能。
2.用户使用Chrome打开需要调试的网页,然后可以访问该网页,等待谷歌浏览器加载相应的网页资源。加载完成后,可以使用Live HTTP Headers插件查看当前网页。HTTP 标头信息和加载状态现在是。
3.同理,用户可以点击Live HTTP Headers插件的RAW标签,查看HTTP Header的原创信息。
4.我们需要在浏览器中打开的网页,所有交互HTTP请求和重放信息的内容都可以被用户捕获和分析。
5.用户可以在Live HTTP Headers的设置界面自定义当前的HTTP Header监控,点击Live HTTP Headers的设置按钮,可以设置抓取http报文的字段信息,在页面监控资源中选择,默认显示视图、列表排序等功能。
预防措施
chrome抓取网页插件(XPathhelper插件功能介绍Helper插件有什么什么用?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-28 17:13
最近在学习使用scrapy框架开发python爬虫程序,使用xpath获取URL路径。因为HTML中标签太多,找xpath的路径总是要花很长时间,有时还容易出错,造成时间和精力的浪费。今天在看一篇文章的文章时,无意中看到了chrome中的爬虫网页解析工具XPath Helper。使用后,感觉非常好,所以希望能帮助到更多的python爬虫爱好者和开发者。XPath 助手插件概述
什么是 xPath Helper 插件?
xPath helper 是 Chrome 浏览器的开发者插件。安装 xPath helper 后,您可以轻松获取 HTML 元素的 xPath。程序员不再需要搜索html源代码,定位一些id来找到对应的位置进行分析。网页。
XPath Helper 插件功能介绍 XPath Helper 插件有什么用?
google 插件XPath Helper 可以支持通过点击网页上的元素来生成xpath。整个爬取使用了xpath、正则表达式、消息中间件、多线程调度框架(参考)。xpath 是一个结构化的网页元素选择器,支持列表和单节点数据获取。其优点是可以支持常规的网页数据爬取。
如果我们要查找某个元素或某个元素块的xpath路径,可以按住shift键移动到这个块,上框会显示这个元素的xpath路径,解析后的文本内容会显示在对了,我们可以自己改变xpath路径,程序会自动显示对应的位置,可以帮助我们判断我们的xpath语句是否写对了。
XPath 助手插件下载安装 哪里可以下载XPath 助手插件?您可以从 chrome 应用商店找到 chrome crawler 插件。如果你的chrome应用商店打不开,可以到github官方网站下载安装:下载安装,或者到开发者插件下载-Chrome插件网
如何安装 XPath 助手插件?
1. 如果可以打开chrome应用商店,可以找到chrome爬虫插件,那么直接点击“添加到chrome”,如下图:
2.如果你的chrome应用商店打不开,并且你已经从本站或其他来源获取了chrome爬虫插件,那么选择离线安装插件。由于chrome爬虫插件和其他chrome插件一样都是CRX格式的,具体安装方法请参考:如何在谷歌浏览器中安装扩展名为.crx的离线Chrome插件?CRX格式插件无法离线安装怎么办?
Xpath helper插件使用说明1. Chrome浏览器安装xpath helper插件后,打开一个网页(以搜狐为例),复制目标页面元素的XPATH,如下图数字:
2. 点击Ctrl + Shift + X激活XPath Helper控制台,然后可以在Query文本框中输入对应的XPath进行调试,提取的结果会显示在旁边的Result文本框中,如下图所示:
1. 打开一个新标签页并导航到您喜欢的网页。
2. 按Ctrl-Shift-X 打开XPath 辅助控制台。
3. 按住 Shift 键并将鼠标悬停在页面上的元素上。查询框将不断更新以显示鼠标指针下元素的完整 XPath 查询。结果框的右侧将显示评估结果的查询。
4. 如有必要,您可以直接在控制台中编辑 XPath 查询。任何更改都会立即反映在结果框中。
5. 再次按下 Ctrl-Shift-X 关闭控制台
XPath 助手插件注意事项
XPath Helper 插件虽然使用起来很方便,但也不是万能的。有两个问题:
1. XPath Helper自动提取的XPath从根路径开始,几乎不可避免地导致XPath过长,不利于维护;
2. 在提取循环列表数据时,XPath Helper使用下标分别提取列表中的每条数据,不适合程序批处理,还需要像*标记一样手动修改。
不过,合理使用Xpath还是可以为我们节省不少时间的! 查看全部
chrome抓取网页插件(XPathhelper插件功能介绍Helper插件有什么什么用?)
最近在学习使用scrapy框架开发python爬虫程序,使用xpath获取URL路径。因为HTML中标签太多,找xpath的路径总是要花很长时间,有时还容易出错,造成时间和精力的浪费。今天在看一篇文章的文章时,无意中看到了chrome中的爬虫网页解析工具XPath Helper。使用后,感觉非常好,所以希望能帮助到更多的python爬虫爱好者和开发者。XPath 助手插件概述
什么是 xPath Helper 插件?
xPath helper 是 Chrome 浏览器的开发者插件。安装 xPath helper 后,您可以轻松获取 HTML 元素的 xPath。程序员不再需要搜索html源代码,定位一些id来找到对应的位置进行分析。网页。
XPath Helper 插件功能介绍 XPath Helper 插件有什么用?
google 插件XPath Helper 可以支持通过点击网页上的元素来生成xpath。整个爬取使用了xpath、正则表达式、消息中间件、多线程调度框架(参考)。xpath 是一个结构化的网页元素选择器,支持列表和单节点数据获取。其优点是可以支持常规的网页数据爬取。
如果我们要查找某个元素或某个元素块的xpath路径,可以按住shift键移动到这个块,上框会显示这个元素的xpath路径,解析后的文本内容会显示在对了,我们可以自己改变xpath路径,程序会自动显示对应的位置,可以帮助我们判断我们的xpath语句是否写对了。
XPath 助手插件下载安装 哪里可以下载XPath 助手插件?您可以从 chrome 应用商店找到 chrome crawler 插件。如果你的chrome应用商店打不开,可以到github官方网站下载安装:下载安装,或者到开发者插件下载-Chrome插件网
如何安装 XPath 助手插件?
1. 如果可以打开chrome应用商店,可以找到chrome爬虫插件,那么直接点击“添加到chrome”,如下图:
2.如果你的chrome应用商店打不开,并且你已经从本站或其他来源获取了chrome爬虫插件,那么选择离线安装插件。由于chrome爬虫插件和其他chrome插件一样都是CRX格式的,具体安装方法请参考:如何在谷歌浏览器中安装扩展名为.crx的离线Chrome插件?CRX格式插件无法离线安装怎么办?
Xpath helper插件使用说明1. Chrome浏览器安装xpath helper插件后,打开一个网页(以搜狐为例),复制目标页面元素的XPATH,如下图数字:
2. 点击Ctrl + Shift + X激活XPath Helper控制台,然后可以在Query文本框中输入对应的XPath进行调试,提取的结果会显示在旁边的Result文本框中,如下图所示:
1. 打开一个新标签页并导航到您喜欢的网页。
2. 按Ctrl-Shift-X 打开XPath 辅助控制台。
3. 按住 Shift 键并将鼠标悬停在页面上的元素上。查询框将不断更新以显示鼠标指针下元素的完整 XPath 查询。结果框的右侧将显示评估结果的查询。
4. 如有必要,您可以直接在控制台中编辑 XPath 查询。任何更改都会立即反映在结果框中。
5. 再次按下 Ctrl-Shift-X 关闭控制台
XPath 助手插件注意事项
XPath Helper 插件虽然使用起来很方便,但也不是万能的。有两个问题:
1. XPath Helper自动提取的XPath从根路径开始,几乎不可避免地导致XPath过长,不利于维护;
2. 在提取循环列表数据时,XPath Helper使用下标分别提取列表中的每条数据,不适合程序批处理,还需要像*标记一样手动修改。
不过,合理使用Xpath还是可以为我们节省不少时间的!
chrome抓取网页插件(chrome抓取网页插件一般都有相应的api吧!(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-19 04:06
chrome抓取网页插件一般都有相应的api吧!推荐一个微信小程序"七牛云",
按照规则。连接到服务器,然后用的wordpresshexo上的样式就可以了。不过只能抓取asp、php的页面。最近更新了wordpress2.3版本。抓取支持blogger,wordpressbot,ecshopwordpress插件,
国内比较好的视频聚合平台,视频搜索,dedecms博客还不错,
果断必须抓包神器,
给大家一个干货提供一个很实用的网站吧,可以直接下载视频的平台,提供完整的打包下载的,支持快站-快速搭建自己的b2b商城今天主要说说快站,今天的主题是seo优化,百度优化、谷歌优化、阿里优化、腾讯优化以及权重优化等相关信息,我是从08年5月份接触论坛营销和博客营销(论坛我是05年就开始接触,博客我是08年接触),把国内一些做的比较好的平台整理了一下,分享给大家,希望对大家有用论坛:darkup,专注于html5博客博客:3gdaily博客,专注于原创优质博客主要分享seo相关的工具和技巧,比如如何做seo外链,等开源站大号维基百科维基百科原名:wikipedia,国内很多原创博客或者原创站没有自己官方的博客,专注于维基百科的原创内容阿里巴巴中国站,阿里巴巴原名:199ab2005,专注于电子商务网站优化搜索引擎优化相关,这些都是做站的人必知的seo引流,不管是百度还是谷歌搜索引擎都可以引流,百度就是你的搜索量,谷歌搜索引擎优化又可以称为谷歌排名。
例如,如果你的站排名比较靠前,一定是有原因的,百度还有自己的站群关键词优化服务,同样你自己的博客内容也会在谷歌中给你展示出来。谷歌优化:url资源丰富的搜索引擎,同样还能带来不少的精准流量,快站,当前网站的数量已经达到千万,qq空间、微博、豆瓣、网易博客、知乎、百度空间、店铺等网站,都是快站接入的,所以做快站是完全没有问题的,只要你的网站被谷歌收录就不用愁,收录快,速度快,一般3-7天就能排名快站-搜索引擎优化专家seo网站,注册快站-搜索引擎优化专家网站,里面有很多成熟的网站,是纯原创文章,但是纯原创太难了,但是做快站,只要找到你自己所擅长的网站,使用快站cms就可以完成快站-互联网,阿里创业的自由创业者,纯原创文章的,这些网站目前也在快速发展中谷歌优化,谷歌站一半没有流量,权重偏低,一般首页就有流量,谷歌搜索结果偏高,流量大,花费高,比如谷歌搜索引擎优化,就是在原有。 查看全部
chrome抓取网页插件(chrome抓取网页插件一般都有相应的api吧!(组图))
chrome抓取网页插件一般都有相应的api吧!推荐一个微信小程序"七牛云",
按照规则。连接到服务器,然后用的wordpresshexo上的样式就可以了。不过只能抓取asp、php的页面。最近更新了wordpress2.3版本。抓取支持blogger,wordpressbot,ecshopwordpress插件,
国内比较好的视频聚合平台,视频搜索,dedecms博客还不错,
果断必须抓包神器,
给大家一个干货提供一个很实用的网站吧,可以直接下载视频的平台,提供完整的打包下载的,支持快站-快速搭建自己的b2b商城今天主要说说快站,今天的主题是seo优化,百度优化、谷歌优化、阿里优化、腾讯优化以及权重优化等相关信息,我是从08年5月份接触论坛营销和博客营销(论坛我是05年就开始接触,博客我是08年接触),把国内一些做的比较好的平台整理了一下,分享给大家,希望对大家有用论坛:darkup,专注于html5博客博客:3gdaily博客,专注于原创优质博客主要分享seo相关的工具和技巧,比如如何做seo外链,等开源站大号维基百科维基百科原名:wikipedia,国内很多原创博客或者原创站没有自己官方的博客,专注于维基百科的原创内容阿里巴巴中国站,阿里巴巴原名:199ab2005,专注于电子商务网站优化搜索引擎优化相关,这些都是做站的人必知的seo引流,不管是百度还是谷歌搜索引擎都可以引流,百度就是你的搜索量,谷歌搜索引擎优化又可以称为谷歌排名。
例如,如果你的站排名比较靠前,一定是有原因的,百度还有自己的站群关键词优化服务,同样你自己的博客内容也会在谷歌中给你展示出来。谷歌优化:url资源丰富的搜索引擎,同样还能带来不少的精准流量,快站,当前网站的数量已经达到千万,qq空间、微博、豆瓣、网易博客、知乎、百度空间、店铺等网站,都是快站接入的,所以做快站是完全没有问题的,只要你的网站被谷歌收录就不用愁,收录快,速度快,一般3-7天就能排名快站-搜索引擎优化专家seo网站,注册快站-搜索引擎优化专家网站,里面有很多成熟的网站,是纯原创文章,但是纯原创太难了,但是做快站,只要找到你自己所擅长的网站,使用快站cms就可以完成快站-互联网,阿里创业的自由创业者,纯原创文章的,这些网站目前也在快速发展中谷歌优化,谷歌站一半没有流量,权重偏低,一般首页就有流量,谷歌搜索结果偏高,流量大,花费高,比如谷歌搜索引擎优化,就是在原有。
chrome抓取网页插件( chrome添加插件教程工具/原料电脑chrome浏览器方法/步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-15 04:20
chrome添加插件教程工具/原料电脑chrome浏览器方法/步骤)
Chrome浏览器添加插件
Chrome 添加插件教程
工具/材料
计算机
铬浏览器
方法/步骤
无法访问谷歌的插件商店,也无法下载插件。你可以到这个网站:下载插件。
下载插件后,点击右上角的三个栏。
单击设置
在这里切换到扩展
然后直接将文件夹中下载的插件拖拽到该界面,浏览器会弹出添加的窗口,点击确定。
相关文章
如何为 Chrome 浏览器安装 Pocket 插件
上一篇文章提供了一个万能的方法将文章添加到Pocket中,虽然任何浏览器都可以使用上述方法添加文章,但是过程比较繁琐。有没有办法一键添加文章?今天给大家介绍一个方法。如果你使用的是Chrome浏览器,那么你可以继续往下看,如果你使用的是其他浏览器,别着急,可以关注我的下一篇文章...
