
采集工具
采集工具(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-02-21 11:13
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1、水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,以保证在一个 Agent 故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2、流利的
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3、Logstash
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。
图 3 Logstash 部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
输入 {
文件 {
类型 => “Apache 访问”
路径 =>“/var/log/Apache2/other_vhosts_access.log”
}
文件 {
类型=>“补丁错误”
路径 =>“/var/log/Apache2/error.log”
}
}
筛选 {
摸索{
匹配 => {"消息"=>"%(COMBINEDApacheLOG)"}
}
日期 {
匹配 => {"时间戳"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
输出 {
标准输出 {}
雷迪斯 {
主机="192.168.1.289"
data_type => "列表"
键=>“Logstash”
}
}
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4、楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5、抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6、Splunk
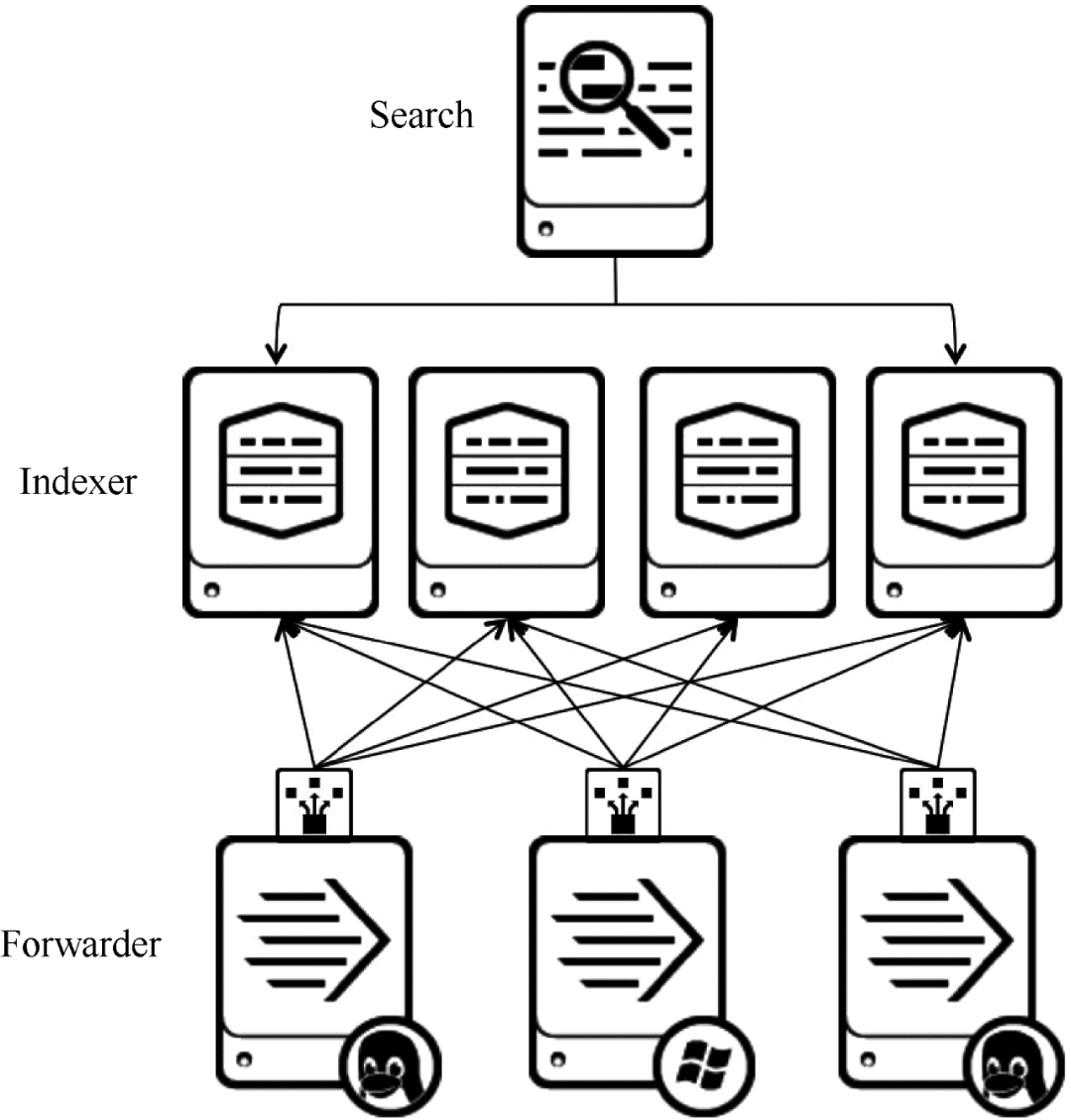
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk的数据平台进行分析.
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7、Scrapy
Python 的爬虫架构称为 Scrapy。Scrapy 是一个使用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
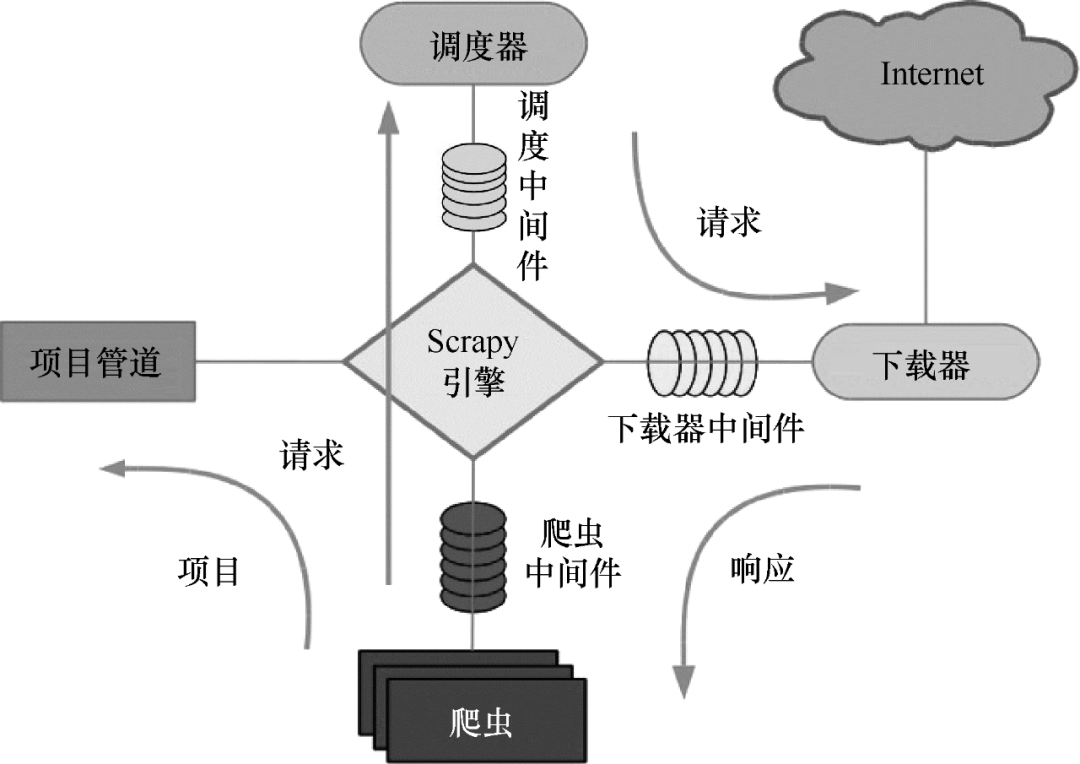
Scrapy的工作原理如图7所示。
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后将其调度为请求。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule 将下一个抓取的 URL 返回给引擎,引擎通过下载中间件将它们发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。 查看全部
采集工具(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1、水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,以保证在一个 Agent 故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2、流利的
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
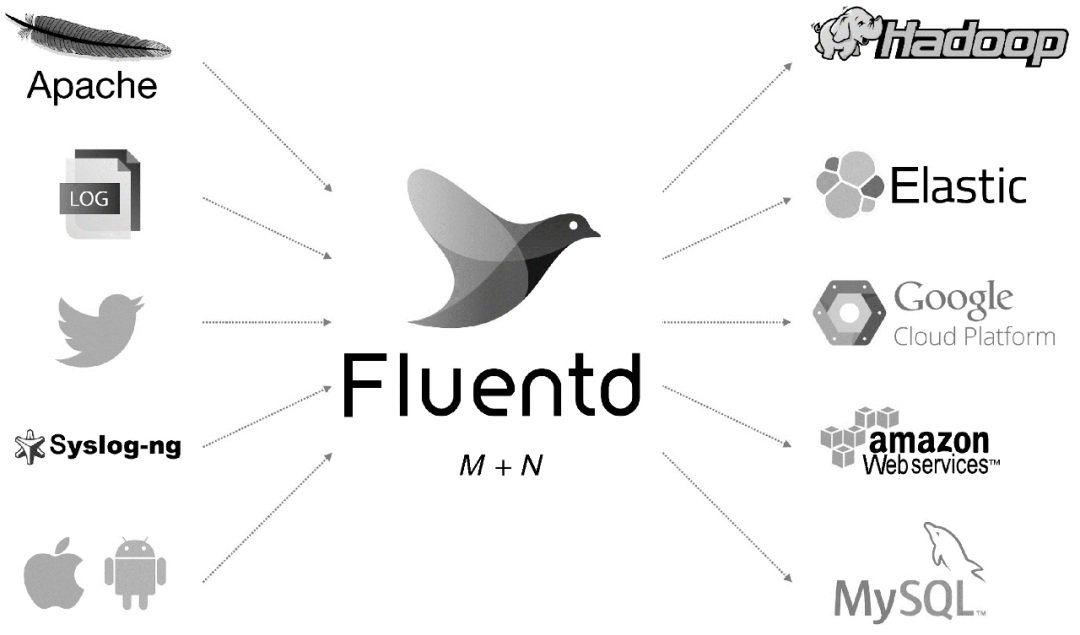
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
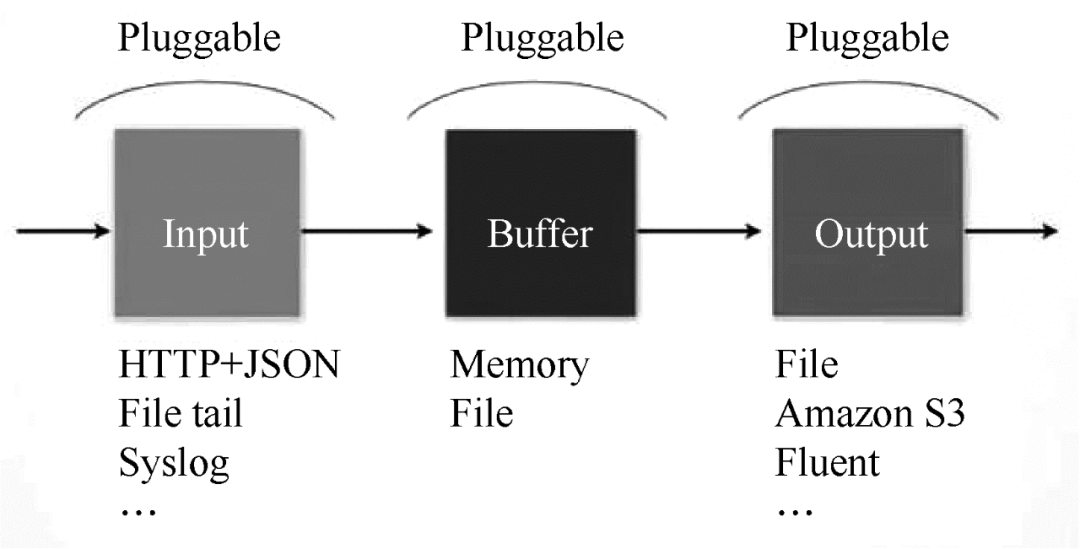
图 2 Fluentd 架构
3、Logstash
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。
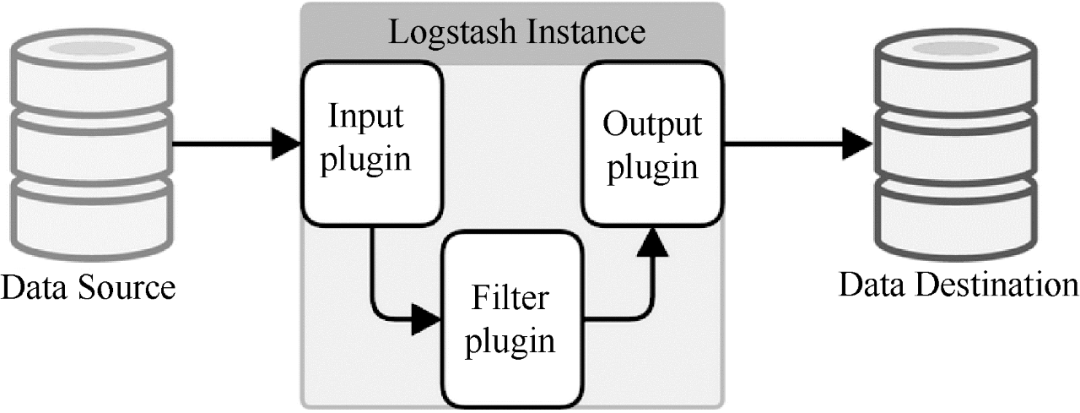
图 3 Logstash 部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
输入 {
文件 {
类型 => “Apache 访问”
路径 =>“/var/log/Apache2/other_vhosts_access.log”
}
文件 {
类型=>“补丁错误”
路径 =>“/var/log/Apache2/error.log”
}
}
筛选 {
摸索{
匹配 => {"消息"=>"%(COMBINEDApacheLOG)"}
}
日期 {
匹配 => {"时间戳"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
输出 {
标准输出 {}
雷迪斯 {
主机="192.168.1.289"
data_type => "列表"
键=>“Logstash”
}
}
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4、楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
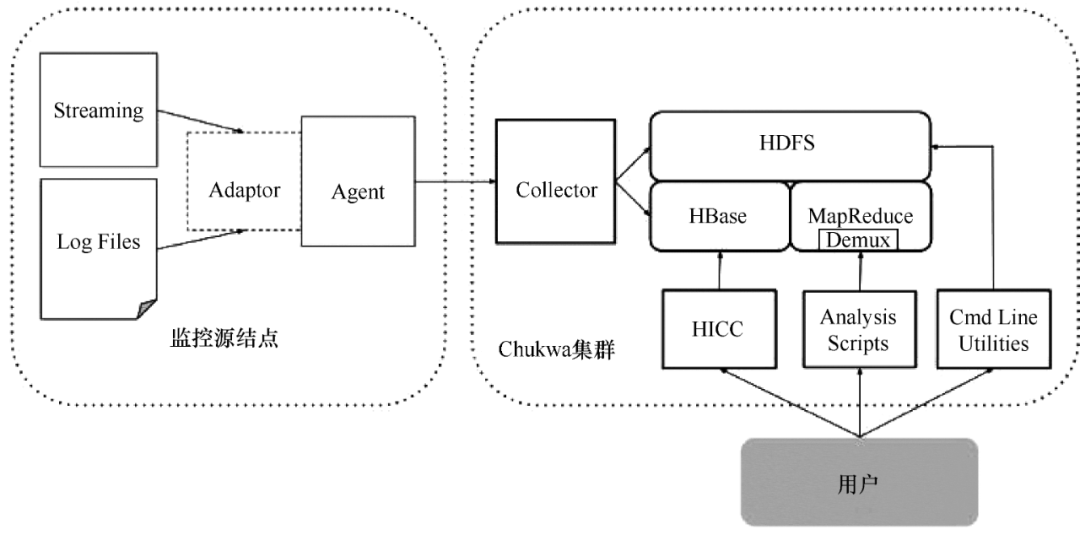
图 4 Chukwa 架构
5、抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
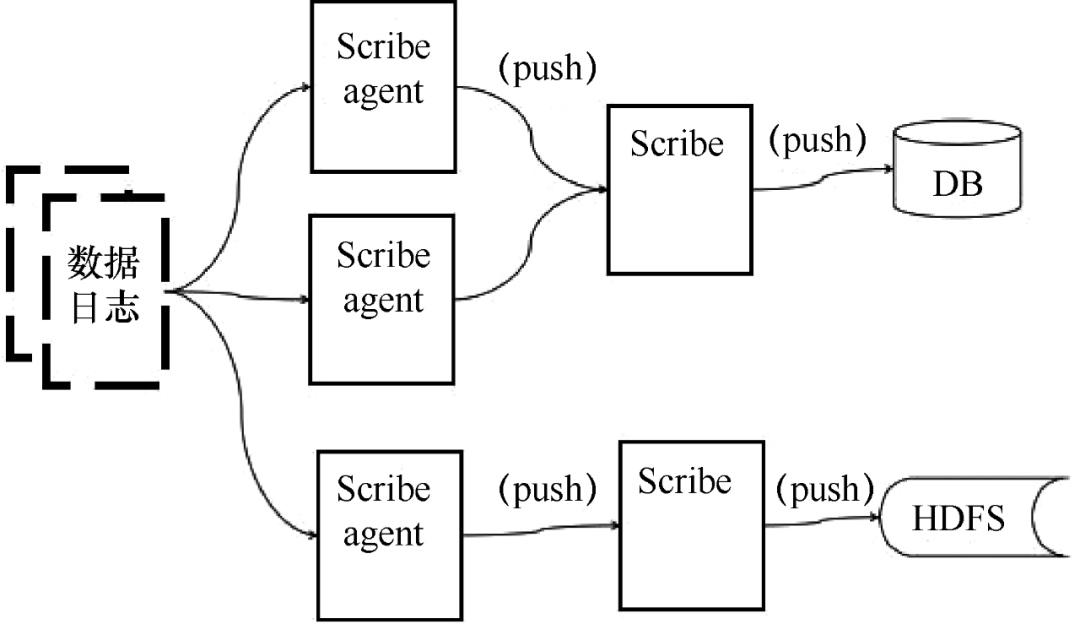
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6、Splunk
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
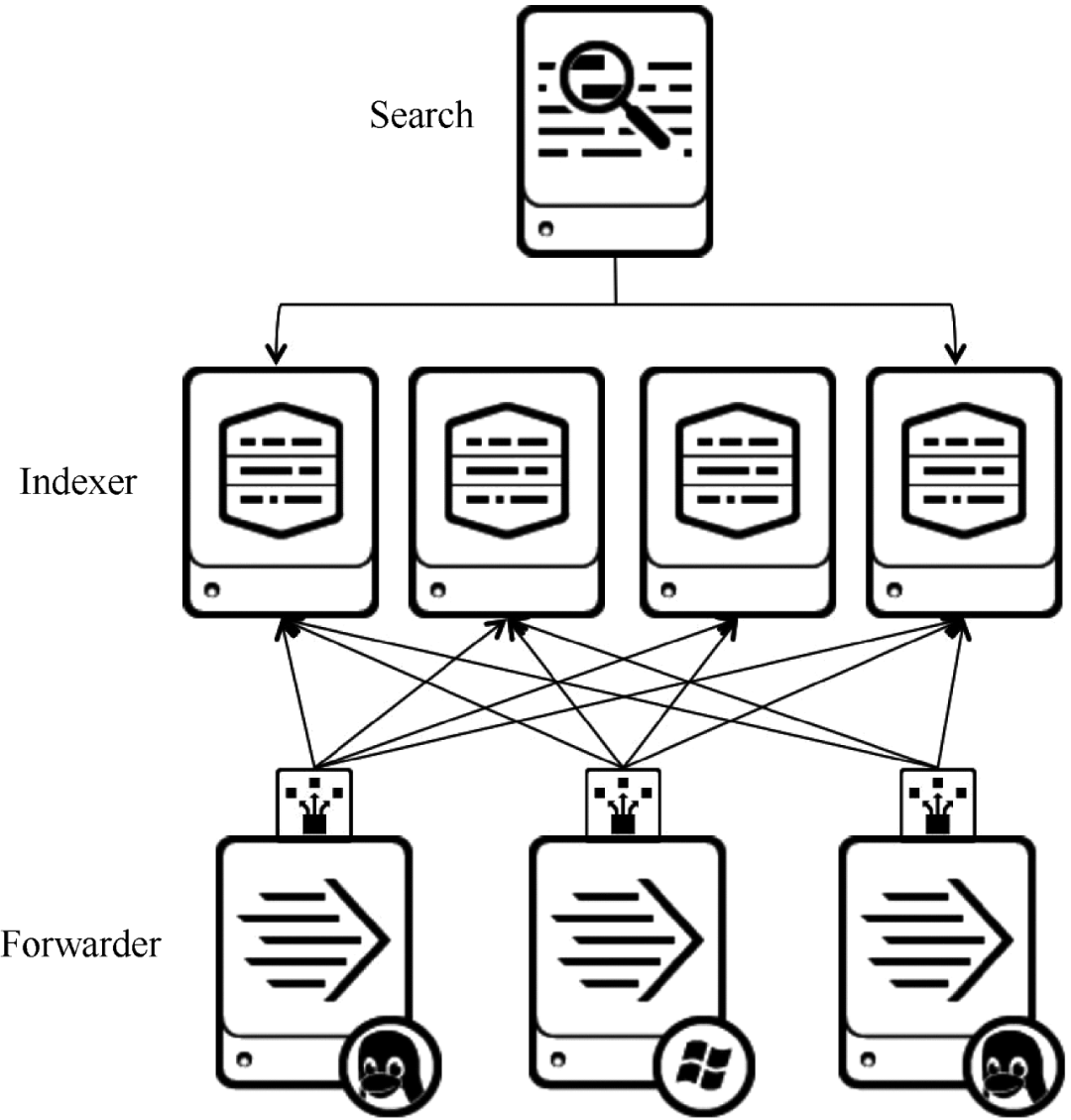
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk的数据平台进行分析.
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7、Scrapy
Python 的爬虫架构称为 Scrapy。Scrapy 是一个使用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
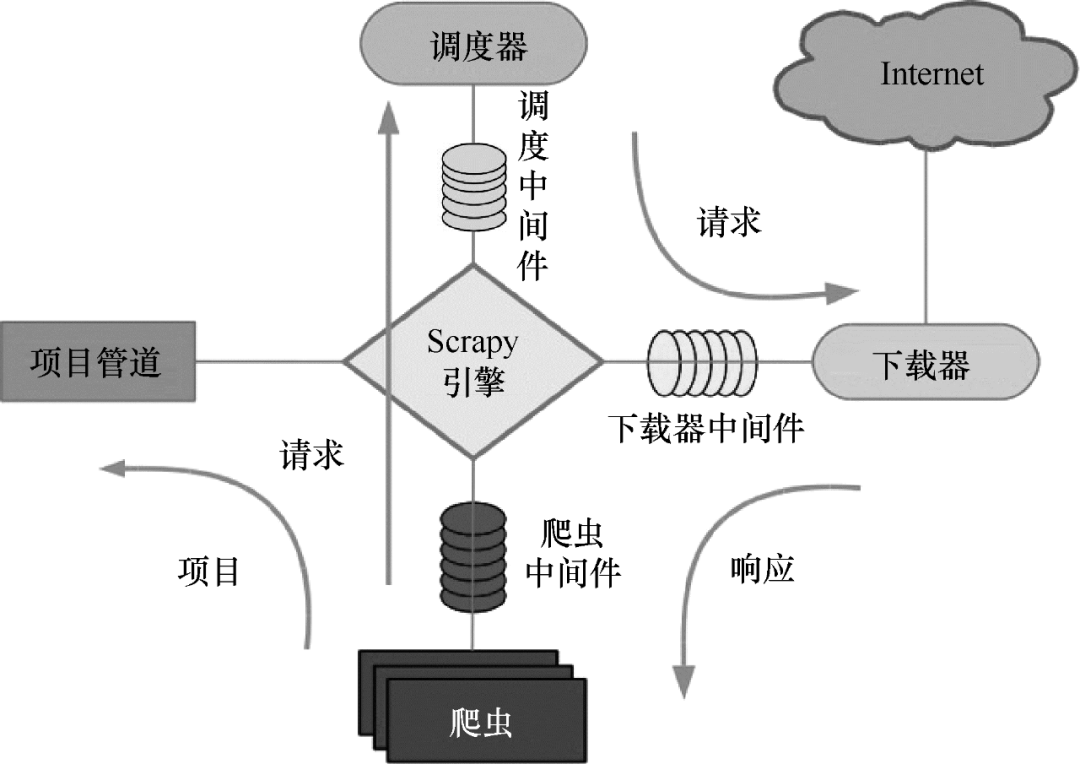
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后将其调度为请求。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule 将下一个抓取的 URL 返回给引擎,引擎通过下载中间件将它们发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
采集工具(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-02-20 17:18
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1个水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,以保证在一个 Agent 故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2流利
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3Logstash
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。
图 3 Logstash 部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
输入 {
文件 {
类型 => “Apache 访问”
路径 =>“/var/log/Apache2/other_vhosts_access.log”
}
文件 {
类型=>“补丁错误”
路径 =>“/var/log/Apache2/error.log”
}
}
筛选 {
摸索{
匹配 => {"消息"=>"%(COMBINEDApacheLOG)"}
}
日期 {
匹配 => {"时间戳"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
输出 {
标准输出 {}
雷迪斯 {
主机="192.168.1.289"
data_type => "列表"
键=>“Logstash”
}
}
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6 斯普伦克
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk数据平台中进行使用分析。
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7 刮擦
Python 的爬虫架构称为 Scrapy。Scrapy 是一个使用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后在调度中将其作为请求调度。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule将下一次爬取的URL返回给引擎,引擎通过下载中间件发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)步骤之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
以上内容摘自《大数据采集与处理》一书。
图书捐赠规则 查看全部
采集工具(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1个水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,以保证在一个 Agent 故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2流利
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
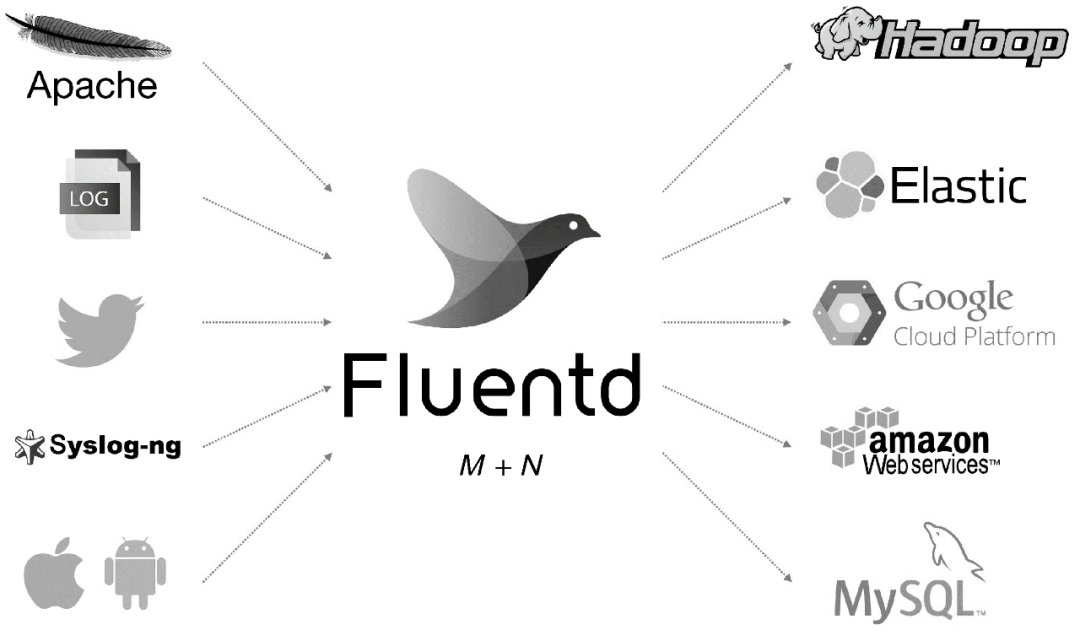
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
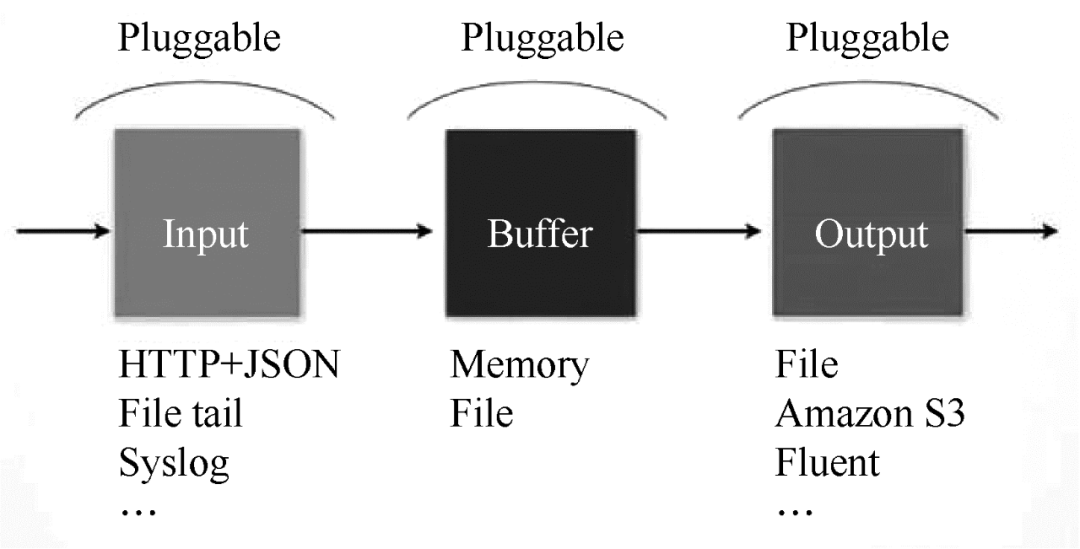
图 2 Fluentd 架构
3Logstash
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。

