
ajax抓取网页内容
如何在nodejs中使用json和path和json?抓取网页内容
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-05-01 06:01
ajax抓取网页内容可以说是基本的前端知识了,目前前端团队对于前端源码的格式化都基本采用xml的方式,比如有人使用xml+json,有人使用javascript的调用,这篇文章介绍一下如何在nodejs中使用json和path。一、json格式jsonjson(javascriptobjectnotation)是javascriptobjecttype的缩写,它是一种数据交换格式,该格式支持传递和索引一个xml或json对象的属性,而不需要将它们传递给解析器。
xml是一种可扩展的语言标记格式,它是由afp(adobeformproject)编写的,是最受欢迎的格式之一。二、pathxmlpathxml是webpagesapi的一个path标签。浏览器端解析成path的格式,将解析为json形式,再由ajax发送给服务器,服务器从json的格式取到内容在处理成前端格式。
<p>path可以为指定的路径,指定属性名,不同的路径有不同的解析规则,这里用前端json数据返回给前端的格式示例。公司简介美团 查看全部
如何在nodejs中使用json和path和json?抓取网页内容
ajax抓取网页内容可以说是基本的前端知识了,目前前端团队对于前端源码的格式化都基本采用xml的方式,比如有人使用xml+json,有人使用javascript的调用,这篇文章介绍一下如何在nodejs中使用json和path。一、json格式jsonjson(javascriptobjectnotation)是javascriptobjecttype的缩写,它是一种数据交换格式,该格式支持传递和索引一个xml或json对象的属性,而不需要将它们传递给解析器。
xml是一种可扩展的语言标记格式,它是由afp(adobeformproject)编写的,是最受欢迎的格式之一。二、pathxmlpathxml是webpagesapi的一个path标签。浏览器端解析成path的格式,将解析为json形式,再由ajax发送给服务器,服务器从json的格式取到内容在处理成前端格式。
<p>path可以为指定的路径,指定属性名,不同的路径有不同的解析规则,这里用前端json数据返回给前端的格式示例。公司简介美团
北京SEO优化,北京网站优化,关键词优化,关键词排名,网站权重提升
网站优化 • 优采云 发表了文章 • 0 个评论 • 361 次浏览 • 2022-04-29 01:14
北京SEO优化,北京网站优化,关键词优化,关键词排名,网站权重提升,抖音SEO优化,快速排名
1、服务器
任何一个网站的流量发展,对服务器都是一个巨大的考验,因此了解服务器本身的运作原理是很有必要的,当网站出现异常时,要能够第一时间知晓事故,并找出原因,当服务器恢复正常后,必须使用站长工具测试一次网站抓取的正常性。
2、HTML
作为一个大站SEO,关注的也许就不仅仅是关键词密度或者是H1标签了,更多的是需要去发现页面上的一些重要内容是否可以在HTML代码中找到,如果无法找到,则可能是采用了Ajax异步加载,这往往导致搜索引擎无法抓取,从而降低页面评分。
3、数据库
关注网站的数据结构,可以帮助你更清晰地定义URL规则以及网站的TKD信息,并且在你优化网页页面质量的时候,更方便地调用你想要的内容信息,所以SEO从业人员必须了解网站的数据结构。
4、内部链接与外链资源
内部链接及外部链接的作用是一样的,都是为了蜘蛛能够顺利爬取,并提升页面质量。利用这些方法,可以有效提升一些目标关键词的排名。
5、关键词挖掘与归类
关键词如何挖掘与归类?这取决于SEO从业者的归类逻辑思维能力。以最常见的电商B2C网站来说,大多数的人分析行业内所有关键词之后,就会发现一些规律,例如流量关键词构成主要是“产品关键词”、“品牌关键词”等,因此对于关键词要善于挖掘与归类。
查看全部
北京SEO优化,北京网站优化,关键词优化,关键词排名,网站权重提升
北京SEO优化,北京网站优化,关键词优化,关键词排名,网站权重提升,抖音SEO优化,快速排名
1、服务器
任何一个网站的流量发展,对服务器都是一个巨大的考验,因此了解服务器本身的运作原理是很有必要的,当网站出现异常时,要能够第一时间知晓事故,并找出原因,当服务器恢复正常后,必须使用站长工具测试一次网站抓取的正常性。
2、HTML
作为一个大站SEO,关注的也许就不仅仅是关键词密度或者是H1标签了,更多的是需要去发现页面上的一些重要内容是否可以在HTML代码中找到,如果无法找到,则可能是采用了Ajax异步加载,这往往导致搜索引擎无法抓取,从而降低页面评分。
3、数据库
关注网站的数据结构,可以帮助你更清晰地定义URL规则以及网站的TKD信息,并且在你优化网页页面质量的时候,更方便地调用你想要的内容信息,所以SEO从业人员必须了解网站的数据结构。
4、内部链接与外链资源
内部链接及外部链接的作用是一样的,都是为了蜘蛛能够顺利爬取,并提升页面质量。利用这些方法,可以有效提升一些目标关键词的排名。
5、关键词挖掘与归类
关键词如何挖掘与归类?这取决于SEO从业者的归类逻辑思维能力。以最常见的电商B2C网站来说,大多数的人分析行业内所有关键词之后,就会发现一些规律,例如流量关键词构成主要是“产品关键词”、“品牌关键词”等,因此对于关键词要善于挖掘与归类。
ajax抓取网页内容(亿速云Key值来获取URL中的请求参数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-04-16 09:25
本文章主要介绍jquery如何获取url和url参数,有一定的参考价值。有兴趣的朋友可以参考一下。我希望您在阅读此文章 后会有所收获。小编带大家一探究竟。
在网页的Get方法中传递参数时,有时会在网页后面添加Get请求参数。在页面的前端,我们可以使用jquery来获取Url地址中的参数信息,通过对URL地址参数进行划分。要获取,可以封装成Jquery方法,通过对应的Key值获取URL中的请求参数。
首先在页面中引入Jquery.js文件,然后在$(document)函数中定义一个公共函数getUrlParam。如下:
(函数($){
$.getUrlParam=函数(名称){
var reg=new RegExp("(^|&)" + name + "=([^&]*)(&|$)");
var r=window.location.search.substr(1).match(reg);
if (r !=null) return unescape(r[2]);返回空值;
}
}) (jQuery);
定义方法后,我们可以使用以下方法获取URL中的参数值。
获取URL中的id值:id=$.getUrlParam("id");
感谢你仔细阅读这篇文章,希望小编分享的《Jquery中如何获取url和url参数》的文章文章对你有所帮助,也希望支持亿速云,关注易速云行业资讯频道,更多相关知识等你学习! 查看全部
ajax抓取网页内容(亿速云Key值来获取URL中的请求参数)
本文章主要介绍jquery如何获取url和url参数,有一定的参考价值。有兴趣的朋友可以参考一下。我希望您在阅读此文章 后会有所收获。小编带大家一探究竟。
在网页的Get方法中传递参数时,有时会在网页后面添加Get请求参数。在页面的前端,我们可以使用jquery来获取Url地址中的参数信息,通过对URL地址参数进行划分。要获取,可以封装成Jquery方法,通过对应的Key值获取URL中的请求参数。
首先在页面中引入Jquery.js文件,然后在$(document)函数中定义一个公共函数getUrlParam。如下:
(函数($){
$.getUrlParam=函数(名称){
var reg=new RegExp("(^|&)" + name + "=([^&]*)(&|$)");
var r=window.location.search.substr(1).match(reg);
if (r !=null) return unescape(r[2]);返回空值;
}
}) (jQuery);
定义方法后,我们可以使用以下方法获取URL中的参数值。
获取URL中的id值:id=$.getUrlParam("id");
感谢你仔细阅读这篇文章,希望小编分享的《Jquery中如何获取url和url参数》的文章文章对你有所帮助,也希望支持亿速云,关注易速云行业资讯频道,更多相关知识等你学习!
ajax抓取网页内容(Web网络爬虫系统的原理及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-04-13 15:01
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发让Nutch适合提取业务,那你基本上会破坏Nutch的框架,把Nutch改得面目全非,而且有能力修改Nutch,还不如自己写一个新的。分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。这个Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发很简单,难点和复杂的问题已经被前人解决了(比如DOM树解析定位、字符集检测、海量URL去重),可以说没有技术含量。包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫是否可以使用代理,爬虫是否可以爬取重复数据,爬虫是否可以爬取JS生成的信息?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?另一个爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,无论大小。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一页面,或者同一账号在短时间内多次执行同一操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理。随机几秒钟的请求可能经常被阻止。如果有多个帐户,切换使用它们会更有效。 查看全部
ajax抓取网页内容(Web网络爬虫系统的原理及应用)
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发让Nutch适合提取业务,那你基本上会破坏Nutch的框架,把Nutch改得面目全非,而且有能力修改Nutch,还不如自己写一个新的。分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。这个Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发很简单,难点和复杂的问题已经被前人解决了(比如DOM树解析定位、字符集检测、海量URL去重),可以说没有技术含量。包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫是否可以使用代理,爬虫是否可以爬取重复数据,爬虫是否可以爬取JS生成的信息?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?另一个爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,无论大小。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一页面,或者同一账号在短时间内多次执行同一操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理。随机几秒钟的请求可能经常被阻止。如果有多个帐户,切换使用它们会更有效。
ajax抓取网页内容( 北京交通大学计算机与信息技术学院北京100044摘要(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-04-13 14:37
北京交通大学计算机与信息技术学院北京100044摘要(组图))
第 38 卷,第 10 期,专辑,2011 年 10 月,计算机科学 Vol38No. 10SuppComputerScience0ct2011采集Ajan Web Crawler Research and Implementation Wang Jia Wei Huiqin 北京交通大学计算机与信息学院 北京 100044 摘要 使用浏览器API操作网页元素,模拟用户行为采集Aj Qiang 网页信息是基于同一个站点上同类型Ajax网页结构的相似性。预处理阶段在系统动态信息前添加采集在Ajax网页中寻找有效触发元素,并制定有效触发元素的规范和模式分类采集规则实现快速Ajax网页信息采集关键词 Ajax 网络爬虫在地图方法分类号 TP393 文档识别码 AResearchandImplementofAjaxWebCrawler 王家卫惠琴计算机系北京交通大学13eijina100044ChinaAhtnct通过浏览器API和模拟WebelementsasuserbehaviortO采集Ajax网页。基于 Ajax 页面的结构相似性,我们在系统的 8 层站点中添加了一个预处理阶段来定位有效的触发 Web 元素。沉积物的代码和模式分类制定了每个站点的采集规则。这些规则实现了 Aiax Web 信息的快速获取。Keywor Taipa AjaxWebcrfwleAquot1 简介随着Web2.0的兴起,越来越多的网站开始应用AjaxAsynchronousJavaScfiptAndXml,即异步JavaScfipt和XML技术。它以异步方式向服务器发送请求并检索所需的数据,从而减少了服务器和浏览器的数量。[11]之间交换的数据量,该技术的应用大大提升了用户体验,节省了存储空间,但是给普通的网络爬虫带来了困难,即采集信息基于网页源文件[21本文使用浏览器AP1并模拟用户行为操作网页元素完成采集 Ajax网页信息之二 相关原理 通常Ajax网站的网页信息是根据请求从数据库中读取数据并嵌入到模板 论文答辩ppt模板 赌博协议模板 国考答题卡国考高考数学答题卡数据图表显示在网页上,因此同类型的mdash站点的网页具有结构相似性【引用mdash Aiax网页有多个网页元素会导致异步交互改变网页信息。其中,能够产生有效信息的网页元素称为有效触发元素。网页中也有一些元素。它的操作往往只是改变字体颜色或本地信息等。如果对这些网页元素进行操作,系统的效率将大大降低。因此,在每个站点的动态信息之前应该增加一个预处理阶段,以找到有效的触发元素并制定采集规则实现Aiax网页信息的快速性采集3铷杯网页信息采集3.1 相关数据结构 Ajax网页有多个网页信息展示 本文将每个网页信息称为Ajax状态 可以引起异步交互网页元素的Ajax网页的Xpath以及对该元素的操作调用hiax 事件。hiax 网页可以显示政党活动家的条目数和毫米数。表示为二元组 VEgtV 表示 hiax 状态 E 是 hiax 事件 [ldquo 如图 1 所示,图一,图一,图一,图一,图一,瓦冈页面状态转换图,王轩大师。主要研究方向是计算机网络与数据库 E-mnilowmgi 婚姻 163.00ln Dian ■ 秦暖教授的研究方向是计算机网络与数据库。middot196middot 此示例图解释如下。点击状态sl的ldquo/body/div[1]/a[2]rdquo表示的网页元素。可以在状态 S3 中转换到状态 SzI。将鼠标移动到ldquoIbodyldiv[1]/a[2]rdquo表示的网页元素上,可以转换为状态s2等。3.2 有效 3.1 相关数据结构 Ajax 网页有多个网页信息显示。在本文中,每个网页信息都称为 Ajax 状态,而能够引起Ajax网页异步交互的网页元素的Xpath以及对该元素的操作称为hiax事件。一个hiax网页可以 党员考核表项数和毫米表 教师职称等级对照表 职工考核评分表 普通年金现值系数表示作为二元组VEgtV表示hiax状态E是hiax事件[ldquo如图1所示图lAj瓦冈页面状态转换图,王艳女大师。主要研究方向是计算机网络与数据库 E-mnilowmgi 婚姻 163.00ln Dian ■ 秦暖教授的研究方向是计算机网络与数据库。middot196middot 此示例图解释如下。点击状态sl的ldquo/body/div[1]/a[2]rdquo表示的网页元素。可以在状态 S3 中转换到状态 SzI。将鼠标移动到ldquoIbodyldiv[1]/a[2]rdquo表示的网页元素上,可以转换为状态s2等。3.2 有效
样例网页采用全检测扫描的方法来查找网页中的有效元素。查找过程如下: 1PrcccdmPmpmcpainitORL2 获取初始状态,构建该状态的DOM,并保存状态的标识和状态的内容。whUe 仍然有未处理的状态 4 如果状态是第一次处理并且 5 保持状态。获取触发事件表 6d7 查询触发事件表 8wⅦe 请说明还有事件需要处理 9 触发事件 10 获取触发事件后的状态 11.1f 给Aiax的新状态有效 12. 添加新的对应标识获得了Ajldquo的野心加状态库到logo库。13. 遇到触发事件前的状态 14. endwhile15endwhile 该流程图中有两个存储结构状态标识库和状态库状态标识库,用于存储每十个Ajax状态标识。状态的hiax事件操作的网页元素的XPath是从状态序号的起始状态和状态的XPath得到的。DOM树组合状态库保存Ajax状态的序号所有内容处理_番口是根据网页链接获取的初始状态浏览器自动执行过程中的重要步骤如下1触发事件列表是通过遍历AjaX 状态的 DOM 树 得到的结果是基于对每个站点的分析。Feng系统中找到的火灾事件的元素仅限于a标签中的元素,div 标签和 spangt 标签。2 必须确定新获得的Ajax状态的有效性。有效性判断不仅要满足hiax状态结构的相似性,还要判断内容的出现。为了改变,系统使用简单的树匹配算法03来检测Ajax状态的结构相似度,如果少数节点的内容发生了变化,则确定Ajax状态下相似度较大的DOM节点的内容。那么就认为是无效的Aj8x状态。将保存的Ajax状态添加到状态库中,相应的标记添加到状态标记库中。3 状态再现由于浏览器目前不支持返回到Aj8X状态的操作,返回执行动作之前的状态是基于从有向状态转移图中得到的4个周期完成对样本触发元素的搜索。由于状态标识符库收录有效的 Ajax 状态标识符,因此可以从页面中提取有效的触发元素 XPeth 和相应的操作。因此,在推理完成后会得到网页中的有效信息。有效触发元素规范 对找到的有效触发元素进行元素序列号规范,其中每个触发元素的名称和动作都相同。例如,对于这种类型的触发元素,ldquo/body/div[8]/div[1]/div[1]/ul/li[3]/adlckrdquoldquo/body/div[8]/div[1]/dlv[1]/ul/li[ 4]/acli baseldquo/body/div[8]/dlv[1]/div[1]/ul/li[5]/ac11cp还原结果为ldquo/lmdy/div[8]/div[1]/div[ 1]/ul/ll[]/aclIckrdquo2 有效触发元素水平分类对这些有效触发元素的研究表明,这些触发元素可以分为两种模式。一种是独立模式,另一种是关联模式——独立模式。这种模式意味着每个元素代表一个 Aj8x 状态。例如图2中,以文本为数字的页面元素,每个A页面元素代表一页评论信息—— Day 1 图2 独立模式 模式2 关联模式 在该模式下,每个状态都与之前的状态相关触发事件。例如,一类对搜狗新闻评论有效的触发元素。@采集系统根据元素的文本信息完成信息的排序采集对于米德兰模式的动态信息搜索系统,系统搜索固定网页元素采集例如,在图3的情况下。系统在当前Ajax状态下寻找带有文本ldquo下一页rdquo的有效触发元素触发该元素完成信息采集设置4j Ajax页面信息采集@ >Stage Ajax网页信息采集Stage是根据上一个stage得到的各个页面的有效页面触发元素的Xpath,以及需要越来越多的事件,以及的pattern信息这样的元素来完成动态信息<
iondick/Motion//带有触发元素的操作Model2/Modell/触发元素模式1为独立模式2为关联模式1etgt下一页/Text//有效触发元素的文本/Option此规则收录有效触发元素的Xpath动作模式文本信息还可以根据系统的需要设置存储路径等信息。4 实验结果对触发元件进行了协议处理。我们没有进一步分类有效的触发元素。我们随机采集 3条腾讯新闻评论为待处理 根据站点有效触发元素规则采集选取网页的实验结果如表1所示。实验结果与测试结果对比数据见表一。@采集 动态信息的效率降低了有效信息的重复采集结束语本文提出了一种高效的动态网页采集该方法首先为每个站点选择一些样本网页,并利用页面的相似度发现网页的有效性触发元素和法规,对有效触发元素进行分类,为每个站点建立动态网页信息采集规则实现Ajax网页有效信息的快速性采集由于Ajax站点信息的动态特性,建立相应的重复采集机制是未来研究的重点[6]参考DudaCFreyCKossmannDeta1。AJAXSearchCrawlingIn-dexingandSearchingW song 2. 0ApplicationsACM2008VLDBEndowmentMesbahA80IXlagEVanDeursenACrawlingAJAXbyInfer-ringUserInterfaceStatechallginfin 口]。IEEE。DOI10.1109/IgtWE200824 夏兵,高军,杨冬青等.一种高效的动态脚本网站有效的页面获取方法[J]. 软件研究所中国科学院 Scimdashenceamp 软件杂志 200920l176-189DudaCFreyCKossmannDeta1. Aj "AXCrawllMakingAJAXApplicationSearchable[J]. IEEE. DOI10.1109/IcDE200990 何欣谢志鹏. 基于简单树匹配算法的网页结构相似度测量[J]. 计算机研究与开发200711mdash1777/TPl1-6 Summer. Ajax站点数据采集研究综述[J].情报分析与研究 2010t52mdash57 续第 185 页 ltluenumerationvaluerdquo2rdquo/gtltxsenumerationvaluerdquo3rdquo/gtltxsenumerationvaluerdquo4rdquo/gtltxsenumerationvaluerdquo5rdquo/gt/xsrestrictionlt/xssimpleTypelt/x。sschema 结语 高职商务日语专业教学资源数据库系统实现了实用日语视听日语报刊杂志、旅游日语等课程的Web教学资源的录入,自我评价和自主 评估大量多媒体材料,引导学生朝着明确的目标朝着更加主动和自主的方向学习。在后续工作中,我们将充分考虑系统的个性化服务功能。不断丰富、拓展和完善教学资源,实现高职院校优质资源的共建。共享服务经济社会发展 参考文献[13 全国信息技术标准化技术委员会教育技术分技术委员会。基础教育教学资源元数据规范。http//万维网。凯尔特人。cllE23 孙波。傅伟。基于webService的开放式教育资源图书馆系统研究D]. 中国电子教育2003.1079[33李家厚. 吴振华。陈双银等。美国教育资源门户及其对我国教育资源建设的启示[J]. 电子教育研究2003.867]]]]]]口心口H口西孙博.傅伟。基于webService的开放式教育资源图书馆系统研究D]. 中国电子教育2003.1079[33李家厚. 吴振华。陈双银等。美国教育资源门户及其对我国教育资源建设的启示[J]. 电子教育研究2003.867]]]]]]口心口H口西孙博.傅伟。基于webService的开放式教育资源图书馆系统研究D]. 中国电子教育2003.1079[33李家厚. 吴振华。陈双银等。美国教育资源门户及其对我国的启示 s 教育资源建设[J].电子教育研究2003.867]]]]]]口心口H口西 查看全部
ajax抓取网页内容(
北京交通大学计算机与信息技术学院北京100044摘要(组图))

第 38 卷,第 10 期,专辑,2011 年 10 月,计算机科学 Vol38No. 10SuppComputerScience0ct2011采集Ajan Web Crawler Research and Implementation Wang Jia Wei Huiqin 北京交通大学计算机与信息学院 北京 100044 摘要 使用浏览器API操作网页元素,模拟用户行为采集Aj Qiang 网页信息是基于同一个站点上同类型Ajax网页结构的相似性。预处理阶段在系统动态信息前添加采集在Ajax网页中寻找有效触发元素,并制定有效触发元素的规范和模式分类采集规则实现快速Ajax网页信息采集关键词 Ajax 网络爬虫在地图方法分类号 TP393 文档识别码 AResearchandImplementofAjaxWebCrawler 王家卫惠琴计算机系北京交通大学13eijina100044ChinaAhtnct通过浏览器API和模拟WebelementsasuserbehaviortO采集Ajax网页。基于 Ajax 页面的结构相似性,我们在系统的 8 层站点中添加了一个预处理阶段来定位有效的触发 Web 元素。沉积物的代码和模式分类制定了每个站点的采集规则。这些规则实现了 Aiax Web 信息的快速获取。Keywor Taipa AjaxWebcrfwleAquot1 简介随着Web2.0的兴起,越来越多的网站开始应用AjaxAsynchronousJavaScfiptAndXml,即异步JavaScfipt和XML技术。它以异步方式向服务器发送请求并检索所需的数据,从而减少了服务器和浏览器的数量。[11]之间交换的数据量,该技术的应用大大提升了用户体验,节省了存储空间,但是给普通的网络爬虫带来了困难,即采集信息基于网页源文件[21本文使用浏览器AP1并模拟用户行为操作网页元素完成采集 Ajax网页信息之二 相关原理 通常Ajax网站的网页信息是根据请求从数据库中读取数据并嵌入到模板 论文答辩ppt模板 赌博协议模板 国考答题卡国考高考数学答题卡数据图表显示在网页上,因此同类型的mdash站点的网页具有结构相似性【引用mdash Aiax网页有多个网页元素会导致异步交互改变网页信息。其中,能够产生有效信息的网页元素称为有效触发元素。网页中也有一些元素。它的操作往往只是改变字体颜色或本地信息等。如果对这些网页元素进行操作,系统的效率将大大降低。因此,在每个站点的动态信息之前应该增加一个预处理阶段,以找到有效的触发元素并制定采集规则实现Aiax网页信息的快速性采集3铷杯网页信息采集3.1 相关数据结构 Ajax网页有多个网页信息展示 本文将每个网页信息称为Ajax状态 可以引起异步交互网页元素的Ajax网页的Xpath以及对该元素的操作调用hiax 事件。hiax 网页可以显示政党活动家的条目数和毫米数。表示为二元组 VEgtV 表示 hiax 状态 E 是 hiax 事件 [ldquo 如图 1 所示,图一,图一,图一,图一,图一,瓦冈页面状态转换图,王轩大师。主要研究方向是计算机网络与数据库 E-mnilowmgi 婚姻 163.00ln Dian ■ 秦暖教授的研究方向是计算机网络与数据库。middot196middot 此示例图解释如下。点击状态sl的ldquo/body/div[1]/a[2]rdquo表示的网页元素。可以在状态 S3 中转换到状态 SzI。将鼠标移动到ldquoIbodyldiv[1]/a[2]rdquo表示的网页元素上,可以转换为状态s2等。3.2 有效 3.1 相关数据结构 Ajax 网页有多个网页信息显示。在本文中,每个网页信息都称为 Ajax 状态,而能够引起Ajax网页异步交互的网页元素的Xpath以及对该元素的操作称为hiax事件。一个hiax网页可以 党员考核表项数和毫米表 教师职称等级对照表 职工考核评分表 普通年金现值系数表示作为二元组VEgtV表示hiax状态E是hiax事件[ldquo如图1所示图lAj瓦冈页面状态转换图,王艳女大师。主要研究方向是计算机网络与数据库 E-mnilowmgi 婚姻 163.00ln Dian ■ 秦暖教授的研究方向是计算机网络与数据库。middot196middot 此示例图解释如下。点击状态sl的ldquo/body/div[1]/a[2]rdquo表示的网页元素。可以在状态 S3 中转换到状态 SzI。将鼠标移动到ldquoIbodyldiv[1]/a[2]rdquo表示的网页元素上,可以转换为状态s2等。3.2 有效

样例网页采用全检测扫描的方法来查找网页中的有效元素。查找过程如下: 1PrcccdmPmpmcpainitORL2 获取初始状态,构建该状态的DOM,并保存状态的标识和状态的内容。whUe 仍然有未处理的状态 4 如果状态是第一次处理并且 5 保持状态。获取触发事件表 6d7 查询触发事件表 8wⅦe 请说明还有事件需要处理 9 触发事件 10 获取触发事件后的状态 11.1f 给Aiax的新状态有效 12. 添加新的对应标识获得了Ajldquo的野心加状态库到logo库。13. 遇到触发事件前的状态 14. endwhile15endwhile 该流程图中有两个存储结构状态标识库和状态库状态标识库,用于存储每十个Ajax状态标识。状态的hiax事件操作的网页元素的XPath是从状态序号的起始状态和状态的XPath得到的。DOM树组合状态库保存Ajax状态的序号所有内容处理_番口是根据网页链接获取的初始状态浏览器自动执行过程中的重要步骤如下1触发事件列表是通过遍历AjaX 状态的 DOM 树 得到的结果是基于对每个站点的分析。Feng系统中找到的火灾事件的元素仅限于a标签中的元素,div 标签和 spangt 标签。2 必须确定新获得的Ajax状态的有效性。有效性判断不仅要满足hiax状态结构的相似性,还要判断内容的出现。为了改变,系统使用简单的树匹配算法03来检测Ajax状态的结构相似度,如果少数节点的内容发生了变化,则确定Ajax状态下相似度较大的DOM节点的内容。那么就认为是无效的Aj8x状态。将保存的Ajax状态添加到状态库中,相应的标记添加到状态标记库中。3 状态再现由于浏览器目前不支持返回到Aj8X状态的操作,返回执行动作之前的状态是基于从有向状态转移图中得到的4个周期完成对样本触发元素的搜索。由于状态标识符库收录有效的 Ajax 状态标识符,因此可以从页面中提取有效的触发元素 XPeth 和相应的操作。因此,在推理完成后会得到网页中的有效信息。有效触发元素规范 对找到的有效触发元素进行元素序列号规范,其中每个触发元素的名称和动作都相同。例如,对于这种类型的触发元素,ldquo/body/div[8]/div[1]/div[1]/ul/li[3]/adlckrdquoldquo/body/div[8]/div[1]/dlv[1]/ul/li[ 4]/acli baseldquo/body/div[8]/dlv[1]/div[1]/ul/li[5]/ac11cp还原结果为ldquo/lmdy/div[8]/div[1]/div[ 1]/ul/ll[]/aclIckrdquo2 有效触发元素水平分类对这些有效触发元素的研究表明,这些触发元素可以分为两种模式。一种是独立模式,另一种是关联模式——独立模式。这种模式意味着每个元素代表一个 Aj8x 状态。例如图2中,以文本为数字的页面元素,每个A页面元素代表一页评论信息—— Day 1 图2 独立模式 模式2 关联模式 在该模式下,每个状态都与之前的状态相关触发事件。例如,一类对搜狗新闻评论有效的触发元素。@采集系统根据元素的文本信息完成信息的排序采集对于米德兰模式的动态信息搜索系统,系统搜索固定网页元素采集例如,在图3的情况下。系统在当前Ajax状态下寻找带有文本ldquo下一页rdquo的有效触发元素触发该元素完成信息采集设置4j Ajax页面信息采集@ >Stage Ajax网页信息采集Stage是根据上一个stage得到的各个页面的有效页面触发元素的Xpath,以及需要越来越多的事件,以及的pattern信息这样的元素来完成动态信息<

iondick/Motion//带有触发元素的操作Model2/Modell/触发元素模式1为独立模式2为关联模式1etgt下一页/Text//有效触发元素的文本/Option此规则收录有效触发元素的Xpath动作模式文本信息还可以根据系统的需要设置存储路径等信息。4 实验结果对触发元件进行了协议处理。我们没有进一步分类有效的触发元素。我们随机采集 3条腾讯新闻评论为待处理 根据站点有效触发元素规则采集选取网页的实验结果如表1所示。实验结果与测试结果对比数据见表一。@采集 动态信息的效率降低了有效信息的重复采集结束语本文提出了一种高效的动态网页采集该方法首先为每个站点选择一些样本网页,并利用页面的相似度发现网页的有效性触发元素和法规,对有效触发元素进行分类,为每个站点建立动态网页信息采集规则实现Ajax网页有效信息的快速性采集由于Ajax站点信息的动态特性,建立相应的重复采集机制是未来研究的重点[6]参考DudaCFreyCKossmannDeta1。AJAXSearchCrawlingIn-dexingandSearchingW song 2. 0ApplicationsACM2008VLDBEndowmentMesbahA80IXlagEVanDeursenACrawlingAJAXbyInfer-ringUserInterfaceStatechallginfin 口]。IEEE。DOI10.1109/IgtWE200824 夏兵,高军,杨冬青等.一种高效的动态脚本网站有效的页面获取方法[J]. 软件研究所中国科学院 Scimdashenceamp 软件杂志 200920l176-189DudaCFreyCKossmannDeta1. Aj "AXCrawllMakingAJAXApplicationSearchable[J]. IEEE. DOI10.1109/IcDE200990 何欣谢志鹏. 基于简单树匹配算法的网页结构相似度测量[J]. 计算机研究与开发200711mdash1777/TPl1-6 Summer. Ajax站点数据采集研究综述[J].情报分析与研究 2010t52mdash57 续第 185 页 ltluenumerationvaluerdquo2rdquo/gtltxsenumerationvaluerdquo3rdquo/gtltxsenumerationvaluerdquo4rdquo/gtltxsenumerationvaluerdquo5rdquo/gt/xsrestrictionlt/xssimpleTypelt/x。sschema 结语 高职商务日语专业教学资源数据库系统实现了实用日语视听日语报刊杂志、旅游日语等课程的Web教学资源的录入,自我评价和自主 评估大量多媒体材料,引导学生朝着明确的目标朝着更加主动和自主的方向学习。在后续工作中,我们将充分考虑系统的个性化服务功能。不断丰富、拓展和完善教学资源,实现高职院校优质资源的共建。共享服务经济社会发展 参考文献[13 全国信息技术标准化技术委员会教育技术分技术委员会。基础教育教学资源元数据规范。http//万维网。凯尔特人。cllE23 孙波。傅伟。基于webService的开放式教育资源图书馆系统研究D]. 中国电子教育2003.1079[33李家厚. 吴振华。陈双银等。美国教育资源门户及其对我国教育资源建设的启示[J]. 电子教育研究2003.867]]]]]]口心口H口西孙博.傅伟。基于webService的开放式教育资源图书馆系统研究D]. 中国电子教育2003.1079[33李家厚. 吴振华。陈双银等。美国教育资源门户及其对我国教育资源建设的启示[J]. 电子教育研究2003.867]]]]]]口心口H口西孙博.傅伟。基于webService的开放式教育资源图书馆系统研究D]. 中国电子教育2003.1079[33李家厚. 吴振华。陈双银等。美国教育资源门户及其对我国的启示 s 教育资源建设[J].电子教育研究2003.867]]]]]]口心口H口西
ajax抓取网页内容(什么是Cookie及模拟登录的操作流程:Ajax加载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-04-13 07:14
我们在使用python进行爬取的时候,可能遇到过一些网页直接请求的html代码,并没有我们需要的数据,也就是我们在浏览器中看到的。
这是因为信息是通过 Ajax 加载并通过 js 渲染生成的。这时,我们需要分析这个网页的请求。
上一篇给大家讲解了什么是cookie以及模拟登录的操作流程。今天给大家带来如何分析网页的ajax请求。
什么是阿贾克斯
AJAX 是“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
AJAX = 异步 JavaScript 和 XML(标准通用标记语言的子集)。
AJAX 是一种用于创建快速、动态网页的技术。
AJAX 是一种无需重新加载整个网页即可更新部分网页的技术。
简单地说,就是加载了网页。浏览器地址栏中的 URL 没有改变。是javascript异步加载的网页,应该是ajax。AJAX一般通过XMLHttpRequest对象接口发送请求,一般简称为XHR。
分析简而言之网站点
我们的目标网站是用壳网来分析。
我们可以看到这个网页没有翻页按钮,当我们不断拉下请求时,网页会自动为我们加载更多内容。但是,当我们查看网页 url 时,它并没有随着页面加载请求而改变。而当我们直接请求这个url时,显然只能获取到第一页的html内容。
那么我们如何获取所有页面的数据呢?
