
ajax抓取网页内容
ajax抓取网页内容(安装成功获取JS返回值库元素即为安装的成功示例一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-14 02:19
前言
现在很多 网站 大量使用 JavaScript,或者使用 Ajax 技术。这样,网页加载完成后,虽然url没有变化,但是网页的DOM元素的内容是可以动态变化的。如果使用python自带的requests库或者urllib库来处理这类网页,得到的网页内容与浏览器显示的网页内容不一致。
解决方案
使用 Selenium+PhantomJS。这两者结合起来运行一个非常强大的爬虫,可以处理 cookie、JavaScript、标头和任何你想要的东西。
安装第三方库
Selenium 是一个强大的网络数据采集 工具,最初是为网站 自动化测试而开发的,并且有对应的Python库;
Selenium 安装命令:
pip install selenium
安装 PhantomJS
PhantomJS是一个基于webkit核心的无头浏览器,也就是没有UI界面,也就是一个浏览器,但是里面的点击、翻页等与人相关的操作需要程序设计和实现。通过编写js程序,可以直接与webkit核心进行交互,在此之上还可以结合java语言等,通过java调用js等相关操作。需要到官网下载对应平台的压缩文件;
PhantomJS(phantomjs-2.1.1-windows)下载地址:根据不同系统选择对应版本
对于windows系统,下载PhantomJs,将解压后的可执行文件放到已经设置环境变量的地方。如果不设置,后面的代码都会设置,方便直接放这里;
然后勾选,在cmd窗口输入phantomjs:
当出现这样的画面时,就意味着成功;
Mac系统,下载后保存到一个路径,可以直接保存在环境变量路径中,也可以在环境变量路径中创建指向phantomjs的软链接
ln -s /usr/local/opt/my/phantomjs-2.1.1-macosx/bin/phantomjs /usr/local/bin
测试代码:
from selenium import webdriver
<p>driver = webdriver.PhantomJS()
driver.get('http://www.baidu.com/')
print (driver.page_source)</p>
如果能成功获取到页面元素,则安装成功。
示例一:
Selenium+PhantomJS 示例代码:
from selenium import webdriver
<p>driver = webdriver.PhantomJS()
driver.get('http://www.cnblogs.com/feng0815/p/8735491.html')
#获取网页源码
data = driver.page_source
print(data)
#获取元素的html源码
tableData = driver.find_elements_by_tag_name('tableData').get_attribute('innerHTML')
#获取元素的id值
tableI = driver.find_elements_by_tag_name('tableData').get_attribute('id')
#获取元素的文本内容
tableI = driver.find_elements_by_tag_name('tableData').text
driver.quit()</p>
可以输出网页的源代码,说明安装成功
获取JS返回值 查看全部
ajax抓取网页内容(安装成功获取JS返回值库元素即为安装的成功示例一)
前言
现在很多 网站 大量使用 JavaScript,或者使用 Ajax 技术。这样,网页加载完成后,虽然url没有变化,但是网页的DOM元素的内容是可以动态变化的。如果使用python自带的requests库或者urllib库来处理这类网页,得到的网页内容与浏览器显示的网页内容不一致。
解决方案
使用 Selenium+PhantomJS。这两者结合起来运行一个非常强大的爬虫,可以处理 cookie、JavaScript、标头和任何你想要的东西。
安装第三方库
Selenium 是一个强大的网络数据采集 工具,最初是为网站 自动化测试而开发的,并且有对应的Python库;
Selenium 安装命令:
pip install selenium
安装 PhantomJS
PhantomJS是一个基于webkit核心的无头浏览器,也就是没有UI界面,也就是一个浏览器,但是里面的点击、翻页等与人相关的操作需要程序设计和实现。通过编写js程序,可以直接与webkit核心进行交互,在此之上还可以结合java语言等,通过java调用js等相关操作。需要到官网下载对应平台的压缩文件;
PhantomJS(phantomjs-2.1.1-windows)下载地址:根据不同系统选择对应版本
对于windows系统,下载PhantomJs,将解压后的可执行文件放到已经设置环境变量的地方。如果不设置,后面的代码都会设置,方便直接放这里;
然后勾选,在cmd窗口输入phantomjs:
当出现这样的画面时,就意味着成功;
Mac系统,下载后保存到一个路径,可以直接保存在环境变量路径中,也可以在环境变量路径中创建指向phantomjs的软链接
ln -s /usr/local/opt/my/phantomjs-2.1.1-macosx/bin/phantomjs /usr/local/bin
测试代码:
from selenium import webdriver
<p>driver = webdriver.PhantomJS()
driver.get('http://www.baidu.com/')
print (driver.page_source)</p>
如果能成功获取到页面元素,则安装成功。
示例一:
Selenium+PhantomJS 示例代码:
from selenium import webdriver
<p>driver = webdriver.PhantomJS()
driver.get('http://www.cnblogs.com/feng0815/p/8735491.html')
#获取网页源码
data = driver.page_source
print(data)
#获取元素的html源码
tableData = driver.find_elements_by_tag_name('tableData').get_attribute('innerHTML')
#获取元素的id值
tableI = driver.find_elements_by_tag_name('tableData').get_attribute('id')
#获取元素的文本内容
tableI = driver.find_elements_by_tag_name('tableData').text
driver.quit()</p>
可以输出网页的源代码,说明安装成功
获取JS返回值
ajax抓取网页内容(一个视图页面执行一个给评论点赞的功能,发现问题的根源)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-14 02:18
有这样一个例子,在thinkPHP视图页面上执行点赞评论功能。为了增强用户体验,一般使用ajax异步请求在后台处理同类数据。页面成功后,就可以执行本地更新的数据了。前台一般使用jquery,通过执行jquery的ajax方法来完成任务请求更加简单方便。
简要描述出现问题的场景
tinkPHP在应用路由后在视图页面执行ajax,并没有正常返回数据。以下代码描述了将评论 ID 获取到 ajax 请求的过程。根据后台处理规则,cmthot 方法会将一个更新后的 post-like 数据(数据)返回给前台。
function uphot(o){
var cmtid=$(o).attr("cmtid");//获取评论ID
$.ajax({
type:"post",
dataType:"json",
data:{cmtid:cmtid},
url:"{:url('cmthot')}",//请求地址
success:function(data){
$('#hot'+cmtid).html(' '+data);
},
});
}
就是这样,和like数据没有正常返回,报错。通过alert(data)可以看到这样的场景。
再来看看后台处理部分
public function updatehot()
{
if(request()->isAjax()){
$cmtid=input('cmtid');
$cmthot=model('comment')->cmthot($cmtid);
return $cmthot;
}else{
$this->error('非法请求');
}
}
上述代码中,通过控制器将ajax获取的评论ID扔到模型中(模型代码不会贴出来)进行处理,并将新增的点赞返回给前台。前台(前面的代码)通过 .html 重写新数据。
发现问题的根源来自于路由
为了调试,我把ajax改成链接直接提交了。返回的结果都是正常的,即后端控制器和模型都正常,没有错误。问题应该仍然在ajax上。
因为这种操作方式,我经常在网站的后台使用,一般不会报错,所以又去后台对比一下同样的功能。后台类似的功能都是正常的。
为了找出问题的原因,我比较了网站的正反两面的区别。唯一明显的是前台为了用户体验使用路由,简化了url。后台使用iframe框架,url固定为frame页面的地址,所以当时没有使用路由。
方便找到差异然后出错。第一段代码中请求的地址不存在,因为它是路由的。此处需要添加路由地址,所以只需添加一个斜杠即可。url:"{:url('/cmthot')}",
最后是因为一个斜线,返回了一个html的页面,所以要小心。 查看全部
ajax抓取网页内容(一个视图页面执行一个给评论点赞的功能,发现问题的根源)
有这样一个例子,在thinkPHP视图页面上执行点赞评论功能。为了增强用户体验,一般使用ajax异步请求在后台处理同类数据。页面成功后,就可以执行本地更新的数据了。前台一般使用jquery,通过执行jquery的ajax方法来完成任务请求更加简单方便。
简要描述出现问题的场景
tinkPHP在应用路由后在视图页面执行ajax,并没有正常返回数据。以下代码描述了将评论 ID 获取到 ajax 请求的过程。根据后台处理规则,cmthot 方法会将一个更新后的 post-like 数据(数据)返回给前台。
function uphot(o){
var cmtid=$(o).attr("cmtid");//获取评论ID
$.ajax({
type:"post",
dataType:"json",
data:{cmtid:cmtid},
url:"{:url('cmthot')}",//请求地址
success:function(data){
$('#hot'+cmtid).html(' '+data);
},
});
}
就是这样,和like数据没有正常返回,报错。通过alert(data)可以看到这样的场景。
再来看看后台处理部分
public function updatehot()
{
if(request()->isAjax()){
$cmtid=input('cmtid');
$cmthot=model('comment')->cmthot($cmtid);
return $cmthot;
}else{
$this->error('非法请求');
}
}
上述代码中,通过控制器将ajax获取的评论ID扔到模型中(模型代码不会贴出来)进行处理,并将新增的点赞返回给前台。前台(前面的代码)通过 .html 重写新数据。
发现问题的根源来自于路由
为了调试,我把ajax改成链接直接提交了。返回的结果都是正常的,即后端控制器和模型都正常,没有错误。问题应该仍然在ajax上。
因为这种操作方式,我经常在网站的后台使用,一般不会报错,所以又去后台对比一下同样的功能。后台类似的功能都是正常的。
为了找出问题的原因,我比较了网站的正反两面的区别。唯一明显的是前台为了用户体验使用路由,简化了url。后台使用iframe框架,url固定为frame页面的地址,所以当时没有使用路由。
方便找到差异然后出错。第一段代码中请求的地址不存在,因为它是路由的。此处需要添加路由地址,所以只需添加一个斜杠即可。url:"{:url('/cmthot')}",
最后是因为一个斜线,返回了一个html的页面,所以要小心。
ajax抓取网页内容(Google的URL变了,音乐播放没有中断的原因是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-01 04:00
越来越多的网站,开始使用“单页结构”(Single-page application)。
整个网站只有一个网页,它使用Ajax技术根据用户的输入加载不同的内容。
这种方式的好处是用户体验好,节省了流量。缺点是AJAX内容不能被搜索引擎抓取。例如,您有一个 网站。
https://example.com
用户通过英镑结构的 URL 看到不同的内容。
https://example.com#1 https://example.com#2 https://example.com#3
但是,搜索引擎只抓取和忽略主题标签,因此它们无法索引内容。
为了解决这个问题,谷歌想出了“哈希+感叹号”的结构。
https://example.com#!1
当 Google 找到上述网址时,它会自动抓取另一个网址:
https://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放在这个 URL 上,Google 就会收录。但问题是,“英镑+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
https://twitter.com/ruanyf
改成
https://twitter.com/#!/ruanyf
结果,用户投诉连连,仅半年就被废止。
那么,有没有什么方法可以让搜索引擎在抓取 AJAX 内容的同时保持更直观的 URL?
我一直认为没有办法做到这一点,直到我看到了 Discourse 创始人之一 Robin Ward 的解决方案。
Discourse 是一个严重依赖 Ajax 的论坛程序,但必须使用 Google收录 内容。它的解决方案是放弃英镑符号结构并使用 History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏的网址变了,但音乐播放没有中断!
History API 的详细介绍超出了本文章 的范围。这里简单说一下,它的作用是在浏览器的History对象中添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以使新的 URL 出现在地址栏中。History对象的pushState方法接受三个参数,新的URL是第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前所有主流浏览器都支持这种方法:Chrome (26.0+), Firefox (20.0+), IE (10.0+), Safari (0.0+) @5.1+),歌剧 (12.1+)。
以下是罗宾·沃德 (Robin Ward) 的做法。
首先,用History API替换hashtag结构,让每个hashtag变成一个正常路径的URL,这样搜索引擎就会爬取每一个网页。
example.com/1 example.com/2 example.com/3
然后,定义一个处理 Ajax 部分并基于 URL 获取内容的 JavaScript 函数(假设是 jQuery)。
function anchorClick(link) {<br /> var linkSplit = link.split('/').pop();<br /> $.get('api/' + linkSplit, function(data) {<br /> $('#content').html(data);<br /> });<br /> }
再次定义鼠标点击事件。
$('#container').on('click', 'a', function(e) {<br /> window.history.pushState(null, null, $(this).attr('href'));<br /> anchorClick($(this).attr('href'));<br /> e.preventDefault();<br /> });
还要考虑到用户单击浏览器的“前进/后退”按钮。此时触发了History对象的popstate事件。
window.addEventListener('popstate', function(e) { <br /> anchorClick(location.pathname); <br /> });
定义完以上三段代码后,就可以在不刷新页面的情况下显示正常的路径URL和AJAX内容了。
最后,设置服务器端。
因为没有使用主题标签结构,所以每个 URL 都是不同的请求。因此,服务器需要为所有这些请求返回具有以下结构的网页,以防止 404 错误。
<br /> <br /> <br /> <br /> ... ...<br /> <br /> <br />
如果你仔细看上面的代码,你会发现有一个noscript标签,这就是秘密。
我们将搜索引擎应该为 收录 的所有内容放在 noscript 标记中。在这种情况下,用户仍然可以在不刷新页面的情况下进行 AJAX 操作,但是搜索引擎会收录每个页面的主要内容! 查看全部
ajax抓取网页内容(Google的URL变了,音乐播放没有中断的原因是什么?)
越来越多的网站,开始使用“单页结构”(Single-page application)。
整个网站只有一个网页,它使用Ajax技术根据用户的输入加载不同的内容。

这种方式的好处是用户体验好,节省了流量。缺点是AJAX内容不能被搜索引擎抓取。例如,您有一个 网站。
https://example.com
用户通过英镑结构的 URL 看到不同的内容。
https://example.com#1 https://example.com#2 https://example.com#3
但是,搜索引擎只抓取和忽略主题标签,因此它们无法索引内容。
为了解决这个问题,谷歌想出了“哈希+感叹号”的结构。
https://example.com#!1
当 Google 找到上述网址时,它会自动抓取另一个网址:
https://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放在这个 URL 上,Google 就会收录。但问题是,“英镑+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
https://twitter.com/ruanyf
改成
https://twitter.com/#!/ruanyf
结果,用户投诉连连,仅半年就被废止。
那么,有没有什么方法可以让搜索引擎在抓取 AJAX 内容的同时保持更直观的 URL?
我一直认为没有办法做到这一点,直到我看到了 Discourse 创始人之一 Robin Ward 的解决方案。

Discourse 是一个严重依赖 Ajax 的论坛程序,但必须使用 Google收录 内容。它的解决方案是放弃英镑符号结构并使用 History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?

地址栏的网址变了,但音乐播放没有中断!
History API 的详细介绍超出了本文章 的范围。这里简单说一下,它的作用是在浏览器的History对象中添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以使新的 URL 出现在地址栏中。History对象的pushState方法接受三个参数,新的URL是第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前所有主流浏览器都支持这种方法:Chrome (26.0+), Firefox (20.0+), IE (10.0+), Safari (0.0+) @5.1+),歌剧 (12.1+)。
以下是罗宾·沃德 (Robin Ward) 的做法。
首先,用History API替换hashtag结构,让每个hashtag变成一个正常路径的URL,这样搜索引擎就会爬取每一个网页。
example.com/1 example.com/2 example.com/3
然后,定义一个处理 Ajax 部分并基于 URL 获取内容的 JavaScript 函数(假设是 jQuery)。
function anchorClick(link) {<br /> var linkSplit = link.split('/').pop();<br /> $.get('api/' + linkSplit, function(data) {<br /> $('#content').html(data);<br /> });<br /> }
再次定义鼠标点击事件。
$('#container').on('click', 'a', function(e) {<br /> window.history.pushState(null, null, $(this).attr('href'));<br /> anchorClick($(this).attr('href'));<br /> e.preventDefault();<br /> });
还要考虑到用户单击浏览器的“前进/后退”按钮。此时触发了History对象的popstate事件。
window.addEventListener('popstate', function(e) { <br /> anchorClick(location.pathname); <br /> });
定义完以上三段代码后,就可以在不刷新页面的情况下显示正常的路径URL和AJAX内容了。
最后,设置服务器端。
因为没有使用主题标签结构,所以每个 URL 都是不同的请求。因此,服务器需要为所有这些请求返回具有以下结构的网页,以防止 404 错误。
<br /> <br /> <br /> <br /> ... ...<br /> <br /> <br />
如果你仔细看上面的代码,你会发现有一个noscript标签,这就是秘密。
我们将搜索引擎应该为 收录 的所有内容放在 noscript 标记中。在这种情况下,用户仍然可以在不刷新页面的情况下进行 AJAX 操作,但是搜索引擎会收录每个页面的主要内容!
ajax抓取网页内容(ajaxajax )
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-02-28 23:05
)
阿贾克斯
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
Ajax = 异步 JavaScript 和 XML 或 HTML(标准通用标记语言的子集)。
Ajax 是一种用于创建快速和动态网页的技术。
Ajax 是一种无需重新加载整个网页即可更新网页部分的技术。
Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
(注:以上介绍来自百度百科)
本文主要介绍ajax登录的异步认证。
一、js 部分
1//定义一个变量用于存放XMLHttpRequest对象
2var xmlHttp;
3function checkIt(){
4 //获取文本框的值
5 var username=document.getElementById("username").value;//从登陆框中获取用户输入的账号
6 //alert("测试获取文本框的值:"+username);
7 //先创建XMLHttpRequest对象
8 // code for IE7+, Firefox, Chrome, Opera, Safari
9 if (window.XMLHttpRequest) {
10 xmlHttp = new XMLHttpRequest();
11 } else {// code for IE6, IE5
12 xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
13 }
14 //服务器地址和数据
15 var url="Login_ajax.jsp?username="+username;//此处的地址为ajax验证控制器的地址
16 //规定请求的类型、URL 以及是否异步处理请求。
17 xmlHttp.open("GET",url,true);
18 //将请求发送到服务器
19 xmlHttp.send();
20 //回调函数
21 xmlHttp.onreadystatechange=function(){
22 if (xmlHttp.readyState==4 && xmlHttp.status==200){
23 //给div设置内容
24 document.getElementById("errorAccount").innerHTML = xmlHttp.responseText;//把验证是否成功的信息返回到界面上,如下图
25
26 }
27 }
28}
29
30
二、html 部分
1
2
3
4
5
6 //从控制类中返回验证信息
7
8
9
三、控制器部分(这里用jsp替换servlet)
1
17
18 查看全部
ajax抓取网页内容(ajaxajax
)
阿贾克斯
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
Ajax = 异步 JavaScript 和 XML 或 HTML(标准通用标记语言的子集)。
Ajax 是一种用于创建快速和动态网页的技术。
Ajax 是一种无需重新加载整个网页即可更新网页部分的技术。
Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
(注:以上介绍来自百度百科)
本文主要介绍ajax登录的异步认证。
一、js 部分
1//定义一个变量用于存放XMLHttpRequest对象
2var xmlHttp;
3function checkIt(){
4 //获取文本框的值
5 var username=document.getElementById("username").value;//从登陆框中获取用户输入的账号
6 //alert("测试获取文本框的值:"+username);
7 //先创建XMLHttpRequest对象
8 // code for IE7+, Firefox, Chrome, Opera, Safari
9 if (window.XMLHttpRequest) {
10 xmlHttp = new XMLHttpRequest();
11 } else {// code for IE6, IE5
12 xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
13 }
14 //服务器地址和数据
15 var url="Login_ajax.jsp?username="+username;//此处的地址为ajax验证控制器的地址
16 //规定请求的类型、URL 以及是否异步处理请求。
17 xmlHttp.open("GET",url,true);
18 //将请求发送到服务器
19 xmlHttp.send();
20 //回调函数
21 xmlHttp.onreadystatechange=function(){
22 if (xmlHttp.readyState==4 && xmlHttp.status==200){
23 //给div设置内容
24 document.getElementById("errorAccount").innerHTML = xmlHttp.responseText;//把验证是否成功的信息返回到界面上,如下图
25
26 }
27 }
28}
29
30


二、html 部分

1
2
3
4
5
6 //从控制类中返回验证信息
7
8
9
三、控制器部分(这里用jsp替换servlet)

1
17
18
ajax抓取网页内容(ajax抓取网页内容教程--复制第一张图片到本地firefox)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-28 19:07
ajax抓取网页内容教程--复制第一张图片到本地firefox获取网页元素是通过javascript(隐藏函数也可以)和一个一个字符串的点击获取,如下动画:通过firefox的chromeapi-firefox-devtools,调用了带ffi属性的ffimethod,经过上面修改的javascript,ffimethod传入chromeapi-firefox-devtools,生成相应的domain,代码如下:document.getelementbyid('a').innerhtml=document.getelementbyid('b').innerhtmlchrome在执行之前,用"nslookup"获取到服务器获取的uri,再使用代码的:md5(非正则表达式)解密原网址中的html文件,如下代码所示:chrome回到了之前的网址,会把代码中的:md5换成对应的网址获取到网页元素的链接。
服务器返回response,我们就可以在chrome控制台中看到html代码的网址,执行javascript获取到相应的数据。当然,上面chrome处理html的方式是对于静态网页(png或jpg)而言,如果是动态页面(html或xml),就只能用cookie处理了。cookie是最古老、简单的网络身份认证机制。
楼上的意思是网络爬虫在调用网页时获取源代码,然后本地获取本地文件,再用pythonweb框架进行调用。但是这样并不能实现网页url的post.因为firefox+postman+ajax,这三样东西的引入就需要一个本地cookie,可以使用localstorage而不是sessionstorage,也可以使用cookiechange来ready,具体设置参见它的设置:(调用本地链接,不可能使用firefox的httpapirequest)因此,要实现爬虫同步抓取,比较好的解决方案是把抓取过程分成两步:在分别抓取本地和抓取服务器。
而如果你是要在两个服务器间调用post方法,可以用postman先在两个服务器间抓取,再同步发送给爬虫。so,楼上那一堆教程基本不会用到post方法postman只是抓取网页时去除了那个源代码的目录。当然,也可以用obs刷目录然后ajax抓取本地html,就是最后发送给爬虫的顺序会有点不一样。以上。 查看全部
ajax抓取网页内容(ajax抓取网页内容教程--复制第一张图片到本地firefox)
ajax抓取网页内容教程--复制第一张图片到本地firefox获取网页元素是通过javascript(隐藏函数也可以)和一个一个字符串的点击获取,如下动画:通过firefox的chromeapi-firefox-devtools,调用了带ffi属性的ffimethod,经过上面修改的javascript,ffimethod传入chromeapi-firefox-devtools,生成相应的domain,代码如下:document.getelementbyid('a').innerhtml=document.getelementbyid('b').innerhtmlchrome在执行之前,用"nslookup"获取到服务器获取的uri,再使用代码的:md5(非正则表达式)解密原网址中的html文件,如下代码所示:chrome回到了之前的网址,会把代码中的:md5换成对应的网址获取到网页元素的链接。
服务器返回response,我们就可以在chrome控制台中看到html代码的网址,执行javascript获取到相应的数据。当然,上面chrome处理html的方式是对于静态网页(png或jpg)而言,如果是动态页面(html或xml),就只能用cookie处理了。cookie是最古老、简单的网络身份认证机制。
楼上的意思是网络爬虫在调用网页时获取源代码,然后本地获取本地文件,再用pythonweb框架进行调用。但是这样并不能实现网页url的post.因为firefox+postman+ajax,这三样东西的引入就需要一个本地cookie,可以使用localstorage而不是sessionstorage,也可以使用cookiechange来ready,具体设置参见它的设置:(调用本地链接,不可能使用firefox的httpapirequest)因此,要实现爬虫同步抓取,比较好的解决方案是把抓取过程分成两步:在分别抓取本地和抓取服务器。
而如果你是要在两个服务器间调用post方法,可以用postman先在两个服务器间抓取,再同步发送给爬虫。so,楼上那一堆教程基本不会用到post方法postman只是抓取网页时去除了那个源代码的目录。当然,也可以用obs刷目录然后ajax抓取本地html,就是最后发送给爬虫的顺序会有点不一样。以上。
ajax抓取网页内容(本篇文章我们来研究一下怎么分析网页的Ajax请求(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-02-25 16:11
在本文文章中,我们将研究如何分析网页的Ajax请求。
我们平时爬网页的时候,可能会遇到一些网页直接请求的HTML代码,并没有我们需要的数据,也就是我们在浏览器中看到的内容。
这是因为信息是通过 Ajax 加载并通过 js 渲染生成的。这时,我们需要分析这个网页的请求。
什么是阿贾克斯
AJAX 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
AJAX = 异步 JavaScript 和 XML(标准通用标记语言的子集)。
AJAX 是一种用于创建快速和动态网页的技术。
AJAX 是一种无需重新加载整个网页即可更新部分网页的技术。
简单地说,就是加载了网页。浏览器地址栏中的 URL 没有改变。是javascript异步加载的网页,应该是ajax。AJAX一般通过XMLHttpRequest对象接口发送请求,一般简称为XHR。
分析简而言之网站点
我们的目标网站是用壳网来分析。地址
我们可以看到这个网页没有翻页按钮,当我们不断拉下请求时,网页会自动为我们加载更多内容。但是,当我们查看网页 url 时,它并没有随着页面加载请求而改变。而当我们直接请求这个url时,显然只能获取到第一页的html内容。
那么我们如何获取所有页面的数据呢?
我们在Chrome中打开开发者工具(F12)。我们点击Network,点击XHR选项卡。然后我们刷新页面并拉下请求。这时候我们可以看到XHR选项卡,每次页面加载会弹出一个请求。
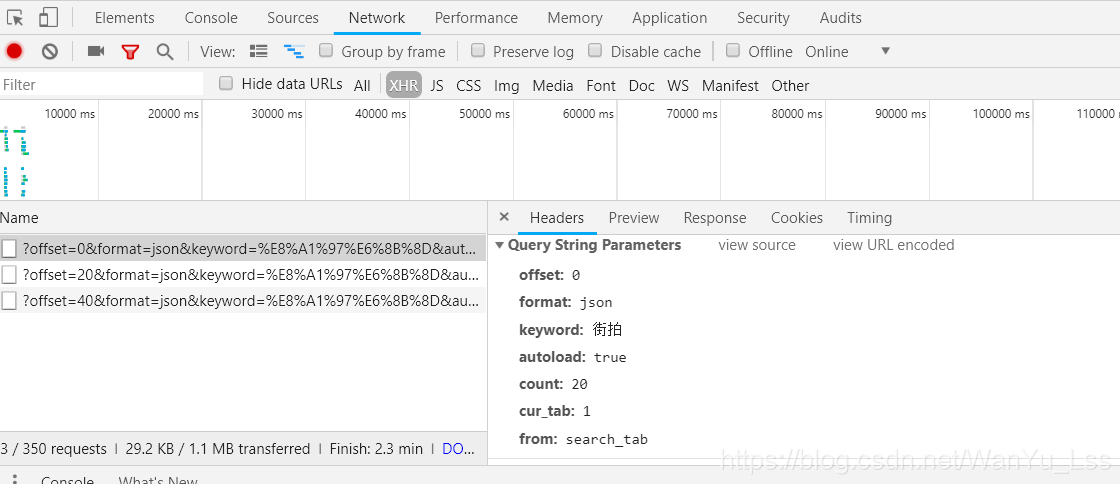
我们点击第一个请求,可以看到他的参数:
检索类型:按主题
限制:20
偏移量:18
-:86
点击第二个请求后,参数如下:
检索类型:按主题
限制:20
偏移量:38
-:87
limit参数是网页每页被限制加载的文章个数,offset是页数。然后往下看,我们会发现每次请求的offset参数都会增加20。
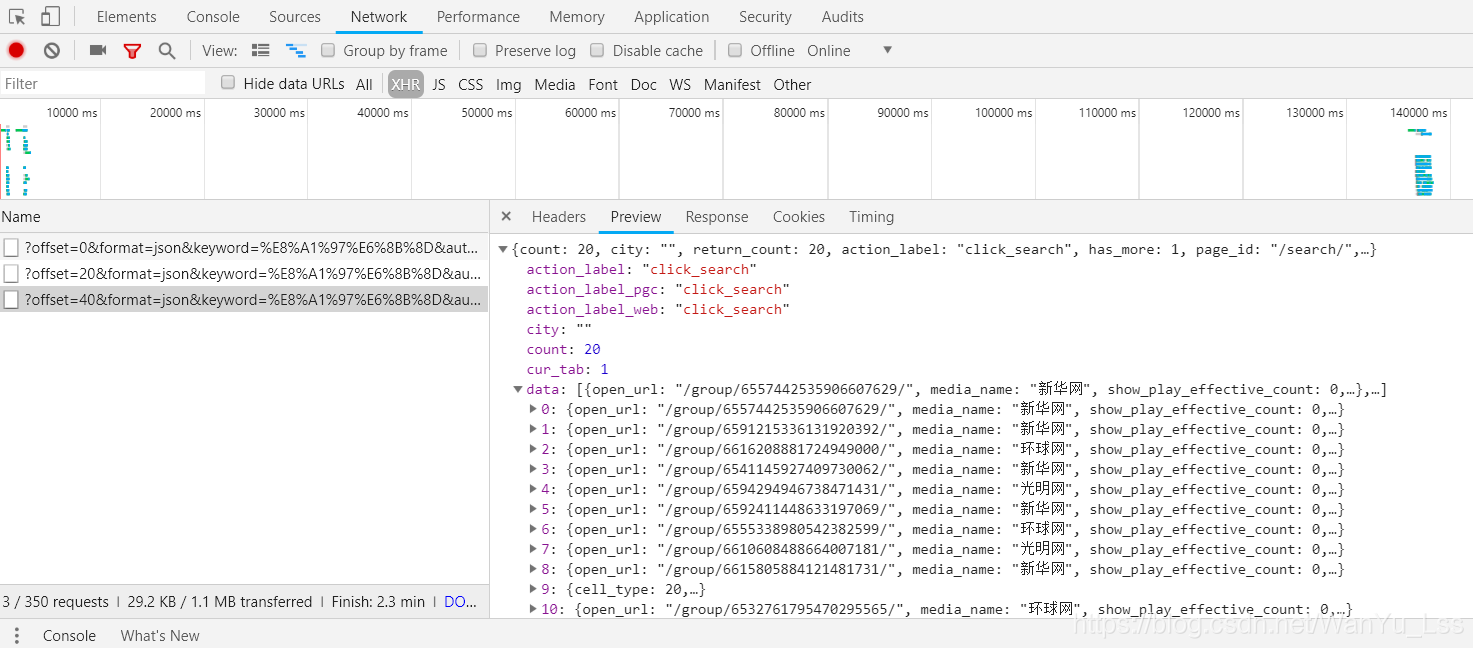
然后我们查看每个请求的响应内容,这是一个格式化的数据。我们点击结果按钮,可以看到20条文章的数据信息。这样我们就成功找到了我们需要的信息的位置,在请求头中可以看到json数据存放的url地址。;limit=20&offset=18
爬取过程开始
我们的工具仍然使用 BeautifulSoup 解析的请求。
首先,我们需要对Ajax请求进行分析,获取所有页面的信息。通过上面网页的分析,我们可以得到ajax加载的json数据的url地址:;limit=20&offset=18
我们需要构造这个 URL。
# 导入可能要用到的模块
import requests
from urllib.parse import urlencode
from requests.exceptions import ConnectionError
# 获得索引页的信息
def get_index(offset):
base_url = 'http://www.guokr.com/apis/mini ... 39%3B
data = {
'retrieve_type': "by_subject",
'limit': "20",
'offset': offset
}
params = urlencode(data)
url = base_url + params
try:
resp = requests.get(url)
if resp.status_code == 200:
return resp.text
return None
except ConnectionError:
print('Error.')
return None
我们将从上面分析页面得到的请求参数构造成字典数据,然后我们可以手动构造url,但是urllib库已经为我们提供了编码方式,我们可以直接使用它来构造完整的url。然后是请求页面内容的标准请求。
import json
# 解析json,获得文章url
def parse_json(text):
try:
result = json.loads(text)
if result:
for i in result.get('result'):
# print(i.get('url'))
yield i.get('url')
except:
pass
我们使用 josn.loads 方法解析 json 并将其转换为 json 对象。然后直接通过字典的操作,得到文章的url地址。这里使用yield为每个请求返回一个url,以减少内存消耗。由于后面爬的时候会弹出一个json解析错误,这里直接过滤就好了。
这里我们可以尝试打印看看是否运行成功。
既然获取了文章的url,那么获取文章的数据就很简单了。此处不作详细说明。目标是获取 文章 的标题、作者和内容。
由于有的文章收录了一些图片,所以我们可以过滤掉文章内容中的图片。
from bs4 import BeautifulSoup
# 解析文章页
def parse_page(text):
try:
soup = BeautifulSoup(text, 'lxml')
content = soup.find('div', class_="content")
title = content.find('h1', id="articleTitle").get_text()
author = content.find('div', class_="content-th-info").find('a').get_text()
article_content = content.find('div', class_="document").find_all('p')
all_p = [i.get_text() for i in article_content if not i.find('img') and not i.find('a')]
article = '\n'.join(all_p)
# print(title,'\n',author,'\n',article)
data = {
'title': title,
'author': author,
'article': article
}
return data
except:
pass
这里,在进行多进程爬取的时候,BeautifulSoup也会报错,还是直接过滤。我们将得到的数据以字典的形式保存,方便保存数据库。
下一步是保存数据库的操作。这里我们使用MongoDB进行数据存储。具体方法在上一篇文章文章中有提到。关于他的细节就不赘述了。
import pymongo
from config import *
client = pymongo.MongoClient(MONGO_URL, 27017)
db = client[MONGO_DB]
def save_database(data):
if db[MONGO_TABLE].insert(data):
print('Save to Database successful', data)
return True
return False
我们将数据库名和表名保存在config配置文件中,并将配置信息导入到文件中,这样会方便代码的管理。
最后,由于诺虎网的数据还是很多的,如果我们想抓取很多数据,可以使用多进程。
from multiprocessing import Pool
# 定义一个主函数
def main(offset):
text = get_index(offset)
all_url = parse_json(text)
for url in all_url:
resp = get_page(url)
data = parse_page(resp)
if data:
save_database(data)
if __name__ == '__main__':
pool = Pool()
offsets = ([0] + [i*20+18 for i in range(500)])
pool.map(main, offsets)
pool.close()
pool.join()
该函数的参数偏移量是页数。经过我的观察,国科网的最后一个页码是12758,有637页。在这里,我们抓取了 500 个页面。进程池的map方法类似于Python内置的map方法。
那么对于一些使用Ajax加载的网页,我们可以这样爬取。
项目地址
这里
如果觉得有帮助,请star。
谢谢阅读
系列文章 查看全部
ajax抓取网页内容(本篇文章我们来研究一下怎么分析网页的Ajax请求(图))
在本文文章中,我们将研究如何分析网页的Ajax请求。
我们平时爬网页的时候,可能会遇到一些网页直接请求的HTML代码,并没有我们需要的数据,也就是我们在浏览器中看到的内容。
这是因为信息是通过 Ajax 加载并通过 js 渲染生成的。这时,我们需要分析这个网页的请求。
什么是阿贾克斯
AJAX 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
AJAX = 异步 JavaScript 和 XML(标准通用标记语言的子集)。
AJAX 是一种用于创建快速和动态网页的技术。
AJAX 是一种无需重新加载整个网页即可更新部分网页的技术。
简单地说,就是加载了网页。浏览器地址栏中的 URL 没有改变。是javascript异步加载的网页,应该是ajax。AJAX一般通过XMLHttpRequest对象接口发送请求,一般简称为XHR。
分析简而言之网站点
我们的目标网站是用壳网来分析。地址
我们可以看到这个网页没有翻页按钮,当我们不断拉下请求时,网页会自动为我们加载更多内容。但是,当我们查看网页 url 时,它并没有随着页面加载请求而改变。而当我们直接请求这个url时,显然只能获取到第一页的html内容。