图 3 Logstash 部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
输入 {
文件 {
类型 => “Apache 访问”
路径 =>“/var/log/Apache2/other_vhosts_access.log”
}
文件 {
类型=>“补丁错误”
路径 =>“/var/log/Apache2/error.log”
}
}
筛选 {
摸索{
匹配 => {"消息"=>"%(COMBINEDApacheLOG)"}
}
日期 {
匹配 => {"时间戳"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
输出 {
标准输出 {}
雷迪斯 {
主机="192.168.1.289"
data_type => "列表"
键=>“Logstash”
}
}
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
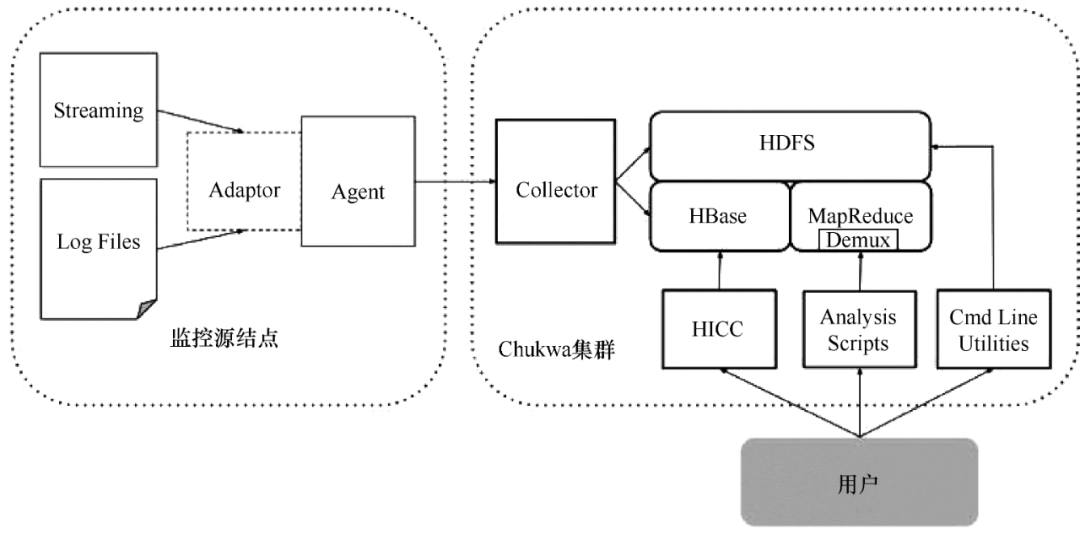
图 4 Chukwa 架构
5抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。

图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6 斯普伦克
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
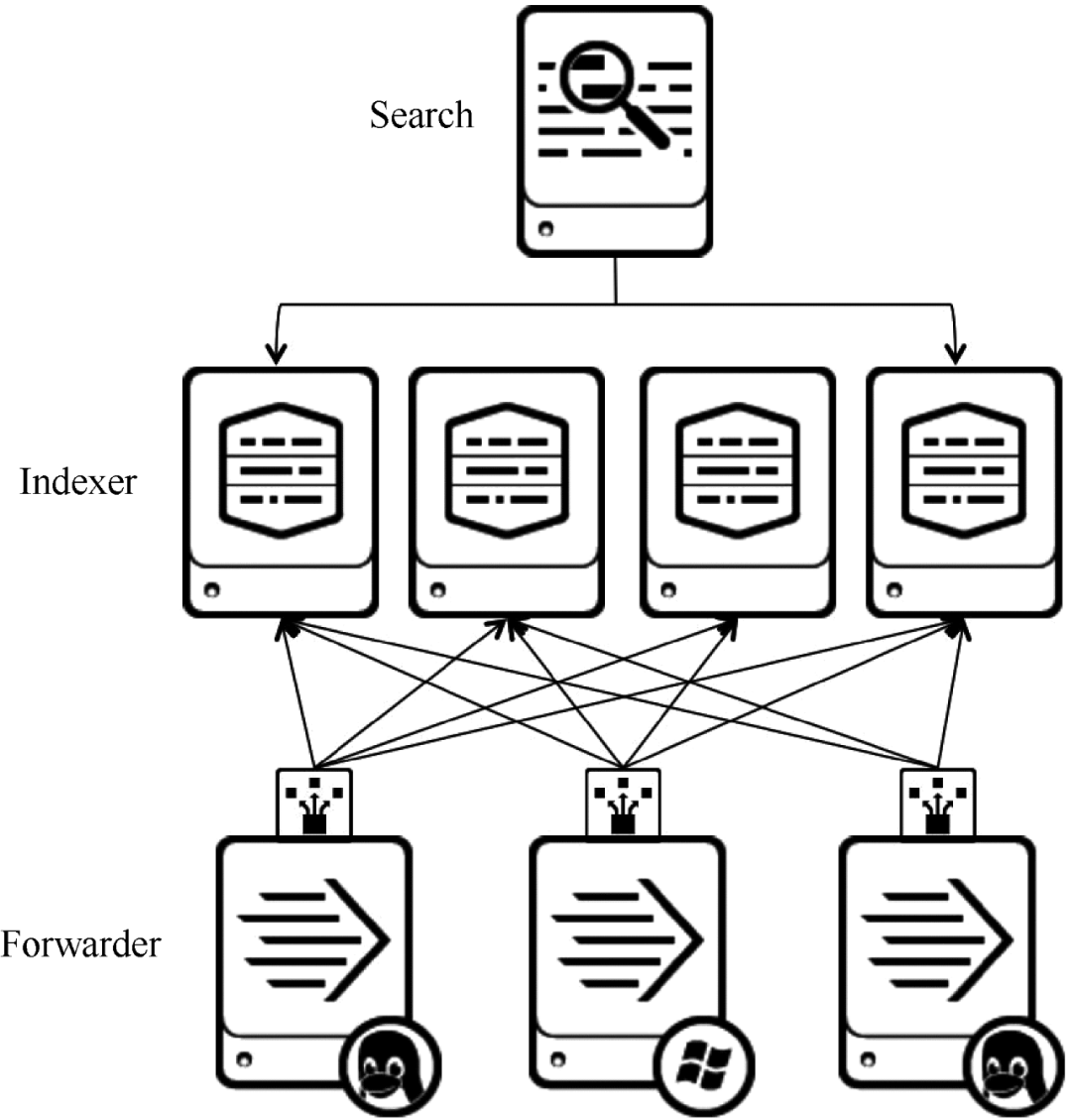
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk数据平台中进行使用分析。
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7 刮擦
Python 的爬虫架构称为 Scrapy。Scrapy 是一个使用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
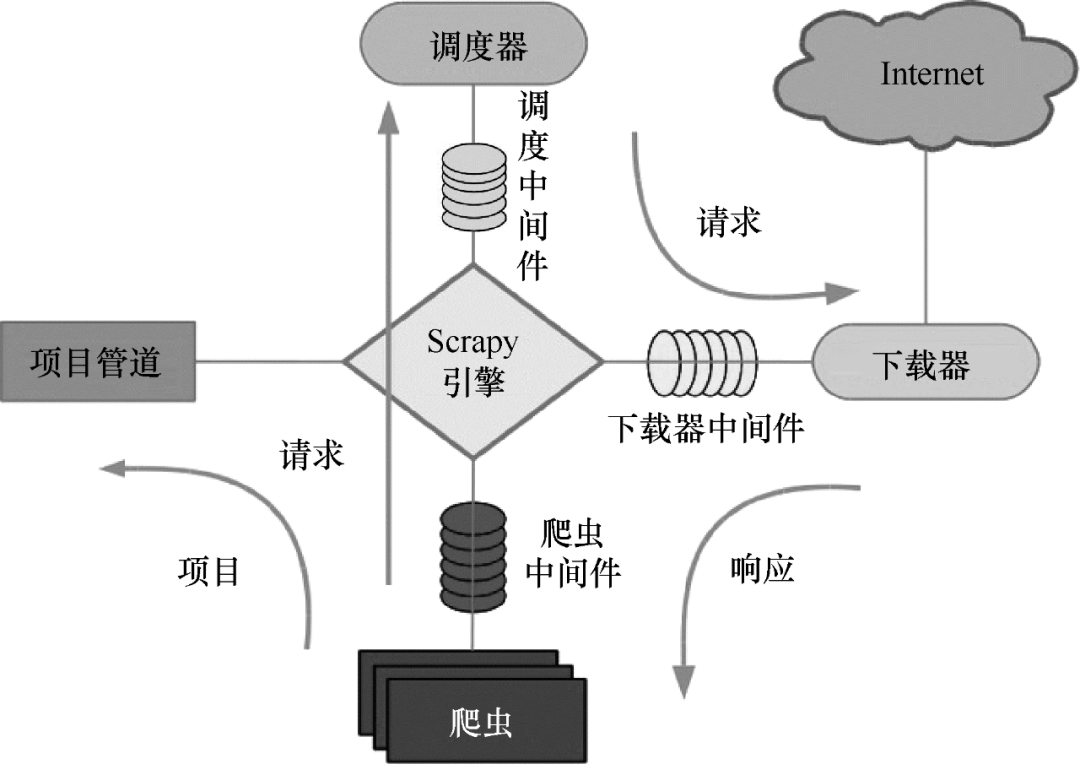
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后在调度中将其作为请求调度。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule将下一次爬取的URL返回给引擎,引擎通过下载中间件发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)步骤之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
以上内容摘自《大数据采集与处理》一书。

图书捐赠规则
采集工具(微博热热搜词采集结果采集步骤介绍及详细步骤详解)
采集交流 • 优采云 发表了文章 • 0 个评论 • 272 次浏览 • 2022-02-10 13:24
采集场景
在微博热搜榜()上,可以实时查看微博热搜排名、热搜关键词和热搜号。点击各个热搜关键词,进入其相关微博列表页面。我们需要采集上面的数据。
采集字段
微博热搜排名、热搜关键词、热搜数、账号、发布内容、发布时间、来源、转发数、评论数、点赞数、采集时间、页面网址。
将鼠标放在图像上,单击鼠标右键,然后选择[在新选项卡中打开图像]以查看高分辨率大图
下面的其他图片也是如此
采集结果
采集结果可以导出为Excel、CSV、HTML、数据库等格式。导出到 Excel 示例:
教程说明
本文制作时间:2020/4/26优采云版本:V8.1.8
如因网页改版导致网站或步骤失效,无法采集目标数据,请联系官方客服,我们会及时更正。
采集步骤
Step一、打开网页,使用【智能识别】生成规则
步骤二、创建一个【循环列表】,采集所有微博列表中的数据
Step三、修改[loop]的XPath,去除冗余列表
步骤四、修改字段的XPath以准确采集所有字段
Step 五、 创建【循环点击元素】,展开微博全文
步骤六、开始采集
以下是具体步骤:
Step一、打开网页,使用【智能识别】生成规则
1、自动识别热搜词列表
在首页输入微博热搜榜网址,点击【开始采集】,优采云会自动打开网页。
点击【自动识别网页】,成功识别微博热搜榜中的榜单数据。
2、点击各个热搜词链接跳转到其相关微博列表页面
在【操作提示】框中,勾选“点击列表中的关键词_链接和采集下一级页面”跳转到其相关的微博列表页面。
3、生成采集 进程
点击【生成采集设置】,自动识别的列表数据和翻页都会生成为采集进程,方便我们使用和修改。
同时会跳转到第一个热搜词相关的微博列表页面。
步骤二、创建一个【循环列表】,采集所有微博列表中的数据
1、创建一个[循环列表]
通过以下3个连续步骤,创建一个【循环列表】,采集所有微博列表中的数据
① 在页面上选择一个微博列表,包括所有字段(微博是一个特殊页面,不能直接选择整个微博列表,可以先选择一个较小的范围,然后在操作提示框中连续点击
按钮,直到所选区域扩展到整个列表,在示例中单击了两次
按钮)
②继续在页面选择1条微博列表,包括所有字段(同①)
③ 点击【采集下面的元素文字】
特别说明:
一个。经过以上3个连续步骤,【循环提取数据】就创建完成了。[圈子]中的项目对应页面上的所有微博列表。但这会将整个列表提取为一个字段。如果需要单独提取字段,请看下面的操作。
湾。为什么可以通过以上3个步骤建立【Cycle-Extract Data】?点击查看更多细节
C。选择范围后,在操作提示框中,点击
按钮将所选图层扩大一层。您可以连续单击多次,每次单击都会将所选范围扩大一级。
2、提取微博列表中的字段
在循环的当前项(红框)中,选择文本,在操作提示框中,选择[采集本元素文本]。
可以通过这种方式提取所有文本字段。在该示例中,提取了帐号、发布内容、发布时间、来源、转发次数、评论数、点赞数、当前采集时间和页面URL等字段。
特别说明:
一个。请注意,该字段必须从循环的当前项中提取出来(当前项将用红色框起来),以形成与循环的链接。否则会重复某条特定的数据采集,无法与循环链接。
3、提取特殊字段,编辑字段
在【当前数据页面预览】中,点击【+】按钮,提取采集时间和页面URL。
进入【提取列表数据】设置页面,可以删除冗余字段、修改字段名称、移动字段顺序等。
4、格式化数据
[转发次数] 和 [评论次数] 这两个字段是特殊的。默认提取的内容与表头有重复,可以通过格式化数据去除重复。
如果您不介意重复,则可以跳过此步骤。
[转发次数] 格式:点击后面的字段
按钮,选择【格式化数据】→点击【添加步骤】→【正则表达式匹配】,输入正则表达式[0-9]+,保存。仅匹配数字,并删除前面的 [forward]。 查看全部
采集工具(微博热热搜词采集结果采集步骤介绍及详细步骤详解)
采集场景
在微博热搜榜()上,可以实时查看微博热搜排名、热搜关键词和热搜号。点击各个热搜关键词,进入其相关微博列表页面。我们需要采集上面的数据。
采集字段
微博热搜排名、热搜关键词、热搜数、账号、发布内容、发布时间、来源、转发数、评论数、点赞数、采集时间、页面网址。
将鼠标放在图像上,单击鼠标右键,然后选择[在新选项卡中打开图像]以查看高分辨率大图
下面的其他图片也是如此
采集结果
采集结果可以导出为Excel、CSV、HTML、数据库等格式。导出到 Excel 示例:
教程说明
本文制作时间:2020/4/26优采云版本:V8.1.8
如因网页改版导致网站或步骤失效,无法采集目标数据,请联系官方客服,我们会及时更正。
采集步骤
Step一、打开网页,使用【智能识别】生成规则
步骤二、创建一个【循环列表】,采集所有微博列表中的数据
Step三、修改[loop]的XPath,去除冗余列表
步骤四、修改字段的XPath以准确采集所有字段
Step 五、 创建【循环点击元素】,展开微博全文
步骤六、开始采集
以下是具体步骤:
Step一、打开网页,使用【智能识别】生成规则
1、自动识别热搜词列表
在首页输入微博热搜榜网址,点击【开始采集】,优采云会自动打开网页。
点击【自动识别网页】,成功识别微博热搜榜中的榜单数据。
2、点击各个热搜词链接跳转到其相关微博列表页面
在【操作提示】框中,勾选“点击列表中的关键词_链接和采集下一级页面”跳转到其相关的微博列表页面。
3、生成采集 进程
点击【生成采集设置】,自动识别的列表数据和翻页都会生成为采集进程,方便我们使用和修改。
同时会跳转到第一个热搜词相关的微博列表页面。
步骤二、创建一个【循环列表】,采集所有微博列表中的数据
1、创建一个[循环列表]
通过以下3个连续步骤,创建一个【循环列表】,采集所有微博列表中的数据
① 在页面上选择一个微博列表,包括所有字段(微博是一个特殊页面,不能直接选择整个微博列表,可以先选择一个较小的范围,然后在操作提示框中连续点击
按钮,直到所选区域扩展到整个列表,在示例中单击了两次
按钮)
②继续在页面选择1条微博列表,包括所有字段(同①)
③ 点击【采集下面的元素文字】
特别说明:
一个。经过以上3个连续步骤,【循环提取数据】就创建完成了。[圈子]中的项目对应页面上的所有微博列表。但这会将整个列表提取为一个字段。如果需要单独提取字段,请看下面的操作。
湾。为什么可以通过以上3个步骤建立【Cycle-Extract Data】?点击查看更多细节
C。选择范围后,在操作提示框中,点击
按钮将所选图层扩大一层。您可以连续单击多次,每次单击都会将所选范围扩大一级。
2、提取微博列表中的字段
在循环的当前项(红框)中,选择文本,在操作提示框中,选择[采集本元素文本]。
可以通过这种方式提取所有文本字段。在该示例中,提取了帐号、发布内容、发布时间、来源、转发次数、评论数、点赞数、当前采集时间和页面URL等字段。
特别说明:
一个。请注意,该字段必须从循环的当前项中提取出来(当前项将用红色框起来),以形成与循环的链接。否则会重复某条特定的数据采集,无法与循环链接。
3、提取特殊字段,编辑字段
在【当前数据页面预览】中,点击【+】按钮,提取采集时间和页面URL。
进入【提取列表数据】设置页面,可以删除冗余字段、修改字段名称、移动字段顺序等。
4、格式化数据
[转发次数] 和 [评论次数] 这两个字段是特殊的。默认提取的内容与表头有重复,可以通过格式化数据去除重复。
如果您不介意重复,则可以跳过此步骤。
[转发次数] 格式:点击后面的字段
按钮,选择【格式化数据】→点击【添加步骤】→【正则表达式匹配】,输入正则表达式[0-9]+,保存。仅匹配数字,并删除前面的 [forward]。
采集工具(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-01-30 02:20
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1、水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,保证在一个 Agent 发生故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2、流利的
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3、Logstash
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。
图3 Logstash的部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
输入{文件{类型=>“Apache-access”路径=>“/var/log/Apache2/other\_vhosts\_access.log”}文件{类型=>“pache-error”路径=>“/var/log /Apache2/error.log" } } filter { grok { match => {"message"=>"%(COMBINEDApacheLOG)"} } date { match => {"timestamp"=>"dd/MMM/yyyy:HH: mm:ss Z"} } } 输出 { 标准输出 {} Redis { host=>"192.168.1.289" data\_type => "list" key => "日志存储" } }
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4、楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5、抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6、Splunk
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
图片
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk数据平台中进行使用分析。
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7、Scrapy
Python 的爬虫架构称为 Scrapy。Scrapy 是一个用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后将其调度为请求。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule 将下一个抓取的 URL 返回给引擎,引擎通过下载中间件将它们发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
【声明】本文版权归原作者所有,内容为作者个人观点。转载的目的是为了传达更多信息。如涉及作品内容、版权等问题,可联系本站删除,谢谢。 查看全部
采集工具(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1、水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,保证在一个 Agent 发生故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2、流利的
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
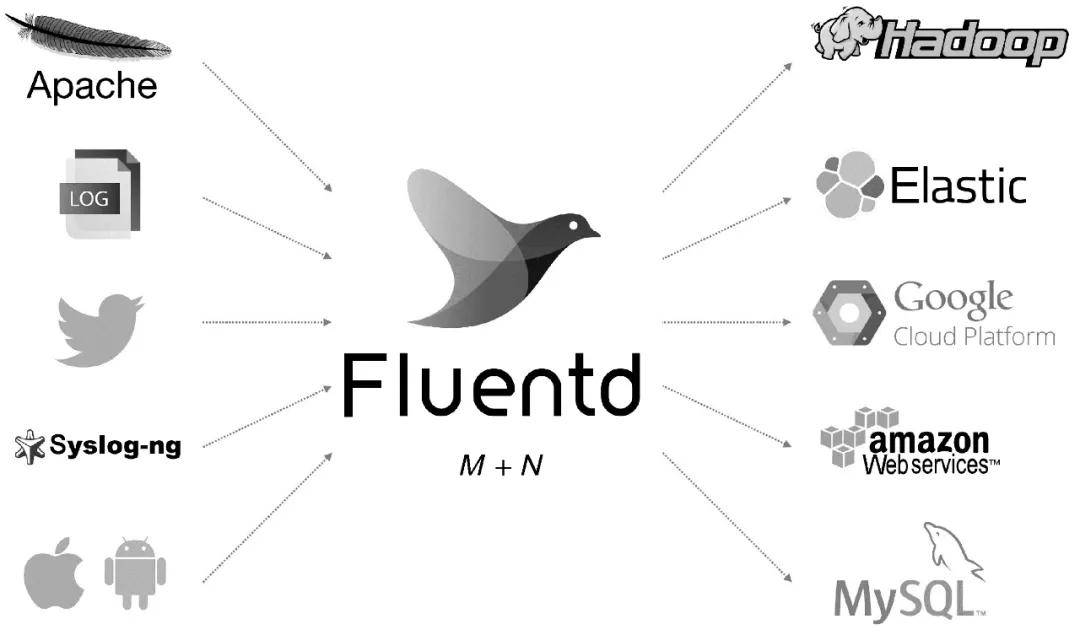
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
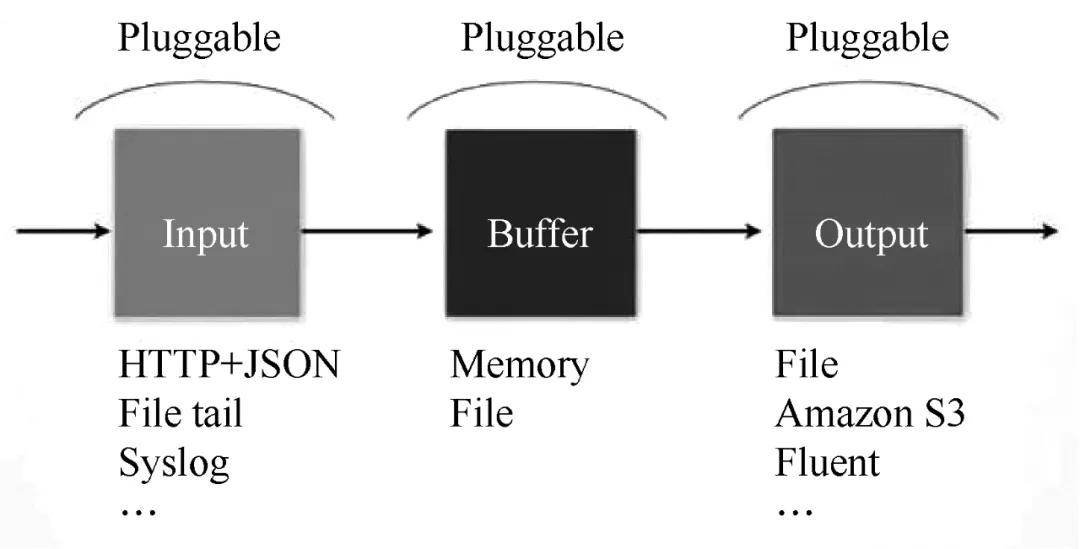
图 2 Fluentd 架构
3、Logstash
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。

图3 Logstash的部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
输入{文件{类型=>“Apache-access”路径=>“/var/log/Apache2/other\_vhosts\_access.log”}文件{类型=>“pache-error”路径=>“/var/log /Apache2/error.log" } } filter { grok { match => {"message"=>"%(COMBINEDApacheLOG)"} } date { match => {"timestamp"=>"dd/MMM/yyyy:HH: mm:ss Z"} } } 输出 { 标准输出 {} Redis { host=>"192.168.1.289" data\_type => "list" key => "日志存储" } }
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4、楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。