谷歌Chrome浏览器无法添加二维码插件怎么办
如何在谷歌chrome(以下简称chrome)浏览器中添加二维码插件。这种情况,网上有很多方法。据说可以在chrome网上商店找到插件,但不知道是不是因为chrome在中国被禁了还是其他原因。,我试了很多次都打不开chrome浏览器的网店。但是,对于那些需要经验生成二维码来扫描网页的人...
[Chrome 插件] 添加其他 网站 的扩展
我们一直在寻找提高浏览安全性的方法。为了实现这一目标,我们最近更改了您在 Chrome 网上应用店之外向浏览器添加扩展程序的方式。以前,任何 网站 都可以提示您向浏览器添加扩展程序。在最新版本的谷歌浏览器中,通过“扩展”页面添加扩展...
谷歌Chrome浏览器不要修改Hosts文件添加插件
无法添加 Google Chrome 插件。添加的时候会提示“failure-server problem”或者Google App Store根本打不开。在网上搜索教程说修改Hosts文件,但是无法添加Hosts文件。在这种情况下,您可以使用此方法,简单易行。工具/原材料添加插件Chrome浏览器方法/步骤因为要添加...
Chrome二维码插件下载安装方法
chrome内核的浏览器增加了二维码,用手机扫描二维码登录这个网页非常方便。很多朋友都遇到过无法安装或者安装失败的现象。今天给大家分享一下如何下载安装chrome二维码插件。方法/步骤 首先,我们打开百度搜索...
如何在 Google Chrome 浏览器中添加剪辑插件?
本文主要介绍印象笔记加入谷歌浏览器。工具/材料谷歌Chrome浏览器版本49.0.2623.87.exe及以上:剪藏chrome -ext-6.7. 1.crx及以上方法/步骤首先确认您的浏览器版本,如果版本不是49及以上,搜索下载最新的谷歌Chrome浏览器。检查版本...
chrome核心第三方浏览器如何添加Google Store扩展
现在chrome核心的第三方浏览器太多了:360浏览器、百度、傲游,还有最新的UC。这些浏览器一般都是双核可选的,都有自己的应用商店供用户随意添加和扩展。但是,这些浏览器的应用商店是扩展的。插件很少,是chrome网上商店无法比拟的。事实上,这些浏览器可以下载chrome在线商店的插件。应用...
Chrome 和 Sublime Text 配置自动网页刷新
以前写前端代码的时候,都是用Sublime Text来写代码的。在浏览器中手动刷新页面并查看效果,然后返回Sublime Text进行修改,然后在浏览器中手动刷新页面——如此来回,非常繁琐。之前看到别人用liveReload来实现web开发的同步更新,感觉很舒服,于是也折腾了一下,发现网上很多资料都有问题。
360极速浏览器安装扩展中心没有的chrome插件
由于360浏览器的版本和轻量级,插件很少。而且一些chrome插件是我们工作和学习所必需的,所以今天就来一步一步教大家如何安装扩展中心里没有的chrome插件。这个以vimium这个非常流行的插件为例:一.vimium是一个插件,它可以让用户只用键盘就可以使用浏览器高效上网。二. ... 查看全部
chrome抓取网页插件(
chrome添加插件教程工具/原料电脑chrome浏览器方法/步骤)
Chrome浏览器添加插件
Chrome 添加插件教程
工具/材料
计算机
铬浏览器
方法/步骤
无法访问谷歌的插件商店,也无法下载插件。你可以到这个网站:下载插件。
下载插件后,点击右上角的三个栏。
单击设置
在这里切换到扩展
然后直接将文件夹中下载的插件拖拽到该界面,浏览器会弹出添加的窗口,点击确定。
相关文章
如何为 Chrome 浏览器安装 Pocket 插件
上一篇文章提供了一个万能的方法将文章添加到Pocket中,虽然任何浏览器都可以使用上述方法添加文章,但是过程比较繁琐。有没有办法一键添加文章?今天给大家介绍一个方法。如果你使用的是Chrome浏览器,那么你可以继续往下看,如果你使用的是其他浏览器,别着急,可以关注我的下一篇文章...
谷歌Chrome浏览器无法添加二维码插件怎么办
如何在谷歌chrome(以下简称chrome)浏览器中添加二维码插件。这种情况,网上有很多方法。据说可以在chrome网上商店找到插件,但不知道是不是因为chrome在中国被禁了还是其他原因。,我试了很多次都打不开chrome浏览器的网店。但是,对于那些需要经验生成二维码来扫描网页的人...
[Chrome 插件] 添加其他 网站 的扩展
我们一直在寻找提高浏览安全性的方法。为了实现这一目标,我们最近更改了您在 Chrome 网上应用店之外向浏览器添加扩展程序的方式。以前,任何 网站 都可以提示您向浏览器添加扩展程序。在最新版本的谷歌浏览器中,通过“扩展”页面添加扩展...
谷歌Chrome浏览器不要修改Hosts文件添加插件
无法添加 Google Chrome 插件。添加的时候会提示“failure-server problem”或者Google App Store根本打不开。在网上搜索教程说修改Hosts文件,但是无法添加Hosts文件。在这种情况下,您可以使用此方法,简单易行。工具/原材料添加插件Chrome浏览器方法/步骤因为要添加...
Chrome二维码插件下载安装方法
chrome内核的浏览器增加了二维码,用手机扫描二维码登录这个网页非常方便。很多朋友都遇到过无法安装或者安装失败的现象。今天给大家分享一下如何下载安装chrome二维码插件。方法/步骤 首先,我们打开百度搜索...
如何在 Google Chrome 浏览器中添加剪辑插件?
本文主要介绍印象笔记加入谷歌浏览器。工具/材料谷歌Chrome浏览器版本49.0.2623.87.exe及以上:剪藏chrome -ext-6.7. 1.crx及以上方法/步骤首先确认您的浏览器版本,如果版本不是49及以上,搜索下载最新的谷歌Chrome浏览器。检查版本...
chrome核心第三方浏览器如何添加Google Store扩展
现在chrome核心的第三方浏览器太多了:360浏览器、百度、傲游,还有最新的UC。这些浏览器一般都是双核可选的,都有自己的应用商店供用户随意添加和扩展。但是,这些浏览器的应用商店是扩展的。插件很少,是chrome网上商店无法比拟的。事实上,这些浏览器可以下载chrome在线商店的插件。应用...
Chrome 和 Sublime Text 配置自动网页刷新
以前写前端代码的时候,都是用Sublime Text来写代码的。在浏览器中手动刷新页面并查看效果,然后返回Sublime Text进行修改,然后在浏览器中手动刷新页面——如此来回,非常繁琐。之前看到别人用liveReload来实现web开发的同步更新,感觉很舒服,于是也折腾了一下,发现网上很多资料都有问题。
360极速浏览器安装扩展中心没有的chrome插件
由于360浏览器的版本和轻量级,插件很少。而且一些chrome插件是我们工作和学习所必需的,所以今天就来一步一步教大家如何安装扩展中心里没有的chrome插件。这个以vimium这个非常流行的插件为例:一.vimium是一个插件,它可以让用户只用键盘就可以使用浏览器高效上网。二. ...
