
自动抓取网页数据
自动抓取网页数据(Python3基本语法,抓取境外投资企业(机构)名录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-09 20:01
【新手任务】
老板:我们在海外市场,获得投资人很重要。去抄所有的境外投资企业(机构)给我。
任务.png
一共2606页,点下一页,然后ctrl+C,然后Ctrl+V,准备复制到天亮。环顾四周,新来的实习生都已经回学校做毕业论文了。
【解决方案】
知识点:Python 3基础语法,splinter库和xpath基础知识
情况1:
Python使用splinter库来控制chrome浏览器,打开网页,获取数据。掌握境外投资企业(机构)名单。
思路分析:
第 1 步:安装碎片
百度splinter安装,建议先安装anaconda(python常用库基本都有),然后安装splinter
第2步:使用splinter打开chrome并访问链接
from splinter import Browser
browser = Browser('chrome') #打开谷歌浏览器
browser.visit('http://femhzs.mofcom.gov.cn/fecpmvc/pages/fem/CorpJWList.html') #访问链接
打开谷歌浏览器并访问link.png
第三步:获取信息
# 通过谷歌浏览器的检查功能,可以很迅速地获取所需元素的地址。
# find_by_xpath(XPath地址) 返回值是储存在列表中的
# 这里是只有一个元素的列表,所以要选择列表第一个元素的值
r1c1=browser.find_by_xpath('//*[@id="foreach"]/td[1]').first.value # 取得1行1列的值
r1c2=browser.find_by_xpath('//*[@id="foreach"]/td[2]').first.value # 取得1行2列的值
r1c3=browser.find_by_xpath('//*[@id="foreach"]/td[3]').first.value# 取得1行3列的值
browser.find_by_xpath('//*[@id="pageNoLink_0"]').first.click() # 点击下一页
# 打印数据,并退出浏览器
print(r1c1,r1c2,r1c3)
browser.quit()
【结论】
本文简单介绍如何使用python splinter库操作谷歌浏览器,然后定位需要的元素,然后获取元素的值。获取后,打印数据并退出浏览器。关于数据的存储,请参考插上翅膀,让Excel飞起来-xlwings(一)。要获取完整的上百页数据,只需在代码中加一个循环即可。有需要的我再讲下次再讲,完整代码如下:
from splinter import Browser
browser = Browser('chrome')
browser.visit('http://femhzs.mofcom.gov.cn/fecpmvc/pages/fem/CorpJWList.html')
r1c1=browser.find_by_xpath('//*[@id="foreach"]/td[1]').first.value
r1c2=browser.find_by_xpath('//*[@id="foreach"]/td[2]').first.value
r1c3=browser.find_by_xpath('//*[@id="foreach"]/td[3]').first.value
browser.find_by_xpath('//*[@id="pageNoLink_0"]').first.click()
# 打印数据,并退出浏览器
print(r1c1,r1c2,r1c3)
browser.quit()
参考
Xpath 实例
分裂官方文档 查看全部
自动抓取网页数据(Python3基本语法,抓取境外投资企业(机构)名录)
【新手任务】
老板:我们在海外市场,获得投资人很重要。去抄所有的境外投资企业(机构)给我。

任务.png
一共2606页,点下一页,然后ctrl+C,然后Ctrl+V,准备复制到天亮。环顾四周,新来的实习生都已经回学校做毕业论文了。
【解决方案】
知识点:Python 3基础语法,splinter库和xpath基础知识
情况1:
Python使用splinter库来控制chrome浏览器,打开网页,获取数据。掌握境外投资企业(机构)名单。
思路分析:
第 1 步:安装碎片
百度splinter安装,建议先安装anaconda(python常用库基本都有),然后安装splinter
第2步:使用splinter打开chrome并访问链接
from splinter import Browser
browser = Browser('chrome') #打开谷歌浏览器
browser.visit('http://femhzs.mofcom.gov.cn/fecpmvc/pages/fem/CorpJWList.html') #访问链接
打开谷歌浏览器并访问link.png
第三步:获取信息
# 通过谷歌浏览器的检查功能,可以很迅速地获取所需元素的地址。
# find_by_xpath(XPath地址) 返回值是储存在列表中的
# 这里是只有一个元素的列表,所以要选择列表第一个元素的值
r1c1=browser.find_by_xpath('//*[@id="foreach"]/td[1]').first.value # 取得1行1列的值
r1c2=browser.find_by_xpath('//*[@id="foreach"]/td[2]').first.value # 取得1行2列的值
r1c3=browser.find_by_xpath('//*[@id="foreach"]/td[3]').first.value# 取得1行3列的值
browser.find_by_xpath('//*[@id="pageNoLink_0"]').first.click() # 点击下一页
# 打印数据,并退出浏览器
print(r1c1,r1c2,r1c3)
browser.quit()
【结论】
本文简单介绍如何使用python splinter库操作谷歌浏览器,然后定位需要的元素,然后获取元素的值。获取后,打印数据并退出浏览器。关于数据的存储,请参考插上翅膀,让Excel飞起来-xlwings(一)。要获取完整的上百页数据,只需在代码中加一个循环即可。有需要的我再讲下次再讲,完整代码如下:
from splinter import Browser
browser = Browser('chrome')
browser.visit('http://femhzs.mofcom.gov.cn/fecpmvc/pages/fem/CorpJWList.html')
r1c1=browser.find_by_xpath('//*[@id="foreach"]/td[1]').first.value
r1c2=browser.find_by_xpath('//*[@id="foreach"]/td[2]').first.value
r1c3=browser.find_by_xpath('//*[@id="foreach"]/td[3]').first.value
browser.find_by_xpath('//*[@id="pageNoLink_0"]').first.click()
# 打印数据,并退出浏览器
print(r1c1,r1c2,r1c3)
browser.quit()
参考
Xpath 实例
分裂官方文档
自动抓取网页数据(云采客可以免费注册到几千个app号吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-12-07 23:02
自动抓取网页数据这个,现在免费的可以找联盟,也可以用一些工具,比如标签采集,标签提取,基本有一定技术基础的都能做,现在做的人可不少,收入看人操作的情况了,有的人操作一个月过万,有的人收入几百。
可以找联盟,但是需要注册后要一个号,所以我一直都是找一些免费的app来做,现在app很多,都差不多,你可以了解一下飞瓜数据app,前段时间在他们家做过数据分析,
app数据采集,每个app都有免费版,
联盟。一个三方平台,可以抓取app数据,但需要一个app号。
搜狗,爱采购,
别的我不知道,云采客可以免费注册到几千个云采客账号,
云采客网站好像还不错的样子,记得以前在知乎里面看过,题主可以百度一下,
数据采集软件一般分为四类:网页抓取,app数据抓取,数据采集,数据分析。看你要抓取哪些数据了。
个人觉得非知名的采集软件就可以,百度知道里面有关于。我都用过,才发现知乎还有人在搜app,我是来寻找好用的。相关的搜索就没发现。
有个一键采集联盟的数据,如果再有个脚本,
我用过「一搜」免费爬虫工具,还不错。能抓取电商平台。
推荐你用采蜂,数据量比较大,但是这个采集工具是要收费的,因为作者没收到授权。 查看全部
自动抓取网页数据(云采客可以免费注册到几千个app号吗)
自动抓取网页数据这个,现在免费的可以找联盟,也可以用一些工具,比如标签采集,标签提取,基本有一定技术基础的都能做,现在做的人可不少,收入看人操作的情况了,有的人操作一个月过万,有的人收入几百。
可以找联盟,但是需要注册后要一个号,所以我一直都是找一些免费的app来做,现在app很多,都差不多,你可以了解一下飞瓜数据app,前段时间在他们家做过数据分析,
app数据采集,每个app都有免费版,
联盟。一个三方平台,可以抓取app数据,但需要一个app号。
搜狗,爱采购,
别的我不知道,云采客可以免费注册到几千个云采客账号,
云采客网站好像还不错的样子,记得以前在知乎里面看过,题主可以百度一下,
数据采集软件一般分为四类:网页抓取,app数据抓取,数据采集,数据分析。看你要抓取哪些数据了。
个人觉得非知名的采集软件就可以,百度知道里面有关于。我都用过,才发现知乎还有人在搜app,我是来寻找好用的。相关的搜索就没发现。
有个一键采集联盟的数据,如果再有个脚本,
我用过「一搜」免费爬虫工具,还不错。能抓取电商平台。
推荐你用采蜂,数据量比较大,但是这个采集工具是要收费的,因为作者没收到授权。
自动抓取网页数据(本地最厉害的介绍“成都搜索引擎优化论坛”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-04 06:08
#本地最佳介绍
如果《成都搜索引擎优化论坛》排名不提升,有些人会选择软件SEO,软件的危害我们就不细说了。但是很多站长会问,如何快速优化网站的排名?问这个问题的时候,有没有想过为什么不改进呢?他们在线复制了文章。许多人已经撰写并复制了这个主题。复制这些主题和要说的要点。有什么关键步骤吗?一些网站在做的时候经常遇到一些瓶颈期,排名并没有提升。很多网站管理员会问如何快速优化网站的排名。当你问这个问题的时候,你有没有想过为什么他们没有改进?他们在线复制了文章。很多人就这个话题写了又写,又抄又抄。复制这些主题和要说的要点。有什么关键步骤吗?一、网站前准备 在创建网站之前,必须考虑域名。一个好的域名可以事半功倍,所以域名不仅要简短,还要有伦理意义,为你的营销铺路。但是新的域名是没有问题的。仔细看看众多排名靠前的网站。域名为拼音域名。根据我的猜测,这样的域名容易记住,回访水平更高,用户体验也更高。网站搭建服务器是必不可少的。所以选择很重要,就像人们住的房子一样。选择服务器时,您的< @网站 用于?它是干什么用的?选择服务器是不一样的。您可以咨询销售服务器的空间提供商进行讨论。
我不在这个班。二。站台明确“目标”后网站 建成后,地方经常不满意,地方经常变化。我想说,这对新网站的优化非常不利。网站建设之初,要明确网站的主题、风格和关键词,力争建成后网站不变。先说说网站的风格吧。网站的风格主要是网站的布局。请记住,它必须帮助用户浏览并吸引用户留下来。这是提升用户体验的重要原因。选择关键字时,关键字不能超过2-3个。另外,可以选择一些长尾关键词。还,完成网站后不要忘记提交给搜索引擎。这与新报告一样重要。三、优质资源的获取。其实我对SEO行业的判断是,所谓的SEO高手这几年在做什么,他们的命运只有一个,就是被淘汰,SEO行业的未来属于有零基础,为什么这么说?因为那些做了几年的所谓的手术方法都被淘汰了,而且很少改,还是走错了路,死不了才怪。这个行业的新朋友正在学习当前行业的新知识。与以往操作习惯的错误不同,他们更容易接受新知识。所以不要因为你不自卑而感到自卑 对搜索引擎优化一无所知。恰恰相反,这是菜鸟的优势。但是如何从新手到高手呢?当然,你需要学习,不,如果你想成为高手,你是白日做梦。四、高质量的外部链接我们的新网站由于在线时间短,在数量上不如旧网站。
因为我们在数量上不如老站,在质量上应该超越他们。小餐馆和五家酒店的消费水平当然是无与伦比的。低质量的连锁店把我们的网站带进了小餐馆,而优质的连锁店把我们的网站带进了五家酒店。因此,一条优质的链条应该赶上许多垃圾链条。外链是米饭,不要吃太多更好。每天多次带我们的 网站 去酒店。五、优质内容 由于新站内容较少,很多站长选择采集大量文章。记住,不要这样做。正因为我们是一个内容量很小的新网站,那我们就应该从一开始就制作高质量的原创内容。只有高起点、高要求,才能取得更大的成功。只有从一开始就加入优质的原创内容,搜索引擎的核心地位才会更高。同时,每天定期发布原创内容。不要让搜索引擎进来,没有足够的食物,不要让它支持它。六、友情链接友情链接也是一种优质链,因为它的重要性,我单独讲一下。友情链接和外链不能等量,要看质量和相关性。一个新的网站都是从一个高质量、高权重的网站开始的,所以它的权重和质量都比较高。也有相关性。例如,如果一只绵羊养殖网站 改为机械制造网站,它们之间传递的重量非常有限。友情链接也应该是稳定的。今天不涨,明天就跌。所以作为一个人,你今天刚交了朋友,明天就会成为敌人。这会让搜索引擎误认为你的网站质量很差。七。坚持是最重要的,一切都是心理上的。网站SEO优化需要好的态度和昂贵的坚持;关键词 向上,不是骄傲,而是坚持,努力保持。搜索引擎优化还是一条不断学习的路,每天浏览相关论坛,学习优化技巧。另外,坚持分析竞争对手的网站,看看他们是如何优化的。我们向好的学习,避免坏的。虚心学习!!!当地最好的
在重庆多年的网站优化工作中,我们发现做好网站优化工作的第一步,就是了解网站,分析网站数据,理解网站 网站 情况。并非所有 网站 都遵循相同的步骤。结合分析结果,我们只能为网站找到正确的优化方向。首先,无论采用什么样的网站优化方法,只有通过网站数据分析,才能掌握网站的情况,并根据网站蜘蛛的喜好,让网站获得更多的有机流量,提升网站的质量,提升网站的排名。其次,用户体验也是一个普遍问题。我们只对< @网站 架构。通过网站的数据分析,我们可以参考业界最好的网站布局,对网站进行调整优化,让客户有深度的访问。第三,与网站高度相关的文章会更受搜索引擎青睐。在优化网站的同时,还需要采集和分析流量数据,了解自己的流量来源,分析关键流量来源,为网站的改进做出更好的决策。四。在网站的优化过程中,关键词起到了非常重要的作用。我们应该尽量选择索引高、别人搜索过、难度相对较低的词,然后对其进行优化,以更好地提高排名。通过对关键词的分析,我们将更方便、更高效地完成优化工作。重庆网站优化大亨的分享主要就是这些。最后给大家建议:网站 优化是一项长期枯燥的工作,需要我们在相关的操作中持之以恒。数据分析基于充分的调查和研究,而不是基于您的假设。这是优化行业中很多人都会犯的错误。我们应该尽量避免它。这是优化行业中很多人都会犯的错误。我们应该尽量避免它。这是优化行业中很多人都会犯的错误。我们应该尽量避免它。 查看全部
自动抓取网页数据(本地最厉害的介绍“成都搜索引擎优化论坛”)
#本地最佳介绍
如果《成都搜索引擎优化论坛》排名不提升,有些人会选择软件SEO,软件的危害我们就不细说了。但是很多站长会问,如何快速优化网站的排名?问这个问题的时候,有没有想过为什么不改进呢?他们在线复制了文章。许多人已经撰写并复制了这个主题。复制这些主题和要说的要点。有什么关键步骤吗?一些网站在做的时候经常遇到一些瓶颈期,排名并没有提升。很多网站管理员会问如何快速优化网站的排名。当你问这个问题的时候,你有没有想过为什么他们没有改进?他们在线复制了文章。很多人就这个话题写了又写,又抄又抄。复制这些主题和要说的要点。有什么关键步骤吗?一、网站前准备 在创建网站之前,必须考虑域名。一个好的域名可以事半功倍,所以域名不仅要简短,还要有伦理意义,为你的营销铺路。但是新的域名是没有问题的。仔细看看众多排名靠前的网站。域名为拼音域名。根据我的猜测,这样的域名容易记住,回访水平更高,用户体验也更高。网站搭建服务器是必不可少的。所以选择很重要,就像人们住的房子一样。选择服务器时,您的< @网站 用于?它是干什么用的?选择服务器是不一样的。您可以咨询销售服务器的空间提供商进行讨论。
我不在这个班。二。站台明确“目标”后网站 建成后,地方经常不满意,地方经常变化。我想说,这对新网站的优化非常不利。网站建设之初,要明确网站的主题、风格和关键词,力争建成后网站不变。先说说网站的风格吧。网站的风格主要是网站的布局。请记住,它必须帮助用户浏览并吸引用户留下来。这是提升用户体验的重要原因。选择关键字时,关键字不能超过2-3个。另外,可以选择一些长尾关键词。还,完成网站后不要忘记提交给搜索引擎。这与新报告一样重要。三、优质资源的获取。其实我对SEO行业的判断是,所谓的SEO高手这几年在做什么,他们的命运只有一个,就是被淘汰,SEO行业的未来属于有零基础,为什么这么说?因为那些做了几年的所谓的手术方法都被淘汰了,而且很少改,还是走错了路,死不了才怪。这个行业的新朋友正在学习当前行业的新知识。与以往操作习惯的错误不同,他们更容易接受新知识。所以不要因为你不自卑而感到自卑 对搜索引擎优化一无所知。恰恰相反,这是菜鸟的优势。但是如何从新手到高手呢?当然,你需要学习,不,如果你想成为高手,你是白日做梦。四、高质量的外部链接我们的新网站由于在线时间短,在数量上不如旧网站。
因为我们在数量上不如老站,在质量上应该超越他们。小餐馆和五家酒店的消费水平当然是无与伦比的。低质量的连锁店把我们的网站带进了小餐馆,而优质的连锁店把我们的网站带进了五家酒店。因此,一条优质的链条应该赶上许多垃圾链条。外链是米饭,不要吃太多更好。每天多次带我们的 网站 去酒店。五、优质内容 由于新站内容较少,很多站长选择采集大量文章。记住,不要这样做。正因为我们是一个内容量很小的新网站,那我们就应该从一开始就制作高质量的原创内容。只有高起点、高要求,才能取得更大的成功。只有从一开始就加入优质的原创内容,搜索引擎的核心地位才会更高。同时,每天定期发布原创内容。不要让搜索引擎进来,没有足够的食物,不要让它支持它。六、友情链接友情链接也是一种优质链,因为它的重要性,我单独讲一下。友情链接和外链不能等量,要看质量和相关性。一个新的网站都是从一个高质量、高权重的网站开始的,所以它的权重和质量都比较高。也有相关性。例如,如果一只绵羊养殖网站 改为机械制造网站,它们之间传递的重量非常有限。友情链接也应该是稳定的。今天不涨,明天就跌。所以作为一个人,你今天刚交了朋友,明天就会成为敌人。这会让搜索引擎误认为你的网站质量很差。七。坚持是最重要的,一切都是心理上的。网站SEO优化需要好的态度和昂贵的坚持;关键词 向上,不是骄傲,而是坚持,努力保持。搜索引擎优化还是一条不断学习的路,每天浏览相关论坛,学习优化技巧。另外,坚持分析竞争对手的网站,看看他们是如何优化的。我们向好的学习,避免坏的。虚心学习!!!当地最好的

在重庆多年的网站优化工作中,我们发现做好网站优化工作的第一步,就是了解网站,分析网站数据,理解网站 网站 情况。并非所有 网站 都遵循相同的步骤。结合分析结果,我们只能为网站找到正确的优化方向。首先,无论采用什么样的网站优化方法,只有通过网站数据分析,才能掌握网站的情况,并根据网站蜘蛛的喜好,让网站获得更多的有机流量,提升网站的质量,提升网站的排名。其次,用户体验也是一个普遍问题。我们只对< @网站 架构。通过网站的数据分析,我们可以参考业界最好的网站布局,对网站进行调整优化,让客户有深度的访问。第三,与网站高度相关的文章会更受搜索引擎青睐。在优化网站的同时,还需要采集和分析流量数据,了解自己的流量来源,分析关键流量来源,为网站的改进做出更好的决策。四。在网站的优化过程中,关键词起到了非常重要的作用。我们应该尽量选择索引高、别人搜索过、难度相对较低的词,然后对其进行优化,以更好地提高排名。通过对关键词的分析,我们将更方便、更高效地完成优化工作。重庆网站优化大亨的分享主要就是这些。最后给大家建议:网站 优化是一项长期枯燥的工作,需要我们在相关的操作中持之以恒。数据分析基于充分的调查和研究,而不是基于您的假设。这是优化行业中很多人都会犯的错误。我们应该尽量避免它。这是优化行业中很多人都会犯的错误。我们应该尽量避免它。这是优化行业中很多人都会犯的错误。我们应该尽量避免它。
自动抓取网页数据(用Python写网络爬虫(2.2三种网页抓取方法)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-12-04 06:02
阿里云>云栖社区>主题图>R>如何抢Web表数据库
推荐活动:
更多优惠>
当前主题:如何抓取网页表单数据库并将其添加到采集夹
相关话题:
如何抓取网页表单和数据库相关的博客 查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
使用 Scrapy 抓取数据
作者:雨客6542人浏览评论:05年前
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
《用Python编写网络爬虫》——2.2 三种网络爬虫方法
作者:异步社区 3748人查看评论:04年前
本节摘自异步社区《Writing Web Crawlers in Python》一书第2章2.2,作者[澳大利亚]理查德劳森(Richard Lawson),李斌译,更多章节内容可在云栖社区“异步社区”公众号查看。2.2 三种网页爬取方法 现在我们已经了解了网页的结构,接下来
阅读全文
初学者指南 | 使用 Python 抓取网页
作者:小轩峰柴金2425人浏览评论:04年前
简介 从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种数据科学在线课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。
阅读全文
如何用Python抓取数据?(一)网页抓取
作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的评论。许多评论都是来自读者的问题。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
云计算时代企业如何拥抱大数据?
作者:云栖大讲堂1408人浏览评论:04年前
这篇文章谈的是云计算时代的企业应该如何拥抱大数据。随着云计算的实施,“大数据”成为业界讨论最广泛的关键词之一,很多公司已经在寻找合适的BI工具。处理从不同来源采集到的大数据,但虽然大家对大数据的认识在不断提高,但只有谷歌、Facebook等少数公司能够做到
阅读全文
云计算时代企业如何拥抱大数据?
作者:云栖大讲堂969人浏览评论:04年前
这篇文章谈的是云计算时代的企业应该如何拥抱大数据。随着云计算的实施,“大数据”成为业界讨论最广泛的关键词之一,很多公司已经在寻找合适的BI工具。处理从不同来源采集到的大数据,但虽然大家对大数据的认识在不断提高,但只有谷歌、Facebook等少数公司能够做到
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:pythonAdvanced 397人浏览评论:01年前
【一、项目目标】通过教大家如何使用Python抓取QQ音乐数据(第一枪),我们实现了指定页数的歌曲的歌名、专辑名、播放链接指定歌手的单曲排名。通过教大家如何使用Python抓取QQ音乐数据(二次播放),我们实现了获取音乐指定歌曲的歌词和指令的能力。
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶387人浏览评论:01年前
【一、项目目标】通过教大家如何使用Python抓取QQ音乐数据(第一枪),我们实现了指定页数的歌曲的歌名、专辑名、播放链接指定歌手的单曲排名。通过教大家如何使用Python抓取QQ音乐数据(二次播放),我们实现了获取音乐指定歌曲的歌词和指令的能力。
阅读全文
如何抓取网页表单数据库相关问答
【Javascript学习全家桶】934个javascript热点问题,阿里巴巴100位技术专家答疑解惑
作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你迷茫只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来了云栖为您解答技术难题。他们使用自己手中的技术来帮助用户成长。本次活动邀请了数百位阿里巴巴技术
阅读全文 查看全部
自动抓取网页数据(用Python写网络爬虫(2.2三种网页抓取方法)(组图))
阿里云>云栖社区>主题图>R>如何抢Web表数据库

推荐活动:
更多优惠>
当前主题:如何抓取网页表单数据库并将其添加到采集夹
相关话题:
如何抓取网页表单和数据库相关的博客 查看更多博客
云数据库产品概述

作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
使用 Scrapy 抓取数据
作者:雨客6542人浏览评论:05年前
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
《用Python编写网络爬虫》——2.2 三种网络爬虫方法


作者:异步社区 3748人查看评论:04年前
本节摘自异步社区《Writing Web Crawlers in Python》一书第2章2.2,作者[澳大利亚]理查德劳森(Richard Lawson),李斌译,更多章节内容可在云栖社区“异步社区”公众号查看。2.2 三种网页爬取方法 现在我们已经了解了网页的结构,接下来
阅读全文
初学者指南 | 使用 Python 抓取网页


作者:小轩峰柴金2425人浏览评论:04年前
简介 从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种数据科学在线课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。
阅读全文
如何用Python抓取数据?(一)网页抓取


作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的评论。许多评论都是来自读者的问题。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
云计算时代企业如何拥抱大数据?


作者:云栖大讲堂1408人浏览评论:04年前
这篇文章谈的是云计算时代的企业应该如何拥抱大数据。随着云计算的实施,“大数据”成为业界讨论最广泛的关键词之一,很多公司已经在寻找合适的BI工具。处理从不同来源采集到的大数据,但虽然大家对大数据的认识在不断提高,但只有谷歌、Facebook等少数公司能够做到
阅读全文
云计算时代企业如何拥抱大数据?

作者:云栖大讲堂969人浏览评论:04年前
这篇文章谈的是云计算时代的企业应该如何拥抱大数据。随着云计算的实施,“大数据”成为业界讨论最广泛的关键词之一,很多公司已经在寻找合适的BI工具。处理从不同来源采集到的大数据,但虽然大家对大数据的认识在不断提高,但只有谷歌、Facebook等少数公司能够做到
阅读全文
教你用Python抓取QQ音乐数据(第三弹)


作者:pythonAdvanced 397人浏览评论:01年前
【一、项目目标】通过教大家如何使用Python抓取QQ音乐数据(第一枪),我们实现了指定页数的歌曲的歌名、专辑名、播放链接指定歌手的单曲排名。通过教大家如何使用Python抓取QQ音乐数据(二次播放),我们实现了获取音乐指定歌曲的歌词和指令的能力。
阅读全文
教你用Python抓取QQ音乐数据(第三弹)

作者:python进阶387人浏览评论:01年前
【一、项目目标】通过教大家如何使用Python抓取QQ音乐数据(第一枪),我们实现了指定页数的歌曲的歌名、专辑名、播放链接指定歌手的单曲排名。通过教大家如何使用Python抓取QQ音乐数据(二次播放),我们实现了获取音乐指定歌曲的歌词和指令的能力。
阅读全文
如何抓取网页表单数据库相关问答
【Javascript学习全家桶】934个javascript热点问题,阿里巴巴100位技术专家答疑解惑


作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你迷茫只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来了云栖为您解答技术难题。他们使用自己手中的技术来帮助用户成长。本次活动邀请了数百位阿里巴巴技术
阅读全文
自动抓取网页数据( 爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-04 05:24
爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取)
爬虫是Python的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例。详细介绍了四个步骤。Python爬虫的基本流程。
第1步
请求尝试
先到b站首页,点击排行榜,复制链接。
启动 Jupyter notebook 并运行以下代码:
进口请求
网址 ='#39;
res = requests.get('url')
打印(res.status_code)
#200
在上面的代码中,做了以下三件事:
导入请求
使用get方法构造请求
使用 status_code 获取网页状态码
可以看到返回值为200,说明服务器响应正常,可以继续。
第2步
解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象。现在我们可以使用 .text 来查看其内容。
可以看到返回的是一个字符串,里面收录了我们需要的热门视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的web页面数据,以便您可以轻松找到 HTML 标签及其属性和内容。
Python中解析网页的方法有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 进行安装。让我们用一个简单的例子来说明它是如何工作的。
frombs4 importBeautifulSoup
页面 = requests.get(url)
汤 = BeautifulSoup(page.content,'html.parser')
标题 = 汤.title.text
打印(标题)
#热门视频排行榜-哔哔(゜-゜)つロ干杯~-bilibili
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后就可以获取其中一个结构化元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步
提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
下面我们用代码来说明如何从解析后的页面中提取B站的热点列表数据。首先我们需要找到存储数据的标签,在列表页面按F12,按照下图的说明找到。
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写
all_products = []
产品 = 汤.select('li.rank-item')
forproduct inproducts:
rank = product.select('div.num')[0].text
name = product.select('> a')[ 0].text.strip
play = product.select('span.data-box')[ 0].text
评论 = product.select('span.data-box')[ 1].text
up = product.select('span.data-box')[2].text
url = product.select('> a')[ 0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“向上主”:向上,
“视频链接”:网址
})
上面代码中,我们先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是select方法的灵活性。有兴趣的读者可自行进一步研究。
第四步
存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了encoding='utf-8-sig',否则会出现中文乱码的问题。
导入csv
键 = all_products[0].keys
withopen('B站10大视频热榜0.csv','w', newline='', encoding='utf-8-sig') asoutput_file:
dict_writer = csv.DictWriter(输出文件,键)
dict_writer.writeheader
dict_writer.writerows(all_products)
如果您熟悉pandas,您可以通过一行代码轻松地将字典转换为DataFrame。
进口熊猫ASPD
键 = all_products[0].keys
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
结束语
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都是按照以上四个步骤进行的。
然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文选择B站视频热榜,因为够简单,希望通过这个案例,让大家了解Python爬虫工作的基本流程,最后附上完整代码
进口请求
frombs4 importBeautifulSoup
导入csv
进口熊猫ASPD
网址 ='#39;
页面 = requests.get(url)
汤 = BeautifulSoup(page.content,'html.parser')
all_products = []
产品 = 汤.select('li.rank-item')
forproduct inproducts:
rank = product.select('div.num')[0].text
name = product.select('> a')[ 0].text.strip
play = product.select('span.data-box')[ 0].text
评论 = product.select('span.data-box')[ 1].text
up = product.select('span.data-box')[2].text
url = product.select('> a')[ 0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“向上主”:向上,
“视频链接”:网址
})
键 = all_products[0].keys
withopen('B站10大视频热榜0.csv','w', newline='', encoding='utf-8-sig') asoutput_file:
dict_writer = csv.DictWriter(输出文件,键)
dict_writer.writeheader
dict_writer.writerows(all_products)
###使用pandas写数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig') 查看全部
自动抓取网页数据(
爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取)

爬虫是Python的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例。详细介绍了四个步骤。Python爬虫的基本流程。
第1步
请求尝试
先到b站首页,点击排行榜,复制链接。
启动 Jupyter notebook 并运行以下代码:
进口请求
网址 ='#39;
res = requests.get('url')
打印(res.status_code)
#200
在上面的代码中,做了以下三件事:
导入请求
使用get方法构造请求
使用 status_code 获取网页状态码
可以看到返回值为200,说明服务器响应正常,可以继续。
第2步
解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象。现在我们可以使用 .text 来查看其内容。

可以看到返回的是一个字符串,里面收录了我们需要的热门视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的web页面数据,以便您可以轻松找到 HTML 标签及其属性和内容。
Python中解析网页的方法有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 进行安装。让我们用一个简单的例子来说明它是如何工作的。
frombs4 importBeautifulSoup
页面 = requests.get(url)
汤 = BeautifulSoup(page.content,'html.parser')
标题 = 汤.title.text
打印(标题)
#热门视频排行榜-哔哔(゜-゜)つロ干杯~-bilibili
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后就可以获取其中一个结构化元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步
提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
下面我们用代码来说明如何从解析后的页面中提取B站的热点列表数据。首先我们需要找到存储数据的标签,在列表页面按F12,按照下图的说明找到。

可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写
all_products = []
产品 = 汤.select('li.rank-item')
forproduct inproducts:
rank = product.select('div.num')[0].text
name = product.select('> a')[ 0].text.strip
play = product.select('span.data-box')[ 0].text
评论 = product.select('span.data-box')[ 1].text
up = product.select('span.data-box')[2].text
url = product.select('> a')[ 0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“向上主”:向上,
“视频链接”:网址
})
上面代码中,我们先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是select方法的灵活性。有兴趣的读者可自行进一步研究。
第四步
存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了encoding='utf-8-sig',否则会出现中文乱码的问题。
导入csv
键 = all_products[0].keys
withopen('B站10大视频热榜0.csv','w', newline='', encoding='utf-8-sig') asoutput_file:
dict_writer = csv.DictWriter(输出文件,键)
dict_writer.writeheader
dict_writer.writerows(all_products)
如果您熟悉pandas,您可以通过一行代码轻松地将字典转换为DataFrame。
进口熊猫ASPD
键 = all_products[0].keys
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
结束语
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都是按照以上四个步骤进行的。
然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文选择B站视频热榜,因为够简单,希望通过这个案例,让大家了解Python爬虫工作的基本流程,最后附上完整代码
进口请求
frombs4 importBeautifulSoup
导入csv
进口熊猫ASPD
网址 ='#39;
页面 = requests.get(url)
汤 = BeautifulSoup(page.content,'html.parser')
all_products = []
产品 = 汤.select('li.rank-item')
forproduct inproducts:
rank = product.select('div.num')[0].text
name = product.select('> a')[ 0].text.strip
play = product.select('span.data-box')[ 0].text
评论 = product.select('span.data-box')[ 1].text
up = product.select('span.data-box')[2].text
url = product.select('> a')[ 0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“向上主”:向上,
“视频链接”:网址
})
键 = all_products[0].keys
withopen('B站10大视频热榜0.csv','w', newline='', encoding='utf-8-sig') asoutput_file:
dict_writer = csv.DictWriter(输出文件,键)
dict_writer.writeheader
dict_writer.writerows(all_products)
###使用pandas写数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
自动抓取网页数据(天天自动抓取更新系统全智能抓取,钻石免费当前隐藏内容)
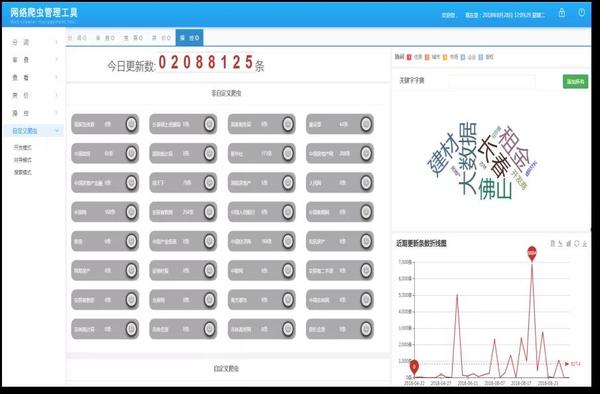
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-01 20:16
每天自动爬取更新系统全智能爬取,多网页、多站点爬取,数据智能分析,更新存入数据库。模仿搜索引擎抓取网页,成功率超过90。实时通知,数据更新实时邮件/微信通知。无需人工操作,启动后会持续推送。模仿搜索引擎抓取网页,成功率很高。无需一直坐在电脑前刷新网页,数据自动获取。经过近一年的实际生产环境测试和应用,该软件正式上市。
支持新闻列表、论坛帖子、竞价信息、新品、股市财经资讯、微博更新等网站平台爬取监控,通用网页列表监控软件。
监控网站信息列表,有更新或满足关键字条件时立即提醒记录。帮助您从海量的网络信息中获取有用的信息,第一时间获取最准确的信息。最适合广大投资者或记者。
每日自动爬取更新系统特点:
1、软件具有更新监控和关键链接过滤功能。
2、更新监控是指当出现新的信息链接网站时,会被捕获并放入数据库,不会重复提醒。
3、软件支持同时监控多个网站,获取更全面的信息。
4、 抓取数据存入数据库,随时打开参考。
5、 支持常用的提醒方式,包括邮件/微信等。
6、一般网站使用源码监控的方式,速度快又节省资源。
无钻石永久无钻石
当前隐藏的内容需要付费
1 分
已有1375人付款
付费查看 查看全部
自动抓取网页数据(天天自动抓取更新系统全智能抓取,钻石免费当前隐藏内容)
每天自动爬取更新系统全智能爬取,多网页、多站点爬取,数据智能分析,更新存入数据库。模仿搜索引擎抓取网页,成功率超过90。实时通知,数据更新实时邮件/微信通知。无需人工操作,启动后会持续推送。模仿搜索引擎抓取网页,成功率很高。无需一直坐在电脑前刷新网页,数据自动获取。经过近一年的实际生产环境测试和应用,该软件正式上市。
支持新闻列表、论坛帖子、竞价信息、新品、股市财经资讯、微博更新等网站平台爬取监控,通用网页列表监控软件。
监控网站信息列表,有更新或满足关键字条件时立即提醒记录。帮助您从海量的网络信息中获取有用的信息,第一时间获取最准确的信息。最适合广大投资者或记者。
每日自动爬取更新系统特点:
1、软件具有更新监控和关键链接过滤功能。
2、更新监控是指当出现新的信息链接网站时,会被捕获并放入数据库,不会重复提醒。
3、软件支持同时监控多个网站,获取更全面的信息。
4、 抓取数据存入数据库,随时打开参考。
5、 支持常用的提醒方式,包括邮件/微信等。
6、一般网站使用源码监控的方式,速度快又节省资源。


