
采集
汇总:如何做好信息采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2022-12-09 07:13
摘 要:信息采集是通过各种渠道搜索、归纳、整理并最终形成所需有效信息的过程。各种渠道包括:一是通过实地调查获得的第一手资料,即直接信息。二是通过媒体间接获得的信息。比如书籍、报纸、电视、网络。当前,互联网技术高度发达,信息量远远超过其他信息载体。因此,我们获取采集信息的主要途径来自互联网。
信息采集是通过各种渠道搜索、归纳、整理并最终形成所需有效信息的过程。各种渠道包括:一是通过实地调查获得的第一手资料,即直接信息。二是通过媒体间接获得的信息。比如书籍、报纸、电视、网络。当前,互联网技术高度发达,信息量远远超过其他信息载体。因此,我们获取采集信息的主要途径来自互联网。
有效信息是我们可以利用的信息,而不是任何一条信息对我们有用。资料采集不是“拿来主义”,不是直接从别人网站复制粘贴的作品。按照我们的目标和原则搜索到的信息,一般不能直接为我们所用,而是需要经过归纳整理,即需要一个数据处理的过程。商业网编辑想宣传自己的产品或网站,最终让自己的产品或网站有一个好的形象,进而达到销售的目的。所以,在做信息采集的时候,想想我们编辑的信息应该体现什么样的价值,不要盲目采集。
在明确了信息的采集用途之后,是时候通过一些合理的渠道来采集我们需要的信息了。
现代社会是信息社会,互联网报告企业信息的及时性是其他方式无法比拟的。通过互联网,您还可以更主动地选择自己需要的信息。需要注意的是,网上垃圾信息很多,垃圾站也很多。如果你没能对付采集一堆病毒,那得不偿失。最好选择国内知名的网站和官方的网站,这样可以大大提高采集信息的可靠性和实用性。
刚才说了,我们主要的信息采集方法是网页信息采集。那么什么是网络信息采集?事实上,目前并没有官方统一的概念。如果有定义的话,就是利用网页信息采集软件,针对某个网页实现针对性的、行业性的、精准的数据抓取。规则和筛选标准用于对数据进行分类并形成数据库文件的过程。当然,这里抓取的数据是公开的,任何人都可以看到,并不是为了窃取别人的后台数据。Web Information采集软件是一款网站定向数据采集、分析、发布的实用软件。可以对指定网站中任意网页进行目标分析,总结采集方案,
这种软件的好处是用户可以针对不同类型的信息设置不同的查询条件,而不是将采集网站中的所有信息一次性全部发到本地,避免了无意义的资源消耗。提高信息使用效率。
采集软件优采云 采集器等目前在互联网上很流行。
优采云采集器交流群:61570666
汇总:爬虫如何采集舆情数据
数据采集通俗地说就是通过爬虫代码访问目标网站的API链接,获取有用的信息。爬虫程序模拟人工从网页中获取所需信息,并自动保存在文档中,应用广泛。如图片、视频、文档、小说等。前提是不做非法经营。
在互联网大数据时代,网络爬虫主要是为搜索引擎提供最全面、最新的数据,网络爬虫也是从互联网上获取采集数据的爬虫。
我们还可以利用网络爬虫获取采集舆情数据、采集新闻、社交网络、论坛、博客等信息数据。这也是常见的舆情数据获取方案之一。一般就是利用爬虫爬虫ip,通过爬虫程序采集一些有意义的网站数据采集。舆情数据也可以在数据交易市场购买,或者由专业的舆情分析团队获取,但一般来说,专业的舆情分析团队也会使用爬虫ip到采集相关数据,从而进行舆情分析数据分析。
由于短视频的流行,我们也可以使用爬虫程序采集抖音和快手来分析抖音和快手两大主流短视频应用的舆情数据。将统计数据生成表格,作为数据报表提供给大家,也可以参考下面的采集程序代码:
// 要访问的目标页面
string targetUrl = "http://httpbin.org/ip";
// 爬虫ip服务器( jshk.com.cn )
string proxyHost = "http://jshk.com.cn/mb/";
string proxyPort = "31111";
// 爬虫ip验证信息
string proxyUser = "username";
string proxyPass = "password";
// 设置爬虫ip服务器
WebProxy proxy = new WebProxy(string.Format("{0}:{1}", proxyHost, proxyPort), true);
<p>
ServicePointManager.Expect100Continue = false;
var request = WebRequest.Create(targetUrl) as HttpWebRequest;
request.AllowAutoRedirect = true;
request.KeepAlive = true;
request.Method = "GET";
request.Proxy = proxy;
//request.Proxy.Credentials = CredentialCache.DefaultCredentials;
request.Proxy.Credentials = new System.Net.NetworkCredential(proxyUser, proxyPass);
// 设置Proxy Tunnel
// Random ran=new Random();
// int tunnel =ran.Next(1,10000);
// request.Headers.Add("Proxy-Tunnel", String.valueOf(tunnel));
//request.Timeout = 20000;
//request.ServicePoint.ConnectionLimit = 512;
//request.UserAgent = "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.82 Safari/537.36";
//request.Headers.Add("Cache-Control", "max-age=0");
//request.Headers.Add("DNT", "1");
//String encoded = System.Convert.ToBase64String(System.Text.Encoding.GetEncoding("ISO-8859-1").GetBytes(proxyUser + ":" + proxyPass));
//request.Headers.Add("Proxy-Authorization", "Basic " + encoded);
using (var response = request.GetResponse() as HttpWebResponse)
using (var sr = new StreamReader(response.GetResponseStream(), Encoding.UTF8))
{
string htmlStr = sr.ReadToEnd();
}
</p> 查看全部
汇总:如何做好信息采集
摘 要:信息采集是通过各种渠道搜索、归纳、整理并最终形成所需有效信息的过程。各种渠道包括:一是通过实地调查获得的第一手资料,即直接信息。二是通过媒体间接获得的信息。比如书籍、报纸、电视、网络。当前,互联网技术高度发达,信息量远远超过其他信息载体。因此,我们获取采集信息的主要途径来自互联网。
信息采集是通过各种渠道搜索、归纳、整理并最终形成所需有效信息的过程。各种渠道包括:一是通过实地调查获得的第一手资料,即直接信息。二是通过媒体间接获得的信息。比如书籍、报纸、电视、网络。当前,互联网技术高度发达,信息量远远超过其他信息载体。因此,我们获取采集信息的主要途径来自互联网。
有效信息是我们可以利用的信息,而不是任何一条信息对我们有用。资料采集不是“拿来主义”,不是直接从别人网站复制粘贴的作品。按照我们的目标和原则搜索到的信息,一般不能直接为我们所用,而是需要经过归纳整理,即需要一个数据处理的过程。商业网编辑想宣传自己的产品或网站,最终让自己的产品或网站有一个好的形象,进而达到销售的目的。所以,在做信息采集的时候,想想我们编辑的信息应该体现什么样的价值,不要盲目采集。

在明确了信息的采集用途之后,是时候通过一些合理的渠道来采集我们需要的信息了。
现代社会是信息社会,互联网报告企业信息的及时性是其他方式无法比拟的。通过互联网,您还可以更主动地选择自己需要的信息。需要注意的是,网上垃圾信息很多,垃圾站也很多。如果你没能对付采集一堆病毒,那得不偿失。最好选择国内知名的网站和官方的网站,这样可以大大提高采集信息的可靠性和实用性。
刚才说了,我们主要的信息采集方法是网页信息采集。那么什么是网络信息采集?事实上,目前并没有官方统一的概念。如果有定义的话,就是利用网页信息采集软件,针对某个网页实现针对性的、行业性的、精准的数据抓取。规则和筛选标准用于对数据进行分类并形成数据库文件的过程。当然,这里抓取的数据是公开的,任何人都可以看到,并不是为了窃取别人的后台数据。Web Information采集软件是一款网站定向数据采集、分析、发布的实用软件。可以对指定网站中任意网页进行目标分析,总结采集方案,

这种软件的好处是用户可以针对不同类型的信息设置不同的查询条件,而不是将采集网站中的所有信息一次性全部发到本地,避免了无意义的资源消耗。提高信息使用效率。
采集软件优采云 采集器等目前在互联网上很流行。
优采云采集器交流群:61570666
汇总:爬虫如何采集舆情数据
数据采集通俗地说就是通过爬虫代码访问目标网站的API链接,获取有用的信息。爬虫程序模拟人工从网页中获取所需信息,并自动保存在文档中,应用广泛。如图片、视频、文档、小说等。前提是不做非法经营。
在互联网大数据时代,网络爬虫主要是为搜索引擎提供最全面、最新的数据,网络爬虫也是从互联网上获取采集数据的爬虫。
我们还可以利用网络爬虫获取采集舆情数据、采集新闻、社交网络、论坛、博客等信息数据。这也是常见的舆情数据获取方案之一。一般就是利用爬虫爬虫ip,通过爬虫程序采集一些有意义的网站数据采集。舆情数据也可以在数据交易市场购买,或者由专业的舆情分析团队获取,但一般来说,专业的舆情分析团队也会使用爬虫ip到采集相关数据,从而进行舆情分析数据分析。
由于短视频的流行,我们也可以使用爬虫程序采集抖音和快手来分析抖音和快手两大主流短视频应用的舆情数据。将统计数据生成表格,作为数据报表提供给大家,也可以参考下面的采集程序代码:
// 要访问的目标页面
string targetUrl = "http://httpbin.org/ip";
// 爬虫ip服务器( jshk.com.cn )
string proxyHost = "http://jshk.com.cn/mb/";
string proxyPort = "31111";
// 爬虫ip验证信息
string proxyUser = "username";
string proxyPass = "password";
// 设置爬虫ip服务器
WebProxy proxy = new WebProxy(string.Format("{0}:{1}", proxyHost, proxyPort), true);
<p>

ServicePointManager.Expect100Continue = false;
var request = WebRequest.Create(targetUrl) as HttpWebRequest;
request.AllowAutoRedirect = true;
request.KeepAlive = true;
request.Method = "GET";
request.Proxy = proxy;
//request.Proxy.Credentials = CredentialCache.DefaultCredentials;
request.Proxy.Credentials = new System.Net.NetworkCredential(proxyUser, proxyPass);
// 设置Proxy Tunnel
// Random ran=new Random();
// int tunnel =ran.Next(1,10000);
// request.Headers.Add("Proxy-Tunnel", String.valueOf(tunnel));

//request.Timeout = 20000;
//request.ServicePoint.ConnectionLimit = 512;
//request.UserAgent = "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.82 Safari/537.36";
//request.Headers.Add("Cache-Control", "max-age=0");
//request.Headers.Add("DNT", "1");
//String encoded = System.Convert.ToBase64String(System.Text.Encoding.GetEncoding("ISO-8859-1").GetBytes(proxyUser + ":" + proxyPass));
//request.Headers.Add("Proxy-Authorization", "Basic " + encoded);
using (var response = request.GetResponse() as HttpWebResponse)
using (var sr = new StreamReader(response.GetResponseStream(), Encoding.UTF8))
{
string htmlStr = sr.ReadToEnd();
}
</p>
技术和经验:大数据技术栈之-数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2022-12-07 05:11
介绍
数据仓库的基础是数据。没有数据,数据仓库就是一个空壳。有许多数据来源。我们需要按照一个规则和流程制定一个采集方案,根据数据的特点和用途选择合适的方案。采集程序和数据采集一般分为全量和增量,对于一些业务场景,需要两者配合使用。
数据采集完整计划
全卷是指一次采集所有的数据,比如按照天数/月数。如果数据量很大,可能会比较耗时,而且会占用大量的存储空间。比如我们MySQL里面的数据,每天都需要同步。如果每天都同步,就会有很多重复数据,因为MySQL每天都在原来的基础上添加数据,每天同步一个完整的副本,所以是冗余的。其余的数据,而且不是实时的,需要每天同步一个时间点。它的优点是数据比较完整,但是会占用很大的存储空间。
增加
因为每天全量同步数据,会占用大量存储空间,效率不高,所以一般采用增量同步,但是增量是基于全量的,所以全量同步是必需的,后面是增量同步,增量意味着数据会增加或者修改,所以同步起来会比较困难。如果不使用工具,需要根据时间戳进行同步,比如增加一个create_time字段和update_time字段。添加数据时,会设置当前时间,修改数据时更新修改时间,然后以当天日期为条件获取符合条件的数据,但有个问题就是数据不是那么真实——时间,因为需要主动获取数据,会因网络等原因造成误差。实时的时候,对数据库的压力比较大,所以我们需要另一种方式,那就是CDC。
CDC全称为Change Data Capture,指的是识别并捕获数据库中数据的修改、删除、添加等变化,然后将这些变化以一定的方式记录下来,通过一定的机制传递给下游的Service,通过这个机制,可以减轻数据库的压力,数据更实时。比如MySQL的binglog机制就是CDC。
数据 采集 工具
数据采集工具分为全量采集和增量采集。
完整的 采集
采集工具有很多,比如Sqoop、kettle、DataX。下面主要说一下DataX。DataX可以实现各种数据之间的转换。如果DataX自带的数据源不能满足我们的需求,也可以自己实现,DataX由一个Writer和一个Reader组成,Reader是数据提供者,Writer是数据需求者,比如mysqlreader,doriswriter,就是将mysql的数据同步到doris。
DataX 只需要简单的安装。安装后只需要写一个json转换文件,然后执行json脚本即可。执行脚本后,数据同步将开始。但是,我们的同步任务可能一天执行一次。如果任务很多,那么每天执行脚本会很麻烦,这时可以使用定时任务,linux可以使用crond进行定时调度,但是如果使用cronb则无法监控任务的成功或失败,而且不能对任务进行统计,所以我们需要一个统一的任务调度平台,比如Azkaban、DepinSchudeler等,后面会用到。
增量采集
对于增量同步,我们需要用到CDC工具,比如Flume可以采集日志,canal可以实时同步mysql数据到其他中间件,而Maxwell,Debezium,Flink也有一个组件flink cdc,我们可以根据到业务需要选择,再说说flink cdc。
在传统的CDC架构中,我们一般是先通过CDC工具将数据写入Kafka,然后通过Flink或者Spark从Kafka中读取数据进行流处理后写入数据仓库,如下图。
使用flink cdc后,整个链接会变得很短,省去了中间的Debezium、kafka和流处理,flink cdc一步到位,flink cdc的底层采集工具也是基于Debezium实现,如下图。
Flink cdc 支持多种数据连接器。可以说我们可能需要写一行代码。我们只需要写sql,做一些简单的配置,就可以实现数据的增量同步。它的本质其实和flink的source sink一样,source是数据的来源,sink同步到对应的目标数据源。如果我们使用flink,我们需要添加一些中间件并编写代码。使用 flink cdc 就简单多了。只需要写sql就可以实现数据的连接、统计等。
❝
今天的分享就到这里了,感谢大家的观看,我们下期再见,如果本文中有任何描述不正确或不合理的地方,请大家提出宝贵意见,让我们在学习中共同成长进步!
解读:上海借助免费快速提升网站收录以及关键词排名的都不清楚
不清楚如何快速提高 网站收录 和 关键词 的免费排名
什么是WPcms插件,顾名思义,WPcms插件是搜索引擎优化过程中使用的辅助插件。今天博主就教大家使用免费的WPcms插件,快速提升网站收录和关键词的排名。这段时间很多SEO新手私信我,说自己对SEO没有完整的了解,不知道网站收录排名如何。今天博主就和大家聊一聊什么是SEO?搜索引擎优化,又称SEO,即是一种分析搜索引擎排名规则的方法,以了解各种搜索引擎如何进行搜索,如何抓取互联网页面,以及如何确定特定关键词的排名搜索结果。技术。
网站搜索引擎优化的任务主要是了解其他搜索引擎如何抓取网页,如何索引,如何确定搜索关键词等相关技术,从而优化本站内容网页,确保与用户浏览习惯一致,在不影响网民体验的情况下提高搜索引擎排名,从而增加网站访问量,最终提高网站宣传或销售能力 现代技术。基于搜索引擎优化处理,其实就是让这个网站更容易被搜索引擎接受。搜索引擎往往会比较不同的网站内容,然后使用浏览器以最完整、最直接、最快捷的方式上传内容。
每个人都想做好seo,但是除了一些做seo多年的seoer对seo有正确的态度,知道要做好seo需要很多东西外,很多seo新手对seo的认识并不完整,特别是提到我对插件或工具不太了解时。今天博主就教大家使用免费的WPcms插件,快速提升网站收录和关键词的排名。
1.使用免费WPcms采集大量文章内容
1.通过WPcms生成行业相关词,关键词来自下拉词、相关搜索词、长尾词。它可以设置为自动删除不相关的单词。通过WPcms插件实现自动化采集行业相关文章,一次可以创建几十个或上百个采集任务,同时支持多个域名任务同时 采集。
2.自动过滤其他网站促销信息
3、支持多采集来源采集(涵盖全网行业新闻源,海量内容库,采集最新内容)
4.支持图片本地化或存储到其他平台
5.全自动批量挂机采集,无缝对接各大cms发布商,采集自动发布并推送至搜索引擎
详细解释:如果一个网站想要有很多关键词的排名,它必须有很多的收录,
要拥有大量 收录,您必须拥有大量内容。而这个 采集 工具就是为了拥有大量的内容!
2.免费WPcms插件-SEO优化功能
1.设置标题的前缀和后缀(标题的区分度更好收录)
2.内容关键词插入(合理增加关键词密度)
3.随机图片插入(文章没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后,主动将文章推送给搜索引擎,保证新链接能及时被搜索引擎收录获取)
5.随机点赞-随机阅读-随机作者(增加页面原创度)
6.内容与标题一致(使内容与标题100%相关)
7、自动内链(在执行发布任务时,在文章内容中自动生成内链,有助于引导页面蜘蛛爬行,增加页面权重)
8、定时发布(定时发布网站内容可以让搜索引擎养成定时抓取网页的习惯,从而提高网站的收录)
详细解释: 通过以上SEO功能,增加网站页面的原创度,增加网页关键词的密度,吸引蜘蛛爬取更多页面。
3.免费WP cms插件-批量管理网站
1. 批量监控不同的cms网站数据(无论你的网站是帝国、易游、ZBLOG、织梦、WP、小旋风、站群、PB、苹果、搜外等各大cms,可以同时管理和批量发布的工具)
2.设置批量发布次数(可设置发布间隔/每天发布总数)
3.可以设置不同的关键词文章发布不同的栏目
4、伪原创保留字(在文章原创中设置核心字不要为伪原创)
5、软件直接监控已发布、待发布、是否伪原创、发布状态、URL、程序、发布时间等。
6、通过软件可以直接查看蜘蛛、收录、网站的每日体重!
详细解释:批量管理网站工具,可以在本地电脑修改,直接批量发布到站点后台,可以批量管理网站和查看网站数据,没有不再需要频繁登录后台查看。
做网站,既要讲究效率,又要讲究细节。如果效率提高了,细节做好了,网站的排名流量自然会增加!看完这篇文章,如果您觉得还不错,不妨采集或转发给有需要的朋友同事二脉! 查看全部
技术和经验:大数据技术栈之-数据采集
介绍
数据仓库的基础是数据。没有数据,数据仓库就是一个空壳。有许多数据来源。我们需要按照一个规则和流程制定一个采集方案,根据数据的特点和用途选择合适的方案。采集程序和数据采集一般分为全量和增量,对于一些业务场景,需要两者配合使用。
数据采集完整计划
全卷是指一次采集所有的数据,比如按照天数/月数。如果数据量很大,可能会比较耗时,而且会占用大量的存储空间。比如我们MySQL里面的数据,每天都需要同步。如果每天都同步,就会有很多重复数据,因为MySQL每天都在原来的基础上添加数据,每天同步一个完整的副本,所以是冗余的。其余的数据,而且不是实时的,需要每天同步一个时间点。它的优点是数据比较完整,但是会占用很大的存储空间。
增加
因为每天全量同步数据,会占用大量存储空间,效率不高,所以一般采用增量同步,但是增量是基于全量的,所以全量同步是必需的,后面是增量同步,增量意味着数据会增加或者修改,所以同步起来会比较困难。如果不使用工具,需要根据时间戳进行同步,比如增加一个create_time字段和update_time字段。添加数据时,会设置当前时间,修改数据时更新修改时间,然后以当天日期为条件获取符合条件的数据,但有个问题就是数据不是那么真实——时间,因为需要主动获取数据,会因网络等原因造成误差。实时的时候,对数据库的压力比较大,所以我们需要另一种方式,那就是CDC。
CDC全称为Change Data Capture,指的是识别并捕获数据库中数据的修改、删除、添加等变化,然后将这些变化以一定的方式记录下来,通过一定的机制传递给下游的Service,通过这个机制,可以减轻数据库的压力,数据更实时。比如MySQL的binglog机制就是CDC。

数据 采集 工具
数据采集工具分为全量采集和增量采集。
完整的 采集
采集工具有很多,比如Sqoop、kettle、DataX。下面主要说一下DataX。DataX可以实现各种数据之间的转换。如果DataX自带的数据源不能满足我们的需求,也可以自己实现,DataX由一个Writer和一个Reader组成,Reader是数据提供者,Writer是数据需求者,比如mysqlreader,doriswriter,就是将mysql的数据同步到doris。
DataX 只需要简单的安装。安装后只需要写一个json转换文件,然后执行json脚本即可。执行脚本后,数据同步将开始。但是,我们的同步任务可能一天执行一次。如果任务很多,那么每天执行脚本会很麻烦,这时可以使用定时任务,linux可以使用crond进行定时调度,但是如果使用cronb则无法监控任务的成功或失败,而且不能对任务进行统计,所以我们需要一个统一的任务调度平台,比如Azkaban、DepinSchudeler等,后面会用到。
增量采集
对于增量同步,我们需要用到CDC工具,比如Flume可以采集日志,canal可以实时同步mysql数据到其他中间件,而Maxwell,Debezium,Flink也有一个组件flink cdc,我们可以根据到业务需要选择,再说说flink cdc。

在传统的CDC架构中,我们一般是先通过CDC工具将数据写入Kafka,然后通过Flink或者Spark从Kafka中读取数据进行流处理后写入数据仓库,如下图。
使用flink cdc后,整个链接会变得很短,省去了中间的Debezium、kafka和流处理,flink cdc一步到位,flink cdc的底层采集工具也是基于Debezium实现,如下图。
Flink cdc 支持多种数据连接器。可以说我们可能需要写一行代码。我们只需要写sql,做一些简单的配置,就可以实现数据的增量同步。它的本质其实和flink的source sink一样,source是数据的来源,sink同步到对应的目标数据源。如果我们使用flink,我们需要添加一些中间件并编写代码。使用 flink cdc 就简单多了。只需要写sql就可以实现数据的连接、统计等。
❝
今天的分享就到这里了,感谢大家的观看,我们下期再见,如果本文中有任何描述不正确或不合理的地方,请大家提出宝贵意见,让我们在学习中共同成长进步!
解读:上海借助免费快速提升网站收录以及关键词排名的都不清楚
不清楚如何快速提高 网站收录 和 关键词 的免费排名
什么是WPcms插件,顾名思义,WPcms插件是搜索引擎优化过程中使用的辅助插件。今天博主就教大家使用免费的WPcms插件,快速提升网站收录和关键词的排名。这段时间很多SEO新手私信我,说自己对SEO没有完整的了解,不知道网站收录排名如何。今天博主就和大家聊一聊什么是SEO?搜索引擎优化,又称SEO,即是一种分析搜索引擎排名规则的方法,以了解各种搜索引擎如何进行搜索,如何抓取互联网页面,以及如何确定特定关键词的排名搜索结果。技术。
网站搜索引擎优化的任务主要是了解其他搜索引擎如何抓取网页,如何索引,如何确定搜索关键词等相关技术,从而优化本站内容网页,确保与用户浏览习惯一致,在不影响网民体验的情况下提高搜索引擎排名,从而增加网站访问量,最终提高网站宣传或销售能力 现代技术。基于搜索引擎优化处理,其实就是让这个网站更容易被搜索引擎接受。搜索引擎往往会比较不同的网站内容,然后使用浏览器以最完整、最直接、最快捷的方式上传内容。
每个人都想做好seo,但是除了一些做seo多年的seoer对seo有正确的态度,知道要做好seo需要很多东西外,很多seo新手对seo的认识并不完整,特别是提到我对插件或工具不太了解时。今天博主就教大家使用免费的WPcms插件,快速提升网站收录和关键词的排名。
1.使用免费WPcms采集大量文章内容
1.通过WPcms生成行业相关词,关键词来自下拉词、相关搜索词、长尾词。它可以设置为自动删除不相关的单词。通过WPcms插件实现自动化采集行业相关文章,一次可以创建几十个或上百个采集任务,同时支持多个域名任务同时 采集。
2.自动过滤其他网站促销信息
3、支持多采集来源采集(涵盖全网行业新闻源,海量内容库,采集最新内容)
4.支持图片本地化或存储到其他平台
5.全自动批量挂机采集,无缝对接各大cms发布商,采集自动发布并推送至搜索引擎
详细解释:如果一个网站想要有很多关键词的排名,它必须有很多的收录,
要拥有大量 收录,您必须拥有大量内容。而这个 采集 工具就是为了拥有大量的内容!
2.免费WPcms插件-SEO优化功能
1.设置标题的前缀和后缀(标题的区分度更好收录)
2.内容关键词插入(合理增加关键词密度)
3.随机图片插入(文章没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后,主动将文章推送给搜索引擎,保证新链接能及时被搜索引擎收录获取)
5.随机点赞-随机阅读-随机作者(增加页面原创度)
6.内容与标题一致(使内容与标题100%相关)
7、自动内链(在执行发布任务时,在文章内容中自动生成内链,有助于引导页面蜘蛛爬行,增加页面权重)
8、定时发布(定时发布网站内容可以让搜索引擎养成定时抓取网页的习惯,从而提高网站的收录)

详细解释: 通过以上SEO功能,增加网站页面的原创度,增加网页关键词的密度,吸引蜘蛛爬取更多页面。
3.免费WP cms插件-批量管理网站
1. 批量监控不同的cms网站数据(无论你的网站是帝国、易游、ZBLOG、织梦、WP、小旋风、站群、PB、苹果、搜外等各大cms,可以同时管理和批量发布的工具)
2.设置批量发布次数(可设置发布间隔/每天发布总数)
3.可以设置不同的关键词文章发布不同的栏目
4、伪原创保留字(在文章原创中设置核心字不要为伪原创)
5、软件直接监控已发布、待发布、是否伪原创、发布状态、URL、程序、发布时间等。
6、通过软件可以直接查看蜘蛛、收录、网站的每日体重!
详细解释:批量管理网站工具,可以在本地电脑修改,直接批量发布到站点后台,可以批量管理网站和查看网站数据,没有不再需要频繁登录后台查看。
做网站,既要讲究效率,又要讲究细节。如果效率提高了,细节做好了,网站的排名流量自然会增加!看完这篇文章,如果您觉得还不错,不妨采集或转发给有需要的朋友同事二脉!
归纳总结:信息处理之信息采集、信息加工和信息编码详解及真题演练
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-11-18 22:25
1. 信息采集
信息采集包括信息的采集和信息的处理。
信息采集是按照一定的目的和要求,挖掘和积累不同时空领域所收录的相关信息的过程。
信息采集需要遵循哪些原则:可靠性、完整性、实时性、准确性、易用性、规划性、可预测性。
2. 信息处理
信息处理是指
通过一定的手段将采集信息进行分析和处理成我们需要的信息,其目的是挖掘信息的价值,以便我们加以利用。
信息处理的重要性体现在:
(1)只有仔细分析和筛选,才能避免真假信息的混杂。
(2)只有对采集信息进行有效的分类和排序,才能更有效地应用信息。
(3)采集信息的信息处理可以创造新的信息,使信息具有更好的使用价值。
3. 信息编码
信息编码的目的是便于信息的存储、检索和使用。信息编码是在处理信息时为信息分配代码的过程。信息编码必须规范化、系统化,设计合理的编码系统是关系信息系统生命力的重要因素。
真正的问题:(
1)人口普查过程中,社工上门登记人口信息的过程属于()。
A. 信息采集
B. 信息编码
C. 信息发布
D. 信息交流(
2)使用电子表格软件对学校运动会各种比赛结果进行汇总和排序的过程是()。
A. 获取信息
B. 信息处理
C. 信息发布
D. 信息存储(
3)使用二维码生成器生成个人信息的二维码属于()过程。
A. 文本识别
B. 图像处理
C. 信息编码
D. 人工智能
总结:逆冬:12.18百度排名算法解析、5大要点很关键!
昨天N兄弟对排名的过度波动做出了反应,我去百度站长工具平台看了看,原来百度出了一个新的算法,今天我就带大家来解读一下百度算法,看看能不能从百度算法中找到一些收录和排名的机会,帮你做得更好的SEO!
1.网页的排序没有提到内容是否原创关于排名
的影响因素我看了整篇文章,影响排名因素和内容的部分是权威性、丰富度、排版等,内容是否原创话题,百度从未提及过!
很多人一直纠结于内容是否原创,是否伪原创,其实这里百度给出的答案,好的内容不一定原创,如果你不了解某个行业,原创是什么意思?
2. 网站权威影响排名
之前,我们谈到了权威,只停留在整体和内容网站。而百度给出了一个权威标准,就是内容的作者。更多指向发表此文章的作者!
3. 网站内页的有效性
这里的时效性也给出了明确的指标,主要分为两个方面:
1.发布时间。其实发布时间早就解释过了,百度有时间因子算法,只是大部分人还没有应用。
2.文章内容的时效性,这个时效性对应发布时间,以图为例,随着时间的推移,内容正文也会根据时间进行更新,比如一些没有确定的事情,是可以确定的。
4. 相关性和用户主要和次要需求
网站相关性是一个比较老的话题,上图只举一个例子,说白了,就像写文章一样,对应文章的主题,不要挂羊头卖狗肉!
比较有意思的一点是:这里还提到了一、二的需求,以鸡胸肉为例,大部分人只是想看看鸡胸肉怎么做,只有一小部分问鸡胸肉的功效!
5.禁止恶意采集(特殊字段方法)
大家仔细看这张图,百度说是恶意的,采集采集后根本没处理,放上去的内容肯定不好,那采集之后排版怎么办?这个百度没说,大家领悟了自己!
医学和法律专业一定要记录,包括内容的权威性;新闻、价格和时效必须做好。
如果不是上述行业,比如L,比如诗歌,你可以想办法增加图文的方式,或者添加视频来提高页面的权威性和相关性。以上
5点就是算法的主要内容,以上就是为大家录制的解读算法对抗寒冬的视频,大家可以跟着看一看!
扫描二维码
获取更多
冬季黑帽搜索引擎优化 查看全部
归纳总结:信息处理之信息采集、信息加工和信息编码详解及真题演练
1. 信息采集
信息采集包括信息的采集和信息的处理。
信息采集是按照一定的目的和要求,挖掘和积累不同时空领域所收录的相关信息的过程。
信息采集需要遵循哪些原则:可靠性、完整性、实时性、准确性、易用性、规划性、可预测性。
2. 信息处理
信息处理是指
通过一定的手段将采集信息进行分析和处理成我们需要的信息,其目的是挖掘信息的价值,以便我们加以利用。
信息处理的重要性体现在:
(1)只有仔细分析和筛选,才能避免真假信息的混杂。

(2)只有对采集信息进行有效的分类和排序,才能更有效地应用信息。
(3)采集信息的信息处理可以创造新的信息,使信息具有更好的使用价值。
3. 信息编码
信息编码的目的是便于信息的存储、检索和使用。信息编码是在处理信息时为信息分配代码的过程。信息编码必须规范化、系统化,设计合理的编码系统是关系信息系统生命力的重要因素。
真正的问题:(
1)人口普查过程中,社工上门登记人口信息的过程属于()。
A. 信息采集
B. 信息编码
C. 信息发布
D. 信息交流(

2)使用电子表格软件对学校运动会各种比赛结果进行汇总和排序的过程是()。
A. 获取信息
B. 信息处理
C. 信息发布
D. 信息存储(
3)使用二维码生成器生成个人信息的二维码属于()过程。
A. 文本识别
B. 图像处理
C. 信息编码
D. 人工智能
总结:逆冬:12.18百度排名算法解析、5大要点很关键!
昨天N兄弟对排名的过度波动做出了反应,我去百度站长工具平台看了看,原来百度出了一个新的算法,今天我就带大家来解读一下百度算法,看看能不能从百度算法中找到一些收录和排名的机会,帮你做得更好的SEO!
1.网页的排序没有提到内容是否原创关于排名
的影响因素我看了整篇文章,影响排名因素和内容的部分是权威性、丰富度、排版等,内容是否原创话题,百度从未提及过!
很多人一直纠结于内容是否原创,是否伪原创,其实这里百度给出的答案,好的内容不一定原创,如果你不了解某个行业,原创是什么意思?
2. 网站权威影响排名
之前,我们谈到了权威,只停留在整体和内容网站。而百度给出了一个权威标准,就是内容的作者。更多指向发表此文章的作者!
3. 网站内页的有效性

这里的时效性也给出了明确的指标,主要分为两个方面:
1.发布时间。其实发布时间早就解释过了,百度有时间因子算法,只是大部分人还没有应用。
2.文章内容的时效性,这个时效性对应发布时间,以图为例,随着时间的推移,内容正文也会根据时间进行更新,比如一些没有确定的事情,是可以确定的。
4. 相关性和用户主要和次要需求
网站相关性是一个比较老的话题,上图只举一个例子,说白了,就像写文章一样,对应文章的主题,不要挂羊头卖狗肉!
比较有意思的一点是:这里还提到了一、二的需求,以鸡胸肉为例,大部分人只是想看看鸡胸肉怎么做,只有一小部分问鸡胸肉的功效!
5.禁止恶意采集(特殊字段方法)
大家仔细看这张图,百度说是恶意的,采集采集后根本没处理,放上去的内容肯定不好,那采集之后排版怎么办?这个百度没说,大家领悟了自己!

医学和法律专业一定要记录,包括内容的权威性;新闻、价格和时效必须做好。
如果不是上述行业,比如L,比如诗歌,你可以想办法增加图文的方式,或者添加视频来提高页面的权威性和相关性。以上
5点就是算法的主要内容,以上就是为大家录制的解读算法对抗寒冬的视频,大家可以跟着看一看!
扫描二维码
获取更多
冬季黑帽搜索引擎优化
直观:如何高效进行数据采集,这里有一套完整方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 249 次浏览 • 2022-11-06 10:41
1、数据质量是数据分析的基石
假设一个场景:我们想要采集一个广告服务页面数据。
首先,我们和我们的技术同学描述了用户在进入应用的打开页面时所面临的场景:浏览-点击-跳转到广告页面;然后,我们提出了埋点的必要性。
点击数据分为有效点击和无效点击两类,但是技术方面的同学不会纠结这个问题。他刚刚从网上下载了一个闪屏页面框架,并集成到项目中。
在这个框架下,点击动作被拆解为:按下、抬起。而我们通常认为的点击动作应该是:在短时间内同时按下和抬起两个动作。
由于该框架的目标是提高点击率,即让更多人看到广告详情页面。因此,当用户按下时,已经触发了跳转到详情页的操作。
大多数非目标客户会不耐烦地退出广告详情页,而真正看到广告并感兴趣的客户会主动进入广告详情页。
由此产生的见解是:点击率高,转化率低。市场方面的同学误认为是广告设计的失败,会影响下一个广告的视觉效果或投放策略。
通过上面的例子,我们得出结论,data采集的时机和技术端的实现方式,会极大地影响业务端的决策。
“九层平台,从土的堆积开始。” 在形成一组有洞察力的数据之前,data采集是最基本也是最关键的一步。只有有了准确的数据,这种洞察力才能帮助您做出业务决策。否则会适得其反,再漂亮的数据分析也不会带来实际效果。
但是,在埋点方案的实际实现中,我们可能会遇到以下困惑:
GrowingIO发现“数据采集引起的数据质量问题”可能已经成为企业普遍存在的问题,这个问题的主要原因如下4点:
数据采集关系到数据质量,需要产品侧和业务侧的同事制定技术实施方案,让技术同学“快懂、快埋、快实施”。
2、GrowingIO为数据效率保驾护航采集
针对这些棘手问题,GrowingIO的非嵌入式技术可以快速定义页面、按钮、文本框等常见的用户行为操作,从而减少一些重复性高的用户常见行为中的嵌入式代码操作量,提供快速数据可视化。方便的。
一、无埋点的定义
什么是无墓地?我们先看看你有没有遇到过以下几种情况:
针对以上问题,没有埋点可以很好的解决。事实上,人、时间、地点、内容、方法的数据采集方法没有埋点。通过GrowingIO的圈选(可视化定义工具)功能,我们可以在所见即所得上定义指标。
无埋点(圈选)的核心思想基于以下5个元数据:
没有埋点可以定义常见的事件类型,尽可能减少代码使用,减少开发工作量。通过GrowingIO的圈选功能,我们可以快速采集数据,定义指标,查看实时数据。
2、如何选择埋点和不埋点?
新的无埋点虽然简单方便,但也有其局限性。同时,我们又离不开业务数据维度,所以不能放弃传统的埋点。
埋入式和不埋入式各有优势。面对不同的场景,需要明确目的,根据具体情况综合判断,选择最优的数据方式采集。
(1) 埋点
缺点适用于“监控和分析”数据场景:
(2) 无墓地
缺点适用于“探索性”数据场景:
基于以上,我们整理了下表,方便大家更好的理解和选择:
总之,埋点技术灵活、稳定、限制低、准确率高,适用于跟踪关键节点、隐藏程序逻辑和业务维度观察到的数据。
无埋技术判断速度快,有历史数据,有预定义维度支持,适用于快速查看某些趋势或过程数据。
当我们选择无嵌入或嵌入时,我们只需要注意:该行为不是核心指标,存在于预定义的无嵌入指标中。
如果有预定义的指标(即无埋点),并且预定义的尺寸也符合要求,那么我们需要观察无埋点的指标和尺寸,您可以放心选择无埋点。如果不存在或预定义的尺寸不能满足观察指标的视角,则需要通过埋点指标上报。
三、全埋点方案设计的四要素
在规划指标体系后,推动落实是价值落实过程中最重要的环节。
许多客户在实施过程中仍然遇到瓶颈,即使他们非常清楚他们想要监控的数据系统。这很大程度上是由于团队协作问题,例如数据嵌入量大,沟通成本高,以及业务方和开发者无法统一目标。
这最终将导致我们看到空的系统和无数的东西。
如果一整套数据采集解决方案直接交给研发方,业务场景描述和逻辑理解的差异会造成很大的沟通成本,最终导致实施效率低下。
因此,我们需要将有组织的指标体系梳理成实施需求。解决这个问题的关键在于以下4个步骤:
1. 确认事件和变量
如果一个问题从不同的角度定位,它的事件和变量也会发生变化。我们需要根据数据需求找到事件和变量组合的最优解。
2.确定事件的触发时机
时机选择没有对错之分,需要根据具体业务需求制定。同时,不同的触发时间会带来不同的数据口径。
3.标准命名
例如,客户在命名双十一时使用了拼音和英文的组合,这会使程序员感到困惑并出错。标准化的命名有助于程序员了解业务需求,高效实施方案。
4. 明确实施重点
通过明确优先级,我们可以专注于产品中真正需要跟踪的重要事件,避免技术冲突,实现价值的持续交付。
基于以上四个要素完成埋点方案的设计,不仅可以提高需求方和开发团队的协作效率,还可以为后期数据提供质量保证。
下表是我们整理出来的模板。本表格充分承担了埋点方案设计的四要素,可直接交由埋点技术方进行。
4、团队合作是跟踪计划实施的关键
接下来,如何快速准确地定义团队中埋点的需求,从而实现埋点计划的高效执行?
1.完成协作流程
从我们服务上千家企业的经验来看,GrowingIO 梳理出了一套完整的协作流程。包括业务需求方、数据规划师和开发团队。
本次三方合作的具体流程和时间安排为:
2.具体场景演示
接下来,我们将以某款APP的注册场景为例,帮助大家了解埋点方案实施的具体流程。
(在注册首页填写手机号-输入注册验证短信验证码-注册信息A、B、C-进入App首页)
(1) 场景一
业务方的需求是:快速分析现有注册流程各步骤之间的转化率,找到损失较大的环节进行优化。
可以看出,业务方只关心流程之间的步骤转换过程,那么我们需要关注用户的浏览行为,指标可以定义为各个步骤之间的页面。
具体来说,登录动作包括登录后从登录到首页的6个步骤,而我们关注的机型、地区、国家等角度不属于业务范畴,而是都在预定义的维度中,这符合我们缺乏埋点指标的定义规则。
因此,我们可以快速定义6个浏览页面指标来完成数据分析。
通过GrowingIO产品分析,我们可以得到下图,可以看到每一步的人数和转化。已经观察到注册验证-注册信息A-注册信息B这三个页面之间的流失率很高,我们这里需要优化一下。
以上是无埋点的快速定义。我们可以实时观察数据并分析事件,而无需等待下一个版本。
(2) 场景二
客户的需求是:查看注册用户的实习行业分布和性别分布。
根据完整埋点方案设计的四要素,我们要一一确认:
根据提供的埋点计划文档,我们不需要反复沟通,程序员可以快速明确业务需求并进行埋点操作。
3.数据验证
数据采集完成后,需要进行最后的确认,也就是我们通常所说的数据校验。
对此,GrowingIO有一套完整的数据验证工具,可以快速定位数据生成的过程。比如浏览了哪些页面,是否触发了事件,埋藏的事件是否对应定义的字段等。
如果某个环节出现了瑕疵,我们可以及时反馈问题,解决问题。
最后在这里和大家分享一句:“强则长,根深则久。” 数据驱动的“根”在于数据采集。只有采集的数据足够准确,才能做出正确的决策,促进企业的可持续发展。
今天的分享到此结束。感谢您的宝贵时间。我希望它对你有帮助。
作者:汪涵GrowingIO高级技术顾问,毕业于北京大学,Extron认证工程师。曾服务过奇瑞汽车、中国铁建、滴滴等龙头企业,拥有丰富的技术部署经验。
整套解决方案:爬虫 全国建筑市场监管服务平台小程序 数据抓取与采集
原帖数次文章关于全国建筑市场监管公共服务平台(四库一平台)平台网站数据采集并截图:
施工资质爬虫——全国建筑市场监管公共服务平台(一)简介 施工资质爬虫——全国建筑市场监管公共服务平台(二)——界面 新版建筑市场(四库一平台)抓取最新资讯(爬虫)
近日,发现建筑市场监管平台推出了自己的小程序“全国建筑市场监管服务平台”。
在使用过程中,发现没有前端辅助验证码,现在也有一些访问权限,于是研究了如何通过小程序抓取数据。经过学习研究,基本完成了采集和数据的抓取。,并记录整个过程。如需相关技术支持和爬虫数据,可以联系我(电话:【微信同号】)。
1.使用爬虫抓包抓取小程序访问链接
我喜欢使用 Fiddler 包捕获工具。我不会在这里详细介绍如何配置和安装它。网上有很多教程。安装配置完成后,我们访问小程序,在Fiddler上查看相关访问链接:
然后通过分析小程序的界面,有两个
所有相关服务都是通过更改参数键来实现的。这里没有很多。通过界面可以轻松分析相关功能。
2.接口认证token和IP限制
首先我们打开一个接口的请求头:
GET https://sky.mohurd.gov.cn/skya ... rd%3D HTTP/1.1
Host: sky.mohurd.gov.cn
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36 MicroMessenger/7.0.9.501 NetType/WIFI MiniProgramEnv/Windows WindowsWechat
cityCode:
content-type: application/json
token: t_b161960b732146379d4b8fc53196c50f
Referer: https://servicewechat.com/wx8f ... .html
Accept-Encoding: gzip, deflate, br
虽然现在小程序接口不多,但我们还是做了一点认证和爬虫。现在,第一个是令牌。这里的token比较简单,可以直接使用捕获到的token作为token。当有一定的访问权限时,后端也会屏蔽该IP。一开始还好几分钟就可以解封了,现在不行,试试用IP代理吧。
3.数据AES加解密
当我们查看返回的数据时,数据如下所示:
{"data":"A3ReBKoR6IDZSR4Jdxq72fXPsnWTZMhOr5sXl/lJ8/3GWFmsy2fTHG/0+Uz8fZmopZ0Ru0cskOWNX8hWlUy19scqauL28x3daP9IQn2……",
"message":null,
"status":1}
这里data的数据是加密的,我们使用的是我们解密的数据:
[{"data":{"asc":true,"current":1,"limit":15,"offset":0,"offsetCurrent":0,"openSort":true,"optimizeCount":false,"pages":14,
"records":[{"legalMan":"张东","address":"重庆市渝北区龙溪街道金山路18号中渝.都会首站4幢9-10","regionFullname":"重庆市",
"corpName":"重庆惠风机电设备有限公司","id":"001903140034193455","corpCode":"91500112054824582M"}],
"searchCount":true,"size":15,"total":200}}] 查看全部
直观:如何高效进行数据采集,这里有一套完整方案
1、数据质量是数据分析的基石
假设一个场景:我们想要采集一个广告服务页面数据。
首先,我们和我们的技术同学描述了用户在进入应用的打开页面时所面临的场景:浏览-点击-跳转到广告页面;然后,我们提出了埋点的必要性。
点击数据分为有效点击和无效点击两类,但是技术方面的同学不会纠结这个问题。他刚刚从网上下载了一个闪屏页面框架,并集成到项目中。
在这个框架下,点击动作被拆解为:按下、抬起。而我们通常认为的点击动作应该是:在短时间内同时按下和抬起两个动作。
由于该框架的目标是提高点击率,即让更多人看到广告详情页面。因此,当用户按下时,已经触发了跳转到详情页的操作。
大多数非目标客户会不耐烦地退出广告详情页,而真正看到广告并感兴趣的客户会主动进入广告详情页。
由此产生的见解是:点击率高,转化率低。市场方面的同学误认为是广告设计的失败,会影响下一个广告的视觉效果或投放策略。
通过上面的例子,我们得出结论,data采集的时机和技术端的实现方式,会极大地影响业务端的决策。
“九层平台,从土的堆积开始。” 在形成一组有洞察力的数据之前,data采集是最基本也是最关键的一步。只有有了准确的数据,这种洞察力才能帮助您做出业务决策。否则会适得其反,再漂亮的数据分析也不会带来实际效果。
但是,在埋点方案的实际实现中,我们可能会遇到以下困惑:
GrowingIO发现“数据采集引起的数据质量问题”可能已经成为企业普遍存在的问题,这个问题的主要原因如下4点:
数据采集关系到数据质量,需要产品侧和业务侧的同事制定技术实施方案,让技术同学“快懂、快埋、快实施”。
2、GrowingIO为数据效率保驾护航采集
针对这些棘手问题,GrowingIO的非嵌入式技术可以快速定义页面、按钮、文本框等常见的用户行为操作,从而减少一些重复性高的用户常见行为中的嵌入式代码操作量,提供快速数据可视化。方便的。
一、无埋点的定义
什么是无墓地?我们先看看你有没有遇到过以下几种情况:
针对以上问题,没有埋点可以很好的解决。事实上,人、时间、地点、内容、方法的数据采集方法没有埋点。通过GrowingIO的圈选(可视化定义工具)功能,我们可以在所见即所得上定义指标。
无埋点(圈选)的核心思想基于以下5个元数据:
没有埋点可以定义常见的事件类型,尽可能减少代码使用,减少开发工作量。通过GrowingIO的圈选功能,我们可以快速采集数据,定义指标,查看实时数据。
2、如何选择埋点和不埋点?
新的无埋点虽然简单方便,但也有其局限性。同时,我们又离不开业务数据维度,所以不能放弃传统的埋点。
埋入式和不埋入式各有优势。面对不同的场景,需要明确目的,根据具体情况综合判断,选择最优的数据方式采集。
(1) 埋点
缺点适用于“监控和分析”数据场景:
(2) 无墓地
缺点适用于“探索性”数据场景:
基于以上,我们整理了下表,方便大家更好的理解和选择:
总之,埋点技术灵活、稳定、限制低、准确率高,适用于跟踪关键节点、隐藏程序逻辑和业务维度观察到的数据。
无埋技术判断速度快,有历史数据,有预定义维度支持,适用于快速查看某些趋势或过程数据。
当我们选择无嵌入或嵌入时,我们只需要注意:该行为不是核心指标,存在于预定义的无嵌入指标中。
如果有预定义的指标(即无埋点),并且预定义的尺寸也符合要求,那么我们需要观察无埋点的指标和尺寸,您可以放心选择无埋点。如果不存在或预定义的尺寸不能满足观察指标的视角,则需要通过埋点指标上报。
三、全埋点方案设计的四要素
在规划指标体系后,推动落实是价值落实过程中最重要的环节。
许多客户在实施过程中仍然遇到瓶颈,即使他们非常清楚他们想要监控的数据系统。这很大程度上是由于团队协作问题,例如数据嵌入量大,沟通成本高,以及业务方和开发者无法统一目标。
这最终将导致我们看到空的系统和无数的东西。
如果一整套数据采集解决方案直接交给研发方,业务场景描述和逻辑理解的差异会造成很大的沟通成本,最终导致实施效率低下。
因此,我们需要将有组织的指标体系梳理成实施需求。解决这个问题的关键在于以下4个步骤:
1. 确认事件和变量
如果一个问题从不同的角度定位,它的事件和变量也会发生变化。我们需要根据数据需求找到事件和变量组合的最优解。
2.确定事件的触发时机
时机选择没有对错之分,需要根据具体业务需求制定。同时,不同的触发时间会带来不同的数据口径。
3.标准命名
例如,客户在命名双十一时使用了拼音和英文的组合,这会使程序员感到困惑并出错。标准化的命名有助于程序员了解业务需求,高效实施方案。
4. 明确实施重点
通过明确优先级,我们可以专注于产品中真正需要跟踪的重要事件,避免技术冲突,实现价值的持续交付。
基于以上四个要素完成埋点方案的设计,不仅可以提高需求方和开发团队的协作效率,还可以为后期数据提供质量保证。
下表是我们整理出来的模板。本表格充分承担了埋点方案设计的四要素,可直接交由埋点技术方进行。
4、团队合作是跟踪计划实施的关键
接下来,如何快速准确地定义团队中埋点的需求,从而实现埋点计划的高效执行?
1.完成协作流程
从我们服务上千家企业的经验来看,GrowingIO 梳理出了一套完整的协作流程。包括业务需求方、数据规划师和开发团队。
本次三方合作的具体流程和时间安排为:
2.具体场景演示
接下来,我们将以某款APP的注册场景为例,帮助大家了解埋点方案实施的具体流程。
(在注册首页填写手机号-输入注册验证短信验证码-注册信息A、B、C-进入App首页)
(1) 场景一
业务方的需求是:快速分析现有注册流程各步骤之间的转化率,找到损失较大的环节进行优化。
可以看出,业务方只关心流程之间的步骤转换过程,那么我们需要关注用户的浏览行为,指标可以定义为各个步骤之间的页面。
具体来说,登录动作包括登录后从登录到首页的6个步骤,而我们关注的机型、地区、国家等角度不属于业务范畴,而是都在预定义的维度中,这符合我们缺乏埋点指标的定义规则。
因此,我们可以快速定义6个浏览页面指标来完成数据分析。
通过GrowingIO产品分析,我们可以得到下图,可以看到每一步的人数和转化。已经观察到注册验证-注册信息A-注册信息B这三个页面之间的流失率很高,我们这里需要优化一下。
以上是无埋点的快速定义。我们可以实时观察数据并分析事件,而无需等待下一个版本。
(2) 场景二
客户的需求是:查看注册用户的实习行业分布和性别分布。
根据完整埋点方案设计的四要素,我们要一一确认:
根据提供的埋点计划文档,我们不需要反复沟通,程序员可以快速明确业务需求并进行埋点操作。
3.数据验证
数据采集完成后,需要进行最后的确认,也就是我们通常所说的数据校验。
对此,GrowingIO有一套完整的数据验证工具,可以快速定位数据生成的过程。比如浏览了哪些页面,是否触发了事件,埋藏的事件是否对应定义的字段等。
如果某个环节出现了瑕疵,我们可以及时反馈问题,解决问题。
最后在这里和大家分享一句:“强则长,根深则久。” 数据驱动的“根”在于数据采集。只有采集的数据足够准确,才能做出正确的决策,促进企业的可持续发展。
今天的分享到此结束。感谢您的宝贵时间。我希望它对你有帮助。
作者:汪涵GrowingIO高级技术顾问,毕业于北京大学,Extron认证工程师。曾服务过奇瑞汽车、中国铁建、滴滴等龙头企业,拥有丰富的技术部署经验。
整套解决方案:爬虫 全国建筑市场监管服务平台小程序 数据抓取与采集
原帖数次文章关于全国建筑市场监管公共服务平台(四库一平台)平台网站数据采集并截图:
施工资质爬虫——全国建筑市场监管公共服务平台(一)简介 施工资质爬虫——全国建筑市场监管公共服务平台(二)——界面 新版建筑市场(四库一平台)抓取最新资讯(爬虫)
近日,发现建筑市场监管平台推出了自己的小程序“全国建筑市场监管服务平台”。
在使用过程中,发现没有前端辅助验证码,现在也有一些访问权限,于是研究了如何通过小程序抓取数据。经过学习研究,基本完成了采集和数据的抓取。,并记录整个过程。如需相关技术支持和爬虫数据,可以联系我(电话:【微信同号】)。
1.使用爬虫抓包抓取小程序访问链接
我喜欢使用 Fiddler 包捕获工具。我不会在这里详细介绍如何配置和安装它。网上有很多教程。安装配置完成后,我们访问小程序,在Fiddler上查看相关访问链接:
然后通过分析小程序的界面,有两个
所有相关服务都是通过更改参数键来实现的。这里没有很多。通过界面可以轻松分析相关功能。
2.接口认证token和IP限制
首先我们打开一个接口的请求头:
GET https://sky.mohurd.gov.cn/skya ... rd%3D HTTP/1.1
Host: sky.mohurd.gov.cn
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36 MicroMessenger/7.0.9.501 NetType/WIFI MiniProgramEnv/Windows WindowsWechat
cityCode:
content-type: application/json
token: t_b161960b732146379d4b8fc53196c50f
Referer: https://servicewechat.com/wx8f ... .html
Accept-Encoding: gzip, deflate, br
虽然现在小程序接口不多,但我们还是做了一点认证和爬虫。现在,第一个是令牌。这里的token比较简单,可以直接使用捕获到的token作为token。当有一定的访问权限时,后端也会屏蔽该IP。一开始还好几分钟就可以解封了,现在不行,试试用IP代理吧。