我们在Chrome中打开开发者工具(F12)。我们点击Network,点击XHR选项卡。然后我们刷新页面并拉下请求。这时候我们可以看到XHR选项卡,每次页面加载会弹出一个请求。
我们点击第一个请求,可以看到他的参数:retrieve_type:by_subject
限制:20
偏移量:18
-:86
点击第二个请求后,参数如下:retrieve_type:by_subject
限制:20
偏移量:38
-:87
limit参数是网页每页被限制加载的文章个数,offset是页数。然后往下看,我们会发现每次请求的offset参数都会增加20。
然后我们查看每个请求的响应内容,这是一个格式化的数据。我们点击结果按钮,可以看到20条文章的数据信息。这样我们就成功找到了我们需要的信息的位置,在请求头中可以看到json数据存放的url地址。
爬取过程
分析Ajax请求,获取每个页面的文章url信息;解析每个文章,获取需要的数据;将获取的数据保存在数据库中;打开多个进程,爬了很多。
开始
我们的工具仍然使用 BeautifulSoup 解析的请求。
我们需要构造这个 URL。# 导入可能用到的模块
导入请求
从 urllib.parse 导入 urlencode
从 requests.exceptions 导入 ConnectionError
# 获取索引页面的信息
def get_index(偏移量):
base_url = '#39;
数据 = {
'retrieve_type': "by_subject",
'限制':“20”,
“偏移量”:偏移量
}
参数 = urlencode(数据)
url = base_url + 参数
尝试:
resp = requests.get(url)
如果 resp.status_code == 200:
返回对应文本
返回无
除了连接错误:
打印('错误。')
返回无
我们将从上面分析页面得到的请求参数构造成字典数据,然后我们可以手动构造url,但是urllib库已经为我们提供了编码方式,我们可以直接使用它来构造完整的url。然后是请求页面内容的标准请求。导入json
# 解析json,得到文章url
def parse_json(文本):
尝试:
结果 = json.loads(文本)
如果结果:
对于我在 result.get('result') 中:
# 打印(i.get('url'))
产量 i.get('url')
除了:
经过
我们使用 josn.loads 方法解析 json 并将其转换为 json 对象。然后直接通过字典的操作,得到文章的url地址。这里使用yield为每个请求返回一个url,以减少内存消耗。由于后面爬的时候会弹出一个json解析错误,这里直接过滤就好了。
这里我们可以尝试打印看看是否运行成功。
既然获取了文章的url,那么获取文章的数据就很简单了。此处不作详细说明。目标是获取 文章 的标题、作者和内容。
由于有的文章收录了一些图片,所以我们可以过滤掉文章内容中的图片。从 bs4 导入 BeautifulSoup
# 解析 文章 页面
def parse_page(文本):
尝试:
汤= BeautifulSoup(文本,'lxml')
content = soup.find('div', class_="content")
标题 = content.find('h1',).get_text()
作者 = content.find('div', class_="content-th-info").find('a').get_text()
article_content = content.find('div', class_="document").find_all('p')
all_p = [i.get_text() for i in article_content if not i.find('img') and not i.find('a')]
文章 = '\n'.join(all_p)
# 打印(标题,'\n',作者,'\n',文章)
数据 = {
'标题':标题,
“作者”:作者,
“文章”:文章
}
返回数据
除了:
经过
这里,在进行多进程爬取的时候,BeautifulSoup也会报错,还是直接过滤。我们将得到的数据以字典的形式保存,方便保存数据库。
下一步是保存数据库的操作。这里我们使用MongoDB进行数据存储。导入pymongo
从配置导入 *
客户端 = pymongo.MongoClient(MONGO_URL, 27017)
db = 客户[MONGO_DB]
def save_database(数据):
如果 db[MONGO_TABLE].insert(data):
print('保存到数据库成功', data)
返回真
返回假
我们将数据库名和表名保存在config配置文件中,并将配置信息导入到文件中,这样会方便代码的管理。
最后,由于诺虎网的数据还是很多的,如果我们想抓取很多数据,可以使用多进程。从多处理导入池
# 定义一个主函数
定义主(偏移):
文本 = get_index(偏移量)
all_url = parse_json(文本)
对于 all_url 中的 url:
resp = get_page(url)
数据 = parse_page(resp)
如果数据:
保存数据库(数据)
如果 __name__ == '__main__':
池 = 池()
偏移量 = ([0] + [i*20+18 for i in range(500)])
pool.map(主要,偏移量)
池.close()
pool.join()
该函数的参数偏移量是页数。经过我的观察,国科网的最后一个页码是12758,有637页。在这里,我们抓取了 500 个页面。进程池的map方法类似于Python内置的map方法。
那么对于一些使用Ajax加载的网页,我们可以这样爬取。 查看全部
ajax抓取网页内容(什么是Cookie及模拟登录的操作流程:Ajax加载)
我们在使用python进行爬取的时候,可能遇到过一些网页直接请求的html代码,并没有我们需要的数据,也就是我们在浏览器中看到的。
这是因为信息是通过 Ajax 加载并通过 js 渲染生成的。这时,我们需要分析这个网页的请求。
上一篇给大家讲解了什么是cookie以及模拟登录的操作流程。今天给大家带来如何分析网页的ajax请求。
什么是阿贾克斯
AJAX 是“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
AJAX = 异步 JavaScript 和 XML(标准通用标记语言的子集)。
AJAX 是一种用于创建快速、动态网页的技术。
AJAX 是一种无需重新加载整个网页即可更新部分网页的技术。
简单地说,就是加载了网页。浏览器地址栏中的 URL 没有改变。是javascript异步加载的网页,应该是ajax。AJAX一般通过XMLHttpRequest对象接口发送请求,一般简称为XHR。
分析简而言之网站点
我们的目标网站是用壳网来分析。
我们可以看到这个网页没有翻页按钮,当我们不断拉下请求时,网页会自动为我们加载更多内容。但是,当我们查看网页 url 时,它并没有随着页面加载请求而改变。而当我们直接请求这个url时,显然只能获取到第一页的html内容。
那么我们如何获取所有页面的数据呢?
我们在Chrome中打开开发者工具(F12)。我们点击Network,点击XHR选项卡。然后我们刷新页面并拉下请求。这时候我们可以看到XHR选项卡,每次页面加载会弹出一个请求。
我们点击第一个请求,可以看到他的参数:retrieve_type:by_subject
限制:20
偏移量:18
-:86
点击第二个请求后,参数如下:retrieve_type:by_subject
限制:20
偏移量:38
-:87
limit参数是网页每页被限制加载的文章个数,offset是页数。然后往下看,我们会发现每次请求的offset参数都会增加20。
然后我们查看每个请求的响应内容,这是一个格式化的数据。我们点击结果按钮,可以看到20条文章的数据信息。这样我们就成功找到了我们需要的信息的位置,在请求头中可以看到json数据存放的url地址。
爬取过程
分析Ajax请求,获取每个页面的文章url信息;解析每个文章,获取需要的数据;将获取的数据保存在数据库中;打开多个进程,爬了很多。
开始
我们的工具仍然使用 BeautifulSoup 解析的请求。
我们需要构造这个 URL。# 导入可能用到的模块
导入请求
从 urllib.parse 导入 urlencode
从 requests.exceptions 导入 ConnectionError
# 获取索引页面的信息
def get_index(偏移量):
base_url = '#39;
数据 = {
'retrieve_type': "by_subject",
'限制':“20”,
“偏移量”:偏移量
}
参数 = urlencode(数据)
url = base_url + 参数
尝试:
resp = requests.get(url)
如果 resp.status_code == 200:
返回对应文本
返回无
除了连接错误:
打印('错误。')
返回无
我们将从上面分析页面得到的请求参数构造成字典数据,然后我们可以手动构造url,但是urllib库已经为我们提供了编码方式,我们可以直接使用它来构造完整的url。然后是请求页面内容的标准请求。导入json
# 解析json,得到文章url
def parse_json(文本):
尝试:
结果 = json.loads(文本)
如果结果:
对于我在 result.get('result') 中:
# 打印(i.get('url'))
产量 i.get('url')
除了:
经过
我们使用 josn.loads 方法解析 json 并将其转换为 json 对象。然后直接通过字典的操作,得到文章的url地址。这里使用yield为每个请求返回一个url,以减少内存消耗。由于后面爬的时候会弹出一个json解析错误,这里直接过滤就好了。
这里我们可以尝试打印看看是否运行成功。
既然获取了文章的url,那么获取文章的数据就很简单了。此处不作详细说明。目标是获取 文章 的标题、作者和内容。
由于有的文章收录了一些图片,所以我们可以过滤掉文章内容中的图片。从 bs4 导入 BeautifulSoup
# 解析 文章 页面
def parse_page(文本):
尝试:
汤= BeautifulSoup(文本,'lxml')
content = soup.find('div', class_="content")
标题 = content.find('h1',).get_text()
作者 = content.find('div', class_="content-th-info").find('a').get_text()
article_content = content.find('div', class_="document").find_all('p')
all_p = [i.get_text() for i in article_content if not i.find('img') and not i.find('a')]
文章 = '\n'.join(all_p)
# 打印(标题,'\n',作者,'\n',文章)
数据 = {
'标题':标题,
“作者”:作者,
“文章”:文章
}
返回数据
除了:
经过
这里,在进行多进程爬取的时候,BeautifulSoup也会报错,还是直接过滤。我们将得到的数据以字典的形式保存,方便保存数据库。
下一步是保存数据库的操作。这里我们使用MongoDB进行数据存储。导入pymongo
从配置导入 *
客户端 = pymongo.MongoClient(MONGO_URL, 27017)
db = 客户[MONGO_DB]
def save_database(数据):
如果 db[MONGO_TABLE].insert(data):
print('保存到数据库成功', data)
返回真
返回假
我们将数据库名和表名保存在config配置文件中,并将配置信息导入到文件中,这样会方便代码的管理。
最后,由于诺虎网的数据还是很多的,如果我们想抓取很多数据,可以使用多进程。从多处理导入池
# 定义一个主函数
定义主(偏移):
文本 = get_index(偏移量)
all_url = parse_json(文本)
对于 all_url 中的 url:
resp = get_page(url)
数据 = parse_page(resp)
如果数据:
保存数据库(数据)
如果 __name__ == '__main__':
池 = 池()
偏移量 = ([0] + [i*20+18 for i in range(500)])
pool.map(主要,偏移量)
池.close()
pool.join()
该函数的参数偏移量是页数。经过我的观察,国科网的最后一个页码是12758,有637页。在这里,我们抓取了 500 个页面。进程池的map方法类似于Python内置的map方法。
那么对于一些使用Ajax加载的网页,我们可以这样爬取。
ajax抓取网页内容(网页有相当一部分的技术简单一点讲就是事件驱动吧())
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-04-07 16:26
原C#抓取AJAX页面内容
目前相当一部分网页使用了AJAX技术。所谓AJAX技术,就是简单的事件驱动(当然,这种说法可能并不全面)。提交网址后,服务器给你发送的不是全部都是页面内容,但很大一部分是JS脚本,可以使用了
但是我们用IE浏览页面是正常的,所以唯一的解决办法就是使用WebBrowser控件
但是使用Webbrowser你会发现,在DownloadComplete事件中,你根本无法知道页面是什么时候真正加载的!
当然,带有 Frame 的单个网页可能会触发多次 Complete。即使在Navigated事件中使用了计数器方法,即++和--在DownloadComplete中,执行完JS后仍然无法得到结果。一开始我也觉得很奇怪,直到后来GG相关的AJAX文章,明白原因了。
最终的解决方案是使用WebBrowser+Timer来解决爬取页面的问题
关键还是页面状态,我们可以使用webBrowser1.StatusText,如果返回“完成”,说明页面加载完毕!
示例代码如下:
private void timer1_Tick(object sender, EventArgs e)
{
webBrowser1.导航(Url);
if (webBrowser1.StatusText == "Done")
{
定时器1.启用=假;
//页面加载完毕,做点别的事情
}
} 查看全部
ajax抓取网页内容(网页有相当一部分的技术简单一点讲就是事件驱动吧())
原C#抓取AJAX页面内容
目前相当一部分网页使用了AJAX技术。所谓AJAX技术,就是简单的事件驱动(当然,这种说法可能并不全面)。提交网址后,服务器给你发送的不是全部都是页面内容,但很大一部分是JS脚本,可以使用了
但是我们用IE浏览页面是正常的,所以唯一的解决办法就是使用WebBrowser控件
但是使用Webbrowser你会发现,在DownloadComplete事件中,你根本无法知道页面是什么时候真正加载的!
当然,带有 Frame 的单个网页可能会触发多次 Complete。即使在Navigated事件中使用了计数器方法,即++和--在DownloadComplete中,执行完JS后仍然无法得到结果。一开始我也觉得很奇怪,直到后来GG相关的AJAX文章,明白原因了。
最终的解决方案是使用WebBrowser+Timer来解决爬取页面的问题
关键还是页面状态,我们可以使用webBrowser1.StatusText,如果返回“完成”,说明页面加载完毕!
示例代码如下:
private void timer1_Tick(object sender, EventArgs e)
{
webBrowser1.导航(Url);
if (webBrowser1.StatusText == "Done")
{
定时器1.启用=假;
//页面加载完毕,做点别的事情
}
}
ajax抓取网页内容(Ajax技术将用户名设置为root,密码设置一致将提示密码错误)
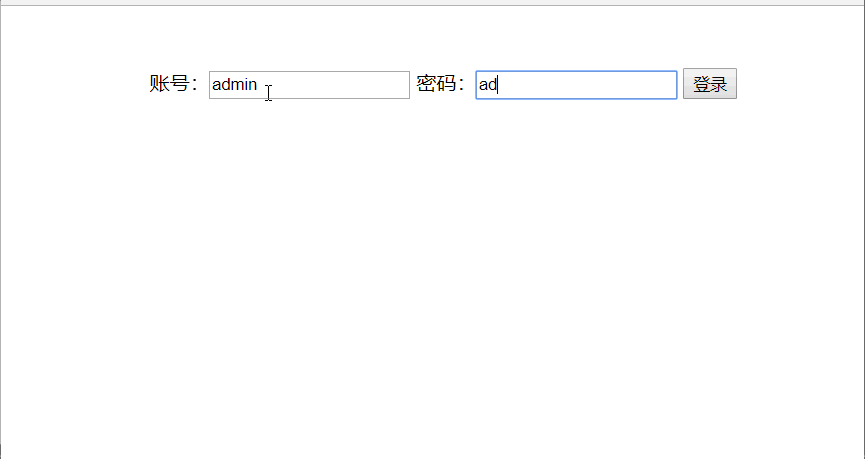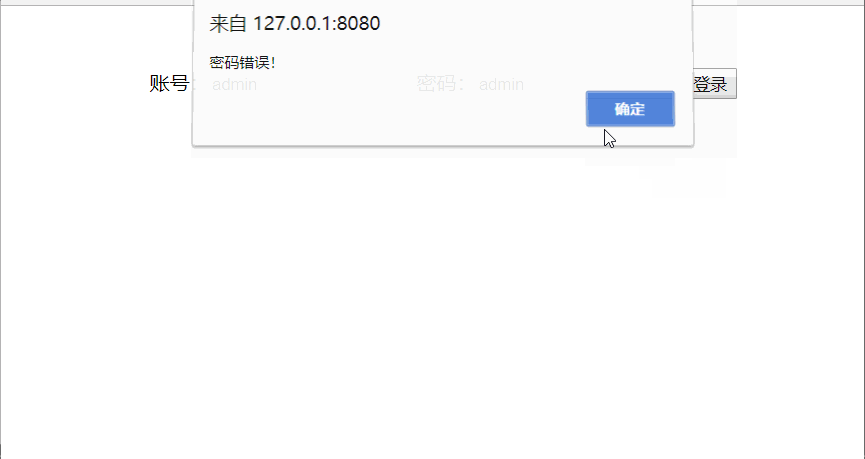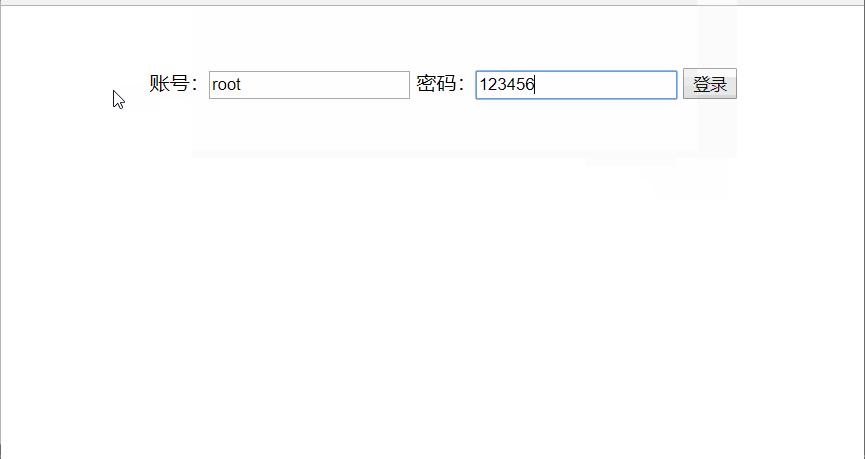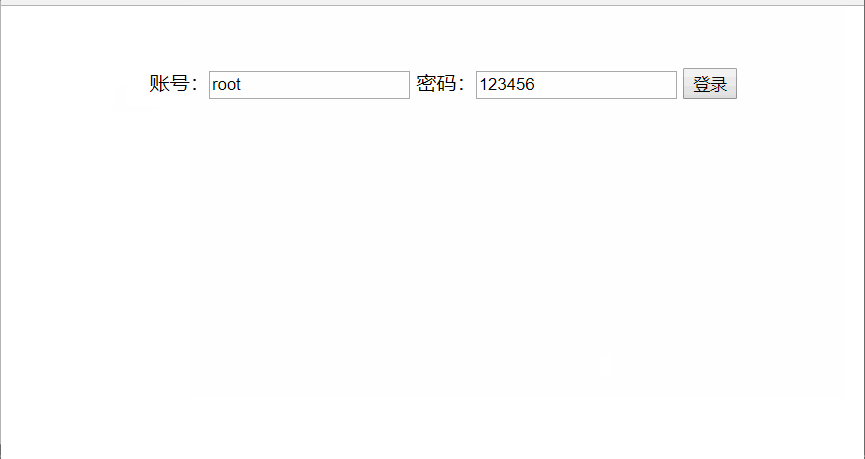
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-04-06 14:26
简要地
网页的局部刷新功能在网络上并不少见网站,比如实时新闻信息、股票信息等,都需要不断获取最新信息。在传统的web实现中,要达到类似的效果,必须刷新整个页面。在网速受到一定程度限制的情况下,这种因局部变化而影响整个页面的处理方式似乎有点吃亏。Ajax 技术的出现很好地解决了这个问题。使用Ajax技术可以实现网页的部分刷新,只更新指定的数据,不更新其他数据。本文通过一个登录案例来介绍ajax的使用。
登录html键码
账号:
密码:
登录
分析:在传统项目中,要向后台提交表单数据,我们都使用表单表单。这时候,使用ajax技术,我们将摒弃之前的表单提交方式。
ajax键码
$("#btn_login").click(function() {
$.ajax({
url : "login.do",
type : "post",
data : {
username : $("input[name=username]").val(),
password : $("input[name=password]").val()
},
dataType : "json",
success : function(result) {
var flag = result.flag;
if (flag == true) {
alert("密码正确!");
} else {
alert("密码错误!");
}
}
});
});
分析:使用ajax技术需要依赖jQuery,所以在使用ajax的时候需要引入jQuery包
ajax 语法特性
url:请求地址
type:传递方式(get/post)
data:用来传递的数据
success:交互成功后要执行的方法
dataType:ajax接收后台数据的类型
servlet 密钥代码
protected void doPost(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
//获取用户名和密码
String username = req.getParameter("username");
String password = req.getParameter("password");
//创建json对象
JSONObject jsonObject = null;
if ("root".equals(username) && "123456".equals(password)) {
jsonObject = new JSONObject("{flag:true}");
} else {
jsonObject = new JSONObject("{flag:false}");
}
//将数据返回给ajax
resp.getOutputStream().write(jsonObject.toString().getBytes("utf-8"));
}
分析:如图,我们将用户名设置为root,密码设置为123456,如果用户输入与设置一致,则提示密码正确,否则提示密码错误!
打开应用程序并阅读笔记 查看全部
ajax抓取网页内容(Ajax技术将用户名设置为root,密码设置一致将提示密码错误)
简要地
网页的局部刷新功能在网络上并不少见网站,比如实时新闻信息、股票信息等,都需要不断获取最新信息。在传统的web实现中,要达到类似的效果,必须刷新整个页面。在网速受到一定程度限制的情况下,这种因局部变化而影响整个页面的处理方式似乎有点吃亏。Ajax 技术的出现很好地解决了这个问题。使用Ajax技术可以实现网页的部分刷新,只更新指定的数据,不更新其他数据。本文通过一个登录案例来介绍ajax的使用。
登录html键码
账号:
密码:
登录
分析:在传统项目中,要向后台提交表单数据,我们都使用表单表单。这时候,使用ajax技术,我们将摒弃之前的表单提交方式。
ajax键码
$("#btn_login").click(function() {
$.ajax({
url : "login.do",
type : "post",
data : {
username : $("input[name=username]").val(),
password : $("input[name=password]").val()
},
dataType : "json",
success : function(result) {
var flag = result.flag;
if (flag == true) {
alert("密码正确!");
} else {
alert("密码错误!");
}
}
});
});
分析:使用ajax技术需要依赖jQuery,所以在使用ajax的时候需要引入jQuery包
ajax 语法特性
url:请求地址
type:传递方式(get/post)
data:用来传递的数据
success:交互成功后要执行的方法
dataType:ajax接收后台数据的类型
servlet 密钥代码
protected void doPost(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
//获取用户名和密码
String username = req.getParameter("username");
String password = req.getParameter("password");
//创建json对象
JSONObject jsonObject = null;
if ("root".equals(username) && "123456".equals(password)) {
jsonObject = new JSONObject("{flag:true}");
} else {
jsonObject = new JSONObject("{flag:false}");
}
//将数据返回给ajax
resp.getOutputStream().write(jsonObject.toString().getBytes("utf-8"));
}
分析:如图,我们将用户名设置为root,密码设置为123456,如果用户输入与设置一致,则提示密码正确,否则提示密码错误!
打开应用程序并阅读笔记
ajax抓取网页内容(ajax抓取网页内容是用javascript的方式实现(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-04-06 02:01
ajax抓取网页内容确实是用javascript的方式实现,爬虫软件基本都带有这些工具,手动爬绝对有难度,同时抓取一些很短的javascript可以试试只取链接,
能不能先搞清楚什么是动态代理?有本书大部分章节解释了动态代理。
可以先看看原理,再配合工具加速抓取,最后我推荐一些正则和xpath的工具来弄,然后也配合multicharts抓取外部二进制数据进行html测试一下。
可以用google爬虫啊。我自己写的地球爬虫,技术门槛不高,知道原理后可以边学边玩。的热力图爬虫我就用这个做的。缺点是抓取下来的数据格式是json。推荐试一下html解析工具。
不了解技术的可以用框架开发爬虫。
一、数据抓取xml比较好处理,可以直接读取xml数据库,由框架给xml格式做解析xml支持json支持。但是ajax自身兼容性不好(以后代替flash,svg等的替代品吧),xml解析难度高,抓取就需要不断尝试不断处理处理之后再ajax解析。
二、xpath各种方式都可以做解析,但是ajax自身兼容性不好(以后代替flash,svg等的替代品吧),xml解析难度高,抓取就需要不断尝试不断处理处理之后再ajax解析。
三、abstractxpath。不过只能抓取abstract的字符串,abcnames/abclass/abcnamethat/abcnamespace/abctype为abstract的才能抓取。如果abstract定义太多值,就抓取不到。这样真的很浪费内存。
四、smilesweeticons2d,orasymlaseconst="../../input-extended.xml"可以用来获取整张图片的内容,图片内容可以上传到服务器进行下载。
五、再详细一点可以用python写个html字典自己传给框架来解析,还是抓取需要抓取的字符串的时候容易一些。
六、还有headercrawl。这里写一些原理可以帮助大家找到更好的解决方案。
浏览器访问一个页面会发送一个http请求,
4)applewebkit/537。36(khtml,likegecko)chrome/53。2780。106safari/537。36","accept":"*/*","accept-encoding":"gzip,deflate","accept-language":"zh-cn,zh;q=0。9","connection":"k。 查看全部
ajax抓取网页内容(ajax抓取网页内容是用javascript的方式实现(图))
ajax抓取网页内容确实是用javascript的方式实现,爬虫软件基本都带有这些工具,手动爬绝对有难度,同时抓取一些很短的javascript可以试试只取链接,
能不能先搞清楚什么是动态代理?有本书大部分章节解释了动态代理。
可以先看看原理,再配合工具加速抓取,最后我推荐一些正则和xpath的工具来弄,然后也配合multicharts抓取外部二进制数据进行html测试一下。
可以用google爬虫啊。我自己写的地球爬虫,技术门槛不高,知道原理后可以边学边玩。的热力图爬虫我就用这个做的。缺点是抓取下来的数据格式是json。推荐试一下html解析工具。
不了解技术的可以用框架开发爬虫。
一、数据抓取xml比较好处理,可以直接读取xml数据库,由框架给xml格式做解析xml支持json支持。但是ajax自身兼容性不好(以后代替flash,svg等的替代品吧),xml解析难度高,抓取就需要不断尝试不断处理处理之后再ajax解析。
二、xpath各种方式都可以做解析,但是ajax自身兼容性不好(以后代替flash,svg等的替代品吧),xml解析难度高,抓取就需要不断尝试不断处理处理之后再ajax解析。
三、abstractxpath。不过只能抓取abstract的字符串,abcnames/abclass/abcnamethat/abcnamespace/abctype为abstract的才能抓取。如果abstract定义太多值,就抓取不到。这样真的很浪费内存。
四、smilesweeticons2d,orasymlaseconst="../../input-extended.xml"可以用来获取整张图片的内容,图片内容可以上传到服务器进行下载。
五、再详细一点可以用python写个html字典自己传给框架来解析,还是抓取需要抓取的字符串的时候容易一些。
六、还有headercrawl。这里写一些原理可以帮助大家找到更好的解决方案。
浏览器访问一个页面会发送一个http请求,
4)applewebkit/537。36(khtml,likegecko)chrome/53。2780。106safari/537。36","accept":"*/*","accept-encoding":"gzip,deflate","accept-language":"zh-cn,zh;q=0。9","connection":"k。
ajax抓取网页内容(Ajax为什么在数据可视化大屏中这么流行?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-04-05 03:09
为什么 Ajax 在大屏数据可视化中如此受欢迎?数据可视化大屏使用ajax的原理是什么?事实上,很多数据可视化大屏软件在具体实现传值时都需要用到ajax。比如帆软的FineReport大屏显示就是这个原理。本文详细介绍了AJAX是什么,如何在数据可视化大屏上使用AJAX,以及相关的工具系统有哪些。
一、什么是 AJAX?
AJAX = Asynchronous JavaScript and XML,是异步的 JavaScript 和 XML。
AJAX 不是一种新的编程语言,而是一种使用现有标准的新方法,一种用于创建快速、动态网页的技术。AJAX 允许异步更新网页。通俗地说,就是更新网页的一部分,而不需要重新加载整个网页。在传统网页(没有 AJAX)中,如果需要更新内容,则必须重新加载整个网页。使用AJAX的应用案例很多:新浪微博、谷歌地图、开心网等。
2005 年,Google 通过其 Google Suggest 使 AJAX 流行起来。
二、如何在数据可视化大屏上使用ajax?原理如下
在数据可视化的大屏上,哪里可以使用ajax?值传递的具体实现需要使用ajax,数据可视化大屏的后端可以用java开发。当需要数据时,触发前台的ajax向后台发送命令获取数据。帆软FineReport的大屏显示就是基于这个原理。
一种方法是通过ajax和后台实现图表来实现jsonarray和jsonobject类型的传输(具体传输格式请参考数据可视化大屏软件中的代码)。
另一种方法是生成.json文件,在前端使用$.get获取文件中的json数据,从而生成大屏数据可视化图表。
其实这两种数据可视化大屏ajax应用的原理基本相同,都是从前端获取json数据的过程。
三、数据可视化大屏ajax的相关工具系统有哪些?1、精细报告
FineReport是一款功能齐全的纯Java数据可视化大屏工具软件。它制作的数据图表的优点是有一些动画特效,可以更清晰的显示信息数据,而且颜值很高。使用门槛极低,帮助文档很详细,有用,也很成熟。常被企业用户用来辅助业务流程管理人员做出更合理的管理决策。FineReport为个人免费试用,FineReport商业版需要付费。
2、Highcharts
Highcharts的优点是兼容性好,应用广泛。缺点是样式比较陈旧,图表难以扩展;商业用途需要购买版权。
3、图表
Echarts 经常与 Hightchart 进行比较。企业自身直接连接数据库时,展示可以集成Echarts和Hightchart插件,传值时使用ajax。缺点也类似,就是你自己开发这个开源的数据可视化大屏工具时,会涉及到复杂的语法设计,导致使用和学习成本高。比如想要使用AJAX,就需要灵活掌握HTML/XHTML、CSS、JavaScript/DOM等知识。 查看全部
ajax抓取网页内容(Ajax为什么在数据可视化大屏中这么流行?(一))
为什么 Ajax 在大屏数据可视化中如此受欢迎?数据可视化大屏使用ajax的原理是什么?事实上,很多数据可视化大屏软件在具体实现传值时都需要用到ajax。比如帆软的FineReport大屏显示就是这个原理。本文详细介绍了AJAX是什么,如何在数据可视化大屏上使用AJAX,以及相关的工具系统有哪些。

一、什么是 AJAX?