chrome抓取网页插件(本文访问Chrome应用店也能安装拓展插件(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-11-10 06:10
本文有同名博客,老枪谈Java:/,每日更新Spring/SpringMvc/SpringBoot/实战项目等信息文章
Chrome作为一款简单快捷的浏览器,深受大家的喜爱。而其超强的稳定性和丰富的扩展插件更是“深入人心”。我经常使用的Chrome插件很多,功能强大。我在这里推荐他们。
在开始之前,让我解释一下。要为 Chrome 下载各种有用的扩展程序,您可以访问 Chrome 网上应用店,搜索并安装它。
那么如果进不了应用商店,可以先搜索安装一个谷歌访问助手来解决。或者这里给大家介绍一个网站,不用去Chrome商店也能轻松安装扩展插件。
Chrome插件下载地址:/
篡改猴子
tampermonkey 被称为油猴。可以自由定制网页,实现各种意想不到的功能。即使Chrome只有油猴,没有其他扩展,也能俘获一大批忠实用户。因为它太强大了。
例如,油猴可以轻松分析观看VIP视频,下载付费音乐,解决百度云大文件需要客户端下载的问题,解决网页无法复制文本的问题,自定义百度云密码,以及在微软官网上隐藏系统镜像。显示等强大的功能。
IDM
Internet 下载管理器缩写为 IDM。它是一个用于嗅探和下载网络视频和音频的扩展插件。无需安装客户端,即可轻松下载音视频。
广告屏蔽加
强大的广告插件,让你告别全屏广告。默认会过滤网页上所有烦人的广告、弹窗等。我亲身体验过,adblock可以和另一个扩展插件“Ad Purifier”配合使用,让你的浏览器零广告。当然,它们的组合可以去除播放视频时的长广告。网站 进入故事片。
千图
一款可以免费下载千途网素材的插件。钱途网是公认的网上资料之一网站,资料很多。如果您需要下载材料,请安装它。
火炮
FireShot,一个“任性”的插件,可以截取整个页面,截取可见部分,截取选定区域等,如果你需要网页的长截图,那就不要错过了。并且还具有涂鸦编辑功能,还可以轻松保存为png图片、PDF格式文档等。
vimium
vimium,你可能对这个名字感到陌生,但你应该在电视上见过一些顶级黑客。他们从来没有用鼠标操作过电脑,完全通过键盘来操作。那么在你安装了这个插件之后你就熟悉了它的快捷键,你也可以像他们一样通过键盘灵活控制浏览器。是不是感觉很酷?你试试就知道了。
关于“强烈推荐的Chrome扩展插件”,我将以上6个分享给大家。当然,也有一些非常有用的,我就不一一赘述了。您需要添加它们。
本内容来源:/question/65580612/ 查看全部
chrome抓取网页插件(本文访问Chrome应用店也能安装拓展插件(组图))
本文有同名博客,老枪谈Java:/,每日更新Spring/SpringMvc/SpringBoot/实战项目等信息文章
Chrome作为一款简单快捷的浏览器,深受大家的喜爱。而其超强的稳定性和丰富的扩展插件更是“深入人心”。我经常使用的Chrome插件很多,功能强大。我在这里推荐他们。
在开始之前,让我解释一下。要为 Chrome 下载各种有用的扩展程序,您可以访问 Chrome 网上应用店,搜索并安装它。
那么如果进不了应用商店,可以先搜索安装一个谷歌访问助手来解决。或者这里给大家介绍一个网站,不用去Chrome商店也能轻松安装扩展插件。
Chrome插件下载地址:/
篡改猴子
tampermonkey 被称为油猴。可以自由定制网页,实现各种意想不到的功能。即使Chrome只有油猴,没有其他扩展,也能俘获一大批忠实用户。因为它太强大了。
例如,油猴可以轻松分析观看VIP视频,下载付费音乐,解决百度云大文件需要客户端下载的问题,解决网页无法复制文本的问题,自定义百度云密码,以及在微软官网上隐藏系统镜像。显示等强大的功能。
IDM
Internet 下载管理器缩写为 IDM。它是一个用于嗅探和下载网络视频和音频的扩展插件。无需安装客户端,即可轻松下载音视频。
广告屏蔽加
强大的广告插件,让你告别全屏广告。默认会过滤网页上所有烦人的广告、弹窗等。我亲身体验过,adblock可以和另一个扩展插件“Ad Purifier”配合使用,让你的浏览器零广告。当然,它们的组合可以去除播放视频时的长广告。网站 进入故事片。
千图
一款可以免费下载千途网素材的插件。钱途网是公认的网上资料之一网站,资料很多。如果您需要下载材料,请安装它。
火炮
FireShot,一个“任性”的插件,可以截取整个页面,截取可见部分,截取选定区域等,如果你需要网页的长截图,那就不要错过了。并且还具有涂鸦编辑功能,还可以轻松保存为png图片、PDF格式文档等。
vimium
vimium,你可能对这个名字感到陌生,但你应该在电视上见过一些顶级黑客。他们从来没有用鼠标操作过电脑,完全通过键盘来操作。那么在你安装了这个插件之后你就熟悉了它的快捷键,你也可以像他们一样通过键盘灵活控制浏览器。是不是感觉很酷?你试试就知道了。
关于“强烈推荐的Chrome扩展插件”,我将以上6个分享给大家。当然,也有一些非常有用的,我就不一一赘述了。您需要添加它们。
本内容来源:/question/65580612/
chrome抓取网页插件(WebScraper(chrome网页官方版浏览器)插件安装使用使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-11-10 03:02
Web Scraper(chrome网页的正式版是Web Scraper(chrome网页的正式版来自网页的正式版规则,以便快速提取网页中需要的内容。Web Scraper(正式版chrome网页的整个爬取逻辑从设置一级Selector(dian)开始,选择爬取范围,然后一级Selector设置二级Selector后,再次选择抓取字段,然后然后就可以抓取Web Scraper(正式版chrome网页了。插件抓取数据后,还可以将数据(chu)导出为CSV文件,欢迎免费下载。
Web Scraper(Chrome 网页正式版介绍
1. 抓取多个页面2、 读取的数据存储在本地存储或 CouchDB 中。Scraper(chrome网页ipt+AJAX官方版)5、浏览抓取的数据6、导出为CSV7、导入、导出站点地图8、只依赖Web Scraper(Chrome网页正式版浏览器,插件安装使用一、安装1、小编这里是Web Scraper(chrome网页正式版浏览器,先进入Web Scraper(chrome网页正式版)://extensions/:回车Web Scraper(正式版chrome网页扩展,解压Web Scraper(你在本页下载的chrome网页正式版,拖入扩展页面。2、 安装完成后抓紧时间)尝试插件的具体功能。3、当然可以先在设置页面中设置插件的存储设置和存储类型功能。二、 安装完成后,使用抓取功能。完成爬取操作需要四步。具体流程如下: 1、 打开Web Scraper(正式版chrome网页首先需要使用这个插件到Web Scraper中(正式版chrome网页需要在开发者工具模式,使用快捷键Ctrl+Shift+I/F12后,在出现的开发工具窗口中找到与插件同名的列。您可以先在设置页面中设置插件的存储设置和存储类型功能。二、 安装完成后,使用抓取功能。完成爬取操作需要四步。具体流程如下: 1、 打开Web Scraper(正式版chrome网页首先需要使用这个插件到Web Scraper中(正式版chrome网页需要在开发者工具模式,使用快捷键Ctrl+Shift+I/F12后,在出现的开发工具窗口中找到与插件同名的列。您可以先在设置页面中设置插件的存储设置和存储类型功能。二、 安装完成后,使用抓取功能。完成爬取操作需要四步。具体流程如下: 1、 打开Web Scraper(正式版chrome网页首先需要使用这个插件到Web Scraper中(正式版chrome网页需要在开发者工具模式,使用快捷键Ctrl+Shift+I/F12后,在出现的开发工具窗口中找到与插件同名的列。
如果我抓取今日头条的数据,那我就用今日头条来命名;网页爬虫(chrome网页官方版itWeb Scraper(chrome网页官方版网址:将网页链接复制到Star URL栏中,例如,在图片中,我将“吴晓波频道”的首页链接复制到该栏,以及然后点击Web Scraper(chrome网页官方版te satWeb Scraper(chrome网页官方版)新建一个SitWeb Scraper(chrome官方版网站)。
3、 设置这个SitWeb Scraper(chrome网页正式版和整个Web Scraper(chrome网页正式版。爬取逻辑是这样的:设置一级Selector,选择爬取range;在第一层SelectWeb Scraper(chrome网页正式版)设置二级Selector,选择捕获字段,然后捕获。对于文章,一级Selector意味着你要圈出元素这个文章,这个元素可能包括标题、作者、发布时间、评论数等,然后我们在二级Selector中挑出我们想要的元素,比如标题、作者、阅读数。让我们拆解这个工作流来设置主次选择器:(1)点击Add nWeb Scraper(官方版chrome网页采集器创建一级Selector。然后按照以下步骤操作:-输入id:id代表你抓取的整个范围,例如这里是文章 ,我们可以命名为wuxiWeb Scraper(chrome网页官方-articles;-Select Type:type代表你抓取的部分的类型,比如element/text/link,因为这是整个< @文章元素范围,我们需要先Use Element整体选择(如果这个网页需要滑动加载更多,则选择ElementWeb Scraper(chrome官方版网页ll Down);-check Multiple:勾选小Multiple前面的框,因为你要选择多个而不是单个元素,当我们勾选时,爬虫插件会帮助我们识别多篇相同类型的文章文章;-保留设置:其余未提及的部分保留默认设置。
所以你可以学习该领域的英语。比如我要选择“作者”,我就写“作者”;-选择类型:选择文本,因为你要抓取的是文本;-不要勾选多个:不要勾选前面的小方框多个,因为我们将在这里抓取单个元素;-保留设置:保留其余未提及部分的默认设置。(4)点击选择,然后点击要爬取的字段,按照以下步骤操作: - 选择一个字段:这里要爬取的字段为单个字段,点击该字段可以选择用鼠标,比如想爬取标题,用鼠标点击某篇文章文章的标题,当字段区域变成红色时选择; - 完成选择:
(5)重复以上操作,直到选中要爬取的字段。4、爬网爬虫(chrome网页正式版后,只需要设置好所有的Selectors,启动:点击Web Scraper(正式版chrome网页,然后点击StartWeb Scraper(正式版chrome网页)。弹出一个小窗口后,爬虫开始工作。你会得到一个列表所有你想要的数据。(2)如果你想对数据进行排序,比如按阅读、喜欢、作者等指标排序,让数据更清晰,那么可以点击Export DatWeb Scraper(官方chrome网页版,导入到Excel表格中。(3)导入Excel表格后,可以过滤数据。
Web Scraper(chrome官方版网页摘要
Web Scraper(chrome Webpage V3.20 是一款适用于ios版其他软件的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友: 查看全部
chrome抓取网页插件(WebScraper(chrome网页官方版浏览器)插件安装使用使用方法)
Web Scraper(chrome网页的正式版是Web Scraper(chrome网页的正式版来自网页的正式版规则,以便快速提取网页中需要的内容。Web Scraper(正式版chrome网页的整个爬取逻辑从设置一级Selector(dian)开始,选择爬取范围,然后一级Selector设置二级Selector后,再次选择抓取字段,然后然后就可以抓取Web Scraper(正式版chrome网页了。插件抓取数据后,还可以将数据(chu)导出为CSV文件,欢迎免费下载。
Web Scraper(Chrome 网页正式版介绍
1. 抓取多个页面2、 读取的数据存储在本地存储或 CouchDB 中。Scraper(chrome网页ipt+AJAX官方版)5、浏览抓取的数据6、导出为CSV7、导入、导出站点地图8、只依赖Web Scraper(Chrome网页正式版浏览器,插件安装使用一、安装1、小编这里是Web Scraper(chrome网页正式版浏览器,先进入Web Scraper(chrome网页正式版)://extensions/:回车Web Scraper(正式版chrome网页扩展,解压Web Scraper(你在本页下载的chrome网页正式版,拖入扩展页面。2、 安装完成后抓紧时间)尝试插件的具体功能。3、当然可以先在设置页面中设置插件的存储设置和存储类型功能。二、 安装完成后,使用抓取功能。完成爬取操作需要四步。具体流程如下: 1、 打开Web Scraper(正式版chrome网页首先需要使用这个插件到Web Scraper中(正式版chrome网页需要在开发者工具模式,使用快捷键Ctrl+Shift+I/F12后,在出现的开发工具窗口中找到与插件同名的列。您可以先在设置页面中设置插件的存储设置和存储类型功能。二、 安装完成后,使用抓取功能。完成爬取操作需要四步。具体流程如下: 1、 打开Web Scraper(正式版chrome网页首先需要使用这个插件到Web Scraper中(正式版chrome网页需要在开发者工具模式,使用快捷键Ctrl+Shift+I/F12后,在出现的开发工具窗口中找到与插件同名的列。您可以先在设置页面中设置插件的存储设置和存储类型功能。二、 安装完成后,使用抓取功能。完成爬取操作需要四步。具体流程如下: 1、 打开Web Scraper(正式版chrome网页首先需要使用这个插件到Web Scraper中(正式版chrome网页需要在开发者工具模式,使用快捷键Ctrl+Shift+I/F12后,在出现的开发工具窗口中找到与插件同名的列。