图 4 Chukwa 架构
5、抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
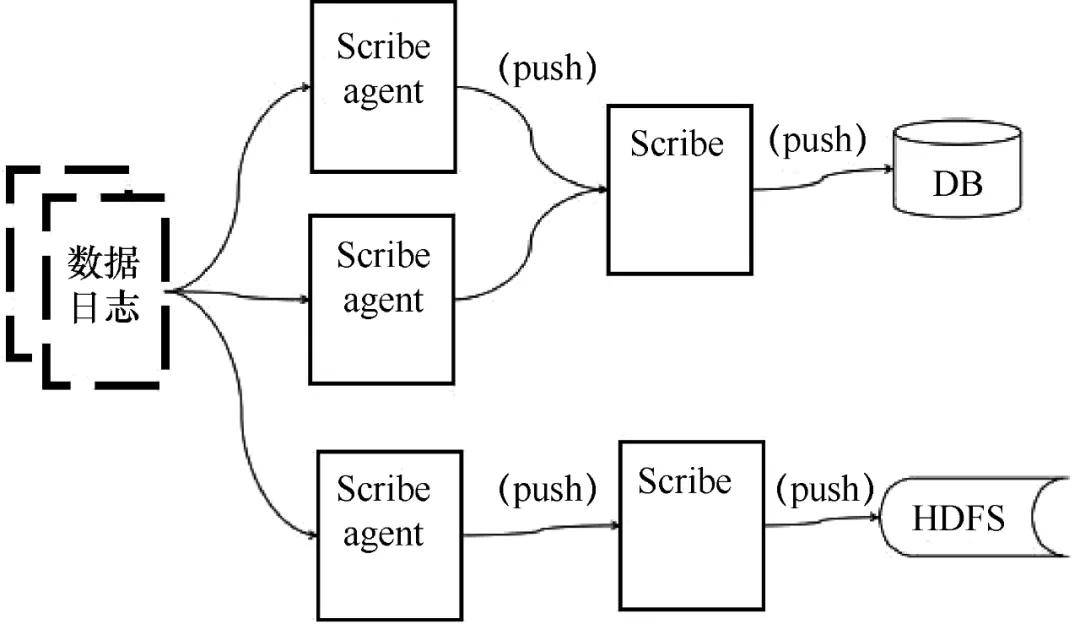
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6、Splunk
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
图片

图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk数据平台中进行使用分析。
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7、Scrapy
Python 的爬虫架构称为 Scrapy。Scrapy 是一个用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。

图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后将其调度为请求。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule 将下一个抓取的 URL 返回给引擎,引擎通过下载中间件将它们发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
【声明】本文版权归原作者所有,内容为作者个人观点。转载的目的是为了传达更多信息。如涉及作品内容、版权等问题,可联系本站删除,谢谢。
采集工具(维护网站自动抓取规则的四个部分1个网站要好几个人才可以)
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-01-30 02:00
采集工具很多啊,我经常使用iptracker,它可以自动抓取网站所有页面。还有crawler,也是一样的功能。现在我们要针对一个网站有效抓取,其实蛮简单的,毕竟我们现在看到的不是所有页面都收录了,所以我们可以去维护自己网站自动抓取规则,现在有很多爬虫软件可以用。
四个部分1一个网站三个人就可以2一个网站一个人就可以3一个网站要好几个人才可以4一个网站如果不是美国站基本没人要还需要就是维护流量这个时候就看你手下人手了
你看看自己公司还缺什么?比如科技或者传媒方面的网站,那就找一些公司或者公司旗下的网站过来就好了,
1个人就可以很简单的搞定如果是美国站,别的国家就需要开发好客户端和后台,
你自己的站,找有稳定流量的公司,找好网站文件,买一个onlineserver每天自动抓取,因为这种需要在短时间内抓取大量的网站,不然收录慢了就要挂掉,
一个人在家,测速仪按照多个ip记录,找出每个ip的人,不要太多。一台手机,一条网线就可以搞定。如果价格可以接受就可以考虑下建站,毕竟现在流量那么贵,维护也需要人。
深圳的话试试土建课堂吧!他们家的网站速度非常快,很多公司都在他们家买的域名、空间、服务器。 查看全部
采集工具(维护网站自动抓取规则的四个部分1个网站要好几个人才可以)
采集工具很多啊,我经常使用iptracker,它可以自动抓取网站所有页面。还有crawler,也是一样的功能。现在我们要针对一个网站有效抓取,其实蛮简单的,毕竟我们现在看到的不是所有页面都收录了,所以我们可以去维护自己网站自动抓取规则,现在有很多爬虫软件可以用。
四个部分1一个网站三个人就可以2一个网站一个人就可以3一个网站要好几个人才可以4一个网站如果不是美国站基本没人要还需要就是维护流量这个时候就看你手下人手了
你看看自己公司还缺什么?比如科技或者传媒方面的网站,那就找一些公司或者公司旗下的网站过来就好了,
1个人就可以很简单的搞定如果是美国站,别的国家就需要开发好客户端和后台,
你自己的站,找有稳定流量的公司,找好网站文件,买一个onlineserver每天自动抓取,因为这种需要在短时间内抓取大量的网站,不然收录慢了就要挂掉,
一个人在家,测速仪按照多个ip记录,找出每个ip的人,不要太多。一台手机,一条网线就可以搞定。如果价格可以接受就可以考虑下建站,毕竟现在流量那么贵,维护也需要人。
深圳的话试试土建课堂吧!他们家的网站速度非常快,很多公司都在他们家买的域名、空间、服务器。
采集工具(掌控安全-Yao谷歌url采集工具批量导入关键词采集url)
采集交流 • 优采云 发表了文章 • 0 个评论 • 346 次浏览 • 2022-01-29 02:11
【图文并茂】2021年3月3日-神马url采集tools google url采集tools批量导入关键词采集url,不限采集的层数,可去重,可根据条件过滤无用URL,帮助您快速获取大量某类URL...[图文]2020年9月21日-Url采集@ >该工具是一款非常实用的url批量采集脚本工具,软件可以帮助用户... 另外,Url采集器免费版还可以对单个URL执行采集 ,非常全面。七夕下载... 2021年2月27日 - 优采云关键词URL采集器可以根据关键词搜索百度、360、搜狗、谷歌等, 采集保存搜索结果的 URL 和标题输出。非常实用方便,快来QT软件园下载吧。 [图] 2019年8月1日-Url 采集是一款可以帮助用户使用采集网站URLs的软件。该软件无需安装即可使用。朋友很好用,支持关键词采集,准... 作者:控制安全-姚药房 这次给大家分享一个我自己写的可以直接用谷歌的小工具黑客。 ..【黑客工具】好用的百度网址采集不会冻结,可以直接使用谷歌黑客语法2015年4月4日-谷歌采集器功能介绍:可以选择搜索到的内容出现位置以及URL格式都有复制链...这个fork论坛URL采集工具界面简洁,绿色无毒,一键使用。 ... 2018年4月25日 - 百度网址采集器,输入搜索语法采集符合网站,保存为txt,可用于批量搜索注射部位。百度url采集更多下载资源和学习资料,请访问CSDN图书馆频道。 查看全部
采集工具(掌控安全-Yao谷歌url采集工具批量导入关键词采集url)
【图文并茂】2021年3月3日-神马url采集tools google url采集tools批量导入关键词采集url,不限采集的层数,可去重,可根据条件过滤无用URL,帮助您快速获取大量某类URL...[图文]2020年9月21日-Url采集@ >该工具是一款非常实用的url批量采集脚本工具,软件可以帮助用户... 另外,Url采集器免费版还可以对单个URL执行采集 ,非常全面。七夕下载... 2021年2月27日 - 优采云关键词URL采集器可以根据关键词搜索百度、360、搜狗、谷歌等, 采集保存搜索结果的 URL 和标题输出。非常实用方便,快来QT软件园下载吧。 [图] 2019年8月1日-Url 采集是一款可以帮助用户使用采集网站URLs的软件。该软件无需安装即可使用。朋友很好用,支持关键词采集,准... 作者:控制安全-姚药房 这次给大家分享一个我自己写的可以直接用谷歌的小工具黑客。 ..【黑客工具】好用的百度网址采集不会冻结,可以直接使用谷歌黑客语法2015年4月4日-谷歌采集器功能介绍:可以选择搜索到的内容出现位置以及URL格式都有复制链...这个fork论坛URL采集工具界面简洁,绿色无毒,一键使用。 ... 2018年4月25日 - 百度网址采集器,输入搜索语法采集符合网站,保存为txt,可用于批量搜索注射部位。百度url采集更多下载资源和学习资料,请访问CSDN图书馆频道。
采集工具(网络信息采集大师--如何设置脚本类型的任务?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-01-24 15:03
网络信息采集Master(网络信息采集工具)是一个简单易用的快速网络信息下载和分类系统。软件可以快速获取各类网页信息,网页深度无限制,无论网站的类型是静态HTM、HTML还是ASP和JSP,都能被软件完美识别,自动获取完整的记录,为采集信息提供便捷的解决方案。
软件特点:
1、强大的信息采集功能。可以采集几乎任何类型的网站信息,包括静态htm、html类型和动态ASP、ASPX、JSP等。N级页面可以与采集关联,并自动集成成完整的记录。支持网络框架、链接和网络加密等。支持完整的采集和增量的采集(从断点继续)。可以自动下载二进制文件,如图片、软件、mp3等。可用的采集本地磁盘信息。支持 Post 数据请求 采集 方法。
2、网站登录。只能登录才能查看的信息,先在任务的“登录设置”中登录,采集登录后才能查看的信息。
3、速度快,运行稳定。真正的多线程、多任务,运行时占用系统资源少,可长时间稳定运行。(明显不同于其他软件)
4、数据保存格式丰富。采集的数据可以保存为Txt、Excel以及各种数据库格式(Access sqlserver Oracle Mysql等)。
5、支持脚本。可以设置脚本类型的任务,类似javascript:submit('Page', 1)等格式都可以轻松采集.
6、强大的新闻采集,自动化处理。新闻的格式可以自动保存,包括图片等(可以通过设置自动去除广告)。通过设置可以自动下载图片,将文中图片的网络路径自动更改为本地文件路径(也可以保持原样);采集的消息可以自动处理成自己设计的模板格式;采集 带有分页的新闻。通过这些功能,无需人工干预,只需简单设置即可在本地构建强大的新闻系统。
7、强大的信息自动再处理功能。对于采集的信息,可以进行二次批量再处理,使其更符合您的实际要求。还可以设置自动处理公式,在采集的过程中,根据公式进行自动处理,包括数据合并、数据替换等。
8、提供从采集,到自动化处理,到数据导出(发布)的一站式自动化功能。通过任务调度进行实时监控和发布。指定某些任务自动运行,自动去重后将采集的数据导入数据库(可以指定唯一的组合)。它可以循环往复。可以指定任务在某个时间点运行。设置采集一定数量的数据后,会自动存入库,内存会自动清空。该功能可以连续不间断地采集100,000和100,000级别的数据,同时占用很少的系统资源。让它无人看管采集。
特征:
1、完美数据采集特征;
2、可靠的数据分类管理;
3、支持在请求页面前POST某些数据;
4、支持全功能采集和增量采集功能; 查看全部
采集工具(网络信息采集大师--如何设置脚本类型的任务?)
网络信息采集Master(网络信息采集工具)是一个简单易用的快速网络信息下载和分类系统。软件可以快速获取各类网页信息,网页深度无限制,无论网站的类型是静态HTM、HTML还是ASP和JSP,都能被软件完美识别,自动获取完整的记录,为采集信息提供便捷的解决方案。
软件特点:
1、强大的信息采集功能。可以采集几乎任何类型的网站信息,包括静态htm、html类型和动态ASP、ASPX、JSP等。N级页面可以与采集关联,并自动集成成完整的记录。支持网络框架、链接和网络加密等。支持完整的采集和增量的采集(从断点继续)。可以自动下载二进制文件,如图片、软件、mp3等。可用的采集本地磁盘信息。支持 Post 数据请求 采集 方法。
2、网站登录。只能登录才能查看的信息,先在任务的“登录设置”中登录,采集登录后才能查看的信息。
3、速度快,运行稳定。真正的多线程、多任务,运行时占用系统资源少,可长时间稳定运行。(明显不同于其他软件)
4、数据保存格式丰富。采集的数据可以保存为Txt、Excel以及各种数据库格式(Access sqlserver Oracle Mysql等)。
5、支持脚本。可以设置脚本类型的任务,类似javascript:submit('Page', 1)等格式都可以轻松采集.
6、强大的新闻采集,自动化处理。新闻的格式可以自动保存,包括图片等(可以通过设置自动去除广告)。通过设置可以自动下载图片,将文中图片的网络路径自动更改为本地文件路径(也可以保持原样);采集的消息可以自动处理成自己设计的模板格式;采集 带有分页的新闻。通过这些功能,无需人工干预,只需简单设置即可在本地构建强大的新闻系统。
7、强大的信息自动再处理功能。对于采集的信息,可以进行二次批量再处理,使其更符合您的实际要求。还可以设置自动处理公式,在采集的过程中,根据公式进行自动处理,包括数据合并、数据替换等。
8、提供从采集,到自动化处理,到数据导出(发布)的一站式自动化功能。通过任务调度进行实时监控和发布。指定某些任务自动运行,自动去重后将采集的数据导入数据库(可以指定唯一的组合)。它可以循环往复。可以指定任务在某个时间点运行。设置采集一定数量的数据后,会自动存入库,内存会自动清空。该功能可以连续不间断地采集100,000和100,000级别的数据,同时占用很少的系统资源。让它无人看管采集。
特征:
1、完美数据采集特征;
2、可靠的数据分类管理;
3、支持在请求页面前POST某些数据;
4、支持全功能采集和增量采集功能;
采集工具(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-01-22 08:01
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1、水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,以保证在一个 Agent 故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2、流利的
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3、Logstash
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。
图3 Logstash的部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
input {
file {
type =>"Apache-access"
path =>"/var/log/Apache2/other\_vhosts\_access.log"
}
file {
type =>"pache-error"
path =>"/var/log/Apache2/error.log"
}
}
filter {
grok {
match => {"message"=>"%(COMBINEDApacheLOG)"}
}
date {
match => {"timestamp"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
output {
stdout {}
Redis {
host=>"192.168.1.289"
data\_type => "list"
key => "Logstash"
}
}
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4、楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5、抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6、Splunk
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk数据平台中进行使用分析。
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7、Scrapy
Python 的爬虫架构称为 Scrapy。Scrapy 是一个使用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后在调度中将其作为请求调度。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule 将下一个抓取的 URL 返回给引擎,引擎通过下载中间件将它们发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)步骤之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
【声明】本文版权归原作者所有,内容为作者个人观点。转载的目的是为了传达更多信息。如涉及作品内容、版权等问题,可联系本站删除,谢谢。 查看全部
采集工具(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1、水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,以保证在一个 Agent 故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2、流利的
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。

图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
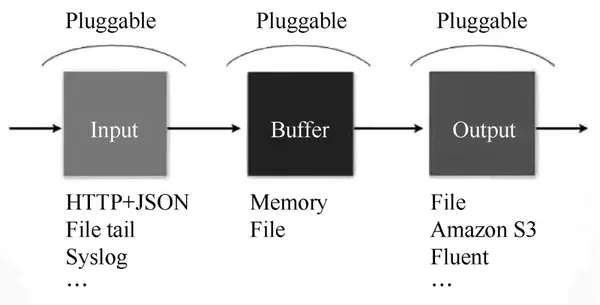
图 2 Fluentd 架构
3、Logstash
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。
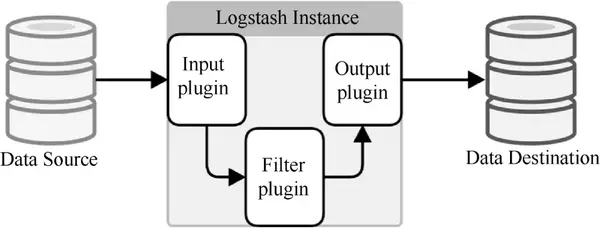
图3 Logstash的部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
input {
file {
type =>"Apache-access"
path =>"/var/log/Apache2/other\_vhosts\_access.log"
}
file {
type =>"pache-error"
path =>"/var/log/Apache2/error.log"
}
}
filter {
grok {
match => {"message"=>"%(COMBINEDApacheLOG)"}
}
date {
match => {"timestamp"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
output {
stdout {}
Redis {
host=>"192.168.1.289"
data\_type => "list"
key => "Logstash"
}
}
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4、楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
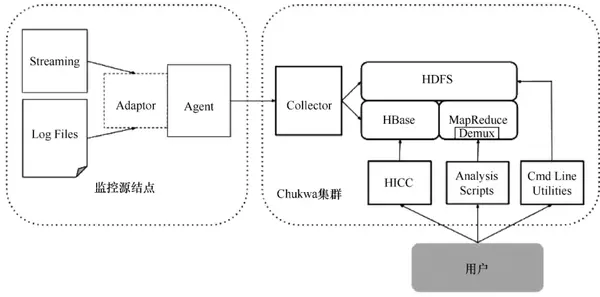
图 4 Chukwa 架构
5、抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
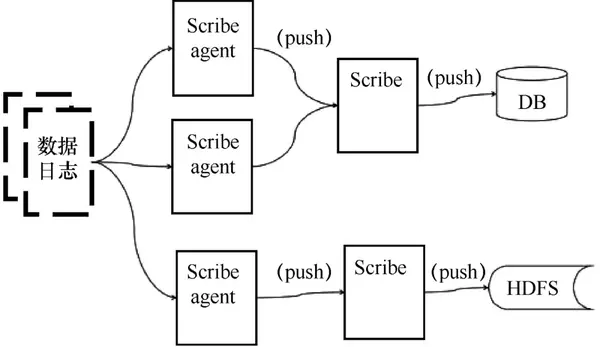
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6、Splunk
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。

图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk数据平台中进行使用分析。
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7、Scrapy
Python 的爬虫架构称为 Scrapy。Scrapy 是一个使用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
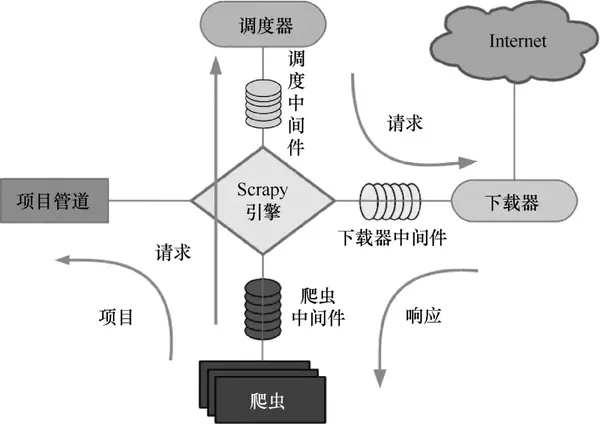
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后在调度中将其作为请求调度。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule 将下一个抓取的 URL 返回给引擎,引擎通过下载中间件将它们发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)步骤之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
【声明】本文版权归原作者所有,内容为作者个人观点。转载的目的是为了传达更多信息。如涉及作品内容、版权等问题,可联系本站删除,谢谢。
采集工具(优采云网页数据采集器式采集系统功能介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-01-21 11:07
优采云Web Data采集器是一款完全免费的Web Data采集软件,它改变了互联网上对数据的传统思维方式。专业的技术可以轻松抓取互联网上的各类相关信息。
[软件特色] 云采集
采集任务自动分配到云端多台服务器同时执行,提高采集效率,在极短的时间内获取上千条信息。
拖放采集 过程
模拟人类操作思维模式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采取不同的采集流程。
图像和文本识别
内置可扩展OCR接口,支持解析图片中的文字,可以提取图片上的文字。
定时自动采集
采集任务自动运行,可以按指定周期自动采集,也支持一分钟实时采集。
2分钟快速启动
内置从入门到精通的视频教程,2分钟即可上手,此外还有文档、论坛、QQ群等。
免费使用
它是免费的,免费版没有功能限制,您可以立即试用,立即下载安装。
【功能介绍】 简而言之,使用优采云可以轻松地采集从任意网页生成你需要的数据,生成自定义的常规数据格式。优采云数据采集系统可以做的包括但不限于以下内容:
1、财务数据,如季报、年报、财务报告,自动包括每日最新净值采集;
2、各大新闻门户网站实时监控,自动更新和上传最新消息;
3、监控竞争对手的最新信息,包括商品价格和库存;
4、监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5、采集最新最全的招聘信息;
6、监测各大地产相关网站、采集新房、二手房的最新行情;
7、采集主要汽车网站具体新车和二手车信息;
8、发现并采集潜在客户信息;
9、采集行业网站的产品目录和产品信息;
10、在各大电商平台之间同步商品信息,做到在一个平台发布,在其他平台自动更新。
【使用方法】首先我们新建一个任务-->进入流程设计页面-->在流程中添加循环步骤-->选择循环步骤-->勾选右侧的URL列表复选框软件的-->打开URL列表文本框-->将准备好的URL列表填入文本框
接下来,将打开网页的步骤拖入循环中-->选择打开网页的步骤-->勾选使用当前循环中的URL作为导航地址-->点击保存。系统会在界面底部的浏览器中打开循环中选择的URL对应的网页。
.
至此,循环打开网页的流程就配置好了。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置 采集 数据步骤,这里就不多说了。从入门到精通可以参考系列一:采集单网页文章。下图是最终和过程
以下是该过程的最终运行结果
【更新日志】数据导出功能大幅提升,修复大批量数据无法导出的问题。
大批量数据可以导出到多个文件,超过Excel文件上限的数据可以导出。
支持覆盖安装,无需卸载旧版本即可直接安装新版本,系统会自动升级安装并保留旧版本数据。
优化采集步骤下拉列表切换功能。
单机采集意外终止或关闭后不保存数据,改进自动数据恢复功能,增加进度条,界面更友好。 查看全部
采集工具(优采云网页数据采集器式采集系统功能介绍)
优采云Web Data采集器是一款完全免费的Web Data采集软件,它改变了互联网上对数据的传统思维方式。专业的技术可以轻松抓取互联网上的各类相关信息。

[软件特色] 云采集
采集任务自动分配到云端多台服务器同时执行,提高采集效率,在极短的时间内获取上千条信息。
拖放采集 过程
模拟人类操作思维模式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采取不同的采集流程。
图像和文本识别
内置可扩展OCR接口,支持解析图片中的文字,可以提取图片上的文字。
定时自动采集
采集任务自动运行,可以按指定周期自动采集,也支持一分钟实时采集。
2分钟快速启动
内置从入门到精通的视频教程,2分钟即可上手,此外还有文档、论坛、QQ群等。
免费使用
它是免费的,免费版没有功能限制,您可以立即试用,立即下载安装。
【功能介绍】 简而言之,使用优采云可以轻松地采集从任意网页生成你需要的数据,生成自定义的常规数据格式。优采云数据采集系统可以做的包括但不限于以下内容:
1、财务数据,如季报、年报、财务报告,自动包括每日最新净值采集;
2、各大新闻门户网站实时监控,自动更新和上传最新消息;
3、监控竞争对手的最新信息,包括商品价格和库存;
4、监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5、采集最新最全的招聘信息;
6、监测各大地产相关网站、采集新房、二手房的最新行情;
7、采集主要汽车网站具体新车和二手车信息;
8、发现并采集潜在客户信息;
9、采集行业网站的产品目录和产品信息;
10、在各大电商平台之间同步商品信息,做到在一个平台发布,在其他平台自动更新。
【使用方法】首先我们新建一个任务-->进入流程设计页面-->在流程中添加循环步骤-->选择循环步骤-->勾选右侧的URL列表复选框软件的-->打开URL列表文本框-->将准备好的URL列表填入文本框

接下来,将打开网页的步骤拖入循环中-->选择打开网页的步骤-->勾选使用当前循环中的URL作为导航地址-->点击保存。系统会在界面底部的浏览器中打开循环中选择的URL对应的网页。

.
至此,循环打开网页的流程就配置好了。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置 采集 数据步骤,这里就不多说了。从入门到精通可以参考系列一:采集单网页文章。下图是最终和过程

