
chrome抓取网页插件
一款你必须会用的 Chrome 爬虫插件
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-06-04 10:28
最近,有同学问我。
我不想写代码,如何快速爬取几个数据量不太大的网页?
这个需求,估计大家很多时候都会遇到,比如,你想爬取秒杀页面的商品信息进行对比;你想爬取国家统计局官网发布的你感兴趣的数据;等等。
既然说到这里,我就简单的介绍一下网络爬虫。网络爬虫的主要目的是爬取互联网上的网页。你可以把互联网中的每一个网页想象成一个点,那么整个互联网将是彼此连通的。是不是很像我们大学学过的图论?如果从任何一个网页出发,在时间资源允许的情况下,使用广度优先算法(BFS)或者深度优先算法(DFS)是可以爬完整个互联网的。对这两种算法不太熟悉的同学可以去背书了。
下面以比较流行的Scrapy 架构图为例,流线为数据流向。
看了这幅图,是不是对一般的爬虫有了大致的了解了。
专业的网络爬虫(比如百度/谷歌的爬虫)为了节约资源和时间,因此,设计是相当复杂的。这些爬虫一般是基于分布式集群构建的,有些机子负责调度,有些机子负责下载,有些机子专门基于网页进行分析,等等。并非简单的用 BFS/DFS 就能解决的,比如,我们以调度器为例,它就需要来管理下载优先级,当引擎发送过来 Request 请求,就需要按照优先级进行整理排列,入队,当引擎需要时,交还给引擎。
虽然关于各种语言的爬虫框架很多,要是用这些框架来爬这点数据,确实有点大材小用了,而且还得要编码调试,各种麻烦!!!
我发现 Chrome 商店里面有一款爬虫插件,刚好解决这个痛点,它的名字叫做 Web Scraper,目前有 22w 的用户下载。
官方网址:
这个爬虫操作特别简单,照着官方文档,几分钟就学会了。
我这里就说几个关键点吧。
1、启动
一般初次使用,不知道怎么打开它,用快捷键 ctrl+shift+i 打开开发者工具。
sitemaps:你所有的爬虫。
create new sitemap:创建一个新爬虫的起始地址。
2、选择器
对于一个选择器而言,就有如下几种元素,它主要作用是为爬虫分析网页的功能,提供了可视化选择的功能,如下图所示。
好了,再来细说一下,选择器内部的几个元素。
Id: 选择器的ID;
Type:要抓取内容的类型,有文本、图片以及元素集等;
Selector:选择器。点击 select 按钮可以选择我们要抓取的内容,点击 element preview 按钮可以预览选择的内容,而点击 data preview 按钮可以预览抓取的数据;
Multiple:勾选了这个按钮可以并联相同的内容;
Regex:正则表达式;
Delay:延迟。为了让页面有足够的时间加载数据;
Parent Selectors:父选择器。
有的同学可能会问,如果我要在一个页面选择多个元素,该怎么办呢?上面的提到的 Type 属性里面的 Element 就起到这个作用,如我这里。
3、关系图
我觉得这个功能特别棒,帮我们看到这个爬虫的层级关系图。
最后,就是爬取数据了,爬取后的数据还可以导出为 excel,便于你分析。
大家可以去玩一下这个爬虫插件,会帮你快速分析一些简单的数据。
就写到这里吧。
由于长期的熬夜,造成近段时间身体不适,需要好好调养。建议大家早点休息,身体是革命的本钱。
如果这篇文章对你有帮助,记得点赞或者转发一下。
---END---
近期热文:
————--^^^--————
看更多好文
请长按下方图片扫码关注
查看全部
一款你必须会用的 Chrome 爬虫插件
最近,有同学问我。
我不想写代码,如何快速爬取几个数据量不太大的网页?
这个需求,估计大家很多时候都会遇到,比如,你想爬取秒杀页面的商品信息进行对比;你想爬取国家统计局官网发布的你感兴趣的数据;等等。
既然说到这里,我就简单的介绍一下网络爬虫。网络爬虫的主要目的是爬取互联网上的网页。你可以把互联网中的每一个网页想象成一个点,那么整个互联网将是彼此连通的。是不是很像我们大学学过的图论?如果从任何一个网页出发,在时间资源允许的情况下,使用广度优先算法(BFS)或者深度优先算法(DFS)是可以爬完整个互联网的。对这两种算法不太熟悉的同学可以去背书了。
下面以比较流行的Scrapy 架构图为例,流线为数据流向。
看了这幅图,是不是对一般的爬虫有了大致的了解了。
专业的网络爬虫(比如百度/谷歌的爬虫)为了节约资源和时间,因此,设计是相当复杂的。这些爬虫一般是基于分布式集群构建的,有些机子负责调度,有些机子负责下载,有些机子专门基于网页进行分析,等等。并非简单的用 BFS/DFS 就能解决的,比如,我们以调度器为例,它就需要来管理下载优先级,当引擎发送过来 Request 请求,就需要按照优先级进行整理排列,入队,当引擎需要时,交还给引擎。
虽然关于各种语言的爬虫框架很多,要是用这些框架来爬这点数据,确实有点大材小用了,而且还得要编码调试,各种麻烦!!!
我发现 Chrome 商店里面有一款爬虫插件,刚好解决这个痛点,它的名字叫做 Web Scraper,目前有 22w 的用户下载。
官方网址:
这个爬虫操作特别简单,照着官方文档,几分钟就学会了。
我这里就说几个关键点吧。
1、启动
一般初次使用,不知道怎么打开它,用快捷键 ctrl+shift+i 打开开发者工具。
sitemaps:你所有的爬虫。
create new sitemap:创建一个新爬虫的起始地址。
2、选择器
对于一个选择器而言,就有如下几种元素,它主要作用是为爬虫分析网页的功能,提供了可视化选择的功能,如下图所示。
好了,再来细说一下,选择器内部的几个元素。
Id: 选择器的ID;
Type:要抓取内容的类型,有文本、图片以及元素集等;
Selector:选择器。点击 select 按钮可以选择我们要抓取的内容,点击 element preview 按钮可以预览选择的内容,而点击 data preview 按钮可以预览抓取的数据;
Multiple:勾选了这个按钮可以并联相同的内容;
Regex:正则表达式;
Delay:延迟。为了让页面有足够的时间加载数据;
Parent Selectors:父选择器。
有的同学可能会问,如果我要在一个页面选择多个元素,该怎么办呢?上面的提到的 Type 属性里面的 Element 就起到这个作用,如我这里。
3、关系图
我觉得这个功能特别棒,帮我们看到这个爬虫的层级关系图。
最后,就是爬取数据了,爬取后的数据还可以导出为 excel,便于你分析。
大家可以去玩一下这个爬虫插件,会帮你快速分析一些简单的数据。
就写到这里吧。
由于长期的熬夜,造成近段时间身体不适,需要好好调养。建议大家早点休息,身体是革命的本钱。
如果这篇文章对你有帮助,记得点赞或者转发一下。
---END---
近期热文:
————--^^^--————
看更多好文
请长按下方图片扫码关注
360浏览器chrome抓取网页插件的原因及解决办法!
网站优化 • 优采云 发表了文章 • 0 个评论 • 651 次浏览 • 2022-05-31 20:04
chrome抓取网页插件,我目前在用这个,自带按钮好像不太好,可以去360云找一个,图标跟chrome一模一样,图片全是一个个透明小图标,直接进网站,
markdowneditor-youcompleteme-youcompre-you-want-to-usechrome-webdevelopment,
重新编译下js,ui,配上chrome,
因为chrome自带了输入法,自动优化了很多。应该是用的第三方的一些插件。好几年前chrome确实有这种问题。
用了第三方扩展程序没有,先从技术原因入手。一般来说,在不扩展插件的情况下,插件会抓取你的脚本对输入关键字进行相应的相应的搜索和提示。比如用fiddler抓到了,然后将它转化为脚本文件。接下来很容易尝试。
可以尝试在360浏览器上禁用ie的headless
确实不能!我从chrome换到firefox实践出来了!
试试fiddler抓包
被抓的不爽还要继续用吗
把输入法改为谷歌拼音吧
改包名,重要的事情说三遍,我试过了ie改包名仍然有问题,
下载greenxml插件,把googleservices改为greenxml,
chromewebdevelopment和插件都改成greenxml再试一下
把搜索源加载掉,如果还不行的话,换本地文件源。 查看全部
360浏览器chrome抓取网页插件的原因及解决办法!
chrome抓取网页插件,我目前在用这个,自带按钮好像不太好,可以去360云找一个,图标跟chrome一模一样,图片全是一个个透明小图标,直接进网站,
markdowneditor-youcompleteme-youcompre-you-want-to-usechrome-webdevelopment,
重新编译下js,ui,配上chrome,
因为chrome自带了输入法,自动优化了很多。应该是用的第三方的一些插件。好几年前chrome确实有这种问题。
用了第三方扩展程序没有,先从技术原因入手。一般来说,在不扩展插件的情况下,插件会抓取你的脚本对输入关键字进行相应的相应的搜索和提示。比如用fiddler抓到了,然后将它转化为脚本文件。接下来很容易尝试。
可以尝试在360浏览器上禁用ie的headless
确实不能!我从chrome换到firefox实践出来了!
试试fiddler抓包
被抓的不爽还要继续用吗
把输入法改为谷歌拼音吧
改包名,重要的事情说三遍,我试过了ie改包名仍然有问题,
下载greenxml插件,把googleservices改为greenxml,
chromewebdevelopment和插件都改成greenxml再试一下
把搜索源加载掉,如果还不行的话,换本地文件源。
一款你必须会用的 Chrome 爬虫插件
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-05-31 06:56
最近,有同学问我。
我不想写代码,如何快速爬取几个数据量不太大的网页?
这个需求,估计大家很多时候都会遇到,比如,你想爬取秒杀页面的商品信息进行对比;你想爬取国家统计局官网发布的你感兴趣的数据;等等。
既然说到这里,我就简单的介绍一下网络爬虫。网络爬虫的主要目的是爬取互联网上的网页。你可以把互联网中的每一个网页想象成一个点,那么整个互联网将是彼此连通的。是不是很像我们大学学过的图论?如果从任何一个网页出发,在时间资源允许的情况下,使用广度优先算法(BFS)或者深度优先算法(DFS)是可以爬完整个互联网的。对这两种算法不太熟悉的同学可以去背书了。
下面以比较流行的Scrapy 架构图为例,流线为数据流向。
看了这幅图,是不是对一般的爬虫有了大致的了解了。
专业的网络爬虫(比如百度/谷歌的爬虫)为了节约资源和时间,因此,设计是相当复杂的。这些爬虫一般是基于分布式集群构建的,有些机子负责调度,有些机子负责下载,有些机子专门基于网页进行分析,等等。并非简单的用 BFS/DFS 就能解决的,比如,我们以调度器为例,它就需要来管理下载优先级,当引擎发送过来 Request 请求,就需要按照优先级进行整理排列,入队,当引擎需要时,交还给引擎。
虽然关于各种语言的爬虫框架很多,要是用这些框架来爬这点数据,确实有点大材小用了,而且还得要编码调试,各种麻烦!!!
我发现 Chrome 商店里面有一款爬虫插件,刚好解决这个痛点,它的名字叫做 Web Scraper,目前有 22w 的用户下载。
官方网址:
这个爬虫操作特别简单,照着官方文档,几分钟就学会了。
我这里就说几个关键点吧。
1、启动
一般初次使用,不知道怎么打开它,用快捷键 ctrl+shift+i 打开开发者工具。
sitemaps:你所有的爬虫。
create new sitemap:创建一个新爬虫的起始地址。
2、选择器
对于一个选择器而言,就有如下几种元素,它主要作用是为爬虫分析网页的功能,提供了可视化选择的功能,如下图所示。
好了,再来细说一下,选择器内部的几个元素。
Id: 选择器的ID;
Type:要抓取内容的类型,有文本、图片以及元素集等;
Selector:选择器。点击 select 按钮可以选择我们要抓取的内容,点击 element preview 按钮可以预览选择的内容,而点击 data preview 按钮可以预览抓取的数据;
Multiple:勾选了这个按钮可以并联相同的内容;
Regex:正则表达式;
Delay:延迟。为了让页面有足够的时间加载数据;
Parent Selectors:父选择器。
有的同学可能会问,如果我要在一个页面选择多个元素,该怎么办呢?上面的提到的 Type 属性里面的 Element 就起到这个作用,如我这里。
3、关系图
我觉得这个功能特别棒,帮我们看到这个爬虫的层级关系图。
最后,就是爬取数据了,爬取后的数据还可以导出为 excel,便于你分析。
大家可以去玩一下这个爬虫插件,会帮你快速分析一些简单的数据。
就写到这里吧。
由于长期的熬夜,造成近段时间身体不适,需要好好调养。建议大家早点休息,身体是革命的本钱。
如果这篇文章对你有帮助,记得点赞或者转发一下。
---END---
近期热文:
————--^^^--————
看更多好文
请长按下方图片扫码关注
查看全部
一款你必须会用的 Chrome 爬虫插件
最近,有同学问我。
我不想写代码,如何快速爬取几个数据量不太大的网页?
这个需求,估计大家很多时候都会遇到,比如,你想爬取秒杀页面的商品信息进行对比;你想爬取国家统计局官网发布的你感兴趣的数据;等等。
既然说到这里,我就简单的介绍一下网络爬虫。网络爬虫的主要目的是爬取互联网上的网页。你可以把互联网中的每一个网页想象成一个点,那么整个互联网将是彼此连通的。是不是很像我们大学学过的图论?如果从任何一个网页出发,在时间资源允许的情况下,使用广度优先算法(BFS)或者深度优先算法(DFS)是可以爬完整个互联网的。对这两种算法不太熟悉的同学可以去背书了。
下面以比较流行的Scrapy 架构图为例,流线为数据流向。
看了这幅图,是不是对一般的爬虫有了大致的了解了。
专业的网络爬虫(比如百度/谷歌的爬虫)为了节约资源和时间,因此,设计是相当复杂的。这些爬虫一般是基于分布式集群构建的,有些机子负责调度,有些机子负责下载,有些机子专门基于网页进行分析,等等。并非简单的用 BFS/DFS 就能解决的,比如,我们以调度器为例,它就需要来管理下载优先级,当引擎发送过来 Request 请求,就需要按照优先级进行整理排列,入队,当引擎需要时,交还给引擎。
虽然关于各种语言的爬虫框架很多,要是用这些框架来爬这点数据,确实有点大材小用了,而且还得要编码调试,各种麻烦!!!
我发现 Chrome 商店里面有一款爬虫插件,刚好解决这个痛点,它的名字叫做 Web Scraper,目前有 22w 的用户下载。
官方网址:
这个爬虫操作特别简单,照着官方文档,几分钟就学会了。
我这里就说几个关键点吧。
1、启动
一般初次使用,不知道怎么打开它,用快捷键 ctrl+shift+i 打开开发者工具。
sitemaps:你所有的爬虫。
create new sitemap:创建一个新爬虫的起始地址。
2、选择器
对于一个选择器而言,就有如下几种元素,它主要作用是为爬虫分析网页的功能,提供了可视化选择的功能,如下图所示。
好了,再来细说一下,选择器内部的几个元素。
Id: 选择器的ID;
Type:要抓取内容的类型,有文本、图片以及元素集等;
Selector:选择器。点击 select 按钮可以选择我们要抓取的内容,点击 element preview 按钮可以预览选择的内容,而点击 data preview 按钮可以预览抓取的数据;
Multiple:勾选了这个按钮可以并联相同的内容;
Regex:正则表达式;
Delay:延迟。为了让页面有足够的时间加载数据;
Parent Selectors:父选择器。
有的同学可能会问,如果我要在一个页面选择多个元素,该怎么办呢?上面的提到的 Type 属性里面的 Element 就起到这个作用,如我这里。
3、关系图
我觉得这个功能特别棒,帮我们看到这个爬虫的层级关系图。
最后,就是爬取数据了,爬取后的数据还可以导出为 excel,便于你分析。
大家可以去玩一下这个爬虫插件,会帮你快速分析一些简单的数据。
就写到这里吧。
由于长期的熬夜,造成近段时间身体不适,需要好好调养。建议大家早点休息,身体是革命的本钱。
如果这篇文章对你有帮助,记得点赞或者转发一下。
---END---
近期热文:
————--^^^--————
看更多好文
请长按下方图片扫码关注
一款你必须会用的 Chrome 爬虫插件
网站优化 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2022-05-28 19:09
最近,有同学问我。
我不想写代码,如何快速爬取几个数据量不太大的网页?
这个需求,估计大家很多时候都会遇到,比如,你想爬取秒杀页面的商品信息进行对比;你想爬取国家统计局官网发布的你感兴趣的数据;等等。
既然说到这里,我就简单的介绍一下网络爬虫。网络爬虫的主要目的是爬取互联网上的网页。你可以把互联网中的每一个网页想象成一个点,那么整个互联网将是彼此连通的。是不是很像我们大学学过的图论?如果从任何一个网页出发,在时间资源允许的情况下,使用广度优先算法(BFS)或者深度优先算法(DFS)是可以爬完整个互联网的。对这两种算法不太熟悉的同学可以去背书了。
下面以比较流行的Scrapy 架构图为例,流线为数据流向。
看了这幅图,是不是对一般的爬虫有了大致的了解了。
专业的网络爬虫(比如百度/谷歌的爬虫)为了节约资源和时间,因此,设计是相当复杂的。这些爬虫一般是基于分布式集群构建的,有些机子负责调度,有些机子负责下载,有些机子专门基于网页进行分析,等等。并非简单的用 BFS/DFS 就能解决的,比如,我们以调度器为例,它就需要来管理下载优先级,当引擎发送过来 Request 请求,就需要按照优先级进行整理排列,入队,当引擎需要时,交还给引擎。
虽然关于各种语言的爬虫框架很多,要是用这些框架来爬这点数据,确实有点大材小用了,而且还得要编码调试,各种麻烦!!!
我发现 Chrome 商店里面有一款爬虫插件,刚好解决这个痛点,它的名字叫做 Web Scraper,目前有 22w 的用户下载。
官方网址:
这个爬虫操作特别简单,照着官方文档,几分钟就学会了。
我这里就说几个关键点吧。
1、启动
一般初次使用,不知道怎么打开它,用快捷键 ctrl+shift+i 打开开发者工具。
sitemaps:你所有的爬虫。
create new sitemap:创建一个新爬虫的起始地址。
2、选择器
对于一个选择器而言,就有如下几种元素,它主要作用是为爬虫分析网页的功能,提供了可视化选择的功能,如下图所示。
好了,再来细说一下,选择器内部的几个元素。
Id: 选择器的ID;
Type:要抓取内容的类型,有文本、图片以及元素集等;
Selector:选择器。点击 select 按钮可以选择我们要抓取的内容,点击 element preview 按钮可以预览选择的内容,而点击 data preview 按钮可以预览抓取的数据;
Multiple:勾选了这个按钮可以并联相同的内容;
Regex:正则表达式;
Delay:延迟。为了让页面有足够的时间加载数据;
Parent Selectors:父选择器。
有的同学可能会问,如果我要在一个页面选择多个元素,该怎么办呢?上面的提到的 Type 属性里面的 Element 就起到这个作用,如我这里。
3、关系图
我觉得这个功能特别棒,帮我们看到这个爬虫的层级关系图。
最后,就是爬取数据了,爬取后的数据还可以导出为 excel,便于你分析。
大家可以去玩一下这个爬虫插件,会帮你快速分析一些简单的数据。
就写到这里吧。
由于长期的熬夜,造成近段时间身体不适,需要好好调养。建议大家早点休息,身体是革命的本钱。
如果这篇文章对你有帮助,记得点赞或者转发一下。
---END---
近期热文:
————--^^^--————
看更多好文
请长按下方图片扫码关注
查看全部
一款你必须会用的 Chrome 爬虫插件
最近,有同学问我。
我不想写代码,如何快速爬取几个数据量不太大的网页?
这个需求,估计大家很多时候都会遇到,比如,你想爬取秒杀页面的商品信息进行对比;你想爬取国家统计局官网发布的你感兴趣的数据;等等。
既然说到这里,我就简单的介绍一下网络爬虫。网络爬虫的主要目的是爬取互联网上的网页。你可以把互联网中的每一个网页想象成一个点,那么整个互联网将是彼此连通的。是不是很像我们大学学过的图论?如果从任何一个网页出发,在时间资源允许的情况下,使用广度优先算法(BFS)或者深度优先算法(DFS)是可以爬完整个互联网的。对这两种算法不太熟悉的同学可以去背书了。
下面以比较流行的Scrapy 架构图为例,流线为数据流向。
看了这幅图,是不是对一般的爬虫有了大致的了解了。
专业的网络爬虫(比如百度/谷歌的爬虫)为了节约资源和时间,因此,设计是相当复杂的。这些爬虫一般是基于分布式集群构建的,有些机子负责调度,有些机子负责下载,有些机子专门基于网页进行分析,等等。并非简单的用 BFS/DFS 就能解决的,比如,我们以调度器为例,它就需要来管理下载优先级,当引擎发送过来 Request 请求,就需要按照优先级进行整理排列,入队,当引擎需要时,交还给引擎。
虽然关于各种语言的爬虫框架很多,要是用这些框架来爬这点数据,确实有点大材小用了,而且还得要编码调试,各种麻烦!!!
我发现 Chrome 商店里面有一款爬虫插件,刚好解决这个痛点,它的名字叫做 Web Scraper,目前有 22w 的用户下载。
官方网址:
这个爬虫操作特别简单,照着官方文档,几分钟就学会了。
我这里就说几个关键点吧。
1、启动
一般初次使用,不知道怎么打开它,用快捷键 ctrl+shift+i 打开开发者工具。
sitemaps:你所有的爬虫。
create new sitemap:创建一个新爬虫的起始地址。
2、选择器
对于一个选择器而言,就有如下几种元素,它主要作用是为爬虫分析网页的功能,提供了可视化选择的功能,如下图所示。
好了,再来细说一下,选择器内部的几个元素。
Id: 选择器的ID;
Type:要抓取内容的类型,有文本、图片以及元素集等;
Selector:选择器。点击 select 按钮可以选择我们要抓取的内容,点击 element preview 按钮可以预览选择的内容,而点击 data preview 按钮可以预览抓取的数据;
Multiple:勾选了这个按钮可以并联相同的内容;
Regex:正则表达式;
Delay:延迟。为了让页面有足够的时间加载数据;
Parent Selectors:父选择器。
有的同学可能会问,如果我要在一个页面选择多个元素,该怎么办呢?上面的提到的 Type 属性里面的 Element 就起到这个作用,如我这里。
3、关系图
我觉得这个功能特别棒,帮我们看到这个爬虫的层级关系图。
最后,就是爬取数据了,爬取后的数据还可以导出为 excel,便于你分析。
大家可以去玩一下这个爬虫插件,会帮你快速分析一些简单的数据。
就写到这里吧。
由于长期的熬夜,造成近段时间身体不适,需要好好调养。建议大家早点休息,身体是革命的本钱。
如果这篇文章对你有帮助,记得点赞或者转发一下。
---END---
近期热文:
————--^^^--————
看更多好文
请长按下方图片扫码关注
一款你必须会用的 Chrome 爬虫插件
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-05-14 02:33
最近,有同学问我。
我不想写代码,如何快速爬取几个数据量不太大的网页?
这个需求,估计大家很多时候都会遇到,比如,你想爬取秒杀页面的商品信息进行对比;你想爬取国家统计局官网发布的你感兴趣的数据;等等。
既然说到这里,我就简单的介绍一下网络爬虫。网络爬虫的主要目的是爬取互联网上的网页。你可以把互联网中的每一个网页想象成一个点,那么整个互联网将是彼此连通的。是不是很像我们大学学过的图论?如果从任何一个网页出发,在时间资源允许的情况下,使用广度优先算法(BFS)或者深度优先算法(DFS)是可以爬完整个互联网的。对这两种算法不太熟悉的同学可以去背书了。
下面以比较流行的Scrapy 架构图为例,流线为数据流向。
看了这幅图,是不是对一般的爬虫有了大致的了解了。
专业的网络爬虫(比如百度/谷歌的爬虫)为了节约资源和时间,因此,设计是相当复杂的。这些爬虫一般是基于分布式集群构建的,有些机子负责调度,有些机子负责下载,有些机子专门基于网页进行分析,等等。并非简单的用 BFS/DFS 就能解决的,比如,我们以调度器为例,它就需要来管理下载优先级,当引擎发送过来 Request 请求,就需要按照优先级进行整理排列,入队,当引擎需要时,交还给引擎。
虽然关于各种语言的爬虫框架很多,要是用这些框架来爬这点数据,确实有点大材小用了,而且还得要编码调试,各种麻烦!!!
我发现 Chrome 商店里面有一款爬虫插件,刚好解决这个痛点,它的名字叫做 Web Scraper,目前有 22w 的用户下载。
官方网址:
这个爬虫操作特别简单,照着官方文档,几分钟就学会了。
我这里就说几个关键点吧。
1、启动
一般初次使用,不知道怎么打开它,用快捷键 ctrl+shift+i 打开开发者工具。
sitemaps:你所有的爬虫。
create new sitemap:创建一个新爬虫的起始地址。
2、选择器
对于一个选择器而言,就有如下几种元素,它主要作用是为爬虫分析网页的功能,提供了可视化选择的功能,如下图所示。
好了,再来细说一下,选择器内部的几个元素。
Id: 选择器的ID;
Type:要抓取内容的类型,有文本、图片以及元素集等;
Selector:选择器。点击 select 按钮可以选择我们要抓取的内容,点击 element preview 按钮可以预览选择的内容,而点击 data preview 按钮可以预览抓取的数据;
Multiple:勾选了这个按钮可以并联相同的内容;
Regex:正则表达式;
Delay:延迟。为了让页面有足够的时间加载数据;
Parent Selectors:父选择器。
有的同学可能会问,如果我要在一个页面选择多个元素,该怎么办呢?上面的提到的 Type 属性里面的 Element 就起到这个作用,如我这里。
3、关系图
我觉得这个功能特别棒,帮我们看到这个爬虫的层级关系图。
最后,就是爬取数据了,爬取后的数据还可以导出为 excel,便于你分析。
大家可以去玩一下这个爬虫插件,会帮你快速分析一些简单的数据。
就写到这里吧。
由于长期的熬夜,造成近段时间身体不适,需要好好调养。建议大家早点休息,身体是革命的本钱。
如果这篇文章对你有帮助,记得点赞或者转发一下。
---END---
近期热文:
————--^^^--————
看更多好文
请长按下方图片扫码关注
查看全部
一款你必须会用的 Chrome 爬虫插件
最近,有同学问我。
我不想写代码,如何快速爬取几个数据量不太大的网页?
这个需求,估计大家很多时候都会遇到,比如,你想爬取秒杀页面的商品信息进行对比;你想爬取国家统计局官网发布的你感兴趣的数据;等等。
既然说到这里,我就简单的介绍一下网络爬虫。网络爬虫的主要目的是爬取互联网上的网页。你可以把互联网中的每一个网页想象成一个点,那么整个互联网将是彼此连通的。是不是很像我们大学学过的图论?如果从任何一个网页出发,在时间资源允许的情况下,使用广度优先算法(BFS)或者深度优先算法(DFS)是可以爬完整个互联网的。对这两种算法不太熟悉的同学可以去背书了。
下面以比较流行的Scrapy 架构图为例,流线为数据流向。
看了这幅图,是不是对一般的爬虫有了大致的了解了。
专业的网络爬虫(比如百度/谷歌的爬虫)为了节约资源和时间,因此,设计是相当复杂的。这些爬虫一般是基于分布式集群构建的,有些机子负责调度,有些机子负责下载,有些机子专门基于网页进行分析,等等。并非简单的用 BFS/DFS 就能解决的,比如,我们以调度器为例,它就需要来管理下载优先级,当引擎发送过来 Request 请求,就需要按照优先级进行整理排列,入队,当引擎需要时,交还给引擎。
虽然关于各种语言的爬虫框架很多,要是用这些框架来爬这点数据,确实有点大材小用了,而且还得要编码调试,各种麻烦!!!
我发现 Chrome 商店里面有一款爬虫插件,刚好解决这个痛点,它的名字叫做 Web Scraper,目前有 22w 的用户下载。
官方网址:
这个爬虫操作特别简单,照着官方文档,几分钟就学会了。
我这里就说几个关键点吧。
1、启动
一般初次使用,不知道怎么打开它,用快捷键 ctrl+shift+i 打开开发者工具。
sitemaps:你所有的爬虫。
create new sitemap:创建一个新爬虫的起始地址。
2、选择器
对于一个选择器而言,就有如下几种元素,它主要作用是为爬虫分析网页的功能,提供了可视化选择的功能,如下图所示。
好了,再来细说一下,选择器内部的几个元素。
Id: 选择器的ID;
Type:要抓取内容的类型,有文本、图片以及元素集等;
Selector:选择器。点击 select 按钮可以选择我们要抓取的内容,点击 element preview 按钮可以预览选择的内容,而点击 data preview 按钮可以预览抓取的数据;
Multiple:勾选了这个按钮可以并联相同的内容;
Regex:正则表达式;
Delay:延迟。为了让页面有足够的时间加载数据;
Parent Selectors:父选择器。
有的同学可能会问,如果我要在一个页面选择多个元素,该怎么办呢?上面的提到的 Type 属性里面的 Element 就起到这个作用,如我这里。
3、关系图
我觉得这个功能特别棒,帮我们看到这个爬虫的层级关系图。
最后,就是爬取数据了,爬取后的数据还可以导出为 excel,便于你分析。
大家可以去玩一下这个爬虫插件,会帮你快速分析一些简单的数据。
就写到这里吧。
由于长期的熬夜,造成近段时间身体不适,需要好好调养。建议大家早点休息,身体是革命的本钱。
如果这篇文章对你有帮助,记得点赞或者转发一下。
---END---
近期热文:
————--^^^--————
看更多好文
请长按下方图片扫码关注
盘点:20个用于网页设计的Chrome扩展程序
网站优化 • 优采云 发表了文章 • 0 个评论 • 265 次浏览 • 2022-05-08 03:09
关
注
点击上方置顶雨果网,不错过跨境电商大小事
Chrome浏览器有很多网页设计扩展插件,可以帮助你进行网站发布、重新设计、布局整体用户体验等活动。
下文是关于谷歌Chrome应用商店的20个网页设计插件。这些插件可以帮你找到正确的字体、开发调色板、发现和创建鼓舞人心的图像、自定义图形、测量元素以及分析页面和竞争对手。
适用于Chrome网页设计的20款插件
1、Pixlr Editor是一个浏览器图片编辑器,可以完全控制图像,包括图层和效果。它包含电脑图形设计应用程序中常见的高级功能,如图层、套索工具、画笔控件、克隆和过滤器。
2、ColorZilla可以从浏览器中的任何位置读取颜色。调整颜色,然后粘贴到另一个程序。它具有CSS渐变生成器,具有七个预安装调色板查看器等。
3、Palette Creator允许你从任何图像创建调色板,以用于进一步创作。你只需右键单击图像,然后选择“Palette Creator”选项即可。
4、WhatFont是识别网页字体的有效方法。可以快速获取鼠标悬停处的文本字体信息,WhatFont还可用于检测字体提供的服务。
5、Font Changer允许你使用Google Web Fonts中的任何字体更改网站上的字体,还可以为所有网站或特定网站设置字体。
6、Evernote Web Clipper帮助你将Web上有趣的内容保存到Evernote帐户中。可用于剪辑任何网页,突出显示重要的内容、注释、截屏,并随时随地访问内容。
7、Amino是一个用于编写持久用户样式表的实时CSS编辑器。可将自定义样式保存并同步到你的谷歌帐户,从多台计算机访问。可自定义页面外观并修复渲染错误。
8、Stylebot允许你使用自定义CSS操纵任何网站的外观。选择一个元素并从编辑器中选择要进行的更改。即可改变字体、颜色、页边距、可见性等等。
9、EnjoyCSS是一个免费的在线CSS3生成器。用于快速调整丰富的图形样式,无需编码。进行二维和三维变换、复杂过渡、线性和径向渐变、文本阴影等,可访问CSS解决方案库。
10、CSS Shapes Editor是一个交互式编辑器,用于为选定的元素创建和调整CSS形状值。
11、Dimensions是一款用于测量屏幕上项目的工具,如区域边界、图像、输入字段、按钮、视频、文本和图标。有助于测量模型。
12、Eye Dropper可以从web页面、颜色选择器或颜色历史记录中选择颜色。
13、Minimalist Markdown Editor是一个简单、方便的Markdown编辑器。只需编写Markdown文本,并在键入时查看它的外观。具有一键式HTML转换、持久标签、离线功能等。
14、BuiltWith Technology Profiler是一个工具,可以让你确定网站的构建技术。在web页面上,单击build twith图标可以查看使用的所有技术。
15、Search Stackoverflow是一个论坛,提供关于许多编码的问题和答案。用户可以提问和回答问题,并编辑内容。
16、Project Naptha是一个工具,可以高突出显示、复制、编辑甚至翻译web上任何图像中的文本。可访问并处理从图像中释放出来的单词。
17、Web Developer Checklist包含有用的实践以及指向支持材料的链接。它是的附加扩展。
18、Checkbot是一个网站审核工具,可以快速地抓取数百个页面,查找与搜索引擎优化、速度和安全性相关的问题。此外,它还可免费检查每个站点250个URL。
19、Web Developer可以添加工具栏按钮和各种Web开发人员工具,这是Firefox的 web开发人员扩展的一部分。
20、StayFocusd通过限制在特定网站上花费的时间来提高你的工作效率。一旦指定的时间用完,你将无法访问所限制的网站。
◎文/雨果网 吕晓琳
雨果网致力为卖家提供优质干货
▼扫码免费领取各平台干货包▼
把时间交给阅读
查看全部
盘点:20个用于网页设计的Chrome扩展程序
关
注
点击上方置顶雨果网,不错过跨境电商大小事
Chrome浏览器有很多网页设计扩展插件,可以帮助你进行网站发布、重新设计、布局整体用户体验等活动。
下文是关于谷歌Chrome应用商店的20个网页设计插件。这些插件可以帮你找到正确的字体、开发调色板、发现和创建鼓舞人心的图像、自定义图形、测量元素以及分析页面和竞争对手。
适用于Chrome网页设计的20款插件
1、Pixlr Editor是一个浏览器图片编辑器,可以完全控制图像,包括图层和效果。它包含电脑图形设计应用程序中常见的高级功能,如图层、套索工具、画笔控件、克隆和过滤器。
2、ColorZilla可以从浏览器中的任何位置读取颜色。调整颜色,然后粘贴到另一个程序。它具有CSS渐变生成器,具有七个预安装调色板查看器等。
3、Palette Creator允许你从任何图像创建调色板,以用于进一步创作。你只需右键单击图像,然后选择“Palette Creator”选项即可。
4、WhatFont是识别网页字体的有效方法。可以快速获取鼠标悬停处的文本字体信息,WhatFont还可用于检测字体提供的服务。
5、Font Changer允许你使用Google Web Fonts中的任何字体更改网站上的字体,还可以为所有网站或特定网站设置字体。
6、Evernote Web Clipper帮助你将Web上有趣的内容保存到Evernote帐户中。可用于剪辑任何网页,突出显示重要的内容、注释、截屏,并随时随地访问内容。
7、Amino是一个用于编写持久用户样式表的实时CSS编辑器。可将自定义样式保存并同步到你的谷歌帐户,从多台计算机访问。可自定义页面外观并修复渲染错误。
8、Stylebot允许你使用自定义CSS操纵任何网站的外观。选择一个元素并从编辑器中选择要进行的更改。即可改变字体、颜色、页边距、可见性等等。
9、EnjoyCSS是一个免费的在线CSS3生成器。用于快速调整丰富的图形样式,无需编码。进行二维和三维变换、复杂过渡、线性和径向渐变、文本阴影等,可访问CSS解决方案库。
10、CSS Shapes Editor是一个交互式编辑器,用于为选定的元素创建和调整CSS形状值。
11、Dimensions是一款用于测量屏幕上项目的工具,如区域边界、图像、输入字段、按钮、视频、文本和图标。有助于测量模型。
12、Eye Dropper可以从web页面、颜色选择器或颜色历史记录中选择颜色。
13、Minimalist Markdown Editor是一个简单、方便的Markdown编辑器。只需编写Markdown文本,并在键入时查看它的外观。具有一键式HTML转换、持久标签、离线功能等。
14、BuiltWith Technology Profiler是一个工具,可以让你确定网站的构建技术。在web页面上,单击build twith图标可以查看使用的所有技术。
15、Search Stackoverflow是一个论坛,提供关于许多编码的问题和答案。用户可以提问和回答问题,并编辑内容。
16、Project Naptha是一个工具,可以高突出显示、复制、编辑甚至翻译web上任何图像中的文本。可访问并处理从图像中释放出来的单词。
17、Web Developer Checklist包含有用的实践以及指向支持材料的链接。它是的附加扩展。
18、Checkbot是一个网站审核工具,可以快速地抓取数百个页面,查找与搜索引擎优化、速度和安全性相关的问题。此外,它还可免费检查每个站点250个URL。
19、Web Developer可以添加工具栏按钮和各种Web开发人员工具,这是Firefox的 web开发人员扩展的一部分。
20、StayFocusd通过限制在特定网站上花费的时间来提高你的工作效率。一旦指定的时间用完,你将无法访问所限制的网站。
◎文/雨果网 吕晓琳
雨果网致力为卖家提供优质干货
▼扫码免费领取各平台干货包▼
把时间交给阅读
有大佬通过研发这款Chrome插件的使用教程,赚了上百万!
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-05-06 04:13
最近,有同学告诉我说,D哥我发现有大佬开发 Chrome 商店里的一款爬虫教程,竟然卖了几千份,每份售价299,为啥有这么多人买呢?
我的原话是,别人的目标群体不是你(程序员),而是不会写代码的人,所以,这钱该别人赚。
毕竟不会写代码的人占了绝大多数,但他们又有如下的痛点:
我不会写代码,但想快速爬取几个数据量不太大的网页,做一下调研分析,该怎么办?
这个需求,估计大家很多时候都会遇到,比如,我想爬取秒杀页面的商品信息进行对比;我想爬取国家统计局官网发布的你感兴趣的数据;等等。
既然说到这里,我就简单的介绍一下网络爬虫。网络爬虫的主要目的是爬取互联网上的网页。你可以把互联网中的每一个网页想象成一个点,那么整个互联网将是彼此连通的。是不是很像我们大学学过的图论?如果从任何一个网页出发,在时间资源允许的情况下,使用广度优先算法(BFS)或者深度优先算法(DFS)是可以爬完整个互联网的。对这两种算法不太熟悉的同学可以去背书了。
下面以比较流行的 Scrapy 架构图为例,流线为数据流向。
看了这幅图,是不是对一般的爬虫有了大致的了解了。
专业的网络爬虫(比如百度/谷歌的爬虫)为了节约资源和时间,因此,设计是相当复杂的。这些爬虫一般是基于分布式集群构建的,有些机子负责调度,有些机子负责下载,有些机子专门基于网页进行分析,等等。并非简单的用 BFS/DFS 就能解决的,比如,我们以调度器为例,它就需要来管理下载优先级,当引擎发送过来 Request 请求,就需要按照优先级进行整理排列,入队,当引擎需要时,交还给引擎。
虽然关于各种语言的爬虫框架很多,要是用这些框架来爬这点数据,确实有点大材小用了,而且还得要编码调试,各种麻烦!!!
那我们就来介绍一下 Chrome 商店里面这一款爬虫插件,刚好解决这个痛点,它的名字叫做 Web Scraper,目前有 22w 的用户下载。
官方网址:
这个爬虫操作特别简单,照着官方文档,几分钟就学会了。
我这里就说几个关键点吧。
1、启动
一般初次使用,不知道怎么打开它,用快捷键 ctrl+shift+i 打开开发者工具。
sitemaps:你所有的爬虫。
create new sitemap:创建一个新爬虫的起始地址。
2、选择器
对于一个选择器而言,就有如下几种元素,它主要作用是为爬虫分析网页的功能,提供了可视化选择的功能,如下图所示。
好了,再来细说一下,选择器内部的几个元素。
Id: 选择器的ID;
Type:要抓取内容的类型,有文本、图片以及元素集等;
Selector:选择器。点击 select 按钮可以选择我们要抓取的内容,点击 element preview 按钮可以预览选择的内容,而点击 data preview 按钮可以预览抓取的数据;
Multiple:勾选了这个按钮可以并联相同的内容;
Regex:正则表达式;
Delay:延迟。为了让页面有足够的时间加载数据;
Parent Selectors:父选择器。
有的同学可能会问,如果我要在一个页面选择多个元素,该怎么办呢?上面的提到的 Type 属性里面的 Element 就起到这个作用,如我这里。
3、关系图
我觉得这个功能特别棒,帮我们看到这个爬虫的层级关系图。
最后,就是爬取数据了,爬取后的数据还可以导出为 excel,便于你分析。
大家可以去玩一下这个爬虫插件,会帮你快速分析一些简单的数据。
就写到这里吧。
特别推荐一个分享架构+算法的优质内容,还没关注的小伙伴,可以长按关注一下:
<p style="font-family: -apple-system-font, system-ui, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;white-space: normal;text-align: center;">
</p>
<p style="font-family: -apple-system-font, system-ui, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;white-space: normal;text-align: center;">长按订阅更多精彩▼
如有收获,点个在看,诚挚感谢</p> 查看全部
有大佬通过研发这款Chrome插件的使用教程,赚了上百万!
最近,有同学告诉我说,D哥我发现有大佬开发 Chrome 商店里的一款爬虫教程,竟然卖了几千份,每份售价299,为啥有这么多人买呢?
我的原话是,别人的目标群体不是你(程序员),而是不会写代码的人,所以,这钱该别人赚。
毕竟不会写代码的人占了绝大多数,但他们又有如下的痛点:
我不会写代码,但想快速爬取几个数据量不太大的网页,做一下调研分析,该怎么办?
这个需求,估计大家很多时候都会遇到,比如,我想爬取秒杀页面的商品信息进行对比;我想爬取国家统计局官网发布的你感兴趣的数据;等等。
既然说到这里,我就简单的介绍一下网络爬虫。网络爬虫的主要目的是爬取互联网上的网页。你可以把互联网中的每一个网页想象成一个点,那么整个互联网将是彼此连通的。是不是很像我们大学学过的图论?如果从任何一个网页出发,在时间资源允许的情况下,使用广度优先算法(BFS)或者深度优先算法(DFS)是可以爬完整个互联网的。对这两种算法不太熟悉的同学可以去背书了。
下面以比较流行的 Scrapy 架构图为例,流线为数据流向。
看了这幅图,是不是对一般的爬虫有了大致的了解了。
专业的网络爬虫(比如百度/谷歌的爬虫)为了节约资源和时间,因此,设计是相当复杂的。这些爬虫一般是基于分布式集群构建的,有些机子负责调度,有些机子负责下载,有些机子专门基于网页进行分析,等等。并非简单的用 BFS/DFS 就能解决的,比如,我们以调度器为例,它就需要来管理下载优先级,当引擎发送过来 Request 请求,就需要按照优先级进行整理排列,入队,当引擎需要时,交还给引擎。
虽然关于各种语言的爬虫框架很多,要是用这些框架来爬这点数据,确实有点大材小用了,而且还得要编码调试,各种麻烦!!!
那我们就来介绍一下 Chrome 商店里面这一款爬虫插件,刚好解决这个痛点,它的名字叫做 Web Scraper,目前有 22w 的用户下载。
官方网址:
这个爬虫操作特别简单,照着官方文档,几分钟就学会了。
我这里就说几个关键点吧。
1、启动
一般初次使用,不知道怎么打开它,用快捷键 ctrl+shift+i 打开开发者工具。
sitemaps:你所有的爬虫。
create new sitemap:创建一个新爬虫的起始地址。
2、选择器
对于一个选择器而言,就有如下几种元素,它主要作用是为爬虫分析网页的功能,提供了可视化选择的功能,如下图所示。
好了,再来细说一下,选择器内部的几个元素。
Id: 选择器的ID;
Type:要抓取内容的类型,有文本、图片以及元素集等;
Selector:选择器。点击 select 按钮可以选择我们要抓取的内容,点击 element preview 按钮可以预览选择的内容,而点击 data preview 按钮可以预览抓取的数据;
Multiple:勾选了这个按钮可以并联相同的内容;
Regex:正则表达式;
Delay:延迟。为了让页面有足够的时间加载数据;
Parent Selectors:父选择器。
有的同学可能会问,如果我要在一个页面选择多个元素,该怎么办呢?上面的提到的 Type 属性里面的 Element 就起到这个作用,如我这里。
3、关系图
我觉得这个功能特别棒,帮我们看到这个爬虫的层级关系图。
最后,就是爬取数据了,爬取后的数据还可以导出为 excel,便于你分析。
大家可以去玩一下这个爬虫插件,会帮你快速分析一些简单的数据。
就写到这里吧。
特别推荐一个分享架构+算法的优质内容,还没关注的小伙伴,可以长按关注一下:
<p style="font-family: -apple-system-font, system-ui, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;white-space: normal;text-align: center;">
<p style="font-family: -apple-system-font, system-ui, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;white-space: normal;text-align: center;">长按订阅更多精彩▼
如有收获,点个在看,诚挚感谢</p>
3个字母,抓取4943条数据,超实用的XPath爬虫工具教学!
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-05-02 11:00
当你想要快速批量采集某个网站的内容时,首先想到的会是什么?
有的朋友可能会想到爬虫工具,但大部分人基本也只是听过,没用过。如果要用的话,会不会很复杂?要不要学习什么技术?
今天就给大家分享一个实用的网页内容批量采集工具XPath,不需要复杂的准备工作,就能快速上手,尤其适用于轻量化的网页内容抓取。
掌握了XPath的用法之后,只需3个字母,就可以抓取4943条数据。接下来,我以一个真实的网页内容抓取需求为例,详细讲解XPath的用法。
假设你正在开展一项研究,需要收集餐饮连锁品牌的名单,这时候找到一个网站:
网站上有数十个餐饮连锁的名单,如果是一个个复制粘贴,50个就需要来回操作上百次,倘若还要搜集其他的名单,这一天下来不仅效率极低,手估计也要废了。
如何能够一键抓取这些品牌的名单呢?这时候XPath就帮大忙啦。
一、准备工作
在正式开始之前我们需要先做好准备工作,这里列出了所有的准备清单。
1、安装Chrome(谷歌)浏览器
2、安装XPath Helper插件方法一:(有梯子可以直接前往chrome应用商店下载,避免安装出错)
方法二:没梯子可下载安装包,可能有的浏览器版本不适配,文末有安装包获取方法
3、抓取的目标网站
4、没接触过XPath的朋友, 可前往此处学习详细的使用教程
所有的案例资料和插件工具,我都打包整理好了,加微信yesaze (备注XPath)即可领取。
二、安装XPath Helper插件
1、打开Chrome浏览器,点击右上角“ ”按钮,选择“更多工具”-> “扩展程序”
2、打开右上角“开发者模式”,点击“加载已压缩的扩展程序”,选择已解压的XPath helper 插件文件夹(XPath helper插件只能在谷歌浏览器中使用)
3、当扩展程序中出现XPath helper时,就代表安装成功了
4、在Macbook上按shift+command+X键,可以快速唤起和隐藏XPath Helper(Windows的快捷键是Ctrl+Shift+X)
三、抓取网页内容
1、什么是XPath?XPath 是一门在 XML 文档中查找信息的语言。而XML是一种结构化的编程语言,如果不理解也没关系。
你只需要知道,我们所看到的的网页,其实是由有规律、有结构的代码组成,我们所要提取的内容,就在这些结构化的代码里面。
XPath可以帮助我们根据网页的结构路径,灵活编写爬虫脚本,定位到我们需要的内容,从而进行抓取。
打开前面案例中的链接: 我们看到的是排布整齐的图文,当我们点击鼠标右键→检查,可以看到页面的内容都是有固定结构的,一级一级向下展开。
XPath 使用路径表达式在 XML 文档中选取节点。如果我们需要提取餐饮品牌的名称,只需要编写对应的路径即可。
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。
KFC肯德基</a>
以上代码是从网站中截取的XML代码,为了便于讲解,做了精简处理。其中文档节点、元素节点、属性节点例子如下:
(文档节点)<a target="_blank">KFC肯德基</a>(元素节点)target="_blank" (属性节点)
在这个案例中,我们可以看到,li里面包含了div,它们统称为节点,li是父节点,div是子节点。依此类推div里面又包含了a,它们又构成父子节点关系。
其中info、_blank等值,没有父或子节点,称之为基本知识,就是最基础的元素。
2、如何编写爬虫路径?理解了节点的概念,我们只需要编写一个路径,从大到小,逐级定位到我们需要的内容节点即可。那要如何编写路径呢?
我们用双斜杠//表示从匹配选择的当前节点选择文档中的节点,而不考虑它们相对位置。如//li,表示选取所有li子元素,而不管它们在文档中的位置。
形如 //li//div//a/text()表示定位到所有li下的所有div,所有div下的所有a,并提取其中的文本内容,(text()表示提取文本内容)
此时我们将语句输入XPath helper,发现有很多空的内容也被抓取了。先别着急,完整的语句应该是://li//div[@class="info"]/a/text()
与前面的语句相比,其中多了一个[@class="info"],这个的意思是选取所有 div 元素,且这些元素拥有值为 info 的 class 属性。这样定位就更精准了。
最后我们只需要全选复制结果即可,通过短短几个语句就能快速采集网页内容。
对于没有接触过XPath的朋友,可能有点晦涩难懂,建议还是详细阅读一下学习教程,半个小时就能掌握语句的含义和用法,能为以后采集内容省去不少时间。
四、补充案例如果说刚才的案例不太好理解,那我们再来看一个简单的案例,如何用3个字母抓取4943条数据?
在网站中,详细罗列了不同的行业类别及子类目,只需要通过//li/a这简短的语句,就能把所有类目抓取下来。
//li/a表示定位到所有li下的a,这个网页结构比较简单,只要能快速识别结构,就能轻松写出路径。
同理如果我们只需要抓取左侧的品牌大类,只需写出相应的路径即可//div[@id="leftcatlist"]/a,表示定位到包含id="leftcatlist"属性的div下的所有a,21个品牌大类的数据就轻松完成采集了。
以上就是XPth案例教学的全部内容,其中只用到了一部分XPath的能力,还有更多功能等待你去探索。想要系统学习推荐前往了解详情,有完整免费的教程内容。
工具就是熟能生巧,长时间不用就容易遗忘,所以想要熟练掌握一是要勤加练习和使用。书到用时方恨少,事到经过才知难。
如果觉得有帮助建议收藏备用,反复阅读。如有任何疑问,也可随时与我交流。领取XPah helper插件安装包及学习资料,请加微信yesaze (备注XPath)
查看全部
3个字母,抓取4943条数据,超实用的XPath爬虫工具教学!
当你想要快速批量采集某个网站的内容时,首先想到的会是什么?
有的朋友可能会想到爬虫工具,但大部分人基本也只是听过,没用过。如果要用的话,会不会很复杂?要不要学习什么技术?
今天就给大家分享一个实用的网页内容批量采集工具XPath,不需要复杂的准备工作,就能快速上手,尤其适用于轻量化的网页内容抓取。
掌握了XPath的用法之后,只需3个字母,就可以抓取4943条数据。接下来,我以一个真实的网页内容抓取需求为例,详细讲解XPath的用法。
假设你正在开展一项研究,需要收集餐饮连锁品牌的名单,这时候找到一个网站:
网站上有数十个餐饮连锁的名单,如果是一个个复制粘贴,50个就需要来回操作上百次,倘若还要搜集其他的名单,这一天下来不仅效率极低,手估计也要废了。
如何能够一键抓取这些品牌的名单呢?这时候XPath就帮大忙啦。
一、准备工作
在正式开始之前我们需要先做好准备工作,这里列出了所有的准备清单。
1、安装Chrome(谷歌)浏览器
2、安装XPath Helper插件方法一:(有梯子可以直接前往chrome应用商店下载,避免安装出错)
方法二:没梯子可下载安装包,可能有的浏览器版本不适配,文末有安装包获取方法
3、抓取的目标网站
4、没接触过XPath的朋友, 可前往此处学习详细的使用教程
所有的案例资料和插件工具,我都打包整理好了,加微信yesaze (备注XPath)即可领取。
二、安装XPath Helper插件
1、打开Chrome浏览器,点击右上角“ ”按钮,选择“更多工具”-> “扩展程序”
2、打开右上角“开发者模式”,点击“加载已压缩的扩展程序”,选择已解压的XPath helper 插件文件夹(XPath helper插件只能在谷歌浏览器中使用)
3、当扩展程序中出现XPath helper时,就代表安装成功了
4、在Macbook上按shift+command+X键,可以快速唤起和隐藏XPath Helper(Windows的快捷键是Ctrl+Shift+X)
三、抓取网页内容
1、什么是XPath?XPath 是一门在 XML 文档中查找信息的语言。而XML是一种结构化的编程语言,如果不理解也没关系。
你只需要知道,我们所看到的的网页,其实是由有规律、有结构的代码组成,我们所要提取的内容,就在这些结构化的代码里面。
XPath可以帮助我们根据网页的结构路径,灵活编写爬虫脚本,定位到我们需要的内容,从而进行抓取。
打开前面案例中的链接: 我们看到的是排布整齐的图文,当我们点击鼠标右键→检查,可以看到页面的内容都是有固定结构的,一级一级向下展开。
XPath 使用路径表达式在 XML 文档中选取节点。如果我们需要提取餐饮品牌的名称,只需要编写对应的路径即可。
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。
KFC肯德基</a>
以上代码是从网站中截取的XML代码,为了便于讲解,做了精简处理。其中文档节点、元素节点、属性节点例子如下:
(文档节点)<a target="_blank">KFC肯德基</a>(元素节点)target="_blank" (属性节点)
在这个案例中,我们可以看到,li里面包含了div,它们统称为节点,li是父节点,div是子节点。依此类推div里面又包含了a,它们又构成父子节点关系。
其中info、_blank等值,没有父或子节点,称之为基本知识,就是最基础的元素。
2、如何编写爬虫路径?理解了节点的概念,我们只需要编写一个路径,从大到小,逐级定位到我们需要的内容节点即可。那要如何编写路径呢?
我们用双斜杠//表示从匹配选择的当前节点选择文档中的节点,而不考虑它们相对位置。如//li,表示选取所有li子元素,而不管它们在文档中的位置。
形如 //li//div//a/text()表示定位到所有li下的所有div,所有div下的所有a,并提取其中的文本内容,(text()表示提取文本内容)
此时我们将语句输入XPath helper,发现有很多空的内容也被抓取了。先别着急,完整的语句应该是://li//div[@class="info"]/a/text()
与前面的语句相比,其中多了一个[@class="info"],这个的意思是选取所有 div 元素,且这些元素拥有值为 info 的 class 属性。这样定位就更精准了。
最后我们只需要全选复制结果即可,通过短短几个语句就能快速采集网页内容。
对于没有接触过XPath的朋友,可能有点晦涩难懂,建议还是详细阅读一下学习教程,半个小时就能掌握语句的含义和用法,能为以后采集内容省去不少时间。
四、补充案例如果说刚才的案例不太好理解,那我们再来看一个简单的案例,如何用3个字母抓取4943条数据?
在网站中,详细罗列了不同的行业类别及子类目,只需要通过//li/a这简短的语句,就能把所有类目抓取下来。
//li/a表示定位到所有li下的a,这个网页结构比较简单,只要能快速识别结构,就能轻松写出路径。
同理如果我们只需要抓取左侧的品牌大类,只需写出相应的路径即可//div[@id="leftcatlist"]/a,表示定位到包含id="leftcatlist"属性的div下的所有a,21个品牌大类的数据就轻松完成采集了。
以上就是XPth案例教学的全部内容,其中只用到了一部分XPath的能力,还有更多功能等待你去探索。想要系统学习推荐前往了解详情,有完整免费的教程内容。
工具就是熟能生巧,长时间不用就容易遗忘,所以想要熟练掌握一是要勤加练习和使用。书到用时方恨少,事到经过才知难。
如果觉得有帮助建议收藏备用,反复阅读。如有任何疑问,也可随时与我交流。领取XPah helper插件安装包及学习资料,请加微信yesaze (备注XPath)
chrome抓取网页插件( PageAnalytics可以从GoogleAnalytics中读取到你的网站数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-04-20 05:17
PageAnalytics可以从GoogleAnalytics中读取到你的网站数据)
Page Analytics 是 Chrome 浏览器上的一个插件。它可以从 Google Analytics 读取您的 网站 数据,并直接在网页周围的链接上显示点击数据。根据这个数据,你可以很容易判断网站的布局是否需要优化。
一、安装教学
安装地址:Chrome Store
打开后点击添加到Chrome(仅支持Chrome浏览器)完成插件安装。
安装完成后,可以在浏览器插件中看到Page Analytics的图标,默认是OFF(关闭),点击就会开启(打开),然后点击下方彩色图标,立即叠加在网站上,通过色块,可以第一时间知道整个网站是如何被用户点击的,哪些区域比较热门。
二、无法捕获数据
这个插件有时候捕获GA数据失败,出现如下错误信息——
大致说明如何做到这一点:
·本插件的原理是加载网站的GA数据。而且我们只能看到自己账号的GA数据,所以用这个插件是看不到别人的数据的网站。
·请先确认您是否已登录GA账号。您可以先尝试登录GA官网。
·确认登录账号后,打开这个插件,几秒后,一般就可以看到你的网站数据了。
·如果还是看不到,请关闭浏览器,重新开始,或刷新页面。
三、无法显示数据的地方
这个插件操作非常简单,界面非常友好。点击哪个按钮和多少个链接,您可以根据数字轻松做出决定。
但请不要相信所有的数据,因为你看到的数字(或数字)可能不是肤浅的认识,也可能导致你做出判断性的决定,反而阻碍了网站的网站.
请务必注意,某些链接或按钮不会看到数据,但这并不意味着访问者不会点击这些地方。
1、GA数据不计入外部链接的点击,比如网站的分享功能,所以插件无法展示。
2、标签链接可能不算数。 GA后端的数据中会有tag数据,可能是插件问题。
3、各种按钮的点击也不会被统计或显示,因为它们根本不是 URL,对吧?
4、数据统计时间跨度过大。例如,它已经被计算了好几年。可能因为点击接近0而无法显示,但是这种情况比较少见。
四、如何判断一个链接的效果
有时一个页面上会有多个相同的链接。比如首页链接会出现在网站的顶部logo、导航栏、底部网页,所以要谨慎对待此类链接的数据。
例如,在一个网页上,三个相同的链接显示了 3% 的点击率,是否可以认为是 3%*3=9% 的点击率?不,这 3% 只显示在同一个链接中。
因此非常遗憾的是,我们无法知道访问者更喜欢在同一页面和多个相同链接上点击哪个链接。
所以如果你想知道同一个链接不同位置的效果,就必须像外链处理方法一样,把GA代码单独放在链接按钮处。
总结
总的来说,这个插件还是挺方便的,它可以让我们很方便的知道某个区域内所有连接的点击率,并且根据点击率的多少,可以提升热门链接的排序和不受欢迎的链接。然后降低他的排名位置,甚至直接去掉,换成更有效的链接。 查看全部
chrome抓取网页插件(
PageAnalytics可以从GoogleAnalytics中读取到你的网站数据)

