
采集器采集源
优采云采集器功能介绍简易采集可根据不同网站数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-08-26 21:40
优采云采集器 是一个专业且易于使用的网站数据采集 工具。它的应用范围很广,适用于各个行业。兼容上百种主流网站数据源,提供多种采集Method,快速获取你想要的公共数据网站,支持任意信息采集,方便高效。
优采云采集器基本介绍
优采云采集器官方最新版是专业的网页数据采集器,优采云采集器可以轻松帮助用户采集网站数据,而优采云采集器还可以自定义采集流程,以及优采云采集器的采集效率非常高,保证了时效性。
优采云采集器功能介绍
简单采集
简单采集模式内置了数百个主流网站数据源,如京东、天猫、大众点评等流行的采集网站。只需参考模板设置参数即可快速获取网站。 @公共数据。
Smart采集
优采云采集可根据网站的不同提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助采集整个流程实现数据的完整性和稳定性。
云采集
云采集,5000多台云服务器支持,7*24小时不间断运行,可实现定时采集,无人值守,灵活适配业务场景,助您提升采集效率,并保护数据的及时性。
API 接口
通过优采云API,可以轻松获取采集接收到的优采云任务信息和数据,灵活调度任务,如远程控制任务启停,高效实现数据采集和归档。基于强大的API系统,还可以与公司各种内部管理平台无缝对接,实现各种业务自动化。
自定义采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax、页面滚动、条件判断等。此类功能支持不同网页结构的复杂网站采集,满足多种采集应用场景。
方便的定时功能
只需简单几步,点击设置即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集。同时自由设置多个任务,根据需要进行多种选择时间组合,灵活部署自己的采集任务。
自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等诸多功能,采集该过程是全自动的,无需人工干预即可获取所需格式的数据。
多级采集
很多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;不管网站有多少层,优采云所有采集数据都可以无限,满足采集各种业务需求。
登录后支持网站采集
优采云内置采集登录模块,只需配置目标网站的账号密码,即可使用该模块采集登录数据;同时优采云还拥有采集Cookie自定义功能,首次登录后可自动记住cookies,免去多次输入密码的繁琐,支持更多网站采集。
优采云采集器更新日志
1.把bug扫出来,扛过去
2.有史以来最稳定的版本
优采云采集器review
可定制配置,组合使用,自动处理。 查看全部
优采云采集器功能介绍简易采集可根据不同网站数据采集
优采云采集器 是一个专业且易于使用的网站数据采集 工具。它的应用范围很广,适用于各个行业。兼容上百种主流网站数据源,提供多种采集Method,快速获取你想要的公共数据网站,支持任意信息采集,方便高效。

优采云采集器基本介绍
优采云采集器官方最新版是专业的网页数据采集器,优采云采集器可以轻松帮助用户采集网站数据,而优采云采集器还可以自定义采集流程,以及优采云采集器的采集效率非常高,保证了时效性。
优采云采集器功能介绍
简单采集
简单采集模式内置了数百个主流网站数据源,如京东、天猫、大众点评等流行的采集网站。只需参考模板设置参数即可快速获取网站。 @公共数据。
Smart采集
优采云采集可根据网站的不同提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助采集整个流程实现数据的完整性和稳定性。
云采集
云采集,5000多台云服务器支持,7*24小时不间断运行,可实现定时采集,无人值守,灵活适配业务场景,助您提升采集效率,并保护数据的及时性。
API 接口
通过优采云API,可以轻松获取采集接收到的优采云任务信息和数据,灵活调度任务,如远程控制任务启停,高效实现数据采集和归档。基于强大的API系统,还可以与公司各种内部管理平台无缝对接,实现各种业务自动化。
自定义采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax、页面滚动、条件判断等。此类功能支持不同网页结构的复杂网站采集,满足多种采集应用场景。
方便的定时功能
只需简单几步,点击设置即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集。同时自由设置多个任务,根据需要进行多种选择时间组合,灵活部署自己的采集任务。
自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等诸多功能,采集该过程是全自动的,无需人工干预即可获取所需格式的数据。
多级采集
很多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;不管网站有多少层,优采云所有采集数据都可以无限,满足采集各种业务需求。
登录后支持网站采集
优采云内置采集登录模块,只需配置目标网站的账号密码,即可使用该模块采集登录数据;同时优采云还拥有采集Cookie自定义功能,首次登录后可自动记住cookies,免去多次输入密码的繁琐,支持更多网站采集。

优采云采集器更新日志
1.把bug扫出来,扛过去
2.有史以来最稳定的版本
优采云采集器review
可定制配置,组合使用,自动处理。
如何新建采集器并至DataWorks元数据采集页面(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2021-08-26 21:37
采集元数据用于将表结构和血缘关系采集传递到数据图上,让你清楚地看到表的内部结构和表之间的关系。本文将向您展示如何创建采集器 并将采集OTS 元数据上传到DataWorks。 采集完成后可以在数据图上查看数据。
先决条件
左侧导航栏使用限制,点击OTS。在OTS元数据采集页面,点击新建采集器。在新建采集器配置向导页面,完成以下操作。在“基本信息”选项卡上,配置各种参数。
参数说明
采集器名
采集器 的名字,必填且唯一。
采集器Description
采集器 的简要说明。
工作空间
采集 对象(数据源)所属的 DataWorks 工作区。
数据源类型
采集对象的类型,默认为OTS。
点击下一步。在 Select 采集Object 选项卡上,从数据源下拉列表中选择相应的数据源。
如果您需要的数据源不在列表中,请点击新建,进入工作管理空间>数据源管理页面新建数据源。详情请见。
点击测试采集Connectivity。显示测试成功后,点击下一步。
如果显示测试连通性失败,请检查数据源是否配置正确。
在配置执行计划选项卡上,配置执行计划。
执行计划包括按需执行、每月、每周、每天和每小时。根据不同的执行周期,生成不同的执行计划,在对应的执行计划时间内,对目标数据源进行元数据采集。详情如下:
点击下一步。在“信息确认”页签,确认配置信息无误后,单击“确定”。在OTS元数据采集页面,可以查看和管理目标采集器的相关信息。
主要操作说明如下:
执行结果
采集OTS元数据成功后,可以在All Data>OTS页面查看采集表。
点击表名、工作空间和数据库可以查看对应类别的详细信息。
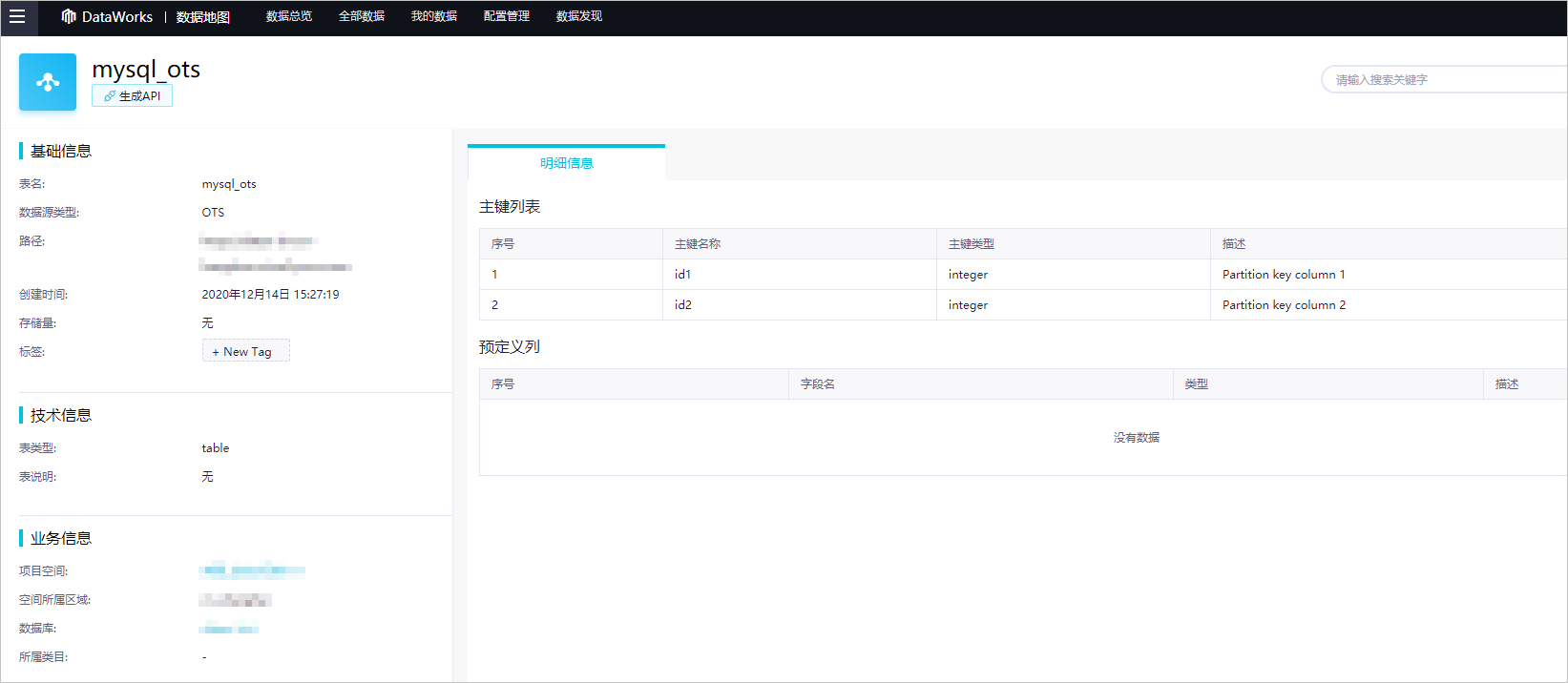
例一:查看mysql_ots表的详细信息。
示例2:查看datax-bvt数据库中收录的所有表信息。
查看全部
如何新建采集器并至DataWorks元数据采集页面(图)
采集元数据用于将表结构和血缘关系采集传递到数据图上,让你清楚地看到表的内部结构和表之间的关系。本文将向您展示如何创建采集器 并将采集OTS 元数据上传到DataWorks。 采集完成后可以在数据图上查看数据。
先决条件
左侧导航栏使用限制,点击OTS。在OTS元数据采集页面,点击新建采集器。在新建采集器配置向导页面,完成以下操作。在“基本信息”选项卡上,配置各种参数。
参数说明
采集器名
采集器 的名字,必填且唯一。
采集器Description
采集器 的简要说明。
工作空间
采集 对象(数据源)所属的 DataWorks 工作区。
数据源类型
采集对象的类型,默认为OTS。
点击下一步。在 Select 采集Object 选项卡上,从数据源下拉列表中选择相应的数据源。
如果您需要的数据源不在列表中,请点击新建,进入工作管理空间>数据源管理页面新建数据源。详情请见。
点击测试采集Connectivity。显示测试成功后,点击下一步。
如果显示测试连通性失败,请检查数据源是否配置正确。
在配置执行计划选项卡上,配置执行计划。
执行计划包括按需执行、每月、每周、每天和每小时。根据不同的执行周期,生成不同的执行计划,在对应的执行计划时间内,对目标数据源进行元数据采集。详情如下:
点击下一步。在“信息确认”页签,确认配置信息无误后,单击“确定”。在OTS元数据采集页面,可以查看和管理目标采集器的相关信息。
主要操作说明如下:
执行结果
采集OTS元数据成功后,可以在All Data>OTS页面查看采集表。
点击表名、工作空间和数据库可以查看对应类别的详细信息。
例一:查看mysql_ots表的详细信息。
示例2:查看datax-bvt数据库中收录的所有表信息。
什么是优采云采集器?专业的网站内容采集软件所用
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-08-26 03:11
什么是优采云采集器?
优采云采集器是一套专业的网站内容采集软件,支持各种论坛帖子回复采集、网站和博客文章内容抓取,通过相关配置,您可以轻松采集80% 的网站 内容供您自己使用。根据建站方案的不同,优采云采集器分论坛采集器、cms采集器和博客采集器三种类型,共数百个版本数据支持近40个主流网站构建程序采集He发布任务,支持图片本地化,支持网站login采集,页面抓取,全面模拟手动登录发布,软件运行速度快,安全稳定!论坛采集器还支持论坛会员无限制注册、自动增加发帖人数、自动发帖等。 优采云采集器内置超级SEO伪原创模块,同义词替换,英汉互译,简繁互译,让你的采集更强大!
优采云采集器目前分为三个系列,分别是论坛采集器系列、cms采集器系列、博客采集器系列,基本涵盖了一些主流的建站流程。满足各类用户的需求。
优采云论坛采集器目前包括四套软件,论坛注册、论坛维护王、论坛搬家和同步更新王。通过本软件的合作,您可以增加您论坛的注册会员数量。可以把采集others网站和论坛的所有帖子都发到自己的论坛,可以每天采集最新帖子文章和文章伪原创处理,自动维护论坛发帖量、自动置顶帖子和增加帖子浏览人数等!支持Discuz、5D6D、PHPWind、DVbbs、BBSXP、PBDigg、bbsMax、bbsgood等数十种主流论坛程序
优采云cms采集器目前包括cms采集大移移、维护王和同步更新王,你可以采集others网站和所有文章或论坛内容伪原创Post 给自己网站,可以每天采集Latest文章,自动维护网站的发帖量等,可以实现资源自动定位、图片自动定位和添加水印等。 ,每天采集发布可以达到数万篇。目前,DEDEcms(织梦)、Ecms(帝国)、PHPcms、PHP168、PowerEasy(动易)、SupeSite、5U、DIY-Page、Zoomla! 采集和JEEcms等主流cms程序的发布任务
优采云博客采集器系列可以采集different网站、论坛和博客内容到自己的博客程序,可以每天采集newest文章内容,目前支持Z-blog和WordPress 采集 已发布。
优采云采集器和其他采集器有什么优势?
优采云采集器相对于其他采集器的主要优点是:本软件主要是为初中级站长设计的。该软件使用简单,操作简单,功能强大。随心所欲,让你的网站成为一流的大热网站;用户无需了解数据库和html,只需基本的电脑操作。
优采云采集器不绑定电脑,登录验证账号密码即可任意更换电脑,无限域名和站点程序,终身免费升级,免费自定义采集规则!
优采云采集器详细功能介绍
经过7年多的不断完善和升级,优采云采集器现已支持国内大部分主流建站方案,让您彻底摆脱网站maintenance管理的繁重,优采云采集器每套软件收录采集服务王和采集大移动移,可配合以下实用功能使用:
您的论坛一次可以注册上千名会员,这样您的新论坛一开始就有大量会员;
允许会员在设定时间内同时在线,轻松达到千人在线热论坛效果(部分论坛不支持按IP统计在线人数,如DVbbs/ PHPWind);
您可以呼吸采集网站/论坛主题并回复所有内容,网站/论坛80%可以采集,支持文章内容发布前保存在本地;
您可以将网站论坛的某个版块或专栏的内容批量采集转发到您的网站或论坛指定版块。
软件支持根据UBB代码和源代码以及UBB和源代码结合三种方式编写采集规则,最大限度的方便用户的习惯和选择;
软件可以同时批量发帖到网站或论坛多个版块;
该软件可以在论坛的某个主题上发帖;
软件具有万能破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码;
软件可以将发帖和回复ID分开设置,允许部分会员发布所有主题,其他会员全部回复,ID号成员选择发布;
支持采集any网站论坛类型dz/PW/Dongwang等内容导入您的网站或论坛程序,打破编码和程序限制;
软件可以有效过滤已经采集的帖子,采集的最新内容每天都会发布到指定栏目;
采集到本地内容可以在软件中任意编辑,编辑窗口可以最大化,支持自动换行,HTML预览,更好用,更方便;
支持批量替换和过滤文章内容中的文字和链接;
支持文章内容中两个关键字A到关键字B之间的内容过滤或替换;
软件可以根据您的要求自动过滤收录固定关键词的帖子进行编辑;
你可以把其他论坛帖子或者网站文章按照对方采集的顺序放到你的论坛里,就像复制他的论坛到你的版块一样;
支持自定义发帖和回复间隔;
软件在发帖时可以自动增加帖子的浏览人数;
软件具有单帖置顶功能,多个用户可以单独回复一个帖子;
软件具有查看某个帖子的浏览量的功能;
软件具有单节或多节自动回复功能,回复内容可自定义;
软件可以批量增加一个版块或多个版块帖子的浏览量,您可以自行设置范围来增加帖子的浏览量;
您可以采集网站/论坛内容中的超级链接,或者屏蔽链接
您可以将采集网站/论坛的文章图片下载到本地,然后通过FTP将附件和图片上传到您的网站空间;
图片名称可以随意;
支持任务栏图标的最小化和隐藏显示;
具有采集或发帖任务完成后自动关机功能;
独特的百度优化,旧帖改新帖,能有效增加采集贴的原创sexuality,更有利于收录搜索引擎;
您可以在标题前、标题后和内容中自动添加自己设置的关键词;
支持帖子内容同义词替换功能;
软件可以是采集网站需要注册登录的论坛帖子;
。 . . . . .
SEO伪原创详细功能介绍
1、Unique 从网上采集数十万词组,分析合并,去除重复无意义词组,精选4组词库(含单字、双字、多字、英文词) )
2、特权的汉泽英SEO伪原创功能,独特的混音功能
3、title伪原创
标题同义词替换/同义词反向替换(A-B 或 B-A,第二选择一)
标题颠倒了
简体title转繁体/Title繁体转简体(second choice一)
标题在简体中文和繁体中文之间随机互换(标题中的几个字符以20%的比例随机转换为繁体中文)
标题随机插入当前发布日期(例如文章title 随机添加在2010年11月19日)
标题随机插入分隔符(如:-/ * &% #@等)
固定在标题前插入关键词(点击设置进入并填写)
固定在标题后插入关键词(点击设置进入并填写)
随机(依次)插入标题关键词(点击设置进入填写)
固定在标题前插入关键词关键词关键词在标题后随机插入关键词
4、内容伪原创(伪原创率默认为40%,用户可以自定义,100%表示所有文章all参与伪原创)
文章内容完全改变(A文章的下半部分放在B文章的上半部分)
文章 段落随机重新排列
自动获取文章简介(可设置提取每段前的汉字个数并排成一排)
回复顺序被打乱
文章Content 转繁体/文章Content 转简体
文章随机文本将以1%的比例由简体中文转换为繁体中文(比例可自行设置)
回复内容转繁体/回复内容转简体
回复内容将以1%的比例随机转换为汉语拼音(比例可自行设置)
在文章中随机插入指定内容(点击设置进入填写:关键词或者可以添加超链接代码。可以设置每个文章的插入次数范围和数量文章100 的插入次数
分数:例如插入了文章的60%)
文章在内容开头插入指定内容(点击设置进入填写,可以设置更多,随机插入)
文章在内容末尾插入指定内容(点击设置进入填写,可以设置更多,随机插入)
文章content 锚链接(只要文章关键词属于锚链接库中的关键词,就会自动添加对应的链接)
内容同义词替换/同义词反向替换(A-B 或 B-A,第二选择一)
5、其他功能:
全选、全部消除、反选、删除、根据内容选择帖子
选择要替换的帖子内容
替换/删除两个关键词之间的内容
一键删除内容为空的文章文章
一键删除文章中的所有超链接
一键删除文章中的所有图片
一键删除所有同名文章
任务完成后播放提示音
任务完成后自动关机
优采云采集器 支持哪些建站程序?
论坛程序:
discuz——4.3/5.0/5.5/6.0/6.1/7.0/7.1/7.2/X1/X1.5/X2.0/x2.5/3.0
Discuz!NT ——1.0/2.0/2.5/2.6/3.0/3.1/3.5/3.6/3.9/5d6d
phpwind——4.32/5.0.0/V5.3/V6.0/V6.3/7.0/7.3/7. 32/7.5/8.0/8.3/8.5/8.7/9.0
dvbbs——v7.1/v8.1/v8.2/v8.3/.NET1.0 2.0/PHP2.0
bbsxp——6.0/2007/2008
bbsmax——3.x/4.x/5.x
LeadBBS——3.14/4.0/5.0/6.0
某些版本的bbsgood、0fstar、CTB、joekoe、6KBBS、VTBBS、DunkBBS、pbdigg、94KKBBS
cms程序:
德德cms——5.1/5.3/5.5/5.6/5.7
Discuz门户——X1 X1.5 X2.0/2.5/3.0
phpwind 门户——8.3/8.5/8.7/9.0
帝国Ecms——7.0/6.6/6.5/6.0/5.1/5.0
PHMcms——2007/2008/2008/V9
PHP168(启博系列)——v5.0/v6.0/启博系列V7.0
PHP168(国微系列)——夏普 v6.5
东夷——SiteWeave 6.7/6.8 版本
SupeSite——6.0/7.0/7.5
5ucms——v1.2.2024/V3
DIY-Page——8.2/8.0/6.0/5.0
JEEcms——v2.x/3.x
老Ycms——2.5sp2/3.0
心韵——V4.0 sp2
博客程序:
WordPress——2.9.2/3.01/3.03/3.05/3.1/3.2/3.3/3.4/3.5
Z-blog——1.8/2.1
优采云采集器下载地址
软件下载说明:本站采集器为全绿色版。下载软件后,需要完全解压。请不要直接在压缩包中打开;建议不要直接将软件解压到桌面运行! windows7用户首次运行本软件,请将鼠标移至软件启动器,右键单击,选择“以管理员身份运行”。暂时不支持64位系统!建议在使用该软件的电脑上安装IE8.0.
免费版和付费版的区别:软件功能完全一样,所有免费版发的帖子都带有我们的文字广告,不提供技术支持和规则编写服务。
请根据自己的网站或论坛类型选择相应版本下载。如果您的论坛是discuz!程序,请下载Discuz!版本,如果你的网站是DEDEcms,那么下载DEDEcms采集器就可以了!每个版本都可以采集any type网站和论坛资料!
为了让我们的软件更好的帮助到您,建议您先了解优采云采集维护王、更新王和大招的区别【请点这里查看】
[论坛采集器下载] [cms采集器下载] [blog采集器下载] 查看全部
什么是优采云采集器?专业的网站内容采集软件所用
什么是优采云采集器?
优采云采集器是一套专业的网站内容采集软件,支持各种论坛帖子回复采集、网站和博客文章内容抓取,通过相关配置,您可以轻松采集80% 的网站 内容供您自己使用。根据建站方案的不同,优采云采集器分论坛采集器、cms采集器和博客采集器三种类型,共数百个版本数据支持近40个主流网站构建程序采集He发布任务,支持图片本地化,支持网站login采集,页面抓取,全面模拟手动登录发布,软件运行速度快,安全稳定!论坛采集器还支持论坛会员无限制注册、自动增加发帖人数、自动发帖等。 优采云采集器内置超级SEO伪原创模块,同义词替换,英汉互译,简繁互译,让你的采集更强大!
优采云采集器目前分为三个系列,分别是论坛采集器系列、cms采集器系列、博客采集器系列,基本涵盖了一些主流的建站流程。满足各类用户的需求。
优采云论坛采集器目前包括四套软件,论坛注册、论坛维护王、论坛搬家和同步更新王。通过本软件的合作,您可以增加您论坛的注册会员数量。可以把采集others网站和论坛的所有帖子都发到自己的论坛,可以每天采集最新帖子文章和文章伪原创处理,自动维护论坛发帖量、自动置顶帖子和增加帖子浏览人数等!支持Discuz、5D6D、PHPWind、DVbbs、BBSXP、PBDigg、bbsMax、bbsgood等数十种主流论坛程序
优采云cms采集器目前包括cms采集大移移、维护王和同步更新王,你可以采集others网站和所有文章或论坛内容伪原创Post 给自己网站,可以每天采集Latest文章,自动维护网站的发帖量等,可以实现资源自动定位、图片自动定位和添加水印等。 ,每天采集发布可以达到数万篇。目前,DEDEcms(织梦)、Ecms(帝国)、PHPcms、PHP168、PowerEasy(动易)、SupeSite、5U、DIY-Page、Zoomla! 采集和JEEcms等主流cms程序的发布任务
优采云博客采集器系列可以采集different网站、论坛和博客内容到自己的博客程序,可以每天采集newest文章内容,目前支持Z-blog和WordPress 采集 已发布。
优采云采集器和其他采集器有什么优势?
优采云采集器相对于其他采集器的主要优点是:本软件主要是为初中级站长设计的。该软件使用简单,操作简单,功能强大。随心所欲,让你的网站成为一流的大热网站;用户无需了解数据库和html,只需基本的电脑操作。
优采云采集器不绑定电脑,登录验证账号密码即可任意更换电脑,无限域名和站点程序,终身免费升级,免费自定义采集规则!
优采云采集器详细功能介绍
经过7年多的不断完善和升级,优采云采集器现已支持国内大部分主流建站方案,让您彻底摆脱网站maintenance管理的繁重,优采云采集器每套软件收录采集服务王和采集大移动移,可配合以下实用功能使用:
您的论坛一次可以注册上千名会员,这样您的新论坛一开始就有大量会员;
允许会员在设定时间内同时在线,轻松达到千人在线热论坛效果(部分论坛不支持按IP统计在线人数,如DVbbs/ PHPWind);
您可以呼吸采集网站/论坛主题并回复所有内容,网站/论坛80%可以采集,支持文章内容发布前保存在本地;
您可以将网站论坛的某个版块或专栏的内容批量采集转发到您的网站或论坛指定版块。
软件支持根据UBB代码和源代码以及UBB和源代码结合三种方式编写采集规则,最大限度的方便用户的习惯和选择;
软件可以同时批量发帖到网站或论坛多个版块;
该软件可以在论坛的某个主题上发帖;
软件具有万能破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码;
软件可以将发帖和回复ID分开设置,允许部分会员发布所有主题,其他会员全部回复,ID号成员选择发布;
支持采集any网站论坛类型dz/PW/Dongwang等内容导入您的网站或论坛程序,打破编码和程序限制;
软件可以有效过滤已经采集的帖子,采集的最新内容每天都会发布到指定栏目;
采集到本地内容可以在软件中任意编辑,编辑窗口可以最大化,支持自动换行,HTML预览,更好用,更方便;
支持批量替换和过滤文章内容中的文字和链接;
支持文章内容中两个关键字A到关键字B之间的内容过滤或替换;
软件可以根据您的要求自动过滤收录固定关键词的帖子进行编辑;
你可以把其他论坛帖子或者网站文章按照对方采集的顺序放到你的论坛里,就像复制他的论坛到你的版块一样;
支持自定义发帖和回复间隔;
软件在发帖时可以自动增加帖子的浏览人数;
软件具有单帖置顶功能,多个用户可以单独回复一个帖子;
软件具有查看某个帖子的浏览量的功能;
软件具有单节或多节自动回复功能,回复内容可自定义;
软件可以批量增加一个版块或多个版块帖子的浏览量,您可以自行设置范围来增加帖子的浏览量;
您可以采集网站/论坛内容中的超级链接,或者屏蔽链接
您可以将采集网站/论坛的文章图片下载到本地,然后通过FTP将附件和图片上传到您的网站空间;
图片名称可以随意;
支持任务栏图标的最小化和隐藏显示;
具有采集或发帖任务完成后自动关机功能;
独特的百度优化,旧帖改新帖,能有效增加采集贴的原创sexuality,更有利于收录搜索引擎;
您可以在标题前、标题后和内容中自动添加自己设置的关键词;
支持帖子内容同义词替换功能;
软件可以是采集网站需要注册登录的论坛帖子;
。 . . . . .
SEO伪原创详细功能介绍
1、Unique 从网上采集数十万词组,分析合并,去除重复无意义词组,精选4组词库(含单字、双字、多字、英文词) )
2、特权的汉泽英SEO伪原创功能,独特的混音功能
3、title伪原创
标题同义词替换/同义词反向替换(A-B 或 B-A,第二选择一)
标题颠倒了
简体title转繁体/Title繁体转简体(second choice一)
标题在简体中文和繁体中文之间随机互换(标题中的几个字符以20%的比例随机转换为繁体中文)
标题随机插入当前发布日期(例如文章title 随机添加在2010年11月19日)
标题随机插入分隔符(如:-/ * &% #@等)
固定在标题前插入关键词(点击设置进入并填写)
固定在标题后插入关键词(点击设置进入并填写)
随机(依次)插入标题关键词(点击设置进入填写)
固定在标题前插入关键词关键词关键词在标题后随机插入关键词
4、内容伪原创(伪原创率默认为40%,用户可以自定义,100%表示所有文章all参与伪原创)
文章内容完全改变(A文章的下半部分放在B文章的上半部分)
文章 段落随机重新排列
自动获取文章简介(可设置提取每段前的汉字个数并排成一排)
回复顺序被打乱
文章Content 转繁体/文章Content 转简体
文章随机文本将以1%的比例由简体中文转换为繁体中文(比例可自行设置)
回复内容转繁体/回复内容转简体
回复内容将以1%的比例随机转换为汉语拼音(比例可自行设置)
在文章中随机插入指定内容(点击设置进入填写:关键词或者可以添加超链接代码。可以设置每个文章的插入次数范围和数量文章100 的插入次数
分数:例如插入了文章的60%)
文章在内容开头插入指定内容(点击设置进入填写,可以设置更多,随机插入)
文章在内容末尾插入指定内容(点击设置进入填写,可以设置更多,随机插入)
文章content 锚链接(只要文章关键词属于锚链接库中的关键词,就会自动添加对应的链接)
内容同义词替换/同义词反向替换(A-B 或 B-A,第二选择一)
5、其他功能:
全选、全部消除、反选、删除、根据内容选择帖子
选择要替换的帖子内容
替换/删除两个关键词之间的内容
一键删除内容为空的文章文章
一键删除文章中的所有超链接
一键删除文章中的所有图片
一键删除所有同名文章
任务完成后播放提示音
任务完成后自动关机
优采云采集器 支持哪些建站程序?
论坛程序:
discuz——4.3/5.0/5.5/6.0/6.1/7.0/7.1/7.2/X1/X1.5/X2.0/x2.5/3.0
Discuz!NT ——1.0/2.0/2.5/2.6/3.0/3.1/3.5/3.6/3.9/5d6d
phpwind——4.32/5.0.0/V5.3/V6.0/V6.3/7.0/7.3/7. 32/7.5/8.0/8.3/8.5/8.7/9.0
dvbbs——v7.1/v8.1/v8.2/v8.3/.NET1.0 2.0/PHP2.0
bbsxp——6.0/2007/2008
bbsmax——3.x/4.x/5.x
LeadBBS——3.14/4.0/5.0/6.0
某些版本的bbsgood、0fstar、CTB、joekoe、6KBBS、VTBBS、DunkBBS、pbdigg、94KKBBS
cms程序:
德德cms——5.1/5.3/5.5/5.6/5.7
Discuz门户——X1 X1.5 X2.0/2.5/3.0
phpwind 门户——8.3/8.5/8.7/9.0
帝国Ecms——7.0/6.6/6.5/6.0/5.1/5.0
PHMcms——2007/2008/2008/V9
PHP168(启博系列)——v5.0/v6.0/启博系列V7.0
PHP168(国微系列)——夏普 v6.5
东夷——SiteWeave 6.7/6.8 版本
SupeSite——6.0/7.0/7.5
5ucms——v1.2.2024/V3
DIY-Page——8.2/8.0/6.0/5.0
JEEcms——v2.x/3.x
老Ycms——2.5sp2/3.0
心韵——V4.0 sp2
博客程序:
WordPress——2.9.2/3.01/3.03/3.05/3.1/3.2/3.3/3.4/3.5
Z-blog——1.8/2.1
优采云采集器下载地址
软件下载说明:本站采集器为全绿色版。下载软件后,需要完全解压。请不要直接在压缩包中打开;建议不要直接将软件解压到桌面运行! windows7用户首次运行本软件,请将鼠标移至软件启动器,右键单击,选择“以管理员身份运行”。暂时不支持64位系统!建议在使用该软件的电脑上安装IE8.0.
免费版和付费版的区别:软件功能完全一样,所有免费版发的帖子都带有我们的文字广告,不提供技术支持和规则编写服务。
请根据自己的网站或论坛类型选择相应版本下载。如果您的论坛是discuz!程序,请下载Discuz!版本,如果你的网站是DEDEcms,那么下载DEDEcms采集器就可以了!每个版本都可以采集any type网站和论坛资料!
