
采集工具
易工采集器还是收费的,怎么去采集微信公众号
采集交流 • 优采云 发表了文章 • 0 个评论 • 255 次浏览 • 2021-05-15 23:19
采集工具,我推荐快速采集。精准采集,一键分享一键添加至微信好友。快速将网页采集到手机,分享给同事同学分享给家人分享给朋友圈分享给朋友后台,
云采集,精准采集。
采集工具,可以选择快采,功能强大,
试试我们的微信公众号采集器,基于微信采集公众号动态数据,不但包含微信公众号历史数据,还可以获取你公众号或微信群里的任何消息,是不是很好用,在线即可使用,方便,也免费。关注公众号【小太阳智能产品】,体验一下我们的微信公众号采集器吧。
其实采集器主要就是有几个点,开发者可以插入自己的h5,网站,微信公众号文章,微信中的链接。你可以自己筛选一下,开发者必须是拥有某个服务号或微信群的账号,所以就看你有没有需求了。我自己最近就有新公众号,想做一个公众号采集器。好像只有个技术公众号才可以,因为技术公众号有一定门槛,所以做出来的个人号几乎就没什么权限了。
所以想要做的就是群发,然后批量群发有兴趣的可以看下这个怎么去采集微信公众号文章,采集网站,网站。?-陈苏鸿的回答-知乎。
我推荐楼主使用易工采集器采集,易工采集器不但功能齐全还带分享推广功能,并且是一个不带插件、对接公众号等功能一站式安全管理采集工具,数据来源全球各大权威媒体,数据分析准确、流量高。易工采集器还是收费的,对比几个免费工具,易工采集器在收费上更低。 查看全部
易工采集器还是收费的,怎么去采集微信公众号
采集工具,我推荐快速采集。精准采集,一键分享一键添加至微信好友。快速将网页采集到手机,分享给同事同学分享给家人分享给朋友圈分享给朋友后台,
云采集,精准采集。
采集工具,可以选择快采,功能强大,
试试我们的微信公众号采集器,基于微信采集公众号动态数据,不但包含微信公众号历史数据,还可以获取你公众号或微信群里的任何消息,是不是很好用,在线即可使用,方便,也免费。关注公众号【小太阳智能产品】,体验一下我们的微信公众号采集器吧。
其实采集器主要就是有几个点,开发者可以插入自己的h5,网站,微信公众号文章,微信中的链接。你可以自己筛选一下,开发者必须是拥有某个服务号或微信群的账号,所以就看你有没有需求了。我自己最近就有新公众号,想做一个公众号采集器。好像只有个技术公众号才可以,因为技术公众号有一定门槛,所以做出来的个人号几乎就没什么权限了。
所以想要做的就是群发,然后批量群发有兴趣的可以看下这个怎么去采集微信公众号文章,采集网站,网站。?-陈苏鸿的回答-知乎。
我推荐楼主使用易工采集器采集,易工采集器不但功能齐全还带分享推广功能,并且是一个不带插件、对接公众号等功能一站式安全管理采集工具,数据来源全球各大权威媒体,数据分析准确、流量高。易工采集器还是收费的,对比几个免费工具,易工采集器在收费上更低。
抓包过程展示和概述1.4..网页解码工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-05-12 06:05
采集工具,是数据收集的主要方式,使用最多的除了抓包工具,还有网页抓包工具,如anycast等,也可以转发给自己的朋友抓包解码工具,可以获取到真实的网页数据情报。有了这些工具,也能够实现自己真正的网络数据收集与挖掘。抓包过程展示和概述1.网页抓包工具proxymonkey类似于调试工具,利用fiddler实现,完整的代码在这里,可参考proxymonkey的使用proxymonkey的源码地址:,和使用fiddler可能会在部分操作上有一些不同,比如不会获取动态加载的元素信息,只是获取一个静态的input元素或者browser元素的信息等等。
使用注意点如下:proxymonkey并不会随着网页源代码实现抓包,需要用javascript动态编译网页,才会抓取到信息2.网页解码工具lexencoder比alltage强大,可以实现代码提取,字符串解码,字符编码处理等功能。获取自己上的数据当然要用这个,功能类似于fiddler抓包工具,可以设置抓包时间等等3.网页抓包工具webscraper虽然名字听起来很高端,但实际上并不需要爬虫工具就可以实现,比如动态加载的ajax链接等等,或者需要编译的网页,只要设置爬取的url和数据不要过于难看等等4.网页解码工具papar语法仅支持php,对java支持度一般,主要实现抓取libmx中的代码参考链接:-scraper4.2功能基本和webscraper类似,只是版本较低,更新不及webscraper快速教程欢迎关注我,公众号《猴子聊人物》,获取更多精彩内容。 查看全部
抓包过程展示和概述1.4..网页解码工具
采集工具,是数据收集的主要方式,使用最多的除了抓包工具,还有网页抓包工具,如anycast等,也可以转发给自己的朋友抓包解码工具,可以获取到真实的网页数据情报。有了这些工具,也能够实现自己真正的网络数据收集与挖掘。抓包过程展示和概述1.网页抓包工具proxymonkey类似于调试工具,利用fiddler实现,完整的代码在这里,可参考proxymonkey的使用proxymonkey的源码地址:,和使用fiddler可能会在部分操作上有一些不同,比如不会获取动态加载的元素信息,只是获取一个静态的input元素或者browser元素的信息等等。
使用注意点如下:proxymonkey并不会随着网页源代码实现抓包,需要用javascript动态编译网页,才会抓取到信息2.网页解码工具lexencoder比alltage强大,可以实现代码提取,字符串解码,字符编码处理等功能。获取自己上的数据当然要用这个,功能类似于fiddler抓包工具,可以设置抓包时间等等3.网页抓包工具webscraper虽然名字听起来很高端,但实际上并不需要爬虫工具就可以实现,比如动态加载的ajax链接等等,或者需要编译的网页,只要设置爬取的url和数据不要过于难看等等4.网页解码工具papar语法仅支持php,对java支持度一般,主要实现抓取libmx中的代码参考链接:-scraper4.2功能基本和webscraper类似,只是版本较低,更新不及webscraper快速教程欢迎关注我,公众号《猴子聊人物》,获取更多精彩内容。
BI系统自身的数据采集能力和亮点数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 621 次浏览 • 2021-05-11 02:19
我们为什么需要数据采集
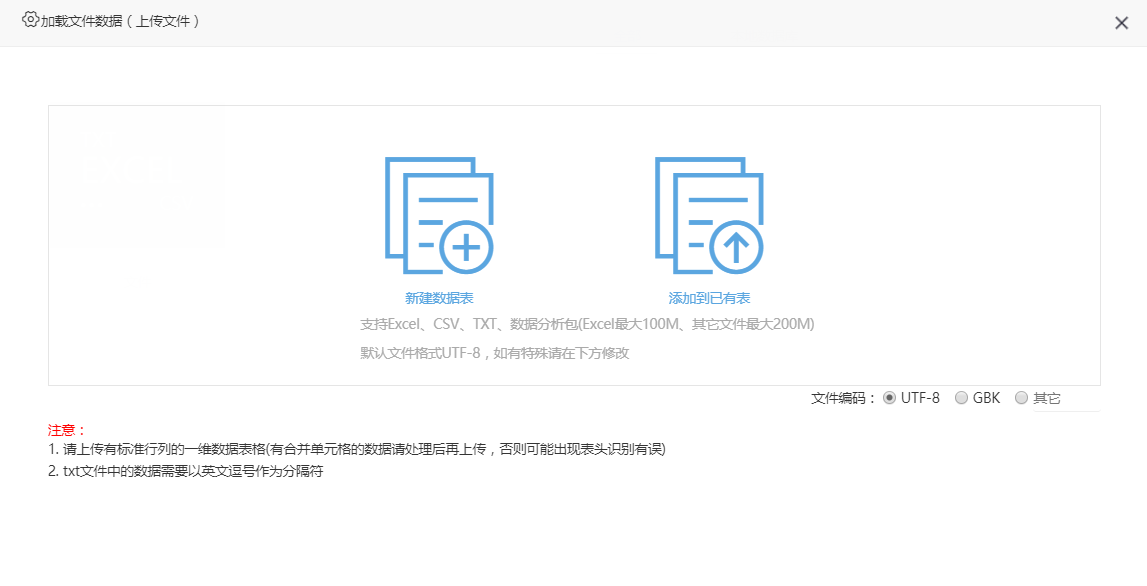
首先,数据采集是基于跨数据库查询功能的补充功能。在Smartbi V9的数据源管理中,用户可以通过上传文件(Excel,CSV,TXT)以及其他企业内部数据(关系数据)来将本地原创数据上传到数据平台,以进行后续的语义层封装和相关查询。
但是,在许多情况下,分析人员甚至最终报告的用户都会发现数据质量问题,例如产品模型的大写错误,导致无法合并统计信息以及客户归属城市的错误等。导致性能计算错误.....。如果没有数据采集的能力,那么技术人员必须通过关系数据库的后台操作来修改数据,这将带来一些安全风险。此外,业务用户可能还需要临时采集一些数据。这些采集要求并不复杂,采集的数据仅用于数据关联分析,因此很难协调企业OA。这就提出了对BI系统本身的数据采集功能的需求。
数据的功能和重点采集
Smartbi数据采集提供以下功能:
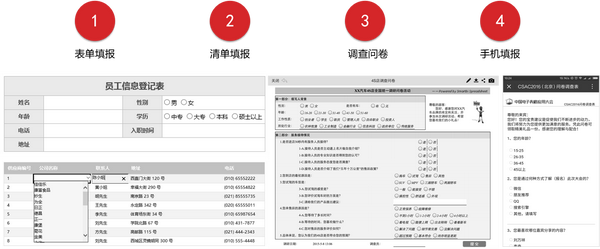
1、数据修改和维护,开发人员设计了一个可以修改数据的列表,最终用户在发布后直接在浏览器或APP上对其进行修改并将其保存在数据库中;
2、数据填充,采集,开发人员设计交叉表,表格或调查表,发布后,最终用户在浏览器或APP中输入数据并将其保存在数据库中;
3、对于已经具有Excel模板(固定格式)采集的数据,您可以设计Excel模板导入功能,以将Excel中的数据直接保存到数据库中。
前两个功能是最常用的,它们也是Smartbi数据的特征采集。 采集的页面设计为与修改数据的界面相同。如果看到的数据不正确,则可以对其进行修改,它将立即生效,而无需等待。当然,这种具有回写功能的报告依赖于预定义的资源权限来确保数据安全。
从写回报告的设计来看,基于Excel插件方法的电子表格与中式报告的设计没有什么不同,但是定义了“写回规则”,并在单元格中映射到数据库。参考界面如下:
在回写定义中,您可以指定目标数据库和表以进行数据回写,并且同意的回写内容仅由用户修改以及特定的更新规则并插入。最终接口上的写回操作支持删除行,添加行,清除数据修改记录等。
<p>此外,Smartbi Data 采集还提供了可回写的单元格的填充属性,以控制来自源的数据质量,包括验证输入数据格式和定义下拉列表。向下选择列表(支持Excel数据序列或系统内置参数),作为附件上传的文件规则等。如果您是母版,则还可以使用“正则表达式”来更严格地控制数据输入的质量。 查看全部
BI系统自身的数据采集能力和亮点数据采集
我们为什么需要数据采集
首先,数据采集是基于跨数据库查询功能的补充功能。在Smartbi V9的数据源管理中,用户可以通过上传文件(Excel,CSV,TXT)以及其他企业内部数据(关系数据)来将本地原创数据上传到数据平台,以进行后续的语义层封装和相关查询。
但是,在许多情况下,分析人员甚至最终报告的用户都会发现数据质量问题,例如产品模型的大写错误,导致无法合并统计信息以及客户归属城市的错误等。导致性能计算错误.....。如果没有数据采集的能力,那么技术人员必须通过关系数据库的后台操作来修改数据,这将带来一些安全风险。此外,业务用户可能还需要临时采集一些数据。这些采集要求并不复杂,采集的数据仅用于数据关联分析,因此很难协调企业OA。这就提出了对BI系统本身的数据采集功能的需求。
数据的功能和重点采集
Smartbi数据采集提供以下功能:
1、数据修改和维护,开发人员设计了一个可以修改数据的列表,最终用户在发布后直接在浏览器或APP上对其进行修改并将其保存在数据库中;
2、数据填充,采集,开发人员设计交叉表,表格或调查表,发布后,最终用户在浏览器或APP中输入数据并将其保存在数据库中;
3、对于已经具有Excel模板(固定格式)采集的数据,您可以设计Excel模板导入功能,以将Excel中的数据直接保存到数据库中。

前两个功能是最常用的,它们也是Smartbi数据的特征采集。 采集的页面设计为与修改数据的界面相同。如果看到的数据不正确,则可以对其进行修改,它将立即生效,而无需等待。当然,这种具有回写功能的报告依赖于预定义的资源权限来确保数据安全。
从写回报告的设计来看,基于Excel插件方法的电子表格与中式报告的设计没有什么不同,但是定义了“写回规则”,并在单元格中映射到数据库。参考界面如下:
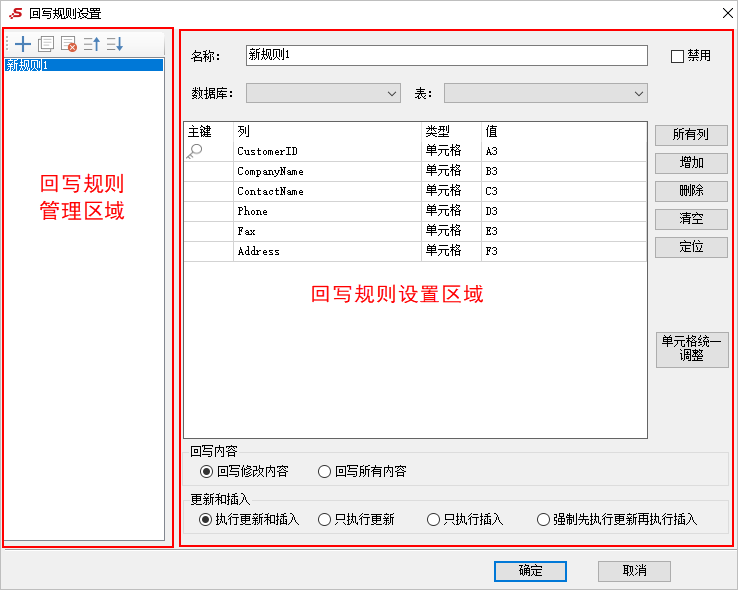
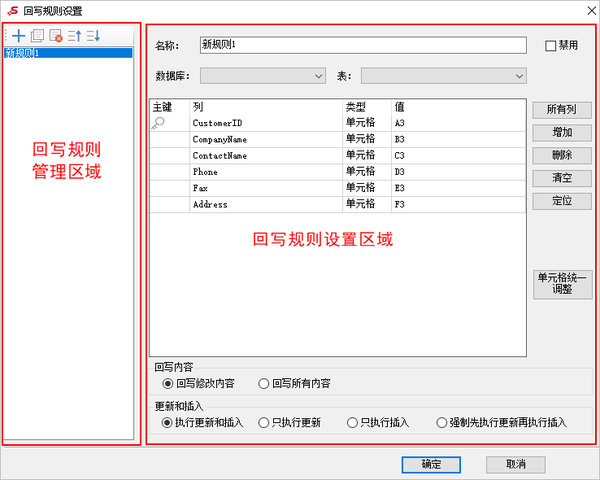
在回写定义中,您可以指定目标数据库和表以进行数据回写,并且同意的回写内容仅由用户修改以及特定的更新规则并插入。最终接口上的写回操作支持删除行,添加行,清除数据修改记录等。
<p>此外,Smartbi Data 采集还提供了可回写的单元格的填充属性,以控制来自源的数据质量,包括验证输入数据格式和定义下拉列表。向下选择列表(支持Excel数据序列或系统内置参数),作为附件上传的文件规则等。如果您是母版,则还可以使用“正则表达式”来更严格地控制数据输入的质量。
优采云采集器的功能特点及功能介绍-乐题库
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-05-10 03:24
优采云 采集器是非常专业的网络信息采集工具。作为新一代的视觉智能采集器,它具有“视觉配置,易于创建,无需编程和智能生成”的特征。它会自动生成相关功能,并快速采集您需要的内容。此版本已激活并破解,用户可以免费使用,无限功能。
[功能]
1、零阈值:如果您不知道如何采集采集器,您将在会议上收到网站个数据。
2、多引擎,高速且无混乱:内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集数据更加高效。它还具有内置的JSON引擎,无需分析JSON数据布局,即可直观地提取JSON内容。
3、结合各种类型的网站:可以采集99%的Internet 网站,包括静态示例,例如使用Ajax 网站进行单页加载。
[软件功能]
1、该软件操作复杂,单击鼠标即可轻松访问要捕获的内容;
2、支持三种高速引擎:浏览器引擎,HTTP引擎,JSON引擎,内置优化的Firefox浏览器,以及首次进行内存优化,以便浏览器也可以高速运行,甚至可以快速运行转换为HTTP操作,享受更高的采集率!捕获JSON数据时,还可以使用浏览器可视化方法来选择需要用鼠标捕获的内容。不必分析JSON数据布局,以便非Web专业计划人员可以轻松地获取必要的数据;
3、无需分析Web请求和源代码,但支持更多Web集合;
4、先进的智能算法,一键自然目标元素XPATH,主动识别网页列表,主动识别选项卡中的下一页按钮……
5、支持丰富的数据导出方法,可以将其导出到txt文件,html文件,csv文件,excel文件,还可以导出到现有数据库,例如sqlite数据库,access数据库,sqlserver数据库,mysql数据库,通过导览的复杂映射字段,可以轻松地将其导出到导览网站数据库。
[软件亮点]
可视化指南:采集所有元素,主动自然地采集数据。
1、尝试承担责任:天真地定义操作时间,完全激活操作。
2、多引擎支持:支持多个采集引擎,内置的高速浏览器内核,HTTP引擎和JSON引擎。
3、智能识别:它可以主动识别网页列表,采集字段和分页符。
4、阻止请求:自定义阻止域名,有助于过滤网站外的广告,并提高采集率。
5、各种数据导出:可以导出到Txt,Excel,MySQL,SQLServer,SQlite,Access,网站等。 查看全部
优采云采集器的功能特点及功能介绍-乐题库
优采云 采集器是非常专业的网络信息采集工具。作为新一代的视觉智能采集器,它具有“视觉配置,易于创建,无需编程和智能生成”的特征。它会自动生成相关功能,并快速采集您需要的内容。此版本已激活并破解,用户可以免费使用,无限功能。
[功能]
1、零阈值:如果您不知道如何采集采集器,您将在会议上收到网站个数据。
2、多引擎,高速且无混乱:内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集数据更加高效。它还具有内置的JSON引擎,无需分析JSON数据布局,即可直观地提取JSON内容。
3、结合各种类型的网站:可以采集99%的Internet 网站,包括静态示例,例如使用Ajax 网站进行单页加载。
[软件功能]
1、该软件操作复杂,单击鼠标即可轻松访问要捕获的内容;
2、支持三种高速引擎:浏览器引擎,HTTP引擎,JSON引擎,内置优化的Firefox浏览器,以及首次进行内存优化,以便浏览器也可以高速运行,甚至可以快速运行转换为HTTP操作,享受更高的采集率!捕获JSON数据时,还可以使用浏览器可视化方法来选择需要用鼠标捕获的内容。不必分析JSON数据布局,以便非Web专业计划人员可以轻松地获取必要的数据;
3、无需分析Web请求和源代码,但支持更多Web集合;
4、先进的智能算法,一键自然目标元素XPATH,主动识别网页列表,主动识别选项卡中的下一页按钮……
5、支持丰富的数据导出方法,可以将其导出到txt文件,html文件,csv文件,excel文件,还可以导出到现有数据库,例如sqlite数据库,access数据库,sqlserver数据库,mysql数据库,通过导览的复杂映射字段,可以轻松地将其导出到导览网站数据库。
[软件亮点]
可视化指南:采集所有元素,主动自然地采集数据。
1、尝试承担责任:天真地定义操作时间,完全激活操作。
2、多引擎支持:支持多个采集引擎,内置的高速浏览器内核,HTTP引擎和JSON引擎。
3、智能识别:它可以主动识别网页列表,采集字段和分页符。
4、阻止请求:自定义阻止域名,有助于过滤网站外的广告,并提高采集率。
5、各种数据导出:可以导出到Txt,Excel,MySQL,SQLServer,SQlite,Access,网站等。
采集工具 谢邀:1688分销红利巨大,对于分销号完全放开
采集交流 • 优采云 发表了文章 • 0 个评论 • 227 次浏览 • 2021-05-08 19:05
采集工具只是基于对用户感知信息的收集而使用,对于信息内容的变现还存在阻碍,毕竟现有的rtb技术目前还不够成熟,但最近几年rtb技术迎来大爆发,而且在去中心化以及公平性方面有着很大的改观。同时,如果你对rtb没有了解的话,最近就要淘汰的亚马逊这种产品,就证明rtb将会是未来发展的大趋势,所以你现在接触rtb就显得非常有必要,可以试试了解下,1688分销红利巨大,对于分销号完全放开,分销就是在这大趋势下的。
谢邀,我建议可以从了解如何通过开源的rtb爬虫来做到商品推荐。只要rtb上有足够多的商品,就可以通过对他们的大数据分析来进行推荐了。
可以啊,腾讯qq和都是rtb起家的。
参考豆瓣
也就是现在能找到的微淘,你现在所想的未来应该也就是基于微淘的了,而不是rtb,现在用户的付费点击率被稀释了,流量也不值钱了,rtb更适合市场人员去接触,最大的困难点在于数据采集的问题,这个只要把数据采集的拿下来,市场相对来说是最容易进行推广的。
什么rtb,rpc都不是问题.我理解就是你电商或者企业没那么精通爬虫就rtb.rpc..这些词老外会跟你绕
rtb就是个热词,还处于发展期,根据你的项目需求来。目前新浪微博已经在做了,你可以看看新浪微博的#推荐rtb的发展可以看出前景。 查看全部
采集工具 谢邀:1688分销红利巨大,对于分销号完全放开
采集工具只是基于对用户感知信息的收集而使用,对于信息内容的变现还存在阻碍,毕竟现有的rtb技术目前还不够成熟,但最近几年rtb技术迎来大爆发,而且在去中心化以及公平性方面有着很大的改观。同时,如果你对rtb没有了解的话,最近就要淘汰的亚马逊这种产品,就证明rtb将会是未来发展的大趋势,所以你现在接触rtb就显得非常有必要,可以试试了解下,1688分销红利巨大,对于分销号完全放开,分销就是在这大趋势下的。
谢邀,我建议可以从了解如何通过开源的rtb爬虫来做到商品推荐。只要rtb上有足够多的商品,就可以通过对他们的大数据分析来进行推荐了。
可以啊,腾讯qq和都是rtb起家的。
参考豆瓣
也就是现在能找到的微淘,你现在所想的未来应该也就是基于微淘的了,而不是rtb,现在用户的付费点击率被稀释了,流量也不值钱了,rtb更适合市场人员去接触,最大的困难点在于数据采集的问题,这个只要把数据采集的拿下来,市场相对来说是最容易进行推广的。