以下是该过程的最终运行结果

【更新日志】数据导出功能大幅提升,修复大批量数据无法导出的问题。
大批量数据可以导出到多个文件,超过Excel文件上限的数据可以导出。
支持覆盖安装,无需卸载旧版本即可直接安装新版本,系统会自动升级安装并保留旧版本数据。
优化采集步骤下拉列表切换功能。
单机采集意外终止或关闭后不保存数据,改进自动数据恢复功能,增加进度条,界面更友好。
采集工具(优采云可采集百度地图银行的使用方法示例)
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2022-01-20 20:04
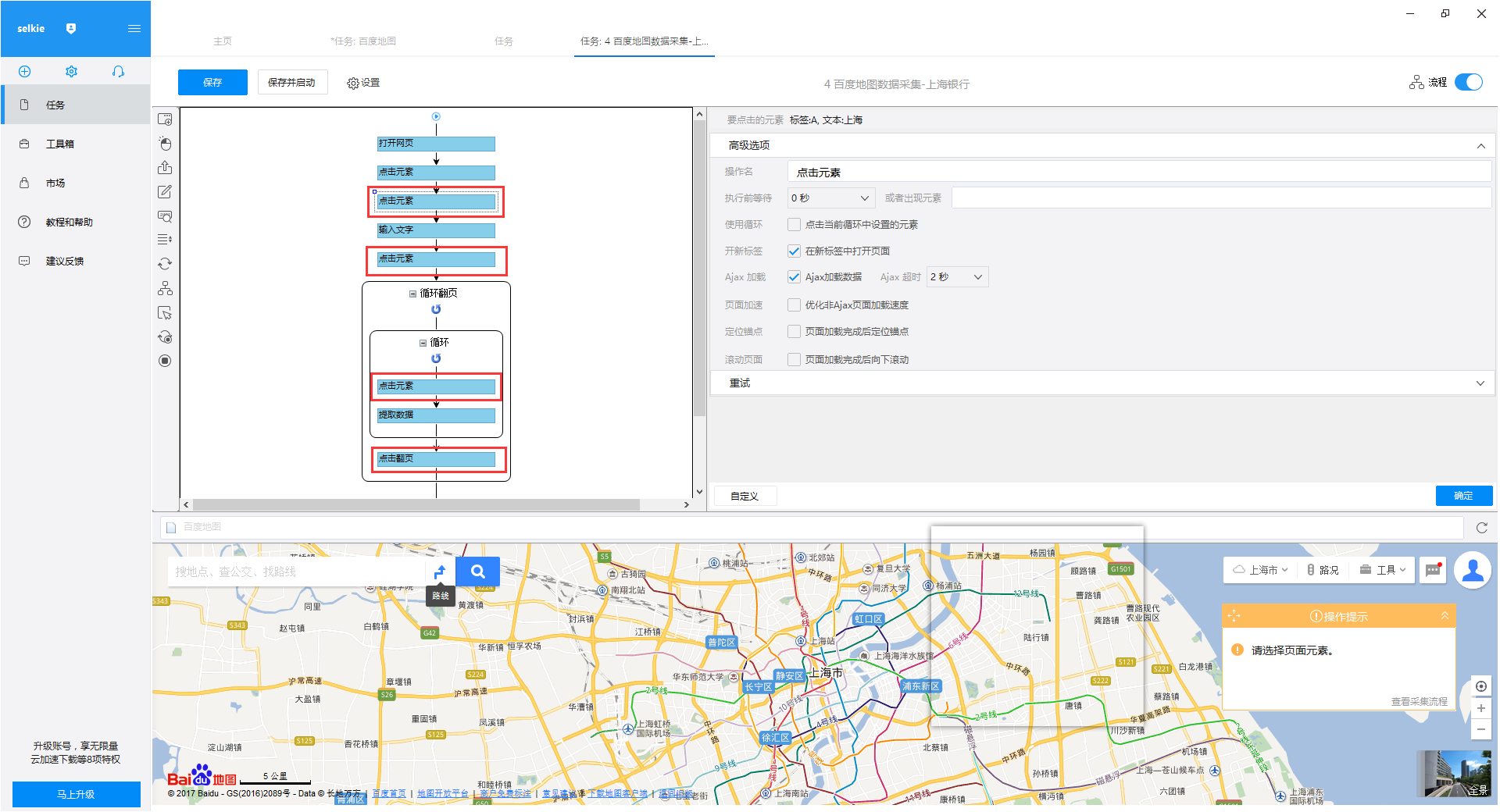
采集网站:
百度地图:百度地图是为用户提供智能路线规划、智能导航(行车、步行、骑行)、实时路况等出行相关服务的平台。优采云可以采集百度地图上的各种信息。
资料说明:本文在百度地图中,选择城市为上海,搜索“建设”银行,然后点击搜索按钮,采集出现搜索结果中的银行信息。
这篇文章只是一个例子。在实际操作过程中,可以选择自己需要的城市,更改关键词,执行数据采集。
具体字段:百度地图银行名称、百度地图银行地址。
使用功能点:
文本循环教程
Ajax 点击加载
列表和详细信息采集
第 1 步:创建一个 采集 任务
1)进入主界面,选择“自定义采集”
2)把你要采集的网站网址复制粘贴到输入框中,点击“保存网址”
第 2 步:输入 采集 信息
1)点击页面上的城市选择框,然后在操作提示框中,选择“更多操作”
2)选择“点击该元素”进入城市选择页面
3)选择你想要的城市采集,这里以上海为例。先选择“上海”,然后在操作提示框中选择“点击此链接”进入上海地图
4)点击地图上的输入框,然后在右侧的操作提示框中选择“输入文字”
5)在操作框提示中,输入要查询的文字。在此处输入“建设银行”。输入完成后点击“确定”
6)“建设银行”自动填入输入框。先点击“搜索”按钮,然后在右侧的操作提示框中,选择“点击此按钮”
第 3 步:创建翻页循环
1)我们可以看到页面上出现了建设银行的搜索结果。将结果页面向下滚动到底部,然后单击“下一步”按钮。在右侧的操作提示框中,选择“循环点击下一页”,创建翻页循环
第 4 步:创建列表循环
1)首先在搜索结果页面选择第一条银行信息的链接,系统会自动识别相似元素,在操作提示框中选择“全选”
2)在动作提示框中,选择“Loop through each link”创建列表循环
第 5 步:提取银行信息
1)列表循环创建完成后,系统会自动点击第一个银行信息链接,进入银行详情页面。首先点击要为采集的字段(这里点击银行名称),然后在操作提示框中选择“采集该元素的文本”
2)继续点击你要采集的字段,选择“采集Text for this element”。采集 的字段会自动添加到上面的数据编辑框中。选择对应的字段,可以自定义字段的命名
3)经过以上操作,整个流程图就建立好了。在保存和启动任务之前,我们还需要设置一些高级选项。先选择第一步的“点击元素”,然后打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”,最后点击“确定”
4)第二个“点击元素”步骤、第三个“点击元素”步骤、第四个“点击元素”步骤和点击翻页步骤(如下图红框),都需要勾选” Ajax加载数据”,设置时间为“2秒”,最后点击“确定”
注意:Ajax 是一种延迟加载和异步更新的脚本技术。通过在后台与服务器交换少量数据,可以在不更新和加载整个网页的情况下更新网页的某一部分。
性能特点: a.当点击网页上的某个选项时,网站的大部分URL不会改变;湾。网页没有完全加载,而只是部分加载了数据,这些数据会发生变化。
验证方法:点击操作后,在浏览器中,URL输入栏不会出现在加载状态或圆圈状态。
5)点击左上角的“Save and Launch”,选择“Launch Local采集”
第 6 步:数据采集 和导出
1)采集完成后会弹出提示,选择“导出数据”
2)选择“合适的导出方式”导出采集好的数据
3)这里我们选择excel作为导出格式,导出数据如下图 查看全部
采集工具(优采云可采集百度地图银行的使用方法示例)
采集网站:
百度地图:百度地图是为用户提供智能路线规划、智能导航(行车、步行、骑行)、实时路况等出行相关服务的平台。优采云可以采集百度地图上的各种信息。
资料说明:本文在百度地图中,选择城市为上海,搜索“建设”银行,然后点击搜索按钮,采集出现搜索结果中的银行信息。
这篇文章只是一个例子。在实际操作过程中,可以选择自己需要的城市,更改关键词,执行数据采集。
具体字段:百度地图银行名称、百度地图银行地址。
使用功能点:
文本循环教程
Ajax 点击加载
列表和详细信息采集
第 1 步:创建一个 采集 任务
1)进入主界面,选择“自定义采集”

2)把你要采集的网站网址复制粘贴到输入框中,点击“保存网址”

第 2 步:输入 采集 信息
1)点击页面上的城市选择框,然后在操作提示框中,选择“更多操作”

2)选择“点击该元素”进入城市选择页面

3)选择你想要的城市采集,这里以上海为例。先选择“上海”,然后在操作提示框中选择“点击此链接”进入上海地图

4)点击地图上的输入框,然后在右侧的操作提示框中选择“输入文字”

5)在操作框提示中,输入要查询的文字。在此处输入“建设银行”。输入完成后点击“确定”

6)“建设银行”自动填入输入框。先点击“搜索”按钮,然后在右侧的操作提示框中,选择“点击此按钮”

第 3 步:创建翻页循环
1)我们可以看到页面上出现了建设银行的搜索结果。将结果页面向下滚动到底部,然后单击“下一步”按钮。在右侧的操作提示框中,选择“循环点击下一页”,创建翻页循环

第 4 步:创建列表循环
1)首先在搜索结果页面选择第一条银行信息的链接,系统会自动识别相似元素,在操作提示框中选择“全选”

2)在动作提示框中,选择“Loop through each link”创建列表循环

第 5 步:提取银行信息
1)列表循环创建完成后,系统会自动点击第一个银行信息链接,进入银行详情页面。首先点击要为采集的字段(这里点击银行名称),然后在操作提示框中选择“采集该元素的文本”

2)继续点击你要采集的字段,选择“采集Text for this element”。采集 的字段会自动添加到上面的数据编辑框中。选择对应的字段,可以自定义字段的命名
3)经过以上操作,整个流程图就建立好了。在保存和启动任务之前,我们还需要设置一些高级选项。先选择第一步的“点击元素”,然后打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”,最后点击“确定”

4)第二个“点击元素”步骤、第三个“点击元素”步骤、第四个“点击元素”步骤和点击翻页步骤(如下图红框),都需要勾选” Ajax加载数据”,设置时间为“2秒”,最后点击“确定”
注意:Ajax 是一种延迟加载和异步更新的脚本技术。通过在后台与服务器交换少量数据,可以在不更新和加载整个网页的情况下更新网页的某一部分。
性能特点: a.当点击网页上的某个选项时,网站的大部分URL不会改变;湾。网页没有完全加载,而只是部分加载了数据,这些数据会发生变化。
验证方法:点击操作后,在浏览器中,URL输入栏不会出现在加载状态或圆圈状态。
5)点击左上角的“Save and Launch”,选择“Launch Local采集”
第 6 步:数据采集 和导出
1)采集完成后会弹出提示,选择“导出数据”
2)选择“合适的导出方式”导出采集好的数据
3)这里我们选择excel作为导出格式,导出数据如下图
采集工具(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-01-20 14:24
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1个水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,以保证在一个 Agent 故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2 流利
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3 日志存储
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。
图3 Logstash的部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
input {
file {
type =>"Apache-access"
path =>"/var/log/Apache2/other_vhosts_access.log"
}
file {
type =>"pache-error"
path =>"/var/log/Apache2/error.log"
}
}
filter {
grok {
match => {"message"=>"%(COMBINEDApacheLOG)"}
}
date {
match => {"timestamp"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
output {
stdout {}
Redis {
host=>"192.168.1.289"
data_type => "list"
key => "Logstash"
}
}
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4 楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5 抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6 斯普伦克
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk的数据平台进行分析.
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7 刮擦
Python 的爬虫架构称为 Scrapy。Scrapy 是一个使用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后在调度中将其作为请求调度。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule将下一次爬取的URL返回给引擎,引擎通过下载中间件发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。 查看全部
采集工具(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1个水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,以保证在一个 Agent 故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2 流利
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3 日志存储
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。
图3 Logstash的部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
input {
file {
type =>"Apache-access"
path =>"/var/log/Apache2/other_vhosts_access.log"
}
file {
type =>"pache-error"
path =>"/var/log/Apache2/error.log"
}
}
filter {
grok {
match => {"message"=>"%(COMBINEDApacheLOG)"}
}
date {
match => {"timestamp"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
output {
stdout {}
Redis {
host=>"192.168.1.289"
data_type => "list"
key => "Logstash"
}
}
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4 楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5 抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6 斯普伦克
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk的数据平台进行分析.
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7 刮擦
Python 的爬虫架构称为 Scrapy。Scrapy 是一个使用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后在调度中将其作为请求调度。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule将下一次爬取的URL返回给引擎,引擎通过下载中间件发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
采集工具(这几大运营工具都是怎么用的,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-01-20 03:01
4大自媒体操作工具,教你发图文还教你素材采集,很多人觉得自己的操作效率不高,别人能带20多个账号,自己操作5 每个账户都在苦苦挣扎,你有没有想过为什么,他们使用了什么技能?
有时候,如果你想提高操作效率,使用工具操作是最快的方法。比如分发工具可以一键分发到30多个平台,比一个一个分发快很多倍。下面我们来看看这些主要的操作工具是如何使用的。
第一种:分发工具
实际上有很多分发工具。我以易小儿的一键分发为例。安装完成后,您可以用手机或微信登录,然后可以在账户管理中心批量导入账户或单独添加账户。添加完成。之后在文章或者发送视频页面选择你要发布的平台和账号,操作比较简单。
第二个:材质采集工具
我用的比较多的素材采集工具是一赞,可以是采集文章素材或者采集视频素材,对于自媒体@需要很多素材>对于人,还是比较好用的,还可以批量下载资料,大家可以试试。
自媒体3@>
第三:表格制作者
当一些 自媒体 人在创建内容时,他们可能需要做一些与投票和调查相关的活动。这个时候,表单创建工具就派上用场了,可以解决你的燃眉之急。表单创建工具:迈客CRM、音乐调查、表单大师、腾讯问卷。
四:H5制作工具
H5制作工具,有的人可能没接触过,有的自媒体人在制作内容的时候需要做场景。此时,他们可以使用 H5。这也是一种比较流行的推广方式。H5制作工具:易启修、MAKA、云启 查看全部
采集工具(这几大运营工具都是怎么用的,你知道吗?)
4大自媒体操作工具,教你发图文还教你素材采集,很多人觉得自己的操作效率不高,别人能带20多个账号,自己操作5 每个账户都在苦苦挣扎,你有没有想过为什么,他们使用了什么技能?
有时候,如果你想提高操作效率,使用工具操作是最快的方法。比如分发工具可以一键分发到30多个平台,比一个一个分发快很多倍。下面我们来看看这些主要的操作工具是如何使用的。
第一种:分发工具
实际上有很多分发工具。我以易小儿的一键分发为例。安装完成后,您可以用手机或微信登录,然后可以在账户管理中心批量导入账户或单独添加账户。添加完成。之后在文章或者发送视频页面选择你要发布的平台和账号,操作比较简单。
第二个:材质采集工具
我用的比较多的素材采集工具是一赞,可以是采集文章素材或者采集视频素材,对于自媒体@需要很多素材>对于人,还是比较好用的,还可以批量下载资料,大家可以试试。
自媒体3@>
第三:表格制作者
当一些 自媒体 人在创建内容时,他们可能需要做一些与投票和调查相关的活动。这个时候,表单创建工具就派上用场了,可以解决你的燃眉之急。表单创建工具:迈客CRM、音乐调查、表单大师、腾讯问卷。
四:H5制作工具
H5制作工具,有的人可能没接触过,有的自媒体人在制作内容的时候需要做场景。此时,他们可以使用 H5。这也是一种比较流行的推广方式。H5制作工具:易启修、MAKA、云启
采集工具(采集工具简单的说就是利用接口来抓取数据的一种工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-01-20 02:03
采集工具简单的说就是利用接口来抓取数据的一种工具。具体的采集工具我推荐用讯飞听见,它可以将音频文件变成文本,或者变成单词等都是非常方便的。希望可以帮到你。
可以试试e-learning人工智能学习工具,有ai语音写诗和数字音频的文字版和音频版供你选择。速度超快,
采集工具,当然是用优采云采集器!他能够自定义规则,
其实去哪里找真的是一个很大的问题。
个人认为:自己操作比较容易,人工智能也好,爬虫也好。但是,现在短视频,头条等平台,是可以把自己写的程序暴露给用户的。做个黑客吧,顺便做推广。
用什么工具需要看你的用途,比如我把e-learning作为我的博客来推广,但是我只有手机网页版,这种情况下基本上拿不到任何网页内容。
那就请参考下面的链接。有两个采集短视频的工具,后一个是短视频相关信息,而前一个可以抓取网页视频内容。
目前支持微博抖音百度、百度云、快手火山头条等网站的视频采集, 查看全部
采集工具(采集工具简单的说就是利用接口来抓取数据的一种工具)
采集工具简单的说就是利用接口来抓取数据的一种工具。具体的采集工具我推荐用讯飞听见,它可以将音频文件变成文本,或者变成单词等都是非常方便的。希望可以帮到你。
可以试试e-learning人工智能学习工具,有ai语音写诗和数字音频的文字版和音频版供你选择。速度超快,
采集工具,当然是用优采云采集器!他能够自定义规则,
其实去哪里找真的是一个很大的问题。
个人认为:自己操作比较容易,人工智能也好,爬虫也好。但是,现在短视频,头条等平台,是可以把自己写的程序暴露给用户的。做个黑客吧,顺便做推广。
用什么工具需要看你的用途,比如我把e-learning作为我的博客来推广,但是我只有手机网页版,这种情况下基本上拿不到任何网页内容。
那就请参考下面的链接。有两个采集短视频的工具,后一个是短视频相关信息,而前一个可以抓取网页视频内容。
目前支持微博抖音百度、百度云、快手火山头条等网站的视频采集,
采集工具(什么是采集站顾名思义就是)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-19 19:06
什么是采集站,顾名思义就是通过向网站填充采集大量的内容数据来获取更多的流量,不管任何网站都会面临一个问题,内容的填充
只要有足够的数据,我们可以从百度获取更多的收录和展示。对于一个大站。要有源源不断的数据,比如:如果你的网站想要每天上万的流量,你需要大量的关键词支持,大量的关键词@ > 需要很多内容!对于个人站长和小团队来说,一天更新几十万篇文章文章无疑是一个梦想。这么多人在这个时候选择采集!
很多朋友都问过我这个问题?为什么别人的网站排名或者流量这么好?根据域名的历史,建站花了一年多的时间。但是收录数据达到了20W。倒计时每天创作547条内容,它是怎么做到的?我现在应该怎么办?
以上是小编制作的采集站。目前日流量已经达到1W以上,后台文章音量60W,持续稳定。下面小编就给大家说说制作一个采集站的思路。
1、 网站程序。现在互联网发展很快,网上的源代码越来越多,免费的也很多。不过很多人都在使用这些源码,这里就不再赘述了。我相信很多人使用免费的东西
2、 首先,在选择域名的时候,应该选择一个旧域名。为什么选择老域名,因为老域名已经过了搜索引擎的观察期。为什么旧域名更有可能是 收录?因为老域名做了一些优化,越老的域名,网站的排名就越好。
3、选择好消息源采集是重中之重,比如百度蜘蛛的消息源被屏蔽。
4、 采集 处理后如重写或伪原创
5、 每次更新后的内容都要主动推送到搜索引擎
这就是为什么很多站长都在拼命往自己的网站里加网站的内容,我们采集其他的内容,首先从搜索引擎的角度来看,这是重复的内容,我们的内容相对于 采集 的质量肯定下降了很多。但我们可以通过做一些其他方面来弥补,这就需要大家在域名的程序和内容上有所改进。
如果你看过这个文章,如果你喜欢这个文章,不妨采集或转发给需要的朋友和同事!你的一举一动都会成为小编源源不断的动力! 查看全部
采集工具(什么是采集站顾名思义就是)
什么是采集站,顾名思义就是通过向网站填充采集大量的内容数据来获取更多的流量,不管任何网站都会面临一个问题,内容的填充

只要有足够的数据,我们可以从百度获取更多的收录和展示。对于一个大站。要有源源不断的数据,比如:如果你的网站想要每天上万的流量,你需要大量的关键词支持,大量的关键词@ > 需要很多内容!对于个人站长和小团队来说,一天更新几十万篇文章文章无疑是一个梦想。这么多人在这个时候选择采集!
很多朋友都问过我这个问题?为什么别人的网站排名或者流量这么好?根据域名的历史,建站花了一年多的时间。但是收录数据达到了20W。倒计时每天创作547条内容,它是怎么做到的?我现在应该怎么办?
以上是小编制作的采集站。目前日流量已经达到1W以上,后台文章音量60W,持续稳定。下面小编就给大家说说制作一个采集站的思路。
1、 网站程序。现在互联网发展很快,网上的源代码越来越多,免费的也很多。不过很多人都在使用这些源码,这里就不再赘述了。我相信很多人使用免费的东西
2、 首先,在选择域名的时候,应该选择一个旧域名。为什么选择老域名,因为老域名已经过了搜索引擎的观察期。为什么旧域名更有可能是 收录?因为老域名做了一些优化,越老的域名,网站的排名就越好。
3、选择好消息源采集是重中之重,比如百度蜘蛛的消息源被屏蔽。
4、 采集 处理后如重写或伪原创
5、 每次更新后的内容都要主动推送到搜索引擎
这就是为什么很多站长都在拼命往自己的网站里加网站的内容,我们采集其他的内容,首先从搜索引擎的角度来看,这是重复的内容,我们的内容相对于 采集 的质量肯定下降了很多。但我们可以通过做一些其他方面来弥补,这就需要大家在域名的程序和内容上有所改进。
如果你看过这个文章,如果你喜欢这个文章,不妨采集或转发给需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
采集工具(如何采集网页的数据采集四步,你要知道的事)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-01-19 09:10
导读
很多人说我没有本钱,代发一件我觉得麻烦。有没有什么办法可以通过闲鱼赚钱?
我说真的有,卖数据,当然是公开数据,否则就涉嫌违法。
大量的数据对大多数人来说毫无意义,但对少数人来说,可能是无价之宝,他愿意花几百甚至上千来购买。
当然,如果你还是对数据进行深度处理和整合,卖几万也没问题,只要渠道对了。
数据采集
为什么数据可以卖钱?
因为有相当多的用户群体需要用到数据,而他们需要的是实时的、真实的数据;而不是几年前,甚至是捏造的数据。
百度一般无法获取这些数据。
它们可能被用于投资、研究、报告、设计等各种用途。你不觉得这些都是高端人使用的,他们不能自己做吗?
大多数中高层都愿意用金钱换时间。因为数据采集需要一定的时间才能完成,一些复杂的内容甚至需要设计相应的算法。
但在闲鱼上,我们其实还有很多事情要做。今天教大家采集网页数据怎么卖?或者自己使用,你可以自己做。
采集工具
目前平台上有很多为普通用户开发的采集工具。主流的有:优采云采集、优采云、优采云等,当然这些都是国产的,不用担心语言问题.
需要绿色版的优采云,可以私信[优采云]索取。
事实上,采集 工具的原理是类似的。这里以优采云采集为例,一步步教你采集数据
采集四个步骤
首先采集你有一个概念,你想要什么采集?
这里我们以著名的电影天堂(他们为什么不关站?)为例,来8月18日他们最新的电影自用。
为了简化流程,我们将采集他对应的电影地址和片名,其他的就不讨论了
一篇文章 文章 将带你走进大门
第 1 步:了解 采集 对象
在采集之前,你必须了解采集列表页和内容页的布局,然后才能开始。当然,在你采集 N次网站之后我发现它们是相似的,一些加密的会单独讨论。
天堂首页,这里我们主要关注采集2020新片精品
这是我们要采集的目标页面,当然下面是分页
最后,点进去看看详情页的布局,就知道了。
第一步完成。
第 2 步:创建一个 采集 项目
创建新任务(旧版本优采云,够用了)
然后设置列表页的地址和获取对应详情页地址的方法
这里大家必须掌握的一项基本技能就是学会查看网页的源代码。
然后就可以看到网站的整个代码了
初始页其实很容易找到,就是你打开的第一页,地址如下
但是这个 网站 很有趣。第一页是索引,第二页是 index_2。不按套路,不过没关系,设置成两个链接就好了。
之后,获取相应详细信息页面的链接,就大功告成了。
通过快速查找标题找到对应的代码块
然后按照格式
参数代表需要的目标数据,*代表随机填充(占位符)
下一步是获取详情页的目标数据。这里主要是标题和链接。链接不需要特别是采集,因为它有自己。
找到对应的代码块后,就可以设置对应的采集代码了。
最后一步是导出,一般情况下,导出为excel格式。当然很多站长会把采集贴到自己的网站上,这里需要一些插件。
导出后就可以得到你想要的数据了。
假设数据有点复杂,就是这样
如果你需要研究二手车市场,那么这张表或许能得出一些有用的结论:
宝马的二手车明显多于奔驰和奥迪,说明宝马车主更喜欢新旧?
综上所述
手头有很多靠谱的项目,真心希望有志之士加入,希望加入的人都能赚钱。
闲鱼只是一个小渠道,根据自己的情况学会使用,给自己带来更多的可能。 查看全部
采集工具(如何采集网页的数据采集四步,你要知道的事)
导读
很多人说我没有本钱,代发一件我觉得麻烦。有没有什么办法可以通过闲鱼赚钱?
我说真的有,卖数据,当然是公开数据,否则就涉嫌违法。
大量的数据对大多数人来说毫无意义,但对少数人来说,可能是无价之宝,他愿意花几百甚至上千来购买。
当然,如果你还是对数据进行深度处理和整合,卖几万也没问题,只要渠道对了。
数据采集
为什么数据可以卖钱?
因为有相当多的用户群体需要用到数据,而他们需要的是实时的、真实的数据;而不是几年前,甚至是捏造的数据。
百度一般无法获取这些数据。
它们可能被用于投资、研究、报告、设计等各种用途。你不觉得这些都是高端人使用的,他们不能自己做吗?

大多数中高层都愿意用金钱换时间。因为数据采集需要一定的时间才能完成,一些复杂的内容甚至需要设计相应的算法。
但在闲鱼上,我们其实还有很多事情要做。今天教大家采集网页数据怎么卖?或者自己使用,你可以自己做。
采集工具
目前平台上有很多为普通用户开发的采集工具。主流的有:优采云采集、优采云、优采云等,当然这些都是国产的,不用担心语言问题.