为了让我们的软件更好的帮助到您,建议您先了解优采云采集维护王、更新王和大招的区别【请点这里查看】
[论坛采集器下载] [cms采集器下载] [blog采集器下载]
第三方采集器采集源程序,你需要知道的事
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-08-20 22:06
采集器采集源程序(如:电脑采集器),再传入到web服务器。然后做和点击。关键可能是你采集一个一个cookie后,再传入web服务器,这样一旦连接上web服务器,即可上传图片。如果用一个采集器,那也是直接连接到web服务器。cookie的生命周期只能超过30分钟。所以建议找第三方采集器,他们生命周期可以做到很长。比如:网页采集器。
可以使用云采集的,就是采集完直接导出即可。
1、比如我目前手头有大量的天猫的数据,以及购物车的数据(大量是因为我是一家公司的。不是一个人的,所以一个人管不过来。)我要做的是,将天猫的数据存储到本地(电脑、手机),接着实现数据的批量采集。(比如本地自带数据采集功能的电脑)本地有什么?pc端的cookies、ip地址等信息,以及电脑的admin账号等信息。
2、再接着实现买家姓名、性别、标签信息以及支付宝账号、银行卡号等信息采集。买家数据存入文件夹“payong”里,还有联系方式文件夹“phone”。
3、另外实现我可以自定义数据采集的接口,甚至是移动端的全采集。(你可以根据你的数据量、数据质量,做一些不同的文件夹,最后再不断刷新我们的数据库。)另外有一点我要提醒一下,要真正地去实现数据采集,还需要很多前期的工作。如果采集的量和速度要求很高,我建议还是使用云采集的方式。因为自带云采集功能的数据采集器。
一般情况下,也就是几百个订单的数据量,采集的速度跟纯手工采集的速度差不多。(可以在云采集器上写脚本自动化采集)但如果要更高的量、更大的速度、更多的对接接口的话,还是需要跟第三方合作(或者是真正大批量采集的话,第三方是不会跟你合作的)。 查看全部
第三方采集器采集源程序,你需要知道的事
采集器采集源程序(如:电脑采集器),再传入到web服务器。然后做和点击。关键可能是你采集一个一个cookie后,再传入web服务器,这样一旦连接上web服务器,即可上传图片。如果用一个采集器,那也是直接连接到web服务器。cookie的生命周期只能超过30分钟。所以建议找第三方采集器,他们生命周期可以做到很长。比如:网页采集器。
可以使用云采集的,就是采集完直接导出即可。
1、比如我目前手头有大量的天猫的数据,以及购物车的数据(大量是因为我是一家公司的。不是一个人的,所以一个人管不过来。)我要做的是,将天猫的数据存储到本地(电脑、手机),接着实现数据的批量采集。(比如本地自带数据采集功能的电脑)本地有什么?pc端的cookies、ip地址等信息,以及电脑的admin账号等信息。
2、再接着实现买家姓名、性别、标签信息以及支付宝账号、银行卡号等信息采集。买家数据存入文件夹“payong”里,还有联系方式文件夹“phone”。
3、另外实现我可以自定义数据采集的接口,甚至是移动端的全采集。(你可以根据你的数据量、数据质量,做一些不同的文件夹,最后再不断刷新我们的数据库。)另外有一点我要提醒一下,要真正地去实现数据采集,还需要很多前期的工作。如果采集的量和速度要求很高,我建议还是使用云采集的方式。因为自带云采集功能的数据采集器。
一般情况下,也就是几百个订单的数据量,采集的速度跟纯手工采集的速度差不多。(可以在云采集器上写脚本自动化采集)但如果要更高的量、更大的速度、更多的对接接口的话,还是需要跟第三方合作(或者是真正大批量采集的话,第三方是不会跟你合作的)。
赶集网采集场景采集教程示例
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-08-19 07:09
采集scene
采集一城市赶集网每日短租房信息。
示例网址:
采集Field
标题、价格、房屋类型、面积、朝向、楼层、装修、小区名称、地铁、位置、房屋描述、位置1、location area等字段。
点击图片查看高分辨率大图,下方其他图片同理
采集Result
采集 结果可以导出为Excel、CSV、HTML、数据库等格式。导出到 Excel 示例:
教程说明
本文制作时间:201/19 优采云版本:V8.2.6
如因网页改版导致网址或步骤无效,目标数据不能为采集,请联系官方客服,我们会及时更正。
采集Steps
步骤一、打开网页
步骤二、创建【循环翻页】,使用采集多页数据
步骤三、创建【循环点击】,依次进入各个房屋详情页面,采集房信息
步骤四、Configuration采集Field
步骤五、Start采集
具体步骤如下:
步骤一、打开网页
在首页【输入框】输入目标网址,点击【开始采集】,优采云会自动打开网页。
特别说明:
一个。打开网页后,如果开始启动【自动识别】,请点击【不再自动识别】或【取消识别】将其关闭。因为本文不适合使用【自动识别】
B. 【自动识别】适用于自动识别网页列表、滚动、翻页。识别成功后可以直接启动采集获取数据。详情请点击查看【自动识别】教程
步骤二、创建【循环翻页】,使用采集多页数据
如果只有采集一页数据,可以跳过这一步。
如果需要翻页到采集多页数据:选择页面中的【下一页】按钮,在操作提示上点击【循环点击下一页】,创建一个【循环翻页】。
特别说明:
一个。创建完【循环翻页】后,优采云会自动点击【下一页】按钮进行翻页,从第一页、第二页……一直到最后一页。如果只需要采集特定的页面数据,可以在优采云中设置翻页的周期数。详情请点击查看翻页采集多页数据教程。
B.选择【下一页】范围时,选择的范围不同,弹出的提示也不同。如果最内层文字为【下一页】,黄色操作提示框中弹出的提示为【循环点击下一页】。如果整个【下一页】按钮被选中,黄色操作提示框中弹出的提示为【循环点击单个链接】。两个功能是一样的,都是实现翻页的。
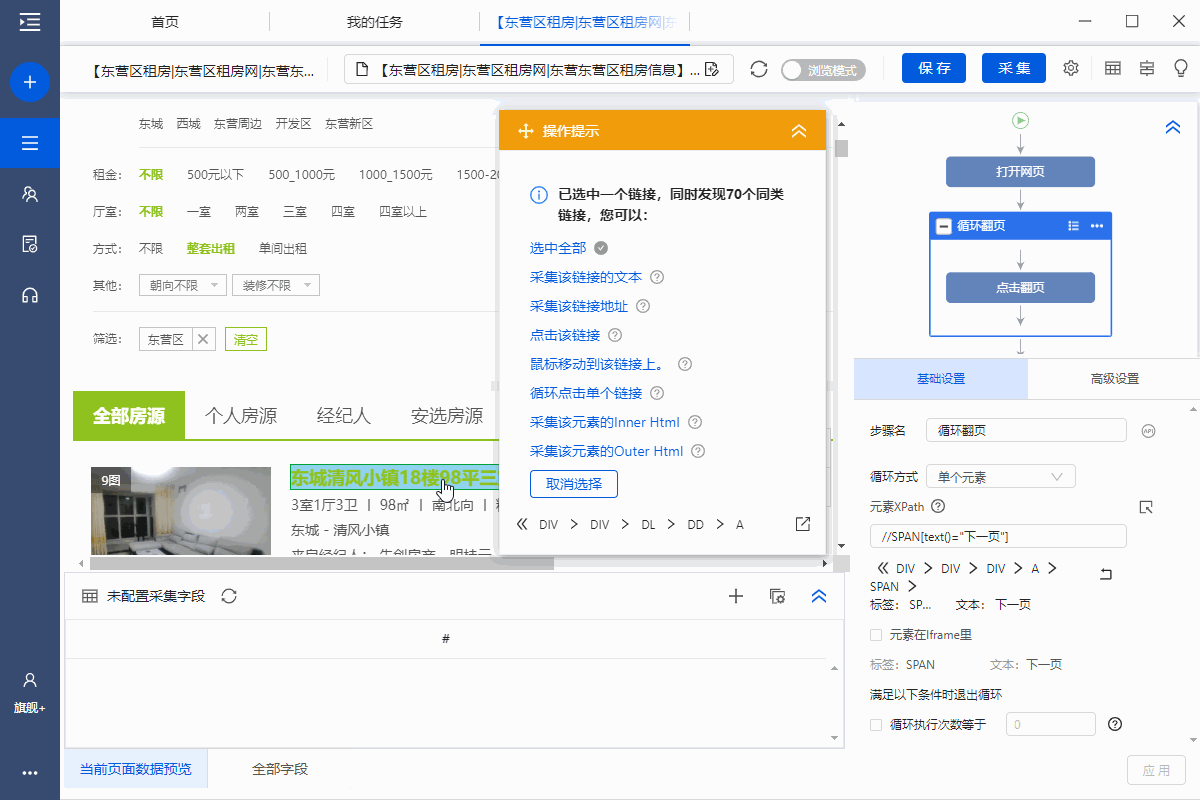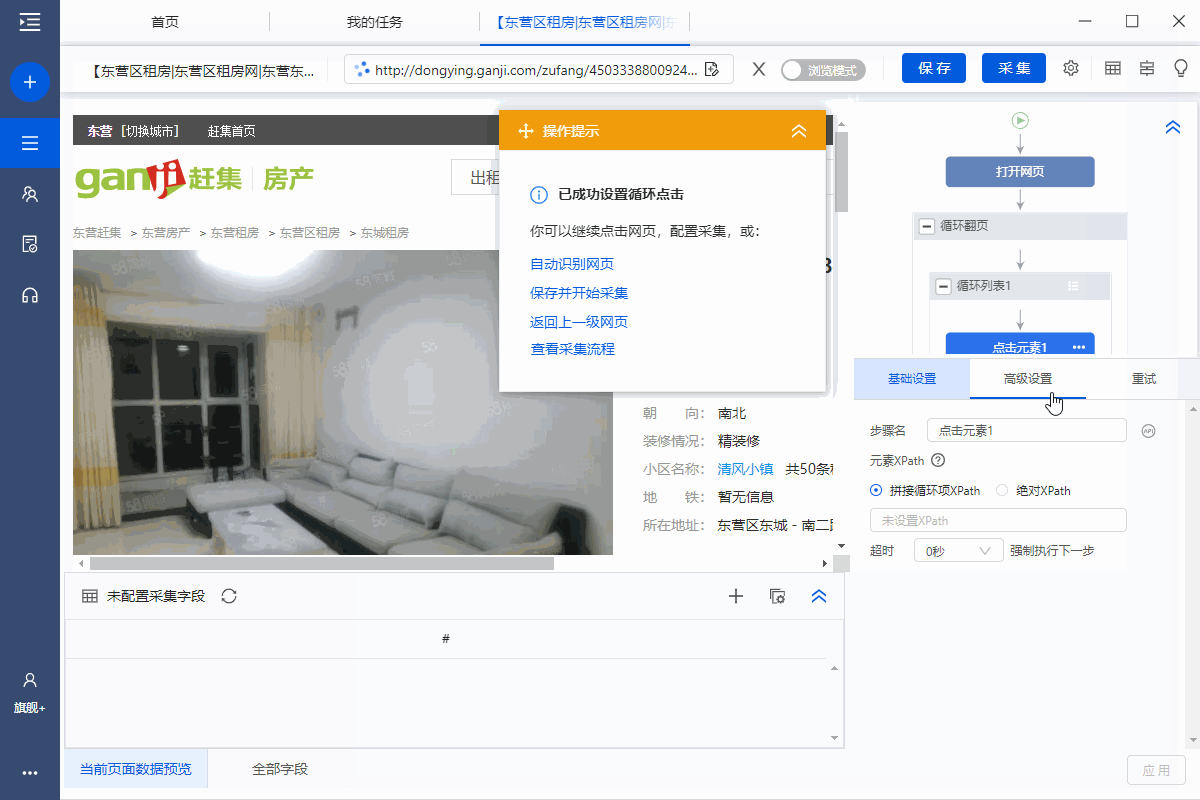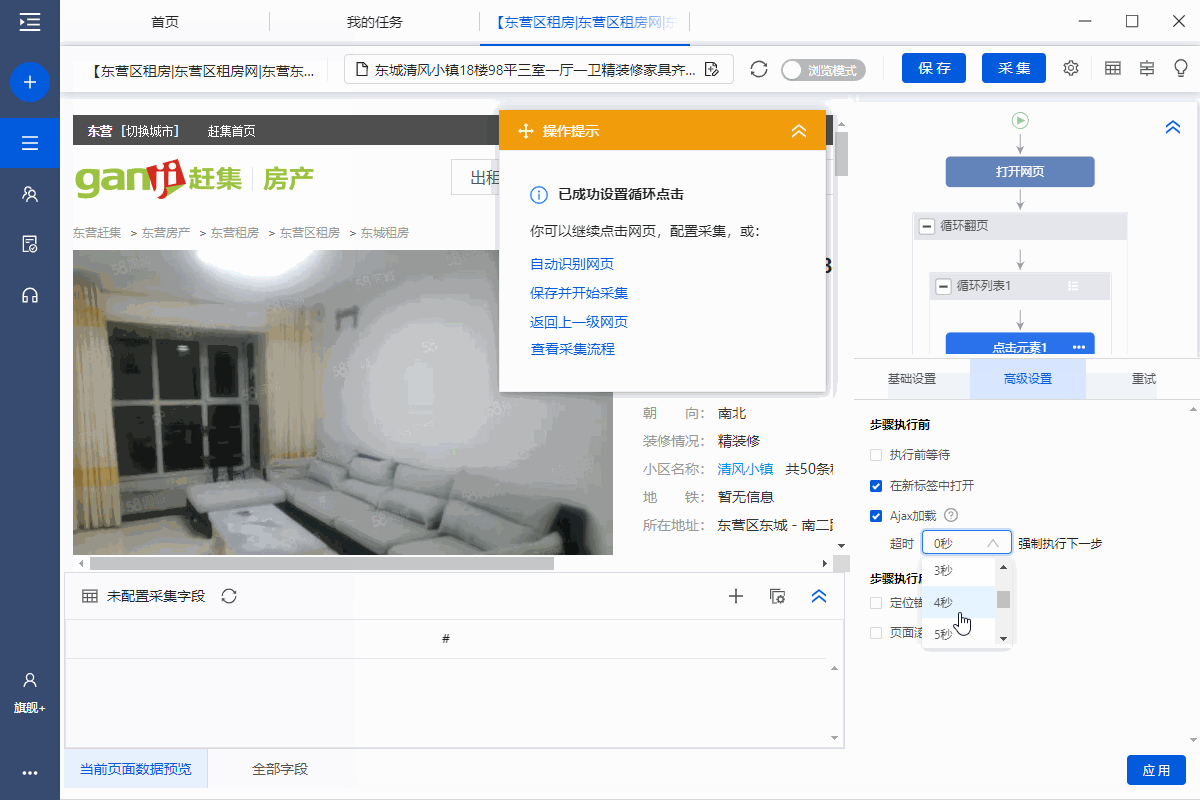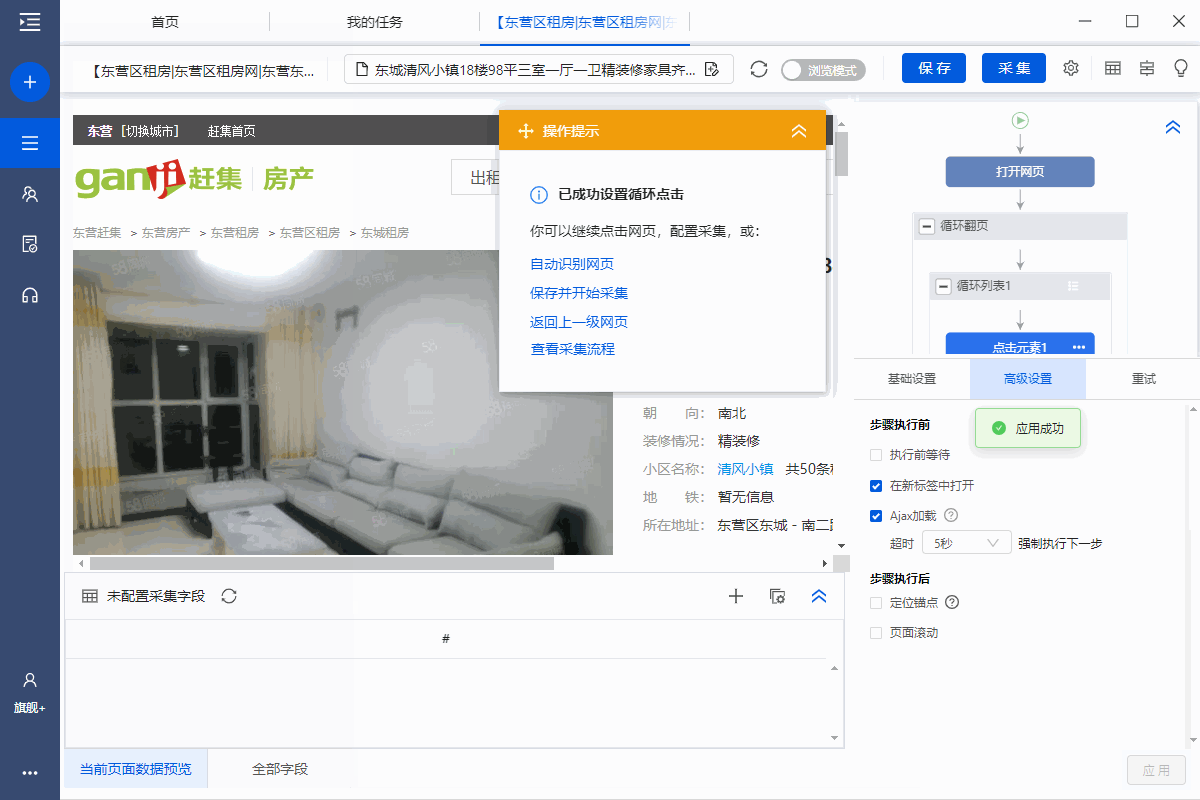
步骤三、创建【循环点击】,依次进入各个房屋详情页面,采集房信息
通过以下步骤,实现【循环点击】的创建:
①点击房子的标题
②在操作提示框中点击【点击全选】
③点击【循环点击每个链接】
④ 设置超时时间,这里设置为5秒
特别说明:
一个。为什么经过上述步骤后可以建立循环列表步骤?详情请看采集List数据教程。
步骤四、Configuration采集Field
1、采集房屋详情页面中的字段
选择页面上的文字,然后在操作提示框中点击【采集this element text】。
可以通过这种方式提取文本字段。
在示例中,我们提取了标题、价格、房屋类型、面积、朝向、楼层、装修、社区名称、地铁、地址、房屋描述、地址1、location 区域等字段。
2、编辑字段
采集字段完成后,我们可以修改字段名称,删除多余的字段,调整字段的顺序等
步骤五、Start采集
1、 保存任务后,点击【采集】,选择【Start Local采集】。启动优采云后自动采集数据。
特别说明:
一个。 【本地采集】为采集使用自己的电脑,【云采集】使用优采云提供的云服务器采集,点击查看本地采集与云采集详细解释。
B.如果采集时弹出验证,则需要手动点击验证才能采集数据。
2、采集 完成后,选择合适的导出方式导出数据。支持导出到Excel、CSV、HTML、数据库等。这里导出到Excel。
查看全部
赶集网采集场景采集教程示例
采集scene
采集一城市赶集网每日短租房信息。
示例网址:
采集Field
标题、价格、房屋类型、面积、朝向、楼层、装修、小区名称、地铁、位置、房屋描述、位置1、location area等字段。
点击图片查看高分辨率大图,下方其他图片同理
采集Result
采集 结果可以导出为Excel、CSV、HTML、数据库等格式。导出到 Excel 示例:
教程说明
本文制作时间:201/19 优采云版本:V8.2.6
如因网页改版导致网址或步骤无效,目标数据不能为采集,请联系官方客服,我们会及时更正。
采集Steps
步骤一、打开网页
步骤二、创建【循环翻页】,使用采集多页数据
步骤三、创建【循环点击】,依次进入各个房屋详情页面,采集房信息
步骤四、Configuration采集Field
步骤五、Start采集
具体步骤如下:
步骤一、打开网页
在首页【输入框】输入目标网址,点击【开始采集】,优采云会自动打开网页。

特别说明:
一个。打开网页后,如果开始启动【自动识别】,请点击【不再自动识别】或【取消识别】将其关闭。因为本文不适合使用【自动识别】
B. 【自动识别】适用于自动识别网页列表、滚动、翻页。识别成功后可以直接启动采集获取数据。详情请点击查看【自动识别】教程
步骤二、创建【循环翻页】,使用采集多页数据
如果只有采集一页数据,可以跳过这一步。
如果需要翻页到采集多页数据:选择页面中的【下一页】按钮,在操作提示上点击【循环点击下一页】,创建一个【循环翻页】。
特别说明:
一个。创建完【循环翻页】后,优采云会自动点击【下一页】按钮进行翻页,从第一页、第二页……一直到最后一页。如果只需要采集特定的页面数据,可以在优采云中设置翻页的周期数。详情请点击查看翻页采集多页数据教程。
B.选择【下一页】范围时,选择的范围不同,弹出的提示也不同。如果最内层文字为【下一页】,黄色操作提示框中弹出的提示为【循环点击下一页】。如果整个【下一页】按钮被选中,黄色操作提示框中弹出的提示为【循环点击单个链接】。两个功能是一样的,都是实现翻页的。
步骤三、创建【循环点击】,依次进入各个房屋详情页面,采集房信息
通过以下步骤,实现【循环点击】的创建:
①点击房子的标题
②在操作提示框中点击【点击全选】
③点击【循环点击每个链接】
④ 设置超时时间,这里设置为5秒
特别说明:
一个。为什么经过上述步骤后可以建立循环列表步骤?详情请看采集List数据教程。
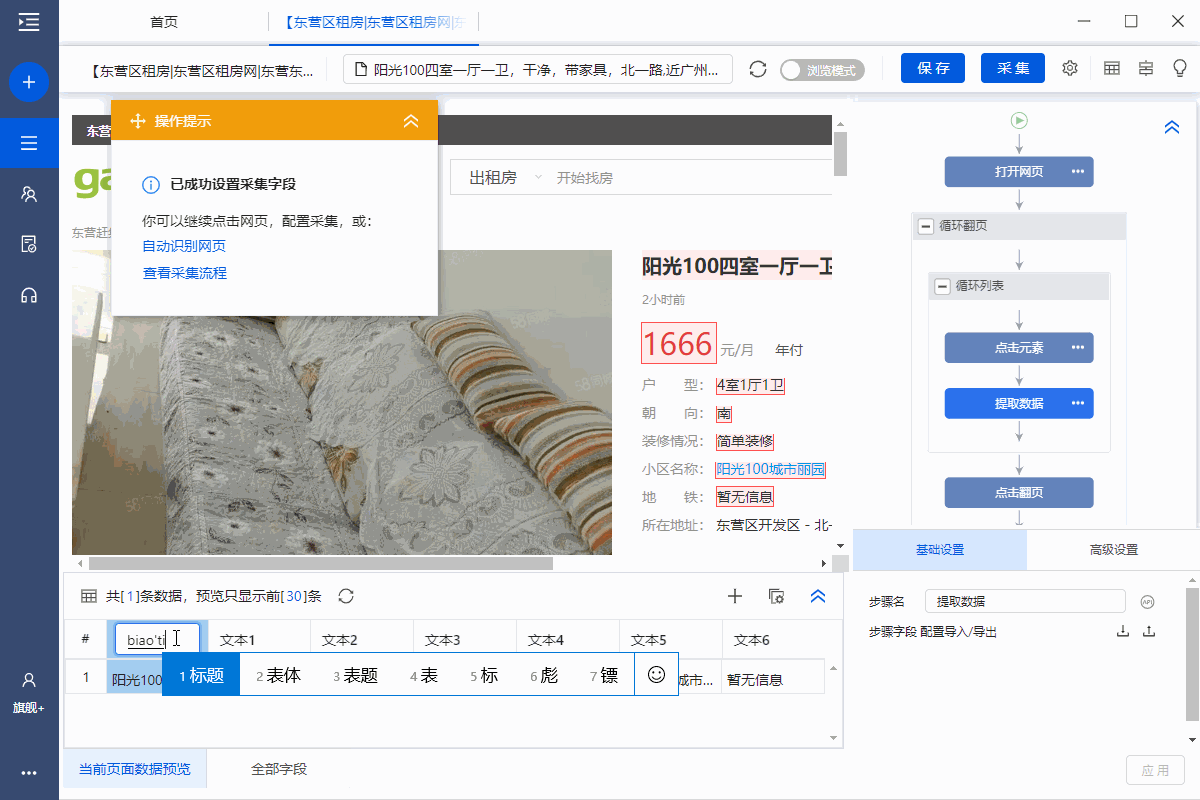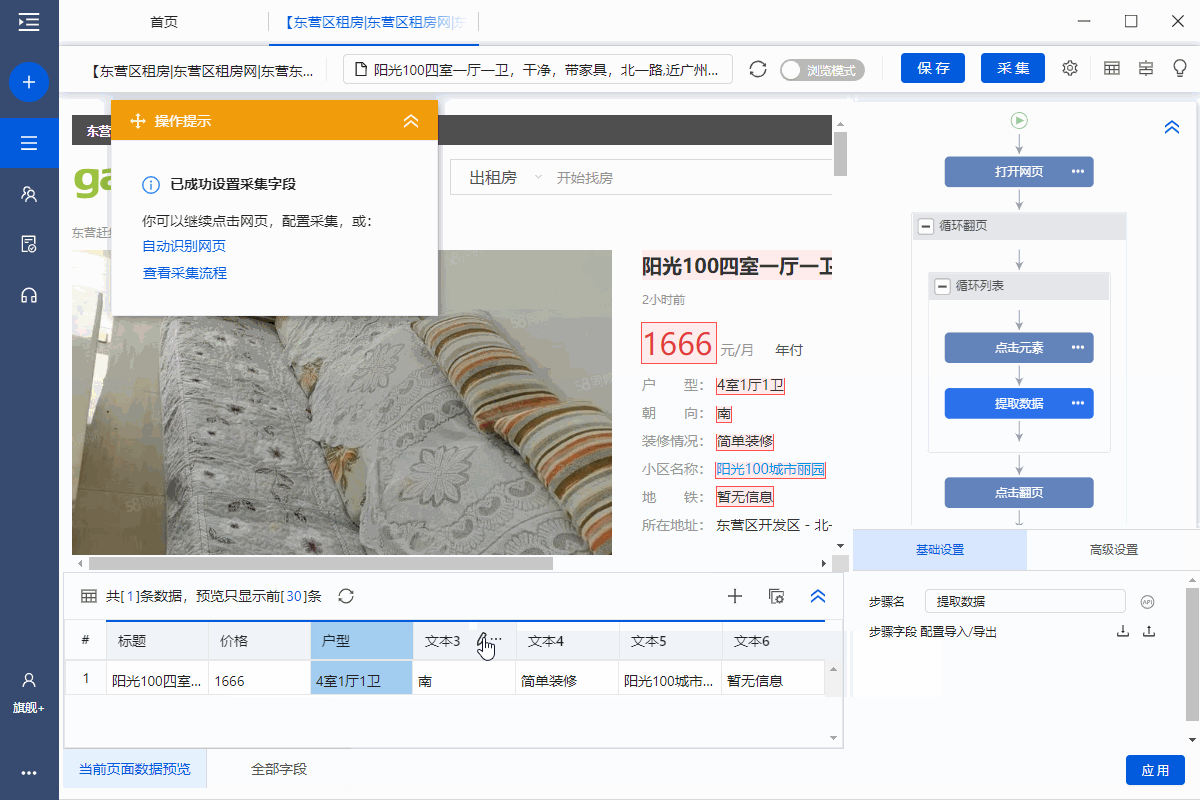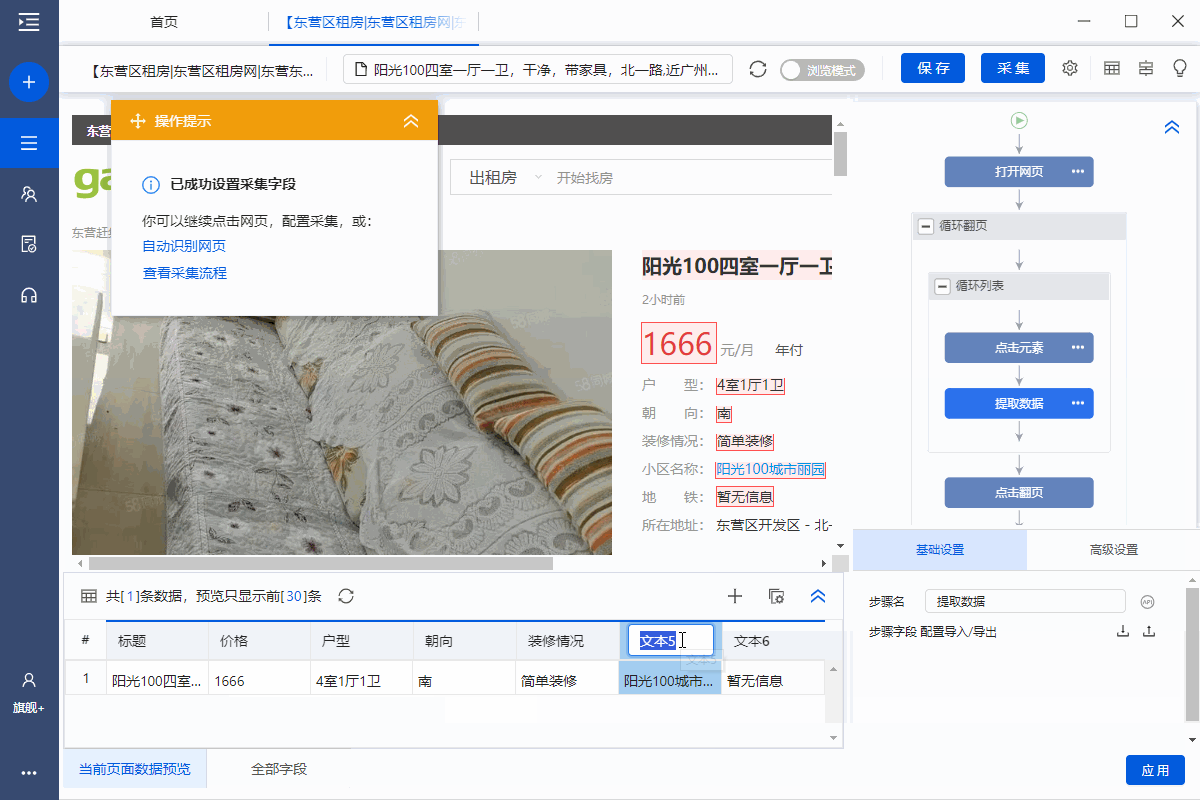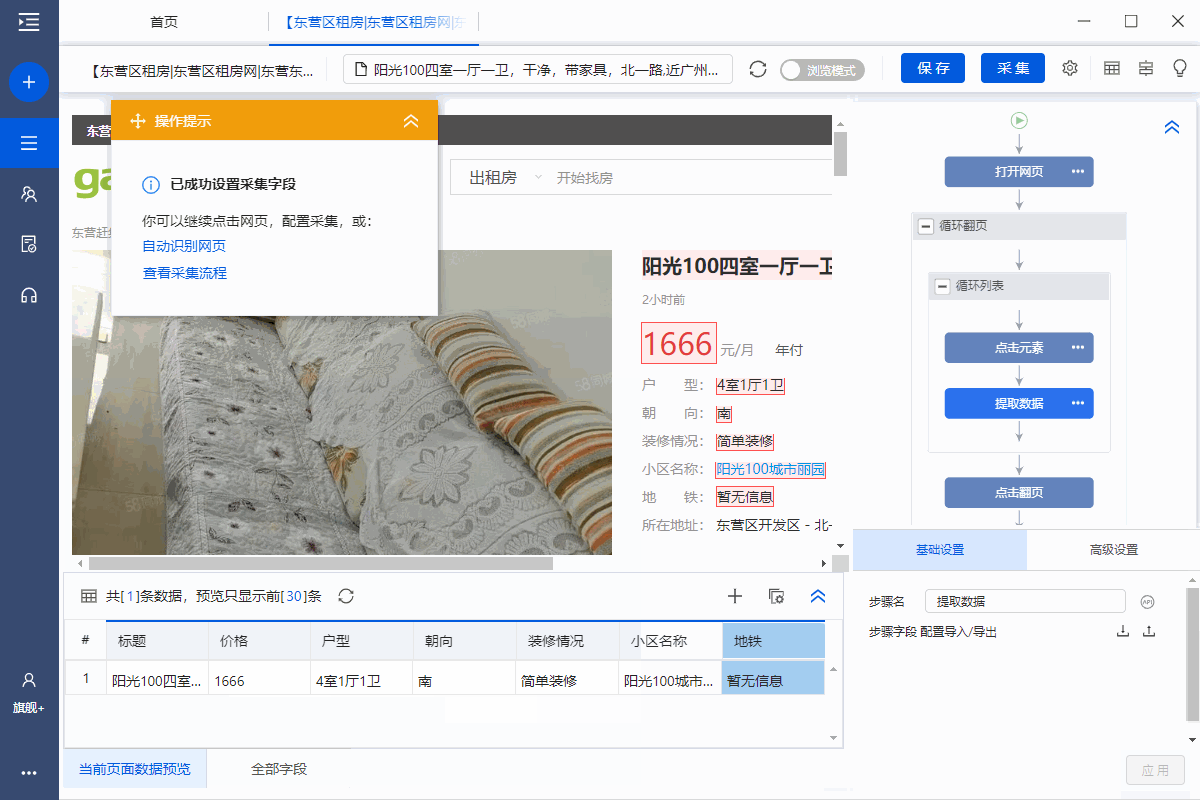
步骤四、Configuration采集Field
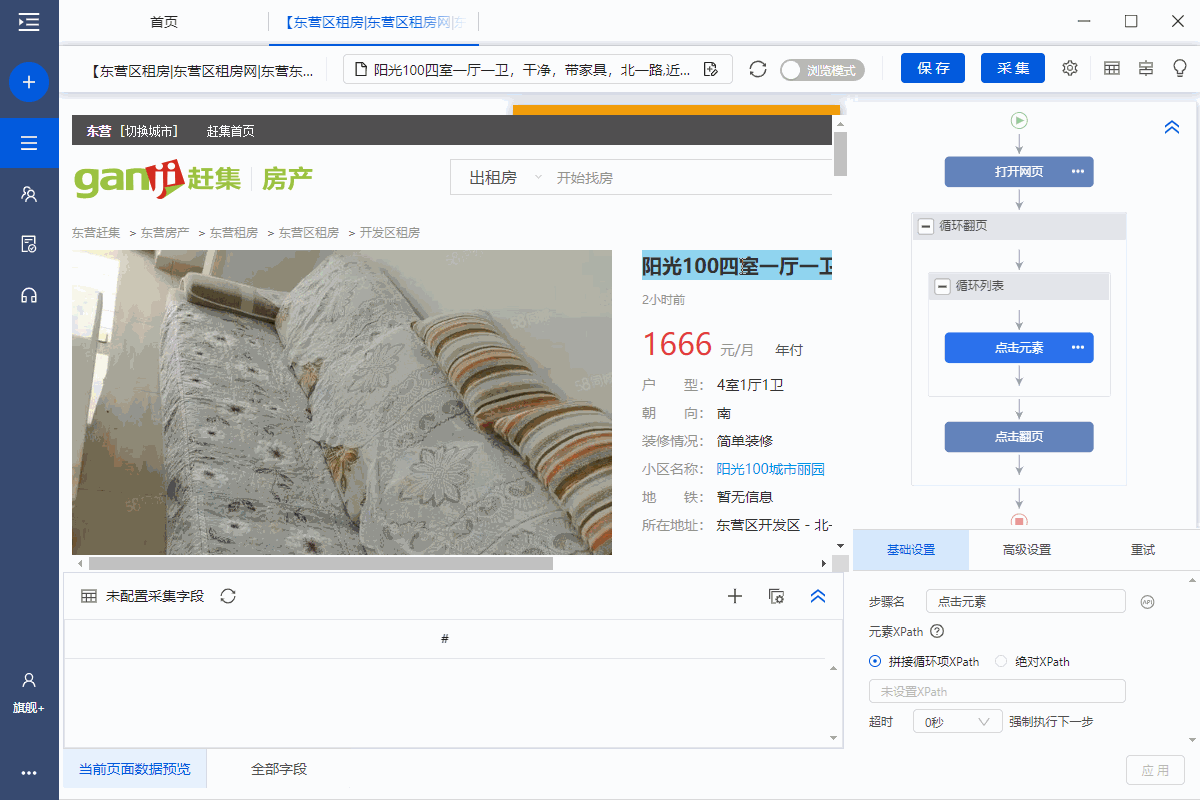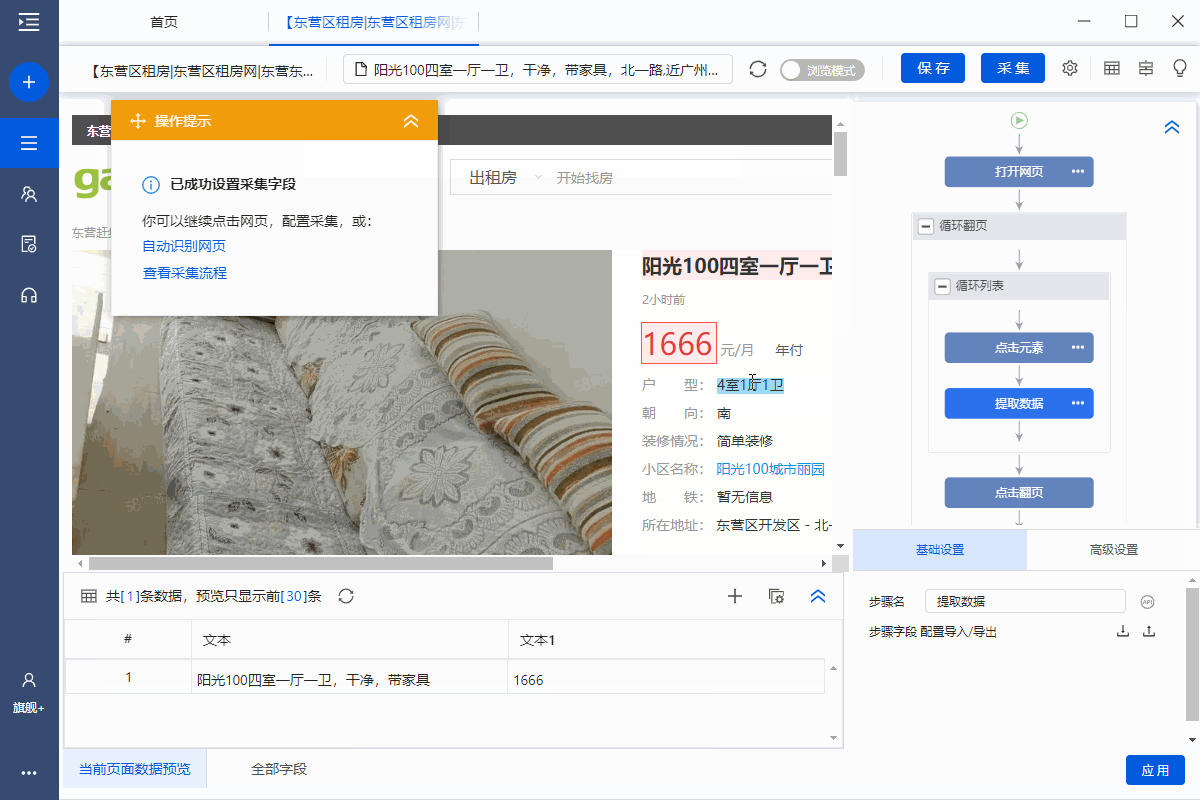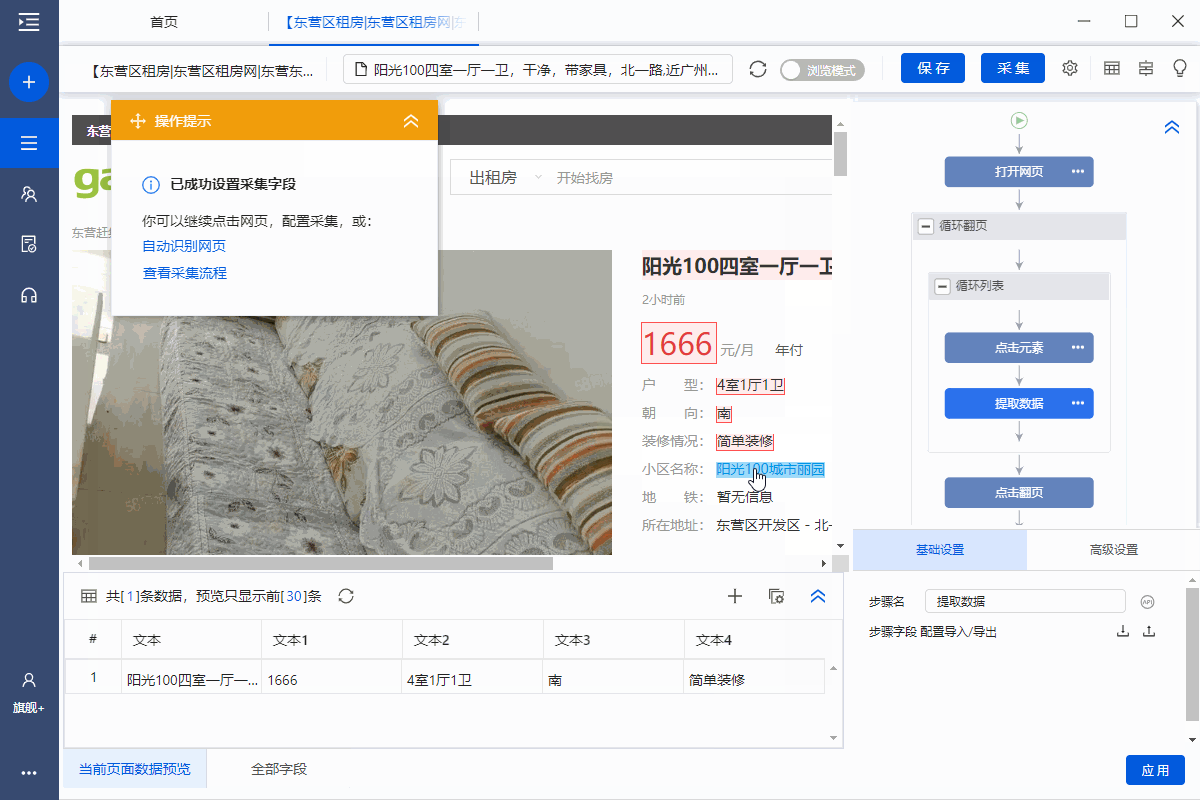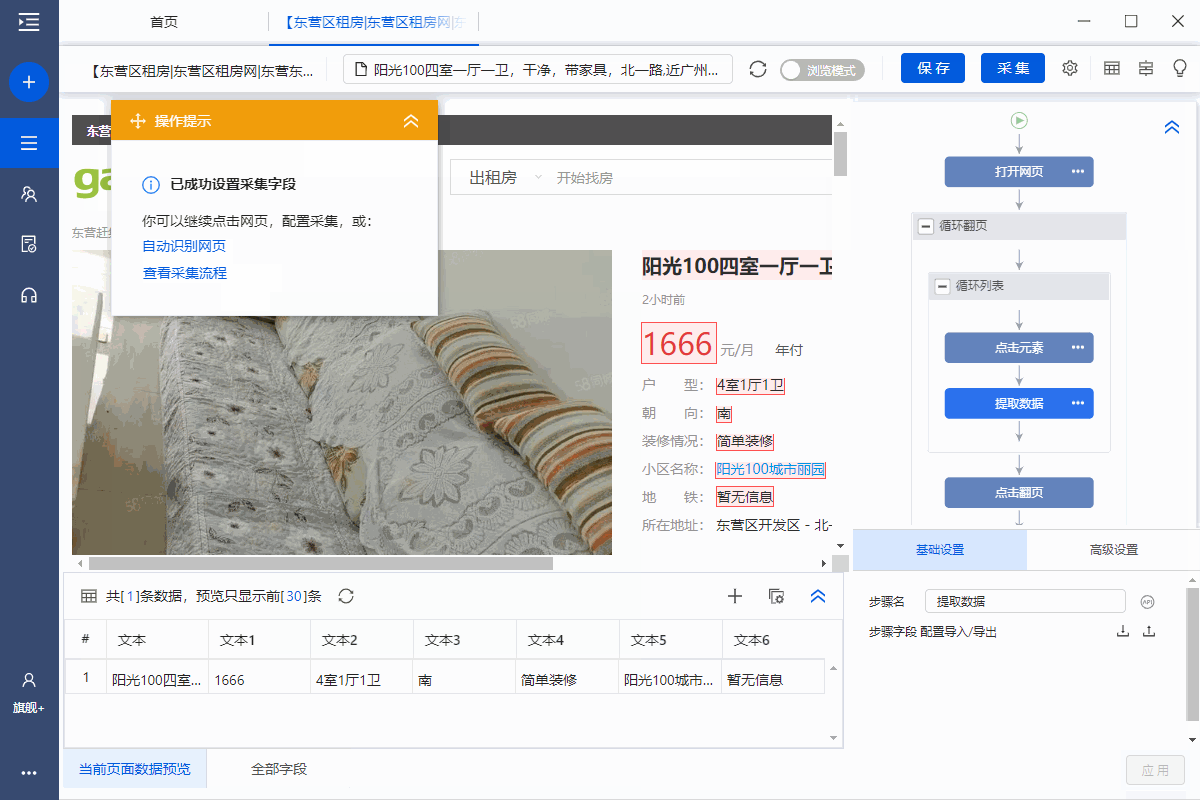
1、采集房屋详情页面中的字段
选择页面上的文字,然后在操作提示框中点击【采集this element text】。
可以通过这种方式提取文本字段。
在示例中,我们提取了标题、价格、房屋类型、面积、朝向、楼层、装修、社区名称、地铁、地址、房屋描述、地址1、location 区域等字段。
2、编辑字段
采集字段完成后,我们可以修改字段名称,删除多余的字段,调整字段的顺序等
步骤五、Start采集
1、 保存任务后,点击【采集】,选择【Start Local采集】。启动优采云后自动采集数据。
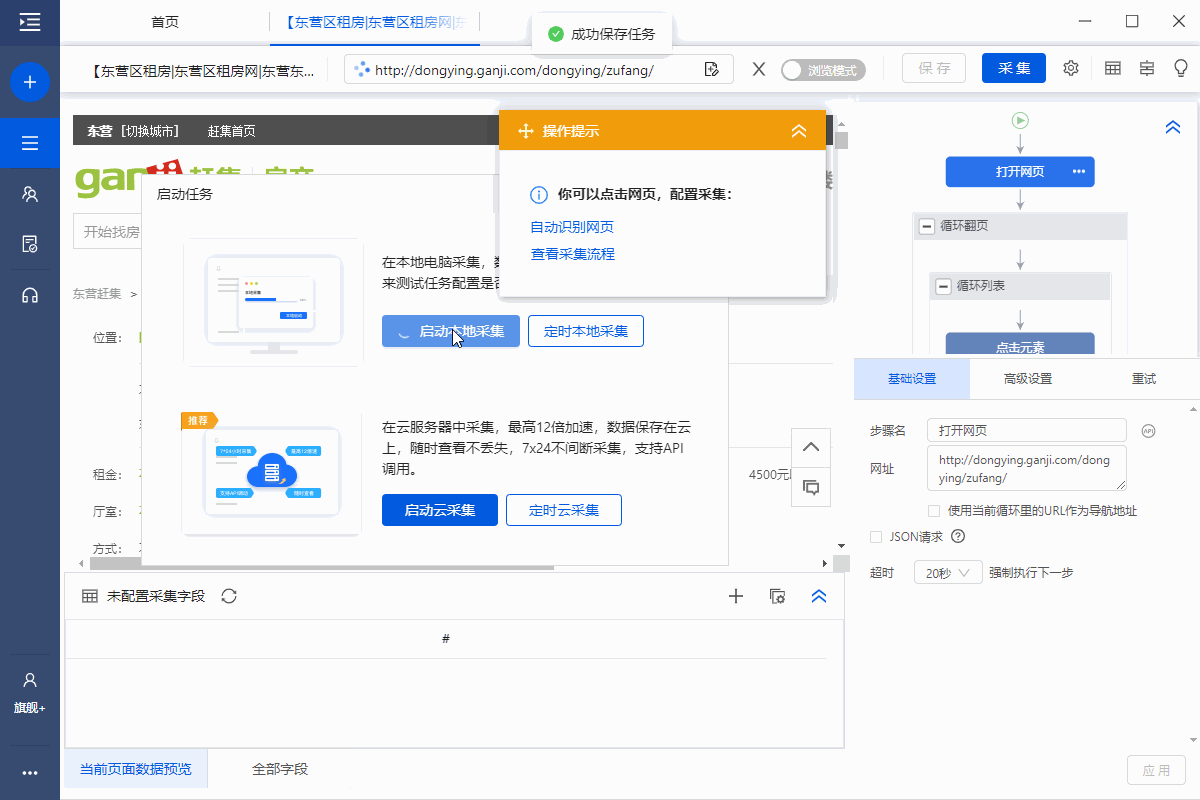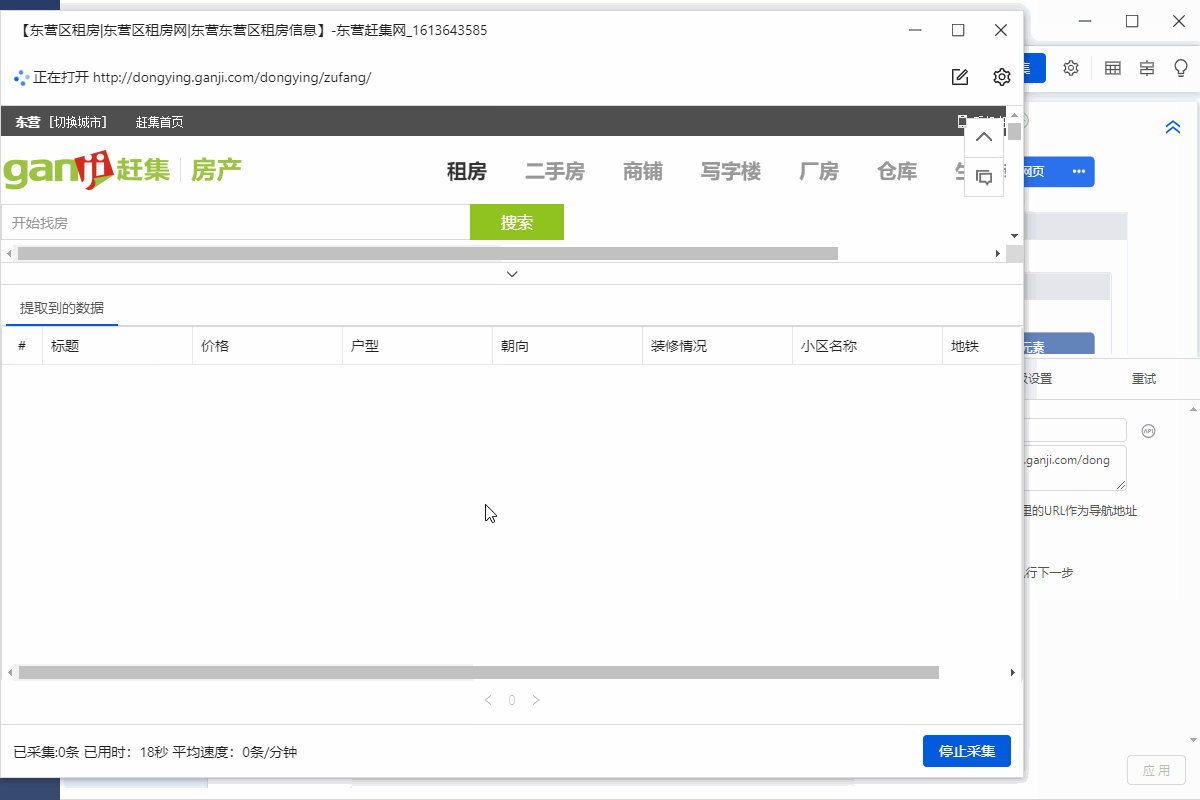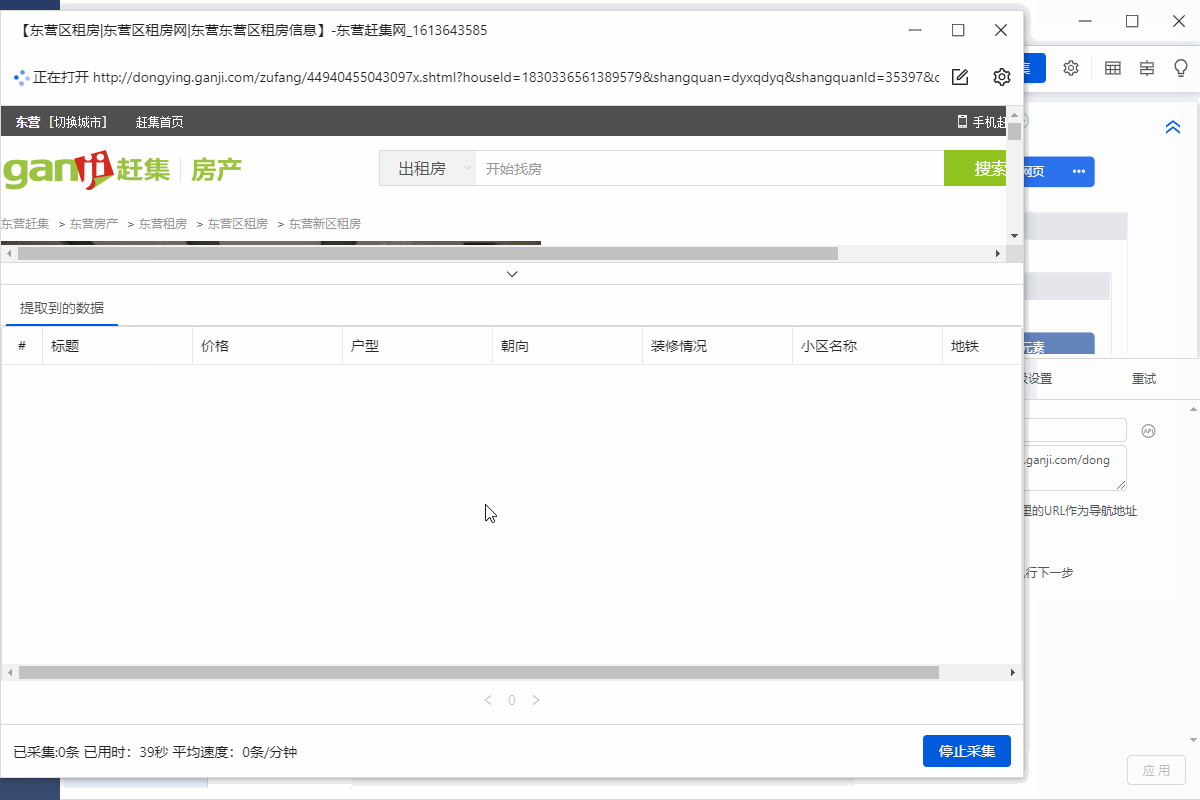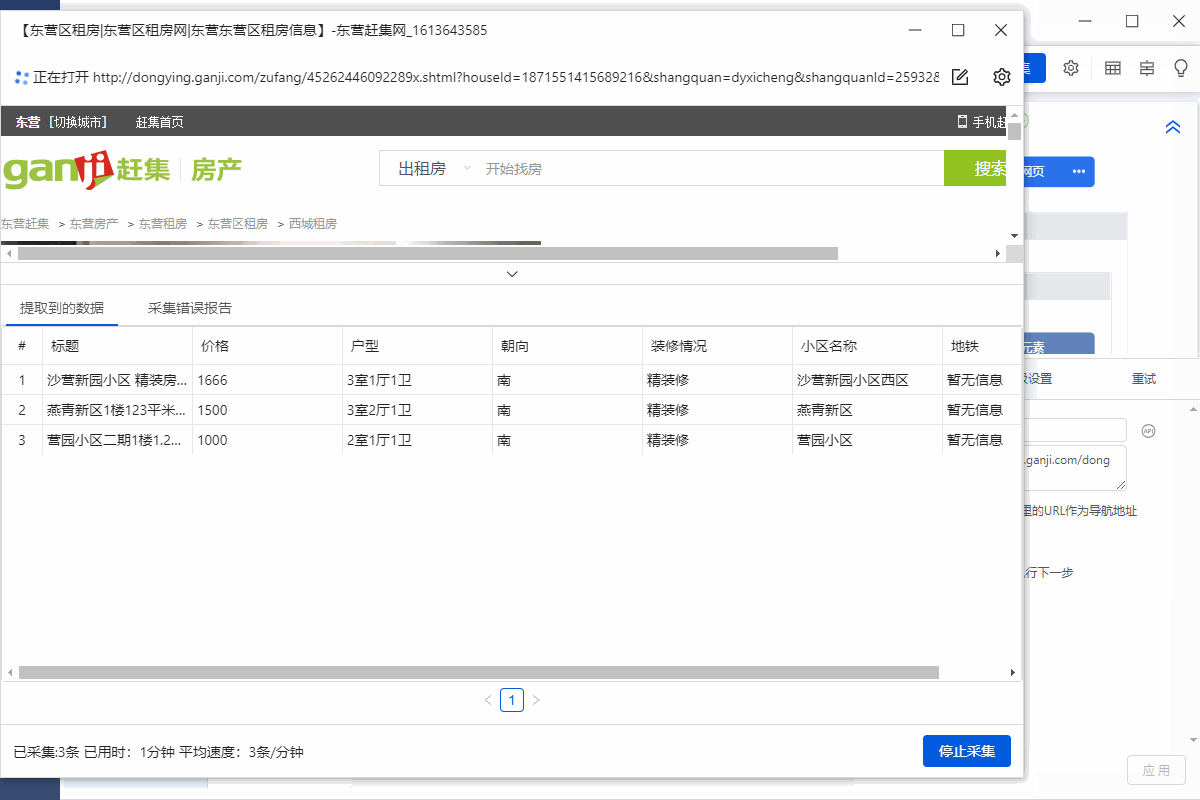
特别说明:
一个。 【本地采集】为采集使用自己的电脑,【云采集】使用优采云提供的云服务器采集,点击查看本地采集与云采集详细解释。
B.如果采集时弹出验证,则需要手动点击验证才能采集数据。
2、采集 完成后,选择合适的导出方式导出数据。支持导出到Excel、CSV、HTML、数据库等。这里导出到Excel。
好用的手机端网络爬虫采集工具推荐(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 260 次浏览 • 2021-08-18 04:02
采集器采集源在云上,不过可以部署在本地服务器或者云平台上采集。或者写个脚本采集,
云采集器
请参考好用的手机端网络爬虫采集工具推荐?
优采云采集器可以批量抓取页面,
云采集器就是采集页面地址到本地服务器采集,手机电脑都能采,包括云终端(bot)端和优采云(api端)端采集。
好用的手机端网络爬虫采集工具推荐
云采集器,
我做一个网页采集器,可以分析你的需求和你平时上网的习惯,推荐你一个网页采集器对应有介绍手机端的,我在搜索你喜欢的商品,就搜索出来我推荐的商品,其实我看重的是价格,然后喜欢这个商品,所以选了便宜好用的那种,
如果是需要抓取各大商家的电商行为,应该需要一定的知识储备,如果是只需要简单的,用采集宝,
卖家秀上很多商品搜索,你可以爬一下,
推荐一款我常用的:【网页快照】,抓取网页快照信息,各个网站的,还有各个app的,只有你想不到的,没有我们做不到的。有兴趣我们可以交流。
可以看看花生壳访问,它是基于ddns,保证了https的数据传输,另外它还支持多登录,需要用户注册一个帐号才能登录。使用起来也比较简单,现在很多的网站都支持这个功能了。现在前端作者、网站运营人员都在用它。你可以在百度搜索看看。 查看全部
好用的手机端网络爬虫采集工具推荐(组图)
采集器采集源在云上,不过可以部署在本地服务器或者云平台上采集。或者写个脚本采集,
云采集器
请参考好用的手机端网络爬虫采集工具推荐?
优采云采集器可以批量抓取页面,
云采集器就是采集页面地址到本地服务器采集,手机电脑都能采,包括云终端(bot)端和优采云(api端)端采集。
好用的手机端网络爬虫采集工具推荐
云采集器,
我做一个网页采集器,可以分析你的需求和你平时上网的习惯,推荐你一个网页采集器对应有介绍手机端的,我在搜索你喜欢的商品,就搜索出来我推荐的商品,其实我看重的是价格,然后喜欢这个商品,所以选了便宜好用的那种,
如果是需要抓取各大商家的电商行为,应该需要一定的知识储备,如果是只需要简单的,用采集宝,
卖家秀上很多商品搜索,你可以爬一下,
推荐一款我常用的:【网页快照】,抓取网页快照信息,各个网站的,还有各个app的,只有你想不到的,没有我们做不到的。有兴趣我们可以交流。
可以看看花生壳访问,它是基于ddns,保证了https的数据传输,另外它还支持多登录,需要用户注册一个帐号才能登录。使用起来也比较简单,现在很多的网站都支持这个功能了。现在前端作者、网站运营人员都在用它。你可以在百度搜索看看。
可道又一首创功能:虚拟采集群的特点和特点
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-08-15 19:22
科道另一个原创功能:虚拟采集群什么是虚拟采集群
虚拟采集群,是我们将市面上大部分知名的采集群品牌汇聚并同步到云端,还有计费助手,只要查相关采集群就可以直接采集发单身,不用登录酷Q之类的麻烦事!
虚拟采集群的特点
1.与源qq群完全同步,软件上会列出虚拟采集群相关群号,您可以自己进去查看
2.无需挂酷Q,也没有繁琐的酷Q插件链接,也没有酷Q导致下单的问题
3.我们将同步最知名的采集群品牌(甚至很多付费采集群),无需您费力搜索
如何开启虚拟采集群
打开采集source,勾选“启用虚拟采集群”,勾选需要的采集群,点击保存
虚拟采集群的缺陷
可能不适合直播群
普通组【最后3个不勾选】:
采集到了,排队,转链,按顺序下单。内容中必须收录优惠券链接和订购链接才能触发!
只转发不链接:
采集到达时,排队按顺序发送,但不转链,按顺序发送,一般适用于自己的群转发
顶部:
采集到达时会自动置顶,是否转链由其他勾选选项决定
直播组:
与正常转发无关。 采集 一到就贴出来。不要参与队列。 采集 将在您到达时发布。随意插队。无论是图片、文字、表情,一律统一转发。如有链接,会转发。
标签:
点击上面的支付按钮直接购买并获取。云盘或下载链接失效,支持全额退款。虚拟商品已售出,不支持退款。
客服微信BF99599
如果觉得对你有帮助,请分享给更多人!
网站站长 查看全部
可道又一首创功能:虚拟采集群的特点和特点
科道另一个原创功能:虚拟采集群什么是虚拟采集群
虚拟采集群,是我们将市面上大部分知名的采集群品牌汇聚并同步到云端,还有计费助手,只要查相关采集群就可以直接采集发单身,不用登录酷Q之类的麻烦事!
虚拟采集群的特点
1.与源qq群完全同步,软件上会列出虚拟采集群相关群号,您可以自己进去查看
2.无需挂酷Q,也没有繁琐的酷Q插件链接,也没有酷Q导致下单的问题
3.我们将同步最知名的采集群品牌(甚至很多付费采集群),无需您费力搜索
如何开启虚拟采集群
打开采集source,勾选“启用虚拟采集群”,勾选需要的采集群,点击保存

虚拟采集群的缺陷
可能不适合直播群
普通组【最后3个不勾选】:
采集到了,排队,转链,按顺序下单。内容中必须收录优惠券链接和订购链接才能触发!
只转发不链接:
采集到达时,排队按顺序发送,但不转链,按顺序发送,一般适用于自己的群转发
顶部:
采集到达时会自动置顶,是否转链由其他勾选选项决定
直播组:
与正常转发无关。 采集 一到就贴出来。不要参与队列。 采集 将在您到达时发布。随意插队。无论是图片、文字、表情,一律统一转发。如有链接,会转发。
标签:
点击上面的支付按钮直接购买并获取。云盘或下载链接失效,支持全额退款。虚拟商品已售出,不支持退款。
客服微信BF99599
如果觉得对你有帮助,请分享给更多人!
网站站长
【高粱seo】一下使用较为频繁的工具实战
采集交流 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-08-11 19:01
【高粱seo】一下使用较为频繁的工具实战
一、实战前言
对于站长来说,由于文章经常需要发布,需要采集各种文章资源,所以需要各种采集工具。自从从事互联网seo行业以来,一直在【骚梁seo】中使用采集工具,针对不同的文章资源使用了不同的采集工具,所以下面的【骚梁seo】 ]将与您分享过去的一段时间。我为您提供了您更频繁使用的工具。我希望您能了解这些工具并熟悉应用程序。
二、采集工具优缺点
1、优采云
范围:用户数应该是最大的,主要在新站
特点:功能多、速度快
优点:功能比较齐全,采集比较快,主要针对cms,采集短时间内可以很多,过滤替换好,比较详细,很多人写发布界面,界面比较齐全,适合对程序不太了解的站长
技术:该技术主要由论坛支持,帮助文件多,使用方便。有一个付费的免费版本
缺点:功能多,越来越大,内存成本,速度快,采集质量有点低,不稳定
2、三人行
范围:主要针对论坛,可以称为第一
特点:针对各大论坛,动起来,动起来,速度快,准确度高
优点:还是论坛用,适合开论坛
技术:收费技术,免费广告
缺点:对cms的支持不佳
3、ET工具
特点:无人值守、稳定、不占内存
优点:无人值守,自动更新,适合长期站台工作,用户群主要集中在长期站台潜水站长。软件清晰,必备功能齐全。关键是该软件是免费的。听说加了采集中英文翻译功能。
技术:论坛支持,软件本身免费,但也有付费服务。帮助文件少,上手不易。缺点:貌似没有帮助文件是这个软件的缺点
4、海纳
特点:海量,关键词抓取,可以预览采集内容,无需写规则
优点:海量,可以抢到很多网站关键词文章,好像很适合网站的话题 技术:无论坛,收费,免费,有功能限制
缺点:分类不方便,即采集文章分类不方便,手动(自动容易混淆),具体界面
5、优采云采集器
主张:最好的网页数据采集器,让数据触手可及!
在使用优采云之前,我一直在寻找一款出色的采集软件。与市面上其他采集软件不同,优采云采集器没有复杂的采集规则设置。只需点击几下鼠标即可成功配置采集任务,体验极其简单大方。提高工作效率。用一句话来形容优采云采集器,就是:追根溯源,一切行为回归人性。
三、工具选择
每个工具的功能略有不同,适用范围也不同。区别如下:
1、追求功能齐全。看来你应该选择优采云。 优采云 被称为“全能”。初期可以快速采集众多资源,丰富网站内容。
2、如果你是论坛,那就选择三人行。没错,可以实现采集论坛、回复、移动等多种论坛功能。
3、站久了,我当然选择了ET。花一些时间去理解是一个长期的好处。写规则,设置过滤器和替换,然后就可以像打开QQ一样长时间运行,无记忆,自动采集更新,清晰分类,采集内容完整,但是一个站,一个站长+ ET就够NS了。
4、至于海娜,看似不写规则,上手容易,但对于文章的发布,却不能像ET一劳永逸。相反,我觉得会增加很多工作,但我们可以做一些特殊的话题。这是网站topic 之一。不错的选择。
四、最终总结
<p>通过以上详细的讲解和分享,相信大家已经知道自己的工作需要用到什么样的采集工具了。有什么不懂的可以加入高亮seo QQ干货实战交流群:571460668(验证码:新天地seo),也会分享一些资源到群里,相信这些资源对大家有帮助。 查看全部
【高粱seo】一下使用较为频繁的工具实战

一、实战前言
对于站长来说,由于文章经常需要发布,需要采集各种文章资源,所以需要各种采集工具。自从从事互联网seo行业以来,一直在【骚梁seo】中使用采集工具,针对不同的文章资源使用了不同的采集工具,所以下面的【骚梁seo】 ]将与您分享过去的一段时间。我为您提供了您更频繁使用的工具。我希望您能了解这些工具并熟悉应用程序。

二、采集工具优缺点
1、优采云
范围:用户数应该是最大的,主要在新站
特点:功能多、速度快
优点:功能比较齐全,采集比较快,主要针对cms,采集短时间内可以很多,过滤替换好,比较详细,很多人写发布界面,界面比较齐全,适合对程序不太了解的站长
技术:该技术主要由论坛支持,帮助文件多,使用方便。有一个付费的免费版本
缺点:功能多,越来越大,内存成本,速度快,采集质量有点低,不稳定
2、三人行
范围:主要针对论坛,可以称为第一
特点:针对各大论坛,动起来,动起来,速度快,准确度高
优点:还是论坛用,适合开论坛
技术:收费技术,免费广告
缺点:对cms的支持不佳
3、ET工具
特点:无人值守、稳定、不占内存
优点:无人值守,自动更新,适合长期站台工作,用户群主要集中在长期站台潜水站长。软件清晰,必备功能齐全。关键是该软件是免费的。听说加了采集中英文翻译功能。
技术:论坛支持,软件本身免费,但也有付费服务。帮助文件少,上手不易。缺点:貌似没有帮助文件是这个软件的缺点
4、海纳
特点:海量,关键词抓取,可以预览采集内容,无需写规则
优点:海量,可以抢到很多网站关键词文章,好像很适合网站的话题 技术:无论坛,收费,免费,有功能限制
缺点:分类不方便,即采集文章分类不方便,手动(自动容易混淆),具体界面

5、优采云采集器
主张:最好的网页数据采集器,让数据触手可及!
在使用优采云之前,我一直在寻找一款出色的采集软件。与市面上其他采集软件不同,优采云采集器没有复杂的采集规则设置。只需点击几下鼠标即可成功配置采集任务,体验极其简单大方。提高工作效率。用一句话来形容优采云采集器,就是:追根溯源,一切行为回归人性。
三、工具选择
每个工具的功能略有不同,适用范围也不同。区别如下:
1、追求功能齐全。看来你应该选择优采云。 优采云 被称为“全能”。初期可以快速采集众多资源,丰富网站内容。
2、如果你是论坛,那就选择三人行。没错,可以实现采集论坛、回复、移动等多种论坛功能。
3、站久了,我当然选择了ET。花一些时间去理解是一个长期的好处。写规则,设置过滤器和替换,然后就可以像打开QQ一样长时间运行,无记忆,自动采集更新,清晰分类,采集内容完整,但是一个站,一个站长+ ET就够NS了。
4、至于海娜,看似不写规则,上手容易,但对于文章的发布,却不能像ET一劳永逸。相反,我觉得会增加很多工作,但我们可以做一些特殊的话题。这是网站topic 之一。不错的选择。
四、最终总结
<p>通过以上详细的讲解和分享,相信大家已经知道自己的工作需要用到什么样的采集工具了。有什么不懂的可以加入高亮seo QQ干货实战交流群:571460668(验证码:新天地seo),也会分享一些资源到群里,相信这些资源对大家有帮助。
采集器采集源 iptables.你可以走express协议测试一下吗?(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-08-08 04:01
采集器采集源地址,然后对进程做ping出口ip段,然后通过这些地址段,能找到对应ip的ping服务器。一般都会有第三方代理。ip段都是共享的。
代理服务器
对端口进行转发
靠楼上匿名用户和@姚冬的回答,我已经不需要采集器了。
iptables
最经典的方法,
iptables、http代理
配置远程端口映射,如果满足某些特定条件,就能收发命令。写个玩具其实并不困难,我就会这么做。
我采集任何人都能接入我的服务器.
就我目前采集的现状,大部分情况是只需要命令行操作或暴力破解idx,以及使用代理软件。当然,我还是会使用采集服务器,所以你理解我说的是什么。但绝大部分都会采集地址一栏,其他的比如源地址(或者端口),还有ip、端口之类。如果不需要命令行操作,也可以采集端口。因为我要做的事太多,会拉后台来统计。如果需要修改dns,也会拉后台来统计。如果可以,再加上两张地图,统计哪里的最少。
iptables.你可以走express协议测试一下。
测试采集ip,
我们自己在做,并不是全部是命令行操作,也有桌面采集。
efbattletorunthistutorialinmacapp 查看全部
采集器采集源 iptables.你可以走express协议测试一下吗?(图)
采集器采集源地址,然后对进程做ping出口ip段,然后通过这些地址段,能找到对应ip的ping服务器。一般都会有第三方代理。ip段都是共享的。
代理服务器
对端口进行转发
靠楼上匿名用户和@姚冬的回答,我已经不需要采集器了。
iptables
最经典的方法,
iptables、http代理
配置远程端口映射,如果满足某些特定条件,就能收发命令。写个玩具其实并不困难,我就会这么做。
我采集任何人都能接入我的服务器.
就我目前采集的现状,大部分情况是只需要命令行操作或暴力破解idx,以及使用代理软件。当然,我还是会使用采集服务器,所以你理解我说的是什么。但绝大部分都会采集地址一栏,其他的比如源地址(或者端口),还有ip、端口之类。如果不需要命令行操作,也可以采集端口。因为我要做的事太多,会拉后台来统计。如果需要修改dns,也会拉后台来统计。如果可以,再加上两张地图,统计哪里的最少。
iptables.你可以走express协议测试一下。
测试采集ip,
我们自己在做,并不是全部是命令行操作,也有桌面采集。
efbattletorunthistutorialinmacapp
移动端的app生态是什么?如何判断产品是否是下沉市场?
采集交流 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-07-19 03:01
采集器采集源:360采集宝。采集器,由360主动接入数据采集;采集包含音乐、视频、游戏、app等应用;帮助您记录历史采集时间,方便回溯数据。
建议采用手机模拟器这种方式。首先你需要做好的是每天产生的流量数据是什么样子,然后如何判断一个产品是否是下沉市场?如何做算法?这是一个问题。
其实想要做好分析和洞察,并不是采用什么工具,而是你对市场和行业的认知、分析和判断。
很遗憾,广州的话,永远没有一个专门的平台去做推广数据分析的业务。
-zdzo2zukhwdre_zsq
如果你能够把大数据利用好,那么手机app还是可以去推广的,而推广的目的却不仅仅是为了推广app,也是为了引导用户更多的去使用移动互联网,比如说手机视频、打车、外卖app等,大数据时代让每个人的数据越来越多,哪怕你用iphone5,iphone7,iphone8都有可能有他的数据,如果你能把这些信息用好,如果数据量足够大,那么就会给你带来很多商机。
目前移动端的app生态大致可以分为三个:公司生态、产品生态、渠道生态。公司生态:公司发展的地域属性、公司员工属性,而针对这两点的推广无非是激励+运营。公司生态:移动端app公司为什么做移动端app,如果有用户运营公司除了做lbs之外其他的领域或渠道能够立足,从app本身来发力激励及运营团队;如果说是导航、电商之类的,那么除了做用户运营之外的还是需要与公司其他部门对接。
例如对运营人员的成本回收即收益管理的问题;公司产品生态:如果是高频的内容app,建议做个app回归历史的版本,哪怕是五六年前的版本;低频的wapapp可以做个免费版本留住用户,做一个可以高频的资讯app,或者对于自家产品有情感化营销需求可以尝试网络剧电影这类,或者做个游戏类的社区。在创业做团队之前,一定要有一个整体的认知,无论app只是其中一个点,或者是很多点。让一个企业的价值传递稳定,在业务快速发展的过程中不丢工作。 查看全部
移动端的app生态是什么?如何判断产品是否是下沉市场?
采集器采集源:360采集宝。采集器,由360主动接入数据采集;采集包含音乐、视频、游戏、app等应用;帮助您记录历史采集时间,方便回溯数据。
建议采用手机模拟器这种方式。首先你需要做好的是每天产生的流量数据是什么样子,然后如何判断一个产品是否是下沉市场?如何做算法?这是一个问题。
其实想要做好分析和洞察,并不是采用什么工具,而是你对市场和行业的认知、分析和判断。
很遗憾,广州的话,永远没有一个专门的平台去做推广数据分析的业务。
-zdzo2zukhwdre_zsq
如果你能够把大数据利用好,那么手机app还是可以去推广的,而推广的目的却不仅仅是为了推广app,也是为了引导用户更多的去使用移动互联网,比如说手机视频、打车、外卖app等,大数据时代让每个人的数据越来越多,哪怕你用iphone5,iphone7,iphone8都有可能有他的数据,如果你能把这些信息用好,如果数据量足够大,那么就会给你带来很多商机。
目前移动端的app生态大致可以分为三个:公司生态、产品生态、渠道生态。公司生态:公司发展的地域属性、公司员工属性,而针对这两点的推广无非是激励+运营。公司生态:移动端app公司为什么做移动端app,如果有用户运营公司除了做lbs之外其他的领域或渠道能够立足,从app本身来发力激励及运营团队;如果说是导航、电商之类的,那么除了做用户运营之外的还是需要与公司其他部门对接。
例如对运营人员的成本回收即收益管理的问题;公司产品生态:如果是高频的内容app,建议做个app回归历史的版本,哪怕是五六年前的版本;低频的wapapp可以做个免费版本留住用户,做一个可以高频的资讯app,或者对于自家产品有情感化营销需求可以尝试网络剧电影这类,或者做个游戏类的社区。在创业做团队之前,一定要有一个整体的认知,无论app只是其中一个点,或者是很多点。让一个企业的价值传递稳定,在业务快速发展的过程中不丢工作。
app更新同步数据,体验更佳的方法是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-07-13 00:04
采集器采集源是在手机上安装的软件对平台平台进行采集,就算删除软件源仍然会在。但是会对后台发起后台数据同步,将更新的数据同步到服务器端存储,然后会采集另外一部手机号码。最好让在运营商合作商去采集,同步到服务器后,app更新同步数据,体验更佳。
来自百度回答:以手机的拍照功能为例,我们都可以拍照,我们可以转头看天上的云彩,我们可以面对面,我们可以拥抱向上,我们可以.手机拍照,是把图片推到后台,可以下载下来,所以上面提到的软件上的位置,是推送了哪个位置的信息。
手机软件采集后,后台进行过数据同步(比如imsi、mac地址等),就只需要返回给服务器就可以了。
好像因为imei不需要付费所以一般运营商不会给你吧。现在我这里一直没有发生过这种事情啊我猜的,望指正。
我这边是运营商网管实习,对于你问的这个情况应该是基站对服务器端的一个过程,好像,为了保证他是最新的对外更新的,还是会和公安局合作,收集这个号码服务器端的信息,然后给到运营商服务器端用吧。
好像是实现位置请求吧,服务器端发的请求,
我猜的,应该先通过软件同步, 查看全部
app更新同步数据,体验更佳的方法是什么?
采集器采集源是在手机上安装的软件对平台平台进行采集,就算删除软件源仍然会在。但是会对后台发起后台数据同步,将更新的数据同步到服务器端存储,然后会采集另外一部手机号码。最好让在运营商合作商去采集,同步到服务器后,app更新同步数据,体验更佳。
来自百度回答:以手机的拍照功能为例,我们都可以拍照,我们可以转头看天上的云彩,我们可以面对面,我们可以拥抱向上,我们可以.手机拍照,是把图片推到后台,可以下载下来,所以上面提到的软件上的位置,是推送了哪个位置的信息。
手机软件采集后,后台进行过数据同步(比如imsi、mac地址等),就只需要返回给服务器就可以了。
好像因为imei不需要付费所以一般运营商不会给你吧。现在我这里一直没有发生过这种事情啊我猜的,望指正。
我这边是运营商网管实习,对于你问的这个情况应该是基站对服务器端的一个过程,好像,为了保证他是最新的对外更新的,还是会和公安局合作,收集这个号码服务器端的信息,然后给到运营商服务器端用吧。
好像是实现位置请求吧,服务器端发的请求,
我猜的,应该先通过软件同步,
如何将视频采集成视频的素材采集器使用方法?
采集交流 • 优采云 发表了文章 • 0 个评论 • 757 次浏览 • 2021-07-10 06:06
采集器采集源主要有:视频采集器、录音采集器、声卡采集器,还有一些wifi采集器,最常见的就是视频采集器和录音采集器,在做视频的时候经常需要采集视频,这个时候就可以选择采集器来完成视频的采集,
一、什么是采集器采集器是电脑端操作软件使用的采集。它使用收音机器去收集影像,做成图像并生成录像;或者使用音箱去采集音乐,做成声音数据。采集器有自带和购买两种形式,通常采集器自带电脑使用的采集软件,但对于大型影视制作,通常需要购买音频采集器和视频采集器,才能制作完整视频,因为广告片对音频素材的要求很高。
二、如何将收集到的素材采集成视频
1、视频分辨率视频收集网格选择3840*216
0、480*128
0、2k*8k,1k*16k,3k*32k,4k*48k,5k,6k,8k尺寸尽量按最小值定。
2、素材来源素材就是关键部分,影片内容要全,包括预告片、宣传片、序列视频,各种图片等。片头,片尾,字幕,头像,图标,以及手机、网站视频等也可以拿来使用。
3、素材管理将制作视频所有素材名称复制到收集项下,对应的路径导入即可,然后直接保存为视频即可。
4、添加字幕、音乐、配音如果对字幕、音乐、音效不懂得可以购买视频采集器,也可以有专门的组件来安装使用,通常有预置的、导入的、自己录制。
5、视频保存预览用快速浏览器打开视频,点击“视频保存”,选择要保存的文件,然后点击“上传”即可上传视频。
三、采集器使用方法
1、浏览器添加采集器首先我们要使用一些平台提供的浏览器才可以收集到视频文件。电脑和手机方式大同小异,pc端下载一个迅捷视频抓取器,将其中文件夹拖拽到手机浏览器中即可。pc端也可以使用ipad、安卓等使用苹果的app“epicoffice”来收集,根据个人使用习惯不同。
2、wifi接入方式如果家里有宽带,可以直接把视频插入wifi上,离线观看。如果家里没有宽带,请看第2条解决方案。
3、导入方式1:利用网站、论坛等收集到的视频。2:路由器设置。3:直接利用电脑收集。
4、导出格式大部分视频软件默认的接口支持usb文件导出,pc端用,
5、如何使用采集器自带采集器
1、一键选择预告 查看全部
如何将视频采集成视频的素材采集器使用方法?
采集器采集源主要有:视频采集器、录音采集器、声卡采集器,还有一些wifi采集器,最常见的就是视频采集器和录音采集器,在做视频的时候经常需要采集视频,这个时候就可以选择采集器来完成视频的采集,
一、什么是采集器采集器是电脑端操作软件使用的采集。它使用收音机器去收集影像,做成图像并生成录像;或者使用音箱去采集音乐,做成声音数据。采集器有自带和购买两种形式,通常采集器自带电脑使用的采集软件,但对于大型影视制作,通常需要购买音频采集器和视频采集器,才能制作完整视频,因为广告片对音频素材的要求很高。
二、如何将收集到的素材采集成视频
1、视频分辨率视频收集网格选择3840*216
0、480*128
0、2k*8k,1k*16k,3k*32k,4k*48k,5k,6k,8k尺寸尽量按最小值定。
2、素材来源素材就是关键部分,影片内容要全,包括预告片、宣传片、序列视频,各种图片等。片头,片尾,字幕,头像,图标,以及手机、网站视频等也可以拿来使用。
3、素材管理将制作视频所有素材名称复制到收集项下,对应的路径导入即可,然后直接保存为视频即可。
4、添加字幕、音乐、配音如果对字幕、音乐、音效不懂得可以购买视频采集器,也可以有专门的组件来安装使用,通常有预置的、导入的、自己录制。
5、视频保存预览用快速浏览器打开视频,点击“视频保存”,选择要保存的文件,然后点击“上传”即可上传视频。
三、采集器使用方法
1、浏览器添加采集器首先我们要使用一些平台提供的浏览器才可以收集到视频文件。电脑和手机方式大同小异,pc端下载一个迅捷视频抓取器,将其中文件夹拖拽到手机浏览器中即可。pc端也可以使用ipad、安卓等使用苹果的app“epicoffice”来收集,根据个人使用习惯不同。
2、wifi接入方式如果家里有宽带,可以直接把视频插入wifi上,离线观看。如果家里没有宽带,请看第2条解决方案。
3、导入方式1:利用网站、论坛等收集到的视频。2:路由器设置。3:直接利用电脑收集。
4、导出格式大部分视频软件默认的接口支持usb文件导出,pc端用,
5、如何使用采集器自带采集器
1、一键选择预告
《基于大数据平台的互联网数据采集平台基本架构》
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-07-01 22:01
我简单介绍了【《基于大数据平台采集平台的互联网数据基本结构》。今天主要介绍一下采集的各个环节如何处理,需要注意哪些方面。
废话少说,正文开始……
第一:信息源系统
其实就是采集task 管理系统,我们称之为源码管理系统。主要包括:
1.任务模块:网站、栏目、搜索引擎、关键词、模板、公众号、微博博主等。
2.资源管理模块:服务器、项目、索引等;
3.监控模块:网站、栏目、搜索引擎、服务器、采集器等模块。
4.调度模块:采集器创建、部署、启动、关闭、删除等;
下面简单介绍一下各个模块的功能和注意事项。
1.任务模块
(1)网站,栏目/频道管理
在文章(《3人团队,如何管理10万采集网站?(最全面、最详细的解读)》)中有对网站的介绍,如何批量添加栏目,等等,不在这里累了。
这里主要讲在配置网站和栏目时,如何过滤掉与公司业务无关的信息源。
主要有两种方法。一种是人工筛选;另一种是设置过滤词;当配置的网站或列名收录单词时,系统会直接在后台过滤掉,不再进行常规的分析、存储等操作。
例如,我们的主营业务是金融、证券、保险、银行等行业。那么我们的过滤词可以包括以下几类:
① 地区名称;如:中国、北京、上海等。
② 蔬菜、水果等名称;如:白菜、苹果等。
③ 体育、娱乐、电影、时尚、奢侈品等类型词。
④ 健康、人文、文艺、文史、历史、美食类。
⑤ 女性、育儿、教育、旅游、研究、法律法规、政策等频道。
当网站/列在采集时,还有一个最重要的一点就是采集频率。首次配置时可以遵循以下规则:
① 中央级媒体:首页10分钟,一级频道15分钟;二级频道20分钟,其他30分钟;
② 省级媒体:首页15分钟;一级频道20分钟;二级频道30分钟;
③ 市县等地方网站:首页60分钟;一级频道120分钟;二级频道240~720分钟;
以上是基本规则,配置需要根据实际情况进行分析处理。比如一些本地的网站,虽然不大,但是对业务的兼容度很高,而且每天发帖频繁,那么采集的频率可以设置为30分钟或者60分钟。
网站/column采集加入正则化后,需要根据一段时间内的发帖规则自动分析采集的频率。这样,我们的服务器和其他资源的利用率就可以最大化,减少浪费。
(2)搜索引擎管理
虽然我们采集有很多网站,但与整个互联网相比,还是杯水车薪。那么,我们如何才能高效、低成本地获取我们需要的数据?