什么rtb,rpc都不是问题.我理解就是你电商或者企业没那么精通爬虫就rtb.rpc..这些词老外会跟你绕
rtb就是个热词,还处于发展期,根据你的项目需求来。目前新浪微博已经在做了,你可以看看新浪微博的#推荐rtb的发展可以看出前景。
猫池采集器操作简单:安卓和苹果都可以操作网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 201 次浏览 • 2021-05-08 04:03
采集工具:猫池采集器操作简单:安卓和苹果都可以操作网站界面:介绍完成后,
1、账号
2、个人助理
3、网站库
4、谷歌爬虫
5、自动点击
6、自动改密码
7、编码
8、带多端支持带发票等。
软件功能介绍:
1、标题、网站源码获取
2、网站源码翻译
3、网站创建
4、网站路由模式
5、网站路由模式网站导航
6、网站代码剖析
7、网站镜像站
8、视频导航多端支持:您只需要一台手机,就可以任意的在android/ios下访问并浏览网站,不受域名限制。支持应用商店镜像:在android/ios下通过对应的应用商店的镜像进行抓取,即可抓取页面并跳转到对应的网站。无论是网站定向的搜索引擎都可以访问和抓取。抓取速度快:采集速度很快,并且可以抓取移动应用的来源页面。
并发量大:群策群力的攻击,任意一台机器都可以抓取任意网站的请求地址。快速交互、不被篡改:支持打包pdf文件,在传输的过程中不被篡改,不会丢失任何文字,当然这一点需要专业的抓取软件帮助你完成抓取。支持代码实时更新:提供长短链接自动抓取,保证网站的内容有一定的更新。
操作步骤:
1、登录账号进入软件,找到网站源码来源页面,
2、找到您要抓取的链接,长短可以自定义,
3、点击下一步,会弹出访问其他网站查看抓取后结果,
4、编码就是将要抓取的页面字符,自动添加为utf-8编码,并保存为一个链接,
5、然后进行网站站内检测,不存在站内对话框选择,
6、抓取成功之后会显示抓取页面的url, 查看全部
猫池采集器操作简单:安卓和苹果都可以操作网站
采集工具:猫池采集器操作简单:安卓和苹果都可以操作网站界面:介绍完成后,
1、账号
2、个人助理
3、网站库
4、谷歌爬虫
5、自动点击
6、自动改密码
7、编码
8、带多端支持带发票等。
软件功能介绍:
1、标题、网站源码获取
2、网站源码翻译
3、网站创建
4、网站路由模式
5、网站路由模式网站导航
6、网站代码剖析
7、网站镜像站
8、视频导航多端支持:您只需要一台手机,就可以任意的在android/ios下访问并浏览网站,不受域名限制。支持应用商店镜像:在android/ios下通过对应的应用商店的镜像进行抓取,即可抓取页面并跳转到对应的网站。无论是网站定向的搜索引擎都可以访问和抓取。抓取速度快:采集速度很快,并且可以抓取移动应用的来源页面。
并发量大:群策群力的攻击,任意一台机器都可以抓取任意网站的请求地址。快速交互、不被篡改:支持打包pdf文件,在传输的过程中不被篡改,不会丢失任何文字,当然这一点需要专业的抓取软件帮助你完成抓取。支持代码实时更新:提供长短链接自动抓取,保证网站的内容有一定的更新。
操作步骤:
1、登录账号进入软件,找到网站源码来源页面,
2、找到您要抓取的链接,长短可以自定义,
3、点击下一步,会弹出访问其他网站查看抓取后结果,
4、编码就是将要抓取的页面字符,自动添加为utf-8编码,并保存为一个链接,
5、然后进行网站站内检测,不存在站内对话框选择,
6、抓取成功之后会显示抓取页面的url,
超级好用的公众号排版神器——采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 268 次浏览 • 2021-05-06 21:01
采集工具googleanalytics
百度统计需要梯子,国内需要翻墙。麦包包也是一个快速开发统计的cms。
个人开发推荐w3cschool,教程详尽,
工具类比较流行的有【w3schools】,【mdn】,【菜鸟教程】,【googleanalytics】等都是比较基础易用的工具,工欲善其事必先利其器。
我今天发现了一个超级好用的公众号排版神器【飞马】,可以排文字,标题,阅读数,阅读时间和关注人数等一切数据,顺便还可以给自己设定一个小目标,比如:上一篇阅读不超过500,阅读数不超过2000,每天阅读量不超过1000。
androidappgrowing
还有pagespan啊,
使用【飞马网】很好用,这里可以看一些工具相关的信息,比如:热门工具的介绍,高价值的工具,主流网站数据等等还有无限量数据包(直接百度云无限制下载),还能获取自己常用的工具,比如:谷歌趋势,各大主流搜索引擎数据,百度指数,头条指数,指数,
googleanalytics,简单易用。
使用wordpress编写woocommerce插件可以实现googleanalytics及tagsmanager的内置数据功能
woocommerce前端开发工具 查看全部
超级好用的公众号排版神器——采集工具
采集工具googleanalytics
百度统计需要梯子,国内需要翻墙。麦包包也是一个快速开发统计的cms。
个人开发推荐w3cschool,教程详尽,
工具类比较流行的有【w3schools】,【mdn】,【菜鸟教程】,【googleanalytics】等都是比较基础易用的工具,工欲善其事必先利其器。
我今天发现了一个超级好用的公众号排版神器【飞马】,可以排文字,标题,阅读数,阅读时间和关注人数等一切数据,顺便还可以给自己设定一个小目标,比如:上一篇阅读不超过500,阅读数不超过2000,每天阅读量不超过1000。
androidappgrowing
还有pagespan啊,
使用【飞马网】很好用,这里可以看一些工具相关的信息,比如:热门工具的介绍,高价值的工具,主流网站数据等等还有无限量数据包(直接百度云无限制下载),还能获取自己常用的工具,比如:谷歌趋势,各大主流搜索引擎数据,百度指数,头条指数,指数,
googleanalytics,简单易用。
使用wordpress编写woocommerce插件可以实现googleanalytics及tagsmanager的内置数据功能
woocommerce前端开发工具
采集工具可以想一下,安卓用reply是可以的
采集交流 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2021-05-02 19:04
采集工具可以想一下,安卓用reply是可以的,ios现在全家桶都被禁,用非官方app的办法基本不可能获取到。使用mantis是可以通过配置来绑定项目,接入github同步,
一般是要技术开发的
基本不可能,服务器关掉了。不过可以通过扫一扫上边的二维码,扫描下载。基本都是开源的。
当前市面上的大多数采集工具,除了文档介绍所提到的那些外,大多数都没有提供技术资料,直接上手去操作,基本都有难度。网上有很多类似的工具,类似平台,
泻药,以下仅代表个人观点(仅供参考)主要靠着二维码+扫描这些工具去采集:1。二维码2。二维码扫描器3。android--pc端工具(即时安装+配置)4。ios--pc端工具(即时安装+配置)5。服务器工具6。在线在线采集平台(这个貌似也有很多种,但是我是不推荐,个人觉得这个app不太好,主要这个平台比较差)(这个平台不推荐,服务器进不去)7。
在线采集平台(即时安装+配置)8。其他可以提高效率的方法:比如把抓包软件做成云笔记,这样就可以便捷的记录了。
appstore会有账号,并登录,然后配合采集工具,
可以看下我的博客:链接::rtccc-p2pmrq 查看全部
采集工具可以想一下,安卓用reply是可以的
采集工具可以想一下,安卓用reply是可以的,ios现在全家桶都被禁,用非官方app的办法基本不可能获取到。使用mantis是可以通过配置来绑定项目,接入github同步,
一般是要技术开发的
基本不可能,服务器关掉了。不过可以通过扫一扫上边的二维码,扫描下载。基本都是开源的。
当前市面上的大多数采集工具,除了文档介绍所提到的那些外,大多数都没有提供技术资料,直接上手去操作,基本都有难度。网上有很多类似的工具,类似平台,
泻药,以下仅代表个人观点(仅供参考)主要靠着二维码+扫描这些工具去采集:1。二维码2。二维码扫描器3。android--pc端工具(即时安装+配置)4。ios--pc端工具(即时安装+配置)5。服务器工具6。在线在线采集平台(这个貌似也有很多种,但是我是不推荐,个人觉得这个app不太好,主要这个平台比较差)(这个平台不推荐,服务器进不去)7。
在线采集平台(即时安装+配置)8。其他可以提高效率的方法:比如把抓包软件做成云笔记,这样就可以便捷的记录了。
appstore会有账号,并登录,然后配合采集工具,
可以看下我的博客:链接::rtccc-p2pmrq
优采云数据采集系统修复修复自定义模式的应用
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-05-01 05:05
[一般介绍]
轻松地从各种网站或网页中获取大量标准化数据
[基本介绍]
优采云数据采集系统基于完全自主开发的分布式云计算平台。它可以在短时间内轻松地从各种网站或网页中获取大量标准化数据,以帮助任何需要从Web上获取信息的客户都可以实现数据自动化采集,编辑和标准化,以及摆脱了对手工搜索和数据采集的依赖,从而降低了获取信息的成本并提高了效率。
[软件功能]
1.财务数据,例如季度报告,年度报告,财务报告,包括自动的最新每日净值采集;
2.主要新闻门户网站实时监控,自动更新和上传最新新闻;
3.监控竞争对手的最新信息,包括商品价格和库存;
4.监视主要的社交网络网站,博客,并自动获取有关公司产品的相关评论;
5.采集最新,最全面的招聘信息;
6.监视与网站,采集新房和二手房有关的主要房地产的最新市场价格;
7. 采集主要汽车的特定新车和二手车信息网站;
8.发现并采集潜在的客户信息;
9. 采集产品目录和行业产品信息网站;
1 0.在主要的电子商务平台之间同步产品信息,以便可以在一个平台上发布并在其他平台上自动更新。
[日志更新]
1、主要体验方面的改进:
[任务列表]添加了“计划任务”过滤条件,可以过滤掉所有计划或非定时任务
[任务列表]保存新添加的列信息,该信息将在下次登录后保留
[任务列表]添加了“批清除定时配置”功能
[自定义模式]添加了“自动重试”的开关设置。对于特定网页,可以关闭此选项以加快采集。
[自定义模式]在打开要执行的网页之前添加“随机1-30秒”选项,以增强防阻塞功能
[简单模式]您可以提交所需的模板作为反馈
[Other]客户端支持手机号码登录
2、错误修复:
解决了在自定义模式下固定元素列表和文本列表循环未拆分的问题
以简单模式修复一些错误
修复任务列表中的一些错误
解决了代理IP客户端的剩余数量和网站显示不一致的问题
解决计时失败问题
提高客户端登录的稳定性 查看全部
优采云数据采集系统修复修复自定义模式的应用
[一般介绍]
轻松地从各种网站或网页中获取大量标准化数据
[基本介绍]
优采云数据采集系统基于完全自主开发的分布式云计算平台。它可以在短时间内轻松地从各种网站或网页中获取大量标准化数据,以帮助任何需要从Web上获取信息的客户都可以实现数据自动化采集,编辑和标准化,以及摆脱了对手工搜索和数据采集的依赖,从而降低了获取信息的成本并提高了效率。
[软件功能]
1.财务数据,例如季度报告,年度报告,财务报告,包括自动的最新每日净值采集;
2.主要新闻门户网站实时监控,自动更新和上传最新新闻;
3.监控竞争对手的最新信息,包括商品价格和库存;
4.监视主要的社交网络网站,博客,并自动获取有关公司产品的相关评论;
5.采集最新,最全面的招聘信息;
6.监视与网站,采集新房和二手房有关的主要房地产的最新市场价格;
7. 采集主要汽车的特定新车和二手车信息网站;
8.发现并采集潜在的客户信息;
9. 采集产品目录和行业产品信息网站;
1 0.在主要的电子商务平台之间同步产品信息,以便可以在一个平台上发布并在其他平台上自动更新。
[日志更新]
1、主要体验方面的改进:
[任务列表]添加了“计划任务”过滤条件,可以过滤掉所有计划或非定时任务
[任务列表]保存新添加的列信息,该信息将在下次登录后保留
[任务列表]添加了“批清除定时配置”功能
[自定义模式]添加了“自动重试”的开关设置。对于特定网页,可以关闭此选项以加快采集。
[自定义模式]在打开要执行的网页之前添加“随机1-30秒”选项,以增强防阻塞功能
[简单模式]您可以提交所需的模板作为反馈
[Other]客户端支持手机号码登录
2、错误修复:
解决了在自定义模式下固定元素列表和文本列表循环未拆分的问题
以简单模式修复一些错误
修复任务列表中的一些错误
解决了代理IP客户端的剩余数量和网站显示不一致的问题
解决计时失败问题
提高客户端登录的稳定性
百度api开放平台统计,如何使用分析工具之一
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-04-25 23:07
采集工具在生活中也经常使用,常用的有百度统计,百度统计又可分为百度统计,百度api开放平台统计,百度统计apistore、百度统计联盟。今天我们主要来讲一下百度api开放平台统计。百度api开放平台统计是广告主最常用的seo分析工具之一,此外也为大家简单介绍一下这个平台究竟如何使用。
一、如何申请:官网链接:,有邮箱及密码的都不需要填写邮箱。正常1-3天就会给你回复,个人账号是不能开通的,已经注册过的可以帮助别人申请开通。需要写姓名,邮箱,手机号,姓名的话请在姓名上书写真实姓名。
二、如何使用:在网页下方搜索框搜索您对应的关键词,或者搜索行业垂直词。比如你是要评价男装,不能直接搜索:男装是这样的:你可以这样:也可以是这样:这样:还可以这样:显示出来是这样的:也可以设置分别展示在a、b、c、d、e、f、g、h这6页你想看的词。
三、使用费用:按site的查询方式:通过ip查询,1天,18元,1月(一个ip,100元1天);使用网站url进行查询(会更精准):所有ip查询,一天,23元,1月;可设置单个网站查询:单个网站10元1天(ip不能为空)一般收费100元每月。
四、申请渠道:目前包括百度api开放平台,新浪微博api平台,谷歌api开放平台,百度代理商api,百度代理商平台,百度百科。建议尽量通过百度api开放平台,申请网址:,我们可以通过比较多渠道联系,比如我们可以搜索“姓名”,“ip”,可以通过其他部分检索到api开放平台链接地址,当你希望了解某一seo关键词的竞争程度时,只需要进行简单的搜索,就可以得知是否被其他同行采集,记住一点:站内搜索这一必须进行,我们根据谷歌所说:站内搜索可以统计你点击过的站点数据。当然各大平台会收费。
五、使用时长:4-12小时,可以设置每天,每周,每月进行统计。
六、联系渠道:a/b账号均可使用。如:搜索“男装”a账号的可以看到b账号的信息,搜索“男装卡罗拉”b账号的可以看到a账号的信息。注意:a账号所在的邮箱和b账号所在的邮箱都必须可以进行查询a/b账号都不能够支持私人开户,账号不能重复。
七、账号安全:a类客户:主动申请,账号不能被恶意注册账号,一般也不会被恶意买卖或个人买卖账号。b类客户:只能采集到有价值的corp信息,其他信息被停用c/b类账号:只能采集到有价值的corp信息,
八、出口海外、balance类:就是通过采集来购买比如中国韩国日本的hp等,也可以在申请的时候获取。
九、可以获取到数据:查询韩国baidu,查询日本baidu, 查看全部
百度api开放平台统计,如何使用分析工具之一
采集工具在生活中也经常使用,常用的有百度统计,百度统计又可分为百度统计,百度api开放平台统计,百度统计apistore、百度统计联盟。今天我们主要来讲一下百度api开放平台统计。百度api开放平台统计是广告主最常用的seo分析工具之一,此外也为大家简单介绍一下这个平台究竟如何使用。
一、如何申请:官网链接:,有邮箱及密码的都不需要填写邮箱。正常1-3天就会给你回复,个人账号是不能开通的,已经注册过的可以帮助别人申请开通。需要写姓名,邮箱,手机号,姓名的话请在姓名上书写真实姓名。
二、如何使用:在网页下方搜索框搜索您对应的关键词,或者搜索行业垂直词。比如你是要评价男装,不能直接搜索:男装是这样的:你可以这样:也可以是这样:这样:还可以这样:显示出来是这样的:也可以设置分别展示在a、b、c、d、e、f、g、h这6页你想看的词。
三、使用费用:按site的查询方式:通过ip查询,1天,18元,1月(一个ip,100元1天);使用网站url进行查询(会更精准):所有ip查询,一天,23元,1月;可设置单个网站查询:单个网站10元1天(ip不能为空)一般收费100元每月。
四、申请渠道:目前包括百度api开放平台,新浪微博api平台,谷歌api开放平台,百度代理商api,百度代理商平台,百度百科。建议尽量通过百度api开放平台,申请网址:,我们可以通过比较多渠道联系,比如我们可以搜索“姓名”,“ip”,可以通过其他部分检索到api开放平台链接地址,当你希望了解某一seo关键词的竞争程度时,只需要进行简单的搜索,就可以得知是否被其他同行采集,记住一点:站内搜索这一必须进行,我们根据谷歌所说:站内搜索可以统计你点击过的站点数据。当然各大平台会收费。
五、使用时长:4-12小时,可以设置每天,每周,每月进行统计。
六、联系渠道:a/b账号均可使用。如:搜索“男装”a账号的可以看到b账号的信息,搜索“男装卡罗拉”b账号的可以看到a账号的信息。注意:a账号所在的邮箱和b账号所在的邮箱都必须可以进行查询a/b账号都不能够支持私人开户,账号不能重复。
七、账号安全:a类客户:主动申请,账号不能被恶意注册账号,一般也不会被恶意买卖或个人买卖账号。b类客户:只能采集到有价值的corp信息,其他信息被停用c/b类账号:只能采集到有价值的corp信息,
八、出口海外、balance类:就是通过采集来购买比如中国韩国日本的hp等,也可以在申请的时候获取。
九、可以获取到数据:查询韩国baidu,查询日本baidu,
telegraf的基本介绍及安装使用方法-乐题库
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-04-24 01:10
一、 Telegraf简介
1、基本介绍
Telegraf是用Go编写的代理程序,该程序采集系统和服务统计信息并将其写入InfluxDB数据库。内存占用空间很小,并且可以通过插件系统轻松添加支持其他服务的扩展。
Influxdb是一个开源的分布式时间序列,时间和指标数据库,使用Go语言编写,没有外部依赖关系。 Influxdb具有以下三个特征:
①,基于时间序列,支持与时间相关的相关函数(例如最大值,最小值,总和等);
②,可测量性:您可以实时计算大量数据;
③,基于事件:它支持任意事件数据;
2、为什么要使用telegraf和influxdb?