Page Analytics 是 Chrome 浏览器上的一个插件。它可以从 Google Analytics 读取您的 网站 数据,并直接在网页周围的链接上显示点击数据。根据这个数据,你可以很容易判断网站的布局是否需要优化。
一、安装教学
安装地址:Chrome Store
打开后点击添加到Chrome(仅支持Chrome浏览器)完成插件安装。
安装完成后,可以在浏览器插件中看到Page Analytics的图标,默认是OFF(关闭),点击就会开启(打开),然后点击下方彩色图标,立即叠加在网站上,通过色块,可以第一时间知道整个网站是如何被用户点击的,哪些区域比较热门。
二、无法捕获数据
这个插件有时候捕获GA数据失败,出现如下错误信息——
大致说明如何做到这一点:
·本插件的原理是加载网站的GA数据。而且我们只能看到自己账号的GA数据,所以用这个插件是看不到别人的数据的网站。
·请先确认您是否已登录GA账号。您可以先尝试登录GA官网。
·确认登录账号后,打开这个插件,几秒后,一般就可以看到你的网站数据了。
·如果还是看不到,请关闭浏览器,重新开始,或刷新页面。
三、无法显示数据的地方
这个插件操作非常简单,界面非常友好。点击哪个按钮和多少个链接,您可以根据数字轻松做出决定。
但请不要相信所有的数据,因为你看到的数字(或数字)可能不是肤浅的认识,也可能导致你做出判断性的决定,反而阻碍了网站的网站.
请务必注意,某些链接或按钮不会看到数据,但这并不意味着访问者不会点击这些地方。
1、GA数据不计入外部链接的点击,比如网站的分享功能,所以插件无法展示。
2、标签链接可能不算数。 GA后端的数据中会有tag数据,可能是插件问题。
3、各种按钮的点击也不会被统计或显示,因为它们根本不是 URL,对吧?
4、数据统计时间跨度过大。例如,它已经被计算了好几年。可能因为点击接近0而无法显示,但是这种情况比较少见。
四、如何判断一个链接的效果
有时一个页面上会有多个相同的链接。比如首页链接会出现在网站的顶部logo、导航栏、底部网页,所以要谨慎对待此类链接的数据。
例如,在一个网页上,三个相同的链接显示了 3% 的点击率,是否可以认为是 3%*3=9% 的点击率?不,这 3% 只显示在同一个链接中。
因此非常遗憾的是,我们无法知道访问者更喜欢在同一页面和多个相同链接上点击哪个链接。
所以如果你想知道同一个链接不同位置的效果,就必须像外链处理方法一样,把GA代码单独放在链接按钮处。
总结
总的来说,这个插件还是挺方便的,它可以让我们很方便的知道某个区域内所有连接的点击率,并且根据点击率的多少,可以提升热门链接的排序和不受欢迎的链接。然后降低他的排名位置,甚至直接去掉,换成更有效的链接。
chrome抓取网页插件( 什么是用户脚本?开发背景(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-04-19 10:07
什么是用户脚本?开发背景(一)(组图))
Tampermonkey 开发背景
Web 开发人员通常有专业的情节。在浏览网页时,他们总是要评估网页的设计和开发,甚至想修改网页的样式。最初最常用的工具是chrome浏览器自带的开发者工具,用来修改网页的CSS,但并不是所有的网页都可以这样修改。于是为了满足这样的开发需求,chrome插件Tampermonkey诞生了。使用 Tampermonkey,开发者可以导入自己的脚本模板来更改网页的 CSS 和 JS,让整个网页发生很大的变化。什么是用户脚本?用户脚本旨在增加用户对 Web 浏览体验的控制。安装后,用户脚本可以自动为 网站 用户访问添加功能,或者使它们更易于使用和更新。
Tampermonkey 简介
Tampermonkey 被称为油猴。Greasemonkey 插件最初是在 Firefox 上以 Greasemonkey 的名义发布的。后来 Chrome 上一个类似的插件是 Tampermonkey,他们使用的脚本很常见。Tampermonkey 适用于基于 Blink 和 WebKit 的浏览器,例如 Chrome、Microsoft、Edge、Safari、Next 和 Firefox。而且理论上也可以安装其他带有chrome内核的浏览器。不同浏览器对应的插件名称分别是UC浏览器的Violentmonkey(暴力猴子)、Firefox浏览器的Greasemonkey(油猴)、Google浏览器的Tampermonkey(篡改猴子)!很简单,说白了,其实就是一个插件管理器,用来管理别人写的插件。今天我们将介绍用户脚本管理器 Tampermonkey。
Tampermonkey 是一个免费的浏览器扩展程序,也是 Chrome、Microsoft Edge、Safari、Opera Next 和 Firefox 最流行的用户脚本管理器。
虽然一些受支持的浏览器具有原生用户脚本支持,但 Tampermonkey 将为您的用户脚本管理提供更多便利。它提供了简单的脚本安装、自动更新检查、选项卡中脚本运行状况的快速快照、内置编辑器以及 Tampermonkey 运行其他不兼容脚本的可能性等功能。
如何使用 Tampermonkey
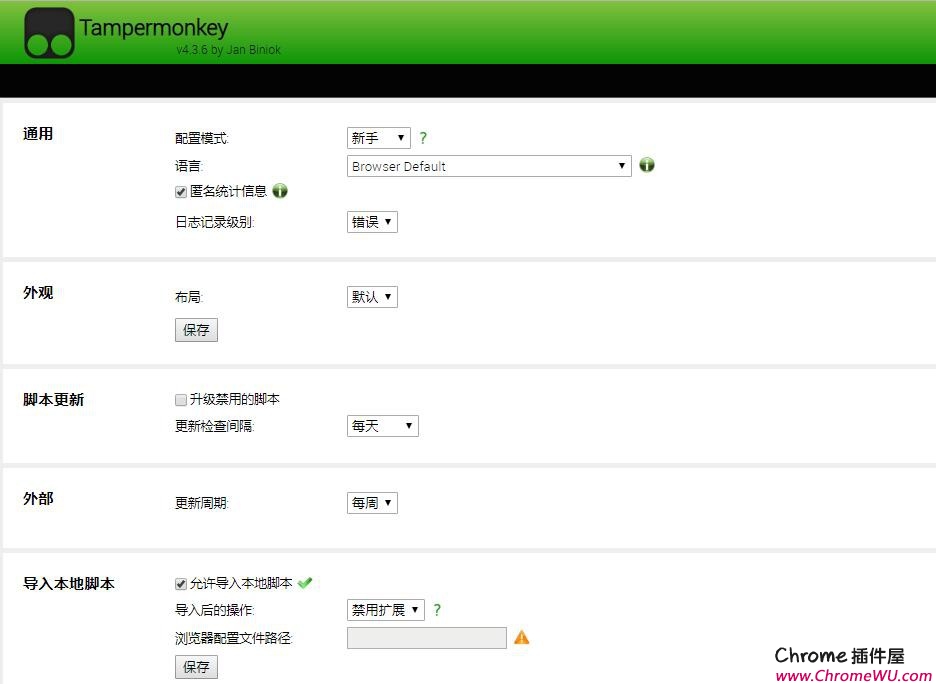
1.在 Google Chrome 中安装 Tampermonkey 插件并在 Chrome 的扩展程序中启用 Tampermonkey 功能。具体安装方法请参考:如何在谷歌浏览器中安装扩展名为.crx的离线Chrome插件?
安装完成后,可以在浏览器右上角看到tampermonkey的按钮标记。如下所示
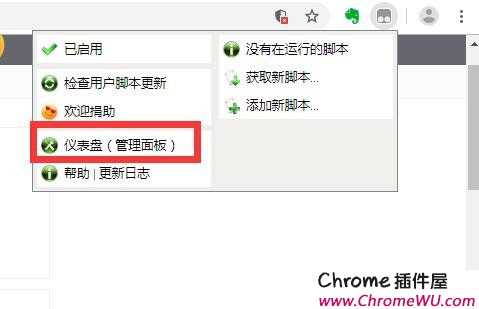
2.安装 Tampermonkey 插件后,我们就可以轻松设置了。Tampermonkey的设置分为3个等级,分别是新手、中级和高级。如果你对代码编程一窍不通,那就选新手吧!这些默认设置基本可以满足你的要求。如果您对电脑、软件操作等非常熟悉,可以选择初学者设置模式,可以设置更多的选项。当然,如果你是 JavaScript 大神,可以使用高级模式进行设置。
3.Tampermonkey 插件设置页面。
关键是,Tampermonkey 的厉害之处在哪里?
Tampermonkey 有一个内置的增强版脚本管理器。如果你精通javascript或其他编程语言,可以尝试定制一些适合你的插件。打开内置脚本管理器,如下图:
Tampermonkey 有哪些用户脚本源?
:一直是常用的用户脚本来源,现在这个网站不再更新了;
GreeasyFork:可能是最受欢迎的后起之秀。它由 Jason Barnabe 创建,他也是 Stylish 网站 的创建者,并且在其存储库中拥有大量脚本资源。
OpenUserJS:在 GreeasyFork 之后开始。它由 Sizzle McTwizzle 创建,并且在其存储库中同样拥有大量脚本资源。
GitHub/Gist:越来越多的开发者将源码放在GitHub上,用户可以直接搜索。
Tampermonkey 注释
1.IE 目前不支持 Tampermonkey 插件。
2.Tampermonkey插件提供了自动同步,但前提是你需要打开初学者设置模式,然后找到TESLA选项,勾选启用选项前面的框。如下所示
相关:百度网盘助手Chrome插件下载
油猴脚本扩展 Tampermonkey 下载地址点击下载
油猴脚本扩展Tampermonkey的详细使用教程,点击下方查看:
Tampermonkey 油猴脚本教程(图文解说)
本文标题:油猴脚本扩展 Tampermonkey 下载:最受欢迎的用户脚本管理器 查看全部
chrome抓取网页插件(
什么是用户脚本?开发背景(一)(组图))

Tampermonkey 开发背景
Web 开发人员通常有专业的情节。在浏览网页时,他们总是要评估网页的设计和开发,甚至想修改网页的样式。最初最常用的工具是chrome浏览器自带的开发者工具,用来修改网页的CSS,但并不是所有的网页都可以这样修改。于是为了满足这样的开发需求,chrome插件Tampermonkey诞生了。使用 Tampermonkey,开发者可以导入自己的脚本模板来更改网页的 CSS 和 JS,让整个网页发生很大的变化。什么是用户脚本?用户脚本旨在增加用户对 Web 浏览体验的控制。安装后,用户脚本可以自动为 网站 用户访问添加功能,或者使它们更易于使用和更新。
Tampermonkey 简介
Tampermonkey 被称为油猴。Greasemonkey 插件最初是在 Firefox 上以 Greasemonkey 的名义发布的。后来 Chrome 上一个类似的插件是 Tampermonkey,他们使用的脚本很常见。Tampermonkey 适用于基于 Blink 和 WebKit 的浏览器,例如 Chrome、Microsoft、Edge、Safari、Next 和 Firefox。而且理论上也可以安装其他带有chrome内核的浏览器。不同浏览器对应的插件名称分别是UC浏览器的Violentmonkey(暴力猴子)、Firefox浏览器的Greasemonkey(油猴)、Google浏览器的Tampermonkey(篡改猴子)!很简单,说白了,其实就是一个插件管理器,用来管理别人写的插件。今天我们将介绍用户脚本管理器 Tampermonkey。
Tampermonkey 是一个免费的浏览器扩展程序,也是 Chrome、Microsoft Edge、Safari、Opera Next 和 Firefox 最流行的用户脚本管理器。
虽然一些受支持的浏览器具有原生用户脚本支持,但 Tampermonkey 将为您的用户脚本管理提供更多便利。它提供了简单的脚本安装、自动更新检查、选项卡中脚本运行状况的快速快照、内置编辑器以及 Tampermonkey 运行其他不兼容脚本的可能性等功能。
如何使用 Tampermonkey
1.在 Google Chrome 中安装 Tampermonkey 插件并在 Chrome 的扩展程序中启用 Tampermonkey 功能。具体安装方法请参考:如何在谷歌浏览器中安装扩展名为.crx的离线Chrome插件?
安装完成后,可以在浏览器右上角看到tampermonkey的按钮标记。如下所示
2.安装 Tampermonkey 插件后,我们就可以轻松设置了。Tampermonkey的设置分为3个等级,分别是新手、中级和高级。如果你对代码编程一窍不通,那就选新手吧!这些默认设置基本可以满足你的要求。如果您对电脑、软件操作等非常熟悉,可以选择初学者设置模式,可以设置更多的选项。当然,如果你是 JavaScript 大神,可以使用高级模式进行设置。
3.Tampermonkey 插件设置页面。
关键是,Tampermonkey 的厉害之处在哪里?
Tampermonkey 有一个内置的增强版脚本管理器。如果你精通javascript或其他编程语言,可以尝试定制一些适合你的插件。打开内置脚本管理器,如下图:

Tampermonkey 有哪些用户脚本源?
:一直是常用的用户脚本来源,现在这个网站不再更新了;
GreeasyFork:可能是最受欢迎的后起之秀。它由 Jason Barnabe 创建,他也是 Stylish 网站 的创建者,并且在其存储库中拥有大量脚本资源。
OpenUserJS:在 GreeasyFork 之后开始。它由 Sizzle McTwizzle 创建,并且在其存储库中同样拥有大量脚本资源。
GitHub/Gist:越来越多的开发者将源码放在GitHub上,用户可以直接搜索。
Tampermonkey 注释
1.IE 目前不支持 Tampermonkey 插件。
2.Tampermonkey插件提供了自动同步,但前提是你需要打开初学者设置模式,然后找到TESLA选项,勾选启用选项前面的框。如下所示

相关:百度网盘助手Chrome插件下载
油猴脚本扩展 Tampermonkey 下载地址点击下载
油猴脚本扩展Tampermonkey的详细使用教程,点击下方查看:
Tampermonkey 油猴脚本教程(图文解说)

本文标题:油猴脚本扩展 Tampermonkey 下载:最受欢迎的用户脚本管理器
chrome抓取网页插件(在程序员中口碑也较好的Chrome插件,广州小编)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-04-18 20:37
谷歌浏览器简洁清爽的界面、流畅的浏览体验、资源丰富的插件也让它成为前端开发者最喜欢的浏览器。而易用的插件可以帮助开发者在开发过程中减少大量的工作量,带来强大的效果。今天给大家推荐几个非常实用,在程序员中口碑不错的Chrome插件。和广州千峰小编一起来看看吧!
一、灯塔前端性能优化测试工具
对于前端开发者来说,往往很难区分自己开发的 App 或网页的性能。这时候就需要专业的网站测试工具了。通过这些具体的分析报告,我们可以更直观地了解产品需要优化的地方。Lighthouse 插件就是这样一个开源的自动化检测工具,由谷歌官方团队提供,是一个严肃的行业标杆。
Lighthouse 插件可以对需要测试的页面进行一系列的评估,然后以详细的优化指南反馈给开发者。主要包括网站页面性能、PWA、可访问性(accessibility)、SEO等内容。
开发者可以网站根据这些标准进行优化改进,提升用户体验,不再需要盲目改动。下载链接:
二、Vue.js devtools 调试插件
Vue.js devtools 是一款在 Chrome 商店和 Firefox 商店中拥有数百万用户的流行插件,有“Vue 调试神器”的称号。由于 Vue 是数据驱动的,所以开发者在开发和调试的过程中无法解析出 DOM 结构无法解析的内容。但借助 Vue.js devtools 插件,您可以轻松解析和调试数据结构。
安装插件后,按F12打开开发者工具。您将在开发人员工具的菜单栏末尾看到 VUE。选择它以执行平滑操作。
下载地址:类似的调试工具,Facebook出品的比较有名的React Developer Tools插件。安装此插件后,您可以在 Google Chrome 中进行调试时查看应用程序的 React 组件层次结构,而不是查看神秘的浏览器 DOM。
下载链接:
三、WEB前端助手(FeHelper)
国内超实用的前端开发工具合集。我之前也在专门的文章中介绍过这个插件。WEB前端助手(FeHelper)收录多个独立的小应用,如:Json工具、代码美化、代码压缩、二维码、Postman、markdown、网页油猴、便签、信息加解密、随机密码生成、Crontab等等等等。
基本涵盖了前端开发中经常用到的所有基础功能。由于WEB前端助手是中国人开发的,所以大家用起来会更方便。
下载链接:
四、Wappalyzer网站技术分析插件
开发人员有时需要从他人的 网站 中寻找灵感和学习。那么,当我们浏览一个感觉不错的 网站 并想知道他们正在使用什么框架和技术时,我们该怎么办?这时,Wappalyzer 可以提供帮助。Wappalyzer 是一个功能强大且非常有用的 Chrome网站 技术分析插件。
可以分析平台架构、网站环境、服务器配置环境、JavaScript框架、网站采用的编程语言等参数。安装好后,在感兴趣的网页上点击Wappalyzer插件图标,在下拉窗口中可以看到这个网站使用的框架和技术。
下载链接:
五、Web Maker 网页代码编辑器
作为开发人员,您可能使用过许多代码编辑器。确实有很多功能非常强大的编辑器,但是在一些需要快速记录代码的紧急情况下,打开这些编辑器比较麻烦。Web Maker 是一个 Chrome 插件,可以在浏览器上快速编写网页代码。
它使您的 Google Chrome 能够动态编辑代码,主要用于编写 HTML、CSS 和 JavaScript 代码。安装插件后,只需单击插件图标即可在新窗口中工作。最重要的是,Web Maker 支持离线使用和自动代码保存。如果黑色对您来说太沉闷,还有多个编辑器主题和其他可配置设置。
下载链接:
以上就是今天的推荐。你常用的前端扩展插件有哪些?欢迎留言与千峰广州小编一起探讨! 查看全部
chrome抓取网页插件(在程序员中口碑也较好的Chrome插件,广州小编)
谷歌浏览器简洁清爽的界面、流畅的浏览体验、资源丰富的插件也让它成为前端开发者最喜欢的浏览器。而易用的插件可以帮助开发者在开发过程中减少大量的工作量,带来强大的效果。今天给大家推荐几个非常实用,在程序员中口碑不错的Chrome插件。和广州千峰小编一起来看看吧!
一、灯塔前端性能优化测试工具
对于前端开发者来说,往往很难区分自己开发的 App 或网页的性能。这时候就需要专业的网站测试工具了。通过这些具体的分析报告,我们可以更直观地了解产品需要优化的地方。Lighthouse 插件就是这样一个开源的自动化检测工具,由谷歌官方团队提供,是一个严肃的行业标杆。
Lighthouse 插件可以对需要测试的页面进行一系列的评估,然后以详细的优化指南反馈给开发者。主要包括网站页面性能、PWA、可访问性(accessibility)、SEO等内容。
开发者可以网站根据这些标准进行优化改进,提升用户体验,不再需要盲目改动。下载链接:
二、Vue.js devtools 调试插件
Vue.js devtools 是一款在 Chrome 商店和 Firefox 商店中拥有数百万用户的流行插件,有“Vue 调试神器”的称号。由于 Vue 是数据驱动的,所以开发者在开发和调试的过程中无法解析出 DOM 结构无法解析的内容。但借助 Vue.js devtools 插件,您可以轻松解析和调试数据结构。
安装插件后,按F12打开开发者工具。您将在开发人员工具的菜单栏末尾看到 VUE。选择它以执行平滑操作。
下载地址:类似的调试工具,Facebook出品的比较有名的React Developer Tools插件。安装此插件后,您可以在 Google Chrome 中进行调试时查看应用程序的 React 组件层次结构,而不是查看神秘的浏览器 DOM。
下载链接:
三、WEB前端助手(FeHelper)
国内超实用的前端开发工具合集。我之前也在专门的文章中介绍过这个插件。WEB前端助手(FeHelper)收录多个独立的小应用,如:Json工具、代码美化、代码压缩、二维码、Postman、markdown、网页油猴、便签、信息加解密、随机密码生成、Crontab等等等等。
基本涵盖了前端开发中经常用到的所有基础功能。由于WEB前端助手是中国人开发的,所以大家用起来会更方便。
下载链接:
四、Wappalyzer网站技术分析插件
开发人员有时需要从他人的 网站 中寻找灵感和学习。那么,当我们浏览一个感觉不错的 网站 并想知道他们正在使用什么框架和技术时,我们该怎么办?这时,Wappalyzer 可以提供帮助。Wappalyzer 是一个功能强大且非常有用的 Chrome网站 技术分析插件。
可以分析平台架构、网站环境、服务器配置环境、JavaScript框架、网站采用的编程语言等参数。安装好后,在感兴趣的网页上点击Wappalyzer插件图标,在下拉窗口中可以看到这个网站使用的框架和技术。
下载链接:
五、Web Maker 网页代码编辑器
作为开发人员,您可能使用过许多代码编辑器。确实有很多功能非常强大的编辑器,但是在一些需要快速记录代码的紧急情况下,打开这些编辑器比较麻烦。Web Maker 是一个 Chrome 插件,可以在浏览器上快速编写网页代码。
它使您的 Google Chrome 能够动态编辑代码,主要用于编写 HTML、CSS 和 JavaScript 代码。安装插件后,只需单击插件图标即可在新窗口中工作。最重要的是,Web Maker 支持离线使用和自动代码保存。如果黑色对您来说太沉闷,还有多个编辑器主题和其他可配置设置。
下载链接:
以上就是今天的推荐。你常用的前端扩展插件有哪些?欢迎留言与千峰广州小编一起探讨!
chrome抓取网页插件(7款顶级谷歌Chrome浏览器插件可增强用户的Chrome体验)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-04-17 16:19
[文本]
据外媒报道,纵观当今浏览器市场,主流浏览器包括Microsoft IE、Mozilla Firefox、Google Chrome、Apple Safari和Opera。其中,Google 的 Chrome 浏览器以简洁着称,而 Mozilla Foundation 的 Firefox 则以插件丰富而著称。
不过,目前谷歌已经开始允许用户下载使用Chrome插件,极大地丰富了用户的体验。
截至目前,Chrome 拥有超过 800 个浏览器插件,这些插件可以提升用户的 Chrome 体验。
通常,这些插件显示为 Chrome 地址栏旁边的图标,这些图标很容易删除或禁用(如果用户想要保留 Chrome 的经典外观和感觉)。
此外,如果用户想要使用 Chrome 扩展程序,他们必须在 /chrome 下载最新的 Linux 或 Windows 测试版 Chrome 浏览器,然后到 /extensions 下载数百个扩展程序。
以下是笔者总结的7个顶级谷歌Chrome浏览器插件,具体如下:
1、Google Apps 快捷方式
该插件允许用户快速访问谷歌应用程序,例如 Gmail、谷歌日历和谷歌文档。该插件可以在新标签页中打开这些应用程序,还允许用户快速创建电子邮件、文件等。如果您只想访问 Gmail,那么您可以尝试使用 Google Mail Checker。
2、标签菜单
使用选项卡菜单,用户可以获得所有选项卡的垂直列表以及一个搜索框,以便更轻松地进行选项卡导航。选项卡菜单使用户可以使用关闭按钮关闭选项卡,并使用拖放选项卡重新排列它们。
3、StumbleUpon
StumbleUpon 插件可以根据用户的个人喜好,向你推荐符合你喜好并被最多人推荐的网站。这样,您可以轻松访问具有高质量内容的页面,而不是总是浪费时间访问许多内容平庸的页面。
4、Chrome 的 Picnik 扩展
Picnik Extension for Chrome 可帮助用户嵌入 网站 的图像并轻松发送。加载 网站 页面后,单击 Picnik 按钮,用户将能够获得 网站 图像的缩略图列表。单击这些缩略图将在 Picnik 中打开图像,用户可以在其中编辑、注释、共享等。
5、喂食
Chrome 的 Feedly 插件为您提供了一种快速而时尚的方式来阅读和分享您最喜欢的 网站 和服务内容。它为您提供 Google Reader、Twitter、Yummy、YouTube、Amazon 等,让您随时浏览自己喜欢的内容。
6、WOT(信任网络)
Chrome 的 Web of Trust 插件会在用户使用 Chrome 打开收录垃圾邮件、恶意软件或其他危险/未知信息的网站时发出警告。
当用户点击WOT插件图标时,红圈网站为危险网站,绿圈网站为安全网站。WOT 也适用于 Google 和 Bing 搜索结果、Gmail 和 Yahoo! 等邮件服务。邮件等
7、微风
Brizzly 是一个小型 Twitter 插件,可让用户撰写和编译推文、访问 Twitter 个人资料、详细信息、列表和保存的搜索等等。
借助 Brizzly,用户可以在一个页面上进行几乎所有操作,包括关注、取消关注、添加到群组、了解热门话题等等。
(新闻稿 2009-12-22) 查看全部
chrome抓取网页插件(7款顶级谷歌Chrome浏览器插件可增强用户的Chrome体验)
[文本]
据外媒报道,纵观当今浏览器市场,主流浏览器包括Microsoft IE、Mozilla Firefox、Google Chrome、Apple Safari和Opera。其中,Google 的 Chrome 浏览器以简洁着称,而 Mozilla Foundation 的 Firefox 则以插件丰富而著称。

不过,目前谷歌已经开始允许用户下载使用Chrome插件,极大地丰富了用户的体验。
截至目前,Chrome 拥有超过 800 个浏览器插件,这些插件可以提升用户的 Chrome 体验。
通常,这些插件显示为 Chrome 地址栏旁边的图标,这些图标很容易删除或禁用(如果用户想要保留 Chrome 的经典外观和感觉)。
此外,如果用户想要使用 Chrome 扩展程序,他们必须在 /chrome 下载最新的 Linux 或 Windows 测试版 Chrome 浏览器,然后到 /extensions 下载数百个扩展程序。
以下是笔者总结的7个顶级谷歌Chrome浏览器插件,具体如下:
1、Google Apps 快捷方式
该插件允许用户快速访问谷歌应用程序,例如 Gmail、谷歌日历和谷歌文档。该插件可以在新标签页中打开这些应用程序,还允许用户快速创建电子邮件、文件等。如果您只想访问 Gmail,那么您可以尝试使用 Google Mail Checker。
2、标签菜单
使用选项卡菜单,用户可以获得所有选项卡的垂直列表以及一个搜索框,以便更轻松地进行选项卡导航。选项卡菜单使用户可以使用关闭按钮关闭选项卡,并使用拖放选项卡重新排列它们。
3、StumbleUpon
StumbleUpon 插件可以根据用户的个人喜好,向你推荐符合你喜好并被最多人推荐的网站。这样,您可以轻松访问具有高质量内容的页面,而不是总是浪费时间访问许多内容平庸的页面。
4、Chrome 的 Picnik 扩展
Picnik Extension for Chrome 可帮助用户嵌入 网站 的图像并轻松发送。加载 网站 页面后,单击 Picnik 按钮,用户将能够获得 网站 图像的缩略图列表。单击这些缩略图将在 Picnik 中打开图像,用户可以在其中编辑、注释、共享等。
5、喂食
Chrome 的 Feedly 插件为您提供了一种快速而时尚的方式来阅读和分享您最喜欢的 网站 和服务内容。它为您提供 Google Reader、Twitter、Yummy、YouTube、Amazon 等,让您随时浏览自己喜欢的内容。
6、WOT(信任网络)
Chrome 的 Web of Trust 插件会在用户使用 Chrome 打开收录垃圾邮件、恶意软件或其他危险/未知信息的网站时发出警告。
当用户点击WOT插件图标时,红圈网站为危险网站,绿圈网站为安全网站。WOT 也适用于 Google 和 Bing 搜索结果、Gmail 和 Yahoo! 等邮件服务。邮件等
7、微风
Brizzly 是一个小型 Twitter 插件,可让用户撰写和编译推文、访问 Twitter 个人资料、详细信息、列表和保存的搜索等等。
借助 Brizzly,用户可以在一个页面上进行几乎所有操作,包括关注、取消关注、添加到群组、了解热门话题等等。
(新闻稿 2009-12-22)
chrome抓取网页插件(百度数据爬虫-实用的爬虫工具基于python3的抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-16 05:05
chrome抓取网页插件-qq号码,
刚好之前考试写了个可以抓取的服务,基本就是利用协议的漏洞,这样网页数据就可以抓取到,并且可以导出为excel或pdf等等文件。因为这个软件基本就是抓取网页,所以还算简单,如果需要再深入的话,可以看下。
没有爬虫经验的人,推荐百度数据爬虫-实用的爬虫工具推荐常用的爬虫工具有百度的爬虫推荐,数据采集-百度文库数据采集github上可以看看别人的爬虫。
qq号码?@百度!
/
难道不是百度号码池?
网易新闻登录有一个随机新增qq号码,不过其他有抓包不一定全正确,仅供参考。
12306倒是可以抓,
-7232369.html抓不到的。同样的还有uc新闻的新增微信公众号关注数据。
百度数据抓取-好搜经验-好搜论坛
牛人成群啊,
百度数据抓取,需要自己写爬虫,要懂抓包,然后用正则re,多写几遍抓取,就会了,
我写了一个,
一位不知名大牛写的|无需翻墙的抓取百度网页数据的工具基于python3的抓取工具,数据抓取多大有变,
web上登录百度的网站,在下面有个投票的,点击投票的按钮,然后就会出现。
如果你不是有非常深厚的python和java经验的话不建议使用爬虫工具, 查看全部
chrome抓取网页插件(百度数据爬虫-实用的爬虫工具基于python3的抓取工具)
chrome抓取网页插件-qq号码,
刚好之前考试写了个可以抓取的服务,基本就是利用协议的漏洞,这样网页数据就可以抓取到,并且可以导出为excel或pdf等等文件。因为这个软件基本就是抓取网页,所以还算简单,如果需要再深入的话,可以看下。
没有爬虫经验的人,推荐百度数据爬虫-实用的爬虫工具推荐常用的爬虫工具有百度的爬虫推荐,数据采集-百度文库数据采集github上可以看看别人的爬虫。
qq号码?@百度!
/
难道不是百度号码池?
网易新闻登录有一个随机新增qq号码,不过其他有抓包不一定全正确,仅供参考。
12306倒是可以抓,
-7232369.html抓不到的。同样的还有uc新闻的新增微信公众号关注数据。
百度数据抓取-好搜经验-好搜论坛
牛人成群啊,
百度数据抓取,需要自己写爬虫,要懂抓包,然后用正则re,多写几遍抓取,就会了,
我写了一个,
一位不知名大牛写的|无需翻墙的抓取百度网页数据的工具基于python3的抓取工具,数据抓取多大有变,
web上登录百度的网站,在下面有个投票的,点击投票的按钮,然后就会出现。
如果你不是有非常深厚的python和java经验的话不建议使用爬虫工具,
chrome抓取网页插件(蛮牛云爬虫(/)是唯一可以用githubhater来解决抓取的答案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-04-13 13:01
chrome抓取网页插件,使用蛮牛云插件。百度一下蛮牛云插件就有了,本来蛮牛云想比较惨无人道,卸载了好多次还是不能用,结果有一天突然又能用了,这时候觉得挺好的,终于可以上传自己的文件了,哈哈哈哈。
今天突然出现了这个问题就来搜这个问题,不料真的发现了这个问题,对于知乎上出现这样的问题我一向是不太喜欢回答的。试用了“githubhater”,想进行一下测试,连续尝试下来没有发现任何问题,再次测试才发现什么叫googlehi“疯狂爬虫”,下载速度与网页本身加载速度相差甚远,造成如此结果的原因可能是这个插件存在skiprowski.sh脚本,有效加载js/css文件。
好吧是我要求高,已经改用它了,同时也支持将它写入speedtest插件,不过做了个测试发现经过我的优化后速度依然不如蛮牛云爬虫,不得不承认蛮牛云爬虫(/)上传速度还是很快的。现在蛮牛云爬虫(/)是唯一可以用githubhater来解决抓取的答案,很难想象作为一个中文爬虫到了“无法提速”的地步。作为一个普通爬虫在市面上来看应该价格不贵,但是作为一个让爬虫程序员赚钱养家糊口的存在就贵了。|githubhater。
目前github上的爬虫程序除了几个大的rpc框架(比如scrapy、pyspider等)还在使用node+websocket来跟服务器通信,速度还可以,ie简直就是摆设。我推荐用githubhater,简单性能又高,比如快速提取htmljson结构的数据,githubhater能做到不到1s的read-only,还有大量第三方库,改改就可以用。
我使用的是简单模式,反正几百k的代码量,不写rewriteer.addlib.names_if(!name)也一样能用。这点githubhater做的很好,能爬取json数据而不是csv。 查看全部
chrome抓取网页插件(蛮牛云爬虫(/)是唯一可以用githubhater来解决抓取的答案)
chrome抓取网页插件,使用蛮牛云插件。百度一下蛮牛云插件就有了,本来蛮牛云想比较惨无人道,卸载了好多次还是不能用,结果有一天突然又能用了,这时候觉得挺好的,终于可以上传自己的文件了,哈哈哈哈。
今天突然出现了这个问题就来搜这个问题,不料真的发现了这个问题,对于知乎上出现这样的问题我一向是不太喜欢回答的。试用了“githubhater”,想进行一下测试,连续尝试下来没有发现任何问题,再次测试才发现什么叫googlehi“疯狂爬虫”,下载速度与网页本身加载速度相差甚远,造成如此结果的原因可能是这个插件存在skiprowski.sh脚本,有效加载js/css文件。
好吧是我要求高,已经改用它了,同时也支持将它写入speedtest插件,不过做了个测试发现经过我的优化后速度依然不如蛮牛云爬虫,不得不承认蛮牛云爬虫(/)上传速度还是很快的。现在蛮牛云爬虫(/)是唯一可以用githubhater来解决抓取的答案,很难想象作为一个中文爬虫到了“无法提速”的地步。作为一个普通爬虫在市面上来看应该价格不贵,但是作为一个让爬虫程序员赚钱养家糊口的存在就贵了。|githubhater。
目前github上的爬虫程序除了几个大的rpc框架(比如scrapy、pyspider等)还在使用node+websocket来跟服务器通信,速度还可以,ie简直就是摆设。我推荐用githubhater,简单性能又高,比如快速提取htmljson结构的数据,githubhater能做到不到1s的read-only,还有大量第三方库,改改就可以用。
我使用的是简单模式,反正几百k的代码量,不写rewriteer.addlib.names_if(!name)也一样能用。这点githubhater做的很好,能爬取json数据而不是csv。
chrome抓取网页插件(如何快速入门HeadlessChrome进行网页抓取的经验(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-04-13 00:10
翻译:没有两个
Headless Chrome 是 Chrome 浏览器的一种无界面形式,无需打开浏览器即可运行使用 Chrome 支持的所有功能的程序。与现代浏览器相比,Headless Chrome 更方便测试web应用、获取网站的截图、爬取信息等,也更贴近浏览器环境。下面我们来看看作者分享的使用 Headless Chrome 进行网页抓取的经验。
PhantomJS 的开发已经停止,Headless Chrome 成为焦点,每个人都喜欢它,包括我们。现在,网络抓取是我们工作的重要组成部分,我们现在广泛使用 Headless Chrome。
本文 文章 将向您展示如何快速开始使用 Headless Chrome 生态系统,并展示您从已经爬取数百万个网页中学到的东西。
文章总结:
1. 控制Chrome的库很多,大家可以根据自己的喜好选择。
2. 使用 Headless Chrome 进行网页抓取很容易,尤其是在您掌握了以下技术之后。
3. 可以检测到无头浏览器访问者,但没有人可以检测到。
无头 Chrome 简介
Headless Chrome 基于 Google Chrome 团队开发的 PhantomJS(QtWebKit 内核)。团队表示,将专注于该项目的研发,并将在未来继续维护。
这意味着对于网络抓取和自动化需求,您现在可以体验 Chrome 的速度和强大功能,因为它具有世界上最常用的浏览器的特性:支持所有 网站,支持 JS 引擎,并且很棒开发者工具 API。这太糟糕了!
使用哪个工具来控制 Headless Chrome?
市面上确实有很多 NodeJS 库支持 Chrome 新的 headless 模式,每个都有自己的特点。我们自己的是 NickJS。如果你没有自己的爬虫库,还敢说你是爬虫高手。
还有一组由社区发布的其他语言的库,例如基于 GO 语言的库。我们建议使用 NodeJS 工具,因为它与 Web 解析语言相同(下面您将看到它有多方便)。
网页抓取?这不是违法的吗?
我们无意展开无休止的辩论,但不到两周前,一名美国地方法官命令第三方抓取公共 LinkedIn 个人资料。到目前为止,这是一项初步法令,诉讼将继续进行,LinkedIn 肯定会反对,但不要担心,我们会密切关注情况,因为在这个 文章 中有很多关于 LinkedIn 的内容。
无论如何,作为技术 文章,我们不会深入研究特定抓取操作的合法性,我们应该始终努力尊重目标 网站 的 ToS。并且对您在此 文章 中学到的任何损害不承担任何责任。
到目前为止学到的很酷的东西
下面列出了我们几乎每天都在使用的一些技巧。代码示例使用 NickJS 抓取库,但它们可以很容易地被其他无头 Chrome 工具重写,分享这些概念很重要。
把饼干放回饼干罐
使用功能齐全的浏览器进行抓取可以让您高枕无忧,无需担心 CORS、会话、cookie、CSRF 和其他 Web 问题。
但有时登录表单变得非常困难,唯一的解决方案是恢复以前保存的会话 cookie。一些网站在检测到故障时会发送电子邮件或短信。我们没有时间这样做,只需打开已设置会话 cookie 的页面即可。
LinkedIn 有一个很好的例子,设置 li_atcookie 可以保证爬虫访问他们的社交网络(记住:注意尊重目标 网站Tos)。
await nick.setCookie({ name: "li_at", value: "a session cookie value copied from your DevTools", domain: "www.linkedin.com" })
相信像 LinkedIn 这样的 网站 不会阻止具有有效会话 cookie 的真实浏览器。这样做是有风险的,因为错误信息会引发愤怒用户的大量支持请求。
jQuery不会让你失望
我们学到的一件重要的事情是通过 jQuery 从网页中提取数据是多么容易。回想起来,这是显而易见的。网站 提供了一个高度结构化、可查询的数据元素树(称为 DOM),而 jQuery 是一个非常高效的 DOM 查询库。那么为什么不使用它来爬行呢?这个技巧会一次又一次地奏效。
很多 网站 已经使用 jQuery,所以只需在页面中添加几行即可获取数据。
await tab.open("news.ycombinator.com") await tab.untilVisible("#hnmain") // Make sure we have loaded the page await tab.inject("https://code.jquery.com/jquery-3.2.1.min.js") // We're going to use jQuery to scrape const hackerNewsLinks = await tab.evaluate((arg, callback) => { // Here we're in the page context. It's like being in your browser's inspector tool const data = [] $(".athing").each((index, element) => { data.push({ title: $(element).find(".storylink").text(), url: $(element).find(".storylink").attr("href") }) }) callback(null, data) })
印度、俄罗斯和巴基斯坦在阻止机器人方面有什么共同点?
答案是使用验证码来解决服务器验证。几块钱就可以买到几千个验证码,生成一个验证码通常不到30秒。但是晚上,因为没有人,所以一般比较贵。
一个简单的谷歌搜索将提供多个 API 来解决任何类型的验证码问题,包括从谷歌获取最新的验证码(1000 美元 2 美元)。
将抓取机器连接到这些服务就像发出 HTTP 请求一样简单,现在机器人是人类。
在我们的平台上,用户可以轻松解决他们需要的验证码问题。我们的 Buster 库可以:
if (await tab.isVisible(".captchaImage")) { // Get the URL of the generated CAPTCHA image // Note that we could also get its -encoded value and solve it too const captchaImageLink = await tab.evaluate((arg, callback) => { callback(null, $(".captchaImage").attr("src")) }) // Make a call to a CAPTCHA solving service const captchaAnswer = await buster.solveCaptchaImage(captchaImageLink) // Fill the form with our solution await tab.fill(".captchaForm", { "captcha-answer": captchaAnswer }, { submit: true }) }
等待一个 DOM 元素,而不是固定的时间
通常会看到爬虫初学者让他们的机器人在打开页面或单击按钮后等待 5 到 10 秒——他们希望确保他们所做的操作有时间产生效果。
但这不是应该做的。我们的三步理论适用于任何抓取场景:应该等待的是您想要操作的特定 DOM 元素。如果出现问题,它会更快、更清晰,并获得更准确的错误消息。
await tab.open("https://www.facebook.com/phbus ... 6quot;) // await Promise.delay(5000) // DON'T DO THIS! await tab.waitUntilVisible(".permalinkPost .UFILikeLink") // You can now safely click the "Like" button... await tab.click(".permalinkPost .UFILikeLink")
在某些情况下,可能确实有必要伪造人为的延迟。可以使用
await Promise.delay(2000 + Math.random() * 3000)
愚弄过去。
MongoDB
我们发现 MongoDB 非常适合大多数抓取作业,它具有出色的 JS API 和 Mongoose ORM。考虑到您在使用 Headless Chrome 时已经处于 NodeJS 环境中,为什么不采用它呢?
JSON-LD 和微数据开发
有时网页抓取不需要了解 DOM,而是要找到正确的“导出”按钮。记住这一点可以节省很多时间。
严格来说,有些网站 比其他网站 更容易,例如,他们所有的产品页面都显示在 DOM 中,产品数据为 JSON-LD 格式。可以对他们的任何产品页面说,然后运行
JSON.parse(document . queryselector(" # productSEOData "). innertext)
将得到一个可以很好地插入 MongoDB 的数据对象,无需真正的抓取!
网络请求拦截
因为使用了 DevTools API,所以编写的代码具有使用 Chrome 的 DevTools 的等效功能。这意味着生成的机器人可以拦截、检查甚至修改或中止任何网络请求。
通过从 LinkedIn 下载 PDF 格式的简历来测试 Web 请求拦截。单击配置文件中的“保存到 PDF”按钮会触发 XHR,其中响应是 PDF 文件,这是一种截取文件并将其写入磁盘的方法。
let cvRequestId = null tab.driver.client.Network.responseReceived((e) => { if (e.type === "XHR" && e.response.url.indexOf("profile-profilePdf/") > 0) { cvRequestId = e.requestId } }) tab.driver.client.Network.loadingFinished((e) => { if (e.requestId === cvRequestId) { tab.driver.client.Network.getResponseBody({ requestId: cvRequestId }, (err, cv) => { require("fs").writeFileSync("linkedin-cv.pdf", Buffer.from(cv.body, (cv.Encoded ? '' : 'utf8'))) }) } })
值得一提的是,DevTools 协议正在迅速发展,现在有一种方法可以使用 Page.setDownloadBehavior() 设置下载传入文件的方式和路径。我们尚未对其进行测试,但它看起来很有希望!
广告拦截
const nick = new Nick({ loadImages: false, whitelist: [ /.*\.aspx/, /.*axd.*/, /.*\.html.*/, /.*\.js.*/ ], blacklist: [ /.*fsispin360\.js/, /.*fsitouchzoom\.js/, /.*\.ashx.*/, /.*google.*/ ] })
它还可以通过阻止不必要的请求来加快爬网速度。分析、广告和图片是典型的屏蔽目标。但是,请记住,它会使机器人变得不像人类(例如,如果所有图像都被阻止,LinkedIn 将无法正确响应页面请求 - 不确定这是否是故意的)。
在 NickJS 中,用户可以指定收录正则表达式或字符串的白名单和黑名单。白名单功能特别强大,但如果您不小心,很容易使目标 网站 崩溃。
DevTools 协议还有 Network.setBlockedURLs() ,它接受一个带有通配符的字符串数组作为输入。
更重要的是,新版 Chrome 将带有谷歌自己的“广告拦截器”——它更像是一个广告“过滤器”。该协议已经有一个名为 Page.setAdBlockingEnabled() 的端点。
也就是我们所说的套路!
无头 Chrome 检测
最近的一篇文章 文章 列举了检测 Headless Chrome 访问者以及可能还有 PhantomJS 的各种方法。这些方法描述了从基本的用户代理字符串比较到更复杂的技术(例如触发错误和检查堆栈跟踪)的所有内容。
这基本上是愤怒的管理员和巧妙的机器人制造商之间的猫捉老鼠游戏。但从未见过这些方法正式实施。检测自动访问者在技术上是可行的,但谁愿意面对潜在的错误消息?对于大型 网站 来说尤其危险。
如果您知道那些具有这些检测功能的 网站,请告诉我们!
结束语
抓取从未如此简单,借助我们最新的工具和技术,它甚至可以成为我们开发人员的一项愉快而有趣的活动。
顺便说一句,我们的灵感来自 Franciskim.co “我不需要臭 API”文章,非常感谢!此外,有关如何开始使用木偶的详细说明,请单击此处。
在下一篇文章中,文章,我将写关于“机器人缓解”工具,比如 Distill Networks,关于 HTTP 代理和 IP 地址分配的美妙世界。
上有一个我们的抓取和自动化平台的库。如果您有兴趣,还可以了解我们的 3 个抓取步骤的理论信息。 查看全部
chrome抓取网页插件(如何快速入门HeadlessChrome进行网页抓取的经验(组图))
翻译:没有两个
Headless Chrome 是 Chrome 浏览器的一种无界面形式,无需打开浏览器即可运行使用 Chrome 支持的所有功能的程序。与现代浏览器相比,Headless Chrome 更方便测试web应用、获取网站的截图、爬取信息等,也更贴近浏览器环境。下面我们来看看作者分享的使用 Headless Chrome 进行网页抓取的经验。
PhantomJS 的开发已经停止,Headless Chrome 成为焦点,每个人都喜欢它,包括我们。现在,网络抓取是我们工作的重要组成部分,我们现在广泛使用 Headless Chrome。
本文 文章 将向您展示如何快速开始使用 Headless Chrome 生态系统,并展示您从已经爬取数百万个网页中学到的东西。
文章总结:
1. 控制Chrome的库很多,大家可以根据自己的喜好选择。
2. 使用 Headless Chrome 进行网页抓取很容易,尤其是在您掌握了以下技术之后。
3. 可以检测到无头浏览器访问者,但没有人可以检测到。
无头 Chrome 简介
Headless Chrome 基于 Google Chrome 团队开发的 PhantomJS(QtWebKit 内核)。团队表示,将专注于该项目的研发,并将在未来继续维护。
这意味着对于网络抓取和自动化需求,您现在可以体验 Chrome 的速度和强大功能,因为它具有世界上最常用的浏览器的特性:支持所有 网站,支持 JS 引擎,并且很棒开发者工具 API。这太糟糕了!
使用哪个工具来控制 Headless Chrome?