3.数据AES加解密
当我们查看返回的数据时,数据如下所示:
{"data":"A3ReBKoR6IDZSR4Jdxq72fXPsnWTZMhOr5sXl/lJ8/3GWFmsy2fTHG/0+Uz8fZmopZ0Ru0cskOWNX8hWlUy19scqauL28x3daP9IQn2……",
"message":null,
"status":1}
这里data的数据是加密的,我们使用的是我们解密的数据:
[{"data":{"asc":true,"current":1,"limit":15,"offset":0,"offsetCurrent":0,"openSort":true,"optimizeCount":false,"pages":14,
"records":[{"legalMan":"张东","address":"重庆市渝北区龙溪街道金山路18号中渝.都会首站4幢9-10","regionFullname":"重庆市",
"corpName":"重庆惠风机电设备有限公司","id":"001903140034193455","corpCode":"91500112054824582M"}],
"searchCount":true,"size":15,"total":200}}]
汇总:信息处理之信息采集、信息加工和信息编码详解及真题演练
采集交流 • 优采云 发表了文章 • 0 个评论 • 255 次浏览 • 2022-10-16 08:44
1.信息采集
信息采集包括信息的采集和处理。
信息采集是根据一定的目的和要求,挖掘和积累不同时空领域所收录的相关信息的过程。
信息采集需要遵循哪些原则:可靠性原则、完整性原则、实时性原则、准确性原则、可用性原则、规划原则、可预测性原则。
2.信息处理
信息处理是指将采集接收到的信息通过一定的方式分析处理成我们需要的信息,其目的是挖掘信息的价值,使我们可以使用它。
信息处理的重要性体现在:
① 只有认真分析筛选,才能避免信息真假混淆。
② 只有对采集接收到的信息进行有效的分类整理,才能更有效地应用信息。
③对采集收到的信息进行处理,可以产生新的信息,使信息具有更好的使用价值。
3.信息编码
信息编码的目的是便于信息的存储、检索和使用。信息编码是在信息处理过程中为信息分配代码的过程。信息编码必须规范化、系统化,设计合理的编码系统是信息系统生机勃勃的重要因素。
真题:
①普查中,社工上门登记人口信息的过程属于( )。
A. 信息采集
B. 信息编码
三、信息发布
D. 交换信息
②用电子表格软件对学校运动会的成绩进行汇总和排序,过程为( )。
A. 信息获取
B. 信息处理
三、信息发布
D. 信息存储
③使用二维码生成器生成个人信息二维码属于()过程。
A. 字符识别
B. 图像处理
C. 信息编码
D、人工智能
归纳总结:白杨SEO:实战分享SEO诊断方案及网站SEO优化清单包含哪些?
前言:这是百洋SEO公众号原创的第92篇。为什么要编写此诊断方案和优化清单?因为我发现很多新的seo都不知道怎么看一个网站的问题,也不知道站内站外优化是什么,所以想分享一下。
1.网站SEO优化列表(37项)
初始设置和网站速度优化列表:
1、百度统计:将百度统计/谷歌分析代码放到你的网站中,以便统计网站流量等以下指标。
2、百度站长平台/谷歌站长平台:将你的网站放入平台,方便你关注网站索引量、爬取情况、网站安全问题等。如图,白杨SEO装修网索引截图。
3、网站地图:创建sitemap.xml站点地图,提交到百度/google站长平台。XML在线生成工具:
4.robots.txt:创建Robots.txt文件。
5.网站速度优化:通过运行网站Ping等测速工具,找出网站的速度,然后进行优化。
6. 网页速度优化:通过运行 网站 审查元素查看您的 网站 元素的每个链接的加载速度。快捷键:F12,然后选择网络,如下图:
关键词挖掘分析方面列表:
7. 用户分析:分析你的潜在客户是谁。他们有什么问题和需求?他们可能需要什么解决方案?你的目标市场是什么?这些是您需要了解和分析的问题,并找出什么样的内容吸引了他们。这一步至关重要,有助于建立用户粘性并带来持久的流量。
无论是百度还是谷歌,都会提到内容优化的重要性。内容优化的重要前提是你的内容必须满足用户的需求。所以要想满足需求,首先要找到什么样的关键词潜在用户可能会使用。
8. 百度下拉和相关网络:了解客户的搜索目标后,在百度搜索框下拉菜单中输入目的关键词 和关键词 短语并查找相关搜索。过滤下拉框和 关键词 相关搜索以合并到您的 关键词 列表中。
注意:有些下拉可能是有人故意刷的,所以你也要学会过滤哦~
9. 扩展您的关键词 列表:使用自动化工具,例如网站管理员工具、爱站、5118 的关键词 发现工具来查找更多关键词 和短语。如果开启百度竞价,使用百度竞价关键词工具会更快~
10. 确定你的关键词 列表:会有很长的关键词 列表或通过该工具发现的短语。通过仔细筛选,删除一些不准确和竞争性的 关键词 。
11. 选择目标关键词 和长尾关键词:一旦你过滤掉不相关的、过度竞争的关键词,在你的行业中选择你的潜在客户正在寻找的关键词应该会更容易关键词。这些 关键词 或 关键词 短语将成为您内容的核心;它们将被放置在 网站 各处。
网站内容方面列表:
12.创建表单或文档:将您的关键词列表中的关键词逐步添加到您的网站内容中,并记录下来以供当前查看和优化。
13、百度索引:使用百度索引需要一张图来查找搜索需求的发展趋势,修改或者写新的内容到你的网站,更好的了解你的潜在客户在找什么。
14、百度搜索文章Title:避免在得到的时候写出与别人相同或非常相似的标题。
15、网站内容:网站除了写成文章的个别文字外,内容还可以用其他方式表达,如:图片、视频、PPT、PDF等。
16. 页面聚合:使用内容聚合页面让您的客户更容易找到他们需要的内容。比如百度百科使用内链聚合,就是最典型的案例。
17、旧页面新优化:通过回复帖子或撰写最新资料等方式应用旧内容、更新补充,使旧的文章页面满足用户的最新需求。
18.title标题标签:网站每个页面都需要一个唯一且不重复的标题。使用 关键词 和您的 关键词 列表中的短语来写问题。标题标签的长度不应超过搜索引擎的显示长度,即 32 个字。在您的头衔之前或之后适当地添加您的品牌或公司名称,以增加品牌曝光度。
19. 描述标签:同样,使用 关键词 和您选择的短语来写一个简短的说明来描述您的页面或您的 网站。200字以内,达到搜索引擎全屏显示的效果可以应用一些提醒或者影响点击效果。
20. 固定链接结构:可以用关键词拼音制作你的网址,搜索引擎会将关键词匹配的网址加粗。使用静态 URL 或伪静态 URL 来实现链接的唯一性和稳定性。例如:
21、H1等标签:准确使用H1标签,让搜索引擎知道你的网页是干什么用的。每个网页只有一个H1标签,其余的使用H2-H6等样式通知搜索引擎该内容的重要内容。
22、图片优化:你推广的内容最好结合图文,然后用你的关键词定义ALT标签。百度图片的抓取会给你带来意想不到的好处~
23、内容和长度:文章最好超过500字,最好在1500字的范围内。但是,如果在 300 字之后没有什么可写的,请不要勉强。质量永远比数量更重要!!
24. 关键词:文章不要一遍又一遍地重新应用相同的关键词,使用相关或相似的关键词来适应你的文章。这使您可以防止过度优化受到惩罚。
25. 网站结构:确保大部分页面内容在您的网站主页点击3次以内。
26. 内部链接:使用您的 文章 内部链接连接到您的 网站 的其他部分或内容。
27. 相关资源的链接:当引用网站上的另一条内容时,链接必须应用相关的锚文本。
异地优化(外链)方面列表:
28. 竞争对手反向链接分析:在寻找新的反向链接时,看看你的竞争对手,看看他们的链接。
29、创建外链工作表:发送外链并做记录,以便更好地查询收录和外链的存在状态。
30、创建好友链记录表:除了发送外链,交换好友链也是你必不可少的工作。记录每个朋友链收录、关键词和权重变化。
31、查看关键词的影响:使用百度索引查看已有关键词的索引和变化。
32、检查现有朋友链:如果有问题,方便与对方沟通,删除或交换朋友链。
33. 垃圾链接:不要与那些损害你排名的网站交换链接,或者发送外部链接。
34.锚文本:查看自己的好友链接,链接到你网站的关键词,防止过度使用同一个关键词。
35、相关性:检查你现有的链接,看是否链接到你的网站对应网页,对方是网站与你网站相关的。可能时间久了,对方换了网页的主题。
用户数据方面列表:
36. 创建相关文档:分析您的潜在客户关注的网站 或在线媒体。
37. 流量分析:当潜在用户搜索您的公司或品牌名称以及产品、服务等相关信息时,注意您的网站流量来源和采访页面数据。
2.网站SEO优化诊断方案
一个好的网站SEO 诊断程序取决于您对网站 的研究深度。白洋SEO实训一期和二期,有一节专门讲网站诊断方案。可以看一下本次培训的介绍:
(阿毛白洋SEO第二期SEO培训截图)
事实上,SEO诊断需要很多时间,可以说是Poplar SEO服务的核心业务之一。分享的原因是更多的人可以编写自己的诊断计划。编写 SEO 诊断计划有四个步骤:
01 首先是了解网站本身
有很多方法可以理解 网站 本身。例如,您可以使用搜索引擎查看,也可以使用 SEO 工具查看。不过最好的办法还是直接找网站的负责人,了解网站的现状和问题,这个最重要!
上面的屏幕截图是针对一个新站点的。如果是旧站点,请添加,例如:您最近在做什么操作?现场技术方面?站外链接等等。
02市场竞争对手分析
迈出第一步后,一定要知道你分析的对象的现状和产品,然后用他的产品找到他的同行,然后找到一个好的网站,这样比较分析,然后看对方网站的优化好点,在哪里建站外的外链等等,下面想出解决方案方便。
03 使用诊断过程进行诊断
网站SEO诊断过程有哪些要点?其实Poplar SEO之前写过2篇文章,这里:
04出具诊断报告,包括解决方案
其实每个SEO人都有自己的经历,但是比如公认的SEO技术点,三要素是一样的。白杨SEO分享了两份付费给他人的SEO诊断报告,相关核心数据被删除。下面的一些截图:
以上两个,一个是外贸独立站优化运营方案,还包括30个SEO技术关卡。另一种是针对某中型化工平台网站的SEO诊断方案。项目最终权重达到目标,收录增加了10倍以上。这两份文件都已上传到 Aspen SEO Marketing Circle Planet。
白洋SEO营销圈为白洋SEO自己支付星球,99元/年,限时返现!2020年开始调整为199元/年,老用户不变。目前已经有近200人加入,不仅有SEO实训干货文档分享,还有SEM、设计、技术、产品、新媒体等行业的资深嘉宾,可以向他们提问。
加入方式:直接在微信上识别上图二维码,或点击“阅读原文”加入白洋SEO营销圈付费星球。友情提示,下载知识星球APP体验更好~
关于杨树: 查看全部
汇总:信息处理之信息采集、信息加工和信息编码详解及真题演练
1.信息采集
信息采集包括信息的采集和处理。
信息采集是根据一定的目的和要求,挖掘和积累不同时空领域所收录的相关信息的过程。
信息采集需要遵循哪些原则:可靠性原则、完整性原则、实时性原则、准确性原则、可用性原则、规划原则、可预测性原则。
2.信息处理
信息处理是指将采集接收到的信息通过一定的方式分析处理成我们需要的信息,其目的是挖掘信息的价值,使我们可以使用它。
信息处理的重要性体现在:
① 只有认真分析筛选,才能避免信息真假混淆。

② 只有对采集接收到的信息进行有效的分类整理,才能更有效地应用信息。
③对采集收到的信息进行处理,可以产生新的信息,使信息具有更好的使用价值。
3.信息编码
信息编码的目的是便于信息的存储、检索和使用。信息编码是在信息处理过程中为信息分配代码的过程。信息编码必须规范化、系统化,设计合理的编码系统是信息系统生机勃勃的重要因素。
真题:
①普查中,社工上门登记人口信息的过程属于( )。
A. 信息采集
B. 信息编码
三、信息发布
D. 交换信息
②用电子表格软件对学校运动会的成绩进行汇总和排序,过程为( )。
A. 信息获取
B. 信息处理
三、信息发布
D. 信息存储
③使用二维码生成器生成个人信息二维码属于()过程。
A. 字符识别
B. 图像处理
C. 信息编码
D、人工智能
归纳总结:白杨SEO:实战分享SEO诊断方案及网站SEO优化清单包含哪些?
前言:这是百洋SEO公众号原创的第92篇。为什么要编写此诊断方案和优化清单?因为我发现很多新的seo都不知道怎么看一个网站的问题,也不知道站内站外优化是什么,所以想分享一下。
1.网站SEO优化列表(37项)
初始设置和网站速度优化列表:
1、百度统计:将百度统计/谷歌分析代码放到你的网站中,以便统计网站流量等以下指标。
2、百度站长平台/谷歌站长平台:将你的网站放入平台,方便你关注网站索引量、爬取情况、网站安全问题等。如图,白杨SEO装修网索引截图。
3、网站地图:创建sitemap.xml站点地图,提交到百度/google站长平台。XML在线生成工具:
4.robots.txt:创建Robots.txt文件。
5.网站速度优化:通过运行网站Ping等测速工具,找出网站的速度,然后进行优化。
6. 网页速度优化:通过运行 网站 审查元素查看您的 网站 元素的每个链接的加载速度。快捷键:F12,然后选择网络,如下图:
关键词挖掘分析方面列表:
7. 用户分析:分析你的潜在客户是谁。他们有什么问题和需求?他们可能需要什么解决方案?你的目标市场是什么?这些是您需要了解和分析的问题,并找出什么样的内容吸引了他们。这一步至关重要,有助于建立用户粘性并带来持久的流量。
无论是百度还是谷歌,都会提到内容优化的重要性。内容优化的重要前提是你的内容必须满足用户的需求。所以要想满足需求,首先要找到什么样的关键词潜在用户可能会使用。
8. 百度下拉和相关网络:了解客户的搜索目标后,在百度搜索框下拉菜单中输入目的关键词 和关键词 短语并查找相关搜索。过滤下拉框和 关键词 相关搜索以合并到您的 关键词 列表中。
注意:有些下拉可能是有人故意刷的,所以你也要学会过滤哦~
9. 扩展您的关键词 列表:使用自动化工具,例如网站管理员工具、爱站、5118 的关键词 发现工具来查找更多关键词 和短语。如果开启百度竞价,使用百度竞价关键词工具会更快~
10. 确定你的关键词 列表:会有很长的关键词 列表或通过该工具发现的短语。通过仔细筛选,删除一些不准确和竞争性的 关键词 。
11. 选择目标关键词 和长尾关键词:一旦你过滤掉不相关的、过度竞争的关键词,在你的行业中选择你的潜在客户正在寻找的关键词应该会更容易关键词。这些 关键词 或 关键词 短语将成为您内容的核心;它们将被放置在 网站 各处。
网站内容方面列表:
12.创建表单或文档:将您的关键词列表中的关键词逐步添加到您的网站内容中,并记录下来以供当前查看和优化。
13、百度索引:使用百度索引需要一张图来查找搜索需求的发展趋势,修改或者写新的内容到你的网站,更好的了解你的潜在客户在找什么。

14、百度搜索文章Title:避免在得到的时候写出与别人相同或非常相似的标题。
15、网站内容:网站除了写成文章的个别文字外,内容还可以用其他方式表达,如:图片、视频、PPT、PDF等。
16. 页面聚合:使用内容聚合页面让您的客户更容易找到他们需要的内容。比如百度百科使用内链聚合,就是最典型的案例。
17、旧页面新优化:通过回复帖子或撰写最新资料等方式应用旧内容、更新补充,使旧的文章页面满足用户的最新需求。
18.title标题标签:网站每个页面都需要一个唯一且不重复的标题。使用 关键词 和您的 关键词 列表中的短语来写问题。标题标签的长度不应超过搜索引擎的显示长度,即 32 个字。在您的头衔之前或之后适当地添加您的品牌或公司名称,以增加品牌曝光度。
19. 描述标签:同样,使用 关键词 和您选择的短语来写一个简短的说明来描述您的页面或您的 网站。200字以内,达到搜索引擎全屏显示的效果可以应用一些提醒或者影响点击效果。
20. 固定链接结构:可以用关键词拼音制作你的网址,搜索引擎会将关键词匹配的网址加粗。使用静态 URL 或伪静态 URL 来实现链接的唯一性和稳定性。例如:
21、H1等标签:准确使用H1标签,让搜索引擎知道你的网页是干什么用的。每个网页只有一个H1标签,其余的使用H2-H6等样式通知搜索引擎该内容的重要内容。
22、图片优化:你推广的内容最好结合图文,然后用你的关键词定义ALT标签。百度图片的抓取会给你带来意想不到的好处~
23、内容和长度:文章最好超过500字,最好在1500字的范围内。但是,如果在 300 字之后没有什么可写的,请不要勉强。质量永远比数量更重要!!
24. 关键词:文章不要一遍又一遍地重新应用相同的关键词,使用相关或相似的关键词来适应你的文章。这使您可以防止过度优化受到惩罚。
25. 网站结构:确保大部分页面内容在您的网站主页点击3次以内。
26. 内部链接:使用您的 文章 内部链接连接到您的 网站 的其他部分或内容。
27. 相关资源的链接:当引用网站上的另一条内容时,链接必须应用相关的锚文本。
异地优化(外链)方面列表:
28. 竞争对手反向链接分析:在寻找新的反向链接时,看看你的竞争对手,看看他们的链接。
29、创建外链工作表:发送外链并做记录,以便更好地查询收录和外链的存在状态。
30、创建好友链记录表:除了发送外链,交换好友链也是你必不可少的工作。记录每个朋友链收录、关键词和权重变化。
31、查看关键词的影响:使用百度索引查看已有关键词的索引和变化。
32、检查现有朋友链:如果有问题,方便与对方沟通,删除或交换朋友链。
33. 垃圾链接:不要与那些损害你排名的网站交换链接,或者发送外部链接。
34.锚文本:查看自己的好友链接,链接到你网站的关键词,防止过度使用同一个关键词。
35、相关性:检查你现有的链接,看是否链接到你的网站对应网页,对方是网站与你网站相关的。可能时间久了,对方换了网页的主题。
用户数据方面列表:
36. 创建相关文档:分析您的潜在客户关注的网站 或在线媒体。
37. 流量分析:当潜在用户搜索您的公司或品牌名称以及产品、服务等相关信息时,注意您的网站流量来源和采访页面数据。
2.网站SEO优化诊断方案
一个好的网站SEO 诊断程序取决于您对网站 的研究深度。白洋SEO实训一期和二期,有一节专门讲网站诊断方案。可以看一下本次培训的介绍:
(阿毛白洋SEO第二期SEO培训截图)
事实上,SEO诊断需要很多时间,可以说是Poplar SEO服务的核心业务之一。分享的原因是更多的人可以编写自己的诊断计划。编写 SEO 诊断计划有四个步骤:
01 首先是了解网站本身
有很多方法可以理解 网站 本身。例如,您可以使用搜索引擎查看,也可以使用 SEO 工具查看。不过最好的办法还是直接找网站的负责人,了解网站的现状和问题,这个最重要!
上面的屏幕截图是针对一个新站点的。如果是旧站点,请添加,例如:您最近在做什么操作?现场技术方面?站外链接等等。
02市场竞争对手分析
迈出第一步后,一定要知道你分析的对象的现状和产品,然后用他的产品找到他的同行,然后找到一个好的网站,这样比较分析,然后看对方网站的优化好点,在哪里建站外的外链等等,下面想出解决方案方便。
03 使用诊断过程进行诊断
网站SEO诊断过程有哪些要点?其实Poplar SEO之前写过2篇文章,这里:
04出具诊断报告,包括解决方案
其实每个SEO人都有自己的经历,但是比如公认的SEO技术点,三要素是一样的。白杨SEO分享了两份付费给他人的SEO诊断报告,相关核心数据被删除。下面的一些截图:
以上两个,一个是外贸独立站优化运营方案,还包括30个SEO技术关卡。另一种是针对某中型化工平台网站的SEO诊断方案。项目最终权重达到目标,收录增加了10倍以上。这两份文件都已上传到 Aspen SEO Marketing Circle Planet。
白洋SEO营销圈为白洋SEO自己支付星球,99元/年,限时返现!2020年开始调整为199元/年,老用户不变。目前已经有近200人加入,不仅有SEO实训干货文档分享,还有SEM、设计、技术、产品、新媒体等行业的资深嘉宾,可以向他们提问。
加入方式:直接在微信上识别上图二维码,或点击“阅读原文”加入白洋SEO营销圈付费星球。友情提示,下载知识星球APP体验更好~
关于杨树:
采集 干货教程:【网站搭建】自采集影视站源码+演示
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2022-10-12 12:32
【网站建设】自采集影视台源代码+演示
演示网站:
自动采集
强大的搜索功能,使用PHP实时抓取可用资源,程序运行速度非常快,可以快速构建自己的电影网站
安装说明:
如果没有数据库,请修改解析配置文件配置文件.js
首页标题等在索引.php文件修改,首页图片在此更改/
static_qq/图片/标志.png、行名和首页图片在此变化/播放/索引.php
配置网站伪静态思维
有些不需要配置,有些可能没有配置,主页顶部会乱码!
蓝拳云
教程:WordPress 隐藏文章内容必须登录才可以查看的完美代码实现(不用插件)
1.创建一个短代码隐藏并将以下代码添加到主题的functions.php文件中。
add_shortcode('hide','loginvisible');
function loginvisible($atts,$content=null){
if(is_user_logged_in() && !is_null($content) && !is_feed()){
return $content;
}
else{
$url = get_permalink().'?'.time();
return '<p>该文章内容需要登录浏览。请点击 [ 此处登录 ] 后查看。';
}
}
</p>
2.编辑文章的内容,将要隐藏的内容用[hide][/hide]包裹起来
[hide]这段文字将被隐藏,登录后可见。[/hide]
三、实际效果
点击登录后,会自动跳转回当前页面,显示隐藏内容。
4.扩展,在后台文本编辑器中添加快捷按钮(注意编辑器的文本编辑状态)。
只需将以下代码添加到主题的 functions.php 文件中。
// 后台文本编辑框中添加隐藏简码按钮
function add_hide_quicktags() {
<p>
if (wp_script_is('quicktags')){
?>
QTags.addButton( 'hide', '隐藏内容', '[hide]隐藏内容[/hide]',"" ); 查看全部
采集 干货教程:【网站搭建】自采集影视站源码+演示
【网站建设】自采集影视台源代码+演示
演示网站:
自动采集
强大的搜索功能,使用PHP实时抓取可用资源,程序运行速度非常快,可以快速构建自己的电影网站
安装说明:
如果没有数据库,请修改解析配置文件配置文件.js
首页标题等在索引.php文件修改,首页图片在此更改/
static_qq/图片/标志.png、行名和首页图片在此变化/播放/索引.php
配置网站伪静态思维
有些不需要配置,有些可能没有配置,主页顶部会乱码!
蓝拳云
教程:WordPress 隐藏文章内容必须登录才可以查看的完美代码实现(不用插件)
1.创建一个短代码隐藏并将以下代码添加到主题的functions.php文件中。
add_shortcode('hide','loginvisible');
function loginvisible($atts,$content=null){
if(is_user_logged_in() && !is_null($content) && !is_feed()){
return $content;
}
else{
$url = get_permalink().'?'.time();
return '<p>该文章内容需要登录浏览。请点击 [ 此处登录 ] 后查看。';
}
}
</p>
2.编辑文章的内容,将要隐藏的内容用[hide][/hide]包裹起来
[hide]这段文字将被隐藏,登录后可见。[/hide]
三、实际效果
点击登录后,会自动跳转回当前页面,显示隐藏内容。
4.扩展,在后台文本编辑器中添加快捷按钮(注意编辑器的文本编辑状态)。
只需将以下代码添加到主题的 functions.php 文件中。
// 后台文本编辑框中添加隐藏简码按钮
function add_hide_quicktags() {
<p>
if (wp_script_is('quicktags')){
?>
QTags.addButton( 'hide', '隐藏内容', '[hide]隐藏内容[/hide]',"" );
采集 经验:做内容采集的话选择哪里的服务器比较好?有没有什么比较便宜的香港服务器推荐?
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2022-09-30 15:18
现在,随着在线访问信息的人的比例和数量的增加。现在有越来越多的用户创建独立的网站。但是很多新的网站,尤其是建在海外服务器上的网站,会发现自己的新网站排名和流量都减少了。所以,除了做原创的内容,很多网站想要快速增加收录和流量,一般采用伪原创和原创的组合,这就需要使用采集内容工具采集。那么什么样的配置才能保证采集工具的前端体验和流畅运行呢?就在这里说吧。
如果是海外机房,用哪个服务器比较好?
如果选择海外机房,如果主要使用大陆的流量,香港的服务器比较多。由于香港服务器不需要备案,搭建简单,自媒体正好合适,那么如何选择合适的香港服务器搭建业务呢?以下是简要介绍。
硬件配置更可靠
在搭建服务器的时候,如果要同时部署网站和采集工具,基本上需要使用windows系统。由于windows系统的配置要求较高,港机房不仅可以提供高性价比的i3,还可以提供适合windows系统的高配置E3和E5。如果不额外租用服务器,需要高性能内存支持来应对采集工具带来的高并发需求,香港服务器可以满足。
可靠的网络条件
在采集工具运行过程中,通常会定期进行自动采集。无论是网络拥塞还是采集的目标网站访问不畅,都可能导致采集的数据出错,甚至出现乱码,对SEO不利。现在香港的服务器都有BGP线路,可以根据IP访问自动选择最合适的线路,保证采集的数据和代码完整无误。
可靠的服务
不仅网络故障会导致发布和采集失败,采集工具本身对系统并发数也有严格要求。如果发生硬件故障(例如内存),采集 工具很有可能会变得无响应。因此,如果出现此类问题,需要专业的硬件工程师尽快处理。香港机房专业运维人员24小时值班。一旦用户需要升级或更改配置,可以立即进入机房进行处理。因此,在选择服务商时,推荐专业的技术支持团队更为可靠。
蓝翼云CDN最大的优势就是其他高防CDN要么需要备案,要么不备案很慢。
蓝云CDN安全盾也利用云架构,将防护提升至最高500G-DDos防护+CC攻击防护,同时提升速度降低网络延迟,非常适合网站、游戏、等一系列互联网应用程序使用!
蓝翼云服务器还提供了一台最低10M起步的香港大带宽云服务器!
更多关于 CDN 和云服务器的 文章:
干货:赶紧收藏这8款自媒体运营软件,小白必备
目前自媒体发展趋势火热,辅助自媒体操作的工具自然而然诞生,包括排版、屏幕视频、视频编辑转换、流行版辅助、图文数据采集、视频采集、热点、视频短片发布等工具,以及集成这些工具的各种自媒体助手。给大家分享8款好用的自媒体操作辅助软件。
自媒体神器
自媒体神器是一款优秀的SEO优化工具,具有一键伪原创、原创检测、MD5批量视频修改、各大自媒体平台视频分析等功能,未来将增加视频水印去除和视频标题编辑等各种功能。
小火花自媒体助理
Little Spark自媒体Assistant 是一种操作工具,自媒体 员工将使用它来提供准确的信息定位。企鹅、今日头条、百家号等平台涵盖了最全面的实时内容。小火助手让运营更高效,一个人操作多平台多账号,流量翻倍!
简易视频下载器
Easy Video Downloader是一款可以下载自媒体视频的软件。可根据自媒体平台、短视频平台、作者过滤、关键词搜索和视频下载。做新媒体运营的朋友不要错过!
迅蟒自媒体助手
迅Python自媒体Assistant,集成了强大的自媒体编辑器,素材丰富,编辑功能强大,多账号登录,复制内容同步,方便快捷。热点风向标,从时事政治新闻到娱乐热点,从微博、微信到豆瓣知乎,为用户呈现最新最热话题,为媒体编辑提供写作素材。更重要的是,我们为自媒体运营商提供了一个平台,让自媒体的流量更有价值。
快友助手
快游助手是小米开发的自媒体操作工具。快游助手让媒体账号的操作更简单,专为矩阵账号的轻松管理或单个大号的深度操作而设计。最好的免费操作工具!
微信编辑
微信编辑器是一款免费的微信公众号图文排版工具,改编自微信在线编辑器,为微信用户提供日常微信文章、微信图文、微信代码、微信编辑等资源。微信编辑器可以制作模板并保存在本地,方便多图编辑,格式统一。
墨云
摩云是一款自媒体辅助软件,具有自媒体运营管理、数据分析软件、视频去重、采集、视频监控等功能。,并且可以免费永久更新和维护。不要担心以后的软件不可用或无人维护。目前功能比较简单,以后软件会根据用户需要进一步完善!
云分发
Cloud Release 自媒体Assistant是为了方便自媒体创作者操作多个账号。云发布包括:账号绑定、一键发布、视频一键发布、查看内容和数据的功能场景。用户可以在云发布中轻松操作多个 自媒体 帐户。可将用户的自媒体账号添加到账号绑定页面,在视频发布页面一键将创作者编辑的内容发布到用户指定的账号。数据查看页面让创作者可以轻松清晰地查看昨天绑定的自媒体账号。 查看全部
采集 经验:做内容采集的话选择哪里的服务器比较好?有没有什么比较便宜的香港服务器推荐?
现在,随着在线访问信息的人的比例和数量的增加。现在有越来越多的用户创建独立的网站。但是很多新的网站,尤其是建在海外服务器上的网站,会发现自己的新网站排名和流量都减少了。所以,除了做原创的内容,很多网站想要快速增加收录和流量,一般采用伪原创和原创的组合,这就需要使用采集内容工具采集。那么什么样的配置才能保证采集工具的前端体验和流畅运行呢?就在这里说吧。
如果是海外机房,用哪个服务器比较好?
如果选择海外机房,如果主要使用大陆的流量,香港的服务器比较多。由于香港服务器不需要备案,搭建简单,自媒体正好合适,那么如何选择合适的香港服务器搭建业务呢?以下是简要介绍。
硬件配置更可靠
在搭建服务器的时候,如果要同时部署网站和采集工具,基本上需要使用windows系统。由于windows系统的配置要求较高,港机房不仅可以提供高性价比的i3,还可以提供适合windows系统的高配置E3和E5。如果不额外租用服务器,需要高性能内存支持来应对采集工具带来的高并发需求,香港服务器可以满足。
可靠的网络条件
在采集工具运行过程中,通常会定期进行自动采集。无论是网络拥塞还是采集的目标网站访问不畅,都可能导致采集的数据出错,甚至出现乱码,对SEO不利。现在香港的服务器都有BGP线路,可以根据IP访问自动选择最合适的线路,保证采集的数据和代码完整无误。
可靠的服务

不仅网络故障会导致发布和采集失败,采集工具本身对系统并发数也有严格要求。如果发生硬件故障(例如内存),采集 工具很有可能会变得无响应。因此,如果出现此类问题,需要专业的硬件工程师尽快处理。香港机房专业运维人员24小时值班。一旦用户需要升级或更改配置,可以立即进入机房进行处理。因此,在选择服务商时,推荐专业的技术支持团队更为可靠。
蓝翼云CDN最大的优势就是其他高防CDN要么需要备案,要么不备案很慢。
蓝云CDN安全盾也利用云架构,将防护提升至最高500G-DDos防护+CC攻击防护,同时提升速度降低网络延迟,非常适合网站、游戏、等一系列互联网应用程序使用!
蓝翼云服务器还提供了一台最低10M起步的香港大带宽云服务器!
更多关于 CDN 和云服务器的 文章:
干货:赶紧收藏这8款自媒体运营软件,小白必备
目前自媒体发展趋势火热,辅助自媒体操作的工具自然而然诞生,包括排版、屏幕视频、视频编辑转换、流行版辅助、图文数据采集、视频采集、热点、视频短片发布等工具,以及集成这些工具的各种自媒体助手。给大家分享8款好用的自媒体操作辅助软件。
自媒体神器
自媒体神器是一款优秀的SEO优化工具,具有一键伪原创、原创检测、MD5批量视频修改、各大自媒体平台视频分析等功能,未来将增加视频水印去除和视频标题编辑等各种功能。
小火花自媒体助理
Little Spark自媒体Assistant 是一种操作工具,自媒体 员工将使用它来提供准确的信息定位。企鹅、今日头条、百家号等平台涵盖了最全面的实时内容。小火助手让运营更高效,一个人操作多平台多账号,流量翻倍!