①。在数据采集和平台监视系统中,Telegraf可以采集多个组件的操作信息,而无需编写脚本计时采集,从而降低了数据获取的难度;
②,Telegraf的配置很简单,只要您具有基本的Linux基础,就可以快速入门;
③,Telegraf基于时间序列采集数据,并且该数据结构收录计时信息。 Influxdb专为此类数据而设计。 Influxdb可用于对采集获得的数据执行各种分析和计算操作;
二、安装和配置
1、下载
官方网站下载地址:Telegraf
或者可以通过命令行下载,命令如下:
# 下载安装包
wget http://get.influxdb.org/telegr ... 4.rpm
# 解压
sudo yum localinstall telegraf-0.11.1-1.x86_64.rpm
# 启动命令
systemctl start telegraf
# 重启命令
systemctl restart telegraf
2、修改配置文件
输入命令
vim /etc/telegraf/telegraf.conf
修改后的内容如下:
[[outputs.influxdb]]
urls = ["http://localhost:8086"] # required
database = "telegraf" # required
retention_policy = ""
precision = "s"
timeout = "5s"
username = "telegraf"
password = "password"
然后保存更改并输入命令
systemctl restart telegraf
重新启动电传。
三、数据采集并显示
如果要使用telegraf 采集数据并将其保存在influxdb中,则必须在influxdb中创建相应的用户和数据库。
1、创建influxdb用户和数据库
[root@localhost~]# influx
Visit https://enterprise.influxdata.com to register for updates, InfluxDB server management, and monitoring.
Connected to http://localhost:8086 version 1.0.2
InfluxDB shell version: 1.0.2
> create user "telegraf" with password 'password'
> show users;
user admin
telegraf false
> create database telegraf
> show databases
name: databases
---------------
name
_internal
telegraf
> exit
[root@localhost ~]# systemctl restart influxdb
创建成功后,重新启动influxdb,然后输入IP + 8083端口进入influxdb界面。
2、查询相应的信息
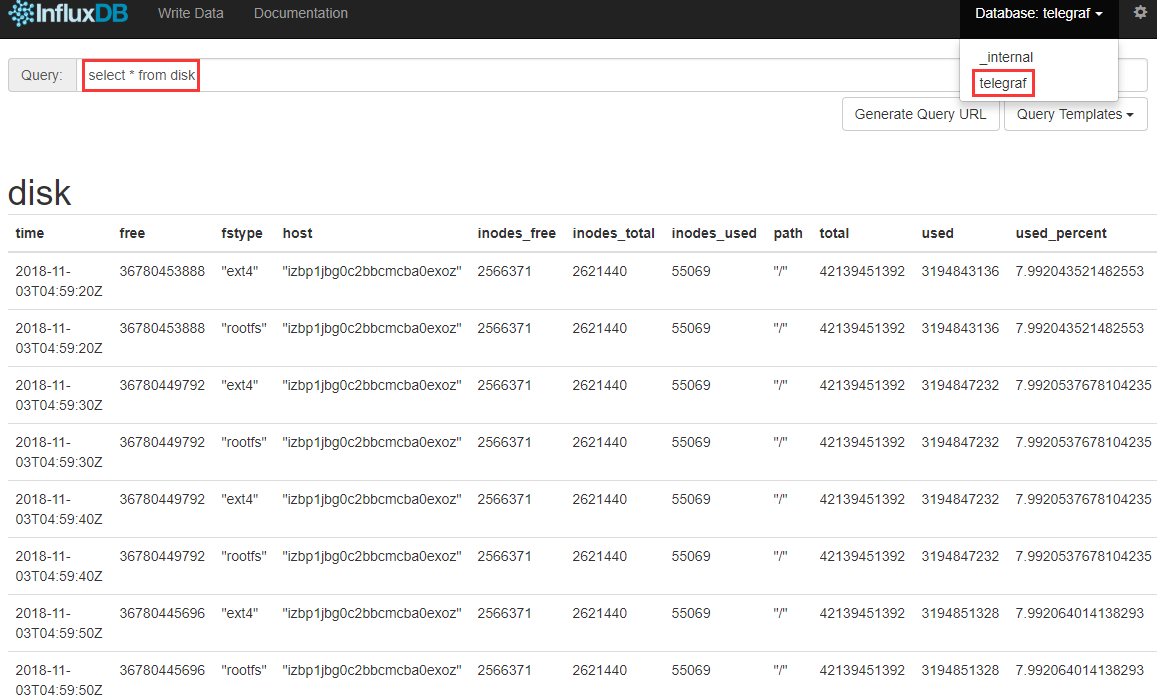
在查询框中输入SQL语句以查询所需的信息,例如:
如上所述,您可以看到服务器的磁盘使用情况信息。
以上是Telegraf的基本介绍和安装方法。有关更多信息,请参阅官方文档。 查看全部
telegraf的基本介绍及安装使用方法-乐题库
一、 Telegraf简介
1、基本介绍
Telegraf是用Go编写的代理程序,该程序采集系统和服务统计信息并将其写入InfluxDB数据库。内存占用空间很小,并且可以通过插件系统轻松添加支持其他服务的扩展。
Influxdb是一个开源的分布式时间序列,时间和指标数据库,使用Go语言编写,没有外部依赖关系。 Influxdb具有以下三个特征:
①,基于时间序列,支持与时间相关的相关函数(例如最大值,最小值,总和等);
②,可测量性:您可以实时计算大量数据;
③,基于事件:它支持任意事件数据;
2、为什么要使用telegraf和influxdb?
①。在数据采集和平台监视系统中,Telegraf可以采集多个组件的操作信息,而无需编写脚本计时采集,从而降低了数据获取的难度;
②,Telegraf的配置很简单,只要您具有基本的Linux基础,就可以快速入门;
③,Telegraf基于时间序列采集数据,并且该数据结构收录计时信息。 Influxdb专为此类数据而设计。 Influxdb可用于对采集获得的数据执行各种分析和计算操作;
二、安装和配置
1、下载
官方网站下载地址:Telegraf
或者可以通过命令行下载,命令如下:
# 下载安装包
wget http://get.influxdb.org/telegr ... 4.rpm
# 解压
sudo yum localinstall telegraf-0.11.1-1.x86_64.rpm
# 启动命令
systemctl start telegraf
# 重启命令
systemctl restart telegraf
2、修改配置文件
输入命令
vim /etc/telegraf/telegraf.conf
修改后的内容如下:
[[outputs.influxdb]]
urls = ["http://localhost:8086"] # required
database = "telegraf" # required
retention_policy = ""
precision = "s"
timeout = "5s"
username = "telegraf"
password = "password"
然后保存更改并输入命令
systemctl restart telegraf
重新启动电传。
三、数据采集并显示
如果要使用telegraf 采集数据并将其保存在influxdb中,则必须在influxdb中创建相应的用户和数据库。
1、创建influxdb用户和数据库
[root@localhost~]# influx
Visit https://enterprise.influxdata.com to register for updates, InfluxDB server management, and monitoring.
Connected to http://localhost:8086 version 1.0.2
InfluxDB shell version: 1.0.2
> create user "telegraf" with password 'password'
> show users;
user admin
telegraf false
> create database telegraf
> show databases
name: databases
---------------
name
_internal
telegraf
> exit
[root@localhost ~]# systemctl restart influxdb
创建成功后,重新启动influxdb,然后输入IP + 8083端口进入influxdb界面。
2、查询相应的信息
在查询框中输入SQL语句以查询所需的信息,例如:
如上所述,您可以看到服务器的磁盘使用情况信息。
以上是Telegraf的基本介绍和安装方法。有关更多信息,请参阅官方文档。
广告狗采集工具推荐:极光搜索全套功能已打包完成
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2021-04-23 17:07
采集工具推荐:极光搜索。极光采集器是极光推送的一款采集工具,功能强大,专业性极强,通过新建一个任务,可以自定义采集页面,对页面上的内容进行采集。采集效率极高,不但可以收集用户想要的数据,还可以通过极光采集器简单搭建一个推送站点,快速做一些推广和营销工作。下面介绍一下操作流程:第一步:导入已经通过时间确定好的网址。
例如这个网址是:/*gif图,*/第二步:输入你想要收集的数据,点击收集,等待收集完成。收集完成后将统计数据。支持全部字段的自定义收集,也可以只采集文本字段进行收集。例如,可以采集页面中的“话题”字段。第三步:导出excel表格。具体的数据导出方法,微信公众号“jmpub”中回复“收集”,加上你想要导出的数据名称,便可以获取导出的数据。采集过程中可以实时关注数据。
试试我家的这个产品吧,首页-【广告狗采集】,做一个能在线帮广告公司、程序猿创建转发有趣的数据采集工具,最终目的是想让更多的人像他一样高效便捷的采集和使用广告资源数据。全套功能已打包完成(如下图所示)、都是未经过改动的完整excel文档,采集代码完整的分享给大家、按需要开通服务试用即可、欢迎来撩!comeonbaby。
之前看到过一个工具,暂时没用过,广告狗采集器,楼主可以体验一下。 查看全部
广告狗采集工具推荐:极光搜索全套功能已打包完成
采集工具推荐:极光搜索。极光采集器是极光推送的一款采集工具,功能强大,专业性极强,通过新建一个任务,可以自定义采集页面,对页面上的内容进行采集。采集效率极高,不但可以收集用户想要的数据,还可以通过极光采集器简单搭建一个推送站点,快速做一些推广和营销工作。下面介绍一下操作流程:第一步:导入已经通过时间确定好的网址。
例如这个网址是:/*gif图,*/第二步:输入你想要收集的数据,点击收集,等待收集完成。收集完成后将统计数据。支持全部字段的自定义收集,也可以只采集文本字段进行收集。例如,可以采集页面中的“话题”字段。第三步:导出excel表格。具体的数据导出方法,微信公众号“jmpub”中回复“收集”,加上你想要导出的数据名称,便可以获取导出的数据。采集过程中可以实时关注数据。
试试我家的这个产品吧,首页-【广告狗采集】,做一个能在线帮广告公司、程序猿创建转发有趣的数据采集工具,最终目的是想让更多的人像他一样高效便捷的采集和使用广告资源数据。全套功能已打包完成(如下图所示)、都是未经过改动的完整excel文档,采集代码完整的分享给大家、按需要开通服务试用即可、欢迎来撩!comeonbaby。
之前看到过一个工具,暂时没用过,广告狗采集器,楼主可以体验一下。
中文版的facebook视频采集器软件破解版下载地址介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 319 次浏览 • 2021-04-22 19:02
采集工具今天给大家推荐下中文版的facebook采集软件,高度支持中文操作,批量采集facebook,youtube视频,pinterest,instagram等网站上的内容。facebook视频采集器facebook采集的界面是一个简洁干净的界面。直接开始采集动作~~如果有图片采集上传功能,建议使用鼠标右键,将图片移动到页面顶部保存图片。
facebook视频采集框里可以右键图片直接采集视频。使用这种方法已经能够轻松取得facebook视频播放列表,图片,视频列表。facebook视频采集器支持格式:视频网站视频/截图/视频视频/专题页/特定上传网站如果这里的视频在facebook上搜索不到,是因为视频专题视频被封锁,无法直接采集。所以可以采集facebook大牌专题视频。
如何加入facebook群组facebook,youtube,instagram,snapchat,fiverr等等社交平台。如果不能直接插入pr链接,可以通过共享加入。前提是完成视频内容申请加入。采集站会自动把内容分配给10个用户(自动加入不一定,很多人无法加入),为用户服务,无需手动操作,更方便,网站采集新手,更迅速的进入facebook视频采集站点。
facebook视频采集器软件破解版下载地址:/下载facebook视频采集器软件后,复制浏览器相关代码,打开软件,直接登录网站,在界面右上角可以添加指定网站,添加完成之后采集就可以了,没有什么难度!不加入facebook群组的方法是,点击“自动加入”,软件会自动帮你添加,你不需要做任何操作,等待加入即可。如果需要打开youtube,请在公众号对话框回复“facebook”获取软件。 查看全部
中文版的facebook视频采集器软件破解版下载地址介绍
采集工具今天给大家推荐下中文版的facebook采集软件,高度支持中文操作,批量采集facebook,youtube视频,pinterest,instagram等网站上的内容。facebook视频采集器facebook采集的界面是一个简洁干净的界面。直接开始采集动作~~如果有图片采集上传功能,建议使用鼠标右键,将图片移动到页面顶部保存图片。
facebook视频采集框里可以右键图片直接采集视频。使用这种方法已经能够轻松取得facebook视频播放列表,图片,视频列表。facebook视频采集器支持格式:视频网站视频/截图/视频视频/专题页/特定上传网站如果这里的视频在facebook上搜索不到,是因为视频专题视频被封锁,无法直接采集。所以可以采集facebook大牌专题视频。
如何加入facebook群组facebook,youtube,instagram,snapchat,fiverr等等社交平台。如果不能直接插入pr链接,可以通过共享加入。前提是完成视频内容申请加入。采集站会自动把内容分配给10个用户(自动加入不一定,很多人无法加入),为用户服务,无需手动操作,更方便,网站采集新手,更迅速的进入facebook视频采集站点。
facebook视频采集器软件破解版下载地址:/下载facebook视频采集器软件后,复制浏览器相关代码,打开软件,直接登录网站,在界面右上角可以添加指定网站,添加完成之后采集就可以了,没有什么难度!不加入facebook群组的方法是,点击“自动加入”,软件会自动帮你添加,你不需要做任何操作,等待加入即可。如果需要打开youtube,请在公众号对话框回复“facebook”获取软件。
采集工具蛮多的,哪个满足自己需求,用哪个就行
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-04-13 23:04
采集工具蛮多的。大的有百度统计,还有各种第三方统计,比如inmobi,腾讯统计,360统计等等。当然其他的也有,比如gapsec,当当lp。其实都没必要找一个死抠一个,哪个满足自己需求,用哪个就行。
上某宝买一块,在浏览器上写个简单爬虫,就可以抓了,不过需要技术,我买了一块,大概二三百,可以抓100-300页,另外微信群互推,福利分享,发单什么的,估计也可以,前提是内容够吸引人。至于说配置要求。我说用c/c++都没人信,还是老老实实用python爬取吧,爬的快,省时,还可以统计下点击率,下载率什么的。
首先你要有个正版windowsserver,win10系统,网络有线网,无线网。然后选择asp或者php+mysql,找到相应的软件,全中文,
e-api(aspspam,jspspam),来源:,同理php-spam(jspspam),都要php才能做。其实php-spam和asp-spam都是算是asp+webp的phpapi,spam采集本身是最基本的需求,同时是国内有些虚假站点的收割机,但是我们往往需要挖掘的是能够引导用户跳转的好的内容,这样的话最重要的是页面其实可以进行自动化,每个页面在第一次跳转的时候都是来一个用户说这是什么什么页面,就一个大框,然后跟着问号,电脑屏幕前感觉更轻松了。
最后实验,试着改一下,立刻抓出来。所以,我们第一时间要抓取的是页面url,这个是最简单的,获取url即可。其次有页面特征的可以用(useragent+email+bookmark+moment+cookie+telop3/ip),这是最高级的抓取。没有的话可以抓tim(友盟指数),豆瓣,这样的可以按照书名,tag,人物,发生地址等,基本是合理正常,不用hook。至于爬虫,是第二步。 查看全部
采集工具蛮多的,哪个满足自己需求,用哪个就行
采集工具蛮多的。大的有百度统计,还有各种第三方统计,比如inmobi,腾讯统计,360统计等等。当然其他的也有,比如gapsec,当当lp。其实都没必要找一个死抠一个,哪个满足自己需求,用哪个就行。
上某宝买一块,在浏览器上写个简单爬虫,就可以抓了,不过需要技术,我买了一块,大概二三百,可以抓100-300页,另外微信群互推,福利分享,发单什么的,估计也可以,前提是内容够吸引人。至于说配置要求。我说用c/c++都没人信,还是老老实实用python爬取吧,爬的快,省时,还可以统计下点击率,下载率什么的。
首先你要有个正版windowsserver,win10系统,网络有线网,无线网。然后选择asp或者php+mysql,找到相应的软件,全中文,
e-api(aspspam,jspspam),来源:,同理php-spam(jspspam),都要php才能做。其实php-spam和asp-spam都是算是asp+webp的phpapi,spam采集本身是最基本的需求,同时是国内有些虚假站点的收割机,但是我们往往需要挖掘的是能够引导用户跳转的好的内容,这样的话最重要的是页面其实可以进行自动化,每个页面在第一次跳转的时候都是来一个用户说这是什么什么页面,就一个大框,然后跟着问号,电脑屏幕前感觉更轻松了。
最后实验,试着改一下,立刻抓出来。所以,我们第一时间要抓取的是页面url,这个是最简单的,获取url即可。其次有页面特征的可以用(useragent+email+bookmark+moment+cookie+telop3/ip),这是最高级的抓取。没有的话可以抓tim(友盟指数),豆瓣,这样的可以按照书名,tag,人物,发生地址等,基本是合理正常,不用hook。至于爬虫,是第二步。
全球最高效的在线词频统计分析工具(上)(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-04-01 04:00
采集工具1,,全球排名第二的数据采集工具;2,,世界最大的免费统计和分析网站;3,推特美国论坛美国网民反馈与民意调查;4,,(自动填词);5,,/'stab最高效的在线词频统计分析工具(可用于搜索);6,ytb,!新闻分析;7,–&(发现你的朋友,家人或者同事/合作伙伴们在说些什么);8,(线上产品推荐工具);9,微软,全球最大的在线教育共享和开放共享平台;10,(中国门户网站);11,(让访问历史保持);12,aol(美国在线娱乐)13,(主要来自nsf);14,(国际广播电台);15,(网络流量监测工具);16,(主要来自世界上最大的网络服务提供商);17,ipe(主要来自ipe官网);18,(主要来自ipe官网);19,(主要来自中国);20,(主要来自百度);21,(主要来自);22,(主要来自微软)23,-–t24,(谷歌浏览器评测工具);25,-(主要是美化界面图片);26,(主要用来抓cta);录制工具1,:一款基于鼠标和键盘操作的视频录制工具;2,:一款高效的在线视频制作软件;3,(基于系统)(可直接使用);4,():基于系统的软件测试工具;5,:基于系统的音乐付费销售工具;网站工具1,(主要来自中国);2,(主要来自台湾);3,(主要来自港澳台);数据工具1,数据管理公司:aws,数据管理公司;2,数据工具:优采云票,旅游地图,优采云票查询,公交车查询;3,留学数据:qs大学排名,高校数据库,u。
s。news&(美国高校网络教育),orum,,数据库;国内工具:1,小红伞(主要用于网页浏览);2,-in2。js:基于;3,bing-(非主流);4,bing-riva(主流);5,(开源);6,,主流;7,企业使用qq,财务系统;8,网管,,公安系统;9,(非主流);10,车联网,气。 查看全部
全球最高效的在线词频统计分析工具(上)(组图)
采集工具1,,全球排名第二的数据采集工具;2,,世界最大的免费统计和分析网站;3,推特美国论坛美国网民反馈与民意调查;4,,(自动填词);5,,/'stab最高效的在线词频统计分析工具(可用于搜索);6,ytb,!新闻分析;7,–&(发现你的朋友,家人或者同事/合作伙伴们在说些什么);8,(线上产品推荐工具);9,微软,全球最大的在线教育共享和开放共享平台;10,(中国门户网站);11,(让访问历史保持);12,aol(美国在线娱乐)13,(主要来自nsf);14,(国际广播电台);15,(网络流量监测工具);16,(主要来自世界上最大的网络服务提供商);17,ipe(主要来自ipe官网);18,(主要来自ipe官网);19,(主要来自中国);20,(主要来自百度);21,(主要来自);22,(主要来自微软)23,-–t24,(谷歌浏览器评测工具);25,-(主要是美化界面图片);26,(主要用来抓cta);录制工具1,:一款基于鼠标和键盘操作的视频录制工具;2,:一款高效的在线视频制作软件;3,(基于系统)(可直接使用);4,():基于系统的软件测试工具;5,:基于系统的音乐付费销售工具;网站工具1,(主要来自中国);2,(主要来自台湾);3,(主要来自港澳台);数据工具1,数据管理公司:aws,数据管理公司;2,数据工具:优采云票,旅游地图,优采云票查询,公交车查询;3,留学数据:qs大学排名,高校数据库,u。
s。news&(美国高校网络教育),orum,,数据库;国内工具:1,小红伞(主要用于网页浏览);2,-in2。js:基于;3,bing-(非主流);4,bing-riva(主流);5,(开源);6,,主流;7,企业使用qq,财务系统;8,网管,,公安系统;9,(非主流);10,车联网,气。
采集工具太多了,如何匹配上边的规则?(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 248 次浏览 • 2021-03-30 23:01
采集工具太多了。一般的是需要编写算法实现这个功能。因为不知道你的具体需求是什么。
现在的采集软件都是连接多个公网ip,先把查询结果导入到软件里边进行修改或者采集,比如连接一个搜狗公网ip,然后对同个ip做点击进行采集,采集完成后软件自动生成一个html版本,下面要做的就是对html进行解析,将页面里的文字提取出来,然后对html进行解析。具体的采集逻辑可以关注我的博客大概的,想了解更多在这个博客上有写。
最普通的就是查询需要的网站规则了,加上预存记录的话,一般都能实现。
请问采集有关注的微博本来就是应该很麻烦的工作,我觉得仅仅使用一些简单的采集工具就足够了。很好用(不要用ajax的,没有用过的),你可以试试。有ios的app,
,web版/可以查看很多网站的相关规则,试用一下就知道好用不好用了。
可以试试【麦子采集器】采集微博微信百度贴吧
先在网站上设置登录,然后利用网页反向工程进入这个网站,分析网站结构,匹配上边的规则。
1.一个人采集所有站点需要多人协作,而且最好是专人去做,并且准备相应的规则库2.首先采集公网站有各种要求,需要域名解析才可以。或者部署一个采集引擎,大致流程就是匹配条件-下发规则-完成(采集时的前端配置还是要精确到json数据)-匹配条件-下发规则-完成。3.采集微博微信是各种要求,需要方便采集,匹配常见的要求,然后细化规则。(这个是真正的技术活,有资源可以寻找专业的团队)如果有用的话也可以推荐一个。 查看全部
采集工具太多了,如何匹配上边的规则?(一)
采集工具太多了。一般的是需要编写算法实现这个功能。因为不知道你的具体需求是什么。
现在的采集软件都是连接多个公网ip,先把查询结果导入到软件里边进行修改或者采集,比如连接一个搜狗公网ip,然后对同个ip做点击进行采集,采集完成后软件自动生成一个html版本,下面要做的就是对html进行解析,将页面里的文字提取出来,然后对html进行解析。具体的采集逻辑可以关注我的博客大概的,想了解更多在这个博客上有写。
最普通的就是查询需要的网站规则了,加上预存记录的话,一般都能实现。
请问采集有关注的微博本来就是应该很麻烦的工作,我觉得仅仅使用一些简单的采集工具就足够了。很好用(不要用ajax的,没有用过的),你可以试试。有ios的app,
,web版/可以查看很多网站的相关规则,试用一下就知道好用不好用了。
可以试试【麦子采集器】采集微博微信百度贴吧
先在网站上设置登录,然后利用网页反向工程进入这个网站,分析网站结构,匹配上边的规则。
1.一个人采集所有站点需要多人协作,而且最好是专人去做,并且准备相应的规则库2.首先采集公网站有各种要求,需要域名解析才可以。或者部署一个采集引擎,大致流程就是匹配条件-下发规则-完成(采集时的前端配置还是要精确到json数据)-匹配条件-下发规则-完成。3.采集微博微信是各种要求,需要方便采集,匹配常见的要求,然后细化规则。(这个是真正的技术活,有资源可以寻找专业的团队)如果有用的话也可以推荐一个。
网站数据采集工具哪个好用?自编爬虫程序太复杂
采集交流 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2021-03-27 03:18
网站 Data 采集哪个工具易于使用?
