
采集规则 采集 data_src
CMDB发布系统2.监控3.配管系统、装机4.堡垒机CMDB目的
采集交流 • 优采云 发表了文章 • 0 个评论 • 262 次浏览 • 2021-08-18 07:02
CMDB-配置管理数据库资产管理
自动化相关平台(基本CMDB):
1.发布系统
2.监控
3. 管道系统,安装
4.堡垒机
CMDB 的目的:
1.替换EXCEL资产管理-不准资产
2.与监控系统联动
3.自动安装
预期:资产管理
实现原理:
1.代理多机器时
2.ssh
3.盐
实现三种模式兼容,可扩展性
基本结构:
1. Asset采集 的代码
2. API
3.管理平台
################
今天的目标:
资产采集:
- Asset采集code
Python 脚本
- api
姜戈
创建项目:
资产采集
auto_client:
代理模式:
1.采集资产信息
2.使用requests模块发送POST请求,将提交的资产信息提交给api持久化
ssh 模式:
1. 获取不是采集 的主机列表
2.远程连接(ssh)指定主机,执行命名采集asset信息
3. 使用requests模块发送POST请求提交资产信息
盐模式:
1. 获取不是采集 的主机列表
2.远程连接(salt)指定主机,执行命名采集asset信息
3. 使用requests模块发送POST请求提交资产信息
知识点:
1. csrf_exempt 一个视图不需要检查CSRF
2. requests module data={} Django 中的 url 编码 request.POST
data = json 字符串 request.POST 没有值——” request.body
3. 处理错误信息:
不要使用 e traceback.format_exc() 错误堆栈
4.唯一ID:
物理机序列号
物理机+虚拟机:
主机名+文件
规则:
1. 新机 使用主机名采集 的空文件将信息保存到当前新的文件中
2. 旧机改主机名,更新文件内容。当前更改和文件名也会更新。
5.返回值:
r1.content, 字节
r1.文本,字符串
r1.json(),反序列化的结果
6.线程池:
从 concurrent.futures 导入 ThreadPoolExecutor
pool = ThreadPoolExecutor(10)
对于host_list中的主机:
pool.submit(task,host)
7. 遵循的原则:
开闭原则:
打开:配置
关闭:源代码
#########################################
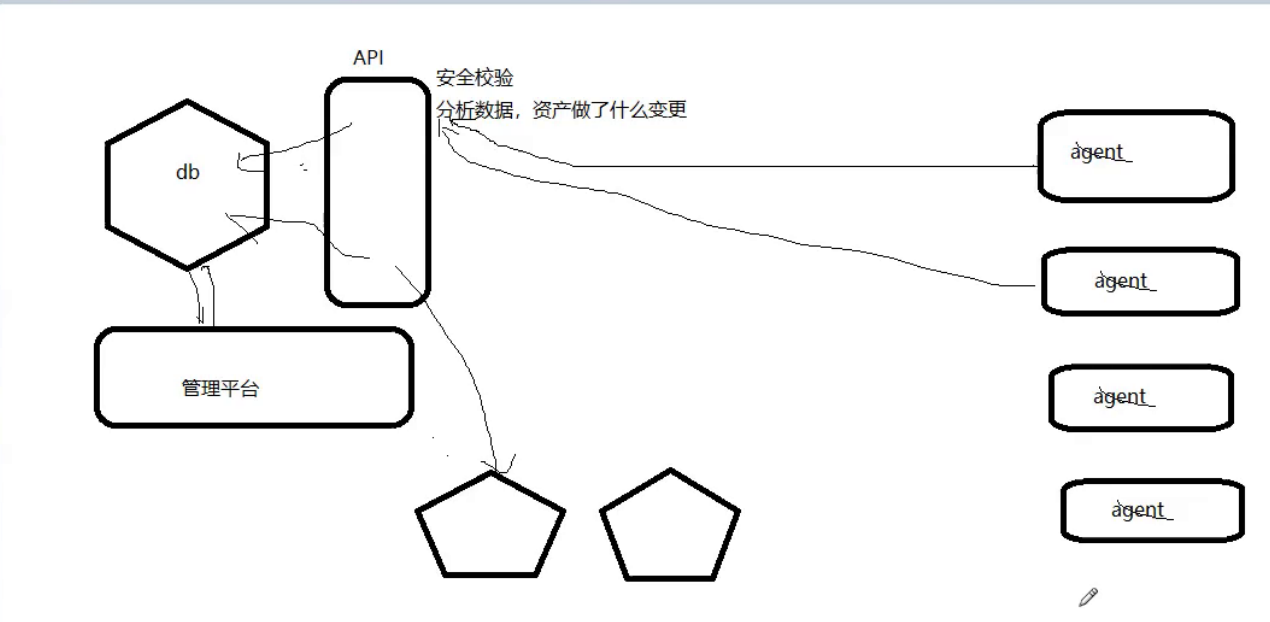
一、模块设计,资产采集方法第一种方法是Agent采集
第二种采集 方法使用中间控制机制。在控制机中,先获取没有采集的数据信息列表,然后到服务器去采集
Asset采集Client 目录规划开始。创建项目目录。这是采集目录,直接运行在服务端程序上。
auto_client 的目录规划
bin 执行文件,
config 配置文件,
lib 公共图书馆,
src 程序逻辑,
日志记录
执行入口bin start
bin
clinet.py
import os, sys
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from src.script import run
if __name__ == '__main__':
run()
逻辑文件
源代码
引擎(创建采集目录)
代理.py
类 AgnetHandler(object):
def handler(self):
"""
Agent模式下处理资产采集
:return:
"""<br /> print('agent模式')<br />
盐.py
class SaltHandler(object):
def handler(self):
"""
Salt模式下处理资产采集
:return:
"""<br /> print(‘salt模式’)<br />
ssh.py
class SSHHandler(object):
def handler(self):
"""
SSH模式下处理资产采集
:return:
"""<br /> print('SSH模式')<br />
脚本.py
from config import setting<br />from src.engine import agent,salt,ssh<br /><br />def run():<br /> """<br /> 资产采集入口<br /> :return:<br /> """<br /> if setting.ENGINE == 'agent':<br /> obj =agent.AgnetHandler()<br /> obj.handler()<br /> elif setting.ENGINE == 'salt':<br /> obj = salt.SaltHandler()<br /> obj.handler()<br /> elif setting.ENGINE == 'ssh':<br /> obj=ssh.SSHHandler()<br /> obj.handler()<br /> else:<br /> print("不支持这个模式采集")
#这种是简单工厂模式<br /><br />
做一个可插拔的程序,写在配置文件中,选择使用采集数据的方式
配置
settings.py
ENGINE='agent' #支持agent,salt,SSH数据采集
########################上面比较低,下面通过反射实现
#利用反射的方式,执行采集方法,首先在配置文件写一个字典
#利用反射执行采集,开发封闭原则
ENGINE_HANDLERS = {
'agent':'src.engine.AgnetHandler',
'salt':'src.engine.SaltHandler',
'ssh':'src.engine.SSHHandler',
}
脚本.py
from config import setting
# from src.engine import agent,salt,ssh
import importlib
def run():
"""
资产采集入口
:return:
"""
# if setting.ENGINE == 'agent':
# obj =agent.AgnetHandler()
# obj.handler()
# elif setting.ENGINE == 'salt':
# obj = salt.SaltHandler()
# obj.handler()
# elif setting.ENGINE == 'ssh':
# obj=ssh.SSHHandler()
# obj.handler()
# else:
# print("不支持这个模式采集")
#利用反射的方式,执行采集方法,首先在配置文件写一个字典
engine_path = setting.ENGINE_HANDLERS.get(setting.ENGINE) #拿到采集模式的脚本的执行路径
#'src.engine.agnet.AgnetHandler' 使用rsplit进行右分割,只是分割一次
path,engine_class=engine_path.rsplit('.',maxsplit=1)
#拿到执行模式脚本的类,使用importlib,导入
# print(path,engine_class)
module = importlib.import_module(path)
# print(module,type(module))
obj=getattr(module,engine_class)() #反射并实例化
obj.handler()
然后就可以将反射写成公共插件了
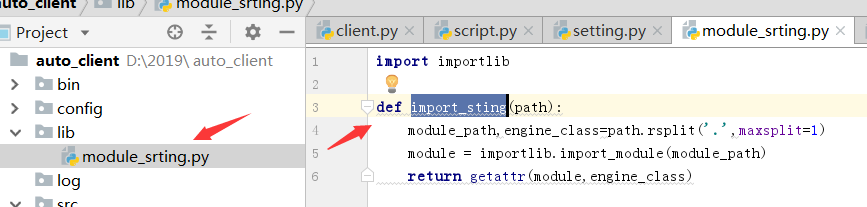
在lib中创建一个文件,module.srting.py
import importlib
def import_sting(path):
module_path,engine_class=path.rsplit('.',maxsplit=1)
module = importlib.import_module(module_path)
return getattr(module,engine_class)
我正在 script.py 中修改
from config import setting
from lib.module_srting import import_sting
def run():
"""
资产采集入口
:return:
"""
#利用反射的方式,执行采集方法,首先在配置文件写一个字典
engine_path = setting.ENGINE_HANDLERS.get(setting.ENGINE) #拿到采集模式的脚本的执行路径
engine_class = import_sting(engine_path)
obj=engine_class() #反射并实例化
obj.handler()
所有采集data 方法都受到约束
class BaseHandler(object):
def handler(self):
'''
约束派生类
:return:
'''
raise NotImplementedError('handler() must Implemented han')
每个方法都必须导入基类才能继承,agent、salt、ssh都必须继承
from .base import BaseHandler
class AgnetHandler(BaseHandler):
def handler(self):
"""
Agent模式下处理资产采集:硬盘、内存、网卡
:return:
"""
print('agent模式')
#调用pulugins.disk /plugins.momory /plugins.nerwork
转载于: 查看全部
CMDB发布系统2.监控3.配管系统、装机4.堡垒机CMDB目的
CMDB-配置管理数据库资产管理
自动化相关平台(基本CMDB):
1.发布系统
2.监控
3. 管道系统,安装
4.堡垒机
CMDB 的目的:
1.替换EXCEL资产管理-不准资产
2.与监控系统联动
3.自动安装
预期:资产管理
实现原理:
1.代理多机器时
2.ssh
3.盐
实现三种模式兼容,可扩展性
基本结构:
1. Asset采集 的代码
2. API
3.管理平台
################
今天的目标:
资产采集:
- Asset采集code
Python 脚本
- api
姜戈
创建项目:
资产采集
auto_client:
代理模式:
1.采集资产信息
2.使用requests模块发送POST请求,将提交的资产信息提交给api持久化
ssh 模式:
1. 获取不是采集 的主机列表
2.远程连接(ssh)指定主机,执行命名采集asset信息
3. 使用requests模块发送POST请求提交资产信息
盐模式:
1. 获取不是采集 的主机列表
2.远程连接(salt)指定主机,执行命名采集asset信息
3. 使用requests模块发送POST请求提交资产信息
知识点:
1. csrf_exempt 一个视图不需要检查CSRF
2. requests module data={} Django 中的 url 编码 request.POST
data = json 字符串 request.POST 没有值——” request.body
3. 处理错误信息:
不要使用 e traceback.format_exc() 错误堆栈
4.唯一ID:
物理机序列号
物理机+虚拟机:
主机名+文件
规则:
1. 新机 使用主机名采集 的空文件将信息保存到当前新的文件中
2. 旧机改主机名,更新文件内容。当前更改和文件名也会更新。
5.返回值:
r1.content, 字节
r1.文本,字符串
r1.json(),反序列化的结果
6.线程池:
从 concurrent.futures 导入 ThreadPoolExecutor
pool = ThreadPoolExecutor(10)
对于host_list中的主机:
pool.submit(task,host)
7. 遵循的原则:
开闭原则:
打开:配置
关闭:源代码
#########################################
一、模块设计,资产采集方法第一种方法是Agent采集
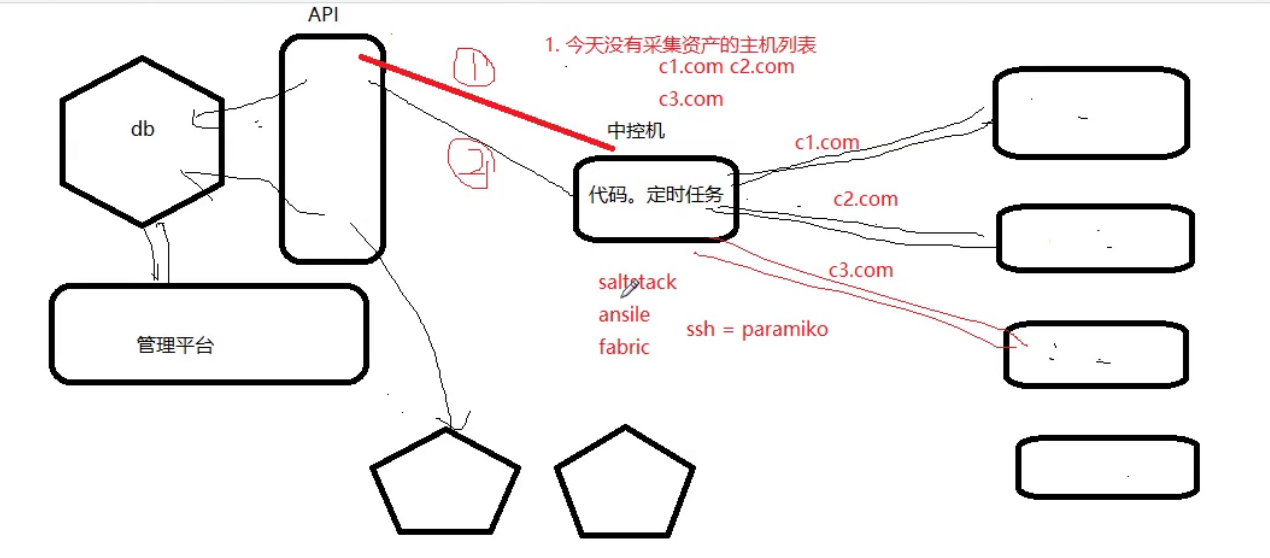
第二种采集 方法使用中间控制机制。在控制机中,先获取没有采集的数据信息列表,然后到服务器去采集
Asset采集Client 目录规划开始。创建项目目录。这是采集目录,直接运行在服务端程序上。
auto_client 的目录规划
bin 执行文件,
config 配置文件,
lib 公共图书馆,
src 程序逻辑,
日志记录
执行入口bin start
bin
clinet.py
import os, sys
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from src.script import run
if __name__ == '__main__':
run()
逻辑文件
源代码
引擎(创建采集目录)
代理.py
类 AgnetHandler(object):
def handler(self):
"""
Agent模式下处理资产采集
:return:
"""<br /> print('agent模式')<br />
盐.py
class SaltHandler(object):
def handler(self):
"""
Salt模式下处理资产采集
:return:
"""<br /> print(‘salt模式’)<br />
ssh.py
class SSHHandler(object):
def handler(self):
"""
SSH模式下处理资产采集
:return:
"""<br /> print('SSH模式')<br />
脚本.py
from config import setting<br />from src.engine import agent,salt,ssh<br /><br />def run():<br /> """<br /> 资产采集入口<br /> :return:<br /> """<br /> if setting.ENGINE == 'agent':<br /> obj =agent.AgnetHandler()<br /> obj.handler()<br /> elif setting.ENGINE == 'salt':<br /> obj = salt.SaltHandler()<br /> obj.handler()<br /> elif setting.ENGINE == 'ssh':<br /> obj=ssh.SSHHandler()<br /> obj.handler()<br /> else:<br /> print("不支持这个模式采集")
#这种是简单工厂模式<br /><br />
做一个可插拔的程序,写在配置文件中,选择使用采集数据的方式
配置
settings.py
ENGINE='agent' #支持agent,salt,SSH数据采集
########################上面比较低,下面通过反射实现
#利用反射的方式,执行采集方法,首先在配置文件写一个字典
#利用反射执行采集,开发封闭原则
ENGINE_HANDLERS = {
'agent':'src.engine.AgnetHandler',
'salt':'src.engine.SaltHandler',
'ssh':'src.engine.SSHHandler',
}
脚本.py
from config import setting
# from src.engine import agent,salt,ssh
import importlib
def run():
"""
资产采集入口
:return:
"""
# if setting.ENGINE == 'agent':
# obj =agent.AgnetHandler()
# obj.handler()
# elif setting.ENGINE == 'salt':
# obj = salt.SaltHandler()
# obj.handler()
# elif setting.ENGINE == 'ssh':
# obj=ssh.SSHHandler()
# obj.handler()
# else:
# print("不支持这个模式采集")
#利用反射的方式,执行采集方法,首先在配置文件写一个字典
engine_path = setting.ENGINE_HANDLERS.get(setting.ENGINE) #拿到采集模式的脚本的执行路径
#'src.engine.agnet.AgnetHandler' 使用rsplit进行右分割,只是分割一次
path,engine_class=engine_path.rsplit('.',maxsplit=1)
#拿到执行模式脚本的类,使用importlib,导入
# print(path,engine_class)
module = importlib.import_module(path)
# print(module,type(module))
obj=getattr(module,engine_class)() #反射并实例化
obj.handler()
然后就可以将反射写成公共插件了
在lib中创建一个文件,module.srting.py
import importlib
def import_sting(path):
module_path,engine_class=path.rsplit('.',maxsplit=1)
module = importlib.import_module(module_path)
return getattr(module,engine_class)
我正在 script.py 中修改
from config import setting
from lib.module_srting import import_sting
def run():
"""
资产采集入口
:return:
"""
#利用反射的方式,执行采集方法,首先在配置文件写一个字典
engine_path = setting.ENGINE_HANDLERS.get(setting.ENGINE) #拿到采集模式的脚本的执行路径
engine_class = import_sting(engine_path)
obj=engine_class() #反射并实例化
obj.handler()
所有采集data 方法都受到约束

class BaseHandler(object):
def handler(self):
'''
约束派生类
:return:
'''
raise NotImplementedError('handler() must Implemented han')
每个方法都必须导入基类才能继承,agent、salt、ssh都必须继承
from .base import BaseHandler
class AgnetHandler(BaseHandler):
def handler(self):
"""
Agent模式下处理资产采集:硬盘、内存、网卡
:return:
"""
print('agent模式')
#调用pulugins.disk /plugins.momory /plugins.nerwork
转载于:
阿里强大的大数据建设方法论是怎样的?(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-08-16 19:16
阿里强大的大数据建设方法论是什么?作者从数据技术、数据模型和数据管理三个部分开始介绍,这将开阔你的视野,也对你有所启发。
最近看了阿里巴巴数据技术与产品部的《大数据之路》一书。本书无论是底层数据技术的沉淀,还是满足各种数据应用场景的产品形态,还是实践中提取的数据。管理理念有助于开阔视野,也可作为自己结合实际情况进行数据建设的参考和参考。
接下来,我们将介绍三个部分:数据技术、数据模型和数据管理。
一、数据技术篇1.1 log采集
阿里巴巴的log采集程序包括两大系统:基于Web的日志采集program Aplus.JS和基于APP的日志采集program UserTrack。
以下是页面浏览日志的采集进程:
浏览器点击链接;浏览器解析请求并按照标准协议向服务器发送HTTP请求(标准HTTP请求包括请求行、请求头和请求体。请求行将包括请求方法是get还是post,以及请求资源URL如HTTP版本协议号,cookie等附加信息会在请求头中体现);服务器接收并解析请求,将处理结果以HTTP响应的形式发送给浏览器(标准HTTP响应包括状态行和响应头、响应体。状态行是一个3位的状态码,用于标识处理服务端的结果,如200/404,响应头中的cookie等附加信息。响应体是可选的,但大多是非空的,包括HTML文档和图片,脚本等);浏览器接收服务器响应,解析并呈现页面。
这是从请求到页面最终显示的标准全过程。浏览器解析服务器的响应如下:
HTML文档解析到某个节点时,JavaScript脚本采集当前页面参数,浏览行为的上下文信息,HTML文档中嵌入的运行环境信息; 采集 完成后发送到日志服务器,通常通过 URL 参数形式体现在请求行中;日志服务器收到日志请求后,立即向请求发送成功响应,并将日志内容写入日志缓冲区;服务端日志处理程序读取日志,解析,保存到标准日志文件中,并注入实时消息通道,供后续程序消费使用。
除了普通的页面浏览日志采集,还有页面交互日志采集,比如采集页面鼠标移动变化,用于准确的用户行为分析。
流程大致如下:
采集代码植入目标页面,绑定到被监控的交互行为;当指定的交互行为产生时,采集代码和正常的业务交互响应代码一起触发; 采集 被发送到采集Server。 1.2数据同步
除了日志采集,数据库同步也是数据访问层的重要组成部分。
数据同步的三种方式:
直接连接同步:通过ODBC或JDBC直接采用标准化统一的标准接口。优点是配置简单,易于实施。但是也有缺点,比如降低了目标系统的性能。建议采用主备策略从备份数据库中提取数据。数据文件同步:约定格式,从源系统生成文本文件,通过FTP服务器传输到目标系统。非常适合收录多个异构数据库系统的数据源,简单实用,另外日志数据通常是文本文件。但是,在上传和下载过程中可能会出现丢包或错误的情况。建议上传时添加验证文件,注明数据量、文件大小等验证信息。数据库日志分析与同步:源系统的日志文件通过TCP/IP三路握手机制依次传输到目标系统。目标系统通过数据加载模块完成数据的导入。数据可实时或准时同步,延迟低,对业务系统影响小。适用于业务系统到数据仓库的增量同步。但缺点是投资较大,需要部署中间系统提取数据,同时存在数据漂移和遗漏问题。
阿里数据仓库同步有两种方式:
1.3线下数据平台
在整体架构中,数据计算层包括数据存储计算平台(MaxCompute、Stream Compute)、数据集成与管理系统(OneData)。
MaxCompute 收录四个部分:
Client:Web,提供restful API的离线数据处理服务;软件开发工具包;客户端工具CLT,可以提交命令完成项目管理、DDL等操作; IDE,上层可视化ETL和BI工具,可完成数据同步、任务调度、报表生成等操作。接入层:提供HTTP服务、Cache、负载均衡,实现用户认证和服务级访问控制。逻辑层:又称控制层,是核心部分,实现命令的分析与执行、数据对象的访问控制与授权等功能。其中,Worker处理所有的RESTful请求; Scheduler 负责 Instance 任务的调度和反汇编;而 Excutor 负责 Instance 的执行。计算层:Apsara Core,包括分布式文件系统、资源调度系统、监控系统等模块。
对于Max Compute,阿里巴巴根据不同场景集成了多个子系统作为统一的开发平台:
除了统一的开发平台,任务调度系统还负责任务的统一调度和管理。它由调度引擎和执行引擎组成。
任务调度系统具有以下特点:
1.4 数据服务
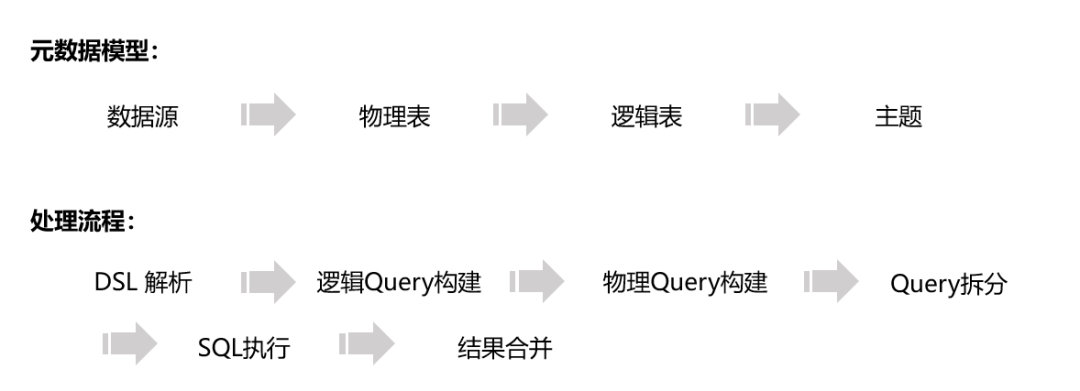
数据服务架构的演进:
SmartDQ的元数据模型和处理流程如下:
SmartDQ 只是满足简单的查询服务。在Oneservice的统计数据服务层中,有如下三个模块:
二、数据模型篇2.1 大数据建模概述
数据模型定义:数据模型是一种数据组织或存储的方法,强调从业务、数据存储和数据使用的角度对数据进行合理的存储。
数据模型的意义:
性能方面,提高查询性能,降低IO吞吐量;在成本方面,减少冗余,结果重用,降低数据存储和计算成本;在效率方面,可以提高数据使用效率;在质量方面,改善统计不一致性。
数据仓库建模方法:
2.2 数据集成与管理系统
Onedata 是阿里巴巴数据公共层建设的指导方法。其定位和价值在于:通过数据服务和数据产品,完成数据公共层的建设,建立标准化、共享的数据服务能力,降低数据互通成本,释放数据计算、存储、人力资源等资源,并消除业务和技术。痛苦。
指标命名约定:
派生指示符 = 时间段 + 修饰符 + 原子指示符
例如,过去7天的新APP用户数。
指标类型可分为:交易指标(如新注册会员数)、存量指标(如产品总数)、综合指标(如比例、变化、变化率、排名,平均值/分位数)统计)。
2.3 维度设计
度量是“事实”,维度是“环境”。维度用于描述事实发生的各种环境,并可用于约束查询、小计和排序。
维度通常使用主键来标识其唯一性。主键有两种类型:具有业务意义的自然键和具有自增列或全局唯一标识符的代理键。
数据仓库的重要特征是反映历史变化,所以如何处理维度变化是维度设计的关键任务。对于缓慢变化的维度,通常有如下三种处理方法:
阿里巴巴使用快照维度表来记录维度变化:基于计算周期,每天可以保留一个完整的快照数据。优点是简单高效,开发维护成本低;缺点是存储成本高。于是阿里提出了一种极限存储的方法。
极限存储采用历史拉链存储的方式,即新的时间字段(start_dt和end_dt)。与全存储相比,优点是不变的数据不会重复存储。
但是历史拉链存储也有缺点,就是下游使用和理解成本高;时间分区可能会超过数据库的分区限制。
所以可以具体优化两点:
透明(即上层对用户进行视图操作和映射关联,用户感知不到极限存储表的存在);每月制作历史拉链表(与每天相比,可以大大减少分区数量)。 2.4事实表设计
事实用于衡量业务流程。常用的事实有以下三种类型:
根据产生方式,事实表可分为以下三种:
事实表的一些设计原则:
事实表的设计方法:选择业务流程→声明粒度→确定维度→确定事实。该方法也适用于采集数据分析需求。
三、数据管理3.1元数据
元数据是数据的数据,记录了数据从生产到消费的全过程:数据仓库中模型的定义,各层级之间的映射关系,监控数据的数据状态,运行状态ETL 任务等。
根据用途,元数据可以细分为技术元数据和业务元数据:
构建统一元数据体系的目标:打通数据访问、处理、消费全环节,提供统一规范的元数据服务出口,保证元数据输出的稳定性和质量。
构建统一元数据系统的目标过程:
结合底层数据,对元数据进行分类,减少数据构建的重复,丰富表和字段的使用说明;构建中间层,在计算、存储、质量、安全等治理领域提供数据支持;为外部服务导出提供统一的元数据。
元数据被广泛使用:
阿里的应用主要有以下几个方面:
(1)Data Profile
建立数据血缘关系图,解决研发前期数据搜索、算法确定、数据处理的复杂困境,节约研发成本,更高效地理解和使用数据,通过标签标记、组织和归档数据。
数据标签主要分为四类:
(2)元数据门户
通过数据地图检索和理解数据,通过数据管理进行计算、存储和安全管理。
(3)血缘关系分析
表级血缘关系、领域血缘关系、间接使用表应用血缘关系用于影响分析、重要性分析、离线分析、离线分析、链接分析、故障排除等。
(4)数据建模
可以实现从经验建模到元数据驱动的升级,提供基于数据的指导,提高建模效率。使用的元数据有:表的基本元数据,比如表的下游情况、查询/关联/聚合的数量;表的关联元数据:关联表、关联类型、关联数、关联字段等;字段的基本元数据,如字段名称、评论、查询/关联/关联/聚合/过滤次数。
(5)drive ETL 开发
OneClick 可用于日常数据运维,如任务查询定位、添加字段、表删除、表备份、任务离线、任务删除等,例如Data Profile判断数据可以离线后,OneClick触发数据离线工作流,直接自动删除数据、删除元数据、离线调度任务、离线DQC监控。
3.2计算管理
计算管理的目的是减少计算资源消耗,提高任务执行性能。计算优化可以分为任务优化和系统优化。
3.3存储和成本管理
从以下几个方面介绍存储优化:
3.4数据质量
数据质量是所有分析有效和准备好的基础和前提,因此数据质量的保证是数据仓库建设的重要环节。
数据质量保证的原则主要有四个方面:
阿里巴巴的数据质量构建方法包括以下几个方面:
摩萨德可以提供强有力的保障监控和自定义警报。围绕运维目标即业务监控设计强保障监控,业务预警时间受到威胁报警。比如业务人员每天的离线数据任务,业务输出时间为9点。 Summer可以根据当前业务中所有任务最近7天的平均运行时间,设置预警时间,如果7点数据没有输出就发出预警。另外,当任务失败时,可以自定义告警配置。 查看全部
阿里强大的大数据建设方法论是怎样的?(组图)
阿里强大的大数据建设方法论是什么?作者从数据技术、数据模型和数据管理三个部分开始介绍,这将开阔你的视野,也对你有所启发。