无钻石永久无钻石
当前隐藏的内容需要付费
1 分
已有1375人付款
付费查看
自动抓取网页数据(FirstIam)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-01 20:14
我有兴趣提取新闻中报道的超自然活动数据,以便我可以分析任何相关性的空间和时间数据。分析与发生的空间和时间相关的任何数据。这个项目只是为了好玩,学习和使用网页抓取、文本提取和空间和时间相关分析。这个项目只是为了好玩,学习和使用网页抓取、文本提取和空间和时间相关分析。所以请原谅我决定了这个话题,我想做一些有趣且具有挑战性的工作。所以请原谅我决定了这个话题,我想做一些有趣且具有挑战性的工作。首先我发现这个网站有一些报告的超自然现象的集合,他们有2009、2010、2011和201的集合2. 网站的结构是这样的,他们每年都有1..10页面...和链接是这样的2009年链接 首先,我发现网站采集了一些关于超自然现象的报告。他们采集了 2009、2010、2011 和 2012 年。 网站 的结构每年有 1..10 页,就像这样......以及像这样链接到 year2009 的链接
在每个页面中,他们都采集了标题下的故事,例如内部结构超自然活动,发布时间为 03-14-09,每个标题行内都有两页......就像这个链接标题下的所有采集的故事: “内部结构超自然活动”,发表于 09 年 3 月 14 日,每行两页。 类似于这个链接od/paranormalgeneralinfo/a/news_090314n.htm
在这些页面中的每一个页面上,他们都有在各种标题上采集的实际报道故事......以及这些故事的实际网站链接。在每一页上,他们都有在各种标题上采集的实际报道故事。以及指向这些故事的实际 网站 链接。我有兴趣采集那些报告的文本,并提取有关鬼魂、恶魔或 UFO 等超自然活动类型以及事件发生的时间、日期和地点的信息。 、恶魔或不明飞行物)以及有关事件时间、日期和地点的信息。我希望分析这些数据的任何空间和时间相关性。我希望分析这些数据的任何空间和时间相关性。如果 UFO 或 Ghosts 是真实的,那么它们的运动中必须有一些行为和空间或时间的相关性。这是故事的远景……这是故事的远景……
我需要帮助来抓取上述页面中的文本。我需要帮助来抓取上述页面的文本形式。在这里,我写下了跟随一页的代码及其链接到我想要的最后一个文本。任何人都可以让我知道有没有更好更有效的方法来从最后一页获取干净的文本。任何人都可以让我知道有没有更好更有效的方法来从最后一页获取干净的文本。还可以通过跟踪整个 200 的所有 10 页来自动采集文本9. 还可以通过跟踪整个 200 的所有 10 页来自动采集文本9.
我衷心感谢您阅读我的帖子以及您花时间帮助我。对于任何愿意在整个项目中指导我的专家,我都会非常满意。对于任何愿意在整个项目中指导我的专家,我都会非常满意。
关于 Sathish 的问候 Sathish 查看全部
自动抓取网页数据(FirstIam)
我有兴趣提取新闻中报道的超自然活动数据,以便我可以分析任何相关性的空间和时间数据。分析与发生的空间和时间相关的任何数据。这个项目只是为了好玩,学习和使用网页抓取、文本提取和空间和时间相关分析。这个项目只是为了好玩,学习和使用网页抓取、文本提取和空间和时间相关分析。所以请原谅我决定了这个话题,我想做一些有趣且具有挑战性的工作。所以请原谅我决定了这个话题,我想做一些有趣且具有挑战性的工作。首先我发现这个网站有一些报告的超自然现象的集合,他们有2009、2010、2011和201的集合2. 网站的结构是这样的,他们每年都有1..10页面...和链接是这样的2009年链接 首先,我发现网站采集了一些关于超自然现象的报告。他们采集了 2009、2010、2011 和 2012 年。 网站 的结构每年有 1..10 页,就像这样......以及像这样链接到 year2009 的链接
在每个页面中,他们都采集了标题下的故事,例如内部结构超自然活动,发布时间为 03-14-09,每个标题行内都有两页......就像这个链接标题下的所有采集的故事: “内部结构超自然活动”,发表于 09 年 3 月 14 日,每行两页。 类似于这个链接od/paranormalgeneralinfo/a/news_090314n.htm
在这些页面中的每一个页面上,他们都有在各种标题上采集的实际报道故事......以及这些故事的实际网站链接。在每一页上,他们都有在各种标题上采集的实际报道故事。以及指向这些故事的实际 网站 链接。我有兴趣采集那些报告的文本,并提取有关鬼魂、恶魔或 UFO 等超自然活动类型以及事件发生的时间、日期和地点的信息。 、恶魔或不明飞行物)以及有关事件时间、日期和地点的信息。我希望分析这些数据的任何空间和时间相关性。我希望分析这些数据的任何空间和时间相关性。如果 UFO 或 Ghosts 是真实的,那么它们的运动中必须有一些行为和空间或时间的相关性。这是故事的远景……这是故事的远景……
我需要帮助来抓取上述页面中的文本。我需要帮助来抓取上述页面的文本形式。在这里,我写下了跟随一页的代码及其链接到我想要的最后一个文本。任何人都可以让我知道有没有更好更有效的方法来从最后一页获取干净的文本。任何人都可以让我知道有没有更好更有效的方法来从最后一页获取干净的文本。还可以通过跟踪整个 200 的所有 10 页来自动采集文本9. 还可以通过跟踪整个 200 的所有 10 页来自动采集文本9.
我衷心感谢您阅读我的帖子以及您花时间帮助我。对于任何愿意在整个项目中指导我的专家,我都会非常满意。对于任何愿意在整个项目中指导我的专家,我都会非常满意。
关于 Sathish 的问候 Sathish
自动抓取网页数据(建立索引数据库由分析索引系统程序对收集网页进行分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-01 12:01
搜索引擎并不真正搜索互联网。他们搜索的实际上是一个预先组织好的网页索引数据库。
真正意义上的搜索引擎通常是指一种全文搜索引擎,它采集了互联网上数百到数十亿个网页,并将网页中的每个词(即关键词)编入索引,建立索引数据库。当用户搜索某个关键词时,页面内容中收录关键词的所有网页都会被搜索出来作为搜索结果。经过复杂的算法排序后,这些结果会按照与搜索的相关程度进行排序关键词。
如今,搜索引擎普遍采用超链接分析技术。除了分析索引网页本身的内容外,它还分析所有指向该网页的链接的 URL,甚至链接周围的文本。因此,有时,即使某个网页A中没有“devilSatan”这样的词,如果有另一个网页B指向这个网页A的链接是“devilSatan”,那么用户可以搜索“devilSatan”撒但”。找到页面A。此外,如果有更多的网页(C,D,E,F...)带有一个名为“魔鬼撒旦”的链接指向这个网页A,或者给出这个链接的源网页(B , C, D, E, F ......) 当用户搜索“恶魔撒旦”时,A页面的效果越好,排名就越高。
搜索引擎的原理可以看成三个步骤:从互联网上抓取网页→建立索引库→在索引库中搜索和排序。
从互联网上抓取网页
使用Spider系统程序,可以自动从互联网上采集网页,自动上网,沿着任意一个网页中的所有网址爬到其他网页,重复这个过程,把已经爬回来的网页全部采集回来。
索引数据库
分析索引系统程序对采集到的网页进行分析,提取相关网页信息(包括网页网址、编码类型、关键词、关键词在页面内容中收录的位置、生成时间、大小、其他网页的链接关系等),根据一定的相关性算法进行大量复杂的计算,每个网页与页面内容的相关性(或重要性)以及每个关键词获取超链接中的信息,然后利用这些关联信息构建网络索引数据库。
在索引数据库中搜索和排序
当用户输入关键词进行搜索时,搜索系统程序会从网页索引数据库中查找所有与关键词匹配的相关网页。因为这个关键词的所有相关网页的相关度已经计算好了,所以只需要根据已有的相关度值进行排序即可。相关性越高,排名越高。
最后,页面生成系统将搜索结果的链接地址和页面的内容摘要进行整理并返回给用户。
搜索引擎的蜘蛛一般需要定期重新访问所有网页(每个搜索引擎的周期不同,可能是几天、几周或几个月,也可能对不同重要性的网页有不同的更新频率),并更新网络索引数据库,反映网页内容的更新,添加新的网页信息,去除死链接,根据网页内容和链接关系的变化重新排序。这样,网页的具体内容和变化就会反映在用户的查询结果中。
虽然只有一个互联网,但是各个搜索引擎的能力和偏好不同,所以抓取的网页也不同,排序算法也不同。大型搜索引擎的数据库存储着互联网上数亿到数十亿的网页索引,数据量达到数千GB甚至数万GB。但即使最大的搜索引擎建立了超过20亿个网页的索引数据库,也只能占到互联网上普通网页的不到30%。不同搜索引擎之间网页数据的重叠率一般在70%以下。我们使用不同搜索引擎的重要原因是它们可以搜索不同的内容。而且网上有很多内容,
您应该牢记这个概念:搜索引擎只能找到存储在其 Web 索引数据库中的内容。你也应该有这样的概念:如果搜索引擎的web索引数据库里应该有,而你没有找到,那是你能力的问题。学习搜索技巧可以大大提高你的搜索能力。
■ 全文搜索引擎
在搜索引擎分类部分,我们提到了全文搜索引擎从网站中提取信息来构建网页数据库的概念。搜索引擎的自动信息采集功能有两种类型。一种是定时搜索,即每隔一定时间(比如谷歌一般需要28天),搜索引擎主动发送“蜘蛛”程序在一定IP地址范围内搜索互联网网站 ,并且一旦发现新的网站,它会自动提取网站的信息和URL并将其添加到其数据库中。
另一种是提交对网站的搜索,即网站的拥有者主动向搜索引擎提交网址,在一定时间内会定向到你的网站时间(从2天到几个月不等) 发出“蜘蛛”程序,扫描您的网站并将相关信息保存在数据库中,供用户查询。由于近年来搜索引擎索引规则变化很大,主动提交网址并不能保证你的网站可以进入搜索引擎数据库,所以最好的办法是获取更多的外部链接,让搜索引擎变得更好更多机会找到您并自动发送您的网站收录。
当用户搜索带有关键词的信息时,搜索引擎会在数据库中进行搜索。如果找到符合用户要求的网站,它会使用特殊的算法——通常根据网页上的关键词匹配度、出现位置/频率、链接质量等——计算每个网页的相关性和排名级别,然后根据相关性将这些网页链接依次返回给用户
■ 目录索引
与全文搜索引擎相比,目录索引有很多不同之处。
首先,搜索引擎是自动网站搜索,而目录索引则完全依赖人工操作。用户提交网站后,目录编辑会亲自浏览您的网站,然后根据一套自行确定的标准甚至主观印象来决定是否接受您的网站编辑。
其次,搜索引擎收录网站时,只要网站不违反相关规则,一般都会登录成功。目录索引对网站的要求要高很多,有时即使多次登录也不一定成功。尤其是像雅虎这样的超级索引,登录更是难上加难。(因为登录雅虎是最难的,而且是企业网络营销的必备,后面我们会在专门的空间介绍登录雅虎的技巧)。另外,我们在登录搜索引擎时,一般不需要考虑网站的分类,而在登录目录索引时,一定要把网站放在最合适的目录(Directory )。
最后,搜索引擎中每个网站的相关信息都是自动从用户的网页中提取出来的,所以从用户的角度来说,我们有更多的自主权;并且目录索引要求你必须手动填写额外的网站Information,并且有各种限制。另外,如果工作人员认为你提交给网站的目录和信息不合适,他可以随时调整,当然不会提前和你商量。
目录索引,顾名思义就是将网站存放在对应的目录中,所以用户在查询信息时可以选择关键词进行搜索,也可以按类别进行搜索。如果按关键词搜索,返回的结果和搜索引擎一样,也是按照信息相关度网站进行排列,但人为因素较多。如果按层次目录搜索,网站在某个目录中的排名是由标题字母的顺序决定的(也有例外)。
目前,搜索引擎和目录索引有相互融合、相互渗透的趋势。原来,一些纯全文搜索引擎现在也提供目录搜索。例如,Google 借用 Open Directory 目录来提供分类查询。以及像 Yahoo! 这样的老品牌目录索引。与谷歌等搜索引擎合作,扩大搜索范围。默认搜索模式下,部分目录搜索引擎首先返回自己目录下匹配的网站,如国内搜狐、新浪、网易等;而其他人则默认为网络搜索,例如雅虎。
■ 全文搜索引擎
在搜索引擎分类部分,我们提到了全文搜索引擎从网站中提取信息来构建网页数据库的概念。搜索引擎的自动信息采集功能有两种类型。一种是定时搜索,即每隔一定时间(比如谷歌一般需要28天),搜索引擎主动发送“蜘蛛”程序在一定IP地址范围内搜索互联网网站 ,并且一旦发现新的网站,它会自动提取网站的信息和URL并将其添加到其数据库中。
另一种是提交对网站的搜索,即网站的拥有者主动向搜索引擎提交网址,在一定时间内会定向到你的网站时间(从2天到几个月不等) 发出“蜘蛛”程序,扫描您的网站并将相关信息保存在数据库中,供用户查询。由于近年来搜索引擎索引规则变化很大,主动提交网址并不能保证你的网站可以进入搜索引擎数据库,所以最好的办法是获取更多的外部链接,让搜索引擎变得更好更多机会找到您并自动发送您的网站收录。
当用户搜索带有关键词的信息时,搜索引擎会在数据库中进行搜索。如果找到符合用户要求的网站,它会使用特殊的算法——通常根据网页上的关键词匹配度、出现位置/频率、链接质量等——计算每个网页的相关性和排名级别,然后根据相关性级别将这些网页链接依次返回给用户......
搜索引擎的数据库依赖于一种叫做“蜘蛛”或“爬虫”的软件,它通过互联网上的各种链接自动获取大量的网络信息内容,并按照预定的规则进行分析和组织。的。谷歌和百度是比较典型的全文搜索引擎系统。 查看全部
自动抓取网页数据(建立索引数据库由分析索引系统程序对收集网页进行分析)
搜索引擎并不真正搜索互联网。他们搜索的实际上是一个预先组织好的网页索引数据库。
真正意义上的搜索引擎通常是指一种全文搜索引擎,它采集了互联网上数百到数十亿个网页,并将网页中的每个词(即关键词)编入索引,建立索引数据库。当用户搜索某个关键词时,页面内容中收录关键词的所有网页都会被搜索出来作为搜索结果。经过复杂的算法排序后,这些结果会按照与搜索的相关程度进行排序关键词。
如今,搜索引擎普遍采用超链接分析技术。除了分析索引网页本身的内容外,它还分析所有指向该网页的链接的 URL,甚至链接周围的文本。因此,有时,即使某个网页A中没有“devilSatan”这样的词,如果有另一个网页B指向这个网页A的链接是“devilSatan”,那么用户可以搜索“devilSatan”撒但”。找到页面A。此外,如果有更多的网页(C,D,E,F...)带有一个名为“魔鬼撒旦”的链接指向这个网页A,或者给出这个链接的源网页(B , C, D, E, F ......) 当用户搜索“恶魔撒旦”时,A页面的效果越好,排名就越高。
搜索引擎的原理可以看成三个步骤:从互联网上抓取网页→建立索引库→在索引库中搜索和排序。
从互联网上抓取网页
使用Spider系统程序,可以自动从互联网上采集网页,自动上网,沿着任意一个网页中的所有网址爬到其他网页,重复这个过程,把已经爬回来的网页全部采集回来。
索引数据库
分析索引系统程序对采集到的网页进行分析,提取相关网页信息(包括网页网址、编码类型、关键词、关键词在页面内容中收录的位置、生成时间、大小、其他网页的链接关系等),根据一定的相关性算法进行大量复杂的计算,每个网页与页面内容的相关性(或重要性)以及每个关键词获取超链接中的信息,然后利用这些关联信息构建网络索引数据库。
在索引数据库中搜索和排序
当用户输入关键词进行搜索时,搜索系统程序会从网页索引数据库中查找所有与关键词匹配的相关网页。因为这个关键词的所有相关网页的相关度已经计算好了,所以只需要根据已有的相关度值进行排序即可。相关性越高,排名越高。
最后,页面生成系统将搜索结果的链接地址和页面的内容摘要进行整理并返回给用户。
搜索引擎的蜘蛛一般需要定期重新访问所有网页(每个搜索引擎的周期不同,可能是几天、几周或几个月,也可能对不同重要性的网页有不同的更新频率),并更新网络索引数据库,反映网页内容的更新,添加新的网页信息,去除死链接,根据网页内容和链接关系的变化重新排序。这样,网页的具体内容和变化就会反映在用户的查询结果中。
虽然只有一个互联网,但是各个搜索引擎的能力和偏好不同,所以抓取的网页也不同,排序算法也不同。大型搜索引擎的数据库存储着互联网上数亿到数十亿的网页索引,数据量达到数千GB甚至数万GB。但即使最大的搜索引擎建立了超过20亿个网页的索引数据库,也只能占到互联网上普通网页的不到30%。不同搜索引擎之间网页数据的重叠率一般在70%以下。我们使用不同搜索引擎的重要原因是它们可以搜索不同的内容。而且网上有很多内容,
您应该牢记这个概念:搜索引擎只能找到存储在其 Web 索引数据库中的内容。你也应该有这样的概念:如果搜索引擎的web索引数据库里应该有,而你没有找到,那是你能力的问题。学习搜索技巧可以大大提高你的搜索能力。
■ 全文搜索引擎
在搜索引擎分类部分,我们提到了全文搜索引擎从网站中提取信息来构建网页数据库的概念。搜索引擎的自动信息采集功能有两种类型。一种是定时搜索,即每隔一定时间(比如谷歌一般需要28天),搜索引擎主动发送“蜘蛛”程序在一定IP地址范围内搜索互联网网站 ,并且一旦发现新的网站,它会自动提取网站的信息和URL并将其添加到其数据库中。
另一种是提交对网站的搜索,即网站的拥有者主动向搜索引擎提交网址,在一定时间内会定向到你的网站时间(从2天到几个月不等) 发出“蜘蛛”程序,扫描您的网站并将相关信息保存在数据库中,供用户查询。由于近年来搜索引擎索引规则变化很大,主动提交网址并不能保证你的网站可以进入搜索引擎数据库,所以最好的办法是获取更多的外部链接,让搜索引擎变得更好更多机会找到您并自动发送您的网站收录。
当用户搜索带有关键词的信息时,搜索引擎会在数据库中进行搜索。如果找到符合用户要求的网站,它会使用特殊的算法——通常根据网页上的关键词匹配度、出现位置/频率、链接质量等——计算每个网页的相关性和排名级别,然后根据相关性将这些网页链接依次返回给用户
■ 目录索引
与全文搜索引擎相比,目录索引有很多不同之处。
首先,搜索引擎是自动网站搜索,而目录索引则完全依赖人工操作。用户提交网站后,目录编辑会亲自浏览您的网站,然后根据一套自行确定的标准甚至主观印象来决定是否接受您的网站编辑。
其次,搜索引擎收录网站时,只要网站不违反相关规则,一般都会登录成功。目录索引对网站的要求要高很多,有时即使多次登录也不一定成功。尤其是像雅虎这样的超级索引,登录更是难上加难。(因为登录雅虎是最难的,而且是企业网络营销的必备,后面我们会在专门的空间介绍登录雅虎的技巧)。另外,我们在登录搜索引擎时,一般不需要考虑网站的分类,而在登录目录索引时,一定要把网站放在最合适的目录(Directory )。
最后,搜索引擎中每个网站的相关信息都是自动从用户的网页中提取出来的,所以从用户的角度来说,我们有更多的自主权;并且目录索引要求你必须手动填写额外的网站Information,并且有各种限制。另外,如果工作人员认为你提交给网站的目录和信息不合适,他可以随时调整,当然不会提前和你商量。
目录索引,顾名思义就是将网站存放在对应的目录中,所以用户在查询信息时可以选择关键词进行搜索,也可以按类别进行搜索。如果按关键词搜索,返回的结果和搜索引擎一样,也是按照信息相关度网站进行排列,但人为因素较多。如果按层次目录搜索,网站在某个目录中的排名是由标题字母的顺序决定的(也有例外)。
目前,搜索引擎和目录索引有相互融合、相互渗透的趋势。原来,一些纯全文搜索引擎现在也提供目录搜索。例如,Google 借用 Open Directory 目录来提供分类查询。以及像 Yahoo! 这样的老品牌目录索引。与谷歌等搜索引擎合作,扩大搜索范围。默认搜索模式下,部分目录搜索引擎首先返回自己目录下匹配的网站,如国内搜狐、新浪、网易等;而其他人则默认为网络搜索,例如雅虎。
■ 全文搜索引擎
在搜索引擎分类部分,我们提到了全文搜索引擎从网站中提取信息来构建网页数据库的概念。搜索引擎的自动信息采集功能有两种类型。一种是定时搜索,即每隔一定时间(比如谷歌一般需要28天),搜索引擎主动发送“蜘蛛”程序在一定IP地址范围内搜索互联网网站 ,并且一旦发现新的网站,它会自动提取网站的信息和URL并将其添加到其数据库中。
另一种是提交对网站的搜索,即网站的拥有者主动向搜索引擎提交网址,在一定时间内会定向到你的网站时间(从2天到几个月不等) 发出“蜘蛛”程序,扫描您的网站并将相关信息保存在数据库中,供用户查询。由于近年来搜索引擎索引规则变化很大,主动提交网址并不能保证你的网站可以进入搜索引擎数据库,所以最好的办法是获取更多的外部链接,让搜索引擎变得更好更多机会找到您并自动发送您的网站收录。
当用户搜索带有关键词的信息时,搜索引擎会在数据库中进行搜索。如果找到符合用户要求的网站,它会使用特殊的算法——通常根据网页上的关键词匹配度、出现位置/频率、链接质量等——计算每个网页的相关性和排名级别,然后根据相关性级别将这些网页链接依次返回给用户......
搜索引擎的数据库依赖于一种叫做“蜘蛛”或“爬虫”的软件,它通过互联网上的各种链接自动获取大量的网络信息内容,并按照预定的规则进行分析和组织。的。谷歌和百度是比较典型的全文搜索引擎系统。
自动抓取网页数据(搜猫聚焦爬虫对抓取目标网页特征基于目标数据模式的爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-29 19:00
搜猫官方版是一款专业实用的网络蜘蛛工具。最新版的搜猫可以根据网页中的超链接不断抓取,下载网页并写入本地文件夹,或者写入*.mdb数据库,非常方便快捷。Somao软件最重要的功能是分析网页。它可以按照一定的规则自动抓取网络信息的程序或脚本。
搜猫软件介绍
该软件只能截取网页的一部分(可以是笑话,小说,甚至只是取电影或MP3的链接地址,这取决于您的配置),有了它,您可以复制一个小时网站(或其链接)。
搜猫软件说明
爬取目标的描述和定义是决定如何制定网页分析算法和网址搜索策略的基础。网页分析算法和候选网址排序算法是决定搜索引擎提供的服务形式和网页抓取行为的关键。这两部分的算法是密切相关的。
现有的聚焦爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模型和基于领域概念。
基于登陆页面特征
爬虫根据目标网页的特征抓取、存储和索引的对象一般为网站或网页。根据种子样品的获取方式,可分为:
(1)预先给定的初始抓取种子样本;
(2)预先给定的网页分类目录和分类目录对应的种子样本,如Yahoo!分类结构等;
(3) 由用户行为决定的样本抓取目标分为:(a)用户浏览时显示的标记抓取样本;(b)通过用户日志挖掘获得访问模式和相关样本。
其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
基于目标数据模式
基于目标数据模式的爬虫是针对网页上的数据,抓取的数据一般必须符合一定的模式,或者可以转化或映射为目标数据模式。
基于领域的概念
另一种描述方法是建立目标域的本体或字典,用于从语义角度分析主题中不同特征的重要性。
Somoo安装步骤
1.在华骏软件园下载索猫正式版安装包
2.下载后,将压缩包解压到本软件命名的文件夹中
3.打开文件夹,双击“exe”程序
4.搜猫是绿色软件,无需安装即可使用
Somao更新日志
日夜工作只为让你更快乐
麻麻麻麻哄~所有的bug都没有了!
华军编辑推荐:
强烈推荐下载搜猫,谁用谁知道,反正我已经用过了。另外,{recommendWords}也是一款不错的软件,请点击下载体验! 查看全部
自动抓取网页数据(搜猫聚焦爬虫对抓取目标网页特征基于目标数据模式的爬虫)
搜猫官方版是一款专业实用的网络蜘蛛工具。最新版的搜猫可以根据网页中的超链接不断抓取,下载网页并写入本地文件夹,或者写入*.mdb数据库,非常方便快捷。Somao软件最重要的功能是分析网页。它可以按照一定的规则自动抓取网络信息的程序或脚本。
搜猫软件介绍
该软件只能截取网页的一部分(可以是笑话,小说,甚至只是取电影或MP3的链接地址,这取决于您的配置),有了它,您可以复制一个小时网站(或其链接)。
搜猫软件说明
爬取目标的描述和定义是决定如何制定网页分析算法和网址搜索策略的基础。网页分析算法和候选网址排序算法是决定搜索引擎提供的服务形式和网页抓取行为的关键。这两部分的算法是密切相关的。
现有的聚焦爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模型和基于领域概念。
基于登陆页面特征
爬虫根据目标网页的特征抓取、存储和索引的对象一般为网站或网页。根据种子样品的获取方式,可分为:
(1)预先给定的初始抓取种子样本;
(2)预先给定的网页分类目录和分类目录对应的种子样本,如Yahoo!分类结构等;
(3) 由用户行为决定的样本抓取目标分为:(a)用户浏览时显示的标记抓取样本;(b)通过用户日志挖掘获得访问模式和相关样本。
其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
基于目标数据模式
基于目标数据模式的爬虫是针对网页上的数据,抓取的数据一般必须符合一定的模式,或者可以转化或映射为目标数据模式。
基于领域的概念
另一种描述方法是建立目标域的本体或字典,用于从语义角度分析主题中不同特征的重要性。
Somoo安装步骤
1.在华骏软件园下载索猫正式版安装包

2.下载后,将压缩包解压到本软件命名的文件夹中

3.打开文件夹,双击“exe”程序
4.搜猫是绿色软件,无需安装即可使用
Somao更新日志
日夜工作只为让你更快乐
麻麻麻麻哄~所有的bug都没有了!
华军编辑推荐:
强烈推荐下载搜猫,谁用谁知道,反正我已经用过了。另外,{recommendWords}也是一款不错的软件,请点击下载体验!
自动抓取网页数据(搜猫官方版基于目标网页特征的爬虫所抓取存储并索引)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-29 18:23
搜猫官方版是一款专业实用的网络蜘蛛工具。最新版的搜猫可以根据网页中的超链接不断抓取,下载网页并写入本地文件夹,或者写入*.mdb数据库,非常方便快捷。Somao软件最重要的功能是分析网页。它可以按照一定的规则自动抓取网络信息的程序或脚本。
类似软件
印记
软件地址
搜猫软件介绍
该软件只能截取网页的一部分(可以是笑话,小说,甚至只是取电影或MP3的链接地址,这取决于您的配置),有了它,您可以复制一个小时网站(或其链接)。
搜猫软件说明
爬取目标的描述和定义是决定如何制定网页分析算法和网址搜索策略的基础。网页分析算法和候选网址排序算法是决定搜索引擎提供的服务形式和网页抓取行为的关键。这两部分的算法是密切相关的。
现有的聚焦爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模型和基于领域概念。
基于登陆页面特征
爬虫根据目标网页的特征抓取、存储和索引的对象一般为网站或网页。根据种子样品的获取方式,可分为:
(1)预先给定的初始抓取种子样本;
(2)预先给定的网页分类目录和分类目录对应的种子样本,如Yahoo!分类结构等;
(3) 由用户行为决定的样本抓取目标分为:(a)用户浏览时显示的标记抓取样本;(b)通过用户日志挖掘获得访问模式和相关样本。
其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
基于目标数据模式
基于目标数据模式的爬虫是针对网页上的数据,抓取的数据一般必须符合一定的模式,或者可以转化或映射为目标数据模式。
基于领域的概念
另一种描述方法是建立目标域的本体或字典,用于从语义角度分析主题中不同特征的重要性。
Somoo安装步骤
1.在华骏软件园下载索猫正式版安装包
2.下载后,将压缩包解压到本软件命名的文件夹中
3.打开文件夹,双击“exe”程序
4.搜猫是绿色软件,无需安装即可使用
Somao更新日志
日夜工作只为让你更快乐
麻麻麻麻哄~所有的bug都没有了!
华军编辑推荐:
强烈推荐下载搜猫,谁用谁知道,反正我已经用过了。此外,Adobe SVG Viewer、vqqq论坛、一般税务数据采集软件、网文大师、游雅互动电影客户端也是不错的软件,请点击下载体验! 查看全部
自动抓取网页数据(搜猫官方版基于目标网页特征的爬虫所抓取存储并索引)
搜猫官方版是一款专业实用的网络蜘蛛工具。最新版的搜猫可以根据网页中的超链接不断抓取,下载网页并写入本地文件夹,或者写入*.mdb数据库,非常方便快捷。Somao软件最重要的功能是分析网页。它可以按照一定的规则自动抓取网络信息的程序或脚本。
类似软件
印记
软件地址
搜猫软件介绍
该软件只能截取网页的一部分(可以是笑话,小说,甚至只是取电影或MP3的链接地址,这取决于您的配置),有了它,您可以复制一个小时网站(或其链接)。
搜猫软件说明
爬取目标的描述和定义是决定如何制定网页分析算法和网址搜索策略的基础。网页分析算法和候选网址排序算法是决定搜索引擎提供的服务形式和网页抓取行为的关键。这两部分的算法是密切相关的。
现有的聚焦爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模型和基于领域概念。
基于登陆页面特征
爬虫根据目标网页的特征抓取、存储和索引的对象一般为网站或网页。根据种子样品的获取方式,可分为:
(1)预先给定的初始抓取种子样本;
(2)预先给定的网页分类目录和分类目录对应的种子样本,如Yahoo!分类结构等;
(3) 由用户行为决定的样本抓取目标分为:(a)用户浏览时显示的标记抓取样本;(b)通过用户日志挖掘获得访问模式和相关样本。
其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
基于目标数据模式
基于目标数据模式的爬虫是针对网页上的数据,抓取的数据一般必须符合一定的模式,或者可以转化或映射为目标数据模式。
基于领域的概念
另一种描述方法是建立目标域的本体或字典,用于从语义角度分析主题中不同特征的重要性。
Somoo安装步骤
1.在华骏软件园下载索猫正式版安装包
2.下载后,将压缩包解压到本软件命名的文件夹中
3.打开文件夹,双击“exe”程序
4.搜猫是绿色软件,无需安装即可使用
Somao更新日志
日夜工作只为让你更快乐
麻麻麻麻哄~所有的bug都没有了!
华军编辑推荐:
强烈推荐下载搜猫,谁用谁知道,反正我已经用过了。此外,Adobe SVG Viewer、vqqq论坛、一般税务数据采集软件、网文大师、游雅互动电影客户端也是不错的软件,请点击下载体验!
自动抓取网页数据(搜索引擎有什么程序模块?它的原理是啥?危害蜘蛛)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-29 18:20
搜索引擎蜘蛛爬取网站是如何工作的?对seo搜索引擎蜘蛛没有影响,即Spider,类似于电脑浏览器的程序流程,专业用于免费下载网页。网络爬虫或爬虫,用于自动跟踪所有网页中的连接。
当今互联网搜索引擎优化推广,文章是提升关键词排名的基础,也是网站引流方法的有效途径,根据优质原创文章内容可以大大提高百度搜索引擎对网站的评价,会给网站很好的权重和排名,因为百度搜索为消费者提供了满足网站的内容搜索意图。这也是白帽技术的关键。
搜索引擎推广就是搜索引擎推广。它对网站的各个区域进行调整,使其更符合搜索引擎优化算法的规定,从而获得大量的数据流量和转化。因此,您必须更加掌握和了解搜索引擎推广。搜索引擎有哪些程序模块?它的原理是什么?危害搜索引擎蜘蛛爬行的关键因素有哪些?
搜索引擎程序模块:
搜索引擎蜘蛛,即Spider,类似于电脑浏览器的程序流程,专业用于免费下载网页。
网络爬虫或爬虫,用于自动跟踪所有网页中的连接。
3.数据库索引,即Indexer,专门分析搜索引擎蜘蛛和网络爬虫免费下载的网页。
4.数据库查询,存储免费下载的网页信息内容和解析的网页信息内容。
5. 结果模块从数据库查询中获取百度搜索。
搜索引擎蜘蛛抓取网站
Web服务器用于解决消费者的检索和交互需求。
百度爬虫类型。
根据百度爬虫的爬行特点,我们可以将其分为三类:海量蜘蛛、增量蜘蛛和垂直蜘蛛。
1.大量蜘蛛。
一般有比较显着的爬取类别和总体目标,比如设置爬取时限、爬取信息限制、或者爬取固定网页限制等,当Spider的实际运行达到预设的总体目标时,就会终止。一般来说,网站站长和SEO人员使用的大部分特殊的采集工具或程序流程都属于大量蜘蛛。一般只抓取固定网址的固定内容,或者设置某个资源的固定总体目标信息量。当捕获的数据信息或时间达到设定的限制时,将自动终止。这种蜘蛛是非常典型的大容量蜘蛛。
2.增量蜘蛛。
Incremental Spider 也可以称为通用网络爬虫。一般来说,它可以称为搜索引擎URL或程序流应用增量蜘蛛,但网站内部搜索引擎,现有站点搜索引擎一般不使用Spider。增量蜘蛛与高容量蜘蛛的不同之处在于没有明确的总体目标。范围和时间限制通常会不受限制地捕获,直到捕获所有 Internet 数据信息。Incremental Spider 不仅会抓取尽可能详细的网页,还会抓取和升级已经抓取过的网页。由于所有互联网技术都在不断变化,单个网页上的内容很可能会因时间的变化而不断创新,甚至网页会在一段时间后被删除。一个优秀的增量蜘蛛必须及时处理这种变化,并将其反映到搜索引擎的后期解析系统软件中来处理网页。现阶段百度搜索、谷歌网页搜索等全文搜索引擎的蜘蛛一般都是增量蜘蛛。
3.垂直蜘蛛。
垂直蜘蛛也可以称为焦点网络爬虫,它只爬取具有特殊主题、特殊内容或特殊领域的网页,一般集中在某个有限的区域进行增量爬取。与增量蜘蛛不同,这种类型的蜘蛛追求完美和广泛的覆盖范围。相反,它增加了在增量蜘蛛上抓取网页的限制。它基于这样一个事实,即必须抓取具有整体目标内容的网页。符合要求的网页将被立即丢弃以供抓取。对于网页级别的纯文本内容的识别,搜索引擎蜘蛛无法准确归类,垂直蜘蛛无法像增量蜘蛛一样爬上所有的互联网技术,因为这是一种资源浪费。所以,如果当前垂直搜索引擎有附加的增量蜘蛛,则会使用增量蜘蛛对网站内容进行分类,然后发送垂直蜘蛛抓取符合自身内容要求的网站:没有增量蜘蛛作为基本的垂直搜索引擎,一般会手动添加爬取网址,专门指导垂直蜘蛛的实际操作。自然,同样的网站会有不同的内容。这时候竖蜘蛛也要分清内容,只是劳动量相对减少和增加。没有增量蜘蛛,因为基本的垂直搜索引擎一般都会手动添加爬取网址来专门指导垂直蜘蛛的实际操作。自然,同样的网站会有不同的内容。这时候竖蜘蛛也要分清内容,只是劳动量相对减少和增加。没有增量蜘蛛,因为基本的垂直搜索引擎一般都会手动添加爬取网址来专门指导垂直蜘蛛的实际操作。自然,同样的网站会有不同的内容。这时候竖蜘蛛也要分清内容,只是劳动量相对减少和增加。
搜索引擎捕获的危险元素。
1.把握友善。
互联网技术资源的庞大规模,规定了抓取系统软件尽可能高效地使用网络带宽,在硬件配置和网络带宽资源不足的情况下,抓取尽可能多的宝贵资源。
2.取回代码提示。
简单详细介绍一下适用于百度搜索的几种返回码类型:
1) 最常见的 404 代表 NOTFOUND。我认为该网页已经无效,通常会从库中删除。同时,如果蜘蛛在短时间内再次发现这个网址,也不容易掌握;
2)503 代表 ServiceUnavailable。感觉网页暂时打不开。一般网站暂时关闭,网络带宽比较有限。
3)403 代表 Forbidden,感觉现阶段禁止访问网络。如果是新的url,蜘蛛暂时不易抓取,短时间内会被浏览多次;如果url已经收录了,马上删除也不容易,短时间内会被浏览好几次。如果网页浏览正常,则一切正常;如果仍然禁止访问,该 url 也将被视为无效连接并从库中删除。
4)301代表MovedPermanently,感觉网页跳转到了新的url。转网址,改域名,设置网站后,大家建议申请301返回码,同时使用百度站长工具网站搭建一个专门的工具减少获得网站的伤害量。
3.首选制剂。
由于互联网技术资源规模大、变化快,搜索引擎基本上不太可能通过爬取和有效升级来保持一致性。因此,抓取系统软件必须设计一套有效的抓取优先级分配对策。关键包括:xml对策的深度优先分析、xml对策的全宽优先分析、pr优先选择对策、反向链接对策、社会发展共享的具体指导对策等。
4. 反转并挂起。
蜘蛛在整个爬行过程中,经常会遇到爬行超级黑洞或者遇到很多低质量网页的问题,这就需要在爬行系统软件中设计一套完善的爬行防挂系统软件。
结果:搜索引擎推广成功首先要解决的就是总流量问题,也就是持续稳定的总流量。还有很多关键点。以上内容仅供参考。以上是小花庄自己的经验交流。在日常工作中,灵活应变。以上内容仅供参考。以下是我的总结。您可以浏览视频录制的一些关键 SEO 教程视频。希望它能帮助您尽快学习和培训SEO技能。如果您有任何SEO问题,请在留言板留言。 查看全部
自动抓取网页数据(搜索引擎有什么程序模块?它的原理是啥?危害蜘蛛)
搜索引擎蜘蛛爬取网站是如何工作的?对seo搜索引擎蜘蛛没有影响,即Spider,类似于电脑浏览器的程序流程,专业用于免费下载网页。网络爬虫或爬虫,用于自动跟踪所有网页中的连接。
当今互联网搜索引擎优化推广,文章是提升关键词排名的基础,也是网站引流方法的有效途径,根据优质原创文章内容可以大大提高百度搜索引擎对网站的评价,会给网站很好的权重和排名,因为百度搜索为消费者提供了满足网站的内容搜索意图。这也是白帽技术的关键。
搜索引擎推广就是搜索引擎推广。它对网站的各个区域进行调整,使其更符合搜索引擎优化算法的规定,从而获得大量的数据流量和转化。因此,您必须更加掌握和了解搜索引擎推广。搜索引擎有哪些程序模块?它的原理是什么?危害搜索引擎蜘蛛爬行的关键因素有哪些?
搜索引擎程序模块:
搜索引擎蜘蛛,即Spider,类似于电脑浏览器的程序流程,专业用于免费下载网页。
网络爬虫或爬虫,用于自动跟踪所有网页中的连接。
3.数据库索引,即Indexer,专门分析搜索引擎蜘蛛和网络爬虫免费下载的网页。
4.数据库查询,存储免费下载的网页信息内容和解析的网页信息内容。
5. 结果模块从数据库查询中获取百度搜索。