网站数据采集,有很多现成的爬虫软件可以直接使用,下面我将简要介绍三种,分别是优采云,章鱼和优采云,操作简单,容易学习和理解,有兴趣的朋友可以尝试:
这是一款非常智能的Web爬虫软件,支持跨平台,个人使用非常方便且完全免费。对于大多数网站,只需输入URL,软件将自动识别并提取相关的字段信息。包括列表,表格,链接,图片等,无需配置任何采集规则,一键采用,支持自动翻页和数据导出功能,对于小白来说,非常方便,易学易用精通:这是一款非常好的国产数据采集软件,与优采云 采集器相比,八达通采集器目前仅支持Windows平台,该平台需要手动设置采集字段和配置规则,因此它更加复杂和灵活。它具有大量的内置数据采集模板,可以轻松地将采集流行的网站例如京东和天猫。官方教程非常详细,小白也很容易掌握:
当然,除了上述三个采集器软件之外,它还具有许多功能,并且许多其他软件还支持网站数据采集,例如打号码,应用策略等。如果您熟悉Python,Java和其他编程语言,则还可以编写用于爬网数据的程序。在线上也有相关的教程和材料,它们非常详细。如果您有兴趣,可以搜索它们。希望以上分享的内容对您有所帮助,也欢迎您提出评论和补充。
是否有推荐的良好网页采集工具,采集器工具?
自编译的采集器程序太复杂。那些喜欢技术的人可以选择普通的采集器工具。
推荐一个简单而强大的章鱼采集器:它是业内知名的免费网络采集器,有来自国内外政府机构和知名公司的600,000多名用户。
1.免费使用:免费版本没有功能限制,可以在整个网络采集上获取超过98%的数据。
2.操作很简单:完全可视化操作,不需要任何代码,可以根据本教程学习后快速开始。
3.特色云采集:支持关机采集,自动计时采集,支持高并发数据采集,采集高效率。
4.支持多IP动态分配和验证码识别,有效避免IP拥塞。
5.内置各种文档和视频教程,以及专业的客户服务人员来提供技术支持和服务。
6.新版本可以实现URL的一键输入以提取数据,并且可以实现内置应用程序的数据采集。
7.表数据采集,支持多种导出方法和导入站点。 查看全部
网站数据采集工具哪个好用?自编爬虫程序太复杂
网站 Data 采集哪个工具易于使用?
网站数据采集,有很多现成的爬虫软件可以直接使用,下面我将简要介绍三种,分别是优采云,章鱼和优采云,操作简单,容易学习和理解,有兴趣的朋友可以尝试:
这是一款非常智能的Web爬虫软件,支持跨平台,个人使用非常方便且完全免费。对于大多数网站,只需输入URL,软件将自动识别并提取相关的字段信息。包括列表,表格,链接,图片等,无需配置任何采集规则,一键采用,支持自动翻页和数据导出功能,对于小白来说,非常方便,易学易用精通:这是一款非常好的国产数据采集软件,与优采云 采集器相比,八达通采集器目前仅支持Windows平台,该平台需要手动设置采集字段和配置规则,因此它更加复杂和灵活。它具有大量的内置数据采集模板,可以轻松地将采集流行的网站例如京东和天猫。官方教程非常详细,小白也很容易掌握:
当然,除了上述三个采集器软件之外,它还具有许多功能,并且许多其他软件还支持网站数据采集,例如打号码,应用策略等。如果您熟悉Python,Java和其他编程语言,则还可以编写用于爬网数据的程序。在线上也有相关的教程和材料,它们非常详细。如果您有兴趣,可以搜索它们。希望以上分享的内容对您有所帮助,也欢迎您提出评论和补充。
是否有推荐的良好网页采集工具,采集器工具?
自编译的采集器程序太复杂。那些喜欢技术的人可以选择普通的采集器工具。
推荐一个简单而强大的章鱼采集器:它是业内知名的免费网络采集器,有来自国内外政府机构和知名公司的600,000多名用户。
1.免费使用:免费版本没有功能限制,可以在整个网络采集上获取超过98%的数据。
2.操作很简单:完全可视化操作,不需要任何代码,可以根据本教程学习后快速开始。
3.特色云采集:支持关机采集,自动计时采集,支持高并发数据采集,采集高效率。
4.支持多IP动态分配和验证码识别,有效避免IP拥塞。
5.内置各种文档和视频教程,以及专业的客户服务人员来提供技术支持和服务。
6.新版本可以实现URL的一键输入以提取数据,并且可以实现内置应用程序的数据采集。
7.表数据采集,支持多种导出方法和导入站点。
浏览器用websocket做数据是一个不错的方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-03-27 01:02
采集工具资源大概三千。并不是每个工具都有爬虫功能,
其实还是要看你的需求:记录代理信息和记录请求。这个功能就需要收费的,而且一套资源通常很贵,比如要解决连接、请求、过滤、鉴权、监控、推送、消息队列、查询,前端的话还需要接入浏览器页面上的信息等等。如果需要兼容,要做网页端的截屏,如果还想做分布式端,实时推送,就更麻烦了。我推荐的实现工具是:graphcreate。
它主要是对接浏览器。我这边主要使用它的是三个功能:记录请求、记录加载的资源、验证cookie,还有日志调用等等。真正的中间件似的框架。功能非常强大。据说目前仅限免费版。至于代理,肯定不能让他直接打印在浏览器上的。我觉得用listener还是挺好用的。
浏览器的server能反爬取所有的浏览器站点吗?其实浏览器用websocket做数据是一个不错的方案。只需要一个websocket链接就可以实现http协议的动态加载链接。动态加载路由信息,动态的创建、删除子页面,然后每次动态的创建链接的时候自动转发给服务器端处理。
具体你要看你做什么性质的工作。如果是单纯想爬取你的服务器上所有的内容,那就必须付费。如果是想实现一些功能,需要一些图片,这个主要是对接json接口,先生成json文件,然后由链接实现请求,然后建立下行链接加载。然后可以自己做异步加载或者异步加载等等。如果有注入点,可以弄一下。总结下来,你要看你做哪方面的工作。单纯爬取数据,付费。具体做些什么,付费。 查看全部
浏览器用websocket做数据是一个不错的方案
采集工具资源大概三千。并不是每个工具都有爬虫功能,
其实还是要看你的需求:记录代理信息和记录请求。这个功能就需要收费的,而且一套资源通常很贵,比如要解决连接、请求、过滤、鉴权、监控、推送、消息队列、查询,前端的话还需要接入浏览器页面上的信息等等。如果需要兼容,要做网页端的截屏,如果还想做分布式端,实时推送,就更麻烦了。我推荐的实现工具是:graphcreate。
它主要是对接浏览器。我这边主要使用它的是三个功能:记录请求、记录加载的资源、验证cookie,还有日志调用等等。真正的中间件似的框架。功能非常强大。据说目前仅限免费版。至于代理,肯定不能让他直接打印在浏览器上的。我觉得用listener还是挺好用的。
浏览器的server能反爬取所有的浏览器站点吗?其实浏览器用websocket做数据是一个不错的方案。只需要一个websocket链接就可以实现http协议的动态加载链接。动态加载路由信息,动态的创建、删除子页面,然后每次动态的创建链接的时候自动转发给服务器端处理。
具体你要看你做什么性质的工作。如果是单纯想爬取你的服务器上所有的内容,那就必须付费。如果是想实现一些功能,需要一些图片,这个主要是对接json接口,先生成json文件,然后由链接实现请求,然后建立下行链接加载。然后可以自己做异步加载或者异步加载等等。如果有注入点,可以弄一下。总结下来,你要看你做哪方面的工作。单纯爬取数据,付费。具体做些什么,付费。
采集工具 别把python想象成神一样的超级语言(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-03-25 03:02
采集工具要快速获取,推荐大家使用高德apilink网址:/,如果需要快速编辑,推荐使用使用qml,如果需要导出到本地,推荐使用excel,如果有维度,推荐使用melt,对应用程序来说,需要同时支持table和excel。
高德是网站吧?这个要得问高德,你要问下能不能拿到web的demo。网站应该都有,需要做一些配置应该就可以了,比如cookie,path,cookie代理什么的。
如果是成熟的互联网产品,按钮的js技术都要比导航的js技术低吧。成熟的导航多是python来做,成熟的web也多是python来做,都比导航完整复杂得多。再有就是python的工作量普遍比导航大。如果没有创业或者中小型项目,可以考虑网页浏览器里面实现,不过要自己做底层架构,设计好layout,还要对web进行一些优化。
我觉得python不合适。应该使用脚本语言。比如webpy,pypiplicas。推荐:pypiplicas1.0.1documentation说白了,手机上用java或者javascript,python只是浏览器和web服务端语言,能post就post,put就put。别把python想象成神一样的超级语言。
python的语法和java也相差甚远,就是java里面一个简单函数换了种方式写。python一般从零开始了解什么是语言,web服务器、linux环境下访问、数据库、http协议、后端等等。大多数it公司会用python的grub之类工具。 查看全部
采集工具 别把python想象成神一样的超级语言(图)
采集工具要快速获取,推荐大家使用高德apilink网址:/,如果需要快速编辑,推荐使用使用qml,如果需要导出到本地,推荐使用excel,如果有维度,推荐使用melt,对应用程序来说,需要同时支持table和excel。
高德是网站吧?这个要得问高德,你要问下能不能拿到web的demo。网站应该都有,需要做一些配置应该就可以了,比如cookie,path,cookie代理什么的。
如果是成熟的互联网产品,按钮的js技术都要比导航的js技术低吧。成熟的导航多是python来做,成熟的web也多是python来做,都比导航完整复杂得多。再有就是python的工作量普遍比导航大。如果没有创业或者中小型项目,可以考虑网页浏览器里面实现,不过要自己做底层架构,设计好layout,还要对web进行一些优化。
我觉得python不合适。应该使用脚本语言。比如webpy,pypiplicas。推荐:pypiplicas1.0.1documentation说白了,手机上用java或者javascript,python只是浏览器和web服务端语言,能post就post,put就put。别把python想象成神一样的超级语言。
python的语法和java也相差甚远,就是java里面一个简单函数换了种方式写。python一般从零开始了解什么是语言,web服务器、linux环境下访问、数据库、http协议、后端等等。大多数it公司会用python的grub之类工具。
社交媒体数据集如何处理社交网络中收集的数据?
采集交流 • 优采云 发表了文章 • 0 个评论 • 262 次浏览 • 2021-03-22 05:35
社交媒体数据爬网工具通常是指可以从社交媒体渠道提取数据的自动化Web爬网程序工具。它不仅包括社交网站,例如Facebook,Twitter,Instagram,LinkedIn等,还包括博客,Wiki和新闻站点。所有这些门户网站都有一个共同点:它们都以非结构化数据的形式生成用户生成的内容,这些内容只能通过Web进行访问。
现在我们知道了社交媒体采集器的定义,我将进一步解释如何将社交媒体数据集用于商业中,并列出我推荐的5种最佳社交媒体数据采集器。
您如何处理在社交网络中采集的数据?
毫无疑问,从社交网络中提取的数据是有关人类行为的最大,最动态的数据集。它为社会科学家和商业专家提供了新的机会来了解个人,团体和社会,并探索隐藏在数据中的巨大财富。
社交网络分析-对技术,工具和平台的调查显示,最早采用社交网络数据分析业务的是零售和金融行业中的典型公司。他们使用社交媒体分析来利用品牌知名度,改进的客户服务和营销策略。甚至欺诈检测。
除了上面提到的应用程序外,如今社交媒体数据集还可以应用于:
从社交媒体渠道采集客户反馈后,您可以通过测量其主题,环境和感觉来分析客户对特定主题或产品的态度。跟踪客户情绪可让您了解总体客户满意度,客户忠诚度和参与意愿。提供有关您当前和将来的营销活动的信息。
识别市场趋势对于调整交易策略以使您的业务与行业变化保持同步至关重要。借助大数据自动化工具,市场趋势分析可通过跟踪行业影响者和在社交媒体上发布的评论来比较特定时间段内的行业数据。
市场上排名前五的社交媒体爬虫
Octoparse
Octoparse作为市场上最好的免费自动网页抓取工具之一,是为非编码人员开发的,可以容纳复杂的网页抓取任务。
当前版本7提供了直观的一键式界面,并支持无限滚动处理,登录身份验证,文本输入(用于获取搜索结果)和下拉菜单选择。采集的数据可以导出到Excel,JSON,HTML或数据库。如果要创建动态刮板以实时从动态网站提取数据,八度分析云提取(费用计划)可以获取动态数据的良好来源,因为它每1分钟支持一次提取过程。
为了从社交媒体中提取数据,Octoparse发布了许多详尽的教程,例如从Twitter抓取推文和从Instagram提取帖子。另外,Octoparse提供了一种数据采集服务,该服务将数据直接传递到您的S3库。如果您没有太多时间,那可能是个不错的选择。
Dexi.io
作为一个基于Web的应用程序,Dexi.io是另一个用于商业目的的直观提取自动化工具,起价为119美元/月。 Dexi.io支持创建三种类型的机器人:提取器,采集器和管道。
Dexi.io需要一些编程技能,但是您可以集成第三方服务来解决验证码问题,云存储,文本分析(MonkeyLearn服务集成),甚至可以将其与AWS,Google云端硬盘和Google表格一起使用。
插件(付费计划)也是Dexi.io的一项革命性功能,并且插件的数量持续增长。使用插件,您可以解锁提取器和管道中可用的更多功能。
3.智囊团
与Octoparse和Dexi.io不同,Outwit Hub提供了一个简单的图形用户界面以及全面的爬网和数据结构识别功能。 Outwit Hub最初是Firefox插件,后来成为可下载的应用程序。
在没有任何编程知识的情况下,OutWit Hub可以将链接,电子邮件地址,RSS新闻提要和数据表提取并导出到Excel,CSV,HTML或SQL数据库。
Outwit Hub具有出色的“快速获取”功能,可以快速删除您输入的URL列表中的数据。但是,由于缺少单击界面应用程序,对于初学者来说,您可能需要阅读一些基本的教程和文档。
4. Scrapinghub
Scrapinghub是基于云的Web抓取平台,可让您扩展跟踪器并提供智能下载程序,从而避免了机器人的对策,交钥匙的Web抓取服务和即用型数据集。
该应用程序收录4个出色的工具:Scrapy Cloud,用于实现和运行基于Python的Web采集器; Portia是一个开源软件,可以不加密就提取数据。 Splash还是一种开放源代码的JavaScript可视化工具,用于使用JavaScript从网页中提取数据; Crawlera是一种避免被网站,来自多个位置和IP的跟踪器阻止的工具。
Scrapehub没有提供完整的软件包,而是市场上一个相当复杂且功能强大的爬行Web平台。 Scrapehub提供的每个工具都需要单独付款。
5. Parsehub
Parsehub是市场上另一种未编码的桌面抓取工具,与Windows,Mac OS X和Linux兼容。它提供了一个图形界面,可以从JavaScript和AJAX页面中选择和提取数据。可以从嵌套的便笺,地图,图像,日历甚至弹出窗口中提取数据。
此外,Parsehub还具有基于浏览器的扩展程序,可以立即启动爬网任务。数据可以导出为Excel,JSON或通过API。
Parsehub的争议与其价格有关。 Parsehub的付费版本起价为每月149美元,高于市场上大多数刮刮产品,这意味着标准的Octoparse计划每个爬网每月无限制页面的成本仅为89美元。有一项免费计划,但不幸的是,它仅限于抓取200页和5个抓取作业。
结论
除了自动网页抓取工具可以执行的操作外,许多社交媒体渠道现在还向用户,学者,研究人员和特殊组织(如汤姆森·路透社和彭博新闻服务,Twitter和Facebook社交媒体)提供付款。 )API。
随着在线经济的增长和繁荣,社交媒体通过更好地倾听客户并以新的方式与现有客户和潜在客户互动,为您的企业在您的领域脱颖而出打开了许多新机会。 查看全部
社交媒体数据集如何处理社交网络中收集的数据?
社交媒体数据爬网工具通常是指可以从社交媒体渠道提取数据的自动化Web爬网程序工具。它不仅包括社交网站,例如Facebook,Twitter,Instagram,LinkedIn等,还包括博客,Wiki和新闻站点。所有这些门户网站都有一个共同点:它们都以非结构化数据的形式生成用户生成的内容,这些内容只能通过Web进行访问。
现在我们知道了社交媒体采集器的定义,我将进一步解释如何将社交媒体数据集用于商业中,并列出我推荐的5种最佳社交媒体数据采集器。
您如何处理在社交网络中采集的数据?