简易视频下载器
Easy Video Downloader是一款可以下载自媒体视频的软件。可根据自媒体平台、短视频平台、作者过滤、关键词搜索和视频下载。做新媒体运营的朋友不要错过!
迅蟒自媒体助手
迅Python自媒体Assistant,集成了强大的自媒体编辑器,素材丰富,编辑功能强大,多账号登录,复制内容同步,方便快捷。热点风向标,从时事政治新闻到娱乐热点,从微博、微信到豆瓣知乎,为用户呈现最新最热话题,为媒体编辑提供写作素材。更重要的是,我们为自媒体运营商提供了一个平台,让自媒体的流量更有价值。
快友助手
快游助手是小米开发的自媒体操作工具。快游助手让媒体账号的操作更简单,专为矩阵账号的轻松管理或单个大号的深度操作而设计。最好的免费操作工具!
微信编辑
微信编辑器是一款免费的微信公众号图文排版工具,改编自微信在线编辑器,为微信用户提供日常微信文章、微信图文、微信代码、微信编辑等资源。微信编辑器可以制作模板并保存在本地,方便多图编辑,格式统一。
墨云
摩云是一款自媒体辅助软件,具有自媒体运营管理、数据分析软件、视频去重、采集、视频监控等功能。,并且可以免费永久更新和维护。不要担心以后的软件不可用或无人维护。目前功能比较简单,以后软件会根据用户需要进一步完善!
云分发
Cloud Release 自媒体Assistant是为了方便自媒体创作者操作多个账号。云发布包括:账号绑定、一键发布、视频一键发布、查看内容和数据的功能场景。用户可以在云发布中轻松操作多个 自媒体 帐户。可将用户的自媒体账号添加到账号绑定页面,在视频发布页面一键将创作者编辑的内容发布到用户指定的账号。数据查看页面让创作者可以轻松清晰地查看昨天绑定的自媒体账号。
采集(fastadmin强大的一键生成功能快速简化你的项目开发流程 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-04-03 18:12
)
fastadmin采集器,FastAdmin 是一个基于 ThinkPHP 和 Bootstrap 的极速后台开发框架。Fastadmin强大的一键生成功能快速简化您的开发流程,加快您的项目开发。fastadmin采集器是目前使用最多的互联网数据采集、处理、分析和挖掘软件。Fastadmin软件以其灵活的配置和强大的性能领先于国内data采集产品,获得了众多用户的一致认可。
fastadmin采集器支持长尾关键词生成文章。找到您的网站正确目标关键词 至关重要。每天都有很多人通过搜索引擎找到自己需要的东西,而我们的SEO优化就是为了得到更好的搜索排名,让更多的潜在用户访问你的网站,进而产生交易,带来收益。关键词和长尾关键词的作用尤为重要,fastadmin采集器可以为你提供长尾关键词,流行的关键词。关键词是我们启动fastadmin采集器的第一步,也是最重要的一步。如果你选错了关键词,你会在整个SEO过程中走很多弯路。关键词还不确定,fastadmin的内容采集不能帮助你网站提高你的网站
数据分析。查看 网站 的统计信息,了解可以优化和改进的内容。采集 仅有内容是不够的。比如你采集提交了一个网站内容,如果其他人采集也提交了这个网站内容,那么就会导致内容同质化,导致结果百度没有收录。
fastadmin采集 支持内容优化处理。包括网站栏目设置、关键词布局、内容优化、内外链建设等,fastadmin采集器可以自动采集优质内容并定期发布;并配置多种数据处理选项,让网站内容独一无二,快速增加网站流量!fastadmin采集器采用分布式高速采集系统,多台服务器同时运行,解决了工作学习中大量数据下载和使用的需求,让您拥有更多的时间做更多的事情。
fastadmin采集器,专业的互联网数据采集、处理、分析、挖掘软件,可以灵活、快速的抓取网页上零散的数据信息,并通过一系列的分析处理,精准挖掘出需要的数据数据。
网站的内容,相当于网站成长的土壤和血液。对于站采集,我们不能做原创,但也要长期提供优质的伪原创内容,这也是使用fastadmin采集的必要条件之一@> 作为 采集 站。无论是您的 网站 域选择、网站 主题、网站 模式、网站 色调、网站 图形、网站 关键字、网站@ >@网站及其代码优化等,都需要简洁友好,准确有效,方便流畅,有吸引力,注意不要作弊。否则,即使你的网站流量很高,你也无法留住客户,也无法通过流量变现,一切都是空谈。
使用 fastadmin采集器 建议你应该构建一个对用户有用的 网站,任何优化都是为了改善用户体验。简单的理解就是把用户体验放在第一位,发布有价值的文章内容,文章的标题和内容板块收录有意义的搜索关键词。企业网站做SEO,就是围绕自己提供的服务或产品发布有价值的内容,让更多与你的产品和服务相关的搜索词获得良好的搜索排名。fastadmin采集器 快速挖掘数据中的新客户;洞察竞争对手的业务数据,分析客户行为以拓展新业务,通过精准营销降低风险和预算。今天关于fastadmin的解释采集器
查看全部
采集(fastadmin强大的一键生成功能快速简化你的项目开发流程
)
fastadmin采集器,FastAdmin 是一个基于 ThinkPHP 和 Bootstrap 的极速后台开发框架。Fastadmin强大的一键生成功能快速简化您的开发流程,加快您的项目开发。fastadmin采集器是目前使用最多的互联网数据采集、处理、分析和挖掘软件。Fastadmin软件以其灵活的配置和强大的性能领先于国内data采集产品,获得了众多用户的一致认可。
fastadmin采集器支持长尾关键词生成文章。找到您的网站正确目标关键词 至关重要。每天都有很多人通过搜索引擎找到自己需要的东西,而我们的SEO优化就是为了得到更好的搜索排名,让更多的潜在用户访问你的网站,进而产生交易,带来收益。关键词和长尾关键词的作用尤为重要,fastadmin采集器可以为你提供长尾关键词,流行的关键词。关键词是我们启动fastadmin采集器的第一步,也是最重要的一步。如果你选错了关键词,你会在整个SEO过程中走很多弯路。关键词还不确定,fastadmin的内容采集不能帮助你网站提高你的网站
数据分析。查看 网站 的统计信息,了解可以优化和改进的内容。采集 仅有内容是不够的。比如你采集提交了一个网站内容,如果其他人采集也提交了这个网站内容,那么就会导致内容同质化,导致结果百度没有收录。
fastadmin采集 支持内容优化处理。包括网站栏目设置、关键词布局、内容优化、内外链建设等,fastadmin采集器可以自动采集优质内容并定期发布;并配置多种数据处理选项,让网站内容独一无二,快速增加网站流量!fastadmin采集器采用分布式高速采集系统,多台服务器同时运行,解决了工作学习中大量数据下载和使用的需求,让您拥有更多的时间做更多的事情。
fastadmin采集器,专业的互联网数据采集、处理、分析、挖掘软件,可以灵活、快速的抓取网页上零散的数据信息,并通过一系列的分析处理,精准挖掘出需要的数据数据。
网站的内容,相当于网站成长的土壤和血液。对于站采集,我们不能做原创,但也要长期提供优质的伪原创内容,这也是使用fastadmin采集的必要条件之一@> 作为 采集 站。无论是您的 网站 域选择、网站 主题、网站 模式、网站 色调、网站 图形、网站 关键字、网站@ >@网站及其代码优化等,都需要简洁友好,准确有效,方便流畅,有吸引力,注意不要作弊。否则,即使你的网站流量很高,你也无法留住客户,也无法通过流量变现,一切都是空谈。
使用 fastadmin采集器 建议你应该构建一个对用户有用的 网站,任何优化都是为了改善用户体验。简单的理解就是把用户体验放在第一位,发布有价值的文章内容,文章的标题和内容板块收录有意义的搜索关键词。企业网站做SEO,就是围绕自己提供的服务或产品发布有价值的内容,让更多与你的产品和服务相关的搜索词获得良好的搜索排名。fastadmin采集器 快速挖掘数据中的新客户;洞察竞争对手的业务数据,分析客户行为以拓展新业务,通过精准营销降低风险和预算。今天关于fastadmin的解释采集器
采集 采集(如何下载打开安卓手机应用商店的应用系统?(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2022-03-29 12:24
)
你体验过采集数据吗?采集小队下达任务后,大家带着专用机器前往现场采集,返回后进行内部检查。办公室处理数据以制作地图。这种单机离线采集模式组织松散,团队成员之间沟通不畅,效率很低。
从事野外数据采集是根据点的地理位置,拍照、GPS轨迹、调查表等,将采集得到的各种GIS数据同步到办公GIS软件中,分析和处理。数据报告。
我们都知道,ArcGIS 提供了几个移动端应用程序,例如 ArcGIS Collector 和 ArcGIS QuickCapture,它们真的很好用,功能强大,并且与内部和外部行业同步。但是,需要 ArcGIS Online 帐户,并且该帐户的公共版本是不可接受的。简而言之,它需要钱。,那么除了上面的软件之外,有没有国产的GIS工具可以替代上面的软件呢?
今天给大家介绍一款领域神器。事实上,它用于工程和地质调查。它可以将自己的采集数据同步到内部的GIS软件。下面将简要介绍其具体功能:
1.集成高清卫星图、地质图、电子导航图,支持添加自定义地图。你知道,像歌曲和地图盒这样的地图都可以使用;
2.GPS轨迹记录,还内置指南针、风水指南针(这是Ovie中的vip功能)免费工具;
3.支持导入kml和shp文件,查看行政边界,查看海拔信息,下载离线地图;
4.基于模板形式采集复杂的野外调查数据,并可将采集的数据一键导出至GIS软件进行分析管理;
5.支持扩展定制开发,可用于行业应用系统的快速定制开发。
如何下载
打开安卓手机应用商店,搜索【Fieldwork Wizard app】,搜索结果应该是这样的。
如何使用
事实上,它的使用非常简单。可以探索和探索。页面上只有几个功能键。下面是几个常用的函数:
1、添加底图。默认只有天兔系列图和地质图。既然在外地,我觉得各种高清影像图都是少不了的。同时支持添加第三方互联网地图(谷歌系列地图、mmapbox图片、高德地图、百度地图等),让你的调查如鱼得水。
如果要在地图中添加内部数据和离线地图数据,可以借助新的地图桌面终端将地图数据转换为LRC地图源或LRP格式文件并添加。
2、启用GPS轨迹路径:我猜这是最实用的功能了。打开后会直接采集元素。当然GPS采集参数需要设置,比如多少米采集一个点。
3、拍照:现场拍照最能反映现场情况。这是证据。
4、导出:这里有很多功能,可以导出多种格式的KML/KMZ/SHP,将采集的数据导入桌面端进行数据管理和分析。
查看全部
采集 采集(如何下载打开安卓手机应用商店的应用系统?(组图)
)
你体验过采集数据吗?采集小队下达任务后,大家带着专用机器前往现场采集,返回后进行内部检查。办公室处理数据以制作地图。这种单机离线采集模式组织松散,团队成员之间沟通不畅,效率很低。

从事野外数据采集是根据点的地理位置,拍照、GPS轨迹、调查表等,将采集得到的各种GIS数据同步到办公GIS软件中,分析和处理。数据报告。

我们都知道,ArcGIS 提供了几个移动端应用程序,例如 ArcGIS Collector 和 ArcGIS QuickCapture,它们真的很好用,功能强大,并且与内部和外部行业同步。但是,需要 ArcGIS Online 帐户,并且该帐户的公共版本是不可接受的。简而言之,它需要钱。,那么除了上面的软件之外,有没有国产的GIS工具可以替代上面的软件呢?
今天给大家介绍一款领域神器。事实上,它用于工程和地质调查。它可以将自己的采集数据同步到内部的GIS软件。下面将简要介绍其具体功能:
1.集成高清卫星图、地质图、电子导航图,支持添加自定义地图。你知道,像歌曲和地图盒这样的地图都可以使用;
2.GPS轨迹记录,还内置指南针、风水指南针(这是Ovie中的vip功能)免费工具;
3.支持导入kml和shp文件,查看行政边界,查看海拔信息,下载离线地图;
4.基于模板形式采集复杂的野外调查数据,并可将采集的数据一键导出至GIS软件进行分析管理;
5.支持扩展定制开发,可用于行业应用系统的快速定制开发。
如何下载
打开安卓手机应用商店,搜索【Fieldwork Wizard app】,搜索结果应该是这样的。
如何使用
事实上,它的使用非常简单。可以探索和探索。页面上只有几个功能键。下面是几个常用的函数:
1、添加底图。默认只有天兔系列图和地质图。既然在外地,我觉得各种高清影像图都是少不了的。同时支持添加第三方互联网地图(谷歌系列地图、mmapbox图片、高德地图、百度地图等),让你的调查如鱼得水。
如果要在地图中添加内部数据和离线地图数据,可以借助新的地图桌面终端将地图数据转换为LRC地图源或LRP格式文件并添加。
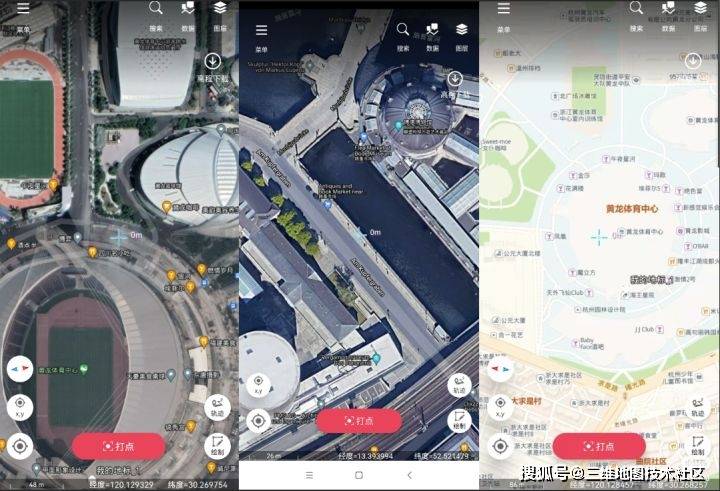
2、启用GPS轨迹路径:我猜这是最实用的功能了。打开后会直接采集元素。当然GPS采集参数需要设置,比如多少米采集一个点。
3、拍照:现场拍照最能反映现场情况。这是证据。
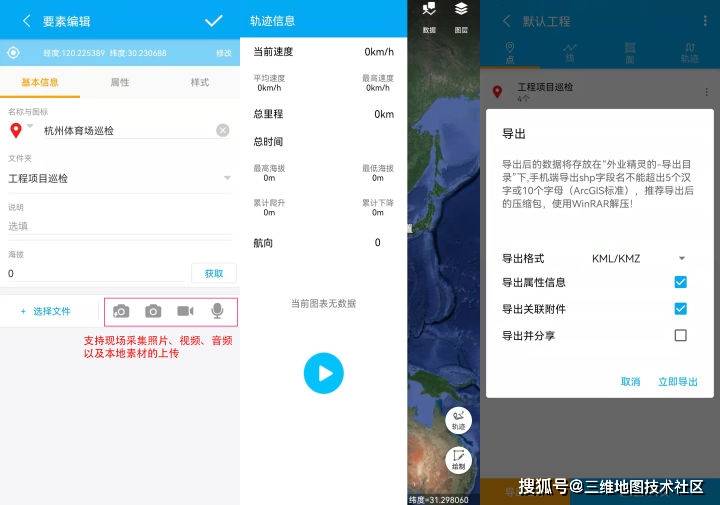
4、导出:这里有很多功能,可以导出多种格式的KML/KMZ/SHP,将采集的数据导入桌面端进行数据管理和分析。
采集 采集(2.分析行业趋势行业对手网站有哪些优化趋势?在哪些平台发布外链? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-03-14 20:02
)
PHP插件是我们做网站SEO时经常用到的插件。PHP插件是我们在执行文章采集和发布伪原创时可以使用的优化工具,具有自动定时采集和发布功能。无需人工值班即可实现24小时挂机。
PHP插件可以进行全网采集或者指定采集,并且可以为我们提供各种需求的原创素材,我们只需要输入相关热词和一个-点击采集,一次可以创建多个采集任务,同时可以执行多个域名任务采集。采集支持图片水印去除,文章敏感信息去除,多格式存储,支持主要cms,设置规则后自动采集,采集后自动发布@> 或 伪原创publish 推送到搜索引擎。
PHP插件内置翻译功能,可以为需要翻译的用户提供支持。它有一个内置的翻译界面,badu/google/youdao和自己的翻译可供选择。PHP插件允许我们在标题前后和内容中插入相关的词。根据设定的规则,随机插入相关的局部图片。
文章发布成功后主动推送,保证新链接能及时收录;发布任务执行时自动生成内部链接,吸引蜘蛛爬取,让蜘蛛养成定时爬取网页的习惯提高网站收录,我们可以完成网站@的一部分> 通过 PHP 插件进行管理和 SEO。对于一些用工具做不到的优化,我们还是要自己做
1.网站布局优化。
一般来说,如果网站的关键词布局不合理,关键词出现在页面的频率太高,密度不利于优化。这时,我们可以在网站底部的不同区域为关键词创建锚文本。关键词布局只有恰到好处才能帮助排名,否则会适得其反,导致网站被降级的危险。由于搜索引擎蜘蛛抓取信息的顺序是上、左、中、下,所以在设计网站布局时要考虑网站结构和关键词布局的合理性,如以方便优化。
2.分析行业趋势
行业竞争对手网站的优化趋势是什么?外部链接发布在哪些平台上?关键词布局如何?如果我们不知道这些基本的优化连同线,那么两年后网站优化可能不会上首页。只有多了解对方的SEO信息,才能从对方的优化重点出发,设定优化目标,然后超越同行,努力找出对方的不足,自己做出调整,让自己轻松超越对方。
3.关键词交通不真实。
为了快速提升网站关键词的排名,很多站长都会使用各种刷流量的软件。出现这种现象是因为关键词排名靠前,主要是每天有大量的搜索点击,网站的流量权重也会增加。但这种方法不可取。这种作弊一旦被搜索引擎发现,直接K。所以我们还是得在搜索引擎规则范围内使用插件。
4、服务器不稳定因素
我们在购买服务器的时候,可能不会注意很多细节。服务器的基本配置影响网站的整体权重和稳定性。如果搜索引擎蜘蛛抓取你的网站,打不开或者打开速度慢,那么搜索引擎就不会给你一个好的网站排名。因此,建议大家在选择服务器时尽量选择国内备案的、拥有独立IP的服务器站点。
不同的PHP插件实现cms网站可以在软件站观察数据,软件可以直接监控是否已发布,待发布,是否为伪原创,发布状态、网址、节目、发布时间等;软件站每天检查收录、权重、蜘蛛等数据,我们可以通过PHP插件数据获取大量数据进行分析,无论是网站本身还是行业大数据,数据分析可以支持我们的理性判断,是我们SEO流程的重要组成部分。
查看全部
采集 采集(2.分析行业趋势行业对手网站有哪些优化趋势?在哪些平台发布外链?
)
PHP插件是我们做网站SEO时经常用到的插件。PHP插件是我们在执行文章采集和发布伪原创时可以使用的优化工具,具有自动定时采集和发布功能。无需人工值班即可实现24小时挂机。

PHP插件可以进行全网采集或者指定采集,并且可以为我们提供各种需求的原创素材,我们只需要输入相关热词和一个-点击采集,一次可以创建多个采集任务,同时可以执行多个域名任务采集。采集支持图片水印去除,文章敏感信息去除,多格式存储,支持主要cms,设置规则后自动采集,采集后自动发布@> 或 伪原创publish 推送到搜索引擎。

PHP插件内置翻译功能,可以为需要翻译的用户提供支持。它有一个内置的翻译界面,badu/google/youdao和自己的翻译可供选择。PHP插件允许我们在标题前后和内容中插入相关的词。根据设定的规则,随机插入相关的局部图片。
文章发布成功后主动推送,保证新链接能及时收录;发布任务执行时自动生成内部链接,吸引蜘蛛爬取,让蜘蛛养成定时爬取网页的习惯提高网站收录,我们可以完成网站@的一部分> 通过 PHP 插件进行管理和 SEO。对于一些用工具做不到的优化,我们还是要自己做

1.网站布局优化。
一般来说,如果网站的关键词布局不合理,关键词出现在页面的频率太高,密度不利于优化。这时,我们可以在网站底部的不同区域为关键词创建锚文本。关键词布局只有恰到好处才能帮助排名,否则会适得其反,导致网站被降级的危险。由于搜索引擎蜘蛛抓取信息的顺序是上、左、中、下,所以在设计网站布局时要考虑网站结构和关键词布局的合理性,如以方便优化。

2.分析行业趋势
行业竞争对手网站的优化趋势是什么?外部链接发布在哪些平台上?关键词布局如何?如果我们不知道这些基本的优化连同线,那么两年后网站优化可能不会上首页。只有多了解对方的SEO信息,才能从对方的优化重点出发,设定优化目标,然后超越同行,努力找出对方的不足,自己做出调整,让自己轻松超越对方。

3.关键词交通不真实。
为了快速提升网站关键词的排名,很多站长都会使用各种刷流量的软件。出现这种现象是因为关键词排名靠前,主要是每天有大量的搜索点击,网站的流量权重也会增加。但这种方法不可取。这种作弊一旦被搜索引擎发现,直接K。所以我们还是得在搜索引擎规则范围内使用插件。
4、服务器不稳定因素
我们在购买服务器的时候,可能不会注意很多细节。服务器的基本配置影响网站的整体权重和稳定性。如果搜索引擎蜘蛛抓取你的网站,打不开或者打开速度慢,那么搜索引擎就不会给你一个好的网站排名。因此,建议大家在选择服务器时尽量选择国内备案的、拥有独立IP的服务器站点。
不同的PHP插件实现cms网站可以在软件站观察数据,软件可以直接监控是否已发布,待发布,是否为伪原创,发布状态、网址、节目、发布时间等;软件站每天检查收录、权重、蜘蛛等数据,我们可以通过PHP插件数据获取大量数据进行分析,无论是网站本身还是行业大数据,数据分析可以支持我们的理性判断,是我们SEO流程的重要组成部分。

采集(网站能采集吗?采集站怎么做?网站怎么采集?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-02-25 15:24
网站采集是大部分站长都离不开的话题,网站你能采集吗? 网站采集怎么样? 采集怎么办?这些都是站长们非常关心的问题。今天给大家讲讲网站采集,小编在这方面还是有一些研究的,网站采集肯定可以做到的,现在大部分网站全部使用采集,关键是采集的内容处理,以及采集的数据源的选择,很好的解决这些问题,哪怕是纯采集 站。快收录,提升你的排名。
网站采集的所有采集功能都是免费的,并提供开源发布接口。它可以爬取单页和多页,并且可以爬取指定URL的内容。然后使用多线程爬取,多任务多线程快速爬取,提高采集的速度。这启用了批处理采集,无论是列表采集、内容采集、内容发布分步,还是组合批处理采集。
网站采集的数据文章内容存储在Mysql数据库中。广泛使用的Mysql数据库存储将更加轻量和高效。包括图片附件的下载和保存,网站采集可以同时保存远程图片定位。加上附件上传,这允许图像附件自动上传到网站。 网站采集,使用通用的网站接口,无论是WordPresscms还是织梦cms,Empirecms等开源程序无缝兼容。
网站采集同时还具有自动缩略图功能,从内容页面中提取第一页图片作为缩略图,使 节点。 采集节点收到爬虫任务后,从资源池中获取相应的系统资源并立即发起请求,将相应的数据发送给目标网站采集,同时启动数据cleaner,并根据相应的数据清洗规则对数据进行清洗。
网站采集完成数据采集后,将对应的结果返回给服务器。为了保证数据能够以最快的速度采集,系统会将采集任务推送到各个算子的采集网络节点,同步发起网络请求。保证可以一直使用最优的网络节点,对应的数据能以最快的速度采集。
网站采集的文章分享就写到这里,希望对广大站长有所帮助。 网站采集并不是唯一的建站方式,而是更方便快捷的方式。单独采集,网站肯定起不来,必须结合SEO优化对网站整体进行优化,才能达到优化效果。返回搜狐,查看更多 查看全部
采集(网站能采集吗?采集站怎么做?网站怎么采集?)
网站采集是大部分站长都离不开的话题,网站你能采集吗? 网站采集怎么样? 采集怎么办?这些都是站长们非常关心的问题。今天给大家讲讲网站采集,小编在这方面还是有一些研究的,网站采集肯定可以做到的,现在大部分网站全部使用采集,关键是采集的内容处理,以及采集的数据源的选择,很好的解决这些问题,哪怕是纯采集 站。快收录,提升你的排名。

网站采集的所有采集功能都是免费的,并提供开源发布接口。它可以爬取单页和多页,并且可以爬取指定URL的内容。然后使用多线程爬取,多任务多线程快速爬取,提高采集的速度。这启用了批处理采集,无论是列表采集、内容采集、内容发布分步,还是组合批处理采集。

网站采集的数据文章内容存储在Mysql数据库中。广泛使用的Mysql数据库存储将更加轻量和高效。包括图片附件的下载和保存,网站采集可以同时保存远程图片定位。加上附件上传,这允许图像附件自动上传到网站。 网站采集,使用通用的网站接口,无论是WordPresscms还是织梦cms,Empirecms等开源程序无缝兼容。
网站采集同时还具有自动缩略图功能,从内容页面中提取第一页图片作为缩略图,使 节点。 采集节点收到爬虫任务后,从资源池中获取相应的系统资源并立即发起请求,将相应的数据发送给目标网站采集,同时启动数据cleaner,并根据相应的数据清洗规则对数据进行清洗。
网站采集完成数据采集后,将对应的结果返回给服务器。为了保证数据能够以最快的速度采集,系统会将采集任务推送到各个算子的采集网络节点,同步发起网络请求。保证可以一直使用最优的网络节点,对应的数据能以最快的速度采集。

网站采集的文章分享就写到这里,希望对广大站长有所帮助。 网站采集并不是唯一的建站方式,而是更方便快捷的方式。单独采集,网站肯定起不来,必须结合SEO优化对网站整体进行优化,才能达到优化效果。返回搜狐,查看更多
采集(想用Drupal采集插件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2022-02-03 13:04
如果要使用 Drupal采集 插件,可以先下载雅爱园 Drupal采集器 发行版,安装,即可使用。里面有详细的文档。雅爱源 Drupal采集器,使用标准的Drupal模块,是完全开源的,但是为了支持中文采集,部分模块做了修改。
我们来介绍一下雅爱园Drupal中采集相关的模块插件采集器:
1、Feeds模块,这个是主模块,是用来导入数据的,开始是收RSS数据,后来发展到导入各种数据,后来发现基于这个模块,可以用于采集网页信息。
2、job_scheduler模块,这是Feeds模块依赖的插件,采集期间的任务调度,很多时候需要依赖这个模块。
3、feeds_tamper模块,该模块用于导入数据时对数据进行预处理,也就是清理工作,非常有用的帮助模块。 采集网页数据必备模块。
4、feeds_xpathparser模块,该模块允许我们使用Xpath规则来解析数据。来自网页 采集 的数据是 HTML 格式,需要使用 Xpath 规则进行解析。这也是必备模块之一。
5、feeds_crawler模块,这是一个小型爬虫,方便采集各种分页列表,非常好用,网页爬取必备模块。
6、feeds_smartparser模块,智能提取HTML页面全文,是网页必备模块之一采集。
7、feeds_selfnode_processor模块,来自采集的节点本身也是一个feed种子。它可以通过HTTP请求捕获更详细的信息,改进自己的节点,是网页的必备模块之一采集。
8、Views/Ctools视图数据导出,将网页采集中的数据导出为各种格式,支持XML、CSV、Excel。
9、feeds_spider模块,采集蜘蛛,类似于feeds_crawler,网页采集模块之一。
相信在熟悉了以上模块之后,即使没有 Drupal采集器,你也可以构建自己的采集网站。
Aiyuan Drupal采集器是基于以上标准模块构建的,结合我们的实际经验,做一个有用的总结和归纳。 查看全部
采集(想用Drupal采集插件)
如果要使用 Drupal采集 插件,可以先下载雅爱园 Drupal采集器 发行版,安装,即可使用。里面有详细的文档。雅爱源 Drupal采集器,使用标准的Drupal模块,是完全开源的,但是为了支持中文采集,部分模块做了修改。
我们来介绍一下雅爱园Drupal中采集相关的模块插件采集器:
1、Feeds模块,这个是主模块,是用来导入数据的,开始是收RSS数据,后来发展到导入各种数据,后来发现基于这个模块,可以用于采集网页信息。
2、job_scheduler模块,这是Feeds模块依赖的插件,采集期间的任务调度,很多时候需要依赖这个模块。
3、feeds_tamper模块,该模块用于导入数据时对数据进行预处理,也就是清理工作,非常有用的帮助模块。 采集网页数据必备模块。
4、feeds_xpathparser模块,该模块允许我们使用Xpath规则来解析数据。来自网页 采集 的数据是 HTML 格式,需要使用 Xpath 规则进行解析。这也是必备模块之一。
5、feeds_crawler模块,这是一个小型爬虫,方便采集各种分页列表,非常好用,网页爬取必备模块。
6、feeds_smartparser模块,智能提取HTML页面全文,是网页必备模块之一采集。
7、feeds_selfnode_processor模块,来自采集的节点本身也是一个feed种子。它可以通过HTTP请求捕获更详细的信息,改进自己的节点,是网页的必备模块之一采集。
8、Views/Ctools视图数据导出,将网页采集中的数据导出为各种格式,支持XML、CSV、Excel。
9、feeds_spider模块,采集蜘蛛,类似于feeds_crawler,网页采集模块之一。
相信在熟悉了以上模块之后,即使没有 Drupal采集器,你也可以构建自己的采集网站。
Aiyuan Drupal采集器是基于以上标准模块构建的,结合我们的实际经验,做一个有用的总结和归纳。
采集 采集(6个K8s日志系统建设中的典型问题,你遇到过几个?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-12-06 19:19
作者 | 元一阿里云存储服务技术专家
简介:上一篇文章主要介绍了Kubernetes日志输出的一些注意事项。日志输出的最终目的是做统一的采集和分析。在 Kubernetes 中,采集 的日志记录方法与普通虚拟机有很大不同。实现的相对难度和部署成本也略高。但是,如果使用得当,它将比传统方法更加自动化且成本更低。本文为文章期刊系列第4篇。
第一篇:《K8s日志系统构建中的6个典型问题,你遇到了几个?》
第二章:《一篇了解K8s日志系统的设计与实践》
第3章:《解决K8s日志输出问题的九个技巧》
Kubernetes 日志 采集 难点
在 Kubernetes 中,日志记录 采集 比传统的虚拟机和物理机复杂得多。最根本的原因是Kubernetes屏蔽了底层的异常,提供更细粒度的资源调度,向上提供稳定动态的环境。所以日志采集面临着更丰富、更动态的环境,需要考虑的点也更多。
例如:
Kubernetes 传统方式
日志类型
文件、标准输出、主机文件、日志
档案、日记
日志来源
业务容器、系统组件、主机
商务、主持人
采集方法
代理(Sidecar、DaemonSet)、直写(DockerEngine、业务)
代理,直接写作
单机应用数量
10-100
1-10
应用动态
高的
低的
节点动态
高的
低的
采集部署方式
手册,Yaml
手动、定制
采集方法:主动或被动
日志的采集方式分为被动采集和主动推送。在K8s中,被动采集一般分为Sidecar和DaemonSet两种方法。主动推送包括DockerEngine推送和业务直推。用两种方式写。
总结一下:
各种采集方法的详细对比如下:
DockerEngine 业务直接写入 DaemonSet 模式 Sidecar 模式
采集日志类型
标准输出
业务日志
标准输出+文件的一部分
文档
部署运维
低,本机支持
低,只需要维护好配置文件
一般需要维护DaemonSet
高,每个需要采集日志的POD都需要部署一个sidecar容器
日志分类存储
达不到
业务独立配置
一般可以通过容器/路径等方式映射。
每个POD可单独配置,灵活性高
多租户隔离
虚弱的
弱,日志直写会与业务逻辑竞争资源
一般只能通过配置室隔离
强,容器隔离,可单独分配资源
支持集群大小
无限本地存储,如果使用syslog、fluentd,会有单点限制
无限
取决于配置的数量
无限
资源占用
低,码头工人
引擎提供
总体最低,节省 采集 开销
下层,每个节点运行一个容器
更高,每个 POD 运行一个容器
查询方便
低,只能grep原创日志
高,可根据业务特点定制
高,可自定义查询统计
高,可根据业务特点定制
可定制
低的
高,可自由扩展
低的
高,每个POD单独配置
耦合
高,与DockerEngine强绑定,修改需要重启DockerEngine
高,采集模块修改/升级需要重新发布业务
低,Agent可独立升级
一般默认采集Sidecar服务对应的Agent升级也会重启(有一些扩展包可以支持Sidecar热升级)
适用场景
非生产场景,例如测试和 POC
对性能要求极高的场景
一个日志分类清晰、功能单一的集群
大规模、混合、PAAS 类型的集群
日志输出:标准输出或文件
与虚拟机/物理机不同,K8s 容器提供标准输出和文件格式。在容器中,标准输出将日志直接输出到stdout或stderr,而DockerEngine接管stdout和stderr文件描述符,接收后根据DockerEngine配置的LogDriver规则对日志进行处理;日志打印到文件和虚拟机/物理机基本相似,只是日志可以使用不同的存储方式,比如默认存储、EmptyDir、HostVolume、NFS等。
虽然Docker官方推荐使用Stdout打印日志,但是大家需要注意:这个推荐是基于容器只作为简单应用的场景。在实际业务场景中,我们仍然建议您尽可能使用文件。主要有以下几点原因:
因此,我们推荐在线应用使用文件输出日志。Stdout 仅用于功能单一的应用或一些 K8s 系统/运维组件。
CICD 集成:日志操作员
Kubernetes 提供了标准化的业务部署方式。您可以使用yaml(K8s API)来声明路由规则、暴露服务、挂载存储、运行业务、定义伸缩规则等,因此Kubernetes很容易与CICD系统集成。日志采集也是运维监控过程的重要组成部分,所有业务上线后的日志都要实时采集。
原来的方法是在发布后手动部署日志采集的逻辑。这种方法需要人工干预,违背了CICD自动化的目的;为了实现自动化,有人开始根据日志打包API/SDK 采集 一个自动部署的服务在发布后通过CICD的webhook调用,但是这种方式的开发成本很高。
在 Kubernetes 中,最标准的日志集成方式是在 Kubernetes 系统中注册一个新的资源,并以 Operator(CRD)的形式对其进行管理和维护。这样CICD系统不需要额外的开发,部署到Kubernetes系统时只需要附加日志相关的配置就可以实现。
Kubernetes 日志采集 方案
早在Kubernetes出现之前,我们就开始针对容器环境开发日志采集解决方案。随着K8s的逐渐稳定,我们开始将很多业务迁移到K8s平台上,所以我们也在之前的基础上开发了一套。K8s 上的日志 采集 方案。主要功能是:
安装日志采集组件
目前,这个采集计划是对公众开放的。我们提供了一个 Helm 安装包,其中包括 Logtail 的 DaemonSet、AliyunlogConfig 的 CRD 语句和 CRD Controller。安装后可以直接使用DaemonSet采集和CRD配置NS。安装方法如下:
阿里云Kubernetes集群可以通过勾选激活时间来安装,这样在集群创建时会自动安装上述组件。如果激活时没有安装,可以手动安装;如果是自建Kubernetes,无论是在阿里云、其他云还是离线自建,也可以使用这个采集方案,具体安装方法参考自建Kubernetes安装。
安装完以上组件后,Logtail和对应的Controller会在集群中运行,但是这些组件默认不会采集任何日志,需要将日志采集规则配置为采集指定 Pod 的各种日志。
采集规则配置:环境变量或CRD
除了在日志服务控制台手动配置外,Kubernetes 还支持两种额外的配置方式:环境变量和 CRD。
该方法部署简单,学习成本低,易学;但是能支持的配置规则很少,很多高级配置(比如解析方法、过滤方法、黑白名单等)都不支持,而且这种声明方式不支持修改/删除,每次修改实际上创建了一个新的 采集 配置。历史采集配置需要手动清理,否则会造成资源浪费。
比如下面的例子是部署一个容器标准输出采集,其中定义要求Stdout和Stderr都为采集,排除环境变量中收录COLLEXT_STDOUT_FLAG:false的容器。
基于CRD的配置方式采用Kubernetes标准资源扩展的方式进行管理,支持完整的配置增删改语义,支持各种高级配置。这是我们强烈推荐的 采集 配置方法。
采集规则的推荐配置方法
在实际应用场景中,一般使用DaemonSet或者DaemonSet和Sidecar的混合。DaemonSet 的优点是资源利用率高。但是存在DaemonSet的所有Logtail共享全局配置的问题,单个Logtail有配置支持的上限。因此,无法支持具有大量应用程序的集群。
以上是我们推荐的配置方式,核心思想是:
实践1-中小型集群
Kubernetes集群绝大多数都是中小型的,中小型并没有明确的定义。一般申请数量小于500,节点大小小于1000。没有功能明确的Kubernetes平台运维。这个场景的应用数量不是特别多,DaemonSet 可以支持所有的采集配置:
练习 2-大型集群
对于一些作为PaaS平台的大型/超大型集群,一般业务在1000以上,节点规模也在1000以上,有专门的Kubernetes平台运维人员。本场景应用数量没有限制,DaemonSet 无法支持,所以必须使用Sidecar。总体规划如下:
有阿里巴巴团队需要你!
云原生应用平台诚邀Kubernetes/容器/Serverless/应用交付技术专家(P7-P8)加入。
简历投递:xining.zj AT。
“阿里云原生专注于微服务、Serverless、容器、Service Mesh等技术领域,关注云原生流行技术趋势、云原生大规模落地实践,是最了解云原生开发者的技术圈.” 查看全部
采集 采集(6个K8s日志系统建设中的典型问题,你遇到过几个?)
作者 | 元一阿里云存储服务技术专家
简介:上一篇文章主要介绍了Kubernetes日志输出的一些注意事项。日志输出的最终目的是做统一的采集和分析。在 Kubernetes 中,采集 的日志记录方法与普通虚拟机有很大不同。实现的相对难度和部署成本也略高。但是,如果使用得当,它将比传统方法更加自动化且成本更低。本文为文章期刊系列第4篇。
第一篇:《K8s日志系统构建中的6个典型问题,你遇到了几个?》
第二章:《一篇了解K8s日志系统的设计与实践》
第3章:《解决K8s日志输出问题的九个技巧》
Kubernetes 日志 采集 难点
在 Kubernetes 中,日志记录 采集 比传统的虚拟机和物理机复杂得多。最根本的原因是Kubernetes屏蔽了底层的异常,提供更细粒度的资源调度,向上提供稳定动态的环境。所以日志采集面临着更丰富、更动态的环境,需要考虑的点也更多。
例如:
Kubernetes 传统方式
日志类型
文件、标准输出、主机文件、日志
档案、日记
日志来源
业务容器、系统组件、主机
商务、主持人
采集方法
代理(Sidecar、DaemonSet)、直写(DockerEngine、业务)
代理,直接写作
单机应用数量
10-100
1-10
应用动态
高的
低的
节点动态
高的
低的
采集部署方式
手册,Yaml
手动、定制
采集方法:主动或被动
日志的采集方式分为被动采集和主动推送。在K8s中,被动采集一般分为Sidecar和DaemonSet两种方法。主动推送包括DockerEngine推送和业务直推。用两种方式写。

总结一下:
各种采集方法的详细对比如下:
DockerEngine 业务直接写入 DaemonSet 模式 Sidecar 模式
采集日志类型
标准输出
业务日志
标准输出+文件的一部分
文档
部署运维
低,本机支持
低,只需要维护好配置文件
一般需要维护DaemonSet
高,每个需要采集日志的POD都需要部署一个sidecar容器
日志分类存储
达不到
业务独立配置
一般可以通过容器/路径等方式映射。
每个POD可单独配置,灵活性高
多租户隔离
虚弱的
弱,日志直写会与业务逻辑竞争资源
一般只能通过配置室隔离
强,容器隔离,可单独分配资源
支持集群大小
无限本地存储,如果使用syslog、fluentd,会有单点限制
无限
取决于配置的数量
无限
资源占用
低,码头工人
引擎提供
总体最低,节省 采集 开销
下层,每个节点运行一个容器
更高,每个 POD 运行一个容器
查询方便
低,只能grep原创日志
高,可根据业务特点定制
高,可自定义查询统计
高,可根据业务特点定制
可定制
低的
高,可自由扩展
低的
高,每个POD单独配置
耦合
高,与DockerEngine强绑定,修改需要重启DockerEngine
高,采集模块修改/升级需要重新发布业务
低,Agent可独立升级
一般默认采集Sidecar服务对应的Agent升级也会重启(有一些扩展包可以支持Sidecar热升级)
适用场景
非生产场景,例如测试和 POC
对性能要求极高的场景
一个日志分类清晰、功能单一的集群
大规模、混合、PAAS 类型的集群
日志输出:标准输出或文件
与虚拟机/物理机不同,K8s 容器提供标准输出和文件格式。在容器中,标准输出将日志直接输出到stdout或stderr,而DockerEngine接管stdout和stderr文件描述符,接收后根据DockerEngine配置的LogDriver规则对日志进行处理;日志打印到文件和虚拟机/物理机基本相似,只是日志可以使用不同的存储方式,比如默认存储、EmptyDir、HostVolume、NFS等。
虽然Docker官方推荐使用Stdout打印日志,但是大家需要注意:这个推荐是基于容器只作为简单应用的场景。在实际业务场景中,我们仍然建议您尽可能使用文件。主要有以下几点原因:
因此,我们推荐在线应用使用文件输出日志。Stdout 仅用于功能单一的应用或一些 K8s 系统/运维组件。
CICD 集成:日志操作员

Kubernetes 提供了标准化的业务部署方式。您可以使用yaml(K8s API)来声明路由规则、暴露服务、挂载存储、运行业务、定义伸缩规则等,因此Kubernetes很容易与CICD系统集成。日志采集也是运维监控过程的重要组成部分,所有业务上线后的日志都要实时采集。
原来的方法是在发布后手动部署日志采集的逻辑。这种方法需要人工干预,违背了CICD自动化的目的;为了实现自动化,有人开始根据日志打包API/SDK 采集 一个自动部署的服务在发布后通过CICD的webhook调用,但是这种方式的开发成本很高。
在 Kubernetes 中,最标准的日志集成方式是在 Kubernetes 系统中注册一个新的资源,并以 Operator(CRD)的形式对其进行管理和维护。这样CICD系统不需要额外的开发,部署到Kubernetes系统时只需要附加日志相关的配置就可以实现。
Kubernetes 日志采集 方案

早在Kubernetes出现之前,我们就开始针对容器环境开发日志采集解决方案。随着K8s的逐渐稳定,我们开始将很多业务迁移到K8s平台上,所以我们也在之前的基础上开发了一套。K8s 上的日志 采集 方案。主要功能是:
安装日志采集组件
目前,这个采集计划是对公众开放的。我们提供了一个 Helm 安装包,其中包括 Logtail 的 DaemonSet、AliyunlogConfig 的 CRD 语句和 CRD Controller。安装后可以直接使用DaemonSet采集和CRD配置NS。安装方法如下:
阿里云Kubernetes集群可以通过勾选激活时间来安装,这样在集群创建时会自动安装上述组件。如果激活时没有安装,可以手动安装;如果是自建Kubernetes,无论是在阿里云、其他云还是离线自建,也可以使用这个采集方案,具体安装方法参考自建Kubernetes安装。
安装完以上组件后,Logtail和对应的Controller会在集群中运行,但是这些组件默认不会采集任何日志,需要将日志采集规则配置为采集指定 Pod 的各种日志。
采集规则配置:环境变量或CRD
除了在日志服务控制台手动配置外,Kubernetes 还支持两种额外的配置方式:环境变量和 CRD。
该方法部署简单,学习成本低,易学;但是能支持的配置规则很少,很多高级配置(比如解析方法、过滤方法、黑白名单等)都不支持,而且这种声明方式不支持修改/删除,每次修改实际上创建了一个新的 采集 配置。历史采集配置需要手动清理,否则会造成资源浪费。

比如下面的例子是部署一个容器标准输出采集,其中定义要求Stdout和Stderr都为采集,排除环境变量中收录COLLEXT_STDOUT_FLAG:false的容器。
基于CRD的配置方式采用Kubernetes标准资源扩展的方式进行管理,支持完整的配置增删改语义,支持各种高级配置。这是我们强烈推荐的 采集 配置方法。

采集规则的推荐配置方法

在实际应用场景中,一般使用DaemonSet或者DaemonSet和Sidecar的混合。DaemonSet 的优点是资源利用率高。但是存在DaemonSet的所有Logtail共享全局配置的问题,单个Logtail有配置支持的上限。因此,无法支持具有大量应用程序的集群。
以上是我们推荐的配置方式,核心思想是:
实践1-中小型集群

Kubernetes集群绝大多数都是中小型的,中小型并没有明确的定义。一般申请数量小于500,节点大小小于1000。没有功能明确的Kubernetes平台运维。这个场景的应用数量不是特别多,DaemonSet 可以支持所有的采集配置:
练习 2-大型集群

对于一些作为PaaS平台的大型/超大型集群,一般业务在1000以上,节点规模也在1000以上,有专门的Kubernetes平台运维人员。本场景应用数量没有限制,DaemonSet 无法支持,所以必须使用Sidecar。总体规划如下:
有阿里巴巴团队需要你!
云原生应用平台诚邀Kubernetes/容器/Serverless/应用交付技术专家(P7-P8)加入。
简历投递:xining.zj AT。