最近看了阿里巴巴数据技术与产品部的《大数据之路》一书。本书无论是底层数据技术的沉淀,还是满足各种数据应用场景的产品形态,还是实践中提取的数据。管理理念有助于开阔视野,也可作为自己结合实际情况进行数据建设的参考和参考。
接下来,我们将介绍三个部分:数据技术、数据模型和数据管理。
一、数据技术篇1.1 log采集
阿里巴巴的log采集程序包括两大系统:基于Web的日志采集program Aplus.JS和基于APP的日志采集program UserTrack。
以下是页面浏览日志的采集进程:
浏览器点击链接;浏览器解析请求并按照标准协议向服务器发送HTTP请求(标准HTTP请求包括请求行、请求头和请求体。请求行将包括请求方法是get还是post,以及请求资源URL如HTTP版本协议号,cookie等附加信息会在请求头中体现);服务器接收并解析请求,将处理结果以HTTP响应的形式发送给浏览器(标准HTTP响应包括状态行和响应头、响应体。状态行是一个3位的状态码,用于标识处理服务端的结果,如200/404,响应头中的cookie等附加信息。响应体是可选的,但大多是非空的,包括HTML文档和图片,脚本等);浏览器接收服务器响应,解析并呈现页面。
这是从请求到页面最终显示的标准全过程。浏览器解析服务器的响应如下:
HTML文档解析到某个节点时,JavaScript脚本采集当前页面参数,浏览行为的上下文信息,HTML文档中嵌入的运行环境信息; 采集 完成后发送到日志服务器,通常通过 URL 参数形式体现在请求行中;日志服务器收到日志请求后,立即向请求发送成功响应,并将日志内容写入日志缓冲区;服务端日志处理程序读取日志,解析,保存到标准日志文件中,并注入实时消息通道,供后续程序消费使用。
除了普通的页面浏览日志采集,还有页面交互日志采集,比如采集页面鼠标移动变化,用于准确的用户行为分析。
流程大致如下:
采集代码植入目标页面,绑定到被监控的交互行为;当指定的交互行为产生时,采集代码和正常的业务交互响应代码一起触发; 采集 被发送到采集Server。 1.2数据同步
除了日志采集,数据库同步也是数据访问层的重要组成部分。
数据同步的三种方式:
直接连接同步:通过ODBC或JDBC直接采用标准化统一的标准接口。优点是配置简单,易于实施。但是也有缺点,比如降低了目标系统的性能。建议采用主备策略从备份数据库中提取数据。数据文件同步:约定格式,从源系统生成文本文件,通过FTP服务器传输到目标系统。非常适合收录多个异构数据库系统的数据源,简单实用,另外日志数据通常是文本文件。但是,在上传和下载过程中可能会出现丢包或错误的情况。建议上传时添加验证文件,注明数据量、文件大小等验证信息。数据库日志分析与同步:源系统的日志文件通过TCP/IP三路握手机制依次传输到目标系统。目标系统通过数据加载模块完成数据的导入。数据可实时或准时同步,延迟低,对业务系统影响小。适用于业务系统到数据仓库的增量同步。但缺点是投资较大,需要部署中间系统提取数据,同时存在数据漂移和遗漏问题。
阿里数据仓库同步有两种方式:
1.3线下数据平台
在整体架构中,数据计算层包括数据存储计算平台(MaxCompute、Stream Compute)、数据集成与管理系统(OneData)。
MaxCompute 收录四个部分:
Client:Web,提供restful API的离线数据处理服务;软件开发工具包;客户端工具CLT,可以提交命令完成项目管理、DDL等操作; IDE,上层可视化ETL和BI工具,可完成数据同步、任务调度、报表生成等操作。接入层:提供HTTP服务、Cache、负载均衡,实现用户认证和服务级访问控制。逻辑层:又称控制层,是核心部分,实现命令的分析与执行、数据对象的访问控制与授权等功能。其中,Worker处理所有的RESTful请求; Scheduler 负责 Instance 任务的调度和反汇编;而 Excutor 负责 Instance 的执行。计算层:Apsara Core,包括分布式文件系统、资源调度系统、监控系统等模块。
对于Max Compute,阿里巴巴根据不同场景集成了多个子系统作为统一的开发平台:
除了统一的开发平台,任务调度系统还负责任务的统一调度和管理。它由调度引擎和执行引擎组成。
任务调度系统具有以下特点:
1.4 数据服务
数据服务架构的演进:
SmartDQ的元数据模型和处理流程如下:
SmartDQ 只是满足简单的查询服务。在Oneservice的统计数据服务层中,有如下三个模块:
二、数据模型篇2.1 大数据建模概述
数据模型定义:数据模型是一种数据组织或存储的方法,强调从业务、数据存储和数据使用的角度对数据进行合理的存储。
数据模型的意义:
性能方面,提高查询性能,降低IO吞吐量;在成本方面,减少冗余,结果重用,降低数据存储和计算成本;在效率方面,可以提高数据使用效率;在质量方面,改善统计不一致性。
数据仓库建模方法:
2.2 数据集成与管理系统
Onedata 是阿里巴巴数据公共层建设的指导方法。其定位和价值在于:通过数据服务和数据产品,完成数据公共层的建设,建立标准化、共享的数据服务能力,降低数据互通成本,释放数据计算、存储、人力资源等资源,并消除业务和技术。痛苦。
指标命名约定:
派生指示符 = 时间段 + 修饰符 + 原子指示符
例如,过去7天的新APP用户数。
指标类型可分为:交易指标(如新注册会员数)、存量指标(如产品总数)、综合指标(如比例、变化、变化率、排名,平均值/分位数)统计)。
2.3 维度设计
度量是“事实”,维度是“环境”。维度用于描述事实发生的各种环境,并可用于约束查询、小计和排序。
维度通常使用主键来标识其唯一性。主键有两种类型:具有业务意义的自然键和具有自增列或全局唯一标识符的代理键。
数据仓库的重要特征是反映历史变化,所以如何处理维度变化是维度设计的关键任务。对于缓慢变化的维度,通常有如下三种处理方法:
阿里巴巴使用快照维度表来记录维度变化:基于计算周期,每天可以保留一个完整的快照数据。优点是简单高效,开发维护成本低;缺点是存储成本高。于是阿里提出了一种极限存储的方法。
极限存储采用历史拉链存储的方式,即新的时间字段(start_dt和end_dt)。与全存储相比,优点是不变的数据不会重复存储。
但是历史拉链存储也有缺点,就是下游使用和理解成本高;时间分区可能会超过数据库的分区限制。
所以可以具体优化两点:
透明(即上层对用户进行视图操作和映射关联,用户感知不到极限存储表的存在);每月制作历史拉链表(与每天相比,可以大大减少分区数量)。 2.4事实表设计
事实用于衡量业务流程。常用的事实有以下三种类型:
根据产生方式,事实表可分为以下三种:
事实表的一些设计原则:
事实表的设计方法:选择业务流程→声明粒度→确定维度→确定事实。该方法也适用于采集数据分析需求。
三、数据管理3.1元数据
元数据是数据的数据,记录了数据从生产到消费的全过程:数据仓库中模型的定义,各层级之间的映射关系,监控数据的数据状态,运行状态ETL 任务等。
根据用途,元数据可以细分为技术元数据和业务元数据:
构建统一元数据体系的目标:打通数据访问、处理、消费全环节,提供统一规范的元数据服务出口,保证元数据输出的稳定性和质量。
构建统一元数据系统的目标过程:
结合底层数据,对元数据进行分类,减少数据构建的重复,丰富表和字段的使用说明;构建中间层,在计算、存储、质量、安全等治理领域提供数据支持;为外部服务导出提供统一的元数据。
元数据被广泛使用:
阿里的应用主要有以下几个方面:
(1)Data Profile
建立数据血缘关系图,解决研发前期数据搜索、算法确定、数据处理的复杂困境,节约研发成本,更高效地理解和使用数据,通过标签标记、组织和归档数据。
数据标签主要分为四类:
(2)元数据门户
通过数据地图检索和理解数据,通过数据管理进行计算、存储和安全管理。
(3)血缘关系分析
表级血缘关系、领域血缘关系、间接使用表应用血缘关系用于影响分析、重要性分析、离线分析、离线分析、链接分析、故障排除等。
(4)数据建模
可以实现从经验建模到元数据驱动的升级,提供基于数据的指导,提高建模效率。使用的元数据有:表的基本元数据,比如表的下游情况、查询/关联/聚合的数量;表的关联元数据:关联表、关联类型、关联数、关联字段等;字段的基本元数据,如字段名称、评论、查询/关联/关联/聚合/过滤次数。
(5)drive ETL 开发
OneClick 可用于日常数据运维,如任务查询定位、添加字段、表删除、表备份、任务离线、任务删除等,例如Data Profile判断数据可以离线后,OneClick触发数据离线工作流,直接自动删除数据、删除元数据、离线调度任务、离线DQC监控。
3.2计算管理
计算管理的目的是减少计算资源消耗,提高任务执行性能。计算优化可以分为任务优化和系统优化。
3.3存储和成本管理
从以下几个方面介绍存储优化:
3.4数据质量
数据质量是所有分析有效和准备好的基础和前提,因此数据质量的保证是数据仓库建设的重要环节。
数据质量保证的原则主要有四个方面:
阿里巴巴的数据质量构建方法包括以下几个方面:
摩萨德可以提供强有力的保障监控和自定义警报。围绕运维目标即业务监控设计强保障监控,业务预警时间受到威胁报警。比如业务人员每天的离线数据任务,业务输出时间为9点。 Summer可以根据当前业务中所有任务最近7天的平均运行时间,设置预警时间,如果7点数据没有输出就发出预警。另外,当任务失败时,可以自定义告警配置。
使用php采集网页数据一般有多种方法,有时候东西以采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-08-15 23:12
php采集网页数据的使用方式一般有很多种。有时我们使用正则去采集页面,但是当我们需要采集有一个很大很大的页面时,就会严重浪费我们的CPU。到时候我们可以用phpQuer来做采集。如果你不了解 phpQuery,你可以去看看这是什么。
以采集此网站为例
假设我们需要采集commodity category Name Price Item No Shelf Time Product Picture Detail Picture
1.首先下载phpQuery类phpQuery.php
2.接下来我们可以创建一个cj.php类
单页采集
php
header("Content-Type: text/html; charset=UTF-8");
require("phpQuery.php"); //引入类
//检测当前链接是否合法
$url = 'http://www.rsq111.com/goods.php?id=15663';
$header_info=getHeaders($url,true);
if ($header_info != 200) {
die;
}
phpQuery::newDocumentFile($url); //获取网页对象内容
//pq() == $(this)
// 商品分类
$arr_check = pq(".breadcrumb");
foreach ($arr_check as $li) {
$cat = pq($li)->text();
}
$category = explode('>', $cat);
//商品标题
$h1_check = pq("#name");
$title = pq($h1_check)->text();
//商品价格
$price_check = pq(".rmbPrice");
$shop_price = [];
foreach ($price_check as $li) {
$shop_price[] = pq($li)->text();
}
$shop_price = array_pop($shop_price);
$shop_price = explode(':', $shop_price);
$price = $shop_price[1];
//商品参数
$prame_check = pq("#summary1 .dd");
$prame = [];
foreach ($prame_check as $li) {
$prame[] = pq($li)->text();
}
$sn = $prame[0];//货号
$brank = $prame[1];//品牌
$time = $prame[2];//上架时间
// 商品图片
$prame_photo_check = pq("#goods_gallery a");
$photo = [];
foreach ($prame_photo_check as $li) {
$src = 'http://www.rsq111.com/'.pq($li)->attr('href');//图片路径
//注释代码为保存图片路劲,下载图片到本地
$localSrc = 'w/'.md5($src).'.jpg';
// $stream = file_get_contents($src);
// file_put_contents($localSrc,$stream);
// pq($li)->attr('src',$localSrc);
$photo[] = $localSrc;
}
//商品详情图片
$info_photo_check = pq(".detail-content img");
$info_photo = [];
foreach ($info_photo_check as $li) {
$src = 'http://www.rsq111.com/'.pq($li)->attr('src');
$localSrc = 'w/'.md5($src).'.jpg';
// $stream = file_get_contents($src);
// file_put_contents($localSrc,$stream);
// pq($li)->attr('src',$localSrc);
$info_photo[] = $localSrc;
}
$data= [
'title' => $title,
'category1' => $category[1],
'category2' => $category[2],
'category3' => $category[3],
'price' => $price,
'sn' => $sn,
'brank' => $brank,
'time' => $time,
'photo' => $photo,
'info_photo' =>$info_photo,
];
}
echo "";
print_r($data);
//检测url是否合法
function getHeaders($url,$data=FALSE){
$_headers = get_headers($url,1);
if( !$data ){return $_headers;}
$curl = curl_init();
curl_setopt($curl,CURLOPT_URL,$url);//获取内容url
curl_setopt($curl,CURLOPT_HEADER,1);//获取http头信息
curl_setopt($curl,CURLOPT_NOBODY,1);//不返回html的body信息
curl_setopt($curl,CURLOPT_RETURNTRANSFER,1);//返回数据流,不直接输出
curl_setopt($curl,CURLOPT_TIMEOUT,30); //超时时长,单位秒
curl_exec($curl);
$rtn= curl_getinfo($curl,CURLINFO_HTTP_CODE);
curl_close($curl);
return $rtn;
}
这种情况下,可以采集到这个页面的数据,但是如果我们需要更多的采集数据页面,比如几万条数据,这种方式会很慢
多页采集
如果我们直接循环获取页面,这样每个页面都需要访问一次,并且爬取数据,费时费力,这就是我们可以有多种方案来优化速度。
一个。使用curl模拟多线程,一次性抓取所有网页,保存在本地给采集,避免重复请求带来的开销
B.使用 swoole 创建多个线程来执行采集。比如我们去采集10个页面,需要10秒。这时候我们创建了多个线程,同事请求分发。网址,你可以提高我们的速度
c.当然,如果我们对数据要求不高,可以使用第三方软件,比如优采云、优采云,这些工具可以采集更快的拿到需要的数据
笔者这里用的是第一种方法,因为是windows环境,如果swoole的话,windows安装有点麻烦
我使用 ajax 轮询,一次 10 个。比如我们从产品id为1采集
的数据开始
phpcj.php
php
//获取开始采集的id
$start_id = $_POST['start_id'];
$end_id = $start_id+10; //每次加10条
if(empty($start_id) || empty($end_id)){
exit(json_encode(['status'=>0,'msg'=>'参数不正确']));
}
$pdo = new PDO('mysql:host=数据库地址;dbname=数据库名','用户','密码',array(PDO::ATTR_PERSISTENT));
header("Content-Type: text/html; charset=UTF-8");
require("phpQuery.php");
//将要采集的地址全部循环出来
for ($i=$start_id; $i < $end_id; $i++) {
$urls[$i] = 'http://www.rsq111.com/goods.php?id='.$i;
}
//判断当前url是否合法,这里我判断的是第一条
$code = getHeaders(array_shift($urls),true);
if($code != 200){
//如果不合法,返回结束id,重新开始执行
exit(json_encode(['status'=>1,'msg'=>'当前id无商品','end_id'=>$end_id]));
}
$save_to='test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,'w+');
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 设置不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
file_put_contents($save_to, '');
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
file_put_contents($save_to, $data); //将抓取到的野蛮写入到文件中
$data = cj($i);
if ($data) {
$add[$i] = $data;
}
}
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
//将采集成功的数据存入数据库
$sql = '';
if(!empty($add))
{
foreach ($add as $key => $value) {
$title = str_replace("'","",$value['title']);
$category1 = $value['category1'];
$category2 = $value['category2'];
$category3 = $value['category3'];
$price = $value['price'];
$sn = $value['sn'];
$brank = $value['brank'];
$time = $value['time'];
$photo = $value['photo'];
$info_photo = $value['info_photo'];
$cj_id = $end_id;
$sql[] = "('$title','$category1','$category2','$category3','$price','$sn','$brank','$time','$photo','$info_photo','$cj_id')";
}
$sqls =implode(',', $sql);
$add_sql = "INSERT into phpcj (title,category1,category2,category3,price,sn,brank,time,photo,info_photo,cj_id) VALUES ".$sqls;
$res = $pdo->exec($add_sql);
if(!$res) {
//采集未成功,返回id,重新开始采集
exit(json_encode(['status'=>0,'msg'=>'本次采集未成功..','start_id'=>$start_id]));
}else{
//采集成功,将最后一条数据返回,用作下此次执行的开始id
exit(json_encode(['status'=>1,'msg'=>'采集成功,正在进行循环采集..','end_id'=>$end_id]));
}
}
//采集方法
function cj($i)
{
$url = 'http://www.***.com/test.txt'; //页面存取的文本路劲
phpQuery::newDocumentFile($url);
// 分类
$arr_check = pq(".breadcrumb");
foreach ($arr_check as $li) {
$cat = pq($li)->text();
}
if(empty($cat)){
return;
}
$category = explode('>', $cat);
//标题
$h1_check = pq("#name");
$title = pq($h1_check)->text();
//价格
$price_check = pq(".rmbPrice");
$shop_price = [];
foreach ($price_check as $li) {
$shop_price[] = pq($li)->text();
}
$shop_price = array_pop($shop_price);
$shop_price = explode(':', $shop_price);
$price = $shop_price[1];
//参数
$prame_check = pq("#summary1 .dd");
$prame = [];
foreach ($prame_check as $li) {
$prame[] = pq($li)->text();
}
$sn = $prame[0];//货号
if(count($prame) > 2){
$brank = $prame[1];//品牌
$time = $prame[2];//上架时间
}else{
$brank = '无';
$time = $prame[1];//上架时间
}
// 商品图片
$prame_photo_check = pq("#goods_gallery a");
$photo = [];
foreach ($prame_photo_check as $li) {
$src = 'http://www.rsq111.com/'.pq($li)->attr('href');
// $localSrc = 'w/'.md5($src).'.jpg';
// $stream = file_get_contents($src);
// file_put_contents($localSrc,$stream);
// pq($li)->attr('src',$localSrc);
// $photo[] = $localSrc;
$photo[] = $src;
}
$photo =json_encode($photo);
//商品详情图片
$info_photo_check = pq(".detail-content img");
$info_photo = [];
foreach ($info_photo_check as $li) {
$src = 'http://www.rsq111.com/'.pq($li)->attr('src');
// $localSrc = 'w/'.md5($src).'.jpg';
// $stream = file_get_contents($src);
// file_put_contents($localSrc,$stream);
// pq($li)->attr('src',$localSrc);
// $info_photo[] = $localSrc;
$info_photo[] = $src;
}
$info_photo = json_encode($info_photo);
//如果商品没有三级分类,给他赋值为空
if(count($category) < 3){
$category[3] = '';
}
$data = [
'title' => $title,
'category1' => $category[1],
'category2' => $category[2],
'category3' => $category[3],
'price' => $price,
'sn' => $sn,
'brank' => $brank,
'time' => $time,
'photo' => $photo,
'info_photo' =>$info_photo,
'cj_id' => $end_id,
];
return $data;
}
//判断url是否合法
function getHeaders($url,$data=FALSE){
$_headers = get_headers($url,1);
if( !$data ){return $_headers;}
$curl = curl_init();
curl_setopt($curl,CURLOPT_URL,$url);//获取内容url
curl_setopt($curl,CURLOPT_HEADER,1);//获取http头信息
curl_setopt($curl,CURLOPT_NOBODY,1);//不返回html的body信息
curl_setopt($curl,CURLOPT_RETURNTRANSFER,1);//返回数据流,不直接输出
curl_setopt($curl,CURLOPT_TIMEOUT,30); //超时时长,单位秒
curl_exec($curl);
$rtn= curl_getinfo($curl,CURLINFO_HTTP_CODE);
curl_close($curl);
return $rtn;
}
这样我们就完成了页面采集的循环
前台代码,使用ajax循环请求(如果使用服务器定时任务,需要注意,对于采集不成功的判断,本节我手动重新填id,因为采集因素不可控,可能是对方页面错了,对方数据库错了,但是我们还是可以正常访问的,所以需要把采集失败或者把采集保留在某个id上,需要加上时效判断。超过多久,默认是当前数据采集不成功,那么下一轮采集就会开始,可以是当前id+1,或者其他规则,反正跳过这个id)
"en">
"UTF-8">
Document
"text" name="start_id" id="start_id" placeholder="采集开始id">
"button" id="btn" value="开始采集">
"zhi">
"text" id="ids" placeholder="采集返回成功条数"> 查看全部
使用php采集网页数据一般有多种方法,有时候东西以采集
php采集网页数据的使用方式一般有很多种。有时我们使用正则去采集页面,但是当我们需要采集有一个很大很大的页面时,就会严重浪费我们的CPU。到时候我们可以用phpQuer来做采集。如果你不了解 phpQuery,你可以去看看这是什么。
以采集此网站为例
假设我们需要采集commodity category Name Price Item No Shelf Time Product Picture Detail Picture
1.首先下载phpQuery类phpQuery.php
2.接下来我们可以创建一个cj.php类
单页采集
php
header("Content-Type: text/html; charset=UTF-8");
require("phpQuery.php"); //引入类
//检测当前链接是否合法
$url = 'http://www.rsq111.com/goods.php?id=15663';
$header_info=getHeaders($url,true);
if ($header_info != 200) {
die;
}
phpQuery::newDocumentFile($url); //获取网页对象内容
//pq() == $(this)
// 商品分类
$arr_check = pq(".breadcrumb");
foreach ($arr_check as $li) {
$cat = pq($li)->text();
}
$category = explode('>', $cat);
//商品标题
$h1_check = pq("#name");
$title = pq($h1_check)->text();
//商品价格
$price_check = pq(".rmbPrice");
$shop_price = [];
foreach ($price_check as $li) {
$shop_price[] = pq($li)->text();
}
$shop_price = array_pop($shop_price);
$shop_price = explode(':', $shop_price);
$price = $shop_price[1];
//商品参数
$prame_check = pq("#summary1 .dd");
$prame = [];
foreach ($prame_check as $li) {
$prame[] = pq($li)->text();
}
$sn = $prame[0];//货号
$brank = $prame[1];//品牌
$time = $prame[2];//上架时间
// 商品图片
$prame_photo_check = pq("#goods_gallery a");
$photo = [];
foreach ($prame_photo_check as $li) {
$src = 'http://www.rsq111.com/'.pq($li)->attr('href');//图片路径
//注释代码为保存图片路劲,下载图片到本地
$localSrc = 'w/'.md5($src).'.jpg';
// $stream = file_get_contents($src);
// file_put_contents($localSrc,$stream);
// pq($li)->attr('src',$localSrc);
$photo[] = $localSrc;
}
//商品详情图片
$info_photo_check = pq(".detail-content img");
$info_photo = [];
foreach ($info_photo_check as $li) {
$src = 'http://www.rsq111.com/'.pq($li)->attr('src');
$localSrc = 'w/'.md5($src).'.jpg';
// $stream = file_get_contents($src);
// file_put_contents($localSrc,$stream);
// pq($li)->attr('src',$localSrc);
$info_photo[] = $localSrc;
}
$data= [
'title' => $title,
'category1' => $category[1],
'category2' => $category[2],
'category3' => $category[3],
'price' => $price,
'sn' => $sn,
'brank' => $brank,
'time' => $time,
'photo' => $photo,
'info_photo' =>$info_photo,
];
}
echo "";
print_r($data);
//检测url是否合法
function getHeaders($url,$data=FALSE){
$_headers = get_headers($url,1);
if( !$data ){return $_headers;}
$curl = curl_init();
curl_setopt($curl,CURLOPT_URL,$url);//获取内容url
curl_setopt($curl,CURLOPT_HEADER,1);//获取http头信息
curl_setopt($curl,CURLOPT_NOBODY,1);//不返回html的body信息
curl_setopt($curl,CURLOPT_RETURNTRANSFER,1);//返回数据流,不直接输出
curl_setopt($curl,CURLOPT_TIMEOUT,30); //超时时长,单位秒
curl_exec($curl);
$rtn= curl_getinfo($curl,CURLINFO_HTTP_CODE);
curl_close($curl);
return $rtn;
}
这种情况下,可以采集到这个页面的数据,但是如果我们需要更多的采集数据页面,比如几万条数据,这种方式会很慢
多页采集
如果我们直接循环获取页面,这样每个页面都需要访问一次,并且爬取数据,费时费力,这就是我们可以有多种方案来优化速度。
一个。使用curl模拟多线程,一次性抓取所有网页,保存在本地给采集,避免重复请求带来的开销
B.使用 swoole 创建多个线程来执行采集。比如我们去采集10个页面,需要10秒。这时候我们创建了多个线程,同事请求分发。网址,你可以提高我们的速度
c.当然,如果我们对数据要求不高,可以使用第三方软件,比如优采云、优采云,这些工具可以采集更快的拿到需要的数据
笔者这里用的是第一种方法,因为是windows环境,如果swoole的话,windows安装有点麻烦
我使用 ajax 轮询,一次 10 个。比如我们从产品id为1采集
的数据开始
phpcj.php
php
//获取开始采集的id
$start_id = $_POST['start_id'];
$end_id = $start_id+10; //每次加10条
if(empty($start_id) || empty($end_id)){
exit(json_encode(['status'=>0,'msg'=>'参数不正确']));
}
$pdo = new PDO('mysql:host=数据库地址;dbname=数据库名','用户','密码',array(PDO::ATTR_PERSISTENT));
header("Content-Type: text/html; charset=UTF-8");
require("phpQuery.php");
//将要采集的地址全部循环出来
for ($i=$start_id; $i < $end_id; $i++) {
$urls[$i] = 'http://www.rsq111.com/goods.php?id='.$i;
}
//判断当前url是否合法,这里我判断的是第一条
$code = getHeaders(array_shift($urls),true);
if($code != 200){
//如果不合法,返回结束id,重新开始执行
exit(json_encode(['status'=>1,'msg'=>'当前id无商品','end_id'=>$end_id]));
}