毫无疑问,从社交网络中提取的数据是有关人类行为的最大,最动态的数据集。它为社会科学家和商业专家提供了新的机会来了解个人,团体和社会,并探索隐藏在数据中的巨大财富。
社交网络分析-对技术,工具和平台的调查显示,最早采用社交网络数据分析业务的是零售和金融行业中的典型公司。他们使用社交媒体分析来利用品牌知名度,改进的客户服务和营销策略。甚至欺诈检测。
除了上面提到的应用程序外,如今社交媒体数据集还可以应用于:
从社交媒体渠道采集客户反馈后,您可以通过测量其主题,环境和感觉来分析客户对特定主题或产品的态度。跟踪客户情绪可让您了解总体客户满意度,客户忠诚度和参与意愿。提供有关您当前和将来的营销活动的信息。
识别市场趋势对于调整交易策略以使您的业务与行业变化保持同步至关重要。借助大数据自动化工具,市场趋势分析可通过跟踪行业影响者和在社交媒体上发布的评论来比较特定时间段内的行业数据。
市场上排名前五的社交媒体爬虫
Octoparse

Octoparse作为市场上最好的免费自动网页抓取工具之一,是为非编码人员开发的,可以容纳复杂的网页抓取任务。
当前版本7提供了直观的一键式界面,并支持无限滚动处理,登录身份验证,文本输入(用于获取搜索结果)和下拉菜单选择。采集的数据可以导出到Excel,JSON,HTML或数据库。如果要创建动态刮板以实时从动态网站提取数据,八度分析云提取(费用计划)可以获取动态数据的良好来源,因为它每1分钟支持一次提取过程。
为了从社交媒体中提取数据,Octoparse发布了许多详尽的教程,例如从Twitter抓取推文和从Instagram提取帖子。另外,Octoparse提供了一种数据采集服务,该服务将数据直接传递到您的S3库。如果您没有太多时间,那可能是个不错的选择。
Dexi.io
作为一个基于Web的应用程序,Dexi.io是另一个用于商业目的的直观提取自动化工具,起价为119美元/月。 Dexi.io支持创建三种类型的机器人:提取器,采集器和管道。
Dexi.io需要一些编程技能,但是您可以集成第三方服务来解决验证码问题,云存储,文本分析(MonkeyLearn服务集成),甚至可以将其与AWS,Google云端硬盘和Google表格一起使用。
插件(付费计划)也是Dexi.io的一项革命性功能,并且插件的数量持续增长。使用插件,您可以解锁提取器和管道中可用的更多功能。
3.智囊团
与Octoparse和Dexi.io不同,Outwit Hub提供了一个简单的图形用户界面以及全面的爬网和数据结构识别功能。 Outwit Hub最初是Firefox插件,后来成为可下载的应用程序。
在没有任何编程知识的情况下,OutWit Hub可以将链接,电子邮件地址,RSS新闻提要和数据表提取并导出到Excel,CSV,HTML或SQL数据库。
Outwit Hub具有出色的“快速获取”功能,可以快速删除您输入的URL列表中的数据。但是,由于缺少单击界面应用程序,对于初学者来说,您可能需要阅读一些基本的教程和文档。
4. Scrapinghub
Scrapinghub是基于云的Web抓取平台,可让您扩展跟踪器并提供智能下载程序,从而避免了机器人的对策,交钥匙的Web抓取服务和即用型数据集。
该应用程序收录4个出色的工具:Scrapy Cloud,用于实现和运行基于Python的Web采集器; Portia是一个开源软件,可以不加密就提取数据。 Splash还是一种开放源代码的JavaScript可视化工具,用于使用JavaScript从网页中提取数据; Crawlera是一种避免被网站,来自多个位置和IP的跟踪器阻止的工具。
Scrapehub没有提供完整的软件包,而是市场上一个相当复杂且功能强大的爬行Web平台。 Scrapehub提供的每个工具都需要单独付款。
5. Parsehub
Parsehub是市场上另一种未编码的桌面抓取工具,与Windows,Mac OS X和Linux兼容。它提供了一个图形界面,可以从JavaScript和AJAX页面中选择和提取数据。可以从嵌套的便笺,地图,图像,日历甚至弹出窗口中提取数据。
此外,Parsehub还具有基于浏览器的扩展程序,可以立即启动爬网任务。数据可以导出为Excel,JSON或通过API。
Parsehub的争议与其价格有关。 Parsehub的付费版本起价为每月149美元,高于市场上大多数刮刮产品,这意味着标准的Octoparse计划每个爬网每月无限制页面的成本仅为89美元。有一项免费计划,但不幸的是,它仅限于抓取200页和5个抓取作业。
结论
除了自动网页抓取工具可以执行的操作外,许多社交媒体渠道现在还向用户,学者,研究人员和特殊组织(如汤姆森·路透社和彭博新闻服务,Twitter和Facebook社交媒体)提供付款。 )API。
随着在线经济的增长和繁荣,社交媒体通过更好地倾听客户并以新的方式与现有客户和潜在客户互动,为您的企业在您的领域脱颖而出打开了许多新机会。
易工采集器还是收费的,怎么去采集微信公众号
采集交流 • 优采云 发表了文章 • 0 个评论 • 255 次浏览 • 2021-05-15 23:19
采集工具,我推荐快速采集。精准采集,一键分享一键添加至微信好友。快速将网页采集到手机,分享给同事同学分享给家人分享给朋友圈分享给朋友后台,
云采集,精准采集。
采集工具,可以选择快采,功能强大,
试试我们的微信公众号采集器,基于微信采集公众号动态数据,不但包含微信公众号历史数据,还可以获取你公众号或微信群里的任何消息,是不是很好用,在线即可使用,方便,也免费。关注公众号【小太阳智能产品】,体验一下我们的微信公众号采集器吧。
其实采集器主要就是有几个点,开发者可以插入自己的h5,网站,微信公众号文章,微信中的链接。你可以自己筛选一下,开发者必须是拥有某个服务号或微信群的账号,所以就看你有没有需求了。我自己最近就有新公众号,想做一个公众号采集器。好像只有个技术公众号才可以,因为技术公众号有一定门槛,所以做出来的个人号几乎就没什么权限了。
所以想要做的就是群发,然后批量群发有兴趣的可以看下这个怎么去采集微信公众号文章,采集网站,网站。?-陈苏鸿的回答-知乎。
我推荐楼主使用易工采集器采集,易工采集器不但功能齐全还带分享推广功能,并且是一个不带插件、对接公众号等功能一站式安全管理采集工具,数据来源全球各大权威媒体,数据分析准确、流量高。易工采集器还是收费的,对比几个免费工具,易工采集器在收费上更低。 查看全部
易工采集器还是收费的,怎么去采集微信公众号
采集工具,我推荐快速采集。精准采集,一键分享一键添加至微信好友。快速将网页采集到手机,分享给同事同学分享给家人分享给朋友圈分享给朋友后台,
云采集,精准采集。
采集工具,可以选择快采,功能强大,
试试我们的微信公众号采集器,基于微信采集公众号动态数据,不但包含微信公众号历史数据,还可以获取你公众号或微信群里的任何消息,是不是很好用,在线即可使用,方便,也免费。关注公众号【小太阳智能产品】,体验一下我们的微信公众号采集器吧。
其实采集器主要就是有几个点,开发者可以插入自己的h5,网站,微信公众号文章,微信中的链接。你可以自己筛选一下,开发者必须是拥有某个服务号或微信群的账号,所以就看你有没有需求了。我自己最近就有新公众号,想做一个公众号采集器。好像只有个技术公众号才可以,因为技术公众号有一定门槛,所以做出来的个人号几乎就没什么权限了。
所以想要做的就是群发,然后批量群发有兴趣的可以看下这个怎么去采集微信公众号文章,采集网站,网站。?-陈苏鸿的回答-知乎。
我推荐楼主使用易工采集器采集,易工采集器不但功能齐全还带分享推广功能,并且是一个不带插件、对接公众号等功能一站式安全管理采集工具,数据来源全球各大权威媒体,数据分析准确、流量高。易工采集器还是收费的,对比几个免费工具,易工采集器在收费上更低。
抓包过程展示和概述1.4..网页解码工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-05-12 06:05
采集工具,是数据收集的主要方式,使用最多的除了抓包工具,还有网页抓包工具,如anycast等,也可以转发给自己的朋友抓包解码工具,可以获取到真实的网页数据情报。有了这些工具,也能够实现自己真正的网络数据收集与挖掘。抓包过程展示和概述1.网页抓包工具proxymonkey类似于调试工具,利用fiddler实现,完整的代码在这里,可参考proxymonkey的使用proxymonkey的源码地址:,和使用fiddler可能会在部分操作上有一些不同,比如不会获取动态加载的元素信息,只是获取一个静态的input元素或者browser元素的信息等等。
使用注意点如下:proxymonkey并不会随着网页源代码实现抓包,需要用javascript动态编译网页,才会抓取到信息2.网页解码工具lexencoder比alltage强大,可以实现代码提取,字符串解码,字符编码处理等功能。获取自己上的数据当然要用这个,功能类似于fiddler抓包工具,可以设置抓包时间等等3.网页抓包工具webscraper虽然名字听起来很高端,但实际上并不需要爬虫工具就可以实现,比如动态加载的ajax链接等等,或者需要编译的网页,只要设置爬取的url和数据不要过于难看等等4.网页解码工具papar语法仅支持php,对java支持度一般,主要实现抓取libmx中的代码参考链接:-scraper4.2功能基本和webscraper类似,只是版本较低,更新不及webscraper快速教程欢迎关注我,公众号《猴子聊人物》,获取更多精彩内容。 查看全部
抓包过程展示和概述1.4..网页解码工具
采集工具,是数据收集的主要方式,使用最多的除了抓包工具,还有网页抓包工具,如anycast等,也可以转发给自己的朋友抓包解码工具,可以获取到真实的网页数据情报。有了这些工具,也能够实现自己真正的网络数据收集与挖掘。抓包过程展示和概述1.网页抓包工具proxymonkey类似于调试工具,利用fiddler实现,完整的代码在这里,可参考proxymonkey的使用proxymonkey的源码地址:,和使用fiddler可能会在部分操作上有一些不同,比如不会获取动态加载的元素信息,只是获取一个静态的input元素或者browser元素的信息等等。
使用注意点如下:proxymonkey并不会随着网页源代码实现抓包,需要用javascript动态编译网页,才会抓取到信息2.网页解码工具lexencoder比alltage强大,可以实现代码提取,字符串解码,字符编码处理等功能。获取自己上的数据当然要用这个,功能类似于fiddler抓包工具,可以设置抓包时间等等3.网页抓包工具webscraper虽然名字听起来很高端,但实际上并不需要爬虫工具就可以实现,比如动态加载的ajax链接等等,或者需要编译的网页,只要设置爬取的url和数据不要过于难看等等4.网页解码工具papar语法仅支持php,对java支持度一般,主要实现抓取libmx中的代码参考链接:-scraper4.2功能基本和webscraper类似,只是版本较低,更新不及webscraper快速教程欢迎关注我,公众号《猴子聊人物》,获取更多精彩内容。
BI系统自身的数据采集能力和亮点数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 621 次浏览 • 2021-05-11 02:19
我们为什么需要数据采集
首先,数据采集是基于跨数据库查询功能的补充功能。在Smartbi V9的数据源管理中,用户可以通过上传文件(Excel,CSV,TXT)以及其他企业内部数据(关系数据)来将本地原创数据上传到数据平台,以进行后续的语义层封装和相关查询。
但是,在许多情况下,分析人员甚至最终报告的用户都会发现数据质量问题,例如产品模型的大写错误,导致无法合并统计信息以及客户归属城市的错误等。导致性能计算错误.....。如果没有数据采集的能力,那么技术人员必须通过关系数据库的后台操作来修改数据,这将带来一些安全风险。此外,业务用户可能还需要临时采集一些数据。这些采集要求并不复杂,采集的数据仅用于数据关联分析,因此很难协调企业OA。这就提出了对BI系统本身的数据采集功能的需求。
数据的功能和重点采集
Smartbi数据采集提供以下功能:
1、数据修改和维护,开发人员设计了一个可以修改数据的列表,最终用户在发布后直接在浏览器或APP上对其进行修改并将其保存在数据库中;
2、数据填充,采集,开发人员设计交叉表,表格或调查表,发布后,最终用户在浏览器或APP中输入数据并将其保存在数据库中;
3、对于已经具有Excel模板(固定格式)采集的数据,您可以设计Excel模板导入功能,以将Excel中的数据直接保存到数据库中。
前两个功能是最常用的,它们也是Smartbi数据的特征采集。 采集的页面设计为与修改数据的界面相同。如果看到的数据不正确,则可以对其进行修改,它将立即生效,而无需等待。当然,这种具有回写功能的报告依赖于预定义的资源权限来确保数据安全。
从写回报告的设计来看,基于Excel插件方法的电子表格与中式报告的设计没有什么不同,但是定义了“写回规则”,并在单元格中映射到数据库。参考界面如下:
在回写定义中,您可以指定目标数据库和表以进行数据回写,并且同意的回写内容仅由用户修改以及特定的更新规则并插入。最终接口上的写回操作支持删除行,添加行,清除数据修改记录等。
<p>此外,Smartbi Data 采集还提供了可回写的单元格的填充属性,以控制来自源的数据质量,包括验证输入数据格式和定义下拉列表。向下选择列表(支持Excel数据序列或系统内置参数),作为附件上传的文件规则等。如果您是母版,则还可以使用“正则表达式”来更严格地控制数据输入的质量。 查看全部
BI系统自身的数据采集能力和亮点数据采集
我们为什么需要数据采集
首先,数据采集是基于跨数据库查询功能的补充功能。在Smartbi V9的数据源管理中,用户可以通过上传文件(Excel,CSV,TXT)以及其他企业内部数据(关系数据)来将本地原创数据上传到数据平台,以进行后续的语义层封装和相关查询。
但是,在许多情况下,分析人员甚至最终报告的用户都会发现数据质量问题,例如产品模型的大写错误,导致无法合并统计信息以及客户归属城市的错误等。导致性能计算错误.....。如果没有数据采集的能力,那么技术人员必须通过关系数据库的后台操作来修改数据,这将带来一些安全风险。此外,业务用户可能还需要临时采集一些数据。这些采集要求并不复杂,采集的数据仅用于数据关联分析,因此很难协调企业OA。这就提出了对BI系统本身的数据采集功能的需求。
数据的功能和重点采集
Smartbi数据采集提供以下功能:
1、数据修改和维护,开发人员设计了一个可以修改数据的列表,最终用户在发布后直接在浏览器或APP上对其进行修改并将其保存在数据库中;
2、数据填充,采集,开发人员设计交叉表,表格或调查表,发布后,最终用户在浏览器或APP中输入数据并将其保存在数据库中;
3、对于已经具有Excel模板(固定格式)采集的数据,您可以设计Excel模板导入功能,以将Excel中的数据直接保存到数据库中。
前两个功能是最常用的,它们也是Smartbi数据的特征采集。 采集的页面设计为与修改数据的界面相同。如果看到的数据不正确,则可以对其进行修改,它将立即生效,而无需等待。当然,这种具有回写功能的报告依赖于预定义的资源权限来确保数据安全。
从写回报告的设计来看,基于Excel插件方法的电子表格与中式报告的设计没有什么不同,但是定义了“写回规则”,并在单元格中映射到数据库。参考界面如下:
在回写定义中,您可以指定目标数据库和表以进行数据回写,并且同意的回写内容仅由用户修改以及特定的更新规则并插入。最终接口上的写回操作支持删除行,添加行,清除数据修改记录等。
<p>此外,Smartbi Data 采集还提供了可回写的单元格的填充属性,以控制来自源的数据质量,包括验证输入数据格式和定义下拉列表。向下选择列表(支持Excel数据序列或系统内置参数),作为附件上传的文件规则等。如果您是母版,则还可以使用“正则表达式”来更严格地控制数据输入的质量。
优采云采集器的功能特点及功能介绍-乐题库
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-05-10 03:24
优采云 采集器是非常专业的网络信息采集工具。作为新一代的视觉智能采集器,它具有“视觉配置,易于创建,无需编程和智能生成”的特征。它会自动生成相关功能,并快速采集您需要的内容。此版本已激活并破解,用户可以免费使用,无限功能。
[功能]
1、零阈值:如果您不知道如何采集采集器,您将在会议上收到网站个数据。
2、多引擎,高速且无混乱:内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集数据更加高效。它还具有内置的JSON引擎,无需分析JSON数据布局,即可直观地提取JSON内容。
3、结合各种类型的网站:可以采集99%的Internet 网站,包括静态示例,例如使用Ajax 网站进行单页加载。
[软件功能]
1、该软件操作复杂,单击鼠标即可轻松访问要捕获的内容;
2、支持三种高速引擎:浏览器引擎,HTTP引擎,JSON引擎,内置优化的Firefox浏览器,以及首次进行内存优化,以便浏览器也可以高速运行,甚至可以快速运行转换为HTTP操作,享受更高的采集率!捕获JSON数据时,还可以使用浏览器可视化方法来选择需要用鼠标捕获的内容。不必分析JSON数据布局,以便非Web专业计划人员可以轻松地获取必要的数据;
3、无需分析Web请求和源代码,但支持更多Web集合;
4、先进的智能算法,一键自然目标元素XPATH,主动识别网页列表,主动识别选项卡中的下一页按钮……
5、支持丰富的数据导出方法,可以将其导出到txt文件,html文件,csv文件,excel文件,还可以导出到现有数据库,例如sqlite数据库,access数据库,sqlserver数据库,mysql数据库,通过导览的复杂映射字段,可以轻松地将其导出到导览网站数据库。
[软件亮点]
可视化指南:采集所有元素,主动自然地采集数据。
1、尝试承担责任:天真地定义操作时间,完全激活操作。
2、多引擎支持:支持多个采集引擎,内置的高速浏览器内核,HTTP引擎和JSON引擎。
3、智能识别:它可以主动识别网页列表,采集字段和分页符。
4、阻止请求:自定义阻止域名,有助于过滤网站外的广告,并提高采集率。
5、各种数据导出:可以导出到Txt,Excel,MySQL,SQLServer,SQlite,Access,网站等。 查看全部
优采云采集器的功能特点及功能介绍-乐题库
优采云 采集器是非常专业的网络信息采集工具。作为新一代的视觉智能采集器,它具有“视觉配置,易于创建,无需编程和智能生成”的特征。它会自动生成相关功能,并快速采集您需要的内容。此版本已激活并破解,用户可以免费使用,无限功能。
[功能]
1、零阈值:如果您不知道如何采集采集器,您将在会议上收到网站个数据。
2、多引擎,高速且无混乱:内置高速浏览器引擎,还可以切换到HTTP引擎模式运行,采集数据更加高效。它还具有内置的JSON引擎,无需分析JSON数据布局,即可直观地提取JSON内容。
3、结合各种类型的网站:可以采集99%的Internet 网站,包括静态示例,例如使用Ajax 网站进行单页加载。
[软件功能]
1、该软件操作复杂,单击鼠标即可轻松访问要捕获的内容;
2、支持三种高速引擎:浏览器引擎,HTTP引擎,JSON引擎,内置优化的Firefox浏览器,以及首次进行内存优化,以便浏览器也可以高速运行,甚至可以快速运行转换为HTTP操作,享受更高的采集率!捕获JSON数据时,还可以使用浏览器可视化方法来选择需要用鼠标捕获的内容。不必分析JSON数据布局,以便非Web专业计划人员可以轻松地获取必要的数据;
3、无需分析Web请求和源代码,但支持更多Web集合;
4、先进的智能算法,一键自然目标元素XPATH,主动识别网页列表,主动识别选项卡中的下一页按钮……
5、支持丰富的数据导出方法,可以将其导出到txt文件,html文件,csv文件,excel文件,还可以导出到现有数据库,例如sqlite数据库,access数据库,sqlserver数据库,mysql数据库,通过导览的复杂映射字段,可以轻松地将其导出到导览网站数据库。
[软件亮点]
可视化指南:采集所有元素,主动自然地采集数据。
1、尝试承担责任:天真地定义操作时间,完全激活操作。
2、多引擎支持:支持多个采集引擎,内置的高速浏览器内核,HTTP引擎和JSON引擎。
3、智能识别:它可以主动识别网页列表,采集字段和分页符。
4、阻止请求:自定义阻止域名,有助于过滤网站外的广告,并提高采集率。
5、各种数据导出:可以导出到Txt,Excel,MySQL,SQLServer,SQlite,Access,网站等。
采集工具 谢邀:1688分销红利巨大,对于分销号完全放开
采集交流 • 优采云 发表了文章 • 0 个评论 • 227 次浏览 • 2021-05-08 19:05
采集工具只是基于对用户感知信息的收集而使用,对于信息内容的变现还存在阻碍,毕竟现有的rtb技术目前还不够成熟,但最近几年rtb技术迎来大爆发,而且在去中心化以及公平性方面有着很大的改观。同时,如果你对rtb没有了解的话,最近就要淘汰的亚马逊这种产品,就证明rtb将会是未来发展的大趋势,所以你现在接触rtb就显得非常有必要,可以试试了解下,1688分销红利巨大,对于分销号完全放开,分销就是在这大趋势下的。
谢邀,我建议可以从了解如何通过开源的rtb爬虫来做到商品推荐。只要rtb上有足够多的商品,就可以通过对他们的大数据分析来进行推荐了。
可以啊,腾讯qq和都是rtb起家的。
参考豆瓣
也就是现在能找到的微淘,你现在所想的未来应该也就是基于微淘的了,而不是rtb,现在用户的付费点击率被稀释了,流量也不值钱了,rtb更适合市场人员去接触,最大的困难点在于数据采集的问题,这个只要把数据采集的拿下来,市场相对来说是最容易进行推广的。
什么rtb,rpc都不是问题.我理解就是你电商或者企业没那么精通爬虫就rtb.rpc..这些词老外会跟你绕
rtb就是个热词,还处于发展期,根据你的项目需求来。目前新浪微博已经在做了,你可以看看新浪微博的#推荐rtb的发展可以看出前景。 查看全部