“阿里云原生专注于微服务、Serverless、容器、Service Mesh等技术领域,关注云原生流行技术趋势、云原生大规模落地实践,是最了解云原生开发者的技术圈.”
采集(网络信息采集指可以将因特网上的网站采集保存到用户的本地数据库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 245 次浏览 • 2021-10-05 19:15
网络信息采集是指可以将Internet上的网站信息采集保存在用户的本地数据库中。它具有以下功能: 规则定义——通过采集规则的定义,可以搜索到几乎所有的网站采集信息。多任务,多线程-多信息采集任务可以同时执行,每个任务可以使用多个线程。所见即所得——所见即所得,在任务采集过程中得到。过程中遍历的链接信息、采集信息、错误信息等都会及时反映在软件界面中。数据存储——数据在采集的同时自动保存到关系数据库中,数据结构可以自动适配。软件可以根据采集的规则自动创建数据库,以及里面的表和字段,也可以灵活设置将数据保存到客户现有的数据库结构中,所有这些都不会对您的数据库和生产造成任何不利影响。Breakpoint Resuming-Information 采集 任务可以在停止采集后从断点继续。从此,您再也不用担心您的采集 任务会被意外中断。网站Login-支持网站登录,并支持网站Cookie,即使需要验证登录,网站也能轻松通过。自动信息识别-提供多种预定义的信息类型,如Email地址、电话号码、号码等。用户可以通过简单的选择,从海量的网络信息中提取特定的信息。文件下载-您可以从采集下载二进制文件(如图片、音乐、软件、文档等)到本地磁盘或采集结果数据库。采集结果分类-可以根据用户定义的分类信息自动对采集结果进行分类。 查看全部
采集(网络信息采集指可以将因特网上的网站采集保存到用户的本地数据库)
网络信息采集是指可以将Internet上的网站信息采集保存在用户的本地数据库中。它具有以下功能: 规则定义——通过采集规则的定义,可以搜索到几乎所有的网站采集信息。多任务,多线程-多信息采集任务可以同时执行,每个任务可以使用多个线程。所见即所得——所见即所得,在任务采集过程中得到。过程中遍历的链接信息、采集信息、错误信息等都会及时反映在软件界面中。数据存储——数据在采集的同时自动保存到关系数据库中,数据结构可以自动适配。软件可以根据采集的规则自动创建数据库,以及里面的表和字段,也可以灵活设置将数据保存到客户现有的数据库结构中,所有这些都不会对您的数据库和生产造成任何不利影响。Breakpoint Resuming-Information 采集 任务可以在停止采集后从断点继续。从此,您再也不用担心您的采集 任务会被意外中断。网站Login-支持网站登录,并支持网站Cookie,即使需要验证登录,网站也能轻松通过。自动信息识别-提供多种预定义的信息类型,如Email地址、电话号码、号码等。用户可以通过简单的选择,从海量的网络信息中提取特定的信息。文件下载-您可以从采集下载二进制文件(如图片、音乐、软件、文档等)到本地磁盘或采集结果数据库。采集结果分类-可以根据用户定义的分类信息自动对采集结果进行分类。
采集( 云捕获客源采集软件的特点及开发方法介绍-苏州安嘉)
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-08-29 22:09
云捕获客源采集软件的特点及开发方法介绍-苏州安嘉)
客户source采集软件操作简单,不懂技术也能轻松操作。只需输入列表页面的 URL 或关键字即可开始采集。无需关心Web源代码,全程鼠标操作。操作界面友好直观。全程智能帮助。功能齐全,功能强大 该软件虽然操作简单,但功能强大,功能全面。可以实现各种复杂的采集需求。多功能采集软件,可用于各种应用。
客户source采集software 可以采集任何网页。只要你能在浏览器中看到内容,几乎所有的网页都可以采集到你需要的格式。
支持JS输出内容的采集。快速采集速度和高数据完整性优采云采集器速度是采集软件中最快的速度之一。
独特的多模板功能+智能纠错模式,保证结果数据100%完整。
Keyuan采集software 具有以下特点:
一键获取
客户source采集software输入获取portal网站URL即可完成并开始采集,输入关键词搜索获取全网。
云捕获
Keyuan采集software。独有的基于点对点网络架构的云端采集功能,解决采集IP封存的行业难题。
多模板自适应
项目可以配置多个模板,运行时软件会自动选择最适合采集匹配的模块。
多功能仿真发布
无需开发针对性发布接口文件,适配任何网站cms后台,使用手动发布页面模拟手动发布。
内容相似度判断基于内容相似度来判断文章的重复性,准确率高。
可以列出相似的文章并输出文章的核心关键字。客户源采集软件可以帮您采集获取您想要的客户电话等信息,相当于一个电话采集软件。
支持复杂的数据关系,支持父子结构的数据逻辑关系。
复杂数据,采集一次完成,采集结果保留原创数据的逻辑关系。 查看全部
采集(
云捕获客源采集软件的特点及开发方法介绍-苏州安嘉)

客户source采集软件操作简单,不懂技术也能轻松操作。只需输入列表页面的 URL 或关键字即可开始采集。无需关心Web源代码,全程鼠标操作。操作界面友好直观。全程智能帮助。功能齐全,功能强大 该软件虽然操作简单,但功能强大,功能全面。可以实现各种复杂的采集需求。多功能采集软件,可用于各种应用。
客户source采集software 可以采集任何网页。只要你能在浏览器中看到内容,几乎所有的网页都可以采集到你需要的格式。
支持JS输出内容的采集。快速采集速度和高数据完整性优采云采集器速度是采集软件中最快的速度之一。
独特的多模板功能+智能纠错模式,保证结果数据100%完整。
Keyuan采集software 具有以下特点:
一键获取
客户source采集software输入获取portal网站URL即可完成并开始采集,输入关键词搜索获取全网。
云捕获
Keyuan采集software。独有的基于点对点网络架构的云端采集功能,解决采集IP封存的行业难题。
多模板自适应
项目可以配置多个模板,运行时软件会自动选择最适合采集匹配的模块。
多功能仿真发布
无需开发针对性发布接口文件,适配任何网站cms后台,使用手动发布页面模拟手动发布。
内容相似度判断基于内容相似度来判断文章的重复性,准确率高。
可以列出相似的文章并输出文章的核心关键字。客户源采集软件可以帮您采集获取您想要的客户电话等信息,相当于一个电话采集软件。
支持复杂的数据关系,支持父子结构的数据逻辑关系。
复杂数据,采集一次完成,采集结果保留原创数据的逻辑关系。
采集( 天目MVC采集程序伪静态版安装地址)
采集交流 • 优采云 发表了文章 • 0 个评论 • 269 次浏览 • 2021-08-29 22:08
天目MVC采集程序伪静态版安装地址)
天木MVC采集plugin v2.03 日期:2021/4/16 8:59:15
小偷采集|共享版本 |大小:27KB |环境:PHP/Mysql |人气:757
天牧MVC采集插件依赖天牧MVC网站管理系统或天牧MVC网站管理系统首页版本运行下载上述任一版本,然后将此子插件复制到应用程序/插件/目录。上述程序安装完毕后,进入后台网站settings-plugin管理进行安装。 ...
随风PHP百度自动问答采集(免维护)v10.8 日期:2021/3/25 8:59:55
小偷采集|试用版 |大小:5.37MB |环境:Linux/PHP/Mysql |人气:1193
随峰PHP问答采集云版使用THINKPHP框架,PHP语言开发,支持LINUX、WINDOWS环境,不用数据库也能正常运行。服务器、虚拟主机和 VPS 都可以运行。如果需要伪静态,则需要空间或服务器支持伪静态。此外,目前还有一些...
大全洲人才网全站采集程序假静版v1.4 日期:2021/2/19 10:17:12
小偷采集 |开源软件 |大小:17KB |环境:PHP |人气:42
大泉州人才网全站采集program 伪静态版是利用最新技术,用几个K文件获取泉州人才网全站海量数据的文档(有上万名企业会员)和超过 100,000 个招聘数据))。轻巧,方便,但功能强大。文件说明:index.php--主站程序m.php--移动版...
大全洲人才网网站采集程序 v1.4 日期:1/28/2021 8:55:20
小偷采集 |开源软件 |大小:15KB |环境:PHP |人气:364
大泉州人才网采集程序是一个利用最新技术,用几个K文件获取泉州人才网海量数据(企业会员数万,招聘数据超10万条)采集的程序@网站系统。轻巧,方便,但功能强大。注:1.必须改index.php、news.php...
优采云采集器 v2.3.3 日期:2020/7/28 13:38:06
小偷采集|免费版 |大小:8.11MB |环境:PHP/Mysql |人气:16222
优采云采集器是一款免费的数据发布软件采集,可以部署在云服务器上,几乎可以采集所有类型的网页,无缝对接各种cms建站程序,无需登录 实时发布数据,软件实现定时定量自动采集发布,无需人工干预!大数据、云时代网站数...
通用镜像系统 v6.21 Date: 2020/1/13 9:49:24
小偷采集|共享版本 |大小:560KB |环境:PHP |人气:11602
万能镜像系统可通过输入目标站地址全自动采集,高智能采集程序,支持子域名自动采集,支持站点高达98%。规则制作非常简单,新手也可以制作。 采集rule,采集不求人-ftp上传需要使用二进制上传方式,请百度-数据正文...
网站publication network (release number) v2.0 日期:2019/9/2 9:26:58
小偷采集|共享版本 |大小:118KB |环境:PHP |人气:803
几个文件,一下子有很多新闻,新闻不时更新,大图,快,下个版本会采集JSON无限加载,几乎整个网站采集都过来了已添加图片加载以改善用户体验。更改说明:LOGO:images/logo.png右侧浮动广告:right.html网站common bottom:foot.ht...
隋峰百度经验采集系统 v1.0 日期:2019/5/15 11:21:15
小偷采集|共享版本 |大小:1.26MB |环境:PHP |人气:431
安装说明,“此版本为测试版,如有需要请联系作者qq” 本程序使用PHP大于5.3(包括5.3)用THINKPHP框架PHP语言编写,安装时不加使用数据库,直接将源码转移到支持PHP语言的空间或服务器,运行index.php即可,以上配置完成...
隋峰百度知道(thief采集)免维护v2.0.0X 日期:2018/7/13 10:47:33
小偷采集|试用版 |大小:13KB |环境:PHP/MSSQL |人气:4210
随风百度知道(thief采集)免维护自动采集百度信息。软件介绍:1、可自定义关键词2、无需人工输入信息,自动系统采集3、支持缓存,减少服务器资源。 (本程序需要安装伪静态插件)有不懂的请联系QQ。当前版本是测试版,购买商业版...
通用简单api接口 v0.1 Date: 2018/5/11 10:42:41
小偷采集 |共享版本 |大小:1KB |环境:PHP |人气:1348
功能介绍:1.api.php放置在需要实现api功能的站点中,调用数据库信息,生成json2.client.php文件放置在站点文件中即需要调用api,解析api.php生成的json实现远程调用api的功能。 查看全部
采集(
天目MVC采集程序伪静态版安装地址)

天木MVC采集plugin v2.03 日期:2021/4/16 8:59:15
小偷采集|共享版本 |大小:27KB |环境:PHP/Mysql |人气:757
天牧MVC采集插件依赖天牧MVC网站管理系统或天牧MVC网站管理系统首页版本运行下载上述任一版本,然后将此子插件复制到应用程序/插件/目录。上述程序安装完毕后,进入后台网站settings-plugin管理进行安装。 ...
随风PHP百度自动问答采集(免维护)v10.8 日期:2021/3/25 8:59:55
小偷采集|试用版 |大小:5.37MB |环境:Linux/PHP/Mysql |人气:1193
随峰PHP问答采集云版使用THINKPHP框架,PHP语言开发,支持LINUX、WINDOWS环境,不用数据库也能正常运行。服务器、虚拟主机和 VPS 都可以运行。如果需要伪静态,则需要空间或服务器支持伪静态。此外,目前还有一些...
大全洲人才网全站采集程序假静版v1.4 日期:2021/2/19 10:17:12
小偷采集 |开源软件 |大小:17KB |环境:PHP |人气:42
大泉州人才网全站采集program 伪静态版是利用最新技术,用几个K文件获取泉州人才网全站海量数据的文档(有上万名企业会员)和超过 100,000 个招聘数据))。轻巧,方便,但功能强大。文件说明:index.php--主站程序m.php--移动版...
大全洲人才网网站采集程序 v1.4 日期:1/28/2021 8:55:20
小偷采集 |开源软件 |大小:15KB |环境:PHP |人气:364
大泉州人才网采集程序是一个利用最新技术,用几个K文件获取泉州人才网海量数据(企业会员数万,招聘数据超10万条)采集的程序@网站系统。轻巧,方便,但功能强大。注:1.必须改index.php、news.php...
优采云采集器 v2.3.3 日期:2020/7/28 13:38:06
小偷采集|免费版 |大小:8.11MB |环境:PHP/Mysql |人气:16222
优采云采集器是一款免费的数据发布软件采集,可以部署在云服务器上,几乎可以采集所有类型的网页,无缝对接各种cms建站程序,无需登录 实时发布数据,软件实现定时定量自动采集发布,无需人工干预!大数据、云时代网站数...
通用镜像系统 v6.21 Date: 2020/1/13 9:49:24
小偷采集|共享版本 |大小:560KB |环境:PHP |人气:11602
万能镜像系统可通过输入目标站地址全自动采集,高智能采集程序,支持子域名自动采集,支持站点高达98%。规则制作非常简单,新手也可以制作。 采集rule,采集不求人-ftp上传需要使用二进制上传方式,请百度-数据正文...
网站publication network (release number) v2.0 日期:2019/9/2 9:26:58
小偷采集|共享版本 |大小:118KB |环境:PHP |人气:803
几个文件,一下子有很多新闻,新闻不时更新,大图,快,下个版本会采集JSON无限加载,几乎整个网站采集都过来了已添加图片加载以改善用户体验。更改说明:LOGO:images/logo.png右侧浮动广告:right.html网站common bottom:foot.ht...
隋峰百度经验采集系统 v1.0 日期:2019/5/15 11:21:15
小偷采集|共享版本 |大小:1.26MB |环境:PHP |人气:431
安装说明,“此版本为测试版,如有需要请联系作者qq” 本程序使用PHP大于5.3(包括5.3)用THINKPHP框架PHP语言编写,安装时不加使用数据库,直接将源码转移到支持PHP语言的空间或服务器,运行index.php即可,以上配置完成...
隋峰百度知道(thief采集)免维护v2.0.0X 日期:2018/7/13 10:47:33
小偷采集|试用版 |大小:13KB |环境:PHP/MSSQL |人气:4210
随风百度知道(thief采集)免维护自动采集百度信息。软件介绍:1、可自定义关键词2、无需人工输入信息,自动系统采集3、支持缓存,减少服务器资源。 (本程序需要安装伪静态插件)有不懂的请联系QQ。当前版本是测试版,购买商业版...
通用简单api接口 v0.1 Date: 2018/5/11 10:42:41
小偷采集 |共享版本 |大小:1KB |环境:PHP |人气:1348
功能介绍:1.api.php放置在需要实现api功能的站点中,调用数据库信息,生成json2.client.php文件放置在站点文件中即需要调用api,解析api.php生成的json实现远程调用api的功能。
采集 采集《python进阶》教程网页:多页面url获取问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-08-25 20:50
首次发布于:
前言
我将主要使用python和爬虫技术。入门级项目简单,适合新手练手。阅读本文之前最好对python和爬虫有一定的了解。
要求
需求名称:采集"python进阶"教程
网页:
要求:采集网页上的所有高级内容,并整理成文档
采集具体进阶教程内容就够了
需求分析
让我们来看看要求。需要采集的东西并不多。我们打开网页看看。
看目录,数据量不是很多
粗略统计,有几十页,很少
对应需求,根据经验,列出一些我们需要解决的问题
单页爬取问题多页url获取问题整理成文档单页爬取问题
这道题其实是看爬取页面的请求结构
我们先看看源码中是否收录我们需要的数据
在页面上找一个稍微特殊的词
例如“小鲜肉”
在键盘上按 ctrl+U 查看源代码
按ctrl+F搜索“小鲜”
可以看到,我们需要的数据直接在源码中,所以可以判断这8个成就是一个get请求
如果没有防爬,会更轻松
尝试直接构建最简单的get请求
import requests
r = requests.get('https://docs.pythontab.com/interpy/')
print(r.text)
print(r)
运行一下,打印出来的就是我们需要的数据(因为太多没有贴出来),完美!
多页网址获取问题
我们可以看到几十个需要采集的页面,并不多。在需求目标方面,我们其实可以一个一个的复制,但是这种方式没有技术范围,如果我们采集的页面很多,成百上千,甚至几十万。人工抄写效率太低
我们打开网页
你可以看到有一个下一步按钮
查看全部
采集 采集《python进阶》教程网页:多页面url获取问题
首次发布于:
前言
我将主要使用python和爬虫技术。入门级项目简单,适合新手练手。阅读本文之前最好对python和爬虫有一定的了解。
要求
需求名称:采集"python进阶"教程
网页:
要求:采集网页上的所有高级内容,并整理成文档
采集具体进阶教程内容就够了

需求分析
让我们来看看要求。需要采集的东西并不多。我们打开网页看看。

看目录,数据量不是很多
粗略统计,有几十页,很少
对应需求,根据经验,列出一些我们需要解决的问题
单页爬取问题多页url获取问题整理成文档单页爬取问题
这道题其实是看爬取页面的请求结构
我们先看看源码中是否收录我们需要的数据
在页面上找一个稍微特殊的词

例如“小鲜肉”
在键盘上按 ctrl+U 查看源代码
按ctrl+F搜索“小鲜”

可以看到,我们需要的数据直接在源码中,所以可以判断这8个成就是一个get请求
如果没有防爬,会更轻松
尝试直接构建最简单的get请求
import requests
r = requests.get('https://docs.pythontab.com/interpy/')
print(r.text)
print(r)
运行一下,打印出来的就是我们需要的数据(因为太多没有贴出来),完美!
多页网址获取问题
我们可以看到几十个需要采集的页面,并不多。在需求目标方面,我们其实可以一个一个的复制,但是这种方式没有技术范围,如果我们采集的页面很多,成百上千,甚至几十万。人工抄写效率太低
我们打开网页
你可以看到有一个下一步按钮

采集 采集《python进阶》教程网页:多页面url获取问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-08-24 07:45
首次发布于:
前言
我将主要使用python和爬虫技术。入门级项目简单,适合新手练手。阅读本文之前最好对python和爬虫有一定的了解。
要求
需求名称:采集"python进阶"教程
网页:
要求:采集网页上的所有高级内容,并整理成文档
采集具体进阶教程内容就够了
需求分析
让我们来看看要求。需要采集的东西并不多。我们打开网页看看。
看目录,数据量不是很多
粗略统计,有几十页,很少
对应需求,根据经验,列出一些我们需要解决的问题
单页爬取问题多页url获取问题整理成文档单页爬取问题
这道题其实是看爬取页面的请求结构
我们先看看源码中是否收录我们需要的数据
在页面上找一个稍微特殊的词
例如“小鲜肉”
在键盘上按 ctrl+U 查看源代码
按ctrl+F搜索“小鲜”
可以看到,我们需要的数据直接在源码中,所以可以判断这8个成就是一个get请求
如果没有防爬,会更轻松
尝试直接构建最简单的get请求
import requests
r = requests.get('https://docs.pythontab.com/interpy/')
print(r.text)
print(r)
运行一下,打印出来的就是我们需要的数据(因为太多没有贴出来),完美!
多页网址获取问题
我们可以看到几十个需要采集的页面,并不多。在需求目标方面,我们其实可以一个一个的复制,但是这种方式没有技术范围,如果我们采集的页面很多,几十万,甚至几十万。人工抄写效率太低
我们打开网页
你可以看到有一个下一步按钮
查看全部
采集 采集《python进阶》教程网页:多页面url获取问题
首次发布于:
前言
我将主要使用python和爬虫技术。入门级项目简单,适合新手练手。阅读本文之前最好对python和爬虫有一定的了解。
要求
需求名称:采集"python进阶"教程
网页:
要求:采集网页上的所有高级内容,并整理成文档
采集具体进阶教程内容就够了
需求分析
让我们来看看要求。需要采集的东西并不多。我们打开网页看看。

看目录,数据量不是很多
粗略统计,有几十页,很少
对应需求,根据经验,列出一些我们需要解决的问题
单页爬取问题多页url获取问题整理成文档单页爬取问题
这道题其实是看爬取页面的请求结构
我们先看看源码中是否收录我们需要的数据
在页面上找一个稍微特殊的词

例如“小鲜肉”
在键盘上按 ctrl+U 查看源代码
按ctrl+F搜索“小鲜”

可以看到,我们需要的数据直接在源码中,所以可以判断这8个成就是一个get请求
如果没有防爬,会更轻松
尝试直接构建最简单的get请求
import requests
r = requests.get('https://docs.pythontab.com/interpy/')
print(r.text)
print(r)
运行一下,打印出来的就是我们需要的数据(因为太多没有贴出来),完美!
多页网址获取问题
我们可以看到几十个需要采集的页面,并不多。在需求目标方面,我们其实可以一个一个的复制,但是这种方式没有技术范围,如果我们采集的页面很多,几十万,甚至几十万。人工抄写效率太低
我们打开网页
你可以看到有一个下一步按钮
网络数据/信息挖掘软件《优采云采集器》9.8正式版下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-08-09 20:23
标签:采集器
51下载网提供功能强大的网络数据/信息挖掘软件《优采云采集器》9.8官方版下载,软件为免费软件,文件大小24.63 MB,推荐指数3星星,作为国产软件的顶级厂商,你可以放心下载!
优采云采集器()是一款专业强大的网络数据/信息挖掘软件。通过灵活配置,可以轻松抓取文字、图片、文件等任何资源,程序支持图片文件远程下载,支持网站post-login信息采集,支持文件真实地址检测,支持代理,支持采集防盗链,支持采集直接数据存储和模仿人手动发布等诸多功能。
主要功能
1、rule定制——通过采集rules的定义,可以搜索到网站采集几乎所有类型的信息
2、Multitasking,多线程-多信息采集任务可以同时执行,每个任务可以使用多个线程
3、所见即所得-任务采集process所见即所得。过程中遍历的链接信息、采集信息、错误信息等会及时反映在软件界面中。
4、Data Storage-Data Edge 采集边自动保存在关系型数据库中,自动适配数据结构。软件可以根据采集规则自动创建数据库,以及其中的表和字段,或者通过引导数据库的方式灵活地将数据保存在客户现有的数据库结构中
5、断点再采-信息采集任务停止后可以从断点继续采集,以后你再也不用担心你的采集任务被意外中断了
6、网站Login-支持网站Cookie,支持网站可视化登录,即使网站登录需要验证码也可以采集
7、Scheduled tasks-这个功能可以让你的采集任务有规律的、定量的或者一直循环执行
8、采集范围限制-采集的范围可以根据采集的深度和URL的标识进行限制
9、File Download-采集收到的二进制文件(如图片、音乐、软件、文档等)可以下载到本地磁盘或采集result数据库
10、Result 替换-可以将采集的结果替换成你按照规则定义的内容
11、条件保存-可以根据一定条件决定保存哪些信息,过滤哪些信息
12、过滤重复内容-软件可以根据用户设置和实际情况自动删除重复内容和重复网址
13、特殊链接识别-使用此功能识别由JavaScript动态生成的链接或其他奇怪链接
14、数据发布-您可以通过自定义接口将采集的结果数据发布到任何内容管理系统和指定的数据库。目前支持的目标发布媒体包括:数据库(access、sql server、my sql、oracle)、静态htm文件
15、预留编程接口-定义多个编程接口,用户可在活动中使用PHP、C#语言编程,扩展采集功能
软件功能
1、 通用性强:无论新闻、论坛、视频、黄页、图片、下载网站,只要是浏览器可以看到的结构化内容,通过指定匹配规则,就可以采集你所需要的
2、稳定高效:五年磨一剑,软件不断更新完善,采集速度快,性能稳定,占用资源少
3、是可扩展的,应用范围很广:自定义网页发布、主流数据库的自定义存储和发布、自定义本地PHP和. net外部编程接口对数据进行处理,使数据可供您使用
4、支持网站所有编码:完美支持采集所有网页编码格式,程序还能自动识别网页编码
5、多种发布方式:支持当前所有主流和非主流cms、BBS等网站节目,通过系统发布可以实现采集器和网站节目的完美结合模块
6、Full-auto:无人值守工作,配置程序后,程序会根据您的设置自动运行,完全无需人工干预。 查看全部
网络数据/信息挖掘软件《优采云采集器》9.8正式版下载
标签:采集器
51下载网提供功能强大的网络数据/信息挖掘软件《优采云采集器》9.8官方版下载,软件为免费软件,文件大小24.63 MB,推荐指数3星星,作为国产软件的顶级厂商,你可以放心下载!
优采云采集器()是一款专业强大的网络数据/信息挖掘软件。通过灵活配置,可以轻松抓取文字、图片、文件等任何资源,程序支持图片文件远程下载,支持网站post-login信息采集,支持文件真实地址检测,支持代理,支持采集防盗链,支持采集直接数据存储和模仿人手动发布等诸多功能。

主要功能
1、rule定制——通过采集rules的定义,可以搜索到网站采集几乎所有类型的信息
2、Multitasking,多线程-多信息采集任务可以同时执行,每个任务可以使用多个线程
3、所见即所得-任务采集process所见即所得。过程中遍历的链接信息、采集信息、错误信息等会及时反映在软件界面中。
4、Data Storage-Data Edge 采集边自动保存在关系型数据库中,自动适配数据结构。软件可以根据采集规则自动创建数据库,以及其中的表和字段,或者通过引导数据库的方式灵活地将数据保存在客户现有的数据库结构中
5、断点再采-信息采集任务停止后可以从断点继续采集,以后你再也不用担心你的采集任务被意外中断了
6、网站Login-支持网站Cookie,支持网站可视化登录,即使网站登录需要验证码也可以采集
7、Scheduled tasks-这个功能可以让你的采集任务有规律的、定量的或者一直循环执行
8、采集范围限制-采集的范围可以根据采集的深度和URL的标识进行限制
9、File Download-采集收到的二进制文件(如图片、音乐、软件、文档等)可以下载到本地磁盘或采集result数据库
10、Result 替换-可以将采集的结果替换成你按照规则定义的内容
11、条件保存-可以根据一定条件决定保存哪些信息,过滤哪些信息
12、过滤重复内容-软件可以根据用户设置和实际情况自动删除重复内容和重复网址
13、特殊链接识别-使用此功能识别由JavaScript动态生成的链接或其他奇怪链接
14、数据发布-您可以通过自定义接口将采集的结果数据发布到任何内容管理系统和指定的数据库。目前支持的目标发布媒体包括:数据库(access、sql server、my sql、oracle)、静态htm文件
15、预留编程接口-定义多个编程接口,用户可在活动中使用PHP、C#语言编程,扩展采集功能
软件功能
1、 通用性强:无论新闻、论坛、视频、黄页、图片、下载网站,只要是浏览器可以看到的结构化内容,通过指定匹配规则,就可以采集你所需要的
2、稳定高效:五年磨一剑,软件不断更新完善,采集速度快,性能稳定,占用资源少
3、是可扩展的,应用范围很广:自定义网页发布、主流数据库的自定义存储和发布、自定义本地PHP和. net外部编程接口对数据进行处理,使数据可供您使用
4、支持网站所有编码:完美支持采集所有网页编码格式,程序还能自动识别网页编码
5、多种发布方式:支持当前所有主流和非主流cms、BBS等网站节目,通过系统发布可以实现采集器和网站节目的完美结合模块
6、Full-auto:无人值守工作,配置程序后,程序会根据您的设置自动运行,完全无需人工干预。
采集 什么是全埋点?什么样的数据适合你?
采集交流 • 优采云 发表了文章 • 0 个评论 • 576 次浏览 • 2021-07-06 23:36
本文约4000字,阅读本文约需15分钟。
1.代码埋点和全埋点的区别
▍1.1 代码埋点
代码埋点,顾名思义,每一个埋点都需要开发和编写。代码埋点是侵入性的,需要工程师为每个需要埋点的位置做点。
▍1.2 所有埋点
全埋点,又称无埋点。只要在应用中集成了全埋点SDK,全埋点SDK会做应用采集中的所有数据。
它们不是替代关系,而是互补关系,以满足不同场景的需求。代码被埋了,上线后才发现被埋了。我应该怎么办?看一下全埋点的数据。虽然没有那么多维度,但总比没有好。因为采集数量充足,在APP中查看用户行为路径、流量趋势等也很方便。
我认为在重视数据的公司中,代码嵌入是必不可少的,全嵌入是锦上添花。下面几页主要讲解代码嵌入SDK。
2.评估SDK优劣的标准是什么?
从企业战略来看,无论是传统企业需要进行数字化转型,还是创业公司需要成为数据驱动的精细化运营,用户行为数据采集只是其中的一小部分数据策略。因此,嵌入式SDK应设计得尽可能简单易用,做到数据易采集,采集接收到的数据易使用。让采集数据成为公司数据驱动的助推器而非阻力。
首先,您应该关注嵌入代码的 SDK 的用户。如果用户对代码感到满意,并且用户也感到满意,则可以认为该 SDK 做得很好。用户是谁?他们关心什么?
采集SDK 的用户是谁:前端和客户端开发、服务端开发、数据测试、大数据团队。
埋点开发者(h5、小程序、iOS、Android开发):
测试埋点的人(数据测试)
接收埋藏数据的人(大数据团队)
一个代码嵌入SDK,满足以上用户需求,可以打95分,也可以在实际业务中应用。
3.代码埋点SDK架构
▍3.1 SDK整体架构
采集数据是否完整、准确、及时,能否连通,直接影响到公司整个数据平台的应用效果。因此,代码嵌入SDK需要一个良好的架构来保证数据的采集。
从SDK的整体设计开始,这部分将分别讲解SDK中的关键模块
1.代码埋点和全埋点的区别
▍1.1 代码埋点
代码埋点,顾名思义,每一个埋点都需要开发和编写。代码埋点是侵入性的,需要工程师为每个需要埋点的位置做点。
▍1.2 所有埋点
全埋点,又称无埋点。只要在应用中集成了全埋点SDK,全埋点SDK会做应用采集中的所有数据。
它们不是替代关系,而是互补关系,以满足不同场景的需求。代码被埋了,上线后才发现被埋了。我应该怎么办?看一下全埋点的数据。虽然没有那么多维度,但总比没有好。因为采集数量充足,在APP中查看用户行为路径、流量趋势等也很方便。
我认为在重视数据的公司中,代码嵌入是必不可少的,全嵌入是锦上添花。下面几页主要讲解代码嵌入SDK。
2.评估SDK优劣的标准是什么?
从企业战略来看,无论是传统企业需要进行数字化转型,还是创业公司需要成为数据驱动的精细化运营,用户行为数据采集只是其中的一小部分数据策略。因此,嵌入式SDK应设计得尽可能简单易用,做到数据易采集,采集接收到的数据易使用。让采集数据成为公司数据驱动的助推器而非阻力。
首先,您应该关注嵌入代码的 SDK 的用户。如果用户对代码感到满意,并且用户也感到满意,则可以认为该 SDK 做得很好。用户是谁?他们关心什么?
采集SDK 的用户是谁:前端和客户端开发、服务端开发、数据测试、大数据团队。
埋点开发者(h5、小程序、iOS、Android开发):
测试埋点的人(数据测试)
接收埋藏数据的人(大数据团队)
一个代码嵌入SDK,满足以上用户需求,可以打95分,也可以在实际业务中应用。
3.代码埋点SDK架构
▍3.1 SDK整体架构
采集数据是否完整、准确、及时,能否连通,直接影响到公司整个数据平台的应用效果。因此,代码嵌入SDK需要一个良好的架构来保证数据的采集。
从SDK的整体设计开始,这部分将分别讲解SDK中的关键模块
▍3.2 SDK采集数据流
对于SDK来说,数据采集是在用户行为被触发时,根据事件模型的数据格式将用户行为发送到服务器。下面结合APP数据上报流程图说明SDK采集data流程。
▍3.3 初始化模块
▍3.4 data采集module
代码被埋没了。 SDK初始化后,SDK提供采集相关接口。开发调用SDK提供的采集接口,将采集事件名称、变量字段等保存在本地,然后按照一定的策略将数据发送到目标数据服务器。 (或直接发送)
代码埋点采集SDK 可以提供以下能力:
▍3.5 数据存储模块
数据存储模块是对埋点数据进行缓存,常见的存储方式有以下几种:
▍3.6 数据发送模块
数据发送模块负责将缓存的数据准确发送到服务器。
说完代码嵌入SDK的整体结构,我们来说说需要重点关注的几个部分:
4. 事件模型
▍4.1 事件模型数据结构
事件模型的本质是用标准化的语言来描述用户行为,即将具体的、丰富多样的用户行为抽象为一个数据模型;
实际上,事件模型很容易理解。我们可以用生活中的例子来类比来理解。你如何向别人描述你在生活中的行为?比如,我会说,我昨晚20:20在我家门口的快递站取了快递。这是描述行为的典型方式。在应用中使用这种描述行为的方法跟踪用户行为就是嵌入点中的事件模型。
事件模型 4W1H 意味着:用户在特定时间点(何时)、某处(何处)以特定方式(如何)完成特定操作(什么)。
一般包括哪些类型的事件:
这些组合可以覆盖用户在应用中99%的用户行为
▍4.2 预设变量
在描述事件时,有些信息是通用的,每次都需要携带。我们可以一次性将这些信息封装在SDK中,这样就不用每次埋点都重复工作了。在事件模型中,我们将这些预设变量放在一个JSON中,即default_variable字段。
▍4.3 事件变量
同样,在描述事件时,有些信息是个性化的,即根据具体业务不同,需要携带的信息也不同。比如商品详情页需要携带商品信息,社区Feed曝光需要携带帖子信息。不是这种情况。每次埋藏代码时,都不可避免地需要开发和携带特定的业务信息。在事件模型中,因为字段是不确定的,所以不管业务变量是什么,业务信息都放在一个JSON中。
5. 如何有效降低数据漏报率?
▍5.1 H5数据通过APP发送
由于用户终端的怪异操作,用户,以及各种无法提前预知的特殊情况,要求100%的埋点不漏点是不现实的。行业内APP误报率在1%左右,H5漏报率在5%左右。
APP可以制定缓存和上报策略,漏报率远低于H5。
APP漏报率为1%,h5漏报率为5%。为了最大程度的避免漏报,大家可以想到一个方法:对于混合应用,我们可以在h5页面里面嵌入一些数据。发送到APP SDK后,经过APP的缓存和上报策略,混合APP中h5页面嵌入点数据的误报率可以从5%降低到1%。
怎么做,主要考虑两点:
▍5.2 APP作为缓存和发送策略
这部分在SDK的数据发送模块中已经介绍过了,不再赘述,简单说一下具体的策略:
满足以上三个发送条件中的任何一个都可以发送数据。
如果数据发送不成功,发送的数据会被保存,满足发送条件后,会尝试与后续数据一起发送。这样可以减少网络请求,节省服务器资源,有效减少发送过程中的一些数据丢失问题。
6. 用户 ID 映射问题
在现实世界中,我们使用身份证来准确识别一个人。在网络世界中,我们应该用什么来识别用户?常用方法存在一些问题:
这需要一个非常系统的方法来识别用户(扩展中不能控制字数,文章稍后更新id-mapping问题,记得关注我) 查看全部
采集 什么是全埋点?什么样的数据适合你?
本文约4000字,阅读本文约需15分钟。
1.代码埋点和全埋点的区别
▍1.1 代码埋点
代码埋点,顾名思义,每一个埋点都需要开发和编写。代码埋点是侵入性的,需要工程师为每个需要埋点的位置做点。
▍1.2 所有埋点
全埋点,又称无埋点。只要在应用中集成了全埋点SDK,全埋点SDK会做应用采集中的所有数据。
它们不是替代关系,而是互补关系,以满足不同场景的需求。代码被埋了,上线后才发现被埋了。我应该怎么办?看一下全埋点的数据。虽然没有那么多维度,但总比没有好。因为采集数量充足,在APP中查看用户行为路径、流量趋势等也很方便。
我认为在重视数据的公司中,代码嵌入是必不可少的,全嵌入是锦上添花。下面几页主要讲解代码嵌入SDK。
2.评估SDK优劣的标准是什么?
从企业战略来看,无论是传统企业需要进行数字化转型,还是创业公司需要成为数据驱动的精细化运营,用户行为数据采集只是其中的一小部分数据策略。因此,嵌入式SDK应设计得尽可能简单易用,做到数据易采集,采集接收到的数据易使用。让采集数据成为公司数据驱动的助推器而非阻力。
首先,您应该关注嵌入代码的 SDK 的用户。如果用户对代码感到满意,并且用户也感到满意,则可以认为该 SDK 做得很好。用户是谁?他们关心什么?
采集SDK 的用户是谁:前端和客户端开发、服务端开发、数据测试、大数据团队。
埋点开发者(h5、小程序、iOS、Android开发):
测试埋点的人(数据测试)
接收埋藏数据的人(大数据团队)
一个代码嵌入SDK,满足以上用户需求,可以打95分,也可以在实际业务中应用。
3.代码埋点SDK架构
▍3.1 SDK整体架构
采集数据是否完整、准确、及时,能否连通,直接影响到公司整个数据平台的应用效果。因此,代码嵌入SDK需要一个良好的架构来保证数据的采集。
从SDK的整体设计开始,这部分将分别讲解SDK中的关键模块
1.代码埋点和全埋点的区别
▍1.1 代码埋点
代码埋点,顾名思义,每一个埋点都需要开发和编写。代码埋点是侵入性的,需要工程师为每个需要埋点的位置做点。
▍1.2 所有埋点
全埋点,又称无埋点。只要在应用中集成了全埋点SDK,全埋点SDK会做应用采集中的所有数据。
它们不是替代关系,而是互补关系,以满足不同场景的需求。代码被埋了,上线后才发现被埋了。我应该怎么办?看一下全埋点的数据。虽然没有那么多维度,但总比没有好。因为采集数量充足,在APP中查看用户行为路径、流量趋势等也很方便。
我认为在重视数据的公司中,代码嵌入是必不可少的,全嵌入是锦上添花。下面几页主要讲解代码嵌入SDK。
2.评估SDK优劣的标准是什么?
从企业战略来看,无论是传统企业需要进行数字化转型,还是创业公司需要成为数据驱动的精细化运营,用户行为数据采集只是其中的一小部分数据策略。因此,嵌入式SDK应设计得尽可能简单易用,做到数据易采集,采集接收到的数据易使用。让采集数据成为公司数据驱动的助推器而非阻力。
首先,您应该关注嵌入代码的 SDK 的用户。如果用户对代码感到满意,并且用户也感到满意,则可以认为该 SDK 做得很好。用户是谁?他们关心什么?
采集SDK 的用户是谁:前端和客户端开发、服务端开发、数据测试、大数据团队。
埋点开发者(h5、小程序、iOS、Android开发):
测试埋点的人(数据测试)
接收埋藏数据的人(大数据团队)
一个代码嵌入SDK,满足以上用户需求,可以打95分,也可以在实际业务中应用。
3.代码埋点SDK架构
▍3.1 SDK整体架构
采集数据是否完整、准确、及时,能否连通,直接影响到公司整个数据平台的应用效果。因此,代码嵌入SDK需要一个良好的架构来保证数据的采集。
从SDK的整体设计开始,这部分将分别讲解SDK中的关键模块


▍3.2 SDK采集数据流
对于SDK来说,数据采集是在用户行为被触发时,根据事件模型的数据格式将用户行为发送到服务器。下面结合APP数据上报流程图说明SDK采集data流程。
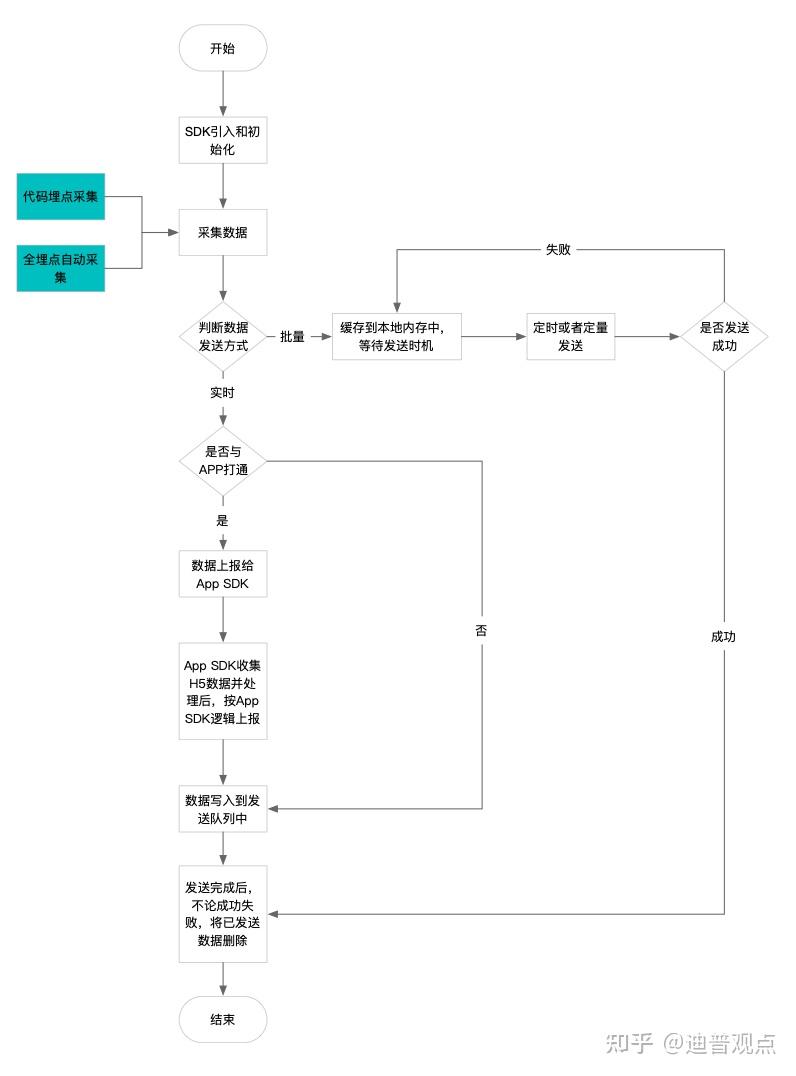
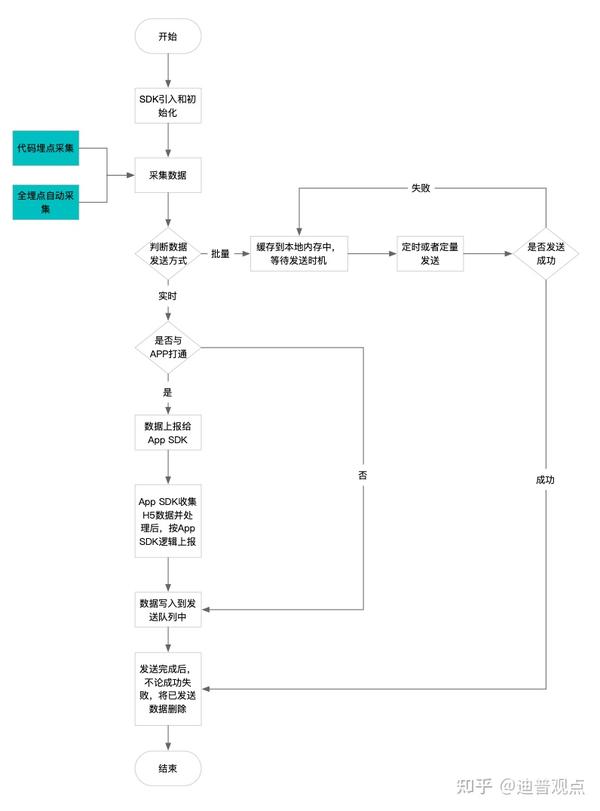
▍3.3 初始化模块
▍3.4 data采集module
代码被埋没了。 SDK初始化后,SDK提供采集相关接口。开发调用SDK提供的采集接口,将采集事件名称、变量字段等保存在本地,然后按照一定的策略将数据发送到目标数据服务器。 (或直接发送)
代码埋点采集SDK 可以提供以下能力:
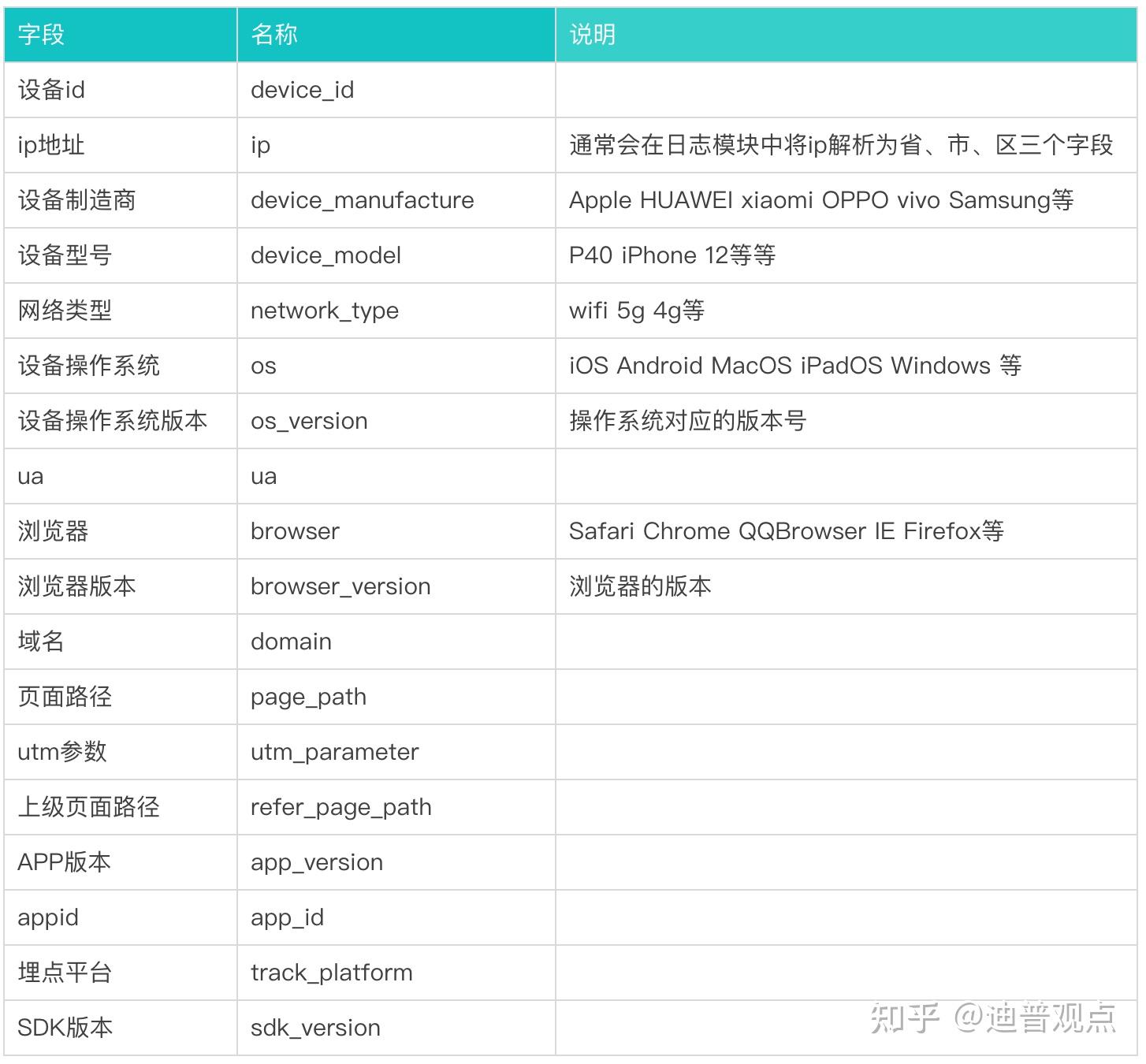
▍3.5 数据存储模块
数据存储模块是对埋点数据进行缓存,常见的存储方式有以下几种:
▍3.6 数据发送模块
数据发送模块负责将缓存的数据准确发送到服务器。
说完代码嵌入SDK的整体结构,我们来说说需要重点关注的几个部分:
4. 事件模型
▍4.1 事件模型数据结构