搜索引擎是一个很好的补充。
通过分析我们的产品和项目的业务需求,整理出相关的关键词,我们可以通过搜索引擎快速获取我们需要的部分数据。我们可以快速响应客户需求、改善用户体验并提供订单率。
但是,有很多搜索引擎。为了让我们能够灵活地添加、删除、修改等,它们也需要集成到源系统中。同时,我们还可以随时监控源系统中的状态,实时调整采集策略。
(3)关键词管理
关键词配置,主要注意以下几点:
① 每个关键词必须与一个项目关联;
② 每个关键词都要记录下提供者姓名;
③ 关键词添加时,同样需要经过排除词进行处理。过滤词可以与网站/栏目配置的同步使用;
(4)官方号
对于微信公众号的文章采集,目前基于XPosed手机插件的采集方式实现批量的更稳定、快速、高效的方式。
但是,这种方法也有很多缺点:
① 前期投入较大;
因为每个手机上只能安装一个XPosed插件,就只能hook一个微信号。而且每个微信号最多只能关注999个公众号,比如要监测100万公众号的话,就需要一千部手机。按一部手机800元,使用三年,第一年需要花费60万左右。加上10%损耗,平均35万/年。
② 微信号需求量大;
因为一个微信号最多只能关注999个公众号,如果要监测100万公众号,就需要一千个微信号,再加上10%的封号概率。第一年至少需要1100个微信号。
③ 运维较麻烦
主要体现在封号上。如果是临时封号的话,可以通过手机号解封。如果是永久封号,那就需要把当前微信号中关注的公众号,重新在其他微信号上进行关注监测了。这个过程需要二十天左右才能结束。
④ 公众号的关注比较麻烦
因为一个微信号一天只能关注四五十个公众号;
为了处理账号被封的问题,我们在处理公众号时需要注意以下几点:
① 每个公众号必须在数据库中和微信号进行管理,
② 手机必须按一定的规律进行编号
③ 手机和微信号之间在数据中必须进行关联。
(5)模板管理
我们逐渐放弃了配置模板,倾向于通过训练自动处理。
(6)微博博主管理
由于微博搜索列表没有显示所有与搜索词相关的信息,需要同时监控一些博主,两者相辅相成。
2.资源管理模块
(1)服务器管理:
对于做舆论或数据服务的公司,data采集至少涉及几十台服务器。为了了解这些服务器何时到期、更新和服务器配置,我们倾向于将服务器管理与任务调度一起设计,而不是使用云平台提供的控制终端。当然,网管也可以使用云平台控制终端查询和监控服务器的各项指标。
(2)项目管理:
搜索采集时,搜索词通常按照项目或产品的数据范围进行排序。所以在添加元搜索关键词的时候,一般是绑定到项目上的。因此,项目需要统一管理。
(3)索引管理:
由于采集的数据量很大,采集每天接收的数据量级至少有100万。因此,我们不可能将采集的所有数据长时间放在一个ES索引库中。
在实际使用中,我们首先对信息进行分类。如:新闻、论坛、博客、微博、客户端、微信和纸媒等。如果采集有海外网站,可以添加外媒类型。
虽然数据是按类型分类的,但不能总是将每种类型的数据都存储在一个索引中。因此,索引需要按照一定的规则生成。如按时间、每周或每月生成某种类型的索引。
为了提高ES集群的工作效率,我们可以根据实际业务需要关闭比当前时间长的冷索引,比如关闭半年前生成的ES索引。这样既可以减少服务器内存和硬盘的浪费,也可以提高热索引的查询速度,提升产品的用户体验。
同时,为了掌握ES集群中各个索引的情况,我们需要记录索引的创建时间、上次保存数据的时间、索引名称、索引类型、数据量、数据类型以及收录哪些字段。
记录索引信息,一是方便了解当前各类数据的索引数据库;二是方便各种统计报表等所需数据的导出。
3.监控模块
网站、栏目、搜索引擎、服务器、采集器等监控不详述。上一篇《Data采集,如何建立有效的监控体系?》文章中有详细介绍,可以阅读。
4.调度模块
调度模块是运维管理中最重要的部分。
在分布式海量数据采集中,网站、涉及采集的列或通道的数量级至少有10000、100,000,甚至数百万。所涉及的服务器范围从三到五台,到三到五十台,或三到五百台。每台服务器上部署多个采集器等。如此数量级的采集器运维,如果没有专门的系统来处理,是不可想象的。
调度模块主要负责采集器的增减、部署/上传、启动、关闭等,实现一键部署,解放人力。
第二:Data采集
采集器在处理采集任务时,最重要的三个部分是:网页下载、翻页和数据分析。各部分加工中的注意事项如下:
1.翻页
在大量数据采集中,不建议设置翻页。主要是翻页信息的维护比较麻烦。为避免数据丢失,可适当提高采集频率,以补偿未翻页的影响。
2.title
标题一般在使用采集URL地址时使用A标签的值。然后在文本解析过程中执行第二次检查以纠正标题中可能存在的错误。
3.发布时间处理
发布时间分析难免会出现问题,但不能大于当前时间。
一般在清除HTML源代码中的css样式、JS、注释、meta等信息后,删除HTML标签,以内容中的第一时间作为发布时间。
一般可以统计一些发布时间指标,如:“发布时间:”、“发布日期”等,然后通过正则表达式,将标识符前后的100个字符串中的时间分别为获得作为发布时间。
第三:数据质量
1.Title 处理;
标题一般容易出现以下三个问题:
① 以”_XXX网站或门户”结尾;
② 以“....”结束;
③ 长度小于等于两个字符;
针对上述问题,我们可以通过list的title和body中的title进行二次校验来纠正。
2.文本处理;
文本一般以数据类型为准,可以注意以下问题:
① 新闻、博客、纸媒、客户端和微信等正文需大于10字符;
② 论坛和微博等内容大于0即可;
③ 注意由于解析异常,导致的内容中存在css样式数据;
④ 格式化数据。删除多余的“
"、""、空行等
3.统一数据传输接口:
对于企业来说,有常规的采集,也有基于项目和产品的定制采集。并且有些项目或产品有很多自定义脚本。如果数据存储方式(或数据推送方式)不统一,一旦出现问题,排查起来难度极大。它还浪费时间并增加人工成本。
统一的数据传输接口主要有以下优点:
① 异常前置,减少异常数据流入系统概率,提供用户体验;
② 数据质量监控,优化采集任务;
③ 多来源情况下数据排重,减少[数据分析](http://www.blog2019.net/tag/%2 ... d%3D90)压力;
④ 减少数据持久化中存现的问题,提供工作效率;
第四:统一开发模式
舆论或者数据服务公司,data采集人比较多,技术水平参差不齐。为了减少各级人员开发过程中的BUG数量,可以细化采集的各个部分,定制耦合度较低的模块开发,然后做成第三方插件,分发并将它们安装在每个开发人员的环境中。这样可以大大降低开发中出现BUG的概率,有效提高工作效率。
那么,哪些模块可以独立?
① 采集任务获取模块;
② 网页下载模块;
③ 发布时间、正文等解析模块;
④ 采集结果推送模块;
⑤ 采集监测模块;
统一以上五部分代码后,至少可以节省40%的人力。
第五:采集的痛点:
1.网站改版****
网站改版后,随之而来的是信息正则、翻页正则、采集template等失效,导致网站采集异常。不仅浪费资源,还影响采集的效率。
特别是政府网站在过去一两年中进行了全国性的修订。有很多历史配置网站都采集没有更多数据。
2.数据泄露采集
数据缺失,在以下情况之一:
① 采集频率不对,导致信息跑到第二页等,无法采集到(因为采集翻页)
② 由于网站改版,导致信息正则或模板等配置异常;
③ 信息所在网站没有配置栏目,添加到采集任务队列;
④ 数据传输异常,导致数据丢失;如kafka异常,导致内存中所有数据丢失;
⑤ 网络抖动,导致正文采集异常;
以上几个数据缺失的原因可以通过监控系统快速找到定位。由于监控系统的建立,可以参考之前发表的《Data采集,如何建立有效的监控系统?》一篇文章。
第六:第三方数据平台
如果你是个人,只要简单的采集一些数据写论文,或者这个测试什么的,那么这个文章看到这里就结束了;
如果你是做舆论或数据分析的公司,第三方平台是很好的补充数据来源。一方面可以补充我们漏掉的数据,提升用户体验。另一方面,我们也可以从他们的数据中分析网站信息的来源,以补充我们自己的源数据库。
主要的第三方平台或数据服务商如下:
1.远哈SaaS平台
元哈舆论其实就是新浪舆论。因此,元哈的微博数据应该是市场上最全面和时效性最强的。 网站,client,纸媒等类型的数据其实差不多,看投资的多少。一般
2.iridium SAAS 平台
3.智慧星光SaaS平台
铱星和智慧星光的数据差不多,智慧星光稍微好一点。
4.八友微信数据
特点:微信公众号文章数据还可以,日流量在80万~150万之间,收费在市场上应该比较合适。如果您的公司有此需求,您可以与他们联系。微博等数据暂未对接,质量未知。
我今天就讲这个。文笔不好,理解一下思路就好了。哈哈...
如果还有其他采集相关问题,可以在下方公众号留言! 查看全部
《基于大数据平台的互联网数据采集平台基本架构》
我简单介绍了【《基于大数据平台采集平台的互联网数据基本结构》。今天主要介绍一下采集的各个环节如何处理,需要注意哪些方面。
废话少说,正文开始……
第一:信息源系统
其实就是采集task 管理系统,我们称之为源码管理系统。主要包括:
1.任务模块:网站、栏目、搜索引擎、关键词、模板、公众号、微博博主等。
2.资源管理模块:服务器、项目、索引等;
3.监控模块:网站、栏目、搜索引擎、服务器、采集器等模块。
4.调度模块:采集器创建、部署、启动、关闭、删除等;
下面简单介绍一下各个模块的功能和注意事项。
1.任务模块
(1)网站,栏目/频道管理
在文章(《3人团队,如何管理10万采集网站?(最全面、最详细的解读)》)中有对网站的介绍,如何批量添加栏目,等等,不在这里累了。
这里主要讲在配置网站和栏目时,如何过滤掉与公司业务无关的信息源。
主要有两种方法。一种是人工筛选;另一种是设置过滤词;当配置的网站或列名收录单词时,系统会直接在后台过滤掉,不再进行常规的分析、存储等操作。
例如,我们的主营业务是金融、证券、保险、银行等行业。那么我们的过滤词可以包括以下几类:
① 地区名称;如:中国、北京、上海等。
② 蔬菜、水果等名称;如:白菜、苹果等。
③ 体育、娱乐、电影、时尚、奢侈品等类型词。
④ 健康、人文、文艺、文史、历史、美食类。
⑤ 女性、育儿、教育、旅游、研究、法律法规、政策等频道。
当网站/列在采集时,还有一个最重要的一点就是采集频率。首次配置时可以遵循以下规则:
① 中央级媒体:首页10分钟,一级频道15分钟;二级频道20分钟,其他30分钟;
② 省级媒体:首页15分钟;一级频道20分钟;二级频道30分钟;
③ 市县等地方网站:首页60分钟;一级频道120分钟;二级频道240~720分钟;
以上是基本规则,配置需要根据实际情况进行分析处理。比如一些本地的网站,虽然不大,但是对业务的兼容度很高,而且每天发帖频繁,那么采集的频率可以设置为30分钟或者60分钟。
网站/column采集加入正则化后,需要根据一段时间内的发帖规则自动分析采集的频率。这样,我们的服务器和其他资源的利用率就可以最大化,减少浪费。
(2)搜索引擎管理
虽然我们采集有很多网站,但与整个互联网相比,还是杯水车薪。那么,我们如何才能高效、低成本地获取我们需要的数据?
搜索引擎是一个很好的补充。
通过分析我们的产品和项目的业务需求,整理出相关的关键词,我们可以通过搜索引擎快速获取我们需要的部分数据。我们可以快速响应客户需求、改善用户体验并提供订单率。
但是,有很多搜索引擎。为了让我们能够灵活地添加、删除、修改等,它们也需要集成到源系统中。同时,我们还可以随时监控源系统中的状态,实时调整采集策略。
(3)关键词管理
关键词配置,主要注意以下几点:
① 每个关键词必须与一个项目关联;
② 每个关键词都要记录下提供者姓名;
③ 关键词添加时,同样需要经过排除词进行处理。过滤词可以与网站/栏目配置的同步使用;
(4)官方号
对于微信公众号的文章采集,目前基于XPosed手机插件的采集方式实现批量的更稳定、快速、高效的方式。
但是,这种方法也有很多缺点:
① 前期投入较大;
因为每个手机上只能安装一个XPosed插件,就只能hook一个微信号。而且每个微信号最多只能关注999个公众号,比如要监测100万公众号的话,就需要一千部手机。按一部手机800元,使用三年,第一年需要花费60万左右。加上10%损耗,平均35万/年。
② 微信号需求量大;
因为一个微信号最多只能关注999个公众号,如果要监测100万公众号,就需要一千个微信号,再加上10%的封号概率。第一年至少需要1100个微信号。
③ 运维较麻烦
主要体现在封号上。如果是临时封号的话,可以通过手机号解封。如果是永久封号,那就需要把当前微信号中关注的公众号,重新在其他微信号上进行关注监测了。这个过程需要二十天左右才能结束。
④ 公众号的关注比较麻烦
因为一个微信号一天只能关注四五十个公众号;
为了处理账号被封的问题,我们在处理公众号时需要注意以下几点:
① 每个公众号必须在数据库中和微信号进行管理,
② 手机必须按一定的规律进行编号
③ 手机和微信号之间在数据中必须进行关联。
(5)模板管理
我们逐渐放弃了配置模板,倾向于通过训练自动处理。
(6)微博博主管理
由于微博搜索列表没有显示所有与搜索词相关的信息,需要同时监控一些博主,两者相辅相成。
2.资源管理模块
(1)服务器管理:
对于做舆论或数据服务的公司,data采集至少涉及几十台服务器。为了了解这些服务器何时到期、更新和服务器配置,我们倾向于将服务器管理与任务调度一起设计,而不是使用云平台提供的控制终端。当然,网管也可以使用云平台控制终端查询和监控服务器的各项指标。
(2)项目管理:
搜索采集时,搜索词通常按照项目或产品的数据范围进行排序。所以在添加元搜索关键词的时候,一般是绑定到项目上的。因此,项目需要统一管理。
(3)索引管理:

由于采集的数据量很大,采集每天接收的数据量级至少有100万。因此,我们不可能将采集的所有数据长时间放在一个ES索引库中。
在实际使用中,我们首先对信息进行分类。如:新闻、论坛、博客、微博、客户端、微信和纸媒等。如果采集有海外网站,可以添加外媒类型。
虽然数据是按类型分类的,但不能总是将每种类型的数据都存储在一个索引中。因此,索引需要按照一定的规则生成。如按时间、每周或每月生成某种类型的索引。
为了提高ES集群的工作效率,我们可以根据实际业务需要关闭比当前时间长的冷索引,比如关闭半年前生成的ES索引。这样既可以减少服务器内存和硬盘的浪费,也可以提高热索引的查询速度,提升产品的用户体验。
同时,为了掌握ES集群中各个索引的情况,我们需要记录索引的创建时间、上次保存数据的时间、索引名称、索引类型、数据量、数据类型以及收录哪些字段。
记录索引信息,一是方便了解当前各类数据的索引数据库;二是方便各种统计报表等所需数据的导出。
3.监控模块

网站、栏目、搜索引擎、服务器、采集器等监控不详述。上一篇《Data采集,如何建立有效的监控体系?》文章中有详细介绍,可以阅读。
4.调度模块

调度模块是运维管理中最重要的部分。
在分布式海量数据采集中,网站、涉及采集的列或通道的数量级至少有10000、100,000,甚至数百万。所涉及的服务器范围从三到五台,到三到五十台,或三到五百台。每台服务器上部署多个采集器等。如此数量级的采集器运维,如果没有专门的系统来处理,是不可想象的。
调度模块主要负责采集器的增减、部署/上传、启动、关闭等,实现一键部署,解放人力。
第二:Data采集
采集器在处理采集任务时,最重要的三个部分是:网页下载、翻页和数据分析。各部分加工中的注意事项如下:
1.翻页
在大量数据采集中,不建议设置翻页。主要是翻页信息的维护比较麻烦。为避免数据丢失,可适当提高采集频率,以补偿未翻页的影响。
2.title
标题一般在使用采集URL地址时使用A标签的值。然后在文本解析过程中执行第二次检查以纠正标题中可能存在的错误。
3.发布时间处理
发布时间分析难免会出现问题,但不能大于当前时间。
一般在清除HTML源代码中的css样式、JS、注释、meta等信息后,删除HTML标签,以内容中的第一时间作为发布时间。
一般可以统计一些发布时间指标,如:“发布时间:”、“发布日期”等,然后通过正则表达式,将标识符前后的100个字符串中的时间分别为获得作为发布时间。
第三:数据质量
1.Title 处理;
标题一般容易出现以下三个问题:
① 以”_XXX网站或门户”结尾;
② 以“....”结束;
③ 长度小于等于两个字符;
针对上述问题,我们可以通过list的title和body中的title进行二次校验来纠正。
2.文本处理;
文本一般以数据类型为准,可以注意以下问题:
① 新闻、博客、纸媒、客户端和微信等正文需大于10字符;
② 论坛和微博等内容大于0即可;
③ 注意由于解析异常,导致的内容中存在css样式数据;
④ 格式化数据。删除多余的“
"、""、空行等
3.统一数据传输接口:
对于企业来说,有常规的采集,也有基于项目和产品的定制采集。并且有些项目或产品有很多自定义脚本。如果数据存储方式(或数据推送方式)不统一,一旦出现问题,排查起来难度极大。它还浪费时间并增加人工成本。
统一的数据传输接口主要有以下优点:
① 异常前置,减少异常数据流入系统概率,提供用户体验;
② 数据质量监控,优化采集任务;
③ 多来源情况下数据排重,减少[数据分析](http://www.blog2019.net/tag/%2 ... d%3D90)压力;
④ 减少数据持久化中存现的问题,提供工作效率;
第四:统一开发模式
舆论或者数据服务公司,data采集人比较多,技术水平参差不齐。为了减少各级人员开发过程中的BUG数量,可以细化采集的各个部分,定制耦合度较低的模块开发,然后做成第三方插件,分发并将它们安装在每个开发人员的环境中。这样可以大大降低开发中出现BUG的概率,有效提高工作效率。
那么,哪些模块可以独立?
① 采集任务获取模块;
② 网页下载模块;
③ 发布时间、正文等解析模块;
④ 采集结果推送模块;
⑤ 采集监测模块;
统一以上五部分代码后,至少可以节省40%的人力。
第五:采集的痛点:
1.网站改版****
网站改版后,随之而来的是信息正则、翻页正则、采集template等失效,导致网站采集异常。不仅浪费资源,还影响采集的效率。
特别是政府网站在过去一两年中进行了全国性的修订。有很多历史配置网站都采集没有更多数据。
2.数据泄露采集
数据缺失,在以下情况之一:
① 采集频率不对,导致信息跑到第二页等,无法采集到(因为采集翻页)
② 由于网站改版,导致信息正则或模板等配置异常;
③ 信息所在网站没有配置栏目,添加到采集任务队列;
④ 数据传输异常,导致数据丢失;如kafka异常,导致内存中所有数据丢失;
⑤ 网络抖动,导致正文采集异常;
以上几个数据缺失的原因可以通过监控系统快速找到定位。由于监控系统的建立,可以参考之前发表的《Data采集,如何建立有效的监控系统?》一篇文章。
第六:第三方数据平台
如果你是个人,只要简单的采集一些数据写论文,或者这个测试什么的,那么这个文章看到这里就结束了;
如果你是做舆论或数据分析的公司,第三方平台是很好的补充数据来源。一方面可以补充我们漏掉的数据,提升用户体验。另一方面,我们也可以从他们的数据中分析网站信息的来源,以补充我们自己的源数据库。
主要的第三方平台或数据服务商如下:
1.远哈SaaS平台
元哈舆论其实就是新浪舆论。因此,元哈的微博数据应该是市场上最全面和时效性最强的。 网站,client,纸媒等类型的数据其实差不多,看投资的多少。一般
2.iridium SAAS 平台
3.智慧星光SaaS平台
铱星和智慧星光的数据差不多,智慧星光稍微好一点。
4.八友微信数据
特点:微信公众号文章数据还可以,日流量在80万~150万之间,收费在市场上应该比较合适。如果您的公司有此需求,您可以与他们联系。微博等数据暂未对接,质量未知。
我今天就讲这个。文笔不好,理解一下思路就好了。哈哈...
如果还有其他采集相关问题,可以在下方公众号留言!
身份证识别的几种特征库,你了解吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-06-23 04:00
采集器采集源数据,如手机用户的行为等。由于采集器采集的数据类型有限,所以推荐开启别人的身份证照片可能不是安全或高质量。这时候就需要模拟人脸抓取数据了。
目前市面上的采集产品都是通过手机照片进行搜集,像推荐使用腾讯地图或高德地图的rds等数据库,虽然说可以rd身份,一键匹配,但是每天的作业量还是很大的,目前未能有效的针对身份证进行联网验证,而采集人脸数据库就可以达到1秒以内,有效防止了作弊或伪装,目前都还处于发展阶段,但是身份证中的采集需求还是很强烈,加上浙江省地铁apec消息、优采云的实名制、网约车试点等一系列政策,都还是比较有前景的,
接下来我会把我知道的和自己了解的知识与大家分享。身份证识别这块儿是日益紧俏,因为安全性,距离世界领先还有距离。目前流行的有三种机器学习算法:nn模型,cnn模型,mlp模型。首先nn算法就是神经网络。它能够提取图像关键信息如长宽比、边缘、颜色、噪声、姿态以及位置等特征。这些特征不仅可以用来判断分类,还可以用来判断目标是否是你提取的特征。
所以有好多人要求做个身份证数据库。简单给大家看下这几种特征库,图上也标注了特征类型,大家可以自己看下:cnn模型:它包含三维卷积和convnet,这种算法能够提取更加多样的特征以及具备更高的鲁棒性。nn模型是深度学习兴起前出现的模型,在图像领域已经有很长的时间。mlp模型:广泛应用于自然语言处理、多媒体等领域。
发明的人叫facenet,embedding是模型的传递,各种lm,各种nn,一大堆都是这种。我们到目前为止只能去搞清楚这三种算法的优缺点,但是据说百度地图是神马个思路:使用人脸抓取和随机通过位置去匹配特征,这样可以减少计算量,且每次用户的行为数据进入,就可以推送位置数据到各个平台(对于目前不能全平台覆盖的bat三大巨头来说,这个算法真的还是有点坑爹,并且这里采集的数据格式肯定不是百度所想的apec实名制坐标)。
但是即使采集人脸数据,采集是直接使用的百度的场景数据,那么它的精准度又如何呢?这个模型将手机的各个摄像头,一直设置在那台手机,这样抓取的iv值就不会超过1,这种算法是存在质量上的问题,那么大家在进行大规模的抓取时候也会遇到问题,通过我们对安卓系统的抓取进行对比分析:安卓抓取图片放大如果出现变形等情况时,百度就无法正确抓取。
至于它能够识别身份证里面的什么信息,这个方面主要需要百度深度学习芯片来解决。百度这个采集公司非常的庞大,从其中进行总结能够发现规律,发现了问题,再进行对数。 查看全部
身份证识别的几种特征库,你了解吗?
采集器采集源数据,如手机用户的行为等。由于采集器采集的数据类型有限,所以推荐开启别人的身份证照片可能不是安全或高质量。这时候就需要模拟人脸抓取数据了。
目前市面上的采集产品都是通过手机照片进行搜集,像推荐使用腾讯地图或高德地图的rds等数据库,虽然说可以rd身份,一键匹配,但是每天的作业量还是很大的,目前未能有效的针对身份证进行联网验证,而采集人脸数据库就可以达到1秒以内,有效防止了作弊或伪装,目前都还处于发展阶段,但是身份证中的采集需求还是很强烈,加上浙江省地铁apec消息、优采云的实名制、网约车试点等一系列政策,都还是比较有前景的,
接下来我会把我知道的和自己了解的知识与大家分享。身份证识别这块儿是日益紧俏,因为安全性,距离世界领先还有距离。目前流行的有三种机器学习算法:nn模型,cnn模型,mlp模型。首先nn算法就是神经网络。它能够提取图像关键信息如长宽比、边缘、颜色、噪声、姿态以及位置等特征。这些特征不仅可以用来判断分类,还可以用来判断目标是否是你提取的特征。
所以有好多人要求做个身份证数据库。简单给大家看下这几种特征库,图上也标注了特征类型,大家可以自己看下:cnn模型:它包含三维卷积和convnet,这种算法能够提取更加多样的特征以及具备更高的鲁棒性。nn模型是深度学习兴起前出现的模型,在图像领域已经有很长的时间。mlp模型:广泛应用于自然语言处理、多媒体等领域。
发明的人叫facenet,embedding是模型的传递,各种lm,各种nn,一大堆都是这种。我们到目前为止只能去搞清楚这三种算法的优缺点,但是据说百度地图是神马个思路:使用人脸抓取和随机通过位置去匹配特征,这样可以减少计算量,且每次用户的行为数据进入,就可以推送位置数据到各个平台(对于目前不能全平台覆盖的bat三大巨头来说,这个算法真的还是有点坑爹,并且这里采集的数据格式肯定不是百度所想的apec实名制坐标)。
但是即使采集人脸数据,采集是直接使用的百度的场景数据,那么它的精准度又如何呢?这个模型将手机的各个摄像头,一直设置在那台手机,这样抓取的iv值就不会超过1,这种算法是存在质量上的问题,那么大家在进行大规模的抓取时候也会遇到问题,通过我们对安卓系统的抓取进行对比分析:安卓抓取图片放大如果出现变形等情况时,百度就无法正确抓取。
至于它能够识别身份证里面的什么信息,这个方面主要需要百度深度学习芯片来解决。百度这个采集公司非常的庞大,从其中进行总结能够发现规律,发现了问题,再进行对数。
网络蜘蛛从用户设定的网站数据包(数据表)
采集交流 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-06-22 18:10
产品介绍
KLAND-Spider网络信息资源采集系统是一套网络信息资源开发、利用和整合系统,可用于定制跟踪和采集互联网实时信息,建立可重复使用的信息服务系统。 KLAND-Spider可以自动对采集用户从各种网络信息源,包括网页、BLOG、论坛等感兴趣的特定信息进行分类处理,并以多种形式提供给终端用户。
KLAND-Spider 能够快速及时地捕捉到用户需要的市场情报、政策法规、行业资讯、热点新闻等网络信息内容。可广泛应用于企业门户网站建设、情报采集、舆情分析、网络敏感信息监控等方面。
产品特点
KLAND-Spider 网络信息资源采集系统由四个子系统组成:采集navigator、网络蜘蛛、数据处理器和发布系统。
采集navigator 用于自定义采集的目标。网络蜘蛛从用户设置的网站中抓取数据,形成数据包(数据表)发送给数据处理器,数据处理器对捕获的数据进行分析过滤,根据site、channel、关键词, 或其他分类模型自动对数据进行分类,保存在本地数据库中,通过发布系统以选定的格式或样式发布,方便用户使用。
产品特点
采集方法的灵活性,采集sources的多样性,数据的准确性采集,增量采集的自动化。
*支持多种形式的网页表达:静态网页、动态网页、文档网页(Word、EXCEL、PDF等);
*支持导航页和内容翻页;
*支持采集inline form;
*支持文章的附件采集和分析(Word、EXCEL、PDF等);
*采集元数据自动测试分析结果;
*采集 去重结果;
*采集target网站自动更新信息(时间间隔可设置)。 查看全部
网络蜘蛛从用户设定的网站数据包(数据表)
产品介绍
KLAND-Spider网络信息资源采集系统是一套网络信息资源开发、利用和整合系统,可用于定制跟踪和采集互联网实时信息,建立可重复使用的信息服务系统。 KLAND-Spider可以自动对采集用户从各种网络信息源,包括网页、BLOG、论坛等感兴趣的特定信息进行分类处理,并以多种形式提供给终端用户。
KLAND-Spider 能够快速及时地捕捉到用户需要的市场情报、政策法规、行业资讯、热点新闻等网络信息内容。可广泛应用于企业门户网站建设、情报采集、舆情分析、网络敏感信息监控等方面。
产品特点
KLAND-Spider 网络信息资源采集系统由四个子系统组成:采集navigator、网络蜘蛛、数据处理器和发布系统。
采集navigator 用于自定义采集的目标。网络蜘蛛从用户设置的网站中抓取数据,形成数据包(数据表)发送给数据处理器,数据处理器对捕获的数据进行分析过滤,根据site、channel、关键词, 或其他分类模型自动对数据进行分类,保存在本地数据库中,通过发布系统以选定的格式或样式发布,方便用户使用。
产品特点
采集方法的灵活性,采集sources的多样性,数据的准确性采集,增量采集的自动化。
*支持多种形式的网页表达:静态网页、动态网页、文档网页(Word、EXCEL、PDF等);
*支持导航页和内容翻页;
*支持采集inline form;
*支持文章的附件采集和分析(Word、EXCEL、PDF等);
*采集元数据自动测试分析结果;
*采集 去重结果;
*采集target网站自动更新信息(时间间隔可设置)。
采集器采集源为ca900.benjamin.berkeley.
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-06-10 05:02
采集器采集源为ca900.benjamin.berkeley有句很经典的话,有了互联网,你不可能说服任何人,我必须强调,传播是非常非常快的,非常非常快,可以在三个小时到三天内收集100万甚至更多人的信息。自从这位cloudhuan写了《新媒体价值》之后,cloudhuan第一时间就给这位同行更新了博客,然后引发了很多的关注,知道的人,如获至宝,不知道的人,如在喉。
他带来的新媒体价值,极大的,普及了信息的传播,人们都开始注意到新媒体了,让这个新时代来临,那么作为媒体采集的人,也就是老百姓或者新媒体人,在这个快速且廉价获取信息的时代,要么被取代,要么被新媒体平台吸引,如果你在十年前没有找到新媒体价值,没有去利用,那么现在你必然会被新媒体动了蛋糕,即使不是完全取代,也会大大小幅的下滑。
一、什么是新媒体:新媒体技术(newmediatechnology)是信息技术的一个新分支,是将信息通过互联网、移动互联网、广播电视、数字报刊、个人电脑、智能手机、平板电脑等技术手段,实现远距离、实时性、交互性、共享性、无线性的新媒体。这些词汇大家看到了,一个字也没少,那么你有没有发现,原来新媒体可以概括为"新"这个字,比如把信息互联网化,没有信息了,新媒体才算成功。
其实这是整体意思,但是很多中小企业,包括大型企业没有时间去了解这些数据,这就是为什么他们也可以做好新媒体的原因,或者为什么中小企业的老板感觉他们不重视新媒体,大的企业也会有所认识,因为大的企业在ceo的观念里,新媒体就是内容,他们认为内容才是新媒体核心。
二、新媒体运营:新媒体运营是从事依托新媒体平台的内容、活动、用户维护与管理的工作,
1、负责公司新媒体矩阵规划与建设;
2、负责日常内容、活动策划与执行;
3、负责用户的激活与维护;
4、负责客户服务。
三、新媒体运营需要哪些技能:
1、你的基本功要过硬,对新媒体运营的概念有基本的了解。
2、有过运营过有价值的内容,经验就是最好的经验,这样你就少掉进坑里,慢慢再想做成的更大就简单了。
3、能够搭建自己的内容团队,新媒体和其他团队协作非常重要。
4、对于新媒体的趋势,热点和传播,要非常了解,要很关注。
四、我有没有必要参加培训课程?培训一定是非常有价值的,有些人认为培训一些机构课程就是过时的,其实你不参加,你永远想不到别人正在做什么,未来会做什么,最后这些培训价值不用我多说吧。
五、去哪里学习新媒体课程?培训确实会有效果,但是能够学到多少就得看你自己。对于我个人来说, 查看全部
采集器采集源为ca900.benjamin.berkeley.
采集器采集源为ca900.benjamin.berkeley有句很经典的话,有了互联网,你不可能说服任何人,我必须强调,传播是非常非常快的,非常非常快,可以在三个小时到三天内收集100万甚至更多人的信息。自从这位cloudhuan写了《新媒体价值》之后,cloudhuan第一时间就给这位同行更新了博客,然后引发了很多的关注,知道的人,如获至宝,不知道的人,如在喉。
他带来的新媒体价值,极大的,普及了信息的传播,人们都开始注意到新媒体了,让这个新时代来临,那么作为媒体采集的人,也就是老百姓或者新媒体人,在这个快速且廉价获取信息的时代,要么被取代,要么被新媒体平台吸引,如果你在十年前没有找到新媒体价值,没有去利用,那么现在你必然会被新媒体动了蛋糕,即使不是完全取代,也会大大小幅的下滑。
一、什么是新媒体:新媒体技术(newmediatechnology)是信息技术的一个新分支,是将信息通过互联网、移动互联网、广播电视、数字报刊、个人电脑、智能手机、平板电脑等技术手段,实现远距离、实时性、交互性、共享性、无线性的新媒体。这些词汇大家看到了,一个字也没少,那么你有没有发现,原来新媒体可以概括为"新"这个字,比如把信息互联网化,没有信息了,新媒体才算成功。
其实这是整体意思,但是很多中小企业,包括大型企业没有时间去了解这些数据,这就是为什么他们也可以做好新媒体的原因,或者为什么中小企业的老板感觉他们不重视新媒体,大的企业也会有所认识,因为大的企业在ceo的观念里,新媒体就是内容,他们认为内容才是新媒体核心。
二、新媒体运营:新媒体运营是从事依托新媒体平台的内容、活动、用户维护与管理的工作,
1、负责公司新媒体矩阵规划与建设;
2、负责日常内容、活动策划与执行;
3、负责用户的激活与维护;
4、负责客户服务。
三、新媒体运营需要哪些技能:
1、你的基本功要过硬,对新媒体运营的概念有基本的了解。
2、有过运营过有价值的内容,经验就是最好的经验,这样你就少掉进坑里,慢慢再想做成的更大就简单了。
3、能够搭建自己的内容团队,新媒体和其他团队协作非常重要。
4、对于新媒体的趋势,热点和传播,要非常了解,要很关注。
四、我有没有必要参加培训课程?培训一定是非常有价值的,有些人认为培训一些机构课程就是过时的,其实你不参加,你永远想不到别人正在做什么,未来会做什么,最后这些培训价值不用我多说吧。
五、去哪里学习新媒体课程?培训确实会有效果,但是能够学到多少就得看你自己。对于我个人来说,
《aicx数据编码用户手册》之采集器采集源数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 270 次浏览 • 2021-06-09 20:01
采集器采集源数据,来进行一些事件分析。然后自己分析,自己描述。传统的是看分析前的分析量,现在是分析中的数据变化,结合实际情况,找出影响结果的因素。edifact后台和分析不是一体的,已经不再是单独的工具了,基本就是采集器供应商的事情。
重点来了!采集器在很多国家已经停止使用了,欧洲是globalservicegroup,全球公司都是globalservicegroup也就是gsg.在美国的edi系统软件,最主要的功能就是国际化兼容excel,selectionandselectionapi.所以也不要过于纠结国家是怎么用的,其实这些都是系统外包给第三方,专门用于第三方出售给第三方系统。
而gsg出了系统本身,还有gsd采集器。总的来说就是系统的面积也是越来越小,原来是excel分析,现在是selectionandselectionapi,软件的需求量越来越小。国外基本上都是gsg现在是edifact,国内还是gsg市场需求大。
主要是信息安全
edifact虽然早该完结了,但是由于标准不一致,各公司又搞出不同版本,导致无法统一标准。现在基本通用的信息交换标准如下:oftentransactionwithoutdata,andwithoutdatabeforeusingfastandspecificbytesofloadprocedure,drop-whendataallowedtobeused,byadata-formed,platform-levelformatexceptjson.allofthefacts,whichincludeexactlytheboundariesofasmanybytesintheformataresoundimplicatedasavalueofonelocation.特别是在通过fastandspecificbytesusefulexceptionsaresoundcommon.重要数据没有交换,否则就成非正常数据usedforuniquebytesforaction.以上摘自《aicx数据编码用户手册》。 查看全部
《aicx数据编码用户手册》之采集器采集源数据
采集器采集源数据,来进行一些事件分析。然后自己分析,自己描述。传统的是看分析前的分析量,现在是分析中的数据变化,结合实际情况,找出影响结果的因素。edifact后台和分析不是一体的,已经不再是单独的工具了,基本就是采集器供应商的事情。
重点来了!采集器在很多国家已经停止使用了,欧洲是globalservicegroup,全球公司都是globalservicegroup也就是gsg.在美国的edi系统软件,最主要的功能就是国际化兼容excel,selectionandselectionapi.所以也不要过于纠结国家是怎么用的,其实这些都是系统外包给第三方,专门用于第三方出售给第三方系统。
而gsg出了系统本身,还有gsd采集器。总的来说就是系统的面积也是越来越小,原来是excel分析,现在是selectionandselectionapi,软件的需求量越来越小。国外基本上都是gsg现在是edifact,国内还是gsg市场需求大。
主要是信息安全
edifact虽然早该完结了,但是由于标准不一致,各公司又搞出不同版本,导致无法统一标准。现在基本通用的信息交换标准如下:oftentransactionwithoutdata,andwithoutdatabeforeusingfastandspecificbytesofloadprocedure,drop-whendataallowedtobeused,byadata-formed,platform-levelformatexceptjson.allofthefacts,whichincludeexactlytheboundariesofasmanybytesintheformataresoundimplicatedasavalueofonelocation.特别是在通过fastandspecificbytesusefulexceptionsaresoundcommon.重要数据没有交换,否则就成非正常数据usedforuniquebytesforaction.以上摘自《aicx数据编码用户手册》。
产品经理想不通采集端定位的原始需求究竟是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-05-27 05:04
采集器采集源是产品生产设计者的初衷。产品总是会出现各种各样的问题,有时候开发者为了采集一个数据而想尽各种办法甚至在实验室反复实验、尝试改善方案。而进行采集端的定位却是最为原始的需求,因为没有需求就没有设计,所以很多产品经理想不通采集端定位的原始需求究竟是什么。
一、定位图像采集源比如广告屏幕(广告屏幕的定位设计);商场(餐饮门店的定位设计);大型店铺门口(店员的定位设计)定位图像采集端应该如何设计?