市面上确实有很多 NodeJS 库支持 Chrome 新的 headless 模式,每个都有自己的特点。我们自己的是 NickJS。如果你没有自己的爬虫库,还敢说你是爬虫高手。
还有一组由社区发布的其他语言的库,例如基于 GO 语言的库。我们建议使用 NodeJS 工具,因为它与 Web 解析语言相同(下面您将看到它有多方便)。
网页抓取?这不是违法的吗?
我们无意展开无休止的辩论,但不到两周前,一名美国地方法官命令第三方抓取公共 LinkedIn 个人资料。到目前为止,这是一项初步法令,诉讼将继续进行,LinkedIn 肯定会反对,但不要担心,我们会密切关注情况,因为在这个 文章 中有很多关于 LinkedIn 的内容。
无论如何,作为技术 文章,我们不会深入研究特定抓取操作的合法性,我们应该始终努力尊重目标 网站 的 ToS。并且对您在此 文章 中学到的任何损害不承担任何责任。
到目前为止学到的很酷的东西
下面列出了我们几乎每天都在使用的一些技巧。代码示例使用 NickJS 抓取库,但它们可以很容易地被其他无头 Chrome 工具重写,分享这些概念很重要。
把饼干放回饼干罐
使用功能齐全的浏览器进行抓取可以让您高枕无忧,无需担心 CORS、会话、cookie、CSRF 和其他 Web 问题。
但有时登录表单变得非常困难,唯一的解决方案是恢复以前保存的会话 cookie。一些网站在检测到故障时会发送电子邮件或短信。我们没有时间这样做,只需打开已设置会话 cookie 的页面即可。
LinkedIn 有一个很好的例子,设置 li_atcookie 可以保证爬虫访问他们的社交网络(记住:注意尊重目标 网站Tos)。
await nick.setCookie({ name: "li_at", value: "a session cookie value copied from your DevTools", domain: "www.linkedin.com" })
相信像 LinkedIn 这样的 网站 不会阻止具有有效会话 cookie 的真实浏览器。这样做是有风险的,因为错误信息会引发愤怒用户的大量支持请求。
jQuery不会让你失望
我们学到的一件重要的事情是通过 jQuery 从网页中提取数据是多么容易。回想起来,这是显而易见的。网站 提供了一个高度结构化、可查询的数据元素树(称为 DOM),而 jQuery 是一个非常高效的 DOM 查询库。那么为什么不使用它来爬行呢?这个技巧会一次又一次地奏效。
很多 网站 已经使用 jQuery,所以只需在页面中添加几行即可获取数据。
await tab.open("news.ycombinator.com") await tab.untilVisible("#hnmain") // Make sure we have loaded the page await tab.inject("https://code.jquery.com/jquery-3.2.1.min.js";) // We're going to use jQuery to scrape const hackerNewsLinks = await tab.evaluate((arg, callback) => { // Here we're in the page context. It's like being in your browser's inspector tool const data = [] $(".athing").each((index, element) => { data.push({ title: $(element).find(".storylink").text(), url: $(element).find(".storylink").attr("href") }) }) callback(null, data) })
印度、俄罗斯和巴基斯坦在阻止机器人方面有什么共同点?

答案是使用验证码来解决服务器验证。几块钱就可以买到几千个验证码,生成一个验证码通常不到30秒。但是晚上,因为没有人,所以一般比较贵。
一个简单的谷歌搜索将提供多个 API 来解决任何类型的验证码问题,包括从谷歌获取最新的验证码(1000 美元 2 美元)。
将抓取机器连接到这些服务就像发出 HTTP 请求一样简单,现在机器人是人类。
在我们的平台上,用户可以轻松解决他们需要的验证码问题。我们的 Buster 库可以:
if (await tab.isVisible(".captchaImage")) { // Get the URL of the generated CAPTCHA image // Note that we could also get its -encoded value and solve it too const captchaImageLink = await tab.evaluate((arg, callback) => { callback(null, $(".captchaImage").attr("src")) }) // Make a call to a CAPTCHA solving service const captchaAnswer = await buster.solveCaptchaImage(captchaImageLink) // Fill the form with our solution await tab.fill(".captchaForm", { "captcha-answer": captchaAnswer }, { submit: true }) }
等待一个 DOM 元素,而不是固定的时间
通常会看到爬虫初学者让他们的机器人在打开页面或单击按钮后等待 5 到 10 秒——他们希望确保他们所做的操作有时间产生效果。
但这不是应该做的。我们的三步理论适用于任何抓取场景:应该等待的是您想要操作的特定 DOM 元素。如果出现问题,它会更快、更清晰,并获得更准确的错误消息。
await tab.open("https://www.facebook.com/phbus ... 6quot;) // await Promise.delay(5000) // DON'T DO THIS! await tab.waitUntilVisible(".permalinkPost .UFILikeLink") // You can now safely click the "Like" button... await tab.click(".permalinkPost .UFILikeLink")
在某些情况下,可能确实有必要伪造人为的延迟。可以使用
await Promise.delay(2000 + Math.random() * 3000)
愚弄过去。
MongoDB
我们发现 MongoDB 非常适合大多数抓取作业,它具有出色的 JS API 和 Mongoose ORM。考虑到您在使用 Headless Chrome 时已经处于 NodeJS 环境中,为什么不采用它呢?
JSON-LD 和微数据开发
有时网页抓取不需要了解 DOM,而是要找到正确的“导出”按钮。记住这一点可以节省很多时间。
严格来说,有些网站 比其他网站 更容易,例如,他们所有的产品页面都显示在 DOM 中,产品数据为 JSON-LD 格式。可以对他们的任何产品页面说,然后运行
JSON.parse(document . queryselector(" # productSEOData "). innertext)
将得到一个可以很好地插入 MongoDB 的数据对象,无需真正的抓取!
网络请求拦截

因为使用了 DevTools API,所以编写的代码具有使用 Chrome 的 DevTools 的等效功能。这意味着生成的机器人可以拦截、检查甚至修改或中止任何网络请求。
通过从 LinkedIn 下载 PDF 格式的简历来测试 Web 请求拦截。单击配置文件中的“保存到 PDF”按钮会触发 XHR,其中响应是 PDF 文件,这是一种截取文件并将其写入磁盘的方法。
let cvRequestId = null tab.driver.client.Network.responseReceived((e) => { if (e.type === "XHR" && e.response.url.indexOf("profile-profilePdf/") > 0) { cvRequestId = e.requestId } }) tab.driver.client.Network.loadingFinished((e) => { if (e.requestId === cvRequestId) { tab.driver.client.Network.getResponseBody({ requestId: cvRequestId }, (err, cv) => { require("fs").writeFileSync("linkedin-cv.pdf", Buffer.from(cv.body, (cv.Encoded ? '' : 'utf8'))) }) } })
值得一提的是,DevTools 协议正在迅速发展,现在有一种方法可以使用 Page.setDownloadBehavior() 设置下载传入文件的方式和路径。我们尚未对其进行测试,但它看起来很有希望!
广告拦截
const nick = new Nick({ loadImages: false, whitelist: [ /.*\.aspx/, /.*axd.*/, /.*\.html.*/, /.*\.js.*/ ], blacklist: [ /.*fsispin360\.js/, /.*fsitouchzoom\.js/, /.*\.ashx.*/, /.*google.*/ ] })
它还可以通过阻止不必要的请求来加快爬网速度。分析、广告和图片是典型的屏蔽目标。但是,请记住,它会使机器人变得不像人类(例如,如果所有图像都被阻止,LinkedIn 将无法正确响应页面请求 - 不确定这是否是故意的)。
在 NickJS 中,用户可以指定收录正则表达式或字符串的白名单和黑名单。白名单功能特别强大,但如果您不小心,很容易使目标 网站 崩溃。
DevTools 协议还有 Network.setBlockedURLs() ,它接受一个带有通配符的字符串数组作为输入。
更重要的是,新版 Chrome 将带有谷歌自己的“广告拦截器”——它更像是一个广告“过滤器”。该协议已经有一个名为 Page.setAdBlockingEnabled() 的端点。
也就是我们所说的套路!
无头 Chrome 检测
最近的一篇文章 文章 列举了检测 Headless Chrome 访问者以及可能还有 PhantomJS 的各种方法。这些方法描述了从基本的用户代理字符串比较到更复杂的技术(例如触发错误和检查堆栈跟踪)的所有内容。
这基本上是愤怒的管理员和巧妙的机器人制造商之间的猫捉老鼠游戏。但从未见过这些方法正式实施。检测自动访问者在技术上是可行的,但谁愿意面对潜在的错误消息?对于大型 网站 来说尤其危险。
如果您知道那些具有这些检测功能的 网站,请告诉我们!
结束语
抓取从未如此简单,借助我们最新的工具和技术,它甚至可以成为我们开发人员的一项愉快而有趣的活动。
顺便说一句,我们的灵感来自 Franciskim.co “我不需要臭 API”文章,非常感谢!此外,有关如何开始使用木偶的详细说明,请单击此处。
在下一篇文章中,文章,我将写关于“机器人缓解”工具,比如 Distill Networks,关于 HTTP 代理和 IP 地址分配的美妙世界。
上有一个我们的抓取和自动化平台的库。如果您有兴趣,还可以了解我们的 3 个抓取步骤的理论信息。
chrome抓取网页插件(科研党必备插件:谷歌学术搜索按钮搞科研的人)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-04-11 01:34
Chrome浏览器凭借其快速的搜索速度、友好的界面、强大的性能和出色的体验,迅速扩大了市场份额,在2012年超越IE浏览器,位居第一。作为科研党,我想写出优秀的科研成果,离不开这样的神器。Chrome浏览器的特点还包括丰富的插件。以下是我常用的一些Chrome浏览器插件。我希望它对每个人都有帮助。
更好的谷歌
1、万能翻译插件:字标翻译
通用翻译插件:字标翻译
做科学研究离不开翻译。无论是英译中还是中译英,这个词标翻译插件不仅可以翻译一些单词、一些短句,还可以翻译整个全文;不仅支持几乎所有语言的翻译,还具有阅读和背诵功能;不仅支持国内百度翻译、有道翻译引擎,还支持国外谷歌翻译、必应翻译;使用非常方便,操作逻辑非常简单。左键选择要翻译的内容,点击绿色按钮自动翻译。
简单易用
2、更改页面颜色插件:更改颜色
更改页面颜色插件:更改颜色
Change Colors是Chrome浏览器的一个插件,可以改变网页的颜色。它几乎是我必须安装的插件,以及夜间模式。使用起来也非常简单。打开更改颜色选项,根据个人喜好设置相关参数。可以换成多种颜色,妈妈再也不用担心你的眼睛了。
上面的绿色是我改的颜色
3、研究党必备插件:谷歌学术按钮
研究党必备插件:Google Scholar 按钮
从事科学研究的人都知道谷歌学术的力量和重要性。谷歌学术按钮插件是一款可以帮助我们搬运工快速获取学术论文全部内容的插件。但前提是你可以正常登录谷歌学术网站。如果不行,可以通过修改Hosts文件等方法解决。
简单易用的页面
4、Google 下载插件:Chrono 下载管理器
Google 下载插件:Chrono 下载管理器
谷歌网页本身的下载界面不是很友好。搭配Chrono下载管理器插件,不仅可以完美替代浏览器自带的下载界面,还可以抓取网页上的一些流媒体、音频、视频。特别好用,断点下载比Chrome本身好很多。
便于使用
5、截图神器:网页截图:注释和评论
截图神器:网页截图:注释和评论
网页截图:Annotation & Annotation 是一个截图插件。我没有遇到过他。QQ截图我都有,但最大的问题是必须联网。使用这个插件,不仅可以截取网页内容的部分截图,而且支持截取整个网页,可以滚动截图,非常棒。此外,该插件还支持对截图进行二次处理,包括添加注解、注解、水印等附加信息。
比QQ截图厉害多了
6、阻止弹出窗口:Poper Blocker
阻止弹出窗口:Poper Blocker
安装 Poper Blocker 插件后,再也不用担心登录那些有弹窗广告的网站了。Poper Blocker插件会乖乖的自动屏蔽网站中的弹窗广告,并且可以显示在浏览器的右上角,可以看到被屏蔽广告的信息。另外,如果想在某个网站上看到弹窗广告,可以设置白名单,网站上的弹窗广告不会被屏蔽。盾。
阻止弹出广告
这些是我目前经常使用的浏览器插件,可以从谷歌应用商店下载。欢迎大家使用,欢迎采集,欢迎讨论。 查看全部
chrome抓取网页插件(科研党必备插件:谷歌学术搜索按钮搞科研的人)
Chrome浏览器凭借其快速的搜索速度、友好的界面、强大的性能和出色的体验,迅速扩大了市场份额,在2012年超越IE浏览器,位居第一。作为科研党,我想写出优秀的科研成果,离不开这样的神器。Chrome浏览器的特点还包括丰富的插件。以下是我常用的一些Chrome浏览器插件。我希望它对每个人都有帮助。

更好的谷歌
1、万能翻译插件:字标翻译

通用翻译插件:字标翻译
做科学研究离不开翻译。无论是英译中还是中译英,这个词标翻译插件不仅可以翻译一些单词、一些短句,还可以翻译整个全文;不仅支持几乎所有语言的翻译,还具有阅读和背诵功能;不仅支持国内百度翻译、有道翻译引擎,还支持国外谷歌翻译、必应翻译;使用非常方便,操作逻辑非常简单。左键选择要翻译的内容,点击绿色按钮自动翻译。

简单易用
2、更改页面颜色插件:更改颜色

更改页面颜色插件:更改颜色
Change Colors是Chrome浏览器的一个插件,可以改变网页的颜色。它几乎是我必须安装的插件,以及夜间模式。使用起来也非常简单。打开更改颜色选项,根据个人喜好设置相关参数。可以换成多种颜色,妈妈再也不用担心你的眼睛了。

上面的绿色是我改的颜色
3、研究党必备插件:谷歌学术按钮

研究党必备插件:Google Scholar 按钮
从事科学研究的人都知道谷歌学术的力量和重要性。谷歌学术按钮插件是一款可以帮助我们搬运工快速获取学术论文全部内容的插件。但前提是你可以正常登录谷歌学术网站。如果不行,可以通过修改Hosts文件等方法解决。

简单易用的页面
4、Google 下载插件:Chrono 下载管理器

Google 下载插件:Chrono 下载管理器
谷歌网页本身的下载界面不是很友好。搭配Chrono下载管理器插件,不仅可以完美替代浏览器自带的下载界面,还可以抓取网页上的一些流媒体、音频、视频。特别好用,断点下载比Chrome本身好很多。

便于使用
5、截图神器:网页截图:注释和评论

截图神器:网页截图:注释和评论
网页截图:Annotation & Annotation 是一个截图插件。我没有遇到过他。QQ截图我都有,但最大的问题是必须联网。使用这个插件,不仅可以截取网页内容的部分截图,而且支持截取整个网页,可以滚动截图,非常棒。此外,该插件还支持对截图进行二次处理,包括添加注解、注解、水印等附加信息。

比QQ截图厉害多了
6、阻止弹出窗口:Poper Blocker

阻止弹出窗口:Poper Blocker
安装 Poper Blocker 插件后,再也不用担心登录那些有弹窗广告的网站了。Poper Blocker插件会乖乖的自动屏蔽网站中的弹窗广告,并且可以显示在浏览器的右上角,可以看到被屏蔽广告的信息。另外,如果想在某个网站上看到弹窗广告,可以设置白名单,网站上的弹窗广告不会被屏蔽。盾。

阻止弹出广告
这些是我目前经常使用的浏览器插件,可以从谷歌应用商店下载。欢迎大家使用,欢迎采集,欢迎讨论。
chrome抓取网页插件(推荐一些中文网站分类.javascript免费学习.remote-similarweb-similarweb(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-10 23:14
chrome抓取网页插件,免费无广告,电脑与手机都可以使用操作界面操作方便,界面很干净,支持谷歌浏览器,firefox浏览器,googlechrome浏览器,百度浏览器,360浏览器,搜狗浏览器,opera浏览器,uc浏览器,edge浏览器,美团网,人人网,uc浏览器,qq浏览器,今日头条,360网络浏览器,猎豹浏览器,清理大师,迅雷极速版,遨游浏览器等手机插件比如在网页上选中一个图片,点一下触屏图标就出来了,配合上chrome浏览器的扩展也是非常强大的,全屏,图片展示,图片传到safari,阅读、记事等。
想知道怎么才能免费下载网上的歌,这个视频给了我答案,很全面,希望对你有用。自从用了safari,每天听歌变成有事没事听着,而且想下载啥就下载啥,很爽,就是有一点,safari不能导出文件。
自用chrome引擎插件w3school:国内资源极少,ideoner和clipboardsweeper等外国资源还是很多的,wikipedia资源库差不多有10000个页面,除了medium、tweetbot、博客园和36kr外,还有财经新闻、blogger和电影天堂等。推荐一些中文网站分类.javascript免费学习.remote-similarweb-similarweb收录互联网上的全部主流和小众网站:.chromewebsitebanks:所有关于web的内容.googlebackgrounddecoratorextensions:可以通过css或者stylekey访问googlebackgrounddecorators来修改页面的背景的颜色.wordpress全面插件教程.webpagechrome,强烈推荐,用于站内搜索,因为我也想知道在chrome中具体的操作方法。不能忽略这个网站和它提供的系列免费插件。 查看全部
chrome抓取网页插件(推荐一些中文网站分类.javascript免费学习.remote-similarweb-similarweb(组图))
chrome抓取网页插件,免费无广告,电脑与手机都可以使用操作界面操作方便,界面很干净,支持谷歌浏览器,firefox浏览器,googlechrome浏览器,百度浏览器,360浏览器,搜狗浏览器,opera浏览器,uc浏览器,edge浏览器,美团网,人人网,uc浏览器,qq浏览器,今日头条,360网络浏览器,猎豹浏览器,清理大师,迅雷极速版,遨游浏览器等手机插件比如在网页上选中一个图片,点一下触屏图标就出来了,配合上chrome浏览器的扩展也是非常强大的,全屏,图片展示,图片传到safari,阅读、记事等。
想知道怎么才能免费下载网上的歌,这个视频给了我答案,很全面,希望对你有用。自从用了safari,每天听歌变成有事没事听着,而且想下载啥就下载啥,很爽,就是有一点,safari不能导出文件。
自用chrome引擎插件w3school:国内资源极少,ideoner和clipboardsweeper等外国资源还是很多的,wikipedia资源库差不多有10000个页面,除了medium、tweetbot、博客园和36kr外,还有财经新闻、blogger和电影天堂等。推荐一些中文网站分类.javascript免费学习.remote-similarweb-similarweb收录互联网上的全部主流和小众网站:.chromewebsitebanks:所有关于web的内容.googlebackgrounddecoratorextensions:可以通过css或者stylekey访问googlebackgrounddecorators来修改页面的背景的颜色.wordpress全面插件教程.webpagechrome,强烈推荐,用于站内搜索,因为我也想知道在chrome中具体的操作方法。不能忽略这个网站和它提供的系列免费插件。
chrome抓取网页插件(chrome抓取网页插件devtools3.7.9版本即将支持iphonexr(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-08 00:04
chrome抓取网页插件devtools3.7.9版本即将支持iphonexr!请去tb购买,本作品不支持android。作者@@国际支付负责人林小云加微信号:zuilin14,欢迎交流,留言无法转载。
applestore商店搜索macbookpro:apple-store,itunesconnect-store&applestorepricing
如果要的是xcode的程序内调用的java和c,用第三方可以实现的,比如clojure,kotlin,还有,但是不通过applemarket。另外git也可以,
一个简单的https程序:/
c++
sublimetext3
chrome或者谷歌maps
:standard-repair-and-repair-on-android-x86-devices
applemarket有专门修复这种问题的插件,
chrome就可以吧,android不像ios可以通过官方xp程序修复,一般都是通过第三方来修复的,我一般用testflight修复,在testflight官网apk扫描的话可以找到的地址,然后可以下载。
applestoregooglemaps
android和ios都有官方的googlemap可以替换了
我一般只测试appstore上的包,
这个问题在知乎上已经有类似的了。而且据我所知目前国内能做到的基本都是借助猎豹安全大师。 查看全部
chrome抓取网页插件(chrome抓取网页插件devtools3.7.9版本即将支持iphonexr(图))
chrome抓取网页插件devtools3.7.9版本即将支持iphonexr!请去tb购买,本作品不支持android。作者@@国际支付负责人林小云加微信号:zuilin14,欢迎交流,留言无法转载。
applestore商店搜索macbookpro:apple-store,itunesconnect-store&applestorepricing
如果要的是xcode的程序内调用的java和c,用第三方可以实现的,比如clojure,kotlin,还有,但是不通过applemarket。另外git也可以,
一个简单的https程序:/
c++
sublimetext3
chrome或者谷歌maps
:standard-repair-and-repair-on-android-x86-devices
applemarket有专门修复这种问题的插件,
chrome就可以吧,android不像ios可以通过官方xp程序修复,一般都是通过第三方来修复的,我一般用testflight修复,在testflight官网apk扫描的话可以找到的地址,然后可以下载。
applestoregooglemaps
android和ios都有官方的googlemap可以替换了
我一般只测试appstore上的包,
这个问题在知乎上已经有类似的了。而且据我所知目前国内能做到的基本都是借助猎豹安全大师。
chrome抓取网页插件(20款为开发者的优质插件,让你随时暂停JS动画)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-07 12:09
毫无疑问,Chrome相对于其他浏览器具有明显的优势,但它的对手火狐却是众多前端围攻者和开发者的挚爱。为了尽可能的提升用户体验,火狐社区开发了并且毫不夸张的说它是网站开发者的首选浏览器。
本文采集了 20 个面向开发人员的高级插件,Web 开发人员可以借助这些插件创建令人惊叹的创意 网站 页面。接下来,我们来看看这些插件。
1. 萤火虫
作为开发领域最著名的插件,Firebug 允许您在浏览器中实时运行 HTML、CSS 等代码。Firebug 内置了强大的 Javascript 调试工具,可以让你随时暂停 JS 动画,观察静态细节。如果觉得效果不明显,也可以用JS分析仪分析校准,找出问题的症结所在。
2. 幽灵
Ghostery 用于检测“不可见的网站”、检测跟踪器、网站 漏洞利用、扫描像素、监控 Facebook 和 Google Analytics 以及 1000 多家其他在线广告提供商、行为数据提供商以及与相关的所有活动数据你网站,包括内容提供者。
3. 网络开发人员
Web Developer 提供广泛的菜单和自定义工具,允许您控制和管理、分析、验证和优化网页。您可以管理 CSS、HTML、表格、测量特定部件的尺寸、实时编辑页面等等。
4. 旗狐
Flagfox 是一个插件,可以使用一个小标志来表示服务器的物理地址。有了这个插件,你会更清楚自己的浏览器连接在哪里,也可以用它来识别服务器所在的地区和语言,查看服务器所在的法律法规是否有特殊限制, 等等。当然,您也可以通过外部操作了解更多信息,也可以自己添加自定义操作,设置快速访问或设置键盘快捷键。
5. Fireftp
除了快速高效地传输文件外,Fireftp 还具有更多高级功能,包括目录比较、同步导航、SFTP、SSL 加密、搜索和过滤、完整性检查、远程编辑、鼠标拖放等。
6. Colorzilla
您可以在 Colorzilla 的帮助下使您浏览的页面更加丰富多彩,该插件可以快速拾取颜色并将它们粘贴到其他程序中。此外,Colorzilla 可以帮助您放大正在查看的页面并测量页面上任意两点之间的距离。Colorzilla 内置了调色板,一方面方便用户获取预设颜色,同时也可以保存从网页抓取的颜色。DOM Spying 功能可以帮助您监控 DOM 元素的各种信息。
7. 快速Java
借助 Quick Java 插件,您无需打开系统设置和插件管理即可快速管理浏览器功能,包括 Java、Javascript、Cookies、动画图片、flash、silverlight、样式表、poxy 以及自动图片加载等功能。对于高级用户来说,这个插件可能是他们的一杯茶。
8. SQLite 管理器
该插件可以帮助您管理系统中的SQLite数据库,方便浏览数据、查表、进行增删改查等一系列操作。使用 SQLite Manger,您可以在操作面板中进行常用操作,轻松访问工具栏、按钮和菜单。
9. 表格工具 2
这是一个专为Web表格设计的工具,通过它可以对HTML表格进行复杂的操作,包括复制表格/行/列/单元格、排序、基于正则表达式的搜索、过滤、生成图表、统计、合并和比较。操作也很简单,选择需要操作的表格,右键菜单,点击“表格工具2”选项。
10. 无脚本安全套装
此插件将帮助您控制 Java 和 Javascript 以及其他可执行内容,以便在您信任和允许的域中运行,例如某些银行网站。它可以帮助您抵御跨站脚本攻击(XSS)、跨域 DNS 绑定和 CSRF 攻击(攻击路由器)、反劫持,并内置独特的 ClearClick 技术。
11. DOM 检查器
DOM Viewer 是一个用于检查和编辑网页或 XUL 应用程序的 DOM 工具。在其两列编辑器中,您可以在多个不同视图中查看文档中的节点。
12. 修改标头
标头编辑器可以为您添加、替换和过滤 HTTP 标头部分并将它们发送到服务器。该工具主要用于移动互联网开发和HTTP测试。
13. 很棒的截图
这个截图工具可以帮助你截取整个网页,或者网页的一部分,可以标记、添加文字、添加图形、箭头,还可以模糊敏感信息。截图处理后,还可以一键上传分享。
经常写Javascript代码的同学可能会喜欢这个JS调试工具。
15. Cookie 管理器
这个cookie管理器允许您查看、编辑和创建新的cookie,也方便您查询一些附加信息,一次编辑多个cookie,以及一键备份/恢复。
16. Yslow
Yslow 可用于分析网页并提供改进网页和改善体验的建议。
17. HTML 验证器
这个 HTML 验证工具根据 Firefox 的内部验证机制监控网页,并用图标标记页面上的错误数量。
18. json 视图
通常当你看到一个 .json 文件时,浏览器会直接下载它而不是打开文件,Json View 允许浏览器像打开 XML 文件一样打开和显示文档。文档的显示是结构化的,特定内容突出显示,数组对象可折叠。即使 JSON 文档收录错误,也会显示原创文本。 查看全部
chrome抓取网页插件(20款为开发者的优质插件,让你随时暂停JS动画)
毫无疑问,Chrome相对于其他浏览器具有明显的优势,但它的对手火狐却是众多前端围攻者和开发者的挚爱。为了尽可能的提升用户体验,火狐社区开发了并且毫不夸张的说它是网站开发者的首选浏览器。
本文采集了 20 个面向开发人员的高级插件,Web 开发人员可以借助这些插件创建令人惊叹的创意 网站 页面。接下来,我们来看看这些插件。
1. 萤火虫

作为开发领域最著名的插件,Firebug 允许您在浏览器中实时运行 HTML、CSS 等代码。Firebug 内置了强大的 Javascript 调试工具,可以让你随时暂停 JS 动画,观察静态细节。如果觉得效果不明显,也可以用JS分析仪分析校准,找出问题的症结所在。
2. 幽灵

Ghostery 用于检测“不可见的网站”、检测跟踪器、网站 漏洞利用、扫描像素、监控 Facebook 和 Google Analytics 以及 1000 多家其他在线广告提供商、行为数据提供商以及与相关的所有活动数据你网站,包括内容提供者。
3. 网络开发人员

Web Developer 提供广泛的菜单和自定义工具,允许您控制和管理、分析、验证和优化网页。您可以管理 CSS、HTML、表格、测量特定部件的尺寸、实时编辑页面等等。
4. 旗狐

Flagfox 是一个插件,可以使用一个小标志来表示服务器的物理地址。有了这个插件,你会更清楚自己的浏览器连接在哪里,也可以用它来识别服务器所在的地区和语言,查看服务器所在的法律法规是否有特殊限制, 等等。当然,您也可以通过外部操作了解更多信息,也可以自己添加自定义操作,设置快速访问或设置键盘快捷键。
5. Fireftp

除了快速高效地传输文件外,Fireftp 还具有更多高级功能,包括目录比较、同步导航、SFTP、SSL 加密、搜索和过滤、完整性检查、远程编辑、鼠标拖放等。
6. Colorzilla

您可以在 Colorzilla 的帮助下使您浏览的页面更加丰富多彩,该插件可以快速拾取颜色并将它们粘贴到其他程序中。此外,Colorzilla 可以帮助您放大正在查看的页面并测量页面上任意两点之间的距离。Colorzilla 内置了调色板,一方面方便用户获取预设颜色,同时也可以保存从网页抓取的颜色。DOM Spying 功能可以帮助您监控 DOM 元素的各种信息。
7. 快速Java

借助 Quick Java 插件,您无需打开系统设置和插件管理即可快速管理浏览器功能,包括 Java、Javascript、Cookies、动画图片、flash、silverlight、样式表、poxy 以及自动图片加载等功能。对于高级用户来说,这个插件可能是他们的一杯茶。
8. SQLite 管理器

该插件可以帮助您管理系统中的SQLite数据库,方便浏览数据、查表、进行增删改查等一系列操作。使用 SQLite Manger,您可以在操作面板中进行常用操作,轻松访问工具栏、按钮和菜单。
9. 表格工具 2

这是一个专为Web表格设计的工具,通过它可以对HTML表格进行复杂的操作,包括复制表格/行/列/单元格、排序、基于正则表达式的搜索、过滤、生成图表、统计、合并和比较。操作也很简单,选择需要操作的表格,右键菜单,点击“表格工具2”选项。
10. 无脚本安全套装

此插件将帮助您控制 Java 和 Javascript 以及其他可执行内容,以便在您信任和允许的域中运行,例如某些银行网站。它可以帮助您抵御跨站脚本攻击(XSS)、跨域 DNS 绑定和 CSRF 攻击(攻击路由器)、反劫持,并内置独特的 ClearClick 技术。
11. DOM 检查器