$save_to='test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,'w+');
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 设置不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
file_put_contents($save_to, '');
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
file_put_contents($save_to, $data); //将抓取到的野蛮写入到文件中
$data = cj($i);
if ($data) {
$add[$i] = $data;
}
}
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
//将采集成功的数据存入数据库
$sql = '';
if(!empty($add))
{
foreach ($add as $key => $value) {
$title = str_replace("'","",$value['title']);
$category1 = $value['category1'];
$category2 = $value['category2'];
$category3 = $value['category3'];
$price = $value['price'];
$sn = $value['sn'];
$brank = $value['brank'];
$time = $value['time'];
$photo = $value['photo'];
$info_photo = $value['info_photo'];
$cj_id = $end_id;
$sql[] = "('$title','$category1','$category2','$category3','$price','$sn','$brank','$time','$photo','$info_photo','$cj_id')";
}
$sqls =implode(',', $sql);
$add_sql = "INSERT into phpcj (title,category1,category2,category3,price,sn,brank,time,photo,info_photo,cj_id) VALUES ".$sqls;
$res = $pdo->exec($add_sql);
if(!$res) {
//采集未成功,返回id,重新开始采集
exit(json_encode(['status'=>0,'msg'=>'本次采集未成功..','start_id'=>$start_id]));
}else{
//采集成功,将最后一条数据返回,用作下此次执行的开始id
exit(json_encode(['status'=>1,'msg'=>'采集成功,正在进行循环采集..','end_id'=>$end_id]));
}
}
//采集方法
function cj($i)
{
$url = 'http://www.***.com/test.txt'; //页面存取的文本路劲
phpQuery::newDocumentFile($url);
// 分类
$arr_check = pq(".breadcrumb");
foreach ($arr_check as $li) {
$cat = pq($li)->text();
}
if(empty($cat)){
return;
}
$category = explode('>', $cat);
//标题
$h1_check = pq("#name");
$title = pq($h1_check)->text();
//价格
$price_check = pq(".rmbPrice");
$shop_price = [];
foreach ($price_check as $li) {
$shop_price[] = pq($li)->text();
}
$shop_price = array_pop($shop_price);
$shop_price = explode(':', $shop_price);
$price = $shop_price[1];
//参数
$prame_check = pq("#summary1 .dd");
$prame = [];
foreach ($prame_check as $li) {
$prame[] = pq($li)->text();
}
$sn = $prame[0];//货号
if(count($prame) > 2){
$brank = $prame[1];//品牌
$time = $prame[2];//上架时间
}else{
$brank = '无';
$time = $prame[1];//上架时间
}
// 商品图片
$prame_photo_check = pq("#goods_gallery a");
$photo = [];
foreach ($prame_photo_check as $li) {
$src = 'http://www.rsq111.com/'.pq($li)->attr('href');
// $localSrc = 'w/'.md5($src).'.jpg';
// $stream = file_get_contents($src);
// file_put_contents($localSrc,$stream);
// pq($li)->attr('src',$localSrc);
// $photo[] = $localSrc;
$photo[] = $src;
}
$photo =json_encode($photo);
//商品详情图片
$info_photo_check = pq(".detail-content img");
$info_photo = [];
foreach ($info_photo_check as $li) {
$src = 'http://www.rsq111.com/'.pq($li)->attr('src');
// $localSrc = 'w/'.md5($src).'.jpg';
// $stream = file_get_contents($src);
// file_put_contents($localSrc,$stream);
// pq($li)->attr('src',$localSrc);
// $info_photo[] = $localSrc;
$info_photo[] = $src;
}
$info_photo = json_encode($info_photo);
//如果商品没有三级分类,给他赋值为空
if(count($category) < 3){
$category[3] = '';
}
$data = [
'title' => $title,
'category1' => $category[1],
'category2' => $category[2],
'category3' => $category[3],
'price' => $price,
'sn' => $sn,
'brank' => $brank,
'time' => $time,
'photo' => $photo,
'info_photo' =>$info_photo,
'cj_id' => $end_id,
];
return $data;
}
//判断url是否合法
function getHeaders($url,$data=FALSE){
$_headers = get_headers($url,1);
if( !$data ){return $_headers;}
$curl = curl_init();
curl_setopt($curl,CURLOPT_URL,$url);//获取内容url
curl_setopt($curl,CURLOPT_HEADER,1);//获取http头信息
curl_setopt($curl,CURLOPT_NOBODY,1);//不返回html的body信息
curl_setopt($curl,CURLOPT_RETURNTRANSFER,1);//返回数据流,不直接输出
curl_setopt($curl,CURLOPT_TIMEOUT,30); //超时时长,单位秒
curl_exec($curl);
$rtn= curl_getinfo($curl,CURLINFO_HTTP_CODE);
curl_close($curl);
return $rtn;
}
这样我们就完成了页面采集的循环
前台代码,使用ajax循环请求(如果使用服务器定时任务,需要注意,对于采集不成功的判断,本节我手动重新填id,因为采集因素不可控,可能是对方页面错了,对方数据库错了,但是我们还是可以正常访问的,所以需要把采集失败或者把采集保留在某个id上,需要加上时效判断。超过多久,默认是当前数据采集不成功,那么下一轮采集就会开始,可以是当前id+1,或者其他规则,反正跳过这个id)
"en">
"UTF-8">
Document
"text" name="start_id" id="start_id" placeholder="采集开始id">
"button" id="btn" value="开始采集">
"zhi">
"text" id="ids" placeholder="采集返回成功条数">
第一步:我们先复制一份原来的规则做模板(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-08-09 01:21
第 1 步:让我们复制原创规则作为模板。比如我今天演示的采集站点是一个叫feiku的小说站点,那么我将我复制的模板规则的副本命名为dhabc。 xml 这个主要是为了方便记忆。第二步:我们在采集器中运行规则管理工具,打开后加载,我们只是将其命名为dhabc。 xml XML文件第三步:开始正式写规则RULEID(规则编号)这个任意GetSiteName(站点名称)这里我们写8E小说GetSiteCharset(站点代码)这里我们打开找到charset=这个=后面的数字就是我们需要的站点代码我们找到的代码是gb2312 GetSiteUrl(站点地址)。不用说,写NovelSearchUrl(网站搜索地址)。这个地址是根据每个网站程序的不同得到的,但是有一个通用的方法是通过抓包来获取你想要的内容。虽然说是抓包得到的,但是你怎么知道得到的就是我们想要的呢?看看我的操作。首先,我们运行数据包工具并选择 IEXPLORE。 EXE进程最好只打开一个网站,也就是只打开你要写规则的网站,保证进程中只有一个IEXPLORE。
EXE 进程。在这里我们可以看到提交的地址是/book/search。 aspx 我们结合得到的地址 SearchKey=%C1%AB%BB%A8&SearchClass=1&SeaButton。 x=26&SeaButton。 y=10 但是对我们有用的是 SearchKey=%C1%AB%BB%A8&SearchClass=1 这里得到的NovelSearchData(搜索提交)这一段,就是用来把这一段改成我们想要的代码。一段%C1%AB%BB%A8换成{SearchKey},表示搜索提交内容的完整代码为SearchKey={SearchKey}&SearchClass=1 然后我们测试一下是否正确。经过测试,我们得到的内容是正确的NovelListUrl(站点最新列表地址)这个我就不说了,因为每个站点不一样。需要自己找FEIKU NovelList_GetNovelKey(从最新列表中获取小说编号。在此规则中,可以同时获取书名。书名是手动获取的。如果要使用手动模式,一定要拿到书名,否则手动模式无法使用)我们打开这个地址查看源文件。当我们写这个规则时,我们找到了我们想要获取内容的地方。比如我们打开地址看到我想获取内容的第一本小说的名字是李迪承德。我们在源文件中找到了我们用来编写规则的代码。实际上,它不是很多。我写规则的原则是先存后存,也就是代码越短越好。除非万不得已,href="越短越好。
8c8e。 com/Book/149539/索引。 html"target="_blank"> 让我们把这一段改成 href="。 8c8e。 com/Book/(\d*)/索引。 html"target="_blank">(.+?) 表示小说名经过测试无误。NovelUrl(小说信息页地址)很容易找到,只要点击小说,比如我们可以看到这本小说我们改一下,随意改一下中间的数字,比如我们得到的错误标记就是没有找到那个编号的书信息!10.NovelName(查看源代码到获取小说名称,我们可以从固定模式开始,比如我们刚刚打开它,在这本小说中,我们看到他的固定小说名称格式是“Landing into a magic”,然后我们找到“Landing into a magic”源代码中的magic”。我们得到的内容是
“站点成恶魔”
让我们改变这一段
"(.+?)"
以下NovelAuthor(获取小说作者) LagerSort(获取小说类别) SmallSort(获取小说类别) NovelIntro(获取小说简介) NovelKeyword(获取小说主角(关键词)) NovelDegree(获取小说封面) (获取小说) (封面) 我就不演示了,这些和上面获取小说名称的方法是一样的,所以叫做One-pass Belden。有时候有些内容你不想要使用,因为格式不固定。有些内容只能先获取,然后用filter函数过滤掉filter的用途。后面,11.NovelInfo_GetNovelPubKey(获取小说公共目录地址page) 这个地址的获取方法和上面一样,这里就不解释 12 PubIndexUrl (公共目录页面的地址)) 来解释一下这个的用法。这个一般在知道采集目标站的动态地址时使用。如果不知道对方的动态地址,知道动态路径{NovelKey}/Index .aspx13.PubVolumeSplit(拆分子卷)这个拆分子卷有什么可写的,就在这写{NovelPubKey}。需要注意的是,如果拆分子卷的规律性不是那么可能对后面的章节名称产生很大的影响。这里我们得到了分割部分的代码。根据我的经验,找到第一个子卷和下面的子卷,看看它们有什么共同点。当我们分析本目录章节中的源代码时,我们可以看到它们有一个共同点。让我们解释一下这一段。
追求力量
\s* \s* 表示匹配任何白色字符,包括空格、制表符、分页符等,也就是说,无论它们之间有多少个空格,都可以用来表示14 PubVolumeName(获取卷名) 要获取准确的子卷名,上面拆分部分的规律必须是正确的。一般拆分部分的子卷名称在块的顶部。我们说明分割部分使用
追求力量
如果你注意这一段,你会发现它收录了我们这一步要获取的子卷名。修改代码
(.+?)
\s* 在我们的测试下,我们可以正常获取子卷,但是如果有这些,我们通常会在过滤规则中将其过滤掉。 PubChapterName(获取章节名) 我们用一段话来说明强大的驯服方法。对于这种时间、日期和更新字数,我们直接忽略,因为这些不是我们想要的。有人问我为什么在这里没用。 () 把它附在这里让我告诉你我们得到的内容就是()中的内容。如果它不是你想要的,但在编写规则时必须使用它,我们可以稍微改变表达式。我们把上面的段落改一下,改成表达式(.+?)就可以正常获取内容了。大家是不是看着这个规则有点别扭?这是因为中间有一个换行符。我没有更改代码。让我们使用\s*。这意味着一个换行符。我们修改后的代码是 (.+?) 现在好点了吗?经过测试,获取内容描述也是正常的。没问题。 16. PubChapter_GetChapterKey(获取章节地址(Chapter Number)) 这里说明一下,下面的PubContentUrl(章节内容页面地址)中使用了这个中的章节号。一般用于知道目标站的动态地址。当目标站未知时,一般不使用静态地址。所以这里我们需要获取章节地址解析(.
+?) 既然这里是获取章节地址,那为什么还要使用章节名称呢?这主要是为了避免获取的章节名称和获取的章节地址不匹配。这是下一章编号的说明。不麻烦,稍微改一下(.+?)改成这个,我们测试一下看看,改一下就可以得到数了。这个数字只有在知道目标站的动态地址的情况下才能获得。最多使用17.PubContentUrl(章节内容页面地址)在上面得到的章节地址中有说明。这是要知道如何使用目标站。 149539 这是新号码。这里我们用{NovelKey}代替3790336 这是在PubChapter_GetChapterKey中获得的章节编号,我们用{ChapterKey}代替组合为{NovelKey}/{ChapterKey}。 ASPX 是我们的动态章节地址。记住,前提是要知道对方的动态地址。如果你不知道对方的动态地址,那么我们这里写的PubContentUrl(章节内容页面地址)就是{ChapterKey} 18. PubContentText(获取章节内容) 这种获取方式和获取章节名称是一样的。这个就不解释了。现在我们解释过滤的用法。这很简单。几个地方是介绍章节名和卷名以及获取的小说章节内容,但是章节内容是替换功能。介绍章节名和卷名暂无替换规则。比如我们获取的卷名是text(),但是我们呢,在获取子卷的时候,只想获取到text的两个词,所以我们这里使用了过滤器。过滤器的格式为过滤后的内容|过滤内容中间使用过滤内容|将介绍章节名、过滤子卷名分开,例如据说我们在获得作者姓名时,书的内容中多了一条内容。作者因他的href="/Author/WB/149539而聚散随风。
html">有的有的没有,所以我们不直接使用 book author\s*(.+?) 来先获取内容。从规则上,我们得到的内容是 href="/作者/WB /149539。 html">随风集散,本段我们要保留的内容:随风集散,我们这样做,因为它是固定的,所以只需添加href="/Author/WB/149539。 html">这是一个改动,我们改一下,改成常规格式 href="/Author/WB/\d*. html">就是这样。让我们添加过滤器 href="/Author/WB/\d*\。 html">|内容是这样的,现在说一下章节内容的替换,章节内容替换规则每行替换一个,格式如下,需要替换的内容用结果替换
这意味着过滤
这意味着替换。例如,本站有一张“飞酷”字样的图片。我们应该做什么?这里我们使用替换。
替换内容只对章节内容有用。这是专用于章节内容。有人问我为什么采集某个站总是空章。可能出现空章的原因可能是目标站刚重启网站你的采集IP被屏蔽了等等……这里我想说明一下,空章是图片章节造成的。 采集器的采集内容的操作流程先检查你采集的章节是不是图片章节?如果你的PubContentImages(从章节内容中提取图片)的规律不正确,如果你没有获取到图片章节内容,你会检查你的采集文字内容PubContentText(获取章节内容)。如果PubContentImages(从章节内容中提取图片)PubContentText(获取章节内容)没有匹配的内容,那么就会出现我们上面说的空章节的原因。既然规则都写好了,我们来测试一下是否可以正常获取规则。获取内容测试表明,我们编写的规则可以正常获取到想要的内容 查看全部
第一步:我们先复制一份原来的规则做模板(图)
第 1 步:让我们复制原创规则作为模板。比如我今天演示的采集站点是一个叫feiku的小说站点,那么我将我复制的模板规则的副本命名为dhabc。 xml 这个主要是为了方便记忆。第二步:我们在采集器中运行规则管理工具,打开后加载,我们只是将其命名为dhabc。 xml XML文件第三步:开始正式写规则RULEID(规则编号)这个任意GetSiteName(站点名称)这里我们写8E小说GetSiteCharset(站点代码)这里我们打开找到charset=这个=后面的数字就是我们需要的站点代码我们找到的代码是gb2312 GetSiteUrl(站点地址)。不用说,写NovelSearchUrl(网站搜索地址)。这个地址是根据每个网站程序的不同得到的,但是有一个通用的方法是通过抓包来获取你想要的内容。虽然说是抓包得到的,但是你怎么知道得到的就是我们想要的呢?看看我的操作。首先,我们运行数据包工具并选择 IEXPLORE。 EXE进程最好只打开一个网站,也就是只打开你要写规则的网站,保证进程中只有一个IEXPLORE。
EXE 进程。在这里我们可以看到提交的地址是/book/search。 aspx 我们结合得到的地址 SearchKey=%C1%AB%BB%A8&SearchClass=1&SeaButton。 x=26&SeaButton。 y=10 但是对我们有用的是 SearchKey=%C1%AB%BB%A8&SearchClass=1 这里得到的NovelSearchData(搜索提交)这一段,就是用来把这一段改成我们想要的代码。一段%C1%AB%BB%A8换成{SearchKey},表示搜索提交内容的完整代码为SearchKey={SearchKey}&SearchClass=1 然后我们测试一下是否正确。经过测试,我们得到的内容是正确的NovelListUrl(站点最新列表地址)这个我就不说了,因为每个站点不一样。需要自己找FEIKU NovelList_GetNovelKey(从最新列表中获取小说编号。在此规则中,可以同时获取书名。书名是手动获取的。如果要使用手动模式,一定要拿到书名,否则手动模式无法使用)我们打开这个地址查看源文件。当我们写这个规则时,我们找到了我们想要获取内容的地方。比如我们打开地址看到我想获取内容的第一本小说的名字是李迪承德。我们在源文件中找到了我们用来编写规则的代码。实际上,它不是很多。我写规则的原则是先存后存,也就是代码越短越好。除非万不得已,href="越短越好。
8c8e。 com/Book/149539/索引。 html"target="_blank"> 让我们把这一段改成 href="。 8c8e。 com/Book/(\d*)/索引。 html"target="_blank">(.+?) 表示小说名经过测试无误。NovelUrl(小说信息页地址)很容易找到,只要点击小说,比如我们可以看到这本小说我们改一下,随意改一下中间的数字,比如我们得到的错误标记就是没有找到那个编号的书信息!10.NovelName(查看源代码到获取小说名称,我们可以从固定模式开始,比如我们刚刚打开它,在这本小说中,我们看到他的固定小说名称格式是“Landing into a magic”,然后我们找到“Landing into a magic”源代码中的magic”。我们得到的内容是
“站点成恶魔”
让我们改变这一段
"(.+?)"
以下NovelAuthor(获取小说作者) LagerSort(获取小说类别) SmallSort(获取小说类别) NovelIntro(获取小说简介) NovelKeyword(获取小说主角(关键词)) NovelDegree(获取小说封面) (获取小说) (封面) 我就不演示了,这些和上面获取小说名称的方法是一样的,所以叫做One-pass Belden。有时候有些内容你不想要使用,因为格式不固定。有些内容只能先获取,然后用filter函数过滤掉filter的用途。后面,11.NovelInfo_GetNovelPubKey(获取小说公共目录地址page) 这个地址的获取方法和上面一样,这里就不解释 12 PubIndexUrl (公共目录页面的地址)) 来解释一下这个的用法。这个一般在知道采集目标站的动态地址时使用。如果不知道对方的动态地址,知道动态路径{NovelKey}/Index .aspx13.PubVolumeSplit(拆分子卷)这个拆分子卷有什么可写的,就在这写{NovelPubKey}。需要注意的是,如果拆分子卷的规律性不是那么可能对后面的章节名称产生很大的影响。这里我们得到了分割部分的代码。根据我的经验,找到第一个子卷和下面的子卷,看看它们有什么共同点。当我们分析本目录章节中的源代码时,我们可以看到它们有一个共同点。让我们解释一下这一段。
追求力量
\s* \s* 表示匹配任何白色字符,包括空格、制表符、分页符等,也就是说,无论它们之间有多少个空格,都可以用来表示14 PubVolumeName(获取卷名) 要获取准确的子卷名,上面拆分部分的规律必须是正确的。一般拆分部分的子卷名称在块的顶部。我们说明分割部分使用
追求力量
如果你注意这一段,你会发现它收录了我们这一步要获取的子卷名。修改代码
(.+?)
\s* 在我们的测试下,我们可以正常获取子卷,但是如果有这些,我们通常会在过滤规则中将其过滤掉。 PubChapterName(获取章节名) 我们用一段话来说明强大的驯服方法。对于这种时间、日期和更新字数,我们直接忽略,因为这些不是我们想要的。有人问我为什么在这里没用。 () 把它附在这里让我告诉你我们得到的内容就是()中的内容。如果它不是你想要的,但在编写规则时必须使用它,我们可以稍微改变表达式。我们把上面的段落改一下,改成表达式(.+?)就可以正常获取内容了。大家是不是看着这个规则有点别扭?这是因为中间有一个换行符。我没有更改代码。让我们使用\s*。这意味着一个换行符。我们修改后的代码是 (.+?) 现在好点了吗?经过测试,获取内容描述也是正常的。没问题。 16. PubChapter_GetChapterKey(获取章节地址(Chapter Number)) 这里说明一下,下面的PubContentUrl(章节内容页面地址)中使用了这个中的章节号。一般用于知道目标站的动态地址。当目标站未知时,一般不使用静态地址。所以这里我们需要获取章节地址解析(.
+?) 既然这里是获取章节地址,那为什么还要使用章节名称呢?这主要是为了避免获取的章节名称和获取的章节地址不匹配。这是下一章编号的说明。不麻烦,稍微改一下(.+?)改成这个,我们测试一下看看,改一下就可以得到数了。这个数字只有在知道目标站的动态地址的情况下才能获得。最多使用17.PubContentUrl(章节内容页面地址)在上面得到的章节地址中有说明。这是要知道如何使用目标站。 149539 这是新号码。这里我们用{NovelKey}代替3790336 这是在PubChapter_GetChapterKey中获得的章节编号,我们用{ChapterKey}代替组合为{NovelKey}/{ChapterKey}。 ASPX 是我们的动态章节地址。记住,前提是要知道对方的动态地址。如果你不知道对方的动态地址,那么我们这里写的PubContentUrl(章节内容页面地址)就是{ChapterKey} 18. PubContentText(获取章节内容) 这种获取方式和获取章节名称是一样的。这个就不解释了。现在我们解释过滤的用法。这很简单。几个地方是介绍章节名和卷名以及获取的小说章节内容,但是章节内容是替换功能。介绍章节名和卷名暂无替换规则。比如我们获取的卷名是text(),但是我们呢,在获取子卷的时候,只想获取到text的两个词,所以我们这里使用了过滤器。过滤器的格式为过滤后的内容|过滤内容中间使用过滤内容|将介绍章节名、过滤子卷名分开,例如据说我们在获得作者姓名时,书的内容中多了一条内容。作者因他的href="/Author/WB/149539而聚散随风。
html">有的有的没有,所以我们不直接使用 book author\s*(.+?) 来先获取内容。从规则上,我们得到的内容是 href="/作者/WB /149539。 html">随风集散,本段我们要保留的内容:随风集散,我们这样做,因为它是固定的,所以只需添加href="/Author/WB/149539。 html">这是一个改动,我们改一下,改成常规格式 href="/Author/WB/\d*. html">就是这样。让我们添加过滤器 href="/Author/WB/\d*\。 html">|内容是这样的,现在说一下章节内容的替换,章节内容替换规则每行替换一个,格式如下,需要替换的内容用结果替换
这意味着过滤
这意味着替换。例如,本站有一张“飞酷”字样的图片。我们应该做什么?这里我们使用替换。
替换内容只对章节内容有用。这是专用于章节内容。有人问我为什么采集某个站总是空章。可能出现空章的原因可能是目标站刚重启网站你的采集IP被屏蔽了等等……这里我想说明一下,空章是图片章节造成的。 采集器的采集内容的操作流程先检查你采集的章节是不是图片章节?如果你的PubContentImages(从章节内容中提取图片)的规律不正确,如果你没有获取到图片章节内容,你会检查你的采集文字内容PubContentText(获取章节内容)。如果PubContentImages(从章节内容中提取图片)PubContentText(获取章节内容)没有匹配的内容,那么就会出现我们上面说的空章节的原因。既然规则都写好了,我们来测试一下是否可以正常获取规则。获取内容测试表明,我们编写的规则可以正常获取到想要的内容
采集规则 采集 data-src Excel教程Excel函数Excel制作表格Excel2010/9/28
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-08-04 07:23
采集scene
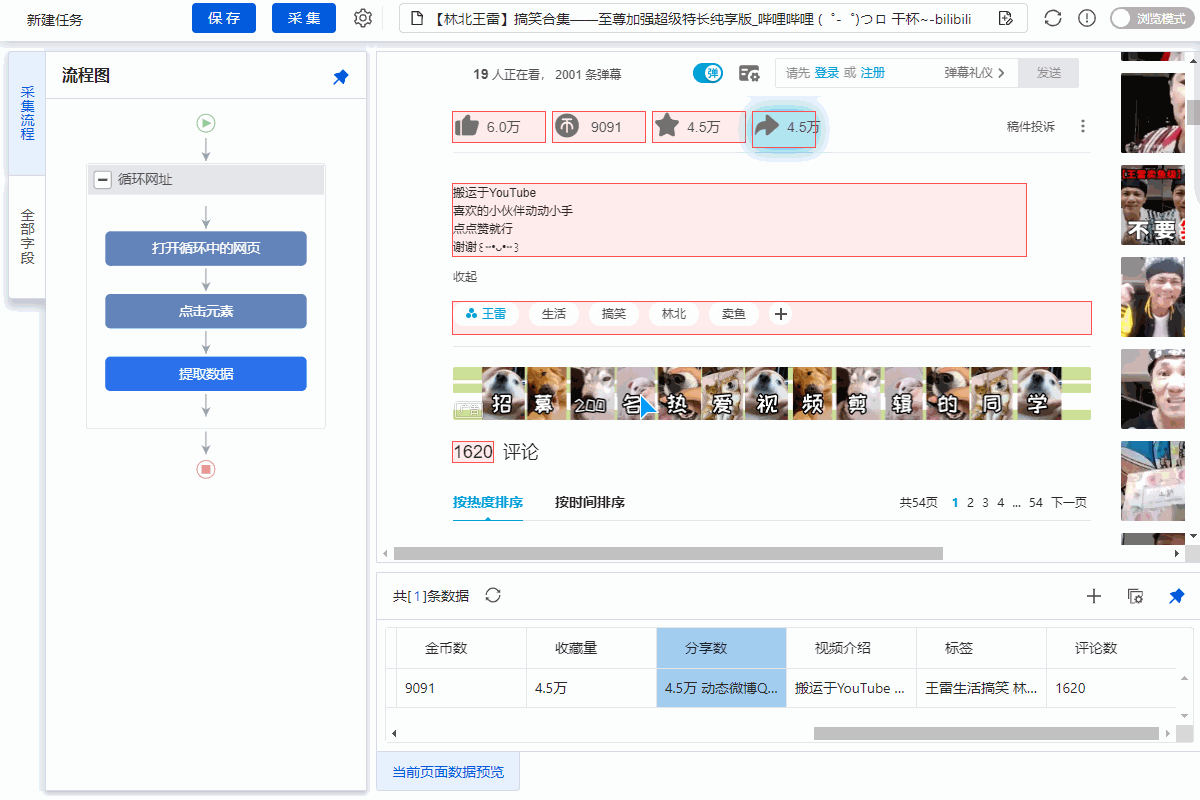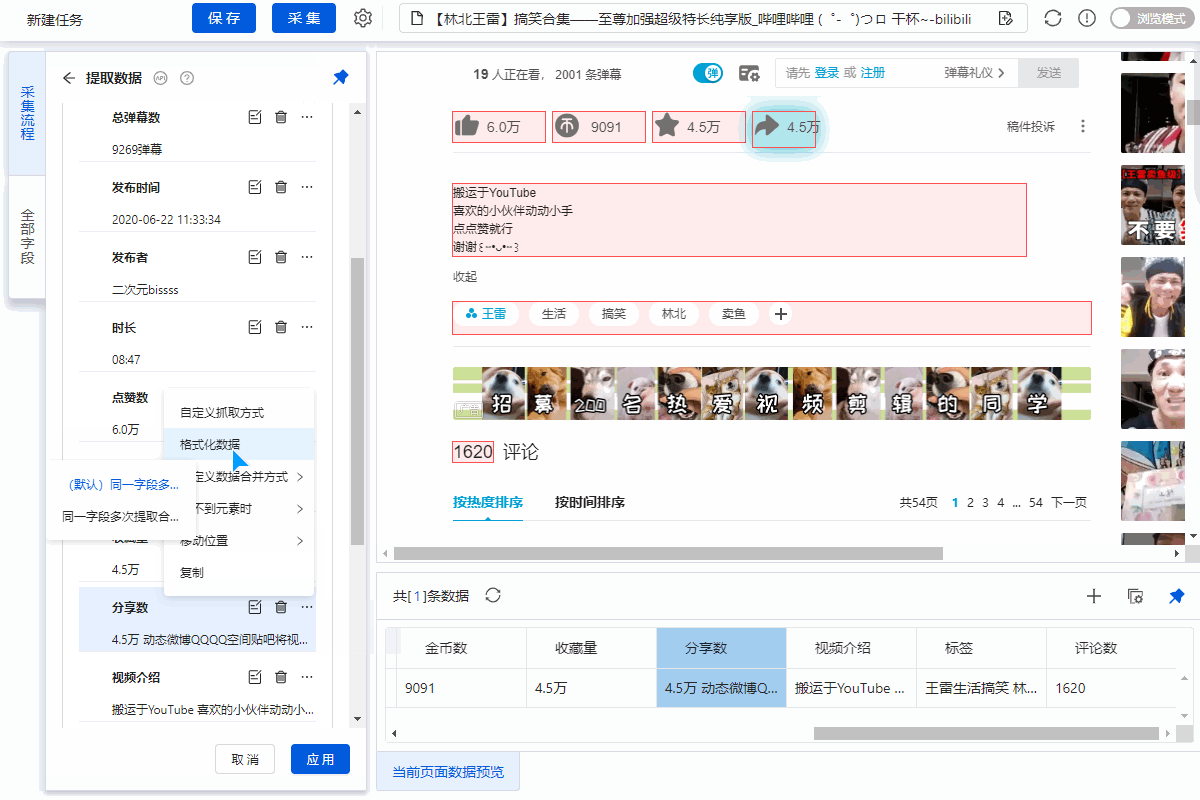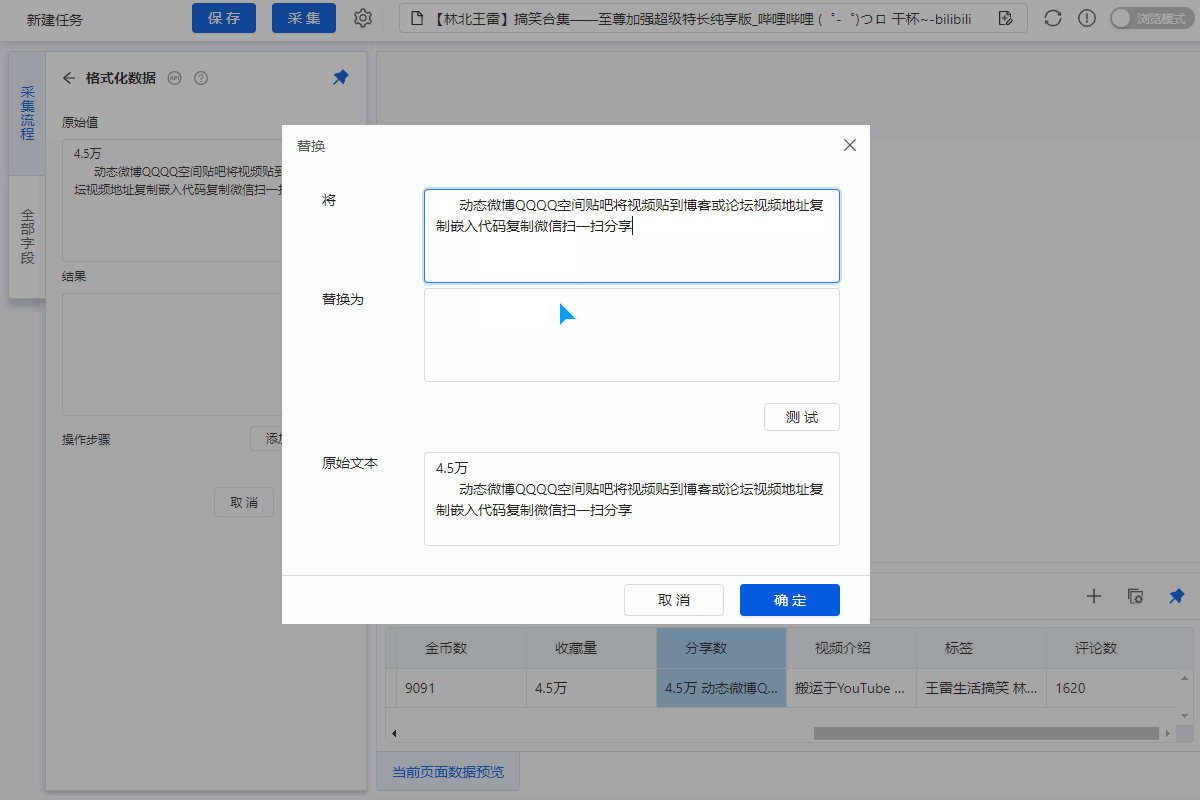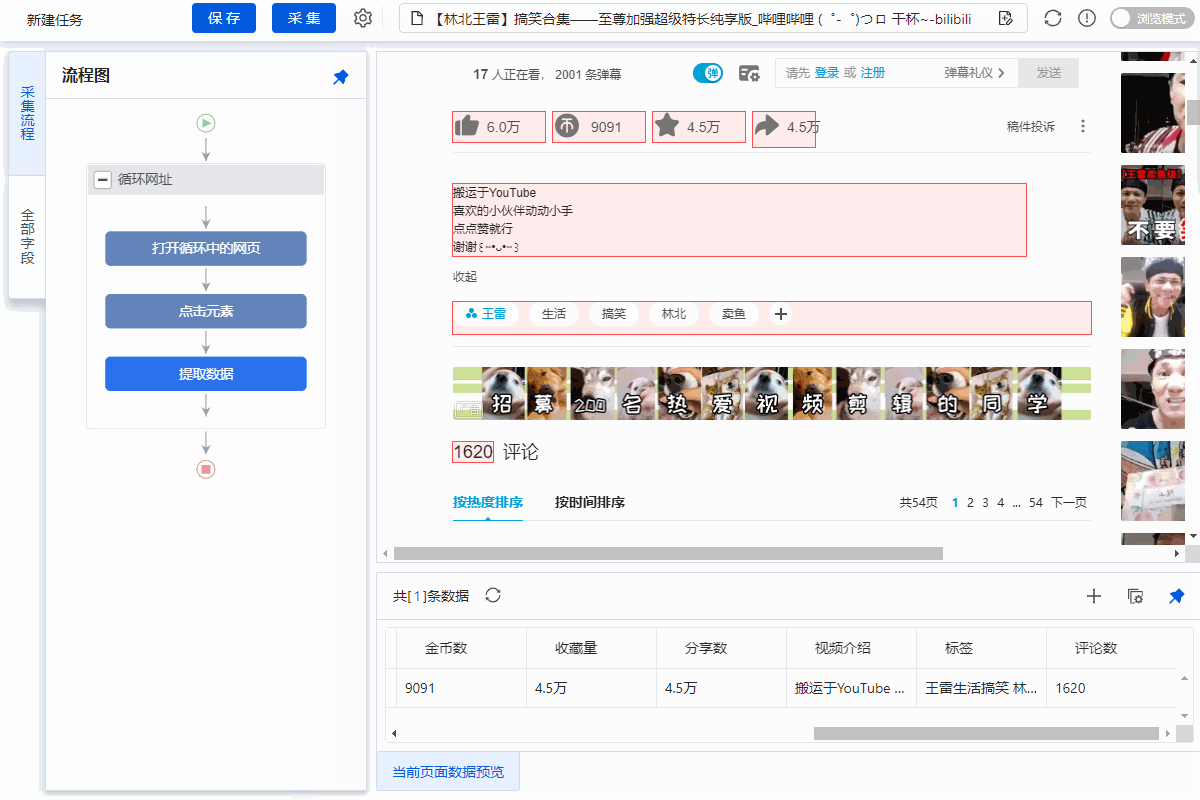
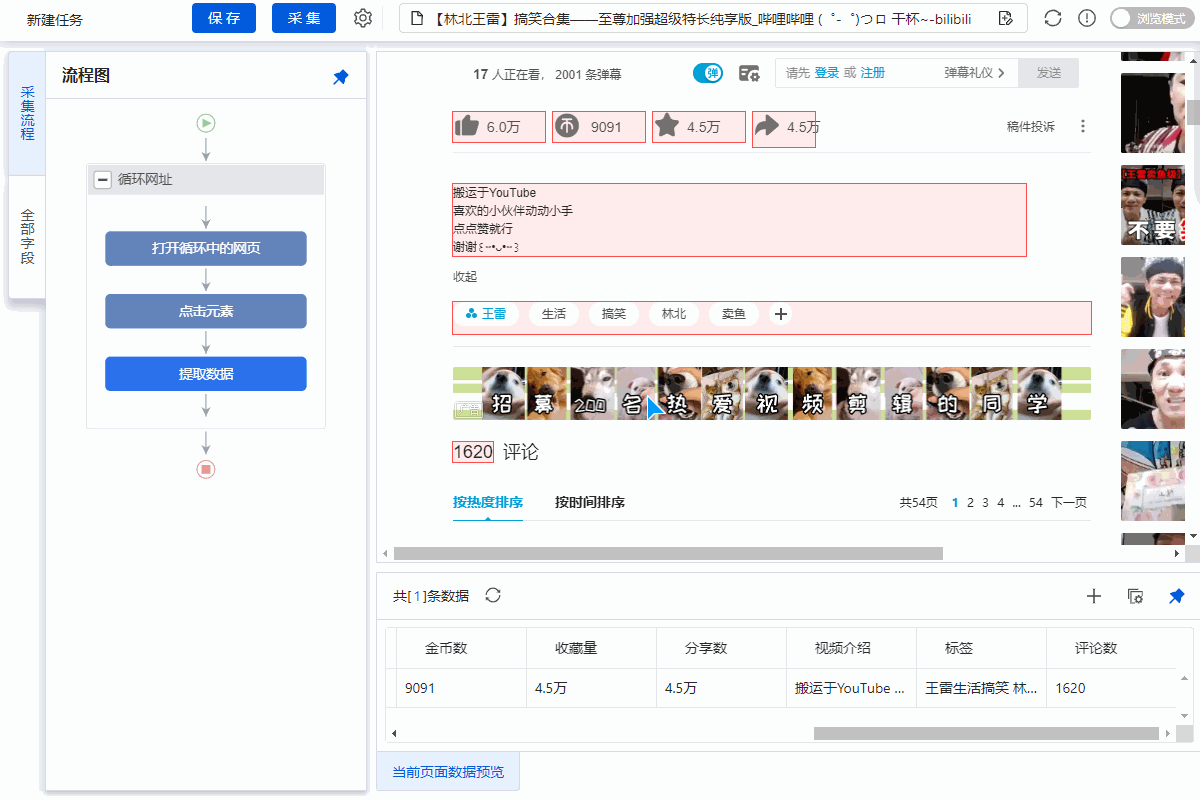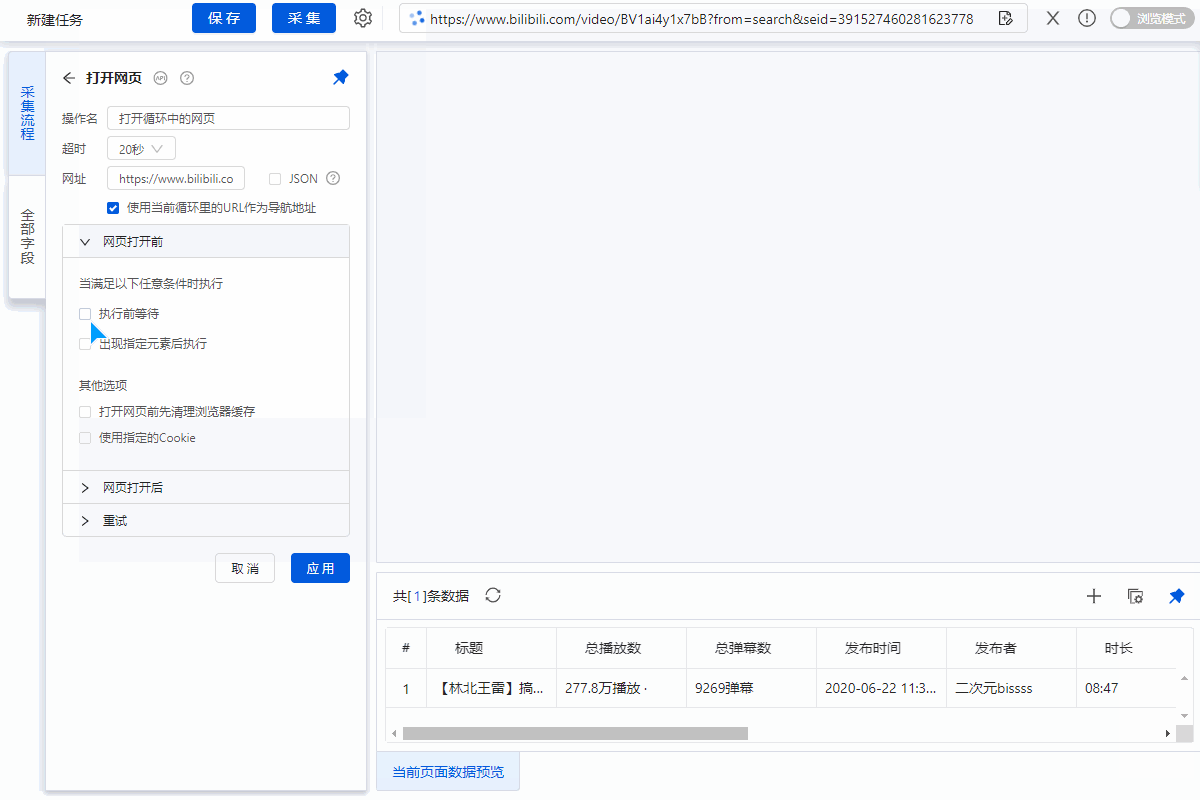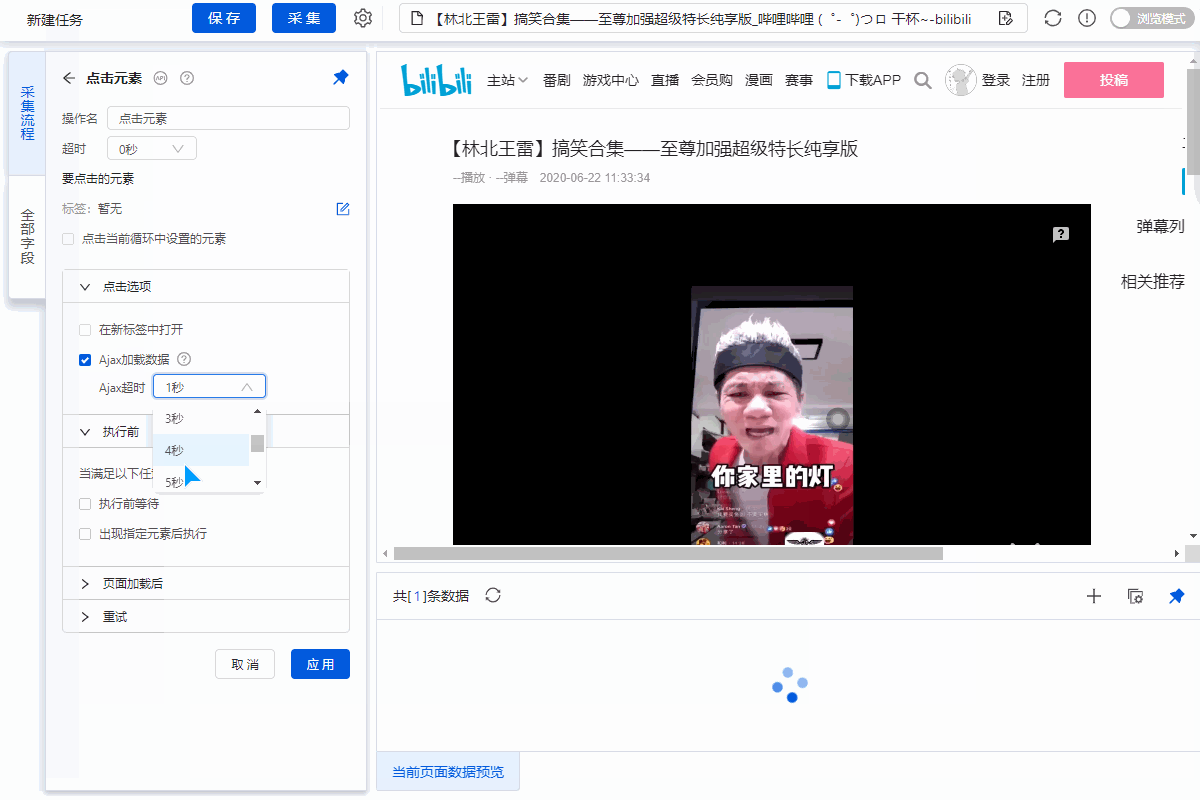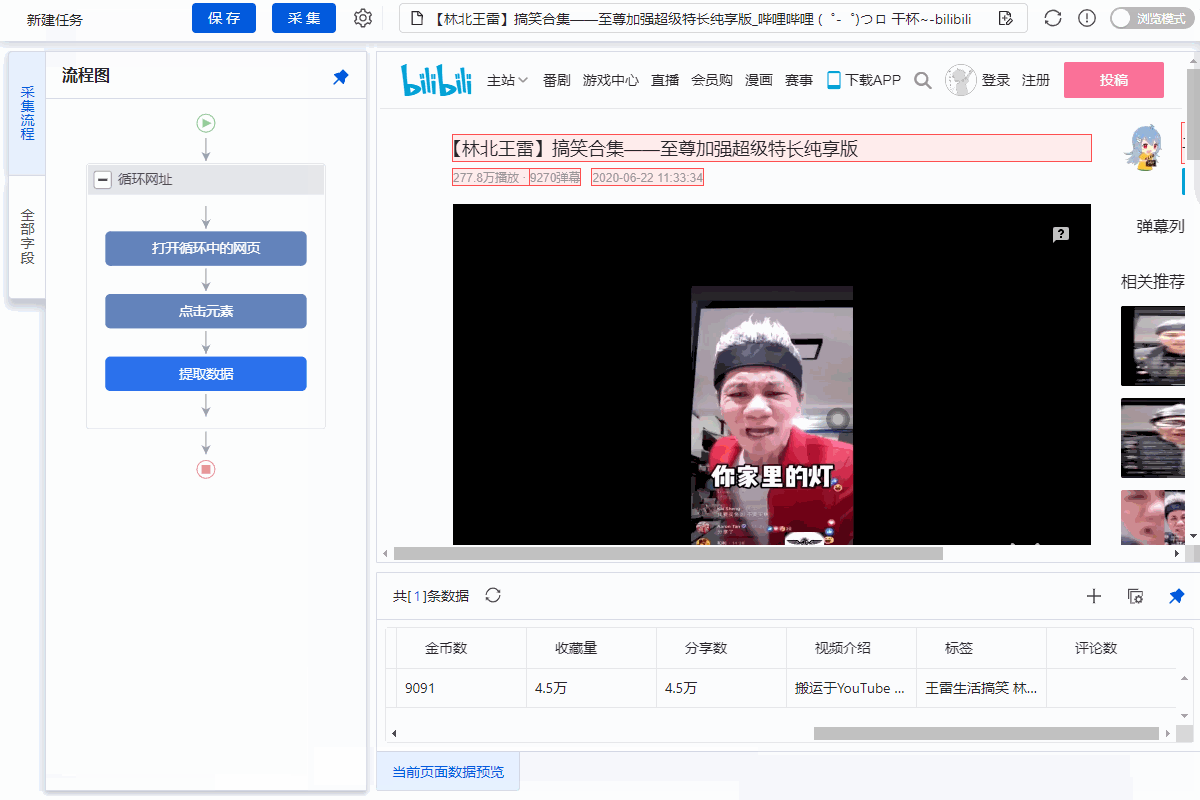
打开B站详情页,采集video详情页数据。
示例网址:
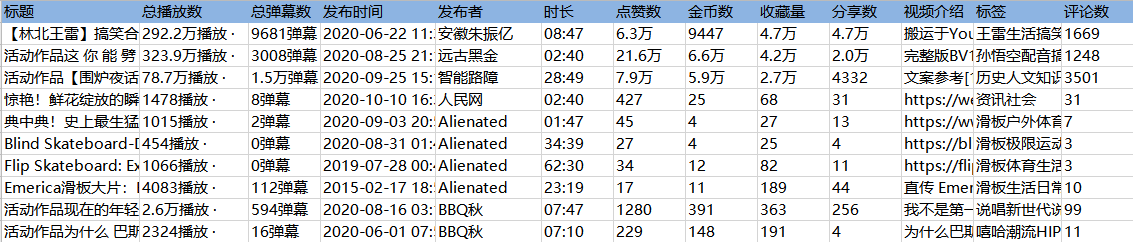
采集Field
标题、时长、发布时间、总播放次数、总发布次数、发布者、币种、采集、点赞数、分享数、视频介绍、视频标签、评论数
点击查看高清大图,下图同理。
采集Result
采集 结果可以导出为Excel、CSV、HTML、数据库等格式。导出到 Excel 示例:
教程说明
本文制作时间:2020/9/28 优采云版本:V8.1.22
如因网页改版导致网址或步骤无效,无法采集到目标数据,请联系官方客服,我们会及时更正。
采集Steps
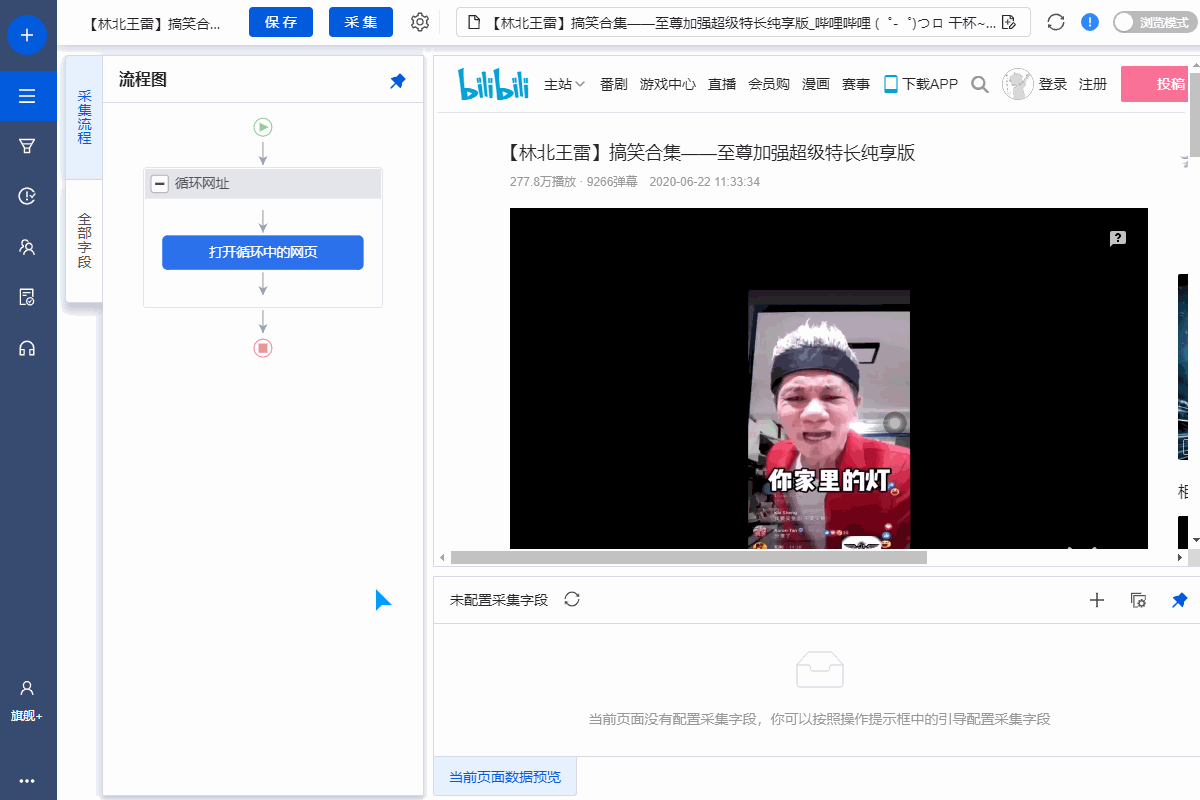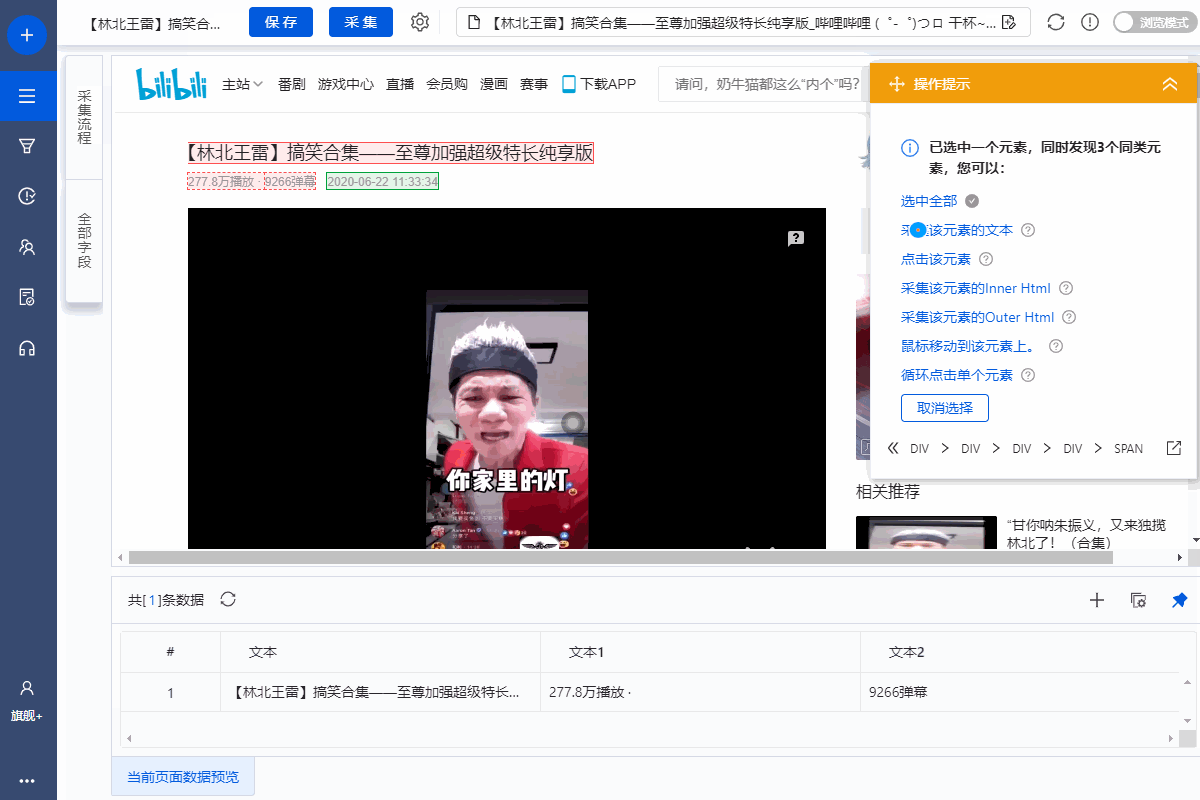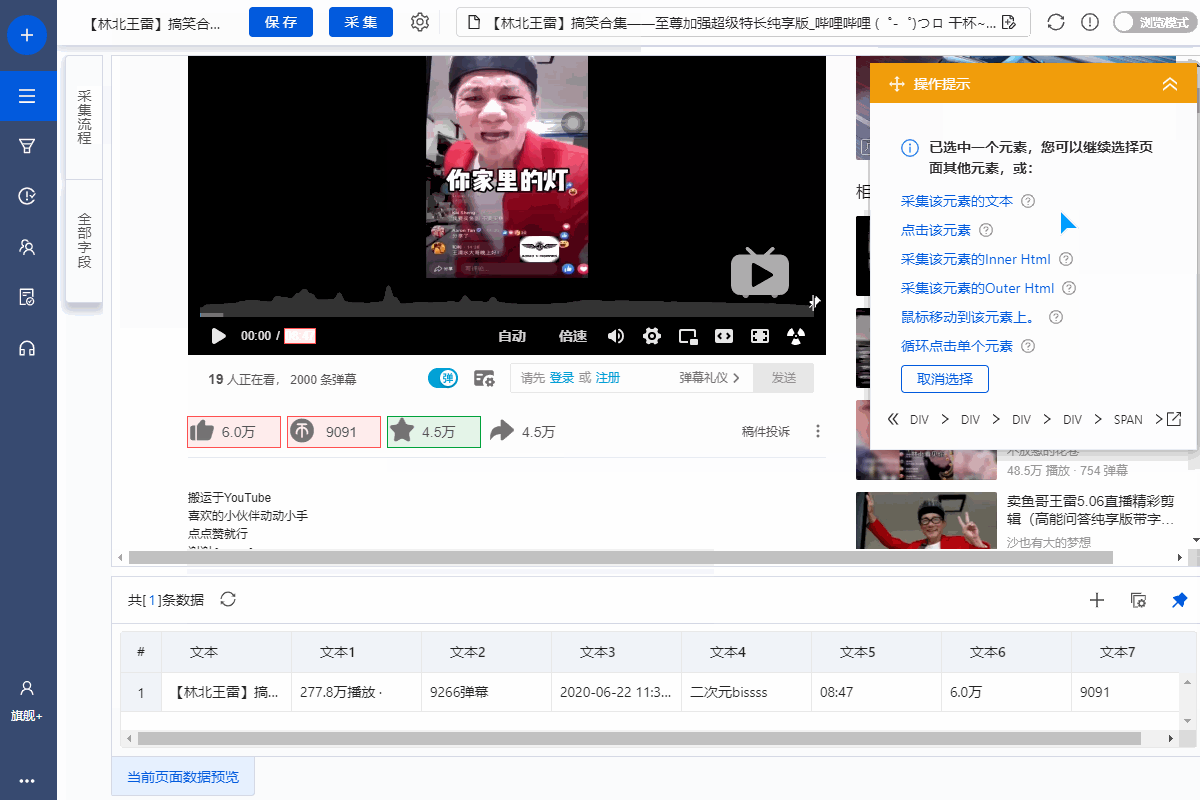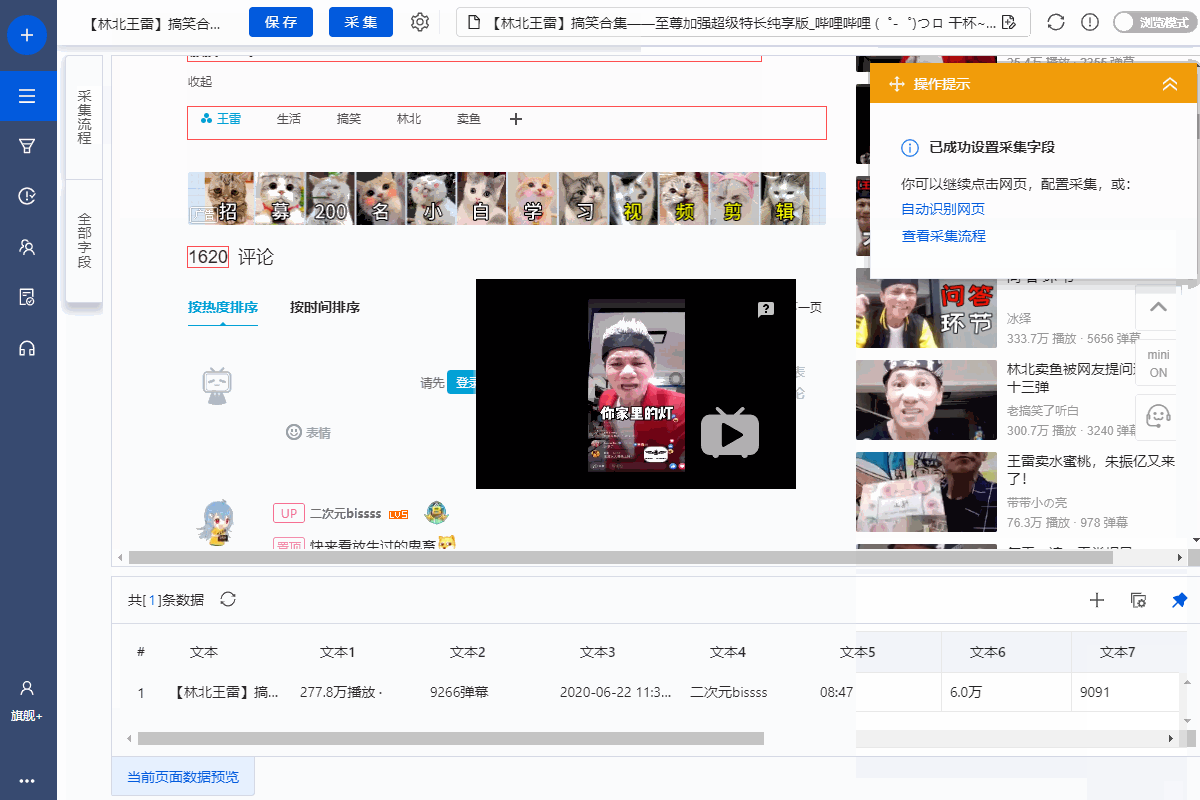
步骤一、打开网页
步骤二、设置页面滚动
步骤三、提取数据
步骤四、rule优化
步骤五、Start采集
具体步骤如下:
步骤一、打开网页
1、打开网页
点击首页左上角的【新建】-【自定义任务】。 URL输入界面默认为【手动输入】。将复制的一批相似网址粘贴到网址输入框中,点击【保存网址】,优采云内置的浏览器会自动打开网页。
同时可以看到[loop-open web page]这一步已经在过程中自动创建了。
示例中输入的网址为:
特别说明:
一个。手动输入的 URL 数量不应超过 10,000。如果url超过10000个,请选择【从文件导入】。详情请参考教程网址输入升级
B.打开网页后,如果开始启动【自动识别】,请点击【不再自动识别】或【取消识别】将其关闭。因为本文不适合使用【自动识别】。
c. 【自动识别】适用于自动识别网页列表、滚动、翻页。识别成功后可以直接启动采集获取数据。详情请点击查看【自动识别】教程
步骤二、设置滚动
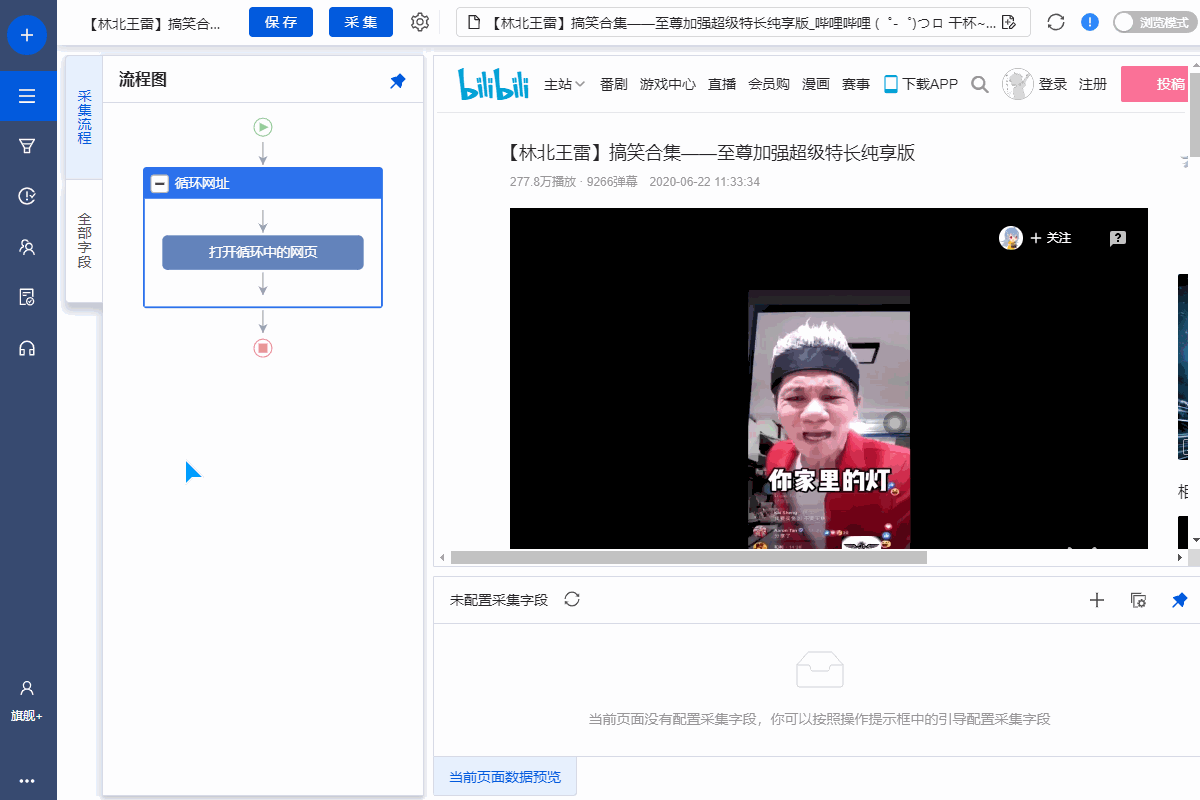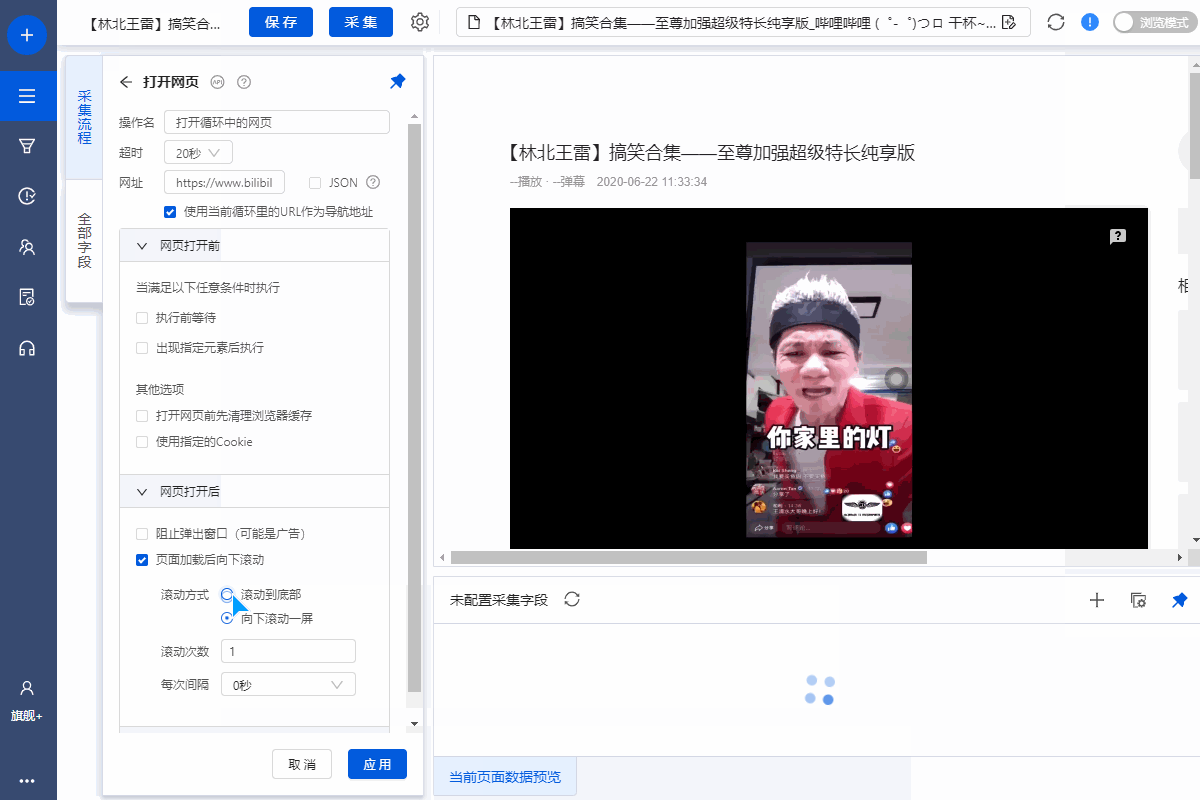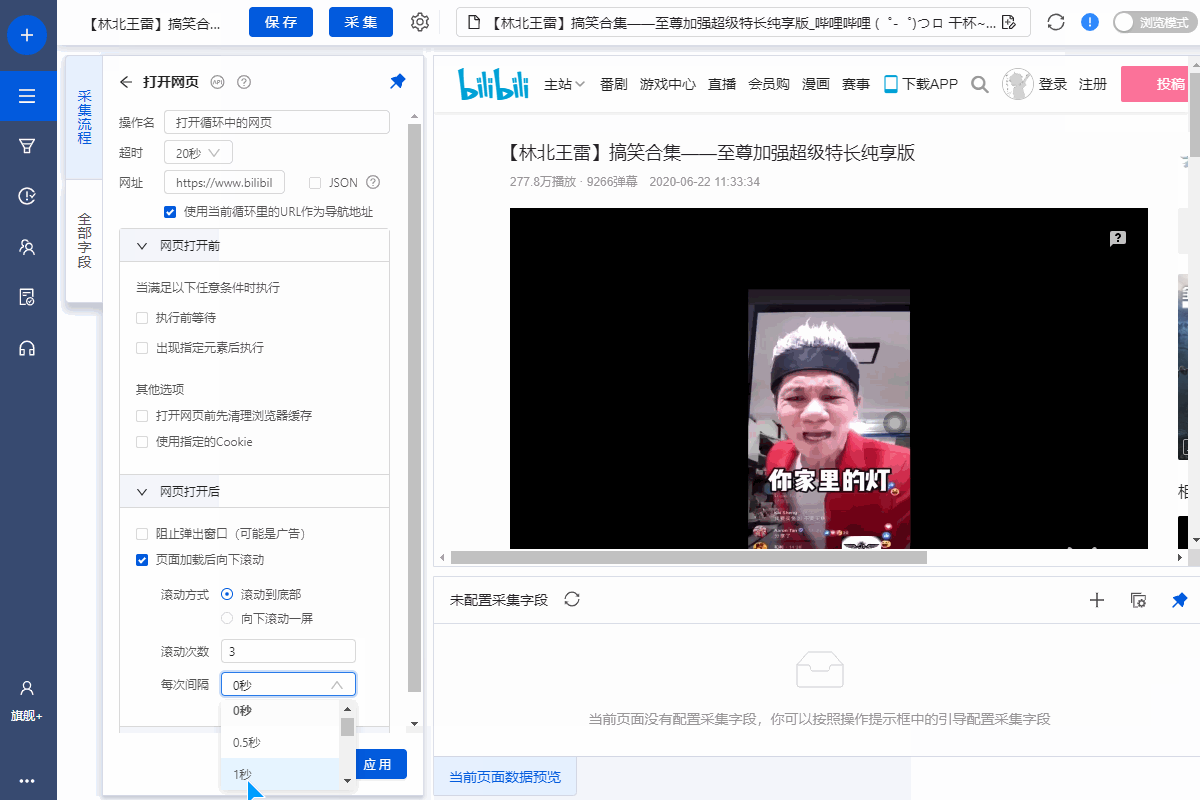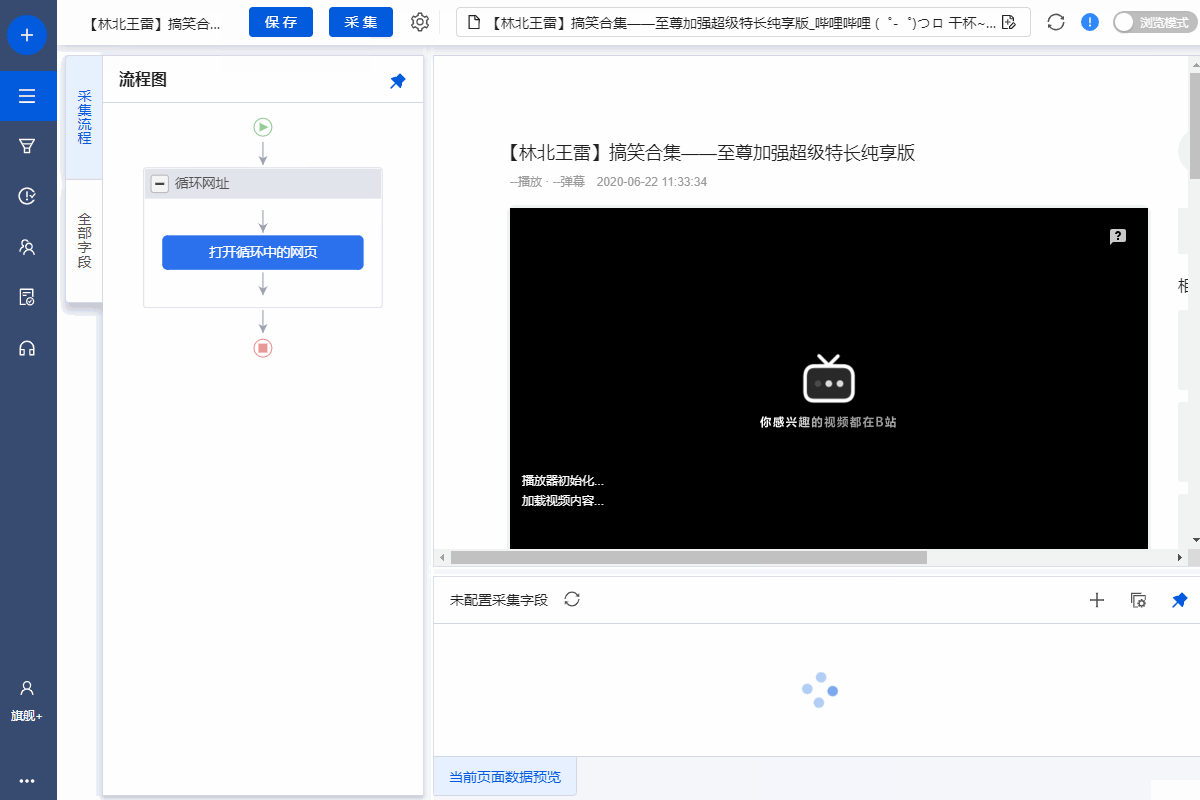
选择【打开网页】设置,勾选【页面加载后向下滚动】,滚动方式为【直接滚动到底部】,滚动次数为3次,每次间隔1s。
特别说明:
一个。设置中的滚动次数和时间间隔,请根据采集要求和网页加载条件进行设置,它们不是一成不变的,详情请点击查看处理滚动加载数据的网页教程
步骤三、提取数据
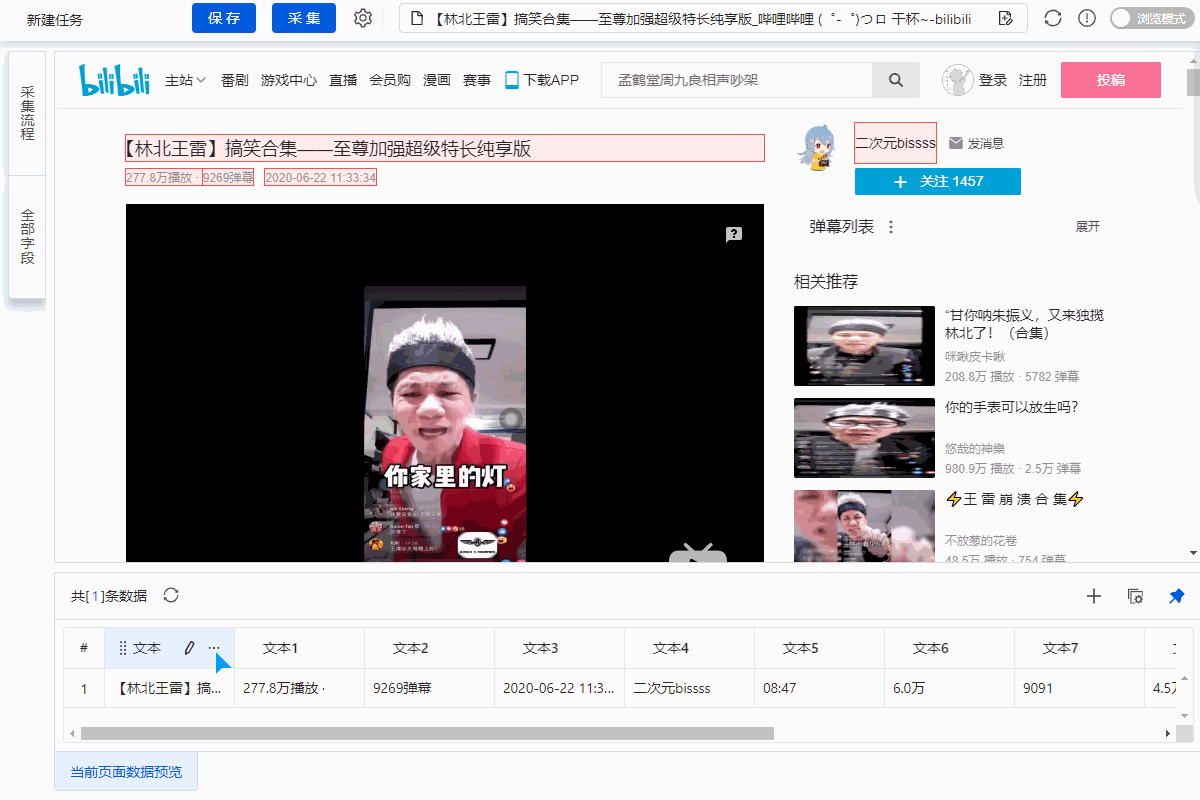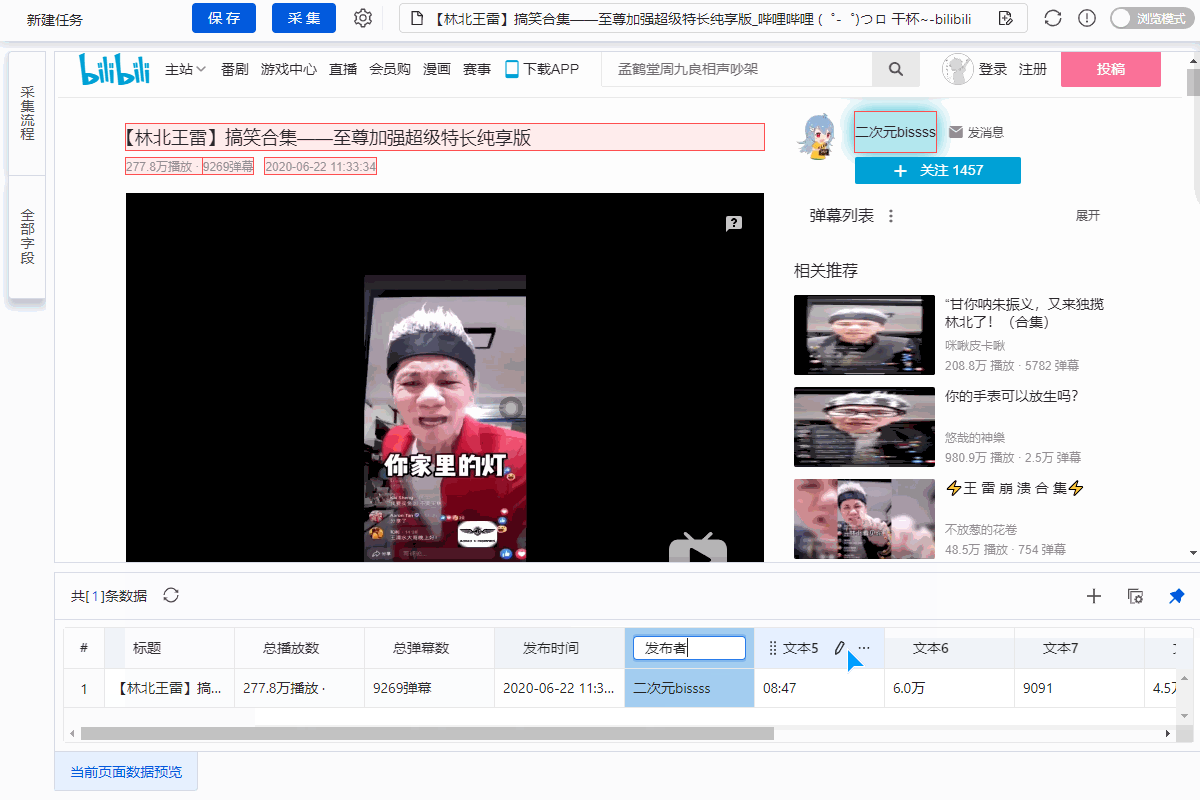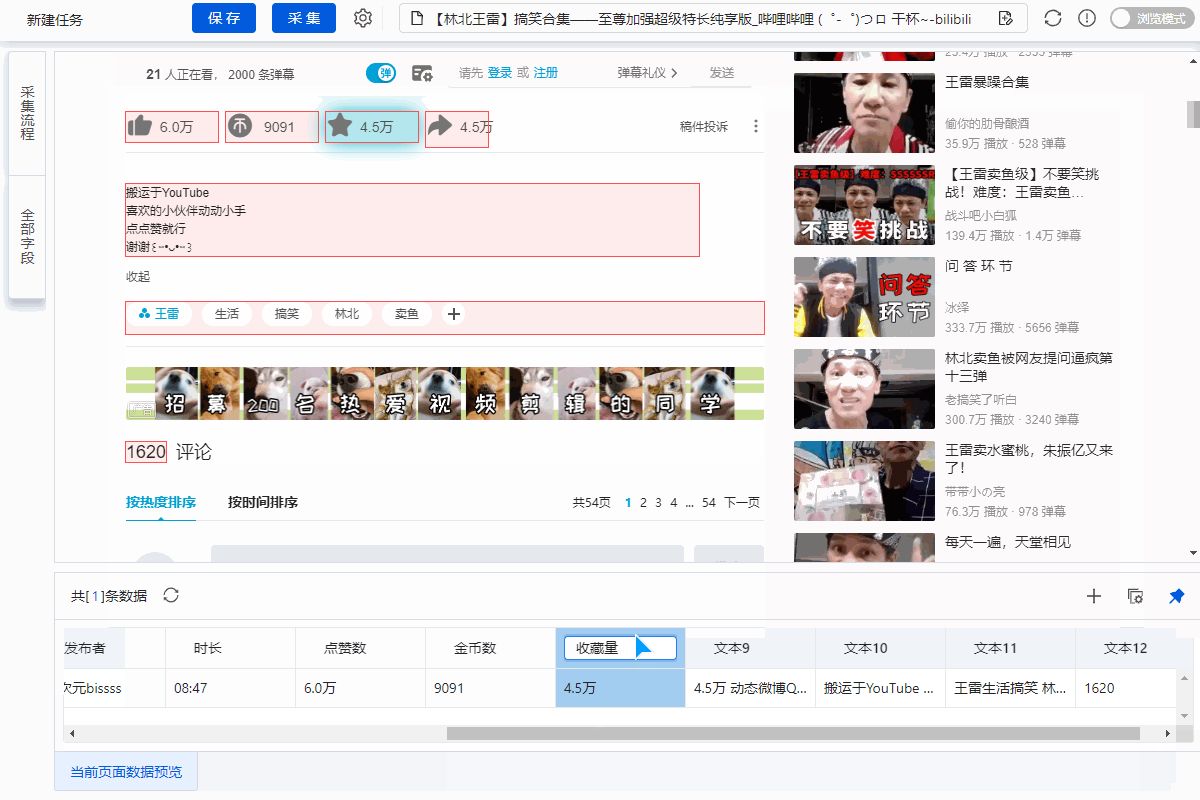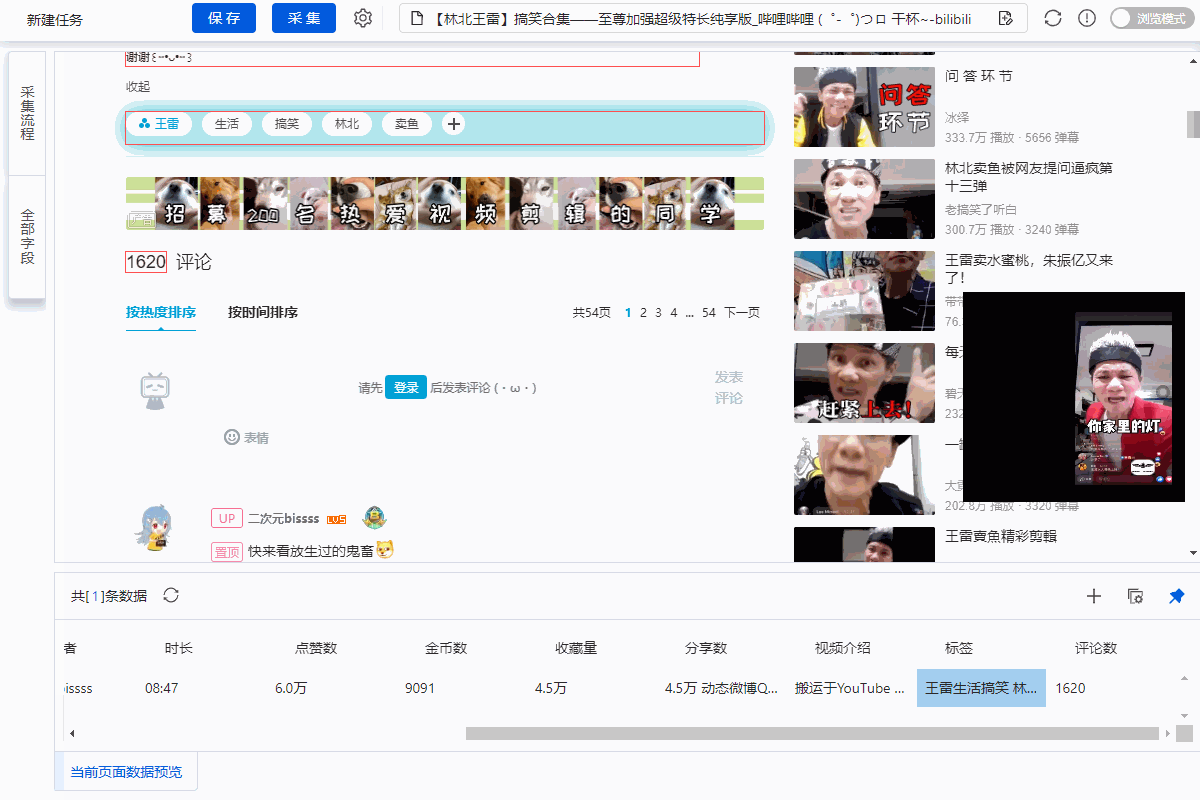
1、采集Field
采集Title、时长、发布时间、总播放次数、总弹数、发布者、币种、采集、点赞、分享、视频介绍、视频标签、评论等字段。
2、编辑字段
在【当前数据预览】面板中,依次修改必填字段的字段名称。
3、设置字段
直接抓取的“股数”字段有问题,需要对字段进行格式化。
进入【提取数据】步骤,选择【格式化数据】→【添加步骤】→【替换】→将【动态微博...分享】替换为【空】,留下我们要分享的版块号。
最后点击【应用】保存。
特别说明:
一个。什么是数据格式化?数据采集下来后,有时格式不是我们想要的,或者我们只是想从一段数据中提取特定的数据,可以通过优采云的【格式数据】功能来实现。详情请点击查看数据格式化教程。
4、Modify field Xpath
为了准确地采集到达所有相似页面的[publisher]字段,我们需要修改这个字段的XPath。
进入【提取数据】设置页面,找到【发布者】字段,点击
按钮,进入【自定义定位元素方法】设置页面,修改XPath为://div[@class="name"]/a[1],然后点击【应用】保存。
步骤四、rule优化
等待5s-10s后执行[循环URL]、[循环中打开网页]、[循环翻页]、[循环列表]、[提取列表数据]。
【点击翻页】设置等待3s执行,Ajax加载超时7s,点击【Apply】保存。
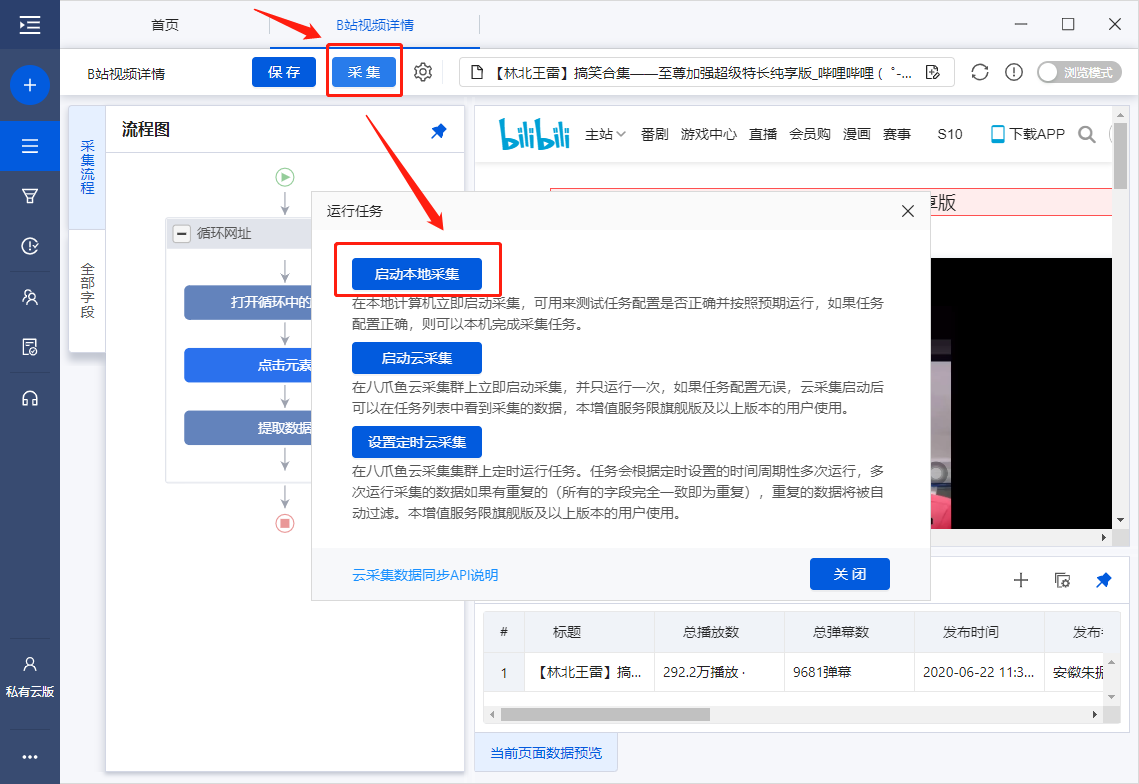
步骤五、Start采集
1、 单击 [采集] 和 [启动本地采集]。启动优采云后自动采集数据。
特别说明:
一个。 【本地采集】为采集使用自己的电脑,【云采集】使用优采云采集提供的云服务器,点击查看本地采集与云采集详细解释。
2、采集 完成后,选择合适的导出方式导出数据。支持导出到 Excel、CSV、HTML、数据库等。这里导出到 Excel。数据示例:
查看全部
采集规则 采集 data-src Excel教程Excel函数Excel制作表格Excel2010/9/28
采集scene
打开B站详情页,采集video详情页数据。
示例网址:
采集Field
标题、时长、发布时间、总播放次数、总发布次数、发布者、币种、采集、点赞数、分享数、视频介绍、视频标签、评论数
点击查看高清大图,下图同理。
采集Result
采集 结果可以导出为Excel、CSV、HTML、数据库等格式。导出到 Excel 示例:
教程说明
本文制作时间:2020/9/28 优采云版本:V8.1.22
如因网页改版导致网址或步骤无效,无法采集到目标数据,请联系官方客服,我们会及时更正。
采集Steps
步骤一、打开网页
步骤二、设置页面滚动
步骤三、提取数据
步骤四、rule优化
步骤五、Start采集
具体步骤如下:
步骤一、打开网页
1、打开网页
点击首页左上角的【新建】-【自定义任务】。 URL输入界面默认为【手动输入】。将复制的一批相似网址粘贴到网址输入框中,点击【保存网址】,优采云内置的浏览器会自动打开网页。
同时可以看到[loop-open web page]这一步已经在过程中自动创建了。
示例中输入的网址为:

特别说明:
一个。手动输入的 URL 数量不应超过 10,000。如果url超过10000个,请选择【从文件导入】。详情请参考教程网址输入升级
B.打开网页后,如果开始启动【自动识别】,请点击【不再自动识别】或【取消识别】将其关闭。因为本文不适合使用【自动识别】。
c. 【自动识别】适用于自动识别网页列表、滚动、翻页。识别成功后可以直接启动采集获取数据。详情请点击查看【自动识别】教程
步骤二、设置滚动
选择【打开网页】设置,勾选【页面加载后向下滚动】,滚动方式为【直接滚动到底部】,滚动次数为3次,每次间隔1s。
特别说明:
一个。设置中的滚动次数和时间间隔,请根据采集要求和网页加载条件进行设置,它们不是一成不变的,详情请点击查看处理滚动加载数据的网页教程
步骤三、提取数据
1、采集Field
采集Title、时长、发布时间、总播放次数、总弹数、发布者、币种、采集、点赞、分享、视频介绍、视频标签、评论等字段。
2、编辑字段
在【当前数据预览】面板中,依次修改必填字段的字段名称。
3、设置字段
直接抓取的“股数”字段有问题,需要对字段进行格式化。
进入【提取数据】步骤,选择【格式化数据】→【添加步骤】→【替换】→将【动态微博...分享】替换为【空】,留下我们要分享的版块号。
最后点击【应用】保存。
特别说明:
一个。什么是数据格式化?数据采集下来后,有时格式不是我们想要的,或者我们只是想从一段数据中提取特定的数据,可以通过优采云的【格式数据】功能来实现。详情请点击查看数据格式化教程。
4、Modify field Xpath
为了准确地采集到达所有相似页面的[publisher]字段,我们需要修改这个字段的XPath。
进入【提取数据】设置页面,找到【发布者】字段,点击