如果我抓取今日头条的数据,那我就用今日头条来命名;网页爬虫(chrome网页官方版itWeb Scraper(chrome网页官方版网址:将网页链接复制到Star URL栏中,例如,在图片中,我将“吴晓波频道”的首页链接复制到该栏,以及然后点击Web Scraper(chrome网页官方版te satWeb Scraper(chrome网页官方版)新建一个SitWeb Scraper(chrome官方版网站)。
3、 设置这个SitWeb Scraper(chrome网页正式版和整个Web Scraper(chrome网页正式版。爬取逻辑是这样的:设置一级Selector,选择爬取range;在第一层SelectWeb Scraper(chrome网页正式版)设置二级Selector,选择捕获字段,然后捕获。对于文章,一级Selector意味着你要圈出元素这个文章,这个元素可能包括标题、作者、发布时间、评论数等,然后我们在二级Selector中挑出我们想要的元素,比如标题、作者、阅读数。让我们拆解这个工作流来设置主次选择器:(1)点击Add nWeb Scraper(官方版chrome网页采集器创建一级Selector。然后按照以下步骤操作:-输入id:id代表你抓取的整个范围,例如这里是文章 ,我们可以命名为wuxiWeb Scraper(chrome网页官方-articles;-Select Type:type代表你抓取的部分的类型,比如element/text/link,因为这是整个< @文章元素范围,我们需要先Use Element整体选择(如果这个网页需要滑动加载更多,则选择ElementWeb Scraper(chrome官方版网页ll Down);-check Multiple:勾选小Multiple前面的框,因为你要选择多个而不是单个元素,当我们勾选时,爬虫插件会帮助我们识别多篇相同类型的文章文章;-保留设置:其余未提及的部分保留默认设置。
所以你可以学习该领域的英语。比如我要选择“作者”,我就写“作者”;-选择类型:选择文本,因为你要抓取的是文本;-不要勾选多个:不要勾选前面的小方框多个,因为我们将在这里抓取单个元素;-保留设置:保留其余未提及部分的默认设置。(4)点击选择,然后点击要爬取的字段,按照以下步骤操作: - 选择一个字段:这里要爬取的字段为单个字段,点击该字段可以选择用鼠标,比如想爬取标题,用鼠标点击某篇文章文章的标题,当字段区域变成红色时选择; - 完成选择:
(5)重复以上操作,直到选中要爬取的字段。4、爬网爬虫(chrome网页正式版后,只需要设置好所有的Selectors,启动:点击Web Scraper(正式版chrome网页,然后点击StartWeb Scraper(正式版chrome网页)。弹出一个小窗口后,爬虫开始工作。你会得到一个列表所有你想要的数据。(2)如果你想对数据进行排序,比如按阅读、喜欢、作者等指标排序,让数据更清晰,那么可以点击Export DatWeb Scraper(官方chrome网页版,导入到Excel表格中。(3)导入Excel表格后,可以过滤数据。
Web Scraper(chrome官方版网页摘要
Web Scraper(chrome Webpage V3.20 是一款适用于ios版其他软件的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友:
chrome抓取网页插件( WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-11-08 20:23
WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
我要分享的工具是一个Chrome插件,叫做:Web Scraper,这是一个Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以将其用作爬虫工具。
也是因为最近在整理36氪文章的一些标签,打算看看其他网站风投相关的标准,所以找了一家公司,名字叫:“艾诺克斯数据” 网站,它提供的一套“行业系统”标签很有参考价值,所以我想抓取页面上的数据,集成到我们自己的标签库中,如红字部分所示下图:
如果数据显示在规则中,也可以用鼠标选中并复制粘贴,但还是得想办法把它嵌入到页面中。这时候想起自己之前安装过Web Scraper,就试了一下。使用起来相当方便,采集效率一下子提高了。也给大家安利~
一年前在一个三班的公开课上看到了Chrome插件Web Scraper。号称是不懂编程也能实现爬虫爬虫的黑科技,但是在三类的官网上好像找不到。你可以百度:“三课爬虫”还是可以搜索到的。名字叫《人人都能学的数据爬虫类》,不过好像要收费100元。我觉得这个东西可以看网上的文章,比如我的文章~
简单的说,Web Scraper是一个基于Chrome的网页元素解析器,可以通过可视化的点击操作,实现自定义区域的数据/元素提取。同时,它还提供了定时自动提取功能,使用该功能可以作为一个简单的爬虫工具。
下面我将解释网页提取器抓取和真实代码抓取器之间的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它允许您定义要抓取的页面上的哪个元素。,以及抓取哪些页面,然后让机器代人操作;而如果你用Python写爬虫,更多的是用网页请求命令下载整个网页,然后用代码解析HTML页面元素,提取你想要的内容,然后不断循环。相比之下,使用代码会更灵活,但解析的成本会更高。如果是简单的页面内容提取,我也推荐使用Web Scraper。
关于Web Scraper的具体安装过程以及完整功能的使用方法,今天的文章不再赘述。一是我只用了自己需要的部分,二是市面上的Web Scraper教程太多了,你可以自己找。
这里只是一个实际的过程,给大家简单介绍一下我的使用方法。
第一步是创建站点地图
打开Chrome浏览器,按F12调出开发者工具。单击最后一个选项卡上的 Web Scraper 后,选择“创建站点地图”菜单并单击“创建站点地图”选项。
首先输入你要爬取的网站 URL,以及你自定义的爬取任务的名称。比如我取的名字是:xiniulevel,网址是:
第二步,创建抓取节点
我要抓取的是一级标签和二级标签,所以先点击进入我刚刚创建的Sitemap,然后点击“添加新选择器”进入抓取节点选择器配置页面,点击“选择”按钮。当你会看到一个浮动层
此时,当您将鼠标移入网页时,它会自动以绿色突出显示您悬停的某个位置。这时候你可以先点击一个你想选择的方块,你会发现方块变成了红色。如果要选择同一层级的所有块,可以继续点击相邻的下一个块,工具会默认选中所有同层级的块,如下图:
我们会发现下面浮动窗口的文本输入框自动填充了块的XPATH路径,然后点击“完成选择!” 结束选择,浮动框消失,选中的XPATH自动填入下面的Selector行。另外,一定要选择“Multiple”来声明要选择多个块。最后,单击保存选择器按钮结束。
第三步,获取元素值
完成Selector的创建后,回到上一页,你会发现Selector表多了一行。然后就可以直接点击Action中的Data preview,查看所有想要获取的元素值。
上图所示的部分是我添加了两个Selector,一个主标签和一个次标签的情况。点击数据预览的弹窗内容其实就是我想要的,复制到EXCEL就好了,不需要太复杂。自动抓取处理。
以上是对Web Scraper的使用过程的简单介绍。当然,我的使用并不是完全高效,因为每次想要获取二级标签,都得先手动切换一级标签,然后再执行抓取指令。应该有更好的方法,但对我来说已经足够了。本文文章主要想和大家普及一下这个工具。这不是教程。更多功能根据自己的需要去探索吧~
怎么样,对你有帮助吗?期待与我分享你的讯息~ 查看全部
chrome抓取网页插件(
WebScraper:如何从网页中提取数据的Chrome网页数据提取插件)
https://www.hxy58.cn/wp-conten ... .jpeg 300w" />我要分享的工具是一个Chrome插件,叫做:Web Scraper,这是一个Chrome网页数据提取插件,可以从网页中提取数据。从某种意义上说,你也可以将其用作爬虫工具。
也是因为最近在整理36氪文章的一些标签,打算看看其他网站风投相关的标准,所以找了一家公司,名字叫:“艾诺克斯数据” 网站,它提供的一套“行业系统”标签很有参考价值,所以我想抓取页面上的数据,集成到我们自己的标签库中,如红字部分所示下图:
https://www.hxy58.cn/wp-conten ... .jpeg 300w" />如果数据显示在规则中,也可以用鼠标选中并复制粘贴,但还是得想办法把它嵌入到页面中。这时候想起自己之前安装过Web Scraper,就试了一下。使用起来相当方便,采集效率一下子提高了。也给大家安利~
一年前在一个三班的公开课上看到了Chrome插件Web Scraper。号称是不懂编程也能实现爬虫爬虫的黑科技,但是在三类的官网上好像找不到。你可以百度:“三课爬虫”还是可以搜索到的。名字叫《人人都能学的数据爬虫类》,不过好像要收费100元。我觉得这个东西可以看网上的文章,比如我的文章~
简单的说,Web Scraper是一个基于Chrome的网页元素解析器,可以通过可视化的点击操作,实现自定义区域的数据/元素提取。同时,它还提供了定时自动提取功能,使用该功能可以作为一个简单的爬虫工具。
下面我将解释网页提取器抓取和真实代码抓取器之间的区别。使用网页提取器自动提取页面数据的过程有点类似于模拟手动点击的机器人。它允许您定义要抓取的页面上的哪个元素。,以及抓取哪些页面,然后让机器代人操作;而如果你用Python写爬虫,更多的是用网页请求命令下载整个网页,然后用代码解析HTML页面元素,提取你想要的内容,然后不断循环。相比之下,使用代码会更灵活,但解析的成本会更高。如果是简单的页面内容提取,我也推荐使用Web Scraper。
关于Web Scraper的具体安装过程以及完整功能的使用方法,今天的文章不再赘述。一是我只用了自己需要的部分,二是市面上的Web Scraper教程太多了,你可以自己找。
这里只是一个实际的过程,给大家简单介绍一下我的使用方法。
第一步是创建站点地图
打开Chrome浏览器,按F12调出开发者工具。单击最后一个选项卡上的 Web Scraper 后,选择“创建站点地图”菜单并单击“创建站点地图”选项。
https://www.hxy58.cn/wp-conten ... .jpeg 300w" />首先输入你要爬取的网站 URL,以及你自定义的爬取任务的名称。比如我取的名字是:xiniulevel,网址是:
第二步,创建抓取节点
我要抓取的是一级标签和二级标签,所以先点击进入我刚刚创建的Sitemap,然后点击“添加新选择器”进入抓取节点选择器配置页面,点击“选择”按钮。当你会看到一个浮动层
https://www.hxy58.cn/wp-conten ... .jpeg 300w, https://www.hxy58.cn/wp-conten ... .jpeg 768w" />此时,当您将鼠标移入网页时,它会自动以绿色突出显示您悬停的某个位置。这时候你可以先点击一个你想选择的方块,你会发现方块变成了红色。如果要选择同一层级的所有块,可以继续点击相邻的下一个块,工具会默认选中所有同层级的块,如下图:
https://www.hxy58.cn/wp-conten ... .jpeg 300w" />我们会发现下面浮动窗口的文本输入框自动填充了块的XPATH路径,然后点击“完成选择!” 结束选择,浮动框消失,选中的XPATH自动填入下面的Selector行。另外,一定要选择“Multiple”来声明要选择多个块。最后,单击保存选择器按钮结束。
https://www.hxy58.cn/wp-conten ... .jpeg 300w, https://www.hxy58.cn/wp-conten ... .jpeg 768w" />第三步,获取元素值
完成Selector的创建后,回到上一页,你会发现Selector表多了一行。然后就可以直接点击Action中的Data preview,查看所有想要获取的元素值。
https://www.hxy58.cn/wp-conten ... .jpeg 300w, https://www.hxy58.cn/wp-conten ... .jpeg 768w" />https://www.hxy58.cn/wp-conten ... .jpeg 300w" />上图所示的部分是我添加了两个Selector,一个主标签和一个次标签的情况。点击数据预览的弹窗内容其实就是我想要的,复制到EXCEL就好了,不需要太复杂。自动抓取处理。
以上是对Web Scraper的使用过程的简单介绍。当然,我的使用并不是完全高效,因为每次想要获取二级标签,都得先手动切换一级标签,然后再执行抓取指令。应该有更好的方法,但对我来说已经足够了。本文文章主要想和大家普及一下这个工具。这不是教程。更多功能根据自己的需要去探索吧~
怎么样,对你有帮助吗?期待与我分享你的讯息~
chrome抓取网页插件(猫抓Chrome插件官方简介-苏州安嘉软件插件 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-11-01 23:17
)
Mozhao Chrome 插件官方介绍 Mozhao 插件是一个插件,支持嗅探和抓取所有 Chrome 内核浏览器安装的网络视频链接。您可以从任何站点获取任何视频数据。使用此插件,一键获取您需要的链接,并自动抓取并保存。使用非常方便,打开需要下载文件的网站。您可以在此页面抓取自定义设置的所有内容,然后选择您要下载的内容下载到您的本地计算机,以方便使用!
墨章Chrome插件使用方法
1、mozhao插件离线安装方式是指chrome插件离线安装方式。输入 chrome://extensions 进入浏览器的扩展程序界面;最新Chrome浏览器下载地址:。点击添加扩展程序,快速将程序添加到谷歌浏览器并在右上角显示;
2、用户可以自定义捕获的视频和音频内容;
3、打开网站,点击猫抓,可以抓取本页内容,后面有复制和下载选项,点击要下载的视频和音频文件,即可下载它!