AJAX = Asynchronous JavaScript and XML,是异步的 JavaScript 和 XML。
AJAX 不是一种新的编程语言,而是一种使用现有标准的新方法,一种用于创建快速、动态网页的技术。AJAX 允许异步更新网页。通俗地说,就是更新网页的一部分,而不需要重新加载整个网页。在传统网页(没有 AJAX)中,如果需要更新内容,则必须重新加载整个网页。使用AJAX的应用案例很多:新浪微博、谷歌地图、开心网等。
2005 年,Google 通过其 Google Suggest 使 AJAX 流行起来。
二、如何在数据可视化大屏上使用ajax?原理如下
在数据可视化的大屏上,哪里可以使用ajax?值传递的具体实现需要使用ajax,数据可视化大屏的后端可以用java开发。当需要数据时,触发前台的ajax向后台发送命令获取数据。帆软FineReport的大屏显示就是基于这个原理。
一种方法是通过ajax和后台实现图表来实现jsonarray和jsonobject类型的传输(具体传输格式请参考数据可视化大屏软件中的代码)。
另一种方法是生成.json文件,在前端使用$.get获取文件中的json数据,从而生成大屏数据可视化图表。
其实这两种数据可视化大屏ajax应用的原理基本相同,都是从前端获取json数据的过程。
三、数据可视化大屏ajax的相关工具系统有哪些?1、精细报告
FineReport是一款功能齐全的纯Java数据可视化大屏工具软件。它制作的数据图表的优点是有一些动画特效,可以更清晰的显示信息数据,而且颜值很高。使用门槛极低,帮助文档很详细,有用,也很成熟。常被企业用户用来辅助业务流程管理人员做出更合理的管理决策。FineReport为个人免费试用,FineReport商业版需要付费。

2、Highcharts
Highcharts的优点是兼容性好,应用广泛。缺点是样式比较陈旧,图表难以扩展;商业用途需要购买版权。
3、图表
Echarts 经常与 Hightchart 进行比较。企业自身直接连接数据库时,展示可以集成Echarts和Hightchart插件,传值时使用ajax。缺点也类似,就是你自己开发这个开源的数据可视化大屏工具时,会涉及到复杂的语法设计,导致使用和学习成本高。比如想要使用AJAX,就需要灵活掌握HTML/XHTML、CSS、JavaScript/DOM等知识。
ajax抓取网页内容(用requests抓取页面的结果是什么?如何去分析和Ajax请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-04 07:19
当我们使用requests对页面进行爬取时,得到的结果可能与我们在浏览器中看到的不一样:在浏览器中正常显示的页面数据,但是使用requests却没有得到任何结果。这是因为请求都是原创的 HTML 文档,而浏览器中的页面是 JavaScript 数据处理的结果。这些数据有多种来源,可能通过 Ajax 加载,可能收录在 HTML 文档中,也可能由 JavaScript 和特定算法生成。
对于第一种情况,数据加载是一种异步加载方式。原创页面将不收录某些数据。只有加载完成后,才会向服务器请求一个接口获取数据,然后将数据处理并呈现给网页。上面,这个过程实际上是向服务器接口发送一个 Ajax 请求。
根据Web的发展趋势,这种形式的页面将会越来越多。网页的原创HTML文档不收录任何数据,通过Ajax统一加载后呈现数据,这样在Web开发中可以分离前后端,服务器直接渲染带来的压力页面缩小。
所以如果遇到这样的页面,直接使用requests之类的库爬取原创页面是无法获取有效数据的。这时候我们就需要分析网页后端向接口发送的Ajax请求了。如果我们可以使用requests来模拟ajax请求,就可以成功抓取。
因此,在本课中,我们将学习什么是 Ajax,以及如何分析和抓取 Ajax 请求。
什么是阿贾克斯
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新网页的部分内容而不刷新页面且页面链接不改变的技术。
传统网页,如果要更新其内容,就必须刷新整个页面。使用 Ajax,可以在不完全刷新的情况下更新页面内容。在这个过程中,页面实际上是在后台与服务器交互的。获取到数据后,使用 JavaScript 改变网页,从而更新网页的内容。
你可以去 W3School 体验几个 demo 来感受一下:
示例介绍
在浏览网页的时候,我们会发现很多网页已经向下滚动,可以查看更多选项。以我的微博主页为例:. 当我们切换到微博页面,发现往下滑了几条微博后,后面的内容并不会直接显示出来,而是会出现一个加载动画。加载完成后,下方会不断出现新的微博内容。这个过程其实就是Ajax加载的过程,如图:
我们注意到页面并没有完全刷新,也就是说页面的链接没有变化,但是页面中有新的内容,也就是后来刷新的新微博。这就是通过 Ajax 获取和呈现新数据的方式。
基本的
在对Ajax有了初步的了解之后,我们再来详细了解一下它的基本原理。向网页更新发送 Ajax 请求的过程可以简单分为以下 3 个步骤:
下面我们将详细描述这些过程中的每一个。
发送请求
我们知道JavaScript可以实现页面的各种交互功能,Ajax也不例外。它由 JavaScript 实现,实际执行如下代码:
这是 JavaScript 对 Ajax 的底层实现。这个过程其实就是新建一个XMLHttpRequest对象,然后调用onreadystatechange属性设置监听,最后调用open()和send()方法向一个链接(即服务器)发送请求。
我们使用 Python 发送请求后,可以得到响应结果,但是这里的请求是通过 JavaScript 发送的。由于设置了监听器,当服务器返回响应时,会触发onreadystatechange对应的方法,我们可以在这个方法中解析响应内容。
解析内容
得到响应后会触发onreadystatechange属性对应的方法,可以通过xmlhttp的responseText属性获取响应内容。这类似于 Python 中使用 requests 向服务器发出请求,然后得到响应的过程。
返回的内容可能是 HTML 或 JSON,然后我们只需要在方法中使用 JavaScript 进一步处理即可。例如,如果返回的内容是 JSON,我们可以对其进行解析和转换。
呈现网页
JavaScript 具有更改网页内容的能力。解析响应内容后,可以调用 JavaScript 对网页进行解析处理。例如,通过document.getElementById().innerHTML的操作,改变一个元素中的源代码,从而改变网页上显示的内容。也称为更改和删除 Document 网页文档等操作。进行 DOM 操作。
在上面的例子中,操作 document.getElementById(“myDiv”).innerHTML=xmlhttp.responseText 会将 ID 为 myDiv 的节点内部的 HTML 代码更改为服务器返回的内容,从而使服务器返回的新内容将显示在 myDiv 元素内。数据,部分页面似乎已更新。
可以看到,发送请求、解析内容、渲染网页这三个步骤实际上都是由 JavaScript 完成的。
回想一下微博的下拉刷新,其实就是一个JavaScript向服务器发送Ajax请求,然后获取新的微博数据,解析,呈现在网页中的过程。
因此,真正的数据实际上是通过一次又一次的ajax请求获得的。如果我们想捕获这些数据,我们需要知道这些请求是如何发送的,发送到哪里,发送了什么参数。如果我们知道这一点,难道我们不能用 Python 来模拟这个发送操作并得到结果吗?
阿贾克斯分析
这里我们还是以之前的微博为例。我们知道拖拽刷新的内容是通过ajax加载的,页面的url没有变化。这时候,我们应该去哪里查看这些Ajax请求呢?
这里还需要用到浏览器的开发者工具。下面是Chrome浏览器的介绍。
首先用Chrome浏览器打开微博链接,然后在页面上右击,在弹出的快捷菜单中选择“检查”选项,会弹出开发者工具,如图:
如前所述,这里是页面加载过程中浏览器和服务器之间发送请求和接收响应的所有记录。
Ajax 有其特殊的请求类型,称为 xhr。在图中,我们可以找到一个以getIndex开头的请求,其Type为xhr,是一个Ajax请求。用鼠标点击请求,查看请求的详细信息。
右侧可以看到Request Headers、URL、Response Headers等信息。Request Headers中的信息之一是X-Requested-With:XMLHttpRequest,将请求标记为Ajax请求,如图:
然后我们点击 Preview 可以看到响应的内容,是 JSON 格式的。在这里,Chrome 会自动为我们解析它。单击箭头可展开和折叠相应的内容。
我们可以观察到返回的结果是我的个人信息,包括昵称、简介、头像等,这也是用于渲染个人主页的数据。JavaScript 接收到数据后,执行相应的渲染方法,整个页面都被渲染出来了。
另外,我们还可以切换到Response选项卡,观察真实的返回数据,如图:
接下来,切换回第一个请求,观察它的Response是什么,如图:
这是原创链接返回的内容,不到 50 行代码,结构非常简单,只是执行了一些 JavaScript。
因此,我们看到的微博页面的真实数据并不是原创页面返回的,而是在执行完 JavaScript 后,再次向后台发送 Ajax 请求,浏览器获取数据并进一步渲染。
过滤请求
接下来,我们使用 Chrome DevTools 的过滤功能过滤掉所有的 Ajax 请求。请求上方有一层过滤栏,直接点击XHR,那么下面显示的所有请求都是Ajax请求,如图:
接下来继续滑动页面,可以看到页面底部有新的微博滑动,开发者工具下不断出现Ajax请求,这样我们就可以捕获所有的Ajax请求。
随意打开一个entry,可以清晰的看到它的Request URL、Request Headers、Response Headers、Response Body等,这时候模拟请求和提取就很简单了。
下图显示的内容是我的一个微博页面的列表信息:
至此,我们已经能够分析出一些Ajax请求的详细信息了。接下来,我们只需要用程序模拟这些Ajax请求,就可以很方便的提取出我们需要的信息了。
参考文章 查看全部
ajax抓取网页内容(用requests抓取页面的结果是什么?如何去分析和Ajax请求)
当我们使用requests对页面进行爬取时,得到的结果可能与我们在浏览器中看到的不一样:在浏览器中正常显示的页面数据,但是使用requests却没有得到任何结果。这是因为请求都是原创的 HTML 文档,而浏览器中的页面是 JavaScript 数据处理的结果。这些数据有多种来源,可能通过 Ajax 加载,可能收录在 HTML 文档中,也可能由 JavaScript 和特定算法生成。
对于第一种情况,数据加载是一种异步加载方式。原创页面将不收录某些数据。只有加载完成后,才会向服务器请求一个接口获取数据,然后将数据处理并呈现给网页。上面,这个过程实际上是向服务器接口发送一个 Ajax 请求。
根据Web的发展趋势,这种形式的页面将会越来越多。网页的原创HTML文档不收录任何数据,通过Ajax统一加载后呈现数据,这样在Web开发中可以分离前后端,服务器直接渲染带来的压力页面缩小。
所以如果遇到这样的页面,直接使用requests之类的库爬取原创页面是无法获取有效数据的。这时候我们就需要分析网页后端向接口发送的Ajax请求了。如果我们可以使用requests来模拟ajax请求,就可以成功抓取。
因此,在本课中,我们将学习什么是 Ajax,以及如何分析和抓取 Ajax 请求。
什么是阿贾克斯
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新网页的部分内容而不刷新页面且页面链接不改变的技术。
传统网页,如果要更新其内容,就必须刷新整个页面。使用 Ajax,可以在不完全刷新的情况下更新页面内容。在这个过程中,页面实际上是在后台与服务器交互的。获取到数据后,使用 JavaScript 改变网页,从而更新网页的内容。
你可以去 W3School 体验几个 demo 来感受一下:
示例介绍
在浏览网页的时候,我们会发现很多网页已经向下滚动,可以查看更多选项。以我的微博主页为例:. 当我们切换到微博页面,发现往下滑了几条微博后,后面的内容并不会直接显示出来,而是会出现一个加载动画。加载完成后,下方会不断出现新的微博内容。这个过程其实就是Ajax加载的过程,如图:
我们注意到页面并没有完全刷新,也就是说页面的链接没有变化,但是页面中有新的内容,也就是后来刷新的新微博。这就是通过 Ajax 获取和呈现新数据的方式。
基本的
在对Ajax有了初步的了解之后,我们再来详细了解一下它的基本原理。向网页更新发送 Ajax 请求的过程可以简单分为以下 3 个步骤:
下面我们将详细描述这些过程中的每一个。
发送请求
我们知道JavaScript可以实现页面的各种交互功能,Ajax也不例外。它由 JavaScript 实现,实际执行如下代码:
这是 JavaScript 对 Ajax 的底层实现。这个过程其实就是新建一个XMLHttpRequest对象,然后调用onreadystatechange属性设置监听,最后调用open()和send()方法向一个链接(即服务器)发送请求。
我们使用 Python 发送请求后,可以得到响应结果,但是这里的请求是通过 JavaScript 发送的。由于设置了监听器,当服务器返回响应时,会触发onreadystatechange对应的方法,我们可以在这个方法中解析响应内容。
解析内容
得到响应后会触发onreadystatechange属性对应的方法,可以通过xmlhttp的responseText属性获取响应内容。这类似于 Python 中使用 requests 向服务器发出请求,然后得到响应的过程。
返回的内容可能是 HTML 或 JSON,然后我们只需要在方法中使用 JavaScript 进一步处理即可。例如,如果返回的内容是 JSON,我们可以对其进行解析和转换。
呈现网页
JavaScript 具有更改网页内容的能力。解析响应内容后,可以调用 JavaScript 对网页进行解析处理。例如,通过document.getElementById().innerHTML的操作,改变一个元素中的源代码,从而改变网页上显示的内容。也称为更改和删除 Document 网页文档等操作。进行 DOM 操作。
在上面的例子中,操作 document.getElementById(“myDiv”).innerHTML=xmlhttp.responseText 会将 ID 为 myDiv 的节点内部的 HTML 代码更改为服务器返回的内容,从而使服务器返回的新内容将显示在 myDiv 元素内。数据,部分页面似乎已更新。
可以看到,发送请求、解析内容、渲染网页这三个步骤实际上都是由 JavaScript 完成的。
回想一下微博的下拉刷新,其实就是一个JavaScript向服务器发送Ajax请求,然后获取新的微博数据,解析,呈现在网页中的过程。
因此,真正的数据实际上是通过一次又一次的ajax请求获得的。如果我们想捕获这些数据,我们需要知道这些请求是如何发送的,发送到哪里,发送了什么参数。如果我们知道这一点,难道我们不能用 Python 来模拟这个发送操作并得到结果吗?
阿贾克斯分析
这里我们还是以之前的微博为例。我们知道拖拽刷新的内容是通过ajax加载的,页面的url没有变化。这时候,我们应该去哪里查看这些Ajax请求呢?
这里还需要用到浏览器的开发者工具。下面是Chrome浏览器的介绍。
首先用Chrome浏览器打开微博链接,然后在页面上右击,在弹出的快捷菜单中选择“检查”选项,会弹出开发者工具,如图:
如前所述,这里是页面加载过程中浏览器和服务器之间发送请求和接收响应的所有记录。
Ajax 有其特殊的请求类型,称为 xhr。在图中,我们可以找到一个以getIndex开头的请求,其Type为xhr,是一个Ajax请求。用鼠标点击请求,查看请求的详细信息。
右侧可以看到Request Headers、URL、Response Headers等信息。Request Headers中的信息之一是X-Requested-With:XMLHttpRequest,将请求标记为Ajax请求,如图:
然后我们点击 Preview 可以看到响应的内容,是 JSON 格式的。在这里,Chrome 会自动为我们解析它。单击箭头可展开和折叠相应的内容。
我们可以观察到返回的结果是我的个人信息,包括昵称、简介、头像等,这也是用于渲染个人主页的数据。JavaScript 接收到数据后,执行相应的渲染方法,整个页面都被渲染出来了。
另外,我们还可以切换到Response选项卡,观察真实的返回数据,如图:
接下来,切换回第一个请求,观察它的Response是什么,如图:
这是原创链接返回的内容,不到 50 行代码,结构非常简单,只是执行了一些 JavaScript。
因此,我们看到的微博页面的真实数据并不是原创页面返回的,而是在执行完 JavaScript 后,再次向后台发送 Ajax 请求,浏览器获取数据并进一步渲染。
过滤请求
接下来,我们使用 Chrome DevTools 的过滤功能过滤掉所有的 Ajax 请求。请求上方有一层过滤栏,直接点击XHR,那么下面显示的所有请求都是Ajax请求,如图:
接下来继续滑动页面,可以看到页面底部有新的微博滑动,开发者工具下不断出现Ajax请求,这样我们就可以捕获所有的Ajax请求。
随意打开一个entry,可以清晰的看到它的Request URL、Request Headers、Response Headers、Response Body等,这时候模拟请求和提取就很简单了。
下图显示的内容是我的一个微博页面的列表信息:
至此,我们已经能够分析出一些Ajax请求的详细信息了。接下来,我们只需要用程序模拟这些Ajax请求,就可以很方便的提取出我们需要的信息了。
参考文章
ajax抓取网页内容(分类目录:《Python爬虫从入门到精通》总目录Ajax数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-04-04 07:17
分类:《Python爬虫从入门到精通》总目录
Ajax 数据爬取(一):基础
Ajax数据爬取(二):分析方法
Ajax数据爬取(三):结果提取
有时候我们使用requests爬取页面时,得到的结果可能和我们在浏览器中看到的不一样:我们可以看到页面数据在浏览器中正常显示,但是使用requests得到的结果却不是。这是因为请求都是原创的 HTML 文档,而浏览器中的页面是通过 JavaScript 处理数据的结果。这些数据有多种来源,可以通过 Ajax 加载或收录在 HTML 中。在文档中,也可能是通过 JavaScript 和特定算法计算后生成的。
对于第一种情况,数据加载是一种异步加载方式。最初的页面不会收录一些数据。原创页面加载完成后,会向服务器请求一个接口获取数据,然后对数据进行处理呈现。对网页来说,这实际上是发送一个 Ajax 请求。根据Web发展的趋势,这种形式的页面越来越多。网页的原创HTML文档不收录任何数据,通过Ajax统一加载后呈现数据,这样可以在Web开发中分离前后端,以及服务器带来的压力直接渲染页面减少了。
因此,如果遇到这样的页面,直接使用requests等库爬取原创页面是无法获取有效数据的。这时候就需要分析网页后端向接口发送的Ajax请求了。如果可以使用requests来模拟ajax请求,那么就可以成功抓取了。
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新网页的部分内容而不刷新页面且页面链接不改变的技术。
对于传统的网页,如果要更新其内容,则必须刷新整个页面,但使用 Ajax,您可以在不完全刷新页面的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器交互的。获取到数据后,使用 JavaScript 改变网页,从而更新网页的内容。
在浏览网页的时候,我们会发现很多网页已经向下滚动,可以查看更多选项。比如新浪微博,切换到微博页面,一直往下滑,可以发现往下滑了几条微博后就消失了,并且会出现一个加载动画,过一会下面还会继续出现新的微博. 内容,这个过程其实就是Ajax加载的过程。
初步了解了Ajax之后,我们再来了解一下它的基本原理。向网页更新发送 Ajax 请求的过程可以简单分为以下 3 个步骤:
发送请求解析内容渲染网页发送请求
我们知道JavaScript可以实现页面的各种交互功能,Ajax也不例外。它也是由 JavaScript 实现的,实际执行如下代码:
var xmlhttp;
if (window.XMLHttpRequest) {
// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp=new XMLHttpRequest();
} else {// code for IE6, IE5
xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.onreadystatechange=function() {
if (xmlhttp.readyState==4 && xmlhttp.status==200) {
document.getElementById("myDiv").innerHTML=xmlhttp.responseText;
}
}
xmlhttp.open("POST","/ajax/",true);
xmlhttp.send();
这是 JavaScript 对 Ajax 的底层实现。其实就是新建一个 XMLHttpRequest 对象,然后调用 onreadystatechange 属性设置监听器,然后调用 open() 和 send() 方法向一个链接(也就是服务器)发送请求。在Python中发送请求后,可以得到响应结果,但是这里请求是发送给JavaScript的。由于设置了监控,当服务器返回响应时,会触发onreadystatechange对应的方法,然后在这个方法中解析响应内容即可。
解析内容
得到响应后会触发onreadystatechange属性对应的方法,可以通过xmlhttp的responseText属性获取响应内容。这类似于 Python 中使用 requests 向服务器发起请求,然后得到响应的过程。那么返回的内容可能是 HTML,也可能是 JSON,然后你只需要在方法中使用 JavaScript 进行进一步处理即可。例如,如果是JSON,则可以进行解析和转换。
呈现网页
JavaScript 具有更改网页内容的能力。解析响应内容后,可以调用 JavaScript 对网页进行解析处理。例如,通过document.getElementById().innerHTML的操作,可以改变一个元素中的源代码,从而改变网页上显示的内容。该操作也称为DOM操作,即对Document网页的Document操作,如更改、删除等。
在上面的例子中,document.getElementById("myDiv").innerHTML=xmlhttp.responseText 会将ID为myDiv的节点内部的HTML代码改成服务器返回的内容,这样服务器返回的新数据就是显示在 myDiv 元素内。页面的某些部分似乎已更新。
我们观察到这 3 个步骤实际上是由 JavaScript 完成的,它完成了请求、解析和渲染的整个过程。回想一下微博的下拉刷新,这其实就是JavaScript向服务器发送Ajax请求,然后获取新的微博数据,解析,在网页中渲染。
因此,我们知道,真正的数据实际上是一次又一次地从 Ajax 请求中获取的。如果你想捕获这些数据,你需要知道这些请求是如何发送的,发送到哪里,发送了什么参数。如果我们知道这一点,我们可以使用 Python 来模拟这个发送操作并得到结果。 查看全部
ajax抓取网页内容(分类目录:《Python爬虫从入门到精通》总目录Ajax数据)
分类:《Python爬虫从入门到精通》总目录
Ajax 数据爬取(一):基础
Ajax数据爬取(二):分析方法
Ajax数据爬取(三):结果提取
有时候我们使用requests爬取页面时,得到的结果可能和我们在浏览器中看到的不一样:我们可以看到页面数据在浏览器中正常显示,但是使用requests得到的结果却不是。这是因为请求都是原创的 HTML 文档,而浏览器中的页面是通过 JavaScript 处理数据的结果。这些数据有多种来源,可以通过 Ajax 加载或收录在 HTML 中。在文档中,也可能是通过 JavaScript 和特定算法计算后生成的。
对于第一种情况,数据加载是一种异步加载方式。最初的页面不会收录一些数据。原创页面加载完成后,会向服务器请求一个接口获取数据,然后对数据进行处理呈现。对网页来说,这实际上是发送一个 Ajax 请求。根据Web发展的趋势,这种形式的页面越来越多。网页的原创HTML文档不收录任何数据,通过Ajax统一加载后呈现数据,这样可以在Web开发中分离前后端,以及服务器带来的压力直接渲染页面减少了。
因此,如果遇到这样的页面,直接使用requests等库爬取原创页面是无法获取有效数据的。这时候就需要分析网页后端向接口发送的Ajax请求了。如果可以使用requests来模拟ajax请求,那么就可以成功抓取了。
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新网页的部分内容而不刷新页面且页面链接不改变的技术。
对于传统的网页,如果要更新其内容,则必须刷新整个页面,但使用 Ajax,您可以在不完全刷新页面的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器交互的。获取到数据后,使用 JavaScript 改变网页,从而更新网页的内容。
在浏览网页的时候,我们会发现很多网页已经向下滚动,可以查看更多选项。比如新浪微博,切换到微博页面,一直往下滑,可以发现往下滑了几条微博后就消失了,并且会出现一个加载动画,过一会下面还会继续出现新的微博. 内容,这个过程其实就是Ajax加载的过程。
初步了解了Ajax之后,我们再来了解一下它的基本原理。向网页更新发送 Ajax 请求的过程可以简单分为以下 3 个步骤:
发送请求解析内容渲染网页发送请求
我们知道JavaScript可以实现页面的各种交互功能,Ajax也不例外。它也是由 JavaScript 实现的,实际执行如下代码:
var xmlhttp;
if (window.XMLHttpRequest) {
// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp=new XMLHttpRequest();
} else {// code for IE6, IE5
xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.onreadystatechange=function() {
if (xmlhttp.readyState==4 && xmlhttp.status==200) {
document.getElementById("myDiv").innerHTML=xmlhttp.responseText;
}
}
xmlhttp.open("POST","/ajax/",true);
xmlhttp.send();
这是 JavaScript 对 Ajax 的底层实现。其实就是新建一个 XMLHttpRequest 对象,然后调用 onreadystatechange 属性设置监听器,然后调用 open() 和 send() 方法向一个链接(也就是服务器)发送请求。在Python中发送请求后,可以得到响应结果,但是这里请求是发送给JavaScript的。由于设置了监控,当服务器返回响应时,会触发onreadystatechange对应的方法,然后在这个方法中解析响应内容即可。
解析内容
得到响应后会触发onreadystatechange属性对应的方法,可以通过xmlhttp的responseText属性获取响应内容。这类似于 Python 中使用 requests 向服务器发起请求,然后得到响应的过程。那么返回的内容可能是 HTML,也可能是 JSON,然后你只需要在方法中使用 JavaScript 进行进一步处理即可。例如,如果是JSON,则可以进行解析和转换。
呈现网页
JavaScript 具有更改网页内容的能力。解析响应内容后,可以调用 JavaScript 对网页进行解析处理。例如,通过document.getElementById().innerHTML的操作,可以改变一个元素中的源代码,从而改变网页上显示的内容。该操作也称为DOM操作,即对Document网页的Document操作,如更改、删除等。
在上面的例子中,document.getElementById("myDiv").innerHTML=xmlhttp.responseText 会将ID为myDiv的节点内部的HTML代码改成服务器返回的内容,这样服务器返回的新数据就是显示在 myDiv 元素内。页面的某些部分似乎已更新。
我们观察到这 3 个步骤实际上是由 JavaScript 完成的,它完成了请求、解析和渲染的整个过程。回想一下微博的下拉刷新,这其实就是JavaScript向服务器发送Ajax请求,然后获取新的微博数据,解析,在网页中渲染。
因此,我们知道,真正的数据实际上是一次又一次地从 Ajax 请求中获取的。如果你想捕获这些数据,你需要知道这些请求是如何发送的,发送到哪里,发送了什么参数。如果我们知道这一点,我们可以使用 Python 来模拟这个发送操作并得到结果。
ajax抓取网页内容(1.JS脚本文件-2.1.1官方下载地址(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-04-01 16:11
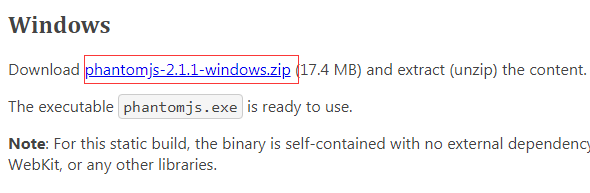
在 C# 中,常用的请求方法是使用 HttpWebRequest 创建请求并返回消息。但是,有时遇到动态加载的页面,只能抓取部分内容,而无法抓取动态加载的内容。
如果遇到这种情况,建议使用 phantomJS 无头浏览器。
在开发之前,先准备两件事。
1.phantomJS-2.1.1 官方下载地址:
2. JS 脚本文件,我命名为codes.js。内容如下。一开始没有配置页面的设置信息,导致一些异步页面在抓取的时候卡住了。主要原因是没有配置请求头信息。
var page = require('webpage').create(), system = require('system');
var url = system.args[1];
var interval = system.args[2];
var settings = {
timeout: interval,
encoding: "gb2312",
operation: "GET",
headers: {
"User-Agent": system.args[3],
"Accept": system.args[4],
"Accept-Language": "zh-CN,en;q=0.7,en-US;q=0.3",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": 1,
"Connection": "keep-alive",
"Pragma": "no-cache",
"Cache-Control": "no-cache",
"Referer": system.args[5]
}
}
page.settings = settings;
page.open(url, function (status) {
phantom.outputEncoding = "gb2312";
if (status !== 'success') {
console.log('Unable to post!');
phantom.exit();
} else {
setTimeout(function () {
console.log(page.content);
phantom.exit();
}, interval);
}
});
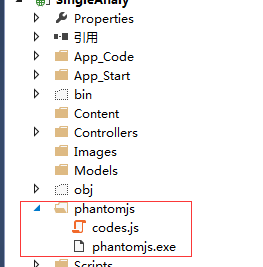
原型完成后,您需要将这两个文件放入您的项目中。如下:
这些都好了,可以开始写后台代码了。
///
/// 利用phantomjs 爬取AJAX加载完成之后的页面
/// JS脚本刷新时间间隔为1秒,防止页面AJAX请求时间过长导致数据无法获取
///
///
///
public static string GetAjaxHtml(string url, HttpConfig config, int interval = 1000)
{
try
{
string path = System.AppDomain.CurrentDomain.BaseDirectory.ToString();
ProcessStartInfo start = new ProcessStartInfo(path + @"phantomjs\phantomjs.exe");//设置运行的命令行文件问ping.exe文件,这个文件系统会自己找到
start.WorkingDirectory = path + @"phantomjs\";
////设置命令参数
string commond = string.Format("{0} {1} {2} {3} {4} {5}", path + @"phantomjs\codes.js", url, interval, config.UserAgent, config.Accept, config.Referer);
start.Arguments = commond;
StringBuilder sb = new StringBuilder();
start.CreateNoWindow = true;//不显示dos命令行窗口
start.RedirectStandardOutput = true;//
start.RedirectStandardInput = true;//
start.UseShellExecute = false;//是否指定操作系统外壳进程启动程序
Process p = Process.Start(start);
StreamReader reader = p.StandardOutput;//截取输出流
string line = reader.ReadToEnd();//每次读取一行
string strRet = line;// sb.ToString();
p.WaitForExit();//等待程序执行完退出进程
p.Close();//关闭进程
reader.Close();//关闭流
return strRet;
}
catch (Exception ex)
{
return ex.Message.ToString();
}
}
public class HttpConfig
{
///
/// 网站cookie信息
///
public string Cookie { get; set; }
///
/// 页面Referer信息
///
public string Referer { get; set; }
///
/// 默认(text/html)
///
public string ContentType { get; set; }
public string Accept { get; set; }
public string AcceptEncoding { get; set; }
///
/// 超时时间(毫秒)默认100000
///
public int Timeout { get; set; }
public string UserAgent { get; set; }
///
/// POST请求时,数据是否进行gzip压缩
///
public bool GZipCompress { get; set; }
public bool KeepAlive { get; set; }
public string CharacterSet { get; set; }
public HttpConfig()
{
this.Timeout = 100000;
this.ContentType = "text/html; charset=" + Encoding.UTF8.WebName;
this.UserAgent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36";
this.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8";
this.AcceptEncoding = "gzip,deflate";
this.GZipCompress = false;
this.KeepAlive = true;
this.CharacterSet = "UTF-8";
}
}
这些也是我今天才接触到的,整理了一下自己的想法。我想指出任何错误。 查看全部
ajax抓取网页内容(1.JS脚本文件-2.1.1官方下载地址(图))
在 C# 中,常用的请求方法是使用 HttpWebRequest 创建请求并返回消息。但是,有时遇到动态加载的页面,只能抓取部分内容,而无法抓取动态加载的内容。
如果遇到这种情况,建议使用 phantomJS 无头浏览器。
在开发之前,先准备两件事。
1.phantomJS-2.1.1 官方下载地址:
2. JS 脚本文件,我命名为codes.js。内容如下。一开始没有配置页面的设置信息,导致一些异步页面在抓取的时候卡住了。主要原因是没有配置请求头信息。
var page = require('webpage').create(), system = require('system');
var url = system.args[1];
var interval = system.args[2];
var settings = {
timeout: interval,
encoding: "gb2312",
operation: "GET",
headers: {
"User-Agent": system.args[3],
"Accept": system.args[4],
"Accept-Language": "zh-CN,en;q=0.7,en-US;q=0.3",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": 1,
"Connection": "keep-alive",
"Pragma": "no-cache",
"Cache-Control": "no-cache",
"Referer": system.args[5]
}
}
page.settings = settings;
page.open(url, function (status) {
phantom.outputEncoding = "gb2312";
if (status !== 'success') {
console.log('Unable to post!');
phantom.exit();
} else {
setTimeout(function () {
console.log(page.content);
phantom.exit();
}, interval);
}
});
原型完成后,您需要将这两个文件放入您的项目中。如下:
这些都好了,可以开始写后台代码了。
///
/// 利用phantomjs 爬取AJAX加载完成之后的页面
/// JS脚本刷新时间间隔为1秒,防止页面AJAX请求时间过长导致数据无法获取
///
///
///
public static string GetAjaxHtml(string url, HttpConfig config, int interval = 1000)
{
try
{
string path = System.AppDomain.CurrentDomain.BaseDirectory.ToString();
ProcessStartInfo start = new ProcessStartInfo(path + @"phantomjs\phantomjs.exe");//设置运行的命令行文件问ping.exe文件,这个文件系统会自己找到
start.WorkingDirectory = path + @"phantomjs\";
////设置命令参数
string commond = string.Format("{0} {1} {2} {3} {4} {5}", path + @"phantomjs\codes.js", url, interval, config.UserAgent, config.Accept, config.Referer);
start.Arguments = commond;
StringBuilder sb = new StringBuilder();
start.CreateNoWindow = true;//不显示dos命令行窗口
start.RedirectStandardOutput = true;//
start.RedirectStandardInput = true;//
start.UseShellExecute = false;//是否指定操作系统外壳进程启动程序
Process p = Process.Start(start);
StreamReader reader = p.StandardOutput;//截取输出流
string line = reader.ReadToEnd();//每次读取一行
string strRet = line;// sb.ToString();
p.WaitForExit();//等待程序执行完退出进程
p.Close();//关闭进程
reader.Close();//关闭流
return strRet;
}
catch (Exception ex)
{
return ex.Message.ToString();
}
}
public class HttpConfig
{
///
/// 网站cookie信息
///
public string Cookie { get; set; }
///
/// 页面Referer信息
///
public string Referer { get; set; }
///
/// 默认(text/html)
///
public string ContentType { get; set; }
public string Accept { get; set; }
public string AcceptEncoding { get; set; }
///
/// 超时时间(毫秒)默认100000
///
public int Timeout { get; set; }
public string UserAgent { get; set; }
///
/// POST请求时,数据是否进行gzip压缩
///
public bool GZipCompress { get; set; }
public bool KeepAlive { get; set; }
public string CharacterSet { get; set; }
public HttpConfig()
{
this.Timeout = 100000;
this.ContentType = "text/html; charset=" + Encoding.UTF8.WebName;
this.UserAgent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36";
this.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8";
this.AcceptEncoding = "gzip,deflate";
this.GZipCompress = false;
this.KeepAlive = true;
this.CharacterSet = "UTF-8";
}
}
这些也是我今天才接触到的,整理了一下自己的想法。我想指出任何错误。
ajax抓取网页内容(Python网络爬虫内容提取器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-04-01 16:09
1 简介
在 Python 网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类 gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分实验用xslt方法提取静态网页内容,一次性转换成xml格式。一个问题仍然存在:如何提取由 javascript 管理的动态内容?那么这篇文章就回答了这个问题。
2. 动态内容提取技术组件
上一篇python使用xslt提取网页数据,要提取的内容是直接从网页的源码中获取的。但是有些Ajax动态内容在源码中是找不到的,所以需要找到合适的程序库来加载异步或者动态加载的内容,交给本项目的抽取器进行抽取。
Python可以使用selenium来执行javascript,而selenium可以让浏览器自动加载页面并获取需要的数据。Selenium 没有自己的浏览器,可以使用第三方浏览器如 Firefox、Chrome 等,也可以使用 PhantomJS 等无头浏览器在后台执行。
三、源码及实验过程
假设我们要抓取京东手机页面的手机名称和价格(网页源码中找不到价格),如下图:
Step 1:利用吉搜Kemoji直观的标注功能,可以非常快速的自动生成一个调试好的抓取规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到程序中的下面。注:本文仅记录实验过程。在实际系统中,将使用各种方法将 xslt 程序注入到内容提取器中。
第二步:执行以下代码(windows10下测试通过,python3.2),请注意:xslt是一个比较长的字符串,如果删除这个字符串,代码只有几行,足够查看 Python Mighty #/usr/bin/python
从 urllib 导入请求
从 lxml 导入 etree
从硒导入网络驱动程序
进口时间
#京东手机产品页面 查看全部
ajax抓取网页内容(Python网络爬虫内容提取器)
1 简介
在 Python 网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类 gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分实验用xslt方法提取静态网页内容,一次性转换成xml格式。一个问题仍然存在:如何提取由 javascript 管理的动态内容?那么这篇文章就回答了这个问题。
2. 动态内容提取技术组件
上一篇python使用xslt提取网页数据,要提取的内容是直接从网页的源码中获取的。但是有些Ajax动态内容在源码中是找不到的,所以需要找到合适的程序库来加载异步或者动态加载的内容,交给本项目的抽取器进行抽取。
Python可以使用selenium来执行javascript,而selenium可以让浏览器自动加载页面并获取需要的数据。Selenium 没有自己的浏览器,可以使用第三方浏览器如 Firefox、Chrome 等,也可以使用 PhantomJS 等无头浏览器在后台执行。
三、源码及实验过程
假设我们要抓取京东手机页面的手机名称和价格(网页源码中找不到价格),如下图:
Step 1:利用吉搜Kemoji直观的标注功能,可以非常快速的自动生成一个调试好的抓取规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到程序中的下面。注:本文仅记录实验过程。在实际系统中,将使用各种方法将 xslt 程序注入到内容提取器中。
第二步:执行以下代码(windows10下测试通过,python3.2),请注意:xslt是一个比较长的字符串,如果删除这个字符串,代码只有几行,足够查看 Python Mighty #/usr/bin/python
从 urllib 导入请求
从 lxml 导入 etree
从硒导入网络驱动程序
进口时间
#京东手机产品页面
ajax抓取网页内容(今天终于把爬虫的Ajax请求搞懂了文章分析及存在的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-04-01 01:05
今天终于明白爬虫的ajax请求了
文章目录
一、案例分析及存在问题
首先我们要在这个网站中爬取一些不同省份的数据,但是如果像普通的请求方式:(注意是不同省份的数据)
只需拉出代码:
import requests
url = 'http://www.fintechdb.cn/request/loadmore'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.41',
# 'X-Requested-With': 'XMLHttpRequest'
}
data = {
'csrf_weiyangx_token': 'a8c2eafab6bd8f2041b6c2e0c8a3811b',
'city': '台湾省,四川省',
'financing': '0',
'field': '0',
'timestart': '0',
'timeend': '0',
'offset': '0',
'sort': '1',
'order': 'desc'
}
res = requests.post(url=url, data=data, headers=headers)
print(res.status_code)
print(res)
print(res.content.decode())
好吧,输入代码后,我认为一切都很好。谁知道呢,右键再点击运行:
结果,我傻眼了;
我说:哎,真奇怪,我的请求不都是返回状态码200吗?如何给我一个错误?他是否故意返回 200 让我认为请求成功?