事件模型的本质是用标准化的语言来描述用户行为,即将具体的、丰富多样的用户行为抽象为一个数据模型;
实际上,事件模型很容易理解。我们可以用生活中的例子来类比来理解。你如何向别人描述你在生活中的行为?比如,我会说,我昨晚20:20在我家门口的快递站取了快递。这是描述行为的典型方式。在应用中使用这种描述行为的方法跟踪用户行为就是嵌入点中的事件模型。
事件模型 4W1H 意味着:用户在特定时间点(何时)、某处(何处)以特定方式(如何)完成特定操作(什么)。
一般包括哪些类型的事件:
这些组合可以覆盖用户在应用中99%的用户行为
▍4.2 预设变量
在描述事件时,有些信息是通用的,每次都需要携带。我们可以一次性将这些信息封装在SDK中,这样就不用每次埋点都重复工作了。在事件模型中,我们将这些预设变量放在一个JSON中,即default_variable字段。
▍4.3 事件变量
同样,在描述事件时,有些信息是个性化的,即根据具体业务不同,需要携带的信息也不同。比如商品详情页需要携带商品信息,社区Feed曝光需要携带帖子信息。不是这种情况。每次埋藏代码时,都不可避免地需要开发和携带特定的业务信息。在事件模型中,因为字段是不确定的,所以不管业务变量是什么,业务信息都放在一个JSON中。
5. 如何有效降低数据漏报率?
▍5.1 H5数据通过APP发送
由于用户终端的怪异操作,用户,以及各种无法提前预知的特殊情况,要求100%的埋点不漏点是不现实的。行业内APP误报率在1%左右,H5漏报率在5%左右。
APP可以制定缓存和上报策略,漏报率远低于H5。
APP漏报率为1%,h5漏报率为5%。为了最大程度的避免漏报,大家可以想到一个方法:对于混合应用,我们可以在h5页面里面嵌入一些数据。发送到APP SDK后,经过APP的缓存和上报策略,混合APP中h5页面嵌入点数据的误报率可以从5%降低到1%。
怎么做,主要考虑两点:
▍5.2 APP作为缓存和发送策略
这部分在SDK的数据发送模块中已经介绍过了,不再赘述,简单说一下具体的策略:
满足以上三个发送条件中的任何一个都可以发送数据。
如果数据发送不成功,发送的数据会被保存,满足发送条件后,会尝试与后续数据一起发送。这样可以减少网络请求,节省服务器资源,有效减少发送过程中的一些数据丢失问题。
6. 用户 ID 映射问题
在现实世界中,我们使用身份证来准确识别一个人。在网络世界中,我们应该用什么来识别用户?常用方法存在一些问题:
这需要一个非常系统的方法来识别用户(扩展中不能控制字数,文章稍后更新id-mapping问题,记得关注我)
汇总:如何做好信息采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2022-12-09 07:13
摘 要:信息采集是通过各种渠道搜索、归纳、整理并最终形成所需有效信息的过程。各种渠道包括:一是通过实地调查获得的第一手资料,即直接信息。二是通过媒体间接获得的信息。比如书籍、报纸、电视、网络。当前,互联网技术高度发达,信息量远远超过其他信息载体。因此,我们获取采集信息的主要途径来自互联网。
信息采集是通过各种渠道搜索、归纳、整理并最终形成所需有效信息的过程。各种渠道包括:一是通过实地调查获得的第一手资料,即直接信息。二是通过媒体间接获得的信息。比如书籍、报纸、电视、网络。当前,互联网技术高度发达,信息量远远超过其他信息载体。因此,我们获取采集信息的主要途径来自互联网。
有效信息是我们可以利用的信息,而不是任何一条信息对我们有用。资料采集不是“拿来主义”,不是直接从别人网站复制粘贴的作品。按照我们的目标和原则搜索到的信息,一般不能直接为我们所用,而是需要经过归纳整理,即需要一个数据处理的过程。商业网编辑想宣传自己的产品或网站,最终让自己的产品或网站有一个好的形象,进而达到销售的目的。所以,在做信息采集的时候,想想我们编辑的信息应该体现什么样的价值,不要盲目采集。
在明确了信息的采集用途之后,是时候通过一些合理的渠道来采集我们需要的信息了。
现代社会是信息社会,互联网报告企业信息的及时性是其他方式无法比拟的。通过互联网,您还可以更主动地选择自己需要的信息。需要注意的是,网上垃圾信息很多,垃圾站也很多。如果你没能对付采集一堆病毒,那得不偿失。最好选择国内知名的网站和官方的网站,这样可以大大提高采集信息的可靠性和实用性。
刚才说了,我们主要的信息采集方法是网页信息采集。那么什么是网络信息采集?事实上,目前并没有官方统一的概念。如果有定义的话,就是利用网页信息采集软件,针对某个网页实现针对性的、行业性的、精准的数据抓取。规则和筛选标准用于对数据进行分类并形成数据库文件的过程。当然,这里抓取的数据是公开的,任何人都可以看到,并不是为了窃取别人的后台数据。Web Information采集软件是一款网站定向数据采集、分析、发布的实用软件。可以对指定网站中任意网页进行目标分析,总结采集方案,
这种软件的好处是用户可以针对不同类型的信息设置不同的查询条件,而不是将采集网站中的所有信息一次性全部发到本地,避免了无意义的资源消耗。提高信息使用效率。
采集软件优采云 采集器等目前在互联网上很流行。
优采云采集器交流群:61570666
汇总:爬虫如何采集舆情数据
数据采集通俗地说就是通过爬虫代码访问目标网站的API链接,获取有用的信息。爬虫程序模拟人工从网页中获取所需信息,并自动保存在文档中,应用广泛。如图片、视频、文档、小说等。前提是不做非法经营。
在互联网大数据时代,网络爬虫主要是为搜索引擎提供最全面、最新的数据,网络爬虫也是从互联网上获取采集数据的爬虫。
我们还可以利用网络爬虫获取采集舆情数据、采集新闻、社交网络、论坛、博客等信息数据。这也是常见的舆情数据获取方案之一。一般就是利用爬虫爬虫ip,通过爬虫程序采集一些有意义的网站数据采集。舆情数据也可以在数据交易市场购买,或者由专业的舆情分析团队获取,但一般来说,专业的舆情分析团队也会使用爬虫ip到采集相关数据,从而进行舆情分析数据分析。
由于短视频的流行,我们也可以使用爬虫程序采集抖音和快手来分析抖音和快手两大主流短视频应用的舆情数据。将统计数据生成表格,作为数据报表提供给大家,也可以参考下面的采集程序代码:
// 要访问的目标页面
string targetUrl = "http://httpbin.org/ip";
// 爬虫ip服务器( jshk.com.cn )
string proxyHost = "http://jshk.com.cn/mb/";
string proxyPort = "31111";
// 爬虫ip验证信息
string proxyUser = "username";
string proxyPass = "password";
// 设置爬虫ip服务器
WebProxy proxy = new WebProxy(string.Format("{0}:{1}", proxyHost, proxyPort), true);
<p>
ServicePointManager.Expect100Continue = false;
var request = WebRequest.Create(targetUrl) as HttpWebRequest;
request.AllowAutoRedirect = true;
request.KeepAlive = true;
request.Method = "GET";
request.Proxy = proxy;
//request.Proxy.Credentials = CredentialCache.DefaultCredentials;
request.Proxy.Credentials = new System.Net.NetworkCredential(proxyUser, proxyPass);
// 设置Proxy Tunnel
// Random ran=new Random();
// int tunnel =ran.Next(1,10000);
// request.Headers.Add("Proxy-Tunnel", String.valueOf(tunnel));
//request.Timeout = 20000;
//request.ServicePoint.ConnectionLimit = 512;
//request.UserAgent = "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.82 Safari/537.36";
//request.Headers.Add("Cache-Control", "max-age=0");
//request.Headers.Add("DNT", "1");
//String encoded = System.Convert.ToBase64String(System.Text.Encoding.GetEncoding("ISO-8859-1").GetBytes(proxyUser + ":" + proxyPass));
//request.Headers.Add("Proxy-Authorization", "Basic " + encoded);
using (var response = request.GetResponse() as HttpWebResponse)
using (var sr = new StreamReader(response.GetResponseStream(), Encoding.UTF8))
{
string htmlStr = sr.ReadToEnd();
}
</p> 查看全部
汇总:如何做好信息采集
摘 要:信息采集是通过各种渠道搜索、归纳、整理并最终形成所需有效信息的过程。各种渠道包括:一是通过实地调查获得的第一手资料,即直接信息。二是通过媒体间接获得的信息。比如书籍、报纸、电视、网络。当前,互联网技术高度发达,信息量远远超过其他信息载体。因此,我们获取采集信息的主要途径来自互联网。
信息采集是通过各种渠道搜索、归纳、整理并最终形成所需有效信息的过程。各种渠道包括:一是通过实地调查获得的第一手资料,即直接信息。二是通过媒体间接获得的信息。比如书籍、报纸、电视、网络。当前,互联网技术高度发达,信息量远远超过其他信息载体。因此,我们获取采集信息的主要途径来自互联网。
有效信息是我们可以利用的信息,而不是任何一条信息对我们有用。资料采集不是“拿来主义”,不是直接从别人网站复制粘贴的作品。按照我们的目标和原则搜索到的信息,一般不能直接为我们所用,而是需要经过归纳整理,即需要一个数据处理的过程。商业网编辑想宣传自己的产品或网站,最终让自己的产品或网站有一个好的形象,进而达到销售的目的。所以,在做信息采集的时候,想想我们编辑的信息应该体现什么样的价值,不要盲目采集。
在明确了信息的采集用途之后,是时候通过一些合理的渠道来采集我们需要的信息了。
现代社会是信息社会,互联网报告企业信息的及时性是其他方式无法比拟的。通过互联网,您还可以更主动地选择自己需要的信息。需要注意的是,网上垃圾信息很多,垃圾站也很多。如果你没能对付采集一堆病毒,那得不偿失。最好选择国内知名的网站和官方的网站,这样可以大大提高采集信息的可靠性和实用性。
刚才说了,我们主要的信息采集方法是网页信息采集。那么什么是网络信息采集?事实上,目前并没有官方统一的概念。如果有定义的话,就是利用网页信息采集软件,针对某个网页实现针对性的、行业性的、精准的数据抓取。规则和筛选标准用于对数据进行分类并形成数据库文件的过程。当然,这里抓取的数据是公开的,任何人都可以看到,并不是为了窃取别人的后台数据。Web Information采集软件是一款网站定向数据采集、分析、发布的实用软件。可以对指定网站中任意网页进行目标分析,总结采集方案,
这种软件的好处是用户可以针对不同类型的信息设置不同的查询条件,而不是将采集网站中的所有信息一次性全部发到本地,避免了无意义的资源消耗。提高信息使用效率。
采集软件优采云 采集器等目前在互联网上很流行。
优采云采集器交流群:61570666
汇总:爬虫如何采集舆情数据
数据采集通俗地说就是通过爬虫代码访问目标网站的API链接,获取有用的信息。爬虫程序模拟人工从网页中获取所需信息,并自动保存在文档中,应用广泛。如图片、视频、文档、小说等。前提是不做非法经营。
在互联网大数据时代,网络爬虫主要是为搜索引擎提供最全面、最新的数据,网络爬虫也是从互联网上获取采集数据的爬虫。
我们还可以利用网络爬虫获取采集舆情数据、采集新闻、社交网络、论坛、博客等信息数据。这也是常见的舆情数据获取方案之一。一般就是利用爬虫爬虫ip,通过爬虫程序采集一些有意义的网站数据采集。舆情数据也可以在数据交易市场购买,或者由专业的舆情分析团队获取,但一般来说,专业的舆情分析团队也会使用爬虫ip到采集相关数据,从而进行舆情分析数据分析。
由于短视频的流行,我们也可以使用爬虫程序采集抖音和快手来分析抖音和快手两大主流短视频应用的舆情数据。将统计数据生成表格,作为数据报表提供给大家,也可以参考下面的采集程序代码:
// 要访问的目标页面
string targetUrl = "http://httpbin.org/ip";
// 爬虫ip服务器( jshk.com.cn )
string proxyHost = "http://jshk.com.cn/mb/";
string proxyPort = "31111";
// 爬虫ip验证信息
string proxyUser = "username";
string proxyPass = "password";
// 设置爬虫ip服务器
WebProxy proxy = new WebProxy(string.Format("{0}:{1}", proxyHost, proxyPort), true);
<p>
ServicePointManager.Expect100Continue = false;
var request = WebRequest.Create(targetUrl) as HttpWebRequest;
request.AllowAutoRedirect = true;
request.KeepAlive = true;
request.Method = "GET";
request.Proxy = proxy;
//request.Proxy.Credentials = CredentialCache.DefaultCredentials;
request.Proxy.Credentials = new System.Net.NetworkCredential(proxyUser, proxyPass);
// 设置Proxy Tunnel
// Random ran=new Random();
// int tunnel =ran.Next(1,10000);
// request.Headers.Add("Proxy-Tunnel", String.valueOf(tunnel));
//request.Timeout = 20000;
//request.ServicePoint.ConnectionLimit = 512;
//request.UserAgent = "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.82 Safari/537.36";
//request.Headers.Add("Cache-Control", "max-age=0");
//request.Headers.Add("DNT", "1");
//String encoded = System.Convert.ToBase64String(System.Text.Encoding.GetEncoding("ISO-8859-1").GetBytes(proxyUser + ":" + proxyPass));
//request.Headers.Add("Proxy-Authorization", "Basic " + encoded);
using (var response = request.GetResponse() as HttpWebResponse)
using (var sr = new StreamReader(response.GetResponseStream(), Encoding.UTF8))
{
string htmlStr = sr.ReadToEnd();
}
</p>
技术和经验:大数据技术栈之-数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2022-12-07 05:11
介绍
数据仓库的基础是数据。没有数据,数据仓库就是一个空壳。有许多数据来源。我们需要按照一个规则和流程制定一个采集方案,根据数据的特点和用途选择合适的方案。采集程序和数据采集一般分为全量和增量,对于一些业务场景,需要两者配合使用。
数据采集完整计划
全卷是指一次采集所有的数据,比如按照天数/月数。如果数据量很大,可能会比较耗时,而且会占用大量的存储空间。比如我们MySQL里面的数据,每天都需要同步。如果每天都同步,就会有很多重复数据,因为MySQL每天都在原来的基础上添加数据,每天同步一个完整的副本,所以是冗余的。其余的数据,而且不是实时的,需要每天同步一个时间点。它的优点是数据比较完整,但是会占用很大的存储空间。
增加
因为每天全量同步数据,会占用大量存储空间,效率不高,所以一般采用增量同步,但是增量是基于全量的,所以全量同步是必需的,后面是增量同步,增量意味着数据会增加或者修改,所以同步起来会比较困难。如果不使用工具,需要根据时间戳进行同步,比如增加一个create_time字段和update_time字段。添加数据时,会设置当前时间,修改数据时更新修改时间,然后以当天日期为条件获取符合条件的数据,但有个问题就是数据不是那么真实——时间,因为需要主动获取数据,会因网络等原因造成误差。实时的时候,对数据库的压力比较大,所以我们需要另一种方式,那就是CDC。
CDC全称为Change Data Capture,指的是识别并捕获数据库中数据的修改、删除、添加等变化,然后将这些变化以一定的方式记录下来,通过一定的机制传递给下游的Service,通过这个机制,可以减轻数据库的压力,数据更实时。比如MySQL的binglog机制就是CDC。
数据 采集 工具
数据采集工具分为全量采集和增量采集。
完整的 采集
采集工具有很多,比如Sqoop、kettle、DataX。下面主要说一下DataX。DataX可以实现各种数据之间的转换。如果DataX自带的数据源不能满足我们的需求,也可以自己实现,DataX由一个Writer和一个Reader组成,Reader是数据提供者,Writer是数据需求者,比如mysqlreader,doriswriter,就是将mysql的数据同步到doris。
DataX 只需要简单的安装。安装后只需要写一个json转换文件,然后执行json脚本即可。执行脚本后,数据同步将开始。但是,我们的同步任务可能一天执行一次。如果任务很多,那么每天执行脚本会很麻烦,这时可以使用定时任务,linux可以使用crond进行定时调度,但是如果使用cronb则无法监控任务的成功或失败,而且不能对任务进行统计,所以我们需要一个统一的任务调度平台,比如Azkaban、DepinSchudeler等,后面会用到。
增量采集
对于增量同步,我们需要用到CDC工具,比如Flume可以采集日志,canal可以实时同步mysql数据到其他中间件,而Maxwell,Debezium,Flink也有一个组件flink cdc,我们可以根据到业务需要选择,再说说flink cdc。
在传统的CDC架构中,我们一般是先通过CDC工具将数据写入Kafka,然后通过Flink或者Spark从Kafka中读取数据进行流处理后写入数据仓库,如下图。
使用flink cdc后,整个链接会变得很短,省去了中间的Debezium、kafka和流处理,flink cdc一步到位,flink cdc的底层采集工具也是基于Debezium实现,如下图。
Flink cdc 支持多种数据连接器。可以说我们可能需要写一行代码。我们只需要写sql,做一些简单的配置,就可以实现数据的增量同步。它的本质其实和flink的source sink一样,source是数据的来源,sink同步到对应的目标数据源。如果我们使用flink,我们需要添加一些中间件并编写代码。使用 flink cdc 就简单多了。只需要写sql就可以实现数据的连接、统计等。
❝
今天的分享就到这里了,感谢大家的观看,我们下期再见,如果本文中有任何描述不正确或不合理的地方,请大家提出宝贵意见,让我们在学习中共同成长进步!
解读:上海借助免费快速提升网站收录以及关键词排名的都不清楚
不清楚如何快速提高 网站收录 和 关键词 的免费排名
什么是WPcms插件,顾名思义,WPcms插件是搜索引擎优化过程中使用的辅助插件。今天博主就教大家使用免费的WPcms插件,快速提升网站收录和关键词的排名。这段时间很多SEO新手私信我,说自己对SEO没有完整的了解,不知道网站收录排名如何。今天博主就和大家聊一聊什么是SEO?搜索引擎优化,又称SEO,即是一种分析搜索引擎排名规则的方法,以了解各种搜索引擎如何进行搜索,如何抓取互联网页面,以及如何确定特定关键词的排名搜索结果。技术。
网站搜索引擎优化的任务主要是了解其他搜索引擎如何抓取网页,如何索引,如何确定搜索关键词等相关技术,从而优化本站内容网页,确保与用户浏览习惯一致,在不影响网民体验的情况下提高搜索引擎排名,从而增加网站访问量,最终提高网站宣传或销售能力 现代技术。基于搜索引擎优化处理,其实就是让这个网站更容易被搜索引擎接受。搜索引擎往往会比较不同的网站内容,然后使用浏览器以最完整、最直接、最快捷的方式上传内容。
每个人都想做好seo,但是除了一些做seo多年的seoer对seo有正确的态度,知道要做好seo需要很多东西外,很多seo新手对seo的认识并不完整,特别是提到我对插件或工具不太了解时。今天博主就教大家使用免费的WPcms插件,快速提升网站收录和关键词的排名。
1.使用免费WPcms采集大量文章内容
1.通过WPcms生成行业相关词,关键词来自下拉词、相关搜索词、长尾词。它可以设置为自动删除不相关的单词。通过WPcms插件实现自动化采集行业相关文章,一次可以创建几十个或上百个采集任务,同时支持多个域名任务同时 采集。
2.自动过滤其他网站促销信息
3、支持多采集来源采集(涵盖全网行业新闻源,海量内容库,采集最新内容)
4.支持图片本地化或存储到其他平台
5.全自动批量挂机采集,无缝对接各大cms发布商,采集自动发布并推送至搜索引擎
详细解释:如果一个网站想要有很多关键词的排名,它必须有很多的收录,
要拥有大量 收录,您必须拥有大量内容。而这个 采集 工具就是为了拥有大量的内容!
2.免费WPcms插件-SEO优化功能
1.设置标题的前缀和后缀(标题的区分度更好收录)
2.内容关键词插入(合理增加关键词密度)
3.随机图片插入(文章没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后,主动将文章推送给搜索引擎,保证新链接能及时被搜索引擎收录获取)
5.随机点赞-随机阅读-随机作者(增加页面原创度)
6.内容与标题一致(使内容与标题100%相关)
7、自动内链(在执行发布任务时,在文章内容中自动生成内链,有助于引导页面蜘蛛爬行,增加页面权重)
8、定时发布(定时发布网站内容可以让搜索引擎养成定时抓取网页的习惯,从而提高网站的收录)
详细解释: 通过以上SEO功能,增加网站页面的原创度,增加网页关键词的密度,吸引蜘蛛爬取更多页面。
3.免费WP cms插件-批量管理网站
1. 批量监控不同的cms网站数据(无论你的网站是帝国、易游、ZBLOG、织梦、WP、小旋风、站群、PB、苹果、搜外等各大cms,可以同时管理和批量发布的工具)
2.设置批量发布次数(可设置发布间隔/每天发布总数)
3.可以设置不同的关键词文章发布不同的栏目
4、伪原创保留字(在文章原创中设置核心字不要为伪原创)
5、软件直接监控已发布、待发布、是否伪原创、发布状态、URL、程序、发布时间等。
6、通过软件可以直接查看蜘蛛、收录、网站的每日体重!
详细解释:批量管理网站工具,可以在本地电脑修改,直接批量发布到站点后台,可以批量管理网站和查看网站数据,没有不再需要频繁登录后台查看。
做网站,既要讲究效率,又要讲究细节。如果效率提高了,细节做好了,网站的排名流量自然会增加!看完这篇文章,如果您觉得还不错,不妨采集或转发给有需要的朋友同事二脉! 查看全部
技术和经验:大数据技术栈之-数据采集
介绍
数据仓库的基础是数据。没有数据,数据仓库就是一个空壳。有许多数据来源。我们需要按照一个规则和流程制定一个采集方案,根据数据的特点和用途选择合适的方案。采集程序和数据采集一般分为全量和增量,对于一些业务场景,需要两者配合使用。
数据采集完整计划
全卷是指一次采集所有的数据,比如按照天数/月数。如果数据量很大,可能会比较耗时,而且会占用大量的存储空间。比如我们MySQL里面的数据,每天都需要同步。如果每天都同步,就会有很多重复数据,因为MySQL每天都在原来的基础上添加数据,每天同步一个完整的副本,所以是冗余的。其余的数据,而且不是实时的,需要每天同步一个时间点。它的优点是数据比较完整,但是会占用很大的存储空间。
增加
因为每天全量同步数据,会占用大量存储空间,效率不高,所以一般采用增量同步,但是增量是基于全量的,所以全量同步是必需的,后面是增量同步,增量意味着数据会增加或者修改,所以同步起来会比较困难。如果不使用工具,需要根据时间戳进行同步,比如增加一个create_time字段和update_time字段。添加数据时,会设置当前时间,修改数据时更新修改时间,然后以当天日期为条件获取符合条件的数据,但有个问题就是数据不是那么真实——时间,因为需要主动获取数据,会因网络等原因造成误差。实时的时候,对数据库的压力比较大,所以我们需要另一种方式,那就是CDC。
CDC全称为Change Data Capture,指的是识别并捕获数据库中数据的修改、删除、添加等变化,然后将这些变化以一定的方式记录下来,通过一定的机制传递给下游的Service,通过这个机制,可以减轻数据库的压力,数据更实时。比如MySQL的binglog机制就是CDC。
数据 采集 工具
数据采集工具分为全量采集和增量采集。
完整的 采集
采集工具有很多,比如Sqoop、kettle、DataX。下面主要说一下DataX。DataX可以实现各种数据之间的转换。如果DataX自带的数据源不能满足我们的需求,也可以自己实现,DataX由一个Writer和一个Reader组成,Reader是数据提供者,Writer是数据需求者,比如mysqlreader,doriswriter,就是将mysql的数据同步到doris。
DataX 只需要简单的安装。安装后只需要写一个json转换文件,然后执行json脚本即可。执行脚本后,数据同步将开始。但是,我们的同步任务可能一天执行一次。如果任务很多,那么每天执行脚本会很麻烦,这时可以使用定时任务,linux可以使用crond进行定时调度,但是如果使用cronb则无法监控任务的成功或失败,而且不能对任务进行统计,所以我们需要一个统一的任务调度平台,比如Azkaban、DepinSchudeler等,后面会用到。
增量采集
对于增量同步,我们需要用到CDC工具,比如Flume可以采集日志,canal可以实时同步mysql数据到其他中间件,而Maxwell,Debezium,Flink也有一个组件flink cdc,我们可以根据到业务需要选择,再说说flink cdc。
在传统的CDC架构中,我们一般是先通过CDC工具将数据写入Kafka,然后通过Flink或者Spark从Kafka中读取数据进行流处理后写入数据仓库,如下图。
使用flink cdc后,整个链接会变得很短,省去了中间的Debezium、kafka和流处理,flink cdc一步到位,flink cdc的底层采集工具也是基于Debezium实现,如下图。
Flink cdc 支持多种数据连接器。可以说我们可能需要写一行代码。我们只需要写sql,做一些简单的配置,就可以实现数据的增量同步。它的本质其实和flink的source sink一样,source是数据的来源,sink同步到对应的目标数据源。如果我们使用flink,我们需要添加一些中间件并编写代码。使用 flink cdc 就简单多了。只需要写sql就可以实现数据的连接、统计等。
❝
今天的分享就到这里了,感谢大家的观看,我们下期再见,如果本文中有任何描述不正确或不合理的地方,请大家提出宝贵意见,让我们在学习中共同成长进步!
解读:上海借助免费快速提升网站收录以及关键词排名的都不清楚
不清楚如何快速提高 网站收录 和 关键词 的免费排名
什么是WPcms插件,顾名思义,WPcms插件是搜索引擎优化过程中使用的辅助插件。今天博主就教大家使用免费的WPcms插件,快速提升网站收录和关键词的排名。这段时间很多SEO新手私信我,说自己对SEO没有完整的了解,不知道网站收录排名如何。今天博主就和大家聊一聊什么是SEO?搜索引擎优化,又称SEO,即是一种分析搜索引擎排名规则的方法,以了解各种搜索引擎如何进行搜索,如何抓取互联网页面,以及如何确定特定关键词的排名搜索结果。技术。
网站搜索引擎优化的任务主要是了解其他搜索引擎如何抓取网页,如何索引,如何确定搜索关键词等相关技术,从而优化本站内容网页,确保与用户浏览习惯一致,在不影响网民体验的情况下提高搜索引擎排名,从而增加网站访问量,最终提高网站宣传或销售能力 现代技术。基于搜索引擎优化处理,其实就是让这个网站更容易被搜索引擎接受。搜索引擎往往会比较不同的网站内容,然后使用浏览器以最完整、最直接、最快捷的方式上传内容。
每个人都想做好seo,但是除了一些做seo多年的seoer对seo有正确的态度,知道要做好seo需要很多东西外,很多seo新手对seo的认识并不完整,特别是提到我对插件或工具不太了解时。今天博主就教大家使用免费的WPcms插件,快速提升网站收录和关键词的排名。
1.使用免费WPcms采集大量文章内容
1.通过WPcms生成行业相关词,关键词来自下拉词、相关搜索词、长尾词。它可以设置为自动删除不相关的单词。通过WPcms插件实现自动化采集行业相关文章,一次可以创建几十个或上百个采集任务,同时支持多个域名任务同时 采集。
2.自动过滤其他网站促销信息
3、支持多采集来源采集(涵盖全网行业新闻源,海量内容库,采集最新内容)
4.支持图片本地化或存储到其他平台
5.全自动批量挂机采集,无缝对接各大cms发布商,采集自动发布并推送至搜索引擎
详细解释:如果一个网站想要有很多关键词的排名,它必须有很多的收录,
要拥有大量 收录,您必须拥有大量内容。而这个 采集 工具就是为了拥有大量的内容!
2.免费WPcms插件-SEO优化功能
1.设置标题的前缀和后缀(标题的区分度更好收录)
2.内容关键词插入(合理增加关键词密度)
3.随机图片插入(文章没有图片可以随机插入相关图片)
4、搜索引擎推送(文章发布成功后,主动将文章推送给搜索引擎,保证新链接能及时被搜索引擎收录获取)
5.随机点赞-随机阅读-随机作者(增加页面原创度)
6.内容与标题一致(使内容与标题100%相关)
7、自动内链(在执行发布任务时,在文章内容中自动生成内链,有助于引导页面蜘蛛爬行,增加页面权重)
8、定时发布(定时发布网站内容可以让搜索引擎养成定时抓取网页的习惯,从而提高网站的收录)
详细解释: 通过以上SEO功能,增加网站页面的原创度,增加网页关键词的密度,吸引蜘蛛爬取更多页面。
3.免费WP cms插件-批量管理网站
1. 批量监控不同的cms网站数据(无论你的网站是帝国、易游、ZBLOG、织梦、WP、小旋风、站群、PB、苹果、搜外等各大cms,可以同时管理和批量发布的工具)
2.设置批量发布次数(可设置发布间隔/每天发布总数)
3.可以设置不同的关键词文章发布不同的栏目
4、伪原创保留字(在文章原创中设置核心字不要为伪原创)
5、软件直接监控已发布、待发布、是否伪原创、发布状态、URL、程序、发布时间等。
6、通过软件可以直接查看蜘蛛、收录、网站的每日体重!
详细解释:批量管理网站工具,可以在本地电脑修改,直接批量发布到站点后台,可以批量管理网站和查看网站数据,没有不再需要频繁登录后台查看。
做网站,既要讲究效率,又要讲究细节。如果效率提高了,细节做好了,网站的排名流量自然会增加!看完这篇文章,如果您觉得还不错,不妨采集或转发给有需要的朋友同事二脉!
归纳总结:信息处理之信息采集、信息加工和信息编码详解及真题演练
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-11-18 22:25
1. 信息采集
信息采集包括信息的采集和信息的处理。
信息采集是按照一定的目的和要求,挖掘和积累不同时空领域所收录的相关信息的过程。
信息采集需要遵循哪些原则:可靠性、完整性、实时性、准确性、易用性、规划性、可预测性。
2. 信息处理
信息处理是指
通过一定的手段将采集信息进行分析和处理成我们需要的信息,其目的是挖掘信息的价值,以便我们加以利用。
信息处理的重要性体现在:
(1)只有仔细分析和筛选,才能避免真假信息的混杂。
(2)只有对采集信息进行有效的分类和排序,才能更有效地应用信息。
(3)采集信息的信息处理可以创造新的信息,使信息具有更好的使用价值。
3. 信息编码
信息编码的目的是便于信息的存储、检索和使用。信息编码是在处理信息时为信息分配代码的过程。信息编码必须规范化、系统化,设计合理的编码系统是关系信息系统生命力的重要因素。
真正的问题:(
1)人口普查过程中,社工上门登记人口信息的过程属于()。
A. 信息采集
B. 信息编码
C. 信息发布
D. 信息交流(
2)使用电子表格软件对学校运动会各种比赛结果进行汇总和排序的过程是()。
A. 获取信息
B. 信息处理
C. 信息发布
D. 信息存储(
3)使用二维码生成器生成个人信息的二维码属于()过程。
A. 文本识别
B. 图像处理
C. 信息编码
D. 人工智能
总结:逆冬:12.18百度排名算法解析、5大要点很关键!
昨天N兄弟对排名的过度波动做出了反应,我去百度站长工具平台看了看,原来百度出了一个新的算法,今天我就带大家来解读一下百度算法,看看能不能从百度算法中找到一些收录和排名的机会,帮你做得更好的SEO!
1.网页的排序没有提到内容是否原创关于排名
的影响因素我看了整篇文章,影响排名因素和内容的部分是权威性、丰富度、排版等,内容是否原创话题,百度从未提及过!
很多人一直纠结于内容是否原创,是否伪原创,其实这里百度给出的答案,好的内容不一定原创,如果你不了解某个行业,原创是什么意思?
2. 网站权威影响排名
之前,我们谈到了权威,只停留在整体和内容网站。而百度给出了一个权威标准,就是内容的作者。更多指向发表此文章的作者!
3. 网站内页的有效性
这里的时效性也给出了明确的指标,主要分为两个方面:
1.发布时间。其实发布时间早就解释过了,百度有时间因子算法,只是大部分人还没有应用。
2.文章内容的时效性,这个时效性对应发布时间,以图为例,随着时间的推移,内容正文也会根据时间进行更新,比如一些没有确定的事情,是可以确定的。
4. 相关性和用户主要和次要需求
网站相关性是一个比较老的话题,上图只举一个例子,说白了,就像写文章一样,对应文章的主题,不要挂羊头卖狗肉!
比较有意思的一点是:这里还提到了一、二的需求,以鸡胸肉为例,大部分人只是想看看鸡胸肉怎么做,只有一小部分问鸡胸肉的功效!
5.禁止恶意采集(特殊字段方法)
大家仔细看这张图,百度说是恶意的,采集采集后根本没处理,放上去的内容肯定不好,那采集之后排版怎么办?这个百度没说,大家领悟了自己!
医学和法律专业一定要记录,包括内容的权威性;新闻、价格和时效必须做好。
如果不是上述行业,比如L,比如诗歌,你可以想办法增加图文的方式,或者添加视频来提高页面的权威性和相关性。以上
5点就是算法的主要内容,以上就是为大家录制的解读算法对抗寒冬的视频,大家可以跟着看一看!
扫描二维码
获取更多
冬季黑帽搜索引擎优化 查看全部
归纳总结:信息处理之信息采集、信息加工和信息编码详解及真题演练
1. 信息采集
信息采集包括信息的采集和信息的处理。
信息采集是按照一定的目的和要求,挖掘和积累不同时空领域所收录的相关信息的过程。
信息采集需要遵循哪些原则:可靠性、完整性、实时性、准确性、易用性、规划性、可预测性。
2. 信息处理
信息处理是指
通过一定的手段将采集信息进行分析和处理成我们需要的信息,其目的是挖掘信息的价值,以便我们加以利用。
信息处理的重要性体现在:
(1)只有仔细分析和筛选,才能避免真假信息的混杂。
(2)只有对采集信息进行有效的分类和排序,才能更有效地应用信息。
(3)采集信息的信息处理可以创造新的信息,使信息具有更好的使用价值。
3. 信息编码
信息编码的目的是便于信息的存储、检索和使用。信息编码是在处理信息时为信息分配代码的过程。信息编码必须规范化、系统化,设计合理的编码系统是关系信息系统生命力的重要因素。
真正的问题:(
1)人口普查过程中,社工上门登记人口信息的过程属于()。
A. 信息采集
B. 信息编码
C. 信息发布
D. 信息交流(
2)使用电子表格软件对学校运动会各种比赛结果进行汇总和排序的过程是()。
A. 获取信息
B. 信息处理
C. 信息发布
D. 信息存储(
3)使用二维码生成器生成个人信息的二维码属于()过程。
A. 文本识别
B. 图像处理
C. 信息编码
D. 人工智能
总结:逆冬:12.18百度排名算法解析、5大要点很关键!
昨天N兄弟对排名的过度波动做出了反应,我去百度站长工具平台看了看,原来百度出了一个新的算法,今天我就带大家来解读一下百度算法,看看能不能从百度算法中找到一些收录和排名的机会,帮你做得更好的SEO!
1.网页的排序没有提到内容是否原创关于排名
的影响因素我看了整篇文章,影响排名因素和内容的部分是权威性、丰富度、排版等,内容是否原创话题,百度从未提及过!
很多人一直纠结于内容是否原创,是否伪原创,其实这里百度给出的答案,好的内容不一定原创,如果你不了解某个行业,原创是什么意思?
2. 网站权威影响排名
之前,我们谈到了权威,只停留在整体和内容网站。而百度给出了一个权威标准,就是内容的作者。更多指向发表此文章的作者!
3. 网站内页的有效性
这里的时效性也给出了明确的指标,主要分为两个方面:
1.发布时间。其实发布时间早就解释过了,百度有时间因子算法,只是大部分人还没有应用。
2.文章内容的时效性,这个时效性对应发布时间,以图为例,随着时间的推移,内容正文也会根据时间进行更新,比如一些没有确定的事情,是可以确定的。
4. 相关性和用户主要和次要需求
网站相关性是一个比较老的话题,上图只举一个例子,说白了,就像写文章一样,对应文章的主题,不要挂羊头卖狗肉!
比较有意思的一点是:这里还提到了一、二的需求,以鸡胸肉为例,大部分人只是想看看鸡胸肉怎么做,只有一小部分问鸡胸肉的功效!
5.禁止恶意采集(特殊字段方法)
大家仔细看这张图,百度说是恶意的,采集采集后根本没处理,放上去的内容肯定不好,那采集之后排版怎么办?这个百度没说,大家领悟了自己!
医学和法律专业一定要记录,包括内容的权威性;新闻、价格和时效必须做好。
如果不是上述行业,比如L,比如诗歌,你可以想办法增加图文的方式,或者添加视频来提高页面的权威性和相关性。以上
5点就是算法的主要内容,以上就是为大家录制的解读算法对抗寒冬的视频,大家可以跟着看一看!
扫描二维码
获取更多
冬季黑帽搜索引擎优化
直观:如何高效进行数据采集,这里有一套完整方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 249 次浏览 • 2022-11-06 10:41
1、数据质量是数据分析的基石
假设一个场景:我们想要采集一个广告服务页面数据。
首先,我们和我们的技术同学描述了用户在进入应用的打开页面时所面临的场景:浏览-点击-跳转到广告页面;然后,我们提出了埋点的必要性。
点击数据分为有效点击和无效点击两类,但是技术方面的同学不会纠结这个问题。他刚刚从网上下载了一个闪屏页面框架,并集成到项目中。
在这个框架下,点击动作被拆解为:按下、抬起。而我们通常认为的点击动作应该是:在短时间内同时按下和抬起两个动作。
由于该框架的目标是提高点击率,即让更多人看到广告详情页面。因此,当用户按下时,已经触发了跳转到详情页的操作。
大多数非目标客户会不耐烦地退出广告详情页,而真正看到广告并感兴趣的客户会主动进入广告详情页。
由此产生的见解是:点击率高,转化率低。市场方面的同学误认为是广告设计的失败,会影响下一个广告的视觉效果或投放策略。
通过上面的例子,我们得出结论,data采集的时机和技术端的实现方式,会极大地影响业务端的决策。
“九层平台,从土的堆积开始。” 在形成一组有洞察力的数据之前,data采集是最基本也是最关键的一步。只有有了准确的数据,这种洞察力才能帮助您做出业务决策。否则会适得其反,再漂亮的数据分析也不会带来实际效果。
但是,在埋点方案的实际实现中,我们可能会遇到以下困惑:
GrowingIO发现“数据采集引起的数据质量问题”可能已经成为企业普遍存在的问题,这个问题的主要原因如下4点:
数据采集关系到数据质量,需要产品侧和业务侧的同事制定技术实施方案,让技术同学“快懂、快埋、快实施”。
2、GrowingIO为数据效率保驾护航采集
针对这些棘手问题,GrowingIO的非嵌入式技术可以快速定义页面、按钮、文本框等常见的用户行为操作,从而减少一些重复性高的用户常见行为中的嵌入式代码操作量,提供快速数据可视化。方便的。
一、无埋点的定义
什么是无墓地?我们先看看你有没有遇到过以下几种情况:
针对以上问题,没有埋点可以很好的解决。事实上,人、时间、地点、内容、方法的数据采集方法没有埋点。通过GrowingIO的圈选(可视化定义工具)功能,我们可以在所见即所得上定义指标。
无埋点(圈选)的核心思想基于以下5个元数据:
没有埋点可以定义常见的事件类型,尽可能减少代码使用,减少开发工作量。通过GrowingIO的圈选功能,我们可以快速采集数据,定义指标,查看实时数据。
2、如何选择埋点和不埋点?
新的无埋点虽然简单方便,但也有其局限性。同时,我们又离不开业务数据维度,所以不能放弃传统的埋点。
埋入式和不埋入式各有优势。面对不同的场景,需要明确目的,根据具体情况综合判断,选择最优的数据方式采集。
(1) 埋点
缺点适用于“监控和分析”数据场景:
(2) 无墓地
缺点适用于“探索性”数据场景:
基于以上,我们整理了下表,方便大家更好的理解和选择:
总之,埋点技术灵活、稳定、限制低、准确率高,适用于跟踪关键节点、隐藏程序逻辑和业务维度观察到的数据。
无埋技术判断速度快,有历史数据,有预定义维度支持,适用于快速查看某些趋势或过程数据。
当我们选择无嵌入或嵌入时,我们只需要注意:该行为不是核心指标,存在于预定义的无嵌入指标中。
如果有预定义的指标(即无埋点),并且预定义的尺寸也符合要求,那么我们需要观察无埋点的指标和尺寸,您可以放心选择无埋点。如果不存在或预定义的尺寸不能满足观察指标的视角,则需要通过埋点指标上报。
三、全埋点方案设计的四要素
在规划指标体系后,推动落实是价值落实过程中最重要的环节。
许多客户在实施过程中仍然遇到瓶颈,即使他们非常清楚他们想要监控的数据系统。这很大程度上是由于团队协作问题,例如数据嵌入量大,沟通成本高,以及业务方和开发者无法统一目标。
这最终将导致我们看到空的系统和无数的东西。
如果一整套数据采集解决方案直接交给研发方,业务场景描述和逻辑理解的差异会造成很大的沟通成本,最终导致实施效率低下。
因此,我们需要将有组织的指标体系梳理成实施需求。解决这个问题的关键在于以下4个步骤:
1. 确认事件和变量
如果一个问题从不同的角度定位,它的事件和变量也会发生变化。我们需要根据数据需求找到事件和变量组合的最优解。
2.确定事件的触发时机
时机选择没有对错之分,需要根据具体业务需求制定。同时,不同的触发时间会带来不同的数据口径。
3.标准命名
例如,客户在命名双十一时使用了拼音和英文的组合,这会使程序员感到困惑并出错。标准化的命名有助于程序员了解业务需求,高效实施方案。
4. 明确实施重点
通过明确优先级,我们可以专注于产品中真正需要跟踪的重要事件,避免技术冲突,实现价值的持续交付。
基于以上四个要素完成埋点方案的设计,不仅可以提高需求方和开发团队的协作效率,还可以为后期数据提供质量保证。
下表是我们整理出来的模板。本表格充分承担了埋点方案设计的四要素,可直接交由埋点技术方进行。
4、团队合作是跟踪计划实施的关键
接下来,如何快速准确地定义团队中埋点的需求,从而实现埋点计划的高效执行?
1.完成协作流程
从我们服务上千家企业的经验来看,GrowingIO 梳理出了一套完整的协作流程。包括业务需求方、数据规划师和开发团队。
本次三方合作的具体流程和时间安排为:
2.具体场景演示
接下来,我们将以某款APP的注册场景为例,帮助大家了解埋点方案实施的具体流程。