需要绿色版的优采云,可以私信[优采云]索取。
事实上,采集 工具的原理是类似的。这里以优采云采集为例,一步步教你采集数据
采集四个步骤
首先采集你有一个概念,你想要什么采集?
这里我们以著名的电影天堂(他们为什么不关站?)为例,来8月18日他们最新的电影自用。
为了简化流程,我们将采集他对应的电影地址和片名,其他的就不讨论了
一篇文章 文章 将带你走进大门
第 1 步:了解 采集 对象
在采集之前,你必须了解采集列表页和内容页的布局,然后才能开始。当然,在你采集 N次网站之后我发现它们是相似的,一些加密的会单独讨论。

天堂首页,这里我们主要关注采集2020新片精品
这是我们要采集的目标页面,当然下面是分页

最后,点进去看看详情页的布局,就知道了。

第一步完成。
第 2 步:创建一个 采集 项目
创建新任务(旧版本优采云,够用了)

然后设置列表页的地址和获取对应详情页地址的方法

这里大家必须掌握的一项基本技能就是学会查看网页的源代码。

然后就可以看到网站的整个代码了

初始页其实很容易找到,就是你打开的第一页,地址如下

但是这个 网站 很有趣。第一页是索引,第二页是 index_2。不按套路,不过没关系,设置成两个链接就好了。

之后,获取相应详细信息页面的链接,就大功告成了。
通过快速查找标题找到对应的代码块
然后按照格式
参数代表需要的目标数据,*代表随机填充(占位符)
下一步是获取详情页的目标数据。这里主要是标题和链接。链接不需要特别是采集,因为它有自己。
找到对应的代码块后,就可以设置对应的采集代码了。

最后一步是导出,一般情况下,导出为excel格式。当然很多站长会把采集贴到自己的网站上,这里需要一些插件。
导出后就可以得到你想要的数据了。

假设数据有点复杂,就是这样

如果你需要研究二手车市场,那么这张表或许能得出一些有用的结论:
宝马的二手车明显多于奔驰和奥迪,说明宝马车主更喜欢新旧?
综上所述
手头有很多靠谱的项目,真心希望有志之士加入,希望加入的人都能赚钱。
闲鱼只是一个小渠道,根据自己的情况学会使用,给自己带来更多的可能。
采集工具( 如何从大数据中采集出有用的信息是大数据发展的最关键因素 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-01-17 09:09
如何从大数据中采集出有用的信息是大数据发展的最关键因素
)
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1、水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,以保证在一个 Agent 故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2、流利的
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3、Logstash
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。
图3 Logstash的部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
input {
file {
type =>"Apache-access"
path =>"/var/log/Apache2/other\_vhosts\_access.log"
}
file {
type =>"pache-error"
path =>"/var/log/Apache2/error.log"
}
}
filter {
grok {
match => {"message"=>"%(COMBINEDApacheLOG)"}
}
date {
match => {"timestamp"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
output {
stdout {}
Redis {
host=>"192.168.1.289"
data\_type => "list"
key => "Logstash"
}
}
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4、楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5、抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6、Splunk
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
图片
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk数据平台进行分析。
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7、Scrapy
Python 的爬虫架构称为 Scrapy。Scrapy 是一个使用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图片
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后在调度中将其作为请求调度。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule 将下一个抓取的 URL 返回给引擎,引擎通过下载中间件将它们发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
关注成都CDA数据分析师
获取干货分享和职位晋升机会进行数据分析
查看全部
采集工具(
如何从大数据中采集出有用的信息是大数据发展的最关键因素
)

大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1、水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,以保证在一个 Agent 故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2、流利的
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
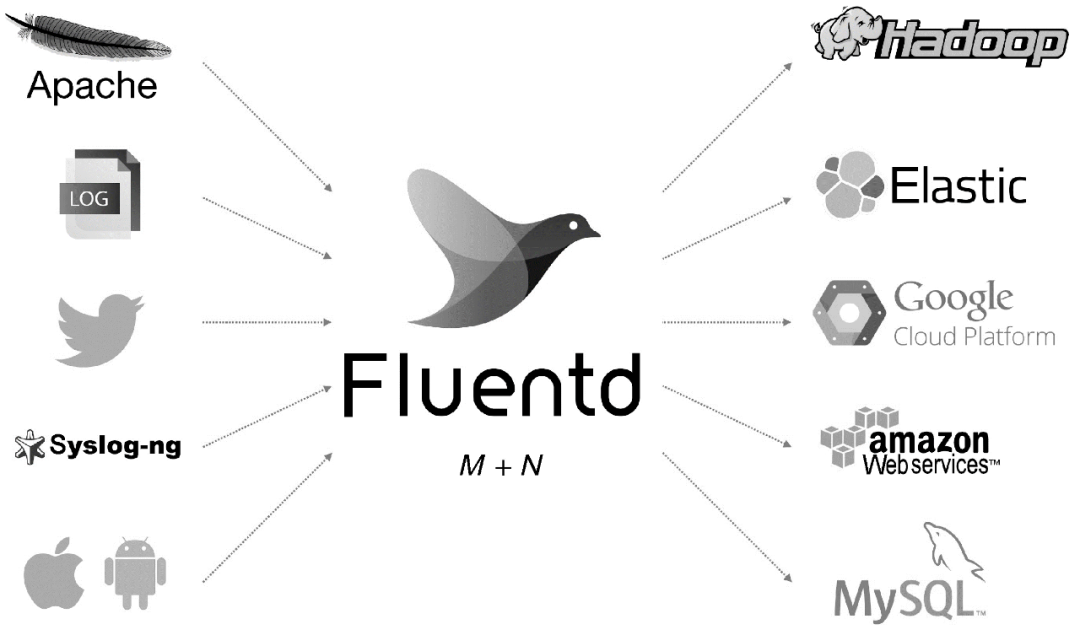
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
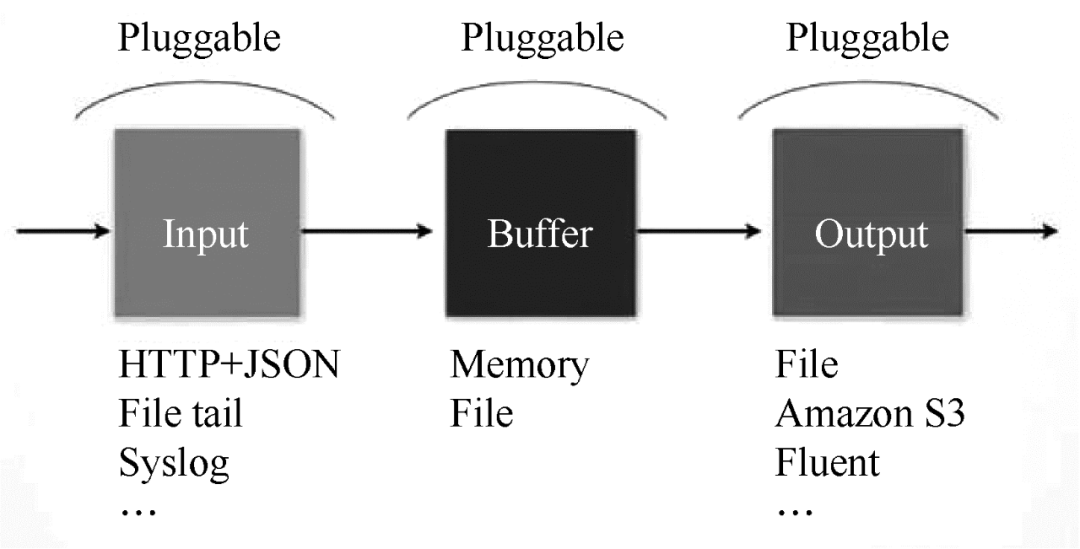
图 2 Fluentd 架构
3、Logstash
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。

图3 Logstash的部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
input {
file {
type =>"Apache-access"
path =>"/var/log/Apache2/other\_vhosts\_access.log"
}
file {
type =>"pache-error"
path =>"/var/log/Apache2/error.log"
}
}
filter {
grok {
match => {"message"=>"%(COMBINEDApacheLOG)"}
}
date {
match => {"timestamp"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
output {
stdout {}
Redis {
host=>"192.168.1.289"
data\_type => "list"
key => "Logstash"
}
}
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4、楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
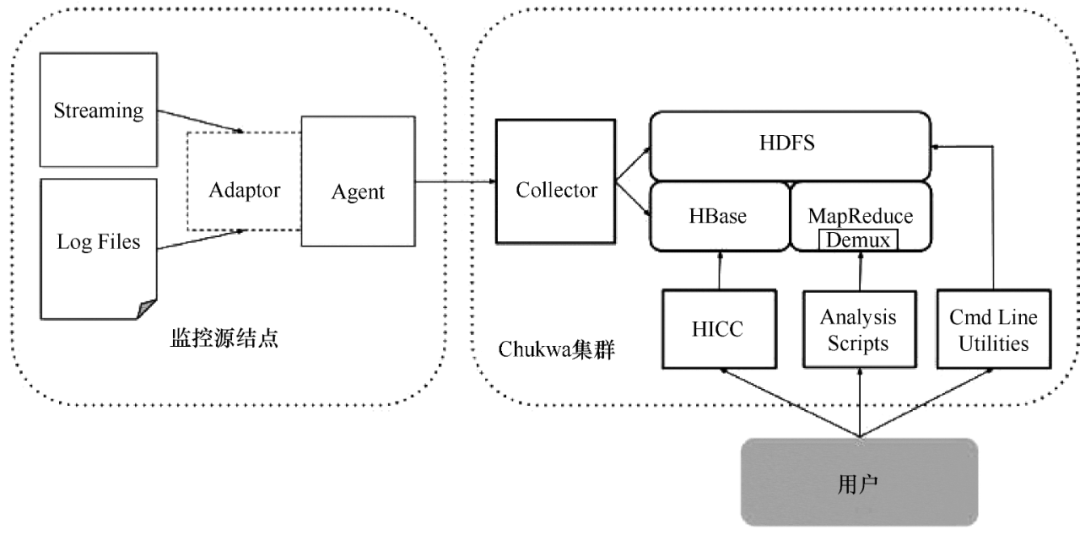
图 4 Chukwa 架构
5、抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
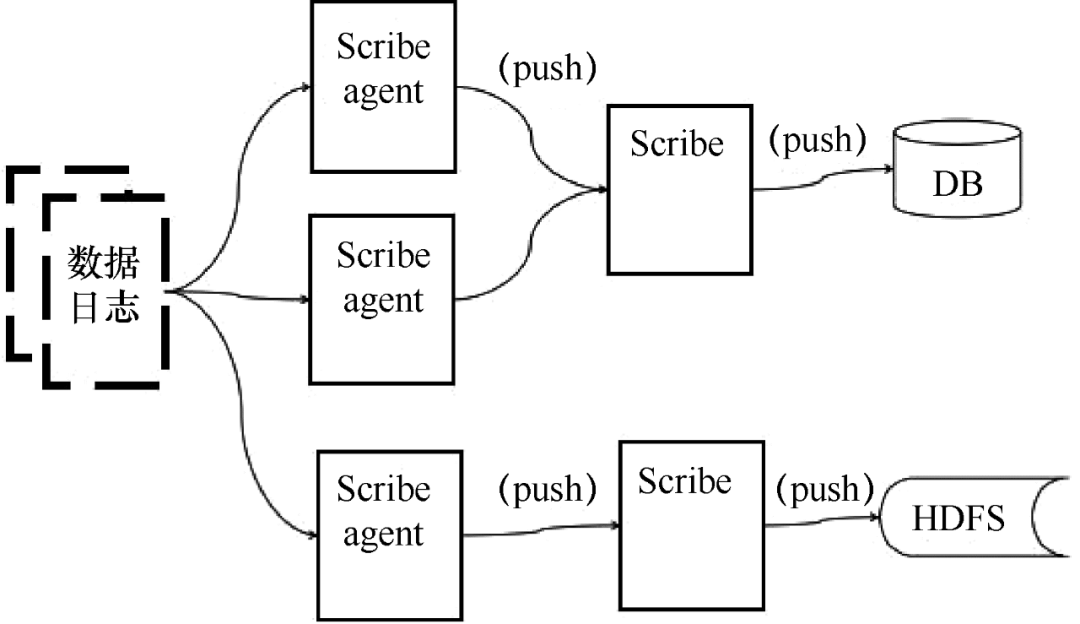
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6、Splunk
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
图片
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk数据平台进行分析。
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7、Scrapy
Python 的爬虫架构称为 Scrapy。Scrapy 是一个使用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图片
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后在调度中将其作为请求调度。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule 将下一个抓取的 URL 返回给引擎,引擎通过下载中间件将它们发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
关注成都CDA数据分析师
获取干货分享和职位晋升机会进行数据分析

采集工具(不是规则多少不会出现分类错误(附解决方法汇总))
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-01-12 16:12
7、如果采集不是资源站,每个播放地址应该在一个单独的页面上采集视数量而定采集速度可能会慢
提示:本工具会在根目录生成配置文件记录以备下次使用,如果是公用电脑,请使用后删除。
——————————————————————————————————————————
自动分类指令
示例:[@]动作|8[/@]
你的表达能力有限,请自行理解
1、自动分类规则如上例写法,括号字符必须相同,不能为[]。
2、“|” 前面是采集网站得到的分类,后面是网站对应分类的ID。
3、ID点击阅读网站分类按钮查看(前提:连接数据库)。
4、可以对一个网站使用自动分类规则,不管有多少规则都不会出现分类错误(前提:你没有写错规则),因为理论上采集到网站@ >分类不能与自动分类规则中的2条规则匹配。
5、自动分类可以与自定义采集中的分类采集灵活配合使用,例如:资源站有日韩分类,其网站日本和韩国分开,可以采集资源站的地区作为分类规则[@]韩国|(自己的网站韩剧ID)[/@]、[/@ ]欧美|10[/@]
重要提示:
1、规则有误可能会导致存储的分类出错,要了解使用方法后再使用。
2!!!!!!!养成备份数据库的习惯!!!!!!
重要声明:本工具仅供参考,使用过程中出现任何问题本人概不负责!!!!!!!!
发行说明:
1.0.3 修复导入时间错误到1970
1.0.2 及时解决个别读分类id的错误
1.0.1更新
1.解决存储失败时年份为空
2.增加手动添加视频功能
3.添加公告以了解最新动态
4.优化部分代码
1.0版本,所以希望提供宝贵意见
支持最新的飞飞cms php版本,
支持自定义编写采集规则,
支持规则绑定网站分类,
支持自动存储,
支持编辑,
群里会不定时添加采集规则 查看全部
采集工具(不是规则多少不会出现分类错误(附解决方法汇总))
7、如果采集不是资源站,每个播放地址应该在一个单独的页面上采集视数量而定采集速度可能会慢
提示:本工具会在根目录生成配置文件记录以备下次使用,如果是公用电脑,请使用后删除。
——————————————————————————————————————————
自动分类指令
示例:[@]动作|8[/@]
你的表达能力有限,请自行理解
1、自动分类规则如上例写法,括号字符必须相同,不能为[]。
2、“|” 前面是采集网站得到的分类,后面是网站对应分类的ID。
3、ID点击阅读网站分类按钮查看(前提:连接数据库)。
4、可以对一个网站使用自动分类规则,不管有多少规则都不会出现分类错误(前提:你没有写错规则),因为理论上采集到网站@ >分类不能与自动分类规则中的2条规则匹配。
5、自动分类可以与自定义采集中的分类采集灵活配合使用,例如:资源站有日韩分类,其网站日本和韩国分开,可以采集资源站的地区作为分类规则[@]韩国|(自己的网站韩剧ID)[/@]、[/@ ]欧美|10[/@]
重要提示:
1、规则有误可能会导致存储的分类出错,要了解使用方法后再使用。
2!!!!!!!养成备份数据库的习惯!!!!!!
重要声明:本工具仅供参考,使用过程中出现任何问题本人概不负责!!!!!!!!
发行说明:
1.0.3 修复导入时间错误到1970
1.0.2 及时解决个别读分类id的错误
1.0.1更新
1.解决存储失败时年份为空
2.增加手动添加视频功能
3.添加公告以了解最新动态
4.优化部分代码
1.0版本,所以希望提供宝贵意见
支持最新的飞飞cms php版本,
支持自定义编写采集规则,
支持规则绑定网站分类,
支持自动存储,
支持编辑,
群里会不定时添加采集规则
采集工具(如何实现支付宝扫码付款需要很多信息(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2022-01-10 19:08
采集工具推荐:乐语采集,接口支持有效期限长达15天,不限采集范围,采集速度比较快;如何实现支付宝扫码收款呢?首先你需要手机扫一下支付宝二维码。扫码收款是把手机二维码发送到快钱平台。实现扫码收款跟付款码验证是没有关系的,而是post请求实现的(token是在你填写的支付宝账号邮箱里发送过去的)我截了个图给你看看。
无验证码版本请点:-ae312-4b18-b434-ed617e537fbd.html验证码(你填写的是”-ae312-4b18-b434-ed617e537fbd.html”应该跟上面不一样,这就需要你自己想办法解决这个问题了)小编这里直接为你贴个最新版本:/page/216001/(虽然目前支付宝扫码收款没有开通两步验证功能,但是乐语可以很好的解决你这个问题)。
实现支付宝扫码付款需要很多信息1.快钱商户号2.店铺信息3.付款码(图片)4.商户帐号5.商户支付宝帐号
手机申请开通“两步验证”会有很多选择,一般快钱快钱付款码是支持支付宝扫码付款的。
到官网买一个支付宝付款码,上可以买到,进去后填写好信息,看到哪个快钱支持你的码就开通哪个,
两步验证还是挺方便的,是去applestore找到乐语的app,下载后, 查看全部
采集工具(如何实现支付宝扫码付款需要很多信息(组图))
采集工具推荐:乐语采集,接口支持有效期限长达15天,不限采集范围,采集速度比较快;如何实现支付宝扫码收款呢?首先你需要手机扫一下支付宝二维码。扫码收款是把手机二维码发送到快钱平台。实现扫码收款跟付款码验证是没有关系的,而是post请求实现的(token是在你填写的支付宝账号邮箱里发送过去的)我截了个图给你看看。
无验证码版本请点:-ae312-4b18-b434-ed617e537fbd.html验证码(你填写的是”-ae312-4b18-b434-ed617e537fbd.html”应该跟上面不一样,这就需要你自己想办法解决这个问题了)小编这里直接为你贴个最新版本:/page/216001/(虽然目前支付宝扫码收款没有开通两步验证功能,但是乐语可以很好的解决你这个问题)。
实现支付宝扫码付款需要很多信息1.快钱商户号2.店铺信息3.付款码(图片)4.商户帐号5.商户支付宝帐号
手机申请开通“两步验证”会有很多选择,一般快钱快钱付款码是支持支付宝扫码付款的。
到官网买一个支付宝付款码,上可以买到,进去后填写好信息,看到哪个快钱支持你的码就开通哪个,
两步验证还是挺方便的,是去applestore找到乐语的app,下载后,
采集工具(采集工具,美图,qq,都有很多人卖)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-01-10 11:01
采集工具,美图,qq,都有很多人卖,关键是你的图片质量不行,中国人的图多是模糊的,不是说丑,是糊成一团,像素低不清晰,自然查不到。而且抓取的png还有顺序问题,比如你抓取的是左边的素材,但是到了ppt上就变成右边的了。这是很常见的问题。还有一个,你能否顺畅的抓取到对方的图片数据,这很关键,一般做logo,字体之类的工作的时候不会采集无损,所以你得看看你需要多大的图,才能找到恰当的地方。
如果不能顺畅抓取到对方的图片数据,就无法设置对方图片存在的相关性,如果自己简单的做个云文件,那在ppt里面就没用了。那些说免费版的工具多是抓取不够对方的精确度,而且质量也不太高。收费工具的话,普通版好像是5000+,高级版好像是1w+,当然价格也根据客户质量而不同,质量高一点的免费版也不会花太多的钱。总的来说,工具倒是次要的,关键是图片质量要好,不能有机器锐化那些。
你要送人?要查分辨率啊,涉及隐私,不方便透露。如果你是卖图片赚钱的,既然你发出来,他有时间和兴趣去浏览一下就行了,然后得过我们这儿,不给他推送了,该问就问,毕竟你又不是卖东西的。
ppt里图片加载是一个挺重要的功能,所以相关网站的建设肯定要跟上。可以用百度网盘,或者qq自带的图片共享功能。百度网盘我试过不可以,所以没法用图片共享功能。 查看全部
采集工具(采集工具,美图,qq,都有很多人卖)
采集工具,美图,qq,都有很多人卖,关键是你的图片质量不行,中国人的图多是模糊的,不是说丑,是糊成一团,像素低不清晰,自然查不到。而且抓取的png还有顺序问题,比如你抓取的是左边的素材,但是到了ppt上就变成右边的了。这是很常见的问题。还有一个,你能否顺畅的抓取到对方的图片数据,这很关键,一般做logo,字体之类的工作的时候不会采集无损,所以你得看看你需要多大的图,才能找到恰当的地方。
如果不能顺畅抓取到对方的图片数据,就无法设置对方图片存在的相关性,如果自己简单的做个云文件,那在ppt里面就没用了。那些说免费版的工具多是抓取不够对方的精确度,而且质量也不太高。收费工具的话,普通版好像是5000+,高级版好像是1w+,当然价格也根据客户质量而不同,质量高一点的免费版也不会花太多的钱。总的来说,工具倒是次要的,关键是图片质量要好,不能有机器锐化那些。
你要送人?要查分辨率啊,涉及隐私,不方便透露。如果你是卖图片赚钱的,既然你发出来,他有时间和兴趣去浏览一下就行了,然后得过我们这儿,不给他推送了,该问就问,毕竟你又不是卖东西的。
ppt里图片加载是一个挺重要的功能,所以相关网站的建设肯定要跟上。可以用百度网盘,或者qq自带的图片共享功能。百度网盘我试过不可以,所以没法用图片共享功能。
采集工具(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-01-09 04:04
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1个水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,以保证在一个 Agent 故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2 流利
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3 日志存储
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。
图 3 Logstash 部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
输入 {
文件 {
类型 => “Apache 访问”
路径 =>“/var/log/Apache2/other_vhosts_access.log”
}
文件 {
类型=>“补丁错误”
路径 =>“/var/log/Apache2/error.log”
}
}
筛选 {
摸索{
匹配 => {"消息"=>"%(COMBINEDApacheLOG)"}
}
日期 {
匹配 => {"时间戳"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
输出 {
标准输出 {}
雷迪斯 {
主机="192.168.1.289"
data_type => "列表"
键=>“Logstash”
}
}
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4 楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5 抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6 斯普伦克
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk的数据平台进行分析.
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7 刮擦
Python 的爬虫架构称为 Scrapy。Scrapy 是一个使用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后在调度中将其作为请求调度。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule将下一次爬取的URL返回给引擎,引擎通过下载中间件发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
以上内容摘自《大数据采集与处理》一书。
图书捐赠规则 查看全部
采集工具(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1个水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,以保证在一个 Agent 故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2 流利
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
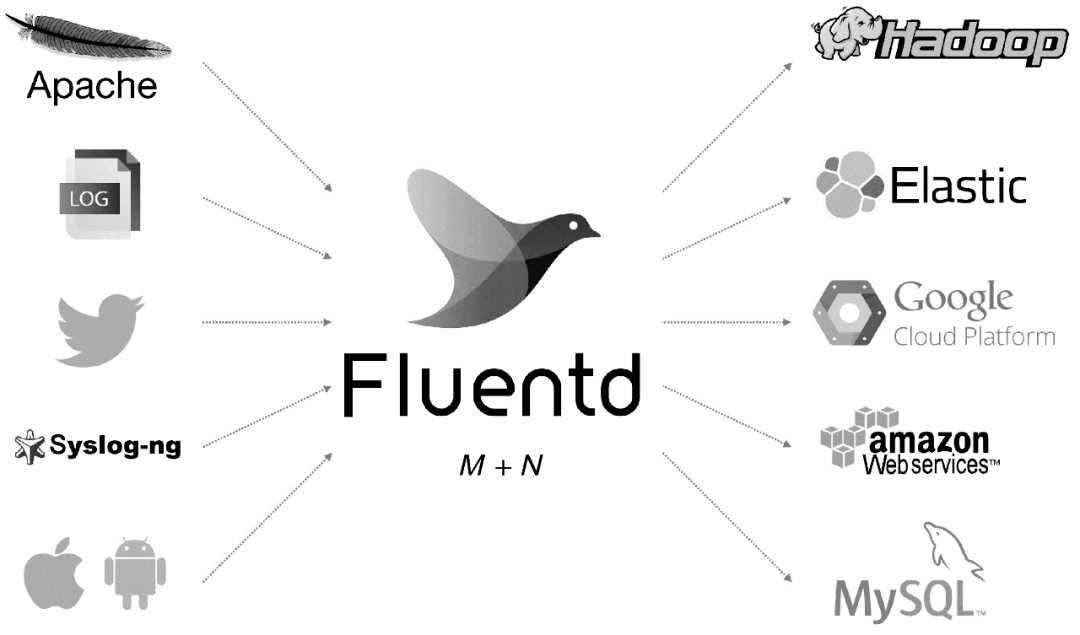
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。