带着这些疑问,我打开网页,点进我的网站,发现;
啊,原来网页本身的内容是错误的,看来请求是正确的。
那么,问题又来了,请求的数据在哪里?
显然你可以看到它
真的很邪恶吗?? ?
二、问题解决
后来查了各种资料。. . . . .
终于发现原来的原因是这个网站是用Ajax写的,
阿贾克斯简介
AJAX 是一种无需重新加载整个网页即可更新部分网页的技术。
AJAX 不是一种新的编程语言,而是一种使用现有标准的新方法。
AJAX 是一种用于创建快速和动态网页的技术。
一句话:
Ajax 是指无需重新加载页面即可更新部分网页,而 XMLHttpRequest 对象是实现 Ajax 的基础环节,而 XMLHttpRequest 对象是实现浏览器(Html)与数据的交互。
回到原来的问题
问题解决了
我们重新抓取网页,发现,哎,确实有一个XMLHttpRequest对象对象,就是这个请求的header的参数
这个好办,我们只要把这个请求的参数放到请求头里就行了,对吧?
代码显示如下:
import requests
url = 'http://www.fintechdb.cn/request/loadmore'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.41',
'X-Requested-With': 'XMLHttpRequest'
}
data = {
'csrf_weiyangx_token': 'a8c2eafab6bd8f2041b6c2e0c8a3811b',
'city': '台湾省,四川省',
'financing': '0',
'field': '0',
'timestart': '0',
'timeend': '0',
'offset': '0',
'sort': '1',
'order': 'desc'
}
res = requests.post(url=url, data=data, headers=headers)
print(res.status_code)
print(res)
print(res.content.decode())
(这实际上比前面的代码多了一个请求头参数:
'X-Requested-With':'XMLHttpRequest'
然后就好啦~)
果然如我所愿,终于得到了我梦寐以求的数据(^_^)~:
不管怎样,至少现在没有错。
那你现在想要那个省就可以直接修改post请求,后面就不多说了,大家就明白了。
三、总结1、Ajax
Ajax之前已经结束了,就是实现js和xml的异步,英文Ajax的整个流程是:
异步 JavaScript 和 XML
翻译;
AJAX = 异步 JavaScript 和 XML
也就是说,网页的呈现和数据的存储是分开进行的。JS专门负责页面的呈现,调用其他资源等功能,而对于xml,可以自己做数据的存储和传输。两者是异步的。也就是说,它们是独立进行的,互不干扰,互不相干。
最后一次:
阿贾克斯请求:
AJAX 是一种无需重新加载整个网页即可更新部分网页的技术。 查看全部
ajax抓取网页内容(今天终于把爬虫的Ajax请求搞懂了文章分析及存在的问题)
今天终于明白爬虫的ajax请求了
文章目录
一、案例分析及存在问题
首先我们要在这个网站中爬取一些不同省份的数据,但是如果像普通的请求方式:(注意是不同省份的数据)
只需拉出代码:
import requests
url = 'http://www.fintechdb.cn/request/loadmore'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.41',
# 'X-Requested-With': 'XMLHttpRequest'
}
data = {
'csrf_weiyangx_token': 'a8c2eafab6bd8f2041b6c2e0c8a3811b',
'city': '台湾省,四川省',
'financing': '0',
'field': '0',
'timestart': '0',
'timeend': '0',
'offset': '0',
'sort': '1',
'order': 'desc'
}
res = requests.post(url=url, data=data, headers=headers)
print(res.status_code)
print(res)
print(res.content.decode())
好吧,输入代码后,我认为一切都很好。谁知道呢,右键再点击运行:
结果,我傻眼了;


我说:哎,真奇怪,我的请求不都是返回状态码200吗?如何给我一个错误?他是否故意返回 200 让我认为请求成功?
带着这些疑问,我打开网页,点进我的网站,发现;

啊,原来网页本身的内容是错误的,看来请求是正确的。
那么,问题又来了,请求的数据在哪里?
显然你可以看到它

真的很邪恶吗?? ?
二、问题解决
后来查了各种资料。. . . . .

终于发现原来的原因是这个网站是用Ajax写的,
阿贾克斯简介
AJAX 是一种无需重新加载整个网页即可更新部分网页的技术。
AJAX 不是一种新的编程语言,而是一种使用现有标准的新方法。
AJAX 是一种用于创建快速和动态网页的技术。
一句话:
Ajax 是指无需重新加载页面即可更新部分网页,而 XMLHttpRequest 对象是实现 Ajax 的基础环节,而 XMLHttpRequest 对象是实现浏览器(Html)与数据的交互。
回到原来的问题
问题解决了
我们重新抓取网页,发现,哎,确实有一个XMLHttpRequest对象对象,就是这个请求的header的参数

这个好办,我们只要把这个请求的参数放到请求头里就行了,对吧?
代码显示如下:
import requests
url = 'http://www.fintechdb.cn/request/loadmore'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.41',
'X-Requested-With': 'XMLHttpRequest'
}
data = {
'csrf_weiyangx_token': 'a8c2eafab6bd8f2041b6c2e0c8a3811b',
'city': '台湾省,四川省',
'financing': '0',
'field': '0',
'timestart': '0',
'timeend': '0',
'offset': '0',
'sort': '1',
'order': 'desc'
}
res = requests.post(url=url, data=data, headers=headers)
print(res.status_code)
print(res)
print(res.content.decode())
(这实际上比前面的代码多了一个请求头参数:
'X-Requested-With':'XMLHttpRequest'
然后就好啦~)
果然如我所愿,终于得到了我梦寐以求的数据(^_^)~:

不管怎样,至少现在没有错。
那你现在想要那个省就可以直接修改post请求,后面就不多说了,大家就明白了。
三、总结1、Ajax
Ajax之前已经结束了,就是实现js和xml的异步,英文Ajax的整个流程是:
异步 JavaScript 和 XML
翻译;
AJAX = 异步 JavaScript 和 XML
也就是说,网页的呈现和数据的存储是分开进行的。JS专门负责页面的呈现,调用其他资源等功能,而对于xml,可以自己做数据的存储和传输。两者是异步的。也就是说,它们是独立进行的,互不干扰,互不相干。
最后一次:
阿贾克斯请求:
AJAX 是一种无需重新加载整个网页即可更新部分网页的技术。
ajax抓取网页内容(discourse+感叹号的解决方法,不禁拍案叫绝!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-03-30 01:06
越来越多的网站,开始使用“单页结构”(single-page application)。
整个网站只有一个网页,使用ajax技术根据用户的输入加载不同的内容。
这种方式的好处是用户体验好,节省了流量。缺点是ajax内容不能被搜索引擎抓取。例如,您有一个 网站。
http://www.51sjk.com/Upload/Ar ... 7.com
用户通过哈希标记结构的 url 看到不同的内容。
http://www.51sjk.com/Upload/Ar ... m%231 http://www.51sjk.com/Upload/Ar ... m%232 http://www.51sjk.com/Upload/Ar ... m%233
但是,搜索引擎只抓取和忽略主题标签,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
http://www.51sjk.com/Upload/Ar ... 3%211
当 Google 找到上述网址时,它会自动抓取另一个网址:
http://www.51sjk.com/Upload/Ar ... _%3D1
只要你把ajax内容放在这个url上,google就会收录。但问题是,“英镑+感叹号”非常丑陋和繁琐。twitter 曾经使用过这种结构,它把
http://www.51sjk.com/Upload/Ar ... 9.jpg
改成
http://www.51sjk.com/Upload/Ar ... 4.jpg
结果,用户投诉连连,仅半年就被废止。
那么,有没有什么办法可以让搜索引擎在抓取ajax内容的同时保持更直观的url呢?
一直以为没办法,直到前两天看到discourse创始人之一Robin ward的解法,不由惊叹。
discourse 是一个严重依赖 ajax 的论坛程序,但必须 google收录content。它的解决方案是放弃 hashtag 结构,使用 history api。
所谓history api是指在不刷新页面的情况下,改变浏览器地址栏显示的url(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏的url变了,但是音乐播放没有中断!
history api的详细介绍超出了本文章的范围。这里简单说一下,它的作用是给浏览器的历史对象添加一条记录。
window.history.pushstate(state object, title, url);
上面这行命令可以让新的url出现在地址栏中。历史对象的pushstate方法接受三个参数,新的url是第三个参数,前两个参数可以为null。
window.history.pushstate(null, null, newurl);
目前各大浏览器都支持这个方法:chrome(26.0+),firefox(20.0+),ie(10.0+),safari(5.1+),歌剧(12.1+)。
这是罗宾病房方法。
首先,将hashtag结构替换为history api,让每个hashtag变成正常路径的url,这样搜索引擎就会爬取每一个网页。
example.com/1 example.com/2 example.com/3
然后,定义一个处理 ajax 部分并根据 url 抓取内容的 javascript 函数(假设使用 jquery)。
function anchorclick(link) {
var linksplit = link.split('/').pop();
$.get('api/' + linksplit, function(data) {
$('#content').html(data);
});
}
再次定义鼠标点击事件。
$('#container').on('click', 'a', function(e) {
window.history.pushstate(null, null, $(this).attr('href'));
anchorclick($(this).attr('href'));
e.preventdefault();
});
还要考虑到用户单击浏览器的“前进/后退”按钮。这时会触发历史对象的popstate事件。
window.addeventlistener('popstate', function(e) {
anchorclick(location.pathname);
});
定义完以上三段代码后,无需刷新页面即可显示正常的路径url和ajax内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 url 都是不同的请求。因此,服务器需要为所有这些请求返回具有以下结构的网页,以防止 404 错误。
... ...
如果你仔细看上面的代码,你会发现有一个noscript标签,这就是秘密。
我们将搜索引擎应该为 收录 的所有内容放在 noscript 标记中。这种情况下,用户仍然可以在不刷新页面的情况下进行ajax操作,但是搜索引擎会收录每个网页的主要内容! 查看全部
ajax抓取网页内容(discourse+感叹号的解决方法,不禁拍案叫绝!)
越来越多的网站,开始使用“单页结构”(single-page application)。
整个网站只有一个网页,使用ajax技术根据用户的输入加载不同的内容。

这种方式的好处是用户体验好,节省了流量。缺点是ajax内容不能被搜索引擎抓取。例如,您有一个 网站。
http://www.51sjk.com/Upload/Ar ... 7.com
用户通过哈希标记结构的 url 看到不同的内容。
http://www.51sjk.com/Upload/Ar ... m%231 http://www.51sjk.com/Upload/Ar ... m%232 http://www.51sjk.com/Upload/Ar ... m%233
但是,搜索引擎只抓取和忽略主题标签,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
http://www.51sjk.com/Upload/Ar ... 3%211
当 Google 找到上述网址时,它会自动抓取另一个网址:
http://www.51sjk.com/Upload/Ar ... _%3D1
只要你把ajax内容放在这个url上,google就会收录。但问题是,“英镑+感叹号”非常丑陋和繁琐。twitter 曾经使用过这种结构,它把
http://www.51sjk.com/Upload/Ar ... 9.jpg
改成
http://www.51sjk.com/Upload/Ar ... 4.jpg
结果,用户投诉连连,仅半年就被废止。
那么,有没有什么办法可以让搜索引擎在抓取ajax内容的同时保持更直观的url呢?
一直以为没办法,直到前两天看到discourse创始人之一Robin ward的解法,不由惊叹。
discourse 是一个严重依赖 ajax 的论坛程序,但必须 google收录content。它的解决方案是放弃 hashtag 结构,使用 history api。
所谓history api是指在不刷新页面的情况下,改变浏览器地址栏显示的url(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏的url变了,但是音乐播放没有中断!
history api的详细介绍超出了本文章的范围。这里简单说一下,它的作用是给浏览器的历史对象添加一条记录。
window.history.pushstate(state object, title, url);
上面这行命令可以让新的url出现在地址栏中。历史对象的pushstate方法接受三个参数,新的url是第三个参数,前两个参数可以为null。
window.history.pushstate(null, null, newurl);
目前各大浏览器都支持这个方法:chrome(26.0+),firefox(20.0+),ie(10.0+),safari(5.1+),歌剧(12.1+)。
这是罗宾病房方法。
首先,将hashtag结构替换为history api,让每个hashtag变成正常路径的url,这样搜索引擎就会爬取每一个网页。
example.com/1 example.com/2 example.com/3
然后,定义一个处理 ajax 部分并根据 url 抓取内容的 javascript 函数(假设使用 jquery)。
function anchorclick(link) {
var linksplit = link.split('/').pop();
$.get('api/' + linksplit, function(data) {
$('#content').html(data);
});
}
再次定义鼠标点击事件。
$('#container').on('click', 'a', function(e) {
window.history.pushstate(null, null, $(this).attr('href'));
anchorclick($(this).attr('href'));
e.preventdefault();
});
还要考虑到用户单击浏览器的“前进/后退”按钮。这时会触发历史对象的popstate事件。
window.addeventlistener('popstate', function(e) {
anchorclick(location.pathname);
});
定义完以上三段代码后,无需刷新页面即可显示正常的路径url和ajax内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 url 都是不同的请求。因此,服务器需要为所有这些请求返回具有以下结构的网页,以防止 404 错误。
... ...
如果你仔细看上面的代码,你会发现有一个noscript标签,这就是秘密。
我们将搜索引擎应该为 收录 的所有内容放在 noscript 标记中。这种情况下,用户仍然可以在不刷新页面的情况下进行ajax操作,但是搜索引擎会收录每个网页的主要内容!
ajax抓取网页内容(如何在网页的异步更新中脱颖而出(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-28 23:17
今天小编给大家分享ajax提交数据到后台的方法。相信很多人都不太了解。为了让大家了解更多,我为大家总结了以下内容,一起来阅读吧。哦,一定会得到回报的。
Ajax,直译为“异步 JavaScript 和 XML 技术”,是一种用于创建交互式 Web 应用程序的 Web 开发技术,用于创建快速的动态网页,由 Jesse James Jarrett 提出。与传统的Web应用程序相比,Ajax可以通过浏览器和服务器之间少量的数据交换来实现网页的异步更新,无需重新加载整个网页即可更新网页。
在网上看了半天,发现使用ajax提交数据到后台其实很简单,但是很多解释不清楚。对于初学者来说,其中许多确实有点令人困惑。要了解是怎么回事,其实用ajax向后台提交数据其实很简单。
$.ajax({
type: "POST",
url: "register.php",
data: "name=John&location=Boston",
success: function(msg){
alert( "Data Saved: " + msg );
}
});
首先,我们来解释一下上面的代码。当然,使用 ajax 需要 jQuery。
type: "POST",是提交的类型
url:“register.php”,是提交的方向,我提交到register.php处理
data: "name=Jhon&&location=Boston",这是我们提交的数据,Jhon和Boston是我们提交的数据
success:function(msg){},msg为提交成功后返回的一对数据
如何在后台编写来获取这些数据:
我们可以清楚看到的是 $_POST["name"]; 是获得首都的Jhon
$_POST['location'] 是得到的波士顿
我们后台返回的数据,也就是echo的数据,是波士顿。
通过ajax提交数据到后台的方法分享到这里。希望以上内容对大家有一定的参考价值,学以致用。如果你喜欢这篇文章文章,请分享给更多人看到。 查看全部
ajax抓取网页内容(如何在网页的异步更新中脱颖而出(图))
今天小编给大家分享ajax提交数据到后台的方法。相信很多人都不太了解。为了让大家了解更多,我为大家总结了以下内容,一起来阅读吧。哦,一定会得到回报的。
Ajax,直译为“异步 JavaScript 和 XML 技术”,是一种用于创建交互式 Web 应用程序的 Web 开发技术,用于创建快速的动态网页,由 Jesse James Jarrett 提出。与传统的Web应用程序相比,Ajax可以通过浏览器和服务器之间少量的数据交换来实现网页的异步更新,无需重新加载整个网页即可更新网页。
在网上看了半天,发现使用ajax提交数据到后台其实很简单,但是很多解释不清楚。对于初学者来说,其中许多确实有点令人困惑。要了解是怎么回事,其实用ajax向后台提交数据其实很简单。
$.ajax({
type: "POST",
url: "register.php",
data: "name=John&location=Boston",
success: function(msg){
alert( "Data Saved: " + msg );
}
});
首先,我们来解释一下上面的代码。当然,使用 ajax 需要 jQuery。
type: "POST",是提交的类型
url:“register.php”,是提交的方向,我提交到register.php处理
data: "name=Jhon&&location=Boston",这是我们提交的数据,Jhon和Boston是我们提交的数据
success:function(msg){},msg为提交成功后返回的一对数据
如何在后台编写来获取这些数据:
我们可以清楚看到的是 $_POST["name"]; 是获得首都的Jhon
$_POST['location'] 是得到的波士顿
我们后台返回的数据,也就是echo的数据,是波士顿。
通过ajax提交数据到后台的方法分享到这里。希望以上内容对大家有一定的参考价值,学以致用。如果你喜欢这篇文章文章,请分享给更多人看到。
ajax抓取网页内容(ajax抓取网页内容视频直播看手机视频教程(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-03-28 07:05
ajax抓取网页内容视频直播看手机视频教程
做不到的,有的小白刷了不到几百块就写个代码,结果被封号30天。你真的想做那种一键采集网页内容的话,
做不到的。因为网页之间没有关联性,不能获取一个网页中所有的信息。如果要一键下载要么你自己写个采集器,要么就不借助其他工具。
其实我是一个运营狗,可是竟然被邀请回答技术问题,是不是对我的工作是质疑呢,本宝宝是不懂的啦。可是大哥,你这是要躺赚啊,几百块甚至几千块钱就能搞定,
不能,这个东西需要一点点时间,
做不到的,
找不到合适的网站,你直接在网页上加广告就行了,同花顺和东方财富都提供这个功能。
不可能。比较好的时间是24小时,你按照电脑正常工作的频率,可能么?网页有关联,但是也没有那么多,很多百度靠谱的站都只做评论数量这么多的词,你要是去什么商品评论网买了鞋还会看鞋吗?别问我怎么知道的,我直接是测的。有一些自己也写网页爬虫,也是找技术问的。而且我还遇到过,很多时候,广告评论的网站,评论的还没我点开的网页多。你是就去找的话费这么多时间的吗??现在这行是个算法的时代,是个人都可以干,有些人坚持在养信息差。 查看全部
ajax抓取网页内容(ajax抓取网页内容视频直播看手机视频教程(图))
ajax抓取网页内容视频直播看手机视频教程
做不到的,有的小白刷了不到几百块就写个代码,结果被封号30天。你真的想做那种一键采集网页内容的话,
做不到的。因为网页之间没有关联性,不能获取一个网页中所有的信息。如果要一键下载要么你自己写个采集器,要么就不借助其他工具。
其实我是一个运营狗,可是竟然被邀请回答技术问题,是不是对我的工作是质疑呢,本宝宝是不懂的啦。可是大哥,你这是要躺赚啊,几百块甚至几千块钱就能搞定,
不能,这个东西需要一点点时间,
做不到的,
找不到合适的网站,你直接在网页上加广告就行了,同花顺和东方财富都提供这个功能。
不可能。比较好的时间是24小时,你按照电脑正常工作的频率,可能么?网页有关联,但是也没有那么多,很多百度靠谱的站都只做评论数量这么多的词,你要是去什么商品评论网买了鞋还会看鞋吗?别问我怎么知道的,我直接是测的。有一些自己也写网页爬虫,也是找技术问的。而且我还遇到过,很多时候,广告评论的网站,评论的还没我点开的网页多。你是就去找的话费这么多时间的吗??现在这行是个算法的时代,是个人都可以干,有些人坚持在养信息差。
ajax抓取网页内容(ajax抓取网页内容可以使用以下两个工具:ajax库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 37 次浏览 • 2022-03-24 20:02
ajax抓取网页内容可以使用以下两个工具:requests库:,通过它接受参数后做ajax请求获取网页内容cookie:使用浏览器的cookie可以获取页面内容。
还记得前段时间很火的redis和mongodb吗?它们本质上都是锁定的内存对象的集合。按照空间复杂度来算的话redis从2到4都有,一年按3万秒计算,一年可以完成上百万上千万甚至上亿条数据的读写;mongodb从5到30万秒都有,一年按100万秒计算,一年也能完成上百万条数据的读写。它们都是共享内存对象,锁定的对象时间越短、空间越小,整体的效率越高。
当然redis的持久化需要自己封装一套。bitcoin在reputation共识中没有持久化对象(只有放着不动的对象),持久化以后一直可以拿来写数据。另外两种分布式都可以满足这些要求。其他分布式不用考虑持久化对象问题,比如memcached中bucket本身就是一个对象。不过,如果你能驾驭mhash,那么可以尝试用自己封装过的redis/mongodb来实现实时数据同步。
可以先看看《黑客与画家》或者《c++primerplus》,因为这两本书把很多知识讲清楚了,其实是讲mongodb最重要的东西,mongodb不会太吃内存,性能也可以。 查看全部
ajax抓取网页内容(ajax抓取网页内容可以使用以下两个工具:ajax库)
ajax抓取网页内容可以使用以下两个工具:requests库:,通过它接受参数后做ajax请求获取网页内容cookie:使用浏览器的cookie可以获取页面内容。
还记得前段时间很火的redis和mongodb吗?它们本质上都是锁定的内存对象的集合。按照空间复杂度来算的话redis从2到4都有,一年按3万秒计算,一年可以完成上百万上千万甚至上亿条数据的读写;mongodb从5到30万秒都有,一年按100万秒计算,一年也能完成上百万条数据的读写。它们都是共享内存对象,锁定的对象时间越短、空间越小,整体的效率越高。
当然redis的持久化需要自己封装一套。bitcoin在reputation共识中没有持久化对象(只有放着不动的对象),持久化以后一直可以拿来写数据。另外两种分布式都可以满足这些要求。其他分布式不用考虑持久化对象问题,比如memcached中bucket本身就是一个对象。不过,如果你能驾驭mhash,那么可以尝试用自己封装过的redis/mongodb来实现实时数据同步。
可以先看看《黑客与画家》或者《c++primerplus》,因为这两本书把很多知识讲清楚了,其实是讲mongodb最重要的东西,mongodb不会太吃内存,性能也可以。
ajax抓取网页内容(Ajax,全称为andXML,即异步的JavaScript和XML)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-21 11:10
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新网页部分而不刷新页面和页面链接不改变的技术。
对于传统的网页,如果要更新它的内容,就必须刷新整个页面,但是使用Ajax,你可以在不刷新整个页面的情况下更新页面的内容。在这个过程中,页面实际上是在后台与服务器交互的。获取到数据后,通过JavaScript来改变网页,从而更新网页的内容。
您可以在 W3School 上体验一些示例来感受一下:。
1.示例介绍
在浏览网页时,我们会发现很多页面已经向下滚动以查看更多选项。比如以微博为例,我们以我的个人主页为例:切换到微博页面,一直往下滑,你会发现往下滑了几条微博,就不会再往下了,一加载就会而是出现。片刻之后,下方不断出现新的微博内容。这个过程其实就是Ajax加载的过程,如图6-1所示。
我们注意到页面并没有完全刷新,也就是说页面上的链接没有变化,但是页面中有新的内容,也就是后来刷新的新微博。这就是通过 Ajax 获取新数据并呈现的内容。
2. 基本原理
在初步了解了Ajax之后,我们再来详细了解一下它的基本原理。向网页更新发送Ajax请求的过程可以简单分为以下3个步骤:
(1) 发送请求;(2) 解析内容;(3) 渲染网页。
我们将在下面详细描述这些过程。
发送请求
我们知道JavaScript可以实现页面的各种交互功能,Ajax也不例外。也是用JavaScript实现的,实际执行如下代码:
var xmlhttp;
if (window.XMLHttpRequest) {
// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp=new XMLHttpRequest();
} else {// code for IE6, IE5
xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.onreadystatechange=function() {
if (xmlhttp.readyState==4 && xmlhttp.status==200) {
document.getElementById("myDiv").innerHTML=xmlhttp.responseText;
}
}
xmlhttp.open("POST","/ajax/",true);
xmlhttp.send();
这是由 JavaScript 实现的 Ajax 的底层实现。其实就是新建一个XMLHttpRequest对象,然后调用onreadystatechange属性设置监听,然后调用open()和send()方法发送到一个链接(也就是服务器)。问。在Python中发送请求后,可以得到响应结果,但是这里请求是发送给JavaScript的。由于设置了监控,所以当服务器返回响应时,会触发onreadystatechange对应的方法,然后在这个方法中解析响应内容即可。
解析内容
得到响应后会触发onreadystatechange属性对应的方法,可以通过xmlhttp的responseText属性获取响应内容。这类似于 Python 中使用 requests 向服务器发起请求,然后得到响应的过程。那么返回的内容可能是 HTML,也可能是 JSON,然后你只需要在方法中使用 JavaScript 进行进一步处理即可。例如,如果是JSON,则可以解析转换。
渲染网页
JavaScript 具有更改网页内容的能力。解析响应内容后,可以调用 JavaScript 对网页进行解析处理。例如,通过document.getElementById().innerHTML等操作,可以改变元素中的源代码,从而改变网页上显示的内容。该操作也称为DOM操作,即对Document网页的Document操作,如更改、删除等。
上面的例子中,document.getElementById("myDiv").innerHTML=xmlhttp.responseText会将ID为myDiv的节点内部的HTML代码改成服务器返回的内容,这样服务器返回的内容将显示在 myDiv 元素内。使用新数据后,页面的某些部分似乎已更新。
我们观察到这3个步骤实际上是由JavaScript完成的,它完成了请求、解析和渲染的整个过程。
回想一下微博的pull-to-refresh,这其实就是JavaScript向服务端发送Ajax请求,然后获取新的微博数据,解析,呈现在网页中。
因此,我们知道,真正的数据实际上是从一次又一次的Ajax请求中获取的。如果你想捕获这些数据,你需要知道这些请求是如何发送的,发送到哪里,发送了什么参数。如果我们知道这一点,难道我们不能用 Python 来模拟这个发送操作并得到结果吗?