DOM Viewer 是一个用于检查和编辑网页或 XUL 应用程序的 DOM 工具。在其两列编辑器中,您可以在多个不同视图中查看文档中的节点。
12. 修改标头

标头编辑器可以为您添加、替换和过滤 HTTP 标头部分并将它们发送到服务器。该工具主要用于移动互联网开发和HTTP测试。
13. 很棒的截图

这个截图工具可以帮助你截取整个网页,或者网页的一部分,可以标记、添加文字、添加图形、箭头,还可以模糊敏感信息。截图处理后,还可以一键上传分享。

经常写Javascript代码的同学可能会喜欢这个JS调试工具。
15. Cookie 管理器

这个cookie管理器允许您查看、编辑和创建新的cookie,也方便您查询一些附加信息,一次编辑多个cookie,以及一键备份/恢复。
16. Yslow

Yslow 可用于分析网页并提供改进网页和改善体验的建议。
17. HTML 验证器

这个 HTML 验证工具根据 Firefox 的内部验证机制监控网页,并用图标标记页面上的错误数量。
18. json 视图

通常当你看到一个 .json 文件时,浏览器会直接下载它而不是打开文件,Json View 允许浏览器像打开 XML 文件一样打开和显示文档。文档的显示是结构化的,特定内容突出显示,数组对象可折叠。即使 JSON 文档收录错误,也会显示原创文本。
chrome抓取网页插件( PageAnalytics可以从GoogleAnalytics中读取到你的网站数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-06 12:30
PageAnalytics可以从GoogleAnalytics中读取到你的网站数据)
Page Analytics 是 Chrome 浏览器上的一个插件。它可以从 Google Analytics 读取您的 网站 数据,并直接在网页上各处的链接上显示点击数据。根据这些数据,你可以很容易地判断 网站 的布局是否需要优化。
一、安装教学
安装地址:Chrome Store
打开后点击添加到Chrome(仅支持Chrome浏览器),完成插件安装。
安装完成后,可以在浏览器插件中看到Page Analytics的图标,默认是OFF(关闭),点击会开启(打开),然后点击下方彩色图标,会立即覆盖在网站上,通过色块,你可以第一时间知道整个网站是如何被用户点击的,哪些区域更受欢迎。
二、无法捕获数据
这个插件有时会捕捉不到GA数据,出现的错误信息如下——
大致解释一下如何做到这一点:
·本插件的原理是加载网站的GA数据。而且我们只能看到自己账号的GA数据,所以使用这个插件是看不到别人网站的数据的。
·请先确认您是否已登录GA账号。您可以先尝试登录GA官网。
·确认登录账号后,打开这个插件,几秒后,一般可以看到你的网站数据。
· 如果仍然看不到它,请关闭浏览器,重新开始,或刷新页面。
三、无法显示数据的地方
这个插件操作非常简单,界面也非常友好。哪个按钮以及链接上的点击次数可以让您轻松地根据数字做出决定。
但请不要相信所有的数据,因为你看到的数字(或数字)很可能不是肤浅的认识,也可能导致你做出判断性决定,反而阻碍了网站的网站。
请务必注意,某些链接或按钮不会看到数据,但这并不意味着访问者不会点击这些地方。
1、GA数据不计算外链点击量,比如网站的分享功能,所以插件无法展示。
2、标签链接可能不算数。GA后端的数据中会有标签数据,可能是插件问题。
3、各种按钮的点击都不会被统计或显示,因为它们根本不是 URL,对吧?
4、数据统计时间跨度过大。例如,它已经被计算了好几年。可能因为点击几乎为0而无法显示。不过这种情况比较少见。
四、如何判断一个链接的效果
有时一个页面上会有多个相同的链接。比如首页链接会出现在网站的顶部logo、导航栏、底部网页中,所以要谨慎对待此类链接的数据。
比如在一个网页上,三个相同的链接点击率是3%,那能算3%*3=9%的点击率吗?不,这 3% 仅由同一链接显示。
因此,遗憾的是,我们无法知道访问者更喜欢在同一个页面和多个相同的链接上点击哪个链接。
所以如果想知道同一个链接不同位置的效果,就必须和外链一样,把GA代码单独放在链接按钮上。
概括
总的来说,这个插件还是挺方便的,它可以让我们很方便的知道某个区域内所有连接的点击率,并且根据点击率,可以增加热门链接的排序,降低排序不受欢迎的链接。,甚至直接去掉,换成更有效的链接。 查看全部
chrome抓取网页插件(
PageAnalytics可以从GoogleAnalytics中读取到你的网站数据)
Page Analytics 是 Chrome 浏览器上的一个插件。它可以从 Google Analytics 读取您的 网站 数据,并直接在网页上各处的链接上显示点击数据。根据这些数据,你可以很容易地判断 网站 的布局是否需要优化。
一、安装教学
安装地址:Chrome Store
打开后点击添加到Chrome(仅支持Chrome浏览器),完成插件安装。
安装完成后,可以在浏览器插件中看到Page Analytics的图标,默认是OFF(关闭),点击会开启(打开),然后点击下方彩色图标,会立即覆盖在网站上,通过色块,你可以第一时间知道整个网站是如何被用户点击的,哪些区域更受欢迎。
二、无法捕获数据
这个插件有时会捕捉不到GA数据,出现的错误信息如下——
大致解释一下如何做到这一点:
·本插件的原理是加载网站的GA数据。而且我们只能看到自己账号的GA数据,所以使用这个插件是看不到别人网站的数据的。
·请先确认您是否已登录GA账号。您可以先尝试登录GA官网。
·确认登录账号后,打开这个插件,几秒后,一般可以看到你的网站数据。
· 如果仍然看不到它,请关闭浏览器,重新开始,或刷新页面。
三、无法显示数据的地方
这个插件操作非常简单,界面也非常友好。哪个按钮以及链接上的点击次数可以让您轻松地根据数字做出决定。
但请不要相信所有的数据,因为你看到的数字(或数字)很可能不是肤浅的认识,也可能导致你做出判断性决定,反而阻碍了网站的网站。
请务必注意,某些链接或按钮不会看到数据,但这并不意味着访问者不会点击这些地方。
1、GA数据不计算外链点击量,比如网站的分享功能,所以插件无法展示。
2、标签链接可能不算数。GA后端的数据中会有标签数据,可能是插件问题。
3、各种按钮的点击都不会被统计或显示,因为它们根本不是 URL,对吧?
4、数据统计时间跨度过大。例如,它已经被计算了好几年。可能因为点击几乎为0而无法显示。不过这种情况比较少见。
四、如何判断一个链接的效果
有时一个页面上会有多个相同的链接。比如首页链接会出现在网站的顶部logo、导航栏、底部网页中,所以要谨慎对待此类链接的数据。
比如在一个网页上,三个相同的链接点击率是3%,那能算3%*3=9%的点击率吗?不,这 3% 仅由同一链接显示。
因此,遗憾的是,我们无法知道访问者更喜欢在同一个页面和多个相同的链接上点击哪个链接。
所以如果想知道同一个链接不同位置的效果,就必须和外链一样,把GA代码单独放在链接按钮上。
概括
总的来说,这个插件还是挺方便的,它可以让我们很方便的知道某个区域内所有连接的点击率,并且根据点击率,可以增加热门链接的排序,降低排序不受欢迎的链接。,甚至直接去掉,换成更有效的链接。
一款你必须会用的 Chrome 爬虫插件
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-06-04 10:28
最近,有同学问我。
我不想写代码,如何快速爬取几个数据量不太大的网页?
这个需求,估计大家很多时候都会遇到,比如,你想爬取秒杀页面的商品信息进行对比;你想爬取国家统计局官网发布的你感兴趣的数据;等等。
既然说到这里,我就简单的介绍一下网络爬虫。网络爬虫的主要目的是爬取互联网上的网页。你可以把互联网中的每一个网页想象成一个点,那么整个互联网将是彼此连通的。是不是很像我们大学学过的图论?如果从任何一个网页出发,在时间资源允许的情况下,使用广度优先算法(BFS)或者深度优先算法(DFS)是可以爬完整个互联网的。对这两种算法不太熟悉的同学可以去背书了。
下面以比较流行的Scrapy 架构图为例,流线为数据流向。
看了这幅图,是不是对一般的爬虫有了大致的了解了。
专业的网络爬虫(比如百度/谷歌的爬虫)为了节约资源和时间,因此,设计是相当复杂的。这些爬虫一般是基于分布式集群构建的,有些机子负责调度,有些机子负责下载,有些机子专门基于网页进行分析,等等。并非简单的用 BFS/DFS 就能解决的,比如,我们以调度器为例,它就需要来管理下载优先级,当引擎发送过来 Request 请求,就需要按照优先级进行整理排列,入队,当引擎需要时,交还给引擎。
虽然关于各种语言的爬虫框架很多,要是用这些框架来爬这点数据,确实有点大材小用了,而且还得要编码调试,各种麻烦!!!
我发现 Chrome 商店里面有一款爬虫插件,刚好解决这个痛点,它的名字叫做 Web Scraper,目前有 22w 的用户下载。
官方网址:
这个爬虫操作特别简单,照着官方文档,几分钟就学会了。
我这里就说几个关键点吧。
1、启动
一般初次使用,不知道怎么打开它,用快捷键 ctrl+shift+i 打开开发者工具。
sitemaps:你所有的爬虫。
create new sitemap:创建一个新爬虫的起始地址。
2、选择器
对于一个选择器而言,就有如下几种元素,它主要作用是为爬虫分析网页的功能,提供了可视化选择的功能,如下图所示。
好了,再来细说一下,选择器内部的几个元素。
Id: 选择器的ID;
Type:要抓取内容的类型,有文本、图片以及元素集等;
Selector:选择器。点击 select 按钮可以选择我们要抓取的内容,点击 element preview 按钮可以预览选择的内容,而点击 data preview 按钮可以预览抓取的数据;
Multiple:勾选了这个按钮可以并联相同的内容;
Regex:正则表达式;
Delay:延迟。为了让页面有足够的时间加载数据;
Parent Selectors:父选择器。
有的同学可能会问,如果我要在一个页面选择多个元素,该怎么办呢?上面的提到的 Type 属性里面的 Element 就起到这个作用,如我这里。
3、关系图
我觉得这个功能特别棒,帮我们看到这个爬虫的层级关系图。
最后,就是爬取数据了,爬取后的数据还可以导出为 excel,便于你分析。
大家可以去玩一下这个爬虫插件,会帮你快速分析一些简单的数据。
就写到这里吧。
由于长期的熬夜,造成近段时间身体不适,需要好好调养。建议大家早点休息,身体是革命的本钱。
如果这篇文章对你有帮助,记得点赞或者转发一下。
---END---
近期热文:
————--^^^--————
看更多好文
请长按下方图片扫码关注
查看全部
一款你必须会用的 Chrome 爬虫插件
最近,有同学问我。
我不想写代码,如何快速爬取几个数据量不太大的网页?
这个需求,估计大家很多时候都会遇到,比如,你想爬取秒杀页面的商品信息进行对比;你想爬取国家统计局官网发布的你感兴趣的数据;等等。
既然说到这里,我就简单的介绍一下网络爬虫。网络爬虫的主要目的是爬取互联网上的网页。你可以把互联网中的每一个网页想象成一个点,那么整个互联网将是彼此连通的。是不是很像我们大学学过的图论?如果从任何一个网页出发,在时间资源允许的情况下,使用广度优先算法(BFS)或者深度优先算法(DFS)是可以爬完整个互联网的。对这两种算法不太熟悉的同学可以去背书了。
下面以比较流行的Scrapy 架构图为例,流线为数据流向。
看了这幅图,是不是对一般的爬虫有了大致的了解了。
专业的网络爬虫(比如百度/谷歌的爬虫)为了节约资源和时间,因此,设计是相当复杂的。这些爬虫一般是基于分布式集群构建的,有些机子负责调度,有些机子负责下载,有些机子专门基于网页进行分析,等等。并非简单的用 BFS/DFS 就能解决的,比如,我们以调度器为例,它就需要来管理下载优先级,当引擎发送过来 Request 请求,就需要按照优先级进行整理排列,入队,当引擎需要时,交还给引擎。
虽然关于各种语言的爬虫框架很多,要是用这些框架来爬这点数据,确实有点大材小用了,而且还得要编码调试,各种麻烦!!!
我发现 Chrome 商店里面有一款爬虫插件,刚好解决这个痛点,它的名字叫做 Web Scraper,目前有 22w 的用户下载。
官方网址:
这个爬虫操作特别简单,照着官方文档,几分钟就学会了。
我这里就说几个关键点吧。
1、启动
一般初次使用,不知道怎么打开它,用快捷键 ctrl+shift+i 打开开发者工具。
sitemaps:你所有的爬虫。
create new sitemap:创建一个新爬虫的起始地址。
2、选择器
对于一个选择器而言,就有如下几种元素,它主要作用是为爬虫分析网页的功能,提供了可视化选择的功能,如下图所示。
好了,再来细说一下,选择器内部的几个元素。
Id: 选择器的ID;
Type:要抓取内容的类型,有文本、图片以及元素集等;
Selector:选择器。点击 select 按钮可以选择我们要抓取的内容,点击 element preview 按钮可以预览选择的内容,而点击 data preview 按钮可以预览抓取的数据;
Multiple:勾选了这个按钮可以并联相同的内容;
Regex:正则表达式;
Delay:延迟。为了让页面有足够的时间加载数据;
Parent Selectors:父选择器。
有的同学可能会问,如果我要在一个页面选择多个元素,该怎么办呢?上面的提到的 Type 属性里面的 Element 就起到这个作用,如我这里。
3、关系图
我觉得这个功能特别棒,帮我们看到这个爬虫的层级关系图。
最后,就是爬取数据了,爬取后的数据还可以导出为 excel,便于你分析。
大家可以去玩一下这个爬虫插件,会帮你快速分析一些简单的数据。
就写到这里吧。
由于长期的熬夜,造成近段时间身体不适,需要好好调养。建议大家早点休息,身体是革命的本钱。
如果这篇文章对你有帮助,记得点赞或者转发一下。
---END---
近期热文:
————--^^^--————
看更多好文
请长按下方图片扫码关注
360浏览器chrome抓取网页插件的原因及解决办法!
网站优化 • 优采云 发表了文章 • 0 个评论 • 651 次浏览 • 2022-05-31 20:04
chrome抓取网页插件,我目前在用这个,自带按钮好像不太好,可以去360云找一个,图标跟chrome一模一样,图片全是一个个透明小图标,直接进网站,
markdowneditor-youcompleteme-youcompre-you-want-to-usechrome-webdevelopment,
重新编译下js,ui,配上chrome,
因为chrome自带了输入法,自动优化了很多。应该是用的第三方的一些插件。好几年前chrome确实有这种问题。
用了第三方扩展程序没有,先从技术原因入手。一般来说,在不扩展插件的情况下,插件会抓取你的脚本对输入关键字进行相应的相应的搜索和提示。比如用fiddler抓到了,然后将它转化为脚本文件。接下来很容易尝试。
可以尝试在360浏览器上禁用ie的headless
确实不能!我从chrome换到firefox实践出来了!
试试fiddler抓包
被抓的不爽还要继续用吗
把输入法改为谷歌拼音吧
改包名,重要的事情说三遍,我试过了ie改包名仍然有问题,
下载greenxml插件,把googleservices改为greenxml,
chromewebdevelopment和插件都改成greenxml再试一下
把搜索源加载掉,如果还不行的话,换本地文件源。 查看全部
360浏览器chrome抓取网页插件的原因及解决办法!
chrome抓取网页插件,我目前在用这个,自带按钮好像不太好,可以去360云找一个,图标跟chrome一模一样,图片全是一个个透明小图标,直接进网站,
markdowneditor-youcompleteme-youcompre-you-want-to-usechrome-webdevelopment,
重新编译下js,ui,配上chrome,
因为chrome自带了输入法,自动优化了很多。应该是用的第三方的一些插件。好几年前chrome确实有这种问题。
用了第三方扩展程序没有,先从技术原因入手。一般来说,在不扩展插件的情况下,插件会抓取你的脚本对输入关键字进行相应的相应的搜索和提示。比如用fiddler抓到了,然后将它转化为脚本文件。接下来很容易尝试。
可以尝试在360浏览器上禁用ie的headless
确实不能!我从chrome换到firefox实践出来了!
试试fiddler抓包
被抓的不爽还要继续用吗
把输入法改为谷歌拼音吧
改包名,重要的事情说三遍,我试过了ie改包名仍然有问题,
下载greenxml插件,把googleservices改为greenxml,
chromewebdevelopment和插件都改成greenxml再试一下
把搜索源加载掉,如果还不行的话,换本地文件源。
一款你必须会用的 Chrome 爬虫插件
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-05-31 06:56
最近,有同学问我。
我不想写代码,如何快速爬取几个数据量不太大的网页?
这个需求,估计大家很多时候都会遇到,比如,你想爬取秒杀页面的商品信息进行对比;你想爬取国家统计局官网发布的你感兴趣的数据;等等。
既然说到这里,我就简单的介绍一下网络爬虫。网络爬虫的主要目的是爬取互联网上的网页。你可以把互联网中的每一个网页想象成一个点,那么整个互联网将是彼此连通的。是不是很像我们大学学过的图论?如果从任何一个网页出发,在时间资源允许的情况下,使用广度优先算法(BFS)或者深度优先算法(DFS)是可以爬完整个互联网的。对这两种算法不太熟悉的同学可以去背书了。
下面以比较流行的Scrapy 架构图为例,流线为数据流向。
看了这幅图,是不是对一般的爬虫有了大致的了解了。
专业的网络爬虫(比如百度/谷歌的爬虫)为了节约资源和时间,因此,设计是相当复杂的。这些爬虫一般是基于分布式集群构建的,有些机子负责调度,有些机子负责下载,有些机子专门基于网页进行分析,等等。并非简单的用 BFS/DFS 就能解决的,比如,我们以调度器为例,它就需要来管理下载优先级,当引擎发送过来 Request 请求,就需要按照优先级进行整理排列,入队,当引擎需要时,交还给引擎。
虽然关于各种语言的爬虫框架很多,要是用这些框架来爬这点数据,确实有点大材小用了,而且还得要编码调试,各种麻烦!!!
我发现 Chrome 商店里面有一款爬虫插件,刚好解决这个痛点,它的名字叫做 Web Scraper,目前有 22w 的用户下载。
官方网址:
这个爬虫操作特别简单,照着官方文档,几分钟就学会了。
我这里就说几个关键点吧。
1、启动
一般初次使用,不知道怎么打开它,用快捷键 ctrl+shift+i 打开开发者工具。
sitemaps:你所有的爬虫。
create new sitemap:创建一个新爬虫的起始地址。
2、选择器
对于一个选择器而言,就有如下几种元素,它主要作用是为爬虫分析网页的功能,提供了可视化选择的功能,如下图所示。
好了,再来细说一下,选择器内部的几个元素。
Id: 选择器的ID;
Type:要抓取内容的类型,有文本、图片以及元素集等;
Selector:选择器。点击 select 按钮可以选择我们要抓取的内容,点击 element preview 按钮可以预览选择的内容,而点击 data preview 按钮可以预览抓取的数据;
Multiple:勾选了这个按钮可以并联相同的内容;
Regex:正则表达式;
Delay:延迟。为了让页面有足够的时间加载数据;
Parent Selectors:父选择器。
有的同学可能会问,如果我要在一个页面选择多个元素,该怎么办呢?上面的提到的 Type 属性里面的 Element 就起到这个作用,如我这里。
3、关系图
我觉得这个功能特别棒,帮我们看到这个爬虫的层级关系图。
最后,就是爬取数据了,爬取后的数据还可以导出为 excel,便于你分析。
大家可以去玩一下这个爬虫插件,会帮你快速分析一些简单的数据。
就写到这里吧。
由于长期的熬夜,造成近段时间身体不适,需要好好调养。建议大家早点休息,身体是革命的本钱。
如果这篇文章对你有帮助,记得点赞或者转发一下。
---END---
近期热文:
————--^^^--————
看更多好文
请长按下方图片扫码关注
查看全部
一款你必须会用的 Chrome 爬虫插件
最近,有同学问我。
我不想写代码,如何快速爬取几个数据量不太大的网页?
这个需求,估计大家很多时候都会遇到,比如,你想爬取秒杀页面的商品信息进行对比;你想爬取国家统计局官网发布的你感兴趣的数据;等等。
既然说到这里,我就简单的介绍一下网络爬虫。网络爬虫的主要目的是爬取互联网上的网页。你可以把互联网中的每一个网页想象成一个点,那么整个互联网将是彼此连通的。是不是很像我们大学学过的图论?如果从任何一个网页出发,在时间资源允许的情况下,使用广度优先算法(BFS)或者深度优先算法(DFS)是可以爬完整个互联网的。对这两种算法不太熟悉的同学可以去背书了。
下面以比较流行的Scrapy 架构图为例,流线为数据流向。
看了这幅图,是不是对一般的爬虫有了大致的了解了。
专业的网络爬虫(比如百度/谷歌的爬虫)为了节约资源和时间,因此,设计是相当复杂的。这些爬虫一般是基于分布式集群构建的,有些机子负责调度,有些机子负责下载,有些机子专门基于网页进行分析,等等。并非简单的用 BFS/DFS 就能解决的,比如,我们以调度器为例,它就需要来管理下载优先级,当引擎发送过来 Request 请求,就需要按照优先级进行整理排列,入队,当引擎需要时,交还给引擎。
虽然关于各种语言的爬虫框架很多,要是用这些框架来爬这点数据,确实有点大材小用了,而且还得要编码调试,各种麻烦!!!
我发现 Chrome 商店里面有一款爬虫插件,刚好解决这个痛点,它的名字叫做 Web Scraper,目前有 22w 的用户下载。
官方网址:
这个爬虫操作特别简单,照着官方文档,几分钟就学会了。
我这里就说几个关键点吧。
1、启动
一般初次使用,不知道怎么打开它,用快捷键 ctrl+shift+i 打开开发者工具。
sitemaps:你所有的爬虫。
create new sitemap:创建一个新爬虫的起始地址。
2、选择器
对于一个选择器而言,就有如下几种元素,它主要作用是为爬虫分析网页的功能,提供了可视化选择的功能,如下图所示。
好了,再来细说一下,选择器内部的几个元素。
Id: 选择器的ID;
Type:要抓取内容的类型,有文本、图片以及元素集等;
Selector:选择器。点击 select 按钮可以选择我们要抓取的内容,点击 element preview 按钮可以预览选择的内容,而点击 data preview 按钮可以预览抓取的数据;
Multiple:勾选了这个按钮可以并联相同的内容;
Regex:正则表达式;
Delay:延迟。为了让页面有足够的时间加载数据;
Parent Selectors:父选择器。
有的同学可能会问,如果我要在一个页面选择多个元素,该怎么办呢?上面的提到的 Type 属性里面的 Element 就起到这个作用,如我这里。
3、关系图
我觉得这个功能特别棒,帮我们看到这个爬虫的层级关系图。
最后,就是爬取数据了,爬取后的数据还可以导出为 excel,便于你分析。
大家可以去玩一下这个爬虫插件,会帮你快速分析一些简单的数据。
就写到这里吧。
由于长期的熬夜,造成近段时间身体不适,需要好好调养。建议大家早点休息,身体是革命的本钱。
如果这篇文章对你有帮助,记得点赞或者转发一下。
---END---
近期热文:
————--^^^--————
看更多好文
请长按下方图片扫码关注
一款你必须会用的 Chrome 爬虫插件
网站优化 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2022-05-28 19:09
最近,有同学问我。
我不想写代码,如何快速爬取几个数据量不太大的网页?
这个需求,估计大家很多时候都会遇到,比如,你想爬取秒杀页面的商品信息进行对比;你想爬取国家统计局官网发布的你感兴趣的数据;等等。
既然说到这里,我就简单的介绍一下网络爬虫。网络爬虫的主要目的是爬取互联网上的网页。你可以把互联网中的每一个网页想象成一个点,那么整个互联网将是彼此连通的。是不是很像我们大学学过的图论?如果从任何一个网页出发,在时间资源允许的情况下,使用广度优先算法(BFS)或者深度优先算法(DFS)是可以爬完整个互联网的。对这两种算法不太熟悉的同学可以去背书了。
下面以比较流行的Scrapy 架构图为例,流线为数据流向。
看了这幅图,是不是对一般的爬虫有了大致的了解了。
专业的网络爬虫(比如百度/谷歌的爬虫)为了节约资源和时间,因此,设计是相当复杂的。这些爬虫一般是基于分布式集群构建的,有些机子负责调度,有些机子负责下载,有些机子专门基于网页进行分析,等等。并非简单的用 BFS/DFS 就能解决的,比如,我们以调度器为例,它就需要来管理下载优先级,当引擎发送过来 Request 请求,就需要按照优先级进行整理排列,入队,当引擎需要时,交还给引擎。
虽然关于各种语言的爬虫框架很多,要是用这些框架来爬这点数据,确实有点大材小用了,而且还得要编码调试,各种麻烦!!!
我发现 Chrome 商店里面有一款爬虫插件,刚好解决这个痛点,它的名字叫做 Web Scraper,目前有 22w 的用户下载。
官方网址:
这个爬虫操作特别简单,照着官方文档,几分钟就学会了。
我这里就说几个关键点吧。
1、启动
一般初次使用,不知道怎么打开它,用快捷键 ctrl+shift+i 打开开发者工具。
sitemaps:你所有的爬虫。
create new sitemap:创建一个新爬虫的起始地址。
2、选择器
对于一个选择器而言,就有如下几种元素,它主要作用是为爬虫分析网页的功能,提供了可视化选择的功能,如下图所示。
好了,再来细说一下,选择器内部的几个元素。
Id: 选择器的ID;
Type:要抓取内容的类型,有文本、图片以及元素集等;
Selector:选择器。点击 select 按钮可以选择我们要抓取的内容,点击 element preview 按钮可以预览选择的内容,而点击 data preview 按钮可以预览抓取的数据;
Multiple:勾选了这个按钮可以并联相同的内容;
Regex:正则表达式;
Delay:延迟。为了让页面有足够的时间加载数据;
Parent Selectors:父选择器。
有的同学可能会问,如果我要在一个页面选择多个元素,该怎么办呢?上面的提到的 Type 属性里面的 Element 就起到这个作用,如我这里。
3、关系图
我觉得这个功能特别棒,帮我们看到这个爬虫的层级关系图。
最后,就是爬取数据了,爬取后的数据还可以导出为 excel,便于你分析。
大家可以去玩一下这个爬虫插件,会帮你快速分析一些简单的数据。
就写到这里吧。
由于长期的熬夜,造成近段时间身体不适,需要好好调养。建议大家早点休息,身体是革命的本钱。
如果这篇文章对你有帮助,记得点赞或者转发一下。
---END---
近期热文:
————--^^^--————
看更多好文
请长按下方图片扫码关注
查看全部
一款你必须会用的 Chrome 爬虫插件
最近,有同学问我。
我不想写代码,如何快速爬取几个数据量不太大的网页?
这个需求,估计大家很多时候都会遇到,比如,你想爬取秒杀页面的商品信息进行对比;你想爬取国家统计局官网发布的你感兴趣的数据;等等。
既然说到这里,我就简单的介绍一下网络爬虫。网络爬虫的主要目的是爬取互联网上的网页。你可以把互联网中的每一个网页想象成一个点,那么整个互联网将是彼此连通的。是不是很像我们大学学过的图论?如果从任何一个网页出发,在时间资源允许的情况下,使用广度优先算法(BFS)或者深度优先算法(DFS)是可以爬完整个互联网的。对这两种算法不太熟悉的同学可以去背书了。
下面以比较流行的Scrapy 架构图为例,流线为数据流向。
看了这幅图,是不是对一般的爬虫有了大致的了解了。
专业的网络爬虫(比如百度/谷歌的爬虫)为了节约资源和时间,因此,设计是相当复杂的。这些爬虫一般是基于分布式集群构建的,有些机子负责调度,有些机子负责下载,有些机子专门基于网页进行分析,等等。并非简单的用 BFS/DFS 就能解决的,比如,我们以调度器为例,它就需要来管理下载优先级,当引擎发送过来 Request 请求,就需要按照优先级进行整理排列,入队,当引擎需要时,交还给引擎。
虽然关于各种语言的爬虫框架很多,要是用这些框架来爬这点数据,确实有点大材小用了,而且还得要编码调试,各种麻烦!!!
我发现 Chrome 商店里面有一款爬虫插件,刚好解决这个痛点,它的名字叫做 Web Scraper,目前有 22w 的用户下载。
官方网址:
这个爬虫操作特别简单,照着官方文档,几分钟就学会了。
我这里就说几个关键点吧。
1、启动
一般初次使用,不知道怎么打开它,用快捷键 ctrl+shift+i 打开开发者工具。
sitemaps:你所有的爬虫。
create new sitemap:创建一个新爬虫的起始地址。
2、选择器
对于一个选择器而言,就有如下几种元素,它主要作用是为爬虫分析网页的功能,提供了可视化选择的功能,如下图所示。
好了,再来细说一下,选择器内部的几个元素。
Id: 选择器的ID;
Type:要抓取内容的类型,有文本、图片以及元素集等;
Selector:选择器。点击 select 按钮可以选择我们要抓取的内容,点击 element preview 按钮可以预览选择的内容,而点击 data preview 按钮可以预览抓取的数据;
Multiple:勾选了这个按钮可以并联相同的内容;
Regex:正则表达式;
Delay:延迟。为了让页面有足够的时间加载数据;
Parent Selectors:父选择器。
有的同学可能会问,如果我要在一个页面选择多个元素,该怎么办呢?上面的提到的 Type 属性里面的 Element 就起到这个作用,如我这里。
3、关系图
我觉得这个功能特别棒,帮我们看到这个爬虫的层级关系图。
最后,就是爬取数据了,爬取后的数据还可以导出为 excel,便于你分析。
大家可以去玩一下这个爬虫插件,会帮你快速分析一些简单的数据。
就写到这里吧。
由于长期的熬夜,造成近段时间身体不适,需要好好调养。建议大家早点休息,身体是革命的本钱。
如果这篇文章对你有帮助,记得点赞或者转发一下。
---END---
近期热文:
————--^^^--————
看更多好文
请长按下方图片扫码关注
一款你必须会用的 Chrome 爬虫插件
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-05-14 02:33
最近,有同学问我。
我不想写代码,如何快速爬取几个数据量不太大的网页?
这个需求,估计大家很多时候都会遇到,比如,你想爬取秒杀页面的商品信息进行对比;你想爬取国家统计局官网发布的你感兴趣的数据;等等。
既然说到这里,我就简单的介绍一下网络爬虫。网络爬虫的主要目的是爬取互联网上的网页。你可以把互联网中的每一个网页想象成一个点,那么整个互联网将是彼此连通的。是不是很像我们大学学过的图论?如果从任何一个网页出发,在时间资源允许的情况下,使用广度优先算法(BFS)或者深度优先算法(DFS)是可以爬完整个互联网的。对这两种算法不太熟悉的同学可以去背书了。
下面以比较流行的Scrapy 架构图为例,流线为数据流向。
看了这幅图,是不是对一般的爬虫有了大致的了解了。
专业的网络爬虫(比如百度/谷歌的爬虫)为了节约资源和时间,因此,设计是相当复杂的。这些爬虫一般是基于分布式集群构建的,有些机子负责调度,有些机子负责下载,有些机子专门基于网页进行分析,等等。并非简单的用 BFS/DFS 就能解决的,比如,我们以调度器为例,它就需要来管理下载优先级,当引擎发送过来 Request 请求,就需要按照优先级进行整理排列,入队,当引擎需要时,交还给引擎。
虽然关于各种语言的爬虫框架很多,要是用这些框架来爬这点数据,确实有点大材小用了,而且还得要编码调试,各种麻烦!!!
我发现 Chrome 商店里面有一款爬虫插件,刚好解决这个痛点,它的名字叫做 Web Scraper,目前有 22w 的用户下载。
官方网址:
这个爬虫操作特别简单,照着官方文档,几分钟就学会了。
我这里就说几个关键点吧。
1、启动
一般初次使用,不知道怎么打开它,用快捷键 ctrl+shift+i 打开开发者工具。
sitemaps:你所有的爬虫。
create new sitemap:创建一个新爬虫的起始地址。
2、选择器
对于一个选择器而言,就有如下几种元素,它主要作用是为爬虫分析网页的功能,提供了可视化选择的功能,如下图所示。
好了,再来细说一下,选择器内部的几个元素。
Id: 选择器的ID;
Type:要抓取内容的类型,有文本、图片以及元素集等;
Selector:选择器。点击 select 按钮可以选择我们要抓取的内容,点击 element preview 按钮可以预览选择的内容,而点击 data preview 按钮可以预览抓取的数据;
Multiple:勾选了这个按钮可以并联相同的内容;
Regex:正则表达式;
Delay:延迟。为了让页面有足够的时间加载数据;
Parent Selectors:父选择器。
有的同学可能会问,如果我要在一个页面选择多个元素,该怎么办呢?上面的提到的 Type 属性里面的 Element 就起到这个作用,如我这里。
3、关系图
我觉得这个功能特别棒,帮我们看到这个爬虫的层级关系图。
最后,就是爬取数据了,爬取后的数据还可以导出为 excel,便于你分析。
大家可以去玩一下这个爬虫插件,会帮你快速分析一些简单的数据。
就写到这里吧。
由于长期的熬夜,造成近段时间身体不适,需要好好调养。建议大家早点休息,身体是革命的本钱。
如果这篇文章对你有帮助,记得点赞或者转发一下。
---END---
近期热文:
————--^^^--————
看更多好文
请长按下方图片扫码关注
查看全部
一款你必须会用的 Chrome 爬虫插件
最近,有同学问我。
我不想写代码,如何快速爬取几个数据量不太大的网页?
这个需求,估计大家很多时候都会遇到,比如,你想爬取秒杀页面的商品信息进行对比;你想爬取国家统计局官网发布的你感兴趣的数据;等等。
既然说到这里,我就简单的介绍一下网络爬虫。网络爬虫的主要目的是爬取互联网上的网页。你可以把互联网中的每一个网页想象成一个点,那么整个互联网将是彼此连通的。是不是很像我们大学学过的图论?如果从任何一个网页出发,在时间资源允许的情况下,使用广度优先算法(BFS)或者深度优先算法(DFS)是可以爬完整个互联网的。对这两种算法不太熟悉的同学可以去背书了。
下面以比较流行的Scrapy 架构图为例,流线为数据流向。
看了这幅图,是不是对一般的爬虫有了大致的了解了。
专业的网络爬虫(比如百度/谷歌的爬虫)为了节约资源和时间,因此,设计是相当复杂的。这些爬虫一般是基于分布式集群构建的,有些机子负责调度,有些机子负责下载,有些机子专门基于网页进行分析,等等。并非简单的用 BFS/DFS 就能解决的,比如,我们以调度器为例,它就需要来管理下载优先级,当引擎发送过来 Request 请求,就需要按照优先级进行整理排列,入队,当引擎需要时,交还给引擎。
虽然关于各种语言的爬虫框架很多,要是用这些框架来爬这点数据,确实有点大材小用了,而且还得要编码调试,各种麻烦!!!
我发现 Chrome 商店里面有一款爬虫插件,刚好解决这个痛点,它的名字叫做 Web Scraper,目前有 22w 的用户下载。
官方网址:
这个爬虫操作特别简单,照着官方文档,几分钟就学会了。
我这里就说几个关键点吧。
1、启动
一般初次使用,不知道怎么打开它,用快捷键 ctrl+shift+i 打开开发者工具。
sitemaps:你所有的爬虫。
create new sitemap:创建一个新爬虫的起始地址。
2、选择器
对于一个选择器而言,就有如下几种元素,它主要作用是为爬虫分析网页的功能,提供了可视化选择的功能,如下图所示。
好了,再来细说一下,选择器内部的几个元素。
Id: 选择器的ID;
Type:要抓取内容的类型,有文本、图片以及元素集等;
Selector:选择器。点击 select 按钮可以选择我们要抓取的内容,点击 element preview 按钮可以预览选择的内容,而点击 data preview 按钮可以预览抓取的数据;
Multiple:勾选了这个按钮可以并联相同的内容;
Regex:正则表达式;
Delay:延迟。为了让页面有足够的时间加载数据;
Parent Selectors:父选择器。
有的同学可能会问,如果我要在一个页面选择多个元素,该怎么办呢?上面的提到的 Type 属性里面的 Element 就起到这个作用,如我这里。
3、关系图
我觉得这个功能特别棒,帮我们看到这个爬虫的层级关系图。
最后,就是爬取数据了,爬取后的数据还可以导出为 excel,便于你分析。
大家可以去玩一下这个爬虫插件,会帮你快速分析一些简单的数据。
就写到这里吧。
由于长期的熬夜,造成近段时间身体不适,需要好好调养。建议大家早点休息,身体是革命的本钱。
如果这篇文章对你有帮助,记得点赞或者转发一下。
---END---
近期热文:
————--^^^--————
看更多好文
请长按下方图片扫码关注
盘点:20个用于网页设计的Chrome扩展程序
网站优化 • 优采云 发表了文章 • 0 个评论 • 265 次浏览 • 2022-05-08 03:09
关
注
点击上方置顶雨果网,不错过跨境电商大小事
Chrome浏览器有很多网页设计扩展插件,可以帮助你进行网站发布、重新设计、布局整体用户体验等活动。
下文是关于谷歌Chrome应用商店的20个网页设计插件。这些插件可以帮你找到正确的字体、开发调色板、发现和创建鼓舞人心的图像、自定义图形、测量元素以及分析页面和竞争对手。
适用于Chrome网页设计的20款插件
1、Pixlr Editor是一个浏览器图片编辑器,可以完全控制图像,包括图层和效果。它包含电脑图形设计应用程序中常见的高级功能,如图层、套索工具、画笔控件、克隆和过滤器。
2、ColorZilla可以从浏览器中的任何位置读取颜色。调整颜色,然后粘贴到另一个程序。它具有CSS渐变生成器,具有七个预安装调色板查看器等。
3、Palette Creator允许你从任何图像创建调色板,以用于进一步创作。你只需右键单击图像,然后选择“Palette Creator”选项即可。
4、WhatFont是识别网页字体的有效方法。可以快速获取鼠标悬停处的文本字体信息,WhatFont还可用于检测字体提供的服务。
5、Font Changer允许你使用Google Web Fonts中的任何字体更改网站上的字体,还可以为所有网站或特定网站设置字体。
6、Evernote Web Clipper帮助你将Web上有趣的内容保存到Evernote帐户中。可用于剪辑任何网页,突出显示重要的内容、注释、截屏,并随时随地访问内容。
7、Amino是一个用于编写持久用户样式表的实时CSS编辑器。可将自定义样式保存并同步到你的谷歌帐户,从多台计算机访问。可自定义页面外观并修复渲染错误。
8、Stylebot允许你使用自定义CSS操纵任何网站的外观。选择一个元素并从编辑器中选择要进行的更改。即可改变字体、颜色、页边距、可见性等等。
9、EnjoyCSS是一个免费的在线CSS3生成器。用于快速调整丰富的图形样式,无需编码。进行二维和三维变换、复杂过渡、线性和径向渐变、文本阴影等,可访问CSS解决方案库。
10、CSS Shapes Editor是一个交互式编辑器,用于为选定的元素创建和调整CSS形状值。