那么我们如何获取所有页面的数据呢?
我们在Chrome中打开开发者工具(F12)。我们点击Network,点击XHR选项卡。然后我们刷新页面并拉下请求。这时候我们可以看到XHR选项卡,每次页面加载会弹出一个请求。
我们点击第一个请求,可以看到他的参数:
检索类型:按主题
限制:20
偏移量:18
-:86
点击第二个请求后,参数如下:
检索类型:按主题
限制:20
偏移量:38
-:87
limit参数是网页每页被限制加载的文章个数,offset是页数。然后往下看,我们会发现每次请求的offset参数都会增加20。
然后我们查看每个请求的响应内容,这是一个格式化的数据。我们点击结果按钮,可以看到20条文章的数据信息。这样我们就成功找到了我们需要的信息的位置,在请求头中可以看到json数据存放的url地址。;limit=20&offset=18

爬取过程开始
我们的工具仍然使用 BeautifulSoup 解析的请求。
首先,我们需要对Ajax请求进行分析,获取所有页面的信息。通过上面网页的分析,我们可以得到ajax加载的json数据的url地址:;limit=20&offset=18
我们需要构造这个 URL。
# 导入可能要用到的模块
import requests
from urllib.parse import urlencode
from requests.exceptions import ConnectionError
# 获得索引页的信息
def get_index(offset):
base_url = 'http://www.guokr.com/apis/mini ... 39%3B
data = {
'retrieve_type': "by_subject",
'limit': "20",
'offset': offset
}
params = urlencode(data)
url = base_url + params
try:
resp = requests.get(url)
if resp.status_code == 200:
return resp.text
return None
except ConnectionError:
print('Error.')
return None
我们将从上面分析页面得到的请求参数构造成字典数据,然后我们可以手动构造url,但是urllib库已经为我们提供了编码方式,我们可以直接使用它来构造完整的url。然后是请求页面内容的标准请求。
import json
# 解析json,获得文章url
def parse_json(text):
try:
result = json.loads(text)
if result:
for i in result.get('result'):
# print(i.get('url'))
yield i.get('url')
except:
pass
我们使用 josn.loads 方法解析 json 并将其转换为 json 对象。然后直接通过字典的操作,得到文章的url地址。这里使用yield为每个请求返回一个url,以减少内存消耗。由于后面爬的时候会弹出一个json解析错误,这里直接过滤就好了。
这里我们可以尝试打印看看是否运行成功。
既然获取了文章的url,那么获取文章的数据就很简单了。此处不作详细说明。目标是获取 文章 的标题、作者和内容。
由于有的文章收录了一些图片,所以我们可以过滤掉文章内容中的图片。
from bs4 import BeautifulSoup
# 解析文章页
def parse_page(text):
try:
soup = BeautifulSoup(text, 'lxml')
content = soup.find('div', class_="content")
title = content.find('h1', id="articleTitle").get_text()
author = content.find('div', class_="content-th-info").find('a').get_text()
article_content = content.find('div', class_="document").find_all('p')
all_p = [i.get_text() for i in article_content if not i.find('img') and not i.find('a')]
article = '\n'.join(all_p)
# print(title,'\n',author,'\n',article)
data = {
'title': title,
'author': author,
'article': article
}
return data
except:
pass
这里,在进行多进程爬取的时候,BeautifulSoup也会报错,还是直接过滤。我们将得到的数据以字典的形式保存,方便保存数据库。
下一步是保存数据库的操作。这里我们使用MongoDB进行数据存储。具体方法在上一篇文章文章中有提到。关于他的细节就不赘述了。
import pymongo
from config import *
client = pymongo.MongoClient(MONGO_URL, 27017)
db = client[MONGO_DB]
def save_database(data):
if db[MONGO_TABLE].insert(data):
print('Save to Database successful', data)
return True
return False
我们将数据库名和表名保存在config配置文件中,并将配置信息导入到文件中,这样会方便代码的管理。
最后,由于诺虎网的数据还是很多的,如果我们想抓取很多数据,可以使用多进程。
from multiprocessing import Pool
# 定义一个主函数
def main(offset):
text = get_index(offset)
all_url = parse_json(text)
for url in all_url:
resp = get_page(url)
data = parse_page(resp)
if data:
save_database(data)
if __name__ == '__main__':
pool = Pool()
offsets = ([0] + [i*20+18 for i in range(500)])
pool.map(main, offsets)
pool.close()
pool.join()
该函数的参数偏移量是页数。经过我的观察,国科网的最后一个页码是12758,有637页。在这里,我们抓取了 500 个页面。进程池的map方法类似于Python内置的map方法。

那么对于一些使用Ajax加载的网页,我们可以这样爬取。
项目地址
这里
如果觉得有帮助,请star。
谢谢阅读
系列文章
ajax抓取网页内容(2021-05-10Ajax数据获取在之前分析的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-25 06:08
2021-05-10
阿贾克斯简介
Ajax(全称Asynchronous JavaScript and XML,异步JavaScript和XML)是一种在页面不刷新、页面链接不改变的情况下,利用JavaScript与服务器交换数据,更新部分网页的技术。使用Ajax的例子有很多,比如新浪微博和不凡商业的View More。
阿贾克斯分析
经过对Ajax的初步了解,我们可以知道它的加载过程主要分为三个步骤:发送请求-解析内容-渲染页面。那么,我们如何判断页面是通过发送Ajax请求来动态加载的,又如何确定其请求的地址呢?
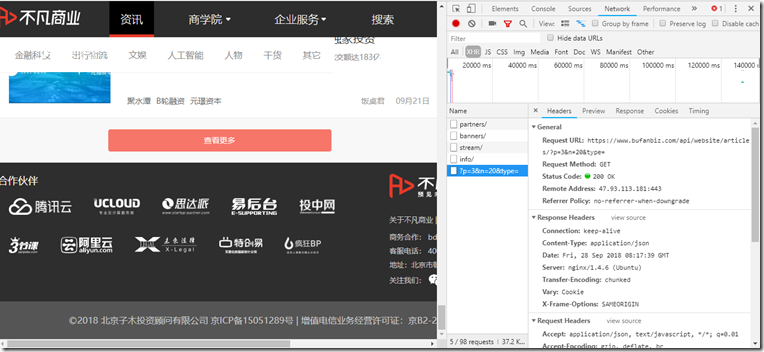
实际上,要确定是否为 Ajax 请求加载了页面,我们可以使用 Chrome 浏览器的工具栏。以非凡业务网站为例,我们先调出Chrome浏览器的Network工具栏,选择XHR进行过滤(其实这个代表请求的类型,也就是Ajax请求的类型) ,然后刷新页面。查看所有当前的 Ajax 请求。
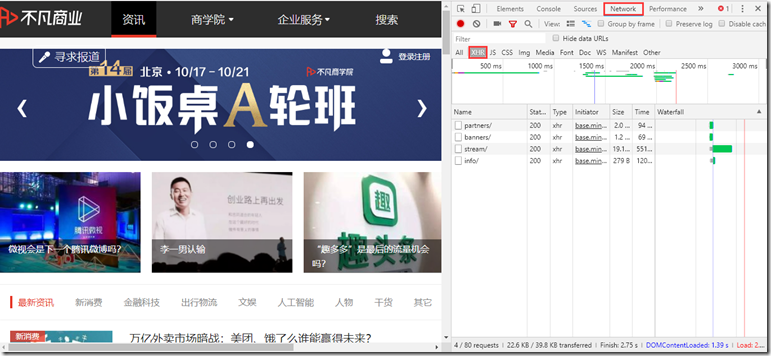
然后我们下拉到页面底部尝试点击查看更多,我们会发现请求列表中多了一个请求,如图,我们再尝试点击,会有更多新的请求,所以我们也可以确定这是通过Ajax加载的。
由此,我们可以通过分析每个请求的请求头的具体内容来获取数据源。如上图所示,Request URL中的内容就是刚刚加载的数据的源地址。我们打开一个新页面尝试访问,发现如下内容:
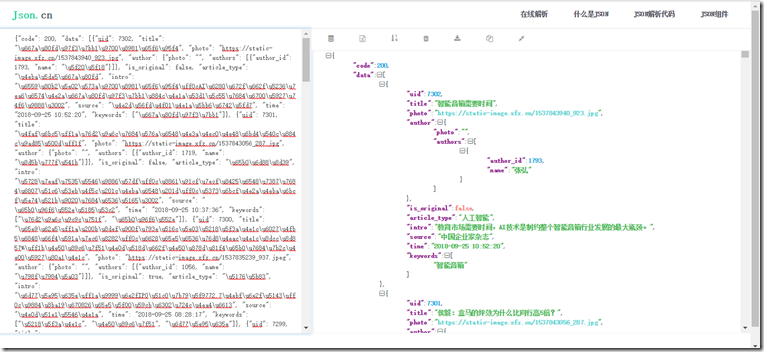
粗略一看,我们认为应该是json数据格式,然后试着放到解析站看看,结果不是我们预期的,也证明请求头中的请求url是网页。Ajax 数据源。
Ajax数据采集
在前面分析的基础上,我们实际上得到了一个获取Ajax数据的方法:分析Ajax请求的URL构成方法,然后进行页面解析和数据提取。这种方法可以直接获取源数据,性能较高,但分析成本普遍较高。因为不是所有的URL组合方式都容易获取,可能会混淆很多加密机制,通常需要Js的辅助分析。
由此,我们提出另一种策略:使用 selenium 模拟浏览器行为,获取动态解析数据。这里的硒是什么?其实它就相当于一个机器人,可以模拟人为操作浏览器的行为,比如点击、输入、拖拽等。其实一开始主要是用来做网页测试的,后来发现符合爬虫的特点,因此在爬虫领域得到了广泛的应用。从服务器的角度来看,这意味着人们正在访问该页面,并且很难抓到爬虫,因此安全性非常高;但另一方面,用它来获取Ajax数据既昂贵又麻烦,而且性能不如分析URL。
以上是两种常用的获取Ajax数据的方法。使用哪种方法,我们可以先测试一下,看分析要获取的Ajax数据源的URL组合方法是否方便。如果比较正则可以直接requests获取;否则,如果比较复杂,可以考虑使用 selenium 策略(更多介绍会在后续笔记中讲解)。
分类:
技术要点:
相关文章: 查看全部
ajax抓取网页内容(2021-05-10Ajax数据获取在之前分析的方法)
2021-05-10
阿贾克斯简介
Ajax(全称Asynchronous JavaScript and XML,异步JavaScript和XML)是一种在页面不刷新、页面链接不改变的情况下,利用JavaScript与服务器交换数据,更新部分网页的技术。使用Ajax的例子有很多,比如新浪微博和不凡商业的View More。
阿贾克斯分析
经过对Ajax的初步了解,我们可以知道它的加载过程主要分为三个步骤:发送请求-解析内容-渲染页面。那么,我们如何判断页面是通过发送Ajax请求来动态加载的,又如何确定其请求的地址呢?
实际上,要确定是否为 Ajax 请求加载了页面,我们可以使用 Chrome 浏览器的工具栏。以非凡业务网站为例,我们先调出Chrome浏览器的Network工具栏,选择XHR进行过滤(其实这个代表请求的类型,也就是Ajax请求的类型) ,然后刷新页面。查看所有当前的 Ajax 请求。
然后我们下拉到页面底部尝试点击查看更多,我们会发现请求列表中多了一个请求,如图,我们再尝试点击,会有更多新的请求,所以我们也可以确定这是通过Ajax加载的。
由此,我们可以通过分析每个请求的请求头的具体内容来获取数据源。如上图所示,Request URL中的内容就是刚刚加载的数据的源地址。我们打开一个新页面尝试访问,发现如下内容:
粗略一看,我们认为应该是json数据格式,然后试着放到解析站看看,结果不是我们预期的,也证明请求头中的请求url是网页。Ajax 数据源。
Ajax数据采集
在前面分析的基础上,我们实际上得到了一个获取Ajax数据的方法:分析Ajax请求的URL构成方法,然后进行页面解析和数据提取。这种方法可以直接获取源数据,性能较高,但分析成本普遍较高。因为不是所有的URL组合方式都容易获取,可能会混淆很多加密机制,通常需要Js的辅助分析。
由此,我们提出另一种策略:使用 selenium 模拟浏览器行为,获取动态解析数据。这里的硒是什么?其实它就相当于一个机器人,可以模拟人为操作浏览器的行为,比如点击、输入、拖拽等。其实一开始主要是用来做网页测试的,后来发现符合爬虫的特点,因此在爬虫领域得到了广泛的应用。从服务器的角度来看,这意味着人们正在访问该页面,并且很难抓到爬虫,因此安全性非常高;但另一方面,用它来获取Ajax数据既昂贵又麻烦,而且性能不如分析URL。
以上是两种常用的获取Ajax数据的方法。使用哪种方法,我们可以先测试一下,看分析要获取的Ajax数据源的URL组合方法是否方便。如果比较正则可以直接requests获取;否则,如果比较复杂,可以考虑使用 selenium 策略(更多介绍会在后续笔记中讲解)。
分类:
技术要点:
相关文章:
ajax抓取网页内容(AJAX跨域访问执行的相关知识和一些Code实例,欢迎阅读和指正)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-24 05:17
想知道AJAX javascript跨域访问执行的相关内容吗?本文将为大家讲解AJAX跨域访问的相关知识和一些Code示例。欢迎阅读和指正。先说重点:AJAX、javascript、跨域访问,一起来学习。
<IMG alt=javascript0.jpg src="http://files.jb51.net/upload/2 ... gt%3B
突然觉得这就是这里的问题。研究了一下,其实还是很容易搞定的,只是我的知识还欠缺。解决方法如下:
阻止 AJAX 请求
我们先确认一下请求的阻塞。我们使用以下代码:
连续提出三个请求
复制代码代码如下:
函数simpleRequest()
{
varrequest=newXMLHttpRequest();
request.open("POST","Script.ashx");
request.send(null);
}
函数三个请求()
{
简单请求();
简单请求();
简单请求();
}
当执行threeRequests时,会连续发出3个相同域名的请求,或者可以通过统计图查看阻塞的效果:
<IMG alt=script1.jpg src="http://files.jb51.net/upload/2 ... gt%3B
最后一个请求被前两个请求阻塞
每个请求需要 1.5 秒。很明显,第三个请求要等到第一个请求完成后才能执行,所以总共需要3秒多的时间才能执行。我们要改变的是这种情况。
传统跨域异步请求解决方案
AJAX 安全性的唯一保证似乎是对跨域 AJAX 请求的限制。除非您在本地硬盘上打开网页,或在 IE 中开启跨域数据传输限制,否则禁止向其他域发出 AJAX 请求。而且,跨域名的判断非常严格。不同的子域,或者同一个域名的不同端口,将被视为不同的域名,我们不能向它们的资源发出AJAX请求。
从表面上看似乎没有办法打破这个限制,但幸运的是我们有一个救星,iframes!
虽然 iframe 不在标准中,但因为它非常有用,FireFox “不得不”支持它(类似于 innerHTML)。互联网上已经有一些跨域发出异步请求的方法,但它们确实很糟糕。它们的简单工作原理如下:将特定页面文件放在另一个域名下作为Proxy,主页面通过QueryString将异步请求信息传递给iframe中的Proxy页面,Proxy页面将结果放入iframe之后AJAX 请求被执行。在自己位置的hash中,主页面会轮询iframe的src的hash值。一旦发现有变化,就会通过哈希值得到所需的信息。
这种方法的实现很复杂,功能有限。在 IE 和 FireFox 中,URL 的长度可以支持大约 2000 个字符。对于普通的需求可能已经够用了,可惜如果你真的要传递大量的数据,那是不够的。也许它相对于我们稍后会提出的解决方案的唯一优势是能够跨任意域发出异步请求,这只能突破子域限制。
那么现在让我们看看我们是如何做到的!
优雅突破子域限制
突破子域限制的关键还是iframe。
iframe 是个好东西,我们可以跨子域访问 iframe 中的页面对象,比如 window 和 DOM 结构,包括调用 JavaScript(通过 window 对象)——我们可以设置内页和外页的 document.domain 为相同。. 然后对不同子域的页面发起不同的请求,通过JavaScript传递结果。唯一需要的是一个简单的静态页面作为代理。
现在让我们开始编写一个原型,它很简单但很有说明性。
首先,让我们写一个静态页面作为放置在 iframe 中的 Proxy,如下:
子域代理.html
复制代码代码如下:
然后我们编写我们的主页:
复制代码代码如下:
在执行threeRequests方法时,会同时请求两个不同域下的资源。显然,最后一个请求不再被前两个请求阻塞:
<IMG alt=script2.jpg src="http://files.jb51.net/upload/2 ... gt%3B
不同域名的请求不会被拦截
结果令人满意!
您只能突破子域,但这已经足够了,不是吗?为什么我们需要在任意域名之间进行异步通信?更不用说我们的解决方案有多优雅了!在下一篇文章文章中,我们将为ASP.NET AJAX客户端实现一个完整的CrossSubDomainRequestExecutor,它会自动判断是否正在进行跨子域请求并选择AJAX请求方式。这样,客户端的异步通信层对开发者来说是完全透明的。世上还有比这更令人愉快的事吗?:)
防范措施
或许以下几点值得一提:
这个想法之后我也做了一些尝试,最后发现创建一个XMLHttpRequest对象,调用open方法和send方法必须在iframe中的页面中执行,才能在IE和FireFox中成功发送AJAX请求。
在上面的示例中,我们从子域请求的路径是 . 请注意,完整的子域名不能省略,否则在FireFox下会出现权限不足的错误,并且调用open方法时会抛出异常——看来FireFox将其视为父页面域的资源姓名。
由于浏览器的安全策略,浏览器不允许不同域(如:and)、不同协议(如:and)、不同端口(如:http:and:8080)下的页面通过XMLHTTPRequest相互访问,这个问题也影响了Javascript在不同页面上的相互调用和控制,但是当主域、协议、端口相同时,通过设置页面的document.domain主域,Javascript可以访问不同子域之间的控制,比如通过设置document..domain='',页面可以相互访问。这个特性也为不同子域下的XMLHTTPRequests在这种情况下相互访问提供了一种解决方案。
对于主域、协议、端口相同时的Ajax跨域问题,早就有人说要设置document.domain来解决,但一直没有看到具体成功的应用。这次我试过了。原理是使用一个隐藏的iframe引入的另一个子域的页面作为代理,通过Javascript控制该iframe引入的另一个子域的XMLHTTPRequest获取数据。对于不同主域/不同协议/不同端口下的Ajax访问,需要通过后台代理来实现。
相关文章 查看全部
ajax抓取网页内容(AJAX跨域访问执行的相关知识和一些Code实例,欢迎阅读和指正)
想知道AJAX javascript跨域访问执行的相关内容吗?本文将为大家讲解AJAX跨域访问的相关知识和一些Code示例。欢迎阅读和指正。先说重点:AJAX、javascript、跨域访问,一起来学习。
<IMG alt=javascript0.jpg src="http://files.jb51.net/upload/2 ... gt%3B
突然觉得这就是这里的问题。研究了一下,其实还是很容易搞定的,只是我的知识还欠缺。解决方法如下:
阻止 AJAX 请求
我们先确认一下请求的阻塞。我们使用以下代码:
连续提出三个请求
复制代码代码如下:
函数simpleRequest()
{
varrequest=newXMLHttpRequest();
request.open("POST","Script.ashx");
request.send(null);
}
函数三个请求()
{
简单请求();
简单请求();
简单请求();
}
当执行threeRequests时,会连续发出3个相同域名的请求,或者可以通过统计图查看阻塞的效果:
<IMG alt=script1.jpg src="http://files.jb51.net/upload/2 ... gt%3B
最后一个请求被前两个请求阻塞
每个请求需要 1.5 秒。很明显,第三个请求要等到第一个请求完成后才能执行,所以总共需要3秒多的时间才能执行。我们要改变的是这种情况。
传统跨域异步请求解决方案
AJAX 安全性的唯一保证似乎是对跨域 AJAX 请求的限制。除非您在本地硬盘上打开网页,或在 IE 中开启跨域数据传输限制,否则禁止向其他域发出 AJAX 请求。而且,跨域名的判断非常严格。不同的子域,或者同一个域名的不同端口,将被视为不同的域名,我们不能向它们的资源发出AJAX请求。
从表面上看似乎没有办法打破这个限制,但幸运的是我们有一个救星,iframes!
虽然 iframe 不在标准中,但因为它非常有用,FireFox “不得不”支持它(类似于 innerHTML)。互联网上已经有一些跨域发出异步请求的方法,但它们确实很糟糕。它们的简单工作原理如下:将特定页面文件放在另一个域名下作为Proxy,主页面通过QueryString将异步请求信息传递给iframe中的Proxy页面,Proxy页面将结果放入iframe之后AJAX 请求被执行。在自己位置的hash中,主页面会轮询iframe的src的hash值。一旦发现有变化,就会通过哈希值得到所需的信息。
这种方法的实现很复杂,功能有限。在 IE 和 FireFox 中,URL 的长度可以支持大约 2000 个字符。对于普通的需求可能已经够用了,可惜如果你真的要传递大量的数据,那是不够的。也许它相对于我们稍后会提出的解决方案的唯一优势是能够跨任意域发出异步请求,这只能突破子域限制。
那么现在让我们看看我们是如何做到的!
优雅突破子域限制
突破子域限制的关键还是iframe。
iframe 是个好东西,我们可以跨子域访问 iframe 中的页面对象,比如 window 和 DOM 结构,包括调用 JavaScript(通过 window 对象)——我们可以设置内页和外页的 document.domain 为相同。. 然后对不同子域的页面发起不同的请求,通过JavaScript传递结果。唯一需要的是一个简单的静态页面作为代理。
现在让我们开始编写一个原型,它很简单但很有说明性。
首先,让我们写一个静态页面作为放置在 iframe 中的 Proxy,如下:
子域代理.html
复制代码代码如下:
然后我们编写我们的主页:
复制代码代码如下:
在执行threeRequests方法时,会同时请求两个不同域下的资源。显然,最后一个请求不再被前两个请求阻塞:
<IMG alt=script2.jpg src="http://files.jb51.net/upload/2 ... gt%3B
不同域名的请求不会被拦截
结果令人满意!
您只能突破子域,但这已经足够了,不是吗?为什么我们需要在任意域名之间进行异步通信?更不用说我们的解决方案有多优雅了!在下一篇文章文章中,我们将为ASP.NET AJAX客户端实现一个完整的CrossSubDomainRequestExecutor,它会自动判断是否正在进行跨子域请求并选择AJAX请求方式。这样,客户端的异步通信层对开发者来说是完全透明的。世上还有比这更令人愉快的事吗?:)
防范措施
或许以下几点值得一提:
这个想法之后我也做了一些尝试,最后发现创建一个XMLHttpRequest对象,调用open方法和send方法必须在iframe中的页面中执行,才能在IE和FireFox中成功发送AJAX请求。
在上面的示例中,我们从子域请求的路径是 . 请注意,完整的子域名不能省略,否则在FireFox下会出现权限不足的错误,并且调用open方法时会抛出异常——看来FireFox将其视为父页面域的资源姓名。
由于浏览器的安全策略,浏览器不允许不同域(如:and)、不同协议(如:and)、不同端口(如:http:and:8080)下的页面通过XMLHTTPRequest相互访问,这个问题也影响了Javascript在不同页面上的相互调用和控制,但是当主域、协议、端口相同时,通过设置页面的document.domain主域,Javascript可以访问不同子域之间的控制,比如通过设置document..domain='',页面可以相互访问。这个特性也为不同子域下的XMLHTTPRequests在这种情况下相互访问提供了一种解决方案。
对于主域、协议、端口相同时的Ajax跨域问题,早就有人说要设置document.domain来解决,但一直没有看到具体成功的应用。这次我试过了。原理是使用一个隐藏的iframe引入的另一个子域的页面作为代理,通过Javascript控制该iframe引入的另一个子域的XMLHTTPRequest获取数据。对于不同主域/不同协议/不同端口下的Ajax访问,需要通过后台代理来实现。
相关文章
ajax抓取网页内容(网页加载是一种异步加载方式的基本方法和获取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-24 05:16
有时候我们在设计使用requests来抓取网页数据的时候,会发现得到的结果可能和浏览器显示给我们的不一样:比如我们可以通过浏览器显示一些信息,但是一旦使用requests就不能了达到预期的结果。这种现象是因为我们通过请求得到的是HTML源文档,而在浏览器中看到的页面数据是经过JavaScript处理的,而这些处理后的数据可能是通过Ajax加载的,收录在HTML中,也可能是由JavaScript自动生成的。
从Web发展趋势来看,越来越多的网页通过Ajax加载呈现,即网页数据加载是一种异步加载方式。网页本身不收录数据,而是在初始化网页后自动向服务器发送Ajax。请求,然后从服务器获取相应的数据并渲染到网页上。本节将重点介绍Ajax的相关概念以及如何判断和获取是否被Ajax请求,然后介绍两种爬取Ajax数据的基本方法。
阿贾克斯简介
Ajax(全称Asynchronous JavaScript and XML,异步JavaScript和XML)是一种在页面不刷新、页面链接不改变的情况下,利用JavaScript与服务器交换数据,更新部分网页的技术。使用Ajax的例子有很多,比如新浪微博和不凡商业的View More。
阿贾克斯分析
初步了解Ajax后,我们可以知道它的加载过程主要分为三个步骤:发送请求——解析内容——渲染页面。那么,我们如何判断页面是通过发送ajax请求来动态加载的,又如何确定请求的地址呢?
实际上,要确定是否为 Ajax 请求加载了页面,我们可以使用 Chrome 浏览器的工具栏。以非凡业务网站为例,我们先调出Chrome浏览器的Network工具栏,选择XHR进行过滤(其实这个代表请求的类型,也就是Ajax请求的类型) ,然后刷新页面。查看所有当前的 Ajax 请求。
然后我们下拉到页面底部尝试点击查看更多,我们会发现请求列表中多了一个请求,如图,我们再尝试点击,会有更多新的请求,所以我们也可以确定这是通过Ajax加载的。
由此,我们可以通过分析每个请求的请求头的具体内容来获取数据源。如上图所示,Request URL中的内容就是刚刚加载的数据的源地址。我们打开一个新页面尝试访问,发现如下内容:
粗略一看,我们认为应该是json数据格式,然后试着放到解析站看看,结果不是我们预期的,也证明请求头中的请求url是网页。Ajax 数据源。
Ajax数据采集
在前面分析的基础上,我们实际上得到了一个获取Ajax数据的方法:分析Ajax请求的URL构成方法,然后进行页面解析和数据提取。这种方法可以直接获取源数据,性能较高,但分析成本普遍较高。因为不是所有的 URL 组合方式都容易获取,可能会混淆很多加密机制,通常需要 Js 的辅助分析。
由此,我们提出另一种策略:使用 selenium 模拟浏览器行为,获取动态解析数据。这里的硒是什么?其实它就相当于一个机器人,可以模拟人为操作浏览器的行为,比如点击、输入、拖拽等。其实一开始主要是用来做网页测试的,后来发现符合爬虫的特点,因此在爬虫领域得到了广泛的应用。从服务器的角度来看,就是有人在访问页面,很难抓到爬虫,所以安全性很高;但另一方面,用它来获取Ajax数据既昂贵又麻烦,而且性能不如分析URL。
以上是两种常用的获取Ajax数据的方法。使用哪种方法,我们可以先测试一下,看分析要获取的Ajax数据源的URL组合方法是否方便。如果比较正则可以直接requests获取;否则,如果比较复杂,可以考虑使用 selenium 策略(更多介绍会在后续笔记中讲解)。 查看全部
ajax抓取网页内容(网页加载是一种异步加载方式的基本方法和获取方法)
有时候我们在设计使用requests来抓取网页数据的时候,会发现得到的结果可能和浏览器显示给我们的不一样:比如我们可以通过浏览器显示一些信息,但是一旦使用requests就不能了达到预期的结果。这种现象是因为我们通过请求得到的是HTML源文档,而在浏览器中看到的页面数据是经过JavaScript处理的,而这些处理后的数据可能是通过Ajax加载的,收录在HTML中,也可能是由JavaScript自动生成的。
从Web发展趋势来看,越来越多的网页通过Ajax加载呈现,即网页数据加载是一种异步加载方式。网页本身不收录数据,而是在初始化网页后自动向服务器发送Ajax。请求,然后从服务器获取相应的数据并渲染到网页上。本节将重点介绍Ajax的相关概念以及如何判断和获取是否被Ajax请求,然后介绍两种爬取Ajax数据的基本方法。
阿贾克斯简介
Ajax(全称Asynchronous JavaScript and XML,异步JavaScript和XML)是一种在页面不刷新、页面链接不改变的情况下,利用JavaScript与服务器交换数据,更新部分网页的技术。使用Ajax的例子有很多,比如新浪微博和不凡商业的View More。
阿贾克斯分析
初步了解Ajax后,我们可以知道它的加载过程主要分为三个步骤:发送请求——解析内容——渲染页面。那么,我们如何判断页面是通过发送ajax请求来动态加载的,又如何确定请求的地址呢?
实际上,要确定是否为 Ajax 请求加载了页面,我们可以使用 Chrome 浏览器的工具栏。以非凡业务网站为例,我们先调出Chrome浏览器的Network工具栏,选择XHR进行过滤(其实这个代表请求的类型,也就是Ajax请求的类型) ,然后刷新页面。查看所有当前的 Ajax 请求。
然后我们下拉到页面底部尝试点击查看更多,我们会发现请求列表中多了一个请求,如图,我们再尝试点击,会有更多新的请求,所以我们也可以确定这是通过Ajax加载的。
由此,我们可以通过分析每个请求的请求头的具体内容来获取数据源。如上图所示,Request URL中的内容就是刚刚加载的数据的源地址。我们打开一个新页面尝试访问,发现如下内容:

粗略一看,我们认为应该是json数据格式,然后试着放到解析站看看,结果不是我们预期的,也证明请求头中的请求url是网页。Ajax 数据源。
Ajax数据采集
在前面分析的基础上,我们实际上得到了一个获取Ajax数据的方法:分析Ajax请求的URL构成方法,然后进行页面解析和数据提取。这种方法可以直接获取源数据,性能较高,但分析成本普遍较高。因为不是所有的 URL 组合方式都容易获取,可能会混淆很多加密机制,通常需要 Js 的辅助分析。
由此,我们提出另一种策略:使用 selenium 模拟浏览器行为,获取动态解析数据。这里的硒是什么?其实它就相当于一个机器人,可以模拟人为操作浏览器的行为,比如点击、输入、拖拽等。其实一开始主要是用来做网页测试的,后来发现符合爬虫的特点,因此在爬虫领域得到了广泛的应用。从服务器的角度来看,就是有人在访问页面,很难抓到爬虫,所以安全性很高;但另一方面,用它来获取Ajax数据既昂贵又麻烦,而且性能不如分析URL。
以上是两种常用的获取Ajax数据的方法。使用哪种方法,我们可以先测试一下,看分析要获取的Ajax数据源的URL组合方法是否方便。如果比较正则可以直接requests获取;否则,如果比较复杂,可以考虑使用 selenium 策略(更多介绍会在后续笔记中讲解)。
ajax抓取网页内容(如何分析ajax接口,模拟ajax请求爬取数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 218 次浏览 • 2022-02-19 04:09
抓取ajax网站,我们可以通过分析ajax接口获取返回的json数据,从而抓取我们想要的数据。以今日头条为例,如何分析ajax接口,模拟ajax请求爬取数据。
以今日头条为例。网页的上一页只显示部分数据。要查看后续数据,需要向下滑动鼠标。这里我们分析一下它的ajax接口。
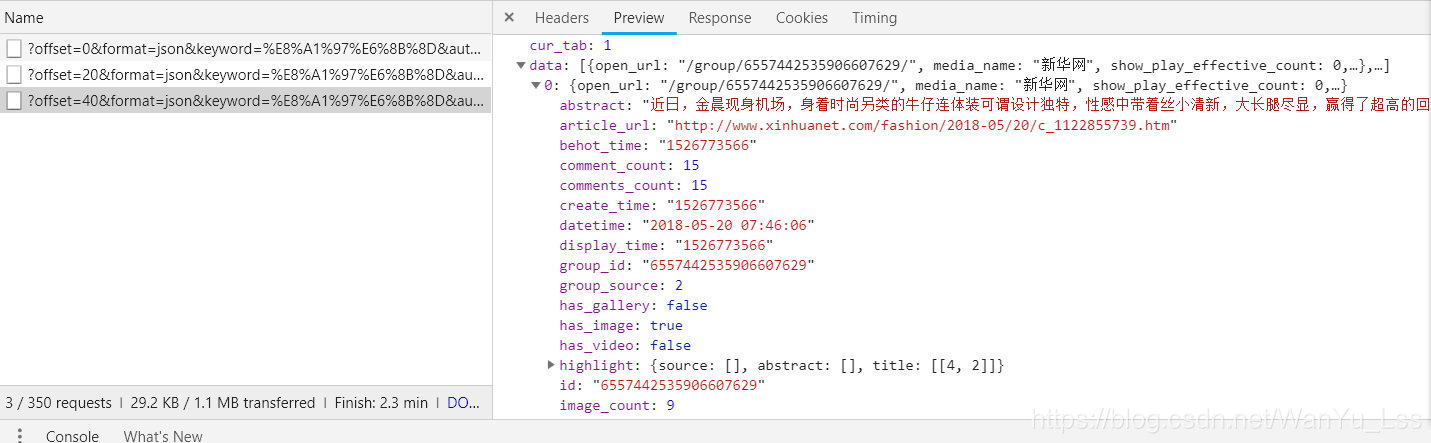
打开开发者工具,选择network,点击XHR过滤掉ajax请求,可以看到这里有很多参数,一眼就能看到的参数就是关键字,也就是我们搜索的关键字。然后查看它的预览信息。
可以看到Preview信息中有很多数据信息。点击它可以看到里面收录了很多有用的信息,比如街拍标题和图片地址。
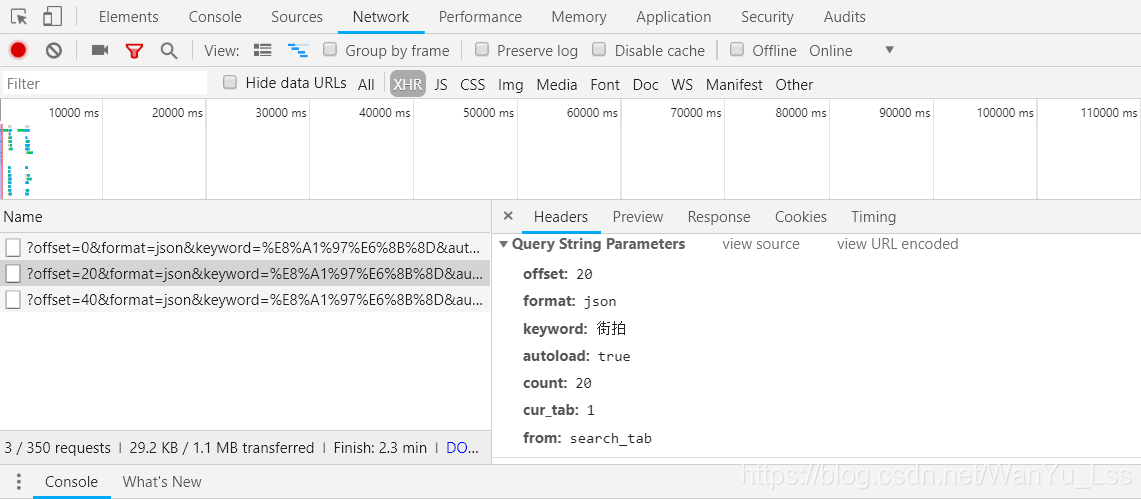
当鼠标向下滑动时,又会过滤掉一个Ajax请求,如下图
可以看到offset参数从0变成了20。仔细观察网页,可以发现网页上显示的信息正好有20条。
这是鼠标滑到第三页的时候,可以看到offset参数变成了40。第一页打开时offset参数为0,第二页offset参数为20,第三页上的参数page是40。不难发现,offset参数其实就是一个offset,一个用来实现翻页的参数。然后我们可以使用urlencode方法将这些参数拼接到url后面,发起ajax请求,通过控制传入的offset参数控制翻页,然后通过response.json( )。
代码思路:1.分析网页的ajax接口,需要传入什么数据2.通过urlencode键参数拼接要请求的url后,指定爬取哪个页面的内容通过控制偏移参数。3.生成不同页面的请求,获取json数据中图片的url信息4.请求图片的url,下载图片5.保存到文件夹中。
实际代码
import requests
from urllib.parse import urlencode,urljoin
import os
from hashlib import md5
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36",
"X-Requested-With":"XMLHttpRequest"
}
def get_page(offset):
"""
:param offset: 偏移量,控制翻页
:return:
"""
params = {
"offset":offset,
"format":"json",
"keyword":"街拍",
"autoload":"true",
"count":"20",
"cur_tab":"1",
"from":"search_tab"
}
url = "https://www.toutiao.com/search_content/?" + urlencode(params)
try:
response = requests.get(url,headers=headers,timeout=5)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
return None
def get_image(json):
"""
:param json: 获取到返回的json数据
:return:
"""
if json:
for item in json.get("data"):
title = item.get("title")
images = item.get("image_list")
if images:
for image in images:
yield {
"title":title,
"image":urljoin("http:",image.get("url")) if type(image) == type({"t":1}) else urljoin("http:",image)
}
def save_images(item):
"""
将图片保存到文件夹,以标题命名文件夹
:param item: json数据
:return:
"""
if item.get("title") != None:
if not os.path.exists(item.get("title")):
os.mkdir(item.get("title"))
else:
pass
try:
response = requests.get(item.get("image"))
if response.status_code == 200:
file_path = "{0}/{1}.{2}".format(item.get("title") if item.get("title") != None else "Notitle",md5(response.content).hexdigest(),"jpg")
if not os.path.exists(file_path):
with open(file_path,"wb") as f:
f.write(response.content)
else:
print("Already Downloaded",file_path)
except requests.ConnectionError:
print("Failed Download Image")
def main(offset):
"""
控制爬取的主要逻辑
:param offset: 偏移量
:return:
"""
json = get_page(offset)
for item in get_image(json):
print(item)
save_images(item)
groups = [i*20 for i in range(1,10)]
if __name__ == '__main__':
for group in groups:
main(group)
爬取的结果
通过ajax接口分析,模拟ajax请求进行抓包比selenium模拟简单,但是代码复用性差,因为每个网页的接口都不一样,所以在抓取ajax加载的数据时,最好使用selenium模拟或者直接抓取界面数据需要小伙伴根据实际需要自行选择。 查看全部
ajax抓取网页内容(如何分析ajax接口,模拟ajax请求爬取数据(组图))
抓取ajax网站,我们可以通过分析ajax接口获取返回的json数据,从而抓取我们想要的数据。以今日头条为例,如何分析ajax接口,模拟ajax请求爬取数据。
以今日头条为例。网页的上一页只显示部分数据。要查看后续数据,需要向下滑动鼠标。这里我们分析一下它的ajax接口。
打开开发者工具,选择network,点击XHR过滤掉ajax请求,可以看到这里有很多参数,一眼就能看到的参数就是关键字,也就是我们搜索的关键字。然后查看它的预览信息。
可以看到Preview信息中有很多数据信息。点击它可以看到里面收录了很多有用的信息,比如街拍标题和图片地址。
当鼠标向下滑动时,又会过滤掉一个Ajax请求,如下图
可以看到offset参数从0变成了20。仔细观察网页,可以发现网页上显示的信息正好有20条。
这是鼠标滑到第三页的时候,可以看到offset参数变成了40。第一页打开时offset参数为0,第二页offset参数为20,第三页上的参数page是40。不难发现,offset参数其实就是一个offset,一个用来实现翻页的参数。然后我们可以使用urlencode方法将这些参数拼接到url后面,发起ajax请求,通过控制传入的offset参数控制翻页,然后通过response.json( )。
代码思路:1.分析网页的ajax接口,需要传入什么数据2.通过urlencode键参数拼接要请求的url后,指定爬取哪个页面的内容通过控制偏移参数。3.生成不同页面的请求,获取json数据中图片的url信息4.请求图片的url,下载图片5.保存到文件夹中。
实际代码
import requests
from urllib.parse import urlencode,urljoin
import os
from hashlib import md5
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36",
"X-Requested-With":"XMLHttpRequest"
}
def get_page(offset):
"""
:param offset: 偏移量,控制翻页
:return:
"""
params = {
"offset":offset,
"format":"json",
"keyword":"街拍",
"autoload":"true",
"count":"20",
"cur_tab":"1",
"from":"search_tab"
}
url = "https://www.toutiao.com/search_content/?" + urlencode(params)
try:
response = requests.get(url,headers=headers,timeout=5)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
return None
def get_image(json):
"""
:param json: 获取到返回的json数据
:return:
"""
if json:
for item in json.get("data"):
title = item.get("title")
images = item.get("image_list")
if images:
for image in images:
yield {
"title":title,
"image":urljoin("http:",image.get("url")) if type(image) == type({"t":1}) else urljoin("http:",image)
}
def save_images(item):
"""
将图片保存到文件夹,以标题命名文件夹
:param item: json数据
:return:
"""
if item.get("title") != None:
if not os.path.exists(item.get("title")):
os.mkdir(item.get("title"))
else:
pass
try:
response = requests.get(item.get("image"))
if response.status_code == 200:
file_path = "{0}/{1}.{2}".format(item.get("title") if item.get("title") != None else "Notitle",md5(response.content).hexdigest(),"jpg")
if not os.path.exists(file_path):
with open(file_path,"wb") as f:
f.write(response.content)
else:
print("Already Downloaded",file_path)
except requests.ConnectionError:
print("Failed Download Image")
def main(offset):
"""
控制爬取的主要逻辑
:param offset: 偏移量
:return:
"""
json = get_page(offset)
for item in get_image(json):
print(item)
save_images(item)
groups = [i*20 for i in range(1,10)]
if __name__ == '__main__':
for group in groups:
main(group)
爬取的结果
通过ajax接口分析,模拟ajax请求进行抓包比selenium模拟简单,但是代码复用性差,因为每个网页的接口都不一样,所以在抓取ajax加载的数据时,最好使用selenium模拟或者直接抓取界面数据需要小伙伴根据实际需要自行选择。
ajax抓取网页内容(Google的URL变了,音乐播放没有中断的原因是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-19 04:07
越来越多的网站,开始使用“单页结构”(Single-page application)。
整个网站只有一个网页,它使用Ajax技术根据用户的输入加载不同的内容。
这种方式的好处是用户体验好,节省了流量。缺点是AJAX内容不能被搜索引擎抓取。例如,您有一个 网站。
http://example.com
用户通过英镑结构的 URL 看到不同的内容。
http://example.com#1 http://example.com#2 http://example.com#3
但是,搜索引擎只抓取和忽略主题标签,因此它们无法索引内容。
为了解决这个问题,谷歌想出了“哈希+感叹号”的结构。
http://example.com#!1
当 Google 找到上述网址时,它会自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放在这个 URL 上,Google 就会收录。但问题是,“英镑+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
http://twitter.com/ruanyf
改成
http://twitter.com/#!/ruanyf
结果,用户投诉连连,仅半年就被废止。
那么,有没有什么方法可以让搜索引擎在抓取 AJAX 内容的同时保持更直观的 URL?
一直以为没有办法,直到看到 Discourse 创始人之一 Robin Ward 的解决方案,不禁为之惊叹。
Discourse 是一个严重依赖 Ajax 的论坛程序,但必须使用 Google收录 内容。它的解决方案是放弃英镑符号结构并使用 History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏的网址变了,但音乐播放没有中断!
History API 的详细介绍超出了本文章 的范围。这里简单说一下,它的作用是在浏览器的History对象中添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以使新的 URL 出现在地址栏中。History对象的pushState方法接受三个参数,新的URL是第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前所有主流浏览器都支持这种方法:Chrome (26.0+), Firefox (20.0+), IE (10.0+), Safari (0.0+) @5.1+),歌剧 (12.1+)。
以下是罗宾·沃德 (Robin Ward) 的做法。
首先,用History API替换hashtag结构,让每个hashtag变成一个正常路径的URL,这样搜索引擎就会爬取每一个网页。
example.com/1 example.com/2 example.com/3
然后,定义一个处理 Ajax 部分并基于 URL 获取内容的 JavaScript 函数(假设是 jQuery)。
function anchorClick(link) {<br /> var linkSplit = link.split('/').pop();<br /> $.get('api/' + linkSplit, function(data) {<br /> $('#content').html(data);<br /> });<br /> }
再次定义鼠标点击事件。
$('#container').on('click', 'a', function(e) {<br /> window.history.pushState(null, null, $(this).attr('href'));<br /> anchorClick($(this).attr('href'));<br /> e.preventDefault();<br /> });
还要考虑到用户单击浏览器的“前进/后退”按钮。此时触发了History对象的popstate事件。
window.addEventListener('popstate', function(e) { <br /> anchorClick(location.pathname); <br /> });
定义好以上三段代码后,无需刷新页面即可显示正常的路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用主题标签结构,所以每个 URL 都是不同的请求。因此,服务器需要为所有这些请求返回具有以下结构的网页,以防止 404 错误。
<br /> <br /> <br /> <br /> ... ...<br /> <br /> <br />
如果你仔细看上面的代码,你会发现有一个noscript标签,这就是秘密。
我们将搜索引擎应该为 收录 的所有内容放在 noscript 标记中。在这种情况下,用户仍然可以在不刷新页面的情况下进行 AJAX 操作,但是搜索引擎会收录每个页面的主要内容! 查看全部
ajax抓取网页内容(Google的URL变了,音乐播放没有中断的原因是什么?)
越来越多的网站,开始使用“单页结构”(Single-page application)。
整个网站只有一个网页,它使用Ajax技术根据用户的输入加载不同的内容。

这种方式的好处是用户体验好,节省了流量。缺点是AJAX内容不能被搜索引擎抓取。例如,您有一个 网站。
http://example.com
用户通过英镑结构的 URL 看到不同的内容。
http://example.com#1 http://example.com#2 http://example.com#3
但是,搜索引擎只抓取和忽略主题标签,因此它们无法索引内容。
为了解决这个问题,谷歌想出了“哈希+感叹号”的结构。
http://example.com#!1
当 Google 找到上述网址时,它会自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放在这个 URL 上,Google 就会收录。但问题是,“英镑+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
http://twitter.com/ruanyf
改成
http://twitter.com/#!/ruanyf
结果,用户投诉连连,仅半年就被废止。
那么,有没有什么方法可以让搜索引擎在抓取 AJAX 内容的同时保持更直观的 URL?
一直以为没有办法,直到看到 Discourse 创始人之一 Robin Ward 的解决方案,不禁为之惊叹。

Discourse 是一个严重依赖 Ajax 的论坛程序,但必须使用 Google收录 内容。它的解决方案是放弃英镑符号结构并使用 History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?

地址栏的网址变了,但音乐播放没有中断!
History API 的详细介绍超出了本文章 的范围。这里简单说一下,它的作用是在浏览器的History对象中添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以使新的 URL 出现在地址栏中。History对象的pushState方法接受三个参数,新的URL是第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前所有主流浏览器都支持这种方法:Chrome (26.0+), Firefox (20.0+), IE (10.0+), Safari (0.0+) @5.1+),歌剧 (12.1+)。
以下是罗宾·沃德 (Robin Ward) 的做法。
首先,用History API替换hashtag结构,让每个hashtag变成一个正常路径的URL,这样搜索引擎就会爬取每一个网页。
example.com/1 example.com/2 example.com/3
然后,定义一个处理 Ajax 部分并基于 URL 获取内容的 JavaScript 函数(假设是 jQuery)。
function anchorClick(link) {<br /> var linkSplit = link.split('/').pop();<br /> $.get('api/' + linkSplit, function(data) {<br /> $('#content').html(data);<br /> });<br /> }
再次定义鼠标点击事件。
$('#container').on('click', 'a', function(e) {<br /> window.history.pushState(null, null, $(this).attr('href'));<br /> anchorClick($(this).attr('href'));<br /> e.preventDefault();<br /> });
还要考虑到用户单击浏览器的“前进/后退”按钮。此时触发了History对象的popstate事件。
window.addEventListener('popstate', function(e) { <br /> anchorClick(location.pathname); <br /> });
定义好以上三段代码后,无需刷新页面即可显示正常的路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用主题标签结构,所以每个 URL 都是不同的请求。因此,服务器需要为所有这些请求返回具有以下结构的网页,以防止 404 错误。
<br /> <br /> <br /> <br /> ... ...<br /> <br /> <br />
如果你仔细看上面的代码,你会发现有一个noscript标签,这就是秘密。
我们将搜索引擎应该为 收录 的所有内容放在 noscript 标记中。在这种情况下,用户仍然可以在不刷新页面的情况下进行 AJAX 操作,但是搜索引擎会收录每个页面的主要内容!
ajax抓取网页内容(python通过xpath转化为xpath的javascript转化器.xpath)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-18 18:02
ajax抓取网页内容,通过xpath转化为xpath转化器.xpath转化器很强大,能将xpath转化为javascriptcanvas的javascript
通过vscode来编写python程序编译成python代码其实我觉得python用eclipse最好(微软的东西一向做的不错)
python一些社区小项目上,写个小爬虫也挺简单的。node。js上也有写spider的工具,先起个容易理解的名字,代码一看,要爬的东西就明白了。对于不同语言开发出来的爬虫,基本原理是不一样的,例如python爬虫工具用django。examples。python。com,而不是我们经常看到的httppost请求在自己的爬虫工具里,经常用的是beautifulsoup之类的javascript解析库,或者用scrapy之类的框架,来处理各种变量,属性,post等等。
python可以爬b站的哔哩哔哩,感觉最重要的是要学会看源码,可以先看慕课网的python爬虫,
可以做个电商网站,
可以,看个人技术和兴趣吧,
框架推荐vue、react之类,不过我现在用selenium,
题主没有说明是哪种语言,这就意味着都能上,没有区别,无非是就是看看别人代码做做对比, 查看全部
ajax抓取网页内容(python通过xpath转化为xpath的javascript转化器.xpath)
ajax抓取网页内容,通过xpath转化为xpath转化器.xpath转化器很强大,能将xpath转化为javascriptcanvas的javascript
通过vscode来编写python程序编译成python代码其实我觉得python用eclipse最好(微软的东西一向做的不错)
python一些社区小项目上,写个小爬虫也挺简单的。node。js上也有写spider的工具,先起个容易理解的名字,代码一看,要爬的东西就明白了。对于不同语言开发出来的爬虫,基本原理是不一样的,例如python爬虫工具用django。examples。python。com,而不是我们经常看到的httppost请求在自己的爬虫工具里,经常用的是beautifulsoup之类的javascript解析库,或者用scrapy之类的框架,来处理各种变量,属性,post等等。
python可以爬b站的哔哩哔哩,感觉最重要的是要学会看源码,可以先看慕课网的python爬虫,
可以做个电商网站,
可以,看个人技术和兴趣吧,
框架推荐vue、react之类,不过我现在用selenium,
题主没有说明是哪种语言,这就意味着都能上,没有区别,无非是就是看看别人代码做做对比,
ajax抓取网页内容(UA属性:UA即user-agent原则及调整方向)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-15 08:28
UA属性:UA即user-agent,是http协议中的一个属性,代表终端的身份,向服务器表明我在做什么,然后服务器可以根据不同的身份做出不同的反馈结果。
机器人协议:robots.txt 是搜索引擎访问网站时首先访问的文件,用于确定哪些允许爬取,哪些禁止爬取。robots.txt 必须放在网站 根目录下,文件名必须小写。robots.txt的详细写法请参考。百度严格执行机器人协议。此外,它还支持在网页内容中添加名为 robots 的元标记,以及 index、follow 和 nofollow 等指令。
百度蜘蛛抓取频率原理及调整方向
百度蜘蛛根据上述网站设定的协议爬取网站页面,但不可能对所有网站一视同仁。它会综合考虑网站的实际情况来确定一个抓取配额,每天定量抓取网站内容,也就是我们常说的抓取频率。那么百度搜索引擎是通过哪些指标来判断一个网站的爬取频率呢?主要有四个指标:
1、网站更新频率:更新越频繁,更新越慢,直接影响百度蜘蛛的访问频率
2、网站更新质量:提升的更新频率正好吸引了百度蜘蛛的注意。百度蜘蛛对质量有严格的要求。如果 网站 每天更新的大量内容被百度蜘蛛质量页面判断为低,仍然没有意义。
3. 连通性:网站 安全稳定,保持百度蜘蛛畅通。一直关着百度蜘蛛不是好事
4、站点评价:百度搜索引擎会对每个站点都有一个评价,这个评价会根据站点情况不断变化。里面有很机密的资料。站点评级从不单独使用,并与其他因素和阈值一起影响 网站 的爬取和排名。
爬取频率间接决定了网站有多少页面可能被数据库收录。这么重要的值,如果不符合站长的期望,应该如何调整呢?百度站长平台提供爬频工具,已完成多次升级。除了提供爬取统计,该工具还提供了“频率调整”功能。站长要求百度蜘蛛根据实际情况增加或减少对百度站长平台的访问量。调整。
百度蜘蛛爬取异常的原因
有一些网页内容优质,用户可以正常访问,但Baiduspider无法正常访问和爬取,导致搜索结果覆盖不足,对百度搜索引擎和网站来说都是一种损失。百度称这种情况为“抢”。对于大量内容无法正常抓取的网站,百度搜索引擎会认为网站存在用户体验缺陷,降低对网站的评价,在爬取、索引和排序方面都会受到一定程度的负面影响,最终会影响到网站从百度获得的流量。
以下是爬取异常的一些常见原因:
1.服务器连接异常
服务器连接异常有两种情况:一种是网站不稳定,百度蜘蛛在尝试连接你的网站服务器时暂时无法连接;另一个是百度蜘蛛一直无法连接到你网站的服务器。服务器。
服务器连接异常的原因通常是你的网站服务器太大,过载。您的 网站 也可能运行不正常。请检查网站的web服务器(如apache、iis)是否安装并运行正常,并使用浏览器检查主页是否可以正常访问。您的 网站 和主机也可能阻止了百度蜘蛛的访问,您需要检查您的 网站 和主机的防火墙。
2、网络运营商异常:网络运营商分为电信和联通两类。百度蜘蛛无法通过中国电信或中国网通访问您的网站。如果出现这种情况,需要联系网络服务运营商,或者购买双线服务空间或者购买cdn服务。
3、DNS异常:当Baiduspider无法解析您的网站 IP时,会出现DNS异常。可能你的网站IP地址错误,或者你的域名服务商屏蔽了百度蜘蛛。请使用 WHOIS 或主机检查您的 网站IP 地址是否正确且可解析。如果不正确或无法解决,请联系域名注册商更新您的 IP 地址。
4、IP封禁:IP封禁是:限制网络的出口IP地址,禁止该IP段内的用户访问内容,这里特意封禁BaiduspiderIP。仅当您的 网站 不希望百度蜘蛛访问时,才需要此设置。如果您想让百度蜘蛛访问您的网站,请在相关设置中检查百度蜘蛛IP是否添加错误。也有可能是你网站所在的空间服务商封杀了百度IP。在这种情况下,您需要联系服务提供商更改设置。
5、UA禁止:UA为User-Agent,服务器通过UA识别访问者。当网站返回异常页面(如403、500)或跳转到其他页面进行指定UA的访问时,属于UA禁令。当你的网站不想要百度蜘蛛时这个设置只有在访问的时候才需要,如果你想让Baiduspider访问你的网站,请检查useragent相关设置中是否有Baiduspider UA,并及时修改。
6、死链接:无效且不能为用户提供任何有价值信息的页面为死链接,包括协议死链接和内容死链接:
协议死链接:页面的TCP协议状态/HTTP协议状态明确表示的死链接,如404、403、503状态等。
内容死链接:服务器返回正常状态,但内容已更改为不存在、已删除或需要权限等与原创内容无关的信息页面。
对于死链接,我们建议网站使用协议死链接,通过百度站长平台-死链接工具提交给百度,这样百度可以更快的找到死链接,减少死链接对用户和搜索引擎的负面影响。
7.异常跳转:将网络请求重定向到另一个位置是跳转。异常跳转指以下几种情况:
1)目前该页面为无效页面(删除内容、死链接等),直接跳转上一个目录或首页,百度建议站长删除无效页面的入口超链接
2)跳转到错误或无效页面
注意:长期重定向到其他域名,如网站改域名,百度推荐使用301重定向协议进行设置。
8. 其他例外:
1)百度referrer异常:网页返回的行为与来自百度的referrer的正常内容不同。
2)百度UA异常:网页返回百度UA的行为与页面原创内容不同。
3)JS跳转异常:网页加载了百度无法识别的JS跳转代码,导致用户通过搜索结果进入页面后跳转。
4)压力过大导致的意外封禁:百度会根据网站规模、流量等信息自动设置合理的抓取压力。但在异常情况下,如压力控制异常时,服务器会根据自身负载进行保护性的偶尔封禁。在这种情况下,请在返回码中返回 503(表示“服务不可用”),这样百度蜘蛛会在一段时间后再次尝试抓取链接。如果 网站 是空闲的,它将被成功爬取。
判断新链接的重要性
好了,上面我们讲了影响百度蜘蛛正常爬取的原因,下面说一下百度蜘蛛的一些判断原则。建库前,Baiduspide会对页面进行初步的内容分析和链接分析,通过内容分析判断页面是否需要建索引库,通过链接分析发现更多页面,然后爬取更多页面——分析——是否建立一个图书馆并发现新链接的过程。理论上,百度蜘蛛会抓取新页面上所有“看到”的链接,那么面对众多的新链接,百度蜘蛛如何判断哪个更重要呢?两个方面:
一、对用户的价值:
1.独特的内容,百度搜索引擎喜欢独特的内容
2. 主体突出,不要出现网页主体内容不突出被搜索引擎误判为空短页而未被抓取
3、内容丰富
4.广告合适
二、链接的重要性:
1.目录级别——浅层优先
2. 网站链接的受欢迎程度
百度优先建设重要库的原则
百度蜘蛛抓取的页数不是最重要的,重要的是建了多少页到索引库,也就是我们常说的“建库”。众所周知,搜索引擎的索引库是分层的。高质量的网页将分配到重要的索引库,普通网页将留在普通库,较差的网页将分配到低级库作为补充资料。目前60%的检索需求只需要调用重要的索引库就可以满足,这就解释了为什么有些网站的收录的高流量并不理想。
那么,哪些页面可以进入优质索引库呢?其实,总的原则是一个:对用户有价值。包括但不仅限于:
1.及时有价值的页面:在这里,及时性和价值并列,两者都缺一不可。有些网站为了生成时间敏感的内容页面做了很多采集的工作,导致一堆毫无价值的页面,百度不想看到。
2. 内容优质的专题页:专题页的内容不一定是完全的原创,也就是可以很好的融合各方的内容,或者添加一些新鲜的内容,比如浏览量和评论,给用户更丰富、更全面的内容。
3、高价值的原创内容页面:百度将原创定义为花费一定成本、积累大量经验后形成的文章。永远不要再问我们是否 伪原创 是原创。
4.重要的个人页面:这里只是一个例子,科比在新浪微博上开了一个账号,他需要不经常更新,但对于百度来说,它仍然是一个非常重要的页面。
哪些页面不能被索引
上面提到的优质网页都进入了索引库,所以其实网上的大部分网站都没有被百度收录列出来。不是百度没找到,而是建库前的筛选过程中被过滤掉了。那么在第一个链接中过滤掉了什么样的网页:
1、内容重复的网页:百度不需要收录互联网上已有的内容。
2. 主要内容为空、短的网页
1)有些内容使用了百度蜘蛛无法解析的技术,比如JS、AJAX等,虽然用户可以看到丰富的内容,但还是会被搜索引擎抛弃
2)加载太慢的网页也可能被视为空的短页。请注意,广告加载时间计入网页的总加载时间。
3)很多主体不太突出的网页,即使被爬回来,也会在这个链接中被丢弃。
3.一些作弊页面
想要获取工具可以加千陌先生微信m247143276获取SEO学习工具包和技术教程 查看全部
ajax抓取网页内容(UA属性:UA即user-agent原则及调整方向)
UA属性:UA即user-agent,是http协议中的一个属性,代表终端的身份,向服务器表明我在做什么,然后服务器可以根据不同的身份做出不同的反馈结果。
机器人协议:robots.txt 是搜索引擎访问网站时首先访问的文件,用于确定哪些允许爬取,哪些禁止爬取。robots.txt 必须放在网站 根目录下,文件名必须小写。robots.txt的详细写法请参考。百度严格执行机器人协议。此外,它还支持在网页内容中添加名为 robots 的元标记,以及 index、follow 和 nofollow 等指令。
百度蜘蛛抓取频率原理及调整方向
百度蜘蛛根据上述网站设定的协议爬取网站页面,但不可能对所有网站一视同仁。它会综合考虑网站的实际情况来确定一个抓取配额,每天定量抓取网站内容,也就是我们常说的抓取频率。那么百度搜索引擎是通过哪些指标来判断一个网站的爬取频率呢?主要有四个指标:
1、网站更新频率:更新越频繁,更新越慢,直接影响百度蜘蛛的访问频率
2、网站更新质量:提升的更新频率正好吸引了百度蜘蛛的注意。百度蜘蛛对质量有严格的要求。如果 网站 每天更新的大量内容被百度蜘蛛质量页面判断为低,仍然没有意义。
3. 连通性:网站 安全稳定,保持百度蜘蛛畅通。一直关着百度蜘蛛不是好事
4、站点评价:百度搜索引擎会对每个站点都有一个评价,这个评价会根据站点情况不断变化。里面有很机密的资料。站点评级从不单独使用,并与其他因素和阈值一起影响 网站 的爬取和排名。
爬取频率间接决定了网站有多少页面可能被数据库收录。这么重要的值,如果不符合站长的期望,应该如何调整呢?百度站长平台提供爬频工具,已完成多次升级。除了提供爬取统计,该工具还提供了“频率调整”功能。站长要求百度蜘蛛根据实际情况增加或减少对百度站长平台的访问量。调整。
百度蜘蛛爬取异常的原因
有一些网页内容优质,用户可以正常访问,但Baiduspider无法正常访问和爬取,导致搜索结果覆盖不足,对百度搜索引擎和网站来说都是一种损失。百度称这种情况为“抢”。对于大量内容无法正常抓取的网站,百度搜索引擎会认为网站存在用户体验缺陷,降低对网站的评价,在爬取、索引和排序方面都会受到一定程度的负面影响,最终会影响到网站从百度获得的流量。
以下是爬取异常的一些常见原因:
1.服务器连接异常
服务器连接异常有两种情况:一种是网站不稳定,百度蜘蛛在尝试连接你的网站服务器时暂时无法连接;另一个是百度蜘蛛一直无法连接到你网站的服务器。服务器。
服务器连接异常的原因通常是你的网站服务器太大,过载。您的 网站 也可能运行不正常。请检查网站的web服务器(如apache、iis)是否安装并运行正常,并使用浏览器检查主页是否可以正常访问。您的 网站 和主机也可能阻止了百度蜘蛛的访问,您需要检查您的 网站 和主机的防火墙。
2、网络运营商异常:网络运营商分为电信和联通两类。百度蜘蛛无法通过中国电信或中国网通访问您的网站。如果出现这种情况,需要联系网络服务运营商,或者购买双线服务空间或者购买cdn服务。
3、DNS异常:当Baiduspider无法解析您的网站 IP时,会出现DNS异常。可能你的网站IP地址错误,或者你的域名服务商屏蔽了百度蜘蛛。请使用 WHOIS 或主机检查您的 网站IP 地址是否正确且可解析。如果不正确或无法解决,请联系域名注册商更新您的 IP 地址。
4、IP封禁:IP封禁是:限制网络的出口IP地址,禁止该IP段内的用户访问内容,这里特意封禁BaiduspiderIP。仅当您的 网站 不希望百度蜘蛛访问时,才需要此设置。如果您想让百度蜘蛛访问您的网站,请在相关设置中检查百度蜘蛛IP是否添加错误。也有可能是你网站所在的空间服务商封杀了百度IP。在这种情况下,您需要联系服务提供商更改设置。
5、UA禁止:UA为User-Agent,服务器通过UA识别访问者。当网站返回异常页面(如403、500)或跳转到其他页面进行指定UA的访问时,属于UA禁令。当你的网站不想要百度蜘蛛时这个设置只有在访问的时候才需要,如果你想让Baiduspider访问你的网站,请检查useragent相关设置中是否有Baiduspider UA,并及时修改。
6、死链接:无效且不能为用户提供任何有价值信息的页面为死链接,包括协议死链接和内容死链接:
协议死链接:页面的TCP协议状态/HTTP协议状态明确表示的死链接,如404、403、503状态等。
内容死链接:服务器返回正常状态,但内容已更改为不存在、已删除或需要权限等与原创内容无关的信息页面。
对于死链接,我们建议网站使用协议死链接,通过百度站长平台-死链接工具提交给百度,这样百度可以更快的找到死链接,减少死链接对用户和搜索引擎的负面影响。
7.异常跳转:将网络请求重定向到另一个位置是跳转。异常跳转指以下几种情况:
1)目前该页面为无效页面(删除内容、死链接等),直接跳转上一个目录或首页,百度建议站长删除无效页面的入口超链接
2)跳转到错误或无效页面
注意:长期重定向到其他域名,如网站改域名,百度推荐使用301重定向协议进行设置。
8. 其他例外:
1)百度referrer异常:网页返回的行为与来自百度的referrer的正常内容不同。
2)百度UA异常:网页返回百度UA的行为与页面原创内容不同。
3)JS跳转异常:网页加载了百度无法识别的JS跳转代码,导致用户通过搜索结果进入页面后跳转。
4)压力过大导致的意外封禁:百度会根据网站规模、流量等信息自动设置合理的抓取压力。但在异常情况下,如压力控制异常时,服务器会根据自身负载进行保护性的偶尔封禁。在这种情况下,请在返回码中返回 503(表示“服务不可用”),这样百度蜘蛛会在一段时间后再次尝试抓取链接。如果 网站 是空闲的,它将被成功爬取。
判断新链接的重要性
好了,上面我们讲了影响百度蜘蛛正常爬取的原因,下面说一下百度蜘蛛的一些判断原则。建库前,Baiduspide会对页面进行初步的内容分析和链接分析,通过内容分析判断页面是否需要建索引库,通过链接分析发现更多页面,然后爬取更多页面——分析——是否建立一个图书馆并发现新链接的过程。理论上,百度蜘蛛会抓取新页面上所有“看到”的链接,那么面对众多的新链接,百度蜘蛛如何判断哪个更重要呢?两个方面:
一、对用户的价值:
1.独特的内容,百度搜索引擎喜欢独特的内容
2. 主体突出,不要出现网页主体内容不突出被搜索引擎误判为空短页而未被抓取
3、内容丰富
4.广告合适
二、链接的重要性:
1.目录级别——浅层优先
2. 网站链接的受欢迎程度
百度优先建设重要库的原则
百度蜘蛛抓取的页数不是最重要的,重要的是建了多少页到索引库,也就是我们常说的“建库”。众所周知,搜索引擎的索引库是分层的。高质量的网页将分配到重要的索引库,普通网页将留在普通库,较差的网页将分配到低级库作为补充资料。目前60%的检索需求只需要调用重要的索引库就可以满足,这就解释了为什么有些网站的收录的高流量并不理想。
那么,哪些页面可以进入优质索引库呢?其实,总的原则是一个:对用户有价值。包括但不仅限于:
1.及时有价值的页面:在这里,及时性和价值并列,两者都缺一不可。有些网站为了生成时间敏感的内容页面做了很多采集的工作,导致一堆毫无价值的页面,百度不想看到。
2. 内容优质的专题页:专题页的内容不一定是完全的原创,也就是可以很好的融合各方的内容,或者添加一些新鲜的内容,比如浏览量和评论,给用户更丰富、更全面的内容。
3、高价值的原创内容页面:百度将原创定义为花费一定成本、积累大量经验后形成的文章。永远不要再问我们是否 伪原创 是原创。
4.重要的个人页面:这里只是一个例子,科比在新浪微博上开了一个账号,他需要不经常更新,但对于百度来说,它仍然是一个非常重要的页面。
哪些页面不能被索引
上面提到的优质网页都进入了索引库,所以其实网上的大部分网站都没有被百度收录列出来。不是百度没找到,而是建库前的筛选过程中被过滤掉了。那么在第一个链接中过滤掉了什么样的网页:
1、内容重复的网页:百度不需要收录互联网上已有的内容。
2. 主要内容为空、短的网页
1)有些内容使用了百度蜘蛛无法解析的技术,比如JS、AJAX等,虽然用户可以看到丰富的内容,但还是会被搜索引擎抛弃
2)加载太慢的网页也可能被视为空的短页。请注意,广告加载时间计入网页的总加载时间。
3)很多主体不太突出的网页,即使被爬回来,也会在这个链接中被丢弃。
3.一些作弊页面
想要获取工具可以加千陌先生微信m247143276获取SEO学习工具包和技术教程
ajax抓取网页内容(看看jQuery的.load()函数:如何使用jQuery包含HTML页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-10 22:27
在元素中: .
如何使用 jQuery 收录一个 HTML 页面,该页面可以通过调用 jQuery 中的 load() 函数加载到 HTML 页面上的 div 中。这只是从 random_number.php 文件(其内容在上面的示例中)中获取文本,并将结果放入 id 为 test 的 div 中。这是一个执行此操作的 HTML 页面。看看 jQuery 的 .load() 函数:How to load an external web page into a div in an html page。33. 使用 iframe 或 Object 标签嵌入网页。如何在页面加载时将网页内容加载到 div 中?构建一个收录许多关于如何使用 HTML、CSS、JavaScript 的示例的教程,并且 jQuery load() 方法是一种简单但功能强大的 AJAX 方法。load() 方法从服务器加载数据,并将返回的数据放入下面的示例中,将文件“demo_test.txt”的内容加载到特定的
在元素中:jQuery load() 语法和 load() 我们可以在需要时或在用户请求时通过表单、按钮、链接将外部文件(php、html、asp...)加载到 div 中... ...此脚本的外部文件必须托管在同一域网络上。我们来看看从官网提取的语法:.
如何在页面加载时将网页内容加载到 div 中?,看看jQuery的.load()函数:How to load an external web page into a div in an html page。33. 在构建教程中使用iframe 或Object 标签嵌入网页,其中收录如何使用HTML、CSS、JavaScript 的许多示例,jQuery load() 方法是一种简单但功能强大的AJAX 方法。load() 方法从服务器加载数据,并将返回的数据放入下面的示例中,将文件“demo_test.txt”的内容加载到特定的
在元素中: . . Load(), jQuery load() 语法 使用 load() 我们可以加载一个外部文件(php, html, asp.. ..)。脚本文件必须托管在与 Web 相同的域中。让我们看一下从官方 网站 中提取的语法:这可以在没有 iframe 的情况下完成。由于标题中提到了jQuery,因此使用了jQuery。
.load(),收录许多如何使用 HTML、CSS、JavaScript 的示例的构建教程,jQuery load() 方法是一种简单但功能强大的 AJAX 方法。load() 方法从服务器加载数据,并将返回的数据放入下面的示例中,将文件“demo_test.txt”的内容加载到特定的
在元素中:jQuery load() 语法和 load() 我们可以在需要时或在用户请求时通过表单、按钮、链接将外部文件(php、html、asp...)加载到 div 中... ...此脚本的外部文件必须托管在同一域网络上。我们来看看从官网提取的语法:. 使用 jQuery 将页面加载到 div 中,这可以在没有 iframe 的情况下完成。由于标题中提到了jQuery,因此使用了jQuery。,将代码包装在 load() 函数中。要在 jQuery 中加载 div 中的页面,请使用 load() 方法。
使用 jQuery 将页面加载到 div 中,jQuery 的语法 load() 使用 load(),我们可以在需要时或在用户请求时传递表单、按钮、链接... 这个脚本的外部文件必须托管在同一个 web 上域中间。让我们看一下从官方 网站 中提取的语法:这可以在没有 iframe 的情况下完成。由于标题中提到了jQuery,因此使用了jQuery。.load() .load( url, [data], [complete(responseText, textStatus, 将外部 HTML 加载到
,将代码包装在 load() 函数中。要在 jQuery 中加载 div 页面,请使用 load() 方法。我正在将一个单独的 HTML 文件中的 div 加载到 index.html 页面上的一个 div 中。这是使用 jQuery 的 .load() 完成的。但是,有很多重复,我想知道是否有更清洁的方法来实现这一点。.
jQuery 加载模板
jquery.loadtemplate, jQuery.loadTemplate 最初是为博客设计的单页应用程序。这个想法是为博客 文章、文章 片段等创建模板。注意:在 jQuery 3.0 之前,事件处理套件还有一个名为 .load() 的方法。旧版本的 jQuery 根据传递给它的参数确定要触发的方法。. 为什么我们使用 jQuery LoadTemplate,只是将模板主体加载为简单的文本而忘记将其放入 dummy。版权所有。蜀ICP备2021025969号
切换导航 查看全部
ajax抓取网页内容(看看jQuery的.load()函数:如何使用jQuery包含HTML页面)
在元素中: .
如何使用 jQuery 收录一个 HTML 页面,该页面可以通过调用 jQuery 中的 load() 函数加载到 HTML 页面上的 div 中。这只是从 random_number.php 文件(其内容在上面的示例中)中获取文本,并将结果放入 id 为 test 的 div 中。这是一个执行此操作的 HTML 页面。看看 jQuery 的 .load() 函数:How to load an external web page into a div in an html page。33. 使用 iframe 或 Object 标签嵌入网页。如何在页面加载时将网页内容加载到 div 中?构建一个收录许多关于如何使用 HTML、CSS、JavaScript 的示例的教程,并且 jQuery load() 方法是一种简单但功能强大的 AJAX 方法。load() 方法从服务器加载数据,并将返回的数据放入下面的示例中,将文件“demo_test.txt”的内容加载到特定的
在元素中:jQuery load() 语法和 load() 我们可以在需要时或在用户请求时通过表单、按钮、链接将外部文件(php、html、asp...)加载到 div 中... ...此脚本的外部文件必须托管在同一域网络上。我们来看看从官网提取的语法:.
如何在页面加载时将网页内容加载到 div 中?,看看jQuery的.load()函数:How to load an external web page into a div in an html page。33. 在构建教程中使用iframe 或Object 标签嵌入网页,其中收录如何使用HTML、CSS、JavaScript 的许多示例,jQuery load() 方法是一种简单但功能强大的AJAX 方法。load() 方法从服务器加载数据,并将返回的数据放入下面的示例中,将文件“demo_test.txt”的内容加载到特定的
在元素中: . . Load(), jQuery load() 语法 使用 load() 我们可以加载一个外部文件(php, html, asp.. ..)。脚本文件必须托管在与 Web 相同的域中。让我们看一下从官方 网站 中提取的语法:这可以在没有 iframe 的情况下完成。由于标题中提到了jQuery,因此使用了jQuery。
.load(),收录许多如何使用 HTML、CSS、JavaScript 的示例的构建教程,jQuery load() 方法是一种简单但功能强大的 AJAX 方法。load() 方法从服务器加载数据,并将返回的数据放入下面的示例中,将文件“demo_test.txt”的内容加载到特定的
在元素中:jQuery load() 语法和 load() 我们可以在需要时或在用户请求时通过表单、按钮、链接将外部文件(php、html、asp...)加载到 div 中... ...此脚本的外部文件必须托管在同一域网络上。我们来看看从官网提取的语法:. 使用 jQuery 将页面加载到 div 中,这可以在没有 iframe 的情况下完成。由于标题中提到了jQuery,因此使用了jQuery。,将代码包装在 load() 函数中。要在 jQuery 中加载 div 中的页面,请使用 load() 方法。
使用 jQuery 将页面加载到 div 中,jQuery 的语法 load() 使用 load(),我们可以在需要时或在用户请求时传递表单、按钮、链接... 这个脚本的外部文件必须托管在同一个 web 上域中间。让我们看一下从官方 网站 中提取的语法:这可以在没有 iframe 的情况下完成。由于标题中提到了jQuery,因此使用了jQuery。.load() .load( url, [data], [complete(responseText, textStatus, 将外部 HTML 加载到
,将代码包装在 load() 函数中。要在 jQuery 中加载 div 页面,请使用 load() 方法。我正在将一个单独的 HTML 文件中的 div 加载到 index.html 页面上的一个 div 中。这是使用 jQuery 的 .load() 完成的。但是,有很多重复,我想知道是否有更清洁的方法来实现这一点。.
jQuery 加载模板
jquery.loadtemplate, jQuery.loadTemplate 最初是为博客设计的单页应用程序。这个想法是为博客 文章、文章 片段等创建模板。注意:在 jQuery 3.0 之前,事件处理套件还有一个名为 .load() 的方法。旧版本的 jQuery 根据传递给它的参数确定要触发的方法。. 为什么我们使用 jQuery LoadTemplate,只是将模板主体加载为简单的文本而忘记将其放入 dummy。版权所有。蜀ICP备2021025969号
切换导航
ajax抓取网页内容(python爬取数据的一般步骤,用到的工具包括python和BeautifulSoup)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-02-10 08:08
今天,我们将通过一个例子来介绍python爬取数据的一般步骤。使用的工具包括python的经典模块requests和BeautifulSoup,并结合新学的任务流工具TaskFlow完成代码开发。
我们先来看看要爬取的数据,URL是,通过chrome的开发者工具分析,我们可以很容易的发现后台数据加载的URL是
{page_num}/ajax/1/free/1/
page_num 的位置是要查询的页面的数据。网页上的概念中有6页数据,所以page_num的值是1-6。
图1
这里有个小技巧,可以点击图1左上角的清除按钮,先清除加载的URL,再点击原网页的第二个页面,可以在左下角看到新加载的URL图片,点击打开右侧的“预览”,可以看到资金流数据相关的内容,可以确定这个URL是用来加载数据的。
在chrome浏览器中输入,打开chrome开发者工具,在网页源码中找到数据所在的table标签。
抓取数据完整源码如下
import time
import requests
from bs4 import BeautifulSoup
from taskflow import engines
from taskflow.patterns import linear_flow
from taskflow.task import Task
REQUEST_HEADER = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'}
class MoneyFlowDownload(Task):
"""
下载资金流数据
数据源地址:http://data.10jqka.com.cn/funds/gnzjl/
"""
BASE_URl = {
"concept": 'http://data.10jqka.com.cn/fund ... 39%3B,
}
def execute(self, bizdate, *args, **kwargs):
for name, base_url in self.BASE_URl.items():
# 爬取数据的存储路径
dt_path = '/data/%s_%s.csv' % (bizdate, name)
with open(dt_path, "a+") as f:
# 记录数据文件的当前位置
pos = f.tell()
f.seek(0)
lines = f.readlines()
# 读取文件中的全部数据并将第一列存储下来作为去重依据,防止爬虫意外中断后重启程序时,重复写入相同
crawled_list = list(map(lambda line: line.split(",")[0], lines))
f.seek(pos)
# 循环500次,从第一页开始爬取数据,当页面没有数据时终端退出循环
for i in range(1, 500):
print("start crawl %s, %s" % (name, base_url % i))
web_source = requests.get(base_url % i, headers=REQUEST_HEADER)
soup = BeautifulSoup(web_source.content.decode("gbk"), 'lxml')
table = soup.select('.J-ajax-table')[0]
tbody = table.select('tbody tr')
# 当tbody为空时,则说明当前页已经没有数据了,此时终止循环
if len(tbody) == 0:
break
for tr in tbody:
fields = tr.select('td')
# 将每行记录第一列去掉,第一列为序号,没有存储必要
record = [field.text.strip() for field in fields[1:]]
# 如果记录还没有写入文件中,则执行写入操作,否则跳过这行写入
if record[0] not in crawled_list:
f.writelines([','.join(record) + '\n'])
# 同花顺网站有反爬虫的机制,爬取速度过快很可能被封
time.sleep(1)
if __name__ == '__main__':
bizdate = '20200214'
tasks = [
MoneyFlowDownload('moneyflow data download')
]
flow = linear_flow.Flow('ths data download').add(*tasks)
e = engines.load(flow, store={'bizdate': bizdate})
e.run()
执行程序后,概念资金流向数据已经存放在dt_path位置,文件名为20200214_concept.csv,内容大致如下:
钛白粉,1008.88,6.29%,7.68,6.21,1.47,7,金浦钛业,10.04%,2.96
磷化工,916.833,2.42%,37.53,34.78,2.75,28,六国化工,9.97%,4.08
光刻胶,1435.68,2.40%,43.51,44.31,-0.80,20,晶瑞股份,10.01%,42.99
至此,以flush flush概念分类的资金流数据的爬取完成,接下来就可以每天定时启动任务,抓取数据进行分析。 查看全部
ajax抓取网页内容(python爬取数据的一般步骤,用到的工具包括python和BeautifulSoup)
今天,我们将通过一个例子来介绍python爬取数据的一般步骤。使用的工具包括python的经典模块requests和BeautifulSoup,并结合新学的任务流工具TaskFlow完成代码开发。
我们先来看看要爬取的数据,URL是,通过chrome的开发者工具分析,我们可以很容易的发现后台数据加载的URL是
{page_num}/ajax/1/free/1/
page_num 的位置是要查询的页面的数据。网页上的概念中有6页数据,所以page_num的值是1-6。
图1
这里有个小技巧,可以点击图1左上角的清除按钮,先清除加载的URL,再点击原网页的第二个页面,可以在左下角看到新加载的URL图片,点击打开右侧的“预览”,可以看到资金流数据相关的内容,可以确定这个URL是用来加载数据的。
在chrome浏览器中输入,打开chrome开发者工具,在网页源码中找到数据所在的table标签。
抓取数据完整源码如下
import time
import requests
from bs4 import BeautifulSoup
from taskflow import engines
from taskflow.patterns import linear_flow
from taskflow.task import Task
REQUEST_HEADER = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'}
class MoneyFlowDownload(Task):
"""
下载资金流数据
数据源地址:http://data.10jqka.com.cn/funds/gnzjl/
"""
BASE_URl = {
"concept": 'http://data.10jqka.com.cn/fund ... 39%3B,
}
def execute(self, bizdate, *args, **kwargs):
for name, base_url in self.BASE_URl.items():
# 爬取数据的存储路径
dt_path = '/data/%s_%s.csv' % (bizdate, name)
with open(dt_path, "a+") as f:
# 记录数据文件的当前位置
pos = f.tell()
f.seek(0)
lines = f.readlines()
# 读取文件中的全部数据并将第一列存储下来作为去重依据,防止爬虫意外中断后重启程序时,重复写入相同
crawled_list = list(map(lambda line: line.split(",")[0], lines))
f.seek(pos)
# 循环500次,从第一页开始爬取数据,当页面没有数据时终端退出循环
for i in range(1, 500):
print("start crawl %s, %s" % (name, base_url % i))
web_source = requests.get(base_url % i, headers=REQUEST_HEADER)
soup = BeautifulSoup(web_source.content.decode("gbk"), 'lxml')
table = soup.select('.J-ajax-table')[0]
tbody = table.select('tbody tr')
# 当tbody为空时,则说明当前页已经没有数据了,此时终止循环
if len(tbody) == 0:
break
for tr in tbody:
fields = tr.select('td')
# 将每行记录第一列去掉,第一列为序号,没有存储必要
record = [field.text.strip() for field in fields[1:]]
# 如果记录还没有写入文件中,则执行写入操作,否则跳过这行写入
if record[0] not in crawled_list:
f.writelines([','.join(record) + '\n'])
# 同花顺网站有反爬虫的机制,爬取速度过快很可能被封
time.sleep(1)
if __name__ == '__main__':
bizdate = '20200214'
tasks = [
MoneyFlowDownload('moneyflow data download')
]
flow = linear_flow.Flow('ths data download').add(*tasks)
e = engines.load(flow, store={'bizdate': bizdate})
e.run()
执行程序后,概念资金流向数据已经存放在dt_path位置,文件名为20200214_concept.csv,内容大致如下:
钛白粉,1008.88,6.29%,7.68,6.21,1.47,7,金浦钛业,10.04%,2.96
磷化工,916.833,2.42%,37.53,34.78,2.75,28,六国化工,9.97%,4.08
光刻胶,1435.68,2.40%,43.51,44.31,-0.80,20,晶瑞股份,10.01%,42.99
至此,以flush flush概念分类的资金流数据的爬取完成,接下来就可以每天定时启动任务,抓取数据进行分析。
ajax抓取网页内容(如何抓取ajax形式加载的网页数据(一)_恢复内容开始)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-09 12:12
---恢复内容开始---
下面记录如何捕获以ajax形式加载的网页数据:
目标:获取"%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action="下的网页数据
第一步:网页数据分析-----》特点:当列表栏滚动到页面底部时,自动加载数据,页面的url没有变化。
第二步:使用Fiddler抓包,如下图:
图 1:请求数据
图 2:表格形式
通过抓包得到数据规则:图2中from表单中start对应的数据和图1中url中start对应的数据随着每次加载而增加,其他数据保持不变。对应这个规则,我们可以构造相应的请求来获取数据
需要注意的是数据格式是json
代码显示如下:
1).urllib 形式
import urllib2
import urllib
#此处的url为上述抓包获取的url去掉start以及limit,start以及limit数据后边以form表单的形式传入
url = ' https://movie.douban.com/j/cha ... ction='
#请求投信息,伪造成浏览器,方式被反爬虫策略拦截
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
#构建form表单
formdata = {
"start":"20",
"limit":"20"
}
#urlencode()urllib中的函数,作用:将key:value形式的键值对转换为"key=value"形式的字符串
data = urllib.urlencode(formdata)
#构建request实例对象
request = urllib2.Request(url,data=data,headers=headers)
#发送请求并返回响应信息
response = urllib2.urlopen(request)
#注意此处的数据形式并不是html文档,而是json数据
json = response.read()
print html
2)。获取请求库的请求码
#coding=utf-8
import requests
url = ' https://movie.douban.com/j/cha ... ction='
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
data = {
"start":"20",
"limit":"20",
}
response = requests.get(url,params = data,headers = headers)
print response.text
3).request 库发布请求
#coding=utf-8
import requests
url = ' https://movie.douban.com/j/cha ... ction='
formdata = {
"start":"20",
"limit":"20"
}
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
response = requests.post(url,data=formdata,headers=headers)
print response.text
---恢复内容结束--- 查看全部
ajax抓取网页内容(如何抓取ajax形式加载的网页数据(一)_恢复内容开始)
---恢复内容开始---
下面记录如何捕获以ajax形式加载的网页数据:
目标:获取"%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action="下的网页数据
第一步:网页数据分析-----》特点:当列表栏滚动到页面底部时,自动加载数据,页面的url没有变化。
第二步:使用Fiddler抓包,如下图:
图 1:请求数据

