汇总:如何做好信息采集
优采云 发布时间: 2022-12-09 07:13汇总:如何做好信息采集
摘 要:信息采集是通过各种渠道搜索、归纳、整理并最终形成所需有效信息的过程。各种渠道包括:一是通过实地调查获得的第一手资料,即直接信息。二是通过媒体间接获得的信息。比如书籍、报纸、电视、网络。当前,互联网技术高度发达,信息量远远超过其他信息载体。因此,我们获取采集信息的主要途径来自互联网。
信息采集是通过各种渠道搜索、归纳、整理并最终形成所需有效信息的过程。各种渠道包括:一是通过实地调查获得的第一手资料,即直接信息。二是通过媒体间接获得的信息。比如书籍、报纸、电视、网络。当前,互联网技术高度发达,信息量远远超过其他信息载体。因此,我们获取采集信息的主要途径来自互联网。
有效信息是我们可以利用的信息,而不是任何一条信息对我们有用。资料采集不是“拿来主义”,不是直接从别人网站复制粘贴的作品。按照我们的目标和原则搜索到的信息,一般不能直接为我们所用,而是需要经过归纳整理,即需要一个数据处理的过程。商业网编辑想宣传自己的产品或网站,最终让自己的产品或网站有一个好的形象,进而达到销售的目的。所以,在做信息采集的时候,想想我们编辑的信息应该体现什么样的价值,不要盲目采集。
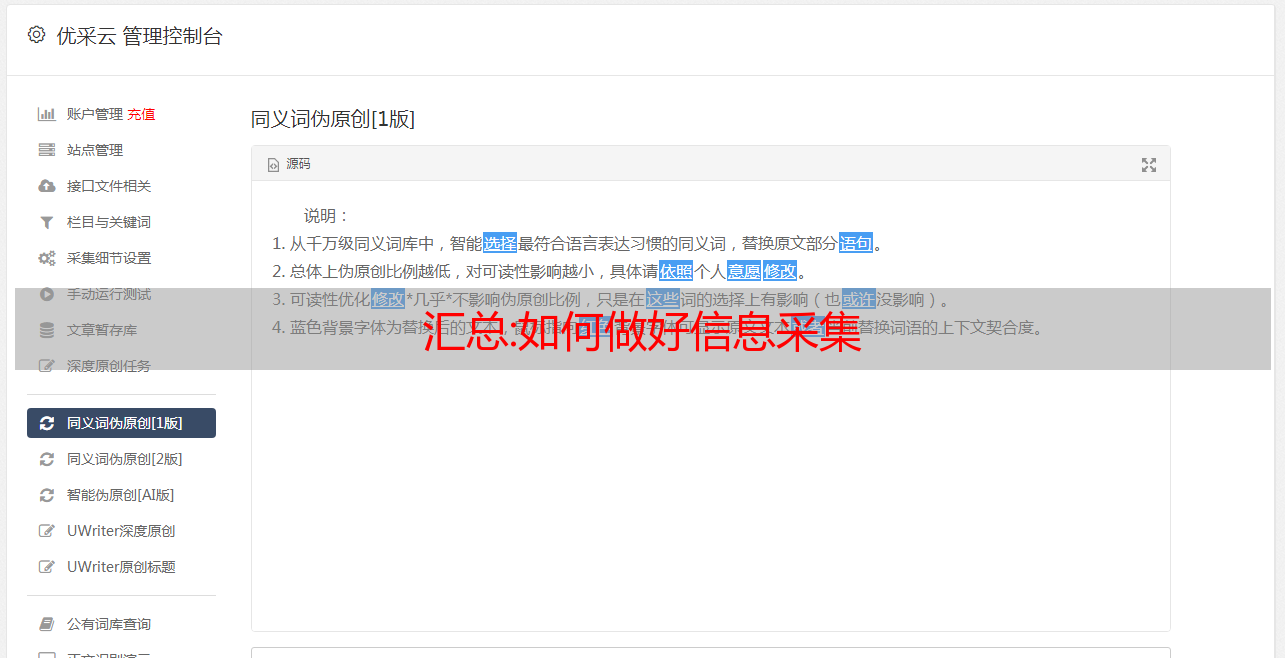
在明确了信息的采集用途之后,是时候通过一些合理的渠道来采集我们需要的信息了。
现代社会是信息社会,互联网报告企业信息的及时性是其他方式无法比拟的。通过互联网,您还可以更主动地选择自己需要的信息。需要注意的是,网上垃圾信息很多,垃圾站也很多。如果你没能对付采集一堆病毒,那得不偿失。最好选择国内知名的网站和官方的网站,这样可以大大提高采集信息的可靠性和实用性。
刚才说了,我们主要的信息采集方法是网页信息采集。那么什么是网络信息采集?事实上,目前并没有官方统一的概念。如果有定义的话,就是利用网页信息采集软件,针对某个网页实现针对性的、行业性的、精准的数据抓取。规则和筛选标准用于对数据进行分类并形成数据库文件的过程。当然,这里抓取的数据是公开的,任何人都可以看到,并不是为了窃取别人的后台数据。Web Information采集软件是一款网站定向数据采集、分析、发布的实用软件。可以对指定网站中任意网页进行目标分析,总结采集方案,
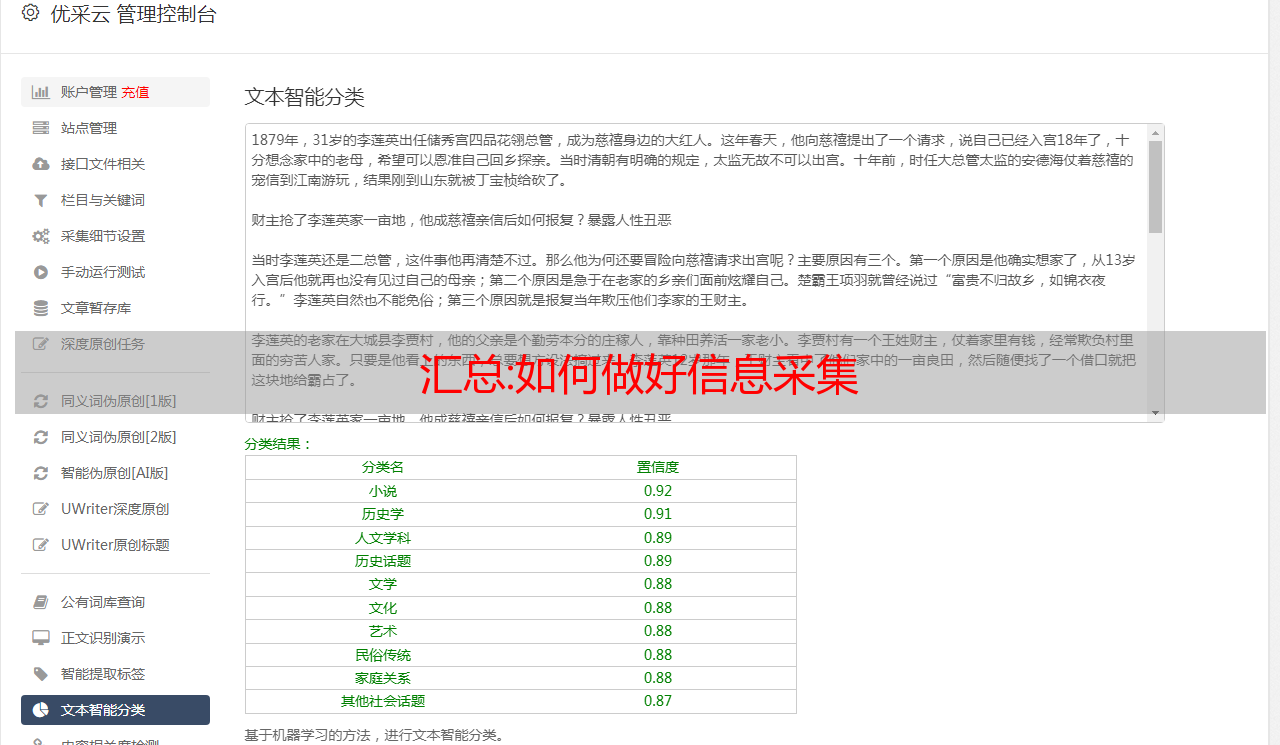