按钮,进入【自定义定位元素方法】设置页面,修改XPath为://div[@class="name"]/a[1],然后点击【应用】保存。
步骤四、rule优化
等待5s-10s后执行[循环URL]、[循环中打开网页]、[循环翻页]、[循环列表]、[提取列表数据]。
【点击翻页】设置等待3s执行,Ajax加载超时7s,点击【Apply】保存。
步骤五、Start采集
1、 单击 [采集] 和 [启动本地采集]。启动优采云后自动采集数据。
特别说明:
一个。 【本地采集】为采集使用自己的电脑,【云采集】使用优采云采集提供的云服务器,点击查看本地采集与云采集详细解释。
2、采集 完成后,选择合适的导出方式导出数据。支持导出到 Excel、CSV、HTML、数据库等。这里导出到 Excel。数据示例:
zabbix的trigger数据采集规则及解决办法(二)——zabbix
采集交流 • 优采云 发表了文章 • 0 个评论 • 382 次浏览 • 2021-08-04 07:21
一、zabbix 的物品数据采集
1、数据采集是zabbix的基础,也是监控的基础。目前,它可以支持主动和被动采集 模式。主动模式定义为:客户端主动上报数据给服务器,被动模式定义为:服务器给客户端采集数据。
2、大家经常使用主动采集模式。除了zabbix自带的常见采集items外,还可以通过自定义采集items来扩展active采集方法。例如,如果需要对系统的全过程做语义监控功能,可以编写脚本,通过自定义采集项来获取脚本执行的结果。
3、 有时候部署代理比较麻烦,可以直接使用zabbix trapper方法:被监控主机主动向zabbix server发送数据,通常可以应用于程序内部的异常消息采集 例如,如果程序内部出现异常,抛出的异常消息可以通过trap方式直接发送到zabbix-server,通过trigger产生事件,通过action发送告警。
总结:总体来说zabbix对采集类型的数据支持还是比较丰富的,但是配置比较复杂。
二、zabbix 的触发监控规则
1、Monitoring 规则是监控系统的核心。阈值被配置为触发异常并生成事件。 Zabbix 有很多内置规则。
2、 通过trigger的Dependencies配置,可以实现简单的事件关联依赖。例如:触发监控有两个,1是监控站点是否可以访问,2是监控主机nginx的80端口是否可达。对于trigger1,可以增加对trigger2的依赖,这样当nginx 80端口不可达时,站点也无法访问,但不会触发站点无法访问的异常事件。
3、 基于以上设置,虽然可以实现简单的事件关联依赖合并,但是监控系统内部屏蔽了异常事件的发生。如果报警涉及到多组运维人员,大家都想看看自己的监控是否可用异常。所以,最好的办法是所有的异常事件都正常产生,在告警通知的时候进行相关性分析。比如上面的例子,运维组A负责trigger1告警,运维组B负责trigger2告警。当trigger2异常时,通知运维组A【不可访问,因为nginx 80端口不可达】,通知运维组B【nginx端口80不可达,导致不可访问】。
总结:Zabbix有更全面的监控规则匹配表达式,但不够灵活,无法配置更复杂的关联监控。
三、zabbix 的动作触发一个动作
根据triiger触发的异常事件,可以触发相应的动作。通常的操作是根据配置的媒体发送警报。 Zabbix报警配置部分,每个报警发送方式需要配置1个媒体,每个用户需要配置相应的发送媒体。
如果把zabbix告警交给灵曦管理,对于用户配置,只需要在zabbix上配置1个用户和1个媒体,会省很多麻烦。
四、灵豹与zabbix的融合:
灵溪云告警是一款专注于告警优化管理的SAAS软件,提供多通道及时准确传输、多人智能分层传输、告警处理协同、故障数据多维统计等功能。
对于zabbix监控系统(2.0、3.0都支持),如果需要使用灵曦的报警优化功能,只需要进行以下步骤:
1、灵豹产品配置:
我还没有灵曦账号。完成引导页面后,进入工作台,点击右下方的开始报警优化之旅,完成页面配置并复制token。
2、zabbix 监控系统配置:
依次增加媒体、用户、动作,完成灵曦对zabbix的告警优化。具体的图形操作请参考:#/access-zabbix。 查看全部
zabbix的trigger数据采集规则及解决办法(二)——zabbix
一、zabbix 的物品数据采集
1、数据采集是zabbix的基础,也是监控的基础。目前,它可以支持主动和被动采集 模式。主动模式定义为:客户端主动上报数据给服务器,被动模式定义为:服务器给客户端采集数据。
2、大家经常使用主动采集模式。除了zabbix自带的常见采集items外,还可以通过自定义采集items来扩展active采集方法。例如,如果需要对系统的全过程做语义监控功能,可以编写脚本,通过自定义采集项来获取脚本执行的结果。
3、 有时候部署代理比较麻烦,可以直接使用zabbix trapper方法:被监控主机主动向zabbix server发送数据,通常可以应用于程序内部的异常消息采集 例如,如果程序内部出现异常,抛出的异常消息可以通过trap方式直接发送到zabbix-server,通过trigger产生事件,通过action发送告警。
总结:总体来说zabbix对采集类型的数据支持还是比较丰富的,但是配置比较复杂。
二、zabbix 的触发监控规则
1、Monitoring 规则是监控系统的核心。阈值被配置为触发异常并生成事件。 Zabbix 有很多内置规则。
2、 通过trigger的Dependencies配置,可以实现简单的事件关联依赖。例如:触发监控有两个,1是监控站点是否可以访问,2是监控主机nginx的80端口是否可达。对于trigger1,可以增加对trigger2的依赖,这样当nginx 80端口不可达时,站点也无法访问,但不会触发站点无法访问的异常事件。
3、 基于以上设置,虽然可以实现简单的事件关联依赖合并,但是监控系统内部屏蔽了异常事件的发生。如果报警涉及到多组运维人员,大家都想看看自己的监控是否可用异常。所以,最好的办法是所有的异常事件都正常产生,在告警通知的时候进行相关性分析。比如上面的例子,运维组A负责trigger1告警,运维组B负责trigger2告警。当trigger2异常时,通知运维组A【不可访问,因为nginx 80端口不可达】,通知运维组B【nginx端口80不可达,导致不可访问】。
总结:Zabbix有更全面的监控规则匹配表达式,但不够灵活,无法配置更复杂的关联监控。
三、zabbix 的动作触发一个动作
根据triiger触发的异常事件,可以触发相应的动作。通常的操作是根据配置的媒体发送警报。 Zabbix报警配置部分,每个报警发送方式需要配置1个媒体,每个用户需要配置相应的发送媒体。
如果把zabbix告警交给灵曦管理,对于用户配置,只需要在zabbix上配置1个用户和1个媒体,会省很多麻烦。
四、灵豹与zabbix的融合:
灵溪云告警是一款专注于告警优化管理的SAAS软件,提供多通道及时准确传输、多人智能分层传输、告警处理协同、故障数据多维统计等功能。
对于zabbix监控系统(2.0、3.0都支持),如果需要使用灵曦的报警优化功能,只需要进行以下步骤:
1、灵豹产品配置:
我还没有灵曦账号。完成引导页面后,进入工作台,点击右下方的开始报警优化之旅,完成页面配置并复制token。
2、zabbix 监控系统配置:
依次增加媒体、用户、动作,完成灵曦对zabbix的告警优化。具体的图形操作请参考:#/access-zabbix。
QueryListrules(array)规则字段解释下面几个复杂的解释
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-06-07 07:37
QueryList 规则(数组 $rules)
//采集规则$rules = array( '规则名' => array('jQuery选择器','要采集的属性'[,"标签过滤列表"][,"回调函数"]), '规则名2' => array('jQuery选择器','要采集的属性'[,"标签过滤列表"][,"回调函数"]), ..........);//注:方括号括起来的参数可选
//采集规则$rules = [ //采集img标签的src属性,也就是采集页面中的图片链接 'name1' => ['img','src'], //采集class为content的div的纯文本内容, //并移除内容中的a标签内容,移除id为footer标签的内容,保留img标签 'name2' => ['div.content','text','-a -#footer img'], //采集第二个div的html内容,并在内容中追加了一些自定义内容 'name3' => ['div:eq(1)','html','',function($content){ $content += 'some str...'; return $content; }]];
规则字段说明
下面分别解释几个复杂的字段。
1.要采集的属性
值有以下3种:
2.tag 过滤列表
设置此选项可用于过滤不需要的内容。多个值用空格分隔。有如下两条规则:
这是中文内容,这里有个链接</a> 这里有一段广告 这里还有一段广告
获取class为article的元素的内部内容,但不想要那段广告文字,则可以设置采集规则为:
//采集规则$rules = [ 'content' => ['.article','html','-.ad1 -.ad2']];
意思是:采集class是article元素里面的html内容,去掉class为ad1,class为ad2的元素的内容。
现在得到的内容是:
这是中文内容,这里有个链接
在实际采集中,我们一般不想要采集其他人的外链,而是想去掉内容中的链接。这时候如果把filter改成-.ad1 -.ad2 -a,采集就会到达内容为:
这是中文内容,
链接去掉了,但实际上我们要保存链接的文本内容,所以过滤器应该改为:-.ad1 -.ad2 a,所以采集到达的内容是:<//p
ppre class="prettyprint linenums prettyprinted" style=""ol class="linenums"li class="L0"codespan class="pun"这是中文内容,这里有个链接/span/code/li/ol/pre/p
p用法/p
ppre class="prettyprint linenums prettyprinted" style=""ol class="linenums"li class="L0"codespan class="pln"$html/spanspan class="pun"=/spanspan class="pln"STR/span/code/lili class="L1"codespan class="pun"/spanspan class="pln"div /spanspan class="kwd"class/spanspan class="pun"=/spanspan class="str""content"/spanspan class="pun"/span/code/lili class="L2"codespan class="pln" /spanspan class="str"div/span/code/lili class="L3"codespan class="pln" /spanspan class="pun"/spanspan class="pln"a href/spanspan class="pun"=/spanspan class="str""https://querylist.cc/1.html"/spanspan class="pun"这是链接一//spanspan class="pln"a/spanspan class="pun"/span/code/lili class="L4"codespan class="pln" /spanspan class="str"span/spanspan class="pun"这是文字一//spanspan class="pln"span/spanspan class="pun"/span/code/lili class="L5"codespan class="pln" /spanspan class="pun"//spanspan class="pln"div/spanspan class="pun"/span/code/lili class="L6"code/code/lili class="L7"codespan class="pln" /spanspan class="str"div/span/code/lili class="L8"codespan class="pln" /spanspan class="pun"/spanspan class="pln"a href/spanspan class="pun"=/spanspan class="str""https://querylist.cc/2.html"/spanspan class="pun"这是链接二//spanspan class="pln"a/spanspan class="pun"/span/code/lili class="L9"codespan class="pln" /spanspan class="str"span/spanspan class="pun"这是文字二//spanspan class="pln"span/spanspan class="pun"/span/code/lili class="L0"codespan class="pln" /spanspan class="pun"//spanspan class="pln"div/spanspan class="pun"/span/code/lili class="L1"code/code/lili class="L2"codespan class="pln" /spanspan class="str"div/span/code/lili class="L3"codespan class="pln" /spanspan class="pun"/spanspan class="pln"a href/spanspan class="pun"=/spanspan class="str""https://querylist.cc/1.html"/spanspan class="pun"这是链接三//spanspan class="pln"a/spanspan class="pun"/span/code/lili class="L4"codespan class="pln" /spanspan class="str"span/spanspan class="pun"这是文字三//spanspan class="pln"span/spanspan class="pun"/span/code/lili class="L5"codespan class="pln" /spanspan class="pun"//spanspan class="pln"div/spanspan class="pun"/span/code/lili class="L6"codespan class="pun"//spanspan class="pln"div/spanspan class="pun"/span/code/lili class="L7"codespan class="pln"STR/spanspan class="pun";/span/code/lili class="L8"code/code/lili class="L9"codespan class="com"//采集规则/span/code/lili class="L0"codespan class="pln"$rules /spanspan class="pun"=/spanspan class="pln" /spanspan class="pun"[/span/code/lili class="L1"codespan class="pln" /spanspan class="com"//采集a标签的href属性/span/code/lili class="L2"codespan class="pln" /spanspan class="str"'link'/spanspan class="pln" /spanspan class="pun"=/spanspan class="pln" /spanspan class="pun"[/spanspan class="str"'a'/spanspan class="pun",/spanspan class="str"'href'/spanspan class="pun"],/span/code/lili class="L3"codespan class="pln" /spanspan class="com"//采集a标签的text文本/span/code/lili class="L4"codespan class="pln" /spanspan class="str"'link_text'/spanspan class="pln" /spanspan class="pun"=/spanspan class="pln" /spanspan class="pun"[/spanspan class="str"'a'/spanspan class="pun",/spanspan class="str"'text'/spanspan class="pun"],/span/code/lili class="L5"codespan class="pln" /spanspan class="com"//采集span标签的text文本/span/code/lili class="L6"codespan class="pln" /spanspan class="str"'txt'/spanspan class="pln" /spanspan class="pun"=/spanspan class="pln" /spanspan class="pun"[/spanspan class="str"'span'/spanspan class="pun",/spanspan class="str"'text'/spanspan class="pun"]/span/code/lili class="L7"codespan class="pun"];/span/code/lili class="L8"code/code/lili class="L9"codespan class="pln"$ql /spanspan class="pun"=/spanspan class="pln" /spanspan class="typ"QueryList/spanspan class="pun"::/spanspan class="pln"html/spanspan class="pun"(/spanspan class="pln"$html/spanspan class="pun")->rules($rules)->query();$data = $ql->getData();print_r($data->all());
采集Result:
Array( [0] => Array ( [link] => https://querylist.cc/1.html [link_text] => 这是链接一 [txt] => 这是文字一 ) [1] => Array ( [link] => https://querylist.cc/2.html [link_text] => 这是链接二 [txt] => 这是文字二 ) [2] => Array ( [link] => https://querylist.cc/1.html [link_text] => 这是链接三 [txt] => 这是文字三 )) 查看全部
QueryListrules(array)规则字段解释下面几个复杂的解释
QueryList 规则(数组 $rules)
//采集规则$rules = array( '规则名' => array('jQuery选择器','要采集的属性'[,"标签过滤列表"][,"回调函数"]), '规则名2' => array('jQuery选择器','要采集的属性'[,"标签过滤列表"][,"回调函数"]), ..........);//注:方括号括起来的参数可选
//采集规则$rules = [ //采集img标签的src属性,也就是采集页面中的图片链接 'name1' => ['img','src'], //采集class为content的div的纯文本内容, //并移除内容中的a标签内容,移除id为footer标签的内容,保留img标签 'name2' => ['div.content','text','-a -#footer img'], //采集第二个div的html内容,并在内容中追加了一些自定义内容 'name3' => ['div:eq(1)','html','',function($content){ $content += 'some str...'; return $content; }]];
规则字段说明
下面分别解释几个复杂的字段。
1.要采集的属性
值有以下3种:
2.tag 过滤列表
设置此选项可用于过滤不需要的内容。多个值用空格分隔。有如下两条规则:
这是中文内容,这里有个链接</a> 这里有一段广告 这里还有一段广告
获取class为article的元素的内部内容,但不想要那段广告文字,则可以设置采集规则为:
//采集规则$rules = [ 'content' => ['.article','html','-.ad1 -.ad2']];
意思是:采集class是article元素里面的html内容,去掉class为ad1,class为ad2的元素的内容。
现在得到的内容是:
这是中文内容,这里有个链接
在实际采集中,我们一般不想要采集其他人的外链,而是想去掉内容中的链接。这时候如果把filter改成-.ad1 -.ad2 -a,采集就会到达内容为:
这是中文内容,
链接去掉了,但实际上我们要保存链接的文本内容,所以过滤器应该改为:-.ad1 -.ad2 a,所以采集到达的内容是:<//p
ppre class="prettyprint linenums prettyprinted" style=""ol class="linenums"li class="L0"codespan class="pun"这是中文内容,这里有个链接/span/code/li/ol/pre/p
p用法/p
ppre class="prettyprint linenums prettyprinted" style=""ol class="linenums"li class="L0"codespan class="pln"$html/spanspan class="pun"=/spanspan class="pln"STR/span/code/lili class="L1"codespan class="pun"/spanspan class="pln"div /spanspan class="kwd"class/spanspan class="pun"=/spanspan class="str""content"/spanspan class="pun"/span/code/lili class="L2"codespan class="pln" /spanspan class="str"div/span/code/lili class="L3"codespan class="pln" /spanspan class="pun"/spanspan class="pln"a href/spanspan class="pun"=/spanspan class="str""https://querylist.cc/1.html"/spanspan class="pun"这是链接一//spanspan class="pln"a/spanspan class="pun"/span/code/lili class="L4"codespan class="pln" /spanspan class="str"span/spanspan class="pun"这是文字一//spanspan class="pln"span/spanspan class="pun"/span/code/lili class="L5"codespan class="pln" /spanspan class="pun"//spanspan class="pln"div/spanspan class="pun"/span/code/lili class="L6"code/code/lili class="L7"codespan class="pln" /spanspan class="str"div/span/code/lili class="L8"codespan class="pln" /spanspan class="pun"/spanspan class="pln"a href/spanspan class="pun"=/spanspan class="str""https://querylist.cc/2.html"/spanspan class="pun"这是链接二//spanspan class="pln"a/spanspan class="pun"/span/code/lili class="L9"codespan class="pln" /spanspan class="str"span/spanspan class="pun"这是文字二//spanspan class="pln"span/spanspan class="pun"/span/code/lili class="L0"codespan class="pln" /spanspan class="pun"//spanspan class="pln"div/spanspan class="pun"/span/code/lili class="L1"code/code/lili class="L2"codespan class="pln" /spanspan class="str"div/span/code/lili class="L3"codespan class="pln" /spanspan class="pun"/spanspan class="pln"a href/spanspan class="pun"=/spanspan class="str""https://querylist.cc/1.html"/spanspan class="pun"这是链接三//spanspan class="pln"a/spanspan class="pun"/span/code/lili class="L4"codespan class="pln" /spanspan class="str"span/spanspan class="pun"这是文字三//spanspan class="pln"span/spanspan class="pun"/span/code/lili class="L5"codespan class="pln" /spanspan class="pun"//spanspan class="pln"div/spanspan class="pun"/span/code/lili class="L6"codespan class="pun"//spanspan class="pln"div/spanspan class="pun"/span/code/lili class="L7"codespan class="pln"STR/spanspan class="pun";/span/code/lili class="L8"code/code/lili class="L9"codespan class="com"//采集规则/span/code/lili class="L0"codespan class="pln"$rules /spanspan class="pun"=/spanspan class="pln" /spanspan class="pun"[/span/code/lili class="L1"codespan class="pln" /spanspan class="com"//采集a标签的href属性/span/code/lili class="L2"codespan class="pln" /spanspan class="str"'link'/spanspan class="pln" /spanspan class="pun"=/spanspan class="pln" /spanspan class="pun"[/spanspan class="str"'a'/spanspan class="pun",/spanspan class="str"'href'/spanspan class="pun"],/span/code/lili class="L3"codespan class="pln" /spanspan class="com"//采集a标签的text文本/span/code/lili class="L4"codespan class="pln" /spanspan class="str"'link_text'/spanspan class="pln" /spanspan class="pun"=/spanspan class="pln" /spanspan class="pun"[/spanspan class="str"'a'/spanspan class="pun",/spanspan class="str"'text'/spanspan class="pun"],/span/code/lili class="L5"codespan class="pln" /spanspan class="com"//采集span标签的text文本/span/code/lili class="L6"codespan class="pln" /spanspan class="str"'txt'/spanspan class="pln" /spanspan class="pun"=/spanspan class="pln" /spanspan class="pun"[/spanspan class="str"'span'/spanspan class="pun",/spanspan class="str"'text'/spanspan class="pun"]/span/code/lili class="L7"codespan class="pun"];/span/code/lili class="L8"code/code/lili class="L9"codespan class="pln"$ql /spanspan class="pun"=/spanspan class="pln" /spanspan class="typ"QueryList/spanspan class="pun"::/spanspan class="pln"html/spanspan class="pun"(/spanspan class="pln"$html/spanspan class="pun")->rules($rules)->query();$data = $ql->getData();print_r($data->all());
采集Result:
Array( [0] => Array ( [link] => https://querylist.cc/1.html [link_text] => 这是链接一 [txt] => 这是文字一 ) [1] => Array ( [link] => https://querylist.cc/2.html [link_text] => 这是链接二 [txt] => 这是文字二 ) [2] => Array ( [link] => https://querylist.cc/1.html [link_text] => 这是链接三 [txt] => 这是文字三 ))
开启全埋点代码示例WebSDK及以上版本代码代码
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-05-25 06:42
打开完整的掩埋点代码示例
var sensors = window['sensorsDataAnalytic201505'];
sensors.init({
server_url: 'http://test-syg.datasink.sensorsdata.cn/sa?token=xxxxx&project=xxxxxx',
is_track_single_page:true, // 单页面配置,默认开启,若页面中有锚点设计,需要将该配置删除,否则触发锚点会多触发 $pageview 事件
use_client_time:true,
send_type:'beacon',
heatmap: {
//是否开启点击图,default 表示开启,自动采集 $WebClick 事件,可以设置 'not_collect' 表示关闭。
clickmap:'default',
//是否开启触达注意力图,not_collect 表示关闭,不会自动采集 $WebStay 事件,可以设置 'default' 表示开启。
scroll_notice_map:'default'
}
});
sensors.quick('autoTrack');
JS
Web JS SDK的完全隐藏点包括三种事件:网页浏览,Web元素单击,Web视口停留,各个对应的配置如下。
网页浏览($ pageview)
// 设置之后,SDK 就会自动收集页面浏览事件,以及设置初始来源。
sensors.quick('autoTrack')
// 另外,如果想加额外的属性,可以如下方式(添加 platform 属性为 h5)
sensors.quick('autoTrack', {
platform:'h5'
})
JS
网页元素点击($ WebClick)
// SDK 初始化参数配置
heatmap: {
// 是否开启点击图,default 表示开启,自动采集 $WebClick 事件,可以设置 'not_collect' 表示关闭。
// 默认只有点击 a input button textarea 四种元素时,才会触发 $WebClick 元素点击事件
clickmap:'default'
}
JS
视口停留事件($ WebStay)
// SDK 初始化参数配置
heatmap: {
//是否开启触达注意力图,default 表示开启,自动采集 $WebStay 事件,可以设置 'not_collect' 表示关闭。
//需要 Web JS SDK 版本号大于 1.9.1
scroll_notice_map:'default'
}
JS
其他元素类型采集的元素单击事件支持自动div类型元素采集
版本要求
Web JS SDK及更高版本
在原创标记(采集 a,按钮,输入,文本区域标签)的基础上将采集添加到div标签中,采集规则为:
当div是叶节点(无子元素)时,采集 div的click div仅具有样式标签(['mark','strong','b','em','i','u ','abbr','ins','del','s','sup'])),点击div或样式标签采集 div点击
使用collect_tags配置是否启用div的完整掩埋点采集,默认值为采集。如果需要启用,请按以下方式配置collect_tags参数(注意:仅支持div配置):
heatmap:{
collect_tags:{
div : true
}
}
JS
支持具有特殊属性的其他类型元素的自动采集配置:data-sensors-click
打开整个掩埋点后,向需要自动采集 click事件的元素添加一个属性:data-sensors-click(注意:添加此属性将不允许该元素可视化整个掩埋点)。
版本要求
Web JS SDK及更高版本
代码示例如下:
我是测试元素
我是测试元素
XML
配置自定义属性
启用完全埋入点后,支持将具有指定属性的页面元素单击配置为自动采集单击事件(注意:添加此属性不能使元素能够显示完全埋入点)
版本要求
Web JS SDK及更高版本
代码示例如下:
var sensors = sensorsDataAnalytic201505;
sensors.init({
server_url: 'SERVER_URL',
heatmap: {
track_attr: ['hotrep', 'anotherprop', "data-prop2"],
clickmap:'default',
scroll_notice_map: 'not_collect'
}
});
...
<p hotrep id="test1">hotrep p tag
another repo a.b.c
strong with prop2 attribute</p>
CODE
代码掩埋点触发元素单击事件
如果您要单击输入按钮文本区域采集以外的其他元素,请在单击该元素时调用我们的方法。
// 下面演示一个 div 标签被点击时触发预置的元素点击事件
提交订单
$('#submit_order').on('click', function() {
sensors.quick('trackHeatMap', this, {
customProp1: 'test1', //如果需要添加自定义属性需要将 SDK 升级到 1.13.7 及以上版本。
customProp2: 'test2'
}, function() {
console.log('callback');
});
});
XML
//注意:调用我们在本机js中绑定的click事件时,它指向元素节点。在其他框架采集 click事件中,该指针也应指向相应的元素节点,例如,在vue中,请参见下面的示例。
点击
export default {
methods: {
track: function(event) {
sensors.quick('trackHeatMap', event.target, {
customProp1: 'test1', //如果需要添加自定义属性需要将 SDK 升级到 1.13.7 及以上版本。
customProp2: 'test2'
}, function() {
console.log('callback');
});
}
}
}
XML
新方法trackAllHeatMap已添加到版本及更高版本的SDK中。调用此方法时,可以在所有标签(包括a,input,button,textarea标签和div,img等)中传递此方法的第二个参数。仅trackHeatMap 采集标签是a,input,button,textarea之外。同时,这两个方法可以设置自定义属性,并支持回调函数(这两个方法的第四个参数可以传递给方法)。
// 下面演示一个 button 按钮被点击时触发预置的元素点击事件
测试按钮
$('#testp').on('click', function() {
sensors.quick('trackAllHeatMap', this, {
customProp1: 'test1', //如果需要添加自定义属性需要将 SDK 升级到 1.13.7 及以上版本。
customProp2: 'test2'
}, function() {
console.log('callback');
});
});
XML
全埋点相关参数配置Web元素单击与热图相关的参数,为$ WebClick事件提供自定义设置和处理。
说明热图相关参数:
参数名称参数值描述备注
点击地图
是否打开点击地图,默认设置是将其打开,并且可以将“ not_collect”设置为关闭。
Web JS SDK版本号必须大于。
scroll_notice_map
是否打开触摸注意力图,将其设置为默认值将其打开,将'not_collect'设置为将其关闭。
Web JS SDK版本号必须大于。
loadTimeout
毫秒
设置开始渲染点击图的毫秒数,因为首次打开页面时尚未加载页面的某些元素。
collect_url
返回true将采集当前页面的元素单击事件,返回false则不是采集当前页面。设置此功能后,如果内容为空,则将返回false。如果未设置此功能,则默认为所有页面采集。
collect_element
当用户单击页面元素时,将触发此函数,您可以确定是否采集当前元素,为采集返回true,为否采集返回false。
custom_property
如果要将自定义属性添加到$ WebClick事件,则可以根据标记的特性来判断是否添加它们。
注意:如果同时使用trackAllHeatMap或trackHeatMap方法设置自定义属性,则此处的自定义属性对象将在具有更高优先级的custom_property返回值中覆盖具有相同名称的属性。
collect_input
考虑到用户隐私,您可以在此处设置输入内容是否为采集。
如果返回true,则表示输入内容为采集,返回false表示不输入内容输入采集,默认值为采集。
element_selector
默认情况下,SDK将元素ID作为选择器采集 click事件的优先级。如果您不想将ID用作选择器,则可以将此参数设置为“ not_use_id”。
受以上版本支持。
renderRefreshTime
毫秒
在第二个版本中,在以毫秒为单位更改页面大小之后,单击滚动条以重新呈现页面。
与热图相关的参数代码示例:
heatmap: {
clickmap:'default',
scroll_notice_map:'default',
loadTimeout: 3000,
collect_url: function(){
//如果只采集首页
if(location.href === 'xxx.com/index.html' || location.href === 'xxx.com/'){
return true;
}
},
//此参数针对预置 $WebClick 事件(包括 quick('trackHeatMap') quick('trackAllHeatMap') 触发的)生效。
collect_element: function(element_target){
// 如果这个元素有属性sensors-disable=true时候,不采集。
if(element_target.getAttribute('sensors-disable') === 'true'){
return false;
}else{
return true;
}
},
//此参数针对预置 $WebClick 事件(包括 quick('trackHeatMap') quick('trackAllHeatMap') 触发的)生效。
custom_property:function( element_target ){
//比如您需要给有 data=test 属性的标签的点击事件增加自定义属性 name:'aa' ,则代码如下:
if(element_target.getAttribute('data') === 'test'){
return {
name:'aa'
}
}
},
collect_input:function(element_target){
//例如如果元素的 id 是a,就采集这个元素里的内容。
if(element_target.id === 'a'){
return true;
}
},
element_selector:'not_use_id',
renderRefreshTime:1000
}
JS
有关Web视口停留的相关参数的说明:
与滚动图相关的参数的描述:
参数名称参数值描述备注
collect_url
返回true将采集当前页面的数据,返回false则不是采集当前页面的数据。设置此功能后,如果内容为空,则将返回false。如果未设置此功能,则默认为所有页面采集。
说明热图相关参数:
参数名称参数值描述备注
scroll_notice_map
是否打开触摸图,将其设置为默认值以将其打开,并设置为'not_collect'以将其关闭。
Web JS SDK版本号必须大于。
scroll_delay_time
毫秒
设置触摸图的有效停留时间,默认停留时间为4秒以上。
scroll_event_duration
秒
预设属性停留时间的event_duration最大值。默认值为18000秒5小时。
与滚动图和热图有关的代码示例:
scrollmap: {
collect_url: function(){
//如果只采集首页
if(location.href === 'xxx.com/index.html' || location.href === 'xxx.com/'){
return true;
}
},
},
heatmap:{
//是否开启触达注意力图,default 表示开启,自动采集 $WebStay 事件,可以设置 'not_collect' 表示关闭。
//需要 Web JS SDK 版本号大于 1.9.1
scroll_notice_map:'not_collect',
scroll_delay_time: 4000,
scroll_event_duration: 18000 //单位秒,预置属性停留时长 event_duration 的最大值。默认5个小时,也就是300分钟,18000秒。
}
JS
单个页面采集中的自动事件
在单个页面中自动显示事件采集,请参阅
网页浏览事件采集自动模式
配置参数为_track_single_page(建议使用此模式),默认值为true,指示是否启用自动采集 Web浏览事件$ pageview功能。
原理是修改窗口对象的pushState和replaceState本机方法,并在更改页面的url之后自动采集 $ pageview事件。如果用户的浏览器不支持这两种方法或使用哈希路由模式,我们还将侦听popstate和hashchange事件以自动触发$ pageview事件。
用法示例:
//SDK版本1.12.18以上支持,默认值为false。
is_track_single_page:true
//注意:如果进首页不会自动 redirect 时,sa.quick('autoTrack') 是需要的,否则不需要。
JS
添加了大于或等于function(){}配置的SDK版本的is_track_single_page参数,并且必须返回一个值。
配置1:返回true表示当前页面将发送数据,
配置2:返回false表示将不发送任何数据,
配置3:返回{}对象,这意味着该对象的属性将被添加到当前的$ pageview中。
用法示例:
is_track_single_page : function (){
return true 时候,使用默认发送的 $pageview
return false 时候,不执行默认的 $pageview
return {} 时候,把对象中的属性,覆盖默认 $pageview 里的属性。
}
//注意:如果进首页不会自动 redirect 时,sa.quick('autoTrack') 是需要的,否则不需要。
JS
还请注意:
必须确保在切换页面之前已执行Shence Web JS SDK,否则在第一次切换页面时可能不会触发$ pageview。
手动模式
切换页面后,手动调用sensor.quick('autoTrackSinglePage')到采集 Web浏览事件$ pageview。切换页面网址后,将调用此方法。
// 比如现在是在 react 中可以在全局的 onUpdate 里来调用。
onUpdate: function(){
sensors.quick('autoTrackSinglePage');
}
//vue 项目在路由切换的时候调用。
router.afterEach((to,from) => {
Vue.nextTick(() => {
sensors.quick("autoTrackSinglePage");
});
});
//注意: vue下因为首页打开时候就会默认触发页面更新,所以需要去掉默认加的 sa.quick('autoTrack')。
JS
此方法还可以添加自定义属性,
sensors.quick("autoTrackSinglePage",{platForm:"H5"});
JS
单页页面标题$ title问题
对于单页项目,Shence SDK的所有点的预设事件采集的页面标题属性中可能会有例外。
具体问题:
1、 title如果没有更新分配,则获得的标题将始终是主页的标题,并且不会更改,并且切换页面发送的数据也不会更新$ title。
2、标题设置时间晚于数据发送时间,通过切换页面发送的$ pageview事件携带的$ title值是前一页的标题。
解决方案:
在切换页面之前完成标题值的更新(以常见的vue为例)
router.beforeEach((to, from, next) => {
document.title = '新页面的 title 值';
next()
})
JS 查看全部
开启全埋点代码示例WebSDK及以上版本代码代码
打开完整的掩埋点代码示例
var sensors = window['sensorsDataAnalytic201505'];
sensors.init({
server_url: 'http://test-syg.datasink.sensorsdata.cn/sa?token=xxxxx&project=xxxxxx',
is_track_single_page:true, // 单页面配置,默认开启,若页面中有锚点设计,需要将该配置删除,否则触发锚点会多触发 $pageview 事件
use_client_time:true,
send_type:'beacon',
heatmap: {
//是否开启点击图,default 表示开启,自动采集 $WebClick 事件,可以设置 'not_collect' 表示关闭。
clickmap:'default',
//是否开启触达注意力图,not_collect 表示关闭,不会自动采集 $WebStay 事件,可以设置 'default' 表示开启。
scroll_notice_map:'default'
}
});
sensors.quick('autoTrack');
JS
Web JS SDK的完全隐藏点包括三种事件:网页浏览,Web元素单击,Web视口停留,各个对应的配置如下。
网页浏览($ pageview)
// 设置之后,SDK 就会自动收集页面浏览事件,以及设置初始来源。
sensors.quick('autoTrack')
// 另外,如果想加额外的属性,可以如下方式(添加 platform 属性为 h5)
sensors.quick('autoTrack', {
platform:'h5'
})
JS
网页元素点击($ WebClick)
// SDK 初始化参数配置
heatmap: {
// 是否开启点击图,default 表示开启,自动采集 $WebClick 事件,可以设置 'not_collect' 表示关闭。
// 默认只有点击 a input button textarea 四种元素时,才会触发 $WebClick 元素点击事件
clickmap:'default'
}
JS
视口停留事件($ WebStay)
// SDK 初始化参数配置
heatmap: {
//是否开启触达注意力图,default 表示开启,自动采集 $WebStay 事件,可以设置 'not_collect' 表示关闭。
//需要 Web JS SDK 版本号大于 1.9.1
scroll_notice_map:'default'
}
JS
其他元素类型采集的元素单击事件支持自动div类型元素采集
版本要求
Web JS SDK及更高版本
在原创标记(采集 a,按钮,输入,文本区域标签)的基础上将采集添加到div标签中,采集规则为:
当div是叶节点(无子元素)时,采集 div的click div仅具有样式标签(['mark','strong','b','em','i','u ','abbr','ins','del','s','sup'])),点击div或样式标签采集 div点击
使用collect_tags配置是否启用div的完整掩埋点采集,默认值为采集。如果需要启用,请按以下方式配置collect_tags参数(注意:仅支持div配置):
heatmap:{
collect_tags:{
div : true
}
}
JS
支持具有特殊属性的其他类型元素的自动采集配置:data-sensors-click
打开整个掩埋点后,向需要自动采集 click事件的元素添加一个属性:data-sensors-click(注意:添加此属性将不允许该元素可视化整个掩埋点)。
版本要求
Web JS SDK及更高版本
代码示例如下:
我是测试元素
我是测试元素
XML
配置自定义属性
启用完全埋入点后,支持将具有指定属性的页面元素单击配置为自动采集单击事件(注意:添加此属性不能使元素能够显示完全埋入点)
版本要求
Web JS SDK及更高版本
代码示例如下:
var sensors = sensorsDataAnalytic201505;
sensors.init({
server_url: 'SERVER_URL',
heatmap: {
track_attr: ['hotrep', 'anotherprop', "data-prop2"],
clickmap:'default',
scroll_notice_map: 'not_collect'
}
});
...
<p hotrep id="test1">hotrep p tag
another repo a.b.c
strong with prop2 attribute</p>
CODE
代码掩埋点触发元素单击事件
如果您要单击输入按钮文本区域采集以外的其他元素,请在单击该元素时调用我们的方法。
// 下面演示一个 div 标签被点击时触发预置的元素点击事件
提交订单
$('#submit_order').on('click', function() {
sensors.quick('trackHeatMap', this, {
customProp1: 'test1', //如果需要添加自定义属性需要将 SDK 升级到 1.13.7 及以上版本。
customProp2: 'test2'
}, function() {
console.log('callback');
});
});
XML
//注意:调用我们在本机js中绑定的click事件时,它指向元素节点。在其他框架采集 click事件中,该指针也应指向相应的元素节点,例如,在vue中,请参见下面的示例。
点击
export default {
methods: {
track: function(event) {
sensors.quick('trackHeatMap', event.target, {
customProp1: 'test1', //如果需要添加自定义属性需要将 SDK 升级到 1.13.7 及以上版本。
customProp2: 'test2'
}, function() {
console.log('callback');
});
}
}
}
XML
新方法trackAllHeatMap已添加到版本及更高版本的SDK中。调用此方法时,可以在所有标签(包括a,input,button,textarea标签和div,img等)中传递此方法的第二个参数。仅trackHeatMap 采集标签是a,input,button,textarea之外。同时,这两个方法可以设置自定义属性,并支持回调函数(这两个方法的第四个参数可以传递给方法)。
// 下面演示一个 button 按钮被点击时触发预置的元素点击事件
测试按钮
$('#testp').on('click', function() {
sensors.quick('trackAllHeatMap', this, {
customProp1: 'test1', //如果需要添加自定义属性需要将 SDK 升级到 1.13.7 及以上版本。
customProp2: 'test2'
}, function() {
console.log('callback');
});
});
XML
全埋点相关参数配置Web元素单击与热图相关的参数,为$ WebClick事件提供自定义设置和处理。
说明热图相关参数:
参数名称参数值描述备注
点击地图
是否打开点击地图,默认设置是将其打开,并且可以将“ not_collect”设置为关闭。
Web JS SDK版本号必须大于。
scroll_notice_map
是否打开触摸注意力图,将其设置为默认值将其打开,将'not_collect'设置为将其关闭。
Web JS SDK版本号必须大于。
loadTimeout
毫秒
设置开始渲染点击图的毫秒数,因为首次打开页面时尚未加载页面的某些元素。
collect_url
返回true将采集当前页面的元素单击事件,返回false则不是采集当前页面。设置此功能后,如果内容为空,则将返回false。如果未设置此功能,则默认为所有页面采集。
collect_element
当用户单击页面元素时,将触发此函数,您可以确定是否采集当前元素,为采集返回true,为否采集返回false。
custom_property
如果要将自定义属性添加到$ WebClick事件,则可以根据标记的特性来判断是否添加它们。
注意:如果同时使用trackAllHeatMap或trackHeatMap方法设置自定义属性,则此处的自定义属性对象将在具有更高优先级的custom_property返回值中覆盖具有相同名称的属性。
collect_input
考虑到用户隐私,您可以在此处设置输入内容是否为采集。
如果返回true,则表示输入内容为采集,返回false表示不输入内容输入采集,默认值为采集。
element_selector
默认情况下,SDK将元素ID作为选择器采集 click事件的优先级。如果您不想将ID用作选择器,则可以将此参数设置为“ not_use_id”。
受以上版本支持。
renderRefreshTime
毫秒
在第二个版本中,在以毫秒为单位更改页面大小之后,单击滚动条以重新呈现页面。
与热图相关的参数代码示例:
heatmap: {
clickmap:'default',
scroll_notice_map:'default',
loadTimeout: 3000,
collect_url: function(){
//如果只采集首页
if(location.href === 'xxx.com/index.html' || location.href === 'xxx.com/'){
return true;
}
},
//此参数针对预置 $WebClick 事件(包括 quick('trackHeatMap') quick('trackAllHeatMap') 触发的)生效。
collect_element: function(element_target){
// 如果这个元素有属性sensors-disable=true时候,不采集。
if(element_target.getAttribute('sensors-disable') === 'true'){
return false;
}else{
return true;
}
},
//此参数针对预置 $WebClick 事件(包括 quick('trackHeatMap') quick('trackAllHeatMap') 触发的)生效。
custom_property:function( element_target ){
//比如您需要给有 data=test 属性的标签的点击事件增加自定义属性 name:'aa' ,则代码如下:
if(element_target.getAttribute('data') === 'test'){
return {
name:'aa'
}
}
},
collect_input:function(element_target){
//例如如果元素的 id 是a,就采集这个元素里的内容。
if(element_target.id === 'a'){
return true;
}
},
element_selector:'not_use_id',
renderRefreshTime:1000
}
JS
有关Web视口停留的相关参数的说明:
与滚动图相关的参数的描述:
参数名称参数值描述备注
collect_url
返回true将采集当前页面的数据,返回false则不是采集当前页面的数据。设置此功能后,如果内容为空,则将返回false。如果未设置此功能,则默认为所有页面采集。
说明热图相关参数:
参数名称参数值描述备注
scroll_notice_map
是否打开触摸图,将其设置为默认值以将其打开,并设置为'not_collect'以将其关闭。
Web JS SDK版本号必须大于。
scroll_delay_time
毫秒
设置触摸图的有效停留时间,默认停留时间为4秒以上。
scroll_event_duration
秒
预设属性停留时间的event_duration最大值。默认值为18000秒5小时。
与滚动图和热图有关的代码示例:
scrollmap: {
collect_url: function(){
//如果只采集首页
if(location.href === 'xxx.com/index.html' || location.href === 'xxx.com/'){
return true;
}
},
},
heatmap:{
//是否开启触达注意力图,default 表示开启,自动采集 $WebStay 事件,可以设置 'not_collect' 表示关闭。
//需要 Web JS SDK 版本号大于 1.9.1
scroll_notice_map:'not_collect',
scroll_delay_time: 4000,
scroll_event_duration: 18000 //单位秒,预置属性停留时长 event_duration 的最大值。默认5个小时,也就是300分钟,18000秒。
}
JS
单个页面采集中的自动事件
在单个页面中自动显示事件采集,请参阅
网页浏览事件采集自动模式
配置参数为_track_single_page(建议使用此模式),默认值为true,指示是否启用自动采集 Web浏览事件$ pageview功能。
原理是修改窗口对象的pushState和replaceState本机方法,并在更改页面的url之后自动采集 $ pageview事件。如果用户的浏览器不支持这两种方法或使用哈希路由模式,我们还将侦听popstate和hashchange事件以自动触发$ pageview事件。
用法示例:
//SDK版本1.12.18以上支持,默认值为false。
is_track_single_page:true
//注意:如果进首页不会自动 redirect 时,sa.quick('autoTrack') 是需要的,否则不需要。
JS
添加了大于或等于function(){}配置的SDK版本的is_track_single_page参数,并且必须返回一个值。
配置1:返回true表示当前页面将发送数据,
配置2:返回false表示将不发送任何数据,
配置3:返回{}对象,这意味着该对象的属性将被添加到当前的$ pageview中。
用法示例:
is_track_single_page : function (){
return true 时候,使用默认发送的 $pageview
return false 时候,不执行默认的 $pageview
return {} 时候,把对象中的属性,覆盖默认 $pageview 里的属性。
}
//注意:如果进首页不会自动 redirect 时,sa.quick('autoTrack') 是需要的,否则不需要。
JS
还请注意:
必须确保在切换页面之前已执行Shence Web JS SDK,否则在第一次切换页面时可能不会触发$ pageview。
手动模式
切换页面后,手动调用sensor.quick('autoTrackSinglePage')到采集 Web浏览事件$ pageview。切换页面网址后,将调用此方法。
// 比如现在是在 react 中可以在全局的 onUpdate 里来调用。
onUpdate: function(){
sensors.quick('autoTrackSinglePage');
}
//vue 项目在路由切换的时候调用。
router.afterEach((to,from) => {
Vue.nextTick(() => {
sensors.quick("autoTrackSinglePage");
});
});
//注意: vue下因为首页打开时候就会默认触发页面更新,所以需要去掉默认加的 sa.quick('autoTrack')。
JS
此方法还可以添加自定义属性,
sensors.quick("autoTrackSinglePage",{platForm:"H5"});
JS
单页页面标题$ title问题
对于单页项目,Shence SDK的所有点的预设事件采集的页面标题属性中可能会有例外。
具体问题:
1、 title如果没有更新分配,则获得的标题将始终是主页的标题,并且不会更改,并且切换页面发送的数据也不会更新$ title。
2、标题设置时间晚于数据发送时间,通过切换页面发送的$ pageview事件携带的$ title值是前一页的标题。
解决方案:
在切换页面之前完成标题值的更新(以常见的vue为例)
router.beforeEach((to, from, next) => {
document.title = '新页面的 title 值';
next()
})
JS
V10及更高数据管家——增强版网络爬虫老版本对应教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-05-16 20:18
支持的软件版本:V10和更高版本的Data Manager-Enhanced Web Crawler
对应的旧版本教程:V9和更低版本。 Jishouke网络抓取工具的相应教程为“ 采集网页数据”
下载并安装了Data Manager之后,我们在Data Manager的浏览器中打开采集页面,单击页面上的鼠标,并将内容标记为采集。此过程称为:使用视觉注释方法定义采集器规则。在本文中,任务和规则是指采集器规则。
注意:本文介绍的视觉注释适用于采集网页上可以看到的内容。如果采集的内容未直接显示在网页上,例如超链接的URL,或者无法用视觉注释准确地标记,则可以使用“内容映射”中说明的方法。
1.步骤(观看视频)
下面以京东网站为例,向您展示如何使用视觉标记的方法定义采集的规则。步骤如下:
2.详细的操作步骤
采集规则:京东数据管家列表的演示规则(点击下载此规则)
示例网址:%E5%86%B0%E7%AE%B1&enc = utf-8&wq =%E5%86%B0%E7%AE%B1&pvid = 2879721c10d54340a16491de943d6886
采集内容:网页上第一个产品的产品标题,价格,评论数和商店名称
第1步:打开网页
1. 1,加载网页并查看内容为采集
打开数据管理器,输入采集的URL,然后按Enter。加载网页后,首先观察采集的内容是否已完全加载。有些网页很长。如果要在网页底部显示采集内容,请确保拉动网页侧面的滚动条以使网页完全加载,然后创建采集任务。
1. 2,创建采集任务
单击左列顶部的“ +”按钮,然后在显示的左列中看到工作台,输入任务名称。
每个任务必须具有唯一的任务名称。如果新名称与其他人的名称相同,则会在界面上以红色提示您,并且必须更改名称,直到被接受为止。如果使用非常通用的名称,则具有相同名称的可能性很高。建议在名称后添加自己的Jishou帐户名。
第2步:标记需要采集的信息
2. 1,在网页上添加注释
例如,如果我们想要采集网页上第一个产品的标题,请用鼠标单击标题,标题文本将被一个细蓝框包围。
双击产品标题,会弹出一个小窗口,要求此采集内容的字段名称,该字段名称与excel中的字段相对应,在这里,我们输入的字段名称是产品标题。
如果这是创建的第一个采集内容,还将要求您输入表名,该表名与采集输出的excel表相对应,并且表名是自定义的。在采集器软件中,我们通常将此表称为“组织框”,这生动地表明我们正在将Web内容组织到一个框中。
通过此标记过程,Web内容将与爬网程序将来输出的excel表建立映射关系。在以下教程中,“映射”一词将被多次提及。网页内容采集是将网页上的内容映射到excel表的过程。
2. 2,标记更多内容
重复上一步以标记价格,评论数和商店名称。
第3步:保存规则并采集数据
3. 1,测试采集是否符合期望
单击“测试”按钮以检查信息的完整性。 采集的内容很可能为空,或者收录许多不必要的内容,或者放错了位置,并且采集到达了相邻的内容。然后,您需要重新调整映射关系。如果视觉注释不正确,则可以转到下面的DOM窗口进行内容映射。
3. 2,点击“保存”
只有保存规则,采集器才能执行规则采集数据。以后可以修改规则。
3. 3,点击“采集数据”
单击“保存”按钮旁边的“采集数据”按钮,爬网程序将打开一个新窗口以启动采集数据,并测试采集规则是否有效。除了使用“采集数据”按钮启动采集任务外,还有其他操作方法。有关详细信息,请参考以下“开始数据采集”教程。
第4步:查看数据
4. 1,开始导出过程
请参考上图。 采集完成后,将显示任务状态页面。单击“导出Excel”按钮,将出现一个提示框。点击确定。
4. 2,下载导出的数据
单击导出数据,单击下载,默认情况下它将保存到计算机的下载文件夹中。
下载的文件是一个ZIP包,并放置在计算机的“下载”文件夹中。您可以单击它以将其自解压缩为excel文件。
提醒:仅本教程采集具有第一个产品的数据。要采集此页面上所有产品的数据,请阅读下一篇文章文章“ Web爬网程序采集列表数据”第三步是复制示例采集列表数据。 查看全部
V10及更高数据管家——增强版网络爬虫老版本对应教程
支持的软件版本:V10和更高版本的Data Manager-Enhanced Web Crawler
对应的旧版本教程:V9和更低版本。 Jishouke网络抓取工具的相应教程为“ 采集网页数据”
下载并安装了Data Manager之后,我们在Data Manager的浏览器中打开采集页面,单击页面上的鼠标,并将内容标记为采集。此过程称为:使用视觉注释方法定义采集器规则。在本文中,任务和规则是指采集器规则。
注意:本文介绍的视觉注释适用于采集网页上可以看到的内容。如果采集的内容未直接显示在网页上,例如超链接的URL,或者无法用视觉注释准确地标记,则可以使用“内容映射”中说明的方法。
1.步骤(观看视频)
下面以京东网站为例,向您展示如何使用视觉标记的方法定义采集的规则。步骤如下:

2.详细的操作步骤
采集规则:京东数据管家列表的演示规则(点击下载此规则)
示例网址:%E5%86%B0%E7%AE%B1&enc = utf-8&wq =%E5%86%B0%E7%AE%B1&pvid = 2879721c10d54340a16491de943d6886
采集内容:网页上第一个产品的产品标题,价格,评论数和商店名称
第1步:打开网页
1. 1,加载网页并查看内容为采集
打开数据管理器,输入采集的URL,然后按Enter。加载网页后,首先观察采集的内容是否已完全加载。有些网页很长。如果要在网页底部显示采集内容,请确保拉动网页侧面的滚动条以使网页完全加载,然后创建采集任务。
1. 2,创建采集任务
单击左列顶部的“ +”按钮,然后在显示的左列中看到工作台,输入任务名称。
每个任务必须具有唯一的任务名称。如果新名称与其他人的名称相同,则会在界面上以红色提示您,并且必须更改名称,直到被接受为止。如果使用非常通用的名称,则具有相同名称的可能性很高。建议在名称后添加自己的Jishou帐户名。

第2步:标记需要采集的信息
2. 1,在网页上添加注释
例如,如果我们想要采集网页上第一个产品的标题,请用鼠标单击标题,标题文本将被一个细蓝框包围。
双击产品标题,会弹出一个小窗口,要求此采集内容的字段名称,该字段名称与excel中的字段相对应,在这里,我们输入的字段名称是产品标题。
如果这是创建的第一个采集内容,还将要求您输入表名,该表名与采集输出的excel表相对应,并且表名是自定义的。在采集器软件中,我们通常将此表称为“组织框”,这生动地表明我们正在将Web内容组织到一个框中。
通过此标记过程,Web内容将与爬网程序将来输出的excel表建立映射关系。在以下教程中,“映射”一词将被多次提及。网页内容采集是将网页上的内容映射到excel表的过程。

2. 2,标记更多内容
重复上一步以标记价格,评论数和商店名称。

第3步:保存规则并采集数据
3. 1,测试采集是否符合期望
单击“测试”按钮以检查信息的完整性。 采集的内容很可能为空,或者收录许多不必要的内容,或者放错了位置,并且采集到达了相邻的内容。然后,您需要重新调整映射关系。如果视觉注释不正确,则可以转到下面的DOM窗口进行内容映射。

3. 2,点击“保存”
只有保存规则,采集器才能执行规则采集数据。以后可以修改规则。

3. 3,点击“采集数据”
单击“保存”按钮旁边的“采集数据”按钮,爬网程序将打开一个新窗口以启动采集数据,并测试采集规则是否有效。除了使用“采集数据”按钮启动采集任务外,还有其他操作方法。有关详细信息,请参考以下“开始数据采集”教程。

第4步:查看数据
4. 1,开始导出过程
请参考上图。 采集完成后,将显示任务状态页面。单击“导出Excel”按钮,将出现一个提示框。点击确定。

4. 2,下载导出的数据
单击导出数据,单击下载,默认情况下它将保存到计算机的下载文件夹中。

下载的文件是一个ZIP包,并放置在计算机的“下载”文件夹中。您可以单击它以将其自解压缩为excel文件。

提醒:仅本教程采集具有第一个产品的数据。要采集此页面上所有产品的数据,请阅读下一篇文章文章“ Web爬网程序采集列表数据”第三步是复制示例采集列表数据。
优采云数据采集原理中的基本流程是怎样的?
采集交流 • 优采云 发表了文章 • 0 个评论 • 271 次浏览 • 2021-03-02 08:04
根据优采云 采集的原理,我们说优采云模拟了人们浏览网络以执行数据采集的行为,例如打开网页,单击按钮等。 优采云 采集器客户端,我们可以自行配置这些流程。
优采云 Data 采集通常具有以下基本过程,其中打开网页和提取数据必不可少,可以根据自己的需要添加或删除其他过程。
1、打开网页
此步骤根据设置的URL打开网页,这通常是网页采集处理的第一步,用于打开指定的网站或网页。如果需要打开多个相似的URL来执行相同的采集流程,则应将它们放在循环中,作为第一步。也就是说,使用URL循环打开网页。
2、点击元素
在此步骤中,用鼠标在网页上的指定元素上执行左键单击操作,例如单击按钮,单击以翻页,单击以跳至其他页面,等等。
3、输入文字
在此步骤中,在输入框中输入指定的文本,例如,输入搜索关键词,输入帐号等。将设置的文本输入到网页的输入框中,例如在使用时输入关键字搜索引擎。
4、循环
此步骤用于重复一系列步骤。根据配置,支持多种循环方法。 1)循环单个元素:循环单击页面上的按钮; 2)循环固定元素列表:循环处理网页中固定数量的元素; 3)循环非固定元素列表:循环处理数量不固定的网页元素; 4)循环URL列表:循环打开具有指定URL的一批网页,然后执行相同的处理步骤; 5)循环文本列表:循环输入一批指定的文本,然后执行相同的处理步骤。
5、提取数据
在此步骤中,根据您自己的需要提取网页中所需的数据字段,然后单击以选择所需的任何字段。除了从网页中提取数据外,您还可以添加特殊字段:当前时间,固定字段,空白字段,当前网页URL等。
完整的采集任务必须收录“提取数据”,并且提取的数据中必须至少有一个字段。否则,程序将在启动采集时报告错误,提示“未配置采集字段”。
此外,优采云的规则市场具有许多已建立的规则,可以直接下载这些规则并将其导入优采云以供使用。
1、如何下载采集条规则
优采云 采集器具有内置的规则市场,用户共享配置的采集规则以互相帮助。使用规则市场下载规则,您无需花费时间研究和配置采集流程。只需下载并运行采集,就可以在规则市场中搜索网站的许多采集规则。
有三种下载规则的方法:打开优采云官方网站()->采集器规则;打开优采云 采集器客户端->市场->采集器规则;直接访问Duoduo()->爬虫规则的官方网站。
2、如何使用规则
通常,从规则市场下载的规则是后缀为.otd的规则文件,并且下载的规则文件将自动以4. *及更高版本导入。在以前的版本中,您需要手动导入下载的规则文件。将下载的规则保存到相应的位置。然后打开优采云客户端->任务->导入->选择任务。通过电子邮件,QQ和微信收到的规则是相同的。
查看全部
优采云数据采集原理中的基本流程是怎样的?
根据优采云 采集的原理,我们说优采云模拟了人们浏览网络以执行数据采集的行为,例如打开网页,单击按钮等。 优采云 采集器客户端,我们可以自行配置这些流程。
优采云 Data 采集通常具有以下基本过程,其中打开网页和提取数据必不可少,可以根据自己的需要添加或删除其他过程。
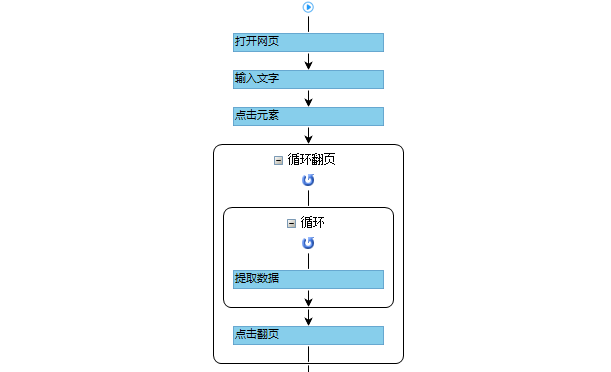
1、打开网页
此步骤根据设置的URL打开网页,这通常是网页采集处理的第一步,用于打开指定的网站或网页。如果需要打开多个相似的URL来执行相同的采集流程,则应将它们放在循环中,作为第一步。也就是说,使用URL循环打开网页。
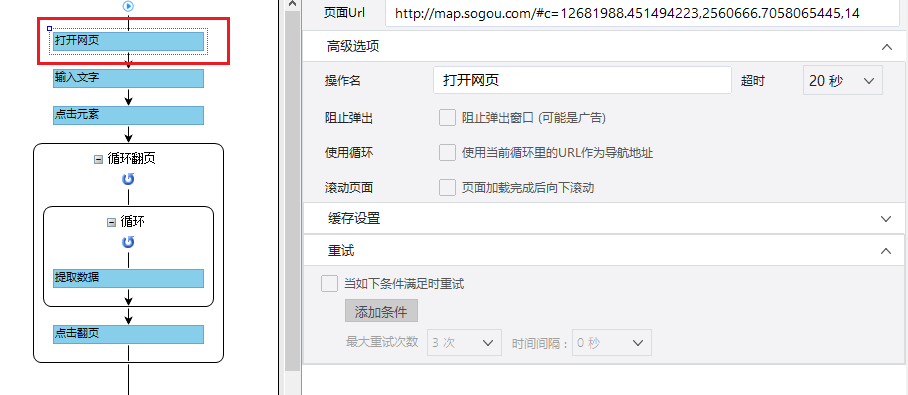
2、点击元素
在此步骤中,用鼠标在网页上的指定元素上执行左键单击操作,例如单击按钮,单击以翻页,单击以跳至其他页面,等等。
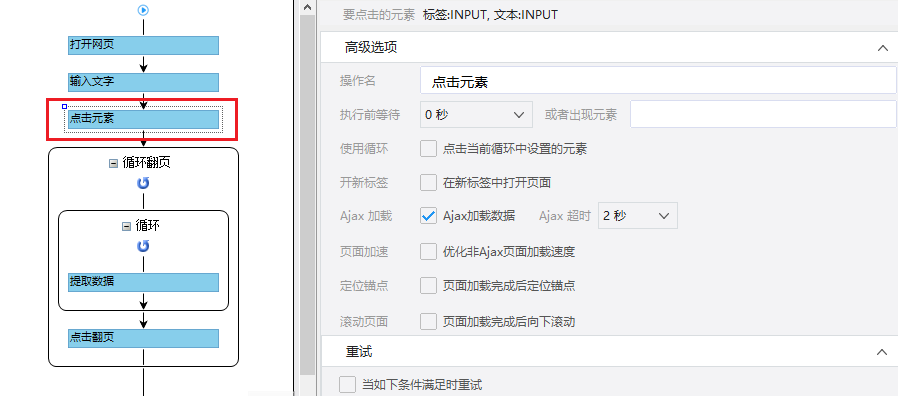
3、输入文字
在此步骤中,在输入框中输入指定的文本,例如,输入搜索关键词,输入帐号等。将设置的文本输入到网页的输入框中,例如在使用时输入关键字搜索引擎。
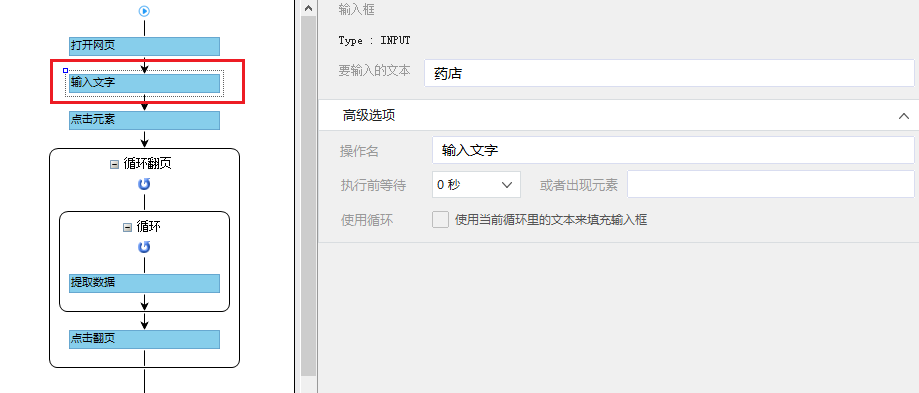
4、循环
此步骤用于重复一系列步骤。根据配置,支持多种循环方法。 1)循环单个元素:循环单击页面上的按钮; 2)循环固定元素列表:循环处理网页中固定数量的元素; 3)循环非固定元素列表:循环处理数量不固定的网页元素; 4)循环URL列表:循环打开具有指定URL的一批网页,然后执行相同的处理步骤; 5)循环文本列表:循环输入一批指定的文本,然后执行相同的处理步骤。
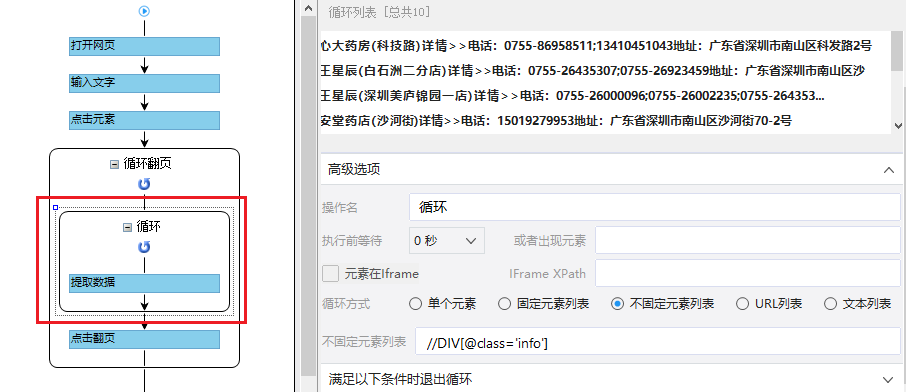
5、提取数据
在此步骤中,根据您自己的需要提取网页中所需的数据字段,然后单击以选择所需的任何字段。除了从网页中提取数据外,您还可以添加特殊字段:当前时间,固定字段,空白字段,当前网页URL等。
完整的采集任务必须收录“提取数据”,并且提取的数据中必须至少有一个字段。否则,程序将在启动采集时报告错误,提示“未配置采集字段”。
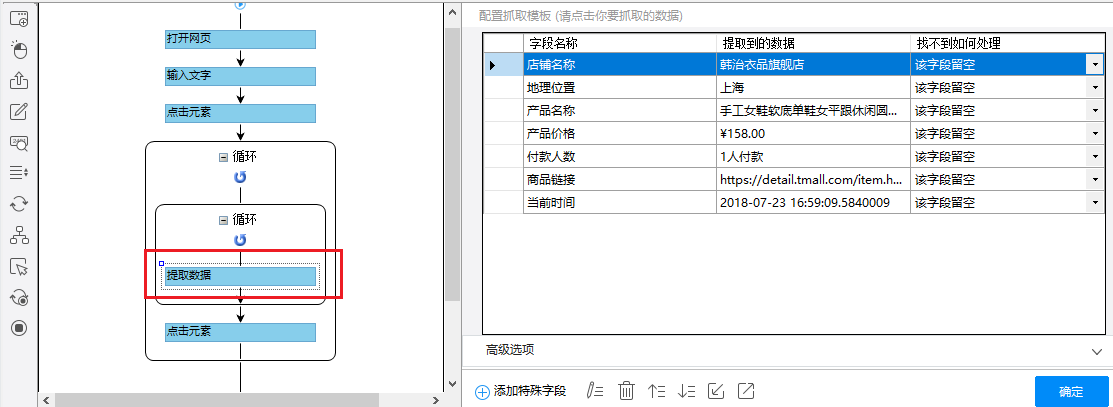
此外,优采云的规则市场具有许多已建立的规则,可以直接下载这些规则并将其导入优采云以供使用。
1、如何下载采集条规则
优采云 采集器具有内置的规则市场,用户共享配置的采集规则以互相帮助。使用规则市场下载规则,您无需花费时间研究和配置采集流程。只需下载并运行采集,就可以在规则市场中搜索网站的许多采集规则。
有三种下载规则的方法:打开优采云官方网站()->采集器规则;打开优采云 采集器客户端->市场->采集器规则;直接访问Duoduo()->爬虫规则的官方网站。
2、如何使用规则
通常,从规则市场下载的规则是后缀为.otd的规则文件,并且下载的规则文件将自动以4. *及更高版本导入。在以前的版本中,您需要手动导入下载的规则文件。将下载的规则保存到相应的位置。然后打开优采云客户端->任务->导入->选择任务。通过电子邮件,QQ和微信收到的规则是相同的。
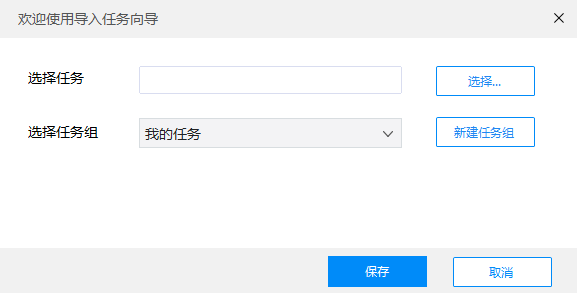
免费获取:易得网站数据采集系统免费下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 407 次浏览 • 2020-10-06 08:00
通过编写或下载规则,轻松获得网站数据采集系统通用版本,可以将采集大部分数据采集保存到选定的网站数据采集系统,并保存图片文件。它是构建网站必不可少的数据采集武器。此外,采集器是带有中文注释的开放源代码,便于修改和学习。
采集系统具有以下特征:
使用php + mysql编写的主流语言,只需安装相应的服务器即可。
完全开源-开源代码,并且代码带有中文注释,便于管理,学习和交流。
规则自定义-采集规则可以自定义,网站的大部分内容可以为采集。
数据修改-自定义修改规则以优化数据内容。
数据存储阵列形式,已序列化的数据保存到文件或数据库中,以方便上载和调用。
图像读取-您可以读取内容的图像并将其保存在本地。
编码控制-转换编码,您可以将gb2312,gbk和其他编码保存为utf-8。
标签清除-您可以自定义保留标签并清除不必要的标签。
安全性能-读取由密码控制,远程读取也很安全。
简单操作-一键式读取操作,您可以按规则分组阅读,或者指定要读取的规则ID,并使用单个ID进行读取。
规则分组读取按规则分组的数据,并及时更新采集个数据。
根据自定义规则ID进行自定义的读取和读取数据,这是有效且及时的。
JS阅读-使用js控制阅读时间并减少服务器负载。
超时控制-可以设置页面执行时间以减少超时错误。
多次读取-您可以设置网页的多次读取控件,以更有效地读取数据。
错误控制-如果存在多个错误,您可以停止阅读以减少服务器资源的使用。
将控件保存数据加载到多个文件夹中,可以有效解决多个文件下的服务器负载。
数据修改-不仅可以浏览数据,还可以修改主数据。
规则分析-您可以与他人共享规则,并让更多的人使用它们。
下载规则-下载共享规则以快速获取所需的内容。
查看全部
轻松获取网站数据采集系统免费下载
通过编写或下载规则,轻松获得网站数据采集系统通用版本,可以将采集大部分数据采集保存到选定的网站数据采集系统,并保存图片文件。它是构建网站必不可少的数据采集武器。此外,采集器是带有中文注释的开放源代码,便于修改和学习。
采集系统具有以下特征:
使用php + mysql编写的主流语言,只需安装相应的服务器即可。
完全开源-开源代码,并且代码带有中文注释,便于管理,学习和交流。
规则自定义-采集规则可以自定义,网站的大部分内容可以为采集。
数据修改-自定义修改规则以优化数据内容。
数据存储阵列形式,已序列化的数据保存到文件或数据库中,以方便上载和调用。
图像读取-您可以读取内容的图像并将其保存在本地。
编码控制-转换编码,您可以将gb2312,gbk和其他编码保存为utf-8。
标签清除-您可以自定义保留标签并清除不必要的标签。
安全性能-读取由密码控制,远程读取也很安全。
简单操作-一键式读取操作,您可以按规则分组阅读,或者指定要读取的规则ID,并使用单个ID进行读取。
规则分组读取按规则分组的数据,并及时更新采集个数据。
根据自定义规则ID进行自定义的读取和读取数据,这是有效且及时的。
JS阅读-使用js控制阅读时间并减少服务器负载。
超时控制-可以设置页面执行时间以减少超时错误。
多次读取-您可以设置网页的多次读取控件,以更有效地读取数据。
错误控制-如果存在多个错误,您可以停止阅读以减少服务器资源的使用。
将控件保存数据加载到多个文件夹中,可以有效解决多个文件下的服务器负载。
数据修改-不仅可以浏览数据,还可以修改主数据。
规则分析-您可以与他人共享规则,并让更多的人使用它们。
下载规则-下载共享规则以快速获取所需的内容。
定位标志采集列表数据——以百度旅游为例
采集交流 • 优采云 发表了文章 • 0 个评论 • 586 次浏览 • 2020-08-22 20:02
定位标志采集列表数据——以百度旅游为例
2016-10-20 16:41|发布者: ym|查看: 11347|评论: 4
摘要: 一、操作步骤 之前的教程早已教过如何用样例复制来采集列表数据,除了用样例复制,还可以用定位标志映射来采集列表数据。 下面用百度旅游作为案例来讲解,操作步骤如下: 二、案例规则+操作步骤 采集规则:百度旅游 ...
注:集搜客GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”统一改为“任务”,在爬虫浏览器里先命名任务再创建规则,然后登陆集搜客官网会员中心的“任务管理”里,就可以查看任务的采集执行情况、管理线索网址以及做调度设置了。
一、操作步骤
之前的教程早已教过如何用样例复制来采集列表数据,除了用样例复制,还可以用定位标志映射来采集列表数据。下面用百度旅游作为案例来讲解,操作步骤如下:
二、案例规则+操作步骤
第一步:打开网页
1.1,打开GS爬虫浏览器,输入网址,按Enter键;
1.2,点击“定义规则”按钮;
1.3,输入主题名,再点击“查重”,提示“该名可以使用”,点击OK。
第二步:标注信息
2.1,双击要采集的内容,输入标签名,按Enter键。
2.2,输入整理箱名称。
2.3,重复步骤2.1来标明目的地、行程天数、复制数和浏览数。
2.4,点击标题,勾上关键内容。
第三步:定位标志映射
3.1,找到收录第一个行程的区块节点LI,选中后右击-定位标志映射-列表。
Tips:区块节点须要有class值或id值能够用作定位标志映射,否则只能做样例复制。
3.2,可以看见列表的定位标志栏填上list-item,点击测试在输出结果窗口可以看见多条旅程信息。
第四步:存规则,爬数据
4.1,点击“存规则”,提示保存成功。
4.2,点击“爬数据”就可以开始采集数据。
上篇文章:《定位标志精确采集范围》 下篇文章:《采集图片网址并下载图片》
若有疑问可以或
4
鲜花
握手
雷人
路过
1
鸡蛋
刚表态过的同学 () 查看全部
定位标志采集列表数据——以百度旅游为例
定位标志采集列表数据——以百度旅游为例
2016-10-20 16:41|发布者: ym|查看: 11347|评论: 4
摘要: 一、操作步骤 之前的教程早已教过如何用样例复制来采集列表数据,除了用样例复制,还可以用定位标志映射来采集列表数据。 下面用百度旅游作为案例来讲解,操作步骤如下: 二、案例规则+操作步骤 采集规则:百度旅游 ...
注:集搜客GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”统一改为“任务”,在爬虫浏览器里先命名任务再创建规则,然后登陆集搜客官网会员中心的“任务管理”里,就可以查看任务的采集执行情况、管理线索网址以及做调度设置了。
一、操作步骤
之前的教程早已教过如何用样例复制来采集列表数据,除了用样例复制,还可以用定位标志映射来采集列表数据。下面用百度旅游作为案例来讲解,操作步骤如下:
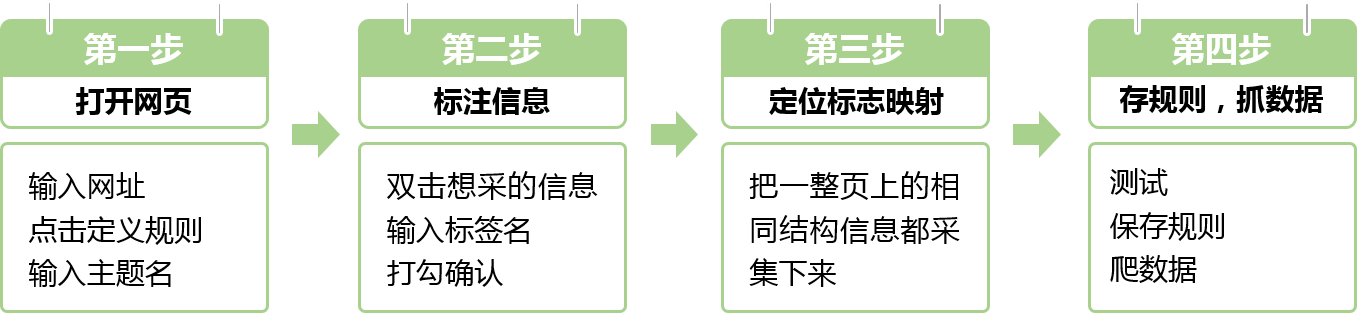
二、案例规则+操作步骤
第一步:打开网页
1.1,打开GS爬虫浏览器,输入网址,按Enter键;
1.2,点击“定义规则”按钮;
1.3,输入主题名,再点击“查重”,提示“该名可以使用”,点击OK。

第二步:标注信息
2.1,双击要采集的内容,输入标签名,按Enter键。
2.2,输入整理箱名称。

2.3,重复步骤2.1来标明目的地、行程天数、复制数和浏览数。
2.4,点击标题,勾上关键内容。

第三步:定位标志映射
3.1,找到收录第一个行程的区块节点LI,选中后右击-定位标志映射-列表。
Tips:区块节点须要有class值或id值能够用作定位标志映射,否则只能做样例复制。