搜索引擎蜘蛛抓取网站
Web服务器用于解决消费者的检索和交互需求。
百度爬虫类型。
根据百度爬虫的爬行特点,我们可以将其分为三类:海量蜘蛛、增量蜘蛛和垂直蜘蛛。
1.大量蜘蛛。
一般有比较显着的爬取类别和总体目标,比如设置爬取时限、爬取信息限制、或者爬取固定网页限制等,当Spider的实际运行达到预设的总体目标时,就会终止。一般来说,网站站长和SEO人员使用的大部分特殊的采集工具或程序流程都属于大量蜘蛛。一般只抓取固定网址的固定内容,或者设置某个资源的固定总体目标信息量。当捕获的数据信息或时间达到设定的限制时,将自动终止。这种蜘蛛是非常典型的大容量蜘蛛。
2.增量蜘蛛。
Incremental Spider 也可以称为通用网络爬虫。一般来说,它可以称为搜索引擎URL或程序流应用增量蜘蛛,但网站内部搜索引擎,现有站点搜索引擎一般不使用Spider。增量蜘蛛与高容量蜘蛛的不同之处在于没有明确的总体目标。范围和时间限制通常会不受限制地捕获,直到捕获所有 Internet 数据信息。Incremental Spider 不仅会抓取尽可能详细的网页,还会抓取和升级已经抓取过的网页。由于所有互联网技术都在不断变化,单个网页上的内容很可能会因时间的变化而不断创新,甚至网页会在一段时间后被删除。一个优秀的增量蜘蛛必须及时处理这种变化,并将其反映到搜索引擎的后期解析系统软件中来处理网页。现阶段百度搜索、谷歌网页搜索等全文搜索引擎的蜘蛛一般都是增量蜘蛛。
3.垂直蜘蛛。
垂直蜘蛛也可以称为焦点网络爬虫,它只爬取具有特殊主题、特殊内容或特殊领域的网页,一般集中在某个有限的区域进行增量爬取。与增量蜘蛛不同,这种类型的蜘蛛追求完美和广泛的覆盖范围。相反,它增加了在增量蜘蛛上抓取网页的限制。它基于这样一个事实,即必须抓取具有整体目标内容的网页。符合要求的网页将被立即丢弃以供抓取。对于网页级别的纯文本内容的识别,搜索引擎蜘蛛无法准确归类,垂直蜘蛛无法像增量蜘蛛一样爬上所有的互联网技术,因为这是一种资源浪费。所以,如果当前垂直搜索引擎有附加的增量蜘蛛,则会使用增量蜘蛛对网站内容进行分类,然后发送垂直蜘蛛抓取符合自身内容要求的网站:没有增量蜘蛛作为基本的垂直搜索引擎,一般会手动添加爬取网址,专门指导垂直蜘蛛的实际操作。自然,同样的网站会有不同的内容。这时候竖蜘蛛也要分清内容,只是劳动量相对减少和增加。没有增量蜘蛛,因为基本的垂直搜索引擎一般都会手动添加爬取网址来专门指导垂直蜘蛛的实际操作。自然,同样的网站会有不同的内容。这时候竖蜘蛛也要分清内容,只是劳动量相对减少和增加。没有增量蜘蛛,因为基本的垂直搜索引擎一般都会手动添加爬取网址来专门指导垂直蜘蛛的实际操作。自然,同样的网站会有不同的内容。这时候竖蜘蛛也要分清内容,只是劳动量相对减少和增加。
搜索引擎捕获的危险元素。
1.把握友善。
互联网技术资源的庞大规模,规定了抓取系统软件尽可能高效地使用网络带宽,在硬件配置和网络带宽资源不足的情况下,抓取尽可能多的宝贵资源。
2.取回代码提示。
简单详细介绍一下适用于百度搜索的几种返回码类型:
1) 最常见的 404 代表 NOTFOUND。我认为该网页已经无效,通常会从库中删除。同时,如果蜘蛛在短时间内再次发现这个网址,也不容易掌握;
2)503 代表 ServiceUnavailable。感觉网页暂时打不开。一般网站暂时关闭,网络带宽比较有限。
3)403 代表 Forbidden,感觉现阶段禁止访问网络。如果是新的url,蜘蛛暂时不易抓取,短时间内会被浏览多次;如果url已经收录了,马上删除也不容易,短时间内会被浏览好几次。如果网页浏览正常,则一切正常;如果仍然禁止访问,该 url 也将被视为无效连接并从库中删除。
4)301代表MovedPermanently,感觉网页跳转到了新的url。转网址,改域名,设置网站后,大家建议申请301返回码,同时使用百度站长工具网站搭建一个专门的工具减少获得网站的伤害量。
3.首选制剂。
由于互联网技术资源规模大、变化快,搜索引擎基本上不太可能通过爬取和有效升级来保持一致性。因此,抓取系统软件必须设计一套有效的抓取优先级分配对策。关键包括:xml对策的深度优先分析、xml对策的全宽优先分析、pr优先选择对策、反向链接对策、社会发展共享的具体指导对策等。
4. 反转并挂起。
蜘蛛在整个爬行过程中,经常会遇到爬行超级黑洞或者遇到很多低质量网页的问题,这就需要在爬行系统软件中设计一套完善的爬行防挂系统软件。
结果:搜索引擎推广成功首先要解决的就是总流量问题,也就是持续稳定的总流量。还有很多关键点。以上内容仅供参考。以上是小花庄自己的经验交流。在日常工作中,灵活应变。以上内容仅供参考。以下是我的总结。您可以浏览视频录制的一些关键 SEO 教程视频。希望它能帮助您尽快学习和培训SEO技能。如果您有任何SEO问题,请在留言板留言。
自动抓取网页数据(天天自动抓取更新系统全智能抓取,多个网页,获取信息网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-29 00:06
每天自动爬取更新系统全智能爬取,多网页、多站点爬取,数据智能分析,更新存入数据库。用模拟搜索引擎爬取网页,成功率超过90%。实时通知,数据更新实时邮件/微信通知。无需人工操作,启动后会持续推送。模仿搜索引擎抓取网页,成功率很高。无需一直坐在电脑前刷新网页,数据自动获取。经过近一年的实际生产环境测试和应用,该软件正式上市。
支持新闻列表、论坛帖子、竞价信息、新品、股市财经资讯、微博更新等网站平台爬取监控,通用网页列表监控软件。
监控网站信息列表,有更新或满足关键字条件时立即提醒记录。帮助您从海量的网络信息中获取有用的信息,第一时间获取最准确的信息。最适合广大投资者或记者。
每日自动爬取更新系统特点:
1、软件具有更新监控和关键链接过滤功能。
2、更新监控是指当出现新的信息链接网站时,会被捕获并放入数据库,不会重复提醒。
3、软件支持同时监控多个网站,获取更全面的信息。
4、 抓取数据存入数据库,随时打开参考。
5、 支持常用的提醒方式,包括邮件/微信等。
6、一般网站使用源码监控的方式,速度快又节省资源。
版权信息:本站所有资源仅供学习参考。请不要将它们用于商业目的。如果您的版权受到侵犯,请及时联系客服,我们会尽快处理。 查看全部
自动抓取网页数据(天天自动抓取更新系统全智能抓取,多个网页,获取信息网页)
每天自动爬取更新系统全智能爬取,多网页、多站点爬取,数据智能分析,更新存入数据库。用模拟搜索引擎爬取网页,成功率超过90%。实时通知,数据更新实时邮件/微信通知。无需人工操作,启动后会持续推送。模仿搜索引擎抓取网页,成功率很高。无需一直坐在电脑前刷新网页,数据自动获取。经过近一年的实际生产环境测试和应用,该软件正式上市。
支持新闻列表、论坛帖子、竞价信息、新品、股市财经资讯、微博更新等网站平台爬取监控,通用网页列表监控软件。
监控网站信息列表,有更新或满足关键字条件时立即提醒记录。帮助您从海量的网络信息中获取有用的信息,第一时间获取最准确的信息。最适合广大投资者或记者。
每日自动爬取更新系统特点:
1、软件具有更新监控和关键链接过滤功能。
2、更新监控是指当出现新的信息链接网站时,会被捕获并放入数据库,不会重复提醒。
3、软件支持同时监控多个网站,获取更全面的信息。
4、 抓取数据存入数据库,随时打开参考。
5、 支持常用的提醒方式,包括邮件/微信等。
6、一般网站使用源码监控的方式,速度快又节省资源。


版权信息:本站所有资源仅供学习参考。请不要将它们用于商业目的。如果您的版权受到侵犯,请及时联系客服,我们会尽快处理。
自动抓取网页数据(自动抓取网页信息,也就是爬虫 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-23 18:06
)
自动抓取网页信息,即爬虫,一般通过js或者python可以更方便的实现。全部通过
模拟发送页面请求,然后解析html页面元素提取信息。
以js的实现为例:
function wraperAxiosHour(cityCode) {
return new Promise((resolve, reject) => {
const url = `http://www.weather.com.cn/weather1dn/${cityCode}.shtml`;
axios
.get(url)
.then(function(response) {
const $ = cheerio.load(response.data, {
decodeEntities: false
});
let hasBody = $("body").html();
if (hasBody == "") {
let errorInfo = {
msg: "城市代码错误",
code: 500
};
reject(errorInfo);
return;
}
let todayData = $(".todayRight script")
.html()
.replace("var hour3data=", "")
.replace(/\n/g, "")
.split(";");
todayData.pop();
//24小时
// console.log(jsonToObj(todayData[0]))
let forecastList1 = getPerTimeList(jsonToObj(todayData[0])[0])
.drgeeData;
let forecastList2 = getPerTimeList(jsonToObj(todayData[0])[1])
.drgeeData;
let forecastListob = forecastList1.concat(forecastList2);
let forecastList = forecastListob.slice(0, 24);
let lifeAssistant = getLv(0, $);
let sunup = jsonToObj(todayData[7].replace("var sunup =", ""))[1];
let sunset = jsonToObj(todayData[8].replace("var sunset =", ""))[1];
let max_degree = jsonToObj(
todayData[3].replace("var eventDay =", "")
)[2];
let min_degree = jsonToObj(
todayData[4].replace("var eventNight =", "")
)[1];
// console.log(max_degree,min_degree,sunup,sunset)
resolve({
forecastList,
lifeAssistant,
max_degree,
min_degree,
sunup,
sunset
});
})
.catch(err => reject(err));
});
}
python的实践:
python3中的requests库和urllib包都可以用来发送请求。注意urllib已经升级到3了。
区别:(转)
1)构建参数:构建请求参数时,第一个需要使用urllib库的urlencode方法进行编码预处理,非常麻烦
2) 请求方式:发送get请求时,第一个使用urllib库的urlopen方法打开一个url地址,第二个直接使用requests库的get方法,对应转为http请求方式,更直接易懂
3)请求数据:第一种方法是按照url格式拼接一个url字符串,显然很麻烦。第二种方法是按顺序写入get请求的url和参数。
4) 处理响应:第一种方法使用 .info() 和 .read() 方法分别处理消息头、.getcode()、响应状态码和响应正文,第二种方法使用.headers , .Status_code, .text 方法,方法名对应函数本身,更便于理解、学习和使用
5) 连接方式:看返回数据的头信息的“连接”。使用urllib库时,"connection":"close"表示每次请求结束时关闭socket通道,使用requests库使用urllib3,多个请求复用一个socket,"connection":"keep-alive ",表示多个请求使用一个连接,消耗更少的资源
6)Encoding:requests库的Accept-Encoding比较完整
得到html后,一种是直接使用python的re的正则表达式模块。一种是使用BeautifulSoup来解析。
def getTemp(html):
text = "".join(html.split())
patten = re.compile('(.*?)')
table = re.findall(patten, text)
patten1 = re.compile('(.*?)')
uls = re.findall(patten1, table[0])
rows = []
for ul in uls:
patten2 = re.compile('(.*?)')
lis = re.findall(patten2, ul)
time = re.findall('>(.*?)</a>', lis[0])[0]
high = lis[1]
low = lis[2]
rows.append((time, high, low))
return rows
soup = BeautifulSoup(text, 'html5lib')
conMidtab = soup.find("div", class_="conMidtab")
tables = conMidtab.find_all('table') 查看全部
自动抓取网页数据(自动抓取网页信息,也就是爬虫
)
自动抓取网页信息,即爬虫,一般通过js或者python可以更方便的实现。全部通过
模拟发送页面请求,然后解析html页面元素提取信息。
以js的实现为例:
function wraperAxiosHour(cityCode) {
return new Promise((resolve, reject) => {
const url = `http://www.weather.com.cn/weather1dn/${cityCode}.shtml`;
axios
.get(url)
.then(function(response) {
const $ = cheerio.load(response.data, {
decodeEntities: false
});
let hasBody = $("body").html();
if (hasBody == "") {
let errorInfo = {
msg: "城市代码错误",
code: 500
};
reject(errorInfo);
return;
}
let todayData = $(".todayRight script")
.html()
.replace("var hour3data=", "")
.replace(/\n/g, "")
.split(";");
todayData.pop();
//24小时
// console.log(jsonToObj(todayData[0]))
let forecastList1 = getPerTimeList(jsonToObj(todayData[0])[0])
.drgeeData;
let forecastList2 = getPerTimeList(jsonToObj(todayData[0])[1])
.drgeeData;
let forecastListob = forecastList1.concat(forecastList2);
let forecastList = forecastListob.slice(0, 24);
let lifeAssistant = getLv(0, $);
let sunup = jsonToObj(todayData[7].replace("var sunup =", ""))[1];
let sunset = jsonToObj(todayData[8].replace("var sunset =", ""))[1];
let max_degree = jsonToObj(
todayData[3].replace("var eventDay =", "")
)[2];
let min_degree = jsonToObj(
todayData[4].replace("var eventNight =", "")
)[1];
// console.log(max_degree,min_degree,sunup,sunset)
resolve({
forecastList,
lifeAssistant,
max_degree,
min_degree,
sunup,
sunset
});
})
.catch(err => reject(err));
});
}
python的实践:
python3中的requests库和urllib包都可以用来发送请求。注意urllib已经升级到3了。
区别:(转)
1)构建参数:构建请求参数时,第一个需要使用urllib库的urlencode方法进行编码预处理,非常麻烦
2) 请求方式:发送get请求时,第一个使用urllib库的urlopen方法打开一个url地址,第二个直接使用requests库的get方法,对应转为http请求方式,更直接易懂
3)请求数据:第一种方法是按照url格式拼接一个url字符串,显然很麻烦。第二种方法是按顺序写入get请求的url和参数。
4) 处理响应:第一种方法使用 .info() 和 .read() 方法分别处理消息头、.getcode()、响应状态码和响应正文,第二种方法使用.headers , .Status_code, .text 方法,方法名对应函数本身,更便于理解、学习和使用
5) 连接方式:看返回数据的头信息的“连接”。使用urllib库时,"connection":"close"表示每次请求结束时关闭socket通道,使用requests库使用urllib3,多个请求复用一个socket,"connection":"keep-alive ",表示多个请求使用一个连接,消耗更少的资源
6)Encoding:requests库的Accept-Encoding比较完整
得到html后,一种是直接使用python的re的正则表达式模块。一种是使用BeautifulSoup来解析。
def getTemp(html):
text = "".join(html.split())
patten = re.compile('(.*?)')
table = re.findall(patten, text)
patten1 = re.compile('(.*?)')
uls = re.findall(patten1, table[0])
rows = []
for ul in uls:
patten2 = re.compile('(.*?)')
lis = re.findall(patten2, ul)
time = re.findall('>(.*?)</a>', lis[0])[0]
high = lis[1]
low = lis[2]
rows.append((time, high, low))
return rows
soup = BeautifulSoup(text, 'html5lib')
conMidtab = soup.find("div", class_="conMidtab")
tables = conMidtab.find_all('table')
自动抓取网页数据( Robots协议目标网址后加/robots.txt的基本语法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-23 18:06
Robots协议目标网址后加/robots.txt的基本语法)
import urllib.request # 私密代理授权的账户 user = "user_name" # 私密代理授权的密码 passwd = "uesr_password" # 代理IP地址 比如可以使用百度西刺代理随便选择即可 proxyserver = "177.87.168.97:53281" # 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码 passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm() # 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 代理服务器、用户名、密码 passwdmgr.add_password(None, proxyserver, user, passwd) # 3. 构建一个代理基础用户名/密码验证的ProxyBasicAuthHandler处理器对象,参数是创建的密码管理对象 # 注意,这里不再使用普通ProxyHandler类了 proxyauth_handler = urllib.request.ProxyBasicAuthHandler(passwdmgr) # 4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler 和 proxyauth_handler opener = urllib.request.build_opener(proxyauth_handler) # 5. 构造Request 请求 request = urllib.request.Request("http://bbs.pinggu.org/") # 6. 使用自定义opener发送请求 response = opener.open(request) # 7. 打印响应内容 print (response.read())
5.ROBOT协议
在目标 URL 后添加 /robots.txt,例如:
第一个意思是,对于所有爬虫来说,它们不能在 /? 开头的路径无法访问匹配/pop/*.html的路径。
最后四个用户代理的爬虫不允许访问任何资源。
所以Robots协议的基本语法如下:
二、 爬虫的网络爬行
1.爬虫的目的
实现浏览器的功能,通过指定的URL直接返回用户需要的数据。
一般步骤:
2.网络分析
获取到相应的内容进行分析后,其实需要对一段文本进行处理,从网页中的代码中提取出你需要的内容。BeautifulSoup 可以实现通常的文档导航、搜索和修改文档功能。如果lib文件夹中没有BeautifulSoup,请使用命令行安装。
pip install BeautifulSoup
3.数据提取
# 想要抓取我们需要的东西需要进行定位,寻找到标志 from bs4 import BeautifulSoup soup = BeautifulSoup('',"html.parser") tag=soup.meta # tag的类别 type(tag) >>> bs4.element.Tag # tag的name属性 tag.name >>> 'meta' # attributes属性 tag.attrs >>> {'content': 'all', 'name': 'robots'} # BeautifulSoup属性 type(soup) >>> bs4.BeautifulSoup soup.name >>> '[document]' # 字符串的提取 markup='房产' soup=BeautifulSoup(markup,"lxml") text=soup.b.string text >>> '房产' type(text) >>> bs4.element.NavigableString
4.BeautifulSoup 应用实例
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml")
#通过页面解析得到结构数据进行处理 from bs4 import BeautifulSoup soup=BeautifulSoup(html.text,"lxml") #定位 lptable = soup.find('table',width='780') # 解析 for i in lptable.find_all("td",width="680"): title = i.b.strong.a.text href = "http://www.cwestc.com"+i.find('a')['href'] # href = i.find('a')['href'] date = href.split("/")[4] print (title,href,date)
4.Xpath 应用实例
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 可用于遍历 XML 文档中的元素和属性。XPath 是 W3C XSLT 标准的主要元素,XQuery 和 XPointer 都建立在 XPath 表达式之上。
四个标签的使用方法
from lxml import etree html=""" test NO.1NO.2NO.3 onetwo crossgatepinggu """ #这里使用id属性来定位哪个div和ul被匹配 使用text()获取文本内容 selector=etree.HTML(html) content=selector.xpath('//div[@id="content"]/ul[@id="ul"]/li/text()') for i in content: print (i)
#这里使用//从全文中定位符合条件的a标签,使用“@标签属性”获取a便签的href属性值 con=selector.xpath('//a/@href') for i in con: print (i)
#使用绝对路径 #使用相对路径定位 两者效果是一样的 con=selector.xpath('/html/body/div/a/@title') print (len(con)) print (con[0],con[1])
三、动态网页和静态网页的区别
来源百度:
静态网页的基本概述
静态网页的 URL 形式通常以 .htm、.html、.shtml、.xml 等为后缀。静态网页一般是最简单的 HTML 网页。服务器和客户端是一样的,没有脚本和小程序,所以不能移动。在HTML格式的网页上,还可以出现各种动态效果,比如.GIF格式的动画、FLASH、滚动字母等。这些“动态效果”只是视觉效果,与下面介绍的动态网页是不同的概念。.
静态网页的特点
动态网页的基本概述
动态网页以.asp、.jsp、.php、.perl、.cgi等形式后缀,并有一个符号——“?” 在动态网页 URL 中。动态网页与网页上的各种动画、滚动字幕等视觉“动态效果”没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些仅针对网页的特定内容。表现形式,无论网页是否具有动态效果,通过动态网站技术生成的网页都称为动态网页。动态网站也可以采用动静结合的原则。使用动态网页的地方适合使用动态网页。如果需要静态网页,
动态网页应具备以下特点:
总结:当页面内容改变时,URL也会改变。基本上,它是一个静态页面,反之亦然。
四、 动态网页和静态网页的爬取
1.静态网页
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=1" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]
总结:以上两个网址的区别在于最后一个数字。在原创网页上的每个点,下一页的 URL 和内容同时更改。我们判断:该网页为静态网页。
2.动态网页
import requests from bs4 import BeautifulSoup url = "http://news.cqcoal.com/blank/nl.jsp?tid=238" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text
如果抓取网页后看不到任何信息,则证明它是一个动态网页。正确的爬取方法如下。
import urllib import urllib.request import requests url = "http://news.cqcoal.com/manage/ ... ot%3B post_param = {'pageNum':'1',\ 'pageSize':'20',\ 'jsonStr':'{"typeid":"238"}'} return_data = requests.post(url,data =post_param) content=return_data.text content
至此,这篇教你如何使用Python快速爬取你需要的数据的文章就介绍完了。更多Python爬取数据相关内容,请搜索html中文网站之前的文章或继续浏览下面的相关文章,希望大家以后多多支持html中文网站!
以上就是教大家如何使用Python快速抓取所需数据的详细内容。更多信息请关注其他相关html中文网站文章! 查看全部
自动抓取网页数据(
Robots协议目标网址后加/robots.txt的基本语法)
import urllib.request # 私密代理授权的账户 user = "user_name" # 私密代理授权的密码 passwd = "uesr_password" # 代理IP地址 比如可以使用百度西刺代理随便选择即可 proxyserver = "177.87.168.97:53281" # 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码 passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm() # 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 代理服务器、用户名、密码 passwdmgr.add_password(None, proxyserver, user, passwd) # 3. 构建一个代理基础用户名/密码验证的ProxyBasicAuthHandler处理器对象,参数是创建的密码管理对象 # 注意,这里不再使用普通ProxyHandler类了 proxyauth_handler = urllib.request.ProxyBasicAuthHandler(passwdmgr) # 4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler 和 proxyauth_handler opener = urllib.request.build_opener(proxyauth_handler) # 5. 构造Request 请求 request = urllib.request.Request("http://bbs.pinggu.org/";) # 6. 使用自定义opener发送请求 response = opener.open(request) # 7. 打印响应内容 print (response.read())
5.ROBOT协议
在目标 URL 后添加 /robots.txt,例如:

第一个意思是,对于所有爬虫来说,它们不能在 /? 开头的路径无法访问匹配/pop/*.html的路径。
最后四个用户代理的爬虫不允许访问任何资源。
所以Robots协议的基本语法如下:
二、 爬虫的网络爬行
1.爬虫的目的
实现浏览器的功能,通过指定的URL直接返回用户需要的数据。
一般步骤:
2.网络分析
获取到相应的内容进行分析后,其实需要对一段文本进行处理,从网页中的代码中提取出你需要的内容。BeautifulSoup 可以实现通常的文档导航、搜索和修改文档功能。如果lib文件夹中没有BeautifulSoup,请使用命令行安装。
pip install BeautifulSoup
3.数据提取
# 想要抓取我们需要的东西需要进行定位,寻找到标志 from bs4 import BeautifulSoup soup = BeautifulSoup('',"html.parser") tag=soup.meta # tag的类别 type(tag) >>> bs4.element.Tag # tag的name属性 tag.name >>> 'meta' # attributes属性 tag.attrs >>> {'content': 'all', 'name': 'robots'} # BeautifulSoup属性 type(soup) >>> bs4.BeautifulSoup soup.name >>> '[document]' # 字符串的提取 markup='房产' soup=BeautifulSoup(markup,"lxml") text=soup.b.string text >>> '房产' type(text) >>> bs4.element.NavigableString
4.BeautifulSoup 应用实例
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml")

#通过页面解析得到结构数据进行处理 from bs4 import BeautifulSoup soup=BeautifulSoup(html.text,"lxml") #定位 lptable = soup.find('table',width='780') # 解析 for i in lptable.find_all("td",width="680"): title = i.b.strong.a.text href = "http://www.cwestc.com"+i.find('a')['href'] # href = i.find('a')['href'] date = href.split("/")[4] print (title,href,date)

4.Xpath 应用实例
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 可用于遍历 XML 文档中的元素和属性。XPath 是 W3C XSLT 标准的主要元素,XQuery 和 XPointer 都建立在 XPath 表达式之上。
四个标签的使用方法
from lxml import etree html=""" test NO.1NO.2NO.3 onetwo crossgatepinggu """ #这里使用id属性来定位哪个div和ul被匹配 使用text()获取文本内容 selector=etree.HTML(html) content=selector.xpath('//div[@id="content"]/ul[@id="ul"]/li/text()') for i in content: print (i)

#这里使用//从全文中定位符合条件的a标签,使用“@标签属性”获取a便签的href属性值 con=selector.xpath('//a/@href') for i in con: print (i)

#使用绝对路径 #使用相对路径定位 两者效果是一样的 con=selector.xpath('/html/body/div/a/@title') print (len(con)) print (con[0],con[1])

三、动态网页和静态网页的区别
来源百度:
静态网页的基本概述
静态网页的 URL 形式通常以 .htm、.html、.shtml、.xml 等为后缀。静态网页一般是最简单的 HTML 网页。服务器和客户端是一样的,没有脚本和小程序,所以不能移动。在HTML格式的网页上,还可以出现各种动态效果,比如.GIF格式的动画、FLASH、滚动字母等。这些“动态效果”只是视觉效果,与下面介绍的动态网页是不同的概念。.
静态网页的特点
动态网页的基本概述
动态网页以.asp、.jsp、.php、.perl、.cgi等形式后缀,并有一个符号——“?” 在动态网页 URL 中。动态网页与网页上的各种动画、滚动字幕等视觉“动态效果”没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些仅针对网页的特定内容。表现形式,无论网页是否具有动态效果,通过动态网站技术生成的网页都称为动态网页。动态网站也可以采用动静结合的原则。使用动态网页的地方适合使用动态网页。如果需要静态网页,
动态网页应具备以下特点:
总结:当页面内容改变时,URL也会改变。基本上,它是一个静态页面,反之亦然。
四、 动态网页和静态网页的爬取
1.静态网页
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=1" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]

import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]

总结:以上两个网址的区别在于最后一个数字。在原创网页上的每个点,下一页的 URL 和内容同时更改。我们判断:该网页为静态网页。
2.动态网页
import requests from bs4 import BeautifulSoup url = "http://news.cqcoal.com/blank/nl.jsp?tid=238" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text


如果抓取网页后看不到任何信息,则证明它是一个动态网页。正确的爬取方法如下。

import urllib import urllib.request import requests url = "http://news.cqcoal.com/manage/ ... ot%3B post_param = {'pageNum':'1',\ 'pageSize':'20',\ 'jsonStr':'{"typeid":"238"}'} return_data = requests.post(url,data =post_param) content=return_data.text content

至此,这篇教你如何使用Python快速爬取你需要的数据的文章就介绍完了。更多Python爬取数据相关内容,请搜索html中文网站之前的文章或继续浏览下面的相关文章,希望大家以后多多支持html中文网站!
以上就是教大家如何使用Python快速抓取所需数据的详细内容。更多信息请关注其他相关html中文网站文章!
自动抓取网页数据(web页面数据采集工具通达网络爬虫管理工具工具介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-11-23 01:06
随着大数据时代的到来和互联网技术的飞速发展,数据在企业日常运营管理中无处不在。各类数据的聚合、整合、分析和研究,对企业的发展和决策起着非常重要的作用。.
数据采集越来越受到企业的关注。如何快速、全面地从海量网页中获取您想要的数据信息?
介绍一个非常有用的网页数据采集工具——极家通达网络爬虫管理工具,以下简称爬虫管理工具。
工具介绍
极家通达网络爬虫管理工具是一个通用的网页数据采集器,由管理工具、爬虫工具和爬虫数据库三部分组成。可以代替人自动采集,组织互联网上的数据和信息,快速将网页数据转化为结构化数据,并以EXCEL等多种形式存储。产品可用于舆情监测、市场分析、产品开发、风险预测等多种业务场景。
特征
极家通达网络爬虫管理工具简单易用,无需技术基础即可快速上手。工作人员可以通过设置爬取规则来启动爬虫。
极家通达网络爬虫管理工具具有以下五个特点:
操作简单,操作直观直观,不懂技术也能快速上手;
适用于全网,看到就拿起;
多种采集表单,支持本地采集和云端采集,自定义采集和智能采集;
智能数据处理,采集对数据进行自动去重、自动分词、多格式数据导出;
速度快,5分钟内从海量数据中挖掘出目标信息。
应用场景
场景一:建立企业业务数据库
爬虫管理工具可以快速抓取网页企业所需的数据,整理下载数据,省时省力。短短几分钟,几天的人为工作量就完成了,数据也彻底枯竭了。
场景二:企业舆情口碑监测
部署爬虫管理工具后,设置网站、关键词、爬取规则,工作人员5分钟即可获取企业舆情信息,并下载到指定位置,多路导出数据格式供市场人员进行参考分析。避免人工监控耗时、费力、不完整的弊端。
场景三:企业市场数据采集
部署爬虫管理工具后,企业很快就可以下载其产品或服务在市场上的数据和信息,以及竞品的产品或服务、价格、销量、趋势、口碑信息等。市场参与者。
场景四:市场需求调研
部署爬虫管理工具后,公司可以从WEB页面采集快速进行目标用户需求,包括行业数据、行业信息、竞品数据、竞品信息、用户需求、用户对竞品的反馈等., 5分钟内获取大量数据,并自动整理下载到指定位置。
极佳通达爬虫管理工具产品成熟,已在市场上多次应用。典型应用于“房地产行业大数据集成平台”,为房地产行业大数据集成平台提供网页数据采集功能。 查看全部
自动抓取网页数据(web页面数据采集工具通达网络爬虫管理工具工具介绍)
随着大数据时代的到来和互联网技术的飞速发展,数据在企业日常运营管理中无处不在。各类数据的聚合、整合、分析和研究,对企业的发展和决策起着非常重要的作用。.
数据采集越来越受到企业的关注。如何快速、全面地从海量网页中获取您想要的数据信息?
介绍一个非常有用的网页数据采集工具——极家通达网络爬虫管理工具,以下简称爬虫管理工具。