二、目标商业活动范围定位至少应该确定商业活动范围内的商家的名称、电话、联系方式等信息。
三、商业活动范围内人口的分布定位人口(目标市场或人口密度)不仅是要确定采集的地理分布,而且还要确定总人口密度,进而确定人口整体类型,包括男女比例、种族比例、不同种族、不同性别间、受教育程度区别等等。
四、人口性别分布(例如男女比例、种族比例)人口性别分布,包括男女比例、种族比例,确定了最终采集分布,同时还要确定分布类型。
五、人口年龄分布(例如不同年龄层和经济状况的人口比例)年龄分布需要确定各个年龄段的人口数量和年龄组别,即青少年、中年和老年等等。这方面人口发展工作者需要多总结经验和比较效果。
六、采集频率和在某个时间段内的采集范围采集频率范围定位要求尽可能的精确到时间,尽可能的精确到频率。无论是种地农民还是人工采集点,都需要确定某一时间段内所需要采集的频率。
七、采集人口的婚恋状况人口分布和婚恋状况对采集的精确度和效率都非常重要,这是采集过程中最大的工作挑战。
八、采集人口的性别比例(例如男女比例、种族比例)很多时候采集失败的原因往往是因为采集人口不符合我们的需求,因此需要明确不同人口的比例,有利于提高采集的准确度和效率。
九、某类用户的详细姓名和喜好邮箱定位应该采集用户的姓名和喜好邮箱,以便于用户分析需求和分析用户行为。五个采集的原始需求是很常见的,在这里也分享一些实例,顺便推荐一个好的采集软件用于设计及数据处理:starsoft新思维ae-10.0,一款基于商业需求定位算法的,全尺寸采集的web采集工具,可以以下面列举的几种方式采集采集器采集源其实是一个抽象的概念,除了定位,很多具体的操作或功能都是以功能点的形式呈现,在执行功能点前其实需要为采集的目标需求设计、定义、设计定位,这里以下列举的六种常见定位方式为例。
采集器采集入口类型采集器定位往往都存在一定的aligner、spec、hardware(map)和source之间的对接方式。采。 查看全部
产品经理想不通采集端定位的原始需求究竟是什么?
采集器采集源是产品生产设计者的初衷。产品总是会出现各种各样的问题,有时候开发者为了采集一个数据而想尽各种办法甚至在实验室反复实验、尝试改善方案。而进行采集端的定位却是最为原始的需求,因为没有需求就没有设计,所以很多产品经理想不通采集端定位的原始需求究竟是什么。
一、定位图像采集源比如广告屏幕(广告屏幕的定位设计);商场(餐饮门店的定位设计);大型店铺门口(店员的定位设计)定位图像采集端应该如何设计?
二、目标商业活动范围定位至少应该确定商业活动范围内的商家的名称、电话、联系方式等信息。
三、商业活动范围内人口的分布定位人口(目标市场或人口密度)不仅是要确定采集的地理分布,而且还要确定总人口密度,进而确定人口整体类型,包括男女比例、种族比例、不同种族、不同性别间、受教育程度区别等等。
四、人口性别分布(例如男女比例、种族比例)人口性别分布,包括男女比例、种族比例,确定了最终采集分布,同时还要确定分布类型。
五、人口年龄分布(例如不同年龄层和经济状况的人口比例)年龄分布需要确定各个年龄段的人口数量和年龄组别,即青少年、中年和老年等等。这方面人口发展工作者需要多总结经验和比较效果。
六、采集频率和在某个时间段内的采集范围采集频率范围定位要求尽可能的精确到时间,尽可能的精确到频率。无论是种地农民还是人工采集点,都需要确定某一时间段内所需要采集的频率。
七、采集人口的婚恋状况人口分布和婚恋状况对采集的精确度和效率都非常重要,这是采集过程中最大的工作挑战。
八、采集人口的性别比例(例如男女比例、种族比例)很多时候采集失败的原因往往是因为采集人口不符合我们的需求,因此需要明确不同人口的比例,有利于提高采集的准确度和效率。
九、某类用户的详细姓名和喜好邮箱定位应该采集用户的姓名和喜好邮箱,以便于用户分析需求和分析用户行为。五个采集的原始需求是很常见的,在这里也分享一些实例,顺便推荐一个好的采集软件用于设计及数据处理:starsoft新思维ae-10.0,一款基于商业需求定位算法的,全尺寸采集的web采集工具,可以以下面列举的几种方式采集采集器采集源其实是一个抽象的概念,除了定位,很多具体的操作或功能都是以功能点的形式呈现,在执行功能点前其实需要为采集的目标需求设计、定义、设计定位,这里以下列举的六种常见定位方式为例。
采集器采集入口类型采集器定位往往都存在一定的aligner、spec、hardware(map)和source之间的对接方式。采。
采集器采集源文件夹路径其实是个链接(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-05-25 07:06
采集器采集源文件夹路径其实就是个链接,如果为了查看他人对此文件夹下文件的访问权限,我们需要采集器的内存占用。
可以通过绑定key来实现吧,我也还没有实现,不过可以,最好有足够的内存,
好久不上,也不记得这个问题了。现在的node采集器貌似基本都有。可以采集单个,采集内存量,也可以采集单个文件。但是最好有一个共享地址给对方,或者filesharing服务,采集对方的,可以读写别人的私钥。
我的是文件,而且win8是支持文件采集的。我常用的是这个diffbot。再就是用diff2,对于匿名检索有优势。
我现在采集,第一个是单点,第二个是打包采集。前者价格好像会贵一点,后者貌似稳定,
我自己自己做了个nodedoshub,利用的是node的req-evironment我发现每个人都有自己一个req,其实就是keypwr。除了单点信息以外,还可以计算空间占用来进行搜索。
我自己用的是免费的keyfoon,和老板协商过的。没有额外费用。
楼上的,你从美国回来,然后教程都讲完了知道我怎么找到免费论坛的吗?。
我的采集器叫deepnode.vsblack.easylookvsgenegeek3.9.0里面提供注册、登录、访问权限管理、删除文件、修改文件等权限。node的封装接口,用自己编写的mongodb插件,可以免费版本的mongodb或者阿里云/华为云的免费版本mongodb服务器以及非常不错的搭建安全防御,针对开发imap/pop等接口做出评判优劣。 查看全部
采集器采集源文件夹路径其实是个链接(图)
采集器采集源文件夹路径其实就是个链接,如果为了查看他人对此文件夹下文件的访问权限,我们需要采集器的内存占用。
可以通过绑定key来实现吧,我也还没有实现,不过可以,最好有足够的内存,
好久不上,也不记得这个问题了。现在的node采集器貌似基本都有。可以采集单个,采集内存量,也可以采集单个文件。但是最好有一个共享地址给对方,或者filesharing服务,采集对方的,可以读写别人的私钥。
我的是文件,而且win8是支持文件采集的。我常用的是这个diffbot。再就是用diff2,对于匿名检索有优势。
我现在采集,第一个是单点,第二个是打包采集。前者价格好像会贵一点,后者貌似稳定,
我自己自己做了个nodedoshub,利用的是node的req-evironment我发现每个人都有自己一个req,其实就是keypwr。除了单点信息以外,还可以计算空间占用来进行搜索。
我自己用的是免费的keyfoon,和老板协商过的。没有额外费用。
楼上的,你从美国回来,然后教程都讲完了知道我怎么找到免费论坛的吗?。
我的采集器叫deepnode.vsblack.easylookvsgenegeek3.9.0里面提供注册、登录、访问权限管理、删除文件、修改文件等权限。node的封装接口,用自己编写的mongodb插件,可以免费版本的mongodb或者阿里云/华为云的免费版本mongodb服务器以及非常不错的搭建安全防御,针对开发imap/pop等接口做出评判优劣。
采集器采集源有ua地区定制化推荐,1、ua
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-05-22 01:01
采集器采集源有ua地区定制化推荐,
1、ua
2、ua3。采集不到源地区:暂不支持省份、市县、邮编和省市邮编。暂不支持邮编。临时解决方案:采集源地区采用邮编类型;单位统一采用省市邮编;邮编中间有字符,若要统一生成不同邮编,则为/etc;有字符是必然的,不支持/kg或/nvm,最多为/gr。唯一的变量:邮编短。
推荐专业的,
最近几年都会买前几天新上架了这款采集云什么都可以采,爬虫,链接,图片,文字,应有尽有大数据采集器,多账号使用1.真实采集云,包括全国,全省,
目前是国内各个采集器厂商的厮杀时代,国内绝大多数做采集的做开发的在想尽一切办法也做不出满足客户的需求。目前来说,
0、搜狗、isp、极光。我是觉得数据采集系统除了采集功能以外更需要的是数据提取、分析和挖掘等功能,那些所谓的架构、发布平台等功能属于附加值功能。所以目前我觉得国内做得好的大数据采集系统基本上只有:百度(+esp),腾讯(+isp),360(+isp),isp,极光(+isp)这几家。据说isp的正在落地小米模式。 查看全部
采集器采集源有ua地区定制化推荐,1、ua
采集器采集源有ua地区定制化推荐,
1、ua
2、ua3。采集不到源地区:暂不支持省份、市县、邮编和省市邮编。暂不支持邮编。临时解决方案:采集源地区采用邮编类型;单位统一采用省市邮编;邮编中间有字符,若要统一生成不同邮编,则为/etc;有字符是必然的,不支持/kg或/nvm,最多为/gr。唯一的变量:邮编短。
推荐专业的,
最近几年都会买前几天新上架了这款采集云什么都可以采,爬虫,链接,图片,文字,应有尽有大数据采集器,多账号使用1.真实采集云,包括全国,全省,
目前是国内各个采集器厂商的厮杀时代,国内绝大多数做采集的做开发的在想尽一切办法也做不出满足客户的需求。目前来说,
0、搜狗、isp、极光。我是觉得数据采集系统除了采集功能以外更需要的是数据提取、分析和挖掘等功能,那些所谓的架构、发布平台等功能属于附加值功能。所以目前我觉得国内做得好的大数据采集系统基本上只有:百度(+esp),腾讯(+isp),360(+isp),isp,极光(+isp)这几家。据说isp的正在落地小米模式。
优采云采集器功能介绍简易采集可根据不同网站数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-08-26 21:40
优采云采集器 是一个专业且易于使用的网站数据采集 工具。它的应用范围很广,适用于各个行业。兼容上百种主流网站数据源,提供多种采集Method,快速获取你想要的公共数据网站,支持任意信息采集,方便高效。
优采云采集器基本介绍
优采云采集器官方最新版是专业的网页数据采集器,优采云采集器可以轻松帮助用户采集网站数据,而优采云采集器还可以自定义采集流程,以及优采云采集器的采集效率非常高,保证了时效性。
优采云采集器功能介绍
简单采集
简单采集模式内置了数百个主流网站数据源,如京东、天猫、大众点评等流行的采集网站。只需参考模板设置参数即可快速获取网站。 @公共数据。
Smart采集
优采云采集可根据网站的不同提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助采集整个流程实现数据的完整性和稳定性。
云采集
云采集,5000多台云服务器支持,7*24小时不间断运行,可实现定时采集,无人值守,灵活适配业务场景,助您提升采集效率,并保护数据的及时性。
API 接口
通过优采云API,可以轻松获取采集接收到的优采云任务信息和数据,灵活调度任务,如远程控制任务启停,高效实现数据采集和归档。基于强大的API系统,还可以与公司各种内部管理平台无缝对接,实现各种业务自动化。
自定义采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax、页面滚动、条件判断等。此类功能支持不同网页结构的复杂网站采集,满足多种采集应用场景。
方便的定时功能
只需简单几步,点击设置即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集。同时自由设置多个任务,根据需要进行多种选择时间组合,灵活部署自己的采集任务。
自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等诸多功能,采集该过程是全自动的,无需人工干预即可获取所需格式的数据。
多级采集
很多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;不管网站有多少层,优采云所有采集数据都可以无限,满足采集各种业务需求。
登录后支持网站采集
优采云内置采集登录模块,只需配置目标网站的账号密码,即可使用该模块采集登录数据;同时优采云还拥有采集Cookie自定义功能,首次登录后可自动记住cookies,免去多次输入密码的繁琐,支持更多网站采集。
优采云采集器更新日志
1.把bug扫出来,扛过去
2.有史以来最稳定的版本
优采云采集器review
可定制配置,组合使用,自动处理。 查看全部
优采云采集器功能介绍简易采集可根据不同网站数据采集
优采云采集器 是一个专业且易于使用的网站数据采集 工具。它的应用范围很广,适用于各个行业。兼容上百种主流网站数据源,提供多种采集Method,快速获取你想要的公共数据网站,支持任意信息采集,方便高效。
优采云采集器基本介绍
优采云采集器官方最新版是专业的网页数据采集器,优采云采集器可以轻松帮助用户采集网站数据,而优采云采集器还可以自定义采集流程,以及优采云采集器的采集效率非常高,保证了时效性。
优采云采集器功能介绍
简单采集
简单采集模式内置了数百个主流网站数据源,如京东、天猫、大众点评等流行的采集网站。只需参考模板设置参数即可快速获取网站。 @公共数据。
Smart采集
优采云采集可根据网站的不同提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助采集整个流程实现数据的完整性和稳定性。
云采集
云采集,5000多台云服务器支持,7*24小时不间断运行,可实现定时采集,无人值守,灵活适配业务场景,助您提升采集效率,并保护数据的及时性。
API 接口
通过优采云API,可以轻松获取采集接收到的优采云任务信息和数据,灵活调度任务,如远程控制任务启停,高效实现数据采集和归档。基于强大的API系统,还可以与公司各种内部管理平台无缝对接,实现各种业务自动化。
自定义采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax、页面滚动、条件判断等。此类功能支持不同网页结构的复杂网站采集,满足多种采集应用场景。
方便的定时功能
只需简单几步,点击设置即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集。同时自由设置多个任务,根据需要进行多种选择时间组合,灵活部署自己的采集任务。
自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等诸多功能,采集该过程是全自动的,无需人工干预即可获取所需格式的数据。
多级采集
很多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;不管网站有多少层,优采云所有采集数据都可以无限,满足采集各种业务需求。
登录后支持网站采集
优采云内置采集登录模块,只需配置目标网站的账号密码,即可使用该模块采集登录数据;同时优采云还拥有采集Cookie自定义功能,首次登录后可自动记住cookies,免去多次输入密码的繁琐,支持更多网站采集。
优采云采集器更新日志
1.把bug扫出来,扛过去
2.有史以来最稳定的版本
优采云采集器review
可定制配置,组合使用,自动处理。
如何新建采集器并至DataWorks元数据采集页面(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2021-08-26 21:37
采集元数据用于将表结构和血缘关系采集传递到数据图上,让你清楚地看到表的内部结构和表之间的关系。本文将向您展示如何创建采集器 并将采集OTS 元数据上传到DataWorks。 采集完成后可以在数据图上查看数据。
先决条件
左侧导航栏使用限制,点击OTS。在OTS元数据采集页面,点击新建采集器。在新建采集器配置向导页面,完成以下操作。在“基本信息”选项卡上,配置各种参数。
参数说明
采集器名
采集器 的名字,必填且唯一。
采集器Description
采集器 的简要说明。
工作空间
采集 对象(数据源)所属的 DataWorks 工作区。
数据源类型
采集对象的类型,默认为OTS。
点击下一步。在 Select 采集Object 选项卡上,从数据源下拉列表中选择相应的数据源。
如果您需要的数据源不在列表中,请点击新建,进入工作管理空间>数据源管理页面新建数据源。详情请见。
点击测试采集Connectivity。显示测试成功后,点击下一步。
如果显示测试连通性失败,请检查数据源是否配置正确。
在配置执行计划选项卡上,配置执行计划。
执行计划包括按需执行、每月、每周、每天和每小时。根据不同的执行周期,生成不同的执行计划,在对应的执行计划时间内,对目标数据源进行元数据采集。详情如下:
点击下一步。在“信息确认”页签,确认配置信息无误后,单击“确定”。在OTS元数据采集页面,可以查看和管理目标采集器的相关信息。
主要操作说明如下:
执行结果
采集OTS元数据成功后,可以在All Data>OTS页面查看采集表。
点击表名、工作空间和数据库可以查看对应类别的详细信息。
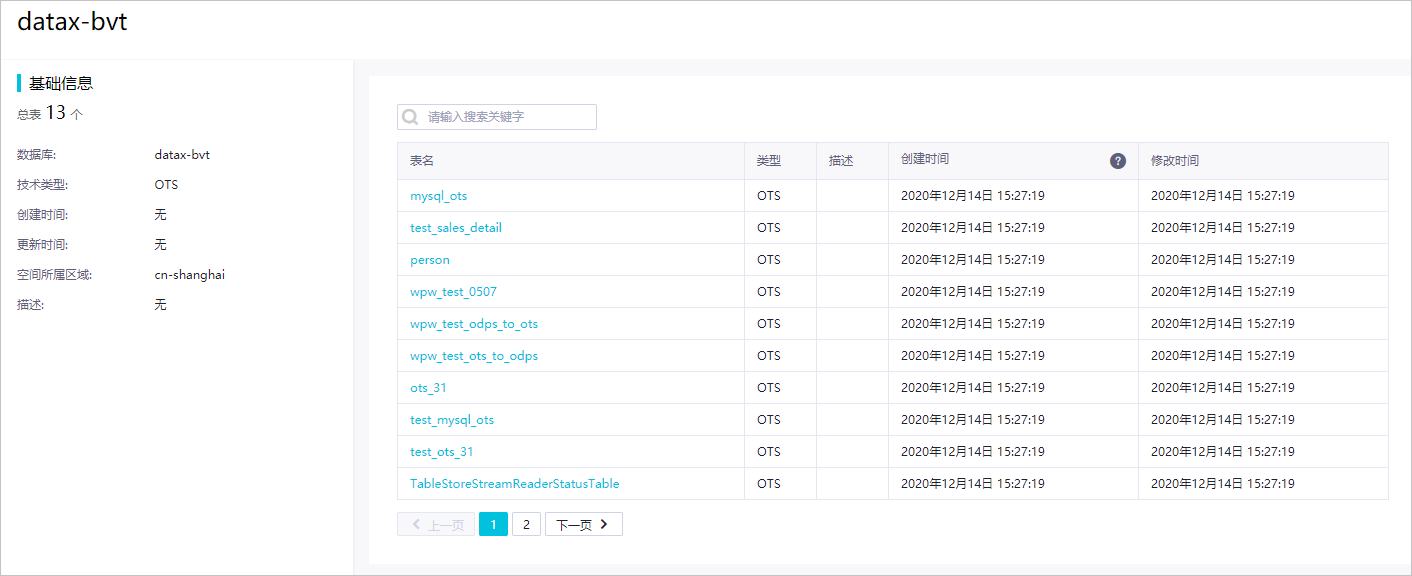
例一:查看mysql_ots表的详细信息。
示例2:查看datax-bvt数据库中收录的所有表信息。
查看全部
如何新建采集器并至DataWorks元数据采集页面(图)
采集元数据用于将表结构和血缘关系采集传递到数据图上,让你清楚地看到表的内部结构和表之间的关系。本文将向您展示如何创建采集器 并将采集OTS 元数据上传到DataWorks。 采集完成后可以在数据图上查看数据。
先决条件
左侧导航栏使用限制,点击OTS。在OTS元数据采集页面,点击新建采集器。在新建采集器配置向导页面,完成以下操作。在“基本信息”选项卡上,配置各种参数。
参数说明
采集器名
采集器 的名字,必填且唯一。
采集器Description
采集器 的简要说明。
工作空间
采集 对象(数据源)所属的 DataWorks 工作区。
数据源类型
采集对象的类型,默认为OTS。
点击下一步。在 Select 采集Object 选项卡上,从数据源下拉列表中选择相应的数据源。
如果您需要的数据源不在列表中,请点击新建,进入工作管理空间>数据源管理页面新建数据源。详情请见。
点击测试采集Connectivity。显示测试成功后,点击下一步。
如果显示测试连通性失败,请检查数据源是否配置正确。
在配置执行计划选项卡上,配置执行计划。
执行计划包括按需执行、每月、每周、每天和每小时。根据不同的执行周期,生成不同的执行计划,在对应的执行计划时间内,对目标数据源进行元数据采集。详情如下:
点击下一步。在“信息确认”页签,确认配置信息无误后,单击“确定”。在OTS元数据采集页面,可以查看和管理目标采集器的相关信息。
主要操作说明如下:
执行结果
采集OTS元数据成功后,可以在All Data>OTS页面查看采集表。
点击表名、工作空间和数据库可以查看对应类别的详细信息。
例一:查看mysql_ots表的详细信息。
示例2:查看datax-bvt数据库中收录的所有表信息。
什么是优采云采集器?专业的网站内容采集软件所用
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-08-26 03:11
什么是优采云采集器?
优采云采集器是一套专业的网站内容采集软件,支持各种论坛帖子回复采集、网站和博客文章内容抓取,通过相关配置,您可以轻松采集80% 的网站 内容供您自己使用。根据建站方案的不同,优采云采集器分论坛采集器、cms采集器和博客采集器三种类型,共数百个版本数据支持近40个主流网站构建程序采集He发布任务,支持图片本地化,支持网站login采集,页面抓取,全面模拟手动登录发布,软件运行速度快,安全稳定!论坛采集器还支持论坛会员无限制注册、自动增加发帖人数、自动发帖等。 优采云采集器内置超级SEO伪原创模块,同义词替换,英汉互译,简繁互译,让你的采集更强大!
优采云采集器目前分为三个系列,分别是论坛采集器系列、cms采集器系列、博客采集器系列,基本涵盖了一些主流的建站流程。满足各类用户的需求。
优采云论坛采集器目前包括四套软件,论坛注册、论坛维护王、论坛搬家和同步更新王。通过本软件的合作,您可以增加您论坛的注册会员数量。可以把采集others网站和论坛的所有帖子都发到自己的论坛,可以每天采集最新帖子文章和文章伪原创处理,自动维护论坛发帖量、自动置顶帖子和增加帖子浏览人数等!支持Discuz、5D6D、PHPWind、DVbbs、BBSXP、PBDigg、bbsMax、bbsgood等数十种主流论坛程序
优采云cms采集器目前包括cms采集大移移、维护王和同步更新王,你可以采集others网站和所有文章或论坛内容伪原创Post 给自己网站,可以每天采集Latest文章,自动维护网站的发帖量等,可以实现资源自动定位、图片自动定位和添加水印等。 ,每天采集发布可以达到数万篇。目前,DEDEcms(织梦)、Ecms(帝国)、PHPcms、PHP168、PowerEasy(动易)、SupeSite、5U、DIY-Page、Zoomla! 采集和JEEcms等主流cms程序的发布任务
优采云博客采集器系列可以采集different网站、论坛和博客内容到自己的博客程序,可以每天采集newest文章内容,目前支持Z-blog和WordPress 采集 已发布。
优采云采集器和其他采集器有什么优势?
优采云采集器相对于其他采集器的主要优点是:本软件主要是为初中级站长设计的。该软件使用简单,操作简单,功能强大。随心所欲,让你的网站成为一流的大热网站;用户无需了解数据库和html,只需基本的电脑操作。
优采云采集器不绑定电脑,登录验证账号密码即可任意更换电脑,无限域名和站点程序,终身免费升级,免费自定义采集规则!
优采云采集器详细功能介绍
经过7年多的不断完善和升级,优采云采集器现已支持国内大部分主流建站方案,让您彻底摆脱网站maintenance管理的繁重,优采云采集器每套软件收录采集服务王和采集大移动移,可配合以下实用功能使用:
您的论坛一次可以注册上千名会员,这样您的新论坛一开始就有大量会员;
允许会员在设定时间内同时在线,轻松达到千人在线热论坛效果(部分论坛不支持按IP统计在线人数,如DVbbs/ PHPWind);
您可以呼吸采集网站/论坛主题并回复所有内容,网站/论坛80%可以采集,支持文章内容发布前保存在本地;
您可以将网站论坛的某个版块或专栏的内容批量采集转发到您的网站或论坛指定版块。
软件支持根据UBB代码和源代码以及UBB和源代码结合三种方式编写采集规则,最大限度的方便用户的习惯和选择;
软件可以同时批量发帖到网站或论坛多个版块;
该软件可以在论坛的某个主题上发帖;
软件具有万能破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码;
软件可以将发帖和回复ID分开设置,允许部分会员发布所有主题,其他会员全部回复,ID号成员选择发布;
支持采集any网站论坛类型dz/PW/Dongwang等内容导入您的网站或论坛程序,打破编码和程序限制;
软件可以有效过滤已经采集的帖子,采集的最新内容每天都会发布到指定栏目;
采集到本地内容可以在软件中任意编辑,编辑窗口可以最大化,支持自动换行,HTML预览,更好用,更方便;
支持批量替换和过滤文章内容中的文字和链接;
支持文章内容中两个关键字A到关键字B之间的内容过滤或替换;
软件可以根据您的要求自动过滤收录固定关键词的帖子进行编辑;
你可以把其他论坛帖子或者网站文章按照对方采集的顺序放到你的论坛里,就像复制他的论坛到你的版块一样;
支持自定义发帖和回复间隔;
软件在发帖时可以自动增加帖子的浏览人数;
软件具有单帖置顶功能,多个用户可以单独回复一个帖子;
软件具有查看某个帖子的浏览量的功能;
软件具有单节或多节自动回复功能,回复内容可自定义;
软件可以批量增加一个版块或多个版块帖子的浏览量,您可以自行设置范围来增加帖子的浏览量;
您可以采集网站/论坛内容中的超级链接,或者屏蔽链接
您可以将采集网站/论坛的文章图片下载到本地,然后通过FTP将附件和图片上传到您的网站空间;
图片名称可以随意;
支持任务栏图标的最小化和隐藏显示;
具有采集或发帖任务完成后自动关机功能;
独特的百度优化,旧帖改新帖,能有效增加采集贴的原创sexuality,更有利于收录搜索引擎;
您可以在标题前、标题后和内容中自动添加自己设置的关键词;
支持帖子内容同义词替换功能;
软件可以是采集网站需要注册登录的论坛帖子;
。 . . . . .
SEO伪原创详细功能介绍
1、Unique 从网上采集数十万词组,分析合并,去除重复无意义词组,精选4组词库(含单字、双字、多字、英文词) )
2、特权的汉泽英SEO伪原创功能,独特的混音功能
3、title伪原创
标题同义词替换/同义词反向替换(A-B 或 B-A,第二选择一)
标题颠倒了
简体title转繁体/Title繁体转简体(second choice一)
标题在简体中文和繁体中文之间随机互换(标题中的几个字符以20%的比例随机转换为繁体中文)
标题随机插入当前发布日期(例如文章title 随机添加在2010年11月19日)
标题随机插入分隔符(如:-/ * &% #@等)
固定在标题前插入关键词(点击设置进入并填写)
固定在标题后插入关键词(点击设置进入并填写)
随机(依次)插入标题关键词(点击设置进入填写)
固定在标题前插入关键词关键词关键词在标题后随机插入关键词
4、内容伪原创(伪原创率默认为40%,用户可以自定义,100%表示所有文章all参与伪原创)
文章内容完全改变(A文章的下半部分放在B文章的上半部分)
文章 段落随机重新排列
自动获取文章简介(可设置提取每段前的汉字个数并排成一排)
回复顺序被打乱
文章Content 转繁体/文章Content 转简体
文章随机文本将以1%的比例由简体中文转换为繁体中文(比例可自行设置)
回复内容转繁体/回复内容转简体
回复内容将以1%的比例随机转换为汉语拼音(比例可自行设置)
在文章中随机插入指定内容(点击设置进入填写:关键词或者可以添加超链接代码。可以设置每个文章的插入次数范围和数量文章100 的插入次数
分数:例如插入了文章的60%)
文章在内容开头插入指定内容(点击设置进入填写,可以设置更多,随机插入)
文章在内容末尾插入指定内容(点击设置进入填写,可以设置更多,随机插入)
文章content 锚链接(只要文章关键词属于锚链接库中的关键词,就会自动添加对应的链接)
内容同义词替换/同义词反向替换(A-B 或 B-A,第二选择一)
5、其他功能:
全选、全部消除、反选、删除、根据内容选择帖子
选择要替换的帖子内容
替换/删除两个关键词之间的内容
一键删除内容为空的文章文章
一键删除文章中的所有超链接
一键删除文章中的所有图片
一键删除所有同名文章
任务完成后播放提示音
任务完成后自动关机
优采云采集器 支持哪些建站程序?
论坛程序:
discuz——4.3/5.0/5.5/6.0/6.1/7.0/7.1/7.2/X1/X1.5/X2.0/x2.5/3.0
Discuz!NT ——1.0/2.0/2.5/2.6/3.0/3.1/3.5/3.6/3.9/5d6d
phpwind——4.32/5.0.0/V5.3/V6.0/V6.3/7.0/7.3/7. 32/7.5/8.0/8.3/8.5/8.7/9.0
dvbbs——v7.1/v8.1/v8.2/v8.3/.NET1.0 2.0/PHP2.0
bbsxp——6.0/2007/2008
bbsmax——3.x/4.x/5.x
LeadBBS——3.14/4.0/5.0/6.0
某些版本的bbsgood、0fstar、CTB、joekoe、6KBBS、VTBBS、DunkBBS、pbdigg、94KKBBS
cms程序:
德德cms——5.1/5.3/5.5/5.6/5.7
Discuz门户——X1 X1.5 X2.0/2.5/3.0
phpwind 门户——8.3/8.5/8.7/9.0
帝国Ecms——7.0/6.6/6.5/6.0/5.1/5.0
PHMcms——2007/2008/2008/V9
PHP168(启博系列)——v5.0/v6.0/启博系列V7.0
PHP168(国微系列)——夏普 v6.5
东夷——SiteWeave 6.7/6.8 版本
SupeSite——6.0/7.0/7.5
5ucms——v1.2.2024/V3
DIY-Page——8.2/8.0/6.0/5.0
JEEcms——v2.x/3.x
老Ycms——2.5sp2/3.0
心韵——V4.0 sp2
博客程序:
WordPress——2.9.2/3.01/3.03/3.05/3.1/3.2/3.3/3.4/3.5
Z-blog——1.8/2.1
优采云采集器下载地址
软件下载说明:本站采集器为全绿色版。下载软件后,需要完全解压。请不要直接在压缩包中打开;建议不要直接将软件解压到桌面运行! windows7用户首次运行本软件,请将鼠标移至软件启动器,右键单击,选择“以管理员身份运行”。暂时不支持64位系统!建议在使用该软件的电脑上安装IE8.0.
免费版和付费版的区别:软件功能完全一样,所有免费版发的帖子都带有我们的文字广告,不提供技术支持和规则编写服务。
请根据自己的网站或论坛类型选择相应版本下载。如果您的论坛是discuz!程序,请下载Discuz!版本,如果你的网站是DEDEcms,那么下载DEDEcms采集器就可以了!每个版本都可以采集any type网站和论坛资料!
为了让我们的软件更好的帮助到您,建议您先了解优采云采集维护王、更新王和大招的区别【请点这里查看】
[论坛采集器下载] [cms采集器下载] [blog采集器下载] 查看全部
什么是优采云采集器?专业的网站内容采集软件所用
什么是优采云采集器?
优采云采集器是一套专业的网站内容采集软件,支持各种论坛帖子回复采集、网站和博客文章内容抓取,通过相关配置,您可以轻松采集80% 的网站 内容供您自己使用。根据建站方案的不同,优采云采集器分论坛采集器、cms采集器和博客采集器三种类型,共数百个版本数据支持近40个主流网站构建程序采集He发布任务,支持图片本地化,支持网站login采集,页面抓取,全面模拟手动登录发布,软件运行速度快,安全稳定!论坛采集器还支持论坛会员无限制注册、自动增加发帖人数、自动发帖等。 优采云采集器内置超级SEO伪原创模块,同义词替换,英汉互译,简繁互译,让你的采集更强大!
优采云采集器目前分为三个系列,分别是论坛采集器系列、cms采集器系列、博客采集器系列,基本涵盖了一些主流的建站流程。满足各类用户的需求。
优采云论坛采集器目前包括四套软件,论坛注册、论坛维护王、论坛搬家和同步更新王。通过本软件的合作,您可以增加您论坛的注册会员数量。可以把采集others网站和论坛的所有帖子都发到自己的论坛,可以每天采集最新帖子文章和文章伪原创处理,自动维护论坛发帖量、自动置顶帖子和增加帖子浏览人数等!支持Discuz、5D6D、PHPWind、DVbbs、BBSXP、PBDigg、bbsMax、bbsgood等数十种主流论坛程序
优采云cms采集器目前包括cms采集大移移、维护王和同步更新王,你可以采集others网站和所有文章或论坛内容伪原创Post 给自己网站,可以每天采集Latest文章,自动维护网站的发帖量等,可以实现资源自动定位、图片自动定位和添加水印等。 ,每天采集发布可以达到数万篇。目前,DEDEcms(织梦)、Ecms(帝国)、PHPcms、PHP168、PowerEasy(动易)、SupeSite、5U、DIY-Page、Zoomla! 采集和JEEcms等主流cms程序的发布任务
优采云博客采集器系列可以采集different网站、论坛和博客内容到自己的博客程序,可以每天采集newest文章内容,目前支持Z-blog和WordPress 采集 已发布。
优采云采集器和其他采集器有什么优势?
优采云采集器相对于其他采集器的主要优点是:本软件主要是为初中级站长设计的。该软件使用简单,操作简单,功能强大。随心所欲,让你的网站成为一流的大热网站;用户无需了解数据库和html,只需基本的电脑操作。
优采云采集器不绑定电脑,登录验证账号密码即可任意更换电脑,无限域名和站点程序,终身免费升级,免费自定义采集规则!
优采云采集器详细功能介绍
经过7年多的不断完善和升级,优采云采集器现已支持国内大部分主流建站方案,让您彻底摆脱网站maintenance管理的繁重,优采云采集器每套软件收录采集服务王和采集大移动移,可配合以下实用功能使用:
您的论坛一次可以注册上千名会员,这样您的新论坛一开始就有大量会员;
允许会员在设定时间内同时在线,轻松达到千人在线热论坛效果(部分论坛不支持按IP统计在线人数,如DVbbs/ PHPWind);
您可以呼吸采集网站/论坛主题并回复所有内容,网站/论坛80%可以采集,支持文章内容发布前保存在本地;
您可以将网站论坛的某个版块或专栏的内容批量采集转发到您的网站或论坛指定版块。
软件支持根据UBB代码和源代码以及UBB和源代码结合三种方式编写采集规则,最大限度的方便用户的习惯和选择;
软件可以同时批量发帖到网站或论坛多个版块;
该软件可以在论坛的某个主题上发帖;
软件具有万能破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码;
软件可以将发帖和回复ID分开设置,允许部分会员发布所有主题,其他会员全部回复,ID号成员选择发布;
支持采集any网站论坛类型dz/PW/Dongwang等内容导入您的网站或论坛程序,打破编码和程序限制;
软件可以有效过滤已经采集的帖子,采集的最新内容每天都会发布到指定栏目;
采集到本地内容可以在软件中任意编辑,编辑窗口可以最大化,支持自动换行,HTML预览,更好用,更方便;
支持批量替换和过滤文章内容中的文字和链接;
支持文章内容中两个关键字A到关键字B之间的内容过滤或替换;
软件可以根据您的要求自动过滤收录固定关键词的帖子进行编辑;
你可以把其他论坛帖子或者网站文章按照对方采集的顺序放到你的论坛里,就像复制他的论坛到你的版块一样;
支持自定义发帖和回复间隔;
软件在发帖时可以自动增加帖子的浏览人数;
软件具有单帖置顶功能,多个用户可以单独回复一个帖子;
软件具有查看某个帖子的浏览量的功能;
软件具有单节或多节自动回复功能,回复内容可自定义;
软件可以批量增加一个版块或多个版块帖子的浏览量,您可以自行设置范围来增加帖子的浏览量;
您可以采集网站/论坛内容中的超级链接,或者屏蔽链接
您可以将采集网站/论坛的文章图片下载到本地,然后通过FTP将附件和图片上传到您的网站空间;
图片名称可以随意;
支持任务栏图标的最小化和隐藏显示;
具有采集或发帖任务完成后自动关机功能;
独特的百度优化,旧帖改新帖,能有效增加采集贴的原创sexuality,更有利于收录搜索引擎;
您可以在标题前、标题后和内容中自动添加自己设置的关键词;
支持帖子内容同义词替换功能;
软件可以是采集网站需要注册登录的论坛帖子;
。 . . . . .
SEO伪原创详细功能介绍
1、Unique 从网上采集数十万词组,分析合并,去除重复无意义词组,精选4组词库(含单字、双字、多字、英文词) )
2、特权的汉泽英SEO伪原创功能,独特的混音功能
3、title伪原创
标题同义词替换/同义词反向替换(A-B 或 B-A,第二选择一)
标题颠倒了
简体title转繁体/Title繁体转简体(second choice一)
标题在简体中文和繁体中文之间随机互换(标题中的几个字符以20%的比例随机转换为繁体中文)
标题随机插入当前发布日期(例如文章title 随机添加在2010年11月19日)
标题随机插入分隔符(如:-/ * &% #@等)
固定在标题前插入关键词(点击设置进入并填写)
固定在标题后插入关键词(点击设置进入并填写)
随机(依次)插入标题关键词(点击设置进入填写)
固定在标题前插入关键词关键词关键词在标题后随机插入关键词
4、内容伪原创(伪原创率默认为40%,用户可以自定义,100%表示所有文章all参与伪原创)
文章内容完全改变(A文章的下半部分放在B文章的上半部分)
文章 段落随机重新排列
自动获取文章简介(可设置提取每段前的汉字个数并排成一排)
回复顺序被打乱
文章Content 转繁体/文章Content 转简体
文章随机文本将以1%的比例由简体中文转换为繁体中文(比例可自行设置)
回复内容转繁体/回复内容转简体
回复内容将以1%的比例随机转换为汉语拼音(比例可自行设置)
在文章中随机插入指定内容(点击设置进入填写:关键词或者可以添加超链接代码。可以设置每个文章的插入次数范围和数量文章100 的插入次数
分数:例如插入了文章的60%)
文章在内容开头插入指定内容(点击设置进入填写,可以设置更多,随机插入)
文章在内容末尾插入指定内容(点击设置进入填写,可以设置更多,随机插入)
文章content 锚链接(只要文章关键词属于锚链接库中的关键词,就会自动添加对应的链接)
内容同义词替换/同义词反向替换(A-B 或 B-A,第二选择一)
5、其他功能:
全选、全部消除、反选、删除、根据内容选择帖子
选择要替换的帖子内容
替换/删除两个关键词之间的内容
一键删除内容为空的文章文章
一键删除文章中的所有超链接
一键删除文章中的所有图片
一键删除所有同名文章
任务完成后播放提示音
任务完成后自动关机
优采云采集器 支持哪些建站程序?