3.2,可以看见列表的定位标志栏填上list-item,点击测试在输出结果窗口可以看见多条旅程信息。

第四步:存规则,爬数据
4.1,点击“存规则”,提示保存成功。
4.2,点击“爬数据”就可以开始采集数据。

上篇文章:《定位标志精确采集范围》 下篇文章:《采集图片网址并下载图片》
若有疑问可以或

4

鲜花

握手

雷人

路过
1

鸡蛋
刚表态过的同学 ()
CMDB发布系统2.监控3.配管系统、装机4.堡垒机CMDB目的
采集交流 • 优采云 发表了文章 • 0 个评论 • 262 次浏览 • 2021-08-18 07:02
CMDB-配置管理数据库资产管理
自动化相关平台(基本CMDB):
1.发布系统
2.监控
3. 管道系统,安装
4.堡垒机
CMDB 的目的:
1.替换EXCEL资产管理-不准资产
2.与监控系统联动
3.自动安装
预期:资产管理
实现原理:
1.代理多机器时
2.ssh
3.盐
实现三种模式兼容,可扩展性
基本结构:
1. Asset采集 的代码
2. API
3.管理平台
################
今天的目标:
资产采集:
- Asset采集code
Python 脚本
- api
姜戈
创建项目:
资产采集
auto_client:
代理模式:
1.采集资产信息
2.使用requests模块发送POST请求,将提交的资产信息提交给api持久化
ssh 模式:
1. 获取不是采集 的主机列表
2.远程连接(ssh)指定主机,执行命名采集asset信息
3. 使用requests模块发送POST请求提交资产信息
盐模式:
1. 获取不是采集 的主机列表
2.远程连接(salt)指定主机,执行命名采集asset信息
3. 使用requests模块发送POST请求提交资产信息
知识点:
1. csrf_exempt 一个视图不需要检查CSRF
2. requests module data={} Django 中的 url 编码 request.POST
data = json 字符串 request.POST 没有值——” request.body
3. 处理错误信息:
不要使用 e traceback.format_exc() 错误堆栈
4.唯一ID:
物理机序列号
物理机+虚拟机:
主机名+文件
规则:
1. 新机 使用主机名采集 的空文件将信息保存到当前新的文件中
2. 旧机改主机名,更新文件内容。当前更改和文件名也会更新。
5.返回值:
r1.content, 字节
r1.文本,字符串
r1.json(),反序列化的结果
6.线程池:
从 concurrent.futures 导入 ThreadPoolExecutor
pool = ThreadPoolExecutor(10)
对于host_list中的主机:
pool.submit(task,host)
7. 遵循的原则:
开闭原则:
打开:配置
关闭:源代码
#########################################
一、模块设计,资产采集方法第一种方法是Agent采集
第二种采集 方法使用中间控制机制。在控制机中,先获取没有采集的数据信息列表,然后到服务器去采集
Asset采集Client 目录规划开始。创建项目目录。这是采集目录,直接运行在服务端程序上。
auto_client 的目录规划
bin 执行文件,
config 配置文件,
lib 公共图书馆,
src 程序逻辑,
日志记录
执行入口bin start
bin
clinet.py
import os, sys
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from src.script import run
if __name__ == '__main__':
run()
逻辑文件
源代码
引擎(创建采集目录)
代理.py
类 AgnetHandler(object):
def handler(self):
"""
Agent模式下处理资产采集
:return:
"""<br /> print('agent模式')<br />
盐.py
class SaltHandler(object):
def handler(self):
"""
Salt模式下处理资产采集
:return:
"""<br /> print(‘salt模式’)<br />
ssh.py
class SSHHandler(object):
def handler(self):
"""
SSH模式下处理资产采集
:return:
"""<br /> print('SSH模式')<br />
脚本.py
from config import setting<br />from src.engine import agent,salt,ssh<br /><br />def run():<br /> """<br /> 资产采集入口<br /> :return:<br /> """<br /> if setting.ENGINE == 'agent':<br /> obj =agent.AgnetHandler()<br /> obj.handler()<br /> elif setting.ENGINE == 'salt':<br /> obj = salt.SaltHandler()<br /> obj.handler()<br /> elif setting.ENGINE == 'ssh':<br /> obj=ssh.SSHHandler()<br /> obj.handler()<br /> else:<br /> print("不支持这个模式采集")
#这种是简单工厂模式<br /><br />
做一个可插拔的程序,写在配置文件中,选择使用采集数据的方式
配置
settings.py
ENGINE='agent' #支持agent,salt,SSH数据采集
########################上面比较低,下面通过反射实现
#利用反射的方式,执行采集方法,首先在配置文件写一个字典
#利用反射执行采集,开发封闭原则
ENGINE_HANDLERS = {
'agent':'src.engine.AgnetHandler',
'salt':'src.engine.SaltHandler',
'ssh':'src.engine.SSHHandler',
}
脚本.py
from config import setting
# from src.engine import agent,salt,ssh
import importlib
def run():
"""
资产采集入口
:return:
"""
# if setting.ENGINE == 'agent':
# obj =agent.AgnetHandler()
# obj.handler()
# elif setting.ENGINE == 'salt':
# obj = salt.SaltHandler()
# obj.handler()
# elif setting.ENGINE == 'ssh':
# obj=ssh.SSHHandler()
# obj.handler()
# else:
# print("不支持这个模式采集")
#利用反射的方式,执行采集方法,首先在配置文件写一个字典
engine_path = setting.ENGINE_HANDLERS.get(setting.ENGINE) #拿到采集模式的脚本的执行路径
#'src.engine.agnet.AgnetHandler' 使用rsplit进行右分割,只是分割一次
path,engine_class=engine_path.rsplit('.',maxsplit=1)
#拿到执行模式脚本的类,使用importlib,导入
# print(path,engine_class)
module = importlib.import_module(path)
# print(module,type(module))
obj=getattr(module,engine_class)() #反射并实例化
obj.handler()
然后就可以将反射写成公共插件了
在lib中创建一个文件,module.srting.py
import importlib
def import_sting(path):
module_path,engine_class=path.rsplit('.',maxsplit=1)
module = importlib.import_module(module_path)
return getattr(module,engine_class)
我正在 script.py 中修改
from config import setting
from lib.module_srting import import_sting
def run():
"""
资产采集入口
:return:
"""
#利用反射的方式,执行采集方法,首先在配置文件写一个字典
engine_path = setting.ENGINE_HANDLERS.get(setting.ENGINE) #拿到采集模式的脚本的执行路径
engine_class = import_sting(engine_path)
obj=engine_class() #反射并实例化
obj.handler()
所有采集data 方法都受到约束
class BaseHandler(object):
def handler(self):
'''
约束派生类
:return:
'''
raise NotImplementedError('handler() must Implemented han')
每个方法都必须导入基类才能继承,agent、salt、ssh都必须继承
from .base import BaseHandler
class AgnetHandler(BaseHandler):
def handler(self):
"""
Agent模式下处理资产采集:硬盘、内存、网卡
:return:
"""
print('agent模式')
#调用pulugins.disk /plugins.momory /plugins.nerwork
转载于: 查看全部
CMDB发布系统2.监控3.配管系统、装机4.堡垒机CMDB目的
CMDB-配置管理数据库资产管理
自动化相关平台(基本CMDB):
1.发布系统
2.监控
3. 管道系统,安装
4.堡垒机
CMDB 的目的:
1.替换EXCEL资产管理-不准资产
2.与监控系统联动
3.自动安装
预期:资产管理
实现原理:
1.代理多机器时
2.ssh
3.盐
实现三种模式兼容,可扩展性
基本结构:
1. Asset采集 的代码
2. API
3.管理平台
################
今天的目标:
资产采集:
- Asset采集code
Python 脚本
- api
姜戈
创建项目:
资产采集
auto_client:
代理模式:
1.采集资产信息
2.使用requests模块发送POST请求,将提交的资产信息提交给api持久化
ssh 模式:
1. 获取不是采集 的主机列表
2.远程连接(ssh)指定主机,执行命名采集asset信息
3. 使用requests模块发送POST请求提交资产信息
盐模式:
1. 获取不是采集 的主机列表
2.远程连接(salt)指定主机,执行命名采集asset信息
3. 使用requests模块发送POST请求提交资产信息
知识点:
1. csrf_exempt 一个视图不需要检查CSRF
2. requests module data={} Django 中的 url 编码 request.POST
data = json 字符串 request.POST 没有值——” request.body
3. 处理错误信息:
不要使用 e traceback.format_exc() 错误堆栈
4.唯一ID:
物理机序列号
物理机+虚拟机:
主机名+文件
规则:
1. 新机 使用主机名采集 的空文件将信息保存到当前新的文件中
2. 旧机改主机名,更新文件内容。当前更改和文件名也会更新。
5.返回值:
r1.content, 字节
r1.文本,字符串
r1.json(),反序列化的结果
6.线程池:
从 concurrent.futures 导入 ThreadPoolExecutor
pool = ThreadPoolExecutor(10)
对于host_list中的主机:
pool.submit(task,host)
7. 遵循的原则:
开闭原则:
打开:配置
关闭:源代码
#########################################
一、模块设计,资产采集方法第一种方法是Agent采集
第二种采集 方法使用中间控制机制。在控制机中,先获取没有采集的数据信息列表,然后到服务器去采集
Asset采集Client 目录规划开始。创建项目目录。这是采集目录,直接运行在服务端程序上。
auto_client 的目录规划
bin 执行文件,
config 配置文件,
lib 公共图书馆,
src 程序逻辑,
日志记录
执行入口bin start
bin
clinet.py
import os, sys
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from src.script import run
if __name__ == '__main__':
run()
逻辑文件
源代码
引擎(创建采集目录)
代理.py
类 AgnetHandler(object):
def handler(self):
"""
Agent模式下处理资产采集
:return:
"""<br /> print('agent模式')<br />
盐.py
class SaltHandler(object):
def handler(self):
"""
Salt模式下处理资产采集
:return:
"""<br /> print(‘salt模式’)<br />
ssh.py
class SSHHandler(object):
def handler(self):
"""
SSH模式下处理资产采集
:return:
"""<br /> print('SSH模式')<br />
脚本.py
from config import setting<br />from src.engine import agent,salt,ssh<br /><br />def run():<br /> """<br /> 资产采集入口<br /> :return:<br /> """<br /> if setting.ENGINE == 'agent':<br /> obj =agent.AgnetHandler()<br /> obj.handler()<br /> elif setting.ENGINE == 'salt':<br /> obj = salt.SaltHandler()<br /> obj.handler()<br /> elif setting.ENGINE == 'ssh':<br /> obj=ssh.SSHHandler()<br /> obj.handler()<br /> else:<br /> print("不支持这个模式采集")
#这种是简单工厂模式<br /><br />
做一个可插拔的程序,写在配置文件中,选择使用采集数据的方式
配置
settings.py
ENGINE='agent' #支持agent,salt,SSH数据采集
########################上面比较低,下面通过反射实现
#利用反射的方式,执行采集方法,首先在配置文件写一个字典
#利用反射执行采集,开发封闭原则
ENGINE_HANDLERS = {
'agent':'src.engine.AgnetHandler',
'salt':'src.engine.SaltHandler',
'ssh':'src.engine.SSHHandler',
}
脚本.py
from config import setting
# from src.engine import agent,salt,ssh
import importlib
def run():
"""
资产采集入口
:return:
"""
# if setting.ENGINE == 'agent':
# obj =agent.AgnetHandler()
# obj.handler()
# elif setting.ENGINE == 'salt':
# obj = salt.SaltHandler()
# obj.handler()
# elif setting.ENGINE == 'ssh':
# obj=ssh.SSHHandler()
# obj.handler()
# else:
# print("不支持这个模式采集")
#利用反射的方式,执行采集方法,首先在配置文件写一个字典
engine_path = setting.ENGINE_HANDLERS.get(setting.ENGINE) #拿到采集模式的脚本的执行路径
#'src.engine.agnet.AgnetHandler' 使用rsplit进行右分割,只是分割一次
path,engine_class=engine_path.rsplit('.',maxsplit=1)
#拿到执行模式脚本的类,使用importlib,导入
# print(path,engine_class)
module = importlib.import_module(path)
# print(module,type(module))
obj=getattr(module,engine_class)() #反射并实例化
obj.handler()
然后就可以将反射写成公共插件了
在lib中创建一个文件,module.srting.py
import importlib
def import_sting(path):
module_path,engine_class=path.rsplit('.',maxsplit=1)
module = importlib.import_module(module_path)
return getattr(module,engine_class)
我正在 script.py 中修改
from config import setting
from lib.module_srting import import_sting
def run():
"""
资产采集入口
:return:
"""
#利用反射的方式,执行采集方法,首先在配置文件写一个字典
engine_path = setting.ENGINE_HANDLERS.get(setting.ENGINE) #拿到采集模式的脚本的执行路径
engine_class = import_sting(engine_path)
obj=engine_class() #反射并实例化
obj.handler()
所有采集data 方法都受到约束
class BaseHandler(object):
def handler(self):
'''
约束派生类
:return:
'''
raise NotImplementedError('handler() must Implemented han')
每个方法都必须导入基类才能继承,agent、salt、ssh都必须继承
from .base import BaseHandler
class AgnetHandler(BaseHandler):
def handler(self):
"""
Agent模式下处理资产采集:硬盘、内存、网卡
:return:
"""
print('agent模式')
#调用pulugins.disk /plugins.momory /plugins.nerwork
转载于:
阿里强大的大数据建设方法论是怎样的?(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-08-16 19:16
阿里强大的大数据建设方法论是什么?作者从数据技术、数据模型和数据管理三个部分开始介绍,这将开阔你的视野,也对你有所启发。
最近看了阿里巴巴数据技术与产品部的《大数据之路》一书。本书无论是底层数据技术的沉淀,还是满足各种数据应用场景的产品形态,还是实践中提取的数据。管理理念有助于开阔视野,也可作为自己结合实际情况进行数据建设的参考和参考。
接下来,我们将介绍三个部分:数据技术、数据模型和数据管理。
一、数据技术篇1.1 log采集
阿里巴巴的log采集程序包括两大系统:基于Web的日志采集program Aplus.JS和基于APP的日志采集program UserTrack。
以下是页面浏览日志的采集进程:
浏览器点击链接;浏览器解析请求并按照标准协议向服务器发送HTTP请求(标准HTTP请求包括请求行、请求头和请求体。请求行将包括请求方法是get还是post,以及请求资源URL如HTTP版本协议号,cookie等附加信息会在请求头中体现);服务器接收并解析请求,将处理结果以HTTP响应的形式发送给浏览器(标准HTTP响应包括状态行和响应头、响应体。状态行是一个3位的状态码,用于标识处理服务端的结果,如200/404,响应头中的cookie等附加信息。响应体是可选的,但大多是非空的,包括HTML文档和图片,脚本等);浏览器接收服务器响应,解析并呈现页面。
这是从请求到页面最终显示的标准全过程。浏览器解析服务器的响应如下:
HTML文档解析到某个节点时,JavaScript脚本采集当前页面参数,浏览行为的上下文信息,HTML文档中嵌入的运行环境信息; 采集 完成后发送到日志服务器,通常通过 URL 参数形式体现在请求行中;日志服务器收到日志请求后,立即向请求发送成功响应,并将日志内容写入日志缓冲区;服务端日志处理程序读取日志,解析,保存到标准日志文件中,并注入实时消息通道,供后续程序消费使用。
除了普通的页面浏览日志采集,还有页面交互日志采集,比如采集页面鼠标移动变化,用于准确的用户行为分析。
流程大致如下:
采集代码植入目标页面,绑定到被监控的交互行为;当指定的交互行为产生时,采集代码和正常的业务交互响应代码一起触发; 采集 被发送到采集Server。 1.2数据同步
除了日志采集,数据库同步也是数据访问层的重要组成部分。
数据同步的三种方式:
直接连接同步:通过ODBC或JDBC直接采用标准化统一的标准接口。优点是配置简单,易于实施。但是也有缺点,比如降低了目标系统的性能。建议采用主备策略从备份数据库中提取数据。数据文件同步:约定格式,从源系统生成文本文件,通过FTP服务器传输到目标系统。非常适合收录多个异构数据库系统的数据源,简单实用,另外日志数据通常是文本文件。但是,在上传和下载过程中可能会出现丢包或错误的情况。建议上传时添加验证文件,注明数据量、文件大小等验证信息。数据库日志分析与同步:源系统的日志文件通过TCP/IP三路握手机制依次传输到目标系统。目标系统通过数据加载模块完成数据的导入。数据可实时或准时同步,延迟低,对业务系统影响小。适用于业务系统到数据仓库的增量同步。但缺点是投资较大,需要部署中间系统提取数据,同时存在数据漂移和遗漏问题。
阿里数据仓库同步有两种方式:
1.3线下数据平台
在整体架构中,数据计算层包括数据存储计算平台(MaxCompute、Stream Compute)、数据集成与管理系统(OneData)。
MaxCompute 收录四个部分:
Client:Web,提供restful API的离线数据处理服务;软件开发工具包;客户端工具CLT,可以提交命令完成项目管理、DDL等操作; IDE,上层可视化ETL和BI工具,可完成数据同步、任务调度、报表生成等操作。接入层:提供HTTP服务、Cache、负载均衡,实现用户认证和服务级访问控制。逻辑层:又称控制层,是核心部分,实现命令的分析与执行、数据对象的访问控制与授权等功能。其中,Worker处理所有的RESTful请求; Scheduler 负责 Instance 任务的调度和反汇编;而 Excutor 负责 Instance 的执行。计算层:Apsara Core,包括分布式文件系统、资源调度系统、监控系统等模块。
对于Max Compute,阿里巴巴根据不同场景集成了多个子系统作为统一的开发平台:
除了统一的开发平台,任务调度系统还负责任务的统一调度和管理。它由调度引擎和执行引擎组成。
任务调度系统具有以下特点:
1.4 数据服务
数据服务架构的演进:
SmartDQ的元数据模型和处理流程如下:
SmartDQ 只是满足简单的查询服务。在Oneservice的统计数据服务层中,有如下三个模块:
二、数据模型篇2.1 大数据建模概述
数据模型定义:数据模型是一种数据组织或存储的方法,强调从业务、数据存储和数据使用的角度对数据进行合理的存储。
数据模型的意义:
性能方面,提高查询性能,降低IO吞吐量;在成本方面,减少冗余,结果重用,降低数据存储和计算成本;在效率方面,可以提高数据使用效率;在质量方面,改善统计不一致性。
数据仓库建模方法:
2.2 数据集成与管理系统
Onedata 是阿里巴巴数据公共层建设的指导方法。其定位和价值在于:通过数据服务和数据产品,完成数据公共层的建设,建立标准化、共享的数据服务能力,降低数据互通成本,释放数据计算、存储、人力资源等资源,并消除业务和技术。痛苦。
指标命名约定:
派生指示符 = 时间段 + 修饰符 + 原子指示符
例如,过去7天的新APP用户数。
指标类型可分为:交易指标(如新注册会员数)、存量指标(如产品总数)、综合指标(如比例、变化、变化率、排名,平均值/分位数)统计)。
2.3 维度设计
度量是“事实”,维度是“环境”。维度用于描述事实发生的各种环境,并可用于约束查询、小计和排序。
维度通常使用主键来标识其唯一性。主键有两种类型:具有业务意义的自然键和具有自增列或全局唯一标识符的代理键。
数据仓库的重要特征是反映历史变化,所以如何处理维度变化是维度设计的关键任务。对于缓慢变化的维度,通常有如下三种处理方法:
阿里巴巴使用快照维度表来记录维度变化:基于计算周期,每天可以保留一个完整的快照数据。优点是简单高效,开发维护成本低;缺点是存储成本高。于是阿里提出了一种极限存储的方法。
极限存储采用历史拉链存储的方式,即新的时间字段(start_dt和end_dt)。与全存储相比,优点是不变的数据不会重复存储。
但是历史拉链存储也有缺点,就是下游使用和理解成本高;时间分区可能会超过数据库的分区限制。
所以可以具体优化两点:
透明(即上层对用户进行视图操作和映射关联,用户感知不到极限存储表的存在);每月制作历史拉链表(与每天相比,可以大大减少分区数量)。 2.4事实表设计
事实用于衡量业务流程。常用的事实有以下三种类型:
根据产生方式,事实表可分为以下三种:
事实表的一些设计原则:
事实表的设计方法:选择业务流程→声明粒度→确定维度→确定事实。该方法也适用于采集数据分析需求。
三、数据管理3.1元数据
元数据是数据的数据,记录了数据从生产到消费的全过程:数据仓库中模型的定义,各层级之间的映射关系,监控数据的数据状态,运行状态ETL 任务等。
根据用途,元数据可以细分为技术元数据和业务元数据:
构建统一元数据体系的目标:打通数据访问、处理、消费全环节,提供统一规范的元数据服务出口,保证元数据输出的稳定性和质量。
构建统一元数据系统的目标过程:
结合底层数据,对元数据进行分类,减少数据构建的重复,丰富表和字段的使用说明;构建中间层,在计算、存储、质量、安全等治理领域提供数据支持;为外部服务导出提供统一的元数据。
元数据被广泛使用:
阿里的应用主要有以下几个方面:
(1)Data Profile
建立数据血缘关系图,解决研发前期数据搜索、算法确定、数据处理的复杂困境,节约研发成本,更高效地理解和使用数据,通过标签标记、组织和归档数据。
数据标签主要分为四类:
(2)元数据门户
通过数据地图检索和理解数据,通过数据管理进行计算、存储和安全管理。
(3)血缘关系分析
表级血缘关系、领域血缘关系、间接使用表应用血缘关系用于影响分析、重要性分析、离线分析、离线分析、链接分析、故障排除等。
(4)数据建模
可以实现从经验建模到元数据驱动的升级,提供基于数据的指导,提高建模效率。使用的元数据有:表的基本元数据,比如表的下游情况、查询/关联/聚合的数量;表的关联元数据:关联表、关联类型、关联数、关联字段等;字段的基本元数据,如字段名称、评论、查询/关联/关联/聚合/过滤次数。
(5)drive ETL 开发
OneClick 可用于日常数据运维,如任务查询定位、添加字段、表删除、表备份、任务离线、任务删除等,例如Data Profile判断数据可以离线后,OneClick触发数据离线工作流,直接自动删除数据、删除元数据、离线调度任务、离线DQC监控。
3.2计算管理
计算管理的目的是减少计算资源消耗,提高任务执行性能。计算优化可以分为任务优化和系统优化。
3.3存储和成本管理
从以下几个方面介绍存储优化:
3.4数据质量
数据质量是所有分析有效和准备好的基础和前提,因此数据质量的保证是数据仓库建设的重要环节。
数据质量保证的原则主要有四个方面:
阿里巴巴的数据质量构建方法包括以下几个方面:
摩萨德可以提供强有力的保障监控和自定义警报。围绕运维目标即业务监控设计强保障监控,业务预警时间受到威胁报警。比如业务人员每天的离线数据任务,业务输出时间为9点。 Summer可以根据当前业务中所有任务最近7天的平均运行时间,设置预警时间,如果7点数据没有输出就发出预警。另外,当任务失败时,可以自定义告警配置。 查看全部
阿里强大的大数据建设方法论是怎样的?(组图)
阿里强大的大数据建设方法论是什么?作者从数据技术、数据模型和数据管理三个部分开始介绍,这将开阔你的视野,也对你有所启发。
最近看了阿里巴巴数据技术与产品部的《大数据之路》一书。本书无论是底层数据技术的沉淀,还是满足各种数据应用场景的产品形态,还是实践中提取的数据。管理理念有助于开阔视野,也可作为自己结合实际情况进行数据建设的参考和参考。
接下来,我们将介绍三个部分:数据技术、数据模型和数据管理。
一、数据技术篇1.1 log采集
阿里巴巴的log采集程序包括两大系统:基于Web的日志采集program Aplus.JS和基于APP的日志采集program UserTrack。
以下是页面浏览日志的采集进程:
浏览器点击链接;浏览器解析请求并按照标准协议向服务器发送HTTP请求(标准HTTP请求包括请求行、请求头和请求体。请求行将包括请求方法是get还是post,以及请求资源URL如HTTP版本协议号,cookie等附加信息会在请求头中体现);服务器接收并解析请求,将处理结果以HTTP响应的形式发送给浏览器(标准HTTP响应包括状态行和响应头、响应体。状态行是一个3位的状态码,用于标识处理服务端的结果,如200/404,响应头中的cookie等附加信息。响应体是可选的,但大多是非空的,包括HTML文档和图片,脚本等);浏览器接收服务器响应,解析并呈现页面。
这是从请求到页面最终显示的标准全过程。浏览器解析服务器的响应如下:
HTML文档解析到某个节点时,JavaScript脚本采集当前页面参数,浏览行为的上下文信息,HTML文档中嵌入的运行环境信息; 采集 完成后发送到日志服务器,通常通过 URL 参数形式体现在请求行中;日志服务器收到日志请求后,立即向请求发送成功响应,并将日志内容写入日志缓冲区;服务端日志处理程序读取日志,解析,保存到标准日志文件中,并注入实时消息通道,供后续程序消费使用。
除了普通的页面浏览日志采集,还有页面交互日志采集,比如采集页面鼠标移动变化,用于准确的用户行为分析。
流程大致如下:
采集代码植入目标页面,绑定到被监控的交互行为;当指定的交互行为产生时,采集代码和正常的业务交互响应代码一起触发; 采集 被发送到采集Server。 1.2数据同步
除了日志采集,数据库同步也是数据访问层的重要组成部分。
数据同步的三种方式:
直接连接同步:通过ODBC或JDBC直接采用标准化统一的标准接口。优点是配置简单,易于实施。但是也有缺点,比如降低了目标系统的性能。建议采用主备策略从备份数据库中提取数据。数据文件同步:约定格式,从源系统生成文本文件,通过FTP服务器传输到目标系统。非常适合收录多个异构数据库系统的数据源,简单实用,另外日志数据通常是文本文件。但是,在上传和下载过程中可能会出现丢包或错误的情况。建议上传时添加验证文件,注明数据量、文件大小等验证信息。数据库日志分析与同步:源系统的日志文件通过TCP/IP三路握手机制依次传输到目标系统。目标系统通过数据加载模块完成数据的导入。数据可实时或准时同步,延迟低,对业务系统影响小。适用于业务系统到数据仓库的增量同步。但缺点是投资较大,需要部署中间系统提取数据,同时存在数据漂移和遗漏问题。
阿里数据仓库同步有两种方式:
1.3线下数据平台
在整体架构中,数据计算层包括数据存储计算平台(MaxCompute、Stream Compute)、数据集成与管理系统(OneData)。
MaxCompute 收录四个部分:
Client:Web,提供restful API的离线数据处理服务;软件开发工具包;客户端工具CLT,可以提交命令完成项目管理、DDL等操作; IDE,上层可视化ETL和BI工具,可完成数据同步、任务调度、报表生成等操作。接入层:提供HTTP服务、Cache、负载均衡,实现用户认证和服务级访问控制。逻辑层:又称控制层,是核心部分,实现命令的分析与执行、数据对象的访问控制与授权等功能。其中,Worker处理所有的RESTful请求; Scheduler 负责 Instance 任务的调度和反汇编;而 Excutor 负责 Instance 的执行。计算层:Apsara Core,包括分布式文件系统、资源调度系统、监控系统等模块。
对于Max Compute,阿里巴巴根据不同场景集成了多个子系统作为统一的开发平台:
除了统一的开发平台,任务调度系统还负责任务的统一调度和管理。它由调度引擎和执行引擎组成。
任务调度系统具有以下特点:
1.4 数据服务
数据服务架构的演进:
SmartDQ的元数据模型和处理流程如下:
SmartDQ 只是满足简单的查询服务。在Oneservice的统计数据服务层中,有如下三个模块:
二、数据模型篇2.1 大数据建模概述
数据模型定义:数据模型是一种数据组织或存储的方法,强调从业务、数据存储和数据使用的角度对数据进行合理的存储。
数据模型的意义:
性能方面,提高查询性能,降低IO吞吐量;在成本方面,减少冗余,结果重用,降低数据存储和计算成本;在效率方面,可以提高数据使用效率;在质量方面,改善统计不一致性。
数据仓库建模方法:
2.2 数据集成与管理系统
Onedata 是阿里巴巴数据公共层建设的指导方法。其定位和价值在于:通过数据服务和数据产品,完成数据公共层的建设,建立标准化、共享的数据服务能力,降低数据互通成本,释放数据计算、存储、人力资源等资源,并消除业务和技术。痛苦。
指标命名约定:
派生指示符 = 时间段 + 修饰符 + 原子指示符
例如,过去7天的新APP用户数。
指标类型可分为:交易指标(如新注册会员数)、存量指标(如产品总数)、综合指标(如比例、变化、变化率、排名,平均值/分位数)统计)。
2.3 维度设计
度量是“事实”,维度是“环境”。维度用于描述事实发生的各种环境,并可用于约束查询、小计和排序。
维度通常使用主键来标识其唯一性。主键有两种类型:具有业务意义的自然键和具有自增列或全局唯一标识符的代理键。
数据仓库的重要特征是反映历史变化,所以如何处理维度变化是维度设计的关键任务。对于缓慢变化的维度,通常有如下三种处理方法:
阿里巴巴使用快照维度表来记录维度变化:基于计算周期,每天可以保留一个完整的快照数据。优点是简单高效,开发维护成本低;缺点是存储成本高。于是阿里提出了一种极限存储的方法。
极限存储采用历史拉链存储的方式,即新的时间字段(start_dt和end_dt)。与全存储相比,优点是不变的数据不会重复存储。
但是历史拉链存储也有缺点,就是下游使用和理解成本高;时间分区可能会超过数据库的分区限制。
所以可以具体优化两点:
透明(即上层对用户进行视图操作和映射关联,用户感知不到极限存储表的存在);每月制作历史拉链表(与每天相比,可以大大减少分区数量)。 2.4事实表设计
事实用于衡量业务流程。常用的事实有以下三种类型:
根据产生方式,事实表可分为以下三种:
事实表的一些设计原则:
事实表的设计方法:选择业务流程→声明粒度→确定维度→确定事实。该方法也适用于采集数据分析需求。
三、数据管理3.1元数据
元数据是数据的数据,记录了数据从生产到消费的全过程:数据仓库中模型的定义,各层级之间的映射关系,监控数据的数据状态,运行状态ETL 任务等。
根据用途,元数据可以细分为技术元数据和业务元数据:
构建统一元数据体系的目标:打通数据访问、处理、消费全环节,提供统一规范的元数据服务出口,保证元数据输出的稳定性和质量。
构建统一元数据系统的目标过程:
结合底层数据,对元数据进行分类,减少数据构建的重复,丰富表和字段的使用说明;构建中间层,在计算、存储、质量、安全等治理领域提供数据支持;为外部服务导出提供统一的元数据。
元数据被广泛使用:
阿里的应用主要有以下几个方面:
(1)Data Profile
建立数据血缘关系图,解决研发前期数据搜索、算法确定、数据处理的复杂困境,节约研发成本,更高效地理解和使用数据,通过标签标记、组织和归档数据。
数据标签主要分为四类:
(2)元数据门户
通过数据地图检索和理解数据,通过数据管理进行计算、存储和安全管理。
(3)血缘关系分析
表级血缘关系、领域血缘关系、间接使用表应用血缘关系用于影响分析、重要性分析、离线分析、离线分析、链接分析、故障排除等。
(4)数据建模
可以实现从经验建模到元数据驱动的升级,提供基于数据的指导,提高建模效率。使用的元数据有:表的基本元数据,比如表的下游情况、查询/关联/聚合的数量;表的关联元数据:关联表、关联类型、关联数、关联字段等;字段的基本元数据,如字段名称、评论、查询/关联/关联/聚合/过滤次数。
(5)drive ETL 开发
OneClick 可用于日常数据运维,如任务查询定位、添加字段、表删除、表备份、任务离线、任务删除等,例如Data Profile判断数据可以离线后,OneClick触发数据离线工作流,直接自动删除数据、删除元数据、离线调度任务、离线DQC监控。
3.2计算管理
计算管理的目的是减少计算资源消耗,提高任务执行性能。计算优化可以分为任务优化和系统优化。
3.3存储和成本管理
从以下几个方面介绍存储优化:
3.4数据质量
数据质量是所有分析有效和准备好的基础和前提,因此数据质量的保证是数据仓库建设的重要环节。
数据质量保证的原则主要有四个方面:
阿里巴巴的数据质量构建方法包括以下几个方面:
摩萨德可以提供强有力的保障监控和自定义警报。围绕运维目标即业务监控设计强保障监控,业务预警时间受到威胁报警。比如业务人员每天的离线数据任务,业务输出时间为9点。 Summer可以根据当前业务中所有任务最近7天的平均运行时间,设置预警时间,如果7点数据没有输出就发出预警。另外,当任务失败时,可以自定义告警配置。
使用php采集网页数据一般有多种方法,有时候东西以采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-08-15 23:12
php采集网页数据的使用方式一般有很多种。有时我们使用正则去采集页面,但是当我们需要采集有一个很大很大的页面时,就会严重浪费我们的CPU。到时候我们可以用phpQuer来做采集。如果你不了解 phpQuery,你可以去看看这是什么。
以采集此网站为例
假设我们需要采集commodity category Name Price Item No Shelf Time Product Picture Detail Picture
1.首先下载phpQuery类phpQuery.php
2.接下来我们可以创建一个cj.php类
单页采集
php
header("Content-Type: text/html; charset=UTF-8");
require("phpQuery.php"); //引入类
//检测当前链接是否合法
$url = 'http://www.rsq111.com/goods.php?id=15663';
$header_info=getHeaders($url,true);
if ($header_info != 200) {
die;
}
phpQuery::newDocumentFile($url); //获取网页对象内容
//pq() == $(this)
// 商品分类
$arr_check = pq(".breadcrumb");
foreach ($arr_check as $li) {
$cat = pq($li)->text();
}
$category = explode('>', $cat);
//商品标题
$h1_check = pq("#name");
$title = pq($h1_check)->text();
//商品价格
$price_check = pq(".rmbPrice");
$shop_price = [];
foreach ($price_check as $li) {
$shop_price[] = pq($li)->text();
}
$shop_price = array_pop($shop_price);
$shop_price = explode(':', $shop_price);
$price = $shop_price[1];
//商品参数
$prame_check = pq("#summary1 .dd");
$prame = [];
foreach ($prame_check as $li) {
$prame[] = pq($li)->text();
}
$sn = $prame[0];//货号
$brank = $prame[1];//品牌
$time = $prame[2];//上架时间
// 商品图片
$prame_photo_check = pq("#goods_gallery a");
$photo = [];
foreach ($prame_photo_check as $li) {
$src = 'http://www.rsq111.com/'.pq($li)->attr('href');//图片路径
//注释代码为保存图片路劲,下载图片到本地
$localSrc = 'w/'.md5($src).'.jpg';
// $stream = file_get_contents($src);
// file_put_contents($localSrc,$stream);
// pq($li)->attr('src',$localSrc);
$photo[] = $localSrc;
}
//商品详情图片
$info_photo_check = pq(".detail-content img");
$info_photo = [];
foreach ($info_photo_check as $li) {
$src = 'http://www.rsq111.com/'.pq($li)->attr('src');
$localSrc = 'w/'.md5($src).'.jpg';
// $stream = file_get_contents($src);
// file_put_contents($localSrc,$stream);
// pq($li)->attr('src',$localSrc);
$info_photo[] = $localSrc;
}
$data= [
'title' => $title,
'category1' => $category[1],
'category2' => $category[2],
'category3' => $category[3],
'price' => $price,
'sn' => $sn,
'brank' => $brank,
'time' => $time,
'photo' => $photo,
'info_photo' =>$info_photo,
];
}
echo "";
print_r($data);
//检测url是否合法
function getHeaders($url,$data=FALSE){
$_headers = get_headers($url,1);
if( !$data ){return $_headers;}
$curl = curl_init();
curl_setopt($curl,CURLOPT_URL,$url);//获取内容url
curl_setopt($curl,CURLOPT_HEADER,1);//获取http头信息
curl_setopt($curl,CURLOPT_NOBODY,1);//不返回html的body信息
curl_setopt($curl,CURLOPT_RETURNTRANSFER,1);//返回数据流,不直接输出
curl_setopt($curl,CURLOPT_TIMEOUT,30); //超时时长,单位秒
curl_exec($curl);
$rtn= curl_getinfo($curl,CURLINFO_HTTP_CODE);
curl_close($curl);
return $rtn;
}
这种情况下,可以采集到这个页面的数据,但是如果我们需要更多的采集数据页面,比如几万条数据,这种方式会很慢
多页采集
如果我们直接循环获取页面,这样每个页面都需要访问一次,并且爬取数据,费时费力,这就是我们可以有多种方案来优化速度。
一个。使用curl模拟多线程,一次性抓取所有网页,保存在本地给采集,避免重复请求带来的开销
B.使用 swoole 创建多个线程来执行采集。比如我们去采集10个页面,需要10秒。这时候我们创建了多个线程,同事请求分发。网址,你可以提高我们的速度
c.当然,如果我们对数据要求不高,可以使用第三方软件,比如优采云、优采云,这些工具可以采集更快的拿到需要的数据
笔者这里用的是第一种方法,因为是windows环境,如果swoole的话,windows安装有点麻烦
我使用 ajax 轮询,一次 10 个。比如我们从产品id为1采集
的数据开始
phpcj.php
php
//获取开始采集的id
$start_id = $_POST['start_id'];
$end_id = $start_id+10; //每次加10条
if(empty($start_id) || empty($end_id)){
exit(json_encode(['status'=>0,'msg'=>'参数不正确']));
}
$pdo = new PDO('mysql:host=数据库地址;dbname=数据库名','用户','密码',array(PDO::ATTR_PERSISTENT));
header("Content-Type: text/html; charset=UTF-8");
require("phpQuery.php");
//将要采集的地址全部循环出来
for ($i=$start_id; $i < $end_id; $i++) {
$urls[$i] = 'http://www.rsq111.com/goods.php?id='.$i;
}
//判断当前url是否合法,这里我判断的是第一条
$code = getHeaders(array_shift($urls),true);
if($code != 200){
//如果不合法,返回结束id,重新开始执行
exit(json_encode(['status'=>1,'msg'=>'当前id无商品','end_id'=>$end_id]));
}
$save_to='test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,'w+');
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 设置不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
file_put_contents($save_to, '');
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
file_put_contents($save_to, $data); //将抓取到的野蛮写入到文件中
$data = cj($i);
if ($data) {
$add[$i] = $data;
}
}
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
//将采集成功的数据存入数据库
$sql = '';
if(!empty($add))
{
foreach ($add as $key => $value) {
$title = str_replace("'","",$value['title']);
$category1 = $value['category1'];
$category2 = $value['category2'];
$category3 = $value['category3'];
$price = $value['price'];
$sn = $value['sn'];
$brank = $value['brank'];
$time = $value['time'];
$photo = $value['photo'];
$info_photo = $value['info_photo'];
$cj_id = $end_id;
$sql[] = "('$title','$category1','$category2','$category3','$price','$sn','$brank','$time','$photo','$info_photo','$cj_id')";
}
$sqls =implode(',', $sql);
$add_sql = "INSERT into phpcj (title,category1,category2,category3,price,sn,brank,time,photo,info_photo,cj_id) VALUES ".$sqls;
$res = $pdo->exec($add_sql);
if(!$res) {
//采集未成功,返回id,重新开始采集
exit(json_encode(['status'=>0,'msg'=>'本次采集未成功..','start_id'=>$start_id]));
}else{
//采集成功,将最后一条数据返回,用作下此次执行的开始id
exit(json_encode(['status'=>1,'msg'=>'采集成功,正在进行循环采集..','end_id'=>$end_id]));
}
}
//采集方法
function cj($i)
{
$url = 'http://www.***.com/test.txt'; //页面存取的文本路劲
phpQuery::newDocumentFile($url);
// 分类
$arr_check = pq(".breadcrumb");
foreach ($arr_check as $li) {
$cat = pq($li)->text();
}
if(empty($cat)){
return;
}
$category = explode('>', $cat);
//标题
$h1_check = pq("#name");
$title = pq($h1_check)->text();
//价格
$price_check = pq(".rmbPrice");
$shop_price = [];
foreach ($price_check as $li) {
$shop_price[] = pq($li)->text();
}
$shop_price = array_pop($shop_price);
$shop_price = explode(':', $shop_price);
$price = $shop_price[1];
//参数
$prame_check = pq("#summary1 .dd");
$prame = [];
foreach ($prame_check as $li) {
$prame[] = pq($li)->text();
}
$sn = $prame[0];//货号
if(count($prame) > 2){
$brank = $prame[1];//品牌
$time = $prame[2];//上架时间
}else{
$brank = '无';
$time = $prame[1];//上架时间
}
// 商品图片
$prame_photo_check = pq("#goods_gallery a");
$photo = [];
foreach ($prame_photo_check as $li) {
$src = 'http://www.rsq111.com/'.pq($li)->attr('href');
// $localSrc = 'w/'.md5($src).'.jpg';
// $stream = file_get_contents($src);
// file_put_contents($localSrc,$stream);
// pq($li)->attr('src',$localSrc);
// $photo[] = $localSrc;
$photo[] = $src;
}
$photo =json_encode($photo);
//商品详情图片
$info_photo_check = pq(".detail-content img");
$info_photo = [];
foreach ($info_photo_check as $li) {
$src = 'http://www.rsq111.com/'.pq($li)->attr('src');
// $localSrc = 'w/'.md5($src).'.jpg';
// $stream = file_get_contents($src);
// file_put_contents($localSrc,$stream);
// pq($li)->attr('src',$localSrc);
// $info_photo[] = $localSrc;
$info_photo[] = $src;
}
$info_photo = json_encode($info_photo);
//如果商品没有三级分类,给他赋值为空
if(count($category) < 3){
$category[3] = '';
}
$data = [
'title' => $title,
'category1' => $category[1],
'category2' => $category[2],
'category3' => $category[3],
'price' => $price,
'sn' => $sn,
'brank' => $brank,
'time' => $time,
'photo' => $photo,
'info_photo' =>$info_photo,
'cj_id' => $end_id,
];
return $data;
}
//判断url是否合法
function getHeaders($url,$data=FALSE){
$_headers = get_headers($url,1);
if( !$data ){return $_headers;}
$curl = curl_init();
curl_setopt($curl,CURLOPT_URL,$url);//获取内容url
curl_setopt($curl,CURLOPT_HEADER,1);//获取http头信息
curl_setopt($curl,CURLOPT_NOBODY,1);//不返回html的body信息
curl_setopt($curl,CURLOPT_RETURNTRANSFER,1);//返回数据流,不直接输出
curl_setopt($curl,CURLOPT_TIMEOUT,30); //超时时长,单位秒
curl_exec($curl);
$rtn= curl_getinfo($curl,CURLINFO_HTTP_CODE);
curl_close($curl);
return $rtn;
}
这样我们就完成了页面采集的循环
前台代码,使用ajax循环请求(如果使用服务器定时任务,需要注意,对于采集不成功的判断,本节我手动重新填id,因为采集因素不可控,可能是对方页面错了,对方数据库错了,但是我们还是可以正常访问的,所以需要把采集失败或者把采集保留在某个id上,需要加上时效判断。超过多久,默认是当前数据采集不成功,那么下一轮采集就会开始,可以是当前id+1,或者其他规则,反正跳过这个id)
"en">
"UTF-8">
Document
"text" name="start_id" id="start_id" placeholder="采集开始id">
"button" id="btn" value="开始采集">
"zhi">
"text" id="ids" placeholder="采集返回成功条数"> 查看全部
使用php采集网页数据一般有多种方法,有时候东西以采集
php采集网页数据的使用方式一般有很多种。有时我们使用正则去采集页面,但是当我们需要采集有一个很大很大的页面时,就会严重浪费我们的CPU。到时候我们可以用phpQuer来做采集。如果你不了解 phpQuery,你可以去看看这是什么。
以采集此网站为例
假设我们需要采集commodity category Name Price Item No Shelf Time Product Picture Detail Picture
1.首先下载phpQuery类phpQuery.php
2.接下来我们可以创建一个cj.php类
单页采集
php
header("Content-Type: text/html; charset=UTF-8");
require("phpQuery.php"); //引入类
//检测当前链接是否合法
$url = 'http://www.rsq111.com/goods.php?id=15663';
$header_info=getHeaders($url,true);
if ($header_info != 200) {
die;
}
phpQuery::newDocumentFile($url); //获取网页对象内容
//pq() == $(this)
// 商品分类
$arr_check = pq(".breadcrumb");
foreach ($arr_check as $li) {
$cat = pq($li)->text();
}
$category = explode('>', $cat);
//商品标题
$h1_check = pq("#name");
$title = pq($h1_check)->text();
//商品价格
$price_check = pq(".rmbPrice");
$shop_price = [];
foreach ($price_check as $li) {
$shop_price[] = pq($li)->text();
}
$shop_price = array_pop($shop_price);
$shop_price = explode(':', $shop_price);
$price = $shop_price[1];
//商品参数
$prame_check = pq("#summary1 .dd");
$prame = [];
foreach ($prame_check as $li) {
$prame[] = pq($li)->text();
}
$sn = $prame[0];//货号
$brank = $prame[1];//品牌
$time = $prame[2];//上架时间
// 商品图片
$prame_photo_check = pq("#goods_gallery a");
$photo = [];
foreach ($prame_photo_check as $li) {
$src = 'http://www.rsq111.com/'.pq($li)->attr('href');//图片路径
//注释代码为保存图片路劲,下载图片到本地
$localSrc = 'w/'.md5($src).'.jpg';
// $stream = file_get_contents($src);
// file_put_contents($localSrc,$stream);
// pq($li)->attr('src',$localSrc);
$photo[] = $localSrc;
}
//商品详情图片
$info_photo_check = pq(".detail-content img");
$info_photo = [];
foreach ($info_photo_check as $li) {
$src = 'http://www.rsq111.com/'.pq($li)->attr('src');
$localSrc = 'w/'.md5($src).'.jpg';
// $stream = file_get_contents($src);
// file_put_contents($localSrc,$stream);
// pq($li)->attr('src',$localSrc);
$info_photo[] = $localSrc;
}
$data= [
'title' => $title,
'category1' => $category[1],
'category2' => $category[2],
'category3' => $category[3],
'price' => $price,
'sn' => $sn,
'brank' => $brank,
'time' => $time,
'photo' => $photo,
'info_photo' =>$info_photo,
];
}
echo "";
print_r($data);
//检测url是否合法
function getHeaders($url,$data=FALSE){
$_headers = get_headers($url,1);
if( !$data ){return $_headers;}
$curl = curl_init();
curl_setopt($curl,CURLOPT_URL,$url);//获取内容url
curl_setopt($curl,CURLOPT_HEADER,1);//获取http头信息
curl_setopt($curl,CURLOPT_NOBODY,1);//不返回html的body信息
curl_setopt($curl,CURLOPT_RETURNTRANSFER,1);//返回数据流,不直接输出
curl_setopt($curl,CURLOPT_TIMEOUT,30); //超时时长,单位秒
curl_exec($curl);
$rtn= curl_getinfo($curl,CURLINFO_HTTP_CODE);
curl_close($curl);
return $rtn;
}
这种情况下,可以采集到这个页面的数据,但是如果我们需要更多的采集数据页面,比如几万条数据,这种方式会很慢
多页采集
如果我们直接循环获取页面,这样每个页面都需要访问一次,并且爬取数据,费时费力,这就是我们可以有多种方案来优化速度。
一个。使用curl模拟多线程,一次性抓取所有网页,保存在本地给采集,避免重复请求带来的开销
B.使用 swoole 创建多个线程来执行采集。比如我们去采集10个页面,需要10秒。这时候我们创建了多个线程,同事请求分发。网址,你可以提高我们的速度
c.当然,如果我们对数据要求不高,可以使用第三方软件,比如优采云、优采云,这些工具可以采集更快的拿到需要的数据
笔者这里用的是第一种方法,因为是windows环境,如果swoole的话,windows安装有点麻烦
我使用 ajax 轮询,一次 10 个。比如我们从产品id为1采集
的数据开始
phpcj.php
php
//获取开始采集的id
$start_id = $_POST['start_id'];
$end_id = $start_id+10; //每次加10条
if(empty($start_id) || empty($end_id)){
exit(json_encode(['status'=>0,'msg'=>'参数不正确']));
}
$pdo = new PDO('mysql:host=数据库地址;dbname=数据库名','用户','密码',array(PDO::ATTR_PERSISTENT));
header("Content-Type: text/html; charset=UTF-8");
require("phpQuery.php");
//将要采集的地址全部循环出来
for ($i=$start_id; $i < $end_id; $i++) {
$urls[$i] = 'http://www.rsq111.com/goods.php?id='.$i;
}
//判断当前url是否合法,这里我判断的是第一条
$code = getHeaders(array_shift($urls),true);
if($code != 200){
//如果不合法,返回结束id,重新开始执行
exit(json_encode(['status'=>1,'msg'=>'当前id无商品','end_id'=>$end_id]));
}
$save_to='test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,'w+');
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 设置不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
file_put_contents($save_to, '');
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
file_put_contents($save_to, $data); //将抓取到的野蛮写入到文件中
$data = cj($i);
if ($data) {
$add[$i] = $data;
}
}
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
//将采集成功的数据存入数据库
$sql = '';
if(!empty($add))
{
foreach ($add as $key => $value) {
$title = str_replace("'","",$value['title']);
$category1 = $value['category1'];
$category2 = $value['category2'];
$category3 = $value['category3'];
$price = $value['price'];
$sn = $value['sn'];
$brank = $value['brank'];
$time = $value['time'];
$photo = $value['photo'];
$info_photo = $value['info_photo'];
$cj_id = $end_id;
$sql[] = "('$title','$category1','$category2','$category3','$price','$sn','$brank','$time','$photo','$info_photo','$cj_id')";
}
$sqls =implode(',', $sql);
$add_sql = "INSERT into phpcj (title,category1,category2,category3,price,sn,brank,time,photo,info_photo,cj_id) VALUES ".$sqls;
$res = $pdo->exec($add_sql);
if(!$res) {
//采集未成功,返回id,重新开始采集
exit(json_encode(['status'=>0,'msg'=>'本次采集未成功..','start_id'=>$start_id]));
}else{
//采集成功,将最后一条数据返回,用作下此次执行的开始id
exit(json_encode(['status'=>1,'msg'=>'采集成功,正在进行循环采集..','end_id'=>$end_id]));
}
}
//采集方法
function cj($i)
{
$url = 'http://www.***.com/test.txt'; //页面存取的文本路劲
phpQuery::newDocumentFile($url);
// 分类
$arr_check = pq(".breadcrumb");
foreach ($arr_check as $li) {
$cat = pq($li)->text();
}
if(empty($cat)){
return;
}
$category = explode('>', $cat);
//标题
$h1_check = pq("#name");
$title = pq($h1_check)->text();
//价格
$price_check = pq(".rmbPrice");
$shop_price = [];
foreach ($price_check as $li) {
$shop_price[] = pq($li)->text();
}
$shop_price = array_pop($shop_price);
$shop_price = explode(':', $shop_price);
$price = $shop_price[1];
//参数
$prame_check = pq("#summary1 .dd");
$prame = [];
foreach ($prame_check as $li) {
$prame[] = pq($li)->text();
}
$sn = $prame[0];//货号
if(count($prame) > 2){
$brank = $prame[1];//品牌
$time = $prame[2];//上架时间
}else{
$brank = '无';
$time = $prame[1];//上架时间
}
// 商品图片
$prame_photo_check = pq("#goods_gallery a");
$photo = [];
foreach ($prame_photo_check as $li) {
$src = 'http://www.rsq111.com/'.pq($li)->attr('href');
// $localSrc = 'w/'.md5($src).'.jpg';
// $stream = file_get_contents($src);
// file_put_contents($localSrc,$stream);
// pq($li)->attr('src',$localSrc);
// $photo[] = $localSrc;
$photo[] = $src;
}
$photo =json_encode($photo);
//商品详情图片
$info_photo_check = pq(".detail-content img");
$info_photo = [];
foreach ($info_photo_check as $li) {
$src = 'http://www.rsq111.com/'.pq($li)->attr('src');
// $localSrc = 'w/'.md5($src).'.jpg';
// $stream = file_get_contents($src);
// file_put_contents($localSrc,$stream);
// pq($li)->attr('src',$localSrc);
// $info_photo[] = $localSrc;
$info_photo[] = $src;
}
$info_photo = json_encode($info_photo);
//如果商品没有三级分类,给他赋值为空
if(count($category) < 3){
$category[3] = '';
}
$data = [
'title' => $title,
'category1' => $category[1],
'category2' => $category[2],
'category3' => $category[3],
'price' => $price,
'sn' => $sn,
'brank' => $brank,
'time' => $time,
'photo' => $photo,
'info_photo' =>$info_photo,
'cj_id' => $end_id,
];
return $data;
}
//判断url是否合法
function getHeaders($url,$data=FALSE){
$_headers = get_headers($url,1);
if( !$data ){return $_headers;}
$curl = curl_init();
curl_setopt($curl,CURLOPT_URL,$url);//获取内容url
curl_setopt($curl,CURLOPT_HEADER,1);//获取http头信息
curl_setopt($curl,CURLOPT_NOBODY,1);//不返回html的body信息
curl_setopt($curl,CURLOPT_RETURNTRANSFER,1);//返回数据流,不直接输出
curl_setopt($curl,CURLOPT_TIMEOUT,30); //超时时长,单位秒
curl_exec($curl);
$rtn= curl_getinfo($curl,CURLINFO_HTTP_CODE);
curl_close($curl);
return $rtn;
}
这样我们就完成了页面采集的循环
前台代码,使用ajax循环请求(如果使用服务器定时任务,需要注意,对于采集不成功的判断,本节我手动重新填id,因为采集因素不可控,可能是对方页面错了,对方数据库错了,但是我们还是可以正常访问的,所以需要把采集失败或者把采集保留在某个id上,需要加上时效判断。超过多久,默认是当前数据采集不成功,那么下一轮采集就会开始,可以是当前id+1,或者其他规则,反正跳过这个id)
"en">
"UTF-8">
Document
"text" name="start_id" id="start_id" placeholder="采集开始id">
"button" id="btn" value="开始采集">
"zhi">
"text" id="ids" placeholder="采集返回成功条数">
第一步:我们先复制一份原来的规则做模板(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-08-09 01:21
第 1 步:让我们复制原创规则作为模板。比如我今天演示的采集站点是一个叫feiku的小说站点,那么我将我复制的模板规则的副本命名为dhabc。 xml 这个主要是为了方便记忆。第二步:我们在采集器中运行规则管理工具,打开后加载,我们只是将其命名为dhabc。 xml XML文件第三步:开始正式写规则RULEID(规则编号)这个任意GetSiteName(站点名称)这里我们写8E小说GetSiteCharset(站点代码)这里我们打开找到charset=这个=后面的数字就是我们需要的站点代码我们找到的代码是gb2312 GetSiteUrl(站点地址)。不用说,写NovelSearchUrl(网站搜索地址)。这个地址是根据每个网站程序的不同得到的,但是有一个通用的方法是通过抓包来获取你想要的内容。虽然说是抓包得到的,但是你怎么知道得到的就是我们想要的呢?看看我的操作。首先,我们运行数据包工具并选择 IEXPLORE。 EXE进程最好只打开一个网站,也就是只打开你要写规则的网站,保证进程中只有一个IEXPLORE。
EXE 进程。在这里我们可以看到提交的地址是/book/search。 aspx 我们结合得到的地址 SearchKey=%C1%AB%BB%A8&SearchClass=1&SeaButton。 x=26&SeaButton。 y=10 但是对我们有用的是 SearchKey=%C1%AB%BB%A8&SearchClass=1 这里得到的NovelSearchData(搜索提交)这一段,就是用来把这一段改成我们想要的代码。一段%C1%AB%BB%A8换成{SearchKey},表示搜索提交内容的完整代码为SearchKey={SearchKey}&SearchClass=1 然后我们测试一下是否正确。经过测试,我们得到的内容是正确的NovelListUrl(站点最新列表地址)这个我就不说了,因为每个站点不一样。需要自己找FEIKU NovelList_GetNovelKey(从最新列表中获取小说编号。在此规则中,可以同时获取书名。书名是手动获取的。如果要使用手动模式,一定要拿到书名,否则手动模式无法使用)我们打开这个地址查看源文件。当我们写这个规则时,我们找到了我们想要获取内容的地方。比如我们打开地址看到我想获取内容的第一本小说的名字是李迪承德。我们在源文件中找到了我们用来编写规则的代码。实际上,它不是很多。我写规则的原则是先存后存,也就是代码越短越好。除非万不得已,href="越短越好。
8c8e。 com/Book/149539/索引。 html"target="_blank"> 让我们把这一段改成 href="。 8c8e。 com/Book/(\d*)/索引。 html"target="_blank">(.+?) 表示小说名经过测试无误。NovelUrl(小说信息页地址)很容易找到,只要点击小说,比如我们可以看到这本小说我们改一下,随意改一下中间的数字,比如我们得到的错误标记就是没有找到那个编号的书信息!10.NovelName(查看源代码到获取小说名称,我们可以从固定模式开始,比如我们刚刚打开它,在这本小说中,我们看到他的固定小说名称格式是“Landing into a magic”,然后我们找到“Landing into a magic”源代码中的magic”。我们得到的内容是
“站点成恶魔”
让我们改变这一段
"(.+?)"
以下NovelAuthor(获取小说作者) LagerSort(获取小说类别) SmallSort(获取小说类别) NovelIntro(获取小说简介) NovelKeyword(获取小说主角(关键词)) NovelDegree(获取小说封面) (获取小说) (封面) 我就不演示了,这些和上面获取小说名称的方法是一样的,所以叫做One-pass Belden。有时候有些内容你不想要使用,因为格式不固定。有些内容只能先获取,然后用filter函数过滤掉filter的用途。后面,11.NovelInfo_GetNovelPubKey(获取小说公共目录地址page) 这个地址的获取方法和上面一样,这里就不解释 12 PubIndexUrl (公共目录页面的地址)) 来解释一下这个的用法。这个一般在知道采集目标站的动态地址时使用。如果不知道对方的动态地址,知道动态路径{NovelKey}/Index .aspx13.PubVolumeSplit(拆分子卷)这个拆分子卷有什么可写的,就在这写{NovelPubKey}。需要注意的是,如果拆分子卷的规律性不是那么可能对后面的章节名称产生很大的影响。这里我们得到了分割部分的代码。根据我的经验,找到第一个子卷和下面的子卷,看看它们有什么共同点。当我们分析本目录章节中的源代码时,我们可以看到它们有一个共同点。让我们解释一下这一段。
追求力量
\s* \s* 表示匹配任何白色字符,包括空格、制表符、分页符等,也就是说,无论它们之间有多少个空格,都可以用来表示14 PubVolumeName(获取卷名) 要获取准确的子卷名,上面拆分部分的规律必须是正确的。一般拆分部分的子卷名称在块的顶部。我们说明分割部分使用
追求力量
如果你注意这一段,你会发现它收录了我们这一步要获取的子卷名。修改代码
(.+?)
\s* 在我们的测试下,我们可以正常获取子卷,但是如果有这些,我们通常会在过滤规则中将其过滤掉。 PubChapterName(获取章节名) 我们用一段话来说明强大的驯服方法。对于这种时间、日期和更新字数,我们直接忽略,因为这些不是我们想要的。有人问我为什么在这里没用。 () 把它附在这里让我告诉你我们得到的内容就是()中的内容。如果它不是你想要的,但在编写规则时必须使用它,我们可以稍微改变表达式。我们把上面的段落改一下,改成表达式(.+?)就可以正常获取内容了。大家是不是看着这个规则有点别扭?这是因为中间有一个换行符。我没有更改代码。让我们使用\s*。这意味着一个换行符。我们修改后的代码是 (.+?) 现在好点了吗?经过测试,获取内容描述也是正常的。没问题。 16. PubChapter_GetChapterKey(获取章节地址(Chapter Number)) 这里说明一下,下面的PubContentUrl(章节内容页面地址)中使用了这个中的章节号。一般用于知道目标站的动态地址。当目标站未知时,一般不使用静态地址。所以这里我们需要获取章节地址解析(.
+?) 既然这里是获取章节地址,那为什么还要使用章节名称呢?这主要是为了避免获取的章节名称和获取的章节地址不匹配。这是下一章编号的说明。不麻烦,稍微改一下(.+?)改成这个,我们测试一下看看,改一下就可以得到数了。这个数字只有在知道目标站的动态地址的情况下才能获得。最多使用17.PubContentUrl(章节内容页面地址)在上面得到的章节地址中有说明。这是要知道如何使用目标站。 149539 这是新号码。这里我们用{NovelKey}代替3790336 这是在PubChapter_GetChapterKey中获得的章节编号,我们用{ChapterKey}代替组合为{NovelKey}/{ChapterKey}。 ASPX 是我们的动态章节地址。记住,前提是要知道对方的动态地址。如果你不知道对方的动态地址,那么我们这里写的PubContentUrl(章节内容页面地址)就是{ChapterKey} 18. PubContentText(获取章节内容) 这种获取方式和获取章节名称是一样的。这个就不解释了。现在我们解释过滤的用法。这很简单。几个地方是介绍章节名和卷名以及获取的小说章节内容,但是章节内容是替换功能。介绍章节名和卷名暂无替换规则。比如我们获取的卷名是text(),但是我们呢,在获取子卷的时候,只想获取到text的两个词,所以我们这里使用了过滤器。过滤器的格式为过滤后的内容|过滤内容中间使用过滤内容|将介绍章节名、过滤子卷名分开,例如据说我们在获得作者姓名时,书的内容中多了一条内容。作者因他的href="/Author/WB/149539而聚散随风。
html">有的有的没有,所以我们不直接使用 book author\s*(.+?) 来先获取内容。从规则上,我们得到的内容是 href="/作者/WB /149539。 html">随风集散,本段我们要保留的内容:随风集散,我们这样做,因为它是固定的,所以只需添加href="/Author/WB/149539。 html">这是一个改动,我们改一下,改成常规格式 href="/Author/WB/\d*. html">就是这样。让我们添加过滤器 href="/Author/WB/\d*\。 html">|内容是这样的,现在说一下章节内容的替换,章节内容替换规则每行替换一个,格式如下,需要替换的内容用结果替换
这意味着过滤
这意味着替换。例如,本站有一张“飞酷”字样的图片。我们应该做什么?这里我们使用替换。
替换内容只对章节内容有用。这是专用于章节内容。有人问我为什么采集某个站总是空章。可能出现空章的原因可能是目标站刚重启网站你的采集IP被屏蔽了等等……这里我想说明一下,空章是图片章节造成的。 采集器的采集内容的操作流程先检查你采集的章节是不是图片章节?如果你的PubContentImages(从章节内容中提取图片)的规律不正确,如果你没有获取到图片章节内容,你会检查你的采集文字内容PubContentText(获取章节内容)。如果PubContentImages(从章节内容中提取图片)PubContentText(获取章节内容)没有匹配的内容,那么就会出现我们上面说的空章节的原因。既然规则都写好了,我们来测试一下是否可以正常获取规则。获取内容测试表明,我们编写的规则可以正常获取到想要的内容 查看全部
第一步:我们先复制一份原来的规则做模板(图)
第 1 步:让我们复制原创规则作为模板。比如我今天演示的采集站点是一个叫feiku的小说站点,那么我将我复制的模板规则的副本命名为dhabc。 xml 这个主要是为了方便记忆。第二步:我们在采集器中运行规则管理工具,打开后加载,我们只是将其命名为dhabc。 xml XML文件第三步:开始正式写规则RULEID(规则编号)这个任意GetSiteName(站点名称)这里我们写8E小说GetSiteCharset(站点代码)这里我们打开找到charset=这个=后面的数字就是我们需要的站点代码我们找到的代码是gb2312 GetSiteUrl(站点地址)。不用说,写NovelSearchUrl(网站搜索地址)。这个地址是根据每个网站程序的不同得到的,但是有一个通用的方法是通过抓包来获取你想要的内容。虽然说是抓包得到的,但是你怎么知道得到的就是我们想要的呢?看看我的操作。首先,我们运行数据包工具并选择 IEXPLORE。 EXE进程最好只打开一个网站,也就是只打开你要写规则的网站,保证进程中只有一个IEXPLORE。
EXE 进程。在这里我们可以看到提交的地址是/book/search。 aspx 我们结合得到的地址 SearchKey=%C1%AB%BB%A8&SearchClass=1&SeaButton。 x=26&SeaButton。 y=10 但是对我们有用的是 SearchKey=%C1%AB%BB%A8&SearchClass=1 这里得到的NovelSearchData(搜索提交)这一段,就是用来把这一段改成我们想要的代码。一段%C1%AB%BB%A8换成{SearchKey},表示搜索提交内容的完整代码为SearchKey={SearchKey}&SearchClass=1 然后我们测试一下是否正确。经过测试,我们得到的内容是正确的NovelListUrl(站点最新列表地址)这个我就不说了,因为每个站点不一样。需要自己找FEIKU NovelList_GetNovelKey(从最新列表中获取小说编号。在此规则中,可以同时获取书名。书名是手动获取的。如果要使用手动模式,一定要拿到书名,否则手动模式无法使用)我们打开这个地址查看源文件。当我们写这个规则时,我们找到了我们想要获取内容的地方。比如我们打开地址看到我想获取内容的第一本小说的名字是李迪承德。我们在源文件中找到了我们用来编写规则的代码。实际上,它不是很多。我写规则的原则是先存后存,也就是代码越短越好。除非万不得已,href="越短越好。
8c8e。 com/Book/149539/索引。 html"target="_blank"> 让我们把这一段改成 href="。 8c8e。 com/Book/(\d*)/索引。 html"target="_blank">(.+?) 表示小说名经过测试无误。NovelUrl(小说信息页地址)很容易找到,只要点击小说,比如我们可以看到这本小说我们改一下,随意改一下中间的数字,比如我们得到的错误标记就是没有找到那个编号的书信息!10.NovelName(查看源代码到获取小说名称,我们可以从固定模式开始,比如我们刚刚打开它,在这本小说中,我们看到他的固定小说名称格式是“Landing into a magic”,然后我们找到“Landing into a magic”源代码中的magic”。我们得到的内容是
“站点成恶魔”
让我们改变这一段
"(.+?)"
以下NovelAuthor(获取小说作者) LagerSort(获取小说类别) SmallSort(获取小说类别) NovelIntro(获取小说简介) NovelKeyword(获取小说主角(关键词)) NovelDegree(获取小说封面) (获取小说) (封面) 我就不演示了,这些和上面获取小说名称的方法是一样的,所以叫做One-pass Belden。有时候有些内容你不想要使用,因为格式不固定。有些内容只能先获取,然后用filter函数过滤掉filter的用途。后面,11.NovelInfo_GetNovelPubKey(获取小说公共目录地址page) 这个地址的获取方法和上面一样,这里就不解释 12 PubIndexUrl (公共目录页面的地址)) 来解释一下这个的用法。这个一般在知道采集目标站的动态地址时使用。如果不知道对方的动态地址,知道动态路径{NovelKey}/Index .aspx13.PubVolumeSplit(拆分子卷)这个拆分子卷有什么可写的,就在这写{NovelPubKey}。需要注意的是,如果拆分子卷的规律性不是那么可能对后面的章节名称产生很大的影响。这里我们得到了分割部分的代码。根据我的经验,找到第一个子卷和下面的子卷,看看它们有什么共同点。当我们分析本目录章节中的源代码时,我们可以看到它们有一个共同点。让我们解释一下这一段。
追求力量
\s* \s* 表示匹配任何白色字符,包括空格、制表符、分页符等,也就是说,无论它们之间有多少个空格,都可以用来表示14 PubVolumeName(获取卷名) 要获取准确的子卷名,上面拆分部分的规律必须是正确的。一般拆分部分的子卷名称在块的顶部。我们说明分割部分使用
追求力量
如果你注意这一段,你会发现它收录了我们这一步要获取的子卷名。修改代码
(.+?)
\s* 在我们的测试下,我们可以正常获取子卷,但是如果有这些,我们通常会在过滤规则中将其过滤掉。 PubChapterName(获取章节名) 我们用一段话来说明强大的驯服方法。对于这种时间、日期和更新字数,我们直接忽略,因为这些不是我们想要的。有人问我为什么在这里没用。 () 把它附在这里让我告诉你我们得到的内容就是()中的内容。如果它不是你想要的,但在编写规则时必须使用它,我们可以稍微改变表达式。我们把上面的段落改一下,改成表达式(.+?)就可以正常获取内容了。大家是不是看着这个规则有点别扭?这是因为中间有一个换行符。我没有更改代码。让我们使用\s*。这意味着一个换行符。我们修改后的代码是 (.+?) 现在好点了吗?经过测试,获取内容描述也是正常的。没问题。 16. PubChapter_GetChapterKey(获取章节地址(Chapter Number)) 这里说明一下,下面的PubContentUrl(章节内容页面地址)中使用了这个中的章节号。一般用于知道目标站的动态地址。当目标站未知时,一般不使用静态地址。所以这里我们需要获取章节地址解析(.
+?) 既然这里是获取章节地址,那为什么还要使用章节名称呢?这主要是为了避免获取的章节名称和获取的章节地址不匹配。这是下一章编号的说明。不麻烦,稍微改一下(.+?)改成这个,我们测试一下看看,改一下就可以得到数了。这个数字只有在知道目标站的动态地址的情况下才能获得。最多使用17.PubContentUrl(章节内容页面地址)在上面得到的章节地址中有说明。这是要知道如何使用目标站。 149539 这是新号码。这里我们用{NovelKey}代替3790336 这是在PubChapter_GetChapterKey中获得的章节编号,我们用{ChapterKey}代替组合为{NovelKey}/{ChapterKey}。 ASPX 是我们的动态章节地址。记住,前提是要知道对方的动态地址。如果你不知道对方的动态地址,那么我们这里写的PubContentUrl(章节内容页面地址)就是{ChapterKey} 18. PubContentText(获取章节内容) 这种获取方式和获取章节名称是一样的。这个就不解释了。现在我们解释过滤的用法。这很简单。几个地方是介绍章节名和卷名以及获取的小说章节内容,但是章节内容是替换功能。介绍章节名和卷名暂无替换规则。比如我们获取的卷名是text(),但是我们呢,在获取子卷的时候,只想获取到text的两个词,所以我们这里使用了过滤器。过滤器的格式为过滤后的内容|过滤内容中间使用过滤内容|将介绍章节名、过滤子卷名分开,例如据说我们在获得作者姓名时,书的内容中多了一条内容。作者因他的href="/Author/WB/149539而聚散随风。
html">有的有的没有,所以我们不直接使用 book author\s*(.+?) 来先获取内容。从规则上,我们得到的内容是 href="/作者/WB /149539。 html">随风集散,本段我们要保留的内容:随风集散,我们这样做,因为它是固定的,所以只需添加href="/Author/WB/149539。 html">这是一个改动,我们改一下,改成常规格式 href="/Author/WB/\d*. html">就是这样。让我们添加过滤器 href="/Author/WB/\d*\。 html">|内容是这样的,现在说一下章节内容的替换,章节内容替换规则每行替换一个,格式如下,需要替换的内容用结果替换
这意味着过滤
这意味着替换。例如,本站有一张“飞酷”字样的图片。我们应该做什么?这里我们使用替换。
替换内容只对章节内容有用。这是专用于章节内容。有人问我为什么采集某个站总是空章。可能出现空章的原因可能是目标站刚重启网站你的采集IP被屏蔽了等等……这里我想说明一下,空章是图片章节造成的。 采集器的采集内容的操作流程先检查你采集的章节是不是图片章节?如果你的PubContentImages(从章节内容中提取图片)的规律不正确,如果你没有获取到图片章节内容,你会检查你的采集文字内容PubContentText(获取章节内容)。如果PubContentImages(从章节内容中提取图片)PubContentText(获取章节内容)没有匹配的内容,那么就会出现我们上面说的空章节的原因。既然规则都写好了,我们来测试一下是否可以正常获取规则。获取内容测试表明,我们编写的规则可以正常获取到想要的内容