在下一节中,我们将学习在哪里可以看到这些后台 Ajax 操作,它是如何发送的,以及发送哪些参数。
以上是Ajax在Python3爬虫中使用的详细内容。关于Python3中Ajax是什么的更多信息,请关注上的其他相关话题文章! 查看全部
ajax抓取网页内容(Ajax,全称为andXML,即异步的JavaScript和XML)
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新网页部分而不刷新页面和页面链接不改变的技术。
对于传统的网页,如果要更新它的内容,就必须刷新整个页面,但是使用Ajax,你可以在不刷新整个页面的情况下更新页面的内容。在这个过程中,页面实际上是在后台与服务器交互的。获取到数据后,通过JavaScript来改变网页,从而更新网页的内容。
您可以在 W3School 上体验一些示例来感受一下:。
1.示例介绍
在浏览网页时,我们会发现很多页面已经向下滚动以查看更多选项。比如以微博为例,我们以我的个人主页为例:切换到微博页面,一直往下滑,你会发现往下滑了几条微博,就不会再往下了,一加载就会而是出现。片刻之后,下方不断出现新的微博内容。这个过程其实就是Ajax加载的过程,如图6-1所示。

我们注意到页面并没有完全刷新,也就是说页面上的链接没有变化,但是页面中有新的内容,也就是后来刷新的新微博。这就是通过 Ajax 获取新数据并呈现的内容。
2. 基本原理
在初步了解了Ajax之后,我们再来详细了解一下它的基本原理。向网页更新发送Ajax请求的过程可以简单分为以下3个步骤:
(1) 发送请求;(2) 解析内容;(3) 渲染网页。
我们将在下面详细描述这些过程。
发送请求
我们知道JavaScript可以实现页面的各种交互功能,Ajax也不例外。也是用JavaScript实现的,实际执行如下代码:
var xmlhttp;
if (window.XMLHttpRequest) {
// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp=new XMLHttpRequest();
} else {// code for IE6, IE5
xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.onreadystatechange=function() {
if (xmlhttp.readyState==4 && xmlhttp.status==200) {
document.getElementById("myDiv").innerHTML=xmlhttp.responseText;
}
}
xmlhttp.open("POST","/ajax/",true);
xmlhttp.send();
这是由 JavaScript 实现的 Ajax 的底层实现。其实就是新建一个XMLHttpRequest对象,然后调用onreadystatechange属性设置监听,然后调用open()和send()方法发送到一个链接(也就是服务器)。问。在Python中发送请求后,可以得到响应结果,但是这里请求是发送给JavaScript的。由于设置了监控,所以当服务器返回响应时,会触发onreadystatechange对应的方法,然后在这个方法中解析响应内容即可。
解析内容
得到响应后会触发onreadystatechange属性对应的方法,可以通过xmlhttp的responseText属性获取响应内容。这类似于 Python 中使用 requests 向服务器发起请求,然后得到响应的过程。那么返回的内容可能是 HTML,也可能是 JSON,然后你只需要在方法中使用 JavaScript 进行进一步处理即可。例如,如果是JSON,则可以解析转换。
渲染网页
JavaScript 具有更改网页内容的能力。解析响应内容后,可以调用 JavaScript 对网页进行解析处理。例如,通过document.getElementById().innerHTML等操作,可以改变元素中的源代码,从而改变网页上显示的内容。该操作也称为DOM操作,即对Document网页的Document操作,如更改、删除等。
上面的例子中,document.getElementById("myDiv").innerHTML=xmlhttp.responseText会将ID为myDiv的节点内部的HTML代码改成服务器返回的内容,这样服务器返回的内容将显示在 myDiv 元素内。使用新数据后,页面的某些部分似乎已更新。
我们观察到这3个步骤实际上是由JavaScript完成的,它完成了请求、解析和渲染的整个过程。
回想一下微博的pull-to-refresh,这其实就是JavaScript向服务端发送Ajax请求,然后获取新的微博数据,解析,呈现在网页中。
因此,我们知道,真正的数据实际上是从一次又一次的Ajax请求中获取的。如果你想捕获这些数据,你需要知道这些请求是如何发送的,发送到哪里,发送了什么参数。如果我们知道这一点,难道我们不能用 Python 来模拟这个发送操作并得到结果吗?
在下一节中,我们将学习在哪里可以看到这些后台 Ajax 操作,它是如何发送的,以及发送哪些参数。
以上是Ajax在Python3爬虫中使用的详细内容。关于Python3中Ajax是什么的更多信息,请关注上的其他相关话题文章!
如何在nodejs中使用json和path和json?抓取网页内容
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-05-01 06:01
ajax抓取网页内容可以说是基本的前端知识了,目前前端团队对于前端源码的格式化都基本采用xml的方式,比如有人使用xml+json,有人使用javascript的调用,这篇文章介绍一下如何在nodejs中使用json和path。一、json格式jsonjson(javascriptobjectnotation)是javascriptobjecttype的缩写,它是一种数据交换格式,该格式支持传递和索引一个xml或json对象的属性,而不需要将它们传递给解析器。
xml是一种可扩展的语言标记格式,它是由afp(adobeformproject)编写的,是最受欢迎的格式之一。二、pathxmlpathxml是webpagesapi的一个path标签。浏览器端解析成path的格式,将解析为json形式,再由ajax发送给服务器,服务器从json的格式取到内容在处理成前端格式。
<p>path可以为指定的路径,指定属性名,不同的路径有不同的解析规则,这里用前端json数据返回给前端的格式示例。公司简介美团 查看全部
如何在nodejs中使用json和path和json?抓取网页内容
ajax抓取网页内容可以说是基本的前端知识了,目前前端团队对于前端源码的格式化都基本采用xml的方式,比如有人使用xml+json,有人使用javascript的调用,这篇文章介绍一下如何在nodejs中使用json和path。一、json格式jsonjson(javascriptobjectnotation)是javascriptobjecttype的缩写,它是一种数据交换格式,该格式支持传递和索引一个xml或json对象的属性,而不需要将它们传递给解析器。
xml是一种可扩展的语言标记格式,它是由afp(adobeformproject)编写的,是最受欢迎的格式之一。二、pathxmlpathxml是webpagesapi的一个path标签。浏览器端解析成path的格式,将解析为json形式,再由ajax发送给服务器,服务器从json的格式取到内容在处理成前端格式。
<p>path可以为指定的路径,指定属性名,不同的路径有不同的解析规则,这里用前端json数据返回给前端的格式示例。公司简介美团
北京SEO优化,北京网站优化,关键词优化,关键词排名,网站权重提升
网站优化 • 优采云 发表了文章 • 0 个评论 • 361 次浏览 • 2022-04-29 01:14
北京SEO优化,北京网站优化,关键词优化,关键词排名,网站权重提升,抖音SEO优化,快速排名
1、服务器
任何一个网站的流量发展,对服务器都是一个巨大的考验,因此了解服务器本身的运作原理是很有必要的,当网站出现异常时,要能够第一时间知晓事故,并找出原因,当服务器恢复正常后,必须使用站长工具测试一次网站抓取的正常性。
2、HTML
作为一个大站SEO,关注的也许就不仅仅是关键词密度或者是H1标签了,更多的是需要去发现页面上的一些重要内容是否可以在HTML代码中找到,如果无法找到,则可能是采用了Ajax异步加载,这往往导致搜索引擎无法抓取,从而降低页面评分。
3、数据库
关注网站的数据结构,可以帮助你更清晰地定义URL规则以及网站的TKD信息,并且在你优化网页页面质量的时候,更方便地调用你想要的内容信息,所以SEO从业人员必须了解网站的数据结构。
4、内部链接与外链资源
内部链接及外部链接的作用是一样的,都是为了蜘蛛能够顺利爬取,并提升页面质量。利用这些方法,可以有效提升一些目标关键词的排名。
5、关键词挖掘与归类
关键词如何挖掘与归类?这取决于SEO从业者的归类逻辑思维能力。以最常见的电商B2C网站来说,大多数的人分析行业内所有关键词之后,就会发现一些规律,例如流量关键词构成主要是“产品关键词”、“品牌关键词”等,因此对于关键词要善于挖掘与归类。
查看全部
北京SEO优化,北京网站优化,关键词优化,关键词排名,网站权重提升
北京SEO优化,北京网站优化,关键词优化,关键词排名,网站权重提升,抖音SEO优化,快速排名
1、服务器
任何一个网站的流量发展,对服务器都是一个巨大的考验,因此了解服务器本身的运作原理是很有必要的,当网站出现异常时,要能够第一时间知晓事故,并找出原因,当服务器恢复正常后,必须使用站长工具测试一次网站抓取的正常性。
2、HTML
作为一个大站SEO,关注的也许就不仅仅是关键词密度或者是H1标签了,更多的是需要去发现页面上的一些重要内容是否可以在HTML代码中找到,如果无法找到,则可能是采用了Ajax异步加载,这往往导致搜索引擎无法抓取,从而降低页面评分。
3、数据库
关注网站的数据结构,可以帮助你更清晰地定义URL规则以及网站的TKD信息,并且在你优化网页页面质量的时候,更方便地调用你想要的内容信息,所以SEO从业人员必须了解网站的数据结构。
4、内部链接与外链资源
内部链接及外部链接的作用是一样的,都是为了蜘蛛能够顺利爬取,并提升页面质量。利用这些方法,可以有效提升一些目标关键词的排名。
5、关键词挖掘与归类
关键词如何挖掘与归类?这取决于SEO从业者的归类逻辑思维能力。以最常见的电商B2C网站来说,大多数的人分析行业内所有关键词之后,就会发现一些规律,例如流量关键词构成主要是“产品关键词”、“品牌关键词”等,因此对于关键词要善于挖掘与归类。
ajax抓取网页内容(亿速云Key值来获取URL中的请求参数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-04-16 09:25
本文章主要介绍jquery如何获取url和url参数,有一定的参考价值。有兴趣的朋友可以参考一下。我希望您在阅读此文章 后会有所收获。小编带大家一探究竟。
在网页的Get方法中传递参数时,有时会在网页后面添加Get请求参数。在页面的前端,我们可以使用jquery来获取Url地址中的参数信息,通过对URL地址参数进行划分。要获取,可以封装成Jquery方法,通过对应的Key值获取URL中的请求参数。
首先在页面中引入Jquery.js文件,然后在$(document)函数中定义一个公共函数getUrlParam。如下:
(函数($){
$.getUrlParam=函数(名称){
var reg=new RegExp("(^|&)" + name + "=([^&]*)(&|$)");
var r=window.location.search.substr(1).match(reg);
if (r !=null) return unescape(r[2]);返回空值;
}
}) (jQuery);
定义方法后,我们可以使用以下方法获取URL中的参数值。
获取URL中的id值:id=$.getUrlParam("id");
感谢你仔细阅读这篇文章,希望小编分享的《Jquery中如何获取url和url参数》的文章文章对你有所帮助,也希望支持亿速云,关注易速云行业资讯频道,更多相关知识等你学习! 查看全部
ajax抓取网页内容(亿速云Key值来获取URL中的请求参数)
本文章主要介绍jquery如何获取url和url参数,有一定的参考价值。有兴趣的朋友可以参考一下。我希望您在阅读此文章 后会有所收获。小编带大家一探究竟。
在网页的Get方法中传递参数时,有时会在网页后面添加Get请求参数。在页面的前端,我们可以使用jquery来获取Url地址中的参数信息,通过对URL地址参数进行划分。要获取,可以封装成Jquery方法,通过对应的Key值获取URL中的请求参数。
首先在页面中引入Jquery.js文件,然后在$(document)函数中定义一个公共函数getUrlParam。如下:
(函数($){
$.getUrlParam=函数(名称){
var reg=new RegExp("(^|&)" + name + "=([^&]*)(&|$)");
var r=window.location.search.substr(1).match(reg);
if (r !=null) return unescape(r[2]);返回空值;
}
}) (jQuery);
定义方法后,我们可以使用以下方法获取URL中的参数值。
获取URL中的id值:id=$.getUrlParam("id");
感谢你仔细阅读这篇文章,希望小编分享的《Jquery中如何获取url和url参数》的文章文章对你有所帮助,也希望支持亿速云,关注易速云行业资讯频道,更多相关知识等你学习!
ajax抓取网页内容(Web网络爬虫系统的原理及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-04-13 15:01
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发让Nutch适合提取业务,那你基本上会破坏Nutch的框架,把Nutch改得面目全非,而且有能力修改Nutch,还不如自己写一个新的。分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。这个Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发很简单,难点和复杂的问题已经被前人解决了(比如DOM树解析定位、字符集检测、海量URL去重),可以说没有技术含量。包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫是否可以使用代理,爬虫是否可以爬取重复数据,爬虫是否可以爬取JS生成的信息?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?另一个爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,无论大小。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一页面,或者同一账号在短时间内多次执行同一操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理。随机几秒钟的请求可能经常被阻止。如果有多个帐户,切换使用它们会更有效。 查看全部
ajax抓取网页内容(Web网络爬虫系统的原理及应用)
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发让Nutch适合提取业务,那你基本上会破坏Nutch的框架,把Nutch改得面目全非,而且有能力修改Nutch,还不如自己写一个新的。分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。这个Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发很简单,难点和复杂的问题已经被前人解决了(比如DOM树解析定位、字符集检测、海量URL去重),可以说没有技术含量。包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫是否可以使用代理,爬虫是否可以爬取重复数据,爬虫是否可以爬取JS生成的信息?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?另一个爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,无论大小。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一页面,或者同一账号在短时间内多次执行同一操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理。随机几秒钟的请求可能经常被阻止。如果有多个帐户,切换使用它们会更有效。
ajax抓取网页内容( 北京交通大学计算机与信息技术学院北京100044摘要(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-04-13 14:37
北京交通大学计算机与信息技术学院北京100044摘要(组图))
第 38 卷,第 10 期,专辑,2011 年 10 月,计算机科学 Vol38No. 10SuppComputerScience0ct2011采集Ajan Web Crawler Research and Implementation Wang Jia Wei Huiqin 北京交通大学计算机与信息学院 北京 100044 摘要 使用浏览器API操作网页元素,模拟用户行为采集Aj Qiang 网页信息是基于同一个站点上同类型Ajax网页结构的相似性。预处理阶段在系统动态信息前添加采集在Ajax网页中寻找有效触发元素,并制定有效触发元素的规范和模式分类采集规则实现快速Ajax网页信息采集关键词 Ajax 网络爬虫在地图方法分类号 TP393 文档识别码 AResearchandImplementofAjaxWebCrawler 王家卫惠琴计算机系北京交通大学13eijina100044ChinaAhtnct通过浏览器API和模拟WebelementsasuserbehaviortO采集Ajax网页。基于 Ajax 页面的结构相似性,我们在系统的 8 层站点中添加了一个预处理阶段来定位有效的触发 Web 元素。沉积物的代码和模式分类制定了每个站点的采集规则。这些规则实现了 Aiax Web 信息的快速获取。Keywor Taipa AjaxWebcrfwleAquot1 简介随着Web2.0的兴起,越来越多的网站开始应用AjaxAsynchronousJavaScfiptAndXml,即异步JavaScfipt和XML技术。它以异步方式向服务器发送请求并检索所需的数据,从而减少了服务器和浏览器的数量。[11]之间交换的数据量,该技术的应用大大提升了用户体验,节省了存储空间,但是给普通的网络爬虫带来了困难,即采集信息基于网页源文件[21本文使用浏览器AP1并模拟用户行为操作网页元素完成采集 Ajax网页信息之二 相关原理 通常Ajax网站的网页信息是根据请求从数据库中读取数据并嵌入到模板 论文答辩ppt模板 赌博协议模板 国考答题卡国考高考数学答题卡数据图表显示在网页上,因此同类型的mdash站点的网页具有结构相似性【引用mdash Aiax网页有多个网页元素会导致异步交互改变网页信息。其中,能够产生有效信息的网页元素称为有效触发元素。网页中也有一些元素。它的操作往往只是改变字体颜色或本地信息等。如果对这些网页元素进行操作,系统的效率将大大降低。因此,在每个站点的动态信息之前应该增加一个预处理阶段,以找到有效的触发元素并制定采集规则实现Aiax网页信息的快速性采集3铷杯网页信息采集3.1 相关数据结构 Ajax网页有多个网页信息展示 本文将每个网页信息称为Ajax状态 可以引起异步交互网页元素的Ajax网页的Xpath以及对该元素的操作调用hiax 事件。hiax 网页可以显示政党活动家的条目数和毫米数。表示为二元组 VEgtV 表示 hiax 状态 E 是 hiax 事件 [ldquo 如图 1 所示,图一,图一,图一,图一,图一,瓦冈页面状态转换图,王轩大师。主要研究方向是计算机网络与数据库 E-mnilowmgi 婚姻 163.00ln Dian ■ 秦暖教授的研究方向是计算机网络与数据库。middot196middot 此示例图解释如下。点击状态sl的ldquo/body/div[1]/a[2]rdquo表示的网页元素。可以在状态 S3 中转换到状态 SzI。将鼠标移动到ldquoIbodyldiv[1]/a[2]rdquo表示的网页元素上,可以转换为状态s2等。3.2 有效 3.1 相关数据结构 Ajax 网页有多个网页信息显示。在本文中,每个网页信息都称为 Ajax 状态,而能够引起Ajax网页异步交互的网页元素的Xpath以及对该元素的操作称为hiax事件。一个hiax网页可以 党员考核表项数和毫米表 教师职称等级对照表 职工考核评分表 普通年金现值系数表示作为二元组VEgtV表示hiax状态E是hiax事件[ldquo如图1所示图lAj瓦冈页面状态转换图,王艳女大师。主要研究方向是计算机网络与数据库 E-mnilowmgi 婚姻 163.00ln Dian ■ 秦暖教授的研究方向是计算机网络与数据库。middot196middot 此示例图解释如下。点击状态sl的ldquo/body/div[1]/a[2]rdquo表示的网页元素。可以在状态 S3 中转换到状态 SzI。将鼠标移动到ldquoIbodyldiv[1]/a[2]rdquo表示的网页元素上,可以转换为状态s2等。3.2 有效
样例网页采用全检测扫描的方法来查找网页中的有效元素。查找过程如下: 1PrcccdmPmpmcpainitORL2 获取初始状态,构建该状态的DOM,并保存状态的标识和状态的内容。whUe 仍然有未处理的状态 4 如果状态是第一次处理并且 5 保持状态。获取触发事件表 6d7 查询触发事件表 8wⅦe 请说明还有事件需要处理 9 触发事件 10 获取触发事件后的状态 11.1f 给Aiax的新状态有效 12. 添加新的对应标识获得了Ajldquo的野心加状态库到logo库。13. 遇到触发事件前的状态 14. endwhile15endwhile 该流程图中有两个存储结构状态标识库和状态库状态标识库,用于存储每十个Ajax状态标识。状态的hiax事件操作的网页元素的XPath是从状态序号的起始状态和状态的XPath得到的。DOM树组合状态库保存Ajax状态的序号所有内容处理_番口是根据网页链接获取的初始状态浏览器自动执行过程中的重要步骤如下1触发事件列表是通过遍历AjaX 状态的 DOM 树 得到的结果是基于对每个站点的分析。Feng系统中找到的火灾事件的元素仅限于a标签中的元素,div 标签和 spangt 标签。2 必须确定新获得的Ajax状态的有效性。有效性判断不仅要满足hiax状态结构的相似性,还要判断内容的出现。为了改变,系统使用简单的树匹配算法03来检测Ajax状态的结构相似度,如果少数节点的内容发生了变化,则确定Ajax状态下相似度较大的DOM节点的内容。那么就认为是无效的Aj8x状态。将保存的Ajax状态添加到状态库中,相应的标记添加到状态标记库中。3 状态再现由于浏览器目前不支持返回到Aj8X状态的操作,返回执行动作之前的状态是基于从有向状态转移图中得到的4个周期完成对样本触发元素的搜索。由于状态标识符库收录有效的 Ajax 状态标识符,因此可以从页面中提取有效的触发元素 XPeth 和相应的操作。因此,在推理完成后会得到网页中的有效信息。有效触发元素规范 对找到的有效触发元素进行元素序列号规范,其中每个触发元素的名称和动作都相同。例如,对于这种类型的触发元素,ldquo/body/div[8]/div[1]/div[1]/ul/li[3]/adlckrdquoldquo/body/div[8]/div[1]/dlv[1]/ul/li[ 4]/acli baseldquo/body/div[8]/dlv[1]/div[1]/ul/li[5]/ac11cp还原结果为ldquo/lmdy/div[8]/div[1]/div[ 1]/ul/ll[]/aclIckrdquo2 有效触发元素水平分类对这些有效触发元素的研究表明,这些触发元素可以分为两种模式。一种是独立模式,另一种是关联模式——独立模式。这种模式意味着每个元素代表一个 Aj8x 状态。例如图2中,以文本为数字的页面元素,每个A页面元素代表一页评论信息—— Day 1 图2 独立模式 模式2 关联模式 在该模式下,每个状态都与之前的状态相关触发事件。例如,一类对搜狗新闻评论有效的触发元素。@采集系统根据元素的文本信息完成信息的排序采集对于米德兰模式的动态信息搜索系统,系统搜索固定网页元素采集例如,在图3的情况下。系统在当前Ajax状态下寻找带有文本ldquo下一页rdquo的有效触发元素触发该元素完成信息采集设置4j Ajax页面信息采集@ >Stage Ajax网页信息采集Stage是根据上一个stage得到的各个页面的有效页面触发元素的Xpath,以及需要越来越多的事件,以及的pattern信息这样的元素来完成动态信息<
iondick/Motion//带有触发元素的操作Model2/Modell/触发元素模式1为独立模式2为关联模式1etgt下一页/Text//有效触发元素的文本/Option此规则收录有效触发元素的Xpath动作模式文本信息还可以根据系统的需要设置存储路径等信息。4 实验结果对触发元件进行了协议处理。我们没有进一步分类有效的触发元素。我们随机采集 3条腾讯新闻评论为待处理 根据站点有效触发元素规则采集选取网页的实验结果如表1所示。实验结果与测试结果对比数据见表一。@采集 动态信息的效率降低了有效信息的重复采集结束语本文提出了一种高效的动态网页采集该方法首先为每个站点选择一些样本网页,并利用页面的相似度发现网页的有效性触发元素和法规,对有效触发元素进行分类,为每个站点建立动态网页信息采集规则实现Ajax网页有效信息的快速性采集由于Ajax站点信息的动态特性,建立相应的重复采集机制是未来研究的重点[6]参考DudaCFreyCKossmannDeta1。AJAXSearchCrawlingIn-dexingandSearchingW song 2. 0ApplicationsACM2008VLDBEndowmentMesbahA80IXlagEVanDeursenACrawlingAJAXbyInfer-ringUserInterfaceStatechallginfin 口]。IEEE。DOI10.1109/IgtWE200824 夏兵,高军,杨冬青等.一种高效的动态脚本网站有效的页面获取方法[J]. 软件研究所中国科学院 Scimdashenceamp 软件杂志 200920l176-189DudaCFreyCKossmannDeta1. Aj "AXCrawllMakingAJAXApplicationSearchable[J]. IEEE. DOI10.1109/IcDE200990 何欣谢志鹏. 基于简单树匹配算法的网页结构相似度测量[J]. 计算机研究与开发200711mdash1777/TPl1-6 Summer. Ajax站点数据采集研究综述[J].情报分析与研究 2010t52mdash57 续第 185 页 ltluenumerationvaluerdquo2rdquo/gtltxsenumerationvaluerdquo3rdquo/gtltxsenumerationvaluerdquo4rdquo/gtltxsenumerationvaluerdquo5rdquo/gt/xsrestrictionlt/xssimpleTypelt/x。sschema 结语 高职商务日语专业教学资源数据库系统实现了实用日语视听日语报刊杂志、旅游日语等课程的Web教学资源的录入,自我评价和自主 评估大量多媒体材料,引导学生朝着明确的目标朝着更加主动和自主的方向学习。在后续工作中,我们将充分考虑系统的个性化服务功能。不断丰富、拓展和完善教学资源,实现高职院校优质资源的共建。共享服务经济社会发展 参考文献[13 全国信息技术标准化技术委员会教育技术分技术委员会。基础教育教学资源元数据规范。http//万维网。凯尔特人。cllE23 孙波。傅伟。基于webService的开放式教育资源图书馆系统研究D]. 中国电子教育2003.1079[33李家厚. 吴振华。陈双银等。美国教育资源门户及其对我国教育资源建设的启示[J]. 电子教育研究2003.867]]]]]]口心口H口西孙博.傅伟。基于webService的开放式教育资源图书馆系统研究D]. 中国电子教育2003.1079[33李家厚. 吴振华。陈双银等。美国教育资源门户及其对我国教育资源建设的启示[J]. 电子教育研究2003.867]]]]]]口心口H口西孙博.傅伟。基于webService的开放式教育资源图书馆系统研究D]. 中国电子教育2003.1079[33李家厚. 吴振华。陈双银等。美国教育资源门户及其对我国的启示 s 教育资源建设[J].电子教育研究2003.867]]]]]]口心口H口西 查看全部
ajax抓取网页内容(
北京交通大学计算机与信息技术学院北京100044摘要(组图))
第 38 卷,第 10 期,专辑,2011 年 10 月,计算机科学 Vol38No. 10SuppComputerScience0ct2011采集Ajan Web Crawler Research and Implementation Wang Jia Wei Huiqin 北京交通大学计算机与信息学院 北京 100044 摘要 使用浏览器API操作网页元素,模拟用户行为采集Aj Qiang 网页信息是基于同一个站点上同类型Ajax网页结构的相似性。预处理阶段在系统动态信息前添加采集在Ajax网页中寻找有效触发元素,并制定有效触发元素的规范和模式分类采集规则实现快速Ajax网页信息采集关键词 Ajax 网络爬虫在地图方法分类号 TP393 文档识别码 AResearchandImplementofAjaxWebCrawler 王家卫惠琴计算机系北京交通大学13eijina100044ChinaAhtnct通过浏览器API和模拟WebelementsasuserbehaviortO采集Ajax网页。基于 Ajax 页面的结构相似性,我们在系统的 8 层站点中添加了一个预处理阶段来定位有效的触发 Web 元素。沉积物的代码和模式分类制定了每个站点的采集规则。这些规则实现了 Aiax Web 信息的快速获取。Keywor Taipa AjaxWebcrfwleAquot1 简介随着Web2.0的兴起,越来越多的网站开始应用AjaxAsynchronousJavaScfiptAndXml,即异步JavaScfipt和XML技术。它以异步方式向服务器发送请求并检索所需的数据,从而减少了服务器和浏览器的数量。[11]之间交换的数据量,该技术的应用大大提升了用户体验,节省了存储空间,但是给普通的网络爬虫带来了困难,即采集信息基于网页源文件[21本文使用浏览器AP1并模拟用户行为操作网页元素完成采集 Ajax网页信息之二 相关原理 通常Ajax网站的网页信息是根据请求从数据库中读取数据并嵌入到模板 论文答辩ppt模板 赌博协议模板 国考答题卡国考高考数学答题卡数据图表显示在网页上,因此同类型的mdash站点的网页具有结构相似性【引用mdash Aiax网页有多个网页元素会导致异步交互改变网页信息。其中,能够产生有效信息的网页元素称为有效触发元素。网页中也有一些元素。它的操作往往只是改变字体颜色或本地信息等。如果对这些网页元素进行操作,系统的效率将大大降低。因此,在每个站点的动态信息之前应该增加一个预处理阶段,以找到有效的触发元素并制定采集规则实现Aiax网页信息的快速性采集3铷杯网页信息采集3.1 相关数据结构 Ajax网页有多个网页信息展示 本文将每个网页信息称为Ajax状态 可以引起异步交互网页元素的Ajax网页的Xpath以及对该元素的操作调用hiax 事件。hiax 网页可以显示政党活动家的条目数和毫米数。表示为二元组 VEgtV 表示 hiax 状态 E 是 hiax 事件 [ldquo 如图 1 所示,图一,图一,图一,图一,图一,瓦冈页面状态转换图,王轩大师。主要研究方向是计算机网络与数据库 E-mnilowmgi 婚姻 163.00ln Dian ■ 秦暖教授的研究方向是计算机网络与数据库。middot196middot 此示例图解释如下。点击状态sl的ldquo/body/div[1]/a[2]rdquo表示的网页元素。可以在状态 S3 中转换到状态 SzI。将鼠标移动到ldquoIbodyldiv[1]/a[2]rdquo表示的网页元素上,可以转换为状态s2等。3.2 有效 3.1 相关数据结构 Ajax 网页有多个网页信息显示。在本文中,每个网页信息都称为 Ajax 状态,而能够引起Ajax网页异步交互的网页元素的Xpath以及对该元素的操作称为hiax事件。一个hiax网页可以 党员考核表项数和毫米表 教师职称等级对照表 职工考核评分表 普通年金现值系数表示作为二元组VEgtV表示hiax状态E是hiax事件[ldquo如图1所示图lAj瓦冈页面状态转换图,王艳女大师。主要研究方向是计算机网络与数据库 E-mnilowmgi 婚姻 163.00ln Dian ■ 秦暖教授的研究方向是计算机网络与数据库。middot196middot 此示例图解释如下。点击状态sl的ldquo/body/div[1]/a[2]rdquo表示的网页元素。可以在状态 S3 中转换到状态 SzI。将鼠标移动到ldquoIbodyldiv[1]/a[2]rdquo表示的网页元素上,可以转换为状态s2等。3.2 有效
样例网页采用全检测扫描的方法来查找网页中的有效元素。查找过程如下: 1PrcccdmPmpmcpainitORL2 获取初始状态,构建该状态的DOM,并保存状态的标识和状态的内容。whUe 仍然有未处理的状态 4 如果状态是第一次处理并且 5 保持状态。获取触发事件表 6d7 查询触发事件表 8wⅦe 请说明还有事件需要处理 9 触发事件 10 获取触发事件后的状态 11.1f 给Aiax的新状态有效 12. 添加新的对应标识获得了Ajldquo的野心加状态库到logo库。13. 遇到触发事件前的状态 14. endwhile15endwhile 该流程图中有两个存储结构状态标识库和状态库状态标识库,用于存储每十个Ajax状态标识。状态的hiax事件操作的网页元素的XPath是从状态序号的起始状态和状态的XPath得到的。DOM树组合状态库保存Ajax状态的序号所有内容处理_番口是根据网页链接获取的初始状态浏览器自动执行过程中的重要步骤如下1触发事件列表是通过遍历AjaX 状态的 DOM 树 得到的结果是基于对每个站点的分析。Feng系统中找到的火灾事件的元素仅限于a标签中的元素,div 标签和 spangt 标签。2 必须确定新获得的Ajax状态的有效性。有效性判断不仅要满足hiax状态结构的相似性,还要判断内容的出现。为了改变,系统使用简单的树匹配算法03来检测Ajax状态的结构相似度,如果少数节点的内容发生了变化,则确定Ajax状态下相似度较大的DOM节点的内容。那么就认为是无效的Aj8x状态。将保存的Ajax状态添加到状态库中,相应的标记添加到状态标记库中。3 状态再现由于浏览器目前不支持返回到Aj8X状态的操作,返回执行动作之前的状态是基于从有向状态转移图中得到的4个周期完成对样本触发元素的搜索。由于状态标识符库收录有效的 Ajax 状态标识符,因此可以从页面中提取有效的触发元素 XPeth 和相应的操作。因此,在推理完成后会得到网页中的有效信息。有效触发元素规范 对找到的有效触发元素进行元素序列号规范,其中每个触发元素的名称和动作都相同。例如,对于这种类型的触发元素,ldquo/body/div[8]/div[1]/div[1]/ul/li[3]/adlckrdquoldquo/body/div[8]/div[1]/dlv[1]/ul/li[ 4]/acli baseldquo/body/div[8]/dlv[1]/div[1]/ul/li[5]/ac11cp还原结果为ldquo/lmdy/div[8]/div[1]/div[ 1]/ul/ll[]/aclIckrdquo2 有效触发元素水平分类对这些有效触发元素的研究表明,这些触发元素可以分为两种模式。一种是独立模式,另一种是关联模式——独立模式。这种模式意味着每个元素代表一个 Aj8x 状态。例如图2中,以文本为数字的页面元素,每个A页面元素代表一页评论信息—— Day 1 图2 独立模式 模式2 关联模式 在该模式下,每个状态都与之前的状态相关触发事件。例如,一类对搜狗新闻评论有效的触发元素。@采集系统根据元素的文本信息完成信息的排序采集对于米德兰模式的动态信息搜索系统,系统搜索固定网页元素采集例如,在图3的情况下。系统在当前Ajax状态下寻找带有文本ldquo下一页rdquo的有效触发元素触发该元素完成信息采集设置4j Ajax页面信息采集@ >Stage Ajax网页信息采集Stage是根据上一个stage得到的各个页面的有效页面触发元素的Xpath,以及需要越来越多的事件,以及的pattern信息这样的元素来完成动态信息<
iondick/Motion//带有触发元素的操作Model2/Modell/触发元素模式1为独立模式2为关联模式1etgt下一页/Text//有效触发元素的文本/Option此规则收录有效触发元素的Xpath动作模式文本信息还可以根据系统的需要设置存储路径等信息。4 实验结果对触发元件进行了协议处理。我们没有进一步分类有效的触发元素。我们随机采集 3条腾讯新闻评论为待处理 根据站点有效触发元素规则采集选取网页的实验结果如表1所示。实验结果与测试结果对比数据见表一。@采集 动态信息的效率降低了有效信息的重复采集结束语本文提出了一种高效的动态网页采集该方法首先为每个站点选择一些样本网页,并利用页面的相似度发现网页的有效性触发元素和法规,对有效触发元素进行分类,为每个站点建立动态网页信息采集规则实现Ajax网页有效信息的快速性采集由于Ajax站点信息的动态特性,建立相应的重复采集机制是未来研究的重点[6]参考DudaCFreyCKossmannDeta1。AJAXSearchCrawlingIn-dexingandSearchingW song 2. 0ApplicationsACM2008VLDBEndowmentMesbahA80IXlagEVanDeursenACrawlingAJAXbyInfer-ringUserInterfaceStatechallginfin 口]。IEEE。DOI10.1109/IgtWE200824 夏兵,高军,杨冬青等.一种高效的动态脚本网站有效的页面获取方法[J]. 软件研究所中国科学院 Scimdashenceamp 软件杂志 200920l176-189DudaCFreyCKossmannDeta1. Aj "AXCrawllMakingAJAXApplicationSearchable[J]. IEEE. DOI10.1109/IcDE200990 何欣谢志鹏. 基于简单树匹配算法的网页结构相似度测量[J]. 计算机研究与开发200711mdash1777/TPl1-6 Summer. Ajax站点数据采集研究综述[J].情报分析与研究 2010t52mdash57 续第 185 页 ltluenumerationvaluerdquo2rdquo/gtltxsenumerationvaluerdquo3rdquo/gtltxsenumerationvaluerdquo4rdquo/gtltxsenumerationvaluerdquo5rdquo/gt/xsrestrictionlt/xssimpleTypelt/x。sschema 结语 高职商务日语专业教学资源数据库系统实现了实用日语视听日语报刊杂志、旅游日语等课程的Web教学资源的录入,自我评价和自主 评估大量多媒体材料,引导学生朝着明确的目标朝着更加主动和自主的方向学习。在后续工作中,我们将充分考虑系统的个性化服务功能。不断丰富、拓展和完善教学资源,实现高职院校优质资源的共建。共享服务经济社会发展 参考文献[13 全国信息技术标准化技术委员会教育技术分技术委员会。基础教育教学资源元数据规范。http//万维网。凯尔特人。cllE23 孙波。傅伟。基于webService的开放式教育资源图书馆系统研究D]. 中国电子教育2003.1079[33李家厚. 吴振华。陈双银等。美国教育资源门户及其对我国教育资源建设的启示[J]. 电子教育研究2003.867]]]]]]口心口H口西孙博.傅伟。基于webService的开放式教育资源图书馆系统研究D]. 中国电子教育2003.1079[33李家厚. 吴振华。陈双银等。美国教育资源门户及其对我国教育资源建设的启示[J]. 电子教育研究2003.867]]]]]]口心口H口西孙博.傅伟。基于webService的开放式教育资源图书馆系统研究D]. 中国电子教育2003.1079[33李家厚. 吴振华。陈双银等。美国教育资源门户及其对我国的启示 s 教育资源建设[J].电子教育研究2003.867]]]]]]口心口H口西
ajax抓取网页内容(什么是Cookie及模拟登录的操作流程:Ajax加载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-04-13 07:14
我们在使用python进行爬取的时候,可能遇到过一些网页直接请求的html代码,并没有我们需要的数据,也就是我们在浏览器中看到的。
这是因为信息是通过 Ajax 加载并通过 js 渲染生成的。这时,我们需要分析这个网页的请求。
上一篇给大家讲解了什么是cookie以及模拟登录的操作流程。今天给大家带来如何分析网页的ajax请求。
什么是阿贾克斯
AJAX 是“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
AJAX = 异步 JavaScript 和 XML(标准通用标记语言的子集)。
AJAX 是一种用于创建快速、动态网页的技术。
AJAX 是一种无需重新加载整个网页即可更新部分网页的技术。
简单地说,就是加载了网页。浏览器地址栏中的 URL 没有改变。是javascript异步加载的网页,应该是ajax。AJAX一般通过XMLHttpRequest对象接口发送请求,一般简称为XHR。
分析简而言之网站点
我们的目标网站是用壳网来分析。
我们可以看到这个网页没有翻页按钮,当我们不断拉下请求时,网页会自动为我们加载更多内容。但是,当我们查看网页 url 时,它并没有随着页面加载请求而改变。而当我们直接请求这个url时,显然只能获取到第一页的html内容。
那么我们如何获取所有页面的数据呢?