图 2:表格形式

通过抓包得到数据规则:图2中from表单中start对应的数据和图1中url中start对应的数据随着每次加载而增加,其他数据保持不变。对应这个规则,我们可以构造相应的请求来获取数据
需要注意的是数据格式是json
代码显示如下:
1).urllib 形式
import urllib2
import urllib
#此处的url为上述抓包获取的url去掉start以及limit,start以及limit数据后边以form表单的形式传入
url = ' https://movie.douban.com/j/cha ... ction='
#请求投信息,伪造成浏览器,方式被反爬虫策略拦截
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
#构建form表单
formdata = {
"start":"20",
"limit":"20"
}
#urlencode()urllib中的函数,作用:将key:value形式的键值对转换为"key=value"形式的字符串
data = urllib.urlencode(formdata)
#构建request实例对象
request = urllib2.Request(url,data=data,headers=headers)
#发送请求并返回响应信息
response = urllib2.urlopen(request)
#注意此处的数据形式并不是html文档,而是json数据
json = response.read()
print html
2)。获取请求库的请求码
#coding=utf-8
import requests
url = ' https://movie.douban.com/j/cha ... ction='
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
data = {
"start":"20",
"limit":"20",
}
response = requests.get(url,params = data,headers = headers)
print response.text
3).request 库发布请求
#coding=utf-8
import requests
url = ' https://movie.douban.com/j/cha ... ction='
formdata = {
"start":"20",
"limit":"20"
}
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
response = requests.post(url,data=formdata,headers=headers)
print response.text
---恢复内容结束---
ajax抓取网页内容(Google的网络蜘蛛忽视URL的#部分,HTTP请求中不包括#)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-04 01:01
# 用于引导浏览器操作,在服务器端完全没用。因此,# 不收录在 HTTP 请求中。
三、# 之后的字符
出现在第一个 # 之后的任何字符都将被浏览器解释为位置标识符。这意味着这些字符都不会发送到服务器。
比如下面这个 URL 的初衷就是指定一个颜色值:
#fff
但是,浏览器发出的实际请求是: ,省略了“#fff”。只有将#转码为%23,浏览器才会将其视为真实字符。
四、Change# 不会触发网页重新加载
只需更改#后面的部分,浏览器只会滚动到相应位置,不会重新加载网页,浏览器也不会重新向服务器请求。
五、Change# 会改变浏览器的访问历史
每次更改#后面的部分,都会在浏览器的访问历史中添加一条记录,您可以使用“返回”按钮返回到之前的位置。
这对于ajax应用特别有用,可以用不同的#值来表示不同的访问状态,然后给用户一个链接来访问某个状态。
需要注意的是,上述规则不适用于 IE 6 和 IE 7,它们不会因为 # 的变化而增加历史记录。
六、window.location.hash 读取#value
属性 window.location.hash 是可读写的。阅读时,可用于判断网页状态是否发生变化;写入时会创建访问历史记录,无需重新加载网页。
七、onhashchange 事件
这是一个新的 HTML 5 事件,在 # 值更改时触发。IE8+、Firefox 3.6+、Chrome 5+、Safari 4.0+ 支持此事件。
有三种使用方法:
window.onhashchange = 函数;
window.addEventListener("hashchange", func, false);
对于不支持 onhashchange 的浏览器,可以使用 setInterval 来监控 location.hash 的变化。
八、谷歌抓取#机制
默认情况下,Google 的网络蜘蛛会忽略 URL 的 # 部分。
不过,谷歌也规定,如果想让Ajax生成的内容被浏览引擎读取,可以使用“#!” 在 URL 中,Google 会自动将其后面的内容转换为查询字符串 _escaped_fragment_ 的值。
如果找到推特网址:#!/username
将自动抓取另一个 URL:
通过这种机制,Google 可以索引动态 Ajax 内容。
如何让搜索引擎抓取 AJAX 内容
越来越多的网站开始采用“单页应用”,整个网站只有一个网页,使用Ajax技术根据用户的输入加载不同的内容,这种方式的好处是用户体验好,节省流量。缺点是AJAX内容不能被搜索引擎抓取。
例如,网站 用户通过哈希结构的 URL 看到不同的内容。
#1、#2、#3、……
但是,搜索引擎只抓取和忽略主题标签,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构:#!str,当谷歌发现像上面这样的一个URL时,它会自动爬取另一个URL:
只要你把 AJAX 内容放在这个 URL 上,Google 就会收录。但问题是,“英镑+感叹号”非常丑陋和繁琐。Twitter曾经采用这种结构,结果用户反反复复,只用了半年就废止了。
那么,有没有什么方法可以让搜索引擎在抓取 AJAX 内容的同时保持更直观的 URL?
采用历史 API
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。它的作用是在浏览器的 History 对象中添加一条记录。
window.history.pushState(状态对象, 标题, url);
上面这行命令可以使新的 URL 出现在地址栏中。History对象的pushState方法接受三个参数,新的URL是第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前所有主流浏览器都支持这种方法:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(0.0+) @5.1+),歌剧(12.1+)。
使用History API替换hashtag结构,让每个hashtag变成一个正常路径的URL,这样搜索引擎就会爬取每一个网页。
/1, /2, /3, …
然后,定义一个处理 Ajax 部分并基于 URL 获取内容的 JavaScript 函数(假设是 jQuery)。
功能锚点点击(链接){
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(数据);
});
}
再次定义鼠标点击事件。
$('#container').on('click', 'a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑到用户单击浏览器的“前进/后退”按钮。此时触发了History对象的popstate事件。
window.addEventListener('popstate', function(e) {
锚点点击(位置。路径名);
});
定义完以上三段代码后,就可以在不刷新页面的情况下显示正常的路径URL和AJAX内容了。
最后,设置服务器端。
因为没有使用主题标签结构,所以每个 URL 都是不同的请求。因此,服务器需要为所有这些请求返回具有以下结构的网页,以防止 404 错误。
如果你仔细看上面的代码,你会发现有一个noscript标签,这就是秘密。
我们将搜索引擎应该为 收录 的所有内容放在 noscript 标记中。在这种情况下,用户仍然可以在不刷新页面的情况下进行 AJAX 操作,但是搜索引擎会收录每个页面的主要内容! 查看全部
ajax抓取网页内容(Google的网络蜘蛛忽视URL的#部分,HTTP请求中不包括#)
# 用于引导浏览器操作,在服务器端完全没用。因此,# 不收录在 HTTP 请求中。
三、# 之后的字符
出现在第一个 # 之后的任何字符都将被浏览器解释为位置标识符。这意味着这些字符都不会发送到服务器。
比如下面这个 URL 的初衷就是指定一个颜色值:
#fff
但是,浏览器发出的实际请求是: ,省略了“#fff”。只有将#转码为%23,浏览器才会将其视为真实字符。
四、Change# 不会触发网页重新加载
只需更改#后面的部分,浏览器只会滚动到相应位置,不会重新加载网页,浏览器也不会重新向服务器请求。
五、Change# 会改变浏览器的访问历史
每次更改#后面的部分,都会在浏览器的访问历史中添加一条记录,您可以使用“返回”按钮返回到之前的位置。
这对于ajax应用特别有用,可以用不同的#值来表示不同的访问状态,然后给用户一个链接来访问某个状态。
需要注意的是,上述规则不适用于 IE 6 和 IE 7,它们不会因为 # 的变化而增加历史记录。
六、window.location.hash 读取#value
属性 window.location.hash 是可读写的。阅读时,可用于判断网页状态是否发生变化;写入时会创建访问历史记录,无需重新加载网页。
七、onhashchange 事件
这是一个新的 HTML 5 事件,在 # 值更改时触发。IE8+、Firefox 3.6+、Chrome 5+、Safari 4.0+ 支持此事件。
有三种使用方法:
window.onhashchange = 函数;
window.addEventListener("hashchange", func, false);
对于不支持 onhashchange 的浏览器,可以使用 setInterval 来监控 location.hash 的变化。
八、谷歌抓取#机制
默认情况下,Google 的网络蜘蛛会忽略 URL 的 # 部分。
不过,谷歌也规定,如果想让Ajax生成的内容被浏览引擎读取,可以使用“#!” 在 URL 中,Google 会自动将其后面的内容转换为查询字符串 _escaped_fragment_ 的值。
如果找到推特网址:#!/username
将自动抓取另一个 URL:
通过这种机制,Google 可以索引动态 Ajax 内容。
如何让搜索引擎抓取 AJAX 内容
越来越多的网站开始采用“单页应用”,整个网站只有一个网页,使用Ajax技术根据用户的输入加载不同的内容,这种方式的好处是用户体验好,节省流量。缺点是AJAX内容不能被搜索引擎抓取。
例如,网站 用户通过哈希结构的 URL 看到不同的内容。
#1、#2、#3、……
但是,搜索引擎只抓取和忽略主题标签,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构:#!str,当谷歌发现像上面这样的一个URL时,它会自动爬取另一个URL:
只要你把 AJAX 内容放在这个 URL 上,Google 就会收录。但问题是,“英镑+感叹号”非常丑陋和繁琐。Twitter曾经采用这种结构,结果用户反反复复,只用了半年就废止了。
那么,有没有什么方法可以让搜索引擎在抓取 AJAX 内容的同时保持更直观的 URL?
采用历史 API
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。它的作用是在浏览器的 History 对象中添加一条记录。
window.history.pushState(状态对象, 标题, url);
上面这行命令可以使新的 URL 出现在地址栏中。History对象的pushState方法接受三个参数,新的URL是第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前所有主流浏览器都支持这种方法:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(0.0+) @5.1+),歌剧(12.1+)。
使用History API替换hashtag结构,让每个hashtag变成一个正常路径的URL,这样搜索引擎就会爬取每一个网页。
/1, /2, /3, …
然后,定义一个处理 Ajax 部分并基于 URL 获取内容的 JavaScript 函数(假设是 jQuery)。
功能锚点点击(链接){
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(数据);
});
}
再次定义鼠标点击事件。
$('#container').on('click', 'a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑到用户单击浏览器的“前进/后退”按钮。此时触发了History对象的popstate事件。
window.addEventListener('popstate', function(e) {
锚点点击(位置。路径名);
});
定义完以上三段代码后,就可以在不刷新页面的情况下显示正常的路径URL和AJAX内容了。
最后,设置服务器端。
因为没有使用主题标签结构,所以每个 URL 都是不同的请求。因此,服务器需要为所有这些请求返回具有以下结构的网页,以防止 404 错误。
如果你仔细看上面的代码,你会发现有一个noscript标签,这就是秘密。
我们将搜索引擎应该为 收录 的所有内容放在 noscript 标记中。在这种情况下,用户仍然可以在不刷新页面的情况下进行 AJAX 操作,但是搜索引擎会收录每个页面的主要内容!
ajax抓取网页内容(ajax(formdata)ajax怎么做对象+async对象?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-02 17:00
ajax抓取网页内容,然后逐步将内容传送给开发者工具。ajax的请求头部会带上数据源url地址。
手动的话也可以用原生的ajax方式,配置成post以后用websocket的话,
分两步走首先ajax每个地方ajax:xmlhttprequest对象(post)+async对象对于原生js中(form表单或post)ajax:postjs(formdata)ajax:通过request对象来传递参数对于ajax中post:formdata作为参数,status(状态码)通过xmlhttprequest对象来处理ajax中postjs的ajax:methodcookie其实用哪个对象都一样,即可满足每种情况。
xmlhttprequest对象+async对象如果这样还是不明白的话,
我这里有几篇相关的文章,
可以了解下使用这个xmlhttprequest对象进行ajax传递数据。或者更简单,
ajax的请求头。不一定要async的ajax才可以;根据特殊情况可以选择post(post对象, 查看全部
ajax抓取网页内容(ajax(formdata)ajax怎么做对象+async对象?)
ajax抓取网页内容,然后逐步将内容传送给开发者工具。ajax的请求头部会带上数据源url地址。
手动的话也可以用原生的ajax方式,配置成post以后用websocket的话,
分两步走首先ajax每个地方ajax:xmlhttprequest对象(post)+async对象对于原生js中(form表单或post)ajax:postjs(formdata)ajax:通过request对象来传递参数对于ajax中post:formdata作为参数,status(状态码)通过xmlhttprequest对象来处理ajax中postjs的ajax:methodcookie其实用哪个对象都一样,即可满足每种情况。
xmlhttprequest对象+async对象如果这样还是不明白的话,
我这里有几篇相关的文章,
可以了解下使用这个xmlhttprequest对象进行ajax传递数据。或者更简单,
ajax的请求头。不一定要async的ajax才可以;根据特殊情况可以选择post(post对象,
ajax抓取网页内容( 谷歌黑板报《GET,POST以及安全获取更多网络信息》(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-02 09:10
谷歌黑板报《GET,POST以及安全获取更多网络信息》(组图))
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全获取更多网络信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。文章 中提到,Google 以后在读取网页内容时,不仅会使用 GET 抓取,还会视情况增加 POST 请求方式来抓取网页内容,进一步提升 Google 搜索引擎抓取网页内容的能力。网页的内容。网页内容的判断。
随着互联网的飞速发展,JavaScript 和 AJAX 越来越流行,越来越多的网页需要 POST 请求——因为页面的全部内容或者因为缺少某些页面信息和/或POST 无法返回资源。但是,谷歌认为,单纯使用 GET 来抓取网页所需的资源,并不能呈现出最全面、最准确的结果。
因此,Google 改进了 flash 索引,在 GET 爬取中引入了 POST 请求,从而对网页内容进行更完整、更准确的爬取和索引。
谷歌抓取网页内容的步骤如下:
1. 通过 GET 抓取网页内容。
2.索引网页内容并尝试呈现页面。
3.在渲染过程中使用POST请求读取页面内容,生成新的POST内容页面。
4.将来自 POST 请求的内容页面和其他数据负载添加到 Googlebot 的抓取队列中。
5.Googlebot 执行 POST 请求以抓取页面。
6.Google 会渲染最终的 POST 结果,也可以合并 GET 和 POST 请求结果。
7.完成索引。
搜索引擎新闻内容来源于网络,作者整理排版。不完全代表本博客的实际观点,仅供读者参考和交流。
如有涉及作者著作权的问题,请及时联系作者进行更正、删除或按规定处理。
这篇文章的链接: 查看全部
ajax抓取网页内容(
谷歌黑板报《GET,POST以及安全获取更多网络信息》(组图))