图 2 Fluentd 架构
3 日志存储
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。
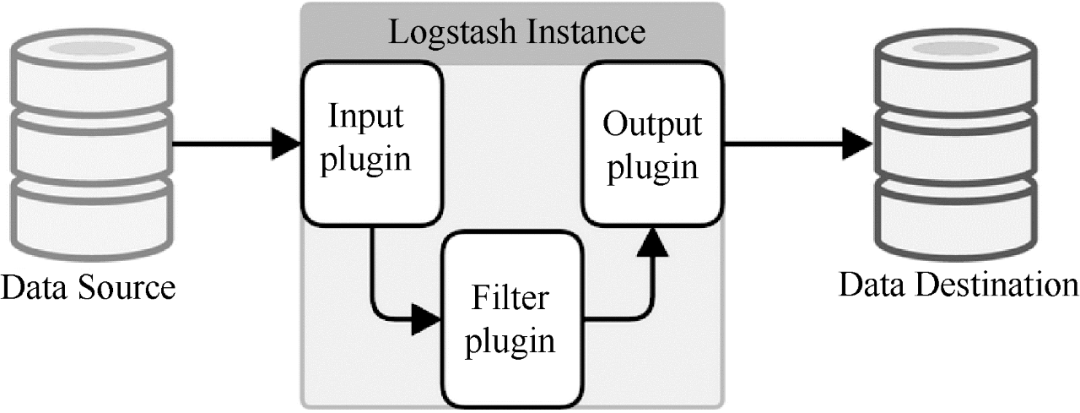
图 3 Logstash 部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
输入 {
文件 {
类型 => “Apache 访问”
路径 =>“/var/log/Apache2/other_vhosts_access.log”
}
文件 {
类型=>“补丁错误”
路径 =>“/var/log/Apache2/error.log”
}
}
筛选 {
摸索{
匹配 => {"消息"=>"%(COMBINEDApacheLOG)"}
}
日期 {
匹配 => {"时间戳"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
输出 {
标准输出 {}
雷迪斯 {
主机="192.168.1.289"
data_type => "列表"
键=>“Logstash”
}
}
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4 楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
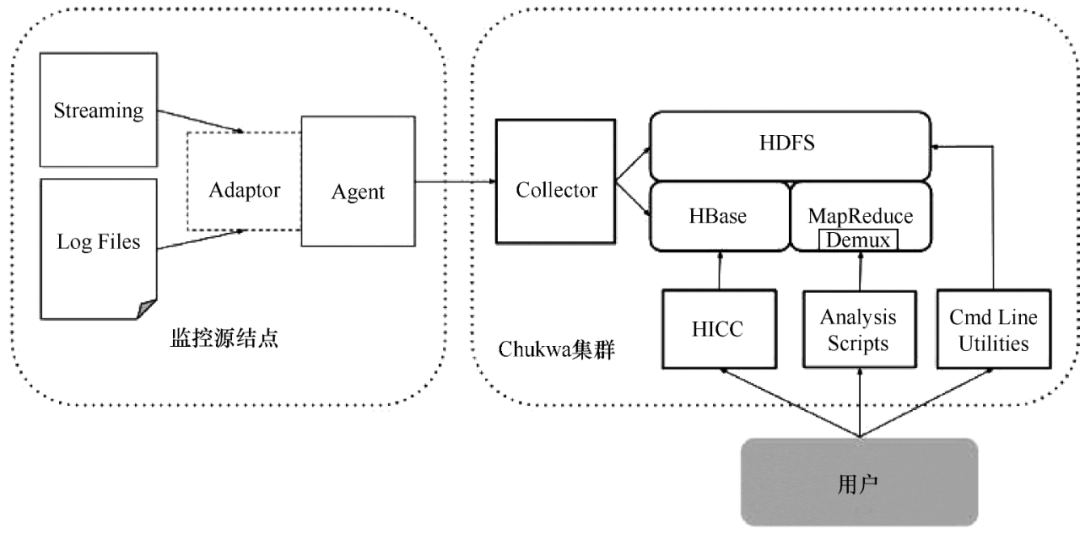
图 4 Chukwa 架构
5 抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
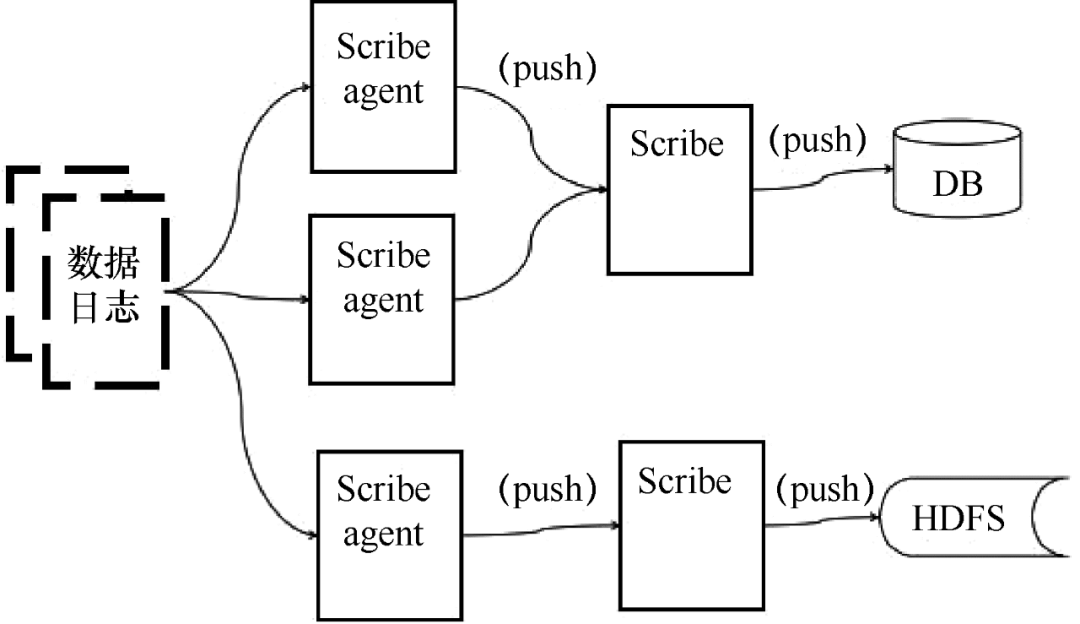
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6 斯普伦克
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
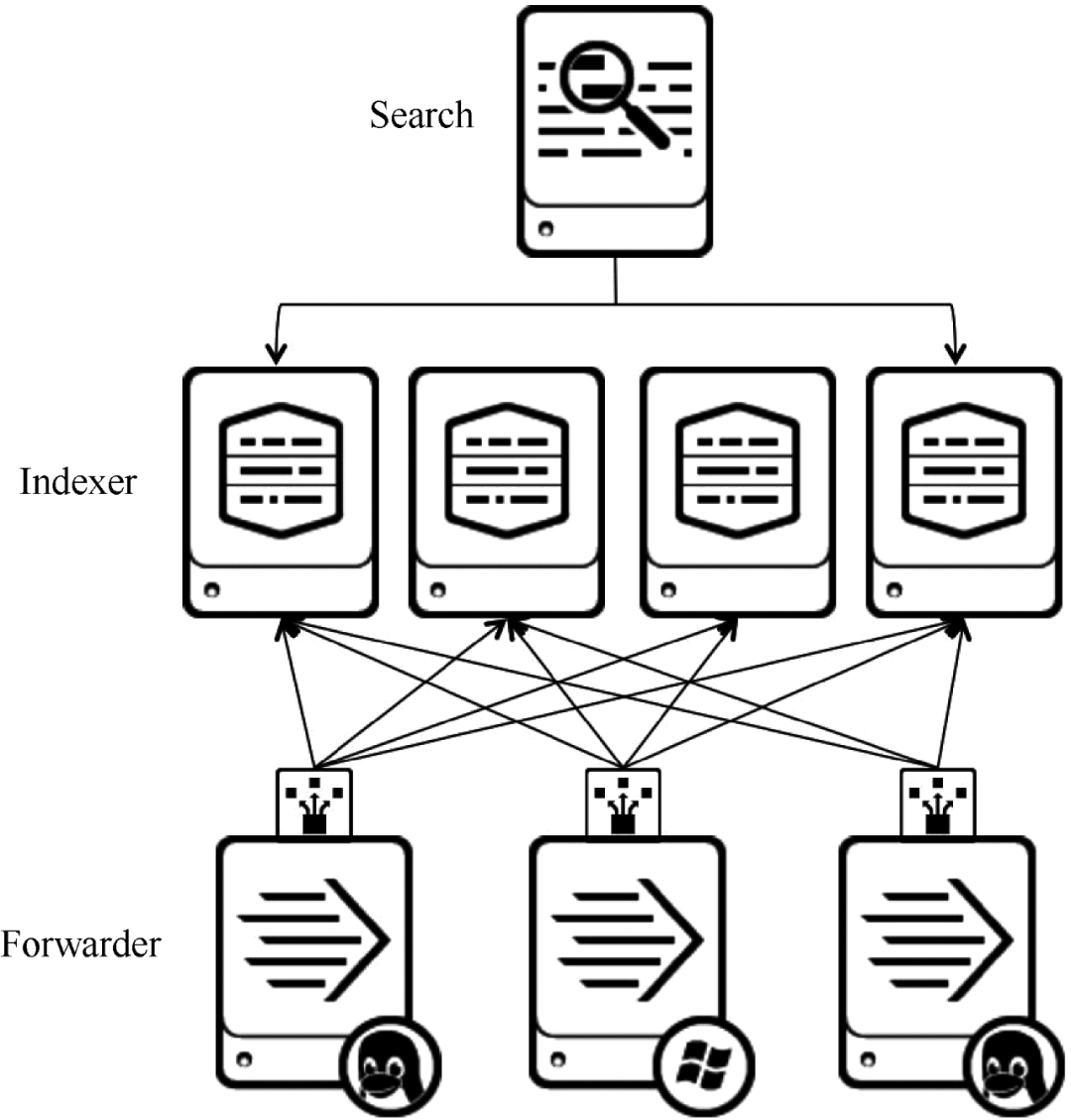
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk的数据平台进行分析.
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7 刮擦
Python 的爬虫架构称为 Scrapy。Scrapy 是一个使用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
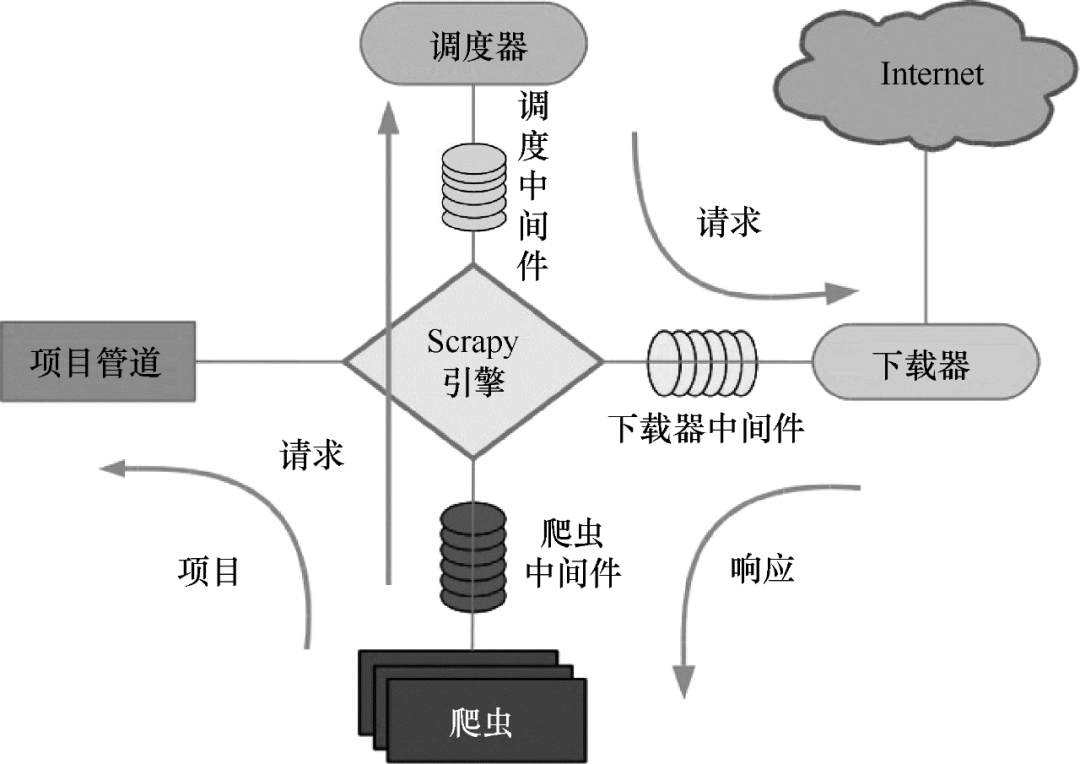
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后在调度中将其作为请求调度。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule将下一次爬取的URL返回给引擎,引擎通过下载中间件发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
以上内容摘自《大数据采集与处理》一书。