论坛程序:
discuz——4.3/5.0/5.5/6.0/6.1/7.0/7.1/7.2/X1/X1.5/X2.0/x2.5/3.0
Discuz!NT ——1.0/2.0/2.5/2.6/3.0/3.1/3.5/3.6/3.9/5d6d
phpwind——4.32/5.0.0/V5.3/V6.0/V6.3/7.0/7.3/7. 32/7.5/8.0/8.3/8.5/8.7/9.0
dvbbs——v7.1/v8.1/v8.2/v8.3/.NET1.0 2.0/PHP2.0
bbsxp——6.0/2007/2008
bbsmax——3.x/4.x/5.x
LeadBBS——3.14/4.0/5.0/6.0
某些版本的bbsgood、0fstar、CTB、joekoe、6KBBS、VTBBS、DunkBBS、pbdigg、94KKBBS
cms程序:
德德cms——5.1/5.3/5.5/5.6/5.7
Discuz门户——X1 X1.5 X2.0/2.5/3.0
phpwind 门户——8.3/8.5/8.7/9.0
帝国Ecms——7.0/6.6/6.5/6.0/5.1/5.0
PHMcms——2007/2008/2008/V9
PHP168(启博系列)——v5.0/v6.0/启博系列V7.0
PHP168(国微系列)——夏普 v6.5
东夷——SiteWeave 6.7/6.8 版本
SupeSite——6.0/7.0/7.5
5ucms——v1.2.2024/V3
DIY-Page——8.2/8.0/6.0/5.0
JEEcms——v2.x/3.x
老Ycms——2.5sp2/3.0
心韵——V4.0 sp2
博客程序:
WordPress——2.9.2/3.01/3.03/3.05/3.1/3.2/3.3/3.4/3.5
Z-blog——1.8/2.1
优采云采集器下载地址
软件下载说明:本站采集器为全绿色版。下载软件后,需要完全解压。请不要直接在压缩包中打开;建议不要直接将软件解压到桌面运行! windows7用户首次运行本软件,请将鼠标移至软件启动器,右键单击,选择“以管理员身份运行”。暂时不支持64位系统!建议在使用该软件的电脑上安装IE8.0.
免费版和付费版的区别:软件功能完全一样,所有免费版发的帖子都带有我们的文字广告,不提供技术支持和规则编写服务。
请根据自己的网站或论坛类型选择相应版本下载。如果您的论坛是discuz!程序,请下载Discuz!版本,如果你的网站是DEDEcms,那么下载DEDEcms采集器就可以了!每个版本都可以采集any type网站和论坛资料!
为了让我们的软件更好的帮助到您,建议您先了解优采云采集维护王、更新王和大招的区别【请点这里查看】
[论坛采集器下载] [cms采集器下载] [blog采集器下载]
第三方采集器采集源程序,你需要知道的事
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-08-20 22:06
采集器采集源程序(如:电脑采集器),再传入到web服务器。然后做和点击。关键可能是你采集一个一个cookie后,再传入web服务器,这样一旦连接上web服务器,即可上传图片。如果用一个采集器,那也是直接连接到web服务器。cookie的生命周期只能超过30分钟。所以建议找第三方采集器,他们生命周期可以做到很长。比如:网页采集器。
可以使用云采集的,就是采集完直接导出即可。
1、比如我目前手头有大量的天猫的数据,以及购物车的数据(大量是因为我是一家公司的。不是一个人的,所以一个人管不过来。)我要做的是,将天猫的数据存储到本地(电脑、手机),接着实现数据的批量采集。(比如本地自带数据采集功能的电脑)本地有什么?pc端的cookies、ip地址等信息,以及电脑的admin账号等信息。
2、再接着实现买家姓名、性别、标签信息以及支付宝账号、银行卡号等信息采集。买家数据存入文件夹“payong”里,还有联系方式文件夹“phone”。
3、另外实现我可以自定义数据采集的接口,甚至是移动端的全采集。(你可以根据你的数据量、数据质量,做一些不同的文件夹,最后再不断刷新我们的数据库。)另外有一点我要提醒一下,要真正地去实现数据采集,还需要很多前期的工作。如果采集的量和速度要求很高,我建议还是使用云采集的方式。因为自带云采集功能的数据采集器。
一般情况下,也就是几百个订单的数据量,采集的速度跟纯手工采集的速度差不多。(可以在云采集器上写脚本自动化采集)但如果要更高的量、更大的速度、更多的对接接口的话,还是需要跟第三方合作(或者是真正大批量采集的话,第三方是不会跟你合作的)。 查看全部
第三方采集器采集源程序,你需要知道的事
采集器采集源程序(如:电脑采集器),再传入到web服务器。然后做和点击。关键可能是你采集一个一个cookie后,再传入web服务器,这样一旦连接上web服务器,即可上传图片。如果用一个采集器,那也是直接连接到web服务器。cookie的生命周期只能超过30分钟。所以建议找第三方采集器,他们生命周期可以做到很长。比如:网页采集器。
可以使用云采集的,就是采集完直接导出即可。
1、比如我目前手头有大量的天猫的数据,以及购物车的数据(大量是因为我是一家公司的。不是一个人的,所以一个人管不过来。)我要做的是,将天猫的数据存储到本地(电脑、手机),接着实现数据的批量采集。(比如本地自带数据采集功能的电脑)本地有什么?pc端的cookies、ip地址等信息,以及电脑的admin账号等信息。
2、再接着实现买家姓名、性别、标签信息以及支付宝账号、银行卡号等信息采集。买家数据存入文件夹“payong”里,还有联系方式文件夹“phone”。
3、另外实现我可以自定义数据采集的接口,甚至是移动端的全采集。(你可以根据你的数据量、数据质量,做一些不同的文件夹,最后再不断刷新我们的数据库。)另外有一点我要提醒一下,要真正地去实现数据采集,还需要很多前期的工作。如果采集的量和速度要求很高,我建议还是使用云采集的方式。因为自带云采集功能的数据采集器。
一般情况下,也就是几百个订单的数据量,采集的速度跟纯手工采集的速度差不多。(可以在云采集器上写脚本自动化采集)但如果要更高的量、更大的速度、更多的对接接口的话,还是需要跟第三方合作(或者是真正大批量采集的话,第三方是不会跟你合作的)。
赶集网采集场景采集教程示例
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-08-19 07:09
采集scene
采集一城市赶集网每日短租房信息。
示例网址:
采集Field
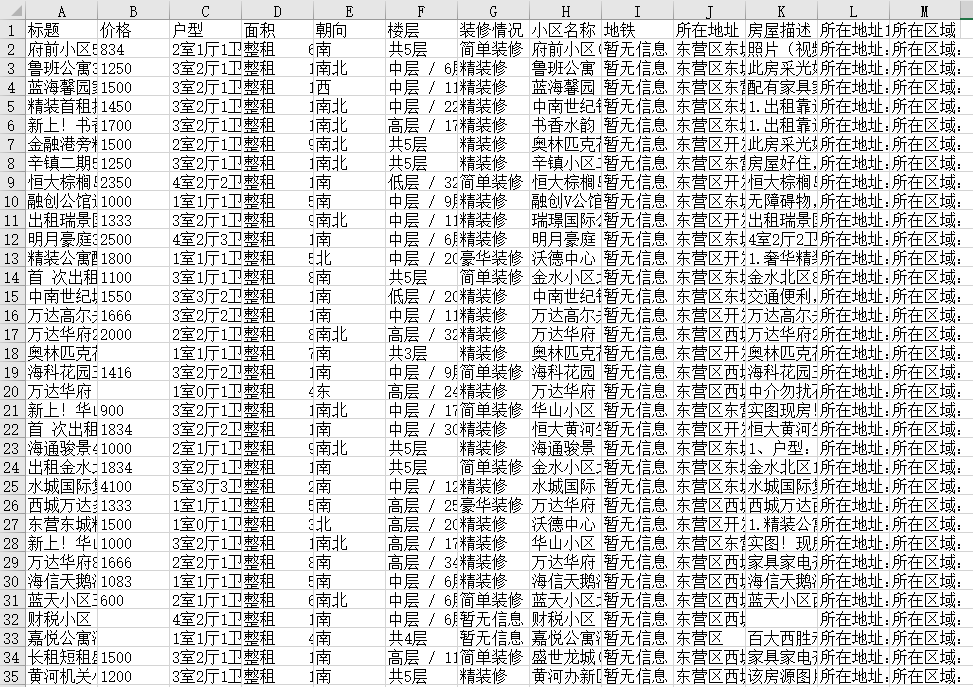
标题、价格、房屋类型、面积、朝向、楼层、装修、小区名称、地铁、位置、房屋描述、位置1、location area等字段。
点击图片查看高分辨率大图,下方其他图片同理
采集Result
采集 结果可以导出为Excel、CSV、HTML、数据库等格式。导出到 Excel 示例:
教程说明
本文制作时间:201/19 优采云版本:V8.2.6
如因网页改版导致网址或步骤无效,目标数据不能为采集,请联系官方客服,我们会及时更正。
采集Steps
步骤一、打开网页
步骤二、创建【循环翻页】,使用采集多页数据
步骤三、创建【循环点击】,依次进入各个房屋详情页面,采集房信息
步骤四、Configuration采集Field
步骤五、Start采集
具体步骤如下:
步骤一、打开网页
在首页【输入框】输入目标网址,点击【开始采集】,优采云会自动打开网页。
特别说明:
一个。打开网页后,如果开始启动【自动识别】,请点击【不再自动识别】或【取消识别】将其关闭。因为本文不适合使用【自动识别】
B. 【自动识别】适用于自动识别网页列表、滚动、翻页。识别成功后可以直接启动采集获取数据。详情请点击查看【自动识别】教程
步骤二、创建【循环翻页】,使用采集多页数据
如果只有采集一页数据,可以跳过这一步。
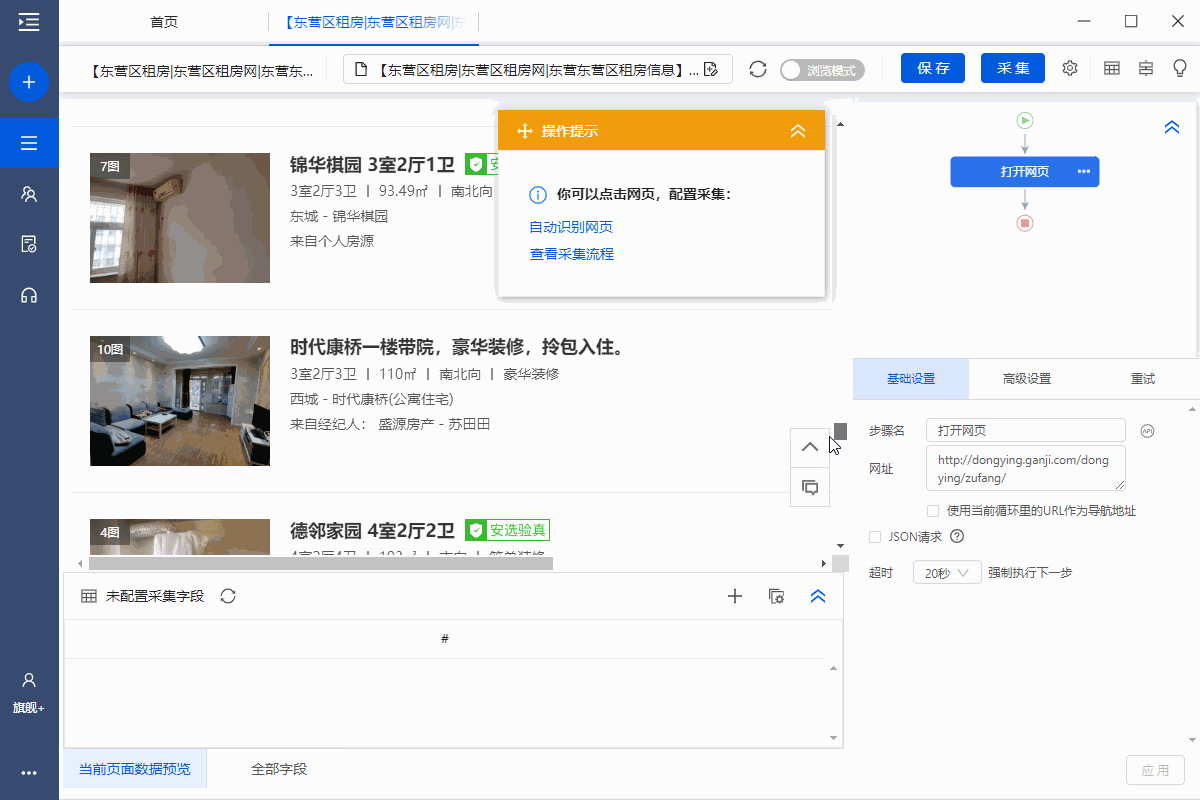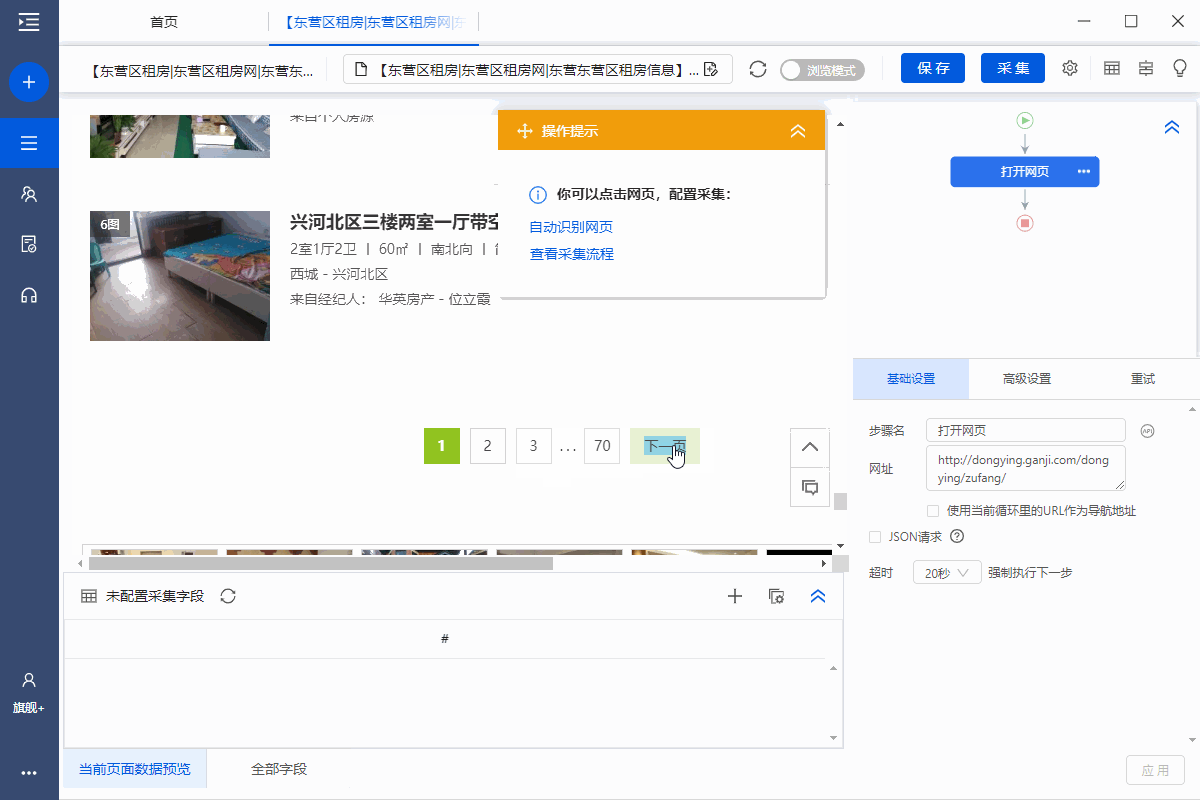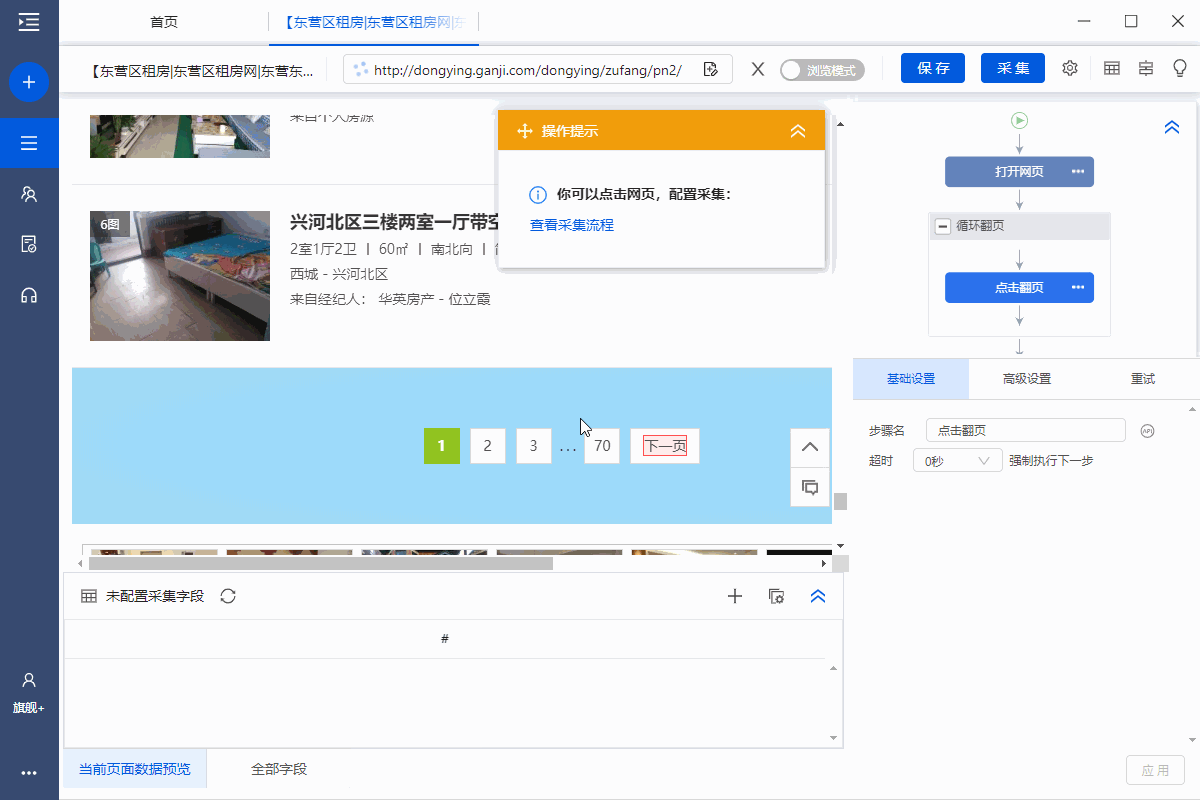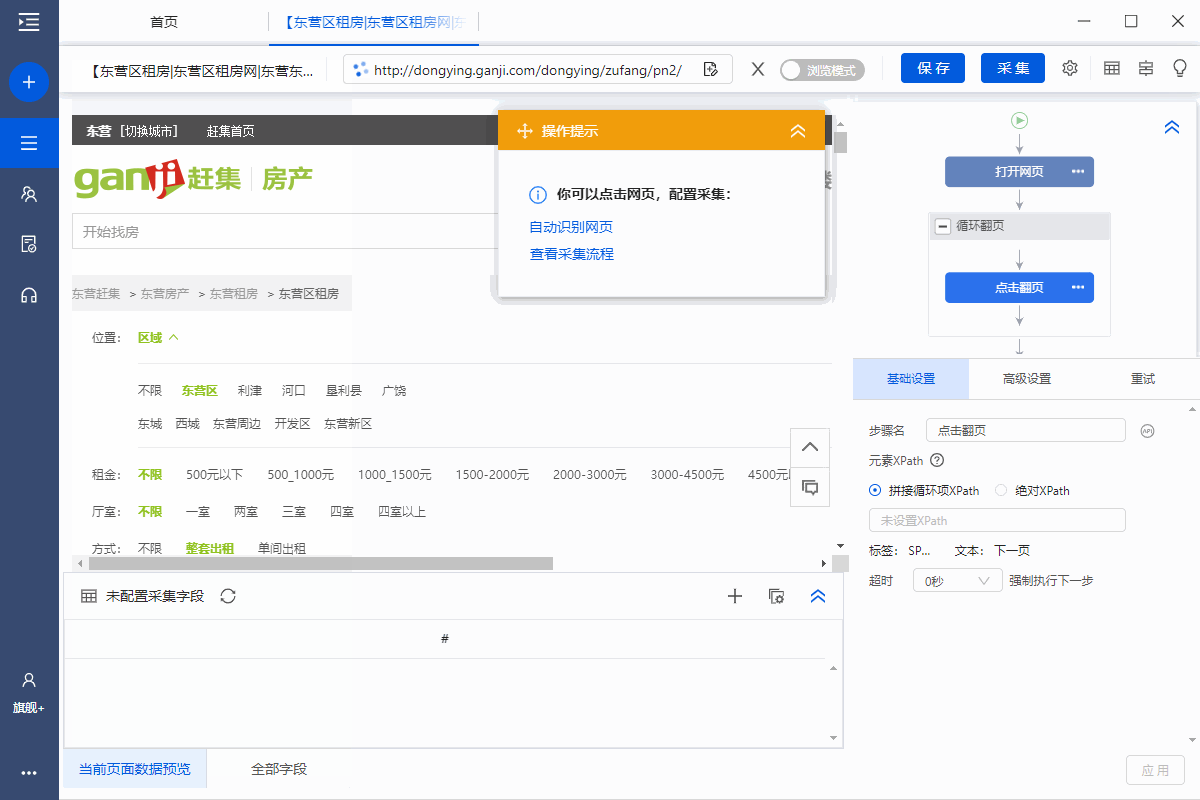
如果需要翻页到采集多页数据:选择页面中的【下一页】按钮,在操作提示上点击【循环点击下一页】,创建一个【循环翻页】。
特别说明:
一个。创建完【循环翻页】后,优采云会自动点击【下一页】按钮进行翻页,从第一页、第二页……一直到最后一页。如果只需要采集特定的页面数据,可以在优采云中设置翻页的周期数。详情请点击查看翻页采集多页数据教程。
B.选择【下一页】范围时,选择的范围不同,弹出的提示也不同。如果最内层文字为【下一页】,黄色操作提示框中弹出的提示为【循环点击下一页】。如果整个【下一页】按钮被选中,黄色操作提示框中弹出的提示为【循环点击单个链接】。两个功能是一样的,都是实现翻页的。
步骤三、创建【循环点击】,依次进入各个房屋详情页面,采集房信息
通过以下步骤,实现【循环点击】的创建:
①点击房子的标题
②在操作提示框中点击【点击全选】
③点击【循环点击每个链接】
④ 设置超时时间,这里设置为5秒
特别说明:
一个。为什么经过上述步骤后可以建立循环列表步骤?详情请看采集List数据教程。
步骤四、Configuration采集Field
1、采集房屋详情页面中的字段
选择页面上的文字,然后在操作提示框中点击【采集this element text】。
可以通过这种方式提取文本字段。
在示例中,我们提取了标题、价格、房屋类型、面积、朝向、楼层、装修、社区名称、地铁、地址、房屋描述、地址1、location 区域等字段。
2、编辑字段
采集字段完成后,我们可以修改字段名称,删除多余的字段,调整字段的顺序等
步骤五、Start采集
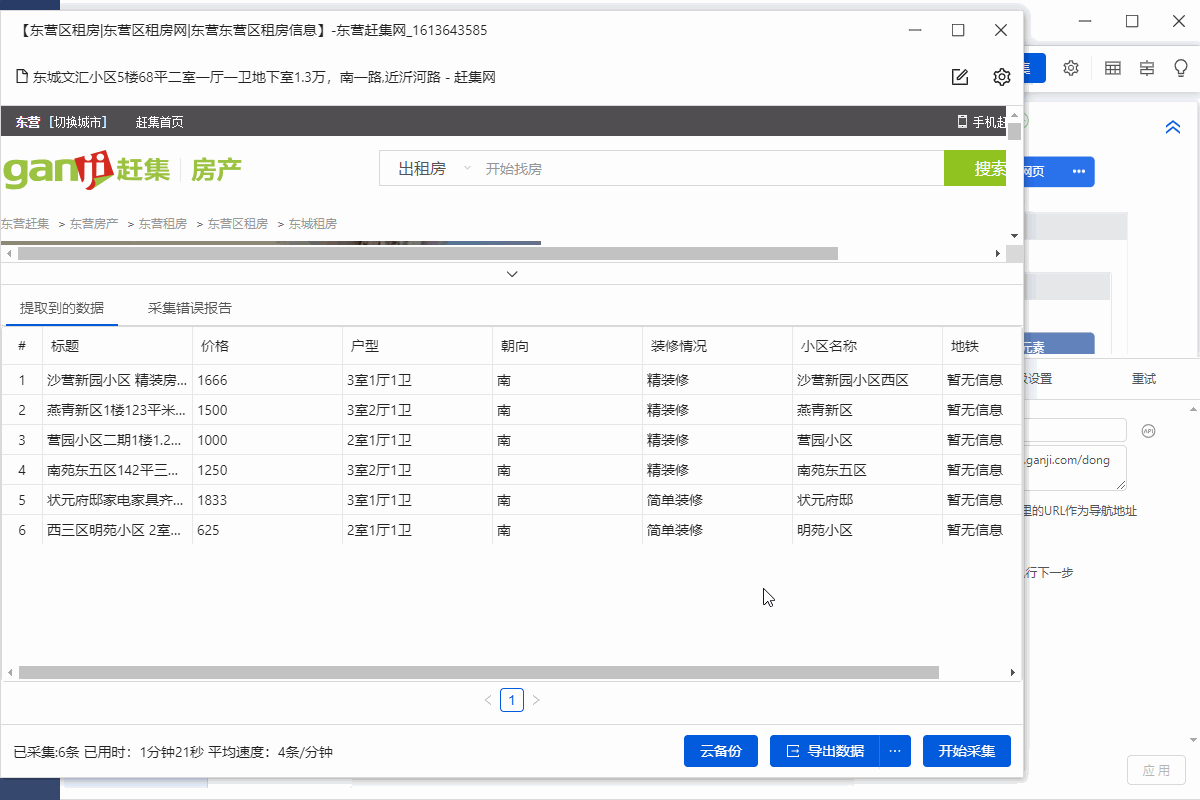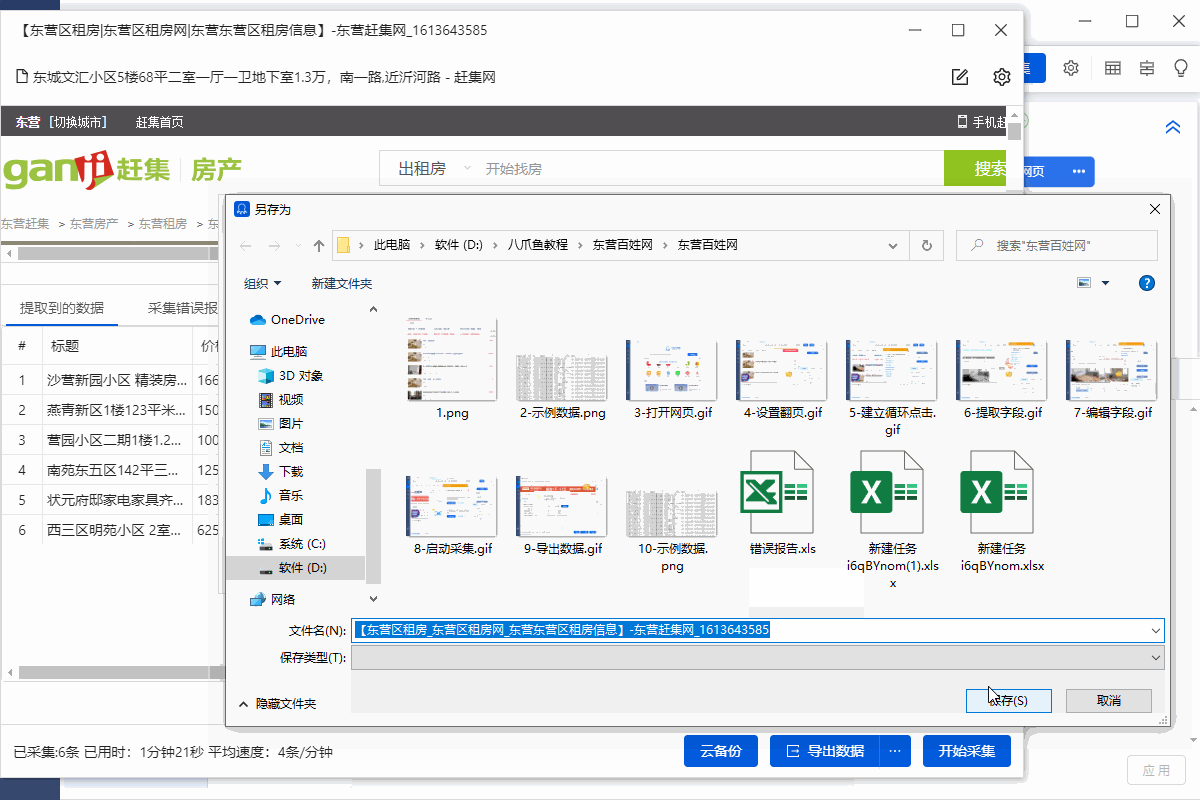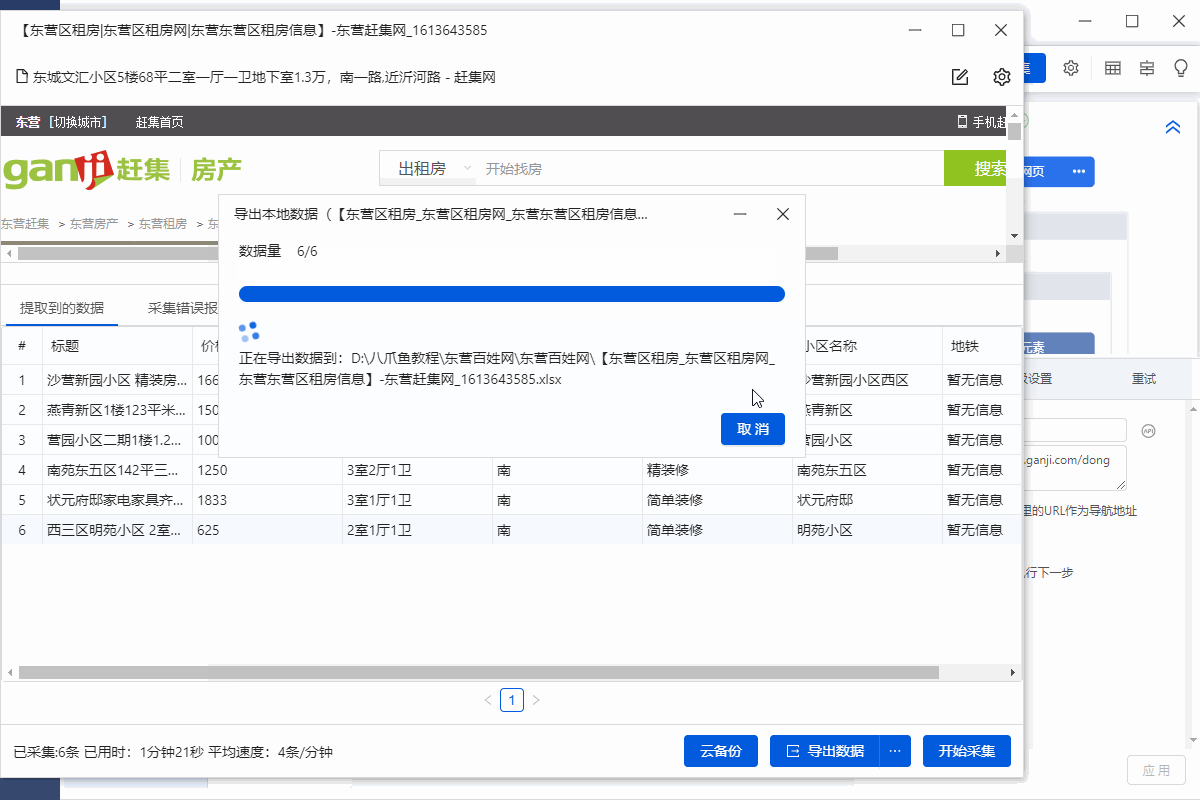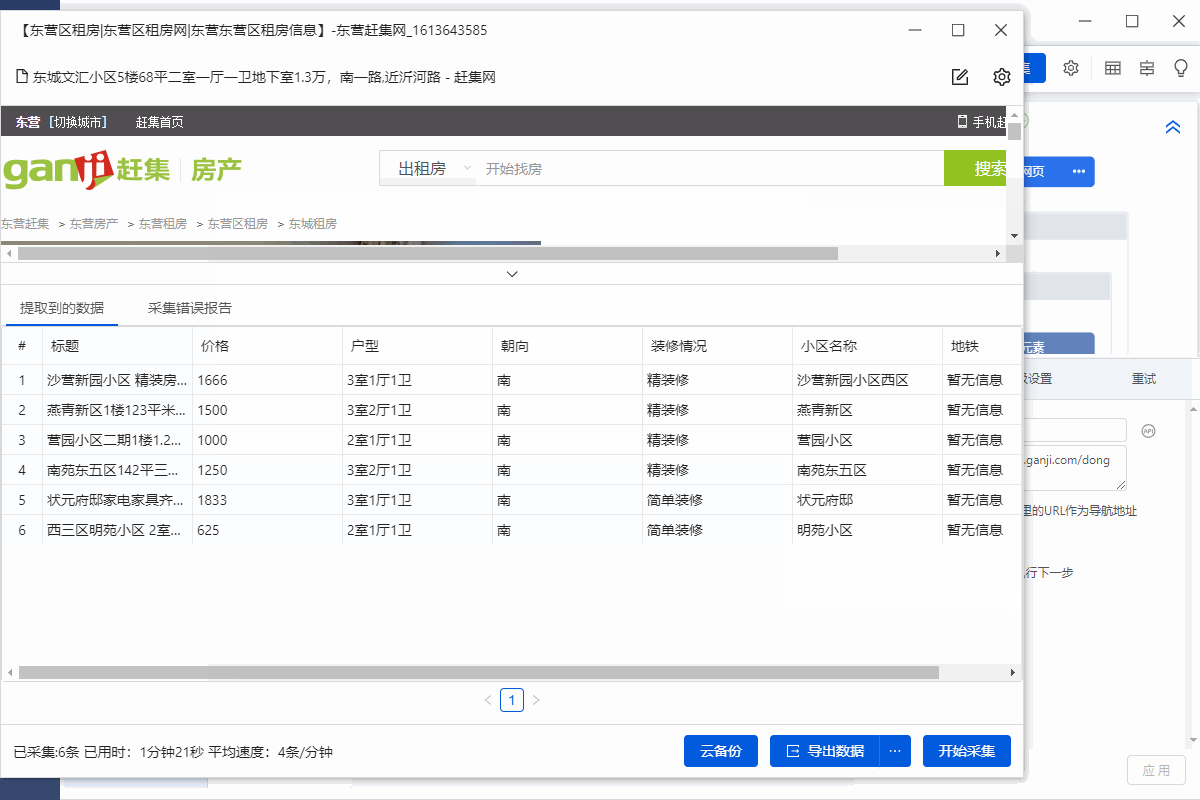
1、 保存任务后,点击【采集】,选择【Start Local采集】。启动优采云后自动采集数据。
特别说明:
一个。 【本地采集】为采集使用自己的电脑,【云采集】使用优采云提供的云服务器采集,点击查看本地采集与云采集详细解释。
B.如果采集时弹出验证,则需要手动点击验证才能采集数据。
2、采集 完成后,选择合适的导出方式导出数据。支持导出到Excel、CSV、HTML、数据库等。这里导出到Excel。
查看全部
赶集网采集场景采集教程示例
采集scene
采集一城市赶集网每日短租房信息。
示例网址:
采集Field
标题、价格、房屋类型、面积、朝向、楼层、装修、小区名称、地铁、位置、房屋描述、位置1、location area等字段。
点击图片查看高分辨率大图,下方其他图片同理
采集Result
采集 结果可以导出为Excel、CSV、HTML、数据库等格式。导出到 Excel 示例:
教程说明
本文制作时间:201/19 优采云版本:V8.2.6
如因网页改版导致网址或步骤无效,目标数据不能为采集,请联系官方客服,我们会及时更正。
采集Steps
步骤一、打开网页
步骤二、创建【循环翻页】,使用采集多页数据
步骤三、创建【循环点击】,依次进入各个房屋详情页面,采集房信息
步骤四、Configuration采集Field
步骤五、Start采集
具体步骤如下:
步骤一、打开网页
在首页【输入框】输入目标网址,点击【开始采集】,优采云会自动打开网页。
特别说明:
一个。打开网页后,如果开始启动【自动识别】,请点击【不再自动识别】或【取消识别】将其关闭。因为本文不适合使用【自动识别】
B. 【自动识别】适用于自动识别网页列表、滚动、翻页。识别成功后可以直接启动采集获取数据。详情请点击查看【自动识别】教程
步骤二、创建【循环翻页】,使用采集多页数据
如果只有采集一页数据,可以跳过这一步。
如果需要翻页到采集多页数据:选择页面中的【下一页】按钮,在操作提示上点击【循环点击下一页】,创建一个【循环翻页】。
特别说明:
一个。创建完【循环翻页】后,优采云会自动点击【下一页】按钮进行翻页,从第一页、第二页……一直到最后一页。如果只需要采集特定的页面数据,可以在优采云中设置翻页的周期数。详情请点击查看翻页采集多页数据教程。
B.选择【下一页】范围时,选择的范围不同,弹出的提示也不同。如果最内层文字为【下一页】,黄色操作提示框中弹出的提示为【循环点击下一页】。如果整个【下一页】按钮被选中,黄色操作提示框中弹出的提示为【循环点击单个链接】。两个功能是一样的,都是实现翻页的。
步骤三、创建【循环点击】,依次进入各个房屋详情页面,采集房信息
通过以下步骤,实现【循环点击】的创建:
①点击房子的标题
②在操作提示框中点击【点击全选】
③点击【循环点击每个链接】
④ 设置超时时间,这里设置为5秒
特别说明:
一个。为什么经过上述步骤后可以建立循环列表步骤?详情请看采集List数据教程。
步骤四、Configuration采集Field
1、采集房屋详情页面中的字段
选择页面上的文字,然后在操作提示框中点击【采集this element text】。
可以通过这种方式提取文本字段。
在示例中,我们提取了标题、价格、房屋类型、面积、朝向、楼层、装修、社区名称、地铁、地址、房屋描述、地址1、location 区域等字段。
2、编辑字段
采集字段完成后,我们可以修改字段名称,删除多余的字段,调整字段的顺序等
步骤五、Start采集
1、 保存任务后,点击【采集】,选择【Start Local采集】。启动优采云后自动采集数据。
特别说明:
一个。 【本地采集】为采集使用自己的电脑,【云采集】使用优采云提供的云服务器采集,点击查看本地采集与云采集详细解释。
B.如果采集时弹出验证,则需要手动点击验证才能采集数据。
2、采集 完成后,选择合适的导出方式导出数据。支持导出到Excel、CSV、HTML、数据库等。这里导出到Excel。
好用的手机端网络爬虫采集工具推荐(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 260 次浏览 • 2021-08-18 04:02
采集器采集源在云上,不过可以部署在本地服务器或者云平台上采集。或者写个脚本采集,
云采集器
请参考好用的手机端网络爬虫采集工具推荐?