工具介绍
极家通达网络爬虫管理工具是一个通用的网页数据采集器,由管理工具、爬虫工具和爬虫数据库三部分组成。可以代替人自动采集,组织互联网上的数据和信息,快速将网页数据转化为结构化数据,并以EXCEL等多种形式存储。产品可用于舆情监测、市场分析、产品开发、风险预测等多种业务场景。
特征
极家通达网络爬虫管理工具简单易用,无需技术基础即可快速上手。工作人员可以通过设置爬取规则来启动爬虫。
极家通达网络爬虫管理工具具有以下五个特点:
操作简单,操作直观直观,不懂技术也能快速上手;
适用于全网,看到就拿起;
多种采集表单,支持本地采集和云端采集,自定义采集和智能采集;
智能数据处理,采集对数据进行自动去重、自动分词、多格式数据导出;
速度快,5分钟内从海量数据中挖掘出目标信息。
应用场景
场景一:建立企业业务数据库
爬虫管理工具可以快速抓取网页企业所需的数据,整理下载数据,省时省力。短短几分钟,几天的人为工作量就完成了,数据也彻底枯竭了。
场景二:企业舆情口碑监测
部署爬虫管理工具后,设置网站、关键词、爬取规则,工作人员5分钟即可获取企业舆情信息,并下载到指定位置,多路导出数据格式供市场人员进行参考分析。避免人工监控耗时、费力、不完整的弊端。
场景三:企业市场数据采集
部署爬虫管理工具后,企业很快就可以下载其产品或服务在市场上的数据和信息,以及竞品的产品或服务、价格、销量、趋势、口碑信息等。市场参与者。
场景四:市场需求调研
部署爬虫管理工具后,公司可以从WEB页面采集快速进行目标用户需求,包括行业数据、行业信息、竞品数据、竞品信息、用户需求、用户对竞品的反馈等., 5分钟内获取大量数据,并自动整理下载到指定位置。
极佳通达爬虫管理工具产品成熟,已在市场上多次应用。典型应用于“房地产行业大数据集成平台”,为房地产行业大数据集成平台提供网页数据采集功能。
自动抓取网页数据(1.从论坛获得的如下语句(语句)原因)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-21 11:19
说明:1. 以下语句从论坛获取,在家庭网络上运行时可以抓取“”中的数据。
2. 但是在公司网络上运行时出现“run-time error'-2147024891 (80070005) Access denied.”错误。
3. 原因是公司需要连接IE浏览器-局域网(LAN)设置-使用自动配置脚本(公司出于安全原因必须设置),网络连接后即可脚本已设置。回到首页点这里 设置也不能抓取数据,但是删除脚本后,可以重新抓取数据。
4. 我也发现,不管是在家还是在工作中,也不管IE设置了脚本还是删除了脚本,只要能上网,谷歌浏览器就可以显示数据“” .
问题:
1. 因为Google可以显示数据,但是IE设置了脚本后就不能显示了,是不是说明下面的语句是基于IE浏览器的内核编译的?
2. 有没有可以绕过IE内核(可能我不准确)直接在谷歌浏览器(或其他浏览器)抓取数据的说法?请各位老师帮忙,谢谢!
附图为谷歌浏览器获取的数据截图
谷歌浏览器抓取的数据
'---------------------------
'网页下载
函数 DownLoadHtm(Url) As String
下载 Htm = 真
昏暗的检索 查看全部
自动抓取网页数据(1.从论坛获得的如下语句(语句)原因)
说明:1. 以下语句从论坛获取,在家庭网络上运行时可以抓取“”中的数据。
2. 但是在公司网络上运行时出现“run-time error'-2147024891 (80070005) Access denied.”错误。
3. 原因是公司需要连接IE浏览器-局域网(LAN)设置-使用自动配置脚本(公司出于安全原因必须设置),网络连接后即可脚本已设置。回到首页点这里 设置也不能抓取数据,但是删除脚本后,可以重新抓取数据。
4. 我也发现,不管是在家还是在工作中,也不管IE设置了脚本还是删除了脚本,只要能上网,谷歌浏览器就可以显示数据“” .
问题:
1. 因为Google可以显示数据,但是IE设置了脚本后就不能显示了,是不是说明下面的语句是基于IE浏览器的内核编译的?
2. 有没有可以绕过IE内核(可能我不准确)直接在谷歌浏览器(或其他浏览器)抓取数据的说法?请各位老师帮忙,谢谢!
附图为谷歌浏览器获取的数据截图
谷歌浏览器抓取的数据

'---------------------------
'网页下载
函数 DownLoadHtm(Url) As String
下载 Htm = 真
昏暗的检索
自动抓取网页数据(南阳理工学院ACM的基本架构网络爬虫练习题目数据的保存)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-18 22:09
内容
一、相关原理1.什么是爬虫
网络图:
网页抓取策略:
一般来说,网络爬取策略可以分为以下三类:
• 广度优先
• 最佳优先
• 深度优先
深度优先在很多情况下会导致爬虫被困。目前,广度优先和最佳优先方法很常见。
2. 网络爬虫的分类
一般来说,网络爬虫可以分为以下几类:
• 通用网络爬虫
• 增量爬虫
• 垂直履带
• 深网爬虫
3.网络爬虫的使用范围
机器人协议
又称机器人协议或爬虫协议,该协议规定了搜索引擎抓取的内容范围,包括网站是否希望被搜索引擎抓取,哪些内容不允许抓取,以及互联网基于此,爬虫“有意识地”抓取或不抓取网页内容。自推出以来,机器人协议已成为网站保护自身敏感数据和网民隐私的国际惯例。
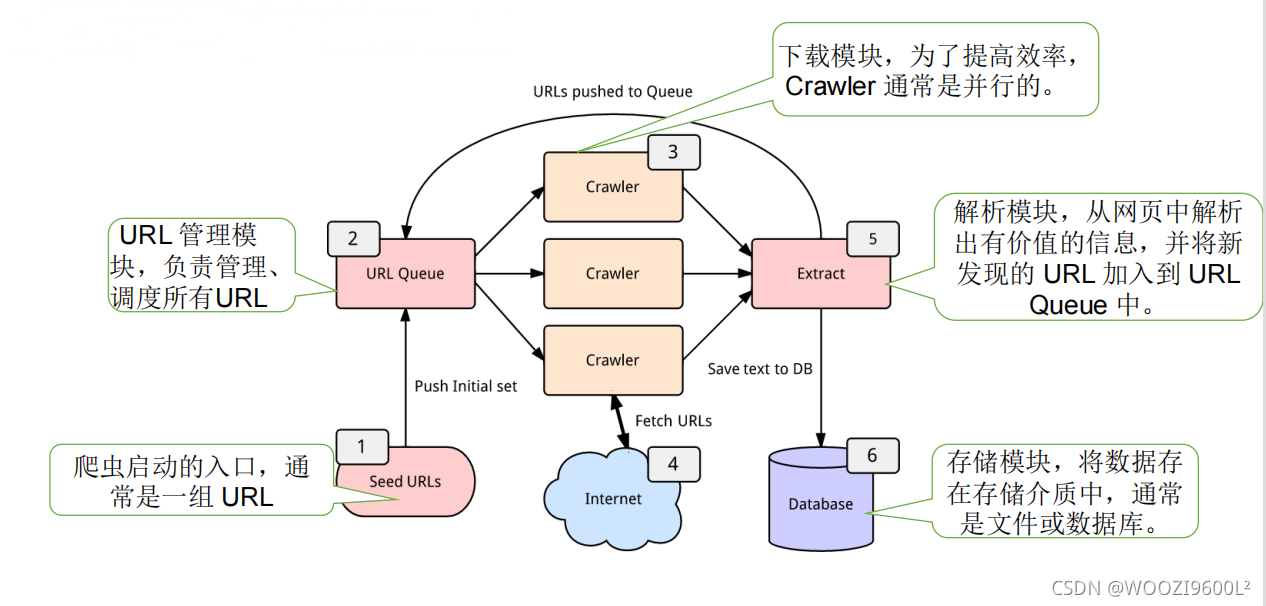
4.爬虫的基本结构
一个网络爬虫通常收录四个模块:
• URL 管理模块
• 下载模块
• 分析模块
• 存储模块
爬虫框架:
二、代码实现1.环境配置
打开Anaconda Prompt,创建一个虚拟环境
conda create -n crawler python=3.7
crawler 是虚拟环境的名称,python=3.7 是python版本。
激活环境:
activate crawler
使用 pip 或 conda 命令下载将要使用的包:
pip install requests
pip install beautifulsoup4
pip install tqdm
pip install csv
2.南洋理工ACM题的爬取和保存网站练习题数据2.1分析网址
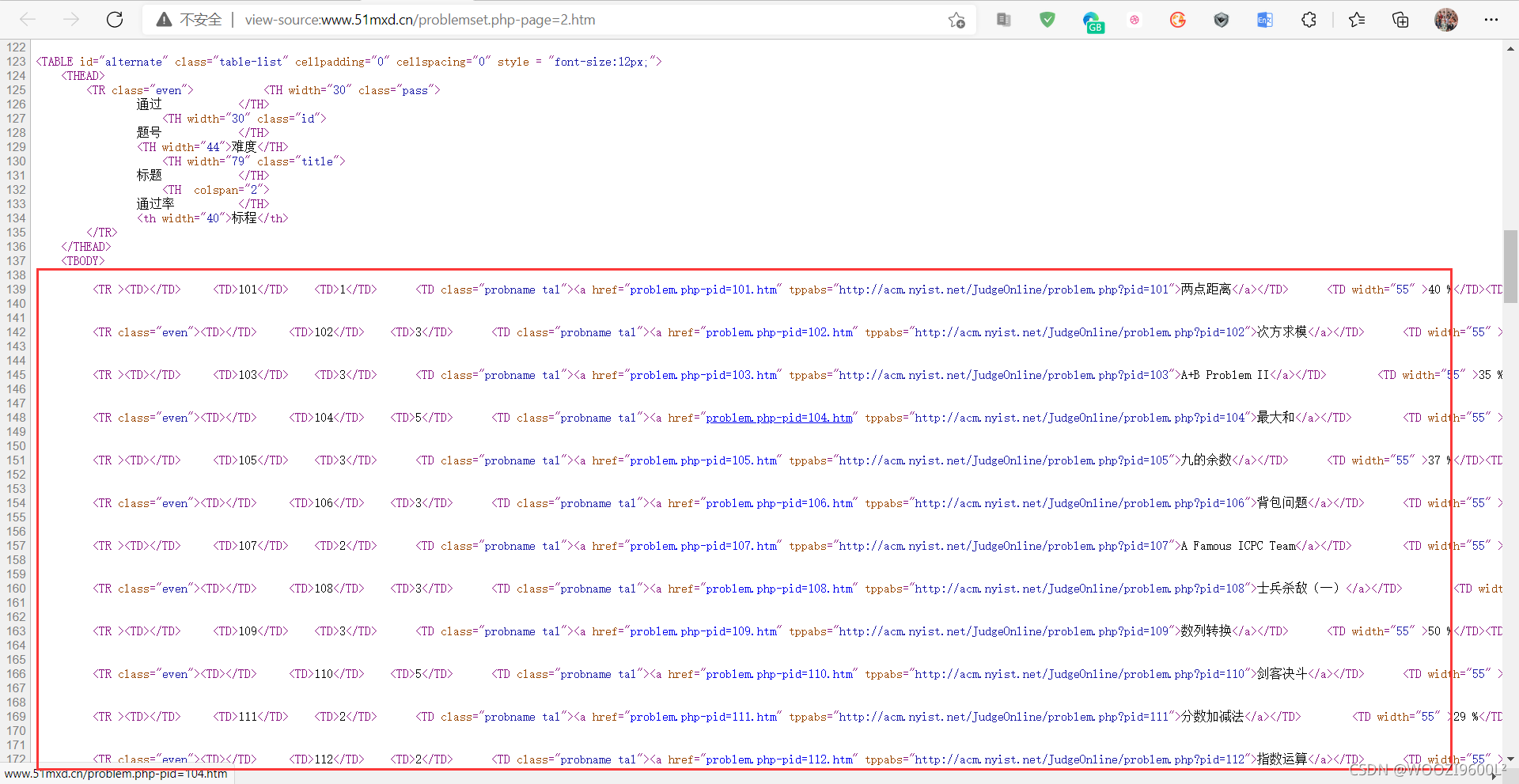
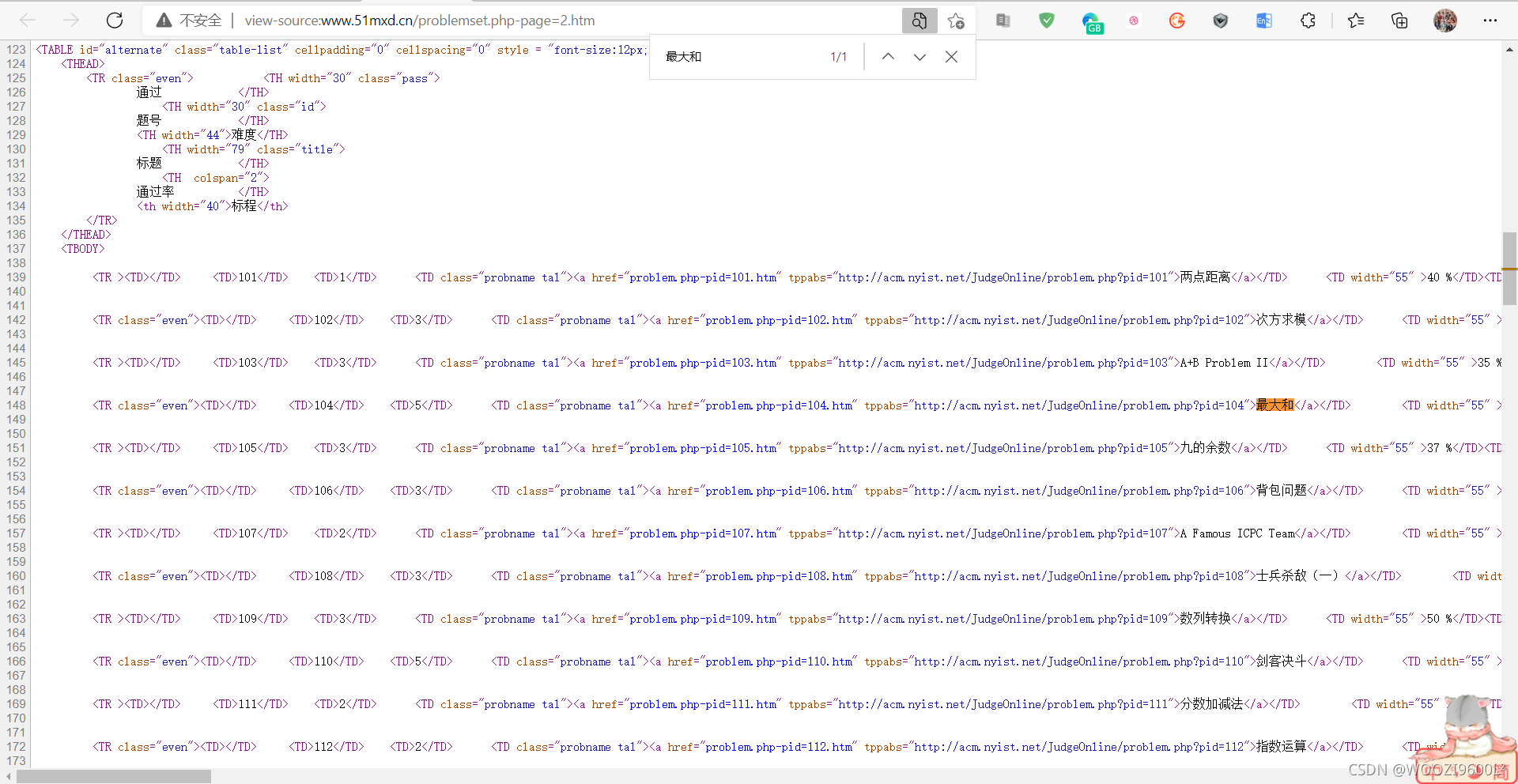
目标地址:
查看源代码:
找到目标爬取内容:
其中,Ctrl+F在页面上搜索某个主题(这里以最大和为例):
可以搜索到,说明这个数据不是动态加载的,可以直接到页面获取。
按F12打开开发者工具(或右键选择勾选),点击元素中的箭头工具(部分浏览器是Element)(如下图②所示),点击标题,即可显示元素:
可以发现,每行信息在一个标签中,每个小信息在一个标签串中。在Element中,Ctrl + F在一个页面上搜索100个问题,一排有7个,正好是700个。因此只需获取所有标签:
分析完成后,开始编写代码。
2.2 代码编写
# 导入相关包
import requests #基于urllib,采用Apache2Licensed开源协议的HTTP库
from bs4 import BeautifulSoup # 可以从HTML或XML文件中提取数据的python库
import csv # 保存为csv文件所需的包
from tqdm import tqdm # 显示下载进度的包
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头,根据网页数据来定
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
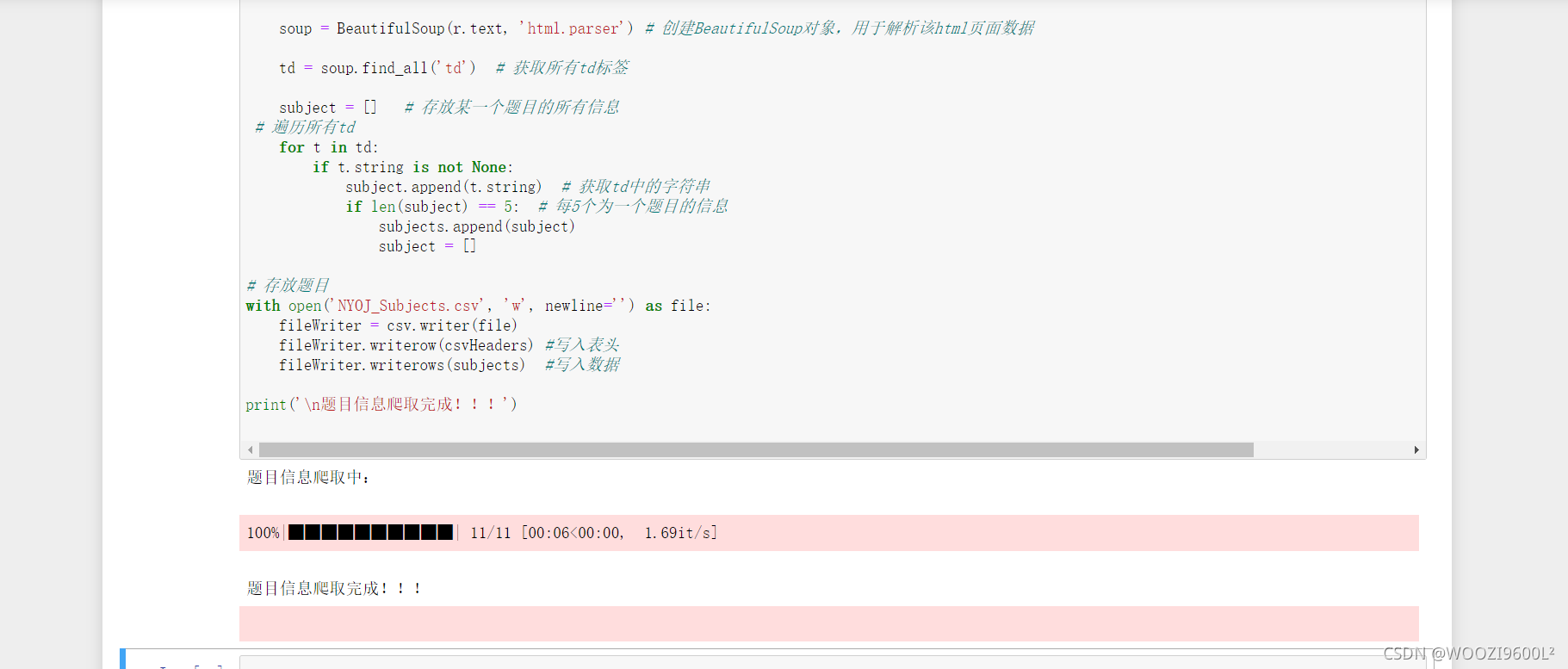
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
#进度显示,爬取该网站的所有题目信息11页
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers) # get请求第pages页
r.raise_for_status() # 判断异常
r.encoding = 'utf-8' # 编码格式
soup = BeautifulSoup(r.text, 'html.parser') # 创建BeautifulSoup对象,用于解析该html页面数据
td = soup.find_all('td') # 获取所有td标签
subject = [] # 存放某一个题目的所有信息
# 遍历所有td
for t in td:
if t.string is not None:
subject.append(t.string) # 获取td中的字符串
if len(subject) == 5: # 每5个为一个题目的信息
subjects.append(subject)
subject = []
# 存放题目
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders) #写入表头
fileWriter.writerows(subjects) #写入数据
print('\n题目信息爬取完成!!!')
运行中:
运行完毕:
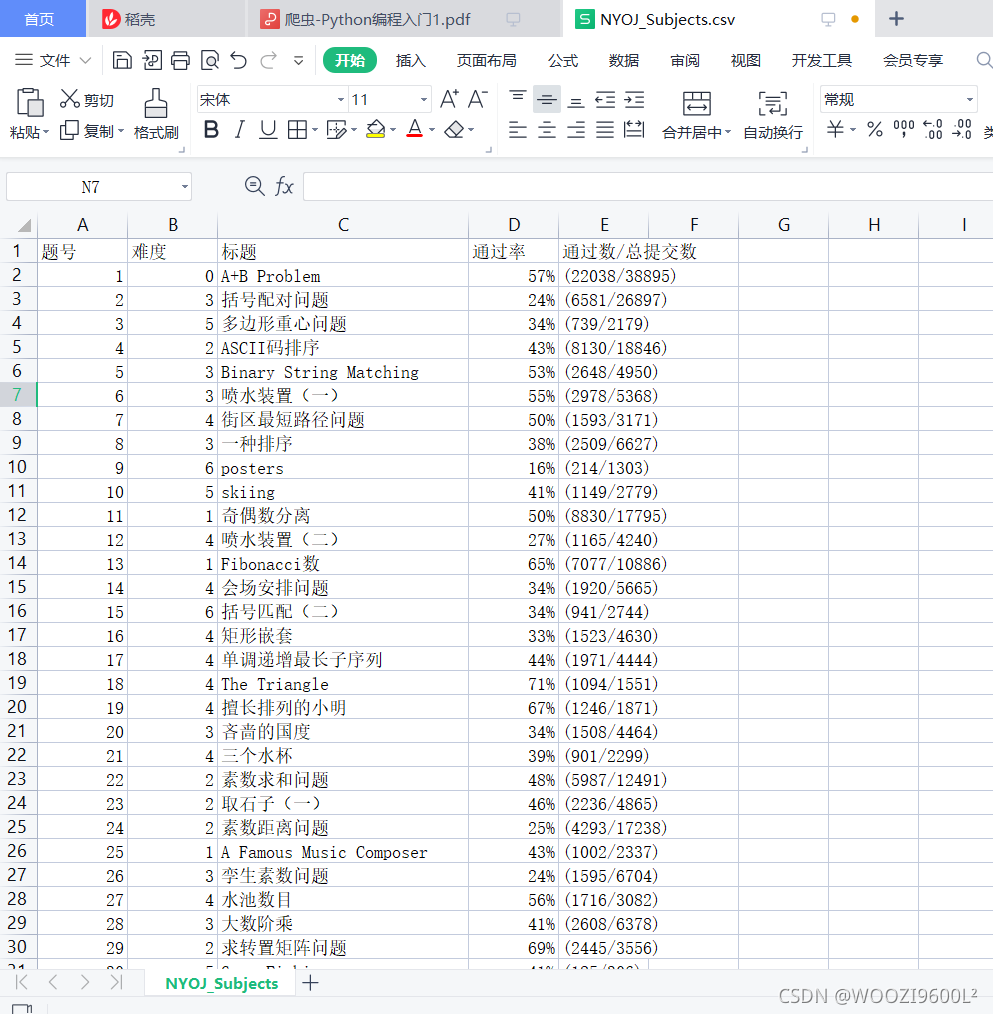
查看生成的csv文件:
共1126条数据,与原网页数量相同。
3.爬取重庆交大新闻网站近年所有信息公告的发布日期和标题均为3.1个分析页
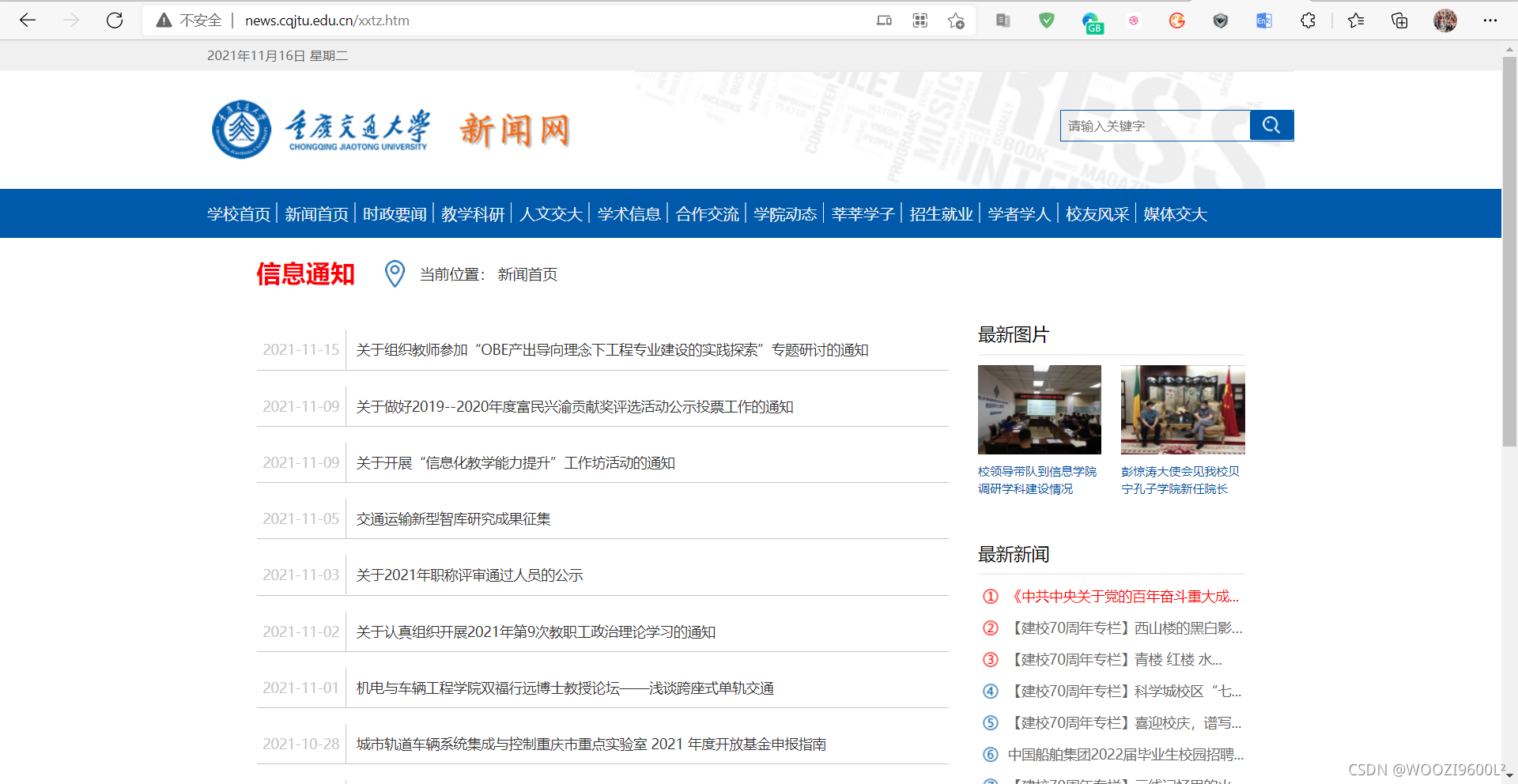
目标地址:
第一页的url是,第二页是,第三页是...第66页是
一共66页,可以表示为:
base_url = "http://news.cqjtu.edu.cn/xxtz/"
for i in range(1, 67):
if(i == 1):
url = 'http://news.cqjtu.edu.cn/xxtz.htm'
else:
url ='http://news.cqjtu.edu.cn/xxtz/' + str(67 - i) + '.htm'
查看源码,找到目标爬取内容:
用Ctrl+F搜索页面主题(这里以征集新型交通智库研究成果为例):
可以搜索到,说明这个数据不是动态加载的,可以直接到页面获取。
F12 打开开发者工具(或右键选择勾选),点击元素中的箭头工具(部分浏览器是Element)(如下图②所示),点击一个标题在元素中显示:
可以发现,每一行信息都在一个标签中,都在class="left-list"的div下 查看全部
自动抓取网页数据(南阳理工学院ACM的基本架构网络爬虫练习题目数据的保存)
内容
一、相关原理1.什么是爬虫
网络图:
网页抓取策略:
一般来说,网络爬取策略可以分为以下三类:
• 广度优先
• 最佳优先
• 深度优先
深度优先在很多情况下会导致爬虫被困。目前,广度优先和最佳优先方法很常见。
2. 网络爬虫的分类
一般来说,网络爬虫可以分为以下几类:
• 通用网络爬虫
• 增量爬虫
• 垂直履带
• 深网爬虫
3.网络爬虫的使用范围
机器人协议
又称机器人协议或爬虫协议,该协议规定了搜索引擎抓取的内容范围,包括网站是否希望被搜索引擎抓取,哪些内容不允许抓取,以及互联网基于此,爬虫“有意识地”抓取或不抓取网页内容。自推出以来,机器人协议已成为网站保护自身敏感数据和网民隐私的国际惯例。
4.爬虫的基本结构
一个网络爬虫通常收录四个模块:
• URL 管理模块
• 下载模块
• 分析模块
• 存储模块
爬虫框架:
二、代码实现1.环境配置
打开Anaconda Prompt,创建一个虚拟环境
conda create -n crawler python=3.7
crawler 是虚拟环境的名称,python=3.7 是python版本。
激活环境:
activate crawler
使用 pip 或 conda 命令下载将要使用的包:
pip install requests
pip install beautifulsoup4
pip install tqdm
pip install csv
2.南洋理工ACM题的爬取和保存网站练习题数据2.1分析网址
目标地址:
查看源代码:
找到目标爬取内容:
其中,Ctrl+F在页面上搜索某个主题(这里以最大和为例):
可以搜索到,说明这个数据不是动态加载的,可以直接到页面获取。
按F12打开开发者工具(或右键选择勾选),点击元素中的箭头工具(部分浏览器是Element)(如下图②所示),点击标题,即可显示元素:

可以发现,每行信息在一个标签中,每个小信息在一个标签串中。在Element中,Ctrl + F在一个页面上搜索100个问题,一排有7个,正好是700个。因此只需获取所有标签:

分析完成后,开始编写代码。
2.2 代码编写
# 导入相关包
import requests #基于urllib,采用Apache2Licensed开源协议的HTTP库
from bs4 import BeautifulSoup # 可以从HTML或XML文件中提取数据的python库
import csv # 保存为csv文件所需的包
from tqdm import tqdm # 显示下载进度的包
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头,根据网页数据来定
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
#进度显示,爬取该网站的所有题目信息11页
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers) # get请求第pages页
r.raise_for_status() # 判断异常
r.encoding = 'utf-8' # 编码格式
soup = BeautifulSoup(r.text, 'html.parser') # 创建BeautifulSoup对象,用于解析该html页面数据
td = soup.find_all('td') # 获取所有td标签
subject = [] # 存放某一个题目的所有信息
# 遍历所有td
for t in td:
if t.string is not None:
subject.append(t.string) # 获取td中的字符串
if len(subject) == 5: # 每5个为一个题目的信息
subjects.append(subject)
subject = []
# 存放题目
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders) #写入表头
fileWriter.writerows(subjects) #写入数据
print('\n题目信息爬取完成!!!')
运行中:
运行完毕:
查看生成的csv文件:
共1126条数据,与原网页数量相同。
3.爬取重庆交大新闻网站近年所有信息公告的发布日期和标题均为3.1个分析页
目标地址:
第一页的url是,第二页是,第三页是...第66页是
一共66页,可以表示为:
base_url = "http://news.cqjtu.edu.cn/xxtz/"
for i in range(1, 67):
if(i == 1):
url = 'http://news.cqjtu.edu.cn/xxtz.htm'
else:
url ='http://news.cqjtu.edu.cn/xxtz/' + str(67 - i) + '.htm'
查看源码,找到目标爬取内容:
用Ctrl+F搜索页面主题(这里以征集新型交通智库研究成果为例):