11、Dimensions是一款用于测量屏幕上项目的工具,如区域边界、图像、输入字段、按钮、视频、文本和图标。有助于测量模型。
12、Eye Dropper可以从web页面、颜色选择器或颜色历史记录中选择颜色。
13、Minimalist Markdown Editor是一个简单、方便的Markdown编辑器。只需编写Markdown文本,并在键入时查看它的外观。具有一键式HTML转换、持久标签、离线功能等。
14、BuiltWith Technology Profiler是一个工具,可以让你确定网站的构建技术。在web页面上,单击build twith图标可以查看使用的所有技术。
15、Search Stackoverflow是一个论坛,提供关于许多编码的问题和答案。用户可以提问和回答问题,并编辑内容。
16、Project Naptha是一个工具,可以高突出显示、复制、编辑甚至翻译web上任何图像中的文本。可访问并处理从图像中释放出来的单词。
17、Web Developer Checklist包含有用的实践以及指向支持材料的链接。它是的附加扩展。
18、Checkbot是一个网站审核工具,可以快速地抓取数百个页面,查找与搜索引擎优化、速度和安全性相关的问题。此外,它还可免费检查每个站点250个URL。
19、Web Developer可以添加工具栏按钮和各种Web开发人员工具,这是Firefox的 web开发人员扩展的一部分。
20、StayFocusd通过限制在特定网站上花费的时间来提高你的工作效率。一旦指定的时间用完,你将无法访问所限制的网站。
◎文/雨果网 吕晓琳
雨果网致力为卖家提供优质干货
▼扫码免费领取各平台干货包▼
把时间交给阅读
查看全部
盘点:20个用于网页设计的Chrome扩展程序
关
注
点击上方置顶雨果网,不错过跨境电商大小事
Chrome浏览器有很多网页设计扩展插件,可以帮助你进行网站发布、重新设计、布局整体用户体验等活动。
下文是关于谷歌Chrome应用商店的20个网页设计插件。这些插件可以帮你找到正确的字体、开发调色板、发现和创建鼓舞人心的图像、自定义图形、测量元素以及分析页面和竞争对手。
适用于Chrome网页设计的20款插件
1、Pixlr Editor是一个浏览器图片编辑器,可以完全控制图像,包括图层和效果。它包含电脑图形设计应用程序中常见的高级功能,如图层、套索工具、画笔控件、克隆和过滤器。
2、ColorZilla可以从浏览器中的任何位置读取颜色。调整颜色,然后粘贴到另一个程序。它具有CSS渐变生成器,具有七个预安装调色板查看器等。
3、Palette Creator允许你从任何图像创建调色板,以用于进一步创作。你只需右键单击图像,然后选择“Palette Creator”选项即可。
4、WhatFont是识别网页字体的有效方法。可以快速获取鼠标悬停处的文本字体信息,WhatFont还可用于检测字体提供的服务。
5、Font Changer允许你使用Google Web Fonts中的任何字体更改网站上的字体,还可以为所有网站或特定网站设置字体。
6、Evernote Web Clipper帮助你将Web上有趣的内容保存到Evernote帐户中。可用于剪辑任何网页,突出显示重要的内容、注释、截屏,并随时随地访问内容。
7、Amino是一个用于编写持久用户样式表的实时CSS编辑器。可将自定义样式保存并同步到你的谷歌帐户,从多台计算机访问。可自定义页面外观并修复渲染错误。
8、Stylebot允许你使用自定义CSS操纵任何网站的外观。选择一个元素并从编辑器中选择要进行的更改。即可改变字体、颜色、页边距、可见性等等。
9、EnjoyCSS是一个免费的在线CSS3生成器。用于快速调整丰富的图形样式,无需编码。进行二维和三维变换、复杂过渡、线性和径向渐变、文本阴影等,可访问CSS解决方案库。
10、CSS Shapes Editor是一个交互式编辑器,用于为选定的元素创建和调整CSS形状值。
11、Dimensions是一款用于测量屏幕上项目的工具,如区域边界、图像、输入字段、按钮、视频、文本和图标。有助于测量模型。
12、Eye Dropper可以从web页面、颜色选择器或颜色历史记录中选择颜色。
13、Minimalist Markdown Editor是一个简单、方便的Markdown编辑器。只需编写Markdown文本,并在键入时查看它的外观。具有一键式HTML转换、持久标签、离线功能等。
14、BuiltWith Technology Profiler是一个工具,可以让你确定网站的构建技术。在web页面上,单击build twith图标可以查看使用的所有技术。
15、Search Stackoverflow是一个论坛,提供关于许多编码的问题和答案。用户可以提问和回答问题,并编辑内容。
16、Project Naptha是一个工具,可以高突出显示、复制、编辑甚至翻译web上任何图像中的文本。可访问并处理从图像中释放出来的单词。
17、Web Developer Checklist包含有用的实践以及指向支持材料的链接。它是的附加扩展。
18、Checkbot是一个网站审核工具,可以快速地抓取数百个页面,查找与搜索引擎优化、速度和安全性相关的问题。此外,它还可免费检查每个站点250个URL。
19、Web Developer可以添加工具栏按钮和各种Web开发人员工具,这是Firefox的 web开发人员扩展的一部分。
20、StayFocusd通过限制在特定网站上花费的时间来提高你的工作效率。一旦指定的时间用完,你将无法访问所限制的网站。
◎文/雨果网 吕晓琳
雨果网致力为卖家提供优质干货
▼扫码免费领取各平台干货包▼
把时间交给阅读
有大佬通过研发这款Chrome插件的使用教程,赚了上百万!
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-05-06 04:13
最近,有同学告诉我说,D哥我发现有大佬开发 Chrome 商店里的一款爬虫教程,竟然卖了几千份,每份售价299,为啥有这么多人买呢?
我的原话是,别人的目标群体不是你(程序员),而是不会写代码的人,所以,这钱该别人赚。
毕竟不会写代码的人占了绝大多数,但他们又有如下的痛点:
我不会写代码,但想快速爬取几个数据量不太大的网页,做一下调研分析,该怎么办?
这个需求,估计大家很多时候都会遇到,比如,我想爬取秒杀页面的商品信息进行对比;我想爬取国家统计局官网发布的你感兴趣的数据;等等。
既然说到这里,我就简单的介绍一下网络爬虫。网络爬虫的主要目的是爬取互联网上的网页。你可以把互联网中的每一个网页想象成一个点,那么整个互联网将是彼此连通的。是不是很像我们大学学过的图论?如果从任何一个网页出发,在时间资源允许的情况下,使用广度优先算法(BFS)或者深度优先算法(DFS)是可以爬完整个互联网的。对这两种算法不太熟悉的同学可以去背书了。
下面以比较流行的 Scrapy 架构图为例,流线为数据流向。
看了这幅图,是不是对一般的爬虫有了大致的了解了。
专业的网络爬虫(比如百度/谷歌的爬虫)为了节约资源和时间,因此,设计是相当复杂的。这些爬虫一般是基于分布式集群构建的,有些机子负责调度,有些机子负责下载,有些机子专门基于网页进行分析,等等。并非简单的用 BFS/DFS 就能解决的,比如,我们以调度器为例,它就需要来管理下载优先级,当引擎发送过来 Request 请求,就需要按照优先级进行整理排列,入队,当引擎需要时,交还给引擎。
虽然关于各种语言的爬虫框架很多,要是用这些框架来爬这点数据,确实有点大材小用了,而且还得要编码调试,各种麻烦!!!
那我们就来介绍一下 Chrome 商店里面这一款爬虫插件,刚好解决这个痛点,它的名字叫做 Web Scraper,目前有 22w 的用户下载。
官方网址:
这个爬虫操作特别简单,照着官方文档,几分钟就学会了。
我这里就说几个关键点吧。
1、启动
一般初次使用,不知道怎么打开它,用快捷键 ctrl+shift+i 打开开发者工具。
sitemaps:你所有的爬虫。
create new sitemap:创建一个新爬虫的起始地址。
2、选择器
对于一个选择器而言,就有如下几种元素,它主要作用是为爬虫分析网页的功能,提供了可视化选择的功能,如下图所示。
好了,再来细说一下,选择器内部的几个元素。
Id: 选择器的ID;
Type:要抓取内容的类型,有文本、图片以及元素集等;
Selector:选择器。点击 select 按钮可以选择我们要抓取的内容,点击 element preview 按钮可以预览选择的内容,而点击 data preview 按钮可以预览抓取的数据;
Multiple:勾选了这个按钮可以并联相同的内容;
Regex:正则表达式;
Delay:延迟。为了让页面有足够的时间加载数据;
Parent Selectors:父选择器。
有的同学可能会问,如果我要在一个页面选择多个元素,该怎么办呢?上面的提到的 Type 属性里面的 Element 就起到这个作用,如我这里。
3、关系图
我觉得这个功能特别棒,帮我们看到这个爬虫的层级关系图。
最后,就是爬取数据了,爬取后的数据还可以导出为 excel,便于你分析。
大家可以去玩一下这个爬虫插件,会帮你快速分析一些简单的数据。
就写到这里吧。
特别推荐一个分享架构+算法的优质内容,还没关注的小伙伴,可以长按关注一下:
<p style="font-family: -apple-system-font, system-ui, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;white-space: normal;text-align: center;">
</p>
<p style="font-family: -apple-system-font, system-ui, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;white-space: normal;text-align: center;">长按订阅更多精彩▼
如有收获,点个在看,诚挚感谢</p> 查看全部
有大佬通过研发这款Chrome插件的使用教程,赚了上百万!
最近,有同学告诉我说,D哥我发现有大佬开发 Chrome 商店里的一款爬虫教程,竟然卖了几千份,每份售价299,为啥有这么多人买呢?
我的原话是,别人的目标群体不是你(程序员),而是不会写代码的人,所以,这钱该别人赚。
毕竟不会写代码的人占了绝大多数,但他们又有如下的痛点:
我不会写代码,但想快速爬取几个数据量不太大的网页,做一下调研分析,该怎么办?
这个需求,估计大家很多时候都会遇到,比如,我想爬取秒杀页面的商品信息进行对比;我想爬取国家统计局官网发布的你感兴趣的数据;等等。
既然说到这里,我就简单的介绍一下网络爬虫。网络爬虫的主要目的是爬取互联网上的网页。你可以把互联网中的每一个网页想象成一个点,那么整个互联网将是彼此连通的。是不是很像我们大学学过的图论?如果从任何一个网页出发,在时间资源允许的情况下,使用广度优先算法(BFS)或者深度优先算法(DFS)是可以爬完整个互联网的。对这两种算法不太熟悉的同学可以去背书了。
下面以比较流行的 Scrapy 架构图为例,流线为数据流向。
看了这幅图,是不是对一般的爬虫有了大致的了解了。
专业的网络爬虫(比如百度/谷歌的爬虫)为了节约资源和时间,因此,设计是相当复杂的。这些爬虫一般是基于分布式集群构建的,有些机子负责调度,有些机子负责下载,有些机子专门基于网页进行分析,等等。并非简单的用 BFS/DFS 就能解决的,比如,我们以调度器为例,它就需要来管理下载优先级,当引擎发送过来 Request 请求,就需要按照优先级进行整理排列,入队,当引擎需要时,交还给引擎。
虽然关于各种语言的爬虫框架很多,要是用这些框架来爬这点数据,确实有点大材小用了,而且还得要编码调试,各种麻烦!!!
那我们就来介绍一下 Chrome 商店里面这一款爬虫插件,刚好解决这个痛点,它的名字叫做 Web Scraper,目前有 22w 的用户下载。
官方网址:
这个爬虫操作特别简单,照着官方文档,几分钟就学会了。
我这里就说几个关键点吧。
1、启动
一般初次使用,不知道怎么打开它,用快捷键 ctrl+shift+i 打开开发者工具。
sitemaps:你所有的爬虫。
create new sitemap:创建一个新爬虫的起始地址。
2、选择器
对于一个选择器而言,就有如下几种元素,它主要作用是为爬虫分析网页的功能,提供了可视化选择的功能,如下图所示。
好了,再来细说一下,选择器内部的几个元素。
Id: 选择器的ID;
Type:要抓取内容的类型,有文本、图片以及元素集等;
Selector:选择器。点击 select 按钮可以选择我们要抓取的内容,点击 element preview 按钮可以预览选择的内容,而点击 data preview 按钮可以预览抓取的数据;
Multiple:勾选了这个按钮可以并联相同的内容;
Regex:正则表达式;
Delay:延迟。为了让页面有足够的时间加载数据;
Parent Selectors:父选择器。
有的同学可能会问,如果我要在一个页面选择多个元素,该怎么办呢?上面的提到的 Type 属性里面的 Element 就起到这个作用,如我这里。
3、关系图
我觉得这个功能特别棒,帮我们看到这个爬虫的层级关系图。
最后,就是爬取数据了,爬取后的数据还可以导出为 excel,便于你分析。
大家可以去玩一下这个爬虫插件,会帮你快速分析一些简单的数据。
就写到这里吧。
特别推荐一个分享架构+算法的优质内容,还没关注的小伙伴,可以长按关注一下:
<p style="font-family: -apple-system-font, system-ui, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;white-space: normal;text-align: center;">
<p style="font-family: -apple-system-font, system-ui, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;white-space: normal;text-align: center;">长按订阅更多精彩▼
如有收获,点个在看,诚挚感谢</p>
3个字母,抓取4943条数据,超实用的XPath爬虫工具教学!
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-05-02 11:00
当你想要快速批量采集某个网站的内容时,首先想到的会是什么?
有的朋友可能会想到爬虫工具,但大部分人基本也只是听过,没用过。如果要用的话,会不会很复杂?要不要学习什么技术?
今天就给大家分享一个实用的网页内容批量采集工具XPath,不需要复杂的准备工作,就能快速上手,尤其适用于轻量化的网页内容抓取。
掌握了XPath的用法之后,只需3个字母,就可以抓取4943条数据。接下来,我以一个真实的网页内容抓取需求为例,详细讲解XPath的用法。
假设你正在开展一项研究,需要收集餐饮连锁品牌的名单,这时候找到一个网站:
网站上有数十个餐饮连锁的名单,如果是一个个复制粘贴,50个就需要来回操作上百次,倘若还要搜集其他的名单,这一天下来不仅效率极低,手估计也要废了。
如何能够一键抓取这些品牌的名单呢?这时候XPath就帮大忙啦。
一、准备工作
在正式开始之前我们需要先做好准备工作,这里列出了所有的准备清单。
1、安装Chrome(谷歌)浏览器
2、安装XPath Helper插件方法一:(有梯子可以直接前往chrome应用商店下载,避免安装出错)
方法二:没梯子可下载安装包,可能有的浏览器版本不适配,文末有安装包获取方法
3、抓取的目标网站
4、没接触过XPath的朋友, 可前往此处学习详细的使用教程
所有的案例资料和插件工具,我都打包整理好了,加微信yesaze (备注XPath)即可领取。
二、安装XPath Helper插件
1、打开Chrome浏览器,点击右上角“ ”按钮,选择“更多工具”-> “扩展程序”
2、打开右上角“开发者模式”,点击“加载已压缩的扩展程序”,选择已解压的XPath helper 插件文件夹(XPath helper插件只能在谷歌浏览器中使用)
3、当扩展程序中出现XPath helper时,就代表安装成功了
4、在Macbook上按shift+command+X键,可以快速唤起和隐藏XPath Helper(Windows的快捷键是Ctrl+Shift+X)
三、抓取网页内容
1、什么是XPath?XPath 是一门在 XML 文档中查找信息的语言。而XML是一种结构化的编程语言,如果不理解也没关系。
你只需要知道,我们所看到的的网页,其实是由有规律、有结构的代码组成,我们所要提取的内容,就在这些结构化的代码里面。
XPath可以帮助我们根据网页的结构路径,灵活编写爬虫脚本,定位到我们需要的内容,从而进行抓取。
打开前面案例中的链接: 我们看到的是排布整齐的图文,当我们点击鼠标右键→检查,可以看到页面的内容都是有固定结构的,一级一级向下展开。
XPath 使用路径表达式在 XML 文档中选取节点。如果我们需要提取餐饮品牌的名称,只需要编写对应的路径即可。
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。
KFC肯德基</a>
以上代码是从网站中截取的XML代码,为了便于讲解,做了精简处理。其中文档节点、元素节点、属性节点例子如下:
(文档节点)<a target="_blank">KFC肯德基</a>(元素节点)target="_blank" (属性节点)
在这个案例中,我们可以看到,li里面包含了div,它们统称为节点,li是父节点,div是子节点。依此类推div里面又包含了a,它们又构成父子节点关系。
其中info、_blank等值,没有父或子节点,称之为基本知识,就是最基础的元素。
2、如何编写爬虫路径?理解了节点的概念,我们只需要编写一个路径,从大到小,逐级定位到我们需要的内容节点即可。那要如何编写路径呢?
我们用双斜杠//表示从匹配选择的当前节点选择文档中的节点,而不考虑它们相对位置。如//li,表示选取所有li子元素,而不管它们在文档中的位置。
形如 //li//div//a/text()表示定位到所有li下的所有div,所有div下的所有a,并提取其中的文本内容,(text()表示提取文本内容)
此时我们将语句输入XPath helper,发现有很多空的内容也被抓取了。先别着急,完整的语句应该是://li//div[@class="info"]/a/text()
与前面的语句相比,其中多了一个[@class="info"],这个的意思是选取所有 div 元素,且这些元素拥有值为 info 的 class 属性。这样定位就更精准了。
最后我们只需要全选复制结果即可,通过短短几个语句就能快速采集网页内容。
对于没有接触过XPath的朋友,可能有点晦涩难懂,建议还是详细阅读一下学习教程,半个小时就能掌握语句的含义和用法,能为以后采集内容省去不少时间。
四、补充案例如果说刚才的案例不太好理解,那我们再来看一个简单的案例,如何用3个字母抓取4943条数据?
在网站中,详细罗列了不同的行业类别及子类目,只需要通过//li/a这简短的语句,就能把所有类目抓取下来。
//li/a表示定位到所有li下的a,这个网页结构比较简单,只要能快速识别结构,就能轻松写出路径。
同理如果我们只需要抓取左侧的品牌大类,只需写出相应的路径即可//div[@id="leftcatlist"]/a,表示定位到包含id="leftcatlist"属性的div下的所有a,21个品牌大类的数据就轻松完成采集了。
以上就是XPth案例教学的全部内容,其中只用到了一部分XPath的能力,还有更多功能等待你去探索。想要系统学习推荐前往了解详情,有完整免费的教程内容。
工具就是熟能生巧,长时间不用就容易遗忘,所以想要熟练掌握一是要勤加练习和使用。书到用时方恨少,事到经过才知难。
如果觉得有帮助建议收藏备用,反复阅读。如有任何疑问,也可随时与我交流。领取XPah helper插件安装包及学习资料,请加微信yesaze (备注XPath)
查看全部
3个字母,抓取4943条数据,超实用的XPath爬虫工具教学!
当你想要快速批量采集某个网站的内容时,首先想到的会是什么?
有的朋友可能会想到爬虫工具,但大部分人基本也只是听过,没用过。如果要用的话,会不会很复杂?要不要学习什么技术?
今天就给大家分享一个实用的网页内容批量采集工具XPath,不需要复杂的准备工作,就能快速上手,尤其适用于轻量化的网页内容抓取。
掌握了XPath的用法之后,只需3个字母,就可以抓取4943条数据。接下来,我以一个真实的网页内容抓取需求为例,详细讲解XPath的用法。
假设你正在开展一项研究,需要收集餐饮连锁品牌的名单,这时候找到一个网站:
网站上有数十个餐饮连锁的名单,如果是一个个复制粘贴,50个就需要来回操作上百次,倘若还要搜集其他的名单,这一天下来不仅效率极低,手估计也要废了。
如何能够一键抓取这些品牌的名单呢?这时候XPath就帮大忙啦。
一、准备工作
在正式开始之前我们需要先做好准备工作,这里列出了所有的准备清单。
1、安装Chrome(谷歌)浏览器
2、安装XPath Helper插件方法一:(有梯子可以直接前往chrome应用商店下载,避免安装出错)
方法二:没梯子可下载安装包,可能有的浏览器版本不适配,文末有安装包获取方法
3、抓取的目标网站
4、没接触过XPath的朋友, 可前往此处学习详细的使用教程
所有的案例资料和插件工具,我都打包整理好了,加微信yesaze (备注XPath)即可领取。
二、安装XPath Helper插件
1、打开Chrome浏览器,点击右上角“ ”按钮,选择“更多工具”-> “扩展程序”
2、打开右上角“开发者模式”,点击“加载已压缩的扩展程序”,选择已解压的XPath helper 插件文件夹(XPath helper插件只能在谷歌浏览器中使用)
3、当扩展程序中出现XPath helper时,就代表安装成功了
4、在Macbook上按shift+command+X键,可以快速唤起和隐藏XPath Helper(Windows的快捷键是Ctrl+Shift+X)
三、抓取网页内容
1、什么是XPath?XPath 是一门在 XML 文档中查找信息的语言。而XML是一种结构化的编程语言,如果不理解也没关系。
你只需要知道,我们所看到的的网页,其实是由有规律、有结构的代码组成,我们所要提取的内容,就在这些结构化的代码里面。
XPath可以帮助我们根据网页的结构路径,灵活编写爬虫脚本,定位到我们需要的内容,从而进行抓取。
打开前面案例中的链接: 我们看到的是排布整齐的图文,当我们点击鼠标右键→检查,可以看到页面的内容都是有固定结构的,一级一级向下展开。
XPath 使用路径表达式在 XML 文档中选取节点。如果我们需要提取餐饮品牌的名称,只需要编写对应的路径即可。
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。
KFC肯德基</a>
以上代码是从网站中截取的XML代码,为了便于讲解,做了精简处理。其中文档节点、元素节点、属性节点例子如下:
(文档节点)<a target="_blank">KFC肯德基</a>(元素节点)target="_blank" (属性节点)
在这个案例中,我们可以看到,li里面包含了div,它们统称为节点,li是父节点,div是子节点。依此类推div里面又包含了a,它们又构成父子节点关系。
其中info、_blank等值,没有父或子节点,称之为基本知识,就是最基础的元素。
2、如何编写爬虫路径?理解了节点的概念,我们只需要编写一个路径,从大到小,逐级定位到我们需要的内容节点即可。那要如何编写路径呢?
我们用双斜杠//表示从匹配选择的当前节点选择文档中的节点,而不考虑它们相对位置。如//li,表示选取所有li子元素,而不管它们在文档中的位置。
形如 //li//div//a/text()表示定位到所有li下的所有div,所有div下的所有a,并提取其中的文本内容,(text()表示提取文本内容)
此时我们将语句输入XPath helper,发现有很多空的内容也被抓取了。先别着急,完整的语句应该是://li//div[@class="info"]/a/text()
与前面的语句相比,其中多了一个[@class="info"],这个的意思是选取所有 div 元素,且这些元素拥有值为 info 的 class 属性。这样定位就更精准了。
最后我们只需要全选复制结果即可,通过短短几个语句就能快速采集网页内容。
对于没有接触过XPath的朋友,可能有点晦涩难懂,建议还是详细阅读一下学习教程,半个小时就能掌握语句的含义和用法,能为以后采集内容省去不少时间。
四、补充案例如果说刚才的案例不太好理解,那我们再来看一个简单的案例,如何用3个字母抓取4943条数据?
在网站中,详细罗列了不同的行业类别及子类目,只需要通过//li/a这简短的语句,就能把所有类目抓取下来。
//li/a表示定位到所有li下的a,这个网页结构比较简单,只要能快速识别结构,就能轻松写出路径。
同理如果我们只需要抓取左侧的品牌大类,只需写出相应的路径即可//div[@id="leftcatlist"]/a,表示定位到包含id="leftcatlist"属性的div下的所有a,21个品牌大类的数据就轻松完成采集了。
以上就是XPth案例教学的全部内容,其中只用到了一部分XPath的能力,还有更多功能等待你去探索。想要系统学习推荐前往了解详情,有完整免费的教程内容。
工具就是熟能生巧,长时间不用就容易遗忘,所以想要熟练掌握一是要勤加练习和使用。书到用时方恨少,事到经过才知难。
如果觉得有帮助建议收藏备用,反复阅读。如有任何疑问,也可随时与我交流。领取XPah helper插件安装包及学习资料,请加微信yesaze (备注XPath)
chrome抓取网页插件( PageAnalytics可以从GoogleAnalytics中读取到你的网站数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-04-20 05:17
PageAnalytics可以从GoogleAnalytics中读取到你的网站数据)
Page Analytics 是 Chrome 浏览器上的一个插件。它可以从 Google Analytics 读取您的 网站 数据,并直接在网页周围的链接上显示点击数据。根据这个数据,你可以很容易判断网站的布局是否需要优化。
一、安装教学
安装地址:Chrome Store
打开后点击添加到Chrome(仅支持Chrome浏览器)完成插件安装。
安装完成后,可以在浏览器插件中看到Page Analytics的图标,默认是OFF(关闭),点击就会开启(打开),然后点击下方彩色图标,立即叠加在网站上,通过色块,可以第一时间知道整个网站是如何被用户点击的,哪些区域比较热门。
二、无法捕获数据
这个插件有时候捕获GA数据失败,出现如下错误信息——
大致说明如何做到这一点:
·本插件的原理是加载网站的GA数据。而且我们只能看到自己账号的GA数据,所以用这个插件是看不到别人的数据的网站。
·请先确认您是否已登录GA账号。您可以先尝试登录GA官网。
·确认登录账号后,打开这个插件,几秒后,一般就可以看到你的网站数据了。
·如果还是看不到,请关闭浏览器,重新开始,或刷新页面。
三、无法显示数据的地方
这个插件操作非常简单,界面非常友好。点击哪个按钮和多少个链接,您可以根据数字轻松做出决定。
但请不要相信所有的数据,因为你看到的数字(或数字)可能不是肤浅的认识,也可能导致你做出判断性的决定,反而阻碍了网站的网站.
请务必注意,某些链接或按钮不会看到数据,但这并不意味着访问者不会点击这些地方。
1、GA数据不计入外部链接的点击,比如网站的分享功能,所以插件无法展示。
2、标签链接可能不算数。 GA后端的数据中会有tag数据,可能是插件问题。
3、各种按钮的点击也不会被统计或显示,因为它们根本不是 URL,对吧?
4、数据统计时间跨度过大。例如,它已经被计算了好几年。可能因为点击接近0而无法显示,但是这种情况比较少见。
四、如何判断一个链接的效果
有时一个页面上会有多个相同的链接。比如首页链接会出现在网站的顶部logo、导航栏、底部网页,所以要谨慎对待此类链接的数据。
例如,在一个网页上,三个相同的链接显示了 3% 的点击率,是否可以认为是 3%*3=9% 的点击率?不,这 3% 只显示在同一个链接中。
因此非常遗憾的是,我们无法知道访问者更喜欢在同一页面和多个相同链接上点击哪个链接。
所以如果你想知道同一个链接不同位置的效果,就必须像外链处理方法一样,把GA代码单独放在链接按钮处。
总结
总的来说,这个插件还是挺方便的,它可以让我们很方便的知道某个区域内所有连接的点击率,并且根据点击率的多少,可以提升热门链接的排序和不受欢迎的链接。然后降低他的排名位置,甚至直接去掉,换成更有效的链接。 查看全部
chrome抓取网页插件(
PageAnalytics可以从GoogleAnalytics中读取到你的网站数据)
Page Analytics 是 Chrome 浏览器上的一个插件。它可以从 Google Analytics 读取您的 网站 数据,并直接在网页周围的链接上显示点击数据。根据这个数据,你可以很容易判断网站的布局是否需要优化。
一、安装教学
安装地址:Chrome Store
打开后点击添加到Chrome(仅支持Chrome浏览器)完成插件安装。
安装完成后,可以在浏览器插件中看到Page Analytics的图标,默认是OFF(关闭),点击就会开启(打开),然后点击下方彩色图标,立即叠加在网站上,通过色块,可以第一时间知道整个网站是如何被用户点击的,哪些区域比较热门。
二、无法捕获数据
这个插件有时候捕获GA数据失败,出现如下错误信息——
大致说明如何做到这一点:
·本插件的原理是加载网站的GA数据。而且我们只能看到自己账号的GA数据,所以用这个插件是看不到别人的数据的网站。
·请先确认您是否已登录GA账号。您可以先尝试登录GA官网。
·确认登录账号后,打开这个插件,几秒后,一般就可以看到你的网站数据了。
·如果还是看不到,请关闭浏览器,重新开始,或刷新页面。
三、无法显示数据的地方
这个插件操作非常简单,界面非常友好。点击哪个按钮和多少个链接,您可以根据数字轻松做出决定。
但请不要相信所有的数据,因为你看到的数字(或数字)可能不是肤浅的认识,也可能导致你做出判断性的决定,反而阻碍了网站的网站.
请务必注意,某些链接或按钮不会看到数据,但这并不意味着访问者不会点击这些地方。
1、GA数据不计入外部链接的点击,比如网站的分享功能,所以插件无法展示。
2、标签链接可能不算数。 GA后端的数据中会有tag数据,可能是插件问题。
3、各种按钮的点击也不会被统计或显示,因为它们根本不是 URL,对吧?
4、数据统计时间跨度过大。例如,它已经被计算了好几年。可能因为点击接近0而无法显示,但是这种情况比较少见。
四、如何判断一个链接的效果
有时一个页面上会有多个相同的链接。比如首页链接会出现在网站的顶部logo、导航栏、底部网页,所以要谨慎对待此类链接的数据。
例如,在一个网页上,三个相同的链接显示了 3% 的点击率,是否可以认为是 3%*3=9% 的点击率?不,这 3% 只显示在同一个链接中。
因此非常遗憾的是,我们无法知道访问者更喜欢在同一页面和多个相同链接上点击哪个链接。
所以如果你想知道同一个链接不同位置的效果,就必须像外链处理方法一样,把GA代码单独放在链接按钮处。
总结
总的来说,这个插件还是挺方便的,它可以让我们很方便的知道某个区域内所有连接的点击率,并且根据点击率的多少,可以提升热门链接的排序和不受欢迎的链接。然后降低他的排名位置,甚至直接去掉,换成更有效的链接。
chrome抓取网页插件( 什么是用户脚本?开发背景(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-04-19 10:07
什么是用户脚本?开发背景(一)(组图))
Tampermonkey 开发背景
Web 开发人员通常有专业的情节。在浏览网页时,他们总是要评估网页的设计和开发,甚至想修改网页的样式。最初最常用的工具是chrome浏览器自带的开发者工具,用来修改网页的CSS,但并不是所有的网页都可以这样修改。于是为了满足这样的开发需求,chrome插件Tampermonkey诞生了。使用 Tampermonkey,开发者可以导入自己的脚本模板来更改网页的 CSS 和 JS,让整个网页发生很大的变化。什么是用户脚本?用户脚本旨在增加用户对 Web 浏览体验的控制。安装后,用户脚本可以自动为 网站 用户访问添加功能,或者使它们更易于使用和更新。
Tampermonkey 简介
Tampermonkey 被称为油猴。Greasemonkey 插件最初是在 Firefox 上以 Greasemonkey 的名义发布的。后来 Chrome 上一个类似的插件是 Tampermonkey,他们使用的脚本很常见。Tampermonkey 适用于基于 Blink 和 WebKit 的浏览器,例如 Chrome、Microsoft、Edge、Safari、Next 和 Firefox。而且理论上也可以安装其他带有chrome内核的浏览器。不同浏览器对应的插件名称分别是UC浏览器的Violentmonkey(暴力猴子)、Firefox浏览器的Greasemonkey(油猴)、Google浏览器的Tampermonkey(篡改猴子)!很简单,说白了,其实就是一个插件管理器,用来管理别人写的插件。今天我们将介绍用户脚本管理器 Tampermonkey。
Tampermonkey 是一个免费的浏览器扩展程序,也是 Chrome、Microsoft Edge、Safari、Opera Next 和 Firefox 最流行的用户脚本管理器。
虽然一些受支持的浏览器具有原生用户脚本支持,但 Tampermonkey 将为您的用户脚本管理提供更多便利。它提供了简单的脚本安装、自动更新检查、选项卡中脚本运行状况的快速快照、内置编辑器以及 Tampermonkey 运行其他不兼容脚本的可能性等功能。
如何使用 Tampermonkey
1.在 Google Chrome 中安装 Tampermonkey 插件并在 Chrome 的扩展程序中启用 Tampermonkey 功能。具体安装方法请参考:如何在谷歌浏览器中安装扩展名为.crx的离线Chrome插件?
安装完成后,可以在浏览器右上角看到tampermonkey的按钮标记。如下所示
2.安装 Tampermonkey 插件后,我们就可以轻松设置了。Tampermonkey的设置分为3个等级,分别是新手、中级和高级。如果你对代码编程一窍不通,那就选新手吧!这些默认设置基本可以满足你的要求。如果您对电脑、软件操作等非常熟悉,可以选择初学者设置模式,可以设置更多的选项。当然,如果你是 JavaScript 大神,可以使用高级模式进行设置。
3.Tampermonkey 插件设置页面。
关键是,Tampermonkey 的厉害之处在哪里?
Tampermonkey 有一个内置的增强版脚本管理器。如果你精通javascript或其他编程语言,可以尝试定制一些适合你的插件。打开内置脚本管理器,如下图:
Tampermonkey 有哪些用户脚本源?
:一直是常用的用户脚本来源,现在这个网站不再更新了;
GreeasyFork:可能是最受欢迎的后起之秀。它由 Jason Barnabe 创建,他也是 Stylish 网站 的创建者,并且在其存储库中拥有大量脚本资源。
OpenUserJS:在 GreeasyFork 之后开始。它由 Sizzle McTwizzle 创建,并且在其存储库中同样拥有大量脚本资源。
GitHub/Gist:越来越多的开发者将源码放在GitHub上,用户可以直接搜索。
Tampermonkey 注释
1.IE 目前不支持 Tampermonkey 插件。
2.Tampermonkey插件提供了自动同步,但前提是你需要打开初学者设置模式,然后找到TESLA选项,勾选启用选项前面的框。如下所示
相关:百度网盘助手Chrome插件下载
油猴脚本扩展 Tampermonkey 下载地址点击下载
油猴脚本扩展Tampermonkey的详细使用教程,点击下方查看:
Tampermonkey 油猴脚本教程(图文解说)
本文标题:油猴脚本扩展 Tampermonkey 下载:最受欢迎的用户脚本管理器 查看全部
chrome抓取网页插件(
什么是用户脚本?开发背景(一)(组图))
Tampermonkey 开发背景
Web 开发人员通常有专业的情节。在浏览网页时,他们总是要评估网页的设计和开发,甚至想修改网页的样式。最初最常用的工具是chrome浏览器自带的开发者工具,用来修改网页的CSS,但并不是所有的网页都可以这样修改。于是为了满足这样的开发需求,chrome插件Tampermonkey诞生了。使用 Tampermonkey,开发者可以导入自己的脚本模板来更改网页的 CSS 和 JS,让整个网页发生很大的变化。什么是用户脚本?用户脚本旨在增加用户对 Web 浏览体验的控制。安装后,用户脚本可以自动为 网站 用户访问添加功能,或者使它们更易于使用和更新。
Tampermonkey 简介
Tampermonkey 被称为油猴。Greasemonkey 插件最初是在 Firefox 上以 Greasemonkey 的名义发布的。后来 Chrome 上一个类似的插件是 Tampermonkey,他们使用的脚本很常见。Tampermonkey 适用于基于 Blink 和 WebKit 的浏览器,例如 Chrome、Microsoft、Edge、Safari、Next 和 Firefox。而且理论上也可以安装其他带有chrome内核的浏览器。不同浏览器对应的插件名称分别是UC浏览器的Violentmonkey(暴力猴子)、Firefox浏览器的Greasemonkey(油猴)、Google浏览器的Tampermonkey(篡改猴子)!很简单,说白了,其实就是一个插件管理器,用来管理别人写的插件。今天我们将介绍用户脚本管理器 Tampermonkey。
Tampermonkey 是一个免费的浏览器扩展程序,也是 Chrome、Microsoft Edge、Safari、Opera Next 和 Firefox 最流行的用户脚本管理器。
虽然一些受支持的浏览器具有原生用户脚本支持,但 Tampermonkey 将为您的用户脚本管理提供更多便利。它提供了简单的脚本安装、自动更新检查、选项卡中脚本运行状况的快速快照、内置编辑器以及 Tampermonkey 运行其他不兼容脚本的可能性等功能。
如何使用 Tampermonkey
1.在 Google Chrome 中安装 Tampermonkey 插件并在 Chrome 的扩展程序中启用 Tampermonkey 功能。具体安装方法请参考:如何在谷歌浏览器中安装扩展名为.crx的离线Chrome插件?
安装完成后,可以在浏览器右上角看到tampermonkey的按钮标记。如下所示
2.安装 Tampermonkey 插件后,我们就可以轻松设置了。Tampermonkey的设置分为3个等级,分别是新手、中级和高级。如果你对代码编程一窍不通,那就选新手吧!这些默认设置基本可以满足你的要求。如果您对电脑、软件操作等非常熟悉,可以选择初学者设置模式,可以设置更多的选项。当然,如果你是 JavaScript 大神,可以使用高级模式进行设置。