采集工具 谢邀:1688分销红利巨大,对于分销号完全放开
采集工具只是基于对用户感知信息的收集而使用,对于信息内容的变现还存在阻碍,毕竟现有的rtb技术目前还不够成熟,但最近几年rtb技术迎来大爆发,而且在去中心化以及公平性方面有着很大的改观。同时,如果你对rtb没有了解的话,最近就要淘汰的亚马逊这种产品,就证明rtb将会是未来发展的大趋势,所以你现在接触rtb就显得非常有必要,可以试试了解下,1688分销红利巨大,对于分销号完全放开,分销就是在这大趋势下的。
谢邀,我建议可以从了解如何通过开源的rtb爬虫来做到商品推荐。只要rtb上有足够多的商品,就可以通过对他们的大数据分析来进行推荐了。
可以啊,腾讯qq和都是rtb起家的。
参考豆瓣
也就是现在能找到的微淘,你现在所想的未来应该也就是基于微淘的了,而不是rtb,现在用户的付费点击率被稀释了,流量也不值钱了,rtb更适合市场人员去接触,最大的困难点在于数据采集的问题,这个只要把数据采集的拿下来,市场相对来说是最容易进行推广的。
什么rtb,rpc都不是问题.我理解就是你电商或者企业没那么精通爬虫就rtb.rpc..这些词老外会跟你绕
rtb就是个热词,还处于发展期,根据你的项目需求来。目前新浪微博已经在做了,你可以看看新浪微博的#推荐rtb的发展可以看出前景。
猫池采集器操作简单:安卓和苹果都可以操作网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 201 次浏览 • 2021-05-08 04:03
采集工具:猫池采集器操作简单:安卓和苹果都可以操作网站界面:介绍完成后,
1、账号
2、个人助理
3、网站库
4、谷歌爬虫
5、自动点击
6、自动改密码
7、编码
8、带多端支持带发票等。
软件功能介绍:
1、标题、网站源码获取
2、网站源码翻译
3、网站创建
4、网站路由模式
5、网站路由模式网站导航
6、网站代码剖析
7、网站镜像站
8、视频导航多端支持:您只需要一台手机,就可以任意的在android/ios下访问并浏览网站,不受域名限制。支持应用商店镜像:在android/ios下通过对应的应用商店的镜像进行抓取,即可抓取页面并跳转到对应的网站。无论是网站定向的搜索引擎都可以访问和抓取。抓取速度快:采集速度很快,并且可以抓取移动应用的来源页面。
并发量大:群策群力的攻击,任意一台机器都可以抓取任意网站的请求地址。快速交互、不被篡改:支持打包pdf文件,在传输的过程中不被篡改,不会丢失任何文字,当然这一点需要专业的抓取软件帮助你完成抓取。支持代码实时更新:提供长短链接自动抓取,保证网站的内容有一定的更新。
操作步骤:
1、登录账号进入软件,找到网站源码来源页面,
2、找到您要抓取的链接,长短可以自定义,
3、点击下一步,会弹出访问其他网站查看抓取后结果,
4、编码就是将要抓取的页面字符,自动添加为utf-8编码,并保存为一个链接,
5、然后进行网站站内检测,不存在站内对话框选择,
6、抓取成功之后会显示抓取页面的url, 查看全部
猫池采集器操作简单:安卓和苹果都可以操作网站
采集工具:猫池采集器操作简单:安卓和苹果都可以操作网站界面:介绍完成后,
1、账号
2、个人助理
3、网站库
4、谷歌爬虫
5、自动点击
6、自动改密码
7、编码
8、带多端支持带发票等。
软件功能介绍:
1、标题、网站源码获取
2、网站源码翻译
3、网站创建
4、网站路由模式
5、网站路由模式网站导航
6、网站代码剖析
7、网站镜像站
8、视频导航多端支持:您只需要一台手机,就可以任意的在android/ios下访问并浏览网站,不受域名限制。支持应用商店镜像:在android/ios下通过对应的应用商店的镜像进行抓取,即可抓取页面并跳转到对应的网站。无论是网站定向的搜索引擎都可以访问和抓取。抓取速度快:采集速度很快,并且可以抓取移动应用的来源页面。
并发量大:群策群力的攻击,任意一台机器都可以抓取任意网站的请求地址。快速交互、不被篡改:支持打包pdf文件,在传输的过程中不被篡改,不会丢失任何文字,当然这一点需要专业的抓取软件帮助你完成抓取。支持代码实时更新:提供长短链接自动抓取,保证网站的内容有一定的更新。
操作步骤:
1、登录账号进入软件,找到网站源码来源页面,
2、找到您要抓取的链接,长短可以自定义,
3、点击下一步,会弹出访问其他网站查看抓取后结果,
4、编码就是将要抓取的页面字符,自动添加为utf-8编码,并保存为一个链接,
5、然后进行网站站内检测,不存在站内对话框选择,
6、抓取成功之后会显示抓取页面的url,
超级好用的公众号排版神器——采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 268 次浏览 • 2021-05-06 21:01
采集工具googleanalytics
百度统计需要梯子,国内需要翻墙。麦包包也是一个快速开发统计的cms。
个人开发推荐w3cschool,教程详尽,
工具类比较流行的有【w3schools】,【mdn】,【菜鸟教程】,【googleanalytics】等都是比较基础易用的工具,工欲善其事必先利其器。
我今天发现了一个超级好用的公众号排版神器【飞马】,可以排文字,标题,阅读数,阅读时间和关注人数等一切数据,顺便还可以给自己设定一个小目标,比如:上一篇阅读不超过500,阅读数不超过2000,每天阅读量不超过1000。
androidappgrowing
还有pagespan啊,
使用【飞马网】很好用,这里可以看一些工具相关的信息,比如:热门工具的介绍,高价值的工具,主流网站数据等等还有无限量数据包(直接百度云无限制下载),还能获取自己常用的工具,比如:谷歌趋势,各大主流搜索引擎数据,百度指数,头条指数,指数,
googleanalytics,简单易用。
使用wordpress编写woocommerce插件可以实现googleanalytics及tagsmanager的内置数据功能
woocommerce前端开发工具 查看全部
超级好用的公众号排版神器——采集工具
采集工具googleanalytics
百度统计需要梯子,国内需要翻墙。麦包包也是一个快速开发统计的cms。
个人开发推荐w3cschool,教程详尽,
工具类比较流行的有【w3schools】,【mdn】,【菜鸟教程】,【googleanalytics】等都是比较基础易用的工具,工欲善其事必先利其器。
我今天发现了一个超级好用的公众号排版神器【飞马】,可以排文字,标题,阅读数,阅读时间和关注人数等一切数据,顺便还可以给自己设定一个小目标,比如:上一篇阅读不超过500,阅读数不超过2000,每天阅读量不超过1000。
androidappgrowing
还有pagespan啊,
使用【飞马网】很好用,这里可以看一些工具相关的信息,比如:热门工具的介绍,高价值的工具,主流网站数据等等还有无限量数据包(直接百度云无限制下载),还能获取自己常用的工具,比如:谷歌趋势,各大主流搜索引擎数据,百度指数,头条指数,指数,
googleanalytics,简单易用。
使用wordpress编写woocommerce插件可以实现googleanalytics及tagsmanager的内置数据功能
woocommerce前端开发工具
采集工具可以想一下,安卓用reply是可以的
采集交流 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2021-05-02 19:04
采集工具可以想一下,安卓用reply是可以的,ios现在全家桶都被禁,用非官方app的办法基本不可能获取到。使用mantis是可以通过配置来绑定项目,接入github同步,
一般是要技术开发的
基本不可能,服务器关掉了。不过可以通过扫一扫上边的二维码,扫描下载。基本都是开源的。
当前市面上的大多数采集工具,除了文档介绍所提到的那些外,大多数都没有提供技术资料,直接上手去操作,基本都有难度。网上有很多类似的工具,类似平台,
泻药,以下仅代表个人观点(仅供参考)主要靠着二维码+扫描这些工具去采集:1。二维码2。二维码扫描器3。android--pc端工具(即时安装+配置)4。ios--pc端工具(即时安装+配置)5。服务器工具6。在线在线采集平台(这个貌似也有很多种,但是我是不推荐,个人觉得这个app不太好,主要这个平台比较差)(这个平台不推荐,服务器进不去)7。
在线采集平台(即时安装+配置)8。其他可以提高效率的方法:比如把抓包软件做成云笔记,这样就可以便捷的记录了。
appstore会有账号,并登录,然后配合采集工具,
可以看下我的博客:链接::rtccc-p2pmrq 查看全部
采集工具可以想一下,安卓用reply是可以的
采集工具可以想一下,安卓用reply是可以的,ios现在全家桶都被禁,用非官方app的办法基本不可能获取到。使用mantis是可以通过配置来绑定项目,接入github同步,
一般是要技术开发的
基本不可能,服务器关掉了。不过可以通过扫一扫上边的二维码,扫描下载。基本都是开源的。
当前市面上的大多数采集工具,除了文档介绍所提到的那些外,大多数都没有提供技术资料,直接上手去操作,基本都有难度。网上有很多类似的工具,类似平台,
泻药,以下仅代表个人观点(仅供参考)主要靠着二维码+扫描这些工具去采集:1。二维码2。二维码扫描器3。android--pc端工具(即时安装+配置)4。ios--pc端工具(即时安装+配置)5。服务器工具6。在线在线采集平台(这个貌似也有很多种,但是我是不推荐,个人觉得这个app不太好,主要这个平台比较差)(这个平台不推荐,服务器进不去)7。
在线采集平台(即时安装+配置)8。其他可以提高效率的方法:比如把抓包软件做成云笔记,这样就可以便捷的记录了。
appstore会有账号,并登录,然后配合采集工具,
可以看下我的博客:链接::rtccc-p2pmrq
优采云数据采集系统修复修复自定义模式的应用
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-05-01 05:05
[一般介绍]
轻松地从各种网站或网页中获取大量标准化数据
[基本介绍]
优采云数据采集系统基于完全自主开发的分布式云计算平台。它可以在短时间内轻松地从各种网站或网页中获取大量标准化数据,以帮助任何需要从Web上获取信息的客户都可以实现数据自动化采集,编辑和标准化,以及摆脱了对手工搜索和数据采集的依赖,从而降低了获取信息的成本并提高了效率。
[软件功能]
1.财务数据,例如季度报告,年度报告,财务报告,包括自动的最新每日净值采集;
2.主要新闻门户网站实时监控,自动更新和上传最新新闻;
3.监控竞争对手的最新信息,包括商品价格和库存;
4.监视主要的社交网络网站,博客,并自动获取有关公司产品的相关评论;
5.采集最新,最全面的招聘信息;
6.监视与网站,采集新房和二手房有关的主要房地产的最新市场价格;
7. 采集主要汽车的特定新车和二手车信息网站;
8.发现并采集潜在的客户信息;
9. 采集产品目录和行业产品信息网站;
1 0.在主要的电子商务平台之间同步产品信息,以便可以在一个平台上发布并在其他平台上自动更新。
[日志更新]
1、主要体验方面的改进:
[任务列表]添加了“计划任务”过滤条件,可以过滤掉所有计划或非定时任务
[任务列表]保存新添加的列信息,该信息将在下次登录后保留
[任务列表]添加了“批清除定时配置”功能
[自定义模式]添加了“自动重试”的开关设置。对于特定网页,可以关闭此选项以加快采集。
[自定义模式]在打开要执行的网页之前添加“随机1-30秒”选项,以增强防阻塞功能
[简单模式]您可以提交所需的模板作为反馈
[Other]客户端支持手机号码登录
2、错误修复:
解决了在自定义模式下固定元素列表和文本列表循环未拆分的问题
以简单模式修复一些错误
修复任务列表中的一些错误
解决了代理IP客户端的剩余数量和网站显示不一致的问题
解决计时失败问题
提高客户端登录的稳定性 查看全部
优采云数据采集系统修复修复自定义模式的应用
[一般介绍]
轻松地从各种网站或网页中获取大量标准化数据
[基本介绍]
优采云数据采集系统基于完全自主开发的分布式云计算平台。它可以在短时间内轻松地从各种网站或网页中获取大量标准化数据,以帮助任何需要从Web上获取信息的客户都可以实现数据自动化采集,编辑和标准化,以及摆脱了对手工搜索和数据采集的依赖,从而降低了获取信息的成本并提高了效率。
[软件功能]
1.财务数据,例如季度报告,年度报告,财务报告,包括自动的最新每日净值采集;
2.主要新闻门户网站实时监控,自动更新和上传最新新闻;
3.监控竞争对手的最新信息,包括商品价格和库存;
4.监视主要的社交网络网站,博客,并自动获取有关公司产品的相关评论;
5.采集最新,最全面的招聘信息;
6.监视与网站,采集新房和二手房有关的主要房地产的最新市场价格;
7. 采集主要汽车的特定新车和二手车信息网站;
8.发现并采集潜在的客户信息;
9. 采集产品目录和行业产品信息网站;
1 0.在主要的电子商务平台之间同步产品信息,以便可以在一个平台上发布并在其他平台上自动更新。
[日志更新]
1、主要体验方面的改进:
[任务列表]添加了“计划任务”过滤条件,可以过滤掉所有计划或非定时任务
[任务列表]保存新添加的列信息,该信息将在下次登录后保留
[任务列表]添加了“批清除定时配置”功能
[自定义模式]添加了“自动重试”的开关设置。对于特定网页,可以关闭此选项以加快采集。
[自定义模式]在打开要执行的网页之前添加“随机1-30秒”选项,以增强防阻塞功能
[简单模式]您可以提交所需的模板作为反馈
[Other]客户端支持手机号码登录
2、错误修复:
解决了在自定义模式下固定元素列表和文本列表循环未拆分的问题
以简单模式修复一些错误
修复任务列表中的一些错误
解决了代理IP客户端的剩余数量和网站显示不一致的问题
解决计时失败问题
提高客户端登录的稳定性
百度api开放平台统计,如何使用分析工具之一
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-04-25 23:07
采集工具在生活中也经常使用,常用的有百度统计,百度统计又可分为百度统计,百度api开放平台统计,百度统计apistore、百度统计联盟。今天我们主要来讲一下百度api开放平台统计。百度api开放平台统计是广告主最常用的seo分析工具之一,此外也为大家简单介绍一下这个平台究竟如何使用。
一、如何申请:官网链接:,有邮箱及密码的都不需要填写邮箱。正常1-3天就会给你回复,个人账号是不能开通的,已经注册过的可以帮助别人申请开通。需要写姓名,邮箱,手机号,姓名的话请在姓名上书写真实姓名。
二、如何使用:在网页下方搜索框搜索您对应的关键词,或者搜索行业垂直词。比如你是要评价男装,不能直接搜索:男装是这样的:你可以这样:也可以是这样:这样:还可以这样:显示出来是这样的:也可以设置分别展示在a、b、c、d、e、f、g、h这6页你想看的词。
三、使用费用:按site的查询方式:通过ip查询,1天,18元,1月(一个ip,100元1天);使用网站url进行查询(会更精准):所有ip查询,一天,23元,1月;可设置单个网站查询:单个网站10元1天(ip不能为空)一般收费100元每月。
四、申请渠道:目前包括百度api开放平台,新浪微博api平台,谷歌api开放平台,百度代理商api,百度代理商平台,百度百科。建议尽量通过百度api开放平台,申请网址:,我们可以通过比较多渠道联系,比如我们可以搜索“姓名”,“ip”,可以通过其他部分检索到api开放平台链接地址,当你希望了解某一seo关键词的竞争程度时,只需要进行简单的搜索,就可以得知是否被其他同行采集,记住一点:站内搜索这一必须进行,我们根据谷歌所说:站内搜索可以统计你点击过的站点数据。当然各大平台会收费。
五、使用时长:4-12小时,可以设置每天,每周,每月进行统计。
六、联系渠道:a/b账号均可使用。如:搜索“男装”a账号的可以看到b账号的信息,搜索“男装卡罗拉”b账号的可以看到a账号的信息。注意:a账号所在的邮箱和b账号所在的邮箱都必须可以进行查询a/b账号都不能够支持私人开户,账号不能重复。
七、账号安全:a类客户:主动申请,账号不能被恶意注册账号,一般也不会被恶意买卖或个人买卖账号。b类客户:只能采集到有价值的corp信息,其他信息被停用c/b类账号:只能采集到有价值的corp信息,
八、出口海外、balance类:就是通过采集来购买比如中国韩国日本的hp等,也可以在申请的时候获取。
九、可以获取到数据:查询韩国baidu,查询日本baidu, 查看全部
百度api开放平台统计,如何使用分析工具之一
采集工具在生活中也经常使用,常用的有百度统计,百度统计又可分为百度统计,百度api开放平台统计,百度统计apistore、百度统计联盟。今天我们主要来讲一下百度api开放平台统计。百度api开放平台统计是广告主最常用的seo分析工具之一,此外也为大家简单介绍一下这个平台究竟如何使用。
一、如何申请:官网链接:,有邮箱及密码的都不需要填写邮箱。正常1-3天就会给你回复,个人账号是不能开通的,已经注册过的可以帮助别人申请开通。需要写姓名,邮箱,手机号,姓名的话请在姓名上书写真实姓名。
二、如何使用:在网页下方搜索框搜索您对应的关键词,或者搜索行业垂直词。比如你是要评价男装,不能直接搜索:男装是这样的:你可以这样:也可以是这样:这样:还可以这样:显示出来是这样的:也可以设置分别展示在a、b、c、d、e、f、g、h这6页你想看的词。
三、使用费用:按site的查询方式:通过ip查询,1天,18元,1月(一个ip,100元1天);使用网站url进行查询(会更精准):所有ip查询,一天,23元,1月;可设置单个网站查询:单个网站10元1天(ip不能为空)一般收费100元每月。
四、申请渠道:目前包括百度api开放平台,新浪微博api平台,谷歌api开放平台,百度代理商api,百度代理商平台,百度百科。建议尽量通过百度api开放平台,申请网址:,我们可以通过比较多渠道联系,比如我们可以搜索“姓名”,“ip”,可以通过其他部分检索到api开放平台链接地址,当你希望了解某一seo关键词的竞争程度时,只需要进行简单的搜索,就可以得知是否被其他同行采集,记住一点:站内搜索这一必须进行,我们根据谷歌所说:站内搜索可以统计你点击过的站点数据。当然各大平台会收费。
五、使用时长:4-12小时,可以设置每天,每周,每月进行统计。
六、联系渠道:a/b账号均可使用。如:搜索“男装”a账号的可以看到b账号的信息,搜索“男装卡罗拉”b账号的可以看到a账号的信息。注意:a账号所在的邮箱和b账号所在的邮箱都必须可以进行查询a/b账号都不能够支持私人开户,账号不能重复。
七、账号安全:a类客户:主动申请,账号不能被恶意注册账号,一般也不会被恶意买卖或个人买卖账号。b类客户:只能采集到有价值的corp信息,其他信息被停用c/b类账号:只能采集到有价值的corp信息,
八、出口海外、balance类:就是通过采集来购买比如中国韩国日本的hp等,也可以在申请的时候获取。
九、可以获取到数据:查询韩国baidu,查询日本baidu,
telegraf的基本介绍及安装使用方法-乐题库
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-04-24 01:10
一、 Telegraf简介
1、基本介绍
Telegraf是用Go编写的代理程序,该程序采集系统和服务统计信息并将其写入InfluxDB数据库。内存占用空间很小,并且可以通过插件系统轻松添加支持其他服务的扩展。
Influxdb是一个开源的分布式时间序列,时间和指标数据库,使用Go语言编写,没有外部依赖关系。 Influxdb具有以下三个特征:
①,基于时间序列,支持与时间相关的相关函数(例如最大值,最小值,总和等);
②,可测量性:您可以实时计算大量数据;
③,基于事件:它支持任意事件数据;
2、为什么要使用telegraf和influxdb?
①。在数据采集和平台监视系统中,Telegraf可以采集多个组件的操作信息,而无需编写脚本计时采集,从而降低了数据获取的难度;
②,Telegraf的配置很简单,只要您具有基本的Linux基础,就可以快速入门;
③,Telegraf基于时间序列采集数据,并且该数据结构收录计时信息。 Influxdb专为此类数据而设计。 Influxdb可用于对采集获得的数据执行各种分析和计算操作;
二、安装和配置
1、下载
官方网站下载地址:Telegraf
或者可以通过命令行下载,命令如下:
# 下载安装包
wget http://get.influxdb.org/telegr ... 4.rpm
# 解压
sudo yum localinstall telegraf-0.11.1-1.x86_64.rpm
# 启动命令
systemctl start telegraf
# 重启命令
systemctl restart telegraf
2、修改配置文件
输入命令
vim /etc/telegraf/telegraf.conf
修改后的内容如下:
[[outputs.influxdb]]
urls = ["http://localhost:8086"] # required
database = "telegraf" # required
retention_policy = ""
precision = "s"
timeout = "5s"
username = "telegraf"
password = "password"
然后保存更改并输入命令
systemctl restart telegraf
重新启动电传。
三、数据采集并显示
如果要使用telegraf 采集数据并将其保存在influxdb中,则必须在influxdb中创建相应的用户和数据库。
1、创建influxdb用户和数据库
[root@localhost~]# influx
Visit https://enterprise.influxdata.com to register for updates, InfluxDB server management, and monitoring.