(在注册首页填写手机号-输入注册验证短信验证码-注册信息A、B、C-进入App首页)
(1) 场景一
业务方的需求是:快速分析现有注册流程各步骤之间的转化率,找到损失较大的环节进行优化。
可以看出,业务方只关心流程之间的步骤转换过程,那么我们需要关注用户的浏览行为,指标可以定义为各个步骤之间的页面。
具体来说,登录动作包括登录后从登录到首页的6个步骤,而我们关注的机型、地区、国家等角度不属于业务范畴,而是都在预定义的维度中,这符合我们缺乏埋点指标的定义规则。
因此,我们可以快速定义6个浏览页面指标来完成数据分析。
通过GrowingIO产品分析,我们可以得到下图,可以看到每一步的人数和转化。已经观察到注册验证-注册信息A-注册信息B这三个页面之间的流失率很高,我们这里需要优化一下。
以上是无埋点的快速定义。我们可以实时观察数据并分析事件,而无需等待下一个版本。
(2) 场景二
客户的需求是:查看注册用户的实习行业分布和性别分布。
根据完整埋点方案设计的四要素,我们要一一确认:
根据提供的埋点计划文档,我们不需要反复沟通,程序员可以快速明确业务需求并进行埋点操作。
3.数据验证
数据采集完成后,需要进行最后的确认,也就是我们通常所说的数据校验。
对此,GrowingIO有一套完整的数据验证工具,可以快速定位数据生成的过程。比如浏览了哪些页面,是否触发了事件,埋藏的事件是否对应定义的字段等。
如果某个环节出现了瑕疵,我们可以及时反馈问题,解决问题。
最后在这里和大家分享一句:“强则长,根深则久。” 数据驱动的“根”在于数据采集。只有采集的数据足够准确,才能做出正确的决策,促进企业的可持续发展。
今天的分享到此结束。感谢您的宝贵时间。我希望它对你有帮助。
作者:汪涵GrowingIO高级技术顾问,毕业于北京大学,Extron认证工程师。曾服务过奇瑞汽车、中国铁建、滴滴等龙头企业,拥有丰富的技术部署经验。
整套解决方案:爬虫 全国建筑市场监管服务平台小程序 数据抓取与采集
原帖数次文章关于全国建筑市场监管公共服务平台(四库一平台)平台网站数据采集并截图:
施工资质爬虫——全国建筑市场监管公共服务平台(一)简介 施工资质爬虫——全国建筑市场监管公共服务平台(二)——界面 新版建筑市场(四库一平台)抓取最新资讯(爬虫)
近日,发现建筑市场监管平台推出了自己的小程序“全国建筑市场监管服务平台”。
在使用过程中,发现没有前端辅助验证码,现在也有一些访问权限,于是研究了如何通过小程序抓取数据。经过学习研究,基本完成了采集和数据的抓取。,并记录整个过程。如需相关技术支持和爬虫数据,可以联系我(电话:【微信同号】)。
1.使用爬虫抓包抓取小程序访问链接
我喜欢使用 Fiddler 包捕获工具。我不会在这里详细介绍如何配置和安装它。网上有很多教程。安装配置完成后,我们访问小程序,在Fiddler上查看相关访问链接:
然后通过分析小程序的界面,有两个
所有相关服务都是通过更改参数键来实现的。这里没有很多。通过界面可以轻松分析相关功能。
2.接口认证token和IP限制
首先我们打开一个接口的请求头:
GET https://sky.mohurd.gov.cn/skya ... rd%3D HTTP/1.1
Host: sky.mohurd.gov.cn
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36 MicroMessenger/7.0.9.501 NetType/WIFI MiniProgramEnv/Windows WindowsWechat
cityCode:
content-type: application/json
token: t_b161960b732146379d4b8fc53196c50f
Referer: https://servicewechat.com/wx8f ... .html
Accept-Encoding: gzip, deflate, br
虽然现在小程序接口不多,但我们还是做了一点认证和爬虫。现在,第一个是令牌。这里的token比较简单,可以直接使用捕获到的token作为token。当有一定的访问权限时,后端也会屏蔽该IP。一开始还好几分钟就可以解封了,现在不行,试试用IP代理吧。
3.数据AES加解密
当我们查看返回的数据时,数据如下所示:
{"data":"A3ReBKoR6IDZSR4Jdxq72fXPsnWTZMhOr5sXl/lJ8/3GWFmsy2fTHG/0+Uz8fZmopZ0Ru0cskOWNX8hWlUy19scqauL28x3daP9IQn2……",
"message":null,
"status":1}
这里data的数据是加密的,我们使用的是我们解密的数据:
[{"data":{"asc":true,"current":1,"limit":15,"offset":0,"offsetCurrent":0,"openSort":true,"optimizeCount":false,"pages":14,
"records":[{"legalMan":"张东","address":"重庆市渝北区龙溪街道金山路18号中渝.都会首站4幢9-10","regionFullname":"重庆市",
"corpName":"重庆惠风机电设备有限公司","id":"001903140034193455","corpCode":"91500112054824582M"}],
"searchCount":true,"size":15,"total":200}}] 查看全部
直观:如何高效进行数据采集,这里有一套完整方案
1、数据质量是数据分析的基石
假设一个场景:我们想要采集一个广告服务页面数据。
首先,我们和我们的技术同学描述了用户在进入应用的打开页面时所面临的场景:浏览-点击-跳转到广告页面;然后,我们提出了埋点的必要性。
点击数据分为有效点击和无效点击两类,但是技术方面的同学不会纠结这个问题。他刚刚从网上下载了一个闪屏页面框架,并集成到项目中。
在这个框架下,点击动作被拆解为:按下、抬起。而我们通常认为的点击动作应该是:在短时间内同时按下和抬起两个动作。
由于该框架的目标是提高点击率,即让更多人看到广告详情页面。因此,当用户按下时,已经触发了跳转到详情页的操作。
大多数非目标客户会不耐烦地退出广告详情页,而真正看到广告并感兴趣的客户会主动进入广告详情页。
由此产生的见解是:点击率高,转化率低。市场方面的同学误认为是广告设计的失败,会影响下一个广告的视觉效果或投放策略。
通过上面的例子,我们得出结论,data采集的时机和技术端的实现方式,会极大地影响业务端的决策。
“九层平台,从土的堆积开始。” 在形成一组有洞察力的数据之前,data采集是最基本也是最关键的一步。只有有了准确的数据,这种洞察力才能帮助您做出业务决策。否则会适得其反,再漂亮的数据分析也不会带来实际效果。
但是,在埋点方案的实际实现中,我们可能会遇到以下困惑:
GrowingIO发现“数据采集引起的数据质量问题”可能已经成为企业普遍存在的问题,这个问题的主要原因如下4点:
数据采集关系到数据质量,需要产品侧和业务侧的同事制定技术实施方案,让技术同学“快懂、快埋、快实施”。
2、GrowingIO为数据效率保驾护航采集
针对这些棘手问题,GrowingIO的非嵌入式技术可以快速定义页面、按钮、文本框等常见的用户行为操作,从而减少一些重复性高的用户常见行为中的嵌入式代码操作量,提供快速数据可视化。方便的。
一、无埋点的定义
什么是无墓地?我们先看看你有没有遇到过以下几种情况:
针对以上问题,没有埋点可以很好的解决。事实上,人、时间、地点、内容、方法的数据采集方法没有埋点。通过GrowingIO的圈选(可视化定义工具)功能,我们可以在所见即所得上定义指标。
无埋点(圈选)的核心思想基于以下5个元数据:
没有埋点可以定义常见的事件类型,尽可能减少代码使用,减少开发工作量。通过GrowingIO的圈选功能,我们可以快速采集数据,定义指标,查看实时数据。
2、如何选择埋点和不埋点?
新的无埋点虽然简单方便,但也有其局限性。同时,我们又离不开业务数据维度,所以不能放弃传统的埋点。
埋入式和不埋入式各有优势。面对不同的场景,需要明确目的,根据具体情况综合判断,选择最优的数据方式采集。
(1) 埋点
缺点适用于“监控和分析”数据场景:
(2) 无墓地
缺点适用于“探索性”数据场景:
基于以上,我们整理了下表,方便大家更好的理解和选择:
总之,埋点技术灵活、稳定、限制低、准确率高,适用于跟踪关键节点、隐藏程序逻辑和业务维度观察到的数据。
无埋技术判断速度快,有历史数据,有预定义维度支持,适用于快速查看某些趋势或过程数据。
当我们选择无嵌入或嵌入时,我们只需要注意:该行为不是核心指标,存在于预定义的无嵌入指标中。
如果有预定义的指标(即无埋点),并且预定义的尺寸也符合要求,那么我们需要观察无埋点的指标和尺寸,您可以放心选择无埋点。如果不存在或预定义的尺寸不能满足观察指标的视角,则需要通过埋点指标上报。
三、全埋点方案设计的四要素
在规划指标体系后,推动落实是价值落实过程中最重要的环节。
许多客户在实施过程中仍然遇到瓶颈,即使他们非常清楚他们想要监控的数据系统。这很大程度上是由于团队协作问题,例如数据嵌入量大,沟通成本高,以及业务方和开发者无法统一目标。
这最终将导致我们看到空的系统和无数的东西。
如果一整套数据采集解决方案直接交给研发方,业务场景描述和逻辑理解的差异会造成很大的沟通成本,最终导致实施效率低下。
因此,我们需要将有组织的指标体系梳理成实施需求。解决这个问题的关键在于以下4个步骤:
1. 确认事件和变量
如果一个问题从不同的角度定位,它的事件和变量也会发生变化。我们需要根据数据需求找到事件和变量组合的最优解。
2.确定事件的触发时机
时机选择没有对错之分,需要根据具体业务需求制定。同时,不同的触发时间会带来不同的数据口径。
3.标准命名
例如,客户在命名双十一时使用了拼音和英文的组合,这会使程序员感到困惑并出错。标准化的命名有助于程序员了解业务需求,高效实施方案。
4. 明确实施重点
通过明确优先级,我们可以专注于产品中真正需要跟踪的重要事件,避免技术冲突,实现价值的持续交付。
基于以上四个要素完成埋点方案的设计,不仅可以提高需求方和开发团队的协作效率,还可以为后期数据提供质量保证。
下表是我们整理出来的模板。本表格充分承担了埋点方案设计的四要素,可直接交由埋点技术方进行。
4、团队合作是跟踪计划实施的关键
接下来,如何快速准确地定义团队中埋点的需求,从而实现埋点计划的高效执行?
1.完成协作流程
从我们服务上千家企业的经验来看,GrowingIO 梳理出了一套完整的协作流程。包括业务需求方、数据规划师和开发团队。
本次三方合作的具体流程和时间安排为:
2.具体场景演示
接下来,我们将以某款APP的注册场景为例,帮助大家了解埋点方案实施的具体流程。
(在注册首页填写手机号-输入注册验证短信验证码-注册信息A、B、C-进入App首页)
(1) 场景一
业务方的需求是:快速分析现有注册流程各步骤之间的转化率,找到损失较大的环节进行优化。
可以看出,业务方只关心流程之间的步骤转换过程,那么我们需要关注用户的浏览行为,指标可以定义为各个步骤之间的页面。
具体来说,登录动作包括登录后从登录到首页的6个步骤,而我们关注的机型、地区、国家等角度不属于业务范畴,而是都在预定义的维度中,这符合我们缺乏埋点指标的定义规则。
因此,我们可以快速定义6个浏览页面指标来完成数据分析。
通过GrowingIO产品分析,我们可以得到下图,可以看到每一步的人数和转化。已经观察到注册验证-注册信息A-注册信息B这三个页面之间的流失率很高,我们这里需要优化一下。
以上是无埋点的快速定义。我们可以实时观察数据并分析事件,而无需等待下一个版本。
(2) 场景二
客户的需求是:查看注册用户的实习行业分布和性别分布。
根据完整埋点方案设计的四要素,我们要一一确认:
根据提供的埋点计划文档,我们不需要反复沟通,程序员可以快速明确业务需求并进行埋点操作。
3.数据验证
数据采集完成后,需要进行最后的确认,也就是我们通常所说的数据校验。
对此,GrowingIO有一套完整的数据验证工具,可以快速定位数据生成的过程。比如浏览了哪些页面,是否触发了事件,埋藏的事件是否对应定义的字段等。
如果某个环节出现了瑕疵,我们可以及时反馈问题,解决问题。
最后在这里和大家分享一句:“强则长,根深则久。” 数据驱动的“根”在于数据采集。只有采集的数据足够准确,才能做出正确的决策,促进企业的可持续发展。
今天的分享到此结束。感谢您的宝贵时间。我希望它对你有帮助。
作者:汪涵GrowingIO高级技术顾问,毕业于北京大学,Extron认证工程师。曾服务过奇瑞汽车、中国铁建、滴滴等龙头企业,拥有丰富的技术部署经验。
整套解决方案:爬虫 全国建筑市场监管服务平台小程序 数据抓取与采集
原帖数次文章关于全国建筑市场监管公共服务平台(四库一平台)平台网站数据采集并截图:
施工资质爬虫——全国建筑市场监管公共服务平台(一)简介 施工资质爬虫——全国建筑市场监管公共服务平台(二)——界面 新版建筑市场(四库一平台)抓取最新资讯(爬虫)
近日,发现建筑市场监管平台推出了自己的小程序“全国建筑市场监管服务平台”。
在使用过程中,发现没有前端辅助验证码,现在也有一些访问权限,于是研究了如何通过小程序抓取数据。经过学习研究,基本完成了采集和数据的抓取。,并记录整个过程。如需相关技术支持和爬虫数据,可以联系我(电话:【微信同号】)。
1.使用爬虫抓包抓取小程序访问链接
我喜欢使用 Fiddler 包捕获工具。我不会在这里详细介绍如何配置和安装它。网上有很多教程。安装配置完成后,我们访问小程序,在Fiddler上查看相关访问链接:
然后通过分析小程序的界面,有两个
所有相关服务都是通过更改参数键来实现的。这里没有很多。通过界面可以轻松分析相关功能。
2.接口认证token和IP限制
首先我们打开一个接口的请求头:
GET https://sky.mohurd.gov.cn/skya ... rd%3D HTTP/1.1
Host: sky.mohurd.gov.cn
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36 MicroMessenger/7.0.9.501 NetType/WIFI MiniProgramEnv/Windows WindowsWechat
cityCode:
content-type: application/json
token: t_b161960b732146379d4b8fc53196c50f
Referer: https://servicewechat.com/wx8f ... .html
Accept-Encoding: gzip, deflate, br
虽然现在小程序接口不多,但我们还是做了一点认证和爬虫。现在,第一个是令牌。这里的token比较简单,可以直接使用捕获到的token作为token。当有一定的访问权限时,后端也会屏蔽该IP。一开始还好几分钟就可以解封了,现在不行,试试用IP代理吧。
3.数据AES加解密
当我们查看返回的数据时,数据如下所示:
{"data":"A3ReBKoR6IDZSR4Jdxq72fXPsnWTZMhOr5sXl/lJ8/3GWFmsy2fTHG/0+Uz8fZmopZ0Ru0cskOWNX8hWlUy19scqauL28x3daP9IQn2……",
"message":null,
"status":1}
这里data的数据是加密的,我们使用的是我们解密的数据:
[{"data":{"asc":true,"current":1,"limit":15,"offset":0,"offsetCurrent":0,"openSort":true,"optimizeCount":false,"pages":14,
"records":[{"legalMan":"张东","address":"重庆市渝北区龙溪街道金山路18号中渝.都会首站4幢9-10","regionFullname":"重庆市",
"corpName":"重庆惠风机电设备有限公司","id":"001903140034193455","corpCode":"91500112054824582M"}],
"searchCount":true,"size":15,"total":200}}]
汇总:信息处理之信息采集、信息加工和信息编码详解及真题演练
采集交流 • 优采云 发表了文章 • 0 个评论 • 255 次浏览 • 2022-10-16 08:44
1.信息采集
信息采集包括信息的采集和处理。
信息采集是根据一定的目的和要求,挖掘和积累不同时空领域所收录的相关信息的过程。
信息采集需要遵循哪些原则:可靠性原则、完整性原则、实时性原则、准确性原则、可用性原则、规划原则、可预测性原则。
2.信息处理
信息处理是指将采集接收到的信息通过一定的方式分析处理成我们需要的信息,其目的是挖掘信息的价值,使我们可以使用它。
信息处理的重要性体现在:
① 只有认真分析筛选,才能避免信息真假混淆。
② 只有对采集接收到的信息进行有效的分类整理,才能更有效地应用信息。
③对采集收到的信息进行处理,可以产生新的信息,使信息具有更好的使用价值。
3.信息编码
信息编码的目的是便于信息的存储、检索和使用。信息编码是在信息处理过程中为信息分配代码的过程。信息编码必须规范化、系统化,设计合理的编码系统是信息系统生机勃勃的重要因素。
真题:
①普查中,社工上门登记人口信息的过程属于( )。
A. 信息采集
B. 信息编码
三、信息发布
D. 交换信息
②用电子表格软件对学校运动会的成绩进行汇总和排序,过程为( )。
A. 信息获取
B. 信息处理
三、信息发布
D. 信息存储
③使用二维码生成器生成个人信息二维码属于()过程。
A. 字符识别
B. 图像处理
C. 信息编码
D、人工智能
归纳总结:白杨SEO:实战分享SEO诊断方案及网站SEO优化清单包含哪些?
前言:这是百洋SEO公众号原创的第92篇。为什么要编写此诊断方案和优化清单?因为我发现很多新的seo都不知道怎么看一个网站的问题,也不知道站内站外优化是什么,所以想分享一下。
1.网站SEO优化列表(37项)
初始设置和网站速度优化列表:
1、百度统计:将百度统计/谷歌分析代码放到你的网站中,以便统计网站流量等以下指标。
2、百度站长平台/谷歌站长平台:将你的网站放入平台,方便你关注网站索引量、爬取情况、网站安全问题等。如图,白杨SEO装修网索引截图。
3、网站地图:创建sitemap.xml站点地图,提交到百度/google站长平台。XML在线生成工具:
4.robots.txt:创建Robots.txt文件。
5.网站速度优化:通过运行网站Ping等测速工具,找出网站的速度,然后进行优化。
6. 网页速度优化:通过运行 网站 审查元素查看您的 网站 元素的每个链接的加载速度。快捷键:F12,然后选择网络,如下图:
关键词挖掘分析方面列表:
7. 用户分析:分析你的潜在客户是谁。他们有什么问题和需求?他们可能需要什么解决方案?你的目标市场是什么?这些是您需要了解和分析的问题,并找出什么样的内容吸引了他们。这一步至关重要,有助于建立用户粘性并带来持久的流量。
无论是百度还是谷歌,都会提到内容优化的重要性。内容优化的重要前提是你的内容必须满足用户的需求。所以要想满足需求,首先要找到什么样的关键词潜在用户可能会使用。
8. 百度下拉和相关网络:了解客户的搜索目标后,在百度搜索框下拉菜单中输入目的关键词 和关键词 短语并查找相关搜索。过滤下拉框和 关键词 相关搜索以合并到您的 关键词 列表中。
注意:有些下拉可能是有人故意刷的,所以你也要学会过滤哦~
9. 扩展您的关键词 列表:使用自动化工具,例如网站管理员工具、爱站、5118 的关键词 发现工具来查找更多关键词 和短语。如果开启百度竞价,使用百度竞价关键词工具会更快~
10. 确定你的关键词 列表:会有很长的关键词 列表或通过该工具发现的短语。通过仔细筛选,删除一些不准确和竞争性的 关键词 。
11. 选择目标关键词 和长尾关键词:一旦你过滤掉不相关的、过度竞争的关键词,在你的行业中选择你的潜在客户正在寻找的关键词应该会更容易关键词。这些 关键词 或 关键词 短语将成为您内容的核心;它们将被放置在 网站 各处。
网站内容方面列表:
12.创建表单或文档:将您的关键词列表中的关键词逐步添加到您的网站内容中,并记录下来以供当前查看和优化。
13、百度索引:使用百度索引需要一张图来查找搜索需求的发展趋势,修改或者写新的内容到你的网站,更好的了解你的潜在客户在找什么。
14、百度搜索文章Title:避免在得到的时候写出与别人相同或非常相似的标题。
15、网站内容:网站除了写成文章的个别文字外,内容还可以用其他方式表达,如:图片、视频、PPT、PDF等。
16. 页面聚合:使用内容聚合页面让您的客户更容易找到他们需要的内容。比如百度百科使用内链聚合,就是最典型的案例。
17、旧页面新优化:通过回复帖子或撰写最新资料等方式应用旧内容、更新补充,使旧的文章页面满足用户的最新需求。
18.title标题标签:网站每个页面都需要一个唯一且不重复的标题。使用 关键词 和您的 关键词 列表中的短语来写问题。标题标签的长度不应超过搜索引擎的显示长度,即 32 个字。在您的头衔之前或之后适当地添加您的品牌或公司名称,以增加品牌曝光度。
19. 描述标签:同样,使用 关键词 和您选择的短语来写一个简短的说明来描述您的页面或您的 网站。200字以内,达到搜索引擎全屏显示的效果可以应用一些提醒或者影响点击效果。
20. 固定链接结构:可以用关键词拼音制作你的网址,搜索引擎会将关键词匹配的网址加粗。使用静态 URL 或伪静态 URL 来实现链接的唯一性和稳定性。例如:
21、H1等标签:准确使用H1标签,让搜索引擎知道你的网页是干什么用的。每个网页只有一个H1标签,其余的使用H2-H6等样式通知搜索引擎该内容的重要内容。
22、图片优化:你推广的内容最好结合图文,然后用你的关键词定义ALT标签。百度图片的抓取会给你带来意想不到的好处~
23、内容和长度:文章最好超过500字,最好在1500字的范围内。但是,如果在 300 字之后没有什么可写的,请不要勉强。质量永远比数量更重要!!
24. 关键词:文章不要一遍又一遍地重新应用相同的关键词,使用相关或相似的关键词来适应你的文章。这使您可以防止过度优化受到惩罚。
25. 网站结构:确保大部分页面内容在您的网站主页点击3次以内。
26. 内部链接:使用您的 文章 内部链接连接到您的 网站 的其他部分或内容。
27. 相关资源的链接:当引用网站上的另一条内容时,链接必须应用相关的锚文本。
异地优化(外链)方面列表:
28. 竞争对手反向链接分析:在寻找新的反向链接时,看看你的竞争对手,看看他们的链接。
29、创建外链工作表:发送外链并做记录,以便更好地查询收录和外链的存在状态。
30、创建好友链记录表:除了发送外链,交换好友链也是你必不可少的工作。记录每个朋友链收录、关键词和权重变化。
31、查看关键词的影响:使用百度索引查看已有关键词的索引和变化。
32、检查现有朋友链:如果有问题,方便与对方沟通,删除或交换朋友链。
33. 垃圾链接:不要与那些损害你排名的网站交换链接,或者发送外部链接。
34.锚文本:查看自己的好友链接,链接到你网站的关键词,防止过度使用同一个关键词。
35、相关性:检查你现有的链接,看是否链接到你的网站对应网页,对方是网站与你网站相关的。可能时间久了,对方换了网页的主题。
用户数据方面列表:
36. 创建相关文档:分析您的潜在客户关注的网站 或在线媒体。
37. 流量分析:当潜在用户搜索您的公司或品牌名称以及产品、服务等相关信息时,注意您的网站流量来源和采访页面数据。
2.网站SEO优化诊断方案
一个好的网站SEO 诊断程序取决于您对网站 的研究深度。白洋SEO实训一期和二期,有一节专门讲网站诊断方案。可以看一下本次培训的介绍:
(阿毛白洋SEO第二期SEO培训截图)
事实上,SEO诊断需要很多时间,可以说是Poplar SEO服务的核心业务之一。分享的原因是更多的人可以编写自己的诊断计划。编写 SEO 诊断计划有四个步骤:
01 首先是了解网站本身
有很多方法可以理解 网站 本身。例如,您可以使用搜索引擎查看,也可以使用 SEO 工具查看。不过最好的办法还是直接找网站的负责人,了解网站的现状和问题,这个最重要!
上面的屏幕截图是针对一个新站点的。如果是旧站点,请添加,例如:您最近在做什么操作?现场技术方面?站外链接等等。
02市场竞争对手分析
迈出第一步后,一定要知道你分析的对象的现状和产品,然后用他的产品找到他的同行,然后找到一个好的网站,这样比较分析,然后看对方网站的优化好点,在哪里建站外的外链等等,下面想出解决方案方便。
03 使用诊断过程进行诊断
网站SEO诊断过程有哪些要点?其实Poplar SEO之前写过2篇文章,这里:
04出具诊断报告,包括解决方案
其实每个SEO人都有自己的经历,但是比如公认的SEO技术点,三要素是一样的。白杨SEO分享了两份付费给他人的SEO诊断报告,相关核心数据被删除。下面的一些截图:
以上两个,一个是外贸独立站优化运营方案,还包括30个SEO技术关卡。另一种是针对某中型化工平台网站的SEO诊断方案。项目最终权重达到目标,收录增加了10倍以上。这两份文件都已上传到 Aspen SEO Marketing Circle Planet。
白洋SEO营销圈为白洋SEO自己支付星球,99元/年,限时返现!2020年开始调整为199元/年,老用户不变。目前已经有近200人加入,不仅有SEO实训干货文档分享,还有SEM、设计、技术、产品、新媒体等行业的资深嘉宾,可以向他们提问。
加入方式:直接在微信上识别上图二维码,或点击“阅读原文”加入白洋SEO营销圈付费星球。友情提示,下载知识星球APP体验更好~
关于杨树: 查看全部
汇总:信息处理之信息采集、信息加工和信息编码详解及真题演练
1.信息采集
信息采集包括信息的采集和处理。
信息采集是根据一定的目的和要求,挖掘和积累不同时空领域所收录的相关信息的过程。
信息采集需要遵循哪些原则:可靠性原则、完整性原则、实时性原则、准确性原则、可用性原则、规划原则、可预测性原则。
2.信息处理
信息处理是指将采集接收到的信息通过一定的方式分析处理成我们需要的信息,其目的是挖掘信息的价值,使我们可以使用它。
信息处理的重要性体现在:
① 只有认真分析筛选,才能避免信息真假混淆。
② 只有对采集接收到的信息进行有效的分类整理,才能更有效地应用信息。
③对采集收到的信息进行处理,可以产生新的信息,使信息具有更好的使用价值。
3.信息编码
信息编码的目的是便于信息的存储、检索和使用。信息编码是在信息处理过程中为信息分配代码的过程。信息编码必须规范化、系统化,设计合理的编码系统是信息系统生机勃勃的重要因素。
真题:
①普查中,社工上门登记人口信息的过程属于( )。
A. 信息采集
B. 信息编码
三、信息发布
D. 交换信息
②用电子表格软件对学校运动会的成绩进行汇总和排序,过程为( )。
A. 信息获取
B. 信息处理
三、信息发布
D. 信息存储
③使用二维码生成器生成个人信息二维码属于()过程。
A. 字符识别
B. 图像处理
C. 信息编码
D、人工智能
归纳总结:白杨SEO:实战分享SEO诊断方案及网站SEO优化清单包含哪些?
前言:这是百洋SEO公众号原创的第92篇。为什么要编写此诊断方案和优化清单?因为我发现很多新的seo都不知道怎么看一个网站的问题,也不知道站内站外优化是什么,所以想分享一下。
1.网站SEO优化列表(37项)
初始设置和网站速度优化列表:
1、百度统计:将百度统计/谷歌分析代码放到你的网站中,以便统计网站流量等以下指标。
2、百度站长平台/谷歌站长平台:将你的网站放入平台,方便你关注网站索引量、爬取情况、网站安全问题等。如图,白杨SEO装修网索引截图。
3、网站地图:创建sitemap.xml站点地图,提交到百度/google站长平台。XML在线生成工具:
4.robots.txt:创建Robots.txt文件。
5.网站速度优化:通过运行网站Ping等测速工具,找出网站的速度,然后进行优化。
6. 网页速度优化:通过运行 网站 审查元素查看您的 网站 元素的每个链接的加载速度。快捷键:F12,然后选择网络,如下图:
关键词挖掘分析方面列表:
7. 用户分析:分析你的潜在客户是谁。他们有什么问题和需求?他们可能需要什么解决方案?你的目标市场是什么?这些是您需要了解和分析的问题,并找出什么样的内容吸引了他们。这一步至关重要,有助于建立用户粘性并带来持久的流量。
无论是百度还是谷歌,都会提到内容优化的重要性。内容优化的重要前提是你的内容必须满足用户的需求。所以要想满足需求,首先要找到什么样的关键词潜在用户可能会使用。
8. 百度下拉和相关网络:了解客户的搜索目标后,在百度搜索框下拉菜单中输入目的关键词 和关键词 短语并查找相关搜索。过滤下拉框和 关键词 相关搜索以合并到您的 关键词 列表中。
注意:有些下拉可能是有人故意刷的,所以你也要学会过滤哦~
9. 扩展您的关键词 列表:使用自动化工具,例如网站管理员工具、爱站、5118 的关键词 发现工具来查找更多关键词 和短语。如果开启百度竞价,使用百度竞价关键词工具会更快~
10. 确定你的关键词 列表:会有很长的关键词 列表或通过该工具发现的短语。通过仔细筛选,删除一些不准确和竞争性的 关键词 。
11. 选择目标关键词 和长尾关键词:一旦你过滤掉不相关的、过度竞争的关键词,在你的行业中选择你的潜在客户正在寻找的关键词应该会更容易关键词。这些 关键词 或 关键词 短语将成为您内容的核心;它们将被放置在 网站 各处。
网站内容方面列表:
12.创建表单或文档:将您的关键词列表中的关键词逐步添加到您的网站内容中,并记录下来以供当前查看和优化。
13、百度索引:使用百度索引需要一张图来查找搜索需求的发展趋势,修改或者写新的内容到你的网站,更好的了解你的潜在客户在找什么。
14、百度搜索文章Title:避免在得到的时候写出与别人相同或非常相似的标题。
15、网站内容:网站除了写成文章的个别文字外,内容还可以用其他方式表达,如:图片、视频、PPT、PDF等。
16. 页面聚合:使用内容聚合页面让您的客户更容易找到他们需要的内容。比如百度百科使用内链聚合,就是最典型的案例。
17、旧页面新优化:通过回复帖子或撰写最新资料等方式应用旧内容、更新补充,使旧的文章页面满足用户的最新需求。
18.title标题标签:网站每个页面都需要一个唯一且不重复的标题。使用 关键词 和您的 关键词 列表中的短语来写问题。标题标签的长度不应超过搜索引擎的显示长度,即 32 个字。在您的头衔之前或之后适当地添加您的品牌或公司名称,以增加品牌曝光度。
19. 描述标签:同样,使用 关键词 和您选择的短语来写一个简短的说明来描述您的页面或您的 网站。200字以内,达到搜索引擎全屏显示的效果可以应用一些提醒或者影响点击效果。
20. 固定链接结构:可以用关键词拼音制作你的网址,搜索引擎会将关键词匹配的网址加粗。使用静态 URL 或伪静态 URL 来实现链接的唯一性和稳定性。例如:
21、H1等标签:准确使用H1标签,让搜索引擎知道你的网页是干什么用的。每个网页只有一个H1标签,其余的使用H2-H6等样式通知搜索引擎该内容的重要内容。
22、图片优化:你推广的内容最好结合图文,然后用你的关键词定义ALT标签。百度图片的抓取会给你带来意想不到的好处~
23、内容和长度:文章最好超过500字,最好在1500字的范围内。但是,如果在 300 字之后没有什么可写的,请不要勉强。质量永远比数量更重要!!
24. 关键词:文章不要一遍又一遍地重新应用相同的关键词,使用相关或相似的关键词来适应你的文章。这使您可以防止过度优化受到惩罚。
25. 网站结构:确保大部分页面内容在您的网站主页点击3次以内。
26. 内部链接:使用您的 文章 内部链接连接到您的 网站 的其他部分或内容。
27. 相关资源的链接:当引用网站上的另一条内容时,链接必须应用相关的锚文本。
异地优化(外链)方面列表:
28. 竞争对手反向链接分析:在寻找新的反向链接时,看看你的竞争对手,看看他们的链接。
29、创建外链工作表:发送外链并做记录,以便更好地查询收录和外链的存在状态。
30、创建好友链记录表:除了发送外链,交换好友链也是你必不可少的工作。记录每个朋友链收录、关键词和权重变化。
31、查看关键词的影响:使用百度索引查看已有关键词的索引和变化。
32、检查现有朋友链:如果有问题,方便与对方沟通,删除或交换朋友链。
33. 垃圾链接:不要与那些损害你排名的网站交换链接,或者发送外部链接。
34.锚文本:查看自己的好友链接,链接到你网站的关键词,防止过度使用同一个关键词。
35、相关性:检查你现有的链接,看是否链接到你的网站对应网页,对方是网站与你网站相关的。可能时间久了,对方换了网页的主题。
用户数据方面列表:
36. 创建相关文档:分析您的潜在客户关注的网站 或在线媒体。
37. 流量分析:当潜在用户搜索您的公司或品牌名称以及产品、服务等相关信息时,注意您的网站流量来源和采访页面数据。
2.网站SEO优化诊断方案
一个好的网站SEO 诊断程序取决于您对网站 的研究深度。白洋SEO实训一期和二期,有一节专门讲网站诊断方案。可以看一下本次培训的介绍:
(阿毛白洋SEO第二期SEO培训截图)
事实上,SEO诊断需要很多时间,可以说是Poplar SEO服务的核心业务之一。分享的原因是更多的人可以编写自己的诊断计划。编写 SEO 诊断计划有四个步骤:
01 首先是了解网站本身
有很多方法可以理解 网站 本身。例如,您可以使用搜索引擎查看,也可以使用 SEO 工具查看。不过最好的办法还是直接找网站的负责人,了解网站的现状和问题,这个最重要!
上面的屏幕截图是针对一个新站点的。如果是旧站点,请添加,例如:您最近在做什么操作?现场技术方面?站外链接等等。
02市场竞争对手分析
迈出第一步后,一定要知道你分析的对象的现状和产品,然后用他的产品找到他的同行,然后找到一个好的网站,这样比较分析,然后看对方网站的优化好点,在哪里建站外的外链等等,下面想出解决方案方便。
03 使用诊断过程进行诊断
网站SEO诊断过程有哪些要点?其实Poplar SEO之前写过2篇文章,这里:
04出具诊断报告,包括解决方案
其实每个SEO人都有自己的经历,但是比如公认的SEO技术点,三要素是一样的。白杨SEO分享了两份付费给他人的SEO诊断报告,相关核心数据被删除。下面的一些截图:
以上两个,一个是外贸独立站优化运营方案,还包括30个SEO技术关卡。另一种是针对某中型化工平台网站的SEO诊断方案。项目最终权重达到目标,收录增加了10倍以上。这两份文件都已上传到 Aspen SEO Marketing Circle Planet。
白洋SEO营销圈为白洋SEO自己支付星球,99元/年,限时返现!2020年开始调整为199元/年,老用户不变。目前已经有近200人加入,不仅有SEO实训干货文档分享,还有SEM、设计、技术、产品、新媒体等行业的资深嘉宾,可以向他们提问。
加入方式:直接在微信上识别上图二维码,或点击“阅读原文”加入白洋SEO营销圈付费星球。友情提示,下载知识星球APP体验更好~
关于杨树:
采集 干货教程:【网站搭建】自采集影视站源码+演示
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2022-10-12 12:32
【网站建设】自采集影视台源代码+演示
演示网站:
自动采集
强大的搜索功能,使用PHP实时抓取可用资源,程序运行速度非常快,可以快速构建自己的电影网站
安装说明:
如果没有数据库,请修改解析配置文件配置文件.js
首页标题等在索引.php文件修改,首页图片在此更改/
static_qq/图片/标志.png、行名和首页图片在此变化/播放/索引.php
配置网站伪静态思维
有些不需要配置,有些可能没有配置,主页顶部会乱码!
蓝拳云
教程:WordPress 隐藏文章内容必须登录才可以查看的完美代码实现(不用插件)
1.创建一个短代码隐藏并将以下代码添加到主题的functions.php文件中。
add_shortcode('hide','loginvisible');
function loginvisible($atts,$content=null){
if(is_user_logged_in() && !is_null($content) && !is_feed()){
return $content;
}
else{
$url = get_permalink().'?'.time();
return '<p>该文章内容需要登录浏览。请点击 [ 此处登录 ] 后查看。';
}
}
</p>
2.编辑文章的内容,将要隐藏的内容用[hide][/hide]包裹起来
[hide]这段文字将被隐藏,登录后可见。[/hide]
三、实际效果
点击登录后,会自动跳转回当前页面,显示隐藏内容。
4.扩展,在后台文本编辑器中添加快捷按钮(注意编辑器的文本编辑状态)。
只需将以下代码添加到主题的 functions.php 文件中。
// 后台文本编辑框中添加隐藏简码按钮
function add_hide_quicktags() {
<p>
if (wp_script_is('quicktags')){
?>
QTags.addButton( 'hide', '隐藏内容', '[hide]隐藏内容[/hide]',"" ); 查看全部
采集 干货教程:【网站搭建】自采集影视站源码+演示
【网站建设】自采集影视台源代码+演示
演示网站:
自动采集
强大的搜索功能,使用PHP实时抓取可用资源,程序运行速度非常快,可以快速构建自己的电影网站
安装说明:
如果没有数据库,请修改解析配置文件配置文件.js
首页标题等在索引.php文件修改,首页图片在此更改/
static_qq/图片/标志.png、行名和首页图片在此变化/播放/索引.php
配置网站伪静态思维
有些不需要配置,有些可能没有配置,主页顶部会乱码!
蓝拳云
教程:WordPress 隐藏文章内容必须登录才可以查看的完美代码实现(不用插件)
1.创建一个短代码隐藏并将以下代码添加到主题的functions.php文件中。
add_shortcode('hide','loginvisible');
function loginvisible($atts,$content=null){
if(is_user_logged_in() && !is_null($content) && !is_feed()){
return $content;
}
else{
$url = get_permalink().'?'.time();
return '<p>该文章内容需要登录浏览。请点击 [ 此处登录 ] 后查看。';
}
}
</p>
2.编辑文章的内容,将要隐藏的内容用[hide][/hide]包裹起来
[hide]这段文字将被隐藏,登录后可见。[/hide]
三、实际效果
点击登录后,会自动跳转回当前页面,显示隐藏内容。
4.扩展,在后台文本编辑器中添加快捷按钮(注意编辑器的文本编辑状态)。
只需将以下代码添加到主题的 functions.php 文件中。
// 后台文本编辑框中添加隐藏简码按钮
function add_hide_quicktags() {
<p>
if (wp_script_is('quicktags')){
?>
QTags.addButton( 'hide', '隐藏内容', '[hide]隐藏内容[/hide]',"" );
采集 经验:做内容采集的话选择哪里的服务器比较好?有没有什么比较便宜的香港服务器推荐?
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2022-09-30 15:18
现在,随着在线访问信息的人的比例和数量的增加。现在有越来越多的用户创建独立的网站。但是很多新的网站,尤其是建在海外服务器上的网站,会发现自己的新网站排名和流量都减少了。所以,除了做原创的内容,很多网站想要快速增加收录和流量,一般采用伪原创和原创的组合,这就需要使用采集内容工具采集。那么什么样的配置才能保证采集工具的前端体验和流畅运行呢?就在这里说吧。
如果是海外机房,用哪个服务器比较好?
如果选择海外机房,如果主要使用大陆的流量,香港的服务器比较多。由于香港服务器不需要备案,搭建简单,自媒体正好合适,那么如何选择合适的香港服务器搭建业务呢?以下是简要介绍。
硬件配置更可靠
在搭建服务器的时候,如果要同时部署网站和采集工具,基本上需要使用windows系统。由于windows系统的配置要求较高,港机房不仅可以提供高性价比的i3,还可以提供适合windows系统的高配置E3和E5。如果不额外租用服务器,需要高性能内存支持来应对采集工具带来的高并发需求,香港服务器可以满足。
可靠的网络条件
在采集工具运行过程中,通常会定期进行自动采集。无论是网络拥塞还是采集的目标网站访问不畅,都可能导致采集的数据出错,甚至出现乱码,对SEO不利。现在香港的服务器都有BGP线路,可以根据IP访问自动选择最合适的线路,保证采集的数据和代码完整无误。
可靠的服务
不仅网络故障会导致发布和采集失败,采集工具本身对系统并发数也有严格要求。如果发生硬件故障(例如内存),采集 工具很有可能会变得无响应。因此,如果出现此类问题,需要专业的硬件工程师尽快处理。香港机房专业运维人员24小时值班。一旦用户需要升级或更改配置,可以立即进入机房进行处理。因此,在选择服务商时,推荐专业的技术支持团队更为可靠。
蓝翼云CDN最大的优势就是其他高防CDN要么需要备案,要么不备案很慢。
蓝云CDN安全盾也利用云架构,将防护提升至最高500G-DDos防护+CC攻击防护,同时提升速度降低网络延迟,非常适合网站、游戏、等一系列互联网应用程序使用!
蓝翼云服务器还提供了一台最低10M起步的香港大带宽云服务器!
更多关于 CDN 和云服务器的 文章:
干货:赶紧收藏这8款自媒体运营软件,小白必备
目前自媒体发展趋势火热,辅助自媒体操作的工具自然而然诞生,包括排版、屏幕视频、视频编辑转换、流行版辅助、图文数据采集、视频采集、热点、视频短片发布等工具,以及集成这些工具的各种自媒体助手。给大家分享8款好用的自媒体操作辅助软件。
自媒体神器
自媒体神器是一款优秀的SEO优化工具,具有一键伪原创、原创检测、MD5批量视频修改、各大自媒体平台视频分析等功能,未来将增加视频水印去除和视频标题编辑等各种功能。
小火花自媒体助理
Little Spark自媒体Assistant 是一种操作工具,自媒体 员工将使用它来提供准确的信息定位。企鹅、今日头条、百家号等平台涵盖了最全面的实时内容。小火助手让运营更高效,一个人操作多平台多账号,流量翻倍!
简易视频下载器
Easy Video Downloader是一款可以下载自媒体视频的软件。可根据自媒体平台、短视频平台、作者过滤、关键词搜索和视频下载。做新媒体运营的朋友不要错过!
迅蟒自媒体助手
迅Python自媒体Assistant,集成了强大的自媒体编辑器,素材丰富,编辑功能强大,多账号登录,复制内容同步,方便快捷。热点风向标,从时事政治新闻到娱乐热点,从微博、微信到豆瓣知乎,为用户呈现最新最热话题,为媒体编辑提供写作素材。更重要的是,我们为自媒体运营商提供了一个平台,让自媒体的流量更有价值。
快友助手
快游助手是小米开发的自媒体操作工具。快游助手让媒体账号的操作更简单,专为矩阵账号的轻松管理或单个大号的深度操作而设计。最好的免费操作工具!
微信编辑
微信编辑器是一款免费的微信公众号图文排版工具,改编自微信在线编辑器,为微信用户提供日常微信文章、微信图文、微信代码、微信编辑等资源。微信编辑器可以制作模板并保存在本地,方便多图编辑,格式统一。
墨云
摩云是一款自媒体辅助软件,具有自媒体运营管理、数据分析软件、视频去重、采集、视频监控等功能。,并且可以免费永久更新和维护。不要担心以后的软件不可用或无人维护。目前功能比较简单,以后软件会根据用户需要进一步完善!
云分发
Cloud Release 自媒体Assistant是为了方便自媒体创作者操作多个账号。云发布包括:账号绑定、一键发布、视频一键发布、查看内容和数据的功能场景。用户可以在云发布中轻松操作多个 自媒体 帐户。可将用户的自媒体账号添加到账号绑定页面,在视频发布页面一键将创作者编辑的内容发布到用户指定的账号。数据查看页面让创作者可以轻松清晰地查看昨天绑定的自媒体账号。 查看全部
采集 经验:做内容采集的话选择哪里的服务器比较好?有没有什么比较便宜的香港服务器推荐?
现在,随着在线访问信息的人的比例和数量的增加。现在有越来越多的用户创建独立的网站。但是很多新的网站,尤其是建在海外服务器上的网站,会发现自己的新网站排名和流量都减少了。所以,除了做原创的内容,很多网站想要快速增加收录和流量,一般采用伪原创和原创的组合,这就需要使用采集内容工具采集。那么什么样的配置才能保证采集工具的前端体验和流畅运行呢?就在这里说吧。
如果是海外机房,用哪个服务器比较好?
如果选择海外机房,如果主要使用大陆的流量,香港的服务器比较多。由于香港服务器不需要备案,搭建简单,自媒体正好合适,那么如何选择合适的香港服务器搭建业务呢?以下是简要介绍。
