V10及更高数据管家——增强版网络爬虫老版本对应教程
优采云 发布时间: 2021-05-16 20:18V10及更高数据管家——增强版网络爬虫老版本对应教程
支持的软件版本:V10和更高版本的Data Manager-Enhanced Web Crawler
对应的旧版本教程:V9和更低版本。 Jishouke网络抓取工具的相应教程为“ 采集网页数据”
下载并安装了Data Manager之后,我们在Data Manager的浏览器中打开采集页面,单击页面上的鼠标,并将内容标记为采集。此过程称为:使用视觉注释方法定义采集器规则。在本文中,任务和规则是指采集器规则。
注意:本文介绍的视觉注释适用于采集网页上可以看到的内容。如果采集的内容未直接显示在网页上,例如超链接的URL,或者无法用视觉注释准确地标记,则可以使用“内容映射”中说明的方法。
1.步骤(观看视频)
下面以京东网站为例,向您展示如何使用视觉标记的方法定义采集的规则。步骤如下:
2.详细的操作步骤
采集规则:京东数据管家列表的演示规则(点击下载此规则)
示例网址:%E5%86%B0%E7%AE%B1&enc = utf-8&wq =%E5%86%B0%E7%AE%B1&pvid = 2879721c10d54340a16491de943d6886
采集内容:网页上第一个产品的产品标题,价格,评论数和商店名称
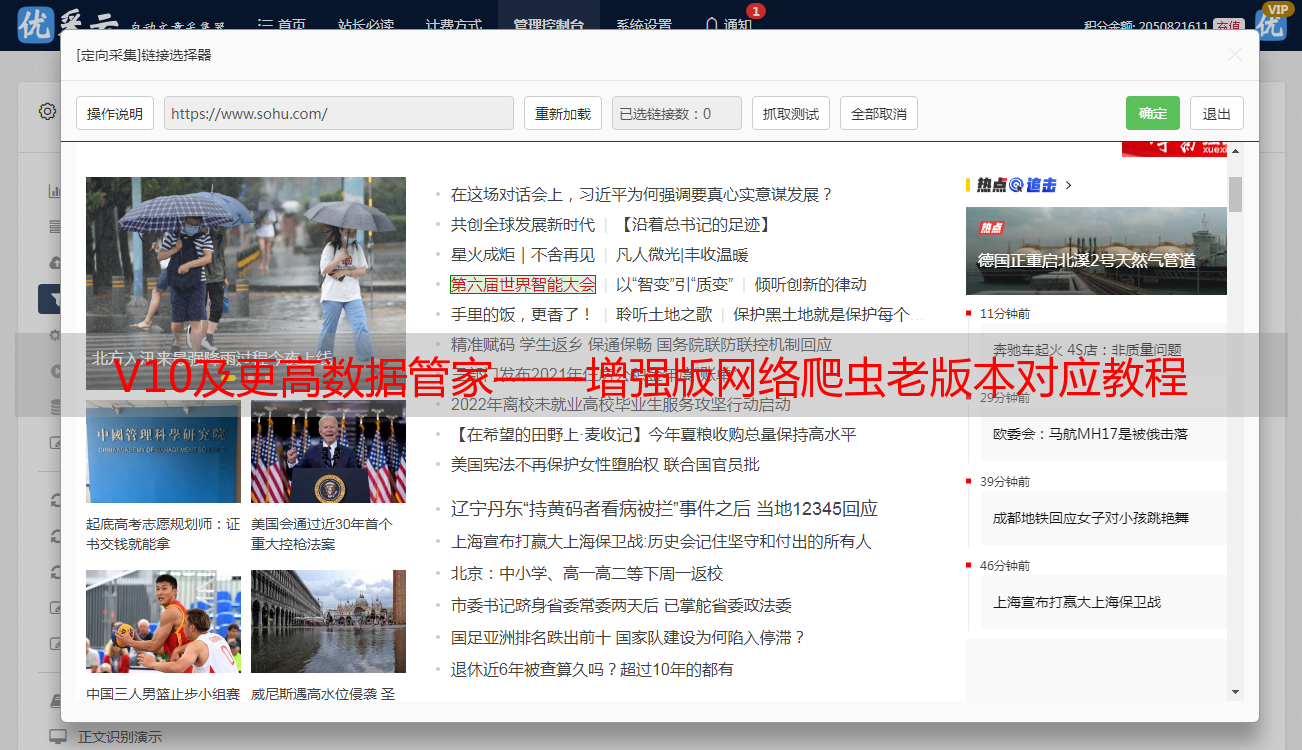
第1步:打开网页
1. 1,加载网页并查看内容为采集
打开数据管理器,输入采集的URL,然后按Enter。加载网页后,首先观察采集的内容是否已完全加载。有些网页很长。如果要在网页底部显示采集内容,请确保拉动网页侧面的滚动条以使网页完全加载,然后创建采集任务。
1. 2,创建采集任务
单击左列顶部的“ +”按钮,然后在显示的左列中看到工作台,输入任务名称。
每个任务必须具有唯一的任务名称。如果新名称与其他人的名称相同,则会在界面上以红色提示您,并且必须更改名称,直到被接受为止。如果使用非常通用的名称,则具有相同名称的可能性很高。建议在名称后添加自己的Jishou帐户名。
第2步:标记需要采集的信息
2. 1,在网页上添加注释
例如,如果我们想要采集网页上第一个产品的标题,请用鼠标单击标题,标题文本将被一个细蓝框包围。