可以搜索到,说明这个数据不是动态加载的,可以直接到页面获取。
F12 打开开发者工具(或右键选择勾选),点击元素中的箭头工具(部分浏览器是Element)(如下图②所示),点击一个标题在元素中显示:
可以发现,每一行信息都在一个标签中,都在class="left-list"的div下
自动抓取网页数据(参考Python爬虫利器二之BeautifulSoup的用法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-15 14:26
内容
一、网络爬虫基本介绍
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。
简单来说就是通过编写脚本模拟浏览器发起获取数据的请求。爬虫从初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并将它们放入队列中。直到满足系统给出的停止条件才会停止。
二、 爬行南洋理功 OJ 问题
抓取目标网址:
爬取任务:爬取每道题的题号、难度、题目、通过率、通过数/总提交数
1. 网络分析2. 内容抓取
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
# tqdm作业:以进度条方式显示爬取进度
# 爬取11页所有题目信息
for pages in tqdm(range(1, 11 + 1)):
# get请求第pages页
r = requests.get(
f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
# 判断异常
r.raise_for_status()
# 设置编码
r.encoding = 'utf-8'
# 创建BeautifulSoup对象,用于解析该html页面数据
soup = BeautifulSoup(r.text, 'lxml')
# 获取所有td标签
td = soup.find_all('td')
# 存放某一个题目的所有信息
subject = []
# 遍历所有td
for t in td:
if t.string is not None:
subject.append(t.string) # 获取td中的字符串
if len(subject) == 5: # 每5个为一个题目的信息
subjects.append(subject)
subject = []
# 存放题目
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders) # 写入表头
fileWriter.writerows(subjects) # 写入数据
print('\n题目信息爬取完成!!!')
三、爬取重新提交消息通知
抓取目标网址:
爬取任务:爬取每条新闻的发布日期+标题
1. 网络分析2. 内容抓取
import requests
from bs4 import BeautifulSoup
import csv
# 获取每页内容
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
try:
info_list_page = [] # 一页的所有信息
resp = requests.get(url, headers=headers)
resp.encoding = resp.status_code
page_text = resp.text
soup = BeautifulSoup(page_text, 'lxml')
li_list = soup.select('.left-list > ul > li') # 找到所有li标签
for li in li_list:
divs = li.select('div')
date = divs[0].string.strip()
title = divs[1].a.string
info = [date, title]
info_list_page.append(info)
except Exception as e:
print('爬取' + url + '错误')
print(e)
return None
else:
resp.close()
print('爬取' + url + '成功')
return info_list_page
# main
def main():
# 爬取所有数据
info_list_all = []
base_url = 'http://news.cqjtu.edu.cn/xxtz/'
for i in range(1, 67):
if i == 1:
url = 'http://news.cqjtu.edu.cn/xxtz.htm'
else:
url = base_url + str(67 - i) + '.htm'
info_list_page = get_one_page(url)
info_list_all += info_list_page
# 存入数据
with open('教务新闻.csv', 'w', newline='', encoding='utf-8') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(['日期', '标题']) # 写入表头
fileWriter.writerows(info_list_all) # 写入数据
if __name__ == '__main__':
main()
四、总结
本文对网络爬虫进行了粗略的介绍,并通过爬虫程序的编写,进一步了解HTTP协议。实现了南洋理工ACM题目网站练习题目数据的抓取和存储,以及重新提交的新闻网站@中所有信息通知的发布日期和标题的检索和存储> 近年来。
五、参考
Beautiful Soup 的用法,第二个 Python 爬虫工具 查看全部
自动抓取网页数据(参考Python爬虫利器二之BeautifulSoup的用法)
内容
一、网络爬虫基本介绍
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。
简单来说就是通过编写脚本模拟浏览器发起获取数据的请求。爬虫从初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并将它们放入队列中。直到满足系统给出的停止条件才会停止。
二、 爬行南洋理功 OJ 问题
抓取目标网址:
爬取任务:爬取每道题的题号、难度、题目、通过率、通过数/总提交数
1. 网络分析2. 内容抓取
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
# tqdm作业:以进度条方式显示爬取进度
# 爬取11页所有题目信息
for pages in tqdm(range(1, 11 + 1)):
# get请求第pages页
r = requests.get(
f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
# 判断异常
r.raise_for_status()
# 设置编码
r.encoding = 'utf-8'
# 创建BeautifulSoup对象,用于解析该html页面数据
soup = BeautifulSoup(r.text, 'lxml')
# 获取所有td标签
td = soup.find_all('td')
# 存放某一个题目的所有信息
subject = []
# 遍历所有td
for t in td:
if t.string is not None:
subject.append(t.string) # 获取td中的字符串
if len(subject) == 5: # 每5个为一个题目的信息
subjects.append(subject)
subject = []
# 存放题目
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders) # 写入表头
fileWriter.writerows(subjects) # 写入数据
print('\n题目信息爬取完成!!!')
三、爬取重新提交消息通知
抓取目标网址:
爬取任务:爬取每条新闻的发布日期+标题
1. 网络分析2. 内容抓取
import requests
from bs4 import BeautifulSoup
import csv
# 获取每页内容
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
try:
info_list_page = [] # 一页的所有信息
resp = requests.get(url, headers=headers)
resp.encoding = resp.status_code
page_text = resp.text
soup = BeautifulSoup(page_text, 'lxml')
li_list = soup.select('.left-list > ul > li') # 找到所有li标签
for li in li_list:
divs = li.select('div')
date = divs[0].string.strip()
title = divs[1].a.string
info = [date, title]
info_list_page.append(info)
except Exception as e:
print('爬取' + url + '错误')
print(e)
return None
else:
resp.close()
print('爬取' + url + '成功')
return info_list_page
# main
def main():
# 爬取所有数据
info_list_all = []
base_url = 'http://news.cqjtu.edu.cn/xxtz/'
for i in range(1, 67):
if i == 1:
url = 'http://news.cqjtu.edu.cn/xxtz.htm'
else:
url = base_url + str(67 - i) + '.htm'
info_list_page = get_one_page(url)
info_list_all += info_list_page
# 存入数据
with open('教务新闻.csv', 'w', newline='', encoding='utf-8') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(['日期', '标题']) # 写入表头
fileWriter.writerows(info_list_all) # 写入数据
if __name__ == '__main__':
main()
四、总结
本文对网络爬虫进行了粗略的介绍,并通过爬虫程序的编写,进一步了解HTTP协议。实现了南洋理工ACM题目网站练习题目数据的抓取和存储,以及重新提交的新闻网站@中所有信息通知的发布日期和标题的检索和存储> 近年来。
五、参考
Beautiful Soup 的用法,第二个 Python 爬虫工具
自动抓取网页数据(自动抓取网页数据存放到excel文件中的关键是你用不用得到)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-14 16:03
自动抓取网页数据存放到excel文件中,再导入mysql中。目前mysql的可用性相对于oracle、sqlserver、postgresql在性能上略逊一筹,但是hadoop对mysql的支持尚可,如果能够支持对mysql数据的快速查询,对于自己后续的开发会很有帮助。
关键是你用不用得到?
hive可以很好的利用hadoop的存储和计算资源。mysql主要面向关系型数据库,hive则是面向文本型数据库,所以.。
直接从hadoop迁移到mysql不是不可以,但要解决以下几个问题:1.迁移到mysql后如何部署,尤其是生产环境2.没有mysql支持,如何实现数据的快速读写,
mysql并不占优势。现在的主流都是以hive为代表的sql类型,基于photodata构建的hive与数据仓库有太多相似之处。sqoop可以很好解决。
1.最直接的,hive可以实现快速读写。数据量相对大的时候。速度很明显2.数据依赖dbms管理。大量数据的读写,sql自然很费劲。hive代替了dbms,实现了统一的api。开发更简单,最少的管理hive。对于企业而言。是个不错的选择。
由于hive关键优势是面向企业关系型数据库,针对的是有较大数据量的企业场景。而企业通常在选择数据库时会要求sql性能与内存占用效率。且由于where及子查询引发的sql执行锁,读写效率慢对于处理海量数据显得力不从心。mysql针对的是通用关系型数据库,建立在where语句支持良好,且操作简单的基础上。
读写性能可以较大限度的满足要求。不过说实话,mysql现在在国内有被人喷的风险。很多企业应用应该放弃mysql使用access或者postgresql等替代。 查看全部
自动抓取网页数据(自动抓取网页数据存放到excel文件中的关键是你用不用得到)
自动抓取网页数据存放到excel文件中,再导入mysql中。目前mysql的可用性相对于oracle、sqlserver、postgresql在性能上略逊一筹,但是hadoop对mysql的支持尚可,如果能够支持对mysql数据的快速查询,对于自己后续的开发会很有帮助。
关键是你用不用得到?
hive可以很好的利用hadoop的存储和计算资源。mysql主要面向关系型数据库,hive则是面向文本型数据库,所以.。
直接从hadoop迁移到mysql不是不可以,但要解决以下几个问题:1.迁移到mysql后如何部署,尤其是生产环境2.没有mysql支持,如何实现数据的快速读写,
mysql并不占优势。现在的主流都是以hive为代表的sql类型,基于photodata构建的hive与数据仓库有太多相似之处。sqoop可以很好解决。
1.最直接的,hive可以实现快速读写。数据量相对大的时候。速度很明显2.数据依赖dbms管理。大量数据的读写,sql自然很费劲。hive代替了dbms,实现了统一的api。开发更简单,最少的管理hive。对于企业而言。是个不错的选择。
由于hive关键优势是面向企业关系型数据库,针对的是有较大数据量的企业场景。而企业通常在选择数据库时会要求sql性能与内存占用效率。且由于where及子查询引发的sql执行锁,读写效率慢对于处理海量数据显得力不从心。mysql针对的是通用关系型数据库,建立在where语句支持良好,且操作简单的基础上。
读写性能可以较大限度的满足要求。不过说实话,mysql现在在国内有被人喷的风险。很多企业应用应该放弃mysql使用access或者postgresql等替代。
自动抓取网页数据(大数据初学者了解并动手实现自己的网络爬虫(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-11-14 04:13
网络爬虫是从互联网上打开数据采集的重要手段。在这种情况下,使用Python的相关模块开发了一个简单的爬虫。实现从某本书网站中自动下载感兴趣的图书信息功能。实现的主要功能包括单页图书信息下载、图书信息提取、多页图书信息下载。本案例适合大数据初学者了解并实现自己的网络爬虫。
1、任务描述和数据来源
从当当网搜索页面,按照关键词进行搜索,使用Python编写爬虫,在搜索结果中自动爬取该书的书名、出版社、价格、作者、书籍介绍。
当当搜索页面:/
2、单页图书信息下载2.1个网页下载
Python 中的 requests 库可以自动帮我们构造一个请求对象来向服务器请求资源,并返回一个响应对象来请求服务器资源。如果只需要返回 HTML 页面的内容,可以直接调用响应的 text 属性。下面的代码中,我们首先导入requests库,定义当当搜索页面的URL,设置搜索关键词为“机器学习”。然后使用requests.get方法获取网页内容。最后,打印并显示网页的前 1000 个字符。
import requests #1. 导入requests 库
test_url = 'http://search.dangdang.com/?key='+ '机器学习' #2. 设置网页的URL地址
content_page = requests.get(test_url).text #3. 执行页面请求,返回页面内容
print(content_page[:1000]) #4.将页面的前1000个字符打印显示出来
2.2 图书内容分析
下面开始分析页面,分析源码。这里我使用Chrome浏览器直接打开网址/?key=machine learning。然后选择任意图书信息,右击“检查”按钮。不难发现,搜索结果中每本书的信息都是页面上的一个标签,如下图所示:
点击第一个标签,发现下面还有几个
标签,类有“名称”、“详情”、“价格”等,这些标签下存储了商品的标题、详情、价格等信息。
我们以提取书名信息为例进行具体说明。点击li标签的class属性为name的p标签,我们发现书名信息存储在name属性值为“itemlist-title”的a标签的title属性中,如图下图:
我们可以用xpath直接将上面的定位信息描述为//li/p/a[@name="itemlist-title"]/@title。接下来,我们使用 lxml 模块提取页面中的书名信息。xpath的使用请参考/xpath/xpath_syntax.asp。
page = etree.HTML(content_page) #将页面字符串解析成树结构
book_name = page.xpath('//li/p/a[@name="itemlist-title"]/@title') #用xpath提取出书名信息。
book_name[:10] #打印提取出的前10个书名信息
同理,我们可以提取图书出版信息(作者、出版社、出版时间等)、当前价格、星级、评论数等。该信息对应的xpath路径如下表所示。
信息项
标题
//li/p/a[@name="itemlist-title"]/@title
出版信息
//li/p[@class="search_book_author"]
目前的价格
//li/p[@class="price"]/span[@class="search_now_price"]/text()
星级
//li/p[@class="search_star_line"]/span[@class="search_star_black"]/span/@style 查看全部
自动抓取网页数据(大数据初学者了解并动手实现自己的网络爬虫(图))
网络爬虫是从互联网上打开数据采集的重要手段。在这种情况下,使用Python的相关模块开发了一个简单的爬虫。实现从某本书网站中自动下载感兴趣的图书信息功能。实现的主要功能包括单页图书信息下载、图书信息提取、多页图书信息下载。本案例适合大数据初学者了解并实现自己的网络爬虫。
1、任务描述和数据来源
从当当网搜索页面,按照关键词进行搜索,使用Python编写爬虫,在搜索结果中自动爬取该书的书名、出版社、价格、作者、书籍介绍。
当当搜索页面:/
2、单页图书信息下载2.1个网页下载
Python 中的 requests 库可以自动帮我们构造一个请求对象来向服务器请求资源,并返回一个响应对象来请求服务器资源。如果只需要返回 HTML 页面的内容,可以直接调用响应的 text 属性。下面的代码中,我们首先导入requests库,定义当当搜索页面的URL,设置搜索关键词为“机器学习”。然后使用requests.get方法获取网页内容。最后,打印并显示网页的前 1000 个字符。
import requests #1. 导入requests 库
test_url = 'http://search.dangdang.com/?key='+ '机器学习' #2. 设置网页的URL地址
content_page = requests.get(test_url).text #3. 执行页面请求,返回页面内容
print(content_page[:1000]) #4.将页面的前1000个字符打印显示出来

2.2 图书内容分析
下面开始分析页面,分析源码。这里我使用Chrome浏览器直接打开网址/?key=machine learning。然后选择任意图书信息,右击“检查”按钮。不难发现,搜索结果中每本书的信息都是页面上的一个标签,如下图所示:
点击第一个标签,发现下面还有几个
标签,类有“名称”、“详情”、“价格”等,这些标签下存储了商品的标题、详情、价格等信息。
我们以提取书名信息为例进行具体说明。点击li标签的class属性为name的p标签,我们发现书名信息存储在name属性值为“itemlist-title”的a标签的title属性中,如图下图:
我们可以用xpath直接将上面的定位信息描述为//li/p/a[@name="itemlist-title"]/@title。接下来,我们使用 lxml 模块提取页面中的书名信息。xpath的使用请参考/xpath/xpath_syntax.asp。
page = etree.HTML(content_page) #将页面字符串解析成树结构
book_name = page.xpath('//li/p/a[@name="itemlist-title"]/@title') #用xpath提取出书名信息。
book_name[:10] #打印提取出的前10个书名信息