硬件配置更可靠
在搭建服务器的时候,如果要同时部署网站和采集工具,基本上需要使用windows系统。由于windows系统的配置要求较高,港机房不仅可以提供高性价比的i3,还可以提供适合windows系统的高配置E3和E5。如果不额外租用服务器,需要高性能内存支持来应对采集工具带来的高并发需求,香港服务器可以满足。
可靠的网络条件
在采集工具运行过程中,通常会定期进行自动采集。无论是网络拥塞还是采集的目标网站访问不畅,都可能导致采集的数据出错,甚至出现乱码,对SEO不利。现在香港的服务器都有BGP线路,可以根据IP访问自动选择最合适的线路,保证采集的数据和代码完整无误。
可靠的服务
不仅网络故障会导致发布和采集失败,采集工具本身对系统并发数也有严格要求。如果发生硬件故障(例如内存),采集 工具很有可能会变得无响应。因此,如果出现此类问题,需要专业的硬件工程师尽快处理。香港机房专业运维人员24小时值班。一旦用户需要升级或更改配置,可以立即进入机房进行处理。因此,在选择服务商时,推荐专业的技术支持团队更为可靠。
蓝翼云CDN最大的优势就是其他高防CDN要么需要备案,要么不备案很慢。
蓝云CDN安全盾也利用云架构,将防护提升至最高500G-DDos防护+CC攻击防护,同时提升速度降低网络延迟,非常适合网站、游戏、等一系列互联网应用程序使用!
蓝翼云服务器还提供了一台最低10M起步的香港大带宽云服务器!
更多关于 CDN 和云服务器的 文章:
干货:赶紧收藏这8款自媒体运营软件,小白必备
目前自媒体发展趋势火热,辅助自媒体操作的工具自然而然诞生,包括排版、屏幕视频、视频编辑转换、流行版辅助、图文数据采集、视频采集、热点、视频短片发布等工具,以及集成这些工具的各种自媒体助手。给大家分享8款好用的自媒体操作辅助软件。
自媒体神器
自媒体神器是一款优秀的SEO优化工具,具有一键伪原创、原创检测、MD5批量视频修改、各大自媒体平台视频分析等功能,未来将增加视频水印去除和视频标题编辑等各种功能。
小火花自媒体助理
Little Spark自媒体Assistant 是一种操作工具,自媒体 员工将使用它来提供准确的信息定位。企鹅、今日头条、百家号等平台涵盖了最全面的实时内容。小火助手让运营更高效,一个人操作多平台多账号,流量翻倍!
简易视频下载器
Easy Video Downloader是一款可以下载自媒体视频的软件。可根据自媒体平台、短视频平台、作者过滤、关键词搜索和视频下载。做新媒体运营的朋友不要错过!
迅蟒自媒体助手
迅Python自媒体Assistant,集成了强大的自媒体编辑器,素材丰富,编辑功能强大,多账号登录,复制内容同步,方便快捷。热点风向标,从时事政治新闻到娱乐热点,从微博、微信到豆瓣知乎,为用户呈现最新最热话题,为媒体编辑提供写作素材。更重要的是,我们为自媒体运营商提供了一个平台,让自媒体的流量更有价值。
快友助手
快游助手是小米开发的自媒体操作工具。快游助手让媒体账号的操作更简单,专为矩阵账号的轻松管理或单个大号的深度操作而设计。最好的免费操作工具!
微信编辑
微信编辑器是一款免费的微信公众号图文排版工具,改编自微信在线编辑器,为微信用户提供日常微信文章、微信图文、微信代码、微信编辑等资源。微信编辑器可以制作模板并保存在本地,方便多图编辑,格式统一。
墨云
摩云是一款自媒体辅助软件,具有自媒体运营管理、数据分析软件、视频去重、采集、视频监控等功能。,并且可以免费永久更新和维护。不要担心以后的软件不可用或无人维护。目前功能比较简单,以后软件会根据用户需要进一步完善!
云分发
Cloud Release 自媒体Assistant是为了方便自媒体创作者操作多个账号。云发布包括:账号绑定、一键发布、视频一键发布、查看内容和数据的功能场景。用户可以在云发布中轻松操作多个 自媒体 帐户。可将用户的自媒体账号添加到账号绑定页面,在视频发布页面一键将创作者编辑的内容发布到用户指定的账号。数据查看页面让创作者可以轻松清晰地查看昨天绑定的自媒体账号。
采集(fastadmin强大的一键生成功能快速简化你的项目开发流程 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-04-03 18:12
)
fastadmin采集器,FastAdmin 是一个基于 ThinkPHP 和 Bootstrap 的极速后台开发框架。Fastadmin强大的一键生成功能快速简化您的开发流程,加快您的项目开发。fastadmin采集器是目前使用最多的互联网数据采集、处理、分析和挖掘软件。Fastadmin软件以其灵活的配置和强大的性能领先于国内data采集产品,获得了众多用户的一致认可。
fastadmin采集器支持长尾关键词生成文章。找到您的网站正确目标关键词 至关重要。每天都有很多人通过搜索引擎找到自己需要的东西,而我们的SEO优化就是为了得到更好的搜索排名,让更多的潜在用户访问你的网站,进而产生交易,带来收益。关键词和长尾关键词的作用尤为重要,fastadmin采集器可以为你提供长尾关键词,流行的关键词。关键词是我们启动fastadmin采集器的第一步,也是最重要的一步。如果你选错了关键词,你会在整个SEO过程中走很多弯路。关键词还不确定,fastadmin的内容采集不能帮助你网站提高你的网站
数据分析。查看 网站 的统计信息,了解可以优化和改进的内容。采集 仅有内容是不够的。比如你采集提交了一个网站内容,如果其他人采集也提交了这个网站内容,那么就会导致内容同质化,导致结果百度没有收录。
fastadmin采集 支持内容优化处理。包括网站栏目设置、关键词布局、内容优化、内外链建设等,fastadmin采集器可以自动采集优质内容并定期发布;并配置多种数据处理选项,让网站内容独一无二,快速增加网站流量!fastadmin采集器采用分布式高速采集系统,多台服务器同时运行,解决了工作学习中大量数据下载和使用的需求,让您拥有更多的时间做更多的事情。
fastadmin采集器,专业的互联网数据采集、处理、分析、挖掘软件,可以灵活、快速的抓取网页上零散的数据信息,并通过一系列的分析处理,精准挖掘出需要的数据数据。
网站的内容,相当于网站成长的土壤和血液。对于站采集,我们不能做原创,但也要长期提供优质的伪原创内容,这也是使用fastadmin采集的必要条件之一@> 作为 采集 站。无论是您的 网站 域选择、网站 主题、网站 模式、网站 色调、网站 图形、网站 关键字、网站@ >@网站及其代码优化等,都需要简洁友好,准确有效,方便流畅,有吸引力,注意不要作弊。否则,即使你的网站流量很高,你也无法留住客户,也无法通过流量变现,一切都是空谈。
使用 fastadmin采集器 建议你应该构建一个对用户有用的 网站,任何优化都是为了改善用户体验。简单的理解就是把用户体验放在第一位,发布有价值的文章内容,文章的标题和内容板块收录有意义的搜索关键词。企业网站做SEO,就是围绕自己提供的服务或产品发布有价值的内容,让更多与你的产品和服务相关的搜索词获得良好的搜索排名。fastadmin采集器 快速挖掘数据中的新客户;洞察竞争对手的业务数据,分析客户行为以拓展新业务,通过精准营销降低风险和预算。今天关于fastadmin的解释采集器
查看全部
采集(fastadmin强大的一键生成功能快速简化你的项目开发流程
)
fastadmin采集器,FastAdmin 是一个基于 ThinkPHP 和 Bootstrap 的极速后台开发框架。Fastadmin强大的一键生成功能快速简化您的开发流程,加快您的项目开发。fastadmin采集器是目前使用最多的互联网数据采集、处理、分析和挖掘软件。Fastadmin软件以其灵活的配置和强大的性能领先于国内data采集产品,获得了众多用户的一致认可。
fastadmin采集器支持长尾关键词生成文章。找到您的网站正确目标关键词 至关重要。每天都有很多人通过搜索引擎找到自己需要的东西,而我们的SEO优化就是为了得到更好的搜索排名,让更多的潜在用户访问你的网站,进而产生交易,带来收益。关键词和长尾关键词的作用尤为重要,fastadmin采集器可以为你提供长尾关键词,流行的关键词。关键词是我们启动fastadmin采集器的第一步,也是最重要的一步。如果你选错了关键词,你会在整个SEO过程中走很多弯路。关键词还不确定,fastadmin的内容采集不能帮助你网站提高你的网站
数据分析。查看 网站 的统计信息,了解可以优化和改进的内容。采集 仅有内容是不够的。比如你采集提交了一个网站内容,如果其他人采集也提交了这个网站内容,那么就会导致内容同质化,导致结果百度没有收录。
fastadmin采集 支持内容优化处理。包括网站栏目设置、关键词布局、内容优化、内外链建设等,fastadmin采集器可以自动采集优质内容并定期发布;并配置多种数据处理选项,让网站内容独一无二,快速增加网站流量!fastadmin采集器采用分布式高速采集系统,多台服务器同时运行,解决了工作学习中大量数据下载和使用的需求,让您拥有更多的时间做更多的事情。
fastadmin采集器,专业的互联网数据采集、处理、分析、挖掘软件,可以灵活、快速的抓取网页上零散的数据信息,并通过一系列的分析处理,精准挖掘出需要的数据数据。
网站的内容,相当于网站成长的土壤和血液。对于站采集,我们不能做原创,但也要长期提供优质的伪原创内容,这也是使用fastadmin采集的必要条件之一@> 作为 采集 站。无论是您的 网站 域选择、网站 主题、网站 模式、网站 色调、网站 图形、网站 关键字、网站@ >@网站及其代码优化等,都需要简洁友好,准确有效,方便流畅,有吸引力,注意不要作弊。否则,即使你的网站流量很高,你也无法留住客户,也无法通过流量变现,一切都是空谈。
使用 fastadmin采集器 建议你应该构建一个对用户有用的 网站,任何优化都是为了改善用户体验。简单的理解就是把用户体验放在第一位,发布有价值的文章内容,文章的标题和内容板块收录有意义的搜索关键词。企业网站做SEO,就是围绕自己提供的服务或产品发布有价值的内容,让更多与你的产品和服务相关的搜索词获得良好的搜索排名。fastadmin采集器 快速挖掘数据中的新客户;洞察竞争对手的业务数据,分析客户行为以拓展新业务,通过精准营销降低风险和预算。今天关于fastadmin的解释采集器
采集 采集(如何下载打开安卓手机应用商店的应用系统?(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2022-03-29 12:24
)
你体验过采集数据吗?采集小队下达任务后,大家带着专用机器前往现场采集,返回后进行内部检查。办公室处理数据以制作地图。这种单机离线采集模式组织松散,团队成员之间沟通不畅,效率很低。
从事野外数据采集是根据点的地理位置,拍照、GPS轨迹、调查表等,将采集得到的各种GIS数据同步到办公GIS软件中,分析和处理。数据报告。
我们都知道,ArcGIS 提供了几个移动端应用程序,例如 ArcGIS Collector 和 ArcGIS QuickCapture,它们真的很好用,功能强大,并且与内部和外部行业同步。但是,需要 ArcGIS Online 帐户,并且该帐户的公共版本是不可接受的。简而言之,它需要钱。,那么除了上面的软件之外,有没有国产的GIS工具可以替代上面的软件呢?
今天给大家介绍一款领域神器。事实上,它用于工程和地质调查。它可以将自己的采集数据同步到内部的GIS软件。下面将简要介绍其具体功能:
1.集成高清卫星图、地质图、电子导航图,支持添加自定义地图。你知道,像歌曲和地图盒这样的地图都可以使用;
2.GPS轨迹记录,还内置指南针、风水指南针(这是Ovie中的vip功能)免费工具;
3.支持导入kml和shp文件,查看行政边界,查看海拔信息,下载离线地图;
4.基于模板形式采集复杂的野外调查数据,并可将采集的数据一键导出至GIS软件进行分析管理;
5.支持扩展定制开发,可用于行业应用系统的快速定制开发。
如何下载
打开安卓手机应用商店,搜索【Fieldwork Wizard app】,搜索结果应该是这样的。
如何使用
事实上,它的使用非常简单。可以探索和探索。页面上只有几个功能键。下面是几个常用的函数:
1、添加底图。默认只有天兔系列图和地质图。既然在外地,我觉得各种高清影像图都是少不了的。同时支持添加第三方互联网地图(谷歌系列地图、mmapbox图片、高德地图、百度地图等),让你的调查如鱼得水。
如果要在地图中添加内部数据和离线地图数据,可以借助新的地图桌面终端将地图数据转换为LRC地图源或LRP格式文件并添加。
2、启用GPS轨迹路径:我猜这是最实用的功能了。打开后会直接采集元素。当然GPS采集参数需要设置,比如多少米采集一个点。
3、拍照:现场拍照最能反映现场情况。这是证据。
4、导出:这里有很多功能,可以导出多种格式的KML/KMZ/SHP,将采集的数据导入桌面端进行数据管理和分析。
查看全部
采集 采集(如何下载打开安卓手机应用商店的应用系统?(组图)
)
你体验过采集数据吗?采集小队下达任务后,大家带着专用机器前往现场采集,返回后进行内部检查。办公室处理数据以制作地图。这种单机离线采集模式组织松散,团队成员之间沟通不畅,效率很低。
从事野外数据采集是根据点的地理位置,拍照、GPS轨迹、调查表等,将采集得到的各种GIS数据同步到办公GIS软件中,分析和处理。数据报告。
我们都知道,ArcGIS 提供了几个移动端应用程序,例如 ArcGIS Collector 和 ArcGIS QuickCapture,它们真的很好用,功能强大,并且与内部和外部行业同步。但是,需要 ArcGIS Online 帐户,并且该帐户的公共版本是不可接受的。简而言之,它需要钱。,那么除了上面的软件之外,有没有国产的GIS工具可以替代上面的软件呢?
今天给大家介绍一款领域神器。事实上,它用于工程和地质调查。它可以将自己的采集数据同步到内部的GIS软件。下面将简要介绍其具体功能:
1.集成高清卫星图、地质图、电子导航图,支持添加自定义地图。你知道,像歌曲和地图盒这样的地图都可以使用;
2.GPS轨迹记录,还内置指南针、风水指南针(这是Ovie中的vip功能)免费工具;
3.支持导入kml和shp文件,查看行政边界,查看海拔信息,下载离线地图;
4.基于模板形式采集复杂的野外调查数据,并可将采集的数据一键导出至GIS软件进行分析管理;
5.支持扩展定制开发,可用于行业应用系统的快速定制开发。
如何下载
打开安卓手机应用商店,搜索【Fieldwork Wizard app】,搜索结果应该是这样的。
如何使用
事实上,它的使用非常简单。可以探索和探索。页面上只有几个功能键。下面是几个常用的函数:
1、添加底图。默认只有天兔系列图和地质图。既然在外地,我觉得各种高清影像图都是少不了的。同时支持添加第三方互联网地图(谷歌系列地图、mmapbox图片、高德地图、百度地图等),让你的调查如鱼得水。
如果要在地图中添加内部数据和离线地图数据,可以借助新的地图桌面终端将地图数据转换为LRC地图源或LRP格式文件并添加。
2、启用GPS轨迹路径:我猜这是最实用的功能了。打开后会直接采集元素。当然GPS采集参数需要设置,比如多少米采集一个点。
3、拍照:现场拍照最能反映现场情况。这是证据。
4、导出:这里有很多功能,可以导出多种格式的KML/KMZ/SHP,将采集的数据导入桌面端进行数据管理和分析。
采集 采集(2.分析行业趋势行业对手网站有哪些优化趋势?在哪些平台发布外链? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-03-14 20:02
)
PHP插件是我们做网站SEO时经常用到的插件。PHP插件是我们在执行文章采集和发布伪原创时可以使用的优化工具,具有自动定时采集和发布功能。无需人工值班即可实现24小时挂机。
PHP插件可以进行全网采集或者指定采集,并且可以为我们提供各种需求的原创素材,我们只需要输入相关热词和一个-点击采集,一次可以创建多个采集任务,同时可以执行多个域名任务采集。采集支持图片水印去除,文章敏感信息去除,多格式存储,支持主要cms,设置规则后自动采集,采集后自动发布@> 或 伪原创publish 推送到搜索引擎。
PHP插件内置翻译功能,可以为需要翻译的用户提供支持。它有一个内置的翻译界面,badu/google/youdao和自己的翻译可供选择。PHP插件允许我们在标题前后和内容中插入相关的词。根据设定的规则,随机插入相关的局部图片。
文章发布成功后主动推送,保证新链接能及时收录;发布任务执行时自动生成内部链接,吸引蜘蛛爬取,让蜘蛛养成定时爬取网页的习惯提高网站收录,我们可以完成网站@的一部分> 通过 PHP 插件进行管理和 SEO。对于一些用工具做不到的优化,我们还是要自己做
1.网站布局优化。
一般来说,如果网站的关键词布局不合理,关键词出现在页面的频率太高,密度不利于优化。这时,我们可以在网站底部的不同区域为关键词创建锚文本。关键词布局只有恰到好处才能帮助排名,否则会适得其反,导致网站被降级的危险。由于搜索引擎蜘蛛抓取信息的顺序是上、左、中、下,所以在设计网站布局时要考虑网站结构和关键词布局的合理性,如以方便优化。
2.分析行业趋势
行业竞争对手网站的优化趋势是什么?外部链接发布在哪些平台上?关键词布局如何?如果我们不知道这些基本的优化连同线,那么两年后网站优化可能不会上首页。只有多了解对方的SEO信息,才能从对方的优化重点出发,设定优化目标,然后超越同行,努力找出对方的不足,自己做出调整,让自己轻松超越对方。
3.关键词交通不真实。
为了快速提升网站关键词的排名,很多站长都会使用各种刷流量的软件。出现这种现象是因为关键词排名靠前,主要是每天有大量的搜索点击,网站的流量权重也会增加。但这种方法不可取。这种作弊一旦被搜索引擎发现,直接K。所以我们还是得在搜索引擎规则范围内使用插件。
4、服务器不稳定因素
我们在购买服务器的时候,可能不会注意很多细节。服务器的基本配置影响网站的整体权重和稳定性。如果搜索引擎蜘蛛抓取你的网站,打不开或者打开速度慢,那么搜索引擎就不会给你一个好的网站排名。因此,建议大家在选择服务器时尽量选择国内备案的、拥有独立IP的服务器站点。
不同的PHP插件实现cms网站可以在软件站观察数据,软件可以直接监控是否已发布,待发布,是否为伪原创,发布状态、网址、节目、发布时间等;软件站每天检查收录、权重、蜘蛛等数据,我们可以通过PHP插件数据获取大量数据进行分析,无论是网站本身还是行业大数据,数据分析可以支持我们的理性判断,是我们SEO流程的重要组成部分。
查看全部
采集 采集(2.分析行业趋势行业对手网站有哪些优化趋势?在哪些平台发布外链?
)
PHP插件是我们做网站SEO时经常用到的插件。PHP插件是我们在执行文章采集和发布伪原创时可以使用的优化工具,具有自动定时采集和发布功能。无需人工值班即可实现24小时挂机。
PHP插件可以进行全网采集或者指定采集,并且可以为我们提供各种需求的原创素材,我们只需要输入相关热词和一个-点击采集,一次可以创建多个采集任务,同时可以执行多个域名任务采集。采集支持图片水印去除,文章敏感信息去除,多格式存储,支持主要cms,设置规则后自动采集,采集后自动发布@> 或 伪原创publish 推送到搜索引擎。
PHP插件内置翻译功能,可以为需要翻译的用户提供支持。它有一个内置的翻译界面,badu/google/youdao和自己的翻译可供选择。PHP插件允许我们在标题前后和内容中插入相关的词。根据设定的规则,随机插入相关的局部图片。
文章发布成功后主动推送,保证新链接能及时收录;发布任务执行时自动生成内部链接,吸引蜘蛛爬取,让蜘蛛养成定时爬取网页的习惯提高网站收录,我们可以完成网站@的一部分> 通过 PHP 插件进行管理和 SEO。对于一些用工具做不到的优化,我们还是要自己做
1.网站布局优化。
一般来说,如果网站的关键词布局不合理,关键词出现在页面的频率太高,密度不利于优化。这时,我们可以在网站底部的不同区域为关键词创建锚文本。关键词布局只有恰到好处才能帮助排名,否则会适得其反,导致网站被降级的危险。由于搜索引擎蜘蛛抓取信息的顺序是上、左、中、下,所以在设计网站布局时要考虑网站结构和关键词布局的合理性,如以方便优化。
2.分析行业趋势
行业竞争对手网站的优化趋势是什么?外部链接发布在哪些平台上?关键词布局如何?如果我们不知道这些基本的优化连同线,那么两年后网站优化可能不会上首页。只有多了解对方的SEO信息,才能从对方的优化重点出发,设定优化目标,然后超越同行,努力找出对方的不足,自己做出调整,让自己轻松超越对方。
3.关键词交通不真实。
为了快速提升网站关键词的排名,很多站长都会使用各种刷流量的软件。出现这种现象是因为关键词排名靠前,主要是每天有大量的搜索点击,网站的流量权重也会增加。但这种方法不可取。这种作弊一旦被搜索引擎发现,直接K。所以我们还是得在搜索引擎规则范围内使用插件。
4、服务器不稳定因素
我们在购买服务器的时候,可能不会注意很多细节。服务器的基本配置影响网站的整体权重和稳定性。如果搜索引擎蜘蛛抓取你的网站,打不开或者打开速度慢,那么搜索引擎就不会给你一个好的网站排名。因此,建议大家在选择服务器时尽量选择国内备案的、拥有独立IP的服务器站点。
不同的PHP插件实现cms网站可以在软件站观察数据,软件可以直接监控是否已发布,待发布,是否为伪原创,发布状态、网址、节目、发布时间等;软件站每天检查收录、权重、蜘蛛等数据,我们可以通过PHP插件数据获取大量数据进行分析,无论是网站本身还是行业大数据,数据分析可以支持我们的理性判断,是我们SEO流程的重要组成部分。
采集(网站能采集吗?采集站怎么做?网站怎么采集?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-02-25 15:24
网站采集是大部分站长都离不开的话题,网站你能采集吗? 网站采集怎么样? 采集怎么办?这些都是站长们非常关心的问题。今天给大家讲讲网站采集,小编在这方面还是有一些研究的,网站采集肯定可以做到的,现在大部分网站全部使用采集,关键是采集的内容处理,以及采集的数据源的选择,很好的解决这些问题,哪怕是纯采集 站。快收录,提升你的排名。
网站采集的所有采集功能都是免费的,并提供开源发布接口。它可以爬取单页和多页,并且可以爬取指定URL的内容。然后使用多线程爬取,多任务多线程快速爬取,提高采集的速度。这启用了批处理采集,无论是列表采集、内容采集、内容发布分步,还是组合批处理采集。
网站采集的数据文章内容存储在Mysql数据库中。广泛使用的Mysql数据库存储将更加轻量和高效。包括图片附件的下载和保存,网站采集可以同时保存远程图片定位。加上附件上传,这允许图像附件自动上传到网站。 网站采集,使用通用的网站接口,无论是WordPresscms还是织梦cms,Empirecms等开源程序无缝兼容。
网站采集同时还具有自动缩略图功能,从内容页面中提取第一页图片作为缩略图,使 节点。 采集节点收到爬虫任务后,从资源池中获取相应的系统资源并立即发起请求,将相应的数据发送给目标网站采集,同时启动数据cleaner,并根据相应的数据清洗规则对数据进行清洗。
网站采集完成数据采集后,将对应的结果返回给服务器。为了保证数据能够以最快的速度采集,系统会将采集任务推送到各个算子的采集网络节点,同步发起网络请求。保证可以一直使用最优的网络节点,对应的数据能以最快的速度采集。
网站采集的文章分享就写到这里,希望对广大站长有所帮助。 网站采集并不是唯一的建站方式,而是更方便快捷的方式。单独采集,网站肯定起不来,必须结合SEO优化对网站整体进行优化,才能达到优化效果。返回搜狐,查看更多 查看全部
采集(网站能采集吗?采集站怎么做?网站怎么采集?)
网站采集是大部分站长都离不开的话题,网站你能采集吗? 网站采集怎么样? 采集怎么办?这些都是站长们非常关心的问题。今天给大家讲讲网站采集,小编在这方面还是有一些研究的,网站采集肯定可以做到的,现在大部分网站全部使用采集,关键是采集的内容处理,以及采集的数据源的选择,很好的解决这些问题,哪怕是纯采集 站。快收录,提升你的排名。
网站采集的所有采集功能都是免费的,并提供开源发布接口。它可以爬取单页和多页,并且可以爬取指定URL的内容。然后使用多线程爬取,多任务多线程快速爬取,提高采集的速度。这启用了批处理采集,无论是列表采集、内容采集、内容发布分步,还是组合批处理采集。
网站采集的数据文章内容存储在Mysql数据库中。广泛使用的Mysql数据库存储将更加轻量和高效。包括图片附件的下载和保存,网站采集可以同时保存远程图片定位。加上附件上传,这允许图像附件自动上传到网站。 网站采集,使用通用的网站接口,无论是WordPresscms还是织梦cms,Empirecms等开源程序无缝兼容。
网站采集同时还具有自动缩略图功能,从内容页面中提取第一页图片作为缩略图,使 节点。 采集节点收到爬虫任务后,从资源池中获取相应的系统资源并立即发起请求,将相应的数据发送给目标网站采集,同时启动数据cleaner,并根据相应的数据清洗规则对数据进行清洗。
网站采集完成数据采集后,将对应的结果返回给服务器。为了保证数据能够以最快的速度采集,系统会将采集任务推送到各个算子的采集网络节点,同步发起网络请求。保证可以一直使用最优的网络节点,对应的数据能以最快的速度采集。
网站采集的文章分享就写到这里,希望对广大站长有所帮助。 网站采集并不是唯一的建站方式,而是更方便快捷的方式。单独采集,网站肯定起不来,必须结合SEO优化对网站整体进行优化,才能达到优化效果。返回搜狐,查看更多
采集(想用Drupal采集插件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2022-02-03 13:04
如果要使用 Drupal采集 插件,可以先下载雅爱园 Drupal采集器 发行版,安装,即可使用。里面有详细的文档。雅爱源 Drupal采集器,使用标准的Drupal模块,是完全开源的,但是为了支持中文采集,部分模块做了修改。
我们来介绍一下雅爱园Drupal中采集相关的模块插件采集器:
1、Feeds模块,这个是主模块,是用来导入数据的,开始是收RSS数据,后来发展到导入各种数据,后来发现基于这个模块,可以用于采集网页信息。
2、job_scheduler模块,这是Feeds模块依赖的插件,采集期间的任务调度,很多时候需要依赖这个模块。
3、feeds_tamper模块,该模块用于导入数据时对数据进行预处理,也就是清理工作,非常有用的帮助模块。 采集网页数据必备模块。
4、feeds_xpathparser模块,该模块允许我们使用Xpath规则来解析数据。来自网页 采集 的数据是 HTML 格式,需要使用 Xpath 规则进行解析。这也是必备模块之一。
5、feeds_crawler模块,这是一个小型爬虫,方便采集各种分页列表,非常好用,网页爬取必备模块。
6、feeds_smartparser模块,智能提取HTML页面全文,是网页必备模块之一采集。
7、feeds_selfnode_processor模块,来自采集的节点本身也是一个feed种子。它可以通过HTTP请求捕获更详细的信息,改进自己的节点,是网页的必备模块之一采集。
8、Views/Ctools视图数据导出,将网页采集中的数据导出为各种格式,支持XML、CSV、Excel。
9、feeds_spider模块,采集蜘蛛,类似于feeds_crawler,网页采集模块之一。
相信在熟悉了以上模块之后,即使没有 Drupal采集器,你也可以构建自己的采集网站。
Aiyuan Drupal采集器是基于以上标准模块构建的,结合我们的实际经验,做一个有用的总结和归纳。 查看全部
采集(想用Drupal采集插件)
如果要使用 Drupal采集 插件,可以先下载雅爱园 Drupal采集器 发行版,安装,即可使用。里面有详细的文档。雅爱源 Drupal采集器,使用标准的Drupal模块,是完全开源的,但是为了支持中文采集,部分模块做了修改。
我们来介绍一下雅爱园Drupal中采集相关的模块插件采集器:
1、Feeds模块,这个是主模块,是用来导入数据的,开始是收RSS数据,后来发展到导入各种数据,后来发现基于这个模块,可以用于采集网页信息。
2、job_scheduler模块,这是Feeds模块依赖的插件,采集期间的任务调度,很多时候需要依赖这个模块。
3、feeds_tamper模块,该模块用于导入数据时对数据进行预处理,也就是清理工作,非常有用的帮助模块。 采集网页数据必备模块。
4、feeds_xpathparser模块,该模块允许我们使用Xpath规则来解析数据。来自网页 采集 的数据是 HTML 格式,需要使用 Xpath 规则进行解析。这也是必备模块之一。
5、feeds_crawler模块,这是一个小型爬虫,方便采集各种分页列表,非常好用,网页爬取必备模块。
6、feeds_smartparser模块,智能提取HTML页面全文,是网页必备模块之一采集。
7、feeds_selfnode_processor模块,来自采集的节点本身也是一个feed种子。它可以通过HTTP请求捕获更详细的信息,改进自己的节点,是网页的必备模块之一采集。
8、Views/Ctools视图数据导出,将网页采集中的数据导出为各种格式,支持XML、CSV、Excel。
9、feeds_spider模块,采集蜘蛛,类似于feeds_crawler,网页采集模块之一。
相信在熟悉了以上模块之后,即使没有 Drupal采集器,你也可以构建自己的采集网站。
Aiyuan Drupal采集器是基于以上标准模块构建的,结合我们的实际经验,做一个有用的总结和归纳。
采集 采集(6个K8s日志系统建设中的典型问题,你遇到过几个?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-12-06 19:19
作者 | 元一阿里云存储服务技术专家
简介:上一篇文章主要介绍了Kubernetes日志输出的一些注意事项。日志输出的最终目的是做统一的采集和分析。在 Kubernetes 中,采集 的日志记录方法与普通虚拟机有很大不同。实现的相对难度和部署成本也略高。但是,如果使用得当,它将比传统方法更加自动化且成本更低。本文为文章期刊系列第4篇。
第一篇:《K8s日志系统构建中的6个典型问题,你遇到了几个?》
第二章:《一篇了解K8s日志系统的设计与实践》
第3章:《解决K8s日志输出问题的九个技巧》
Kubernetes 日志 采集 难点
在 Kubernetes 中,日志记录 采集 比传统的虚拟机和物理机复杂得多。最根本的原因是Kubernetes屏蔽了底层的异常,提供更细粒度的资源调度,向上提供稳定动态的环境。所以日志采集面临着更丰富、更动态的环境,需要考虑的点也更多。
例如:
Kubernetes 传统方式
日志类型
文件、标准输出、主机文件、日志
档案、日记
日志来源
业务容器、系统组件、主机
商务、主持人
采集方法
代理(Sidecar、DaemonSet)、直写(DockerEngine、业务)
代理,直接写作
单机应用数量
10-100
1-10
应用动态
高的
低的
节点动态
高的
低的
采集部署方式
手册,Yaml
手动、定制
采集方法:主动或被动
日志的采集方式分为被动采集和主动推送。在K8s中,被动采集一般分为Sidecar和DaemonSet两种方法。主动推送包括DockerEngine推送和业务直推。用两种方式写。
总结一下:
各种采集方法的详细对比如下:
DockerEngine 业务直接写入 DaemonSet 模式 Sidecar 模式
采集日志类型
标准输出
业务日志
标准输出+文件的一部分
文档
部署运维
低,本机支持
低,只需要维护好配置文件
一般需要维护DaemonSet
高,每个需要采集日志的POD都需要部署一个sidecar容器
日志分类存储
达不到
业务独立配置
一般可以通过容器/路径等方式映射。
每个POD可单独配置,灵活性高
多租户隔离
虚弱的
弱,日志直写会与业务逻辑竞争资源
一般只能通过配置室隔离
强,容器隔离,可单独分配资源
支持集群大小
无限本地存储,如果使用syslog、fluentd,会有单点限制
无限
取决于配置的数量
无限
资源占用
低,码头工人
引擎提供
总体最低,节省 采集 开销
下层,每个节点运行一个容器
更高,每个 POD 运行一个容器
查询方便
低,只能grep原创日志
高,可根据业务特点定制
高,可自定义查询统计
高,可根据业务特点定制
可定制
低的
高,可自由扩展
低的
高,每个POD单独配置
耦合
高,与DockerEngine强绑定,修改需要重启DockerEngine
高,采集模块修改/升级需要重新发布业务
低,Agent可独立升级
一般默认采集Sidecar服务对应的Agent升级也会重启(有一些扩展包可以支持Sidecar热升级)
适用场景
非生产场景,例如测试和 POC
对性能要求极高的场景
一个日志分类清晰、功能单一的集群
大规模、混合、PAAS 类型的集群
日志输出:标准输出或文件
与虚拟机/物理机不同,K8s 容器提供标准输出和文件格式。在容器中,标准输出将日志直接输出到stdout或stderr,而DockerEngine接管stdout和stderr文件描述符,接收后根据DockerEngine配置的LogDriver规则对日志进行处理;日志打印到文件和虚拟机/物理机基本相似,只是日志可以使用不同的存储方式,比如默认存储、EmptyDir、HostVolume、NFS等。
虽然Docker官方推荐使用Stdout打印日志,但是大家需要注意:这个推荐是基于容器只作为简单应用的场景。在实际业务场景中,我们仍然建议您尽可能使用文件。主要有以下几点原因:
因此,我们推荐在线应用使用文件输出日志。Stdout 仅用于功能单一的应用或一些 K8s 系统/运维组件。
CICD 集成:日志操作员
Kubernetes 提供了标准化的业务部署方式。您可以使用yaml(K8s API)来声明路由规则、暴露服务、挂载存储、运行业务、定义伸缩规则等,因此Kubernetes很容易与CICD系统集成。日志采集也是运维监控过程的重要组成部分,所有业务上线后的日志都要实时采集。
原来的方法是在发布后手动部署日志采集的逻辑。这种方法需要人工干预,违背了CICD自动化的目的;为了实现自动化,有人开始根据日志打包API/SDK 采集 一个自动部署的服务在发布后通过CICD的webhook调用,但是这种方式的开发成本很高。
在 Kubernetes 中,最标准的日志集成方式是在 Kubernetes 系统中注册一个新的资源,并以 Operator(CRD)的形式对其进行管理和维护。这样CICD系统不需要额外的开发,部署到Kubernetes系统时只需要附加日志相关的配置就可以实现。
Kubernetes 日志采集 方案
早在Kubernetes出现之前,我们就开始针对容器环境开发日志采集解决方案。随着K8s的逐渐稳定,我们开始将很多业务迁移到K8s平台上,所以我们也在之前的基础上开发了一套。K8s 上的日志 采集 方案。主要功能是:
安装日志采集组件
目前,这个采集计划是对公众开放的。我们提供了一个 Helm 安装包,其中包括 Logtail 的 DaemonSet、AliyunlogConfig 的 CRD 语句和 CRD Controller。安装后可以直接使用DaemonSet采集和CRD配置NS。安装方法如下:
阿里云Kubernetes集群可以通过勾选激活时间来安装,这样在集群创建时会自动安装上述组件。如果激活时没有安装,可以手动安装;如果是自建Kubernetes,无论是在阿里云、其他云还是离线自建,也可以使用这个采集方案,具体安装方法参考自建Kubernetes安装。
安装完以上组件后,Logtail和对应的Controller会在集群中运行,但是这些组件默认不会采集任何日志,需要将日志采集规则配置为采集指定 Pod 的各种日志。
采集规则配置:环境变量或CRD
除了在日志服务控制台手动配置外,Kubernetes 还支持两种额外的配置方式:环境变量和 CRD。
该方法部署简单,学习成本低,易学;但是能支持的配置规则很少,很多高级配置(比如解析方法、过滤方法、黑白名单等)都不支持,而且这种声明方式不支持修改/删除,每次修改实际上创建了一个新的 采集 配置。历史采集配置需要手动清理,否则会造成资源浪费。
比如下面的例子是部署一个容器标准输出采集,其中定义要求Stdout和Stderr都为采集,排除环境变量中收录COLLEXT_STDOUT_FLAG:false的容器。
基于CRD的配置方式采用Kubernetes标准资源扩展的方式进行管理,支持完整的配置增删改语义,支持各种高级配置。这是我们强烈推荐的 采集 配置方法。
采集规则的推荐配置方法
在实际应用场景中,一般使用DaemonSet或者DaemonSet和Sidecar的混合。DaemonSet 的优点是资源利用率高。但是存在DaemonSet的所有Logtail共享全局配置的问题,单个Logtail有配置支持的上限。因此,无法支持具有大量应用程序的集群。
以上是我们推荐的配置方式,核心思想是:
实践1-中小型集群
Kubernetes集群绝大多数都是中小型的,中小型并没有明确的定义。一般申请数量小于500,节点大小小于1000。没有功能明确的Kubernetes平台运维。这个场景的应用数量不是特别多,DaemonSet 可以支持所有的采集配置:
练习 2-大型集群
对于一些作为PaaS平台的大型/超大型集群,一般业务在1000以上,节点规模也在1000以上,有专门的Kubernetes平台运维人员。本场景应用数量没有限制,DaemonSet 无法支持,所以必须使用Sidecar。总体规划如下:
有阿里巴巴团队需要你!
云原生应用平台诚邀Kubernetes/容器/Serverless/应用交付技术专家(P7-P8)加入。
简历投递:xining.zj AT。
“阿里云原生专注于微服务、Serverless、容器、Service Mesh等技术领域,关注云原生流行技术趋势、云原生大规模落地实践,是最了解云原生开发者的技术圈.” 查看全部
采集 采集(6个K8s日志系统建设中的典型问题,你遇到过几个?)
作者 | 元一阿里云存储服务技术专家
简介:上一篇文章主要介绍了Kubernetes日志输出的一些注意事项。日志输出的最终目的是做统一的采集和分析。在 Kubernetes 中,采集 的日志记录方法与普通虚拟机有很大不同。实现的相对难度和部署成本也略高。但是,如果使用得当,它将比传统方法更加自动化且成本更低。本文为文章期刊系列第4篇。
第一篇:《K8s日志系统构建中的6个典型问题,你遇到了几个?》
第二章:《一篇了解K8s日志系统的设计与实践》
第3章:《解决K8s日志输出问题的九个技巧》
Kubernetes 日志 采集 难点
在 Kubernetes 中,日志记录 采集 比传统的虚拟机和物理机复杂得多。最根本的原因是Kubernetes屏蔽了底层的异常,提供更细粒度的资源调度,向上提供稳定动态的环境。所以日志采集面临着更丰富、更动态的环境,需要考虑的点也更多。
例如:
Kubernetes 传统方式
日志类型
文件、标准输出、主机文件、日志
档案、日记
日志来源
业务容器、系统组件、主机
商务、主持人
采集方法
代理(Sidecar、DaemonSet)、直写(DockerEngine、业务)
代理,直接写作
单机应用数量
10-100
1-10
应用动态
高的
低的
节点动态
高的
低的
采集部署方式
手册,Yaml
手动、定制
采集方法:主动或被动
日志的采集方式分为被动采集和主动推送。在K8s中,被动采集一般分为Sidecar和DaemonSet两种方法。主动推送包括DockerEngine推送和业务直推。用两种方式写。
总结一下:
各种采集方法的详细对比如下:
DockerEngine 业务直接写入 DaemonSet 模式 Sidecar 模式
采集日志类型
标准输出
业务日志
标准输出+文件的一部分
文档
部署运维
低,本机支持
低,只需要维护好配置文件
一般需要维护DaemonSet
高,每个需要采集日志的POD都需要部署一个sidecar容器
日志分类存储
达不到
业务独立配置
一般可以通过容器/路径等方式映射。
每个POD可单独配置,灵活性高
多租户隔离
虚弱的
弱,日志直写会与业务逻辑竞争资源
一般只能通过配置室隔离
强,容器隔离,可单独分配资源
支持集群大小
无限本地存储,如果使用syslog、fluentd,会有单点限制
无限
取决于配置的数量
无限
资源占用
低,码头工人
引擎提供
总体最低,节省 采集 开销
下层,每个节点运行一个容器
更高,每个 POD 运行一个容器
查询方便
低,只能grep原创日志
高,可根据业务特点定制
高,可自定义查询统计
高,可根据业务特点定制
可定制
低的
高,可自由扩展
低的
高,每个POD单独配置
耦合
高,与DockerEngine强绑定,修改需要重启DockerEngine
高,采集模块修改/升级需要重新发布业务
低,Agent可独立升级
一般默认采集Sidecar服务对应的Agent升级也会重启(有一些扩展包可以支持Sidecar热升级)
适用场景
非生产场景,例如测试和 POC
对性能要求极高的场景
一个日志分类清晰、功能单一的集群
大规模、混合、PAAS 类型的集群
日志输出:标准输出或文件
与虚拟机/物理机不同,K8s 容器提供标准输出和文件格式。在容器中,标准输出将日志直接输出到stdout或stderr,而DockerEngine接管stdout和stderr文件描述符,接收后根据DockerEngine配置的LogDriver规则对日志进行处理;日志打印到文件和虚拟机/物理机基本相似,只是日志可以使用不同的存储方式,比如默认存储、EmptyDir、HostVolume、NFS等。
虽然Docker官方推荐使用Stdout打印日志,但是大家需要注意:这个推荐是基于容器只作为简单应用的场景。在实际业务场景中,我们仍然建议您尽可能使用文件。主要有以下几点原因:
因此,我们推荐在线应用使用文件输出日志。Stdout 仅用于功能单一的应用或一些 K8s 系统/运维组件。
CICD 集成:日志操作员
Kubernetes 提供了标准化的业务部署方式。您可以使用yaml(K8s API)来声明路由规则、暴露服务、挂载存储、运行业务、定义伸缩规则等,因此Kubernetes很容易与CICD系统集成。日志采集也是运维监控过程的重要组成部分,所有业务上线后的日志都要实时采集。
原来的方法是在发布后手动部署日志采集的逻辑。这种方法需要人工干预,违背了CICD自动化的目的;为了实现自动化,有人开始根据日志打包API/SDK 采集 一个自动部署的服务在发布后通过CICD的webhook调用,但是这种方式的开发成本很高。
在 Kubernetes 中,最标准的日志集成方式是在 Kubernetes 系统中注册一个新的资源,并以 Operator(CRD)的形式对其进行管理和维护。这样CICD系统不需要额外的开发,部署到Kubernetes系统时只需要附加日志相关的配置就可以实现。
Kubernetes 日志采集 方案
早在Kubernetes出现之前,我们就开始针对容器环境开发日志采集解决方案。随着K8s的逐渐稳定,我们开始将很多业务迁移到K8s平台上,所以我们也在之前的基础上开发了一套。K8s 上的日志 采集 方案。主要功能是:
安装日志采集组件
目前,这个采集计划是对公众开放的。我们提供了一个 Helm 安装包,其中包括 Logtail 的 DaemonSet、AliyunlogConfig 的 CRD 语句和 CRD Controller。安装后可以直接使用DaemonSet采集和CRD配置NS。安装方法如下:
阿里云Kubernetes集群可以通过勾选激活时间来安装,这样在集群创建时会自动安装上述组件。如果激活时没有安装,可以手动安装;如果是自建Kubernetes,无论是在阿里云、其他云还是离线自建,也可以使用这个采集方案,具体安装方法参考自建Kubernetes安装。
安装完以上组件后,Logtail和对应的Controller会在集群中运行,但是这些组件默认不会采集任何日志,需要将日志采集规则配置为采集指定 Pod 的各种日志。
采集规则配置:环境变量或CRD
除了在日志服务控制台手动配置外,Kubernetes 还支持两种额外的配置方式:环境变量和 CRD。
该方法部署简单,学习成本低,易学;但是能支持的配置规则很少,很多高级配置(比如解析方法、过滤方法、黑白名单等)都不支持,而且这种声明方式不支持修改/删除,每次修改实际上创建了一个新的 采集 配置。历史采集配置需要手动清理,否则会造成资源浪费。
比如下面的例子是部署一个容器标准输出采集,其中定义要求Stdout和Stderr都为采集,排除环境变量中收录COLLEXT_STDOUT_FLAG:false的容器。
基于CRD的配置方式采用Kubernetes标准资源扩展的方式进行管理,支持完整的配置增删改语义,支持各种高级配置。这是我们强烈推荐的 采集 配置方法。
采集规则的推荐配置方法