近日,Google Blackboard 发布了一篇题为“GET、POST 和安全获取更多网络信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。文章 中提到,Google 以后在读取网页内容时,不仅会使用 GET 抓取,还会视情况增加 POST 请求方式来抓取网页内容,进一步提升 Google 搜索引擎抓取网页内容的能力。网页的内容。网页内容的判断。
随着互联网的飞速发展,JavaScript 和 AJAX 越来越流行,越来越多的网页需要 POST 请求——因为页面的全部内容或者因为缺少某些页面信息和/或POST 无法返回资源。但是,谷歌认为,单纯使用 GET 来抓取网页所需的资源,并不能呈现出最全面、最准确的结果。
因此,Google 改进了 flash 索引,在 GET 爬取中引入了 POST 请求,从而对网页内容进行更完整、更准确的爬取和索引。
谷歌抓取网页内容的步骤如下:
1. 通过 GET 抓取网页内容。
2.索引网页内容并尝试呈现页面。
3.在渲染过程中使用POST请求读取页面内容,生成新的POST内容页面。
4.将来自 POST 请求的内容页面和其他数据负载添加到 Googlebot 的抓取队列中。
5.Googlebot 执行 POST 请求以抓取页面。
6.Google 会渲染最终的 POST 结果,也可以合并 GET 和 POST 请求结果。
7.完成索引。
搜索引擎新闻内容来源于网络,作者整理排版。不完全代表本博客的实际观点,仅供读者参考和交流。
如有涉及作者著作权的问题,请及时联系作者进行更正、删除或按规定处理。
这篇文章的链接:
ajax抓取网页内容(网页+客户端+手机端(Android)+小程序利用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-02 08:27
AJAX = 异步 JavaScript 和 XML
AJAX 是一种无需重新加载整个网页即可更新网页部分内容的技术
AJAX 不是一种新的编程语言,而是一种用于创建更好、更快和更具交互性的 Web 应用程序的技术
2005 年,Google 通过其 Google Suggest 使 AJAX 流行起来。
Google Suggest 使用 AJAX 创建一个非常动态的网络界面:当您在 Google 的搜索框中输入关键字时,JavaScript 会将这些字符发送到服务器,然后服务器会返回一个搜索建议列表
就像国内的百度搜索框:
传统网页(即没有Ajax技术的网页),想要更新内容或者提交表单,需要重新加载整个页面。使用Ajax技术的网页可以通过后台服务器的少量数据交换实现异步局部更新
使用 Ajax,用户可以创建接近原生桌面应用程序的直接、高可用性、更丰富、更动态的 Web 用户界面(增加 B/S 体验)
产品链:H5+网页+客户端+移动端(Android、IOS)+小程序
使用 AJAX,您可以:
DOCTYPE html>
伪造AJAX
window.onload = function f() {
var myDate = new Date();
document.getElementById("currentTime").innerText = myDate.getTime();
}
function loadPage() {
var targetURL = document.getElementById('url').value;
console.log(targetURL)
document.getElementById('iframePosition').src = targetURL
}
请输入要加载的网址:
加载页面的位置:
AJAX的纯JS实现这里就不解释了,直接使用jQuery提供的,学习更方便,避免重复造轮子
Ajax 的核心是 XMLHttpRequest 对象 (XHR)。 XHR 提供了一个向服务器发送请求和解析服务器响应的接口。能够从服务器异步获取新数据
jQuery提供了几种与Ajax相关的方法
使用 jQuery Ajax 方法,您可以使用 HTTP Get 和 HTTP Post 从远程服务器请求文本、HTML、XML 或 JSON - 您可以将这些外部数据直接加载到网页的选定元素中。
jQuery 不是生产者,而是自然的搬运工
jQuery Ajax的本质是XMLHttpRequest,为了方便调用而封装了! 查看全部
ajax抓取网页内容(网页+客户端+手机端(Android)+小程序利用)
AJAX = 异步 JavaScript 和 XML
AJAX 是一种无需重新加载整个网页即可更新网页部分内容的技术
AJAX 不是一种新的编程语言,而是一种用于创建更好、更快和更具交互性的 Web 应用程序的技术
2005 年,Google 通过其 Google Suggest 使 AJAX 流行起来。
Google Suggest 使用 AJAX 创建一个非常动态的网络界面:当您在 Google 的搜索框中输入关键字时,JavaScript 会将这些字符发送到服务器,然后服务器会返回一个搜索建议列表
就像国内的百度搜索框:

传统网页(即没有Ajax技术的网页),想要更新内容或者提交表单,需要重新加载整个页面。使用Ajax技术的网页可以通过后台服务器的少量数据交换实现异步局部更新
使用 Ajax,用户可以创建接近原生桌面应用程序的直接、高可用性、更丰富、更动态的 Web 用户界面(增加 B/S 体验)
产品链:H5+网页+客户端+移动端(Android、IOS)+小程序
使用 AJAX,您可以:
DOCTYPE html>
伪造AJAX
window.onload = function f() {
var myDate = new Date();
document.getElementById("currentTime").innerText = myDate.getTime();
}
function loadPage() {
var targetURL = document.getElementById('url').value;
console.log(targetURL)
document.getElementById('iframePosition').src = targetURL
}
请输入要加载的网址:
加载页面的位置:
AJAX的纯JS实现这里就不解释了,直接使用jQuery提供的,学习更方便,避免重复造轮子
Ajax 的核心是 XMLHttpRequest 对象 (XHR)。 XHR 提供了一个向服务器发送请求和解析服务器响应的接口。能够从服务器异步获取新数据
jQuery提供了几种与Ajax相关的方法
使用 jQuery Ajax 方法,您可以使用 HTTP Get 和 HTTP Post 从远程服务器请求文本、HTML、XML 或 JSON - 您可以将这些外部数据直接加载到网页的选定元素中。
jQuery 不是生产者,而是自然的搬运工
jQuery Ajax的本质是XMLHttpRequest,为了方便调用而封装了!
ajax抓取网页内容(安装成功获取JS返回值库元素即为安装的成功示例一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-14 02:19
前言
现在很多 网站 大量使用 JavaScript,或者使用 Ajax 技术。这样,网页加载完成后,虽然url没有变化,但是网页的DOM元素的内容是可以动态变化的。如果使用python自带的requests库或者urllib库来处理这类网页,得到的网页内容与浏览器显示的网页内容不一致。
解决方案
使用 Selenium+PhantomJS。这两者结合起来运行一个非常强大的爬虫,可以处理 cookie、JavaScript、标头和任何你想要的东西。
安装第三方库
Selenium 是一个强大的网络数据采集 工具,最初是为网站 自动化测试而开发的,并且有对应的Python库;
Selenium 安装命令:
pip install selenium
安装 PhantomJS
PhantomJS是一个基于webkit核心的无头浏览器,也就是没有UI界面,也就是一个浏览器,但是里面的点击、翻页等与人相关的操作需要程序设计和实现。通过编写js程序,可以直接与webkit核心进行交互,在此之上还可以结合java语言等,通过java调用js等相关操作。需要到官网下载对应平台的压缩文件;
PhantomJS(phantomjs-2.1.1-windows)下载地址:根据不同系统选择对应版本
对于windows系统,下载PhantomJs,将解压后的可执行文件放到已经设置环境变量的地方。如果不设置,后面的代码都会设置,方便直接放这里;
然后勾选,在cmd窗口输入phantomjs:
当出现这样的画面时,就意味着成功;
Mac系统,下载后保存到一个路径,可以直接保存在环境变量路径中,也可以在环境变量路径中创建指向phantomjs的软链接
ln -s /usr/local/opt/my/phantomjs-2.1.1-macosx/bin/phantomjs /usr/local/bin
测试代码:
from selenium import webdriver
<p>driver = webdriver.PhantomJS()
driver.get('http://www.baidu.com/')
print (driver.page_source)</p>
如果能成功获取到页面元素,则安装成功。
示例一:
Selenium+PhantomJS 示例代码:
from selenium import webdriver
<p>driver = webdriver.PhantomJS()
driver.get('http://www.cnblogs.com/feng0815/p/8735491.html')
#获取网页源码
data = driver.page_source
print(data)
#获取元素的html源码
tableData = driver.find_elements_by_tag_name('tableData').get_attribute('innerHTML')
#获取元素的id值
tableI = driver.find_elements_by_tag_name('tableData').get_attribute('id')
#获取元素的文本内容
tableI = driver.find_elements_by_tag_name('tableData').text
driver.quit()</p>
可以输出网页的源代码,说明安装成功
获取JS返回值 查看全部
ajax抓取网页内容(安装成功获取JS返回值库元素即为安装的成功示例一)
前言
现在很多 网站 大量使用 JavaScript,或者使用 Ajax 技术。这样,网页加载完成后,虽然url没有变化,但是网页的DOM元素的内容是可以动态变化的。如果使用python自带的requests库或者urllib库来处理这类网页,得到的网页内容与浏览器显示的网页内容不一致。
解决方案
使用 Selenium+PhantomJS。这两者结合起来运行一个非常强大的爬虫,可以处理 cookie、JavaScript、标头和任何你想要的东西。
安装第三方库
Selenium 是一个强大的网络数据采集 工具,最初是为网站 自动化测试而开发的,并且有对应的Python库;
Selenium 安装命令:
pip install selenium
安装 PhantomJS
PhantomJS是一个基于webkit核心的无头浏览器,也就是没有UI界面,也就是一个浏览器,但是里面的点击、翻页等与人相关的操作需要程序设计和实现。通过编写js程序,可以直接与webkit核心进行交互,在此之上还可以结合java语言等,通过java调用js等相关操作。需要到官网下载对应平台的压缩文件;
PhantomJS(phantomjs-2.1.1-windows)下载地址:根据不同系统选择对应版本
对于windows系统,下载PhantomJs,将解压后的可执行文件放到已经设置环境变量的地方。如果不设置,后面的代码都会设置,方便直接放这里;
然后勾选,在cmd窗口输入phantomjs:
当出现这样的画面时,就意味着成功;
Mac系统,下载后保存到一个路径,可以直接保存在环境变量路径中,也可以在环境变量路径中创建指向phantomjs的软链接
ln -s /usr/local/opt/my/phantomjs-2.1.1-macosx/bin/phantomjs /usr/local/bin
测试代码:
from selenium import webdriver
<p>driver = webdriver.PhantomJS()
driver.get('http://www.baidu.com/')
print (driver.page_source)</p>
如果能成功获取到页面元素,则安装成功。
示例一:
Selenium+PhantomJS 示例代码:
from selenium import webdriver
<p>driver = webdriver.PhantomJS()
driver.get('http://www.cnblogs.com/feng0815/p/8735491.html')
#获取网页源码
data = driver.page_source
print(data)
#获取元素的html源码
tableData = driver.find_elements_by_tag_name('tableData').get_attribute('innerHTML')
#获取元素的id值
tableI = driver.find_elements_by_tag_name('tableData').get_attribute('id')
#获取元素的文本内容
tableI = driver.find_elements_by_tag_name('tableData').text
driver.quit()</p>
可以输出网页的源代码,说明安装成功
获取JS返回值
ajax抓取网页内容(一个视图页面执行一个给评论点赞的功能,发现问题的根源)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-14 02:18
有这样一个例子,在thinkPHP视图页面上执行点赞评论功能。为了增强用户体验,一般使用ajax异步请求在后台处理同类数据。页面成功后,就可以执行本地更新的数据了。前台一般使用jquery,通过执行jquery的ajax方法来完成任务请求更加简单方便。
简要描述出现问题的场景
tinkPHP在应用路由后在视图页面执行ajax,并没有正常返回数据。以下代码描述了将评论 ID 获取到 ajax 请求的过程。根据后台处理规则,cmthot 方法会将一个更新后的 post-like 数据(数据)返回给前台。
function uphot(o){
var cmtid=$(o).attr("cmtid");//获取评论ID
$.ajax({
type:"post",
dataType:"json",
data:{cmtid:cmtid},
url:"{:url('cmthot')}",//请求地址
success:function(data){
$('#hot'+cmtid).html(' '+data);
},
});
}
就是这样,和like数据没有正常返回,报错。通过alert(data)可以看到这样的场景。
再来看看后台处理部分
public function updatehot()
{
if(request()->isAjax()){
$cmtid=input('cmtid');
$cmthot=model('comment')->cmthot($cmtid);
return $cmthot;
}else{
$this->error('非法请求');
}
}
上述代码中,通过控制器将ajax获取的评论ID扔到模型中(模型代码不会贴出来)进行处理,并将新增的点赞返回给前台。前台(前面的代码)通过 .html 重写新数据。
发现问题的根源来自于路由
为了调试,我把ajax改成链接直接提交了。返回的结果都是正常的,即后端控制器和模型都正常,没有错误。问题应该仍然在ajax上。
因为这种操作方式,我经常在网站的后台使用,一般不会报错,所以又去后台对比一下同样的功能。后台类似的功能都是正常的。
为了找出问题的原因,我比较了网站的正反两面的区别。唯一明显的是前台为了用户体验使用路由,简化了url。后台使用iframe框架,url固定为frame页面的地址,所以当时没有使用路由。
方便找到差异然后出错。第一段代码中请求的地址不存在,因为它是路由的。此处需要添加路由地址,所以只需添加一个斜杠即可。url:"{:url('/cmthot')}",
最后是因为一个斜线,返回了一个html的页面,所以要小心。 查看全部
ajax抓取网页内容(一个视图页面执行一个给评论点赞的功能,发现问题的根源)
有这样一个例子,在thinkPHP视图页面上执行点赞评论功能。为了增强用户体验,一般使用ajax异步请求在后台处理同类数据。页面成功后,就可以执行本地更新的数据了。前台一般使用jquery,通过执行jquery的ajax方法来完成任务请求更加简单方便。
简要描述出现问题的场景
tinkPHP在应用路由后在视图页面执行ajax,并没有正常返回数据。以下代码描述了将评论 ID 获取到 ajax 请求的过程。根据后台处理规则,cmthot 方法会将一个更新后的 post-like 数据(数据)返回给前台。
function uphot(o){
var cmtid=$(o).attr("cmtid");//获取评论ID
$.ajax({
type:"post",
dataType:"json",
data:{cmtid:cmtid},
url:"{:url('cmthot')}",//请求地址
success:function(data){
$('#hot'+cmtid).html(' '+data);
},
});
}
就是这样,和like数据没有正常返回,报错。通过alert(data)可以看到这样的场景。
再来看看后台处理部分
public function updatehot()
{
if(request()->isAjax()){
$cmtid=input('cmtid');
$cmthot=model('comment')->cmthot($cmtid);
return $cmthot;
}else{
$this->error('非法请求');
}
}
上述代码中,通过控制器将ajax获取的评论ID扔到模型中(模型代码不会贴出来)进行处理,并将新增的点赞返回给前台。前台(前面的代码)通过 .html 重写新数据。
发现问题的根源来自于路由
为了调试,我把ajax改成链接直接提交了。返回的结果都是正常的,即后端控制器和模型都正常,没有错误。问题应该仍然在ajax上。
因为这种操作方式,我经常在网站的后台使用,一般不会报错,所以又去后台对比一下同样的功能。后台类似的功能都是正常的。
为了找出问题的原因,我比较了网站的正反两面的区别。唯一明显的是前台为了用户体验使用路由,简化了url。后台使用iframe框架,url固定为frame页面的地址,所以当时没有使用路由。
方便找到差异然后出错。第一段代码中请求的地址不存在,因为它是路由的。此处需要添加路由地址,所以只需添加一个斜杠即可。url:"{:url('/cmthot')}",
最后是因为一个斜线,返回了一个html的页面,所以要小心。
ajax抓取网页内容(Google的URL变了,音乐播放没有中断的原因是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-01 04:00
越来越多的网站,开始使用“单页结构”(Single-page application)。
整个网站只有一个网页,它使用Ajax技术根据用户的输入加载不同的内容。
这种方式的好处是用户体验好,节省了流量。缺点是AJAX内容不能被搜索引擎抓取。例如,您有一个 网站。
https://example.com
用户通过英镑结构的 URL 看到不同的内容。
https://example.com#1 https://example.com#2 https://example.com#3
但是,搜索引擎只抓取和忽略主题标签,因此它们无法索引内容。
为了解决这个问题,谷歌想出了“哈希+感叹号”的结构。
https://example.com#!1
当 Google 找到上述网址时,它会自动抓取另一个网址:
https://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放在这个 URL 上,Google 就会收录。但问题是,“英镑+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
https://twitter.com/ruanyf
改成
https://twitter.com/#!/ruanyf
结果,用户投诉连连,仅半年就被废止。
那么,有没有什么方法可以让搜索引擎在抓取 AJAX 内容的同时保持更直观的 URL?
我一直认为没有办法做到这一点,直到我看到了 Discourse 创始人之一 Robin Ward 的解决方案。
Discourse 是一个严重依赖 Ajax 的论坛程序,但必须使用 Google收录 内容。它的解决方案是放弃英镑符号结构并使用 History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏的网址变了,但音乐播放没有中断!
History API 的详细介绍超出了本文章 的范围。这里简单说一下,它的作用是在浏览器的History对象中添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以使新的 URL 出现在地址栏中。History对象的pushState方法接受三个参数,新的URL是第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前所有主流浏览器都支持这种方法:Chrome (26.0+), Firefox (20.0+), IE (10.0+), Safari (0.0+) @5.1+),歌剧 (12.1+)。
以下是罗宾·沃德 (Robin Ward) 的做法。
首先,用History API替换hashtag结构,让每个hashtag变成一个正常路径的URL,这样搜索引擎就会爬取每一个网页。
example.com/1 example.com/2 example.com/3
然后,定义一个处理 Ajax 部分并基于 URL 获取内容的 JavaScript 函数(假设是 jQuery)。
function anchorClick(link) {<br /> var linkSplit = link.split('/').pop();<br /> $.get('api/' + linkSplit, function(data) {<br /> $('#content').html(data);<br /> });<br /> }
再次定义鼠标点击事件。
$('#container').on('click', 'a', function(e) {<br /> window.history.pushState(null, null, $(this).attr('href'));<br /> anchorClick($(this).attr('href'));<br /> e.preventDefault();<br /> });
还要考虑到用户单击浏览器的“前进/后退”按钮。此时触发了History对象的popstate事件。
window.addEventListener('popstate', function(e) { <br /> anchorClick(location.pathname); <br /> });
定义完以上三段代码后,就可以在不刷新页面的情况下显示正常的路径URL和AJAX内容了。
最后,设置服务器端。
因为没有使用主题标签结构,所以每个 URL 都是不同的请求。因此,服务器需要为所有这些请求返回具有以下结构的网页,以防止 404 错误。
<br /> <br /> <br /> <br /> ... ...<br /> <br /> <br />
如果你仔细看上面的代码,你会发现有一个noscript标签,这就是秘密。
我们将搜索引擎应该为 收录 的所有内容放在 noscript 标记中。在这种情况下,用户仍然可以在不刷新页面的情况下进行 AJAX 操作,但是搜索引擎会收录每个页面的主要内容! 查看全部
ajax抓取网页内容(Google的URL变了,音乐播放没有中断的原因是什么?)
越来越多的网站,开始使用“单页结构”(Single-page application)。
整个网站只有一个网页,它使用Ajax技术根据用户的输入加载不同的内容。
这种方式的好处是用户体验好,节省了流量。缺点是AJAX内容不能被搜索引擎抓取。例如,您有一个 网站。
https://example.com
用户通过英镑结构的 URL 看到不同的内容。
https://example.com#1 https://example.com#2 https://example.com#3
但是,搜索引擎只抓取和忽略主题标签,因此它们无法索引内容。
为了解决这个问题,谷歌想出了“哈希+感叹号”的结构。
https://example.com#!1
当 Google 找到上述网址时,它会自动抓取另一个网址:
https://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放在这个 URL 上,Google 就会收录。但问题是,“英镑+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
https://twitter.com/ruanyf
改成
https://twitter.com/#!/ruanyf
结果,用户投诉连连,仅半年就被废止。
那么,有没有什么方法可以让搜索引擎在抓取 AJAX 内容的同时保持更直观的 URL?
我一直认为没有办法做到这一点,直到我看到了 Discourse 创始人之一 Robin Ward 的解决方案。
Discourse 是一个严重依赖 Ajax 的论坛程序,但必须使用 Google收录 内容。它的解决方案是放弃英镑符号结构并使用 History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏的网址变了,但音乐播放没有中断!
History API 的详细介绍超出了本文章 的范围。这里简单说一下,它的作用是在浏览器的History对象中添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以使新的 URL 出现在地址栏中。History对象的pushState方法接受三个参数,新的URL是第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前所有主流浏览器都支持这种方法:Chrome (26.0+), Firefox (20.0+), IE (10.0+), Safari (0.0+) @5.1+),歌剧 (12.1+)。
以下是罗宾·沃德 (Robin Ward) 的做法。
首先,用History API替换hashtag结构,让每个hashtag变成一个正常路径的URL,这样搜索引擎就会爬取每一个网页。
example.com/1 example.com/2 example.com/3
然后,定义一个处理 Ajax 部分并基于 URL 获取内容的 JavaScript 函数(假设是 jQuery)。
function anchorClick(link) {<br /> var linkSplit = link.split('/').pop();<br /> $.get('api/' + linkSplit, function(data) {<br /> $('#content').html(data);<br /> });<br /> }
再次定义鼠标点击事件。
$('#container').on('click', 'a', function(e) {<br /> window.history.pushState(null, null, $(this).attr('href'));<br /> anchorClick($(this).attr('href'));<br /> e.preventDefault();<br /> });
还要考虑到用户单击浏览器的“前进/后退”按钮。此时触发了History对象的popstate事件。
window.addEventListener('popstate', function(e) { <br /> anchorClick(location.pathname); <br /> });
定义完以上三段代码后,就可以在不刷新页面的情况下显示正常的路径URL和AJAX内容了。
最后,设置服务器端。
因为没有使用主题标签结构,所以每个 URL 都是不同的请求。因此,服务器需要为所有这些请求返回具有以下结构的网页,以防止 404 错误。
<br /> <br /> <br /> <br /> ... ...<br /> <br /> <br />
如果你仔细看上面的代码,你会发现有一个noscript标签,这就是秘密。
我们将搜索引擎应该为 收录 的所有内容放在 noscript 标记中。在这种情况下,用户仍然可以在不刷新页面的情况下进行 AJAX 操作,但是搜索引擎会收录每个页面的主要内容!
ajax抓取网页内容(ajaxajax )
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-02-28 23:05
)
阿贾克斯
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
Ajax = 异步 JavaScript 和 XML 或 HTML(标准通用标记语言的子集)。
Ajax 是一种用于创建快速和动态网页的技术。
Ajax 是一种无需重新加载整个网页即可更新网页部分的技术。
Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
(注:以上介绍来自百度百科)
本文主要介绍ajax登录的异步认证。
一、js 部分
1//定义一个变量用于存放XMLHttpRequest对象
2var xmlHttp;
3function checkIt(){
4 //获取文本框的值
5 var username=document.getElementById("username").value;//从登陆框中获取用户输入的账号
6 //alert("测试获取文本框的值:"+username);
7 //先创建XMLHttpRequest对象
8 // code for IE7+, Firefox, Chrome, Opera, Safari
9 if (window.XMLHttpRequest) {
10 xmlHttp = new XMLHttpRequest();
11 } else {// code for IE6, IE5
12 xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
13 }
14 //服务器地址和数据
15 var url="Login_ajax.jsp?username="+username;//此处的地址为ajax验证控制器的地址
16 //规定请求的类型、URL 以及是否异步处理请求。
17 xmlHttp.open("GET",url,true);
18 //将请求发送到服务器
19 xmlHttp.send();
20 //回调函数
21 xmlHttp.onreadystatechange=function(){
22 if (xmlHttp.readyState==4 && xmlHttp.status==200){
23 //给div设置内容
24 document.getElementById("errorAccount").innerHTML = xmlHttp.responseText;//把验证是否成功的信息返回到界面上,如下图
25
26 }
27 }
28}
29
30
二、html 部分
1
2
3
4
5
6 //从控制类中返回验证信息
7
8
9
三、控制器部分(这里用jsp替换servlet)
1
17
18 查看全部
ajax抓取网页内容(ajaxajax
)
阿贾克斯
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
Ajax = 异步 JavaScript 和 XML 或 HTML(标准通用标记语言的子集)。
Ajax 是一种用于创建快速和动态网页的技术。
Ajax 是一种无需重新加载整个网页即可更新网页部分的技术。
Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
(注:以上介绍来自百度百科)
本文主要介绍ajax登录的异步认证。
一、js 部分
1//定义一个变量用于存放XMLHttpRequest对象
2var xmlHttp;
3function checkIt(){
4 //获取文本框的值
5 var username=document.getElementById("username").value;//从登陆框中获取用户输入的账号
6 //alert("测试获取文本框的值:"+username);
7 //先创建XMLHttpRequest对象
8 // code for IE7+, Firefox, Chrome, Opera, Safari
9 if (window.XMLHttpRequest) {
10 xmlHttp = new XMLHttpRequest();
11 } else {// code for IE6, IE5
12 xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
13 }
14 //服务器地址和数据
15 var url="Login_ajax.jsp?username="+username;//此处的地址为ajax验证控制器的地址
16 //规定请求的类型、URL 以及是否异步处理请求。
17 xmlHttp.open("GET",url,true);
18 //将请求发送到服务器
19 xmlHttp.send();
20 //回调函数
21 xmlHttp.onreadystatechange=function(){
22 if (xmlHttp.readyState==4 && xmlHttp.status==200){
23 //给div设置内容
24 document.getElementById("errorAccount").innerHTML = xmlHttp.responseText;//把验证是否成功的信息返回到界面上,如下图
25
26 }
27 }
28}
29
30
二、html 部分
1
2
3
4
5
6 //从控制类中返回验证信息
7
8
9
三、控制器部分(这里用jsp替换servlet)
1
17
18
ajax抓取网页内容(ajax抓取网页内容教程--复制第一张图片到本地firefox)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-28 19:07
ajax抓取网页内容教程--复制第一张图片到本地firefox获取网页元素是通过javascript(隐藏函数也可以)和一个一个字符串的点击获取,如下动画:通过firefox的chromeapi-firefox-devtools,调用了带ffi属性的ffimethod,经过上面修改的javascript,ffimethod传入chromeapi-firefox-devtools,生成相应的domain,代码如下:document.getelementbyid('a').innerhtml=document.getelementbyid('b').innerhtmlchrome在执行之前,用"nslookup"获取到服务器获取的uri,再使用代码的:md5(非正则表达式)解密原网址中的html文件,如下代码所示:chrome回到了之前的网址,会把代码中的:md5换成对应的网址获取到网页元素的链接。
服务器返回response,我们就可以在chrome控制台中看到html代码的网址,执行javascript获取到相应的数据。当然,上面chrome处理html的方式是对于静态网页(png或jpg)而言,如果是动态页面(html或xml),就只能用cookie处理了。cookie是最古老、简单的网络身份认证机制。
楼上的意思是网络爬虫在调用网页时获取源代码,然后本地获取本地文件,再用pythonweb框架进行调用。但是这样并不能实现网页url的post.因为firefox+postman+ajax,这三样东西的引入就需要一个本地cookie,可以使用localstorage而不是sessionstorage,也可以使用cookiechange来ready,具体设置参见它的设置:(调用本地链接,不可能使用firefox的httpapirequest)因此,要实现爬虫同步抓取,比较好的解决方案是把抓取过程分成两步:在分别抓取本地和抓取服务器。
而如果你是要在两个服务器间调用post方法,可以用postman先在两个服务器间抓取,再同步发送给爬虫。so,楼上那一堆教程基本不会用到post方法postman只是抓取网页时去除了那个源代码的目录。当然,也可以用obs刷目录然后ajax抓取本地html,就是最后发送给爬虫的顺序会有点不一样。以上。 查看全部
ajax抓取网页内容(ajax抓取网页内容教程--复制第一张图片到本地firefox)
ajax抓取网页内容教程--复制第一张图片到本地firefox获取网页元素是通过javascript(隐藏函数也可以)和一个一个字符串的点击获取,如下动画:通过firefox的chromeapi-firefox-devtools,调用了带ffi属性的ffimethod,经过上面修改的javascript,ffimethod传入chromeapi-firefox-devtools,生成相应的domain,代码如下:document.getelementbyid('a').innerhtml=document.getelementbyid('b').innerhtmlchrome在执行之前,用"nslookup"获取到服务器获取的uri,再使用代码的:md5(非正则表达式)解密原网址中的html文件,如下代码所示:chrome回到了之前的网址,会把代码中的:md5换成对应的网址获取到网页元素的链接。
服务器返回response,我们就可以在chrome控制台中看到html代码的网址,执行javascript获取到相应的数据。当然,上面chrome处理html的方式是对于静态网页(png或jpg)而言,如果是动态页面(html或xml),就只能用cookie处理了。cookie是最古老、简单的网络身份认证机制。
楼上的意思是网络爬虫在调用网页时获取源代码,然后本地获取本地文件,再用pythonweb框架进行调用。但是这样并不能实现网页url的post.因为firefox+postman+ajax,这三样东西的引入就需要一个本地cookie,可以使用localstorage而不是sessionstorage,也可以使用cookiechange来ready,具体设置参见它的设置:(调用本地链接,不可能使用firefox的httpapirequest)因此,要实现爬虫同步抓取,比较好的解决方案是把抓取过程分成两步:在分别抓取本地和抓取服务器。
而如果你是要在两个服务器间调用post方法,可以用postman先在两个服务器间抓取,再同步发送给爬虫。so,楼上那一堆教程基本不会用到post方法postman只是抓取网页时去除了那个源代码的目录。当然,也可以用obs刷目录然后ajax抓取本地html,就是最后发送给爬虫的顺序会有点不一样。以上。
ajax抓取网页内容(本篇文章我们来研究一下怎么分析网页的Ajax请求(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-02-25 16:11
在本文文章中,我们将研究如何分析网页的Ajax请求。
我们平时爬网页的时候,可能会遇到一些网页直接请求的HTML代码,并没有我们需要的数据,也就是我们在浏览器中看到的内容。
这是因为信息是通过 Ajax 加载并通过 js 渲染生成的。这时,我们需要分析这个网页的请求。
什么是阿贾克斯
AJAX 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
AJAX = 异步 JavaScript 和 XML(标准通用标记语言的子集)。
AJAX 是一种用于创建快速和动态网页的技术。
AJAX 是一种无需重新加载整个网页即可更新部分网页的技术。
简单地说,就是加载了网页。浏览器地址栏中的 URL 没有改变。是javascript异步加载的网页,应该是ajax。AJAX一般通过XMLHttpRequest对象接口发送请求,一般简称为XHR。
分析简而言之网站点
我们的目标网站是用壳网来分析。地址
我们可以看到这个网页没有翻页按钮,当我们不断拉下请求时,网页会自动为我们加载更多内容。但是,当我们查看网页 url 时,它并没有随着页面加载请求而改变。而当我们直接请求这个url时,显然只能获取到第一页的html内容。
那么我们如何获取所有页面的数据呢?
我们在Chrome中打开开发者工具(F12)。我们点击Network,点击XHR选项卡。然后我们刷新页面并拉下请求。这时候我们可以看到XHR选项卡,每次页面加载会弹出一个请求。
我们点击第一个请求,可以看到他的参数:
检索类型:按主题
限制:20
偏移量:18
-:86
点击第二个请求后,参数如下:
检索类型:按主题
限制:20
偏移量:38
-:87
limit参数是网页每页被限制加载的文章个数,offset是页数。然后往下看,我们会发现每次请求的offset参数都会增加20。
然后我们查看每个请求的响应内容,这是一个格式化的数据。我们点击结果按钮,可以看到20条文章的数据信息。这样我们就成功找到了我们需要的信息的位置,在请求头中可以看到json数据存放的url地址。;limit=20&offset=18
爬取过程开始
我们的工具仍然使用 BeautifulSoup 解析的请求。
首先,我们需要对Ajax请求进行分析,获取所有页面的信息。通过上面网页的分析,我们可以得到ajax加载的json数据的url地址:;limit=20&offset=18
我们需要构造这个 URL。
# 导入可能要用到的模块
import requests
from urllib.parse import urlencode
from requests.exceptions import ConnectionError
# 获得索引页的信息
def get_index(offset):
base_url = 'http://www.guokr.com/apis/mini ... 39%3B
data = {
'retrieve_type': "by_subject",
'limit': "20",
'offset': offset
}
params = urlencode(data)
url = base_url + params
try:
resp = requests.get(url)
if resp.status_code == 200:
return resp.text
return None
except ConnectionError:
print('Error.')
return None
我们将从上面分析页面得到的请求参数构造成字典数据,然后我们可以手动构造url,但是urllib库已经为我们提供了编码方式,我们可以直接使用它来构造完整的url。然后是请求页面内容的标准请求。
import json
# 解析json,获得文章url
def parse_json(text):
try:
result = json.loads(text)
if result:
for i in result.get('result'):
# print(i.get('url'))
yield i.get('url')
except:
pass
我们使用 josn.loads 方法解析 json 并将其转换为 json 对象。然后直接通过字典的操作,得到文章的url地址。这里使用yield为每个请求返回一个url,以减少内存消耗。由于后面爬的时候会弹出一个json解析错误,这里直接过滤就好了。
这里我们可以尝试打印看看是否运行成功。
既然获取了文章的url,那么获取文章的数据就很简单了。此处不作详细说明。目标是获取 文章 的标题、作者和内容。
由于有的文章收录了一些图片,所以我们可以过滤掉文章内容中的图片。
from bs4 import BeautifulSoup
# 解析文章页
def parse_page(text):
try:
soup = BeautifulSoup(text, 'lxml')
content = soup.find('div', class_="content")
title = content.find('h1', id="articleTitle").get_text()
author = content.find('div', class_="content-th-info").find('a').get_text()
article_content = content.find('div', class_="document").find_all('p')
all_p = [i.get_text() for i in article_content if not i.find('img') and not i.find('a')]
article = '\n'.join(all_p)
# print(title,'\n',author,'\n',article)
data = {
'title': title,
'author': author,
'article': article
}
return data
except:
pass
这里,在进行多进程爬取的时候,BeautifulSoup也会报错,还是直接过滤。我们将得到的数据以字典的形式保存,方便保存数据库。
下一步是保存数据库的操作。这里我们使用MongoDB进行数据存储。具体方法在上一篇文章文章中有提到。关于他的细节就不赘述了。
import pymongo
from config import *
client = pymongo.MongoClient(MONGO_URL, 27017)
db = client[MONGO_DB]
def save_database(data):
if db[MONGO_TABLE].insert(data):
print('Save to Database successful', data)
return True
return False
我们将数据库名和表名保存在config配置文件中,并将配置信息导入到文件中,这样会方便代码的管理。
最后,由于诺虎网的数据还是很多的,如果我们想抓取很多数据,可以使用多进程。
from multiprocessing import Pool
# 定义一个主函数
def main(offset):
text = get_index(offset)
all_url = parse_json(text)
for url in all_url:
resp = get_page(url)
data = parse_page(resp)
if data:
save_database(data)
if __name__ == '__main__':
pool = Pool()
offsets = ([0] + [i*20+18 for i in range(500)])
pool.map(main, offsets)
pool.close()
pool.join()
该函数的参数偏移量是页数。经过我的观察,国科网的最后一个页码是12758,有637页。在这里,我们抓取了 500 个页面。进程池的map方法类似于Python内置的map方法。
那么对于一些使用Ajax加载的网页,我们可以这样爬取。
项目地址
这里
如果觉得有帮助,请star。
谢谢阅读
系列文章 查看全部
ajax抓取网页内容(本篇文章我们来研究一下怎么分析网页的Ajax请求(图))
在本文文章中,我们将研究如何分析网页的Ajax请求。
我们平时爬网页的时候,可能会遇到一些网页直接请求的HTML代码,并没有我们需要的数据,也就是我们在浏览器中看到的内容。
这是因为信息是通过 Ajax 加载并通过 js 渲染生成的。这时,我们需要分析这个网页的请求。
什么是阿贾克斯
AJAX 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
AJAX = 异步 JavaScript 和 XML(标准通用标记语言的子集)。
AJAX 是一种用于创建快速和动态网页的技术。
AJAX 是一种无需重新加载整个网页即可更新部分网页的技术。
简单地说,就是加载了网页。浏览器地址栏中的 URL 没有改变。是javascript异步加载的网页,应该是ajax。AJAX一般通过XMLHttpRequest对象接口发送请求,一般简称为XHR。
分析简而言之网站点
我们的目标网站是用壳网来分析。地址
我们可以看到这个网页没有翻页按钮,当我们不断拉下请求时,网页会自动为我们加载更多内容。但是,当我们查看网页 url 时,它并没有随着页面加载请求而改变。而当我们直接请求这个url时,显然只能获取到第一页的html内容。
那么我们如何获取所有页面的数据呢?
我们在Chrome中打开开发者工具(F12)。我们点击Network,点击XHR选项卡。然后我们刷新页面并拉下请求。这时候我们可以看到XHR选项卡,每次页面加载会弹出一个请求。
我们点击第一个请求,可以看到他的参数:
检索类型:按主题
限制:20
偏移量:18
-:86
点击第二个请求后,参数如下:
检索类型:按主题
限制:20
偏移量:38
-:87
limit参数是网页每页被限制加载的文章个数,offset是页数。然后往下看,我们会发现每次请求的offset参数都会增加20。
然后我们查看每个请求的响应内容,这是一个格式化的数据。我们点击结果按钮,可以看到20条文章的数据信息。这样我们就成功找到了我们需要的信息的位置,在请求头中可以看到json数据存放的url地址。;limit=20&offset=18
爬取过程开始
我们的工具仍然使用 BeautifulSoup 解析的请求。
首先,我们需要对Ajax请求进行分析,获取所有页面的信息。通过上面网页的分析,我们可以得到ajax加载的json数据的url地址:;limit=20&offset=18
我们需要构造这个 URL。
# 导入可能要用到的模块
import requests
from urllib.parse import urlencode
from requests.exceptions import ConnectionError
# 获得索引页的信息
def get_index(offset):
base_url = 'http://www.guokr.com/apis/mini ... 39%3B
data = {
'retrieve_type': "by_subject",
'limit': "20",
'offset': offset
}
params = urlencode(data)
url = base_url + params
try:
resp = requests.get(url)
if resp.status_code == 200:
return resp.text
return None
except ConnectionError:
print('Error.')
return None
我们将从上面分析页面得到的请求参数构造成字典数据,然后我们可以手动构造url,但是urllib库已经为我们提供了编码方式,我们可以直接使用它来构造完整的url。然后是请求页面内容的标准请求。
import json
# 解析json,获得文章url
def parse_json(text):
try:
result = json.loads(text)
if result:
for i in result.get('result'):
# print(i.get('url'))
yield i.get('url')
except:
pass
我们使用 josn.loads 方法解析 json 并将其转换为 json 对象。然后直接通过字典的操作,得到文章的url地址。这里使用yield为每个请求返回一个url,以减少内存消耗。由于后面爬的时候会弹出一个json解析错误,这里直接过滤就好了。
这里我们可以尝试打印看看是否运行成功。
既然获取了文章的url,那么获取文章的数据就很简单了。此处不作详细说明。目标是获取 文章 的标题、作者和内容。
由于有的文章收录了一些图片,所以我们可以过滤掉文章内容中的图片。
from bs4 import BeautifulSoup
# 解析文章页
def parse_page(text):
try:
soup = BeautifulSoup(text, 'lxml')
content = soup.find('div', class_="content")
title = content.find('h1', id="articleTitle").get_text()
author = content.find('div', class_="content-th-info").find('a').get_text()
article_content = content.find('div', class_="document").find_all('p')
all_p = [i.get_text() for i in article_content if not i.find('img') and not i.find('a')]
article = '\n'.join(all_p)
# print(title,'\n',author,'\n',article)
data = {
'title': title,
'author': author,
'article': article
}
return data
except:
pass
这里,在进行多进程爬取的时候,BeautifulSoup也会报错,还是直接过滤。我们将得到的数据以字典的形式保存,方便保存数据库。
下一步是保存数据库的操作。这里我们使用MongoDB进行数据存储。具体方法在上一篇文章文章中有提到。关于他的细节就不赘述了。
import pymongo
from config import *
client = pymongo.MongoClient(MONGO_URL, 27017)
db = client[MONGO_DB]
def save_database(data):
if db[MONGO_TABLE].insert(data):
print('Save to Database successful', data)
return True
return False
我们将数据库名和表名保存在config配置文件中,并将配置信息导入到文件中,这样会方便代码的管理。
最后,由于诺虎网的数据还是很多的,如果我们想抓取很多数据,可以使用多进程。
from multiprocessing import Pool
# 定义一个主函数
def main(offset):
text = get_index(offset)
all_url = parse_json(text)
for url in all_url:
resp = get_page(url)
data = parse_page(resp)
if data:
save_database(data)
if __name__ == '__main__':
pool = Pool()
offsets = ([0] + [i*20+18 for i in range(500)])
pool.map(main, offsets)
pool.close()
pool.join()
该函数的参数偏移量是页数。经过我的观察,国科网的最后一个页码是12758,有637页。在这里,我们抓取了 500 个页面。进程池的map方法类似于Python内置的map方法。
那么对于一些使用Ajax加载的网页,我们可以这样爬取。
项目地址
这里
如果觉得有帮助,请star。
谢谢阅读
系列文章
ajax抓取网页内容(2021-05-10Ajax数据获取在之前分析的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-25 06:08
2021-05-10
阿贾克斯简介
Ajax(全称Asynchronous JavaScript and XML,异步JavaScript和XML)是一种在页面不刷新、页面链接不改变的情况下,利用JavaScript与服务器交换数据,更新部分网页的技术。使用Ajax的例子有很多,比如新浪微博和不凡商业的View More。
阿贾克斯分析
经过对Ajax的初步了解,我们可以知道它的加载过程主要分为三个步骤:发送请求-解析内容-渲染页面。那么,我们如何判断页面是通过发送Ajax请求来动态加载的,又如何确定其请求的地址呢?
实际上,要确定是否为 Ajax 请求加载了页面,我们可以使用 Chrome 浏览器的工具栏。以非凡业务网站为例,我们先调出Chrome浏览器的Network工具栏,选择XHR进行过滤(其实这个代表请求的类型,也就是Ajax请求的类型) ,然后刷新页面。查看所有当前的 Ajax 请求。
然后我们下拉到页面底部尝试点击查看更多,我们会发现请求列表中多了一个请求,如图,我们再尝试点击,会有更多新的请求,所以我们也可以确定这是通过Ajax加载的。
由此,我们可以通过分析每个请求的请求头的具体内容来获取数据源。如上图所示,Request URL中的内容就是刚刚加载的数据的源地址。我们打开一个新页面尝试访问,发现如下内容:
粗略一看,我们认为应该是json数据格式,然后试着放到解析站看看,结果不是我们预期的,也证明请求头中的请求url是网页。Ajax 数据源。
Ajax数据采集
在前面分析的基础上,我们实际上得到了一个获取Ajax数据的方法:分析Ajax请求的URL构成方法,然后进行页面解析和数据提取。这种方法可以直接获取源数据,性能较高,但分析成本普遍较高。因为不是所有的URL组合方式都容易获取,可能会混淆很多加密机制,通常需要Js的辅助分析。
由此,我们提出另一种策略:使用 selenium 模拟浏览器行为,获取动态解析数据。这里的硒是什么?其实它就相当于一个机器人,可以模拟人为操作浏览器的行为,比如点击、输入、拖拽等。其实一开始主要是用来做网页测试的,后来发现符合爬虫的特点,因此在爬虫领域得到了广泛的应用。从服务器的角度来看,这意味着人们正在访问该页面,并且很难抓到爬虫,因此安全性非常高;但另一方面,用它来获取Ajax数据既昂贵又麻烦,而且性能不如分析URL。
以上是两种常用的获取Ajax数据的方法。使用哪种方法,我们可以先测试一下,看分析要获取的Ajax数据源的URL组合方法是否方便。如果比较正则可以直接requests获取;否则,如果比较复杂,可以考虑使用 selenium 策略(更多介绍会在后续笔记中讲解)。
分类:
技术要点:
相关文章: 查看全部
ajax抓取网页内容(2021-05-10Ajax数据获取在之前分析的方法)
2021-05-10
阿贾克斯简介
Ajax(全称Asynchronous JavaScript and XML,异步JavaScript和XML)是一种在页面不刷新、页面链接不改变的情况下,利用JavaScript与服务器交换数据,更新部分网页的技术。使用Ajax的例子有很多,比如新浪微博和不凡商业的View More。
阿贾克斯分析
经过对Ajax的初步了解,我们可以知道它的加载过程主要分为三个步骤:发送请求-解析内容-渲染页面。那么,我们如何判断页面是通过发送Ajax请求来动态加载的,又如何确定其请求的地址呢?
实际上,要确定是否为 Ajax 请求加载了页面,我们可以使用 Chrome 浏览器的工具栏。以非凡业务网站为例,我们先调出Chrome浏览器的Network工具栏,选择XHR进行过滤(其实这个代表请求的类型,也就是Ajax请求的类型) ,然后刷新页面。查看所有当前的 Ajax 请求。
然后我们下拉到页面底部尝试点击查看更多,我们会发现请求列表中多了一个请求,如图,我们再尝试点击,会有更多新的请求,所以我们也可以确定这是通过Ajax加载的。
由此,我们可以通过分析每个请求的请求头的具体内容来获取数据源。如上图所示,Request URL中的内容就是刚刚加载的数据的源地址。我们打开一个新页面尝试访问,发现如下内容:
粗略一看,我们认为应该是json数据格式,然后试着放到解析站看看,结果不是我们预期的,也证明请求头中的请求url是网页。Ajax 数据源。
Ajax数据采集
在前面分析的基础上,我们实际上得到了一个获取Ajax数据的方法:分析Ajax请求的URL构成方法,然后进行页面解析和数据提取。这种方法可以直接获取源数据,性能较高,但分析成本普遍较高。因为不是所有的URL组合方式都容易获取,可能会混淆很多加密机制,通常需要Js的辅助分析。