4. 以优酷土豆视频为例,点击图标即可:
猫抓扩展方法嗅探和爬虫工具依赖chrome API...如果需要更完善,请尝试IDM甚至Wireshark等软件...非常感谢热心的朋友不断提交可以的网址没抓住。有一些网站a站可以在设置中添加MIME类型的application/octet-stream来解决。这将捕获所有非媒体文件。知道地址可能下载不了流媒体(所以从1.0.7开始干掉)
查看全部
chrome抓取网页插件(猫抓Chrome插件官方简介-苏州安嘉软件插件
)
Mozhao Chrome 插件官方介绍 Mozhao 插件是一个插件,支持嗅探和抓取所有 Chrome 内核浏览器安装的网络视频链接。您可以从任何站点获取任何视频数据。使用此插件,一键获取您需要的链接,并自动抓取并保存。使用非常方便,打开需要下载文件的网站。您可以在此页面抓取自定义设置的所有内容,然后选择您要下载的内容下载到您的本地计算机,以方便使用!
墨章Chrome插件使用方法
1、mozhao插件离线安装方式是指chrome插件离线安装方式。输入 chrome://extensions 进入浏览器的扩展程序界面;最新Chrome浏览器下载地址:。点击添加扩展程序,快速将程序添加到谷歌浏览器并在右上角显示;
2、用户可以自定义捕获的视频和音频内容;
3、打开网站,点击猫抓,可以抓取本页内容,后面有复制和下载选项,点击要下载的视频和音频文件,即可下载它!
4. 以优酷土豆视频为例,点击图标即可:
猫抓扩展方法嗅探和爬虫工具依赖chrome API...如果需要更完善,请尝试IDM甚至Wireshark等软件...非常感谢热心的朋友不断提交可以的网址没抓住。有一些网站a站可以在设置中添加MIME类型的application/octet-stream来解决。这将捕获所有非媒体文件。知道地址可能下载不了流媒体(所以从1.0.7开始干掉)
chrome抓取网页插件(几款必备的Chrome插件工具,你知道吗?(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-31 14:05
)
使用 Chrome 浏览器的优势之一是插件极其丰富。只有你想不到的,没有你找不到的。今天为大家推荐几款必备的Chrome插件工具。
Fehelper-前端人员神器
一个由中国人开发的强大插件,相当于一个工具箱,这个插件收录了前端程序员需要的各种功能。
收录多个独立的小应用,如:Json工具、代码美化、代码压缩、二维码、Postman、markdown、网页油猴、备忘录、信息加解密、随机密码生成、Crontab等。
类似站点——查找相关网站
当我们经常浏览一个很棒的网站时,您可能会想到哪些网站与其“相似”,尤其是一些资源网站。如果这个站点没有它,它可能有类似的站点!
这个插件在这个时候尤为重要。SimilarSites 最大的作用只有一个:你可以通过互联网搜索找到类似的网站!
简单允许复制 - 通用复制
相信很多人在尝试复制网上的一些内容时都遇到过,发现需要收费VIP才能复制,快捷键不够用。在这种情况下,不要花钱,只需要一个插件就可以做到。
Simple Allow Copy 插件可以解除限制,右键复制。安装插件后,点击浏览器右上角的插件图标,图标由浅灰色变为深黑色,解除限制。
可选基金助理
很多朋友平时喜欢炒股,但股市有风险,投资需谨慎。可选基金助手是一款开源监控插件,可以帮助您实时查看您关心的基金涨跌情况。
无需跳转页面,您可以随时快速获取自选基金的实时估值,并根据您的需要及时自由增减自选基金。
您可以在任何网站上使用本插件查看您自选基金的实时估值,包括基金总收益,并且本插件有专门的关注功能角落提醒,所以您不用不错过任何信息。
听 1
听1**汇集了网易云、虾米、QQ音乐、酷狗、酷我、咪咕音乐、哔哩哔哩七大平台的歌曲!**欧式、美式、中式、日式、韩式、古风、轻音乐等,所有风格的音乐都包括在内。
播放器中的所有歌曲都是免费的。比如周杰伦的歌在其他平台基本都是收费的,你可以在listen 1音乐播放器上听!
网页截图-FireShot
======================
网页内截图一直是截图软件无法解决的问题,因为截图软件只能截取当前屏幕的内容。
这时候就需要FireShot插件来执行了!选择你需要的抓图方式,直接拖拽截图即可!在弹出的页面中选择保存格式即可保存。
推荐完Chrome插件之后,再给大家推荐三个非常好用的工具!
思维导图
GitMind是一款全新的云端思维导图和流程图制作软件,简单易用的免费在线制图工具,这是一款通用工具,无论是安卓、苹果、电脑、网页,甚至是ipad都可以使用。
GitMind 拥有丰富的图形模板。除了绘制常规的思维导图,还会制作组织结构图、泳道图、ER图、拓扑图等,还有各种模板,用于项目管理、学习、知识梳理等,最重要的是它们可以免费使用。
PDF 饼图
PDF Pie为我们提供了20款好用的在线PDF转换工具,关键是它们是完全免费的,包括PDF转换、PDF合并拆分、加密解密PDF、压缩PDF等,所有功能简单易用。
只需上传文件,稍等片刻即可下载,无需下载软件,用户体验非常好。
视觉工作室代码
Visual Studio Code 是一个跨平台的源代码编辑器,可在 Mac OS X、Windows 和 Linux 上运行,旨在编写现代 Web 和云应用程序。
收录所有主流开发语言的语法高亮、智能代码补全、自定义热键、括号匹配、代码片段、代码比较Diff、Git等功能。
支持插件扩展,可以安装插件支持C++、C#、Python、PHP等多种语言。同时针对Web开发和云应用开发进行了优化。
技术交流
欢迎转载,采集,并获得一些好评和支持!
目前已开通技术交流群,群内好友达2000余人。添加时备注最好的方式是:来源+兴趣方向,方便找志同道合的朋友
查看全部
chrome抓取网页插件(几款必备的Chrome插件工具,你知道吗?(上)
)
使用 Chrome 浏览器的优势之一是插件极其丰富。只有你想不到的,没有你找不到的。今天为大家推荐几款必备的Chrome插件工具。
Fehelper-前端人员神器
一个由中国人开发的强大插件,相当于一个工具箱,这个插件收录了前端程序员需要的各种功能。
收录多个独立的小应用,如:Json工具、代码美化、代码压缩、二维码、Postman、markdown、网页油猴、备忘录、信息加解密、随机密码生成、Crontab等。
类似站点——查找相关网站
当我们经常浏览一个很棒的网站时,您可能会想到哪些网站与其“相似”,尤其是一些资源网站。如果这个站点没有它,它可能有类似的站点!
这个插件在这个时候尤为重要。SimilarSites 最大的作用只有一个:你可以通过互联网搜索找到类似的网站!
简单允许复制 - 通用复制
相信很多人在尝试复制网上的一些内容时都遇到过,发现需要收费VIP才能复制,快捷键不够用。在这种情况下,不要花钱,只需要一个插件就可以做到。
Simple Allow Copy 插件可以解除限制,右键复制。安装插件后,点击浏览器右上角的插件图标,图标由浅灰色变为深黑色,解除限制。
可选基金助理
很多朋友平时喜欢炒股,但股市有风险,投资需谨慎。可选基金助手是一款开源监控插件,可以帮助您实时查看您关心的基金涨跌情况。
无需跳转页面,您可以随时快速获取自选基金的实时估值,并根据您的需要及时自由增减自选基金。
您可以在任何网站上使用本插件查看您自选基金的实时估值,包括基金总收益,并且本插件有专门的关注功能角落提醒,所以您不用不错过任何信息。
听 1
听1**汇集了网易云、虾米、QQ音乐、酷狗、酷我、咪咕音乐、哔哩哔哩七大平台的歌曲!**欧式、美式、中式、日式、韩式、古风、轻音乐等,所有风格的音乐都包括在内。
播放器中的所有歌曲都是免费的。比如周杰伦的歌在其他平台基本都是收费的,你可以在listen 1音乐播放器上听!
网页截图-FireShot
======================
网页内截图一直是截图软件无法解决的问题,因为截图软件只能截取当前屏幕的内容。
这时候就需要FireShot插件来执行了!选择你需要的抓图方式,直接拖拽截图即可!在弹出的页面中选择保存格式即可保存。
推荐完Chrome插件之后,再给大家推荐三个非常好用的工具!
思维导图
GitMind是一款全新的云端思维导图和流程图制作软件,简单易用的免费在线制图工具,这是一款通用工具,无论是安卓、苹果、电脑、网页,甚至是ipad都可以使用。
GitMind 拥有丰富的图形模板。除了绘制常规的思维导图,还会制作组织结构图、泳道图、ER图、拓扑图等,还有各种模板,用于项目管理、学习、知识梳理等,最重要的是它们可以免费使用。
PDF 饼图
PDF Pie为我们提供了20款好用的在线PDF转换工具,关键是它们是完全免费的,包括PDF转换、PDF合并拆分、加密解密PDF、压缩PDF等,所有功能简单易用。
只需上传文件,稍等片刻即可下载,无需下载软件,用户体验非常好。
视觉工作室代码
Visual Studio Code 是一个跨平台的源代码编辑器,可在 Mac OS X、Windows 和 Linux 上运行,旨在编写现代 Web 和云应用程序。
收录所有主流开发语言的语法高亮、智能代码补全、自定义热键、括号匹配、代码片段、代码比较Diff、Git等功能。
支持插件扩展,可以安装插件支持C++、C#、Python、PHP等多种语言。同时针对Web开发和云应用开发进行了优化。
技术交流
欢迎转载,采集,并获得一些好评和支持!
目前已开通技术交流群,群内好友达2000余人。添加时备注最好的方式是:来源+兴趣方向,方便找志同道合的朋友
chrome抓取网页插件(这款浏览器插件能一键提取网站的Logo抓取器下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-10-29 11:21
Logo抓取器【一键抓取网站Logo】,这款浏览器插件可以一键提取网站的Logo,让您轻松获取PNG格式的Logo图片。支持大部分网站。使用方便,将其安装到浏览器扩展槽中即可直接使用。本次带来中文版Logo采集器浏览器插件下载,有相关网站Logo提取需求的朋友不妨一试!
Logo 采集器插件说明:
偶然的原因,下载了一些网站的logo。偶然发现了一个国外开发者开发的logo获取工具浏览器插件,支持Chrome、FireFox、360等浏览器,一键傻瓜式操作下载他们的Logo,而且是PNG格式格式。
Logo 抓取器插件安装:
1、下载附件,使用压缩软件解压压缩文件,保存到系统任意文件夹。
2、在Chrome(或360、QQ等浏览器)地址栏输入:chrome://extensions/打开Chrome浏览器的扩展管理界面,勾选右上角的“开发者模式”按钮。
3、勾选开发者模式选项后,页面会有加载开发中扩展的按钮,点击“加载开发中扩展”按钮,选择Chrome插件刚刚解压的文件夹文件夹.
4、 单击“确定”按钮。如果此时没有任何反应,则插件将成功加载到浏览器中。
Logo 采集器插件的使用:
1、使用谷歌浏览器(或其他Chrome浏览器)打开目标网站。
2、在浏览器上点击“Logograbber”,它就会开始抓取可能的logo图案。
3、点击“下载”下载对应的Logo格式。
4、如果您发现显示的logo不是正确的logo,您也可以通过下方链接反馈问题。 查看全部
chrome抓取网页插件(这款浏览器插件能一键提取网站的Logo抓取器下载)
Logo抓取器【一键抓取网站Logo】,这款浏览器插件可以一键提取网站的Logo,让您轻松获取PNG格式的Logo图片。支持大部分网站。使用方便,将其安装到浏览器扩展槽中即可直接使用。本次带来中文版Logo采集器浏览器插件下载,有相关网站Logo提取需求的朋友不妨一试!