3.Tampermonkey 插件设置页面。
关键是,Tampermonkey 的厉害之处在哪里?
Tampermonkey 有一个内置的增强版脚本管理器。如果你精通javascript或其他编程语言,可以尝试定制一些适合你的插件。打开内置脚本管理器,如下图:
Tampermonkey 有哪些用户脚本源?
:一直是常用的用户脚本来源,现在这个网站不再更新了;
GreeasyFork:可能是最受欢迎的后起之秀。它由 Jason Barnabe 创建,他也是 Stylish 网站 的创建者,并且在其存储库中拥有大量脚本资源。
OpenUserJS:在 GreeasyFork 之后开始。它由 Sizzle McTwizzle 创建,并且在其存储库中同样拥有大量脚本资源。
GitHub/Gist:越来越多的开发者将源码放在GitHub上,用户可以直接搜索。
Tampermonkey 注释
1.IE 目前不支持 Tampermonkey 插件。
2.Tampermonkey插件提供了自动同步,但前提是你需要打开初学者设置模式,然后找到TESLA选项,勾选启用选项前面的框。如下所示
相关:百度网盘助手Chrome插件下载
油猴脚本扩展 Tampermonkey 下载地址点击下载
油猴脚本扩展Tampermonkey的详细使用教程,点击下方查看:
Tampermonkey 油猴脚本教程(图文解说)
本文标题:油猴脚本扩展 Tampermonkey 下载:最受欢迎的用户脚本管理器
chrome抓取网页插件(在程序员中口碑也较好的Chrome插件,广州小编)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-04-18 20:37
谷歌浏览器简洁清爽的界面、流畅的浏览体验、资源丰富的插件也让它成为前端开发者最喜欢的浏览器。而易用的插件可以帮助开发者在开发过程中减少大量的工作量,带来强大的效果。今天给大家推荐几个非常实用,在程序员中口碑不错的Chrome插件。和广州千峰小编一起来看看吧!
一、灯塔前端性能优化测试工具
对于前端开发者来说,往往很难区分自己开发的 App 或网页的性能。这时候就需要专业的网站测试工具了。通过这些具体的分析报告,我们可以更直观地了解产品需要优化的地方。Lighthouse 插件就是这样一个开源的自动化检测工具,由谷歌官方团队提供,是一个严肃的行业标杆。
Lighthouse 插件可以对需要测试的页面进行一系列的评估,然后以详细的优化指南反馈给开发者。主要包括网站页面性能、PWA、可访问性(accessibility)、SEO等内容。
开发者可以网站根据这些标准进行优化改进,提升用户体验,不再需要盲目改动。下载链接:
二、Vue.js devtools 调试插件
Vue.js devtools 是一款在 Chrome 商店和 Firefox 商店中拥有数百万用户的流行插件,有“Vue 调试神器”的称号。由于 Vue 是数据驱动的,所以开发者在开发和调试的过程中无法解析出 DOM 结构无法解析的内容。但借助 Vue.js devtools 插件,您可以轻松解析和调试数据结构。
安装插件后,按F12打开开发者工具。您将在开发人员工具的菜单栏末尾看到 VUE。选择它以执行平滑操作。
下载地址:类似的调试工具,Facebook出品的比较有名的React Developer Tools插件。安装此插件后,您可以在 Google Chrome 中进行调试时查看应用程序的 React 组件层次结构,而不是查看神秘的浏览器 DOM。
下载链接:
三、WEB前端助手(FeHelper)
国内超实用的前端开发工具合集。我之前也在专门的文章中介绍过这个插件。WEB前端助手(FeHelper)收录多个独立的小应用,如:Json工具、代码美化、代码压缩、二维码、Postman、markdown、网页油猴、便签、信息加解密、随机密码生成、Crontab等等等等。
基本涵盖了前端开发中经常用到的所有基础功能。由于WEB前端助手是中国人开发的,所以大家用起来会更方便。
下载链接:
四、Wappalyzer网站技术分析插件
开发人员有时需要从他人的 网站 中寻找灵感和学习。那么,当我们浏览一个感觉不错的 网站 并想知道他们正在使用什么框架和技术时,我们该怎么办?这时,Wappalyzer 可以提供帮助。Wappalyzer 是一个功能强大且非常有用的 Chrome网站 技术分析插件。
可以分析平台架构、网站环境、服务器配置环境、JavaScript框架、网站采用的编程语言等参数。安装好后,在感兴趣的网页上点击Wappalyzer插件图标,在下拉窗口中可以看到这个网站使用的框架和技术。
下载链接:
五、Web Maker 网页代码编辑器
作为开发人员,您可能使用过许多代码编辑器。确实有很多功能非常强大的编辑器,但是在一些需要快速记录代码的紧急情况下,打开这些编辑器比较麻烦。Web Maker 是一个 Chrome 插件,可以在浏览器上快速编写网页代码。
它使您的 Google Chrome 能够动态编辑代码,主要用于编写 HTML、CSS 和 JavaScript 代码。安装插件后,只需单击插件图标即可在新窗口中工作。最重要的是,Web Maker 支持离线使用和自动代码保存。如果黑色对您来说太沉闷,还有多个编辑器主题和其他可配置设置。
下载链接:
以上就是今天的推荐。你常用的前端扩展插件有哪些?欢迎留言与千峰广州小编一起探讨! 查看全部
chrome抓取网页插件(在程序员中口碑也较好的Chrome插件,广州小编)
谷歌浏览器简洁清爽的界面、流畅的浏览体验、资源丰富的插件也让它成为前端开发者最喜欢的浏览器。而易用的插件可以帮助开发者在开发过程中减少大量的工作量,带来强大的效果。今天给大家推荐几个非常实用,在程序员中口碑不错的Chrome插件。和广州千峰小编一起来看看吧!
一、灯塔前端性能优化测试工具
对于前端开发者来说,往往很难区分自己开发的 App 或网页的性能。这时候就需要专业的网站测试工具了。通过这些具体的分析报告,我们可以更直观地了解产品需要优化的地方。Lighthouse 插件就是这样一个开源的自动化检测工具,由谷歌官方团队提供,是一个严肃的行业标杆。
Lighthouse 插件可以对需要测试的页面进行一系列的评估,然后以详细的优化指南反馈给开发者。主要包括网站页面性能、PWA、可访问性(accessibility)、SEO等内容。
开发者可以网站根据这些标准进行优化改进,提升用户体验,不再需要盲目改动。下载链接:
二、Vue.js devtools 调试插件
Vue.js devtools 是一款在 Chrome 商店和 Firefox 商店中拥有数百万用户的流行插件,有“Vue 调试神器”的称号。由于 Vue 是数据驱动的,所以开发者在开发和调试的过程中无法解析出 DOM 结构无法解析的内容。但借助 Vue.js devtools 插件,您可以轻松解析和调试数据结构。
安装插件后,按F12打开开发者工具。您将在开发人员工具的菜单栏末尾看到 VUE。选择它以执行平滑操作。
下载地址:类似的调试工具,Facebook出品的比较有名的React Developer Tools插件。安装此插件后,您可以在 Google Chrome 中进行调试时查看应用程序的 React 组件层次结构,而不是查看神秘的浏览器 DOM。
下载链接:
三、WEB前端助手(FeHelper)
国内超实用的前端开发工具合集。我之前也在专门的文章中介绍过这个插件。WEB前端助手(FeHelper)收录多个独立的小应用,如:Json工具、代码美化、代码压缩、二维码、Postman、markdown、网页油猴、便签、信息加解密、随机密码生成、Crontab等等等等。
基本涵盖了前端开发中经常用到的所有基础功能。由于WEB前端助手是中国人开发的,所以大家用起来会更方便。
下载链接:
四、Wappalyzer网站技术分析插件
开发人员有时需要从他人的 网站 中寻找灵感和学习。那么,当我们浏览一个感觉不错的 网站 并想知道他们正在使用什么框架和技术时,我们该怎么办?这时,Wappalyzer 可以提供帮助。Wappalyzer 是一个功能强大且非常有用的 Chrome网站 技术分析插件。
可以分析平台架构、网站环境、服务器配置环境、JavaScript框架、网站采用的编程语言等参数。安装好后,在感兴趣的网页上点击Wappalyzer插件图标,在下拉窗口中可以看到这个网站使用的框架和技术。
下载链接:
五、Web Maker 网页代码编辑器
作为开发人员,您可能使用过许多代码编辑器。确实有很多功能非常强大的编辑器,但是在一些需要快速记录代码的紧急情况下,打开这些编辑器比较麻烦。Web Maker 是一个 Chrome 插件,可以在浏览器上快速编写网页代码。
它使您的 Google Chrome 能够动态编辑代码,主要用于编写 HTML、CSS 和 JavaScript 代码。安装插件后,只需单击插件图标即可在新窗口中工作。最重要的是,Web Maker 支持离线使用和自动代码保存。如果黑色对您来说太沉闷,还有多个编辑器主题和其他可配置设置。
下载链接:
以上就是今天的推荐。你常用的前端扩展插件有哪些?欢迎留言与千峰广州小编一起探讨!
chrome抓取网页插件(7款顶级谷歌Chrome浏览器插件可增强用户的Chrome体验)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-04-17 16:19
[文本]
据外媒报道,纵观当今浏览器市场,主流浏览器包括Microsoft IE、Mozilla Firefox、Google Chrome、Apple Safari和Opera。其中,Google 的 Chrome 浏览器以简洁着称,而 Mozilla Foundation 的 Firefox 则以插件丰富而著称。
不过,目前谷歌已经开始允许用户下载使用Chrome插件,极大地丰富了用户的体验。
截至目前,Chrome 拥有超过 800 个浏览器插件,这些插件可以提升用户的 Chrome 体验。
通常,这些插件显示为 Chrome 地址栏旁边的图标,这些图标很容易删除或禁用(如果用户想要保留 Chrome 的经典外观和感觉)。
此外,如果用户想要使用 Chrome 扩展程序,他们必须在 /chrome 下载最新的 Linux 或 Windows 测试版 Chrome 浏览器,然后到 /extensions 下载数百个扩展程序。
以下是笔者总结的7个顶级谷歌Chrome浏览器插件,具体如下:
1、Google Apps 快捷方式
该插件允许用户快速访问谷歌应用程序,例如 Gmail、谷歌日历和谷歌文档。该插件可以在新标签页中打开这些应用程序,还允许用户快速创建电子邮件、文件等。如果您只想访问 Gmail,那么您可以尝试使用 Google Mail Checker。
2、标签菜单
使用选项卡菜单,用户可以获得所有选项卡的垂直列表以及一个搜索框,以便更轻松地进行选项卡导航。选项卡菜单使用户可以使用关闭按钮关闭选项卡,并使用拖放选项卡重新排列它们。
3、StumbleUpon
StumbleUpon 插件可以根据用户的个人喜好,向你推荐符合你喜好并被最多人推荐的网站。这样,您可以轻松访问具有高质量内容的页面,而不是总是浪费时间访问许多内容平庸的页面。
4、Chrome 的 Picnik 扩展
Picnik Extension for Chrome 可帮助用户嵌入 网站 的图像并轻松发送。加载 网站 页面后,单击 Picnik 按钮,用户将能够获得 网站 图像的缩略图列表。单击这些缩略图将在 Picnik 中打开图像,用户可以在其中编辑、注释、共享等。
5、喂食
Chrome 的 Feedly 插件为您提供了一种快速而时尚的方式来阅读和分享您最喜欢的 网站 和服务内容。它为您提供 Google Reader、Twitter、Yummy、YouTube、Amazon 等,让您随时浏览自己喜欢的内容。
6、WOT(信任网络)
Chrome 的 Web of Trust 插件会在用户使用 Chrome 打开收录垃圾邮件、恶意软件或其他危险/未知信息的网站时发出警告。
当用户点击WOT插件图标时,红圈网站为危险网站,绿圈网站为安全网站。WOT 也适用于 Google 和 Bing 搜索结果、Gmail 和 Yahoo! 等邮件服务。邮件等
7、微风
Brizzly 是一个小型 Twitter 插件,可让用户撰写和编译推文、访问 Twitter 个人资料、详细信息、列表和保存的搜索等等。
借助 Brizzly,用户可以在一个页面上进行几乎所有操作,包括关注、取消关注、添加到群组、了解热门话题等等。
(新闻稿 2009-12-22) 查看全部
chrome抓取网页插件(7款顶级谷歌Chrome浏览器插件可增强用户的Chrome体验)
[文本]
据外媒报道,纵观当今浏览器市场,主流浏览器包括Microsoft IE、Mozilla Firefox、Google Chrome、Apple Safari和Opera。其中,Google 的 Chrome 浏览器以简洁着称,而 Mozilla Foundation 的 Firefox 则以插件丰富而著称。
不过,目前谷歌已经开始允许用户下载使用Chrome插件,极大地丰富了用户的体验。
截至目前,Chrome 拥有超过 800 个浏览器插件,这些插件可以提升用户的 Chrome 体验。
通常,这些插件显示为 Chrome 地址栏旁边的图标,这些图标很容易删除或禁用(如果用户想要保留 Chrome 的经典外观和感觉)。
此外,如果用户想要使用 Chrome 扩展程序,他们必须在 /chrome 下载最新的 Linux 或 Windows 测试版 Chrome 浏览器,然后到 /extensions 下载数百个扩展程序。
以下是笔者总结的7个顶级谷歌Chrome浏览器插件,具体如下:
1、Google Apps 快捷方式
该插件允许用户快速访问谷歌应用程序,例如 Gmail、谷歌日历和谷歌文档。该插件可以在新标签页中打开这些应用程序,还允许用户快速创建电子邮件、文件等。如果您只想访问 Gmail,那么您可以尝试使用 Google Mail Checker。
2、标签菜单
使用选项卡菜单,用户可以获得所有选项卡的垂直列表以及一个搜索框,以便更轻松地进行选项卡导航。选项卡菜单使用户可以使用关闭按钮关闭选项卡,并使用拖放选项卡重新排列它们。
3、StumbleUpon
StumbleUpon 插件可以根据用户的个人喜好,向你推荐符合你喜好并被最多人推荐的网站。这样,您可以轻松访问具有高质量内容的页面,而不是总是浪费时间访问许多内容平庸的页面。
4、Chrome 的 Picnik 扩展
Picnik Extension for Chrome 可帮助用户嵌入 网站 的图像并轻松发送。加载 网站 页面后,单击 Picnik 按钮,用户将能够获得 网站 图像的缩略图列表。单击这些缩略图将在 Picnik 中打开图像,用户可以在其中编辑、注释、共享等。
5、喂食
Chrome 的 Feedly 插件为您提供了一种快速而时尚的方式来阅读和分享您最喜欢的 网站 和服务内容。它为您提供 Google Reader、Twitter、Yummy、YouTube、Amazon 等,让您随时浏览自己喜欢的内容。
6、WOT(信任网络)
Chrome 的 Web of Trust 插件会在用户使用 Chrome 打开收录垃圾邮件、恶意软件或其他危险/未知信息的网站时发出警告。
当用户点击WOT插件图标时,红圈网站为危险网站,绿圈网站为安全网站。WOT 也适用于 Google 和 Bing 搜索结果、Gmail 和 Yahoo! 等邮件服务。邮件等
7、微风
Brizzly 是一个小型 Twitter 插件,可让用户撰写和编译推文、访问 Twitter 个人资料、详细信息、列表和保存的搜索等等。
借助 Brizzly,用户可以在一个页面上进行几乎所有操作,包括关注、取消关注、添加到群组、了解热门话题等等。
(新闻稿 2009-12-22)
chrome抓取网页插件(百度数据爬虫-实用的爬虫工具基于python3的抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-16 05:05
chrome抓取网页插件-qq号码,
刚好之前考试写了个可以抓取的服务,基本就是利用协议的漏洞,这样网页数据就可以抓取到,并且可以导出为excel或pdf等等文件。因为这个软件基本就是抓取网页,所以还算简单,如果需要再深入的话,可以看下。
没有爬虫经验的人,推荐百度数据爬虫-实用的爬虫工具推荐常用的爬虫工具有百度的爬虫推荐,数据采集-百度文库数据采集github上可以看看别人的爬虫。
qq号码?@百度!
/
难道不是百度号码池?
网易新闻登录有一个随机新增qq号码,不过其他有抓包不一定全正确,仅供参考。
12306倒是可以抓,
-7232369.html抓不到的。同样的还有uc新闻的新增微信公众号关注数据。
百度数据抓取-好搜经验-好搜论坛
牛人成群啊,
百度数据抓取,需要自己写爬虫,要懂抓包,然后用正则re,多写几遍抓取,就会了,
我写了一个,
一位不知名大牛写的|无需翻墙的抓取百度网页数据的工具基于python3的抓取工具,数据抓取多大有变,
web上登录百度的网站,在下面有个投票的,点击投票的按钮,然后就会出现。
如果你不是有非常深厚的python和java经验的话不建议使用爬虫工具, 查看全部
chrome抓取网页插件(百度数据爬虫-实用的爬虫工具基于python3的抓取工具)
chrome抓取网页插件-qq号码,
刚好之前考试写了个可以抓取的服务,基本就是利用协议的漏洞,这样网页数据就可以抓取到,并且可以导出为excel或pdf等等文件。因为这个软件基本就是抓取网页,所以还算简单,如果需要再深入的话,可以看下。
没有爬虫经验的人,推荐百度数据爬虫-实用的爬虫工具推荐常用的爬虫工具有百度的爬虫推荐,数据采集-百度文库数据采集github上可以看看别人的爬虫。
qq号码?@百度!
/
难道不是百度号码池?
网易新闻登录有一个随机新增qq号码,不过其他有抓包不一定全正确,仅供参考。
12306倒是可以抓,
-7232369.html抓不到的。同样的还有uc新闻的新增微信公众号关注数据。
百度数据抓取-好搜经验-好搜论坛
牛人成群啊,
百度数据抓取,需要自己写爬虫,要懂抓包,然后用正则re,多写几遍抓取,就会了,
我写了一个,
一位不知名大牛写的|无需翻墙的抓取百度网页数据的工具基于python3的抓取工具,数据抓取多大有变,
web上登录百度的网站,在下面有个投票的,点击投票的按钮,然后就会出现。
如果你不是有非常深厚的python和java经验的话不建议使用爬虫工具,
chrome抓取网页插件(蛮牛云爬虫(/)是唯一可以用githubhater来解决抓取的答案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-04-13 13:01
chrome抓取网页插件,使用蛮牛云插件。百度一下蛮牛云插件就有了,本来蛮牛云想比较惨无人道,卸载了好多次还是不能用,结果有一天突然又能用了,这时候觉得挺好的,终于可以上传自己的文件了,哈哈哈哈。
今天突然出现了这个问题就来搜这个问题,不料真的发现了这个问题,对于知乎上出现这样的问题我一向是不太喜欢回答的。试用了“githubhater”,想进行一下测试,连续尝试下来没有发现任何问题,再次测试才发现什么叫googlehi“疯狂爬虫”,下载速度与网页本身加载速度相差甚远,造成如此结果的原因可能是这个插件存在skiprowski.sh脚本,有效加载js/css文件。
好吧是我要求高,已经改用它了,同时也支持将它写入speedtest插件,不过做了个测试发现经过我的优化后速度依然不如蛮牛云爬虫,不得不承认蛮牛云爬虫(/)上传速度还是很快的。现在蛮牛云爬虫(/)是唯一可以用githubhater来解决抓取的答案,很难想象作为一个中文爬虫到了“无法提速”的地步。作为一个普通爬虫在市面上来看应该价格不贵,但是作为一个让爬虫程序员赚钱养家糊口的存在就贵了。|githubhater。
目前github上的爬虫程序除了几个大的rpc框架(比如scrapy、pyspider等)还在使用node+websocket来跟服务器通信,速度还可以,ie简直就是摆设。我推荐用githubhater,简单性能又高,比如快速提取htmljson结构的数据,githubhater能做到不到1s的read-only,还有大量第三方库,改改就可以用。
我使用的是简单模式,反正几百k的代码量,不写rewriteer.addlib.names_if(!name)也一样能用。这点githubhater做的很好,能爬取json数据而不是csv。 查看全部
chrome抓取网页插件(蛮牛云爬虫(/)是唯一可以用githubhater来解决抓取的答案)
chrome抓取网页插件,使用蛮牛云插件。百度一下蛮牛云插件就有了,本来蛮牛云想比较惨无人道,卸载了好多次还是不能用,结果有一天突然又能用了,这时候觉得挺好的,终于可以上传自己的文件了,哈哈哈哈。
今天突然出现了这个问题就来搜这个问题,不料真的发现了这个问题,对于知乎上出现这样的问题我一向是不太喜欢回答的。试用了“githubhater”,想进行一下测试,连续尝试下来没有发现任何问题,再次测试才发现什么叫googlehi“疯狂爬虫”,下载速度与网页本身加载速度相差甚远,造成如此结果的原因可能是这个插件存在skiprowski.sh脚本,有效加载js/css文件。
好吧是我要求高,已经改用它了,同时也支持将它写入speedtest插件,不过做了个测试发现经过我的优化后速度依然不如蛮牛云爬虫,不得不承认蛮牛云爬虫(/)上传速度还是很快的。现在蛮牛云爬虫(/)是唯一可以用githubhater来解决抓取的答案,很难想象作为一个中文爬虫到了“无法提速”的地步。作为一个普通爬虫在市面上来看应该价格不贵,但是作为一个让爬虫程序员赚钱养家糊口的存在就贵了。|githubhater。
目前github上的爬虫程序除了几个大的rpc框架(比如scrapy、pyspider等)还在使用node+websocket来跟服务器通信,速度还可以,ie简直就是摆设。我推荐用githubhater,简单性能又高,比如快速提取htmljson结构的数据,githubhater能做到不到1s的read-only,还有大量第三方库,改改就可以用。
我使用的是简单模式,反正几百k的代码量,不写rewriteer.addlib.names_if(!name)也一样能用。这点githubhater做的很好,能爬取json数据而不是csv。
chrome抓取网页插件(如何快速入门HeadlessChrome进行网页抓取的经验(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-04-13 00:10
翻译:没有两个
Headless Chrome 是 Chrome 浏览器的一种无界面形式,无需打开浏览器即可运行使用 Chrome 支持的所有功能的程序。与现代浏览器相比,Headless Chrome 更方便测试web应用、获取网站的截图、爬取信息等,也更贴近浏览器环境。下面我们来看看作者分享的使用 Headless Chrome 进行网页抓取的经验。
PhantomJS 的开发已经停止,Headless Chrome 成为焦点,每个人都喜欢它,包括我们。现在,网络抓取是我们工作的重要组成部分,我们现在广泛使用 Headless Chrome。
本文 文章 将向您展示如何快速开始使用 Headless Chrome 生态系统,并展示您从已经爬取数百万个网页中学到的东西。
文章总结:
1. 控制Chrome的库很多,大家可以根据自己的喜好选择。
2. 使用 Headless Chrome 进行网页抓取很容易,尤其是在您掌握了以下技术之后。
3. 可以检测到无头浏览器访问者,但没有人可以检测到。
无头 Chrome 简介
Headless Chrome 基于 Google Chrome 团队开发的 PhantomJS(QtWebKit 内核)。团队表示,将专注于该项目的研发,并将在未来继续维护。
这意味着对于网络抓取和自动化需求,您现在可以体验 Chrome 的速度和强大功能,因为它具有世界上最常用的浏览器的特性:支持所有 网站,支持 JS 引擎,并且很棒开发者工具 API。这太糟糕了!
使用哪个工具来控制 Headless Chrome?
市面上确实有很多 NodeJS 库支持 Chrome 新的 headless 模式,每个都有自己的特点。我们自己的是 NickJS。如果你没有自己的爬虫库,还敢说你是爬虫高手。
还有一组由社区发布的其他语言的库,例如基于 GO 语言的库。我们建议使用 NodeJS 工具,因为它与 Web 解析语言相同(下面您将看到它有多方便)。
网页抓取?这不是违法的吗?
我们无意展开无休止的辩论,但不到两周前,一名美国地方法官命令第三方抓取公共 LinkedIn 个人资料。到目前为止,这是一项初步法令,诉讼将继续进行,LinkedIn 肯定会反对,但不要担心,我们会密切关注情况,因为在这个 文章 中有很多关于 LinkedIn 的内容。
无论如何,作为技术 文章,我们不会深入研究特定抓取操作的合法性,我们应该始终努力尊重目标 网站 的 ToS。并且对您在此 文章 中学到的任何损害不承担任何责任。
到目前为止学到的很酷的东西
下面列出了我们几乎每天都在使用的一些技巧。代码示例使用 NickJS 抓取库,但它们可以很容易地被其他无头 Chrome 工具重写,分享这些概念很重要。
把饼干放回饼干罐
使用功能齐全的浏览器进行抓取可以让您高枕无忧,无需担心 CORS、会话、cookie、CSRF 和其他 Web 问题。
但有时登录表单变得非常困难,唯一的解决方案是恢复以前保存的会话 cookie。一些网站在检测到故障时会发送电子邮件或短信。我们没有时间这样做,只需打开已设置会话 cookie 的页面即可。
LinkedIn 有一个很好的例子,设置 li_atcookie 可以保证爬虫访问他们的社交网络(记住:注意尊重目标 网站Tos)。
await nick.setCookie({ name: "li_at", value: "a session cookie value copied from your DevTools", domain: "www.linkedin.com" })
相信像 LinkedIn 这样的 网站 不会阻止具有有效会话 cookie 的真实浏览器。这样做是有风险的,因为错误信息会引发愤怒用户的大量支持请求。
jQuery不会让你失望
我们学到的一件重要的事情是通过 jQuery 从网页中提取数据是多么容易。回想起来,这是显而易见的。网站 提供了一个高度结构化、可查询的数据元素树(称为 DOM),而 jQuery 是一个非常高效的 DOM 查询库。那么为什么不使用它来爬行呢?这个技巧会一次又一次地奏效。
很多 网站 已经使用 jQuery,所以只需在页面中添加几行即可获取数据。
await tab.open("news.ycombinator.com") await tab.untilVisible("#hnmain") // Make sure we have loaded the page await tab.inject("https://code.jquery.com/jquery-3.2.1.min.js") // We're going to use jQuery to scrape const hackerNewsLinks = await tab.evaluate((arg, callback) => { // Here we're in the page context. It's like being in your browser's inspector tool const data = [] $(".athing").each((index, element) => { data.push({ title: $(element).find(".storylink").text(), url: $(element).find(".storylink").attr("href") }) }) callback(null, data) })
印度、俄罗斯和巴基斯坦在阻止机器人方面有什么共同点?
答案是使用验证码来解决服务器验证。几块钱就可以买到几千个验证码,生成一个验证码通常不到30秒。但是晚上,因为没有人,所以一般比较贵。
一个简单的谷歌搜索将提供多个 API 来解决任何类型的验证码问题,包括从谷歌获取最新的验证码(1000 美元 2 美元)。
将抓取机器连接到这些服务就像发出 HTTP 请求一样简单,现在机器人是人类。
在我们的平台上,用户可以轻松解决他们需要的验证码问题。我们的 Buster 库可以:
if (await tab.isVisible(".captchaImage")) { // Get the URL of the generated CAPTCHA image // Note that we could also get its -encoded value and solve it too const captchaImageLink = await tab.evaluate((arg, callback) => { callback(null, $(".captchaImage").attr("src")) }) // Make a call to a CAPTCHA solving service const captchaAnswer = await buster.solveCaptchaImage(captchaImageLink) // Fill the form with our solution await tab.fill(".captchaForm", { "captcha-answer": captchaAnswer }, { submit: true }) }
等待一个 DOM 元素,而不是固定的时间
通常会看到爬虫初学者让他们的机器人在打开页面或单击按钮后等待 5 到 10 秒——他们希望确保他们所做的操作有时间产生效果。
但这不是应该做的。我们的三步理论适用于任何抓取场景:应该等待的是您想要操作的特定 DOM 元素。如果出现问题,它会更快、更清晰,并获得更准确的错误消息。
await tab.open("https://www.facebook.com/phbus ... 6quot;) // await Promise.delay(5000) // DON'T DO THIS! await tab.waitUntilVisible(".permalinkPost .UFILikeLink") // You can now safely click the "Like" button... await tab.click(".permalinkPost .UFILikeLink")
在某些情况下,可能确实有必要伪造人为的延迟。可以使用
await Promise.delay(2000 + Math.random() * 3000)
愚弄过去。
MongoDB
我们发现 MongoDB 非常适合大多数抓取作业,它具有出色的 JS API 和 Mongoose ORM。考虑到您在使用 Headless Chrome 时已经处于 NodeJS 环境中,为什么不采用它呢?
JSON-LD 和微数据开发
有时网页抓取不需要了解 DOM,而是要找到正确的“导出”按钮。记住这一点可以节省很多时间。
严格来说,有些网站 比其他网站 更容易,例如,他们所有的产品页面都显示在 DOM 中,产品数据为 JSON-LD 格式。可以对他们的任何产品页面说,然后运行
JSON.parse(document . queryselector(" # productSEOData "). innertext)
将得到一个可以很好地插入 MongoDB 的数据对象,无需真正的抓取!
网络请求拦截
因为使用了 DevTools API,所以编写的代码具有使用 Chrome 的 DevTools 的等效功能。这意味着生成的机器人可以拦截、检查甚至修改或中止任何网络请求。
通过从 LinkedIn 下载 PDF 格式的简历来测试 Web 请求拦截。单击配置文件中的“保存到 PDF”按钮会触发 XHR,其中响应是 PDF 文件,这是一种截取文件并将其写入磁盘的方法。
let cvRequestId = null tab.driver.client.Network.responseReceived((e) => { if (e.type === "XHR" && e.response.url.indexOf("profile-profilePdf/") > 0) { cvRequestId = e.requestId } }) tab.driver.client.Network.loadingFinished((e) => { if (e.requestId === cvRequestId) { tab.driver.client.Network.getResponseBody({ requestId: cvRequestId }, (err, cv) => { require("fs").writeFileSync("linkedin-cv.pdf", Buffer.from(cv.body, (cv.Encoded ? '' : 'utf8'))) }) } })
值得一提的是,DevTools 协议正在迅速发展,现在有一种方法可以使用 Page.setDownloadBehavior() 设置下载传入文件的方式和路径。我们尚未对其进行测试,但它看起来很有希望!
广告拦截
const nick = new Nick({ loadImages: false, whitelist: [ /.*\.aspx/, /.*axd.*/, /.*\.html.*/, /.*\.js.*/ ], blacklist: [ /.*fsispin360\.js/, /.*fsitouchzoom\.js/, /.*\.ashx.*/, /.*google.*/ ] })
它还可以通过阻止不必要的请求来加快爬网速度。分析、广告和图片是典型的屏蔽目标。但是,请记住,它会使机器人变得不像人类(例如,如果所有图像都被阻止,LinkedIn 将无法正确响应页面请求 - 不确定这是否是故意的)。
在 NickJS 中,用户可以指定收录正则表达式或字符串的白名单和黑名单。白名单功能特别强大,但如果您不小心,很容易使目标 网站 崩溃。
DevTools 协议还有 Network.setBlockedURLs() ,它接受一个带有通配符的字符串数组作为输入。
更重要的是,新版 Chrome 将带有谷歌自己的“广告拦截器”——它更像是一个广告“过滤器”。该协议已经有一个名为 Page.setAdBlockingEnabled() 的端点。
也就是我们所说的套路!
无头 Chrome 检测
最近的一篇文章 文章 列举了检测 Headless Chrome 访问者以及可能还有 PhantomJS 的各种方法。这些方法描述了从基本的用户代理字符串比较到更复杂的技术(例如触发错误和检查堆栈跟踪)的所有内容。
这基本上是愤怒的管理员和巧妙的机器人制造商之间的猫捉老鼠游戏。但从未见过这些方法正式实施。检测自动访问者在技术上是可行的,但谁愿意面对潜在的错误消息?对于大型 网站 来说尤其危险。
如果您知道那些具有这些检测功能的 网站,请告诉我们!
结束语
抓取从未如此简单,借助我们最新的工具和技术,它甚至可以成为我们开发人员的一项愉快而有趣的活动。
顺便说一句,我们的灵感来自 Franciskim.co “我不需要臭 API”文章,非常感谢!此外,有关如何开始使用木偶的详细说明,请单击此处。
在下一篇文章中,文章,我将写关于“机器人缓解”工具,比如 Distill Networks,关于 HTTP 代理和 IP 地址分配的美妙世界。
上有一个我们的抓取和自动化平台的库。如果您有兴趣,还可以了解我们的 3 个抓取步骤的理论信息。 查看全部
chrome抓取网页插件(如何快速入门HeadlessChrome进行网页抓取的经验(组图))
翻译:没有两个
Headless Chrome 是 Chrome 浏览器的一种无界面形式,无需打开浏览器即可运行使用 Chrome 支持的所有功能的程序。与现代浏览器相比,Headless Chrome 更方便测试web应用、获取网站的截图、爬取信息等,也更贴近浏览器环境。下面我们来看看作者分享的使用 Headless Chrome 进行网页抓取的经验。
PhantomJS 的开发已经停止,Headless Chrome 成为焦点,每个人都喜欢它,包括我们。现在,网络抓取是我们工作的重要组成部分,我们现在广泛使用 Headless Chrome。
本文 文章 将向您展示如何快速开始使用 Headless Chrome 生态系统,并展示您从已经爬取数百万个网页中学到的东西。
文章总结:
1. 控制Chrome的库很多,大家可以根据自己的喜好选择。
2. 使用 Headless Chrome 进行网页抓取很容易,尤其是在您掌握了以下技术之后。
3. 可以检测到无头浏览器访问者,但没有人可以检测到。
无头 Chrome 简介
Headless Chrome 基于 Google Chrome 团队开发的 PhantomJS(QtWebKit 内核)。团队表示,将专注于该项目的研发,并将在未来继续维护。
这意味着对于网络抓取和自动化需求,您现在可以体验 Chrome 的速度和强大功能,因为它具有世界上最常用的浏览器的特性:支持所有 网站,支持 JS 引擎,并且很棒开发者工具 API。这太糟糕了!
使用哪个工具来控制 Headless Chrome?
市面上确实有很多 NodeJS 库支持 Chrome 新的 headless 模式,每个都有自己的特点。我们自己的是 NickJS。如果你没有自己的爬虫库,还敢说你是爬虫高手。
还有一组由社区发布的其他语言的库,例如基于 GO 语言的库。我们建议使用 NodeJS 工具,因为它与 Web 解析语言相同(下面您将看到它有多方便)。
网页抓取?这不是违法的吗?
我们无意展开无休止的辩论,但不到两周前,一名美国地方法官命令第三方抓取公共 LinkedIn 个人资料。到目前为止,这是一项初步法令,诉讼将继续进行,LinkedIn 肯定会反对,但不要担心,我们会密切关注情况,因为在这个 文章 中有很多关于 LinkedIn 的内容。
无论如何,作为技术 文章,我们不会深入研究特定抓取操作的合法性,我们应该始终努力尊重目标 网站 的 ToS。并且对您在此 文章 中学到的任何损害不承担任何责任。
到目前为止学到的很酷的东西
下面列出了我们几乎每天都在使用的一些技巧。代码示例使用 NickJS 抓取库,但它们可以很容易地被其他无头 Chrome 工具重写,分享这些概念很重要。
把饼干放回饼干罐
使用功能齐全的浏览器进行抓取可以让您高枕无忧,无需担心 CORS、会话、cookie、CSRF 和其他 Web 问题。
但有时登录表单变得非常困难,唯一的解决方案是恢复以前保存的会话 cookie。一些网站在检测到故障时会发送电子邮件或短信。我们没有时间这样做,只需打开已设置会话 cookie 的页面即可。