由此,我们提出另一种策略:使用 selenium 模拟浏览器行为,获取动态解析数据。这里的硒是什么?其实它就相当于一个机器人,可以模拟人为操作浏览器的行为,比如点击、输入、拖拽等。其实一开始主要是用来做网页测试的,后来发现符合爬虫的特点,因此在爬虫领域得到了广泛的应用。从服务器的角度来看,这意味着人们正在访问该页面,并且很难抓到爬虫,因此安全性非常高;但另一方面,用它来获取Ajax数据既昂贵又麻烦,而且性能不如分析URL。
以上是两种常用的获取Ajax数据的方法。使用哪种方法,我们可以先测试一下,看分析要获取的Ajax数据源的URL组合方法是否方便。如果比较正则可以直接requests获取;否则,如果比较复杂,可以考虑使用 selenium 策略(更多介绍会在后续笔记中讲解)。
分类:
技术要点:
相关文章:
ajax抓取网页内容(AJAX跨域访问执行的相关知识和一些Code实例,欢迎阅读和指正)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-24 05:17
想知道AJAX javascript跨域访问执行的相关内容吗?本文将为大家讲解AJAX跨域访问的相关知识和一些Code示例。欢迎阅读和指正。先说重点:AJAX、javascript、跨域访问,一起来学习。
<IMG alt=javascript0.jpg src="http://files.jb51.net/upload/2 ... gt%3B
突然觉得这就是这里的问题。研究了一下,其实还是很容易搞定的,只是我的知识还欠缺。解决方法如下:
阻止 AJAX 请求
我们先确认一下请求的阻塞。我们使用以下代码:
连续提出三个请求
复制代码代码如下:
函数simpleRequest()
{
varrequest=newXMLHttpRequest();
request.open("POST","Script.ashx");
request.send(null);
}
函数三个请求()
{
简单请求();
简单请求();
简单请求();
}
当执行threeRequests时,会连续发出3个相同域名的请求,或者可以通过统计图查看阻塞的效果:
<IMG alt=script1.jpg src="http://files.jb51.net/upload/2 ... gt%3B
最后一个请求被前两个请求阻塞
每个请求需要 1.5 秒。很明显,第三个请求要等到第一个请求完成后才能执行,所以总共需要3秒多的时间才能执行。我们要改变的是这种情况。
传统跨域异步请求解决方案
AJAX 安全性的唯一保证似乎是对跨域 AJAX 请求的限制。除非您在本地硬盘上打开网页,或在 IE 中开启跨域数据传输限制,否则禁止向其他域发出 AJAX 请求。而且,跨域名的判断非常严格。不同的子域,或者同一个域名的不同端口,将被视为不同的域名,我们不能向它们的资源发出AJAX请求。
从表面上看似乎没有办法打破这个限制,但幸运的是我们有一个救星,iframes!
虽然 iframe 不在标准中,但因为它非常有用,FireFox “不得不”支持它(类似于 innerHTML)。互联网上已经有一些跨域发出异步请求的方法,但它们确实很糟糕。它们的简单工作原理如下:将特定页面文件放在另一个域名下作为Proxy,主页面通过QueryString将异步请求信息传递给iframe中的Proxy页面,Proxy页面将结果放入iframe之后AJAX 请求被执行。在自己位置的hash中,主页面会轮询iframe的src的hash值。一旦发现有变化,就会通过哈希值得到所需的信息。
这种方法的实现很复杂,功能有限。在 IE 和 FireFox 中,URL 的长度可以支持大约 2000 个字符。对于普通的需求可能已经够用了,可惜如果你真的要传递大量的数据,那是不够的。也许它相对于我们稍后会提出的解决方案的唯一优势是能够跨任意域发出异步请求,这只能突破子域限制。
那么现在让我们看看我们是如何做到的!
优雅突破子域限制
突破子域限制的关键还是iframe。
iframe 是个好东西,我们可以跨子域访问 iframe 中的页面对象,比如 window 和 DOM 结构,包括调用 JavaScript(通过 window 对象)——我们可以设置内页和外页的 document.domain 为相同。. 然后对不同子域的页面发起不同的请求,通过JavaScript传递结果。唯一需要的是一个简单的静态页面作为代理。
现在让我们开始编写一个原型,它很简单但很有说明性。
首先,让我们写一个静态页面作为放置在 iframe 中的 Proxy,如下:
子域代理.html
复制代码代码如下:
然后我们编写我们的主页:
复制代码代码如下:
在执行threeRequests方法时,会同时请求两个不同域下的资源。显然,最后一个请求不再被前两个请求阻塞:
<IMG alt=script2.jpg src="http://files.jb51.net/upload/2 ... gt%3B
不同域名的请求不会被拦截
结果令人满意!
您只能突破子域,但这已经足够了,不是吗?为什么我们需要在任意域名之间进行异步通信?更不用说我们的解决方案有多优雅了!在下一篇文章文章中,我们将为ASP.NET AJAX客户端实现一个完整的CrossSubDomainRequestExecutor,它会自动判断是否正在进行跨子域请求并选择AJAX请求方式。这样,客户端的异步通信层对开发者来说是完全透明的。世上还有比这更令人愉快的事吗?:)
防范措施
或许以下几点值得一提:
这个想法之后我也做了一些尝试,最后发现创建一个XMLHttpRequest对象,调用open方法和send方法必须在iframe中的页面中执行,才能在IE和FireFox中成功发送AJAX请求。
在上面的示例中,我们从子域请求的路径是 . 请注意,完整的子域名不能省略,否则在FireFox下会出现权限不足的错误,并且调用open方法时会抛出异常——看来FireFox将其视为父页面域的资源姓名。
由于浏览器的安全策略,浏览器不允许不同域(如:and)、不同协议(如:and)、不同端口(如:http:and:8080)下的页面通过XMLHTTPRequest相互访问,这个问题也影响了Javascript在不同页面上的相互调用和控制,但是当主域、协议、端口相同时,通过设置页面的document.domain主域,Javascript可以访问不同子域之间的控制,比如通过设置document..domain='',页面可以相互访问。这个特性也为不同子域下的XMLHTTPRequests在这种情况下相互访问提供了一种解决方案。
对于主域、协议、端口相同时的Ajax跨域问题,早就有人说要设置document.domain来解决,但一直没有看到具体成功的应用。这次我试过了。原理是使用一个隐藏的iframe引入的另一个子域的页面作为代理,通过Javascript控制该iframe引入的另一个子域的XMLHTTPRequest获取数据。对于不同主域/不同协议/不同端口下的Ajax访问,需要通过后台代理来实现。
相关文章 查看全部
ajax抓取网页内容(AJAX跨域访问执行的相关知识和一些Code实例,欢迎阅读和指正)
想知道AJAX javascript跨域访问执行的相关内容吗?本文将为大家讲解AJAX跨域访问的相关知识和一些Code示例。欢迎阅读和指正。先说重点:AJAX、javascript、跨域访问,一起来学习。
<IMG alt=javascript0.jpg src="http://files.jb51.net/upload/2 ... gt%3B
突然觉得这就是这里的问题。研究了一下,其实还是很容易搞定的,只是我的知识还欠缺。解决方法如下:
阻止 AJAX 请求
我们先确认一下请求的阻塞。我们使用以下代码:
连续提出三个请求
复制代码代码如下:
函数simpleRequest()
{
varrequest=newXMLHttpRequest();
request.open("POST","Script.ashx");
request.send(null);
}
函数三个请求()
{
简单请求();
简单请求();
简单请求();
}
当执行threeRequests时,会连续发出3个相同域名的请求,或者可以通过统计图查看阻塞的效果:
<IMG alt=script1.jpg src="http://files.jb51.net/upload/2 ... gt%3B
最后一个请求被前两个请求阻塞
每个请求需要 1.5 秒。很明显,第三个请求要等到第一个请求完成后才能执行,所以总共需要3秒多的时间才能执行。我们要改变的是这种情况。
传统跨域异步请求解决方案
AJAX 安全性的唯一保证似乎是对跨域 AJAX 请求的限制。除非您在本地硬盘上打开网页,或在 IE 中开启跨域数据传输限制,否则禁止向其他域发出 AJAX 请求。而且,跨域名的判断非常严格。不同的子域,或者同一个域名的不同端口,将被视为不同的域名,我们不能向它们的资源发出AJAX请求。
从表面上看似乎没有办法打破这个限制,但幸运的是我们有一个救星,iframes!
虽然 iframe 不在标准中,但因为它非常有用,FireFox “不得不”支持它(类似于 innerHTML)。互联网上已经有一些跨域发出异步请求的方法,但它们确实很糟糕。它们的简单工作原理如下:将特定页面文件放在另一个域名下作为Proxy,主页面通过QueryString将异步请求信息传递给iframe中的Proxy页面,Proxy页面将结果放入iframe之后AJAX 请求被执行。在自己位置的hash中,主页面会轮询iframe的src的hash值。一旦发现有变化,就会通过哈希值得到所需的信息。
这种方法的实现很复杂,功能有限。在 IE 和 FireFox 中,URL 的长度可以支持大约 2000 个字符。对于普通的需求可能已经够用了,可惜如果你真的要传递大量的数据,那是不够的。也许它相对于我们稍后会提出的解决方案的唯一优势是能够跨任意域发出异步请求,这只能突破子域限制。
那么现在让我们看看我们是如何做到的!
优雅突破子域限制
突破子域限制的关键还是iframe。
iframe 是个好东西,我们可以跨子域访问 iframe 中的页面对象,比如 window 和 DOM 结构,包括调用 JavaScript(通过 window 对象)——我们可以设置内页和外页的 document.domain 为相同。. 然后对不同子域的页面发起不同的请求,通过JavaScript传递结果。唯一需要的是一个简单的静态页面作为代理。
现在让我们开始编写一个原型,它很简单但很有说明性。
首先,让我们写一个静态页面作为放置在 iframe 中的 Proxy,如下:
子域代理.html
复制代码代码如下:
然后我们编写我们的主页:
复制代码代码如下:
在执行threeRequests方法时,会同时请求两个不同域下的资源。显然,最后一个请求不再被前两个请求阻塞:
<IMG alt=script2.jpg src="http://files.jb51.net/upload/2 ... gt%3B
不同域名的请求不会被拦截
结果令人满意!
您只能突破子域,但这已经足够了,不是吗?为什么我们需要在任意域名之间进行异步通信?更不用说我们的解决方案有多优雅了!在下一篇文章文章中,我们将为ASP.NET AJAX客户端实现一个完整的CrossSubDomainRequestExecutor,它会自动判断是否正在进行跨子域请求并选择AJAX请求方式。这样,客户端的异步通信层对开发者来说是完全透明的。世上还有比这更令人愉快的事吗?:)
防范措施
或许以下几点值得一提:
这个想法之后我也做了一些尝试,最后发现创建一个XMLHttpRequest对象,调用open方法和send方法必须在iframe中的页面中执行,才能在IE和FireFox中成功发送AJAX请求。
在上面的示例中,我们从子域请求的路径是 . 请注意,完整的子域名不能省略,否则在FireFox下会出现权限不足的错误,并且调用open方法时会抛出异常——看来FireFox将其视为父页面域的资源姓名。
由于浏览器的安全策略,浏览器不允许不同域(如:and)、不同协议(如:and)、不同端口(如:http:and:8080)下的页面通过XMLHTTPRequest相互访问,这个问题也影响了Javascript在不同页面上的相互调用和控制,但是当主域、协议、端口相同时,通过设置页面的document.domain主域,Javascript可以访问不同子域之间的控制,比如通过设置document..domain='',页面可以相互访问。这个特性也为不同子域下的XMLHTTPRequests在这种情况下相互访问提供了一种解决方案。
对于主域、协议、端口相同时的Ajax跨域问题,早就有人说要设置document.domain来解决,但一直没有看到具体成功的应用。这次我试过了。原理是使用一个隐藏的iframe引入的另一个子域的页面作为代理,通过Javascript控制该iframe引入的另一个子域的XMLHTTPRequest获取数据。对于不同主域/不同协议/不同端口下的Ajax访问,需要通过后台代理来实现。
相关文章
ajax抓取网页内容(网页加载是一种异步加载方式的基本方法和获取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-24 05:16
有时候我们在设计使用requests来抓取网页数据的时候,会发现得到的结果可能和浏览器显示给我们的不一样:比如我们可以通过浏览器显示一些信息,但是一旦使用requests就不能了达到预期的结果。这种现象是因为我们通过请求得到的是HTML源文档,而在浏览器中看到的页面数据是经过JavaScript处理的,而这些处理后的数据可能是通过Ajax加载的,收录在HTML中,也可能是由JavaScript自动生成的。
从Web发展趋势来看,越来越多的网页通过Ajax加载呈现,即网页数据加载是一种异步加载方式。网页本身不收录数据,而是在初始化网页后自动向服务器发送Ajax。请求,然后从服务器获取相应的数据并渲染到网页上。本节将重点介绍Ajax的相关概念以及如何判断和获取是否被Ajax请求,然后介绍两种爬取Ajax数据的基本方法。
阿贾克斯简介
Ajax(全称Asynchronous JavaScript and XML,异步JavaScript和XML)是一种在页面不刷新、页面链接不改变的情况下,利用JavaScript与服务器交换数据,更新部分网页的技术。使用Ajax的例子有很多,比如新浪微博和不凡商业的View More。
阿贾克斯分析
初步了解Ajax后,我们可以知道它的加载过程主要分为三个步骤:发送请求——解析内容——渲染页面。那么,我们如何判断页面是通过发送ajax请求来动态加载的,又如何确定请求的地址呢?
实际上,要确定是否为 Ajax 请求加载了页面,我们可以使用 Chrome 浏览器的工具栏。以非凡业务网站为例,我们先调出Chrome浏览器的Network工具栏,选择XHR进行过滤(其实这个代表请求的类型,也就是Ajax请求的类型) ,然后刷新页面。查看所有当前的 Ajax 请求。
然后我们下拉到页面底部尝试点击查看更多,我们会发现请求列表中多了一个请求,如图,我们再尝试点击,会有更多新的请求,所以我们也可以确定这是通过Ajax加载的。
由此,我们可以通过分析每个请求的请求头的具体内容来获取数据源。如上图所示,Request URL中的内容就是刚刚加载的数据的源地址。我们打开一个新页面尝试访问,发现如下内容:
粗略一看,我们认为应该是json数据格式,然后试着放到解析站看看,结果不是我们预期的,也证明请求头中的请求url是网页。Ajax 数据源。
Ajax数据采集
在前面分析的基础上,我们实际上得到了一个获取Ajax数据的方法:分析Ajax请求的URL构成方法,然后进行页面解析和数据提取。这种方法可以直接获取源数据,性能较高,但分析成本普遍较高。因为不是所有的 URL 组合方式都容易获取,可能会混淆很多加密机制,通常需要 Js 的辅助分析。
由此,我们提出另一种策略:使用 selenium 模拟浏览器行为,获取动态解析数据。这里的硒是什么?其实它就相当于一个机器人,可以模拟人为操作浏览器的行为,比如点击、输入、拖拽等。其实一开始主要是用来做网页测试的,后来发现符合爬虫的特点,因此在爬虫领域得到了广泛的应用。从服务器的角度来看,就是有人在访问页面,很难抓到爬虫,所以安全性很高;但另一方面,用它来获取Ajax数据既昂贵又麻烦,而且性能不如分析URL。
以上是两种常用的获取Ajax数据的方法。使用哪种方法,我们可以先测试一下,看分析要获取的Ajax数据源的URL组合方法是否方便。如果比较正则可以直接requests获取;否则,如果比较复杂,可以考虑使用 selenium 策略(更多介绍会在后续笔记中讲解)。 查看全部
ajax抓取网页内容(网页加载是一种异步加载方式的基本方法和获取方法)
有时候我们在设计使用requests来抓取网页数据的时候,会发现得到的结果可能和浏览器显示给我们的不一样:比如我们可以通过浏览器显示一些信息,但是一旦使用requests就不能了达到预期的结果。这种现象是因为我们通过请求得到的是HTML源文档,而在浏览器中看到的页面数据是经过JavaScript处理的,而这些处理后的数据可能是通过Ajax加载的,收录在HTML中,也可能是由JavaScript自动生成的。
从Web发展趋势来看,越来越多的网页通过Ajax加载呈现,即网页数据加载是一种异步加载方式。网页本身不收录数据,而是在初始化网页后自动向服务器发送Ajax。请求,然后从服务器获取相应的数据并渲染到网页上。本节将重点介绍Ajax的相关概念以及如何判断和获取是否被Ajax请求,然后介绍两种爬取Ajax数据的基本方法。
阿贾克斯简介
Ajax(全称Asynchronous JavaScript and XML,异步JavaScript和XML)是一种在页面不刷新、页面链接不改变的情况下,利用JavaScript与服务器交换数据,更新部分网页的技术。使用Ajax的例子有很多,比如新浪微博和不凡商业的View More。
阿贾克斯分析
初步了解Ajax后,我们可以知道它的加载过程主要分为三个步骤:发送请求——解析内容——渲染页面。那么,我们如何判断页面是通过发送ajax请求来动态加载的,又如何确定请求的地址呢?
实际上,要确定是否为 Ajax 请求加载了页面,我们可以使用 Chrome 浏览器的工具栏。以非凡业务网站为例,我们先调出Chrome浏览器的Network工具栏,选择XHR进行过滤(其实这个代表请求的类型,也就是Ajax请求的类型) ,然后刷新页面。查看所有当前的 Ajax 请求。
然后我们下拉到页面底部尝试点击查看更多,我们会发现请求列表中多了一个请求,如图,我们再尝试点击,会有更多新的请求,所以我们也可以确定这是通过Ajax加载的。
由此,我们可以通过分析每个请求的请求头的具体内容来获取数据源。如上图所示,Request URL中的内容就是刚刚加载的数据的源地址。我们打开一个新页面尝试访问,发现如下内容:
粗略一看,我们认为应该是json数据格式,然后试着放到解析站看看,结果不是我们预期的,也证明请求头中的请求url是网页。Ajax 数据源。
Ajax数据采集
在前面分析的基础上,我们实际上得到了一个获取Ajax数据的方法:分析Ajax请求的URL构成方法,然后进行页面解析和数据提取。这种方法可以直接获取源数据,性能较高,但分析成本普遍较高。因为不是所有的 URL 组合方式都容易获取,可能会混淆很多加密机制,通常需要 Js 的辅助分析。
由此,我们提出另一种策略:使用 selenium 模拟浏览器行为,获取动态解析数据。这里的硒是什么?其实它就相当于一个机器人,可以模拟人为操作浏览器的行为,比如点击、输入、拖拽等。其实一开始主要是用来做网页测试的,后来发现符合爬虫的特点,因此在爬虫领域得到了广泛的应用。从服务器的角度来看,就是有人在访问页面,很难抓到爬虫,所以安全性很高;但另一方面,用它来获取Ajax数据既昂贵又麻烦,而且性能不如分析URL。
以上是两种常用的获取Ajax数据的方法。使用哪种方法,我们可以先测试一下,看分析要获取的Ajax数据源的URL组合方法是否方便。如果比较正则可以直接requests获取;否则,如果比较复杂,可以考虑使用 selenium 策略(更多介绍会在后续笔记中讲解)。
ajax抓取网页内容(如何分析ajax接口,模拟ajax请求爬取数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 218 次浏览 • 2022-02-19 04:09
抓取ajax网站,我们可以通过分析ajax接口获取返回的json数据,从而抓取我们想要的数据。以今日头条为例,如何分析ajax接口,模拟ajax请求爬取数据。
以今日头条为例。网页的上一页只显示部分数据。要查看后续数据,需要向下滑动鼠标。这里我们分析一下它的ajax接口。
打开开发者工具,选择network,点击XHR过滤掉ajax请求,可以看到这里有很多参数,一眼就能看到的参数就是关键字,也就是我们搜索的关键字。然后查看它的预览信息。
可以看到Preview信息中有很多数据信息。点击它可以看到里面收录了很多有用的信息,比如街拍标题和图片地址。
当鼠标向下滑动时,又会过滤掉一个Ajax请求,如下图
可以看到offset参数从0变成了20。仔细观察网页,可以发现网页上显示的信息正好有20条。
这是鼠标滑到第三页的时候,可以看到offset参数变成了40。第一页打开时offset参数为0,第二页offset参数为20,第三页上的参数page是40。不难发现,offset参数其实就是一个offset,一个用来实现翻页的参数。然后我们可以使用urlencode方法将这些参数拼接到url后面,发起ajax请求,通过控制传入的offset参数控制翻页,然后通过response.json( )。
代码思路:1.分析网页的ajax接口,需要传入什么数据2.通过urlencode键参数拼接要请求的url后,指定爬取哪个页面的内容通过控制偏移参数。3.生成不同页面的请求,获取json数据中图片的url信息4.请求图片的url,下载图片5.保存到文件夹中。
实际代码
import requests
from urllib.parse import urlencode,urljoin
import os
from hashlib import md5
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36",
"X-Requested-With":"XMLHttpRequest"
}
def get_page(offset):
"""
:param offset: 偏移量,控制翻页
:return:
"""
params = {
"offset":offset,
"format":"json",
"keyword":"街拍",
"autoload":"true",
"count":"20",
"cur_tab":"1",
"from":"search_tab"
}
url = "https://www.toutiao.com/search_content/?" + urlencode(params)
try:
response = requests.get(url,headers=headers,timeout=5)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
return None
def get_image(json):
"""
:param json: 获取到返回的json数据
:return:
"""
if json:
for item in json.get("data"):
title = item.get("title")
images = item.get("image_list")
if images:
for image in images:
yield {
"title":title,
"image":urljoin("http:",image.get("url")) if type(image) == type({"t":1}) else urljoin("http:",image)
}
def save_images(item):
"""
将图片保存到文件夹,以标题命名文件夹
:param item: json数据
:return:
"""
if item.get("title") != None:
if not os.path.exists(item.get("title")):
os.mkdir(item.get("title"))
else:
pass
try:
response = requests.get(item.get("image"))
if response.status_code == 200:
file_path = "{0}/{1}.{2}".format(item.get("title") if item.get("title") != None else "Notitle",md5(response.content).hexdigest(),"jpg")
if not os.path.exists(file_path):
with open(file_path,"wb") as f:
f.write(response.content)
else:
print("Already Downloaded",file_path)
except requests.ConnectionError:
print("Failed Download Image")
def main(offset):
"""
控制爬取的主要逻辑
:param offset: 偏移量
:return:
"""
json = get_page(offset)
for item in get_image(json):
print(item)
save_images(item)
groups = [i*20 for i in range(1,10)]
if __name__ == '__main__':
for group in groups:
main(group)
爬取的结果
通过ajax接口分析,模拟ajax请求进行抓包比selenium模拟简单,但是代码复用性差,因为每个网页的接口都不一样,所以在抓取ajax加载的数据时,最好使用selenium模拟或者直接抓取界面数据需要小伙伴根据实际需要自行选择。 查看全部
ajax抓取网页内容(如何分析ajax接口,模拟ajax请求爬取数据(组图))
抓取ajax网站,我们可以通过分析ajax接口获取返回的json数据,从而抓取我们想要的数据。以今日头条为例,如何分析ajax接口,模拟ajax请求爬取数据。
以今日头条为例。网页的上一页只显示部分数据。要查看后续数据,需要向下滑动鼠标。这里我们分析一下它的ajax接口。
打开开发者工具,选择network,点击XHR过滤掉ajax请求,可以看到这里有很多参数,一眼就能看到的参数就是关键字,也就是我们搜索的关键字。然后查看它的预览信息。
可以看到Preview信息中有很多数据信息。点击它可以看到里面收录了很多有用的信息,比如街拍标题和图片地址。
当鼠标向下滑动时,又会过滤掉一个Ajax请求,如下图
可以看到offset参数从0变成了20。仔细观察网页,可以发现网页上显示的信息正好有20条。
这是鼠标滑到第三页的时候,可以看到offset参数变成了40。第一页打开时offset参数为0,第二页offset参数为20,第三页上的参数page是40。不难发现,offset参数其实就是一个offset,一个用来实现翻页的参数。然后我们可以使用urlencode方法将这些参数拼接到url后面,发起ajax请求,通过控制传入的offset参数控制翻页,然后通过response.json( )。
代码思路:1.分析网页的ajax接口,需要传入什么数据2.通过urlencode键参数拼接要请求的url后,指定爬取哪个页面的内容通过控制偏移参数。3.生成不同页面的请求,获取json数据中图片的url信息4.请求图片的url,下载图片5.保存到文件夹中。
实际代码
import requests
from urllib.parse import urlencode,urljoin
import os
from hashlib import md5
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36",
"X-Requested-With":"XMLHttpRequest"
}
def get_page(offset):
"""
:param offset: 偏移量,控制翻页
:return:
"""
params = {
"offset":offset,
"format":"json",
"keyword":"街拍",
"autoload":"true",
"count":"20",
"cur_tab":"1",
"from":"search_tab"
}
url = "https://www.toutiao.com/search_content/?" + urlencode(params)
try:
response = requests.get(url,headers=headers,timeout=5)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
return None
def get_image(json):
"""
:param json: 获取到返回的json数据
:return:
"""
if json:
for item in json.get("data"):
title = item.get("title")
images = item.get("image_list")
if images:
for image in images:
yield {
"title":title,
"image":urljoin("http:",image.get("url")) if type(image) == type({"t":1}) else urljoin("http:",image)
}
def save_images(item):
"""
将图片保存到文件夹,以标题命名文件夹
:param item: json数据
:return:
"""
if item.get("title") != None:
if not os.path.exists(item.get("title")):
os.mkdir(item.get("title"))
else:
pass
try:
response = requests.get(item.get("image"))
if response.status_code == 200:
file_path = "{0}/{1}.{2}".format(item.get("title") if item.get("title") != None else "Notitle",md5(response.content).hexdigest(),"jpg")
if not os.path.exists(file_path):
with open(file_path,"wb") as f:
f.write(response.content)
else:
print("Already Downloaded",file_path)
except requests.ConnectionError:
print("Failed Download Image")
def main(offset):
"""
控制爬取的主要逻辑
:param offset: 偏移量
:return:
"""
json = get_page(offset)
for item in get_image(json):
print(item)
save_images(item)
groups = [i*20 for i in range(1,10)]
if __name__ == '__main__':
for group in groups:
main(group)
爬取的结果
通过ajax接口分析,模拟ajax请求进行抓包比selenium模拟简单,但是代码复用性差,因为每个网页的接口都不一样,所以在抓取ajax加载的数据时,最好使用selenium模拟或者直接抓取界面数据需要小伙伴根据实际需要自行选择。
ajax抓取网页内容(Google的URL变了,音乐播放没有中断的原因是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-19 04:07
越来越多的网站,开始使用“单页结构”(Single-page application)。
整个网站只有一个网页,它使用Ajax技术根据用户的输入加载不同的内容。
这种方式的好处是用户体验好,节省了流量。缺点是AJAX内容不能被搜索引擎抓取。例如,您有一个 网站。
http://example.com
用户通过英镑结构的 URL 看到不同的内容。
http://example.com#1 http://example.com#2 http://example.com#3
但是,搜索引擎只抓取和忽略主题标签,因此它们无法索引内容。
为了解决这个问题,谷歌想出了“哈希+感叹号”的结构。
http://example.com#!1
当 Google 找到上述网址时,它会自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放在这个 URL 上,Google 就会收录。但问题是,“英镑+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
http://twitter.com/ruanyf
改成
http://twitter.com/#!/ruanyf
结果,用户投诉连连,仅半年就被废止。
那么,有没有什么方法可以让搜索引擎在抓取 AJAX 内容的同时保持更直观的 URL?
一直以为没有办法,直到看到 Discourse 创始人之一 Robin Ward 的解决方案,不禁为之惊叹。
Discourse 是一个严重依赖 Ajax 的论坛程序,但必须使用 Google收录 内容。它的解决方案是放弃英镑符号结构并使用 History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏的网址变了,但音乐播放没有中断!
History API 的详细介绍超出了本文章 的范围。这里简单说一下,它的作用是在浏览器的History对象中添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以使新的 URL 出现在地址栏中。History对象的pushState方法接受三个参数,新的URL是第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前所有主流浏览器都支持这种方法:Chrome (26.0+), Firefox (20.0+), IE (10.0+), Safari (0.0+) @5.1+),歌剧 (12.1+)。
以下是罗宾·沃德 (Robin Ward) 的做法。
首先,用History API替换hashtag结构,让每个hashtag变成一个正常路径的URL,这样搜索引擎就会爬取每一个网页。
example.com/1 example.com/2 example.com/3
然后,定义一个处理 Ajax 部分并基于 URL 获取内容的 JavaScript 函数(假设是 jQuery)。
function anchorClick(link) {<br /> var linkSplit = link.split('/').pop();<br /> $.get('api/' + linkSplit, function(data) {<br /> $('#content').html(data);<br /> });<br /> }
再次定义鼠标点击事件。
$('#container').on('click', 'a', function(e) {<br /> window.history.pushState(null, null, $(this).attr('href'));<br /> anchorClick($(this).attr('href'));<br /> e.preventDefault();<br /> });
还要考虑到用户单击浏览器的“前进/后退”按钮。此时触发了History对象的popstate事件。
window.addEventListener('popstate', function(e) { <br /> anchorClick(location.pathname); <br /> });
定义好以上三段代码后,无需刷新页面即可显示正常的路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用主题标签结构,所以每个 URL 都是不同的请求。因此,服务器需要为所有这些请求返回具有以下结构的网页,以防止 404 错误。
<br /> <br /> <br /> <br /> ... ...<br /> <br /> <br />
如果你仔细看上面的代码,你会发现有一个noscript标签,这就是秘密。
我们将搜索引擎应该为 收录 的所有内容放在 noscript 标记中。在这种情况下,用户仍然可以在不刷新页面的情况下进行 AJAX 操作,但是搜索引擎会收录每个页面的主要内容! 查看全部
ajax抓取网页内容(Google的URL变了,音乐播放没有中断的原因是什么?)
越来越多的网站,开始使用“单页结构”(Single-page application)。
整个网站只有一个网页,它使用Ajax技术根据用户的输入加载不同的内容。
这种方式的好处是用户体验好,节省了流量。缺点是AJAX内容不能被搜索引擎抓取。例如,您有一个 网站。
http://example.com
用户通过英镑结构的 URL 看到不同的内容。
http://example.com#1 http://example.com#2 http://example.com#3
但是,搜索引擎只抓取和忽略主题标签,因此它们无法索引内容。
为了解决这个问题,谷歌想出了“哈希+感叹号”的结构。
http://example.com#!1
当 Google 找到上述网址时,它会自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放在这个 URL 上,Google 就会收录。但问题是,“英镑+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
http://twitter.com/ruanyf
改成
http://twitter.com/#!/ruanyf
结果,用户投诉连连,仅半年就被废止。
那么,有没有什么方法可以让搜索引擎在抓取 AJAX 内容的同时保持更直观的 URL?
一直以为没有办法,直到看到 Discourse 创始人之一 Robin Ward 的解决方案,不禁为之惊叹。
Discourse 是一个严重依赖 Ajax 的论坛程序,但必须使用 Google收录 内容。它的解决方案是放弃英镑符号结构并使用 History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏的网址变了,但音乐播放没有中断!
History API 的详细介绍超出了本文章 的范围。这里简单说一下,它的作用是在浏览器的History对象中添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以使新的 URL 出现在地址栏中。History对象的pushState方法接受三个参数,新的URL是第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前所有主流浏览器都支持这种方法:Chrome (26.0+), Firefox (20.0+), IE (10.0+), Safari (0.0+) @5.1+),歌剧 (12.1+)。
以下是罗宾·沃德 (Robin Ward) 的做法。
首先,用History API替换hashtag结构,让每个hashtag变成一个正常路径的URL,这样搜索引擎就会爬取每一个网页。
example.com/1 example.com/2 example.com/3
然后,定义一个处理 Ajax 部分并基于 URL 获取内容的 JavaScript 函数(假设是 jQuery)。
function anchorClick(link) {<br /> var linkSplit = link.split('/').pop();<br /> $.get('api/' + linkSplit, function(data) {<br /> $('#content').html(data);<br /> });<br /> }
再次定义鼠标点击事件。
$('#container').on('click', 'a', function(e) {<br /> window.history.pushState(null, null, $(this).attr('href'));<br /> anchorClick($(this).attr('href'));<br /> e.preventDefault();<br /> });
还要考虑到用户单击浏览器的“前进/后退”按钮。此时触发了History对象的popstate事件。
window.addEventListener('popstate', function(e) { <br /> anchorClick(location.pathname); <br /> });
定义好以上三段代码后,无需刷新页面即可显示正常的路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用主题标签结构,所以每个 URL 都是不同的请求。因此,服务器需要为所有这些请求返回具有以下结构的网页,以防止 404 错误。
<br /> <br /> <br /> <br /> ... ...<br /> <br /> <br />
如果你仔细看上面的代码,你会发现有一个noscript标签,这就是秘密。
我们将搜索引擎应该为 收录 的所有内容放在 noscript 标记中。在这种情况下,用户仍然可以在不刷新页面的情况下进行 AJAX 操作,但是搜索引擎会收录每个页面的主要内容!
ajax抓取网页内容(python通过xpath转化为xpath的javascript转化器.xpath)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-18 18:02
ajax抓取网页内容,通过xpath转化为xpath转化器.xpath转化器很强大,能将xpath转化为javascriptcanvas的javascript
通过vscode来编写python程序编译成python代码其实我觉得python用eclipse最好(微软的东西一向做的不错)
python一些社区小项目上,写个小爬虫也挺简单的。node。js上也有写spider的工具,先起个容易理解的名字,代码一看,要爬的东西就明白了。对于不同语言开发出来的爬虫,基本原理是不一样的,例如python爬虫工具用django。examples。python。com,而不是我们经常看到的httppost请求在自己的爬虫工具里,经常用的是beautifulsoup之类的javascript解析库,或者用scrapy之类的框架,来处理各种变量,属性,post等等。
python可以爬b站的哔哩哔哩,感觉最重要的是要学会看源码,可以先看慕课网的python爬虫,
可以做个电商网站,
可以,看个人技术和兴趣吧,
框架推荐vue、react之类,不过我现在用selenium,
题主没有说明是哪种语言,这就意味着都能上,没有区别,无非是就是看看别人代码做做对比, 查看全部
ajax抓取网页内容(python通过xpath转化为xpath的javascript转化器.xpath)
ajax抓取网页内容,通过xpath转化为xpath转化器.xpath转化器很强大,能将xpath转化为javascriptcanvas的javascript
通过vscode来编写python程序编译成python代码其实我觉得python用eclipse最好(微软的东西一向做的不错)
python一些社区小项目上,写个小爬虫也挺简单的。node。js上也有写spider的工具,先起个容易理解的名字,代码一看,要爬的东西就明白了。对于不同语言开发出来的爬虫,基本原理是不一样的,例如python爬虫工具用django。examples。python。com,而不是我们经常看到的httppost请求在自己的爬虫工具里,经常用的是beautifulsoup之类的javascript解析库,或者用scrapy之类的框架,来处理各种变量,属性,post等等。
python可以爬b站的哔哩哔哩,感觉最重要的是要学会看源码,可以先看慕课网的python爬虫,
可以做个电商网站,
可以,看个人技术和兴趣吧,
框架推荐vue、react之类,不过我现在用selenium,
题主没有说明是哪种语言,这就意味着都能上,没有区别,无非是就是看看别人代码做做对比,
ajax抓取网页内容(UA属性:UA即user-agent原则及调整方向)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-15 08:28
UA属性:UA即user-agent,是http协议中的一个属性,代表终端的身份,向服务器表明我在做什么,然后服务器可以根据不同的身份做出不同的反馈结果。
机器人协议:robots.txt 是搜索引擎访问网站时首先访问的文件,用于确定哪些允许爬取,哪些禁止爬取。robots.txt 必须放在网站 根目录下,文件名必须小写。robots.txt的详细写法请参考。百度严格执行机器人协议。此外,它还支持在网页内容中添加名为 robots 的元标记,以及 index、follow 和 nofollow 等指令。
百度蜘蛛抓取频率原理及调整方向
百度蜘蛛根据上述网站设定的协议爬取网站页面,但不可能对所有网站一视同仁。它会综合考虑网站的实际情况来确定一个抓取配额,每天定量抓取网站内容,也就是我们常说的抓取频率。那么百度搜索引擎是通过哪些指标来判断一个网站的爬取频率呢?主要有四个指标:
1、网站更新频率:更新越频繁,更新越慢,直接影响百度蜘蛛的访问频率
2、网站更新质量:提升的更新频率正好吸引了百度蜘蛛的注意。百度蜘蛛对质量有严格的要求。如果 网站 每天更新的大量内容被百度蜘蛛质量页面判断为低,仍然没有意义。
3. 连通性:网站 安全稳定,保持百度蜘蛛畅通。一直关着百度蜘蛛不是好事
4、站点评价:百度搜索引擎会对每个站点都有一个评价,这个评价会根据站点情况不断变化。里面有很机密的资料。站点评级从不单独使用,并与其他因素和阈值一起影响 网站 的爬取和排名。
爬取频率间接决定了网站有多少页面可能被数据库收录。这么重要的值,如果不符合站长的期望,应该如何调整呢?百度站长平台提供爬频工具,已完成多次升级。除了提供爬取统计,该工具还提供了“频率调整”功能。站长要求百度蜘蛛根据实际情况增加或减少对百度站长平台的访问量。调整。
百度蜘蛛爬取异常的原因
有一些网页内容优质,用户可以正常访问,但Baiduspider无法正常访问和爬取,导致搜索结果覆盖不足,对百度搜索引擎和网站来说都是一种损失。百度称这种情况为“抢”。对于大量内容无法正常抓取的网站,百度搜索引擎会认为网站存在用户体验缺陷,降低对网站的评价,在爬取、索引和排序方面都会受到一定程度的负面影响,最终会影响到网站从百度获得的流量。
以下是爬取异常的一些常见原因:
1.服务器连接异常
服务器连接异常有两种情况:一种是网站不稳定,百度蜘蛛在尝试连接你的网站服务器时暂时无法连接;另一个是百度蜘蛛一直无法连接到你网站的服务器。服务器。
服务器连接异常的原因通常是你的网站服务器太大,过载。您的 网站 也可能运行不正常。请检查网站的web服务器(如apache、iis)是否安装并运行正常,并使用浏览器检查主页是否可以正常访问。您的 网站 和主机也可能阻止了百度蜘蛛的访问,您需要检查您的 网站 和主机的防火墙。
2、网络运营商异常:网络运营商分为电信和联通两类。百度蜘蛛无法通过中国电信或中国网通访问您的网站。如果出现这种情况,需要联系网络服务运营商,或者购买双线服务空间或者购买cdn服务。
3、DNS异常:当Baiduspider无法解析您的网站 IP时,会出现DNS异常。可能你的网站IP地址错误,或者你的域名服务商屏蔽了百度蜘蛛。请使用 WHOIS 或主机检查您的 网站IP 地址是否正确且可解析。如果不正确或无法解决,请联系域名注册商更新您的 IP 地址。
4、IP封禁:IP封禁是:限制网络的出口IP地址,禁止该IP段内的用户访问内容,这里特意封禁BaiduspiderIP。仅当您的 网站 不希望百度蜘蛛访问时,才需要此设置。如果您想让百度蜘蛛访问您的网站,请在相关设置中检查百度蜘蛛IP是否添加错误。也有可能是你网站所在的空间服务商封杀了百度IP。在这种情况下,您需要联系服务提供商更改设置。
5、UA禁止:UA为User-Agent,服务器通过UA识别访问者。当网站返回异常页面(如403、500)或跳转到其他页面进行指定UA的访问时,属于UA禁令。当你的网站不想要百度蜘蛛时这个设置只有在访问的时候才需要,如果你想让Baiduspider访问你的网站,请检查useragent相关设置中是否有Baiduspider UA,并及时修改。
6、死链接:无效且不能为用户提供任何有价值信息的页面为死链接,包括协议死链接和内容死链接:
协议死链接:页面的TCP协议状态/HTTP协议状态明确表示的死链接,如404、403、503状态等。
内容死链接:服务器返回正常状态,但内容已更改为不存在、已删除或需要权限等与原创内容无关的信息页面。
对于死链接,我们建议网站使用协议死链接,通过百度站长平台-死链接工具提交给百度,这样百度可以更快的找到死链接,减少死链接对用户和搜索引擎的负面影响。
7.异常跳转:将网络请求重定向到另一个位置是跳转。异常跳转指以下几种情况:
1)目前该页面为无效页面(删除内容、死链接等),直接跳转上一个目录或首页,百度建议站长删除无效页面的入口超链接
2)跳转到错误或无效页面
注意:长期重定向到其他域名,如网站改域名,百度推荐使用301重定向协议进行设置。
8. 其他例外:
1)百度referrer异常:网页返回的行为与来自百度的referrer的正常内容不同。
2)百度UA异常:网页返回百度UA的行为与页面原创内容不同。
3)JS跳转异常:网页加载了百度无法识别的JS跳转代码,导致用户通过搜索结果进入页面后跳转。
4)压力过大导致的意外封禁:百度会根据网站规模、流量等信息自动设置合理的抓取压力。但在异常情况下,如压力控制异常时,服务器会根据自身负载进行保护性的偶尔封禁。在这种情况下,请在返回码中返回 503(表示“服务不可用”),这样百度蜘蛛会在一段时间后再次尝试抓取链接。如果 网站 是空闲的,它将被成功爬取。
判断新链接的重要性
好了,上面我们讲了影响百度蜘蛛正常爬取的原因,下面说一下百度蜘蛛的一些判断原则。建库前,Baiduspide会对页面进行初步的内容分析和链接分析,通过内容分析判断页面是否需要建索引库,通过链接分析发现更多页面,然后爬取更多页面——分析——是否建立一个图书馆并发现新链接的过程。理论上,百度蜘蛛会抓取新页面上所有“看到”的链接,那么面对众多的新链接,百度蜘蛛如何判断哪个更重要呢?两个方面:
一、对用户的价值:
1.独特的内容,百度搜索引擎喜欢独特的内容
2. 主体突出,不要出现网页主体内容不突出被搜索引擎误判为空短页而未被抓取
3、内容丰富
4.广告合适
二、链接的重要性:
1.目录级别——浅层优先
2. 网站链接的受欢迎程度
百度优先建设重要库的原则
百度蜘蛛抓取的页数不是最重要的,重要的是建了多少页到索引库,也就是我们常说的“建库”。众所周知,搜索引擎的索引库是分层的。高质量的网页将分配到重要的索引库,普通网页将留在普通库,较差的网页将分配到低级库作为补充资料。目前60%的检索需求只需要调用重要的索引库就可以满足,这就解释了为什么有些网站的收录的高流量并不理想。
那么,哪些页面可以进入优质索引库呢?其实,总的原则是一个:对用户有价值。包括但不仅限于:
1.及时有价值的页面:在这里,及时性和价值并列,两者都缺一不可。有些网站为了生成时间敏感的内容页面做了很多采集的工作,导致一堆毫无价值的页面,百度不想看到。
2. 内容优质的专题页:专题页的内容不一定是完全的原创,也就是可以很好的融合各方的内容,或者添加一些新鲜的内容,比如浏览量和评论,给用户更丰富、更全面的内容。
3、高价值的原创内容页面:百度将原创定义为花费一定成本、积累大量经验后形成的文章。永远不要再问我们是否 伪原创 是原创。
4.重要的个人页面:这里只是一个例子,科比在新浪微博上开了一个账号,他需要不经常更新,但对于百度来说,它仍然是一个非常重要的页面。
哪些页面不能被索引
上面提到的优质网页都进入了索引库,所以其实网上的大部分网站都没有被百度收录列出来。不是百度没找到,而是建库前的筛选过程中被过滤掉了。那么在第一个链接中过滤掉了什么样的网页:
1、内容重复的网页:百度不需要收录互联网上已有的内容。
2. 主要内容为空、短的网页
1)有些内容使用了百度蜘蛛无法解析的技术,比如JS、AJAX等,虽然用户可以看到丰富的内容,但还是会被搜索引擎抛弃
2)加载太慢的网页也可能被视为空的短页。请注意,广告加载时间计入网页的总加载时间。
3)很多主体不太突出的网页,即使被爬回来,也会在这个链接中被丢弃。
3.一些作弊页面
想要获取工具可以加千陌先生微信m247143276获取SEO学习工具包和技术教程 查看全部
ajax抓取网页内容(UA属性:UA即user-agent原则及调整方向)
UA属性:UA即user-agent,是http协议中的一个属性,代表终端的身份,向服务器表明我在做什么,然后服务器可以根据不同的身份做出不同的反馈结果。
机器人协议:robots.txt 是搜索引擎访问网站时首先访问的文件,用于确定哪些允许爬取,哪些禁止爬取。robots.txt 必须放在网站 根目录下,文件名必须小写。robots.txt的详细写法请参考。百度严格执行机器人协议。此外,它还支持在网页内容中添加名为 robots 的元标记,以及 index、follow 和 nofollow 等指令。
百度蜘蛛抓取频率原理及调整方向
百度蜘蛛根据上述网站设定的协议爬取网站页面,但不可能对所有网站一视同仁。它会综合考虑网站的实际情况来确定一个抓取配额,每天定量抓取网站内容,也就是我们常说的抓取频率。那么百度搜索引擎是通过哪些指标来判断一个网站的爬取频率呢?主要有四个指标:
1、网站更新频率:更新越频繁,更新越慢,直接影响百度蜘蛛的访问频率
2、网站更新质量:提升的更新频率正好吸引了百度蜘蛛的注意。百度蜘蛛对质量有严格的要求。如果 网站 每天更新的大量内容被百度蜘蛛质量页面判断为低,仍然没有意义。
3. 连通性:网站 安全稳定,保持百度蜘蛛畅通。一直关着百度蜘蛛不是好事
4、站点评价:百度搜索引擎会对每个站点都有一个评价,这个评价会根据站点情况不断变化。里面有很机密的资料。站点评级从不单独使用,并与其他因素和阈值一起影响 网站 的爬取和排名。
爬取频率间接决定了网站有多少页面可能被数据库收录。这么重要的值,如果不符合站长的期望,应该如何调整呢?百度站长平台提供爬频工具,已完成多次升级。除了提供爬取统计,该工具还提供了“频率调整”功能。站长要求百度蜘蛛根据实际情况增加或减少对百度站长平台的访问量。调整。
百度蜘蛛爬取异常的原因
有一些网页内容优质,用户可以正常访问,但Baiduspider无法正常访问和爬取,导致搜索结果覆盖不足,对百度搜索引擎和网站来说都是一种损失。百度称这种情况为“抢”。对于大量内容无法正常抓取的网站,百度搜索引擎会认为网站存在用户体验缺陷,降低对网站的评价,在爬取、索引和排序方面都会受到一定程度的负面影响,最终会影响到网站从百度获得的流量。
以下是爬取异常的一些常见原因:
1.服务器连接异常
服务器连接异常有两种情况:一种是网站不稳定,百度蜘蛛在尝试连接你的网站服务器时暂时无法连接;另一个是百度蜘蛛一直无法连接到你网站的服务器。服务器。