我们在Chrome中打开开发者工具(F12)。我们点击Network,点击XHR选项卡。然后我们刷新页面并拉下请求。这时候我们可以看到XHR选项卡,每次页面加载会弹出一个请求。
我们点击第一个请求,可以看到他的参数:retrieve_type:by_subject
限制:20
偏移量:18
-:86
点击第二个请求后,参数如下:retrieve_type:by_subject
限制:20
偏移量:38
-:87
limit参数是网页每页被限制加载的文章个数,offset是页数。然后往下看,我们会发现每次请求的offset参数都会增加20。
然后我们查看每个请求的响应内容,这是一个格式化的数据。我们点击结果按钮,可以看到20条文章的数据信息。这样我们就成功找到了我们需要的信息的位置,在请求头中可以看到json数据存放的url地址。
爬取过程
分析Ajax请求,获取每个页面的文章url信息;解析每个文章,获取需要的数据;将获取的数据保存在数据库中;打开多个进程,爬了很多。
开始
我们的工具仍然使用 BeautifulSoup 解析的请求。
我们需要构造这个 URL。# 导入可能用到的模块
导入请求
从 urllib.parse 导入 urlencode
从 requests.exceptions 导入 ConnectionError
# 获取索引页面的信息
def get_index(偏移量):
base_url = '#39;
数据 = {
'retrieve_type': "by_subject",
'限制':“20”,
“偏移量”:偏移量
}
参数 = urlencode(数据)
url = base_url + 参数
尝试:
resp = requests.get(url)
如果 resp.status_code == 200:
返回对应文本
返回无
除了连接错误:
打印('错误。')
返回无
我们将从上面分析页面得到的请求参数构造成字典数据,然后我们可以手动构造url,但是urllib库已经为我们提供了编码方式,我们可以直接使用它来构造完整的url。然后是请求页面内容的标准请求。导入json
# 解析json,得到文章url
def parse_json(文本):
尝试:
结果 = json.loads(文本)
如果结果:
对于我在 result.get('result') 中:
# 打印(i.get('url'))
产量 i.get('url')
除了:
经过
我们使用 josn.loads 方法解析 json 并将其转换为 json 对象。然后直接通过字典的操作,得到文章的url地址。这里使用yield为每个请求返回一个url,以减少内存消耗。由于后面爬的时候会弹出一个json解析错误,这里直接过滤就好了。
这里我们可以尝试打印看看是否运行成功。
既然获取了文章的url,那么获取文章的数据就很简单了。此处不作详细说明。目标是获取 文章 的标题、作者和内容。
由于有的文章收录了一些图片,所以我们可以过滤掉文章内容中的图片。从 bs4 导入 BeautifulSoup
# 解析 文章 页面
def parse_page(文本):
尝试:
汤= BeautifulSoup(文本,'lxml')
content = soup.find('div', class_="content")
标题 = content.find('h1',).get_text()
作者 = content.find('div', class_="content-th-info").find('a').get_text()
article_content = content.find('div', class_="document").find_all('p')
all_p = [i.get_text() for i in article_content if not i.find('img') and not i.find('a')]
文章 = '\n'.join(all_p)
# 打印(标题,'\n',作者,'\n',文章)
数据 = {
'标题':标题,
“作者”:作者,
“文章”:文章
}
返回数据
除了:
经过
这里,在进行多进程爬取的时候,BeautifulSoup也会报错,还是直接过滤。我们将得到的数据以字典的形式保存,方便保存数据库。
下一步是保存数据库的操作。这里我们使用MongoDB进行数据存储。导入pymongo
从配置导入 *
客户端 = pymongo.MongoClient(MONGO_URL, 27017)
db = 客户[MONGO_DB]
def save_database(数据):
如果 db[MONGO_TABLE].insert(data):
print('保存到数据库成功', data)
返回真
返回假
我们将数据库名和表名保存在config配置文件中,并将配置信息导入到文件中,这样会方便代码的管理。
最后,由于诺虎网的数据还是很多的,如果我们想抓取很多数据,可以使用多进程。从多处理导入池
# 定义一个主函数
定义主(偏移):
文本 = get_index(偏移量)
all_url = parse_json(文本)
对于 all_url 中的 url:
resp = get_page(url)
数据 = parse_page(resp)
如果数据:
保存数据库(数据)
如果 __name__ == '__main__':
池 = 池()
偏移量 = ([0] + [i*20+18 for i in range(500)])
pool.map(主要,偏移量)
池.close()
pool.join()
该函数的参数偏移量是页数。经过我的观察,国科网的最后一个页码是12758,有637页。在这里,我们抓取了 500 个页面。进程池的map方法类似于Python内置的map方法。
那么对于一些使用Ajax加载的网页,我们可以这样爬取。 查看全部
ajax抓取网页内容(什么是Cookie及模拟登录的操作流程:Ajax加载)
我们在使用python进行爬取的时候,可能遇到过一些网页直接请求的html代码,并没有我们需要的数据,也就是我们在浏览器中看到的。
这是因为信息是通过 Ajax 加载并通过 js 渲染生成的。这时,我们需要分析这个网页的请求。
上一篇给大家讲解了什么是cookie以及模拟登录的操作流程。今天给大家带来如何分析网页的ajax请求。
什么是阿贾克斯
AJAX 是“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),它指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
AJAX = 异步 JavaScript 和 XML(标准通用标记语言的子集)。
AJAX 是一种用于创建快速、动态网页的技术。
AJAX 是一种无需重新加载整个网页即可更新部分网页的技术。
简单地说,就是加载了网页。浏览器地址栏中的 URL 没有改变。是javascript异步加载的网页,应该是ajax。AJAX一般通过XMLHttpRequest对象接口发送请求,一般简称为XHR。
分析简而言之网站点
我们的目标网站是用壳网来分析。
我们可以看到这个网页没有翻页按钮,当我们不断拉下请求时,网页会自动为我们加载更多内容。但是,当我们查看网页 url 时,它并没有随着页面加载请求而改变。而当我们直接请求这个url时,显然只能获取到第一页的html内容。
那么我们如何获取所有页面的数据呢?
我们在Chrome中打开开发者工具(F12)。我们点击Network,点击XHR选项卡。然后我们刷新页面并拉下请求。这时候我们可以看到XHR选项卡,每次页面加载会弹出一个请求。
我们点击第一个请求,可以看到他的参数:retrieve_type:by_subject
限制:20
偏移量:18
-:86
点击第二个请求后,参数如下:retrieve_type:by_subject
限制:20
偏移量:38
-:87
limit参数是网页每页被限制加载的文章个数,offset是页数。然后往下看,我们会发现每次请求的offset参数都会增加20。
然后我们查看每个请求的响应内容,这是一个格式化的数据。我们点击结果按钮,可以看到20条文章的数据信息。这样我们就成功找到了我们需要的信息的位置,在请求头中可以看到json数据存放的url地址。
爬取过程
分析Ajax请求,获取每个页面的文章url信息;解析每个文章,获取需要的数据;将获取的数据保存在数据库中;打开多个进程,爬了很多。
开始
我们的工具仍然使用 BeautifulSoup 解析的请求。
我们需要构造这个 URL。# 导入可能用到的模块
导入请求
从 urllib.parse 导入 urlencode
从 requests.exceptions 导入 ConnectionError
# 获取索引页面的信息
def get_index(偏移量):
base_url = '#39;
数据 = {
'retrieve_type': "by_subject",
'限制':“20”,
“偏移量”:偏移量
}
参数 = urlencode(数据)
url = base_url + 参数
尝试:
resp = requests.get(url)
如果 resp.status_code == 200:
返回对应文本
返回无
除了连接错误:
打印('错误。')
返回无
我们将从上面分析页面得到的请求参数构造成字典数据,然后我们可以手动构造url,但是urllib库已经为我们提供了编码方式,我们可以直接使用它来构造完整的url。然后是请求页面内容的标准请求。导入json
# 解析json,得到文章url
def parse_json(文本):
尝试:
结果 = json.loads(文本)
如果结果:
对于我在 result.get('result') 中:
# 打印(i.get('url'))
产量 i.get('url')
除了:
经过
我们使用 josn.loads 方法解析 json 并将其转换为 json 对象。然后直接通过字典的操作,得到文章的url地址。这里使用yield为每个请求返回一个url,以减少内存消耗。由于后面爬的时候会弹出一个json解析错误,这里直接过滤就好了。
这里我们可以尝试打印看看是否运行成功。
既然获取了文章的url,那么获取文章的数据就很简单了。此处不作详细说明。目标是获取 文章 的标题、作者和内容。
由于有的文章收录了一些图片,所以我们可以过滤掉文章内容中的图片。从 bs4 导入 BeautifulSoup
# 解析 文章 页面
def parse_page(文本):
尝试:
汤= BeautifulSoup(文本,'lxml')
content = soup.find('div', class_="content")
标题 = content.find('h1',).get_text()
作者 = content.find('div', class_="content-th-info").find('a').get_text()
article_content = content.find('div', class_="document").find_all('p')
all_p = [i.get_text() for i in article_content if not i.find('img') and not i.find('a')]
文章 = '\n'.join(all_p)
# 打印(标题,'\n',作者,'\n',文章)
数据 = {
'标题':标题,
“作者”:作者,
“文章”:文章
}
返回数据
除了:
经过
这里,在进行多进程爬取的时候,BeautifulSoup也会报错,还是直接过滤。我们将得到的数据以字典的形式保存,方便保存数据库。
下一步是保存数据库的操作。这里我们使用MongoDB进行数据存储。导入pymongo
从配置导入 *
客户端 = pymongo.MongoClient(MONGO_URL, 27017)
db = 客户[MONGO_DB]
def save_database(数据):
如果 db[MONGO_TABLE].insert(data):
print('保存到数据库成功', data)
返回真
返回假
我们将数据库名和表名保存在config配置文件中,并将配置信息导入到文件中,这样会方便代码的管理。
最后,由于诺虎网的数据还是很多的,如果我们想抓取很多数据,可以使用多进程。从多处理导入池
# 定义一个主函数
定义主(偏移):
文本 = get_index(偏移量)
all_url = parse_json(文本)
对于 all_url 中的 url:
resp = get_page(url)
数据 = parse_page(resp)
如果数据:
保存数据库(数据)
如果 __name__ == '__main__':
池 = 池()
偏移量 = ([0] + [i*20+18 for i in range(500)])
pool.map(主要,偏移量)
池.close()
pool.join()
该函数的参数偏移量是页数。经过我的观察,国科网的最后一个页码是12758,有637页。在这里,我们抓取了 500 个页面。进程池的map方法类似于Python内置的map方法。
那么对于一些使用Ajax加载的网页,我们可以这样爬取。
ajax抓取网页内容(网页有相当一部分的技术简单一点讲就是事件驱动吧())
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-04-07 16:26
原C#抓取AJAX页面内容
目前相当一部分网页使用了AJAX技术。所谓AJAX技术,就是简单的事件驱动(当然,这种说法可能并不全面)。提交网址后,服务器给你发送的不是全部都是页面内容,但很大一部分是JS脚本,可以使用了
但是我们用IE浏览页面是正常的,所以唯一的解决办法就是使用WebBrowser控件
但是使用Webbrowser你会发现,在DownloadComplete事件中,你根本无法知道页面是什么时候真正加载的!
当然,带有 Frame 的单个网页可能会触发多次 Complete。即使在Navigated事件中使用了计数器方法,即++和--在DownloadComplete中,执行完JS后仍然无法得到结果。一开始我也觉得很奇怪,直到后来GG相关的AJAX文章,明白原因了。
最终的解决方案是使用WebBrowser+Timer来解决爬取页面的问题
关键还是页面状态,我们可以使用webBrowser1.StatusText,如果返回“完成”,说明页面加载完毕!
示例代码如下:
private void timer1_Tick(object sender, EventArgs e)
{
webBrowser1.导航(Url);
if (webBrowser1.StatusText == "Done")
{
定时器1.启用=假;
//页面加载完毕,做点别的事情
}
} 查看全部
ajax抓取网页内容(网页有相当一部分的技术简单一点讲就是事件驱动吧())
原C#抓取AJAX页面内容
目前相当一部分网页使用了AJAX技术。所谓AJAX技术,就是简单的事件驱动(当然,这种说法可能并不全面)。提交网址后,服务器给你发送的不是全部都是页面内容,但很大一部分是JS脚本,可以使用了
但是我们用IE浏览页面是正常的,所以唯一的解决办法就是使用WebBrowser控件
但是使用Webbrowser你会发现,在DownloadComplete事件中,你根本无法知道页面是什么时候真正加载的!
当然,带有 Frame 的单个网页可能会触发多次 Complete。即使在Navigated事件中使用了计数器方法,即++和--在DownloadComplete中,执行完JS后仍然无法得到结果。一开始我也觉得很奇怪,直到后来GG相关的AJAX文章,明白原因了。
最终的解决方案是使用WebBrowser+Timer来解决爬取页面的问题
关键还是页面状态,我们可以使用webBrowser1.StatusText,如果返回“完成”,说明页面加载完毕!
示例代码如下:
private void timer1_Tick(object sender, EventArgs e)
{
webBrowser1.导航(Url);
if (webBrowser1.StatusText == "Done")
{
定时器1.启用=假;
//页面加载完毕,做点别的事情
}
}
ajax抓取网页内容(Ajax技术将用户名设置为root,密码设置一致将提示密码错误)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-04-06 14:26
简要地
网页的局部刷新功能在网络上并不少见网站,比如实时新闻信息、股票信息等,都需要不断获取最新信息。在传统的web实现中,要达到类似的效果,必须刷新整个页面。在网速受到一定程度限制的情况下,这种因局部变化而影响整个页面的处理方式似乎有点吃亏。Ajax 技术的出现很好地解决了这个问题。使用Ajax技术可以实现网页的部分刷新,只更新指定的数据,不更新其他数据。本文通过一个登录案例来介绍ajax的使用。
登录html键码
账号:
密码:
登录
分析:在传统项目中,要向后台提交表单数据,我们都使用表单表单。这时候,使用ajax技术,我们将摒弃之前的表单提交方式。
ajax键码
$("#btn_login").click(function() {
$.ajax({
url : "login.do",
type : "post",
data : {
username : $("input[name=username]").val(),
password : $("input[name=password]").val()
},
dataType : "json",
success : function(result) {
var flag = result.flag;
if (flag == true) {
alert("密码正确!");
} else {
alert("密码错误!");
}
}
});
});
分析:使用ajax技术需要依赖jQuery,所以在使用ajax的时候需要引入jQuery包
ajax 语法特性
url:请求地址
type:传递方式(get/post)
data:用来传递的数据
success:交互成功后要执行的方法
dataType:ajax接收后台数据的类型
servlet 密钥代码
protected void doPost(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
//获取用户名和密码
String username = req.getParameter("username");
String password = req.getParameter("password");
//创建json对象
JSONObject jsonObject = null;
if ("root".equals(username) && "123456".equals(password)) {
jsonObject = new JSONObject("{flag:true}");
} else {
jsonObject = new JSONObject("{flag:false}");
}
//将数据返回给ajax
resp.getOutputStream().write(jsonObject.toString().getBytes("utf-8"));
}
分析:如图,我们将用户名设置为root,密码设置为123456,如果用户输入与设置一致,则提示密码正确,否则提示密码错误!
打开应用程序并阅读笔记 查看全部
ajax抓取网页内容(Ajax技术将用户名设置为root,密码设置一致将提示密码错误)
简要地
网页的局部刷新功能在网络上并不少见网站,比如实时新闻信息、股票信息等,都需要不断获取最新信息。在传统的web实现中,要达到类似的效果,必须刷新整个页面。在网速受到一定程度限制的情况下,这种因局部变化而影响整个页面的处理方式似乎有点吃亏。Ajax 技术的出现很好地解决了这个问题。使用Ajax技术可以实现网页的部分刷新,只更新指定的数据,不更新其他数据。本文通过一个登录案例来介绍ajax的使用。
登录html键码
账号:
密码:
登录
分析:在传统项目中,要向后台提交表单数据,我们都使用表单表单。这时候,使用ajax技术,我们将摒弃之前的表单提交方式。
ajax键码
$("#btn_login").click(function() {
$.ajax({
url : "login.do",
type : "post",
data : {
username : $("input[name=username]").val(),
password : $("input[name=password]").val()
},
dataType : "json",
success : function(result) {
var flag = result.flag;
if (flag == true) {
alert("密码正确!");
} else {
alert("密码错误!");
}
}
});
});
分析:使用ajax技术需要依赖jQuery,所以在使用ajax的时候需要引入jQuery包
ajax 语法特性
url:请求地址
type:传递方式(get/post)
data:用来传递的数据
success:交互成功后要执行的方法
dataType:ajax接收后台数据的类型
servlet 密钥代码
protected void doPost(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
//获取用户名和密码
String username = req.getParameter("username");
String password = req.getParameter("password");
//创建json对象
JSONObject jsonObject = null;
if ("root".equals(username) && "123456".equals(password)) {
jsonObject = new JSONObject("{flag:true}");
} else {
jsonObject = new JSONObject("{flag:false}");
}
//将数据返回给ajax
resp.getOutputStream().write(jsonObject.toString().getBytes("utf-8"));
}
分析:如图,我们将用户名设置为root,密码设置为123456,如果用户输入与设置一致,则提示密码正确,否则提示密码错误!
打开应用程序并阅读笔记
ajax抓取网页内容(ajax抓取网页内容是用javascript的方式实现(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-04-06 02:01
ajax抓取网页内容确实是用javascript的方式实现,爬虫软件基本都带有这些工具,手动爬绝对有难度,同时抓取一些很短的javascript可以试试只取链接,
能不能先搞清楚什么是动态代理?有本书大部分章节解释了动态代理。
可以先看看原理,再配合工具加速抓取,最后我推荐一些正则和xpath的工具来弄,然后也配合multicharts抓取外部二进制数据进行html测试一下。
可以用google爬虫啊。我自己写的地球爬虫,技术门槛不高,知道原理后可以边学边玩。的热力图爬虫我就用这个做的。缺点是抓取下来的数据格式是json。推荐试一下html解析工具。
不了解技术的可以用框架开发爬虫。
一、数据抓取xml比较好处理,可以直接读取xml数据库,由框架给xml格式做解析xml支持json支持。但是ajax自身兼容性不好(以后代替flash,svg等的替代品吧),xml解析难度高,抓取就需要不断尝试不断处理处理之后再ajax解析。
二、xpath各种方式都可以做解析,但是ajax自身兼容性不好(以后代替flash,svg等的替代品吧),xml解析难度高,抓取就需要不断尝试不断处理处理之后再ajax解析。
三、abstractxpath。不过只能抓取abstract的字符串,abcnames/abclass/abcnamethat/abcnamespace/abctype为abstract的才能抓取。如果abstract定义太多值,就抓取不到。这样真的很浪费内存。
四、smilesweeticons2d,orasymlaseconst="../../input-extended.xml"可以用来获取整张图片的内容,图片内容可以上传到服务器进行下载。
五、再详细一点可以用python写个html字典自己传给框架来解析,还是抓取需要抓取的字符串的时候容易一些。
六、还有headercrawl。这里写一些原理可以帮助大家找到更好的解决方案。
浏览器访问一个页面会发送一个http请求,
4)applewebkit/537。36(khtml,likegecko)chrome/53。2780。106safari/537。36","accept":"*/*","accept-encoding":"gzip,deflate","accept-language":"zh-cn,zh;q=0。9","connection":"k。 查看全部
ajax抓取网页内容(ajax抓取网页内容是用javascript的方式实现(图))
ajax抓取网页内容确实是用javascript的方式实现,爬虫软件基本都带有这些工具,手动爬绝对有难度,同时抓取一些很短的javascript可以试试只取链接,
能不能先搞清楚什么是动态代理?有本书大部分章节解释了动态代理。
可以先看看原理,再配合工具加速抓取,最后我推荐一些正则和xpath的工具来弄,然后也配合multicharts抓取外部二进制数据进行html测试一下。
可以用google爬虫啊。我自己写的地球爬虫,技术门槛不高,知道原理后可以边学边玩。的热力图爬虫我就用这个做的。缺点是抓取下来的数据格式是json。推荐试一下html解析工具。
不了解技术的可以用框架开发爬虫。
一、数据抓取xml比较好处理,可以直接读取xml数据库,由框架给xml格式做解析xml支持json支持。但是ajax自身兼容性不好(以后代替flash,svg等的替代品吧),xml解析难度高,抓取就需要不断尝试不断处理处理之后再ajax解析。
二、xpath各种方式都可以做解析,但是ajax自身兼容性不好(以后代替flash,svg等的替代品吧),xml解析难度高,抓取就需要不断尝试不断处理处理之后再ajax解析。
三、abstractxpath。不过只能抓取abstract的字符串,abcnames/abclass/abcnamethat/abcnamespace/abctype为abstract的才能抓取。如果abstract定义太多值,就抓取不到。这样真的很浪费内存。
四、smilesweeticons2d,orasymlaseconst="../../input-extended.xml"可以用来获取整张图片的内容,图片内容可以上传到服务器进行下载。
五、再详细一点可以用python写个html字典自己传给框架来解析,还是抓取需要抓取的字符串的时候容易一些。
六、还有headercrawl。这里写一些原理可以帮助大家找到更好的解决方案。
浏览器访问一个页面会发送一个http请求,
4)applewebkit/537。36(khtml,likegecko)chrome/53。2780。106safari/537。36","accept":"*/*","accept-encoding":"gzip,deflate","accept-language":"zh-cn,zh;q=0。9","connection":"k。
ajax抓取网页内容(Ajax为什么在数据可视化大屏中这么流行?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-04-05 03:09
为什么 Ajax 在大屏数据可视化中如此受欢迎?数据可视化大屏使用ajax的原理是什么?事实上,很多数据可视化大屏软件在具体实现传值时都需要用到ajax。比如帆软的FineReport大屏显示就是这个原理。本文详细介绍了AJAX是什么,如何在数据可视化大屏上使用AJAX,以及相关的工具系统有哪些。
一、什么是 AJAX?
AJAX = Asynchronous JavaScript and XML,是异步的 JavaScript 和 XML。
AJAX 不是一种新的编程语言,而是一种使用现有标准的新方法,一种用于创建快速、动态网页的技术。AJAX 允许异步更新网页。通俗地说,就是更新网页的一部分,而不需要重新加载整个网页。在传统网页(没有 AJAX)中,如果需要更新内容,则必须重新加载整个网页。使用AJAX的应用案例很多:新浪微博、谷歌地图、开心网等。
2005 年,Google 通过其 Google Suggest 使 AJAX 流行起来。
二、如何在数据可视化大屏上使用ajax?原理如下
在数据可视化的大屏上,哪里可以使用ajax?值传递的具体实现需要使用ajax,数据可视化大屏的后端可以用java开发。当需要数据时,触发前台的ajax向后台发送命令获取数据。帆软FineReport的大屏显示就是基于这个原理。
一种方法是通过ajax和后台实现图表来实现jsonarray和jsonobject类型的传输(具体传输格式请参考数据可视化大屏软件中的代码)。
另一种方法是生成.json文件,在前端使用$.get获取文件中的json数据,从而生成大屏数据可视化图表。
其实这两种数据可视化大屏ajax应用的原理基本相同,都是从前端获取json数据的过程。
三、数据可视化大屏ajax的相关工具系统有哪些?1、精细报告
FineReport是一款功能齐全的纯Java数据可视化大屏工具软件。它制作的数据图表的优点是有一些动画特效,可以更清晰的显示信息数据,而且颜值很高。使用门槛极低,帮助文档很详细,有用,也很成熟。常被企业用户用来辅助业务流程管理人员做出更合理的管理决策。FineReport为个人免费试用,FineReport商业版需要付费。
2、Highcharts
Highcharts的优点是兼容性好,应用广泛。缺点是样式比较陈旧,图表难以扩展;商业用途需要购买版权。
3、图表
Echarts 经常与 Hightchart 进行比较。企业自身直接连接数据库时,展示可以集成Echarts和Hightchart插件,传值时使用ajax。缺点也类似,就是你自己开发这个开源的数据可视化大屏工具时,会涉及到复杂的语法设计,导致使用和学习成本高。比如想要使用AJAX,就需要灵活掌握HTML/XHTML、CSS、JavaScript/DOM等知识。 查看全部
ajax抓取网页内容(Ajax为什么在数据可视化大屏中这么流行?(一))
为什么 Ajax 在大屏数据可视化中如此受欢迎?数据可视化大屏使用ajax的原理是什么?事实上,很多数据可视化大屏软件在具体实现传值时都需要用到ajax。比如帆软的FineReport大屏显示就是这个原理。本文详细介绍了AJAX是什么,如何在数据可视化大屏上使用AJAX,以及相关的工具系统有哪些。
一、什么是 AJAX?
AJAX = Asynchronous JavaScript and XML,是异步的 JavaScript 和 XML。
AJAX 不是一种新的编程语言,而是一种使用现有标准的新方法,一种用于创建快速、动态网页的技术。AJAX 允许异步更新网页。通俗地说,就是更新网页的一部分,而不需要重新加载整个网页。在传统网页(没有 AJAX)中,如果需要更新内容,则必须重新加载整个网页。使用AJAX的应用案例很多:新浪微博、谷歌地图、开心网等。
2005 年,Google 通过其 Google Suggest 使 AJAX 流行起来。
二、如何在数据可视化大屏上使用ajax?原理如下
在数据可视化的大屏上,哪里可以使用ajax?值传递的具体实现需要使用ajax,数据可视化大屏的后端可以用java开发。当需要数据时,触发前台的ajax向后台发送命令获取数据。帆软FineReport的大屏显示就是基于这个原理。
一种方法是通过ajax和后台实现图表来实现jsonarray和jsonobject类型的传输(具体传输格式请参考数据可视化大屏软件中的代码)。
另一种方法是生成.json文件,在前端使用$.get获取文件中的json数据,从而生成大屏数据可视化图表。
其实这两种数据可视化大屏ajax应用的原理基本相同,都是从前端获取json数据的过程。
三、数据可视化大屏ajax的相关工具系统有哪些?1、精细报告
FineReport是一款功能齐全的纯Java数据可视化大屏工具软件。它制作的数据图表的优点是有一些动画特效,可以更清晰的显示信息数据,而且颜值很高。使用门槛极低,帮助文档很详细,有用,也很成熟。常被企业用户用来辅助业务流程管理人员做出更合理的管理决策。FineReport为个人免费试用,FineReport商业版需要付费。
2、Highcharts
Highcharts的优点是兼容性好,应用广泛。缺点是样式比较陈旧,图表难以扩展;商业用途需要购买版权。
3、图表
Echarts 经常与 Hightchart 进行比较。企业自身直接连接数据库时,展示可以集成Echarts和Hightchart插件,传值时使用ajax。缺点也类似,就是你自己开发这个开源的数据可视化大屏工具时,会涉及到复杂的语法设计,导致使用和学习成本高。比如想要使用AJAX,就需要灵活掌握HTML/XHTML、CSS、JavaScript/DOM等知识。
ajax抓取网页内容(用requests抓取页面的结果是什么?如何去分析和Ajax请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-04 07:19
当我们使用requests对页面进行爬取时,得到的结果可能与我们在浏览器中看到的不一样:在浏览器中正常显示的页面数据,但是使用requests却没有得到任何结果。这是因为请求都是原创的 HTML 文档,而浏览器中的页面是 JavaScript 数据处理的结果。这些数据有多种来源,可能通过 Ajax 加载,可能收录在 HTML 文档中,也可能由 JavaScript 和特定算法生成。
对于第一种情况,数据加载是一种异步加载方式。原创页面将不收录某些数据。只有加载完成后,才会向服务器请求一个接口获取数据,然后将数据处理并呈现给网页。上面,这个过程实际上是向服务器接口发送一个 Ajax 请求。
根据Web的发展趋势,这种形式的页面将会越来越多。网页的原创HTML文档不收录任何数据,通过Ajax统一加载后呈现数据,这样在Web开发中可以分离前后端,服务器直接渲染带来的压力页面缩小。
所以如果遇到这样的页面,直接使用requests之类的库爬取原创页面是无法获取有效数据的。这时候我们就需要分析网页后端向接口发送的Ajax请求了。如果我们可以使用requests来模拟ajax请求,就可以成功抓取。
因此,在本课中,我们将学习什么是 Ajax,以及如何分析和抓取 Ajax 请求。
什么是阿贾克斯
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新网页的部分内容而不刷新页面且页面链接不改变的技术。
传统网页,如果要更新其内容,就必须刷新整个页面。使用 Ajax,可以在不完全刷新的情况下更新页面内容。在这个过程中,页面实际上是在后台与服务器交互的。获取到数据后,使用 JavaScript 改变网页,从而更新网页的内容。
你可以去 W3School 体验几个 demo 来感受一下:
示例介绍
在浏览网页的时候,我们会发现很多网页已经向下滚动,可以查看更多选项。以我的微博主页为例:. 当我们切换到微博页面,发现往下滑了几条微博后,后面的内容并不会直接显示出来,而是会出现一个加载动画。加载完成后,下方会不断出现新的微博内容。这个过程其实就是Ajax加载的过程,如图:
我们注意到页面并没有完全刷新,也就是说页面的链接没有变化,但是页面中有新的内容,也就是后来刷新的新微博。这就是通过 Ajax 获取和呈现新数据的方式。
基本的
在对Ajax有了初步的了解之后,我们再来详细了解一下它的基本原理。向网页更新发送 Ajax 请求的过程可以简单分为以下 3 个步骤:
下面我们将详细描述这些过程中的每一个。
发送请求
我们知道JavaScript可以实现页面的各种交互功能,Ajax也不例外。它由 JavaScript 实现,实际执行如下代码:
这是 JavaScript 对 Ajax 的底层实现。这个过程其实就是新建一个XMLHttpRequest对象,然后调用onreadystatechange属性设置监听,最后调用open()和send()方法向一个链接(即服务器)发送请求。
我们使用 Python 发送请求后,可以得到响应结果,但是这里的请求是通过 JavaScript 发送的。由于设置了监听器,当服务器返回响应时,会触发onreadystatechange对应的方法,我们可以在这个方法中解析响应内容。
解析内容
得到响应后会触发onreadystatechange属性对应的方法,可以通过xmlhttp的responseText属性获取响应内容。这类似于 Python 中使用 requests 向服务器发出请求,然后得到响应的过程。
返回的内容可能是 HTML 或 JSON,然后我们只需要在方法中使用 JavaScript 进一步处理即可。例如,如果返回的内容是 JSON,我们可以对其进行解析和转换。
呈现网页
JavaScript 具有更改网页内容的能力。解析响应内容后,可以调用 JavaScript 对网页进行解析处理。例如,通过document.getElementById().innerHTML的操作,改变一个元素中的源代码,从而改变网页上显示的内容。也称为更改和删除 Document 网页文档等操作。进行 DOM 操作。
在上面的例子中,操作 document.getElementById(“myDiv”).innerHTML=xmlhttp.responseText 会将 ID 为 myDiv 的节点内部的 HTML 代码更改为服务器返回的内容,从而使服务器返回的新内容将显示在 myDiv 元素内。数据,部分页面似乎已更新。
可以看到,发送请求、解析内容、渲染网页这三个步骤实际上都是由 JavaScript 完成的。
回想一下微博的下拉刷新,其实就是一个JavaScript向服务器发送Ajax请求,然后获取新的微博数据,解析,呈现在网页中的过程。
因此,真正的数据实际上是通过一次又一次的ajax请求获得的。如果我们想捕获这些数据,我们需要知道这些请求是如何发送的,发送到哪里,发送了什么参数。如果我们知道这一点,难道我们不能用 Python 来模拟这个发送操作并得到结果吗?