Logo 采集器插件说明:
偶然的原因,下载了一些网站的logo。偶然发现了一个国外开发者开发的logo获取工具浏览器插件,支持Chrome、FireFox、360等浏览器,一键傻瓜式操作下载他们的Logo,而且是PNG格式格式。
Logo 抓取器插件安装:
1、下载附件,使用压缩软件解压压缩文件,保存到系统任意文件夹。
2、在Chrome(或360、QQ等浏览器)地址栏输入:chrome://extensions/打开Chrome浏览器的扩展管理界面,勾选右上角的“开发者模式”按钮。
3、勾选开发者模式选项后,页面会有加载开发中扩展的按钮,点击“加载开发中扩展”按钮,选择Chrome插件刚刚解压的文件夹文件夹.
4、 单击“确定”按钮。如果此时没有任何反应,则插件将成功加载到浏览器中。
Logo 采集器插件的使用:
1、使用谷歌浏览器(或其他Chrome浏览器)打开目标网站。
2、在浏览器上点击“Logograbber”,它就会开始抓取可能的logo图案。
3、点击“下载”下载对应的Logo格式。
4、如果您发现显示的logo不是正确的logo,您也可以通过下方链接反馈问题。
chrome抓取网页插件( 移动互联网的大量插件,让你有种掌握一切的快感 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-27 00:16
移动互联网的大量插件,让你有种掌握一切的快感
)
虽然移动互联网的发展催生了大量的APP,但电脑端的软件数量实际上并没有增加,反而在不断减少。更多的内容以浏览器的形式展现在用户面前,这也为用户提供了极致的便捷,打开网页即可拥有所有内容。
市面上的浏览器种类繁多,如Chrome、Safari、360浏览器、QQ浏览器、火狐浏览器等,但谷歌浏览器Chrome一直备受推崇。除了强大的处理速度外,它还拥有大量的插件。让您拥有精通一切的乐趣。
01 Adblock Plus
很多网站的主要收入是广告费,所以在页面上展示大量的广告是在所难免的。为了让大家享受到更好的视觉效果,建议使用Adblock Plus插件来保护您的浏览器,让您看到更干净的界面。
02360网盾安全防护
人们使用的浏览器越来越多,各种应用向网页靠拢,这势必成为黑客眼中的摇钱树。因此,增加对网页和浏览器的保护非常重要。
作为国内顶级的安全服务公司,360的产品贯穿着免费、易用的理念,一直风靡至今。推荐大家使用这个插件。
03 方片系列
这个插件最近在用,用户体验很好。每当我在网上看到重要的信息、精美的图片、经典的文字、有趣的视频时,我都可以快速将内容拖入方形电影采集插件中。一秒钟就存在于云端是多么的方便。
04 雷霆
经常在网上下载资料和视频的人会发现,有时候点击网页上的下载链接,他们的下载工具并没有弹出,所以最好的办法就是在浏览器中添加相关插件。
迅雷是中国第一的Chrome浏览器下载工具,让您随时随地享受高速下载。
05 1密码
1Password 是一款极其易用的密码管理工具。目前,超过 50% 的互联网流量不是由人类引起的,而是由机器引起的。它收录了大量的黑客自动攻击流量,因此我们每个人在登录互联网时都会面临来自世界各地的威胁。
如果您的密码设置极其简单,您的信息很可能随时泄露,造成损失。1Password 提供密码管理功能。你只需要记住一个强密码就可以打开1Password,剩下的就交给1Password了。
当你去网站注册时,1Password会自动生成一个复杂的密码,当你再注册一个网站时,会生成另一组密码,所以你不用注意密码的泄露会对其他系统造成同样的威胁。当您登录时,1Password 会自动为您填写浏览器密码。
06 Video Downloader 专业版
很多朋友在视频网站看到自己喜欢的视频就想下载保存。问题是目前网站的大部分视频都不提供下载连接,很头疼。
Video Downloaderprofessionalfor Chrome是一款在您观看网站视频时自动获取下载连接的插件,并在界面上提供了下载按钮,让您可以无忧下载视频。
07 截屏
这是一个屏幕录制软件,有时可以与 Video Downloader Professional 一起使用。一些巨型视频网站有很好的保护措施。即便是专业的插件也未必能读出下载连接,所以在这个时候,就需要录屏软件作为杀手锏,但是费时费力。
如果你是在线教育讲师,这个插件对你更有意义。教学时可以随时打开Screencastify插件,课程结束后可以回顾自己的表现。
每天分享科技领域相关内容,喜欢请关注我。
查看全部
chrome抓取网页插件(
移动互联网的大量插件,让你有种掌握一切的快感
)
虽然移动互联网的发展催生了大量的APP,但电脑端的软件数量实际上并没有增加,反而在不断减少。更多的内容以浏览器的形式展现在用户面前,这也为用户提供了极致的便捷,打开网页即可拥有所有内容。
市面上的浏览器种类繁多,如Chrome、Safari、360浏览器、QQ浏览器、火狐浏览器等,但谷歌浏览器Chrome一直备受推崇。除了强大的处理速度外,它还拥有大量的插件。让您拥有精通一切的乐趣。
01 Adblock Plus
很多网站的主要收入是广告费,所以在页面上展示大量的广告是在所难免的。为了让大家享受到更好的视觉效果,建议使用Adblock Plus插件来保护您的浏览器,让您看到更干净的界面。
02360网盾安全防护
人们使用的浏览器越来越多,各种应用向网页靠拢,这势必成为黑客眼中的摇钱树。因此,增加对网页和浏览器的保护非常重要。
作为国内顶级的安全服务公司,360的产品贯穿着免费、易用的理念,一直风靡至今。推荐大家使用这个插件。
03 方片系列
这个插件最近在用,用户体验很好。每当我在网上看到重要的信息、精美的图片、经典的文字、有趣的视频时,我都可以快速将内容拖入方形电影采集插件中。一秒钟就存在于云端是多么的方便。
04 雷霆
经常在网上下载资料和视频的人会发现,有时候点击网页上的下载链接,他们的下载工具并没有弹出,所以最好的办法就是在浏览器中添加相关插件。
迅雷是中国第一的Chrome浏览器下载工具,让您随时随地享受高速下载。
05 1密码
1Password 是一款极其易用的密码管理工具。目前,超过 50% 的互联网流量不是由人类引起的,而是由机器引起的。它收录了大量的黑客自动攻击流量,因此我们每个人在登录互联网时都会面临来自世界各地的威胁。
如果您的密码设置极其简单,您的信息很可能随时泄露,造成损失。1Password 提供密码管理功能。你只需要记住一个强密码就可以打开1Password,剩下的就交给1Password了。
当你去网站注册时,1Password会自动生成一个复杂的密码,当你再注册一个网站时,会生成另一组密码,所以你不用注意密码的泄露会对其他系统造成同样的威胁。当您登录时,1Password 会自动为您填写浏览器密码。
06 Video Downloader 专业版
很多朋友在视频网站看到自己喜欢的视频就想下载保存。问题是目前网站的大部分视频都不提供下载连接,很头疼。
Video Downloaderprofessionalfor Chrome是一款在您观看网站视频时自动获取下载连接的插件,并在界面上提供了下载按钮,让您可以无忧下载视频。
07 截屏
这是一个屏幕录制软件,有时可以与 Video Downloader Professional 一起使用。一些巨型视频网站有很好的保护措施。即便是专业的插件也未必能读出下载连接,所以在这个时候,就需要录屏软件作为杀手锏,但是费时费力。
如果你是在线教育讲师,这个插件对你更有意义。教学时可以随时打开Screencastify插件,课程结束后可以回顾自己的表现。
每天分享科技领域相关内容,喜欢请关注我。
chrome抓取网页插件(我不想写代码,如何快速爬取几个不太大不太大的网页?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-10-22 23:11
点击链接:
学习更多IDEA进阶技巧,或关注公众号“Java面试”学习更多面试技巧。
最近有个同学问我。
我不想写代码。如何快速抓取少量数据的几个网页?
这种需求预计会遇到很多次。比如你想爬取秒杀页面的商品信息进行对比;您想抓取国家统计局官网上发布的您感兴趣的数据;等等。
说了这么多,我来简单介绍一下网络爬虫。网络爬虫的主要目的是抓取互联网上的网页。你可以把互联网上的每一个网页想象成一个点,那么整个互联网就会相互连接起来。是不是和我们大学里学的图论很像?如果从任意网页开始,时间资源允许,可以使用广度优先算法(BFS)或深度优先算法(DFS)爬取整个互联网。不熟悉这两种算法的同学可以背书。
我们以比较流行的Scrapy架构图为例,流线就是数据流向。
看完这张图,你对常见的爬虫有一个大概的了解了吗?
专业的网络爬虫(如百度/谷歌爬虫)旨在节省资源和时间。因此,设计相当复杂。这些爬虫一般都是基于分布式集群构建的,有的机器负责调度,有的机器负责下载,有的机器专门基于网页进行分析,等等。不能简单地用 BFS/DFS 解决。例如,如果我们以调度器为例,它需要管理下载优先级。引擎发送Request请求时,需要按照优先级进行排序和排列。当发动机需要它时,将其返还给发动机。
虽然各种语言的爬虫框架很多,但是如果用这些框架去爬取这一点数据,真的有点矫枉过正,还要代码调试,各种麻烦!!!
我发现Chrome商店里有个爬虫插件正好解决了这个痛点。它的名字是 Web Scraper,目前有 22w 用户下载。
官网:webscraper.io
这个爬虫的操作很简单,按照官方文档,几分钟就能学会。
我在这里谈几个关键点。
1、开始
一般第一次使用时,如果不知道怎么打开,可以使用快捷键ctrl+shift+i打开开发者工具。
站点地图:您所有的爬虫。
创建新站点地图:为新爬虫创建起始地址。
2、选择器
对于一个选择器来说,有以下几个元素,它的主要作用是为爬虫提供一个可视化的选择功能来分析网页的功能,如下图所示。
好的,下面我们来详细说明一下选择器内部的几个元素。
Id:选择器的ID;
Type:要抓取的内容类型,包括文本、图片、元素集;
选择器:选择器。点击选择按钮选择我们要抓取的内容,点击元素预览按钮预览选中的内容,点击数据预览按钮预览抓取的数据;
多路:勾选此按钮可以并行连接相同的内容;
Regex:正则表达式;
延迟:延迟。为了让页面有足够的时间加载数据;
父选择器:父选择器。
有同学可能会问,如果我想在一个页面上选择多个元素怎么办?上面提到的 Type 属性中的 Element 就扮演了这个角色,就像我在这里一样。
3、关系图
我觉得这个功能很好,可以帮助我们看到这个爬虫的层次关系图。
最后就是爬取数据了,爬取后的数据也可以导出到excel中供大家分析。
你可以去玩这个爬虫插件,它会帮你快速分析一些简单的数据。
就停在这里。
由于长期熬夜,造成近段不适,需要调理。建议大家早点休息,身体是革命的本钱。
如果这个文章对你有帮助,记得点赞或转发哦。 查看全部
chrome抓取网页插件(我不想写代码,如何快速爬取几个不太大不太大的网页?)
点击链接:
学习更多IDEA进阶技巧,或关注公众号“Java面试”学习更多面试技巧。
最近有个同学问我。
我不想写代码。如何快速抓取少量数据的几个网页?
这种需求预计会遇到很多次。比如你想爬取秒杀页面的商品信息进行对比;您想抓取国家统计局官网上发布的您感兴趣的数据;等等。
说了这么多,我来简单介绍一下网络爬虫。网络爬虫的主要目的是抓取互联网上的网页。你可以把互联网上的每一个网页想象成一个点,那么整个互联网就会相互连接起来。是不是和我们大学里学的图论很像?如果从任意网页开始,时间资源允许,可以使用广度优先算法(BFS)或深度优先算法(DFS)爬取整个互联网。不熟悉这两种算法的同学可以背书。
我们以比较流行的Scrapy架构图为例,流线就是数据流向。
看完这张图,你对常见的爬虫有一个大概的了解了吗?