双击产品标题,会弹出一个小窗口,要求此采集内容的字段名称,该字段名称与excel中的字段相对应,在这里,我们输入的字段名称是产品标题。
如果这是创建的第一个采集内容,还将要求您输入表名,该表名与采集输出的excel表相对应,并且表名是自定义的。在采集器软件中,我们通常将此表称为“组织框”,这生动地表明我们正在将Web内容组织到一个框中。
通过此标记过程,Web内容将与爬网程序将来输出的excel表建立映射关系。在以下教程中,“映射”一词将被多次提及。网页内容采集是将网页上的内容映射到excel表的过程。
2. 2,标记更多内容
重复上一步以标记价格,评论数和商店名称。
第3步:保存规则并采集数据
3. 1,测试采集是否符合期望
单击“测试”按钮以检查信息的完整性。 采集的内容很可能为空,或者收录许多不必要的内容,或者放错了位置,并且采集到达了相邻的内容。然后,您需要重新调整映射关系。如果视觉注释不正确,则可以转到下面的DOM窗口进行内容映射。
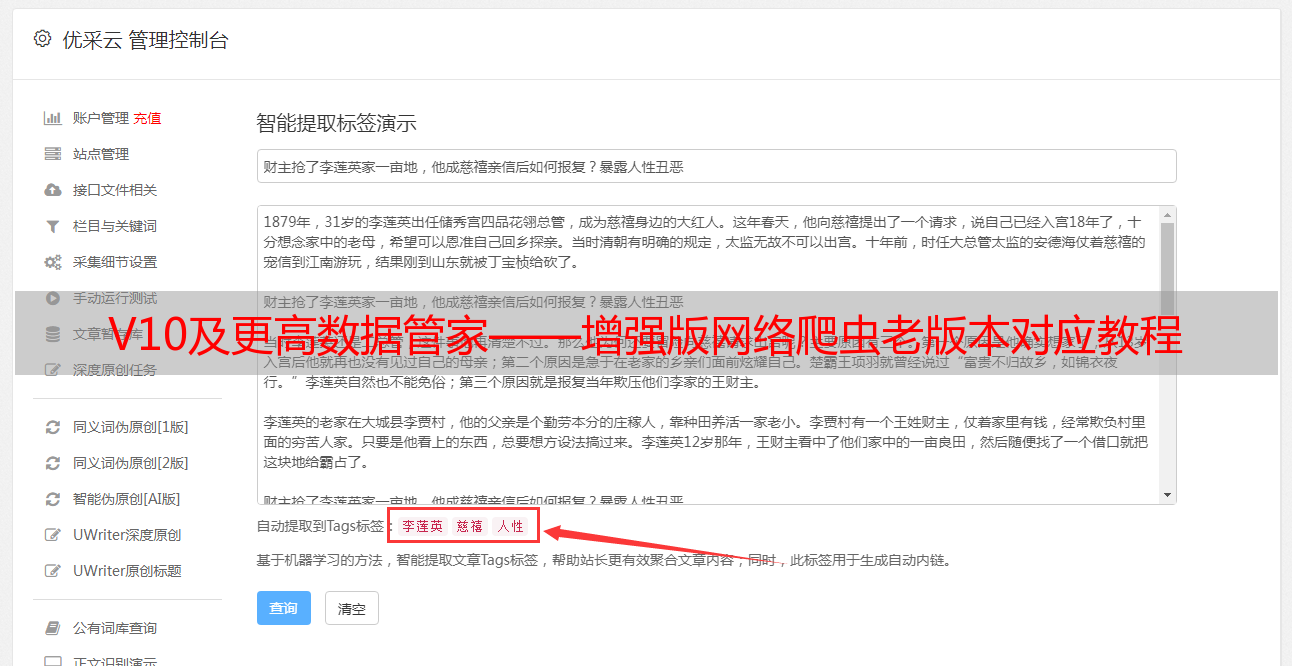
3. 2,点击“保存”
只有保存规则,采集器才能执行规则采集数据。以后可以修改规则。