采集规则 采集 data-src Excel教程Excel函数Excel制作表格Excel2010/9/28
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-08-04 07:23
采集scene
打开B站详情页,采集video详情页数据。
示例网址:
采集Field
标题、时长、发布时间、总播放次数、总发布次数、发布者、币种、采集、点赞数、分享数、视频介绍、视频标签、评论数
点击查看高清大图,下图同理。
采集Result
采集 结果可以导出为Excel、CSV、HTML、数据库等格式。导出到 Excel 示例:
教程说明
本文制作时间:2020/9/28 优采云版本:V8.1.22
如因网页改版导致网址或步骤无效,无法采集到目标数据,请联系官方客服,我们会及时更正。
采集Steps
步骤一、打开网页
步骤二、设置页面滚动
步骤三、提取数据
步骤四、rule优化
步骤五、Start采集
具体步骤如下:
步骤一、打开网页
1、打开网页
点击首页左上角的【新建】-【自定义任务】。 URL输入界面默认为【手动输入】。将复制的一批相似网址粘贴到网址输入框中,点击【保存网址】,优采云内置的浏览器会自动打开网页。
同时可以看到[loop-open web page]这一步已经在过程中自动创建了。
示例中输入的网址为:
特别说明:
一个。手动输入的 URL 数量不应超过 10,000。如果url超过10000个,请选择【从文件导入】。详情请参考教程网址输入升级
B.打开网页后,如果开始启动【自动识别】,请点击【不再自动识别】或【取消识别】将其关闭。因为本文不适合使用【自动识别】。
c. 【自动识别】适用于自动识别网页列表、滚动、翻页。识别成功后可以直接启动采集获取数据。详情请点击查看【自动识别】教程
步骤二、设置滚动
选择【打开网页】设置,勾选【页面加载后向下滚动】,滚动方式为【直接滚动到底部】,滚动次数为3次,每次间隔1s。
特别说明:
一个。设置中的滚动次数和时间间隔,请根据采集要求和网页加载条件进行设置,它们不是一成不变的,详情请点击查看处理滚动加载数据的网页教程
步骤三、提取数据
1、采集Field
采集Title、时长、发布时间、总播放次数、总弹数、发布者、币种、采集、点赞、分享、视频介绍、视频标签、评论等字段。
2、编辑字段
在【当前数据预览】面板中,依次修改必填字段的字段名称。
3、设置字段
直接抓取的“股数”字段有问题,需要对字段进行格式化。
进入【提取数据】步骤,选择【格式化数据】→【添加步骤】→【替换】→将【动态微博...分享】替换为【空】,留下我们要分享的版块号。
最后点击【应用】保存。
特别说明:
一个。什么是数据格式化?数据采集下来后,有时格式不是我们想要的,或者我们只是想从一段数据中提取特定的数据,可以通过优采云的【格式数据】功能来实现。详情请点击查看数据格式化教程。
4、Modify field Xpath
为了准确地采集到达所有相似页面的[publisher]字段,我们需要修改这个字段的XPath。
进入【提取数据】设置页面,找到【发布者】字段,点击
按钮,进入【自定义定位元素方法】设置页面,修改XPath为://div[@class="name"]/a[1],然后点击【应用】保存。
步骤四、rule优化
等待5s-10s后执行[循环URL]、[循环中打开网页]、[循环翻页]、[循环列表]、[提取列表数据]。
【点击翻页】设置等待3s执行,Ajax加载超时7s,点击【Apply】保存。
步骤五、Start采集
1、 单击 [采集] 和 [启动本地采集]。启动优采云后自动采集数据。
特别说明:
一个。 【本地采集】为采集使用自己的电脑,【云采集】使用优采云采集提供的云服务器,点击查看本地采集与云采集详细解释。
2、采集 完成后,选择合适的导出方式导出数据。支持导出到 Excel、CSV、HTML、数据库等。这里导出到 Excel。数据示例:
查看全部
采集规则 采集 data-src Excel教程Excel函数Excel制作表格Excel2010/9/28
采集scene
打开B站详情页,采集video详情页数据。
示例网址:
采集Field
标题、时长、发布时间、总播放次数、总发布次数、发布者、币种、采集、点赞数、分享数、视频介绍、视频标签、评论数
点击查看高清大图,下图同理。
采集Result
采集 结果可以导出为Excel、CSV、HTML、数据库等格式。导出到 Excel 示例:
教程说明
本文制作时间:2020/9/28 优采云版本:V8.1.22
如因网页改版导致网址或步骤无效,无法采集到目标数据,请联系官方客服,我们会及时更正。
采集Steps
步骤一、打开网页
步骤二、设置页面滚动
步骤三、提取数据
步骤四、rule优化
步骤五、Start采集
具体步骤如下:
步骤一、打开网页
1、打开网页
点击首页左上角的【新建】-【自定义任务】。 URL输入界面默认为【手动输入】。将复制的一批相似网址粘贴到网址输入框中,点击【保存网址】,优采云内置的浏览器会自动打开网页。
同时可以看到[loop-open web page]这一步已经在过程中自动创建了。
示例中输入的网址为:
特别说明:
一个。手动输入的 URL 数量不应超过 10,000。如果url超过10000个,请选择【从文件导入】。详情请参考教程网址输入升级
B.打开网页后,如果开始启动【自动识别】,请点击【不再自动识别】或【取消识别】将其关闭。因为本文不适合使用【自动识别】。
c. 【自动识别】适用于自动识别网页列表、滚动、翻页。识别成功后可以直接启动采集获取数据。详情请点击查看【自动识别】教程
步骤二、设置滚动
选择【打开网页】设置,勾选【页面加载后向下滚动】,滚动方式为【直接滚动到底部】,滚动次数为3次,每次间隔1s。
特别说明:
一个。设置中的滚动次数和时间间隔,请根据采集要求和网页加载条件进行设置,它们不是一成不变的,详情请点击查看处理滚动加载数据的网页教程
步骤三、提取数据
1、采集Field
采集Title、时长、发布时间、总播放次数、总弹数、发布者、币种、采集、点赞、分享、视频介绍、视频标签、评论等字段。
2、编辑字段
在【当前数据预览】面板中,依次修改必填字段的字段名称。
3、设置字段
直接抓取的“股数”字段有问题,需要对字段进行格式化。
进入【提取数据】步骤,选择【格式化数据】→【添加步骤】→【替换】→将【动态微博...分享】替换为【空】,留下我们要分享的版块号。
最后点击【应用】保存。
特别说明:
一个。什么是数据格式化?数据采集下来后,有时格式不是我们想要的,或者我们只是想从一段数据中提取特定的数据,可以通过优采云的【格式数据】功能来实现。详情请点击查看数据格式化教程。
4、Modify field Xpath
为了准确地采集到达所有相似页面的[publisher]字段,我们需要修改这个字段的XPath。
进入【提取数据】设置页面,找到【发布者】字段,点击
按钮,进入【自定义定位元素方法】设置页面,修改XPath为://div[@class="name"]/a[1],然后点击【应用】保存。
步骤四、rule优化
等待5s-10s后执行[循环URL]、[循环中打开网页]、[循环翻页]、[循环列表]、[提取列表数据]。
【点击翻页】设置等待3s执行,Ajax加载超时7s,点击【Apply】保存。
步骤五、Start采集
1、 单击 [采集] 和 [启动本地采集]。启动优采云后自动采集数据。
特别说明:
一个。 【本地采集】为采集使用自己的电脑,【云采集】使用优采云采集提供的云服务器,点击查看本地采集与云采集详细解释。
2、采集 完成后,选择合适的导出方式导出数据。支持导出到 Excel、CSV、HTML、数据库等。这里导出到 Excel。数据示例:
zabbix的trigger数据采集规则及解决办法(二)——zabbix
采集交流 • 优采云 发表了文章 • 0 个评论 • 382 次浏览 • 2021-08-04 07:21
一、zabbix 的物品数据采集
1、数据采集是zabbix的基础,也是监控的基础。目前,它可以支持主动和被动采集 模式。主动模式定义为:客户端主动上报数据给服务器,被动模式定义为:服务器给客户端采集数据。
2、大家经常使用主动采集模式。除了zabbix自带的常见采集items外,还可以通过自定义采集items来扩展active采集方法。例如,如果需要对系统的全过程做语义监控功能,可以编写脚本,通过自定义采集项来获取脚本执行的结果。
3、 有时候部署代理比较麻烦,可以直接使用zabbix trapper方法:被监控主机主动向zabbix server发送数据,通常可以应用于程序内部的异常消息采集 例如,如果程序内部出现异常,抛出的异常消息可以通过trap方式直接发送到zabbix-server,通过trigger产生事件,通过action发送告警。
总结:总体来说zabbix对采集类型的数据支持还是比较丰富的,但是配置比较复杂。
二、zabbix 的触发监控规则
1、Monitoring 规则是监控系统的核心。阈值被配置为触发异常并生成事件。 Zabbix 有很多内置规则。
2、 通过trigger的Dependencies配置,可以实现简单的事件关联依赖。例如:触发监控有两个,1是监控站点是否可以访问,2是监控主机nginx的80端口是否可达。对于trigger1,可以增加对trigger2的依赖,这样当nginx 80端口不可达时,站点也无法访问,但不会触发站点无法访问的异常事件。
3、 基于以上设置,虽然可以实现简单的事件关联依赖合并,但是监控系统内部屏蔽了异常事件的发生。如果报警涉及到多组运维人员,大家都想看看自己的监控是否可用异常。所以,最好的办法是所有的异常事件都正常产生,在告警通知的时候进行相关性分析。比如上面的例子,运维组A负责trigger1告警,运维组B负责trigger2告警。当trigger2异常时,通知运维组A【不可访问,因为nginx 80端口不可达】,通知运维组B【nginx端口80不可达,导致不可访问】。
总结:Zabbix有更全面的监控规则匹配表达式,但不够灵活,无法配置更复杂的关联监控。
三、zabbix 的动作触发一个动作
根据triiger触发的异常事件,可以触发相应的动作。通常的操作是根据配置的媒体发送警报。 Zabbix报警配置部分,每个报警发送方式需要配置1个媒体,每个用户需要配置相应的发送媒体。
如果把zabbix告警交给灵曦管理,对于用户配置,只需要在zabbix上配置1个用户和1个媒体,会省很多麻烦。
四、灵豹与zabbix的融合:
灵溪云告警是一款专注于告警优化管理的SAAS软件,提供多通道及时准确传输、多人智能分层传输、告警处理协同、故障数据多维统计等功能。
对于zabbix监控系统(2.0、3.0都支持),如果需要使用灵曦的报警优化功能,只需要进行以下步骤:
1、灵豹产品配置:
我还没有灵曦账号。完成引导页面后,进入工作台,点击右下方的开始报警优化之旅,完成页面配置并复制token。
2、zabbix 监控系统配置:
依次增加媒体、用户、动作,完成灵曦对zabbix的告警优化。具体的图形操作请参考:#/access-zabbix。 查看全部
zabbix的trigger数据采集规则及解决办法(二)——zabbix
一、zabbix 的物品数据采集
1、数据采集是zabbix的基础,也是监控的基础。目前,它可以支持主动和被动采集 模式。主动模式定义为:客户端主动上报数据给服务器,被动模式定义为:服务器给客户端采集数据。
2、大家经常使用主动采集模式。除了zabbix自带的常见采集items外,还可以通过自定义采集items来扩展active采集方法。例如,如果需要对系统的全过程做语义监控功能,可以编写脚本,通过自定义采集项来获取脚本执行的结果。
3、 有时候部署代理比较麻烦,可以直接使用zabbix trapper方法:被监控主机主动向zabbix server发送数据,通常可以应用于程序内部的异常消息采集 例如,如果程序内部出现异常,抛出的异常消息可以通过trap方式直接发送到zabbix-server,通过trigger产生事件,通过action发送告警。
总结:总体来说zabbix对采集类型的数据支持还是比较丰富的,但是配置比较复杂。
二、zabbix 的触发监控规则
1、Monitoring 规则是监控系统的核心。阈值被配置为触发异常并生成事件。 Zabbix 有很多内置规则。
2、 通过trigger的Dependencies配置,可以实现简单的事件关联依赖。例如:触发监控有两个,1是监控站点是否可以访问,2是监控主机nginx的80端口是否可达。对于trigger1,可以增加对trigger2的依赖,这样当nginx 80端口不可达时,站点也无法访问,但不会触发站点无法访问的异常事件。
3、 基于以上设置,虽然可以实现简单的事件关联依赖合并,但是监控系统内部屏蔽了异常事件的发生。如果报警涉及到多组运维人员,大家都想看看自己的监控是否可用异常。所以,最好的办法是所有的异常事件都正常产生,在告警通知的时候进行相关性分析。比如上面的例子,运维组A负责trigger1告警,运维组B负责trigger2告警。当trigger2异常时,通知运维组A【不可访问,因为nginx 80端口不可达】,通知运维组B【nginx端口80不可达,导致不可访问】。
总结:Zabbix有更全面的监控规则匹配表达式,但不够灵活,无法配置更复杂的关联监控。
三、zabbix 的动作触发一个动作
根据triiger触发的异常事件,可以触发相应的动作。通常的操作是根据配置的媒体发送警报。 Zabbix报警配置部分,每个报警发送方式需要配置1个媒体,每个用户需要配置相应的发送媒体。
如果把zabbix告警交给灵曦管理,对于用户配置,只需要在zabbix上配置1个用户和1个媒体,会省很多麻烦。
四、灵豹与zabbix的融合:
灵溪云告警是一款专注于告警优化管理的SAAS软件,提供多通道及时准确传输、多人智能分层传输、告警处理协同、故障数据多维统计等功能。
对于zabbix监控系统(2.0、3.0都支持),如果需要使用灵曦的报警优化功能,只需要进行以下步骤:
1、灵豹产品配置:
我还没有灵曦账号。完成引导页面后,进入工作台,点击右下方的开始报警优化之旅,完成页面配置并复制token。
2、zabbix 监控系统配置:
依次增加媒体、用户、动作,完成灵曦对zabbix的告警优化。具体的图形操作请参考:#/access-zabbix。
QueryListrules(array)规则字段解释下面几个复杂的解释
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-06-07 07:37
QueryList 规则(数组 $rules)
//采集规则$rules = array( '规则名' => array('jQuery选择器','要采集的属性'[,"标签过滤列表"][,"回调函数"]), '规则名2' => array('jQuery选择器','要采集的属性'[,"标签过滤列表"][,"回调函数"]), ..........);//注:方括号括起来的参数可选
//采集规则$rules = [ //采集img标签的src属性,也就是采集页面中的图片链接 'name1' => ['img','src'], //采集class为content的div的纯文本内容, //并移除内容中的a标签内容,移除id为footer标签的内容,保留img标签 'name2' => ['div.content','text','-a -#footer img'], //采集第二个div的html内容,并在内容中追加了一些自定义内容 'name3' => ['div:eq(1)','html','',function($content){ $content += 'some str...'; return $content; }]];
规则字段说明
下面分别解释几个复杂的字段。
1.要采集的属性
值有以下3种:
2.tag 过滤列表
设置此选项可用于过滤不需要的内容。多个值用空格分隔。有如下两条规则:
这是中文内容,这里有个链接</a> 这里有一段广告 这里还有一段广告
获取class为article的元素的内部内容,但不想要那段广告文字,则可以设置采集规则为:
//采集规则$rules = [ 'content' => ['.article','html','-.ad1 -.ad2']];
意思是:采集class是article元素里面的html内容,去掉class为ad1,class为ad2的元素的内容。
现在得到的内容是:
这是中文内容,这里有个链接
在实际采集中,我们一般不想要采集其他人的外链,而是想去掉内容中的链接。这时候如果把filter改成-.ad1 -.ad2 -a,采集就会到达内容为:
这是中文内容,
链接去掉了,但实际上我们要保存链接的文本内容,所以过滤器应该改为:-.ad1 -.ad2 a,所以采集到达的内容是:<//p
ppre class="prettyprint linenums prettyprinted" style=""ol class="linenums"li class="L0"codespan class="pun"这是中文内容,这里有个链接/span/code/li/ol/pre/p
p用法/p
ppre class="prettyprint linenums prettyprinted" style=""ol class="linenums"li class="L0"codespan class="pln"$html/spanspan class="pun"=/spanspan class="pln"STR/span/code/lili class="L1"codespan class="pun"/spanspan class="pln"div /spanspan class="kwd"class/spanspan class="pun"=/spanspan class="str""content"/spanspan class="pun"/span/code/lili class="L2"codespan class="pln" /spanspan class="str"div/span/code/lili class="L3"codespan class="pln" /spanspan class="pun"/spanspan class="pln"a href/spanspan class="pun"=/spanspan class="str""https://querylist.cc/1.html"/spanspan class="pun"这是链接一//spanspan class="pln"a/spanspan class="pun"/span/code/lili class="L4"codespan class="pln" /spanspan class="str"span/spanspan class="pun"这是文字一//spanspan class="pln"span/spanspan class="pun"/span/code/lili class="L5"codespan class="pln" /spanspan class="pun"//spanspan class="pln"div/spanspan class="pun"/span/code/lili class="L6"code/code/lili class="L7"codespan class="pln" /spanspan class="str"div/span/code/lili class="L8"codespan class="pln" /spanspan class="pun"/spanspan class="pln"a href/spanspan class="pun"=/spanspan class="str""https://querylist.cc/2.html"/spanspan class="pun"这是链接二//spanspan class="pln"a/spanspan class="pun"/span/code/lili class="L9"codespan class="pln" /spanspan class="str"span/spanspan class="pun"这是文字二//spanspan class="pln"span/spanspan class="pun"/span/code/lili class="L0"codespan class="pln" /spanspan class="pun"//spanspan class="pln"div/spanspan class="pun"/span/code/lili class="L1"code/code/lili class="L2"codespan class="pln" /spanspan class="str"div/span/code/lili class="L3"codespan class="pln" /spanspan class="pun"/spanspan class="pln"a href/spanspan class="pun"=/spanspan class="str""https://querylist.cc/1.html"/spanspan class="pun"这是链接三//spanspan class="pln"a/spanspan class="pun"/span/code/lili class="L4"codespan class="pln" /spanspan class="str"span/spanspan class="pun"这是文字三//spanspan class="pln"span/spanspan class="pun"/span/code/lili class="L5"codespan class="pln" /spanspan class="pun"//spanspan class="pln"div/spanspan class="pun"/span/code/lili class="L6"codespan class="pun"//spanspan class="pln"div/spanspan class="pun"/span/code/lili class="L7"codespan class="pln"STR/spanspan class="pun";/span/code/lili class="L8"code/code/lili class="L9"codespan class="com"//采集规则/span/code/lili class="L0"codespan class="pln"$rules /spanspan class="pun"=/spanspan class="pln" /spanspan class="pun"[/span/code/lili class="L1"codespan class="pln" /spanspan class="com"//采集a标签的href属性/span/code/lili class="L2"codespan class="pln" /spanspan class="str"'link'/spanspan class="pln" /spanspan class="pun"=/spanspan class="pln" /spanspan class="pun"[/spanspan class="str"'a'/spanspan class="pun",/spanspan class="str"'href'/spanspan class="pun"],/span/code/lili class="L3"codespan class="pln" /spanspan class="com"//采集a标签的text文本/span/code/lili class="L4"codespan class="pln" /spanspan class="str"'link_text'/spanspan class="pln" /spanspan class="pun"=/spanspan class="pln" /spanspan class="pun"[/spanspan class="str"'a'/spanspan class="pun",/spanspan class="str"'text'/spanspan class="pun"],/span/code/lili class="L5"codespan class="pln" /spanspan class="com"//采集span标签的text文本/span/code/lili class="L6"codespan class="pln" /spanspan class="str"'txt'/spanspan class="pln" /spanspan class="pun"=/spanspan class="pln" /spanspan class="pun"[/spanspan class="str"'span'/spanspan class="pun",/spanspan class="str"'text'/spanspan class="pun"]/span/code/lili class="L7"codespan class="pun"];/span/code/lili class="L8"code/code/lili class="L9"codespan class="pln"$ql /spanspan class="pun"=/spanspan class="pln" /spanspan class="typ"QueryList/spanspan class="pun"::/spanspan class="pln"html/spanspan class="pun"(/spanspan class="pln"$html/spanspan class="pun")->rules($rules)->query();$data = $ql->getData();print_r($data->all());
采集Result:
Array( [0] => Array ( [link] => https://querylist.cc/1.html [link_text] => 这是链接一 [txt] => 这是文字一 ) [1] => Array ( [link] => https://querylist.cc/2.html [link_text] => 这是链接二 [txt] => 这是文字二 ) [2] => Array ( [link] => https://querylist.cc/1.html [link_text] => 这是链接三 [txt] => 这是文字三 )) 查看全部
QueryListrules(array)规则字段解释下面几个复杂的解释
QueryList 规则(数组 $rules)
//采集规则$rules = array( '规则名' => array('jQuery选择器','要采集的属性'[,"标签过滤列表"][,"回调函数"]), '规则名2' => array('jQuery选择器','要采集的属性'[,"标签过滤列表"][,"回调函数"]), ..........);//注:方括号括起来的参数可选
//采集规则$rules = [ //采集img标签的src属性,也就是采集页面中的图片链接 'name1' => ['img','src'], //采集class为content的div的纯文本内容, //并移除内容中的a标签内容,移除id为footer标签的内容,保留img标签 'name2' => ['div.content','text','-a -#footer img'], //采集第二个div的html内容,并在内容中追加了一些自定义内容 'name3' => ['div:eq(1)','html','',function($content){ $content += 'some str...'; return $content; }]];
规则字段说明
下面分别解释几个复杂的字段。
1.要采集的属性
值有以下3种:
2.tag 过滤列表
设置此选项可用于过滤不需要的内容。多个值用空格分隔。有如下两条规则:
这是中文内容,这里有个链接</a> 这里有一段广告 这里还有一段广告
获取class为article的元素的内部内容,但不想要那段广告文字,则可以设置采集规则为:
//采集规则$rules = [ 'content' => ['.article','html','-.ad1 -.ad2']];
意思是:采集class是article元素里面的html内容,去掉class为ad1,class为ad2的元素的内容。
现在得到的内容是:
这是中文内容,这里有个链接
在实际采集中,我们一般不想要采集其他人的外链,而是想去掉内容中的链接。这时候如果把filter改成-.ad1 -.ad2 -a,采集就会到达内容为:
这是中文内容,
链接去掉了,但实际上我们要保存链接的文本内容,所以过滤器应该改为:-.ad1 -.ad2 a,所以采集到达的内容是:<//p
ppre class="prettyprint linenums prettyprinted" style=""ol class="linenums"li class="L0"codespan class="pun"这是中文内容,这里有个链接/span/code/li/ol/pre/p
p用法/p
ppre class="prettyprint linenums prettyprinted" style=""ol class="linenums"li class="L0"codespan class="pln"$html/spanspan class="pun"=/spanspan class="pln"STR/span/code/lili class="L1"codespan class="pun"/spanspan class="pln"div /spanspan class="kwd"class/spanspan class="pun"=/spanspan class="str""content"/spanspan class="pun"/span/code/lili class="L2"codespan class="pln" /spanspan class="str"div/span/code/lili class="L3"codespan class="pln" /spanspan class="pun"/spanspan class="pln"a href/spanspan class="pun"=/spanspan class="str""https://querylist.cc/1.html"/spanspan class="pun"这是链接一//spanspan class="pln"a/spanspan class="pun"/span/code/lili class="L4"codespan class="pln" /spanspan class="str"span/spanspan class="pun"这是文字一//spanspan class="pln"span/spanspan class="pun"/span/code/lili class="L5"codespan class="pln" /spanspan class="pun"//spanspan class="pln"div/spanspan class="pun"/span/code/lili class="L6"code/code/lili class="L7"codespan class="pln" /spanspan class="str"div/span/code/lili class="L8"codespan class="pln" /spanspan class="pun"/spanspan class="pln"a href/spanspan class="pun"=/spanspan class="str""https://querylist.cc/2.html"/spanspan class="pun"这是链接二//spanspan class="pln"a/spanspan class="pun"/span/code/lili class="L9"codespan class="pln" /spanspan class="str"span/spanspan class="pun"这是文字二//spanspan class="pln"span/spanspan class="pun"/span/code/lili class="L0"codespan class="pln" /spanspan class="pun"//spanspan class="pln"div/spanspan class="pun"/span/code/lili class="L1"code/code/lili class="L2"codespan class="pln" /spanspan class="str"div/span/code/lili class="L3"codespan class="pln" /spanspan class="pun"/spanspan class="pln"a href/spanspan class="pun"=/spanspan class="str""https://querylist.cc/1.html"/spanspan class="pun"这是链接三//spanspan class="pln"a/spanspan class="pun"/span/code/lili class="L4"codespan class="pln" /spanspan class="str"span/spanspan class="pun"这是文字三//spanspan class="pln"span/spanspan class="pun"/span/code/lili class="L5"codespan class="pln" /spanspan class="pun"//spanspan class="pln"div/spanspan class="pun"/span/code/lili class="L6"codespan class="pun"//spanspan class="pln"div/spanspan class="pun"/span/code/lili class="L7"codespan class="pln"STR/spanspan class="pun";/span/code/lili class="L8"code/code/lili class="L9"codespan class="com"//采集规则/span/code/lili class="L0"codespan class="pln"$rules /spanspan class="pun"=/spanspan class="pln" /spanspan class="pun"[/span/code/lili class="L1"codespan class="pln" /spanspan class="com"//采集a标签的href属性/span/code/lili class="L2"codespan class="pln" /spanspan class="str"'link'/spanspan class="pln" /spanspan class="pun"=/spanspan class="pln" /spanspan class="pun"[/spanspan class="str"'a'/spanspan class="pun",/spanspan class="str"'href'/spanspan class="pun"],/span/code/lili class="L3"codespan class="pln" /spanspan class="com"//采集a标签的text文本/span/code/lili class="L4"codespan class="pln" /spanspan class="str"'link_text'/spanspan class="pln" /spanspan class="pun"=/spanspan class="pln" /spanspan class="pun"[/spanspan class="str"'a'/spanspan class="pun",/spanspan class="str"'text'/spanspan class="pun"],/span/code/lili class="L5"codespan class="pln" /spanspan class="com"//采集span标签的text文本/span/code/lili class="L6"codespan class="pln" /spanspan class="str"'txt'/spanspan class="pln" /spanspan class="pun"=/spanspan class="pln" /spanspan class="pun"[/spanspan class="str"'span'/spanspan class="pun",/spanspan class="str"'text'/spanspan class="pun"]/span/code/lili class="L7"codespan class="pun"];/span/code/lili class="L8"code/code/lili class="L9"codespan class="pln"$ql /spanspan class="pun"=/spanspan class="pln" /spanspan class="typ"QueryList/spanspan class="pun"::/spanspan class="pln"html/spanspan class="pun"(/spanspan class="pln"$html/spanspan class="pun")->rules($rules)->query();$data = $ql->getData();print_r($data->all());
采集Result:
Array( [0] => Array ( [link] => https://querylist.cc/1.html [link_text] => 这是链接一 [txt] => 这是文字一 ) [1] => Array ( [link] => https://querylist.cc/2.html [link_text] => 这是链接二 [txt] => 这是文字二 ) [2] => Array ( [link] => https://querylist.cc/1.html [link_text] => 这是链接三 [txt] => 这是文字三 ))
开启全埋点代码示例WebSDK及以上版本代码代码
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-05-25 06:42
打开完整的掩埋点代码示例
var sensors = window['sensorsDataAnalytic201505'];
sensors.init({
server_url: 'http://test-syg.datasink.sensorsdata.cn/sa?token=xxxxx&project=xxxxxx',
is_track_single_page:true, // 单页面配置,默认开启,若页面中有锚点设计,需要将该配置删除,否则触发锚点会多触发 $pageview 事件
use_client_time:true,
send_type:'beacon',
heatmap: {
//是否开启点击图,default 表示开启,自动采集 $WebClick 事件,可以设置 'not_collect' 表示关闭。
clickmap:'default',
//是否开启触达注意力图,not_collect 表示关闭,不会自动采集 $WebStay 事件,可以设置 'default' 表示开启。
scroll_notice_map:'default'
}
});
sensors.quick('autoTrack');
JS
Web JS SDK的完全隐藏点包括三种事件:网页浏览,Web元素单击,Web视口停留,各个对应的配置如下。
网页浏览($ pageview)
// 设置之后,SDK 就会自动收集页面浏览事件,以及设置初始来源。
sensors.quick('autoTrack')
// 另外,如果想加额外的属性,可以如下方式(添加 platform 属性为 h5)
sensors.quick('autoTrack', {
platform:'h5'
})
JS
网页元素点击($ WebClick)
// SDK 初始化参数配置
heatmap: {
// 是否开启点击图,default 表示开启,自动采集 $WebClick 事件,可以设置 'not_collect' 表示关闭。
// 默认只有点击 a input button textarea 四种元素时,才会触发 $WebClick 元素点击事件
clickmap:'default'
}
JS
视口停留事件($ WebStay)
// SDK 初始化参数配置
heatmap: {
//是否开启触达注意力图,default 表示开启,自动采集 $WebStay 事件,可以设置 'not_collect' 表示关闭。
//需要 Web JS SDK 版本号大于 1.9.1
scroll_notice_map:'default'
}
JS
其他元素类型采集的元素单击事件支持自动div类型元素采集
版本要求
Web JS SDK及更高版本
在原创标记(采集 a,按钮,输入,文本区域标签)的基础上将采集添加到div标签中,采集规则为:
当div是叶节点(无子元素)时,采集 div的click div仅具有样式标签(['mark','strong','b','em','i','u ','abbr','ins','del','s','sup'])),点击div或样式标签采集 div点击
使用collect_tags配置是否启用div的完整掩埋点采集,默认值为采集。如果需要启用,请按以下方式配置collect_tags参数(注意:仅支持div配置):
heatmap:{
collect_tags:{
div : true
}
}
JS
支持具有特殊属性的其他类型元素的自动采集配置:data-sensors-click
打开整个掩埋点后,向需要自动采集 click事件的元素添加一个属性:data-sensors-click(注意:添加此属性将不允许该元素可视化整个掩埋点)。
版本要求
Web JS SDK及更高版本
代码示例如下:
我是测试元素
我是测试元素
XML
配置自定义属性
启用完全埋入点后,支持将具有指定属性的页面元素单击配置为自动采集单击事件(注意:添加此属性不能使元素能够显示完全埋入点)
版本要求
Web JS SDK及更高版本
代码示例如下:
var sensors = sensorsDataAnalytic201505;
sensors.init({
server_url: 'SERVER_URL',
heatmap: {
track_attr: ['hotrep', 'anotherprop', "data-prop2"],
clickmap:'default',
scroll_notice_map: 'not_collect'
}
});
...
<p hotrep id="test1">hotrep p tag
another repo a.b.c
strong with prop2 attribute</p>
CODE
代码掩埋点触发元素单击事件
如果您要单击输入按钮文本区域采集以外的其他元素,请在单击该元素时调用我们的方法。
// 下面演示一个 div 标签被点击时触发预置的元素点击事件
提交订单
$('#submit_order').on('click', function() {
sensors.quick('trackHeatMap', this, {
customProp1: 'test1', //如果需要添加自定义属性需要将 SDK 升级到 1.13.7 及以上版本。
customProp2: 'test2'
}, function() {
console.log('callback');
});
});
XML
//注意:调用我们在本机js中绑定的click事件时,它指向元素节点。在其他框架采集 click事件中,该指针也应指向相应的元素节点,例如,在vue中,请参见下面的示例。
点击
export default {
methods: {
track: function(event) {
sensors.quick('trackHeatMap', event.target, {
customProp1: 'test1', //如果需要添加自定义属性需要将 SDK 升级到 1.13.7 及以上版本。
customProp2: 'test2'
}, function() {
console.log('callback');
});
}
}
}
XML
新方法trackAllHeatMap已添加到版本及更高版本的SDK中。调用此方法时,可以在所有标签(包括a,input,button,textarea标签和div,img等)中传递此方法的第二个参数。仅trackHeatMap 采集标签是a,input,button,textarea之外。同时,这两个方法可以设置自定义属性,并支持回调函数(这两个方法的第四个参数可以传递给方法)。
// 下面演示一个 button 按钮被点击时触发预置的元素点击事件
测试按钮
$('#testp').on('click', function() {
sensors.quick('trackAllHeatMap', this, {
customProp1: 'test1', //如果需要添加自定义属性需要将 SDK 升级到 1.13.7 及以上版本。
customProp2: 'test2'
}, function() {
console.log('callback');
});
});
XML
全埋点相关参数配置Web元素单击与热图相关的参数,为$ WebClick事件提供自定义设置和处理。
说明热图相关参数:
参数名称参数值描述备注
点击地图
是否打开点击地图,默认设置是将其打开,并且可以将“ not_collect”设置为关闭。
Web JS SDK版本号必须大于。
scroll_notice_map
是否打开触摸注意力图,将其设置为默认值将其打开,将'not_collect'设置为将其关闭。
Web JS SDK版本号必须大于。
loadTimeout
毫秒
设置开始渲染点击图的毫秒数,因为首次打开页面时尚未加载页面的某些元素。
collect_url
返回true将采集当前页面的元素单击事件,返回false则不是采集当前页面。设置此功能后,如果内容为空,则将返回false。如果未设置此功能,则默认为所有页面采集。
collect_element
当用户单击页面元素时,将触发此函数,您可以确定是否采集当前元素,为采集返回true,为否采集返回false。
custom_property
如果要将自定义属性添加到$ WebClick事件,则可以根据标记的特性来判断是否添加它们。
注意:如果同时使用trackAllHeatMap或trackHeatMap方法设置自定义属性,则此处的自定义属性对象将在具有更高优先级的custom_property返回值中覆盖具有相同名称的属性。
collect_input
考虑到用户隐私,您可以在此处设置输入内容是否为采集。
如果返回true,则表示输入内容为采集,返回false表示不输入内容输入采集,默认值为采集。
element_selector
默认情况下,SDK将元素ID作为选择器采集 click事件的优先级。如果您不想将ID用作选择器,则可以将此参数设置为“ not_use_id”。
受以上版本支持。
renderRefreshTime
毫秒
在第二个版本中,在以毫秒为单位更改页面大小之后,单击滚动条以重新呈现页面。
与热图相关的参数代码示例:
heatmap: {
clickmap:'default',
scroll_notice_map:'default',
loadTimeout: 3000,
collect_url: function(){
//如果只采集首页
if(location.href === 'xxx.com/index.html' || location.href === 'xxx.com/'){
return true;
}
},
//此参数针对预置 $WebClick 事件(包括 quick('trackHeatMap') quick('trackAllHeatMap') 触发的)生效。
collect_element: function(element_target){
// 如果这个元素有属性sensors-disable=true时候,不采集。
if(element_target.getAttribute('sensors-disable') === 'true'){
return false;
}else{
return true;
}
},
//此参数针对预置 $WebClick 事件(包括 quick('trackHeatMap') quick('trackAllHeatMap') 触发的)生效。
custom_property:function( element_target ){
//比如您需要给有 data=test 属性的标签的点击事件增加自定义属性 name:'aa' ,则代码如下:
if(element_target.getAttribute('data') === 'test'){
return {
name:'aa'
}
}
},
collect_input:function(element_target){
//例如如果元素的 id 是a,就采集这个元素里的内容。
if(element_target.id === 'a'){
return true;
}
},
element_selector:'not_use_id',
renderRefreshTime:1000
}
JS
有关Web视口停留的相关参数的说明:
与滚动图相关的参数的描述:
参数名称参数值描述备注
collect_url
返回true将采集当前页面的数据,返回false则不是采集当前页面的数据。设置此功能后,如果内容为空,则将返回false。如果未设置此功能,则默认为所有页面采集。
说明热图相关参数:
参数名称参数值描述备注
scroll_notice_map
是否打开触摸图,将其设置为默认值以将其打开,并设置为'not_collect'以将其关闭。
Web JS SDK版本号必须大于。
scroll_delay_time
毫秒
设置触摸图的有效停留时间,默认停留时间为4秒以上。
scroll_event_duration
秒
预设属性停留时间的event_duration最大值。默认值为18000秒5小时。
与滚动图和热图有关的代码示例:
scrollmap: {
collect_url: function(){
//如果只采集首页
if(location.href === 'xxx.com/index.html' || location.href === 'xxx.com/'){
return true;
}
},
},
heatmap:{
//是否开启触达注意力图,default 表示开启,自动采集 $WebStay 事件,可以设置 'not_collect' 表示关闭。
//需要 Web JS SDK 版本号大于 1.9.1
scroll_notice_map:'not_collect',
scroll_delay_time: 4000,
scroll_event_duration: 18000 //单位秒,预置属性停留时长 event_duration 的最大值。默认5个小时,也就是300分钟,18000秒。
}
JS
单个页面采集中的自动事件
在单个页面中自动显示事件采集,请参阅
网页浏览事件采集自动模式
配置参数为_track_single_page(建议使用此模式),默认值为true,指示是否启用自动采集 Web浏览事件$ pageview功能。
原理是修改窗口对象的pushState和replaceState本机方法,并在更改页面的url之后自动采集 $ pageview事件。如果用户的浏览器不支持这两种方法或使用哈希路由模式,我们还将侦听popstate和hashchange事件以自动触发$ pageview事件。
用法示例:
//SDK版本1.12.18以上支持,默认值为false。
is_track_single_page:true
//注意:如果进首页不会自动 redirect 时,sa.quick('autoTrack') 是需要的,否则不需要。
JS
添加了大于或等于function(){}配置的SDK版本的is_track_single_page参数,并且必须返回一个值。
配置1:返回true表示当前页面将发送数据,
配置2:返回false表示将不发送任何数据,
配置3:返回{}对象,这意味着该对象的属性将被添加到当前的$ pageview中。
用法示例:
is_track_single_page : function (){
return true 时候,使用默认发送的 $pageview
return false 时候,不执行默认的 $pageview
return {} 时候,把对象中的属性,覆盖默认 $pageview 里的属性。
}
//注意:如果进首页不会自动 redirect 时,sa.quick('autoTrack') 是需要的,否则不需要。
JS
还请注意:
必须确保在切换页面之前已执行Shence Web JS SDK,否则在第一次切换页面时可能不会触发$ pageview。
手动模式
切换页面后,手动调用sensor.quick('autoTrackSinglePage')到采集 Web浏览事件$ pageview。切换页面网址后,将调用此方法。
// 比如现在是在 react 中可以在全局的 onUpdate 里来调用。
onUpdate: function(){
sensors.quick('autoTrackSinglePage');
}
//vue 项目在路由切换的时候调用。
router.afterEach((to,from) => {
Vue.nextTick(() => {
sensors.quick("autoTrackSinglePage");
});
});
//注意: vue下因为首页打开时候就会默认触发页面更新,所以需要去掉默认加的 sa.quick('autoTrack')。
JS
此方法还可以添加自定义属性,
sensors.quick("autoTrackSinglePage",{platForm:"H5"});
JS
单页页面标题$ title问题
对于单页项目,Shence SDK的所有点的预设事件采集的页面标题属性中可能会有例外。
具体问题:
1、 title如果没有更新分配,则获得的标题将始终是主页的标题,并且不会更改,并且切换页面发送的数据也不会更新$ title。
2、标题设置时间晚于数据发送时间,通过切换页面发送的$ pageview事件携带的$ title值是前一页的标题。
解决方案:
在切换页面之前完成标题值的更新(以常见的vue为例)
router.beforeEach((to, from, next) => {
document.title = '新页面的 title 值';
next()
})
JS 查看全部
开启全埋点代码示例WebSDK及以上版本代码代码
打开完整的掩埋点代码示例
var sensors = window['sensorsDataAnalytic201505'];
sensors.init({
server_url: 'http://test-syg.datasink.sensorsdata.cn/sa?token=xxxxx&project=xxxxxx',
is_track_single_page:true, // 单页面配置,默认开启,若页面中有锚点设计,需要将该配置删除,否则触发锚点会多触发 $pageview 事件
use_client_time:true,
send_type:'beacon',
heatmap: {
//是否开启点击图,default 表示开启,自动采集 $WebClick 事件,可以设置 'not_collect' 表示关闭。
clickmap:'default',
//是否开启触达注意力图,not_collect 表示关闭,不会自动采集 $WebStay 事件,可以设置 'default' 表示开启。
scroll_notice_map:'default'
}
});
sensors.quick('autoTrack');
JS
Web JS SDK的完全隐藏点包括三种事件:网页浏览,Web元素单击,Web视口停留,各个对应的配置如下。
网页浏览($ pageview)
// 设置之后,SDK 就会自动收集页面浏览事件,以及设置初始来源。
sensors.quick('autoTrack')
// 另外,如果想加额外的属性,可以如下方式(添加 platform 属性为 h5)
sensors.quick('autoTrack', {
platform:'h5'
})
JS
网页元素点击($ WebClick)
// SDK 初始化参数配置
heatmap: {
// 是否开启点击图,default 表示开启,自动采集 $WebClick 事件,可以设置 'not_collect' 表示关闭。
// 默认只有点击 a input button textarea 四种元素时,才会触发 $WebClick 元素点击事件
clickmap:'default'
}
JS
视口停留事件($ WebStay)
// SDK 初始化参数配置
heatmap: {
//是否开启触达注意力图,default 表示开启,自动采集 $WebStay 事件,可以设置 'not_collect' 表示关闭。
//需要 Web JS SDK 版本号大于 1.9.1
scroll_notice_map:'default'
}
JS
其他元素类型采集的元素单击事件支持自动div类型元素采集
版本要求
Web JS SDK及更高版本
在原创标记(采集 a,按钮,输入,文本区域标签)的基础上将采集添加到div标签中,采集规则为:
当div是叶节点(无子元素)时,采集 div的click div仅具有样式标签(['mark','strong','b','em','i','u ','abbr','ins','del','s','sup'])),点击div或样式标签采集 div点击
使用collect_tags配置是否启用div的完整掩埋点采集,默认值为采集。如果需要启用,请按以下方式配置collect_tags参数(注意:仅支持div配置):
heatmap:{
collect_tags:{
div : true
}
}
JS
支持具有特殊属性的其他类型元素的自动采集配置:data-sensors-click
打开整个掩埋点后,向需要自动采集 click事件的元素添加一个属性:data-sensors-click(注意:添加此属性将不允许该元素可视化整个掩埋点)。
版本要求
Web JS SDK及更高版本
代码示例如下:
我是测试元素
我是测试元素
XML
配置自定义属性
启用完全埋入点后,支持将具有指定属性的页面元素单击配置为自动采集单击事件(注意:添加此属性不能使元素能够显示完全埋入点)
版本要求
Web JS SDK及更高版本
代码示例如下:
var sensors = sensorsDataAnalytic201505;
sensors.init({
server_url: 'SERVER_URL',
heatmap: {
track_attr: ['hotrep', 'anotherprop', "data-prop2"],
clickmap:'default',
scroll_notice_map: 'not_collect'
}
});
...
<p hotrep id="test1">hotrep p tag
another repo a.b.c
strong with prop2 attribute</p>
CODE
代码掩埋点触发元素单击事件
如果您要单击输入按钮文本区域采集以外的其他元素,请在单击该元素时调用我们的方法。
// 下面演示一个 div 标签被点击时触发预置的元素点击事件
提交订单
$('#submit_order').on('click', function() {
sensors.quick('trackHeatMap', this, {
customProp1: 'test1', //如果需要添加自定义属性需要将 SDK 升级到 1.13.7 及以上版本。
customProp2: 'test2'
}, function() {
console.log('callback');
});
});
XML
//注意:调用我们在本机js中绑定的click事件时,它指向元素节点。在其他框架采集 click事件中,该指针也应指向相应的元素节点,例如,在vue中,请参见下面的示例。
点击
export default {
methods: {
track: function(event) {
sensors.quick('trackHeatMap', event.target, {
customProp1: 'test1', //如果需要添加自定义属性需要将 SDK 升级到 1.13.7 及以上版本。
customProp2: 'test2'
}, function() {
console.log('callback');
});
}
}
}
XML
新方法trackAllHeatMap已添加到版本及更高版本的SDK中。调用此方法时,可以在所有标签(包括a,input,button,textarea标签和div,img等)中传递此方法的第二个参数。仅trackHeatMap 采集标签是a,input,button,textarea之外。同时,这两个方法可以设置自定义属性,并支持回调函数(这两个方法的第四个参数可以传递给方法)。
// 下面演示一个 button 按钮被点击时触发预置的元素点击事件
测试按钮
$('#testp').on('click', function() {
sensors.quick('trackAllHeatMap', this, {
customProp1: 'test1', //如果需要添加自定义属性需要将 SDK 升级到 1.13.7 及以上版本。
customProp2: 'test2'
}, function() {
console.log('callback');
});
});
XML
全埋点相关参数配置Web元素单击与热图相关的参数,为$ WebClick事件提供自定义设置和处理。
说明热图相关参数:
参数名称参数值描述备注
点击地图
是否打开点击地图,默认设置是将其打开,并且可以将“ not_collect”设置为关闭。
Web JS SDK版本号必须大于。
scroll_notice_map
是否打开触摸注意力图,将其设置为默认值将其打开,将'not_collect'设置为将其关闭。
Web JS SDK版本号必须大于。
loadTimeout
毫秒
设置开始渲染点击图的毫秒数,因为首次打开页面时尚未加载页面的某些元素。
collect_url
返回true将采集当前页面的元素单击事件,返回false则不是采集当前页面。设置此功能后,如果内容为空,则将返回false。如果未设置此功能,则默认为所有页面采集。
collect_element
当用户单击页面元素时,将触发此函数,您可以确定是否采集当前元素,为采集返回true,为否采集返回false。
custom_property
如果要将自定义属性添加到$ WebClick事件,则可以根据标记的特性来判断是否添加它们。
注意:如果同时使用trackAllHeatMap或trackHeatMap方法设置自定义属性,则此处的自定义属性对象将在具有更高优先级的custom_property返回值中覆盖具有相同名称的属性。
collect_input
考虑到用户隐私,您可以在此处设置输入内容是否为采集。
如果返回true,则表示输入内容为采集,返回false表示不输入内容输入采集,默认值为采集。
element_selector
默认情况下,SDK将元素ID作为选择器采集 click事件的优先级。如果您不想将ID用作选择器,则可以将此参数设置为“ not_use_id”。
受以上版本支持。
renderRefreshTime
毫秒
在第二个版本中,在以毫秒为单位更改页面大小之后,单击滚动条以重新呈现页面。
与热图相关的参数代码示例:
heatmap: {
clickmap:'default',
scroll_notice_map:'default',
loadTimeout: 3000,
collect_url: function(){
//如果只采集首页
if(location.href === 'xxx.com/index.html' || location.href === 'xxx.com/'){
return true;
}
},
//此参数针对预置 $WebClick 事件(包括 quick('trackHeatMap') quick('trackAllHeatMap') 触发的)生效。
collect_element: function(element_target){
// 如果这个元素有属性sensors-disable=true时候,不采集。
if(element_target.getAttribute('sensors-disable') === 'true'){
return false;
}else{
return true;
}
},
//此参数针对预置 $WebClick 事件(包括 quick('trackHeatMap') quick('trackAllHeatMap') 触发的)生效。
custom_property:function( element_target ){
//比如您需要给有 data=test 属性的标签的点击事件增加自定义属性 name:'aa' ,则代码如下:
if(element_target.getAttribute('data') === 'test'){
return {
name:'aa'
}
}
},
collect_input:function(element_target){
//例如如果元素的 id 是a,就采集这个元素里的内容。
if(element_target.id === 'a'){
return true;
}
},
element_selector:'not_use_id',
renderRefreshTime:1000
}
JS
有关Web视口停留的相关参数的说明:
与滚动图相关的参数的描述:
参数名称参数值描述备注
collect_url
返回true将采集当前页面的数据,返回false则不是采集当前页面的数据。设置此功能后,如果内容为空,则将返回false。如果未设置此功能,则默认为所有页面采集。
说明热图相关参数:
参数名称参数值描述备注
scroll_notice_map
是否打开触摸图,将其设置为默认值以将其打开,并设置为'not_collect'以将其关闭。
Web JS SDK版本号必须大于。
scroll_delay_time
毫秒
设置触摸图的有效停留时间,默认停留时间为4秒以上。
scroll_event_duration
秒
预设属性停留时间的event_duration最大值。默认值为18000秒5小时。
与滚动图和热图有关的代码示例:
scrollmap: {
collect_url: function(){
//如果只采集首页
if(location.href === 'xxx.com/index.html' || location.href === 'xxx.com/'){
return true;
}
},
},
heatmap:{
//是否开启触达注意力图,default 表示开启,自动采集 $WebStay 事件,可以设置 'not_collect' 表示关闭。
//需要 Web JS SDK 版本号大于 1.9.1
scroll_notice_map:'not_collect',
scroll_delay_time: 4000,
scroll_event_duration: 18000 //单位秒,预置属性停留时长 event_duration 的最大值。默认5个小时,也就是300分钟,18000秒。
}
JS
单个页面采集中的自动事件
在单个页面中自动显示事件采集,请参阅
网页浏览事件采集自动模式
配置参数为_track_single_page(建议使用此模式),默认值为true,指示是否启用自动采集 Web浏览事件$ pageview功能。
原理是修改窗口对象的pushState和replaceState本机方法,并在更改页面的url之后自动采集 $ pageview事件。如果用户的浏览器不支持这两种方法或使用哈希路由模式,我们还将侦听popstate和hashchange事件以自动触发$ pageview事件。
用法示例:
//SDK版本1.12.18以上支持,默认值为false。
is_track_single_page:true
//注意:如果进首页不会自动 redirect 时,sa.quick('autoTrack') 是需要的,否则不需要。
JS
添加了大于或等于function(){}配置的SDK版本的is_track_single_page参数,并且必须返回一个值。
配置1:返回true表示当前页面将发送数据,
配置2:返回false表示将不发送任何数据,
配置3:返回{}对象,这意味着该对象的属性将被添加到当前的$ pageview中。
用法示例:
is_track_single_page : function (){
return true 时候,使用默认发送的 $pageview
return false 时候,不执行默认的 $pageview
return {} 时候,把对象中的属性,覆盖默认 $pageview 里的属性。
}
//注意:如果进首页不会自动 redirect 时,sa.quick('autoTrack') 是需要的,否则不需要。
JS
还请注意:
必须确保在切换页面之前已执行Shence Web JS SDK,否则在第一次切换页面时可能不会触发$ pageview。
手动模式
切换页面后,手动调用sensor.quick('autoTrackSinglePage')到采集 Web浏览事件$ pageview。切换页面网址后,将调用此方法。
// 比如现在是在 react 中可以在全局的 onUpdate 里来调用。
onUpdate: function(){
sensors.quick('autoTrackSinglePage');
}
//vue 项目在路由切换的时候调用。
router.afterEach((to,from) => {
Vue.nextTick(() => {
sensors.quick("autoTrackSinglePage");
});
});
//注意: vue下因为首页打开时候就会默认触发页面更新,所以需要去掉默认加的 sa.quick('autoTrack')。
JS
此方法还可以添加自定义属性,
sensors.quick("autoTrackSinglePage",{platForm:"H5"});
JS
单页页面标题$ title问题
对于单页项目,Shence SDK的所有点的预设事件采集的页面标题属性中可能会有例外。
具体问题:
1、 title如果没有更新分配,则获得的标题将始终是主页的标题,并且不会更改,并且切换页面发送的数据也不会更新$ title。
2、标题设置时间晚于数据发送时间,通过切换页面发送的$ pageview事件携带的$ title值是前一页的标题。
解决方案:
在切换页面之前完成标题值的更新(以常见的vue为例)
router.beforeEach((to, from, next) => {
document.title = '新页面的 title 值';
next()
})
JS
V10及更高数据管家——增强版网络爬虫老版本对应教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-05-16 20:18
支持的软件版本:V10和更高版本的Data Manager-Enhanced Web Crawler
对应的旧版本教程:V9和更低版本。 Jishouke网络抓取工具的相应教程为“ 采集网页数据”
下载并安装了Data Manager之后,我们在Data Manager的浏览器中打开采集页面,单击页面上的鼠标,并将内容标记为采集。此过程称为:使用视觉注释方法定义采集器规则。在本文中,任务和规则是指采集器规则。
注意:本文介绍的视觉注释适用于采集网页上可以看到的内容。如果采集的内容未直接显示在网页上,例如超链接的URL,或者无法用视觉注释准确地标记,则可以使用“内容映射”中说明的方法。
1.步骤(观看视频)
下面以京东网站为例,向您展示如何使用视觉标记的方法定义采集的规则。步骤如下:
2.详细的操作步骤
采集规则:京东数据管家列表的演示规则(点击下载此规则)
示例网址:%E5%86%B0%E7%AE%B1&enc = utf-8&wq =%E5%86%B0%E7%AE%B1&pvid = 2879721c10d54340a16491de943d6886
采集内容:网页上第一个产品的产品标题,价格,评论数和商店名称
第1步:打开网页
1. 1,加载网页并查看内容为采集
打开数据管理器,输入采集的URL,然后按Enter。加载网页后,首先观察采集的内容是否已完全加载。有些网页很长。如果要在网页底部显示采集内容,请确保拉动网页侧面的滚动条以使网页完全加载,然后创建采集任务。
1. 2,创建采集任务
单击左列顶部的“ +”按钮,然后在显示的左列中看到工作台,输入任务名称。
每个任务必须具有唯一的任务名称。如果新名称与其他人的名称相同,则会在界面上以红色提示您,并且必须更改名称,直到被接受为止。如果使用非常通用的名称,则具有相同名称的可能性很高。建议在名称后添加自己的Jishou帐户名。
第2步:标记需要采集的信息
2. 1,在网页上添加注释
例如,如果我们想要采集网页上第一个产品的标题,请用鼠标单击标题,标题文本将被一个细蓝框包围。
双击产品标题,会弹出一个小窗口,要求此采集内容的字段名称,该字段名称与excel中的字段相对应,在这里,我们输入的字段名称是产品标题。
如果这是创建的第一个采集内容,还将要求您输入表名,该表名与采集输出的excel表相对应,并且表名是自定义的。在采集器软件中,我们通常将此表称为“组织框”,这生动地表明我们正在将Web内容组织到一个框中。
通过此标记过程,Web内容将与爬网程序将来输出的excel表建立映射关系。在以下教程中,“映射”一词将被多次提及。网页内容采集是将网页上的内容映射到excel表的过程。
2. 2,标记更多内容
重复上一步以标记价格,评论数和商店名称。
第3步:保存规则并采集数据
3. 1,测试采集是否符合期望
单击“测试”按钮以检查信息的完整性。 采集的内容很可能为空,或者收录许多不必要的内容,或者放错了位置,并且采集到达了相邻的内容。然后,您需要重新调整映射关系。如果视觉注释不正确,则可以转到下面的DOM窗口进行内容映射。
3. 2,点击“保存”
只有保存规则,采集器才能执行规则采集数据。以后可以修改规则。
3. 3,点击“采集数据”
单击“保存”按钮旁边的“采集数据”按钮,爬网程序将打开一个新窗口以启动采集数据,并测试采集规则是否有效。除了使用“采集数据”按钮启动采集任务外,还有其他操作方法。有关详细信息,请参考以下“开始数据采集”教程。
第4步:查看数据
4. 1,开始导出过程
请参考上图。 采集完成后,将显示任务状态页面。单击“导出Excel”按钮,将出现一个提示框。点击确定。
4. 2,下载导出的数据
单击导出数据,单击下载,默认情况下它将保存到计算机的下载文件夹中。
下载的文件是一个ZIP包,并放置在计算机的“下载”文件夹中。您可以单击它以将其自解压缩为excel文件。
提醒:仅本教程采集具有第一个产品的数据。要采集此页面上所有产品的数据,请阅读下一篇文章文章“ Web爬网程序采集列表数据”第三步是复制示例采集列表数据。 查看全部
V10及更高数据管家——增强版网络爬虫老版本对应教程
支持的软件版本:V10和更高版本的Data Manager-Enhanced Web Crawler
对应的旧版本教程:V9和更低版本。 Jishouke网络抓取工具的相应教程为“ 采集网页数据”
下载并安装了Data Manager之后,我们在Data Manager的浏览器中打开采集页面,单击页面上的鼠标,并将内容标记为采集。此过程称为:使用视觉注释方法定义采集器规则。在本文中,任务和规则是指采集器规则。
注意:本文介绍的视觉注释适用于采集网页上可以看到的内容。如果采集的内容未直接显示在网页上,例如超链接的URL,或者无法用视觉注释准确地标记,则可以使用“内容映射”中说明的方法。
1.步骤(观看视频)
下面以京东网站为例,向您展示如何使用视觉标记的方法定义采集的规则。步骤如下:
2.详细的操作步骤
采集规则:京东数据管家列表的演示规则(点击下载此规则)
示例网址:%E5%86%B0%E7%AE%B1&enc = utf-8&wq =%E5%86%B0%E7%AE%B1&pvid = 2879721c10d54340a16491de943d6886
采集内容:网页上第一个产品的产品标题,价格,评论数和商店名称
第1步:打开网页
1. 1,加载网页并查看内容为采集
打开数据管理器,输入采集的URL,然后按Enter。加载网页后,首先观察采集的内容是否已完全加载。有些网页很长。如果要在网页底部显示采集内容,请确保拉动网页侧面的滚动条以使网页完全加载,然后创建采集任务。
1. 2,创建采集任务
单击左列顶部的“ +”按钮,然后在显示的左列中看到工作台,输入任务名称。
每个任务必须具有唯一的任务名称。如果新名称与其他人的名称相同,则会在界面上以红色提示您,并且必须更改名称,直到被接受为止。如果使用非常通用的名称,则具有相同名称的可能性很高。建议在名称后添加自己的Jishou帐户名。
第2步:标记需要采集的信息
2. 1,在网页上添加注释
例如,如果我们想要采集网页上第一个产品的标题,请用鼠标单击标题,标题文本将被一个细蓝框包围。
双击产品标题,会弹出一个小窗口,要求此采集内容的字段名称,该字段名称与excel中的字段相对应,在这里,我们输入的字段名称是产品标题。
如果这是创建的第一个采集内容,还将要求您输入表名,该表名与采集输出的excel表相对应,并且表名是自定义的。在采集器软件中,我们通常将此表称为“组织框”,这生动地表明我们正在将Web内容组织到一个框中。
通过此标记过程,Web内容将与爬网程序将来输出的excel表建立映射关系。在以下教程中,“映射”一词将被多次提及。网页内容采集是将网页上的内容映射到excel表的过程。
2. 2,标记更多内容
重复上一步以标记价格,评论数和商店名称。
第3步:保存规则并采集数据
3. 1,测试采集是否符合期望
单击“测试”按钮以检查信息的完整性。 采集的内容很可能为空,或者收录许多不必要的内容,或者放错了位置,并且采集到达了相邻的内容。然后,您需要重新调整映射关系。如果视觉注释不正确,则可以转到下面的DOM窗口进行内容映射。
3. 2,点击“保存”
只有保存规则,采集器才能执行规则采集数据。以后可以修改规则。
3. 3,点击“采集数据”
单击“保存”按钮旁边的“采集数据”按钮,爬网程序将打开一个新窗口以启动采集数据,并测试采集规则是否有效。除了使用“采集数据”按钮启动采集任务外,还有其他操作方法。有关详细信息,请参考以下“开始数据采集”教程。
第4步:查看数据
4. 1,开始导出过程
请参考上图。 采集完成后,将显示任务状态页面。单击“导出Excel”按钮,将出现一个提示框。点击确定。
4. 2,下载导出的数据
单击导出数据,单击下载,默认情况下它将保存到计算机的下载文件夹中。
下载的文件是一个ZIP包,并放置在计算机的“下载”文件夹中。您可以单击它以将其自解压缩为excel文件。
提醒:仅本教程采集具有第一个产品的数据。要采集此页面上所有产品的数据,请阅读下一篇文章文章“ Web爬网程序采集列表数据”第三步是复制示例采集列表数据。
优采云数据采集原理中的基本流程是怎样的?
采集交流 • 优采云 发表了文章 • 0 个评论 • 271 次浏览 • 2021-03-02 08:04
根据优采云 采集的原理,我们说优采云模拟了人们浏览网络以执行数据采集的行为,例如打开网页,单击按钮等。 优采云 采集器客户端,我们可以自行配置这些流程。
优采云 Data 采集通常具有以下基本过程,其中打开网页和提取数据必不可少,可以根据自己的需要添加或删除其他过程。
1、打开网页
此步骤根据设置的URL打开网页,这通常是网页采集处理的第一步,用于打开指定的网站或网页。如果需要打开多个相似的URL来执行相同的采集流程,则应将它们放在循环中,作为第一步。也就是说,使用URL循环打开网页。
2、点击元素
在此步骤中,用鼠标在网页上的指定元素上执行左键单击操作,例如单击按钮,单击以翻页,单击以跳至其他页面,等等。
3、输入文字
在此步骤中,在输入框中输入指定的文本,例如,输入搜索关键词,输入帐号等。将设置的文本输入到网页的输入框中,例如在使用时输入关键字搜索引擎。
4、循环
此步骤用于重复一系列步骤。根据配置,支持多种循环方法。 1)循环单个元素:循环单击页面上的按钮; 2)循环固定元素列表:循环处理网页中固定数量的元素; 3)循环非固定元素列表:循环处理数量不固定的网页元素; 4)循环URL列表:循环打开具有指定URL的一批网页,然后执行相同的处理步骤; 5)循环文本列表:循环输入一批指定的文本,然后执行相同的处理步骤。
5、提取数据
在此步骤中,根据您自己的需要提取网页中所需的数据字段,然后单击以选择所需的任何字段。除了从网页中提取数据外,您还可以添加特殊字段:当前时间,固定字段,空白字段,当前网页URL等。
完整的采集任务必须收录“提取数据”,并且提取的数据中必须至少有一个字段。否则,程序将在启动采集时报告错误,提示“未配置采集字段”。
此外,优采云的规则市场具有许多已建立的规则,可以直接下载这些规则并将其导入优采云以供使用。
1、如何下载采集条规则
优采云 采集器具有内置的规则市场,用户共享配置的采集规则以互相帮助。使用规则市场下载规则,您无需花费时间研究和配置采集流程。只需下载并运行采集,就可以在规则市场中搜索网站的许多采集规则。
有三种下载规则的方法:打开优采云官方网站()->采集器规则;打开优采云 采集器客户端->市场->采集器规则;直接访问Duoduo()->爬虫规则的官方网站。
2、如何使用规则
通常,从规则市场下载的规则是后缀为.otd的规则文件,并且下载的规则文件将自动以4. *及更高版本导入。在以前的版本中,您需要手动导入下载的规则文件。将下载的规则保存到相应的位置。然后打开优采云客户端->任务->导入->选择任务。通过电子邮件,QQ和微信收到的规则是相同的。
查看全部
优采云数据采集原理中的基本流程是怎样的?
根据优采云 采集的原理,我们说优采云模拟了人们浏览网络以执行数据采集的行为,例如打开网页,单击按钮等。 优采云 采集器客户端,我们可以自行配置这些流程。
优采云 Data 采集通常具有以下基本过程,其中打开网页和提取数据必不可少,可以根据自己的需要添加或删除其他过程。
1、打开网页
此步骤根据设置的URL打开网页,这通常是网页采集处理的第一步,用于打开指定的网站或网页。如果需要打开多个相似的URL来执行相同的采集流程,则应将它们放在循环中,作为第一步。也就是说,使用URL循环打开网页。
2、点击元素
在此步骤中,用鼠标在网页上的指定元素上执行左键单击操作,例如单击按钮,单击以翻页,单击以跳至其他页面,等等。
3、输入文字
在此步骤中,在输入框中输入指定的文本,例如,输入搜索关键词,输入帐号等。将设置的文本输入到网页的输入框中,例如在使用时输入关键字搜索引擎。
4、循环
此步骤用于重复一系列步骤。根据配置,支持多种循环方法。 1)循环单个元素:循环单击页面上的按钮; 2)循环固定元素列表:循环处理网页中固定数量的元素; 3)循环非固定元素列表:循环处理数量不固定的网页元素; 4)循环URL列表:循环打开具有指定URL的一批网页,然后执行相同的处理步骤; 5)循环文本列表:循环输入一批指定的文本,然后执行相同的处理步骤。
5、提取数据
在此步骤中,根据您自己的需要提取网页中所需的数据字段,然后单击以选择所需的任何字段。除了从网页中提取数据外,您还可以添加特殊字段:当前时间,固定字段,空白字段,当前网页URL等。
完整的采集任务必须收录“提取数据”,并且提取的数据中必须至少有一个字段。否则,程序将在启动采集时报告错误,提示“未配置采集字段”。
此外,优采云的规则市场具有许多已建立的规则,可以直接下载这些规则并将其导入优采云以供使用。
1、如何下载采集条规则
优采云 采集器具有内置的规则市场,用户共享配置的采集规则以互相帮助。使用规则市场下载规则,您无需花费时间研究和配置采集流程。只需下载并运行采集,就可以在规则市场中搜索网站的许多采集规则。
有三种下载规则的方法:打开优采云官方网站()->采集器规则;打开优采云 采集器客户端->市场->采集器规则;直接访问Duoduo()->爬虫规则的官方网站。
2、如何使用规则
通常,从规则市场下载的规则是后缀为.otd的规则文件,并且下载的规则文件将自动以4. *及更高版本导入。在以前的版本中,您需要手动导入下载的规则文件。将下载的规则保存到相应的位置。然后打开优采云客户端->任务->导入->选择任务。通过电子邮件,QQ和微信收到的规则是相同的。
免费获取:易得网站数据采集系统免费下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 407 次浏览 • 2020-10-06 08:00
通过编写或下载规则,轻松获得网站数据采集系统通用版本,可以将采集大部分数据采集保存到选定的网站数据采集系统,并保存图片文件。它是构建网站必不可少的数据采集武器。此外,采集器是带有中文注释的开放源代码,便于修改和学习。
采集系统具有以下特征:
使用php + mysql编写的主流语言,只需安装相应的服务器即可。
完全开源-开源代码,并且代码带有中文注释,便于管理,学习和交流。
规则自定义-采集规则可以自定义,网站的大部分内容可以为采集。
数据修改-自定义修改规则以优化数据内容。
数据存储阵列形式,已序列化的数据保存到文件或数据库中,以方便上载和调用。
图像读取-您可以读取内容的图像并将其保存在本地。
编码控制-转换编码,您可以将gb2312,gbk和其他编码保存为utf-8。
标签清除-您可以自定义保留标签并清除不必要的标签。
安全性能-读取由密码控制,远程读取也很安全。
简单操作-一键式读取操作,您可以按规则分组阅读,或者指定要读取的规则ID,并使用单个ID进行读取。
规则分组读取按规则分组的数据,并及时更新采集个数据。
根据自定义规则ID进行自定义的读取和读取数据,这是有效且及时的。
JS阅读-使用js控制阅读时间并减少服务器负载。
超时控制-可以设置页面执行时间以减少超时错误。
多次读取-您可以设置网页的多次读取控件,以更有效地读取数据。
错误控制-如果存在多个错误,您可以停止阅读以减少服务器资源的使用。
将控件保存数据加载到多个文件夹中,可以有效解决多个文件下的服务器负载。
数据修改-不仅可以浏览数据,还可以修改主数据。
规则分析-您可以与他人共享规则,并让更多的人使用它们。
下载规则-下载共享规则以快速获取所需的内容。
查看全部
轻松获取网站数据采集系统免费下载
通过编写或下载规则,轻松获得网站数据采集系统通用版本,可以将采集大部分数据采集保存到选定的网站数据采集系统,并保存图片文件。它是构建网站必不可少的数据采集武器。此外,采集器是带有中文注释的开放源代码,便于修改和学习。
采集系统具有以下特征:
使用php + mysql编写的主流语言,只需安装相应的服务器即可。
完全开源-开源代码,并且代码带有中文注释,便于管理,学习和交流。
规则自定义-采集规则可以自定义,网站的大部分内容可以为采集。
数据修改-自定义修改规则以优化数据内容。
数据存储阵列形式,已序列化的数据保存到文件或数据库中,以方便上载和调用。
图像读取-您可以读取内容的图像并将其保存在本地。
编码控制-转换编码,您可以将gb2312,gbk和其他编码保存为utf-8。
标签清除-您可以自定义保留标签并清除不必要的标签。
安全性能-读取由密码控制,远程读取也很安全。
简单操作-一键式读取操作,您可以按规则分组阅读,或者指定要读取的规则ID,并使用单个ID进行读取。
规则分组读取按规则分组的数据,并及时更新采集个数据。
根据自定义规则ID进行自定义的读取和读取数据,这是有效且及时的。
JS阅读-使用js控制阅读时间并减少服务器负载。
超时控制-可以设置页面执行时间以减少超时错误。
多次读取-您可以设置网页的多次读取控件,以更有效地读取数据。
错误控制-如果存在多个错误,您可以停止阅读以减少服务器资源的使用。
将控件保存数据加载到多个文件夹中,可以有效解决多个文件下的服务器负载。
数据修改-不仅可以浏览数据,还可以修改主数据。
规则分析-您可以与他人共享规则,并让更多的人使用它们。
下载规则-下载共享规则以快速获取所需的内容。
定位标志采集列表数据——以百度旅游为例
采集交流 • 优采云 发表了文章 • 0 个评论 • 586 次浏览 • 2020-08-22 20:02
定位标志采集列表数据——以百度旅游为例
2016-10-20 16:41|发布者: ym|查看: 11347|评论: 4
摘要: 一、操作步骤 之前的教程早已教过如何用样例复制来采集列表数据,除了用样例复制,还可以用定位标志映射来采集列表数据。 下面用百度旅游作为案例来讲解,操作步骤如下: 二、案例规则+操作步骤 采集规则:百度旅游 ...
注:集搜客GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”统一改为“任务”,在爬虫浏览器里先命名任务再创建规则,然后登陆集搜客官网会员中心的“任务管理”里,就可以查看任务的采集执行情况、管理线索网址以及做调度设置了。
一、操作步骤
之前的教程早已教过如何用样例复制来采集列表数据,除了用样例复制,还可以用定位标志映射来采集列表数据。下面用百度旅游作为案例来讲解,操作步骤如下:
二、案例规则+操作步骤
第一步:打开网页
1.1,打开GS爬虫浏览器,输入网址,按Enter键;
1.2,点击“定义规则”按钮;
1.3,输入主题名,再点击“查重”,提示“该名可以使用”,点击OK。
第二步:标注信息
2.1,双击要采集的内容,输入标签名,按Enter键。
2.2,输入整理箱名称。
2.3,重复步骤2.1来标明目的地、行程天数、复制数和浏览数。
2.4,点击标题,勾上关键内容。
第三步:定位标志映射
3.1,找到收录第一个行程的区块节点LI,选中后右击-定位标志映射-列表。
Tips:区块节点须要有class值或id值能够用作定位标志映射,否则只能做样例复制。
3.2,可以看见列表的定位标志栏填上list-item,点击测试在输出结果窗口可以看见多条旅程信息。
第四步:存规则,爬数据
4.1,点击“存规则”,提示保存成功。
4.2,点击“爬数据”就可以开始采集数据。
上篇文章:《定位标志精确采集范围》 下篇文章:《采集图片网址并下载图片》
若有疑问可以或
4
鲜花
握手
雷人
路过
1
鸡蛋
刚表态过的同学 () 查看全部
定位标志采集列表数据——以百度旅游为例
定位标志采集列表数据——以百度旅游为例
2016-10-20 16:41|发布者: ym|查看: 11347|评论: 4
摘要: 一、操作步骤 之前的教程早已教过如何用样例复制来采集列表数据,除了用样例复制,还可以用定位标志映射来采集列表数据。 下面用百度旅游作为案例来讲解,操作步骤如下: 二、案例规则+操作步骤 采集规则:百度旅游 ...
注:集搜客GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”统一改为“任务”,在爬虫浏览器里先命名任务再创建规则,然后登陆集搜客官网会员中心的“任务管理”里,就可以查看任务的采集执行情况、管理线索网址以及做调度设置了。
一、操作步骤
之前的教程早已教过如何用样例复制来采集列表数据,除了用样例复制,还可以用定位标志映射来采集列表数据。下面用百度旅游作为案例来讲解,操作步骤如下:
二、案例规则+操作步骤
第一步:打开网页
1.1,打开GS爬虫浏览器,输入网址,按Enter键;
1.2,点击“定义规则”按钮;
1.3,输入主题名,再点击“查重”,提示“该名可以使用”,点击OK。
第二步:标注信息
2.1,双击要采集的内容,输入标签名,按Enter键。
2.2,输入整理箱名称。
2.3,重复步骤2.1来标明目的地、行程天数、复制数和浏览数。
2.4,点击标题,勾上关键内容。
第三步:定位标志映射
3.1,找到收录第一个行程的区块节点LI,选中后右击-定位标志映射-列表。
Tips:区块节点须要有class值或id值能够用作定位标志映射,否则只能做样例复制。
3.2,可以看见列表的定位标志栏填上list-item,点击测试在输出结果窗口可以看见多条旅程信息。
第四步:存规则,爬数据
4.1,点击“存规则”,提示保存成功。
4.2,点击“爬数据”就可以开始采集数据。
上篇文章:《定位标志精确采集范围》 下篇文章:《采集图片网址并下载图片》
若有疑问可以或
4
鲜花
握手
雷人
路过
1
鸡蛋
刚表态过的同学 ()