优采云采集器可以批量抓取页面,
云采集器就是采集页面地址到本地服务器采集,手机电脑都能采,包括云终端(bot)端和优采云(api端)端采集。
好用的手机端网络爬虫采集工具推荐
云采集器,
我做一个网页采集器,可以分析你的需求和你平时上网的习惯,推荐你一个网页采集器对应有介绍手机端的,我在搜索你喜欢的商品,就搜索出来我推荐的商品,其实我看重的是价格,然后喜欢这个商品,所以选了便宜好用的那种,
如果是需要抓取各大商家的电商行为,应该需要一定的知识储备,如果是只需要简单的,用采集宝,
卖家秀上很多商品搜索,你可以爬一下,
推荐一款我常用的:【网页快照】,抓取网页快照信息,各个网站的,还有各个app的,只有你想不到的,没有我们做不到的。有兴趣我们可以交流。
可以看看花生壳访问,它是基于ddns,保证了https的数据传输,另外它还支持多登录,需要用户注册一个帐号才能登录。使用起来也比较简单,现在很多的网站都支持这个功能了。现在前端作者、网站运营人员都在用它。你可以在百度搜索看看。 查看全部
好用的手机端网络爬虫采集工具推荐(组图)
采集器采集源在云上,不过可以部署在本地服务器或者云平台上采集。或者写个脚本采集,
云采集器
请参考好用的手机端网络爬虫采集工具推荐?
优采云采集器可以批量抓取页面,
云采集器就是采集页面地址到本地服务器采集,手机电脑都能采,包括云终端(bot)端和优采云(api端)端采集。
好用的手机端网络爬虫采集工具推荐
云采集器,
我做一个网页采集器,可以分析你的需求和你平时上网的习惯,推荐你一个网页采集器对应有介绍手机端的,我在搜索你喜欢的商品,就搜索出来我推荐的商品,其实我看重的是价格,然后喜欢这个商品,所以选了便宜好用的那种,
如果是需要抓取各大商家的电商行为,应该需要一定的知识储备,如果是只需要简单的,用采集宝,
卖家秀上很多商品搜索,你可以爬一下,
推荐一款我常用的:【网页快照】,抓取网页快照信息,各个网站的,还有各个app的,只有你想不到的,没有我们做不到的。有兴趣我们可以交流。
可以看看花生壳访问,它是基于ddns,保证了https的数据传输,另外它还支持多登录,需要用户注册一个帐号才能登录。使用起来也比较简单,现在很多的网站都支持这个功能了。现在前端作者、网站运营人员都在用它。你可以在百度搜索看看。
可道又一首创功能:虚拟采集群的特点和特点
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-08-15 19:22
科道另一个原创功能:虚拟采集群什么是虚拟采集群
虚拟采集群,是我们将市面上大部分知名的采集群品牌汇聚并同步到云端,还有计费助手,只要查相关采集群就可以直接采集发单身,不用登录酷Q之类的麻烦事!
虚拟采集群的特点
1.与源qq群完全同步,软件上会列出虚拟采集群相关群号,您可以自己进去查看
2.无需挂酷Q,也没有繁琐的酷Q插件链接,也没有酷Q导致下单的问题
3.我们将同步最知名的采集群品牌(甚至很多付费采集群),无需您费力搜索
如何开启虚拟采集群
打开采集source,勾选“启用虚拟采集群”,勾选需要的采集群,点击保存
虚拟采集群的缺陷
可能不适合直播群
普通组【最后3个不勾选】:
采集到了,排队,转链,按顺序下单。内容中必须收录优惠券链接和订购链接才能触发!
只转发不链接:
采集到达时,排队按顺序发送,但不转链,按顺序发送,一般适用于自己的群转发
顶部:
采集到达时会自动置顶,是否转链由其他勾选选项决定
直播组:
与正常转发无关。 采集 一到就贴出来。不要参与队列。 采集 将在您到达时发布。随意插队。无论是图片、文字、表情,一律统一转发。如有链接,会转发。
标签:
点击上面的支付按钮直接购买并获取。云盘或下载链接失效,支持全额退款。虚拟商品已售出,不支持退款。
客服微信BF99599
如果觉得对你有帮助,请分享给更多人!
网站站长 查看全部
可道又一首创功能:虚拟采集群的特点和特点
科道另一个原创功能:虚拟采集群什么是虚拟采集群
虚拟采集群,是我们将市面上大部分知名的采集群品牌汇聚并同步到云端,还有计费助手,只要查相关采集群就可以直接采集发单身,不用登录酷Q之类的麻烦事!
虚拟采集群的特点
1.与源qq群完全同步,软件上会列出虚拟采集群相关群号,您可以自己进去查看
2.无需挂酷Q,也没有繁琐的酷Q插件链接,也没有酷Q导致下单的问题
3.我们将同步最知名的采集群品牌(甚至很多付费采集群),无需您费力搜索
如何开启虚拟采集群
打开采集source,勾选“启用虚拟采集群”,勾选需要的采集群,点击保存
虚拟采集群的缺陷
可能不适合直播群
普通组【最后3个不勾选】:
采集到了,排队,转链,按顺序下单。内容中必须收录优惠券链接和订购链接才能触发!
只转发不链接:
采集到达时,排队按顺序发送,但不转链,按顺序发送,一般适用于自己的群转发
顶部:
采集到达时会自动置顶,是否转链由其他勾选选项决定
直播组:
与正常转发无关。 采集 一到就贴出来。不要参与队列。 采集 将在您到达时发布。随意插队。无论是图片、文字、表情,一律统一转发。如有链接,会转发。
标签:
点击上面的支付按钮直接购买并获取。云盘或下载链接失效,支持全额退款。虚拟商品已售出,不支持退款。
客服微信BF99599
如果觉得对你有帮助,请分享给更多人!
网站站长
【高粱seo】一下使用较为频繁的工具实战
采集交流 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-08-11 19:01
【高粱seo】一下使用较为频繁的工具实战
一、实战前言
对于站长来说,由于文章经常需要发布,需要采集各种文章资源,所以需要各种采集工具。自从从事互联网seo行业以来,一直在【骚梁seo】中使用采集工具,针对不同的文章资源使用了不同的采集工具,所以下面的【骚梁seo】 ]将与您分享过去的一段时间。我为您提供了您更频繁使用的工具。我希望您能了解这些工具并熟悉应用程序。
二、采集工具优缺点
1、优采云
范围:用户数应该是最大的,主要在新站
特点:功能多、速度快
优点:功能比较齐全,采集比较快,主要针对cms,采集短时间内可以很多,过滤替换好,比较详细,很多人写发布界面,界面比较齐全,适合对程序不太了解的站长
技术:该技术主要由论坛支持,帮助文件多,使用方便。有一个付费的免费版本
缺点:功能多,越来越大,内存成本,速度快,采集质量有点低,不稳定
2、三人行
范围:主要针对论坛,可以称为第一
特点:针对各大论坛,动起来,动起来,速度快,准确度高
优点:还是论坛用,适合开论坛
技术:收费技术,免费广告
缺点:对cms的支持不佳
3、ET工具
特点:无人值守、稳定、不占内存
优点:无人值守,自动更新,适合长期站台工作,用户群主要集中在长期站台潜水站长。软件清晰,必备功能齐全。关键是该软件是免费的。听说加了采集中英文翻译功能。
技术:论坛支持,软件本身免费,但也有付费服务。帮助文件少,上手不易。缺点:貌似没有帮助文件是这个软件的缺点
4、海纳
特点:海量,关键词抓取,可以预览采集内容,无需写规则
优点:海量,可以抢到很多网站关键词文章,好像很适合网站的话题 技术:无论坛,收费,免费,有功能限制
缺点:分类不方便,即采集文章分类不方便,手动(自动容易混淆),具体界面
5、优采云采集器
主张:最好的网页数据采集器,让数据触手可及!
在使用优采云之前,我一直在寻找一款出色的采集软件。与市面上其他采集软件不同,优采云采集器没有复杂的采集规则设置。只需点击几下鼠标即可成功配置采集任务,体验极其简单大方。提高工作效率。用一句话来形容优采云采集器,就是:追根溯源,一切行为回归人性。
三、工具选择
每个工具的功能略有不同,适用范围也不同。区别如下:
1、追求功能齐全。看来你应该选择优采云。 优采云 被称为“全能”。初期可以快速采集众多资源,丰富网站内容。
2、如果你是论坛,那就选择三人行。没错,可以实现采集论坛、回复、移动等多种论坛功能。
3、站久了,我当然选择了ET。花一些时间去理解是一个长期的好处。写规则,设置过滤器和替换,然后就可以像打开QQ一样长时间运行,无记忆,自动采集更新,清晰分类,采集内容完整,但是一个站,一个站长+ ET就够NS了。
4、至于海娜,看似不写规则,上手容易,但对于文章的发布,却不能像ET一劳永逸。相反,我觉得会增加很多工作,但我们可以做一些特殊的话题。这是网站topic 之一。不错的选择。
四、最终总结
<p>通过以上详细的讲解和分享,相信大家已经知道自己的工作需要用到什么样的采集工具了。有什么不懂的可以加入高亮seo QQ干货实战交流群:571460668(验证码:新天地seo),也会分享一些资源到群里,相信这些资源对大家有帮助。 查看全部
【高粱seo】一下使用较为频繁的工具实战
一、实战前言
对于站长来说,由于文章经常需要发布,需要采集各种文章资源,所以需要各种采集工具。自从从事互联网seo行业以来,一直在【骚梁seo】中使用采集工具,针对不同的文章资源使用了不同的采集工具,所以下面的【骚梁seo】 ]将与您分享过去的一段时间。我为您提供了您更频繁使用的工具。我希望您能了解这些工具并熟悉应用程序。
二、采集工具优缺点
1、优采云
范围:用户数应该是最大的,主要在新站
特点:功能多、速度快
优点:功能比较齐全,采集比较快,主要针对cms,采集短时间内可以很多,过滤替换好,比较详细,很多人写发布界面,界面比较齐全,适合对程序不太了解的站长
技术:该技术主要由论坛支持,帮助文件多,使用方便。有一个付费的免费版本
缺点:功能多,越来越大,内存成本,速度快,采集质量有点低,不稳定
2、三人行
范围:主要针对论坛,可以称为第一
特点:针对各大论坛,动起来,动起来,速度快,准确度高
优点:还是论坛用,适合开论坛
技术:收费技术,免费广告
缺点:对cms的支持不佳
3、ET工具
特点:无人值守、稳定、不占内存
优点:无人值守,自动更新,适合长期站台工作,用户群主要集中在长期站台潜水站长。软件清晰,必备功能齐全。关键是该软件是免费的。听说加了采集中英文翻译功能。
技术:论坛支持,软件本身免费,但也有付费服务。帮助文件少,上手不易。缺点:貌似没有帮助文件是这个软件的缺点
4、海纳
特点:海量,关键词抓取,可以预览采集内容,无需写规则
优点:海量,可以抢到很多网站关键词文章,好像很适合网站的话题 技术:无论坛,收费,免费,有功能限制
缺点:分类不方便,即采集文章分类不方便,手动(自动容易混淆),具体界面
5、优采云采集器
主张:最好的网页数据采集器,让数据触手可及!
在使用优采云之前,我一直在寻找一款出色的采集软件。与市面上其他采集软件不同,优采云采集器没有复杂的采集规则设置。只需点击几下鼠标即可成功配置采集任务,体验极其简单大方。提高工作效率。用一句话来形容优采云采集器,就是:追根溯源,一切行为回归人性。
三、工具选择
每个工具的功能略有不同,适用范围也不同。区别如下:
1、追求功能齐全。看来你应该选择优采云。 优采云 被称为“全能”。初期可以快速采集众多资源,丰富网站内容。
2、如果你是论坛,那就选择三人行。没错,可以实现采集论坛、回复、移动等多种论坛功能。
3、站久了,我当然选择了ET。花一些时间去理解是一个长期的好处。写规则,设置过滤器和替换,然后就可以像打开QQ一样长时间运行,无记忆,自动采集更新,清晰分类,采集内容完整,但是一个站,一个站长+ ET就够NS了。
4、至于海娜,看似不写规则,上手容易,但对于文章的发布,却不能像ET一劳永逸。相反,我觉得会增加很多工作,但我们可以做一些特殊的话题。这是网站topic 之一。不错的选择。
四、最终总结
<p>通过以上详细的讲解和分享,相信大家已经知道自己的工作需要用到什么样的采集工具了。有什么不懂的可以加入高亮seo QQ干货实战交流群:571460668(验证码:新天地seo),也会分享一些资源到群里,相信这些资源对大家有帮助。
采集器采集源 iptables.你可以走express协议测试一下吗?(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-08-08 04:01
采集器采集源地址,然后对进程做ping出口ip段,然后通过这些地址段,能找到对应ip的ping服务器。一般都会有第三方代理。ip段都是共享的。
代理服务器
对端口进行转发
靠楼上匿名用户和@姚冬的回答,我已经不需要采集器了。
iptables
最经典的方法,
iptables、http代理
配置远程端口映射,如果满足某些特定条件,就能收发命令。写个玩具其实并不困难,我就会这么做。
我采集任何人都能接入我的服务器.
就我目前采集的现状,大部分情况是只需要命令行操作或暴力破解idx,以及使用代理软件。当然,我还是会使用采集服务器,所以你理解我说的是什么。但绝大部分都会采集地址一栏,其他的比如源地址(或者端口),还有ip、端口之类。如果不需要命令行操作,也可以采集端口。因为我要做的事太多,会拉后台来统计。如果需要修改dns,也会拉后台来统计。如果可以,再加上两张地图,统计哪里的最少。
iptables.你可以走express协议测试一下。
测试采集ip,
我们自己在做,并不是全部是命令行操作,也有桌面采集。
efbattletorunthistutorialinmacapp 查看全部
采集器采集源 iptables.你可以走express协议测试一下吗?(图)
采集器采集源地址,然后对进程做ping出口ip段,然后通过这些地址段,能找到对应ip的ping服务器。一般都会有第三方代理。ip段都是共享的。
代理服务器
对端口进行转发
靠楼上匿名用户和@姚冬的回答,我已经不需要采集器了。
iptables
最经典的方法,
iptables、http代理
配置远程端口映射,如果满足某些特定条件,就能收发命令。写个玩具其实并不困难,我就会这么做。
我采集任何人都能接入我的服务器.
就我目前采集的现状,大部分情况是只需要命令行操作或暴力破解idx,以及使用代理软件。当然,我还是会使用采集服务器,所以你理解我说的是什么。但绝大部分都会采集地址一栏,其他的比如源地址(或者端口),还有ip、端口之类。如果不需要命令行操作,也可以采集端口。因为我要做的事太多,会拉后台来统计。如果需要修改dns,也会拉后台来统计。如果可以,再加上两张地图,统计哪里的最少。
iptables.你可以走express协议测试一下。
测试采集ip,
我们自己在做,并不是全部是命令行操作,也有桌面采集。
efbattletorunthistutorialinmacapp
移动端的app生态是什么?如何判断产品是否是下沉市场?
采集交流 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-07-19 03:01
采集器采集源:360采集宝。采集器,由360主动接入数据采集;采集包含音乐、视频、游戏、app等应用;帮助您记录历史采集时间,方便回溯数据。
建议采用手机模拟器这种方式。首先你需要做好的是每天产生的流量数据是什么样子,然后如何判断一个产品是否是下沉市场?如何做算法?这是一个问题。
其实想要做好分析和洞察,并不是采用什么工具,而是你对市场和行业的认知、分析和判断。
很遗憾,广州的话,永远没有一个专门的平台去做推广数据分析的业务。
-zdzo2zukhwdre_zsq
如果你能够把大数据利用好,那么手机app还是可以去推广的,而推广的目的却不仅仅是为了推广app,也是为了引导用户更多的去使用移动互联网,比如说手机视频、打车、外卖app等,大数据时代让每个人的数据越来越多,哪怕你用iphone5,iphone7,iphone8都有可能有他的数据,如果你能把这些信息用好,如果数据量足够大,那么就会给你带来很多商机。
目前移动端的app生态大致可以分为三个:公司生态、产品生态、渠道生态。公司生态:公司发展的地域属性、公司员工属性,而针对这两点的推广无非是激励+运营。公司生态:移动端app公司为什么做移动端app,如果有用户运营公司除了做lbs之外其他的领域或渠道能够立足,从app本身来发力激励及运营团队;如果说是导航、电商之类的,那么除了做用户运营之外的还是需要与公司其他部门对接。
例如对运营人员的成本回收即收益管理的问题;公司产品生态:如果是高频的内容app,建议做个app回归历史的版本,哪怕是五六年前的版本;低频的wapapp可以做个免费版本留住用户,做一个可以高频的资讯app,或者对于自家产品有情感化营销需求可以尝试网络剧电影这类,或者做个游戏类的社区。在创业做团队之前,一定要有一个整体的认知,无论app只是其中一个点,或者是很多点。让一个企业的价值传递稳定,在业务快速发展的过程中不丢工作。 查看全部
移动端的app生态是什么?如何判断产品是否是下沉市场?
采集器采集源:360采集宝。采集器,由360主动接入数据采集;采集包含音乐、视频、游戏、app等应用;帮助您记录历史采集时间,方便回溯数据。
建议采用手机模拟器这种方式。首先你需要做好的是每天产生的流量数据是什么样子,然后如何判断一个产品是否是下沉市场?如何做算法?这是一个问题。
其实想要做好分析和洞察,并不是采用什么工具,而是你对市场和行业的认知、分析和判断。
很遗憾,广州的话,永远没有一个专门的平台去做推广数据分析的业务。
-zdzo2zukhwdre_zsq
如果你能够把大数据利用好,那么手机app还是可以去推广的,而推广的目的却不仅仅是为了推广app,也是为了引导用户更多的去使用移动互联网,比如说手机视频、打车、外卖app等,大数据时代让每个人的数据越来越多,哪怕你用iphone5,iphone7,iphone8都有可能有他的数据,如果你能把这些信息用好,如果数据量足够大,那么就会给你带来很多商机。
目前移动端的app生态大致可以分为三个:公司生态、产品生态、渠道生态。公司生态:公司发展的地域属性、公司员工属性,而针对这两点的推广无非是激励+运营。公司生态:移动端app公司为什么做移动端app,如果有用户运营公司除了做lbs之外其他的领域或渠道能够立足,从app本身来发力激励及运营团队;如果说是导航、电商之类的,那么除了做用户运营之外的还是需要与公司其他部门对接。
例如对运营人员的成本回收即收益管理的问题;公司产品生态:如果是高频的内容app,建议做个app回归历史的版本,哪怕是五六年前的版本;低频的wapapp可以做个免费版本留住用户,做一个可以高频的资讯app,或者对于自家产品有情感化营销需求可以尝试网络剧电影这类,或者做个游戏类的社区。在创业做团队之前,一定要有一个整体的认知,无论app只是其中一个点,或者是很多点。让一个企业的价值传递稳定,在业务快速发展的过程中不丢工作。
app更新同步数据,体验更佳的方法是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-07-13 00:04
采集器采集源是在手机上安装的软件对平台平台进行采集,就算删除软件源仍然会在。但是会对后台发起后台数据同步,将更新的数据同步到服务器端存储,然后会采集另外一部手机号码。最好让在运营商合作商去采集,同步到服务器后,app更新同步数据,体验更佳。
来自百度回答:以手机的拍照功能为例,我们都可以拍照,我们可以转头看天上的云彩,我们可以面对面,我们可以拥抱向上,我们可以.手机拍照,是把图片推到后台,可以下载下来,所以上面提到的软件上的位置,是推送了哪个位置的信息。
手机软件采集后,后台进行过数据同步(比如imsi、mac地址等),就只需要返回给服务器就可以了。
好像因为imei不需要付费所以一般运营商不会给你吧。现在我这里一直没有发生过这种事情啊我猜的,望指正。
我这边是运营商网管实习,对于你问的这个情况应该是基站对服务器端的一个过程,好像,为了保证他是最新的对外更新的,还是会和公安局合作,收集这个号码服务器端的信息,然后给到运营商服务器端用吧。
好像是实现位置请求吧,服务器端发的请求,
我猜的,应该先通过软件同步, 查看全部
app更新同步数据,体验更佳的方法是什么?
采集器采集源是在手机上安装的软件对平台平台进行采集,就算删除软件源仍然会在。但是会对后台发起后台数据同步,将更新的数据同步到服务器端存储,然后会采集另外一部手机号码。最好让在运营商合作商去采集,同步到服务器后,app更新同步数据,体验更佳。
来自百度回答:以手机的拍照功能为例,我们都可以拍照,我们可以转头看天上的云彩,我们可以面对面,我们可以拥抱向上,我们可以.手机拍照,是把图片推到后台,可以下载下来,所以上面提到的软件上的位置,是推送了哪个位置的信息。
手机软件采集后,后台进行过数据同步(比如imsi、mac地址等),就只需要返回给服务器就可以了。
好像因为imei不需要付费所以一般运营商不会给你吧。现在我这里一直没有发生过这种事情啊我猜的,望指正。
我这边是运营商网管实习,对于你问的这个情况应该是基站对服务器端的一个过程,好像,为了保证他是最新的对外更新的,还是会和公安局合作,收集这个号码服务器端的信息,然后给到运营商服务器端用吧。
好像是实现位置请求吧,服务器端发的请求,
我猜的,应该先通过软件同步,
如何将视频采集成视频的素材采集器使用方法?
采集交流 • 优采云 发表了文章 • 0 个评论 • 757 次浏览 • 2021-07-10 06:06
采集器采集源主要有:视频采集器、录音采集器、声卡采集器,还有一些wifi采集器,最常见的就是视频采集器和录音采集器,在做视频的时候经常需要采集视频,这个时候就可以选择采集器来完成视频的采集,
一、什么是采集器采集器是电脑端操作软件使用的采集。它使用收音机器去收集影像,做成图像并生成录像;或者使用音箱去采集音乐,做成声音数据。采集器有自带和购买两种形式,通常采集器自带电脑使用的采集软件,但对于大型影视制作,通常需要购买音频采集器和视频采集器,才能制作完整视频,因为广告片对音频素材的要求很高。
二、如何将收集到的素材采集成视频
1、视频分辨率视频收集网格选择3840*216
0、480*128
0、2k*8k,1k*16k,3k*32k,4k*48k,5k,6k,8k尺寸尽量按最小值定。
2、素材来源素材就是关键部分,影片内容要全,包括预告片、宣传片、序列视频,各种图片等。片头,片尾,字幕,头像,图标,以及手机、网站视频等也可以拿来使用。
3、素材管理将制作视频所有素材名称复制到收集项下,对应的路径导入即可,然后直接保存为视频即可。
4、添加字幕、音乐、配音如果对字幕、音乐、音效不懂得可以购买视频采集器,也可以有专门的组件来安装使用,通常有预置的、导入的、自己录制。
5、视频保存预览用快速浏览器打开视频,点击“视频保存”,选择要保存的文件,然后点击“上传”即可上传视频。
三、采集器使用方法
1、浏览器添加采集器首先我们要使用一些平台提供的浏览器才可以收集到视频文件。电脑和手机方式大同小异,pc端下载一个迅捷视频抓取器,将其中文件夹拖拽到手机浏览器中即可。pc端也可以使用ipad、安卓等使用苹果的app“epicoffice”来收集,根据个人使用习惯不同。
2、wifi接入方式如果家里有宽带,可以直接把视频插入wifi上,离线观看。如果家里没有宽带,请看第2条解决方案。
3、导入方式1:利用网站、论坛等收集到的视频。2:路由器设置。3:直接利用电脑收集。
4、导出格式大部分视频软件默认的接口支持usb文件导出,pc端用,
5、如何使用采集器自带采集器
1、一键选择预告 查看全部
如何将视频采集成视频的素材采集器使用方法?
采集器采集源主要有:视频采集器、录音采集器、声卡采集器,还有一些wifi采集器,最常见的就是视频采集器和录音采集器,在做视频的时候经常需要采集视频,这个时候就可以选择采集器来完成视频的采集,
一、什么是采集器采集器是电脑端操作软件使用的采集。它使用收音机器去收集影像,做成图像并生成录像;或者使用音箱去采集音乐,做成声音数据。采集器有自带和购买两种形式,通常采集器自带电脑使用的采集软件,但对于大型影视制作,通常需要购买音频采集器和视频采集器,才能制作完整视频,因为广告片对音频素材的要求很高。
二、如何将收集到的素材采集成视频
1、视频分辨率视频收集网格选择3840*216
0、480*128
0、2k*8k,1k*16k,3k*32k,4k*48k,5k,6k,8k尺寸尽量按最小值定。
2、素材来源素材就是关键部分,影片内容要全,包括预告片、宣传片、序列视频,各种图片等。片头,片尾,字幕,头像,图标,以及手机、网站视频等也可以拿来使用。
3、素材管理将制作视频所有素材名称复制到收集项下,对应的路径导入即可,然后直接保存为视频即可。
4、添加字幕、音乐、配音如果对字幕、音乐、音效不懂得可以购买视频采集器,也可以有专门的组件来安装使用,通常有预置的、导入的、自己录制。
5、视频保存预览用快速浏览器打开视频,点击“视频保存”,选择要保存的文件,然后点击“上传”即可上传视频。
三、采集器使用方法
1、浏览器添加采集器首先我们要使用一些平台提供的浏览器才可以收集到视频文件。电脑和手机方式大同小异,pc端下载一个迅捷视频抓取器,将其中文件夹拖拽到手机浏览器中即可。pc端也可以使用ipad、安卓等使用苹果的app“epicoffice”来收集,根据个人使用习惯不同。
2、wifi接入方式如果家里有宽带,可以直接把视频插入wifi上,离线观看。如果家里没有宽带,请看第2条解决方案。
3、导入方式1:利用网站、论坛等收集到的视频。2:路由器设置。3:直接利用电脑收集。
4、导出格式大部分视频软件默认的接口支持usb文件导出,pc端用,
5、如何使用采集器自带采集器
1、一键选择预告
《基于大数据平台的互联网数据采集平台基本架构》
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-07-01 22:01
我简单介绍了【《基于大数据平台采集平台的互联网数据基本结构》。今天主要介绍一下采集的各个环节如何处理,需要注意哪些方面。
废话少说,正文开始……
第一:信息源系统
其实就是采集task 管理系统,我们称之为源码管理系统。主要包括:
1.任务模块:网站、栏目、搜索引擎、关键词、模板、公众号、微博博主等。
2.资源管理模块:服务器、项目、索引等;
3.监控模块:网站、栏目、搜索引擎、服务器、采集器等模块。
4.调度模块:采集器创建、部署、启动、关闭、删除等;
下面简单介绍一下各个模块的功能和注意事项。
1.任务模块
(1)网站,栏目/频道管理
在文章(《3人团队,如何管理10万采集网站?(最全面、最详细的解读)》)中有对网站的介绍,如何批量添加栏目,等等,不在这里累了。
这里主要讲在配置网站和栏目时,如何过滤掉与公司业务无关的信息源。
主要有两种方法。一种是人工筛选;另一种是设置过滤词;当配置的网站或列名收录单词时,系统会直接在后台过滤掉,不再进行常规的分析、存储等操作。
例如,我们的主营业务是金融、证券、保险、银行等行业。那么我们的过滤词可以包括以下几类:
① 地区名称;如:中国、北京、上海等。
② 蔬菜、水果等名称;如:白菜、苹果等。
③ 体育、娱乐、电影、时尚、奢侈品等类型词。
④ 健康、人文、文艺、文史、历史、美食类。
⑤ 女性、育儿、教育、旅游、研究、法律法规、政策等频道。
当网站/列在采集时,还有一个最重要的一点就是采集频率。首次配置时可以遵循以下规则:
① 中央级媒体:首页10分钟,一级频道15分钟;二级频道20分钟,其他30分钟;
② 省级媒体:首页15分钟;一级频道20分钟;二级频道30分钟;
③ 市县等地方网站:首页60分钟;一级频道120分钟;二级频道240~720分钟;
以上是基本规则,配置需要根据实际情况进行分析处理。比如一些本地的网站,虽然不大,但是对业务的兼容度很高,而且每天发帖频繁,那么采集的频率可以设置为30分钟或者60分钟。
网站/column采集加入正则化后,需要根据一段时间内的发帖规则自动分析采集的频率。这样,我们的服务器和其他资源的利用率就可以最大化,减少浪费。
(2)搜索引擎管理
虽然我们采集有很多网站,但与整个互联网相比,还是杯水车薪。那么,我们如何才能高效、低成本地获取我们需要的数据?
搜索引擎是一个很好的补充。
通过分析我们的产品和项目的业务需求,整理出相关的关键词,我们可以通过搜索引擎快速获取我们需要的部分数据。我们可以快速响应客户需求、改善用户体验并提供订单率。
但是,有很多搜索引擎。为了让我们能够灵活地添加、删除、修改等,它们也需要集成到源系统中。同时,我们还可以随时监控源系统中的状态,实时调整采集策略。
(3)关键词管理
关键词配置,主要注意以下几点:
① 每个关键词必须与一个项目关联;
② 每个关键词都要记录下提供者姓名;
③ 关键词添加时,同样需要经过排除词进行处理。过滤词可以与网站/栏目配置的同步使用;
(4)官方号
对于微信公众号的文章采集,目前基于XPosed手机插件的采集方式实现批量的更稳定、快速、高效的方式。
但是,这种方法也有很多缺点:
① 前期投入较大;
因为每个手机上只能安装一个XPosed插件,就只能hook一个微信号。而且每个微信号最多只能关注999个公众号,比如要监测100万公众号的话,就需要一千部手机。按一部手机800元,使用三年,第一年需要花费60万左右。加上10%损耗,平均35万/年。
② 微信号需求量大;
因为一个微信号最多只能关注999个公众号,如果要监测100万公众号,就需要一千个微信号,再加上10%的封号概率。第一年至少需要1100个微信号。
③ 运维较麻烦
主要体现在封号上。如果是临时封号的话,可以通过手机号解封。如果是永久封号,那就需要把当前微信号中关注的公众号,重新在其他微信号上进行关注监测了。这个过程需要二十天左右才能结束。
④ 公众号的关注比较麻烦
因为一个微信号一天只能关注四五十个公众号;
为了处理账号被封的问题,我们在处理公众号时需要注意以下几点:
① 每个公众号必须在数据库中和微信号进行管理,
② 手机必须按一定的规律进行编号
③ 手机和微信号之间在数据中必须进行关联。
(5)模板管理
我们逐渐放弃了配置模板,倾向于通过训练自动处理。
(6)微博博主管理
由于微博搜索列表没有显示所有与搜索词相关的信息,需要同时监控一些博主,两者相辅相成。
2.资源管理模块
(1)服务器管理:
对于做舆论或数据服务的公司,data采集至少涉及几十台服务器。为了了解这些服务器何时到期、更新和服务器配置,我们倾向于将服务器管理与任务调度一起设计,而不是使用云平台提供的控制终端。当然,网管也可以使用云平台控制终端查询和监控服务器的各项指标。
(2)项目管理:
搜索采集时,搜索词通常按照项目或产品的数据范围进行排序。所以在添加元搜索关键词的时候,一般是绑定到项目上的。因此,项目需要统一管理。
(3)索引管理:
由于采集的数据量很大,采集每天接收的数据量级至少有100万。因此,我们不可能将采集的所有数据长时间放在一个ES索引库中。
在实际使用中,我们首先对信息进行分类。如:新闻、论坛、博客、微博、客户端、微信和纸媒等。如果采集有海外网站,可以添加外媒类型。
虽然数据是按类型分类的,但不能总是将每种类型的数据都存储在一个索引中。因此,索引需要按照一定的规则生成。如按时间、每周或每月生成某种类型的索引。
为了提高ES集群的工作效率,我们可以根据实际业务需要关闭比当前时间长的冷索引,比如关闭半年前生成的ES索引。这样既可以减少服务器内存和硬盘的浪费,也可以提高热索引的查询速度,提升产品的用户体验。
同时,为了掌握ES集群中各个索引的情况,我们需要记录索引的创建时间、上次保存数据的时间、索引名称、索引类型、数据量、数据类型以及收录哪些字段。
记录索引信息,一是方便了解当前各类数据的索引数据库;二是方便各种统计报表等所需数据的导出。
3.监控模块
网站、栏目、搜索引擎、服务器、采集器等监控不详述。上一篇《Data采集,如何建立有效的监控体系?》文章中有详细介绍,可以阅读。
4.调度模块
调度模块是运维管理中最重要的部分。
在分布式海量数据采集中,网站、涉及采集的列或通道的数量级至少有10000、100,000,甚至数百万。所涉及的服务器范围从三到五台,到三到五十台,或三到五百台。每台服务器上部署多个采集器等。如此数量级的采集器运维,如果没有专门的系统来处理,是不可想象的。
调度模块主要负责采集器的增减、部署/上传、启动、关闭等,实现一键部署,解放人力。
第二:Data采集
采集器在处理采集任务时,最重要的三个部分是:网页下载、翻页和数据分析。各部分加工中的注意事项如下:
1.翻页
在大量数据采集中,不建议设置翻页。主要是翻页信息的维护比较麻烦。为避免数据丢失,可适当提高采集频率,以补偿未翻页的影响。
2.title
标题一般在使用采集URL地址时使用A标签的值。然后在文本解析过程中执行第二次检查以纠正标题中可能存在的错误。
3.发布时间处理
发布时间分析难免会出现问题,但不能大于当前时间。
一般在清除HTML源代码中的css样式、JS、注释、meta等信息后,删除HTML标签,以内容中的第一时间作为发布时间。
一般可以统计一些发布时间指标,如:“发布时间:”、“发布日期”等,然后通过正则表达式,将标识符前后的100个字符串中的时间分别为获得作为发布时间。
第三:数据质量
1.Title 处理;
标题一般容易出现以下三个问题:
① 以”_XXX网站或门户”结尾;
② 以“....”结束;
③ 长度小于等于两个字符;
针对上述问题,我们可以通过list的title和body中的title进行二次校验来纠正。
2.文本处理;
文本一般以数据类型为准,可以注意以下问题:
① 新闻、博客、纸媒、客户端和微信等正文需大于10字符;
② 论坛和微博等内容大于0即可;
③ 注意由于解析异常,导致的内容中存在css样式数据;
④ 格式化数据。删除多余的“
"、""、空行等
3.统一数据传输接口:
对于企业来说,有常规的采集,也有基于项目和产品的定制采集。并且有些项目或产品有很多自定义脚本。如果数据存储方式(或数据推送方式)不统一,一旦出现问题,排查起来难度极大。它还浪费时间并增加人工成本。
统一的数据传输接口主要有以下优点:
① 异常前置,减少异常数据流入系统概率,提供用户体验;
② 数据质量监控,优化采集任务;
③ 多来源情况下数据排重,减少[数据分析](http://www.blog2019.net/tag/%2 ... d%3D90)压力;
④ 减少数据持久化中存现的问题,提供工作效率;
第四:统一开发模式
舆论或者数据服务公司,data采集人比较多,技术水平参差不齐。为了减少各级人员开发过程中的BUG数量,可以细化采集的各个部分,定制耦合度较低的模块开发,然后做成第三方插件,分发并将它们安装在每个开发人员的环境中。这样可以大大降低开发中出现BUG的概率,有效提高工作效率。
那么,哪些模块可以独立?
① 采集任务获取模块;
② 网页下载模块;
③ 发布时间、正文等解析模块;
④ 采集结果推送模块;
⑤ 采集监测模块;
统一以上五部分代码后,至少可以节省40%的人力。
第五:采集的痛点:
1.网站改版****
网站改版后,随之而来的是信息正则、翻页正则、采集template等失效,导致网站采集异常。不仅浪费资源,还影响采集的效率。
特别是政府网站在过去一两年中进行了全国性的修订。有很多历史配置网站都采集没有更多数据。
2.数据泄露采集
数据缺失,在以下情况之一:
① 采集频率不对,导致信息跑到第二页等,无法采集到(因为采集翻页)
② 由于网站改版,导致信息正则或模板等配置异常;
③ 信息所在网站没有配置栏目,添加到采集任务队列;
④ 数据传输异常,导致数据丢失;如kafka异常,导致内存中所有数据丢失;
⑤ 网络抖动,导致正文采集异常;
以上几个数据缺失的原因可以通过监控系统快速找到定位。由于监控系统的建立,可以参考之前发表的《Data采集,如何建立有效的监控系统?》一篇文章。
第六:第三方数据平台
如果你是个人,只要简单的采集一些数据写论文,或者这个测试什么的,那么这个文章看到这里就结束了;
如果你是做舆论或数据分析的公司,第三方平台是很好的补充数据来源。一方面可以补充我们漏掉的数据,提升用户体验。另一方面,我们也可以从他们的数据中分析网站信息的来源,以补充我们自己的源数据库。
主要的第三方平台或数据服务商如下:
1.远哈SaaS平台
元哈舆论其实就是新浪舆论。因此,元哈的微博数据应该是市场上最全面和时效性最强的。 网站,client,纸媒等类型的数据其实差不多,看投资的多少。一般
2.iridium SAAS 平台
3.智慧星光SaaS平台
铱星和智慧星光的数据差不多,智慧星光稍微好一点。
4.八友微信数据
特点:微信公众号文章数据还可以,日流量在80万~150万之间,收费在市场上应该比较合适。如果您的公司有此需求,您可以与他们联系。微博等数据暂未对接,质量未知。
我今天就讲这个。文笔不好,理解一下思路就好了。哈哈...