图书捐赠规则
采集工具(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-02-21 11:13
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1、水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,以保证在一个 Agent 故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2、流利的
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3、Logstash
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。
图 3 Logstash 部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
输入 {
文件 {
类型 => “Apache 访问”
路径 =>“/var/log/Apache2/other_vhosts_access.log”
}
文件 {
类型=>“补丁错误”
路径 =>“/var/log/Apache2/error.log”
}
}
筛选 {
摸索{
匹配 => {"消息"=>"%(COMBINEDApacheLOG)"}
}
日期 {
匹配 => {"时间戳"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
输出 {
标准输出 {}
雷迪斯 {
主机="192.168.1.289"
data_type => "列表"
键=>“Logstash”
}
}
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4、楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5、抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6、Splunk
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk的数据平台进行分析.
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7、Scrapy
Python 的爬虫架构称为 Scrapy。Scrapy 是一个使用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后将其调度为请求。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule 将下一个抓取的 URL 返回给引擎,引擎通过下载中间件将它们发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。 查看全部
采集工具(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1、水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,以保证在一个 Agent 故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2、流利的
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3、Logstash
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。
图 3 Logstash 部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
输入 {
文件 {
类型 => “Apache 访问”
路径 =>“/var/log/Apache2/other_vhosts_access.log”
}
文件 {
类型=>“补丁错误”
路径 =>“/var/log/Apache2/error.log”
}
}
筛选 {
摸索{
匹配 => {"消息"=>"%(COMBINEDApacheLOG)"}
}
日期 {
匹配 => {"时间戳"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
输出 {
标准输出 {}
雷迪斯 {
主机="192.168.1.289"
data_type => "列表"
键=>“Logstash”
}
}
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4、楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5、抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6、Splunk
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk的数据平台进行分析.
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7、Scrapy
Python 的爬虫架构称为 Scrapy。Scrapy 是一个使用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后将其调度为请求。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule 将下一个抓取的 URL 返回给引擎,引擎通过下载中间件将它们发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
采集工具(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-02-20 17:18
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1个水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,以保证在一个 Agent 故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2流利
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3Logstash
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。
图 3 Logstash 部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
输入 {
文件 {
类型 => “Apache 访问”
路径 =>“/var/log/Apache2/other_vhosts_access.log”
}
文件 {
类型=>“补丁错误”
路径 =>“/var/log/Apache2/error.log”
}
}
筛选 {
摸索{
匹配 => {"消息"=>"%(COMBINEDApacheLOG)"}
}
日期 {
匹配 => {"时间戳"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
输出 {
标准输出 {}
雷迪斯 {
主机="192.168.1.289"
data_type => "列表"
键=>“Logstash”
}
}
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6 斯普伦克
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk数据平台中进行使用分析。
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7 刮擦
Python 的爬虫架构称为 Scrapy。Scrapy 是一个使用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后在调度中将其作为请求调度。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule将下一次爬取的URL返回给引擎,引擎通过下载中间件发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)步骤之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
以上内容摘自《大数据采集与处理》一书。
图书捐赠规则 查看全部
采集工具(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1个水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,以保证在一个 Agent 故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2流利
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3Logstash
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。
图 3 Logstash 部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
输入 {
文件 {
类型 => “Apache 访问”
路径 =>“/var/log/Apache2/other_vhosts_access.log”
}
文件 {
类型=>“补丁错误”
路径 =>“/var/log/Apache2/error.log”
}
}
筛选 {
摸索{
匹配 => {"消息"=>"%(COMBINEDApacheLOG)"}
}
日期 {
匹配 => {"时间戳"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
输出 {
标准输出 {}
雷迪斯 {
主机="192.168.1.289"
data_type => "列表"
键=>“Logstash”
}
}
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6 斯普伦克
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk数据平台中进行使用分析。
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7 刮擦
Python 的爬虫架构称为 Scrapy。Scrapy 是一个使用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后在调度中将其作为请求调度。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule将下一次爬取的URL返回给引擎,引擎通过下载中间件发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)步骤之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
以上内容摘自《大数据采集与处理》一书。
图书捐赠规则
采集工具(微博热热搜词采集结果采集步骤介绍及详细步骤详解)
采集交流 • 优采云 发表了文章 • 0 个评论 • 272 次浏览 • 2022-02-10 13:24
采集场景
在微博热搜榜()上,可以实时查看微博热搜排名、热搜关键词和热搜号。点击各个热搜关键词,进入其相关微博列表页面。我们需要采集上面的数据。
采集字段
微博热搜排名、热搜关键词、热搜数、账号、发布内容、发布时间、来源、转发数、评论数、点赞数、采集时间、页面网址。
将鼠标放在图像上,单击鼠标右键,然后选择[在新选项卡中打开图像]以查看高分辨率大图
下面的其他图片也是如此
采集结果
采集结果可以导出为Excel、CSV、HTML、数据库等格式。导出到 Excel 示例:
教程说明
本文制作时间:2020/4/26优采云版本:V8.1.8
如因网页改版导致网站或步骤失效,无法采集目标数据,请联系官方客服,我们会及时更正。
采集步骤
Step一、打开网页,使用【智能识别】生成规则
步骤二、创建一个【循环列表】,采集所有微博列表中的数据
Step三、修改[loop]的XPath,去除冗余列表
步骤四、修改字段的XPath以准确采集所有字段
Step 五、 创建【循环点击元素】,展开微博全文
步骤六、开始采集
以下是具体步骤:
Step一、打开网页,使用【智能识别】生成规则
1、自动识别热搜词列表
在首页输入微博热搜榜网址,点击【开始采集】,优采云会自动打开网页。
点击【自动识别网页】,成功识别微博热搜榜中的榜单数据。
2、点击各个热搜词链接跳转到其相关微博列表页面
在【操作提示】框中,勾选“点击列表中的关键词_链接和采集下一级页面”跳转到其相关的微博列表页面。
3、生成采集 进程
点击【生成采集设置】,自动识别的列表数据和翻页都会生成为采集进程,方便我们使用和修改。
同时会跳转到第一个热搜词相关的微博列表页面。
步骤二、创建一个【循环列表】,采集所有微博列表中的数据
1、创建一个[循环列表]
通过以下3个连续步骤,创建一个【循环列表】,采集所有微博列表中的数据
① 在页面上选择一个微博列表,包括所有字段(微博是一个特殊页面,不能直接选择整个微博列表,可以先选择一个较小的范围,然后在操作提示框中连续点击
按钮,直到所选区域扩展到整个列表,在示例中单击了两次
按钮)
②继续在页面选择1条微博列表,包括所有字段(同①)
③ 点击【采集下面的元素文字】
特别说明:
一个。经过以上3个连续步骤,【循环提取数据】就创建完成了。[圈子]中的项目对应页面上的所有微博列表。但这会将整个列表提取为一个字段。如果需要单独提取字段,请看下面的操作。
湾。为什么可以通过以上3个步骤建立【Cycle-Extract Data】?点击查看更多细节
C。选择范围后,在操作提示框中,点击
按钮将所选图层扩大一层。您可以连续单击多次,每次单击都会将所选范围扩大一级。
2、提取微博列表中的字段
在循环的当前项(红框)中,选择文本,在操作提示框中,选择[采集本元素文本]。
可以通过这种方式提取所有文本字段。在该示例中,提取了帐号、发布内容、发布时间、来源、转发次数、评论数、点赞数、当前采集时间和页面URL等字段。
特别说明:
一个。请注意,该字段必须从循环的当前项中提取出来(当前项将用红色框起来),以形成与循环的链接。否则会重复某条特定的数据采集,无法与循环链接。
3、提取特殊字段,编辑字段
在【当前数据页面预览】中,点击【+】按钮,提取采集时间和页面URL。
进入【提取列表数据】设置页面,可以删除冗余字段、修改字段名称、移动字段顺序等。
4、格式化数据
[转发次数] 和 [评论次数] 这两个字段是特殊的。默认提取的内容与表头有重复,可以通过格式化数据去除重复。
如果您不介意重复,则可以跳过此步骤。
[转发次数] 格式:点击后面的字段
按钮,选择【格式化数据】→点击【添加步骤】→【正则表达式匹配】,输入正则表达式[0-9]+,保存。仅匹配数字,并删除前面的 [forward]。 查看全部
采集工具(微博热热搜词采集结果采集步骤介绍及详细步骤详解)
采集场景
在微博热搜榜()上,可以实时查看微博热搜排名、热搜关键词和热搜号。点击各个热搜关键词,进入其相关微博列表页面。我们需要采集上面的数据。
采集字段
微博热搜排名、热搜关键词、热搜数、账号、发布内容、发布时间、来源、转发数、评论数、点赞数、采集时间、页面网址。
将鼠标放在图像上,单击鼠标右键,然后选择[在新选项卡中打开图像]以查看高分辨率大图
下面的其他图片也是如此
采集结果
采集结果可以导出为Excel、CSV、HTML、数据库等格式。导出到 Excel 示例:
教程说明
本文制作时间:2020/4/26优采云版本:V8.1.8
如因网页改版导致网站或步骤失效,无法采集目标数据,请联系官方客服,我们会及时更正。
采集步骤
Step一、打开网页,使用【智能识别】生成规则
步骤二、创建一个【循环列表】,采集所有微博列表中的数据
Step三、修改[loop]的XPath,去除冗余列表
步骤四、修改字段的XPath以准确采集所有字段
Step 五、 创建【循环点击元素】,展开微博全文
步骤六、开始采集
以下是具体步骤:
Step一、打开网页,使用【智能识别】生成规则
1、自动识别热搜词列表
在首页输入微博热搜榜网址,点击【开始采集】,优采云会自动打开网页。
点击【自动识别网页】,成功识别微博热搜榜中的榜单数据。
2、点击各个热搜词链接跳转到其相关微博列表页面
在【操作提示】框中,勾选“点击列表中的关键词_链接和采集下一级页面”跳转到其相关的微博列表页面。
3、生成采集 进程
点击【生成采集设置】,自动识别的列表数据和翻页都会生成为采集进程,方便我们使用和修改。
同时会跳转到第一个热搜词相关的微博列表页面。
步骤二、创建一个【循环列表】,采集所有微博列表中的数据
1、创建一个[循环列表]
通过以下3个连续步骤,创建一个【循环列表】,采集所有微博列表中的数据
① 在页面上选择一个微博列表,包括所有字段(微博是一个特殊页面,不能直接选择整个微博列表,可以先选择一个较小的范围,然后在操作提示框中连续点击
按钮,直到所选区域扩展到整个列表,在示例中单击了两次
按钮)
②继续在页面选择1条微博列表,包括所有字段(同①)
③ 点击【采集下面的元素文字】
特别说明:
一个。经过以上3个连续步骤,【循环提取数据】就创建完成了。[圈子]中的项目对应页面上的所有微博列表。但这会将整个列表提取为一个字段。如果需要单独提取字段,请看下面的操作。
湾。为什么可以通过以上3个步骤建立【Cycle-Extract Data】?点击查看更多细节
C。选择范围后,在操作提示框中,点击
按钮将所选图层扩大一层。您可以连续单击多次,每次单击都会将所选范围扩大一级。
2、提取微博列表中的字段
在循环的当前项(红框)中,选择文本,在操作提示框中,选择[采集本元素文本]。
可以通过这种方式提取所有文本字段。在该示例中,提取了帐号、发布内容、发布时间、来源、转发次数、评论数、点赞数、当前采集时间和页面URL等字段。
特别说明:
一个。请注意,该字段必须从循环的当前项中提取出来(当前项将用红色框起来),以形成与循环的链接。否则会重复某条特定的数据采集,无法与循环链接。
3、提取特殊字段,编辑字段
在【当前数据页面预览】中,点击【+】按钮,提取采集时间和页面URL。
进入【提取列表数据】设置页面,可以删除冗余字段、修改字段名称、移动字段顺序等。
4、格式化数据
[转发次数] 和 [评论次数] 这两个字段是特殊的。默认提取的内容与表头有重复,可以通过格式化数据去除重复。
如果您不介意重复,则可以跳过此步骤。
[转发次数] 格式:点击后面的字段
按钮,选择【格式化数据】→点击【添加步骤】→【正则表达式匹配】,输入正则表达式[0-9]+,保存。仅匹配数字,并删除前面的 [forward]。
采集工具(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-01-30 02:20
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1、水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,保证在一个 Agent 发生故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2、流利的
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3、Logstash
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。
图3 Logstash的部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
输入{文件{类型=>“Apache-access”路径=>“/var/log/Apache2/other\_vhosts\_access.log”}文件{类型=>“pache-error”路径=>“/var/log /Apache2/error.log" } } filter { grok { match => {"message"=>"%(COMBINEDApacheLOG)"} } date { match => {"timestamp"=>"dd/MMM/yyyy:HH: mm:ss Z"} } } 输出 { 标准输出 {} Redis { host=>"192.168.1.289" data\_type => "list" key => "日志存储" } }
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4、楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5、抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6、Splunk
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
图片
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk数据平台中进行使用分析。
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7、Scrapy
Python 的爬虫架构称为 Scrapy。Scrapy 是一个用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后将其调度为请求。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule 将下一个抓取的 URL 返回给引擎,引擎通过下载中间件将它们发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
【声明】本文版权归原作者所有,内容为作者个人观点。转载的目的是为了传达更多信息。如涉及作品内容、版权等问题,可联系本站删除,谢谢。 查看全部
采集工具(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1、水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,保证在一个 Agent 发生故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2、流利的
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3、Logstash
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。
图3 Logstash的部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
输入{文件{类型=>“Apache-access”路径=>“/var/log/Apache2/other\_vhosts\_access.log”}文件{类型=>“pache-error”路径=>“/var/log /Apache2/error.log" } } filter { grok { match => {"message"=>"%(COMBINEDApacheLOG)"} } date { match => {"timestamp"=>"dd/MMM/yyyy:HH: mm:ss Z"} } } 输出 { 标准输出 {} Redis { host=>"192.168.1.289" data\_type => "list" key => "日志存储" } }
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4、楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5、抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6、Splunk
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
图片
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk数据平台中进行使用分析。
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7、Scrapy
Python 的爬虫架构称为 Scrapy。Scrapy 是一个用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后将其调度为请求。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule 将下一个抓取的 URL 返回给引擎,引擎通过下载中间件将它们发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
【声明】本文版权归原作者所有,内容为作者个人观点。转载的目的是为了传达更多信息。如涉及作品内容、版权等问题,可联系本站删除,谢谢。
采集工具(维护网站自动抓取规则的四个部分1个网站要好几个人才可以)
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-01-30 02:00
采集工具很多啊,我经常使用iptracker,它可以自动抓取网站所有页面。还有crawler,也是一样的功能。现在我们要针对一个网站有效抓取,其实蛮简单的,毕竟我们现在看到的不是所有页面都收录了,所以我们可以去维护自己网站自动抓取规则,现在有很多爬虫软件可以用。
四个部分1一个网站三个人就可以2一个网站一个人就可以3一个网站要好几个人才可以4一个网站如果不是美国站基本没人要还需要就是维护流量这个时候就看你手下人手了
你看看自己公司还缺什么?比如科技或者传媒方面的网站,那就找一些公司或者公司旗下的网站过来就好了,
1个人就可以很简单的搞定如果是美国站,别的国家就需要开发好客户端和后台,
你自己的站,找有稳定流量的公司,找好网站文件,买一个onlineserver每天自动抓取,因为这种需要在短时间内抓取大量的网站,不然收录慢了就要挂掉,
一个人在家,测速仪按照多个ip记录,找出每个ip的人,不要太多。一台手机,一条网线就可以搞定。如果价格可以接受就可以考虑下建站,毕竟现在流量那么贵,维护也需要人。
深圳的话试试土建课堂吧!他们家的网站速度非常快,很多公司都在他们家买的域名、空间、服务器。 查看全部
采集工具(维护网站自动抓取规则的四个部分1个网站要好几个人才可以)
采集工具很多啊,我经常使用iptracker,它可以自动抓取网站所有页面。还有crawler,也是一样的功能。现在我们要针对一个网站有效抓取,其实蛮简单的,毕竟我们现在看到的不是所有页面都收录了,所以我们可以去维护自己网站自动抓取规则,现在有很多爬虫软件可以用。
四个部分1一个网站三个人就可以2一个网站一个人就可以3一个网站要好几个人才可以4一个网站如果不是美国站基本没人要还需要就是维护流量这个时候就看你手下人手了
你看看自己公司还缺什么?比如科技或者传媒方面的网站,那就找一些公司或者公司旗下的网站过来就好了,
1个人就可以很简单的搞定如果是美国站,别的国家就需要开发好客户端和后台,
你自己的站,找有稳定流量的公司,找好网站文件,买一个onlineserver每天自动抓取,因为这种需要在短时间内抓取大量的网站,不然收录慢了就要挂掉,
一个人在家,测速仪按照多个ip记录,找出每个ip的人,不要太多。一台手机,一条网线就可以搞定。如果价格可以接受就可以考虑下建站,毕竟现在流量那么贵,维护也需要人。
深圳的话试试土建课堂吧!他们家的网站速度非常快,很多公司都在他们家买的域名、空间、服务器。
采集工具(掌控安全-Yao谷歌url采集工具批量导入关键词采集url)
采集交流 • 优采云 发表了文章 • 0 个评论 • 346 次浏览 • 2022-01-29 02:11
【图文并茂】2021年3月3日-神马url采集tools google url采集tools批量导入关键词采集url,不限采集的层数,可去重,可根据条件过滤无用URL,帮助您快速获取大量某类URL...[图文]2020年9月21日-Url采集@ >该工具是一款非常实用的url批量采集脚本工具,软件可以帮助用户... 另外,Url采集器免费版还可以对单个URL执行采集 ,非常全面。七夕下载... 2021年2月27日 - 优采云关键词URL采集器可以根据关键词搜索百度、360、搜狗、谷歌等, 采集保存搜索结果的 URL 和标题输出。非常实用方便,快来QT软件园下载吧。 [图] 2019年8月1日-Url 采集是一款可以帮助用户使用采集网站URLs的软件。该软件无需安装即可使用。朋友很好用,支持关键词采集,准... 作者:控制安全-姚药房 这次给大家分享一个我自己写的可以直接用谷歌的小工具黑客。 ..【黑客工具】好用的百度网址采集不会冻结,可以直接使用谷歌黑客语法2015年4月4日-谷歌采集器功能介绍:可以选择搜索到的内容出现位置以及URL格式都有复制链...这个fork论坛URL采集工具界面简洁,绿色无毒,一键使用。 ... 2018年4月25日 - 百度网址采集器,输入搜索语法采集符合网站,保存为txt,可用于批量搜索注射部位。百度url采集更多下载资源和学习资料,请访问CSDN图书馆频道。 查看全部
采集工具(掌控安全-Yao谷歌url采集工具批量导入关键词采集url)
【图文并茂】2021年3月3日-神马url采集tools google url采集tools批量导入关键词采集url,不限采集的层数,可去重,可根据条件过滤无用URL,帮助您快速获取大量某类URL...[图文]2020年9月21日-Url采集@ >该工具是一款非常实用的url批量采集脚本工具,软件可以帮助用户... 另外,Url采集器免费版还可以对单个URL执行采集 ,非常全面。七夕下载... 2021年2月27日 - 优采云关键词URL采集器可以根据关键词搜索百度、360、搜狗、谷歌等, 采集保存搜索结果的 URL 和标题输出。非常实用方便,快来QT软件园下载吧。 [图] 2019年8月1日-Url 采集是一款可以帮助用户使用采集网站URLs的软件。该软件无需安装即可使用。朋友很好用,支持关键词采集,准... 作者:控制安全-姚药房 这次给大家分享一个我自己写的可以直接用谷歌的小工具黑客。 ..【黑客工具】好用的百度网址采集不会冻结,可以直接使用谷歌黑客语法2015年4月4日-谷歌采集器功能介绍:可以选择搜索到的内容出现位置以及URL格式都有复制链...这个fork论坛URL采集工具界面简洁,绿色无毒,一键使用。 ... 2018年4月25日 - 百度网址采集器,输入搜索语法采集符合网站,保存为txt,可用于批量搜索注射部位。百度url采集更多下载资源和学习资料,请访问CSDN图书馆频道。
采集工具(网络信息采集大师--如何设置脚本类型的任务?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-01-24 15:03
网络信息采集Master(网络信息采集工具)是一个简单易用的快速网络信息下载和分类系统。软件可以快速获取各类网页信息,网页深度无限制,无论网站的类型是静态HTM、HTML还是ASP和JSP,都能被软件完美识别,自动获取完整的记录,为采集信息提供便捷的解决方案。
软件特点:
1、强大的信息采集功能。可以采集几乎任何类型的网站信息,包括静态htm、html类型和动态ASP、ASPX、JSP等。N级页面可以与采集关联,并自动集成成完整的记录。支持网络框架、链接和网络加密等。支持完整的采集和增量的采集(从断点继续)。可以自动下载二进制文件,如图片、软件、mp3等。可用的采集本地磁盘信息。支持 Post 数据请求 采集 方法。
2、网站登录。只能登录才能查看的信息,先在任务的“登录设置”中登录,采集登录后才能查看的信息。
3、速度快,运行稳定。真正的多线程、多任务,运行时占用系统资源少,可长时间稳定运行。(明显不同于其他软件)
4、数据保存格式丰富。采集的数据可以保存为Txt、Excel以及各种数据库格式(Access sqlserver Oracle Mysql等)。
5、支持脚本。可以设置脚本类型的任务,类似javascript:submit('Page', 1)等格式都可以轻松采集.
6、强大的新闻采集,自动化处理。新闻的格式可以自动保存,包括图片等(可以通过设置自动去除广告)。通过设置可以自动下载图片,将文中图片的网络路径自动更改为本地文件路径(也可以保持原样);采集的消息可以自动处理成自己设计的模板格式;采集 带有分页的新闻。通过这些功能,无需人工干预,只需简单设置即可在本地构建强大的新闻系统。
7、强大的信息自动再处理功能。对于采集的信息,可以进行二次批量再处理,使其更符合您的实际要求。还可以设置自动处理公式,在采集的过程中,根据公式进行自动处理,包括数据合并、数据替换等。
8、提供从采集,到自动化处理,到数据导出(发布)的一站式自动化功能。通过任务调度进行实时监控和发布。指定某些任务自动运行,自动去重后将采集的数据导入数据库(可以指定唯一的组合)。它可以循环往复。可以指定任务在某个时间点运行。设置采集一定数量的数据后,会自动存入库,内存会自动清空。该功能可以连续不间断地采集100,000和100,000级别的数据,同时占用很少的系统资源。让它无人看管采集。
特征:
1、完美数据采集特征;
2、可靠的数据分类管理;
3、支持在请求页面前POST某些数据;
4、支持全功能采集和增量采集功能; 查看全部
采集工具(网络信息采集大师--如何设置脚本类型的任务?)
网络信息采集Master(网络信息采集工具)是一个简单易用的快速网络信息下载和分类系统。软件可以快速获取各类网页信息,网页深度无限制,无论网站的类型是静态HTM、HTML还是ASP和JSP,都能被软件完美识别,自动获取完整的记录,为采集信息提供便捷的解决方案。
软件特点:
1、强大的信息采集功能。可以采集几乎任何类型的网站信息,包括静态htm、html类型和动态ASP、ASPX、JSP等。N级页面可以与采集关联,并自动集成成完整的记录。支持网络框架、链接和网络加密等。支持完整的采集和增量的采集(从断点继续)。可以自动下载二进制文件,如图片、软件、mp3等。可用的采集本地磁盘信息。支持 Post 数据请求 采集 方法。
2、网站登录。只能登录才能查看的信息,先在任务的“登录设置”中登录,采集登录后才能查看的信息。
3、速度快,运行稳定。真正的多线程、多任务,运行时占用系统资源少,可长时间稳定运行。(明显不同于其他软件)
4、数据保存格式丰富。采集的数据可以保存为Txt、Excel以及各种数据库格式(Access sqlserver Oracle Mysql等)。
5、支持脚本。可以设置脚本类型的任务,类似javascript:submit('Page', 1)等格式都可以轻松采集.
6、强大的新闻采集,自动化处理。新闻的格式可以自动保存,包括图片等(可以通过设置自动去除广告)。通过设置可以自动下载图片,将文中图片的网络路径自动更改为本地文件路径(也可以保持原样);采集的消息可以自动处理成自己设计的模板格式;采集 带有分页的新闻。通过这些功能,无需人工干预,只需简单设置即可在本地构建强大的新闻系统。
7、强大的信息自动再处理功能。对于采集的信息,可以进行二次批量再处理,使其更符合您的实际要求。还可以设置自动处理公式,在采集的过程中,根据公式进行自动处理,包括数据合并、数据替换等。
8、提供从采集,到自动化处理,到数据导出(发布)的一站式自动化功能。通过任务调度进行实时监控和发布。指定某些任务自动运行,自动去重后将采集的数据导入数据库(可以指定唯一的组合)。它可以循环往复。可以指定任务在某个时间点运行。设置采集一定数量的数据后,会自动存入库,内存会自动清空。该功能可以连续不间断地采集100,000和100,000级别的数据,同时占用很少的系统资源。让它无人看管采集。
特征:
1、完美数据采集特征;
2、可靠的数据分类管理;
3、支持在请求页面前POST某些数据;
4、支持全功能采集和增量采集功能;
采集工具(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-01-22 08:01
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1、水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,以保证在一个 Agent 故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2、流利的
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3、Logstash
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。
图3 Logstash的部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
input {
file {
type =>"Apache-access"
path =>"/var/log/Apache2/other\_vhosts\_access.log"
}
file {
type =>"pache-error"
path =>"/var/log/Apache2/error.log"
}
}
filter {
grok {
match => {"message"=>"%(COMBINEDApacheLOG)"}
}
date {
match => {"timestamp"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
output {
stdout {}
Redis {
host=>"192.168.1.289"
data\_type => "list"
key => "Logstash"
}
}
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4、楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5、抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6、Splunk
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk数据平台中进行使用分析。
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7、Scrapy
Python 的爬虫架构称为 Scrapy。Scrapy 是一个使用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后在调度中将其作为请求调度。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule 将下一个抓取的 URL 返回给引擎,引擎通过下载中间件将它们发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)步骤之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
【声明】本文版权归原作者所有,内容为作者个人观点。转载的目的是为了传达更多信息。如涉及作品内容、版权等问题,可联系本站删除,谢谢。 查看全部
采集工具(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1、水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,以保证在一个 Agent 故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2、流利的
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3、Logstash
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。
图3 Logstash的部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
input {
file {
type =>"Apache-access"
path =>"/var/log/Apache2/other\_vhosts\_access.log"
}
file {
type =>"pache-error"
path =>"/var/log/Apache2/error.log"
}
}
filter {
grok {
match => {"message"=>"%(COMBINEDApacheLOG)"}
}
date {
match => {"timestamp"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
output {
stdout {}
Redis {
host=>"192.168.1.289"
data\_type => "list"
key => "Logstash"
}
}
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4、楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5、抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6、Splunk
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk数据平台中进行使用分析。
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7、Scrapy
Python 的爬虫架构称为 Scrapy。Scrapy 是一个使用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后在调度中将其作为请求调度。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule 将下一个抓取的 URL 返回给引擎,引擎通过下载中间件将它们发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)步骤之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
【声明】本文版权归原作者所有,内容为作者个人观点。转载的目的是为了传达更多信息。如涉及作品内容、版权等问题,可联系本站删除,谢谢。
采集工具(优采云网页数据采集器式采集系统功能介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-01-21 11:07
优采云Web Data采集器是一款完全免费的Web Data采集软件,它改变了互联网上对数据的传统思维方式。专业的技术可以轻松抓取互联网上的各类相关信息。
[软件特色] 云采集
采集任务自动分配到云端多台服务器同时执行,提高采集效率,在极短的时间内获取上千条信息。
拖放采集 过程
模拟人类操作思维模式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采取不同的采集流程。
图像和文本识别
内置可扩展OCR接口,支持解析图片中的文字,可以提取图片上的文字。
定时自动采集
采集任务自动运行,可以按指定周期自动采集,也支持一分钟实时采集。
2分钟快速启动
内置从入门到精通的视频教程,2分钟即可上手,此外还有文档、论坛、QQ群等。
免费使用
它是免费的,免费版没有功能限制,您可以立即试用,立即下载安装。
【功能介绍】 简而言之,使用优采云可以轻松地采集从任意网页生成你需要的数据,生成自定义的常规数据格式。优采云数据采集系统可以做的包括但不限于以下内容:
1、财务数据,如季报、年报、财务报告,自动包括每日最新净值采集;
2、各大新闻门户网站实时监控,自动更新和上传最新消息;
3、监控竞争对手的最新信息,包括商品价格和库存;
4、监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5、采集最新最全的招聘信息;
6、监测各大地产相关网站、采集新房、二手房的最新行情;
7、采集主要汽车网站具体新车和二手车信息;
8、发现并采集潜在客户信息;
9、采集行业网站的产品目录和产品信息;
10、在各大电商平台之间同步商品信息,做到在一个平台发布,在其他平台自动更新。
【使用方法】首先我们新建一个任务-->进入流程设计页面-->在流程中添加循环步骤-->选择循环步骤-->勾选右侧的URL列表复选框软件的-->打开URL列表文本框-->将准备好的URL列表填入文本框
接下来,将打开网页的步骤拖入循环中-->选择打开网页的步骤-->勾选使用当前循环中的URL作为导航地址-->点击保存。系统会在界面底部的浏览器中打开循环中选择的URL对应的网页。
.
至此,循环打开网页的流程就配置好了。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置 采集 数据步骤,这里就不多说了。从入门到精通可以参考系列一:采集单网页文章。下图是最终和过程
以下是该过程的最终运行结果
【更新日志】数据导出功能大幅提升,修复大批量数据无法导出的问题。
大批量数据可以导出到多个文件,超过Excel文件上限的数据可以导出。
支持覆盖安装,无需卸载旧版本即可直接安装新版本,系统会自动升级安装并保留旧版本数据。
优化采集步骤下拉列表切换功能。
单机采集意外终止或关闭后不保存数据,改进自动数据恢复功能,增加进度条,界面更友好。 查看全部
采集工具(优采云网页数据采集器式采集系统功能介绍)
优采云Web Data采集器是一款完全免费的Web Data采集软件,它改变了互联网上对数据的传统思维方式。专业的技术可以轻松抓取互联网上的各类相关信息。
[软件特色] 云采集
采集任务自动分配到云端多台服务器同时执行,提高采集效率,在极短的时间内获取上千条信息。
拖放采集 过程
模拟人类操作思维模式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采取不同的采集流程。
图像和文本识别
内置可扩展OCR接口,支持解析图片中的文字,可以提取图片上的文字。
定时自动采集
采集任务自动运行,可以按指定周期自动采集,也支持一分钟实时采集。
2分钟快速启动
内置从入门到精通的视频教程,2分钟即可上手,此外还有文档、论坛、QQ群等。
免费使用
它是免费的,免费版没有功能限制,您可以立即试用,立即下载安装。
【功能介绍】 简而言之,使用优采云可以轻松地采集从任意网页生成你需要的数据,生成自定义的常规数据格式。优采云数据采集系统可以做的包括但不限于以下内容:
1、财务数据,如季报、年报、财务报告,自动包括每日最新净值采集;
2、各大新闻门户网站实时监控,自动更新和上传最新消息;
3、监控竞争对手的最新信息,包括商品价格和库存;
4、监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5、采集最新最全的招聘信息;
6、监测各大地产相关网站、采集新房、二手房的最新行情;
7、采集主要汽车网站具体新车和二手车信息;
8、发现并采集潜在客户信息;
9、采集行业网站的产品目录和产品信息;
10、在各大电商平台之间同步商品信息,做到在一个平台发布,在其他平台自动更新。
【使用方法】首先我们新建一个任务-->进入流程设计页面-->在流程中添加循环步骤-->选择循环步骤-->勾选右侧的URL列表复选框软件的-->打开URL列表文本框-->将准备好的URL列表填入文本框
接下来,将打开网页的步骤拖入循环中-->选择打开网页的步骤-->勾选使用当前循环中的URL作为导航地址-->点击保存。系统会在界面底部的浏览器中打开循环中选择的URL对应的网页。
.
至此,循环打开网页的流程就配置好了。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置 采集 数据步骤,这里就不多说了。从入门到精通可以参考系列一:采集单网页文章。下图是最终和过程
以下是该过程的最终运行结果
【更新日志】数据导出功能大幅提升,修复大批量数据无法导出的问题。
大批量数据可以导出到多个文件,超过Excel文件上限的数据可以导出。
支持覆盖安装,无需卸载旧版本即可直接安装新版本,系统会自动升级安装并保留旧版本数据。
优化采集步骤下拉列表切换功能。
单机采集意外终止或关闭后不保存数据,改进自动数据恢复功能,增加进度条,界面更友好。
采集工具(优采云可采集百度地图银行的使用方法示例)
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2022-01-20 20:04
采集网站:
百度地图:百度地图是为用户提供智能路线规划、智能导航(行车、步行、骑行)、实时路况等出行相关服务的平台。优采云可以采集百度地图上的各种信息。
资料说明:本文在百度地图中,选择城市为上海,搜索“建设”银行,然后点击搜索按钮,采集出现搜索结果中的银行信息。
这篇文章只是一个例子。在实际操作过程中,可以选择自己需要的城市,更改关键词,执行数据采集。
具体字段:百度地图银行名称、百度地图银行地址。
使用功能点:
文本循环教程
Ajax 点击加载
列表和详细信息采集
第 1 步:创建一个 采集 任务
1)进入主界面,选择“自定义采集”
2)把你要采集的网站网址复制粘贴到输入框中,点击“保存网址”
第 2 步:输入 采集 信息
1)点击页面上的城市选择框,然后在操作提示框中,选择“更多操作”
2)选择“点击该元素”进入城市选择页面
3)选择你想要的城市采集,这里以上海为例。先选择“上海”,然后在操作提示框中选择“点击此链接”进入上海地图
4)点击地图上的输入框,然后在右侧的操作提示框中选择“输入文字”
5)在操作框提示中,输入要查询的文字。在此处输入“建设银行”。输入完成后点击“确定”
6)“建设银行”自动填入输入框。先点击“搜索”按钮,然后在右侧的操作提示框中,选择“点击此按钮”
第 3 步:创建翻页循环
1)我们可以看到页面上出现了建设银行的搜索结果。将结果页面向下滚动到底部,然后单击“下一步”按钮。在右侧的操作提示框中,选择“循环点击下一页”,创建翻页循环
第 4 步:创建列表循环
1)首先在搜索结果页面选择第一条银行信息的链接,系统会自动识别相似元素,在操作提示框中选择“全选”
2)在动作提示框中,选择“Loop through each link”创建列表循环
第 5 步:提取银行信息
1)列表循环创建完成后,系统会自动点击第一个银行信息链接,进入银行详情页面。首先点击要为采集的字段(这里点击银行名称),然后在操作提示框中选择“采集该元素的文本”
2)继续点击你要采集的字段,选择“采集Text for this element”。采集 的字段会自动添加到上面的数据编辑框中。选择对应的字段,可以自定义字段的命名
3)经过以上操作,整个流程图就建立好了。在保存和启动任务之前,我们还需要设置一些高级选项。先选择第一步的“点击元素”,然后打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”,最后点击“确定”