服务器连接异常的原因通常是你的网站服务器太大,过载。您的 网站 也可能运行不正常。请检查网站的web服务器(如apache、iis)是否安装并运行正常,并使用浏览器检查主页是否可以正常访问。您的 网站 和主机也可能阻止了百度蜘蛛的访问,您需要检查您的 网站 和主机的防火墙。
2、网络运营商异常:网络运营商分为电信和联通两类。百度蜘蛛无法通过中国电信或中国网通访问您的网站。如果出现这种情况,需要联系网络服务运营商,或者购买双线服务空间或者购买cdn服务。
3、DNS异常:当Baiduspider无法解析您的网站 IP时,会出现DNS异常。可能你的网站IP地址错误,或者你的域名服务商屏蔽了百度蜘蛛。请使用 WHOIS 或主机检查您的 网站IP 地址是否正确且可解析。如果不正确或无法解决,请联系域名注册商更新您的 IP 地址。
4、IP封禁:IP封禁是:限制网络的出口IP地址,禁止该IP段内的用户访问内容,这里特意封禁BaiduspiderIP。仅当您的 网站 不希望百度蜘蛛访问时,才需要此设置。如果您想让百度蜘蛛访问您的网站,请在相关设置中检查百度蜘蛛IP是否添加错误。也有可能是你网站所在的空间服务商封杀了百度IP。在这种情况下,您需要联系服务提供商更改设置。
5、UA禁止:UA为User-Agent,服务器通过UA识别访问者。当网站返回异常页面(如403、500)或跳转到其他页面进行指定UA的访问时,属于UA禁令。当你的网站不想要百度蜘蛛时这个设置只有在访问的时候才需要,如果你想让Baiduspider访问你的网站,请检查useragent相关设置中是否有Baiduspider UA,并及时修改。
6、死链接:无效且不能为用户提供任何有价值信息的页面为死链接,包括协议死链接和内容死链接:
协议死链接:页面的TCP协议状态/HTTP协议状态明确表示的死链接,如404、403、503状态等。
内容死链接:服务器返回正常状态,但内容已更改为不存在、已删除或需要权限等与原创内容无关的信息页面。
对于死链接,我们建议网站使用协议死链接,通过百度站长平台-死链接工具提交给百度,这样百度可以更快的找到死链接,减少死链接对用户和搜索引擎的负面影响。
7.异常跳转:将网络请求重定向到另一个位置是跳转。异常跳转指以下几种情况:
1)目前该页面为无效页面(删除内容、死链接等),直接跳转上一个目录或首页,百度建议站长删除无效页面的入口超链接
2)跳转到错误或无效页面
注意:长期重定向到其他域名,如网站改域名,百度推荐使用301重定向协议进行设置。
8. 其他例外:
1)百度referrer异常:网页返回的行为与来自百度的referrer的正常内容不同。
2)百度UA异常:网页返回百度UA的行为与页面原创内容不同。
3)JS跳转异常:网页加载了百度无法识别的JS跳转代码,导致用户通过搜索结果进入页面后跳转。
4)压力过大导致的意外封禁:百度会根据网站规模、流量等信息自动设置合理的抓取压力。但在异常情况下,如压力控制异常时,服务器会根据自身负载进行保护性的偶尔封禁。在这种情况下,请在返回码中返回 503(表示“服务不可用”),这样百度蜘蛛会在一段时间后再次尝试抓取链接。如果 网站 是空闲的,它将被成功爬取。
判断新链接的重要性
好了,上面我们讲了影响百度蜘蛛正常爬取的原因,下面说一下百度蜘蛛的一些判断原则。建库前,Baiduspide会对页面进行初步的内容分析和链接分析,通过内容分析判断页面是否需要建索引库,通过链接分析发现更多页面,然后爬取更多页面——分析——是否建立一个图书馆并发现新链接的过程。理论上,百度蜘蛛会抓取新页面上所有“看到”的链接,那么面对众多的新链接,百度蜘蛛如何判断哪个更重要呢?两个方面:
一、对用户的价值:
1.独特的内容,百度搜索引擎喜欢独特的内容
2. 主体突出,不要出现网页主体内容不突出被搜索引擎误判为空短页而未被抓取
3、内容丰富
4.广告合适
二、链接的重要性:
1.目录级别——浅层优先
2. 网站链接的受欢迎程度
百度优先建设重要库的原则
百度蜘蛛抓取的页数不是最重要的,重要的是建了多少页到索引库,也就是我们常说的“建库”。众所周知,搜索引擎的索引库是分层的。高质量的网页将分配到重要的索引库,普通网页将留在普通库,较差的网页将分配到低级库作为补充资料。目前60%的检索需求只需要调用重要的索引库就可以满足,这就解释了为什么有些网站的收录的高流量并不理想。
那么,哪些页面可以进入优质索引库呢?其实,总的原则是一个:对用户有价值。包括但不仅限于:
1.及时有价值的页面:在这里,及时性和价值并列,两者都缺一不可。有些网站为了生成时间敏感的内容页面做了很多采集的工作,导致一堆毫无价值的页面,百度不想看到。
2. 内容优质的专题页:专题页的内容不一定是完全的原创,也就是可以很好的融合各方的内容,或者添加一些新鲜的内容,比如浏览量和评论,给用户更丰富、更全面的内容。
3、高价值的原创内容页面:百度将原创定义为花费一定成本、积累大量经验后形成的文章。永远不要再问我们是否 伪原创 是原创。
4.重要的个人页面:这里只是一个例子,科比在新浪微博上开了一个账号,他需要不经常更新,但对于百度来说,它仍然是一个非常重要的页面。
哪些页面不能被索引
上面提到的优质网页都进入了索引库,所以其实网上的大部分网站都没有被百度收录列出来。不是百度没找到,而是建库前的筛选过程中被过滤掉了。那么在第一个链接中过滤掉了什么样的网页:
1、内容重复的网页:百度不需要收录互联网上已有的内容。
2. 主要内容为空、短的网页
1)有些内容使用了百度蜘蛛无法解析的技术,比如JS、AJAX等,虽然用户可以看到丰富的内容,但还是会被搜索引擎抛弃
2)加载太慢的网页也可能被视为空的短页。请注意,广告加载时间计入网页的总加载时间。
3)很多主体不太突出的网页,即使被爬回来,也会在这个链接中被丢弃。
3.一些作弊页面
想要获取工具可以加千陌先生微信m247143276获取SEO学习工具包和技术教程
ajax抓取网页内容(看看jQuery的.load()函数:如何使用jQuery包含HTML页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-10 22:27
在元素中: .
如何使用 jQuery 收录一个 HTML 页面,该页面可以通过调用 jQuery 中的 load() 函数加载到 HTML 页面上的 div 中。这只是从 random_number.php 文件(其内容在上面的示例中)中获取文本,并将结果放入 id 为 test 的 div 中。这是一个执行此操作的 HTML 页面。看看 jQuery 的 .load() 函数:How to load an external web page into a div in an html page。33. 使用 iframe 或 Object 标签嵌入网页。如何在页面加载时将网页内容加载到 div 中?构建一个收录许多关于如何使用 HTML、CSS、JavaScript 的示例的教程,并且 jQuery load() 方法是一种简单但功能强大的 AJAX 方法。load() 方法从服务器加载数据,并将返回的数据放入下面的示例中,将文件“demo_test.txt”的内容加载到特定的
在元素中:jQuery load() 语法和 load() 我们可以在需要时或在用户请求时通过表单、按钮、链接将外部文件(php、html、asp...)加载到 div 中... ...此脚本的外部文件必须托管在同一域网络上。我们来看看从官网提取的语法:.
如何在页面加载时将网页内容加载到 div 中?,看看jQuery的.load()函数:How to load an external web page into a div in an html page。33. 在构建教程中使用iframe 或Object 标签嵌入网页,其中收录如何使用HTML、CSS、JavaScript 的许多示例,jQuery load() 方法是一种简单但功能强大的AJAX 方法。load() 方法从服务器加载数据,并将返回的数据放入下面的示例中,将文件“demo_test.txt”的内容加载到特定的
在元素中: . . Load(), jQuery load() 语法 使用 load() 我们可以加载一个外部文件(php, html, asp.. ..)。脚本文件必须托管在与 Web 相同的域中。让我们看一下从官方 网站 中提取的语法:这可以在没有 iframe 的情况下完成。由于标题中提到了jQuery,因此使用了jQuery。
.load(),收录许多如何使用 HTML、CSS、JavaScript 的示例的构建教程,jQuery load() 方法是一种简单但功能强大的 AJAX 方法。load() 方法从服务器加载数据,并将返回的数据放入下面的示例中,将文件“demo_test.txt”的内容加载到特定的
在元素中:jQuery load() 语法和 load() 我们可以在需要时或在用户请求时通过表单、按钮、链接将外部文件(php、html、asp...)加载到 div 中... ...此脚本的外部文件必须托管在同一域网络上。我们来看看从官网提取的语法:. 使用 jQuery 将页面加载到 div 中,这可以在没有 iframe 的情况下完成。由于标题中提到了jQuery,因此使用了jQuery。,将代码包装在 load() 函数中。要在 jQuery 中加载 div 中的页面,请使用 load() 方法。
使用 jQuery 将页面加载到 div 中,jQuery 的语法 load() 使用 load(),我们可以在需要时或在用户请求时传递表单、按钮、链接... 这个脚本的外部文件必须托管在同一个 web 上域中间。让我们看一下从官方 网站 中提取的语法:这可以在没有 iframe 的情况下完成。由于标题中提到了jQuery,因此使用了jQuery。.load() .load( url, [data], [complete(responseText, textStatus, 将外部 HTML 加载到
,将代码包装在 load() 函数中。要在 jQuery 中加载 div 页面,请使用 load() 方法。我正在将一个单独的 HTML 文件中的 div 加载到 index.html 页面上的一个 div 中。这是使用 jQuery 的 .load() 完成的。但是,有很多重复,我想知道是否有更清洁的方法来实现这一点。.
jQuery 加载模板
jquery.loadtemplate, jQuery.loadTemplate 最初是为博客设计的单页应用程序。这个想法是为博客 文章、文章 片段等创建模板。注意:在 jQuery 3.0 之前,事件处理套件还有一个名为 .load() 的方法。旧版本的 jQuery 根据传递给它的参数确定要触发的方法。. 为什么我们使用 jQuery LoadTemplate,只是将模板主体加载为简单的文本而忘记将其放入 dummy。版权所有。蜀ICP备2021025969号
切换导航 查看全部
ajax抓取网页内容(看看jQuery的.load()函数:如何使用jQuery包含HTML页面)
在元素中: .
如何使用 jQuery 收录一个 HTML 页面,该页面可以通过调用 jQuery 中的 load() 函数加载到 HTML 页面上的 div 中。这只是从 random_number.php 文件(其内容在上面的示例中)中获取文本,并将结果放入 id 为 test 的 div 中。这是一个执行此操作的 HTML 页面。看看 jQuery 的 .load() 函数:How to load an external web page into a div in an html page。33. 使用 iframe 或 Object 标签嵌入网页。如何在页面加载时将网页内容加载到 div 中?构建一个收录许多关于如何使用 HTML、CSS、JavaScript 的示例的教程,并且 jQuery load() 方法是一种简单但功能强大的 AJAX 方法。load() 方法从服务器加载数据,并将返回的数据放入下面的示例中,将文件“demo_test.txt”的内容加载到特定的
在元素中:jQuery load() 语法和 load() 我们可以在需要时或在用户请求时通过表单、按钮、链接将外部文件(php、html、asp...)加载到 div 中... ...此脚本的外部文件必须托管在同一域网络上。我们来看看从官网提取的语法:.
如何在页面加载时将网页内容加载到 div 中?,看看jQuery的.load()函数:How to load an external web page into a div in an html page。33. 在构建教程中使用iframe 或Object 标签嵌入网页,其中收录如何使用HTML、CSS、JavaScript 的许多示例,jQuery load() 方法是一种简单但功能强大的AJAX 方法。load() 方法从服务器加载数据,并将返回的数据放入下面的示例中,将文件“demo_test.txt”的内容加载到特定的
在元素中: . . Load(), jQuery load() 语法 使用 load() 我们可以加载一个外部文件(php, html, asp.. ..)。脚本文件必须托管在与 Web 相同的域中。让我们看一下从官方 网站 中提取的语法:这可以在没有 iframe 的情况下完成。由于标题中提到了jQuery,因此使用了jQuery。
.load(),收录许多如何使用 HTML、CSS、JavaScript 的示例的构建教程,jQuery load() 方法是一种简单但功能强大的 AJAX 方法。load() 方法从服务器加载数据,并将返回的数据放入下面的示例中,将文件“demo_test.txt”的内容加载到特定的
在元素中:jQuery load() 语法和 load() 我们可以在需要时或在用户请求时通过表单、按钮、链接将外部文件(php、html、asp...)加载到 div 中... ...此脚本的外部文件必须托管在同一域网络上。我们来看看从官网提取的语法:. 使用 jQuery 将页面加载到 div 中,这可以在没有 iframe 的情况下完成。由于标题中提到了jQuery,因此使用了jQuery。,将代码包装在 load() 函数中。要在 jQuery 中加载 div 中的页面,请使用 load() 方法。
使用 jQuery 将页面加载到 div 中,jQuery 的语法 load() 使用 load(),我们可以在需要时或在用户请求时传递表单、按钮、链接... 这个脚本的外部文件必须托管在同一个 web 上域中间。让我们看一下从官方 网站 中提取的语法:这可以在没有 iframe 的情况下完成。由于标题中提到了jQuery,因此使用了jQuery。.load() .load( url, [data], [complete(responseText, textStatus, 将外部 HTML 加载到
,将代码包装在 load() 函数中。要在 jQuery 中加载 div 页面,请使用 load() 方法。我正在将一个单独的 HTML 文件中的 div 加载到 index.html 页面上的一个 div 中。这是使用 jQuery 的 .load() 完成的。但是,有很多重复,我想知道是否有更清洁的方法来实现这一点。.
jQuery 加载模板
jquery.loadtemplate, jQuery.loadTemplate 最初是为博客设计的单页应用程序。这个想法是为博客 文章、文章 片段等创建模板。注意:在 jQuery 3.0 之前,事件处理套件还有一个名为 .load() 的方法。旧版本的 jQuery 根据传递给它的参数确定要触发的方法。. 为什么我们使用 jQuery LoadTemplate,只是将模板主体加载为简单的文本而忘记将其放入 dummy。版权所有。蜀ICP备2021025969号
切换导航
ajax抓取网页内容(python爬取数据的一般步骤,用到的工具包括python和BeautifulSoup)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-02-10 08:08
今天,我们将通过一个例子来介绍python爬取数据的一般步骤。使用的工具包括python的经典模块requests和BeautifulSoup,并结合新学的任务流工具TaskFlow完成代码开发。
我们先来看看要爬取的数据,URL是,通过chrome的开发者工具分析,我们可以很容易的发现后台数据加载的URL是
{page_num}/ajax/1/free/1/
page_num 的位置是要查询的页面的数据。网页上的概念中有6页数据,所以page_num的值是1-6。
图1
这里有个小技巧,可以点击图1左上角的清除按钮,先清除加载的URL,再点击原网页的第二个页面,可以在左下角看到新加载的URL图片,点击打开右侧的“预览”,可以看到资金流数据相关的内容,可以确定这个URL是用来加载数据的。
在chrome浏览器中输入,打开chrome开发者工具,在网页源码中找到数据所在的table标签。
抓取数据完整源码如下
import time
import requests
from bs4 import BeautifulSoup
from taskflow import engines
from taskflow.patterns import linear_flow
from taskflow.task import Task
REQUEST_HEADER = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'}
class MoneyFlowDownload(Task):
"""
下载资金流数据
数据源地址:http://data.10jqka.com.cn/funds/gnzjl/
"""
BASE_URl = {
"concept": 'http://data.10jqka.com.cn/fund ... 39%3B,
}
def execute(self, bizdate, *args, **kwargs):
for name, base_url in self.BASE_URl.items():
# 爬取数据的存储路径
dt_path = '/data/%s_%s.csv' % (bizdate, name)
with open(dt_path, "a+") as f:
# 记录数据文件的当前位置
pos = f.tell()
f.seek(0)
lines = f.readlines()
# 读取文件中的全部数据并将第一列存储下来作为去重依据,防止爬虫意外中断后重启程序时,重复写入相同
crawled_list = list(map(lambda line: line.split(",")[0], lines))
f.seek(pos)
# 循环500次,从第一页开始爬取数据,当页面没有数据时终端退出循环
for i in range(1, 500):
print("start crawl %s, %s" % (name, base_url % i))
web_source = requests.get(base_url % i, headers=REQUEST_HEADER)
soup = BeautifulSoup(web_source.content.decode("gbk"), 'lxml')
table = soup.select('.J-ajax-table')[0]
tbody = table.select('tbody tr')
# 当tbody为空时,则说明当前页已经没有数据了,此时终止循环
if len(tbody) == 0:
break
for tr in tbody:
fields = tr.select('td')
# 将每行记录第一列去掉,第一列为序号,没有存储必要
record = [field.text.strip() for field in fields[1:]]
# 如果记录还没有写入文件中,则执行写入操作,否则跳过这行写入
if record[0] not in crawled_list:
f.writelines([','.join(record) + '\n'])
# 同花顺网站有反爬虫的机制,爬取速度过快很可能被封
time.sleep(1)
if __name__ == '__main__':
bizdate = '20200214'
tasks = [
MoneyFlowDownload('moneyflow data download')
]
flow = linear_flow.Flow('ths data download').add(*tasks)
e = engines.load(flow, store={'bizdate': bizdate})
e.run()
执行程序后,概念资金流向数据已经存放在dt_path位置,文件名为20200214_concept.csv,内容大致如下:
钛白粉,1008.88,6.29%,7.68,6.21,1.47,7,金浦钛业,10.04%,2.96
磷化工,916.833,2.42%,37.53,34.78,2.75,28,六国化工,9.97%,4.08
光刻胶,1435.68,2.40%,43.51,44.31,-0.80,20,晶瑞股份,10.01%,42.99
至此,以flush flush概念分类的资金流数据的爬取完成,接下来就可以每天定时启动任务,抓取数据进行分析。 查看全部
ajax抓取网页内容(python爬取数据的一般步骤,用到的工具包括python和BeautifulSoup)
今天,我们将通过一个例子来介绍python爬取数据的一般步骤。使用的工具包括python的经典模块requests和BeautifulSoup,并结合新学的任务流工具TaskFlow完成代码开发。
我们先来看看要爬取的数据,URL是,通过chrome的开发者工具分析,我们可以很容易的发现后台数据加载的URL是
{page_num}/ajax/1/free/1/
page_num 的位置是要查询的页面的数据。网页上的概念中有6页数据,所以page_num的值是1-6。
图1
这里有个小技巧,可以点击图1左上角的清除按钮,先清除加载的URL,再点击原网页的第二个页面,可以在左下角看到新加载的URL图片,点击打开右侧的“预览”,可以看到资金流数据相关的内容,可以确定这个URL是用来加载数据的。
在chrome浏览器中输入,打开chrome开发者工具,在网页源码中找到数据所在的table标签。
抓取数据完整源码如下
import time
import requests
from bs4 import BeautifulSoup
from taskflow import engines
from taskflow.patterns import linear_flow
from taskflow.task import Task
REQUEST_HEADER = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'}
class MoneyFlowDownload(Task):
"""
下载资金流数据
数据源地址:http://data.10jqka.com.cn/funds/gnzjl/
"""
BASE_URl = {
"concept": 'http://data.10jqka.com.cn/fund ... 39%3B,
}
def execute(self, bizdate, *args, **kwargs):
for name, base_url in self.BASE_URl.items():
# 爬取数据的存储路径
dt_path = '/data/%s_%s.csv' % (bizdate, name)
with open(dt_path, "a+") as f:
# 记录数据文件的当前位置
pos = f.tell()
f.seek(0)
lines = f.readlines()
# 读取文件中的全部数据并将第一列存储下来作为去重依据,防止爬虫意外中断后重启程序时,重复写入相同
crawled_list = list(map(lambda line: line.split(",")[0], lines))
f.seek(pos)
# 循环500次,从第一页开始爬取数据,当页面没有数据时终端退出循环
for i in range(1, 500):
print("start crawl %s, %s" % (name, base_url % i))
web_source = requests.get(base_url % i, headers=REQUEST_HEADER)
soup = BeautifulSoup(web_source.content.decode("gbk"), 'lxml')
table = soup.select('.J-ajax-table')[0]
tbody = table.select('tbody tr')
# 当tbody为空时,则说明当前页已经没有数据了,此时终止循环
if len(tbody) == 0:
break
for tr in tbody:
fields = tr.select('td')
# 将每行记录第一列去掉,第一列为序号,没有存储必要
record = [field.text.strip() for field in fields[1:]]
# 如果记录还没有写入文件中,则执行写入操作,否则跳过这行写入
if record[0] not in crawled_list:
f.writelines([','.join(record) + '\n'])
# 同花顺网站有反爬虫的机制,爬取速度过快很可能被封
time.sleep(1)
if __name__ == '__main__':
bizdate = '20200214'
tasks = [
MoneyFlowDownload('moneyflow data download')
]
flow = linear_flow.Flow('ths data download').add(*tasks)
e = engines.load(flow, store={'bizdate': bizdate})
e.run()
执行程序后,概念资金流向数据已经存放在dt_path位置,文件名为20200214_concept.csv,内容大致如下:
钛白粉,1008.88,6.29%,7.68,6.21,1.47,7,金浦钛业,10.04%,2.96
磷化工,916.833,2.42%,37.53,34.78,2.75,28,六国化工,9.97%,4.08
光刻胶,1435.68,2.40%,43.51,44.31,-0.80,20,晶瑞股份,10.01%,42.99
至此,以flush flush概念分类的资金流数据的爬取完成,接下来就可以每天定时启动任务,抓取数据进行分析。
ajax抓取网页内容(如何抓取ajax形式加载的网页数据(一)_恢复内容开始)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-09 12:12
---恢复内容开始---
下面记录如何捕获以ajax形式加载的网页数据:
目标:获取"%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action="下的网页数据
第一步:网页数据分析-----》特点:当列表栏滚动到页面底部时,自动加载数据,页面的url没有变化。
第二步:使用Fiddler抓包,如下图:
图 1:请求数据
图 2:表格形式
通过抓包得到数据规则:图2中from表单中start对应的数据和图1中url中start对应的数据随着每次加载而增加,其他数据保持不变。对应这个规则,我们可以构造相应的请求来获取数据
需要注意的是数据格式是json
代码显示如下:
1).urllib 形式
import urllib2
import urllib
#此处的url为上述抓包获取的url去掉start以及limit,start以及limit数据后边以form表单的形式传入
url = ' https://movie.douban.com/j/cha ... ction='
#请求投信息,伪造成浏览器,方式被反爬虫策略拦截
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
#构建form表单
formdata = {
"start":"20",
"limit":"20"
}
#urlencode()urllib中的函数,作用:将key:value形式的键值对转换为"key=value"形式的字符串
data = urllib.urlencode(formdata)
#构建request实例对象
request = urllib2.Request(url,data=data,headers=headers)
#发送请求并返回响应信息
response = urllib2.urlopen(request)
#注意此处的数据形式并不是html文档,而是json数据
json = response.read()
print html
2)。获取请求库的请求码
#coding=utf-8
import requests
url = ' https://movie.douban.com/j/cha ... ction='
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
data = {
"start":"20",
"limit":"20",
}
response = requests.get(url,params = data,headers = headers)
print response.text
3).request 库发布请求
#coding=utf-8
import requests
url = ' https://movie.douban.com/j/cha ... ction='
formdata = {
"start":"20",
"limit":"20"
}
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
response = requests.post(url,data=formdata,headers=headers)
print response.text
---恢复内容结束--- 查看全部
ajax抓取网页内容(如何抓取ajax形式加载的网页数据(一)_恢复内容开始)
---恢复内容开始---
下面记录如何捕获以ajax形式加载的网页数据:
目标:获取"%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action="下的网页数据
第一步:网页数据分析-----》特点:当列表栏滚动到页面底部时,自动加载数据,页面的url没有变化。
第二步:使用Fiddler抓包,如下图:
图 1:请求数据
图 2:表格形式
通过抓包得到数据规则:图2中from表单中start对应的数据和图1中url中start对应的数据随着每次加载而增加,其他数据保持不变。对应这个规则,我们可以构造相应的请求来获取数据
需要注意的是数据格式是json
代码显示如下:
1).urllib 形式
import urllib2
import urllib
#此处的url为上述抓包获取的url去掉start以及limit,start以及limit数据后边以form表单的形式传入
url = ' https://movie.douban.com/j/cha ... ction='
#请求投信息,伪造成浏览器,方式被反爬虫策略拦截
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
#构建form表单
formdata = {
"start":"20",
"limit":"20"
}
#urlencode()urllib中的函数,作用:将key:value形式的键值对转换为"key=value"形式的字符串
data = urllib.urlencode(formdata)
#构建request实例对象
request = urllib2.Request(url,data=data,headers=headers)
#发送请求并返回响应信息
response = urllib2.urlopen(request)
#注意此处的数据形式并不是html文档,而是json数据
json = response.read()
print html
2)。获取请求库的请求码
#coding=utf-8
import requests
url = ' https://movie.douban.com/j/cha ... ction='
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
data = {
"start":"20",
"limit":"20",
}
response = requests.get(url,params = data,headers = headers)
print response.text
3).request 库发布请求
#coding=utf-8
import requests
url = ' https://movie.douban.com/j/cha ... ction='
formdata = {
"start":"20",
"limit":"20"
}
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
response = requests.post(url,data=formdata,headers=headers)
print response.text
---恢复内容结束---
ajax抓取网页内容(Google的网络蜘蛛忽视URL的#部分,HTTP请求中不包括#)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-04 01:01
# 用于引导浏览器操作,在服务器端完全没用。因此,# 不收录在 HTTP 请求中。
三、# 之后的字符
出现在第一个 # 之后的任何字符都将被浏览器解释为位置标识符。这意味着这些字符都不会发送到服务器。
比如下面这个 URL 的初衷就是指定一个颜色值:
#fff
但是,浏览器发出的实际请求是: ,省略了“#fff”。只有将#转码为%23,浏览器才会将其视为真实字符。
四、Change# 不会触发网页重新加载
只需更改#后面的部分,浏览器只会滚动到相应位置,不会重新加载网页,浏览器也不会重新向服务器请求。
五、Change# 会改变浏览器的访问历史
每次更改#后面的部分,都会在浏览器的访问历史中添加一条记录,您可以使用“返回”按钮返回到之前的位置。
这对于ajax应用特别有用,可以用不同的#值来表示不同的访问状态,然后给用户一个链接来访问某个状态。
需要注意的是,上述规则不适用于 IE 6 和 IE 7,它们不会因为 # 的变化而增加历史记录。
六、window.location.hash 读取#value
属性 window.location.hash 是可读写的。阅读时,可用于判断网页状态是否发生变化;写入时会创建访问历史记录,无需重新加载网页。
七、onhashchange 事件
这是一个新的 HTML 5 事件,在 # 值更改时触发。IE8+、Firefox 3.6+、Chrome 5+、Safari 4.0+ 支持此事件。
有三种使用方法:
window.onhashchange = 函数;
window.addEventListener("hashchange", func, false);
对于不支持 onhashchange 的浏览器,可以使用 setInterval 来监控 location.hash 的变化。
八、谷歌抓取#机制
默认情况下,Google 的网络蜘蛛会忽略 URL 的 # 部分。
不过,谷歌也规定,如果想让Ajax生成的内容被浏览引擎读取,可以使用“#!” 在 URL 中,Google 会自动将其后面的内容转换为查询字符串 _escaped_fragment_ 的值。
如果找到推特网址:#!/username
将自动抓取另一个 URL:
通过这种机制,Google 可以索引动态 Ajax 内容。
如何让搜索引擎抓取 AJAX 内容
越来越多的网站开始采用“单页应用”,整个网站只有一个网页,使用Ajax技术根据用户的输入加载不同的内容,这种方式的好处是用户体验好,节省流量。缺点是AJAX内容不能被搜索引擎抓取。
例如,网站 用户通过哈希结构的 URL 看到不同的内容。
#1、#2、#3、……
但是,搜索引擎只抓取和忽略主题标签,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构:#!str,当谷歌发现像上面这样的一个URL时,它会自动爬取另一个URL:
只要你把 AJAX 内容放在这个 URL 上,Google 就会收录。但问题是,“英镑+感叹号”非常丑陋和繁琐。Twitter曾经采用这种结构,结果用户反反复复,只用了半年就废止了。
那么,有没有什么方法可以让搜索引擎在抓取 AJAX 内容的同时保持更直观的 URL?
采用历史 API
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。它的作用是在浏览器的 History 对象中添加一条记录。
window.history.pushState(状态对象, 标题, url);
上面这行命令可以使新的 URL 出现在地址栏中。History对象的pushState方法接受三个参数,新的URL是第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前所有主流浏览器都支持这种方法:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(0.0+) @5.1+),歌剧(12.1+)。
使用History API替换hashtag结构,让每个hashtag变成一个正常路径的URL,这样搜索引擎就会爬取每一个网页。
/1, /2, /3, …
然后,定义一个处理 Ajax 部分并基于 URL 获取内容的 JavaScript 函数(假设是 jQuery)。
功能锚点点击(链接){
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(数据);
});
}
再次定义鼠标点击事件。
$('#container').on('click', 'a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑到用户单击浏览器的“前进/后退”按钮。此时触发了History对象的popstate事件。
window.addEventListener('popstate', function(e) {
锚点点击(位置。路径名);
});
定义完以上三段代码后,就可以在不刷新页面的情况下显示正常的路径URL和AJAX内容了。
最后,设置服务器端。
因为没有使用主题标签结构,所以每个 URL 都是不同的请求。因此,服务器需要为所有这些请求返回具有以下结构的网页,以防止 404 错误。
如果你仔细看上面的代码,你会发现有一个noscript标签,这就是秘密。
我们将搜索引擎应该为 收录 的所有内容放在 noscript 标记中。在这种情况下,用户仍然可以在不刷新页面的情况下进行 AJAX 操作,但是搜索引擎会收录每个页面的主要内容! 查看全部
ajax抓取网页内容(Google的网络蜘蛛忽视URL的#部分,HTTP请求中不包括#)
# 用于引导浏览器操作,在服务器端完全没用。因此,# 不收录在 HTTP 请求中。
三、# 之后的字符
出现在第一个 # 之后的任何字符都将被浏览器解释为位置标识符。这意味着这些字符都不会发送到服务器。
比如下面这个 URL 的初衷就是指定一个颜色值:
#fff
但是,浏览器发出的实际请求是: ,省略了“#fff”。只有将#转码为%23,浏览器才会将其视为真实字符。
四、Change# 不会触发网页重新加载
只需更改#后面的部分,浏览器只会滚动到相应位置,不会重新加载网页,浏览器也不会重新向服务器请求。
五、Change# 会改变浏览器的访问历史
每次更改#后面的部分,都会在浏览器的访问历史中添加一条记录,您可以使用“返回”按钮返回到之前的位置。
这对于ajax应用特别有用,可以用不同的#值来表示不同的访问状态,然后给用户一个链接来访问某个状态。
需要注意的是,上述规则不适用于 IE 6 和 IE 7,它们不会因为 # 的变化而增加历史记录。
六、window.location.hash 读取#value
属性 window.location.hash 是可读写的。阅读时,可用于判断网页状态是否发生变化;写入时会创建访问历史记录,无需重新加载网页。
七、onhashchange 事件
这是一个新的 HTML 5 事件,在 # 值更改时触发。IE8+、Firefox 3.6+、Chrome 5+、Safari 4.0+ 支持此事件。
有三种使用方法:
window.onhashchange = 函数;
window.addEventListener("hashchange", func, false);
对于不支持 onhashchange 的浏览器,可以使用 setInterval 来监控 location.hash 的变化。
八、谷歌抓取#机制
默认情况下,Google 的网络蜘蛛会忽略 URL 的 # 部分。
不过,谷歌也规定,如果想让Ajax生成的内容被浏览引擎读取,可以使用“#!” 在 URL 中,Google 会自动将其后面的内容转换为查询字符串 _escaped_fragment_ 的值。
如果找到推特网址:#!/username
将自动抓取另一个 URL:
通过这种机制,Google 可以索引动态 Ajax 内容。
如何让搜索引擎抓取 AJAX 内容
越来越多的网站开始采用“单页应用”,整个网站只有一个网页,使用Ajax技术根据用户的输入加载不同的内容,这种方式的好处是用户体验好,节省流量。缺点是AJAX内容不能被搜索引擎抓取。
例如,网站 用户通过哈希结构的 URL 看到不同的内容。
#1、#2、#3、……
但是,搜索引擎只抓取和忽略主题标签,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构:#!str,当谷歌发现像上面这样的一个URL时,它会自动爬取另一个URL:
只要你把 AJAX 内容放在这个 URL 上,Google 就会收录。但问题是,“英镑+感叹号”非常丑陋和繁琐。Twitter曾经采用这种结构,结果用户反反复复,只用了半年就废止了。
那么,有没有什么方法可以让搜索引擎在抓取 AJAX 内容的同时保持更直观的 URL?
采用历史 API
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。它的作用是在浏览器的 History 对象中添加一条记录。
window.history.pushState(状态对象, 标题, url);
上面这行命令可以使新的 URL 出现在地址栏中。History对象的pushState方法接受三个参数,新的URL是第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前所有主流浏览器都支持这种方法:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(0.0+) @5.1+),歌剧(12.1+)。
使用History API替换hashtag结构,让每个hashtag变成一个正常路径的URL,这样搜索引擎就会爬取每一个网页。
/1, /2, /3, …
然后,定义一个处理 Ajax 部分并基于 URL 获取内容的 JavaScript 函数(假设是 jQuery)。
功能锚点点击(链接){
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(数据);
});
}
再次定义鼠标点击事件。
$('#container').on('click', 'a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑到用户单击浏览器的“前进/后退”按钮。此时触发了History对象的popstate事件。
window.addEventListener('popstate', function(e) {
锚点点击(位置。路径名);
});
定义完以上三段代码后,就可以在不刷新页面的情况下显示正常的路径URL和AJAX内容了。
最后,设置服务器端。
因为没有使用主题标签结构,所以每个 URL 都是不同的请求。因此,服务器需要为所有这些请求返回具有以下结构的网页,以防止 404 错误。
如果你仔细看上面的代码,你会发现有一个noscript标签,这就是秘密。
我们将搜索引擎应该为 收录 的所有内容放在 noscript 标记中。在这种情况下,用户仍然可以在不刷新页面的情况下进行 AJAX 操作,但是搜索引擎会收录每个页面的主要内容!
ajax抓取网页内容(ajax(formdata)ajax怎么做对象+async对象?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-02 17:00
ajax抓取网页内容,然后逐步将内容传送给开发者工具。ajax的请求头部会带上数据源url地址。
手动的话也可以用原生的ajax方式,配置成post以后用websocket的话,
分两步走首先ajax每个地方ajax:xmlhttprequest对象(post)+async对象对于原生js中(form表单或post)ajax:postjs(formdata)ajax:通过request对象来传递参数对于ajax中post:formdata作为参数,status(状态码)通过xmlhttprequest对象来处理ajax中postjs的ajax:methodcookie其实用哪个对象都一样,即可满足每种情况。
xmlhttprequest对象+async对象如果这样还是不明白的话,
我这里有几篇相关的文章,
可以了解下使用这个xmlhttprequest对象进行ajax传递数据。或者更简单,
ajax的请求头。不一定要async的ajax才可以;根据特殊情况可以选择post(post对象, 查看全部
ajax抓取网页内容(ajax(formdata)ajax怎么做对象+async对象?)
ajax抓取网页内容,然后逐步将内容传送给开发者工具。ajax的请求头部会带上数据源url地址。
手动的话也可以用原生的ajax方式,配置成post以后用websocket的话,
分两步走首先ajax每个地方ajax:xmlhttprequest对象(post)+async对象对于原生js中(form表单或post)ajax:postjs(formdata)ajax:通过request对象来传递参数对于ajax中post:formdata作为参数,status(状态码)通过xmlhttprequest对象来处理ajax中postjs的ajax:methodcookie其实用哪个对象都一样,即可满足每种情况。
xmlhttprequest对象+async对象如果这样还是不明白的话,
我这里有几篇相关的文章,
可以了解下使用这个xmlhttprequest对象进行ajax传递数据。或者更简单,
ajax的请求头。不一定要async的ajax才可以;根据特殊情况可以选择post(post对象,
ajax抓取网页内容( 谷歌黑板报《GET,POST以及安全获取更多网络信息》(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-02 09:10
谷歌黑板报《GET,POST以及安全获取更多网络信息》(组图))
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全获取更多网络信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。文章 中提到,Google 以后在读取网页内容时,不仅会使用 GET 抓取,还会视情况增加 POST 请求方式来抓取网页内容,进一步提升 Google 搜索引擎抓取网页内容的能力。网页的内容。网页内容的判断。
随着互联网的飞速发展,JavaScript 和 AJAX 越来越流行,越来越多的网页需要 POST 请求——因为页面的全部内容或者因为缺少某些页面信息和/或POST 无法返回资源。但是,谷歌认为,单纯使用 GET 来抓取网页所需的资源,并不能呈现出最全面、最准确的结果。
因此,Google 改进了 flash 索引,在 GET 爬取中引入了 POST 请求,从而对网页内容进行更完整、更准确的爬取和索引。
谷歌抓取网页内容的步骤如下:
1. 通过 GET 抓取网页内容。
2.索引网页内容并尝试呈现页面。
3.在渲染过程中使用POST请求读取页面内容,生成新的POST内容页面。
4.将来自 POST 请求的内容页面和其他数据负载添加到 Googlebot 的抓取队列中。
5.Googlebot 执行 POST 请求以抓取页面。
6.Google 会渲染最终的 POST 结果,也可以合并 GET 和 POST 请求结果。
7.完成索引。
搜索引擎新闻内容来源于网络,作者整理排版。不完全代表本博客的实际观点,仅供读者参考和交流。
如有涉及作者著作权的问题,请及时联系作者进行更正、删除或按规定处理。
这篇文章的链接: 查看全部
ajax抓取网页内容(
谷歌黑板报《GET,POST以及安全获取更多网络信息》(组图))
近日,Google Blackboard 发布了一篇题为“GET、POST 和安全获取更多网络信息”的博文。文章详细说明 Google 最近对抓取网页内容的方式所做的改进。文章 中提到,Google 以后在读取网页内容时,不仅会使用 GET 抓取,还会视情况增加 POST 请求方式来抓取网页内容,进一步提升 Google 搜索引擎抓取网页内容的能力。网页的内容。网页内容的判断。
随着互联网的飞速发展,JavaScript 和 AJAX 越来越流行,越来越多的网页需要 POST 请求——因为页面的全部内容或者因为缺少某些页面信息和/或POST 无法返回资源。但是,谷歌认为,单纯使用 GET 来抓取网页所需的资源,并不能呈现出最全面、最准确的结果。
因此,Google 改进了 flash 索引,在 GET 爬取中引入了 POST 请求,从而对网页内容进行更完整、更准确的爬取和索引。
谷歌抓取网页内容的步骤如下:
1. 通过 GET 抓取网页内容。
2.索引网页内容并尝试呈现页面。
3.在渲染过程中使用POST请求读取页面内容,生成新的POST内容页面。
4.将来自 POST 请求的内容页面和其他数据负载添加到 Googlebot 的抓取队列中。
5.Googlebot 执行 POST 请求以抓取页面。
6.Google 会渲染最终的 POST 结果,也可以合并 GET 和 POST 请求结果。
7.完成索引。
搜索引擎新闻内容来源于网络,作者整理排版。不完全代表本博客的实际观点,仅供读者参考和交流。
如有涉及作者著作权的问题,请及时联系作者进行更正、删除或按规定处理。
这篇文章的链接:
ajax抓取网页内容(网页+客户端+手机端(Android)+小程序利用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-02 08:27
AJAX = 异步 JavaScript 和 XML
AJAX 是一种无需重新加载整个网页即可更新网页部分内容的技术
AJAX 不是一种新的编程语言,而是一种用于创建更好、更快和更具交互性的 Web 应用程序的技术
2005 年,Google 通过其 Google Suggest 使 AJAX 流行起来。
Google Suggest 使用 AJAX 创建一个非常动态的网络界面:当您在 Google 的搜索框中输入关键字时,JavaScript 会将这些字符发送到服务器,然后服务器会返回一个搜索建议列表
就像国内的百度搜索框:
传统网页(即没有Ajax技术的网页),想要更新内容或者提交表单,需要重新加载整个页面。使用Ajax技术的网页可以通过后台服务器的少量数据交换实现异步局部更新
使用 Ajax,用户可以创建接近原生桌面应用程序的直接、高可用性、更丰富、更动态的 Web 用户界面(增加 B/S 体验)
产品链:H5+网页+客户端+移动端(Android、IOS)+小程序
使用 AJAX,您可以:
DOCTYPE html>
伪造AJAX
window.onload = function f() {
var myDate = new Date();
document.getElementById("currentTime").innerText = myDate.getTime();
}
function loadPage() {
var targetURL = document.getElementById('url').value;
console.log(targetURL)
document.getElementById('iframePosition').src = targetURL
}
请输入要加载的网址:
加载页面的位置:
AJAX的纯JS实现这里就不解释了,直接使用jQuery提供的,学习更方便,避免重复造轮子
Ajax 的核心是 XMLHttpRequest 对象 (XHR)。 XHR 提供了一个向服务器发送请求和解析服务器响应的接口。能够从服务器异步获取新数据
jQuery提供了几种与Ajax相关的方法
使用 jQuery Ajax 方法,您可以使用 HTTP Get 和 HTTP Post 从远程服务器请求文本、HTML、XML 或 JSON - 您可以将这些外部数据直接加载到网页的选定元素中。
jQuery 不是生产者,而是自然的搬运工
jQuery Ajax的本质是XMLHttpRequest,为了方便调用而封装了! 查看全部
ajax抓取网页内容(网页+客户端+手机端(Android)+小程序利用)
AJAX = 异步 JavaScript 和 XML
AJAX 是一种无需重新加载整个网页即可更新网页部分内容的技术
AJAX 不是一种新的编程语言,而是一种用于创建更好、更快和更具交互性的 Web 应用程序的技术
2005 年,Google 通过其 Google Suggest 使 AJAX 流行起来。
Google Suggest 使用 AJAX 创建一个非常动态的网络界面:当您在 Google 的搜索框中输入关键字时,JavaScript 会将这些字符发送到服务器,然后服务器会返回一个搜索建议列表
就像国内的百度搜索框:
传统网页(即没有Ajax技术的网页),想要更新内容或者提交表单,需要重新加载整个页面。使用Ajax技术的网页可以通过后台服务器的少量数据交换实现异步局部更新
使用 Ajax,用户可以创建接近原生桌面应用程序的直接、高可用性、更丰富、更动态的 Web 用户界面(增加 B/S 体验)
产品链:H5+网页+客户端+移动端(Android、IOS)+小程序
使用 AJAX,您可以:
DOCTYPE html>
伪造AJAX
window.onload = function f() {
var myDate = new Date();
document.getElementById("currentTime").innerText = myDate.getTime();
}
function loadPage() {
var targetURL = document.getElementById('url').value;
console.log(targetURL)
document.getElementById('iframePosition').src = targetURL
}
请输入要加载的网址:
加载页面的位置:
AJAX的纯JS实现这里就不解释了,直接使用jQuery提供的,学习更方便,避免重复造轮子
Ajax 的核心是 XMLHttpRequest 对象 (XHR)。 XHR 提供了一个向服务器发送请求和解析服务器响应的接口。能够从服务器异步获取新数据
jQuery提供了几种与Ajax相关的方法
使用 jQuery Ajax 方法,您可以使用 HTTP Get 和 HTTP Post 从远程服务器请求文本、HTML、XML 或 JSON - 您可以将这些外部数据直接加载到网页的选定元素中。
jQuery 不是生产者,而是自然的搬运工
jQuery Ajax的本质是XMLHttpRequest,为了方便调用而封装了!