Connected to http://localhost:8086 version 1.0.2
InfluxDB shell version: 1.0.2
> create user "telegraf" with password 'password'
> show users;
user admin
telegraf false
> create database telegraf
> show databases
name: databases
---------------
name
_internal
telegraf
> exit
[root@localhost ~]# systemctl restart influxdb
创建成功后,重新启动influxdb,然后输入IP + 8083端口进入influxdb界面。
2、查询相应的信息
在查询框中输入SQL语句以查询所需的信息,例如:
如上所述,您可以看到服务器的磁盘使用情况信息。
以上是Telegraf的基本介绍和安装方法。有关更多信息,请参阅官方文档。 查看全部
telegraf的基本介绍及安装使用方法-乐题库
一、 Telegraf简介
1、基本介绍
Telegraf是用Go编写的代理程序,该程序采集系统和服务统计信息并将其写入InfluxDB数据库。内存占用空间很小,并且可以通过插件系统轻松添加支持其他服务的扩展。
Influxdb是一个开源的分布式时间序列,时间和指标数据库,使用Go语言编写,没有外部依赖关系。 Influxdb具有以下三个特征:
①,基于时间序列,支持与时间相关的相关函数(例如最大值,最小值,总和等);
②,可测量性:您可以实时计算大量数据;
③,基于事件:它支持任意事件数据;
2、为什么要使用telegraf和influxdb?
①。在数据采集和平台监视系统中,Telegraf可以采集多个组件的操作信息,而无需编写脚本计时采集,从而降低了数据获取的难度;
②,Telegraf的配置很简单,只要您具有基本的Linux基础,就可以快速入门;
③,Telegraf基于时间序列采集数据,并且该数据结构收录计时信息。 Influxdb专为此类数据而设计。 Influxdb可用于对采集获得的数据执行各种分析和计算操作;
二、安装和配置
1、下载
官方网站下载地址:Telegraf
或者可以通过命令行下载,命令如下:
# 下载安装包
wget http://get.influxdb.org/telegr ... 4.rpm
# 解压
sudo yum localinstall telegraf-0.11.1-1.x86_64.rpm
# 启动命令
systemctl start telegraf
# 重启命令
systemctl restart telegraf
2、修改配置文件
输入命令
vim /etc/telegraf/telegraf.conf
修改后的内容如下:
[[outputs.influxdb]]
urls = ["http://localhost:8086"] # required
database = "telegraf" # required
retention_policy = ""
precision = "s"
timeout = "5s"
username = "telegraf"
password = "password"
然后保存更改并输入命令
systemctl restart telegraf
重新启动电传。
三、数据采集并显示
如果要使用telegraf 采集数据并将其保存在influxdb中,则必须在influxdb中创建相应的用户和数据库。
1、创建influxdb用户和数据库
[root@localhost~]# influx
Visit https://enterprise.influxdata.com to register for updates, InfluxDB server management, and monitoring.
Connected to http://localhost:8086 version 1.0.2
InfluxDB shell version: 1.0.2
> create user "telegraf" with password 'password'
> show users;
user admin
telegraf false
> create database telegraf
> show databases
name: databases
---------------
name
_internal
telegraf
> exit
[root@localhost ~]# systemctl restart influxdb
创建成功后,重新启动influxdb,然后输入IP + 8083端口进入influxdb界面。
2、查询相应的信息
在查询框中输入SQL语句以查询所需的信息,例如:
如上所述,您可以看到服务器的磁盘使用情况信息。
以上是Telegraf的基本介绍和安装方法。有关更多信息,请参阅官方文档。
广告狗采集工具推荐:极光搜索全套功能已打包完成
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2021-04-23 17:07
采集工具推荐:极光搜索。极光采集器是极光推送的一款采集工具,功能强大,专业性极强,通过新建一个任务,可以自定义采集页面,对页面上的内容进行采集。采集效率极高,不但可以收集用户想要的数据,还可以通过极光采集器简单搭建一个推送站点,快速做一些推广和营销工作。下面介绍一下操作流程:第一步:导入已经通过时间确定好的网址。
例如这个网址是:/*gif图,*/第二步:输入你想要收集的数据,点击收集,等待收集完成。收集完成后将统计数据。支持全部字段的自定义收集,也可以只采集文本字段进行收集。例如,可以采集页面中的“话题”字段。第三步:导出excel表格。具体的数据导出方法,微信公众号“jmpub”中回复“收集”,加上你想要导出的数据名称,便可以获取导出的数据。采集过程中可以实时关注数据。
试试我家的这个产品吧,首页-【广告狗采集】,做一个能在线帮广告公司、程序猿创建转发有趣的数据采集工具,最终目的是想让更多的人像他一样高效便捷的采集和使用广告资源数据。全套功能已打包完成(如下图所示)、都是未经过改动的完整excel文档,采集代码完整的分享给大家、按需要开通服务试用即可、欢迎来撩!comeonbaby。
之前看到过一个工具,暂时没用过,广告狗采集器,楼主可以体验一下。 查看全部
广告狗采集工具推荐:极光搜索全套功能已打包完成
采集工具推荐:极光搜索。极光采集器是极光推送的一款采集工具,功能强大,专业性极强,通过新建一个任务,可以自定义采集页面,对页面上的内容进行采集。采集效率极高,不但可以收集用户想要的数据,还可以通过极光采集器简单搭建一个推送站点,快速做一些推广和营销工作。下面介绍一下操作流程:第一步:导入已经通过时间确定好的网址。
例如这个网址是:/*gif图,*/第二步:输入你想要收集的数据,点击收集,等待收集完成。收集完成后将统计数据。支持全部字段的自定义收集,也可以只采集文本字段进行收集。例如,可以采集页面中的“话题”字段。第三步:导出excel表格。具体的数据导出方法,微信公众号“jmpub”中回复“收集”,加上你想要导出的数据名称,便可以获取导出的数据。采集过程中可以实时关注数据。
试试我家的这个产品吧,首页-【广告狗采集】,做一个能在线帮广告公司、程序猿创建转发有趣的数据采集工具,最终目的是想让更多的人像他一样高效便捷的采集和使用广告资源数据。全套功能已打包完成(如下图所示)、都是未经过改动的完整excel文档,采集代码完整的分享给大家、按需要开通服务试用即可、欢迎来撩!comeonbaby。
之前看到过一个工具,暂时没用过,广告狗采集器,楼主可以体验一下。
中文版的facebook视频采集器软件破解版下载地址介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 319 次浏览 • 2021-04-22 19:02
采集工具今天给大家推荐下中文版的facebook采集软件,高度支持中文操作,批量采集facebook,youtube视频,pinterest,instagram等网站上的内容。facebook视频采集器facebook采集的界面是一个简洁干净的界面。直接开始采集动作~~如果有图片采集上传功能,建议使用鼠标右键,将图片移动到页面顶部保存图片。
facebook视频采集框里可以右键图片直接采集视频。使用这种方法已经能够轻松取得facebook视频播放列表,图片,视频列表。facebook视频采集器支持格式:视频网站视频/截图/视频视频/专题页/特定上传网站如果这里的视频在facebook上搜索不到,是因为视频专题视频被封锁,无法直接采集。所以可以采集facebook大牌专题视频。
如何加入facebook群组facebook,youtube,instagram,snapchat,fiverr等等社交平台。如果不能直接插入pr链接,可以通过共享加入。前提是完成视频内容申请加入。采集站会自动把内容分配给10个用户(自动加入不一定,很多人无法加入),为用户服务,无需手动操作,更方便,网站采集新手,更迅速的进入facebook视频采集站点。
facebook视频采集器软件破解版下载地址:/下载facebook视频采集器软件后,复制浏览器相关代码,打开软件,直接登录网站,在界面右上角可以添加指定网站,添加完成之后采集就可以了,没有什么难度!不加入facebook群组的方法是,点击“自动加入”,软件会自动帮你添加,你不需要做任何操作,等待加入即可。如果需要打开youtube,请在公众号对话框回复“facebook”获取软件。 查看全部
中文版的facebook视频采集器软件破解版下载地址介绍
采集工具今天给大家推荐下中文版的facebook采集软件,高度支持中文操作,批量采集facebook,youtube视频,pinterest,instagram等网站上的内容。facebook视频采集器facebook采集的界面是一个简洁干净的界面。直接开始采集动作~~如果有图片采集上传功能,建议使用鼠标右键,将图片移动到页面顶部保存图片。
facebook视频采集框里可以右键图片直接采集视频。使用这种方法已经能够轻松取得facebook视频播放列表,图片,视频列表。facebook视频采集器支持格式:视频网站视频/截图/视频视频/专题页/特定上传网站如果这里的视频在facebook上搜索不到,是因为视频专题视频被封锁,无法直接采集。所以可以采集facebook大牌专题视频。
如何加入facebook群组facebook,youtube,instagram,snapchat,fiverr等等社交平台。如果不能直接插入pr链接,可以通过共享加入。前提是完成视频内容申请加入。采集站会自动把内容分配给10个用户(自动加入不一定,很多人无法加入),为用户服务,无需手动操作,更方便,网站采集新手,更迅速的进入facebook视频采集站点。
facebook视频采集器软件破解版下载地址:/下载facebook视频采集器软件后,复制浏览器相关代码,打开软件,直接登录网站,在界面右上角可以添加指定网站,添加完成之后采集就可以了,没有什么难度!不加入facebook群组的方法是,点击“自动加入”,软件会自动帮你添加,你不需要做任何操作,等待加入即可。如果需要打开youtube,请在公众号对话框回复“facebook”获取软件。
采集工具蛮多的,哪个满足自己需求,用哪个就行
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-04-13 23:04
采集工具蛮多的。大的有百度统计,还有各种第三方统计,比如inmobi,腾讯统计,360统计等等。当然其他的也有,比如gapsec,当当lp。其实都没必要找一个死抠一个,哪个满足自己需求,用哪个就行。
上某宝买一块,在浏览器上写个简单爬虫,就可以抓了,不过需要技术,我买了一块,大概二三百,可以抓100-300页,另外微信群互推,福利分享,发单什么的,估计也可以,前提是内容够吸引人。至于说配置要求。我说用c/c++都没人信,还是老老实实用python爬取吧,爬的快,省时,还可以统计下点击率,下载率什么的。
首先你要有个正版windowsserver,win10系统,网络有线网,无线网。然后选择asp或者php+mysql,找到相应的软件,全中文,
e-api(aspspam,jspspam),来源:,同理php-spam(jspspam),都要php才能做。其实php-spam和asp-spam都是算是asp+webp的phpapi,spam采集本身是最基本的需求,同时是国内有些虚假站点的收割机,但是我们往往需要挖掘的是能够引导用户跳转的好的内容,这样的话最重要的是页面其实可以进行自动化,每个页面在第一次跳转的时候都是来一个用户说这是什么什么页面,就一个大框,然后跟着问号,电脑屏幕前感觉更轻松了。
最后实验,试着改一下,立刻抓出来。所以,我们第一时间要抓取的是页面url,这个是最简单的,获取url即可。其次有页面特征的可以用(useragent+email+bookmark+moment+cookie+telop3/ip),这是最高级的抓取。没有的话可以抓tim(友盟指数),豆瓣,这样的可以按照书名,tag,人物,发生地址等,基本是合理正常,不用hook。至于爬虫,是第二步。 查看全部
采集工具蛮多的,哪个满足自己需求,用哪个就行
采集工具蛮多的。大的有百度统计,还有各种第三方统计,比如inmobi,腾讯统计,360统计等等。当然其他的也有,比如gapsec,当当lp。其实都没必要找一个死抠一个,哪个满足自己需求,用哪个就行。
上某宝买一块,在浏览器上写个简单爬虫,就可以抓了,不过需要技术,我买了一块,大概二三百,可以抓100-300页,另外微信群互推,福利分享,发单什么的,估计也可以,前提是内容够吸引人。至于说配置要求。我说用c/c++都没人信,还是老老实实用python爬取吧,爬的快,省时,还可以统计下点击率,下载率什么的。
首先你要有个正版windowsserver,win10系统,网络有线网,无线网。然后选择asp或者php+mysql,找到相应的软件,全中文,
e-api(aspspam,jspspam),来源:,同理php-spam(jspspam),都要php才能做。其实php-spam和asp-spam都是算是asp+webp的phpapi,spam采集本身是最基本的需求,同时是国内有些虚假站点的收割机,但是我们往往需要挖掘的是能够引导用户跳转的好的内容,这样的话最重要的是页面其实可以进行自动化,每个页面在第一次跳转的时候都是来一个用户说这是什么什么页面,就一个大框,然后跟着问号,电脑屏幕前感觉更轻松了。
最后实验,试着改一下,立刻抓出来。所以,我们第一时间要抓取的是页面url,这个是最简单的,获取url即可。其次有页面特征的可以用(useragent+email+bookmark+moment+cookie+telop3/ip),这是最高级的抓取。没有的话可以抓tim(友盟指数),豆瓣,这样的可以按照书名,tag,人物,发生地址等,基本是合理正常,不用hook。至于爬虫,是第二步。
全球最高效的在线词频统计分析工具(上)(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-04-01 04:00
采集工具1,,全球排名第二的数据采集工具;2,,世界最大的免费统计和分析网站;3,推特美国论坛美国网民反馈与民意调查;4,,(自动填词);5,,/'stab最高效的在线词频统计分析工具(可用于搜索);6,ytb,!新闻分析;7,–&(发现你的朋友,家人或者同事/合作伙伴们在说些什么);8,(线上产品推荐工具);9,微软,全球最大的在线教育共享和开放共享平台;10,(中国门户网站);11,(让访问历史保持);12,aol(美国在线娱乐)13,(主要来自nsf);14,(国际广播电台);15,(网络流量监测工具);16,(主要来自世界上最大的网络服务提供商);17,ipe(主要来自ipe官网);18,(主要来自ipe官网);19,(主要来自中国);20,(主要来自百度);21,(主要来自);22,(主要来自微软)23,-–t24,(谷歌浏览器评测工具);25,-(主要是美化界面图片);26,(主要用来抓cta);录制工具1,:一款基于鼠标和键盘操作的视频录制工具;2,:一款高效的在线视频制作软件;3,(基于系统)(可直接使用);4,():基于系统的软件测试工具;5,:基于系统的音乐付费销售工具;网站工具1,(主要来自中国);2,(主要来自台湾);3,(主要来自港澳台);数据工具1,数据管理公司:aws,数据管理公司;2,数据工具:优采云票,旅游地图,优采云票查询,公交车查询;3,留学数据:qs大学排名,高校数据库,u。
s。news&(美国高校网络教育),orum,,数据库;国内工具:1,小红伞(主要用于网页浏览);2,-in2。js:基于;3,bing-(非主流);4,bing-riva(主流);5,(开源);6,,主流;7,企业使用qq,财务系统;8,网管,,公安系统;9,(非主流);10,车联网,气。 查看全部
全球最高效的在线词频统计分析工具(上)(组图)
采集工具1,,全球排名第二的数据采集工具;2,,世界最大的免费统计和分析网站;3,推特美国论坛美国网民反馈与民意调查;4,,(自动填词);5,,/'stab最高效的在线词频统计分析工具(可用于搜索);6,ytb,!新闻分析;7,–&(发现你的朋友,家人或者同事/合作伙伴们在说些什么);8,(线上产品推荐工具);9,微软,全球最大的在线教育共享和开放共享平台;10,(中国门户网站);11,(让访问历史保持);12,aol(美国在线娱乐)13,(主要来自nsf);14,(国际广播电台);15,(网络流量监测工具);16,(主要来自世界上最大的网络服务提供商);17,ipe(主要来自ipe官网);18,(主要来自ipe官网);19,(主要来自中国);20,(主要来自百度);21,(主要来自);22,(主要来自微软)23,-–t24,(谷歌浏览器评测工具);25,-(主要是美化界面图片);26,(主要用来抓cta);录制工具1,:一款基于鼠标和键盘操作的视频录制工具;2,:一款高效的在线视频制作软件;3,(基于系统)(可直接使用);4,():基于系统的软件测试工具;5,:基于系统的音乐付费销售工具;网站工具1,(主要来自中国);2,(主要来自台湾);3,(主要来自港澳台);数据工具1,数据管理公司:aws,数据管理公司;2,数据工具:优采云票,旅游地图,优采云票查询,公交车查询;3,留学数据:qs大学排名,高校数据库,u。
s。news&(美国高校网络教育),orum,,数据库;国内工具:1,小红伞(主要用于网页浏览);2,-in2。js:基于;3,bing-(非主流);4,bing-riva(主流);5,(开源);6,,主流;7,企业使用qq,财务系统;8,网管,,公安系统;9,(非主流);10,车联网,气。
采集工具太多了,如何匹配上边的规则?(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 248 次浏览 • 2021-03-30 23:01
采集工具太多了。一般的是需要编写算法实现这个功能。因为不知道你的具体需求是什么。
现在的采集软件都是连接多个公网ip,先把查询结果导入到软件里边进行修改或者采集,比如连接一个搜狗公网ip,然后对同个ip做点击进行采集,采集完成后软件自动生成一个html版本,下面要做的就是对html进行解析,将页面里的文字提取出来,然后对html进行解析。具体的采集逻辑可以关注我的博客大概的,想了解更多在这个博客上有写。
最普通的就是查询需要的网站规则了,加上预存记录的话,一般都能实现。
请问采集有关注的微博本来就是应该很麻烦的工作,我觉得仅仅使用一些简单的采集工具就足够了。很好用(不要用ajax的,没有用过的),你可以试试。有ios的app,
,web版/可以查看很多网站的相关规则,试用一下就知道好用不好用了。
可以试试【麦子采集器】采集微博微信百度贴吧
先在网站上设置登录,然后利用网页反向工程进入这个网站,分析网站结构,匹配上边的规则。
1.一个人采集所有站点需要多人协作,而且最好是专人去做,并且准备相应的规则库2.首先采集公网站有各种要求,需要域名解析才可以。或者部署一个采集引擎,大致流程就是匹配条件-下发规则-完成(采集时的前端配置还是要精确到json数据)-匹配条件-下发规则-完成。3.采集微博微信是各种要求,需要方便采集,匹配常见的要求,然后细化规则。(这个是真正的技术活,有资源可以寻找专业的团队)如果有用的话也可以推荐一个。 查看全部
采集工具太多了,如何匹配上边的规则?(一)
采集工具太多了。一般的是需要编写算法实现这个功能。因为不知道你的具体需求是什么。
现在的采集软件都是连接多个公网ip,先把查询结果导入到软件里边进行修改或者采集,比如连接一个搜狗公网ip,然后对同个ip做点击进行采集,采集完成后软件自动生成一个html版本,下面要做的就是对html进行解析,将页面里的文字提取出来,然后对html进行解析。具体的采集逻辑可以关注我的博客大概的,想了解更多在这个博客上有写。
最普通的就是查询需要的网站规则了,加上预存记录的话,一般都能实现。
请问采集有关注的微博本来就是应该很麻烦的工作,我觉得仅仅使用一些简单的采集工具就足够了。很好用(不要用ajax的,没有用过的),你可以试试。有ios的app,
,web版/可以查看很多网站的相关规则,试用一下就知道好用不好用了。
可以试试【麦子采集器】采集微博微信百度贴吧
先在网站上设置登录,然后利用网页反向工程进入这个网站,分析网站结构,匹配上边的规则。
1.一个人采集所有站点需要多人协作,而且最好是专人去做,并且准备相应的规则库2.首先采集公网站有各种要求,需要域名解析才可以。或者部署一个采集引擎,大致流程就是匹配条件-下发规则-完成(采集时的前端配置还是要精确到json数据)-匹配条件-下发规则-完成。3.采集微博微信是各种要求,需要方便采集,匹配常见的要求,然后细化规则。(这个是真正的技术活,有资源可以寻找专业的团队)如果有用的话也可以推荐一个。
网站数据采集工具哪个好用?自编爬虫程序太复杂
采集交流 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2021-03-27 03:18
网站 Data 采集哪个工具易于使用?