阿贾克斯分析
这里我们还是以之前的微博为例。我们知道拖拽刷新的内容是通过ajax加载的,页面的url没有变化。这时候,我们应该去哪里查看这些Ajax请求呢?
这里还需要用到浏览器的开发者工具。下面是Chrome浏览器的介绍。
首先用Chrome浏览器打开微博链接,然后在页面上右击,在弹出的快捷菜单中选择“检查”选项,会弹出开发者工具,如图:
如前所述,这里是页面加载过程中浏览器和服务器之间发送请求和接收响应的所有记录。
Ajax 有其特殊的请求类型,称为 xhr。在图中,我们可以找到一个以getIndex开头的请求,其Type为xhr,是一个Ajax请求。用鼠标点击请求,查看请求的详细信息。
右侧可以看到Request Headers、URL、Response Headers等信息。Request Headers中的信息之一是X-Requested-With:XMLHttpRequest,将请求标记为Ajax请求,如图:
然后我们点击 Preview 可以看到响应的内容,是 JSON 格式的。在这里,Chrome 会自动为我们解析它。单击箭头可展开和折叠相应的内容。
我们可以观察到返回的结果是我的个人信息,包括昵称、简介、头像等,这也是用于渲染个人主页的数据。JavaScript 接收到数据后,执行相应的渲染方法,整个页面都被渲染出来了。
另外,我们还可以切换到Response选项卡,观察真实的返回数据,如图:
接下来,切换回第一个请求,观察它的Response是什么,如图:
这是原创链接返回的内容,不到 50 行代码,结构非常简单,只是执行了一些 JavaScript。
因此,我们看到的微博页面的真实数据并不是原创页面返回的,而是在执行完 JavaScript 后,再次向后台发送 Ajax 请求,浏览器获取数据并进一步渲染。
过滤请求
接下来,我们使用 Chrome DevTools 的过滤功能过滤掉所有的 Ajax 请求。请求上方有一层过滤栏,直接点击XHR,那么下面显示的所有请求都是Ajax请求,如图:
接下来继续滑动页面,可以看到页面底部有新的微博滑动,开发者工具下不断出现Ajax请求,这样我们就可以捕获所有的Ajax请求。
随意打开一个entry,可以清晰的看到它的Request URL、Request Headers、Response Headers、Response Body等,这时候模拟请求和提取就很简单了。
下图显示的内容是我的一个微博页面的列表信息:
至此,我们已经能够分析出一些Ajax请求的详细信息了。接下来,我们只需要用程序模拟这些Ajax请求,就可以很方便的提取出我们需要的信息了。
参考文章 查看全部
ajax抓取网页内容(用requests抓取页面的结果是什么?如何去分析和Ajax请求)
当我们使用requests对页面进行爬取时,得到的结果可能与我们在浏览器中看到的不一样:在浏览器中正常显示的页面数据,但是使用requests却没有得到任何结果。这是因为请求都是原创的 HTML 文档,而浏览器中的页面是 JavaScript 数据处理的结果。这些数据有多种来源,可能通过 Ajax 加载,可能收录在 HTML 文档中,也可能由 JavaScript 和特定算法生成。
对于第一种情况,数据加载是一种异步加载方式。原创页面将不收录某些数据。只有加载完成后,才会向服务器请求一个接口获取数据,然后将数据处理并呈现给网页。上面,这个过程实际上是向服务器接口发送一个 Ajax 请求。
根据Web的发展趋势,这种形式的页面将会越来越多。网页的原创HTML文档不收录任何数据,通过Ajax统一加载后呈现数据,这样在Web开发中可以分离前后端,服务器直接渲染带来的压力页面缩小。
所以如果遇到这样的页面,直接使用requests之类的库爬取原创页面是无法获取有效数据的。这时候我们就需要分析网页后端向接口发送的Ajax请求了。如果我们可以使用requests来模拟ajax请求,就可以成功抓取。
因此,在本课中,我们将学习什么是 Ajax,以及如何分析和抓取 Ajax 请求。
什么是阿贾克斯
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新网页的部分内容而不刷新页面且页面链接不改变的技术。
传统网页,如果要更新其内容,就必须刷新整个页面。使用 Ajax,可以在不完全刷新的情况下更新页面内容。在这个过程中,页面实际上是在后台与服务器交互的。获取到数据后,使用 JavaScript 改变网页,从而更新网页的内容。
你可以去 W3School 体验几个 demo 来感受一下:
示例介绍
在浏览网页的时候,我们会发现很多网页已经向下滚动,可以查看更多选项。以我的微博主页为例:. 当我们切换到微博页面,发现往下滑了几条微博后,后面的内容并不会直接显示出来,而是会出现一个加载动画。加载完成后,下方会不断出现新的微博内容。这个过程其实就是Ajax加载的过程,如图:
我们注意到页面并没有完全刷新,也就是说页面的链接没有变化,但是页面中有新的内容,也就是后来刷新的新微博。这就是通过 Ajax 获取和呈现新数据的方式。
基本的
在对Ajax有了初步的了解之后,我们再来详细了解一下它的基本原理。向网页更新发送 Ajax 请求的过程可以简单分为以下 3 个步骤:
下面我们将详细描述这些过程中的每一个。
发送请求
我们知道JavaScript可以实现页面的各种交互功能,Ajax也不例外。它由 JavaScript 实现,实际执行如下代码:
这是 JavaScript 对 Ajax 的底层实现。这个过程其实就是新建一个XMLHttpRequest对象,然后调用onreadystatechange属性设置监听,最后调用open()和send()方法向一个链接(即服务器)发送请求。
我们使用 Python 发送请求后,可以得到响应结果,但是这里的请求是通过 JavaScript 发送的。由于设置了监听器,当服务器返回响应时,会触发onreadystatechange对应的方法,我们可以在这个方法中解析响应内容。
解析内容
得到响应后会触发onreadystatechange属性对应的方法,可以通过xmlhttp的responseText属性获取响应内容。这类似于 Python 中使用 requests 向服务器发出请求,然后得到响应的过程。
返回的内容可能是 HTML 或 JSON,然后我们只需要在方法中使用 JavaScript 进一步处理即可。例如,如果返回的内容是 JSON,我们可以对其进行解析和转换。
呈现网页
JavaScript 具有更改网页内容的能力。解析响应内容后,可以调用 JavaScript 对网页进行解析处理。例如,通过document.getElementById().innerHTML的操作,改变一个元素中的源代码,从而改变网页上显示的内容。也称为更改和删除 Document 网页文档等操作。进行 DOM 操作。
在上面的例子中,操作 document.getElementById(“myDiv”).innerHTML=xmlhttp.responseText 会将 ID 为 myDiv 的节点内部的 HTML 代码更改为服务器返回的内容,从而使服务器返回的新内容将显示在 myDiv 元素内。数据,部分页面似乎已更新。
可以看到,发送请求、解析内容、渲染网页这三个步骤实际上都是由 JavaScript 完成的。
回想一下微博的下拉刷新,其实就是一个JavaScript向服务器发送Ajax请求,然后获取新的微博数据,解析,呈现在网页中的过程。
因此,真正的数据实际上是通过一次又一次的ajax请求获得的。如果我们想捕获这些数据,我们需要知道这些请求是如何发送的,发送到哪里,发送了什么参数。如果我们知道这一点,难道我们不能用 Python 来模拟这个发送操作并得到结果吗?
阿贾克斯分析
这里我们还是以之前的微博为例。我们知道拖拽刷新的内容是通过ajax加载的,页面的url没有变化。这时候,我们应该去哪里查看这些Ajax请求呢?
这里还需要用到浏览器的开发者工具。下面是Chrome浏览器的介绍。
首先用Chrome浏览器打开微博链接,然后在页面上右击,在弹出的快捷菜单中选择“检查”选项,会弹出开发者工具,如图:
如前所述,这里是页面加载过程中浏览器和服务器之间发送请求和接收响应的所有记录。
Ajax 有其特殊的请求类型,称为 xhr。在图中,我们可以找到一个以getIndex开头的请求,其Type为xhr,是一个Ajax请求。用鼠标点击请求,查看请求的详细信息。
右侧可以看到Request Headers、URL、Response Headers等信息。Request Headers中的信息之一是X-Requested-With:XMLHttpRequest,将请求标记为Ajax请求,如图:
然后我们点击 Preview 可以看到响应的内容,是 JSON 格式的。在这里,Chrome 会自动为我们解析它。单击箭头可展开和折叠相应的内容。
我们可以观察到返回的结果是我的个人信息,包括昵称、简介、头像等,这也是用于渲染个人主页的数据。JavaScript 接收到数据后,执行相应的渲染方法,整个页面都被渲染出来了。
另外,我们还可以切换到Response选项卡,观察真实的返回数据,如图:
接下来,切换回第一个请求,观察它的Response是什么,如图:
这是原创链接返回的内容,不到 50 行代码,结构非常简单,只是执行了一些 JavaScript。
因此,我们看到的微博页面的真实数据并不是原创页面返回的,而是在执行完 JavaScript 后,再次向后台发送 Ajax 请求,浏览器获取数据并进一步渲染。
过滤请求
接下来,我们使用 Chrome DevTools 的过滤功能过滤掉所有的 Ajax 请求。请求上方有一层过滤栏,直接点击XHR,那么下面显示的所有请求都是Ajax请求,如图:
接下来继续滑动页面,可以看到页面底部有新的微博滑动,开发者工具下不断出现Ajax请求,这样我们就可以捕获所有的Ajax请求。
随意打开一个entry,可以清晰的看到它的Request URL、Request Headers、Response Headers、Response Body等,这时候模拟请求和提取就很简单了。
下图显示的内容是我的一个微博页面的列表信息:
至此,我们已经能够分析出一些Ajax请求的详细信息了。接下来,我们只需要用程序模拟这些Ajax请求,就可以很方便的提取出我们需要的信息了。
参考文章
ajax抓取网页内容(分类目录:《Python爬虫从入门到精通》总目录Ajax数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-04-04 07:17
分类:《Python爬虫从入门到精通》总目录
Ajax 数据爬取(一):基础
Ajax数据爬取(二):分析方法
Ajax数据爬取(三):结果提取
有时候我们使用requests爬取页面时,得到的结果可能和我们在浏览器中看到的不一样:我们可以看到页面数据在浏览器中正常显示,但是使用requests得到的结果却不是。这是因为请求都是原创的 HTML 文档,而浏览器中的页面是通过 JavaScript 处理数据的结果。这些数据有多种来源,可以通过 Ajax 加载或收录在 HTML 中。在文档中,也可能是通过 JavaScript 和特定算法计算后生成的。
对于第一种情况,数据加载是一种异步加载方式。最初的页面不会收录一些数据。原创页面加载完成后,会向服务器请求一个接口获取数据,然后对数据进行处理呈现。对网页来说,这实际上是发送一个 Ajax 请求。根据Web发展的趋势,这种形式的页面越来越多。网页的原创HTML文档不收录任何数据,通过Ajax统一加载后呈现数据,这样可以在Web开发中分离前后端,以及服务器带来的压力直接渲染页面减少了。
因此,如果遇到这样的页面,直接使用requests等库爬取原创页面是无法获取有效数据的。这时候就需要分析网页后端向接口发送的Ajax请求了。如果可以使用requests来模拟ajax请求,那么就可以成功抓取了。
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新网页的部分内容而不刷新页面且页面链接不改变的技术。
对于传统的网页,如果要更新其内容,则必须刷新整个页面,但使用 Ajax,您可以在不完全刷新页面的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器交互的。获取到数据后,使用 JavaScript 改变网页,从而更新网页的内容。
在浏览网页的时候,我们会发现很多网页已经向下滚动,可以查看更多选项。比如新浪微博,切换到微博页面,一直往下滑,可以发现往下滑了几条微博后就消失了,并且会出现一个加载动画,过一会下面还会继续出现新的微博. 内容,这个过程其实就是Ajax加载的过程。
初步了解了Ajax之后,我们再来了解一下它的基本原理。向网页更新发送 Ajax 请求的过程可以简单分为以下 3 个步骤:
发送请求解析内容渲染网页发送请求
我们知道JavaScript可以实现页面的各种交互功能,Ajax也不例外。它也是由 JavaScript 实现的,实际执行如下代码:
var xmlhttp;
if (window.XMLHttpRequest) {
// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp=new XMLHttpRequest();
} else {// code for IE6, IE5
xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.onreadystatechange=function() {
if (xmlhttp.readyState==4 && xmlhttp.status==200) {
document.getElementById("myDiv").innerHTML=xmlhttp.responseText;
}
}
xmlhttp.open("POST","/ajax/",true);
xmlhttp.send();
这是 JavaScript 对 Ajax 的底层实现。其实就是新建一个 XMLHttpRequest 对象,然后调用 onreadystatechange 属性设置监听器,然后调用 open() 和 send() 方法向一个链接(也就是服务器)发送请求。在Python中发送请求后,可以得到响应结果,但是这里请求是发送给JavaScript的。由于设置了监控,当服务器返回响应时,会触发onreadystatechange对应的方法,然后在这个方法中解析响应内容即可。
解析内容
得到响应后会触发onreadystatechange属性对应的方法,可以通过xmlhttp的responseText属性获取响应内容。这类似于 Python 中使用 requests 向服务器发起请求,然后得到响应的过程。那么返回的内容可能是 HTML,也可能是 JSON,然后你只需要在方法中使用 JavaScript 进行进一步处理即可。例如,如果是JSON,则可以进行解析和转换。
呈现网页
JavaScript 具有更改网页内容的能力。解析响应内容后,可以调用 JavaScript 对网页进行解析处理。例如,通过document.getElementById().innerHTML的操作,可以改变一个元素中的源代码,从而改变网页上显示的内容。该操作也称为DOM操作,即对Document网页的Document操作,如更改、删除等。
在上面的例子中,document.getElementById("myDiv").innerHTML=xmlhttp.responseText 会将ID为myDiv的节点内部的HTML代码改成服务器返回的内容,这样服务器返回的新数据就是显示在 myDiv 元素内。页面的某些部分似乎已更新。
我们观察到这 3 个步骤实际上是由 JavaScript 完成的,它完成了请求、解析和渲染的整个过程。回想一下微博的下拉刷新,这其实就是JavaScript向服务器发送Ajax请求,然后获取新的微博数据,解析,在网页中渲染。
因此,我们知道,真正的数据实际上是一次又一次地从 Ajax 请求中获取的。如果你想捕获这些数据,你需要知道这些请求是如何发送的,发送到哪里,发送了什么参数。如果我们知道这一点,我们可以使用 Python 来模拟这个发送操作并得到结果。 查看全部
ajax抓取网页内容(分类目录:《Python爬虫从入门到精通》总目录Ajax数据)
分类:《Python爬虫从入门到精通》总目录
Ajax 数据爬取(一):基础
Ajax数据爬取(二):分析方法
Ajax数据爬取(三):结果提取
有时候我们使用requests爬取页面时,得到的结果可能和我们在浏览器中看到的不一样:我们可以看到页面数据在浏览器中正常显示,但是使用requests得到的结果却不是。这是因为请求都是原创的 HTML 文档,而浏览器中的页面是通过 JavaScript 处理数据的结果。这些数据有多种来源,可以通过 Ajax 加载或收录在 HTML 中。在文档中,也可能是通过 JavaScript 和特定算法计算后生成的。
对于第一种情况,数据加载是一种异步加载方式。最初的页面不会收录一些数据。原创页面加载完成后,会向服务器请求一个接口获取数据,然后对数据进行处理呈现。对网页来说,这实际上是发送一个 Ajax 请求。根据Web发展的趋势,这种形式的页面越来越多。网页的原创HTML文档不收录任何数据,通过Ajax统一加载后呈现数据,这样可以在Web开发中分离前后端,以及服务器带来的压力直接渲染页面减少了。
因此,如果遇到这样的页面,直接使用requests等库爬取原创页面是无法获取有效数据的。这时候就需要分析网页后端向接口发送的Ajax请求了。如果可以使用requests来模拟ajax请求,那么就可以成功抓取了。
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新网页的部分内容而不刷新页面且页面链接不改变的技术。
对于传统的网页,如果要更新其内容,则必须刷新整个页面,但使用 Ajax,您可以在不完全刷新页面的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器交互的。获取到数据后,使用 JavaScript 改变网页,从而更新网页的内容。
在浏览网页的时候,我们会发现很多网页已经向下滚动,可以查看更多选项。比如新浪微博,切换到微博页面,一直往下滑,可以发现往下滑了几条微博后就消失了,并且会出现一个加载动画,过一会下面还会继续出现新的微博. 内容,这个过程其实就是Ajax加载的过程。
初步了解了Ajax之后,我们再来了解一下它的基本原理。向网页更新发送 Ajax 请求的过程可以简单分为以下 3 个步骤:
发送请求解析内容渲染网页发送请求
我们知道JavaScript可以实现页面的各种交互功能,Ajax也不例外。它也是由 JavaScript 实现的,实际执行如下代码:
var xmlhttp;
if (window.XMLHttpRequest) {
// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp=new XMLHttpRequest();
} else {// code for IE6, IE5
xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.onreadystatechange=function() {
if (xmlhttp.readyState==4 && xmlhttp.status==200) {
document.getElementById("myDiv").innerHTML=xmlhttp.responseText;
}
}
xmlhttp.open("POST","/ajax/",true);
xmlhttp.send();
这是 JavaScript 对 Ajax 的底层实现。其实就是新建一个 XMLHttpRequest 对象,然后调用 onreadystatechange 属性设置监听器,然后调用 open() 和 send() 方法向一个链接(也就是服务器)发送请求。在Python中发送请求后,可以得到响应结果,但是这里请求是发送给JavaScript的。由于设置了监控,当服务器返回响应时,会触发onreadystatechange对应的方法,然后在这个方法中解析响应内容即可。
解析内容
得到响应后会触发onreadystatechange属性对应的方法,可以通过xmlhttp的responseText属性获取响应内容。这类似于 Python 中使用 requests 向服务器发起请求,然后得到响应的过程。那么返回的内容可能是 HTML,也可能是 JSON,然后你只需要在方法中使用 JavaScript 进行进一步处理即可。例如,如果是JSON,则可以进行解析和转换。
呈现网页
JavaScript 具有更改网页内容的能力。解析响应内容后,可以调用 JavaScript 对网页进行解析处理。例如,通过document.getElementById().innerHTML的操作,可以改变一个元素中的源代码,从而改变网页上显示的内容。该操作也称为DOM操作,即对Document网页的Document操作,如更改、删除等。
在上面的例子中,document.getElementById("myDiv").innerHTML=xmlhttp.responseText 会将ID为myDiv的节点内部的HTML代码改成服务器返回的内容,这样服务器返回的新数据就是显示在 myDiv 元素内。页面的某些部分似乎已更新。
我们观察到这 3 个步骤实际上是由 JavaScript 完成的,它完成了请求、解析和渲染的整个过程。回想一下微博的下拉刷新,这其实就是JavaScript向服务器发送Ajax请求,然后获取新的微博数据,解析,在网页中渲染。
因此,我们知道,真正的数据实际上是一次又一次地从 Ajax 请求中获取的。如果你想捕获这些数据,你需要知道这些请求是如何发送的,发送到哪里,发送了什么参数。如果我们知道这一点,我们可以使用 Python 来模拟这个发送操作并得到结果。
ajax抓取网页内容(1.JS脚本文件-2.1.1官方下载地址(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-04-01 16:11
在 C# 中,常用的请求方法是使用 HttpWebRequest 创建请求并返回消息。但是,有时遇到动态加载的页面,只能抓取部分内容,而无法抓取动态加载的内容。
如果遇到这种情况,建议使用 phantomJS 无头浏览器。
在开发之前,先准备两件事。
1.phantomJS-2.1.1 官方下载地址:
2. JS 脚本文件,我命名为codes.js。内容如下。一开始没有配置页面的设置信息,导致一些异步页面在抓取的时候卡住了。主要原因是没有配置请求头信息。
var page = require('webpage').create(), system = require('system');
var url = system.args[1];
var interval = system.args[2];
var settings = {
timeout: interval,
encoding: "gb2312",
operation: "GET",
headers: {
"User-Agent": system.args[3],
"Accept": system.args[4],
"Accept-Language": "zh-CN,en;q=0.7,en-US;q=0.3",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": 1,
"Connection": "keep-alive",
"Pragma": "no-cache",
"Cache-Control": "no-cache",
"Referer": system.args[5]
}
}
page.settings = settings;
page.open(url, function (status) {
phantom.outputEncoding = "gb2312";
if (status !== 'success') {
console.log('Unable to post!');
phantom.exit();
} else {
setTimeout(function () {
console.log(page.content);
phantom.exit();
}, interval);
}
});
原型完成后,您需要将这两个文件放入您的项目中。如下:
这些都好了,可以开始写后台代码了。
///
/// 利用phantomjs 爬取AJAX加载完成之后的页面
/// JS脚本刷新时间间隔为1秒,防止页面AJAX请求时间过长导致数据无法获取
///
///
///
public static string GetAjaxHtml(string url, HttpConfig config, int interval = 1000)
{
try
{
string path = System.AppDomain.CurrentDomain.BaseDirectory.ToString();
ProcessStartInfo start = new ProcessStartInfo(path + @"phantomjs\phantomjs.exe");//设置运行的命令行文件问ping.exe文件,这个文件系统会自己找到
start.WorkingDirectory = path + @"phantomjs\";
////设置命令参数
string commond = string.Format("{0} {1} {2} {3} {4} {5}", path + @"phantomjs\codes.js", url, interval, config.UserAgent, config.Accept, config.Referer);
start.Arguments = commond;
StringBuilder sb = new StringBuilder();
start.CreateNoWindow = true;//不显示dos命令行窗口
start.RedirectStandardOutput = true;//
start.RedirectStandardInput = true;//
start.UseShellExecute = false;//是否指定操作系统外壳进程启动程序
Process p = Process.Start(start);
StreamReader reader = p.StandardOutput;//截取输出流
string line = reader.ReadToEnd();//每次读取一行
string strRet = line;// sb.ToString();
p.WaitForExit();//等待程序执行完退出进程
p.Close();//关闭进程
reader.Close();//关闭流
return strRet;
}
catch (Exception ex)
{
return ex.Message.ToString();
}
}
public class HttpConfig
{
///
/// 网站cookie信息
///
public string Cookie { get; set; }
///
/// 页面Referer信息
///
public string Referer { get; set; }
///
/// 默认(text/html)
///
public string ContentType { get; set; }
public string Accept { get; set; }
public string AcceptEncoding { get; set; }
///
/// 超时时间(毫秒)默认100000
///
public int Timeout { get; set; }
public string UserAgent { get; set; }
///
/// POST请求时,数据是否进行gzip压缩
///
public bool GZipCompress { get; set; }
public bool KeepAlive { get; set; }
public string CharacterSet { get; set; }
public HttpConfig()
{
this.Timeout = 100000;
this.ContentType = "text/html; charset=" + Encoding.UTF8.WebName;
this.UserAgent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36";
this.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8";
this.AcceptEncoding = "gzip,deflate";
this.GZipCompress = false;
this.KeepAlive = true;
this.CharacterSet = "UTF-8";
}
}
这些也是我今天才接触到的,整理了一下自己的想法。我想指出任何错误。 查看全部
ajax抓取网页内容(1.JS脚本文件-2.1.1官方下载地址(图))
在 C# 中,常用的请求方法是使用 HttpWebRequest 创建请求并返回消息。但是,有时遇到动态加载的页面,只能抓取部分内容,而无法抓取动态加载的内容。
如果遇到这种情况,建议使用 phantomJS 无头浏览器。
在开发之前,先准备两件事。
1.phantomJS-2.1.1 官方下载地址:
2. JS 脚本文件,我命名为codes.js。内容如下。一开始没有配置页面的设置信息,导致一些异步页面在抓取的时候卡住了。主要原因是没有配置请求头信息。
var page = require('webpage').create(), system = require('system');
var url = system.args[1];
var interval = system.args[2];
var settings = {
timeout: interval,
encoding: "gb2312",
operation: "GET",
headers: {
"User-Agent": system.args[3],
"Accept": system.args[4],
"Accept-Language": "zh-CN,en;q=0.7,en-US;q=0.3",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": 1,
"Connection": "keep-alive",
"Pragma": "no-cache",
"Cache-Control": "no-cache",
"Referer": system.args[5]
}
}
page.settings = settings;
page.open(url, function (status) {
phantom.outputEncoding = "gb2312";
if (status !== 'success') {
console.log('Unable to post!');
phantom.exit();
} else {
setTimeout(function () {
console.log(page.content);
phantom.exit();
}, interval);
}
});
原型完成后,您需要将这两个文件放入您的项目中。如下:
这些都好了,可以开始写后台代码了。
///
/// 利用phantomjs 爬取AJAX加载完成之后的页面
/// JS脚本刷新时间间隔为1秒,防止页面AJAX请求时间过长导致数据无法获取
///
///
///
public static string GetAjaxHtml(string url, HttpConfig config, int interval = 1000)
{
try
{
string path = System.AppDomain.CurrentDomain.BaseDirectory.ToString();
ProcessStartInfo start = new ProcessStartInfo(path + @"phantomjs\phantomjs.exe");//设置运行的命令行文件问ping.exe文件,这个文件系统会自己找到
start.WorkingDirectory = path + @"phantomjs\";
////设置命令参数
string commond = string.Format("{0} {1} {2} {3} {4} {5}", path + @"phantomjs\codes.js", url, interval, config.UserAgent, config.Accept, config.Referer);
start.Arguments = commond;
StringBuilder sb = new StringBuilder();
start.CreateNoWindow = true;//不显示dos命令行窗口
start.RedirectStandardOutput = true;//
start.RedirectStandardInput = true;//
start.UseShellExecute = false;//是否指定操作系统外壳进程启动程序
Process p = Process.Start(start);
StreamReader reader = p.StandardOutput;//截取输出流
string line = reader.ReadToEnd();//每次读取一行
string strRet = line;// sb.ToString();
p.WaitForExit();//等待程序执行完退出进程
p.Close();//关闭进程
reader.Close();//关闭流
return strRet;
}
catch (Exception ex)
{
return ex.Message.ToString();
}
}
public class HttpConfig
{
///
/// 网站cookie信息
///
public string Cookie { get; set; }
///
/// 页面Referer信息
///
public string Referer { get; set; }
///
/// 默认(text/html)
///
public string ContentType { get; set; }
public string Accept { get; set; }
public string AcceptEncoding { get; set; }
///
/// 超时时间(毫秒)默认100000
///
public int Timeout { get; set; }
public string UserAgent { get; set; }
///
/// POST请求时,数据是否进行gzip压缩
///
public bool GZipCompress { get; set; }
public bool KeepAlive { get; set; }
public string CharacterSet { get; set; }
public HttpConfig()
{
this.Timeout = 100000;
this.ContentType = "text/html; charset=" + Encoding.UTF8.WebName;
this.UserAgent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36";
this.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8";
this.AcceptEncoding = "gzip,deflate";
this.GZipCompress = false;
this.KeepAlive = true;
this.CharacterSet = "UTF-8";
}
}
这些也是我今天才接触到的,整理了一下自己的想法。我想指出任何错误。
ajax抓取网页内容(Python网络爬虫内容提取器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-04-01 16:09
1 简介
在 Python 网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类 gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分实验用xslt方法提取静态网页内容,一次性转换成xml格式。一个问题仍然存在:如何提取由 javascript 管理的动态内容?那么这篇文章就回答了这个问题。
2. 动态内容提取技术组件
上一篇python使用xslt提取网页数据,要提取的内容是直接从网页的源码中获取的。但是有些Ajax动态内容在源码中是找不到的,所以需要找到合适的程序库来加载异步或者动态加载的内容,交给本项目的抽取器进行抽取。
Python可以使用selenium来执行javascript,而selenium可以让浏览器自动加载页面并获取需要的数据。Selenium 没有自己的浏览器,可以使用第三方浏览器如 Firefox、Chrome 等,也可以使用 PhantomJS 等无头浏览器在后台执行。
三、源码及实验过程
假设我们要抓取京东手机页面的手机名称和价格(网页源码中找不到价格),如下图:
Step 1:利用吉搜Kemoji直观的标注功能,可以非常快速的自动生成一个调试好的抓取规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到程序中的下面。注:本文仅记录实验过程。在实际系统中,将使用各种方法将 xslt 程序注入到内容提取器中。
第二步:执行以下代码(windows10下测试通过,python3.2),请注意:xslt是一个比较长的字符串,如果删除这个字符串,代码只有几行,足够查看 Python Mighty #/usr/bin/python
从 urllib 导入请求
从 lxml 导入 etree
从硒导入网络驱动程序
进口时间
#京东手机产品页面 查看全部
ajax抓取网页内容(Python网络爬虫内容提取器)
1 简介
在 Python 网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类 gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分实验用xslt方法提取静态网页内容,一次性转换成xml格式。一个问题仍然存在:如何提取由 javascript 管理的动态内容?那么这篇文章就回答了这个问题。
2. 动态内容提取技术组件
上一篇python使用xslt提取网页数据,要提取的内容是直接从网页的源码中获取的。但是有些Ajax动态内容在源码中是找不到的,所以需要找到合适的程序库来加载异步或者动态加载的内容,交给本项目的抽取器进行抽取。
Python可以使用selenium来执行javascript,而selenium可以让浏览器自动加载页面并获取需要的数据。Selenium 没有自己的浏览器,可以使用第三方浏览器如 Firefox、Chrome 等,也可以使用 PhantomJS 等无头浏览器在后台执行。
三、源码及实验过程
假设我们要抓取京东手机页面的手机名称和价格(网页源码中找不到价格),如下图:
Step 1:利用吉搜Kemoji直观的标注功能,可以非常快速的自动生成一个调试好的抓取规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到程序中的下面。注:本文仅记录实验过程。在实际系统中,将使用各种方法将 xslt 程序注入到内容提取器中。
第二步:执行以下代码(windows10下测试通过,python3.2),请注意:xslt是一个比较长的字符串,如果删除这个字符串,代码只有几行,足够查看 Python Mighty #/usr/bin/python
从 urllib 导入请求
从 lxml 导入 etree
从硒导入网络驱动程序
进口时间
#京东手机产品页面
ajax抓取网页内容(今天终于把爬虫的Ajax请求搞懂了文章分析及存在的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-04-01 01:05
今天终于明白爬虫的ajax请求了
文章目录
一、案例分析及存在问题
首先我们要在这个网站中爬取一些不同省份的数据,但是如果像普通的请求方式:(注意是不同省份的数据)
只需拉出代码:
import requests
url = 'http://www.fintechdb.cn/request/loadmore'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.41',
# 'X-Requested-With': 'XMLHttpRequest'
}
data = {
'csrf_weiyangx_token': 'a8c2eafab6bd8f2041b6c2e0c8a3811b',
'city': '台湾省,四川省',
'financing': '0',
'field': '0',
'timestart': '0',
'timeend': '0',
'offset': '0',
'sort': '1',
'order': 'desc'
}
res = requests.post(url=url, data=data, headers=headers)
print(res.status_code)
print(res)
print(res.content.decode())
好吧,输入代码后,我认为一切都很好。谁知道呢,右键再点击运行:
结果,我傻眼了;
我说:哎,真奇怪,我的请求不都是返回状态码200吗?如何给我一个错误?他是否故意返回 200 让我认为请求成功?