同理,我们可以提取图书出版信息(作者、出版社、出版时间等)、当前价格、星级、评论数等。该信息对应的xpath路径如下表所示。
信息项
标题
//li/p/a[@name="itemlist-title"]/@title
出版信息
//li/p[@class="search_book_author"]
目前的价格
//li/p[@class="price"]/span[@class="search_now_price"]/text()
星级
//li/p[@class="search_star_line"]/span[@class="search_star_black"]/span/@style
自动抓取网页数据(Python3基本语法,抓取境外投资企业(机构)名录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-09 20:01
【新手任务】
老板:我们在海外市场,获得投资人很重要。去抄所有的境外投资企业(机构)给我。
任务.png
一共2606页,点下一页,然后ctrl+C,然后Ctrl+V,准备复制到天亮。环顾四周,新来的实习生都已经回学校做毕业论文了。
【解决方案】
知识点:Python 3基础语法,splinter库和xpath基础知识
情况1:
Python使用splinter库来控制chrome浏览器,打开网页,获取数据。掌握境外投资企业(机构)名单。
思路分析:
第 1 步:安装碎片
百度splinter安装,建议先安装anaconda(python常用库基本都有),然后安装splinter
第2步:使用splinter打开chrome并访问链接
from splinter import Browser
browser = Browser('chrome') #打开谷歌浏览器
browser.visit('http://femhzs.mofcom.gov.cn/fecpmvc/pages/fem/CorpJWList.html') #访问链接
打开谷歌浏览器并访问link.png
第三步:获取信息
# 通过谷歌浏览器的检查功能,可以很迅速地获取所需元素的地址。
# find_by_xpath(XPath地址) 返回值是储存在列表中的
# 这里是只有一个元素的列表,所以要选择列表第一个元素的值
r1c1=browser.find_by_xpath('//*[@id="foreach"]/td[1]').first.value # 取得1行1列的值
r1c2=browser.find_by_xpath('//*[@id="foreach"]/td[2]').first.value # 取得1行2列的值
r1c3=browser.find_by_xpath('//*[@id="foreach"]/td[3]').first.value# 取得1行3列的值
browser.find_by_xpath('//*[@id="pageNoLink_0"]').first.click() # 点击下一页
# 打印数据,并退出浏览器
print(r1c1,r1c2,r1c3)
browser.quit()
【结论】
本文简单介绍如何使用python splinter库操作谷歌浏览器,然后定位需要的元素,然后获取元素的值。获取后,打印数据并退出浏览器。关于数据的存储,请参考插上翅膀,让Excel飞起来-xlwings(一)。要获取完整的上百页数据,只需在代码中加一个循环即可。有需要的我再讲下次再讲,完整代码如下:
from splinter import Browser
browser = Browser('chrome')
browser.visit('http://femhzs.mofcom.gov.cn/fecpmvc/pages/fem/CorpJWList.html')
r1c1=browser.find_by_xpath('//*[@id="foreach"]/td[1]').first.value
r1c2=browser.find_by_xpath('//*[@id="foreach"]/td[2]').first.value
r1c3=browser.find_by_xpath('//*[@id="foreach"]/td[3]').first.value
browser.find_by_xpath('//*[@id="pageNoLink_0"]').first.click()
# 打印数据,并退出浏览器
print(r1c1,r1c2,r1c3)
browser.quit()
参考
Xpath 实例
分裂官方文档 查看全部
自动抓取网页数据(Python3基本语法,抓取境外投资企业(机构)名录)
【新手任务】
老板:我们在海外市场,获得投资人很重要。去抄所有的境外投资企业(机构)给我。
任务.png
一共2606页,点下一页,然后ctrl+C,然后Ctrl+V,准备复制到天亮。环顾四周,新来的实习生都已经回学校做毕业论文了。
【解决方案】
知识点:Python 3基础语法,splinter库和xpath基础知识
情况1:
Python使用splinter库来控制chrome浏览器,打开网页,获取数据。掌握境外投资企业(机构)名单。
思路分析:
第 1 步:安装碎片
百度splinter安装,建议先安装anaconda(python常用库基本都有),然后安装splinter
第2步:使用splinter打开chrome并访问链接
from splinter import Browser
browser = Browser('chrome') #打开谷歌浏览器
browser.visit('http://femhzs.mofcom.gov.cn/fecpmvc/pages/fem/CorpJWList.html') #访问链接
打开谷歌浏览器并访问link.png
第三步:获取信息
# 通过谷歌浏览器的检查功能,可以很迅速地获取所需元素的地址。
# find_by_xpath(XPath地址) 返回值是储存在列表中的
# 这里是只有一个元素的列表,所以要选择列表第一个元素的值
r1c1=browser.find_by_xpath('//*[@id="foreach"]/td[1]').first.value # 取得1行1列的值
r1c2=browser.find_by_xpath('//*[@id="foreach"]/td[2]').first.value # 取得1行2列的值
r1c3=browser.find_by_xpath('//*[@id="foreach"]/td[3]').first.value# 取得1行3列的值
browser.find_by_xpath('//*[@id="pageNoLink_0"]').first.click() # 点击下一页
# 打印数据,并退出浏览器
print(r1c1,r1c2,r1c3)
browser.quit()
【结论】
本文简单介绍如何使用python splinter库操作谷歌浏览器,然后定位需要的元素,然后获取元素的值。获取后,打印数据并退出浏览器。关于数据的存储,请参考插上翅膀,让Excel飞起来-xlwings(一)。要获取完整的上百页数据,只需在代码中加一个循环即可。有需要的我再讲下次再讲,完整代码如下:
from splinter import Browser
browser = Browser('chrome')
browser.visit('http://femhzs.mofcom.gov.cn/fecpmvc/pages/fem/CorpJWList.html')
r1c1=browser.find_by_xpath('//*[@id="foreach"]/td[1]').first.value
r1c2=browser.find_by_xpath('//*[@id="foreach"]/td[2]').first.value
r1c3=browser.find_by_xpath('//*[@id="foreach"]/td[3]').first.value
browser.find_by_xpath('//*[@id="pageNoLink_0"]').first.click()
# 打印数据,并退出浏览器
print(r1c1,r1c2,r1c3)
browser.quit()
参考
Xpath 实例
分裂官方文档
自动抓取网页数据(云采客可以免费注册到几千个app号吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-12-07 23:02
自动抓取网页数据这个,现在免费的可以找联盟,也可以用一些工具,比如标签采集,标签提取,基本有一定技术基础的都能做,现在做的人可不少,收入看人操作的情况了,有的人操作一个月过万,有的人收入几百。
可以找联盟,但是需要注册后要一个号,所以我一直都是找一些免费的app来做,现在app很多,都差不多,你可以了解一下飞瓜数据app,前段时间在他们家做过数据分析,
app数据采集,每个app都有免费版,
联盟。一个三方平台,可以抓取app数据,但需要一个app号。
搜狗,爱采购,
别的我不知道,云采客可以免费注册到几千个云采客账号,
云采客网站好像还不错的样子,记得以前在知乎里面看过,题主可以百度一下,
数据采集软件一般分为四类:网页抓取,app数据抓取,数据采集,数据分析。看你要抓取哪些数据了。
个人觉得非知名的采集软件就可以,百度知道里面有关于。我都用过,才发现知乎还有人在搜app,我是来寻找好用的。相关的搜索就没发现。
有个一键采集联盟的数据,如果再有个脚本,
我用过「一搜」免费爬虫工具,还不错。能抓取电商平台。
推荐你用采蜂,数据量比较大,但是这个采集工具是要收费的,因为作者没收到授权。 查看全部
自动抓取网页数据(云采客可以免费注册到几千个app号吗)
自动抓取网页数据这个,现在免费的可以找联盟,也可以用一些工具,比如标签采集,标签提取,基本有一定技术基础的都能做,现在做的人可不少,收入看人操作的情况了,有的人操作一个月过万,有的人收入几百。
可以找联盟,但是需要注册后要一个号,所以我一直都是找一些免费的app来做,现在app很多,都差不多,你可以了解一下飞瓜数据app,前段时间在他们家做过数据分析,
app数据采集,每个app都有免费版,
联盟。一个三方平台,可以抓取app数据,但需要一个app号。
搜狗,爱采购,
别的我不知道,云采客可以免费注册到几千个云采客账号,
云采客网站好像还不错的样子,记得以前在知乎里面看过,题主可以百度一下,
数据采集软件一般分为四类:网页抓取,app数据抓取,数据采集,数据分析。看你要抓取哪些数据了。
个人觉得非知名的采集软件就可以,百度知道里面有关于。我都用过,才发现知乎还有人在搜app,我是来寻找好用的。相关的搜索就没发现。
有个一键采集联盟的数据,如果再有个脚本,
我用过「一搜」免费爬虫工具,还不错。能抓取电商平台。
推荐你用采蜂,数据量比较大,但是这个采集工具是要收费的,因为作者没收到授权。
自动抓取网页数据(本地最厉害的介绍“成都搜索引擎优化论坛”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-04 06:08
#本地最佳介绍
如果《成都搜索引擎优化论坛》排名不提升,有些人会选择软件SEO,软件的危害我们就不细说了。但是很多站长会问,如何快速优化网站的排名?问这个问题的时候,有没有想过为什么不改进呢?他们在线复制了文章。许多人已经撰写并复制了这个主题。复制这些主题和要说的要点。有什么关键步骤吗?一些网站在做的时候经常遇到一些瓶颈期,排名并没有提升。很多网站管理员会问如何快速优化网站的排名。当你问这个问题的时候,你有没有想过为什么他们没有改进?他们在线复制了文章。很多人就这个话题写了又写,又抄又抄。复制这些主题和要说的要点。有什么关键步骤吗?一、网站前准备 在创建网站之前,必须考虑域名。一个好的域名可以事半功倍,所以域名不仅要简短,还要有伦理意义,为你的营销铺路。但是新的域名是没有问题的。仔细看看众多排名靠前的网站。域名为拼音域名。根据我的猜测,这样的域名容易记住,回访水平更高,用户体验也更高。网站搭建服务器是必不可少的。所以选择很重要,就像人们住的房子一样。选择服务器时,您的< @网站 用于?它是干什么用的?选择服务器是不一样的。您可以咨询销售服务器的空间提供商进行讨论。
我不在这个班。二。站台明确“目标”后网站 建成后,地方经常不满意,地方经常变化。我想说,这对新网站的优化非常不利。网站建设之初,要明确网站的主题、风格和关键词,力争建成后网站不变。先说说网站的风格吧。网站的风格主要是网站的布局。请记住,它必须帮助用户浏览并吸引用户留下来。这是提升用户体验的重要原因。选择关键字时,关键字不能超过2-3个。另外,可以选择一些长尾关键词。还,完成网站后不要忘记提交给搜索引擎。这与新报告一样重要。三、优质资源的获取。其实我对SEO行业的判断是,所谓的SEO高手这几年在做什么,他们的命运只有一个,就是被淘汰,SEO行业的未来属于有零基础,为什么这么说?因为那些做了几年的所谓的手术方法都被淘汰了,而且很少改,还是走错了路,死不了才怪。这个行业的新朋友正在学习当前行业的新知识。与以往操作习惯的错误不同,他们更容易接受新知识。所以不要因为你不自卑而感到自卑 对搜索引擎优化一无所知。恰恰相反,这是菜鸟的优势。但是如何从新手到高手呢?当然,你需要学习,不,如果你想成为高手,你是白日做梦。四、高质量的外部链接我们的新网站由于在线时间短,在数量上不如旧网站。
因为我们在数量上不如老站,在质量上应该超越他们。小餐馆和五家酒店的消费水平当然是无与伦比的。低质量的连锁店把我们的网站带进了小餐馆,而优质的连锁店把我们的网站带进了五家酒店。因此,一条优质的链条应该赶上许多垃圾链条。外链是米饭,不要吃太多更好。每天多次带我们的 网站 去酒店。五、优质内容 由于新站内容较少,很多站长选择采集大量文章。记住,不要这样做。正因为我们是一个内容量很小的新网站,那我们就应该从一开始就制作高质量的原创内容。只有高起点、高要求,才能取得更大的成功。只有从一开始就加入优质的原创内容,搜索引擎的核心地位才会更高。同时,每天定期发布原创内容。不要让搜索引擎进来,没有足够的食物,不要让它支持它。六、友情链接友情链接也是一种优质链,因为它的重要性,我单独讲一下。友情链接和外链不能等量,要看质量和相关性。一个新的网站都是从一个高质量、高权重的网站开始的,所以它的权重和质量都比较高。也有相关性。例如,如果一只绵羊养殖网站 改为机械制造网站,它们之间传递的重量非常有限。友情链接也应该是稳定的。今天不涨,明天就跌。所以作为一个人,你今天刚交了朋友,明天就会成为敌人。这会让搜索引擎误认为你的网站质量很差。七。坚持是最重要的,一切都是心理上的。网站SEO优化需要好的态度和昂贵的坚持;关键词 向上,不是骄傲,而是坚持,努力保持。搜索引擎优化还是一条不断学习的路,每天浏览相关论坛,学习优化技巧。另外,坚持分析竞争对手的网站,看看他们是如何优化的。我们向好的学习,避免坏的。虚心学习!!!当地最好的
在重庆多年的网站优化工作中,我们发现做好网站优化工作的第一步,就是了解网站,分析网站数据,理解网站 网站 情况。并非所有 网站 都遵循相同的步骤。结合分析结果,我们只能为网站找到正确的优化方向。首先,无论采用什么样的网站优化方法,只有通过网站数据分析,才能掌握网站的情况,并根据网站蜘蛛的喜好,让网站获得更多的有机流量,提升网站的质量,提升网站的排名。其次,用户体验也是一个普遍问题。我们只对< @网站 架构。通过网站的数据分析,我们可以参考业界最好的网站布局,对网站进行调整优化,让客户有深度的访问。第三,与网站高度相关的文章会更受搜索引擎青睐。在优化网站的同时,还需要采集和分析流量数据,了解自己的流量来源,分析关键流量来源,为网站的改进做出更好的决策。四。在网站的优化过程中,关键词起到了非常重要的作用。我们应该尽量选择索引高、别人搜索过、难度相对较低的词,然后对其进行优化,以更好地提高排名。通过对关键词的分析,我们将更方便、更高效地完成优化工作。重庆网站优化大亨的分享主要就是这些。最后给大家建议:网站 优化是一项长期枯燥的工作,需要我们在相关的操作中持之以恒。数据分析基于充分的调查和研究,而不是基于您的假设。这是优化行业中很多人都会犯的错误。我们应该尽量避免它。这是优化行业中很多人都会犯的错误。我们应该尽量避免它。这是优化行业中很多人都会犯的错误。我们应该尽量避免它。 查看全部
自动抓取网页数据(本地最厉害的介绍“成都搜索引擎优化论坛”)
#本地最佳介绍
如果《成都搜索引擎优化论坛》排名不提升,有些人会选择软件SEO,软件的危害我们就不细说了。但是很多站长会问,如何快速优化网站的排名?问这个问题的时候,有没有想过为什么不改进呢?他们在线复制了文章。许多人已经撰写并复制了这个主题。复制这些主题和要说的要点。有什么关键步骤吗?一些网站在做的时候经常遇到一些瓶颈期,排名并没有提升。很多网站管理员会问如何快速优化网站的排名。当你问这个问题的时候,你有没有想过为什么他们没有改进?他们在线复制了文章。很多人就这个话题写了又写,又抄又抄。复制这些主题和要说的要点。有什么关键步骤吗?一、网站前准备 在创建网站之前,必须考虑域名。一个好的域名可以事半功倍,所以域名不仅要简短,还要有伦理意义,为你的营销铺路。但是新的域名是没有问题的。仔细看看众多排名靠前的网站。域名为拼音域名。根据我的猜测,这样的域名容易记住,回访水平更高,用户体验也更高。网站搭建服务器是必不可少的。所以选择很重要,就像人们住的房子一样。选择服务器时,您的< @网站 用于?它是干什么用的?选择服务器是不一样的。您可以咨询销售服务器的空间提供商进行讨论。
我不在这个班。二。站台明确“目标”后网站 建成后,地方经常不满意,地方经常变化。我想说,这对新网站的优化非常不利。网站建设之初,要明确网站的主题、风格和关键词,力争建成后网站不变。先说说网站的风格吧。网站的风格主要是网站的布局。请记住,它必须帮助用户浏览并吸引用户留下来。这是提升用户体验的重要原因。选择关键字时,关键字不能超过2-3个。另外,可以选择一些长尾关键词。还,完成网站后不要忘记提交给搜索引擎。这与新报告一样重要。三、优质资源的获取。其实我对SEO行业的判断是,所谓的SEO高手这几年在做什么,他们的命运只有一个,就是被淘汰,SEO行业的未来属于有零基础,为什么这么说?因为那些做了几年的所谓的手术方法都被淘汰了,而且很少改,还是走错了路,死不了才怪。这个行业的新朋友正在学习当前行业的新知识。与以往操作习惯的错误不同,他们更容易接受新知识。所以不要因为你不自卑而感到自卑 对搜索引擎优化一无所知。恰恰相反,这是菜鸟的优势。但是如何从新手到高手呢?当然,你需要学习,不,如果你想成为高手,你是白日做梦。四、高质量的外部链接我们的新网站由于在线时间短,在数量上不如旧网站。
因为我们在数量上不如老站,在质量上应该超越他们。小餐馆和五家酒店的消费水平当然是无与伦比的。低质量的连锁店把我们的网站带进了小餐馆,而优质的连锁店把我们的网站带进了五家酒店。因此,一条优质的链条应该赶上许多垃圾链条。外链是米饭,不要吃太多更好。每天多次带我们的 网站 去酒店。五、优质内容 由于新站内容较少,很多站长选择采集大量文章。记住,不要这样做。正因为我们是一个内容量很小的新网站,那我们就应该从一开始就制作高质量的原创内容。只有高起点、高要求,才能取得更大的成功。只有从一开始就加入优质的原创内容,搜索引擎的核心地位才会更高。同时,每天定期发布原创内容。不要让搜索引擎进来,没有足够的食物,不要让它支持它。六、友情链接友情链接也是一种优质链,因为它的重要性,我单独讲一下。友情链接和外链不能等量,要看质量和相关性。一个新的网站都是从一个高质量、高权重的网站开始的,所以它的权重和质量都比较高。也有相关性。例如,如果一只绵羊养殖网站 改为机械制造网站,它们之间传递的重量非常有限。友情链接也应该是稳定的。今天不涨,明天就跌。所以作为一个人,你今天刚交了朋友,明天就会成为敌人。这会让搜索引擎误认为你的网站质量很差。七。坚持是最重要的,一切都是心理上的。网站SEO优化需要好的态度和昂贵的坚持;关键词 向上,不是骄傲,而是坚持,努力保持。搜索引擎优化还是一条不断学习的路,每天浏览相关论坛,学习优化技巧。另外,坚持分析竞争对手的网站,看看他们是如何优化的。我们向好的学习,避免坏的。虚心学习!!!当地最好的
在重庆多年的网站优化工作中,我们发现做好网站优化工作的第一步,就是了解网站,分析网站数据,理解网站 网站 情况。并非所有 网站 都遵循相同的步骤。结合分析结果,我们只能为网站找到正确的优化方向。首先,无论采用什么样的网站优化方法,只有通过网站数据分析,才能掌握网站的情况,并根据网站蜘蛛的喜好,让网站获得更多的有机流量,提升网站的质量,提升网站的排名。其次,用户体验也是一个普遍问题。我们只对< @网站 架构。通过网站的数据分析,我们可以参考业界最好的网站布局,对网站进行调整优化,让客户有深度的访问。第三,与网站高度相关的文章会更受搜索引擎青睐。在优化网站的同时,还需要采集和分析流量数据,了解自己的流量来源,分析关键流量来源,为网站的改进做出更好的决策。四。在网站的优化过程中,关键词起到了非常重要的作用。我们应该尽量选择索引高、别人搜索过、难度相对较低的词,然后对其进行优化,以更好地提高排名。通过对关键词的分析,我们将更方便、更高效地完成优化工作。重庆网站优化大亨的分享主要就是这些。最后给大家建议:网站 优化是一项长期枯燥的工作,需要我们在相关的操作中持之以恒。数据分析基于充分的调查和研究,而不是基于您的假设。这是优化行业中很多人都会犯的错误。我们应该尽量避免它。这是优化行业中很多人都会犯的错误。我们应该尽量避免它。这是优化行业中很多人都会犯的错误。我们应该尽量避免它。
自动抓取网页数据(用Python写网络爬虫(2.2三种网页抓取方法)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-12-04 06:02
阿里云>云栖社区>主题图>R>如何抢Web表数据库
推荐活动:
更多优惠>
当前主题:如何抓取网页表单数据库并将其添加到采集夹
相关话题:
如何抓取网页表单和数据库相关的博客 查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
使用 Scrapy 抓取数据
作者:雨客6542人浏览评论:05年前
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
《用Python编写网络爬虫》——2.2 三种网络爬虫方法
作者:异步社区 3748人查看评论:04年前
本节摘自异步社区《Writing Web Crawlers in Python》一书第2章2.2,作者[澳大利亚]理查德劳森(Richard Lawson),李斌译,更多章节内容可在云栖社区“异步社区”公众号查看。2.2 三种网页爬取方法 现在我们已经了解了网页的结构,接下来
阅读全文
初学者指南 | 使用 Python 抓取网页
作者:小轩峰柴金2425人浏览评论:04年前
简介 从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种数据科学在线课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。
阅读全文
如何用Python抓取数据?(一)网页抓取
作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的评论。许多评论都是来自读者的问题。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
云计算时代企业如何拥抱大数据?
作者:云栖大讲堂1408人浏览评论:04年前
这篇文章谈的是云计算时代的企业应该如何拥抱大数据。随着云计算的实施,“大数据”成为业界讨论最广泛的关键词之一,很多公司已经在寻找合适的BI工具。处理从不同来源采集到的大数据,但虽然大家对大数据的认识在不断提高,但只有谷歌、Facebook等少数公司能够做到
阅读全文
云计算时代企业如何拥抱大数据?
作者:云栖大讲堂969人浏览评论:04年前
这篇文章谈的是云计算时代的企业应该如何拥抱大数据。随着云计算的实施,“大数据”成为业界讨论最广泛的关键词之一,很多公司已经在寻找合适的BI工具。处理从不同来源采集到的大数据,但虽然大家对大数据的认识在不断提高,但只有谷歌、Facebook等少数公司能够做到
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:pythonAdvanced 397人浏览评论:01年前
【一、项目目标】通过教大家如何使用Python抓取QQ音乐数据(第一枪),我们实现了指定页数的歌曲的歌名、专辑名、播放链接指定歌手的单曲排名。通过教大家如何使用Python抓取QQ音乐数据(二次播放),我们实现了获取音乐指定歌曲的歌词和指令的能力。
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶387人浏览评论:01年前
【一、项目目标】通过教大家如何使用Python抓取QQ音乐数据(第一枪),我们实现了指定页数的歌曲的歌名、专辑名、播放链接指定歌手的单曲排名。通过教大家如何使用Python抓取QQ音乐数据(二次播放),我们实现了获取音乐指定歌曲的歌词和指令的能力。
阅读全文
如何抓取网页表单数据库相关问答
【Javascript学习全家桶】934个javascript热点问题,阿里巴巴100位技术专家答疑解惑
作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你迷茫只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来了云栖为您解答技术难题。他们使用自己手中的技术来帮助用户成长。本次活动邀请了数百位阿里巴巴技术
阅读全文 查看全部
自动抓取网页数据(用Python写网络爬虫(2.2三种网页抓取方法)(组图))
阿里云>云栖社区>主题图>R>如何抢Web表数据库
推荐活动:
更多优惠>
当前主题:如何抓取网页表单数据库并将其添加到采集夹
相关话题:
如何抓取网页表单和数据库相关的博客 查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
使用 Scrapy 抓取数据
作者:雨客6542人浏览评论:05年前
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
《用Python编写网络爬虫》——2.2 三种网络爬虫方法
作者:异步社区 3748人查看评论:04年前
本节摘自异步社区《Writing Web Crawlers in Python》一书第2章2.2,作者[澳大利亚]理查德劳森(Richard Lawson),李斌译,更多章节内容可在云栖社区“异步社区”公众号查看。2.2 三种网页爬取方法 现在我们已经了解了网页的结构,接下来
阅读全文
初学者指南 | 使用 Python 抓取网页
作者:小轩峰柴金2425人浏览评论:04年前
简介 从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种数据科学在线课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。
阅读全文
如何用Python抓取数据?(一)网页抓取
作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的评论。许多评论都是来自读者的问题。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
云计算时代企业如何拥抱大数据?
作者:云栖大讲堂1408人浏览评论:04年前
这篇文章谈的是云计算时代的企业应该如何拥抱大数据。随着云计算的实施,“大数据”成为业界讨论最广泛的关键词之一,很多公司已经在寻找合适的BI工具。处理从不同来源采集到的大数据,但虽然大家对大数据的认识在不断提高,但只有谷歌、Facebook等少数公司能够做到
阅读全文
云计算时代企业如何拥抱大数据?
作者:云栖大讲堂969人浏览评论:04年前
这篇文章谈的是云计算时代的企业应该如何拥抱大数据。随着云计算的实施,“大数据”成为业界讨论最广泛的关键词之一,很多公司已经在寻找合适的BI工具。处理从不同来源采集到的大数据,但虽然大家对大数据的认识在不断提高,但只有谷歌、Facebook等少数公司能够做到
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:pythonAdvanced 397人浏览评论:01年前
【一、项目目标】通过教大家如何使用Python抓取QQ音乐数据(第一枪),我们实现了指定页数的歌曲的歌名、专辑名、播放链接指定歌手的单曲排名。通过教大家如何使用Python抓取QQ音乐数据(二次播放),我们实现了获取音乐指定歌曲的歌词和指令的能力。
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶387人浏览评论:01年前
【一、项目目标】通过教大家如何使用Python抓取QQ音乐数据(第一枪),我们实现了指定页数的歌曲的歌名、专辑名、播放链接指定歌手的单曲排名。通过教大家如何使用Python抓取QQ音乐数据(二次播放),我们实现了获取音乐指定歌曲的歌词和指令的能力。
阅读全文
如何抓取网页表单数据库相关问答
【Javascript学习全家桶】934个javascript热点问题,阿里巴巴100位技术专家答疑解惑
作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你迷茫只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来了云栖为您解答技术难题。他们使用自己手中的技术来帮助用户成长。本次活动邀请了数百位阿里巴巴技术
阅读全文
自动抓取网页数据( 爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-04 05:24
爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取)
爬虫是Python的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例。详细介绍了四个步骤。Python爬虫的基本流程。
第1步
请求尝试
先到b站首页,点击排行榜,复制链接。
启动 Jupyter notebook 并运行以下代码:
进口请求
网址 ='#39;
res = requests.get('url')
打印(res.status_code)
#200
在上面的代码中,做了以下三件事:
导入请求
使用get方法构造请求
使用 status_code 获取网页状态码
可以看到返回值为200,说明服务器响应正常,可以继续。
第2步
解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象。现在我们可以使用 .text 来查看其内容。
可以看到返回的是一个字符串,里面收录了我们需要的热门视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的web页面数据,以便您可以轻松找到 HTML 标签及其属性和内容。
Python中解析网页的方法有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 进行安装。让我们用一个简单的例子来说明它是如何工作的。
frombs4 importBeautifulSoup
页面 = requests.get(url)
汤 = BeautifulSoup(page.content,'html.parser')
标题 = 汤.title.text
打印(标题)
#热门视频排行榜-哔哔(゜-゜)つロ干杯~-bilibili
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后就可以获取其中一个结构化元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步
提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
下面我们用代码来说明如何从解析后的页面中提取B站的热点列表数据。首先我们需要找到存储数据的标签,在列表页面按F12,按照下图的说明找到。
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写
all_products = []
产品 = 汤.select('li.rank-item')
forproduct inproducts:
rank = product.select('div.num')[0].text
name = product.select('> a')[ 0].text.strip
play = product.select('span.data-box')[ 0].text
评论 = product.select('span.data-box')[ 1].text
up = product.select('span.data-box')[2].text
url = product.select('> a')[ 0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“向上主”:向上,
“视频链接”:网址
})
上面代码中,我们先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是select方法的灵活性。有兴趣的读者可自行进一步研究。
第四步
存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了encoding='utf-8-sig',否则会出现中文乱码的问题。
导入csv
键 = all_products[0].keys
withopen('B站10大视频热榜0.csv','w', newline='', encoding='utf-8-sig') asoutput_file:
dict_writer = csv.DictWriter(输出文件,键)
dict_writer.writeheader
dict_writer.writerows(all_products)
如果您熟悉pandas,您可以通过一行代码轻松地将字典转换为DataFrame。
进口熊猫ASPD
键 = all_products[0].keys
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
结束语
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都是按照以上四个步骤进行的。
然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文选择B站视频热榜,因为够简单,希望通过这个案例,让大家了解Python爬虫工作的基本流程,最后附上完整代码
进口请求
frombs4 importBeautifulSoup
导入csv
进口熊猫ASPD
网址 ='#39;
页面 = requests.get(url)
汤 = BeautifulSoup(page.content,'html.parser')
all_products = []
产品 = 汤.select('li.rank-item')
forproduct inproducts:
rank = product.select('div.num')[0].text
name = product.select('> a')[ 0].text.strip
play = product.select('span.data-box')[ 0].text
评论 = product.select('span.data-box')[ 1].text
up = product.select('span.data-box')[2].text
url = product.select('> a')[ 0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“向上主”:向上,
“视频链接”:网址
})
键 = all_products[0].keys
withopen('B站10大视频热榜0.csv','w', newline='', encoding='utf-8-sig') asoutput_file:
dict_writer = csv.DictWriter(输出文件,键)
dict_writer.writeheader
dict_writer.writerows(all_products)
###使用pandas写数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig') 查看全部
自动抓取网页数据(
爬虫是Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取)
爬虫是Python的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例。详细介绍了四个步骤。Python爬虫的基本流程。
第1步
请求尝试
先到b站首页,点击排行榜,复制链接。
启动 Jupyter notebook 并运行以下代码:
进口请求
网址 ='#39;
res = requests.get('url')
打印(res.status_code)
#200
在上面的代码中,做了以下三件事:
导入请求
使用get方法构造请求
使用 status_code 获取网页状态码
可以看到返回值为200,说明服务器响应正常,可以继续。
第2步
解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象。现在我们可以使用 .text 来查看其内容。
可以看到返回的是一个字符串,里面收录了我们需要的热门视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的web页面数据,以便您可以轻松找到 HTML 标签及其属性和内容。
Python中解析网页的方法有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 进行安装。让我们用一个简单的例子来说明它是如何工作的。
frombs4 importBeautifulSoup
页面 = requests.get(url)
汤 = BeautifulSoup(page.content,'html.parser')
标题 = 汤.title.text
打印(标题)
#热门视频排行榜-哔哔(゜-゜)つロ干杯~-bilibili
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。
然后就可以获取其中一个结构化元素及其属性,比如使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任意需要的元素。
第 3 步
提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取需要的内容。
在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。
下面我们用代码来说明如何从解析后的页面中提取B站的热点列表数据。首先我们需要找到存储数据的标签,在列表页面按F12,按照下图的说明找到。
可以看到每条视频信息都包裹在class="rank-item"的li标签下,那么代码可以这样写
all_products = []
产品 = 汤.select('li.rank-item')
forproduct inproducts:
rank = product.select('div.num')[0].text
name = product.select('> a')[ 0].text.strip
play = product.select('span.data-box')[ 0].text
评论 = product.select('span.data-box')[ 1].text
up = product.select('span.data-box')[2].text
url = product.select('> a')[ 0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“向上主”:向上,
“视频链接”:网址
})
上面代码中,我们先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,依然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。
可以注意到,我使用了多种选择方法来提取元素。这也是select方法的灵活性。有兴趣的读者可自行进一步研究。
第四步
存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了encoding='utf-8-sig',否则会出现中文乱码的问题。
导入csv
键 = all_products[0].keys
withopen('B站10大视频热榜0.csv','w', newline='', encoding='utf-8-sig') asoutput_file:
dict_writer = csv.DictWriter(输出文件,键)
dict_writer.writeheader
dict_writer.writerows(all_products)
如果您熟悉pandas,您可以通过一行代码轻松地将字典转换为DataFrame。
进口熊猫ASPD
键 = all_products[0].keys
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
结束语
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都是按照以上四个步骤进行的。
然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文选择B站视频热榜,因为够简单,希望通过这个案例,让大家了解Python爬虫工作的基本流程,最后附上完整代码
进口请求
frombs4 importBeautifulSoup
导入csv
进口熊猫ASPD
网址 ='#39;
页面 = requests.get(url)
汤 = BeautifulSoup(page.content,'html.parser')
all_products = []
产品 = 汤.select('li.rank-item')
forproduct inproducts:
rank = product.select('div.num')[0].text
name = product.select('> a')[ 0].text.strip
play = product.select('span.data-box')[ 0].text
评论 = product.select('span.data-box')[ 1].text
up = product.select('span.data-box')[2].text
url = product.select('> a')[ 0].attrs['href']
all_products.append({
“视频排名”:排名,
“视频名称”:名称,
“播放音量”:播放,
“弹幕”:评论,
“向上主”:向上,
“视频链接”:网址
})
键 = all_products[0].keys
withopen('B站10大视频热榜0.csv','w', newline='', encoding='utf-8-sig') asoutput_file:
dict_writer = csv.DictWriter(输出文件,键)
dict_writer.writeheader
dict_writer.writerows(all_products)
###使用pandas写数据
pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
自动抓取网页数据(天天自动抓取更新系统全智能抓取,钻石免费当前隐藏内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-01 20:16
每天自动爬取更新系统全智能爬取,多网页、多站点爬取,数据智能分析,更新存入数据库。模仿搜索引擎抓取网页,成功率超过90。实时通知,数据更新实时邮件/微信通知。无需人工操作,启动后会持续推送。模仿搜索引擎抓取网页,成功率很高。无需一直坐在电脑前刷新网页,数据自动获取。经过近一年的实际生产环境测试和应用,该软件正式上市。
支持新闻列表、论坛帖子、竞价信息、新品、股市财经资讯、微博更新等网站平台爬取监控,通用网页列表监控软件。
监控网站信息列表,有更新或满足关键字条件时立即提醒记录。帮助您从海量的网络信息中获取有用的信息,第一时间获取最准确的信息。最适合广大投资者或记者。
每日自动爬取更新系统特点:
1、软件具有更新监控和关键链接过滤功能。
2、更新监控是指当出现新的信息链接网站时,会被捕获并放入数据库,不会重复提醒。
3、软件支持同时监控多个网站,获取更全面的信息。
4、 抓取数据存入数据库,随时打开参考。
5、 支持常用的提醒方式,包括邮件/微信等。
6、一般网站使用源码监控的方式,速度快又节省资源。
无钻石永久无钻石
当前隐藏的内容需要付费
1 分
已有1375人付款
付费查看 查看全部
自动抓取网页数据(天天自动抓取更新系统全智能抓取,钻石免费当前隐藏内容)
每天自动爬取更新系统全智能爬取,多网页、多站点爬取,数据智能分析,更新存入数据库。模仿搜索引擎抓取网页,成功率超过90。实时通知,数据更新实时邮件/微信通知。无需人工操作,启动后会持续推送。模仿搜索引擎抓取网页,成功率很高。无需一直坐在电脑前刷新网页,数据自动获取。经过近一年的实际生产环境测试和应用,该软件正式上市。
支持新闻列表、论坛帖子、竞价信息、新品、股市财经资讯、微博更新等网站平台爬取监控,通用网页列表监控软件。
监控网站信息列表,有更新或满足关键字条件时立即提醒记录。帮助您从海量的网络信息中获取有用的信息,第一时间获取最准确的信息。最适合广大投资者或记者。
每日自动爬取更新系统特点:
1、软件具有更新监控和关键链接过滤功能。
2、更新监控是指当出现新的信息链接网站时,会被捕获并放入数据库,不会重复提醒。
3、软件支持同时监控多个网站,获取更全面的信息。
4、 抓取数据存入数据库,随时打开参考。
5、 支持常用的提醒方式,包括邮件/微信等。
6、一般网站使用源码监控的方式,速度快又节省资源。
无钻石永久无钻石
当前隐藏的内容需要付费
1 分
已有1375人付款
付费查看
自动抓取网页数据(FirstIam)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-01 20:14
我有兴趣提取新闻中报道的超自然活动数据,以便我可以分析任何相关性的空间和时间数据。分析与发生的空间和时间相关的任何数据。这个项目只是为了好玩,学习和使用网页抓取、文本提取和空间和时间相关分析。这个项目只是为了好玩,学习和使用网页抓取、文本提取和空间和时间相关分析。所以请原谅我决定了这个话题,我想做一些有趣且具有挑战性的工作。所以请原谅我决定了这个话题,我想做一些有趣且具有挑战性的工作。首先我发现这个网站有一些报告的超自然现象的集合,他们有2009、2010、2011和201的集合2. 网站的结构是这样的,他们每年都有1..10页面...和链接是这样的2009年链接 首先,我发现网站采集了一些关于超自然现象的报告。他们采集了 2009、2010、2011 和 2012 年。 网站 的结构每年有 1..10 页,就像这样......以及像这样链接到 year2009 的链接
在每个页面中,他们都采集了标题下的故事,例如内部结构超自然活动,发布时间为 03-14-09,每个标题行内都有两页......就像这个链接标题下的所有采集的故事: “内部结构超自然活动”,发表于 09 年 3 月 14 日,每行两页。 类似于这个链接od/paranormalgeneralinfo/a/news_090314n.htm
在这些页面中的每一个页面上,他们都有在各种标题上采集的实际报道故事......以及这些故事的实际网站链接。在每一页上,他们都有在各种标题上采集的实际报道故事。以及指向这些故事的实际 网站 链接。我有兴趣采集那些报告的文本,并提取有关鬼魂、恶魔或 UFO 等超自然活动类型以及事件发生的时间、日期和地点的信息。 、恶魔或不明飞行物)以及有关事件时间、日期和地点的信息。我希望分析这些数据的任何空间和时间相关性。我希望分析这些数据的任何空间和时间相关性。如果 UFO 或 Ghosts 是真实的,那么它们的运动中必须有一些行为和空间或时间的相关性。这是故事的远景……这是故事的远景……
我需要帮助来抓取上述页面中的文本。我需要帮助来抓取上述页面的文本形式。在这里,我写下了跟随一页的代码及其链接到我想要的最后一个文本。任何人都可以让我知道有没有更好更有效的方法来从最后一页获取干净的文本。任何人都可以让我知道有没有更好更有效的方法来从最后一页获取干净的文本。还可以通过跟踪整个 200 的所有 10 页来自动采集文本9. 还可以通过跟踪整个 200 的所有 10 页来自动采集文本9.
我衷心感谢您阅读我的帖子以及您花时间帮助我。对于任何愿意在整个项目中指导我的专家,我都会非常满意。对于任何愿意在整个项目中指导我的专家,我都会非常满意。
关于 Sathish 的问候 Sathish 查看全部
自动抓取网页数据(FirstIam)
我有兴趣提取新闻中报道的超自然活动数据,以便我可以分析任何相关性的空间和时间数据。分析与发生的空间和时间相关的任何数据。这个项目只是为了好玩,学习和使用网页抓取、文本提取和空间和时间相关分析。这个项目只是为了好玩,学习和使用网页抓取、文本提取和空间和时间相关分析。所以请原谅我决定了这个话题,我想做一些有趣且具有挑战性的工作。所以请原谅我决定了这个话题,我想做一些有趣且具有挑战性的工作。首先我发现这个网站有一些报告的超自然现象的集合,他们有2009、2010、2011和201的集合2. 网站的结构是这样的,他们每年都有1..10页面...和链接是这样的2009年链接 首先,我发现网站采集了一些关于超自然现象的报告。他们采集了 2009、2010、2011 和 2012 年。 网站 的结构每年有 1..10 页,就像这样......以及像这样链接到 year2009 的链接
在每个页面中,他们都采集了标题下的故事,例如内部结构超自然活动,发布时间为 03-14-09,每个标题行内都有两页......就像这个链接标题下的所有采集的故事: “内部结构超自然活动”,发表于 09 年 3 月 14 日,每行两页。 类似于这个链接od/paranormalgeneralinfo/a/news_090314n.htm
在这些页面中的每一个页面上,他们都有在各种标题上采集的实际报道故事......以及这些故事的实际网站链接。在每一页上,他们都有在各种标题上采集的实际报道故事。以及指向这些故事的实际 网站 链接。我有兴趣采集那些报告的文本,并提取有关鬼魂、恶魔或 UFO 等超自然活动类型以及事件发生的时间、日期和地点的信息。 、恶魔或不明飞行物)以及有关事件时间、日期和地点的信息。我希望分析这些数据的任何空间和时间相关性。我希望分析这些数据的任何空间和时间相关性。如果 UFO 或 Ghosts 是真实的,那么它们的运动中必须有一些行为和空间或时间的相关性。这是故事的远景……这是故事的远景……
我需要帮助来抓取上述页面中的文本。我需要帮助来抓取上述页面的文本形式。在这里,我写下了跟随一页的代码及其链接到我想要的最后一个文本。任何人都可以让我知道有没有更好更有效的方法来从最后一页获取干净的文本。任何人都可以让我知道有没有更好更有效的方法来从最后一页获取干净的文本。还可以通过跟踪整个 200 的所有 10 页来自动采集文本9. 还可以通过跟踪整个 200 的所有 10 页来自动采集文本9.
我衷心感谢您阅读我的帖子以及您花时间帮助我。对于任何愿意在整个项目中指导我的专家,我都会非常满意。对于任何愿意在整个项目中指导我的专家,我都会非常满意。
关于 Sathish 的问候 Sathish
自动抓取网页数据(建立索引数据库由分析索引系统程序对收集网页进行分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-01 12:01
搜索引擎并不真正搜索互联网。他们搜索的实际上是一个预先组织好的网页索引数据库。
真正意义上的搜索引擎通常是指一种全文搜索引擎,它采集了互联网上数百到数十亿个网页,并将网页中的每个词(即关键词)编入索引,建立索引数据库。当用户搜索某个关键词时,页面内容中收录关键词的所有网页都会被搜索出来作为搜索结果。经过复杂的算法排序后,这些结果会按照与搜索的相关程度进行排序关键词。
如今,搜索引擎普遍采用超链接分析技术。除了分析索引网页本身的内容外,它还分析所有指向该网页的链接的 URL,甚至链接周围的文本。因此,有时,即使某个网页A中没有“devilSatan”这样的词,如果有另一个网页B指向这个网页A的链接是“devilSatan”,那么用户可以搜索“devilSatan”撒但”。找到页面A。此外,如果有更多的网页(C,D,E,F...)带有一个名为“魔鬼撒旦”的链接指向这个网页A,或者给出这个链接的源网页(B , C, D, E, F ......) 当用户搜索“恶魔撒旦”时,A页面的效果越好,排名就越高。
搜索引擎的原理可以看成三个步骤:从互联网上抓取网页→建立索引库→在索引库中搜索和排序。
从互联网上抓取网页
使用Spider系统程序,可以自动从互联网上采集网页,自动上网,沿着任意一个网页中的所有网址爬到其他网页,重复这个过程,把已经爬回来的网页全部采集回来。
索引数据库