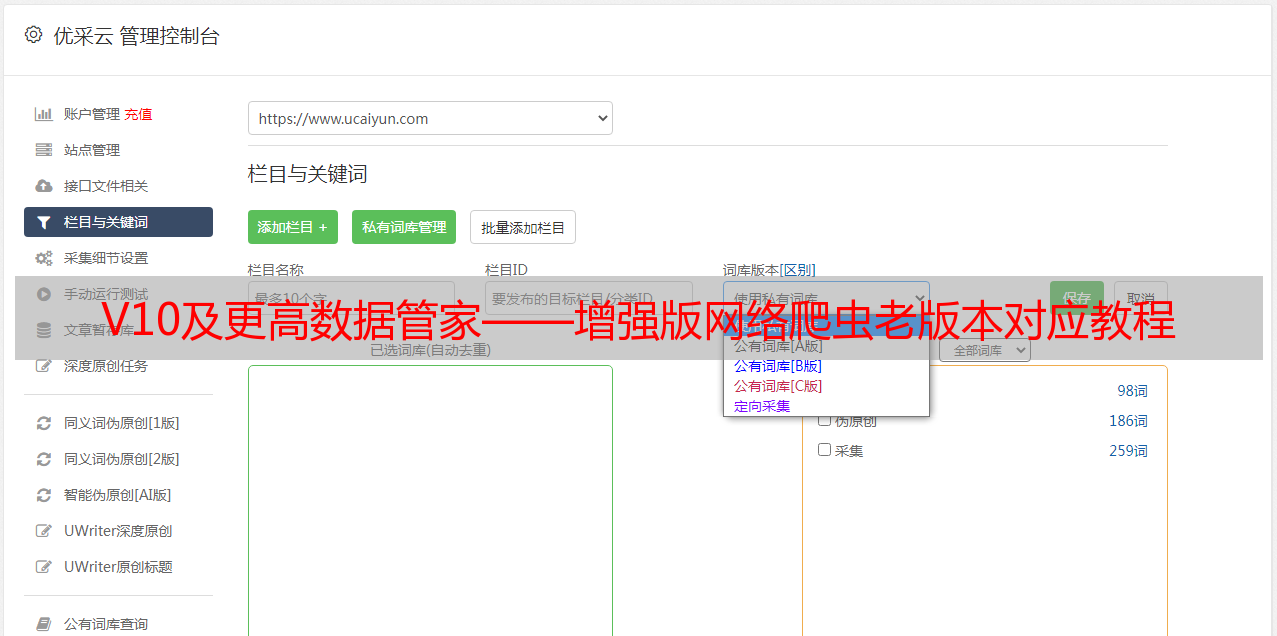
3. 3,点击“采集数据”
单击“保存”按钮旁边的“采集数据”按钮,爬网程序将打开一个新窗口以启动采集数据,并测试采集规则是否有效。除了使用“采集数据”按钮启动采集任务外,还有其他操作方法。有关详细信息,请参考以下“开始数据采集”教程。
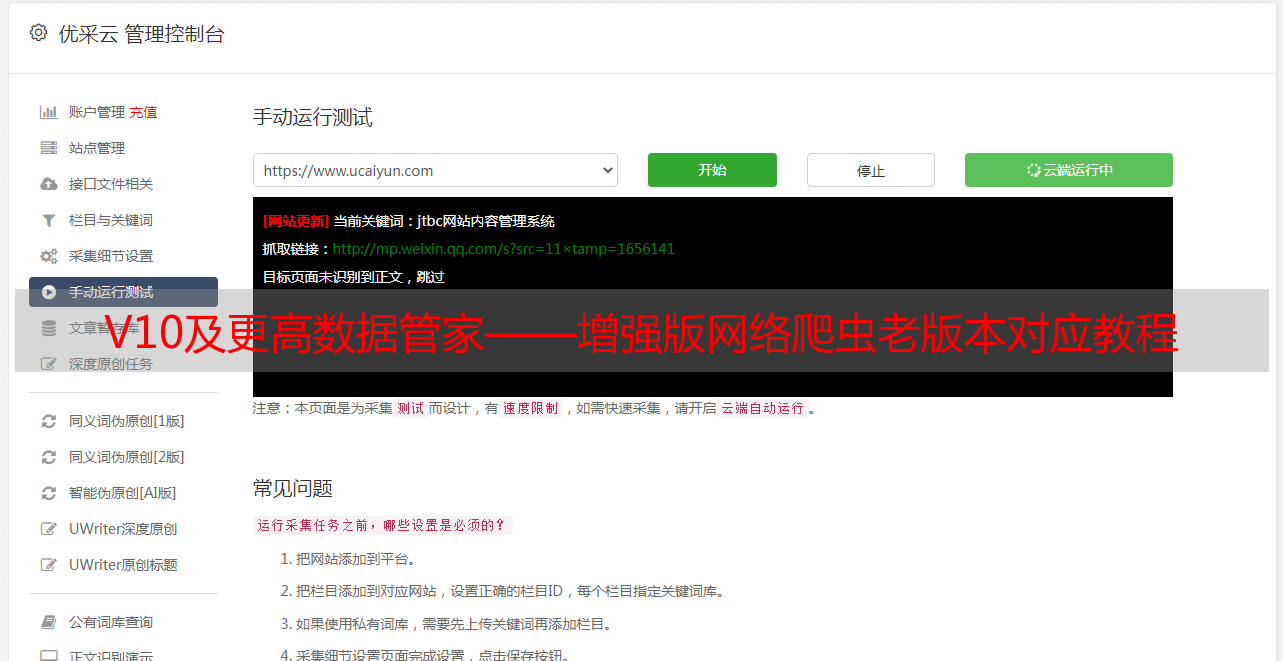
第4步:查看数据
4. 1,开始导出过程
请参考上图。 采集完成后,将显示任务状态页面。单击“导出Excel”按钮,将出现一个提示框。点击确定。
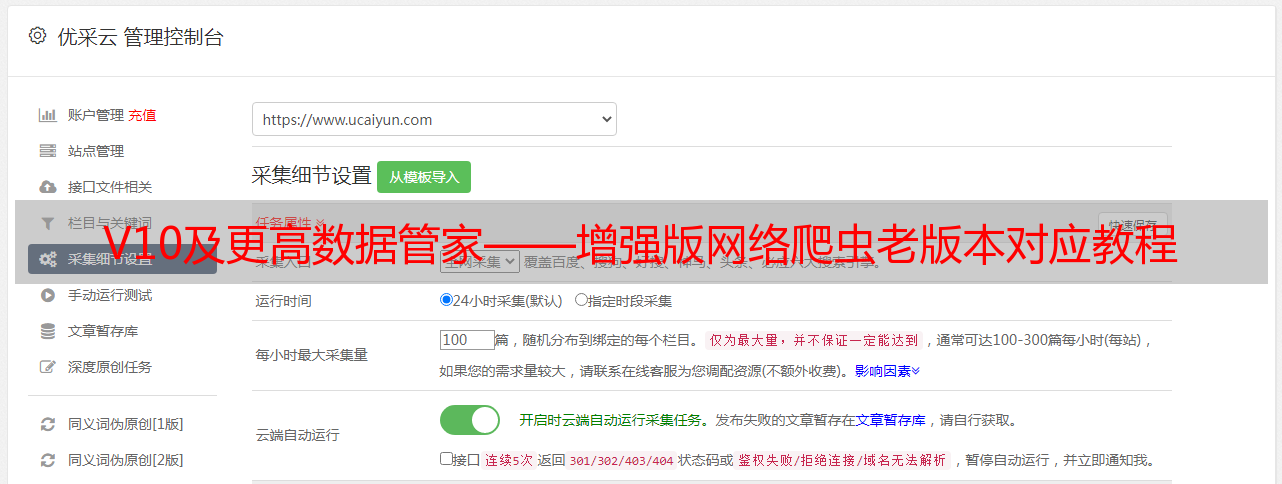
4. 2,下载导出的数据
单击导出数据,单击下载,默认情况下它将保存到计算机的下载文件夹中。
下载的文件是一个ZIP包,并放置在计算机的“下载”文件夹中。您可以单击它以将其自解压缩为excel文件。
提醒:仅本教程采集具有第一个产品的数据。要采集此页面上所有产品的数据,请阅读下一篇文章文章“ Web爬网程序采集列表数据”第三步是复制示例采集列表数据。