专业的网络爬虫(如百度/谷歌爬虫)旨在节省资源和时间。因此,设计相当复杂。这些爬虫一般都是基于分布式集群构建的,有的机器负责调度,有的机器负责下载,有的机器专门基于网页进行分析,等等。不能简单地用 BFS/DFS 解决。例如,如果我们以调度器为例,它需要管理下载优先级。引擎发送Request请求时,需要按照优先级进行排序和排列。当发动机需要它时,将其返还给发动机。
虽然各种语言的爬虫框架很多,但是如果用这些框架去爬取这一点数据,真的有点矫枉过正,还要代码调试,各种麻烦!!!
我发现Chrome商店里有个爬虫插件正好解决了这个痛点。它的名字是 Web Scraper,目前有 22w 用户下载。
官网:webscraper.io
这个爬虫的操作很简单,按照官方文档,几分钟就能学会。
我在这里谈几个关键点。
1、开始
一般第一次使用时,如果不知道怎么打开,可以使用快捷键ctrl+shift+i打开开发者工具。
站点地图:您所有的爬虫。
创建新站点地图:为新爬虫创建起始地址。
2、选择器
对于一个选择器来说,有以下几个元素,它的主要作用是为爬虫提供一个可视化的选择功能来分析网页的功能,如下图所示。
好的,下面我们来详细说明一下选择器内部的几个元素。
Id:选择器的ID;
Type:要抓取的内容类型,包括文本、图片、元素集;
选择器:选择器。点击选择按钮选择我们要抓取的内容,点击元素预览按钮预览选中的内容,点击数据预览按钮预览抓取的数据;
多路:勾选此按钮可以并行连接相同的内容;
Regex:正则表达式;
延迟:延迟。为了让页面有足够的时间加载数据;
父选择器:父选择器。
有同学可能会问,如果我想在一个页面上选择多个元素怎么办?上面提到的 Type 属性中的 Element 就扮演了这个角色,就像我在这里一样。
3、关系图
我觉得这个功能很好,可以帮助我们看到这个爬虫的层次关系图。
最后就是爬取数据了,爬取后的数据也可以导出到excel中供大家分析。
你可以去玩这个爬虫插件,它会帮你快速分析一些简单的数据。
就停在这里。
由于长期熬夜,造成近段不适,需要调理。建议大家早点休息,身体是革命的本钱。
如果这个文章对你有帮助,记得点赞或转发哦。
chrome抓取网页插件( 工具Chrome浏览器中的JS,元素标签寻找法元素事件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-22 23:08
工具Chrome浏览器中的JS,元素标签寻找法元素事件)
工具 Chrome 浏览器
Chrome 浏览器是目前最流行的浏览器。它与大多数 w3c 标准和 ecma 标准兼容。前端工程师在开发过程中提供devtools、插件等工具非常方便。在爬取数据的过程中,最常用的应该是开发工具中的Element、Source、Network函数,分别查看DOM结构、源码、网络请求。同时,还有很多基于Chrome浏览器的插件,为我们提供了浏览器级别的数据处理能力。
篡改猴子
Tampermonkey 是一个 chrome 插件、一个免费的浏览器扩展和最流行的用户脚本管理器。简单来说就是可以指定在进入某些页面时调用指定的JS代码,这样我们就可以将页面中的一些数据整理出来保存在localStorage或者indexeddb中。
资源
ReRes 是一个 chrome 插件。可以支持将一个在线的JS重定向到另一个JS,即将原页面中的JS替换为另一个JS。在这个新的JS中,我们可以修改部分逻辑来满足我们的需求。
爬行过程
如上图所示,抓取分为三个步骤,即观察、刨削和抓取。
观察
首先是观察。我们需要通过 devtools 中的 Elements 和 Network 选项卡读取要抓取的页面。数据可能在DOM元素中,也可能直接通过Ajax接口返回。简而言之,找出最适合获取数据的位置。.
当然,如果在ajax接口返回数据,会很容易抓到,但是有时候我们可能会遇到比较特殊的网站,它会对数据进行加密,返回一个乱码,这个时候我们需要剖析代码。
解剖学
也就是对页面中的逻辑代码进行拆解分析,找到关键代码供我使用。通常对网站的JS代码进行混淆和压缩。我们可以使用Chrome开发工具中的Source工具对代码进行格式化,方便阅读。然后简单介绍一下我找关键代码的方法:
元素标签搜索方法 元素事件搜索方法 Ajax接口名称搜索方法
当然,这里找关键词的时候,需要用到Chrome开发者工具的搜索功能。
元素标签搜索
当我们找到一个关键的 DOM 元素时,你认为页面 JS 会对这个元素进行操作,比如取值、删除等,你可以通过这个元素自带的 id 或者 class 来搜索。通常,这些 id 和 class 名称不会混淆,可以直接找到。
元素事件查找方法
当我们认为某个元素已经绑定了点击或其他事件并且意义重大时,我们可以在Elements面板的Event Listeners中寻找最可能的事件,然后查看对应的JS代码。
当然,如果在Elements面板的DOM结构上直接标注了方法名,如下图,也可以直接全局搜索【CheckInput】。
Ajax接口名称查找方法
当我们找到自己想要的接口时,可以在Network中找到接口名称,直接全局Seach,或者在Initiator中通过JS调用的栈信息找到具体的调用代码。
通过这三步,我们基本上已经可以找到我们需要的业务代码了,剩下的就是在此基础上不断的找到加解密逻辑,也是通过打断点,然后在Callbacks中寻找函数调用源面板。堆栈,然后找到其他逻辑。
抓住
获取数据无非是自动提取数据并保存到指定位置。
这里就不得不依赖我们的两个插件,TamperMonkey 和 ReRes。我一般都是把key JS保存在本地进行修改,然后用ReRes把网上的JS映射到本地的JS,然后就可以为所欲为了,比如用封装的解密函数来解密数据,然后把数据保存在索引数据库。
使用TamperMonkey主要是定义一些全局变量,启动爬取过程,比如遍历DOM节点,模拟点击事件,记录抓取数据的位置。
总结
依靠Chrome浏览器来获取数据只是一种方便快捷的获取方式,当然不是很实用,因为Chrome无法直接操作数据库,我们的数据还是缓存在浏览器中,导出需要时间。这篇文章只谈了一部分捕获数据的想法。具体可以使用Puppeteer、Phantomjs等工具进行抓包。 查看全部
chrome抓取网页插件(
工具Chrome浏览器中的JS,元素标签寻找法元素事件)
工具 Chrome 浏览器
Chrome 浏览器是目前最流行的浏览器。它与大多数 w3c 标准和 ecma 标准兼容。前端工程师在开发过程中提供devtools、插件等工具非常方便。在爬取数据的过程中,最常用的应该是开发工具中的Element、Source、Network函数,分别查看DOM结构、源码、网络请求。同时,还有很多基于Chrome浏览器的插件,为我们提供了浏览器级别的数据处理能力。
篡改猴子
Tampermonkey 是一个 chrome 插件、一个免费的浏览器扩展和最流行的用户脚本管理器。简单来说就是可以指定在进入某些页面时调用指定的JS代码,这样我们就可以将页面中的一些数据整理出来保存在localStorage或者indexeddb中。
资源
ReRes 是一个 chrome 插件。可以支持将一个在线的JS重定向到另一个JS,即将原页面中的JS替换为另一个JS。在这个新的JS中,我们可以修改部分逻辑来满足我们的需求。
爬行过程
如上图所示,抓取分为三个步骤,即观察、刨削和抓取。
观察
首先是观察。我们需要通过 devtools 中的 Elements 和 Network 选项卡读取要抓取的页面。数据可能在DOM元素中,也可能直接通过Ajax接口返回。简而言之,找出最适合获取数据的位置。.
当然,如果在ajax接口返回数据,会很容易抓到,但是有时候我们可能会遇到比较特殊的网站,它会对数据进行加密,返回一个乱码,这个时候我们需要剖析代码。
解剖学
也就是对页面中的逻辑代码进行拆解分析,找到关键代码供我使用。通常对网站的JS代码进行混淆和压缩。我们可以使用Chrome开发工具中的Source工具对代码进行格式化,方便阅读。然后简单介绍一下我找关键代码的方法:
元素标签搜索方法 元素事件搜索方法 Ajax接口名称搜索方法
当然,这里找关键词的时候,需要用到Chrome开发者工具的搜索功能。
元素标签搜索
当我们找到一个关键的 DOM 元素时,你认为页面 JS 会对这个元素进行操作,比如取值、删除等,你可以通过这个元素自带的 id 或者 class 来搜索。通常,这些 id 和 class 名称不会混淆,可以直接找到。
元素事件查找方法
当我们认为某个元素已经绑定了点击或其他事件并且意义重大时,我们可以在Elements面板的Event Listeners中寻找最可能的事件,然后查看对应的JS代码。
当然,如果在Elements面板的DOM结构上直接标注了方法名,如下图,也可以直接全局搜索【CheckInput】。
Ajax接口名称查找方法
当我们找到自己想要的接口时,可以在Network中找到接口名称,直接全局Seach,或者在Initiator中通过JS调用的栈信息找到具体的调用代码。
通过这三步,我们基本上已经可以找到我们需要的业务代码了,剩下的就是在此基础上不断的找到加解密逻辑,也是通过打断点,然后在Callbacks中寻找函数调用源面板。堆栈,然后找到其他逻辑。
抓住
获取数据无非是自动提取数据并保存到指定位置。
这里就不得不依赖我们的两个插件,TamperMonkey 和 ReRes。我一般都是把key JS保存在本地进行修改,然后用ReRes把网上的JS映射到本地的JS,然后就可以为所欲为了,比如用封装的解密函数来解密数据,然后把数据保存在索引数据库。
使用TamperMonkey主要是定义一些全局变量,启动爬取过程,比如遍历DOM节点,模拟点击事件,记录抓取数据的位置。
总结
依靠Chrome浏览器来获取数据只是一种方便快捷的获取方式,当然不是很实用,因为Chrome无法直接操作数据库,我们的数据还是缓存在浏览器中,导出需要时间。这篇文章只谈了一部分捕获数据的想法。具体可以使用Puppeteer、Phantomjs等工具进行抓包。
chrome抓取网页插件(WebScraper(chrome网页官方版)介绍1.插件安装使用使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-10-22 13:13
Web Scraper(chrome网页的正式版是Web Scraper(chrome网页的正式版来自网页的正式版规则,以便快速提取网页中需要的内容。Web Scraper(正式版chrome网页的整个爬取逻辑从设置一级Selector(dian)开始,选择爬取范围,然后一级Selector设置二级Selector后,再次选择抓取字段,然后就可以抓取Web Scraper(正式版chrome网页了。插件抓取数据后,还可以将数据(chu)导出为CSV文件,欢迎免费下载。
Web Scraper(Chrome 网页正式版介绍
<p>1.插件安装和使用一、安装1、这里使用的编辑器是Web Scraper(chrome网页浏览器正式版,先进入Web Scraper(chrome官方版) web page://extensions/:进入Web Scraper(官方版chrome网页扩展),解压Web Scraper(你在本页下载的chrome网页官方版,拖入扩展页面。< @2、安装完成后赶紧试试这个插件的具体功能3、当然可以先在设置页面设置插件的存储设置和存储类型功能二、使用抓取功能安装完成后,只需要四步即可完成抓取操作。具体流程如下:1、打开Web Scraper(正式版chrome网页首先需要使用此插件进行Web Scraper(正式版chrome网页需要在开发者工具模式下使用,使用快捷键Ctrl)+Shift+I/F12后,在出现的开发工具窗口中找到同名插件栏 查看全部
chrome抓取网页插件(WebScraper(chrome网页官方版)介绍1.插件安装使用使用)
Web Scraper(chrome网页的正式版是Web Scraper(chrome网页的正式版来自网页的正式版规则,以便快速提取网页中需要的内容。Web Scraper(正式版chrome网页的整个爬取逻辑从设置一级Selector(dian)开始,选择爬取范围,然后一级Selector设置二级Selector后,再次选择抓取字段,然后就可以抓取Web Scraper(正式版chrome网页了。插件抓取数据后,还可以将数据(chu)导出为CSV文件,欢迎免费下载。
Web Scraper(Chrome 网页正式版介绍