在实际应用场景中,一般使用DaemonSet或者DaemonSet和Sidecar的混合。DaemonSet 的优点是资源利用率高。但是存在DaemonSet的所有Logtail共享全局配置的问题,单个Logtail有配置支持的上限。因此,无法支持具有大量应用程序的集群。
以上是我们推荐的配置方式,核心思想是:
实践1-中小型集群
Kubernetes集群绝大多数都是中小型的,中小型并没有明确的定义。一般申请数量小于500,节点大小小于1000。没有功能明确的Kubernetes平台运维。这个场景的应用数量不是特别多,DaemonSet 可以支持所有的采集配置:
练习 2-大型集群
对于一些作为PaaS平台的大型/超大型集群,一般业务在1000以上,节点规模也在1000以上,有专门的Kubernetes平台运维人员。本场景应用数量没有限制,DaemonSet 无法支持,所以必须使用Sidecar。总体规划如下:
有阿里巴巴团队需要你!
云原生应用平台诚邀Kubernetes/容器/Serverless/应用交付技术专家(P7-P8)加入。
简历投递:xining.zj AT。
“阿里云原生专注于微服务、Serverless、容器、Service Mesh等技术领域,关注云原生流行技术趋势、云原生大规模落地实践,是最了解云原生开发者的技术圈.”
采集(网络信息采集指可以将因特网上的网站采集保存到用户的本地数据库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 245 次浏览 • 2021-10-05 19:15
网络信息采集是指可以将Internet上的网站信息采集保存在用户的本地数据库中。它具有以下功能: 规则定义——通过采集规则的定义,可以搜索到几乎所有的网站采集信息。多任务,多线程-多信息采集任务可以同时执行,每个任务可以使用多个线程。所见即所得——所见即所得,在任务采集过程中得到。过程中遍历的链接信息、采集信息、错误信息等都会及时反映在软件界面中。数据存储——数据在采集的同时自动保存到关系数据库中,数据结构可以自动适配。软件可以根据采集的规则自动创建数据库,以及里面的表和字段,也可以灵活设置将数据保存到客户现有的数据库结构中,所有这些都不会对您的数据库和生产造成任何不利影响。Breakpoint Resuming-Information 采集 任务可以在停止采集后从断点继续。从此,您再也不用担心您的采集 任务会被意外中断。网站Login-支持网站登录,并支持网站Cookie,即使需要验证登录,网站也能轻松通过。自动信息识别-提供多种预定义的信息类型,如Email地址、电话号码、号码等。用户可以通过简单的选择,从海量的网络信息中提取特定的信息。文件下载-您可以从采集下载二进制文件(如图片、音乐、软件、文档等)到本地磁盘或采集结果数据库。采集结果分类-可以根据用户定义的分类信息自动对采集结果进行分类。 查看全部
采集(网络信息采集指可以将因特网上的网站采集保存到用户的本地数据库)
网络信息采集是指可以将Internet上的网站信息采集保存在用户的本地数据库中。它具有以下功能: 规则定义——通过采集规则的定义,可以搜索到几乎所有的网站采集信息。多任务,多线程-多信息采集任务可以同时执行,每个任务可以使用多个线程。所见即所得——所见即所得,在任务采集过程中得到。过程中遍历的链接信息、采集信息、错误信息等都会及时反映在软件界面中。数据存储——数据在采集的同时自动保存到关系数据库中,数据结构可以自动适配。软件可以根据采集的规则自动创建数据库,以及里面的表和字段,也可以灵活设置将数据保存到客户现有的数据库结构中,所有这些都不会对您的数据库和生产造成任何不利影响。Breakpoint Resuming-Information 采集 任务可以在停止采集后从断点继续。从此,您再也不用担心您的采集 任务会被意外中断。网站Login-支持网站登录,并支持网站Cookie,即使需要验证登录,网站也能轻松通过。自动信息识别-提供多种预定义的信息类型,如Email地址、电话号码、号码等。用户可以通过简单的选择,从海量的网络信息中提取特定的信息。文件下载-您可以从采集下载二进制文件(如图片、音乐、软件、文档等)到本地磁盘或采集结果数据库。采集结果分类-可以根据用户定义的分类信息自动对采集结果进行分类。
采集( 云捕获客源采集软件的特点及开发方法介绍-苏州安嘉)
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-08-29 22:09
云捕获客源采集软件的特点及开发方法介绍-苏州安嘉)
客户source采集软件操作简单,不懂技术也能轻松操作。只需输入列表页面的 URL 或关键字即可开始采集。无需关心Web源代码,全程鼠标操作。操作界面友好直观。全程智能帮助。功能齐全,功能强大 该软件虽然操作简单,但功能强大,功能全面。可以实现各种复杂的采集需求。多功能采集软件,可用于各种应用。
客户source采集software 可以采集任何网页。只要你能在浏览器中看到内容,几乎所有的网页都可以采集到你需要的格式。
支持JS输出内容的采集。快速采集速度和高数据完整性优采云采集器速度是采集软件中最快的速度之一。
独特的多模板功能+智能纠错模式,保证结果数据100%完整。
Keyuan采集software 具有以下特点:
一键获取
客户source采集software输入获取portal网站URL即可完成并开始采集,输入关键词搜索获取全网。
云捕获
Keyuan采集software。独有的基于点对点网络架构的云端采集功能,解决采集IP封存的行业难题。
多模板自适应
项目可以配置多个模板,运行时软件会自动选择最适合采集匹配的模块。
多功能仿真发布
无需开发针对性发布接口文件,适配任何网站cms后台,使用手动发布页面模拟手动发布。
内容相似度判断基于内容相似度来判断文章的重复性,准确率高。
可以列出相似的文章并输出文章的核心关键字。客户源采集软件可以帮您采集获取您想要的客户电话等信息,相当于一个电话采集软件。
支持复杂的数据关系,支持父子结构的数据逻辑关系。
复杂数据,采集一次完成,采集结果保留原创数据的逻辑关系。 查看全部
采集(
云捕获客源采集软件的特点及开发方法介绍-苏州安嘉)
客户source采集软件操作简单,不懂技术也能轻松操作。只需输入列表页面的 URL 或关键字即可开始采集。无需关心Web源代码,全程鼠标操作。操作界面友好直观。全程智能帮助。功能齐全,功能强大 该软件虽然操作简单,但功能强大,功能全面。可以实现各种复杂的采集需求。多功能采集软件,可用于各种应用。
客户source采集software 可以采集任何网页。只要你能在浏览器中看到内容,几乎所有的网页都可以采集到你需要的格式。
支持JS输出内容的采集。快速采集速度和高数据完整性优采云采集器速度是采集软件中最快的速度之一。
独特的多模板功能+智能纠错模式,保证结果数据100%完整。
Keyuan采集software 具有以下特点:
一键获取
客户source采集software输入获取portal网站URL即可完成并开始采集,输入关键词搜索获取全网。
云捕获
Keyuan采集software。独有的基于点对点网络架构的云端采集功能,解决采集IP封存的行业难题。
多模板自适应
项目可以配置多个模板,运行时软件会自动选择最适合采集匹配的模块。
多功能仿真发布
无需开发针对性发布接口文件,适配任何网站cms后台,使用手动发布页面模拟手动发布。
内容相似度判断基于内容相似度来判断文章的重复性,准确率高。
可以列出相似的文章并输出文章的核心关键字。客户源采集软件可以帮您采集获取您想要的客户电话等信息,相当于一个电话采集软件。
支持复杂的数据关系,支持父子结构的数据逻辑关系。
复杂数据,采集一次完成,采集结果保留原创数据的逻辑关系。
采集( 天目MVC采集程序伪静态版安装地址)
采集交流 • 优采云 发表了文章 • 0 个评论 • 269 次浏览 • 2021-08-29 22:08
天目MVC采集程序伪静态版安装地址)
天木MVC采集plugin v2.03 日期:2021/4/16 8:59:15
小偷采集|共享版本 |大小:27KB |环境:PHP/Mysql |人气:757
天牧MVC采集插件依赖天牧MVC网站管理系统或天牧MVC网站管理系统首页版本运行下载上述任一版本,然后将此子插件复制到应用程序/插件/目录。上述程序安装完毕后,进入后台网站settings-plugin管理进行安装。 ...
随风PHP百度自动问答采集(免维护)v10.8 日期:2021/3/25 8:59:55
小偷采集|试用版 |大小:5.37MB |环境:Linux/PHP/Mysql |人气:1193
随峰PHP问答采集云版使用THINKPHP框架,PHP语言开发,支持LINUX、WINDOWS环境,不用数据库也能正常运行。服务器、虚拟主机和 VPS 都可以运行。如果需要伪静态,则需要空间或服务器支持伪静态。此外,目前还有一些...
大全洲人才网全站采集程序假静版v1.4 日期:2021/2/19 10:17:12
小偷采集 |开源软件 |大小:17KB |环境:PHP |人气:42
大泉州人才网全站采集program 伪静态版是利用最新技术,用几个K文件获取泉州人才网全站海量数据的文档(有上万名企业会员)和超过 100,000 个招聘数据))。轻巧,方便,但功能强大。文件说明:index.php--主站程序m.php--移动版...
大全洲人才网网站采集程序 v1.4 日期:1/28/2021 8:55:20
小偷采集 |开源软件 |大小:15KB |环境:PHP |人气:364
大泉州人才网采集程序是一个利用最新技术,用几个K文件获取泉州人才网海量数据(企业会员数万,招聘数据超10万条)采集的程序@网站系统。轻巧,方便,但功能强大。注:1.必须改index.php、news.php...
优采云采集器 v2.3.3 日期:2020/7/28 13:38:06
小偷采集|免费版 |大小:8.11MB |环境:PHP/Mysql |人气:16222
优采云采集器是一款免费的数据发布软件采集,可以部署在云服务器上,几乎可以采集所有类型的网页,无缝对接各种cms建站程序,无需登录 实时发布数据,软件实现定时定量自动采集发布,无需人工干预!大数据、云时代网站数...
通用镜像系统 v6.21 Date: 2020/1/13 9:49:24
小偷采集|共享版本 |大小:560KB |环境:PHP |人气:11602
万能镜像系统可通过输入目标站地址全自动采集,高智能采集程序,支持子域名自动采集,支持站点高达98%。规则制作非常简单,新手也可以制作。 采集rule,采集不求人-ftp上传需要使用二进制上传方式,请百度-数据正文...
网站publication network (release number) v2.0 日期:2019/9/2 9:26:58
小偷采集|共享版本 |大小:118KB |环境:PHP |人气:803
几个文件,一下子有很多新闻,新闻不时更新,大图,快,下个版本会采集JSON无限加载,几乎整个网站采集都过来了已添加图片加载以改善用户体验。更改说明:LOGO:images/logo.png右侧浮动广告:right.html网站common bottom:foot.ht...
隋峰百度经验采集系统 v1.0 日期:2019/5/15 11:21:15
小偷采集|共享版本 |大小:1.26MB |环境:PHP |人气:431
安装说明,“此版本为测试版,如有需要请联系作者qq” 本程序使用PHP大于5.3(包括5.3)用THINKPHP框架PHP语言编写,安装时不加使用数据库,直接将源码转移到支持PHP语言的空间或服务器,运行index.php即可,以上配置完成...
隋峰百度知道(thief采集)免维护v2.0.0X 日期:2018/7/13 10:47:33
小偷采集|试用版 |大小:13KB |环境:PHP/MSSQL |人气:4210
随风百度知道(thief采集)免维护自动采集百度信息。软件介绍:1、可自定义关键词2、无需人工输入信息,自动系统采集3、支持缓存,减少服务器资源。 (本程序需要安装伪静态插件)有不懂的请联系QQ。当前版本是测试版,购买商业版...
通用简单api接口 v0.1 Date: 2018/5/11 10:42:41
小偷采集 |共享版本 |大小:1KB |环境:PHP |人气:1348
功能介绍:1.api.php放置在需要实现api功能的站点中,调用数据库信息,生成json2.client.php文件放置在站点文件中即需要调用api,解析api.php生成的json实现远程调用api的功能。 查看全部
采集(
天目MVC采集程序伪静态版安装地址)
天木MVC采集plugin v2.03 日期:2021/4/16 8:59:15
小偷采集|共享版本 |大小:27KB |环境:PHP/Mysql |人气:757
天牧MVC采集插件依赖天牧MVC网站管理系统或天牧MVC网站管理系统首页版本运行下载上述任一版本,然后将此子插件复制到应用程序/插件/目录。上述程序安装完毕后,进入后台网站settings-plugin管理进行安装。 ...
随风PHP百度自动问答采集(免维护)v10.8 日期:2021/3/25 8:59:55
小偷采集|试用版 |大小:5.37MB |环境:Linux/PHP/Mysql |人气:1193
随峰PHP问答采集云版使用THINKPHP框架,PHP语言开发,支持LINUX、WINDOWS环境,不用数据库也能正常运行。服务器、虚拟主机和 VPS 都可以运行。如果需要伪静态,则需要空间或服务器支持伪静态。此外,目前还有一些...
大全洲人才网全站采集程序假静版v1.4 日期:2021/2/19 10:17:12
小偷采集 |开源软件 |大小:17KB |环境:PHP |人气:42
大泉州人才网全站采集program 伪静态版是利用最新技术,用几个K文件获取泉州人才网全站海量数据的文档(有上万名企业会员)和超过 100,000 个招聘数据))。轻巧,方便,但功能强大。文件说明:index.php--主站程序m.php--移动版...
大全洲人才网网站采集程序 v1.4 日期:1/28/2021 8:55:20
小偷采集 |开源软件 |大小:15KB |环境:PHP |人气:364
大泉州人才网采集程序是一个利用最新技术,用几个K文件获取泉州人才网海量数据(企业会员数万,招聘数据超10万条)采集的程序@网站系统。轻巧,方便,但功能强大。注:1.必须改index.php、news.php...
优采云采集器 v2.3.3 日期:2020/7/28 13:38:06
小偷采集|免费版 |大小:8.11MB |环境:PHP/Mysql |人气:16222
优采云采集器是一款免费的数据发布软件采集,可以部署在云服务器上,几乎可以采集所有类型的网页,无缝对接各种cms建站程序,无需登录 实时发布数据,软件实现定时定量自动采集发布,无需人工干预!大数据、云时代网站数...
通用镜像系统 v6.21 Date: 2020/1/13 9:49:24
小偷采集|共享版本 |大小:560KB |环境:PHP |人气:11602
万能镜像系统可通过输入目标站地址全自动采集,高智能采集程序,支持子域名自动采集,支持站点高达98%。规则制作非常简单,新手也可以制作。 采集rule,采集不求人-ftp上传需要使用二进制上传方式,请百度-数据正文...
网站publication network (release number) v2.0 日期:2019/9/2 9:26:58
小偷采集|共享版本 |大小:118KB |环境:PHP |人气:803
几个文件,一下子有很多新闻,新闻不时更新,大图,快,下个版本会采集JSON无限加载,几乎整个网站采集都过来了已添加图片加载以改善用户体验。更改说明:LOGO:images/logo.png右侧浮动广告:right.html网站common bottom:foot.ht...
隋峰百度经验采集系统 v1.0 日期:2019/5/15 11:21:15
小偷采集|共享版本 |大小:1.26MB |环境:PHP |人气:431
安装说明,“此版本为测试版,如有需要请联系作者qq” 本程序使用PHP大于5.3(包括5.3)用THINKPHP框架PHP语言编写,安装时不加使用数据库,直接将源码转移到支持PHP语言的空间或服务器,运行index.php即可,以上配置完成...
隋峰百度知道(thief采集)免维护v2.0.0X 日期:2018/7/13 10:47:33
小偷采集|试用版 |大小:13KB |环境:PHP/MSSQL |人气:4210
随风百度知道(thief采集)免维护自动采集百度信息。软件介绍:1、可自定义关键词2、无需人工输入信息,自动系统采集3、支持缓存,减少服务器资源。 (本程序需要安装伪静态插件)有不懂的请联系QQ。当前版本是测试版,购买商业版...
通用简单api接口 v0.1 Date: 2018/5/11 10:42:41
小偷采集 |共享版本 |大小:1KB |环境:PHP |人气:1348
功能介绍:1.api.php放置在需要实现api功能的站点中,调用数据库信息,生成json2.client.php文件放置在站点文件中即需要调用api,解析api.php生成的json实现远程调用api的功能。
采集 采集《python进阶》教程网页:多页面url获取问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-08-25 20:50
首次发布于:
前言
我将主要使用python和爬虫技术。入门级项目简单,适合新手练手。阅读本文之前最好对python和爬虫有一定的了解。
要求
需求名称:采集"python进阶"教程
网页:
要求:采集网页上的所有高级内容,并整理成文档
采集具体进阶教程内容就够了
需求分析
让我们来看看要求。需要采集的东西并不多。我们打开网页看看。
看目录,数据量不是很多
粗略统计,有几十页,很少
对应需求,根据经验,列出一些我们需要解决的问题
单页爬取问题多页url获取问题整理成文档单页爬取问题
这道题其实是看爬取页面的请求结构
我们先看看源码中是否收录我们需要的数据
在页面上找一个稍微特殊的词
例如“小鲜肉”
在键盘上按 ctrl+U 查看源代码
按ctrl+F搜索“小鲜”
可以看到,我们需要的数据直接在源码中,所以可以判断这8个成就是一个get请求
如果没有防爬,会更轻松
尝试直接构建最简单的get请求
import requests
r = requests.get('https://docs.pythontab.com/interpy/')
print(r.text)
print(r)
运行一下,打印出来的就是我们需要的数据(因为太多没有贴出来),完美!
多页网址获取问题
我们可以看到几十个需要采集的页面,并不多。在需求目标方面,我们其实可以一个一个的复制,但是这种方式没有技术范围,如果我们采集的页面很多,成百上千,甚至几十万。人工抄写效率太低
我们打开网页
你可以看到有一个下一步按钮
查看全部
采集 采集《python进阶》教程网页:多页面url获取问题
首次发布于:
前言
我将主要使用python和爬虫技术。入门级项目简单,适合新手练手。阅读本文之前最好对python和爬虫有一定的了解。
要求
需求名称:采集"python进阶"教程
网页:
要求:采集网页上的所有高级内容,并整理成文档
采集具体进阶教程内容就够了
需求分析
让我们来看看要求。需要采集的东西并不多。我们打开网页看看。
看目录,数据量不是很多
粗略统计,有几十页,很少
对应需求,根据经验,列出一些我们需要解决的问题
单页爬取问题多页url获取问题整理成文档单页爬取问题
这道题其实是看爬取页面的请求结构
我们先看看源码中是否收录我们需要的数据
在页面上找一个稍微特殊的词
例如“小鲜肉”
在键盘上按 ctrl+U 查看源代码
按ctrl+F搜索“小鲜”
可以看到,我们需要的数据直接在源码中,所以可以判断这8个成就是一个get请求
如果没有防爬,会更轻松
尝试直接构建最简单的get请求
import requests
r = requests.get('https://docs.pythontab.com/interpy/')
print(r.text)
print(r)
运行一下,打印出来的就是我们需要的数据(因为太多没有贴出来),完美!
多页网址获取问题
我们可以看到几十个需要采集的页面,并不多。在需求目标方面,我们其实可以一个一个的复制,但是这种方式没有技术范围,如果我们采集的页面很多,成百上千,甚至几十万。人工抄写效率太低
我们打开网页
你可以看到有一个下一步按钮
采集 采集《python进阶》教程网页:多页面url获取问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-08-24 07:45
首次发布于:
前言
我将主要使用python和爬虫技术。入门级项目简单,适合新手练手。阅读本文之前最好对python和爬虫有一定的了解。
要求
需求名称:采集"python进阶"教程
网页:
要求:采集网页上的所有高级内容,并整理成文档
采集具体进阶教程内容就够了
需求分析
让我们来看看要求。需要采集的东西并不多。我们打开网页看看。
看目录,数据量不是很多
粗略统计,有几十页,很少
对应需求,根据经验,列出一些我们需要解决的问题
单页爬取问题多页url获取问题整理成文档单页爬取问题
这道题其实是看爬取页面的请求结构
我们先看看源码中是否收录我们需要的数据
在页面上找一个稍微特殊的词
例如“小鲜肉”
在键盘上按 ctrl+U 查看源代码
按ctrl+F搜索“小鲜”
可以看到,我们需要的数据直接在源码中,所以可以判断这8个成就是一个get请求
如果没有防爬,会更轻松
尝试直接构建最简单的get请求
import requests
r = requests.get('https://docs.pythontab.com/interpy/')
print(r.text)
print(r)
运行一下,打印出来的就是我们需要的数据(因为太多没有贴出来),完美!
多页网址获取问题
我们可以看到几十个需要采集的页面,并不多。在需求目标方面,我们其实可以一个一个的复制,但是这种方式没有技术范围,如果我们采集的页面很多,几十万,甚至几十万。人工抄写效率太低
我们打开网页
你可以看到有一个下一步按钮
查看全部
采集 采集《python进阶》教程网页:多页面url获取问题
首次发布于:
前言
我将主要使用python和爬虫技术。入门级项目简单,适合新手练手。阅读本文之前最好对python和爬虫有一定的了解。
要求
需求名称:采集"python进阶"教程
网页:
要求:采集网页上的所有高级内容,并整理成文档
采集具体进阶教程内容就够了
需求分析
让我们来看看要求。需要采集的东西并不多。我们打开网页看看。
看目录,数据量不是很多
粗略统计,有几十页,很少
对应需求,根据经验,列出一些我们需要解决的问题
单页爬取问题多页url获取问题整理成文档单页爬取问题
这道题其实是看爬取页面的请求结构
我们先看看源码中是否收录我们需要的数据
在页面上找一个稍微特殊的词
例如“小鲜肉”
在键盘上按 ctrl+U 查看源代码
按ctrl+F搜索“小鲜”
可以看到,我们需要的数据直接在源码中,所以可以判断这8个成就是一个get请求
如果没有防爬,会更轻松
尝试直接构建最简单的get请求
import requests
r = requests.get('https://docs.pythontab.com/interpy/')
print(r.text)
print(r)
运行一下,打印出来的就是我们需要的数据(因为太多没有贴出来),完美!
多页网址获取问题
我们可以看到几十个需要采集的页面,并不多。在需求目标方面,我们其实可以一个一个的复制,但是这种方式没有技术范围,如果我们采集的页面很多,几十万,甚至几十万。人工抄写效率太低
我们打开网页
你可以看到有一个下一步按钮
网络数据/信息挖掘软件《优采云采集器》9.8正式版下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-08-09 20:23
标签:采集器
51下载网提供功能强大的网络数据/信息挖掘软件《优采云采集器》9.8官方版下载,软件为免费软件,文件大小24.63 MB,推荐指数3星星,作为国产软件的顶级厂商,你可以放心下载!
优采云采集器()是一款专业强大的网络数据/信息挖掘软件。通过灵活配置,可以轻松抓取文字、图片、文件等任何资源,程序支持图片文件远程下载,支持网站post-login信息采集,支持文件真实地址检测,支持代理,支持采集防盗链,支持采集直接数据存储和模仿人手动发布等诸多功能。
主要功能
1、rule定制——通过采集rules的定义,可以搜索到网站采集几乎所有类型的信息
2、Multitasking,多线程-多信息采集任务可以同时执行,每个任务可以使用多个线程
3、所见即所得-任务采集process所见即所得。过程中遍历的链接信息、采集信息、错误信息等会及时反映在软件界面中。
4、Data Storage-Data Edge 采集边自动保存在关系型数据库中,自动适配数据结构。软件可以根据采集规则自动创建数据库,以及其中的表和字段,或者通过引导数据库的方式灵活地将数据保存在客户现有的数据库结构中
5、断点再采-信息采集任务停止后可以从断点继续采集,以后你再也不用担心你的采集任务被意外中断了
6、网站Login-支持网站Cookie,支持网站可视化登录,即使网站登录需要验证码也可以采集
7、Scheduled tasks-这个功能可以让你的采集任务有规律的、定量的或者一直循环执行
8、采集范围限制-采集的范围可以根据采集的深度和URL的标识进行限制
9、File Download-采集收到的二进制文件(如图片、音乐、软件、文档等)可以下载到本地磁盘或采集result数据库
10、Result 替换-可以将采集的结果替换成你按照规则定义的内容
11、条件保存-可以根据一定条件决定保存哪些信息,过滤哪些信息
12、过滤重复内容-软件可以根据用户设置和实际情况自动删除重复内容和重复网址
13、特殊链接识别-使用此功能识别由JavaScript动态生成的链接或其他奇怪链接
14、数据发布-您可以通过自定义接口将采集的结果数据发布到任何内容管理系统和指定的数据库。目前支持的目标发布媒体包括:数据库(access、sql server、my sql、oracle)、静态htm文件
15、预留编程接口-定义多个编程接口,用户可在活动中使用PHP、C#语言编程,扩展采集功能
软件功能
1、 通用性强:无论新闻、论坛、视频、黄页、图片、下载网站,只要是浏览器可以看到的结构化内容,通过指定匹配规则,就可以采集你所需要的
2、稳定高效:五年磨一剑,软件不断更新完善,采集速度快,性能稳定,占用资源少
3、是可扩展的,应用范围很广:自定义网页发布、主流数据库的自定义存储和发布、自定义本地PHP和. net外部编程接口对数据进行处理,使数据可供您使用
4、支持网站所有编码:完美支持采集所有网页编码格式,程序还能自动识别网页编码
5、多种发布方式:支持当前所有主流和非主流cms、BBS等网站节目,通过系统发布可以实现采集器和网站节目的完美结合模块
6、Full-auto:无人值守工作,配置程序后,程序会根据您的设置自动运行,完全无需人工干预。 查看全部
网络数据/信息挖掘软件《优采云采集器》9.8正式版下载
标签:采集器
51下载网提供功能强大的网络数据/信息挖掘软件《优采云采集器》9.8官方版下载,软件为免费软件,文件大小24.63 MB,推荐指数3星星,作为国产软件的顶级厂商,你可以放心下载!
优采云采集器()是一款专业强大的网络数据/信息挖掘软件。通过灵活配置,可以轻松抓取文字、图片、文件等任何资源,程序支持图片文件远程下载,支持网站post-login信息采集,支持文件真实地址检测,支持代理,支持采集防盗链,支持采集直接数据存储和模仿人手动发布等诸多功能。
主要功能
1、rule定制——通过采集rules的定义,可以搜索到网站采集几乎所有类型的信息
2、Multitasking,多线程-多信息采集任务可以同时执行,每个任务可以使用多个线程
3、所见即所得-任务采集process所见即所得。过程中遍历的链接信息、采集信息、错误信息等会及时反映在软件界面中。
4、Data Storage-Data Edge 采集边自动保存在关系型数据库中,自动适配数据结构。软件可以根据采集规则自动创建数据库,以及其中的表和字段,或者通过引导数据库的方式灵活地将数据保存在客户现有的数据库结构中
5、断点再采-信息采集任务停止后可以从断点继续采集,以后你再也不用担心你的采集任务被意外中断了
6、网站Login-支持网站Cookie,支持网站可视化登录,即使网站登录需要验证码也可以采集
7、Scheduled tasks-这个功能可以让你的采集任务有规律的、定量的或者一直循环执行
8、采集范围限制-采集的范围可以根据采集的深度和URL的标识进行限制
9、File Download-采集收到的二进制文件(如图片、音乐、软件、文档等)可以下载到本地磁盘或采集result数据库
10、Result 替换-可以将采集的结果替换成你按照规则定义的内容
11、条件保存-可以根据一定条件决定保存哪些信息,过滤哪些信息
12、过滤重复内容-软件可以根据用户设置和实际情况自动删除重复内容和重复网址
13、特殊链接识别-使用此功能识别由JavaScript动态生成的链接或其他奇怪链接
14、数据发布-您可以通过自定义接口将采集的结果数据发布到任何内容管理系统和指定的数据库。目前支持的目标发布媒体包括:数据库(access、sql server、my sql、oracle)、静态htm文件
15、预留编程接口-定义多个编程接口,用户可在活动中使用PHP、C#语言编程,扩展采集功能
软件功能
1、 通用性强:无论新闻、论坛、视频、黄页、图片、下载网站,只要是浏览器可以看到的结构化内容,通过指定匹配规则,就可以采集你所需要的
2、稳定高效:五年磨一剑,软件不断更新完善,采集速度快,性能稳定,占用资源少
3、是可扩展的,应用范围很广:自定义网页发布、主流数据库的自定义存储和发布、自定义本地PHP和. net外部编程接口对数据进行处理,使数据可供您使用
4、支持网站所有编码:完美支持采集所有网页编码格式,程序还能自动识别网页编码
5、多种发布方式:支持当前所有主流和非主流cms、BBS等网站节目,通过系统发布可以实现采集器和网站节目的完美结合模块
6、Full-auto:无人值守工作,配置程序后,程序会根据您的设置自动运行,完全无需人工干预。
采集 什么是全埋点?什么样的数据适合你?
采集交流 • 优采云 发表了文章 • 0 个评论 • 576 次浏览 • 2021-07-06 23:36
本文约4000字,阅读本文约需15分钟。
1.代码埋点和全埋点的区别
▍1.1 代码埋点
代码埋点,顾名思义,每一个埋点都需要开发和编写。代码埋点是侵入性的,需要工程师为每个需要埋点的位置做点。
▍1.2 所有埋点
全埋点,又称无埋点。只要在应用中集成了全埋点SDK,全埋点SDK会做应用采集中的所有数据。
它们不是替代关系,而是互补关系,以满足不同场景的需求。代码被埋了,上线后才发现被埋了。我应该怎么办?看一下全埋点的数据。虽然没有那么多维度,但总比没有好。因为采集数量充足,在APP中查看用户行为路径、流量趋势等也很方便。
我认为在重视数据的公司中,代码嵌入是必不可少的,全嵌入是锦上添花。下面几页主要讲解代码嵌入SDK。
2.评估SDK优劣的标准是什么?
从企业战略来看,无论是传统企业需要进行数字化转型,还是创业公司需要成为数据驱动的精细化运营,用户行为数据采集只是其中的一小部分数据策略。因此,嵌入式SDK应设计得尽可能简单易用,做到数据易采集,采集接收到的数据易使用。让采集数据成为公司数据驱动的助推器而非阻力。
首先,您应该关注嵌入代码的 SDK 的用户。如果用户对代码感到满意,并且用户也感到满意,则可以认为该 SDK 做得很好。用户是谁?他们关心什么?
采集SDK 的用户是谁:前端和客户端开发、服务端开发、数据测试、大数据团队。
埋点开发者(h5、小程序、iOS、Android开发):
测试埋点的人(数据测试)
接收埋藏数据的人(大数据团队)
一个代码嵌入SDK,满足以上用户需求,可以打95分,也可以在实际业务中应用。
3.代码埋点SDK架构
▍3.1 SDK整体架构
采集数据是否完整、准确、及时,能否连通,直接影响到公司整个数据平台的应用效果。因此,代码嵌入SDK需要一个良好的架构来保证数据的采集。
从SDK的整体设计开始,这部分将分别讲解SDK中的关键模块
1.代码埋点和全埋点的区别
▍1.1 代码埋点
代码埋点,顾名思义,每一个埋点都需要开发和编写。代码埋点是侵入性的,需要工程师为每个需要埋点的位置做点。
▍1.2 所有埋点
全埋点,又称无埋点。只要在应用中集成了全埋点SDK,全埋点SDK会做应用采集中的所有数据。
它们不是替代关系,而是互补关系,以满足不同场景的需求。代码被埋了,上线后才发现被埋了。我应该怎么办?看一下全埋点的数据。虽然没有那么多维度,但总比没有好。因为采集数量充足,在APP中查看用户行为路径、流量趋势等也很方便。
我认为在重视数据的公司中,代码嵌入是必不可少的,全嵌入是锦上添花。下面几页主要讲解代码嵌入SDK。
2.评估SDK优劣的标准是什么?
从企业战略来看,无论是传统企业需要进行数字化转型,还是创业公司需要成为数据驱动的精细化运营,用户行为数据采集只是其中的一小部分数据策略。因此,嵌入式SDK应设计得尽可能简单易用,做到数据易采集,采集接收到的数据易使用。让采集数据成为公司数据驱动的助推器而非阻力。
首先,您应该关注嵌入代码的 SDK 的用户。如果用户对代码感到满意,并且用户也感到满意,则可以认为该 SDK 做得很好。用户是谁?他们关心什么?
采集SDK 的用户是谁:前端和客户端开发、服务端开发、数据测试、大数据团队。
埋点开发者(h5、小程序、iOS、Android开发):
测试埋点的人(数据测试)
接收埋藏数据的人(大数据团队)
一个代码嵌入SDK,满足以上用户需求,可以打95分,也可以在实际业务中应用。
3.代码埋点SDK架构
▍3.1 SDK整体架构
采集数据是否完整、准确、及时,能否连通,直接影响到公司整个数据平台的应用效果。因此,代码嵌入SDK需要一个良好的架构来保证数据的采集。
从SDK的整体设计开始,这部分将分别讲解SDK中的关键模块
▍3.2 SDK采集数据流
对于SDK来说,数据采集是在用户行为被触发时,根据事件模型的数据格式将用户行为发送到服务器。下面结合APP数据上报流程图说明SDK采集data流程。
▍3.3 初始化模块
▍3.4 data采集module
代码被埋没了。 SDK初始化后,SDK提供采集相关接口。开发调用SDK提供的采集接口,将采集事件名称、变量字段等保存在本地,然后按照一定的策略将数据发送到目标数据服务器。 (或直接发送)
代码埋点采集SDK 可以提供以下能力:
▍3.5 数据存储模块
数据存储模块是对埋点数据进行缓存,常见的存储方式有以下几种:
▍3.6 数据发送模块
数据发送模块负责将缓存的数据准确发送到服务器。
说完代码嵌入SDK的整体结构,我们来说说需要重点关注的几个部分:
4. 事件模型
▍4.1 事件模型数据结构
事件模型的本质是用标准化的语言来描述用户行为,即将具体的、丰富多样的用户行为抽象为一个数据模型;
实际上,事件模型很容易理解。我们可以用生活中的例子来类比来理解。你如何向别人描述你在生活中的行为?比如,我会说,我昨晚20:20在我家门口的快递站取了快递。这是描述行为的典型方式。在应用中使用这种描述行为的方法跟踪用户行为就是嵌入点中的事件模型。
事件模型 4W1H 意味着:用户在特定时间点(何时)、某处(何处)以特定方式(如何)完成特定操作(什么)。
一般包括哪些类型的事件:
这些组合可以覆盖用户在应用中99%的用户行为
▍4.2 预设变量
在描述事件时,有些信息是通用的,每次都需要携带。我们可以一次性将这些信息封装在SDK中,这样就不用每次埋点都重复工作了。在事件模型中,我们将这些预设变量放在一个JSON中,即default_variable字段。
▍4.3 事件变量
同样,在描述事件时,有些信息是个性化的,即根据具体业务不同,需要携带的信息也不同。比如商品详情页需要携带商品信息,社区Feed曝光需要携带帖子信息。不是这种情况。每次埋藏代码时,都不可避免地需要开发和携带特定的业务信息。在事件模型中,因为字段是不确定的,所以不管业务变量是什么,业务信息都放在一个JSON中。
5. 如何有效降低数据漏报率?
▍5.1 H5数据通过APP发送
由于用户终端的怪异操作,用户,以及各种无法提前预知的特殊情况,要求100%的埋点不漏点是不现实的。行业内APP误报率在1%左右,H5漏报率在5%左右。
APP可以制定缓存和上报策略,漏报率远低于H5。
APP漏报率为1%,h5漏报率为5%。为了最大程度的避免漏报,大家可以想到一个方法:对于混合应用,我们可以在h5页面里面嵌入一些数据。发送到APP SDK后,经过APP的缓存和上报策略,混合APP中h5页面嵌入点数据的误报率可以从5%降低到1%。
怎么做,主要考虑两点:
▍5.2 APP作为缓存和发送策略
这部分在SDK的数据发送模块中已经介绍过了,不再赘述,简单说一下具体的策略:
满足以上三个发送条件中的任何一个都可以发送数据。
如果数据发送不成功,发送的数据会被保存,满足发送条件后,会尝试与后续数据一起发送。这样可以减少网络请求,节省服务器资源,有效减少发送过程中的一些数据丢失问题。
6. 用户 ID 映射问题
在现实世界中,我们使用身份证来准确识别一个人。在网络世界中,我们应该用什么来识别用户?常用方法存在一些问题:
这需要一个非常系统的方法来识别用户(扩展中不能控制字数,文章稍后更新id-mapping问题,记得关注我) 查看全部
采集 什么是全埋点?什么样的数据适合你?
本文约4000字,阅读本文约需15分钟。
1.代码埋点和全埋点的区别
▍1.1 代码埋点
代码埋点,顾名思义,每一个埋点都需要开发和编写。代码埋点是侵入性的,需要工程师为每个需要埋点的位置做点。
▍1.2 所有埋点
全埋点,又称无埋点。只要在应用中集成了全埋点SDK,全埋点SDK会做应用采集中的所有数据。
它们不是替代关系,而是互补关系,以满足不同场景的需求。代码被埋了,上线后才发现被埋了。我应该怎么办?看一下全埋点的数据。虽然没有那么多维度,但总比没有好。因为采集数量充足,在APP中查看用户行为路径、流量趋势等也很方便。
我认为在重视数据的公司中,代码嵌入是必不可少的,全嵌入是锦上添花。下面几页主要讲解代码嵌入SDK。
2.评估SDK优劣的标准是什么?
从企业战略来看,无论是传统企业需要进行数字化转型,还是创业公司需要成为数据驱动的精细化运营,用户行为数据采集只是其中的一小部分数据策略。因此,嵌入式SDK应设计得尽可能简单易用,做到数据易采集,采集接收到的数据易使用。让采集数据成为公司数据驱动的助推器而非阻力。
首先,您应该关注嵌入代码的 SDK 的用户。如果用户对代码感到满意,并且用户也感到满意,则可以认为该 SDK 做得很好。用户是谁?他们关心什么?
采集SDK 的用户是谁:前端和客户端开发、服务端开发、数据测试、大数据团队。
埋点开发者(h5、小程序、iOS、Android开发):
测试埋点的人(数据测试)
接收埋藏数据的人(大数据团队)
一个代码嵌入SDK,满足以上用户需求,可以打95分,也可以在实际业务中应用。
3.代码埋点SDK架构
▍3.1 SDK整体架构
采集数据是否完整、准确、及时,能否连通,直接影响到公司整个数据平台的应用效果。因此,代码嵌入SDK需要一个良好的架构来保证数据的采集。
从SDK的整体设计开始,这部分将分别讲解SDK中的关键模块
1.代码埋点和全埋点的区别
▍1.1 代码埋点
代码埋点,顾名思义,每一个埋点都需要开发和编写。代码埋点是侵入性的,需要工程师为每个需要埋点的位置做点。
▍1.2 所有埋点
全埋点,又称无埋点。只要在应用中集成了全埋点SDK,全埋点SDK会做应用采集中的所有数据。
它们不是替代关系,而是互补关系,以满足不同场景的需求。代码被埋了,上线后才发现被埋了。我应该怎么办?看一下全埋点的数据。虽然没有那么多维度,但总比没有好。因为采集数量充足,在APP中查看用户行为路径、流量趋势等也很方便。
我认为在重视数据的公司中,代码嵌入是必不可少的,全嵌入是锦上添花。下面几页主要讲解代码嵌入SDK。
2.评估SDK优劣的标准是什么?
从企业战略来看,无论是传统企业需要进行数字化转型,还是创业公司需要成为数据驱动的精细化运营,用户行为数据采集只是其中的一小部分数据策略。因此,嵌入式SDK应设计得尽可能简单易用,做到数据易采集,采集接收到的数据易使用。让采集数据成为公司数据驱动的助推器而非阻力。
首先,您应该关注嵌入代码的 SDK 的用户。如果用户对代码感到满意,并且用户也感到满意,则可以认为该 SDK 做得很好。用户是谁?他们关心什么?
采集SDK 的用户是谁:前端和客户端开发、服务端开发、数据测试、大数据团队。
埋点开发者(h5、小程序、iOS、Android开发):
测试埋点的人(数据测试)
接收埋藏数据的人(大数据团队)
一个代码嵌入SDK,满足以上用户需求,可以打95分,也可以在实际业务中应用。
3.代码埋点SDK架构
▍3.1 SDK整体架构
采集数据是否完整、准确、及时,能否连通,直接影响到公司整个数据平台的应用效果。因此,代码嵌入SDK需要一个良好的架构来保证数据的采集。
从SDK的整体设计开始,这部分将分别讲解SDK中的关键模块
▍3.2 SDK采集数据流
对于SDK来说,数据采集是在用户行为被触发时,根据事件模型的数据格式将用户行为发送到服务器。下面结合APP数据上报流程图说明SDK采集data流程。
▍3.3 初始化模块
▍3.4 data采集module
代码被埋没了。 SDK初始化后,SDK提供采集相关接口。开发调用SDK提供的采集接口,将采集事件名称、变量字段等保存在本地,然后按照一定的策略将数据发送到目标数据服务器。 (或直接发送)
代码埋点采集SDK 可以提供以下能力:
▍3.5 数据存储模块
数据存储模块是对埋点数据进行缓存,常见的存储方式有以下几种:
▍3.6 数据发送模块
数据发送模块负责将缓存的数据准确发送到服务器。
说完代码嵌入SDK的整体结构,我们来说说需要重点关注的几个部分:
4. 事件模型
▍4.1 事件模型数据结构
事件模型的本质是用标准化的语言来描述用户行为,即将具体的、丰富多样的用户行为抽象为一个数据模型;
实际上,事件模型很容易理解。我们可以用生活中的例子来类比来理解。你如何向别人描述你在生活中的行为?比如,我会说,我昨晚20:20在我家门口的快递站取了快递。这是描述行为的典型方式。在应用中使用这种描述行为的方法跟踪用户行为就是嵌入点中的事件模型。
事件模型 4W1H 意味着:用户在特定时间点(何时)、某处(何处)以特定方式(如何)完成特定操作(什么)。
一般包括哪些类型的事件:
这些组合可以覆盖用户在应用中99%的用户行为
▍4.2 预设变量
在描述事件时,有些信息是通用的,每次都需要携带。我们可以一次性将这些信息封装在SDK中,这样就不用每次埋点都重复工作了。在事件模型中,我们将这些预设变量放在一个JSON中,即default_variable字段。
▍4.3 事件变量
同样,在描述事件时,有些信息是个性化的,即根据具体业务不同,需要携带的信息也不同。比如商品详情页需要携带商品信息,社区Feed曝光需要携带帖子信息。不是这种情况。每次埋藏代码时,都不可避免地需要开发和携带特定的业务信息。在事件模型中,因为字段是不确定的,所以不管业务变量是什么,业务信息都放在一个JSON中。
5. 如何有效降低数据漏报率?
▍5.1 H5数据通过APP发送
由于用户终端的怪异操作,用户,以及各种无法提前预知的特殊情况,要求100%的埋点不漏点是不现实的。行业内APP误报率在1%左右,H5漏报率在5%左右。
APP可以制定缓存和上报策略,漏报率远低于H5。
APP漏报率为1%,h5漏报率为5%。为了最大程度的避免漏报,大家可以想到一个方法:对于混合应用,我们可以在h5页面里面嵌入一些数据。发送到APP SDK后,经过APP的缓存和上报策略,混合APP中h5页面嵌入点数据的误报率可以从5%降低到1%。
怎么做,主要考虑两点:
▍5.2 APP作为缓存和发送策略
这部分在SDK的数据发送模块中已经介绍过了,不再赘述,简单说一下具体的策略:
满足以上三个发送条件中的任何一个都可以发送数据。
如果数据发送不成功,发送的数据会被保存,满足发送条件后,会尝试与后续数据一起发送。这样可以减少网络请求,节省服务器资源,有效减少发送过程中的一些数据丢失问题。
6. 用户 ID 映射问题
在现实世界中,我们使用身份证来准确识别一个人。在网络世界中,我们应该用什么来识别用户?常用方法存在一些问题:
这需要一个非常系统的方法来识别用户(扩展中不能控制字数,文章稍后更新id-mapping问题,记得关注我)