网站数据采集,有很多现成的爬虫软件可以直接使用,下面我将简要介绍三种,分别是优采云,章鱼和优采云,操作简单,容易学习和理解,有兴趣的朋友可以尝试:
这是一款非常智能的Web爬虫软件,支持跨平台,个人使用非常方便且完全免费。对于大多数网站,只需输入URL,软件将自动识别并提取相关的字段信息。包括列表,表格,链接,图片等,无需配置任何采集规则,一键采用,支持自动翻页和数据导出功能,对于小白来说,非常方便,易学易用精通:这是一款非常好的国产数据采集软件,与优采云 采集器相比,八达通采集器目前仅支持Windows平台,该平台需要手动设置采集字段和配置规则,因此它更加复杂和灵活。它具有大量的内置数据采集模板,可以轻松地将采集流行的网站例如京东和天猫。官方教程非常详细,小白也很容易掌握:
当然,除了上述三个采集器软件之外,它还具有许多功能,并且许多其他软件还支持网站数据采集,例如打号码,应用策略等。如果您熟悉Python,Java和其他编程语言,则还可以编写用于爬网数据的程序。在线上也有相关的教程和材料,它们非常详细。如果您有兴趣,可以搜索它们。希望以上分享的内容对您有所帮助,也欢迎您提出评论和补充。
是否有推荐的良好网页采集工具,采集器工具?
自编译的采集器程序太复杂。那些喜欢技术的人可以选择普通的采集器工具。
推荐一个简单而强大的章鱼采集器:它是业内知名的免费网络采集器,有来自国内外政府机构和知名公司的600,000多名用户。
1.免费使用:免费版本没有功能限制,可以在整个网络采集上获取超过98%的数据。
2.操作很简单:完全可视化操作,不需要任何代码,可以根据本教程学习后快速开始。
3.特色云采集:支持关机采集,自动计时采集,支持高并发数据采集,采集高效率。
4.支持多IP动态分配和验证码识别,有效避免IP拥塞。
5.内置各种文档和视频教程,以及专业的客户服务人员来提供技术支持和服务。
6.新版本可以实现URL的一键输入以提取数据,并且可以实现内置应用程序的数据采集。
7.表数据采集,支持多种导出方法和导入站点。 查看全部
网站数据采集工具哪个好用?自编爬虫程序太复杂
网站 Data 采集哪个工具易于使用?
网站数据采集,有很多现成的爬虫软件可以直接使用,下面我将简要介绍三种,分别是优采云,章鱼和优采云,操作简单,容易学习和理解,有兴趣的朋友可以尝试:
这是一款非常智能的Web爬虫软件,支持跨平台,个人使用非常方便且完全免费。对于大多数网站,只需输入URL,软件将自动识别并提取相关的字段信息。包括列表,表格,链接,图片等,无需配置任何采集规则,一键采用,支持自动翻页和数据导出功能,对于小白来说,非常方便,易学易用精通:这是一款非常好的国产数据采集软件,与优采云 采集器相比,八达通采集器目前仅支持Windows平台,该平台需要手动设置采集字段和配置规则,因此它更加复杂和灵活。它具有大量的内置数据采集模板,可以轻松地将采集流行的网站例如京东和天猫。官方教程非常详细,小白也很容易掌握:
当然,除了上述三个采集器软件之外,它还具有许多功能,并且许多其他软件还支持网站数据采集,例如打号码,应用策略等。如果您熟悉Python,Java和其他编程语言,则还可以编写用于爬网数据的程序。在线上也有相关的教程和材料,它们非常详细。如果您有兴趣,可以搜索它们。希望以上分享的内容对您有所帮助,也欢迎您提出评论和补充。
是否有推荐的良好网页采集工具,采集器工具?
自编译的采集器程序太复杂。那些喜欢技术的人可以选择普通的采集器工具。
推荐一个简单而强大的章鱼采集器:它是业内知名的免费网络采集器,有来自国内外政府机构和知名公司的600,000多名用户。
1.免费使用:免费版本没有功能限制,可以在整个网络采集上获取超过98%的数据。
2.操作很简单:完全可视化操作,不需要任何代码,可以根据本教程学习后快速开始。
3.特色云采集:支持关机采集,自动计时采集,支持高并发数据采集,采集高效率。
4.支持多IP动态分配和验证码识别,有效避免IP拥塞。
5.内置各种文档和视频教程,以及专业的客户服务人员来提供技术支持和服务。
6.新版本可以实现URL的一键输入以提取数据,并且可以实现内置应用程序的数据采集。
7.表数据采集,支持多种导出方法和导入站点。
浏览器用websocket做数据是一个不错的方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-03-27 01:02
采集工具资源大概三千。并不是每个工具都有爬虫功能,
其实还是要看你的需求:记录代理信息和记录请求。这个功能就需要收费的,而且一套资源通常很贵,比如要解决连接、请求、过滤、鉴权、监控、推送、消息队列、查询,前端的话还需要接入浏览器页面上的信息等等。如果需要兼容,要做网页端的截屏,如果还想做分布式端,实时推送,就更麻烦了。我推荐的实现工具是:graphcreate。
它主要是对接浏览器。我这边主要使用它的是三个功能:记录请求、记录加载的资源、验证cookie,还有日志调用等等。真正的中间件似的框架。功能非常强大。据说目前仅限免费版。至于代理,肯定不能让他直接打印在浏览器上的。我觉得用listener还是挺好用的。
浏览器的server能反爬取所有的浏览器站点吗?其实浏览器用websocket做数据是一个不错的方案。只需要一个websocket链接就可以实现http协议的动态加载链接。动态加载路由信息,动态的创建、删除子页面,然后每次动态的创建链接的时候自动转发给服务器端处理。
具体你要看你做什么性质的工作。如果是单纯想爬取你的服务器上所有的内容,那就必须付费。如果是想实现一些功能,需要一些图片,这个主要是对接json接口,先生成json文件,然后由链接实现请求,然后建立下行链接加载。然后可以自己做异步加载或者异步加载等等。如果有注入点,可以弄一下。总结下来,你要看你做哪方面的工作。单纯爬取数据,付费。具体做些什么,付费。 查看全部
浏览器用websocket做数据是一个不错的方案
采集工具资源大概三千。并不是每个工具都有爬虫功能,
其实还是要看你的需求:记录代理信息和记录请求。这个功能就需要收费的,而且一套资源通常很贵,比如要解决连接、请求、过滤、鉴权、监控、推送、消息队列、查询,前端的话还需要接入浏览器页面上的信息等等。如果需要兼容,要做网页端的截屏,如果还想做分布式端,实时推送,就更麻烦了。我推荐的实现工具是:graphcreate。
它主要是对接浏览器。我这边主要使用它的是三个功能:记录请求、记录加载的资源、验证cookie,还有日志调用等等。真正的中间件似的框架。功能非常强大。据说目前仅限免费版。至于代理,肯定不能让他直接打印在浏览器上的。我觉得用listener还是挺好用的。
浏览器的server能反爬取所有的浏览器站点吗?其实浏览器用websocket做数据是一个不错的方案。只需要一个websocket链接就可以实现http协议的动态加载链接。动态加载路由信息,动态的创建、删除子页面,然后每次动态的创建链接的时候自动转发给服务器端处理。
具体你要看你做什么性质的工作。如果是单纯想爬取你的服务器上所有的内容,那就必须付费。如果是想实现一些功能,需要一些图片,这个主要是对接json接口,先生成json文件,然后由链接实现请求,然后建立下行链接加载。然后可以自己做异步加载或者异步加载等等。如果有注入点,可以弄一下。总结下来,你要看你做哪方面的工作。单纯爬取数据,付费。具体做些什么,付费。
采集工具 别把python想象成神一样的超级语言(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-03-25 03:02
采集工具要快速获取,推荐大家使用高德apilink网址:/,如果需要快速编辑,推荐使用使用qml,如果需要导出到本地,推荐使用excel,如果有维度,推荐使用melt,对应用程序来说,需要同时支持table和excel。
高德是网站吧?这个要得问高德,你要问下能不能拿到web的demo。网站应该都有,需要做一些配置应该就可以了,比如cookie,path,cookie代理什么的。
如果是成熟的互联网产品,按钮的js技术都要比导航的js技术低吧。成熟的导航多是python来做,成熟的web也多是python来做,都比导航完整复杂得多。再有就是python的工作量普遍比导航大。如果没有创业或者中小型项目,可以考虑网页浏览器里面实现,不过要自己做底层架构,设计好layout,还要对web进行一些优化。
我觉得python不合适。应该使用脚本语言。比如webpy,pypiplicas。推荐:pypiplicas1.0.1documentation说白了,手机上用java或者javascript,python只是浏览器和web服务端语言,能post就post,put就put。别把python想象成神一样的超级语言。
python的语法和java也相差甚远,就是java里面一个简单函数换了种方式写。python一般从零开始了解什么是语言,web服务器、linux环境下访问、数据库、http协议、后端等等。大多数it公司会用python的grub之类工具。 查看全部
采集工具 别把python想象成神一样的超级语言(图)
采集工具要快速获取,推荐大家使用高德apilink网址:/,如果需要快速编辑,推荐使用使用qml,如果需要导出到本地,推荐使用excel,如果有维度,推荐使用melt,对应用程序来说,需要同时支持table和excel。
高德是网站吧?这个要得问高德,你要问下能不能拿到web的demo。网站应该都有,需要做一些配置应该就可以了,比如cookie,path,cookie代理什么的。
如果是成熟的互联网产品,按钮的js技术都要比导航的js技术低吧。成熟的导航多是python来做,成熟的web也多是python来做,都比导航完整复杂得多。再有就是python的工作量普遍比导航大。如果没有创业或者中小型项目,可以考虑网页浏览器里面实现,不过要自己做底层架构,设计好layout,还要对web进行一些优化。
我觉得python不合适。应该使用脚本语言。比如webpy,pypiplicas。推荐:pypiplicas1.0.1documentation说白了,手机上用java或者javascript,python只是浏览器和web服务端语言,能post就post,put就put。别把python想象成神一样的超级语言。
python的语法和java也相差甚远,就是java里面一个简单函数换了种方式写。python一般从零开始了解什么是语言,web服务器、linux环境下访问、数据库、http协议、后端等等。大多数it公司会用python的grub之类工具。
社交媒体数据集如何处理社交网络中收集的数据?
采集交流 • 优采云 发表了文章 • 0 个评论 • 262 次浏览 • 2021-03-22 05:35
社交媒体数据爬网工具通常是指可以从社交媒体渠道提取数据的自动化Web爬网程序工具。它不仅包括社交网站,例如Facebook,Twitter,Instagram,LinkedIn等,还包括博客,Wiki和新闻站点。所有这些门户网站都有一个共同点:它们都以非结构化数据的形式生成用户生成的内容,这些内容只能通过Web进行访问。
现在我们知道了社交媒体采集器的定义,我将进一步解释如何将社交媒体数据集用于商业中,并列出我推荐的5种最佳社交媒体数据采集器。
您如何处理在社交网络中采集的数据?
毫无疑问,从社交网络中提取的数据是有关人类行为的最大,最动态的数据集。它为社会科学家和商业专家提供了新的机会来了解个人,团体和社会,并探索隐藏在数据中的巨大财富。
社交网络分析-对技术,工具和平台的调查显示,最早采用社交网络数据分析业务的是零售和金融行业中的典型公司。他们使用社交媒体分析来利用品牌知名度,改进的客户服务和营销策略。甚至欺诈检测。
除了上面提到的应用程序外,如今社交媒体数据集还可以应用于:
从社交媒体渠道采集客户反馈后,您可以通过测量其主题,环境和感觉来分析客户对特定主题或产品的态度。跟踪客户情绪可让您了解总体客户满意度,客户忠诚度和参与意愿。提供有关您当前和将来的营销活动的信息。
识别市场趋势对于调整交易策略以使您的业务与行业变化保持同步至关重要。借助大数据自动化工具,市场趋势分析可通过跟踪行业影响者和在社交媒体上发布的评论来比较特定时间段内的行业数据。
市场上排名前五的社交媒体爬虫
Octoparse
Octoparse作为市场上最好的免费自动网页抓取工具之一,是为非编码人员开发的,可以容纳复杂的网页抓取任务。
当前版本7提供了直观的一键式界面,并支持无限滚动处理,登录身份验证,文本输入(用于获取搜索结果)和下拉菜单选择。采集的数据可以导出到Excel,JSON,HTML或数据库。如果要创建动态刮板以实时从动态网站提取数据,八度分析云提取(费用计划)可以获取动态数据的良好来源,因为它每1分钟支持一次提取过程。
为了从社交媒体中提取数据,Octoparse发布了许多详尽的教程,例如从Twitter抓取推文和从Instagram提取帖子。另外,Octoparse提供了一种数据采集服务,该服务将数据直接传递到您的S3库。如果您没有太多时间,那可能是个不错的选择。
Dexi.io
作为一个基于Web的应用程序,Dexi.io是另一个用于商业目的的直观提取自动化工具,起价为119美元/月。 Dexi.io支持创建三种类型的机器人:提取器,采集器和管道。
Dexi.io需要一些编程技能,但是您可以集成第三方服务来解决验证码问题,云存储,文本分析(MonkeyLearn服务集成),甚至可以将其与AWS,Google云端硬盘和Google表格一起使用。
插件(付费计划)也是Dexi.io的一项革命性功能,并且插件的数量持续增长。使用插件,您可以解锁提取器和管道中可用的更多功能。
3.智囊团
与Octoparse和Dexi.io不同,Outwit Hub提供了一个简单的图形用户界面以及全面的爬网和数据结构识别功能。 Outwit Hub最初是Firefox插件,后来成为可下载的应用程序。
在没有任何编程知识的情况下,OutWit Hub可以将链接,电子邮件地址,RSS新闻提要和数据表提取并导出到Excel,CSV,HTML或SQL数据库。
Outwit Hub具有出色的“快速获取”功能,可以快速删除您输入的URL列表中的数据。但是,由于缺少单击界面应用程序,对于初学者来说,您可能需要阅读一些基本的教程和文档。
4. Scrapinghub
Scrapinghub是基于云的Web抓取平台,可让您扩展跟踪器并提供智能下载程序,从而避免了机器人的对策,交钥匙的Web抓取服务和即用型数据集。
该应用程序收录4个出色的工具:Scrapy Cloud,用于实现和运行基于Python的Web采集器; Portia是一个开源软件,可以不加密就提取数据。 Splash还是一种开放源代码的JavaScript可视化工具,用于使用JavaScript从网页中提取数据; Crawlera是一种避免被网站,来自多个位置和IP的跟踪器阻止的工具。
Scrapehub没有提供完整的软件包,而是市场上一个相当复杂且功能强大的爬行Web平台。 Scrapehub提供的每个工具都需要单独付款。
5. Parsehub
Parsehub是市场上另一种未编码的桌面抓取工具,与Windows,Mac OS X和Linux兼容。它提供了一个图形界面,可以从JavaScript和AJAX页面中选择和提取数据。可以从嵌套的便笺,地图,图像,日历甚至弹出窗口中提取数据。
此外,Parsehub还具有基于浏览器的扩展程序,可以立即启动爬网任务。数据可以导出为Excel,JSON或通过API。
Parsehub的争议与其价格有关。 Parsehub的付费版本起价为每月149美元,高于市场上大多数刮刮产品,这意味着标准的Octoparse计划每个爬网每月无限制页面的成本仅为89美元。有一项免费计划,但不幸的是,它仅限于抓取200页和5个抓取作业。
结论
除了自动网页抓取工具可以执行的操作外,许多社交媒体渠道现在还向用户,学者,研究人员和特殊组织(如汤姆森·路透社和彭博新闻服务,Twitter和Facebook社交媒体)提供付款。 )API。
随着在线经济的增长和繁荣,社交媒体通过更好地倾听客户并以新的方式与现有客户和潜在客户互动,为您的企业在您的领域脱颖而出打开了许多新机会。 查看全部
社交媒体数据集如何处理社交网络中收集的数据?
社交媒体数据爬网工具通常是指可以从社交媒体渠道提取数据的自动化Web爬网程序工具。它不仅包括社交网站,例如Facebook,Twitter,Instagram,LinkedIn等,还包括博客,Wiki和新闻站点。所有这些门户网站都有一个共同点:它们都以非结构化数据的形式生成用户生成的内容,这些内容只能通过Web进行访问。
现在我们知道了社交媒体采集器的定义,我将进一步解释如何将社交媒体数据集用于商业中,并列出我推荐的5种最佳社交媒体数据采集器。
您如何处理在社交网络中采集的数据?
毫无疑问,从社交网络中提取的数据是有关人类行为的最大,最动态的数据集。它为社会科学家和商业专家提供了新的机会来了解个人,团体和社会,并探索隐藏在数据中的巨大财富。
社交网络分析-对技术,工具和平台的调查显示,最早采用社交网络数据分析业务的是零售和金融行业中的典型公司。他们使用社交媒体分析来利用品牌知名度,改进的客户服务和营销策略。甚至欺诈检测。
除了上面提到的应用程序外,如今社交媒体数据集还可以应用于:
从社交媒体渠道采集客户反馈后,您可以通过测量其主题,环境和感觉来分析客户对特定主题或产品的态度。跟踪客户情绪可让您了解总体客户满意度,客户忠诚度和参与意愿。提供有关您当前和将来的营销活动的信息。
识别市场趋势对于调整交易策略以使您的业务与行业变化保持同步至关重要。借助大数据自动化工具,市场趋势分析可通过跟踪行业影响者和在社交媒体上发布的评论来比较特定时间段内的行业数据。
市场上排名前五的社交媒体爬虫
Octoparse
Octoparse作为市场上最好的免费自动网页抓取工具之一,是为非编码人员开发的,可以容纳复杂的网页抓取任务。
当前版本7提供了直观的一键式界面,并支持无限滚动处理,登录身份验证,文本输入(用于获取搜索结果)和下拉菜单选择。采集的数据可以导出到Excel,JSON,HTML或数据库。如果要创建动态刮板以实时从动态网站提取数据,八度分析云提取(费用计划)可以获取动态数据的良好来源,因为它每1分钟支持一次提取过程。
为了从社交媒体中提取数据,Octoparse发布了许多详尽的教程,例如从Twitter抓取推文和从Instagram提取帖子。另外,Octoparse提供了一种数据采集服务,该服务将数据直接传递到您的S3库。如果您没有太多时间,那可能是个不错的选择。
Dexi.io
作为一个基于Web的应用程序,Dexi.io是另一个用于商业目的的直观提取自动化工具,起价为119美元/月。 Dexi.io支持创建三种类型的机器人:提取器,采集器和管道。
Dexi.io需要一些编程技能,但是您可以集成第三方服务来解决验证码问题,云存储,文本分析(MonkeyLearn服务集成),甚至可以将其与AWS,Google云端硬盘和Google表格一起使用。
插件(付费计划)也是Dexi.io的一项革命性功能,并且插件的数量持续增长。使用插件,您可以解锁提取器和管道中可用的更多功能。
3.智囊团
与Octoparse和Dexi.io不同,Outwit Hub提供了一个简单的图形用户界面以及全面的爬网和数据结构识别功能。 Outwit Hub最初是Firefox插件,后来成为可下载的应用程序。
在没有任何编程知识的情况下,OutWit Hub可以将链接,电子邮件地址,RSS新闻提要和数据表提取并导出到Excel,CSV,HTML或SQL数据库。
Outwit Hub具有出色的“快速获取”功能,可以快速删除您输入的URL列表中的数据。但是,由于缺少单击界面应用程序,对于初学者来说,您可能需要阅读一些基本的教程和文档。
4. Scrapinghub
Scrapinghub是基于云的Web抓取平台,可让您扩展跟踪器并提供智能下载程序,从而避免了机器人的对策,交钥匙的Web抓取服务和即用型数据集。
该应用程序收录4个出色的工具:Scrapy Cloud,用于实现和运行基于Python的Web采集器; Portia是一个开源软件,可以不加密就提取数据。 Splash还是一种开放源代码的JavaScript可视化工具,用于使用JavaScript从网页中提取数据; Crawlera是一种避免被网站,来自多个位置和IP的跟踪器阻止的工具。
Scrapehub没有提供完整的软件包,而是市场上一个相当复杂且功能强大的爬行Web平台。 Scrapehub提供的每个工具都需要单独付款。
5. Parsehub
Parsehub是市场上另一种未编码的桌面抓取工具,与Windows,Mac OS X和Linux兼容。它提供了一个图形界面,可以从JavaScript和AJAX页面中选择和提取数据。可以从嵌套的便笺,地图,图像,日历甚至弹出窗口中提取数据。
此外,Parsehub还具有基于浏览器的扩展程序,可以立即启动爬网任务。数据可以导出为Excel,JSON或通过API。
Parsehub的争议与其价格有关。 Parsehub的付费版本起价为每月149美元,高于市场上大多数刮刮产品,这意味着标准的Octoparse计划每个爬网每月无限制页面的成本仅为89美元。有一项免费计划,但不幸的是,它仅限于抓取200页和5个抓取作业。
结论
除了自动网页抓取工具可以执行的操作外,许多社交媒体渠道现在还向用户,学者,研究人员和特殊组织(如汤姆森·路透社和彭博新闻服务,Twitter和Facebook社交媒体)提供付款。 )API。
随着在线经济的增长和繁荣,社交媒体通过更好地倾听客户并以新的方式与现有客户和潜在客户互动,为您的企业在您的领域脱颖而出打开了许多新机会。