分析索引系统程序对采集到的网页进行分析,提取相关网页信息(包括网页网址、编码类型、关键词、关键词在页面内容中收录的位置、生成时间、大小、其他网页的链接关系等),根据一定的相关性算法进行大量复杂的计算,每个网页与页面内容的相关性(或重要性)以及每个关键词获取超链接中的信息,然后利用这些关联信息构建网络索引数据库。
在索引数据库中搜索和排序
当用户输入关键词进行搜索时,搜索系统程序会从网页索引数据库中查找所有与关键词匹配的相关网页。因为这个关键词的所有相关网页的相关度已经计算好了,所以只需要根据已有的相关度值进行排序即可。相关性越高,排名越高。
最后,页面生成系统将搜索结果的链接地址和页面的内容摘要进行整理并返回给用户。
搜索引擎的蜘蛛一般需要定期重新访问所有网页(每个搜索引擎的周期不同,可能是几天、几周或几个月,也可能对不同重要性的网页有不同的更新频率),并更新网络索引数据库,反映网页内容的更新,添加新的网页信息,去除死链接,根据网页内容和链接关系的变化重新排序。这样,网页的具体内容和变化就会反映在用户的查询结果中。
虽然只有一个互联网,但是各个搜索引擎的能力和偏好不同,所以抓取的网页也不同,排序算法也不同。大型搜索引擎的数据库存储着互联网上数亿到数十亿的网页索引,数据量达到数千GB甚至数万GB。但即使最大的搜索引擎建立了超过20亿个网页的索引数据库,也只能占到互联网上普通网页的不到30%。不同搜索引擎之间网页数据的重叠率一般在70%以下。我们使用不同搜索引擎的重要原因是它们可以搜索不同的内容。而且网上有很多内容,
您应该牢记这个概念:搜索引擎只能找到存储在其 Web 索引数据库中的内容。你也应该有这样的概念:如果搜索引擎的web索引数据库里应该有,而你没有找到,那是你能力的问题。学习搜索技巧可以大大提高你的搜索能力。
■ 全文搜索引擎
在搜索引擎分类部分,我们提到了全文搜索引擎从网站中提取信息来构建网页数据库的概念。搜索引擎的自动信息采集功能有两种类型。一种是定时搜索,即每隔一定时间(比如谷歌一般需要28天),搜索引擎主动发送“蜘蛛”程序在一定IP地址范围内搜索互联网网站 ,并且一旦发现新的网站,它会自动提取网站的信息和URL并将其添加到其数据库中。
另一种是提交对网站的搜索,即网站的拥有者主动向搜索引擎提交网址,在一定时间内会定向到你的网站时间(从2天到几个月不等) 发出“蜘蛛”程序,扫描您的网站并将相关信息保存在数据库中,供用户查询。由于近年来搜索引擎索引规则变化很大,主动提交网址并不能保证你的网站可以进入搜索引擎数据库,所以最好的办法是获取更多的外部链接,让搜索引擎变得更好更多机会找到您并自动发送您的网站收录。
当用户搜索带有关键词的信息时,搜索引擎会在数据库中进行搜索。如果找到符合用户要求的网站,它会使用特殊的算法——通常根据网页上的关键词匹配度、出现位置/频率、链接质量等——计算每个网页的相关性和排名级别,然后根据相关性将这些网页链接依次返回给用户
■ 目录索引
与全文搜索引擎相比,目录索引有很多不同之处。
首先,搜索引擎是自动网站搜索,而目录索引则完全依赖人工操作。用户提交网站后,目录编辑会亲自浏览您的网站,然后根据一套自行确定的标准甚至主观印象来决定是否接受您的网站编辑。
其次,搜索引擎收录网站时,只要网站不违反相关规则,一般都会登录成功。目录索引对网站的要求要高很多,有时即使多次登录也不一定成功。尤其是像雅虎这样的超级索引,登录更是难上加难。(因为登录雅虎是最难的,而且是企业网络营销的必备,后面我们会在专门的空间介绍登录雅虎的技巧)。另外,我们在登录搜索引擎时,一般不需要考虑网站的分类,而在登录目录索引时,一定要把网站放在最合适的目录(Directory )。
最后,搜索引擎中每个网站的相关信息都是自动从用户的网页中提取出来的,所以从用户的角度来说,我们有更多的自主权;并且目录索引要求你必须手动填写额外的网站Information,并且有各种限制。另外,如果工作人员认为你提交给网站的目录和信息不合适,他可以随时调整,当然不会提前和你商量。
目录索引,顾名思义就是将网站存放在对应的目录中,所以用户在查询信息时可以选择关键词进行搜索,也可以按类别进行搜索。如果按关键词搜索,返回的结果和搜索引擎一样,也是按照信息相关度网站进行排列,但人为因素较多。如果按层次目录搜索,网站在某个目录中的排名是由标题字母的顺序决定的(也有例外)。
目前,搜索引擎和目录索引有相互融合、相互渗透的趋势。原来,一些纯全文搜索引擎现在也提供目录搜索。例如,Google 借用 Open Directory 目录来提供分类查询。以及像 Yahoo! 这样的老品牌目录索引。与谷歌等搜索引擎合作,扩大搜索范围。默认搜索模式下,部分目录搜索引擎首先返回自己目录下匹配的网站,如国内搜狐、新浪、网易等;而其他人则默认为网络搜索,例如雅虎。
■ 全文搜索引擎
在搜索引擎分类部分,我们提到了全文搜索引擎从网站中提取信息来构建网页数据库的概念。搜索引擎的自动信息采集功能有两种类型。一种是定时搜索,即每隔一定时间(比如谷歌一般需要28天),搜索引擎主动发送“蜘蛛”程序在一定IP地址范围内搜索互联网网站 ,并且一旦发现新的网站,它会自动提取网站的信息和URL并将其添加到其数据库中。
另一种是提交对网站的搜索,即网站的拥有者主动向搜索引擎提交网址,在一定时间内会定向到你的网站时间(从2天到几个月不等) 发出“蜘蛛”程序,扫描您的网站并将相关信息保存在数据库中,供用户查询。由于近年来搜索引擎索引规则变化很大,主动提交网址并不能保证你的网站可以进入搜索引擎数据库,所以最好的办法是获取更多的外部链接,让搜索引擎变得更好更多机会找到您并自动发送您的网站收录。
当用户搜索带有关键词的信息时,搜索引擎会在数据库中进行搜索。如果找到符合用户要求的网站,它会使用特殊的算法——通常根据网页上的关键词匹配度、出现位置/频率、链接质量等——计算每个网页的相关性和排名级别,然后根据相关性级别将这些网页链接依次返回给用户......
搜索引擎的数据库依赖于一种叫做“蜘蛛”或“爬虫”的软件,它通过互联网上的各种链接自动获取大量的网络信息内容,并按照预定的规则进行分析和组织。的。谷歌和百度是比较典型的全文搜索引擎系统。 查看全部
自动抓取网页数据(建立索引数据库由分析索引系统程序对收集网页进行分析)
搜索引擎并不真正搜索互联网。他们搜索的实际上是一个预先组织好的网页索引数据库。
真正意义上的搜索引擎通常是指一种全文搜索引擎,它采集了互联网上数百到数十亿个网页,并将网页中的每个词(即关键词)编入索引,建立索引数据库。当用户搜索某个关键词时,页面内容中收录关键词的所有网页都会被搜索出来作为搜索结果。经过复杂的算法排序后,这些结果会按照与搜索的相关程度进行排序关键词。
如今,搜索引擎普遍采用超链接分析技术。除了分析索引网页本身的内容外,它还分析所有指向该网页的链接的 URL,甚至链接周围的文本。因此,有时,即使某个网页A中没有“devilSatan”这样的词,如果有另一个网页B指向这个网页A的链接是“devilSatan”,那么用户可以搜索“devilSatan”撒但”。找到页面A。此外,如果有更多的网页(C,D,E,F...)带有一个名为“魔鬼撒旦”的链接指向这个网页A,或者给出这个链接的源网页(B , C, D, E, F ......) 当用户搜索“恶魔撒旦”时,A页面的效果越好,排名就越高。
搜索引擎的原理可以看成三个步骤:从互联网上抓取网页→建立索引库→在索引库中搜索和排序。
从互联网上抓取网页
使用Spider系统程序,可以自动从互联网上采集网页,自动上网,沿着任意一个网页中的所有网址爬到其他网页,重复这个过程,把已经爬回来的网页全部采集回来。
索引数据库
分析索引系统程序对采集到的网页进行分析,提取相关网页信息(包括网页网址、编码类型、关键词、关键词在页面内容中收录的位置、生成时间、大小、其他网页的链接关系等),根据一定的相关性算法进行大量复杂的计算,每个网页与页面内容的相关性(或重要性)以及每个关键词获取超链接中的信息,然后利用这些关联信息构建网络索引数据库。
在索引数据库中搜索和排序
当用户输入关键词进行搜索时,搜索系统程序会从网页索引数据库中查找所有与关键词匹配的相关网页。因为这个关键词的所有相关网页的相关度已经计算好了,所以只需要根据已有的相关度值进行排序即可。相关性越高,排名越高。
最后,页面生成系统将搜索结果的链接地址和页面的内容摘要进行整理并返回给用户。
搜索引擎的蜘蛛一般需要定期重新访问所有网页(每个搜索引擎的周期不同,可能是几天、几周或几个月,也可能对不同重要性的网页有不同的更新频率),并更新网络索引数据库,反映网页内容的更新,添加新的网页信息,去除死链接,根据网页内容和链接关系的变化重新排序。这样,网页的具体内容和变化就会反映在用户的查询结果中。
虽然只有一个互联网,但是各个搜索引擎的能力和偏好不同,所以抓取的网页也不同,排序算法也不同。大型搜索引擎的数据库存储着互联网上数亿到数十亿的网页索引,数据量达到数千GB甚至数万GB。但即使最大的搜索引擎建立了超过20亿个网页的索引数据库,也只能占到互联网上普通网页的不到30%。不同搜索引擎之间网页数据的重叠率一般在70%以下。我们使用不同搜索引擎的重要原因是它们可以搜索不同的内容。而且网上有很多内容,
您应该牢记这个概念:搜索引擎只能找到存储在其 Web 索引数据库中的内容。你也应该有这样的概念:如果搜索引擎的web索引数据库里应该有,而你没有找到,那是你能力的问题。学习搜索技巧可以大大提高你的搜索能力。
■ 全文搜索引擎
在搜索引擎分类部分,我们提到了全文搜索引擎从网站中提取信息来构建网页数据库的概念。搜索引擎的自动信息采集功能有两种类型。一种是定时搜索,即每隔一定时间(比如谷歌一般需要28天),搜索引擎主动发送“蜘蛛”程序在一定IP地址范围内搜索互联网网站 ,并且一旦发现新的网站,它会自动提取网站的信息和URL并将其添加到其数据库中。
另一种是提交对网站的搜索,即网站的拥有者主动向搜索引擎提交网址,在一定时间内会定向到你的网站时间(从2天到几个月不等) 发出“蜘蛛”程序,扫描您的网站并将相关信息保存在数据库中,供用户查询。由于近年来搜索引擎索引规则变化很大,主动提交网址并不能保证你的网站可以进入搜索引擎数据库,所以最好的办法是获取更多的外部链接,让搜索引擎变得更好更多机会找到您并自动发送您的网站收录。
当用户搜索带有关键词的信息时,搜索引擎会在数据库中进行搜索。如果找到符合用户要求的网站,它会使用特殊的算法——通常根据网页上的关键词匹配度、出现位置/频率、链接质量等——计算每个网页的相关性和排名级别,然后根据相关性将这些网页链接依次返回给用户
■ 目录索引
与全文搜索引擎相比,目录索引有很多不同之处。
首先,搜索引擎是自动网站搜索,而目录索引则完全依赖人工操作。用户提交网站后,目录编辑会亲自浏览您的网站,然后根据一套自行确定的标准甚至主观印象来决定是否接受您的网站编辑。
其次,搜索引擎收录网站时,只要网站不违反相关规则,一般都会登录成功。目录索引对网站的要求要高很多,有时即使多次登录也不一定成功。尤其是像雅虎这样的超级索引,登录更是难上加难。(因为登录雅虎是最难的,而且是企业网络营销的必备,后面我们会在专门的空间介绍登录雅虎的技巧)。另外,我们在登录搜索引擎时,一般不需要考虑网站的分类,而在登录目录索引时,一定要把网站放在最合适的目录(Directory )。
最后,搜索引擎中每个网站的相关信息都是自动从用户的网页中提取出来的,所以从用户的角度来说,我们有更多的自主权;并且目录索引要求你必须手动填写额外的网站Information,并且有各种限制。另外,如果工作人员认为你提交给网站的目录和信息不合适,他可以随时调整,当然不会提前和你商量。
目录索引,顾名思义就是将网站存放在对应的目录中,所以用户在查询信息时可以选择关键词进行搜索,也可以按类别进行搜索。如果按关键词搜索,返回的结果和搜索引擎一样,也是按照信息相关度网站进行排列,但人为因素较多。如果按层次目录搜索,网站在某个目录中的排名是由标题字母的顺序决定的(也有例外)。
目前,搜索引擎和目录索引有相互融合、相互渗透的趋势。原来,一些纯全文搜索引擎现在也提供目录搜索。例如,Google 借用 Open Directory 目录来提供分类查询。以及像 Yahoo! 这样的老品牌目录索引。与谷歌等搜索引擎合作,扩大搜索范围。默认搜索模式下,部分目录搜索引擎首先返回自己目录下匹配的网站,如国内搜狐、新浪、网易等;而其他人则默认为网络搜索,例如雅虎。
■ 全文搜索引擎
在搜索引擎分类部分,我们提到了全文搜索引擎从网站中提取信息来构建网页数据库的概念。搜索引擎的自动信息采集功能有两种类型。一种是定时搜索,即每隔一定时间(比如谷歌一般需要28天),搜索引擎主动发送“蜘蛛”程序在一定IP地址范围内搜索互联网网站 ,并且一旦发现新的网站,它会自动提取网站的信息和URL并将其添加到其数据库中。
另一种是提交对网站的搜索,即网站的拥有者主动向搜索引擎提交网址,在一定时间内会定向到你的网站时间(从2天到几个月不等) 发出“蜘蛛”程序,扫描您的网站并将相关信息保存在数据库中,供用户查询。由于近年来搜索引擎索引规则变化很大,主动提交网址并不能保证你的网站可以进入搜索引擎数据库,所以最好的办法是获取更多的外部链接,让搜索引擎变得更好更多机会找到您并自动发送您的网站收录。
当用户搜索带有关键词的信息时,搜索引擎会在数据库中进行搜索。如果找到符合用户要求的网站,它会使用特殊的算法——通常根据网页上的关键词匹配度、出现位置/频率、链接质量等——计算每个网页的相关性和排名级别,然后根据相关性级别将这些网页链接依次返回给用户......
搜索引擎的数据库依赖于一种叫做“蜘蛛”或“爬虫”的软件,它通过互联网上的各种链接自动获取大量的网络信息内容,并按照预定的规则进行分析和组织。的。谷歌和百度是比较典型的全文搜索引擎系统。
自动抓取网页数据(搜猫聚焦爬虫对抓取目标网页特征基于目标数据模式的爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-29 19:00
搜猫官方版是一款专业实用的网络蜘蛛工具。最新版的搜猫可以根据网页中的超链接不断抓取,下载网页并写入本地文件夹,或者写入*.mdb数据库,非常方便快捷。Somao软件最重要的功能是分析网页。它可以按照一定的规则自动抓取网络信息的程序或脚本。
搜猫软件介绍
该软件只能截取网页的一部分(可以是笑话,小说,甚至只是取电影或MP3的链接地址,这取决于您的配置),有了它,您可以复制一个小时网站(或其链接)。
搜猫软件说明
爬取目标的描述和定义是决定如何制定网页分析算法和网址搜索策略的基础。网页分析算法和候选网址排序算法是决定搜索引擎提供的服务形式和网页抓取行为的关键。这两部分的算法是密切相关的。
现有的聚焦爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模型和基于领域概念。
基于登陆页面特征
爬虫根据目标网页的特征抓取、存储和索引的对象一般为网站或网页。根据种子样品的获取方式,可分为:
(1)预先给定的初始抓取种子样本;
(2)预先给定的网页分类目录和分类目录对应的种子样本,如Yahoo!分类结构等;
(3) 由用户行为决定的样本抓取目标分为:(a)用户浏览时显示的标记抓取样本;(b)通过用户日志挖掘获得访问模式和相关样本。
其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
基于目标数据模式
基于目标数据模式的爬虫是针对网页上的数据,抓取的数据一般必须符合一定的模式,或者可以转化或映射为目标数据模式。
基于领域的概念
另一种描述方法是建立目标域的本体或字典,用于从语义角度分析主题中不同特征的重要性。
Somoo安装步骤
1.在华骏软件园下载索猫正式版安装包
2.下载后,将压缩包解压到本软件命名的文件夹中
3.打开文件夹,双击“exe”程序
4.搜猫是绿色软件,无需安装即可使用
Somao更新日志
日夜工作只为让你更快乐
麻麻麻麻哄~所有的bug都没有了!
华军编辑推荐:
强烈推荐下载搜猫,谁用谁知道,反正我已经用过了。另外,{recommendWords}也是一款不错的软件,请点击下载体验! 查看全部
自动抓取网页数据(搜猫聚焦爬虫对抓取目标网页特征基于目标数据模式的爬虫)
搜猫官方版是一款专业实用的网络蜘蛛工具。最新版的搜猫可以根据网页中的超链接不断抓取,下载网页并写入本地文件夹,或者写入*.mdb数据库,非常方便快捷。Somao软件最重要的功能是分析网页。它可以按照一定的规则自动抓取网络信息的程序或脚本。
搜猫软件介绍
该软件只能截取网页的一部分(可以是笑话,小说,甚至只是取电影或MP3的链接地址,这取决于您的配置),有了它,您可以复制一个小时网站(或其链接)。
搜猫软件说明
爬取目标的描述和定义是决定如何制定网页分析算法和网址搜索策略的基础。网页分析算法和候选网址排序算法是决定搜索引擎提供的服务形式和网页抓取行为的关键。这两部分的算法是密切相关的。
现有的聚焦爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模型和基于领域概念。
基于登陆页面特征
爬虫根据目标网页的特征抓取、存储和索引的对象一般为网站或网页。根据种子样品的获取方式,可分为:
(1)预先给定的初始抓取种子样本;
(2)预先给定的网页分类目录和分类目录对应的种子样本,如Yahoo!分类结构等;
(3) 由用户行为决定的样本抓取目标分为:(a)用户浏览时显示的标记抓取样本;(b)通过用户日志挖掘获得访问模式和相关样本。
其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
基于目标数据模式
基于目标数据模式的爬虫是针对网页上的数据,抓取的数据一般必须符合一定的模式,或者可以转化或映射为目标数据模式。
基于领域的概念
另一种描述方法是建立目标域的本体或字典,用于从语义角度分析主题中不同特征的重要性。
Somoo安装步骤
1.在华骏软件园下载索猫正式版安装包
2.下载后,将压缩包解压到本软件命名的文件夹中
3.打开文件夹,双击“exe”程序
4.搜猫是绿色软件,无需安装即可使用
Somao更新日志
日夜工作只为让你更快乐
麻麻麻麻哄~所有的bug都没有了!
华军编辑推荐:
强烈推荐下载搜猫,谁用谁知道,反正我已经用过了。另外,{recommendWords}也是一款不错的软件,请点击下载体验!
自动抓取网页数据(搜猫官方版基于目标网页特征的爬虫所抓取存储并索引)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-29 18:23
搜猫官方版是一款专业实用的网络蜘蛛工具。最新版的搜猫可以根据网页中的超链接不断抓取,下载网页并写入本地文件夹,或者写入*.mdb数据库,非常方便快捷。Somao软件最重要的功能是分析网页。它可以按照一定的规则自动抓取网络信息的程序或脚本。
类似软件
印记
软件地址
搜猫软件介绍
该软件只能截取网页的一部分(可以是笑话,小说,甚至只是取电影或MP3的链接地址,这取决于您的配置),有了它,您可以复制一个小时网站(或其链接)。
搜猫软件说明
爬取目标的描述和定义是决定如何制定网页分析算法和网址搜索策略的基础。网页分析算法和候选网址排序算法是决定搜索引擎提供的服务形式和网页抓取行为的关键。这两部分的算法是密切相关的。
现有的聚焦爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模型和基于领域概念。
基于登陆页面特征
爬虫根据目标网页的特征抓取、存储和索引的对象一般为网站或网页。根据种子样品的获取方式,可分为:
(1)预先给定的初始抓取种子样本;
(2)预先给定的网页分类目录和分类目录对应的种子样本,如Yahoo!分类结构等;
(3) 由用户行为决定的样本抓取目标分为:(a)用户浏览时显示的标记抓取样本;(b)通过用户日志挖掘获得访问模式和相关样本。
其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
基于目标数据模式
基于目标数据模式的爬虫是针对网页上的数据,抓取的数据一般必须符合一定的模式,或者可以转化或映射为目标数据模式。
基于领域的概念
另一种描述方法是建立目标域的本体或字典,用于从语义角度分析主题中不同特征的重要性。
Somoo安装步骤
1.在华骏软件园下载索猫正式版安装包
2.下载后,将压缩包解压到本软件命名的文件夹中
3.打开文件夹,双击“exe”程序
4.搜猫是绿色软件,无需安装即可使用
Somao更新日志
日夜工作只为让你更快乐
麻麻麻麻哄~所有的bug都没有了!
华军编辑推荐:
强烈推荐下载搜猫,谁用谁知道,反正我已经用过了。此外,Adobe SVG Viewer、vqqq论坛、一般税务数据采集软件、网文大师、游雅互动电影客户端也是不错的软件,请点击下载体验! 查看全部
自动抓取网页数据(搜猫官方版基于目标网页特征的爬虫所抓取存储并索引)
搜猫官方版是一款专业实用的网络蜘蛛工具。最新版的搜猫可以根据网页中的超链接不断抓取,下载网页并写入本地文件夹,或者写入*.mdb数据库,非常方便快捷。Somao软件最重要的功能是分析网页。它可以按照一定的规则自动抓取网络信息的程序或脚本。
类似软件
印记
软件地址
搜猫软件介绍
该软件只能截取网页的一部分(可以是笑话,小说,甚至只是取电影或MP3的链接地址,这取决于您的配置),有了它,您可以复制一个小时网站(或其链接)。
搜猫软件说明
爬取目标的描述和定义是决定如何制定网页分析算法和网址搜索策略的基础。网页分析算法和候选网址排序算法是决定搜索引擎提供的服务形式和网页抓取行为的关键。这两部分的算法是密切相关的。
现有的聚焦爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模型和基于领域概念。
基于登陆页面特征
爬虫根据目标网页的特征抓取、存储和索引的对象一般为网站或网页。根据种子样品的获取方式,可分为:
(1)预先给定的初始抓取种子样本;
(2)预先给定的网页分类目录和分类目录对应的种子样本,如Yahoo!分类结构等;
(3) 由用户行为决定的样本抓取目标分为:(a)用户浏览时显示的标记抓取样本;(b)通过用户日志挖掘获得访问模式和相关样本。
其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
基于目标数据模式
基于目标数据模式的爬虫是针对网页上的数据,抓取的数据一般必须符合一定的模式,或者可以转化或映射为目标数据模式。
基于领域的概念
另一种描述方法是建立目标域的本体或字典,用于从语义角度分析主题中不同特征的重要性。
Somoo安装步骤
1.在华骏软件园下载索猫正式版安装包
2.下载后,将压缩包解压到本软件命名的文件夹中
3.打开文件夹,双击“exe”程序
4.搜猫是绿色软件,无需安装即可使用
Somao更新日志
日夜工作只为让你更快乐
麻麻麻麻哄~所有的bug都没有了!
华军编辑推荐:
强烈推荐下载搜猫,谁用谁知道,反正我已经用过了。此外,Adobe SVG Viewer、vqqq论坛、一般税务数据采集软件、网文大师、游雅互动电影客户端也是不错的软件,请点击下载体验!
自动抓取网页数据(搜索引擎有什么程序模块?它的原理是啥?危害蜘蛛)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-29 18:20
搜索引擎蜘蛛爬取网站是如何工作的?对seo搜索引擎蜘蛛没有影响,即Spider,类似于电脑浏览器的程序流程,专业用于免费下载网页。网络爬虫或爬虫,用于自动跟踪所有网页中的连接。
当今互联网搜索引擎优化推广,文章是提升关键词排名的基础,也是网站引流方法的有效途径,根据优质原创文章内容可以大大提高百度搜索引擎对网站的评价,会给网站很好的权重和排名,因为百度搜索为消费者提供了满足网站的内容搜索意图。这也是白帽技术的关键。
搜索引擎推广就是搜索引擎推广。它对网站的各个区域进行调整,使其更符合搜索引擎优化算法的规定,从而获得大量的数据流量和转化。因此,您必须更加掌握和了解搜索引擎推广。搜索引擎有哪些程序模块?它的原理是什么?危害搜索引擎蜘蛛爬行的关键因素有哪些?
搜索引擎程序模块:
搜索引擎蜘蛛,即Spider,类似于电脑浏览器的程序流程,专业用于免费下载网页。
网络爬虫或爬虫,用于自动跟踪所有网页中的连接。
3.数据库索引,即Indexer,专门分析搜索引擎蜘蛛和网络爬虫免费下载的网页。
4.数据库查询,存储免费下载的网页信息内容和解析的网页信息内容。
5. 结果模块从数据库查询中获取百度搜索。
搜索引擎蜘蛛抓取网站
Web服务器用于解决消费者的检索和交互需求。
百度爬虫类型。
根据百度爬虫的爬行特点,我们可以将其分为三类:海量蜘蛛、增量蜘蛛和垂直蜘蛛。
1.大量蜘蛛。
一般有比较显着的爬取类别和总体目标,比如设置爬取时限、爬取信息限制、或者爬取固定网页限制等,当Spider的实际运行达到预设的总体目标时,就会终止。一般来说,网站站长和SEO人员使用的大部分特殊的采集工具或程序流程都属于大量蜘蛛。一般只抓取固定网址的固定内容,或者设置某个资源的固定总体目标信息量。当捕获的数据信息或时间达到设定的限制时,将自动终止。这种蜘蛛是非常典型的大容量蜘蛛。
2.增量蜘蛛。
Incremental Spider 也可以称为通用网络爬虫。一般来说,它可以称为搜索引擎URL或程序流应用增量蜘蛛,但网站内部搜索引擎,现有站点搜索引擎一般不使用Spider。增量蜘蛛与高容量蜘蛛的不同之处在于没有明确的总体目标。范围和时间限制通常会不受限制地捕获,直到捕获所有 Internet 数据信息。Incremental Spider 不仅会抓取尽可能详细的网页,还会抓取和升级已经抓取过的网页。由于所有互联网技术都在不断变化,单个网页上的内容很可能会因时间的变化而不断创新,甚至网页会在一段时间后被删除。一个优秀的增量蜘蛛必须及时处理这种变化,并将其反映到搜索引擎的后期解析系统软件中来处理网页。现阶段百度搜索、谷歌网页搜索等全文搜索引擎的蜘蛛一般都是增量蜘蛛。
3.垂直蜘蛛。
垂直蜘蛛也可以称为焦点网络爬虫,它只爬取具有特殊主题、特殊内容或特殊领域的网页,一般集中在某个有限的区域进行增量爬取。与增量蜘蛛不同,这种类型的蜘蛛追求完美和广泛的覆盖范围。相反,它增加了在增量蜘蛛上抓取网页的限制。它基于这样一个事实,即必须抓取具有整体目标内容的网页。符合要求的网页将被立即丢弃以供抓取。对于网页级别的纯文本内容的识别,搜索引擎蜘蛛无法准确归类,垂直蜘蛛无法像增量蜘蛛一样爬上所有的互联网技术,因为这是一种资源浪费。所以,如果当前垂直搜索引擎有附加的增量蜘蛛,则会使用增量蜘蛛对网站内容进行分类,然后发送垂直蜘蛛抓取符合自身内容要求的网站:没有增量蜘蛛作为基本的垂直搜索引擎,一般会手动添加爬取网址,专门指导垂直蜘蛛的实际操作。自然,同样的网站会有不同的内容。这时候竖蜘蛛也要分清内容,只是劳动量相对减少和增加。没有增量蜘蛛,因为基本的垂直搜索引擎一般都会手动添加爬取网址来专门指导垂直蜘蛛的实际操作。自然,同样的网站会有不同的内容。这时候竖蜘蛛也要分清内容,只是劳动量相对减少和增加。没有增量蜘蛛,因为基本的垂直搜索引擎一般都会手动添加爬取网址来专门指导垂直蜘蛛的实际操作。自然,同样的网站会有不同的内容。这时候竖蜘蛛也要分清内容,只是劳动量相对减少和增加。
搜索引擎捕获的危险元素。
1.把握友善。
互联网技术资源的庞大规模,规定了抓取系统软件尽可能高效地使用网络带宽,在硬件配置和网络带宽资源不足的情况下,抓取尽可能多的宝贵资源。
2.取回代码提示。
简单详细介绍一下适用于百度搜索的几种返回码类型:
1) 最常见的 404 代表 NOTFOUND。我认为该网页已经无效,通常会从库中删除。同时,如果蜘蛛在短时间内再次发现这个网址,也不容易掌握;
2)503 代表 ServiceUnavailable。感觉网页暂时打不开。一般网站暂时关闭,网络带宽比较有限。
3)403 代表 Forbidden,感觉现阶段禁止访问网络。如果是新的url,蜘蛛暂时不易抓取,短时间内会被浏览多次;如果url已经收录了,马上删除也不容易,短时间内会被浏览好几次。如果网页浏览正常,则一切正常;如果仍然禁止访问,该 url 也将被视为无效连接并从库中删除。
4)301代表MovedPermanently,感觉网页跳转到了新的url。转网址,改域名,设置网站后,大家建议申请301返回码,同时使用百度站长工具网站搭建一个专门的工具减少获得网站的伤害量。
3.首选制剂。
由于互联网技术资源规模大、变化快,搜索引擎基本上不太可能通过爬取和有效升级来保持一致性。因此,抓取系统软件必须设计一套有效的抓取优先级分配对策。关键包括:xml对策的深度优先分析、xml对策的全宽优先分析、pr优先选择对策、反向链接对策、社会发展共享的具体指导对策等。
4. 反转并挂起。
蜘蛛在整个爬行过程中,经常会遇到爬行超级黑洞或者遇到很多低质量网页的问题,这就需要在爬行系统软件中设计一套完善的爬行防挂系统软件。
结果:搜索引擎推广成功首先要解决的就是总流量问题,也就是持续稳定的总流量。还有很多关键点。以上内容仅供参考。以上是小花庄自己的经验交流。在日常工作中,灵活应变。以上内容仅供参考。以下是我的总结。您可以浏览视频录制的一些关键 SEO 教程视频。希望它能帮助您尽快学习和培训SEO技能。如果您有任何SEO问题,请在留言板留言。 查看全部
自动抓取网页数据(搜索引擎有什么程序模块?它的原理是啥?危害蜘蛛)
搜索引擎蜘蛛爬取网站是如何工作的?对seo搜索引擎蜘蛛没有影响,即Spider,类似于电脑浏览器的程序流程,专业用于免费下载网页。网络爬虫或爬虫,用于自动跟踪所有网页中的连接。
当今互联网搜索引擎优化推广,文章是提升关键词排名的基础,也是网站引流方法的有效途径,根据优质原创文章内容可以大大提高百度搜索引擎对网站的评价,会给网站很好的权重和排名,因为百度搜索为消费者提供了满足网站的内容搜索意图。这也是白帽技术的关键。
搜索引擎推广就是搜索引擎推广。它对网站的各个区域进行调整,使其更符合搜索引擎优化算法的规定,从而获得大量的数据流量和转化。因此,您必须更加掌握和了解搜索引擎推广。搜索引擎有哪些程序模块?它的原理是什么?危害搜索引擎蜘蛛爬行的关键因素有哪些?
搜索引擎程序模块:
搜索引擎蜘蛛,即Spider,类似于电脑浏览器的程序流程,专业用于免费下载网页。
网络爬虫或爬虫,用于自动跟踪所有网页中的连接。
3.数据库索引,即Indexer,专门分析搜索引擎蜘蛛和网络爬虫免费下载的网页。
4.数据库查询,存储免费下载的网页信息内容和解析的网页信息内容。
5. 结果模块从数据库查询中获取百度搜索。
搜索引擎蜘蛛抓取网站
Web服务器用于解决消费者的检索和交互需求。
百度爬虫类型。
根据百度爬虫的爬行特点,我们可以将其分为三类:海量蜘蛛、增量蜘蛛和垂直蜘蛛。
1.大量蜘蛛。
一般有比较显着的爬取类别和总体目标,比如设置爬取时限、爬取信息限制、或者爬取固定网页限制等,当Spider的实际运行达到预设的总体目标时,就会终止。一般来说,网站站长和SEO人员使用的大部分特殊的采集工具或程序流程都属于大量蜘蛛。一般只抓取固定网址的固定内容,或者设置某个资源的固定总体目标信息量。当捕获的数据信息或时间达到设定的限制时,将自动终止。这种蜘蛛是非常典型的大容量蜘蛛。
2.增量蜘蛛。
Incremental Spider 也可以称为通用网络爬虫。一般来说,它可以称为搜索引擎URL或程序流应用增量蜘蛛,但网站内部搜索引擎,现有站点搜索引擎一般不使用Spider。增量蜘蛛与高容量蜘蛛的不同之处在于没有明确的总体目标。范围和时间限制通常会不受限制地捕获,直到捕获所有 Internet 数据信息。Incremental Spider 不仅会抓取尽可能详细的网页,还会抓取和升级已经抓取过的网页。由于所有互联网技术都在不断变化,单个网页上的内容很可能会因时间的变化而不断创新,甚至网页会在一段时间后被删除。一个优秀的增量蜘蛛必须及时处理这种变化,并将其反映到搜索引擎的后期解析系统软件中来处理网页。现阶段百度搜索、谷歌网页搜索等全文搜索引擎的蜘蛛一般都是增量蜘蛛。
3.垂直蜘蛛。
垂直蜘蛛也可以称为焦点网络爬虫,它只爬取具有特殊主题、特殊内容或特殊领域的网页,一般集中在某个有限的区域进行增量爬取。与增量蜘蛛不同,这种类型的蜘蛛追求完美和广泛的覆盖范围。相反,它增加了在增量蜘蛛上抓取网页的限制。它基于这样一个事实,即必须抓取具有整体目标内容的网页。符合要求的网页将被立即丢弃以供抓取。对于网页级别的纯文本内容的识别,搜索引擎蜘蛛无法准确归类,垂直蜘蛛无法像增量蜘蛛一样爬上所有的互联网技术,因为这是一种资源浪费。所以,如果当前垂直搜索引擎有附加的增量蜘蛛,则会使用增量蜘蛛对网站内容进行分类,然后发送垂直蜘蛛抓取符合自身内容要求的网站:没有增量蜘蛛作为基本的垂直搜索引擎,一般会手动添加爬取网址,专门指导垂直蜘蛛的实际操作。自然,同样的网站会有不同的内容。这时候竖蜘蛛也要分清内容,只是劳动量相对减少和增加。没有增量蜘蛛,因为基本的垂直搜索引擎一般都会手动添加爬取网址来专门指导垂直蜘蛛的实际操作。自然,同样的网站会有不同的内容。这时候竖蜘蛛也要分清内容,只是劳动量相对减少和增加。没有增量蜘蛛,因为基本的垂直搜索引擎一般都会手动添加爬取网址来专门指导垂直蜘蛛的实际操作。自然,同样的网站会有不同的内容。这时候竖蜘蛛也要分清内容,只是劳动量相对减少和增加。
搜索引擎捕获的危险元素。
1.把握友善。
互联网技术资源的庞大规模,规定了抓取系统软件尽可能高效地使用网络带宽,在硬件配置和网络带宽资源不足的情况下,抓取尽可能多的宝贵资源。
2.取回代码提示。
简单详细介绍一下适用于百度搜索的几种返回码类型:
1) 最常见的 404 代表 NOTFOUND。我认为该网页已经无效,通常会从库中删除。同时,如果蜘蛛在短时间内再次发现这个网址,也不容易掌握;
2)503 代表 ServiceUnavailable。感觉网页暂时打不开。一般网站暂时关闭,网络带宽比较有限。
3)403 代表 Forbidden,感觉现阶段禁止访问网络。如果是新的url,蜘蛛暂时不易抓取,短时间内会被浏览多次;如果url已经收录了,马上删除也不容易,短时间内会被浏览好几次。如果网页浏览正常,则一切正常;如果仍然禁止访问,该 url 也将被视为无效连接并从库中删除。
4)301代表MovedPermanently,感觉网页跳转到了新的url。转网址,改域名,设置网站后,大家建议申请301返回码,同时使用百度站长工具网站搭建一个专门的工具减少获得网站的伤害量。
3.首选制剂。
由于互联网技术资源规模大、变化快,搜索引擎基本上不太可能通过爬取和有效升级来保持一致性。因此,抓取系统软件必须设计一套有效的抓取优先级分配对策。关键包括:xml对策的深度优先分析、xml对策的全宽优先分析、pr优先选择对策、反向链接对策、社会发展共享的具体指导对策等。
4. 反转并挂起。
蜘蛛在整个爬行过程中,经常会遇到爬行超级黑洞或者遇到很多低质量网页的问题,这就需要在爬行系统软件中设计一套完善的爬行防挂系统软件。
结果:搜索引擎推广成功首先要解决的就是总流量问题,也就是持续稳定的总流量。还有很多关键点。以上内容仅供参考。以上是小花庄自己的经验交流。在日常工作中,灵活应变。以上内容仅供参考。以下是我的总结。您可以浏览视频录制的一些关键 SEO 教程视频。希望它能帮助您尽快学习和培训SEO技能。如果您有任何SEO问题,请在留言板留言。
自动抓取网页数据(天天自动抓取更新系统全智能抓取,多个网页,获取信息网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-29 00:06
每天自动爬取更新系统全智能爬取,多网页、多站点爬取,数据智能分析,更新存入数据库。用模拟搜索引擎爬取网页,成功率超过90%。实时通知,数据更新实时邮件/微信通知。无需人工操作,启动后会持续推送。模仿搜索引擎抓取网页,成功率很高。无需一直坐在电脑前刷新网页,数据自动获取。经过近一年的实际生产环境测试和应用,该软件正式上市。
支持新闻列表、论坛帖子、竞价信息、新品、股市财经资讯、微博更新等网站平台爬取监控,通用网页列表监控软件。
监控网站信息列表,有更新或满足关键字条件时立即提醒记录。帮助您从海量的网络信息中获取有用的信息,第一时间获取最准确的信息。最适合广大投资者或记者。
每日自动爬取更新系统特点:
1、软件具有更新监控和关键链接过滤功能。
2、更新监控是指当出现新的信息链接网站时,会被捕获并放入数据库,不会重复提醒。
3、软件支持同时监控多个网站,获取更全面的信息。
4、 抓取数据存入数据库,随时打开参考。
5、 支持常用的提醒方式,包括邮件/微信等。
6、一般网站使用源码监控的方式,速度快又节省资源。
版权信息:本站所有资源仅供学习参考。请不要将它们用于商业目的。如果您的版权受到侵犯,请及时联系客服,我们会尽快处理。 查看全部
自动抓取网页数据(天天自动抓取更新系统全智能抓取,多个网页,获取信息网页)
每天自动爬取更新系统全智能爬取,多网页、多站点爬取,数据智能分析,更新存入数据库。用模拟搜索引擎爬取网页,成功率超过90%。实时通知,数据更新实时邮件/微信通知。无需人工操作,启动后会持续推送。模仿搜索引擎抓取网页,成功率很高。无需一直坐在电脑前刷新网页,数据自动获取。经过近一年的实际生产环境测试和应用,该软件正式上市。
支持新闻列表、论坛帖子、竞价信息、新品、股市财经资讯、微博更新等网站平台爬取监控,通用网页列表监控软件。
监控网站信息列表,有更新或满足关键字条件时立即提醒记录。帮助您从海量的网络信息中获取有用的信息,第一时间获取最准确的信息。最适合广大投资者或记者。
每日自动爬取更新系统特点:
1、软件具有更新监控和关键链接过滤功能。
2、更新监控是指当出现新的信息链接网站时,会被捕获并放入数据库,不会重复提醒。
3、软件支持同时监控多个网站,获取更全面的信息。
4、 抓取数据存入数据库,随时打开参考。
5、 支持常用的提醒方式,包括邮件/微信等。
6、一般网站使用源码监控的方式,速度快又节省资源。
版权信息:本站所有资源仅供学习参考。请不要将它们用于商业目的。如果您的版权受到侵犯,请及时联系客服,我们会尽快处理。
自动抓取网页数据(自动抓取网页信息,也就是爬虫 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-23 18:06
)
自动抓取网页信息,即爬虫,一般通过js或者python可以更方便的实现。全部通过
模拟发送页面请求,然后解析html页面元素提取信息。
以js的实现为例:
function wraperAxiosHour(cityCode) {
return new Promise((resolve, reject) => {
const url = `http://www.weather.com.cn/weather1dn/${cityCode}.shtml`;
axios
.get(url)
.then(function(response) {
const $ = cheerio.load(response.data, {
decodeEntities: false
});
let hasBody = $("body").html();
if (hasBody == "") {
let errorInfo = {
msg: "城市代码错误",
code: 500
};
reject(errorInfo);
return;
}
let todayData = $(".todayRight script")
.html()
.replace("var hour3data=", "")
.replace(/\n/g, "")
.split(";");
todayData.pop();
//24小时
// console.log(jsonToObj(todayData[0]))
let forecastList1 = getPerTimeList(jsonToObj(todayData[0])[0])
.drgeeData;
let forecastList2 = getPerTimeList(jsonToObj(todayData[0])[1])
.drgeeData;
let forecastListob = forecastList1.concat(forecastList2);
let forecastList = forecastListob.slice(0, 24);
let lifeAssistant = getLv(0, $);
let sunup = jsonToObj(todayData[7].replace("var sunup =", ""))[1];
let sunset = jsonToObj(todayData[8].replace("var sunset =", ""))[1];
let max_degree = jsonToObj(
todayData[3].replace("var eventDay =", "")
)[2];
let min_degree = jsonToObj(
todayData[4].replace("var eventNight =", "")
)[1];
// console.log(max_degree,min_degree,sunup,sunset)
resolve({
forecastList,
lifeAssistant,
max_degree,
min_degree,
sunup,
sunset
});
})
.catch(err => reject(err));
});
}
python的实践:
python3中的requests库和urllib包都可以用来发送请求。注意urllib已经升级到3了。
区别:(转)
1)构建参数:构建请求参数时,第一个需要使用urllib库的urlencode方法进行编码预处理,非常麻烦
2) 请求方式:发送get请求时,第一个使用urllib库的urlopen方法打开一个url地址,第二个直接使用requests库的get方法,对应转为http请求方式,更直接易懂
3)请求数据:第一种方法是按照url格式拼接一个url字符串,显然很麻烦。第二种方法是按顺序写入get请求的url和参数。
4) 处理响应:第一种方法使用 .info() 和 .read() 方法分别处理消息头、.getcode()、响应状态码和响应正文,第二种方法使用.headers , .Status_code, .text 方法,方法名对应函数本身,更便于理解、学习和使用
5) 连接方式:看返回数据的头信息的“连接”。使用urllib库时,"connection":"close"表示每次请求结束时关闭socket通道,使用requests库使用urllib3,多个请求复用一个socket,"connection":"keep-alive ",表示多个请求使用一个连接,消耗更少的资源
6)Encoding:requests库的Accept-Encoding比较完整
得到html后,一种是直接使用python的re的正则表达式模块。一种是使用BeautifulSoup来解析。
def getTemp(html):
text = "".join(html.split())
patten = re.compile('(.*?)')
table = re.findall(patten, text)
patten1 = re.compile('(.*?)')
uls = re.findall(patten1, table[0])
rows = []
for ul in uls:
patten2 = re.compile('(.*?)')
lis = re.findall(patten2, ul)
time = re.findall('>(.*?)</a>', lis[0])[0]
high = lis[1]
low = lis[2]
rows.append((time, high, low))
return rows
soup = BeautifulSoup(text, 'html5lib')
conMidtab = soup.find("div", class_="conMidtab")
tables = conMidtab.find_all('table') 查看全部
自动抓取网页数据(自动抓取网页信息,也就是爬虫
)
自动抓取网页信息,即爬虫,一般通过js或者python可以更方便的实现。全部通过
模拟发送页面请求,然后解析html页面元素提取信息。
以js的实现为例:
function wraperAxiosHour(cityCode) {
return new Promise((resolve, reject) => {
const url = `http://www.weather.com.cn/weather1dn/${cityCode}.shtml`;
axios
.get(url)
.then(function(response) {
const $ = cheerio.load(response.data, {
decodeEntities: false
});
let hasBody = $("body").html();
if (hasBody == "") {
let errorInfo = {
msg: "城市代码错误",
code: 500
};
reject(errorInfo);
return;
}
let todayData = $(".todayRight script")
.html()
.replace("var hour3data=", "")
.replace(/\n/g, "")
.split(";");
todayData.pop();
//24小时
// console.log(jsonToObj(todayData[0]))
let forecastList1 = getPerTimeList(jsonToObj(todayData[0])[0])
.drgeeData;
let forecastList2 = getPerTimeList(jsonToObj(todayData[0])[1])
.drgeeData;
let forecastListob = forecastList1.concat(forecastList2);
let forecastList = forecastListob.slice(0, 24);
let lifeAssistant = getLv(0, $);
let sunup = jsonToObj(todayData[7].replace("var sunup =", ""))[1];
let sunset = jsonToObj(todayData[8].replace("var sunset =", ""))[1];
let max_degree = jsonToObj(
todayData[3].replace("var eventDay =", "")
)[2];
let min_degree = jsonToObj(
todayData[4].replace("var eventNight =", "")
)[1];
// console.log(max_degree,min_degree,sunup,sunset)
resolve({
forecastList,
lifeAssistant,
max_degree,
min_degree,
sunup,
sunset
});
})
.catch(err => reject(err));
});
}
python的实践:
python3中的requests库和urllib包都可以用来发送请求。注意urllib已经升级到3了。
区别:(转)
1)构建参数:构建请求参数时,第一个需要使用urllib库的urlencode方法进行编码预处理,非常麻烦
2) 请求方式:发送get请求时,第一个使用urllib库的urlopen方法打开一个url地址,第二个直接使用requests库的get方法,对应转为http请求方式,更直接易懂
3)请求数据:第一种方法是按照url格式拼接一个url字符串,显然很麻烦。第二种方法是按顺序写入get请求的url和参数。
4) 处理响应:第一种方法使用 .info() 和 .read() 方法分别处理消息头、.getcode()、响应状态码和响应正文,第二种方法使用.headers , .Status_code, .text 方法,方法名对应函数本身,更便于理解、学习和使用
5) 连接方式:看返回数据的头信息的“连接”。使用urllib库时,"connection":"close"表示每次请求结束时关闭socket通道,使用requests库使用urllib3,多个请求复用一个socket,"connection":"keep-alive ",表示多个请求使用一个连接,消耗更少的资源
6)Encoding:requests库的Accept-Encoding比较完整
得到html后,一种是直接使用python的re的正则表达式模块。一种是使用BeautifulSoup来解析。
def getTemp(html):
text = "".join(html.split())
patten = re.compile('(.*?)')
table = re.findall(patten, text)
patten1 = re.compile('(.*?)')
uls = re.findall(patten1, table[0])
rows = []
for ul in uls:
patten2 = re.compile('(.*?)')
lis = re.findall(patten2, ul)
time = re.findall('>(.*?)</a>', lis[0])[0]
high = lis[1]
low = lis[2]
rows.append((time, high, low))
return rows
soup = BeautifulSoup(text, 'html5lib')
conMidtab = soup.find("div", class_="conMidtab")
tables = conMidtab.find_all('table')
自动抓取网页数据( Robots协议目标网址后加/robots.txt的基本语法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-23 18:06
Robots协议目标网址后加/robots.txt的基本语法)
import urllib.request # 私密代理授权的账户 user = "user_name" # 私密代理授权的密码 passwd = "uesr_password" # 代理IP地址 比如可以使用百度西刺代理随便选择即可 proxyserver = "177.87.168.97:53281" # 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码 passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm() # 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 代理服务器、用户名、密码 passwdmgr.add_password(None, proxyserver, user, passwd) # 3. 构建一个代理基础用户名/密码验证的ProxyBasicAuthHandler处理器对象,参数是创建的密码管理对象 # 注意,这里不再使用普通ProxyHandler类了 proxyauth_handler = urllib.request.ProxyBasicAuthHandler(passwdmgr) # 4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler 和 proxyauth_handler opener = urllib.request.build_opener(proxyauth_handler) # 5. 构造Request 请求 request = urllib.request.Request("http://bbs.pinggu.org/") # 6. 使用自定义opener发送请求 response = opener.open(request) # 7. 打印响应内容 print (response.read())
5.ROBOT协议
在目标 URL 后添加 /robots.txt,例如:
第一个意思是,对于所有爬虫来说,它们不能在 /? 开头的路径无法访问匹配/pop/*.html的路径。
最后四个用户代理的爬虫不允许访问任何资源。
所以Robots协议的基本语法如下:
二、 爬虫的网络爬行
1.爬虫的目的
实现浏览器的功能,通过指定的URL直接返回用户需要的数据。
一般步骤:
2.网络分析
获取到相应的内容进行分析后,其实需要对一段文本进行处理,从网页中的代码中提取出你需要的内容。BeautifulSoup 可以实现通常的文档导航、搜索和修改文档功能。如果lib文件夹中没有BeautifulSoup,请使用命令行安装。
pip install BeautifulSoup
3.数据提取
# 想要抓取我们需要的东西需要进行定位,寻找到标志 from bs4 import BeautifulSoup soup = BeautifulSoup('',"html.parser") tag=soup.meta # tag的类别 type(tag) >>> bs4.element.Tag # tag的name属性 tag.name >>> 'meta' # attributes属性 tag.attrs >>> {'content': 'all', 'name': 'robots'} # BeautifulSoup属性 type(soup) >>> bs4.BeautifulSoup soup.name >>> '[document]' # 字符串的提取 markup='房产' soup=BeautifulSoup(markup,"lxml") text=soup.b.string text >>> '房产' type(text) >>> bs4.element.NavigableString
4.BeautifulSoup 应用实例
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml")
#通过页面解析得到结构数据进行处理 from bs4 import BeautifulSoup soup=BeautifulSoup(html.text,"lxml") #定位 lptable = soup.find('table',width='780') # 解析 for i in lptable.find_all("td",width="680"): title = i.b.strong.a.text href = "http://www.cwestc.com"+i.find('a')['href'] # href = i.find('a')['href'] date = href.split("/")[4] print (title,href,date)