如果还有其他采集相关问题,可以在下方公众号留言! 查看全部
《基于大数据平台的互联网数据采集平台基本架构》
我简单介绍了【《基于大数据平台采集平台的互联网数据基本结构》。今天主要介绍一下采集的各个环节如何处理,需要注意哪些方面。
废话少说,正文开始……
第一:信息源系统
其实就是采集task 管理系统,我们称之为源码管理系统。主要包括:
1.任务模块:网站、栏目、搜索引擎、关键词、模板、公众号、微博博主等。
2.资源管理模块:服务器、项目、索引等;
3.监控模块:网站、栏目、搜索引擎、服务器、采集器等模块。
4.调度模块:采集器创建、部署、启动、关闭、删除等;
下面简单介绍一下各个模块的功能和注意事项。
1.任务模块
(1)网站,栏目/频道管理
在文章(《3人团队,如何管理10万采集网站?(最全面、最详细的解读)》)中有对网站的介绍,如何批量添加栏目,等等,不在这里累了。
这里主要讲在配置网站和栏目时,如何过滤掉与公司业务无关的信息源。
主要有两种方法。一种是人工筛选;另一种是设置过滤词;当配置的网站或列名收录单词时,系统会直接在后台过滤掉,不再进行常规的分析、存储等操作。
例如,我们的主营业务是金融、证券、保险、银行等行业。那么我们的过滤词可以包括以下几类:
① 地区名称;如:中国、北京、上海等。
② 蔬菜、水果等名称;如:白菜、苹果等。
③ 体育、娱乐、电影、时尚、奢侈品等类型词。
④ 健康、人文、文艺、文史、历史、美食类。
⑤ 女性、育儿、教育、旅游、研究、法律法规、政策等频道。
当网站/列在采集时,还有一个最重要的一点就是采集频率。首次配置时可以遵循以下规则:
① 中央级媒体:首页10分钟,一级频道15分钟;二级频道20分钟,其他30分钟;
② 省级媒体:首页15分钟;一级频道20分钟;二级频道30分钟;
③ 市县等地方网站:首页60分钟;一级频道120分钟;二级频道240~720分钟;
以上是基本规则,配置需要根据实际情况进行分析处理。比如一些本地的网站,虽然不大,但是对业务的兼容度很高,而且每天发帖频繁,那么采集的频率可以设置为30分钟或者60分钟。
网站/column采集加入正则化后,需要根据一段时间内的发帖规则自动分析采集的频率。这样,我们的服务器和其他资源的利用率就可以最大化,减少浪费。
(2)搜索引擎管理
虽然我们采集有很多网站,但与整个互联网相比,还是杯水车薪。那么,我们如何才能高效、低成本地获取我们需要的数据?
搜索引擎是一个很好的补充。
通过分析我们的产品和项目的业务需求,整理出相关的关键词,我们可以通过搜索引擎快速获取我们需要的部分数据。我们可以快速响应客户需求、改善用户体验并提供订单率。
但是,有很多搜索引擎。为了让我们能够灵活地添加、删除、修改等,它们也需要集成到源系统中。同时,我们还可以随时监控源系统中的状态,实时调整采集策略。
(3)关键词管理
关键词配置,主要注意以下几点:
① 每个关键词必须与一个项目关联;
② 每个关键词都要记录下提供者姓名;
③ 关键词添加时,同样需要经过排除词进行处理。过滤词可以与网站/栏目配置的同步使用;
(4)官方号
对于微信公众号的文章采集,目前基于XPosed手机插件的采集方式实现批量的更稳定、快速、高效的方式。
但是,这种方法也有很多缺点:
① 前期投入较大;
因为每个手机上只能安装一个XPosed插件,就只能hook一个微信号。而且每个微信号最多只能关注999个公众号,比如要监测100万公众号的话,就需要一千部手机。按一部手机800元,使用三年,第一年需要花费60万左右。加上10%损耗,平均35万/年。
② 微信号需求量大;
因为一个微信号最多只能关注999个公众号,如果要监测100万公众号,就需要一千个微信号,再加上10%的封号概率。第一年至少需要1100个微信号。
③ 运维较麻烦
主要体现在封号上。如果是临时封号的话,可以通过手机号解封。如果是永久封号,那就需要把当前微信号中关注的公众号,重新在其他微信号上进行关注监测了。这个过程需要二十天左右才能结束。
④ 公众号的关注比较麻烦
因为一个微信号一天只能关注四五十个公众号;
为了处理账号被封的问题,我们在处理公众号时需要注意以下几点:
① 每个公众号必须在数据库中和微信号进行管理,
② 手机必须按一定的规律进行编号
③ 手机和微信号之间在数据中必须进行关联。
(5)模板管理
我们逐渐放弃了配置模板,倾向于通过训练自动处理。
(6)微博博主管理
由于微博搜索列表没有显示所有与搜索词相关的信息,需要同时监控一些博主,两者相辅相成。
2.资源管理模块
(1)服务器管理:
对于做舆论或数据服务的公司,data采集至少涉及几十台服务器。为了了解这些服务器何时到期、更新和服务器配置,我们倾向于将服务器管理与任务调度一起设计,而不是使用云平台提供的控制终端。当然,网管也可以使用云平台控制终端查询和监控服务器的各项指标。
(2)项目管理:
搜索采集时,搜索词通常按照项目或产品的数据范围进行排序。所以在添加元搜索关键词的时候,一般是绑定到项目上的。因此,项目需要统一管理。
(3)索引管理:
由于采集的数据量很大,采集每天接收的数据量级至少有100万。因此,我们不可能将采集的所有数据长时间放在一个ES索引库中。
在实际使用中,我们首先对信息进行分类。如:新闻、论坛、博客、微博、客户端、微信和纸媒等。如果采集有海外网站,可以添加外媒类型。
虽然数据是按类型分类的,但不能总是将每种类型的数据都存储在一个索引中。因此,索引需要按照一定的规则生成。如按时间、每周或每月生成某种类型的索引。
为了提高ES集群的工作效率,我们可以根据实际业务需要关闭比当前时间长的冷索引,比如关闭半年前生成的ES索引。这样既可以减少服务器内存和硬盘的浪费,也可以提高热索引的查询速度,提升产品的用户体验。
同时,为了掌握ES集群中各个索引的情况,我们需要记录索引的创建时间、上次保存数据的时间、索引名称、索引类型、数据量、数据类型以及收录哪些字段。
记录索引信息,一是方便了解当前各类数据的索引数据库;二是方便各种统计报表等所需数据的导出。
3.监控模块
网站、栏目、搜索引擎、服务器、采集器等监控不详述。上一篇《Data采集,如何建立有效的监控体系?》文章中有详细介绍,可以阅读。
4.调度模块
调度模块是运维管理中最重要的部分。
在分布式海量数据采集中,网站、涉及采集的列或通道的数量级至少有10000、100,000,甚至数百万。所涉及的服务器范围从三到五台,到三到五十台,或三到五百台。每台服务器上部署多个采集器等。如此数量级的采集器运维,如果没有专门的系统来处理,是不可想象的。
调度模块主要负责采集器的增减、部署/上传、启动、关闭等,实现一键部署,解放人力。
第二:Data采集
采集器在处理采集任务时,最重要的三个部分是:网页下载、翻页和数据分析。各部分加工中的注意事项如下:
1.翻页
在大量数据采集中,不建议设置翻页。主要是翻页信息的维护比较麻烦。为避免数据丢失,可适当提高采集频率,以补偿未翻页的影响。
2.title
标题一般在使用采集URL地址时使用A标签的值。然后在文本解析过程中执行第二次检查以纠正标题中可能存在的错误。
3.发布时间处理
发布时间分析难免会出现问题,但不能大于当前时间。
一般在清除HTML源代码中的css样式、JS、注释、meta等信息后,删除HTML标签,以内容中的第一时间作为发布时间。
一般可以统计一些发布时间指标,如:“发布时间:”、“发布日期”等,然后通过正则表达式,将标识符前后的100个字符串中的时间分别为获得作为发布时间。
第三:数据质量
1.Title 处理;
标题一般容易出现以下三个问题:
① 以”_XXX网站或门户”结尾;
② 以“....”结束;
③ 长度小于等于两个字符;
针对上述问题,我们可以通过list的title和body中的title进行二次校验来纠正。
2.文本处理;
文本一般以数据类型为准,可以注意以下问题:
① 新闻、博客、纸媒、客户端和微信等正文需大于10字符;
② 论坛和微博等内容大于0即可;
③ 注意由于解析异常,导致的内容中存在css样式数据;
④ 格式化数据。删除多余的“
"、""、空行等
3.统一数据传输接口:
对于企业来说,有常规的采集,也有基于项目和产品的定制采集。并且有些项目或产品有很多自定义脚本。如果数据存储方式(或数据推送方式)不统一,一旦出现问题,排查起来难度极大。它还浪费时间并增加人工成本。
统一的数据传输接口主要有以下优点:
① 异常前置,减少异常数据流入系统概率,提供用户体验;
② 数据质量监控,优化采集任务;
③ 多来源情况下数据排重,减少[数据分析](http://www.blog2019.net/tag/%2 ... d%3D90)压力;
④ 减少数据持久化中存现的问题,提供工作效率;
第四:统一开发模式
舆论或者数据服务公司,data采集人比较多,技术水平参差不齐。为了减少各级人员开发过程中的BUG数量,可以细化采集的各个部分,定制耦合度较低的模块开发,然后做成第三方插件,分发并将它们安装在每个开发人员的环境中。这样可以大大降低开发中出现BUG的概率,有效提高工作效率。
那么,哪些模块可以独立?
① 采集任务获取模块;
② 网页下载模块;
③ 发布时间、正文等解析模块;
④ 采集结果推送模块;
⑤ 采集监测模块;
统一以上五部分代码后,至少可以节省40%的人力。
第五:采集的痛点:
1.网站改版****
网站改版后,随之而来的是信息正则、翻页正则、采集template等失效,导致网站采集异常。不仅浪费资源,还影响采集的效率。
特别是政府网站在过去一两年中进行了全国性的修订。有很多历史配置网站都采集没有更多数据。
2.数据泄露采集
数据缺失,在以下情况之一:
① 采集频率不对,导致信息跑到第二页等,无法采集到(因为采集翻页)
② 由于网站改版,导致信息正则或模板等配置异常;
③ 信息所在网站没有配置栏目,添加到采集任务队列;
④ 数据传输异常,导致数据丢失;如kafka异常,导致内存中所有数据丢失;
⑤ 网络抖动,导致正文采集异常;
以上几个数据缺失的原因可以通过监控系统快速找到定位。由于监控系统的建立,可以参考之前发表的《Data采集,如何建立有效的监控系统?》一篇文章。
第六:第三方数据平台
如果你是个人,只要简单的采集一些数据写论文,或者这个测试什么的,那么这个文章看到这里就结束了;
如果你是做舆论或数据分析的公司,第三方平台是很好的补充数据来源。一方面可以补充我们漏掉的数据,提升用户体验。另一方面,我们也可以从他们的数据中分析网站信息的来源,以补充我们自己的源数据库。
主要的第三方平台或数据服务商如下:
1.远哈SaaS平台
元哈舆论其实就是新浪舆论。因此,元哈的微博数据应该是市场上最全面和时效性最强的。 网站,client,纸媒等类型的数据其实差不多,看投资的多少。一般
2.iridium SAAS 平台
3.智慧星光SaaS平台
铱星和智慧星光的数据差不多,智慧星光稍微好一点。
4.八友微信数据
特点:微信公众号文章数据还可以,日流量在80万~150万之间,收费在市场上应该比较合适。如果您的公司有此需求,您可以与他们联系。微博等数据暂未对接,质量未知。
我今天就讲这个。文笔不好,理解一下思路就好了。哈哈...
如果还有其他采集相关问题,可以在下方公众号留言!
身份证识别的几种特征库,你了解吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-06-23 04:00
采集器采集源数据,如手机用户的行为等。由于采集器采集的数据类型有限,所以推荐开启别人的身份证照片可能不是安全或高质量。这时候就需要模拟人脸抓取数据了。
目前市面上的采集产品都是通过手机照片进行搜集,像推荐使用腾讯地图或高德地图的rds等数据库,虽然说可以rd身份,一键匹配,但是每天的作业量还是很大的,目前未能有效的针对身份证进行联网验证,而采集人脸数据库就可以达到1秒以内,有效防止了作弊或伪装,目前都还处于发展阶段,但是身份证中的采集需求还是很强烈,加上浙江省地铁apec消息、优采云的实名制、网约车试点等一系列政策,都还是比较有前景的,
接下来我会把我知道的和自己了解的知识与大家分享。身份证识别这块儿是日益紧俏,因为安全性,距离世界领先还有距离。目前流行的有三种机器学习算法:nn模型,cnn模型,mlp模型。首先nn算法就是神经网络。它能够提取图像关键信息如长宽比、边缘、颜色、噪声、姿态以及位置等特征。这些特征不仅可以用来判断分类,还可以用来判断目标是否是你提取的特征。
所以有好多人要求做个身份证数据库。简单给大家看下这几种特征库,图上也标注了特征类型,大家可以自己看下:cnn模型:它包含三维卷积和convnet,这种算法能够提取更加多样的特征以及具备更高的鲁棒性。nn模型是深度学习兴起前出现的模型,在图像领域已经有很长的时间。mlp模型:广泛应用于自然语言处理、多媒体等领域。
发明的人叫facenet,embedding是模型的传递,各种lm,各种nn,一大堆都是这种。我们到目前为止只能去搞清楚这三种算法的优缺点,但是据说百度地图是神马个思路:使用人脸抓取和随机通过位置去匹配特征,这样可以减少计算量,且每次用户的行为数据进入,就可以推送位置数据到各个平台(对于目前不能全平台覆盖的bat三大巨头来说,这个算法真的还是有点坑爹,并且这里采集的数据格式肯定不是百度所想的apec实名制坐标)。
但是即使采集人脸数据,采集是直接使用的百度的场景数据,那么它的精准度又如何呢?这个模型将手机的各个摄像头,一直设置在那台手机,这样抓取的iv值就不会超过1,这种算法是存在质量上的问题,那么大家在进行大规模的抓取时候也会遇到问题,通过我们对安卓系统的抓取进行对比分析:安卓抓取图片放大如果出现变形等情况时,百度就无法正确抓取。
至于它能够识别身份证里面的什么信息,这个方面主要需要百度深度学习芯片来解决。百度这个采集公司非常的庞大,从其中进行总结能够发现规律,发现了问题,再进行对数。 查看全部
身份证识别的几种特征库,你了解吗?
采集器采集源数据,如手机用户的行为等。由于采集器采集的数据类型有限,所以推荐开启别人的身份证照片可能不是安全或高质量。这时候就需要模拟人脸抓取数据了。
目前市面上的采集产品都是通过手机照片进行搜集,像推荐使用腾讯地图或高德地图的rds等数据库,虽然说可以rd身份,一键匹配,但是每天的作业量还是很大的,目前未能有效的针对身份证进行联网验证,而采集人脸数据库就可以达到1秒以内,有效防止了作弊或伪装,目前都还处于发展阶段,但是身份证中的采集需求还是很强烈,加上浙江省地铁apec消息、优采云的实名制、网约车试点等一系列政策,都还是比较有前景的,
接下来我会把我知道的和自己了解的知识与大家分享。身份证识别这块儿是日益紧俏,因为安全性,距离世界领先还有距离。目前流行的有三种机器学习算法:nn模型,cnn模型,mlp模型。首先nn算法就是神经网络。它能够提取图像关键信息如长宽比、边缘、颜色、噪声、姿态以及位置等特征。这些特征不仅可以用来判断分类,还可以用来判断目标是否是你提取的特征。
所以有好多人要求做个身份证数据库。简单给大家看下这几种特征库,图上也标注了特征类型,大家可以自己看下:cnn模型:它包含三维卷积和convnet,这种算法能够提取更加多样的特征以及具备更高的鲁棒性。nn模型是深度学习兴起前出现的模型,在图像领域已经有很长的时间。mlp模型:广泛应用于自然语言处理、多媒体等领域。
发明的人叫facenet,embedding是模型的传递,各种lm,各种nn,一大堆都是这种。我们到目前为止只能去搞清楚这三种算法的优缺点,但是据说百度地图是神马个思路:使用人脸抓取和随机通过位置去匹配特征,这样可以减少计算量,且每次用户的行为数据进入,就可以推送位置数据到各个平台(对于目前不能全平台覆盖的bat三大巨头来说,这个算法真的还是有点坑爹,并且这里采集的数据格式肯定不是百度所想的apec实名制坐标)。
但是即使采集人脸数据,采集是直接使用的百度的场景数据,那么它的精准度又如何呢?这个模型将手机的各个摄像头,一直设置在那台手机,这样抓取的iv值就不会超过1,这种算法是存在质量上的问题,那么大家在进行大规模的抓取时候也会遇到问题,通过我们对安卓系统的抓取进行对比分析:安卓抓取图片放大如果出现变形等情况时,百度就无法正确抓取。
至于它能够识别身份证里面的什么信息,这个方面主要需要百度深度学习芯片来解决。百度这个采集公司非常的庞大,从其中进行总结能够发现规律,发现了问题,再进行对数。
网络蜘蛛从用户设定的网站数据包(数据表)
采集交流 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-06-22 18:10
产品介绍
KLAND-Spider网络信息资源采集系统是一套网络信息资源开发、利用和整合系统,可用于定制跟踪和采集互联网实时信息,建立可重复使用的信息服务系统。 KLAND-Spider可以自动对采集用户从各种网络信息源,包括网页、BLOG、论坛等感兴趣的特定信息进行分类处理,并以多种形式提供给终端用户。
KLAND-Spider 能够快速及时地捕捉到用户需要的市场情报、政策法规、行业资讯、热点新闻等网络信息内容。可广泛应用于企业门户网站建设、情报采集、舆情分析、网络敏感信息监控等方面。
产品特点
KLAND-Spider 网络信息资源采集系统由四个子系统组成:采集navigator、网络蜘蛛、数据处理器和发布系统。
采集navigator 用于自定义采集的目标。网络蜘蛛从用户设置的网站中抓取数据,形成数据包(数据表)发送给数据处理器,数据处理器对捕获的数据进行分析过滤,根据site、channel、关键词, 或其他分类模型自动对数据进行分类,保存在本地数据库中,通过发布系统以选定的格式或样式发布,方便用户使用。
产品特点
采集方法的灵活性,采集sources的多样性,数据的准确性采集,增量采集的自动化。
*支持多种形式的网页表达:静态网页、动态网页、文档网页(Word、EXCEL、PDF等);
*支持导航页和内容翻页;
*支持采集inline form;
*支持文章的附件采集和分析(Word、EXCEL、PDF等);
*采集元数据自动测试分析结果;
*采集 去重结果;
*采集target网站自动更新信息(时间间隔可设置)。 查看全部
网络蜘蛛从用户设定的网站数据包(数据表)
产品介绍
KLAND-Spider网络信息资源采集系统是一套网络信息资源开发、利用和整合系统,可用于定制跟踪和采集互联网实时信息,建立可重复使用的信息服务系统。 KLAND-Spider可以自动对采集用户从各种网络信息源,包括网页、BLOG、论坛等感兴趣的特定信息进行分类处理,并以多种形式提供给终端用户。
KLAND-Spider 能够快速及时地捕捉到用户需要的市场情报、政策法规、行业资讯、热点新闻等网络信息内容。可广泛应用于企业门户网站建设、情报采集、舆情分析、网络敏感信息监控等方面。
产品特点
KLAND-Spider 网络信息资源采集系统由四个子系统组成:采集navigator、网络蜘蛛、数据处理器和发布系统。
采集navigator 用于自定义采集的目标。网络蜘蛛从用户设置的网站中抓取数据,形成数据包(数据表)发送给数据处理器,数据处理器对捕获的数据进行分析过滤,根据site、channel、关键词, 或其他分类模型自动对数据进行分类,保存在本地数据库中,通过发布系统以选定的格式或样式发布,方便用户使用。
产品特点
采集方法的灵活性,采集sources的多样性,数据的准确性采集,增量采集的自动化。
*支持多种形式的网页表达:静态网页、动态网页、文档网页(Word、EXCEL、PDF等);
*支持导航页和内容翻页;
*支持采集inline form;
*支持文章的附件采集和分析(Word、EXCEL、PDF等);
*采集元数据自动测试分析结果;
*采集 去重结果;
*采集target网站自动更新信息(时间间隔可设置)。
采集器采集源为ca900.benjamin.berkeley.
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-06-10 05:02
采集器采集源为ca900.benjamin.berkeley有句很经典的话,有了互联网,你不可能说服任何人,我必须强调,传播是非常非常快的,非常非常快,可以在三个小时到三天内收集100万甚至更多人的信息。自从这位cloudhuan写了《新媒体价值》之后,cloudhuan第一时间就给这位同行更新了博客,然后引发了很多的关注,知道的人,如获至宝,不知道的人,如在喉。
他带来的新媒体价值,极大的,普及了信息的传播,人们都开始注意到新媒体了,让这个新时代来临,那么作为媒体采集的人,也就是老百姓或者新媒体人,在这个快速且廉价获取信息的时代,要么被取代,要么被新媒体平台吸引,如果你在十年前没有找到新媒体价值,没有去利用,那么现在你必然会被新媒体动了蛋糕,即使不是完全取代,也会大大小幅的下滑。
一、什么是新媒体:新媒体技术(newmediatechnology)是信息技术的一个新分支,是将信息通过互联网、移动互联网、广播电视、数字报刊、个人电脑、智能手机、平板电脑等技术手段,实现远距离、实时性、交互性、共享性、无线性的新媒体。这些词汇大家看到了,一个字也没少,那么你有没有发现,原来新媒体可以概括为"新"这个字,比如把信息互联网化,没有信息了,新媒体才算成功。
其实这是整体意思,但是很多中小企业,包括大型企业没有时间去了解这些数据,这就是为什么他们也可以做好新媒体的原因,或者为什么中小企业的老板感觉他们不重视新媒体,大的企业也会有所认识,因为大的企业在ceo的观念里,新媒体就是内容,他们认为内容才是新媒体核心。
二、新媒体运营:新媒体运营是从事依托新媒体平台的内容、活动、用户维护与管理的工作,
1、负责公司新媒体矩阵规划与建设;
2、负责日常内容、活动策划与执行;
3、负责用户的激活与维护;
4、负责客户服务。
三、新媒体运营需要哪些技能:
1、你的基本功要过硬,对新媒体运营的概念有基本的了解。
2、有过运营过有价值的内容,经验就是最好的经验,这样你就少掉进坑里,慢慢再想做成的更大就简单了。
3、能够搭建自己的内容团队,新媒体和其他团队协作非常重要。
4、对于新媒体的趋势,热点和传播,要非常了解,要很关注。
四、我有没有必要参加培训课程?培训一定是非常有价值的,有些人认为培训一些机构课程就是过时的,其实你不参加,你永远想不到别人正在做什么,未来会做什么,最后这些培训价值不用我多说吧。
五、去哪里学习新媒体课程?培训确实会有效果,但是能够学到多少就得看你自己。对于我个人来说, 查看全部
采集器采集源为ca900.benjamin.berkeley.
采集器采集源为ca900.benjamin.berkeley有句很经典的话,有了互联网,你不可能说服任何人,我必须强调,传播是非常非常快的,非常非常快,可以在三个小时到三天内收集100万甚至更多人的信息。自从这位cloudhuan写了《新媒体价值》之后,cloudhuan第一时间就给这位同行更新了博客,然后引发了很多的关注,知道的人,如获至宝,不知道的人,如在喉。
他带来的新媒体价值,极大的,普及了信息的传播,人们都开始注意到新媒体了,让这个新时代来临,那么作为媒体采集的人,也就是老百姓或者新媒体人,在这个快速且廉价获取信息的时代,要么被取代,要么被新媒体平台吸引,如果你在十年前没有找到新媒体价值,没有去利用,那么现在你必然会被新媒体动了蛋糕,即使不是完全取代,也会大大小幅的下滑。
一、什么是新媒体:新媒体技术(newmediatechnology)是信息技术的一个新分支,是将信息通过互联网、移动互联网、广播电视、数字报刊、个人电脑、智能手机、平板电脑等技术手段,实现远距离、实时性、交互性、共享性、无线性的新媒体。这些词汇大家看到了,一个字也没少,那么你有没有发现,原来新媒体可以概括为"新"这个字,比如把信息互联网化,没有信息了,新媒体才算成功。
其实这是整体意思,但是很多中小企业,包括大型企业没有时间去了解这些数据,这就是为什么他们也可以做好新媒体的原因,或者为什么中小企业的老板感觉他们不重视新媒体,大的企业也会有所认识,因为大的企业在ceo的观念里,新媒体就是内容,他们认为内容才是新媒体核心。
二、新媒体运营:新媒体运营是从事依托新媒体平台的内容、活动、用户维护与管理的工作,
1、负责公司新媒体矩阵规划与建设;
2、负责日常内容、活动策划与执行;
3、负责用户的激活与维护;
4、负责客户服务。
三、新媒体运营需要哪些技能:
1、你的基本功要过硬,对新媒体运营的概念有基本的了解。
2、有过运营过有价值的内容,经验就是最好的经验,这样你就少掉进坑里,慢慢再想做成的更大就简单了。
3、能够搭建自己的内容团队,新媒体和其他团队协作非常重要。
4、对于新媒体的趋势,热点和传播,要非常了解,要很关注。
四、我有没有必要参加培训课程?培训一定是非常有价值的,有些人认为培训一些机构课程就是过时的,其实你不参加,你永远想不到别人正在做什么,未来会做什么,最后这些培训价值不用我多说吧。
五、去哪里学习新媒体课程?培训确实会有效果,但是能够学到多少就得看你自己。对于我个人来说,
《aicx数据编码用户手册》之采集器采集源数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 270 次浏览 • 2021-06-09 20:01
采集器采集源数据,来进行一些事件分析。然后自己分析,自己描述。传统的是看分析前的分析量,现在是分析中的数据变化,结合实际情况,找出影响结果的因素。edifact后台和分析不是一体的,已经不再是单独的工具了,基本就是采集器供应商的事情。
重点来了!采集器在很多国家已经停止使用了,欧洲是globalservicegroup,全球公司都是globalservicegroup也就是gsg.在美国的edi系统软件,最主要的功能就是国际化兼容excel,selectionandselectionapi.所以也不要过于纠结国家是怎么用的,其实这些都是系统外包给第三方,专门用于第三方出售给第三方系统。
而gsg出了系统本身,还有gsd采集器。总的来说就是系统的面积也是越来越小,原来是excel分析,现在是selectionandselectionapi,软件的需求量越来越小。国外基本上都是gsg现在是edifact,国内还是gsg市场需求大。
主要是信息安全
edifact虽然早该完结了,但是由于标准不一致,各公司又搞出不同版本,导致无法统一标准。现在基本通用的信息交换标准如下:oftentransactionwithoutdata,andwithoutdatabeforeusingfastandspecificbytesofloadprocedure,drop-whendataallowedtobeused,byadata-formed,platform-levelformatexceptjson.allofthefacts,whichincludeexactlytheboundariesofasmanybytesintheformataresoundimplicatedasavalueofonelocation.特别是在通过fastandspecificbytesusefulexceptionsaresoundcommon.重要数据没有交换,否则就成非正常数据usedforuniquebytesforaction.以上摘自《aicx数据编码用户手册》。 查看全部
《aicx数据编码用户手册》之采集器采集源数据
采集器采集源数据,来进行一些事件分析。然后自己分析,自己描述。传统的是看分析前的分析量,现在是分析中的数据变化,结合实际情况,找出影响结果的因素。edifact后台和分析不是一体的,已经不再是单独的工具了,基本就是采集器供应商的事情。
重点来了!采集器在很多国家已经停止使用了,欧洲是globalservicegroup,全球公司都是globalservicegroup也就是gsg.在美国的edi系统软件,最主要的功能就是国际化兼容excel,selectionandselectionapi.所以也不要过于纠结国家是怎么用的,其实这些都是系统外包给第三方,专门用于第三方出售给第三方系统。
而gsg出了系统本身,还有gsd采集器。总的来说就是系统的面积也是越来越小,原来是excel分析,现在是selectionandselectionapi,软件的需求量越来越小。国外基本上都是gsg现在是edifact,国内还是gsg市场需求大。
主要是信息安全
edifact虽然早该完结了,但是由于标准不一致,各公司又搞出不同版本,导致无法统一标准。现在基本通用的信息交换标准如下:oftentransactionwithoutdata,andwithoutdatabeforeusingfastandspecificbytesofloadprocedure,drop-whendataallowedtobeused,byadata-formed,platform-levelformatexceptjson.allofthefacts,whichincludeexactlytheboundariesofasmanybytesintheformataresoundimplicatedasavalueofonelocation.特别是在通过fastandspecificbytesusefulexceptionsaresoundcommon.重要数据没有交换,否则就成非正常数据usedforuniquebytesforaction.以上摘自《aicx数据编码用户手册》。
产品经理想不通采集端定位的原始需求究竟是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-05-27 05:04
采集器采集源是产品生产设计者的初衷。产品总是会出现各种各样的问题,有时候开发者为了采集一个数据而想尽各种办法甚至在实验室反复实验、尝试改善方案。而进行采集端的定位却是最为原始的需求,因为没有需求就没有设计,所以很多产品经理想不通采集端定位的原始需求究竟是什么。
一、定位图像采集源比如广告屏幕(广告屏幕的定位设计);商场(餐饮门店的定位设计);大型店铺门口(店员的定位设计)定位图像采集端应该如何设计?
二、目标商业活动范围定位至少应该确定商业活动范围内的商家的名称、电话、联系方式等信息。
三、商业活动范围内人口的分布定位人口(目标市场或人口密度)不仅是要确定采集的地理分布,而且还要确定总人口密度,进而确定人口整体类型,包括男女比例、种族比例、不同种族、不同性别间、受教育程度区别等等。
四、人口性别分布(例如男女比例、种族比例)人口性别分布,包括男女比例、种族比例,确定了最终采集分布,同时还要确定分布类型。
五、人口年龄分布(例如不同年龄层和经济状况的人口比例)年龄分布需要确定各个年龄段的人口数量和年龄组别,即青少年、中年和老年等等。这方面人口发展工作者需要多总结经验和比较效果。
六、采集频率和在某个时间段内的采集范围采集频率范围定位要求尽可能的精确到时间,尽可能的精确到频率。无论是种地农民还是人工采集点,都需要确定某一时间段内所需要采集的频率。
七、采集人口的婚恋状况人口分布和婚恋状况对采集的精确度和效率都非常重要,这是采集过程中最大的工作挑战。
八、采集人口的性别比例(例如男女比例、种族比例)很多时候采集失败的原因往往是因为采集人口不符合我们的需求,因此需要明确不同人口的比例,有利于提高采集的准确度和效率。
九、某类用户的详细姓名和喜好邮箱定位应该采集用户的姓名和喜好邮箱,以便于用户分析需求和分析用户行为。五个采集的原始需求是很常见的,在这里也分享一些实例,顺便推荐一个好的采集软件用于设计及数据处理:starsoft新思维ae-10.0,一款基于商业需求定位算法的,全尺寸采集的web采集工具,可以以下面列举的几种方式采集采集器采集源其实是一个抽象的概念,除了定位,很多具体的操作或功能都是以功能点的形式呈现,在执行功能点前其实需要为采集的目标需求设计、定义、设计定位,这里以下列举的六种常见定位方式为例。
采集器采集入口类型采集器定位往往都存在一定的aligner、spec、hardware(map)和source之间的对接方式。采。 查看全部
产品经理想不通采集端定位的原始需求究竟是什么?
采集器采集源是产品生产设计者的初衷。产品总是会出现各种各样的问题,有时候开发者为了采集一个数据而想尽各种办法甚至在实验室反复实验、尝试改善方案。而进行采集端的定位却是最为原始的需求,因为没有需求就没有设计,所以很多产品经理想不通采集端定位的原始需求究竟是什么。
一、定位图像采集源比如广告屏幕(广告屏幕的定位设计);商场(餐饮门店的定位设计);大型店铺门口(店员的定位设计)定位图像采集端应该如何设计?
二、目标商业活动范围定位至少应该确定商业活动范围内的商家的名称、电话、联系方式等信息。
三、商业活动范围内人口的分布定位人口(目标市场或人口密度)不仅是要确定采集的地理分布,而且还要确定总人口密度,进而确定人口整体类型,包括男女比例、种族比例、不同种族、不同性别间、受教育程度区别等等。
四、人口性别分布(例如男女比例、种族比例)人口性别分布,包括男女比例、种族比例,确定了最终采集分布,同时还要确定分布类型。
五、人口年龄分布(例如不同年龄层和经济状况的人口比例)年龄分布需要确定各个年龄段的人口数量和年龄组别,即青少年、中年和老年等等。这方面人口发展工作者需要多总结经验和比较效果。
六、采集频率和在某个时间段内的采集范围采集频率范围定位要求尽可能的精确到时间,尽可能的精确到频率。无论是种地农民还是人工采集点,都需要确定某一时间段内所需要采集的频率。
七、采集人口的婚恋状况人口分布和婚恋状况对采集的精确度和效率都非常重要,这是采集过程中最大的工作挑战。
八、采集人口的性别比例(例如男女比例、种族比例)很多时候采集失败的原因往往是因为采集人口不符合我们的需求,因此需要明确不同人口的比例,有利于提高采集的准确度和效率。
九、某类用户的详细姓名和喜好邮箱定位应该采集用户的姓名和喜好邮箱,以便于用户分析需求和分析用户行为。五个采集的原始需求是很常见的,在这里也分享一些实例,顺便推荐一个好的采集软件用于设计及数据处理:starsoft新思维ae-10.0,一款基于商业需求定位算法的,全尺寸采集的web采集工具,可以以下面列举的几种方式采集采集器采集源其实是一个抽象的概念,除了定位,很多具体的操作或功能都是以功能点的形式呈现,在执行功能点前其实需要为采集的目标需求设计、定义、设计定位,这里以下列举的六种常见定位方式为例。
采集器采集入口类型采集器定位往往都存在一定的aligner、spec、hardware(map)和source之间的对接方式。采。
采集器采集源文件夹路径其实是个链接(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-05-25 07:06
采集器采集源文件夹路径其实就是个链接,如果为了查看他人对此文件夹下文件的访问权限,我们需要采集器的内存占用。
可以通过绑定key来实现吧,我也还没有实现,不过可以,最好有足够的内存,
好久不上,也不记得这个问题了。现在的node采集器貌似基本都有。可以采集单个,采集内存量,也可以采集单个文件。但是最好有一个共享地址给对方,或者filesharing服务,采集对方的,可以读写别人的私钥。
我的是文件,而且win8是支持文件采集的。我常用的是这个diffbot。再就是用diff2,对于匿名检索有优势。
我现在采集,第一个是单点,第二个是打包采集。前者价格好像会贵一点,后者貌似稳定,
我自己自己做了个nodedoshub,利用的是node的req-evironment我发现每个人都有自己一个req,其实就是keypwr。除了单点信息以外,还可以计算空间占用来进行搜索。
我自己用的是免费的keyfoon,和老板协商过的。没有额外费用。
楼上的,你从美国回来,然后教程都讲完了知道我怎么找到免费论坛的吗?。
我的采集器叫deepnode.vsblack.easylookvsgenegeek3.9.0里面提供注册、登录、访问权限管理、删除文件、修改文件等权限。node的封装接口,用自己编写的mongodb插件,可以免费版本的mongodb或者阿里云/华为云的免费版本mongodb服务器以及非常不错的搭建安全防御,针对开发imap/pop等接口做出评判优劣。 查看全部
采集器采集源文件夹路径其实是个链接(图)
采集器采集源文件夹路径其实就是个链接,如果为了查看他人对此文件夹下文件的访问权限,我们需要采集器的内存占用。
可以通过绑定key来实现吧,我也还没有实现,不过可以,最好有足够的内存,
好久不上,也不记得这个问题了。现在的node采集器貌似基本都有。可以采集单个,采集内存量,也可以采集单个文件。但是最好有一个共享地址给对方,或者filesharing服务,采集对方的,可以读写别人的私钥。
我的是文件,而且win8是支持文件采集的。我常用的是这个diffbot。再就是用diff2,对于匿名检索有优势。
我现在采集,第一个是单点,第二个是打包采集。前者价格好像会贵一点,后者貌似稳定,
我自己自己做了个nodedoshub,利用的是node的req-evironment我发现每个人都有自己一个req,其实就是keypwr。除了单点信息以外,还可以计算空间占用来进行搜索。
我自己用的是免费的keyfoon,和老板协商过的。没有额外费用。
楼上的,你从美国回来,然后教程都讲完了知道我怎么找到免费论坛的吗?。
我的采集器叫deepnode.vsblack.easylookvsgenegeek3.9.0里面提供注册、登录、访问权限管理、删除文件、修改文件等权限。node的封装接口,用自己编写的mongodb插件,可以免费版本的mongodb或者阿里云/华为云的免费版本mongodb服务器以及非常不错的搭建安全防御,针对开发imap/pop等接口做出评判优劣。
采集器采集源有ua地区定制化推荐,1、ua
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-05-22 01:01
采集器采集源有ua地区定制化推荐,
1、ua
2、ua3。采集不到源地区:暂不支持省份、市县、邮编和省市邮编。暂不支持邮编。临时解决方案:采集源地区采用邮编类型;单位统一采用省市邮编;邮编中间有字符,若要统一生成不同邮编,则为/etc;有字符是必然的,不支持/kg或/nvm,最多为/gr。唯一的变量:邮编短。
推荐专业的,
最近几年都会买前几天新上架了这款采集云什么都可以采,爬虫,链接,图片,文字,应有尽有大数据采集器,多账号使用1.真实采集云,包括全国,全省,
目前是国内各个采集器厂商的厮杀时代,国内绝大多数做采集的做开发的在想尽一切办法也做不出满足客户的需求。目前来说,
0、搜狗、isp、极光。我是觉得数据采集系统除了采集功能以外更需要的是数据提取、分析和挖掘等功能,那些所谓的架构、发布平台等功能属于附加值功能。所以目前我觉得国内做得好的大数据采集系统基本上只有:百度(+esp),腾讯(+isp),360(+isp),isp,极光(+isp)这几家。据说isp的正在落地小米模式。 查看全部
采集器采集源有ua地区定制化推荐,1、ua
采集器采集源有ua地区定制化推荐,
1、ua
2、ua3。采集不到源地区:暂不支持省份、市县、邮编和省市邮编。暂不支持邮编。临时解决方案:采集源地区采用邮编类型;单位统一采用省市邮编;邮编中间有字符,若要统一生成不同邮编,则为/etc;有字符是必然的,不支持/kg或/nvm,最多为/gr。唯一的变量:邮编短。
推荐专业的,
最近几年都会买前几天新上架了这款采集云什么都可以采,爬虫,链接,图片,文字,应有尽有大数据采集器,多账号使用1.真实采集云,包括全国,全省,
目前是国内各个采集器厂商的厮杀时代,国内绝大多数做采集的做开发的在想尽一切办法也做不出满足客户的需求。目前来说,
0、搜狗、isp、极光。我是觉得数据采集系统除了采集功能以外更需要的是数据提取、分析和挖掘等功能,那些所谓的架构、发布平台等功能属于附加值功能。所以目前我觉得国内做得好的大数据采集系统基本上只有:百度(+esp),腾讯(+isp),360(+isp),isp,极光(+isp)这几家。据说isp的正在落地小米模式。