4)第二个“点击元素”步骤、第三个“点击元素”步骤、第四个“点击元素”步骤和点击翻页步骤(如下图红框),都需要勾选” Ajax加载数据”,设置时间为“2秒”,最后点击“确定”
注意:Ajax 是一种延迟加载和异步更新的脚本技术。通过在后台与服务器交换少量数据,可以在不更新和加载整个网页的情况下更新网页的某一部分。
性能特点: a.当点击网页上的某个选项时,网站的大部分URL不会改变;湾。网页没有完全加载,而只是部分加载了数据,这些数据会发生变化。
验证方法:点击操作后,在浏览器中,URL输入栏不会出现在加载状态或圆圈状态。
5)点击左上角的“Save and Launch”,选择“Launch Local采集”
第 6 步:数据采集 和导出
1)采集完成后会弹出提示,选择“导出数据”
2)选择“合适的导出方式”导出采集好的数据
3)这里我们选择excel作为导出格式,导出数据如下图 查看全部
采集工具(优采云可采集百度地图银行的使用方法示例)
采集网站:
百度地图:百度地图是为用户提供智能路线规划、智能导航(行车、步行、骑行)、实时路况等出行相关服务的平台。优采云可以采集百度地图上的各种信息。
资料说明:本文在百度地图中,选择城市为上海,搜索“建设”银行,然后点击搜索按钮,采集出现搜索结果中的银行信息。
这篇文章只是一个例子。在实际操作过程中,可以选择自己需要的城市,更改关键词,执行数据采集。
具体字段:百度地图银行名称、百度地图银行地址。
使用功能点:
文本循环教程
Ajax 点击加载
列表和详细信息采集
第 1 步:创建一个 采集 任务
1)进入主界面,选择“自定义采集”
2)把你要采集的网站网址复制粘贴到输入框中,点击“保存网址”
第 2 步:输入 采集 信息
1)点击页面上的城市选择框,然后在操作提示框中,选择“更多操作”
2)选择“点击该元素”进入城市选择页面
3)选择你想要的城市采集,这里以上海为例。先选择“上海”,然后在操作提示框中选择“点击此链接”进入上海地图
4)点击地图上的输入框,然后在右侧的操作提示框中选择“输入文字”
5)在操作框提示中,输入要查询的文字。在此处输入“建设银行”。输入完成后点击“确定”
6)“建设银行”自动填入输入框。先点击“搜索”按钮,然后在右侧的操作提示框中,选择“点击此按钮”
第 3 步:创建翻页循环
1)我们可以看到页面上出现了建设银行的搜索结果。将结果页面向下滚动到底部,然后单击“下一步”按钮。在右侧的操作提示框中,选择“循环点击下一页”,创建翻页循环
第 4 步:创建列表循环
1)首先在搜索结果页面选择第一条银行信息的链接,系统会自动识别相似元素,在操作提示框中选择“全选”
2)在动作提示框中,选择“Loop through each link”创建列表循环
第 5 步:提取银行信息
1)列表循环创建完成后,系统会自动点击第一个银行信息链接,进入银行详情页面。首先点击要为采集的字段(这里点击银行名称),然后在操作提示框中选择“采集该元素的文本”
2)继续点击你要采集的字段,选择“采集Text for this element”。采集 的字段会自动添加到上面的数据编辑框中。选择对应的字段,可以自定义字段的命名
3)经过以上操作,整个流程图就建立好了。在保存和启动任务之前,我们还需要设置一些高级选项。先选择第一步的“点击元素”,然后打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”,最后点击“确定”
4)第二个“点击元素”步骤、第三个“点击元素”步骤、第四个“点击元素”步骤和点击翻页步骤(如下图红框),都需要勾选” Ajax加载数据”,设置时间为“2秒”,最后点击“确定”
注意:Ajax 是一种延迟加载和异步更新的脚本技术。通过在后台与服务器交换少量数据,可以在不更新和加载整个网页的情况下更新网页的某一部分。
性能特点: a.当点击网页上的某个选项时,网站的大部分URL不会改变;湾。网页没有完全加载,而只是部分加载了数据,这些数据会发生变化。
验证方法:点击操作后,在浏览器中,URL输入栏不会出现在加载状态或圆圈状态。
5)点击左上角的“Save and Launch”,选择“Launch Local采集”
第 6 步:数据采集 和导出
1)采集完成后会弹出提示,选择“导出数据”
2)选择“合适的导出方式”导出采集好的数据
3)这里我们选择excel作为导出格式,导出数据如下图
采集工具(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-01-20 14:24
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1个水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,以保证在一个 Agent 故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2 流利
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3 日志存储
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。
图3 Logstash的部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
input {
file {
type =>"Apache-access"
path =>"/var/log/Apache2/other_vhosts_access.log"
}
file {
type =>"pache-error"
path =>"/var/log/Apache2/error.log"
}
}
filter {
grok {
match => {"message"=>"%(COMBINEDApacheLOG)"}
}
date {
match => {"timestamp"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
output {
stdout {}
Redis {
host=>"192.168.1.289"
data_type => "list"
key => "Logstash"
}
}
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4 楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5 抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6 斯普伦克
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk的数据平台进行分析.
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7 刮擦
Python 的爬虫架构称为 Scrapy。Scrapy 是一个使用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后在调度中将其作为请求调度。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule将下一次爬取的URL返回给引擎,引擎通过下载中间件发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。 查看全部
采集工具(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1个水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,以保证在一个 Agent 故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2 流利
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3 日志存储
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。
图3 Logstash的部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
input {
file {
type =>"Apache-access"
path =>"/var/log/Apache2/other_vhosts_access.log"
}
file {
type =>"pache-error"
path =>"/var/log/Apache2/error.log"
}
}
filter {
grok {
match => {"message"=>"%(COMBINEDApacheLOG)"}
}
date {
match => {"timestamp"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
output {
stdout {}
Redis {
host=>"192.168.1.289"
data_type => "list"
key => "Logstash"
}
}
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4 楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5 抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6 斯普伦克
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk的数据平台进行分析.
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7 刮擦
Python 的爬虫架构称为 Scrapy。Scrapy 是一个使用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后在调度中将其作为请求调度。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule将下一次爬取的URL返回给引擎,引擎通过下载中间件发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
采集工具(这几大运营工具都是怎么用的,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-01-20 03:01
4大自媒体操作工具,教你发图文还教你素材采集,很多人觉得自己的操作效率不高,别人能带20多个账号,自己操作5 每个账户都在苦苦挣扎,你有没有想过为什么,他们使用了什么技能?
有时候,如果你想提高操作效率,使用工具操作是最快的方法。比如分发工具可以一键分发到30多个平台,比一个一个分发快很多倍。下面我们来看看这些主要的操作工具是如何使用的。
第一种:分发工具
实际上有很多分发工具。我以易小儿的一键分发为例。安装完成后,您可以用手机或微信登录,然后可以在账户管理中心批量导入账户或单独添加账户。添加完成。之后在文章或者发送视频页面选择你要发布的平台和账号,操作比较简单。
第二个:材质采集工具
我用的比较多的素材采集工具是一赞,可以是采集文章素材或者采集视频素材,对于自媒体@需要很多素材>对于人,还是比较好用的,还可以批量下载资料,大家可以试试。
自媒体3@>
第三:表格制作者
当一些 自媒体 人在创建内容时,他们可能需要做一些与投票和调查相关的活动。这个时候,表单创建工具就派上用场了,可以解决你的燃眉之急。表单创建工具:迈客CRM、音乐调查、表单大师、腾讯问卷。
四:H5制作工具
H5制作工具,有的人可能没接触过,有的自媒体人在制作内容的时候需要做场景。此时,他们可以使用 H5。这也是一种比较流行的推广方式。H5制作工具:易启修、MAKA、云启 查看全部
采集工具(这几大运营工具都是怎么用的,你知道吗?)
4大自媒体操作工具,教你发图文还教你素材采集,很多人觉得自己的操作效率不高,别人能带20多个账号,自己操作5 每个账户都在苦苦挣扎,你有没有想过为什么,他们使用了什么技能?
有时候,如果你想提高操作效率,使用工具操作是最快的方法。比如分发工具可以一键分发到30多个平台,比一个一个分发快很多倍。下面我们来看看这些主要的操作工具是如何使用的。
第一种:分发工具
实际上有很多分发工具。我以易小儿的一键分发为例。安装完成后,您可以用手机或微信登录,然后可以在账户管理中心批量导入账户或单独添加账户。添加完成。之后在文章或者发送视频页面选择你要发布的平台和账号,操作比较简单。
第二个:材质采集工具
我用的比较多的素材采集工具是一赞,可以是采集文章素材或者采集视频素材,对于自媒体@需要很多素材>对于人,还是比较好用的,还可以批量下载资料,大家可以试试。
自媒体3@>
第三:表格制作者
当一些 自媒体 人在创建内容时,他们可能需要做一些与投票和调查相关的活动。这个时候,表单创建工具就派上用场了,可以解决你的燃眉之急。表单创建工具:迈客CRM、音乐调查、表单大师、腾讯问卷。
四:H5制作工具
H5制作工具,有的人可能没接触过,有的自媒体人在制作内容的时候需要做场景。此时,他们可以使用 H5。这也是一种比较流行的推广方式。H5制作工具:易启修、MAKA、云启
采集工具(采集工具简单的说就是利用接口来抓取数据的一种工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-01-20 02:03
采集工具简单的说就是利用接口来抓取数据的一种工具。具体的采集工具我推荐用讯飞听见,它可以将音频文件变成文本,或者变成单词等都是非常方便的。希望可以帮到你。
可以试试e-learning人工智能学习工具,有ai语音写诗和数字音频的文字版和音频版供你选择。速度超快,
采集工具,当然是用优采云采集器!他能够自定义规则,
其实去哪里找真的是一个很大的问题。
个人认为:自己操作比较容易,人工智能也好,爬虫也好。但是,现在短视频,头条等平台,是可以把自己写的程序暴露给用户的。做个黑客吧,顺便做推广。
用什么工具需要看你的用途,比如我把e-learning作为我的博客来推广,但是我只有手机网页版,这种情况下基本上拿不到任何网页内容。
那就请参考下面的链接。有两个采集短视频的工具,后一个是短视频相关信息,而前一个可以抓取网页视频内容。
目前支持微博抖音百度、百度云、快手火山头条等网站的视频采集, 查看全部
采集工具(采集工具简单的说就是利用接口来抓取数据的一种工具)
采集工具简单的说就是利用接口来抓取数据的一种工具。具体的采集工具我推荐用讯飞听见,它可以将音频文件变成文本,或者变成单词等都是非常方便的。希望可以帮到你。
可以试试e-learning人工智能学习工具,有ai语音写诗和数字音频的文字版和音频版供你选择。速度超快,
采集工具,当然是用优采云采集器!他能够自定义规则,
其实去哪里找真的是一个很大的问题。
个人认为:自己操作比较容易,人工智能也好,爬虫也好。但是,现在短视频,头条等平台,是可以把自己写的程序暴露给用户的。做个黑客吧,顺便做推广。
用什么工具需要看你的用途,比如我把e-learning作为我的博客来推广,但是我只有手机网页版,这种情况下基本上拿不到任何网页内容。
那就请参考下面的链接。有两个采集短视频的工具,后一个是短视频相关信息,而前一个可以抓取网页视频内容。
目前支持微博抖音百度、百度云、快手火山头条等网站的视频采集,
采集工具(什么是采集站顾名思义就是)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-19 19:06
什么是采集站,顾名思义就是通过向网站填充采集大量的内容数据来获取更多的流量,不管任何网站都会面临一个问题,内容的填充
只要有足够的数据,我们可以从百度获取更多的收录和展示。对于一个大站。要有源源不断的数据,比如:如果你的网站想要每天上万的流量,你需要大量的关键词支持,大量的关键词@ > 需要很多内容!对于个人站长和小团队来说,一天更新几十万篇文章文章无疑是一个梦想。这么多人在这个时候选择采集!
很多朋友都问过我这个问题?为什么别人的网站排名或者流量这么好?根据域名的历史,建站花了一年多的时间。但是收录数据达到了20W。倒计时每天创作547条内容,它是怎么做到的?我现在应该怎么办?
以上是小编制作的采集站。目前日流量已经达到1W以上,后台文章音量60W,持续稳定。下面小编就给大家说说制作一个采集站的思路。
1、 网站程序。现在互联网发展很快,网上的源代码越来越多,免费的也很多。不过很多人都在使用这些源码,这里就不再赘述了。我相信很多人使用免费的东西
2、 首先,在选择域名的时候,应该选择一个旧域名。为什么选择老域名,因为老域名已经过了搜索引擎的观察期。为什么旧域名更有可能是 收录?因为老域名做了一些优化,越老的域名,网站的排名就越好。
3、选择好消息源采集是重中之重,比如百度蜘蛛的消息源被屏蔽。
4、 采集 处理后如重写或伪原创
5、 每次更新后的内容都要主动推送到搜索引擎
这就是为什么很多站长都在拼命往自己的网站里加网站的内容,我们采集其他的内容,首先从搜索引擎的角度来看,这是重复的内容,我们的内容相对于 采集 的质量肯定下降了很多。但我们可以通过做一些其他方面来弥补,这就需要大家在域名的程序和内容上有所改进。
如果你看过这个文章,如果你喜欢这个文章,不妨采集或转发给需要的朋友和同事!你的一举一动都会成为小编源源不断的动力! 查看全部
采集工具(什么是采集站顾名思义就是)
什么是采集站,顾名思义就是通过向网站填充采集大量的内容数据来获取更多的流量,不管任何网站都会面临一个问题,内容的填充
只要有足够的数据,我们可以从百度获取更多的收录和展示。对于一个大站。要有源源不断的数据,比如:如果你的网站想要每天上万的流量,你需要大量的关键词支持,大量的关键词@ > 需要很多内容!对于个人站长和小团队来说,一天更新几十万篇文章文章无疑是一个梦想。这么多人在这个时候选择采集!
很多朋友都问过我这个问题?为什么别人的网站排名或者流量这么好?根据域名的历史,建站花了一年多的时间。但是收录数据达到了20W。倒计时每天创作547条内容,它是怎么做到的?我现在应该怎么办?
以上是小编制作的采集站。目前日流量已经达到1W以上,后台文章音量60W,持续稳定。下面小编就给大家说说制作一个采集站的思路。
1、 网站程序。现在互联网发展很快,网上的源代码越来越多,免费的也很多。不过很多人都在使用这些源码,这里就不再赘述了。我相信很多人使用免费的东西
2、 首先,在选择域名的时候,应该选择一个旧域名。为什么选择老域名,因为老域名已经过了搜索引擎的观察期。为什么旧域名更有可能是 收录?因为老域名做了一些优化,越老的域名,网站的排名就越好。
3、选择好消息源采集是重中之重,比如百度蜘蛛的消息源被屏蔽。
4、 采集 处理后如重写或伪原创
5、 每次更新后的内容都要主动推送到搜索引擎
这就是为什么很多站长都在拼命往自己的网站里加网站的内容,我们采集其他的内容,首先从搜索引擎的角度来看,这是重复的内容,我们的内容相对于 采集 的质量肯定下降了很多。但我们可以通过做一些其他方面来弥补,这就需要大家在域名的程序和内容上有所改进。
如果你看过这个文章,如果你喜欢这个文章,不妨采集或转发给需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
采集工具(如何采集网页的数据采集四步,你要知道的事)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-01-19 09:10
导读
很多人说我没有本钱,代发一件我觉得麻烦。有没有什么办法可以通过闲鱼赚钱?
我说真的有,卖数据,当然是公开数据,否则就涉嫌违法。
大量的数据对大多数人来说毫无意义,但对少数人来说,可能是无价之宝,他愿意花几百甚至上千来购买。
当然,如果你还是对数据进行深度处理和整合,卖几万也没问题,只要渠道对了。
数据采集
为什么数据可以卖钱?
因为有相当多的用户群体需要用到数据,而他们需要的是实时的、真实的数据;而不是几年前,甚至是捏造的数据。
百度一般无法获取这些数据。
它们可能被用于投资、研究、报告、设计等各种用途。你不觉得这些都是高端人使用的,他们不能自己做吗?
大多数中高层都愿意用金钱换时间。因为数据采集需要一定的时间才能完成,一些复杂的内容甚至需要设计相应的算法。
但在闲鱼上,我们其实还有很多事情要做。今天教大家采集网页数据怎么卖?或者自己使用,你可以自己做。
采集工具
目前平台上有很多为普通用户开发的采集工具。主流的有:优采云采集、优采云、优采云等,当然这些都是国产的,不用担心语言问题.
需要绿色版的优采云,可以私信[优采云]索取。
事实上,采集 工具的原理是类似的。这里以优采云采集为例,一步步教你采集数据
采集四个步骤
首先采集你有一个概念,你想要什么采集?
这里我们以著名的电影天堂(他们为什么不关站?)为例,来8月18日他们最新的电影自用。
为了简化流程,我们将采集他对应的电影地址和片名,其他的就不讨论了
一篇文章 文章 将带你走进大门
第 1 步:了解 采集 对象
在采集之前,你必须了解采集列表页和内容页的布局,然后才能开始。当然,在你采集 N次网站之后我发现它们是相似的,一些加密的会单独讨论。
天堂首页,这里我们主要关注采集2020新片精品
这是我们要采集的目标页面,当然下面是分页
最后,点进去看看详情页的布局,就知道了。
第一步完成。
第 2 步:创建一个 采集 项目
创建新任务(旧版本优采云,够用了)
然后设置列表页的地址和获取对应详情页地址的方法
这里大家必须掌握的一项基本技能就是学会查看网页的源代码。
然后就可以看到网站的整个代码了
初始页其实很容易找到,就是你打开的第一页,地址如下
但是这个 网站 很有趣。第一页是索引,第二页是 index_2。不按套路,不过没关系,设置成两个链接就好了。
之后,获取相应详细信息页面的链接,就大功告成了。
通过快速查找标题找到对应的代码块
然后按照格式
参数代表需要的目标数据,*代表随机填充(占位符)
下一步是获取详情页的目标数据。这里主要是标题和链接。链接不需要特别是采集,因为它有自己。
找到对应的代码块后,就可以设置对应的采集代码了。
最后一步是导出,一般情况下,导出为excel格式。当然很多站长会把采集贴到自己的网站上,这里需要一些插件。
导出后就可以得到你想要的数据了。
假设数据有点复杂,就是这样
如果你需要研究二手车市场,那么这张表或许能得出一些有用的结论:
宝马的二手车明显多于奔驰和奥迪,说明宝马车主更喜欢新旧?
综上所述
手头有很多靠谱的项目,真心希望有志之士加入,希望加入的人都能赚钱。
闲鱼只是一个小渠道,根据自己的情况学会使用,给自己带来更多的可能。 查看全部
采集工具(如何采集网页的数据采集四步,你要知道的事)
导读
很多人说我没有本钱,代发一件我觉得麻烦。有没有什么办法可以通过闲鱼赚钱?
我说真的有,卖数据,当然是公开数据,否则就涉嫌违法。
大量的数据对大多数人来说毫无意义,但对少数人来说,可能是无价之宝,他愿意花几百甚至上千来购买。
当然,如果你还是对数据进行深度处理和整合,卖几万也没问题,只要渠道对了。
数据采集
为什么数据可以卖钱?
因为有相当多的用户群体需要用到数据,而他们需要的是实时的、真实的数据;而不是几年前,甚至是捏造的数据。
百度一般无法获取这些数据。
它们可能被用于投资、研究、报告、设计等各种用途。你不觉得这些都是高端人使用的,他们不能自己做吗?
大多数中高层都愿意用金钱换时间。因为数据采集需要一定的时间才能完成,一些复杂的内容甚至需要设计相应的算法。
但在闲鱼上,我们其实还有很多事情要做。今天教大家采集网页数据怎么卖?或者自己使用,你可以自己做。
采集工具
目前平台上有很多为普通用户开发的采集工具。主流的有:优采云采集、优采云、优采云等,当然这些都是国产的,不用担心语言问题.
需要绿色版的优采云,可以私信[优采云]索取。
事实上,采集 工具的原理是类似的。这里以优采云采集为例,一步步教你采集数据
采集四个步骤
首先采集你有一个概念,你想要什么采集?
这里我们以著名的电影天堂(他们为什么不关站?)为例,来8月18日他们最新的电影自用。
为了简化流程,我们将采集他对应的电影地址和片名,其他的就不讨论了
一篇文章 文章 将带你走进大门
第 1 步:了解 采集 对象
在采集之前,你必须了解采集列表页和内容页的布局,然后才能开始。当然,在你采集 N次网站之后我发现它们是相似的,一些加密的会单独讨论。
天堂首页,这里我们主要关注采集2020新片精品
这是我们要采集的目标页面,当然下面是分页
最后,点进去看看详情页的布局,就知道了。
第一步完成。
第 2 步:创建一个 采集 项目
创建新任务(旧版本优采云,够用了)
然后设置列表页的地址和获取对应详情页地址的方法
这里大家必须掌握的一项基本技能就是学会查看网页的源代码。
然后就可以看到网站的整个代码了
初始页其实很容易找到,就是你打开的第一页,地址如下
但是这个 网站 很有趣。第一页是索引,第二页是 index_2。不按套路,不过没关系,设置成两个链接就好了。
之后,获取相应详细信息页面的链接,就大功告成了。
通过快速查找标题找到对应的代码块
然后按照格式
参数代表需要的目标数据,*代表随机填充(占位符)
下一步是获取详情页的目标数据。这里主要是标题和链接。链接不需要特别是采集,因为它有自己。
找到对应的代码块后,就可以设置对应的采集代码了。
最后一步是导出,一般情况下,导出为excel格式。当然很多站长会把采集贴到自己的网站上,这里需要一些插件。
导出后就可以得到你想要的数据了。
假设数据有点复杂,就是这样
如果你需要研究二手车市场,那么这张表或许能得出一些有用的结论:
宝马的二手车明显多于奔驰和奥迪,说明宝马车主更喜欢新旧?
综上所述
手头有很多靠谱的项目,真心希望有志之士加入,希望加入的人都能赚钱。
闲鱼只是一个小渠道,根据自己的情况学会使用,给自己带来更多的可能。
采集工具( 如何从大数据中采集出有用的信息是大数据发展的最关键因素 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-01-17 09:09
如何从大数据中采集出有用的信息是大数据发展的最关键因素
)
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1、水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,以保证在一个 Agent 故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2、流利的
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3、Logstash
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。
图3 Logstash的部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
input {
file {
type =>"Apache-access"
path =>"/var/log/Apache2/other\_vhosts\_access.log"
}
file {
type =>"pache-error"
path =>"/var/log/Apache2/error.log"
}
}
filter {
grok {
match => {"message"=>"%(COMBINEDApacheLOG)"}
}
date {
match => {"timestamp"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
output {
stdout {}
Redis {
host=>"192.168.1.289"
data\_type => "list"
key => "Logstash"
}
}
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4、楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5、抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6、Splunk
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
图片
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk数据平台进行分析。
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7、Scrapy
Python 的爬虫架构称为 Scrapy。Scrapy 是一个使用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图片
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后在调度中将其作为请求调度。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule 将下一个抓取的 URL 返回给引擎,引擎通过下载中间件将它们发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
关注成都CDA数据分析师
获取干货分享和职位晋升机会进行数据分析
查看全部
采集工具(
如何从大数据中采集出有用的信息是大数据发展的最关键因素
)
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1、水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,以保证在一个 Agent 故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2、流利的
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3、Logstash
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。
图3 Logstash的部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
input {
file {
type =>"Apache-access"
path =>"/var/log/Apache2/other\_vhosts\_access.log"
}
file {
type =>"pache-error"
path =>"/var/log/Apache2/error.log"
}
}
filter {
grok {
match => {"message"=>"%(COMBINEDApacheLOG)"}
}
date {
match => {"timestamp"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
output {
stdout {}
Redis {
host=>"192.168.1.289"
data\_type => "list"
key => "Logstash"
}
}
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4、楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5、抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6、Splunk
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
图片
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk数据平台进行分析。
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7、Scrapy
Python 的爬虫架构称为 Scrapy。Scrapy 是一个使用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图片
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后在调度中将其作为请求调度。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule 将下一个抓取的 URL 返回给引擎,引擎通过下载中间件将它们发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
关注成都CDA数据分析师
获取干货分享和职位晋升机会进行数据分析
采集工具(不是规则多少不会出现分类错误(附解决方法汇总))
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-01-12 16:12
7、如果采集不是资源站,每个播放地址应该在一个单独的页面上采集视数量而定采集速度可能会慢
提示:本工具会在根目录生成配置文件记录以备下次使用,如果是公用电脑,请使用后删除。
——————————————————————————————————————————
自动分类指令
示例:[@]动作|8[/@]
你的表达能力有限,请自行理解
1、自动分类规则如上例写法,括号字符必须相同,不能为[]。
2、“|” 前面是采集网站得到的分类,后面是网站对应分类的ID。
3、ID点击阅读网站分类按钮查看(前提:连接数据库)。
4、可以对一个网站使用自动分类规则,不管有多少规则都不会出现分类错误(前提:你没有写错规则),因为理论上采集到网站@ >分类不能与自动分类规则中的2条规则匹配。
5、自动分类可以与自定义采集中的分类采集灵活配合使用,例如:资源站有日韩分类,其网站日本和韩国分开,可以采集资源站的地区作为分类规则[@]韩国|(自己的网站韩剧ID)[/@]、[/@ ]欧美|10[/@]
重要提示:
1、规则有误可能会导致存储的分类出错,要了解使用方法后再使用。
2!!!!!!!养成备份数据库的习惯!!!!!!
重要声明:本工具仅供参考,使用过程中出现任何问题本人概不负责!!!!!!!!
发行说明:
1.0.3 修复导入时间错误到1970
1.0.2 及时解决个别读分类id的错误
1.0.1更新
1.解决存储失败时年份为空
2.增加手动添加视频功能
3.添加公告以了解最新动态
4.优化部分代码
1.0版本,所以希望提供宝贵意见
支持最新的飞飞cms php版本,
支持自定义编写采集规则,
支持规则绑定网站分类,
支持自动存储,
支持编辑,
群里会不定时添加采集规则 查看全部
采集工具(不是规则多少不会出现分类错误(附解决方法汇总))
7、如果采集不是资源站,每个播放地址应该在一个单独的页面上采集视数量而定采集速度可能会慢
提示:本工具会在根目录生成配置文件记录以备下次使用,如果是公用电脑,请使用后删除。
——————————————————————————————————————————
自动分类指令
示例:[@]动作|8[/@]
你的表达能力有限,请自行理解
1、自动分类规则如上例写法,括号字符必须相同,不能为[]。
2、“|” 前面是采集网站得到的分类,后面是网站对应分类的ID。
3、ID点击阅读网站分类按钮查看(前提:连接数据库)。
4、可以对一个网站使用自动分类规则,不管有多少规则都不会出现分类错误(前提:你没有写错规则),因为理论上采集到网站@ >分类不能与自动分类规则中的2条规则匹配。
5、自动分类可以与自定义采集中的分类采集灵活配合使用,例如:资源站有日韩分类,其网站日本和韩国分开,可以采集资源站的地区作为分类规则[@]韩国|(自己的网站韩剧ID)[/@]、[/@ ]欧美|10[/@]
重要提示:
1、规则有误可能会导致存储的分类出错,要了解使用方法后再使用。
2!!!!!!!养成备份数据库的习惯!!!!!!
重要声明:本工具仅供参考,使用过程中出现任何问题本人概不负责!!!!!!!!
发行说明:
1.0.3 修复导入时间错误到1970
1.0.2 及时解决个别读分类id的错误
1.0.1更新
1.解决存储失败时年份为空
2.增加手动添加视频功能
3.添加公告以了解最新动态
4.优化部分代码
1.0版本,所以希望提供宝贵意见
支持最新的飞飞cms php版本,
支持自定义编写采集规则,
支持规则绑定网站分类,
支持自动存储,
支持编辑,
群里会不定时添加采集规则
采集工具(如何实现支付宝扫码付款需要很多信息(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2022-01-10 19:08
采集工具推荐:乐语采集,接口支持有效期限长达15天,不限采集范围,采集速度比较快;如何实现支付宝扫码收款呢?首先你需要手机扫一下支付宝二维码。扫码收款是把手机二维码发送到快钱平台。实现扫码收款跟付款码验证是没有关系的,而是post请求实现的(token是在你填写的支付宝账号邮箱里发送过去的)我截了个图给你看看。
无验证码版本请点:-ae312-4b18-b434-ed617e537fbd.html验证码(你填写的是”-ae312-4b18-b434-ed617e537fbd.html”应该跟上面不一样,这就需要你自己想办法解决这个问题了)小编这里直接为你贴个最新版本:/page/216001/(虽然目前支付宝扫码收款没有开通两步验证功能,但是乐语可以很好的解决你这个问题)。
实现支付宝扫码付款需要很多信息1.快钱商户号2.店铺信息3.付款码(图片)4.商户帐号5.商户支付宝帐号
手机申请开通“两步验证”会有很多选择,一般快钱快钱付款码是支持支付宝扫码付款的。
到官网买一个支付宝付款码,上可以买到,进去后填写好信息,看到哪个快钱支持你的码就开通哪个,
两步验证还是挺方便的,是去applestore找到乐语的app,下载后, 查看全部
采集工具(如何实现支付宝扫码付款需要很多信息(组图))
采集工具推荐:乐语采集,接口支持有效期限长达15天,不限采集范围,采集速度比较快;如何实现支付宝扫码收款呢?首先你需要手机扫一下支付宝二维码。扫码收款是把手机二维码发送到快钱平台。实现扫码收款跟付款码验证是没有关系的,而是post请求实现的(token是在你填写的支付宝账号邮箱里发送过去的)我截了个图给你看看。
无验证码版本请点:-ae312-4b18-b434-ed617e537fbd.html验证码(你填写的是”-ae312-4b18-b434-ed617e537fbd.html”应该跟上面不一样,这就需要你自己想办法解决这个问题了)小编这里直接为你贴个最新版本:/page/216001/(虽然目前支付宝扫码收款没有开通两步验证功能,但是乐语可以很好的解决你这个问题)。
实现支付宝扫码付款需要很多信息1.快钱商户号2.店铺信息3.付款码(图片)4.商户帐号5.商户支付宝帐号
手机申请开通“两步验证”会有很多选择,一般快钱快钱付款码是支持支付宝扫码付款的。
到官网买一个支付宝付款码,上可以买到,进去后填写好信息,看到哪个快钱支持你的码就开通哪个,
两步验证还是挺方便的,是去applestore找到乐语的app,下载后,
采集工具(采集工具,美图,qq,都有很多人卖)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-01-10 11:01
采集工具,美图,qq,都有很多人卖,关键是你的图片质量不行,中国人的图多是模糊的,不是说丑,是糊成一团,像素低不清晰,自然查不到。而且抓取的png还有顺序问题,比如你抓取的是左边的素材,但是到了ppt上就变成右边的了。这是很常见的问题。还有一个,你能否顺畅的抓取到对方的图片数据,这很关键,一般做logo,字体之类的工作的时候不会采集无损,所以你得看看你需要多大的图,才能找到恰当的地方。
如果不能顺畅抓取到对方的图片数据,就无法设置对方图片存在的相关性,如果自己简单的做个云文件,那在ppt里面就没用了。那些说免费版的工具多是抓取不够对方的精确度,而且质量也不太高。收费工具的话,普通版好像是5000+,高级版好像是1w+,当然价格也根据客户质量而不同,质量高一点的免费版也不会花太多的钱。总的来说,工具倒是次要的,关键是图片质量要好,不能有机器锐化那些。
你要送人?要查分辨率啊,涉及隐私,不方便透露。如果你是卖图片赚钱的,既然你发出来,他有时间和兴趣去浏览一下就行了,然后得过我们这儿,不给他推送了,该问就问,毕竟你又不是卖东西的。
ppt里图片加载是一个挺重要的功能,所以相关网站的建设肯定要跟上。可以用百度网盘,或者qq自带的图片共享功能。百度网盘我试过不可以,所以没法用图片共享功能。 查看全部
采集工具(采集工具,美图,qq,都有很多人卖)
采集工具,美图,qq,都有很多人卖,关键是你的图片质量不行,中国人的图多是模糊的,不是说丑,是糊成一团,像素低不清晰,自然查不到。而且抓取的png还有顺序问题,比如你抓取的是左边的素材,但是到了ppt上就变成右边的了。这是很常见的问题。还有一个,你能否顺畅的抓取到对方的图片数据,这很关键,一般做logo,字体之类的工作的时候不会采集无损,所以你得看看你需要多大的图,才能找到恰当的地方。
如果不能顺畅抓取到对方的图片数据,就无法设置对方图片存在的相关性,如果自己简单的做个云文件,那在ppt里面就没用了。那些说免费版的工具多是抓取不够对方的精确度,而且质量也不太高。收费工具的话,普通版好像是5000+,高级版好像是1w+,当然价格也根据客户质量而不同,质量高一点的免费版也不会花太多的钱。总的来说,工具倒是次要的,关键是图片质量要好,不能有机器锐化那些。
你要送人?要查分辨率啊,涉及隐私,不方便透露。如果你是卖图片赚钱的,既然你发出来,他有时间和兴趣去浏览一下就行了,然后得过我们这儿,不给他推送了,该问就问,毕竟你又不是卖东西的。
ppt里图片加载是一个挺重要的功能,所以相关网站的建设肯定要跟上。可以用百度网盘,或者qq自带的图片共享功能。百度网盘我试过不可以,所以没法用图片共享功能。
采集工具(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-01-09 04:04
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1个水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,以保证在一个 Agent 故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2 流利
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3 日志存储
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。
图 3 Logstash 部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
输入 {
文件 {
类型 => “Apache 访问”
路径 =>“/var/log/Apache2/other_vhosts_access.log”
}
文件 {
类型=>“补丁错误”
路径 =>“/var/log/Apache2/error.log”
}
}
筛选 {
摸索{
匹配 => {"消息"=>"%(COMBINEDApacheLOG)"}
}
日期 {
匹配 => {"时间戳"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
输出 {
标准输出 {}
雷迪斯 {
主机="192.168.1.289"
data_type => "列表"
键=>“Logstash”
}
}
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4 楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5 抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6 斯普伦克
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk的数据平台进行分析.
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7 刮擦
Python 的爬虫架构称为 Scrapy。Scrapy 是一个使用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后在调度中将其作为请求调度。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule将下一次爬取的URL返回给引擎,引擎通过下载中间件发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
以上内容摘自《大数据采集与处理》一书。
图书捐赠规则 查看全部
采集工具(如何从大数据中采集出有用的信息是大数据发展的最关键因素)
大数据有多种来源。在大数据时代背景下,如何从大数据中获取有用信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效地采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台。下面介绍一些常用的大数据采集平台和工具。
1个水槽
Flume 作为 Hadoop 的一个组件,是 Cloudera 专门开发的分布式日志采集系统。尤其是近年来,随着 Flume 的不断完善,用户在开发过程中的便利性有了很大的提升,Flume 现已成为 Apache Top 项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用了多 Master 的方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。Gossip 协议用于在 Flume Master 节点之间同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集的场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。Flume 被设计成一种分布式管道架构,可以看作是数据源和目的地之间的代理网络,以支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,以保证在一个 Agent 故障时整个系统仍然可以正常采集数据。Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持用户定制开发。Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端是 Avro、Log4J、Syslog 和 HTTP Post。
2 流利
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 是用 C/Ruby 开发的,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
图 1 Fluentd 架构
Fluentd 具有多种特性:易于安装、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲和日志转发。为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。与 Flume 相比,Fluentd 的配置相对简单。
Fluentd 的扩展性很强,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3 日志存储
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。Logstash的部署架构如图3所示。当然,这只是一个部署选项。
图 3 Logstash 部署架构
一个典型的 Logstash 配置如下,包括 Input 和 Filter 的 Output 的设置。
输入 {
文件 {
类型 => “Apache 访问”
路径 =>“/var/log/Apache2/other_vhosts_access.log”
}
文件 {
类型=>“补丁错误”
路径 =>“/var/log/Apache2/error.log”
}
}
筛选 {
摸索{
匹配 => {"消息"=>"%(COMBINEDApacheLOG)"}
}
日期 {
匹配 => {"时间戳"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
输出 {
标准输出 {}
雷迪斯 {
主机="192.168.1.289"
data_type => "列表"
键=>“Logstash”
}
}
几乎在大多数情况下,ELK 同时用作堆栈。在您的数据系统使用 ElasticSearch 的情况下,Logstash 是首选。
4 楚夸
Chukwa 是 Apache 旗下的另一个开源数据采集平台,知名度远不如其他平台。Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)用于分析采集的大规模数据的适当架构。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5 抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。Scribe 通常与 Hadoop 结合使用,将日志推送(push)到 HDFS 中,由 MapReduce 作业定期处理。
Scribe 架构如图 5 所示。
图 5 Scribe 架构
Scribe 架构比较简单,主要包括三个部分,即 Scribe 代理、Scribe 和存储系统。
6 斯普伦克
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。Splunk 是一个分布式机器数据平台,具有三个主要角色。Splunk 架构如图 6 所示。
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk的数据平台进行分析.
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器出现故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7 刮擦
Python 的爬虫架构称为 Scrapy。Scrapy 是一个使用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一种任何人都可以根据需要轻松修改的架构。还提供了各类爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图 7 Scrapy 运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。Scrapy运行过程如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后在调度中将其作为请求调度。
(3)Scrapy 引擎从调度程序获取要抓取的下一页。
(4)Schedule将下一次爬取的URL返回给引擎,引擎通过下载中间件发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎接收到下载器的响应,通过爬虫中间件发送给爬虫进行处理。
(7)爬虫处理响应并返回爬取的项目,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道并向调度程序发送请求。
(9)系统重复(2)之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
以上内容摘自《大数据采集与处理》一书。
图书捐赠规则