4.Xpath 应用实例
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 可用于遍历 XML 文档中的元素和属性。XPath 是 W3C XSLT 标准的主要元素,XQuery 和 XPointer 都建立在 XPath 表达式之上。
四个标签的使用方法
from lxml import etree html=""" test NO.1NO.2NO.3 onetwo crossgatepinggu """ #这里使用id属性来定位哪个div和ul被匹配 使用text()获取文本内容 selector=etree.HTML(html) content=selector.xpath('//div[@id="content"]/ul[@id="ul"]/li/text()') for i in content: print (i)
#这里使用//从全文中定位符合条件的a标签,使用“@标签属性”获取a便签的href属性值 con=selector.xpath('//a/@href') for i in con: print (i)
#使用绝对路径 #使用相对路径定位 两者效果是一样的 con=selector.xpath('/html/body/div/a/@title') print (len(con)) print (con[0],con[1])
三、动态网页和静态网页的区别
来源百度:
静态网页的基本概述
静态网页的 URL 形式通常以 .htm、.html、.shtml、.xml 等为后缀。静态网页一般是最简单的 HTML 网页。服务器和客户端是一样的,没有脚本和小程序,所以不能移动。在HTML格式的网页上,还可以出现各种动态效果,比如.GIF格式的动画、FLASH、滚动字母等。这些“动态效果”只是视觉效果,与下面介绍的动态网页是不同的概念。.
静态网页的特点
动态网页的基本概述
动态网页以.asp、.jsp、.php、.perl、.cgi等形式后缀,并有一个符号——“?” 在动态网页 URL 中。动态网页与网页上的各种动画、滚动字幕等视觉“动态效果”没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些仅针对网页的特定内容。表现形式,无论网页是否具有动态效果,通过动态网站技术生成的网页都称为动态网页。动态网站也可以采用动静结合的原则。使用动态网页的地方适合使用动态网页。如果需要静态网页,
动态网页应具备以下特点:
总结:当页面内容改变时,URL也会改变。基本上,它是一个静态页面,反之亦然。
四、 动态网页和静态网页的爬取
1.静态网页
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=1" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]
总结:以上两个网址的区别在于最后一个数字。在原创网页上的每个点,下一页的 URL 和内容同时更改。我们判断:该网页为静态网页。
2.动态网页
import requests from bs4 import BeautifulSoup url = "http://news.cqcoal.com/blank/nl.jsp?tid=238" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text
如果抓取网页后看不到任何信息,则证明它是一个动态网页。正确的爬取方法如下。
import urllib import urllib.request import requests url = "http://news.cqcoal.com/manage/ ... ot%3B post_param = {'pageNum':'1',\ 'pageSize':'20',\ 'jsonStr':'{"typeid":"238"}'} return_data = requests.post(url,data =post_param) content=return_data.text content
至此,这篇教你如何使用Python快速爬取你需要的数据的文章就介绍完了。更多Python爬取数据相关内容,请搜索html中文网站之前的文章或继续浏览下面的相关文章,希望大家以后多多支持html中文网站!
以上就是教大家如何使用Python快速抓取所需数据的详细内容。更多信息请关注其他相关html中文网站文章! 查看全部
自动抓取网页数据(
Robots协议目标网址后加/robots.txt的基本语法)
import urllib.request # 私密代理授权的账户 user = "user_name" # 私密代理授权的密码 passwd = "uesr_password" # 代理IP地址 比如可以使用百度西刺代理随便选择即可 proxyserver = "177.87.168.97:53281" # 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码 passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm() # 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 代理服务器、用户名、密码 passwdmgr.add_password(None, proxyserver, user, passwd) # 3. 构建一个代理基础用户名/密码验证的ProxyBasicAuthHandler处理器对象,参数是创建的密码管理对象 # 注意,这里不再使用普通ProxyHandler类了 proxyauth_handler = urllib.request.ProxyBasicAuthHandler(passwdmgr) # 4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler 和 proxyauth_handler opener = urllib.request.build_opener(proxyauth_handler) # 5. 构造Request 请求 request = urllib.request.Request("http://bbs.pinggu.org/";) # 6. 使用自定义opener发送请求 response = opener.open(request) # 7. 打印响应内容 print (response.read())
5.ROBOT协议
在目标 URL 后添加 /robots.txt,例如:
第一个意思是,对于所有爬虫来说,它们不能在 /? 开头的路径无法访问匹配/pop/*.html的路径。
最后四个用户代理的爬虫不允许访问任何资源。
所以Robots协议的基本语法如下:
二、 爬虫的网络爬行
1.爬虫的目的
实现浏览器的功能,通过指定的URL直接返回用户需要的数据。
一般步骤:
2.网络分析
获取到相应的内容进行分析后,其实需要对一段文本进行处理,从网页中的代码中提取出你需要的内容。BeautifulSoup 可以实现通常的文档导航、搜索和修改文档功能。如果lib文件夹中没有BeautifulSoup,请使用命令行安装。
pip install BeautifulSoup
3.数据提取
# 想要抓取我们需要的东西需要进行定位,寻找到标志 from bs4 import BeautifulSoup soup = BeautifulSoup('',"html.parser") tag=soup.meta # tag的类别 type(tag) >>> bs4.element.Tag # tag的name属性 tag.name >>> 'meta' # attributes属性 tag.attrs >>> {'content': 'all', 'name': 'robots'} # BeautifulSoup属性 type(soup) >>> bs4.BeautifulSoup soup.name >>> '[document]' # 字符串的提取 markup='房产' soup=BeautifulSoup(markup,"lxml") text=soup.b.string text >>> '房产' type(text) >>> bs4.element.NavigableString
4.BeautifulSoup 应用实例
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml")
#通过页面解析得到结构数据进行处理 from bs4 import BeautifulSoup soup=BeautifulSoup(html.text,"lxml") #定位 lptable = soup.find('table',width='780') # 解析 for i in lptable.find_all("td",width="680"): title = i.b.strong.a.text href = "http://www.cwestc.com"+i.find('a')['href'] # href = i.find('a')['href'] date = href.split("/")[4] print (title,href,date)
4.Xpath 应用实例
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 可用于遍历 XML 文档中的元素和属性。XPath 是 W3C XSLT 标准的主要元素,XQuery 和 XPointer 都建立在 XPath 表达式之上。
四个标签的使用方法
from lxml import etree html=""" test NO.1NO.2NO.3 onetwo crossgatepinggu """ #这里使用id属性来定位哪个div和ul被匹配 使用text()获取文本内容 selector=etree.HTML(html) content=selector.xpath('//div[@id="content"]/ul[@id="ul"]/li/text()') for i in content: print (i)
#这里使用//从全文中定位符合条件的a标签,使用“@标签属性”获取a便签的href属性值 con=selector.xpath('//a/@href') for i in con: print (i)
#使用绝对路径 #使用相对路径定位 两者效果是一样的 con=selector.xpath('/html/body/div/a/@title') print (len(con)) print (con[0],con[1])
三、动态网页和静态网页的区别
来源百度:
静态网页的基本概述
静态网页的 URL 形式通常以 .htm、.html、.shtml、.xml 等为后缀。静态网页一般是最简单的 HTML 网页。服务器和客户端是一样的,没有脚本和小程序,所以不能移动。在HTML格式的网页上,还可以出现各种动态效果,比如.GIF格式的动画、FLASH、滚动字母等。这些“动态效果”只是视觉效果,与下面介绍的动态网页是不同的概念。.
静态网页的特点
动态网页的基本概述
动态网页以.asp、.jsp、.php、.perl、.cgi等形式后缀,并有一个符号——“?” 在动态网页 URL 中。动态网页与网页上的各种动画、滚动字幕等视觉“动态效果”没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些仅针对网页的特定内容。表现形式,无论网页是否具有动态效果,通过动态网站技术生成的网页都称为动态网页。动态网站也可以采用动静结合的原则。使用动态网页的地方适合使用动态网页。如果需要静态网页,
动态网页应具备以下特点:
总结:当页面内容改变时,URL也会改变。基本上,它是一个静态页面,反之亦然。
四、 动态网页和静态网页的爬取
1.静态网页
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=1" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]
总结:以上两个网址的区别在于最后一个数字。在原创网页上的每个点,下一页的 URL 和内容同时更改。我们判断:该网页为静态网页。
2.动态网页
import requests from bs4 import BeautifulSoup url = "http://news.cqcoal.com/blank/nl.jsp?tid=238" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text
如果抓取网页后看不到任何信息,则证明它是一个动态网页。正确的爬取方法如下。
import urllib import urllib.request import requests url = "http://news.cqcoal.com/manage/ ... ot%3B post_param = {'pageNum':'1',\ 'pageSize':'20',\ 'jsonStr':'{"typeid":"238"}'} return_data = requests.post(url,data =post_param) content=return_data.text content
至此,这篇教你如何使用Python快速爬取你需要的数据的文章就介绍完了。更多Python爬取数据相关内容,请搜索html中文网站之前的文章或继续浏览下面的相关文章,希望大家以后多多支持html中文网站!
以上就是教大家如何使用Python快速抓取所需数据的详细内容。更多信息请关注其他相关html中文网站文章!
自动抓取网页数据(web页面数据采集工具通达网络爬虫管理工具工具介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-11-23 01:06
随着大数据时代的到来和互联网技术的飞速发展,数据在企业日常运营管理中无处不在。各类数据的聚合、整合、分析和研究,对企业的发展和决策起着非常重要的作用。.
数据采集越来越受到企业的关注。如何快速、全面地从海量网页中获取您想要的数据信息?
介绍一个非常有用的网页数据采集工具——极家通达网络爬虫管理工具,以下简称爬虫管理工具。
工具介绍
极家通达网络爬虫管理工具是一个通用的网页数据采集器,由管理工具、爬虫工具和爬虫数据库三部分组成。可以代替人自动采集,组织互联网上的数据和信息,快速将网页数据转化为结构化数据,并以EXCEL等多种形式存储。产品可用于舆情监测、市场分析、产品开发、风险预测等多种业务场景。
特征
极家通达网络爬虫管理工具简单易用,无需技术基础即可快速上手。工作人员可以通过设置爬取规则来启动爬虫。
极家通达网络爬虫管理工具具有以下五个特点:
操作简单,操作直观直观,不懂技术也能快速上手;
适用于全网,看到就拿起;
多种采集表单,支持本地采集和云端采集,自定义采集和智能采集;
智能数据处理,采集对数据进行自动去重、自动分词、多格式数据导出;
速度快,5分钟内从海量数据中挖掘出目标信息。
应用场景
场景一:建立企业业务数据库
爬虫管理工具可以快速抓取网页企业所需的数据,整理下载数据,省时省力。短短几分钟,几天的人为工作量就完成了,数据也彻底枯竭了。
场景二:企业舆情口碑监测
部署爬虫管理工具后,设置网站、关键词、爬取规则,工作人员5分钟即可获取企业舆情信息,并下载到指定位置,多路导出数据格式供市场人员进行参考分析。避免人工监控耗时、费力、不完整的弊端。
场景三:企业市场数据采集
部署爬虫管理工具后,企业很快就可以下载其产品或服务在市场上的数据和信息,以及竞品的产品或服务、价格、销量、趋势、口碑信息等。市场参与者。
场景四:市场需求调研
部署爬虫管理工具后,公司可以从WEB页面采集快速进行目标用户需求,包括行业数据、行业信息、竞品数据、竞品信息、用户需求、用户对竞品的反馈等., 5分钟内获取大量数据,并自动整理下载到指定位置。
极佳通达爬虫管理工具产品成熟,已在市场上多次应用。典型应用于“房地产行业大数据集成平台”,为房地产行业大数据集成平台提供网页数据采集功能。 查看全部
自动抓取网页数据(web页面数据采集工具通达网络爬虫管理工具工具介绍)
随着大数据时代的到来和互联网技术的飞速发展,数据在企业日常运营管理中无处不在。各类数据的聚合、整合、分析和研究,对企业的发展和决策起着非常重要的作用。.
数据采集越来越受到企业的关注。如何快速、全面地从海量网页中获取您想要的数据信息?
介绍一个非常有用的网页数据采集工具——极家通达网络爬虫管理工具,以下简称爬虫管理工具。
工具介绍
极家通达网络爬虫管理工具是一个通用的网页数据采集器,由管理工具、爬虫工具和爬虫数据库三部分组成。可以代替人自动采集,组织互联网上的数据和信息,快速将网页数据转化为结构化数据,并以EXCEL等多种形式存储。产品可用于舆情监测、市场分析、产品开发、风险预测等多种业务场景。
特征
极家通达网络爬虫管理工具简单易用,无需技术基础即可快速上手。工作人员可以通过设置爬取规则来启动爬虫。
极家通达网络爬虫管理工具具有以下五个特点:
操作简单,操作直观直观,不懂技术也能快速上手;
适用于全网,看到就拿起;
多种采集表单,支持本地采集和云端采集,自定义采集和智能采集;
智能数据处理,采集对数据进行自动去重、自动分词、多格式数据导出;
速度快,5分钟内从海量数据中挖掘出目标信息。
应用场景
场景一:建立企业业务数据库
爬虫管理工具可以快速抓取网页企业所需的数据,整理下载数据,省时省力。短短几分钟,几天的人为工作量就完成了,数据也彻底枯竭了。
场景二:企业舆情口碑监测
部署爬虫管理工具后,设置网站、关键词、爬取规则,工作人员5分钟即可获取企业舆情信息,并下载到指定位置,多路导出数据格式供市场人员进行参考分析。避免人工监控耗时、费力、不完整的弊端。
场景三:企业市场数据采集
部署爬虫管理工具后,企业很快就可以下载其产品或服务在市场上的数据和信息,以及竞品的产品或服务、价格、销量、趋势、口碑信息等。市场参与者。
场景四:市场需求调研
部署爬虫管理工具后,公司可以从WEB页面采集快速进行目标用户需求,包括行业数据、行业信息、竞品数据、竞品信息、用户需求、用户对竞品的反馈等., 5分钟内获取大量数据,并自动整理下载到指定位置。
极佳通达爬虫管理工具产品成熟,已在市场上多次应用。典型应用于“房地产行业大数据集成平台”,为房地产行业大数据集成平台提供网页数据采集功能。
自动抓取网页数据(1.从论坛获得的如下语句(语句)原因)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-21 11:19
说明:1. 以下语句从论坛获取,在家庭网络上运行时可以抓取“”中的数据。
2. 但是在公司网络上运行时出现“run-time error'-2147024891 (80070005) Access denied.”错误。
3. 原因是公司需要连接IE浏览器-局域网(LAN)设置-使用自动配置脚本(公司出于安全原因必须设置),网络连接后即可脚本已设置。回到首页点这里 设置也不能抓取数据,但是删除脚本后,可以重新抓取数据。
4. 我也发现,不管是在家还是在工作中,也不管IE设置了脚本还是删除了脚本,只要能上网,谷歌浏览器就可以显示数据“” .
问题:
1. 因为Google可以显示数据,但是IE设置了脚本后就不能显示了,是不是说明下面的语句是基于IE浏览器的内核编译的?
2. 有没有可以绕过IE内核(可能我不准确)直接在谷歌浏览器(或其他浏览器)抓取数据的说法?请各位老师帮忙,谢谢!
附图为谷歌浏览器获取的数据截图
谷歌浏览器抓取的数据
'---------------------------
'网页下载
函数 DownLoadHtm(Url) As String
下载 Htm = 真
昏暗的检索 查看全部
自动抓取网页数据(1.从论坛获得的如下语句(语句)原因)
说明:1. 以下语句从论坛获取,在家庭网络上运行时可以抓取“”中的数据。
2. 但是在公司网络上运行时出现“run-time error'-2147024891 (80070005) Access denied.”错误。
3. 原因是公司需要连接IE浏览器-局域网(LAN)设置-使用自动配置脚本(公司出于安全原因必须设置),网络连接后即可脚本已设置。回到首页点这里 设置也不能抓取数据,但是删除脚本后,可以重新抓取数据。
4. 我也发现,不管是在家还是在工作中,也不管IE设置了脚本还是删除了脚本,只要能上网,谷歌浏览器就可以显示数据“” .
问题:
1. 因为Google可以显示数据,但是IE设置了脚本后就不能显示了,是不是说明下面的语句是基于IE浏览器的内核编译的?
2. 有没有可以绕过IE内核(可能我不准确)直接在谷歌浏览器(或其他浏览器)抓取数据的说法?请各位老师帮忙,谢谢!
附图为谷歌浏览器获取的数据截图
谷歌浏览器抓取的数据
'---------------------------
'网页下载
函数 DownLoadHtm(Url) As String
下载 Htm = 真
昏暗的检索
自动抓取网页数据(南阳理工学院ACM的基本架构网络爬虫练习题目数据的保存)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-18 22:09
内容
一、相关原理1.什么是爬虫
网络图:
网页抓取策略:
一般来说,网络爬取策略可以分为以下三类:
• 广度优先
• 最佳优先
• 深度优先
深度优先在很多情况下会导致爬虫被困。目前,广度优先和最佳优先方法很常见。
2. 网络爬虫的分类
一般来说,网络爬虫可以分为以下几类:
• 通用网络爬虫
• 增量爬虫
• 垂直履带
• 深网爬虫
3.网络爬虫的使用范围
机器人协议
又称机器人协议或爬虫协议,该协议规定了搜索引擎抓取的内容范围,包括网站是否希望被搜索引擎抓取,哪些内容不允许抓取,以及互联网基于此,爬虫“有意识地”抓取或不抓取网页内容。自推出以来,机器人协议已成为网站保护自身敏感数据和网民隐私的国际惯例。
4.爬虫的基本结构
一个网络爬虫通常收录四个模块:
• URL 管理模块
• 下载模块
• 分析模块
• 存储模块
爬虫框架:
二、代码实现1.环境配置
打开Anaconda Prompt,创建一个虚拟环境
conda create -n crawler python=3.7
crawler 是虚拟环境的名称,python=3.7 是python版本。
激活环境:
activate crawler
使用 pip 或 conda 命令下载将要使用的包:
pip install requests
pip install beautifulsoup4
pip install tqdm
pip install csv
2.南洋理工ACM题的爬取和保存网站练习题数据2.1分析网址
目标地址:
查看源代码:
找到目标爬取内容:
其中,Ctrl+F在页面上搜索某个主题(这里以最大和为例):
可以搜索到,说明这个数据不是动态加载的,可以直接到页面获取。
按F12打开开发者工具(或右键选择勾选),点击元素中的箭头工具(部分浏览器是Element)(如下图②所示),点击标题,即可显示元素:
可以发现,每行信息在一个标签中,每个小信息在一个标签串中。在Element中,Ctrl + F在一个页面上搜索100个问题,一排有7个,正好是700个。因此只需获取所有标签:
分析完成后,开始编写代码。
2.2 代码编写
# 导入相关包
import requests #基于urllib,采用Apache2Licensed开源协议的HTTP库
from bs4 import BeautifulSoup # 可以从HTML或XML文件中提取数据的python库
import csv # 保存为csv文件所需的包
from tqdm import tqdm # 显示下载进度的包
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头,根据网页数据来定
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
#进度显示,爬取该网站的所有题目信息11页
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers) # get请求第pages页
r.raise_for_status() # 判断异常
r.encoding = 'utf-8' # 编码格式
soup = BeautifulSoup(r.text, 'html.parser') # 创建BeautifulSoup对象,用于解析该html页面数据
td = soup.find_all('td') # 获取所有td标签
subject = [] # 存放某一个题目的所有信息
# 遍历所有td
for t in td:
if t.string is not None:
subject.append(t.string) # 获取td中的字符串
if len(subject) == 5: # 每5个为一个题目的信息
subjects.append(subject)
subject = []
# 存放题目
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders) #写入表头
fileWriter.writerows(subjects) #写入数据
print('\n题目信息爬取完成!!!')
运行中:
运行完毕:
查看生成的csv文件:
共1126条数据,与原网页数量相同。
3.爬取重庆交大新闻网站近年所有信息公告的发布日期和标题均为3.1个分析页
目标地址:
第一页的url是,第二页是,第三页是...第66页是
一共66页,可以表示为:
base_url = "http://news.cqjtu.edu.cn/xxtz/"
for i in range(1, 67):
if(i == 1):
url = 'http://news.cqjtu.edu.cn/xxtz.htm'
else:
url ='http://news.cqjtu.edu.cn/xxtz/' + str(67 - i) + '.htm'
查看源码,找到目标爬取内容:
用Ctrl+F搜索页面主题(这里以征集新型交通智库研究成果为例):
可以搜索到,说明这个数据不是动态加载的,可以直接到页面获取。
F12 打开开发者工具(或右键选择勾选),点击元素中的箭头工具(部分浏览器是Element)(如下图②所示),点击一个标题在元素中显示:
可以发现,每一行信息都在一个标签中,都在class="left-list"的div下 查看全部
自动抓取网页数据(南阳理工学院ACM的基本架构网络爬虫练习题目数据的保存)
内容
一、相关原理1.什么是爬虫
网络图:
网页抓取策略:
一般来说,网络爬取策略可以分为以下三类:
• 广度优先
• 最佳优先
• 深度优先
深度优先在很多情况下会导致爬虫被困。目前,广度优先和最佳优先方法很常见。
2. 网络爬虫的分类
一般来说,网络爬虫可以分为以下几类:
• 通用网络爬虫
• 增量爬虫
• 垂直履带
• 深网爬虫
3.网络爬虫的使用范围
机器人协议
又称机器人协议或爬虫协议,该协议规定了搜索引擎抓取的内容范围,包括网站是否希望被搜索引擎抓取,哪些内容不允许抓取,以及互联网基于此,爬虫“有意识地”抓取或不抓取网页内容。自推出以来,机器人协议已成为网站保护自身敏感数据和网民隐私的国际惯例。
4.爬虫的基本结构
一个网络爬虫通常收录四个模块:
• URL 管理模块
• 下载模块
• 分析模块
• 存储模块
爬虫框架:
二、代码实现1.环境配置
打开Anaconda Prompt,创建一个虚拟环境
conda create -n crawler python=3.7
crawler 是虚拟环境的名称,python=3.7 是python版本。
激活环境:
activate crawler
使用 pip 或 conda 命令下载将要使用的包:
pip install requests
pip install beautifulsoup4
pip install tqdm
pip install csv
2.南洋理工ACM题的爬取和保存网站练习题数据2.1分析网址
目标地址:
查看源代码:
找到目标爬取内容:
其中,Ctrl+F在页面上搜索某个主题(这里以最大和为例):
可以搜索到,说明这个数据不是动态加载的,可以直接到页面获取。
按F12打开开发者工具(或右键选择勾选),点击元素中的箭头工具(部分浏览器是Element)(如下图②所示),点击标题,即可显示元素:
可以发现,每行信息在一个标签中,每个小信息在一个标签串中。在Element中,Ctrl + F在一个页面上搜索100个问题,一排有7个,正好是700个。因此只需获取所有标签:
分析完成后,开始编写代码。
2.2 代码编写
# 导入相关包
import requests #基于urllib,采用Apache2Licensed开源协议的HTTP库
from bs4 import BeautifulSoup # 可以从HTML或XML文件中提取数据的python库
import csv # 保存为csv文件所需的包
from tqdm import tqdm # 显示下载进度的包
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头,根据网页数据来定
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
#进度显示,爬取该网站的所有题目信息11页
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers) # get请求第pages页
r.raise_for_status() # 判断异常
r.encoding = 'utf-8' # 编码格式
soup = BeautifulSoup(r.text, 'html.parser') # 创建BeautifulSoup对象,用于解析该html页面数据
td = soup.find_all('td') # 获取所有td标签
subject = [] # 存放某一个题目的所有信息
# 遍历所有td
for t in td:
if t.string is not None:
subject.append(t.string) # 获取td中的字符串
if len(subject) == 5: # 每5个为一个题目的信息
subjects.append(subject)
subject = []
# 存放题目
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders) #写入表头
fileWriter.writerows(subjects) #写入数据
print('\n题目信息爬取完成!!!')
运行中:
运行完毕:
查看生成的csv文件:
共1126条数据,与原网页数量相同。
3.爬取重庆交大新闻网站近年所有信息公告的发布日期和标题均为3.1个分析页
目标地址:
第一页的url是,第二页是,第三页是...第66页是
一共66页,可以表示为:
base_url = "http://news.cqjtu.edu.cn/xxtz/"
for i in range(1, 67):
if(i == 1):
url = 'http://news.cqjtu.edu.cn/xxtz.htm'
else:
url ='http://news.cqjtu.edu.cn/xxtz/' + str(67 - i) + '.htm'
查看源码,找到目标爬取内容:
用Ctrl+F搜索页面主题(这里以征集新型交通智库研究成果为例):
可以搜索到,说明这个数据不是动态加载的,可以直接到页面获取。
F12 打开开发者工具(或右键选择勾选),点击元素中的箭头工具(部分浏览器是Element)(如下图②所示),点击一个标题在元素中显示:
可以发现,每一行信息都在一个标签中,都在class="left-list"的div下
自动抓取网页数据(参考Python爬虫利器二之BeautifulSoup的用法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-15 14:26
内容
一、网络爬虫基本介绍
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。
简单来说就是通过编写脚本模拟浏览器发起获取数据的请求。爬虫从初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并将它们放入队列中。直到满足系统给出的停止条件才会停止。
二、 爬行南洋理功 OJ 问题
抓取目标网址:
爬取任务:爬取每道题的题号、难度、题目、通过率、通过数/总提交数
1. 网络分析2. 内容抓取
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
# tqdm作业:以进度条方式显示爬取进度
# 爬取11页所有题目信息
for pages in tqdm(range(1, 11 + 1)):
# get请求第pages页
r = requests.get(
f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
# 判断异常
r.raise_for_status()
# 设置编码
r.encoding = 'utf-8'
# 创建BeautifulSoup对象,用于解析该html页面数据
soup = BeautifulSoup(r.text, 'lxml')
# 获取所有td标签
td = soup.find_all('td')
# 存放某一个题目的所有信息
subject = []
# 遍历所有td
for t in td:
if t.string is not None:
subject.append(t.string) # 获取td中的字符串
if len(subject) == 5: # 每5个为一个题目的信息
subjects.append(subject)
subject = []
# 存放题目
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders) # 写入表头
fileWriter.writerows(subjects) # 写入数据
print('\n题目信息爬取完成!!!')
三、爬取重新提交消息通知
抓取目标网址:
爬取任务:爬取每条新闻的发布日期+标题
1. 网络分析2. 内容抓取
import requests
from bs4 import BeautifulSoup
import csv
# 获取每页内容
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
try:
info_list_page = [] # 一页的所有信息
resp = requests.get(url, headers=headers)
resp.encoding = resp.status_code
page_text = resp.text
soup = BeautifulSoup(page_text, 'lxml')
li_list = soup.select('.left-list > ul > li') # 找到所有li标签
for li in li_list:
divs = li.select('div')
date = divs[0].string.strip()
title = divs[1].a.string
info = [date, title]
info_list_page.append(info)
except Exception as e:
print('爬取' + url + '错误')
print(e)
return None
else:
resp.close()
print('爬取' + url + '成功')
return info_list_page
# main
def main():
# 爬取所有数据
info_list_all = []
base_url = 'http://news.cqjtu.edu.cn/xxtz/'
for i in range(1, 67):
if i == 1:
url = 'http://news.cqjtu.edu.cn/xxtz.htm'
else:
url = base_url + str(67 - i) + '.htm'
info_list_page = get_one_page(url)
info_list_all += info_list_page
# 存入数据
with open('教务新闻.csv', 'w', newline='', encoding='utf-8') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(['日期', '标题']) # 写入表头
fileWriter.writerows(info_list_all) # 写入数据
if __name__ == '__main__':
main()
四、总结
本文对网络爬虫进行了粗略的介绍,并通过爬虫程序的编写,进一步了解HTTP协议。实现了南洋理工ACM题目网站练习题目数据的抓取和存储,以及重新提交的新闻网站@中所有信息通知的发布日期和标题的检索和存储> 近年来。
五、参考
Beautiful Soup 的用法,第二个 Python 爬虫工具 查看全部
自动抓取网页数据(参考Python爬虫利器二之BeautifulSoup的用法)
内容
一、网络爬虫基本介绍
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。
简单来说就是通过编写脚本模拟浏览器发起获取数据的请求。爬虫从初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并将它们放入队列中。直到满足系统给出的停止条件才会停止。
二、 爬行南洋理功 OJ 问题
抓取目标网址:
爬取任务:爬取每道题的题号、难度、题目、通过率、通过数/总提交数
1. 网络分析2. 内容抓取
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
# tqdm作业:以进度条方式显示爬取进度
# 爬取11页所有题目信息
for pages in tqdm(range(1, 11 + 1)):
# get请求第pages页
r = requests.get(
f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
# 判断异常
r.raise_for_status()
# 设置编码
r.encoding = 'utf-8'
# 创建BeautifulSoup对象,用于解析该html页面数据
soup = BeautifulSoup(r.text, 'lxml')
# 获取所有td标签
td = soup.find_all('td')
# 存放某一个题目的所有信息
subject = []
# 遍历所有td
for t in td:
if t.string is not None:
subject.append(t.string) # 获取td中的字符串
if len(subject) == 5: # 每5个为一个题目的信息
subjects.append(subject)
subject = []
# 存放题目
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders) # 写入表头
fileWriter.writerows(subjects) # 写入数据
print('\n题目信息爬取完成!!!')
三、爬取重新提交消息通知
抓取目标网址:
爬取任务:爬取每条新闻的发布日期+标题
1. 网络分析2. 内容抓取
import requests
from bs4 import BeautifulSoup
import csv
# 获取每页内容
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
try:
info_list_page = [] # 一页的所有信息
resp = requests.get(url, headers=headers)
resp.encoding = resp.status_code
page_text = resp.text
soup = BeautifulSoup(page_text, 'lxml')
li_list = soup.select('.left-list > ul > li') # 找到所有li标签
for li in li_list:
divs = li.select('div')
date = divs[0].string.strip()
title = divs[1].a.string
info = [date, title]
info_list_page.append(info)
except Exception as e:
print('爬取' + url + '错误')
print(e)
return None
else:
resp.close()
print('爬取' + url + '成功')
return info_list_page
# main
def main():
# 爬取所有数据
info_list_all = []
base_url = 'http://news.cqjtu.edu.cn/xxtz/'
for i in range(1, 67):
if i == 1:
url = 'http://news.cqjtu.edu.cn/xxtz.htm'
else:
url = base_url + str(67 - i) + '.htm'
info_list_page = get_one_page(url)
info_list_all += info_list_page
# 存入数据
with open('教务新闻.csv', 'w', newline='', encoding='utf-8') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(['日期', '标题']) # 写入表头
fileWriter.writerows(info_list_all) # 写入数据
if __name__ == '__main__':
main()
四、总结
本文对网络爬虫进行了粗略的介绍,并通过爬虫程序的编写,进一步了解HTTP协议。实现了南洋理工ACM题目网站练习题目数据的抓取和存储,以及重新提交的新闻网站@中所有信息通知的发布日期和标题的检索和存储> 近年来。
五、参考
Beautiful Soup 的用法,第二个 Python 爬虫工具
自动抓取网页数据(自动抓取网页数据存放到excel文件中的关键是你用不用得到)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-14 16:03
自动抓取网页数据存放到excel文件中,再导入mysql中。目前mysql的可用性相对于oracle、sqlserver、postgresql在性能上略逊一筹,但是hadoop对mysql的支持尚可,如果能够支持对mysql数据的快速查询,对于自己后续的开发会很有帮助。
关键是你用不用得到?
hive可以很好的利用hadoop的存储和计算资源。mysql主要面向关系型数据库,hive则是面向文本型数据库,所以.。
直接从hadoop迁移到mysql不是不可以,但要解决以下几个问题:1.迁移到mysql后如何部署,尤其是生产环境2.没有mysql支持,如何实现数据的快速读写,
mysql并不占优势。现在的主流都是以hive为代表的sql类型,基于photodata构建的hive与数据仓库有太多相似之处。sqoop可以很好解决。
1.最直接的,hive可以实现快速读写。数据量相对大的时候。速度很明显2.数据依赖dbms管理。大量数据的读写,sql自然很费劲。hive代替了dbms,实现了统一的api。开发更简单,最少的管理hive。对于企业而言。是个不错的选择。
由于hive关键优势是面向企业关系型数据库,针对的是有较大数据量的企业场景。而企业通常在选择数据库时会要求sql性能与内存占用效率。且由于where及子查询引发的sql执行锁,读写效率慢对于处理海量数据显得力不从心。mysql针对的是通用关系型数据库,建立在where语句支持良好,且操作简单的基础上。
读写性能可以较大限度的满足要求。不过说实话,mysql现在在国内有被人喷的风险。很多企业应用应该放弃mysql使用access或者postgresql等替代。 查看全部
自动抓取网页数据(自动抓取网页数据存放到excel文件中的关键是你用不用得到)
自动抓取网页数据存放到excel文件中,再导入mysql中。目前mysql的可用性相对于oracle、sqlserver、postgresql在性能上略逊一筹,但是hadoop对mysql的支持尚可,如果能够支持对mysql数据的快速查询,对于自己后续的开发会很有帮助。
关键是你用不用得到?
hive可以很好的利用hadoop的存储和计算资源。mysql主要面向关系型数据库,hive则是面向文本型数据库,所以.。
直接从hadoop迁移到mysql不是不可以,但要解决以下几个问题:1.迁移到mysql后如何部署,尤其是生产环境2.没有mysql支持,如何实现数据的快速读写,
mysql并不占优势。现在的主流都是以hive为代表的sql类型,基于photodata构建的hive与数据仓库有太多相似之处。sqoop可以很好解决。
1.最直接的,hive可以实现快速读写。数据量相对大的时候。速度很明显2.数据依赖dbms管理。大量数据的读写,sql自然很费劲。hive代替了dbms,实现了统一的api。开发更简单,最少的管理hive。对于企业而言。是个不错的选择。
由于hive关键优势是面向企业关系型数据库,针对的是有较大数据量的企业场景。而企业通常在选择数据库时会要求sql性能与内存占用效率。且由于where及子查询引发的sql执行锁,读写效率慢对于处理海量数据显得力不从心。mysql针对的是通用关系型数据库,建立在where语句支持良好,且操作简单的基础上。
读写性能可以较大限度的满足要求。不过说实话,mysql现在在国内有被人喷的风险。很多企业应用应该放弃mysql使用access或者postgresql等替代。
自动抓取网页数据(大数据初学者了解并动手实现自己的网络爬虫(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-11-14 04:13
网络爬虫是从互联网上打开数据采集的重要手段。在这种情况下,使用Python的相关模块开发了一个简单的爬虫。实现从某本书网站中自动下载感兴趣的图书信息功能。实现的主要功能包括单页图书信息下载、图书信息提取、多页图书信息下载。本案例适合大数据初学者了解并实现自己的网络爬虫。
1、任务描述和数据来源
从当当网搜索页面,按照关键词进行搜索,使用Python编写爬虫,在搜索结果中自动爬取该书的书名、出版社、价格、作者、书籍介绍。
当当搜索页面:/
2、单页图书信息下载2.1个网页下载
Python 中的 requests 库可以自动帮我们构造一个请求对象来向服务器请求资源,并返回一个响应对象来请求服务器资源。如果只需要返回 HTML 页面的内容,可以直接调用响应的 text 属性。下面的代码中,我们首先导入requests库,定义当当搜索页面的URL,设置搜索关键词为“机器学习”。然后使用requests.get方法获取网页内容。最后,打印并显示网页的前 1000 个字符。
import requests #1. 导入requests 库
test_url = 'http://search.dangdang.com/?key='+ '机器学习' #2. 设置网页的URL地址
content_page = requests.get(test_url).text #3. 执行页面请求,返回页面内容
print(content_page[:1000]) #4.将页面的前1000个字符打印显示出来
2.2 图书内容分析
下面开始分析页面,分析源码。这里我使用Chrome浏览器直接打开网址/?key=machine learning。然后选择任意图书信息,右击“检查”按钮。不难发现,搜索结果中每本书的信息都是页面上的一个标签,如下图所示:
点击第一个标签,发现下面还有几个
标签,类有“名称”、“详情”、“价格”等,这些标签下存储了商品的标题、详情、价格等信息。
我们以提取书名信息为例进行具体说明。点击li标签的class属性为name的p标签,我们发现书名信息存储在name属性值为“itemlist-title”的a标签的title属性中,如图下图:
我们可以用xpath直接将上面的定位信息描述为//li/p/a[@name="itemlist-title"]/@title。接下来,我们使用 lxml 模块提取页面中的书名信息。xpath的使用请参考/xpath/xpath_syntax.asp。
page = etree.HTML(content_page) #将页面字符串解析成树结构
book_name = page.xpath('//li/p/a[@name="itemlist-title"]/@title') #用xpath提取出书名信息。
book_name[:10] #打印提取出的前10个书名信息
同理,我们可以提取图书出版信息(作者、出版社、出版时间等)、当前价格、星级、评论数等。该信息对应的xpath路径如下表所示。
信息项
标题
//li/p/a[@name="itemlist-title"]/@title
出版信息
//li/p[@class="search_book_author"]
目前的价格
//li/p[@class="price"]/span[@class="search_now_price"]/text()
星级
//li/p[@class="search_star_line"]/span[@class="search_star_black"]/span/@style 查看全部
自动抓取网页数据(大数据初学者了解并动手实现自己的网络爬虫(图))
网络爬虫是从互联网上打开数据采集的重要手段。在这种情况下,使用Python的相关模块开发了一个简单的爬虫。实现从某本书网站中自动下载感兴趣的图书信息功能。实现的主要功能包括单页图书信息下载、图书信息提取、多页图书信息下载。本案例适合大数据初学者了解并实现自己的网络爬虫。
1、任务描述和数据来源
从当当网搜索页面,按照关键词进行搜索,使用Python编写爬虫,在搜索结果中自动爬取该书的书名、出版社、价格、作者、书籍介绍。
当当搜索页面:/
2、单页图书信息下载2.1个网页下载
Python 中的 requests 库可以自动帮我们构造一个请求对象来向服务器请求资源,并返回一个响应对象来请求服务器资源。如果只需要返回 HTML 页面的内容,可以直接调用响应的 text 属性。下面的代码中,我们首先导入requests库,定义当当搜索页面的URL,设置搜索关键词为“机器学习”。然后使用requests.get方法获取网页内容。最后,打印并显示网页的前 1000 个字符。
import requests #1. 导入requests 库
test_url = 'http://search.dangdang.com/?key='+ '机器学习' #2. 设置网页的URL地址
content_page = requests.get(test_url).text #3. 执行页面请求,返回页面内容
print(content_page[:1000]) #4.将页面的前1000个字符打印显示出来
2.2 图书内容分析
下面开始分析页面,分析源码。这里我使用Chrome浏览器直接打开网址/?key=machine learning。然后选择任意图书信息,右击“检查”按钮。不难发现,搜索结果中每本书的信息都是页面上的一个标签,如下图所示:
点击第一个标签,发现下面还有几个
标签,类有“名称”、“详情”、“价格”等,这些标签下存储了商品的标题、详情、价格等信息。
我们以提取书名信息为例进行具体说明。点击li标签的class属性为name的p标签,我们发现书名信息存储在name属性值为“itemlist-title”的a标签的title属性中,如图下图:
我们可以用xpath直接将上面的定位信息描述为//li/p/a[@name="itemlist-title"]/@title。接下来,我们使用 lxml 模块提取页面中的书名信息。xpath的使用请参考/xpath/xpath_syntax.asp。
page = etree.HTML(content_page) #将页面字符串解析成树结构
book_name = page.xpath('//li/p/a[@name="itemlist-title"]/@title') #用xpath提取出书名信息。
book_name[:10] #打印提取出的前10个书名信息
同理,我们可以提取图书出版信息(作者、出版社、出版时间等)、当前价格、星级、评论数等。该信息对应的xpath路径如下表所示。
信息项
标题
//li/p/a[@name="itemlist-title"]/@title
出版信息
//li/p[@class="search_book_author"]
目前的价格
//li/p[@class="price"]/span[@class="search_now_price"]/text()
星级
//li/p[@class="search_star_line"]/span[@class="search_star_black"]/span/@style