LinkedIn 有一个很好的例子,设置 li_atcookie 可以保证爬虫访问他们的社交网络(记住:注意尊重目标 网站Tos)。
await nick.setCookie({ name: "li_at", value: "a session cookie value copied from your DevTools", domain: "www.linkedin.com" })
相信像 LinkedIn 这样的 网站 不会阻止具有有效会话 cookie 的真实浏览器。这样做是有风险的,因为错误信息会引发愤怒用户的大量支持请求。
jQuery不会让你失望
我们学到的一件重要的事情是通过 jQuery 从网页中提取数据是多么容易。回想起来,这是显而易见的。网站 提供了一个高度结构化、可查询的数据元素树(称为 DOM),而 jQuery 是一个非常高效的 DOM 查询库。那么为什么不使用它来爬行呢?这个技巧会一次又一次地奏效。
很多 网站 已经使用 jQuery,所以只需在页面中添加几行即可获取数据。
await tab.open("news.ycombinator.com") await tab.untilVisible("#hnmain") // Make sure we have loaded the page await tab.inject("https://code.jquery.com/jquery-3.2.1.min.js";) // We're going to use jQuery to scrape const hackerNewsLinks = await tab.evaluate((arg, callback) => { // Here we're in the page context. It's like being in your browser's inspector tool const data = [] $(".athing").each((index, element) => { data.push({ title: $(element).find(".storylink").text(), url: $(element).find(".storylink").attr("href") }) }) callback(null, data) })
印度、俄罗斯和巴基斯坦在阻止机器人方面有什么共同点?
答案是使用验证码来解决服务器验证。几块钱就可以买到几千个验证码,生成一个验证码通常不到30秒。但是晚上,因为没有人,所以一般比较贵。
一个简单的谷歌搜索将提供多个 API 来解决任何类型的验证码问题,包括从谷歌获取最新的验证码(1000 美元 2 美元)。
将抓取机器连接到这些服务就像发出 HTTP 请求一样简单,现在机器人是人类。
在我们的平台上,用户可以轻松解决他们需要的验证码问题。我们的 Buster 库可以:
if (await tab.isVisible(".captchaImage")) { // Get the URL of the generated CAPTCHA image // Note that we could also get its -encoded value and solve it too const captchaImageLink = await tab.evaluate((arg, callback) => { callback(null, $(".captchaImage").attr("src")) }) // Make a call to a CAPTCHA solving service const captchaAnswer = await buster.solveCaptchaImage(captchaImageLink) // Fill the form with our solution await tab.fill(".captchaForm", { "captcha-answer": captchaAnswer }, { submit: true }) }
等待一个 DOM 元素,而不是固定的时间
通常会看到爬虫初学者让他们的机器人在打开页面或单击按钮后等待 5 到 10 秒——他们希望确保他们所做的操作有时间产生效果。
但这不是应该做的。我们的三步理论适用于任何抓取场景:应该等待的是您想要操作的特定 DOM 元素。如果出现问题,它会更快、更清晰,并获得更准确的错误消息。
await tab.open("https://www.facebook.com/phbus ... 6quot;) // await Promise.delay(5000) // DON'T DO THIS! await tab.waitUntilVisible(".permalinkPost .UFILikeLink") // You can now safely click the "Like" button... await tab.click(".permalinkPost .UFILikeLink")
在某些情况下,可能确实有必要伪造人为的延迟。可以使用
await Promise.delay(2000 + Math.random() * 3000)
愚弄过去。
MongoDB
我们发现 MongoDB 非常适合大多数抓取作业,它具有出色的 JS API 和 Mongoose ORM。考虑到您在使用 Headless Chrome 时已经处于 NodeJS 环境中,为什么不采用它呢?
JSON-LD 和微数据开发
有时网页抓取不需要了解 DOM,而是要找到正确的“导出”按钮。记住这一点可以节省很多时间。
严格来说,有些网站 比其他网站 更容易,例如,他们所有的产品页面都显示在 DOM 中,产品数据为 JSON-LD 格式。可以对他们的任何产品页面说,然后运行
JSON.parse(document . queryselector(" # productSEOData "). innertext)
将得到一个可以很好地插入 MongoDB 的数据对象,无需真正的抓取!
网络请求拦截
因为使用了 DevTools API,所以编写的代码具有使用 Chrome 的 DevTools 的等效功能。这意味着生成的机器人可以拦截、检查甚至修改或中止任何网络请求。
通过从 LinkedIn 下载 PDF 格式的简历来测试 Web 请求拦截。单击配置文件中的“保存到 PDF”按钮会触发 XHR,其中响应是 PDF 文件,这是一种截取文件并将其写入磁盘的方法。
let cvRequestId = null tab.driver.client.Network.responseReceived((e) => { if (e.type === "XHR" && e.response.url.indexOf("profile-profilePdf/") > 0) { cvRequestId = e.requestId } }) tab.driver.client.Network.loadingFinished((e) => { if (e.requestId === cvRequestId) { tab.driver.client.Network.getResponseBody({ requestId: cvRequestId }, (err, cv) => { require("fs").writeFileSync("linkedin-cv.pdf", Buffer.from(cv.body, (cv.Encoded ? '' : 'utf8'))) }) } })
值得一提的是,DevTools 协议正在迅速发展,现在有一种方法可以使用 Page.setDownloadBehavior() 设置下载传入文件的方式和路径。我们尚未对其进行测试,但它看起来很有希望!
广告拦截
const nick = new Nick({ loadImages: false, whitelist: [ /.*\.aspx/, /.*axd.*/, /.*\.html.*/, /.*\.js.*/ ], blacklist: [ /.*fsispin360\.js/, /.*fsitouchzoom\.js/, /.*\.ashx.*/, /.*google.*/ ] })
它还可以通过阻止不必要的请求来加快爬网速度。分析、广告和图片是典型的屏蔽目标。但是,请记住,它会使机器人变得不像人类(例如,如果所有图像都被阻止,LinkedIn 将无法正确响应页面请求 - 不确定这是否是故意的)。
在 NickJS 中,用户可以指定收录正则表达式或字符串的白名单和黑名单。白名单功能特别强大,但如果您不小心,很容易使目标 网站 崩溃。
DevTools 协议还有 Network.setBlockedURLs() ,它接受一个带有通配符的字符串数组作为输入。
更重要的是,新版 Chrome 将带有谷歌自己的“广告拦截器”——它更像是一个广告“过滤器”。该协议已经有一个名为 Page.setAdBlockingEnabled() 的端点。
也就是我们所说的套路!
无头 Chrome 检测
最近的一篇文章 文章 列举了检测 Headless Chrome 访问者以及可能还有 PhantomJS 的各种方法。这些方法描述了从基本的用户代理字符串比较到更复杂的技术(例如触发错误和检查堆栈跟踪)的所有内容。
这基本上是愤怒的管理员和巧妙的机器人制造商之间的猫捉老鼠游戏。但从未见过这些方法正式实施。检测自动访问者在技术上是可行的,但谁愿意面对潜在的错误消息?对于大型 网站 来说尤其危险。
如果您知道那些具有这些检测功能的 网站,请告诉我们!
结束语
抓取从未如此简单,借助我们最新的工具和技术,它甚至可以成为我们开发人员的一项愉快而有趣的活动。
顺便说一句,我们的灵感来自 Franciskim.co “我不需要臭 API”文章,非常感谢!此外,有关如何开始使用木偶的详细说明,请单击此处。
在下一篇文章中,文章,我将写关于“机器人缓解”工具,比如 Distill Networks,关于 HTTP 代理和 IP 地址分配的美妙世界。
上有一个我们的抓取和自动化平台的库。如果您有兴趣,还可以了解我们的 3 个抓取步骤的理论信息。
chrome抓取网页插件(科研党必备插件:谷歌学术搜索按钮搞科研的人)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-04-11 01:34
Chrome浏览器凭借其快速的搜索速度、友好的界面、强大的性能和出色的体验,迅速扩大了市场份额,在2012年超越IE浏览器,位居第一。作为科研党,我想写出优秀的科研成果,离不开这样的神器。Chrome浏览器的特点还包括丰富的插件。以下是我常用的一些Chrome浏览器插件。我希望它对每个人都有帮助。
更好的谷歌
1、万能翻译插件:字标翻译
通用翻译插件:字标翻译
做科学研究离不开翻译。无论是英译中还是中译英,这个词标翻译插件不仅可以翻译一些单词、一些短句,还可以翻译整个全文;不仅支持几乎所有语言的翻译,还具有阅读和背诵功能;不仅支持国内百度翻译、有道翻译引擎,还支持国外谷歌翻译、必应翻译;使用非常方便,操作逻辑非常简单。左键选择要翻译的内容,点击绿色按钮自动翻译。
简单易用
2、更改页面颜色插件:更改颜色
更改页面颜色插件:更改颜色
Change Colors是Chrome浏览器的一个插件,可以改变网页的颜色。它几乎是我必须安装的插件,以及夜间模式。使用起来也非常简单。打开更改颜色选项,根据个人喜好设置相关参数。可以换成多种颜色,妈妈再也不用担心你的眼睛了。
上面的绿色是我改的颜色
3、研究党必备插件:谷歌学术按钮
研究党必备插件:Google Scholar 按钮
从事科学研究的人都知道谷歌学术的力量和重要性。谷歌学术按钮插件是一款可以帮助我们搬运工快速获取学术论文全部内容的插件。但前提是你可以正常登录谷歌学术网站。如果不行,可以通过修改Hosts文件等方法解决。
简单易用的页面
4、Google 下载插件:Chrono 下载管理器
Google 下载插件:Chrono 下载管理器
谷歌网页本身的下载界面不是很友好。搭配Chrono下载管理器插件,不仅可以完美替代浏览器自带的下载界面,还可以抓取网页上的一些流媒体、音频、视频。特别好用,断点下载比Chrome本身好很多。
便于使用
5、截图神器:网页截图:注释和评论
截图神器:网页截图:注释和评论
网页截图:Annotation & Annotation 是一个截图插件。我没有遇到过他。QQ截图我都有,但最大的问题是必须联网。使用这个插件,不仅可以截取网页内容的部分截图,而且支持截取整个网页,可以滚动截图,非常棒。此外,该插件还支持对截图进行二次处理,包括添加注解、注解、水印等附加信息。
比QQ截图厉害多了
6、阻止弹出窗口:Poper Blocker
阻止弹出窗口:Poper Blocker
安装 Poper Blocker 插件后,再也不用担心登录那些有弹窗广告的网站了。Poper Blocker插件会乖乖的自动屏蔽网站中的弹窗广告,并且可以显示在浏览器的右上角,可以看到被屏蔽广告的信息。另外,如果想在某个网站上看到弹窗广告,可以设置白名单,网站上的弹窗广告不会被屏蔽。盾。
阻止弹出广告
这些是我目前经常使用的浏览器插件,可以从谷歌应用商店下载。欢迎大家使用,欢迎采集,欢迎讨论。 查看全部
chrome抓取网页插件(科研党必备插件:谷歌学术搜索按钮搞科研的人)
Chrome浏览器凭借其快速的搜索速度、友好的界面、强大的性能和出色的体验,迅速扩大了市场份额,在2012年超越IE浏览器,位居第一。作为科研党,我想写出优秀的科研成果,离不开这样的神器。Chrome浏览器的特点还包括丰富的插件。以下是我常用的一些Chrome浏览器插件。我希望它对每个人都有帮助。
更好的谷歌
1、万能翻译插件:字标翻译
通用翻译插件:字标翻译
做科学研究离不开翻译。无论是英译中还是中译英,这个词标翻译插件不仅可以翻译一些单词、一些短句,还可以翻译整个全文;不仅支持几乎所有语言的翻译,还具有阅读和背诵功能;不仅支持国内百度翻译、有道翻译引擎,还支持国外谷歌翻译、必应翻译;使用非常方便,操作逻辑非常简单。左键选择要翻译的内容,点击绿色按钮自动翻译。
简单易用
2、更改页面颜色插件:更改颜色
更改页面颜色插件:更改颜色
Change Colors是Chrome浏览器的一个插件,可以改变网页的颜色。它几乎是我必须安装的插件,以及夜间模式。使用起来也非常简单。打开更改颜色选项,根据个人喜好设置相关参数。可以换成多种颜色,妈妈再也不用担心你的眼睛了。
上面的绿色是我改的颜色
3、研究党必备插件:谷歌学术按钮
研究党必备插件:Google Scholar 按钮
从事科学研究的人都知道谷歌学术的力量和重要性。谷歌学术按钮插件是一款可以帮助我们搬运工快速获取学术论文全部内容的插件。但前提是你可以正常登录谷歌学术网站。如果不行,可以通过修改Hosts文件等方法解决。
简单易用的页面
4、Google 下载插件:Chrono 下载管理器
Google 下载插件:Chrono 下载管理器
谷歌网页本身的下载界面不是很友好。搭配Chrono下载管理器插件,不仅可以完美替代浏览器自带的下载界面,还可以抓取网页上的一些流媒体、音频、视频。特别好用,断点下载比Chrome本身好很多。
便于使用
5、截图神器:网页截图:注释和评论
截图神器:网页截图:注释和评论
网页截图:Annotation & Annotation 是一个截图插件。我没有遇到过他。QQ截图我都有,但最大的问题是必须联网。使用这个插件,不仅可以截取网页内容的部分截图,而且支持截取整个网页,可以滚动截图,非常棒。此外,该插件还支持对截图进行二次处理,包括添加注解、注解、水印等附加信息。
比QQ截图厉害多了
6、阻止弹出窗口:Poper Blocker
阻止弹出窗口:Poper Blocker
安装 Poper Blocker 插件后,再也不用担心登录那些有弹窗广告的网站了。Poper Blocker插件会乖乖的自动屏蔽网站中的弹窗广告,并且可以显示在浏览器的右上角,可以看到被屏蔽广告的信息。另外,如果想在某个网站上看到弹窗广告,可以设置白名单,网站上的弹窗广告不会被屏蔽。盾。
阻止弹出广告
这些是我目前经常使用的浏览器插件,可以从谷歌应用商店下载。欢迎大家使用,欢迎采集,欢迎讨论。
chrome抓取网页插件(推荐一些中文网站分类.javascript免费学习.remote-similarweb-similarweb(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-10 23:14
chrome抓取网页插件,免费无广告,电脑与手机都可以使用操作界面操作方便,界面很干净,支持谷歌浏览器,firefox浏览器,googlechrome浏览器,百度浏览器,360浏览器,搜狗浏览器,opera浏览器,uc浏览器,edge浏览器,美团网,人人网,uc浏览器,qq浏览器,今日头条,360网络浏览器,猎豹浏览器,清理大师,迅雷极速版,遨游浏览器等手机插件比如在网页上选中一个图片,点一下触屏图标就出来了,配合上chrome浏览器的扩展也是非常强大的,全屏,图片展示,图片传到safari,阅读、记事等。
想知道怎么才能免费下载网上的歌,这个视频给了我答案,很全面,希望对你有用。自从用了safari,每天听歌变成有事没事听着,而且想下载啥就下载啥,很爽,就是有一点,safari不能导出文件。
自用chrome引擎插件w3school:国内资源极少,ideoner和clipboardsweeper等外国资源还是很多的,wikipedia资源库差不多有10000个页面,除了medium、tweetbot、博客园和36kr外,还有财经新闻、blogger和电影天堂等。推荐一些中文网站分类.javascript免费学习.remote-similarweb-similarweb收录互联网上的全部主流和小众网站:.chromewebsitebanks:所有关于web的内容.googlebackgrounddecoratorextensions:可以通过css或者stylekey访问googlebackgrounddecorators来修改页面的背景的颜色.wordpress全面插件教程.webpagechrome,强烈推荐,用于站内搜索,因为我也想知道在chrome中具体的操作方法。不能忽略这个网站和它提供的系列免费插件。 查看全部
chrome抓取网页插件(推荐一些中文网站分类.javascript免费学习.remote-similarweb-similarweb(组图))
chrome抓取网页插件,免费无广告,电脑与手机都可以使用操作界面操作方便,界面很干净,支持谷歌浏览器,firefox浏览器,googlechrome浏览器,百度浏览器,360浏览器,搜狗浏览器,opera浏览器,uc浏览器,edge浏览器,美团网,人人网,uc浏览器,qq浏览器,今日头条,360网络浏览器,猎豹浏览器,清理大师,迅雷极速版,遨游浏览器等手机插件比如在网页上选中一个图片,点一下触屏图标就出来了,配合上chrome浏览器的扩展也是非常强大的,全屏,图片展示,图片传到safari,阅读、记事等。
想知道怎么才能免费下载网上的歌,这个视频给了我答案,很全面,希望对你有用。自从用了safari,每天听歌变成有事没事听着,而且想下载啥就下载啥,很爽,就是有一点,safari不能导出文件。
自用chrome引擎插件w3school:国内资源极少,ideoner和clipboardsweeper等外国资源还是很多的,wikipedia资源库差不多有10000个页面,除了medium、tweetbot、博客园和36kr外,还有财经新闻、blogger和电影天堂等。推荐一些中文网站分类.javascript免费学习.remote-similarweb-similarweb收录互联网上的全部主流和小众网站:.chromewebsitebanks:所有关于web的内容.googlebackgrounddecoratorextensions:可以通过css或者stylekey访问googlebackgrounddecorators来修改页面的背景的颜色.wordpress全面插件教程.webpagechrome,强烈推荐,用于站内搜索,因为我也想知道在chrome中具体的操作方法。不能忽略这个网站和它提供的系列免费插件。
chrome抓取网页插件(chrome抓取网页插件devtools3.7.9版本即将支持iphonexr(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-08 00:04
chrome抓取网页插件devtools3.7.9版本即将支持iphonexr!请去tb购买,本作品不支持android。作者@@国际支付负责人林小云加微信号:zuilin14,欢迎交流,留言无法转载。
applestore商店搜索macbookpro:apple-store,itunesconnect-store&applestorepricing
如果要的是xcode的程序内调用的java和c,用第三方可以实现的,比如clojure,kotlin,还有,但是不通过applemarket。另外git也可以,
一个简单的https程序:/
c++
sublimetext3
chrome或者谷歌maps
:standard-repair-and-repair-on-android-x86-devices
applemarket有专门修复这种问题的插件,
chrome就可以吧,android不像ios可以通过官方xp程序修复,一般都是通过第三方来修复的,我一般用testflight修复,在testflight官网apk扫描的话可以找到的地址,然后可以下载。
applestoregooglemaps
android和ios都有官方的googlemap可以替换了
我一般只测试appstore上的包,
这个问题在知乎上已经有类似的了。而且据我所知目前国内能做到的基本都是借助猎豹安全大师。 查看全部
chrome抓取网页插件(chrome抓取网页插件devtools3.7.9版本即将支持iphonexr(图))
chrome抓取网页插件devtools3.7.9版本即将支持iphonexr!请去tb购买,本作品不支持android。作者@@国际支付负责人林小云加微信号:zuilin14,欢迎交流,留言无法转载。
applestore商店搜索macbookpro:apple-store,itunesconnect-store&applestorepricing
如果要的是xcode的程序内调用的java和c,用第三方可以实现的,比如clojure,kotlin,还有,但是不通过applemarket。另外git也可以,
一个简单的https程序:/
c++
sublimetext3
chrome或者谷歌maps
:standard-repair-and-repair-on-android-x86-devices
applemarket有专门修复这种问题的插件,
chrome就可以吧,android不像ios可以通过官方xp程序修复,一般都是通过第三方来修复的,我一般用testflight修复,在testflight官网apk扫描的话可以找到的地址,然后可以下载。
applestoregooglemaps
android和ios都有官方的googlemap可以替换了
我一般只测试appstore上的包,
这个问题在知乎上已经有类似的了。而且据我所知目前国内能做到的基本都是借助猎豹安全大师。
chrome抓取网页插件(20款为开发者的优质插件,让你随时暂停JS动画)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-07 12:09
毫无疑问,Chrome相对于其他浏览器具有明显的优势,但它的对手火狐却是众多前端围攻者和开发者的挚爱。为了尽可能的提升用户体验,火狐社区开发了并且毫不夸张的说它是网站开发者的首选浏览器。
本文采集了 20 个面向开发人员的高级插件,Web 开发人员可以借助这些插件创建令人惊叹的创意 网站 页面。接下来,我们来看看这些插件。
1. 萤火虫
作为开发领域最著名的插件,Firebug 允许您在浏览器中实时运行 HTML、CSS 等代码。Firebug 内置了强大的 Javascript 调试工具,可以让你随时暂停 JS 动画,观察静态细节。如果觉得效果不明显,也可以用JS分析仪分析校准,找出问题的症结所在。
2. 幽灵
Ghostery 用于检测“不可见的网站”、检测跟踪器、网站 漏洞利用、扫描像素、监控 Facebook 和 Google Analytics 以及 1000 多家其他在线广告提供商、行为数据提供商以及与相关的所有活动数据你网站,包括内容提供者。
3. 网络开发人员
Web Developer 提供广泛的菜单和自定义工具,允许您控制和管理、分析、验证和优化网页。您可以管理 CSS、HTML、表格、测量特定部件的尺寸、实时编辑页面等等。
4. 旗狐
Flagfox 是一个插件,可以使用一个小标志来表示服务器的物理地址。有了这个插件,你会更清楚自己的浏览器连接在哪里,也可以用它来识别服务器所在的地区和语言,查看服务器所在的法律法规是否有特殊限制, 等等。当然,您也可以通过外部操作了解更多信息,也可以自己添加自定义操作,设置快速访问或设置键盘快捷键。
5. Fireftp
除了快速高效地传输文件外,Fireftp 还具有更多高级功能,包括目录比较、同步导航、SFTP、SSL 加密、搜索和过滤、完整性检查、远程编辑、鼠标拖放等。
6. Colorzilla
您可以在 Colorzilla 的帮助下使您浏览的页面更加丰富多彩,该插件可以快速拾取颜色并将它们粘贴到其他程序中。此外,Colorzilla 可以帮助您放大正在查看的页面并测量页面上任意两点之间的距离。Colorzilla 内置了调色板,一方面方便用户获取预设颜色,同时也可以保存从网页抓取的颜色。DOM Spying 功能可以帮助您监控 DOM 元素的各种信息。
7. 快速Java
借助 Quick Java 插件,您无需打开系统设置和插件管理即可快速管理浏览器功能,包括 Java、Javascript、Cookies、动画图片、flash、silverlight、样式表、poxy 以及自动图片加载等功能。对于高级用户来说,这个插件可能是他们的一杯茶。
8. SQLite 管理器
该插件可以帮助您管理系统中的SQLite数据库,方便浏览数据、查表、进行增删改查等一系列操作。使用 SQLite Manger,您可以在操作面板中进行常用操作,轻松访问工具栏、按钮和菜单。
9. 表格工具 2
这是一个专为Web表格设计的工具,通过它可以对HTML表格进行复杂的操作,包括复制表格/行/列/单元格、排序、基于正则表达式的搜索、过滤、生成图表、统计、合并和比较。操作也很简单,选择需要操作的表格,右键菜单,点击“表格工具2”选项。
10. 无脚本安全套装
此插件将帮助您控制 Java 和 Javascript 以及其他可执行内容,以便在您信任和允许的域中运行,例如某些银行网站。它可以帮助您抵御跨站脚本攻击(XSS)、跨域 DNS 绑定和 CSRF 攻击(攻击路由器)、反劫持,并内置独特的 ClearClick 技术。
11. DOM 检查器
DOM Viewer 是一个用于检查和编辑网页或 XUL 应用程序的 DOM 工具。在其两列编辑器中,您可以在多个不同视图中查看文档中的节点。
12. 修改标头
标头编辑器可以为您添加、替换和过滤 HTTP 标头部分并将它们发送到服务器。该工具主要用于移动互联网开发和HTTP测试。
13. 很棒的截图
这个截图工具可以帮助你截取整个网页,或者网页的一部分,可以标记、添加文字、添加图形、箭头,还可以模糊敏感信息。截图处理后,还可以一键上传分享。
经常写Javascript代码的同学可能会喜欢这个JS调试工具。
15. Cookie 管理器
这个cookie管理器允许您查看、编辑和创建新的cookie,也方便您查询一些附加信息,一次编辑多个cookie,以及一键备份/恢复。
16. Yslow
Yslow 可用于分析网页并提供改进网页和改善体验的建议。
17. HTML 验证器
这个 HTML 验证工具根据 Firefox 的内部验证机制监控网页,并用图标标记页面上的错误数量。
18. json 视图
通常当你看到一个 .json 文件时,浏览器会直接下载它而不是打开文件,Json View 允许浏览器像打开 XML 文件一样打开和显示文档。文档的显示是结构化的,特定内容突出显示,数组对象可折叠。即使 JSON 文档收录错误,也会显示原创文本。 查看全部
chrome抓取网页插件(20款为开发者的优质插件,让你随时暂停JS动画)
毫无疑问,Chrome相对于其他浏览器具有明显的优势,但它的对手火狐却是众多前端围攻者和开发者的挚爱。为了尽可能的提升用户体验,火狐社区开发了并且毫不夸张的说它是网站开发者的首选浏览器。
本文采集了 20 个面向开发人员的高级插件,Web 开发人员可以借助这些插件创建令人惊叹的创意 网站 页面。接下来,我们来看看这些插件。
1. 萤火虫
作为开发领域最著名的插件,Firebug 允许您在浏览器中实时运行 HTML、CSS 等代码。Firebug 内置了强大的 Javascript 调试工具,可以让你随时暂停 JS 动画,观察静态细节。如果觉得效果不明显,也可以用JS分析仪分析校准,找出问题的症结所在。
2. 幽灵
Ghostery 用于检测“不可见的网站”、检测跟踪器、网站 漏洞利用、扫描像素、监控 Facebook 和 Google Analytics 以及 1000 多家其他在线广告提供商、行为数据提供商以及与相关的所有活动数据你网站,包括内容提供者。
3. 网络开发人员
Web Developer 提供广泛的菜单和自定义工具,允许您控制和管理、分析、验证和优化网页。您可以管理 CSS、HTML、表格、测量特定部件的尺寸、实时编辑页面等等。
4. 旗狐
Flagfox 是一个插件,可以使用一个小标志来表示服务器的物理地址。有了这个插件,你会更清楚自己的浏览器连接在哪里,也可以用它来识别服务器所在的地区和语言,查看服务器所在的法律法规是否有特殊限制, 等等。当然,您也可以通过外部操作了解更多信息,也可以自己添加自定义操作,设置快速访问或设置键盘快捷键。
5. Fireftp
除了快速高效地传输文件外,Fireftp 还具有更多高级功能,包括目录比较、同步导航、SFTP、SSL 加密、搜索和过滤、完整性检查、远程编辑、鼠标拖放等。
6. Colorzilla
您可以在 Colorzilla 的帮助下使您浏览的页面更加丰富多彩,该插件可以快速拾取颜色并将它们粘贴到其他程序中。此外,Colorzilla 可以帮助您放大正在查看的页面并测量页面上任意两点之间的距离。Colorzilla 内置了调色板,一方面方便用户获取预设颜色,同时也可以保存从网页抓取的颜色。DOM Spying 功能可以帮助您监控 DOM 元素的各种信息。
7. 快速Java
借助 Quick Java 插件,您无需打开系统设置和插件管理即可快速管理浏览器功能,包括 Java、Javascript、Cookies、动画图片、flash、silverlight、样式表、poxy 以及自动图片加载等功能。对于高级用户来说,这个插件可能是他们的一杯茶。
8. SQLite 管理器
该插件可以帮助您管理系统中的SQLite数据库,方便浏览数据、查表、进行增删改查等一系列操作。使用 SQLite Manger,您可以在操作面板中进行常用操作,轻松访问工具栏、按钮和菜单。
9. 表格工具 2
这是一个专为Web表格设计的工具,通过它可以对HTML表格进行复杂的操作,包括复制表格/行/列/单元格、排序、基于正则表达式的搜索、过滤、生成图表、统计、合并和比较。操作也很简单,选择需要操作的表格,右键菜单,点击“表格工具2”选项。
10. 无脚本安全套装
此插件将帮助您控制 Java 和 Javascript 以及其他可执行内容,以便在您信任和允许的域中运行,例如某些银行网站。它可以帮助您抵御跨站脚本攻击(XSS)、跨域 DNS 绑定和 CSRF 攻击(攻击路由器)、反劫持,并内置独特的 ClearClick 技术。
11. DOM 检查器
DOM Viewer 是一个用于检查和编辑网页或 XUL 应用程序的 DOM 工具。在其两列编辑器中,您可以在多个不同视图中查看文档中的节点。
12. 修改标头
标头编辑器可以为您添加、替换和过滤 HTTP 标头部分并将它们发送到服务器。该工具主要用于移动互联网开发和HTTP测试。
13. 很棒的截图
这个截图工具可以帮助你截取整个网页,或者网页的一部分,可以标记、添加文字、添加图形、箭头,还可以模糊敏感信息。截图处理后,还可以一键上传分享。
经常写Javascript代码的同学可能会喜欢这个JS调试工具。
15. Cookie 管理器
这个cookie管理器允许您查看、编辑和创建新的cookie,也方便您查询一些附加信息,一次编辑多个cookie,以及一键备份/恢复。
16. Yslow
Yslow 可用于分析网页并提供改进网页和改善体验的建议。
17. HTML 验证器
这个 HTML 验证工具根据 Firefox 的内部验证机制监控网页,并用图标标记页面上的错误数量。
18. json 视图
通常当你看到一个 .json 文件时,浏览器会直接下载它而不是打开文件,Json View 允许浏览器像打开 XML 文件一样打开和显示文档。文档的显示是结构化的,特定内容突出显示,数组对象可折叠。即使 JSON 文档收录错误,也会显示原创文本。
chrome抓取网页插件( PageAnalytics可以从GoogleAnalytics中读取到你的网站数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-06 12:30
PageAnalytics可以从GoogleAnalytics中读取到你的网站数据)
Page Analytics 是 Chrome 浏览器上的一个插件。它可以从 Google Analytics 读取您的 网站 数据,并直接在网页上各处的链接上显示点击数据。根据这些数据,你可以很容易地判断 网站 的布局是否需要优化。
一、安装教学
安装地址:Chrome Store
打开后点击添加到Chrome(仅支持Chrome浏览器),完成插件安装。
安装完成后,可以在浏览器插件中看到Page Analytics的图标,默认是OFF(关闭),点击会开启(打开),然后点击下方彩色图标,会立即覆盖在网站上,通过色块,你可以第一时间知道整个网站是如何被用户点击的,哪些区域更受欢迎。
二、无法捕获数据
这个插件有时会捕捉不到GA数据,出现的错误信息如下——
大致解释一下如何做到这一点:
·本插件的原理是加载网站的GA数据。而且我们只能看到自己账号的GA数据,所以使用这个插件是看不到别人网站的数据的。
·请先确认您是否已登录GA账号。您可以先尝试登录GA官网。
·确认登录账号后,打开这个插件,几秒后,一般可以看到你的网站数据。
· 如果仍然看不到它,请关闭浏览器,重新开始,或刷新页面。
三、无法显示数据的地方
这个插件操作非常简单,界面也非常友好。哪个按钮以及链接上的点击次数可以让您轻松地根据数字做出决定。
但请不要相信所有的数据,因为你看到的数字(或数字)很可能不是肤浅的认识,也可能导致你做出判断性决定,反而阻碍了网站的网站。
请务必注意,某些链接或按钮不会看到数据,但这并不意味着访问者不会点击这些地方。
1、GA数据不计算外链点击量,比如网站的分享功能,所以插件无法展示。
2、标签链接可能不算数。GA后端的数据中会有标签数据,可能是插件问题。
3、各种按钮的点击都不会被统计或显示,因为它们根本不是 URL,对吧?
4、数据统计时间跨度过大。例如,它已经被计算了好几年。可能因为点击几乎为0而无法显示。不过这种情况比较少见。
四、如何判断一个链接的效果
有时一个页面上会有多个相同的链接。比如首页链接会出现在网站的顶部logo、导航栏、底部网页中,所以要谨慎对待此类链接的数据。
比如在一个网页上,三个相同的链接点击率是3%,那能算3%*3=9%的点击率吗?不,这 3% 仅由同一链接显示。
因此,遗憾的是,我们无法知道访问者更喜欢在同一个页面和多个相同的链接上点击哪个链接。
所以如果想知道同一个链接不同位置的效果,就必须和外链一样,把GA代码单独放在链接按钮上。
概括
总的来说,这个插件还是挺方便的,它可以让我们很方便的知道某个区域内所有连接的点击率,并且根据点击率,可以增加热门链接的排序,降低排序不受欢迎的链接。,甚至直接去掉,换成更有效的链接。 查看全部
chrome抓取网页插件(
PageAnalytics可以从GoogleAnalytics中读取到你的网站数据)
Page Analytics 是 Chrome 浏览器上的一个插件。它可以从 Google Analytics 读取您的 网站 数据,并直接在网页上各处的链接上显示点击数据。根据这些数据,你可以很容易地判断 网站 的布局是否需要优化。
一、安装教学
安装地址:Chrome Store
打开后点击添加到Chrome(仅支持Chrome浏览器),完成插件安装。
安装完成后,可以在浏览器插件中看到Page Analytics的图标,默认是OFF(关闭),点击会开启(打开),然后点击下方彩色图标,会立即覆盖在网站上,通过色块,你可以第一时间知道整个网站是如何被用户点击的,哪些区域更受欢迎。
二、无法捕获数据
这个插件有时会捕捉不到GA数据,出现的错误信息如下——
大致解释一下如何做到这一点:
·本插件的原理是加载网站的GA数据。而且我们只能看到自己账号的GA数据,所以使用这个插件是看不到别人网站的数据的。
·请先确认您是否已登录GA账号。您可以先尝试登录GA官网。
·确认登录账号后,打开这个插件,几秒后,一般可以看到你的网站数据。
· 如果仍然看不到它,请关闭浏览器,重新开始,或刷新页面。
三、无法显示数据的地方
这个插件操作非常简单,界面也非常友好。哪个按钮以及链接上的点击次数可以让您轻松地根据数字做出决定。
但请不要相信所有的数据,因为你看到的数字(或数字)很可能不是肤浅的认识,也可能导致你做出判断性决定,反而阻碍了网站的网站。
请务必注意,某些链接或按钮不会看到数据,但这并不意味着访问者不会点击这些地方。
1、GA数据不计算外链点击量,比如网站的分享功能,所以插件无法展示。
2、标签链接可能不算数。GA后端的数据中会有标签数据,可能是插件问题。
3、各种按钮的点击都不会被统计或显示,因为它们根本不是 URL,对吧?
4、数据统计时间跨度过大。例如,它已经被计算了好几年。可能因为点击几乎为0而无法显示。不过这种情况比较少见。
四、如何判断一个链接的效果
有时一个页面上会有多个相同的链接。比如首页链接会出现在网站的顶部logo、导航栏、底部网页中,所以要谨慎对待此类链接的数据。
比如在一个网页上,三个相同的链接点击率是3%,那能算3%*3=9%的点击率吗?不,这 3% 仅由同一链接显示。
因此,遗憾的是,我们无法知道访问者更喜欢在同一个页面和多个相同的链接上点击哪个链接。
所以如果想知道同一个链接不同位置的效果,就必须和外链一样,把GA代码单独放在链接按钮上。
概括
总的来说,这个插件还是挺方便的,它可以让我们很方便的知道某个区域内所有连接的点击率,并且根据点击率,可以增加热门链接的排序,降低排序不受欢迎的链接。,甚至直接去掉,换成更有效的链接。