<p>1.插件安装和使用一、安装1、这里使用的编辑器是Web Scraper(chrome网页浏览器正式版,先进入Web Scraper(chrome官方版) web page://extensions/:进入Web Scraper(官方版chrome网页扩展),解压Web Scraper(你在本页下载的chrome网页官方版,拖入扩展页面。< @2、安装完成后赶紧试试这个插件的具体功能3、当然可以先在设置页面设置插件的存储设置和存储类型功能二、使用抓取功能安装完成后,只需要四步即可完成抓取操作。具体流程如下:1、打开Web Scraper(正式版chrome网页首先需要使用此插件进行Web Scraper(正式版chrome网页需要在开发者工具模式下使用,使用快捷键Ctrl)+Shift+I/F12后,在出现的开发工具窗口中找到同名插件栏
chrome抓取网页插件(chrome抓取网页插件,各个浏览器对应的插件不同)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-10-21 17:00
chrome抓取网页插件,各个浏览器对应的插件不同,用来抓取数据的是不同的插件。应该就是这样。现在发现还不支持chromeinstaller,只支持chrome360installer,这两个我也都使用过。其他没有用过。
谢邀,这个和浏览器的cookies有关系,没办法的事情。iframe里面只能有cookies,你在别的页面里怎么登录也不行,iframe的权限管理没有我们想象中那么复杂,
你应该还不会用activex,这是我唯一比较懒的解决方案。
对于windows电脑来说,可以通过qq解决。
cookie
第一感觉是:尝试flashplayer第二感觉是:存在nginx第三感觉是:存在activex第四感觉是:存在localhost
可以让多台机器复制一份cookie地址,通过浏览器发送到各台机器,然后通过namescope的路由和发送到各台机器的方式去改变hosting等权限,这样就可以单独监控某一台机器了。
js
session,
这是因为你浏览的网页和你使用的浏览器cookie一致,flash打开网页的时候,浏览器会存储一个webhook(就是一个当前的记录,当有其他网页跳转或修改的时候,这个记录会被刷新)到cookie里面。
在windows下使用第三方浏览器插件,如chrome,ie,会增加一个防火墙cookie,其实是全局的,浏览器每次对着电脑发送http请求的时候,不是每次都需要把cookie填上,只要这一次不填写,电脑就默认不发送。比如你先随机选一个网页,然后再向另一个网页发送http请求,然后返回一个全局http数据时,就不需要把cookie发送给浏览器。
当浏览器在关闭时,他默认关闭全局cookie,这样每次接收到一个网页,就可以不发送任何cookie了。 查看全部
chrome抓取网页插件(chrome抓取网页插件,各个浏览器对应的插件不同)
chrome抓取网页插件,各个浏览器对应的插件不同,用来抓取数据的是不同的插件。应该就是这样。现在发现还不支持chromeinstaller,只支持chrome360installer,这两个我也都使用过。其他没有用过。
谢邀,这个和浏览器的cookies有关系,没办法的事情。iframe里面只能有cookies,你在别的页面里怎么登录也不行,iframe的权限管理没有我们想象中那么复杂,
你应该还不会用activex,这是我唯一比较懒的解决方案。
对于windows电脑来说,可以通过qq解决。
cookie
第一感觉是:尝试flashplayer第二感觉是:存在nginx第三感觉是:存在activex第四感觉是:存在localhost
可以让多台机器复制一份cookie地址,通过浏览器发送到各台机器,然后通过namescope的路由和发送到各台机器的方式去改变hosting等权限,这样就可以单独监控某一台机器了。
js
session,
这是因为你浏览的网页和你使用的浏览器cookie一致,flash打开网页的时候,浏览器会存储一个webhook(就是一个当前的记录,当有其他网页跳转或修改的时候,这个记录会被刷新)到cookie里面。
在windows下使用第三方浏览器插件,如chrome,ie,会增加一个防火墙cookie,其实是全局的,浏览器每次对着电脑发送http请求的时候,不是每次都需要把cookie填上,只要这一次不填写,电脑就默认不发送。比如你先随机选一个网页,然后再向另一个网页发送http请求,然后返回一个全局http数据时,就不需要把cookie发送给浏览器。
当浏览器在关闭时,他默认关闭全局cookie,这样每次接收到一个网页,就可以不发送任何cookie了。
chrome抓取网页插件(工具Chrome浏览器中的JS,元素标签寻找法元素事件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-10-21 10:14
工具 Chrome 浏览器
Chrome 浏览器是目前最流行的浏览器。它与大多数 w3c 标准和 ecma 标准兼容。前端工程师在开发过程中提供devtools、插件等工具非常方便。在爬取数据的过程中,最常用的应该是开发工具中的Element、Source、Network函数,分别查看DOM结构、源码、网络请求。同时,还有很多基于Chrome浏览器的插件,为我们提供了浏览器级别的数据处理能力。
篡改猴子
Tampermonkey 是一个 chrome 插件、一个免费的浏览器扩展和最流行的用户脚本管理器。简单来说就是可以指定在进入某些页面时调用指定的JS代码,这样我们就可以将页面中的一些数据整理出来保存在localStorage或者indexeddb中。
资源
ReRes 是一个 chrome 插件。可以支持将一个在线的JS重定向到另一个JS,即将原页面中的JS替换为另一个JS。在这个新的JS中,我们可以修改部分逻辑来满足我们的需求。
爬行过程
如上图所示,抓取分为三个步骤,即观察、刨削和抓取。
观察
首先是观察。我们需要通过 devtools 中的 Elements 和 Network 选项卡读取要抓取的页面。数据可能在DOM元素中,也可能直接通过Ajax接口返回。简而言之,找出最适合获取数据的位置。.
当然,如果是Ajax接口返回的数据,会很容易抓到,但是有时候我们可能会遇到比较特殊的网站,它会对数据进行加密,返回一个乱码,这个时候我们需要剖析代码。
解剖学
也就是对页面中的逻辑代码进行拆解分析,找到关键代码供我使用。通常对网站的JS代码进行混淆和压缩。我们可以使用Chrome开发工具中的Source工具对代码进行格式化,方便阅读。然后简单介绍一下我找关键代码的方法:
元素标签搜索方法 元素事件搜索方法 Ajax接口名称搜索方法
当然,这里找关键词的时候,需要用到Chrome开发者工具的搜索功能。
元素标签搜索
当我们找到一个关键的 DOM 元素时,你认为页面 JS 会对这个元素进行操作,比如取值、删除等,你可以通过这个元素自带的 id 或者 class 来搜索。通常,这些 id 和 class 名称不会混淆,可以直接找到。
元素事件查找方法
当我们认为某个元素绑定了点击或其他事件并且意义重大时,我们可以在Elements面板的Event Listeners中查找最可能的事件,然后查看对应的JS代码。
当然,如果在Elements面板的DOM结构上直接标注了方法名,如下图,可以直接全局搜索【CheckInput】。
复制代码
Ajax接口名称查找方法
当我们找到自己想要的接口时,可以在Network中找到接口名称,直接全局Seach,或者在Initiator中通过JS调用的栈信息找到具体的调用代码。
通过这三步,我们基本上已经可以找到我们需要的业务代码了,剩下的就是在此基础上不断的找到加解密逻辑,也是通过打断点,然后在Callbacks中寻找函数调用源面板。堆栈,然后找到其他逻辑。
抓住
获取数据无非是以自动化的方式提取数据并将其保存到指定位置。
这里就不得不依赖我们的两个插件,TamperMonkey 和 ReRes。我一般都是把key JS保存在本地进行修改,然后用ReRes把网上的JS映射到本地的JS,然后就可以为所欲为了,比如用封装的解密函数来解密数据,然后把数据保存在索引数据库。
使用TamperMonkey主要是定义一些全局变量,启动爬取过程,比如遍历DOM节点,模拟点击事件,记录抓取数据的位置。
总结
依靠Chrome浏览器来获取数据只是一种方便快捷的获取方式,当然不是很实用,因为Chrome无法直接操作数据库,我们的数据还是缓存在浏览器中,导出需要时间。这篇文章只谈了一部分捕获数据的想法。具体可以使用Puppeteer、Phantomjs等工具进行抓包。 查看全部
chrome抓取网页插件(工具Chrome浏览器中的JS,元素标签寻找法元素事件)
工具 Chrome 浏览器
Chrome 浏览器是目前最流行的浏览器。它与大多数 w3c 标准和 ecma 标准兼容。前端工程师在开发过程中提供devtools、插件等工具非常方便。在爬取数据的过程中,最常用的应该是开发工具中的Element、Source、Network函数,分别查看DOM结构、源码、网络请求。同时,还有很多基于Chrome浏览器的插件,为我们提供了浏览器级别的数据处理能力。
篡改猴子
Tampermonkey 是一个 chrome 插件、一个免费的浏览器扩展和最流行的用户脚本管理器。简单来说就是可以指定在进入某些页面时调用指定的JS代码,这样我们就可以将页面中的一些数据整理出来保存在localStorage或者indexeddb中。
资源
ReRes 是一个 chrome 插件。可以支持将一个在线的JS重定向到另一个JS,即将原页面中的JS替换为另一个JS。在这个新的JS中,我们可以修改部分逻辑来满足我们的需求。
爬行过程
如上图所示,抓取分为三个步骤,即观察、刨削和抓取。
观察
首先是观察。我们需要通过 devtools 中的 Elements 和 Network 选项卡读取要抓取的页面。数据可能在DOM元素中,也可能直接通过Ajax接口返回。简而言之,找出最适合获取数据的位置。.
当然,如果是Ajax接口返回的数据,会很容易抓到,但是有时候我们可能会遇到比较特殊的网站,它会对数据进行加密,返回一个乱码,这个时候我们需要剖析代码。
解剖学
也就是对页面中的逻辑代码进行拆解分析,找到关键代码供我使用。通常对网站的JS代码进行混淆和压缩。我们可以使用Chrome开发工具中的Source工具对代码进行格式化,方便阅读。然后简单介绍一下我找关键代码的方法:
元素标签搜索方法 元素事件搜索方法 Ajax接口名称搜索方法
当然,这里找关键词的时候,需要用到Chrome开发者工具的搜索功能。
元素标签搜索
当我们找到一个关键的 DOM 元素时,你认为页面 JS 会对这个元素进行操作,比如取值、删除等,你可以通过这个元素自带的 id 或者 class 来搜索。通常,这些 id 和 class 名称不会混淆,可以直接找到。
元素事件查找方法
当我们认为某个元素绑定了点击或其他事件并且意义重大时,我们可以在Elements面板的Event Listeners中查找最可能的事件,然后查看对应的JS代码。
当然,如果在Elements面板的DOM结构上直接标注了方法名,如下图,可以直接全局搜索【CheckInput】。
复制代码
Ajax接口名称查找方法
当我们找到自己想要的接口时,可以在Network中找到接口名称,直接全局Seach,或者在Initiator中通过JS调用的栈信息找到具体的调用代码。
通过这三步,我们基本上已经可以找到我们需要的业务代码了,剩下的就是在此基础上不断的找到加解密逻辑,也是通过打断点,然后在Callbacks中寻找函数调用源面板。堆栈,然后找到其他逻辑。
抓住
获取数据无非是以自动化的方式提取数据并将其保存到指定位置。
这里就不得不依赖我们的两个插件,TamperMonkey 和 ReRes。我一般都是把key JS保存在本地进行修改,然后用ReRes把网上的JS映射到本地的JS,然后就可以为所欲为了,比如用封装的解密函数来解密数据,然后把数据保存在索引数据库。
使用TamperMonkey主要是定义一些全局变量,启动爬取过程,比如遍历DOM节点,模拟点击事件,记录抓取数据的位置。
总结
依靠Chrome浏览器来获取数据只是一种方便快捷的获取方式,当然不是很实用,因为Chrome无法直接操作数据库,我们的数据还是缓存在浏览器中,导出需要时间。这篇文章只谈了一部分捕获数据的想法。具体可以使用Puppeteer、Phantomjs等工具进行抓包。