这种软件的好处是用户可以针对不同类型的信息设置不同的查询条件,而不是将采集网站中的所有信息一次性全部发到本地,避免了无意义的资源消耗。提高信息使用效率。
采集软件优采云 采集器等目前在互联网上很流行。
优采云采集器交流群:61570666
汇总:爬虫如何采集舆情数据
数据采集通俗地说就是通过爬虫代码访问目标网站的API链接,获取有用的信息。爬虫程序模拟人工从网页中获取所需信息,并自动保存在文档中,应用广泛。如图片、视频、文档、小说等。前提是不做非法经营。
在互联网大数据时代,网络爬虫主要是为搜索引擎提供最全面、最新的数据,网络爬虫也是从互联网上获取采集数据的爬虫。
我们还可以利用网络爬虫获取采集舆情数据、采集新闻、社交网络、论坛、博客等信息数据。这也是常见的舆情数据获取方案之一。一般就是利用爬虫爬虫ip,通过爬虫程序采集一些有意义的网站数据采集。舆情数据也可以在数据交易市场购买,或者由专业的舆情分析团队获取,但一般来说,专业的舆情分析团队也会使用爬虫ip到采集相关数据,从而进行舆情分析数据分析。
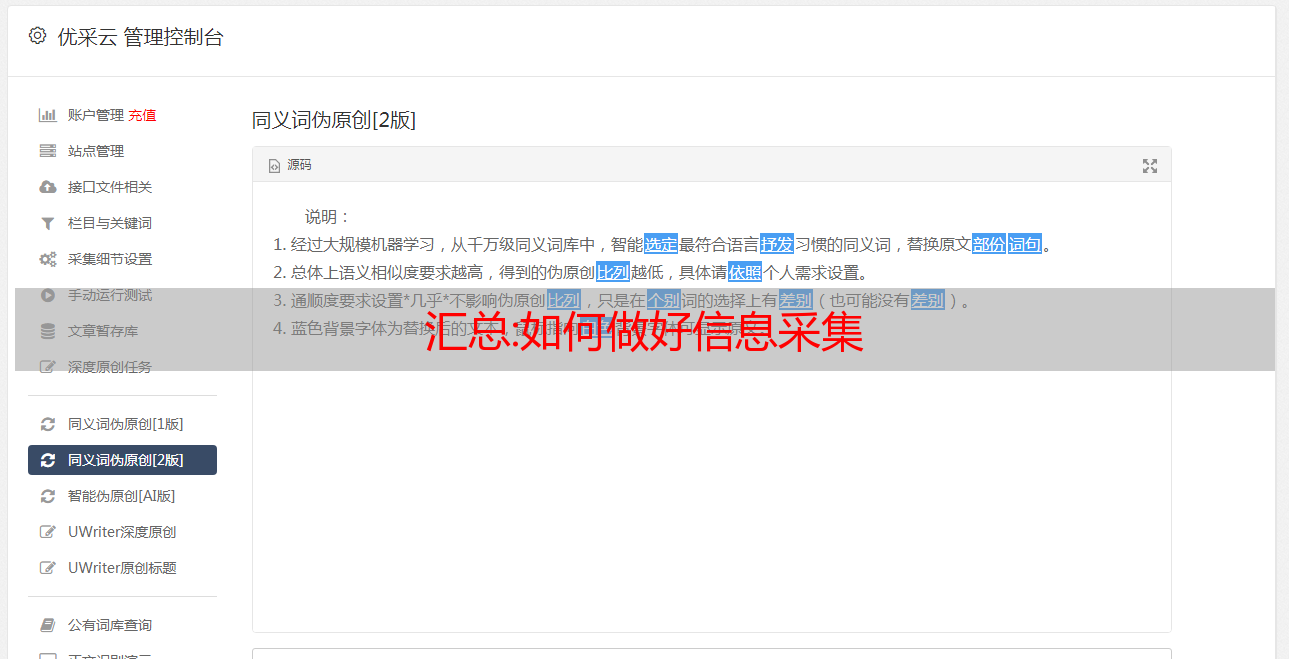
由于短视频的流行,我们也可以使用爬虫程序采集抖音和快手来分析抖音和快手两大主流短视频应用的舆情数据。将统计数据生成表格,作为数据报表提供给大家,也可以参考下面的采集程序代码:
// 要访问的目标页面
string targetUrl = "http://httpbin.org/ip";
// 爬虫ip服务器( jshk.com.cn )
string proxyHost = "http://jshk.com.cn/mb/";
string proxyPort = "31111";
// 爬虫ip验证信息
string proxyUser = "username";
string proxyPass = "password";
// 设置爬虫ip服务器
WebProxy proxy = new WebProxy(string.Format("{0}:{1}", proxyHost, proxyPort), true);
<p>
ServicePointManager.Expect100Continue = false;
var request = WebRequest.Create(targetUrl) as HttpWebRequest;
request.AllowAutoRedirect = true;
request.KeepAlive = true;
request.Method = "GET";
request.Proxy = proxy;
//request.Proxy.Credentials = CredentialCache.DefaultCredentials;
request.Proxy.Credentials = new System.Net.NetworkCredential(proxyUser, proxyPass);
// 设置Proxy Tunnel
// Random ran=new Random();
// int tunnel =ran.Next(1,10000);
// request.Headers.Add("Proxy-Tunnel", String.valueOf(tunnel));
//request.Timeout = 20000;
//request.ServicePoint.ConnectionLimit = 512;
//request.UserAgent = "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.82 Safari/537.36";
//request.Headers.Add("Cache-Control", "max-age=0");
//request.Headers.Add("DNT", "1");
//String encoded = System.Convert.ToBase64String(System.Text.Encoding.GetEncoding("ISO-8859-1").GetBytes(proxyUser + ":" + proxyPass));
//request.Headers.Add("Proxy-Authorization", "Basic " + encoded);
using (var response = request.GetResponse() as HttpWebResponse)
using (var sr = new StreamReader(response.GetResponseStream(), Encoding.UTF8))
{
string htmlStr = sr.ReadToEnd();
}
</p>