带着这些疑问,我打开网页,点进我的网站,发现;
啊,原来网页本身的内容是错误的,看来请求是正确的。
那么,问题又来了,请求的数据在哪里?
显然你可以看到它
真的很邪恶吗?? ?
二、问题解决
后来查了各种资料。. . . . .
终于发现原来的原因是这个网站是用Ajax写的,
阿贾克斯简介
AJAX 是一种无需重新加载整个网页即可更新部分网页的技术。
AJAX 不是一种新的编程语言,而是一种使用现有标准的新方法。
AJAX 是一种用于创建快速和动态网页的技术。
一句话:
Ajax 是指无需重新加载页面即可更新部分网页,而 XMLHttpRequest 对象是实现 Ajax 的基础环节,而 XMLHttpRequest 对象是实现浏览器(Html)与数据的交互。
回到原来的问题
问题解决了
我们重新抓取网页,发现,哎,确实有一个XMLHttpRequest对象对象,就是这个请求的header的参数
这个好办,我们只要把这个请求的参数放到请求头里就行了,对吧?
代码显示如下:
import requests
url = 'http://www.fintechdb.cn/request/loadmore'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.41',
'X-Requested-With': 'XMLHttpRequest'
}
data = {
'csrf_weiyangx_token': 'a8c2eafab6bd8f2041b6c2e0c8a3811b',
'city': '台湾省,四川省',
'financing': '0',
'field': '0',
'timestart': '0',
'timeend': '0',
'offset': '0',
'sort': '1',
'order': 'desc'
}
res = requests.post(url=url, data=data, headers=headers)
print(res.status_code)
print(res)
print(res.content.decode())
(这实际上比前面的代码多了一个请求头参数:
'X-Requested-With':'XMLHttpRequest'
然后就好啦~)
果然如我所愿,终于得到了我梦寐以求的数据(^_^)~:
不管怎样,至少现在没有错。
那你现在想要那个省就可以直接修改post请求,后面就不多说了,大家就明白了。
三、总结1、Ajax
Ajax之前已经结束了,就是实现js和xml的异步,英文Ajax的整个流程是:
异步 JavaScript 和 XML
翻译;
AJAX = 异步 JavaScript 和 XML
也就是说,网页的呈现和数据的存储是分开进行的。JS专门负责页面的呈现,调用其他资源等功能,而对于xml,可以自己做数据的存储和传输。两者是异步的。也就是说,它们是独立进行的,互不干扰,互不相干。
最后一次:
阿贾克斯请求:
AJAX 是一种无需重新加载整个网页即可更新部分网页的技术。 查看全部
ajax抓取网页内容(今天终于把爬虫的Ajax请求搞懂了文章分析及存在的问题)
今天终于明白爬虫的ajax请求了
文章目录
一、案例分析及存在问题
首先我们要在这个网站中爬取一些不同省份的数据,但是如果像普通的请求方式:(注意是不同省份的数据)
只需拉出代码:
import requests
url = 'http://www.fintechdb.cn/request/loadmore'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.41',
# 'X-Requested-With': 'XMLHttpRequest'
}
data = {
'csrf_weiyangx_token': 'a8c2eafab6bd8f2041b6c2e0c8a3811b',
'city': '台湾省,四川省',
'financing': '0',
'field': '0',
'timestart': '0',
'timeend': '0',
'offset': '0',
'sort': '1',
'order': 'desc'
}
res = requests.post(url=url, data=data, headers=headers)
print(res.status_code)
print(res)
print(res.content.decode())
好吧,输入代码后,我认为一切都很好。谁知道呢,右键再点击运行:
结果,我傻眼了;
我说:哎,真奇怪,我的请求不都是返回状态码200吗?如何给我一个错误?他是否故意返回 200 让我认为请求成功?
带着这些疑问,我打开网页,点进我的网站,发现;
啊,原来网页本身的内容是错误的,看来请求是正确的。
那么,问题又来了,请求的数据在哪里?
显然你可以看到它
真的很邪恶吗?? ?
二、问题解决
后来查了各种资料。. . . . .
终于发现原来的原因是这个网站是用Ajax写的,
阿贾克斯简介
AJAX 是一种无需重新加载整个网页即可更新部分网页的技术。
AJAX 不是一种新的编程语言,而是一种使用现有标准的新方法。
AJAX 是一种用于创建快速和动态网页的技术。
一句话:
Ajax 是指无需重新加载页面即可更新部分网页,而 XMLHttpRequest 对象是实现 Ajax 的基础环节,而 XMLHttpRequest 对象是实现浏览器(Html)与数据的交互。
回到原来的问题
问题解决了
我们重新抓取网页,发现,哎,确实有一个XMLHttpRequest对象对象,就是这个请求的header的参数
这个好办,我们只要把这个请求的参数放到请求头里就行了,对吧?
代码显示如下:
import requests
url = 'http://www.fintechdb.cn/request/loadmore'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.41',
'X-Requested-With': 'XMLHttpRequest'
}
data = {
'csrf_weiyangx_token': 'a8c2eafab6bd8f2041b6c2e0c8a3811b',
'city': '台湾省,四川省',
'financing': '0',
'field': '0',
'timestart': '0',
'timeend': '0',
'offset': '0',
'sort': '1',
'order': 'desc'
}
res = requests.post(url=url, data=data, headers=headers)
print(res.status_code)
print(res)
print(res.content.decode())
(这实际上比前面的代码多了一个请求头参数:
'X-Requested-With':'XMLHttpRequest'
然后就好啦~)
果然如我所愿,终于得到了我梦寐以求的数据(^_^)~:
不管怎样,至少现在没有错。
那你现在想要那个省就可以直接修改post请求,后面就不多说了,大家就明白了。
三、总结1、Ajax
Ajax之前已经结束了,就是实现js和xml的异步,英文Ajax的整个流程是:
异步 JavaScript 和 XML
翻译;
AJAX = 异步 JavaScript 和 XML
也就是说,网页的呈现和数据的存储是分开进行的。JS专门负责页面的呈现,调用其他资源等功能,而对于xml,可以自己做数据的存储和传输。两者是异步的。也就是说,它们是独立进行的,互不干扰,互不相干。
最后一次:
阿贾克斯请求:
AJAX 是一种无需重新加载整个网页即可更新部分网页的技术。
ajax抓取网页内容(discourse+感叹号的解决方法,不禁拍案叫绝!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-03-30 01:06
越来越多的网站,开始使用“单页结构”(single-page application)。
整个网站只有一个网页,使用ajax技术根据用户的输入加载不同的内容。
这种方式的好处是用户体验好,节省了流量。缺点是ajax内容不能被搜索引擎抓取。例如,您有一个 网站。
http://www.51sjk.com/Upload/Ar ... 7.com
用户通过哈希标记结构的 url 看到不同的内容。
http://www.51sjk.com/Upload/Ar ... m%231 http://www.51sjk.com/Upload/Ar ... m%232 http://www.51sjk.com/Upload/Ar ... m%233
但是,搜索引擎只抓取和忽略主题标签,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
http://www.51sjk.com/Upload/Ar ... 3%211
当 Google 找到上述网址时,它会自动抓取另一个网址:
http://www.51sjk.com/Upload/Ar ... _%3D1
只要你把ajax内容放在这个url上,google就会收录。但问题是,“英镑+感叹号”非常丑陋和繁琐。twitter 曾经使用过这种结构,它把
http://www.51sjk.com/Upload/Ar ... 9.jpg
改成
http://www.51sjk.com/Upload/Ar ... 4.jpg
结果,用户投诉连连,仅半年就被废止。
那么,有没有什么办法可以让搜索引擎在抓取ajax内容的同时保持更直观的url呢?
一直以为没办法,直到前两天看到discourse创始人之一Robin ward的解法,不由惊叹。
discourse 是一个严重依赖 ajax 的论坛程序,但必须 google收录content。它的解决方案是放弃 hashtag 结构,使用 history api。
所谓history api是指在不刷新页面的情况下,改变浏览器地址栏显示的url(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏的url变了,但是音乐播放没有中断!
history api的详细介绍超出了本文章的范围。这里简单说一下,它的作用是给浏览器的历史对象添加一条记录。
window.history.pushstate(state object, title, url);
上面这行命令可以让新的url出现在地址栏中。历史对象的pushstate方法接受三个参数,新的url是第三个参数,前两个参数可以为null。
window.history.pushstate(null, null, newurl);
目前各大浏览器都支持这个方法:chrome(26.0+),firefox(20.0+),ie(10.0+),safari(5.1+),歌剧(12.1+)。
这是罗宾病房方法。
首先,将hashtag结构替换为history api,让每个hashtag变成正常路径的url,这样搜索引擎就会爬取每一个网页。
example.com/1 example.com/2 example.com/3
然后,定义一个处理 ajax 部分并根据 url 抓取内容的 javascript 函数(假设使用 jquery)。
function anchorclick(link) {
var linksplit = link.split('/').pop();
$.get('api/' + linksplit, function(data) {
$('#content').html(data);
});
}
再次定义鼠标点击事件。
$('#container').on('click', 'a', function(e) {
window.history.pushstate(null, null, $(this).attr('href'));
anchorclick($(this).attr('href'));
e.preventdefault();
});
还要考虑到用户单击浏览器的“前进/后退”按钮。这时会触发历史对象的popstate事件。
window.addeventlistener('popstate', function(e) {
anchorclick(location.pathname);
});
定义完以上三段代码后,无需刷新页面即可显示正常的路径url和ajax内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 url 都是不同的请求。因此,服务器需要为所有这些请求返回具有以下结构的网页,以防止 404 错误。
... ...
如果你仔细看上面的代码,你会发现有一个noscript标签,这就是秘密。
我们将搜索引擎应该为 收录 的所有内容放在 noscript 标记中。这种情况下,用户仍然可以在不刷新页面的情况下进行ajax操作,但是搜索引擎会收录每个网页的主要内容! 查看全部
ajax抓取网页内容(discourse+感叹号的解决方法,不禁拍案叫绝!)
越来越多的网站,开始使用“单页结构”(single-page application)。
整个网站只有一个网页,使用ajax技术根据用户的输入加载不同的内容。
这种方式的好处是用户体验好,节省了流量。缺点是ajax内容不能被搜索引擎抓取。例如,您有一个 网站。
http://www.51sjk.com/Upload/Ar ... 7.com
用户通过哈希标记结构的 url 看到不同的内容。
http://www.51sjk.com/Upload/Ar ... m%231 http://www.51sjk.com/Upload/Ar ... m%232 http://www.51sjk.com/Upload/Ar ... m%233
但是,搜索引擎只抓取和忽略主题标签,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
http://www.51sjk.com/Upload/Ar ... 3%211
当 Google 找到上述网址时,它会自动抓取另一个网址:
http://www.51sjk.com/Upload/Ar ... _%3D1
只要你把ajax内容放在这个url上,google就会收录。但问题是,“英镑+感叹号”非常丑陋和繁琐。twitter 曾经使用过这种结构,它把
http://www.51sjk.com/Upload/Ar ... 9.jpg
改成
http://www.51sjk.com/Upload/Ar ... 4.jpg
结果,用户投诉连连,仅半年就被废止。
那么,有没有什么办法可以让搜索引擎在抓取ajax内容的同时保持更直观的url呢?
一直以为没办法,直到前两天看到discourse创始人之一Robin ward的解法,不由惊叹。
discourse 是一个严重依赖 ajax 的论坛程序,但必须 google收录content。它的解决方案是放弃 hashtag 结构,使用 history api。
所谓history api是指在不刷新页面的情况下,改变浏览器地址栏显示的url(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏的url变了,但是音乐播放没有中断!
history api的详细介绍超出了本文章的范围。这里简单说一下,它的作用是给浏览器的历史对象添加一条记录。
window.history.pushstate(state object, title, url);
上面这行命令可以让新的url出现在地址栏中。历史对象的pushstate方法接受三个参数,新的url是第三个参数,前两个参数可以为null。
window.history.pushstate(null, null, newurl);
目前各大浏览器都支持这个方法:chrome(26.0+),firefox(20.0+),ie(10.0+),safari(5.1+),歌剧(12.1+)。
这是罗宾病房方法。
首先,将hashtag结构替换为history api,让每个hashtag变成正常路径的url,这样搜索引擎就会爬取每一个网页。
example.com/1 example.com/2 example.com/3
然后,定义一个处理 ajax 部分并根据 url 抓取内容的 javascript 函数(假设使用 jquery)。
function anchorclick(link) {
var linksplit = link.split('/').pop();
$.get('api/' + linksplit, function(data) {
$('#content').html(data);
});
}
再次定义鼠标点击事件。
$('#container').on('click', 'a', function(e) {
window.history.pushstate(null, null, $(this).attr('href'));
anchorclick($(this).attr('href'));
e.preventdefault();
});
还要考虑到用户单击浏览器的“前进/后退”按钮。这时会触发历史对象的popstate事件。
window.addeventlistener('popstate', function(e) {
anchorclick(location.pathname);
});
定义完以上三段代码后,无需刷新页面即可显示正常的路径url和ajax内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 url 都是不同的请求。因此,服务器需要为所有这些请求返回具有以下结构的网页,以防止 404 错误。
... ...
如果你仔细看上面的代码,你会发现有一个noscript标签,这就是秘密。
我们将搜索引擎应该为 收录 的所有内容放在 noscript 标记中。这种情况下,用户仍然可以在不刷新页面的情况下进行ajax操作,但是搜索引擎会收录每个网页的主要内容!
ajax抓取网页内容(如何在网页的异步更新中脱颖而出(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-28 23:17
今天小编给大家分享ajax提交数据到后台的方法。相信很多人都不太了解。为了让大家了解更多,我为大家总结了以下内容,一起来阅读吧。哦,一定会得到回报的。
Ajax,直译为“异步 JavaScript 和 XML 技术”,是一种用于创建交互式 Web 应用程序的 Web 开发技术,用于创建快速的动态网页,由 Jesse James Jarrett 提出。与传统的Web应用程序相比,Ajax可以通过浏览器和服务器之间少量的数据交换来实现网页的异步更新,无需重新加载整个网页即可更新网页。
在网上看了半天,发现使用ajax提交数据到后台其实很简单,但是很多解释不清楚。对于初学者来说,其中许多确实有点令人困惑。要了解是怎么回事,其实用ajax向后台提交数据其实很简单。
$.ajax({
type: "POST",
url: "register.php",
data: "name=John&location=Boston",
success: function(msg){
alert( "Data Saved: " + msg );
}
});
首先,我们来解释一下上面的代码。当然,使用 ajax 需要 jQuery。
type: "POST",是提交的类型
url:“register.php”,是提交的方向,我提交到register.php处理
data: "name=Jhon&&location=Boston",这是我们提交的数据,Jhon和Boston是我们提交的数据
success:function(msg){},msg为提交成功后返回的一对数据
如何在后台编写来获取这些数据:
我们可以清楚看到的是 $_POST["name"]; 是获得首都的Jhon
$_POST['location'] 是得到的波士顿
我们后台返回的数据,也就是echo的数据,是波士顿。
通过ajax提交数据到后台的方法分享到这里。希望以上内容对大家有一定的参考价值,学以致用。如果你喜欢这篇文章文章,请分享给更多人看到。 查看全部
ajax抓取网页内容(如何在网页的异步更新中脱颖而出(图))
今天小编给大家分享ajax提交数据到后台的方法。相信很多人都不太了解。为了让大家了解更多,我为大家总结了以下内容,一起来阅读吧。哦,一定会得到回报的。
Ajax,直译为“异步 JavaScript 和 XML 技术”,是一种用于创建交互式 Web 应用程序的 Web 开发技术,用于创建快速的动态网页,由 Jesse James Jarrett 提出。与传统的Web应用程序相比,Ajax可以通过浏览器和服务器之间少量的数据交换来实现网页的异步更新,无需重新加载整个网页即可更新网页。
在网上看了半天,发现使用ajax提交数据到后台其实很简单,但是很多解释不清楚。对于初学者来说,其中许多确实有点令人困惑。要了解是怎么回事,其实用ajax向后台提交数据其实很简单。
$.ajax({
type: "POST",
url: "register.php",
data: "name=John&location=Boston",
success: function(msg){
alert( "Data Saved: " + msg );
}
});
首先,我们来解释一下上面的代码。当然,使用 ajax 需要 jQuery。
type: "POST",是提交的类型
url:“register.php”,是提交的方向,我提交到register.php处理
data: "name=Jhon&&location=Boston",这是我们提交的数据,Jhon和Boston是我们提交的数据
success:function(msg){},msg为提交成功后返回的一对数据
如何在后台编写来获取这些数据:
我们可以清楚看到的是 $_POST["name"]; 是获得首都的Jhon
$_POST['location'] 是得到的波士顿
我们后台返回的数据,也就是echo的数据,是波士顿。
通过ajax提交数据到后台的方法分享到这里。希望以上内容对大家有一定的参考价值,学以致用。如果你喜欢这篇文章文章,请分享给更多人看到。
ajax抓取网页内容(ajax抓取网页内容视频直播看手机视频教程(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-03-28 07:05
ajax抓取网页内容视频直播看手机视频教程
做不到的,有的小白刷了不到几百块就写个代码,结果被封号30天。你真的想做那种一键采集网页内容的话,
做不到的。因为网页之间没有关联性,不能获取一个网页中所有的信息。如果要一键下载要么你自己写个采集器,要么就不借助其他工具。
其实我是一个运营狗,可是竟然被邀请回答技术问题,是不是对我的工作是质疑呢,本宝宝是不懂的啦。可是大哥,你这是要躺赚啊,几百块甚至几千块钱就能搞定,
不能,这个东西需要一点点时间,
做不到的,
找不到合适的网站,你直接在网页上加广告就行了,同花顺和东方财富都提供这个功能。
不可能。比较好的时间是24小时,你按照电脑正常工作的频率,可能么?网页有关联,但是也没有那么多,很多百度靠谱的站都只做评论数量这么多的词,你要是去什么商品评论网买了鞋还会看鞋吗?别问我怎么知道的,我直接是测的。有一些自己也写网页爬虫,也是找技术问的。而且我还遇到过,很多时候,广告评论的网站,评论的还没我点开的网页多。你是就去找的话费这么多时间的吗??现在这行是个算法的时代,是个人都可以干,有些人坚持在养信息差。 查看全部
ajax抓取网页内容(ajax抓取网页内容视频直播看手机视频教程(图))
ajax抓取网页内容视频直播看手机视频教程
做不到的,有的小白刷了不到几百块就写个代码,结果被封号30天。你真的想做那种一键采集网页内容的话,
做不到的。因为网页之间没有关联性,不能获取一个网页中所有的信息。如果要一键下载要么你自己写个采集器,要么就不借助其他工具。
其实我是一个运营狗,可是竟然被邀请回答技术问题,是不是对我的工作是质疑呢,本宝宝是不懂的啦。可是大哥,你这是要躺赚啊,几百块甚至几千块钱就能搞定,
不能,这个东西需要一点点时间,
做不到的,
找不到合适的网站,你直接在网页上加广告就行了,同花顺和东方财富都提供这个功能。
不可能。比较好的时间是24小时,你按照电脑正常工作的频率,可能么?网页有关联,但是也没有那么多,很多百度靠谱的站都只做评论数量这么多的词,你要是去什么商品评论网买了鞋还会看鞋吗?别问我怎么知道的,我直接是测的。有一些自己也写网页爬虫,也是找技术问的。而且我还遇到过,很多时候,广告评论的网站,评论的还没我点开的网页多。你是就去找的话费这么多时间的吗??现在这行是个算法的时代,是个人都可以干,有些人坚持在养信息差。
ajax抓取网页内容(ajax抓取网页内容可以使用以下两个工具:ajax库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 37 次浏览 • 2022-03-24 20:02
ajax抓取网页内容可以使用以下两个工具:requests库:,通过它接受参数后做ajax请求获取网页内容cookie:使用浏览器的cookie可以获取页面内容。
还记得前段时间很火的redis和mongodb吗?它们本质上都是锁定的内存对象的集合。按照空间复杂度来算的话redis从2到4都有,一年按3万秒计算,一年可以完成上百万上千万甚至上亿条数据的读写;mongodb从5到30万秒都有,一年按100万秒计算,一年也能完成上百万条数据的读写。它们都是共享内存对象,锁定的对象时间越短、空间越小,整体的效率越高。
当然redis的持久化需要自己封装一套。bitcoin在reputation共识中没有持久化对象(只有放着不动的对象),持久化以后一直可以拿来写数据。另外两种分布式都可以满足这些要求。其他分布式不用考虑持久化对象问题,比如memcached中bucket本身就是一个对象。不过,如果你能驾驭mhash,那么可以尝试用自己封装过的redis/mongodb来实现实时数据同步。
可以先看看《黑客与画家》或者《c++primerplus》,因为这两本书把很多知识讲清楚了,其实是讲mongodb最重要的东西,mongodb不会太吃内存,性能也可以。 查看全部
ajax抓取网页内容(ajax抓取网页内容可以使用以下两个工具:ajax库)
ajax抓取网页内容可以使用以下两个工具:requests库:,通过它接受参数后做ajax请求获取网页内容cookie:使用浏览器的cookie可以获取页面内容。
还记得前段时间很火的redis和mongodb吗?它们本质上都是锁定的内存对象的集合。按照空间复杂度来算的话redis从2到4都有,一年按3万秒计算,一年可以完成上百万上千万甚至上亿条数据的读写;mongodb从5到30万秒都有,一年按100万秒计算,一年也能完成上百万条数据的读写。它们都是共享内存对象,锁定的对象时间越短、空间越小,整体的效率越高。
当然redis的持久化需要自己封装一套。bitcoin在reputation共识中没有持久化对象(只有放着不动的对象),持久化以后一直可以拿来写数据。另外两种分布式都可以满足这些要求。其他分布式不用考虑持久化对象问题,比如memcached中bucket本身就是一个对象。不过,如果你能驾驭mhash,那么可以尝试用自己封装过的redis/mongodb来实现实时数据同步。
可以先看看《黑客与画家》或者《c++primerplus》,因为这两本书把很多知识讲清楚了,其实是讲mongodb最重要的东西,mongodb不会太吃内存,性能也可以。
ajax抓取网页内容(Ajax,全称为andXML,即异步的JavaScript和XML)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-21 11:10
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新网页部分而不刷新页面和页面链接不改变的技术。
对于传统的网页,如果要更新它的内容,就必须刷新整个页面,但是使用Ajax,你可以在不刷新整个页面的情况下更新页面的内容。在这个过程中,页面实际上是在后台与服务器交互的。获取到数据后,通过JavaScript来改变网页,从而更新网页的内容。
您可以在 W3School 上体验一些示例来感受一下:。
1.示例介绍
在浏览网页时,我们会发现很多页面已经向下滚动以查看更多选项。比如以微博为例,我们以我的个人主页为例:切换到微博页面,一直往下滑,你会发现往下滑了几条微博,就不会再往下了,一加载就会而是出现。片刻之后,下方不断出现新的微博内容。这个过程其实就是Ajax加载的过程,如图6-1所示。
我们注意到页面并没有完全刷新,也就是说页面上的链接没有变化,但是页面中有新的内容,也就是后来刷新的新微博。这就是通过 Ajax 获取新数据并呈现的内容。
2. 基本原理
在初步了解了Ajax之后,我们再来详细了解一下它的基本原理。向网页更新发送Ajax请求的过程可以简单分为以下3个步骤:
(1) 发送请求;(2) 解析内容;(3) 渲染网页。
我们将在下面详细描述这些过程。
发送请求
我们知道JavaScript可以实现页面的各种交互功能,Ajax也不例外。也是用JavaScript实现的,实际执行如下代码:
var xmlhttp;
if (window.XMLHttpRequest) {
// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp=new XMLHttpRequest();
} else {// code for IE6, IE5
xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.onreadystatechange=function() {
if (xmlhttp.readyState==4 && xmlhttp.status==200) {
document.getElementById("myDiv").innerHTML=xmlhttp.responseText;
}
}
xmlhttp.open("POST","/ajax/",true);
xmlhttp.send();
这是由 JavaScript 实现的 Ajax 的底层实现。其实就是新建一个XMLHttpRequest对象,然后调用onreadystatechange属性设置监听,然后调用open()和send()方法发送到一个链接(也就是服务器)。问。在Python中发送请求后,可以得到响应结果,但是这里请求是发送给JavaScript的。由于设置了监控,所以当服务器返回响应时,会触发onreadystatechange对应的方法,然后在这个方法中解析响应内容即可。
解析内容
得到响应后会触发onreadystatechange属性对应的方法,可以通过xmlhttp的responseText属性获取响应内容。这类似于 Python 中使用 requests 向服务器发起请求,然后得到响应的过程。那么返回的内容可能是 HTML,也可能是 JSON,然后你只需要在方法中使用 JavaScript 进行进一步处理即可。例如,如果是JSON,则可以解析转换。
渲染网页
JavaScript 具有更改网页内容的能力。解析响应内容后,可以调用 JavaScript 对网页进行解析处理。例如,通过document.getElementById().innerHTML等操作,可以改变元素中的源代码,从而改变网页上显示的内容。该操作也称为DOM操作,即对Document网页的Document操作,如更改、删除等。
上面的例子中,document.getElementById("myDiv").innerHTML=xmlhttp.responseText会将ID为myDiv的节点内部的HTML代码改成服务器返回的内容,这样服务器返回的内容将显示在 myDiv 元素内。使用新数据后,页面的某些部分似乎已更新。
我们观察到这3个步骤实际上是由JavaScript完成的,它完成了请求、解析和渲染的整个过程。
回想一下微博的pull-to-refresh,这其实就是JavaScript向服务端发送Ajax请求,然后获取新的微博数据,解析,呈现在网页中。
因此,我们知道,真正的数据实际上是从一次又一次的Ajax请求中获取的。如果你想捕获这些数据,你需要知道这些请求是如何发送的,发送到哪里,发送了什么参数。如果我们知道这一点,难道我们不能用 Python 来模拟这个发送操作并得到结果吗?
在下一节中,我们将学习在哪里可以看到这些后台 Ajax 操作,它是如何发送的,以及发送哪些参数。
以上是Ajax在Python3爬虫中使用的详细内容。关于Python3中Ajax是什么的更多信息,请关注上的其他相关话题文章! 查看全部
ajax抓取网页内容(Ajax,全称为andXML,即异步的JavaScript和XML)
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新网页部分而不刷新页面和页面链接不改变的技术。
对于传统的网页,如果要更新它的内容,就必须刷新整个页面,但是使用Ajax,你可以在不刷新整个页面的情况下更新页面的内容。在这个过程中,页面实际上是在后台与服务器交互的。获取到数据后,通过JavaScript来改变网页,从而更新网页的内容。
您可以在 W3School 上体验一些示例来感受一下:。
1.示例介绍
在浏览网页时,我们会发现很多页面已经向下滚动以查看更多选项。比如以微博为例,我们以我的个人主页为例:切换到微博页面,一直往下滑,你会发现往下滑了几条微博,就不会再往下了,一加载就会而是出现。片刻之后,下方不断出现新的微博内容。这个过程其实就是Ajax加载的过程,如图6-1所示。
我们注意到页面并没有完全刷新,也就是说页面上的链接没有变化,但是页面中有新的内容,也就是后来刷新的新微博。这就是通过 Ajax 获取新数据并呈现的内容。
2. 基本原理
在初步了解了Ajax之后,我们再来详细了解一下它的基本原理。向网页更新发送Ajax请求的过程可以简单分为以下3个步骤:
(1) 发送请求;(2) 解析内容;(3) 渲染网页。
我们将在下面详细描述这些过程。
发送请求
我们知道JavaScript可以实现页面的各种交互功能,Ajax也不例外。也是用JavaScript实现的,实际执行如下代码:
var xmlhttp;
if (window.XMLHttpRequest) {
// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp=new XMLHttpRequest();
} else {// code for IE6, IE5
xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.onreadystatechange=function() {
if (xmlhttp.readyState==4 && xmlhttp.status==200) {
document.getElementById("myDiv").innerHTML=xmlhttp.responseText;
}
}
xmlhttp.open("POST","/ajax/",true);
xmlhttp.send();
这是由 JavaScript 实现的 Ajax 的底层实现。其实就是新建一个XMLHttpRequest对象,然后调用onreadystatechange属性设置监听,然后调用open()和send()方法发送到一个链接(也就是服务器)。问。在Python中发送请求后,可以得到响应结果,但是这里请求是发送给JavaScript的。由于设置了监控,所以当服务器返回响应时,会触发onreadystatechange对应的方法,然后在这个方法中解析响应内容即可。
解析内容
得到响应后会触发onreadystatechange属性对应的方法,可以通过xmlhttp的responseText属性获取响应内容。这类似于 Python 中使用 requests 向服务器发起请求,然后得到响应的过程。那么返回的内容可能是 HTML,也可能是 JSON,然后你只需要在方法中使用 JavaScript 进行进一步处理即可。例如,如果是JSON,则可以解析转换。
渲染网页
JavaScript 具有更改网页内容的能力。解析响应内容后,可以调用 JavaScript 对网页进行解析处理。例如,通过document.getElementById().innerHTML等操作,可以改变元素中的源代码,从而改变网页上显示的内容。该操作也称为DOM操作,即对Document网页的Document操作,如更改、删除等。
上面的例子中,document.getElementById("myDiv").innerHTML=xmlhttp.responseText会将ID为myDiv的节点内部的HTML代码改成服务器返回的内容,这样服务器返回的内容将显示在 myDiv 元素内。使用新数据后,页面的某些部分似乎已更新。
我们观察到这3个步骤实际上是由JavaScript完成的,它完成了请求、解析和渲染的整个过程。
回想一下微博的pull-to-refresh,这其实就是JavaScript向服务端发送Ajax请求,然后获取新的微博数据,解析,呈现在网页中。
因此,我们知道,真正的数据实际上是从一次又一次的Ajax请求中获取的。如果你想捕获这些数据,你需要知道这些请求是如何发送的,发送到哪里,发送了什么参数。如果我们知道这一点,难道我们不能用 Python 来模拟这个发送操作并得到结果吗?
在下一节中,我们将学习在哪里可以看到这些后台 Ajax 操作,它是如何发送的,以及发送哪些参数。
以上是Ajax在Python3爬虫中使用的详细内容。关于Python3中Ajax是什么的更多信息,请关注上的其他相关话题文章!

